├── utils
├── __init__.py
├── decoding.py
├── lr_scheduler.py
└── box_utils.py
├── inference
├── __init__.py
├── trt_inference
│ ├── __init__.py
│ ├── cls.py
│ ├── cerberus_trt.py
│ └── trt_infer.py
├── profiler.py
├── postproc.py
├── run_tensorrt.py
└── run.py
├── conf
├── __init__.py
├── experiments
│ ├── resnet101_bifpn.json
│ ├── resnet34_bifpn.json
│ ├── resnet50_bifpn.json
│ ├── mobilenetv2_bifpn.json
│ ├── efficientnetb2_bifpn.json
│ └── resnet34_simple.json
└── conf.py
├── models
├── __init__.py
├── losses
│ ├── __init__.py
│ ├── multitask_loss.py
│ ├── task_losses.py
│ └── heatmap_loss.py
├── backbones
│ ├── __init__.py
│ ├── misc.py
│ ├── mobilenetv2.py
│ ├── resnet.py
│ └── efficientnet.py
├── heads.py
├── layers.py
├── cerberus.py
└── necks.py
├── docs
├── paper.pdf
├── architecutre_github.png
└── deps.sh
├── dataset
├── utils
│ ├── __init__.py
│ ├── cls.py
│ ├── transforms.py
│ ├── heatmaps.py
│ ├── process_detection.py
│ └── process_lanes.py
├── __init__.py
├── collate.py
└── multitask_dataset.py
├── requirements.txt
├── .gitignore
├── data
├── heatmap_utils.py
├── lane_heatmaps.py
├── tools.py
└── bdd100k_lane_keypoints.py
├── main.py
├── trainer.py
├── evaluate.py
└── Readme.md
/utils/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/inference/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/inference/trt_inference/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/conf/__init__.py:
--------------------------------------------------------------------------------
1 | from conf.conf import Conf
2 |
--------------------------------------------------------------------------------
/models/__init__.py:
--------------------------------------------------------------------------------
1 | from models.cerberus import CerberusModel
2 |
--------------------------------------------------------------------------------
/docs/paper.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cscribano/CERBERUS/HEAD/docs/paper.pdf
--------------------------------------------------------------------------------
/models/losses/__init__.py:
--------------------------------------------------------------------------------
1 | from models.losses.multitask_loss import MultiTaskLoss
2 |
--------------------------------------------------------------------------------
/docs/architecutre_github.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cscribano/CERBERUS/HEAD/docs/architecutre_github.png
--------------------------------------------------------------------------------
/dataset/utils/__init__.py:
--------------------------------------------------------------------------------
1 | from .process_lanes import LaneProcessor
2 | from .process_detection import DetProcessor
3 |
--------------------------------------------------------------------------------
/models/backbones/__init__.py:
--------------------------------------------------------------------------------
1 | from models.backbones.resnet import *
2 | from models.backbones.efficientnet import *
3 |
--------------------------------------------------------------------------------
/dataset/__init__.py:
--------------------------------------------------------------------------------
1 | from dataset.multitask_dataset import MultitaskDataset
2 | from dataset.collate import ignore_collate
3 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | python-dateutil>=2.7.3
2 | pytz==2021.1
3 | click==8.1.2
4 | pytorch_lightning==1.6.2
5 | opencv-contrib-python==4.1.2.30
6 | numpy==1.21.0
7 | albumentations==1.1.0
8 | onnx==1.11.0
9 | onnxsim==0.4.8.0
10 | scipy==1.7.2
11 | pycuda==2021.1
12 | cupy-cuda111==10.5.0
13 | numba==0.55.1
14 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | ### Pycharm stuffs
2 | .idea/
3 | *__pycache__/
4 |
5 | ### Pytorch model weights
6 | *.pth
7 | *.pt
8 | *.onnx
9 | ./weights
10 |
11 | ### logs
12 | /log/*
13 |
14 | ### onnx
15 | /weights/*
16 |
17 | ## python
18 | .ipynb_checkpoints
19 |
20 | ### images
21 | *.jpg
22 | *.jpeg
23 | *.png
24 | *.tif
25 | *.tiff
26 | *.avi
27 | *.mp4
28 |
29 | # misc
30 | /experimental/*
31 | /scripts/*
32 |
--------------------------------------------------------------------------------
/docs/deps.sh:
--------------------------------------------------------------------------------
1 | sudo apt-get install -y libhdf5-serial-dev hdf5-tools libcanberra-gtk-module
2 | sudo -H pip3 install Cython
3 | sudo pip3 -H install numpy==1.19
4 |
5 | # SciPy and Sklearn
6 | sudo apt-get install -y libatlas-base-dev gfortran
7 | sudo apt-get install -y libpcap-dev libpq-dev
8 | sudo -H pip3 install scikit-learn
9 |
10 | # Numba
11 | sudo apt-get install -y llvm-8 llvm-8-dev
12 | sudo -H LLVM_CONFIG=/usr/bin/llvm-config-8 pip3 install numba==0.48
13 |
14 | # CuPy
15 | echo "Installing CuPy, this may take a while..."
16 | sudo -H CUPY_NVCC_GENERATE_CODE="current" CUPY_NUM_BUILD_JOBS=$(nproc) pip3 install cupy==9.2
17 |
18 | # end
19 | echo " ===================================="
20 | echo " | REBOOT IS REQUIRED |"
21 | echo " ===================================="
22 |
--------------------------------------------------------------------------------
/inference/profiler.py:
--------------------------------------------------------------------------------
1 | import time
2 | from collections import Counter
3 |
4 |
5 | class Profiler:
6 | __call_count = Counter()
7 | __time_elapsed = Counter()
8 | warmup = 0
9 |
10 | def __init__(self, name, aggregate=False):
11 | self.name = name
12 | if not aggregate and Profiler.warmup == 0:
13 | Profiler.__call_count[self.name] += 1
14 |
15 | def __enter__(self):
16 | self.start = time.perf_counter()
17 | return self
18 |
19 | def __exit__(self, type, value, traceback):
20 | self.end = time.perf_counter()
21 | self.duration = self.end - self.start
22 | if Profiler.warmup == 0:
23 | Profiler.__time_elapsed[self.name] += self.duration
24 | else:
25 | Profiler.warmup -= 1
26 |
27 | @classmethod
28 | def set_warmup(cls, warmup):
29 | cls.warmup = warmup
30 |
31 | @classmethod
32 | def reset(cls):
33 | cls.__call_count.clear()
34 | cls.__time_elapsed.clear()
35 |
36 | @classmethod
37 | def get_avg_millis(cls, name):
38 | call_count = cls.__call_count[name]
39 | if call_count == 0:
40 | return 0.
41 | return cls.__time_elapsed[name] * 1000 / call_count
42 |
--------------------------------------------------------------------------------
/dataset/utils/cls.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | LANE_CLS = {
5 | 'single yellow': 0,
6 | 'single white': 1,
7 | 'crosswalk': 2,
8 | 'double white': 3,
9 | 'double other': 4,
10 | 'road curb': 5,
11 | 'single other': 6,
12 | 'double yellow': 7
13 | }
14 |
15 | DET_CLS = {
16 | 'pedestrian' : 0,
17 | 'rider' : 1,
18 | 'car' : 2,
19 | 'truck' : 3,
20 | 'bus' : 4,
21 | 'train' : 5,
22 | 'motorcycle' : 6,
23 | 'bicycle' : 7,
24 | 'traffic light' : 8,
25 | 'traffic sign' : 9,
26 | 'other vehicle': 10,
27 | 'other person': 11,
28 | 'trailer': 12
29 | }
30 |
31 | OCL_VEHICLES = [2, 3, 4, 6] #<- not used!
32 |
33 | """
34 | - weather: "rainy|snowy|clear|overcast|undefined|partly cloudy|foggy"
35 | - scene: "tunnel|residential|parking lot|undefined|city street|gas stations|highway|"
36 | - timeofday: "daytime|night|dawn/dusk|undefined"
37 |
38 | """
39 |
40 | WTR_CLS = {
41 | "rainy": 0,
42 | "snowy": 1,
43 | "clear": 2,
44 | "overcast": 3,
45 | "partly cloudy": 4,
46 | "foggy": 5,
47 | "undefined": 6
48 | }
49 |
50 | SN_CLS = {
51 | "tunnel": 0,
52 | "residential": 1,
53 | "parking lot": 2,
54 | "city street": 3,
55 | "gas stations": 4,
56 | "highway": 5,
57 | "undefined": 6
58 | }
59 |
60 | TD_CLS = {
61 | "daytime": 0,
62 | "night": 1,
63 | "dawn/dusk": 2,
64 | "undefined": 3
65 | }
66 |
--------------------------------------------------------------------------------
/inference/trt_inference/cls.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | LANE_CLS = {
5 | 'single yellow': 0,
6 | 'single white': 1,
7 | 'crosswalk': 2,
8 | 'double white': 3,
9 | 'double other': 4,
10 | 'road curb': 5,
11 | 'single other': 6,
12 | 'double yellow': 7
13 | }
14 |
15 | DET_CLS = {
16 | 'pedestrian' : 0,
17 | 'rider' : 1,
18 | 'car' : 2,
19 | 'truck' : 3,
20 | 'bus' : 4,
21 | 'train' : 5,
22 | 'motorcycle' : 6,
23 | 'bicycle' : 7,
24 | 'traffic light' : 8,
25 | 'traffic sign' : 9,
26 | 'other vehicle': 10,
27 | 'other person': 11,
28 | 'trailer': 12
29 | }
30 |
31 | DET_CLS_IND = list(DET_CLS.keys())
32 | OCL_VEHICLES = [2, 3, 4, 6]
33 |
34 | """
35 | - weather: "rainy|snowy|clear|overcast|undefined|partly cloudy|foggy"
36 | - scene: "tunnel|residential|parking lot|undefined|city street|gas stations|highway|"
37 | - timeofday: "daytime|night|dawn/dusk|undefined"
38 |
39 | """
40 |
41 | WTR_CLS = {
42 | "rainy": 0,
43 | "snowy": 1,
44 | "clear": 2,
45 | "overcast": 3,
46 | "partly cloudy": 4,
47 | "foggy": 5,
48 | "undefined": 6
49 | }
50 |
51 | SN_CLS = {
52 | "tunnel": 0,
53 | "residential": 1,
54 | "parking lot": 2,
55 | "city street": 3,
56 | "gas stations": 4,
57 | "highway": 5,
58 | "undefined": 6
59 | }
60 |
61 | TD_CLS = {
62 | "daytime": 0,
63 | "night": 1,
64 | "dawn/dusk": 2,
65 | "undefined": 3
66 | }
67 |
--------------------------------------------------------------------------------
/utils/decoding.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | from typing import List, Tuple
5 | import torch
6 |
7 | class PseudoNMS(torch.nn.Module):
8 | def __init__(self, nms_kernels):
9 | # type: (List[Tuple[int, int]]) -> None
10 |
11 | super().__init__()
12 |
13 | pooling = []
14 | for k in nms_kernels:
15 | padding = ((k[0] - 1) // 2, (k[1] - 1) // 2)
16 | pool = torch.nn.MaxPool2d(kernel_size=k, stride=1, padding=padding)
17 | pooling.append(pool)
18 |
19 | self.pooling = torch.nn.ModuleList(pooling)
20 |
21 | def forward(self, heatmap):
22 |
23 | masks = []
24 | for pool in self.pooling:
25 | nms_mask = pool(heatmap)
26 | nms_mask = (nms_mask == heatmap)
27 | masks.append(nms_mask)
28 |
29 | for mask in masks:
30 | heatmap = heatmap * mask
31 |
32 | return heatmap
33 |
34 |
35 | def kp_from_heatmap(heatmap, th, nms_kernel=3, pseudo_nms=True):
36 |
37 | # 1. pseudo-nms via max pool
38 | if pseudo_nms:
39 | padding = (nms_kernel - 1) // 2
40 | mask = torch.nn.functional.max_pool2d(heatmap, kernel_size=nms_kernel, stride=1, padding=padding) == heatmap
41 | heatmap = heatmap * mask
42 |
43 | # Get best candidate at each heatmap location, since box regression is shared
44 | heatmap, labels = torch.max(heatmap, dim=1)
45 |
46 | # Flatten and get values
47 | indices = torch.nonzero(heatmap.gt(th), as_tuple=False).flip(1)
48 | scores = heatmap[0, indices[:, 1], indices[:, 0]]
49 | labels = labels[0, indices[:, 1], indices[:, 0]]
50 |
51 | return scores, indices, labels
52 |
--------------------------------------------------------------------------------
/models/losses/multitask_loss.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import torch
5 | from torch import nn
6 | from models.losses.task_losses import ObjectsLoss, LanesLoss, ClsLoss
7 | from models.losses.heatmap_loss import *
8 |
9 | from conf import Conf
10 |
11 | class MultiTaskLoss(nn.Module):
12 |
13 | def __init__(self, cnf):
14 | # type: (Conf) -> ()
15 |
16 | super().__init__()
17 | self.cnf = cnf
18 |
19 | # Configuration
20 | self.lane_det = cnf.base.get("lane_det", True)
21 | self.obj_det = cnf.base.get("object_det", True)
22 | self.scene_cls = cnf.base.get("scene_cls", False)
23 |
24 | # Task specific losses
25 | self.lanes_loss = LanesLoss(cnf)
26 | self.objects_loss = ObjectsLoss(cnf)
27 | self.cls_loss = ClsLoss(cnf)
28 |
29 | def forward(self, preds, targets):
30 | # type: (dict[torch.tensor, ...], dict[torch.tensor, ...]) -> torch.tensor
31 |
32 | l_loss, d_loss, scn_loss = 0.0, 0.0, 0.0
33 | l_detail, d_detail, s_detail = {}, {}, {}
34 |
35 | #lane_pred, det_pred, scn_pred = preds
36 |
37 | # Lane estimation loss (only heatmaps)
38 | if self.lane_det:
39 | lane_true = targets["lane_det"]
40 | lane_pred = preds["lane_det"]
41 | l_loss, l_detail = self.lanes_loss(lane_pred, lane_true)
42 |
43 | # Object detection loss (only heatmaps)
44 | if self.obj_det:
45 | det_true = targets["obj_det"]
46 | det_pred = preds["obj_det"]
47 | d_loss, d_detail = self.objects_loss(det_pred, det_true)
48 |
49 | # Scene classification loss
50 | if self.scene_cls:
51 | scn_true = targets["scn_cls"]
52 | scn_pred = preds["scn_cls"]
53 | scn_loss, s_detail = self.cls_loss(scn_pred, scn_true)
54 |
55 | loss_detail = {k : v for d in (d_detail, l_detail, s_detail) for k,v in d.items()}
56 |
57 | return l_loss + d_loss + scn_loss, loss_detail
58 |
--------------------------------------------------------------------------------
/data/heatmap_utils.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import torch
5 |
6 | def kps_to_heatmaps(annotation, w, h, sigma):
7 |
8 | heatmaps_list = []
9 |
10 | for cls_keypoints in annotation:
11 |
12 | # generate heatmap from list of (x, y, z) coordinates
13 | # retrieve one (W,H) heatmap for each keypoint
14 | if len(cls_keypoints) != 0:
15 | # Normalize coordinates
16 | # cls_keypoints = torch.tensor(cls_keypoints) / torch.tensor([IMG_HEIGHT, IMG_WIDTH])
17 |
18 | # Generate heatmap
19 | kern = make_gkern_2d(h, w, sigma)
20 | heatmaps = torch.stack([kern(x) for x in cls_keypoints], dim=0)
21 | else:
22 | heatmaps = torch.zeros(1, h, w)
23 |
24 | # Combine individual heatmaps in a single tensor
25 | heatmap = torch.max(heatmaps, dim=0)[0]
26 | heatmaps_list.append(heatmap)
27 |
28 | # Combine keypoints heatmaps in a single tensor
29 | total_heatmap = torch.stack(heatmaps_list, 0)
30 |
31 | return total_heatmap
32 |
33 | def make_gkern_2d(h, w, s, device='cpu'):
34 | def gk(head):
35 | return gkern_2d(h, w, head, s, device=device)
36 |
37 | return gk
38 |
39 | def gkern_2d(h, w, center, s, device='cuda'):
40 | # type: (int, int, Tuple[int, int], float, str) -> torch.Tensor
41 | """
42 | :param h: heatmap image height
43 | :param w: heatmap image width
44 | :param center: Gaussian center (x,y,z)
45 | :param s: Gaussian sigma
46 | :param device: 'cuda' or 'cpu' -> device used do compute heatmaps
47 | :return: Torch tensor with shape (h, w, d) with A Gaussian centered in `center`
48 | """
49 |
50 | x = torch.arange(0, w, 1).type('torch.FloatTensor').to(device)
51 | y = torch.arange(0, h, 1).type('torch.FloatTensor').to(device)
52 |
53 | y = y.unsqueeze(1)
54 |
55 | x0 = center[0] * w
56 | y0 = center[1] * h
57 |
58 | return torch.exp(-1 * ((x - x0) ** 2 + (y - y0) ** 2) / s ** 2)
59 |
--------------------------------------------------------------------------------
/main.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import torch
5 | import logging
6 | from conf import Conf
7 |
8 | import click
9 | import torch.backends.cudnn as cudnn
10 |
11 | from trainer import trainer_run
12 |
13 | torch.backends.cudnn.deterministic = True
14 | torch.backends.cudnn.benchmark = False
15 |
16 | @click.command()
17 | @click.option('--exp_name', type=str, default=None)
18 | @click.option('--conf_file_path', type=str, default=None)
19 | @click.option('--seed', type=int, default=None)
20 | def main(exp_name, conf_file_path, seed):
21 | # type: (str, str, int) -> None
22 |
23 | assert torch.backends.cudnn.enabled, "Running without cuDNN is discouraged"
24 |
25 | # if `exp_name` is None,
26 | # ask the user to enter it
27 | if exp_name is None:
28 | exp_name = input('>> experiment name: ')
29 |
30 | # if `exp_name` contains '!',
31 | # `log_each_step` becomes `False`
32 | log_each_step = True
33 | if '!' in exp_name:
34 | exp_name = exp_name.replace('!', '')
35 | log_each_step = False
36 |
37 | # if `exp_name` contains a '@' character,
38 | # the number following '@' is considered as
39 | # the desired random seed for the experiment
40 | split = exp_name.split('@')
41 | if len(split) == 2:
42 | seed = int(split[1])
43 | exp_name = split[0]
44 |
45 | cnf = Conf(conf_file_path=conf_file_path, seed=seed,
46 | exp_name=exp_name, log_each_step=log_each_step)
47 | print(f'\n▶ Starting Experiment \'{exp_name}\' [seed: {cnf.seed}]')
48 |
49 | # Setup logging
50 | logging.basicConfig(
51 | format='[%(asctime)s] [p%(process)s] [%(pathname)s:%(lineno)d] [%(levelname)s] %(message)s',
52 | level=logging.INFO,
53 | )
54 |
55 | cnf_attrs = vars(cnf)
56 | for k in cnf_attrs:
57 | s = f'{k} : {cnf_attrs[k]}'
58 | logging.info(s)
59 |
60 | # Run training
61 | trainer_run(cnf)
62 |
63 | if __name__ == '__main__':
64 | main()
65 |
--------------------------------------------------------------------------------
/data/lane_heatmaps.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import cv2
5 | import click
6 | from pathlib import Path
7 |
8 | from math import ceil
9 | import numpy as np
10 | import torch
11 |
12 | from heatmap_utils import kps_to_heatmaps
13 |
14 | IMG_WIDTH = 1280
15 | IMG_HEIGHT = 720
16 |
17 | I_SCALE = 2
18 | O_SCALE = 4
19 |
20 | PPK = 25 # Number of pixels per keypoint
21 |
22 | CLS = {
23 | 'single yellow': 0,
24 | 'single white': 1,
25 | 'crosswalk': 2,
26 | 'double white': 3,
27 | 'double other': 4,
28 | 'road curb': 5,
29 | 'single other': 6,
30 | 'double yellow': 7
31 | }
32 |
33 | @click.command()
34 | @click.option('--img_root', '-i', type=click.Path(exists=True), default=None, required=False)
35 | def main(img_root):
36 | # type: (Path) -> None
37 |
38 | split = "val"
39 |
40 | # Load Images
41 | img_root = Path(img_root) / split
42 | images = {p.name: p for p in img_root.glob("*.jpg")}
43 | # Load annotation file
44 | annot_file = Path(f"{split}_{PPK}.pt")
45 | annotations = torch.load(annot_file)
46 |
47 | # List lane classes
48 | classes = set([l['category'] for a in annotations for l in a.get('labels', [])])
49 | print(classes)
50 |
51 | w = ceil(IMG_WIDTH / O_SCALE)
52 | h = ceil(IMG_HEIGHT / O_SCALE)
53 |
54 |
55 | for lanes in annotations:
56 | lbc = [[] for _ in range(8)]
57 |
58 | labels = lanes.get("labels", [])
59 | for l in labels:
60 | cls_id = CLS[l['category']]
61 | lbc[cls_id] += l["keypoints"]
62 |
63 | # Load image
64 | image_file = img_root / images[lanes["name"]]
65 | frame = cv2.imread(str(image_file))
66 |
67 | # Numpy
68 | lane_np = np.concatenate([np.array(l['keypoints']) for l in labels]).astype(np.int32)
69 | for c in lane_np:
70 | frame = cv2.circle(frame, (c[0], c[1]), 3, (0, 255, 0), thickness=3)
71 |
72 | # Generate heatmaps
73 | n = torch.tensor([IMG_WIDTH, IMG_HEIGHT])
74 | lbc = [torch.tensor(l) / n if len(l) > 0 else torch.tensor(l) for l in lbc]
75 | heatmaps = kps_to_heatmaps(lbc, w, h, sigma=2)
76 |
77 | # Display
78 | hm_show, _ = torch.max(heatmaps, dim=0)
79 | hm_show = hm_show.numpy() * 255
80 | hm_show = hm_show.astype(np.uint8)
81 | hm_show = cv2.applyColorMap(hm_show, cv2.COLORMAP_JET)
82 |
83 |
84 |
85 | cv2.imshow("heatmap", hm_show)
86 | cv2.imshow("frame", frame)
87 | while cv2.waitKey(1) != ord('q'):
88 | pass
89 |
90 |
91 | if __name__ == '__main__':
92 | main()
93 |
--------------------------------------------------------------------------------
/conf/experiments/resnet101_bifpn.json:
--------------------------------------------------------------------------------
1 | {
2 | "experiment" : {
3 | "epochs": 75,
4 | "device": "cuda",
5 | "ck_epoch_step": 1,
6 | "val_epoch_step": 1,
7 | "logdir": "/data/logs"
8 | },
9 |
10 | "base": {
11 | "lane_det": true,
12 | "object_det": true,
13 | "scene_cls": true,
14 | "lane_classes": 8,
15 | "det_classes": 10,
16 |
17 | "scn_classes": {
18 | "weather": 7,
19 | "scene": 7,
20 | "timeofday": 4
21 | }
22 | },
23 |
24 | "model": {
25 | "backbone": {
26 | "name": "resnet101",
27 | "args": {
28 | "pretrained": true
29 | }
30 | },
31 | "neck": {
32 | "name": "BiFPNNeck",
33 | "args": {}
34 | },
35 | "head_channel": 64,
36 | "bn_momentum": 0.1
37 | },
38 |
39 | "optimizer": {
40 | "name": "Adam",
41 | "args": {
42 | "lr": 2.5e-4
43 | }
44 | },
45 |
46 | "lr_scheduler": {
47 | "name": "WarmupMultiStepLR",
48 | "args": {
49 | "milestones": [100000, 200000],
50 | "gamma": 0.5,
51 | "warmup_iters": 3500
52 | }
53 | },
54 |
55 | "loss": {
56 | "heatmap_loss": {
57 | "name": "WMSELoss",
58 | "args": {}
59 | },
60 | "scn_loss": {
61 | "name": "nn.CrossEntropyLoss",
62 | "args": {}
63 | }
64 | },
65 |
66 |
67 | "dataset" : {
68 | "images_root": "/data/BDD100K/bdd100k_images/bdd100k_images/images/100k",
69 |
70 | "input_w": 640,
71 | "input_h": 320,
72 | "output_stride": 4,
73 |
74 | "lane_det": {
75 | "data_root": "/data/BDD100K",
76 | "ppm": 25,
77 | "sigma": {
78 | "name": "CornerNetRadius",
79 | "args": {}
80 | }
81 | },
82 | "obj_det": {
83 | "data_root": "/data/BDD100K/bdd100k_det/labels/det_20"
84 | },
85 |
86 | "train_dataset": {
87 | "name": "MultitaskDataset",
88 | "args": {
89 | "mode": "train"
90 | },
91 | "loader_args": {
92 | "shuffle": true,
93 | "batch_size": 32,
94 | "num_workers": 6
95 | }
96 | },
97 |
98 | "val_dataset": {
99 | "name": "MultitaskDataset",
100 | "args": {
101 | "mode": "val"
102 | },
103 | "loader_args": {
104 | "shuffle": false,
105 | "batch_size": 16,
106 | "num_workers": 4
107 | }
108 | }
109 | }
110 | }
111 |
--------------------------------------------------------------------------------
/conf/experiments/resnet34_bifpn.json:
--------------------------------------------------------------------------------
1 | {
2 | "experiment" : {
3 | "epochs": 75,
4 | "device": "cuda",
5 | "ck_epoch_step": 1,
6 | "val_epoch_step": 1,
7 | "logdir": "/data/logs"
8 | },
9 |
10 | "base": {
11 | "lane_det": true,
12 | "object_det": true,
13 | "scene_cls": true,
14 | "lane_classes": 8,
15 | "det_classes": 10,
16 |
17 | "scn_classes": {
18 | "weather": 7,
19 | "scene": 7,
20 | "timeofday": 4
21 | }
22 | },
23 |
24 | "model": {
25 | "backbone": {
26 | "name": "resnet34",
27 | "args": {
28 | "pretrained": true
29 | }
30 | },
31 | "neck": {
32 | "name": "BiFPNNeck",
33 | "args": {}
34 | },
35 | "head_channel": 64,
36 | "bn_momentum": 0.1
37 | },
38 |
39 | "optimizer": {
40 | "name": "Adam",
41 | "args": {
42 | "lr": 2.5e-4
43 | }
44 | },
45 |
46 | "lr_scheduler": {
47 | "name": "WarmupMultiStepLR",
48 | "args": {
49 | "milestones": [100000, 200000],
50 | "gamma": 0.5,
51 | "warmup_iters": 3500
52 | }
53 | },
54 |
55 | "loss": {
56 | "heatmap_loss": {
57 | "name": "WMSELoss",
58 | "args": {}
59 | },
60 | "scn_loss": {
61 | "name": "nn.CrossEntropyLoss",
62 | "args": {}
63 | }
64 | },
65 |
66 |
67 | "dataset" : {
68 | "images_root": "/data/BDD100K/bdd100k_images/bdd100k_images/images/100k",
69 |
70 | "input_w": 640,
71 | "input_h": 320,
72 | "output_stride": 4,
73 |
74 | "lane_det": {
75 | "data_root": "/data/BDD100K",
76 | "ppm": 25,
77 | "sigma": {
78 | "name": "CornerNetRadius",
79 | "args": {}
80 | }
81 | },
82 | "obj_det": {
83 | "data_root": "/data/BDD100K/bdd100k_det/labels/det_20"
84 | },
85 |
86 | "train_dataset": {
87 | "name": "MultitaskDataset",
88 | "args": {
89 | "mode": "train"
90 | },
91 | "loader_args": {
92 | "shuffle": true,
93 | "batch_size": 32,
94 | "num_workers": 6
95 | }
96 | },
97 |
98 | "val_dataset": {
99 | "name": "MultitaskDataset",
100 | "args": {
101 | "mode": "val"
102 | },
103 | "loader_args": {
104 | "shuffle": false,
105 | "batch_size": 16,
106 | "num_workers": 4
107 | }
108 | }
109 | }
110 | }
111 |
--------------------------------------------------------------------------------
/conf/experiments/resnet50_bifpn.json:
--------------------------------------------------------------------------------
1 | {
2 | "experiment" : {
3 | "epochs": 75,
4 | "device": "cuda",
5 | "ck_epoch_step": 1,
6 | "val_epoch_step": 1,
7 | "logdir": "/data/logs"
8 | },
9 |
10 | "base": {
11 | "lane_det": true,
12 | "object_det": true,
13 | "scene_cls": true,
14 | "lane_classes": 8,
15 | "det_classes": 10,
16 |
17 | "scn_classes": {
18 | "weather": 7,
19 | "scene": 7,
20 | "timeofday": 4
21 | }
22 | },
23 |
24 | "model": {
25 | "backbone": {
26 | "name": "resnet50",
27 | "args": {
28 | "pretrained": true
29 | }
30 | },
31 | "neck": {
32 | "name": "BiFPNNeck",
33 | "args": {}
34 | },
35 | "head_channel": 64,
36 | "bn_momentum": 0.1
37 | },
38 |
39 | "optimizer": {
40 | "name": "Adam",
41 | "args": {
42 | "lr": 2.5e-4
43 | }
44 | },
45 |
46 | "lr_scheduler": {
47 | "name": "WarmupMultiStepLR",
48 | "args": {
49 | "milestones": [100000, 200000],
50 | "gamma": 0.5,
51 | "warmup_iters": 3500
52 | }
53 | },
54 |
55 | "loss": {
56 | "heatmap_loss": {
57 | "name": "WMSELoss",
58 | "args": {}
59 | },
60 | "scn_loss": {
61 | "name": "nn.CrossEntropyLoss",
62 | "args": {}
63 | }
64 | },
65 |
66 |
67 | "dataset" : {
68 | "images_root": "/data/BDD100K/bdd100k_images/bdd100k_images/images/100k",
69 |
70 | "input_w": 640,
71 | "input_h": 320,
72 | "output_stride": 4,
73 |
74 | "lane_det": {
75 | "data_root": "/data/BDD100K",
76 | "ppm": 25,
77 | "sigma": {
78 | "name": "CornerNetRadius",
79 | "args": {}
80 | }
81 | },
82 | "obj_det": {
83 | "data_root": "/data/BDD100K/bdd100k_det/labels/det_20"
84 | },
85 |
86 | "train_dataset": {
87 | "name": "MultitaskDataset",
88 | "args": {
89 | "mode": "train"
90 | },
91 | "loader_args": {
92 | "shuffle": true,
93 | "batch_size": 32,
94 | "num_workers": 6
95 | }
96 | },
97 |
98 | "val_dataset": {
99 | "name": "MultitaskDataset",
100 | "args": {
101 | "mode": "val"
102 | },
103 | "loader_args": {
104 | "shuffle": false,
105 | "batch_size": 16,
106 | "num_workers": 4
107 | }
108 | }
109 | }
110 | }
111 |
--------------------------------------------------------------------------------
/conf/experiments/mobilenetv2_bifpn.json:
--------------------------------------------------------------------------------
1 | {
2 | "experiment" : {
3 | "epochs": 75,
4 | "device": "cuda",
5 | "ck_epoch_step": 1,
6 | "val_epoch_step": 1,
7 | "logdir": "/data/logs"
8 | },
9 |
10 | "base": {
11 | "lane_det": true,
12 | "object_det": true,
13 | "scene_cls": true,
14 | "lane_classes": 8,
15 | "det_classes": 10,
16 |
17 | "scn_classes": {
18 | "weather": 7,
19 | "scene": 7,
20 | "timeofday": 4
21 | }
22 | },
23 |
24 | "model": {
25 | "backbone": {
26 | "name": "mobilenet_v2",
27 | "args": {
28 | "pretrained": true
29 | }
30 | },
31 | "neck": {
32 | "name": "BiFPNNeck",
33 | "args": {}
34 | },
35 | "head_channel": 64,
36 | "bn_momentum": 0.1
37 | },
38 |
39 | "optimizer": {
40 | "name": "Adam",
41 | "args": {
42 | "lr": 2.5e-4
43 | }
44 | },
45 |
46 | "lr_scheduler": {
47 | "name": "WarmupMultiStepLR",
48 | "args": {
49 | "milestones": [100000, 200000],
50 | "gamma": 0.5,
51 | "warmup_iters": 3500
52 | }
53 | },
54 |
55 | "loss": {
56 | "heatmap_loss": {
57 | "name": "WMSELoss",
58 | "args": {}
59 | },
60 | "scn_loss": {
61 | "name": "nn.CrossEntropyLoss",
62 | "args": {}
63 | }
64 | },
65 |
66 |
67 | "dataset" : {
68 | "images_root": "/data/BDD100K/bdd100k_images/bdd100k_images/images/100k",
69 |
70 | "input_w": 640,
71 | "input_h": 320,
72 | "output_stride": 4,
73 |
74 | "lane_det": {
75 | "data_root": "/data/BDD100K",
76 | "ppm": 25,
77 | "sigma": {
78 | "name": "CornerNetRadius",
79 | "args": {}
80 | }
81 | },
82 | "obj_det": {
83 | "data_root": "/data/BDD100K/bdd100k_det/labels/det_20"
84 | },
85 |
86 | "train_dataset": {
87 | "name": "MultitaskDataset",
88 | "args": {
89 | "mode": "train"
90 | },
91 | "loader_args": {
92 | "shuffle": true,
93 | "batch_size": 32,
94 | "num_workers": 6
95 | }
96 | },
97 |
98 | "val_dataset": {
99 | "name": "MultitaskDataset",
100 | "args": {
101 | "mode": "val"
102 | },
103 | "loader_args": {
104 | "shuffle": false,
105 | "batch_size": 16,
106 | "num_workers": 4
107 | }
108 | }
109 | }
110 | }
111 |
--------------------------------------------------------------------------------
/conf/experiments/efficientnetb2_bifpn.json:
--------------------------------------------------------------------------------
1 | {
2 | "experiment" : {
3 | "epochs": 75,
4 | "device": "cuda",
5 | "ck_epoch_step": 1,
6 | "val_epoch_step": 1,
7 | "logdir": "/data/logs"
8 | },
9 |
10 | "base": {
11 | "lane_det": true,
12 | "object_det": true,
13 | "scene_cls": true,
14 | "lane_classes": 8,
15 | "det_classes": 10,
16 |
17 | "scn_classes": {
18 | "weather": 7,
19 | "scene": 7,
20 | "timeofday": 4
21 | }
22 | },
23 |
24 | "model": {
25 | "backbone": {
26 | "name": "efficientnet_b2",
27 | "args": {
28 | "pretrained": true
29 | }
30 | },
31 | "neck": {
32 | "name": "BiFPNNeck",
33 | "args": {}
34 | },
35 | "head_channel": 64,
36 | "bn_momentum": 0.1
37 | },
38 |
39 | "optimizer": {
40 | "name": "Adam",
41 | "args": {
42 | "lr": 2.5e-4
43 | }
44 | },
45 |
46 | "lr_scheduler": {
47 | "name": "WarmupMultiStepLR",
48 | "args": {
49 | "milestones": [100000, 200000],
50 | "gamma": 0.5,
51 | "warmup_iters": 3500
52 | }
53 | },
54 |
55 | "loss": {
56 | "heatmap_loss": {
57 | "name": "WMSELoss",
58 | "args": {}
59 | },
60 | "scn_loss": {
61 | "name": "nn.CrossEntropyLoss",
62 | "args": {}
63 | }
64 | },
65 |
66 |
67 | "dataset" : {
68 | "images_root": "/data/BDD100K/bdd100k_images/bdd100k_images/images/100k",
69 |
70 | "input_w": 640,
71 | "input_h": 320,
72 | "output_stride": 4,
73 |
74 | "lane_det": {
75 | "data_root": "/data/BDD100K",
76 | "ppm": 25,
77 | "sigma": {
78 | "name": "CornerNetRadius",
79 | "args": {}
80 | }
81 | },
82 | "obj_det": {
83 | "data_root": "/data/BDD100K/bdd100k_det/labels/det_20"
84 | },
85 |
86 | "train_dataset": {
87 | "name": "MultitaskDataset",
88 | "args": {
89 | "mode": "train"
90 | },
91 | "loader_args": {
92 | "shuffle": true,
93 | "batch_size": 32,
94 | "num_workers": 6
95 | }
96 | },
97 |
98 | "val_dataset": {
99 | "name": "MultitaskDataset",
100 | "args": {
101 | "mode": "val"
102 | },
103 | "loader_args": {
104 | "shuffle": false,
105 | "batch_size": 16,
106 | "num_workers": 4
107 | }
108 | }
109 | }
110 | }
111 |
--------------------------------------------------------------------------------
/conf/experiments/resnet34_simple.json:
--------------------------------------------------------------------------------
1 | {
2 | "experiment" : {
3 | "epochs": 75,
4 | "device": "cuda",
5 | "ck_epoch_step": 1,
6 | "val_epoch_step": 1,
7 | "logdir": "/data/logs"
8 | },
9 |
10 | "base": {
11 | "lane_det": true,
12 | "object_det": true,
13 | "scene_cls": true,
14 | "lane_classes": 8,
15 | "det_classes": 10,
16 |
17 | "scn_classes": {
18 | "weather": 7,
19 | "scene": 7,
20 | "timeofday": 4
21 | }
22 | },
23 |
24 | "model": {
25 | "backbone": {
26 | "name": "resnet34",
27 | "args": {
28 | "pretrained": true
29 | }
30 | },
31 | "neck": {
32 | "name": "SimpleNeck",
33 | "args": {
34 | "upsample_channels": [256, 256, 256]
35 | }
36 | },
37 | "head_channel": 64,
38 | "bn_momentum": 0.1
39 | },
40 |
41 | "optimizer": {
42 | "name": "Adam",
43 | "args": {
44 | "lr": 2.5e-4
45 | }
46 | },
47 |
48 | "lr_scheduler": {
49 | "name": "WarmupMultiStepLR",
50 | "args": {
51 | "milestones": [100000, 200000],
52 | "gamma": 0.5,
53 | "warmup_iters": 3500
54 | }
55 | },
56 |
57 | "loss": {
58 | "heatmap_loss": {
59 | "name": "WMSELoss",
60 | "args": {}
61 | },
62 | "scn_loss": {
63 | "name": "nn.CrossEntropyLoss",
64 | "args": {}
65 | }
66 | },
67 |
68 |
69 | "dataset" : {
70 | "images_root": "/data/BDD100K/bdd100k_images/bdd100k_images/images/100k",
71 |
72 | "input_w": 640,
73 | "input_h": 320,
74 | "output_stride": 4,
75 |
76 | "lane_det": {
77 | "data_root": "/data/BDD100K",
78 | "ppm": 25,
79 | "sigma": {
80 | "name": "CornerNetRadius",
81 | "args": {}
82 | }
83 | },
84 | "obj_det": {
85 | "data_root": "/data/BDD100K/bdd100k_det/labels/det_20"
86 | },
87 |
88 | "train_dataset": {
89 | "name": "MultitaskDataset",
90 | "args": {
91 | "mode": "train"
92 | },
93 | "loader_args": {
94 | "shuffle": true,
95 | "batch_size": 32,
96 | "num_workers": 6
97 | }
98 | },
99 |
100 | "val_dataset": {
101 | "name": "MultitaskDataset",
102 | "args": {
103 | "mode": "val"
104 | },
105 | "loader_args": {
106 | "shuffle": false,
107 | "batch_size": 16,
108 | "num_workers": 4
109 | }
110 | }
111 | }
112 | }
113 |
--------------------------------------------------------------------------------
/dataset/utils/transforms.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 | from abc import ABCMeta
4 |
5 | from albumentations import Compose, KeypointParams, BboxParams, \
6 | RandomBrightnessContrast, GaussNoise, RGBShift, CLAHE,\
7 | RandomGamma, HorizontalFlip, Resize, Normalize, CenterCrop, RandomCrop, ShiftScaleRotate
8 | from albumentations.pytorch.transforms import ToTensorV2
9 |
10 | class BaseTransform(object, metaclass=ABCMeta):
11 | def __init__(self, w, h, input_w, input_h):
12 |
13 | # Find resize dimension (before crop)
14 | ws = w // input_w
15 | hs = h // input_h
16 | s = min(ws, hs)
17 | self.rw, self.rh = int(w // s), int(h // s)
18 |
19 | self.tsfm = ...
