 69 |
70 | 客户端:
71 |
72 |
69 |
70 | 客户端:
71 |
72 |  73 |
74 | - - -
75 |
76 | ## TCP套接字编程
77 |
78 | ### 1. 描述
79 |
80 | 《自顶向下方法(原书第7版)》第2.7.2节给出了一个使用Python的TCP套接字编程实例。实现了一个简单的TCP通信程序。
81 |
82 | ### 2. 代码
83 |
84 | 客户端程序`TCPClient.py`创建一个TCP套接字,然后向指定服务器地址和端口发起连接,等待服务器连接后,再将用户输入的字符串通过套接字发送,其后将服务器返回的消息显示出来。
85 |
86 | 服务端程序`TCPServer.py`一直保持一个TCP欢迎套接字,可接收任何客户端的连接请求。在接收到客户端的连接请求后,创建一个新的TCP连接套接字用于单独与该客户通信,同时显示客户端地址和端口。在接收到客户端发来的字符串后,将其改为大写,然后向客户端返回修改后的字符串。最后,关闭TCP连接套接字。
87 |
88 | 1. [TCPClient.py](TCPClient.py)
89 |
90 | ```python
91 | '''TCPClient.py'''
92 |
93 | from socket import *
94 |
95 | serverName = input('Please enter the hostname of server: ') # 提供服务器的地址或主机名的字符串
96 | serverPort = 12000 # 指定服务器端口
97 |
98 | # 建立客户端的套接字。
99 | # 第二个参数SOCK_STREAM表明是TCP类型的套接字。
100 | # 创建客户端套接字时不用指定端口号,操作系统会进行分配
101 | clientSocket = socket(AF_INET, SOCK_STREAM)
102 |
103 | clientSocket.connect((serverName, serverPort)) # 客户端向服务器发起连接,执行三次握手,建立起TCP连接
104 |
105 | sentence = input('Input lowercase sentence: ') # 用户在客户端中输入信息
106 |
107 | # 将信息发送到服务器
108 | # 与UDP连接不同的是,TCP socket并不显式地创建一个分组并附上目的地址,而只是将分组放入TCP连接中
109 | clientSocket.send(sentence.encode())
110 |
111 | modifiedSentence = clientSocket.recvfrom(2048) # 从服务器接收信息
112 |
113 | print('From server: ', modifiedSentence[0].decode()) # 显示信息
114 |
115 | clientSocket.close() # 关闭套接字,因此关闭客户端和服务器之间的TCP连接
116 | ```
117 |
118 | 2. [TCPServer.py](TCPServer.py)
119 |
120 | ```python
121 | '''TCPServer.py'''
122 |
123 | from socket import *
124 |
125 | serverPort = 12000
126 |
127 | serverSocket = socket(AF_INET, SOCK_STREAM) # 创建TCP欢迎套接字
128 | serverSocket.bind(('',serverPort)) # 将服务器端口号serverPort与该套接字绑定起来
129 | serverSocket.listen(10) # 服务器聆听来自客户端的TCP连接请求。最大连接数设置为10
130 | print("The server in ready to receive")
131 |
132 | while True:
133 | connectionSocket, addr = serverSocket.accept() # 接收到客户连接请求后,调用accept函数建立新的TCP连接套接字
134 |
135 | sentence = connectionSocket.recv(2048).decode() # 获取客户发送的字符串
136 | capitalizedSentence = sentence.upper() # 将字符串改为大写
137 | connectionSocket.send(capitalizedSentence.encode()) # 向用户发送修改后的字符串
138 | connectionSocket.close() # 关闭TCP连接套接字
139 | ```
140 |
141 | ### 3. 运行
142 |
143 | 先在一台机器上启动服务器程序,然后在另一台机器上启动客户端程序。运行效果如下:
144 |
145 | 服务器端:
146 |
147 |
73 |
74 | - - -
75 |
76 | ## TCP套接字编程
77 |
78 | ### 1. 描述
79 |
80 | 《自顶向下方法(原书第7版)》第2.7.2节给出了一个使用Python的TCP套接字编程实例。实现了一个简单的TCP通信程序。
81 |
82 | ### 2. 代码
83 |
84 | 客户端程序`TCPClient.py`创建一个TCP套接字,然后向指定服务器地址和端口发起连接,等待服务器连接后,再将用户输入的字符串通过套接字发送,其后将服务器返回的消息显示出来。
85 |
86 | 服务端程序`TCPServer.py`一直保持一个TCP欢迎套接字,可接收任何客户端的连接请求。在接收到客户端的连接请求后,创建一个新的TCP连接套接字用于单独与该客户通信,同时显示客户端地址和端口。在接收到客户端发来的字符串后,将其改为大写,然后向客户端返回修改后的字符串。最后,关闭TCP连接套接字。
87 |
88 | 1. [TCPClient.py](TCPClient.py)
89 |
90 | ```python
91 | '''TCPClient.py'''
92 |
93 | from socket import *
94 |
95 | serverName = input('Please enter the hostname of server: ') # 提供服务器的地址或主机名的字符串
96 | serverPort = 12000 # 指定服务器端口
97 |
98 | # 建立客户端的套接字。
99 | # 第二个参数SOCK_STREAM表明是TCP类型的套接字。
100 | # 创建客户端套接字时不用指定端口号,操作系统会进行分配
101 | clientSocket = socket(AF_INET, SOCK_STREAM)
102 |
103 | clientSocket.connect((serverName, serverPort)) # 客户端向服务器发起连接,执行三次握手,建立起TCP连接
104 |
105 | sentence = input('Input lowercase sentence: ') # 用户在客户端中输入信息
106 |
107 | # 将信息发送到服务器
108 | # 与UDP连接不同的是,TCP socket并不显式地创建一个分组并附上目的地址,而只是将分组放入TCP连接中
109 | clientSocket.send(sentence.encode())
110 |
111 | modifiedSentence = clientSocket.recvfrom(2048) # 从服务器接收信息
112 |
113 | print('From server: ', modifiedSentence[0].decode()) # 显示信息
114 |
115 | clientSocket.close() # 关闭套接字,因此关闭客户端和服务器之间的TCP连接
116 | ```
117 |
118 | 2. [TCPServer.py](TCPServer.py)
119 |
120 | ```python
121 | '''TCPServer.py'''
122 |
123 | from socket import *
124 |
125 | serverPort = 12000
126 |
127 | serverSocket = socket(AF_INET, SOCK_STREAM) # 创建TCP欢迎套接字
128 | serverSocket.bind(('',serverPort)) # 将服务器端口号serverPort与该套接字绑定起来
129 | serverSocket.listen(10) # 服务器聆听来自客户端的TCP连接请求。最大连接数设置为10
130 | print("The server in ready to receive")
131 |
132 | while True:
133 | connectionSocket, addr = serverSocket.accept() # 接收到客户连接请求后,调用accept函数建立新的TCP连接套接字
134 |
135 | sentence = connectionSocket.recv(2048).decode() # 获取客户发送的字符串
136 | capitalizedSentence = sentence.upper() # 将字符串改为大写
137 | connectionSocket.send(capitalizedSentence.encode()) # 向用户发送修改后的字符串
138 | connectionSocket.close() # 关闭TCP连接套接字
139 | ```
140 |
141 | ### 3. 运行
142 |
143 | 先在一台机器上启动服务器程序,然后在另一台机器上启动客户端程序。运行效果如下:
144 |
145 | 服务器端:
146 |
147 |  148 |
149 | 客户端:
150 |
151 |
148 |
149 | 客户端:
150 |
151 |  --------------------------------------------------------------------------------
/Log_of_ComputerNetworking-ATopDownApproach_7th/chapter0.md:
--------------------------------------------------------------------------------
1 | # 计算机网络——自顶向下方法 7th
2 |
3 | 中国科学技术大学 郑烇教授 2020年秋季 自动化系
4 |
5 | ## 0. 课程主要内容
6 |
7 | 1. 计算机网络和互联网
8 | 2. 应用层
9 | 3. 传输层
10 | 4. 网络层:数据平面
11 | 5. 网络层:控制平面
12 | 6. 数据链路层和局域网
13 | 7. 网络安全
14 | 8. 无线和移动网络
15 | 9. 多媒体网络
16 | 10. 网络管理
17 |
--------------------------------------------------------------------------------
/Log_of_ComputerNetworking-ATopDownApproach_7th/chapter1.md:
--------------------------------------------------------------------------------
1 | # 计算机网络——自顶向下方法 7th
2 |
3 | 中国科学技术大学 郑烇教授 2020年秋季 自动化系
4 |
5 | ## 1. 计算机网络概述
6 |
7 | 了解基本术语和概念;掌握网络的基本原理;方法:以Internet为例
8 |
9 | ### 1.1 什么是Internet?
10 |
11 | - 网络:电话网、蜘蛛网、神经元网络等
12 | - 节点和边的关系,与大小形状无关
13 | - 计算机网络:联网的计算机构成的系统
14 | - 节点:
15 | - 主机节点(数据的源、目标):Web服务器、手机、电脑、联网的冰箱等 主机及其上运行的应用程序
16 | - 数据交换节点(不是源、目标,转发数据的中转节点):路由器(网络层)、交换机(链路层)等 网络交换设备
17 | - 链路(连接节点,构成网络的边),分为两类:
18 | - 接入网链路:主机通过以太网的网线接入最近的交换机,连接到互联网
19 | - 主干链路:路由器之间的链路
20 | - 协议:支撑互联网工作的重要标准,网络设备遵守协议进行交互;不同层有不同的协议,每一层有多个协议
21 | - 互联网:以TCP协议和IP协议为主的一簇协议支撑起工作的网络
22 |
23 |
24 | 什么是Internet:1. 从具体构成角度
25 | - 数以亿计的、互联的计算设备:
26 | - 主机 = 端系统(host、end_system)
27 | - 运行网络应用程序
28 | - 通信链路
29 | - 光纤、同轴电缆、无线电、卫星
30 | - 传输速率 = 带宽(比特/秒:bit/s or bps)
31 | - 分组交换设备:转发分组(packets)
32 | - 路由器和交换机
33 | - 协议控制发送、接收消息
34 | - 如TCP、IP、HTTP、FTP、PPP
35 | - Internet:“网络的网络”
36 | - 松散的层次结构,互连的ISP
37 | - 公共Internet vs. 专用intranet
38 | - Internet标准
39 | - RFC: Request for comments 请求评述
40 | - IETF: Internet Engineering Task Force 所有协议都以RFC文档形式在IETF上发布
41 |
42 | 什么是协议?
43 |
44 | - 人类协议:“几点了?”、“我有个问题”、你好
45 | - ...发送特定的消息
46 | - ...收到消息时采取的特定行动或其他事件
47 | - 网络协议:
48 | - 类似人类协议
49 | - 机器之间的协议而非人与人之间的协议
50 | - Internet中所有的通信行为都受协议制约
51 |
52 | 协议定义了在两个或多个通信实体之间交换的**报文格式**和**次序**,以及在报文传输和/或接收或其他事件方面所采取的**动作**。
53 |
54 | 报文格式:语法和语义 【PDU(协议数据单元)】;
55 | 次序(时序);
56 | 动作:收到报文后做出的内部处理的动作
57 |
58 |
--------------------------------------------------------------------------------
/Log_of_ComputerNetworking-ATopDownApproach_7th/chapter0.md:
--------------------------------------------------------------------------------
1 | # 计算机网络——自顶向下方法 7th
2 |
3 | 中国科学技术大学 郑烇教授 2020年秋季 自动化系
4 |
5 | ## 0. 课程主要内容
6 |
7 | 1. 计算机网络和互联网
8 | 2. 应用层
9 | 3. 传输层
10 | 4. 网络层:数据平面
11 | 5. 网络层:控制平面
12 | 6. 数据链路层和局域网
13 | 7. 网络安全
14 | 8. 无线和移动网络
15 | 9. 多媒体网络
16 | 10. 网络管理
17 |
--------------------------------------------------------------------------------
/Log_of_ComputerNetworking-ATopDownApproach_7th/chapter1.md:
--------------------------------------------------------------------------------
1 | # 计算机网络——自顶向下方法 7th
2 |
3 | 中国科学技术大学 郑烇教授 2020年秋季 自动化系
4 |
5 | ## 1. 计算机网络概述
6 |
7 | 了解基本术语和概念;掌握网络的基本原理;方法:以Internet为例
8 |
9 | ### 1.1 什么是Internet?
10 |
11 | - 网络:电话网、蜘蛛网、神经元网络等
12 | - 节点和边的关系,与大小形状无关
13 | - 计算机网络:联网的计算机构成的系统
14 | - 节点:
15 | - 主机节点(数据的源、目标):Web服务器、手机、电脑、联网的冰箱等 主机及其上运行的应用程序
16 | - 数据交换节点(不是源、目标,转发数据的中转节点):路由器(网络层)、交换机(链路层)等 网络交换设备
17 | - 链路(连接节点,构成网络的边),分为两类:
18 | - 接入网链路:主机通过以太网的网线接入最近的交换机,连接到互联网
19 | - 主干链路:路由器之间的链路
20 | - 协议:支撑互联网工作的重要标准,网络设备遵守协议进行交互;不同层有不同的协议,每一层有多个协议
21 | - 互联网:以TCP协议和IP协议为主的一簇协议支撑起工作的网络
22 |
23 |
24 | 什么是Internet:1. 从具体构成角度
25 | - 数以亿计的、互联的计算设备:
26 | - 主机 = 端系统(host、end_system)
27 | - 运行网络应用程序
28 | - 通信链路
29 | - 光纤、同轴电缆、无线电、卫星
30 | - 传输速率 = 带宽(比特/秒:bit/s or bps)
31 | - 分组交换设备:转发分组(packets)
32 | - 路由器和交换机
33 | - 协议控制发送、接收消息
34 | - 如TCP、IP、HTTP、FTP、PPP
35 | - Internet:“网络的网络”
36 | - 松散的层次结构,互连的ISP
37 | - 公共Internet vs. 专用intranet
38 | - Internet标准
39 | - RFC: Request for comments 请求评述
40 | - IETF: Internet Engineering Task Force 所有协议都以RFC文档形式在IETF上发布
41 |
42 | 什么是协议?
43 |
44 | - 人类协议:“几点了?”、“我有个问题”、你好
45 | - ...发送特定的消息
46 | - ...收到消息时采取的特定行动或其他事件
47 | - 网络协议:
48 | - 类似人类协议
49 | - 机器之间的协议而非人与人之间的协议
50 | - Internet中所有的通信行为都受协议制约
51 |
52 | 协议定义了在两个或多个通信实体之间交换的**报文格式**和**次序**,以及在报文传输和/或接收或其他事件方面所采取的**动作**。
53 |
54 | 报文格式:语法和语义 【PDU(协议数据单元)】;
55 | 次序(时序);
56 | 动作:收到报文后做出的内部处理的动作
57 |
58 |  59 |
60 | 什么是Internet:2. 从服务角度
61 |
62 | 分布式应用进程以及为分布式应用进程提供通信服务的基础设施
63 |
64 | 基础设施包括:主机应用层以下的所有运行中的协议实体、目标主机应用层以下的所有运行中的协议实体、所有的网络部分
65 |
66 | - 使用通信设施进行通信的分布式应用
67 | - Web、VoIP、email、分布式游戏、电子商务、社交网络......
68 | - 通信基础设施为apps提供编程接口(通信服务)
69 | - 将发送和接收数据的apps与互联网连接起来
70 | - 为app应用提供服务选择,类似于邮政服务:
71 | - 无连接不可靠服务 —— UDP协议
72 | - 面向连接的可靠服务 —— TCP/IP协议
73 |
74 | ### 1.2 网络边缘
75 |
76 | 网络结构:
77 | - 网络边缘(edge):
78 | - 主机
79 | - 应用程序(客户端和服务器)
80 | - 网络核心(core):数据交换作用
81 | - 互连着的路由器
82 | - 网络的网络
83 | - 接入网、物理媒体(access):将边缘的端系统(主机)接入到核心,使任意两个端系统可以通信
84 | - 有线或者无线通信链路
85 |
86 | 网络边缘:
87 | - 端系统(主机):
88 | - 运行应用程序
89 | - 如Web、email
90 | - 在“网络的边缘”
91 | - 客户端(Client)/服务器(Server)模式(C/S模式):主-从模式,存在可扩展性的问题
92 | - 客户端向服务器请求、接收服务,通常是桌面PC、移动PC和智能手机等
93 | - 服务器是更为强大的机器,用于存储和发布Web页面、流视频、中继电子邮件等,大部分都属于大型数据中心
94 | - 如Web浏览器/服务器;email客户端/服务器
95 | - 对等(peer-peer)模式:每个节点既是客户端,又是服务器,通讯是分布式的
96 | - 很少(甚至没有)专门的服务器
97 | - 如Gnutella、KaZaA、Emule电驴、迅雷等分布式文件分发系统
98 |
99 | 基础设施为网络应用提供的服务又有两种方式:
100 |
101 | 1.网络边缘:采用网络设施的面向连接服务:先建立连接,做好准备,两个应用进程再通信
102 | - 目标:在端系统之间传输数据
103 | - 握手:在数据传输之前做好准备
104 | - 人类协议中:你好、你好
105 | - 两个通信主机之间为连接建立状态
106 | - TCP——传输控制协议(Transmission Control Protocol)
107 | - Internet上面向连接的服务
108 | - TCP服务[RFC 793]
109 | - 可靠地、按顺序地传送数据:不重复、不丢失、不失序
110 | - 确认和重传
111 | - 流量控制(考虑接收方的处理能力)
112 | - 发送方不会淹没接收方,协调发送/接受速度,实现有序通信
113 | - 拥塞控制(考虑网络路径的通行能力)
114 | - 当网络拥塞时,发送方降低发送速率
115 |
116 |
117 | *注:面向连接和有连接有区别:*
118 | *面向连接:通信状态只在端系统中维护,网络不知道*
119 | *有连接:中间的所有节点都知道*
120 | [点击返回“数据报与虚电路”](#JumpBack1)
121 |
122 | 2.网络边缘:采用基础设施的无连接服务:不用先握手
123 | - 目标:在端系统之间传输数据
124 | - 无连接服务
125 | - UDP——用户数据报协议(User Datagram Protocol)[RFC 768]:将主机-主机通过UDP端口细分到进程-进程;速度快,适合于实时多媒体应用
126 | - 无连接
127 | - 不可靠数据传输
128 | - 无流量控制、无拥塞控制:发送速度等于接收速度
129 | - 使用TCP的应用:对于可靠性要求较高
130 | - HTTP(Web),FTP(文件传送),Telnet(远程登录),SMTP(email)
131 | - 使用UDP的应用:
132 | - 流媒体、远程会议、DNS、Internet电话、一些事物性应用(如域名解析等)
133 |
134 | ### 1.3 网络核心
135 |
136 | 网络核心:路由器的网状网络
137 | 作用:数据交换
138 |
139 | 基本问题:数据怎样通过网络进行传输?
140 | - 电路交换(circuit switching):为每个呼叫预留一条专有电路:如电话网
141 | - 分组交换(packet switching):互联网和几乎所有计算机网络都运用分组交换;以分组为单位,存储转发
142 | - 将要传送的数据分成一个个单位:分组
143 | - 将分组从一个路由器传到相邻路由器(hop),一段段最终从源端传到目标端
144 | - 每段:采用链路的最大传输能力(带宽)
145 |
146 | 网络核心:电路交换
147 |
148 | 首先通过**信令系统**,在网络核心中为两者之间的通信分配一条独享的线路。
149 | 交换节点和交换节点之间的链路较粗,带宽较大,可以采用时分多路复用、频分多路复用、码分多路复用(多用于接入网)、波分多路复用(多用于光纤(光通信))等多种方法分解成小片(pieces)。
150 | 通过信令系统,可以挑出每两个节点之间当前没有用的片,串在一起,形成两台主机之间的独享线路
151 |
152 | 端到端的资源被分配给从源端到目标端的呼叫“call”:
153 | - 图中,每段链路有4条线路:
154 | - 该呼叫采用了上面链路的第2个线路,右边链路的第1个线路(piece)
155 | - 独享资源:不同享
156 | - 每个呼叫一旦建立起来就能够保证性能
157 | - 如果呼叫没有数据发送,被分配的资源就会被浪费(no sharing)
158 | - 通常被传统电话网络采用
159 |
160 |
59 |
60 | 什么是Internet:2. 从服务角度
61 |
62 | 分布式应用进程以及为分布式应用进程提供通信服务的基础设施
63 |
64 | 基础设施包括:主机应用层以下的所有运行中的协议实体、目标主机应用层以下的所有运行中的协议实体、所有的网络部分
65 |
66 | - 使用通信设施进行通信的分布式应用
67 | - Web、VoIP、email、分布式游戏、电子商务、社交网络......
68 | - 通信基础设施为apps提供编程接口(通信服务)
69 | - 将发送和接收数据的apps与互联网连接起来
70 | - 为app应用提供服务选择,类似于邮政服务:
71 | - 无连接不可靠服务 —— UDP协议
72 | - 面向连接的可靠服务 —— TCP/IP协议
73 |
74 | ### 1.2 网络边缘
75 |
76 | 网络结构:
77 | - 网络边缘(edge):
78 | - 主机
79 | - 应用程序(客户端和服务器)
80 | - 网络核心(core):数据交换作用
81 | - 互连着的路由器
82 | - 网络的网络
83 | - 接入网、物理媒体(access):将边缘的端系统(主机)接入到核心,使任意两个端系统可以通信
84 | - 有线或者无线通信链路
85 |
86 | 网络边缘:
87 | - 端系统(主机):
88 | - 运行应用程序
89 | - 如Web、email
90 | - 在“网络的边缘”
91 | - 客户端(Client)/服务器(Server)模式(C/S模式):主-从模式,存在可扩展性的问题
92 | - 客户端向服务器请求、接收服务,通常是桌面PC、移动PC和智能手机等
93 | - 服务器是更为强大的机器,用于存储和发布Web页面、流视频、中继电子邮件等,大部分都属于大型数据中心
94 | - 如Web浏览器/服务器;email客户端/服务器
95 | - 对等(peer-peer)模式:每个节点既是客户端,又是服务器,通讯是分布式的
96 | - 很少(甚至没有)专门的服务器
97 | - 如Gnutella、KaZaA、Emule电驴、迅雷等分布式文件分发系统
98 |
99 | 基础设施为网络应用提供的服务又有两种方式:
100 |
101 | 1.网络边缘:采用网络设施的面向连接服务:先建立连接,做好准备,两个应用进程再通信
102 | - 目标:在端系统之间传输数据
103 | - 握手:在数据传输之前做好准备
104 | - 人类协议中:你好、你好
105 | - 两个通信主机之间为连接建立状态
106 | - TCP——传输控制协议(Transmission Control Protocol)
107 | - Internet上面向连接的服务
108 | - TCP服务[RFC 793]
109 | - 可靠地、按顺序地传送数据:不重复、不丢失、不失序
110 | - 确认和重传
111 | - 流量控制(考虑接收方的处理能力)
112 | - 发送方不会淹没接收方,协调发送/接受速度,实现有序通信
113 | - 拥塞控制(考虑网络路径的通行能力)
114 | - 当网络拥塞时,发送方降低发送速率
115 |
116 |
117 | *注:面向连接和有连接有区别:*
118 | *面向连接:通信状态只在端系统中维护,网络不知道*
119 | *有连接:中间的所有节点都知道*
120 | [点击返回“数据报与虚电路”](#JumpBack1)
121 |
122 | 2.网络边缘:采用基础设施的无连接服务:不用先握手
123 | - 目标:在端系统之间传输数据
124 | - 无连接服务
125 | - UDP——用户数据报协议(User Datagram Protocol)[RFC 768]:将主机-主机通过UDP端口细分到进程-进程;速度快,适合于实时多媒体应用
126 | - 无连接
127 | - 不可靠数据传输
128 | - 无流量控制、无拥塞控制:发送速度等于接收速度
129 | - 使用TCP的应用:对于可靠性要求较高
130 | - HTTP(Web),FTP(文件传送),Telnet(远程登录),SMTP(email)
131 | - 使用UDP的应用:
132 | - 流媒体、远程会议、DNS、Internet电话、一些事物性应用(如域名解析等)
133 |
134 | ### 1.3 网络核心
135 |
136 | 网络核心:路由器的网状网络
137 | 作用:数据交换
138 |
139 | 基本问题:数据怎样通过网络进行传输?
140 | - 电路交换(circuit switching):为每个呼叫预留一条专有电路:如电话网
141 | - 分组交换(packet switching):互联网和几乎所有计算机网络都运用分组交换;以分组为单位,存储转发
142 | - 将要传送的数据分成一个个单位:分组
143 | - 将分组从一个路由器传到相邻路由器(hop),一段段最终从源端传到目标端
144 | - 每段:采用链路的最大传输能力(带宽)
145 |
146 | 网络核心:电路交换
147 |
148 | 首先通过**信令系统**,在网络核心中为两者之间的通信分配一条独享的线路。
149 | 交换节点和交换节点之间的链路较粗,带宽较大,可以采用时分多路复用、频分多路复用、码分多路复用(多用于接入网)、波分多路复用(多用于光纤(光通信))等多种方法分解成小片(pieces)。
150 | 通过信令系统,可以挑出每两个节点之间当前没有用的片,串在一起,形成两台主机之间的独享线路
151 |
152 | 端到端的资源被分配给从源端到目标端的呼叫“call”:
153 | - 图中,每段链路有4条线路:
154 | - 该呼叫采用了上面链路的第2个线路,右边链路的第1个线路(piece)
155 | - 独享资源:不同享
156 | - 每个呼叫一旦建立起来就能够保证性能
157 | - 如果呼叫没有数据发送,被分配的资源就会被浪费(no sharing)
158 | - 通常被传统电话网络采用
159 |
160 |  161 |
162 | 为呼叫预留端-端资源
163 | - 链路带宽、交换能力
164 | - 专用资源:不共享
165 | - 保证性能
166 | - 要求建立呼叫连接
167 |
168 | 网络资源(如带宽)被分成片
169 | - 为呼叫分配片
170 | - 如果某个呼叫没有数据,则其资源片处于空闲状态(不共享)
171 | - 将带宽分成片,怎么分?
172 | - 频分(Frequency-division multiplexing):将可用通讯频率覆盖范围分为多个频段
173 | - 时分(Time-division multiplexing):将节点和节点之间的通信能力按时间分为T为单位的周期,每个T中分为若干小片,每个周期的第i片被第i个用户所使用
174 | - 波分(Wave-division multiplexing):采用光电路,将可用波段分为若干个小的波段,每个用户使用其中一个小波段
175 |
176 | 频分FDM与时分TDM
177 |
178 |
161 |
162 | 为呼叫预留端-端资源
163 | - 链路带宽、交换能力
164 | - 专用资源:不共享
165 | - 保证性能
166 | - 要求建立呼叫连接
167 |
168 | 网络资源(如带宽)被分成片
169 | - 为呼叫分配片
170 | - 如果某个呼叫没有数据,则其资源片处于空闲状态(不共享)
171 | - 将带宽分成片,怎么分?
172 | - 频分(Frequency-division multiplexing):将可用通讯频率覆盖范围分为多个频段
173 | - 时分(Time-division multiplexing):将节点和节点之间的通信能力按时间分为T为单位的周期,每个T中分为若干小片,每个周期的第i片被第i个用户所使用
174 | - 波分(Wave-division multiplexing):采用光电路,将可用波段分为若干个小的波段,每个用户使用其中一个小波段
175 |
176 | 频分FDM与时分TDM
177 |
178 | 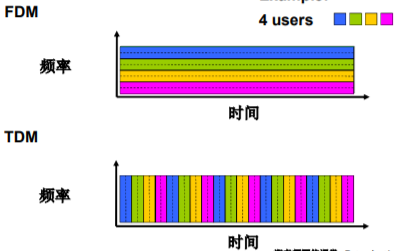 179 |
180 | > 计算举例:
181 | >
182 | > 在一个电路交换网络上,从主机$A$到主机$B$发送一个$640,000$比特的文件需要多长时间?
183 | > 其中:
184 | > 所有的链路速率为$1.536Mbps$;
185 | > 每条链路使用时隙数为$24$的TDM;
186 | > 建立端-端的电路需$500ms$
187 | > 解:
188 | > 每条链路的速率(一个时间片):$1.536Mbps/24=64kbps$;
189 | > 传输时间:$640kb/64kps=10s$;
190 | > 共用时间:传输时间+建立链路时间=$10s$+$500ms$=$10.5s$
191 | >
192 | > *注:此处未考虑传播延迟:相隔距离/光速;在局域网下,传播延迟可忽略不计,广域网的情况则不可以*
193 |
194 | 电路交换不适合计算机之间的通信
195 | - 连接建立时间长
196 | - 计算机之间的通信有突发性,如果使用线路交换/电路交换,则浪费的片较多
197 | - 即使这个呼叫没有数据传递,其所占据的片也不能够被别的呼叫使用
198 | - 可靠性不高?
199 |
200 | 网络核心:分组交换
201 |
202 | 以分组为单位存储-转发方式
203 | - 网络带宽资源不再分分为一个个片,传输时使用**全部带宽**
204 | - 主机之间传输的数据被分为一个个单位,这个单位叫**分组**(packet)
205 |
206 | 资源共享,按需使用:
207 | - 存储-转发:分组每次移动一跳(hop)
208 | - 在转发之前,节点必须收到整个分组
209 | - 延迟比线路交换要大
210 | - 排队时间
211 |
212 | 1.分组交换:存储-转发
213 |
214 | - 被传输到下一个链路之前,以分组为单位,整个分组必须到达路由器并存储下来:存储-转发的方式
215 | - 在一个速率为$R(bps)$的链路,一个长度为$L(bits)$的分组的存储转发延时为$L/R(s)$
216 |
217 | > Example:
218 | >
219 | > $L=7.5Mbits$;
220 | > $R=1.5Mbps$;
221 | > 则$3$次存储转发的延时=$3L/R$=$15s$
222 | > *注:发送/接收是一件事情的两个方面,只能算一次,也可以认为发送/接收是同时进行的。*
223 |
224 | 若不采用存储-转发的方式,没有将整个分组先存储下来再转发,就会占用整个链路,该链路就不能用于其他主机对之间的通信,而变为独享;而存储-转发的方式决定了当前链路在被使用时,下一条链路可以被另外一个主机对使用。
225 |
226 | 电路交换中每个交换节点只耽误1个比特的时间,分组交换在每个交换节点耽误的时间为整个分组的存储时间,所以延迟更高,但是换取共享性。
227 | 此外,若当前节点正在存储或转发其他信息,则又会有排队时延。
228 |
229 | 2.分组交换: 排队延迟和丢失
230 |
231 | 排队和延迟:
232 | - 如果到达速率>链路的输出速率(相当于总体上为净流入):
233 | - 分组将会排队,等待传输
234 | - 端口的输出队列可能是一个有限值,如果路由器的缓存用完了,分组将会被抛弃(drop)
235 |
236 | 网络核心的关键功能
237 | - 路由:决定分组采用的源到目标的路径;全局的
238 | - 路由算法
239 | - 转发:局部的;通过查询路由表(由路由器/路由软件/路由模块计算得出),决定从一个端口传过来的内容存储之后通过哪条链路转发到另外一个端口
240 | - 将分组从路由器的输入链路转移到输出链路
241 |
242 | 分组交换:统计多路复用
243 |
244 | A&B 时分复用 链路资源
245 |
246 | A & B 虽然仍采用划分时间片的方式,但是分组没有固定的模式,即不一定每个周期的第i片被第i个用户所使用-->统计多路复用
247 |
248 | 结论:
249 | 分组交换 vs. 电路交换:
250 | 1. 分组交换允许更多的用户使用网络
251 |
252 | > Example:
253 | >
254 | > $1Mb/s$链路;$N$个用户
255 | > 每个用户:
256 | > 活动时$100kb/s$;
257 | > $10\%$的时间是活动的
258 | > 则:
259 | > 1. 电路交换能支持多少用户?$1_{(Mb/s)}/100_{(kb/s)}=10$用户
260 | > 2. 假设$N=35$,若采用分组交换:$35$用户时,$>=10$个用户活动的概率为$0.0004$
261 | > $$1-\sum_{n=0}^{9}\binom{35}{n}p^n(1-p)^{35-n}$$
262 | > 说明$99.96\%$的情况下每个时刻有少于$10$个用户在活动,此时没有超出链路带宽,说明分组交换模式能够很好地支持$35$个用户,而电路交换最多只能支持$10$个。
263 |
264 | 2. 分组交换是“突发数据的胜利者?”
265 | - 适合于对**突发式数据**传输
266 | - 资源共享而非独享
267 | - 简单,不必建立呼叫
268 | - 过度使用会造成**网络拥塞**:分组延时和丢失
269 | - 对可靠地数据传输需要协议来约束:拥塞控制
270 | - Q:怎样提供类似电路交换的服务?
271 | - 保证音频/视频应用需要的带宽
272 | - 一个仍未解决的问题(chapter7)
273 |
274 | 分组交换网络:存储-转发
275 | - 分组交换: 分组的存储转发一段一段从源端传到目标端,按照有无网络层的连接,分成:
276 | 1. **数据报网络**:不用先建立连接;交换节点中不用维护通信状态(无状态路由器);每个分组都携带目标主机的完整地址;每个分组传送都是独立的
277 | - 分组的目标地址决定下一跳
278 | - 在不同的阶段,路由可以改变
279 | - 类似:问路,寄信
280 | - Internet
281 | 2. **虚电路网络**:主机和目标主机通信前先握手,在交换节点之间建立一条虚拟线路(通过信令建立),每个分组携带一条虚电路号而非目标主机的完整地址进行标识;中间的路由器维护通信状态(有连接)(*注:分清楚有连接、面向连接和无连接*[点击跳转](#Jump1))连接称为网络层的连接
282 | - 每个分组都带标签(虚电路标识 VC ID),标签决定下一跳
283 | - 在呼叫建立时决定路径,在整个呼叫中路径保持不变
284 | - 路由器维持每个呼叫的状态信息
285 | - X.25和ATM
286 |
287 | 数据报(datagram)的工作原理:
288 | - 在通信之前,无须建立起一个连接,有数据就传输
289 | - 每一个分组都独立路由(有可能走不同路径,可能会失序)
290 | - 路由器根据分组的目标地址进行路由
291 |
292 | 虚电路(virtual circuit)的工作原理
293 |
294 |
179 |
180 | > 计算举例:
181 | >
182 | > 在一个电路交换网络上,从主机$A$到主机$B$发送一个$640,000$比特的文件需要多长时间?
183 | > 其中:
184 | > 所有的链路速率为$1.536Mbps$;
185 | > 每条链路使用时隙数为$24$的TDM;
186 | > 建立端-端的电路需$500ms$
187 | > 解:
188 | > 每条链路的速率(一个时间片):$1.536Mbps/24=64kbps$;
189 | > 传输时间:$640kb/64kps=10s$;
190 | > 共用时间:传输时间+建立链路时间=$10s$+$500ms$=$10.5s$
191 | >
192 | > *注:此处未考虑传播延迟:相隔距离/光速;在局域网下,传播延迟可忽略不计,广域网的情况则不可以*
193 |
194 | 电路交换不适合计算机之间的通信
195 | - 连接建立时间长
196 | - 计算机之间的通信有突发性,如果使用线路交换/电路交换,则浪费的片较多
197 | - 即使这个呼叫没有数据传递,其所占据的片也不能够被别的呼叫使用
198 | - 可靠性不高?
199 |
200 | 网络核心:分组交换
201 |
202 | 以分组为单位存储-转发方式
203 | - 网络带宽资源不再分分为一个个片,传输时使用**全部带宽**
204 | - 主机之间传输的数据被分为一个个单位,这个单位叫**分组**(packet)
205 |
206 | 资源共享,按需使用:
207 | - 存储-转发:分组每次移动一跳(hop)
208 | - 在转发之前,节点必须收到整个分组
209 | - 延迟比线路交换要大
210 | - 排队时间
211 |
212 | 1.分组交换:存储-转发
213 |
214 | - 被传输到下一个链路之前,以分组为单位,整个分组必须到达路由器并存储下来:存储-转发的方式
215 | - 在一个速率为$R(bps)$的链路,一个长度为$L(bits)$的分组的存储转发延时为$L/R(s)$
216 |
217 | > Example:
218 | >
219 | > $L=7.5Mbits$;
220 | > $R=1.5Mbps$;
221 | > 则$3$次存储转发的延时=$3L/R$=$15s$
222 | > *注:发送/接收是一件事情的两个方面,只能算一次,也可以认为发送/接收是同时进行的。*
223 |
224 | 若不采用存储-转发的方式,没有将整个分组先存储下来再转发,就会占用整个链路,该链路就不能用于其他主机对之间的通信,而变为独享;而存储-转发的方式决定了当前链路在被使用时,下一条链路可以被另外一个主机对使用。
225 |
226 | 电路交换中每个交换节点只耽误1个比特的时间,分组交换在每个交换节点耽误的时间为整个分组的存储时间,所以延迟更高,但是换取共享性。
227 | 此外,若当前节点正在存储或转发其他信息,则又会有排队时延。
228 |
229 | 2.分组交换: 排队延迟和丢失
230 |
231 | 排队和延迟:
232 | - 如果到达速率>链路的输出速率(相当于总体上为净流入):
233 | - 分组将会排队,等待传输
234 | - 端口的输出队列可能是一个有限值,如果路由器的缓存用完了,分组将会被抛弃(drop)
235 |
236 | 网络核心的关键功能
237 | - 路由:决定分组采用的源到目标的路径;全局的
238 | - 路由算法
239 | - 转发:局部的;通过查询路由表(由路由器/路由软件/路由模块计算得出),决定从一个端口传过来的内容存储之后通过哪条链路转发到另外一个端口
240 | - 将分组从路由器的输入链路转移到输出链路
241 |
242 | 分组交换:统计多路复用
243 |
244 | A&B 时分复用 链路资源
245 |
246 | A & B 虽然仍采用划分时间片的方式,但是分组没有固定的模式,即不一定每个周期的第i片被第i个用户所使用-->统计多路复用
247 |
248 | 结论:
249 | 分组交换 vs. 电路交换:
250 | 1. 分组交换允许更多的用户使用网络
251 |
252 | > Example:
253 | >
254 | > $1Mb/s$链路;$N$个用户
255 | > 每个用户:
256 | > 活动时$100kb/s$;
257 | > $10\%$的时间是活动的
258 | > 则:
259 | > 1. 电路交换能支持多少用户?$1_{(Mb/s)}/100_{(kb/s)}=10$用户
260 | > 2. 假设$N=35$,若采用分组交换:$35$用户时,$>=10$个用户活动的概率为$0.0004$
261 | > $$1-\sum_{n=0}^{9}\binom{35}{n}p^n(1-p)^{35-n}$$
262 | > 说明$99.96\%$的情况下每个时刻有少于$10$个用户在活动,此时没有超出链路带宽,说明分组交换模式能够很好地支持$35$个用户,而电路交换最多只能支持$10$个。
263 |
264 | 2. 分组交换是“突发数据的胜利者?”
265 | - 适合于对**突发式数据**传输
266 | - 资源共享而非独享
267 | - 简单,不必建立呼叫
268 | - 过度使用会造成**网络拥塞**:分组延时和丢失
269 | - 对可靠地数据传输需要协议来约束:拥塞控制
270 | - Q:怎样提供类似电路交换的服务?
271 | - 保证音频/视频应用需要的带宽
272 | - 一个仍未解决的问题(chapter7)
273 |
274 | 分组交换网络:存储-转发
275 | - 分组交换: 分组的存储转发一段一段从源端传到目标端,按照有无网络层的连接,分成:
276 | 1. **数据报网络**:不用先建立连接;交换节点中不用维护通信状态(无状态路由器);每个分组都携带目标主机的完整地址;每个分组传送都是独立的
277 | - 分组的目标地址决定下一跳
278 | - 在不同的阶段,路由可以改变
279 | - 类似:问路,寄信
280 | - Internet
281 | 2. **虚电路网络**:主机和目标主机通信前先握手,在交换节点之间建立一条虚拟线路(通过信令建立),每个分组携带一条虚电路号而非目标主机的完整地址进行标识;中间的路由器维护通信状态(有连接)(*注:分清楚有连接、面向连接和无连接*[点击跳转](#Jump1))连接称为网络层的连接
282 | - 每个分组都带标签(虚电路标识 VC ID),标签决定下一跳
283 | - 在呼叫建立时决定路径,在整个呼叫中路径保持不变
284 | - 路由器维持每个呼叫的状态信息
285 | - X.25和ATM
286 |
287 | 数据报(datagram)的工作原理:
288 | - 在通信之前,无须建立起一个连接,有数据就传输
289 | - 每一个分组都独立路由(有可能走不同路径,可能会失序)
290 | - 路由器根据分组的目标地址进行路由
291 |
292 | 虚电路(virtual circuit)的工作原理
293 |
294 | 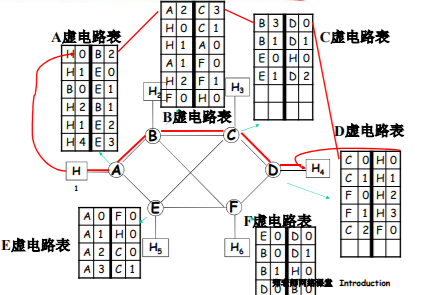 295 |
296 | 如图,A的表象分为两块:输入部分和输出部分。输入部分分为两块:来自于哪里,第几号虚电路;输出部分也分为两块:往哪里走(如图中即为往B走还是往E走),第几号虚电路。
297 |
298 | 总结:网络分类
299 | ```mermaid
300 | graph TD
301 | A(通信网络)
302 | A-->B1(电路交换网络)
303 | A-->B2(分组交换网络)
304 | B1-->C1(FDM)
305 | B1-->C2(TDM)
306 | B2-->D1(虚电路网络)
307 | B2-->D2(数据报网络)
308 | ```
309 |
310 | ### 1.4 接入网和物理媒体
311 |
312 | *注:核心网(骨干网)中也有物理媒体*
313 |
314 | 怎样将端系统和边缘路由器连接?
315 | 住宅接入网络;
316 | 单位接入网络(学校、公司);
317 | 无线接入网络(局域/广域)
318 |
319 | 重要指标:接入网的带宽(bits per second);共享/专用
320 |
321 | 住宅接入:**modem调制解调器**
322 | - 将上网数据调制加载音频信号上,在电话线上传输,在局端将其中的数据解调出来;反之亦然
323 | - 调频
324 | - 调幅
325 | - 调相位
326 | - 综合调制
327 | - 拨号调制解调器
328 | - 带宽窄:$56Kbps$的速率直接接入路由器(通常更低)
329 | - 不能同时上网和打电话:不能总是在线
330 |
331 | 目前该方式(电话拨号上网)已经基本被淘汰,目前主要使用**接入网**(digital subscriber line,缩写DSL)的方式其采取如下方式:
332 | $4Khz$以下用于语音通信,$4Khz$以上按照非对称的方式,一段用于上行,一段用于下行,用于下行的带宽更大,上下行数据仍然按照调制解调的方式工作。
333 | 可行的原因:电话线离最近的交换机较近,线路质量较好,$4Khz$以下有保障,且$4Khz$以上又有可以挖掘的资源。
334 |
335 |
295 |
296 | 如图,A的表象分为两块:输入部分和输出部分。输入部分分为两块:来自于哪里,第几号虚电路;输出部分也分为两块:往哪里走(如图中即为往B走还是往E走),第几号虚电路。
297 |
298 | 总结:网络分类
299 | ```mermaid
300 | graph TD
301 | A(通信网络)
302 | A-->B1(电路交换网络)
303 | A-->B2(分组交换网络)
304 | B1-->C1(FDM)
305 | B1-->C2(TDM)
306 | B2-->D1(虚电路网络)
307 | B2-->D2(数据报网络)
308 | ```
309 |
310 | ### 1.4 接入网和物理媒体
311 |
312 | *注:核心网(骨干网)中也有物理媒体*
313 |
314 | 怎样将端系统和边缘路由器连接?
315 | 住宅接入网络;
316 | 单位接入网络(学校、公司);
317 | 无线接入网络(局域/广域)
318 |
319 | 重要指标:接入网的带宽(bits per second);共享/专用
320 |
321 | 住宅接入:**modem调制解调器**
322 | - 将上网数据调制加载音频信号上,在电话线上传输,在局端将其中的数据解调出来;反之亦然
323 | - 调频
324 | - 调幅
325 | - 调相位
326 | - 综合调制
327 | - 拨号调制解调器
328 | - 带宽窄:$56Kbps$的速率直接接入路由器(通常更低)
329 | - 不能同时上网和打电话:不能总是在线
330 |
331 | 目前该方式(电话拨号上网)已经基本被淘汰,目前主要使用**接入网**(digital subscriber line,缩写DSL)的方式其采取如下方式:
332 | $4Khz$以下用于语音通信,$4Khz$以上按照非对称的方式,一段用于上行,一段用于下行,用于下行的带宽更大,上下行数据仍然按照调制解调的方式工作。
333 | 可行的原因:电话线离最近的交换机较近,线路质量较好,$4Khz$以下有保障,且$4Khz$以上又有可以挖掘的资源。
334 |
335 | 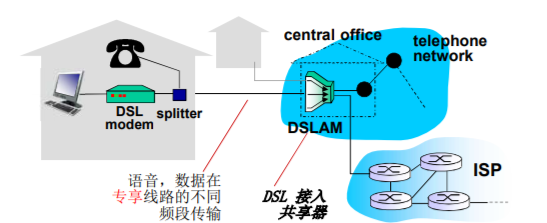 336 |
337 | - 采用现存的到交换局DSLAM的电话线
338 | - DSL线路上的数据被传到互联网
339 | - DSL线路上的语音被传到电话网
340 | - 上行传输速率小于$2.5Mbps$(通常小于$1Mbps$)
341 | - 下行传输速率小于$24Mbps$(通常小于$10Mbps$)
342 |
343 | 若上下行带宽的划分为非对称的,又称为ADSL。
344 |
345 | 这保证了上网和打电话同时的可行性。
346 |
347 | 还有一种方式为**线缆网络**。
348 |
349 |
336 |
337 | - 采用现存的到交换局DSLAM的电话线
338 | - DSL线路上的数据被传到互联网
339 | - DSL线路上的语音被传到电话网
340 | - 上行传输速率小于$2.5Mbps$(通常小于$1Mbps$)
341 | - 下行传输速率小于$24Mbps$(通常小于$10Mbps$)
342 |
343 | 若上下行带宽的划分为非对称的,又称为ADSL。
344 |
345 | 这保证了上网和打电话同时的可行性。
346 |
347 | 还有一种方式为**线缆网络**。
348 |
349 | 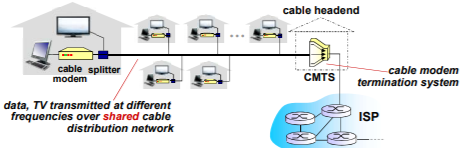 350 |
351 | 将有线电视信号线缆数字化双向改造(对应了上文中的电话线)
352 |
353 | FDM:在不同频段传输不同信道的数据,数字电视(和数字广播)和上网数据(上下行),上行带宽是多用户共享,下行的带宽是头端通过互联网往下面发送
354 | - HFC:hybrid fiber coax
355 | - 非对称:最高$30Mbps$的下行传输速率,$2Mbps$上行传输
356 | 速率
357 | - 线缆和光纤网络将个家庭用户接入到ISP路由器
358 | - 各用户共享到线缆头端的接入网络
359 | - 与DSL不同,DSL每个用户一个专用线路到CO(central office)
360 |
361 | 除了电信运营商、有线电视公司运营商,电力公司的线缆资源也可以被应用于上网。
362 |
363 | 电缆模式:光纤+同轴电缆
364 |
365 | 近些年光纤到户的方式逐渐流行开来。
366 |
367 | **无线接入网络**
368 | - 各无线端系统共享无线接入网络(端系统到无线路由器)
369 | - 通过基站或者叫接入点
370 | - 无线LANs:
371 | - 建筑物内部(100 ft)
372 | - 802.11b/g (WiFi):11, 54Mbps传输速率
373 | - 广域无线接入
374 | - 由电信运营商提供(cellular),10’s km
375 | - 1到10Mbps
376 | - 3G,4G:LTE
377 |
378 | 物理媒体
379 | - Bit:在发送-接收对间传播
380 | - 物理链路:连接每个发送-接收对之间的物理媒体
381 | - 导引型媒体:有形介质
382 | - 信号沿着固体媒介被导引:同轴电缆、光纤、 双绞线
383 | - 非导引型媒体:无形介质
384 | - 开放的空间传输电磁波或者光信号,在电磁或者光信号中承载数字数据
385 |
386 | 常见的导引型媒体:
387 | - 双绞线 (TP)
388 | - 两根绝缘铜导线拧合
389 | - 5类:100Mbps以太网,Gbps千兆位以太网
390 | - 6类:10Gbps万兆以太网
391 | - 同轴电缆:
392 | - 两根同轴的铜导线
393 | - 双向
394 | - 基带电缆:
395 | - 电缆上一个单个信道
396 | - Ethernet
397 | - 宽带电缆:同时有多个频段在工作,对应窄带电缆(细缆)只有一个频段在工作
398 | - 电缆上有多个信道
399 | - HFC
400 | - 光纤和光缆:
401 | - 光脉冲,每个脉冲表示一个bit,在玻璃纤维中传输
402 | - 高速:
403 | - 点到点的高速传输(如10Gps-100Gbps传输速率)
404 | - 低误码率:在两个中继器之间可以有很长的距离,不受电磁噪声的干扰
405 | - 安全
406 |
407 | 常见的非导引型电缆(无线链路):
408 | - 开放空间传输电磁波,携带要传输的数据
409 | - 无需物理“线缆”
410 | - 双向
411 | - 传播环境效应:
412 | - 反射
413 | - 吸收
414 | - 干扰
415 | - 无线链路类型:
416 | - 地面微波
417 | - e.g. up to 45 Mbps channels
418 | - LAN (e.g., WiFi)
419 | - 11Mbps, 54 Mbps, 540Mbps...
420 | - wide-area (e.g., 蜂窝)
421 | - 3G cellular: ~ few Mbps
422 | - 4G 10Mbps
423 | - 5G few Gbps
424 | - 卫星
425 | - 每个信道Kbps到45Mbps(或者多个聚集信道)
426 | - 270 msec端到端延迟
427 | - 同步静止卫星和低轨卫星
428 |
429 | ### 1.5 Internet结构和ISP
430 |
431 | 前面的Internet结构划分是按照节点和链路的类型来划分(边缘、核心和接入网),现在采用一种不同的划分方式,将一些关系较密集的、处于同一网络的设备称之为一个ISP的网络,互联网由很多个ISP的网络构成,通过网络互联设备连接在一起。
432 |
433 | 互联网络结构:网络的网络
434 | - 端系统通过接入**ISPs**(Internet Service Providers)连接到互联网:如手机通过移动/联通这个ISP接入互联网
435 | - 住宅,公司和大学的ISPs
436 | - 接入ISPs相应的必须是互联的
437 | - 因此任何2个端系统可相互发送分组到对方
438 | - 导致的“网络的网络”非常复杂
439 | - 发展和演化是通过经济的和国家的政策来驱动的
440 | - 让我们采用渐进方法来描述当前互联网的结构
441 |
442 | 问题:给定数百万接入ISPs,如何将它们互联到一起?
443 |
444 | 将每两个ISPs直接相连,不可扩展,需要$O(N^2)$连接
445 |
446 | 另一个选项: 将每个接入ISP都连接到全局ISP(全局范围内覆盖)?
447 | 客户ISPs和提供者ISPs有经济合约
448 | - 竞争:但如果全局ISP是有利可为的业务,那会有竞争者
449 | - 合作:通过ISP之间的合作可以完成业务的扩展,肯定会有互联,对等互联的结算关系
450 |
451 | ...然后业务会细分(全球接入和区域接入),区域网络将出现,用与将接入ISPs连接到全局ISPs。
452 |
453 | 然后内容提供商网络(Internet Content Providers,e.g., Google, Microsoft, Akamai)可能会构建它们自己的网络,将它们的服务、内容更加靠近端用户,向用户提供更好的服务,减少自己的运营支出
454 |
455 | 最终:
456 | 在网络的最中心,一些为数不多的充分连接的大范围网络(分布广、节点有限、 但是之间有着多重连接)
457 | - “tier-1” commercial ISPs (e.g., Level 3, Sprint, AT&T, NTT),国家或者国际范围的覆盖
458 | - content provider network (e.g., Google):将它们的数据中心接入ISP,方便周边用户的访问;通常私有网络之间用专网绕过第一层ISP和区域
459 |
460 | 松散的层次模型
461 | - 中心:第一层ISP(如UUNet, BBN/Genuity, Sprint, AT&T)国家/国际覆盖,速率极高,部署的点少
462 | - 直接与其他第一层ISP相连
463 | - 与大量的第二层ISP和其他客户网络相连(PoP)
464 | - 第二层ISP:更小些的(通常是区域性的)ISP
465 | - 与一个或多个第一层ISPs,也可能与其他第二层ISP
466 | - 第三层ISP与其他本地ISP(local ISP)
467 | - 接入网(与端系统最近)
468 |
469 | 一个分组要经过许多网络!
470 |
471 | 很多内容提供商(如:Google, Akamai)可能会部署自己的网络,连接自己的在各地的DC(数据中心),走自己的数据
472 |
473 | 连接若干local ISP和各级(包括一层)ISP,更加靠近用户
474 |
475 | 经济考虑:少付费;用户体验考虑:更快
476 |
477 | ISP之间的连接:
478 | - POP: 高层ISP面向客户网络的接入点,涉及费用结算
479 | - 如一个低层ISP接入多个高层ISP,多宿(multi home)
480 | - 对等接入:2个ISP对等互接,不涉及费用结算
481 | - IXP:多个对等ISP互联互通之处,通常不涉及费用结算
482 | - 对等接入
483 | - ICP(Internet Content Provider, 互联网内容提供商)自己部署专用网络,同时和各级ISP连接
484 |
485 | ### 1.6 分组延时、丢失和吞吐量
486 |
487 | 相比较于电路交换,分组交换有更多的延时以及可能的丢失。
488 |
489 | 分组丢失和延时是怎样发生的?
490 |
491 | 在路由器缓冲区的分组队列发生**延时**:
492 | - 分组到达链路的速率超过了链路输出的能力
493 | - 分组等待排到队头、被传输
494 |
495 | 可用的缓冲区:分组到达时,如果没有可用的缓冲区,则该分组被丢掉(分组**丢失**)。
496 | *注:分组直接丢失而非扩大缓冲区存储更多分组:若队列过长,则传输延时过长,此时与其保证信息完整,不如直接丢弃*
497 |
498 | 四种分组延时
499 | 1. 节点处理延时:
500 | - 检查bit级差错
501 | - 检查分组首部和决定将分组导向何处
502 | 2. 排队延时
503 | - 在输出链路上等待传输的时间
504 | - 依赖于路由器的拥塞程度,时长随机
505 | 3. 传输延时:打出分组(L个比特)所需要的时间
506 | - $R=$链路带宽$(bps)$
507 | - $L=$分组长度$(bits)$
508 | - 将分组发送到链路上的时间$=L/R$
509 | - 存储转发延时
510 | 4. 传播延时:1跳/段(hop)的时间
511 | - $d=$物理链路的长度
512 | - $s=$在媒体上的传播速度(~$2*10^8m/s$)
513 | - 传播延时$=d/s$
514 |
515 | > 车队类比:
516 | >
517 | > 汽车以$100km/h$的速度传播;
518 | > 收费站服务每辆车需$12s$(传输时间)
519 | >
520 | > 汽车-bit;车队-分组
521 | >
522 | > Q:在车队在第二个收费站排列好之前需要多长时间?即从车队的第一辆车到达第一个收费站开始计时,到这个车队的最后一辆车离开第二个收费站,共需要多少时间?
