 13 |
14 | Bengio发现,我们可以使用映射层的权值作为词向量表征。但是,由于参数空间非常庞大,NNLM模型的训练速度非常慢,在百万级的数据集上需要耗时数周才能得到相对不错的结果,而在千万级甚至更大的数据集上,几乎无法得到结果。
15 |
16 | Mikolov发现,NNLM模型可以被拆分成两个步骤:
17 |
18 | - 用一个简单的模型训练出一个连续的词向量(映射层)
19 | - 基于词向量表征,训练出一个N-Gram神经网络模型(隐含层+输出层)
20 |
21 | 而模型的计算瓶颈主要在第二步,特别是输出层的Sigmoid归一化部分。如果我们只是想得到词向量,可以对第二步的神经网络模型进行简化,从而提高模型的训练效率。因此,Mikolov对NNLM模型进行了以下几个部分的修改:
22 |
23 | - 舍弃了隐含层。
24 | - NNLM在利用上文词预测目标词时,对上文词的词向量进行了拼接,Word2Vec模型对其直接进行了求和,从而降低了隐含元的维度。
25 | - NNLM在进行Sigmoid归一化时需要遍历整个词汇表,Word2Vec模型提出了Hierarchical Softmax与Negative Sampling两种策略进行优化。
26 | - 依据分布式假设(上下文环境相似的两个词有着相近的语义),将下文单词也纳入训练环境,并提出了两种训练策略,一种是用上下文预测中心词,称为CBOW,另一种是用中心词预测上下文,称为Skip-Gram。
27 |
28 |
13 |
14 | Bengio发现,我们可以使用映射层的权值作为词向量表征。但是,由于参数空间非常庞大,NNLM模型的训练速度非常慢,在百万级的数据集上需要耗时数周才能得到相对不错的结果,而在千万级甚至更大的数据集上,几乎无法得到结果。
15 |
16 | Mikolov发现,NNLM模型可以被拆分成两个步骤:
17 |
18 | - 用一个简单的模型训练出一个连续的词向量(映射层)
19 | - 基于词向量表征,训练出一个N-Gram神经网络模型(隐含层+输出层)
20 |
21 | 而模型的计算瓶颈主要在第二步,特别是输出层的Sigmoid归一化部分。如果我们只是想得到词向量,可以对第二步的神经网络模型进行简化,从而提高模型的训练效率。因此,Mikolov对NNLM模型进行了以下几个部分的修改:
22 |
23 | - 舍弃了隐含层。
24 | - NNLM在利用上文词预测目标词时,对上文词的词向量进行了拼接,Word2Vec模型对其直接进行了求和,从而降低了隐含元的维度。
25 | - NNLM在进行Sigmoid归一化时需要遍历整个词汇表,Word2Vec模型提出了Hierarchical Softmax与Negative Sampling两种策略进行优化。
26 | - 依据分布式假设(上下文环境相似的两个词有着相近的语义),将下文单词也纳入训练环境,并提出了两种训练策略,一种是用上下文预测中心词,称为CBOW,另一种是用中心词预测上下文,称为Skip-Gram。
27 |
28 |  29 |
30 | ## 1.2 CBOW模型
31 |
32 | 假设我们的语料是**"NLP is so interesting and challenging"**。循环使用每个词作为中心词,来其上下文词来预测中心词。我们通常使用一个指定长度的窗口,根据马尔可夫性质,忽略窗口以外的单词。
33 |
34 | | 中心词 | 上下文 |
35 | | :---------: | :--------------------------: |
36 | | NLP | is, so |
37 | | is | NLP, so, interesting |
38 | | so | NLP, is, interesting, and |
39 | | interesting | is, so, and, challenging |
40 | | and | so, interesting, challenging |
41 | | challenging | interesting, and |
42 |
43 | 我们的目标是通过上下文来预测中心词,也就是给定上下文词,出现该中心词的概率最大。这和完形填空颇有点异曲同工之妙。也即$\max P(\text{NLP|is, so})*P(\text{is|NLP, so, interesting})*\dots$
44 |
45 | 用公式表示如下:
46 | $$
47 | \begin{align}
48 | \max\limits_{\theta} L(\theta)&=\prod\limits_{w\in D}p(w|C(w)) \\
49 | &=\sum\limits_{w \in D}\log p(w|C(w))
50 | \end{align}
51 | $$
52 |
53 | 其中$w$指中心词,$C(w)$指上下文词集,$D$指语料库,也即所有中心词的词集。
54 |
55 | 问题的核心变成了如何构造$\log p(w|C(w))$。我们知道,NNLM模型的瓶颈在Sigmoid归一化上,Mikolov提出了两种改进思路来绕过Sigmoid归一化这一操作。一种思想是将输出改为一个霍夫曼树,每一个单词的概率用其路径上的权重乘积来表示,从而减少高频词的搜索时间;另一种思想是将预测每一个单词的概率,概率最高的单词是中心词改为预测该单词是不是正样本,通过负采样减少负样本数量,从而减少训练时间。
56 |
57 | ### 1.2.1 Hierarchical Softmax
58 |
59 | ### 1.2.2 Negative Sampling
60 |
61 | 基于Hierachical Softmax的模型使用Huffman树代替了传统的线性神经网络,可以提高模型训练的效率。但是,如果训练样本的中心词是一个很生僻的词,那么在Huffman树中仍旧需要进行很复杂的搜索。负采样方法的核心思想是:设计一个分类器, 对于我们需要预测的样本,设为正样本;而对于不是我们需要的样本,设置成负样本。在CBOW模型中,我们需要预测中心词$w$,因此正样本只有$w$,也即$\text{Pos}(w)=\{w\}$,而负样本为除了$w$之外的所有词。对负样本进行**随机采样**,得到$\text{Neg}(w)$,大大简化了模型的计算。
62 |
63 | 我们首先将$C(w)$输入映射层并求和得到隐含表征$h_w=\sum\limits_{u \in C(w)}\vec v(u)$
64 |
65 | 从而,
66 | $$
67 | \begin{align}
68 | p(u|C(w))&=
69 | \begin{cases}
70 | \sigma(h_w^T\theta_u), &\mathcal{D}(w,u)=1 \\
71 | 1-\sigma(h_w^T\theta_u), &\mathcal{D}(w,u)=0 \\
72 | \end{cases}\\
73 | &=[\sigma(h_w^T\theta_u)]^{\mathcal{D}(w,u)} \cdot [1-\sigma(h_w^T\theta_u)]^{1-\mathcal{D}(w,u)}
74 | \end{align}
75 | $$
76 |
77 | 从而,
78 | $$
79 | \begin{align}
80 | \max\limits_{\theta} L(\theta)&=\sum\limits_{w \in D}\log p(w|C(w))\\
81 | &=\sum\limits_{w \in D}\log \prod\limits_{u \in D}p(u|C(w)) \\
82 | &\approx\sum\limits_{w \in D}\log \prod\limits_{u \in \text{Pos(w)}\cup \text{Neg(w)} }p(u|C(w))\\
83 | &=\sum\limits_{w \in D}\log\prod\limits_{u \in \text{Pos(w)}\cup \text{Neg(w)}}[\sigma(h_w^T\theta_u)]^{\mathcal{D}(w,u)} \cdot [1-\sigma(h_w^T\theta_u)]^{1-\mathcal{D}(w,u)} \\
84 | &=\sum\limits_{w \in D}\sum\limits_{u \in \text{Pos}(w)\cup \text{Neg}(w)}\mathcal{D}(w,u)\cdot\log \sigma(h_w^T\theta_u)+[1-\mathcal{D}(w,u)]\cdot \log [1-\sigma(h_w^T\theta_u)]\\
85 | &=\sum\limits_{w \in D}\left\{\sum\limits_{u \in \text{Pos}(w)}\log \sigma(h_w^T\theta_u)+\sum\limits_{u \in \text{Neg}(w)}\log [1-\sigma(h_w^T\theta_u)]\right\}
86 | \end{align}
87 | $$
88 |
89 | 由于上式是一个最大化问题,因此使用随机梯度上升法对问题进行求解。
90 |
91 | 令$L(w,u,\theta)=\mathcal{D}(w,u)\cdot\log \sigma(h_w^T\theta_u)+[1-\mathcal{D}(w,u)]\cdot \log [1-\sigma(h_w^T\theta_u)]$
92 |
93 | 则$\frac{\partial L}{\partial\theta_u}=\mathcal{D}(w,u)\cdot[1-\sigma(h_w^T\theta_u)]h_w+[1-\mathcal{D}(w,u)]\cdot \sigma(h_w^T\theta_u)h_w=[\mathcal{D}(w,u)-\sigma(h_w^T\theta_u)]h_w$
94 |
95 | 因此$\theta_u$的更新公式为:$\theta_u:=\theta_u+\eta[\mathcal{D}(w,u)-\sigma(h_w^T\theta_u)]h_w$
96 |
97 | 同样地,$\frac{\partial L}{\partial h_w}=[\mathcal{D}(w,u)-\sigma(h_w^T\theta_u)]\theta_u$
98 |
