├── LICENSE
├── README.md
├── SA_Index_Workshop.tar
├── astra.json
└── slides
└── Presentation.pdf
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | ## 🎓🔥 Scalable Indexing for Cassandra using DataStax Astra 🔥🎓
2 |
3 | [](http://www.apache.org/licenses/LICENSE-2.0)
4 | [](https://discord.com/widget?id=685554030159593522&theme=dark)
5 |
6 | 
7 |
8 | Welcome to the 'Scalable Indexing for Cassandra using DataStax Astra' workshop! In this two-hour workshop, the Developer Advocate team of DataStax will explain the new Storage Attached Indexing (SAI) feature using Astra, the cloud based Cassandra-as-a-Service platform delivered by DataStax, to demonstrate how you can use them to add some much wanted flexibility to your Cassandra data model by querying outside of primary key fields.
9 |
10 | **To date, SAI is currently supported on DataStax Astra and DataStax Enterprise 6.8.3+. There is a currently a [CEP](https://cwiki.apache.org/confluence/display/CASSANDRA/CEP-7%3A+Storage+Attached+Index) to bring this functionality into Open Source Apache Cassandra.**
11 |
12 | It doesn't matter if you join our workshop live or you prefer to do at your own pace, we have you covered. In this repository, you'll find everything you need for this workshop:
13 |
14 | - Materials used during presentations
15 | - Hands-on exercises
16 | - Workshop videos
17 | - [First workshop](https://www.youtube.com/watch?v=GLJc1Uz9dqw) [NAM Time]
18 | - [Second workshop](https://www.youtube.com/watch?v=yNQYQjXtV30) [IST Time]
19 | - [Discord chat](https://bit.ly/cassandra-workshop)
20 | - [Questions and Answers](https://community.datastax.com/)
21 |
22 | ## Table of Contents
23 |
24 | | Title | Description
25 | |---|---|
26 | | **Slide deck** | [Slide deck for the workshop](slides/Presentation.pdf) |
27 | | **Exercise Notebook** | [Exercises in Studio Notebook for Astra](SA_Index_Workshop.tar) |
28 | | **SAI Documentation** | [SAI Documentation](https://docs.datastax.com/en/storage-attached-index/6.8/sai/saiQuickStart.html) |
29 | | **1. Create your Astra instance** | [Create your Astra instance](#1-create-your-astra-instance) |
30 | | **2. Getting started with SAI** | [Getting started with SAI](#2-getting-started-with-sai-storage-attached-index) |
31 | | **3. IoT sensor data model use case** | [IoT sensor data model use case](#3-iot-sensor-data-model-use-case) |
32 |
33 |
34 |
35 | ## 1. Create your Astra instance
36 |
37 | `ASTRA` service is available at url [https://astra.datastax.com](https://dtsx.io/workshop). `ASTRA` is the simplest way to run Cassandra with zero operations at all - just push the button and get your cluster. `Astra` offers **5 Gb Tier Free Forever** and you **don't need a credit card** or anything to sign-up and use it.
38 |
39 | **✅ Step 1a. Register (if needed) and Sign In to Astra** : You can use your `Github`, `Google` accounts or register with an `email`.
40 |
41 | Make sure to chose a password with minimum 8 characters, containing upper and lowercase letters, at least one number and special character
42 |
43 | - [Registration Page](https://dtsx.io/workshop)
44 |
45 | 
46 |
47 | - [Authentication Page](https://dtsx.io/workshop)
48 |
49 | 
50 |
51 |
52 | **✅ Step 1b. Choose the free plan and select your region**
53 |
54 | 
55 |
56 | - **Select the free tier**: 5GB storage, no obligation
57 |
58 | - **Select the region**: This is the region where your database will reside physically (choose one close to you or your users). For people in EMEA please use `europe-west-1` idea here is to reduce latency.
59 |
60 | **✅ Step 1c. Configure and create your database**
61 |
62 | You will find below which values to enter for each field.
63 |
64 | 
65 |
66 | - **Fill in the database name** - `sa_index_workshop_db.` While Astra allows you to fill in these fields with values of your own choosing, please follow our reccomendations to make the rest of the exercises easier to follow. If you don't, you are on your own! :)
67 |
68 | - **Fill in the keyspace name** - `sa_index`. It's really important that you use the name sa_index here in order for all the exercises to work well. We realize you want to be creative, but please just roll with this one today.
69 |
70 | - **Fill in the Database User name** - `index_user`. Note the user name is case-sensitive. Please use the case we suggest here.
71 |
72 | - **Fill in the password** - `index_password1`. Fill in both the password and the confirmation fields. Note that the password is also case-sensitive. Please use the case we suggest here.
73 |
74 | - **Create the database**. Review all the fields to make sure they are as shown, and click the `Create Database` button.
75 |
76 | You will see your new database `pending` in the Dashboard.
77 |
78 | 
79 |
80 | The status will change to `Active` when the database is ready, this will only take 2-3 minutes. You will also receive an email address when it is ready.
81 |
82 | **✅ Step 1d. View your Database and connect**
83 |
84 | Let’s review the database you have configured. Select your new database in the lefthand column.
85 |
86 | Now you can select to connect, to park the database, to access CQL console or Studio.
87 |
88 | 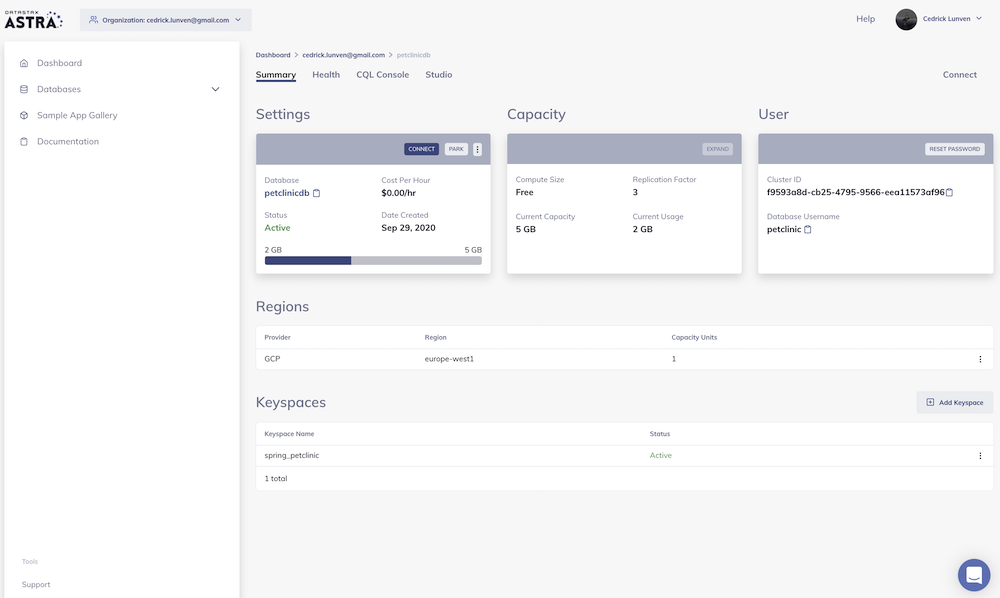
89 |
90 |
91 | [🏠 Back to Table of Contents](#table-of-contents)
92 |
93 | ## 2. Getting started with SAI (Storage Attached Index)
94 | **SAI** is short for **Storage Attached Indexes**, it allows us to build indexes on Cassandra tables that dramatically improve the flexibility of Cassandra queries.
95 |
96 | For a **non-technical introduction** to **SAI**, have a look at this [recent blog post](https://www.datastax.com/blog/get-your-head-clouds-part-1-3-build-cloud-native-apps-datastax-astra-dbaas-now-aws-gcp).
97 |
98 | To learn more about **SAI** from a **technical perspective**, have a look at our [docs on SAI](https://docs.datastax.com/en/storage-attached-index/6.8/sai/saiQuickStart.html). Honestly, these docs are pretty great IMO especially the [SAI FAQ](https://docs.datastax.com/en/storage-attached-index/6.8/sai/saiFaqs.html). Definitely take a moment to read through these to get a better understanding of how all of this works and even more examples on top of what we are presenting in this repo.
99 |
100 | Now, let's get into some examples. The first thing we'll need is a table and some data to work with. For that we need to talk about my dentist, or really, a contrived example of a client data model a dentist might need to use.
101 |
102 | **✅ Step 2a. Navigate to the CQL Console and login to the database**
103 |
104 | In the Summary screen for your database, select **_CQL Console_** from the top menu in the main window. This will take you to the CQL Console with a login prompt.
105 |
106 | 
107 |
108 | Once you click the _`CQL Console`_ tab it will automatically log you in and present you with a `token@cqlsh>` prompt.
109 |
110 |
111 | **✅ Step 2b. Describe keyspaces and USE `sa_index`**
112 |
113 | Ok, you're logged in, and now we're ready to rock. Creating tables is quite easy, but before we create one we need to tell the database which keyspace we are working with.
114 |
115 | First, let's **_DESCRIBE_** all of the keyspaces that are in the database. This will give us a list of the available keyspaces.
116 |
117 | 📘 **Command to execute**
118 | ```
119 | desc KEYSPACES;
120 | ```
121 | _"desc" is short for "describe", either is valid_
122 |
123 | 📗 **Expected output**
124 |
125 | 
126 |
127 | Depending on your setup you might see a different set of keyspaces then in the image. The one we care about for now is **_sa_index_**. From here, execute the **_USE_** command with the **_sa_index_** keyspace to tell the database our context is within **_sa_index_**.