20 |
21 | def __call__(self, img, keypoints=None, kp_labels=None, kp_ids = None, bboxes=None, bb_labels=None, bb_occl=None):
22 | if keypoints is None:
23 | keypoints = []
24 | kp_labels = []
25 | kp_ids = []
26 | if bboxes is None:
27 | bboxes = []
28 | bb_labels = []
29 | bb_occl = []
30 |
31 | augmented = self.tsfm(image=img, keypoints=keypoints, kp_labels=kp_labels,
32 | kp_ids=kp_ids, bboxes=bboxes, bb_labels=bb_labels, bb_occl=bb_occl)
33 | img, kp, kp_l, kp_i, bb, bb_l, bb_o = augmented['image'], augmented['keypoints'], augmented['kp_labels'],\
34 | augmented['kp_ids'], augmented['bboxes'], augmented['bb_labels'], augmented['bb_occl']
35 | return img, kp, kp_l, kp_i, bb, bb_l, bb_o
36 |
37 | class RandomAspect(BaseTransform):
38 | def __init__(self, w, h, input_w, input_h):
39 | super().__init__(w, h, input_w, input_h)
40 |
41 | self.tsfm = Compose([
42 | Resize(self.rh, self.rw),
43 | ShiftScaleRotate(),
44 | # CenterCrop(320, 640),
45 | RandomCrop(320, 640),
46 | HorizontalFlip(),
47 | RandomBrightnessContrast(0.4, 0.4),
48 | GaussNoise(),
49 | RGBShift(),
50 | CLAHE(),
51 | RandomGamma(),
52 | Normalize(),
53 | ToTensorV2()
54 | ], keypoint_params=KeypointParams(format='xy', label_fields=['kp_labels', 'kp_ids']),
55 | bbox_params=BboxParams(format='pascal_voc', label_fields=['bb_labels', 'bb_occl']))
56 |
57 |
58 | class Preproc(BaseTransform):
59 | def __init__(self, w, h, input_w, input_h):
60 | super().__init__(w, h, input_w, input_h)
61 |
62 | self.tsfm = Compose([
63 | Resize(self.rh, self.rw),
64 | CenterCrop(320, 640),
65 | Normalize(),
66 | ToTensorV2()
67 | ], keypoint_params=KeypointParams(format='xy', label_fields=['kp_labels', 'kp_ids']),
68 | bbox_params=BboxParams(format='pascal_voc', label_fields=['bb_labels', 'bb_occl']))
69 |
70 |
--------------------------------------------------------------------------------
/utils/lr_scheduler.py:
--------------------------------------------------------------------------------
1 | import math
2 | from bisect import bisect_right
3 | from torch.optim.lr_scheduler import _LRScheduler
4 |
5 | __all__ = ['WarmupMultiStepLR', 'WarmupCosineLR']
6 |
7 | class WarmupMultiStepLR(_LRScheduler):
8 | def __init__(
9 | self,
10 | optimizer,
11 | milestones,
12 | gamma=0.1,
13 | warmup_factor=0.001,
14 | warmup_iters=1000,
15 | warmup_method="linear",
16 | last_epoch=-1,
17 | ):
18 | if not list(milestones) == sorted(milestones):
19 | raise ValueError(
20 | "Milestones should be a list of" " increasing integers. Got {}",
21 | milestones,
22 | )
23 | self.milestones = milestones
24 | self.gamma = gamma
25 | self.warmup_factor = warmup_factor
26 | self.warmup_iters = warmup_iters
27 | self.warmup_method = warmup_method
28 | super().__init__(optimizer, last_epoch)
29 |
30 | def get_lr(self):
31 | warmup_factor = _get_warmup_factor_at_iter(
32 | self.warmup_method, self.last_epoch, self.warmup_iters, self.warmup_factor
33 | )
34 | return [
35 | base_lr * warmup_factor
36 | * self.gamma ** bisect_right(self.milestones, self.last_epoch)
37 | for base_lr in self.base_lrs
38 | ]
39 |
40 | def _compute_values(self):
41 | return self.get_lr()
42 |
43 |
44 | class WarmupCosineLR(_LRScheduler):
45 | def __init__(
46 | self,
47 | optimizer,
48 | max_iters,
49 | warmup_factor=0.001,
50 | warmup_iters=1000,
51 | warmup_method="linear",
52 | last_epoch=-1,
53 | ):
54 | self.max_iters = max_iters
55 | self.warmup_factor = warmup_factor
56 | self.warmup_iters = warmup_iters
57 | self.warmup_method = warmup_method
58 | super().__init__(optimizer, last_epoch)
59 |
60 | def get_lr(self):
61 | warmup_factor = _get_warmup_factor_at_iter(
62 | self.warmup_method, self.last_epoch, self.warmup_iters, self.warmup_factor
63 | )
64 |
65 | return [
66 | base_lr * warmup_factor * 0.5
67 | * (1.0 + math.cos(math.pi * self.last_epoch / self.max_iters))
68 | for base_lr in self.base_lrs
69 | ]
70 |
71 | def _compute_values(self):
72 | return self.get_lr()
73 |
74 |
75 | def _get_warmup_factor_at_iter(method, iter, warmup_iters, warmup_factor):
76 | if iter >= warmup_iters:
77 | return 1.0
78 |
79 | if method == "constant":
80 | return warmup_factor
81 | elif method == "linear":
82 | alpha = iter / warmup_iters
83 | return warmup_factor * (1 - alpha) + alpha
84 | elif method == "burnin":
85 | return (iter / warmup_iters) ** 4
86 | else:
87 | raise ValueError("Unknown warmup method: {}".format(method))
88 |
--------------------------------------------------------------------------------
/utils/box_utils.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | from __future__ import division
5 | import scipy.optimize
6 | import numpy as np
7 |
8 |
9 | def bbox_iou(boxA, boxB):
10 | # https://www.pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/
11 | # ^^ corrected.
12 |
13 | # Determine the (x, y)-coordinates of the intersection rectangle
14 | xA = max(boxA[0], boxB[0])
15 | yA = max(boxA[1], boxB[1])
16 | xB = min(boxA[2], boxB[2])
17 | yB = min(boxA[3], boxB[3])
18 |
19 | interW = xB - xA + 1
20 | interH = yB - yA + 1
21 |
22 | # Correction: reject non-overlapping boxes
23 | if interW <= 0 or interH <= 0:
24 | return -1.0
25 |
26 | interArea = interW * interH
27 | boxAArea = (boxA[2] - boxA[0] + 1) * (boxA[3] - boxA[1] + 1)
28 | boxBArea = (boxB[2] - boxB[0] + 1) * (boxB[3] - boxB[1] + 1)
29 | iou = interArea / float(boxAArea + boxBArea - interArea)
30 | return iou
31 |
32 |
33 | def match_bboxes(bbox_gt, bbox_pred, IOU_THRESH=0.5):
34 | '''
35 | Given sets of true and predicted bounding-boxes,
36 | determine the best possible match.
37 |
38 | Parameters
39 | ----------
40 | bbox_gt, bbox_pred : N1x4 and N2x4 np array of bboxes [x1,y1,x2,y2].
41 | The number of bboxes, N1 and N2, need not be the same.
42 |
43 | Returns
44 | -------
45 | (idxs_true, idxs_pred, ious, labels)
46 | idxs_true, idxs_pred : indices into gt and pred for matches
47 | ious : corresponding IOU value of each match
48 | labels: vector of 0/1 values for the list of detections
49 | '''
50 | n_true = bbox_gt.shape[0]
51 | n_pred = bbox_pred.shape[0]
52 | MAX_DIST = 1.0
53 | MIN_IOU = 0.0
54 |
55 | # NUM_GT x NUM_PRED
56 | iou_matrix = np.zeros((n_true, n_pred))
57 | for i in range(n_true):
58 | for j in range(n_pred):
59 | iou_matrix[i, j] = bbox_iou(bbox_gt[i, :], bbox_pred[j, :])
60 |
61 | if n_pred > n_true:
62 | # there are more predictions than ground-truth - add dummy rows
63 | diff = n_pred - n_true
64 | iou_matrix = np.concatenate((iou_matrix,
65 | np.full((diff, n_pred), MIN_IOU)),
66 | axis=0)
67 |
68 | if n_true > n_pred:
69 | # more ground-truth than predictions - add dummy columns
70 | diff = n_true - n_pred
71 | iou_matrix = np.concatenate((iou_matrix,
72 | np.full((n_true, diff), MIN_IOU)),
73 | axis=1)
74 |
75 | # call the Hungarian matching
76 | idxs_true, idxs_pred = scipy.optimize.linear_sum_assignment(1 - iou_matrix)
77 |
78 | if (not idxs_true.size) or (not idxs_pred.size):
79 | ious = np.array([])
80 | else:
81 | ious = iou_matrix[idxs_true, idxs_pred]
82 |
83 | # remove dummy assignments
84 | sel_pred = idxs_pred < n_pred
85 | idx_pred_actual = idxs_pred[sel_pred]
86 | idx_gt_actual = idxs_true[sel_pred]
87 | ious_actual = iou_matrix[idx_gt_actual, idx_pred_actual]
88 | sel_valid = (ious_actual > IOU_THRESH)
89 | label = sel_valid.astype(int)
90 |
91 | return idx_gt_actual[sel_valid], idx_pred_actual[sel_valid], ious_actual[sel_valid], label
92 |
93 |
--------------------------------------------------------------------------------
/models/heads.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import torch
5 | from torch import nn
6 | from abc import ABCMeta, abstractmethod
7 |
8 | from utils.decoding import PseudoNMS
9 | from .layers import make_conv, ConvReluConv
10 |
11 | class BaseHead(nn.Module, metaclass=ABCMeta):
12 |
13 | def __init__(self):
14 | # type: () -> None
15 | super().__init__()
16 |
17 | def forward(self, x, decode):
18 | # type: (torch.Tensor, bool) -> dict[str, torch.Tensor, ...]
19 | ...
20 |
21 | class ObjectHead(BaseHead):
22 |
23 | def __init__(self, num_classes=80, in_channels=256, conv_channels=64):
24 |
25 | super(ObjectHead, self).__init__()
26 | self.cls_head = ConvReluConv(in_channels, conv_channels, num_classes, bias_fill=True, bias_value=-4.6)
27 | self.ofs_out = ConvReluConv(in_channels, in_channels, 4)
28 | self.occl = ConvReluConv(in_channels, in_channels, 1)
29 |
30 | self.nms = PseudoNMS(nms_kernels=[(3, 3)])
31 |
32 | def forward(self, x, nms=False):
33 | hm = self.cls_head(x).sigmoid()
34 | wh = self.ofs_out(x)
35 | oc = self.occl(x)
36 |
37 | if nms:
38 | hm = self.nms(hm)
39 |
40 | ret = {
41 | "heatmaps": hm,
42 | "offsets": wh,
43 | "occlusion": oc
44 | }
45 |
46 | return ret
47 |
48 | class LaneHead(BaseHead):
49 |
50 | def __init__(self, num_classes=80, in_channels=256, quant_offsets=False, conv_channels=64):
51 | super(LaneHead, self).__init__()
52 | self.cls_head = ConvReluConv(in_channels, conv_channels, num_classes, bias_fill=True, bias_value=-4.6)
53 | self.emb_out = ConvReluConv(in_channels, in_channels, 2, bias_fill=True, bias_value=0.1)
54 |
55 | # Dequantizzation offsets
56 | self.quant_offsets = quant_offsets
57 | if quant_offsets:
58 | self.quant_out = ConvReluConv(in_channels, in_channels, 2, bias_fill=True, bias_value=0.1)
59 |
60 | self.nms = PseudoNMS(nms_kernels=[(1, 3), (3, 1)])
61 |
62 | def forward(self, x, nms=False):
63 | hm = self.cls_head(x).sigmoid()
64 | emb = self.emb_out(x)
65 |
66 | if nms:
67 | hm = self.nms(hm)
68 |
69 | ret = {
70 | "heatmaps": hm,
71 | "offsets": emb,
72 | }
73 |
74 | if self.quant_offsets:
75 | quant = self.quant_out(x)
76 | ret["quant"] = quant
77 |
78 | return ret
79 |
80 | class ScnHead(BaseHead):
81 | def __init__(self, classes, in_channels):
82 | super(ScnHead, self).__init__()
83 |
84 | self.cls_splits = classes
85 |
86 | self.c1 = make_conv(in_channels, 64)
87 | self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
88 | self.fc = nn.Linear(64, sum(classes))
89 |
90 | def forward(self, x, argmax=False):
91 | x = self.c1(x)
92 | x = self.avgpool(x)
93 | x = torch.flatten(x, 1)
94 | x = self.fc(x)
95 |
96 | w_pred, s_pred, t_pred = torch.split(x, self.cls_splits, 1)
97 |
98 | if argmax:
99 | w_pred = w_pred.argmax(-1)
100 | s_pred = s_pred.argmax(-1)
101 | t_pred = t_pred.argmax(-1)
102 |
103 | ret = {
104 | "weather": w_pred,
105 | "scene": s_pred,
106 | "timeofday": t_pred
107 | }
108 |
109 | return ret
110 |
--------------------------------------------------------------------------------
/inference/postproc.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import numpy as np
5 | from sklearn.metrics import mean_squared_error
6 | from sklearn.cluster import AgglomerativeClustering
7 | from sklearn.linear_model import RANSACRegressor
8 |
9 | import warnings
10 | warnings.simplefilter('ignore', np.RankWarning)
11 |
12 | def get_clusters(X, y):
13 | s = np.argsort(y)
14 | return np.split(X[s], np.unique(y[s], return_index=True)[1][1:])
15 |
16 | class PolynomialRegression(object):
17 | def __init__(self, degree=2, coeffs=None):
18 | self.degree = degree
19 | self.coeffs = coeffs
20 |
21 | def fit(self, X, y):
22 | self.coeffs = np.polyfit(X.ravel(), y, self.degree)
23 |
24 | def get_params(self, deep=False):
25 | return {'coeffs': self.coeffs}
26 |
27 | def set_params(self, coeffs=None, random_state=None):
28 | self.coeffs = coeffs
29 |
30 | def predict(self, X):
31 | poly_eqn = np.poly1d(self.coeffs)
32 | y_hat = poly_eqn(X.ravel())
33 | return y_hat
34 |
35 | def score(self, X, y):
36 | return mean_squared_error(y, self.predict(X))
37 |
38 | def cluster_lane_preds(lanes, lanes_cls, lanes_votes):
39 | lane_clusters = [[] for _ in range(8)]
40 | for lc in range(8):
41 | current_cls = lanes_cls.eq(lc).nonzero()
42 | lind = lanes[current_cls, :2].squeeze()
43 | votes = lanes_votes[:, current_cls].squeeze()
44 |
45 | if lind.shape[0] == 0 or len(lind.shape) != 2:
46 | continue
47 |
48 | votes = (votes.T + lind).cpu().numpy()
49 | clusters = AgglomerativeClustering(n_clusters=None,
50 | distance_threshold=8.0 * 4, linkage='ward').fit_predict(votes)
51 |
52 | clusters = get_clusters(lind.cpu().numpy(), clusters)
53 | lane_clusters[lc] += clusters
54 |
55 | return lane_clusters
56 |
57 | def fast_clustering(lanes, lanes_cls, lanes_votes):
58 | lane_clusters = [[] for _ in range(8)]
59 | for lc in range(8):
60 | current_cls = (lanes_cls == lc).nonzero()
61 | lind = lanes[current_cls, :2].squeeze()
62 | votes = lanes_votes[:, current_cls].squeeze()
63 |
64 | if lind.shape[0] == 0 or len(lind.shape) != 2:
65 | continue
66 |
67 | votes = (votes.T + lind) # .cpu().numpy()
68 | clusters = AgglomerativeClustering(n_clusters=None,
69 | distance_threshold=8.0 * 4, linkage='ward').fit_predict(votes)
70 |
71 | clusters = get_clusters(lind, clusters)
72 | lane_clusters[lc] += clusters
73 | return lane_clusters
74 |
75 | def fit_lanes(lane_clusters):
76 |
77 | lanes_fitted = {i : [] for i in range(len(lane_clusters))}
78 |
79 | for cla, cls_clusters in enumerate(lane_clusters):
80 | for cl in cls_clusters:
81 |
82 | if cl.shape[0] < 5:
83 | continue
84 |
85 | x = cl[:, 0]
86 | y = cl[:, 1]
87 |
88 | ransac = RANSACRegressor(PolynomialRegression(degree=3),
89 | residual_threshold=0.5 * np.std(x),
90 | random_state=0)
91 |
92 | # calculate polynomial
93 | try:
94 | ransac.fit(np.expand_dims(x, axis=1), y)
95 | except ValueError:
96 | continue
97 |
98 | # calculate new x's and y's
99 | x_new = np.linspace(min(x), max(x), len(x))
100 | y_new = ransac.predict(np.expand_dims(x_new, axis=1))
101 |
102 | newlane = np.stack([x_new, y_new], axis=-1)
103 | lanes_fitted[cla].append(newlane)
104 |
105 | return lanes_fitted
106 |
--------------------------------------------------------------------------------
/dataset/utils/heatmaps.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import numpy as np
5 | import torch
6 |
7 | class FixedRadius:
8 | def __init__(self, r: float = 1.):
9 | self.r = r
10 |
11 | def __call__(self, w, h):
12 | return self.r#, self.r
13 |
14 | class CornerNetRadius:
15 | def __init__(self, min_overlap: float = 0.7):
16 | self.min_overlap = min_overlap
17 |
18 | # Explanation: https://github.com/princeton-vl/CornerNet/issues/110
19 | # Source: https://github.com/princeton-vl/CornerNet/blob/master/sample/utils.py
20 | def __call__(self, width, height):
21 | a1 = 1
22 | b1 = (height + width)
23 | c1 = width * height * (1 - self.min_overlap) / (1 + self.min_overlap)
24 | sq1 = np.sqrt(b1 ** 2 - 4 * a1 * c1)
25 | r1 = (b1 + sq1) / 2
26 |
27 | a2 = 4
28 | b2 = 2 * (height + width)
29 | c2 = (1 - self.min_overlap) * width * height
30 | sq2 = np.sqrt(b2 ** 2 - 4 * a2 * c2)
31 | r2 = (b2 + sq2) / 2
32 |
33 | a3 = 4 * self.min_overlap
34 | b3 = -2 * self.min_overlap * (height + width)
35 | c3 = (self.min_overlap - 1) * width * height
36 | sq3 = np.sqrt(b3 ** 2 - 4 * a3 * c3)
37 | r3 = (b3 + sq3) / 2
38 | return max(min(r1, r2, r3) / 6, 2)
39 |
40 | def kps_to_heatmaps(annotation, w, h, sigma=None):
41 |
42 | heatmaps_list = []
43 |
44 | for cls_keypoints in annotation:
45 |
46 | # generate heatmap from list of (x, y, z) coordinates
47 | # retrieve one (W,H) heatmap for each keypoint
48 | if len(cls_keypoints) != 0:
49 | # Normalize coordinates
50 | # cls_keypoints = torch.tensor(cls_keypoints) / torch.tensor([IMG_HEIGHT, IMG_WIDTH])
51 |
52 | # Generate heatmap
53 | if sigma is None:
54 | assert cls_keypoints.shape[-1] == 3
55 | kern = make_gkern_2d(h, w, None)
56 | heatmaps = torch.stack([kern(x, s) for x, s in zip(cls_keypoints[..., :2],
57 | cls_keypoints[..., -1])], dim=0)
58 | else:
59 | assert cls_keypoints.shape[-1] == 2
60 | kern = make_gkern_2d(h, w, sigma)
61 | heatmaps = torch.stack([kern(x) for x in cls_keypoints], dim=0)
62 | else:
63 | heatmaps = torch.zeros(1, h, w)
64 |
65 | # Combine individual heatmaps in a single tensor
66 | heatmap = torch.max(heatmaps, dim=0)[0]
67 | heatmaps_list.append(heatmap)
68 |
69 | # Combine keypoints heatmaps in a single tensor
70 | total_heatmap = torch.stack(heatmaps_list, 0)
71 |
72 | return total_heatmap
73 |
74 | def make_gkern_2d(h, w, s=None, device='cpu'):
75 | if s is None:
76 | def gk(x, s):
77 | return gkern_2d(h, w, x, s, device=device)
78 | else:
79 | def gk(x):
80 | return gkern_2d(h, w, x, s, device=device)
81 |
82 | return gk
83 |
84 | def gkern_2d(h, w, center, s, device='cuda'):
85 | # type: (int, int, Tuple[int, int], float, str) -> torch.Tensor
86 | """
87 | :param h: heatmap image height
88 | :param w: heatmap image width
89 | :param center: Gaussian center (x,y,z)
90 | :param s: Gaussian sigma
91 | :param device: 'cuda' or 'cpu' -> device used do compute heatmaps
92 | :return: Torch tensor with shape (h, w, d) with A Gaussian centered in `center`
93 | """
94 |
95 | x = torch.arange(0, w, 1).type('torch.FloatTensor').to(device)
96 | y = torch.arange(0, h, 1).type('torch.FloatTensor').to(device)
97 |
98 | y = y.unsqueeze(1)
99 |
100 | x0 = center[0] # * w
101 | y0 = center[1] # * h
102 |
103 | g = torch.exp(-1 * ((x - x0) ** 2 + (y - y0) ** 2) / s ** 2)
104 |
105 | return g
106 |
--------------------------------------------------------------------------------
/dataset/collate.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import abc
5 | import torch
6 | import re
7 | import collections
8 | from torch._six import string_classes
9 |
10 | np_str_obj_array_pattern = re.compile(r'[SaUO]')
11 |
12 | default_collate_err_msg_format = (
13 | "default_collate: batch must contain tensors, numpy arrays, numbers, "
14 | "dicts or lists; found {}")
15 |
16 | def ignore_collate(ignore_keys):
17 |
18 | def collate_fn(batch):
19 | return _default_collate(batch, ignore_keys)
20 | return collate_fn
21 |
22 | def _default_collate(batch, ignore_keys):
23 | elem = batch[0]
24 | elem_type = type(elem)
25 | if isinstance(elem, torch.Tensor):
26 | out = None
27 | if torch.utils.data.get_worker_info() is not None:
28 | # If we're in a background process, concatenate directly into a
29 | # shared memory tensor to avoid an extra copy
30 | numel = sum(x.numel() for x in batch)
31 | storage = elem.storage()._new_shared(numel)
32 | out = elem.new(storage).resize_(len(batch), *list(elem.size()))
33 | return torch.stack(batch, 0, out=out)
34 | elif elem_type.__module__ == 'numpy' and elem_type.__name__ != 'str_' \
35 | and elem_type.__name__ != 'string_':
36 | if elem_type.__name__ == 'ndarray' or elem_type.__name__ == 'memmap':
37 | # array of string classes and object
38 | if np_str_obj_array_pattern.search(elem.dtype.str) is not None:
39 | raise TypeError(default_collate_err_msg_format.format(elem.dtype))
40 |
41 | return _default_collate([torch.as_tensor(b) for b in batch], ignore_keys)
42 | elif elem.shape == (): # scalars
43 | return torch.as_tensor(batch)
44 | elif isinstance(elem, float):
45 | return torch.tensor(batch, dtype=torch.float64)
46 | elif isinstance(elem, int):
47 | return torch.tensor(batch)
48 | elif isinstance(elem, string_classes):
49 | return batch
50 | elif isinstance(elem, collections.abc.Mapping):
51 | try:
52 | return elem_type({key: _default_collate([d[key] for d in batch], ignore_keys)
53 | if key not in ignore_keys else [d[key] for d in batch] for key in elem})
54 | except TypeError:
55 | # The mapping type may not support `__init__(iterable)`.