523 | > A:
524 | > 将车队从收费站输送到公路上的时间 $=12*10=120s$(传输延时);
525 | > 最后一辆车从第一个收费站到第二个收费站的传播时间:$100km/(100km/h)=1h$(传播延时);
526 | > 总共 $1h+120s=62minutes$
527 | > 汽车以$1000km/h$的速度传播汽车;收费站服务每辆车需$1$分钟
528 | >
529 | > Q:在所有的汽车被第一个收费站服务之前,汽车会到达第二个收费站吗?
530 | > Yes!$7$分钟后,第一辆汽车到达了第二个收费站,而第一个收费站仍有3辆汽车
531 | >
532 | > 在整个分组被第一个路由器传输之前,第一个比特已经到达了第二个路由器!
533 | >
534 | > *注:对比以上两种情况,第一种的**信道容量**大,可以传很多分组,而第一种甚至传不完一个分组;第一种类比WAN的情况,第二种类比LAN的情况*
535 |
536 | 节点延时
537 | $$d_{nodal} = d_{proc} + d_{queue} + d_{trans} + d_{prop}$$
538 | - $d_{proc}=$ 处理延时:通常是微秒数量级或更少
539 | - $d_{queue}=$ 排队延时:取决于拥塞程度,随机的
540 | - $d_{trans}=$ 传输延时:$=L/R$,对低速率的链路而言很大(如拨号),通常为微秒级到毫秒级
541 | - $d_{prop}=$ 传播延时:几微秒到几百毫秒
542 |
543 | 排队延时取决于流量强度:
544 |
545 | - 定义:
546 | R=链路带宽(bps);
547 | L=分组长度(bits);
548 | a=分组到达队列的平均速率(单位时间到达的分组数量)
549 | - 流量强度(Intensity)=La/R,量纲为1,值为0~1
550 | - La/R ~ 0:平均排队延时很小
551 | - La/R -> 1:延时变得很大
552 | - La/R > 1:比特到达队列的速率超过了从该队列输出的速率,平均排队延时将趋向无穷大!
553 | - 设计系统时流量强度不能大于1!
554 |
555 | > Internet的延时和路由可以通过TraceRoute诊断程序查看。
556 | >
557 | > 命令行中输入:
558 | > ```shell
559 | > tracert
350 |
351 | 将有线电视信号线缆数字化双向改造(对应了上文中的电话线)
352 |
353 | FDM:在不同频段传输不同信道的数据,数字电视(和数字广播)和上网数据(上下行),上行带宽是多用户共享,下行的带宽是头端通过互联网往下面发送
354 | - HFC:hybrid fiber coax
355 | - 非对称:最高$30Mbps$的下行传输速率,$2Mbps$上行传输
356 | 速率
357 | - 线缆和光纤网络将个家庭用户接入到ISP路由器
358 | - 各用户共享到线缆头端的接入网络
359 | - 与DSL不同,DSL每个用户一个专用线路到CO(central office)
360 |
361 | 除了电信运营商、有线电视公司运营商,电力公司的线缆资源也可以被应用于上网。
362 |
363 | 电缆模式:光纤+同轴电缆
364 |
365 | 近些年光纤到户的方式逐渐流行开来。
366 |
367 | **无线接入网络**
368 | - 各无线端系统共享无线接入网络(端系统到无线路由器)
369 | - 通过基站或者叫接入点
370 | - 无线LANs:
371 | - 建筑物内部(100 ft)
372 | - 802.11b/g (WiFi):11, 54Mbps传输速率
373 | - 广域无线接入
374 | - 由电信运营商提供(cellular),10’s km
375 | - 1到10Mbps
376 | - 3G,4G:LTE
377 |
378 | 物理媒体
379 | - Bit:在发送-接收对间传播
380 | - 物理链路:连接每个发送-接收对之间的物理媒体
381 | - 导引型媒体:有形介质
382 | - 信号沿着固体媒介被导引:同轴电缆、光纤、 双绞线
383 | - 非导引型媒体:无形介质
384 | - 开放的空间传输电磁波或者光信号,在电磁或者光信号中承载数字数据
385 |
386 | 常见的导引型媒体:
387 | - 双绞线 (TP)
388 | - 两根绝缘铜导线拧合
389 | - 5类:100Mbps以太网,Gbps千兆位以太网
390 | - 6类:10Gbps万兆以太网
391 | - 同轴电缆:
392 | - 两根同轴的铜导线
393 | - 双向
394 | - 基带电缆:
395 | - 电缆上一个单个信道
396 | - Ethernet
397 | - 宽带电缆:同时有多个频段在工作,对应窄带电缆(细缆)只有一个频段在工作
398 | - 电缆上有多个信道
399 | - HFC
400 | - 光纤和光缆:
401 | - 光脉冲,每个脉冲表示一个bit,在玻璃纤维中传输
402 | - 高速:
403 | - 点到点的高速传输(如10Gps-100Gbps传输速率)
404 | - 低误码率:在两个中继器之间可以有很长的距离,不受电磁噪声的干扰
405 | - 安全
406 |
407 | 常见的非导引型电缆(无线链路):
408 | - 开放空间传输电磁波,携带要传输的数据
409 | - 无需物理“线缆”
410 | - 双向
411 | - 传播环境效应:
412 | - 反射
413 | - 吸收
414 | - 干扰
415 | - 无线链路类型:
416 | - 地面微波
417 | - e.g. up to 45 Mbps channels
418 | - LAN (e.g., WiFi)
419 | - 11Mbps, 54 Mbps, 540Mbps...
420 | - wide-area (e.g., 蜂窝)
421 | - 3G cellular: ~ few Mbps
422 | - 4G 10Mbps
423 | - 5G few Gbps
424 | - 卫星
425 | - 每个信道Kbps到45Mbps(或者多个聚集信道)
426 | - 270 msec端到端延迟
427 | - 同步静止卫星和低轨卫星
428 |
429 | ### 1.5 Internet结构和ISP
430 |
431 | 前面的Internet结构划分是按照节点和链路的类型来划分(边缘、核心和接入网),现在采用一种不同的划分方式,将一些关系较密集的、处于同一网络的设备称之为一个ISP的网络,互联网由很多个ISP的网络构成,通过网络互联设备连接在一起。
432 |
433 | 互联网络结构:网络的网络
434 | - 端系统通过接入**ISPs**(Internet Service Providers)连接到互联网:如手机通过移动/联通这个ISP接入互联网
435 | - 住宅,公司和大学的ISPs
436 | - 接入ISPs相应的必须是互联的
437 | - 因此任何2个端系统可相互发送分组到对方
438 | - 导致的“网络的网络”非常复杂
439 | - 发展和演化是通过经济的和国家的政策来驱动的
440 | - 让我们采用渐进方法来描述当前互联网的结构
441 |
442 | 问题:给定数百万接入ISPs,如何将它们互联到一起?
443 |
444 | 将每两个ISPs直接相连,不可扩展,需要$O(N^2)$连接
445 |
446 | 另一个选项: 将每个接入ISP都连接到全局ISP(全局范围内覆盖)?
447 | 客户ISPs和提供者ISPs有经济合约
448 | - 竞争:但如果全局ISP是有利可为的业务,那会有竞争者
449 | - 合作:通过ISP之间的合作可以完成业务的扩展,肯定会有互联,对等互联的结算关系
450 |
451 | ...然后业务会细分(全球接入和区域接入),区域网络将出现,用与将接入ISPs连接到全局ISPs。
452 |
453 | 然后内容提供商网络(Internet Content Providers,e.g., Google, Microsoft, Akamai)可能会构建它们自己的网络,将它们的服务、内容更加靠近端用户,向用户提供更好的服务,减少自己的运营支出
454 |
455 | 最终:
456 | 在网络的最中心,一些为数不多的充分连接的大范围网络(分布广、节点有限、 但是之间有着多重连接)
457 | - “tier-1” commercial ISPs (e.g., Level 3, Sprint, AT&T, NTT),国家或者国际范围的覆盖
458 | - content provider network (e.g., Google):将它们的数据中心接入ISP,方便周边用户的访问;通常私有网络之间用专网绕过第一层ISP和区域
459 |
460 | 松散的层次模型
461 | - 中心:第一层ISP(如UUNet, BBN/Genuity, Sprint, AT&T)国家/国际覆盖,速率极高,部署的点少
462 | - 直接与其他第一层ISP相连
463 | - 与大量的第二层ISP和其他客户网络相连(PoP)
464 | - 第二层ISP:更小些的(通常是区域性的)ISP
465 | - 与一个或多个第一层ISPs,也可能与其他第二层ISP
466 | - 第三层ISP与其他本地ISP(local ISP)
467 | - 接入网(与端系统最近)
468 |
469 | 一个分组要经过许多网络!
470 |
471 | 很多内容提供商(如:Google, Akamai)可能会部署自己的网络,连接自己的在各地的DC(数据中心),走自己的数据
472 |
473 | 连接若干local ISP和各级(包括一层)ISP,更加靠近用户
474 |
475 | 经济考虑:少付费;用户体验考虑:更快
476 |
477 | ISP之间的连接:
478 | - POP: 高层ISP面向客户网络的接入点,涉及费用结算
479 | - 如一个低层ISP接入多个高层ISP,多宿(multi home)
480 | - 对等接入:2个ISP对等互接,不涉及费用结算
481 | - IXP:多个对等ISP互联互通之处,通常不涉及费用结算
482 | - 对等接入
483 | - ICP(Internet Content Provider, 互联网内容提供商)自己部署专用网络,同时和各级ISP连接
484 |
485 | ### 1.6 分组延时、丢失和吞吐量
486 |
487 | 相比较于电路交换,分组交换有更多的延时以及可能的丢失。
488 |
489 | 分组丢失和延时是怎样发生的?
490 |
491 | 在路由器缓冲区的分组队列发生**延时**:
492 | - 分组到达链路的速率超过了链路输出的能力
493 | - 分组等待排到队头、被传输
494 |
495 | 可用的缓冲区:分组到达时,如果没有可用的缓冲区,则该分组被丢掉(分组**丢失**)。
496 | *注:分组直接丢失而非扩大缓冲区存储更多分组:若队列过长,则传输延时过长,此时与其保证信息完整,不如直接丢弃*
497 |
498 | 四种分组延时
499 | 1. 节点处理延时:
500 | - 检查bit级差错
501 | - 检查分组首部和决定将分组导向何处
502 | 2. 排队延时
503 | - 在输出链路上等待传输的时间
504 | - 依赖于路由器的拥塞程度,时长随机
505 | 3. 传输延时:打出分组(L个比特)所需要的时间
506 | - $R=$链路带宽$(bps)$
507 | - $L=$分组长度$(bits)$
508 | - 将分组发送到链路上的时间$=L/R$
509 | - 存储转发延时
510 | 4. 传播延时:1跳/段(hop)的时间
511 | - $d=$物理链路的长度
512 | - $s=$在媒体上的传播速度(~$2*10^8m/s$)
513 | - 传播延时$=d/s$
514 |
515 | > 车队类比:
516 | >
517 | > 汽车以$100km/h$的速度传播;
518 | > 收费站服务每辆车需$12s$(传输时间)
519 | >
520 | > 汽车-bit;车队-分组
521 | >
522 | > Q:在车队在第二个收费站排列好之前需要多长时间?即从车队的第一辆车到达第一个收费站开始计时,到这个车队的最后一辆车离开第二个收费站,共需要多少时间?
523 | > A:
524 | > 将车队从收费站输送到公路上的时间 $=12*10=120s$(传输延时);
525 | > 最后一辆车从第一个收费站到第二个收费站的传播时间:$100km/(100km/h)=1h$(传播延时);
526 | > 总共 $1h+120s=62minutes$
527 | > 汽车以$1000km/h$的速度传播汽车;收费站服务每辆车需$1$分钟
528 | >
529 | > Q:在所有的汽车被第一个收费站服务之前,汽车会到达第二个收费站吗?
530 | > Yes!$7$分钟后,第一辆汽车到达了第二个收费站,而第一个收费站仍有3辆汽车
531 | >
532 | > 在整个分组被第一个路由器传输之前,第一个比特已经到达了第二个路由器!
533 | >
534 | > *注:对比以上两种情况,第一种的**信道容量**大,可以传很多分组,而第一种甚至传不完一个分组;第一种类比WAN的情况,第二种类比LAN的情况*
535 |
536 | 节点延时
537 | $$d_{nodal} = d_{proc} + d_{queue} + d_{trans} + d_{prop}$$
538 | - $d_{proc}=$ 处理延时:通常是微秒数量级或更少
539 | - $d_{queue}=$ 排队延时:取决于拥塞程度,随机的
540 | - $d_{trans}=$ 传输延时:$=L/R$,对低速率的链路而言很大(如拨号),通常为微秒级到毫秒级
541 | - $d_{prop}=$ 传播延时:几微秒到几百毫秒
542 |
543 | 排队延时取决于流量强度:
544 |
545 | - 定义:
546 | R=链路带宽(bps);
547 | L=分组长度(bits);
548 | a=分组到达队列的平均速率(单位时间到达的分组数量)
549 | - 流量强度(Intensity)=La/R,量纲为1,值为0~1
550 | - La/R ~ 0:平均排队延时很小
551 | - La/R -> 1:延时变得很大
552 | - La/R > 1:比特到达队列的速率超过了从该队列输出的速率,平均排队延时将趋向无穷大!
553 | - 设计系统时流量强度不能大于1!
554 |
555 | > Internet的延时和路由可以通过TraceRoute诊断程序查看。
556 | >
557 | > 命令行中输入:
558 | > ```shell
559 | > tracert 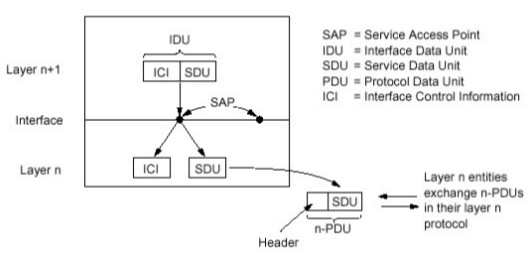 647 |
648 | 第n层是当前层,n+1层是用户,n-1层是服务提供者。
649 | n+1层将服务数据单元(SDU)传给第n层,接口控制信息(ICI)用于将数据穿过层间接口,ICI和SDU打包为IDU一起传输。在穿过层间接口后,ICI就没用了,将SDU加上本层的一些交换信息在第n层头部(n-header)形成第n层PDU(n-PDU),第n层的PDU再作为第n-1层的IDU进行层间传输。**上层的PDU对于本层是SDU,封装后对于本层是PDU。**
650 |
651 | 当SDU较大时,在穿过层间接口时,就将SDU分为小块,每个小块加上第n层的头部形成合适大小的第n层的PDU,一一对应。
652 | 当SDU非常小时,在穿过层间接口时,将若干个SDU合在一起,再加上第n层的头部信息形成第n层的PDU。
653 |
654 |
655 | 每一层的协议数据单元(PDU)都有特定的称呼。应用层的数据单元称为应用报文;传输层的称为报文段(TCP协议)/数据段(UDP协议),简称为段;网络层的通常称为分组,若网络是无连接方式工作,又称为数据报;链路层的称为帧(frame);物理层的称为位/比特……([参考跳转](#Jump2))
656 |
657 | 分层处理和实现复杂系统的好处
658 | - 概念化:结构清晰,便于标示网络组件,以及描述其相互关系
659 | - 分层参考模型
660 | - 结构化:模块化更易于维护和系统升级
661 | - 改变某一层服务的实现不影响系统中的其他层次
662 | - 对于其他层次而言是透明的
663 | - 如改变登机程序并不影响系统的其它部分
664 | - 改变2个秘书使用的通信方式不影响2个翻译的工作
665 | - 改变2个翻译使用的语言也不影响上下2个层次的工作
666 | - 分层思想被认为有害的地方?子系统之间交换信息效率低等等
667 |
668 | Internet协议栈:应用层——传输层——网络层——链路层——物理层
669 | - 应用层:网络应用
670 | - 为人类用户或者其他应用进程提供网络应用服务
671 | - FTP,SMTP,HTTP,DNS
672 | - 传输层:主机之间的数据传输
673 | - 在网络层提供的端到端通信基础上,细分为进程到进程;TCP将IP提供的不可靠的通信变成可靠地通信
674 | - TCP,UDP
675 | - 网络层:为数据报从源到目的选择路由
676 | - 主机主机之间的通信,端到端通信,不可靠
677 | - IP,路由协议
678 | - 链路层:相邻网络节点间的数据传输(从比特流确定一帧的开始和结束,以帧为单位进行传输)
679 | - 相邻两点的通信,点到点通信,可靠或不可靠
680 | - 点对点协议PPP,802.11(wifi),Ethernet
681 | - 物理层:在线路上传送bit
682 |
683 | ISO/OSI参考模型:应用层——表示层——会话层——传输层——网络层——链路层——物理层
684 | - 表示层:允许应用解释传输的数据,e.g.,加密,压缩,机器相关的表示转换,应用层就只用关心语义上的信息,在TCP/IP协议栈中通过应用层自己实现。
685 | - 会话层:数据交换的同步,检查点,恢复
686 | - 互联网协议栈没有这两层!
687 | - 这些服务,如果需要的话,必须被应用实现
688 |
689 | 封装和解封装
690 |
691 |
647 |
648 | 第n层是当前层,n+1层是用户,n-1层是服务提供者。
649 | n+1层将服务数据单元(SDU)传给第n层,接口控制信息(ICI)用于将数据穿过层间接口,ICI和SDU打包为IDU一起传输。在穿过层间接口后,ICI就没用了,将SDU加上本层的一些交换信息在第n层头部(n-header)形成第n层PDU(n-PDU),第n层的PDU再作为第n-1层的IDU进行层间传输。**上层的PDU对于本层是SDU,封装后对于本层是PDU。**
650 |
651 | 当SDU较大时,在穿过层间接口时,就将SDU分为小块,每个小块加上第n层的头部形成合适大小的第n层的PDU,一一对应。
652 | 当SDU非常小时,在穿过层间接口时,将若干个SDU合在一起,再加上第n层的头部信息形成第n层的PDU。
653 |
654 |
655 | 每一层的协议数据单元(PDU)都有特定的称呼。应用层的数据单元称为应用报文;传输层的称为报文段(TCP协议)/数据段(UDP协议),简称为段;网络层的通常称为分组,若网络是无连接方式工作,又称为数据报;链路层的称为帧(frame);物理层的称为位/比特……([参考跳转](#Jump2))
656 |
657 | 分层处理和实现复杂系统的好处
658 | - 概念化:结构清晰,便于标示网络组件,以及描述其相互关系
659 | - 分层参考模型
660 | - 结构化:模块化更易于维护和系统升级
661 | - 改变某一层服务的实现不影响系统中的其他层次
662 | - 对于其他层次而言是透明的
663 | - 如改变登机程序并不影响系统的其它部分
664 | - 改变2个秘书使用的通信方式不影响2个翻译的工作
665 | - 改变2个翻译使用的语言也不影响上下2个层次的工作
666 | - 分层思想被认为有害的地方?子系统之间交换信息效率低等等
667 |
668 | Internet协议栈:应用层——传输层——网络层——链路层——物理层
669 | - 应用层:网络应用
670 | - 为人类用户或者其他应用进程提供网络应用服务
671 | - FTP,SMTP,HTTP,DNS
672 | - 传输层:主机之间的数据传输
673 | - 在网络层提供的端到端通信基础上,细分为进程到进程;TCP将IP提供的不可靠的通信变成可靠地通信
674 | - TCP,UDP
675 | - 网络层:为数据报从源到目的选择路由
676 | - 主机主机之间的通信,端到端通信,不可靠
677 | - IP,路由协议
678 | - 链路层:相邻网络节点间的数据传输(从比特流确定一帧的开始和结束,以帧为单位进行传输)
679 | - 相邻两点的通信,点到点通信,可靠或不可靠
680 | - 点对点协议PPP,802.11(wifi),Ethernet
681 | - 物理层:在线路上传送bit
682 |
683 | ISO/OSI参考模型:应用层——表示层——会话层——传输层——网络层——链路层——物理层
684 | - 表示层:允许应用解释传输的数据,e.g.,加密,压缩,机器相关的表示转换,应用层就只用关心语义上的信息,在TCP/IP协议栈中通过应用层自己实现。
685 | - 会话层:数据交换的同步,检查点,恢复
686 | - 互联网协议栈没有这两层!
687 | - 这些服务,如果需要的话,必须被应用实现
688 |
689 | 封装和解封装
690 |
691 | 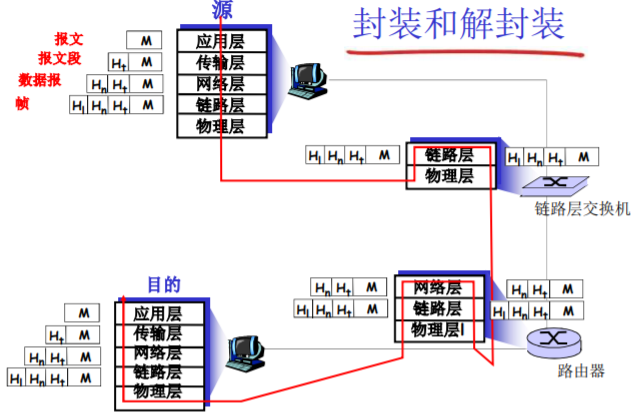 692 |
693 | 链路层交换机主要用于组建局域网,而路由器则主要负责连接外网并寻找网络中最合适数据传输的路径。
694 | 最后需要说明的是:路由器一般都具有防火墙功能,能够对一些网络数据包选择性的进行过滤。现在的一些路由器都具备交换机的功能,也有具备路由器功能的交换机,称为三层交换机。相比较而言,路由器的功能较交换机要强大,但是速度也相对较慢,价格较为昂贵,而三层交换机既有交换机的线性转发报文的能力,又有路由器的路由功能,因此得到了广泛的应用。
695 |
696 |
697 | 各层次的协议数据单元(PDU)[参考对应上文](#JumpBack2)
698 | - 应用层:报文(message)
699 | - 传输层:报文段(segment):TCP段,UDP数据报
700 | - 网络层:分组packet(如果无连接方式:数据报datagram)
701 | - 数据链路层:帧(frame)
702 | - 物理层:位(bit)
703 |
704 | ### 1.8 Internet历史
705 |
706 |
692 |
693 | 链路层交换机主要用于组建局域网,而路由器则主要负责连接外网并寻找网络中最合适数据传输的路径。
694 | 最后需要说明的是:路由器一般都具有防火墙功能,能够对一些网络数据包选择性的进行过滤。现在的一些路由器都具备交换机的功能,也有具备路由器功能的交换机,称为三层交换机。相比较而言,路由器的功能较交换机要强大,但是速度也相对较慢,价格较为昂贵,而三层交换机既有交换机的线性转发报文的能力,又有路由器的路由功能,因此得到了广泛的应用。
695 |
696 |
697 | 各层次的协议数据单元(PDU)[参考对应上文](#JumpBack2)
698 | - 应用层:报文(message)
699 | - 传输层:报文段(segment):TCP段,UDP数据报
700 | - 网络层:分组packet(如果无连接方式:数据报datagram)
701 | - 数据链路层:帧(frame)
702 | - 物理层:位(bit)
703 |
704 | ### 1.8 Internet历史
705 |
706 |  707 |
708 | 1. 早期(1960以前)计算机网络
709 | - 线路交换网络
710 | - 线路交换的特性使得其不适合计算机之间的通信
711 | - 线路建立时间过长
712 | - 独享方式占用通信资源,不适合突发性很强的计算机之间的通信
713 | - 可靠性不高,一个节点损毁影响整条链路:非常不适合军事通信
714 | - 三个小组独立地开展分组交换的研究
715 | - 1961: Kleinrock(MIT),排队论,展现了分组交换的有效性
716 | - 1964: Baran(美国兰德公司) – 军用网络上的分组交换
717 | - 1964:Donald(英国)等,NPL
718 |
719 | 2. 1961-1972:早期的分组交换概念
720 | - 1967:美国高级研究计划研究局考虑ARPAnet
721 | - Kleinrock在MIT的同事
722 | - 1969:第一个 ARPAnet节点开始工作,UCLA
723 | - IMP:接口报文处理机
724 | - 1969年底:4个节点
725 | - 1972:
726 | - ARPAnet公众演示
727 | - 网络控制协议是第一个端系统直接的主机-主机协议
728 | - NCP协议:相当于传输层和网络层在一起,支持应用开发
729 | - 第一个e-mail程序(BBN)
730 | - ARPAnet有15个节点
731 | 3. 1972-1980:专用网络和网络互联
732 | - 出现了很多对以后来说重要的网络形式,雨后春笋
733 | - 1970:ALOHAnet,夏威夷上的微波网络
734 | - 1973:Metcalfe在博士论文中提出了Ethernet
735 | - ATM网络
736 | - ALOHAnet,Telenet,Cyclades法国等
737 | - 1970后期,网络体系结构的必要性
738 | - 专用的体系结构:DECnet,SNA,XNA
739 | - 标准化的体系结构
740 | - 1974:网际互联的Cerf and Kahn体系结构
741 | - 1979:ARPAnet的规模在持续增加,体系结构也在酝酿着变化,以支持网络互联和其他目的(性能)需求
742 | - 节点数目增加,有200个节点
743 |
744 | *注:*
745 | *Cerf and Kahn网络互联原则定义了今天的Internet体系结构:*
746 | *1.极简、自治*
747 | *2.尽力而为(best effort)服务模型*
748 | *3.无状态的路由器*
749 | *4.分布控制*
750 |
751 | 4. 1980-1990:体系结构变化,网络数量激增,应用丰富
752 | - 1983:TCP/IP部署,标记日
753 | - NCP分化成2个层次,TCP/IP,从而出现UDP
754 | - 覆盖式IP解决网络互联问题
755 | - 主机设备和网络交换设备分开
756 | - 1982:smtp e-mail协议定义
757 | - 1983:DNS定义,完成域名到IP地址的转换
758 | - 1985:ftp 协议定义
759 | - 1988:TCP拥塞控制
760 | - 其他网络形式的发展
761 | - 新的国家级网络:Csnet,BITnet,NSFnet,Minitel
762 | - 1985年:ISO/OSI提出,时机不对且太繁琐,
763 | - 100,000主机连接到网络联邦
764 |
765 | 5. 1990,2000’s:商业化,Web,新的应用
766 | - 1990年代初:NSF对ARPAnet的访问网,双主干,ARPAnet退役
767 | - 1991:NSF放宽了对NSFnet用于商业目的的限制(1995退役),ASFNET非盈利性机构维护,后面叫Internet
768 | - UNIX中TCP/IP的免费捆绑
769 | - 1990年代初:Web
770 | - hypertext [Bush 1945, Nelson 1960’s]
771 | - HTML, HTTP: Berners-Lee
772 | - 1994: Mosaic (Netscape,andreesen)
773 | - 1990年代后期:Web的商业化
774 | - 1990后期 – 21世纪:
775 | - TCP/IP体系结构的包容性,在其上部署应用便捷,出现非常多的应用
776 | - 新一代杀手级应用(即时讯息,P2P文件共享,社交网络等)更进一步促进互联网的发展
777 | - 安全问题不断出现和修订(互联网的补丁对策)
778 | - 2001网络泡沫,使得一些好公司沉淀下来(谷歌,微软,苹果,Yahoo,思科)
779 | - 主干网的速率达到Gbps
780 |
781 | 6. 2005-现在
782 | - ~50+亿主机:包括智能手机和平板
783 | - 宽带接入的快速部署
784 | - 高速无线接入无处不在:移动互联时代
785 | - 4G部署,5G蓄势待发
786 | - 带宽大,终端性能高,价格便宜,应用不断增多
787 | - 在线社交网络等新型应用的出现:
788 | - Facebook:10亿用户
789 | - 微信,qq:数十亿用户
790 | - 内容提供商 (Google, Microsoft)创建他们自己的网络
791 | - 通过自己的专用网络提供对搜索、视频内容和电子邮件的即刻访问
792 | - 电子商务,大学,企业在云中运行他们的服务(eg, Amazon EC2)
793 | - 体系结构酝酿着大的变化,未来网络蠢蠢欲动
794 |
795 | ### 1.9 小结
796 |
797 | 1. Internet
798 | 2. 什么是协议
799 | 3. 网络边缘,核心,接入网络
800 | - 分组交换 vs. 电路交换
801 | 4. Internet/ISP 结构
802 | 5. 性能: 丢失,延时,吞吐量
803 | 6. 层次模型和服务模型
804 | 7. 历史
805 |
806 | - 组成角度看 什么是互联网
807 | - 边缘:端系统(包括应用) + 接入网
808 | - 核心:网络交换设备 + 通信链路
809 | - 协议:对等层实体通信过程中遵守的规则的集合
810 | - 语法,语义,时序
811 | - 为了实现复杂的网络功能,采用分层方式设计、实现和调试
812 | - 应用层,传输层,网络层,数据链路层,物理层
813 | - 协议数据单位:
814 | - 报文,报文段,分组,帧,位
815 | - 从服务角度看互联网
816 | - 通信服务基础设施
817 | - 提供的通信服务:面向连接 无连接
818 | - 应用
819 | - 应用之间的交互
820 | - C/S模式
821 | - P2P模式
822 | - 数据交换
823 | - 分组数据交换
824 | - 线路交换
825 | - 比较 线路交换和分组交换
826 | - 分组交换的2种方式
827 | - 虚电路
828 | - 数据报
829 | - 接入网和物理媒介
830 | - 接入网技术:
831 | - 住宅:ADSL,拨号,cable modem
832 | - 单位:以太网
833 | - 无线接入方式
834 | - 物理媒介
835 | - 光纤,同轴电缆,以太网,双绞线
836 | - ISP层次结构
837 | - 分组交换网络中延迟和丢失是如何发生的
838 | - 延迟的组成:处理、传输、传播、排队
839 | - 网络的分层体系结构
840 | - 分层体系结构
841 | - 服务
842 | - 协议数据单元
843 | - 封装与解封装
844 | - 历史
845 |
--------------------------------------------------------------------------------
/Log_of_ComputerNetworking-ATopDownApproach_7th/chapter3.md:
--------------------------------------------------------------------------------
1 | # 计算机网络——自顶向下方法 7th
2 |
3 | 中国科学技术大学 郑烇教授 2020年秋季 自动化系
4 |
5 | ## 3. 传输层
6 |
7 | 目标:
8 | - 理解传输层的工作原理
9 | - 多路复用/解复用
10 | - 可靠数据传输(reliable data transfer, RDT)
11 | - 流量控制
12 | - 拥塞控制
13 | - 学习Internet的传输层协议
14 | - UDP:无连接传输
15 | - TCP:面向连接的可靠传输
16 | - TCP的拥塞控制
17 |
18 | ### 3.1 概述和传输层服务
19 |
20 | 传输服务和协议
21 | - 为运行在不同主机上的应用进程提供**逻辑通信**(看上去是通过socket api将数据传给另一个进程,实际上报文需要通过层间接口交给传输层,通过两个传输层之间的相互配合交给另一方对等的应用进程)
22 | - 传输协议运行在端系统
23 | - 发送方:将应用层的报文分成报文段,然后传递给网络层
24 | - 接收方:将报文段重组成报文,然后传递给应用层
25 | - 有多个传输层协议可供应用选择
26 | - Internet:TCP和UDP
27 |
28 | 传输层 vs. 网络层
29 | - 网络层服务(IP协议):主机之间的逻辑通信
30 | - 传输层服务:将主机-主机的通信细分为进程间的逻辑通信
31 | - 依赖于网络层的服务(IP协议),依靠传输层无法加强
32 | - 延时(传输、传播、排队等)、带宽(吞吐量,瓶颈链路)
33 | - 并对网络层的服务进行增强(IP向上层提供的服务不可靠,TCP将不可靠变为可靠:RDT。通过SSL将TCP由不安全变为安全)
34 | - 数据丢失、顺序混乱、加密
35 |
36 | > 复用/解复用:类比:东、西2个家庭的通信
37 | >
38 | > Ann家的12个小孩给另Bill家的12个小孩发信
39 | > - 主机 = 家庭
40 | > - 进程 = 小孩
41 | > - 应用层报文 = 信封中的信件
42 | > - 传输协议 = Ann 和 Bill
43 | > - 为家庭小孩提供复用、解复用服务(Ann将信件复用(打包)发给邮政服务,Bill从邮政服务收到后进行解复用(拆包分发))
44 | > - 网络层协议 = 邮政服务
45 | > - 家庭-家庭的邮包传输服务
46 |
47 | 有些服务是可以加强的:不可靠 -> 可靠;安全
48 | 但有些服务是不可以被加强的:带宽,延迟
49 |
50 | Internet传输层协议
51 | - 可靠的、保序的传输:TCP
52 | - 多路复用、解复用
53 | - 拥塞控制
54 | - 流量控制
55 | - 建立连接
56 | - 不可靠、不保序的传输:UDP
57 | - 多路复用、解复用
58 | - 没有为尽力而为的IP服务添加更多的其它额外服务
59 | - 都不提供的服务(依赖于网络层):
60 | - 延时保证
61 | - 带宽保证
62 |
63 | ### 3.2 多路复用与解复用
64 |
65 | 复用:多个进程应用进程借助一个TCP或UDP实体来发送
66 |
67 | 在发送方主机多路复用:
68 | 从多个套接字接收来自多个进程的报文,根据套接字对应的IP地址和端口号等信息对报文段用头部加以封装(该头部信息用于以后的解复用)
69 | - TCP复用:source port and destination port (TCP header) + message,通过层间接口来到网络层,加上IP头部:IP header(source IP and destination IP) + TCP header + message
70 | - UDP复用:应用进程往下交 1.message 2.socket(source IP and source port) 3.&cad(destination IP and destination port) 给UDP传输层,UDP得到源端口和目标端口并封装信息交给IP网络层,IP知道源IP、目标IP,即可将报文打出
71 |
72 | 在接收方主机多路解复用:
73 | 根据报文段的头部信息中的IP地址和端口号将接收到的报文段发给正确的套接字(和对应的应用进程)
74 | - TCP解复用:收到IP数据报后,拿出IP body部分即TCP段,从TCP头部提取源端口、目标端口,从IP头部提取出源IP、目标IP,从而查询到相应的socket,进而发给相应的进程
75 | - UDP解复用:IP传上来的报文中有源端口和目标端口,通过查询相应的socket发给相应的进程
76 |
77 | 多路解复用工作原理(UDP和TCP不同)
78 | - 解复用作用:TCP或者UDP实体采用哪些信息,将报文段的数据部分交给正确的socket,从而交给正确的进程
79 | - 主机收到IP数据报
80 | - 每个数据报有源IP地址和目标地址
81 | - 每个数据报承载一个传输层报文段
82 | - 每个报文段有一个源端口号和目标端口号(特定应用有著名的端口号)
83 | - 主机联合使用**IP地址**和**端口号**将报文段发送给合适的套接字
84 |
85 | |TCP/UDP报文段格式(32 bit)|
86 | |:---:|
87 | |source port and destination port|
88 | |other header|
89 | |application layer message|
90 |
91 | 无连接(UDP)多路解复用
92 | - 创建套接字:
93 | - 服务器端:serverSocket 和 Sad 指定的端口号捆绑
94 | ```UDP
95 | serverSocket = socket(PF_INET, SOCK_DGRAM, 0);
96 | bind(serverSocket, &sad, sizeof(sad));
97 | ```
98 | - 客户端:没有 Bind,ClientSocket 和 OS 为之分配的某个端口号捆绑(客户端使用什么端口号无所谓,客户端主动找服务器)
99 | ```UDP
100 | ClientSocket=socket(PF_INET, SOCK_DGRAM, 0);
101 | ```
102 | - 在接收端,UDP套接字用二元组标识:(destination IP address, destination port)
103 | - 当主机收到UDP报文段:
104 | - 检查报文段的目标端口号
105 | - 用该端口号将报文段定位给套接字
106 | - 如果两个不同源IP地址/源端口号的数据报,但是有相同的目标IP地址和端口号,则被定位到相同的目标UDP套接字。
107 | > 例子:
108 | >
109 | >
707 |
708 | 1. 早期(1960以前)计算机网络
709 | - 线路交换网络
710 | - 线路交换的特性使得其不适合计算机之间的通信
711 | - 线路建立时间过长
712 | - 独享方式占用通信资源,不适合突发性很强的计算机之间的通信
713 | - 可靠性不高,一个节点损毁影响整条链路:非常不适合军事通信
714 | - 三个小组独立地开展分组交换的研究
715 | - 1961: Kleinrock(MIT),排队论,展现了分组交换的有效性
716 | - 1964: Baran(美国兰德公司) – 军用网络上的分组交换
717 | - 1964:Donald(英国)等,NPL
718 |
719 | 2. 1961-1972:早期的分组交换概念
720 | - 1967:美国高级研究计划研究局考虑ARPAnet
721 | - Kleinrock在MIT的同事
722 | - 1969:第一个 ARPAnet节点开始工作,UCLA
723 | - IMP:接口报文处理机
724 | - 1969年底:4个节点
725 | - 1972:
726 | - ARPAnet公众演示
727 | - 网络控制协议是第一个端系统直接的主机-主机协议
728 | - NCP协议:相当于传输层和网络层在一起,支持应用开发
729 | - 第一个e-mail程序(BBN)
730 | - ARPAnet有15个节点
731 | 3. 1972-1980:专用网络和网络互联
732 | - 出现了很多对以后来说重要的网络形式,雨后春笋
733 | - 1970:ALOHAnet,夏威夷上的微波网络
734 | - 1973:Metcalfe在博士论文中提出了Ethernet
735 | - ATM网络
736 | - ALOHAnet,Telenet,Cyclades法国等
737 | - 1970后期,网络体系结构的必要性
738 | - 专用的体系结构:DECnet,SNA,XNA
739 | - 标准化的体系结构
740 | - 1974:网际互联的Cerf and Kahn体系结构
741 | - 1979:ARPAnet的规模在持续增加,体系结构也在酝酿着变化,以支持网络互联和其他目的(性能)需求
742 | - 节点数目增加,有200个节点
743 |
744 | *注:*
745 | *Cerf and Kahn网络互联原则定义了今天的Internet体系结构:*
746 | *1.极简、自治*
747 | *2.尽力而为(best effort)服务模型*
748 | *3.无状态的路由器*
749 | *4.分布控制*
750 |
751 | 4. 1980-1990:体系结构变化,网络数量激增,应用丰富
752 | - 1983:TCP/IP部署,标记日
753 | - NCP分化成2个层次,TCP/IP,从而出现UDP
754 | - 覆盖式IP解决网络互联问题
755 | - 主机设备和网络交换设备分开
756 | - 1982:smtp e-mail协议定义
757 | - 1983:DNS定义,完成域名到IP地址的转换
758 | - 1985:ftp 协议定义
759 | - 1988:TCP拥塞控制
760 | - 其他网络形式的发展
761 | - 新的国家级网络:Csnet,BITnet,NSFnet,Minitel
762 | - 1985年:ISO/OSI提出,时机不对且太繁琐,
763 | - 100,000主机连接到网络联邦
764 |
765 | 5. 1990,2000’s:商业化,Web,新的应用
766 | - 1990年代初:NSF对ARPAnet的访问网,双主干,ARPAnet退役
767 | - 1991:NSF放宽了对NSFnet用于商业目的的限制(1995退役),ASFNET非盈利性机构维护,后面叫Internet
768 | - UNIX中TCP/IP的免费捆绑
769 | - 1990年代初:Web
770 | - hypertext [Bush 1945, Nelson 1960’s]
771 | - HTML, HTTP: Berners-Lee
772 | - 1994: Mosaic (Netscape,andreesen)
773 | - 1990年代后期:Web的商业化
774 | - 1990后期 – 21世纪:
775 | - TCP/IP体系结构的包容性,在其上部署应用便捷,出现非常多的应用
776 | - 新一代杀手级应用(即时讯息,P2P文件共享,社交网络等)更进一步促进互联网的发展
777 | - 安全问题不断出现和修订(互联网的补丁对策)
778 | - 2001网络泡沫,使得一些好公司沉淀下来(谷歌,微软,苹果,Yahoo,思科)
779 | - 主干网的速率达到Gbps
780 |
781 | 6. 2005-现在
782 | - ~50+亿主机:包括智能手机和平板
783 | - 宽带接入的快速部署
784 | - 高速无线接入无处不在:移动互联时代
785 | - 4G部署,5G蓄势待发
786 | - 带宽大,终端性能高,价格便宜,应用不断增多
787 | - 在线社交网络等新型应用的出现:
788 | - Facebook:10亿用户
789 | - 微信,qq:数十亿用户
790 | - 内容提供商 (Google, Microsoft)创建他们自己的网络
791 | - 通过自己的专用网络提供对搜索、视频内容和电子邮件的即刻访问
792 | - 电子商务,大学,企业在云中运行他们的服务(eg, Amazon EC2)
793 | - 体系结构酝酿着大的变化,未来网络蠢蠢欲动
794 |
795 | ### 1.9 小结
796 |
797 | 1. Internet
798 | 2. 什么是协议
799 | 3. 网络边缘,核心,接入网络
800 | - 分组交换 vs. 电路交换
801 | 4. Internet/ISP 结构
802 | 5. 性能: 丢失,延时,吞吐量
803 | 6. 层次模型和服务模型
804 | 7. 历史
805 |
806 | - 组成角度看 什么是互联网
807 | - 边缘:端系统(包括应用) + 接入网
808 | - 核心:网络交换设备 + 通信链路
809 | - 协议:对等层实体通信过程中遵守的规则的集合
810 | - 语法,语义,时序
811 | - 为了实现复杂的网络功能,采用分层方式设计、实现和调试
812 | - 应用层,传输层,网络层,数据链路层,物理层
813 | - 协议数据单位:
814 | - 报文,报文段,分组,帧,位
815 | - 从服务角度看互联网
816 | - 通信服务基础设施
817 | - 提供的通信服务:面向连接 无连接
818 | - 应用
819 | - 应用之间的交互
820 | - C/S模式
821 | - P2P模式
822 | - 数据交换
823 | - 分组数据交换
824 | - 线路交换
825 | - 比较 线路交换和分组交换
826 | - 分组交换的2种方式
827 | - 虚电路
828 | - 数据报
829 | - 接入网和物理媒介
830 | - 接入网技术:
831 | - 住宅:ADSL,拨号,cable modem
832 | - 单位:以太网
833 | - 无线接入方式
834 | - 物理媒介
835 | - 光纤,同轴电缆,以太网,双绞线
836 | - ISP层次结构
837 | - 分组交换网络中延迟和丢失是如何发生的
838 | - 延迟的组成:处理、传输、传播、排队
839 | - 网络的分层体系结构
840 | - 分层体系结构
841 | - 服务
842 | - 协议数据单元
843 | - 封装与解封装
844 | - 历史
845 |
--------------------------------------------------------------------------------
/Log_of_ComputerNetworking-ATopDownApproach_7th/chapter3.md:
--------------------------------------------------------------------------------
1 | # 计算机网络——自顶向下方法 7th
2 |
3 | 中国科学技术大学 郑烇教授 2020年秋季 自动化系
4 |
5 | ## 3. 传输层
6 |
7 | 目标:
8 | - 理解传输层的工作原理
9 | - 多路复用/解复用
10 | - 可靠数据传输(reliable data transfer, RDT)
11 | - 流量控制
12 | - 拥塞控制
13 | - 学习Internet的传输层协议
14 | - UDP:无连接传输
15 | - TCP:面向连接的可靠传输
16 | - TCP的拥塞控制
17 |
18 | ### 3.1 概述和传输层服务
19 |
20 | 传输服务和协议
21 | - 为运行在不同主机上的应用进程提供**逻辑通信**(看上去是通过socket api将数据传给另一个进程,实际上报文需要通过层间接口交给传输层,通过两个传输层之间的相互配合交给另一方对等的应用进程)
22 | - 传输协议运行在端系统
23 | - 发送方:将应用层的报文分成报文段,然后传递给网络层
24 | - 接收方:将报文段重组成报文,然后传递给应用层
25 | - 有多个传输层协议可供应用选择
26 | - Internet:TCP和UDP
27 |
28 | 传输层 vs. 网络层
29 | - 网络层服务(IP协议):主机之间的逻辑通信
30 | - 传输层服务:将主机-主机的通信细分为进程间的逻辑通信
31 | - 依赖于网络层的服务(IP协议),依靠传输层无法加强
32 | - 延时(传输、传播、排队等)、带宽(吞吐量,瓶颈链路)
33 | - 并对网络层的服务进行增强(IP向上层提供的服务不可靠,TCP将不可靠变为可靠:RDT。通过SSL将TCP由不安全变为安全)
34 | - 数据丢失、顺序混乱、加密
35 |
36 | > 复用/解复用:类比:东、西2个家庭的通信
37 | >
38 | > Ann家的12个小孩给另Bill家的12个小孩发信
39 | > - 主机 = 家庭
40 | > - 进程 = 小孩
41 | > - 应用层报文 = 信封中的信件
42 | > - 传输协议 = Ann 和 Bill
43 | > - 为家庭小孩提供复用、解复用服务(Ann将信件复用(打包)发给邮政服务,Bill从邮政服务收到后进行解复用(拆包分发))
44 | > - 网络层协议 = 邮政服务
45 | > - 家庭-家庭的邮包传输服务
46 |
47 | 有些服务是可以加强的:不可靠 -> 可靠;安全
48 | 但有些服务是不可以被加强的:带宽,延迟
49 |
50 | Internet传输层协议
51 | - 可靠的、保序的传输:TCP
52 | - 多路复用、解复用
53 | - 拥塞控制
54 | - 流量控制
55 | - 建立连接
56 | - 不可靠、不保序的传输:UDP
57 | - 多路复用、解复用
58 | - 没有为尽力而为的IP服务添加更多的其它额外服务
59 | - 都不提供的服务(依赖于网络层):
60 | - 延时保证
61 | - 带宽保证
62 |
63 | ### 3.2 多路复用与解复用
64 |
65 | 复用:多个进程应用进程借助一个TCP或UDP实体来发送
66 |
67 | 在发送方主机多路复用:
68 | 从多个套接字接收来自多个进程的报文,根据套接字对应的IP地址和端口号等信息对报文段用头部加以封装(该头部信息用于以后的解复用)
69 | - TCP复用:source port and destination port (TCP header) + message,通过层间接口来到网络层,加上IP头部:IP header(source IP and destination IP) + TCP header + message
70 | - UDP复用:应用进程往下交 1.message 2.socket(source IP and source port) 3.&cad(destination IP and destination port) 给UDP传输层,UDP得到源端口和目标端口并封装信息交给IP网络层,IP知道源IP、目标IP,即可将报文打出
71 |
72 | 在接收方主机多路解复用:
73 | 根据报文段的头部信息中的IP地址和端口号将接收到的报文段发给正确的套接字(和对应的应用进程)
74 | - TCP解复用:收到IP数据报后,拿出IP body部分即TCP段,从TCP头部提取源端口、目标端口,从IP头部提取出源IP、目标IP,从而查询到相应的socket,进而发给相应的进程
75 | - UDP解复用:IP传上来的报文中有源端口和目标端口,通过查询相应的socket发给相应的进程
76 |
77 | 多路解复用工作原理(UDP和TCP不同)
78 | - 解复用作用:TCP或者UDP实体采用哪些信息,将报文段的数据部分交给正确的socket,从而交给正确的进程
79 | - 主机收到IP数据报
80 | - 每个数据报有源IP地址和目标地址
81 | - 每个数据报承载一个传输层报文段
82 | - 每个报文段有一个源端口号和目标端口号(特定应用有著名的端口号)
83 | - 主机联合使用**IP地址**和**端口号**将报文段发送给合适的套接字
84 |
85 | |TCP/UDP报文段格式(32 bit)|
86 | |:---:|
87 | |source port and destination port|
88 | |other header|
89 | |application layer message|
90 |
91 | 无连接(UDP)多路解复用
92 | - 创建套接字:
93 | - 服务器端:serverSocket 和 Sad 指定的端口号捆绑
94 | ```UDP
95 | serverSocket = socket(PF_INET, SOCK_DGRAM, 0);
96 | bind(serverSocket, &sad, sizeof(sad));
97 | ```
98 | - 客户端:没有 Bind,ClientSocket 和 OS 为之分配的某个端口号捆绑(客户端使用什么端口号无所谓,客户端主动找服务器)
99 | ```UDP
100 | ClientSocket=socket(PF_INET, SOCK_DGRAM, 0);
101 | ```
102 | - 在接收端,UDP套接字用二元组标识:(destination IP address, destination port)
103 | - 当主机收到UDP报文段:
104 | - 检查报文段的目标端口号
105 | - 用该端口号将报文段定位给套接字
106 | - 如果两个不同源IP地址/源端口号的数据报,但是有相同的目标IP地址和端口号,则被定位到相同的目标UDP套接字。
107 | > 例子:
108 | >
109 | >  110 |
111 | 面向连接(TCP)的多路复用
112 | - TCP套接字:四元组本地标识:(源IP地址, 源端口号, 目标IP地址, 目标端口号)
113 | - 解复用:接收主机用这四个值来将数据报定位到合适的套接字
114 | - 服务器能够在一个TCP端口上同时支持多个TCP套接字:
115 | - 每个套接字由其四元组标识(有不同的源IP和源PORT)
116 | > 例子:
117 | >
118 | >
110 |
111 | 面向连接(TCP)的多路复用
112 | - TCP套接字:四元组本地标识:(源IP地址, 源端口号, 目标IP地址, 目标端口号)
113 | - 解复用:接收主机用这四个值来将数据报定位到合适的套接字
114 | - 服务器能够在一个TCP端口上同时支持多个TCP套接字:
115 | - 每个套接字由其四元组标识(有不同的源IP和源PORT)
116 | > 例子:
117 | >
118 | >  119 | - Web服务器对每个连接客户端有不同的套接字
120 | - 非持久对每个请求有不同的套接字
121 |
122 | 面向连接的多路复用:多线程Web Server
123 | - 一个进程下面可能有多个线程:由多个线程分别为客户提供服务
124 | - 在这个场景下,还是根据4元组决定将报文段内容同一个进程下的不同线程
125 | - 解复用到不同线程(与解复用到不同进程相似)
126 |
127 | ### 3.3 无连接传输:UDP
128 |
129 | UDP(User Datagram Protocol [RFC 768]):用户数据报协议
130 | - “no frills,” “bare bones”Internet传输协议
131 | - “尽力而为”的服务,报文段可能丢失也可能送到应用进程的报文段乱序
132 | - 无连接:
133 | - UDP发送端和接收端之间没有握手
134 | - 每个UDP报文段都被独立地处理
135 | - UDP被用于:
136 | - 流媒体(丢失不敏感,速率敏感、应用可控制传输速率)
137 | - DNS
138 | - SNMP(简单网络管理协议)
139 | - 在UDP上可行可靠传输:
140 | - 在应用层增加可靠性
141 | - 应用特定的差错恢复
142 |
143 | UDP报文段格式
144 |
145 |
119 | - Web服务器对每个连接客户端有不同的套接字
120 | - 非持久对每个请求有不同的套接字
121 |
122 | 面向连接的多路复用:多线程Web Server
123 | - 一个进程下面可能有多个线程:由多个线程分别为客户提供服务
124 | - 在这个场景下,还是根据4元组决定将报文段内容同一个进程下的不同线程
125 | - 解复用到不同线程(与解复用到不同进程相似)
126 |
127 | ### 3.3 无连接传输:UDP
128 |
129 | UDP(User Datagram Protocol [RFC 768]):用户数据报协议
130 | - “no frills,” “bare bones”Internet传输协议
131 | - “尽力而为”的服务,报文段可能丢失也可能送到应用进程的报文段乱序
132 | - 无连接:
133 | - UDP发送端和接收端之间没有握手
134 | - 每个UDP报文段都被独立地处理
135 | - UDP被用于:
136 | - 流媒体(丢失不敏感,速率敏感、应用可控制传输速率)
137 | - DNS
138 | - SNMP(简单网络管理协议)
139 | - 在UDP上可行可靠传输:
140 | - 在应用层增加可靠性
141 | - 应用特定的差错恢复
142 |
143 | UDP报文段格式
144 |
145 |  146 |
147 | 为什么要有UDP?
148 | - 不建立连接(若要先建立连接则会增加延时)
149 | - 简单:在发送端和接收端没有连接状态
150 | - 报文段的头部很小(开销小:头部只有8个字节,而TCP有20个字节)
151 | - 无拥塞控制和流量控制:UDP可以尽可能快的发送报文段
152 | - 应用层->传输层的速率 = 主机->网络的速率 (上面来多快,往下发就多快)
153 |
154 | UDP校验和(校验和:EDC,差错检测码)
155 | - 目标:检测在被传输报文段中的差错(如比特反转),若出错,这个UDP数据报就会被扔掉(表现为丢失)
156 | - 发送方:
157 | - 将报文段的内容视为16比特的整数(每16bit切一段,得到一系列二进制整数)
158 | - 校验和:报文段的加法和(1的补运算)
159 | - 发送方将校验和放在UDP的校验和字段
160 | - 接收方:
161 | - 计算接收到的报文段的校验和
162 | - 检查计算出的校验和与校验和字段的内容是否相等:
163 | - 不相等 --> 检测到差错
164 | - 相等 --> 没有检测到差错,但也许还是有差错
165 | - 残存错误(校验范围 + 校验和 = 1111111111111111,但是两个加数都出错了)
166 |
167 | > Internet校验和的例子:两个16bit的整数相加
168 | >
169 | > 注意:当数字相加时,在最高位的进位要回卷,再加到结果上(即最高位的进位数字与末位相加,重新计算得到和)
170 | >
171 | >
146 |
147 | 为什么要有UDP?