128 |
129 | 📘 **Command to execute**
130 | ```
131 | use sa_index;
132 | ```
133 |
134 | 📗 **Expected output**
135 |
136 | 
137 |
138 | Notice how the prompt displays `token@cqlsh:sa_index>` informing us we are **using** the **_sa_index_** keyspace. Now we are ready to create our tables.
139 |
140 | **✅ Step 2c. Create a _`clients`_ table and insert some data**
141 |
142 | Create the table.
143 |
144 | 📘 **Command to execute**
145 |
146 | ```SQL
147 | CREATE TABLE IF NOT EXISTS clients (
148 | uniqueid uuid primary key,
149 | firstname text,
150 | lastname text,
151 | birthday date,
152 | nextappt timestamp,
153 | newpatient boolean,
154 | photo text
155 | );
156 | ```
157 |
158 | Insert some data into the table.
159 |
160 | _We don't have real image URLs, so we're just using a placeholder string._
161 |
162 | 📘 **Commands to execute**
163 | ```SQL
164 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
165 | VALUES (D85745B1-4BEC-43D7-8B77-DD164CB9D1B8, 'Alice', 'Apple', '1984-01-24', '2020-10-20 12:00:00', true, 'imageurl');
166 |
167 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
168 | VALUES (2A4F139F-0BBF-4A6F-B982-5400F11D2F2B, 'Zeke', 'Apple', '1961-12-30', '2020-10-20 12:30:00', false, 'imageurl');
169 |
170 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
171 | VALUES (DF649261-89CB-446B-9998-FFA2D17506F9, 'Lorenzo', 'Banana', '1963-09-03', '2020-10-20 13:00:00', false, 'imageurl');
172 |
173 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
174 | VALUES (808E6BBF-A0F4-4E4C-9C97-E36751D51A8B, 'Miley', 'Banana', '1969-02-06', '2020-10-20 13:30:00', false, 'imageurl');
175 |
176 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
177 | VALUES (3D458A4D-2F54-4271-BEDC-1FC316B3CC96, 'Cheryl', 'Banana', '1970-07-11', '2020-10-20 14:00:00', false, 'imageurl');
178 |
179 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
180 | VALUES (287AB6B4-1AA6-45DF-B6F8-2BE253B9AACE, 'Red', 'Currant', '1974-02-18', '2020-10-20 15:00:00', false, 'imageurl');
181 |
182 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
183 | VALUES (AB49D151-CC04-40DC-AEEA-0A4E5F59D69A, 'Matthew', 'Durian', '1976-11-11', '2020-10-19 12:30:00', false, 'imageurl');
184 |
185 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
186 | VALUES (783CE790-16B4-4645-B27C-4FDF3994A755, 'Vanessa', 'Elderberry', '1977-12-03', '2020-10-20 15:30:00', false, 'imageurl');
187 |
188 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
189 | VALUES (D23997E4-CCCB-46BB-B92F-0D4582A68809, 'Elaine', 'Elderberry', '1979-11-16', '2020-10-20 10:00:00', true, 'imageurl');
190 |
191 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
192 | VALUES (36C386C1-3C3B-49FC-81B1-391D5537453D, 'Phoebe', 'Fig', '1986-01-27', '2020-10-21 11:00:00', false, 'imageurl');
193 |
194 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
195 | VALUES (00FEE7EE-8F93-4C2E-A8BE-3ADD81235822, 'Patricia', 'Grape', '1986-06-24', '2020-10-21 12:00:00', false, 'imageurl');
196 |
197 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
198 | VALUES (B9DB7E99-AD1C-49B1-97C6-87154663AEF4, 'Herb', 'Huckleberry', '1990-07-09', '2020-10-21 13:00:00', false, 'imageurl');
199 |
200 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
201 | VALUES (F4DB7673-CA4E-4382-BDCD-2C1704363590, 'John-Henry', 'Huckleberry', '1979-11-16', '2020-10-21 14:00:00', false, 'imageurl');
202 |
203 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
204 | VALUES (F4DB7673-CA4E-4382-BDCD-2C1704363595, 'Sven', 'Åskådare', '1967-11-07', '2020-10-21 14:00:00', false, 'imageurl');
205 | ```
206 |
207 | **✅ Step 2d. Verify data exists**
208 |
209 | Now let's take a look at the data we just inserted.
210 |
211 | 📘 **Command to execute**
212 | ```
213 | SELECT * FROM clients;
214 | ```
215 |
216 | 📗 **Expected output**
217 |
218 | 
219 |
220 | **✅ Step 2e. Create some indexes**
221 |
222 | Ok great, we have data in our table, but remember we used **_`uniqueid`_** as our **primary key** when we created the table. If we want to query a single patient, we'd have to do that by the **_`uniqueid`_** column because that's our **partition key** _(don't forget, a single value in the primary key is always the partition key)_.
223 |
224 | As a matter of fact, let's try an example. Let's say I want to find a user by their lastname.
225 |
226 | 📘 **Command to execute**
227 | ```SQL
228 | SELECT * FROM clients WHERE lastname = 'Apple';
229 | ```
230 | 📗 **Expected output**
231 |
232 | 
233 |
234 | Right, the database is telling me here I **CANNOT** query against the **lastname** column because it is NOT in my primary key **_`uniqueid`_**.
235 |
236 | But how would we search for users outside of using their unique ID's? We need to look for clients based on information they give us when they walk in the office. Namely, information like first and last name, or birthdate. Maybe a combination of those. Let's set up some indexes to do that.
237 |
238 | _Don't worry about options in the below statements just yet. We'll get to that. For now, just execute the commands to create your indexes._
239 |
240 | 📘 **Commands to execute**
241 | ```SQL
242 | CREATE CUSTOM INDEX IF NOT EXISTS ON clients(firstname) USING 'StorageAttachedIndex'
243 | WITH OPTIONS = {'case_sensitive': false, 'normalize': true };
244 |
245 | CREATE CUSTOM INDEX IF NOT EXISTS ON clients(lastname) USING 'StorageAttachedIndex'
246 | WITH OPTIONS = {'case_sensitive': false, 'normalize': true };
247 |
248 | CREATE CUSTOM INDEX IF NOT EXISTS ON clients(birthday) USING 'StorageAttachedIndex';
249 | ```
250 |
251 | **✅ Step 2f. Execute queries that use firstname, lastname, and birthday using our indexes**
252 |
253 | Remember, the **`clients`** table data model only includes **`uniqueid`** in the primary key. In the traditional Cassandra sense I can only query against the **`uniqueid`** column in the **WHERE** clause. However, with our **SAIndexes** now added we can do a lot more.
254 |
255 | 📘 **Command to execute**
256 | ```SQL
257 | // Look for a client by ONLY their lastname. Notice the case used.
258 | SELECT * FROM clients WHERE lastname = 'Apple';
259 | ```
260 |
261 | 📗 **Expected output**
262 |
263 | 
264 |
265 | 📘 **Command to execute**
266 | ```SQL
267 | // Look for a client by their lastname and firstname. Notice the case used.
268 | SELECT * FROM clients WHERE lastname = 'apple' AND firstname = 'alice';
269 | ```
270 |
271 | 📗 **Expected output**
272 |
273 | 
274 |
275 | 📘 **Command to execute**
276 | ```SQL
277 | // Look for a client by an exact match to their birthday.
278 | SELECT * FROM clients WHERE birthday = '1984-01-24';
279 | ```
280 |
281 | 📗 **Expected output**
282 |
283 | 
284 |
285 | 📘 **Command to execute**
286 | ```SQL
287 | // Look for a client by a range match for the year of their birthday.
288 | SELECT * FROM clients WHERE birthday > '1984-01-01' AND birthday < '1985-01-01';
289 | ```
290 |
291 | 📗 **Expected output**
292 |
293 | 
294 |
295 | 📘 **Command to execute**
296 | ```SQL
297 | // Look for a client by their firstname
298 | // and a range match for the year of their birthday. Again, notice the case used.
299 | SELECT * FROM clients
300 | WHERE firstname = 'aLicE'
301 | AND birthday > '1984-01-01' AND birthday < '1985-01-01';
302 | ```
303 |
304 | 📗 **Expected output**
305 |
306 | 
307 |
308 | **✅ Step 2g. Digest everything we just did there**
309 |
310 | Ok, so let's break that all down. I said earlier when we created the indexes I would explain the options included with some of the indexes.
311 | ```SQL
312 | WITH OPTIONS = {'case_sensitive': false, 'normalize': true };
313 | ```
314 | So what does the **“WITH OPTIONS”** part mean?
315 |
316 | Well, [case_sensitive](https://docs.datastax.com/en/dse/6.8/cql/cql/cql_reference/cql_commands/cqlCreateCustomIndex.html#cqlCreateCustomIndex__cqlCreateCustomIndexOptions) is fairly straightforward. Setting this **false** allows us to match any combination of case for the terms we are querying against, **firstname** or **lastname** fields according to the indexes we created.
317 |
318 | This is why I kept varying the case used in our queries above. You could **NOT** have done does this with a traditional Cassandra query.
319 |
320 | How about [normalize](https://docs.datastax.com/en/dse/6.8/cql/cql/cql_reference/cql_commands/cqlCreateCustomIndex.html#cqlCreateCustomIndex__cqlCreateCustomIndexOptions)? Basically, this means that special characters, like vowels with diacritics can be represented by multiple binary representations for the same character, which also makes things easier to match.
321 |
322 | An example would be a row with a column value that contained the character `Å (U+212B)`. With **normalize** enabled a query that used the character `Å (U+00C5)` would find that row. This saves from the need to find all unicode variations for a single character.
323 |
324 | 📘 **Command to execute**
325 |
326 | ```SQL
327 | SELECT * FROM clients WHERE lastname = 'Åskådare';
328 | ```
329 |
330 | _To be clear, this is not Ascii folding where I might insert code that uses `é` and a select using `e`. This is coming as a future feature._
331 |
332 | To sum up, we queried against a combination of string and date fields using exact matches, multiple string cases, and date ranges. Just by adding an index on 3 fields we significantly expanded the flexibility of our data model.