56 | return {key: _default_collate([d[key] for d in batch], ignore_keys) for key in elem}
57 | elif isinstance(elem, tuple) and hasattr(elem, '_fields'): # namedtuple
58 | return elem_type(*(_default_collate(samples, ignore_keys) for samples in zip(*batch)))
59 | elif isinstance(elem, collections.abc.Sequence):
60 | # check to make sure that the elements in batch have consistent size
61 | it = iter(batch)
62 | elem_size = len(next(it))
63 | if not all(len(elem) == elem_size for elem in it):
64 | raise RuntimeError('each element in list of batch should be of equal size')
65 | transposed = list(zip(*batch)) # It may be accessed twice, so we use a list.
66 |
67 | if isinstance(elem, tuple):
68 | return [_default_collate(samples, ignore_keys) for samples in transposed] # Backwards compatibility.
69 | else:
70 | try:
71 | return elem_type([_default_collate(samples, ignore_keys) for samples in transposed])
72 | except TypeError:
73 | # The sequence type may not support `__init__(iterable)` (e.g., `range`).
74 | return [_default_collate(samples, ignore_keys) for samples in transposed]
75 |
76 | raise TypeError(default_collate_err_msg_format.format(elem_type))
77 |
--------------------------------------------------------------------------------
/dataset/utils/process_detection.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import torch
5 | import numpy as np
6 |
7 | from .heatmaps import kps_to_heatmaps
8 | from .heatmaps import CornerNetRadius, FixedRadius
9 | from .cls import DET_CLS, WTR_CLS, TD_CLS, SN_CLS
10 |
11 |
12 | class DetProcessor:
13 |
14 | def __init__(self, classes, output_s, target_w, target_h):
15 | # type: (int, int, int, int) -> None
16 | """
17 | :param classes: Number of lane classes
18 | :param output_s: Output stride wrt input shape
19 | :param target_w: output width (output_s * input width)
20 | :param target_h: output height (output_s * input height)
21 | """
22 |
23 | self.classes = classes
24 | self.output_s = output_s
25 | self.target_w = target_w
26 | self.target_h = target_h
27 |
28 | self.sigma = CornerNetRadius()
29 |
30 | def bounding_boxes(self, annot):
31 | # Preprocess label (boxes)
32 | labels = annot.get("labels", None)
33 | if labels is not None:
34 | boxes = torch.stack([torch.tensor([*l['box2d'].values()]) for l in labels]) # x1,y1,x2,y2
35 | classes = [DET_CLS[l['category']] for l in labels]
36 | occlusion = [l['attributes']['occluded'] for l in labels]
37 |
38 | # Remove 'other vehicle'
39 | io = [i for i, v in enumerate(classes) if v >= 10]
40 | boxes = [k for i, k in enumerate(boxes) if i not in io]
41 | classes = [c for i, c in enumerate(classes) if i not in io]
42 | occlusion = [o for i, o in enumerate(occlusion) if i not in io]
43 |
44 | else:
45 | boxes = []
46 | classes = []
47 | occlusion = []
48 |
49 | return labels, boxes, classes, occlusion
50 |
51 | def scene_classification(self, annot):
52 | attrs = annot.get("attributes", None)
53 | cls = {}
54 |
55 | if attrs is not None:
56 | cls["weather"] = WTR_CLS[attrs["weather"]]
57 | cls["scene"] = SN_CLS[attrs["scene"]]
58 | cls["timeofday"] = TD_CLS[attrs["timeofday"]]
59 |
60 | return cls
61 |
62 | def targets(self, labels, bboxes, classes):
63 | if labels is not None and len(bboxes) > 0:
64 |
65 | # Obtain box centers in output space
66 | boxes_pt = torch.tensor(bboxes) / self.output_s
67 | boxes_cwh = self.xyxy2cxcywh(boxes_pt)
68 | radii = torch.tensor([self.sigma(w, h) for w, h in boxes_cwh[..., 2:] * self.output_s])
69 |
70 | # Clip and round
71 | centers = boxes_cwh[:, :2]
72 | centers[:, 0] = torch.clip(centers[:, 0], 0, self.target_w - 1)
73 | centers[:, 1] = torch.clip(centers[:, 1], 0, self.target_h - 1)
74 | centers = torch.round(centers)
75 |
76 | assert centers[:, 0].max() < self.target_w and centers[:, 1].max() < self.target_h # <-- shit here
77 | assert centers[:, 0].min() >= 0 and centers[:, 1].min() >= 0
78 |
79 | # Compute target heatmaps
80 | kp_cls = [[] for _ in range(self.classes)]
81 | for ic, c in enumerate(classes):
82 | kp_cls[c].append(torch.cat([centers[ic], radii[ic].unsqueeze(0)])) # cx, cy, sigma
83 |
84 | kp_cls = [torch.stack(t) if len(t) > 0 else torch.tensor([]) for t in kp_cls]
85 |
86 | # Generate target (Heatmap)
87 | heatmap = kps_to_heatmaps(kp_cls, self.target_w, self.target_h, sigma=None)
88 |
89 | # Compute target offsets
90 | ofs_x = boxes_pt[..., 0::2] - centers[..., 0].unsqueeze(-1)
91 | ofs_y = boxes_pt[..., 1::2] - centers[..., 1].unsqueeze(-1)
92 | ofs = torch.cat([ofs_x, ofs_y], dim=-1) # (x1-cx, x2-cx), (y1-cy, y2-cy)
93 |
94 | else:
95 | heatmap = torch.zeros((self.classes, self.target_h, self.target_w), dtype=torch.float32)
96 | centers = torch.zeros((0, 2), dtype=torch.int)
97 | ofs = torch.zeros((0, 4), dtype=torch.float32)
98 |
99 | return heatmap, centers, ofs
100 |
101 | @staticmethod
102 | def xyxy2cxcywh(boxes):
103 | w = (boxes[:, 2] - boxes[:, 0])
104 | h = (boxes[:, 3] - boxes[:, 1])
105 | cx = boxes[:, 0] + w / 2
106 | cy = boxes[:, 1] + h / 2
107 |
108 | return torch.stack([cx, cy, w, h], dim=1)
109 |
--------------------------------------------------------------------------------
/data/tools.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import numpy as np
5 |
6 | from scipy.special import comb
7 | from scipy.spatial.distance import cdist
8 | from scipy.optimize import linear_sum_assignment
9 |
10 | def bernstein_poly(i, n, t):
11 | """
12 | The Bernstein polynomial of n, i as a function of t
13 | """
14 |
15 | return comb(n, i) * ( t**(n-i) ) * (1 - t)**i
16 |
17 |
18 | def bezier_curve(points, nTimes=1000):
19 | """
20 | Given a set of control points, return the
21 | bezier curve defined by the control points.
22 |
23 | points should be a list of lists, or list of tuples
24 | such as [ [1,1],
25 | [2,3],
26 | [4,5], ..[Xn, Yn] ]
27 | nTimes is the number of time steps, defaults to 1000
28 |
29 | See http://processingjs.nihongoresources.com/bezierinfo/
30 | """
31 |
32 | nPoints = len(points)
33 | xPoints = np.array([p[0] for p in points])
34 | yPoints = np.array([p[1] for p in points])
35 |
36 | t = np.linspace(0.0, 1.0, nTimes)
37 |
38 | polynomial_array = np.array([ bernstein_poly(i, nPoints-1, t) for i in range(0, nPoints) ])
39 |
40 | xvals = np.dot(xPoints, polynomial_array)
41 | yvals = np.dot(yPoints, polynomial_array)
42 |
43 | return xvals, yvals
44 |
45 | def get_bezier_parameters(X, Y, degree=3):
46 | """ Least square qbezier fit using penrose pseudoinverse.
47 |
48 | Parameters:
49 |
50 | X: array of x data.
51 | Y: array of y data. Y[0] is the y point for X[0].
52 | degree: degree of the Bézier curve. 2 for quadratic, 3 for cubic.
53 |
54 | Based on https://stackoverflow.com/questions/12643079/b%C3%A9zier-curve-fitting-with-scipy
55 | and probably on the 1998 thesis by Tim Andrew Pastva, "Bézier Curve Fitting".
56 | """
57 | if degree < 1:
58 | raise ValueError('degree must be 1 or greater.')
59 |
60 | if len(X) != len(Y):
61 | raise ValueError('X and Y must be of the same length.')
62 |
63 | if len(X) < degree + 1:
64 | raise ValueError(f'There must be at least {degree + 1} points to '
65 | f'determine the parameters of a degree {degree} curve. '
66 | f'Got only {len(X)} points.')
67 |
68 | def bpoly(n, t, k):
69 | """ Bernstein polynomial when a = 0 and b = 1. """
70 | return t ** k * (1 - t) ** (n - k) * comb(n, k)
71 |
72 | # return comb(n, i) * ( t**(n-i) ) * (1 - t)**i
73 |
74 | def bmatrix(T):
75 | """ Bernstein matrix for Bézier curves. """
76 | return np.matrix([[bpoly(degree, t, k) for k in range(degree + 1)] for t in T])
77 |
78 | def least_square_fit(points, M):
79 | M_ = np.linalg.pinv(M)
80 | return M_ * points
81 |
82 | T = np.linspace(0, 1, len(X))
83 | M = bmatrix(T)
84 | points = np.array(list(zip(X, Y)))
85 |
86 | final = least_square_fit(points, M).tolist()
87 | final[0] = [X[0], Y[0]]
88 | final[len(final) - 1] = [X[len(X) - 1], Y[len(Y) - 1]]
89 | return final
90 |
91 |
92 | def compare_labels(l1, l2):
93 |
94 | pt1 = l1["keypoints"]
95 | pt2 = l2["keypoints"]
96 |
97 | l = max(len(pt1), len(pt2))
98 | assert l >= 3
99 |
100 | if len(pt1) == l:
101 | pts = l2["poly2d"][0]['vertices']
102 | xvals, yvals = bezier_curve(pts, nTimes=l)
103 | pt2 = np.stack([xvals, yvals], axis=-1)
104 | else:
105 | pts = l1["poly2d"][0]['vertices']
106 | xvals, yvals = bezier_curve(pts, nTimes=l)
107 | pt1 = np.stack([xvals, yvals], axis=-1)
108 |
109 | pt1, pt2 = np.array(pt1), np.array(pt2)
110 | closest = cdist(pt1, pt2).argmin(0)
111 |
112 | return pt1, pt2[closest]
113 |
114 | def dist(k1, k2):
115 |
116 | if k1 is None or k2 is None:
117 | return 1e5
118 |
119 | if k1['id'] == k2['id']:
120 | return 1e5
121 |
122 | c1 = (k1['attributes']['laneDirection'] == k1['attributes']['laneDirection'] == 'parallel')
123 | c2 = k1['category'] == k2['category']
124 | c3 =True #"double" not in k1['category']
125 |
126 | if not (c1 and c2 and c3):
127 | return 1e5
128 |
129 | pt1, pt2 = compare_labels(k1, k2)
130 | dist = np.linalg.norm(pt1 - pt2, axis=-1).mean()
131 |
132 | return dist
133 |
--------------------------------------------------------------------------------
/dataset/utils/process_lanes.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 | import torch
4 | import numpy as np
5 |
6 | from dataset.utils.heatmaps import kps_to_heatmaps
7 | from dataset.utils.cls import LANE_CLS
8 |
9 | class LaneProcessor:
10 |
11 | def __init__(self, classes, output_s, target_w, target_h):
12 | # type: (int, int, int, int) -> None
13 | """
14 | :param classes: Number of lane classes
15 | :param output_s: Output stride wrt input shape
16 | :param target_w: output width (output_s * input width)
17 | :param target_h: output height (output_s * input height)
18 | """
19 |
20 | self.classes = classes
21 | self.output_s = output_s
22 | self.target_w = target_w
23 | self.target_h = target_h
24 |
25 | def keypoints(self, annot):
26 | # type: (dict) -> (list, list, list, list)
27 | """
28 | :param annot:
29 | :return:
30 | """
31 |
32 | labels = annot.get("labels", None)
33 | if labels is not None:
34 | labels = [l for l in labels if l is not None]
35 | if len(labels) == 0:
36 | return labels, [], [], []
37 |
38 | keypoints = torch.cat([torch.tensor(l['keypoints']) for l in labels])
39 | assert len(keypoints.shape) == 2 and keypoints.shape[0] >= 1
40 |
41 | lenghts = [len(l['keypoints']) for l in labels]
42 | cls = [LANE_CLS[l['category']] for i, l in enumerate(labels) for _ in range(lenghts[i])]
43 | ids = [int(l['id']) for i, l in enumerate(labels) for _ in range(lenghts[i])]
44 |
45 | # Remove non visible keypoints
46 | visible = torch.stack([keypoints[:, 0].ceil() < 1280, keypoints[:, 1].ceil() < 720,
47 | keypoints[:, 0].floor() >= 0, keypoints[:, 1].floor() >= 0])
48 | assert len(visible.shape) == 2 and visible.shape[0] >= 1
49 | visible = visible.min(dim=0)[0]
50 |
51 | keypoints = keypoints[visible.nonzero().squeeze(1)].tolist()
52 | classes = [cls[c] for c in visible.nonzero().squeeze(1)]
53 | ids = [ids[c] for c in visible.nonzero().squeeze(1)]
54 |
55 | return labels, keypoints, classes, ids
56 |
57 | return labels, [], [], []
58 |
59 | def targets(self, labels, keypoints, classes, ids):
60 |
61 | if labels is not None and len(keypoints) > 0:
62 |
63 | all_ids = set(ids)
64 |
65 | # Clip and round
66 | keypoints = torch.tensor(keypoints) / self.output_s
67 | centers = keypoints.clone()
68 |
69 | centers[:, 0] = torch.clip(centers[:, 0], 0, self.target_w - 1)
70 | centers[:, 1] = torch.clip(centers[:, 1], 0, self.target_h - 1)
71 | centers = torch.round(
72 | centers)
73 |
74 | assert centers[:, 0].max() < self.target_w and centers[:, 1].max() < self.target_h
75 | assert centers[:, 0].min() >= 0 and centers[:, 1].min() >= 0
76 |
77 | # Generate target (Heatmap)
78 | kp_cls = [[] for _ in range(self.classes)]
79 | for ic, c in enumerate(classes):
80 | # kp_cls[c].append(centers[ic]) #<--- to enable rounding
81 | kp_cls[c].append(keypoints[ic])
82 |
83 | kp_cls = [torch.stack(t) if len(t) > 0 else torch.tensor([]) for t in kp_cls]
84 | heatmap = kps_to_heatmaps(kp_cls, self.target_w, self.target_h, sigma=2)
85 |
86 | # Generate dequantizzation offsets
87 | quant_offsets = (keypoints - centers).to(torch.float32)
88 |
89 | # Group keypoints belonging to the same lane
90 | lane_ids = torch.tensor(ids)
91 | lanes_kp = [keypoints[lane_ids.eq(i).nonzero().squeeze(1)] for i in all_ids]
92 | centers = [centers[lane_ids.eq(i).nonzero().squeeze(1)] for i in all_ids]
93 | quant_offsets = [quant_offsets[lane_ids.eq(i).nonzero().squeeze(1)] for i in all_ids]
94 |
95 | # Generate offsets to lane center
96 | l_offsets = [b[len(b) // 2] - b for b in centers]
97 |
98 | # Flatten
99 | centers = torch.cat(centers)
100 | center_offsets = torch.cat(l_offsets)
101 | quant_offsets = torch.cat(quant_offsets)
102 |
103 | else:
104 | heatmap = torch.zeros((self.classes, self.target_h, self.target_w), dtype=torch.float32)
105 | centers = torch.zeros((0, 2), dtype=torch.int)
106 | lanes_kp = torch.zeros((0, 2), dtype=torch.float32)
107 | center_offsets = torch.zeros((0, 2), dtype=torch.float32)
108 | quant_offsets = torch.zeros((0, 2), dtype=torch.float32)
109 |
110 | return heatmap, centers, center_offsets, quant_offsets, lanes_kp
111 |
--------------------------------------------------------------------------------
/models/losses/task_losses.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import torch
5 | from torch import nn
6 | import torch.nn.functional as F
7 | from models.losses.heatmap_loss import *
8 |
9 | from conf import Conf
10 |
11 | class LanesLoss(nn.Module):
12 |
13 | def __init__(self, cnf):
14 | # type: (Conf) -> ()
15 |
16 | super().__init__()
17 | self.cnf = cnf
18 | self.q_offsets = cnf.base.get("lane_q_offsets", False)
19 |
20 | heatmap_loss = self.cnf.loss.heatmap_loss.get("name", "nn.MSELoss")
21 | self.heatmap_loss = eval(heatmap_loss)(**self.cnf.loss.heatmap_loss.args)
22 | self.offset_loss = nn.L1Loss()
23 |
24 | def forward(self, preds, targets):
25 | # type: (dict[torch.tensor, ...], dict[torch.tensor, ...]) -> torch.tensor
26 |
27 | hm_true, kp_true, ofs_true, q_ofs = targets["heatmaps"], targets["keypoints"], \
28 | targets["offsets"], targets["quant_offsets"]
29 |
30 | hm_pred, ofs_pred = preds["heatmaps"], preds["offsets"]
31 |
32 | # Heatmap
33 | hm_loss = self.heatmap_loss(hm_pred, hm_true)
34 |
35 | # Embeddings
36 | b_idx = torch.tensor([i for i, b in enumerate(kp_true) for _ in range(b.shape[0])])
37 | kp_true = torch.cat(kp_true).long()
38 |
39 | embs_pred = ofs_pred[b_idx, :, kp_true[:, 1], kp_true[:, 0]]
40 | embs_true = torch.cat(ofs_true)
41 |
42 | embd_loss = self.offset_loss(embs_pred, embs_true) * 0.8 # 0.4
43 |
44 | # Dequantizzation offsets
45 | quant_loss = torch.tensor(0, device=hm_true.device)
46 | if self.q_offsets:
47 | q_pred = targets["quant"]
48 | q_pred = q_pred[b_idx, :, kp_true[:, 1], kp_true[:, 0]]
49 | q_ofs = torch.cat(q_ofs)
50 |
51 | quant_loss = self.offset_loss(q_pred, q_ofs)
52 |
53 | return embd_loss + hm_loss + quant_loss, {"l_heat": hm_loss.item(),
54 | "l_emb": embd_loss.item(), "l_quant": quant_loss.item()}
55 |
56 | class ObjectsLoss(nn.Module):
57 |
58 | def __init__(self, cnf):
59 | # type: (Conf) -> ()
60 |
61 | super().__init__()
62 | self.cnf = cnf
63 | self.occlusion = cnf.base.get("occlusion_cls", True)
64 |
65 | # Task specific losses
66 | heatmap_loss = self.cnf.loss.heatmap_loss.get("name", "nn.MSELoss")
67 | self.heatmap_loss = eval(heatmap_loss)(**self.cnf.loss.heatmap_loss.args)
68 | self.offset_loss = nn.L1Loss()
69 |
70 | def forward(self, preds, targets):
71 | # type: (dict[torch.tensor, ...], dict[torch.tensor, ...]) -> torch.tensor
72 |
73 | hm_true, oc_true, ofs_true, ocl_true = targets["heatmaps"], targets["centers"], \
74 | targets["offsets"], targets["occlusion"]
75 |
76 | hm_pred, ofs_pred, ocl_pred = preds["heatmaps"], preds["offsets"], preds["occlusion"]
77 |
78 | # Heatmap
79 | hm_loss = self.heatmap_loss(hm_pred, hm_true)
80 |
81 | # xxyy offsets
82 | # (x1-cx, x2-cx), (y1-cy, y2-cy)
83 | b_idx = torch.tensor([i for i, b in enumerate(oc_true) for _ in range(b.shape[0])])
84 | oc_true = torch.cat(oc_true).long()
85 |
86 | ofs_pred = ofs_pred[b_idx, :, oc_true[:, 1], oc_true[:, 0]]
87 | ofs_true = torch.cat(ofs_true)
88 |
89 | ofs_loss = self.offset_loss(ofs_pred, ofs_true)
90 |
91 | # Occlusion classification
92 | if self.occlusion:
93 | ocl_pred = ocl_pred[b_idx, :, oc_true[:, 1], oc_true[:, 0]]
94 | ocl_true = torch.cat(ocl_true)
95 | ocl_loss = F.binary_cross_entropy_with_logits(ocl_pred.squeeze(-1), ocl_true) #* 0.5
96 | else:
97 | ocl_loss = torch.tensor(0.0, device=hm_pred.device)
98 |
99 |
100 | return hm_loss + ofs_loss + ocl_loss, {"d_heat": hm_loss.item(),
101 | "d_ofs": ofs_loss.item(), "d_ocl": ocl_loss.item()}
102 |
103 | class ClsLoss(nn.Module):
104 |
105 | def __init__(self, cnf):
106 | # type: (Conf) -> ()
107 |
108 | super().__init__()
109 | self.cnf = cnf
110 |
111 | scn_loss = self.cnf.loss.scn_loss.get("name", "nn.CrossEntropyLoss")
112 | self.scn_loss = eval(scn_loss)(**self.cnf.loss.scn_loss.args)
113 |
114 | def forward(self, preds, targets):
115 | # type: (dict[torch.tensor, ...], dict[torch.tensor, ...]) -> torch.tensor
116 |
117 | # weather, scene, timeofday
118 | w_pred = preds["weather"]
119 | s_pred = preds["scene"]
120 | t_pred = preds["timeofday"]
121 |
122 | s1 = self.scn_loss(w_pred, targets["weather"])
123 | s2 = self.scn_loss(s_pred, targets["scene"])
124 | s3 = self.scn_loss(t_pred, targets["timeofday"])
125 |
126 | scn_loss = (s1 + s2 + s3) * 0.1
127 |
128 | return scn_loss, {"scn": scn_loss.item()}
129 |
--------------------------------------------------------------------------------
/inference/trt_inference/cerberus_trt.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 | import numpy as np
3 | import numba as nb
4 |
5 | from profiler import Profiler
6 | from .trt_infer import TRTModel, TRTInference
7 |
8 | def cerberus_model(model):
9 |
10 | class Cerberus(TRTModel):
11 | if model is None:
12 | ENGINE_PATH = Path(__file__).parent.parent.parent / 'weights' / 'last_sim.trt'
13 | MODEL_PATH = Path(__file__).parent.parent.parent / 'weights' / 'last_sim.onnx'
14 | else:
15 | MODEL_PATH = Path(model)
16 | ENGINE_PATH = Path(model).with_suffix('.trt')
17 |
18 | INPUT_SHAPE = (3, 320, 640)
19 | OUTPUT_LAYOUT = 1
20 |
21 | return Cerberus
22 |
23 | class CerberusInference:
24 | def __init__(self, model=None):
25 |
26 | self.model = cerberus_model(model)
27 | self.batch_size = 1
28 |
29 | self.backend = TRTInference(self.model, 1)
30 | self.inp_handle = self.backend.input.host.reshape(*self.model.INPUT_SHAPE)
31 |
32 | self.preds = []
33 |
34 | def __call__(self, frame, raw=False):
35 | """Extract feature embeddings from bounding boxes synchronously."""
36 | self.extract_async(frame)
37 | return self.postprocess(raw)
38 |
39 | def extract_async(self, frame):
40 | # pipeline inference and preprocessing the next batch in parallel
41 | self._preprocess(frame)
42 | self.backend.infer_async()
43 |
44 | def postprocess(self, raw=False):
45 | """Synchronizes, applies postprocessing, and returns a NxM matrix of N
46 | extracted embeddings with dimension M.
47 | This API should be called after `extract_async`.
48 | """
49 |
50 | preds_out = self.backend.synchronize()
51 |
52 | if raw:
53 | return preds_out
54 |
55 | with Profiler('inference_decode'):
56 | ## Decode boxes
57 | d_offsets = preds_out[2].reshape(-1, 80, 160)
58 | d_heatmaps = preds_out[4].reshape(-1, 80, 160)
59 | d_occl = preds_out[3].reshape(-1, 80, 160)
60 |
61 | d_scores, d_indices, d_labels = self._decode_heatmap(d_heatmaps, th=0.6)
62 | d_occl = self._sigmoid(d_occl[0, d_indices[:, 1], d_indices[:, 0]])
63 |
64 | bb_ofs = d_offsets[:, d_indices[:, 1], d_indices[:, 0]]
65 | x1x2 = (bb_ofs[:2] + d_indices[..., 0][np.newaxis, :]) * 4
66 | y1y2 = (bb_ofs[2:] + d_indices[..., 1][np.newaxis, :]) * 4
67 | boxes = np.stack([x1x2[0], y1y2[0], x1x2[1], y1y2[1], d_scores, d_labels, d_occl], axis=-1)
68 |
69 | # Decode lanes
70 | l_heatmaps = preds_out[1].reshape(-1, 80, 160) # 8
71 | l_offsets = preds_out[0].reshape(-1, 80, 160) # 2
72 |
73 | l_scores, l_indices, l_labels = self._decode_heatmap(l_heatmaps, th=0.6)
74 |
75 | l_votes = l_offsets[:, l_indices[:, 1], l_indices[:, 0]] * 4
76 | l_indices = l_indices * 4
77 | lanes = np.concatenate([l_indices.astype(np.float32), l_scores[..., np.newaxis]], axis=-1)
78 |
79 | # Decode classification results
80 | cls = tuple(preds_out[5:])
81 |
82 | return boxes, (lanes, l_labels, l_votes), cls
83 |
84 |
85 | @staticmethod
86 | def _decode_heatmap(heatmap, th=0.6):
87 | labels = np.argmax(heatmap, axis=0)
88 | heatmap = np.take_along_axis(heatmap, labels[np.newaxis,], 0)[0]
89 |
90 | indices = np.stack(np.nonzero(heatmap > th), axis=-1)[:, ::-1]
91 | scores = heatmap[indices[:, 1], indices[:, 0]]
92 | labels = labels[indices[:, 1], indices[:, 0]]
93 |
94 | return scores, indices, labels
95 |
96 | def _preprocess(self, img):
97 | self._normalize(img, self.inp_handle)
98 |
99 | @staticmethod
100 | @nb.njit(fastmath=True, nogil=True, cache=True)
101 | def _normalize(img, out):
102 | # HWC -> CHW
103 | chw = img.transpose(2, 0, 1)
104 | # Normalize using ImageNet's mean and std
105 | out[0, ...] = (chw[0, ...] / 255. - 0.485) / 0.229
106 | out[1, ...] = (chw[1, ...] / 255. - 0.456) / 0.224
107 | out[2, ...] = (chw[2, ...] / 255. - 0.406) / 0.225
108 | @staticmethod
109 | @nb.njit(fastmath=True, nogil=True, cache=True)
110 | def _sigmoid(z):
111 | return 1 / (1 + np.exp(-z))
112 |
113 | if __name__ == '__main__':
114 | cb = CerberusInference()
115 |
116 | mdt = 0
117 | for _ in range(100):
118 | src = np.random.rand(320, 640, 3)
119 | y = cb(src)
120 | dt = cb.backend.get_infer_time()
121 | mdt += dt
122 | print(mdt/100)
123 |
--------------------------------------------------------------------------------
/data/bdd100k_lane_keypoints.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import os
5 | import cv2
6 | import click
7 | import json
8 | from pathlib import Path
9 |
10 | import torch
11 | from tqdm import tqdm
12 |
13 | import numpy as np
14 | import cv2
15 |
16 | from tools import *
17 |
18 | IMG_WIDTH = 1280
19 | IMG_HEIGHT = 720
20 |
21 | I_SCALE = 2
22 | O_SCALE = 8
23 |
24 | PPK = 25 # Number of pixels per keypoint
25 |
26 |
27 | @click.command()
28 | @click.option('--img_root', '-i', type=click.Path(exists=True), default=None, required=False)
29 | @click.option('--labels_root', '-l', type=click.Path(exists=True), default=None, required=True)
30 | @click.option('--display', '-d', type=bool, default=True, required=False)
31 | @click.option('--out', '-o', type=click.Path(), default=Path('.'), required=True)
32 | def main(img_root, labels_root, display, out):
33 | # type: (Path, Path, bool, Path) -> None
34 |
35 | if display:
36 | assert img_root is not None
37 |
38 | img_root = Path(img_root)
39 | labels_root = Path(labels_root)
40 |
41 | for split in ["val"]: #, "train"]:
42 |
43 | print(f"=> Processing split {split}")
44 |
45 | out_file = out / f"{split}_{PPK}_new.pt"
46 |
47 | # Load annotation file
48 | masks_path = labels_root / "masks"/ split
49 |
50 | polygons_file = labels_root / "polygons" / f"lane_{split}.json"
51 | polygons = json.load(open(polygons_file, "r"))
52 |
53 | for p_index, p_lane in enumerate(tqdm(polygons)):
54 |
55 | frame = None
56 | lanes = None
57 |
58 | # Broken annotation, skip....