99 | 上下文词的更新公式为:$v(\tilde{w}):=v(\tilde{w})+\eta\sum\limits_{u \in \text{Pos}(w)\cup \text{Neg}(w)}[\mathcal{D}(w,u)-\sigma(h_w^T\theta_u)]\theta_u$
100 |
101 | ## 1.3 Skip-Gram模型
102 |
103 | 仍旧使用上文的语料库**"NLP is so interesting and challenging"**,这次,我们的目标是通过中心词来预测上下文,也就是给定中心词,出现这些上下文词的概率最大。也即$\max P(is|NLP)*P(so|NLP)*P(NLP|is)*P(so|is)*P(interesting|is)*\dots$
104 |
105 | 用公式表示如下:
106 | $$
107 | \begin{align}
108 | \max\limits_{\theta} L(\theta)&=\prod\limits_{w\in D}\prod\limits_{c \in C(w)}p(c|w) \\
109 | &=\sum\limits_{w \in D}\sum\limits_{c \in C(w)}\log p(c|w)
110 | \end{align}
111 | $$
112 |
113 | ### 1.3.1 Hierarchical Softmax
114 |
115 | ### 1.3.2 Negative Sampling
116 |
117 | # 2 常见面试问题
118 |
119 | **Q1:介绍一下Word2Vec模型。**
120 |
121 | > A:两个模型:CBOW/Skip-Gram
122 | >
123 | > 两种加速方案:Hierarchical Softmax/Negative Sampling
124 |
125 | **Q2:Word2Vec模型为什么要定义两套词向量?**
126 |
127 | > A:因为每个单词承担了两个角色:中心词和上下文词。通过定义两套词向量,可以将两种角色分开。cs224n中提到是为了更方便地求梯度。参考见:https://www.zhihu.com/answer/706466139
128 |
129 | **Q3:Hierarchial Softmax 和 Negative Sampling对比**
130 |
131 | > A:基于Huffman树的Hierarchial Softmax 虽然在一定程度上能够提升模型运算效率,但是,如果中心词是生僻词,那么在Huffman树中仍旧需要进行很复杂的搜索$(O(\log N))$。而Negative Sampling通过随机负采样来提升运算效率,其复杂度和设定的负样本数$K$线性相关$(O(K))$,当$K$取较小的常数时,负采样在每⼀步的梯度计算开销都较小。
132 |
133 | **Q4:HS为什么用霍夫曼树而不用其他二叉树?**
134 |
135 | > 这是因为Huffman树对于高频词会赋予更短的编码,使得高频词离根节点距离更近,从而使得训练速度加快。
136 |
137 | **Q5:Word2Vec模型为什么要进行负采样?**
138 |
139 | > A:因为负样本的数量很庞大,是$O(|V^2|)$。
140 |
141 | **Q6:负采样为什么要用词频来做采样概率?**
142 |
143 | > 为这样可以让频率高的词先学习,然后带动其他词的学习。
144 |
145 | **Q7:One-hot模型与Word2Vec模型比较?**
146 |
147 | > A:One-hot模型的缺点
148 | >
149 | > - 稀疏 Sparsity
150 | > - 只能表示维度数量的单词 Capacity
151 | > - 无法表示单词的语义 Meaning
152 |
153 | **Q8:Word2Vec模型在NNLM模型上做了哪些改进?**
154 |
155 | > A:相同点:其本质都可以看作是语言模型;
156 | >
157 | > 不同点:词向量只不过 NNLM 一个产物,Word2vec 虽然其本质也是语言模型,但是其专注于词向量本身,因此做了许多优化来提高计算效率:
158 | >
159 | > - 与 NNLM 相比,词向量直接 sum,不再拼接,并舍弃隐层;
160 | >
161 | > - 考虑到 sofmax 归一化需要遍历整个词汇表,采用 hierarchical softmax 和 negative sampling 进行优化,hierarchical softmax 实质上生成一颗带权路径最小的哈夫曼树,让高频词搜索路劲变小;negative sampling 更为直接,实质上对每一个样本中每一个词都进行负例采样;
162 |
163 | **Q9:Word2Vec与LSA对比?**
164 |
165 | > A:LSA是基于共现矩阵构建词向量,本质上是基于全局语料进行SVD矩阵分解,计算效率低;
166 | >
167 | > 而Word2Vec是基于上下文局部语料计算共现概率,计算效率高。
168 |
169 | **Q10:Word2Vec的缺点?**
170 |
171 | > 忽略了词语的语序;
172 | >
173 | > 没有考虑一词多义现象
174 |
175 | **Q11:怎么从语言模型理解词向量?怎么理解分布式假设?**
176 |
177 | > 词向量是语言模型的一个副产物,可以理解为,在语言模型训练的过程中,势必在一定程度上理解了每个单词的含义。而这在计算机的表示下就是词向量。
178 | >
179 | > 分布式假设指的是相同上下文语境的词有似含义。
180 |
181 | **参考资料**
182 |
183 | word2vec 中的数学原理详解 https://blog.csdn.net/itplus/article/details/37969519
184 |
185 | Word2Vec原理介绍 https://www.cnblogs.com/pinard/p/7160330.html
186 |
187 | 词向量介绍 https://www.cnblogs.com/sandwichnlp/p/11596848.html
188 |
189 | 一些关于词向量的问题 https://zhuanlan.zhihu.com/p/56382372
190 |
191 | 一个在线尝试Word2Vec的小demo https://ronxin.github.io/wevi/
192 |
--------------------------------------------------------------------------------
/AI算法/NLP/文本表示/Word2Vec详解.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/文本表示/Word2Vec详解.pdf
--------------------------------------------------------------------------------
/AI算法/NLP/文本表示/文本结构理解.md:
--------------------------------------------------------------------------------
1 | # 基于词角度
2 |
3 | ## 知识体系
4 |
5 | 基于词角度的文本结构理解主要包括分词、词性标注和命名实体识别。对于文本未切分的语言,分词一般会作为自然语言处理的第一步。即使到了字粒度的 BERT 时代, WWM 效果也要更好一些。从大的方面看有两种不同的分词方式:基于词典和基于序列标注。后者也可用于词性标注和命名实体识别任务。
6 |
7 |
8 | ## Questions
9 |
10 | ### 常用的分词方法有哪些?
11 |
12 | 常用分词方法有两种:基于词典的方法和基于序列标注的方法。前者又包括字符串匹配方法和统计语言模型方法;后者包括统计方法和深度学习方法。
13 |
14 | ### 字符串匹配分词的优缺点是什么?
15 |
16 | 优点:方法简单可控、速度快;缺点:难以解决歧义及新词问题。
17 |
18 | ### 结巴分词原理?
19 |
20 | 基于词典构造有向无环图,计算最大概率路径。新词发现使用 HMM,弥补了 Ngram 难以发现新词的不足。
21 |
22 | ### HMM 怎么做分词的?
23 |
24 | HMM 使用序列标注法进行分词,以 BEMS 标签为例,此为隐状态取值空间。模型需要估计隐状态初始概率、隐状态之间的转移概率和隐状态到观测序列的发射概率。可以使用有监督或无监督学习算法,有监督学习根据标注数据利用极大似然法进行估计,无监督学习使用 Baum-Welch 算法。实际使用时使用维特比算法进行解码,得到最可能的隐状态序列。
25 |
26 | ### MEMM 是什么?
27 |
28 | HMM 有两个基本假设:齐次一阶马尔科夫和观测独立假设。也就是 t 时刻的状态仅仅与前一个状态有关,同时观测序列仅仅取决于它对应的隐状态。这就和实际不符,因为隐状态往往和上下文信息都有关系。于是在 HMM 的基础上引入了 MEMM,即最大熵马尔科夫模型。它打破了 HMM 的观测独立假设,考虑了整个观测序列。HMM 是一种对隐状态序列和观测状态序列联合概率进行建模的生成式模型;MEMM 是直接对标注后的后验概率进行建模的判别式模型。
29 |
30 | ### 什么是标注偏置问题?如何解决?
31 |
32 | 在 MEMM 中需要对局部进行归一化,因此隐状态会倾向于转移到那些后续状态可能更少的状态上(以提高整体的后验概率),这就是标注偏置问题。CRF,条件随机场在 MEMM 的基础上进行了全局归一化,解决了标注偏置问题。这其实已经打破了 HMM 的第一个假设(齐次马尔科夫),将有向变成了无向。
33 |
34 | ### BILSTM-CRF 原理
35 |
36 | BiLSTM 是双向 RNN 模型,每一个 Token 对应一个 Label,可以直接用来做序列标注任务。但是 BiLSTM 在 NER 问题上有个问题,因为 NER 的标签之间往往也有关系,比如形容词后面一半会接名词(中文为例),动词后面会接副词,LSTM 没办法获取这部分特征。这时候我们就需要 CRF 层,简单来说,就是加入 Label 之间的关系特征。也就是说,每一个 Label 在预测时都会考虑全局其他的 Label。
37 |
38 | ### 如何解决序列标注标签不均衡问题?