333 |
334 | Let's do more.
335 |
336 | **✅ Step 2h. Add another index to support a new data model requirement**
337 |
338 | Imagine a case where we now have a requirement to find clients based off of their next appointment.
339 |
340 | Prior to **SAI**, if I wanted to accomplish this same thing in Cassandra, I would set up a new table using the **date** as the **partition key**, and I'd probably have the **appointment** slots as a **clustering column**, along with the **`uniqueid`** rounding out the primary key.
341 |
342 | Then, I would retrieve the days partition to get a list of the appointments for the day. Now, I have **two tables** that I need to worry about to support that query.
343 |
344 | Let's see what this looks like with **SAI**.
345 |
346 | 📘 **Command to execute**
347 | ```SQL
348 | CREATE CUSTOM INDEX IF NOT EXISTS ON clients(nextappt) USING 'StorageAttachedIndex';
349 | ```
350 |
351 | 📘 **Command to execute**
352 | ```SQL
353 | SELECT * FROM clients WHERE nextappt > '2020-10-20 09:00:00';
354 | ```
355 |
356 | 📗 **Expected output**
357 |
358 | 
359 |
360 | [🏠 Back to Table of Contents](#table-of-contents)
361 |
362 | ## 3. IoT sensor data model use case
363 | Time to swtich gears to a real IoT data model use case.
364 |
365 | In the following case, an organization recieved a feed of sensor data that always included all of the fields that the sensor kept track of, even if those fields hadn't changed since the last reading.
366 |
367 | **All of the data was sent whenever a single field changed values.**
368 |
369 | Now, this isn't necessarily something that has to be difficult to deal with, if all of the key fields are the same, **we can easily overwrite redundant data without doing a read-before-write** and all of that non-changing, redundant data will just compact away.
370 |
371 | But, a **problem arises** if we need to **query** based on **something other than the primary key**.
372 |
373 | If this table is instead organized to be physically efficient for querying, then I may not be able to easily upsert the data from the sensor without 1) creating a lot of unnecessary records, or 2) being forced to do a read-before-write to check if a record already exists.
374 |
375 | In this case, the **user was stuck with option 1**, because **it was cheaper to store more data than it was to have the compute resources for all of that extra query power for the 20x read workload that was required just to check to see if a sensor reading was already in the database.**
376 |
377 | For this section we will continue by using [this Studio notebook](SA_Index_Workshop.tar) in Astra. Please right-click on the link provided and choose **Copy Link Address**. From there, follow the instructions to import into Astra.
378 |
379 | Click on the **`Studio`** tab within your Astra console.
380 | 
381 |
382 | This will launch **Studio** in a new tab.
383 |
384 | Click the **`+`** icon to import a notebook.
385 | 
386 |
387 | Choose **`IMPORT FROM URL`**.
388 | 
389 |
390 | Paste in the link address you copied and click **`Import`**.
391 | 
392 |
393 | From there the notebook will be imported and opened automatically. Navigate down to Section **3. IoT sensor data model use case** to continue on.
394 | 
395 |
396 |
--------------------------------------------------------------------------------
/SA_Index_Workshop.tar:
--------------------------------------------------------------------------------
1 | notebook.bin����������������������������������������������������������������������������������������0100644 0000000 0000000 00000111012 13746302451 012120� 0����������������������������������������������������������������������������������������������������ustar�00����������������������������������������������������������������0000000 0000000 �����������������������������������������������������������������������������������������������������������������������������������������������������������������������json_notebook_v1����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������{"1":"3757cf55-34a8-49fb-b25e-ab28906e544a","10":"0c93b668-0c49-4347-a945-28a383f07539","11":"SAI Tutorial","12":{"1":1603896207,"2":581000000},"13":{"1":1603896562,"2":222000000},"14":false,"15":[{"1":"4fdfcc06-08d5-4065-9d4c-7d477a3d41db","10":4,"11":"This notebook is desinged to be used in conjunction with the Storage Attached Indexes Workshop GitHub Repo [HERE](https://github.com/DataStax-Academy/workshop-storage-attached-indexes). \n\nPlease note **section 2** as you see it below is a continuation from content within the repo.","12":"markdown","13":{"1":"1c2ef400-87e1-4c35-917d-0182272c5dde","10":{"9":"This notebook is desinged to be used in conjunction with the Storage Attached Indexes Workshop GitHub Repo HERE.
\nPlease note section 2 as you see it below is a continuation from content within the repo.
\n"},"11":4,"12":false,"17":1603828635992},"16":true,"17":true,"18":{},"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"bd259bdc-b5ad-4452-8f07-23fedc1430ec","10":4,"11":"##2. Getting Started with SAI\n\n**SAI** is short for **Storage Attached Indexes**, it allows us to build indexes on Cassandra tables that dramatically improve the flexibility of Cassandra queries.\n\nFor a **non-technical introduction** to **SAI**, have a look at this [recent blog post](https://www.datastax.com/blog/get-your-head-clouds-part-1-3-build-cloud-native-apps-datastax-astra-dbaas-now-aws-gcp).\n\nTo learn more about **SAI** from a **technical perspective**, have a look at our [docs on SAI](https://docs.datastax.com/en/storage-attached-index/6.8/sai/saiQuickStart.html). Honestly, these docs are pretty great IMO especially the [SAI FAQ](https://docs.datastax.com/en/storage-attached-index/6.8/sai/saiFaqs.html). Definitely take a moment to read through these to get a better understanding of how all of this works and even more examples on top of what we are presenting in this repo.\n\nNow, let's get into some examples. The first thing we'll need is a table and some data to work with. For that we need to talk about my dentist, or really, a contrived example of a client data model a dentist might need to use.","12":"markdown","13":{"1":"84fbe21a-9bdc-413d-b66b-69d8f89e2512","10":{"9":"2. Getting Started with SAI
\nSAI is short for Storage Attached Indexes, it allows us to build indexes on Cassandra tables that dramatically improve the flexibility of Cassandra queries.
\nFor a non-technical introduction to SAI, have a look at this recent blog post.
\nTo learn more about SAI from a technical perspective, have a look at our docs on SAI. Honestly, these docs are pretty great IMO especially the SAI FAQ. Definitely take a moment to read through these to get a better understanding of how all of this works and even more examples on top of what we are presenting in this repo.
\nNow, let's get into some examples. The first thing we'll need is a table and some data to work with. For that we need to talk about my dentist, or really, a contrived example of a client data model a dentist might need to use.
\n"},"11":4,"12":false,"17":1603828604394},"16":true,"17":true,"18":{},"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"94bc0e40-230f-4f29-83a9-3b6238bc7c2e","10":4,"11":"**✅ Step 2c. Create a _`clients`_ table and insert some data**\n\nCreate the table.","12":"markdown","13":{"1":"6a1a5bac-4cb3-472c-aa15-dc7892f8fcee","10":{"9":"✅ Step 2c. Create a clients table and insert some data
\nCreate the table.
\n"},"11":4,"12":false,"17":1603823064726},"16":true,"17":true,"18":{},"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"bf8e0324-6924-498d-b522-12fcb5b930aa","11":"CREATE TABLE IF NOT EXISTS clients (\n uniqueid uuid primary key,\n firstname text,\n lastname text,\n birthday date,\n nextappt timestamp,\n newpatient boolean,\n photo text\n);","12":"cql","16":true,"17":false,"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"9a2de505-349f-42c4-8e22-69baa6699b03","10":4,"11":"Insert some data into the table.\n\n_We don't have real image URLs, so we're just using a placeholder string._","12":"markdown","13":{"1":"76af2d36-51f9-4510-87fb-0e6f9502a954","10":{"9":"Insert some data into the table.
\nWe don't have real image URLs, so we're just using a placeholder string.