59 | if type(p_lane) == list:
60 | continue
61 |
62 | if display:
63 |
64 | # Load frame
65 | image_file = p_lane['name']
66 | image_file = img_root / split / image_file
67 | frame = cv2.imread(str(image_file))
68 |
69 | # Load mask
70 | mask_file = Path(p_lane['name']).stem + '.png'
71 | mask_file = masks_path / mask_file
72 | mask = cv2.imread(str(mask_file))#[..., 0]
73 |
74 | """
75 | for p in mask[mask != 255]:
76 | d = (p & 32) >> 5 # direction (parallel or perpendicular)
77 | s = (p & 16) >> 4 # style (full or dashed)
78 | b = (p & 8) >> 3 # background (lane (0) or background (1))
79 | c = (p & 7) # class (road curb, crosswalk, double white, double yellow, double other color,
80 | # single white, single yellow, single other color.) (8)
81 | """
82 | lanes = 1-((mask & 8) >> 3) # direction (parallel or perpendicular)
83 |
84 | labels = p_lane.get('labels', None)
85 | if labels is None:
86 | continue
87 |
88 | for il, l in enumerate(labels):
89 | assert len(l["poly2d"]) == 1
90 | pts = l["poly2d"][0]['vertices']
91 |
92 | # Define number of points according to length
93 | nppt = np.array(pts)
94 | tot_l = 0
95 | for ip, p in enumerate(nppt):
96 | if ip == len(pts) - 1:
97 | break
98 |
99 | l = np.linalg.norm(p-nppt[ip+1])
100 | tot_l += l
101 |
102 | # Compute beizer cube curve
103 | xvals, yvals = bezier_curve(pts, nTimes=max(3, int(tot_l//PPK)))
104 | pt = np.stack([xvals, yvals], axis=-1) #.astype(np.int32)
105 | labels[il]['keypoints'] = pt#.tolist()
106 |
107 | # ---- Filter double lines ----
108 | all_dist = []
109 | for i1, l1 in enumerate(labels):
110 |
111 | i_dist = []
112 | for i2, l2 in enumerate(labels):
113 | d = dist(l1, l2)
114 | i_dist.append(d)
115 |
116 | all_dist.append(i_dist)
117 |
118 | all_dist = np.array(all_dist)
119 | min_dist = np.argmin(all_dist, -1)
120 |
121 | pairs = []
122 | for id, d in enumerate(min_dist):
123 | if min_dist[id] == d and min_dist[d] == id:
124 | if [d, id] not in pairs:
125 | pairs.append([id, d])
126 |
127 | # Replace double lines with mean line
128 | for p in pairs:
129 | if all_dist[p[0], p[1]] < 80:
130 |
131 | # Compute mean line
132 | l1 = labels[p[0]]
133 | l2 = labels[p[1]]
134 | pt1, pt2 = compare_labels(l1, l2)
135 | pt3 = (pt1 + pt2) / 2
136 |
137 | # Fit new curve
138 | n = pt3.shape[0]
139 | x, y = pt3[:, 0], pt3[:, 1]
140 |
141 | if n > 3:
142 | v = get_bezier_parameters(x, y)
143 | xvals, yvals = bezier_curve(v, nTimes=n)
144 | pt3 = np.stack([xvals, yvals], axis=-1)
145 |
146 | # Update
147 | labels[p[0]]["keypoints"] = pt3
148 | labels[p[1]] = None
149 |
150 | # plot
151 | if display:
152 | for l in labels:
153 | if l is None:
154 | continue
155 |
156 | pt = l["keypoints"]
157 | pt = np.array(pt).astype(np.int32)
158 | for c in pt:
159 | frame = cv2.circle(frame, (c[0], c[1]), 3, (0,255,0), thickness=3)
160 |
161 | # Append
162 | polygons[p_index]['labels'] = labels
163 |
164 | # Display result
165 | if display:
166 | cv2.imshow("frame", frame)
167 | cv2.imshow("lanes", lanes * 255)
168 |
169 | while cv2.waitKey(1) != ord('q'):
170 | pass
171 |
172 | # Save
173 | #torch.save(polygons, out_file)
174 |
175 |
176 | if __name__ == '__main__':
177 | main()
178 | """
179 | -i /home/carmelo/DATASETS/BDD100K/bdd100k_images/images/100k
180 | -l /home/carmelo/DATASETS/BDD100K/bdd100k_lanes/labels/lane
181 | """
182 |
--------------------------------------------------------------------------------
/models/losses/heatmap_loss.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import torch
5 | from torch import nn
6 | import torch.nn.functional as F
7 |
8 | __all__ = [
9 | 'CornerNetFocalLoss', 'QualityFocalLoss', 'AdaptiveWingLoss', 'WMSELoss'
10 | ]
11 |
12 | # reference: https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/losses/gaussian_focal_loss.py
13 | # https://github.com/gau-nernst/centernet-lightning/blob/9fa4571904f1d68703f1cf4fa6e93e3c53d2971f/centernet_lightning/losses/heatmap_losses.py
14 | class CornerNetFocalLoss(nn.Module):
15 | """CornerNet Focal Loss. Use logits to improve numerical stability. CornerNet: https://arxiv.org/abs/1808.01244
16 | """
17 |
18 | # reference implementations
19 | # https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/losses/gaussian_focal_loss.py
20 | def __init__(self, alpha: float = 2, beta: float = 2, reduction: str = "mean"):
21 | """CornerNet Focal Loss. Default values from the paper
22 |
23 | Args:
24 | alpha: control the modulating factor to reduce the impact of easy examples. This is gamma in the original Focal loss
25 | beta: control the additional weight for negative examples when y is between 0 and 1
26 | reduction: either none, sum, or mean
27 | """
28 | super().__init__()
29 | assert reduction in ("none", "sum", "mean")
30 | self.alpha = alpha
31 | self.beta = beta
32 | self.reduction = reduction
33 |
34 | def forward(self, inputs: torch.Tensor, targets: torch.Tensor):
35 |
36 | pos_inds = targets.eq(1).float()
37 | neg_inds = targets.lt(1).float()
38 |
39 | neg_weights = torch.pow(1 - targets, 4)
40 | # clamp min value is set to 1e-12 to maintain the numerical stability
41 | pred = torch.clamp(inputs, 1e-12)
42 |
43 | pos_loss = torch.log(pred) * torch.pow(1 - pred, 2) * pos_inds
44 | neg_loss = torch.log(1 - pred) * torch.pow(pred, 2) * neg_weights * neg_inds
45 |
46 | num_pos = pos_inds.float().sum()
47 | pos_loss = pos_loss.sum()
48 | neg_loss = neg_loss.sum()
49 |
50 | if num_pos == 0:
51 | loss = -neg_loss
52 | else:
53 | loss = -(pos_loss + neg_loss) / num_pos
54 |
55 | return loss
56 |
57 | class WMSELoss(nn.Module):
58 |
59 | def __init__(self, alpha: float=4, beta: float = 2, reduction: str = 'mean'):
60 |
61 | super().__init__()
62 | assert reduction in ('none', 'sum', 'mean')
63 | self.alpha = alpha
64 | self.beta = beta
65 | self.reduction = reduction
66 |
67 | def forward(self, inputs: torch.Tensor, targets: torch.Tensor):
68 |
69 | mse = F.mse_loss(inputs, targets, reduction='none')
70 | mf_t = (torch.pow(1 + targets, self.alpha))
71 | mf_p = (torch.pow(1 + inputs.detach(), self.beta))
72 | modulating_factor = torch.maximum(mf_t, mf_p)
73 | # modulating_factor = torch.pow(1 + torch.abs(targets.detach() - inputs), self.beta)
74 |
75 | loss = modulating_factor * mse
76 | if self.reduction == 'none':
77 | return loss
78 |
79 | bs = loss.shape[0]
80 | loss = torch.sum(loss)
81 | if self.reduction == 'mean':
82 | loss = loss / (1 + targets.gt(0.96).sum().float())
83 | loss = loss / bs
84 |
85 | return loss
86 |
87 |
88 | class QualityFocalLoss(nn.Module):
89 | """Quality Focal Loss. Generalized Focal Loss: https://arxiv.org/abs/2006.04388
90 | """
91 |
92 | def __init__(self, beta: float = 2, reduction: str = "mean"):
93 | """Quality Focal Loss. Default values are from the paper
94 |
95 | Args:
96 | beta: control the scaling/modulating factor to reduce the impact of easy examples
97 | reduction: either none, sum, or mean
98 | """
99 | super().__init__()
100 | assert reduction in ("none", "sum", "mean")
101 | self.beta = beta
102 | self.reduction = reduction
103 |
104 | def forward(self, inputs: torch.Tensor, targets: torch.Tensor):
105 | probs = torch.sigmoid(inputs)
106 |
107 | ce_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction="none")
108 | modulating_factor = torch.abs(targets - probs) ** self.beta
109 |
110 | loss = modulating_factor * ce_loss
111 |
112 | if self.reduction == "sum":
113 | return torch.sum(loss)
114 |
115 | if self.reduction == "mean":
116 | return torch.sum(loss) / targets.eq(1).float().sum()
117 |
118 | return loss
119 |
120 | # torch.log and math.log is e based
121 | # https://github.com/elliottzheng/AdaptiveWingLoss/blob/master/adaptive_wing_loss.py
122 | class AdaptiveWingLoss(nn.Module):
123 | def __init__(self, omega=14, theta=0.5, epsilon=1, alpha=2.1):
124 | super(AdaptiveWingLoss, self).__init__()
125 | self.omega = omega
126 | self.theta = theta
127 | self.epsilon = epsilon
128 | self.alpha = alpha
129 |
130 | def forward(self, inputs: torch.Tensor, targets: torch.Tensor):
131 | '''
132 | :param pred: BxNxHxH
133 | :param target: BxNxHxH
134 | :return:
135 | '''
136 |
137 | y = targets
138 | y_hat = inputs
139 | delta_y = (y - y_hat).abs()
140 | delta_y1 = delta_y[delta_y < self.theta]
141 | delta_y2 = delta_y[delta_y >= self.theta]
142 | y1 = y[delta_y < self.theta]
143 | y2 = y[delta_y >= self.theta]
144 | loss1 = self.omega * torch.log(1 + torch.pow(delta_y1 / self.omega, self.alpha - y1))
145 | A = self.omega * (1 / (1 + torch.pow(self.theta / self.epsilon, self.alpha - y2))) * (self.alpha - y2) * (
146 | torch.pow(self.theta / self.epsilon, self.alpha - y2 - 1)) * (1 / self.epsilon)
147 | C = self.theta * A - self.omega * torch.log(1 + torch.pow(self.theta / self.epsilon, self.alpha - y2))
148 | loss2 = A * delta_y2 - C
149 | return (loss1.sum() + loss2.sum()) / (len(loss1) + len(loss2))
150 |
--------------------------------------------------------------------------------
/inference/run_tensorrt.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import click
5 |
6 | import cv2
7 | import numpy as np
8 | import logging
9 | from time import time, sleep
10 |
11 | from trt_inference.cerberus_trt import CerberusInference
12 | from trt_inference.cls import WTR_CLS, SN_CLS, TD_CLS, DET_CLS_IND
13 | from postproc import get_clusters, fast_clustering
14 |
15 | from profiler import Profiler
16 |
17 | logging.basicConfig(format='%(asctime)s [%(levelname)8s] %(message)s', datefmt='%Y-%m-%d %H:%M:%S')
18 | LOGGER = logging.getLogger(__name__)
19 | LOGGER.setLevel(logging.DEBUG)
20 | Profiler.set_warmup(25)
21 |
22 | cls_col = [(153, 255, 102), (255, 255, 255), (0, 255, 255), (52, 255, 52), (51, 153, 51),
23 | (0, 255, 0), (153, 51, 51), (0, 0, 255), (255, 0, 0)]
24 |
25 | lancol = [(0, 255, 255), (255, 255, 255), (255, 150, 50), (0, 0, 255),
26 | (102, 0, 102), (10, 255, 0), (255, 255, 0), (0, 153, 255)]
27 |
28 | @click.command()
29 | @click.option('--model_file', '-m', type=click.Path(exists=True), default=None, required=False)
30 | @click.option('--video', '-v', type=click.Path(exists=True), default=None, required=True)
31 | @click.option('--max_frames', '-f', type=int, default=None, required=False)
32 | @click.option('--infer_only', '-i', type=click.BOOL, default=False, required=False)
33 | def main(model_file, video, max_frames, infer_only):
34 |
35 | # load video
36 | # video = "../videos/dashcam_demo.mp4"
37 | cap = cv2.VideoCapture(video)
38 | cap.set(cv2.CAP_PROP_POS_FRAMES, 150 * 30)
39 |
40 | """# writer
41 | fourcc = cv2.VideoWriter_fourcc(*"MJPG")
42 | writer = cv2.VideoWriter('../videos/result_trt.avi', fourcc, 80, (640, 320))"""
43 |
44 | # Classes
45 | wtr = {v: k for k, v in WTR_CLS.items()}
46 | scn = {v: k for k, v in SN_CLS.items()}
47 | td = {v: k for k, v in TD_CLS.items()}
48 |
49 | model = CerberusInference(model_file)
50 |
51 | times = []
52 | infer_times = []
53 | frames = 0
54 | while cap.isOpened():
55 | t = time()
56 |
57 | with Profiler('acquire'):
58 | _, frame = cap.read()
59 | frame = cv2.resize(frame, (640, 360))
60 | frame = frame[20:340, :, :]
61 |
62 | with Profiler('inference_all'):
63 | preds = model(frame, raw=infer_only)
64 |
65 | it = model.backend.get_infer_time()
66 | infer_times.append(it)
67 |
68 | if not infer_only:
69 |
70 | det_out, lane_out, scn_out = preds
71 | boxes = det_out
72 | lanes, lanes_cls, lanes_votes = lane_out
73 |
74 | # Classification results
75 | w_cls = wtr[scn_out[0].item()]
76 | s_cls = scn[scn_out[1].item()]
77 | td_cls = td[scn_out[2].item()]
78 |
79 | # Lane clustering
80 | with Profiler('lane_clustering'):
81 | lane_clusters = fast_clustering(lanes, lanes_cls, lanes_votes)
82 |
83 | # Draw keypoints
84 | with Profiler('lane_drawing'):
85 | for cla, cls_clusters in enumerate(lane_clusters):
86 | for cl in cls_clusters:
87 |
88 | col = lancol[cla]
89 | if cl.shape[0] < 5:
90 | continue
91 |
92 | x = cl[:, 0]
93 | y = cl[:, 1]
94 |
95 | # calculate polynomial
96 | try:
97 | z = np.polyfit(x, y, 2)
98 | f = np.poly1d(z)
99 | except ValueError:
100 | continue
101 |
102 | # calculate new x's and y's
103 | x_new = np.linspace(min(x), max(x), len(x) * 2)
104 | y_new = f(x_new)
105 |
106 | for cx, cy in zip(x_new, y_new):
107 | frame = cv2.circle(frame, (int(cx), int(cy)), 1, col, thickness=2, )
108 |
109 | # Draw boxes
110 | with Profiler('det_drawing'):
111 | for b in boxes:
112 | cls = DET_CLS_IND[int(b[5])].split(" ")[-1]
113 | tl = (int(b[2]), int(b[3]))
114 | br = (int(b[0]), int(b[1]))
115 |
116 | color = (0, 255, 0) if b[6] < 0.5 else (0,0,255)
117 | cv2.rectangle(frame, tl, br, color, 2)
118 |
119 | (text_width, text_height), _ = cv2.getTextSize(cls, cv2.FONT_HERSHEY_DUPLEX, 0.3, 1)
120 | cv2.rectangle(frame, br, (br[0] + text_width - 1, br[1] + text_height - 1),
121 | color, cv2.FILLED)
122 | cv2.putText(frame, cls, (br[0], br[1] + text_height - 1), cv2.FONT_HERSHEY_DUPLEX,
123 | 0.3, 0, 1, cv2.LINE_AA)
124 |
125 | # Add text
126 | with Profiler('cls_drawing'):
127 | text = f"WEATHER: {w_cls} SCENE: {s_cls} DAYTIME: {td_cls}"
128 | frame = cv2.rectangle(frame, (10, 5), (550, 25), (0, 0, 0), -1)
129 | frame = cv2.putText(frame, text, (15, 20), cv2.FONT_HERSHEY_DUPLEX, 0.5,
130 | (255,255,255), 1, cv2.LINE_AA, False)
131 |
132 | # writer.write(frame)
133 | cv2.imshow("result", frame)
134 |
135 | dt = time() - t
136 | times.append(dt)
137 | frames +=1
138 |
139 | if cv2.waitKey(1) == ord('q') or (frames == max_frames):
140 | print('=================Timing Stats=================')
141 | print(f"{'Frame Acquiring:':<37}{Profiler.get_avg_millis('acquire'):>6.3f} ms")
142 | print(f"{'Inference total:':<37}{Profiler.get_avg_millis('inference_all'):>6.3f} ms")
143 | print(f"\t{'Inference DNN:':<37}{np.array(infer_times[10:]).mean():>6.3f} ms")
144 | print(f"\t{'Inference Decoding:':<37}{Profiler.get_avg_millis('inference_decode'):>6.3f} ms")
145 | print('----------------------------------------------')
146 | print(f"{'Lanes clustering:':<37}{Profiler.get_avg_millis('lane_clustering'):>6.3f} ms")
147 | print(f"{'Lanes Fitting and Drawing:':<37}{Profiler.get_avg_millis('lane_drawing'):>6.3f} ms")
148 | print(f"{'Detection Drawing:':<37}{Profiler.get_avg_millis('det_drawing'):>6.3f} ms")
149 | print(f"{'Cls Drawing:':<37}{Profiler.get_avg_millis('cls_drawing'):>6.3f} ms")
150 | print(f"{'AVERAGE TIME:':<37}{np.array(times[10:]).mean()*1000:>6.3f} ms")
151 | break
152 |
153 | cap.release()
154 | # writer.release()
155 |
156 |
157 | if __name__ == '__main__':
158 | main()
159 |
--------------------------------------------------------------------------------
/trainer.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | from conf import Conf
5 |
6 | import torch
7 | import numpy as np
8 | import cv2
9 |
10 | import pytorch_lightning as pl
11 | import torchvision as tv
12 | from torch.utils.data import DataLoader
13 | from pytorch_lightning import loggers as pl_loggers
14 |
15 | from torch.optim import *
16 | from utils.lr_scheduler import *
17 |
18 | from models import CerberusModel
19 | from models.losses import MultiTaskLoss
20 | from dataset import MultitaskDataset, ignore_collate
21 |
22 |
23 | class PL_trainable(pl.LightningModule):
24 | def __init__(self, cnf):
25 | super().__init__()
26 |
27 | self.cnf = cnf
28 | self.backbone = CerberusModel(cnf)
29 | self.criterion = MultiTaskLoss(cnf)
30 |
31 | self.plot_images = 10
32 |
33 | def forward(self, img):
34 | pred = self.backbone(img)
35 | return pred
36 |
37 | def training_step(self, batch, batch_idx):
38 |
39 | img, targets = batch
40 | preds = self.forward(img)
41 |
42 | # Loss
43 | loss, loss_detail = self.criterion(preds, targets)
44 |
45 | # single scheduler
46 | sch = self.lr_schedulers()
47 | sch.step()
48 |
49 | lr = sch.get_last_lr()[0]
50 | self.log('train_loss', loss, on_step=True, on_epoch=False)
51 | self.log('lr', lr, on_step=True, on_epoch=False)
52 | for k, v in loss_detail.items():
53 | self.log(f'train_{k}_loss', v, on_step=True, on_epoch=False)
54 |
55 | return loss
56 |
57 | def validation_step(self, batch, batch_idx):
58 | # Inference
59 | img, targets = batch
60 | preds = self.forward(img)
61 |
62 | # Loss
63 | loss, loss_detail = self.criterion(preds, targets)
64 |
65 | # plot
66 | if self.plot_images > 0:
67 | true, pred = [], []
68 |
69 | if self.cnf.base.get("object_det", False):
70 | true.append(targets["obj_det"]["heatmaps"])
71 | pred.append(preds["obj_det"]["heatmaps"])
72 |
73 | if self.cnf.base.get("lane_det", False):
74 | true.append(targets["lane_det"]["heatmaps"])
75 | pred.append(preds["lane_det"]["heatmaps"])
76 |
77 | true = torch.cat(true, dim=1)
78 | pred = torch.cat(pred, dim=1)
79 | img_resize = torch_input_img(img[0].cpu().detach())
80 | hm_true = torch_heatmap_img(true[0].cpu().detach())
81 | hm_pred = torch_heatmap_img(pred[0].cpu().detach())
82 | grid = torch.stack([img_resize, hm_true, hm_pred], dim=0)
83 |
84 | grid = tv.utils.make_grid(grid.float())
85 | self.logger.experiment.add_image(tag=f'results_{self.plot_images}',
86 | img_tensor=grid, global_step=self.global_step)
87 | self.plot_images -= 1
88 |
89 | # Log
90 | self.log('val_loss', loss, on_step=False, on_epoch=True)
91 |
92 | for k, v in loss_detail.items():
93 | self.log(f'val_{k}_loss', v, on_step=False, on_epoch=True)
94 |
95 | return loss
96 |
97 |
98 | def test_step(self, batch, batch_idx):
99 | pass
100 |
101 | def validation_epoch_end(self, outputs) -> None:
102 | self.plot_images = 10
103 |
104 | def configure_optimizers(self):
105 | optimizer = eval(self.cnf.optimizer.name)(self.parameters(), **self.cnf.optimizer.args)
106 |
107 | if self.cnf.lr_scheduler.get("name", None) is not None:
108 | scheduler = eval(self.cnf.lr_scheduler.name)(optimizer, **self.cnf.lr_scheduler.args)
109 | return [optimizer], [scheduler]
110 | return [optimizer]
111 |
112 | def on_validation_epoch_end(self):
113 | torch.save(self.backbone.state_dict(), f'{self.cnf.exp_log_path}/last.pth')
114 |
115 |
116 | def torch_heatmap_img(heatmap):
117 | hm_show, _ = torch.max(heatmap, dim=0)
118 | hm_show = hm_show.numpy() * 255
119 | hm_show = hm_show.astype(np.uint8)
120 | hm_show = cv2.applyColorMap(hm_show, cv2.COLORMAP_JET)
121 | hm_show = cv2.cvtColor(hm_show, cv2.COLOR_BGR2RGB)
122 | hm_show = cv2.resize(hm_show, (640, 480)) / 255
123 |
124 | return torch.from_numpy(hm_show).permute(2, 0, 1)
125 |
126 |
127 | def torch_input_img(img):
128 | invTrans = tv.transforms.Compose([tv.transforms.Normalize(mean=[0., 0., 0.],
129 | std=[1 / 0.229, 1 / 0.224, 1 / 0.225]),
130 | tv.transforms.Normalize(mean=[-0.485, -0.456, -0.406],
131 | std=[1., 1., 1.]),
132 | ])
133 | img = invTrans(img)
134 | img = tv.transforms.Resize((480, 640))(img)
135 | return img
136 |
137 | def trainer_run(cnf):
138 | # type: (Conf) -> None
139 |
140 | # ------------
141 | # data
142 | # ------------
143 | trainset = MultitaskDataset(cnf, mode="train")
144 | valset = MultitaskDataset(cnf, mode="val")
145 |
146 | collate_fn = ignore_collate(["centers", "offsets", "keypoints", "occlusion", "quant_offsets"])
147 | train_loader = DataLoader(trainset, collate_fn=collate_fn, **cnf.dataset.train_dataset.loader_args)
148 | val_loader = DataLoader(valset, collate_fn=collate_fn, **cnf.dataset.val_dataset.loader_args)
149 |
150 | # ------------
151 | # model
152 | # ------------
153 | model = PL_trainable(cnf)
154 |
155 | # ------------
156 | # training
157 | # ------------
158 | gpus = [0]
159 | tb_logger = pl_loggers.TensorBoardLogger(save_dir=cnf.exp_log_path, name="", version="")
160 |
161 | trainer = pl.Trainer(default_root_dir=cnf.exp_log_path, logger=tb_logger,
162 | max_epochs=cnf.epochs, gpus=gpus)
163 | trainer.fit(model, train_loader, val_loader)
164 |
165 |
--------------------------------------------------------------------------------
/models/layers.py:
--------------------------------------------------------------------------------
1 | import math
2 |
3 | import torch
4 | from torch import nn
5 | import torch.nn.functional as F
6 |
7 |
8 | def ConvReluConv(in_channel, conv_channels, out_channel, bias_fill=False, bias_value=0.0):
9 | """ Userful for Head output"""
10 | feat_conv = nn.Conv2d(in_channel, conv_channels, kernel_size=3, padding=1, bias=True)
11 | relu = nn.ReLU()
12 | out_conv = nn.Conv2d(conv_channels, out_channel, kernel_size=1, stride=1, padding=0)
13 | if bias_fill:
14 | out_conv.bias.data.fill_(bias_value)
15 |
16 | return nn.Sequential(feat_conv, relu, out_conv)
17 |
18 | def make_conv(in_channels, out_channels, conv_type="normal", kernel_size=3, padding=None, stride=1,
19 | depth_multiplier=1, **kwargs):
20 | """Create a convolution layer. Options: deformable, separable, or normal convolution
21 | """
22 | assert conv_type in ("separable", "normal")
23 | if padding is None:
24 | padding = (kernel_size - 1) // 2
25 |
26 | if conv_type == "separable":
27 | hidden_channels = in_channels * depth_multiplier
28 | conv_layer = nn.Sequential(
29 | # dw
30 | nn.Conv2d(in_channels, hidden_channels, kernel_size, padding=padding, stride=stride,
31 | groups=in_channels, bias=False),
32 | nn.BatchNorm2d(in_channels),
33 | nn.ReLU6(inplace=True),
34 | # pw
35 | nn.Conv2d(hidden_channels, out_channels, 1, bias=False, stride=stride),
36 | nn.BatchNorm2d(out_channels),
37 | nn.ReLU6(inplace=True)
38 | )
39 | nn.init.kaiming_normal_(conv_layer[0].weight, mode="fan_out", nonlinearity="relu")
40 | nn.init.kaiming_normal_(conv_layer[3].weight, mode="fan_out", nonlinearity="relu")
41 |
42 | else: # normal convolution
43 | conv_layer = nn.Sequential(
44 | nn.Conv2d(in_channels, out_channels, kernel_size, padding=padding, stride=stride, bias=False),
45 | nn.BatchNorm2d(out_channels),
46 | nn.ReLU(inplace=True)
47 | )
48 | nn.init.kaiming_normal_(conv_layer[0].weight, mode="fan_out", nonlinearity="relu")
49 |
50 | return conv_layer
51 |
52 |
53 | def make_upsample(upsample_type="nearest", deconv_channels=None, deconv_kernel=4, deconv_init_bilinear=True, **kwargs):
54 | """Create an upsample layer. Options: convolution transpose, bilinear upsampling, or nearest upsampling
55 | """
56 | assert upsample_type in ("conv_transpose", "bilinear", "nearest")
57 |
58 | if upsample_type == "conv_transpose":
59 | output_padding = deconv_kernel % 2
60 | padding = (deconv_kernel + output_padding) // 2 - 1
61 |
62 | upsample = nn.ConvTranspose2d(deconv_channels, deconv_channels, deconv_kernel, stride=2, padding=padding,
63 | output_padding=output_padding, bias=False)
64 | bn = nn.BatchNorm2d(deconv_channels)
65 | relu = nn.ReLU(inplace=True)
66 | upsample_layer = nn.Sequential(upsample, bn, relu)
67 |
68 | if deconv_init_bilinear: # TF CenterNet does not do this
69 | _init_bilinear_upsampling(upsample)
70 |
71 | else:
72 | upsample_layer = nn.Upsample(scale_factor=2, mode=upsample_type)
73 |
74 | return upsample_layer
75 |
76 |
77 | def _init_bilinear_upsampling(deconv_layer):
78 | """Initialize convolution transpose layer as bilinear upsampling to help with training stability
79 | """
80 | # https://github.com/ucbdrive/dla/blob/master/dla_up.py#L26-L33
81 | w = deconv_layer.weight.data
82 | f = math.ceil(w.size(2) / 2)
83 | c = (2 * f - 1 - f % 2) / (f * 2.)
84 |
85 | for i in range(w.size(2)):
86 | for j in range(w.size(3)):
87 | w[0, 0, i, j] = (1 - math.fabs(i / f - c)) * (1 - math.fabs(j / f - c))
88 |
89 | for c in range(1, w.size(0)):
90 | w[c, 0, :, :] = w[0, 0, :, :]
91 |
92 |
93 | def make_downsample(downsample_type="max", conv_channels=None, conv_kernel=3, **kwargs):
94 | """Create a downsample layer. Options: convolution, max pooling, or average pooling
95 | """
96 | assert downsample_type in ("max", "average", "conv")
97 |
98 | if downsample_type == "conv":
99 | downsample = nn.Conv2d(conv_channels, conv_channels, conv_kernel, stride=2, padding="same", bias=False)
100 | bn = nn.BatchNorm2d(conv_channels)
101 | relu = nn.ReLU(inplace=True)
102 | downsample_layer = nn.Sequential(downsample, bn, relu)
103 |
104 | nn.init.kaiming_normal_(downsample.weight, mode="fan_out", nonlinearity="relu")
105 |
106 | elif downsample_type == "max":
107 | downsample_layer = nn.MaxPool2d(2, 2)
108 | else:
109 | downsample_layer = nn.AvgPool2d(2, 2)
110 |
111 | return downsample_layer
112 |
113 |
114 | class Fuse(nn.Module):
115 | """Fusion node to be used for feature fusion. To be used in `BiFPNNeck` and `IDANeck`. The last input will be resized.
116 |
117 | Formula
118 | no weight: out = conv(in1 + resize(in2))
119 | weighted: out = conv((in1*w1 + resize(in2)*w2) / (w1 + w2 + eps))
120 | """
121 |
122 | def __init__(self, num_fused, out, resize, upsample="nearest", downsample="max", conv_type="normal",
123 | weighted_fusion=False):
124 | super().__init__()
125 | assert resize in ("up", "down")
126 | assert num_fused >= 2
127 |
128 | self.weighted_fusion = weighted_fusion
129 | self.num_fused = num_fused
130 | if weighted_fusion:
131 | self.weights = nn.Parameter(torch.ones(num_fused), requires_grad=True)
132 |
133 | if resize == "up":
134 | self.resize = make_upsample(upsample_type=upsample, deconv_channels=out)
135 | else:
136 | self.resize = make_downsample(downsample=downsample, conv_channels=out)
137 |
138 | self.output_conv = make_conv(out, out, conv_type=conv_type)
139 |
140 | def forward(self, *features, eps=1e-6):
141 |
142 | last = self.resize(features[-1])
143 |
144 | if self.weighted_fusion:
145 | weights = F.relu(self.weights)
146 | weights = weights / (torch.sum(weights) + eps)
147 | out = features[0] * weights[0]
148 | for i in range(1, self.num_fused-1):
149 | out = out + (features[i] * weights[i])
150 | out = out + (last * weights[-1])
151 | else:
152 | out = features[0]
153 | for i in range(1, self.num_fused-1):
154 | out = out + features[i]
155 | out = out + last
156 |
157 | out = self.output_conv(out)
158 | return out
159 |
160 |
161 |
162 |
163 |
--------------------------------------------------------------------------------
/models/cerberus.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import torch
5 | from torch import nn
6 |
7 | from models.backbones.resnet import *
8 | from models.backbones.efficientnet import *
9 | from models.backbones.mobilenetv2 import *
10 |
11 | from models.necks import SimpleNeck, BiFPNNeck
12 | from models.heads import ScnHead, ObjectHead, LaneHead
13 | from utils.decoding import kp_from_heatmap
14 |
15 | from conf import Conf
16 |
17 | class CerberusModel(nn.Module):
18 | def __init__(self, cnf):
19 | # type: (Conf) -> None
20 | super(CerberusModel, self).__init__()
21 | self.cnf = cnf
22 |
23 | # Configuration
24 | self.lane_det = cnf.base.get("lane_det", True)
25 | self.obj_det = cnf.base.get("object_det", True)
26 | self.scene_cls = cnf.base.get("scene_cls", True)
27 | self.obj_occl = cnf.base.get("occlusion_cls", True)
28 |
29 | self.det_classes = cnf.base.get("det_classes", 10)
30 | self.lane_classes = cnf.base.get("lane_classes", 8)
31 | scn_classes = cnf.base.get("scn_classes", {})
32 | self.scn_classes = [v for v in scn_classes.values()]
33 |
34 | # Backbone
35 | assert self.lane_det or self.obj_det, "At least one task must be enabled!"