148 | - 不建立连接(若要先建立连接则会增加延时)
149 | - 简单:在发送端和接收端没有连接状态
150 | - 报文段的头部很小(开销小:头部只有8个字节,而TCP有20个字节)
151 | - 无拥塞控制和流量控制:UDP可以尽可能快的发送报文段
152 | - 应用层->传输层的速率 = 主机->网络的速率 (上面来多快,往下发就多快)
153 |
154 | UDP校验和(校验和:EDC,差错检测码)
155 | - 目标:检测在被传输报文段中的差错(如比特反转),若出错,这个UDP数据报就会被扔掉(表现为丢失)
156 | - 发送方:
157 | - 将报文段的内容视为16比特的整数(每16bit切一段,得到一系列二进制整数)
158 | - 校验和:报文段的加法和(1的补运算)
159 | - 发送方将校验和放在UDP的校验和字段
160 | - 接收方:
161 | - 计算接收到的报文段的校验和
162 | - 检查计算出的校验和与校验和字段的内容是否相等:
163 | - 不相等 --> 检测到差错
164 | - 相等 --> 没有检测到差错,但也许还是有差错
165 | - 残存错误(校验范围 + 校验和 = 1111111111111111,但是两个加数都出错了)
166 |
167 | > Internet校验和的例子:两个16bit的整数相加
168 | >
169 | > 注意:当数字相加时,在最高位的进位要回卷,再加到结果上(即最高位的进位数字与末位相加,重新计算得到和)
170 | >
171 | >  172 | >
173 | > - 目标端:校验范围 + 校验和 = 1111111111111111 通过校验
174 | > - 否则没有通过校验
175 | > - 注:求和时,必须将进位回卷到结果上
176 |
177 | ### 3.4 可靠数据传输(rdt)的原理
178 |
179 | rdt在应用层、传输层和数据链路层都很重要,是网络Top 10问题之一。
180 |
181 | 信道的不可靠特点(只是“尽力而为”)决定了可靠数据传输协议(rdt)的复杂性。
182 |
183 | 可靠数据传输:问题描述
184 |
185 |
172 | >
173 | > - 目标端:校验范围 + 校验和 = 1111111111111111 通过校验
174 | > - 否则没有通过校验
175 | > - 注:求和时,必须将进位回卷到结果上
176 |
177 | ### 3.4 可靠数据传输(rdt)的原理
178 |
179 | rdt在应用层、传输层和数据链路层都很重要,是网络Top 10问题之一。
180 |
181 | 信道的不可靠特点(只是“尽力而为”)决定了可靠数据传输协议(rdt)的复杂性。
182 |
183 | 可靠数据传输:问题描述
184 |
185 |  186 |
187 | *udt:不可靠数据传递*
188 |
189 | 我们将在本层进行如下工作:
190 | - 渐增式地开发可靠数据传输协议(rdt)的发送方和接收方(渐增式:从下层可靠、不丢失开始,一步步去掉假设,使下层变得越来越不可靠,从而完善rdt协议)
191 | - 只考虑单向数据传输
192 | - 但控制信息是双向流动的!(有一些反馈机制)
193 | - 双向的数据传输问题实际上是2个单向数据传输问题的综合(两个过程具有对称性)
194 | - 使用有限状态机(FSM)来描述发送方和接收方(有限状态机实际上就是描述协议如何工作的一个形式化的描述方案,比语言更加简洁易懂、便于检查)
195 |
196 | 状态:在该状态时,下一个状态只由下一个事件唯一确定。
197 | 节点之间有个状态变迁的边(edge)连在一起,代表状态1变成状态2在变迁的这条有限边上有标注。
198 | 标注有分子和分母: $\frac{引起状态变化的事件}{状态变迁时采取的动作}$
199 |
200 | 下面进行渐进式开发: Rdt1.0 --> Rdt2.0 --> Rdt2.1 --> Rdt2.2 --> Rdt 3.0
201 |
202 | Rdt1.0:在可靠信道上的可靠数据传输
203 | - 下层的信道是完全可靠的
204 | - 没有比特出错
205 | - 没有分组丢失
206 | - 发送方和接收方的FSM
207 | - 发送方将数据发送到下层信道(只进行接收、封装、打走的动作,不进行其他动作)
208 | - 接收方从下层信道接收数据(解封装、交付)
209 |
210 | Rdt2.0:去掉一个假设,变为具有比特差错(如0和1的反转)的信道
211 | - 下层信道可能会出错:将分组中的比特翻转
212 | - 用校验和来检测比特差错
213 | - 问题:怎样从差错中恢复:
214 | - **确认(ACK)**:接收方显式地告诉发送方分组已被正确接收(send ACK)
215 | - **否定确认(NAK)**:接收方显式地告诉发送方分组发生了差错(send NAK)
216 | - 发送方收到NAK后,发送方重传分组(之前发送完之后需要保存一个副本)
217 | - rdt2.0中的新机制:采用差错控制编码进行差错检测
218 | - 发送方差错控制编码、缓存
219 | - 接收方使用编码检错
220 | - 接收方的反馈:控制报文(ACK,NAK):接收方->发送方
221 | - 发送方收到反馈相应的动作(发送新的或者重发老的)
222 |
223 | Rdt2.0:FSM描述
224 |
225 |
186 |
187 | *udt:不可靠数据传递*
188 |
189 | 我们将在本层进行如下工作:
190 | - 渐增式地开发可靠数据传输协议(rdt)的发送方和接收方(渐增式:从下层可靠、不丢失开始,一步步去掉假设,使下层变得越来越不可靠,从而完善rdt协议)
191 | - 只考虑单向数据传输
192 | - 但控制信息是双向流动的!(有一些反馈机制)
193 | - 双向的数据传输问题实际上是2个单向数据传输问题的综合(两个过程具有对称性)
194 | - 使用有限状态机(FSM)来描述发送方和接收方(有限状态机实际上就是描述协议如何工作的一个形式化的描述方案,比语言更加简洁易懂、便于检查)
195 |
196 | 状态:在该状态时,下一个状态只由下一个事件唯一确定。
197 | 节点之间有个状态变迁的边(edge)连在一起,代表状态1变成状态2在变迁的这条有限边上有标注。
198 | 标注有分子和分母: $\frac{引起状态变化的事件}{状态变迁时采取的动作}$
199 |
200 | 下面进行渐进式开发: Rdt1.0 --> Rdt2.0 --> Rdt2.1 --> Rdt2.2 --> Rdt 3.0
201 |
202 | Rdt1.0:在可靠信道上的可靠数据传输
203 | - 下层的信道是完全可靠的
204 | - 没有比特出错
205 | - 没有分组丢失
206 | - 发送方和接收方的FSM
207 | - 发送方将数据发送到下层信道(只进行接收、封装、打走的动作,不进行其他动作)
208 | - 接收方从下层信道接收数据(解封装、交付)
209 |
210 | Rdt2.0:去掉一个假设,变为具有比特差错(如0和1的反转)的信道
211 | - 下层信道可能会出错:将分组中的比特翻转
212 | - 用校验和来检测比特差错
213 | - 问题:怎样从差错中恢复:
214 | - **确认(ACK)**:接收方显式地告诉发送方分组已被正确接收(send ACK)
215 | - **否定确认(NAK)**:接收方显式地告诉发送方分组发生了差错(send NAK)
216 | - 发送方收到NAK后,发送方重传分组(之前发送完之后需要保存一个副本)
217 | - rdt2.0中的新机制:采用差错控制编码进行差错检测
218 | - 发送方差错控制编码、缓存
219 | - 接收方使用编码检错
220 | - 接收方的反馈:控制报文(ACK,NAK):接收方->发送方
221 | - 发送方收到反馈相应的动作(发送新的或者重发老的)
222 |
223 | Rdt2.0:FSM描述
224 |
225 |  226 |
227 |
228 | Rdt2.0的致命缺陷!-> Rdt2.1
229 | - 如果ACK/NAK出错?
230 | - 发送方不知道接收方发生了什么事情!(既不是ACK也不是NAK)
231 | - 发送方如何做?
232 | - 重传?可能重复
233 | - 不重传?可能死锁(或出错)
234 | - 需要引入新的机制
235 | - **序号**
236 | - 处理重复:
237 | - 发送方在每个分组中加入序号
238 | - 如果ACK/NAK出错,发送方重传当前分组
239 | - 接收方丢弃(不发给上层)重复分组
240 |
241 | *停止等待协议(stop and wait):发送方发送一个分组,然后等待接收方的应答*
242 |
243 | 讨论
244 | - 发送方:
245 | - 在分组中加入序列号
246 | - 只需要一位即两个序列号(0,1)就足够了
247 | - 一次只发送一个未经确认的分组(注:若接收方等待的是1号分组,而传来0号未出错的分组,则接收方传回ack,与发送方调成同步)
248 | - 必须检测ACK/NAK是否出错(需要EDC)
249 | - 状态数变成了两倍
250 | - 必须记住当前分组的序列号为0还是1
251 | - 接收方:
252 | - 必须检测接收到的分组是否是重复的
253 | - 状态会指示希望接收到的分组的序号为0还是1
254 | - 注意:接收方并不知道发送方是否正确收到了其最后发送的ACK/NAK
255 | - 发送方不对收到的ack/nak给确认,没有所谓的确认的确认;
256 | - 接收方发送ack,如果后面接收方收到的是:
257 | - 老分组p0?则ack错误
258 | - 下一个分组?P1,ack正确
259 |
260 |
226 |
227 |
228 | Rdt2.0的致命缺陷!-> Rdt2.1
229 | - 如果ACK/NAK出错?
230 | - 发送方不知道接收方发生了什么事情!(既不是ACK也不是NAK)
231 | - 发送方如何做?
232 | - 重传?可能重复
233 | - 不重传?可能死锁(或出错)
234 | - 需要引入新的机制
235 | - **序号**
236 | - 处理重复:
237 | - 发送方在每个分组中加入序号
238 | - 如果ACK/NAK出错,发送方重传当前分组
239 | - 接收方丢弃(不发给上层)重复分组
240 |
241 | *停止等待协议(stop and wait):发送方发送一个分组,然后等待接收方的应答*
242 |
243 | 讨论
244 | - 发送方:
245 | - 在分组中加入序列号
246 | - 只需要一位即两个序列号(0,1)就足够了
247 | - 一次只发送一个未经确认的分组(注:若接收方等待的是1号分组,而传来0号未出错的分组,则接收方传回ack,与发送方调成同步)
248 | - 必须检测ACK/NAK是否出错(需要EDC)
249 | - 状态数变成了两倍
250 | - 必须记住当前分组的序列号为0还是1
251 | - 接收方:
252 | - 必须检测接收到的分组是否是重复的
253 | - 状态会指示希望接收到的分组的序号为0还是1
254 | - 注意:接收方并不知道发送方是否正确收到了其最后发送的ACK/NAK
255 | - 发送方不对收到的ack/nak给确认,没有所谓的确认的确认;
256 | - 接收方发送ack,如果后面接收方收到的是:
257 | - 老分组p0?则ack错误
258 | - 下一个分组?P1,ack正确
259 |
260 |  261 |
262 | Rdt2.2:无NAK、只有ACK的协议(NAK free)
263 | - 功能同rdt2.1,但只使用ACK(ack 要编号)
264 | - 接收方对**最后正确接收的分组发ACK**,以替代NAK(对当前分组的反向确认可由对前一项分组的正向确认代表,如用ack0代表nak1、用ack1代表nak0等等)
265 | - 接收方必须显式地包含被正确接收分组的序号
266 | - 当收到重复的ACK(如:再次收到ack0)时,发送方与收到NAK采取相同的动作:重传当前分组
267 | - 为后面的一次发送多个数据单位做一个准备
268 | - 一次能够发送多个
269 | - 每一个的应答都有:ACK,NACK;麻烦
270 | - 使用对前一个数据单位的ACK,代替本数据单位的nak
271 | - 确认信息减少一半,协议处理简单
272 |
273 | Rdt2.2的运行
274 |
275 |
261 |
262 | Rdt2.2:无NAK、只有ACK的协议(NAK free)
263 | - 功能同rdt2.1,但只使用ACK(ack 要编号)
264 | - 接收方对**最后正确接收的分组发ACK**,以替代NAK(对当前分组的反向确认可由对前一项分组的正向确认代表,如用ack0代表nak1、用ack1代表nak0等等)
265 | - 接收方必须显式地包含被正确接收分组的序号
266 | - 当收到重复的ACK(如:再次收到ack0)时,发送方与收到NAK采取相同的动作:重传当前分组
267 | - 为后面的一次发送多个数据单位做一个准备
268 | - 一次能够发送多个
269 | - 每一个的应答都有:ACK,NACK;麻烦
270 | - 使用对前一个数据单位的ACK,代替本数据单位的nak
271 | - 确认信息减少一半,协议处理简单
272 |
273 | Rdt2.2的运行
274 |
275 |  276 |
276 |  277 |
278 | Rdt3.0:具有比特差错和分组丢失的信道
279 | - 新的假设:下层信道可能会丢失分组(数据或ACK)
280 | - 会死锁(发送方等待确认,接收方等待分组)
281 | - 机制还不够处理这种状况:
282 | - 检验和
283 | - 序列号
284 | - ACK
285 | - 重传
286 | - 方法:发送方等待ACK一段合理的时间(链路层的timeout时间是确定的,传输层timeout时间是适应式的(需要动态地计算))
287 | - 发送端**超时重传**:如果到时没有收到ACK->重传
288 | - 问题:如果分组(或ACK)只是被延迟了:
289 | - 重传将会导致数据重复,但利用序列号已经可以处理这个问题
290 | - 接收方必须指明被正确接收的序列号
291 | - 需要一个倒计数定时器
292 |
293 | Rdt3.0的运行
294 |
295 |
277 |
278 | Rdt3.0:具有比特差错和分组丢失的信道
279 | - 新的假设:下层信道可能会丢失分组(数据或ACK)
280 | - 会死锁(发送方等待确认,接收方等待分组)
281 | - 机制还不够处理这种状况:
282 | - 检验和
283 | - 序列号
284 | - ACK
285 | - 重传
286 | - 方法:发送方等待ACK一段合理的时间(链路层的timeout时间是确定的,传输层timeout时间是适应式的(需要动态地计算))
287 | - 发送端**超时重传**:如果到时没有收到ACK->重传
288 | - 问题:如果分组(或ACK)只是被延迟了:
289 | - 重传将会导致数据重复,但利用序列号已经可以处理这个问题
290 | - 接收方必须指明被正确接收的序列号
291 | - 需要一个倒计数定时器
292 |
293 | Rdt3.0的运行
294 |
295 |  296 |
296 |  297 |
298 | - 过早超时(延迟的ACK)也能够正常工作;但是效率较低,一半的分组和确认是重复的;
299 | - 设置一个**合理的超时时间**也是比较重要的
300 |
301 | Rdt3.0的性能
302 | - rdt3.0停等协议可以工作,但链路容量比较大的情况下(分组全部放完时,分组的第一个比特离接收方还很远),性能很差
303 | - 链路容量比较大,一次发一个PDU的不能够充分利用链路的传输能力(信道明明可容纳很多很多包,每次却只有一个包处于信道中,信道利用率极低)
304 |
305 | > 例:
306 | > $1Gbps$ 的链路, $15ms$ 端-端传播延时( $RTT = 30ms$ ),分组大小为 $1kB = 1000Bytes = 8000bits$ :
307 | > $$T_{transmit} = \frac{L(分组长度, 比特)}{R(传输速率, bps)} = \frac{8kb/pkt}{10^9 b/sec} = 8\mu{s}$$
308 | > $$U_{sender} = \frac{L/R}{RTT+L/R} = \frac{{0.008}}{30.008} = 0.00027$$
309 | > - $U_{sender}$ :利用率 – 忙于发送的时间比例
310 | > - 每 $30ms$ 发送 $1KB$ 的分组 --> $270kbps=33.75kB/s$ 的吞吐量(在 $1Gbps$ 链路上)
311 | > - 瓶颈在于:网络协议限制了物理资源的利用!
312 |
313 | 其中Rdt3.0:停-等操作
314 |
315 |
297 |
298 | - 过早超时(延迟的ACK)也能够正常工作;但是效率较低,一半的分组和确认是重复的;
299 | - 设置一个**合理的超时时间**也是比较重要的
300 |
301 | Rdt3.0的性能
302 | - rdt3.0停等协议可以工作,但链路容量比较大的情况下(分组全部放完时,分组的第一个比特离接收方还很远),性能很差
303 | - 链路容量比较大,一次发一个PDU的不能够充分利用链路的传输能力(信道明明可容纳很多很多包,每次却只有一个包处于信道中,信道利用率极低)
304 |
305 | > 例:
306 | > $1Gbps$ 的链路, $15ms$ 端-端传播延时( $RTT = 30ms$ ),分组大小为 $1kB = 1000Bytes = 8000bits$ :
307 | > $$T_{transmit} = \frac{L(分组长度, 比特)}{R(传输速率, bps)} = \frac{8kb/pkt}{10^9 b/sec} = 8\mu{s}$$
308 | > $$U_{sender} = \frac{L/R}{RTT+L/R} = \frac{{0.008}}{30.008} = 0.00027$$
309 | > - $U_{sender}$ :利用率 – 忙于发送的时间比例
310 | > - 每 $30ms$ 发送 $1KB$ 的分组 --> $270kbps=33.75kB/s$ 的吞吐量(在 $1Gbps$ 链路上)
311 | > - 瓶颈在于:网络协议限制了物理资源的利用!
312 |
313 | 其中Rdt3.0:停-等操作
314 |
315 |  316 |
317 | 如何提高链路利用率?流水线(pipeline)
318 |
319 |
316 |
317 | 如何提高链路利用率?流水线(pipeline)
318 |
319 |  320 |
321 | - 增加 $n$ (如这里从 $n=1$ 变为 $n=3$ ),能提高链路利用率
322 | - 但当达到某个 $n$ ,其 $u=100\%$ 时,无法再通过增加 $n$ ,提高利用率
323 | - 瓶颈转移了 --> 链路带宽(此时可将 $1Gbps$ 链路升级为 $10Gbps$ 链路)
324 |
325 | 流水线协议(流水线:允许发送方在未得到对方确认的情况下一次发送多个分组)
326 | - 必须增加序号的范围:用多个bit表示分组的序号(若分组的序号用 $N$ 个比特表示,则整个分组的空间占用是 $2^N$ )
327 | - 在发送方/接收方要有缓冲区
328 | - 发送方缓冲:未得到确认,可能需要重传;
329 | - 接收方缓存:上层用户取用数据的速率 $\neq$ 接收到的数据速率,需要缓冲来对抗数据的不一致性;接收到的数据可能乱序,排序交付(可靠)
330 | - 两种通用的流水线协议:**回退N步(GBN)** 和 **选择重传(SR)**
331 |
332 | 为讲解GBN和SR协议的差别,先引入slide window协议
333 |
334 | 通用:滑动窗口(slide window)协议
335 |
336 | | sending window | receiving window | |
337 | |:---:|:---:|:---:|
338 | | = 1 | = 1 | stop-wait |
339 | | > 1 | = 1 | GBN |
340 | | > 1 | > 1 | SR |
341 |
342 | 其中 sw(sending window) > 1 时也称为流水线协议
343 |
344 | 几个概念:
345 | - 发送缓冲区
346 | - 形式:内存中的一个区域,落入缓冲区的分组可以进行检错重发、超时重发
347 | - 功能:用于存放已发送,但是没有得到确认的分组
348 | - 必要性:需要重发时可用
349 | - 发送缓冲区的大小:一次最多可以发送多少个未经确认的分组
350 | - 停止等待协议=1
351 | - 流水线协议>1,合理的值,不能很大,链路利用率不能超100%
352 | - 发送缓冲区中的分组
353 | - 未发送的:落入发送缓冲区的分组,可以连续发送出去;
354 | - 已经发送出去的、等待对方确认的分组:发送缓冲区的分组只有得到确认才能删除
355 | - 发送窗口:发送缓冲区内容的一个范围(发送缓冲区的子集)
356 | - 存放那些已发送但是未经确认分组的序号构成的空间
357 | - 发送窗口的最大值 <= 发送缓冲区的值
358 | - 一开始:没有发送任何一个分组
359 | - 后沿 = 前沿
360 | - 之间为发送窗口的尺寸 = 0
361 | - 发送窗口的移动——前沿移动
362 | - 每发送一个分组,前沿前移一个单位
363 | - 发送窗口前沿移动的极限:(前沿和后沿的距离)不能够超过发送缓冲区
364 | - 发送窗口的移动——后沿移动
365 | - 条件:收到老分组的确认
366 | - 结果:发送缓冲区罩住新的分组,来了分组可以发送
367 | - 移动的极限:不能够超过前沿
368 | - 发送窗口滑动过程——相对表示方法(只是为了方便理解)
369 | - 采用相对移动方式表示,分组不动,窗口向前滑动(实际上真正的滑动过程为窗口不动,分组向前滑动)
370 | - 可缓冲范围移动,代表一段可以发送的权力
371 |
372 |
320 |
321 | - 增加 $n$ (如这里从 $n=1$ 变为 $n=3$ ),能提高链路利用率
322 | - 但当达到某个 $n$ ,其 $u=100\%$ 时,无法再通过增加 $n$ ,提高利用率
323 | - 瓶颈转移了 --> 链路带宽(此时可将 $1Gbps$ 链路升级为 $10Gbps$ 链路)
324 |
325 | 流水线协议(流水线:允许发送方在未得到对方确认的情况下一次发送多个分组)
326 | - 必须增加序号的范围:用多个bit表示分组的序号(若分组的序号用 $N$ 个比特表示,则整个分组的空间占用是 $2^N$ )
327 | - 在发送方/接收方要有缓冲区
328 | - 发送方缓冲:未得到确认,可能需要重传;
329 | - 接收方缓存:上层用户取用数据的速率 $\neq$ 接收到的数据速率,需要缓冲来对抗数据的不一致性;接收到的数据可能乱序,排序交付(可靠)
330 | - 两种通用的流水线协议:**回退N步(GBN)** 和 **选择重传(SR)**
331 |
332 | 为讲解GBN和SR协议的差别,先引入slide window协议
333 |
334 | 通用:滑动窗口(slide window)协议
335 |
336 | | sending window | receiving window | |
337 | |:---:|:---:|:---:|
338 | | = 1 | = 1 | stop-wait |
339 | | > 1 | = 1 | GBN |
340 | | > 1 | > 1 | SR |
341 |
342 | 其中 sw(sending window) > 1 时也称为流水线协议
343 |
344 | 几个概念:
345 | - 发送缓冲区
346 | - 形式:内存中的一个区域,落入缓冲区的分组可以进行检错重发、超时重发
347 | - 功能:用于存放已发送,但是没有得到确认的分组
348 | - 必要性:需要重发时可用
349 | - 发送缓冲区的大小:一次最多可以发送多少个未经确认的分组
350 | - 停止等待协议=1
351 | - 流水线协议>1,合理的值,不能很大,链路利用率不能超100%
352 | - 发送缓冲区中的分组
353 | - 未发送的:落入发送缓冲区的分组,可以连续发送出去;
354 | - 已经发送出去的、等待对方确认的分组:发送缓冲区的分组只有得到确认才能删除
355 | - 发送窗口:发送缓冲区内容的一个范围(发送缓冲区的子集)
356 | - 存放那些已发送但是未经确认分组的序号构成的空间
357 | - 发送窗口的最大值 <= 发送缓冲区的值
358 | - 一开始:没有发送任何一个分组
359 | - 后沿 = 前沿
360 | - 之间为发送窗口的尺寸 = 0
361 | - 发送窗口的移动——前沿移动
362 | - 每发送一个分组,前沿前移一个单位
363 | - 发送窗口前沿移动的极限:(前沿和后沿的距离)不能够超过发送缓冲区
364 | - 发送窗口的移动——后沿移动
365 | - 条件:收到老分组的确认
366 | - 结果:发送缓冲区罩住新的分组,来了分组可以发送
367 | - 移动的极限:不能够超过前沿
368 | - 发送窗口滑动过程——相对表示方法(只是为了方便理解)
369 | - 采用相对移动方式表示,分组不动,窗口向前滑动(实际上真正的滑动过程为窗口不动,分组向前滑动)
370 | - 可缓冲范围移动,代表一段可以发送的权力
371 |
372 |  373 |
374 | - 接收窗口(receiving window)=接收缓冲区
375 | - 接收窗口用于控制哪些分组可以接收;
376 | - 只有收到的分组序号落入接收窗口内才允许接收
377 | - 若序号在接收窗口之外,则丢弃;
378 | - 接收窗口尺寸Wr=1,则只能顺序接收;
379 | - 接收窗口尺寸Wr>1,则可以乱序接收
380 | - 但提交给上层的分组,要按序
381 | - 例如:Wr=1,在0的位置;只有0号分组可以接收;向前滑动一个,罩在1的位置,此时如果来了第2号分组,则第2号分组为乱序分组,则丢弃,并给出确认:对顺序到来的最高序号的分组给确认(如此时给出ack0 注:这里的分组序号不再只有0、1两个,即不进行模2运算,只有0、1的是 停止-等待(sw)协议);
382 | 再例如接收窗口尺寸Wr=4>1时(此时到来的分组是乱序但是落在接收缓冲区的范围之内,则也进行接收并发出确认,直到该分组之前的分组都接收到了,接收窗口才进行滑动,如下图中收到1,2分组先不滑动,收到0分组后,2分组前的分组全部收到,此时进行滑动到3号分组开始;若第一次接收到的是0号分组,则接收缓冲区立即向后滑动到1开始):
383 |
373 |
374 | - 接收窗口(receiving window)=接收缓冲区
375 | - 接收窗口用于控制哪些分组可以接收;
376 | - 只有收到的分组序号落入接收窗口内才允许接收
377 | - 若序号在接收窗口之外,则丢弃;
378 | - 接收窗口尺寸Wr=1,则只能顺序接收;
379 | - 接收窗口尺寸Wr>1,则可以乱序接收
380 | - 但提交给上层的分组,要按序
381 | - 例如:Wr=1,在0的位置;只有0号分组可以接收;向前滑动一个,罩在1的位置,此时如果来了第2号分组,则第2号分组为乱序分组,则丢弃,并给出确认:对顺序到来的最高序号的分组给确认(如此时给出ack0 注:这里的分组序号不再只有0、1两个,即不进行模2运算,只有0、1的是 停止-等待(sw)协议);
382 | 再例如接收窗口尺寸Wr=4>1时(此时到来的分组是乱序但是落在接收缓冲区的范围之内,则也进行接收并发出确认,直到该分组之前的分组都接收到了,接收窗口才进行滑动,如下图中收到1,2分组先不滑动,收到0分组后,2分组前的分组全部收到,此时进行滑动到3号分组开始;若第一次接收到的是0号分组,则接收缓冲区立即向后滑动到1开始):
383 |  384 | - 接收窗口的滑动和发送确认
385 | - 滑动:
386 | - 低序号的分组到来,接收窗口移动;
387 | - 高序号分组乱序到,缓存但不交付(因为要实现rdt,不允许失序),不滑动
388 | - 发送确认:
389 | - 接收窗口尺寸=1;发送连续收到的最大的分组确认(累计确认:这之前的分组都正确收到了)
390 | - 接收窗口尺寸>1;收到分组,发送那个分组的确认(单独确认,非累计确认:只代表正确收到了这个分组)
391 |
392 | 发送窗口-接收窗口的互动
393 | - 正常情况下的2个窗口互动
394 | - 发送窗口
395 | - 有新的分组落入发送缓冲区范围,发送->前沿滑动
396 | - 来了老的低序号分组的确认->后沿向前滑动->新的分组可以落入发送缓冲区的范围
397 | - 接收窗口
398 | - 收到分组,落入到接收窗口范围内,接收
399 | - 是低序号,发送确认给对方
400 | - 发送端上面来了分组->发送窗口滑动->接收窗口滑动->发确认
401 | - 异常情况下GBN(wr=1)的2窗口互动
402 | - 发送窗口
403 | - 新分组落入发送缓冲区范围,发送->前沿滑动
404 | - 超时重发机制让发送端将发送窗口中的所有分组发送出去
405 | - 来了老分组的重复确认->后沿不向前滑动->新的分组无法落入发送缓冲区的范围(此时如果发送缓冲区有新的分组可以发送)
406 | - 接收窗口
407 | - 收到乱序分组,没有落入到接收窗口范围内,抛弃
408 | - (重复)发送老分组的确认,累计确认
409 | - 异常情况下SR(wr>1)的2窗口互动
410 | - 发送窗口
411 | - 新分组落入发送缓冲区范围,发送->前沿滑动
412 | - 超时重发机制让发送端将超时的分组重新发送出去(不像GBN需要将发送窗口中的所有分组全部重发)
413 | - 来了乱序分组的确认->后沿不向前滑动->新的分组无法落入发送缓冲区的范围(此时如果发送缓冲区有新的分组可以发送)
414 | - 接收窗口
415 | - 收到乱序分组,落入到接收窗口范围内,接收
416 | - 发送该分组的确认,单独确认
417 |
418 | GBN协议和SR协议的异同
419 | - 相同之处
420 | - 发送窗口>1
421 | - 一次能够可发送多个未经确认的分组
422 | - 不同之处
423 | - GBN:接收窗口尺寸=1
424 | - 接收端:只能顺序接收(对顺序接收的最高序号的分组进行确认-累计确认)
425 | - 对乱序的分组:
426 | - 丢弃(不缓存)
427 | - 在接收方不被缓存!
428 | - 发送端:从表现来看,一旦一个分组没有发成功,如:0,1,2,3,4,假如1未成功,234都发送出去了,要返回1再发送;GB1
429 | - 只发送ACK:对顺序接收的最高序号的分组
430 | - 可能会产生重复的ACK
431 | - 只需记住expectedseqnum;接收窗口=1
432 | - 只一个变量就可表示接收窗口
433 | - SR:接收窗口尺寸>1
434 | - 接收端:可以乱序接收
435 | - 发送端:发送0,1,2,3,4,一旦1未成功,2,3,4,已发送,无需重发,选择性发送1
436 |
437 | 流水线协议:总结
438 | - Go-back-N (GBN) :
439 | - 发送端最多在流水线中有N个未确认的分组
440 | - 接收端只是发送累计型确认cumulative ack
441 | - 接收端如果发现gap,不确认新到来的分组
442 | - 发送端拥有对最老的未确认分组的定时器
443 | - 只需设置一个定时器
444 | - 当定时器到时时,重传所有未确认分组
445 | - Selective Repeat (SR) :
446 | - 发送端最多在流水线中有N个未确认的分组
447 | - 接收方对每个到来的分组单独确认individual ack(非累计确认/单独确认)
448 | - 发送方为每个未确认的分组保持一个定时器
449 | - 当超时定时器到时,只是重发到时的未确认分组
450 |
451 | GBN的运行
452 |
453 |
384 | - 接收窗口的滑动和发送确认
385 | - 滑动:
386 | - 低序号的分组到来,接收窗口移动;
387 | - 高序号分组乱序到,缓存但不交付(因为要实现rdt,不允许失序),不滑动
388 | - 发送确认:
389 | - 接收窗口尺寸=1;发送连续收到的最大的分组确认(累计确认:这之前的分组都正确收到了)
390 | - 接收窗口尺寸>1;收到分组,发送那个分组的确认(单独确认,非累计确认:只代表正确收到了这个分组)
391 |
392 | 发送窗口-接收窗口的互动
393 | - 正常情况下的2个窗口互动
394 | - 发送窗口
395 | - 有新的分组落入发送缓冲区范围,发送->前沿滑动
396 | - 来了老的低序号分组的确认->后沿向前滑动->新的分组可以落入发送缓冲区的范围
397 | - 接收窗口
398 | - 收到分组,落入到接收窗口范围内,接收
399 | - 是低序号,发送确认给对方
400 | - 发送端上面来了分组->发送窗口滑动->接收窗口滑动->发确认
401 | - 异常情况下GBN(wr=1)的2窗口互动
402 | - 发送窗口
403 | - 新分组落入发送缓冲区范围,发送->前沿滑动
404 | - 超时重发机制让发送端将发送窗口中的所有分组发送出去
405 | - 来了老分组的重复确认->后沿不向前滑动->新的分组无法落入发送缓冲区的范围(此时如果发送缓冲区有新的分组可以发送)
406 | - 接收窗口
407 | - 收到乱序分组,没有落入到接收窗口范围内,抛弃
408 | - (重复)发送老分组的确认,累计确认
409 | - 异常情况下SR(wr>1)的2窗口互动
410 | - 发送窗口
411 | - 新分组落入发送缓冲区范围,发送->前沿滑动
412 | - 超时重发机制让发送端将超时的分组重新发送出去(不像GBN需要将发送窗口中的所有分组全部重发)
413 | - 来了乱序分组的确认->后沿不向前滑动->新的分组无法落入发送缓冲区的范围(此时如果发送缓冲区有新的分组可以发送)
414 | - 接收窗口
415 | - 收到乱序分组,落入到接收窗口范围内,接收
416 | - 发送该分组的确认,单独确认
417 |
418 | GBN协议和SR协议的异同
419 | - 相同之处
420 | - 发送窗口>1
421 | - 一次能够可发送多个未经确认的分组
422 | - 不同之处
423 | - GBN:接收窗口尺寸=1
424 | - 接收端:只能顺序接收(对顺序接收的最高序号的分组进行确认-累计确认)
425 | - 对乱序的分组:
426 | - 丢弃(不缓存)
427 | - 在接收方不被缓存!
428 | - 发送端:从表现来看,一旦一个分组没有发成功,如:0,1,2,3,4,假如1未成功,234都发送出去了,要返回1再发送;GB1
429 | - 只发送ACK:对顺序接收的最高序号的分组
430 | - 可能会产生重复的ACK
431 | - 只需记住expectedseqnum;接收窗口=1
432 | - 只一个变量就可表示接收窗口
433 | - SR:接收窗口尺寸>1
434 | - 接收端:可以乱序接收
435 | - 发送端:发送0,1,2,3,4,一旦1未成功,2,3,4,已发送,无需重发,选择性发送1
436 |
437 | 流水线协议:总结
438 | - Go-back-N (GBN) :
439 | - 发送端最多在流水线中有N个未确认的分组
440 | - 接收端只是发送累计型确认cumulative ack
441 | - 接收端如果发现gap,不确认新到来的分组
442 | - 发送端拥有对最老的未确认分组的定时器
443 | - 只需设置一个定时器
444 | - 当定时器到时时,重传所有未确认分组
445 | - Selective Repeat (SR) :
446 | - 发送端最多在流水线中有N个未确认的分组
447 | - 接收方对每个到来的分组单独确认individual ack(非累计确认/单独确认)
448 | - 发送方为每个未确认的分组保持一个定时器
449 | - 当超时定时器到时,只是重发到时的未确认分组
450 |
451 | GBN的运行
452 |
453 |  454 |
455 | 选择重传SR的运行
456 |
457 |
454 |
455 | 选择重传SR的运行
456 |
457 |  458 |
459 | 选择重传SR
460 | - 接收方对每个正确接收的分组,分别发送ACKn(非累积确认)
461 | - 接收窗口>1
462 | - 可以缓存乱序的分组
463 | - 最终将分组按顺序交付给上层
464 | - 发送方只对那些没有收到ACK的分组进行重发-选择性重发(而非整个发送窗口中的分组)
465 | - 发送方为每个未确认的分组设定一个定时器
466 | - 发送窗口的最大值(发送缓冲区)限制发送未确认分组的个数
467 | - 发送方
468 | - 从上层接收数据:
469 | - 如果下一个可用于该分组的序号可在发送窗口中,则发送
470 | - timeout(n):
471 | - 重新发送分组n,重新设定定时器
472 | - ACK(n) in [sendbase,sendbase+N]:
473 | - 将分组n标记为已接收
474 | - 如n为最小未确认的分组序号,将base移到下一个未确认序号
475 | - 接收方
476 | - 分组n [rcvbase, rcvbase+N-1]
477 | - 发送ACK(n)
478 | - 乱序:缓存
479 | - 有序:该分组及以前缓存的序号连续的分组交付给上层,然后将窗口移到下一个仍未被接收的分组
480 | - 分组n [rcvbase-N, rcvbase-1]
481 | - ACK(n)
482 | - 其它:
483 | - 忽略该分组
484 |
485 | 对比GBN和SR
486 | | | GBN | SR |
487 | |:---:|:---:|:---:|
488 | | 优点 | 简单,所需资源少(接收方一个缓存单元)| 出错时,重传一个代价小 |
489 | | 缺点 | 一旦出错,回退N步代价大 | 复杂,所需要资源多(接收方多个缓存单元)|
490 | - 适用范围
491 | - 出错率低:比较适合GBN,出错非常罕见,没有必要用复杂的SR,为罕见的事件做日常的准备和复杂处理
492 | - 链路容量大(延迟大、带宽大):比较适合SR而不是GBN,一点出错代价太大
493 |
494 | 窗口的最大尺寸(若整个的序号空间是 $2^n$ )
495 | - GBN: $2^n-1$ ,如 $n=2$ 时 $GBN=3$
496 | - SR: $2^{n-1}$ ,如 $n=2$ 时 $SR=2$
497 | - SR的例子:
498 | - 接收方看不到二者的区别!
499 | - 将重复数据误认为新数据(a)
500 |
501 | ### 3.5 面向连接的传输:TCP
502 |
503 | #### 3.5.1 段结构
504 |
505 | TCP:概述 RFCs: 793, 1122, 1323, 2018, 2581
506 | - 向应用进程提供**点对点**的服务:
507 | - 一个发送方,一个接收方(单点到单点)
508 | - 可靠的、按顺序的字节流:
509 | - 没有报文边界,报文界限靠应用进程自己区分
510 | - 管道化(流水线):
511 | - TCP拥塞控制和流量控制设置窗口大小
512 | - 发送和接收缓存
513 | - 发送缓存区:发完后需要检错重发、超时重传
514 | - 接收缓存区:发送方的发送速率不等于接收方的接收速率,需要接收缓存区匹配速度的不一致性
515 | - 全双工数据:
516 | - 在同一连接中数据流双向流动(同时、双向)
517 | - MSS:最大报文段大小。TCP按照MSS进行报文段的切分,每个MSS报文段前加上TCP头部形成TCP报文段(IP header + TCP header + MSS = MTU(Maixum Transfer Unit, 最大传送单元,表示IP数据报的最大长度(不包括帧头尾),单位为字节))
518 | - 面向连接:
519 | - 在数据交换之前,先建立连接,通过握手(交换控制报文)初始化发送方、接收方的状态变量
520 | - 有流量控制:
521 | - 发送方不会淹没接收方
522 |
523 | TCP报文段结构
524 |
525 |
458 |
459 | 选择重传SR
460 | - 接收方对每个正确接收的分组,分别发送ACKn(非累积确认)
461 | - 接收窗口>1
462 | - 可以缓存乱序的分组
463 | - 最终将分组按顺序交付给上层
464 | - 发送方只对那些没有收到ACK的分组进行重发-选择性重发(而非整个发送窗口中的分组)
465 | - 发送方为每个未确认的分组设定一个定时器
466 | - 发送窗口的最大值(发送缓冲区)限制发送未确认分组的个数
467 | - 发送方
468 | - 从上层接收数据:
469 | - 如果下一个可用于该分组的序号可在发送窗口中,则发送
470 | - timeout(n):
471 | - 重新发送分组n,重新设定定时器
472 | - ACK(n) in [sendbase,sendbase+N]:
473 | - 将分组n标记为已接收
474 | - 如n为最小未确认的分组序号,将base移到下一个未确认序号
475 | - 接收方
476 | - 分组n [rcvbase, rcvbase+N-1]
477 | - 发送ACK(n)
478 | - 乱序:缓存
479 | - 有序:该分组及以前缓存的序号连续的分组交付给上层,然后将窗口移到下一个仍未被接收的分组
480 | - 分组n [rcvbase-N, rcvbase-1]
481 | - ACK(n)
482 | - 其它:
483 | - 忽略该分组
484 |
485 | 对比GBN和SR
486 | | | GBN | SR |
487 | |:---:|:---:|:---:|
488 | | 优点 | 简单,所需资源少(接收方一个缓存单元)| 出错时,重传一个代价小 |
489 | | 缺点 | 一旦出错,回退N步代价大 | 复杂,所需要资源多(接收方多个缓存单元)|
490 | - 适用范围
491 | - 出错率低:比较适合GBN,出错非常罕见,没有必要用复杂的SR,为罕见的事件做日常的准备和复杂处理
492 | - 链路容量大(延迟大、带宽大):比较适合SR而不是GBN,一点出错代价太大
493 |
494 | 窗口的最大尺寸(若整个的序号空间是 $2^n$ )
495 | - GBN: $2^n-1$ ,如 $n=2$ 时 $GBN=3$
496 | - SR: $2^{n-1}$ ,如 $n=2$ 时 $SR=2$
497 | - SR的例子:
498 | - 接收方看不到二者的区别!
499 | - 将重复数据误认为新数据(a)
500 |
501 | ### 3.5 面向连接的传输:TCP
502 |
503 | #### 3.5.1 段结构
504 |
505 | TCP:概述 RFCs: 793, 1122, 1323, 2018, 2581
506 | - 向应用进程提供**点对点**的服务:
507 | - 一个发送方,一个接收方(单点到单点)
508 | - 可靠的、按顺序的字节流:
509 | - 没有报文边界,报文界限靠应用进程自己区分
510 | - 管道化(流水线):
511 | - TCP拥塞控制和流量控制设置窗口大小
512 | - 发送和接收缓存
513 | - 发送缓存区:发完后需要检错重发、超时重传
514 | - 接收缓存区:发送方的发送速率不等于接收方的接收速率,需要接收缓存区匹配速度的不一致性
515 | - 全双工数据:
516 | - 在同一连接中数据流双向流动(同时、双向)
517 | - MSS:最大报文段大小。TCP按照MSS进行报文段的切分,每个MSS报文段前加上TCP头部形成TCP报文段(IP header + TCP header + MSS = MTU(Maixum Transfer Unit, 最大传送单元,表示IP数据报的最大长度(不包括帧头尾),单位为字节))
518 | - 面向连接:
519 | - 在数据交换之前,先建立连接,通过握手(交换控制报文)初始化发送方、接收方的状态变量
520 | - 有流量控制:
521 | - 发送方不会淹没接收方
522 |
523 | TCP报文段结构
524 |
525 |  526 |
527 | 注:这里第二行的“序号”不是前面讲的PDU的序号(不是分组号),而是字节的序号:body部分的第一个字节在整个字节流中的偏移量offset(第 $i$ 个MSS的第一个字节在字节流中的位置,初始的序号称为 $X$ , $X$ 在建立连接时两个进程商量好,第 $n$ 个的序号为 $X+n*MSS$ )
528 |
529 | TCP序号,确认号
530 | - 序号(sequence number, 简写seq):
531 | - 报文段首字节的在字节流的编号
532 | - 确认号(acknowledgement number, 简写ack):
533 | - 期望从另一方收到的下一个字节的序号
534 | - 累积确认(如假设ack=555,则表示接收方已经收到了554及之前的所有字节)
535 | - Q:接收方如何处理乱序的报文段? 没有规定(可以缓存,也可以抛弃,取决于实现者自己)
536 |
537 |
526 |
527 | 注:这里第二行的“序号”不是前面讲的PDU的序号(不是分组号),而是字节的序号:body部分的第一个字节在整个字节流中的偏移量offset(第 $i$ 个MSS的第一个字节在字节流中的位置,初始的序号称为 $X$ , $X$ 在建立连接时两个进程商量好,第 $n$ 个的序号为 $X+n*MSS$ )
528 |
529 | TCP序号,确认号
530 | - 序号(sequence number, 简写seq):
531 | - 报文段首字节的在字节流的编号
532 | - 确认号(acknowledgement number, 简写ack):
533 | - 期望从另一方收到的下一个字节的序号
534 | - 累积确认(如假设ack=555,则表示接收方已经收到了554及之前的所有字节)
535 | - Q:接收方如何处理乱序的报文段? 没有规定(可以缓存,也可以抛弃,取决于实现者自己)
536 |
537 |  538 |
539 | > 例:Host A - Host B (双向数据传递)
540 | >
541 | > 1. A(User types 'C') --> B(host ACKs receipt of 'C', echoes back 'C'): Seq = $42$ , ACK = $79$ , data = 'C';
542 | > 2. B(host ACKs receipt of 'C', echoes back 'C') --> A(host ACKs receipt of echoed 'C'): Seq = $79$ , ACK = $43$ , data = 'C';
543 | > 3. A(host ACKs receipt of echoed 'C') --> B: Seq = $43$ , ACK = $80$ , data = ...
544 | > 4. ...
545 |
546 | TCP往返延时(RTT)和超时
547 | - Q:怎样设置TCP超时定时器?
548 | - 比RTT要长
549 | - 但RTT是变化的
550 | - 太短:太早超时
551 | - 不必要的重传
552 | - 太长:对报文段丢失反应太慢,消极
553 | - Q:怎样估计RTT?
554 | - SampleRTT:测量从报文段发出到收到确认的时间,得到往返延时
555 | - 如果有重传,忽略此次测量
556 | - SampleRTT会变化,因此估计的RTT应该比较平滑
557 | - 对几个最近的测量值求平均,而不是仅用当前的SampleRTT
558 | - RTT不是一个固定的值,而是一个适应式的测量。由于每个分组经历不一样,严重依赖于网络状况,则SampleRTT变化非常大,用SampleRTT建立超时定时器不合理,需要用SampleRTT的平均值EstimatedRTT(滤波算法)
559 | - $[EstimatedRTT] = (1-\alpha) * [(previous)EstimatedRTT] + \alpha * SampleRTT$
560 | - 指数加权移动平均
561 | - 过去样本的影响呈指数衰减
562 | - 推荐值: $\alpha = 0.125$
563 |
564 |
538 |
539 | > 例:Host A - Host B (双向数据传递)
540 | >
541 | > 1. A(User types 'C') --> B(host ACKs receipt of 'C', echoes back 'C'): Seq = $42$ , ACK = $79$ , data = 'C';
542 | > 2. B(host ACKs receipt of 'C', echoes back 'C') --> A(host ACKs receipt of echoed 'C'): Seq = $79$ , ACK = $43$ , data = 'C';
543 | > 3. A(host ACKs receipt of echoed 'C') --> B: Seq = $43$ , ACK = $80$ , data = ...
544 | > 4. ...
545 |
546 | TCP往返延时(RTT)和超时
547 | - Q:怎样设置TCP超时定时器?
548 | - 比RTT要长
549 | - 但RTT是变化的
550 | - 太短:太早超时
551 | - 不必要的重传
552 | - 太长:对报文段丢失反应太慢,消极
553 | - Q:怎样估计RTT?
554 | - SampleRTT:测量从报文段发出到收到确认的时间,得到往返延时
555 | - 如果有重传,忽略此次测量
556 | - SampleRTT会变化,因此估计的RTT应该比较平滑
557 | - 对几个最近的测量值求平均,而不是仅用当前的SampleRTT
558 | - RTT不是一个固定的值,而是一个适应式的测量。由于每个分组经历不一样,严重依赖于网络状况,则SampleRTT变化非常大,用SampleRTT建立超时定时器不合理,需要用SampleRTT的平均值EstimatedRTT(滤波算法)
559 | - $[EstimatedRTT] = (1-\alpha) * [(previous)EstimatedRTT] + \alpha * SampleRTT$
560 | - 指数加权移动平均
561 | - 过去样本的影响呈指数衰减
562 | - 推荐值: $\alpha = 0.125$
563 |
564 |  565 |
566 | - 设置超时
567 | - EstimtedRTT + 安全边界时间(safety margin)
568 | - EstimatedRTT变化大(方差大)
569 | - 较大的安全边界时间
570 | - SampleRTT会偏离EstimatedRTT多远:
571 | - $[DevRTT] = (1-\alpha) * [(previous)DevRTT] + \alpha * |SampleRTT-EstimatedRTT|$
572 | - 推荐值: $\alpha = 0.25$
573 | - 超时时间间隔设置为:
574 | - $TimeoutInterval = EstimatedRTT + 4*DevRTT$
575 |
576 | #### 3.5.2 可靠数据传输
577 |
578 | TCP:可靠数据传输
579 | - TCP在IP不可靠服务的基础上建立了rdt
580 | - 管道化的报文段
581 | - GBN or SR
582 | - 累积确认,期望从另一方收到的下一个字节的序号,对顺序到来的最后一个字节给予确认(像GBN)
583 | - 单个重传定时器(像GBN),只和最老的段相关联,一旦超时就将最老的段重发一遍(像SR)
584 | - 是否可以接受乱序的,没有规范
585 | - 通过以下事件触发重传
586 | - 超时(只重发那个最早的未确认段:SR)
587 | - 重复的确认(又收到3个冗余确认)(又叫快速重传)
588 | - 例子:收到了ACK50,之后又收到3个ACK50
589 | - 首先考虑简化的TCP发送方:
590 | - 忽略重复的确认
591 | - 忽略流量控制和拥塞控制
592 |
593 | TCP发送方事件:
594 | - 从应用层接收数据:
595 | - 用nextseq创建报文段
596 | - 序号nextseq为报文段首字节的字节流编号
597 | - 如果还没有运行,启动定时器
598 | - 定时器与最早未确认的报文段关联
599 | - 过期间隔:TimeOutInterval
600 | - 超时:
601 | - 重传 后沿最老的报文段
602 | - 重新启动定时器
603 | - 收到确认:
604 | - 如果是对尚未确认的报文段确认
605 | - 更新已被确认的报文序号
606 | - 如果当前还有未被确认的报文段,重新启动定时器
607 |
608 | TCP:重传
609 |
610 |
565 |
566 | - 设置超时
567 | - EstimtedRTT + 安全边界时间(safety margin)
568 | - EstimatedRTT变化大(方差大)
569 | - 较大的安全边界时间
570 | - SampleRTT会偏离EstimatedRTT多远:
571 | - $[DevRTT] = (1-\alpha) * [(previous)DevRTT] + \alpha * |SampleRTT-EstimatedRTT|$
572 | - 推荐值: $\alpha = 0.25$
573 | - 超时时间间隔设置为:
574 | - $TimeoutInterval = EstimatedRTT + 4*DevRTT$
575 |
576 | #### 3.5.2 可靠数据传输
577 |
578 | TCP:可靠数据传输
579 | - TCP在IP不可靠服务的基础上建立了rdt
580 | - 管道化的报文段
581 | - GBN or SR
582 | - 累积确认,期望从另一方收到的下一个字节的序号,对顺序到来的最后一个字节给予确认(像GBN)
583 | - 单个重传定时器(像GBN),只和最老的段相关联,一旦超时就将最老的段重发一遍(像SR)
584 | - 是否可以接受乱序的,没有规范
585 | - 通过以下事件触发重传
586 | - 超时(只重发那个最早的未确认段:SR)
587 | - 重复的确认(又收到3个冗余确认)(又叫快速重传)
588 | - 例子:收到了ACK50,之后又收到3个ACK50
589 | - 首先考虑简化的TCP发送方:
590 | - 忽略重复的确认
591 | - 忽略流量控制和拥塞控制
592 |
593 | TCP发送方事件:
594 | - 从应用层接收数据:
595 | - 用nextseq创建报文段
596 | - 序号nextseq为报文段首字节的字节流编号
597 | - 如果还没有运行,启动定时器
598 | - 定时器与最早未确认的报文段关联
599 | - 过期间隔:TimeOutInterval
600 | - 超时:
601 | - 重传 后沿最老的报文段
602 | - 重新启动定时器
603 | - 收到确认:
604 | - 如果是对尚未确认的报文段确认
605 | - 更新已被确认的报文序号
606 | - 如果当前还有未被确认的报文段,重新启动定时器
607 |
608 | TCP:重传
609 |
610 | 
 611 |
612 | 产生TCP ACK的建议 [RFC 1122, RFC 2581]
613 | | 接收方的事件 | TCP接收方动作 |
614 | | --- | --- |
615 | | 所期望序号的报文段按序到达。所有在期望序号之前的数据都已经被确认 | 延迟的ACK(提高效率,少发一个ACK)。对另一个按序报文段的到达最多等待500ms。如果下一个报文段在这个时间间隔内没有到达,则发送一个ACK。|
616 | | 有期望序号的报文段到达。另一个按序报文段等待发送ACK | 立即发送单个累积ACK,以确认两个按序报文段。|
617 | | 比期望序号大的报文段乱序到达。检测出数据流中的间隔 | 立即发送重复的ACK,指明下一个期待字节的序号 |
618 | | 能部分或完全填充接收数据间隔的报文段到达 | 若该报文段起始于间隔(gap)的低端,则立即发送ACK(给确认并反映下一段的需求)。 |
619 |
620 | 快速重传(3个冗余ACK触发的重发)
621 |
622 |
611 |
612 | 产生TCP ACK的建议 [RFC 1122, RFC 2581]
613 | | 接收方的事件 | TCP接收方动作 |
614 | | --- | --- |
615 | | 所期望序号的报文段按序到达。所有在期望序号之前的数据都已经被确认 | 延迟的ACK(提高效率,少发一个ACK)。对另一个按序报文段的到达最多等待500ms。如果下一个报文段在这个时间间隔内没有到达,则发送一个ACK。|
616 | | 有期望序号的报文段到达。另一个按序报文段等待发送ACK | 立即发送单个累积ACK,以确认两个按序报文段。|
617 | | 比期望序号大的报文段乱序到达。检测出数据流中的间隔 | 立即发送重复的ACK,指明下一个期待字节的序号 |
618 | | 能部分或完全填充接收数据间隔的报文段到达 | 若该报文段起始于间隔(gap)的低端,则立即发送ACK(给确认并反映下一段的需求)。 |
619 |
620 | 快速重传(3个冗余ACK触发的重发)
621 |
622 |  623 |
624 | - 超时周期往往太长:
625 | - 在重传丢失报文段之前的延时太长
626 | - 通过重复的ACK来检测报文段丢失
627 | - 发送方通常连续发送大量报文段
628 | - 如果报文段丢失,通常会引起多个重复的ACK
629 | - 如果发送方收到同一数据的3个冗余ACK,重传最小序号的段;
630 | - 快速重传:在定时器过时之前重发报文段
631 | - 它假设跟在被确认的数据后面的数据丢失了
632 | - 第一个ACK是正常的;
633 | - 收到第二个该段的ACK,表示接收方收到一个该段后的乱序段;
634 | - 收到第3,4个该段的ack,表示接收方收到该段之后的2、3个乱序段,有非常大的可能性为段丢失了
635 |
636 | 三重ACK接收后的快速重传
637 |
638 |
623 |
624 | - 超时周期往往太长:
625 | - 在重传丢失报文段之前的延时太长
626 | - 通过重复的ACK来检测报文段丢失
627 | - 发送方通常连续发送大量报文段
628 | - 如果报文段丢失,通常会引起多个重复的ACK
629 | - 如果发送方收到同一数据的3个冗余ACK,重传最小序号的段;
630 | - 快速重传:在定时器过时之前重发报文段
631 | - 它假设跟在被确认的数据后面的数据丢失了
632 | - 第一个ACK是正常的;
633 | - 收到第二个该段的ACK,表示接收方收到一个该段后的乱序段;
634 | - 收到第3,4个该段的ack,表示接收方收到该段之后的2、3个乱序段,有非常大的可能性为段丢失了
635 |
636 | 三重ACK接收后的快速重传
637 |
638 |  639 |
640 | #### 3.5.3 流量控制
641 |
642 | 目的:接收方控制发送方,不让发送方发送的太多、太快,超过了接收方的处理能力,以至于让接收方的接收缓冲区溢出
643 |
644 | TCP流量控制
645 | - 接收方在其向发送方的TCP段头部的rwnd字段“通告”其空闲buffer大小
646 | - RcvBuffer大小通过socket选项设置(典型默认大小为4096字节)
647 | - 很多操作系统自动调整RcvBuffer
648 | - 发送方限制未确认(“in-flight”)字节的个数小于等于接收方发送过来的 rwnd 值
649 | - 保证接收方不会被淹没
650 | - 假设TCP接收方丢弃乱序的报文段,则缓存中的可用的空间:
651 | $RcvWindow = RcvBuffer - [LastByteRcvd - LastByteRead]$
652 |
653 |
639 |
640 | #### 3.5.3 流量控制
641 |
642 | 目的:接收方控制发送方,不让发送方发送的太多、太快,超过了接收方的处理能力,以至于让接收方的接收缓冲区溢出
643 |
644 | TCP流量控制
645 | - 接收方在其向发送方的TCP段头部的rwnd字段“通告”其空闲buffer大小
646 | - RcvBuffer大小通过socket选项设置(典型默认大小为4096字节)
647 | - 很多操作系统自动调整RcvBuffer
648 | - 发送方限制未确认(“in-flight”)字节的个数小于等于接收方发送过来的 rwnd 值
649 | - 保证接收方不会被淹没
650 | - 假设TCP接收方丢弃乱序的报文段,则缓存中的可用的空间:
651 | $RcvWindow = RcvBuffer - [LastByteRcvd - LastByteRead]$
652 |
653 |  654 |
655 | #### 3.5.4 连接管理
656 |
657 | 连接
658 | - 两个应用进程建立起的TCP连接
659 | - 连接的本质:
660 | - 双方知道要和对方通信
661 | - 为这次通信建立好缓冲区,准备好资源
662 | - 一些控制变量需要做置位,两者需要互相告知自己的初始序号,初始化的RcvBuffer
663 |
664 | 在正式交换数据之前,发送方和接收方握手建立通信关系:
665 | - 同意建立连接(每一方都知道对方愿意建立连接)
666 | - 同意连接参数
667 |
668 | 同意建立连接
669 | - Q:在网络中,2次握手建立连接总是可行吗?不行
670 | - 变化的延迟(连接请求的段没有丢,但可能超时)
671 | - 由于丢失造成的重传(e.g. req_conn(x))
672 | - 报文乱序
673 | - 相互看不到对方
674 | - 2次握手的失败场景:
675 |
676 |
654 |
655 | #### 3.5.4 连接管理
656 |
657 | 连接
658 | - 两个应用进程建立起的TCP连接
659 | - 连接的本质:
660 | - 双方知道要和对方通信
661 | - 为这次通信建立好缓冲区,准备好资源
662 | - 一些控制变量需要做置位,两者需要互相告知自己的初始序号,初始化的RcvBuffer
663 |
664 | 在正式交换数据之前,发送方和接收方握手建立通信关系:
665 | - 同意建立连接(每一方都知道对方愿意建立连接)
666 | - 同意连接参数
667 |
668 | 同意建立连接
669 | - Q:在网络中,2次握手建立连接总是可行吗?不行
670 | - 变化的延迟(连接请求的段没有丢,但可能超时)
671 | - 由于丢失造成的重传(e.g. req_conn(x))
672 | - 报文乱序
673 | - 相互看不到对方
674 | - 2次握手的失败场景:
675 |
676 |  677 |
678 | 解决方案:TCP **3次握手**(变化的初始序号+双方确认对方的序号)
679 | - 第一次:client-->server:客户端一方的初始序号 $x$
680 | - 第二次:server-->client:发送确认 $ACKnum=x+1$ 和服务器一方的初始序号 $y$ (捎带)
681 | - 第三次:client-->server:发送确认 $ACKnum=y+1$ 和客户端data(捎带)
682 |
683 |
677 |
678 | 解决方案:TCP **3次握手**(变化的初始序号+双方确认对方的序号)
679 | - 第一次:client-->server:客户端一方的初始序号 $x$
680 | - 第二次:server-->client:发送确认 $ACKnum=x+1$ 和服务器一方的初始序号 $y$ (捎带)
681 | - 第三次:client-->server:发送确认 $ACKnum=y+1$ 和客户端data(捎带)
682 |
683 |  684 |
685 | 3次握手解决:半连接和接收老数据问题
686 |
687 |
684 |
685 | 3次握手解决:半连接和接收老数据问题
686 |
687 |  688 |
689 | 1. 二次握手:可能发送半连接(只在服务器维护了连接);三次握手:客户端在第三次握手拒绝连接请求 服务器二次握手后的连接请求
690 | 2. 二次握手:老的数据被当成新的数据接收了;三次握手:未建立连接(无半连接),故将发来的数据丢掉(扔掉:连接不存在,没建立起来;连接的序号不在当前连接的范围之内)
691 | 3. 若一个数据滞留时间足够长导致在TCP第二次连接(两个三次握手后)到来,这个数据包大概率也会被丢弃,因为初始序号seq不一样,而seq又与时间有关(时钟周期的第k位)
692 |
693 | TCP:关闭连接(连接释放):**4次挥手**
694 | - 客户端,服务器分别关闭它自己这一侧的连接
695 | - 发送FIN bit = 1的TCP段
696 | - 一旦接收到FIN,用ACK回应
697 | - 接到FIN段,ACK可以和它自己发出的FIN段一起发送
698 | - 可以处理同时的FIN交换
699 | - “对称释放,并不完美”
700 |
701 |
688 |
689 | 1. 二次握手:可能发送半连接(只在服务器维护了连接);三次握手:客户端在第三次握手拒绝连接请求 服务器二次握手后的连接请求
690 | 2. 二次握手:老的数据被当成新的数据接收了;三次握手:未建立连接(无半连接),故将发来的数据丢掉(扔掉:连接不存在,没建立起来;连接的序号不在当前连接的范围之内)
691 | 3. 若一个数据滞留时间足够长导致在TCP第二次连接(两个三次握手后)到来,这个数据包大概率也会被丢弃,因为初始序号seq不一样,而seq又与时间有关(时钟周期的第k位)
692 |
693 | TCP:关闭连接(连接释放):**4次挥手**
694 | - 客户端,服务器分别关闭它自己这一侧的连接
695 | - 发送FIN bit = 1的TCP段
696 | - 一旦接收到FIN,用ACK回应
697 | - 接到FIN段,ACK可以和它自己发出的FIN段一起发送
698 | - 可以处理同时的FIN交换
699 | - “对称释放,并不完美”
700 |
701 |  702 |
703 | 假设Client端发起中断连接请求,也就是发送FIN报文。Server端接到FIN报文后,意思是说“我Client端没有数据要发给你了”,但是如果你还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以你先发送ACK,告诉Client端:“你的请求我收到了,但是我还没准备好,请继续你等我的消息”。这个时候Client端就进入FIN_WAIT状态,继续等待Server端的FIN报文。当Server端确定数据已发送完成,则向Client端发送FIN报文,告诉Client端:“好了,我这边数据发完了,准备好关闭连接了”。Client端收到FIN报文后,就知道可以关闭连接了,但是他还是不相信网络,怕Server端不知道要关闭,所以发送ACK后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传。Server端收到ACK后,就知道可以断开连接了。Client端等待了2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,我Client端也可以关闭连接了。Ok,TCP连接就这样关闭了!