\n"},"11":4,"12":false,"17":1603823045609},"16":true,"17":true,"18":{},"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"9772d4ab-33b2-464b-9477-dd5092078d5b","11":"INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo) \nVALUES (D85745B1-4BEC-43D7-8B77-DD164CB9D1B8, 'Alice', 'Apple', '1984-01-24', '2020-10-20 12:00:00', true, 'imageurl');\n\nINSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo) \nVALUES (2A4F139F-0BBF-4A6F-B982-5400F11D2F2B, 'Zeke', 'Apple', '1961-12-30', '2020-10-20 12:30:00', false, 'imageurl');\n\nINSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo) \nVALUES (DF649261-89CB-446B-9998-FFA2D17506F9, 'Lorenzo', 'Banana', '1963-09-03', '2020-10-20 13:00:00', false, 'imageurl');\n\nINSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo) \nVALUES (808E6BBF-A0F4-4E4C-9C97-E36751D51A8B, 'Miley', 'Banana', '1969-02-06', '2020-10-20 13:30:00', false, 'imageurl');\n\nINSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo) \nVALUES (3D458A4D-2F54-4271-BEDC-1FC316B3CC96, 'Cheryl', 'Banana', '1970-07-11', '2020-10-20 14:00:00', false, 'imageurl');\n\nINSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo) \nVALUES (287AB6B4-1AA6-45DF-B6F8-2BE253B9AACE, 'Red', 'Currant', '1974-02-18', '2020-10-20 15:00:00', false, 'imageurl');\n\nINSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo) \nVALUES (AB49D151-CC04-40DC-AEEA-0A4E5F59D69A, 'Matthew', 'Durian', '1976-11-11', '2020-10-19 12:30:00', false, 'imageurl');\n\nINSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo) \nVALUES (783CE790-16B4-4645-B27C-4FDF3994A755, 'Vanessa', 'Elderberry', '1977-12-03', '2020-10-20 15:30:00', false, 'imageurl');\n\nINSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo) \nVALUES (D23997E4-CCCB-46BB-B92F-0D4582A68809, 'Elaine', 'Elderberry', '1979-11-16', '2020-10-20 10:00:00', true, 'imageurl');\n\nINSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo) \nVALUES (36C386C1-3C3B-49FC-81B1-391D5537453D, 'Phoebe', 'Fig', '1986-01-27', '2020-10-21 11:00:00', false, 'imageurl');\n\nINSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo) \nVALUES (00FEE7EE-8F93-4C2E-A8BE-3ADD81235822, 'Patricia', 'Grape', '1986-06-24', '2020-10-21 12:00:00', false, 'imageurl');\n\nINSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo) \nVALUES (B9DB7E99-AD1C-49B1-97C6-87154663AEF4, 'Herb', 'Huckleberry', '1990-07-09', '2020-10-21 13:00:00', false, 'imageurl');\n\nINSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo) \nVALUES (F4DB7673-CA4E-4382-BDCD-2C1704363590, 'John-Henry', 'Huckleberry', '1979-11-16', '2020-10-21 14:00:00', false, 'imageurl');\n\nINSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo) \nVALUES (F4DB7673-CA4E-4382-BDCD-2C1704363595, 'Sven', 'Åskådare', '1967-11-07', '2020-10-21 14:00:00', false, 'imageurl');","12":"cql","16":true,"17":false,"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"7921fdf8-f8c8-427f-8e94-8bf8b7839d18","10":4,"11":"**✅ Step 2d. Verify data exists**\n\nNow let's take a look at the data we just inserted.","12":"markdown","13":{"1":"7490aa81-2682-43da-9078-5ae9d4a71088","10":{"9":"✅ Step 2d. Verify data exists
\nNow let's take a look at the data we just inserted.
\n"},"11":4,"12":false,"17":1603823018785},"16":true,"17":true,"18":{},"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"aceb83c2-0405-4a18-a81b-75393baac2bb","11":"// Now let's take a look at the data we just inserted.\nselect * from clients;","12":"cql","16":true,"17":false,"18":{},"22":596,"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"c1a3b303-185d-43e8-bdca-755bb4828ade","10":4,"11":"**✅ Step 2e. Create some indexes**\n\nOk great, we have data in our table, but remember we used **_`uniqueid`_** as our **primary key** when we created the table. If we want to query a single patient, we'd have to do that by the **_`uniqueid`_** column because that's our **partition key** _(don't forget, a single value in the primary key is always the partition key)_. \n\nAs a matter of fact, let's try an example. Let's say I want to find a user by their lastname. ","12":"markdown","13":{"1":"c625fa9e-176a-4e19-805c-28a80b16ce04","10":{"9":"✅ Step 2e. Create some indexes
\nOk great, we have data in our table, but remember we used uniqueid as our primary key when we created the table. If we want to query a single patient, we'd have to do that by the uniqueid column because that's our partition key (don't forget, a single value in the primary key is always the partition key).
\nAs a matter of fact, let's try an example. Let's say I want to find a user by their lastname.
\n"},"11":4,"12":false,"17":1603822994911},"16":true,"17":true,"18":{},"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"c97b3b6a-f447-4245-858e-c0b8b3d9d25e","11":"CREATE CUSTOM INDEX IF NOT EXISTS ON clients(firstname) USING 'StorageAttachedIndex' \nWITH OPTIONS = {'case_sensitive': false, 'normalize': true };\n\nCREATE CUSTOM INDEX IF NOT EXISTS ON clients(lastname) USING 'StorageAttachedIndex' \nWITH OPTIONS = {'case_sensitive': false, 'normalize': true };\n\nCREATE CUSTOM INDEX IF NOT EXISTS ON clients(birthday) USING 'StorageAttachedIndex';\n","12":"cql","16":true,"17":false,"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"3c81381b-4361-44e1-9b4d-b1238da538a7","10":4,"11":"**✅ Step 2f. Execute queries that use firstname, lastname, and birthday using our indexes**\n\nRemember, the **`clients`** table data model only includes **`uniqueid`** in the primary key. In the traditional Cassandra sense I can only query against the **`uniqueid`** column in the **WHERE** clause. However, with our **SAIndexes** now added we can do a lot more.","12":"markdown","13":{"1":"268d0101-995d-46d3-8307-a93b6e508fb0","10":{"9":"✅ Step 2f. Execute queries that use firstname, lastname, and birthday using our indexes
\nRemember, the clients table data model only includes uniqueid in the primary key. In the traditional Cassandra sense I can only query against the uniqueid column in the WHERE clause. However, with our SAIndexes now added we can do a lot more.
\n"},"11":4,"12":false,"17":1603822972359},"16":true,"17":true,"18":{},"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"e0cadfc6-acfe-404b-8d24-d96a42b7f45e","11":"//To execute any of these, highlight the query and then hit the run button in the upper left\n\n// Look for a client by ONLY their lastname. Notice the case used.\nSELECT * FROM clients WHERE lastname = 'Apple';\n\n// Look for a client by their lastname and firstname. Notice the case used.\nSELECT * FROM clients WHERE lastname = 'apple' AND firstname = 'alice';\n\n// Look for a client by an exact match to their birthday.\nSELECT * FROM clients WHERE birthday = '1984-01-24';\n\n// Look for a client by a range match for the year of their birthday.\nSELECT * FROM clients WHERE birthday > '1984-01-01' AND birthday < '1985-01-01';\n\n// Look for a client by their firstname \n// and a range match for the year of their birthday. Again, notice the case used.\nSELECT * FROM clients \nWHERE firstname = 'aLicE'\nAND birthday > '1984-01-01' AND birthday < '1985-01-01';","12":"cql","16":true,"17":false,"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"cf125062-3162-4a0a-900b-fc03af7ee47a","10":4,"11":"**✅ Step 2g. Digest everything we just did there**\n\nOk, so let's break that all down. I said earlier when we created the indexes I would explain the options included with some of the indexes. \n```SQL\nWITH OPTIONS = {'case_sensitive': false, 'normalize': true };\n```\nSo what does the **“WITH OPTIONS”** part mean? \n\nWell, [case_sensitive](https://docs.datastax.com/en/dse/6.8/cql/cql/cql_reference/cql_commands/cqlCreateCustomIndex.html#cqlCreateCustomIndex__cqlCreateCustomIndexOptions) is fairly straightforward. Setting this **false** allows us to match any combination of case for the terms we are querying against, **firstname** or **lastname** fields according to the indexes we created. \n\nThis is why I kept varying the case used in our queries above. You could **NOT** have done does this with a traditional Cassandra query.\n\nHow about [normalize](https://docs.datastax.com/en/dse/6.8/cql/cql/cql_reference/cql_commands/cqlCreateCustomIndex.html#cqlCreateCustomIndex__cqlCreateCustomIndexOptions)? Basically, this means that special characters, like vowels with diacritics can be represented by multiple binary representations for the same character, which also makes things easier to match. \n\nAn example would be a row with a column value that contained the character `Å (U+212B)`. With **normalize** enabled a query that used the character `Å (U+00C5)` would find that row. This saves from the need to find all unicode variations for a single character.\n\n_To be clear, this is not Ascii folding where I might insert code that uses `é` and a select using `e`. This is coming as a future feature._\n\nTo sum up, we queried against a combination of string and date fields using exact matches, multiple string cases, and date ranges. Just by adding an index on 3 fields we significantly expanded the flexibility of our data model.\n\nLet's do more.","12":"markdown","13":{"1":"35a70086-9e16-419f-b9bb-40620e87b2c1","10":{"9":"✅ Step 2g. Digest everything we just did there
\nOk, so let's break that all down. I said earlier when we created the indexes I would explain the options included with some of the indexes.
\nWITH OPTIONS = {'case_sensitive': false, 'normalize': true };\n
\nSo what does the “WITH OPTIONS” part mean?
\nWell, case_sensitive is fairly straightforward. Setting this false allows us to match any combination of case for the terms we are querying against, firstname or lastname fields according to the indexes we created.
\nThis is why I kept varying the case used in our queries above. You could NOT have done does this with a traditional Cassandra query.
\nHow about normalize? Basically, this means that special characters, like vowels with diacritics can be represented by multiple binary representations for the same character, which also makes things easier to match.
\nAn example would be a row with a column value that contained the character Å (U+212B). With normalize enabled a query that used the character Å (U+00C5) would find that row. This saves from the need to find all unicode variations for a single character.
\nTo be clear, this is not Ascii folding where I might insert code that uses é and a select using e. This is coming as a future feature.
\nTo sum up, we queried against a combination of string and date fields using exact matches, multiple string cases, and date ranges. Just by adding an index on 3 fields we significantly expanded the flexibility of our data model.
\nLet's do more.
\n"},"11":4,"12":false,"17":1603822950491},"16":true,"17":true,"18":{},"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"856778a2-2aa7-4ca4-8a75-f6bb06a240ed","11":"SELECT * FROM clients WHERE lastname = 'Åskådare';","12":"cql","16":true,"17":false,"18":{},"22":174,"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"c8cdaa61-277f-4578-9176-e934f5af60ff","10":4,"11":"**✅ Step 2h. Add another index to support a new data model requirement**\n\nImagine a case where we now have a requirement to find clients based off of their next appointment. \n\nPrior to **SAI**, if I wanted to accomplish this same thing in Cassandra, I would set up a new table using the **date** as the **partition key**, and I'd probably have the **appointment** slots as a **clustering column**, along with the **`uniqueid`** rounding out the primary key. \n\nThen, I would retrieve the days partition to get a list of the appointments for the day. Now, I have **two tables** that I need to worry about to support that query. \n\nLet's see what this looks like with **SAI**.","12":"markdown","13":{"1":"8db61d47-aed5-48b3-b0b4-3fced5867416","10":{"9":"✅ Step 2h. Add another index to support a new data model requirement
\nImagine a case where we now have a requirement to find clients based off of their next appointment.