36 | self.backbone = eval(cnf.model.backbone.name)(**cnf.model.backbone.args)
37 |
38 | # Neck
39 | self.neck = eval(cnf.model.neck.name)(self.backbone.outplanes, **cnf.model.neck.args)
40 |
41 | # LANE DETECTION HEAD
42 | if self.lane_det:
43 | self.lane_q_offsets = cnf.base.get("lane_q_offsets", False)
44 | self.head_lane = LaneHead(num_classes=self.lane_classes, in_channels=self.neck.out_channels,
45 | conv_channels=cnf.model.head_channel, quant_offsets=self.lane_q_offsets)
46 |
47 | # OBJECT DETECTION HEAD
48 | if self.obj_det:
49 | self.head_obj = ObjectHead(num_classes=self.det_classes,
50 | in_channels=self.neck.out_channels, conv_channels=cnf.model.head_channel)
51 |
52 | # SCENE CLASSIFICATION HEAD
53 | if self.scene_cls:
54 | self.head_scn = ScnHead(in_channels=self.neck.out_channels,
55 | classes=self.scn_classes)
56 |
57 | def forward(self, x, inference=False):
58 | # type: (torch.tensor, bool) -> dict[str, torch.Tensor, ...]
59 |
60 | # Features
61 | feats = self.backbone(x)
62 |
63 | # Upsample
64 | big, small = self.neck(feats)
65 |
66 | # Output
67 | outputs = {}
68 |
69 | if self.lane_det:
70 | lane_out = self.head_lane(big, nms=inference)
71 | outputs["lane_det"] = lane_out
72 |
73 | if self.obj_det:
74 | obj_out = self.head_obj(big, nms=inference)
75 | outputs["obj_det"] = obj_out
76 |
77 | if self.scene_cls:
78 | scn_out = self.head_scn(small, argmax=inference)
79 | outputs["scn_cls"] = scn_out
80 |
81 | return outputs
82 |
83 | def inference(self, x, benchmarking=False):
84 |
85 | assert x.shape[0] == 1, "Only BS=1 is supported!"
86 |
87 | # inference
88 | predictions = self.forward(x, inference=True)
89 |
90 | if benchmarking:
91 | return predictions
92 |
93 | # ------------------
94 | # Lane decoding
95 | # ------------------
96 | if self.lane_det:
97 | lane_preds = predictions["lane_det"]
98 | hm_lane, ofs_lane, = lane_preds["heatmaps"], lane_preds["offsets"]
99 |
100 | l_scores, l_indices, l_labels = kp_from_heatmap(hm_lane, th=0.6, pseudo_nms=False)
101 | l_votes = ofs_lane[0, :, l_indices[:, 1], l_indices[:, 0]] * 4
102 |
103 | if self.lane_q_offsets:
104 | quant_ofs = lane_preds["quant"]
105 | quant_ofs = quant_ofs[0, :, l_indices[:, 1], l_indices[:, 0]]
106 | l_indices = l_indices.float()
107 | l_indices[:, 1] += quant_ofs[1]
108 | l_indices[:, 0] += quant_ofs[0]
109 |
110 | l_indices = l_indices * 4
111 | lanes = torch.cat([l_indices.float(), l_scores.unsqueeze(-1)], dim=-1)
112 |
113 | lane_pred = {
114 | "lanes": lanes,
115 | "lanes_labels": l_labels,
116 | "lanes_votes": l_votes
117 | }
118 |
119 | predictions["lane_det"]["decoded"] = lane_pred
120 |
121 | # ------------------
122 | # Boxes decoding
123 | # ------------------
124 | if self.obj_det:
125 | det_preds = predictions["obj_det"]
126 | hm_det, ofs_det, occlu_det = det_preds["heatmaps"], det_preds["offsets"], det_preds["occlusion"]
127 | d_scores, d_indices, d_labels = kp_from_heatmap(hm_det, th=0.6, pseudo_nms=False)
128 |
129 | bb_ofs = ofs_det[0, :, d_indices[:, 1], d_indices[:, 0]]
130 | x1x2 = (bb_ofs[:2] + d_indices[..., 0].unsqueeze(0)) * 4
131 | y1y2 = (bb_ofs[2:] + d_indices[..., 1].unsqueeze(0)) * 4
132 |
133 | # better safe than sorry
134 | x1x2 = torch.clip(x1x2, 0, 640)
135 | y1y2 = torch.clip(y1y2, 0, 320)
136 |
137 | boxes = torch.stack([x1x2[0], y1y2[0], x1x2[1], y1y2[1], d_scores], dim=-1)
138 |
139 | det_pred = {
140 | "boxes": boxes,
141 | "labels": d_labels
142 | }
143 |
144 | if self.obj_occl:
145 | occl = occlu_det[0, 0, d_indices[:, 1], d_indices[:, 0]].sigmoid()
146 | det_pred["occlusion"] = occl
147 |
148 | predictions["obj_det"]["decoded"] = det_pred
149 |
150 | return predictions
151 |
152 | if __name__ == '__main__':
153 | from torchinfo import summary
154 |
155 | cnf = Conf(exp_name='mobilenetv2_bifpn', log=False)
156 | model = CerberusModel(cnf).cuda()
157 | summary(model, input_size=(1, 3, 640,320), depth=5)
158 |
159 | x = torch.rand((1,3,320,640), dtype=torch.float32).cuda()
160 | y = model(x)
161 |
--------------------------------------------------------------------------------
/models/necks.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import nn
3 | import torch.nn.functional as F
4 |
5 | from .layers import Fuse, make_conv, make_upsample
6 |
7 | class SimpleNeck(nn.Module):
8 | """(conv + upsample) a few times (first proposed in PoseNet https://arxiv.org/abs/1804.06208)
9 |
10 | Equations
11 | stride 16: out_4 = up(conv(in_5))
12 | stride 8: out_3 = up(conv(out_4))
13 | stride 4: out_2 = up(conv(out_3))
14 | """
15 |
16 | def __init__(self, backbone_channels, upsample_channels=[256, 128, 64], conv_type="normal",
17 | upsample_type="conv_transpose", **kwargs):
18 | super().__init__()
19 | layers = []
20 |
21 | # first (conv + upsample) from backbone
22 | self.conv_layer = make_conv(backbone_channels[-1], upsample_channels[0], conv_type=conv_type)
23 |
24 | up_layer = make_upsample(upsample_type, upsample_channels[0], **kwargs)
25 | layers.append(up_layer)
26 |
27 | for i in range(1, len(upsample_channels)):
28 | conv_layer = make_conv(upsample_channels[i - 1], upsample_channels[i], conv_type=conv_type)
29 | up_layer = make_upsample(upsample_type, upsample_channels[i], deconv_init_bilinear=True, **kwargs)
30 | layers.append(conv_layer)
31 | layers.append(up_layer)
32 |
33 | self.upsample = nn.Sequential(*layers)
34 | self.out_channels = upsample_channels[-1]
35 | self.upsample_stride = 2 ** len(upsample_channels)
36 |
37 | def forward(self, features):
38 | small = self.conv_layer(features[-1])
39 | big = self.upsample(small)
40 | return big, small
41 |
42 |
43 | class FPNNeck(nn.Module):
44 | """FPN neck with some modifications. Paper: https://arxiv.org/abs/1612.03144
45 | - Weighted fusion is used in Bi-FPN: https://arxiv.org/abs/1911.09070
46 | - Fusion factor (same as weighted fusion): https://arxiv.org/abs/2011.02298
47 |
48 | Equations
49 | stride 32: out_5 = conv_skip(in_5)
50 | stride 16: out_4 = conv(skip(in_4) + up(out_5) x w_4)
51 | stride 8: out_3 = conv(skip(in_3) + up(out_4) x w_3)
52 | stride 4: out_2 = conv(skip(in_2) + up(out_3) x w_2)
53 | """
54 |
55 | def __init__(self, backbone_channels, upsample_channels=[256, 128, 64], upsample_type="nearest", conv_type="normal",
56 | weighted_fusion=False, **kwargs):
57 | super().__init__()
58 | self.top_conv = nn.Conv2d(backbone_channels[-1], upsample_channels[0], 1)
59 | self.skip_connections = nn.ModuleList()
60 | self.up_layers = nn.ModuleList()
61 | self.conv_layers = nn.ModuleList()
62 | if weighted_fusion:
63 | # indexing ParameterList of scalars might be slightly faster than indexing Parameter of 1-d tensor
64 | self.weights = [nn.Parameter(torch.tensor(1., dtype=torch.float32, requires_grad=True)) for _ in
65 | range(len(upsample_channels))]
66 | self.weights = nn.ParameterList(self.weights)
67 | else:
68 | self.weights = None
69 |
70 | for i in range(len(upsample_channels)):
71 | # build skip connections
72 | in_channels = backbone_channels[-2 - i]
73 | out_channels = upsample_channels[i]
74 | skip_conv = nn.Conv2d(in_channels, out_channels, 1)
75 | self.skip_connections.append(skip_conv)
76 |
77 | # build upsample layers
78 | upsample = make_upsample(upsample_type=upsample_type, deconv_channels=out_channels, **kwargs)
79 | self.up_layers.append(upsample)
80 |
81 | # build output conv layers
82 | out_conv_channels = upsample_channels[i + 1] if i < len(upsample_channels) - 1 else upsample_channels[-1]
83 | conv = make_conv(out_channels, out_conv_channels, conv_type=conv_type, **kwargs)
84 | self.conv_layers.append(conv)
85 |
86 | self.out_channels = upsample_channels[-1]
87 | self.upsample_stride = 2 ** len(upsample_channels)
88 |
89 | def forward(self, features):
90 | out = features[-1]
91 | out = self.top_conv(out)
92 |
93 | for i in range(len(self.conv_layers)):
94 | skip = self.skip_connections[i](features[-2 - i]) # skip connection
95 | up = self.up_layers[i](out) # upsample
96 |
97 | if self.weights is not None:
98 | w = F.relu(self.weights[i])
99 | out = (skip + up * w) / (1 + w) # combine with fusion weight
100 | else:
101 | out = skip + up
102 | out = self.conv_layers[i](out) # output conv
103 |
104 | return out
105 |
106 | class BiFPNLayer(nn.Module):
107 | """"""
108 |
109 | def __init__(self, num_features=4, num_channels=64, upsample_type="nearest", downsample_type="max",
110 | conv_type="normal", weighted_fusion=True, **kwargs):
111 | super().__init__()
112 | assert isinstance(num_channels, int)
113 | self.num_features = num_features
114 | self.top_down = nn.ModuleList()
115 | self.bottom_up = nn.ModuleList()
116 |
117 | # build top down
118 | for _ in range(num_features - 1):
119 | fuse = Fuse(2, num_channels, "up", upsample=upsample_type, conv_type=conv_type,
120 | weighted_fusion=weighted_fusion)
121 | self.top_down.append(fuse)
122 |
123 | # build bottom up
124 | for _ in range(1, num_features - 1):
125 | fuse = Fuse(3, num_channels, "down", downsample=downsample_type, conv_type=conv_type,
126 | weighted_fusion=weighted_fusion)
127 | self.bottom_up.append(fuse)
128 |
129 | self.last_fuse = Fuse(2, num_channels, "down", downsample=downsample_type, conv_type=conv_type,
130 | weighted_fusion=weighted_fusion)
131 |
132 | def forward(self, features):
133 | # top down: Ptd_6 = conv(Pin_6 + up(Ptd_7))
134 | topdowns = [None] * len(features)
135 | topdowns[-1] = features[-1]
136 | for i in range(len(self.top_down)):
137 | topdowns[-2 - i] = self.top_down[i](features[-2 - i], topdowns[-1 - i])
138 |
139 | # bottom up: Pout_6 = conv(Pin_6 + Ptd_6 + down(Pout_5))
140 | out = [None] * len(features)
141 | out[0] = topdowns[0]
142 | for i in range(len(self.bottom_up)):
143 | out[i + 1] = self.bottom_up[i](features[i + 1], topdowns[i + 1], out[i])
144 | out[-1] = self.last_fuse(features[-1], out[-2])
145 |
146 | return out
147 |
148 |
149 | class BiFPNNeck(nn.Module):
150 | def __init__(self, backbone_channels, num_layers=3, num_features=4, num_channels=64, upsample_type="nearest",
151 | downsample_type="max", conv_type="normal", weighted_fusion=True, **kwargs):
152 | super().__init__()
153 | self.project = nn.ModuleList()
154 | self.layers = nn.ModuleList()
155 | self.num_features = num_features
156 |
157 | for b_channels in backbone_channels[-num_features:]:
158 | conv = nn.Conv2d(b_channels, num_channels, 1)
159 | self.project.append(conv)
160 |
161 | for _ in range(num_layers):
162 | bifpn_layer = BiFPNLayer(num_features=num_features, num_channels=num_channels, upsample_type=upsample_type,
163 | downsample_type=downsample_type, conv_type=conv_type,
164 | weighted_fusion=weighted_fusion, **kwargs)
165 | self.layers.append(bifpn_layer)
166 |
167 | self.out_channels = num_channels
168 | self.upsample_stride = 2 ** (num_features - 1)
169 |
170 | def forward(self, features):
171 | out = [project(x) for project, x in zip(self.project, features[-self.num_features:])]
172 |
173 | for bifpn_layer in self.layers:
174 | out = bifpn_layer(out)
175 |
176 | return out[0], out[-1]
177 |
--------------------------------------------------------------------------------
/models/backbones/misc.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import torch
5 | from typing import Optional
6 |
7 | def _make_divisible(v: float, divisor: int, min_value: Optional[int] = None) -> int:
8 | """
9 | This function is taken from the original tf repo.
10 | It ensures that all layers have a channel number that is divisible by 8
11 | It can be seen here:
12 | https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
13 | """
14 | if min_value is None:
15 | min_value = divisor
16 | new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
17 | # Make sure that round down does not go down by more than 10%.
18 | if new_v < 0.9 * v:
19 | new_v += divisor
20 | return new_v
21 |
22 | class FrozenBatchNorm2d(torch.nn.Module):
23 | # https://github.com/facebookresearch/detr/blob/master/models/backbone.py
24 | """
25 | BatchNorm2d where the batch statistics and the affine parameters are fixed.
26 | Copy-paste from torchvision.misc.ops with added eps before rqsrt,
27 | without which any other models than torchvision.models.resnet[18,34,50,101]
28 | produce nans.
29 | """
30 |
31 | def __init__(self, n):
32 | super(FrozenBatchNorm2d, self).__init__()
33 | self.register_buffer("weight", torch.ones(n))
34 | self.register_buffer("bias", torch.zeros(n))
35 | self.register_buffer("running_mean", torch.zeros(n))
36 | self.register_buffer("running_var", torch.ones(n))
37 |
38 | def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict,
39 | missing_keys, unexpected_keys, error_msgs):
40 | num_batches_tracked_key = prefix + 'num_batches_tracked'
41 | if num_batches_tracked_key in state_dict:
42 | del state_dict[num_batches_tracked_key]
43 |
44 | super(FrozenBatchNorm2d, self)._load_from_state_dict(
45 | state_dict, prefix, local_metadata, strict,
46 | missing_keys, unexpected_keys, error_msgs)
47 |
48 | def forward(self, x):
49 | # move reshapes to the beginning
50 | # to make it fuser-friendly
51 | w = self.weight.reshape(1, -1, 1, 1)
52 | b = self.bias.reshape(1, -1, 1, 1)
53 | rv = self.running_var.reshape(1, -1, 1, 1)
54 | rm = self.running_mean.reshape(1, -1, 1, 1)
55 | eps = 1e-5
56 | scale = w * (rv + eps).rsqrt()
57 | bias = b - rm * scale
58 | return x * scale + bias
59 |
60 | class ConvNormActivation(torch.nn.Sequential):
61 | """
62 | Configurable block used for Convolution-Normalzation-Activation blocks.
63 |
64 | Args:
65 | in_channels (int): Number of channels in the input image
66 | out_channels (int): Number of channels produced by the Convolution-Normalzation-Activation block
67 | kernel_size: (int, optional): Size of the convolving kernel. Default: 3
68 | stride (int, optional): Stride of the convolution. Default: 1
69 | padding (int, tuple or str, optional): Padding added to all four sides of the input. Default: None, in wich case it will calculated as ``padding = (kernel_size - 1) // 2 * dilation``
70 | groups (int, optional): Number of blocked connections from input channels to output channels. Default: 1
71 | norm_layer (Callable[..., torch.nn.Module], optional): Norm layer that will be stacked on top of the convolutiuon layer. If ``None`` this layer wont be used. Default: ``torch.nn.BatchNorm2d``
72 | activation_layer (Callable[..., torch.nn.Module], optinal): Activation function which will be stacked on top of the normalization layer (if not None), otherwise on top of the conv layer. If ``None`` this layer wont be used. Default: ``torch.nn.ReLU``
73 | dilation (int): Spacing between kernel elements. Default: 1
74 | inplace (bool): Parameter for the activation layer, which can optionally do the operation in-place. Default ``True``
75 | bias (bool, optional): Whether to use bias in the convolution layer. By default, biases are included if ``norm_layer is None``.
76 |
77 | """
78 |
79 | def __init__(
80 | self,
81 | in_channels: int,
82 | out_channels: int,
83 | kernel_size: int = 3,
84 | stride: int = 1,
85 | padding: int = None,
86 | groups: int = 1,
87 | norm_layer: torch.nn.Module = torch.nn.BatchNorm2d,
88 | activation_layer: torch.nn.Module = torch.nn.ReLU,
89 | dilation: int = 1,
90 | inplace: bool = True,
91 | bias: bool = None,
92 | ) -> None:
93 | if padding is None:
94 | padding = (kernel_size - 1) // 2 * dilation
95 | if bias is None:
96 | bias = norm_layer is None
97 | layers = [
98 | torch.nn.Conv2d(
99 | in_channels,
100 | out_channels,
101 | kernel_size,
102 | stride,
103 | padding,
104 | dilation=dilation,
105 | groups=groups,
106 | bias=bias,
107 | )
108 | ]
109 | if norm_layer is not None:
110 | layers.append(norm_layer(out_channels))
111 | if activation_layer is not None:
112 | params = {} if inplace is None else {"inplace": inplace}
113 | layers.append(activation_layer(**params))
114 | super().__init__(*layers)
115 | self.out_channels = out_channels
116 |
117 |
118 | class SqueezeExcitation(torch.nn.Module):
119 | """
120 | This block implements the Squeeze-and-Excitation block from https://arxiv.org/abs/1709.01507 (see Fig. 1).
121 | Parameters ``activation``, and ``scale_activation`` correspond to ``delta`` and ``sigma`` in in eq. 3.
122 |
123 | Args:
124 | input_channels (int): Number of channels in the input image
125 | squeeze_channels (int): Number of squeeze channels
126 | activation (Callable[..., torch.nn.Module], optional): ``delta`` activation. Default: ``torch.nn.ReLU``
127 | scale_activation (Callable[..., torch.nn.Module]): ``sigma`` activation. Default: ``torch.nn.Sigmoid``
128 | """
129 |
130 | def __init__(
131 | self,
132 | input_channels: int,
133 | squeeze_channels: int,
134 | activation: torch.nn.Module = torch.nn.ReLU,
135 | scale_activation: torch.nn.Module = torch.nn.Sigmoid,
136 | ) -> None:
137 | super().__init__()
138 | self.avgpool = torch.nn.AdaptiveAvgPool2d(1)
139 | self.fc1 = torch.nn.Conv2d(input_channels, squeeze_channels, 1)
140 | self.fc2 = torch.nn.Conv2d(squeeze_channels, input_channels, 1)
141 | self.activation = activation()
142 | self.scale_activation = scale_activation()
143 |
144 | def _scale(self, input: torch.Tensor) -> torch.Tensor:
145 | scale = self.avgpool(input)
146 | scale = self.fc1(scale)
147 | scale = self.activation(scale)
148 | scale = self.fc2(scale)
149 | return self.scale_activation(scale)
150 |
151 | def forward(self, input: torch.Tensor) -> torch.Tensor:
152 | scale = self._scale(input)
153 | return scale * input
154 |
--------------------------------------------------------------------------------
/evaluate.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | from tqdm import tqdm
5 | from pprint import pprint
6 |
7 | import cv2
8 | import click
9 | import torch
10 | import numpy as np
11 |
12 | from torchinfo import summary
13 | from torch.utils.data import DataLoader
14 | from torchmetrics.detection.mean_ap import MeanAveragePrecision
15 | from torchmetrics.classification import F1Score, Accuracy
16 | from torchmetrics import JaccardIndex
17 | from torchvision import transforms
18 |
19 | from conf import Conf
20 | from models import CerberusModel
21 | from utils.box_utils import match_bboxes
22 | from inference.postproc import cluster_lane_preds, fit_lanes
23 | from dataset import MultitaskDataset, ignore_collate
24 |
25 |
26 | @click.command()
27 | @click.option('--conf_file', '-c', type=click.Path(exists=True), default=None, required=True)
28 | @click.option('--weights_file', '-w', type=click.Path(exists=True), default=None, required=False)
29 | @click.option('--show', '-s', type=click.BOOL, default=False, required=False)
30 | def main(conf_file, weights_file, show):
31 |
32 | cnf = Conf(conf_file_path=conf_file, log=False)
33 | cnf.dataset.images_root = "/home/carmelo/DATASETS/BDD100K/bdd100k_images/images/100k"
34 | cnf.dataset.lane_det.data_root = "/home/carmelo/CEMP/MT_ADASNET/data"
35 | cnf.dataset.obj_det.data_root = "/home/carmelo/DATASETS/BDD100K/bdd100k_det/labels/det_20"
36 |
37 | # Select tasks
38 | eval_lane_det = cnf.base.get("lane_det", True)
39 | eval_obj_det = cnf.base.get("object_det", True)
40 | eval_obj_occl = cnf.base.get("occlusion_cls", True)
41 | eval_scene_cls = cnf.base.get("scene_cls", True)
42 |
43 | device = "cuda" if torch.cuda.is_available() else 'cpu'
44 |
45 | # Inverse normalization (for display)
46 | invTrans = transforms.Compose([transforms.Normalize(mean=[0., 0., 0.],
47 | std=[1 / 0.229, 1 / 0.224, 1 / 0.225]),
48 | transforms.Normalize(mean=[-0.485, -0.456, -0.406],
49 | std=[1., 1., 1.]),
50 | ])
51 |
52 | # Torchmetrics
53 | map = MeanAveragePrecision()
54 | iou = JaccardIndex(num_classes=2)
55 |
56 | wtr_f1 = F1Score(num_classes=7, average='micro')
57 | scn_f1 = F1Score(num_classes=7, average='micro')
58 | td_f1 = F1Score(num_classes=4, average='micro')
59 |
60 | occl_acc = Accuracy()
61 |
62 | # Load data
63 | collate_fn = ignore_collate(["centers", "offsets", "keypoints",
64 | "occlusion", "boxes", "classes", "lanes"])
65 |
66 | valset = MultitaskDataset(cnf, mode="val", gt=True)
67 | val_loader = DataLoader(valset, collate_fn=collate_fn, batch_size=1)
68 |
69 | # load model
70 | model = CerberusModel(cnf).to(device)
71 | ck = torch.load(weights_file, map_location=device)
72 | model.load_state_dict(ck, strict=True)
73 |
74 | model.eval()
75 |
76 | # Print stats
77 | # summary(model, input_size=(1, 3, 640, 320))
78 |
79 | # Run evaluation loop
80 | for batch_idx, batch in enumerate(tqdm(val_loader)):
81 | img, targets = batch
82 | img = img.to(cnf.device)
83 |
84 | with torch.no_grad():
85 | pred = model.inference(img)
86 |
87 | """det_out, lane_out, scn_out, heatmaps_out = pred
88 | boxes, boxes_cls, boxes_occl =
89 | lanes, lanes_cls, lanes_votes = lane_out"""
90 |
91 | # =======================
92 | # Object detection metric
93 | # =======================
94 | if eval_obj_det:
95 | det_out = pred["obj_det"]["decoded"]
96 | boxes, boxes_cls = det_out["boxes"], det_out["labels"]
97 |
98 | car_pred = torch.nonzero(boxes_cls == 2).squeeze(1)
99 | det_pred = {
100 | 'boxes': boxes[:, :4].cpu(),
101 | 'scores': boxes[:, 4].cpu(),
102 | 'labels': boxes_cls.cpu(),
103 | }
104 |
105 | car_true = (targets["obj_det"]["classes"][0] == 2).nonzero().squeeze(1)
106 | det_target = {
107 | 'boxes': targets["obj_det"]["boxes"][0],
108 | 'labels': targets["obj_det"]["classes"][0],
109 | }
110 |
111 | if eval_obj_occl:
112 | boxes_occl = det_out["occlusion"]
113 | det_pred['occlusion'] = boxes_occl.cpu()
114 | det_target['occlusion'] = targets["obj_det"]["occlusion"][0]
115 |
116 | # TODO: testare con decodifica del GT!
117 | map.update([det_pred], [det_target])
118 |
119 | # -------------------------------
120 | # Occlusion Classification Metric
121 | # -------------------------------
122 | if eval_obj_occl:
123 | gt_valid, pred_valid, _, _ = match_bboxes(det_target["boxes"][car_true], det_pred["boxes"][car_pred])
124 | occlu_true = det_target["occlusion"][car_true][gt_valid].int()
125 | occlu_pred = det_pred["occlusion"][car_pred][pred_valid]
126 |
127 | if len(gt_valid) >= 1:
128 | occl_acc.update(occlu_pred, occlu_true)
129 |
130 | # ===============================
131 | # Scene Classification Metric
132 | # ===============================
133 | if eval_scene_cls:
134 | scn_out = pred["scene_cls"]
135 | wtr_f1.update(scn_out['weather'].cpu(), targets['scn_cls']['weather'])
136 | scn_f1.update(scn_out['scene'].cpu(), targets['scn_cls']['scene'])
137 | td_f1.update(scn_out['timeofday'].cpu(), targets['scn_cls']['timeofday'])
138 |
139 | # =======================
140 | # Lane Estimation Metric
141 | # =======================
142 | if eval_lane_det:
143 | lane_out = pred["lane_est"]["decoded"]
144 | lanes, lanes_cls, lanes_votes = lane_out["lanes"], lane_out["lanes_labels"], lane_out["lanes_votes"]
145 |
146 | # Build GT mask
147 | gt_lanes = targets["lane_det"]["lanes"][0]
148 | gt_lanes = [l.numpy() * 4 for l in gt_lanes]
149 | gt_mask = lanes_to_mask(gt_lanes, cnf.dataset.input_h, cnf.dataset.input_w)
150 | gm = torch.from_numpy(gt_mask).long().unsqueeze(0)
151 |
152 | # Build predicted mask
153 | lane_clusters = cluster_lane_preds(lanes, lanes_cls, lanes_votes)
154 | lanes_pred = fit_lanes(lane_clusters)
155 |
156 | pred_lanes = []
157 | for i in range(8):
158 | pred_lanes += lanes_pred[i]
159 |
160 | pred_mask = lanes_to_mask(pred_lanes, cnf.dataset.input_h, cnf.dataset.input_w)
161 | pm = torch.from_numpy(pred_mask).long().unsqueeze(0)
162 |
163 | iou.update(gm, pm)
164 |
165 | #if batch_idx > 500:
166 | # break
167 |
168 | # Display results
169 | if show:
170 | frame = invTrans(img[0])
171 | frame = frame.cpu().numpy().transpose(1, 2, 0)
172 |
173 | if eval_obj_det:
174 | # true
175 | boxes_pred = boxes[:, :4].cpu().numpy()
176 | for b in boxes_pred:
177 | color = (0, 255, 0)
178 | frame = cv2.rectangle(frame, (int(b[2]), int(b[3])), (int(b[0]), int(b[1])), color, 2)
179 |
180 | # objects pred
181 | boxes_true = targets["obj_det"]["boxes"][0]
182 | for b in boxes_true:
183 | color = (0, 0, 255)
184 | frame = cv2.rectangle(frame, (int(b[2]), int(b[3])), (int(b[0]), int(b[1])), color, 2)
185 |
186 | #Lane masks
187 | if eval_lane_det:
188 | all_mask = np.zeros((cnf.dataset.input_h, cnf.dataset.input_w, 3), dtype=np.uint8)
189 | all_mask[:, :, 1] = pred_mask*255
190 | all_mask[:, :, 2] = gt_mask*255
191 |
192 | while cv2.waitKey(1) != ord('q'):
193 | if eval_obj_det: cv2.imshow("detection", frame)
194 | if eval_lane_det: cv2.imshow("lanes", all_mask)
195 |
196 |
197 |
198 | if eval_obj_det:
199 | print("--- OBJECT DETECTION ---")
200 | pprint(map.compute())
201 |
202 | if eval_lane_det:
203 | print("--- LANE ESTIMATION ---")
204 | pprint(iou.compute())
205 |
206 | if eval_scene_cls:
207 | print("--- SCENE CLASSIFICATION F1 (weather, scene, time of day) ---")
208 | pprint(wtr_f1.compute())
209 | pprint(scn_f1.compute())
210 | pprint(td_f1.compute())
211 |
212 | if eval_obj_det and eval_obj_occl:
213 | print("--- OCCLUSION CLASSIFICATION ACCURACY ---")
214 | pprint(occl_acc.compute())
215 |
216 | def lanes_to_mask(lanes, h, w):
217 | gt_mask = np.zeros((h, w), dtype=np.uint8)
218 | for l in lanes:
219 | points = l.astype(np.int32)
220 |
221 | # Draw mask
222 | points = points.reshape((-1, 1, 2))
223 | gt_mask = cv2.polylines(gt_mask, [points], False, (1), 2)
224 |
225 | return gt_mask
226 |
227 | if __name__ == '__main__':
228 | # baseline: 'map_50': tensor(0.5604),
229 | main()
230 |
231 |
--------------------------------------------------------------------------------
/Readme.md:
--------------------------------------------------------------------------------
1 | # CERBERUS: CEnterR Based Ent-to-end peRception Using a Single model [[arXiv]](https://arxiv.org/abs/2210.00756)
2 |
3 | This is the official code repository for **"CERBERUS: Simple and Effective All-In-One Automotive Perception
4 | Model with Multi Task Learning"**
5 |
6 | ## Model
7 |
8 |
9 |  10 |
10 |
11 |
12 | CERBERUS is a Deep-Learning based model for automotive perception with a Multi-task learning approach.
13 | It simultaneously perform object detection (with classification of the occlusion state), lane estimation and scene classification.
14 | This model is trained on BDD100k and perform well on real world driving footage, moreover we provide code for inference on Nvidia Jetson boards using the TensorRT framework.
15 |
16 | ## Demo
17 | [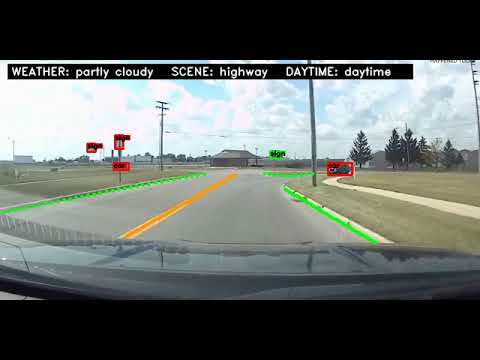](https://www.youtube.com/watch?v=npSDJ8seJ7E)
18 |
19 | **(Video, click image to reproduce)**
20 |
21 | ## Requirements
22 |
23 | This codebase is built using PyTorch and PyTorch-Lightning,
24 | together with several other libraries. To replicate our experimental
25 | setup we highly recommend to create and Ananconda environment, if you don't have
26 | Anaconda installed yet you can [install it](https://docs.anaconda.com/anaconda/install/).