704 |
705 | 【问题1】为什么连接的时候是三次握手,关闭的时候却是四次握手?
706 | 答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,“你发的FIN报文我收到了”。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
707 |
708 | ### 3.6 拥塞控制原理
709 |
710 | 拥塞:
711 | - 非正式的定义:“太多的数据需要网络传输,超过了网络的处理能力”
712 | - 与流量控制不同,流量控制是我到你的问题,拥塞控制是网络的问题
713 | - 拥塞的表现:
714 | - 分组丢失(路由器缓冲区溢出)
715 | - 分组经历比较长的延迟(在路由器的队列中排队)
716 | - 网络中前10位的问题!
717 |
718 | 拥塞的原因/代价:场景1
719 | - 2个发送端,2个接收端
720 | - 1个路由器,具备无限大的缓冲
721 | - 输出链路带宽: $R$
722 | - 没有重传
723 | - 每个连接的最大吞吐量: $R/2$ ;当进入的速率 $\lambda_{in}$ 接近链路链路带宽 $R$ 时,延迟增大(此时流量强度趋于1)
724 |
725 |
702 |
703 | 假设Client端发起中断连接请求,也就是发送FIN报文。Server端接到FIN报文后,意思是说“我Client端没有数据要发给你了”,但是如果你还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以你先发送ACK,告诉Client端:“你的请求我收到了,但是我还没准备好,请继续你等我的消息”。这个时候Client端就进入FIN_WAIT状态,继续等待Server端的FIN报文。当Server端确定数据已发送完成,则向Client端发送FIN报文,告诉Client端:“好了,我这边数据发完了,准备好关闭连接了”。Client端收到FIN报文后,就知道可以关闭连接了,但是他还是不相信网络,怕Server端不知道要关闭,所以发送ACK后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传。Server端收到ACK后,就知道可以断开连接了。Client端等待了2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,我Client端也可以关闭连接了。Ok,TCP连接就这样关闭了!
704 |
705 | 【问题1】为什么连接的时候是三次握手,关闭的时候却是四次握手?
706 | 答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,“你发的FIN报文我收到了”。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
707 |
708 | ### 3.6 拥塞控制原理
709 |
710 | 拥塞:
711 | - 非正式的定义:“太多的数据需要网络传输,超过了网络的处理能力”
712 | - 与流量控制不同,流量控制是我到你的问题,拥塞控制是网络的问题
713 | - 拥塞的表现:
714 | - 分组丢失(路由器缓冲区溢出)
715 | - 分组经历比较长的延迟(在路由器的队列中排队)
716 | - 网络中前10位的问题!
717 |
718 | 拥塞的原因/代价:场景1
719 | - 2个发送端,2个接收端
720 | - 1个路由器,具备无限大的缓冲
721 | - 输出链路带宽: $R$
722 | - 没有重传
723 | - 每个连接的最大吞吐量: $R/2$ ;当进入的速率 $\lambda_{in}$ 接近链路链路带宽 $R$ 时,延迟增大(此时流量强度趋于1)
724 |
725 |  726 |
727 | 拥塞的原因/代价:场景2
728 | - 1个路由器,有限的缓冲
729 | - 分组丢失时,发送端重传
730 | - 应用层的输入=应用层输出: $\lambda_{in} = \lambda_{out}$
731 | - 传输层的输入包括重传: $\lambda_{in}^{'} \geq \lambda_{in}$,且当流量强度越趋于1, $\lambda_{in}^{'}$ 将比 $\lambda_{in}$ 大得多(很多都需要重传)
732 |
733 |
726 |
727 | 拥塞的原因/代价:场景2
728 | - 1个路由器,有限的缓冲
729 | - 分组丢失时,发送端重传
730 | - 应用层的输入=应用层输出: $\lambda_{in} = \lambda_{out}$
731 | - 传输层的输入包括重传: $\lambda_{in}^{'} \geq \lambda_{in}$,且当流量强度越趋于1, $\lambda_{in}^{'}$ 将比 $\lambda_{in}$ 大得多(很多都需要重传)
732 |
733 |  734 |
735 | 场景2:
736 | 1. 理想化:发送端有完美的信息
737 | - 发送端知道什么时候路由器的缓冲是可用的
738 | - 只在缓冲可用时发送
739 | - 不会丢失:$\lambda_{in}^{'} = \lambda_{in}$
740 | 2. 理想化:掌握丢失信息
741 | - 分组可以丢失,在路由器由于缓冲器满而被丢弃
742 | - 如果知道分组丢失了,发送方重传分组
743 | 3. 现实情况:重复
744 | - 分组可能丢失,由于缓冲器满而被丢弃
745 | - 发送端最终超时,发送第2个拷贝,2个分组都被传出
746 | - 此时随着 $\lambda_{in}$ 的增大, $\lambda_{out}$ 也增大,但是由于超时重传的比例越来越大, $\lambda_{out}$ 越来越小于 $\lambda_{in}$
747 | - 输出比输入少原因:1)重传的丢失分组;2)没有必要重传的重复分组
748 |
749 | 拥塞的“代价”:
750 | - 延时大
751 | - 为了达到一个有效输出,网络需要做更多的泵入(重传)
752 | - 没有必要的重传,链路中包括了多个分组的拷贝
753 | - 是那些没有丢失,经历的时间比较长(拥塞状态)但是超时的分组,重发没有必要,对本就拥塞的网络雪上加霜(网络加速变坏,非线性)
754 | - 降低了的“goodput”
755 |
756 | 拥塞的原因/代价:场景3
757 | - 4个发送端
758 | - 多重路径
759 | - 超时/重传
760 | - Q:当 $\lambda_{in}^{'}$ 、 $\lambda_{in}$ 增加时,会发生什么?
761 | A:当红色的 $\lambda_{in}^{'}$ 增加时,所有到来的蓝色分组都在最上方的队列中丢弃了,蓝色吞吐->0
762 |
763 |
734 |
735 | 场景2:
736 | 1. 理想化:发送端有完美的信息
737 | - 发送端知道什么时候路由器的缓冲是可用的
738 | - 只在缓冲可用时发送
739 | - 不会丢失:$\lambda_{in}^{'} = \lambda_{in}$
740 | 2. 理想化:掌握丢失信息
741 | - 分组可以丢失,在路由器由于缓冲器满而被丢弃
742 | - 如果知道分组丢失了,发送方重传分组
743 | 3. 现实情况:重复
744 | - 分组可能丢失,由于缓冲器满而被丢弃
745 | - 发送端最终超时,发送第2个拷贝,2个分组都被传出
746 | - 此时随着 $\lambda_{in}$ 的增大, $\lambda_{out}$ 也增大,但是由于超时重传的比例越来越大, $\lambda_{out}$ 越来越小于 $\lambda_{in}$
747 | - 输出比输入少原因:1)重传的丢失分组;2)没有必要重传的重复分组
748 |
749 | 拥塞的“代价”:
750 | - 延时大
751 | - 为了达到一个有效输出,网络需要做更多的泵入(重传)
752 | - 没有必要的重传,链路中包括了多个分组的拷贝
753 | - 是那些没有丢失,经历的时间比较长(拥塞状态)但是超时的分组,重发没有必要,对本就拥塞的网络雪上加霜(网络加速变坏,非线性)
754 | - 降低了的“goodput”
755 |
756 | 拥塞的原因/代价:场景3
757 | - 4个发送端
758 | - 多重路径
759 | - 超时/重传
760 | - Q:当 $\lambda_{in}^{'}$ 、 $\lambda_{in}$ 增加时,会发生什么?
761 | A:当红色的 $\lambda_{in}^{'}$ 增加时,所有到来的蓝色分组都在最上方的队列中丢弃了,蓝色吞吐->0
762 |
763 | 
 764 |
765 | 又一个拥塞的代价:当分组丢失时,任何“关于这个分组的上游传输能力”都被浪费了,严重时导致整个网络死锁
766 |
767 | 2种常用的拥塞控制方法:
768 | - **端到端拥塞控制**(自身判断)
769 | - 没有来自网络的显式反馈
770 | - 端系统根据延迟和丢失事件自身推断是否有拥塞
771 | - TCP采用的方法
772 | - **网络辅助的拥塞控制**(路由器反馈)
773 | - 路由器提供给端系统以反馈信息
774 | - 单个bit置位,显示有拥塞 (SNA, DECbit, TCP/IP ECN, ATM)
775 | - 显式提供发送端可以采用的速率
776 |
777 | > 案例:ATM ABR 拥塞控制(网络辅助的拥塞控制)
778 | >
779 | > ATM网络数据交换的单位叫 信元(一个小分组,53字节:5字节的头部+48字节的数据载荷)。
780 | >
781 | > 信元每个分组数据量较小,在每个交换节点存储-转发耽误的时间比分组交换小,且时间固定,便于调度。ATM网络集合了分组交换和线路交换的特性。
782 | >
783 | > ATM虽然不是大众常用网络,但是在一些专用场合用处较大
784 | >
785 | > ATM网络有很多模式,其中一个模式是ABR: available bit rate:
786 | > - 提供“弹性服务”
787 | > - 如果发送端的路径“轻载”不发生拥塞
788 | > - 发送方尽可能地使用可用带宽(“市场调控”)
789 | > - 如果发送方的路径拥塞了
790 | > - 发送方限制其发送的速度到一个最小保障速率上(“配给制”)
791 | >
792 | > ATM网络中的信元可以分为2种:大部分是数据信元,另一种为间或地插入到数据信元当中的资源管理信元。
793 | >
794 | > RM(资源管理)信元:
795 | > - 由发送端发送,在数据信元中间隔插入
796 | > - RM信元中的比特被交换机设置(“网络辅助”)
797 | > - NI bit: no increase in rate (轻微拥塞)速率不要增加了,轻微拥塞时设置为1
798 | > - CI bit: congestion indication 拥塞指示,拥塞时设置为1
799 | > - 发送端发送的RM信元被接收端返回,接收端不做任何改变
800 | > - 在RM信元中的2个字节ER(explicit rate)字段
801 | > - 拥塞的交换机可能会降低信元中ER的值
802 | > - 发送端发送速度因此是最低的可支持速率
803 | > - 数据信元中的EFCI bit:被拥塞的交换机设置成1
804 | > - 如果在管理信元RM前面的数据信元EFCI被设置成了1,接端在返回的RM信元中设置CI bit
805 | >
806 | > 总结:网络提供一些信息,包括一些标志位的置位以及字段 (为两主机间的通信提供多大的带宽)
807 |
808 | ### 3.7 TCP拥塞控制
809 |
810 | - TCP拥塞控制采用端到端的拥塞控制机制
811 | - 路由器不向主机有关拥塞的反馈信息
812 | - 路由器的负担较轻
813 | - 符合网络核心简单的TCP/IP架构原则,网络核心提供最小的服务集
814 | - 端系统根据自身得到的信息,判断是否发生拥塞,从而采取动作
815 | - 拥塞控制的几个问题
816 | - 如何检测拥塞
817 | - 轻微拥塞
818 | - 拥塞
819 | - 控制策略
820 | - 在拥塞发送时如何动作,降低速率
821 | - 轻微拥塞,如何降低
822 | - 拥塞时,如何降低
823 | - 在拥塞缓解时如何动作,尽可能增加速率
824 |
825 | 拥塞感知:发送端如何探测到拥塞?
826 | - 某个段超时了(丢失事件):拥塞
827 | - 超时时间到,某个段的确认没有来
828 | - 原因1:网络拥塞(某个路由器缓冲区没空间了,被丢弃) 概率大
829 | - 原因2:出错被丢弃了(各级错误,没有通过校验,被丢弃) 概率小。此时不应该降低发送速率
830 | - 一旦超时,就认为拥塞了,有一定误判(原因2,但概率小),但是总体控制方向是对的
831 | - 有关某个段的3次重复ACK:轻微拥塞
832 | - 段的第1个ack,正常,确认绿段,期待红段
833 | - 段的第2个重复ack,意味着红段的后一段收到了,蓝段乱序到达
834 | - 段的第2、3、4个ack重复,意味着红段的后第2、3、4个段收到了,橙段乱序到达,同时红段丢失的可能性很大(后面3个段都到了,红段都没到)
835 | - 网络这时还能够进行一定程度的传输,拥塞但情况要比第一种好
836 |
837 | 速率控制方法:如何控制发送端发送的速率
838 | - 维持一个拥塞窗口的值:CongWin(以字节为单位,表示发送方在对方未确认的情况下往网络中注入多少字节)
839 | - 发送端限制已发送但是未确认的数据量(的上限):
840 | $$LastByteSent - LastByteAcked \leq CongWin$$
841 | - 从而粗略地控制发送方的往网络中注入的速率
842 |
843 |
764 |
765 | 又一个拥塞的代价:当分组丢失时,任何“关于这个分组的上游传输能力”都被浪费了,严重时导致整个网络死锁
766 |
767 | 2种常用的拥塞控制方法:
768 | - **端到端拥塞控制**(自身判断)
769 | - 没有来自网络的显式反馈
770 | - 端系统根据延迟和丢失事件自身推断是否有拥塞
771 | - TCP采用的方法
772 | - **网络辅助的拥塞控制**(路由器反馈)
773 | - 路由器提供给端系统以反馈信息
774 | - 单个bit置位,显示有拥塞 (SNA, DECbit, TCP/IP ECN, ATM)
775 | - 显式提供发送端可以采用的速率
776 |
777 | > 案例:ATM ABR 拥塞控制(网络辅助的拥塞控制)
778 | >
779 | > ATM网络数据交换的单位叫 信元(一个小分组,53字节:5字节的头部+48字节的数据载荷)。
780 | >
781 | > 信元每个分组数据量较小,在每个交换节点存储-转发耽误的时间比分组交换小,且时间固定,便于调度。ATM网络集合了分组交换和线路交换的特性。
782 | >
783 | > ATM虽然不是大众常用网络,但是在一些专用场合用处较大
784 | >
785 | > ATM网络有很多模式,其中一个模式是ABR: available bit rate:
786 | > - 提供“弹性服务”
787 | > - 如果发送端的路径“轻载”不发生拥塞
788 | > - 发送方尽可能地使用可用带宽(“市场调控”)
789 | > - 如果发送方的路径拥塞了
790 | > - 发送方限制其发送的速度到一个最小保障速率上(“配给制”)
791 | >
792 | > ATM网络中的信元可以分为2种:大部分是数据信元,另一种为间或地插入到数据信元当中的资源管理信元。
793 | >
794 | > RM(资源管理)信元:
795 | > - 由发送端发送,在数据信元中间隔插入
796 | > - RM信元中的比特被交换机设置(“网络辅助”)
797 | > - NI bit: no increase in rate (轻微拥塞)速率不要增加了,轻微拥塞时设置为1
798 | > - CI bit: congestion indication 拥塞指示,拥塞时设置为1
799 | > - 发送端发送的RM信元被接收端返回,接收端不做任何改变
800 | > - 在RM信元中的2个字节ER(explicit rate)字段
801 | > - 拥塞的交换机可能会降低信元中ER的值
802 | > - 发送端发送速度因此是最低的可支持速率
803 | > - 数据信元中的EFCI bit:被拥塞的交换机设置成1
804 | > - 如果在管理信元RM前面的数据信元EFCI被设置成了1,接端在返回的RM信元中设置CI bit
805 | >
806 | > 总结:网络提供一些信息,包括一些标志位的置位以及字段 (为两主机间的通信提供多大的带宽)
807 |
808 | ### 3.7 TCP拥塞控制
809 |
810 | - TCP拥塞控制采用端到端的拥塞控制机制
811 | - 路由器不向主机有关拥塞的反馈信息
812 | - 路由器的负担较轻
813 | - 符合网络核心简单的TCP/IP架构原则,网络核心提供最小的服务集
814 | - 端系统根据自身得到的信息,判断是否发生拥塞,从而采取动作
815 | - 拥塞控制的几个问题
816 | - 如何检测拥塞
817 | - 轻微拥塞
818 | - 拥塞
819 | - 控制策略
820 | - 在拥塞发送时如何动作,降低速率
821 | - 轻微拥塞,如何降低
822 | - 拥塞时,如何降低
823 | - 在拥塞缓解时如何动作,尽可能增加速率
824 |
825 | 拥塞感知:发送端如何探测到拥塞?
826 | - 某个段超时了(丢失事件):拥塞
827 | - 超时时间到,某个段的确认没有来
828 | - 原因1:网络拥塞(某个路由器缓冲区没空间了,被丢弃) 概率大
829 | - 原因2:出错被丢弃了(各级错误,没有通过校验,被丢弃) 概率小。此时不应该降低发送速率
830 | - 一旦超时,就认为拥塞了,有一定误判(原因2,但概率小),但是总体控制方向是对的
831 | - 有关某个段的3次重复ACK:轻微拥塞
832 | - 段的第1个ack,正常,确认绿段,期待红段
833 | - 段的第2个重复ack,意味着红段的后一段收到了,蓝段乱序到达
834 | - 段的第2、3、4个ack重复,意味着红段的后第2、3、4个段收到了,橙段乱序到达,同时红段丢失的可能性很大(后面3个段都到了,红段都没到)
835 | - 网络这时还能够进行一定程度的传输,拥塞但情况要比第一种好
836 |
837 | 速率控制方法:如何控制发送端发送的速率
838 | - 维持一个拥塞窗口的值:CongWin(以字节为单位,表示发送方在对方未确认的情况下往网络中注入多少字节)
839 | - 发送端限制已发送但是未确认的数据量(的上限):
840 | $$LastByteSent - LastByteAcked \leq CongWin$$
841 | - 从而粗略地控制发送方的往网络中注入的速率
842 |
843 |  844 |
845 | - CongWin是动态的,是感知到的网络拥塞程度的函数
846 | - 超时或者3个重复ack,CongWin下降
847 | - 超时:CongWin降为1MSS,进入SS阶段然后再倍增到CongWin/2(每个RTT),从而进入CA阶段
848 | - 3个重复ack:CongWin降为CongWin/2, CA阶段
849 | - 否则(正常收到Ack,没有发送以上情况):CongWin跃跃欲试(上升)
850 | - SS阶段(慢启动阶段):每经过一个RTT进行CongWin的加倍
851 | - CA阶段(拥塞避免阶段):每经过一个RTT进行1个MSS的线性增加
852 |
853 | TCP拥塞控制和流量控制的联合动作
854 | - 联合控制的方法:
855 | - 发送端控制发送但是未确认的量同时也不能够超过接收窗口的空闲尺寸(接收方在返回给发送方的报文中捎带),满足流量控制要求
856 | - $SendWin = \min(CongWin, RecvWin)$
857 | - 同时满足 拥塞控制 和 流量控制 要求
858 |
859 | TCP 拥塞控制:策略概述
860 | - 慢启动
861 | - 连接刚建立, $CongWin = 1MSS$
862 | - 如: $MSS = 1460bytes$ & $RTT = 200msec$
863 | - 则可计算得初始速率为 $MSS/RTT = 58.4kbps$ ,这是一个很小的速率,可用带宽可能远远大于它,应当尽快着手增速,到达希望的速率
864 | - 当连接开始时,指数性(后一次速率是前一次的2倍)增加发送速率,直到发生丢失的事件
865 | - 启动初值很低
866 | - 但是速度很快(指数增加,SS时间很短,长期来看可以忽略)
867 | - 当连接开始时,指数性增加(每个RTT)发送速率直到发生丢失事件
868 | - 每一个RTT,CongWin加倍
869 | - 每收到一个ACK时,CongWin加1(等价于每个RTT,CongWin翻倍)
870 | - 慢启动阶段:只要不超时或3个重复ack,一个RTT后CongWin加倍
871 | - AIMD:线性增、乘性减少
872 | - 乘性减:
873 | - 丢失事件后将CongWin降为1,将CongWin/2作为阈值,进入慢启动阶段(倍增直到CongWin/2)
874 | - 加性增:
875 | - 当CongWin>阈值时,一个RTT如没有发生丢失事件,将CongWin加1MSS:探测
876 | - 当收到3个重复的ACKs:(3个重复的ACK表示网络还有一定的段传输能力(轻微拥塞),超时之前的3个重复的ACK表示“警报”)
877 | - CongWin减半
878 | - 窗口(缓冲区大小)之后线性增长
879 | - 当超时事件发生时:
880 | - CongWin被设置成 1MSS,进入SS阶段
881 | - 之后窗口指数增长
882 | - 增长到一个阈值(上次发生拥塞的窗口的一半)时,再线性增加
883 | - 超时事件后的保守策略
884 | - Q:什么时候应该将指数性增长变成线性?
885 | - A:在超时之前,当CongWin变成上次发生超时的窗口的一半
886 | - 实现:
887 | - 变量:Threshold
888 | - 出现丢失,Threshold设置成CongWin的1/2
889 |
890 | 总结:TCP拥塞控制
891 | - 当CongWin < Threshold,发送端处于慢启动阶段(slow-start),窗口指数性增长。
892 | - 当CongWin > Threshold,发送端处于拥塞避免阶段(congestion-avoidance),窗口线性增长。
893 | - 当收到三个重复的ACKs(triple duplicate ACK),Threshold设置成CongWin/2,CongWin=Threshold+3。
894 | - 当超时事件发生时timeout,Threshold=CongWin/2,CongWin=1MSS,进入SS阶段
895 |
896 | TCP 发送端拥塞控制
897 | | 事件 | 状态 | TCP 发送端行为 | 解释|
898 | | --- | --- | --- | --- |
899 | | 以前没有收到ACK的data被ACKed | 慢启动(SS) | CongWin = CongWin + MSS
844 |
845 | - CongWin是动态的,是感知到的网络拥塞程度的函数
846 | - 超时或者3个重复ack,CongWin下降
847 | - 超时:CongWin降为1MSS,进入SS阶段然后再倍增到CongWin/2(每个RTT),从而进入CA阶段
848 | - 3个重复ack:CongWin降为CongWin/2, CA阶段
849 | - 否则(正常收到Ack,没有发送以上情况):CongWin跃跃欲试(上升)
850 | - SS阶段(慢启动阶段):每经过一个RTT进行CongWin的加倍
851 | - CA阶段(拥塞避免阶段):每经过一个RTT进行1个MSS的线性增加
852 |
853 | TCP拥塞控制和流量控制的联合动作
854 | - 联合控制的方法:
855 | - 发送端控制发送但是未确认的量同时也不能够超过接收窗口的空闲尺寸(接收方在返回给发送方的报文中捎带),满足流量控制要求
856 | - $SendWin = \min(CongWin, RecvWin)$
857 | - 同时满足 拥塞控制 和 流量控制 要求
858 |
859 | TCP 拥塞控制:策略概述
860 | - 慢启动
861 | - 连接刚建立, $CongWin = 1MSS$
862 | - 如: $MSS = 1460bytes$ & $RTT = 200msec$
863 | - 则可计算得初始速率为 $MSS/RTT = 58.4kbps$ ,这是一个很小的速率,可用带宽可能远远大于它,应当尽快着手增速,到达希望的速率
864 | - 当连接开始时,指数性(后一次速率是前一次的2倍)增加发送速率,直到发生丢失的事件
865 | - 启动初值很低
866 | - 但是速度很快(指数增加,SS时间很短,长期来看可以忽略)
867 | - 当连接开始时,指数性增加(每个RTT)发送速率直到发生丢失事件
868 | - 每一个RTT,CongWin加倍
869 | - 每收到一个ACK时,CongWin加1(等价于每个RTT,CongWin翻倍)
870 | - 慢启动阶段:只要不超时或3个重复ack,一个RTT后CongWin加倍
871 | - AIMD:线性增、乘性减少
872 | - 乘性减:
873 | - 丢失事件后将CongWin降为1,将CongWin/2作为阈值,进入慢启动阶段(倍增直到CongWin/2)
874 | - 加性增:
875 | - 当CongWin>阈值时,一个RTT如没有发生丢失事件,将CongWin加1MSS:探测
876 | - 当收到3个重复的ACKs:(3个重复的ACK表示网络还有一定的段传输能力(轻微拥塞),超时之前的3个重复的ACK表示“警报”)
877 | - CongWin减半
878 | - 窗口(缓冲区大小)之后线性增长
879 | - 当超时事件发生时:
880 | - CongWin被设置成 1MSS,进入SS阶段
881 | - 之后窗口指数增长
882 | - 增长到一个阈值(上次发生拥塞的窗口的一半)时,再线性增加
883 | - 超时事件后的保守策略
884 | - Q:什么时候应该将指数性增长变成线性?
885 | - A:在超时之前,当CongWin变成上次发生超时的窗口的一半
886 | - 实现:
887 | - 变量:Threshold
888 | - 出现丢失,Threshold设置成CongWin的1/2
889 |
890 | 总结:TCP拥塞控制
891 | - 当CongWin < Threshold,发送端处于慢启动阶段(slow-start),窗口指数性增长。
892 | - 当CongWin > Threshold,发送端处于拥塞避免阶段(congestion-avoidance),窗口线性增长。
893 | - 当收到三个重复的ACKs(triple duplicate ACK),Threshold设置成CongWin/2,CongWin=Threshold+3。
894 | - 当超时事件发生时timeout,Threshold=CongWin/2,CongWin=1MSS,进入SS阶段
895 |
896 | TCP 发送端拥塞控制
897 | | 事件 | 状态 | TCP 发送端行为 | 解释|
898 | | --- | --- | --- | --- |
899 | | 以前没有收到ACK的data被ACKed | 慢启动(SS) | CongWin = CongWin + MSS If (CongWin > Threshold)
状态变成 “CA” | 每一个RTT,CongWin加倍 | 900 | | 以前没有收到ACK的data被ACKed | 拥塞避免(CA) | CongWin = CongWin + MSS*(MSS/CongWin)| 加性增加,每一个RTT对CongWin加一个1MSS | 901 | | 通过收到3个重复的ACK,发现丢失的事件 | SS or CA |Threshold = CongWin/2
CongWin = Threshold+3
状态变成“CA” | 快速重传,实现乘性的减。
CongWin没有变成1MSS。| 902 | | 超时 | SS or CA | Threshold = CongWin/2
CongWin = 1MSS
状态变成“SS” | 进入slow start| 903 | | 重复的ACK | SS or CA | 对被ACKed的segment,增加重复ACK的计数 | CongWin and Threshold 不变 | 904 | 905 | TCP 吞吐量 906 | - TCP的平均吞吐量是多少,使用窗口window尺寸W和RTT来描述? 907 | - 忽略慢启动阶段,假设发送端总有数据传输 908 | - 定义W为发生丢失事件时的窗口尺寸(单位:字节),则全过程在W/2和W之间变化 909 | - 平均窗口尺寸(#in-flight字节):3/4W 910 | - 平均吞吐量:RTT时间吞吐3/4W 911 | $$avg TCP thruput = \frac{3}{4} \frac{W}{RTT} bytes/sec$$ 912 | 913 | TCP公平性 914 | - 公平性目标:如果 $K$ 个TCP会话分享一个链路带宽为 $R$ 的瓶颈,每一个会话的有效带宽为 $R/K$ 915 | - TCP为什么是公平的? 916 | - 考虑2个竞争的TCP会话: 917 | - 加性增加,斜率为1,吞吐量增加 918 | - 乘性减,吞吐量比例减少 919 | - 公平性和UDP 920 | - 多媒体应用通常不是用TCP 921 | - 应用发送的数据速率希望不受拥塞控制的节制 922 | - 使用UDP: 923 | - 音视频应用泵出数据的速率是恒定的,忽略数据的丢失 924 | - 研究领域:TCP友好性 925 | - 公平性和并行TCP连接 926 | - 2个主机间可以打开多个并行的TCP连接 927 | - Web浏览器 928 | - 例如:带宽为R的链路支持了9个连接 929 | - 如果新的应用要求建1个TCP连接,获得带宽R/10 930 | - 如果新的应用要求建11个TCP连接,获得带宽R/2 931 | 932 | ### 3.8 总结 & 展望 933 | 934 | - 传输层提供的服务 935 | - 应用进程间的逻辑通信 936 | - Vs 网络层提供的是主机到主机的通信服务 937 | - 互联网上传输层协议:UDP TCP 938 | - 特性 939 | - 多路复用和解复用 940 | - 端口:传输层的SAP 941 | - 无连接的多路复用和解复用 942 | - 面向连接的多路复用和解复用 943 | - 实例1:无连接传输层协议 UDP 944 | - 多路复用解复用 945 | - UDP报文格式 946 | - 检错机制:校验和 947 | - 可靠数据传输原理 948 | - 问题描述 949 | - 停止等待协议 950 | - Rdt 1.0, 2.0, 2.1, 2.2, 3.0 951 | - 流水线协议 952 | - GBN 953 | - SR(Selective Repeat) 954 | - 实例2:面向连接的传输层协议-TCP 955 | - 概述:TCP特性 956 | - 报文段格式 957 | - 序号,超时机制及时间 958 | - TCP可靠传输机制 959 | - 重传,快速重传 960 | - 流量控制 961 | - 连接管理 962 | - 三次握手 963 | - 对称连接释放 964 | - 拥塞控制原理 965 | - 网络辅助的拥塞控制 966 | - 端到端的拥塞控制 967 | - TCP的拥塞控制 968 | - AIMD 969 | - 慢启动 970 | - 超时之后的保守策略 971 | - 展望下2章: 972 | - 离开网络“边缘”(应用层和传输层) 973 | - 深入到网络的“核心” 974 | - 2个关于网络层的章 975 | - 数据平面 976 | - 控制平面 977 | -------------------------------------------------------------------------------- /Log_of_ComputerNetworking-ATopDownApproach_7th/chapter4.md: -------------------------------------------------------------------------------- 1 | # 计算机网络——自顶向下方法 7th 2 | 3 | 中国科学技术大学 郑烇教授 2020年秋季 自动化系 4 | 5 | ## 4. 网络层——数据平面 6 | 7 | 目标: 8 | - 理解网络服务的基本原理,聚焦于其数据平面 9 | - 网络服务模型 10 | - 转发(数据平面)和路由(控制平面),各有2种方式:传统方式和SDN方式 11 | - 路由器工作原理 12 | - 通用转发 13 | - 互联网中网络层协议的实例和实现 14 | 15 | ### 4.1 导论 16 | 17 | 网络层服务 18 | - 在发送主机和接收主机对之间传送段(segment) 19 | - 在发送端将段封装到数据报中 20 | - 在接收端,将段上交给传输层实体 21 | - 网络层协议存在于**每一个**主机和路由器(每一个都需要封装和解封装) 22 | - 路由器检查每一个经过它的IP数据报的头部 23 | 24 |
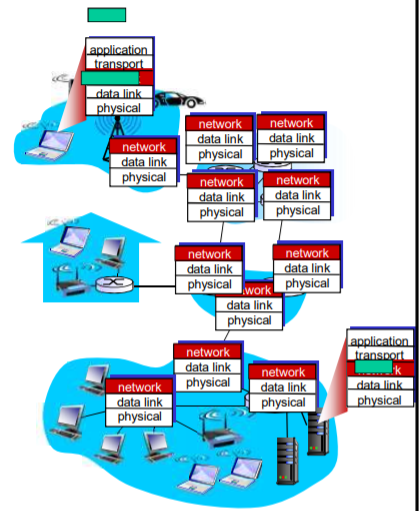 25 |
26 | 网络层的关键功能
27 | - 网络层功能:
28 | - **转发**(一个局部的概念,数据平面):将分组从路由器的输入接口转发到合适的输出接口
29 | - **路由**(一个全局的功能,控制平面):使用路由算法来决定分组从发送主机到目标接收主机的路径
30 | - 路由选择算法
31 | - 路由选择协议
32 | - 旅行的类比:
33 | - 转发:通过单个路口的过程
34 | - 路由:从源到目的的路由路径规划过程
35 |
36 | 网络层:数据平面、控制平面
37 | - 数据平面:分组从哪个端口输入,从哪个端口输出
38 | - 本地,每个路由器功能
39 | - 决定从路由器输入端口到达的分组如何转发到输出端口
40 | - 转发功能:
41 | - 传统方式:基于目标IP地址得知哪个端口输入 + 转发表(路由表)决定哪个端口输出
42 | - SDN方式:基于多个字段 + 与 流表 做匹配,通过匹配的表象进行相应的动作(如转发、阻止、泛洪、修改等)(不像传统方式只进行转发,更加灵活)
43 | - 控制平面:决定分组在整个网络中的路径
44 | - 控制网络范围内的逻辑
45 | - 决定数据报如何在路由器之间路由,决定数据报从源到目标主机之间的端到端路径
46 | - 2个控制平面方法:
47 | - 传统的路由算法:在路由器中被实现,得到路由表
48 | - software-defined networking (SDN,软件定义网络):在远程的服务器中实现,计算出流表通过南向接口交给分组交换设备,进而与分组的多个字段相匹配并根据匹配结果进行相应的动作
49 |
50 | 传统方式:每-路由器(Per-router)控制平面
51 | - 在每一个路由器中的单独路由器算法元件,在控制平面进行交互
52 | - 控制平面和数据平面紧耦合(集中于一台设备上实现),分布式计算路由表,难以修改路由设备的运行逻辑,模式僵化
53 |
54 |
25 |
26 | 网络层的关键功能
27 | - 网络层功能:
28 | - **转发**(一个局部的概念,数据平面):将分组从路由器的输入接口转发到合适的输出接口
29 | - **路由**(一个全局的功能,控制平面):使用路由算法来决定分组从发送主机到目标接收主机的路径
30 | - 路由选择算法
31 | - 路由选择协议
32 | - 旅行的类比:
33 | - 转发:通过单个路口的过程
34 | - 路由:从源到目的的路由路径规划过程
35 |
36 | 网络层:数据平面、控制平面
37 | - 数据平面:分组从哪个端口输入,从哪个端口输出
38 | - 本地,每个路由器功能
39 | - 决定从路由器输入端口到达的分组如何转发到输出端口
40 | - 转发功能:
41 | - 传统方式:基于目标IP地址得知哪个端口输入 + 转发表(路由表)决定哪个端口输出
42 | - SDN方式:基于多个字段 + 与 流表 做匹配,通过匹配的表象进行相应的动作(如转发、阻止、泛洪、修改等)(不像传统方式只进行转发,更加灵活)
43 | - 控制平面:决定分组在整个网络中的路径
44 | - 控制网络范围内的逻辑
45 | - 决定数据报如何在路由器之间路由,决定数据报从源到目标主机之间的端到端路径
46 | - 2个控制平面方法:
47 | - 传统的路由算法:在路由器中被实现,得到路由表
48 | - software-defined networking (SDN,软件定义网络):在远程的服务器中实现,计算出流表通过南向接口交给分组交换设备,进而与分组的多个字段相匹配并根据匹配结果进行相应的动作
49 |
50 | 传统方式:每-路由器(Per-router)控制平面
51 | - 在每一个路由器中的单独路由器算法元件,在控制平面进行交互
52 | - 控制平面和数据平面紧耦合(集中于一台设备上实现),分布式计算路由表,难以修改路由设备的运行逻辑,模式僵化
53 |
54 |  55 |
56 | 传统方式:路由和转发的相互作用
57 |
58 |
55 |
56 | 传统方式:路由和转发的相互作用
57 |
58 |  59 |
60 | SDN方式:逻辑集中的控制平面
61 | - 一个不同的(通常是远程的)控制器与本地控制代理(CAs)交互,只用在控制器处改变流表就可以改变网络设备的行为逻辑,易修改、可编程
62 |
63 |
59 |
60 | SDN方式:逻辑集中的控制平面
61 | - 一个不同的(通常是远程的)控制器与本地控制代理(CAs)交互,只用在控制器处改变流表就可以改变网络设备的行为逻辑,易修改、可编程
62 |
63 |  64 |
65 | 网络服务模型
66 | - Q:从发送方主机到接收方主机传输数据报的“通道”,网络提供什么样的服务模型(service model)?服务模型有一系列的指标
67 | - 对于单个数据报的服务:
68 | - 可靠传送
69 | - 延迟保证,如:少于40ms的延迟
70 | - 对于数据报流(一系列分组的序列)的服务:
71 | - 保序数据报传送
72 | - 保证流的最小带宽
73 | - 分组之间的延迟差(jitter)
74 |
75 | 连接建立
76 | - 在某些网络架构中是第三个重要的功能(继 路由、转发 之后)
77 | - ATM(有连接:建立连接&路径上所有主机进行维护), frame relay, X.25
78 | - 在分组传输之前,在两个主机之间,在通过一些路由器所构成的路径上建立一个网络层连接
79 | - 涉及到路由器
80 | - 网络层和传输层连接服务区别:
81 | - 网络层:在2个主机之间,涉及到路径上的一些路由器,有连接
82 | - 传输层:在2个进程之间,很可能只体现在端系统上(TCP连接),面向连接
83 |
84 | 网络层服务模型:
85 | |网络架构|服务模型|保证带宽|不丢失|保序|延迟保证|拥塞反馈|
86 | |:---:|:---:|:---:|:---:|:---:|:---:|:---:|
87 | |Internet|best effort “尽力而为”|none|no|no|no|no (inferred via loss)|
88 | |ATM|CBR(恒定速率)|constant rate|yes|yes|yes|no congestion|
89 | |ATM|VBR(变化速率)|guaranteed rate|yes|yes|yes|no congestion|
90 | |ATM|ABR(可用比特率)|guaranteed minimum|no|yes|no|yes|
91 | |ATM|UBR(不指名比特率)|none|no|yes|no|no|
92 |
93 | ### 4.2 路由器组成
94 |
95 | 路由器结构概况
96 | - 高层面(非常简化的)通用路由器体系架构:输入端口 + 输出端口 + 交换结构
97 | - 路由:运行路由选择算法/协议 (RIP, OSPF, BGP)-生成路由表
98 | - 转发:从输入到输出链路交换数据报-根据路由表进行分组的转发
99 |
100 |
64 |
65 | 网络服务模型
66 | - Q:从发送方主机到接收方主机传输数据报的“通道”,网络提供什么样的服务模型(service model)?服务模型有一系列的指标
67 | - 对于单个数据报的服务:
68 | - 可靠传送
69 | - 延迟保证,如:少于40ms的延迟
70 | - 对于数据报流(一系列分组的序列)的服务:
71 | - 保序数据报传送
72 | - 保证流的最小带宽
73 | - 分组之间的延迟差(jitter)
74 |
75 | 连接建立
76 | - 在某些网络架构中是第三个重要的功能(继 路由、转发 之后)
77 | - ATM(有连接:建立连接&路径上所有主机进行维护), frame relay, X.25
78 | - 在分组传输之前,在两个主机之间,在通过一些路由器所构成的路径上建立一个网络层连接
79 | - 涉及到路由器
80 | - 网络层和传输层连接服务区别:
81 | - 网络层:在2个主机之间,涉及到路径上的一些路由器,有连接
82 | - 传输层:在2个进程之间,很可能只体现在端系统上(TCP连接),面向连接
83 |
84 | 网络层服务模型:
85 | |网络架构|服务模型|保证带宽|不丢失|保序|延迟保证|拥塞反馈|
86 | |:---:|:---:|:---:|:---:|:---:|:---:|:---:|
87 | |Internet|best effort “尽力而为”|none|no|no|no|no (inferred via loss)|
88 | |ATM|CBR(恒定速率)|constant rate|yes|yes|yes|no congestion|
89 | |ATM|VBR(变化速率)|guaranteed rate|yes|yes|yes|no congestion|
90 | |ATM|ABR(可用比特率)|guaranteed minimum|no|yes|no|yes|
91 | |ATM|UBR(不指名比特率)|none|no|yes|no|no|
92 |
93 | ### 4.2 路由器组成
94 |
95 | 路由器结构概况
96 | - 高层面(非常简化的)通用路由器体系架构:输入端口 + 输出端口 + 交换结构
97 | - 路由:运行路由选择算法/协议 (RIP, OSPF, BGP)-生成路由表
98 | - 转发:从输入到输出链路交换数据报-根据路由表进行分组的转发
99 |
100 |  101 |
102 | 注:输入/出端口的三个块代表网络层(红色)、链路层、物理层
103 | 注2:输入/出端口通常是整合在一起的,分开描述是为了方便
104 |
105 | 输入端口
106 | - 输入端口功能:物理层链路上的物理信号转换为数字信号,数据链路层封装成帧并进行一定的判断,将帧当中的数据部分取出,交给网络层实体
107 |
108 |
101 |
102 | 注:输入/出端口的三个块代表网络层(红色)、链路层、物理层
103 | 注2:输入/出端口通常是整合在一起的,分开描述是为了方便
104 |
105 | 输入端口
106 | - 输入端口功能:物理层链路上的物理信号转换为数字信号,数据链路层封装成帧并进行一定的判断,将帧当中的数据部分取出,交给网络层实体
107 |
108 |  109 |
110 | - 输入端口需要有一个队列——输入端口缓存:下层交上来的速度于与交给分组交换结构的速度可能不匹配
111 | - 当交换机构的速率小于输入端口的汇聚速率时,在输入端口可能要排队
112 | - 排队延迟以及由于输入缓存溢出造成丢失!
113 | - Head-of-the-Line (HOL) blocking:排在队头的数据报阻止了队列中其他数据报向前移动
114 |
115 |
109 |
110 | - 输入端口需要有一个队列——输入端口缓存:下层交上来的速度于与交给分组交换结构的速度可能不匹配
111 | - 当交换机构的速率小于输入端口的汇聚速率时,在输入端口可能要排队
112 | - 排队延迟以及由于输入缓存溢出造成丢失!
113 | - Head-of-the-Line (HOL) blocking:排在队头的数据报阻止了队列中其他数据报向前移动
114 |
115 |  116 |
117 | 交换结构:将分组从输入缓冲区传输到合适的输出端口
118 | - 交换速率:分组可以按照该速率从输入传输到输出
119 | - 运行速度经常是输入/输出链路速率的若干倍
120 | - N个输入端口:交换机构的交换速度是输入线路速度的N倍比较理想,才不会成为瓶颈
121 | - 3种典型的交换机构:memory, bus, crossbar
122 |
123 |
116 |
117 | 交换结构:将分组从输入缓冲区传输到合适的输出端口
118 | - 交换速率:分组可以按照该速率从输入传输到输出
119 | - 运行速度经常是输入/输出链路速率的若干倍
120 | - N个输入端口:交换机构的交换速度是输入线路速度的N倍比较理想,才不会成为瓶颈
121 | - 3种典型的交换机构:memory, bus, crossbar
122 |
123 |  124 |
125 | - 通过内存交换(**memory**) —— 第一代路由器:
126 | - 在CPU直接控制下的交换,采用传统的计算机
127 | - 分组被拷贝到系统内存,CPU从分组的头部提取出目标地址,查找转发表,找到对应的输出端口,拷贝到输出端口
128 | - 转发速率被内存的带宽限制(数据报通过BUS两遍(进+出),系统总线本身就会成为瓶颈,速率低)
129 | - 一次只能转发一个分组
130 |
131 |
124 |
125 | - 通过内存交换(**memory**) —— 第一代路由器:
126 | - 在CPU直接控制下的交换,采用传统的计算机
127 | - 分组被拷贝到系统内存,CPU从分组的头部提取出目标地址,查找转发表,找到对应的输出端口,拷贝到输出端口
128 | - 转发速率被内存的带宽限制(数据报通过BUS两遍(进+出),系统总线本身就会成为瓶颈,速率低)
129 | - 一次只能转发一个分组
130 |
131 |  132 |
133 | - 通过总线交换(**bus**) —— 第二代路由器
134 | - 数据报通过共享总线,从输入端口转发到输出端口
135 | - 虽然相比于memory方式,只经过bus一次,交换速率大大提升,但是还是有问题 —— 总线竞争:交换速度受限于总线带宽
136 | - 1次处理一个分组
137 | - 1 Gbps bus, Cisco 1900; 32 Gbps bus, Cisco 5600;对于接入或企业级路由器,速度足够(但不适合区域或骨干网络)
138 |
139 |
132 |
133 | - 通过总线交换(**bus**) —— 第二代路由器
134 | - 数据报通过共享总线,从输入端口转发到输出端口
135 | - 虽然相比于memory方式,只经过bus一次,交换速率大大提升,但是还是有问题 —— 总线竞争:交换速度受限于总线带宽
136 | - 1次处理一个分组
137 | - 1 Gbps bus, Cisco 1900; 32 Gbps bus, Cisco 5600;对于接入或企业级路由器,速度足够(但不适合区域或骨干网络)
138 |
139 |  140 |
141 | - 通过互联网络(**crossbar**等)的交换
142 | - 同时并发转发多个分组,克服总线带宽限制
143 | - Banyan(榕树)网络,crossbar(纵横)和其它的互联网络被开发,将多个处理器连接成多处理器
144 | - 当分组从端口A到达,转给端口Y;控制器短接相应的两个总线
145 | - 高级设计:将数据报分片为固定长度的信元,通过交换网络交换
146 | - Cisco12000:以60Gbps的交换速率通过互联网络
147 |
148 |
140 |
141 | - 通过互联网络(**crossbar**等)的交换
142 | - 同时并发转发多个分组,克服总线带宽限制
143 | - Banyan(榕树)网络,crossbar(纵横)和其它的互联网络被开发,将多个处理器连接成多处理器
144 | - 当分组从端口A到达,转给端口Y;控制器短接相应的两个总线
145 | - 高级设计:将数据报分片为固定长度的信元,通过交换网络交换
146 | - Cisco12000:以60Gbps的交换速率通过互联网络
147 |
148 |  149 |
150 | 输出端口
151 |
152 |
149 |
150 | 输出端口
151 |
152 |  153 |
154 | - 当数据报从交换机构的到达速度比传输速率快就需要输出端口缓存(输出端口排队)
155 | - 假设交换速率 $R_{switch}$ 是 $R_{line}$ 的N倍(N:输入端口的数量)
156 | - 当多个输入端口同时向输出端口发送时,缓冲该分组(当通过交换网络到达的速率超过输出速率则缓存)
157 | - 排队带来延迟,由于输出端口缓存溢出则丢弃数据报
158 |
159 |
153 |
154 | - 当数据报从交换机构的到达速度比传输速率快就需要输出端口缓存(输出端口排队)
155 | - 假设交换速率 $R_{switch}$ 是 $R_{line}$ 的N倍(N:输入端口的数量)
156 | - 当多个输入端口同时向输出端口发送时,缓冲该分组(当通过交换网络到达的速率超过输出速率则缓存)
157 | - 排队带来延迟,由于输出端口缓存溢出则丢弃数据报
158 |
159 |  160 |
161 | - 由**调度规则**选择排队的数据报进行传输(先来的不一定先传)
162 | - 调度:选择下一个要通过链路传输的分组
163 | - 调度策略:
164 | - FIFO (first in first out) scheduling:按照分组到来的次序发送(先到先服务)
165 | - 现实例子?
166 | - 丢弃策略:如果分组到达一个满的队列,哪个分组将会被抛弃?
167 | - tail drop:丢弃刚到达的分组(抛尾部)
168 | - priority:根据优先权丢失/移除分组
169 | - random:随机地丢弃/移除
170 | - 优先权调度:发送最高优先权的分组
171 | - 多类,不同类别有不同的优先权
172 | - 类别可能依赖于标记或者其他的头部字段,e.g. IP source/dest, port numbers, ds, etc.
173 | - 先传高优先级的队列中的分组,除非没有
174 | - 高(低)优先权中的分组传输次序:FIFO
175 | - 现实生活中的例子?
176 |
177 |
160 |
161 | - 由**调度规则**选择排队的数据报进行传输(先来的不一定先传)
162 | - 调度:选择下一个要通过链路传输的分组
163 | - 调度策略:
164 | - FIFO (first in first out) scheduling:按照分组到来的次序发送(先到先服务)
165 | - 现实例子?
166 | - 丢弃策略:如果分组到达一个满的队列,哪个分组将会被抛弃?
167 | - tail drop:丢弃刚到达的分组(抛尾部)
168 | - priority:根据优先权丢失/移除分组
169 | - random:随机地丢弃/移除
170 | - 优先权调度:发送最高优先权的分组
171 | - 多类,不同类别有不同的优先权
172 | - 类别可能依赖于标记或者其他的头部字段,e.g. IP source/dest, port numbers, ds, etc.
173 | - 先传高优先级的队列中的分组,除非没有
174 | - 高(低)优先权中的分组传输次序:FIFO
175 | - 现实生活中的例子?
176 |
177 |  178 |
179 | 如上图:只要有红的就不传绿的,直到红色传完才开始传绿的
180 |
181 | - Round Robin (RR) scheduling:
182 | - 多类
183 | - 循环扫描不同类型的队列,发送完一类的一个分组,再发送下一个类的一个分组,循环所有类
184 | - 现实例子?
185 |
186 |
178 |
179 | 如上图:只要有红的就不传绿的,直到红色传完才开始传绿的
180 |
181 | - Round Robin (RR) scheduling:
182 | - 多类
183 | - 循环扫描不同类型的队列,发送完一类的一个分组,再发送下一个类的一个分组,循环所有类
184 | - 现实例子?
185 |
186 |  187 |
188 | 如上图:第一轮传完红的传绿的,第二轮传完绿的传红的,如此往复
189 |
190 | - Weighted Fair Queuing (WFQ):
191 | - 一般化的Round Robin
192 | - 在一段时间内,每个队列得到的服务时间是: $(W_i/\sum{W_i}) * t$ ,和权重成正比
193 | - 每个类在每一个循环中获得不同权重的服务量
194 | - 现实例子?
195 |
196 |
187 |
188 | 如上图:第一轮传完红的传绿的,第二轮传完绿的传红的,如此往复
189 |
190 | - Weighted Fair Queuing (WFQ):
191 | - 一般化的Round Robin
192 | - 在一段时间内,每个队列得到的服务时间是: $(W_i/\sum{W_i}) * t$ ,和权重成正比
193 | - 每个类在每一个循环中获得不同权重的服务量
194 | - 现实例子?