39 |
40 | 在 NER 任务中,标签不均衡一般是指要标注的实体较少,大多数标签为 O 的情况,以及部分实体过多,其他实体过少的情况。一般可以有以下几种处理思路:
41 |
42 | - 数据增强,主要是词替换(包括同类实体词替换、同义词替换、代词替换等)、随机增删实体词以外的词构建新样本、继续增加新样本、半监督方法等
43 | - 损失函数,给 loss 增加权重惩罚、Dice Loss 等
44 | - 迁移学习,借助预训练模型已经学到的丰富知识
45 |
46 |
47 |
48 |
--------------------------------------------------------------------------------
/AI算法/NLP/文本表示/文本表征方式.md:
--------------------------------------------------------------------------------
1 | # 静态语义表示方法
2 |
3 | ## 知识体系
4 |
5 | 主要包括词袋模型 BoW、TFIDF、LDA、Word2vec、Golve、Doc2Vec 等。
6 |
7 |
8 | ## Questions
9 | ### 在小数据集中 Skip-Gram 和 CBoW 哪种表现更好?
10 |
11 | Skip-Gram 是用一个 Center Word 预测其 Context 里的 Word;而 CBoW 是用 Context 里的所有 Word 去预测一个 Center Word。显然,前者对训练数据的利用更高效(构造的数据集多),因此,对于较小的语料库,Skip-Gram是更好的选择。
12 |
13 | ### 为什么要使用HS(Hierarchical Softmax )和负采样(Negative Sampling)?
14 |
15 | 两个模型的原始做法都是做内积,经过 Softmax 后得到概率,因此复杂度很高。假设我们拥有一个百万量级的词典,每一步训练都需要计算上百万次词向量的内积,显然这是无法容忍的。因此人们提出了两种较为实用的训练技巧,即 HS 和 Negative Sampling。
16 |
17 | ### 介绍一下HS(Hierarchical Softmax )
18 |
19 | HS 是试图用词频建立一棵哈夫曼树,那么经常出现的词路径会比较短。树的叶子节点表示词,共词典大小多个,而非叶子结点是模型的参数,比词典个数少一个。要预测的词,转化成预测从根节点到该词所在叶子节点的路径,是多个二分类问题。本质是把 N 分类问题变成 log(N) 次二分类
20 |
21 | ### 介绍一下负采样(Negative Sampling)
22 |
23 | 把原来的 Softmax 多分类问题,直接转化成一个正例和多个负例的二分类问题。让正例预测 1,负例预测 0,这样子更新局部的参数。.
24 |
25 | ### 负采样为什么要用词频来做采样概率?
26 |
27 | 可以让频率高的词先学习,然后带动其他词的学习。
28 |
29 | ### 负采样有什么作用?
30 |
31 | - 可以大大降低计算量,加快模型训练时间
32 | - 保证模型训练效果,因为目标词只跟相近的词有关,没有必要使用全部的单词作为负例来更新它们的权重
33 |
34 | ### 对比 Skip-Gram 和 CBOW
35 |
36 | CBOW 会比 Skip-Gram 训练速度更快,因为前者每次会更新 Context(w) 的词向量,而 Skip-Gram 只更新核心词的词向量。
37 | Skip-Gram 对低频词效果比 CBOW 好,因为 SkipGram 是尝试用当前词去预测上下文,当前词是低频词还是高频词没有区别。但是 CBOW 相当于是完形填空,会选择最常见或者说概率最大的词来补全,因此不太会选择低频词。
38 |
39 | ### 对比字向量和词向量
40 |
41 | 字向量可以解决未登录词的问题,以及可以避免分词;词向量包含的语义空间更大,更加丰富,如果语料足够的情况下,词向量是能够学到更多的语义信息。
42 |
43 | ### 如何衡量 Word2vec 得出的词/字向量的质量?
44 |
45 | 在实际工程中一般以 Word Embedding 对于实际任务的收益为评价标准,包括词汇类比任务(如 king – queen = man - woman)以及 NLP 中常见的应用任务,比如命名实体识别(NER),关系抽取(RE)等。
46 |
47 | ### 神经网络框架里的 Embedding 层和 Word Embedding 有什么关系?
48 |
49 | Embedding 层就是以 One-Hot 为输入(实际一般输入字或词的 id)、中间层节点为字向量维数的全连接层。而这个全连接层的参数,就是一个 “词向量表”,即 Word Embedding。
50 | ### Word2vec 的缺点?
51 | 没有考虑词序,因为它假设了词的上下文无关(把概率变为连乘);没有考虑全局的统计信息。
52 |
53 | ### LDA 的原理?
54 |
55 | LDA 是 pLSA 的贝叶斯版本,pLSA 是使用生成模型建模文章的生成过程,它假定 K 个主题 Z,对于文档集 D 中每个文档 Di 都包含 Ni 个词 W,对每个 Wi,最大化给定文档 Di 生成主题 Zi,再根据 Di 和 Zi 生成 Wi 的概率,最终生成整个文档序列。
56 |
57 | LDA 将每篇文章的主题分布和每个主题对应的词分布看成是一种先验分布,即狄利克雷分布。之所以选择该分布,是因为它是多项式分布的共轭先验概率分布,后验分布依然服从狄利克雷分布,方便计算。
58 |
59 | 具体过程为:首先从超参数为 α 的狄利克雷分布中抽样生成给定文档的主题分布 θ,对于文档中的每一个词,从多项式分布 θ 中抽样生成对应的主题 z,从超参数为 β 的狄利克雷分布中抽样生成给定主题 z 的词分布 φ,从多项式分布 φ 中抽样生成词 w。
60 |
61 | LDA 的主题数为超参数,一般使用验证集评估 ppl 或 HDP-LDA。
62 |
63 | ### Word2vec 和 TF-IDF 在计算相似度时的区别?
64 |
65 | - 前者是稠密向量,后者是稀疏向量
66 | - 前者维度低很多,计算更快
67 | - 前者可以表达语义信息,后者不行
68 | - 前者可以通过计算余弦相似度计算两个向量的相似度,后者不行
69 |
70 | ### 为什么训练得到的字词向量会有如下一些性质,比如向量的夹角余弦、向量的欧氏距离都能在一定程度上反应字词之间的相似性?
71 |
72 | 因为我们在用语言模型无监督训练时,是开了窗口的,通过前 n 个字预测下一个字的概率,这个 n 就是窗口的大小,同一个窗口内的词语,会有相似的更新,这些更新会累积,而具有相似模式的词语就会把这些相似更新累积到可观的程度。
73 |
74 | ### Word2vec 与 Glove的异同?
75 |
76 | 在 Word2vec 中,高频的词共现只是产生了更多的训练数据,并没有携带额外的信息;Glove 加入词的全局共现频率信息。它基于词上下文矩阵的矩阵分解技术,首先构建一个大的单词×上下文共现矩阵,然后学习低维表示,可以视为共现矩阵的重构问题。
77 |
78 | - Word2vec 是局部语料训练,特征提取基于滑动窗口;Glove 的滑动窗口是为了构建共现矩阵,统计全部语料在固定窗口内词的共现频次。
79 | - Word2vec 损失函数是带权重的交叉熵;Glove 的损失函数是最小平方损失
80 | - Glove 利用了全局信息,训练时收敛更快
81 |
82 | ### Word2vec 相比之前的 Word Embedding 方法好在什么地方?
83 |
84 | 考虑了上下文。
85 |
86 | ### Doc2vec 原理?
87 |
88 | Doc2vec 是训练文档表征的,在输入层增加了一个 Doc 向量。有两种不同的训练方法:Distributed Memory 是给定上下文和段落向量的情况下预测单词的概率。在一个句子或者段落文档训练过程中,段落 ID 保存不变,共享同一个段落向量。Distributed Bag of Words 则在只给定段落向量的情况下预测段落中一组随机单词的概率。使用时固定词向量,随机初始化 Doc 向量,训练几个步骤后得到最终 Doc 向量。
89 |
90 | ### FastText 相比 Word2vec 有哪些不同?