27 |
28 | * Clone this repository
29 | ```
30 | git clone git@github.com:cscribano/CERBERUS.git
31 | cd CERBERUS
32 | ```
33 | * Create a new Aanaconda environment
34 | ```
35 | conda create -n cerberus python=3.8
36 | ```
37 | * Install requirements
38 | ```
39 | conda activate cerberus
40 | conda install pytorch==1.8.1 torchvision==0.9.1 cudatoolkit=11.1 -c pytorch -c conda-forge -y
41 | pip install -r requirements.txt
42 | ```
43 |
44 | To perform inference using TensorRT the framework must be installed following the NVidia [documentation](https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html).
45 | We officially supportonly TensorRT version 8.4.0.
46 |
47 | ## Inference
48 |
49 | We provide a set of pretrained models above (`Model Zoo`) both as pytorch checkpoints and exported to onnx (for inference
50 | using TensorRT).
51 |
52 | ### Inference using PyTorch
53 | * Download the configuration file and the corresponding `.pth` checkpoint.
54 | * The sample inference script perform inference on a video file, as an example you can find the public footage used for our demo [here](https://drive.google.com/file/d/1zS3L01VHwtPS9WrmOUD5G2V_A4rK7fB-/view?usp=sharing) ([credit](https://www.youtube.com/watch?v=zEl-EUIJTOU))
55 | * Perform inference:
56 | ```
57 | cd CERBERUS
58 | python inference/run.py -c .json -w .pth -v .mp4
59 | ```
60 |
61 | * In addition you can add the option `-o true` to perform conversion to `.onnx`
62 |
63 | ### Interence using TensorRT
64 | The sample inference code is similar to the PyTorch version, but it requires as input the `.onnx` model and the video file.
65 | When a model is loaded for the first time it is converted to tensorrt, this process usually takes a very long time.
66 |
67 | ```
68 | cd CERBERUS
69 | python inference/run_tensorrt.py -m .onnx -v .mp4
70 | ```
71 |
72 | ### Running on NVidia Jetson
73 | We provide a script to automatically install all the requirements on an Nvidia board, it is only tested on Jetson AGX Xavier
74 | and Jetson Nano on a fresh install of JetPack 4.6.1
75 |
76 | ```
77 | git clone git@github.com:cscribano/CERBERUS.git
78 | cd CERBERUS/docs
79 | chmod +x deps.sh
80 | ./deps.sh
81 | ```
82 |
83 | The installation process require a very long time, at the end reboot is required. When done inference can be performed using TensorRT as described above.
84 |
85 | ### Model Zoo
86 | | **Model** | **configuration** | **weights** | **onnx** |
87 | |:--------------------:|:-----------------------------:|:----------------------------:|:---------------------------------:|
88 | | **resnet34_simple** | [resnet34_simple.json](https://drive.google.com/file/d/1uZqNuCwI3OHAUNG450XZQD2pQT7YIpDr/view?usp=sharing) | [resnet34_simple.pth](https://drive.google.com/file/d/1v5pa3LdXgjjsAiMxMgitBiy6brObskht/view?usp=sharing) | [resnet34_simple_sim.onnx](https://drive.google.com/file/d/1MOBMinfU0PrT8hPjjc7gXG4HOHYGCP7K/view?usp=sharing) |
89 | | **resnet34_bifpn** | [resnet34_bifpn.json](https://drive.google.com/file/d/1Ixuj72Rj2zFasyB-mu7rQiNuA6Yv2ZGg/view?usp=sharing) | [resnet34_bifpn.pth](https://drive.google.com/file/d/16jXHf1kEhR3QaXkJxijDxKbGwhNkbUEe/view?usp=sharing) | [resnet34_bifpn_sim.onnx](https://drive.google.com/file/d/18xoh22M0wR5O5yu4mDyKcytQaqxhN4hP/view?usp=sharing) |
90 | | **resnet50_bifpn** | [resnet50_bifpn.json](https://drive.google.com/file/d/1eXv7JJGFqHXy3Am0G-xu2ulKm4iRmEz5/view?usp=sharing) | [resnet50_bifpn.pth](https://drive.google.com/file/d/1Sm33JXcWo9a0uiOoqv02yKss1SkEUOWT/view?usp=sharing) | [resnet50_bifpn_sim.onnx](https://drive.google.com/file/d/1ER6weOsLPgX-GdS53ikr0oI-al2g7Yv8/view?usp=sharing) |
91 | | **resnet101_bifpn** | [resnet101_bifpn.json](https://drive.google.com/file/d/1-5aEQMul1j-Wr8jrOB2CH8yhYysuuXe5/view?usp=sharing) | [resnet101_bifpn.pth](https://drive.google.com/file/d/1Fc2yXc04CB1vsZnZSy1WT6rxjOJPMLjc/view?usp=sharing) | [resnet101_bifpn_sim.onnx](https://drive.google.com/file/d/1hCdz6o0PvNf5IF0-27tVPrh9OJKLD0W7/view?usp=sharing) |
92 | | **efficientnetb2_bifpn** | [efficientnetb2_bifpn.json](https://drive.google.com/file/d/1_F6JBX5i6wxV_MmcyaWnt95dOg3WlYUo/view?usp=sharing) | [efficientnetb2_bifpn.pth](https://drive.google.com/file/d/16wJCSj7bSAt_iPdPytWtH6TOtL8_LQ0x/view?usp=sharing) | [efficientnetb2_bifpn_sim.onnx](https://drive.google.com/file/d/1AkLHe8-KtsZ6sD-qLYl4DLlhYqaT_gdA/view?usp=sharing) |
93 | | **mobilenetv2_bifpn** | [mobilenetv2_bifpn.json](https://drive.google.com/file/d/1ikR9ia9k9zVMznfuRbGryecfrVfB_GXU/view?usp=sharing) | [mobilenetv2_bifpn.pth](https://drive.google.com/file/d/1WZ3vPPSAF23yGpMIA4DINaBE-6-v2ZH9/view?usp=sharing) | [mobilenetv2_bifpn_sim.onnx](https://drive.google.com/file/d/1YUYp-QqSzvJDJj5bbdrA4crZBn_xMpvf/view?usp=sharing) |
94 |
95 |
96 | ## Training
97 |
98 | ### Dataset
99 | Only BDD100K is supported, the dataset is available for free from the autors (https://bdd-data.berkeley.edu/).
100 | After downloading the dataset a pre-processing step is required to encode the lane makins annotations in the format required by Cerberus,
101 | we provide the script `data/bdd100k_lane_keypoints.py` to take care of this step.
102 |
103 | ```
104 | cd CERBERUS/data
105 | python bdd100k_lane_keypoints.py -i /bdd100k_images/images/100k -l /bdd100k_lanes/labels/lane
106 | ```
107 |
108 | The files `train_25_new.pt` and `val_25_new.pt` will be saved in the `/data` directory. If you have any problem in this step we provide the preprocessed labels [here](https://drive.google.com/file/d/1Cz7GByXW57IiVzHNY5SyDW3LuRt_GuMp/view?usp=sharing)
109 |
110 | ### Start training
111 | * Adjust the configuration `.json` file in `./conf/experiments` accordingly to the directories where you extracted the dataset and the processet lane labels.
112 | * Run the training loop:
113 | ```
114 | python main.py --exp_name=
115 | ```
116 |
117 | Please notice that the `.json` extension is NOT part of the experiment name:
118 | ```i.e, conf file is "experiments/resnet34_bifpn.json" --> --exp_name=resnet34_bifpn```
119 |
120 |
121 | ## References
122 | Presented at [PNARUDE](https://iros2022-pnarude.github.io/) Workshop @ IROS
123 |
124 | If you use CERBERUS in your research, please cite the following paper.
125 | ```
126 | @article{scribano2022cerberus,
127 | title={CERBERUS: Simple and Effective All-In-One Automotive Perception Model with Multi Task Learning},
128 | author={Scribano, Carmelo and Franchini, Giorgia and Olmedo, Ignacio Sanudo and Bertogna, Marko},
129 | journal={arXiv preprint arXiv:2210.00756},
130 | year={2022}
131 | }
132 | ```
133 |
134 | For use in commercial solutions, write at carmelo.scribano@unimore.it or refer to https://hipert.unimore.it/ .
135 |
--------------------------------------------------------------------------------
/inference/trt_inference/trt_infer.py:
--------------------------------------------------------------------------------
1 | import ctypes
2 | import cupy as cp
3 | import cupyx
4 | import tensorrt as trt
5 | import logging
6 |
7 | EXPLICIT_BATCH = 1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
8 | LOGGER = logging.getLogger(__name__)
9 |
10 | class HostDeviceMem:
11 | def __init__(self, size, dtype):
12 | self.size = size
13 | self.dtype = dtype
14 | self.host = cupyx.empty_pinned(size, dtype)
15 | self.device = cp.empty(size, dtype)
16 |
17 | def __str__(self):
18 | return "Host:\n" + str(self.host) + "\nDevice:\n" + str(self.device)
19 |
20 | def __repr__(self):
21 | return self.__str__()
22 |
23 | @property
24 | def nbytes(self):
25 | return self.host.nbytes
26 |
27 | @property
28 | def hostptr(self):
29 | return self.host.ctypes.data
30 |
31 | @property
32 | def devptr(self):
33 | return self.device.data.ptr
34 |
35 | def copy_htod_async(self, stream):
36 | self.device.data.copy_from_host_async(self.hostptr, self.nbytes, stream)
37 |
38 | def copy_dtoh_async(self, stream):
39 | self.device.data.copy_to_host_async(self.hostptr, self.nbytes, stream)
40 |
41 | class TRTModel:
42 | """Base class for TRT models.
43 |
44 | Attributes
45 | ----------
46 | PLUGIN_PATH : Path, optional
47 | Path to TensorRT plugin.
48 | ENGINE_PATH : Path
49 | Path to TensorRT engine.
50 | If not found, TensorRT engine will be converted from the ONNX model
51 | at runtime and cached for later use.
52 | MODEL_PATH : Path
53 | Path to ONNX model.
54 | INPUT_SHAPE : tuple
55 | Input size in the format `(channel, height, width)`.
56 | OUTPUT_LAYOUT : int
57 | Feature dimension output by the model.
58 | """
59 | __registry = {}
60 |
61 | PLUGIN_PATH = None
62 | ENGINE_PATH = None
63 | MODEL_PATH = None
64 | INPUT_SHAPE = None
65 | OUTPUT_LAYOUT = None
66 |
67 | def __init_subclass__(cls, model=None, **kwargs):
68 | super().__init_subclass__(**kwargs)
69 | cls.__registry[cls.__name__] = cls
70 |
71 | @classmethod
72 | def get_model(cls, name):
73 | return cls.__registry[name]
74 |
75 | @classmethod
76 | def build_engine(cls, trt_logger, batch_size):
77 | with trt.Builder(trt_logger) as builder, builder.create_network(EXPLICIT_BATCH) as network, \
78 | trt.OnnxParser(network, trt_logger) as parser:
79 |
80 | builder.max_batch_size = batch_size
81 | LOGGER.info('Building engine with batch size: %d', batch_size)
82 | LOGGER.info('This may take a while...')
83 |
84 | # parse model file
85 | with open(cls.MODEL_PATH, 'rb') as model_file:
86 | if not parser.parse(model_file.read()):
87 | LOGGER.critical('Failed to parse the ONNX file')
88 | for err in range(parser.num_errors):
89 | LOGGER.error(parser.get_error(err))
90 | return None
91 |
92 | # reshape input to the right batch size
93 | net_input = network.get_input(0)
94 | assert cls.INPUT_SHAPE == net_input.shape[1:]
95 | net_input.shape = (batch_size, *cls.INPUT_SHAPE)
96 |
97 | config = builder.create_builder_config()
98 | config.max_workspace_size = 1 << 30
99 | if builder.platform_has_fast_fp16:
100 | LOGGER.debug("TensorRT is using FP16")
101 | config.set_flag(trt.BuilderFlag.FP16)
102 |
103 | profile = builder.create_optimization_profile()
104 | profile.set_shape(
105 | net_input.name, # input tensor name
106 | (batch_size, *cls.INPUT_SHAPE), # min shape
107 | (batch_size, *cls.INPUT_SHAPE), # opt shape
108 | (batch_size, *cls.INPUT_SHAPE) # max shape
109 | )
110 | config.add_optimization_profile(profile)
111 |
112 | # engine = builder.build_cuda_engine(network)
113 | engine = builder.build_engine(network, config)
114 | if engine is None:
115 | LOGGER.critical('Failed to build engine')
116 | return None
117 |
118 | LOGGER.info("Completed creating engine")
119 | with open(cls.ENGINE_PATH, 'wb') as engine_file:
120 | engine_file.write(engine.serialize())
121 | return engine
122 |
123 | class TRTInference:
124 | # initialize TensorRT
125 | TRT_LOGGER = trt.Logger(trt.Logger.ERROR)
126 | trt.init_libnvinfer_plugins(TRT_LOGGER, '')
127 |
128 | def __init__(self, model, batch_size):
129 | self.model = model
130 | self.batch_size = batch_size
131 |
132 | # load plugin if the model requires one
133 | if self.model.PLUGIN_PATH is not None:
134 | try:
135 | ctypes.cdll.LoadLibrary(self.model.PLUGIN_PATH)
136 | except OSError as err:
137 | raise RuntimeError('Plugin not found') from err
138 |
139 | # load trt engine or build one if not found
140 | if not self.model.ENGINE_PATH.exists():
141 | print("Building TRT Model...")
142 | self.engine = self.model.build_engine(TRTInference.TRT_LOGGER, self.batch_size)
143 | else:
144 | runtime = trt.Runtime(TRTInference.TRT_LOGGER)
145 | with open(self.model.ENGINE_PATH, 'rb') as engine_file:
146 | self.engine = runtime.deserialize_cuda_engine(engine_file.read())
147 | if self.engine is None:
148 | raise RuntimeError('Unable to load the engine file')
149 | if self.engine.has_implicit_batch_dimension:
150 | assert self.batch_size <= self.engine.max_batch_size
151 | self.context = self.engine.create_execution_context()
152 | self.stream = cp.cuda.Stream()
153 |
154 | # allocate buffers
155 | self.bindings = []
156 | self.outputs = []
157 | self.input = None
158 | for binding in self.engine:
159 | shape = self.engine.get_binding_shape(binding)
160 | size = trt.volume(shape)
161 | if self.engine.has_implicit_batch_dimension:
162 | size *= self.batch_size
163 | dtype = trt.nptype(self.engine.get_binding_dtype(binding))
164 | # allocate host and device buffers
165 | buffer = HostDeviceMem(size, dtype)
166 | # append the device buffer to device bindings
167 | self.bindings.append(buffer.devptr)
168 | if self.engine.binding_is_input(binding):
169 | if not self.engine.has_implicit_batch_dimension:
170 | assert self.batch_size == shape[0]
171 | # expect one input
172 | self.input = buffer
173 | else:
174 | self.outputs.append(buffer)
175 | assert self.input is not None
176 |
177 | # timing events
178 | self.start = cp.cuda.Event()
179 | self.end = cp.cuda.Event()
180 |
181 | print("TensorRT Model Ready!")
182 |
183 | def __del__(self):
184 | if hasattr(self, 'context'):
185 | self.context.__del__()
186 | if hasattr(self, 'engine'):
187 | self.engine.__del__()
188 |
189 | def infer(self):
190 | self.infer_async()
191 | return self.synchronize()
192 |
193 | def infer_async(self, from_device=False):
194 | self.start.record(self.stream)
195 | if not from_device:
196 | self.input.copy_htod_async(self.stream)
197 | if self.engine.has_implicit_batch_dimension:
198 | self.context.execute_async(batch_size=self.batch_size, bindings=self.bindings,
199 | stream_handle=self.stream.ptr)
200 | else:
201 | self.context.execute_async_v2(bindings=self.bindings, stream_handle=self.stream.ptr)
202 | for out in self.outputs:
203 | out.copy_dtoh_async(self.stream)
204 | self.end.record(self.stream)
205 |
206 | def synchronize(self):
207 | self.stream.synchronize()
208 | return [out.host for out in self.outputs]
209 |
210 | def get_infer_time(self):
211 | self.end.synchronize()
212 | return cp.cuda.get_elapsed_time(self.start, self.end)
213 |
214 |
--------------------------------------------------------------------------------
/dataset/multitask_dataset.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | from pathlib import Path
5 |
6 | import cv2
7 | import json
8 | import torch
9 | from torch.utils.data import Dataset
10 | from torchvision import transforms
11 |
12 | from dataset.utils import LaneProcessor, DetProcessor
13 | from dataset.utils.heatmaps import CornerNetRadius, FixedRadius
14 | from dataset.utils.transforms import RandomAspect, Preproc
15 |
16 | from conf import Conf
17 |
18 | class MultitaskDataset(Dataset):
19 |
20 | WIDTH = 1280
21 | HEIGHT = 720
22 |
23 | def __init__(self, cnf, mode='train', gt=False):
24 | # type: (Conf,str, bool) -> None
25 | """
26 | :param cnf: Configuration file
27 | :param mode: mode string (only train supported)
28 | :param gt: return GT data for test
29 | """
30 |
31 | self.cnf = cnf
32 | self.mode = mode
33 | self.return_gt = gt
34 | assert mode in ['train', 'val']
35 |
36 | # Image and heatmap sizes
37 | self.det_classes = cnf.base.get("det_classes", 10)
38 | self.lane_classes = cnf.base.get("lane_classes", 8)
39 |
40 | self.output_s = cnf.dataset.output_stride
41 | self.input_w, self.input_h = cnf.dataset.input_w, cnf.dataset.input_h
42 | self.target_w, self.target_h = int(self.input_w // self.output_s), int(self.input_h // self.output_s)
43 |
44 | # transforms
45 | self.transforms = RandomAspect(self.WIDTH, self.HEIGHT, self.input_w, self.input_h) \
46 | if mode in ["train", "train_all"] else Preproc(self.WIDTH, self.HEIGHT, self.input_w, self.input_h)
47 |
48 | # Image files
49 | self.images_root = Path(cnf.dataset.images_root) / mode
50 | self.image_files = {p.name: p for p in self.images_root.rglob("*.jpg")}
51 |
52 | # Lane keypoints
53 | self.lane_det = cnf.base.get("lane_det", False)
54 | if self.lane_det:
55 | lane_annot_file = Path(cnf.dataset.lane_det.data_root) / f"{mode}_{cnf.dataset.lane_det.ppm}_new.pt"
56 | lane_annotations = torch.load(lane_annot_file)
57 | self.lane_annotations = {v["name"]: v for v in lane_annotations}
58 | else:
59 | lane_annotations = []
60 | self.lane_annotations = {}
61 |
62 | # Object detection annotations
63 | self.obj_det = cnf.base.get("object_det", False)
64 | if self.obj_det:
65 | det_annot_file = Path(cnf.dataset.obj_det.data_root) / f"det_{mode}.json"
66 | det_annotations = json.load(open(det_annot_file, "r"))
67 | self.det_annotations = {v["name"]: v for v in det_annotations}
68 |
69 | # Heatmaps configuration
70 | s = cnf.dataset.obj_det.get("sigma", None)
71 | if s is not None:
72 | self.det_sigma = eval(s.name)(**s.args)
73 | else:
74 | self.det_sigma = FixedRadius(r=2)
75 |
76 | else:
77 | det_annotations = []
78 | self.det_annotations = {}
79 | self.det_sigma = lambda x, y: 1 # Identity
80 |
81 | # Target generators
82 | self.lane_processor = LaneProcessor(self.lane_classes, self.output_s, self.target_w, self.target_h)
83 | self.det_processor = DetProcessor(self.det_classes, self.output_s, self.target_w, self.target_h)
84 |
85 | # Multi-Task worthy dataset elements
86 | if self.obj_det and self.lane_det:
87 | # Intersection
88 | self.annot_keys = set([v['name'] for v in det_annotations]) & \
89 | set([v['name'] for v in lane_annotations])
90 | self.annot_keys = list(self.annot_keys)
91 |
92 | else:
93 | # Concatenation (one list will be empty)
94 | self.annot_keys = [v['name'] for v in det_annotations] +\
95 | [v['name'] for v in lane_annotations]
96 |
97 | self.annot_keys.sort() # For Validation reproducibility
98 |
99 | assert len(self.annot_keys) > 0
100 |
101 | def __len__(self):
102 | # type: () -> int
103 | return len(self.annot_keys)
104 |
105 | def __getitem__(self, i):
106 | # type: (int) -> tuple[torch.tensor, ...]
107 |
108 | target = {}
109 |
110 | # Select annotation
111 | annot_name = self.annot_keys[i]
112 |
113 | # Load image
114 | img_file = self.image_files[annot_name]
115 | image = cv2.imread(str(img_file))
116 |
117 | # Retrieve LANE keypoints
118 | lane_annot = self.lane_annotations.get(annot_name, {})
119 | lane_labels, lane_kp, lane_cls, lane_ids = self.lane_processor.keypoints(lane_annot)
120 |
121 | # Retrieve OBJECTS boxes
122 | det_annot = self.det_annotations.get(annot_name, {})
123 | det_labels, det_bbs, det_cls, occl_cls = self.det_processor.bounding_boxes(det_annot)
124 | scene_cls = self.det_processor.scene_classification(det_annot)
125 | target["scn_cls"] = scene_cls
126 |
127 | # Apply transforms
128 | image, lane_kp, lane_cls, lane_ids, det_bb, det_cls, occl_cls = self.transforms(image, keypoints=lane_kp, kp_labels=lane_cls,
129 | kp_ids=lane_ids, bboxes=det_bbs, bb_labels=det_cls, bb_occl=occl_cls)
130 |
131 | # Generate Object detection Target
132 | if self.obj_det:
133 | heatmap_det, centers, offsets = self.det_processor.targets(det_labels, det_bb, det_cls)
134 | occl_cls = torch.tensor(occl_cls).float()
135 |
136 | target["obj_det"] = {
137 | "heatmaps": heatmap_det,
138 | "centers": centers,
139 | "offsets": offsets,
140 | "occlusion": occl_cls
141 | }
142 |
143 | if self.return_gt:
144 | target["obj_det"]["boxes"] = torch.tensor(det_bb)
145 | target["obj_det"]["classes"] = torch.tensor(det_cls)
146 |
147 | ofstrue = torch.zeros(4, self.target_h, self.target_w)
148 | ofstrue[:, centers[:, 1].long(), centers[:, 0].long()] = offsets.t().float()
149 | target["obj_det"]["ofstrue"] = ofstrue
150 |
151 | if self.lane_det:
152 | # Target heatmap
153 | heatmap_lane, l_centers, l_offsets,\
154 | quant_offsets, l_keypoints = self.lane_processor.targets(lane_labels, lane_kp, lane_cls, lane_ids)
155 |
156 | target["lane_det"] = {
157 | "heatmaps": heatmap_lane,
158 | "keypoints": l_centers,
159 | "offsets": l_offsets,
160 | "quant_offsets": quant_offsets
161 | }
162 |
163 | if self.return_gt:
164 | target["lane_det"]["classes"] = torch.tensor(lane_cls)
165 | target["lane_det"]["lanes"] = l_keypoints
166 |
167 | return image, target
168 |
169 | if __name__ == '__main__':
170 |
171 | from tqdm import tqdm
172 | import numpy as np
173 | from torch.utils.data import DataLoader
174 |
175 | invTrans = transforms.Compose([transforms.Normalize(mean=[0., 0., 0.],
176 | std=[1 / 0.229, 1 / 0.224, 1 / 0.225]),
177 | transforms.Normalize(mean=[-0.485, -0.456, -0.406],
178 | std=[1., 1., 1.]),
179 | ])
180 |
181 | cnf = Conf(exp_name='resnet34_bifpn', log=False)
182 | ds = MultitaskDataset(cnf, **cnf.dataset.train_dataset.args)
183 | l = len(ds)
184 |
185 | for frame, target in ds:
186 |
187 | hm_det = target["obj_det"]["heatmaps"]
188 | hm_lane = target["lane_det"]["heatmaps"]
189 |
190 | frame = invTrans(frame)
191 | frame = frame.numpy().transpose(1, 2, 0)
192 |
193 | hm = torch.cat([hm_det, hm_lane], dim=0)
194 | hm_show, _ = torch.max(hm, dim=0)
195 | hm_show = hm_show.numpy() * 255
196 | hm_show = hm_show.astype(np.uint8)
197 | hm_show = cv2.applyColorMap(hm_show, cv2.COLORMAP_JET)
198 | hm_show = cv2.resize(hm_show, (cnf.dataset.input_w, cnf.dataset.input_h))
199 |
200 | super_imposed_img = cv2.addWeighted(hm_show.astype(np.float32) / 255, 0.5, frame, 0.5, 0)
201 |
202 | while cv2.waitKey(1) != ord('q'):
203 | cv2.imshow("heatmap", hm_show)
204 | cv2.imshow("frame", super_imposed_img)
205 |
--------------------------------------------------------------------------------
/inference/run.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import sys
5 | import click
6 | import torch
7 | from pathlib import Path
8 | import logging
9 | from random import randint
10 |
11 | import cv2
12 | from torchvision import transforms
13 | from torchinfo import summary
14 |
15 | import torch.onnx
16 | import onnx
17 | import onnxsim
18 |
19 | from dataset.utils.transforms import Preproc
20 | from dataset.utils.cls import WTR_CLS, SN_CLS, TD_CLS
21 | from models import CerberusModel
22 | from conf import Conf
23 | from inference.postproc import *
24 |
25 | from profiler import Profiler
26 |
27 | logging.basicConfig(format='%(asctime)s [%(levelname)8s] %(message)s', datefmt='%Y-%m-%d %H:%M:%S')
28 | LOGGER = logging.getLogger(__name__)
29 | LOGGER.setLevel(logging.DEBUG)
30 | LOGGER.addHandler(logging.StreamHandler(sys.stdout))
31 |
32 | Profiler.set_warmup(10)
33 |
34 | cls_col = [(153, 255, 102), (255,255,255), (0, 255, 255), (52, 255, 52), (51, 153, 51),
35 | (0,255,0), (153,51,51), (0,0,255), (255, 0, 0)]
36 |
37 | lancol = [(0,255,255), (255,255,255), (255, 150, 50),(0,0,255),
38 | (102, 0, 102), (10, 255, 0), (255, 255, 0), (0, 153, 255)]
39 |
40 | @click.command()
41 | @click.option('--conf_file', '-c', type=click.Path(exists=True), default=None, required=True)
42 | @click.option('--weights_file', '-w', type=click.Path(exists=True), default=None, required=False)
43 | @click.option('--video', '-v', type=click.Path(exists=True), default=None, required=True)
44 | @click.option('--onnx_export', '-o', type=click.BOOL, default=False, required=False)
45 | @click.option('--max_frames', '-f', type=int, default=None, required=False)
46 | def main(conf_file, weights_file, video, onnx_export, max_frames):
47 |
48 | cnf = Conf(conf_file_path=conf_file, log=False)
49 | device = "cuda" if torch.cuda.is_available() else 'cpu'
50 |
51 | # load video
52 | # video = "../videos/dashcam_demo.mp4"
53 | cap = cv2.VideoCapture(video)
54 | # cap.set(cv2.CAP_PROP_POS_FRAMES, 150*30)
55 |
56 | # Classes
57 | wtr = {v: k for k, v in WTR_CLS.items()}
58 | scn = {v: k for k, v in SN_CLS.items()}
59 | td = {v: k for k, v in TD_CLS.items()}
60 |
61 | # writer
62 | fourcc = cv2.VideoWriter_fourcc('m', 'p', '4', 'v')
63 | writer = cv2.VideoWriter('../videos/result.mp4', fourcc, 35, (cnf.dataset.input_w*2, cnf.dataset.input_h+40))
64 |
65 | # load model
66 | model = CerberusModel(cnf).to(device)
67 |
68 | if weights_file is not None:
69 | ck = torch.load(weights_file, map_location=device)
70 | model.load_state_dict(ck, strict=True)
71 | else:
72 | logging.debug("Weights file not exists!")
73 |
74 | model.eval()
75 |
76 | # Print stats
77 | summary(model, input_size=(1, 3, 640, 320))
78 |
79 | if onnx_export:
80 | # Convert to onnx
81 | print("Converting model to ONNX...")
82 | dummy_input = torch.randn(1, 3, cnf.dataset.input_h, cnf.dataset.input_w, requires_grad=True)
83 | dummy_input = dummy_input.to(device)
84 |
85 | base_file = Path(conf_file).stem
86 | out_file = Path(__file__).parent.parent / 'weights' / f'{base_file}.onnx'
87 | torch.onnx.export(model, (dummy_input, True), out_file,
88 | input_names=["x"], opset_version=11) # dynamic_axes= {"x": {0: "bs"}},
89 |
90 | # Simplify
91 | print("Simplifing...")
92 | model_opt = onnxsim.simplify(str(out_file), skip_fuse_bn=True, dynamic_input_shape=True)
93 | out_file_sim = Path(__file__).parent.parent / 'weights' / f'{base_file}_sim.onnx'
94 | onnx.save(model_opt[0], str(out_file_sim))
95 | print("onnx model simplify Ok!")