\nPrior to SAI, if I wanted to accomplish this same thing in Cassandra, I would set up a new table using the date as the partition key, and I'd probably have the appointment slots as a clustering column, along with the uniqueid rounding out the primary key.
\nThen, I would retrieve the days partition to get a list of the appointments for the day. Now, I have two tables that I need to worry about to support that query.
\nLet's see what this looks like with SAI.
\n"},"11":4,"12":false,"17":1603822933363},"16":true,"17":true,"18":{},"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"7dc3f325-90e8-4ba5-a8d7-b9b286bfc115","11":"CREATE CUSTOM INDEX IF NOT EXISTS ON clients(nextappt) USING 'StorageAttachedIndex';","12":"cql","16":true,"17":false,"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"32ed52ea-9c40-4458-82f7-6fd078fecaff","11":"SELECT * FROM clients WHERE nextappt > '2020-10-20 09:00:00';","12":"cql","16":true,"17":false,"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"eb58a8bc-6b45-49ae-b946-c74228bc73eb","10":4,"11":"## 3. IoT sensor data model use case\nTime to swtich gears to a real IoT data model use case. \n\nIn the following case, an organization recieved a feed of sensor data that always included all of the fields that the sensor kept track of, even if those fields hadn't changed since the last reading. \n\n**All of the data was sent whenever a single field changed values.**\n\nNow, this isn't necessarily something that has to be difficult to deal with, if all of the key fields are the same, **we can easily overwrite redundant data without doing a read-before-write** and all of that non-changing, redundant data will just compact away.\n\nBut, a **problem arises** if we need to **query** based on **something other than the primary key**.\n\nIf this table is instead organized to be physically efficient for querying, then I may not be able to easily upsert the data from the sensor without 1) creating a lot of unnecessary records, or 2) being forced to do a read-before-write to check if a record already exists. \n\nIn this case, the **user was stuck with option 1**, because **it was cheaper to store more data than it was to have the compute resources for all of that extra query power for the 20x read workload that was required just to check to see if a sensor reading was already in the database.**","12":"markdown","13":{"1":"42295dba-e28a-4b0a-9beb-41bab3ba97de","10":{"9":"3. IoT sensor data model use case
\nTime to swtich gears to a real IoT data model use case.
\nIn the following case, an organization recieved a feed of sensor data that always included all of the fields that the sensor kept track of, even if those fields hadn't changed since the last reading.
\nAll of the data was sent whenever a single field changed values.
\nNow, this isn't necessarily something that has to be difficult to deal with, if all of the key fields are the same, we can easily overwrite redundant data without doing a read-before-write and all of that non-changing, redundant data will just compact away.
\nBut, a problem arises if we need to query based on something other than the primary key.
\nIf this table is instead organized to be physically efficient for querying, then I may not be able to easily upsert the data from the sensor without 1) creating a lot of unnecessary records, or 2) being forced to do a read-before-write to check if a record already exists.
\nIn this case, the user was stuck with option 1, because it was cheaper to store more data than it was to have the compute resources for all of that extra query power for the 20x read workload that was required just to check to see if a sensor reading was already in the database.
\n"},"11":4,"12":false,"17":1603823220341},"16":true,"17":true,"18":{},"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"7e0faffa-220b-4ce5-afa5-de7466678439","10":4,"11":"**✅ Step 3a. Create our `sensordata` table**\n\n- This table will create a partition for every hour of every day for each location.\n- In this case, we have between 1,000 and 10,000 locations, and there are potentially dozens of devices per location.\n- The **`updated`** **STATIC** column will show the last time that the values in **`payload`** were updated that hour.\n- As hours go by, we will naturally create a snapshot of the last hour.\n- This might be undesirable if I didn't know that \n- I get at least one sensor payload per hour unless a device is offline.","12":"markdown","13":{"1":"5e224d72-368d-4e81-9ef0-7e217e5f4a9d","10":{"9":"✅ Step 3a. Create our sensordata table
\n\n- This table will create a partition for every hour of every day for each location.
\n- In this case, we have between 1,000 and 10,000 locations, and there are potentially dozens of devices per location.
\n- The
updated STATIC column will show the last time that the values in payload were updated that hour. \n- As hours go by, we will naturally create a snapshot of the last hour.
\n- This might be undesirable if I didn't know that
\n- I get at least one sensor payload per hour unless a device is offline.
\n
\n"},"11":4,"12":false,"17":1603823250652},"16":true,"17":true,"18":{},"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"5682fc01-c218-4af2-b7e6-b86a37521444","11":"CREATE TABLE sensordata (\n location text,\n dayhour timestamp,\n device_id text,\n device_name text,\n updated timestamp STATIC,\n payload map,\n PRIMARY KEY ((location, dayhour), device_id)\n) WITH CLUSTERING ORDER BY (device_id ASC);","12":"cql","16":true,"17":false,"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"4aa1353d-2bb9-480f-9c73-1d516ceebca5","10":4,"11":"**✅ Step 3b. Create indexes to address query needs outside of our primary key**\n\nOK, so this table organizes the data the way we want it to be space efficient, and it gets rid of redundant records by virtue of the physical organziation that it creates on disk. \n\nWe get the snapshot view that we want each hour, and if most of the values in “payload” don't change over the course an hour, then we avoid both having to do a read before write, and we avoid storing extra copies of that data. \n\nWhere does **SAI** come into the picture? Well, the trick is that queries against this data use the non-unique **`device_name`** field along with the **`dayhour`** that we're looking for, but we also sometimes need to query by the key in the **`payload`** map. \n\nBeing able to query with those inputs, and also organize the data as efficiently as we can is nearly impossible without **SAI**. \n\nLet's look at the indexes we need to make as well as load some sample data that we can query.","12":"markdown","13":{"1":"8b4f8826-84a8-47f4-b97a-c155c4cfa882","10":{"9":"✅ Step 3b. Create indexes to address query needs outside of our primary key
\nOK, so this table organizes the data the way we want it to be space efficient, and it gets rid of redundant records by virtue of the physical organziation that it creates on disk.
\nWe get the snapshot view that we want each hour, and if most of the values in “payload” don't change over the course an hour, then we avoid both having to do a read before write, and we avoid storing extra copies of that data.
\nWhere does SAI come into the picture? Well, the trick is that queries against this data use the non-unique device_name field along with the dayhour that we're looking for, but we also sometimes need to query by the key in the payload map.
\nBeing able to query with those inputs, and also organize the data as efficiently as we can is nearly impossible without SAI.
\nLet's look at the indexes we need to make as well as load some sample data that we can query.
\n"},"11":4,"12":false,"17":1603823279303},"16":true,"17":true,"18":{},"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"3c3ffa53-2151-4d52-bc8d-16a1b3f3c32c","11":"CREATE CUSTOM INDEX IF NOT EXISTS ON sensordata(device_name) USING 'StorageAttachedIndex'\nWITH OPTIONS = {'case_sensitive': false, 'normalize': true };\n\nCREATE CUSTOM INDEX IF NOT EXISTS ON sensordata(dayhour) USING 'StorageAttachedIndex';\n\nCREATE CUSTOM INDEX IF NOT EXISTS ON sensordata(keys(payload)) USING 'StorageAttachedIndex' \nWITH OPTIONS = {'case_sensitive': false, 'normalize': true };","12":"cql","16":true,"17":false,"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"615e9750-5fdb-4cd3-aba4-8b4d323d4374","10":4,"11":"_That last **CREATE CUSTOM INDEX** command uses the [keys()](https://docs.datastax.com/en/storage-attached-index/6.8/sai/saiUsing.html#SAIcollectionmapexampleswithkeys,values,andentries) function to index only the map keys in the **payload** map. That lets us **search for entries** with a **specific key name**, which in this case allows us to query for a particular sensor reading._ \n\nSo, now that we have our table structure, let's load some data and query it.","12":"markdown","13":{"1":"5d0288fb-2b39-463d-a1b0-061491b706fe","10":{"9":"That last CREATE CUSTOM INDEX command uses the keys() function to index only the map keys in the payload map. That lets us search for entries with a specific key name, which in this case allows us to query for a particular sensor reading.
\nSo, now that we have our table structure, let's load some data and query it.
\n"},"11":4,"12":false,"17":1603823303214},"16":true,"17":true,"18":{},"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"21ae9641-0c0a-4470-bf2b-69421bb120ad","10":4,"11":"**✅ Step 3c. Insert data**\n\n_Note that the UUIDs here are only increasing by one because it's an expedient thing to do when manually generating data, in the real world, don't do that._","12":"markdown","13":{"1":"8bc8c5c0-b637-4bc1-abe4-8ae29556e269","10":{"9":"✅ Step 3c. Insert data
\nNote that the UUIDs here are only increasing by one because it's an expedient thing to do when manually generating data, in the real world, don't do that.