91 |
92 | - FastText 增加了 Ngram 特征,可以更好地解决未登录词及在小数据集上训练的问题
93 | - FastText 是一个工具包,除了可以训练词向量还可以训练有监督的文本分类模型
94 |
95 | ## 参考链接
96 |
97 | 1. [https://blog.csdn.net/zhangxb35/article/details/74716245](https://blog.csdn.net/zhangxb35/article/details/74716245)
98 | 2. [https://spaces.ac.cn/archives/4122](https://spaces.ac.cn/archives/4122)
99 |
100 |
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/20191017120044663-16497775072026.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/20191017120044663-16497775072026.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/20191017120044663.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/20191017120044663.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/image-20211101145141135-16497775072021.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/image-20211101145141135-16497775072021.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/image-20211101145141135.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/image-20211101145141135.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/layernorm1-16497775072023.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/layernorm1-16497775072023.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/layernorm1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/layernorm1.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/layernorm2-16497775072024.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/layernorm2-16497775072024.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/layernorm2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/layernorm2.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/layernorm3-16497775072025.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/layernorm3-16497775072025.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/layernorm3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/layernorm3.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/qkv-16497775072022.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/qkv-16497775072022.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/qkv.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/qkv.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/v2-fb520ebe418cab927efb64d6a6ae019e_720w-16497775072037.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/v2-fb520ebe418cab927efb64d6a6ae019e_720w-16497775072037.jpg
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/v2-fb520ebe418cab927efb64d6a6ae019e_720w.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/v2-fb520ebe418cab927efb64d6a6ae019e_720w.jpg
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/基于深度学习的模型.md:
--------------------------------------------------------------------------------
1 | # 基于深度学习的模型
2 |
3 |
4 | ## 知识体系
5 |
6 | 主要包括深度学习相关的特征抽取模型,包括卷积网络、循环网络、注意力机制、预训练模型等。
7 |
8 | ### CNN
9 |
10 | TextCNN 是 CNN 的 NLP 版本,来自 Kim 的 [[1408.5882] Convolutional Neural Networks for Sentence Classification](https://arxiv.org/abs/1408.5882)
11 |
12 | 结构如下:
13 |
14 | 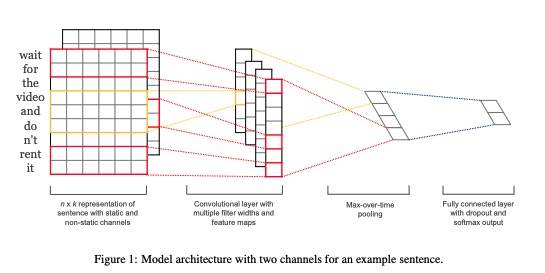
15 |
16 | 大致原理是使用多个不同大小的 filter(也叫 kernel) 对文本进行特征提取,如上图所示:
17 |
18 | - 首先通过 Embedding 将输入的句子映射为一个 `n_seq * embed_size` 大小的张量(实际中一般还会有 batch_size)
19 | - 使用 `(filter_size, embed_size)` 大小的 filter 在输入句子序列上平滑移动,这里使用不同的 padding 策略,会得到不同 size 的输出
20 | - 由于有 `num_filters` 个输出通道,所以上面的输出会有 `num_filters` 个
21 | - 使用 `Max Pooling` 或 `Average Pooling`,沿着序列方向得到结果,最终每个 filter 的输出 size 为 `num_filters`
22 | - 将不同 filter 的输出拼接后展开,作为句子的表征
23 |
24 | ### RNN
25 |
26 | RNN 的历史比 CNN 要悠久的多,常见的类型包括:
27 |
28 | - 一对一(单个 Cell):给定单个 Token 输出单个结果
29 | - 一对多:给定单个字符,在时间步向前时同时输出结果序列
30 | - 多对一:给定文本序列,在时间步向前执行完后输出单个结果
31 | - 多对多1:给定文本序列,在时间步向前时同时输出结果序列
32 | - 多对多2:给定文本序列,在时间步向前执行完后才开始输出结果序列
33 |
34 | 由于 RNN 在长文本上有梯度消失和梯度爆炸的问题,它的两个变种在实际中使用的更多。当然,它们本身也是有一些变种的,这里我们只介绍主要的模型。
35 |
36 | - LSTM:全称 Long Short-Term Memory,一篇 Sepp Hochreiter 等早在 1997 年的论文[《LONG SHORT-TERM MEMORY》](https://www.bioinf.jku.at/publications/older/2604.pdf)中被提出。主要通过对原始的 RNN 添加三个门(遗忘门、更新门、输出门)和一个记忆层使其在长文本上表现更佳。
37 |
38 | 
39 |
40 | - GRU:全称 Gated Recurrent Units,由 Kyunghyun Cho 等人 2014 年在论文[《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》](https://arxiv.org/pdf/1406.1078v3.pdf) 中首次被提出。主要将 LSTM 的三个门调整为两个门(更新门和重置门),同时将记忆状态和输出状态合二为一,在效果没有明显下降的同时,极大地提升了计算效率。
41 |
42 | 
43 |
44 | ## Questions
45 |
46 | ### CNN相关
47 |
48 | #### CNN 有什么好处?
49 |
50 | - 稀疏(局部)连接:卷积核尺寸远小于输入特征尺寸,输出层的每个节点都只与部分输入层连接
51 | - 参数共享:卷积核的滑动窗在不同位置的权值是一样的
52 | - 等价表示(输入/输出数据的结构化):输入和输出在结构上保持对应关系(长文本处理容易)
53 |
54 | #### CNN 有什么不足?
55 |
56 | - 只有局部语义,无法从整体获取句子语义
57 | - 没有位置信息,丢失了前后顺序信息
58 |
59 | #### 卷积层输出 size?
60 |
61 | 给定 n×n 输入,f×f 卷积核,padding p,stride s,输出的尺寸为:
62 |
63 | $$
64 | \lfloor \frac{n+2p-f}{s} + 1 \rfloor \times \lfloor \frac{n+2p-f}{s} + 1 \rfloor
65 | $$
66 |
67 | ### RNN
68 |
69 | #### LSTM 网络结构?
70 |
71 | LSTM 即长短时记忆网络,包括三个门:更新门(输入门)、遗忘门和输出门。公式如下:
72 |
73 | $$
74 | \hat{c}^{
29 |
30 | ## 1.2 CBOW模型
31 |
32 | 假设我们的语料是**"NLP is so interesting and challenging"**。循环使用每个词作为中心词,来其上下文词来预测中心词。我们通常使用一个指定长度的窗口,根据马尔可夫性质,忽略窗口以外的单词。
33 |
34 | | 中心词 | 上下文 |
35 | | :---------: | :--------------------------: |
36 | | NLP | is, so |
37 | | is | NLP, so, interesting |
38 | | so | NLP, is, interesting, and |
39 | | interesting | is, so, and, challenging |
40 | | and | so, interesting, challenging |
41 | | challenging | interesting, and |
42 |
43 | 我们的目标是通过上下文来预测中心词,也就是给定上下文词,出现该中心词的概率最大。这和完形填空颇有点异曲同工之妙。也即$\max P(\text{NLP|is, so})*P(\text{is|NLP, so, interesting})*\dots$
44 |
45 | 用公式表示如下:
46 | $$
47 | \begin{align}
48 | \max\limits_{\theta} L(\theta)&=\prod\limits_{w\in D}p(w|C(w)) \\
49 | &=\sum\limits_{w \in D}\log p(w|C(w))
50 | \end{align}
51 | $$
52 |
53 | 其中$w$指中心词,$C(w)$指上下文词集,$D$指语料库,也即所有中心词的词集。
54 |