195 |
196 |  197 |
198 | 如上图:一个传输周期内,蓝色传输时间占 $40\%$ ,红色传输时间占 $40\%$ ,绿色传输时间占 $20\%$
199 |
200 | ### 4.3 IP:Internet Protocol
201 |
202 | IP协议主要实现数据平面的转发功能
203 |
204 | #### 4.3.1 数据报格式
205 |
206 | 主机,路由器中的网络层功能:
207 |
208 |
197 |
198 | 如上图:一个传输周期内,蓝色传输时间占 $40\%$ ,红色传输时间占 $40\%$ ,绿色传输时间占 $20\%$
199 |
200 | ### 4.3 IP:Internet Protocol
201 |
202 | IP协议主要实现数据平面的转发功能
203 |
204 | #### 4.3.1 数据报格式
205 |
206 | 主机,路由器中的网络层功能:
207 |
208 |  209 |
210 | ICMP协议:信令协议(如Ping命令等)
211 |
212 | IP数据报格式
213 |
214 |
209 |
210 | ICMP协议:信令协议(如Ping命令等)
211 |
212 | IP数据报格式
213 |
214 |  215 |
216 | #### 4.3.2 IP分片和重组(Fragmentation & Reassembly)
217 |
218 | IP 分片和重组
219 | - 网络链路有MTU(最大传输单元) —— 链路层帧所携带的最大数据长度
220 | - 不同的链路类型
221 | - 不同的MTU
222 | - 大的IP数据报在网络上被分片(“fragmented”)
223 | - 一个数据报被分割成若干个小的数据报
224 | - 相同的ID,知道属于同一个数据报
225 | - 不同的偏移量(offset):小数据报的第一个字节在字节流中的位置除以8
226 | - 最后一个分片标记为0(fragflag标识位),其他分片的fragflag标识位标记为1
227 | - “重组”只在最终的目标主机进行(不占用路由器的资源)
228 | - IP头部的信息被用于标识,排序相关分片
229 | - 若某一片丢失,整个全部丢弃
230 |
231 |
215 |
216 | #### 4.3.2 IP分片和重组(Fragmentation & Reassembly)
217 |
218 | IP 分片和重组
219 | - 网络链路有MTU(最大传输单元) —— 链路层帧所携带的最大数据长度
220 | - 不同的链路类型
221 | - 不同的MTU
222 | - 大的IP数据报在网络上被分片(“fragmented”)
223 | - 一个数据报被分割成若干个小的数据报
224 | - 相同的ID,知道属于同一个数据报
225 | - 不同的偏移量(offset):小数据报的第一个字节在字节流中的位置除以8
226 | - 最后一个分片标记为0(fragflag标识位),其他分片的fragflag标识位标记为1
227 | - “重组”只在最终的目标主机进行(不占用路由器的资源)
228 | - IP头部的信息被用于标识,排序相关分片
229 | - 若某一片丢失,整个全部丢弃
230 |
231 |  232 |
233 | > 例:
234 | >
235 | > - $4000$ 字节数据报
236 | > - $20$ 字节头部
237 | > - $3980$ 字节数据
238 | > - $MTU = 1500 bytes$
239 | > - 第一片: $20$ 字节头部 + $1480$ 字节数据
240 | > - 偏移量: $0$
241 | > - 第二片: $20$ 字节头部 + $1480$ 字节数据( $1480$ 字节应用数据)
242 | > - 偏移量: $1480/8=185$
243 | > - 第三片: $20$ 字节头部 + $1020$ 字节数据(应用数据)
244 | > - 偏移量: $2960/8=370$
245 |
246 | #### 4.3.3 IPv4地址
247 |
248 | IP 编址:引论
249 | - IP地址:32位标示,对主机或者路由器的接口编址(注:标识的是接口而非主机)
250 | - 接口:主机/路由器和物理链路的连接处
251 | - 路由器通常拥有多个接口(路由器连接若干个物理网络,在多个物理网络之间进行分组转发)
252 | - 主机也有可能有多个接口
253 | - IP地址和每一个接口关联
254 | - 一个IP地址和一个接口相关联
255 |
256 |
232 |
233 | > 例:
234 | >
235 | > - $4000$ 字节数据报
236 | > - $20$ 字节头部
237 | > - $3980$ 字节数据
238 | > - $MTU = 1500 bytes$
239 | > - 第一片: $20$ 字节头部 + $1480$ 字节数据
240 | > - 偏移量: $0$
241 | > - 第二片: $20$ 字节头部 + $1480$ 字节数据( $1480$ 字节应用数据)
242 | > - 偏移量: $1480/8=185$
243 | > - 第三片: $20$ 字节头部 + $1020$ 字节数据(应用数据)
244 | > - 偏移量: $2960/8=370$
245 |
246 | #### 4.3.3 IPv4地址
247 |
248 | IP 编址:引论
249 | - IP地址:32位标示,对主机或者路由器的接口编址(注:标识的是接口而非主机)
250 | - 接口:主机/路由器和物理链路的连接处
251 | - 路由器通常拥有多个接口(路由器连接若干个物理网络,在多个物理网络之间进行分组转发)
252 | - 主机也有可能有多个接口
253 | - IP地址和每一个接口关联
254 | - 一个IP地址和一个接口相关联
255 |
256 |  257 |
258 | Q:这些接口是如何连接的?
259 | A:有线以太网网口链接到以太网络交换机连接
260 | 目前:无需担心一个接口是如何接到另外一个接口(中间没有路由器,一跳可达)
261 |
262 | 子网(Subnets)
263 | - IP地址:
264 | - 子网部分(高位bits)
265 | - 主机部分(地位bits)
266 | - 什么是子网(subnet)?
267 | - 一个子网内的节点(主机或者路由器)它们的**IP地址的高位部分相同**,这些节点构成的网络的一部分叫做子网
268 | - **无需路由器介入**,子网内各主机可以在物理上相互直接到达,在IP层面一跳可达(但是在数据链路层可能需要借助交换机)
269 |
270 |
257 |
258 | Q:这些接口是如何连接的?
259 | A:有线以太网网口链接到以太网络交换机连接
260 | 目前:无需担心一个接口是如何接到另外一个接口(中间没有路由器,一跳可达)
261 |
262 | 子网(Subnets)
263 | - IP地址:
264 | - 子网部分(高位bits)
265 | - 主机部分(地位bits)
266 | - 什么是子网(subnet)?
267 | - 一个子网内的节点(主机或者路由器)它们的**IP地址的高位部分相同**,这些节点构成的网络的一部分叫做子网
268 | - **无需路由器介入**,子网内各主机可以在物理上相互直接到达,在IP层面一跳可达(但是在数据链路层可能需要借助交换机)
269 |
270 |  271 |
272 | 子网判断方法:
273 | - 要判断一个子网,将每一个接口从主机或者路由器上分开,构成了一个个网络的孤岛
274 | - 每一个孤岛(网络)都是一个都可以被称之为subnet。
275 |
276 | 长途链路 —— 点到点的形式 如:中国到日本的链路
277 | 计算机局域网 —— 多点连接的方式
278 |
279 | 子网掩码: 11111111 11111111 11111111 00000000
280 | Subnet mask:/24
281 |
282 | IP地址分类
283 | - Class A:126 networks ( $2^7-2$ , 0.0.0.0 and 1.1.1.1 not available), 16 million hosts ( $2^{24}-2$ , 0.0.0.0 and 1.1.1.1 not available)
284 | - Class B:16382 networks ( $2^{14}-2$ , 0.0.0.0 and 1.1.1.1 not available), 64 K hosts ( $2^{16}-2$ , 0.0.0.0 and 1.1.1.1 not available)
285 | - Class C:2 million networks, 254 host ( $2^8-2$ , 0.0.0.0 and 1.1.1.1 not available)
286 | - Class D:multicast
287 | - Class E:reserved for future
288 |
289 | *注:A、B、C类称为 单播地址 (发送给单个),D类称为 主播地址 (发送给特定的组的所有人)*
290 |
291 | 互联网中的路由通过网络号进行一个个子网的计算,以网络为单位进行传输,而非具体到单个主机
292 |
293 |
271 |
272 | 子网判断方法:
273 | - 要判断一个子网,将每一个接口从主机或者路由器上分开,构成了一个个网络的孤岛
274 | - 每一个孤岛(网络)都是一个都可以被称之为subnet。
275 |
276 | 长途链路 —— 点到点的形式 如:中国到日本的链路
277 | 计算机局域网 —— 多点连接的方式
278 |
279 | 子网掩码: 11111111 11111111 11111111 00000000
280 | Subnet mask:/24
281 |
282 | IP地址分类
283 | - Class A:126 networks ( $2^7-2$ , 0.0.0.0 and 1.1.1.1 not available), 16 million hosts ( $2^{24}-2$ , 0.0.0.0 and 1.1.1.1 not available)
284 | - Class B:16382 networks ( $2^{14}-2$ , 0.0.0.0 and 1.1.1.1 not available), 64 K hosts ( $2^{16}-2$ , 0.0.0.0 and 1.1.1.1 not available)
285 | - Class C:2 million networks, 254 host ( $2^8-2$ , 0.0.0.0 and 1.1.1.1 not available)
286 | - Class D:multicast
287 | - Class E:reserved for future
288 |
289 | *注:A、B、C类称为 单播地址 (发送给单个),D类称为 主播地址 (发送给特定的组的所有人)*
290 |
291 | 互联网中的路由通过网络号进行一个个子网的计算,以网络为单位进行传输,而非具体到单个主机
292 |
293 |  294 |
295 | 特殊IP地址
296 | - 一些约定:
297 | - 子网部分:全为0---本网络
298 | - 主机部分:全为0---本主机
299 | - 主机部分:全为1---广播地址,这个网络的所有主机
300 | - 特殊IP地址
301 |
302 |
294 |
295 | 特殊IP地址
296 | - 一些约定:
297 | - 子网部分:全为0---本网络
298 | - 主机部分:全为0---本主机
299 | - 主机部分:全为1---广播地址,这个网络的所有主机
300 | - 特殊IP地址
301 |
302 |  303 |
304 | 内网(专用)IP地址
305 | - 专用地址:地址空间的一部份供专用地址使用
306 | - 永远不会被当做公用地址来分配,不会与公用地址重复
307 | - 只在局部网络中有意义,用来区分不同的设备
308 | - 路由器不对目标地址是专用地址的分组进行转发
309 | - 专用地址范围
310 | - Class A 10.0.0.0-10.255.255.255 MASK 255.0.0.0
311 | - Class B 172.16.0.0-172.31.255.255 MASK 255.255.0.0
312 | - Class C 192.168.0.0-192.168.255.255 MASK 255.255.255.0
313 |
314 | IP 编址:CIDR(Classless InterDomain Routing, 无类域间路由)
315 | - 子网部分可以在任意的位置,按需划分
316 | - 地址格式:a.b.c.d/x,其中 x 是 地址中子网号的长度(网络号的长度)
317 |
318 |
303 |
304 | 内网(专用)IP地址
305 | - 专用地址:地址空间的一部份供专用地址使用
306 | - 永远不会被当做公用地址来分配,不会与公用地址重复
307 | - 只在局部网络中有意义,用来区分不同的设备
308 | - 路由器不对目标地址是专用地址的分组进行转发
309 | - 专用地址范围
310 | - Class A 10.0.0.0-10.255.255.255 MASK 255.0.0.0
311 | - Class B 172.16.0.0-172.31.255.255 MASK 255.255.0.0
312 | - Class C 192.168.0.0-192.168.255.255 MASK 255.255.255.0
313 |
314 | IP 编址:CIDR(Classless InterDomain Routing, 无类域间路由)
315 | - 子网部分可以在任意的位置,按需划分
316 | - 地址格式:a.b.c.d/x,其中 x 是 地址中子网号的长度(网络号的长度)
317 |
318 |  319 |
320 | 如上图,根据子网掩码,前23位为网络号,后9位为主机号
321 |
322 | 子网掩码(subnet mask)
323 | - 32bits , 0 or 1 in each bit
324 | - 1:bit位置表示子网部分
325 | - 0:bit位置表示主机部分(主机号在查询路由表时没有意义,路由信息的计算以网络为单位)
326 | - 原始的A、B、C类网络的子网掩码分别是
327 | - A:255.0.0.0:11111111 00000000 0000000 00000000
328 | - B:255.255.0.0:11111111 11111111 0000000 00000000
329 | - C:255.255.255.0:11111111 11111111 11111111 00000000
330 | - CIDR下的子网掩码例子:
331 | - 11111111 11111111 11111100 00000000
332 | - 另外的一种表示子网掩码的表达方式
333 | - /# : 例如 /22 表示前面22个bit为子网部分
334 |
335 | 转发表和转发算法
336 | |Destination Subnet Num |Mask |Next hop |Interface|
337 | |:---:|:---:|:---:|:---:|
338 | |202.38.73.0 |255.255.255.192 |IPx |Lan1 |
339 | |202.38.64.0 |255.255.255.192 |IPy |Lan2 |
340 | |...|...|...|...|
341 | |Default |- |IPz |Lan0 |
342 | - 获得IP数据报的目标地址
343 | - 对于转发表中的每一个表项
344 | - 如 (IP Des addr) & (mask)== destination,则按照表项对应的接口转发该数据报
345 | - 如果都没有找到,则使用默认表项,通过默认端口(通常是一个网络的出口路由器所对应的IP)转发数据报
346 |
347 | 主机如何获得一个IP地址?
348 | - 系统管理员将地址配置在一个文件中
349 | - Wintel: control-panel -> network -> configuration -> tcp/ip -> properties
350 | - UNIX: /etc/rc.config
351 | - DHCP(Dynamic Host Configuration Protocol):从服务器中动态获得一个IP地址(以及子网掩码Mask( 指示地址部分的网络号和主机号)、local name server(DNS服务器的域名和IP地址)、default getaway(第一跳路由器的IP地址(默认网关)))
352 | - “plug-and-play”,自动配置,接上即用;且只用在用户上网时分配IP地址,其余时间该IP可以被其他上网用户使用,提高效率
353 |
354 | DHCP(Dynamic Host Configuration Protocol, 动态主机配置协议)
355 | - 目标:允许主机在加入网络的时候,动态地从服务器那里获得IP地址:
356 | - 可以更新对主机在用IP地址的租用期——租期快到了
357 | - 重新启动时,允许重新使用以前用过的IP地址
358 | - 支持移动用户加入到该网络(短期在网)
359 | - DHCP工作概况:
360 | - 主机上线时广播“DHCP discover” 报文(可选)(目标IP:255.255.255.255,进行广播)
361 | - DHCP服务器用 “DHCP offer”提供报文响应(可选)
362 | - 主机请求IP地址:发送 “DHCP request” 报文(这第二次握手是因为可能有多个DHCP服务器,要确认用哪一个)
363 | - DHCP服务器发送地址:“DHCP ack” 报文
364 |
365 | DHCP client-server scenario
366 |
367 |
319 |
320 | 如上图,根据子网掩码,前23位为网络号,后9位为主机号
321 |
322 | 子网掩码(subnet mask)
323 | - 32bits , 0 or 1 in each bit
324 | - 1:bit位置表示子网部分
325 | - 0:bit位置表示主机部分(主机号在查询路由表时没有意义,路由信息的计算以网络为单位)
326 | - 原始的A、B、C类网络的子网掩码分别是
327 | - A:255.0.0.0:11111111 00000000 0000000 00000000
328 | - B:255.255.0.0:11111111 11111111 0000000 00000000
329 | - C:255.255.255.0:11111111 11111111 11111111 00000000
330 | - CIDR下的子网掩码例子:
331 | - 11111111 11111111 11111100 00000000
332 | - 另外的一种表示子网掩码的表达方式
333 | - /# : 例如 /22 表示前面22个bit为子网部分
334 |
335 | 转发表和转发算法
336 | |Destination Subnet Num |Mask |Next hop |Interface|
337 | |:---:|:---:|:---:|:---:|
338 | |202.38.73.0 |255.255.255.192 |IPx |Lan1 |
339 | |202.38.64.0 |255.255.255.192 |IPy |Lan2 |
340 | |...|...|...|...|
341 | |Default |- |IPz |Lan0 |
342 | - 获得IP数据报的目标地址
343 | - 对于转发表中的每一个表项
344 | - 如 (IP Des addr) & (mask)== destination,则按照表项对应的接口转发该数据报
345 | - 如果都没有找到,则使用默认表项,通过默认端口(通常是一个网络的出口路由器所对应的IP)转发数据报
346 |
347 | 主机如何获得一个IP地址?
348 | - 系统管理员将地址配置在一个文件中
349 | - Wintel: control-panel -> network -> configuration -> tcp/ip -> properties
350 | - UNIX: /etc/rc.config
351 | - DHCP(Dynamic Host Configuration Protocol):从服务器中动态获得一个IP地址(以及子网掩码Mask( 指示地址部分的网络号和主机号)、local name server(DNS服务器的域名和IP地址)、default getaway(第一跳路由器的IP地址(默认网关)))
352 | - “plug-and-play”,自动配置,接上即用;且只用在用户上网时分配IP地址,其余时间该IP可以被其他上网用户使用,提高效率
353 |
354 | DHCP(Dynamic Host Configuration Protocol, 动态主机配置协议)
355 | - 目标:允许主机在加入网络的时候,动态地从服务器那里获得IP地址:
356 | - 可以更新对主机在用IP地址的租用期——租期快到了
357 | - 重新启动时,允许重新使用以前用过的IP地址
358 | - 支持移动用户加入到该网络(短期在网)
359 | - DHCP工作概况:
360 | - 主机上线时广播“DHCP discover” 报文(可选)(目标IP:255.255.255.255,进行广播)
361 | - DHCP服务器用 “DHCP offer”提供报文响应(可选)
362 | - 主机请求IP地址:发送 “DHCP request” 报文(这第二次握手是因为可能有多个DHCP服务器,要确认用哪一个)
363 | - DHCP服务器发送地址:“DHCP ack” 报文
364 |
365 | DHCP client-server scenario
366 |
367 |  368 |
369 | > DHCP实例:
370 | >
371 | >
368 |
369 | > DHCP实例:
370 | >
371 | >  372 | >
373 | > - 第一次握手
374 | > - 联网笔记本需要获取自己的IP地址,第一跳路由器地址和DNS服务器:采用DHCP协议
375 | > - DHCP请求被封装在UDP段中,封装在IP数据报中,封装在以太网的帧中
376 | > - 以太网帧在局域网范围内广播(dest: FFFFFFFFFFFF),被运行DHCP服务的路由器收到
377 | > - 以太网帧解封装成IP,IP解封装成UDP,解封装成DHCP
378 | > - DHCP服务器生成DHCP ACK,包含客户端的IP地址,第一跳路由器的IP地址和DNS域名服务器的IP地址
379 | > - DHCP服务器封装的报文所在的帧转发到客户端,在客户端解封装成DHCP报文
380 | > - 客户端知道它自己的IP地址,DNS服务器的名字和IP地址,第一跳路由器的IP地址
381 | > - 第二次握手 略
382 |
383 | 如何获得一个IP地址
384 | - Q1:如何获得一个网络的子网部分?
385 | - A1:从ISP获得地址块中分配一个小地址块
386 |
387 | > 例:
388 | >
389 | > ISP's block 11001000 00010111 00010000 00000000 200.23.16.0/20
390 | > *前20位为网络号,后12位为主机号*
391 | > Organization0 11001000 00010111 00010000 00000000 200.23.16.0/23
392 | > Organization1 11001000 00010111 00010010 00000000 200.23.18.0/23
393 | > Organization2 11001000 00010111 00010100 00000000 200.23.20.0/23
394 | > ......
395 | > Organization7 11001000 00010111 00011110 00000000 200.23.30.0/23
396 |
397 | - Q2:一个ISP如何获得一个地址块?
398 | - A2:ICANN(Internet Corporation for Assigned Names and Numbers)
399 | - 分配地址
400 | - 管理DNS
401 | - 分配域名,解决冲突
402 |
403 | 层次编址:路由聚集(route aggregation)
404 | - 层次编址允许路由信息的有效广播
405 |
406 |
372 | >
373 | > - 第一次握手
374 | > - 联网笔记本需要获取自己的IP地址,第一跳路由器地址和DNS服务器:采用DHCP协议
375 | > - DHCP请求被封装在UDP段中,封装在IP数据报中,封装在以太网的帧中
376 | > - 以太网帧在局域网范围内广播(dest: FFFFFFFFFFFF),被运行DHCP服务的路由器收到
377 | > - 以太网帧解封装成IP,IP解封装成UDP,解封装成DHCP
378 | > - DHCP服务器生成DHCP ACK,包含客户端的IP地址,第一跳路由器的IP地址和DNS域名服务器的IP地址
379 | > - DHCP服务器封装的报文所在的帧转发到客户端,在客户端解封装成DHCP报文
380 | > - 客户端知道它自己的IP地址,DNS服务器的名字和IP地址,第一跳路由器的IP地址
381 | > - 第二次握手 略
382 |
383 | 如何获得一个IP地址
384 | - Q1:如何获得一个网络的子网部分?
385 | - A1:从ISP获得地址块中分配一个小地址块
386 |
387 | > 例:
388 | >
389 | > ISP's block 11001000 00010111 00010000 00000000 200.23.16.0/20
390 | > *前20位为网络号,后12位为主机号*
391 | > Organization0 11001000 00010111 00010000 00000000 200.23.16.0/23
392 | > Organization1 11001000 00010111 00010010 00000000 200.23.18.0/23
393 | > Organization2 11001000 00010111 00010100 00000000 200.23.20.0/23
394 | > ......
395 | > Organization7 11001000 00010111 00011110 00000000 200.23.30.0/23
396 |
397 | - Q2:一个ISP如何获得一个地址块?
398 | - A2:ICANN(Internet Corporation for Assigned Names and Numbers)
399 | - 分配地址
400 | - 管理DNS
401 | - 分配域名,解决冲突
402 |
403 | 层次编址:路由聚集(route aggregation)
404 | - 层次编址允许路由信息的有效广播
405 |
406 |  407 |
408 | 层次编址:特殊路由信息(more specific routes)
409 | - ISPs-R-Us拥有一个对组织1更加精确的路由
410 | - 匹配冲突时候,采取的是最长前缀匹配(匹配最精确)
411 |
412 |
407 |
408 | 层次编址:特殊路由信息(more specific routes)
409 | - ISPs-R-Us拥有一个对组织1更加精确的路由
410 | - 匹配冲突时候,采取的是最长前缀匹配(匹配最精确)
411 |
412 |  413 |
414 | 下面来看内网地址。因为内网地址无法路由到,所以通过NAT技术,出去时共用一个机构的IP地址,回来时再转换为内网地址。
415 |
416 | NAT(Network Address Translation)
417 |
418 |
413 |
414 | 下面来看内网地址。因为内网地址无法路由到,所以通过NAT技术,出去时共用一个机构的IP地址,回来时再转换为内网地址。
415 |
416 | NAT(Network Address Translation)
417 |
418 |  419 |
420 | - 动机:本地网络只有一个有效IP地址:
421 | - 不需要从ISP分配一块地址,可用一个IP地址用于所有的(局域网)设备 —— 省钱
422 | - 可以在局域网改变设备的地址情况下而无须通知外界
423 | - 可以改变ISP(地址变化)而不需要改变内部的设备地址
424 | - 局域网内部的设备没有明确的地址,对外是不可见的 —— 安全
425 | - 实现:NAT路由器必须:
426 | - 数据包外出:替换源地址和端口号为NAT IP地址和新的端口号,目标IP和端口不变
427 | - 远端的C/S将会用NAP IP地址,新端口号作为目标地址
428 | - 记住每个转换替换对(在NAT转换表中)
429 | - 源IP,端口 vs NAP IP ,新端口
430 | - 数据包进入:替换目标IP地址和端口号,采用存储在NAT表中的mapping表项,用(源IP,端口)
431 |
432 |
419 |
420 | - 动机:本地网络只有一个有效IP地址:
421 | - 不需要从ISP分配一块地址,可用一个IP地址用于所有的(局域网)设备 —— 省钱
422 | - 可以在局域网改变设备的地址情况下而无须通知外界
423 | - 可以改变ISP(地址变化)而不需要改变内部的设备地址
424 | - 局域网内部的设备没有明确的地址,对外是不可见的 —— 安全
425 | - 实现:NAT路由器必须:
426 | - 数据包外出:替换源地址和端口号为NAT IP地址和新的端口号,目标IP和端口不变
427 | - 远端的C/S将会用NAP IP地址,新端口号作为目标地址
428 | - 记住每个转换替换对(在NAT转换表中)
429 | - 源IP,端口 vs NAP IP ,新端口
430 | - 数据包进入:替换目标IP地址和端口号,采用存储在NAT表中的mapping表项,用(源IP,端口)
431 |
432 |  433 |
434 | *实际上就是用外网的某个IP代替内网里面的网络号*
435 | *出去的时候替换 原来IP 和 端口号*
436 | *进来的时候替换 目标IP 和 端口号*
437 |
438 | - 16-bit端口字段:
439 | - 6万多个同时连接,一个局域网!
440 | - 对NAT是有争议的:
441 | - 路由器只应该对第3层做信息处理,而这里对端口号(4层)作了处理
442 | - 违反了end-to-end 原则
443 | - 端到端原则:复杂性放到网络边缘
444 | - 无需借助中转和变换,就可以直接传送到目标主机
445 | - NAT可能要被一些应用设计者考虑, eg, P2P applications
446 | - 外网的机器无法主动连接到内网的机器上
447 | - 地址短缺问题可以被IPv6 解决
448 |
449 | 同时,采用NAT技术,如果客户端需要连接在NAT后面的服务器,会出现NAT穿透问题:出去没问题,可以找得到服务器,但是若外面想进来和内网的主机通信确做不到,无法找到通信主机。如客户端需要连接地址为10.0.0.1的服务器,但是服务器地址10.0.0.1是LAN本地地址(客户端不能够使用其作为目标地址),整网只有一个外部可见地址:138.76.29.7
450 | 有以下解决方案:
451 | - 方案1:静态配置NAT:转发进来的对服务器特定端口连接请求
452 | - e.g. (123.76.29.7, port 2500) 总是转发到10.0.0.1 port 25000
453 | - 方案2:Universal Plug and Play (UPnP)Internet Gateway Device (IGD) 协议。允许NATted主机可以:
454 | - 获知网络的公共IP地址(138.76.29.7)
455 | - 列举存在的端口映射
456 | - 增/删端口映射(在租用时间内)
457 | - i.e. 自动化静态NAT端口映射配置
458 |
459 |
433 |
434 | *实际上就是用外网的某个IP代替内网里面的网络号*
435 | *出去的时候替换 原来IP 和 端口号*
436 | *进来的时候替换 目标IP 和 端口号*
437 |
438 | - 16-bit端口字段:
439 | - 6万多个同时连接,一个局域网!
440 | - 对NAT是有争议的:
441 | - 路由器只应该对第3层做信息处理,而这里对端口号(4层)作了处理
442 | - 违反了end-to-end 原则
443 | - 端到端原则:复杂性放到网络边缘
444 | - 无需借助中转和变换,就可以直接传送到目标主机
445 | - NAT可能要被一些应用设计者考虑, eg, P2P applications
446 | - 外网的机器无法主动连接到内网的机器上
447 | - 地址短缺问题可以被IPv6 解决
448 |
449 | 同时,采用NAT技术,如果客户端需要连接在NAT后面的服务器,会出现NAT穿透问题:出去没问题,可以找得到服务器,但是若外面想进来和内网的主机通信确做不到,无法找到通信主机。如客户端需要连接地址为10.0.0.1的服务器,但是服务器地址10.0.0.1是LAN本地地址(客户端不能够使用其作为目标地址),整网只有一个外部可见地址:138.76.29.7
450 | 有以下解决方案:
451 | - 方案1:静态配置NAT:转发进来的对服务器特定端口连接请求
452 | - e.g. (123.76.29.7, port 2500) 总是转发到10.0.0.1 port 25000
453 | - 方案2:Universal Plug and Play (UPnP)Internet Gateway Device (IGD) 协议。允许NATted主机可以:
454 | - 获知网络的公共IP地址(138.76.29.7)
455 | - 列举存在的端口映射
456 | - 增/删端口映射(在租用时间内)
457 | - i.e. 自动化静态NAT端口映射配置
458 |
459 |  460 |
461 | - 方案3:中继(used in Skype)
462 | - NAT后面的服务器建立和中继的连接
463 | - 外部的客户端链接到中继
464 | - 中继在2个连接之间桥接
465 |
466 |
460 |
461 | - 方案3:中继(used in Skype)
462 | - NAT后面的服务器建立和中继的连接
463 | - 外部的客户端链接到中继
464 | - 中继在2个连接之间桥接
465 |
466 |  467 |
468 | #### 4.3.4 IPv6
469 |
470 | 动机
471 | - 初始动机:32-bit地址空间将会被很快用完
472 | - 另外的动机:
473 | - 头部格式改变帮助加速处理和转发
474 | - TTL-1
475 | - 头部checksum
476 | - 分片
477 | - 头部格式改变帮助QoS
478 |
479 | IPv6数据报格式:
480 | - 固定的40字节头部
481 | - 数据报传输过程中,不允许分片,而是路由器返回一个错误报告告诉源主机分组太大了,需要源主机将分组变小一点
482 |
483 | IPv6头部(Cont)
484 | - Priority:标示流中数据报的优先级
485 | - Flow Label:标示数据报在一个“flow.” (“flow”的概念没有被严格的定义)
486 | - Next header标示上层协议
487 |
488 |
467 |
468 | #### 4.3.4 IPv6
469 |
470 | 动机
471 | - 初始动机:32-bit地址空间将会被很快用完
472 | - 另外的动机:
473 | - 头部格式改变帮助加速处理和转发
474 | - TTL-1
475 | - 头部checksum
476 | - 分片
477 | - 头部格式改变帮助QoS
478 |
479 | IPv6数据报格式:
480 | - 固定的40字节头部
481 | - 数据报传输过程中,不允许分片,而是路由器返回一个错误报告告诉源主机分组太大了,需要源主机将分组变小一点
482 |
483 | IPv6头部(Cont)
484 | - Priority:标示流中数据报的优先级
485 | - Flow Label:标示数据报在一个“flow.” (“flow”的概念没有被严格的定义)
486 | - Next header标示上层协议
487 |
488 |  489 |
490 | 和IPv4的其它变化
491 | - Checksum:被移除掉,降低在每一段中的处理速度
492 | - Options:允许,但是在头部之外,被 “Next Header” 字段标示
493 | - ICMPv6:ICMP的新版本
494 | - 附加了报文类型,e.g. “Packet Too Big”(IPv6无法切片)
495 | - 多播组管理功能
496 |
497 | 从IPv4到IPv6的平移(过渡)
498 | - 不是所有的路由器都能够同时升级的
499 | - 没有一个标记日 “flag days”,在那一天全部宕机升级
500 | - 在IPv4和IPv6路由器混合时,网络如何运转?
501 | - 隧道:在IPv4路由器之间传输的IPv4数据报中携带IPv6数据报
502 |
503 |
489 |
490 | 和IPv4的其它变化
491 | - Checksum:被移除掉,降低在每一段中的处理速度
492 | - Options:允许,但是在头部之外,被 “Next Header” 字段标示
493 | - ICMPv6:ICMP的新版本
494 | - 附加了报文类型,e.g. “Packet Too Big”(IPv6无法切片)
495 | - 多播组管理功能
496 |
497 | 从IPv4到IPv6的平移(过渡)
498 | - 不是所有的路由器都能够同时升级的
499 | - 没有一个标记日 “flag days”,在那一天全部宕机升级
500 | - 在IPv4和IPv6路由器混合时,网络如何运转?
501 | - 隧道:在IPv4路由器之间传输的IPv4数据报中携带IPv6数据报
502 |
503 |  504 |
505 | 隧道(Tunneling)
506 |
507 |
504 |
505 | 隧道(Tunneling)
506 |
507 |  508 |
508 | 509 |
 510 |
511 | IPv6:应用
512 | - Google估计:8%的客户通过IPv6访问谷歌服务
513 | - NIST估计:全美国1/3的政府域支持IPv6
514 | - 估计还需要很长时间进行部署
515 | - 20年以上!
516 | - 看看过去20年来应用层面的变化:WWW, Facebook, streaming media, Skype, …
517 | - 为什么?
518 |
519 | ### 4.4 通用转发和SDN
520 |
521 | 之前介绍的路由大部分都是传统方式,下面来看通用转发和SDN的方式。
522 |
523 | 传统方式:1. 每台设备上既实现控制功能,又实现数据平面 2. 控制功能分布式实现 3. 路由表-粘连
524 | - 传统方式的缺陷:
525 | - 垂直集成(每台路由器或其他网络设备,包括:1.专用的硬件、私有的操作系统;2.互联网标准协议(IP, RIP, IS-IS, OSPF, BGP)的私有实现;从上到下都由一个厂商提供(代价大、被设备上“绑架”“)) --> 昂贵、不便于创新的生态
526 | - 分布式、固化设备功能 --> 网络设备种类繁多
527 | - 交换机;防火墙;NAT;IDS;负载均衡设备
528 | - 未来:不断增加的需求和相应的网络设备
529 | - 需要不同的设备去实现不同的网络功能
530 | - 每台设备集成了控制平面和数据平面的功能
531 | - 控制平面分布式地实现了各种控制平面功能
532 | - 升级和部署网络设备非常困难
533 | - 无法改变路由等工作逻辑,设备基本上只能(分布式升级困难)按照固定方式工作,控制逻辑固化,无法实现流量工程等高级特性
534 | - 配置错误影响全网运行;升级和维护会涉及到全网设备:管理困难
535 | - 要增加新的网络功能,需要设计、实现以及部署新的特定设备,设备种类繁
536 |
537 | 考虑到以上缺点,在2005年前后,开始重新思考网络控制平面的处理方式:SDN
538 | - 集中:远程的控制器集中实现控制逻辑,通过南向接口将流表发送给每个设备中的控制代理
539 | - 远程:数据平面和控制平面的分离
540 |
541 | SDN:逻辑上集中的控制平面
542 | - 一个不同的(通常是远程)控制器和CA交互,控制器决定分组转发的逻辑(可编程),CA所在设备执行逻辑
543 |
544 |
510 |
511 | IPv6:应用
512 | - Google估计:8%的客户通过IPv6访问谷歌服务
513 | - NIST估计:全美国1/3的政府域支持IPv6
514 | - 估计还需要很长时间进行部署
515 | - 20年以上!
516 | - 看看过去20年来应用层面的变化:WWW, Facebook, streaming media, Skype, …
517 | - 为什么?
518 |
519 | ### 4.4 通用转发和SDN
520 |
521 | 之前介绍的路由大部分都是传统方式,下面来看通用转发和SDN的方式。
522 |
523 | 传统方式:1. 每台设备上既实现控制功能,又实现数据平面 2. 控制功能分布式实现 3. 路由表-粘连
524 | - 传统方式的缺陷:
525 | - 垂直集成(每台路由器或其他网络设备,包括:1.专用的硬件、私有的操作系统;2.互联网标准协议(IP, RIP, IS-IS, OSPF, BGP)的私有实现;从上到下都由一个厂商提供(代价大、被设备上“绑架”“)) --> 昂贵、不便于创新的生态
526 | - 分布式、固化设备功能 --> 网络设备种类繁多
527 | - 交换机;防火墙;NAT;IDS;负载均衡设备
528 | - 未来:不断增加的需求和相应的网络设备
529 | - 需要不同的设备去实现不同的网络功能
530 | - 每台设备集成了控制平面和数据平面的功能
531 | - 控制平面分布式地实现了各种控制平面功能
532 | - 升级和部署网络设备非常困难
533 | - 无法改变路由等工作逻辑,设备基本上只能(分布式升级困难)按照固定方式工作,控制逻辑固化,无法实现流量工程等高级特性
534 | - 配置错误影响全网运行;升级和维护会涉及到全网设备:管理困难
535 | - 要增加新的网络功能,需要设计、实现以及部署新的特定设备,设备种类繁
536 |
537 | 考虑到以上缺点,在2005年前后,开始重新思考网络控制平面的处理方式:SDN
538 | - 集中:远程的控制器集中实现控制逻辑,通过南向接口将流表发送给每个设备中的控制代理
539 | - 远程:数据平面和控制平面的分离
540 |
541 | SDN:逻辑上集中的控制平面
542 | - 一个不同的(通常是远程)控制器和CA交互,控制器决定分组转发的逻辑(可编程),CA所在设备执行逻辑
543 |
544 |  545 |
546 | SDN的主要思路
547 | - 网络设备数据平面和控制平面分离
548 | - 数据平面-分组交换机
549 | - 将路由器、交换机和目前大多数网络设备的功能进一步抽象成:按照流表(由控制平面设置的控制逻辑)进行PDU(帧、分组)的动作(包括转发、丢弃、拷贝、泛洪、阻塞)
550 | - 统一化设备功能:SDN交换机(分组交换机),执行控制逻辑
551 | - 控制平面-控制器+网络应用
552 | - 分离、集中
553 | - 计算和下发控制逻辑:流表
554 |
555 | SDN控制平面和数据平面分离的优势
556 | - **水平集成**控制平面的开放实现(而非私有实现),创造出好的产业生态,促进发展
557 | - 分组交换机、控制器和各种控制逻辑网络应用app可由不同厂商生产,专业化,引入竞争形成良好生态
558 | - **集中式**实现控制逻辑,网络管理容易:
559 | - 集中式控制器了解网络状况,编程简单,传统方式困难
560 | - 避免路由器的误配置
561 | - 基于流表的匹配+行动的工作方式允许“**可编程的**”分组交换机
562 | - 实现流量工程等高级特性
563 | - 在此框架下实现各种新型(未来)的网络设备
564 |
565 |
545 |
546 | SDN的主要思路
547 | - 网络设备数据平面和控制平面分离
548 | - 数据平面-分组交换机
549 | - 将路由器、交换机和目前大多数网络设备的功能进一步抽象成:按照流表(由控制平面设置的控制逻辑)进行PDU(帧、分组)的动作(包括转发、丢弃、拷贝、泛洪、阻塞)
550 | - 统一化设备功能:SDN交换机(分组交换机),执行控制逻辑
551 | - 控制平面-控制器+网络应用
552 | - 分离、集中
553 | - 计算和下发控制逻辑:流表
554 |
555 | SDN控制平面和数据平面分离的优势
556 | - **水平集成**控制平面的开放实现(而非私有实现),创造出好的产业生态,促进发展
557 | - 分组交换机、控制器和各种控制逻辑网络应用app可由不同厂商生产,专业化,引入竞争形成良好生态
558 | - **集中式**实现控制逻辑,网络管理容易:
559 | - 集中式控制器了解网络状况,编程简单,传统方式困难
560 | - 避免路由器的误配置
561 | - 基于流表的匹配+行动的工作方式允许“**可编程的**”分组交换机
562 | - 实现流量工程等高级特性
563 | - 在此框架下实现各种新型(未来)的网络设备
564 |
565 |  566 |
567 | 流量工程:传统路由比较困难
568 |
569 |
566 |
567 | 流量工程:传统路由比较困难
568 |
569 | 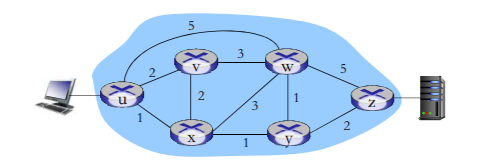 570 |
571 | Q1:网管如果需要u到z的流量走uvwz,x到z的流量走xwyz,怎么办?
572 | A1:需要定义链路的代价,流量路由算法以此运算(IP路由面向目标,无法操作)(或者需要新的路由算法)
573 | *链路权重只是控制旋钮,错!*
574 |
575 |
570 |
571 | Q1:网管如果需要u到z的流量走uvwz,x到z的流量走xwyz,怎么办?
572 | A1:需要定义链路的代价,流量路由算法以此运算(IP路由面向目标,无法操作)(或者需要新的路由算法)
573 | *链路权重只是控制旋钮,错!*
574 |
575 | 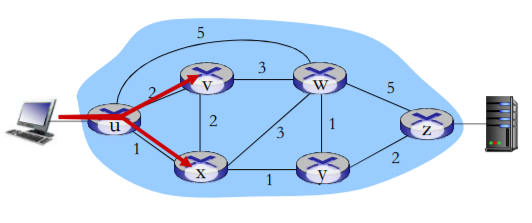 576 |
577 | Q2:如果网管需要将u到z的流量分成2路:uvwz和uxyz(负载均衡),怎么办?(IP路由面向目标)
578 | A2:无法完成(在原有体系下只有使用新的路由选择算法,而在全网部署新的路由算法是个大的事情)
579 |
580 |
576 |
577 | Q2:如果网管需要将u到z的流量分成2路:uvwz和uxyz(负载均衡),怎么办?(IP路由面向目标)
578 | A2:无法完成(在原有体系下只有使用新的路由选择算法,而在全网部署新的路由算法是个大的事情)
579 |
580 | 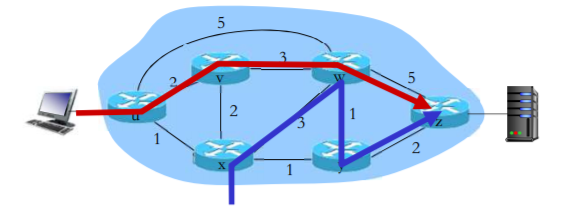 581 |
582 | Q3:如果需要w对蓝色的和红色的流量采用不同的路由,怎么办?
583 | A3:无法操作(基于目标的转发,采用LS,DV路由)
584 |
585 | SDN特点
586 |
587 |
581 |
582 | Q3:如果需要w对蓝色的和红色的流量采用不同的路由,怎么办?
583 | A3:无法操作(基于目标的转发,采用LS,DV路由)
584 |
585 | SDN特点
586 |
587 | 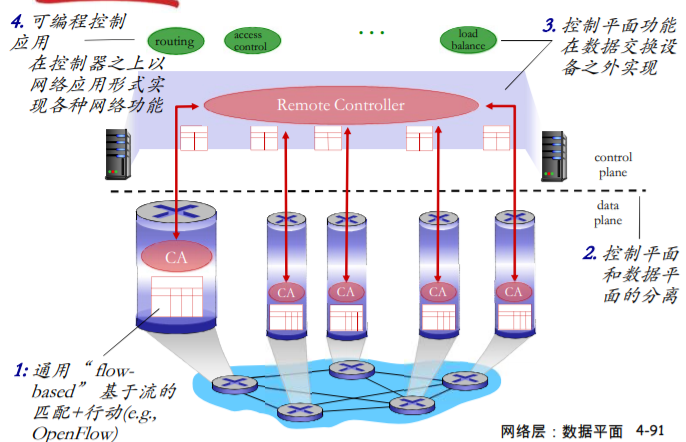 588 |
589 | SDN架构
590 | - 数据平面交换机
591 | - 快速,简单,商业化交换设备采用硬件实现通用转发功能
592 | - 流表被控制器计算和安装
593 | - 基于南向API(例如OpenFlow),SDN控制器访问基于流的交换机
594 | - 定义了哪些可以被控制哪些不能
595 | - 也定义了和控制器的协议(e.g., OpenFlow)
596 | - SDN控制器(网络OS):
597 | - 维护网络状态信息
598 | - 通过上面的北向API和网络控制应用交互
599 | - 通过下面的南向API和网络交换机交互
600 | - 逻辑上集中,但是在实现上通常由于性能、可扩展性、容错性以及鲁棒性在物理上采用分布式方法
601 | - 网络控制应用:
602 | - 控制的大脑:采用下层提供的服务(SDN控制器提供的API),实现网络功能
603 | - 路由器 交换机
604 | - 接入控制 防火墙
605 | - 负载均衡
606 | - 其他功能
607 | - 非绑定:可以被第三方提供,与控制器厂商以通常上不同,与分组交换机厂商也可以不同
608 |
609 | 通用转发和SDN:每个路由器包含一个流表(被逻辑上集中的控制器计算和分发)
610 |
611 |
588 |
589 | SDN架构
590 | - 数据平面交换机
591 | - 快速,简单,商业化交换设备采用硬件实现通用转发功能
592 | - 流表被控制器计算和安装
593 | - 基于南向API(例如OpenFlow),SDN控制器访问基于流的交换机
594 | - 定义了哪些可以被控制哪些不能
595 | - 也定义了和控制器的协议(e.g., OpenFlow)
596 | - SDN控制器(网络OS):
597 | - 维护网络状态信息
598 | - 通过上面的北向API和网络控制应用交互
599 | - 通过下面的南向API和网络交换机交互
600 | - 逻辑上集中,但是在实现上通常由于性能、可扩展性、容错性以及鲁棒性在物理上采用分布式方法
601 | - 网络控制应用:
602 | - 控制的大脑:采用下层提供的服务(SDN控制器提供的API),实现网络功能
603 | - 路由器 交换机
604 | - 接入控制 防火墙
605 | - 负载均衡
606 | - 其他功能
607 | - 非绑定:可以被第三方提供,与控制器厂商以通常上不同,与分组交换机厂商也可以不同
608 |
609 | 通用转发和SDN:每个路由器包含一个流表(被逻辑上集中的控制器计算和分发)
610 |
611 | 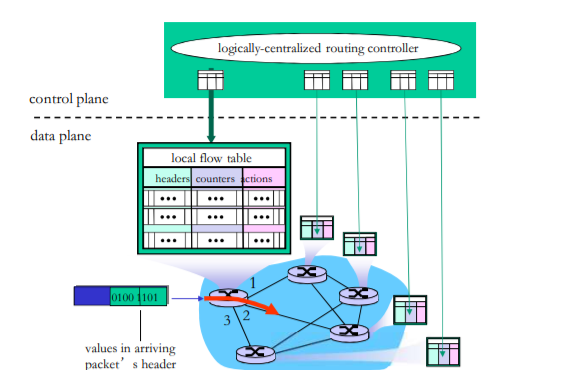 612 |
613 | OpenFlow数据平面抽象
614 | - 流:由分组(帧)头部字段所定义
615 | - 通用转发:简单的分组处理规则
616 | - 模式(pattern):将分组头部字段和流表进行匹配(路由器中的流表定义了路由器的匹配+行动规则(流表由控制器计算并下发))
617 | - 行动(action):对于匹配上的分组,可以是丢弃、转发、修改、将匹配的分组发送给控制器
618 | - 优先权Priority:几个模式匹配了,优先采用哪个,消除歧义
619 | - 计数器Counters:#bytes 以及 #packets
620 |
621 | OpenFlow: 流表的表项结构
622 |
623 |
612 |
613 | OpenFlow数据平面抽象
614 | - 流:由分组(帧)头部字段所定义
615 | - 通用转发:简单的分组处理规则
616 | - 模式(pattern):将分组头部字段和流表进行匹配(路由器中的流表定义了路由器的匹配+行动规则(流表由控制器计算并下发))
617 | - 行动(action):对于匹配上的分组,可以是丢弃、转发、修改、将匹配的分组发送给控制器
618 | - 优先权Priority:几个模式匹配了,优先采用哪个,消除歧义
619 | - 计数器Counters:#bytes 以及 #packets
620 |
621 | OpenFlow: 流表的表项结构
622 |
623 | 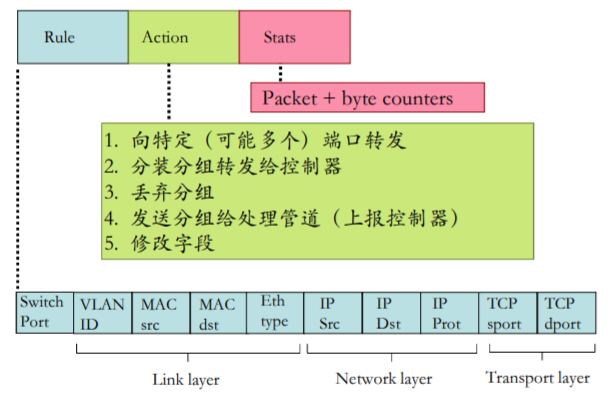 624 |
625 | OpenFlow抽象
626 | - match + action:统一化各种网络设备提供的功能 *目前几乎所有的网络设备都可以在这个 匹配+行动 模式框架进行描述,具体化为各种网络设备包括未来的网络设备*
627 | - 路由器
628 | - match:最长前缀匹配
629 | - action:通过一条链路转发
630 | - 交换机
631 | - match:目标MAC地址
632 | - action:转发或者泛洪
633 | - 防火墙
634 | - match:IP地址和TCP/UDP端口号
635 | - action:允许或者禁止
636 | - NAT
637 | - match:IP地址和端口号
638 | - action:重写地址和端口号
639 |
640 | > OpenFlow例子
641 | >
642 | >
624 |
625 | OpenFlow抽象
626 | - match + action:统一化各种网络设备提供的功能 *目前几乎所有的网络设备都可以在这个 匹配+行动 模式框架进行描述,具体化为各种网络设备包括未来的网络设备*
627 | - 路由器
628 | - match:最长前缀匹配
629 | - action:通过一条链路转发
630 | - 交换机
631 | - match:目标MAC地址
632 | - action:转发或者泛洪
633 | - 防火墙
634 | - match:IP地址和TCP/UDP端口号
635 | - action:允许或者禁止
636 | - NAT
637 | - match:IP地址和端口号
638 | - action:重写地址和端口号
639 |
640 | > OpenFlow例子
641 | >
642 | >  643 |
644 | ### 4.5 总结
645 |
646 | - 导论
647 | - 数据平面
648 | - 控制平面
649 | - 路由器组成
650 | - IP: Internet Protocol
651 | - 数据报格式
652 | - 分片
653 | - IPv4地址
654 | - NAT:网络地址转换
655 | - IPv6
656 | - 通用转发和SDN
657 | - SDN架构
658 | - 匹配
659 | - 行动
660 | - OpenFLow有关“匹配+行动”的运行实例
661 | - 问题:转发表(基于目标的转发)和流表(通用转发)是如何计算出来的?
662 | - 答案:通过控制平面,详见chapter5
663 |
--------------------------------------------------------------------------------
/Log_of_ComputerNetworking-ATopDownApproach_7th/chapter5.md:
--------------------------------------------------------------------------------
1 | # 计算机网络——自顶向下方法 7th
2 |
3 | 中国科学技术大学 郑烇教授 2020年秋季 自动化系
4 |
5 | ## 5. 网络层——控制平面
6 |
7 | 本章目标:
8 | - 理解网络层控制平面的工作原理
9 | - 传统路由选择算法
10 | - SDN控制器
11 | - ICMP:Internet Control Message Protocol
12 | - 网络管理(略)
13 | - 以及它们在互联网上的实例和实现:
14 | - OSPF, BGP, OpenFlow, ODL 和ONOS控制器, ICMP, SNMP
15 |
16 | ### 5.1 导论
17 |
18 | - 路由(route):按照某种指标(传输延迟,所经过的站点数目等)找到一条从源节点到目标节点的较好路径
19 | - 较好路径:按照某种指标较小的路径
20 | - 指标:站数,延迟,费用,队列长度等,或者是一些单纯指标的加权平均
21 | - 采用什么样的指标,表示网络使用者希望网络在什么方面表现突出,什么指标网络使用者比较重视
22 | - 以网络为单位(子网到子网)进行路由(路由信息通告+路由计算),而非主机到主机(主机到主机的路由规模比子网到子网大2-3个数量级)
23 | - 网络为单位进行路由,路由信息传输、计算和匹配的代价低
24 | - 前提条件是:一个网络所有节点地址前缀相同,且物理上聚集
25 | - 路由就是:计算网络到其他网络如何走的问题
26 | - 网络到网络的路由 = 路由器-路由器之间路由
27 | - 网络对应的路由器到其他网络对应的路由器的路由
28 | - 在一个网络中:路由器-主机之间的通信,链路层解决
29 | - 到了这个路由器就是到了这个网络
30 | - 路由选择算法(routing algorithm):网络层软件的一部分,完成路由功能
31 |
32 | 网络的图抽象
33 |
34 |
643 |
644 | ### 4.5 总结
645 |
646 | - 导论
647 | - 数据平面
648 | - 控制平面
649 | - 路由器组成
650 | - IP: Internet Protocol
651 | - 数据报格式
652 | - 分片
653 | - IPv4地址
654 | - NAT:网络地址转换
655 | - IPv6
656 | - 通用转发和SDN
657 | - SDN架构
658 | - 匹配
659 | - 行动
660 | - OpenFLow有关“匹配+行动”的运行实例
661 | - 问题:转发表(基于目标的转发)和流表(通用转发)是如何计算出来的?
662 | - 答案:通过控制平面,详见chapter5
663 |
--------------------------------------------------------------------------------
/Log_of_ComputerNetworking-ATopDownApproach_7th/chapter5.md:
--------------------------------------------------------------------------------
1 | # 计算机网络——自顶向下方法 7th
2 |
3 | 中国科学技术大学 郑烇教授 2020年秋季 自动化系
4 |
5 | ## 5. 网络层——控制平面
6 |
7 | 本章目标:
8 | - 理解网络层控制平面的工作原理
9 | - 传统路由选择算法
10 | - SDN控制器
11 | - ICMP:Internet Control Message Protocol
12 | - 网络管理(略)
13 | - 以及它们在互联网上的实例和实现:
14 | - OSPF, BGP, OpenFlow, ODL 和ONOS控制器, ICMP, SNMP
15 |
16 | ### 5.1 导论
17 |
18 | - 路由(route):按照某种指标(传输延迟,所经过的站点数目等)找到一条从源节点到目标节点的较好路径
19 | - 较好路径:按照某种指标较小的路径
20 | - 指标:站数,延迟,费用,队列长度等,或者是一些单纯指标的加权平均
21 | - 采用什么样的指标,表示网络使用者希望网络在什么方面表现突出,什么指标网络使用者比较重视
22 | - 以网络为单位(子网到子网)进行路由(路由信息通告+路由计算),而非主机到主机(主机到主机的路由规模比子网到子网大2-3个数量级)
23 | - 网络为单位进行路由,路由信息传输、计算和匹配的代价低
24 | - 前提条件是:一个网络所有节点地址前缀相同,且物理上聚集
25 | - 路由就是:计算网络到其他网络如何走的问题
26 | - 网络到网络的路由 = 路由器-路由器之间路由
27 | - 网络对应的路由器到其他网络对应的路由器的路由
28 | - 在一个网络中:路由器-主机之间的通信,链路层解决
29 | - 到了这个路由器就是到了这个网络
30 | - 路由选择算法(routing algorithm):网络层软件的一部分,完成路由功能
31 |
32 | 网络的图抽象
33 |
34 |  35 |
36 | *注:图抽象在其他网络场景中也十分有用,例如在P2P中,N是peer节点,E是TCP的连接*
37 |
38 | 图抽象:边和路径的代价
39 | - c(x, x') = 链路的代价 (x, x')
40 | - e.g., c(w, z) = 5
41 | - 代价可能总为1
42 | - 或是 链路带宽的倒数
43 | - 或是 拥塞情况的倒数
44 |
45 | $$ \text{Cost of path } (x_1, x_2, x_3, ... , x_p) = c(x_1, x_2) + c(x_2, x_3) + ... + c(x_{p-1}, x_p) $$
46 |
47 | 最优化原则(optimality principle)
48 | - 汇集树(sink tree)
49 | - 此节点到所有其它节点的最优路径形成的树
50 | - 路由选择算法就是为所有路由器找到并使用汇集树
51 |
52 | 路由选择算法的原则
53 | - 正确性(correctness):算法必须是正确的和完整的,使分组一站一站接力,正确发向目标站;完整:目标所有的站地址,在路由表中都能找到相应的表项;没有处理不了的目标站地址;
54 | - 简单性(simplicity):算法在计算机上应简单:最优但复杂的算法,时间上延迟很大,不实用,不应为了获取路由信息增加很多的通信量;
55 | - 健壮性(robustness):算法应能适应通信量和网络拓扑的变化:通信量变化,网络拓扑的变化算法能很快适应;不向很拥挤的链路发数据,不向断了的链路发送数据;
56 | - 稳定性(stability):产生的路由不应该摇摆
57 | - 公平性(fairness):对每一个站点都公平
58 | - 最优性(optimality):某一个指标的最优,时间上,费用上,等指标,或综合指标;实际上,获取最优的结果代价较高,可以是次优的
59 |
60 | 路由算法分类
61 | - 全局或者局部路由信息?