\n"},"11":4,"12":false,"17":1603823320256},"16":true,"17":true,"18":{},"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"4cc64898-f017-4a5d-98bf-99c62f4a9931","11":"INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('ABC','2020-10-20 01:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB78','device1','2020-10-20 01:30:00',{'temp':'freezing!', 'humidity':'low'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('ABC','2020-10-20 01:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB79','device1','2020-10-20 01:31:00',{'temp':'freezing!', 'humidity':'low', 'mood':'hungry'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('ABC','2020-10-20 01:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB79','device1','2020-10-20 01:32:00',{'temp':'freezing!', 'humidity':'low', 'mood':'full'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('ABC','2020-10-20 02:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB80','device2','2020-10-20 02:30:00',{'speed':'stopped', 'color':'blue'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('ABC','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB81','device2','2020-10-20 03:30:00',{'speed':'slow', 'color':'blue'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('DEF','2020-10-20 00:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB82','dev1','2020-10-20 00:30:00',{'temp':'hot!', 'humidity':'sticky'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('DEF','2020-10-20 01:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB83','dev2','2020-10-20 01:30:00',{'temp':'warm', 'humidity':'muggy'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('DEF','2020-10-20 02:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB84','dev3','2020-10-20 02:30:00',{'temp':'freezing!', 'humidity':'my beard is growing icicles'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('GHI','2020-10-20 00:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB85','doohickey','2020-10-20 00:30:00',{'temp':'hot!', 'humidity':'dry', 'orientation':'rightside up'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('GHI','2020-10-20 01:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB86','doohickey','2020-10-20 01:30:00',{'temp':'hot!', 'humidity':'dry', 'orientation':'upside down'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('GHI','2020-10-20 02:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB87','doohickey','2020-10-20 02:30:00',{'temp':'hot!', 'humidity':'dry', 'orientation':'forwards'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('GHI','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB85','doohickey','2020-10-20 03:30:00',{'temp':'hot!', 'humidity':'dry', 'orientation':'backwards'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('ABC','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB78','device1','2020-10-20 03:31:00',{'temp':'freezing!', 'humidity':'low', 'mood':'hungry again'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('ABC','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB78','device1','2020-10-20 03:35:00',{'temp':'freezing!', 'humidity':'low', 'mood':'full'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('ABC','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB78','device1','2020-10-20 03:40:00',{'temp':'freezing!', 'humidity':'low', 'mood':'no, still peckish'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('DEF','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB93','dev4','2020-10-20 03:30:00',{'temp':'/tmp', 'speed':'low'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('DEF','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB93','dev4','2020-10-20 03:40:00',{'temp':'/var/lib/tmp', 'speed':'low', 'color':'green'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('DEF','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB94','dev5','2020-10-20 03:45:00',{'temp':'freezing!', 'humidity':'low', 'mood':'hungry'});\n\nINSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)\nVALUES('DEF','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB95','dev6','2020-10-20 03:50:00',{'temp':'freezing!', 'humidity':'low', 'mood':'hungry'});","12":"cql","16":true,"17":false,"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"7d20a29c-c6ec-446d-9e67-0876d5a7e5b4","10":4,"11":"_It is worth pointing out that doing an **INSERT** on a **Map** column like this will **always replace the full map**. In this case, I know that's OK for my use case because I always get a full input file that has all the sensor readings in it. Sometimes, this isn't what you want, and you'll need to use the **SET** keyword to **set a specific value in the map**._","12":"markdown","13":{"1":"a25e4966-9c66-47e8-9e7f-f42f1489cb53","10":{"9":"It is worth pointing out that doing an INSERT on a Map column like this will always replace the full map. In this case, I know that's OK for my use case because I always get a full input file that has all the sensor readings in it. Sometimes, this isn't what you want, and you'll need to use the SET keyword to set a specific value in the map.
\n"},"11":4,"12":false,"17":1603823415787},"16":true,"17":true,"18":{},"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"36df1f43-5ff5-4d9a-a697-ddf288e39288","10":4,"11":"**✅ Step 3d. Execute queries that use device_name, dayhour, and payload map keys using our indexes**","12":"markdown","13":{"1":"c96374ff-19c4-48d5-83bc-00ef86df35f5","10":{"9":"✅ Step 3d. Execute queries that use device_name, dayhour, and payload map keys using our indexes
\n"},"11":4,"12":false,"17":1603823429846},"16":true,"17":true,"18":{},"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"add13384-ad37-4079-800e-9ec419b22a8a","11":"// Now let's run some queries, again, highlight individual queries and hit the run button in the upper left of this cell to execute.\n\nSELECT * FROM sensordata \nWHERE device_name='doohickey';\n\nSELECT * FROM sensordata \nWHERE device_name = 'device1' \nAND dayhour = '2020-10-20 01:00:00';\n\nSELECT * FROM sensordata\nWHERE dayhour = '2020-10-20 01:00:00';\n\n// Exercise for the reader: can you perform a range query over the dayhour column? Why or why not?\n\nSELECT * FROM sensordata\nWHERE payload CONTAINS KEY 'speed';\n\nSELECT * FROM sensordata\nWHERE device_name = 'device1'\nAND payload CONTAINS KEY 'mood';","12":"cql","16":true,"17":false,"24":"sa_index","25":"LOCAL.QUORUM"},{"1":"f8ba2888-74ad-4b7c-9344-15cf96e04cc0","10":4,"11":"You should experiment with these queries and also try loading the above records one at a time to see what happens. If you need to clear out your table, run \"TRUNCATE sensordata\" from your keyspace in cqlsh. If you need help, or have questions, please don't hesitate to reach out to us. You can find help via [Astra](https://astra.datastax.com) using the chat widget in the lower right of the console.","12":"markdown","13":{"1":"3c617c7f-dc8b-4327-97e1-e047ac696ab2","10":{"9":"You should experiment with these queries and also try loading the above records one at a time to see what happens. If you need to clear out your table, run “TRUNCATE sensordata” from your keyspace in cqlsh. If you need help, or have questions, please don't hesitate to reach out to us. You can find help via Astra using the chat widget in the lower right of the console.
\n"},"11":4,"12":false,"17":1603823601376},"16":true,"17":true,"18":{},"24":"sa_index","25":"LOCAL.QUORUM"}],"16":{"1":{}},"17":"","19":false}����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������code.txt��������������������������������������������������������������������������������������������0100644 0000000 0000000 00000052312 13746302451 011270� 0����������������������������������������������������������������������������������������������������ustar�00����������������������������������������������������������������0000000 0000000 �����������������������������������������������������������������������������������������������������������������������������������������������������������������������--------------------NOTEBOOK_SAI Tutorial--------------------
2 | --------------------CELL_MARKDOWN_1--------------------
3 | This notebook is desinged to be used in conjunction with the Storage Attached Indexes Workshop GitHub Repo [HERE](https://github.com/DataStax-Academy/workshop-storage-attached-indexes).
4 |
5 | Please note **section 2** as you see it below is a continuation from content within the repo.
6 | --------------------CELL_MARKDOWN_2--------------------
7 | ##2. Getting Started with SAI
8 |
9 | **SAI** is short for **Storage Attached Indexes**, it allows us to build indexes on Cassandra tables that dramatically improve the flexibility of Cassandra queries.
10 |
11 | For a **non-technical introduction** to **SAI**, have a look at this [recent blog post](https://www.datastax.com/blog/get-your-head-clouds-part-1-3-build-cloud-native-apps-datastax-astra-dbaas-now-aws-gcp).
12 |
13 | To learn more about **SAI** from a **technical perspective**, have a look at our [docs on SAI](https://docs.datastax.com/en/storage-attached-index/6.8/sai/saiQuickStart.html). Honestly, these docs are pretty great IMO especially the [SAI FAQ](https://docs.datastax.com/en/storage-attached-index/6.8/sai/saiFaqs.html). Definitely take a moment to read through these to get a better understanding of how all of this works and even more examples on top of what we are presenting in this repo.
14 |
15 | Now, let's get into some examples. The first thing we'll need is a table and some data to work with. For that we need to talk about my dentist, or really, a contrived example of a client data model a dentist might need to use.
16 | --------------------CELL_MARKDOWN_3--------------------
17 | **✅ Step 2c. Create a _`clients`_ table and insert some data**
18 |
19 | Create the table.
20 | --------------------CELL_CQL_4--------------------
21 | CREATE TABLE IF NOT EXISTS clients (
22 | uniqueid uuid primary key,
23 | firstname text,
24 | lastname text,
25 | birthday date,
26 | nextappt timestamp,
27 | newpatient boolean,
28 | photo text
29 | );
30 | --------------------CELL_MARKDOWN_5--------------------
31 | Insert some data into the table.