55 | 问题的核心变成了如何构造$\log p(w|C(w))$。我们知道,NNLM模型的瓶颈在Sigmoid归一化上,Mikolov提出了两种改进思路来绕过Sigmoid归一化这一操作。一种思想是将输出改为一个霍夫曼树,每一个单词的概率用其路径上的权重乘积来表示,从而减少高频词的搜索时间;另一种思想是将预测每一个单词的概率,概率最高的单词是中心词改为预测该单词是不是正样本,通过负采样减少负样本数量,从而减少训练时间。
56 |
57 | ### 1.2.1 Hierarchical Softmax
58 |
59 | ### 1.2.2 Negative Sampling
60 |
61 | 基于Hierachical Softmax的模型使用Huffman树代替了传统的线性神经网络,可以提高模型训练的效率。但是,如果训练样本的中心词是一个很生僻的词,那么在Huffman树中仍旧需要进行很复杂的搜索。负采样方法的核心思想是:设计一个分类器, 对于我们需要预测的样本,设为正样本;而对于不是我们需要的样本,设置成负样本。在CBOW模型中,我们需要预测中心词$w$,因此正样本只有$w$,也即$\text{Pos}(w)=\{w\}$,而负样本为除了$w$之外的所有词。对负样本进行**随机采样**,得到$\text{Neg}(w)$,大大简化了模型的计算。
62 |
63 | 我们首先将$C(w)$输入映射层并求和得到隐含表征$h_w=\sum\limits_{u \in C(w)}\vec v(u)$
64 |
65 | 从而,
66 | $$
67 | \begin{align}
68 | p(u|C(w))&=
69 | \begin{cases}
70 | \sigma(h_w^T\theta_u), &\mathcal{D}(w,u)=1 \\
71 | 1-\sigma(h_w^T\theta_u), &\mathcal{D}(w,u)=0 \\
72 | \end{cases}\\
73 | &=[\sigma(h_w^T\theta_u)]^{\mathcal{D}(w,u)} \cdot [1-\sigma(h_w^T\theta_u)]^{1-\mathcal{D}(w,u)}
74 | \end{align}
75 | $$
76 |
77 | 从而,
78 | $$
79 | \begin{align}
80 | \max\limits_{\theta} L(\theta)&=\sum\limits_{w \in D}\log p(w|C(w))\\
81 | &=\sum\limits_{w \in D}\log \prod\limits_{u \in D}p(u|C(w)) \\
82 | &\approx\sum\limits_{w \in D}\log \prod\limits_{u \in \text{Pos(w)}\cup \text{Neg(w)} }p(u|C(w))\\
83 | &=\sum\limits_{w \in D}\log\prod\limits_{u \in \text{Pos(w)}\cup \text{Neg(w)}}[\sigma(h_w^T\theta_u)]^{\mathcal{D}(w,u)} \cdot [1-\sigma(h_w^T\theta_u)]^{1-\mathcal{D}(w,u)} \\
84 | &=\sum\limits_{w \in D}\sum\limits_{u \in \text{Pos}(w)\cup \text{Neg}(w)}\mathcal{D}(w,u)\cdot\log \sigma(h_w^T\theta_u)+[1-\mathcal{D}(w,u)]\cdot \log [1-\sigma(h_w^T\theta_u)]\\
85 | &=\sum\limits_{w \in D}\left\{\sum\limits_{u \in \text{Pos}(w)}\log \sigma(h_w^T\theta_u)+\sum\limits_{u \in \text{Neg}(w)}\log [1-\sigma(h_w^T\theta_u)]\right\}
86 | \end{align}
87 | $$
88 |
89 | 由于上式是一个最大化问题,因此使用随机梯度上升法对问题进行求解。
90 |
91 | 令$L(w,u,\theta)=\mathcal{D}(w,u)\cdot\log \sigma(h_w^T\theta_u)+[1-\mathcal{D}(w,u)]\cdot \log [1-\sigma(h_w^T\theta_u)]$
92 |
93 | 则$\frac{\partial L}{\partial\theta_u}=\mathcal{D}(w,u)\cdot[1-\sigma(h_w^T\theta_u)]h_w+[1-\mathcal{D}(w,u)]\cdot \sigma(h_w^T\theta_u)h_w=[\mathcal{D}(w,u)-\sigma(h_w^T\theta_u)]h_w$
94 |
95 | 因此$\theta_u$的更新公式为:$\theta_u:=\theta_u+\eta[\mathcal{D}(w,u)-\sigma(h_w^T\theta_u)]h_w$
96 |
97 | 同样地,$\frac{\partial L}{\partial h_w}=[\mathcal{D}(w,u)-\sigma(h_w^T\theta_u)]\theta_u$
98 |
99 | 上下文词的更新公式为:$v(\tilde{w}):=v(\tilde{w})+\eta\sum\limits_{u \in \text{Pos}(w)\cup \text{Neg}(w)}[\mathcal{D}(w,u)-\sigma(h_w^T\theta_u)]\theta_u$
100 |
101 | ## 1.3 Skip-Gram模型
102 |
103 | 仍旧使用上文的语料库**"NLP is so interesting and challenging"**,这次,我们的目标是通过中心词来预测上下文,也就是给定中心词,出现这些上下文词的概率最大。也即$\max P(is|NLP)*P(so|NLP)*P(NLP|is)*P(so|is)*P(interesting|is)*\dots$
104 |
105 | 用公式表示如下:
106 | $$
107 | \begin{align}
108 | \max\limits_{\theta} L(\theta)&=\prod\limits_{w\in D}\prod\limits_{c \in C(w)}p(c|w) \\
109 | &=\sum\limits_{w \in D}\sum\limits_{c \in C(w)}\log p(c|w)
110 | \end{align}
111 | $$
112 |
113 | ### 1.3.1 Hierarchical Softmax
114 |
115 | ### 1.3.2 Negative Sampling
116 |
117 | # 2 常见面试问题
118 |
119 | **Q1:介绍一下Word2Vec模型。**
120 |
121 | > A:两个模型:CBOW/Skip-Gram
122 | >
123 | > 两种加速方案:Hierarchical Softmax/Negative Sampling
124 |
125 | **Q2:Word2Vec模型为什么要定义两套词向量?**
126 |
127 | > A:因为每个单词承担了两个角色:中心词和上下文词。通过定义两套词向量,可以将两种角色分开。cs224n中提到是为了更方便地求梯度。参考见:https://www.zhihu.com/answer/706466139
128 |
129 | **Q3:Hierarchial Softmax 和 Negative Sampling对比**
130 |
131 | > A:基于Huffman树的Hierarchial Softmax 虽然在一定程度上能够提升模型运算效率,但是,如果中心词是生僻词,那么在Huffman树中仍旧需要进行很复杂的搜索$(O(\log N))$。而Negative Sampling通过随机负采样来提升运算效率,其复杂度和设定的负样本数$K$线性相关$(O(K))$,当$K$取较小的常数时,负采样在每⼀步的梯度计算开销都较小。
132 |
133 | **Q4:HS为什么用霍夫曼树而不用其他二叉树?**
134 |
135 | > 这是因为Huffman树对于高频词会赋予更短的编码,使得高频词离根节点距离更近,从而使得训练速度加快。
136 |
137 | **Q5:Word2Vec模型为什么要进行负采样?**
138 |
139 | > A:因为负样本的数量很庞大,是$O(|V^2|)$。
140 |
141 | **Q6:负采样为什么要用词频来做采样概率?**
142 |
143 | > 为这样可以让频率高的词先学习,然后带动其他词的学习。
144 |
145 | **Q7:One-hot模型与Word2Vec模型比较?**
146 |
147 | > A:One-hot模型的缺点
148 | >
149 | > - 稀疏 Sparsity
150 | > - 只能表示维度数量的单词 Capacity
151 | > - 无法表示单词的语义 Meaning
152 |
153 | **Q8:Word2Vec模型在NNLM模型上做了哪些改进?**
154 |
155 | > A:相同点:其本质都可以看作是语言模型;
156 | >
157 | > 不同点:词向量只不过 NNLM 一个产物,Word2vec 虽然其本质也是语言模型,但是其专注于词向量本身,因此做了许多优化来提高计算效率:
158 | >
159 | > - 与 NNLM 相比,词向量直接 sum,不再拼接,并舍弃隐层;
160 | >
161 | > - 考虑到 sofmax 归一化需要遍历整个词汇表,采用 hierarchical softmax 和 negative sampling 进行优化,hierarchical softmax 实质上生成一颗带权路径最小的哈夫曼树,让高频词搜索路劲变小;negative sampling 更为直接,实质上对每一个样本中每一个词都进行负例采样;
162 |
163 | **Q9:Word2Vec与LSA对比?**
164 |
165 | > A:LSA是基于共现矩阵构建词向量,本质上是基于全局语料进行SVD矩阵分解,计算效率低;
166 | >
167 | > 而Word2Vec是基于上下文局部语料计算共现概率,计算效率高。
168 |
169 | **Q10:Word2Vec的缺点?**
170 |
171 | > 忽略了词语的语序;
172 | >
173 | > 没有考虑一词多义现象
174 |
175 | **Q11:怎么从语言模型理解词向量?怎么理解分布式假设?**
176 |
177 | > 词向量是语言模型的一个副产物,可以理解为,在语言模型训练的过程中,势必在一定程度上理解了每个单词的含义。而这在计算机的表示下就是词向量。
178 | >
179 | > 分布式假设指的是相同上下文语境的词有似含义。
180 |
181 | **参考资料**
182 |
183 | word2vec 中的数学原理详解 https://blog.csdn.net/itplus/article/details/37969519
184 |
185 | Word2Vec原理介绍 https://www.cnblogs.com/pinard/p/7160330.html
186 |
187 | 词向量介绍 https://www.cnblogs.com/sandwichnlp/p/11596848.html
188 |
189 | 一些关于词向量的问题 https://zhuanlan.zhihu.com/p/56382372
190 |
191 | 一个在线尝试Word2Vec的小demo https://ronxin.github.io/wevi/
192 |
--------------------------------------------------------------------------------
/AI算法/NLP/文本表示/Word2Vec详解.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/文本表示/Word2Vec详解.pdf
--------------------------------------------------------------------------------
/AI算法/NLP/文本表示/文本结构理解.md:
--------------------------------------------------------------------------------
1 | # 基于词角度
2 |
3 | ## 知识体系
4 |
5 | 基于词角度的文本结构理解主要包括分词、词性标注和命名实体识别。对于文本未切分的语言,分词一般会作为自然语言处理的第一步。即使到了字粒度的 BERT 时代, WWM 效果也要更好一些。从大的方面看有两种不同的分词方式:基于词典和基于序列标注。后者也可用于词性标注和命名实体识别任务。
6 |
7 |
8 | ## Questions
9 |
10 | ### 常用的分词方法有哪些?