62 | - 全局:
63 | - 所有的路由器拥有完整的拓扑和边的代价的信息(上帝视角)
64 | - “link state”算法
65 | - 分布式:
66 | - 路由器只知道与它有物理连接关系的邻居路由器,和到相应邻居路由器的代价值
67 | - 叠代地与邻居交换路由信息、计算路由信息
68 | - “distance vector”算法
69 | - 静态或者动态的?
70 | - 静态:
71 | - 路由随时间变化缓慢
72 | - 动态:
73 | - 路由变化很快
74 | - 周期性更新
75 | - 根据链路代价的变化而变化
76 | - 静态-->非自适应算法(non-adaptive algorithm):不能适应网络拓扑和通信量的变化,路由表是事先计算好的
77 | - 动态-->自适应路由选择(adaptive algorithm):能适应网络拓扑和通信量的变化
78 |
79 | ### 5.2 路由选择算法
80 |
81 | #### 5.2.1 link state 链路状态算法
82 |
83 | LS路由的工作过程
84 | - 配置LS路由选择算法的路由工作过程
85 | - 各点通过各种渠道(如泛洪等)获得整个网络拓扑,网络中所有链路代价等信息(这部分和算法没关系,属于协议和实现)
86 | - 使用LS路由算法计算本站点到其它站点的最优路径(汇集树),得到路由表
87 | - 按照此路由表转发分组(datagram方式)
88 | - 严格意义上说不是路由的一个步骤
89 | - 分发到输入端口的网络层
90 |
91 | ```mermaid
92 | graph LR
93 |
94 | A[获得网络拓扑和链路代价信息]
95 | B[使用最短路由算法得到路由表]
96 | C[使用此路由表]
97 |
98 | A-->B
99 | B-->C
100 | ```
101 |
102 | 链路状态路由选择(link state routing)
103 | - LS路由的基本工作过程
104 | 1. 发现相邻节点,获知对方网络地址
105 | - 一个路由器上电之后,向所有线路发送HELLO分组
106 | - 其它路由器收到HELLO分组,回送应答,在应答分组中,告知自己的名字(全局唯一)
107 | - 在LAN中,通过广播HELLO分组,获得其它路由器的信息,可以认为引入一个人工节点
108 | 2. 测量到相邻节点的代价(延迟,开销)
109 | - 实测法,发送一个分组要求对方立即响应
110 | - 回送一个ECHO分组
111 | - 通过测量时间可以估算出延迟情况
112 | 3. 组装一个LS分组,描述它到相邻节点的代价情况
113 | - 发送者名称
114 | - 序号,年龄
115 | - 列表:给出它相邻节点,和它到相邻节点的延迟
116 | 4. 将分组通过扩散的方法(泛洪)发到所有其它路由器(以上4步让每个路由器获得拓扑和边代价)
117 | - 顺序号:用于控制无穷的扩散,每个路由器都记录(源路由器,顺序号),发现重复的或老的就不扩散
118 | - 具体问题1:循环使用问题
119 | - 具体问题2:路由器崩溃之后序号从0开始
120 | - 具体问题3:序号出现错误
121 | - 解决问题的办法:年龄字段(age)
122 | - 生成一个分组时,年龄字段不为0
123 | - 每个一个时间段,AGE字段减1
124 | - AGE字段为0的分组将被抛弃
125 | - 关于扩散分组的数据结构
126 | - Source:从哪个节点收到LS分组
127 | - Seq.,Age:序号,年龄
128 | - Send flags:发送标记,必须向指定的哪些相邻站点转发LS分组
129 | - ACK flags:本站点必须向哪些相邻站点发送应答
130 | - DATA:来自source站点的LS分组
131 | - 如:节点B的数据结构
132 |
133 |
35 |
36 | *注:图抽象在其他网络场景中也十分有用,例如在P2P中,N是peer节点,E是TCP的连接*
37 |
38 | 图抽象:边和路径的代价
39 | - c(x, x') = 链路的代价 (x, x')
40 | - e.g., c(w, z) = 5
41 | - 代价可能总为1
42 | - 或是 链路带宽的倒数
43 | - 或是 拥塞情况的倒数
44 |
45 | $$ \text{Cost of path } (x_1, x_2, x_3, ... , x_p) = c(x_1, x_2) + c(x_2, x_3) + ... + c(x_{p-1}, x_p) $$
46 |
47 | 最优化原则(optimality principle)
48 | - 汇集树(sink tree)
49 | - 此节点到所有其它节点的最优路径形成的树
50 | - 路由选择算法就是为所有路由器找到并使用汇集树
51 |
52 | 路由选择算法的原则
53 | - 正确性(correctness):算法必须是正确的和完整的,使分组一站一站接力,正确发向目标站;完整:目标所有的站地址,在路由表中都能找到相应的表项;没有处理不了的目标站地址;
54 | - 简单性(simplicity):算法在计算机上应简单:最优但复杂的算法,时间上延迟很大,不实用,不应为了获取路由信息增加很多的通信量;
55 | - 健壮性(robustness):算法应能适应通信量和网络拓扑的变化:通信量变化,网络拓扑的变化算法能很快适应;不向很拥挤的链路发数据,不向断了的链路发送数据;
56 | - 稳定性(stability):产生的路由不应该摇摆
57 | - 公平性(fairness):对每一个站点都公平
58 | - 最优性(optimality):某一个指标的最优,时间上,费用上,等指标,或综合指标;实际上,获取最优的结果代价较高,可以是次优的
59 |
60 | 路由算法分类
61 | - 全局或者局部路由信息?
62 | - 全局:
63 | - 所有的路由器拥有完整的拓扑和边的代价的信息(上帝视角)
64 | - “link state”算法
65 | - 分布式:
66 | - 路由器只知道与它有物理连接关系的邻居路由器,和到相应邻居路由器的代价值
67 | - 叠代地与邻居交换路由信息、计算路由信息
68 | - “distance vector”算法
69 | - 静态或者动态的?
70 | - 静态:
71 | - 路由随时间变化缓慢
72 | - 动态:
73 | - 路由变化很快
74 | - 周期性更新
75 | - 根据链路代价的变化而变化
76 | - 静态-->非自适应算法(non-adaptive algorithm):不能适应网络拓扑和通信量的变化,路由表是事先计算好的
77 | - 动态-->自适应路由选择(adaptive algorithm):能适应网络拓扑和通信量的变化
78 |
79 | ### 5.2 路由选择算法
80 |
81 | #### 5.2.1 link state 链路状态算法
82 |
83 | LS路由的工作过程
84 | - 配置LS路由选择算法的路由工作过程
85 | - 各点通过各种渠道(如泛洪等)获得整个网络拓扑,网络中所有链路代价等信息(这部分和算法没关系,属于协议和实现)
86 | - 使用LS路由算法计算本站点到其它站点的最优路径(汇集树),得到路由表
87 | - 按照此路由表转发分组(datagram方式)
88 | - 严格意义上说不是路由的一个步骤
89 | - 分发到输入端口的网络层
90 |
91 | ```mermaid
92 | graph LR
93 |
94 | A[获得网络拓扑和链路代价信息]
95 | B[使用最短路由算法得到路由表]
96 | C[使用此路由表]
97 |
98 | A-->B
99 | B-->C
100 | ```
101 |
102 | 链路状态路由选择(link state routing)
103 | - LS路由的基本工作过程
104 | 1. 发现相邻节点,获知对方网络地址
105 | - 一个路由器上电之后,向所有线路发送HELLO分组
106 | - 其它路由器收到HELLO分组,回送应答,在应答分组中,告知自己的名字(全局唯一)
107 | - 在LAN中,通过广播HELLO分组,获得其它路由器的信息,可以认为引入一个人工节点
108 | 2. 测量到相邻节点的代价(延迟,开销)
109 | - 实测法,发送一个分组要求对方立即响应
110 | - 回送一个ECHO分组
111 | - 通过测量时间可以估算出延迟情况
112 | 3. 组装一个LS分组,描述它到相邻节点的代价情况
113 | - 发送者名称
114 | - 序号,年龄
115 | - 列表:给出它相邻节点,和它到相邻节点的延迟
116 | 4. 将分组通过扩散的方法(泛洪)发到所有其它路由器(以上4步让每个路由器获得拓扑和边代价)
117 | - 顺序号:用于控制无穷的扩散,每个路由器都记录(源路由器,顺序号),发现重复的或老的就不扩散
118 | - 具体问题1:循环使用问题
119 | - 具体问题2:路由器崩溃之后序号从0开始
120 | - 具体问题3:序号出现错误
121 | - 解决问题的办法:年龄字段(age)
122 | - 生成一个分组时,年龄字段不为0
123 | - 每个一个时间段,AGE字段减1
124 | - AGE字段为0的分组将被抛弃
125 | - 关于扩散分组的数据结构
126 | - Source:从哪个节点收到LS分组
127 | - Seq.,Age:序号,年龄
128 | - Send flags:发送标记,必须向指定的哪些相邻站点转发LS分组
129 | - ACK flags:本站点必须向哪些相邻站点发送应答
130 | - DATA:来自source站点的LS分组
131 | - 如:节点B的数据结构
132 |
133 |  134 |
135 |
134 |
135 |  136 |
137 | 5. 通过Dijkstra算法找出最短路径(这才是路由算法)
138 | - 每个节点独立算出来到其他节点(路由器=网络)的最短路径
139 | - 迭代算法:第k步能够知道本节点到k个其他节点的最短路径
140 | 1. 路由器获得各站点LS分组和整个网络的拓扑
141 | 2. 通过Dijkstra算法计算出到其它各路由器的最短路径(汇集树:该源节点的路由表)
142 | 3. 将计算结果安装到路由表中
143 | - LS的应用情况
144 | - OSPF协议是一种LS协议,被用于Internet上
145 | - IS-IS(intermediate system-intermediate system):被用于Internet主干中,Netware
146 | - 符号标记:
147 | - c(i, j):从节点i到j的链路代价(初始状态下非相邻节点之间的链路代价为 $\infty$ )
148 | - D(v):从源节点到节点V的当前路径代价(节点的代价)
149 | - p(v):从源到节点V的路径前序节点
150 | - N':当前已经知道最优路径的的节点集合(永久节点的集合)
151 |
152 |
136 |
137 | 5. 通过Dijkstra算法找出最短路径(这才是路由算法)
138 | - 每个节点独立算出来到其他节点(路由器=网络)的最短路径
139 | - 迭代算法:第k步能够知道本节点到k个其他节点的最短路径
140 | 1. 路由器获得各站点LS分组和整个网络的拓扑
141 | 2. 通过Dijkstra算法计算出到其它各路由器的最短路径(汇集树:该源节点的路由表)
142 | 3. 将计算结果安装到路由表中
143 | - LS的应用情况
144 | - OSPF协议是一种LS协议,被用于Internet上
145 | - IS-IS(intermediate system-intermediate system):被用于Internet主干中,Netware
146 | - 符号标记:
147 | - c(i, j):从节点i到j的链路代价(初始状态下非相邻节点之间的链路代价为 $\infty$ )
148 | - D(v):从源节点到节点V的当前路径代价(节点的代价)
149 | - p(v):从源到节点V的路径前序节点
150 | - N':当前已经知道最优路径的的节点集合(永久节点的集合)
151 |
152 |  153 |
154 | - LS路由选择算法的工作原理
155 | - 节点标记:每一个节点使用(D(v), p(v)) 如:(3, B)标记
156 | - D(v)从源节点由已知最优路径到达本节点的距离
157 | - P(v)前序节点来标注
158 | - 2类节点
159 | - 临时节点(tentative node):还没有找到从源节点到此节点的最优路径的节点
160 | - 永久节点(permanent node) N':已经找到了从源节点到此节点的最优路径的节点
161 | - Dijkstra算法的框架
162 | 1. 初始化
163 | - 除了源节点外,所有节点都为临时节点
164 | - 节点代价除了与源节点代价相邻的节点外,都为 $\infty$
165 | 2. 从所有临时节点中找到一个节点代价最小的临时节点,将之变成永久节点(当前节点)W
166 | 3. 对此节点的所有在临时节点集合中的邻节点(V)
167 | - 如果 D(v) > D(w) + C(w, v),则重新标注此点为 (D(v) + C(w, v), W)
168 | - 否则,不重新标注
169 | 4. 开始一个新的循环(第2步)
170 | 5. 最终搜索得源节点到所有节点的最优路径,算法终止
171 | - 例子
172 |
173 |
153 |
154 | - LS路由选择算法的工作原理
155 | - 节点标记:每一个节点使用(D(v), p(v)) 如:(3, B)标记
156 | - D(v)从源节点由已知最优路径到达本节点的距离
157 | - P(v)前序节点来标注
158 | - 2类节点
159 | - 临时节点(tentative node):还没有找到从源节点到此节点的最优路径的节点
160 | - 永久节点(permanent node) N':已经找到了从源节点到此节点的最优路径的节点
161 | - Dijkstra算法的框架
162 | 1. 初始化
163 | - 除了源节点外,所有节点都为临时节点
164 | - 节点代价除了与源节点代价相邻的节点外,都为 $\infty$
165 | 2. 从所有临时节点中找到一个节点代价最小的临时节点,将之变成永久节点(当前节点)W
166 | 3. 对此节点的所有在临时节点集合中的邻节点(V)
167 | - 如果 D(v) > D(w) + C(w, v),则重新标注此点为 (D(v) + C(w, v), W)
168 | - 否则,不重新标注
169 | 4. 开始一个新的循环(第2步)
170 | 5. 最终搜索得源节点到所有节点的最优路径,算法终止
171 | - 例子
172 |
173 |  174 |
175 | - Dijkstra算法的讨论
176 | - 算法复杂度:考虑 $n$ 节点的情况
177 | - 每一次迭代:需要检查所有不在永久集合N中的节点
178 | - $n(n+1)/2$ 次比较: $O(n^2)$
179 | - 有很有效的实现: $O(n\log{n})$ 最小堆 or 斐波那契堆
180 | - 可能的震荡:
181 | - e.g., 链路代价 = 链路承载的流量:切换路径过快
182 |
183 |
174 |
175 | - Dijkstra算法的讨论
176 | - 算法复杂度:考虑 $n$ 节点的情况
177 | - 每一次迭代:需要检查所有不在永久集合N中的节点
178 | - $n(n+1)/2$ 次比较: $O(n^2)$
179 | - 有很有效的实现: $O(n\log{n})$ 最小堆 or 斐波那契堆
180 | - 可能的震荡:
181 | - e.g., 链路代价 = 链路承载的流量:切换路径过快
182 |
183 |  184 |
185 | #### 5.2.2 distance vector 距离矢量算法
186 |
187 | 距离矢量路由选择(distance vector routing):迭代式算法
188 | - 动态路由算法之一
189 | - DV算法历史及应用情况
190 | - 1957 Bellman, 1962 Ford Fulkerson
191 | - 用于ARPANET, Internet(RIP) DECnet, Novell, ApplTalk
192 | - 距离矢量路由选择的基本思想
193 | - 各路由器维护一张路由表,结构如图(其它代价)
194 |
195 |
184 |
185 | #### 5.2.2 distance vector 距离矢量算法
186 |
187 | 距离矢量路由选择(distance vector routing):迭代式算法
188 | - 动态路由算法之一
189 | - DV算法历史及应用情况
190 | - 1957 Bellman, 1962 Ford Fulkerson
191 | - 用于ARPANET, Internet(RIP) DECnet, Novell, ApplTalk
192 | - 距离矢量路由选择的基本思想
193 | - 各路由器维护一张路由表,结构如图(其它代价)
194 |
195 |  196 |
197 | - 各路由器与相邻路由器交换路由表
198 | - 根据获得的路由信息,更新路由表
199 | - 代价及相邻节点间代价的获得
200 | - 跳数(hops),延迟(delay),队列长度
201 | - 相邻节点间代价的获得:通过实测
202 | - 路由信息的更新(定期测量它到相邻节点的代价,定期与相邻节点交换路由表(DV),这里的距离矢量(DV)实际上为约定次序的往各个目标节点的代价向量:(目标, 代价)列表)
203 | - 根据实测 得到本节点A到相邻站点的代价(如:延迟)
204 | - 根据各相邻站点声称它们到目标站点B的代价
205 | - 计算出本站点A经过各相邻站点到目标站点B的代价
206 | - 找到一个最小的代价,和相应的下一个节点Z,到达节点B经过此节点Z,并且代价为A-Z-B的代价
207 | - 其它所有的目标节点一个计算法
208 |
209 | > 例子:
210 | >
211 | >
196 |
197 | - 各路由器与相邻路由器交换路由表
198 | - 根据获得的路由信息,更新路由表
199 | - 代价及相邻节点间代价的获得
200 | - 跳数(hops),延迟(delay),队列长度
201 | - 相邻节点间代价的获得:通过实测
202 | - 路由信息的更新(定期测量它到相邻节点的代价,定期与相邻节点交换路由表(DV),这里的距离矢量(DV)实际上为约定次序的往各个目标节点的代价向量:(目标, 代价)列表)
203 | - 根据实测 得到本节点A到相邻站点的代价(如:延迟)
204 | - 根据各相邻站点声称它们到目标站点B的代价
205 | - 计算出本站点A经过各相邻站点到目标站点B的代价
206 | - 找到一个最小的代价,和相应的下一个节点Z,到达节点B经过此节点Z,并且代价为A-Z-B的代价
207 | - 其它所有的目标节点一个计算法
208 |
209 | > 例子:
210 | >
211 | >  212 | >
213 | > 以当前节点J为例,相邻节点A, I, H, K
214 | > - J测得到A, I, H, K的延迟为8ms, 10ms, 12ms, 6ms
215 | > - 通过交换DV,从A, I, H, K获得到它们到G的延迟为18ms, 31ms, 6ms, 31ms
216 | > - 因此从J经过A, I, H, K到G的延迟为26ms, 41ms, 18ms, 37ms
217 | > - 将到G的路由表项更新为18ms, 下一跳为:H
218 | > - 其它目标一样,除了本节点J
219 |
220 | 距离矢量算法(Bellman-Ford)
221 | - Bellman-Ford方程(动态规划) *递归风车*
222 | - 设 $d_x(y)$ 为从 $x$ 到 $y$ 的最小路径代价,那么 $$d_x(y) = \min_v(c(x, v) + d_v(y))$$
223 | - 其中 $c(x, v)$ 为 $x$ 到邻居 $v$ 的代价, $d_v(y)$ 为从邻居 $v$ 到目标 $y$ 的代价, $\min_v$ 为取所有 $x$ 的邻居取最小的 $v$
224 | - Bellman-Ford例子
225 |
226 |
212 | >
213 | > 以当前节点J为例,相邻节点A, I, H, K
214 | > - J测得到A, I, H, K的延迟为8ms, 10ms, 12ms, 6ms
215 | > - 通过交换DV,从A, I, H, K获得到它们到G的延迟为18ms, 31ms, 6ms, 31ms
216 | > - 因此从J经过A, I, H, K到G的延迟为26ms, 41ms, 18ms, 37ms
217 | > - 将到G的路由表项更新为18ms, 下一跳为:H
218 | > - 其它目标一样,除了本节点J
219 |
220 | 距离矢量算法(Bellman-Ford)
221 | - Bellman-Ford方程(动态规划) *递归风车*
222 | - 设 $d_x(y)$ 为从 $x$ 到 $y$ 的最小路径代价,那么 $$d_x(y) = \min_v(c(x, v) + d_v(y))$$
223 | - 其中 $c(x, v)$ 为 $x$ 到邻居 $v$ 的代价, $d_v(y)$ 为从邻居 $v$ 到目标 $y$ 的代价, $\min_v$ 为取所有 $x$ 的邻居取最小的 $v$
224 | - Bellman-Ford例子
225 |
226 |  227 |
228 | - 明显的: $d_v(z) = 5$ , $d_x(z) = 3$ , $d_w(z) = 3$
229 | - 由B-F方程得到:
230 | $$d_u(z) = \min(c(u,v) + d_v(z), c(u,x) + d_x(z), c(u,w) + d_w(z)) = \min(2+5, 1+3, 5+3) = 4 $$
231 | - 那个能够达到目标 $z$ 最小代价的节点 $x$ ,就在到目标节点的下一条路径上,在转发表中使用
232 | - $D_x(y)$ 为节点 $x$ 到 $y$ 代价最小值的估计
233 | - $x$ 节点维护距离矢量 $D_x = [D_x(y): y \in N]$
234 | - 节点 $x$ :
235 | - 知道到所有邻居 $v$ 的代价记为 $c(x,v)$
236 | - 收到并维护一个它邻居的距离矢量集
237 | - 对于每个邻居, $x$ 维护 $D_v = [D_v(y): y \in N]$
238 | - 核心思路:
239 | - 每个节点都将自己的距离矢量估计值传送给邻居,定时或者DV有变化时,让对方去算
240 | - 当 $x$ 从邻居收到DV时,自己运算,更新它自己的距离矢量
241 | - 采用B-F equation:
242 | $$D_x(y) \leftarrow \min_v{c(x,v) + D_v(y)}, \qquad \text{for every $y \in N$ } $$ 其中 $D_x(y)$ 为 $x$ 往 $y$ 的代价, $c(x,v)$ 为 $x$ 到邻居 $v$ 代价, $D_v(y)$ 为 $v$ 声称到 $y$ 的代价
243 | - $D_x(y)$ 估计值最终收敛于实际的最小代价值 $d_x(y)$
244 | - 分布式、迭代算法
245 | - 异步式,迭代:每次本地迭代被以下事件触发:
246 | - 本地链路代价变化了
247 | - 从邻居来了DV的更新消息
248 | - 分布式:
249 | - 每个节点只是在自己的DV改变之后向邻居通告
250 | - 然后邻居们在有必要的时候通知他们的邻居
251 | - 每个节点:
252 |
253 | ```mermaid
254 | graph TD
255 |
256 | A[等待本地链路代价变化或者从邻居传送新的DV报文]
257 | B[重新计算各目标代价估计值]
258 | C[如果到任何目标的DV发生变化则通告邻居]
259 |
260 | A-->B
261 | B-->C
262 | C-->A
263 | ```
264 |
265 | DV的无穷计算问题
266 | - DV的特点
267 | - 好消息传的快,坏消息传的慢
268 | - 好消息的传播以每一个交换周期前进一个路由器的速度进行
269 | - 好消息:某个路由器接入或有更短的路径(链路由断变为通,链路代价由大变小),举例:
270 |
271 |
227 |
228 | - 明显的: $d_v(z) = 5$ , $d_x(z) = 3$ , $d_w(z) = 3$
229 | - 由B-F方程得到:
230 | $$d_u(z) = \min(c(u,v) + d_v(z), c(u,x) + d_x(z), c(u,w) + d_w(z)) = \min(2+5, 1+3, 5+3) = 4 $$
231 | - 那个能够达到目标 $z$ 最小代价的节点 $x$ ,就在到目标节点的下一条路径上,在转发表中使用
232 | - $D_x(y)$ 为节点 $x$ 到 $y$ 代价最小值的估计
233 | - $x$ 节点维护距离矢量 $D_x = [D_x(y): y \in N]$
234 | - 节点 $x$ :
235 | - 知道到所有邻居 $v$ 的代价记为 $c(x,v)$
236 | - 收到并维护一个它邻居的距离矢量集
237 | - 对于每个邻居, $x$ 维护 $D_v = [D_v(y): y \in N]$
238 | - 核心思路:
239 | - 每个节点都将自己的距离矢量估计值传送给邻居,定时或者DV有变化时,让对方去算
240 | - 当 $x$ 从邻居收到DV时,自己运算,更新它自己的距离矢量
241 | - 采用B-F equation:
242 | $$D_x(y) \leftarrow \min_v{c(x,v) + D_v(y)}, \qquad \text{for every $y \in N$ } $$ 其中 $D_x(y)$ 为 $x$ 往 $y$ 的代价, $c(x,v)$ 为 $x$ 到邻居 $v$ 代价, $D_v(y)$ 为 $v$ 声称到 $y$ 的代价
243 | - $D_x(y)$ 估计值最终收敛于实际的最小代价值 $d_x(y)$
244 | - 分布式、迭代算法
245 | - 异步式,迭代:每次本地迭代被以下事件触发:
246 | - 本地链路代价变化了
247 | - 从邻居来了DV的更新消息
248 | - 分布式:
249 | - 每个节点只是在自己的DV改变之后向邻居通告
250 | - 然后邻居们在有必要的时候通知他们的邻居
251 | - 每个节点:
252 |
253 | ```mermaid
254 | graph TD
255 |
256 | A[等待本地链路代价变化或者从邻居传送新的DV报文]
257 | B[重新计算各目标代价估计值]
258 | C[如果到任何目标的DV发生变化则通告邻居]
259 |
260 | A-->B
261 | B-->C
262 | C-->A
263 | ```
264 |
265 | DV的无穷计算问题
266 | - DV的特点
267 | - 好消息传的快,坏消息传的慢
268 | - 好消息的传播以每一个交换周期前进一个路由器的速度进行
269 | - 好消息:某个路由器接入或有更短的路径(链路由断变为通,链路代价由大变小),举例:
270 |
271 |  272 |
273 | - 坏消息的传播速度非常慢(无穷计算问题)
274 | - 例子:第一次交换之后,B从C处获得信息,C可以到达A(C-A,要经过B本身),但是路径是2,因此B变成3,从C处走;第二次交换,C从B处获得消息,B可以到达A,路径为3,因此,C到A从B走,代价为3;无限此之后,到A的距离变成INF,不可达
275 |
276 |
272 |
273 | - 坏消息的传播速度非常慢(无穷计算问题)
274 | - 例子:第一次交换之后,B从C处获得信息,C可以到达A(C-A,要经过B本身),但是路径是2,因此B变成3,从C处走;第二次交换,C从B处获得消息,B可以到达A,路径为3,因此,C到A从B走,代价为3;无限此之后,到A的距离变成INF,不可达
275 |
276 |  277 |
278 | 通过 水平分裂(split horizon)算法 减少上面所说的坏消息的环路的情况
279 | - 一种对无穷计算问题的解决办法
280 | - C知道要经过B才能到达A,所以C向B报告它到A的距离为INF;C 告诉D它到A的真实距离
281 | - D告诉E,它到A的距离,但D告诉C它通向A的距离为INF
282 | - 第一次交换:B通过测试发现到A的路径为INF,而C也告诉B到A的距离为INF,因此,B到A的距离为INF
283 | - 第二次交换:C从B和D那里获知,到A的距离为INF,因此将它到A的距离为INF
284 | - ……坏消息以一次交换一个节点的速度传播
285 | - 水平分裂的问题:在某些拓扑形式下会失败(存在环路)
286 | - 例子:
287 | - A,B到D的距离为2,C到D的距离为1
288 | - 如果C-D路径失败
289 | - C获知到D为INF,从A,B获知到D的距离为INF,因此C认为D不可达
290 | - A从C获知D的距离为INF,但从B处获知它到D的距离为2。因此A到B的距离为3,从B走
291 | - B也有类似的问题
292 | - 经过无限次之后,A和B都知道到D的距离为INF
293 |
294 | > DV完整例子:
295 | >
296 | >
277 |
278 | 通过 水平分裂(split horizon)算法 减少上面所说的坏消息的环路的情况
279 | - 一种对无穷计算问题的解决办法
280 | - C知道要经过B才能到达A,所以C向B报告它到A的距离为INF;C 告诉D它到A的真实距离
281 | - D告诉E,它到A的距离,但D告诉C它通向A的距离为INF
282 | - 第一次交换:B通过测试发现到A的路径为INF,而C也告诉B到A的距离为INF,因此,B到A的距离为INF
283 | - 第二次交换:C从B和D那里获知,到A的距离为INF,因此将它到A的距离为INF
284 | - ……坏消息以一次交换一个节点的速度传播
285 | - 水平分裂的问题:在某些拓扑形式下会失败(存在环路)
286 | - 例子:
287 | - A,B到D的距离为2,C到D的距离为1
288 | - 如果C-D路径失败
289 | - C获知到D为INF,从A,B获知到D的距离为INF,因此C认为D不可达
290 | - A从C获知D的距离为INF,但从B处获知它到D的距离为2。因此A到B的距离为3,从B走
291 | - B也有类似的问题
292 | - 经过无限次之后,A和B都知道到D的距离为INF
293 |
294 | > DV完整例子:
295 | >
296 | >  297 |
298 | LS 和 DV 算法的比较 *2种路由选择算法都有其优缺点,而且在互联网上都有应用*
299 | - 消息复杂度(DV胜出)
300 | - LS:有n节点,E条链路,发送报文O(nE)个
301 | - 局部的路由信息;全局传播
302 | - DV:只和邻居交换信息
303 | - 全局的路由信息;局部传播
304 | - 收敛时间(LS胜出)
305 | - LS: $O(n^2)$ 算法
306 | - 有可能震荡
307 | - DV:收敛较慢
308 | - 可能存在路由环路
309 | - count-to-infinity 问题
310 | - 健壮性:路由器故障会发生什么(LS胜出)
311 | - LS:
312 | - 节点会通告不正确的链路代价
313 | - 每个节点只计算自己的路由表
314 | - 错误信息影响较小,局部,路由较健壮
315 | - DV:
316 | - DV节点可能通告对全网所有节点的不正确路径代价
317 | - 距离矢量
318 | - 每一个节点的路由表可能被其它节点使用
319 | - 错误可以扩散到全网
320 |
321 | ### 5.3 因特网中自治系统内部的路由选择(内部网关协议)
322 |
323 | 互联网中的内部网关协议有两种常见协议:RIP 和 OSPF
324 |
325 | #### 5.3.1 RIP
326 |
327 | RIP(Routing Information Protocol)
328 | - 在1982年发布的BSD-UNIX中实现
329 | - 基于 Distance vector 算法
330 | - 距离矢量:每条链路cost=1,# of hops (max = 15 hops) 跳数 (跳数为16表示目标不可达)
331 | - DV每隔30秒和邻居交换DV,通告(AD)
332 | - 每个通告包括:最多25个目标子网
333 |
334 |
297 |
298 | LS 和 DV 算法的比较 *2种路由选择算法都有其优缺点,而且在互联网上都有应用*
299 | - 消息复杂度(DV胜出)
300 | - LS:有n节点,E条链路,发送报文O(nE)个
301 | - 局部的路由信息;全局传播
302 | - DV:只和邻居交换信息
303 | - 全局的路由信息;局部传播
304 | - 收敛时间(LS胜出)
305 | - LS: $O(n^2)$ 算法
306 | - 有可能震荡
307 | - DV:收敛较慢
308 | - 可能存在路由环路
309 | - count-to-infinity 问题
310 | - 健壮性:路由器故障会发生什么(LS胜出)
311 | - LS:
312 | - 节点会通告不正确的链路代价
313 | - 每个节点只计算自己的路由表
314 | - 错误信息影响较小,局部,路由较健壮
315 | - DV:
316 | - DV节点可能通告对全网所有节点的不正确路径代价
317 | - 距离矢量
318 | - 每一个节点的路由表可能被其它节点使用
319 | - 错误可以扩散到全网
320 |
321 | ### 5.3 因特网中自治系统内部的路由选择(内部网关协议)
322 |
323 | 互联网中的内部网关协议有两种常见协议:RIP 和 OSPF
324 |
325 | #### 5.3.1 RIP
326 |
327 | RIP(Routing Information Protocol)
328 | - 在1982年发布的BSD-UNIX中实现
329 | - 基于 Distance vector 算法
330 | - 距离矢量:每条链路cost=1,# of hops (max = 15 hops) 跳数 (跳数为16表示目标不可达)
331 | - DV每隔30秒和邻居交换DV,通告(AD)
332 | - 每个通告包括:最多25个目标子网
333 |
334 |  335 |
336 | RIP 通告(advertisements)
337 | - DV:在邻居之间每30秒交换通告报文
338 | - 定期,而且在改变路由的时候发送通告报文
339 | - 在对方的请求下可以发送通告报文
340 | - 每一个通告:至多AS内部的25个目标网络的DV(用于小型网,代价小,简单)
341 | - 目标网络 + 跳数
342 |
343 | > 例子:
344 | >
345 | >
335 |
336 | RIP 通告(advertisements)
337 | - DV:在邻居之间每30秒交换通告报文
338 | - 定期,而且在改变路由的时候发送通告报文
339 | - 在对方的请求下可以发送通告报文
340 | - 每一个通告:至多AS内部的25个目标网络的DV(用于小型网,代价小,简单)
341 | - 目标网络 + 跳数
342 |
343 | > 例子:
344 | >
345 | >  346 | >
346 | > 347 | >
 348 |
349 | RIP:链路失效和恢复
350 | - 如果180秒没有收到通告信息-->邻居或者链路失效
351 | - 发现经过这个邻居的路由已失效
352 | - 新的通告报文会传递给邻居
353 | - 邻居因此发出新的通告(如果路由变化的话)
354 | - 链路失效快速(?)地在整网中传输
355 | - 使用毒性逆转(poison reverse)阻止ping-pong回路(不可达的距离:跳数无限 = 16 段)
356 |
357 | RIP进程处理
358 | - RIP以应用进程的方式实现:route-d (daemon)
359 | - 通告报文通过UDP报文传送,周期性重复
360 | - 网络层的协议使用了传输层的服务,以应用层实体的方式实现
361 |
362 |
348 |
349 | RIP:链路失效和恢复
350 | - 如果180秒没有收到通告信息-->邻居或者链路失效
351 | - 发现经过这个邻居的路由已失效
352 | - 新的通告报文会传递给邻居
353 | - 邻居因此发出新的通告(如果路由变化的话)
354 | - 链路失效快速(?)地在整网中传输
355 | - 使用毒性逆转(poison reverse)阻止ping-pong回路(不可达的距离:跳数无限 = 16 段)
356 |
357 | RIP进程处理
358 | - RIP以应用进程的方式实现:route-d (daemon)
359 | - 通告报文通过UDP报文传送,周期性重复
360 | - 网络层的协议使用了传输层的服务,以应用层实体的方式实现
361 |
362 |  363 |
364 | #### 5.3.2 OSPF
365 |
366 | OSPF(Open Shortest Path First) 开放最短路径优先协议
367 | - “open”:标准可公开获得
368 | - 使用LS算法
369 | - LS分组在网络中(一个AS内部)分发
370 | - 全局网络拓扑、代价在每一个节点中都保持
371 | - 路由计算采用Dijkstra算法
372 | - OSPF通告信息中携带:每一个邻居路由器一个表项
373 | - 通告信息会传遍AS全部(通过泛洪)
374 | - 在IP数据报上直接传送OSPF报文(而不是通过UDP和TCP)
375 | - IS-IS路由协议:几乎和OSPF一样
376 |
377 | OSPF“高级”特性(在RIP中的没有的)
378 | - 安全:所有的OSPF报文都是经过认证的(防止恶意的攻击)
379 | - 允许有多个代价相同的路径存在(在RIP协议中只有一个),可以在多条路径之上做负载均衡
380 | - 对于每一个链路,对于不同的TOS有多重代价矩阵
381 | - 例如:卫星链路代价对于尽力而为的服务代价设置比较低,对实时服务代价设置的比较高
382 | - 支持按照不同的代价计算最优路径,如:按照时间和延迟分别计算最优路径
383 | - 对单播和多播的集成支持:
384 | - Multicast OSPF (MOSPF) 使用相同的拓扑数据库,就像在OSPF中一样
385 | - 在大型网络中支持层次性OSPF
386 |
387 | 层次化的OSPF路由
388 |
389 |
363 |
364 | #### 5.3.2 OSPF
365 |
366 | OSPF(Open Shortest Path First) 开放最短路径优先协议
367 | - “open”:标准可公开获得
368 | - 使用LS算法
369 | - LS分组在网络中(一个AS内部)分发
370 | - 全局网络拓扑、代价在每一个节点中都保持
371 | - 路由计算采用Dijkstra算法
372 | - OSPF通告信息中携带:每一个邻居路由器一个表项
373 | - 通告信息会传遍AS全部(通过泛洪)
374 | - 在IP数据报上直接传送OSPF报文(而不是通过UDP和TCP)
375 | - IS-IS路由协议:几乎和OSPF一样
376 |
377 | OSPF“高级”特性(在RIP中的没有的)
378 | - 安全:所有的OSPF报文都是经过认证的(防止恶意的攻击)
379 | - 允许有多个代价相同的路径存在(在RIP协议中只有一个),可以在多条路径之上做负载均衡
380 | - 对于每一个链路,对于不同的TOS有多重代价矩阵
381 | - 例如:卫星链路代价对于尽力而为的服务代价设置比较低,对实时服务代价设置的比较高
382 | - 支持按照不同的代价计算最优路径,如:按照时间和延迟分别计算最优路径
383 | - 对单播和多播的集成支持:
384 | - Multicast OSPF (MOSPF) 使用相同的拓扑数据库,就像在OSPF中一样
385 | - 在大型网络中支持层次性OSPF
386 |
387 | 层次化的OSPF路由
388 |
389 |  390 |
391 | - 2个级别的层次性:本地区域,骨干区域
392 | - 链路状态通告仅仅在本地区域Area范围内进行
393 | - 每一个节点拥有本地区域的拓扑信息;
394 | - 关于其他区域,知道去它的方向,通过区域边界路由器(最短路径)传到其他区域
395 | - 区域边界路由器:“汇总(聚集)”到自己区域内网络的距离,向其它区域边界路由器通告(区域边界路由器参与多个区域的计算)
396 | - 骨干路由器:仅仅在骨干区域内,运行OSPF路由
397 | - 边界路由器:连接其它的AS’s
398 | - 层次性的好处:每个链路状态分组仅仅在一个区域内进行泛洪
399 |
400 | ### 5.4 ISP之间的路由选择(外部网关协议):BGP(边界网关协议)
401 |
402 | 平面路由
403 | - 一个平面的路由
404 | - 一个网络中的所有路由器的地位一样
405 | - 通过LS,DV,或者其他路由算法,所有路由器都要知道其他所有路由器(子网)如何走
406 | - 所有路由器在一个平面
407 | - 平面路由的问题
408 | - 规模巨大的网络中,路由信息的存储、传输和计算代价巨大
409 | - DV:距离矢量很大,且不能够收敛
410 | - LS:几百万个节点的LS分组的泛洪传输,存储以及最短路径算法的计算
411 | - 管理问题:
412 | - 不同的网络所有者希望按照自己的方式管理网络
413 | - 希望对外隐藏自己网络的细节
414 | - 当然,还希望和其它网络互联
415 | - 所以需要层次化路由!
416 |
417 | 层次路由
418 | - 层次路由:将互联网分成一个个AS(路由器区域)
419 | - 某个区域内的路由器集合,自治系统“autonomous systems”(AS)
420 | - 一个AS用AS Number(ASN)唯一标示
421 | - 一个ISP可能包括1个或者多个AS
422 | - 路由变成了:2个层次路由:自治区域内+自治区域间
423 | - AS内部路由:在同一个AS内路由器运行相同的路由协议
424 | - “intra-AS” routing protocol:内部网关协议
425 | - 不同的AS可能运行着不同的内部网关协议(私有)
426 | - 能够解决规模和管理问题
427 | - 如:RIP, OSPF, IGRP
428 | - 网关路由器:AS边缘路由器,可以连接到其他AS
429 | - AS间运行AS间路由协议(每个自治区域只表现为一个点)
430 | - “inter-AS” routing protocol:外部网关协议
431 | - 解决AS之间的路由问题,完成AS之间的互联互通
432 |
433 | 层次路由的优点
434 | - 解决了规模问题
435 | - 内部网关协议解决:AS内部数量有限的路由器相互到达的问题,AS内部规模可控
436 | - 如AS节点太多,可分割AS,使得AS内部的节点数量有限
437 | - AS之间的路由的规模问题
438 | - 增加一个AS,对于AS之间的路由从总体上来说,只是增加了一个节点=子网(每个AS可以用一个点来表示)
439 | - 对于其他AS来说只是增加了一个表项,就是这个新增的AS如何走的问题
440 | - 扩展性强:规模增大,性能不会减得太多
441 | - 解决了管理问题
442 | - 各个AS可以运行不同的内部网关协议(私有)
443 | - 可以使自己网络的细节不向外透露(安全)
444 |
445 | 互联网AS间路由:BGP
446 | - BGP (Border Gateway Protocol):自治区域间路由协议“事实上的”标准(非某机构制定,而是大家约定俗成)
447 | - “将互联网各个AS粘在一起的胶水”
448 | - BGP 提供给每个AS以以下方法:
449 | - eBGP:从相邻的ASes那里获得子网可达信息
450 | - iBGP:将获得的子网可达信息传遍到AS内部的所有路由器
451 | - 根据子网可达信息和策略来决定到达子网的“好”路径
452 | - 注:eBGP, iBGP 连接
453 |
454 |
390 |
391 | - 2个级别的层次性:本地区域,骨干区域
392 | - 链路状态通告仅仅在本地区域Area范围内进行
393 | - 每一个节点拥有本地区域的拓扑信息;
394 | - 关于其他区域,知道去它的方向,通过区域边界路由器(最短路径)传到其他区域
395 | - 区域边界路由器:“汇总(聚集)”到自己区域内网络的距离,向其它区域边界路由器通告(区域边界路由器参与多个区域的计算)
396 | - 骨干路由器:仅仅在骨干区域内,运行OSPF路由
397 | - 边界路由器:连接其它的AS’s
398 | - 层次性的好处:每个链路状态分组仅仅在一个区域内进行泛洪
399 |
400 | ### 5.4 ISP之间的路由选择(外部网关协议):BGP(边界网关协议)
401 |
402 | 平面路由
403 | - 一个平面的路由
404 | - 一个网络中的所有路由器的地位一样
405 | - 通过LS,DV,或者其他路由算法,所有路由器都要知道其他所有路由器(子网)如何走
406 | - 所有路由器在一个平面
407 | - 平面路由的问题
408 | - 规模巨大的网络中,路由信息的存储、传输和计算代价巨大
409 | - DV:距离矢量很大,且不能够收敛
410 | - LS:几百万个节点的LS分组的泛洪传输,存储以及最短路径算法的计算
411 | - 管理问题:
412 | - 不同的网络所有者希望按照自己的方式管理网络
413 | - 希望对外隐藏自己网络的细节
414 | - 当然,还希望和其它网络互联
415 | - 所以需要层次化路由!
416 |
417 | 层次路由
418 | - 层次路由:将互联网分成一个个AS(路由器区域)
419 | - 某个区域内的路由器集合,自治系统“autonomous systems”(AS)
420 | - 一个AS用AS Number(ASN)唯一标示
421 | - 一个ISP可能包括1个或者多个AS
422 | - 路由变成了:2个层次路由:自治区域内+自治区域间
423 | - AS内部路由:在同一个AS内路由器运行相同的路由协议
424 | - “intra-AS” routing protocol:内部网关协议
425 | - 不同的AS可能运行着不同的内部网关协议(私有)
426 | - 能够解决规模和管理问题
427 | - 如:RIP, OSPF, IGRP
428 | - 网关路由器:AS边缘路由器,可以连接到其他AS
429 | - AS间运行AS间路由协议(每个自治区域只表现为一个点)
430 | - “inter-AS” routing protocol:外部网关协议
431 | - 解决AS之间的路由问题,完成AS之间的互联互通
432 |
433 | 层次路由的优点
434 | - 解决了规模问题
435 | - 内部网关协议解决:AS内部数量有限的路由器相互到达的问题,AS内部规模可控
436 | - 如AS节点太多,可分割AS,使得AS内部的节点数量有限
437 | - AS之间的路由的规模问题
438 | - 增加一个AS,对于AS之间的路由从总体上来说,只是增加了一个节点=子网(每个AS可以用一个点来表示)
439 | - 对于其他AS来说只是增加了一个表项,就是这个新增的AS如何走的问题
440 | - 扩展性强:规模增大,性能不会减得太多
441 | - 解决了管理问题
442 | - 各个AS可以运行不同的内部网关协议(私有)
443 | - 可以使自己网络的细节不向外透露(安全)
444 |
445 | 互联网AS间路由:BGP
446 | - BGP (Border Gateway Protocol):自治区域间路由协议“事实上的”标准(非某机构制定,而是大家约定俗成)
447 | - “将互联网各个AS粘在一起的胶水”
448 | - BGP 提供给每个AS以以下方法:
449 | - eBGP:从相邻的ASes那里获得子网可达信息
450 | - iBGP:将获得的子网可达信息传遍到AS内部的所有路由器
451 | - 根据子网可达信息和策略来决定到达子网的“好”路径
452 | - 注:eBGP, iBGP 连接
453 |
454 |  455 |
456 | - 允许子网向互联网其他网络通告“我在这里”
457 | - 基于改进后的距离矢量算法(路径矢量)
458 | - 不仅仅是距离矢量,还包括到达各个目标网络的详细路径(AS序号的列表)能够避免简单DV算法的路由环路问题和无穷式的计算迭代
459 |
460 | BGP基础
461 | - BGP会话:2个BGP路由器(“peers”)在一个半永久的TCP连接上交换BGP报文:
462 | - 通告向不同目标子网前缀的“路径”(BGP是一个“路径矢量”协议)
463 | - 当AS3网关路由器3a向AS2的网关路由器2c通告路径:AS3,X
464 | - 3a参与AS内路由运算,知道本AS所有子网X信息
465 | - 语义上:AS3向AS2承诺,它可以向子网X转发数据报
466 | - 3a是2c关于X的下一跳(next hop)
467 |
468 | 路径的属性 & BGP路由
469 | - 当通告一个子网前缀时,通告包括 BGP 属性
470 | - prefix + attributes = “route”
471 | - 2个重要的属性:
472 | - AS-PATH:前缀的通告所经过的AS列表: AS 67 AS 17
473 | - 检测环路;多路径选择
474 | - 在向其它AS转发时,需要将自己的AS号加在路径上
475 | - NEXT-HOP:从当前AS到下一跳AS有多个链路,在NETX-HOP属性中,告诉对方通过那个I转发。
476 | - 其它属性:路由偏好指标,如何被插入的属性
477 | - 基于策略的路由:
478 | - 当一个网关路由器接收到了一个路由通告,使用输入策略来接受或过滤(accept/decline)
479 | - 过滤原因例1:不想经过某个AS,转发某些前缀的分组
480 | - 过滤原因例2:已经有了一条往某前缀的偏好路径
481 | - 策略也决定了是否向它别的邻居通告收到的这个路由信息
482 |
483 | > BGP 路径通告例子:
484 | >
485 | > - 路由器AS2.2c从AS3.3a接收到的AS3,X路由通告(通过eBGP)
486 | > - 基于AS2的输入策略,AS2.2c决定接收AS3,X的通告,而且通过iBGP)向AS2的所有路由器进行通告
487 | > - 基于AS2的策略,AS2路由器2a通过eBGP向AS1.1c路由器通告AS2,AS3,X 路由信息
488 | > - 路径上加上了AS2自己作为AS序列的一跳
489 | >
455 |
456 | - 允许子网向互联网其他网络通告“我在这里”
457 | - 基于改进后的距离矢量算法(路径矢量)
458 | - 不仅仅是距离矢量,还包括到达各个目标网络的详细路径(AS序号的列表)能够避免简单DV算法的路由环路问题和无穷式的计算迭代
459 |
460 | BGP基础
461 | - BGP会话:2个BGP路由器(“peers”)在一个半永久的TCP连接上交换BGP报文:
462 | - 通告向不同目标子网前缀的“路径”(BGP是一个“路径矢量”协议)
463 | - 当AS3网关路由器3a向AS2的网关路由器2c通告路径:AS3,X
464 | - 3a参与AS内路由运算,知道本AS所有子网X信息
465 | - 语义上:AS3向AS2承诺,它可以向子网X转发数据报
466 | - 3a是2c关于X的下一跳(next hop)
467 |
468 | 路径的属性 & BGP路由
469 | - 当通告一个子网前缀时,通告包括 BGP 属性
470 | - prefix + attributes = “route”
471 | - 2个重要的属性:
472 | - AS-PATH:前缀的通告所经过的AS列表: AS 67 AS 17
473 | - 检测环路;多路径选择
474 | - 在向其它AS转发时,需要将自己的AS号加在路径上
475 | - NEXT-HOP:从当前AS到下一跳AS有多个链路,在NETX-HOP属性中,告诉对方通过那个I转发。
476 | - 其它属性:路由偏好指标,如何被插入的属性
477 | - 基于策略的路由:
478 | - 当一个网关路由器接收到了一个路由通告,使用输入策略来接受或过滤(accept/decline)
479 | - 过滤原因例1:不想经过某个AS,转发某些前缀的分组
480 | - 过滤原因例2:已经有了一条往某前缀的偏好路径
481 | - 策略也决定了是否向它别的邻居通告收到的这个路由信息
482 |
483 | > BGP 路径通告例子:
484 | >
485 | > - 路由器AS2.2c从AS3.3a接收到的AS3,X路由通告(通过eBGP)
486 | > - 基于AS2的输入策略,AS2.2c决定接收AS3,X的通告,而且通过iBGP)向AS2的所有路由器进行通告
487 | > - 基于AS2的策略,AS2路由器2a通过eBGP向AS1.1c路由器通告AS2,AS3,X 路由信息
488 | > - 路径上加上了AS2自己作为AS序列的一跳
489 | > 490 | > - 网关路由器可能获取有关一个子网X的多条路径,从多个eBGP会话上: 491 | > - AS1网关路由器1c从2a学习到路径:AS2,AS3,X 492 | > - AS1网关路由器1c从3a处学习到路径AS3,X 493 | > - 基于策略(对路径进行打分,考虑政治上、经济上等),AS1路由器1c选择了路径:AS3,X,而且通过iBGP告诉所有AS1内部的路由器 494 | 495 | BGP报文 496 | - 使用TCP协议交换BGP报文。 497 | - BGP 报文: 498 | - OPEN:打开TCP连接,认证发送方 499 | - UPDATE:通告新路径(或者撤销原路径) 500 | - KEEPALIVE:在没有更新时保持连接,也用于对OPEN 请求确认NOTIFICATION:报告以前消息的错误,也用来关闭连接 501 | 502 | 关于其他自治区域的可达信息,是由内部网关运算和外部网关运算协议的结果共同决定的。首先由外部网关协议规划到目标子网的路径,然后信息传输进入各子网内部后由内部网关协议决定出入口如何走 503 | 504 | BGP 路径选择 505 | - 路由器可能获得一个网络前缀的多个路径,路由器必须进行路径的选择,路由选择可以基于: 506 | - 本地偏好值属性:偏好策略决定 507 | - 最短AS-PATH:AS的跳数 508 | - 最近的NEXT-HOP路由器:热土豆路由 509 | - 附加的判据:使用BGP标示 510 | - 一个前缀对应着多种路径,采用消除规则直到留下一条路径 511 | 512 | 热土豆路由 513 | - 假设2d通过iBGP获知,它可以通过2a或者2c到达X 514 | - 热土豆策略(“赶紧甩掉烫手的山芋”):选择具备最小内部区域代价的网关作为往X的出口(如:2d选择2a,即使往X可能有比较多的AS跳数):不要操心域间的代价! 515 | 516 | 为什么内部网关协议和外部网关协议如此不同?(内部网关协议更关注性能,外部网关协议更关注策略) 517 | - 策略: 518 | - Inter-AS:管理员需要控制通信路径,谁在使用它的网络进行数据传输; 519 | - Intra-AS:一个管理者,所以无需策略; 520 | - AS内部的各子网的主机尽可能地利用资源进行快速路由 521 | - 规模: 522 | - AS间路由必须考虑规模问题,以便支持全网的数据转发 523 | - AS内部路由规模不是一个大的问题 524 | - 如果AS太大,可将此AS分成小的AS;规模可控 525 | - AS之间只不过多了一个点而已 526 | - 或者AS内部路由支持层次性,层次性路由节约了表空间,降低了更新的数据流量 527 | - 性能: 528 | - Intra-AS:关注性能 529 | - Inter-AS:策略可能比性能更重要 530 | 531 | ### 5.5 SDN控制平面 532 | 533 | 前面关注了控制平面的传统方式,现在聚焦于SDN方式。 534 | 535 | OpenFlow:控制器<-->交换机报文 536 | - 一些关键的控制器到交换机的报文 537 | - 特性:控制器查询交换机特性,交换机应答 538 | - 配置:交换机查询/设置交换机的配置参数 539 | - 修改状态:增加删除修改OpenFlow表中的流表 540 | - packet-out:控制器可以将分组通过特定的端口发出 541 | - 一些关键的交换机到控制器的报文 542 | - 分组进入:将分组(和它的控制)传给控制器,见来自控制器的packet-out报文 543 | - 流移除:在交换机上删除流表项 544 | - 端口状态:通告控制器端口的变化 545 | 546 | *幸运的是,网络管理员不需要直接通过创建/发送流表来编程交换机,而是采用在控制器上的app自动运算和配置* 547 | 548 | OpenDaylight (ODL) 控制器 549 | - ODL Lithium 控制器 550 | - 网络应用可以在SDN控制内或者外面 551 | - 服务抽象层SAL:和内部以及外部的应用以及服务进行交互 552 | 553 | ONOS 控制器 554 | - 控制应用和控制器分离(应用app在控制器外部) 555 | - 意图框架:服务的高级规范:描述什么而不是如何 556 | - 相当多的重点聚焦在分布式核心上,以提高服务的可靠性,性能的可扩展性 557 | 558 | SDN:面临的挑战 559 | - 强化控制平面:可信、可靠、性能可扩展性、安全的分布式系统 560 | - 对于失效的鲁棒性:利用为控制平面可靠分布式系统的强大理论 561 | - 可信任,安全:从开始就进行铸造 562 | - 网络、协议满足特殊任务的需求 563 | - e.g., 实时性,超高可靠性、超高安全性 564 | - 互联网络范围内的扩展性 565 | - 而不是仅仅在一个AS的内部部署,全网部署 566 | 567 | ### 5.6 总结 568 | - 网络层控制平面的方法 569 | - 每个路由器控制(传统方法) 570 | - 逻辑上集中的控制(software defined networking) 571 | - 传统路由选择算法 572 | - 在互联网上的实现:RIP, OSPF, BGP 573 | - SDN控制器 574 | - 实际中的实现:ODL, ONOS 575 | - Internet Control Message Protocol 576 | - 网络管理和SNMP协议 577 | -------------------------------------------------------------------------------- /Log_of_ComputerNetworking-ATopDownApproach_7th/chapter6.md: -------------------------------------------------------------------------------- 1 | # 计算机网络——自顶向下方法 7th 2 | 3 | 中国科学技术大学 郑烇教授 2020年秋季 自动化系 4 | 5 | ## 6. 链路层和局域网 6 | 7 | 网络层解决了一个网络如何到达另外一个网络的路由问题。在**一个网络内部**如何**由一个节点(主机或者路由器)到达另外一个相邻节点**则需要用到链路层的**点到点**传输层功能 8 | 9 | 目标: 10 | - 理解数据链路层服务的原理: 11 | - 检错和纠错 12 | - 共享广播信道:多点接入(多路访问) 13 | - 链路层寻址 14 | - LAN:以太网、WLAN、VLANs 15 | - 可靠数据传输,流控制:解决! 16 | - 实例和各种链路层技术的实现 17 | 18 | 网络节点的连接方式:一个子网中的若干节点是如何连接到一起的? 19 | - 点到点连接(广域),只有封装/解封装的功能 20 | - 多点连接:(局域),“一发全收”,有寻址和MAC问题,链路层的功能更加复杂,有两种方式实现: 21 | - 通过共享型介质,如同轴电缆 22 | - 通过网络交换机 23 | 24 | 数据链路层和局域网 25 | - WAN:网络形式采用点到点链路 26 | - 带宽大、距离远(延迟大) 27 | - 带宽延迟积大 28 | - 如果采用多点连接方式 29 | - 竞争方式:一旦冲突代价大 30 | - 令牌等协调方式:在其中协调节点的发送代价大 31 | - 点到点链路的链路层服务实现非常简单,封装和解封装 32 | - LAN一般采用多点连接方式 33 | - 连接节点非常方便 34 | - 接到共享型介质上(或网络交换机),就可以连接所有其他节点 35 | - 多点连接方式网络的链路层功能实现相当复杂 36 | - 多点接入:协调各节点对共享性介质的访问和使用 37 | - 竞争方式:冲突之后的协调; 38 | - 令牌方式:令牌产生,占有和释放等 39 | 40 | ### 6.1 引论和服务 41 | 42 | 链路层:导论 43 | - 一些术语: 44 | - 主机和路由器是**节点**(网桥和交换机也是):**nodes** 45 | - 沿着通信路径,连接个相邻节点通信信道的是**链路**:**links** 46 | - 有线链路 47 | - 无线链路 48 | - 局域网,共享性链路 49 | - 第二层协议数据单元**帧frame**,封装数据报 50 | 51 | 数据链路层负责从一个节点通过链路将(**帧**中的)数据报发送到相邻的物理节点(一个子网内部的2节点) 52 | 53 | 链路层:点到点,传输帧 54 | 网络层:端到端 55 | 传输层:进程到进程,不可靠-->可靠 56 | 应用层:交换报文,实现网络应用 57 | 58 | 链路层:上下文 59 | - 数据报(分组)在不同的链路上以不同的链路协议传送: 60 | - 第一跳链路:以太网 61 | - 中间链路:帧中继链路 62 | - 最后一跳802.11: 63 | - 不同的链路协议提供不同的服务 64 | - e.g., 比如在链路层上提供(或没有)可靠数据传送 65 | 66 | > 传输类比 67 | > - 从Princeton到Lausanne 68 | > - 轿车:Princeton to JFK 69 | > - 飞机:JFK to Geneva 70 | > - 火车:Geneva to Lausanne 71 | > - 旅行者 = 数据报 datagram 72 | > - 交通段 = 通信链路 communication link 73 | > - 交通模式 = 链路层协议:数据链路层和局域网protocol 74 | > - 票务代理 = 路由算法 routing algorithm 75 | 76 | 链路层服务(一般化的链路层服务,不是所有的链路层都提供这些服务一个特定的链路层只是提供其中一部分的服务(子集)) 77 | - 成帧,链路接入: 78 | - 将数据报封装在帧中,加上帧头、帧尾部 79 | - 如果采用的是共享性介质,信道接入获得信道访问权 80 | - 在帧头部使用“MAC”(物理)地址来标示源和目的 81 | - 不同于IP地址 82 | - 在(一个网络内)相邻两个节点完成可靠数据传递 83 | - 已经学过了(传输层) 84 | - 在低出错率的链路上(光纤和双绞线电缆)很少使用 85 | - 在无线链路经常使用:出错率高 86 | - Q:为什么在链路层和传输层都实现了可靠性 87 | - 在相邻节点间(一个子网内)进行可靠的转发 88 | - 已经学习过(传输层) 89 | - 在低差错链路上很少使用(光纤,一些双绞线) 90 | - 出错率低,没有必要在每一个帧中做差错控制的工作,协议复杂 91 | - 发送端对每一帧进行差错控制编码,根据反馈做相应的动作 92 | - 接收端进行差错控制解码,反馈给发送端(ACK,NAK) 93 | - 在本层放弃可靠控制的工作,在网络层或者是传输层做可靠控制的工作,或者根本就不做可靠控制的工作 94 | - 在高差错链路上需要进行可靠的数据传送 95 | - 高差错链路:无线链路: 96 | - Q:为什么要在采用无线链路的网络上,链路层做可靠数据传输工作;还要在传输层做端到端的可靠性工作? 97 | - 原因:出错率高,如果在链路层不做差错控制工作,漏出去的错误比较高;到了上层如果需要可靠控制的数据传输代价会很大 98 | - 如不做local recovery工作,总体代价大 99 | - 流量控制: 100 | - 使得相邻的发送和接收方节点的速度匹配 101 | - 错误检测: 102 | - 差错由信号衰减和噪声引起 103 | - 接收方检测出的错误: 104 | - 通知发送端进行重传或丢弃帧 105 | - 差错纠正: 106 | - 错误不太严重时,接收端检查和根据网络编码纠正bit错误,不通过重传来纠正错误 107 | - 半双工和全双工: 108 | - 半双工:链路可以双向传输,但一次只有一个方向 109 | 110 | 链路层在哪里实现? 111 | - 在每一个主机上,网卡实现链路层和物理层的功能 112 | - 也在每个路由器上,插多个网卡,实现链路层和相应物理层的功能 113 | - 交换机的每个端口上 114 | - 链路层功能在“适配器”上实现(也叫 network interface card, NIC) 或者在一个芯片组上 115 | - 以太网卡,802.11网卡;以太网芯片组 116 | - 实现链路层和相应的物理层功能 117 | - 接到主机的系统总线上 118 | - 硬件、软件和固件的综合体 119 | 120 |
 121 |
122 | 适配器(网卡)通信
123 | - 发送方:
124 | - 在帧中封装数据报
125 | - 加上差错控制编码,实现RDT和流量控制功能等
126 | - 交给物理层打出
127 | - 接收方
128 | - 从物理层接收bit
129 | - 检查有无出错,执行rdt和流量控制功能等
130 | - 解封装数据报,将帧交给上层
131 |
132 |
121 |
122 | 适配器(网卡)通信
123 | - 发送方:
124 | - 在帧中封装数据报
125 | - 加上差错控制编码,实现RDT和流量控制功能等
126 | - 交给物理层打出
127 | - 接收方
128 | - 从物理层接收bit
129 | - 检查有无出错,执行rdt和流量控制功能等
130 | - 解封装数据报,将帧交给上层
131 |
132 |  133 |
134 | 适配器是半自治的,实现了链路和物理层功能
135 |
136 | ### 6.2 差错检测和纠正
137 |
138 | 错误检测
139 | - EDC = 差错检测和纠正位(冗余位)
140 | - D = 数据由差错检测保护,可以包含头部字段
141 | - 错误检测不是100%可靠的!