32 |
33 | _We don't have real image URLs, so we're just using a placeholder string._
34 | --------------------CELL_CQL_6--------------------
35 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
36 | VALUES (D85745B1-4BEC-43D7-8B77-DD164CB9D1B8, 'Alice', 'Apple', '1984-01-24', '2020-10-20 12:00:00', true, 'imageurl');
37 |
38 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
39 | VALUES (2A4F139F-0BBF-4A6F-B982-5400F11D2F2B, 'Zeke', 'Apple', '1961-12-30', '2020-10-20 12:30:00', false, 'imageurl');
40 |
41 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
42 | VALUES (DF649261-89CB-446B-9998-FFA2D17506F9, 'Lorenzo', 'Banana', '1963-09-03', '2020-10-20 13:00:00', false, 'imageurl');
43 |
44 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
45 | VALUES (808E6BBF-A0F4-4E4C-9C97-E36751D51A8B, 'Miley', 'Banana', '1969-02-06', '2020-10-20 13:30:00', false, 'imageurl');
46 |
47 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
48 | VALUES (3D458A4D-2F54-4271-BEDC-1FC316B3CC96, 'Cheryl', 'Banana', '1970-07-11', '2020-10-20 14:00:00', false, 'imageurl');
49 |
50 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
51 | VALUES (287AB6B4-1AA6-45DF-B6F8-2BE253B9AACE, 'Red', 'Currant', '1974-02-18', '2020-10-20 15:00:00', false, 'imageurl');
52 |
53 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
54 | VALUES (AB49D151-CC04-40DC-AEEA-0A4E5F59D69A, 'Matthew', 'Durian', '1976-11-11', '2020-10-19 12:30:00', false, 'imageurl');
55 |
56 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
57 | VALUES (783CE790-16B4-4645-B27C-4FDF3994A755, 'Vanessa', 'Elderberry', '1977-12-03', '2020-10-20 15:30:00', false, 'imageurl');
58 |
59 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
60 | VALUES (D23997E4-CCCB-46BB-B92F-0D4582A68809, 'Elaine', 'Elderberry', '1979-11-16', '2020-10-20 10:00:00', true, 'imageurl');
61 |
62 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
63 | VALUES (36C386C1-3C3B-49FC-81B1-391D5537453D, 'Phoebe', 'Fig', '1986-01-27', '2020-10-21 11:00:00', false, 'imageurl');
64 |
65 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
66 | VALUES (00FEE7EE-8F93-4C2E-A8BE-3ADD81235822, 'Patricia', 'Grape', '1986-06-24', '2020-10-21 12:00:00', false, 'imageurl');
67 |
68 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
69 | VALUES (B9DB7E99-AD1C-49B1-97C6-87154663AEF4, 'Herb', 'Huckleberry', '1990-07-09', '2020-10-21 13:00:00', false, 'imageurl');
70 |
71 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
72 | VALUES (F4DB7673-CA4E-4382-BDCD-2C1704363590, 'John-Henry', 'Huckleberry', '1979-11-16', '2020-10-21 14:00:00', false, 'imageurl');
73 |
74 | INSERT INTO clients (uniqueid, firstname, lastname, birthday, nextappt, newpatient, photo)
75 | VALUES (F4DB7673-CA4E-4382-BDCD-2C1704363595, 'Sven', 'Åskådare', '1967-11-07', '2020-10-21 14:00:00', false, 'imageurl');
76 | --------------------CELL_MARKDOWN_7--------------------
77 | **✅ Step 2d. Verify data exists**
78 |
79 | Now let's take a look at the data we just inserted.
80 | --------------------CELL_CQL_8--------------------
81 | // Now let's take a look at the data we just inserted.
82 | select * from clients;
83 | --------------------CELL_MARKDOWN_9--------------------
84 | **✅ Step 2e. Create some indexes**
85 |
86 | Ok great, we have data in our table, but remember we used **_`uniqueid`_** as our **primary key** when we created the table. If we want to query a single patient, we'd have to do that by the **_`uniqueid`_** column because that's our **partition key** _(don't forget, a single value in the primary key is always the partition key)_.
87 |
88 | As a matter of fact, let's try an example. Let's say I want to find a user by their lastname.
89 | --------------------CELL_CQL_10--------------------
90 | CREATE CUSTOM INDEX IF NOT EXISTS ON clients(firstname) USING 'StorageAttachedIndex'
91 | WITH OPTIONS = {'case_sensitive': false, 'normalize': true };
92 |
93 | CREATE CUSTOM INDEX IF NOT EXISTS ON clients(lastname) USING 'StorageAttachedIndex'
94 | WITH OPTIONS = {'case_sensitive': false, 'normalize': true };
95 |
96 | CREATE CUSTOM INDEX IF NOT EXISTS ON clients(birthday) USING 'StorageAttachedIndex';
97 |
98 | --------------------CELL_MARKDOWN_11--------------------
99 | **✅ Step 2f. Execute queries that use firstname, lastname, and birthday using our indexes**
100 |
101 | Remember, the **`clients`** table data model only includes **`uniqueid`** in the primary key. In the traditional Cassandra sense I can only query against the **`uniqueid`** column in the **WHERE** clause. However, with our **SAIndexes** now added we can do a lot more.
102 | --------------------CELL_CQL_12--------------------
103 | //To execute any of these, highlight the query and then hit the run button in the upper left
104 |
105 | // Look for a client by ONLY their lastname. Notice the case used.
106 | SELECT * FROM clients WHERE lastname = 'Apple';
107 |
108 | // Look for a client by their lastname and firstname. Notice the case used.
109 | SELECT * FROM clients WHERE lastname = 'apple' AND firstname = 'alice';
110 |
111 | // Look for a client by an exact match to their birthday.
112 | SELECT * FROM clients WHERE birthday = '1984-01-24';
113 |
114 | // Look for a client by a range match for the year of their birthday.
115 | SELECT * FROM clients WHERE birthday > '1984-01-01' AND birthday < '1985-01-01';
116 |
117 | // Look for a client by their firstname
118 | // and a range match for the year of their birthday. Again, notice the case used.
119 | SELECT * FROM clients
120 | WHERE firstname = 'aLicE'
121 | AND birthday > '1984-01-01' AND birthday < '1985-01-01';
122 | --------------------CELL_MARKDOWN_13--------------------
123 | **✅ Step 2g. Digest everything we just did there**
124 |
125 | Ok, so let's break that all down. I said earlier when we created the indexes I would explain the options included with some of the indexes.
126 | ```SQL
127 | WITH OPTIONS = {'case_sensitive': false, 'normalize': true };
128 | ```
129 | So what does the **“WITH OPTIONS”** part mean?
130 |
131 | Well, [case_sensitive](https://docs.datastax.com/en/dse/6.8/cql/cql/cql_reference/cql_commands/cqlCreateCustomIndex.html#cqlCreateCustomIndex__cqlCreateCustomIndexOptions) is fairly straightforward. Setting this **false** allows us to match any combination of case for the terms we are querying against, **firstname** or **lastname** fields according to the indexes we created.
132 |
133 | This is why I kept varying the case used in our queries above. You could **NOT** have done does this with a traditional Cassandra query.
134 |
135 | How about [normalize](https://docs.datastax.com/en/dse/6.8/cql/cql/cql_reference/cql_commands/cqlCreateCustomIndex.html#cqlCreateCustomIndex__cqlCreateCustomIndexOptions)? Basically, this means that special characters, like vowels with diacritics can be represented by multiple binary representations for the same character, which also makes things easier to match.
136 |
137 | An example would be a row with a column value that contained the character `Å (U+212B)`. With **normalize** enabled a query that used the character `Å (U+00C5)` would find that row. This saves from the need to find all unicode variations for a single character.
138 |
139 | _To be clear, this is not Ascii folding where I might insert code that uses `é` and a select using `e`. This is coming as a future feature._
140 |
141 | To sum up, we queried against a combination of string and date fields using exact matches, multiple string cases, and date ranges. Just by adding an index on 3 fields we significantly expanded the flexibility of our data model.
142 |
143 | Let's do more.
144 | --------------------CELL_CQL_14--------------------
145 | SELECT * FROM clients WHERE lastname = 'Åskådare';
146 | --------------------CELL_MARKDOWN_15--------------------
147 | **✅ Step 2h. Add another index to support a new data model requirement**
148 |
149 | Imagine a case where we now have a requirement to find clients based off of their next appointment.
150 |
151 | Prior to **SAI**, if I wanted to accomplish this same thing in Cassandra, I would set up a new table using the **date** as the **partition key**, and I'd probably have the **appointment** slots as a **clustering column**, along with the **`uniqueid`** rounding out the primary key.
152 |
153 | Then, I would retrieve the days partition to get a list of the appointments for the day. Now, I have **two tables** that I need to worry about to support that query.
154 |
155 | Let's see what this looks like with **SAI**.
156 | --------------------CELL_CQL_16--------------------
157 | CREATE CUSTOM INDEX IF NOT EXISTS ON clients(nextappt) USING 'StorageAttachedIndex';
158 | --------------------CELL_CQL_17--------------------
159 | SELECT * FROM clients WHERE nextappt > '2020-10-20 09:00:00';
160 | --------------------CELL_MARKDOWN_18--------------------
161 | ## 3. IoT sensor data model use case
162 | Time to swtich gears to a real IoT data model use case.
163 |
164 | In the following case, an organization recieved a feed of sensor data that always included all of the fields that the sensor kept track of, even if those fields hadn't changed since the last reading.
165 |
166 | **All of the data was sent whenever a single field changed values.**
167 |
168 | Now, this isn't necessarily something that has to be difficult to deal with, if all of the key fields are the same, **we can easily overwrite redundant data without doing a read-before-write** and all of that non-changing, redundant data will just compact away.
169 |
170 | But, a **problem arises** if we need to **query** based on **something other than the primary key**.
171 |
172 | If this table is instead organized to be physically efficient for querying, then I may not be able to easily upsert the data from the sensor without 1) creating a lot of unnecessary records, or 2) being forced to do a read-before-write to check if a record already exists.
173 |
174 | In this case, the **user was stuck with option 1**, because **it was cheaper to store more data than it was to have the compute resources for all of that extra query power for the 20x read workload that was required just to check to see if a sensor reading was already in the database.**
175 | --------------------CELL_MARKDOWN_19--------------------
176 | **✅ Step 3a. Create our `sensordata` table**
177 |
178 | - This table will create a partition for every hour of every day for each location.
179 | - In this case, we have between 1,000 and 10,000 locations, and there are potentially dozens of devices per location.
180 | - The **`updated`** **STATIC** column will show the last time that the values in **`payload`** were updated that hour.
181 | - As hours go by, we will naturally create a snapshot of the last hour.
182 | - This might be undesirable if I didn't know that
183 | - I get at least one sensor payload per hour unless a device is offline.
184 | --------------------CELL_CQL_20--------------------
185 | CREATE TABLE sensordata (
186 | location text,
187 | dayhour timestamp,
188 | device_id text,
189 | device_name text,
190 | updated timestamp STATIC,
191 | payload map,
192 | PRIMARY KEY ((location, dayhour), device_id)
193 | ) WITH CLUSTERING ORDER BY (device_id ASC);
194 | --------------------CELL_MARKDOWN_21--------------------
195 | **✅ Step 3b. Create indexes to address query needs outside of our primary key**
196 |
197 | OK, so this table organizes the data the way we want it to be space efficient, and it gets rid of redundant records by virtue of the physical organziation that it creates on disk.
