├── 0001
├── dantezhao-note.md
├── sxComLee-note.md
├── rebiekong.md
├── mk-note.md
├── 数据管理系统.png
├── Goods_design.png
├── bigablecat_Metadata.png
├── bigablecat_semi_lattice.png
├── bigablecat_path_dimensions.png
├── bigablecat_distribution_cluster.png
├── bigablecat_propagation_metadata.png
├── BacJiang-note.md
└── bigablecat.md
├── zhaomengbin-note.md
├── .gitignore
├── 0003
├── WDL.png
├── Table_1.gif
├── kiwi87-pic.png
├── bigablecat_wide_deep_model.gif
├── dantezhao-note.md
├── bigablecat_hidden_layer_computation.gif
├── bigablecat_cross_product_transformation.gif
├── bigablecat_Wide_and_Deep_model_structure.png
├── Wide & Deep Learning for Recommender Systems.pdf
├── bigablecat_Overview_of_the_recommender_system.png
├── bigablecat_Apps_recommendation_pipeline_overview.png
├── bigablecat_The_spectrum_of_Wide_And_Deep_models.png
├── lilong-note.md
├── wdl
├── yangminghan-note.md
└── bigablecat.md
├── 0002
├── yhw-note.txt
├── hapream_note.png
├── The Wisdom of the Few.pdf
├── BacJiang-note.md
├── Leo_Yang_note.md
├── dantezhao-note.md
└── bigablecat.md
├── 0004
├── FastText.png
├── lilong_CBOW.png
├── lilong_Glove.png
├── lilong_fastText.png
├── bigablecat_node_probability.gif
├── bigablecat_softmax_function.gif
├── bigablecat_model_architecture_of_fasttext.png
├── Bag of Tricks for Efficient Text Classification.pdf
├── bot
├── lilong-note.md
└── bigablecat.md
├── 0005
└── NatureDeepReview.pdf
└── README.md
/0001/dantezhao-note.md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/0001/sxComLee-note.md:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/zhaomengbin-note.md:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/0001/rebiekong.md:
--------------------------------------------------------------------------------
1 | placeholder
2 |
--------------------------------------------------------------------------------
/0001/mk-note.md:
--------------------------------------------------------------------------------
1 | 占坑
2 | =======
3 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | .DS_Store
2 | /.project
3 | /.gitignore
4 |
--------------------------------------------------------------------------------
/0003/WDL.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0003/WDL.png
--------------------------------------------------------------------------------
/0001/数据管理系统.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0001/数据管理系统.png
--------------------------------------------------------------------------------
/0002/yhw-note.txt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0002/yhw-note.txt
--------------------------------------------------------------------------------
/0003/Table_1.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0003/Table_1.gif
--------------------------------------------------------------------------------
/0004/FastText.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0004/FastText.png
--------------------------------------------------------------------------------
/0003/kiwi87-pic.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0003/kiwi87-pic.png
--------------------------------------------------------------------------------
/0004/lilong_CBOW.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0004/lilong_CBOW.png
--------------------------------------------------------------------------------
/0001/Goods_design.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0001/Goods_design.png
--------------------------------------------------------------------------------
/0002/hapream_note.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0002/hapream_note.png
--------------------------------------------------------------------------------
/0004/lilong_Glove.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0004/lilong_Glove.png
--------------------------------------------------------------------------------
/0004/lilong_fastText.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0004/lilong_fastText.png
--------------------------------------------------------------------------------
/0005/NatureDeepReview.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0005/NatureDeepReview.pdf
--------------------------------------------------------------------------------
/0001/bigablecat_Metadata.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0001/bigablecat_Metadata.png
--------------------------------------------------------------------------------
/0002/The Wisdom of the Few.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0002/The Wisdom of the Few.pdf
--------------------------------------------------------------------------------
/0001/bigablecat_semi_lattice.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0001/bigablecat_semi_lattice.png
--------------------------------------------------------------------------------
/0001/bigablecat_path_dimensions.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0001/bigablecat_path_dimensions.png
--------------------------------------------------------------------------------
/0003/bigablecat_wide_deep_model.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0003/bigablecat_wide_deep_model.gif
--------------------------------------------------------------------------------
/0003/dantezhao-note.md:
--------------------------------------------------------------------------------
1 | ## 0x01 前言
2 |
3 | 问题:
4 | 1. Why:为什么提出 WDL,它解决了什么问题?
5 | 2. What:什么是 WDL?优点是什么?
6 | 3. HOW:WDL 的原理是什么?
7 |
--------------------------------------------------------------------------------
/0004/bigablecat_node_probability.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0004/bigablecat_node_probability.gif
--------------------------------------------------------------------------------
/0004/bigablecat_softmax_function.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0004/bigablecat_softmax_function.gif
--------------------------------------------------------------------------------
/0001/bigablecat_distribution_cluster.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0001/bigablecat_distribution_cluster.png
--------------------------------------------------------------------------------
/0001/bigablecat_propagation_metadata.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0001/bigablecat_propagation_metadata.png
--------------------------------------------------------------------------------
/0003/bigablecat_hidden_layer_computation.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0003/bigablecat_hidden_layer_computation.gif
--------------------------------------------------------------------------------
/0003/bigablecat_cross_product_transformation.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0003/bigablecat_cross_product_transformation.gif
--------------------------------------------------------------------------------
/0003/bigablecat_Wide_and_Deep_model_structure.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0003/bigablecat_Wide_and_Deep_model_structure.png
--------------------------------------------------------------------------------
/0004/bigablecat_model_architecture_of_fasttext.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0004/bigablecat_model_architecture_of_fasttext.png
--------------------------------------------------------------------------------
/0003/Wide & Deep Learning for Recommender Systems.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0003/Wide & Deep Learning for Recommender Systems.pdf
--------------------------------------------------------------------------------
/0003/bigablecat_Overview_of_the_recommender_system.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0003/bigablecat_Overview_of_the_recommender_system.png
--------------------------------------------------------------------------------
/0003/bigablecat_Apps_recommendation_pipeline_overview.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0003/bigablecat_Apps_recommendation_pipeline_overview.png
--------------------------------------------------------------------------------
/0003/bigablecat_The_spectrum_of_Wide_And_Deep_models.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0003/bigablecat_The_spectrum_of_Wide_And_Deep_models.png
--------------------------------------------------------------------------------
/0004/Bag of Tricks for Efficient Text Classification.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/dantezhao/paper-notes/HEAD/0004/Bag of Tricks for Efficient Text Classification.pdf
--------------------------------------------------------------------------------
/0004/bot:
--------------------------------------------------------------------------------
1 | 这是一个简单有效的文本分类算法
2 | 优势:可以在排序限制、低损失近似值下以10Min极短的时间训练出百万级的模型
3 |
4 | 架构:
5 | 整体与cbow类似:cbow根据上下文推测某个单词出现的最大概率
6 | 对基于词袋bow的句子文本进行一个简单和有效的线性分类
7 | 该分类可以选择逻辑回归或者SVM
8 | 为了使输入简单,使用一个look-up table查找表,把单词平均转化到文本形式
9 | -使用softmax来计算预定义类的概率分布,目的是为了加快运行
10 | 使用哈佛曼编码树,减少预测目标数量(频率越高的单词离树距离越近)
11 | 时间方面比CNN等深度学习模型快几个数量级,可以在多核普通单机上完成训练
12 | -词袋(bow)是没有顺序特征的,所以用的是N-gram特征向量来表示,该向量
13 | 的假设和隐马尔可夫类似,该单词只与其前面的n个单词有关,具体n可以设定。
14 | 使用了hash函数对n-grams进行了内存映射。
15 |
16 | 总结:将它与各个深度学习的模型进行了比较,性能上相差无几,但是训练时间上优势
17 | 很大,不在一个数量级。
18 | 且支持了大型数据和多种语言的文本识别
19 |
--------------------------------------------------------------------------------
/0002/BacJiang-note.md:
--------------------------------------------------------------------------------
1 | 论文阅读第二期的文章《[The Wisdom of the few](https://github.com/dantezhao/paper-notes/blob/master/0002/The%20Wisdom%20of%20the%20Few.pdf)》讲的是基于专家观点的协同过滤推荐算法,是一篇2009年的文章。作者[Xavier Amatriain](https://xamat.github.io//)是推荐系统领域的一位大牛,最早主导了Netflix的推荐系统,后来去了Quora,现在自己创办公司Curai研究AI。因为本人对推荐系统了解比较少,所以只是略读了文章,做一个简单的总结:1. 文章摘要;2.什么是协同过滤
2 | ## 1. 文章摘要
3 | 近邻协同过滤是一种有效的互联网用户推荐方法,但是传统的方法有几个明显的缺点:数据稀疏、噪声数据、冷启动等问题,Xavier Amatriain等人就提出了一种基于专家观点的协同过滤算法,用一个独立数据集中的专家评价代替传统的用户评分数据,专家观点的权重根据其与推荐用户的相似度来确定。经过在Netflix部分用户数据上的验证,该算法解决了传统算法的几个缺点,并且能取得相近的准确度,作者还专门设计获得了一个USER-STUDY数据集,对算法进行验证。
4 | ## 2. 协同过滤
5 | 1. 什么是协同过滤?
6 | 协同过滤主要是基于相似性进行推荐,包括基于用户的推荐、基于物品的推荐、基于模型的推荐等
7 |
8 | 2. 为什么文章作者说协同过滤是一种互联网用户有效的推荐方式?
9 | 在做互联网产品的时候有一个词叫“UGC”-用户产生内容,比如美团、淘宝这些平台上用户对商品及店家的评价,以及前段时间被扒皮说是用户评价数据造假的某旅游APP。用户的参与与输出能反映用户的偏好及习惯,基于此进行推荐,当然能有一定的效果。
10 |
11 | 3. 协同过滤的难点
12 | 正如文章中所说,协同过滤推荐系统存在很多难点:
13 | |- 数据稀疏性
14 | |- 数据噪声
15 | |- 冷启动
16 | |- 相似度度量
17 | |- 可扩展性
18 |
19 |
20 |
21 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | ## 0x00 前言
2 |