96 |
97 | # Image preproc
98 | pp = Preproc(1280, 720, cnf.dataset.input_w, cnf.dataset.input_h)
99 |
100 | invTrans = transforms.Compose([transforms.Normalize(mean=[0., 0., 0.],
101 | std=[1 / 0.229, 1 / 0.224, 1 / 0.225]),
102 | transforms.Normalize(mean=[-0.485, -0.456, -0.406],
103 | std=[1., 1., 1.]),
104 | ])
105 |
106 | frames = 0
107 | while cap.isOpened():
108 | with Profiler('acquire'):
109 | _, frame = cap.read()
110 | frame_pt = pp(frame)[0]
111 | frame_pt = frame_pt.unsqueeze(0)
112 | frame_pt = frame_pt.to(device)
113 |
114 | # Inference
115 | with torch.no_grad():
116 | with Profiler('inference_all'):
117 | pred = model.inference(frame_pt, benchmarking=max_frames is not None)
118 | if max_frames is not None:
119 | torch.cuda.synchronize(0)
120 |
121 | if max_frames is None:
122 |
123 | det_out = pred.get("obj_det", None)
124 | lane_out = pred.get("lane_det", None)
125 | scn_out = pred.get("scn_cls", None)
126 |
127 | # TODO: exlude disablee tasks
128 | lane_dec = lane_out["decoded"]
129 | lanes, lanes_cls, lanes_votes = lane_dec["lanes"], lane_dec["lanes_labels"], lane_dec["lanes_votes"]
130 |
131 | det_dec = det_out["decoded"]
132 | boxes, boxes_cls, boxes_occl = det_dec["boxes"], det_dec["labels"], det_dec["occlusion"]
133 |
134 | # Show result
135 | frame = frame_pt[0].cpu()
136 | frame = invTrans(frame)
137 | frame = frame.numpy().transpose(1, 2, 0)
138 |
139 | # Classification results
140 | if scn_out is not None:
141 | w_cls = wtr[scn_out['weather'].item()]
142 | s_cls = scn[scn_out['scene'].item()]
143 | td_cls = td[scn_out['timeofday'].item()]
144 | else:
145 | w_cls, s_cls, td_cls = "", "", ""
146 |
147 | with Profiler('lane_clustering'):
148 | # Lane clustering
149 | lane_clusters = cluster_lane_preds(lanes, lanes_cls, lanes_votes)
150 |
151 | # Superimpose
152 | hm_lane, hm_det = lane_out["heatmaps"], det_out["heatmaps"]
153 | heatmap = torch.cat([hm_lane, hm_det], dim=1)
154 |
155 | hm = heatmap[0].cpu().detach()
156 | hm_show, _ = torch.max(hm, dim=0)
157 | hm_show = hm_show.numpy() * 255
158 | hm_show = hm_show.astype(np.uint8)
159 | hm_show = cv2.applyColorMap(hm_show, cv2.COLORMAP_JET)
160 | hm_show = cv2.resize(hm_show, (cnf.dataset.input_w, cnf.dataset.input_h), cv2.INTER_LINEAR)
161 |
162 | super_imposed_img = cv2.addWeighted(hm_show.astype(np.float32) / 255, 0.5, frame, 0.5, 0)
163 |
164 | with Profiler('lane_drawing'):
165 | # Draw keypoints
166 | frame = (frame*255).astype(np.uint8)
167 | lanes_pred = fit_lanes(lane_clusters)
168 |
169 | for lane_cls in range(len(lane_clusters)):
170 | lanes_pred_cls = lanes_pred[lane_cls]
171 | col = cls_col[lane_cls]
172 |
173 | for lane_pred in lanes_pred_cls:
174 | x_new = lane_pred[:, 0]
175 | y_new = lane_pred[:, 1]
176 |
177 | for cx, cy in zip(x_new, y_new):
178 | frame = cv2.circle(frame, (int(cx), int(cy)), 1, col, thickness=2, )
179 |
180 | with Profiler('det_drawing'):
181 |
182 | # Draw boxes
183 | for b, bo in zip(boxes, boxes_occl):
184 | color = (0, 255, 0) if bo < 0.5 else (0,0,255)
185 | frame = cv2.rectangle(frame, (int(b[2]), int(b[3])), (int(b[0]), int(b[1])), color, 2)
186 |
187 | write_img = (super_imposed_img * 255).astype(np.uint8)
188 | write_img = np.concatenate([write_img, frame], axis=1)
189 |
190 | with Profiler('cls_drawing'):
191 | show_img = np.zeros((cnf.dataset.input_h + 40, cnf.dataset.input_w*2, 3), dtype=np.uint8)
192 | text = f"WEATHER: {w_cls} SCENE: {s_cls} DAYTIME: {td_cls}"
193 | show_img = cv2.putText(show_img, text, (15, 30), cv2.FONT_HERSHEY_DUPLEX, 0.8,
194 | (255,255,255), 1, cv2.LINE_AA, False)
195 | show_img[40:, :, :] = write_img
196 |
197 | writer.write(show_img)
198 | cv2.imshow("result", show_img)
199 |
200 | frames += 1
201 | k = cv2.waitKey(1)
202 | if k == ord('q') or (frames == max_frames):
203 | LOGGER.debug('=================Timing Stats=================')
204 | LOGGER.debug(f"{'Frame Acquiring:':<37}{Profiler.get_avg_millis('acquire'):>6.3f} ms")
205 | LOGGER.debug(f"{'Inference total:':<37}{Profiler.get_avg_millis('inference_all'):>6.3f} ms")
206 | LOGGER.debug(f"{'Lane Clustering:':<37}{Profiler.get_avg_millis('lane_clustering'):>6.3f} ms")
207 | LOGGER.debug(f"{'Lane Poly and drawing:':<37}{Profiler.get_avg_millis('lane_drawing'):>6.3f} ms")
208 | LOGGER.debug(f"{'Detection Drawing:':<37}{Profiler.get_avg_millis('lane_drawing'):>6.3f} ms")
209 | LOGGER.debug(f"{'Cls Drawing:':<37}{Profiler.get_avg_millis('cls_drawing'):>6.3f} ms")
210 |
211 | break
212 | elif k == ord('c'):
213 | cv2.imwrite(f"result_{randint(0, 100)}.png", show_img)
214 |
215 |
216 | cap.release()
217 | writer.release()
218 |
219 | if __name__ == '__main__':
220 | """
221 | -c ../conf/experiments/efficientnetb2_fpn.json
222 | -w ../log/MT_ADASNET/efficientnetb2_fpn.2022.6.17.15.34.8.8uvc1bun/last.pth
223 | """
224 | main()
225 |
226 |
--------------------------------------------------------------------------------
/conf/conf.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # ---------------------
3 |
4 | import os
5 |
6 | PYTHONPATH = '..:.'
7 | if os.environ.get('PYTHONPATH', default=None) is None:
8 | os.environ['PYTHONPATH'] = PYTHONPATH
9 | else:
10 | os.environ['PYTHONPATH'] += (':' + PYTHONPATH)
11 |
12 | import json
13 | import datetime
14 | import pytz
15 | import string
16 |
17 | import socket
18 | import random
19 | import torch
20 | import numpy as np
21 | from path import Path
22 | from typing import Optional
23 | from types import SimpleNamespace
24 | from collections.abc import Mapping
25 |
26 | def set_seed(seed=None):
27 | # type: (Optional[int]) -> int
28 | """
29 | set the random seed using the required value (`seed`)
30 | or a random value if `seed` is `None`
31 | :return: the newly set seed
32 | """
33 | if seed is None:
34 | seed = random.randint(1, 10000)
35 |
36 | random.seed(seed)
37 | np.random.seed(seed)
38 | torch.manual_seed(seed)
39 | torch.cuda.manual_seed_all(seed)
40 |
41 | return seed
42 |
43 | def get_unique_identifier(length: int = 8) -> str:
44 | """Create a unique identifier by choosing `length`
45 | random characters from list of ascii characters and numbers
46 | """
47 | alphabet = string.ascii_lowercase + string.digits
48 | uuid = "".join(alphabet[ix] for ix in np.random.choice(len(alphabet), length))
49 | return uuid
50 |
51 | def find_free_port():
52 | s = socket.socket()
53 | s.bind(('', 0)) # Bind to a free port provided by the host.
54 | return s.getsockname()[1] # Return the port number assigned.
55 |
56 | class ConfigDecoder(json.JSONDecoder):
57 | def __init__(self, **kwargs):
58 | json.JSONDecoder.__init__(self, **kwargs)
59 | # Use the custom JSONArray
60 | self.parse_array = self.JSONArray
61 | # Use the python implemenation of the scanner
62 | self.scan_once = json.scanner.py_make_scanner(self)
63 |
64 | def JSONArray(self, s_and_end, scan_once, **kwargs):
65 | values, end = json.decoder.JSONArray(s_and_end, scan_once, **kwargs)
66 | return tuple(values), end
67 |
68 | class DefaultNamespace(SimpleNamespace, Mapping):
69 | def __init__(self, **kwargs):
70 | super().__init__(**kwargs)
71 |
72 | def __iter__(self):
73 | return self.__dict__.__iter__()
74 |
75 | def __len__(self):
76 | return self.__dict__.__len__()
77 |
78 | def __getitem__(self, item):
79 | return self.__dict__.__getitem__(item)
80 |
81 | def json(self):
82 | o = json.dumps(self, default=lambda o: getattr(o, '__dict__', str(o)))
83 | return o
84 |
85 | def todict(self):
86 | o = json.loads(self.json())
87 | return o
88 |
89 | def get(self, key, default=None):
90 | try:
91 | y = self.__dict__[key]
92 | return y
93 | except KeyError:
94 | return default
95 |
96 |
97 | class Conf(object):
98 | # HOSTNAME = socket.gethostname()
99 | HOSTNAME = socket.gethostname() # socket.gethostbyname(socket.gethostname())
100 | PORT = find_free_port()
101 | OUT_PATH = Path(__file__).parent.parent
102 |
103 | def __init__(self, conf_file_path=None, data_root=None, seed=None, exp_name=None,
104 | resume=False, log_each_step=True, log=True, device='cuda'):
105 | # type: (str, int, str, str, bool, bool, bool, str) -> None
106 | """
107 | :param conf_file_path: optional path of the configuration file, if `resume` is true then this
108 | will be the path to the experiment log dir
109 | :param data_root: Overrides data_root from configuration file
110 | :param seed: desired seed for the RNG; if `None`, it will be chosen randomly
111 | :param exp_name: name of the experiment
112 | :param resume: `False` to start a new experiment, `True` to resume an existing one
113 | :param log: `False` if you want to enable experiment logging; `False` otherwise
114 | :param log_each_step: `True` if you want to log each step; `False` otherwise
115 | :param device: torch device you want to use for train/test
116 | :example values: 'cpu', 'cuda', 'cuda:5', ...
117 | """
118 | self.exp_name = exp_name
119 | self.log_enabled = log
120 | self.log_each_step = log_each_step
121 | self.device = device
122 | self.resume = resume
123 |
124 | self.hostname = Conf.HOSTNAME
125 | self.port = Conf.PORT
126 |
127 | # Placeholders, warning: MUST call setup_device_id before any training can happen!
128 | self.rank = 0
129 | self.local_rank = -1
130 |
131 | # Check if we are running a slurm job
132 | self.slurm = os.environ.get("SLURM_TASK_PID") is not None
133 | if self.slurm:
134 | print(">> Detected SLURM")
135 | self.tmpdir = os.environ.get("TMPDIR")
136 | else:
137 | self.tmpdir = None
138 |
139 | # DDP STUFF
140 | self.gpu_id = 0
141 | if not self.slurm:
142 | self.world_size = torch.cuda.device_count()
143 | self.jobid = None
144 | else:
145 | self.world_size = int(os.environ["SLURM_NPROCS"])
146 | assert (self.world_size % torch.cuda.device_count()) == 0, "Use 1 task per GPU!"
147 | self.jobid = os.environ["SLURM_JOBID"]
148 |
149 | print(f"Training on {self.world_size} GPUs")
150 |
151 | # print project name and host name
152 | self.project_name = Path(__file__).parent.parent.basename()
153 | m_str = f'┃ {self.project_name}@{Conf.HOSTNAME} ┃'
154 | u_str = '┏' + '━' * (len(m_str) - 2) + '┓'
155 | b_str = '┗' + '━' * (len(m_str) - 2) + '┛'
156 | print(u_str + '\n' + m_str + '\n' + b_str)
157 |
158 | # project root
159 | self.project_root = Conf.OUT_PATH
160 |
161 | # set random seed
162 | self.seed = set_seed(seed) # type: int
163 |
164 | # if the configuration file is not specified
165 | # try to load a configuration file based on the experiment name
166 | if not resume:
167 | tmp = Path(os.path.join(os.path.dirname(__file__), 'experiments', f"{self.exp_name}.json"))
168 | if conf_file_path is None and tmp.exists():
169 | conf_file_path = tmp
170 | else:
171 | tmp = Path(os.path.join(conf_file_path, 'configuration.json'))
172 | conf_file_path = tmp
173 |
174 | # read the JSON configuration file
175 | self.y = {}
176 | if conf_file_path is None:
177 | raise Exception(f"No model configuration file found {conf_file_path}")
178 | else:
179 | conf_file = open(conf_file_path, 'r')
180 | self.y = json.load(conf_file, cls=ConfigDecoder, object_hook=lambda d: DefaultNamespace(**d))
181 |
182 | # read configuration parameters from JSON file
183 | # or set their default value
184 | self.base_opts = self.y.get('experiment', {}) # type: dict
185 | self.epochs = self.base_opts.get('epochs', -1) # type: int
186 | if self.device == 'cuda' and self.base_opts.get('device', None) is not None:
187 | self.device = self.base_opts.get('device') # type: str
188 | self.val_epoch_step = self.base_opts.get('val_epoch_step', 1) # type: int
189 | self.ck_epoch_step = self.base_opts.get('ck_epoch_step', 1) # type: int
190 | self.finetune = self.base_opts.get("is_finetune", False) # type: bool
191 |
192 | # define output paths
193 | if self.log_enabled:
194 | # Todo: be careful in multi-process!
195 | logdir = self.base_opts.get('logdir', '') # type: Path
196 | if logdir != '':
197 | logdir = Path(logdir)
198 | self.project_log_path = Path(logdir / 'log' / self.project_name)
199 | else:
200 | self.project_log_path = Path(Conf.OUT_PATH / 'log' / self.project_name)
201 |
202 | current_time = datetime.datetime.now(pytz.timezone("Europe/Rome"))
203 | if not resume:
204 | self.exp_full_name = f"{exp_name}.{current_time.year}.{current_time.month}.{current_time.day}.{current_time.hour}." \
205 | f"{current_time.minute}.{current_time.second}.{get_unique_identifier()}"
206 | else:
207 | self.exp_full_name = conf_file_path.split('/')[-2]
208 |
209 | if not resume:
210 | self.exp_log_path = self.project_log_path / self.exp_full_name
211 | if not os.path.exists(self.exp_log_path):
212 | os.makedirs(self.exp_log_path, exist_ok=True)
213 | else:
214 | self.exp_log_path = conf_file_path.parent
215 | else:
216 | self.exp_full_name = conf_file_path.split('/')[-2]
217 |
218 | """
219 | if self.world_size > 1:
220 | print(f"[WARNING]: Batch size is divided across {self.world_size} GPUs!")
221 | assert self.batch_size % self.world_size == 0
222 | self.batch_size = self.batch_size // self.world_size
223 | """
224 |
225 | if data_root is not None:
226 | self.y.dataset.data_root = data_root
227 |
228 | def __getattr__(self, item):
229 | d = self.y.get(item, {})
230 |
231 | return d
232 |
233 | @property
234 | def is_cuda(self):
235 | # type: () -> bool
236 | """
237 | :return: `True` if the required device is 'cuda'; `False` otherwise
238 | """
239 | return 'cuda' in self.device
240 |
241 | def setup_device_id(self, rank):
242 |
243 | self.rank = rank
244 | self.local_rank = int(os.environ.get('LOCAL_RANK', -1))
245 |
246 | if self.slurm:
247 | self.gpu_id = rank % torch.cuda.device_count() # Assuming an equal number of gpus per node
248 | else:
249 | self.gpu_id = rank
250 |
251 | if self.device == "cuda":
252 | self.device = f"cuda:{self.gpu_id}"
253 |
--------------------------------------------------------------------------------
/models/backbones/mobilenetv2.py:
--------------------------------------------------------------------------------
1 | import warnings
2 | from typing import Callable, Any, Optional, List, Union
3 |
4 | import torch
5 | from torch import Tensor
6 | from torch import nn
7 |
8 | from .misc import ConvNormActivation
9 | from .misc import _make_divisible
10 | from collections import OrderedDict
11 |
12 | import warnings
13 | from torch.hub import load_state_dict_from_url
14 |
15 | __all__ = ["MobileNetV2", "mobilenet_v2"]
16 |
17 |
18 | model_urls = {
19 | "mobilenet_v2": "https://download.pytorch.org/models/mobilenet_v2-b0353104.pth",
20 | }
21 |
22 |
23 | # necessary for backwards compatibility
24 | class _DeprecatedConvBNAct(ConvNormActivation):
25 | def __init__(self, *args, **kwargs):
26 | warnings.warn(
27 | "The ConvBNReLU/ConvBNActivation classes are deprecated since 0.12 and will be removed in 0.14. "
28 | "Use torchvision.ops.misc.ConvNormActivation instead.",
29 | FutureWarning,
30 | )
31 | if kwargs.get("norm_layer", None) is None:
32 | kwargs["norm_layer"] = nn.BatchNorm2d
33 | if kwargs.get("activation_layer", None) is None:
34 | kwargs["activation_layer"] = nn.ReLU6
35 | super().__init__(*args, **kwargs)
36 |
37 |
38 | ConvBNReLU = _DeprecatedConvBNAct
39 | ConvBNActivation = _DeprecatedConvBNAct
40 |
41 |
42 | class InvertedResidual(nn.Module):
43 | def __init__(
44 | self, inp: int, oup: int, stride: int, expand_ratio: int, norm_layer: Optional[Callable[..., nn.Module]] = None
45 | ) -> None:
46 | super().__init__()
47 | self.stride = stride
48 | assert stride in [1, 2]
49 |
50 | if norm_layer is None:
51 | norm_layer = nn.BatchNorm2d
52 |
53 | hidden_dim = int(round(inp * expand_ratio))
54 | self.use_res_connect = self.stride == 1 and inp == oup
55 |
56 | layers: List[nn.Module] = []
57 | if expand_ratio != 1:
58 | # pw
59 | layers.append(
60 | ConvNormActivation(inp, hidden_dim, kernel_size=1, norm_layer=norm_layer, activation_layer=nn.ReLU6)
61 | )
62 | layers.extend(
63 | [
64 | # dw
65 | ConvNormActivation(
66 | hidden_dim,
67 | hidden_dim,
68 | stride=stride,
69 | groups=hidden_dim,
70 | norm_layer=norm_layer,
71 | activation_layer=nn.ReLU6,
72 | ),
73 | # pw-linear
74 | nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
75 | norm_layer(oup),
76 | ]
77 | )
78 | self.conv = nn.Sequential(*layers)
79 | self.out_channels = oup
80 | self._is_cn = stride > 1
81 |
82 | def forward(self, x: Tensor) -> Tensor:
83 | if self.use_res_connect:
84 | return x + self.conv(x)
85 | else:
86 | return self.conv(x)
87 |
88 |
89 | class MobileNetV2(nn.Module):
90 | def __init__(
91 | self,
92 | num_classes: int = 1000,
93 | width_mult: float = 1.0,
94 | inverted_residual_setting: Optional[List[List[int]]] = None,
95 | round_nearest: int = 8,
96 | block: Optional[Callable[..., nn.Module]] = None,
97 | norm_layer: Optional[Callable[..., nn.Module]] = None,
98 | dropout: float = 0.2,
99 | ) -> None:
100 | """
101 | MobileNet V2 main class
102 |
103 | Args:
104 | num_classes (int): Number of classes
105 | width_mult (float): Width multiplier - adjusts number of channels in each layer by this amount
106 | inverted_residual_setting: Network structure
107 | round_nearest (int): Round the number of channels in each layer to be a multiple of this number
108 | Set to 1 to turn off rounding
109 | block: Module specifying inverted residual building block for mobilenet
110 | norm_layer: Module specifying the normalization layer to use
111 | dropout (float): The droupout probability
112 |
113 | """
114 | super().__init__()
115 |
116 | if block is None:
117 | block = InvertedResidual
118 |
119 | if norm_layer is None:
120 | norm_layer = nn.BatchNorm2d
121 |
122 | input_channel = 32
123 | last_channel = 1280
124 |
125 | if inverted_residual_setting is None:
126 | inverted_residual_setting = [
127 | # t, c, n, s
128 | [1, 16, 1, 1],
129 | [6, 24, 2, 2],
130 | [6, 32, 3, 2],
131 | [6, 64, 4, 2],
132 | [6, 96, 3, 1],
133 | [6, 160, 3, 2],
134 | [6, 320, 1, 1],
135 | ]
136 |
137 | # only check the first element, assuming user knows t,c,n,s are required
138 | if len(inverted_residual_setting) == 0 or len(inverted_residual_setting[0]) != 4:
139 | raise ValueError(
140 | f"inverted_residual_setting should be non-empty or a 4-element list, got {inverted_residual_setting}"
141 | )
142 |
143 | # building first layer
144 | outplanes = [input_channel]
145 | input_channel = _make_divisible(input_channel * width_mult, round_nearest)
146 | self.last_channel = _make_divisible(last_channel * max(1.0, width_mult), round_nearest)
147 | features: List[nn.Module] = [
148 | ConvNormActivation(3, input_channel, stride=2, norm_layer=norm_layer, activation_layer=nn.ReLU6)
149 | ]
150 | # building inverted residual blocks
151 | for t, c, n, s in inverted_residual_setting:
152 | output_channel = _make_divisible(c * width_mult, round_nearest)
153 | for i in range(n):
154 | stride = s if i == 0 else 1
155 | features.append(block(input_channel, output_channel, stride, expand_ratio=t, norm_layer=norm_layer))
156 | input_channel = output_channel
157 | outplanes.append(output_channel)
158 |
159 | """
160 | # building last several layers
161 | features.append(
162 | ConvNormActivation(
163 | input_channel, self.last_channel, kernel_size=1, norm_layer=norm_layer, activation_layer=nn.ReLU6
164 | )
165 | )
166 | """
167 | # make it nn.Sequential
168 | self.features = nn.ModuleList(features)
169 |
170 | self.gates = [4, 7, 14, 18]
171 | self.outplanes = [outplanes[g-1] for g in self.gates]
172 |
173 | # weight initialization
174 | for m in self.modules():
175 | if isinstance(m, nn.Conv2d):
176 | nn.init.kaiming_normal_(m.weight, mode="fan_out")
177 | if m.bias is not None:
178 | nn.init.zeros_(m.bias)
179 | elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
180 | nn.init.ones_(m.weight)
181 | nn.init.zeros_(m.bias)
182 | elif isinstance(m, nn.Linear):
183 | nn.init.normal_(m.weight, 0, 0.01)
184 | nn.init.zeros_(m.bias)
185 |
186 | def _forward_impl(self, x: Tensor) -> Union[Tensor, Any]:
187 |
188 | for n in range(0, self.gates[0]):
189 | x = self.features[n](x)
190 | x1 = x
191 |
192 | for n in range(self.gates[0], self.gates[1]):
193 | x = self.features[n](x)
194 | x2 = x
195 |
196 | for n in range(self.gates[1], self.gates[2]):
197 | x = self.features[n](x)
198 | x3 = x
199 |
200 | for n in range(self.gates[2], self.gates[3]):
201 | x = self.features[n](x)
202 |
203 | return x1, x2, x3, x
204 |
205 | def forward(self, x: Tensor) -> Union[Tensor, Any]:
206 | return self._forward_impl(x)
207 |
208 |
209 | def mobilenet_v2(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> MobileNetV2:
210 | """
211 | Constructs a MobileNetV2 architecture from
212 | `"MobileNetV2: Inverted Residuals and Linear Bottlenecks" `_.
213 |
214 | Args:
215 | pretrained (bool): If True, returns a model pre-trained on ImageNet
216 | progress (bool): If True, displays a progress bar of the download to stderr
217 | """
218 | model = MobileNetV2(**kwargs)
219 | if pretrained:
220 | arch = "mobilenet_v2"
221 | if model_urls.get(arch, None) is None:
222 | raise ValueError(f"No checkpoint is available for model type {arch}")
223 | state_dict = load_state_dict_from_url(model_urls[arch], progress=progress)
224 |
225 | # Discard removed layers
226 | model_dict = model.state_dict()
227 | matched_layers, discarded_layers = [], []
228 | new_state_dict = OrderedDict()
229 |
230 | for k, v in state_dict.items():
231 |
232 | if k in model_dict and model_dict[k].size() == v.size():
233 | new_state_dict[k] = v
234 | matched_layers.append(k)
235 | else:
236 | discarded_layers.append(k)
237 |
238 | model_dict.update(new_state_dict)
239 |
240 | if len(matched_layers) == 0:
241 | warnings.warn(
242 | 'The pretrained weights for "{}" cannot be loaded, '
243 | 'please check the key names manually '
244 | '(** ignored and continue **)'.format(arch)
245 | )
246 | else:
247 | print(
248 | 'Successfully loaded imagenet pretrained weights for "{}"'.
249 | format(arch)
250 | )
251 | if len(discarded_layers) > 0:
252 | print(
253 | '** The following layers are discarded '
254 | 'due to unmatched keys or layer size: {}'.
255 | format(discarded_layers)
256 | )
257 |
258 | model.load_state_dict(model_dict)
259 |
260 | return model
261 |
262 | if __name__ == '__main__':
263 | m = mobilenet_v2(pretrained=True)
264 | x = torch.rand((1,3,320,640), dtype=torch.float32)
265 | y = m(x)
266 | print(m.outplanes)
267 |
268 | """
269 | 0 torch.Size([1, 32, 160, 320])
270 | 1 torch.Size([1, 16, 160, 320])
271 | 2 torch.Size([1, 24, 80, 160])
272 | 3 torch.Size([1, 24, 80, 160])
273 | 4 torch.Size([1, 32, 40, 80])
274 | 5 torch.Size([1, 32, 40, 80])
275 | 6 torch.Size([1, 32, 40, 80])
276 | 7 torch.Size([1, 64, 20, 40])
277 | 8 torch.Size([1, 64, 20, 40])
278 | 9 torch.Size([1, 64, 20, 40])
279 | 10 torch.Size([1, 64, 20, 40])
280 | 11 torch.Size([1, 96, 20, 40])
281 | 12 torch.Size([1, 96, 20, 40])
282 | 13 torch.Size([1, 96, 20, 40])
283 | 14 torch.Size([1, 160, 10, 20])
284 | 15 torch.Size([1, 160, 10, 20])
285 | 16 torch.Size([1, 160, 10, 20])
286 | 17 torch.Size([1, 320, 10, 20])
287 |
288 | [24, 32, 96, 320]
289 |
290 | """
291 |
--------------------------------------------------------------------------------
/models/backbones/resnet.py:
--------------------------------------------------------------------------------
1 | from typing import Type, Any, Callable, Union, List, Optional
2 |
3 | import torch
4 | import torch.nn as nn
5 | from torch import Tensor
6 |
7 | from collections import OrderedDict
8 |
9 | import warnings
10 | from torch.hub import load_state_dict_from_url
11 |
12 | from .misc import FrozenBatchNorm2d
13 |
14 | __all__ = [
15 | "ResNet",
16 | "resnet18",
17 | "resnet34",
18 | "resnet50",
19 | "resnet101",
20 | "resnet152",
21 | "resnext50_32x4d",
22 | "resnext101_32x8d",
23 | "wide_resnet50_2",
24 | "wide_resnet101_2",
25 | ]
26 |
27 |
28 | model_urls = {
29 | "resnet18": "https://download.pytorch.org/models/resnet18-f37072fd.pth",
30 | "resnet34": "https://download.pytorch.org/models/resnet34-b627a593.pth",
31 | "resnet50": "https://download.pytorch.org/models/resnet50-0676ba61.pth",
32 | "resnet101": "https://download.pytorch.org/models/resnet101-63fe2227.pth",
33 | "resnet152": "https://download.pytorch.org/models/resnet152-394f9c45.pth",
34 | "resnext50_32x4d": "https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth",
35 | "resnext101_32x8d": "https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth",
36 | "wide_resnet50_2": "https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth",
37 | "wide_resnet101_2": "https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth",
38 | }
39 |
40 |
41 | def conv3x3(in_planes: int, out_planes: int, stride: int = 1, groups: int = 1, dilation: int = 1) -> nn.Conv2d:
42 | """3x3 convolution with padding"""
43 | return nn.Conv2d(
44 | in_planes,
45 | out_planes,
46 | kernel_size=3,
47 | stride=stride,
48 | padding=dilation,
49 | groups=groups,
50 | bias=False,
51 | dilation=dilation,
52 | )
53 |
54 |
55 | def conv1x1(in_planes: int, out_planes: int, stride: int = 1) -> nn.Conv2d:
56 | """1x1 convolution"""
57 | return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
58 |
59 |
60 | class BasicBlock(nn.Module):
61 | expansion: int = 1
62 |
63 | def __init__(
64 | self,
65 | inplanes: int,
66 | planes: int,
67 | stride: int = 1,
68 | downsample: Optional[nn.Module] = None,
69 | groups: int = 1,
70 | base_width: int = 64,
71 | dilation: int = 1,
72 | norm_layer: Optional[Callable[..., nn.Module]] = None,
73 | ) -> None:
74 | super().__init__()
75 | if norm_layer is None:
76 | norm_layer = nn.BatchNorm2d
77 | if groups != 1 or base_width != 64:
78 | raise ValueError("BasicBlock only supports groups=1 and base_width=64")
79 | if dilation > 1:
80 | raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
81 | # Both self.conv1 and self.downsample layers downsample the input when stride != 1
82 | self.conv1 = conv3x3(inplanes, planes, stride)
83 | self.bn1 = norm_layer(planes)
84 | self.relu = nn.ReLU(inplace=True)
85 | self.conv2 = conv3x3(planes, planes)
86 | self.bn2 = norm_layer(planes)
87 | self.downsample = downsample
88 | self.stride = stride
89 |
90 | def forward(self, x: Tensor) -> Tensor:
91 | identity = x
92 |
93 | out = self.conv1(x)
94 | out = self.bn1(out)
95 | out = self.relu(out)
96 |
97 | out = self.conv2(out)
98 | out = self.bn2(out)
99 |
100 | if self.downsample is not None:
101 | identity = self.downsample(x)
102 |
103 | out += identity
104 | out = self.relu(out)
105 |
106 | return out
107 |
108 |
109 | class Bottleneck(nn.Module):
110 | # Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
111 | # while original implementation places the stride at the first 1x1 convolution(self.conv1)
112 | # according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
113 | # This variant is also known as ResNet V1.5 and improves accuracy according to
114 | # https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
115 |
116 | expansion: int = 4
117 |
118 | def __init__(
119 | self,
120 | inplanes: int,
121 | planes: int,
122 | stride: int = 1,
123 | downsample: Optional[nn.Module] = None,
124 | groups: int = 1,
125 | base_width: int = 64,
126 | dilation: int = 1,
127 | norm_layer: Optional[Callable[..., nn.Module]] = None,
128 | ) -> None:
129 | super().__init__()
130 | if norm_layer is None:
131 | norm_layer = nn.BatchNorm2d
132 | width = int(planes * (base_width / 64.0)) * groups
133 | # Both self.conv2 and self.downsample layers downsample the input when stride != 1
134 | self.conv1 = conv1x1(inplanes, width)
135 | self.bn1 = norm_layer(width)
136 | self.conv2 = conv3x3(width, width, stride, groups, dilation)
137 | self.bn2 = norm_layer(width)
138 | self.conv3 = conv1x1(width, planes * self.expansion)
139 | self.bn3 = norm_layer(planes * self.expansion)
140 | self.relu = nn.ReLU(inplace=True)
141 | self.downsample = downsample
142 | self.stride = stride
143 |
144 | def forward(self, x: Tensor) -> Tensor:
145 | identity = x
146 |
147 | out = self.conv1(x)
148 | out = self.bn1(out)
149 | out = self.relu(out)
150 |
151 | out = self.conv2(out)
152 | out = self.bn2(out)
153 | out = self.relu(out)
154 |
155 | out = self.conv3(out)
156 | out = self.bn3(out)
157 |
158 | if self.downsample is not None:
159 | identity = self.downsample(x)
160 |
161 | out += identity
162 | out = self.relu(out)
163 |
164 | return out
165 |
166 |
167 | class ResNet(nn.Module):
168 | def __init__(
169 | self,
170 | block: Type[Union[BasicBlock, Bottleneck]],
171 | layers: List[int],
172 | num_classes: int = 1000,
173 | zero_init_residual: bool = False,
174 | groups: int = 1,
175 | width_per_group: int = 64,
176 | replace_stride_with_dilation: Optional[List[bool]] = None,
177 | norm_layer: Optional[Callable[..., nn.Module]] = None,
178 | ) -> None:
179 | super().__init__()
180 |
181 | if norm_layer is None:
182 | norm_layer = nn.BatchNorm2d
183 | elif type(norm_layer) == str:
184 | norm_layer = eval(norm_layer)
185 |
186 | self._norm_layer = norm_layer
187 |
188 | self.inplanes = 64
189 | self.dilation = 1
190 | if replace_stride_with_dilation is None:
191 | # each element in the tuple indicates if we should replace
192 | # the 2x2 stride with a dilated convolution instead
193 | replace_stride_with_dilation = [False, False, False]
194 | if len(replace_stride_with_dilation) != 3:
195 | raise ValueError(
196 | "replace_stride_with_dilation should be None "
197 | f"or a 3-element tuple, got {replace_stride_with_dilation}"
198 | )
199 | self.groups = groups
200 | self.base_width = width_per_group
201 | self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
202 | self.bn1 = norm_layer(self.inplanes)
203 | self.relu = nn.ReLU(inplace=True)
204 | self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
205 | self.layer1 = self._make_layer(block, 64, layers[0])
206 | self.layer2 = self._make_layer(block, 128, layers[1], stride=2, dilate=replace_stride_with_dilation[0])
207 | self.layer3 = self._make_layer(block, 256, layers[2], stride=2, dilate=replace_stride_with_dilation[1])
208 | self.layer4 = self._make_layer(block, 512, layers[3], stride=2, dilate=replace_stride_with_dilation[2])
209 |
210 | self.outplanes = [64, 128, 256, 512] if block == BasicBlock else [256, 512, 1024, 2048]
211 |
212 | for m in self.modules():
213 | if isinstance(m, nn.Conv2d):
214 | nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
215 | elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
216 | nn.init.constant_(m.weight, 1)
217 | nn.init.constant_(m.bias, 0)
218 |
219 | # Zero-initialize the last BN in each residual branch,
220 | # so that the residual branch starts with zeros, and each residual block behaves like an identity.