11 |
12 | 常用分词方法有两种:基于词典的方法和基于序列标注的方法。前者又包括字符串匹配方法和统计语言模型方法;后者包括统计方法和深度学习方法。
13 |
14 | ### 字符串匹配分词的优缺点是什么?
15 |
16 | 优点:方法简单可控、速度快;缺点:难以解决歧义及新词问题。
17 |
18 | ### 结巴分词原理?
19 |
20 | 基于词典构造有向无环图,计算最大概率路径。新词发现使用 HMM,弥补了 Ngram 难以发现新词的不足。
21 |
22 | ### HMM 怎么做分词的?
23 |
24 | HMM 使用序列标注法进行分词,以 BEMS 标签为例,此为隐状态取值空间。模型需要估计隐状态初始概率、隐状态之间的转移概率和隐状态到观测序列的发射概率。可以使用有监督或无监督学习算法,有监督学习根据标注数据利用极大似然法进行估计,无监督学习使用 Baum-Welch 算法。实际使用时使用维特比算法进行解码,得到最可能的隐状态序列。
25 |
26 | ### MEMM 是什么?
27 |
28 | HMM 有两个基本假设:齐次一阶马尔科夫和观测独立假设。也就是 t 时刻的状态仅仅与前一个状态有关,同时观测序列仅仅取决于它对应的隐状态。这就和实际不符,因为隐状态往往和上下文信息都有关系。于是在 HMM 的基础上引入了 MEMM,即最大熵马尔科夫模型。它打破了 HMM 的观测独立假设,考虑了整个观测序列。HMM 是一种对隐状态序列和观测状态序列联合概率进行建模的生成式模型;MEMM 是直接对标注后的后验概率进行建模的判别式模型。
29 |
30 | ### 什么是标注偏置问题?如何解决?
31 |
32 | 在 MEMM 中需要对局部进行归一化,因此隐状态会倾向于转移到那些后续状态可能更少的状态上(以提高整体的后验概率),这就是标注偏置问题。CRF,条件随机场在 MEMM 的基础上进行了全局归一化,解决了标注偏置问题。这其实已经打破了 HMM 的第一个假设(齐次马尔科夫),将有向变成了无向。
33 |
34 | ### BILSTM-CRF 原理
35 |
36 | BiLSTM 是双向 RNN 模型,每一个 Token 对应一个 Label,可以直接用来做序列标注任务。但是 BiLSTM 在 NER 问题上有个问题,因为 NER 的标签之间往往也有关系,比如形容词后面一半会接名词(中文为例),动词后面会接副词,LSTM 没办法获取这部分特征。这时候我们就需要 CRF 层,简单来说,就是加入 Label 之间的关系特征。也就是说,每一个 Label 在预测时都会考虑全局其他的 Label。
37 |
38 | ### 如何解决序列标注标签不均衡问题?
39 |
40 | 在 NER 任务中,标签不均衡一般是指要标注的实体较少,大多数标签为 O 的情况,以及部分实体过多,其他实体过少的情况。一般可以有以下几种处理思路:
41 |
42 | - 数据增强,主要是词替换(包括同类实体词替换、同义词替换、代词替换等)、随机增删实体词以外的词构建新样本、继续增加新样本、半监督方法等
43 | - 损失函数,给 loss 增加权重惩罚、Dice Loss 等
44 | - 迁移学习,借助预训练模型已经学到的丰富知识
45 |
46 |
47 |
48 |
--------------------------------------------------------------------------------
/AI算法/NLP/文本表示/文本表征方式.md:
--------------------------------------------------------------------------------
1 | # 静态语义表示方法
2 |
3 | ## 知识体系
4 |
5 | 主要包括词袋模型 BoW、TFIDF、LDA、Word2vec、Golve、Doc2Vec 等。
6 |
7 |
8 | ## Questions
9 | ### 在小数据集中 Skip-Gram 和 CBoW 哪种表现更好?
10 |
11 | Skip-Gram 是用一个 Center Word 预测其 Context 里的 Word;而 CBoW 是用 Context 里的所有 Word 去预测一个 Center Word。显然,前者对训练数据的利用更高效(构造的数据集多),因此,对于较小的语料库,Skip-Gram是更好的选择。
12 |
13 | ### 为什么要使用HS(Hierarchical Softmax )和负采样(Negative Sampling)?
14 |
15 | 两个模型的原始做法都是做内积,经过 Softmax 后得到概率,因此复杂度很高。假设我们拥有一个百万量级的词典,每一步训练都需要计算上百万次词向量的内积,显然这是无法容忍的。因此人们提出了两种较为实用的训练技巧,即 HS 和 Negative Sampling。
16 |
17 | ### 介绍一下HS(Hierarchical Softmax )
18 |
19 | HS 是试图用词频建立一棵哈夫曼树,那么经常出现的词路径会比较短。树的叶子节点表示词,共词典大小多个,而非叶子结点是模型的参数,比词典个数少一个。要预测的词,转化成预测从根节点到该词所在叶子节点的路径,是多个二分类问题。本质是把 N 分类问题变成 log(N) 次二分类
20 |
21 | ### 介绍一下负采样(Negative Sampling)
22 |
23 | 把原来的 Softmax 多分类问题,直接转化成一个正例和多个负例的二分类问题。让正例预测 1,负例预测 0,这样子更新局部的参数。.
24 |
25 | ### 负采样为什么要用词频来做采样概率?
26 |
27 | 可以让频率高的词先学习,然后带动其他词的学习。
28 |
29 | ### 负采样有什么作用?
30 |
31 | - 可以大大降低计算量,加快模型训练时间
32 | - 保证模型训练效果,因为目标词只跟相近的词有关,没有必要使用全部的单词作为负例来更新它们的权重
33 |
34 | ### 对比 Skip-Gram 和 CBOW
35 |
36 | CBOW 会比 Skip-Gram 训练速度更快,因为前者每次会更新 Context(w) 的词向量,而 Skip-Gram 只更新核心词的词向量。
37 | Skip-Gram 对低频词效果比 CBOW 好,因为 SkipGram 是尝试用当前词去预测上下文,当前词是低频词还是高频词没有区别。但是 CBOW 相当于是完形填空,会选择最常见或者说概率最大的词来补全,因此不太会选择低频词。
38 |
39 | ### 对比字向量和词向量
40 |
41 | 字向量可以解决未登录词的问题,以及可以避免分词;词向量包含的语义空间更大,更加丰富,如果语料足够的情况下,词向量是能够学到更多的语义信息。
42 |
43 | ### 如何衡量 Word2vec 得出的词/字向量的质量?
44 |
45 | 在实际工程中一般以 Word Embedding 对于实际任务的收益为评价标准,包括词汇类比任务(如 king – queen = man - woman)以及 NLP 中常见的应用任务,比如命名实体识别(NER),关系抽取(RE)等。
46 |
47 | ### 神经网络框架里的 Embedding 层和 Word Embedding 有什么关系?
48 |
49 | Embedding 层就是以 One-Hot 为输入(实际一般输入字或词的 id)、中间层节点为字向量维数的全连接层。而这个全连接层的参数,就是一个 “词向量表”,即 Word Embedding。
50 | ### Word2vec 的缺点?
51 | 没有考虑词序,因为它假设了词的上下文无关(把概率变为连乘);没有考虑全局的统计信息。
52 |
53 | ### LDA 的原理?
54 |
55 | LDA 是 pLSA 的贝叶斯版本,pLSA 是使用生成模型建模文章的生成过程,它假定 K 个主题 Z,对于文档集 D 中每个文档 Di 都包含 Ni 个词 W,对每个 Wi,最大化给定文档 Di 生成主题 Zi,再根据 Di 和 Zi 生成 Wi 的概率,最终生成整个文档序列。
56 |
57 | LDA 将每篇文章的主题分布和每个主题对应的词分布看成是一种先验分布,即狄利克雷分布。之所以选择该分布,是因为它是多项式分布的共轭先验概率分布,后验分布依然服从狄利克雷分布,方便计算。
58 |
59 | 具体过程为:首先从超参数为 α 的狄利克雷分布中抽样生成给定文档的主题分布 θ,对于文档中的每一个词,从多项式分布 θ 中抽样生成对应的主题 z,从超参数为 β 的狄利克雷分布中抽样生成给定主题 z 的词分布 φ,从多项式分布 φ 中抽样生成词 w。
60 |
61 | LDA 的主题数为超参数,一般使用验证集评估 ppl 或 HDP-LDA。
62 |
63 | ### Word2vec 和 TF-IDF 在计算相似度时的区别?