3 | 为了扩大自己的知识面,保持持续学习的状态,数据茶水间的几个小伙伴一起开始了论文阅读的活动。
4 |
5 | ### 活动形式
6 |
7 | 1. 参与活动的童鞋一起推荐和选择数据和算法方面的论文
8 | 2. 每两周阅读一篇论文,进度快的童鞋,可自行穿插阅读更多内容
9 | 3. 每篇论文都需要提交一篇相应的论文笔记
10 | 4. 每两周,有一名同学进行论文分享,一起线上交流学习内容
11 |
12 | ### 注意事项
13 |
14 | 1. 论文选择下面是进度内的论文,对所列论文完全不感兴趣的,可以自己坚持论文阅读,不用参加本活动
15 | 2. 加入活动的同学,必须提交阅读的第一篇论文的阅读笔记,借此过滤掉一时头脑发热的同学
16 | 3. 连续两次不提交论文笔记的(一个月不参与),视为退出活动
17 | 4. 笔记提交形式:每位同学的阅读笔记放在该论文的目录下,所有自己的笔记均命名为github_name-note.md,比如我的dantezhao-note.md,其它资源如图片的方式,类似,比如dantezhao-pic.jpg。
18 |
19 | 想加入的童鞋,加微信:mdjs91。
20 |
21 | ## 0x01 进度
22 |
23 | 如下是论文阅读计划的排期表
24 |
25 | |序号|论文|简介|阅读日期|分享人|
26 | |---|---|---|---|---|
27 | |0001|Goods: Organizing Google’s Datasets|google关于元数据管理的论文|20181022-20181104| |
28 | |0002|The Wisdom of the Few|基于专家意见的协调过滤算法|20181105-20181118| dantezhao |
29 | |0003|Wide & Deep Learning for Recommender Systems|推荐系统中比较流行的 wide and deep learning|20181119-20181202| Long Li |
30 | |0004|Bag of Tricks for Efficient Text Classification|提出fasttext的论文,经典|20181203-20181216| theta666 |
31 | |0005|Deep Learning|LeCun,Bengio和Hinton三位人工智能大佬在Nature上刊发的一篇Review|20181217-20181230| |
32 |
--------------------------------------------------------------------------------
/0002/Leo_Yang_note.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: The Wisdom of the Few
4 | date: 2018-11-14
5 | categories: blog
6 | tags: [文献阅读]
7 | description:
8 | ---
9 |
10 | # The Wisdom of the Few
11 | ## A Collaborative Filtering Approach Based on expert Opinions from the Web
12 | ### 1.Introduction
13 |
14 | 协同过滤算法是现在推荐系统的主流方法,但是协同过滤算法存在着一些问题:数据稀疏,数据噪声,冷启动问题,可扩展性问题。这篇论文,提供了一种新的推荐方法:基于专家观点的推荐系统。这篇论文不希望单纯的探索如何提高推荐系统的准确率,而是希望尝试:
15 | 1. 如何使用较小的数据集预测大量人群;
16 | 2. 如果使用独立并且不相关的数据集来产生推荐;
17 | 3. 分析专业人士是否是普通用户很好的预测者;
18 | 4. 探索新的方法可不可以避开传统协同过滤的缺陷。
19 |
20 | ### 2.Mining the web for expert ratings
21 |
22 | 这篇论文通过爬取烂番茄网站,得到了两组数据,第一组数据是用户对于电影的评价,选取了17,700部电影中的8000部电影,第二组数据是专家对于这8000部电影的评价,这里论文给出了一个threshold,只有评价超过250部电影的专家才被纳入到数据集中,最后1750个专家中有169个被纳入到数据集中。
23 |
24 | #### 2.1 Dateset analysis: User and Experts
25 |
26 | 将专家数据和普通用户数据集进行比较我们可以发现,普通用户数据集要比专家数据集存在着很大的不同:
27 | 1. 普通用户数据更稀疏:(sparsity coefficient:the user data 0.01,the expert set 0.07);
28 | 2. 专家对于所有电影都存在打分,没有了普通用户只对那些流行的电影打分的偏倚;
29 | 3. 专家似乎在一些好的电影上得出了相当一致的结论,他们比普通的用户更容易得出同样的结论。
30 |
31 | ### 3.Expert nearest-neighbors
32 | 传统的CF使用KNN算法来预测用户的排名,度量距离的方法是余弦相似度。这篇论文提供了一种新的思路,即,寻找和用户相似度大于δ的专家,用来预测用户对于特定物品的排名。
33 | ### 4.Results
34 | 最终的结果是新方法在准确度和覆盖率上都超过了传统方法的协同过滤系统。
35 | ### 5.User Study
36 | ### 6.Discussion
37 |
38 | 基于专家数据的协同过滤算法有效的解决了以下传统算法的缺点:
39 | 1. 数据稀疏:普通用户数据要比专家数据更稀疏,所以解决数据稀疏的问题。
40 | 2. 噪声和恶意打分:专家在评分的时候,更加一致和稳定,因此可以避免这样的问题。
41 | 3. 冷启动问题:在传统的CF系统中,新的物品缺少评价数据因此不会被推荐,但是这个领域的专家会主动给新的物品打分,这样就可以解决冷启动问题。
42 | 4. 可扩展性:基于专家数据的系统计算量小,因此可扩展性好。
43 | 5. 隐私问题
44 |
45 |
--------------------------------------------------------------------------------
/0001/BacJiang-note.md:
--------------------------------------------------------------------------------
1 | 论文阅读第一期的文章《Goods:Organizing Google’s Datasets》讲的是关于谷歌在海量元数据管理方面的实践。本篇总结主要从3个方面进行展开:1.什么是元数据;2.如何管理元数据;3.启发与总结
2 | ## 1.什么是元数据
3 | 元数据被称之为描述数据的数据,记录的是文件的特征,包括数据属性、拥有者、权限、数据块等信息。无论是mysql、oracle这样的关系型数据库,还是Hive、HBase以及图数据库,都需要管理组织元数据,用户才能顺利地获取并使用相关的数据及文件,足以看出元数据管理的重要性。
4 | 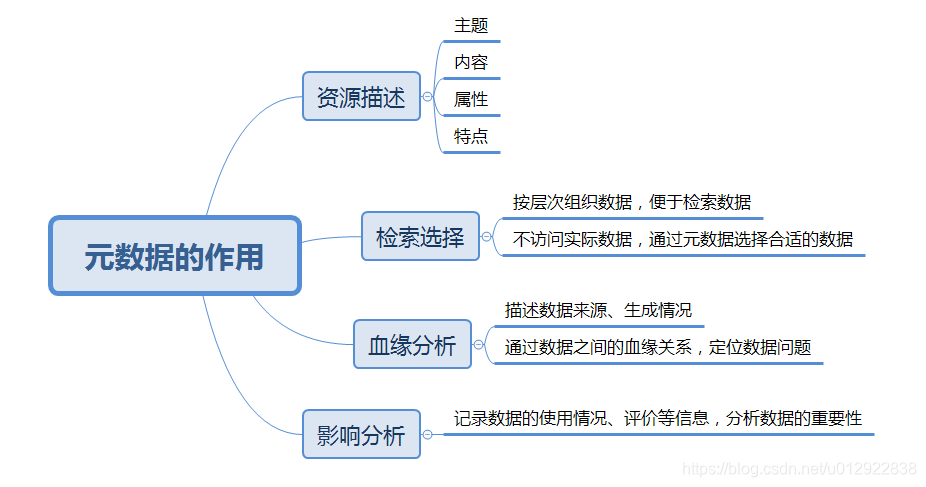
5 | ## 2.如何管理元数据
6 | 元数据的组织和管理十分重要,但随着企业的发展,不同的生产系统产生了成千上万甚至几十亿的数据集,如何有效地管理这海量的元数据便成了一个挑战。Google在[Goods](https://github.com/dantezhao/paper-notes/blob/master/0001/Goods%20Organizing%20Google%E2%80%99s%20Datasets.pdf)这篇文章介绍相关理论和实践。LinkedIn也开源了元数据管理系统[WhereHows](https://github.com/linkedin/WhereHows)
7 |
8 | - Goods:Google Dataset Search
9 |
10 | Google构建了一个*元数据目录*来管理几十亿数据集的元数据,以供工程师们了解Google有哪些数据,哪些数据比较常用(数据排名,类似网页的PageRank)。其结构如下图所示:整个系统分为3层,底层以无侵扰的方式获取不同数据库和文件系统的元数据,中间为存储在Bigtable中形成元数据目录,上层则是提供的各类服务,包括搜索、监控、血缘可视化、增加备注等功能。
11 |
12 | 比较重要的两个点是:
13 | **1. 元数据的获取是事后型无侵扰的,不会干扰原有业务系统的正常运转;
14 | 2. 数据搜素:搜索功能能有效地用户筛选数据并提高利用率,搜素是Google的强项,但文中说数据重要性排名,他们也没处理好还存在一些挑战。**
15 | 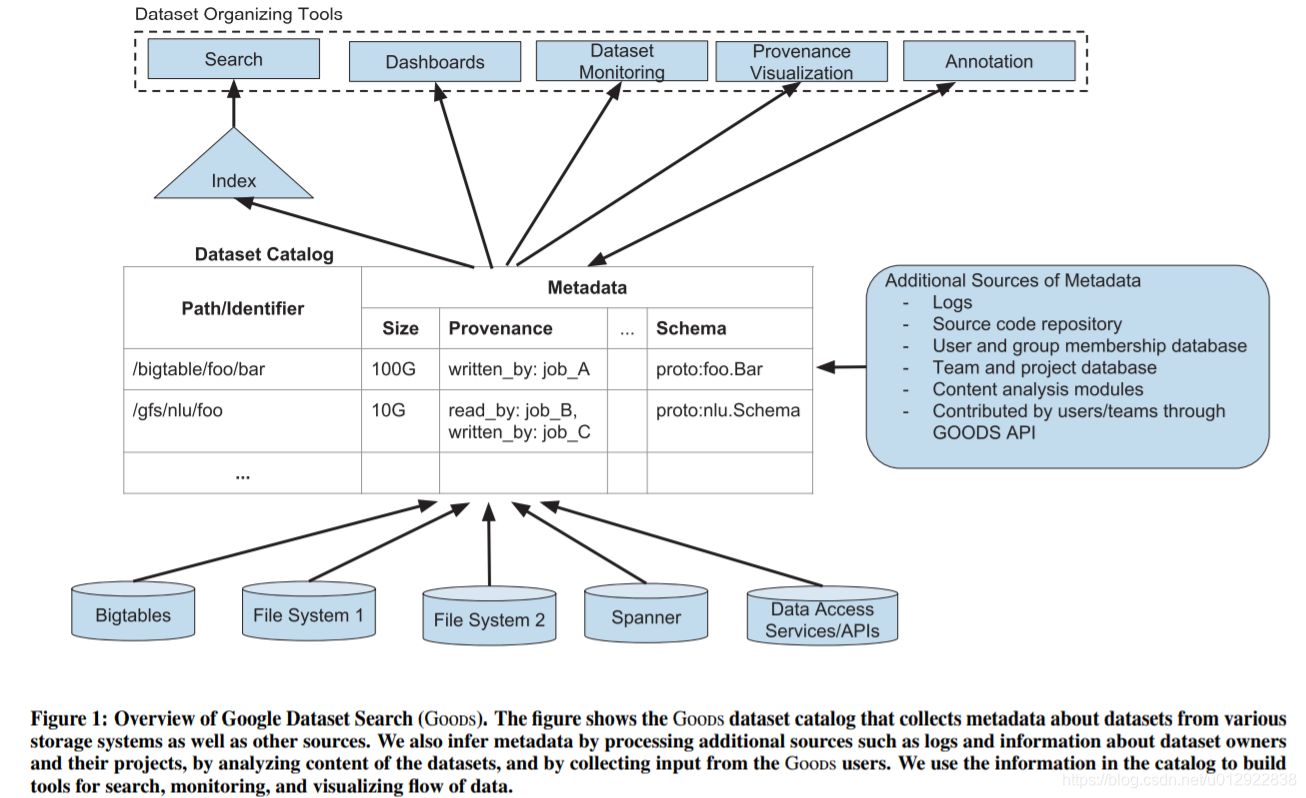
16 | - WhereHows
17 | WhereHows是LinkedIn开源的一个元数据管理系统,一直都有在更新维护。WhereHows: *WHERE is the data, and HOW is it produced/consumed.数据在哪里,数据是生成和消费的*。 它也提供后端元数据抽取工具,以及前端的搜素、分析工具。
18 | 
19 | 和Google类似,也是通过一个高可读权限的账户爬取各类文件系统的元数据,并通过*分析日志获得操作记录、血缘关系等数据*,最后组织存储在MySQL中以供上层使用。
20 | WhereHows主要包含4类数据:
21 | 
22 | ### 3.启发和总结
23 | 以往认为在构建数据仓库或者数据管理平台的时候,首先是要把所有的汇聚到一起,然后再做上层的各类应用,但往往在实践过程会发现自己有哪些数据,要哪些数据,能做什么。如果能先构建出一个元数据管理系统,既能增加对数据的熟悉度,也能增加数据管理的有效性。
24 |
--------------------------------------------------------------------------------
/0004/lilong-note.md:
--------------------------------------------------------------------------------
1 | # 论文阅读Bag of Tricks for Efficient Text Classification
2 |
3 | 这篇文章提出的fastText既是一种词向量训练工具又是一种文本分类工具。它同时具备这两项功能是因为它在训练分类器的同时也训练了词向量。我们知道,词向量训练的思路无非就是让模型在做有监督的任务过程中,学习得到词向量的表达。即使Word2Vec号称是利用无标签文本做无监督学习,其实在训练的时候也是在无标签文本上面构建了有监督学习的任务——利用上下文单词预测中间单词(CBOW)。fastText训练词向量也是这个思路,让模型在做有监督的文本分类任务过程中学习词向量。
4 |
5 | ## fastText模型结构
6 |
7 | 相比于其它深度的分类模型,fastText模型结构非常浅,非常简单,如下图所示。
8 |
9 | 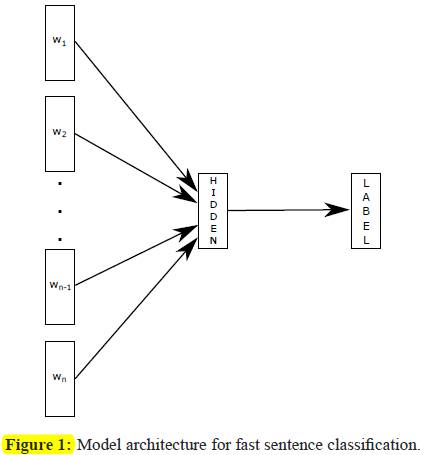
10 |
11 | 可以看到,fastText模型只包含输入层、一层隐含层、输出层,总共三层。输入层就是某条文本中的单词序列w1,w2,...wn-1,wn。当然这里不是单词的符号,而是单词的词向量,其实前面还有一层embedding层,可以看做词向量的lookup table,输入单词符号或索引就可以找到对应的词向量。当然训练开始前,lookup table 里面的词向量是随机初始化的。中间的隐层也很简单,并没有多余的参数,就是把所有单词的词向量相加,得到的向量可以看做是这个文本的embedding,然后加一个softmax激活函数。输出层就是文本属于每个类别的概率,这里的类别是事先定义好的,训练文本也是有类别标签的。
12 |
13 | ## N-gram feature
14 |
15 | fastText值得一说的一个改进在于N-gram 特征。fastText采用字符级别的N-gram。以trigram为例,单词就可以分为。那么在输入层就要做修改,lookup table 里随机初始化的是trigram的向量,由于字符的个数很有限(26个字母加几个特殊字符),所以其实trigram总的数量并不会很多。以单词apple为例,有了trigram向量,就可以将拆分的所有trigram向量SUM起来就得到了apple词向量。用N-gram feature的好处是能让词向量能学习到单词的morphology(词形)信息。比如change和changed其实是一个意思,如果用word2vec训练,它两的词向量可能很不一样,但是用fastText训练它两的词向量就很接近。另外的好处就是有了N-gram向量也能生成未登录词(out-of-vocabulary)的词向量。
16 |
17 | ## 层次化softmax
18 |
19 | 层次化softmax是fastText从Word2Vec借鉴过来的,主要作用是降低softmax的复杂度。如果用一般的softmax,由于类别太多,每个类别都要计算概率。采用层次化softmax时,由于Hoffman树特有的性质,只要计算几次可能就能分到正确的类别。
20 |
21 | ## fastText、Word2Vec、Glove对比
22 |
23 | fastText的模型结构跟Word2Vec中的CBOW模型非常像。如下图所示,唯一的差别是CBOW是利用上下文单词预测中间单词,而fastText是根据文本中全部单词预测它的分类。另外就是CBOW没有引入N-gram特征。fastText的训练同时得到了一个文本分类器。
24 |
25 | 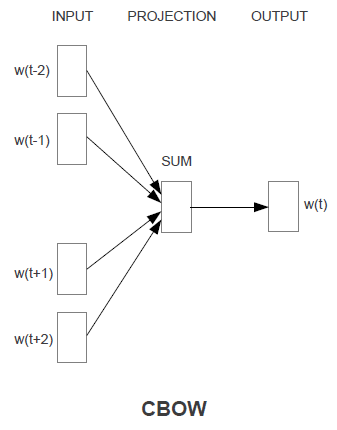
26 |
27 | 还有一个比较常用的词向量训练工具是Glove。相比于Word2Vec,Glove更加简洁。GLove主要利用单词在文本中的“co-occurance”信息来构建一个加权最小二乘回归模型,通过最优化这个最小二乘回归模型,就得到了每个单词的词向量。构建的最小二乘回归模型如下:
28 |
29 | 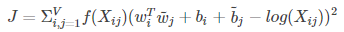
30 |
31 | 其中f(Xij)是权重函数,V是词汇集,wi是单词i的词向量,Xij是单词i和单词j的共现概率。
32 |
33 | 所以,可以把Word2Vec和fastText是“predictive”模型,而Glove是“count-based”模型。
34 |
35 | 显然在训练速度上,GLove比Word2Vec和fastText都更快。
36 |
37 | 一般认为在词向量的性能上CBOW < skip-Gram == Glove < fastText。
38 |
--------------------------------------------------------------------------------
/0003/lilong-note.md:
--------------------------------------------------------------------------------
1 | ## Wide & Deep Learning for Recommender Systems 阅读笔记
2 |
3 |
4 | ### 0 现有方法的不足
5 |
6 | 现有wide模型memorization能力强,不具备generalization能力。deep模型具备generalization能力,但在数据稀疏的情况下也存在过于“泛化”,进而推荐不相关物品的情况。
7 |
8 | ### 1 WDL是如何解决这个问题的
9 |
10 | WDL将wide linear model 和deep neural network 结合起来,一起训练。WDL模型的优势在于同时获得了wide模型的memorization(“记忆”)能力,和deep模型的generalization(“泛化”)能力。
11 |
12 | ### 2 两个问题
13 |
14 | 什么是“记忆”能力和“泛化”能力?
15 |
16 | 为什么wide模型的“记忆”能力强?deep模型的“泛化”能力强?
17 |
18 | (1)什么是“记忆”能力和“泛化”能力
19 |
20 | Memorization can be loosely defined as learning the frequent co-occurrence of items or features and exploiting the correlation available in the historical data.
21 |
22 | “记忆”能力是指对历史数据集中已经出现过的特征、特征关联及其与label之间关系进行很好的学习。即对历史数据中已经出现过的模式进行很好的学习。
23 |
24 | Generalization, is based on transitivity of correlation and explores new feature combinations that have never or rarely occurred in the past.
25 |
26 | “泛化”能力指能将从历史数据集中学到的模式迁移,用于对包含未出现特征组合的样本进行预测。
27 |
28 | (2)**为什么wide模型的“记忆”能力强?deep模型的“泛化”能力强?**
29 |
30 | wide模型以逻辑回归(LR)模型为例,deep模型以深度神经网络为例。
31 |
32 | **主要差异在于两者的特征组合能力不一样。**
33 |
34 | LR是属于广义线性模型,本身不具备对特征之间非线性关系进行建模。所以通过人工构建特征组合(交叉特征)的方式来给LR模型增加非线性建模能力。特征组合文中的例子如下:
35 |
36 | AND(user_installed_app=netflix, impression_app=pandora"), whose value is 1 if the user installed Netflix and then is later shown Pandora.
37 |
38 | 可以看出来人工构建组合特征,主要基于历史数据集中已经出现过的特征取值组合,而对于未出现过的特征取值组合没有办法构建组合特征。所以LR模型具备很好的记忆能力,但没有泛化能力。
39 |
40 | 深度神经网络模型无需人工构建组合特征,有自动做特征组合的能力。而且由于加入非线性的激活函数,神经网络模型具备非线性建模能力。神经网络模型的泛化能力除了因为它自动特征组合的能力,还因为它对类别特征的取值做embedding。这样,由于embedding的特性,即使没出现过的特征取值组合,神经网络模型也可以计算得到组合特征的值。WDL模型的架构图如下:
41 |
42 | 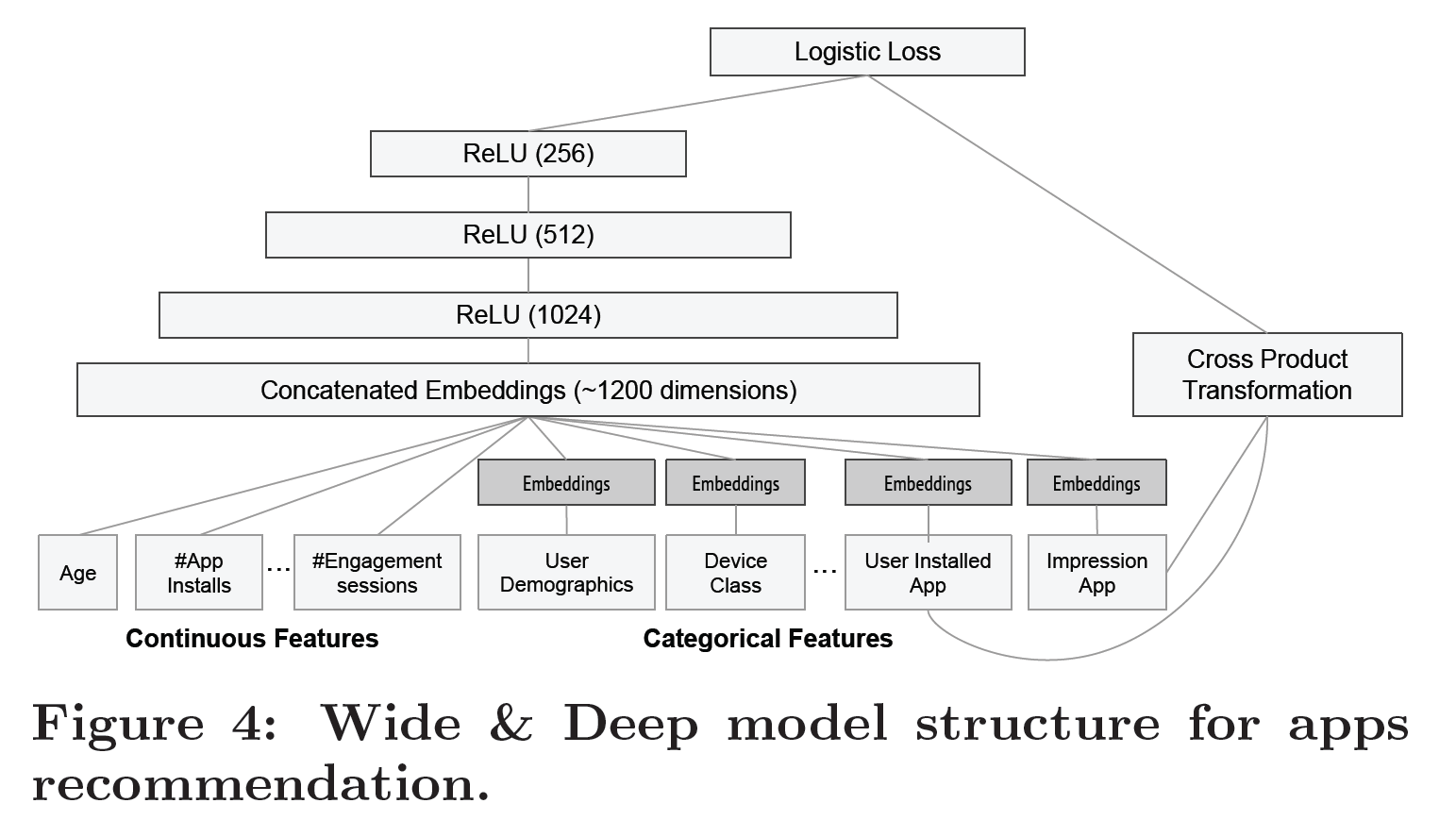
43 |
44 |
45 | WDL模型的函数表达如下:
46 |
47 | 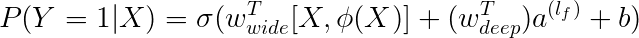
48 |
49 |
50 | ### 3 WDL模型与ensemble的区别
51 |
52 | 本文将wide模型和deep模型联合训练不同于一般的模型融合(ensemble)。
53 |
54 | ensemble时,单个的基模型在训练的时候是彼此独立的。只有在做预测的时候,才将多个基模型的预测结果进行融合得到最终的预测结果。
55 |
56 | WDL是将wide模型和deep模型作为一个整体进行训练,意味着同步用反向传播技术更新wide模型和deep模型的参数
57 |
58 | ### 4 实验结果
59 |
60 | 实验结果也表明,WDL模型不管是在线下还是线上相比于单独的wide模型和单独的deep模型,效果都有明显提升。
61 |
62 | 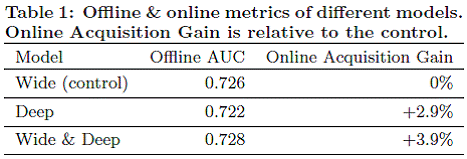
63 |
--------------------------------------------------------------------------------
/0003/wdl:
--------------------------------------------------------------------------------
1 | 摘要
2 | - 线性回归可用非线性的特征值转换做预测和分类问题,且具有较好的记忆性:利用对数据集进行点乘,但是需要大量特征值。
3 | - 神经网络可以在较少特征值情况下作出好的预测,因为它可以忽视特征值组合通过从系数特征中学习低维的密集embedding(embedding就是把字词用向量表示出来,相当于是对字词做encoding)
4 | 然而深度学习会造成过拟合,甚至推一些没关联的商品,当两个商品相互作用强且稀疏时
5 | 本文结合两种模型,同时具有记忆性和广泛率的优点
6 |
7 | 介绍
8 | 推荐系统其实可以看做一个排序系统。
9 | 记忆性:定义 获取商品或者是特征间共同发生的频率 利用历史数据中的相关性
10 | 特点 更大的局部性,对用户已有的购买行为有直接的关联
11 | 应用 一般用logistic回归,使用带有one-hot encodin的二分稀疏特征值(独热码,在英文文献中称做 one-hot code, 直观来说就是有多少个状态就有多少比特,而且只有一个比特为1,其他全为0的一种码制)
12 | 优点 直接展示了共同发生的特征对和目标标签的关系,通过点积得到记忆性用很少的参数
13 | 缺点 不会推广到没有出现在训练集中的数据
14 |
15 |
16 | 广泛性:定义 根据传递相关性和探索没有出现的或者是很少出现的新特征值组合
17 | 特点:趋向于提高推荐商品的多样性,加入粒度更粗的特征
18 | 应用 嵌入式模型factorization machines or deep neural networks(分解机和神经网络),可以拓展以前没有过的特征对通过学习低维的密集embedding
19 | 缺点 当用户有特别偏好时(两商品矩阵稀疏且相关性强)很难得到一个有效的低维模型,通过稠密的embedding得到的可能过拟合没有什么相关性
20 | 改进 这时用线性就能很好的记住这些异常规则用很少的参数
21 |
22 |
23 | 概述推荐系统
24 | - 一个带有用户多样性特征值的查询会在用户访问app的时候产生,推荐系统会给用户推荐一系列的app列表
25 | 这些用户的行为,伴随着查询和展示的app列表都会被记录在logs日志里用来训练模型
26 | - 但是在成千上万app的数据库中以低服务器延迟查询所有数据是很困难的
27 | 因此,我们的第一步是对查询语句检索(提取关键信息)
28 | 这个检索系统会返回一小部分匹配度很高的app,这部分操作是结合了通过机器学习模型和人为规则筛选出来的
29 | 最后聚合到一个候选池中,排序系统会根据得分(得分:p(y|x),各种特征为x时用户标签为y的概率)高低进行排序
30 |
31 | 宽度与广度的学习
32 | 宽度
33 | -对于普通线性方程y=wTx+b(T是w的T次),y是预测值、x是特征值、b是偏差、w是模型参数
34 | -特征值集包括了输入的特征值和转化而来的特征值,这里使用了二值化利用公式将特征值化为了0和1,当且仅当所有特征值符合才为1,否则就为0.