221 | # This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
222 | if zero_init_residual:
223 | for m in self.modules():
224 | if isinstance(m, Bottleneck):
225 | nn.init.constant_(m.bn3.weight, 0) # type: ignore[arg-type]
226 | elif isinstance(m, BasicBlock):
227 | nn.init.constant_(m.bn2.weight, 0) # type: ignore[arg-type]
228 |
229 | def _make_layer(
230 | self,
231 | block: Type[Union[BasicBlock, Bottleneck]],
232 | planes: int,
233 | blocks: int,
234 | stride: int = 1,
235 | dilate: bool = False,
236 | ) -> nn.Sequential:
237 | norm_layer = self._norm_layer
238 | downsample = None
239 | previous_dilation = self.dilation
240 | if dilate:
241 | self.dilation *= stride
242 | stride = 1
243 | if stride != 1 or self.inplanes != planes * block.expansion:
244 | downsample = nn.Sequential(
245 | conv1x1(self.inplanes, planes * block.expansion, stride),
246 | norm_layer(planes * block.expansion),
247 | )
248 |
249 | layers = []
250 | layers.append(
251 | block(
252 | self.inplanes, planes, stride, downsample, self.groups, self.base_width, previous_dilation, norm_layer
253 | )
254 | )
255 | self.inplanes = planes * block.expansion
256 | for _ in range(1, blocks):
257 | layers.append(
258 | block(
259 | self.inplanes,
260 | planes,
261 | groups=self.groups,
262 | base_width=self.base_width,
263 | dilation=self.dilation,
264 | norm_layer=norm_layer,
265 | )
266 | )
267 |
268 | return nn.Sequential(*layers)
269 |
270 | def _forward_impl(self, x: Tensor) -> Union[Tensor, Any]:
271 | # See note [TorchScript super()]
272 | enc0 = self.conv1(x)
273 | enc0 = self.bn1(enc0)
274 | enc0 = self.relu(enc0)
275 | enc0 = self.maxpool(enc0)
276 |
277 | enc1 = self.layer1(enc0)
278 | enc2 = self.layer2(enc1)
279 | enc3 = self.layer3(enc2)
280 | enc4 = self.layer4(enc3)
281 |
282 | return enc1, enc2, enc3, enc4
283 |
284 | def forward(self, x: Tensor) -> Union[Tensor, Any]:
285 | return self._forward_impl(x)
286 |
287 |
288 | def _resnet(
289 | arch: str,
290 | block: Type[Union[BasicBlock, Bottleneck]],
291 | layers: List[int],
292 | pretrained: bool,
293 | progress: bool,
294 | **kwargs: Any,
295 | ) -> ResNet:
296 | model = ResNet(block, layers, **kwargs)
297 | if pretrained:
298 | if model_urls.get(arch, None) is None:
299 | raise ValueError(f"No checkpoint is available for model type {arch}")
300 | state_dict = load_state_dict_from_url(model_urls[arch], progress=progress)
301 |
302 | # Discard removed layers
303 | model_dict = model.state_dict()
304 | matched_layers, discarded_layers = [], []
305 | new_state_dict = OrderedDict()
306 |
307 | for k, v in state_dict.items():
308 |
309 | if k in model_dict and model_dict[k].size() == v.size():
310 | new_state_dict[k] = v
311 | matched_layers.append(k)
312 | else:
313 | discarded_layers.append(k)
314 |
315 | model_dict.update(new_state_dict)
316 |
317 | if len(matched_layers) == 0:
318 | warnings.warn(
319 | 'The pretrained weights for "{}" cannot be loaded, '
320 | 'please check the key names manually '
321 | '(** ignored and continue **)'.format(arch)
322 | )
323 | else:
324 | print(
325 | 'Successfully loaded imagenet pretrained weights for "{}"'.
326 | format(arch)
327 | )
328 | if len(discarded_layers) > 0:
329 | print(
330 | '** The following layers are discarded '
331 | 'due to unmatched keys or layer size: {}'.
332 | format(discarded_layers)
333 | )
334 |
335 | model.load_state_dict(model_dict)
336 |
337 | return model
338 |
339 |
340 | def resnet18(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
341 | r"""ResNet-18 model from
342 | `"Deep Residual Learning for Image Recognition" `_.
343 |
344 | Args:
345 | pretrained (bool): If True, returns a model pre-trained on ImageNet
346 | progress (bool): If True, displays a progress bar of the download to stderr
347 | """
348 | return _resnet("resnet18", BasicBlock, [2, 2, 2, 2], pretrained, progress, **kwargs)
349 |
350 |
351 | def resnet34(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
352 | r"""ResNet-34 model from
353 | `"Deep Residual Learning for Image Recognition" `_.
354 |
355 | Args:
356 | pretrained (bool): If True, returns a model pre-trained on ImageNet
357 | progress (bool): If True, displays a progress bar of the download to stderr
358 | """
359 | return _resnet("resnet34", BasicBlock, [3, 4, 6, 3], pretrained, progress, **kwargs)
360 |
361 |
362 | def resnet50(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
363 | r"""ResNet-50 model from
364 | `"Deep Residual Learning for Image Recognition" `_.
365 |
366 | Args:
367 | pretrained (bool): If True, returns a model pre-trained on ImageNet
368 | progress (bool): If True, displays a progress bar of the download to stderr
369 | """
370 | return _resnet("resnet50", Bottleneck, [3, 4, 6, 3], pretrained, progress, **kwargs)
371 |
372 |
373 | def resnet101(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
374 | r"""ResNet-101 model from
375 | `"Deep Residual Learning for Image Recognition" `_.
376 |
377 | Args:
378 | pretrained (bool): If True, returns a model pre-trained on ImageNet
379 | progress (bool): If True, displays a progress bar of the download to stderr
380 | """
381 | return _resnet("resnet101", Bottleneck, [3, 4, 23, 3], pretrained, progress, **kwargs)
382 |
383 |
384 | def resnet152(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
385 | r"""ResNet-152 model from
386 | `"Deep Residual Learning for Image Recognition" `_.
387 |
388 | Args:
389 | pretrained (bool): If True, returns a model pre-trained on ImageNet
390 | progress (bool): If True, displays a progress bar of the download to stderr
391 | """
392 | return _resnet("resnet152", Bottleneck, [3, 8, 36, 3], pretrained, progress, **kwargs)
393 |
394 |
395 | def resnext50_32x4d(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
396 | r"""ResNeXt-50 32x4d model from
397 | `"Aggregated Residual Transformation for Deep Neural Networks" `_.
398 |
399 | Args:
400 | pretrained (bool): If True, returns a model pre-trained on ImageNet
401 | progress (bool): If True, displays a progress bar of the download to stderr
402 | """
403 | kwargs["groups"] = 32
404 | kwargs["width_per_group"] = 4
405 | return _resnet("resnext50_32x4d", Bottleneck, [3, 4, 6, 3], pretrained, progress, **kwargs)
406 |
407 |
408 | def resnext101_32x8d(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
409 | r"""ResNeXt-101 32x8d model from
410 | `"Aggregated Residual Transformation for Deep Neural Networks" `_.
411 |
412 | Args:
413 | pretrained (bool): If True, returns a model pre-trained on ImageNet
414 | progress (bool): If True, displays a progress bar of the download to stderr
415 | """
416 | kwargs["groups"] = 32
417 | kwargs["width_per_group"] = 8
418 | return _resnet("resnext101_32x8d", Bottleneck, [3, 4, 23, 3], pretrained, progress, **kwargs)
419 |
420 |
421 | def wide_resnet50_2(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
422 | r"""Wide ResNet-50-2 model from
423 | `"Wide Residual Networks" `_.
424 |
425 | The model is the same as ResNet except for the bottleneck number of channels
426 | which is twice larger in every block. The number of channels in outer 1x1
427 | convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
428 | channels, and in Wide ResNet-50-2 has 2048-1024-2048.
429 |
430 | Args:
431 | pretrained (bool): If True, returns a model pre-trained on ImageNet
432 | progress (bool): If True, displays a progress bar of the download to stderr
433 | """
434 | kwargs["width_per_group"] = 64 * 2
435 | return _resnet("wide_resnet50_2", Bottleneck, [3, 4, 6, 3], pretrained, progress, **kwargs)
436 |
437 |
438 | def wide_resnet101_2(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
439 | r"""Wide ResNet-101-2 model from
440 | `"Wide Residual Networks" `_.
441 |
442 | The model is the same as ResNet except for the bottleneck number of channels
443 | which is twice larger in every block. The number of channels in outer 1x1
444 | convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
445 | channels, and in Wide ResNet-50-2 has 2048-1024-2048.
446 |
447 | Args:
448 | pretrained (bool): If True, returns a model pre-trained on ImageNet
449 | progress (bool): If True, displays a progress bar of the download to stderr
450 | """
451 | kwargs["width_per_group"] = 64 * 2
452 | return _resnet("wide_resnet101_2", Bottleneck, [3, 4, 23, 3], pretrained, progress, **kwargs)
453 |
454 | if __name__ == '__main__':
455 | m = resnet18(pretrained=True)
456 | x = torch.rand((1,3,320,640), dtype=torch.float32)
457 | y = m(x)
458 | print(m.outplanes)
459 |
--------------------------------------------------------------------------------
/models/backbones/efficientnet.py:
--------------------------------------------------------------------------------
1 | import copy
2 | import math
3 | from functools import partial
4 | from typing import Any, Callable, Optional, List, Sequence, Union
5 | from .misc import _make_divisible
6 |
7 | import torch
8 | from torch import nn, Tensor
9 | from torchvision.ops import StochasticDepth
10 | from collections import OrderedDict
11 |
12 | import warnings
13 | from torch.hub import load_state_dict_from_url
14 | from models.backbones.misc import ConvNormActivation, SqueezeExcitation
15 |
16 | __all__ = [
17 | "EfficientNet",
18 | "efficientnet_b0",
19 | "efficientnet_b1",
20 | "efficientnet_b2",
21 | "efficientnet_b3",
22 | "efficientnet_b4",
23 | "efficientnet_b5",
24 | "efficientnet_b6",
25 | "efficientnet_b7",
26 | ]
27 |
28 |
29 | model_urls = {
30 | # Weights ported from https://github.com/rwightman/pytorch-image-models/
31 | "efficientnet_b0": "https://download.pytorch.org/models/efficientnet_b0_rwightman-3dd342df.pth",
32 | "efficientnet_b1": "https://download.pytorch.org/models/efficientnet_b1_rwightman-533bc792.pth",
33 | "efficientnet_b2": "https://download.pytorch.org/models/efficientnet_b2_rwightman-bcdf34b7.pth",
34 | "efficientnet_b3": "https://download.pytorch.org/models/efficientnet_b3_rwightman-cf984f9c.pth",
35 | "efficientnet_b4": "https://download.pytorch.org/models/efficientnet_b4_rwightman-7eb33cd5.pth",
36 | # Weights ported from https://github.com/lukemelas/EfficientNet-PyTorch/
37 | "efficientnet_b5": "https://download.pytorch.org/models/efficientnet_b5_lukemelas-b6417697.pth",
38 | "efficientnet_b6": "https://download.pytorch.org/models/efficientnet_b6_lukemelas-c76e70fd.pth",
39 | "efficientnet_b7": "https://download.pytorch.org/models/efficientnet_b7_lukemelas-dcc49843.pth",
40 | }
41 |
42 |
43 | class MBConvConfig:
44 | # Stores information listed at Table 1 of the EfficientNet paper
45 | def __init__(
46 | self,
47 | expand_ratio: float,
48 | kernel: int,
49 | stride: int,
50 | input_channels: int,
51 | out_channels: int,
52 | num_layers: int,
53 | width_mult: float,
54 | depth_mult: float,
55 | ) -> None:
56 | self.expand_ratio = expand_ratio
57 | self.kernel = kernel
58 | self.stride = stride
59 | self.input_channels = self.adjust_channels(input_channels, width_mult)
60 | self.out_channels = self.adjust_channels(out_channels, width_mult)
61 | self.num_layers = self.adjust_depth(num_layers, depth_mult)
62 |
63 | def __repr__(self) -> str:
64 | s = (
65 | f"{self.__class__.__name__}("
66 | f"expand_ratio={self.expand_ratio}"
67 | f", kernel={self.kernel}"
68 | f", stride={self.stride}"
69 | f", input_channels={self.input_channels}"
70 | f", out_channels={self.out_channels}"
71 | f", num_layers={self.num_layers}"
72 | f")"
73 | )
74 | return s
75 |
76 | @staticmethod
77 | def adjust_channels(channels: int, width_mult: float, min_value: Optional[int] = None) -> int:
78 | return _make_divisible(channels * width_mult, 8, min_value)
79 |
80 | @staticmethod
81 | def adjust_depth(num_layers: int, depth_mult: float):
82 | return int(math.ceil(num_layers * depth_mult))
83 |
84 |
85 | class MBConv(nn.Module):
86 | def __init__(
87 | self,
88 | cnf: MBConvConfig,
89 | stochastic_depth_prob: float,
90 | norm_layer: Callable[..., nn.Module],
91 | se_layer: Callable[..., nn.Module] = SqueezeExcitation,
92 | ) -> None:
93 | super().__init__()
94 |
95 | if not (1 <= cnf.stride <= 2):
96 | raise ValueError("illegal stride value")
97 |
98 | self.use_res_connect = cnf.stride == 1 and cnf.input_channels == cnf.out_channels
99 |
100 | layers: List[nn.Module] = []
101 | activation_layer = nn.SiLU
102 |
103 | # expand
104 | expanded_channels = cnf.adjust_channels(cnf.input_channels, cnf.expand_ratio)
105 | if expanded_channels != cnf.input_channels:
106 | layers.append(
107 | ConvNormActivation(
108 | cnf.input_channels,
109 | expanded_channels,
110 | kernel_size=1,
111 | norm_layer=norm_layer,
112 | activation_layer=activation_layer,
113 | )
114 | )
115 |
116 | # depthwise
117 | layers.append(
118 | ConvNormActivation(
119 | expanded_channels,
120 | expanded_channels,
121 | kernel_size=cnf.kernel,
122 | stride=cnf.stride,
123 | groups=expanded_channels,
124 | norm_layer=norm_layer,
125 | activation_layer=activation_layer,
126 | )
127 | )
128 |
129 | # squeeze and excitation
130 | squeeze_channels = max(1, cnf.input_channels // 4)
131 | layers.append(se_layer(expanded_channels, squeeze_channels, activation=partial(nn.SiLU, inplace=True)))
132 |
133 | # project
134 | layers.append(
135 | ConvNormActivation(
136 | expanded_channels, cnf.out_channels, kernel_size=1, norm_layer=norm_layer, activation_layer=None
137 | )
138 | )
139 |
140 | self.block = nn.Sequential(*layers)
141 | self.stochastic_depth = StochasticDepth(stochastic_depth_prob, "row")
142 | self.out_channels = cnf.out_channels
143 |
144 | def forward(self, input: Tensor) -> Tensor:
145 | result = self.block(input)
146 | if self.use_res_connect:
147 | result = self.stochastic_depth(result)
148 | result += input
149 | return result
150 |
151 |
152 | class EfficientNet(nn.Module):
153 | def __init__(
154 | self,
155 | inverted_residual_setting: List[MBConvConfig],
156 | dropout: float,
157 | stochastic_depth_prob: float = 0.2,
158 | num_classes: int = 1000,
159 | block: Optional[Callable[..., nn.Module]] = None,
160 | norm_layer: Optional[Callable[..., nn.Module]] = None,
161 | **kwargs: Any,
162 | ) -> None:
163 | """
164 | EfficientNet main class
165 |
166 | Args:
167 | inverted_residual_setting (List[MBConvConfig]): Network structure
168 | dropout (float): The droupout probability
169 | stochastic_depth_prob (float): The stochastic depth probability
170 | num_classes (int): Number of classes
171 | block (Optional[Callable[..., nn.Module]]): Module specifying inverted residual building block for mobilenet
172 | norm_layer (Optional[Callable[..., nn.Module]]): Module specifying the normalization layer to use
173 | """
174 | super().__init__()
175 |
176 | if not inverted_residual_setting:
177 | raise ValueError("The inverted_residual_setting should not be empty")
178 | elif not (
179 | isinstance(inverted_residual_setting, Sequence)
180 | and all([isinstance(s, MBConvConfig) for s in inverted_residual_setting])
181 | ):
182 | raise TypeError("The inverted_residual_setting should be List[MBConvConfig]")
183 |
184 | if block is None:
185 | block = MBConv
186 |
187 | if norm_layer is None:
188 | norm_layer = nn.BatchNorm2d
189 |
190 | layers: List[nn.Module] = []
191 | outplanes = [inverted_residual_setting[0].input_channels] + \
192 | [i.out_channels for i in inverted_residual_setting]
193 |
194 | # building first layer
195 | firstconv_output_channels = inverted_residual_setting[0].input_channels
196 | layers.append(
197 | ConvNormActivation(
198 | 3, firstconv_output_channels, kernel_size=3, stride=2, norm_layer=norm_layer, activation_layer=nn.SiLU
199 | )
200 | )
201 |
202 | # building inverted residual blocks
203 | total_stage_blocks = sum(cnf.num_layers for cnf in inverted_residual_setting)
204 | stage_block_id = 0
205 | for cnf in inverted_residual_setting:
206 | stage: List[nn.Module] = []
207 | for _ in range(cnf.num_layers):
208 | # copy to avoid modifications. shallow copy is enough
209 | block_cnf = copy.copy(cnf)
210 |
211 | # overwrite info if not the first conv in the stage
212 | if stage:
213 | block_cnf.input_channels = block_cnf.out_channels
214 | block_cnf.stride = 1
215 |
216 | # adjust stochastic depth probability based on the depth of the stage block
217 | sd_prob = stochastic_depth_prob * float(stage_block_id) / total_stage_blocks
218 |
219 | stage.append(block(block_cnf, sd_prob, norm_layer))
220 | stage_block_id += 1
221 |
222 | layers.append(nn.Sequential(*stage))
223 |
224 | # building last several layers
225 | lastconv_input_channels = inverted_residual_setting[-1].out_channels
226 | lastconv_output_channels = 4 * lastconv_input_channels
227 | layers.append(
228 | ConvNormActivation(
229 | lastconv_input_channels,
230 | lastconv_output_channels,
231 | kernel_size=1,
232 | norm_layer=norm_layer,
233 | activation_layer=nn.SiLU,
234 | )
235 | )
236 | outplanes.append(lastconv_output_channels)
237 | self.features = nn.ModuleList(layers)
238 |
239 | self.gates = [3, 4, 5, 9]
240 | self.outplanes = [outplanes[g-1] for g in self.gates]
241 |
242 | for m in self.modules():
243 | if isinstance(m, nn.Conv2d):
244 | nn.init.kaiming_normal_(m.weight, mode="fan_out")
245 | if m.bias is not None:
246 | nn.init.zeros_(m.bias)
247 | elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
248 | nn.init.ones_(m.weight)
249 | nn.init.zeros_(m.bias)
250 | elif isinstance(m, nn.Linear):
251 | init_range = 1.0 / math.sqrt(m.out_features)
252 | nn.init.uniform_(m.weight, -init_range, init_range)
253 | nn.init.zeros_(m.bias)
254 |
255 | def _forward_impl(self, x: Tensor) -> Union[Tensor, Any]:
256 |
257 | for n in range(0, self.gates[0]):
258 | x = self.features[n](x)
259 | x1 = x
260 |
261 | for n in range(self.gates[0], self.gates[1]):
262 | x = self.features[n](x)
263 | x2 = x
264 |
265 | for n in range(self.gates[1], self.gates[2]):
266 | x = self.features[n](x)
267 | x3 = x
268 |
269 | for n in range(self.gates[2], self.gates[3]):
270 | x = self.features[n](x)
271 |
272 | return x1, x2, x3, x
273 |
274 | def forward(self, x: Tensor) -> Union[Tensor, Any]:
275 | return self._forward_impl(x)
276 |
277 | def _efficientnet(
278 | arch: str,
279 | width_mult: float,
280 | depth_mult: float,
281 | dropout: float,
282 | pretrained: bool,
283 | progress: bool,
284 | **kwargs: Any,
285 | ) -> EfficientNet:
286 | bneck_conf = partial(MBConvConfig, width_mult=width_mult, depth_mult=depth_mult)
287 | inverted_residual_setting = [
288 | bneck_conf(1, 3, 1, 32, 16, 1),
289 | bneck_conf(6, 3, 2, 16, 24, 2),
290 | bneck_conf(6, 5, 2, 24, 40, 2),
291 | bneck_conf(6, 3, 2, 40, 80, 3),
292 | bneck_conf(6, 5, 1, 80, 112, 3),
293 | bneck_conf(6, 5, 2, 112, 192, 4),
294 | bneck_conf(6, 3, 1, 192, 320, 1),
295 | ]
296 | model = EfficientNet(inverted_residual_setting, dropout, **kwargs)
297 | if pretrained:
298 | if model_urls.get(arch, None) is None:
299 | raise ValueError(f"No checkpoint is available for model type {arch}")
300 | state_dict = load_state_dict_from_url(model_urls[arch], progress=progress)
301 |
302 | # Discard removed layers
303 | model_dict = model.state_dict()
304 | matched_layers, discarded_layers = [], []
305 | new_state_dict = OrderedDict()
306 |
307 | for k, v in state_dict.items():
308 |
309 | if k in model_dict and model_dict[k].size() == v.size():
310 | new_state_dict[k] = v
311 | matched_layers.append(k)
312 | else:
313 | discarded_layers.append(k)
314 |
315 | model_dict.update(new_state_dict)
316 |
317 | if len(matched_layers) == 0:
318 | warnings.warn(
319 | 'The pretrained weights for "{}" cannot be loaded, '
320 | 'please check the key names manually '
321 | '(** ignored and continue **)'.format(arch)
322 | )
323 | else:
324 | print(
325 | 'Successfully loaded imagenet pretrained weights for "{}"'.
326 | format(arch)
327 | )
328 | if len(discarded_layers) > 0:
329 | print(
330 | '** The following layers are discarded '
331 | 'due to unmatched keys or layer size: {}'.
332 | format(discarded_layers)
333 | )
334 |
335 | model.load_state_dict(model_dict)
336 |
337 | return model
338 |
339 |
340 | def efficientnet_b0(pretrained: bool = True, progress: bool = True, **kwargs: Any) -> EfficientNet:
341 | """
342 | Constructs a EfficientNet B0 architecture from
343 | `"EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks" `_.
344 |
345 | Args:
346 | pretrained (bool): If True, returns a model pre-trained on ImageNet
347 | progress (bool): If True, displays a progress bar of the download to stderr
348 | """
349 | return _efficientnet("efficientnet_b0", 1.0, 1.0, 0.2, pretrained, progress, **kwargs)
350 |
351 |
352 | def efficientnet_b1(pretrained: bool = True, progress: bool = True, **kwargs: Any) -> EfficientNet:
353 | """
354 | Constructs a EfficientNet B1 architecture from
355 | `"EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks" `_.
356 |
357 | Args:
358 | pretrained (bool): If True, returns a model pre-trained on ImageNet
359 | progress (bool): If True, displays a progress bar of the download to stderr
360 | """
361 | return _efficientnet("efficientnet_b1", 1.0, 1.1, 0.2, pretrained, progress, **kwargs)
362 |
363 |
364 | def efficientnet_b2(pretrained: bool = True, progress: bool = True, **kwargs: Any) -> EfficientNet:
365 | """
366 | Constructs a EfficientNet B2 architecture from
367 | `"EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks" `_.
368 |
369 | Args:
370 | pretrained (bool): If True, returns a model pre-trained on ImageNet
371 | progress (bool): If True, displays a progress bar of the download to stderr
372 | """
373 | return _efficientnet("efficientnet_b2", 1.1, 1.2, 0.3, pretrained, progress, **kwargs)
374 |
375 |
376 | def efficientnet_b3(pretrained: bool = True, progress: bool = True, **kwargs: Any) -> EfficientNet:
377 | """
378 | Constructs a EfficientNet B3 architecture from
379 | `"EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks" `_.
380 |
381 | Args:
382 | pretrained (bool): If True, returns a model pre-trained on ImageNet
383 | progress (bool): If True, displays a progress bar of the download to stderr
384 | """
385 | return _efficientnet("efficientnet_b3", 1.2, 1.4, 0.3, pretrained, progress, **kwargs)
386 |
387 |
388 | def efficientnet_b4(pretrained: bool = True, progress: bool = True, **kwargs: Any) -> EfficientNet:
389 | """
390 | Constructs a EfficientNet B4 architecture from
391 | `"EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks" `_.
392 |
393 | Args:
394 | pretrained (bool): If True, returns a model pre-trained on ImageNet
395 | progress (bool): If True, displays a progress bar of the download to stderr
396 | """
397 | return _efficientnet("efficientnet_b4", 1.4, 1.8, 0.4, pretrained, progress, **kwargs)
398 |
399 |
400 | def efficientnet_b5(pretrained: bool = True, progress: bool = True, **kwargs: Any) -> EfficientNet:
401 | """
402 | Constructs a EfficientNet B5 architecture from
403 | `"EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks" `_.
404 |
405 | Args:
406 | pretrained (bool): If True, returns a model pre-trained on ImageNet
407 | progress (bool): If True, displays a progress bar of the download to stderr
408 | """
409 | return _efficientnet(
410 | "efficientnet_b5",
411 | 1.6,
412 | 2.2,
413 | 0.4,
414 | pretrained,
415 | progress,
416 | norm_layer=partial(nn.BatchNorm2d, eps=0.001, momentum=0.01),
417 | **kwargs,
418 | )
419 |
420 |
421 | def efficientnet_b6(pretrained: bool = True, progress: bool = True, **kwargs: Any) -> EfficientNet:
422 | """
423 | Constructs a EfficientNet B6 architecture from
424 | `"EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks" `_.
425 |
426 | Args:
427 | pretrained (bool): If True, returns a model pre-trained on ImageNet
428 | progress (bool): If True, displays a progress bar of the download to stderr
429 | """
430 | return _efficientnet(
431 | "efficientnet_b6",
432 | 1.8,
433 | 2.6,
434 | 0.5,
435 | pretrained,
436 | progress,
437 | norm_layer=partial(nn.BatchNorm2d, eps=0.001, momentum=0.01),
438 | **kwargs,
439 | )
440 |
441 |
442 | def efficientnet_b7(pretrained: bool = True, progress: bool = True, **kwargs: Any) -> EfficientNet:
443 | """
444 | Constructs a EfficientNet B7 architecture from
445 | `"EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks" `_.
446 |
447 | Args:
448 | pretrained (bool): If True, returns a model pre-trained on ImageNet
449 | progress (bool): If True, displays a progress bar of the download to stderr
450 | """
451 | return _efficientnet(
452 | "efficientnet_b7",
453 | 2.0,
454 | 3.1,
455 | 0.5,
456 | pretrained,
457 | progress,
458 | norm_layer=partial(nn.BatchNorm2d, eps=0.001, momentum=0.01),
459 | **kwargs,
460 | )
461 |
462 | if __name__ == '__main__':
463 | m = efficientnet_b2(pretrained=True)
464 | x = torch.rand((1,3,320,640), dtype=torch.float32)
465 | y = m(x)
466 | print(m.outplanes)
467 |
468 | """
469 | b0
470 | torch.Size([1, 24, 80, 160])
471 | torch.Size([1, 40, 40, 80])
472 | torch.Size([1, 80, 20, 40])
473 | torch.Size([1, 1280, 10, 20])
474 | [24, 40, 80, 1280]
475 | ---
476 | b1
477 | torch.Size([1, 24, 80, 160])
478 | torch.Size([1, 40, 40, 80])
479 | torch.Size([1, 80, 20, 40])
480 | torch.Size([1, 1280, 10, 20])
481 | [24, 40, 80, 1280]
482 | ---
483 | b2 <===*
484 | torch.Size([1, 24, 80, 160])
485 | torch.Size([1, 48, 40, 80])
486 | torch.Size([1, 88, 20, 40])
487 | torch.Size([1, 1408, 10, 20])
488 | ---
489 | b3
490 | torch.Size([1, 32, 80, 160])
491 | torch.Size([1, 48, 40, 80])
492 | torch.Size([1, 96, 20, 40])
493 | torch.Size([1, 1536, 10, 20])
494 | ---
495 | b4
496 | torch.Size([1, 32, 80, 160])
497 | torch.Size([1, 56, 40, 80])
498 | torch.Size([1, 112, 20, 40])
499 | torch.Size([1, 1792, 10, 20])
500 | ---
501 | b5
502 | torch.Size([1, 40, 80, 160])
503 | torch.Size([1, 64, 40, 80])
504 | torch.Size([1, 128, 20, 40])
505 | torch.Size([1, 2048, 10, 20])
506 | ---
507 | b6
508 | torch.Size([1, 40, 80, 160])
509 | torch.Size([1, 72, 40, 80])
510 | torch.Size([1, 144, 20, 40])
511 | torch.Size([1, 2304, 10, 20])
512 | ---
513 | torch.Size([1, 48, 80, 160])
514 | torch.Size([1, 80, 40, 80])
515 | torch.Size([1, 160, 20, 40])
516 | torch.Size([1, 2560, 10, 20])
517 | """
518 |
519 |
--------------------------------------------------------------------------------