142 | - 协议会漏检一些错误,但是很少
143 | - 更长的EDC字段可以得到更好的检测和纠正效果
144 |
145 |
133 |
134 | 适配器是半自治的,实现了链路和物理层功能
135 |
136 | ### 6.2 差错检测和纠正
137 |
138 | 错误检测
139 | - EDC = 差错检测和纠正位(冗余位)
140 | - D = 数据由差错检测保护,可以包含头部字段
141 | - 错误检测不是100%可靠的!
142 | - 协议会漏检一些错误,但是很少
143 | - 更长的EDC字段可以得到更好的检测和纠正效果
144 |
145 |  146 |
147 | 奇偶校验
148 | - 加一个校验位,使得整个出现的1的个数是奇数还是偶数,是奇数->奇校验,是偶数->偶校验
149 |
150 |
146 |
147 | 奇偶校验
148 | - 加一个校验位,使得整个出现的1的个数是奇数还是偶数,是奇数->奇校验,是偶数->偶校验
149 |
150 |  151 |
152 | Internet校验和
153 | - 目标:检测在传输报文段时的错误(如位翻转),(注:仅仅用在传输层)
154 | - 发送方:
155 | - 将报文段看成16-bit整数
156 | - 报文段的校验和:和(1’的补码和)
157 | - 发送方将checksum的值放在“UDP校验和”字段
158 | - 接收方:
159 | - 计算接收到的报文段的校验和
160 | - 检查是否与携带校验和字段值一致:
161 | - 不一致:检出错误
162 | - 一致:没有检出错误,但可能还是有错误
163 | - 有更简单的检查方法 —— 全部加起来看是不是全1
164 |
165 | 检验和:CRC(循环冗余校验)
166 | 1. 模2运算(加法不进位,减法不借位,位和位之间没有关系):同0异1,异或运算
167 | 2. 位串的两种表示:位串 or 多项式 的表示方式
168 | $$1011 \iff 1 * x^3 + 0 * x^2 + 1 * x^1 + 1 * x^0 = x^3 + x + 1$$
169 | 3. 生成多项式:r次方(r+1位)
170 | 4. 约定:在发送方发送的D位数据比特后附上r位的冗余位R(R是余数,具体见下),使得序列正好被生成多项式整除,则没有出错
171 | - 强大的差错检测码
172 | - 将数据比特D,看成是二进制的数据
173 | - 生成多项式G:双方协商r+1位模式(r次方)
174 | - 生成和检查所使用的位模式
175 | - 目标:选择r位CRC附加位R,使得
176 | -
151 |
152 | Internet校验和
153 | - 目标:检测在传输报文段时的错误(如位翻转),(注:仅仅用在传输层)
154 | - 发送方:
155 | - 将报文段看成16-bit整数
156 | - 报文段的校验和:和(1’的补码和)
157 | - 发送方将checksum的值放在“UDP校验和”字段
158 | - 接收方:
159 | - 计算接收到的报文段的校验和
160 | - 检查是否与携带校验和字段值一致:
161 | - 不一致:检出错误
162 | - 一致:没有检出错误,但可能还是有错误
163 | - 有更简单的检查方法 —— 全部加起来看是不是全1
164 |
165 | 检验和:CRC(循环冗余校验)
166 | 1. 模2运算(加法不进位,减法不借位,位和位之间没有关系):同0异1,异或运算
167 | 2. 位串的两种表示:位串 or 多项式 的表示方式
168 | $$1011 \iff 1 * x^3 + 0 * x^2 + 1 * x^1 + 1 * x^0 = x^3 + x + 1$$
169 | 3. 生成多项式:r次方(r+1位)
170 | 4. 约定:在发送方发送的D位数据比特后附上r位的冗余位R(R是余数,具体见下),使得序列正好被生成多项式整除,则没有出错
171 | - 强大的差错检测码
172 | - 将数据比特D,看成是二进制的数据
173 | - 生成多项式G:双方协商r+1位模式(r次方)
174 | - 生成和检查所使用的位模式
175 | - 目标:选择r位CRC附加位R,使得
176 | -  182 |
183 | CRC例子
184 | - 需要: $\text{D} * 2^r \text{ XOR R} = n\text{G}$
185 | - 等价于: $\text{D} * 2^r = n\text{G } \text{XOR R} $
186 | - 等价于:两边同除G,得到余数R
187 | $$R = \text{remainder}[\frac{\text{D} * 2^r}{\text{G}}]$$
188 | 其中 remainder 表示余数运算,当余数R不足r位时进行补0
189 |
190 |
182 |
183 | CRC例子
184 | - 需要: $\text{D} * 2^r \text{ XOR R} = n\text{G}$
185 | - 等价于: $\text{D} * 2^r = n\text{G } \text{XOR R} $
186 | - 等价于:两边同除G,得到余数R
187 | $$R = \text{remainder}[\frac{\text{D} * 2^r}{\text{G}}]$$
188 | 其中 remainder 表示余数运算,当余数R不足r位时进行补0
189 |
190 |  191 |
192 | RC性能分析
193 | - 突发错误和突发长度
194 | - CRC检错性能描述
195 | - 能够检查出所有的1bit错误
196 | - 能够检查出所有的双bits的错误
197 | - 能够检查出所有长度小于等于r位的错误
198 | - 出现长度为r+1的突发错误,检查不出的概率是 $\frac{1}{2^{r-1}}$
199 | - 出现长度大于r+1的突发错误,检查不出的概率是 $\frac{1}{2^r}$
200 |
201 | ### 6.3 多点访问协议
202 |
203 | 点到点不存在多点访问的问题(两个访问端都确定好了),多点连接则需要考虑。
204 |
205 | 多路访问链路和协议
206 | - 两种类型的链路(一个子网内部链路连接形式):
207 | - 点对点
208 | - 拨号访问的PPP
209 | - 以太网交换机和主机之间的点对点链路
210 | - 广播(共享线路或媒体),也称为多点连接的网络
211 | - 传统以太网(同轴电缆连接所有节点,所有节点通过比较MAC地址确认帧发送的目标地址)
212 | - HFC上行链路
213 | - 802.11无线局域网
214 |
215 | 多路访问协议(介质访问控制协议:MAC)
216 | - 单个共享的广播型链路
217 | - 2个或更多站点同时传送:冲突(collision)
218 | - 多个节点在同一个时刻发送,则会收到2个或多个信号叠加
219 | - 分布式算法-决定节点如何使用共享信道,即:决定节点什么时候可以发送?
220 | - 关于共享控制的通信必须用借助信道本身传输!
221 | - 没有带外的信道,只有这一个信道,各节点使用其协调信道使用
222 | - 用于传输控制信息
223 |
224 | 理想的多路访问协议
225 | - 给定:Rbps的广播信道
226 | - 必要条件:
227 | 1. 当一个节点要发送时,可以R速率发送 —— 满速。
228 | 2. 当M个节点要发送,每个可以以R/M的平均速率发送 —— 公平、均分
229 | 3. 完全分布的:
230 | - 没有特殊节点协调发送
231 | - 没有时钟和时隙的同步
232 | 4. 简单
233 |
234 | MAC(媒体访问控制)协议:分类:3大类:
235 | - 信道划分(partition)
236 | - 把信道划分成小片(时间、频率、编码)
237 | - 分配片给每个节点专用
238 | - 随机访问(random):“想用就用”
239 | - 信道不划分,允许冲突/碰撞
240 | - 检测冲突,冲突后恢复
241 | - 依次轮流:分为 完全分布式的(令牌方式) 和 主节点协调式的(主节点轮流询问)
242 | - 节点依次轮流
243 | - 但是有很多数据传输的节点可以获得较长的信道使用权
244 |
245 | a. 信道划分MAC协议
246 | - TDMA(time division multiple access)分时复用
247 | - 轮流使用信道,信道的时间分为周期
248 | - 每个站点使用每周期中固定的时隙(长度=帧传输时间)传输帧
249 | - 如果站点无帧传输,时隙空闲->浪费
250 | - 如:6站LAN,1、3、4有数据报,时隙2、5、6空闲
251 | - FDMA(frequency division multiple access)频分复用
252 | - 信道的有效频率范围被分成一个个小的频段
253 | - 每个站点被分配一个固定的频段
254 | - 分配给站点的频段如果没有被使用,则空闲
255 | - 例如:6站LAN,1、3、4有数据报,频段2、5、6空闲
256 | - CDMA(code division multiple access)码分复用
257 | - 有站点在整个频段上同时进行传输,采用编码原理加以区分
258 | - 完全无冲突
259 | - 假定:信号同步很好,线性叠加
260 | - 比方
261 | - TDM:不同的人在不同的时刻讲话
262 | - FDM:不同的组在不同的小房间里通信
263 | - CDMA:不同的人使用不同的语言讲话
264 |
265 | b. 随机存取协议
266 | - 当节点有帧要发送时
267 | - 以信道带宽的全部Rbps发送
268 | - 没有节点间的预先协调
269 | - 两个或更多节点同时传输,会发生->冲突“collision”
270 | - 随机存取协议规定:
271 | - 如何检测冲突
272 | - 如何从冲突中恢复(如:通过稍后的重传)
273 | - 随机MAC协议:
274 | - 时隙ALOHA
275 | - 纯ALOHA(非时隙)
276 | - CSMA, CSMA/CD, CSMA/CA
277 |
278 | b.1 时隙ALOHA
279 | - 假设
280 | - 所有帧是等长的,能够持续一个时隙
281 | - 时间被划分成相等的时隙/时槽,每个时隙可发送一帧
282 | - 节点只在时隙开始时发送帧
283 | - 共享信道的所有节点在时钟上是同步的
284 | - 如果两个或多个节点在一个时隙传输,所有的站点都能检测到冲突
285 | - 运行
286 | - 当节点获取新的帧,在下一个时隙传输
287 | - 传输时没有检测到冲突(可从信道内的信息能量的幅度判断),成功
288 | - 节点能够在下一时隙发送新帧
289 | - 检测时如果检测到冲突,失败
290 | - 节点在每一个随后的时隙以概率p重传帧直到成功(可能仍然发生冲突,但是时间越长,冲突概率越低)
291 | - 优点
292 | - 节点可以以信道带宽全速连续传输
293 | - 高度分布:仅需要节点之间在时隙上的同步
294 | - 简单
295 | - 缺点
296 | - 存在冲突,浪费时隙
297 | - 即使有帧要发送,仍然有可能存在空闲的时隙
298 | - 节点检测冲突的时间 小于 帧传输的时间
299 | - 必须传完
300 | - 需要时钟上同步
301 |
302 | 时隙ALOHA的效率(Efficiency)
303 | 注:效率:当有很多节点,每个节点有很多帧要发送时,x%的时隙是成功传输帧的时隙
304 | - 假设N个节点,每个节点都有很多帧要发送,在每个时隙中的传输概率是 $p$
305 | - 一个节点成功传输概率是 $p(1-p)^{N-1}$
306 | - 任何一个节点的成功概率是 $N * p(1-p)^{N-1}$
307 | - $N$ 个节点的最大效率:求出使 $f(P) = N * p(1-p)^{N-1}$ 最大的 $p^{ * }$
308 | - 代入 $p^{ * }$ 得到最大 $f(p^{ * }) = N * p^{ * }(1-p^{ * })^{N-1}$
309 | - $N$ 为无穷大时的极限为 $1/e=0.37$ ,即最好情况:信道利用率 $37$ %
310 |
311 | b.2 纯ALOHA(非时隙):数据帧一形成立即发送
312 | - 无时隙ALOHA:简单、无须节点间在时间上同步
313 | - 当有帧需要传输:马上传输
314 | - 冲突的概率增加:
315 | - 帧在 $t_0$发送,和其它在 $[t_0-1, t_0+1]$ 区间内开始发送的帧冲突
316 | - 和当前帧冲突的区间(其他帧在此区间开始传输)增大了一倍
317 |
318 | 纯ALOHA的效率
319 |
320 | $$
321 | \begin{split}
322 | P(\text{指定节点成功}) &= P(\text{节点传输}) \times \\
323 | &\quad P(\text{其它节点在 $[t_0-1, t_0]$ 不传}) \times \\
324 | &\quad P(\text{其它节点在 $[t_0, t_0+1\text{不传}]$ }) \\
325 | &= p(1-p)^{N-1}(1-p)^{N-1} \\
326 | &= p(1-p)^{2(N-1)}
327 | \end{split}
328 | $$
329 |
330 | 选择最佳的 $p$ 且 $N$ 趋向无穷大时,效率为 $1/(2e) = 17.5$ %,效率比时隙ALOHA更差了!
331 |
332 | 如何提升 纯ALOHA 的效率?CSMA
333 |
334 | b.3 CSMA(载波侦听多路访问) —— “说之前听”
335 | - Aloha:如何提高ALOHA的效率
336 | - 发之前不管有无其他节点在传输
337 | - CSMA:在传输前先侦听信道:
338 | - 如果侦听到信道空闲,传送整个帧
339 | - 如果侦听到信道忙,推迟传送
340 | - 人类类比:不要打断别人正在进行的说话!
341 |
342 | CSMA冲突
343 | - 冲突仍然可能发生:
344 | - 由传播延迟造成:两个节点可能侦听不到正在进行的传输
345 | - 冲突:
346 | - 整个冲突帧的传输时间都被浪费了,是无效的传输
347 | - 注意:
348 | - 传播延迟(距离)决定了冲突的概率
349 |
350 | 本质上是节点依据本地的信道使用情况来判断全部信道的使用情况。
351 | 距离越远,延时越大,发生冲突的可能性就越大
352 |
353 | 可以改进CSMA --> CSMA/CD(目前有形介质的局域网如“以太网”采用的方式
354 |
355 | b.4 CSMA/CD(冲突检测) —— “边说边听”
356 | - 载波侦听CSMA:和在CSMA中一样发送前侦听信道
357 | - 没有传完一个帧就可以在短时间内检测到冲突
358 | - 冲突发生时则传输终止,减少对信道的浪费
359 | - 冲突检测CD技术,有线局域网中容易实现:
360 | - 检测信号强度,比较传输与接收到的信号是否相同
361 | - 通过周期的过零点检测
362 | - 人类类比:礼貌的对话人
363 |
364 |
191 |
192 | RC性能分析
193 | - 突发错误和突发长度
194 | - CRC检错性能描述
195 | - 能够检查出所有的1bit错误
196 | - 能够检查出所有的双bits的错误
197 | - 能够检查出所有长度小于等于r位的错误
198 | - 出现长度为r+1的突发错误,检查不出的概率是 $\frac{1}{2^{r-1}}$
199 | - 出现长度大于r+1的突发错误,检查不出的概率是 $\frac{1}{2^r}$
200 |
201 | ### 6.3 多点访问协议
202 |
203 | 点到点不存在多点访问的问题(两个访问端都确定好了),多点连接则需要考虑。
204 |
205 | 多路访问链路和协议
206 | - 两种类型的链路(一个子网内部链路连接形式):
207 | - 点对点
208 | - 拨号访问的PPP
209 | - 以太网交换机和主机之间的点对点链路
210 | - 广播(共享线路或媒体),也称为多点连接的网络
211 | - 传统以太网(同轴电缆连接所有节点,所有节点通过比较MAC地址确认帧发送的目标地址)
212 | - HFC上行链路
213 | - 802.11无线局域网
214 |
215 | 多路访问协议(介质访问控制协议:MAC)
216 | - 单个共享的广播型链路
217 | - 2个或更多站点同时传送:冲突(collision)
218 | - 多个节点在同一个时刻发送,则会收到2个或多个信号叠加
219 | - 分布式算法-决定节点如何使用共享信道,即:决定节点什么时候可以发送?
220 | - 关于共享控制的通信必须用借助信道本身传输!
221 | - 没有带外的信道,只有这一个信道,各节点使用其协调信道使用
222 | - 用于传输控制信息
223 |
224 | 理想的多路访问协议
225 | - 给定:Rbps的广播信道
226 | - 必要条件:
227 | 1. 当一个节点要发送时,可以R速率发送 —— 满速。
228 | 2. 当M个节点要发送,每个可以以R/M的平均速率发送 —— 公平、均分
229 | 3. 完全分布的:
230 | - 没有特殊节点协调发送
231 | - 没有时钟和时隙的同步
232 | 4. 简单
233 |
234 | MAC(媒体访问控制)协议:分类:3大类:
235 | - 信道划分(partition)
236 | - 把信道划分成小片(时间、频率、编码)
237 | - 分配片给每个节点专用
238 | - 随机访问(random):“想用就用”
239 | - 信道不划分,允许冲突/碰撞
240 | - 检测冲突,冲突后恢复
241 | - 依次轮流:分为 完全分布式的(令牌方式) 和 主节点协调式的(主节点轮流询问)
242 | - 节点依次轮流
243 | - 但是有很多数据传输的节点可以获得较长的信道使用权
244 |
245 | a. 信道划分MAC协议
246 | - TDMA(time division multiple access)分时复用
247 | - 轮流使用信道,信道的时间分为周期
248 | - 每个站点使用每周期中固定的时隙(长度=帧传输时间)传输帧
249 | - 如果站点无帧传输,时隙空闲->浪费
250 | - 如:6站LAN,1、3、4有数据报,时隙2、5、6空闲
251 | - FDMA(frequency division multiple access)频分复用
252 | - 信道的有效频率范围被分成一个个小的频段
253 | - 每个站点被分配一个固定的频段
254 | - 分配给站点的频段如果没有被使用,则空闲
255 | - 例如:6站LAN,1、3、4有数据报,频段2、5、6空闲
256 | - CDMA(code division multiple access)码分复用
257 | - 有站点在整个频段上同时进行传输,采用编码原理加以区分
258 | - 完全无冲突
259 | - 假定:信号同步很好,线性叠加
260 | - 比方
261 | - TDM:不同的人在不同的时刻讲话
262 | - FDM:不同的组在不同的小房间里通信
263 | - CDMA:不同的人使用不同的语言讲话
264 |
265 | b. 随机存取协议
266 | - 当节点有帧要发送时
267 | - 以信道带宽的全部Rbps发送
268 | - 没有节点间的预先协调
269 | - 两个或更多节点同时传输,会发生->冲突“collision”
270 | - 随机存取协议规定:
271 | - 如何检测冲突
272 | - 如何从冲突中恢复(如:通过稍后的重传)
273 | - 随机MAC协议:
274 | - 时隙ALOHA
275 | - 纯ALOHA(非时隙)
276 | - CSMA, CSMA/CD, CSMA/CA
277 |
278 | b.1 时隙ALOHA
279 | - 假设
280 | - 所有帧是等长的,能够持续一个时隙
281 | - 时间被划分成相等的时隙/时槽,每个时隙可发送一帧
282 | - 节点只在时隙开始时发送帧
283 | - 共享信道的所有节点在时钟上是同步的
284 | - 如果两个或多个节点在一个时隙传输,所有的站点都能检测到冲突
285 | - 运行
286 | - 当节点获取新的帧,在下一个时隙传输
287 | - 传输时没有检测到冲突(可从信道内的信息能量的幅度判断),成功
288 | - 节点能够在下一时隙发送新帧
289 | - 检测时如果检测到冲突,失败
290 | - 节点在每一个随后的时隙以概率p重传帧直到成功(可能仍然发生冲突,但是时间越长,冲突概率越低)
291 | - 优点
292 | - 节点可以以信道带宽全速连续传输
293 | - 高度分布:仅需要节点之间在时隙上的同步
294 | - 简单
295 | - 缺点
296 | - 存在冲突,浪费时隙
297 | - 即使有帧要发送,仍然有可能存在空闲的时隙
298 | - 节点检测冲突的时间 小于 帧传输的时间
299 | - 必须传完
300 | - 需要时钟上同步
301 |
302 | 时隙ALOHA的效率(Efficiency)
303 | 注:效率:当有很多节点,每个节点有很多帧要发送时,x%的时隙是成功传输帧的时隙
304 | - 假设N个节点,每个节点都有很多帧要发送,在每个时隙中的传输概率是 $p$
305 | - 一个节点成功传输概率是 $p(1-p)^{N-1}$
306 | - 任何一个节点的成功概率是 $N * p(1-p)^{N-1}$
307 | - $N$ 个节点的最大效率:求出使 $f(P) = N * p(1-p)^{N-1}$ 最大的 $p^{ * }$
308 | - 代入 $p^{ * }$ 得到最大 $f(p^{ * }) = N * p^{ * }(1-p^{ * })^{N-1}$
309 | - $N$ 为无穷大时的极限为 $1/e=0.37$ ,即最好情况:信道利用率 $37$ %
310 |
311 | b.2 纯ALOHA(非时隙):数据帧一形成立即发送
312 | - 无时隙ALOHA:简单、无须节点间在时间上同步
313 | - 当有帧需要传输:马上传输
314 | - 冲突的概率增加:
315 | - 帧在 $t_0$发送,和其它在 $[t_0-1, t_0+1]$ 区间内开始发送的帧冲突
316 | - 和当前帧冲突的区间(其他帧在此区间开始传输)增大了一倍
317 |
318 | 纯ALOHA的效率
319 |
320 | $$
321 | \begin{split}
322 | P(\text{指定节点成功}) &= P(\text{节点传输}) \times \\
323 | &\quad P(\text{其它节点在 $[t_0-1, t_0]$ 不传}) \times \\
324 | &\quad P(\text{其它节点在 $[t_0, t_0+1\text{不传}]$ }) \\
325 | &= p(1-p)^{N-1}(1-p)^{N-1} \\
326 | &= p(1-p)^{2(N-1)}
327 | \end{split}
328 | $$
329 |
330 | 选择最佳的 $p$ 且 $N$ 趋向无穷大时,效率为 $1/(2e) = 17.5$ %,效率比时隙ALOHA更差了!
331 |
332 | 如何提升 纯ALOHA 的效率?CSMA
333 |
334 | b.3 CSMA(载波侦听多路访问) —— “说之前听”
335 | - Aloha:如何提高ALOHA的效率
336 | - 发之前不管有无其他节点在传输
337 | - CSMA:在传输前先侦听信道:
338 | - 如果侦听到信道空闲,传送整个帧
339 | - 如果侦听到信道忙,推迟传送
340 | - 人类类比:不要打断别人正在进行的说话!
341 |
342 | CSMA冲突
343 | - 冲突仍然可能发生:
344 | - 由传播延迟造成:两个节点可能侦听不到正在进行的传输
345 | - 冲突:
346 | - 整个冲突帧的传输时间都被浪费了,是无效的传输
347 | - 注意:
348 | - 传播延迟(距离)决定了冲突的概率
349 |
350 | 本质上是节点依据本地的信道使用情况来判断全部信道的使用情况。
351 | 距离越远,延时越大,发生冲突的可能性就越大
352 |
353 | 可以改进CSMA --> CSMA/CD(目前有形介质的局域网如“以太网”采用的方式
354 |
355 | b.4 CSMA/CD(冲突检测) —— “边说边听”
356 | - 载波侦听CSMA:和在CSMA中一样发送前侦听信道
357 | - 没有传完一个帧就可以在短时间内检测到冲突
358 | - 冲突发生时则传输终止,减少对信道的浪费
359 | - 冲突检测CD技术,有线局域网中容易实现:
360 | - 检测信号强度,比较传输与接收到的信号是否相同
361 | - 通过周期的过零点检测
362 | - 人类类比:礼貌的对话人
363 |
364 |  365 |
366 | 以太网CSMA/CD算法
367 | 1. 适配器获取数据报,创建帧
368 | 2. 发送前:侦听信道CS
369 | - 闲:开始传送帧
370 | - 忙:一直等到闲再发送
371 | 3. 发送过程中,冲突检测CD
372 | - 没有冲突:成功
373 | - 检测到冲突:放弃,之后尝试重发
374 | 4. 发送方适配器检测到冲突,除放弃外,还发送一个Jam信号,所有听到冲突的适配器也是如此
375 | - 强化冲突:让所有站点都知道冲突(如何实现:信号强度大,持续时间长) 强化冲突的原因:放弃的信号可能持续时间很短,其他节点可能会接收不到,认为没有发生冲突,导致接受失败
376 | 5. 如果放弃,适配器进入指数退避状态 *exponential backoff 二进制指数退避算法*
377 | - 在第m次失败后,适配器随机选择一个{ 0,1,2,……,2^m-1}中的K,等待K*512位时,然后转到步骤2
378 | - 此时若两个站点继续选择了同一个K,则在K*512位时两者又同时重发,又会产生冲突
379 | - 随着m的增大,成功的概率越来越大,但是平均等待时间会变长
380 | - 注:指数退避:
381 | - 目标:适配器试图适应当前负载(自适应算法),在一个变化的碰撞窗口中随机选择时间点尝试重发
382 | - 高负载(重传节点多):重传窗口时间大,减少冲突,但等待时间长
383 | - 低负载(重传节点少):使得各站点等待时间少,但冲突概率大
384 |
385 | CSMA/CD效率
386 | - $t_{prop}$ 为LAN上2个节点的最大传播延迟
387 | - $t_{trans}$ 为传输最大帧的时间
388 | - 则:
389 |
390 | $$ efficiency = \frac{1}{1 + 5 * t_{prop} / t_{trans}} $$
391 |
392 | - 效率变为 $1$ :
393 | - 当 $t_{prop}$ 变成 $0$ 时
394 | - 当 $t_{trans}$ 变成无穷大时
395 | - 比ALOHA更好的性能,而且简单,廉价,分布式!
396 |
397 | b.5 无线局域网CSMA/CA
398 |
399 | WLAN由于是无线形式,更加倾向于选择CSMA/CA
400 |
401 |
365 |
366 | 以太网CSMA/CD算法
367 | 1. 适配器获取数据报,创建帧
368 | 2. 发送前:侦听信道CS
369 | - 闲:开始传送帧
370 | - 忙:一直等到闲再发送
371 | 3. 发送过程中,冲突检测CD
372 | - 没有冲突:成功
373 | - 检测到冲突:放弃,之后尝试重发
374 | 4. 发送方适配器检测到冲突,除放弃外,还发送一个Jam信号,所有听到冲突的适配器也是如此
375 | - 强化冲突:让所有站点都知道冲突(如何实现:信号强度大,持续时间长) 强化冲突的原因:放弃的信号可能持续时间很短,其他节点可能会接收不到,认为没有发生冲突,导致接受失败
376 | 5. 如果放弃,适配器进入指数退避状态 *exponential backoff 二进制指数退避算法*
377 | - 在第m次失败后,适配器随机选择一个{ 0,1,2,……,2^m-1}中的K,等待K*512位时,然后转到步骤2
378 | - 此时若两个站点继续选择了同一个K,则在K*512位时两者又同时重发,又会产生冲突
379 | - 随着m的增大,成功的概率越来越大,但是平均等待时间会变长
380 | - 注:指数退避:
381 | - 目标:适配器试图适应当前负载(自适应算法),在一个变化的碰撞窗口中随机选择时间点尝试重发
382 | - 高负载(重传节点多):重传窗口时间大,减少冲突,但等待时间长
383 | - 低负载(重传节点少):使得各站点等待时间少,但冲突概率大
384 |
385 | CSMA/CD效率
386 | - $t_{prop}$ 为LAN上2个节点的最大传播延迟
387 | - $t_{trans}$ 为传输最大帧的时间
388 | - 则:
389 |
390 | $$ efficiency = \frac{1}{1 + 5 * t_{prop} / t_{trans}} $$
391 |
392 | - 效率变为 $1$ :
393 | - 当 $t_{prop}$ 变成 $0$ 时
394 | - 当 $t_{trans}$ 变成无穷大时
395 | - 比ALOHA更好的性能,而且简单,廉价,分布式!
396 |
397 | b.5 无线局域网CSMA/CA
398 |
399 | WLAN由于是无线形式,更加倾向于选择CSMA/CA
400 |
401 |  402 |
403 | 无线局域网中的 MAC:CSMA/CA —— 冲突控制
404 | - 冲突: $2^+$ 站点(AP或者站点)在同一个时刻发送
405 | - 802.11:CSMA —— 发送前侦听信道,实现事先避免冲突
406 | - 不会和其它节点正在进行的传输发生冲突
407 | - 802.11:没有冲突检测!
408 | - 无法检测冲突:自身信号远远大于其他节点信号(无线情况下,电磁波信号成平方反比衰减)
409 | - 即使能CD:不冲突 $\neq$ 成功 (有 隐藏终端 的问题:A的电磁波信号到达B时,C与A的距离比B与A的距离远,故此时电磁波到达不了C,即检测不到冲突,但是B周边会有A、C的电磁波的叠加干扰),同时 冲突 $\neq$ 不成功
410 | - 目标:avoid collisions:CSMA/C(ollision)A(voidance)
411 | - 无法CD,一旦发送一股脑全部发送完毕,不CD
412 | - 为了避免无CD带来的信道利用率低的问题,事前进行冲突避免
413 |
414 | 无线局域网:CSMA/CA
415 | - 发送方
416 | - 如果站点侦测到信道空闲持续DIFS长,则传输整个帧 (no CD)
417 | - 如果侦测到信道忙碌,那么 选择一个随机回退值,并在信道空闲时递减该值;如果信道忙碌,回退值不会变化;到数到0时(只生在信道闲时)发送整个帧。如果没有收到ACK,增加回退值,重复这段的整个过程
418 | - 802.11 接收方
419 | - 如果帧正确,则在SIFS后发送ACK
420 |
421 | (无线链路特性,需要每帧确认(有线网由于边发边确认,不需要接收ACK信息就可以知道是否发送成功);例如:由于隐藏终端问题,在接收端可能形成干扰,接收方没有正确地收到。链路层可靠机制)
422 |
423 | IEEE 802.11 MAC 协议: CSMA/CA
424 | - 在count down时,侦听到了信道空闲为什么不发送,而要等到0时在发送?以下例子可以很好地说明这一点
425 | - 2个站点有数据帧需要发送,第三个节点正在发送
426 | - LAN CD:让2者听完第三个节点发完,立即发送
427 | - 冲突:放弃当前的发送,避免了信道的浪费于无用冲突帧的发送
428 | - 代价不昂贵
429 | - WLAN:CA
430 | - 无法CD,一旦发送就必须发完,如冲突信道浪费严重,代价高昂
431 | - 思想:尽量事先避免冲突,而不是在发生冲突时放弃然后重发
432 | - 听到发送的站点,分别选择随机值,回退到0发送
433 | - 不同的随机值,一个站点会胜利
434 | - 失败站点会冻结计数器,当胜利节点发完再发
435 | - 无法完全避免冲突
436 | - 两个站点相互隐藏:
437 | - A,B 相互隐藏,C在传输
438 | - A,B选择了随机回退值
439 | - 一个节点如A胜利了,发送
440 | - 而B节点收不到,顺利count down到0 发送
441 | - A,B的发送在C附近形成了干扰
442 | - 选择了非常靠近的随机回退值:
443 | - A,B选择的值非常近
444 | - A到0后发送
445 | - 但是这个信号还没到达B时
446 | - B也到0了,发送
447 | - 冲突
448 |
449 | 冲突避免:RTS-CTS交换 —— 对长帧的可选项
450 | - 思想:允许发送方“预约”信道,而不是随机访问该信道:避免长数据帧的冲突(可选项)
451 | - 发送方首先使用CSMA向BS发送一个小的RTS分组
452 | - RTS可能会冲突(但是由于比较短,浪费信道较少)
453 | - BS广播 clear-to-send CTS,作为RTS的响应
454 | - CTS能够被所有涉及到的节点听到
455 | - 发送方发送数据帧
456 | - 其它节点抑制发送
457 |
458 | 采用小的预约分组,可以完全避免数据帧的冲突
459 |
460 |
402 |
403 | 无线局域网中的 MAC:CSMA/CA —— 冲突控制
404 | - 冲突: $2^+$ 站点(AP或者站点)在同一个时刻发送
405 | - 802.11:CSMA —— 发送前侦听信道,实现事先避免冲突
406 | - 不会和其它节点正在进行的传输发生冲突
407 | - 802.11:没有冲突检测!
408 | - 无法检测冲突:自身信号远远大于其他节点信号(无线情况下,电磁波信号成平方反比衰减)
409 | - 即使能CD:不冲突 $\neq$ 成功 (有 隐藏终端 的问题:A的电磁波信号到达B时,C与A的距离比B与A的距离远,故此时电磁波到达不了C,即检测不到冲突,但是B周边会有A、C的电磁波的叠加干扰),同时 冲突 $\neq$ 不成功
410 | - 目标:avoid collisions:CSMA/C(ollision)A(voidance)
411 | - 无法CD,一旦发送一股脑全部发送完毕,不CD
412 | - 为了避免无CD带来的信道利用率低的问题,事前进行冲突避免
413 |
414 | 无线局域网:CSMA/CA
415 | - 发送方
416 | - 如果站点侦测到信道空闲持续DIFS长,则传输整个帧 (no CD)
417 | - 如果侦测到信道忙碌,那么 选择一个随机回退值,并在信道空闲时递减该值;如果信道忙碌,回退值不会变化;到数到0时(只生在信道闲时)发送整个帧。如果没有收到ACK,增加回退值,重复这段的整个过程
418 | - 802.11 接收方
419 | - 如果帧正确,则在SIFS后发送ACK
420 |
421 | (无线链路特性,需要每帧确认(有线网由于边发边确认,不需要接收ACK信息就可以知道是否发送成功);例如:由于隐藏终端问题,在接收端可能形成干扰,接收方没有正确地收到。链路层可靠机制)
422 |
423 | IEEE 802.11 MAC 协议: CSMA/CA
424 | - 在count down时,侦听到了信道空闲为什么不发送,而要等到0时在发送?以下例子可以很好地说明这一点
425 | - 2个站点有数据帧需要发送,第三个节点正在发送
426 | - LAN CD:让2者听完第三个节点发完,立即发送
427 | - 冲突:放弃当前的发送,避免了信道的浪费于无用冲突帧的发送
428 | - 代价不昂贵
429 | - WLAN:CA
430 | - 无法CD,一旦发送就必须发完,如冲突信道浪费严重,代价高昂
431 | - 思想:尽量事先避免冲突,而不是在发生冲突时放弃然后重发
432 | - 听到发送的站点,分别选择随机值,回退到0发送
433 | - 不同的随机值,一个站点会胜利
434 | - 失败站点会冻结计数器,当胜利节点发完再发
435 | - 无法完全避免冲突
436 | - 两个站点相互隐藏:
437 | - A,B 相互隐藏,C在传输
438 | - A,B选择了随机回退值
439 | - 一个节点如A胜利了,发送
440 | - 而B节点收不到,顺利count down到0 发送
441 | - A,B的发送在C附近形成了干扰
442 | - 选择了非常靠近的随机回退值:
443 | - A,B选择的值非常近
444 | - A到0后发送
445 | - 但是这个信号还没到达B时
446 | - B也到0了,发送
447 | - 冲突
448 |
449 | 冲突避免:RTS-CTS交换 —— 对长帧的可选项
450 | - 思想:允许发送方“预约”信道,而不是随机访问该信道:避免长数据帧的冲突(可选项)
451 | - 发送方首先使用CSMA向BS发送一个小的RTS分组
452 | - RTS可能会冲突(但是由于比较短,浪费信道较少)
453 | - BS广播 clear-to-send CTS,作为RTS的响应
454 | - CTS能够被所有涉及到的节点听到
455 | - 发送方发送数据帧
456 | - 其它节点抑制发送
457 |
458 | 采用小的预约分组,可以完全避免数据帧的冲突
459 |
460 |  461 |
462 | b.6 线缆接入网络 —— 有线电视公司提供
463 |
464 | - 多个40Mbps下行(广播)信道,FDM
465 | - 下行:通过FDM分成若干信道,互联网、数字电视等
466 | - 互联网信道:只有1个用户(不存在竞争) —— CMTS在其上传输,将数据往下放
467 | - 多个30Mbps上行的信道,FDM
468 | - 多路访问:所有用户使用;接着TDM分成微时隙
469 | - 部分时隙:分配(预约);部分时隙:竞争;
470 |
471 | DOCSIS:data over cable service interface spec
472 | - 采用FDM进行信道的划分:若干上行、下行信道
473 | - 下行信道:
474 | - 在下行MAP帧中:CMTS告诉各节点微时隙分配方案,分配给各站点的上行微时隙
475 | - 另外:头端传输下行数据(给各个用户)
476 | - TDM上行信道
477 | - 采用TDM的方式将上行信道分成若干微时隙:MAP指定
478 | - 站点采用分配给它的微时隙上行数据传输:分配
479 | - 在特殊的上行微时隙中,各站点请求上行微时隙:竞争
480 | - 各站点对于该时隙的使用是随机访问的
481 | - 一旦碰撞(请求不成功,结果是:在下行的MAP中没有为它分配,则二进制退避)选择时隙上传输
482 |
483 | c. 轮流(Taking Turns)MAC协议
484 | - 信道划分MAC协议:固定分配、平分
485 | - 共享信道在高负载时是有效和公平的
486 | - 在低负载时效率低下
487 | - 只能等到自己的时隙开始发送或者利用1/N的信道频率发送
488 | - 当只有一个节点有帧传时,也只能够得到1/N个带宽分配
489 | - 随机访问MAC协议
490 | - 在低负载时效率高:单个节点可以完全利用信道全部带宽
491 | - 高负载时:冲突开销较大,效率极低,时间很多浪费在冲突中
492 | - 轮流协议
493 | - 有2者的优点
494 | - 缺点:复杂
495 |
496 | 轮流MAC协议
497 | - 轮询:(本身有一个主节点)
498 | - 主节点邀请从节点依次传送
499 | - 从节点一般比较“dumb”
500 | - 缺点:
501 | - 轮询开销:轮询本身消耗信道带宽
502 | - 等待时间:每个节点需等到主节点轮询后开始传输,即使只有一个节点,也需要等到轮询一周后才能够发送
503 | - 单点故障 <-- 本身可靠性差:主节点失效时造成整个系统无法工作
504 | - 令牌传递:(没有主节点)
505 | - 控制令牌(token)循环从一个节点到下一个节点传递 (“击鼓传花”)。如果令牌到达的节点需要发送信息,就将令牌位置位为0,将令牌帧变为数据帧,发送的数据绕行一周后再由自己收下(为什么不是由目标节点收下?“一发多收”,目标节点有多个,如果由目标节点收下会导致后面的目标节点收不到,所以需要轮转一圈,确认经过了所有节点后由自己收下)
506 | - 令牌报文:特殊的帧
507 | - 缺点:
508 | - 令牌开销:本身消耗带宽
509 | - 延迟:只有等到抓住令牌,才可传输
510 | - 单点故障(token):
511 | - 令牌丢失系统级故障,整个系统无法传输
512 | - 复杂机制重新生成令牌
513 |
514 | MAC协议总结
515 | - 多点接入问题:对于一个共享型介质,各个节点如何协调对它的访问和使用?
516 | - 信道划分:按时间、频率或者编码
517 | - TDMA、FDMA、CDMA
518 | - 随机访问(动态)
519 | - ALOHA, S-ALOHA, CSMA, CSMA/CD
520 | - 载波侦听:在有些介质上很容易(wire:有线介质),但在有些介质上比较困难(wireless:无线)
521 | - CSMA/CD:802.3 Ethernet网中使用
522 | - CSMA/CA:802.11WLAN中使用
523 | - 依次轮流协议
524 | - 集中:由一个中心节点轮询;分布:通过令牌控制
525 | - 蓝牙、FDDI、令牌环
526 |
527 | ### 6.4 LANS
528 |
529 | #### 6.4.1 addressing, ARP
530 |
531 | - MAC地址和ARP
532 | - 32bit IP地址:
533 | - 网络层地址
534 | - 前n-1跳:用于使数据报到达目的IP子网 —— IP地址的网络号部分
535 | - 最后一跳:到达子网中的目标节点 —— IP地址的主机号部分
536 | - LAN(MAC/物理/以太网)地址:
537 | - 用于使帧从一个网卡传递到与其物理连接的另一个网卡(在同一个物理网络中)
538 | - 48bit MAC地址固化在适配器的ROM,有时也可以通过软件设定
539 | - 理论上全球任何2个网卡的MAC地址都不相同
540 | - e.g., 1A-2F-BB-76-09-AD <-- 16进制表示(每一位代表4个bits)
541 |
542 | 网络地址和mac地址分离
543 | - IP地址和MAC地址的作用不同
544 | - a) IP地址是分层的
545 | - 一个子网所有站点网络号一致,路由聚集,减少路由表
546 | - 需要一个网络中的站点地址网络号一致,如果捆绑需要定制网卡非常麻烦
547 | - 希望网络层地址是配置的;IP地址完成网络到网络的交付
548 | - b) mac地址是一个平面的
549 | - 网卡在生产时不知道被用于哪个网络,因此给网卡一个唯一的标示,用于区分一个网络内部不同的网卡即可
550 | - 可以完成一个物理网络内部的节点到节点的数据交付网络地址和mac地址分离
551 | - 分离好处
552 | - a) 网卡坏了,ip不变,可以捆绑到另外一个网卡的mac上
553 | - b) 物理网络还可以除IP之外支持其他网络层协议,链路协议为任意上层网络协议,如IPX等
554 | - 捆绑的问题
555 | - a) 如果仅仅使用IP地址,不用mac地址,那么它仅支持IP协议
556 | - b) 每次上电都要重新写入网卡IP地址;
557 | - c) 另外一个选择就是不使用任何地址;不用MAC地址,则每到来一个帧都要上传到IP层次,由它判断是不是需要接受,干扰一次
558 |
559 | > 假设网络上要将一个数据包(名为PAC)由北京的一台主机(名称为A,IP地址为IP_A,MAC地址为MAC_A)发送到华盛顿的一台主机(名称为B,IP地址为IP_B,MAC地址为MAC_B)。
560 | > 这两台主机之间不可能是直接连接起来的,因而数据包在传递时必然要经过许多中间节点(如路由器,服务器等等),我们假定在传输过程中要经过C1、C2、C3(其MAC地址分别为M1,M2,M3)三个节点。
561 | > A在将PAC发出之前,先发送一个ARP请求,找到其要到达IP_B所必须经历的第一个中间节点C1的MAC地址M1,然后在其数据包中封装(Encapsulation)这些地址:IP_A、IP_B,MAC_A和M1。当PAC传到C1后,再由ARP根据其目的IP地址IP_B,找到其要经历的第二个中间节点C2的MAC地址M2,然后再将带有M2的数据包传送到C2。如此类推,直到最后找到带有IP地址为IP_B的B主机的地址MAC_B,最终传送给主机B。
562 |
563 | LAN地址和ARP
564 | - 局域网上每个适配器都有一个唯一的LAN地址
565 |
566 |
461 |
462 | b.6 线缆接入网络 —— 有线电视公司提供
463 |
464 | - 多个40Mbps下行(广播)信道,FDM
465 | - 下行:通过FDM分成若干信道,互联网、数字电视等
466 | - 互联网信道:只有1个用户(不存在竞争) —— CMTS在其上传输,将数据往下放
467 | - 多个30Mbps上行的信道,FDM
468 | - 多路访问:所有用户使用;接着TDM分成微时隙
469 | - 部分时隙:分配(预约);部分时隙:竞争;
470 |
471 | DOCSIS:data over cable service interface spec
472 | - 采用FDM进行信道的划分:若干上行、下行信道
473 | - 下行信道:
474 | - 在下行MAP帧中:CMTS告诉各节点微时隙分配方案,分配给各站点的上行微时隙
475 | - 另外:头端传输下行数据(给各个用户)
476 | - TDM上行信道
477 | - 采用TDM的方式将上行信道分成若干微时隙:MAP指定
478 | - 站点采用分配给它的微时隙上行数据传输:分配
479 | - 在特殊的上行微时隙中,各站点请求上行微时隙:竞争
480 | - 各站点对于该时隙的使用是随机访问的
481 | - 一旦碰撞(请求不成功,结果是:在下行的MAP中没有为它分配,则二进制退避)选择时隙上传输
482 |
483 | c. 轮流(Taking Turns)MAC协议
484 | - 信道划分MAC协议:固定分配、平分
485 | - 共享信道在高负载时是有效和公平的
486 | - 在低负载时效率低下
487 | - 只能等到自己的时隙开始发送或者利用1/N的信道频率发送
488 | - 当只有一个节点有帧传时,也只能够得到1/N个带宽分配
489 | - 随机访问MAC协议
490 | - 在低负载时效率高:单个节点可以完全利用信道全部带宽
491 | - 高负载时:冲突开销较大,效率极低,时间很多浪费在冲突中
492 | - 轮流协议
493 | - 有2者的优点
494 | - 缺点:复杂
495 |
496 | 轮流MAC协议
497 | - 轮询:(本身有一个主节点)
498 | - 主节点邀请从节点依次传送
499 | - 从节点一般比较“dumb”
500 | - 缺点:
501 | - 轮询开销:轮询本身消耗信道带宽
502 | - 等待时间:每个节点需等到主节点轮询后开始传输,即使只有一个节点,也需要等到轮询一周后才能够发送
503 | - 单点故障 <-- 本身可靠性差:主节点失效时造成整个系统无法工作
504 | - 令牌传递:(没有主节点)
505 | - 控制令牌(token)循环从一个节点到下一个节点传递 (“击鼓传花”)。如果令牌到达的节点需要发送信息,就将令牌位置位为0,将令牌帧变为数据帧,发送的数据绕行一周后再由自己收下(为什么不是由目标节点收下?“一发多收”,目标节点有多个,如果由目标节点收下会导致后面的目标节点收不到,所以需要轮转一圈,确认经过了所有节点后由自己收下)
506 | - 令牌报文:特殊的帧
507 | - 缺点:
508 | - 令牌开销:本身消耗带宽
509 | - 延迟:只有等到抓住令牌,才可传输
510 | - 单点故障(token):
511 | - 令牌丢失系统级故障,整个系统无法传输
512 | - 复杂机制重新生成令牌
513 |
514 | MAC协议总结
515 | - 多点接入问题:对于一个共享型介质,各个节点如何协调对它的访问和使用?
516 | - 信道划分:按时间、频率或者编码
517 | - TDMA、FDMA、CDMA
518 | - 随机访问(动态)
519 | - ALOHA, S-ALOHA, CSMA, CSMA/CD
520 | - 载波侦听:在有些介质上很容易(wire:有线介质),但在有些介质上比较困难(wireless:无线)
521 | - CSMA/CD:802.3 Ethernet网中使用
522 | - CSMA/CA:802.11WLAN中使用
523 | - 依次轮流协议
524 | - 集中:由一个中心节点轮询;分布:通过令牌控制
525 | - 蓝牙、FDDI、令牌环
526 |
527 | ### 6.4 LANS
528 |
529 | #### 6.4.1 addressing, ARP
530 |
531 | - MAC地址和ARP
532 | - 32bit IP地址:
533 | - 网络层地址
534 | - 前n-1跳:用于使数据报到达目的IP子网 —— IP地址的网络号部分
535 | - 最后一跳:到达子网中的目标节点 —— IP地址的主机号部分
536 | - LAN(MAC/物理/以太网)地址:
537 | - 用于使帧从一个网卡传递到与其物理连接的另一个网卡(在同一个物理网络中)
538 | - 48bit MAC地址固化在适配器的ROM,有时也可以通过软件设定
539 | - 理论上全球任何2个网卡的MAC地址都不相同
540 | - e.g., 1A-2F-BB-76-09-AD <-- 16进制表示(每一位代表4个bits)
541 |
542 | 网络地址和mac地址分离
543 | - IP地址和MAC地址的作用不同
544 | - a) IP地址是分层的
545 | - 一个子网所有站点网络号一致,路由聚集,减少路由表
546 | - 需要一个网络中的站点地址网络号一致,如果捆绑需要定制网卡非常麻烦
547 | - 希望网络层地址是配置的;IP地址完成网络到网络的交付
548 | - b) mac地址是一个平面的
549 | - 网卡在生产时不知道被用于哪个网络,因此给网卡一个唯一的标示,用于区分一个网络内部不同的网卡即可
550 | - 可以完成一个物理网络内部的节点到节点的数据交付网络地址和mac地址分离
551 | - 分离好处
552 | - a) 网卡坏了,ip不变,可以捆绑到另外一个网卡的mac上
553 | - b) 物理网络还可以除IP之外支持其他网络层协议,链路协议为任意上层网络协议,如IPX等
554 | - 捆绑的问题
555 | - a) 如果仅仅使用IP地址,不用mac地址,那么它仅支持IP协议
556 | - b) 每次上电都要重新写入网卡IP地址;
557 | - c) 另外一个选择就是不使用任何地址;不用MAC地址,则每到来一个帧都要上传到IP层次,由它判断是不是需要接受,干扰一次
558 |
559 | > 假设网络上要将一个数据包(名为PAC)由北京的一台主机(名称为A,IP地址为IP_A,MAC地址为MAC_A)发送到华盛顿的一台主机(名称为B,IP地址为IP_B,MAC地址为MAC_B)。
560 | > 这两台主机之间不可能是直接连接起来的,因而数据包在传递时必然要经过许多中间节点(如路由器,服务器等等),我们假定在传输过程中要经过C1、C2、C3(其MAC地址分别为M1,M2,M3)三个节点。
561 | > A在将PAC发出之前,先发送一个ARP请求,找到其要到达IP_B所必须经历的第一个中间节点C1的MAC地址M1,然后在其数据包中封装(Encapsulation)这些地址:IP_A、IP_B,MAC_A和M1。当PAC传到C1后,再由ARP根据其目的IP地址IP_B,找到其要经历的第二个中间节点C2的MAC地址M2,然后再将带有M2的数据包传送到C2。如此类推,直到最后找到带有IP地址为IP_B的B主机的地址MAC_B,最终传送给主机B。
562 |
563 | LAN地址和ARP
564 | - 局域网上每个适配器都有一个唯一的LAN地址
565 |
566 |  567 |
568 | - MAC地址由IEEE管理和分配
569 | - 制造商购入MAC地址空间(保证唯一性)
570 | - 类比:
571 | - (a)MAC地址:社会安全号、身份证号码
572 | - (b)IP地址:通讯地址、住址
573 | - MAC平面地址 --> 支持移动
574 | - 可以将网卡到接到其它网络
575 | - IP地址有层次 --> 不能移动
576 | - 依赖于节点连接的IP子网,与子网的网络号相同(有与其相连的子网相同的网络前缀)
577 |
578 | ARP(Address Resolution Protocol)
579 | - 问题:已知B的IP地址,如何确定B的MAC地址?ARP协议
580 | - 在LAN上的每个IP节点都有一个ARP表
581 | - ARP表:包括一些LAN节点IP/MAC地址的映射
582 | `
567 |
568 | - MAC地址由IEEE管理和分配
569 | - 制造商购入MAC地址空间(保证唯一性)
570 | - 类比:
571 | - (a)MAC地址:社会安全号、身份证号码
572 | - (b)IP地址:通讯地址、住址
573 | - MAC平面地址 --> 支持移动
574 | - 可以将网卡到接到其它网络
575 | - IP地址有层次 --> 不能移动
576 | - 依赖于节点连接的IP子网,与子网的网络号相同(有与其相连的子网相同的网络前缀)
577 |
578 | ARP(Address Resolution Protocol)
579 | - 问题:已知B的IP地址,如何确定B的MAC地址?ARP协议
580 | - 在LAN上的每个IP节点都有一个ARP表
581 | - ARP表:包括一些LAN节点IP/MAC地址的映射
582 | ` 607 | >
608 | > - 编址:
609 | > - A创建数据报,源IP地址:A;目标IP地址:B
610 | > - A创建一个链路层的帧,目标MAC地址是R,该帧包含A到B的IP数据报
611 | > - 帧从A发送到R
612 | > - 帧被R接收到,从中提取出IP分组,交给上层IP协议实体
613 | > - R转发数据报,数据报源IP地址为A,目标IP地址为B
614 | > - R创建一个链路层的帧,目标MAC地址为B,帧中包含A到B的IP数据报
615 |
616 | #### 6.4.2 Ethernet
617 |
618 | 以太网
619 | - 目前最主流的LAN技术:98%占有率
620 | - 廉价:30元RMB 100Mbps!