35 | -捕获两个二值化特征值的关系后,把这个非线性的因素加入到线性模型中
36 | 深度
37 | -深度使用的是基于前反馈的神经网络。
38 | -由于确切的特征值是以字符串输入,我们需要把每个特征值从高维、字符串 转化为 低维、密集的实数
39 | 我们将转化得到的向量成为嵌入向量(embedding vecto) 这个转化是一个重点->从字符串到实数,用到的方法可能有one-hot(二值且互斥特征)
40 | 将这个嵌入向量随机初始化中后,训练出使随时函数最小化的模型
41 | -最后将这个低维的向量投入神经网络的隐藏层进行向前传递
42 | -每层的神经元都满足一个计算,a(l+1)神经元的激活(将最为该元的输出),a(l)上一层的激活(输出),w层间神经元间权重,b偏移
43 |
44 |
45 | 联合训练
46 | 深度和广度相结合并使用一个log odds(可能性取对数)作出预测,投入到logistic损失函数。
47 | 联合训练和整体训练
48 | -整体训练:单个模型的独立性太强,预测整合在结果阶段,需要很大单个模型来使精度达标
49 | -联合训练:同时优化宽度和广度的参数及他们的权重,广度部分只需要利用少量数据的点乘进行特征值转换来弥补部分深度缺陷,而不用使用整个广度部分
50 | 模型的建立通过向后传播梯度(深度广度都同时会向后传播修正参数)
51 | 使用FTRL回归和L1范数优化器,用Adagrad解决深度中不同参数应该使用不同的更新速率的问题
52 |
53 |
54 | 系统实现
55 | -数据生成:使用分类映射表,将string->integer,当一个特征值字符串出现超过一定次数,会被记录在表中
56 | 把所有真实值都归一到[0,1]中,通过分位来映射
57 | -模型训练:输入层接受训练集、词汇以及生成稀疏矩阵和详细的特征值带有的标签
58 | 广度组件包括了user installed apps and impression apps的点乘转换
59 | 部分的深度模型,将32维嵌入向量输入,我们将串联所有的嵌入向量变为了1200
60 | 因为每次有新的训练数据到达都重新训练的话会造成很大的开销和延迟,所以实现了一个热启动系统:初始化一个带权重的新的嵌入模型、线性模型从先前的模型中
61 | -模型服务:每个请求到达,计算候选app的评分。加入并行多线程加快速度
62 |
--------------------------------------------------------------------------------
/0002/dantezhao-note.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 少数人的智慧:基于专家意见的协同过滤
3 | categories:
4 | - 技术
5 | tags:
6 | - 推荐系统
7 | date: 2018/11/10 13:25:25
8 | ---
9 |
10 | ## 0x00 摘要
11 |
12 | 基于最近邻算法的协同过滤(nearest-neighbor collaborative filtering)是一种十分成功的推荐方法。然而,这种方法存在一些缺点,比如数据稀疏性、脏数据、冷启动问题以及可扩展性。
13 |
14 | 本文将介绍一种基于专家意见向用户推荐内容的新方法,该方法是传统协同过滤的一种变体,它的不同之处在于:**该方法不再将最邻近算法用于用户评级数据,而是使用一组独立的专家数据集来计算预测专家意见和用户之间相似性。该方法能在解决传统协同过滤问题的同时保持相近的准确性。**
15 |
16 |
17 |
18 | ## 0x01 简介
19 |
20 | CF(collaborative filtering)是目前构建推荐系统的主流算法。CF 算法假设为了向用户推荐 Items,可以从过去其他类似用户的喜好中提取信息。 例如,最近邻算法通过为每个用户找到许多类似用户来实现这一目的,这些用户的画像随后可用于预测建议。然而,定义用户之间的相似性并不是一件容易的事:它受到数据中的稀疏性和噪声的限制,并且计算量很大。
21 |
22 | 本文将探讨特定领域的专业评估者(即专家)如何预测一般人群的行为。 在最近的工作中,我们发现传统 CF 算法中的很大一部分误差是来自于用户反馈中的噪声。 因此,本文的目标是使用噪声较小的来源(即专家)的反馈来建立推荐系统。
23 |
24 | *关于专家的定义,我们认为专家是能对特定领域物品给出经过深思熟虑的、一致且可靠评级的人。*
25 |
26 | ## 0x02 专家协同过滤
27 |
28 | ### 传统 CF 方法
29 |
30 | 传统 CF 方法使用 KNN 算法来预测用户的评级,该算法基于最近的 k 个邻居来计算 user-item 对的预测结果,计算过程既可以是 item-based 也可以是 user-based,本文选择 user-based (基于用户的 CF )方法。整个计算流程可以拆解为下面几个阶段:
31 |
32 | 1. 构造 user-item评分矩阵
33 | 2. 通过预定义的相似度计算方法,计算所有 user-item 对的相似性
34 | 3. 排序,生成推荐结果
35 |
36 | 关于相似度的计算方式,我们可以使用余弦相似度的变体:在余弦相似度的基础上加入调整因子,用以调整两个用户共同评定的物品数量。计算公式如下图:
37 |
38 | 
39 |
40 | 公式中各部分的含义:
41 |
42 | - 用户:a,b
43 | - 物品:i
44 | - user-item 打分:rai,rbi
45 | - 用户打分的 item 的数量:Na,Nb
46 | - 用户共同打分的数量:Naub
47 |
48 | ### 专家 CF 方法
49 |
50 | 基于专家意见的协同过滤(后文简称**专家 CF**)的不同之处在于,它不需要构造 user-item 评分矩阵,而是构建了一个每个用户和专家集之间的相似性矩阵。
51 |
52 | 专家 CF 的核心思想是这样的:**为了预测用户对特定物品的评级,我们需要找到和给定用户的相似度大于 δ 的专家。 **
53 |
54 | 整个算法可以分下面几块来理解:
55 |
56 | 一、给定用户和专家的空间 V 和相似性度量 sim:V×V→R,我们定义一组专家 E = {e1,...,ek}⊆V 和一组用户 U = {u1 ,...,uN} ⊆ V。 给定一个特定的用户 u⊆U 和一个值 δ,我们找到专家组 E'⊆E,使得:∀e⊆E'⇒sim(u,e)≥ δ。
57 |
58 | 二、使用固定阈值 δ 的一个缺点是存在找到很少邻居的风险;此外,找到的那些可能没有评定当前项目。 为了解决这个问题,我们将置信度阈值 τ 定义为必须对项目进行评级以信任其预测的最小专家邻居数量。
59 |
60 | 三、假设上一步中发现的专家组 E' 和 物品 i,我们发现 E' 的子集 E′′ 存在这种关系:∀e ⊆ E′′⇒ rei,其中 rei 专家 e ⊆E' 对 物品 i 的评级 。
61 |
62 | 四、经过前面的计算,我们得到了专家组 E′′ = e1e2…en,如果 n 的数量小于 τ,再不返回预测结果,如果 n 的数量大于 τ ,则使用如下计算公式算得用户和物品的相似度:
63 |
64 | 
65 |
66 | ## 0x03 优点
67 |
68 | - 数据稀疏性:推荐数据集固有的数据稀疏问题会因为信息量不足而带来一些额外的问题,专家收藏的数据稀疏度要比全体用户收藏的稀疏程度要低,即有更多的可参考的信息。
69 |
70 | - 噪声评分:无论用户是有意的还是无意的,数据集里面难免会存在一些噪声评分。而专家在这方面则可靠得多,而且个人意见也比较容易保持一致。
71 |
72 | - 冷启动问题:这是专家CF的一大优势。对于用户冷启动,由于数据稀疏性与噪声问题而造成的问题,在专家CF里得到了不错的解决。对于新物品的冷启动问题,由于专家更具有前瞻性,所以新物品更容易通过专家而进入到推荐池中。
73 |
74 | - 可扩展性:如果直接使用基于用户相似度的CF算法进行推荐,在实际系统中难度是相当大的,因为构造一个用户相似度矩阵是如此地庞大。而使用量要少得多的专家作为相似度矩阵的一个维度,矩阵的规模则现实得多。
75 |
76 | - 隐私:这里还考虑了这样的一种可能性,即不需要你把数据传递到服务器,只需要把专家喜好传递到客户端,与你本地的收藏相匹配,然后服务器给你返回相应的推荐,避免了服务器记录你的收藏。
77 |
78 | ## 0xFF 总结
79 |
80 | 本文是论文《The Wisdom of the Few》的阅读笔记,算是论文一个简短的总结。
81 |
82 | 另外,本文略去了论文中关于数据集的介绍以及算法最终效果评估这两部分内容,对该部分内容感兴趣或者想深入研究原文的可以下载论文阅读。
83 |
--------------------------------------------------------------------------------
/0003/yangminghan-note.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Wide & Deep Learning for Recommender Systems
4 | date: 2018-11-17
5 | categories: blog
6 | tags: [文献阅读]
7 | description:
8 | ---
9 |
10 | # Wide & Deep Learning for Recommender Systems
11 |
12 | 1. what(是什么): Wide & Deep Learning是谷歌提出的一个推荐系统算法,该算法结合广义线性模型和深度学习模型的优点。
13 | 2. why (为什么): 广义线性模型需要较为复杂的特征工程,但是在处理稀疏数据时效果较好,深度学习模型可以生成以前没有推荐,并且不需要复杂的特征工程,该模型希望规避两者的缺点,同时兼顾两者的优点。
14 | 3. how (怎么做): 文章给出了使用TensorFlow实现的方法。
15 |
16 | ### Abstract
17 | 广义线性模型在大型的回归和分类问题中有着很广泛的应用,其优势在于可以“记忆”(memorization)用户的喜好,但是,该模型需要花费很多的时间在特征工程上。深度神经网络可以通过low-dense embeddings生成以前没有的特征组合,并且不需要花费很长的时间在特征工程上。然而,深度神经网络在数据比较稀疏并且比较集中的时候,会发生过拟合,生成一些相关性比较小的推荐。在这篇文章中,作者提出了一种新的模型 **Wide and Deep Learning**希望可以结合两者的优点,既可以“记忆”用户的喜好,推荐给他们最相关的产品,又可以生成新的推荐。
18 |
19 | ### 1.Introduction
20 | 一个推荐系统可以看做一个搜索排序系统,输入的是查询是一个用户与文本信息的集合,输出是一个物品的排名。推荐系统是在数据库中选择相关的物品(items),然后把这些物品根据特定的目标(such as clicks or purchases)进行一个排名。
21 | 推荐系统的一个挑战就是如何能同事做到“记忆”(memorization)和“生成”(generalization)。“记忆”可以简单的理解为学习物品或者特征在历史数据中同时出现的频率和相关性。“生成”则是关注相关的可推广性和探索以前没有过的,新的物品和特征组合。
22 | “记忆”在推荐系统的体现为根据用户已经有的行为(更多的基于历史数据),推荐同一个主题下的物品或者直接与之相关的物品。“生成”则表现为提高推荐物品的多样性。
23 | 这篇论文,我们将注意力放在Google的App Store的推荐系统上,但是该模型具有较强的泛化能力。这篇文章的主要关注点:
24 | - The Wide & Deep learning framework for jointly training feed-forward neural networks with embeddings and linear model with feature transformations for generic recommender systems with sparse inputs.
25 | - The implementation and evaluation of the Wide & Deep recommender system productionized on Google Play, a mobile app store with over one billion active users and over one million apps.
26 |
27 | ### 2.Recommender System Overview
28 | 用户发送给推荐系统一个查询请求,推荐系统返回给用户一个推荐的list。通常情况下,在数据库中有着大量的app,所以在这种时候,很难在短时间内给每一个查询的app都有一个精确的评分,所以推荐系统的第一步通常是retrieval,这个步骤类似于粗排,返回一个和查询最匹配的较短的物品的清单。得到这个清单的方式一般是使用机器学习模型和规则进行匹配。然后,再根据这个粗排的list,继续精排,这个分数由ranking system继续给出。那这篇文章提出的W&D模型主要是做精排。
29 | 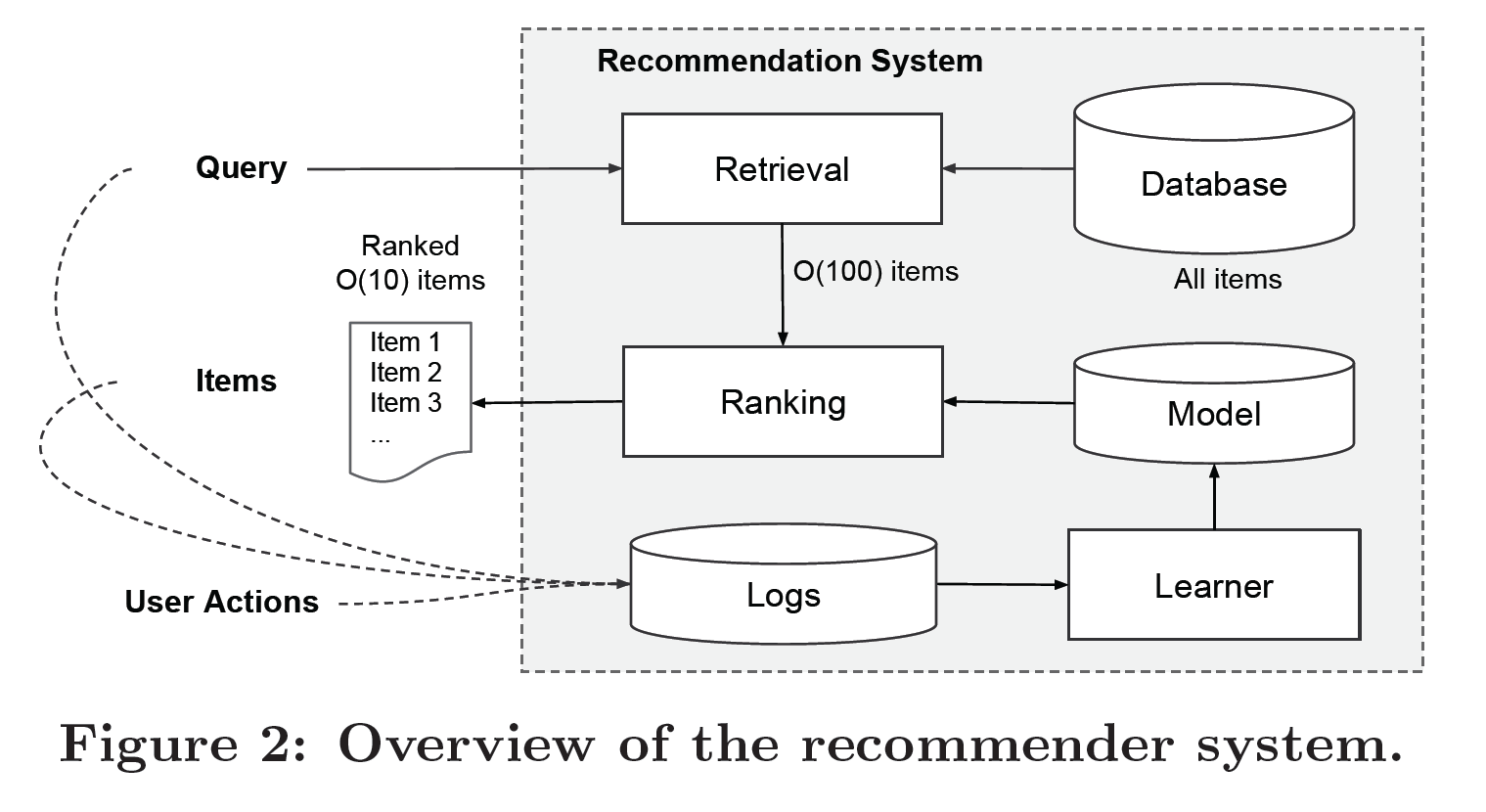
30 | ### 3.Wide & Deep Learning
31 | #### 3.1 The Wide Component
32 | #### cross-product transformation
33 | 借着看论文的机会,我回去好好复习了一下线性代数的相关概念,线性代数中cross-product翻译成叉乘,表示两个向量叉乘后得到一个新的向量,该向量与原来两个向量张成的平面垂直,长度等于两个向量所围成的平行四边形的面积(行列式的值)。但是在这篇论文中做这项变换的是下面的公式,这个有待进一步对线性代数进行研究。
34 |
35 | 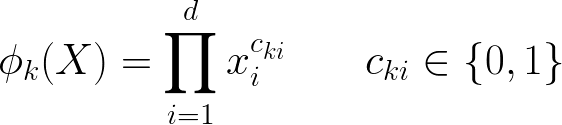
36 | #### 3.2 The Deep Component
37 | 深度这一块,原始模型用的激活函数是Relu。
38 |
39 | 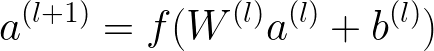
40 | #### 3.3 Joint Traing of Wide & Deep Model
41 | Joint training和ensemble的区别:在ensemble中,每一个独立的模型在训练的时候是相互独立的,他们的结果是在最后做出推断的时候才被合并起来,而不是在训练的时候进行合并。与ensemble相反,joint training在训练的时候就将wide,deep两部分和这两部分所占的比重同时进行训练。在模型的规模方面,ensemble的每一个独立的模型规模一般都大一点,而W&D的模型规模比较小,这意味着较少规模的叉乘特征转换。
42 |
43 | 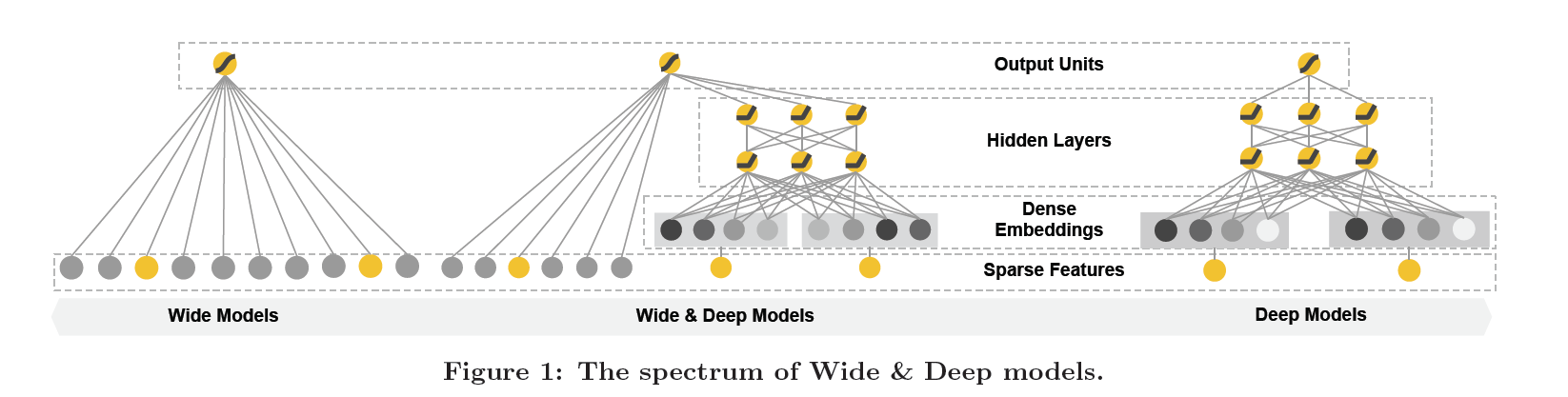
44 | 最后整个W&D的模型的整个模型结构,经过我们讨论,认为可以把Wide部分和Deep部分都看成是特征工程,Wide部分使用的方式是cross product transform,Deep部分使用的embedding。
45 | 
46 |
47 |
48 | ### Embedding
49 | Embedding这一项的操作是将分类变量映射到多维空间,这个我最困惑的问题是映射到多维空间的初始值是怎么设定的?随机设定,就和神经网络的参数一开始随机设定一样,再由BP算法对这些值进行更新就可以了。
50 |
51 | [Google AI Blog: Wide & Deep Learning: Better Together with TensorFlow ](https://ai.googleblog.com/2016/06/wide-deep-learning-better-together-with.html)
52 |
53 | [3Blue1Brown: Cross products in the light of linear transformations | Essence of linear algebra chapter 11](https://www.youtube.com/watch?v=BaM7OCEm3G0)
54 |
--------------------------------------------------------------------------------
/0004/bigablecat.md:
--------------------------------------------------------------------------------
1 | #### [Bag of Tricks for Efficient Text Classification](https://github.com/dantezhao/paper-notes/blob/master/0004/Bag%20of%20Tricks%20for%20Efficient%20Text%20Classification.pdf)
2 |
3 | #### <阅读笔记>
4 |
5 | ```shell
6 | 本文介绍了一款基于线性模型的文本分类神器fastText
7 |
8 | 带着问题阅读:
9 | 1. how: fastText是如何实现高效文本分类的
10 | ```
11 |
12 | **0. 摘要**
13 |
14 | ```shell
15 |
16 | fastText是一个简单高效的文本分类器
17 |
18 | 在准确度方面可与深度学习分类器比肩
19 |
20 | 在训练和评估方面甚至比深度学习快了多个数量级
21 |
22 | 具体有多快呢?