198 |
199 | We get the snapshot view that we want each hour, and if most of the values in “payload” don't change over the course an hour, then we avoid both having to do a read before write, and we avoid storing extra copies of that data.
200 |
201 | Where does **SAI** come into the picture? Well, the trick is that queries against this data use the non-unique **`device_name`** field along with the **`dayhour`** that we're looking for, but we also sometimes need to query by the key in the **`payload`** map.
202 |
203 | Being able to query with those inputs, and also organize the data as efficiently as we can is nearly impossible without **SAI**.
204 |
205 | Let's look at the indexes we need to make as well as load some sample data that we can query.
206 | --------------------CELL_CQL_22--------------------
207 | CREATE CUSTOM INDEX IF NOT EXISTS ON sensordata(device_name) USING 'StorageAttachedIndex'
208 | WITH OPTIONS = {'case_sensitive': false, 'normalize': true };
209 |
210 | CREATE CUSTOM INDEX IF NOT EXISTS ON sensordata(dayhour) USING 'StorageAttachedIndex';
211 |
212 | CREATE CUSTOM INDEX IF NOT EXISTS ON sensordata(keys(payload)) USING 'StorageAttachedIndex'
213 | WITH OPTIONS = {'case_sensitive': false, 'normalize': true };
214 | --------------------CELL_MARKDOWN_23--------------------
215 | _That last **CREATE CUSTOM INDEX** command uses the [keys()](https://docs.datastax.com/en/storage-attached-index/6.8/sai/saiUsing.html#SAIcollectionmapexampleswithkeys,values,andentries) function to index only the map keys in the **payload** map. That lets us **search for entries** with a **specific key name**, which in this case allows us to query for a particular sensor reading._
216 |
217 | So, now that we have our table structure, let's load some data and query it.
218 | --------------------CELL_MARKDOWN_24--------------------
219 | **✅ Step 3c. Insert data**
220 |
221 | _Note that the UUIDs here are only increasing by one because it's an expedient thing to do when manually generating data, in the real world, don't do that._
222 | --------------------CELL_CQL_25--------------------
223 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
224 | VALUES('ABC','2020-10-20 01:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB78','device1','2020-10-20 01:30:00',{'temp':'freezing!', 'humidity':'low'});
225 |
226 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
227 | VALUES('ABC','2020-10-20 01:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB79','device1','2020-10-20 01:31:00',{'temp':'freezing!', 'humidity':'low', 'mood':'hungry'});
228 |
229 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
230 | VALUES('ABC','2020-10-20 01:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB79','device1','2020-10-20 01:32:00',{'temp':'freezing!', 'humidity':'low', 'mood':'full'});
231 |
232 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
233 | VALUES('ABC','2020-10-20 02:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB80','device2','2020-10-20 02:30:00',{'speed':'stopped', 'color':'blue'});
234 |
235 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
236 | VALUES('ABC','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB81','device2','2020-10-20 03:30:00',{'speed':'slow', 'color':'blue'});
237 |
238 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
239 | VALUES('DEF','2020-10-20 00:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB82','dev1','2020-10-20 00:30:00',{'temp':'hot!', 'humidity':'sticky'});
240 |
241 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
242 | VALUES('DEF','2020-10-20 01:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB83','dev2','2020-10-20 01:30:00',{'temp':'warm', 'humidity':'muggy'});
243 |
244 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
245 | VALUES('DEF','2020-10-20 02:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB84','dev3','2020-10-20 02:30:00',{'temp':'freezing!', 'humidity':'my beard is growing icicles'});
246 |
247 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
248 | VALUES('GHI','2020-10-20 00:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB85','doohickey','2020-10-20 00:30:00',{'temp':'hot!', 'humidity':'dry', 'orientation':'rightside up'});
249 |
250 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
251 | VALUES('GHI','2020-10-20 01:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB86','doohickey','2020-10-20 01:30:00',{'temp':'hot!', 'humidity':'dry', 'orientation':'upside down'});
252 |
253 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
254 | VALUES('GHI','2020-10-20 02:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB87','doohickey','2020-10-20 02:30:00',{'temp':'hot!', 'humidity':'dry', 'orientation':'forwards'});
255 |
256 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
257 | VALUES('GHI','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB85','doohickey','2020-10-20 03:30:00',{'temp':'hot!', 'humidity':'dry', 'orientation':'backwards'});
258 |
259 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
260 | VALUES('ABC','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB78','device1','2020-10-20 03:31:00',{'temp':'freezing!', 'humidity':'low', 'mood':'hungry again'});
261 |
262 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
263 | VALUES('ABC','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB78','device1','2020-10-20 03:35:00',{'temp':'freezing!', 'humidity':'low', 'mood':'full'});
264 |
265 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
266 | VALUES('ABC','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB78','device1','2020-10-20 03:40:00',{'temp':'freezing!', 'humidity':'low', 'mood':'no, still peckish'});
267 |
268 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
269 | VALUES('DEF','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB93','dev4','2020-10-20 03:30:00',{'temp':'/tmp', 'speed':'low'});
270 |
271 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
272 | VALUES('DEF','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB93','dev4','2020-10-20 03:40:00',{'temp':'/var/lib/tmp', 'speed':'low', 'color':'green'});
273 |
274 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
275 | VALUES('DEF','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB94','dev5','2020-10-20 03:45:00',{'temp':'freezing!', 'humidity':'low', 'mood':'hungry'});
276 |
277 | INSERT INTO sensordata(location, dayhour, device_id, device_name, updated, payload)
278 | VALUES('DEF','2020-10-20 03:00:00','87C5EFE5-1849-4C0B-BBCD-F4FB84F6FB95','dev6','2020-10-20 03:50:00',{'temp':'freezing!', 'humidity':'low', 'mood':'hungry'});
279 | --------------------CELL_MARKDOWN_26--------------------
280 | _It is worth pointing out that doing an **INSERT** on a **Map** column like this will **always replace the full map**. In this case, I know that's OK for my use case because I always get a full input file that has all the sensor readings in it. Sometimes, this isn't what you want, and you'll need to use the **SET** keyword to **set a specific value in the map**._
281 | --------------------CELL_MARKDOWN_27--------------------
282 | **✅ Step 3d. Execute queries that use device_name, dayhour, and payload map keys using our indexes**
283 | --------------------CELL_CQL_28--------------------
284 | // Now let's run some queries, again, highlight individual queries and hit the run button in the upper left of this cell to execute.
285 |
286 | SELECT * FROM sensordata
287 | WHERE device_name='doohickey';
288 |
289 | SELECT * FROM sensordata
290 | WHERE device_name = 'device1'
291 | AND dayhour = '2020-10-20 01:00:00';
292 |
293 | SELECT * FROM sensordata
294 | WHERE dayhour = '2020-10-20 01:00:00';
295 |
296 | // Exercise for the reader: can you perform a range query over the dayhour column? Why or why not?
297 |
298 | SELECT * FROM sensordata
299 | WHERE payload CONTAINS KEY 'speed';
300 |
301 | SELECT * FROM sensordata
302 | WHERE device_name = 'device1'
303 | AND payload CONTAINS KEY 'mood';
304 | --------------------CELL_MARKDOWN_29--------------------
305 | You should experiment with these queries and also try loading the above records one at a time to see what happens. If you need to clear out your table, run "TRUNCATE sensordata" from your keyspace in cqlsh. If you need help, or have questions, please don't hesitate to reach out to us. You can find help via [Astra](https://astra.datastax.com) using the chat widget in the lower right of the console.
306 | ����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������versions-info.txt�����������������������������������������������������������������������������������0100644 0000000 0000000 00000000036 13746302451 013153� 0����������������������������������������������������������������������������������������������������ustar�00����������������������������������������������������������������0000000 0000000 �����������������������������������������������������������������������������������������������������������������������������������������������������������������������Studio Version: 6.8.2-f4ee64a
307 | ����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
--------------------------------------------------------------------------------
/astra.json:
--------------------------------------------------------------------------------
1 | {
2 | "name": "Scalable Indexing for Cassandra using DataStax Astra",
3 | "description": "Welcome to the 'Scalable Indexing for Cassandra using DataStax Astra' workshop! In this two-hour workshop, the Developer Advocate team of DataStax will explain the new Storage Attached Indexing (SAI) feature using Astra, the cloud based Cassandra-as-a-Service platform delivered by DataStax, to demonstrate how you can use them to add some much wanted flexibility to your Cassandra data model by querying outside of primary key fields.",
4 | "duration": "50 minutes",
5 | "skillLevel": "Advanced",
6 | "language":["CQL"],
7 | "stack":["cassandra"],
8 | "githubUrl": "https://github.com/datastaxdevs/workshop-storage-attached-indexes",
9 | "badge": "https://media.badgr.com/uploads/badges/2d92d254-5275-4e39-b59a-23d70b101f0c.png",
10 | "youTubeUrl": [ "https://www.youtube.com/watch?v=GLJc1Uz9dqw"],
11 | "tags": [
12 | { "name": "workshop" },
13 | { "name":"cassandra" },
14 | { "name":"search" },
15 | { "name":"sai" }
16 | ],
17 | "category": "workshop",
18 | "usecases": ["search"]
19 | }
20 |
--------------------------------------------------------------------------------
/slides/Presentation.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datastaxdevs/workshop-storage-attached-indexes/8b52374335ec23887a909822c5ec89631a91a3f2/slides/Presentation.pdf
--------------------------------------------------------------------------------