64 |
65 | - 前者是稠密向量,后者是稀疏向量
66 | - 前者维度低很多,计算更快
67 | - 前者可以表达语义信息,后者不行
68 | - 前者可以通过计算余弦相似度计算两个向量的相似度,后者不行
69 |
70 | ### 为什么训练得到的字词向量会有如下一些性质,比如向量的夹角余弦、向量的欧氏距离都能在一定程度上反应字词之间的相似性?
71 |
72 | 因为我们在用语言模型无监督训练时,是开了窗口的,通过前 n 个字预测下一个字的概率,这个 n 就是窗口的大小,同一个窗口内的词语,会有相似的更新,这些更新会累积,而具有相似模式的词语就会把这些相似更新累积到可观的程度。
73 |
74 | ### Word2vec 与 Glove的异同?
75 |
76 | 在 Word2vec 中,高频的词共现只是产生了更多的训练数据,并没有携带额外的信息;Glove 加入词的全局共现频率信息。它基于词上下文矩阵的矩阵分解技术,首先构建一个大的单词×上下文共现矩阵,然后学习低维表示,可以视为共现矩阵的重构问题。
77 |
78 | - Word2vec 是局部语料训练,特征提取基于滑动窗口;Glove 的滑动窗口是为了构建共现矩阵,统计全部语料在固定窗口内词的共现频次。
79 | - Word2vec 损失函数是带权重的交叉熵;Glove 的损失函数是最小平方损失
80 | - Glove 利用了全局信息,训练时收敛更快
81 |
82 | ### Word2vec 相比之前的 Word Embedding 方法好在什么地方?
83 |
84 | 考虑了上下文。
85 |
86 | ### Doc2vec 原理?
87 |
88 | Doc2vec 是训练文档表征的,在输入层增加了一个 Doc 向量。有两种不同的训练方法:Distributed Memory 是给定上下文和段落向量的情况下预测单词的概率。在一个句子或者段落文档训练过程中,段落 ID 保存不变,共享同一个段落向量。Distributed Bag of Words 则在只给定段落向量的情况下预测段落中一组随机单词的概率。使用时固定词向量,随机初始化 Doc 向量,训练几个步骤后得到最终 Doc 向量。
89 |
90 | ### FastText 相比 Word2vec 有哪些不同?
91 |
92 | - FastText 增加了 Ngram 特征,可以更好地解决未登录词及在小数据集上训练的问题
93 | - FastText 是一个工具包,除了可以训练词向量还可以训练有监督的文本分类模型
94 |
95 | ## 参考链接
96 |
97 | 1. [https://blog.csdn.net/zhangxb35/article/details/74716245](https://blog.csdn.net/zhangxb35/article/details/74716245)
98 | 2. [https://spaces.ac.cn/archives/4122](https://spaces.ac.cn/archives/4122)
99 |
100 |
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/20191017120044663-16497775072026.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/20191017120044663-16497775072026.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/20191017120044663.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/20191017120044663.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/image-20211101145141135-16497775072021.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/image-20211101145141135-16497775072021.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/image-20211101145141135.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/image-20211101145141135.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/layernorm1-16497775072023.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/layernorm1-16497775072023.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/layernorm1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/layernorm1.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/layernorm2-16497775072024.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/layernorm2-16497775072024.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/layernorm2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/layernorm2.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/layernorm3-16497775072025.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/layernorm3-16497775072025.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/layernorm3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/layernorm3.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/qkv-16497775072022.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/qkv-16497775072022.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/qkv.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/qkv.png
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/v2-fb520ebe418cab927efb64d6a6ae019e_720w-16497775072037.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/v2-fb520ebe418cab927efb64d6a6ae019e_720w-16497775072037.jpg
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/BERT/img/v2-fb520ebe418cab927efb64d6a6ae019e_720w.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/AI算法/NLP/特征挖掘/BERT/img/v2-fb520ebe418cab927efb64d6a6ae019e_720w.jpg
--------------------------------------------------------------------------------
/AI算法/NLP/特征挖掘/基于深度学习的模型.md:
--------------------------------------------------------------------------------
1 | # 基于深度学习的模型
2 |
3 |
4 | ## 知识体系
5 |
6 | 主要包括深度学习相关的特征抽取模型,包括卷积网络、循环网络、注意力机制、预训练模型等。
7 |
8 | ### CNN
9 |
10 | TextCNN 是 CNN 的 NLP 版本,来自 Kim 的 [[1408.5882] Convolutional Neural Networks for Sentence Classification](https://arxiv.org/abs/1408.5882)
11 |
12 | 结构如下:
13 |
14 | 
15 |
16 | 大致原理是使用多个不同大小的 filter(也叫 kernel) 对文本进行特征提取,如上图所示:
17 |
18 | - 首先通过 Embedding 将输入的句子映射为一个 `n_seq * embed_size` 大小的张量(实际中一般还会有 batch_size)
19 | - 使用 `(filter_size, embed_size)` 大小的 filter 在输入句子序列上平滑移动,这里使用不同的 padding 策略,会得到不同 size 的输出
20 | - 由于有 `num_filters` 个输出通道,所以上面的输出会有 `num_filters` 个
21 | - 使用 `Max Pooling` 或 `Average Pooling`,沿着序列方向得到结果,最终每个 filter 的输出 size 为 `num_filters`
22 | - 将不同 filter 的输出拼接后展开,作为句子的表征
23 |
24 | ### RNN
25 |
26 | RNN 的历史比 CNN 要悠久的多,常见的类型包括:
27 |
28 | - 一对一(单个 Cell):给定单个 Token 输出单个结果
29 | - 一对多:给定单个字符,在时间步向前时同时输出结果序列
30 | - 多对一:给定文本序列,在时间步向前执行完后输出单个结果
31 | - 多对多1:给定文本序列,在时间步向前时同时输出结果序列
32 | - 多对多2:给定文本序列,在时间步向前执行完后才开始输出结果序列
33 |
34 | 由于 RNN 在长文本上有梯度消失和梯度爆炸的问题,它的两个变种在实际中使用的更多。当然,它们本身也是有一些变种的,这里我们只介绍主要的模型。
35 |
36 | - LSTM:全称 Long Short-Term Memory,一篇 Sepp Hochreiter 等早在 1997 年的论文[《LONG SHORT-TERM MEMORY》](https://www.bioinf.jku.at/publications/older/2604.pdf)中被提出。主要通过对原始的 RNN 添加三个门(遗忘门、更新门、输出门)和一个记忆层使其在长文本上表现更佳。
37 |
38 | 
39 |
40 | - GRU:全称 Gated Recurrent Units,由 Kyunghyun Cho 等人 2014 年在论文[《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》](https://arxiv.org/pdf/1406.1078v3.pdf) 中首次被提出。主要将 LSTM 的三个门调整为两个门(更新门和重置门),同时将记忆状态和输出状态合二为一,在效果没有明显下降的同时,极大地提升了计算效率。
41 |
42 | 
43 |
44 | ## Questions
45 |
46 | ### CNN相关
47 |
48 | #### CNN 有什么好处?
49 |
50 | - 稀疏(局部)连接:卷积核尺寸远小于输入特征尺寸,输出层的每个节点都只与部分输入层连接
51 | - 参数共享:卷积核的滑动窗在不同位置的权值是一样的
52 | - 等价表示(输入/输出数据的结构化):输入和输出在结构上保持对应关系(长文本处理容易)
53 |
54 | #### CNN 有什么不足?
55 |
56 | - 只有局部语义,无法从整体获取句子语义
57 | - 没有位置信息,丢失了前后顺序信息
58 |
59 | #### 卷积层输出 size?
60 |
61 | 给定 n×n 输入,f×f 卷积核,padding p,stride s,输出的尺寸为:
62 |
63 | $$
64 | \lfloor \frac{n+2p-f}{s} + 1 \rfloor \times \lfloor \frac{n+2p-f}{s} + 1 \rfloor
65 | $$
66 |
67 | ### RNN
68 |
69 | #### LSTM 网络结构?