23 |
24 | 使用一个标准的多核CPU,fastText能够
25 |
26 | 1) 在10分钟内训练10亿个单词的文本
27 |
28 | 2) 在一分钟内从31万2000个类型中,为50万个语句分类
29 |
30 | ```
31 |
32 |
33 |
34 | **1. 导言**
35 |
36 | * 简单介绍
37 |
38 | ```shell
39 |
40 | 1) 文本分类(Text classification)是自然语言处理的重要应用,
41 | 常用于网络搜索,信息检索,排序和文件分类
42 |
43 | 2) 基于神经网络的文本分类器效果很好,
44 | 但是在训练和测试时间上相对较慢,
45 | 限制了它们在超大数据集上的应用
46 |
47 | 3) 线性分类器虽然简单,
48 | 但是如果特征应用得当,
49 | 可以取得非常好的效果,
50 | 在超大文本上也能使用。
51 |
52 | ```
53 |
54 | * 本文内容
55 |
56 | ```shell
57 |
58 | 本文探讨如何在超大输出空间的超大文本上实现文本分类
59 |
60 | 在线性模型使用rank constraint和fast loss approximation
61 |
62 | 能够实现10分钟训练10亿级的单词量,并取得与前沿技术等同的效果
63 |
64 | 文章通过标签预测和情感分析这两个任务来评估fastText的效果
65 |
66 | ```
67 |
68 |
69 |
70 | **2. 模型设计(Model architecture)**
71 |
72 | * 原有线性模型文本分类器的一些问题
73 |
74 | ```shell
75 |
76 | 句子分类最简单直接的一种方式:
77 | 使用词袋模型(bag of words, BoW)并训练一个线性分类器,如逻辑回归或者支持向量机(SVM)
78 |
79 | 线性分类器的一个问题是无法在特征和类型之间共享参数
80 |
81 | 这个问题有可能限制了线性模型在超大输出空间的文本上进行泛化,
82 | 因为超大空间中有一些类型样本极少
83 |
84 | 通常的解决方案有:
85 | a) 将线性模型因式分解为低秩矩阵(low rank matrices)
86 | b) 或者使用多层神经网络
87 |
88 | ```
89 |
90 | * 秩约束矩阵
91 |
92 | 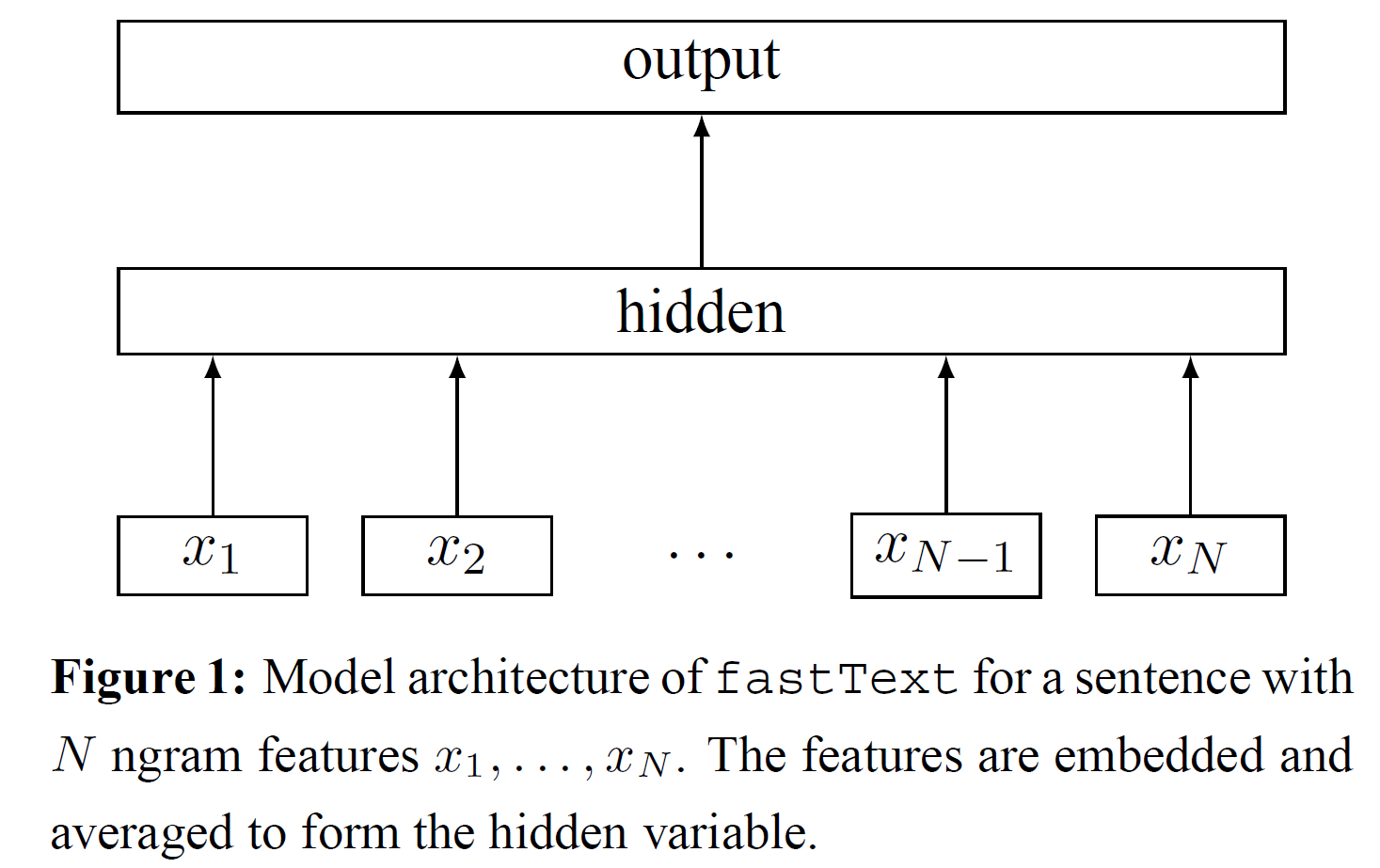
93 |
94 | >Figure 1 秩约束矩阵
95 |
96 | ```shell
97 |
98 | 第一权矩阵A可以看做一个查词表
99 |
100 | 词汇表征被平均到文本表征,文本表征又被用于线性分类器
101 |
102 | 文本表征是能够被重用的隐含变量
103 |
104 | 我们使用柔性最大函数f(softmax function f)计算预定义类型的概率分布
105 |
106 | 对于N个文件的集合,柔性最大函数能将类型的负对数似然估计最小化
107 |
108 | ```
109 |
110 | * 柔性最大函数softmax fuction
111 |
112 | 
113 |
114 | >xn是第n个文本的标准化特征包(normalized bag of features)
115 |
116 | >yn表示标签(label)
117 |
118 | >A和B代表权重矩阵(weight matrices)
119 |
120 | >这个模型使用随机梯度下降(stochastic gradient descent)和线性衰减学习速率(linearly decaying learning rate)在多核CPU上进行异步训练
121 |
122 | **2.1 层次softmax函数(Hierarchical softmax)**
123 |
124 | * 改善计算复杂度
125 |
126 | ```shell
127 |
128 | 当类型的数量非常庞大时,线性分类器的计算代价太高
129 |
130 | 为了降低运行时间,模型引入了:
131 | 基于霍夫曼编码树(Huffman coding tree)的层次softmax函数(Hierarchical softmax)
132 |
133 | ```
134 |
135 | * 训练(training):
136 |
137 | >1) 普通线性分类器:
138 | O(kh),k是类型数量,h是文本表征的维度
139 |
140 | >2) 层次softmax函数:
141 | O(hlog2(k))
142 |
143 | * 测试(test):
144 |
145 | >1) 普通线性分类器:
146 | O(kh),k是类型数量,h是文本表征的维度
147 |
148 | >2) 层次softmax函数:
149 | O(hlog2(k))
150 |
151 | >3) 在层次softmax函数基础上引入二叉堆(binary heap)计算T-top节点:
152 | O(log(T))
153 |
154 | * 对测试(test)时节点概率的进一步解释
155 |
156 | 
157 |
158 | >上面的公式用于表示与节点相关的概率
159 |
160 | >(l + 1) 表示节点深度(depth)
161 |
162 | >n1,...,nl 表示节点的所有父节点
163 |
164 | >每个节点都与根节点到该节点路径的概率相关
165 |
166 | ```shell
167 |
168 | 每个节点的概率总是小于其父节点的概率
169 |
170 | 搜索树时直接从最大概率的叶子节点开始查找
171 |
172 | 舍弃小概率的叶子节点
173 |
174 | 上述操作降低了测试的计算复杂度
175 |
176 | ```
177 |
178 | **2.2 N-gram分词特征(N-gram features)**
179 |
180 | ```shell
181 | 词袋(bag of words)的词序相对不变
182 |
183 | 计算时直接使用原词序计算成本高
184 |
185 | 使用一个包含n-grams分词的词袋作为捕捉词序的附加特征
186 | 能够达到与直接使用词序近似的效果
187 |
188 | 我们使用哈希(hashing trick)来维护一个快速且高效存储的n-grams映射
189 |
190 | 使用二元分词(bigrams)只需10M的bins存储空间,否则需要100M的空间
191 |
192 | ```
193 |
194 |
195 |
196 | **3. 实验(Experiments)**
197 |
198 | ```shell
199 | 本文使用两项任务来衡量fastText
200 |
201 | 1) 与现有的文本分类器在情感分析问题上比对
202 |
203 | 2) 在具有大量输出空间的标签预测数据集上测试大数据计算能力
204 |
205 | 经实践测试,本文使用的模型在两项对比中至少快出2到5倍
206 |
207 | ```
208 |
209 | **3.1 情感分析(Sentiment analysis)**
210 |
211 | ```shell
212 | 情感分析进行了两组实验
213 |
214 | 第一组实验将fastText和另外6个模型在8个数据集上进行对比
215 |
216 | 第二组实验将fastText和另外4个模型在4个数据集上进行对比
217 | ```
218 |
219 |
220 | * 第一组实验(Table 1)
221 |
222 | ```shell
223 |
224 | fastText, h=10
225 |
226 | fastText, h=10, bigram
227 |
228 | 其他模型:
229 |
230 | 1) BoW
231 |
232 | 2) n-grams
233 |
234 | 3) TF-IDF(term frequency–inverse document frequency)
235 |
236 | 4) char-CNN,字符级卷积神经网络(character level convolutional model)
237 |
238 | 5) char-CRNN,字符级循环卷积神经网络(character based convolution recurrent network)
239 |
240 | 6) VDCNN,超深卷积神经网络(very deep convolutional network)
241 |
242 | ```
243 |
244 | * 第二组实验(Table 3)
245 |
246 | ```shell
247 |
248 | fastText
249 |
250 | 模型:
251 |
252 | 1) SVM+TF
253 |
254 | 2) CNN
255 |
256 | 3) Conv-GRNN
257 |
258 | 4) LSTM-GRNN
259 |
260 | ```
261 |
262 | * 结果
263 |
264 | ```shell
265 |
266 | Table 1:
267 |
268 | fastText使用10个隐藏层(hidden units)运行5个回合(epochs)
269 |
270 | 学习率(learning rate)从验证集{0.05, 0.1, 0.25, 0.5}中获取
271 |
272 | 添加二元分词(bigram)信息可以将整体表现提升1~4%
273 |
274 | 整体来看fastText准确率比char-CNN和char-CRNN稍高,略差于VDCNN
275 |
276 | 使用更多分词可以略微提高准确率,如三元分词(trigrams)可将Sogou数据集上的准确率提升至97.1%
277 |
278 |
279 | Table 3:
280 |
281 | fastText比Table 3中其他几种方法都好
282 |
283 | 调整验证集中的超参(hyper-parameters)发现n-grams为5时模型效果最好
284 |
285 | fastText没有使用预训练的词嵌入(pre-trained word embeddings)可能是1%准确率差异的原因
286 |
287 | ```
288 |
289 | * 训练时间(training time)
290 |
291 | ```shell
292 | char-CNN和VDCNN都在NVIDIA tESLA K40 GPU上进行训练
293 |
294 | fastText在20个线程的CPU上训练
295 |
296 |
297 | Table 2显示使用卷积的方法比fastText慢了若干个数量级
298 |
299 | 如果char-CNN使用更新的CUDA卷积实现,速度能够加快10倍
300 |
301 | fastText在一分钟内就能在同样的数据集上完成训练
302 |
303 | GRNN方法在单线程的CPU上一个回合(epoch)耗费12个小时
304 |
305 | 相比于神经网络方法,fastText随着数据量增大至少增速15000倍
306 |
307 | ```
308 |
309 | **3.1 情感分析(Sentiment analysis)**
310 |
311 | ```shell
312 |
313 |
314 | ```
315 |
316 |
317 |
318 |
319 | **4. 探讨和结论**
320 |
321 | ```shell
322 |
323 | 本文展示了一个文本分类的简单方法
324 |
325 | 与word2vec所得的非监督训练词向量不同的是,
326 | 该方法的词特征可以进一步合成整句特征
327 |
328 | fastText最终效果比肩深度学习方法且速度更快
329 |
330 | 理论上深度神经网络比浅层模型表现力更强,
331 | 但是在处理类似情感分析这样的简单文本分类问题时,
332 | 深度神经网络并不一定是最佳选择
333 |
334 | ```
335 |
336 |
337 |
338 |
339 |
340 | ##### <参考资料>:
341 |
342 | a) [神经网络训练中,Epoch、Batch Size和迭代傻傻分不清](https://cloud.tencent.com/developer/article/1117838)
343 | b) [Training Hidden Units with Back Propagation](https://web.stanford.edu/group/pdplab/pdphandbook/handbookch6.html)
344 |
--------------------------------------------------------------------------------
/0002/bigablecat.md:
--------------------------------------------------------------------------------
1 | #### [The Wisdom of the Few](https://github.com/dantezhao/paper-notes/blob/master/0002/The%20Wisdom%20of%20the%20Few.pdf)
2 | ##### <阅读笔记>
3 |
4 | ```shell
5 | 最近邻协同过滤做用户推荐,
6 | 一种传统的方法是,将近邻算法应用于用户打分数据并得出结果;
7 | 另一种非传统的方法是,基于一个独立数据集的专家打分数据
8 |
9 | 本文介绍了非传统的方法,在专家数据的基础上,使用最近邻协同过滤生成推荐
10 |
11 | 这种方法在文中也被称为少数智慧方法(The Wisdom of the Few approach)
12 |
13 | 该方法主要用于解决冷启动问题
14 |
15 | 带着问题阅读:
16 | 1. what: 最近邻协同过滤和专家数据的概念
17 | 2. why: 为什么使用专家数据代替传统的用户数据
18 | 3. how: 如何用这种方式实现用户推荐
19 | ```
20 |
21 |
22 |
23 | **0. 摘要**
24 |
25 | ```shell
26 | 最近邻系统过滤做用户推荐的缺点:
27 | a) 数据稀疏和噪音
28 | b) 冷启动问题
29 | c) 可扩展性
30 |
31 | 传统最近邻协同过滤基于用户打分数据(user-rating data)
32 |
33 | 新方法则基于独立数据集的专家近邻(expert neighbors)数据
34 |
35 | 新方法既能克服传统方法的缺点,又能保证相对的精确性
36 |
37 | 本文从Netflix的数据集爬取专家评分作为基础数据,从预测准确性和推荐精准度两方面来分析结果
38 |
39 | 最后本文还会给出一个用户使用报告,评估用本文方法生成的推荐
40 | ```
41 |
42 |
43 |
44 | **1. 导言**
45 |
46 | * 协同过滤和最近邻算法
47 |
48 | ```shell
49 | 协同过滤(Collaborative filtering, CF)是构建用户推荐系统的主流方法
50 |
51 | CF算法基于其他相似用户的打分,向特定用户推荐产品
52 |
53 | 最近邻算法(The Nearest Neighbor algorithm)就是为每个用户找出一批相似的用户,通过相似用户的资料做出推荐
54 |
55 | 然而,再做出推荐之前,找出相似用户面临如下问题:
56 | a) 数据稀疏性和噪声
57 | b) 计算成本高
58 | ```
59 |
60 | * 数据来源
61 |
62 | ```shell
63 | 本文探索如何从特定群体(专家群体expert)的专业评分来预测大众行为
64 |
65 | 新近的研究发现,基于反馈(feedback-based)的CF算法有相当一部分误差(error)来自于用户反馈的噪声
66 |
67 | 所以本文使用了掺杂较少噪声的专家数据源来做推荐
68 |
69 | 本文关于专家(expert)的定义:
70 | 在某个特定群体中,对产品的评估(打分)有见解、质量稳定、可信度高的一批人
71 | ```
72 |
73 | * 研究目标
74 |
75 | ```shell
76 | 本文的研究目的不是提高协同过滤算法的准确性(accuracy)
77 |
78 | 本文主要关注如下几点:
79 | a) 如何从一个小群体用户推测大范围用户的行为
80 |
81 | b) 发掘从一个独立不相关的数据集生成推荐的潜在效果
82 |
83 | c) 分析专业评分者能否为普通用户提供良好的预测
84 |
85 | d) 论述本文使用的方法能否解决传统CF算法的缺陷
86 |
87 | ```
88 |
89 | * 本文贡献
90 |
91 | ```shell
92 | 1) 收集并比较了两个数据集的特点:Netflix用户的电影评分数据集vs.网络搜集的150个专业影评人影评数据
93 |
94 | 2) 设计了一套基于专家意见预测个人评分的方法
95 |
96 | 3) 从两方面评估使用专家意见来预测用户选择的效果:
97 | a) 预测准确性
98 | b) 推荐列表精确度
99 | ```
100 |
101 |
102 |
103 | **2. 从网络挖掘专家打分数据**
104 |
105 | * 获取数据
106 |
107 | ```shell
108 | 作者在第一个段落简单说明了获取专家打分数据有两种途径:
109 | a) 从可靠数据源获取原始评测数据,使用模型推算出打分
110 | b) 从网络爬取线程的数据
111 |
112 | 本文的专家影评数据爬取自烂番茄网站
113 |
114 | 这些专家数据可以匹配到Netflix影库(17770部影片)中的8000部
115 |
116 | 虽然舍弃了很多数据,但是50%(8000比17770粗略地视为50%)左右的Netflix影片数据已经足够用于计算
117 |
118 | 为了更为精确,本文为专家设定了一个最少观影量ρ=250,又从1750位专家中筛选出169位作为最终的专家数据集
119 |
120 | 极少的数据量印证了本文所用新方法的潜力
121 | ```
122 |
123 | **2.1 数据集分析,用户和专家**
124 |
125 | * 打分数量和数据稀疏性(Figure 2a, 2b)
126 |
127 | ```shell
128 | 用户数据来自Netflix,专家数据来自烂番茄(Rotten Tomatoes)
129 |
130 | 1) 数据稀疏性
131 | a) 用户数据的稀疏性系数约为0.01,表明用户矩阵中只有1%的位置有非零值
132 |
133 | b) 专家数据的稀疏性系数约为0.07
134 |
135 | 2) Figure 2b: 每个用户/每个专家的打分数据累积分布函数(CDF of ratings per user and expert)
136 |
137 | a) 平均每个Netflix用户为少于100部电影打分,其中只有10%的用户为超过400部电影打分
138 |
139 | b) 平均每个专家为400多部电影打分,其中10%的专家为1000部以上的电影打分
140 |
141 | 3) Figure 2a: 每部影片的打分数据累积分布函数(CDF of ratings per movie)
142 |
143 | a) 平均每部影片有1000个Netflix用户打分
144 |
145 | b) 平均每部影片有100个专家打分
146 |
147 | 总结:专家矩阵比用户矩阵稀疏性更弱,分布更为均匀
148 | ```
149 |
150 | * 平均打分分布(Figure 3a, 3b)
151 |
152 | ```shell
153 | 1) Figure 3a:基于影片的平均分数分布情况
154 |
155 | a) Netflix影库中每部电影平均得分为0.55(3.2星),10%的影片分数在0.45(2.8星)或更少
156 |
157 | b) 专家数据集的影片平均得分为0.6(3.5星),有10%的影片分数低于0.4(2星),另有10%的影片分数高于0.8(0.8~1之间)
158 |
159 |
160 | 2) Figure 3b描绘了基于用户/专家的平均打分分布情况
161 |
162 | a) Netflix用户评分正态分布在0.7(0.4星)左右
163 |
164 | b) 专家评分的正态分布在0.6(3.5星)左右
165 |
166 |
167 | 3) 由图所得结论
168 |
169 | a) 基于影片(per movice)的专家评分,差异性大于基于用户(per user)的专家评分
170 | 原因可能是专家有更强的评分意识,无论电影是否喜欢都会去观看并打分
171 | 普通用户倾向于观看受好评的影片
172 |
173 | b) 大部分的高分电影专家都会打高分,说明专家对优秀电影的看法较为一致
174 |
175 | ```
176 |
177 | * 打分的标准差(Figure 4a, 4b)
178 |
179 | ```shell
180 | 1) Figure 4a: 基于影片的标准差分布(std per movie)
181 |
182 | a) Netflix库内影片得分的标准差在0.25(1星)左右,差异性比较小
183 |
184 | b) 专家库内影片得分的标准差在0.15左右,差异性稍大
185 |
186 |