621 | - 最早广泛应用的LAN技术
622 | - 比令牌网和ATM网络简单、廉价
623 | - 带宽不断提升:10M, 100M, 1G, 10G
624 |
625 |
607 | >
608 | > - 编址:
609 | > - A创建数据报,源IP地址:A;目标IP地址:B
610 | > - A创建一个链路层的帧,目标MAC地址是R,该帧包含A到B的IP数据报
611 | > - 帧从A发送到R
612 | > - 帧被R接收到,从中提取出IP分组,交给上层IP协议实体
613 | > - R转发数据报,数据报源IP地址为A,目标IP地址为B
614 | > - R创建一个链路层的帧,目标MAC地址为B,帧中包含A到B的IP数据报
615 |
616 | #### 6.4.2 Ethernet
617 |
618 | 以太网
619 | - 目前最主流的LAN技术:98%占有率
620 | - 廉价:30元RMB 100Mbps!
621 | - 最早广泛应用的LAN技术
622 | - 比令牌网和ATM网络简单、廉价
623 | - 带宽不断提升:10M, 100M, 1G, 10G
624 |
625 |  626 |
627 | 以太网:物理拓扑
628 | - 总线:在上个世纪90年代中期很流行
629 | - 所有节点在一个碰撞域内,一次只允许一个节点发送
630 | - 可靠性差,如果介质破损(总线长,破损概率大),截面形成信号的反射,发送节点误认为是冲突,总是冲突 —— 需要中继器吸收电磁能量
631 | - 星型:目前最主流
632 | - 连接选择:hub 或者 switch
633 | - 现在一般是交换机在中心
634 | - 每个节点以及相连的交换机端口使用(独立的)以太网协议(不会和其他节点的发送产生碰撞)
635 |
636 |
626 |
627 | 以太网:物理拓扑
628 | - 总线:在上个世纪90年代中期很流行
629 | - 所有节点在一个碰撞域内,一次只允许一个节点发送
630 | - 可靠性差,如果介质破损(总线长,破损概率大),截面形成信号的反射,发送节点误认为是冲突,总是冲突 —— 需要中继器吸收电磁能量
631 | - 星型:目前最主流
632 | - 连接选择:hub 或者 switch
633 | - 现在一般是交换机在中心
634 | - 每个节点以及相连的交换机端口使用(独立的)以太网协议(不会和其他节点的发送产生碰撞)
635 |
636 |  637 |
638 | 以太帧结构
639 | - 发送方适配器在以太网帧中封装IP数据报,或其他网络层协议数据单元
640 |
641 | |preamble|destination address|source address|type|data(payload)|CRC|
642 | |:---:|:---:|:---:|:---:|:---:|:---:|
643 |
644 | - 前导码:
645 | - 7B 10101010 + 1B 10101011
646 | - 用来同步接收方和发送方的时钟速率
647 | - 使得接收方将自己的时钟调到发送端的时钟
648 | - 从而可以按照发送端的时钟来接收所发送的帧
649 | - 地址:6字节源MAC地址,目标MAC地址
650 | - 如:帧目标地址=本站MAC地址,或是广播地址,接收,递交帧中的数据到网络层
651 | - 否则,适配器忽略该帧
652 | - 类型:指出高层协(大多情况下是IP,但也支持其它网络层协议Novell IPX和AppleTalk)
653 | - CRC:在接收方校验
654 | - 如果没有通过校验,丢弃错误帧
655 |
656 | 以太网:无连接、不可靠的服务(有形介质,出错概率较低)
657 | - 无连接:帧传输前,发送方和接收方之间没有握手
658 | - 不可靠:接收方适配器不发送ACKs或NAKs给发送方
659 | - 递交给网络层的数据报流可能有gap
660 | - 如上层使用像传输层TCP协议这样的rdt,gap会被补上(源主机,TCP实体)
661 | - 否则,应用层就会看到gap
662 | - 以太网的MAC协议:采用二进制退避的CSMA/CD介质访问控制形式
663 |
664 | 802.3 以太网标准:链路和物理层
665 | - 很多不同的以太网标准
666 | - 相同的MAC协议(介质访问控制)和帧结构
667 | - 不同的速率:2Mbps、10Mbps 、100Mbps 、1Gbps、10Gbps
668 | - 不同的物理层标准
669 | - 不同的物理层媒介:光纤,同轴电缆和双绞线
670 |
671 | 以太网使用CSMA/CD
672 | - 没有时隙
673 | - NIC如果侦听到其它NIC在发送就不发送:载波侦听(carrier sense)
674 | - 发送时,适配器当侦听到其它适配器在发送就放弃对当前帧的发送,冲突检测(collision detection)
675 | - 冲突后尝试重传,重传前适配器等待一个随机时间,随机访问(random access)
676 |
677 | *具体看上面的CSMA/CD部分*
678 |
679 | 以太网在低负载和高负载的情况下都较好。低负载时好是由于CDMA/CD,高负载时好是由于引入了交换机,端口可以并发
680 |
681 | 10BaseT and 100BaseT
682 | - 100Mbps速率也被称之为“fast ethernet”
683 | - T代表双绞线
684 | - 节点连接到HUB上:“star topology”物理上星型
685 | - 逻辑上总线型,盒中总线
686 | - 节点和HUB间的最大距离是100m
687 |
688 |
637 |
638 | 以太帧结构
639 | - 发送方适配器在以太网帧中封装IP数据报,或其他网络层协议数据单元
640 |
641 | |preamble|destination address|source address|type|data(payload)|CRC|
642 | |:---:|:---:|:---:|:---:|:---:|:---:|
643 |
644 | - 前导码:
645 | - 7B 10101010 + 1B 10101011
646 | - 用来同步接收方和发送方的时钟速率
647 | - 使得接收方将自己的时钟调到发送端的时钟
648 | - 从而可以按照发送端的时钟来接收所发送的帧
649 | - 地址:6字节源MAC地址,目标MAC地址
650 | - 如:帧目标地址=本站MAC地址,或是广播地址,接收,递交帧中的数据到网络层
651 | - 否则,适配器忽略该帧
652 | - 类型:指出高层协(大多情况下是IP,但也支持其它网络层协议Novell IPX和AppleTalk)
653 | - CRC:在接收方校验
654 | - 如果没有通过校验,丢弃错误帧
655 |
656 | 以太网:无连接、不可靠的服务(有形介质,出错概率较低)
657 | - 无连接:帧传输前,发送方和接收方之间没有握手
658 | - 不可靠:接收方适配器不发送ACKs或NAKs给发送方
659 | - 递交给网络层的数据报流可能有gap
660 | - 如上层使用像传输层TCP协议这样的rdt,gap会被补上(源主机,TCP实体)
661 | - 否则,应用层就会看到gap
662 | - 以太网的MAC协议:采用二进制退避的CSMA/CD介质访问控制形式
663 |
664 | 802.3 以太网标准:链路和物理层
665 | - 很多不同的以太网标准
666 | - 相同的MAC协议(介质访问控制)和帧结构
667 | - 不同的速率:2Mbps、10Mbps 、100Mbps 、1Gbps、10Gbps
668 | - 不同的物理层标准
669 | - 不同的物理层媒介:光纤,同轴电缆和双绞线
670 |
671 | 以太网使用CSMA/CD
672 | - 没有时隙
673 | - NIC如果侦听到其它NIC在发送就不发送:载波侦听(carrier sense)
674 | - 发送时,适配器当侦听到其它适配器在发送就放弃对当前帧的发送,冲突检测(collision detection)
675 | - 冲突后尝试重传,重传前适配器等待一个随机时间,随机访问(random access)
676 |
677 | *具体看上面的CSMA/CD部分*
678 |
679 | 以太网在低负载和高负载的情况下都较好。低负载时好是由于CDMA/CD,高负载时好是由于引入了交换机,端口可以并发
680 |
681 | 10BaseT and 100BaseT
682 | - 100Mbps速率也被称之为“fast ethernet”
683 | - T代表双绞线
684 | - 节点连接到HUB上:“star topology”物理上星型
685 | - 逻辑上总线型,盒中总线
686 | - 节点和HUB间的最大距离是100m
687 |
688 |  689 |
690 | Hubs
691 | - Hubs本质上是物理层的中继器:
692 | - 从一个端口收,转发到所有其他端口
693 | - 速率一致
694 | - 没有帧的缓存
695 | - 在hub端口上没有CSMA/CD机制:适配器检测冲突
696 | - 提供网络管理功能
697 |
698 | Manchester编码 —— 物理层
699 | - 在10BaseT中使用
700 | - 每一个bit的位时中间有一个信号跳变,传送1时信号周期的中间有一个向下的跳变,传送0时信号周期的中间有一个向上的跳变(为什么要跳变?为了在电磁波信号中将时钟信号通过一些简单的电路抽取出来)
701 | - 允许在接收方和发送方节点之间进行时钟同步
702 | - 节点间不需要集中的和全局的时钟
703 | - 10Mbps,使用20M带宽,效率50%
704 | - Hey, this is physical-layer stuff!
705 |
706 |
689 |
690 | Hubs
691 | - Hubs本质上是物理层的中继器:
692 | - 从一个端口收,转发到所有其他端口
693 | - 速率一致
694 | - 没有帧的缓存
695 | - 在hub端口上没有CSMA/CD机制:适配器检测冲突
696 | - 提供网络管理功能
697 |
698 | Manchester编码 —— 物理层
699 | - 在10BaseT中使用
700 | - 每一个bit的位时中间有一个信号跳变,传送1时信号周期的中间有一个向下的跳变,传送0时信号周期的中间有一个向上的跳变(为什么要跳变?为了在电磁波信号中将时钟信号通过一些简单的电路抽取出来)
701 | - 允许在接收方和发送方节点之间进行时钟同步
702 | - 节点间不需要集中的和全局的时钟
703 | - 10Mbps,使用20M带宽,效率50%
704 | - Hey, this is physical-layer stuff!
705 |
706 |  707 |
708 | 100BaseT中的4b5b编码(5个bit代表4个bit)
709 |
710 |
707 |
708 | 100BaseT中的4b5b编码(5个bit代表4个bit)
709 |
710 |  711 |
712 | 千兆以太网
713 | - 采用标准的以太帧格式
714 | - 允许点对点链路和共享广播信道
715 | - 物理编码:8b10b编码
716 | - 在共享模式,继续使用CSMA/CD MAC技术,节点间需要较短距离以提高利用率
717 | - 交换模式:全双工千兆可用于点对点链路
718 | - 站点使用专用信道,基本不会冲突,效率高
719 | - 除非发往同一个目标站点
720 | - 10Gbps now!
721 |
722 | #### 6.4.3 switches 链路层交换机
723 |
724 | Hub:集线器 (星形)
725 | - 网段(LAN segments):可以允许一个站点发送的网络范围
726 | - 在一个碰撞域,同时只允许一个站点在发送(发之前先侦听,做信道检测)
727 | - 如果有2个节点同时发送,则会碰撞
728 | - 通常拥有相同的前缀,比IP子网更详细的前缀
729 | - HUB可以级联,所有以hub连到一起的站点处在一个网段/碰撞域(一个碰撞域内一次只能有一个节点发送,两个站点同步发送会导致碰撞,会采用CSMA/CD的方式尝试再次重发)
730 | - 骨干hub将所有网段连到了一起
731 | - 通过hub可扩展节点之间的最大距离
732 | - 通过HUB,不能将10BaseT和100BaseT的网络连接到一起
733 |
734 |
711 |
712 | 千兆以太网
713 | - 采用标准的以太帧格式
714 | - 允许点对点链路和共享广播信道
715 | - 物理编码:8b10b编码
716 | - 在共享模式,继续使用CSMA/CD MAC技术,节点间需要较短距离以提高利用率
717 | - 交换模式:全双工千兆可用于点对点链路
718 | - 站点使用专用信道,基本不会冲突,效率高
719 | - 除非发往同一个目标站点
720 | - 10Gbps now!
721 |
722 | #### 6.4.3 switches 链路层交换机
723 |
724 | Hub:集线器 (星形)
725 | - 网段(LAN segments):可以允许一个站点发送的网络范围
726 | - 在一个碰撞域,同时只允许一个站点在发送(发之前先侦听,做信道检测)
727 | - 如果有2个节点同时发送,则会碰撞
728 | - 通常拥有相同的前缀,比IP子网更详细的前缀
729 | - HUB可以级联,所有以hub连到一起的站点处在一个网段/碰撞域(一个碰撞域内一次只能有一个节点发送,两个站点同步发送会导致碰撞,会采用CSMA/CD的方式尝试再次重发)
730 | - 骨干hub将所有网段连到了一起
731 | - 通过hub可扩展节点之间的最大距离
732 | - 通过HUB,不能将10BaseT和100BaseT的网络连接到一起
733 |
734 |  735 |
736 | 高负载情况下,由于CSMA/CD的限制,一般选择将HUB升级为交换机。(HUB“一发全收”,交换机只会存储帧并转发给确定的端口“选择性转发”,并行性强)
737 |
738 | 交换机
739 | - 链路层设备:扮演主动角色(端口执行以太网协议)
740 | - 对帧进行存储和转发
741 | - 对于到来的帧,检查帧头,根据目标MAC地址进行选择性转发(而HUB是“一发全收”)
742 | - 当帧需要向某个(些)网段进行转发,需要使用CSMA/CD进行接入控制
743 | - 通常一个交换机端口一个独立网段,允许多个节点同时发送,并发性强
744 | - 交换机也可以级联,多级结构中通过自学习连接源站点和目标站点
745 | - 透明:主机对交换机的存在可以不关心
746 | - 通过交换机相联的各节点好像这些站点是直接相联的一样(因为交换机处于链路层,路由节点/主机处于网络层)
747 | - 有MAC地址;无IP地址
748 | - 即插即用,自学习(self learning):
749 | - 交换机无需配置
750 |
751 | 交换机:多路同时传输
752 | - 主机有一个专用和直接到交换机的连接
753 | - 交换机缓存到来的帧
754 | - 对每个帧进入的链路使用以太网协议,没有碰撞;全双工
755 | - 每条链路都是一个独立的碰撞域
756 | - MAC协议在其中的作用弱化了,基本上就是一个交换设备
757 | - 交换:A-to-A' 和 B-to-B' 可以同时传输,没有碰撞
758 |
759 | 交换机转发表(转发表是自学习的,不用网络管理员配置)
760 | - Q:交换机如何知道通过接口1到达A,通过接口5到达B'?
761 | - A:每个交换机都有一个交换表 switch table,每个表项:
762 | - (主机的MAC地址,到达该MAC经过的接口,时戳)
763 | - 比较像路由表!
764 | - Q:每个表项是如何创建的?如何维护的?
765 | - 有点像路由协议?
766 |
767 | 交换机:自学习
768 | - 交换机通过学习得到哪些主机(mac地址)可以通过哪些端口到达
769 | - 当接收到帧,交换机学习到发送站点所在的端口(网段)
770 | - 在交换表中记录发送方MAC地址/进入端口映射关系(软状态维护:通过时戳,隔一段时间就删掉这个表项)
771 |
772 |
735 |
736 | 高负载情况下,由于CSMA/CD的限制,一般选择将HUB升级为交换机。(HUB“一发全收”,交换机只会存储帧并转发给确定的端口“选择性转发”,并行性强)
737 |
738 | 交换机
739 | - 链路层设备:扮演主动角色(端口执行以太网协议)
740 | - 对帧进行存储和转发
741 | - 对于到来的帧,检查帧头,根据目标MAC地址进行选择性转发(而HUB是“一发全收”)
742 | - 当帧需要向某个(些)网段进行转发,需要使用CSMA/CD进行接入控制
743 | - 通常一个交换机端口一个独立网段,允许多个节点同时发送,并发性强
744 | - 交换机也可以级联,多级结构中通过自学习连接源站点和目标站点
745 | - 透明:主机对交换机的存在可以不关心
746 | - 通过交换机相联的各节点好像这些站点是直接相联的一样(因为交换机处于链路层,路由节点/主机处于网络层)
747 | - 有MAC地址;无IP地址
748 | - 即插即用,自学习(self learning):
749 | - 交换机无需配置
750 |
751 | 交换机:多路同时传输
752 | - 主机有一个专用和直接到交换机的连接
753 | - 交换机缓存到来的帧
754 | - 对每个帧进入的链路使用以太网协议,没有碰撞;全双工
755 | - 每条链路都是一个独立的碰撞域
756 | - MAC协议在其中的作用弱化了,基本上就是一个交换设备
757 | - 交换:A-to-A' 和 B-to-B' 可以同时传输,没有碰撞
758 |
759 | 交换机转发表(转发表是自学习的,不用网络管理员配置)
760 | - Q:交换机如何知道通过接口1到达A,通过接口5到达B'?
761 | - A:每个交换机都有一个交换表 switch table,每个表项:
762 | - (主机的MAC地址,到达该MAC经过的接口,时戳)
763 | - 比较像路由表!
764 | - Q:每个表项是如何创建的?如何维护的?
765 | - 有点像路由协议?
766 |
767 | 交换机:自学习
768 | - 交换机通过学习得到哪些主机(mac地址)可以通过哪些端口到达
769 | - 当接收到帧,交换机学习到发送站点所在的端口(网段)
770 | - 在交换表中记录发送方MAC地址/进入端口映射关系(软状态维护:通过时戳,隔一段时间就删掉这个表项)
771 |
772 |  773 |
774 | 交换机:过滤/转发
775 | - 当交换机收到一个帧:
776 | 1. 记录进入链路,发送主机的MAC地址
777 | 2. 使用目标MAC地址对交换表进行索引
778 | 3. ```
779 | if entry found for destination{ // 选择性转发
780 | if dest on segment from which frame arrived{
781 | drop the frame // 过滤
782 | }
783 | else forward the frame on interface indicated // 转发
784 | }
785 | else flood // 泛洪:除了帧到达的网段,向所有网络接口发送
786 | ```
787 |
788 | > 自学习,转发的例子:
789 | > - 帧的目标:A',不知道其位置在哪:泛洪
790 | > - 知道目标A对应的链路:选择性发送到那个端口
791 | >
792 | >
773 |
774 | 交换机:过滤/转发
775 | - 当交换机收到一个帧:
776 | 1. 记录进入链路,发送主机的MAC地址
777 | 2. 使用目标MAC地址对交换表进行索引
778 | 3. ```
779 | if entry found for destination{ // 选择性转发
780 | if dest on segment from which frame arrived{
781 | drop the frame // 过滤
782 | }
783 | else forward the frame on interface indicated // 转发
784 | }
785 | else flood // 泛洪:除了帧到达的网段,向所有网络接口发送
786 | ```
787 |
788 | > 自学习,转发的例子:
789 | > - 帧的目标:A',不知道其位置在哪:泛洪
790 | > - 知道目标A对应的链路:选择性发送到那个端口
791 | >
792 | >  793 | >
793 | > 794 | >
 795 |
796 | 交换机 vs. 路由器
797 | - 都是存储转发设备,但层次不同
798 | - 交换机:链路层设备(检查链路层头部)
799 | - 路由器:网络层设备(检查网络层的头部)
800 | - 都有转发表:
801 | - 交换机:维护交换表,按照MAC地址转发
802 | - 执行过滤、自学习和生成树算法
803 | - 即插即用;二层设备,速率高
804 | - 执行生成树算法,限制广播帧的转发
805 | - ARP表项随着站点数量增多而增多
806 | - 路由器:路由器维护路由表,执行路由算法
807 | - 路由算法能够避免环路,无需执行生成树算法,可以以各种拓扑构建网络
808 | - 对广播分组做限制
809 | - 不是即插即用的,配置网络地址(子网前缀)
810 | - 三层设备,速率低
811 |
812 | ### 6.5 链路虚拟化:MPLS
813 |
814 | MPLS:多协议标记交换。按照标签label来交换分组,而非按照目标IP查询路由表进行存储转发,效率更高
815 |
816 | ### 6.6 数据中心网络
817 |
818 | 数万-数十万台主机构成DC网络
819 |
820 | 在交换机之间,机器阵列之间有丰富的互连措施:
821 | - 在阵列之间增加吞吐(多个可能的路由路径)
822 | - 通过冗余度增加可靠性
823 |
824 | ### 6.7 a day in the life of web request
825 |
826 | 回顾:页面请求的历程(以一个web页面请求的例子:综述!)
827 | - 目标:标示、回顾和理解涉及到的协议(所有层次),以一个看似简单的场景:请求www页面
828 | - 场景:学生在校园启动一台笔记本电脑:请求和接受 www.google.com
829 |
830 | 日常场景
831 |
832 |
795 |
796 | 交换机 vs. 路由器
797 | - 都是存储转发设备,但层次不同
798 | - 交换机:链路层设备(检查链路层头部)
799 | - 路由器:网络层设备(检查网络层的头部)
800 | - 都有转发表:
801 | - 交换机:维护交换表,按照MAC地址转发
802 | - 执行过滤、自学习和生成树算法
803 | - 即插即用;二层设备,速率高
804 | - 执行生成树算法,限制广播帧的转发
805 | - ARP表项随着站点数量增多而增多
806 | - 路由器:路由器维护路由表,执行路由算法
807 | - 路由算法能够避免环路,无需执行生成树算法,可以以各种拓扑构建网络
808 | - 对广播分组做限制
809 | - 不是即插即用的,配置网络地址(子网前缀)
810 | - 三层设备,速率低
811 |
812 | ### 6.5 链路虚拟化:MPLS
813 |
814 | MPLS:多协议标记交换。按照标签label来交换分组,而非按照目标IP查询路由表进行存储转发,效率更高
815 |
816 | ### 6.6 数据中心网络
817 |
818 | 数万-数十万台主机构成DC网络
819 |
820 | 在交换机之间,机器阵列之间有丰富的互连措施:
821 | - 在阵列之间增加吞吐(多个可能的路由路径)
822 | - 通过冗余度增加可靠性
823 |
824 | ### 6.7 a day in the life of web request
825 |
826 | 回顾:页面请求的历程(以一个web页面请求的例子:综述!)
827 | - 目标:标示、回顾和理解涉及到的协议(所有层次),以一个看似简单的场景:请求www页面
828 | - 场景:学生在校园启动一台笔记本电脑:请求和接受 www.google.com
829 |
830 | 日常场景
831 |
832 |  833 |
834 | 1. 连接到互联网
835 | - 笔记本需要一个IP地址,第一跳路由器的IP地址,DNS的地址:采用DHCP
836 | - DHCP请求被封装在UDP中,进而封装在IP,进而封装在802.3以太网帧中
837 | - 以太网的帧在LAN上广播(destination: FFFFFFFFFFFF),被运行中的DHCP服务器接收到
838 | - 以太网帧中解封装IP分组,解封装UDP,解封装DHCP
839 | - DHCP 服务器生成DHCP ACK 包括客户端IP地址,第一跳路由器IP地址和DNS名字服务器地址
840 | - 在DHCP服务器封装,帧通过LAN转发(交换机学习)在客户端段解封装
841 | - 客户端接收DHCP ACK应答
842 | - 此时:客户端便有了IP地址,知道了DNS域名服务器的名字和IP地址第一跳路由器的IP地址
843 |
844 | 2. ARP(DNS之前,HTTP之前)
845 | - 在发送HTTP request请求之前,需要知道 www.google.com 的IP地址:DNS
846 | - DNS查询被创建,封装在UDP段中,封装在IP数据报中,封装在以太网的帧中。将帧传递给路由器,但是需要知道路由器的接口:MAC地址:ARP
847 | - ARP查询广播,被路由器接收,路由器用ARP应答,给出其IP地址某个端口的MAC地址
848 | - 客户端现在知道第一跳路由器MAC地址,所以可以发送DNS查询帧了
849 |
850 | 3. 使用DNS
851 | - 包含了DNS查询的IP数据报通过LAN交换机转发,从客户端到第一跳路由器
852 | - IP数据报被转发,从校园到达comcast网络,路由(路由表被RIP,OSPF,IS-IS 和/或 BGP协议创建)到DNS服务器
853 | - 被DNS服务器解封装
854 | - DNS服务器回复给客户端: www.google.com 的IP地址
855 |
856 | 4. TCP连接携带HTTP报文
857 | - 为了发送HTTP请求,客户端打开到达web服务器的TCP sockect
858 | - TCP SYN 段(3次握手的第1次握手)域间路由到web服务
859 | - web服务器用TCP SYNACK应答(3次握手的第2次握手)
860 | - 客户端再次进行ACK确认的发送(3次握手的第3次握手)
861 | - TCP连接建立了!
862 |
863 | 5. HTTP请求和应答
864 | - HTTP请求发送到TCP socket中
865 | - IP数据报包含HTTP请求,最终路由到 www.google.com
866 | - IP数据报包含HTTP应答最后被路由到客户端
867 | - web页面最后显示出来了!
868 |
869 | ### 6.8 总结
870 |
871 | - 数据链路层服务背后的原理:
872 | - 检错、纠错
873 | - 共享广播式信道:多路访问
874 | - 链路编址
875 | - 各种链路层技术的实例和实现
876 | - Ethernet
877 | - 交换式LANS,VLANs
878 | - 虚拟成链路层的网络:MPLS
879 | - 综合:一个web页面请求的日常场景
880 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 计算机网络 学习日志
2 |
3 | 参考书目为 **《计算机网络——自顶向下方法》第7版**
4 |
5 | 配套课程为 **中国科学技术大学 郑烇教授 2020年秋季 自动化系 《计算机网络》** 课程
6 |
7 | 其中:
8 |
9 | - `郑铨-中科大\` 文件夹中为**上课ppt**
10 | - `Supplements-ComputerNetworking-ATopDownApproach-7th-ed\` 文件夹中为计算机网络(自顶向下方法)第七版的**书籍补充材料**。包括Wireshark实验指导、PPT和程序题解
11 | - `Log_of_ComputerNetworking-ATopDownApproach_7th\` 文件夹中为**学习笔记**,分章节记录
12 | - `ComputerNetworking_ ATopDownApproach_7th.pdf` 为**参考书籍**——《计算机网络——自顶向下方法》英文第7版
13 | - `7th-勘误-Errata.pdf` 为参考书籍——《计算机网络——自顶向下方法》英文第7版的**勘误**
14 | - `Solutions-7th-Edition.pdf` 为参考书籍——《计算机网络——自顶向下方法》英文第7版的**习题解答**
15 |
--------------------------------------------------------------------------------
/Solutions-7th-Edition.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Solutions-7th-Edition.pdf
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_1_V7.01.ppt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_1_V7.01.ppt
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_2_V7.01.ppt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_2_V7.01.ppt
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_3_V7.01.ppt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_3_V7.01.ppt
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_4_V7.01.ppt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_4_V7.01.ppt
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_5_V7.01.pptx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_5_V7.01.pptx
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_6_V7.01.pptx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_6_V7.01.pptx
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_7_V7.0.pptx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_7_V7.0.pptx
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_8_V7.0.pptx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_8_V7.0.pptx
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_9_V7.0.pptx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_9_V7.0.pptx
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/README.md:
--------------------------------------------------------------------------------
1 | # Supplements-ComputerNetworking-ATopDownApproach-7th-ed
2 | Supplements material of Computer Networking: A Top-Down Approach, 7th ed. (By J.F. Kurose and K.W. Ross), including wireshark labs guides and powerpoint slides.
3 |
4 | ##### Source:
5 |
6 | Wireshark Labs: http://www-net.cs.umass.edu/wireshark-labs/
7 |
8 | Powerpoint slides: http://www-net.cs.umass.edu/kurose-ross-ppt-7e/
9 |
10 | --------------------------
11 |
12 | 计算机网络(自顶向下方法)第七版的补充材料。包括Wireshark实验指导和PPT。
13 |
14 | ##### 文件来源:
15 |
16 | Wireshark实验指导:http://www-net.cs.umass.edu/wireshark-labs/
17 |
18 | PPT:http://www-net.cs.umass.edu/kurose-ross-ppt-7e/
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Solutions-of-Socket-Programming-Assignment/1_WebServer/HelloWorld.html:
--------------------------------------------------------------------------------
1 | Hello world!
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Solutions-of-Socket-Programming-Assignment/1_WebServer/Socket1_WebServer.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Solutions-of-Socket-Programming-Assignment/1_WebServer/Socket1_WebServer.pdf
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Solutions-of-Socket-Programming-Assignment/1_WebServer/Solutions_Programming_Assignment_1.md:
--------------------------------------------------------------------------------
1 | # Solution of Assignment_1:Web Server
2 |
3 | ## 作业描述
4 |
5 | 《计算机网络:自顶向下方法》中第二章末尾给出了此编程作业的简单描述:
6 |
7 | > 在这个编程作业中,你将用Python语言开发一个简单的Web服务器,它仅能处理一个请求。具体而言,你的Web服务器将:
8 | > 1. 当一个客户(浏览器)联系时创建一个连接套接字;
9 | > 2. 从这个连接套接字接收HTTP请求;
10 | > 3. 解释该请求以确定所请求的特定文件;
11 | > 4. 从服务器的文件系统获得请求的文件;
12 | > 5. 创建一个由请求的文件组成的HTTP响应报文,报文前面有首部行;
13 | > 6. 经TCP连接向请求浏览器发送响应。如果浏览器请求一个在该服务器种不存在的文件,服务器应当返回一个“404 Not Found”差错报文。
14 | >
15 | > 在配套网站中,我们提供了用于该服务器的框架代码,我们提供了用于该服务器的框架代码。你的任务是完善该代码,运行服务器,通过在不同主机上运行的浏览器发送请求来测试该服务器。如果运行你服务器的主机上已经有一个Web服务器在运行,你应当为该服务器使用一个不同于80端口的其他端口。
16 |
17 | ## 详细描述
18 |
19 | 官方文档:[Socket1_WebServer.pdf](Socket1_WebServer.pdf)
20 |
21 | 翻译:[Translations_Programming_Assignment_1.md](Translations_Programming_Assignment_1.md)
22 |
23 | ## 实现
24 |
25 | 建立一个只允许一个连接的服务器,在指定端口监听客户端的请求,从客户端发送的请求中提取文件名,若该文件存在于服务器上(如下文的"HelloWorld.html"),则生成一个状态码200的POST报文,并返回该文件;若该文件不存在,则返回一个404 Not Found报文。
26 |
27 | ## 代码
28 |
29 | 详见:
30 |
31 | [WebServer.py](WebServer.py)
32 |
33 | [HelloWorld.html](HelloWorld.html)
34 |
35 | ## 运行
36 |
37 | 服务器端:
38 |
39 | 在一台主机上的同一目录下放入`WebServer.py`和`HelloWorld.html`两个文件,并运行`WebServer.py`,作为服务器。
40 |
41 |
833 |
834 | 1. 连接到互联网
835 | - 笔记本需要一个IP地址,第一跳路由器的IP地址,DNS的地址:采用DHCP
836 | - DHCP请求被封装在UDP中,进而封装在IP,进而封装在802.3以太网帧中
837 | - 以太网的帧在LAN上广播(destination: FFFFFFFFFFFF),被运行中的DHCP服务器接收到
838 | - 以太网帧中解封装IP分组,解封装UDP,解封装DHCP
839 | - DHCP 服务器生成DHCP ACK 包括客户端IP地址,第一跳路由器IP地址和DNS名字服务器地址
840 | - 在DHCP服务器封装,帧通过LAN转发(交换机学习)在客户端段解封装
841 | - 客户端接收DHCP ACK应答
842 | - 此时:客户端便有了IP地址,知道了DNS域名服务器的名字和IP地址第一跳路由器的IP地址
843 |
844 | 2. ARP(DNS之前,HTTP之前)
845 | - 在发送HTTP request请求之前,需要知道 www.google.com 的IP地址:DNS
846 | - DNS查询被创建,封装在UDP段中,封装在IP数据报中,封装在以太网的帧中。将帧传递给路由器,但是需要知道路由器的接口:MAC地址:ARP
847 | - ARP查询广播,被路由器接收,路由器用ARP应答,给出其IP地址某个端口的MAC地址
848 | - 客户端现在知道第一跳路由器MAC地址,所以可以发送DNS查询帧了
849 |
850 | 3. 使用DNS
851 | - 包含了DNS查询的IP数据报通过LAN交换机转发,从客户端到第一跳路由器
852 | - IP数据报被转发,从校园到达comcast网络,路由(路由表被RIP,OSPF,IS-IS 和/或 BGP协议创建)到DNS服务器
853 | - 被DNS服务器解封装
854 | - DNS服务器回复给客户端: www.google.com 的IP地址
855 |
856 | 4. TCP连接携带HTTP报文
857 | - 为了发送HTTP请求,客户端打开到达web服务器的TCP sockect
858 | - TCP SYN 段(3次握手的第1次握手)域间路由到web服务
859 | - web服务器用TCP SYNACK应答(3次握手的第2次握手)
860 | - 客户端再次进行ACK确认的发送(3次握手的第3次握手)
861 | - TCP连接建立了!
862 |
863 | 5. HTTP请求和应答
864 | - HTTP请求发送到TCP socket中
865 | - IP数据报包含HTTP请求,最终路由到 www.google.com
866 | - IP数据报包含HTTP应答最后被路由到客户端
867 | - web页面最后显示出来了!
868 |
869 | ### 6.8 总结
870 |
871 | - 数据链路层服务背后的原理:
872 | - 检错、纠错
873 | - 共享广播式信道:多路访问
874 | - 链路编址
875 | - 各种链路层技术的实例和实现
876 | - Ethernet
877 | - 交换式LANS,VLANs
878 | - 虚拟成链路层的网络:MPLS
879 | - 综合:一个web页面请求的日常场景
880 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 计算机网络 学习日志
2 |
3 | 参考书目为 **《计算机网络——自顶向下方法》第7版**
4 |
5 | 配套课程为 **中国科学技术大学 郑烇教授 2020年秋季 自动化系 《计算机网络》** 课程
6 |
7 | 其中:
8 |
9 | - `郑铨-中科大\` 文件夹中为**上课ppt**
10 | - `Supplements-ComputerNetworking-ATopDownApproach-7th-ed\` 文件夹中为计算机网络(自顶向下方法)第七版的**书籍补充材料**。包括Wireshark实验指导、PPT和程序题解
11 | - `Log_of_ComputerNetworking-ATopDownApproach_7th\` 文件夹中为**学习笔记**,分章节记录
12 | - `ComputerNetworking_ ATopDownApproach_7th.pdf` 为**参考书籍**——《计算机网络——自顶向下方法》英文第7版
13 | - `7th-勘误-Errata.pdf` 为参考书籍——《计算机网络——自顶向下方法》英文第7版的**勘误**
14 | - `Solutions-7th-Edition.pdf` 为参考书籍——《计算机网络——自顶向下方法》英文第7版的**习题解答**
15 |
--------------------------------------------------------------------------------
/Solutions-7th-Edition.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Solutions-7th-Edition.pdf
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_1_V7.01.ppt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_1_V7.01.ppt
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_2_V7.01.ppt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_2_V7.01.ppt
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_3_V7.01.ppt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_3_V7.01.ppt
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_4_V7.01.ppt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_4_V7.01.ppt
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_5_V7.01.pptx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_5_V7.01.pptx
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_6_V7.01.pptx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_6_V7.01.pptx
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_7_V7.0.pptx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_7_V7.0.pptx
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_8_V7.0.pptx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_8_V7.0.pptx
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_9_V7.0.pptx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Powerpoint Slides/Chapter_9_V7.0.pptx
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/README.md:
--------------------------------------------------------------------------------
1 | # Supplements-ComputerNetworking-ATopDownApproach-7th-ed
2 | Supplements material of Computer Networking: A Top-Down Approach, 7th ed. (By J.F. Kurose and K.W. Ross), including wireshark labs guides and powerpoint slides.
3 |
4 | ##### Source:
5 |
6 | Wireshark Labs: http://www-net.cs.umass.edu/wireshark-labs/
7 |
8 | Powerpoint slides: http://www-net.cs.umass.edu/kurose-ross-ppt-7e/
9 |
10 | --------------------------
11 |
12 | 计算机网络(自顶向下方法)第七版的补充材料。包括Wireshark实验指导和PPT。
13 |
14 | ##### 文件来源:
15 |
16 | Wireshark实验指导:http://www-net.cs.umass.edu/wireshark-labs/
17 |
18 | PPT:http://www-net.cs.umass.edu/kurose-ross-ppt-7e/
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Solutions-of-Socket-Programming-Assignment/1_WebServer/HelloWorld.html:
--------------------------------------------------------------------------------
1 | Hello world!
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Solutions-of-Socket-Programming-Assignment/1_WebServer/Socket1_WebServer.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cy-Yin/ComputerNetworking-ATopDownApproach/0d52e0212a03df5c6741a3326eeec65929e0db5d/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Solutions-of-Socket-Programming-Assignment/1_WebServer/Socket1_WebServer.pdf
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Solutions-of-Socket-Programming-Assignment/1_WebServer/Solutions_Programming_Assignment_1.md:
--------------------------------------------------------------------------------
1 | # Solution of Assignment_1:Web Server
2 |
3 | ## 作业描述
4 |
5 | 《计算机网络:自顶向下方法》中第二章末尾给出了此编程作业的简单描述:
6 |
7 | > 在这个编程作业中,你将用Python语言开发一个简单的Web服务器,它仅能处理一个请求。具体而言,你的Web服务器将:
8 | > 1. 当一个客户(浏览器)联系时创建一个连接套接字;
9 | > 2. 从这个连接套接字接收HTTP请求;
10 | > 3. 解释该请求以确定所请求的特定文件;
11 | > 4. 从服务器的文件系统获得请求的文件;
12 | > 5. 创建一个由请求的文件组成的HTTP响应报文,报文前面有首部行;
13 | > 6. 经TCP连接向请求浏览器发送响应。如果浏览器请求一个在该服务器种不存在的文件,服务器应当返回一个“404 Not Found”差错报文。
14 | >
15 | > 在配套网站中,我们提供了用于该服务器的框架代码,我们提供了用于该服务器的框架代码。你的任务是完善该代码,运行服务器,通过在不同主机上运行的浏览器发送请求来测试该服务器。如果运行你服务器的主机上已经有一个Web服务器在运行,你应当为该服务器使用一个不同于80端口的其他端口。
16 |
17 | ## 详细描述
18 |
19 | 官方文档:[Socket1_WebServer.pdf](Socket1_WebServer.pdf)
20 |
21 | 翻译:[Translations_Programming_Assignment_1.md](Translations_Programming_Assignment_1.md)
22 |
23 | ## 实现
24 |
25 | 建立一个只允许一个连接的服务器,在指定端口监听客户端的请求,从客户端发送的请求中提取文件名,若该文件存在于服务器上(如下文的"HelloWorld.html"),则生成一个状态码200的POST报文,并返回该文件;若该文件不存在,则返回一个404 Not Found报文。
26 |
27 | ## 代码
28 |
29 | 详见:
30 |
31 | [WebServer.py](WebServer.py)
32 |
33 | [HelloWorld.html](HelloWorld.html)
34 |
35 | ## 运行
36 |
37 | 服务器端:
38 |
39 | 在一台主机上的同一目录下放入`WebServer.py`和`HelloWorld.html`两个文件,并运行`WebServer.py`,作为服务器。
40 |
41 |  42 |
43 | 客户端:
44 |
45 | 在另一台主机上打开浏览器,并输入"http://XXX.XXX.XXX.XXX:6789/HelloWorld.html" (其中"XXX.XXX.XXX.XXX"是服务器IP地址),以获取服务器上的`HelloWorld.html`文件。
46 |
47 | 一切正常的话,可以看到如下页面:
48 |
49 |
42 |
43 | 客户端:
44 |
45 | 在另一台主机上打开浏览器,并输入"http://XXX.XXX.XXX.XXX:6789/HelloWorld.html" (其中"XXX.XXX.XXX.XXX"是服务器IP地址),以获取服务器上的`HelloWorld.html`文件。
46 |
47 | 一切正常的话,可以看到如下页面:
48 |
49 |  50 |
51 | 输入新地址"http://XXX.XXX.XXX.XXX:6789/abc.html",以获取服务器上不存在的`abc.html`。
52 |
53 | 将出现以下页面(注意页面中的"HTTP ERROR 404"):
54 |
55 |
50 |
51 | 输入新地址"http://XXX.XXX.XXX.XXX:6789/abc.html",以获取服务器上不存在的`abc.html`。
52 |
53 | 将出现以下页面(注意页面中的"HTTP ERROR 404"):
54 |
55 |  --------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Solutions-of-Socket-Programming-Assignment/1_WebServer/Translations_Programming_Assignment_1.md:
--------------------------------------------------------------------------------
1 | # Translation of Assignment_1:Web Server
2 |
3 | 在本实验中,您将学习Python中TCP连接的套接字编程的基础知识:如何创建套接字,将其绑定到特定的地址和端口,以及发送和接收HTTP数据包。您还将学习一些HTTP首部格式的基础知识。
4 |
5 | 您将开发一个处理一个HTTP请求的Web服务器。您的Web服务器应该接受并解析HTTP请求,然后从服务器的文件系统获取所请求的文件,创建一个由响应文件组成的HTTP响应消息,前面是首部行,然后将响应直接发送给客户端。如果请求的文件不存在于服务器中,则服务器应该向客户端发送“404 Not Found”差错报文。
6 |
7 | ## 代码
8 |
9 | 在文件下面你会找到Web服务器的代码框架。您需要填写这个代码。而且需要在标有#Fill in start 和 # Fill in end的地方填写代码。另外,每个地方都可能需要不止一行代码。
10 |
11 | ## 运行服务器
12 |
13 | 将HTML文件(例如HelloWorld.html)放在服务器所在的目录中。运行服务器程序。确认运行服务器的主机的IP地址(例如128.238.251.26)。从另一个主机,打开浏览器并提供相应的URL。例如:
14 |
15 | http://128.238.251.26:6789/HelloWorld.html
16 |
17 | “HelloWorld.html”是您放在服务器目录中的文件。还要注意使用冒号后的端口号。您需要使用服务器代码中使用的端口号来替换此端口号。在上面的例子中,我们使用了端口号6789. 浏览器应该显示HelloWorld.html的内容。如果省略“:6789”,浏览器将使用默认端口80,只有当您的服务器正在端口80监听时,才会从服务器获取网页。
18 |
19 | 然后用客户端尝试获取服务器上不存在的文件。你应该会得到一个“404 Not Found”消息。
20 |
21 | ## 需要上交的内容
22 |
23 | 您需要上交完整的服务器代码,以及客户端浏览器的屏幕截图,用于验证您是否从服务器实际接收到HTML文件内容。
24 |
25 | ## Web服务器的Python代码框架
26 | ```python
27 | # import socket module
28 | from socket import *
29 | serverSocket = socket(AF_INET, SOCK_STREAM)
30 | # Prepare a sever socket
31 | # Fill in start
32 | # Fill in end
33 | while True:
34 | # Establish the connection
35 | print('Ready to serve...')
36 | connectionSocket, addr = # Fill in start #Fill in end
37 | try:
38 | message = # Fill in start # Fill in end
39 | filename = message.split()[1]
40 | f = open(filename[1:])
41 | outputdata = # Fill in start # Fill in end
42 | # Send one HTTP header line into socket
43 | # Fill in start
44 | # Fill in end
45 |
46 | # Send the content of the requested file to the client
47 | for i in range(0, len(outputdata)):
48 | connectionSocket.send(outputdata[i])
49 | connectionSocket.close()
50 | except IOError:
51 | # Send response message for file not found
52 | # Fill in start
53 | # Fill in end
54 |
55 | # Close client socket
56 | # Fill in start
57 | # Fill in end
58 | serverSocket.close()
59 | ```
60 |
61 | ## 可选练习
62 |
63 | 1. 目前,这个Web服务器一次只处理一个HTTP请求。请实现一个能够同时处理多个请求的多线程服务器。使用线程,首先创建一个主线程,在固定端口监听客户端请求。当从客户端收到TCP连接请求时,它将通过另一个端口建立TCP连接,并在另外的单独线程中为客户端请求提供服务。这样在每个请求/响应对的独立线程中将有一个独立的TCP连接。
64 |
65 | 2. 不使用浏览器,编写自己的HTTP客户端来测试你的服务器。您的客户端将使用一个TCP连接用于连接到服务器,向服务器发送HTTP请求,并将服务器响应显示出来。您可以假定发送的HTTP请求将使用GET方法。
66 | 客户端应使用命令行参数指定服务器IP地址或主机名,服务器正在监听的端口,以及被请求对象在服务器上的路径。以下是运行客户端的输入命令格式。
67 | ```shell
68 | client.py server_host server_port filename
69 | ```
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Solutions-of-Socket-Programming-Assignment/1_WebServer/WebServer.py:
--------------------------------------------------------------------------------
1 | # Import socket module
2 | from socket import *
3 | import sys # In order to terminate the program
4 |
5 | # Create a TCP server socket
6 | # (AF_INET is used for IPv4 protocols)
7 | # (SOCK_STREAM is used for TCP)
8 |
9 | serverSocket = socket(AF_INET, SOCK_STREAM)
10 |
11 | # Assign a port number
12 | serverPort = 6789
13 |
14 | # Bind the socket to server address and server port
15 | serverSocket.bind(("", serverPort))
16 |
17 | # Listen to at most 1 connection at a time
18 | serverSocket.listen(1)
19 |
20 | # Server should be up and running and listening to the incoming connections
21 |
22 | while True:
23 | print('The server is ready to receive')
24 |
25 | # Set up a new connection from the client
26 | connectionSocket, addr = serverSocket.accept()
27 |
28 | # If an exception occurs during the execution of try clause
29 | # the rest of the clause is skipped
30 | # If the exception type matches the word after except
31 | # the except clause is executed
32 | try:
33 | # Receives the request message from the client
34 | message = connectionSocket.recv(1024).decode()
35 | # Extract the path of the requested object from the message
36 | # The path is the second part of HTTP header, identified by [1]
37 | filename = message.split()[1]
38 | # Because the extracted path of the HTTP request includes
39 | # a character '\', we read the path from the second character
40 | f = open(filename[1:])
41 | # Store the entire contenet of the requested file in a temporary buffer
42 | outputdata = f.read()
43 | # Send the HTTP response header line to the connection socket
44 | connectionSocket.send("HTTP/1.1 200 OK\r\n\r\n".encode())
45 |
46 | # Send the content of the requested file to the connection socket
47 | for i in range(0, len(outputdata)):
48 | connectionSocket.send(outputdata[i].encode())
49 | connectionSocket.send("\r\n".encode())
50 |
51 | # Close the client connection socket
52 | connectionSocket.close()
53 |
54 | except IOError:
55 | # Send HTTP response message for file not found
56 | connectionSocket.send("HTTP/1.1 404 Not Found\r\n\r\n".encode())
57 | connectionSocket.send("
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Solutions-of-Socket-Programming-Assignment/1_WebServer/Translations_Programming_Assignment_1.md:
--------------------------------------------------------------------------------
1 | # Translation of Assignment_1:Web Server
2 |
3 | 在本实验中,您将学习Python中TCP连接的套接字编程的基础知识:如何创建套接字,将其绑定到特定的地址和端口,以及发送和接收HTTP数据包。您还将学习一些HTTP首部格式的基础知识。
4 |
5 | 您将开发一个处理一个HTTP请求的Web服务器。您的Web服务器应该接受并解析HTTP请求,然后从服务器的文件系统获取所请求的文件,创建一个由响应文件组成的HTTP响应消息,前面是首部行,然后将响应直接发送给客户端。如果请求的文件不存在于服务器中,则服务器应该向客户端发送“404 Not Found”差错报文。
6 |
7 | ## 代码
8 |
9 | 在文件下面你会找到Web服务器的代码框架。您需要填写这个代码。而且需要在标有#Fill in start 和 # Fill in end的地方填写代码。另外,每个地方都可能需要不止一行代码。
10 |
11 | ## 运行服务器
12 |
13 | 将HTML文件(例如HelloWorld.html)放在服务器所在的目录中。运行服务器程序。确认运行服务器的主机的IP地址(例如128.238.251.26)。从另一个主机,打开浏览器并提供相应的URL。例如:
14 |
15 | http://128.238.251.26:6789/HelloWorld.html
16 |
17 | “HelloWorld.html”是您放在服务器目录中的文件。还要注意使用冒号后的端口号。您需要使用服务器代码中使用的端口号来替换此端口号。在上面的例子中,我们使用了端口号6789. 浏览器应该显示HelloWorld.html的内容。如果省略“:6789”,浏览器将使用默认端口80,只有当您的服务器正在端口80监听时,才会从服务器获取网页。
18 |
19 | 然后用客户端尝试获取服务器上不存在的文件。你应该会得到一个“404 Not Found”消息。
20 |
21 | ## 需要上交的内容
22 |
23 | 您需要上交完整的服务器代码,以及客户端浏览器的屏幕截图,用于验证您是否从服务器实际接收到HTML文件内容。
24 |
25 | ## Web服务器的Python代码框架
26 | ```python
27 | # import socket module
28 | from socket import *
29 | serverSocket = socket(AF_INET, SOCK_STREAM)
30 | # Prepare a sever socket
31 | # Fill in start
32 | # Fill in end
33 | while True:
34 | # Establish the connection
35 | print('Ready to serve...')
36 | connectionSocket, addr = # Fill in start #Fill in end
37 | try:
38 | message = # Fill in start # Fill in end
39 | filename = message.split()[1]
40 | f = open(filename[1:])
41 | outputdata = # Fill in start # Fill in end
42 | # Send one HTTP header line into socket
43 | # Fill in start
44 | # Fill in end
45 |
46 | # Send the content of the requested file to the client
47 | for i in range(0, len(outputdata)):
48 | connectionSocket.send(outputdata[i])
49 | connectionSocket.close()
50 | except IOError:
51 | # Send response message for file not found
52 | # Fill in start
53 | # Fill in end
54 |
55 | # Close client socket
56 | # Fill in start
57 | # Fill in end
58 | serverSocket.close()
59 | ```
60 |
61 | ## 可选练习
62 |
63 | 1. 目前,这个Web服务器一次只处理一个HTTP请求。请实现一个能够同时处理多个请求的多线程服务器。使用线程,首先创建一个主线程,在固定端口监听客户端请求。当从客户端收到TCP连接请求时,它将通过另一个端口建立TCP连接,并在另外的单独线程中为客户端请求提供服务。这样在每个请求/响应对的独立线程中将有一个独立的TCP连接。
64 |
65 | 2. 不使用浏览器,编写自己的HTTP客户端来测试你的服务器。您的客户端将使用一个TCP连接用于连接到服务器,向服务器发送HTTP请求,并将服务器响应显示出来。您可以假定发送的HTTP请求将使用GET方法。
66 | 客户端应使用命令行参数指定服务器IP地址或主机名,服务器正在监听的端口,以及被请求对象在服务器上的路径。以下是运行客户端的输入命令格式。
67 | ```shell
68 | client.py server_host server_port filename
69 | ```
--------------------------------------------------------------------------------
/Supplements-ComputerNetworking-ATopDownApproach-7th-ed/Solutions-of-Socket-Programming-Assignment/1_WebServer/WebServer.py:
--------------------------------------------------------------------------------
1 | # Import socket module
2 | from socket import *
3 | import sys # In order to terminate the program
4 |
5 | # Create a TCP server socket
6 | # (AF_INET is used for IPv4 protocols)
7 | # (SOCK_STREAM is used for TCP)
8 |
9 | serverSocket = socket(AF_INET, SOCK_STREAM)
10 |
11 | # Assign a port number
12 | serverPort = 6789
13 |
14 | # Bind the socket to server address and server port
15 | serverSocket.bind(("", serverPort))
16 |
17 | # Listen to at most 1 connection at a time
18 | serverSocket.listen(1)
19 |
20 | # Server should be up and running and listening to the incoming connections
21 |
22 | while True:
23 | print('The server is ready to receive')
24 |
25 | # Set up a new connection from the client
26 | connectionSocket, addr = serverSocket.accept()
27 |
28 | # If an exception occurs during the execution of try clause
29 | # the rest of the clause is skipped
30 | # If the exception type matches the word after except
31 | # the except clause is executed
32 | try:
33 | # Receives the request message from the client
34 | message = connectionSocket.recv(1024).decode()
35 | # Extract the path of the requested object from the message
36 | # The path is the second part of HTTP header, identified by [1]
37 | filename = message.split()[1]
38 | # Because the extracted path of the HTTP request includes
39 | # a character '\', we read the path from the second character
40 | f = open(filename[1:])
41 | # Store the entire contenet of the requested file in a temporary buffer
42 | outputdata = f.read()
43 | # Send the HTTP response header line to the connection socket
44 | connectionSocket.send("HTTP/1.1 200 OK\r\n\r\n".encode())
45 |
46 | # Send the content of the requested file to the connection socket
47 | for i in range(0, len(outputdata)):
48 | connectionSocket.send(outputdata[i].encode())
49 | connectionSocket.send("\r\n".encode())
50 |
51 | # Close the client connection socket
52 | connectionSocket.close()
53 |
54 | except IOError:
55 | # Send HTTP response message for file not found
56 | connectionSocket.send("HTTP/1.1 404 Not Found\r\n\r\n".encode())
57 | connectionSocket.send("