187 | 2) Figure 4: 基于影片的标准差分布(std per user)
188 |
189 | a) 基于Netflix用户的标准差大约为0.25,差异性大于基于影片的标准差
190 |
191 | b) 基于专家用户的标准差大约为0.2,差异性较小
192 |
193 | ```
194 |
195 | * 总结
196 |
197 | ```shell
198 | 上述数据分析展现了普通用户和专家的异同:
199 |
200 | 1) 专家数据稀疏性更比普通用户小
201 |
202 | 2) 专家为大部分的电影打分,而不是只评受欢迎的影片
203 |
204 | 3) 对于优秀的电影,专家和大众看法一致
205 |
206 | 4) 基于电影的标准差,专家和普通用户一样偏低,说明专家和普通用户观点趋于一致
207 |
208 | 5) 基于专家的标准差比基于普通用户的标准差低,说明专家个人平均打分相差不大
209 | ```
210 |
211 |
212 |
213 | **3. 专家最近邻**
214 |
215 | ```shell
216 | 这一段主要解释了最近邻方法的使用和公式的构成
217 | ```
218 |
219 | * 方法介绍:协同过滤通常会使用KNN(k-NearestNeighbor)算法
220 |
221 | ```shell
222 | a) 基于k个最近邻,计算出用户-物品预测值
223 |
224 | b) k近邻可以是用户的最近邻也可以是物品的最近邻
225 |
226 | c) 本文选取基于用户的最近邻,正好适合专家数据
227 | ```
228 |
229 | * 计算步骤拆解
230 |
231 | ```shell
232 | 1) 首先,计算出用户-物品的分数矩阵
233 |
234 | 2) 接着,计算所有用户的相似度
235 | 2.1) 选用一个余弦相似度(variation of the cosine similarity)的变体
236 |
237 | 2.2) 该余弦相似度包含一个校正系数(adjusting factor)
238 |
239 | 2.3) 这个校正系数含有与两类用户都相关的物品的数量
240 | ```
241 |
242 | * 与传统CF计算的不同
243 |
244 | ```shell
245 | a) 只选用专家数据预测用户打分
246 |
247 | b) 生成一个相似度矩阵,将每个用户和专家数据集进行比较
248 |
249 | c) 选用与普通用户的相似度超过δ(Delta)的专家,用于预测用户对特定物品的打分
250 | ```
251 |
252 | * 选用固定阈值(fixed threshold) δ 遇到的问题和解决方法
253 |
254 | ```shell
255 | a) 有可能只找到非常少的近邻
256 |
257 | b) 即便找到了近邻,这个近邻也有可能没为当前物品打分
258 |
259 | c) 为了解决上述两个问题,方法中引入一个置信阈值τ(Tau)
260 |
261 | d) τ用来限定专家所拥有的最少近邻数,而且这些近邻必须为当前物品打过分
262 | ```
263 |
264 | * 下一段落预告
265 |
266 | ```shell
267 | 下一段落主要介绍 δ 和 τ 两个参数的相互作用
268 |
269 | 这两个参数的最优设置取决于数据集和实现方法的设计
270 |
271 | 为了与传统的CF方法作比较,本文采用基于相同阈值的最近邻方法
272 |
273 | ```
274 |
275 |
276 |
277 | **4. 结果解释**
278 |
279 | ```shell
280 |
281 | 基于前述数据,为了验证169个专家预测10000个Netflix用户的效果如何
282 |
283 | 设计了两套实验:
284 |
285 | 1) 衡量预测推荐的平均误差(mean error)和覆盖率
286 |
287 | 2) 衡量推荐列表的精准度(precision)
288 |
289 | ```
290 |
291 | **4.1 推荐误差**
292 |
293 | * 拆分数据集
294 |
295 | ```shell
296 | 为了评估专家打分的预测潜力,我们用随机抽样将用户数据集分成两部分
297 | a) 80%的训练数据集
298 | b) 20%的测试数据集
299 |
300 | 最终使用k折叠交叉验证的平均结果,k值为5(5-fold cross validation)
301 | ```
302 |
303 | * 平均绝对误差(MAE, mean average error)和覆盖率(coverage)
304 |
305 | ```shell
306 | 1) 专家选择(Critics' Choice)
307 | 用所有专家比上每个给定物品,得出一个平均值
308 | 这个平均值作为最差结果衡量基线(worst-case baseline measure)
309 | 可以看成一种非个性化的专家选择推荐(Critics' Choice)
310 | 专家选择推荐的平均绝对误差是0.885,覆盖率是全覆盖(100%)
311 |
312 | 2) 专家协同过滤(Expert-CF)
313 | 同样使用专家数据,将置信阈值τ设为10,最小相似度δ设为0.01
314 | 这种情况下平均绝对误差为0.781,覆盖率为97.7%
315 |
316 | 3) 标准近邻协同过滤(Standard neighbor-CF)
317 | 忽略专家数据集,仅使用Netflix用户,置信阈值τ取值10,最小相似度δ取值0.01
318 | 得到平均绝对误差0.704,覆盖率92.9%
319 |
320 | 对比专家选择的平均值,专家协同过滤(Expert-CF)在准确度方面有显著提升
321 |
322 | 将覆盖率考虑进来,置信阈值τ和最小相似度δ两个参数的设置只带来了很小的损失
323 |
324 | ```
325 |
326 |
327 |
328 |
329 | **6. 论述**
330 |
331 | **6.1 本文论述涉及的几个点**
332 |
333 | ```shell
334 | 本文介绍了一种基于少数专家评分为大众用户生成预测的推荐系统
335 |
336 | 数据来源于网络上的专家影评
337 |
338 | 本文采用的专家评测体系与可信度(trust)相关
339 | 在可信度敏感的推荐系统中,近邻的影响力可以通过他们对现有用户是否可靠来权衡
340 |
341 | 基于专家数据的近邻协同过滤在预测准确性方面并没有比原始的方法更优越
342 | ```
343 |
344 | **6.2 专家数据如何解决传统方法的缺陷**
345 | * 1) 数据稀疏(Data Sparsity)
346 |
347 | ```shell
348 | 从上下文看,本文所说的数据稀疏是指用户的打分比较分散
349 |
350 | 在标准的协同推荐系统中,用户打分数据的稀疏导致了数据不一致性和噪声
351 |
352 | 专家打分往往会涵盖大部分的评测对象,解决了数据稀疏问题
353 | ```
354 |
355 | * 2) 噪声和恶意打分(Noise and Malicious Ratings)
356 |
357 | ```shell
358 | 普通用户打分会因为草率或恶意操作带来数据噪声,影响预测质量
359 |
360 | 专家的评分质量稳定(consistent),打分时有较强的主观意识,因而减少了数据噪声
361 |
362 | 同时,专家数据集更为可控和稳定,可以规避恶意评测和用户注入攻击的问题
363 | ```
364 |
365 | * 3) 冷启动问题(Cold Start)
366 |
367 | ```shell
368 | 冷启动是指评分系统中新增的评测对象因缺少评分数据而无法被推荐的问题
369 |
370 | 新加入系统的用户也面临冷启动的问题
371 |
372 | 专家在得知新评测对象的时候往往会立即打分,从而减弱了冷启动问题
373 |
374 | 专家打分的数据集具备较少的稀疏性和噪声,也能够改善冷启动问题
375 | ```
376 |
377 | * 4) 可扩展性(Scalability)
378 |
379 | ```shell
380 | 计算N个用户和M个评测对象的矩阵,复杂度是O(N²M)
381 |
382 | 每当新的评测对象加入系统时,都需要更新矩阵
383 |
384 | CF算法的可扩展性受到了算法复杂度的限制
385 |
386 | 虽然k-means聚类等方法可以用来应对可扩展性问题,但是可扩展性仍然是CF算法的主要研究议题
387 |
388 | 基于专家数据的方法,因为数据集小,对数据量的扩充并不敏感,也就没有显著的可扩展性问题
389 | ```
390 |
391 | * 5) 隐私(privacy)
392 |
393 | ```shell
394 | 为了维护和更新相似矩阵,系统必须传输所有用户评分到某个中央节点用于统一计算
395 |
396 | 专家数据集容量非常小,传输方便,在客户端本地即可实现运算
397 | ```
398 |
399 | **7. 结论**
400 | * 方法的使用
401 |
402 | ```shell
403 | 本文所述的"少数人智慧"的方法,基于外部独立的数据源中少量的专家打分,对大众用户打分进行预测
404 |
405 | 基于专家数据的方法与传统CF方法具有可比性
406 |
407 | 当前方法使用169个专家打分数据来预测Netflix电影打分数据,在平均误差上与传统方法相当
408 |
409 | 同时该方法也在top-N推荐设置里进行了验证
410 |
411 | 用户调研显示,在冷启动场景中,新方法比传统的近邻协同过滤更好
412 |
413 | 新方法在一定程度上解决了传统方法的几个缺陷:
414 | a) 数据稀疏
415 | b) 可扩展性
416 | c) 用户反馈中的噪声
417 | d) 隐私
418 | e) 冷启动
419 |
420 | ```
421 |
422 | * 改进和发展
423 |
424 | ```shell
425 | 1) 本文论述了专家协同过滤算法在特定领域的应用,在拥有专家打分体系的其他领域也可以采用
426 |
427 | 2) 外部专家数据可以和传统CF算法相结合,以改善整体的准确性
428 |
429 | 3) 本文仅限于基于用户的近邻协同过滤算法,但是其他形式的协同过滤算法也可以使用专家数据这种方式,例如:
430 | a) 基于物品/评测对象(item-based)的算法
431 | b) 基于模型(model-based)的算法
432 |
433 | ```
--------------------------------------------------------------------------------
/0003/bigablecat.md:
--------------------------------------------------------------------------------
1 | #### [Wide & Deep Learning for Recommender Systems](https://github.com/dantezhao/paper-notes/blob/master/0003/Wide%20%26%20Deep%20Learning%20for%20Recommender%20Systems.pdf)
2 |
3 | #### <阅读笔记>
4 |
5 | ```shell
6 | 本文讲解了广度和深度学习相结合的方法,并以Google Play为例,介绍了该方法在推荐系统实践中的应用
7 |
8 | 带着问题阅读:
9 | 1. what: Wide & Deep Learning的两部分,分别是什么
10 | 2. why: 为什么将二者相结合
11 | 3. how: 广度和深度相结合的具体实现
12 | ```
13 |
14 | **0. 摘要**
15 |
16 | ```shell
17 | 对已知特征,广度线性模型(wide linear models)有很好的记忆(Memorization)能力
18 |
19 | 对低维未知特征,深度神经网络(deep netural network)具有很好的泛化(Generalization)能力
20 |
21 | 本文将广度线性模型的记忆能力和深度神经网络的泛化能力相结合
22 |
23 | 这套方法被应用于Google Play,10亿活跃用户,1百万apps的手机应用市场
24 |
25 | 相比仅用广度和仅用深度,广度深度相结合的方法明显改善了app的获得率
26 |
27 | 广度和深度学习(wide & deep learning)方法的实现已经开源到TensorFlow中
28 | ```
29 |
30 |
31 |
32 | **1. 导言**
33 |
34 | * 推荐系统也是一种搜索排序系统
35 |
36 | ```shell
37 | 推荐系统可以视为一个搜索排序(search ranking)系统
38 |
39 | 在这个搜索排序系统中
40 |
41 | 输入查询可以看作用户和上下文信息的集合
42 |
43 | 输出可以看作物品的排序列表
44 |
45 | ```
46 |
47 | * 记忆(Memorization)和泛化(Generalization)
48 |
49 | ```shell
50 | 推荐系统和搜索排序系统,都要实现记忆和泛化
51 |
52 | 1) 记忆
53 |
54 | 学习物品或特征同时出现的频率
55 |
56 | 从历史数据发掘可用的关联关系
57 |
58 | 基于记忆的推荐系统称为"主题相关",直接关联被用户行为所作用的物品
59 |
60 | 2) 泛化
61 |
62 | 泛化则是基于关联关系的可传递性,发掘历史数据中从未出现或极少出现的特征组合
63 |
64 | 泛化用于改善推荐物品的多样性
65 |
66 | ```
67 |
68 | * 线性模型
69 |
70 | ```shell
71 | 广义线性模型(generalized linear models)简单、可扩展、可解释
72 |
73 | 被广泛应用于工业级的大规模在线推荐和排序系统
74 |
75 | 广义线性模型通常是基于二进制化的稀疏特征训练的
76 |
77 | 这些特征使用了独热编码(one-hot encoding)
78 |
79 | 例如:
80 | user_installed_app=netflix值为1
81 | 当出现AND(user_installed_app=netflix, impression_app=pandora)时
82 | 如果用户安装了netflix,那么这个组合的值为1,推荐系统就会显示pandora给用户
83 |
84 | 向量叉积变换(cross-product transformation)的局限之一是
85 | 无法泛化出训练数据中没有出现过的"查询-物品"特征组合(query-item feature pair)
86 |
87 | ```
88 |
89 | * 泛化
90 |
91 | ```shell
92 | 泛化的一种形式是加入粒度更粗的特征
93 |
94 | 比如上面的例子
95 | 将AND(user_installed_app=netflix, impression_app=pandora)
96 | 变为AND(user_installed_category=video, impression_category=music)
97 |
98 | 通过学习每个查询(query)和每个物品(item)特征的低维密集嵌入向量(low-dimensional dense embedding vecotr)
99 |
100 | 嵌入式模型(Embedding-based models),如分解机(factorization machines)或深度神经网络(deep neural networks)
101 | 可以泛化出之前没见过的"查询-物品"特征组合
102 |
103 | 如果潜在的"查询-物品"矩阵过于稀疏或高阶,就很难从这类数据中学习到有效的"查询-商品"低维组合
104 |
105 | 比如有特殊偏好的用户或者仅有少数拥趸的小众商品
106 |
107 | "查询-物品"组合之间没有相关性,而密集嵌入又会为所有的组合泛化出预测结果
108 |
109 | 这种情况带来了过度泛化和相关性很弱的推荐
110 |
111 | 而具有向量叉积变换的线性模型,就能记住这些参数极少的异常规则(exception rules)
112 | ```
113 |
114 | * 广度和深度学习框架
115 |
116 | 
117 |
118 | >Figure 1:广度和深度模型图谱
119 |
120 | ```shell
121 | 综上所述,本文对一个线性模型模块和一个神经网络模块进行联合训练(joint training)
122 |
123 | 将记忆和泛化融入一个模型
124 | ```
125 |
126 | * 本文的主要贡献
127 |
128 | ```shell
129 | 1) 开发了一套广度和深度相结合的学习框架,用于稀疏输入的推荐系统
130 | 这套框架对"带嵌入的前馈神经网络"和"特征变换线性模型"进行联合训练(joint trainning)
131 |
132 | 2) 实现并评测了广度和深度推荐系统在Google Play市场的产品化
133 |
134 | 3) 以API的形式在TensorFlow上开源了广度和深度学习系统的具体实现代码
135 |
136 | 广度和深度学习框架的思路简单,在满足训练和服务速度的前提下,显著改善了移动应用市场的app获得率
137 | ```
138 |
139 |
140 |
141 | **2. 推荐系统概述**
142 |
143 | 
144 |
145 | >Figure 2 展示了手机应用推荐系统的基本架构
146 |
147 | * 查询(Query)和用户行为(User Action)
148 |
149 | ```shell
150 | 当用户访问app商店时,查询(Query)就产生了,查询可以包括各类用户和文本特征
151 |
152 | 推荐系统首先展示一个应用列表(也被称为 展示impression)
153 |
154 | 用户可以点击或者购买应用列表上的应用
155 |
156 | 用户的查询(queries)和展示(impressions)被记入日志,作为学习器的训练数据
157 | ```
158 |
159 | * 召回和排序(Retrieval and Ranking)
160 |
161 | ```shell
162 | 推荐系统有一个服务延迟上限(serving latency requirements),通常是O(10)毫秒
163 |
164 | 在时限内为每个查询穷尽百万app计算每个app的分数是不可能的
165 |
166 | 这种情况下,推荐系统在收到查询的第一步是召回(retrieval)
167 |
168 | 召回系统为用户返回一个与查询匹配度最佳的简短物品列表
169 |
170 | 返回这个列表的依据通常是机器学习模型或者人工定义的规则
171 |
172 | 缩小了备选池(candidate pool)的规模之后,排序(ranking)系统为备选列表中的所有物品排序
173 |
174 | 分数通常是P(y|X),代表给定特征x时,用户行为标签y的概率
175 |
176 | 特征x包括:
177 | a) 用户特征:国籍、语言、人口统计学
178 | b) 文本特征:设备、当前时间
179 | c) 展示特征(impression feature):app年龄,app历史数据
180 |
181 | 本文将广度和深度学习框架应用于上述第二个步骤排序系统中
182 |
183 | ```
184 |
185 |
186 |
187 | **3. 广度和深度学习**
188 |
189 | **3.1 广度部分**
190 |
191 | ```shell
192 | 广度部分是广义线性模型,如图Figure 1 左侧所示
193 | ```
194 |
195 | * 广义线性模型公式
196 | >y = wTx + b
197 | >
198 | >y表示预测值
199 | x=[x1, x2,..., xd] 是d个特征的向量
200 | w=[w1, w2,..., wd] 是模型的参数
201 | b 是bias(偏差)
202 |
203 | ```shell
204 | 特征集包括原始特征输入和变换后的特征
205 |
206 | 其中最重要的一个变换就是向量叉积变换
207 | ```
208 |
209 | * 向量叉积变换(cross product transformation)公式
210 | 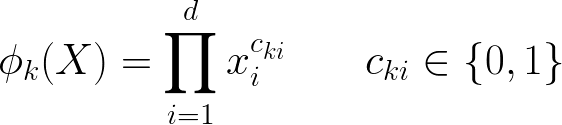
211 |
212 | >其中Cki是一个布尔变量
213 | 如果第i个特征属于第k个变换Ø k
214 | 那么Cki的值为1,否则为0
215 |
216 | ```shell
217 | 对于二进制特征,当且仅当组成特征都为1,它的向量叉积变换才是1,否则向量叉积为0
218 |
219 | 通过这种方式捕获二进制特征之间的交互,为广义线性模型增加非线性
220 | ```
221 |
222 | **3.2 深度部分**
223 |
224 | ```shell
225 | 深度部分是图Figure 1右侧的前馈神经网络
226 |
227 | 分类特征的原始输入是特征字符串(如"language=en")
228 |
229 | 每一个稀疏高维的分类特征都被转为低维密集的真值向量,通常被称为嵌入向量
230 |
231 | 嵌入的维度大约在O(10)到O(100)的范围内
232 |
233 | 嵌入向量先被随机初始化,然后它们的值在模型训练期间被用于最小化最终损失函数
234 |
235 | 这些低维密集嵌入向量在前馈传递中被送入神经网络的隐藏层
236 | ```
237 |
238 | * 隐藏层使用的计算公式
239 | 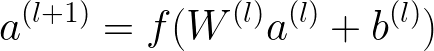
240 |
241 | >其中l是层数
242 | f是激活函数,通常是一个线性整流函数ReLUs(rectified linear units)
243 | a(l)是第l层的激活值(activations)
244 | b(l)是第l层的偏差(bias)
245 | W(l)的第l层的模型权重
246 |
247 | **3.3 广度和深度模型的联合训练(joint training)**
248 |
249 | * 联合训练(Joint Training)
250 |
251 | ```shell
252 | 广度部分和深度部分相结合时,使用了输出(output)对数几率(log odds)的加权和作为预测
253 |
254 | 这个加权和被送入一个通用的逻辑损失函数(logistic loss function)进行联合训练
255 | ```
256 |
257 | * 联合训练(Joint Training)和集成训练(Ensemble)
258 |
259 | ```shell
260 | 1) 集成训练中
261 |
262 | 每个模型都是独立训练,模型产生的预测在推导阶段整合而不是在训练阶段
263 |
264 | 因为独立训练,模型的规模更大(更多特征和变换)以达到合理的准确性
265 |
266 | 2) 联合训练中
267 |
268 | 在训练阶段就同时优化了所有参数,包括广度部分和深度部分以及它们的加权和
269 |
270 | 广度部分只需少量向量叉积特征变换补充深度部分即可,无需动用整个广度模型
271 |
272 | ```
273 |
274 | * FTRL算法
275 |
276 | >联合训练中,使用了Follow-the-regularized-leader(FTRL)算法
277 | 模型广度部分使用L1范数(regularization)作为优化器
278 | 模型深度部分使用了AdaGrad
279 | 模型图示在图Figure 1的中间部分
280 |
281 | * 模型的计算公式
282 | 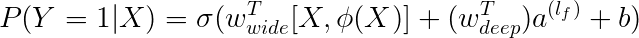
283 |
284 | >Y表示二进制分类标签
285 | σ(·)表示反曲函数
286 | Ø(X)表示原始特征x的向量叉积变换
287 | b表示偏差(bias)项
288 | Wwide表示所有广度模型权重的向量
289 | Wdeep表示应用于最终激活值a(lf)的权重
290 |
291 |
292 |
293 | **4. 推荐系统实现**
294 |
295 | ```shell
296 | 实现推荐系统包括三个步骤(如图Figure 3所示):
297 | 1) 数据生成(data generation)
298 |
299 | 2) 模型训练(model Training)
300 |
301 | 3) 模型提供服务(model serving)
302 | ```
303 |
304 | * 应用推荐系统管线概览(Figure 3)
305 |
306 | 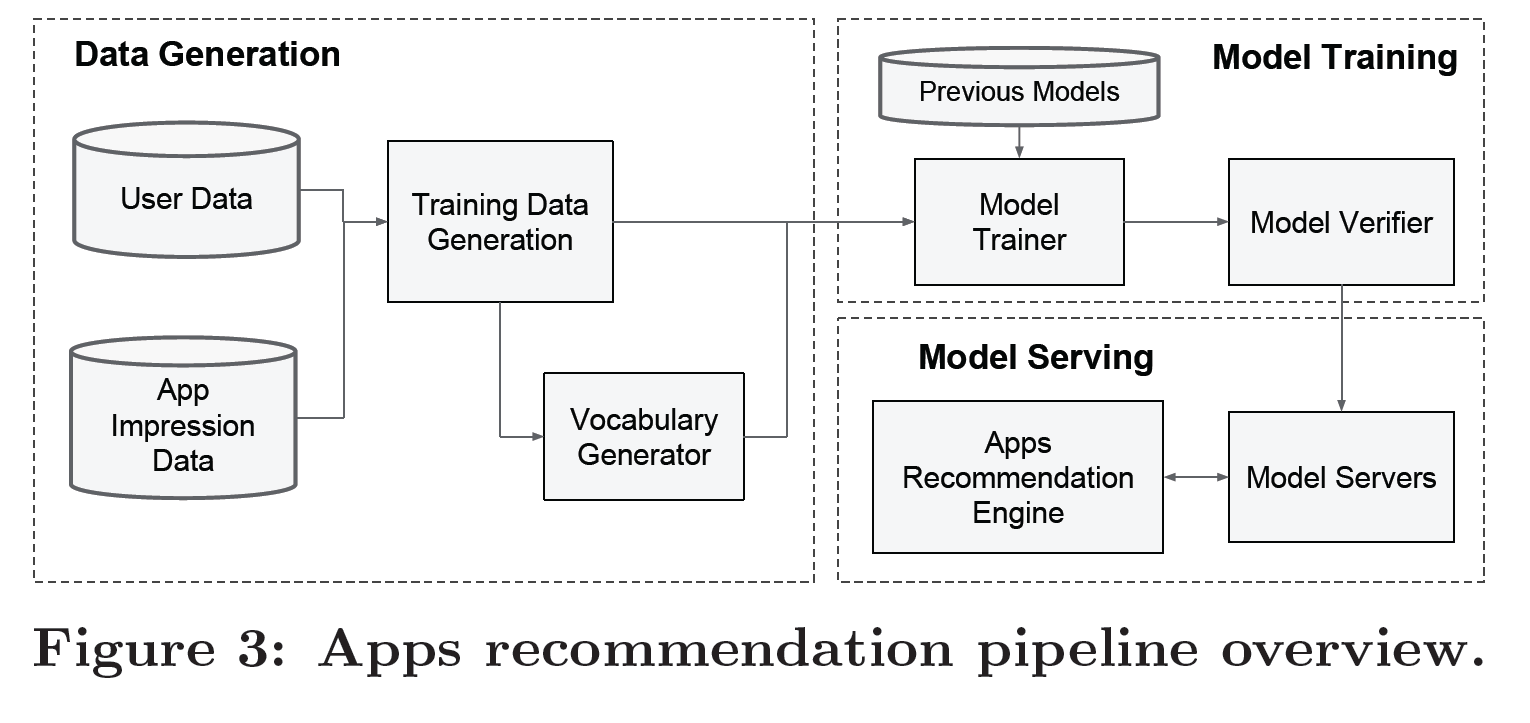
307 |
308 | **4.1 数据生成(data generation)**
309 | * 训练数据(training data)
310 |
311 | ```shell
312 | 用户和应用在一段时间内的展示数据(impression data)用于生成训练数据
313 |
314 | 每个样本都对应一个展示(impression)
315 |
316 | 这个展示的标签就是"应用获取率(app acquisition)":
317 | 如果展示应用被安装,数值为1,否则数值为0
318 | ```
319 |
320 | * 词汇数据(vocabularies)
321 |
322 | ```shell
323 | 词汇数据实际上是数据表
324 | 这些表将分类特征字符串(categorical feature strings)映射为整型ID(integer IDs)
325 |
326 | 所有出现超过一定次数的字符串特征值,系统都会计算它们的ID空间(ID space)
327 |
328 | ```
329 |
330 | >通过映射特征值x到它的累计分布函数P(X≤x)
331 | 再分为nq个分位数
332 | 连续真值特征会被归一化为[0,1]
333 | 在第i个分位数的值被归一化为 (i-1)/(nq-1)
334 | 分位数的边界是在数据生成阶段计算出来的
335 |
336 |
337 | **4.2 模型训练(Model Training)**
338 |
339 | 
340 |
341 | ```shell
342 | 模型结构如图Figure 4所示
343 |
344 | 1) 输入层(input layer)
345 | 训练阶段,输入层获取训练数据和词汇数据并生成带标签的稀疏或密集特征
346 |
347 | 2) 广度部分(wide component)
348 |
349 | 模型的广度部分包括用户已安装应用和展示应用的向量叉积变换
350 |
351 | 3) 深度部分(deep component)
352 |
353 | 模型的深度部分,从每个分类特征学习得到一个对应的32维嵌入向量
354 |
355 | 模型将所有嵌入及密集特征合并到一起,生成一个大约1200维的密集向量
356 |
357 | 合并所得的向量先被传入3个线性整流函数层,最终到达逻辑输出单元
358 |
359 | 4) 模型训练的效率问题
360 |
361 | 广度和深度组合模型在5000亿个样本上训练
362 |
363 | 每加入一个新的训练数据集,模型都需要重新训练
364 |
365 | 重新训练计算成本高昂且延迟了从加入新数据到更新模型的时间
366 |
367 | 5) 热启动系统(warm-starting system)
368 |
369 | 为解决重新训练的效率问题,模型使用了一种热启动模式
370 |
371 | 热启动模式在每次重新训练时都初始化一个新模型
372 |
373 | 新模型包括了新数据嵌入和之前模型的线性模型权重
374 |
375 | 6) 试运行(dry run)
376 |
377 | 模型加载到模型服务器前,会进行一次试运行(dry run),以确保线上实时场景不会出问题
378 |
379 | 上线前通过对比之前的模型,检验新模型运转正常
380 |
381 | ```
382 |
383 | **4.2 模型提供服务(Model Serving)**
384 |
385 | ```shell
386 | 1) 模型训练完成并验证功能后,将加载到模型服务器
387 |
388 | 2) 模型为推荐系统提供服务的流程如下:
389 |
390 | a) 每一次请求,服务都会通过应用召回系统和用户特征获取一个备选应用列表,并为其中的应用打分
391 |
392 | b) 应用按照分数从高到低排列并展示给用户
393 |
394 | 3) 分数计算
395 |
396 | 系统给应用的评分,是通过在广度和深度组合模型上运行一个正向推断(forward inference)计算而来的
397 |
398 | 4) 提升服务时效
399 |
400 | 为了将每次请求响应控制在10毫秒内,系统通过多线程并行对性能进行了优化
401 |
402 | 之前在一个批次内计算所有备选应用的分数
403 |
404 | 优化后并行计算更小批次里的备选应用的分数
405 |
406 | ```
407 |
408 |
409 |
410 | **5. 实验结果**
411 |
412 | ```shell
413 | 本文主要从app获取率和服务性能两方面验证广度和深度学习模型的效果
414 | ```
415 |
416 | **5.1 应用获取率(app aquisitions)**
417 |
418 | ```shell
419 | 本文采用A/B测试进行了为期3周的在线实验
420 |
421 | 分别随机选取了三组各1%的用户作为随机实验对象
422 |
423 | 三组对象分别应用了三类模型的推荐系统:
424 | 1) 高度优化的广度逻辑回归模型,具有丰富的向量叉积特征变换(cross-product feature transformations)
425 | 2) 具有相同特征和深度神经网络的深度模型
426 | 3) 具有相同特征的深度广度结合模型
427 |
428 | 其中第一组作为控制组
429 |
430 | 实验结果表明,在应用获得率(app aquisitions)上:
431 | 广度和深度相结合比仅用广度高出3.9%
432 | 广度和深度相结合比仅用深度高出1%
433 |
434 | 除了在线实验,本文使用留出法(hold-out)测试了与线上数据互斥的线下数据集
435 |
436 | 广度和深度相结合的方法相比仅用广度和仅用深度,只有略微偏高的AUC*值
437 |
438 | 广度和深度相结合在线上比线下更为显著
439 |
440 | 原因可能是线下系统的展示(impression)和标签的数据是固定的
441 | 线上系统可以混合记忆与泛化生成新的推荐
442 | 线上系统也会从新的用户回馈中持续学习
443 |
444 | *AUC备注
445 | AUC(Area Under Receiver Operator Characteristic Curve)
446 | ROC全称是"受试者工作特征"(Receiver Operating Characteristic)
447 | ROC曲线的面积就是AUC(Area Under the Curve)
448 | AUC用于衡量"二分类问题"机器学习算法性能(泛化能力)
449 | ```
450 |
451 | **5.2 服务性能(serving performance)**
452 |
453 | ```shell
454 | 在商用应用商店,需要同时满足高吞吐和低延迟
455 |
456 | 峰值流量时,推荐系统服务器需要每秒为上百万个应用评分
457 |
458 | 单线程处理单个批次的全部备选项需要31毫秒
459 |
460 | 拆分批次为体量更小的批次,同时使用多线程处理,能够将客户端延迟有效降低到14毫秒
461 |
462 | ```
463 |
464 |
465 |
466 | **6. 相关研究**
467 |
468 | * 分解机(factorization machines)
469 |
470 | ```shell
471 | 使用因式分解的方式泛化线性模型,即将2个变量间的关联转成两个低维嵌入向量之间的点积
472 |
473 | 本文通过学习神经网络嵌入之间的高度非线性关联,替代点积,从而扩展了模型的能力
474 | ```
475 |
476 | * 语言模型中的RNN
477 |
478 | ```shell
479 | 对
480 | 递归神经网络RNNs(Recurrent Neural Networks)和
481 | 带语言模型特征的最大熵模型(Maximum entopy models with n-gram features)
482 | 进行联合训练(joint training)
483 |
484 | 学习输入和输出的直接权重,从而显著降低RNN的复杂度
485 | ```
486 |
487 | * 计算机视觉
488 |
489 | ```shell
490 | 1) 深度残差网络
491 | a) 降低训练更深度模型的难度
492 | b) 通过跳跃传递(shortcut connections)来提高准确性
493 |
494 | 2) 对带图像模型的神经网络进行联合训练(joint training)可以从图片中识别人体姿势
495 | ```
496 |
497 | * 推荐系统
498 |
499 | ```shell
500 | 1) 内容信息深度学习和协同过滤评分矩阵合二为一,组成协同深度学习(collaborative deep learning)
501 |
502 | 2) app推荐系统AppJoy,对用户使用记录使用协同过滤
503 | ```
504 |
505 | * 本文所用方法
506 |
507 | ```shell
508 | 本文对前馈神经网络和线性模型进行联合训练(joint training)
509 | 将稀疏特征和输出单元直接关联
510 | 用于稀疏输入数据的推荐和排序问题
511 |
512 | 之前类似研究使用的方法基于协同过滤或基于内容
513 | 本文在用户和展示数据(impression data)的基础上训练广度和深度相结合的模型
514 |
515 | ```
516 |
517 |
518 |
519 | **7. 总结**
520 |
521 | ```shell
522 | 记忆和泛化是推荐系统重要的两个方面
523 |
524 | 广度线性模型借助向量叉积变换,能够有效记忆稀疏特征的关联
525 |
526 | 深度神经网络可以通过低维嵌入,泛化出之前未见的特征关联
527 |
528 | 广度和深度结合的学习框架(Wide & Deep learning framework)结合了两种方式的优点
529 |
530 | 本文将该方法在Google Play产品化,并评估了它的效果
531 |
532 | 在线实现结果显示,相较于单纯的广度或深度模型,广度和深度结合的模型显著改善了app获得率
533 |
534 | ```
535 |
536 |
537 |
538 | ##### <参考资料>:
539 | a) [TensorFlow Wide And Deep 模型详解与应用(作者:汪剑)](https://blog.csdn.net/heyc861221/article/details/80131369?_blank)
540 | b) [TensorFlow Wide And Deep 模型详解与应用(二)(作者:汪剑)](https://blog.csdn.net/heyc861221/article/details/80131373?_blank)
541 | c) [ROC与AUC的定义与使用详解](https://blog.csdn.net/shenxiaoming77/article/details/72627882?_blank)
542 |
--------------------------------------------------------------------------------
/0001/bigablecat.md:
--------------------------------------------------------------------------------
1 | #### [](https://storage.googleapis.com/pub-tools-public-publication-data/pdf/45390.pdf)
2 | ##### 阅读笔记
3 |
4 | ```shell
5 | Google Dataset Search (GooDs)是一个以元数据的形式管理数据集的企业内部系统
6 | 这篇论文介绍了GooDs的设计和用途
7 |
8 | 带着问题阅读:
9 | 1. what: GooDs系统是做什么的
10 | 2. why: 为什么需要GooDs系统
11 | 3. how: GooDs系统是如何设计的
12 | ```
13 |
14 | **0. 摘要**
15 |
16 | **0.1 文章目标**
17 |
18 | * 探讨实现数据管理所面临的技术挑战 (Challenges)
19 |
20 | ```shell
21 | 从亿万级数据源爬取和推断元数据
22 |
23 | 维持大规模元数据目录的一致性
24 |
25 | 使用元数据为用户提供服务
26 | ```
27 |
28 | * 对于打造大规模企业级数据管理系统的借鉴意义
29 |
30 | **1. 引言**
31 |
32 | **1.1 企业数据管理的两种形式**
33 |
34 | * Enterprise Data Management (EDM)
35 |
36 | ```shell
37 | 生成数据集和管理数据集都在一套系统内
38 |
39 | 系统本身限制了数据的生产和流转
40 | ```
41 |
42 | * Data Lake
43 |
44 | ```shell
45 | 与EDM不同的是,Data Lake采取事后(post-hoc)模式
46 |
47 | 不介入数据的生产和使用
48 |
49 | 只为已经生成的数据提供一套有效的管理工具
50 |
51 | 所以这是一种事后(post-hoc)行为
52 |
53 | lake的比喻很形象,数据不断生成和累积汇聚成湖,查找数据就像从湖中钓鱼("fish the right data")
54 | ```
55 |
56 | **1.2 Google Dataset Search (GooDs)**
57 |
58 | * GooDs是一个静默的服务者
59 |
60 | ```shell
61 | GooDs的全称是Google Dataset Search,但它的功能不限于search
62 |
63 | GooDs采用了类似Data Lake的形式,对数据进行事后(post-hoc)管理
64 |
65 | post-hoc将在文中多次出现,强调GooDs是静默的辅助工具
66 |
67 | 作者还用非侵扰(non-intrusive)表明GooDs既不影响数据本身,也不影响数据的生产者和使用者
68 | ```
69 |
70 | **1.3 GooDs的运作机制**
71 |
72 | 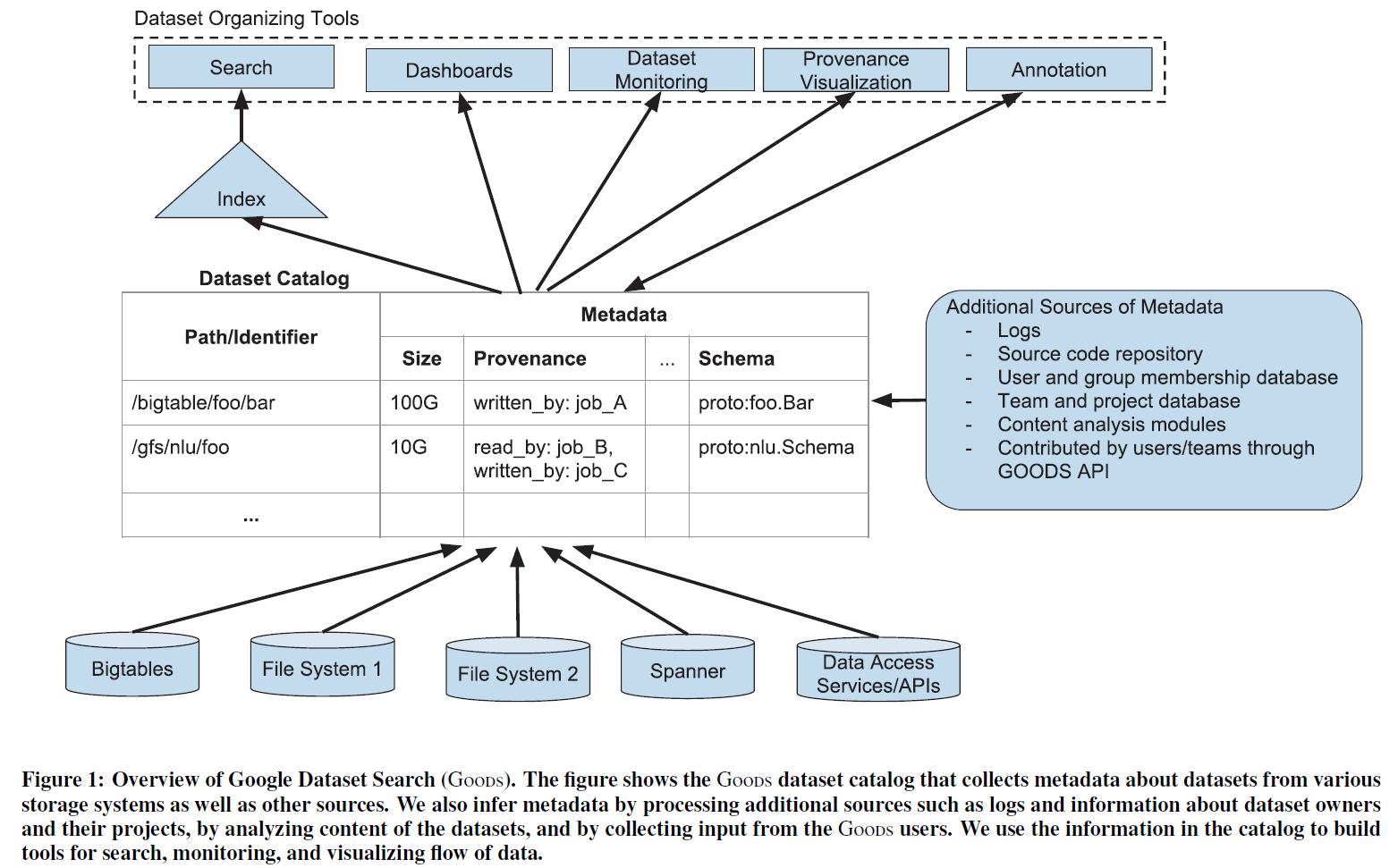
73 | >图:GooDs设计概览
74 |
75 | * 分层介绍
76 |
77 | ```shell
78 | 1) GooDs持续地爬取(crawls)各类存储系统和业务线,
79 | 从中发现数据集(datasets)并收集数据集的元数据(datasets)信息和使用情况(usage)
80 | (见图最底层)
81 |
82 | 2) GooDs将元数据聚合为一个中央目录(central catalog),同时把特定数据集的元数据与其他数据集的信息相互关联
83 | (见图中间层)
84 |
85 | 3) GooDs用这套目录的信息构建搜索、监控和数据流可视化等工具,
86 | 从而为Google工程师提供数据管理服务
87 | (见图最上层)
88 | ```
89 |
90 | * 关于元数据(metadata)
91 |
92 | ```shell
93 | 1) 元数据信息的一个来源是直接从数据源收集
94 |
95 | 2) 元数据的另一个来源是对数据内容的推断(inference):
96 | a. 处理附加的数据源,如日志、数据集所有者和项目信息等
97 | c. 分析数据集的内容
98 | d. 收集GooDs使用者输入
99 |
100 | 3) GooDs收集的元数据可能包括:
101 | a. 数据所有者 (owners)
102 | b. 访问时间 (time of access)
103 | c. 内容特征 (content features)
104 | d. 生产管线的访问记录 (accesses by production pipelines)
105 | ```
106 |
107 | **1.4 GooDs提供的一些工具**
108 |
109 | * dashboard 仪表板
110 |
111 | ```shell
112 | 展示所有数据集
113 |
114 | 提供多条件检索
115 |
116 | 可以横跨不同的存储系统
117 |
118 | 可以获得数据集和所有依赖的数据集
119 | ```
120 |
121 | * monitor 监控
122 |
123 | ```shell
124 | 监控内容特征:如大小、数值的分布、是否可用
125 |
126 | 在特征发生意外改变时通知数据所有者
127 | ```
128 |
129 | * provenance 数据血缘关系
130 |
131 | ```shell
132 | 生成某个数据集的上游数据
133 |
134 | 依赖某个数据集的下游数据
135 | ```
136 |
137 | * search engine 搜索引擎
138 |
139 | ```shell
140 | 缩小搜索范围
141 | ```
142 |
143 | * GooDs API
144 |
145 | ```shell
146 | 通过暴露接口,所有的团队都能为元数据目录做贡献,形成一种crowd-sourced(众包)的方式
147 |
148 | 数据使用者能够共享和交换数据集的信息
149 | ```
150 |
151 | **2. GooDs系统的技术挑战**
152 |
153 | **2.1 天量数据规模**
154 |
155 | ```shell
156 | GooDs系统为超过260亿个数据集建立了索引
157 |
158 | 260亿这个数字仅包括对全体google员工开放权限的数据集
159 |
160 | 如果GooDs为更高级别权限的数据集建立索引,同时支持更多存储系统,规模可能在260亿的基础上翻倍
161 | (double in the number of datasets)
162 |
163 | 即使每秒处理一个数据集,260亿也需要一千台并行的机器运转300天
164 |
165 | 对元数据的推断(inference)也因为计算量呈指数级增长而完全不可行
166 | ```
167 |
168 | **2.2 多样性**
169 |
170 | ```shell
171 | 数据集以各种格式存储,来自各式存储系统,多样性成为数据统一管理问题之一
172 |
173 | GooDs需要将各种格式的数据以同一种形式展示给用户
174 |
175 | 数据集的类型和大小不同或者元数据的类型不同,抽离元数据的成本也会不同
176 |
177 | GooDs系统在推断元数据的时候,需要考量元数据的成本和收益
178 |
179 | 多样性也体现在数据集的相互关系中,而数据集的相互关系反过来影响元数据在GooDs目录的计算和存储
180 | ```
181 |
182 | **2.3 目录条目(Catalog Entries)的变动**
183 |
184 | ```shell
185 | GooDs目录条目中,每天约有5%左右的数据集被删除
186 |
187 | 优先计算哪些数据集的元数据,将哪些数据集加入目录,都会受到新旧数据集交替的影响
188 |
189 | 生存周期time-to-live(TTL)长的数据集相对比较重要
190 |
191 | 短周期数据集可能关联长周期数据集,所以GooDs系统不可能排除短周期数据集
192 | ```
193 |
194 | **2.4 元数据的不确定性**
195 |
196 | ```shell
197 | GooDs系统采取事后(post-hoc)非侵入(non-invasive)的方式,无法全程把握数据集的产生
198 |
199 | GooDs根据已有数据推断和计算出的元数据,在一定程度并不精准
200 | ```
201 |
202 | **2.5 计算数据集重要性**
203 |
204 | ```shell
205 | 推算数据集对使用者的重要性和在网页检索中推算网页的重要性不同
206 |
207 | 网页用于排序和检索的许多特性(如锚文本anchor text),数据集并不具备
208 |
209 | 不过数据集可以提供结构性的上下文,这是网页所没有的
210 |
211 | 数据集之间的唯一联系就是来源关联,而这种关联并不能完全决定数据集的重要性
212 |
213 | 为哪些数据集优先计算元数据,也可以作为数据集重要性的一项参考
214 | ```
215 |
216 | **2.6 复原数据集语义**
217 |
218 | ```shell
219 | 数据集的语义可以通俗地理解为数据集的某项内容代表了什么
220 |
221 | 文中举的例子是,从一个数据集中推断出一批整型数值代表了地理坐标的ID
222 |
223 | 这样的数据集语义,在用户检索地理数据时就能排上用场
224 |
225 | 将无意义的原始数据升华为包含意义的内容对推断元数据非常有用
226 |
227 | 但是发现数据集语义本身也是一项非常困难的工作
228 | ```
229 |
230 | **3. GooDs系统的目录(Catalog)**
231 |
232 | ```shell
233 | Google内部每个存储系统都可能维护着自己的catalog,每个catalog还会有自己的metadata
234 |
235 | 数据在不同的数据集和存储系统之间自由流转是常态
236 |
237 | GooDs所做的就是为所有存储系统和数据集建立统一的目录
238 |
239 | Catalog上的一条记录称之为条目(entry),原则上每个entry对应一个数据集(dataset)的元数据
240 |
241 | 当出现一些特征相似度高的集群时,GooDs会将它们归并为一个集群(cluster),建立单个条目(entry)
242 |
243 | 集群的一个典型例子就是相同数据集的不同版本
244 | ```
245 |
246 | **3.1 元数据(Metadata)**
247 |
248 | * 概要
249 |
250 | ```shell
251 | 终于讲到了GooDs系统的关键要素————元数据(metadata)
252 |
253 | 元数据(metadata)包含很多信息,总结起来就是用于描述数据集的信息,即"数据的数据"
254 | ```
255 |
256 | * 元数据的来源
257 |
258 | ```shell
259 | 元数据的途径有两种:
260 |
261 | 第一种可以通过直接访问获取:
262 |
263 | GooDs系统在爬取数据集的时候,会顺带获取一些元数据,如数据集的大小、所有者、访问权限等
264 |
265 | 但是数据集并没有保存所有的元数据信息,比如生成数据集的作业(jobs),数据集的访问者等
266 |
267 | 不能从数据集直接获取的元数据往往存在于日志中
268 |
269 | 第二种通过GooDs系统计算得出:
270 |
271 | GooDs除了爬取获得元数据外,还会通过推断(inference)获取元数据
272 | ```
273 |
274 | 
275 | >Table2: 元数据(Metadata)和元数据组(Metadata Group)
276 |
277 | * 基础元数据(Basic Metadata)
278 |
279 | ```shell
280 | 包括时间戳、文件格式、所有者、访问权限等
281 |
282 | 基础元数据一般由GooDs系统爬取存储系统直接获得,无需推断
283 |
284 | GooDs的其他模块通常将基础元数据作为行为依据之一
285 | ```
286 |
287 | * 数据血缘/数据谱系(Provenance)
288 |
289 | ```shell
290 | GooDs中的元数据血缘关系来自数据集的生产和消费过程、数据集上下游依赖
291 |
292 | GooDs通过分析生产日志来确定元数据的血缘信息
293 |
294 | GooDs用时间顺序决定依赖关系,即晚发生的依赖于早发生的
295 |
296 | 在计算血缘关系时,GooDs为了效率可能会牺牲信息的完整性
297 | ```
298 |
299 | * 结构信息(Schema)
300 |
301 | ```shell
302 | Google内几乎所有结构化数据集都是基于serialized protocol buffer编码的
303 |
304 | 推断数据集使用了哪种形式的protocol buffer编码会产生多个结论
305 |
306 | GooDs系统把所有可能的protocol buffer形式都记录在元数据中
307 | ```
308 |
309 | * Content summary
310 |
311 | ```shell
312 | Content summary按照字面直译为内容摘要反而不容易理解
313 |
314 | 实际上,元数据记录的content summary可以看成一套数据的关键字合集
315 |
316 | 文中举了三个summary的例子:
317 | a) 抽样(sampling)产生的frequent token
318 | b) 分析字段(fields)得出的键(key for data)
319 | c) 有校验和(checksums)的fingerprints
320 |
321 | GooDs通过summary来判断来自不同数据集的内容或者字段是否相似和相等,
322 | ```
323 |
324 | * 用户注释(User-provided annotations)
325 |
326 | ```shell
327 | 一般用户做注释都是为了明确告知数据集的使用者有必要知晓的信息
328 |
329 | GooDs的元数据通过分析注释来优化排序或者规避数据隐私
330 | ```
331 |
332 | * 语义学信息(Semantics)
333 |
334 | ```shell
335 | 数据集的语义学信息可以帮助理解数据集
336 |
337 | 如果数据集使用了特定的protocol buffer,GooDs可以分析源码提取有用的备注(comment)信息
338 |
339 | 本段中举了个例子,比如数据集中一个名为"mpn"的字段,通过分析备注,发现mpn是"//Model Product Number"的缩写
340 | 这就是获取备注(comment)信息在语义学方面的作用
341 |
342 | Google的知识图谱可以作为一个资源库,GooDs系统将数据集内容与知识图谱匹配,识别不同字段中包含什么样的条目信息(如位置信息,业务信息)
343 | ```
344 |
345 |
346 | * 其他
347 |
348 | ```shell
349 | 除上述类型的元数据外,GooDs系统还会将以下信息作为元数据的内容:
350 | a) 获取一个标识,通过该标识可以确认拥有数据集的团队(team)
351 | b) 数据集所属项目的描述
352 | c) 数据集元数据的变更历史
353 |
354 | 此外,GooDs允许团队在目录添加自定义的元数据,从而为所有使用者提供统一管理元数据的平台
355 | ```
356 |
357 | **3.2 数据集群(cluster)**
358 |
359 | * 数据集重复问题
360 |
361 | ```shell
362 | GooDs目录上的260亿个数据集并非完全独立,很多数据集存在内容重复,比如:
363 |
364 | a) 相同数据集的不同版本
365 |
366 | b) 相同数据集复制到不同的数据中心
367 |
368 | c) 大数据集被切分为小数据集
369 |
370 | ...
371 | ```
372 |
373 | * 数据集集群化的好处
374 |
375 | ```shell
376 |
377 | 针对上述问题,将类似数据集归纳为集群有如下好处:
378 |
379 | a) 为用户提供合乎逻辑的数据集分组
380 |
381 | b) 只需计算集群中的少量数据集的元数据,节约计算成本
382 |
383 | ```
384 |
385 | * 集群化的技术考量
386 |
387 | ```shell
388 | 将数据集集群化的计算成本要足够低,才值得使用
389 |
390 | 生成集群的计算成本不能高于重复计算相似数据集的成本
391 |
392 | ```
393 |
394 | * 根据路径(path)层级(hierarchies)生成集群
395 |
396 | ```shell
397 | 数据集的路径可以提供划分集群的思路
398 |
399 | 某个数据集路径
400 | dataset/2015-10-10/daily_scan
401 |
402 | 按天分类
403 | dataset/2015-10-/daily_scan
404 |
405 | 按月份和日期分类
406 | dataset/2015--/daily_scan
407 | ```
408 |
409 | * 多粒度的半网格结构(granularity semi-lattice)
410 |
411 | 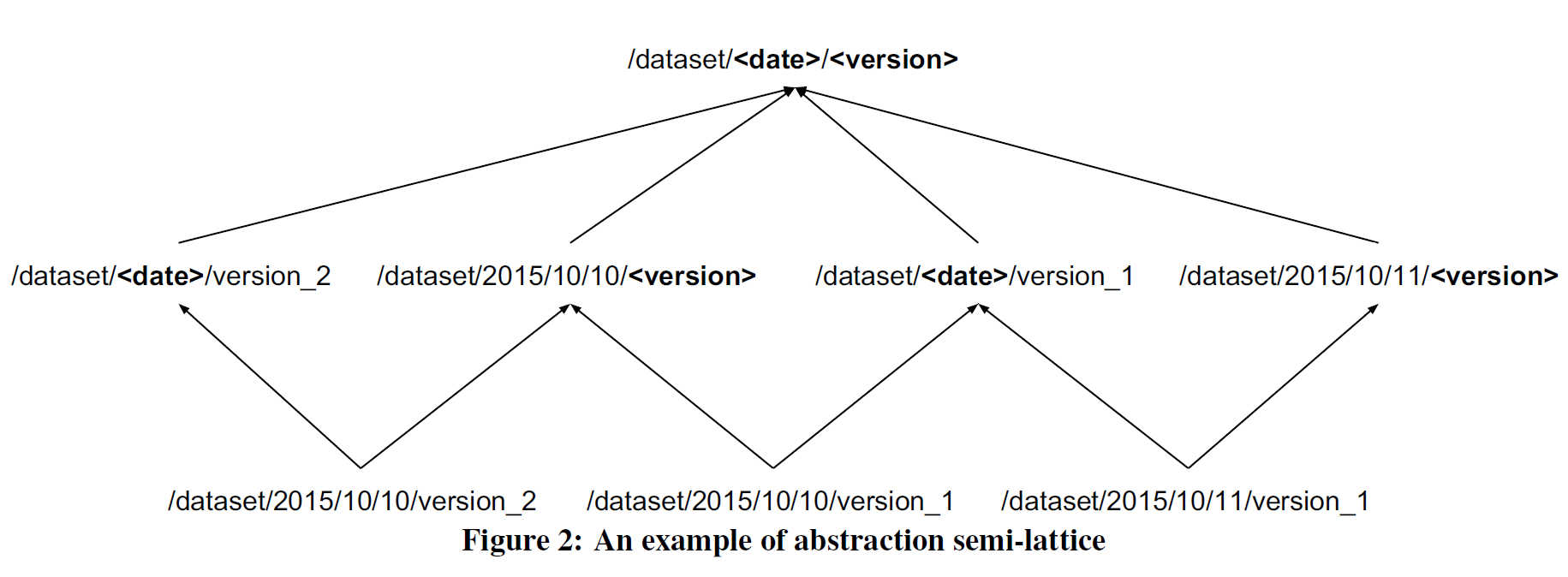
412 | >Figure 2展示了两种层次的集群划分:按天划分和按版本号划分
413 |
414 | 
415 | >Table 3展示了构建集群所依赖的数据集维度
416 |
417 | ```shell
418 | 从数据集的路径抽离出不同维度(dimensions,如日期、版本号)
419 | 为每个数据集构建一个半网格(semi-lattice)结构
420 |
421 | 在Figure 2所示的半网格结构中,非叶子节点代表了数据集的分组依据
422 | ```
423 |
424 | * 集群的日常更新和重复映射问题
425 |
426 | ```shell
427 | 如果分组情况每天计算和更新,可能造成用户每天都看到不同的集群
428 |
429 | 为了解决这个问题,GooDs只为每个半网格的顶层元素创建条目(entry)
430 |
431 | 如Figure 2,目录将只有顶层的条目/dataset//,
432 | 对应网格底层的三个数据集
433 |
434 | 采用这种方式可以保证每个数据集只映射到一个集群,
435 | 总的集群条目数量也会下降
436 | ```
437 |
438 | * 集群的元数据
439 |
440 | 
441 | > Figure 4 将3个数据集的元数据汇总成集群元数据
442 |
443 | ```shell
444 | GooDs系统通过汇总集群中各个数据集的元数据,生成该集群的元数据
445 |
446 | 集群的元数据以实时计算的方式产生,用于区分通过分析推断得出的元数据
447 | ```
448 |
449 | * 数据集在集群中的分布
450 |
451 | 
452 | > Figure 3 用柱状图的方式展示了数据集在集群中的分布情况
453 |
454 | ```shell
455 | 集群化可以将"物理"集群压缩为"逻辑"集群
456 |
457 | 极大地降低了元数据的计算成本
458 |
459 | 用户可以通过集群更方便地查阅GooDs系统的目录
460 | ```
461 |
462 |
463 |
464 | **4 后端实现(Backend Implementation)**
465 |
466 | ```shell
467 | 本节主要讨论:
468 |
469 | GooDs系统目录(catalog)的物理结构
470 |
471 | 向目录中不断增加新模块的方法
472 |
473 | 目录数据的一致性
474 |
475 | 目录的容错机制
476 | ```
477 |
478 | **4.1 目录存储(Catalog storage)**
479 |
480 | * Bigtable的行存储
481 |
482 | ```shell
483 | a) 目录使用Bigtable作为存储中介
484 |
485 | Bigtable是一种可伸缩的,键值对存储系统
486 |
487 | 在目录中,Bigtable中的一行代表一个数据集或一个集群
488 |
489 | Bigtable提供了单行事务一致性(per-row transactional consistency)
490 |
491 | 数据集路径或者集群路径作为这一行的键
492 |
493 | 通过这种方式,数据集对应单行,无需查找多余信息
494 |
495 | b) GooDs系统中与单行单个数据集处理方式相左的特性
496 |
497 | 数据集提取半网格结构时,将多行信息整合到逻辑数据集中
498 |
499 | 累计同个集群中不同数据集的元数据
500 |
501 | 不过这种元数据累加并不需要强一致性
502 | ```
503 |
504 | * Bigtable的列族(column families)
505 |
506 | ```shell
507 | 一张Bigtable表格包含多个独立的列族
508 |
509 | GooDs的Bigtable中还设置了一些独立列族专门进行批量处理(高压缩率,非内存驻留)
510 |
511 | 只能通过批处理任务访问的数据就存在这些列族中
512 |
513 | 比如GooDs系统中最大的列族,就包含了用于计算血缘图谱的原始血缘数据
514 |
515 | 这些血缘数据内容不直接面向前端,仅为部分集群提供服务,因而可以高度压缩
516 | ```
517 |
518 | * 元数据在Bigtable中的存储
519 |
520 | ```shell
521 | 在目录的Bigtable中,每行存储两种元数据信息:
522 |
523 | a) 数据集的元数据
524 |
525 | b) 状态元数据(status metadata):对某个数据集处理后生成的结果
526 |
527 | ```
528 |
529 | * 状态元数据(status metadata)
530 |
531 | ```sehll
532 | 状态元数据列出了用于处理条目的(entry)每一个模块
533 |
534 | 状态元数据可能包含时间戳,成功状态,错误信息等内容
535 |
536 | GooDs使用状态元数据协调模块的执行
537 |
538 | 状态元数据也可以检测系统,比如通过成功状态观察数据集,收集出现次数最多的错误码
539 |
540 | 与Bigtable的临时数据模型配合,状态元数据还能用于调试(debugging)
541 |
542 | 通过配置Bigtable,保留若干代的状态元数据
543 |
544 | 这些代际数据能够揭示模块的历史表现
545 | ```
546 |
547 | **4.2 批量任务的性能和调度(Batch job performance and scheduling)**
548 |
549 | * 任务分类和系统可扩展性
550 |
551 | ```shell
552 | GooDs系统的任务可以分为两大类
553 |
554 | 1) 数量庞大的各类批处理任务
555 |
556 | 2) 少数为前端和API提供服务的任务
557 |
558 | GooDs系统具有可扩展性,为爬取新增资源提供了便利,如:
559 | a) 新增的数据源
560 | b) 血缘信息和其他元数据信息
561 | c) 新的分析模块
562 | ```
563 |
564 | * GooDs系统对任务的安排
565 |
566 | ```shell
567 | 运行时间长达几天的任务会被分配到距离数据集最近的地理位置
568 |
569 | 所有任务都独立运行,不限制先后顺序或是否并发
570 |
571 | 如果任务中断,系统可以将其临时下线
572 | ```
573 |
574 | * 任务中的模块(modules)
575 |
576 | ```shell
577 | 每个任务都可能包括一个或多个模块,如爬虫或分析器
578 |
579 | 模块通常会依赖其他模块,如等待其他模块的计算结果
580 |
581 | 模块之间通过状态元数据协调执行顺序,粒度精确到Bigtable中的一行
582 |
583 | 如果模块A必须在模块B之前处理某行数据,
584 | 模块B会检查该行的状态元数据,是否标记为被模块A成功处理
585 | 如果模块A尚未处理,模块B会跳过该行,在下次运行时再重新检查,
586 | 如果模块A重新处理了该行,模块B也会重新处理,以保证元数据最新
587 |
588 | 模块也会使用自身的状态元数据以避免在设定时间窗口内重复处理数据
589 |
590 | 大多数任务每天运行,并在24小时候内完工
591 |
592 | GooDs会优化超时运行的任务,或者使用并行任务分摊工作量
593 |
594 | 这些额外添加的任务,以24小时为周期处理,
595 | 专门处理新增目录行或者重新处理超出时间窗口的数据
596 | ```
597 |
598 | * 重要数据集优先处理
599 |
600 | ```shell
601 | 在大量新数据集涌入系统的时候,
602 | 系统分析器(Schema Analyzer)作为最重量级的任务,
603 | 往往需要几天甚至几周才能跟上进度,
604 |
605 | 为了保证最重要的数据集不被忽略,
606 | 那些用户加注释或者血缘集中度高的数据集标注被标注为"重要"
607 |
608 | 每个任务将分成两个实例,
609 | 一个实例只处理重要数据集,
610 | 另一个实例处理所有数据集,并在一天的末尾处理一小部分重要数据集
611 |
612 | 实践中,通过网络爬取,保证最重要的那部分数据被充分覆盖率并且持续更新,
613 | 足以应对大多数的用户场景
614 | ```
615 |
616 | * 数据盲写
617 |
618 | ```shell
619 | 负责爬取数据的任务通常使用盲写(blind write)的方式向目录添加数据
620 |
621 | Bigtable不区分插入和更新
622 |
623 | 这种无指令(no-op)方式比读取目录后再进行反连接(anti-join)操作更高效
624 |
625 | 某些情形应当禁用无指令存储,否则会导致依赖的模块重新运行或者阻塞垃圾回收
626 | ```
627 |
628 |
629 | **4.3 容错机制(Fault tolerance)**
630 | ```shell
631 | 因为数据集数量庞大种类繁多,GooDs系统遇到了各种问题
632 | ```
633 |
634 | * 独立数据集和相互依赖的数据集
635 |
636 | ```shell
637 | 模块处理相互独立的数据集时:
638 | 错误信息会记录在单个数据集的状态元数据上;
639 | 如果状态元数据显示某个模块错误终止,将触发一定次数的重试
640 |
641 | 模块处理相互依赖的数据集时:
642 | 错误信息会记录在任务(job)的状态元数据上
643 |
644 | 例如:
645 | 有血缘关联的模块,
646 | 将一个数据集任务链接(dataset-job link)纳入血缘图谱前,
647 | 首先会查看这个任务链接的时间戳(timestamp),
648 | 只有时间戳比模块的最近成功执行时间(last successful execution)更晚,
649 | 模块才会整合该任务链接
650 |
651 | 上述方法有些保守,如果模块的最近一次执行有部分失败,
652 | 系统可能会重复执行一些Bigtable的录入;
653 | 但是这种方法能够保证血缘图谱的正确性,
654 | 因为Bigtable的录入是幂等的;
655 | 同时这种方法允许系统将任务血缘信息记录为"已消费",
656 | "已消费"属性在垃圾回收中非常重要
657 | ```
658 |
659 | * 模块依赖库依赖造成的问题
660 |
661 | ```shell
662 | 一些用于检测数据集内容的模块会使用各种库(libraries)
663 |
664 | 每个库都有可能专门用于处理特定的文件类型
665 |
666 | 库有时会崩溃或者陷入死循环
667 |
668 | 但是由库带来的问题并不能彻底消除,
669 | 因为系统不允许长时间运行的分析任务崩溃或挂起
670 |
671 | 一些危险的任务会被沙盒封装到单独的进程中,
672 | 看门狗线程会将长期停滞的任务转为崩溃状态,
673 | 这样管线上的其他任务能够继续运转
674 | ```
675 |
676 | * 目录(catalog)的多地冗余
677 |
678 | ```shell
679 | 系统会在不同的地理位置冗余多份目录(catalog)
680 |
681 | 在master节点进行录入时,会同步在其他地方复制
682 |
683 | ```
684 |
685 | **4.4 元数据的垃圾回收(metadata)**
686 |
687 | * 垃圾回收策略的演进
688 |
689 | ```shell
690 | GooDs系统每天都会吸收和生产大量数据,
691 | 其中相当一部分是临时数据
692 |
693 | 只要模块已经消费了数据集关联的元数据并更新了目录,
694 | 系统就可以删除目录上那些对应数据集已经被删除的条目
695 |
696 | 系统初始阶段,系统使用了简单保守的垃圾回收策略,
697 | 一条数据记录一周不再更新才会被删除
698 |
699 | 这种保守策略导致了若干起目录严重臃肿的问题,
700 | 使我们意识到有必要采取激进的垃圾回收策略
701 |
702 | 早期曾有两次,系统被迫中止了所有的爬虫和垃圾回收无关的分析模块,
703 | 直到数天后才从故障中恢复
704 |
705 | ```
706 |
707 | * 垃圾回收机制的三大约束条件(constraints)
708 |
709 | ```shell
710 | 在实践中,GooDs系统垃圾回收系统的使用总结了一些实用经验
711 |
712 | 1) 对Bigtable中一行数据做删除时,删除条件最好的表达方式是说明性的断言,
713 | 断言中使用其他模块对该行数据访问和更新时记录的元数据和状态信息;
714 | 如:该数据集已从存储系统中删除,
715 | 血缘相关的另一个模块(已成功结束)对其最近更新的血缘信息进行过处理。
716 |
717 | 2) 因为Bigtable不区分插入和更新,从目录中删除一条记录时,
718 | 必须保证其他正在运行的模块没有将这条数据的部分信息重新插入目录,
719 | 这种情况被称为"dangling rows"
720 |
721 | 3) 所有其他模块都必须独立于垃圾回收模块,并和垃圾回收同时运行
722 |
723 | ```
724 |
725 | * 垃圾回收的非事务性(non-transactional)
726 |
727 | ```shell
728 | Bigtable支持"conditional mutation",
729 | 即根据指定的条件断言删除或更新一条数据,遵循事务原则
730 |
731 | 所有模块的更新都要依赖未被删除的单条记录,
732 | Bigtable的conditional mutation带来了极大的日志结构读取开销
733 |
734 | GooDs系统优化了设计,允许所有垃圾回收以外的模块进行非事务(non-transactional)的更新
735 |
736 | 垃圾回收在两阶段发生:
737 |
738 | a) 第一阶段,垃圾回收使用声明断言的方式删除一条数据,
739 | 此时数据并没有真正删除,而是被标记了一个墓碑(tombstone)
740 |
741 | b) 第二阶段,24小时之后,如果该行数据仍然符合删除标准,
742 | 垃圾回收会真正删除这行数据,否则将墓碑移除
743 |
744 | 与此同时,其他模块遵从下列规则:
745 |
746 | a) 可以进行非事务更新
747 |
748 | b) 更新时忽略标记了墓碑的数据
749 |
750 | c) 模块的单次迭代不能存活超过24小时
751 |
752 | 这种设计在保证了系统高效的同时,也能够满足垃圾回收的三大约束条件
753 | ```
754 |
755 |
756 |
757 |
758 | **5 GooDs系统的前端,为目录服务(Front end: serving the catalog)**
759 |
760 | ```shell
761 | 前几节内容主要关注了GooDs系统目录的创建和维护,
762 |
763 | 本节主要讲述与元数据相关的服务
764 | ```
765 |
766 | **5.1 数据集基本信息页(Dataset profile pages)**
767 |
768 | * 展示
769 |
770 | ```shell
771 | 输入路径,得到数据集或集群的元数据展示在HTML页面
772 |
773 | 在本文第三节介绍的大部分元数据信息都会被展示
774 |
775 | 用户可以通过编辑元数据的特定部分,讨论或修改目录中的元数据信息
776 | ```
777 |
778 | * 信息量
779 |
780 | ```sehll
781 | 展示在页面的元数据信息必须兼顾完整性和合理的信息含量
782 |
783 | 为了不让用户被信息淹没,同时避免大量数据的传输,
784 | GooDs系统使用本文3.2节介绍的机制,将血缘元数据离线压缩
785 |
786 | 如果血缘数据的压缩版本仍然很大,系统只能保留最新的记录
787 | ```
788 |
789 | * 与各类的工具的交叉关联
790 |
791 | ```shell
792 | 数据集的信息页会将元数据与其他工具交叉关联
793 |
794 | 比如某个数据集的信息页,会将血缘元数据,
795 | 和任务中心(job-centric tools)的任务详情页相关联,
796 | 这些任务生产了当前数据集,
797 | 任务中心就是管理任务的工具
798 |
799 | 又如架构(schema)元数据会和代码管理工具连接,
800 | 代码管理工具中有当前架构的定义
801 |
802 | 同时,这些工具又回链到GooDs系统,帮助用户获取数据集的更多信息
803 | ```
804 |
805 | * 代码段工具(access snippets)
806 |
807 | ```shell
808 | 信息页同时提供了多语言的代码段工具(access snippets)来访问数据集的内容
809 |
810 | GooDs为特定数据集定制代码段,
811 | 用户可以复制粘贴代码段到特定的开发环境
812 |
813 | 代码段的目标是补充信息页的元数据内容:
814 |
815 | 元数据提供了数据集内容的架构级信息,
816 |
817 | 而代码段提供了通过代码快速访问和分析数据集实际内容的途径
818 | ```
819 |
820 | **5.2 数据集搜索(Dataset search)**
821 |
822 | * 关键字查询和索引
823 |
824 | ```shell
825 | 数据集检索允许用户通过简单的关键字查询找到数据集
826 |
827 | 搜索服务依赖常规的倒排索引实现文件检索
828 |
829 | 每个数据集都被视为一个文件(document),
830 | 系统从数据集的元数据子集中提取索引令牌(index token),
831 | 每个令牌都会关联索引的特定部分,
832 | 如path开头关联的是索引的路径
833 |
834 | 索引令牌的提取视查询类型而定
835 |
836 | 以路径为例,
837 | 数据集的路径按分隔符拆分,每个令牌对应它在路径中的位置,
838 | 如"a/x/y/b"会映射到索引令牌"a","x","y","b",并且顺序不变
839 |
840 | protocol buffer的名称也用相同的方式索引,
841 | 用户可以搜索到schema匹配特定protocol buffer命名空间的所有数据集
842 | ```
843 |
844 | * 打分函数(scoring function)
845 |
846 | ```shell
847 | 关键字搜索到数据集是第一步骤,
848 | 第二步骤是生成一个打分函数来为匹配的数据集排序
849 |
850 | GooDs系统会根据用户的使用经验不断调整打分函数
851 |
852 | 打分函数的几个设计经验:
853 |
854 | a) 数据集的重要性依赖于它的类型:
855 |
856 | 比如打分系统认为Dremel Table比file dataset重要,
857 | 因为Dremel Table需要用户注册,使其对更多用户可见
858 |
859 | b) 关键字匹配的重要性依赖于索引的位置
860 |
861 | 比如匹配数据集路径的关键字,
862 | 比匹配读写数据集任务的关键字重要性更强
863 |
864 | c) 血缘谱系(lineage fan-out)是数据集重要性的重要指标
865 |
866 | 数据集的读取任务越多,下游数据集越多,则数据集越重要;
867 | 这个准则有时会给一些数据集打出不合理的高分,
868 | 这些数据集可能只是被大量的内部管线间接访问,
869 | 但是对大多数用户没用,比如Google的网页爬取信息
870 |
871 | d) 带有用户描述信息的数据集重要性更高
872 |
873 | 除了上述几点,打分函数还会参考其他信号作为打分依据
874 | ```
875 |
876 | * facet
877 |
878 | ```shell
879 | 在关键字检索之外,GooDs系统还会展示元数据的facets
880 |
881 | 如数据集的所有者,数据集的文件类型等
882 |
883 | 这些facet能帮助用户构建更好的搜索关键词
884 | ```
885 |
886 | **5.3 团队仪表板(Team dashboards)**
887 |
888 | ```shell
889 | GooDs系统的仪表板是一个可配置的一站式数据集展示窗口,
890 | 能够显示某个团队生成的所有数据集和每个数据集的元数据
891 |
892 | GooDs系统自动更新仪表板的内容
893 |
894 | 用户可以将仪表板页面嵌入其他文件并将仪表板与他人共享
895 |
896 | GooDs系统还提供了监控数据集特定属性并警示的功能
897 |
898 | 用户可以通过极少的操作自行设置需要监控的属性
899 |
900 | 除了预设的监控属性,GooDs系统还能够通过分析趋势,
901 | 自动监控数据集的一些公共属性
902 | ```
903 |
904 |
905 |
906 | **6 经验总结(lessons learned)**
907 |
908 | * 随着使用不断演进(evolve as you go)
909 |
910 | ```shell
911 | GooDs系统期初的设计只是为数据集提供一个目录,
912 | 随着不断使用,GooDs系统也演化出各种用途:
913 |
914 | 1) 监测protocol buffer
915 | protocol buffer可能包含隐私信息
916 |
917 | 使用GooDs系统,工程师可以找到所有符合敏感protocol buffer的数据集
918 |
919 | 一旦有违规,GooDs系统会提醒数据集所有者
920 |
921 |
922 | 2) 重新查找数据集(re-find datasets)
923 |
924 | 工程师经常会生成一些测试数据集,但是事后忘记了数据集路径,
925 |
926 | 通过GooDs系统的关键字查询,能够找回这些数据集
927 |
928 |
929 | 3) 读懂老代码(understand legacy code)
930 |
931 | 老代码因缺乏最新的文档而难读
932 |
933 | 工程师通过GooDs系统提供的血缘图谱,
934 | 能够找到老代码之前的执行过程以及输入输出数据集,
935 | 从而帮助理解老代码的逻辑
936 |
937 |
938 | 4) 标注数据集(bookmark datasets)
939 |
940 | 数据集的信息页可以作为数据集天然的信息展示窗口
941 |
942 | 用户可以标注信息页并将数据集与其他用户共享
943 |
944 |
945 | 5) 注释数据集(annotate datasets)
946 |
947 | GooDs目录类似中转枢纽,数据集注释得以在不同的团队之间共享
948 |
949 | ```
950 |
951 | * 在排序中使用某个领域特有的信号(use domain-specific signals for ranking)
952 |
953 | ```shell
954 | 本文第二节中提到,数据集排序问题有自己的特性,
955 | 与其他领域的排序不同(如网页排序)
956 |
957 | 根据GooDs系统的使用经验,
958 | 不同数据集之间的血缘关系就为排序提供了领域特有的信号
959 |
960 | 比如很多团队会为主数据集(master dataset)生成多个非规范化(denomalized)的版本
961 |
962 | 这些非规范化版本的数据集和主数据集匹配相同的关键字
963 |
964 | 但是显而易见,GooDs系统会在常规查询或者元数据提取中给主数据集更高的排序
965 | ```
966 |
967 | * 预见并处理非常规数据集(expect and handle unusual datasets)
968 |
969 | ```shell
970 | 目录中庞大的数据集数量在GooDs系统早期产生了许多意外场景
971 |
972 | 在经验中GooDs系统形成了处理非常规数据集的策略:
973 | 首先提供最简单的特定问题解决方案,
974 | 接着在必要时归纳出同一类问题的总体解决方案
975 | ```
976 |
977 | * 按需导出数据(export data as required)
978 |
979 | ```shell
980 | GooDs目录的存储中介是键值对存储系统,
981 | 搜索服务依赖的是传统倒排索引,
982 | 二者均不适合对血缘图谱可视化或者执行复杂的路径查询
983 |
984 | 为了满足上述需求,
985 | GooDs系统会将目录数据按主谓宾的三元组结构(subject-predicate-object triples)导出
986 |
987 | GooDs系统会将这项元组数据导入到一个基于图形的存储系统,
988 | 支持路径查询并暴露更适合可视化的API
989 |
990 | 如果用户需要更强大的查询能力,现有存储系统无法支持,
991 | 最简单的方式就是将目录数据导出到一个合适的专门引擎中
992 | ```
993 |
994 | * 保证可恢复性(ensure recoverability)
995 |
996 | ```shell
997 | 从数以十亿计的数据集提取元数据的计算成本非常高
998 |
999 | 稳定状态下,GooDs系统在单日内处理一天量的新数据集
1000 |
1001 | 丢失或损毁目录的重要部分可能需要数周恢复,
1002 | 而且部分元数据在数据丢失后无法重现计算
1003 |
1004 | 为了保证可恢复性,GooDs系统将Bigtable设置为保留若干天内的滚动窗口快照
1005 |
1006 | GooDs系统自身也有有量身定制的恢复方案:
1007 |
1008 | a) 新设一个进程,在独立的目录,专门为重要的数据集拍摄快照
1009 |
1010 | b) 另一个进程则备份目录中提供信息页的子集,
1011 | 在主目录掉线时数据集信息页服务仍然可用
1012 |
1013 | c) 此外,GooDs自身也启用了数据集监控服务,
1014 | 保证尽早检测到数据损毁或丢失
1015 |
1016 | 上述措施都是在修复目录的经验中总结出的方案,
1017 | 其中有一些曾导致用户交互服务出现严重中断事故
1018 | ```
1019 |
1020 |
1021 |
1022 | **7 相关研究(related work)**
1023 |
1024 | ```shell
1025 | 这一节列举了一些类似的数据管理系统
1026 |
1027 | 这些系统中的某些用途和GooDs系统差不多,
1028 | 但是GooDs系统还需要从各方面解决自身面临的需求痛点
1029 | ```
1030 |
1031 | * 数据湖(data lake)
1032 |
1033 | ```shell
1034 | GooDs系统可以看做一个数据湖,一种用于存储海量数据且访问便捷的仓库,
1035 | 数据在生成的时候无需重新分类
1036 |
1037 | GooDs是用于组织和索引数据湖的系统,这个数据湖包含了Google内部所有的数据集
1038 |
1039 | 其他公司也有类似的系统,
1040 | Google与之不同的地方在于数据湖的规模和post-hoc的元数据推断方式
1041 |
1042 | ```
1043 |
1044 | * 元数据的生成方式不同
1045 |
1046 | ```shell
1047 | DataHub, Microsoft Azure Marketplace等数据集版本管理系统中,
1048 | 数据集所有者可以选择主动参与元数据的生成
1049 |
1050 | GooDs系统采用了post-hoc方式生成目录,
1051 | 工程师在生成和维护数据集的时候无需考虑GooDs系统的存在
1052 | ```
1053 |
1054 | * 数据集与网页表格的不同
1055 |
1056 | ```shell
1057 | 有一些系统可以从html页面中提取表格
1058 |
1059 | GooDs系统处理的数据集和这些表格中的数据结构不同
1060 |
1061 | 这些表格数据没有元数据,而元数据对于数据集又想当重要
1062 | ```
1063 |
1064 | * 快速和高效的搜索
1065 |
1066 | ```shell
1067 | Spyglass等系统提供了强大的基于元数据的搜索功能
1068 |
1069 | GooDs系统处理的数据集不在一个存储系统中,
1070 | 没有足够多的现成元数据,
1071 | 而且GooDs系统旨在提供比搜索更丰富的功能
1072 | ```
1073 |
1074 | * 对超大数据集进行索引和搜索
1075 |
1076 | ```shell
1077 | 已经有研究在探索对超大数据集进行索引和搜索
1078 |
1079 | GooDs系统需要解决本文第二节中列举的各类问题
1080 |
1081 | 如果GooDs要搜索数据集的实际内容而不是元数据时,
1082 | 这些研究或许相关性更大
1083 | ```
1084 |
1085 | * 血缘关系管理
1086 |
1087 | ```shell
1088 | PASS和Trio等系统也会维护文件的血缘关系,
1089 | 但是前提是这些血缘信息都是已知的或者能够从访问数据的进程中获得
1090 |
1091 | GooDs系统需要依赖一些微弱的信号推断血缘信息,
1092 | 但是却将血缘信息当做数据集排序的强信号
1093 | ```
1094 |
1095 |
1096 |
1097 | **8 结论和展望(conclusions and future work)**
1098 |
1099 | * 总结
1100 |
1101 | ```shell
1102 | 本文介绍的数据管理系统,可访问企业内部数以十亿计的数据集的元数据
1103 | ```
1104 |
1105 | * 挑战
1106 |
1107 | ```shell
1108 | 1) 对数据集全排列,鉴别重要数据集,数据集的排序方法是否和网页排序方法类似
1109 |
1110 | 2) 完善元数据需要依赖各种资源和信息
1111 |
1112 | 3) 理解隐含在数据集中的语义信息能为用户提供更有效的搜索服务,
1113 | 而对语义的理解也需要借助其他资源比如Google的知识图谱(Knowledge Graph)
1114 |
1115 | 4) 数据集产生的时候就在GooDs上注册能够保持目录更新,
1116 | 而这种方式需要修改现有的存储系统,与GooDs非侵入式的理念冲突,
1117 | 如何结合非侵入式和侵入式仍然有待解决
1118 |
1119 | ```
1120 |
1121 | * 期望
1122 |
1123 | ```shell
1124 | 希望类似GooDs的数据管理系统能够助推数据导向型公司培养一种数据文化
1125 |
1126 | 企业将数据当作企业核心资产,发展出类似"代码规约"的"数据规约(data discipline)"
1127 |
1128 | ```
--------------------------------------------------------------------------------