70 |
71 | LSTM 即长短时记忆网络,包括三个门:更新门(输入门)、遗忘门和输出门。公式如下:
72 |
73 | $$
74 | \hat{c}^{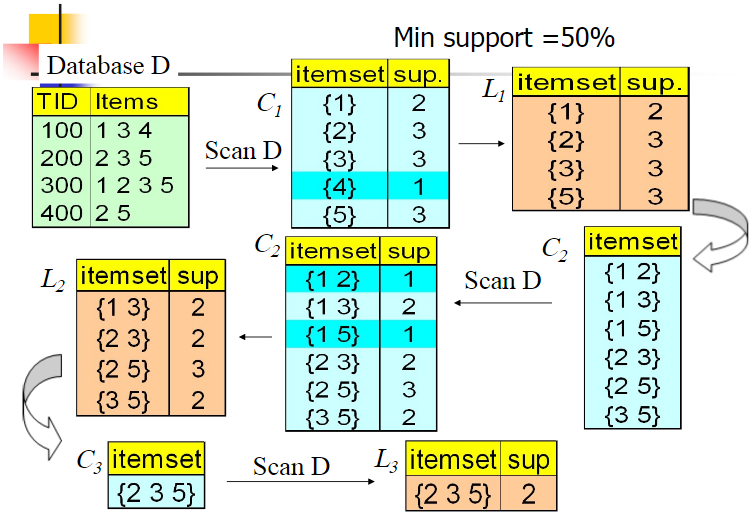 103 |
104 | ## 5. 使用Aprior算法找出强关联规则
105 |
106 | - 强关联规则:
107 |
108 | - 如果规则$R$:$\Rightarrow $满足 :
109 |
110 | $$
111 | \tag{1} { support }(X \Rightarrow Y) \geq \min {sup}
112 | $$
113 |
114 | $$
115 | \tag{2} confidence (X \Rightarrow Y) \geq \min conf
116 | $$
117 |
118 | 称关联规则$X\Rightarrow Y$为强关联规则,否则称关联规则$X\Rightarrow Y$为弱关联规则。在挖掘关联规则时,产生的关联规则要经过$\min sup$和$\min conf$的衡量筛选出来的强关联规则才能用商家的决策
119 |
120 |
--------------------------------------------------------------------------------
/AI算法/machine-learning/CRF.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # 条件随机场面试题
4 |
5 | Author: 李文乐; Email: cocoleYY@outlook.com
6 |
7 |
8 | ## 1. 简单介绍条件随机场 ##
9 |
10 | ------------------------------------------------------------
11 | 条件随机场(conditional random field,简称 CRF)是给定一组输入随机变量条 件下另一组输出随机变量的条件概率分布模型,其特点是**假设输出随机变量构成马尔可夫随机场**,是一种鉴别式机率模型,是随机场的一种,常用于标注或分析序列资料,如自然语言文字或是生物序列。
12 | 如同马尔可夫随机场,条件随机场为无向图模型,图中的顶点代表随机变量,顶点间的连线代表随机变量间的相依关系,在条件随机场当中,随机变量 Y 的分布为条件机率,给定的观察值则为随机变量 X。
13 | 原则上,条件随机场的图模型布局是可以任意给定的,一般**常用的布局是链接式**的架构,链接式架构不论在训练(training)、推论(inference)、或是解码(decoding)上,都存在有效率的算法可供演算。
14 | 条件随机场跟隐马尔可夫模型常被一起提及,条件随机场对于输入和输出的机率分布,没有如隐马尔可夫模型那般强烈的假设存在 [补充:因为HMM模型假设后面状态和前面无关]。
15 |
16 | ##2. 条件随机场预测的维特比算法求解过程:
17 |
18 | 输入:模型特征向量F(y,x)和权值向量w,观测序列$x=(x_1,x_2,…,x_n)$;
19 | 输出:最优路径$y^*=(y_1^*,y_2^*,…,y_n^*) $
20 |
21 | 初始化:
22 | $$
23 | \delta_{1}(j)=w \cdot F_{1}\left(y_{0}=\operatorname{start}, y_{1}=j, x\right), \quad j=1,2, \cdots, m
24 | $$
25 | 递推:
26 | $$
27 | \delta_{i}(l)=\max _{1
103 |
104 | ## 5. 使用Aprior算法找出强关联规则
105 |
106 | - 强关联规则:
107 |
108 | - 如果规则$R$:$\Rightarrow $满足 :
109 |
110 | $$
111 | \tag{1} { support }(X \Rightarrow Y) \geq \min {sup}
112 | $$
113 |
114 | $$
115 | \tag{2} confidence (X \Rightarrow Y) \geq \min conf
116 | $$
117 |
118 | 称关联规则$X\Rightarrow Y$为强关联规则,否则称关联规则$X\Rightarrow Y$为弱关联规则。在挖掘关联规则时,产生的关联规则要经过$\min sup$和$\min conf$的衡量筛选出来的强关联规则才能用商家的决策
119 |
120 |
--------------------------------------------------------------------------------
/AI算法/machine-learning/CRF.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # 条件随机场面试题
4 |
5 | Author: 李文乐; Email: cocoleYY@outlook.com
6 |
7 |
8 | ## 1. 简单介绍条件随机场 ##
9 |
10 | ------------------------------------------------------------
11 | 条件随机场(conditional random field,简称 CRF)是给定一组输入随机变量条 件下另一组输出随机变量的条件概率分布模型,其特点是**假设输出随机变量构成马尔可夫随机场**,是一种鉴别式机率模型,是随机场的一种,常用于标注或分析序列资料,如自然语言文字或是生物序列。
12 | 如同马尔可夫随机场,条件随机场为无向图模型,图中的顶点代表随机变量,顶点间的连线代表随机变量间的相依关系,在条件随机场当中,随机变量 Y 的分布为条件机率,给定的观察值则为随机变量 X。
13 | 原则上,条件随机场的图模型布局是可以任意给定的,一般**常用的布局是链接式**的架构,链接式架构不论在训练(training)、推论(inference)、或是解码(decoding)上,都存在有效率的算法可供演算。
14 | 条件随机场跟隐马尔可夫模型常被一起提及,条件随机场对于输入和输出的机率分布,没有如隐马尔可夫模型那般强烈的假设存在 [补充:因为HMM模型假设后面状态和前面无关]。
15 |
16 | ##2. 条件随机场预测的维特比算法求解过程:
17 |
18 | 输入:模型特征向量F(y,x)和权值向量w,观测序列$x=(x_1,x_2,…,x_n)$;
19 | 输出:最优路径$y^*=(y_1^*,y_2^*,…,y_n^*) $
20 |
21 | 初始化:
22 | $$
23 | \delta_{1}(j)=w \cdot F_{1}\left(y_{0}=\operatorname{start}, y_{1}=j, x\right), \quad j=1,2, \cdots, m
24 | $$
25 | 递推:
26 | $$
27 | \delta_{i}(l)=\max _{1 30 | 解答(详细过程请参考《数据挖掘概念与技术第三版》 p250)
31 |
30 | 解答(详细过程请参考《数据挖掘概念与技术第三版》 p250)
31 |  32 |
33 | ## FPTree
34 | FPTree是基于频繁模式的增长,不产生候选挖掘频繁项集的挖掘方法,
35 | 使用频繁模式增长方法,我们重新考察例图6.2事务数据库 D 的挖掘。
36 | 数据库的第一次扫描与 Apriori 相同,它导出频繁项(1-项集)的集合,并得到它们的支持度计数(频繁性)。设最小支持度计数为 2。频繁项的集合按支持度计数的递减序排序。结果集或表记作 L 。这样,我们有:
37 | L = [I2:7, I1:6, I3:6, I4:2, I5:2]。
38 | FP-树构造如下:
39 | 1. 首先,创建树的根结点,用“null”标记。
40 | 2. 二次扫描数据库 D。每个事务中的项按 L 中的次序处理(即,根据递减支持度计数排序)并对每个事务创建一个分枝.
41 | 3. 例如,
42 | 第一个事务“T100: I1, I2, I5”按 L 的次序包含三个项{ I2, I1, I5},导致构造树的第一个分
43 | 枝<(I2:1), (I1:1), (I5:1)>。该分枝具有三个结点,其中,I2 作为根的子女链接,I1 链接到 I2,
44 | I5 链接到 I1。第二个事务 T200 按 L 的次序包含项 I2 和 I4,它导致一个分枝,其中,I2 链接到根,
45 | I4 链接到 I2。然而,该分枝应当与 T100 已存在的路径共享前缀
32 |
33 | ## FPTree
34 | FPTree是基于频繁模式的增长,不产生候选挖掘频繁项集的挖掘方法,
35 | 使用频繁模式增长方法,我们重新考察例图6.2事务数据库 D 的挖掘。
36 | 数据库的第一次扫描与 Apriori 相同,它导出频繁项(1-项集)的集合,并得到它们的支持度计数(频繁性)。设最小支持度计数为 2。频繁项的集合按支持度计数的递减序排序。结果集或表记作 L 。这样,我们有:
37 | L = [I2:7, I1:6, I3:6, I4:2, I5:2]。
38 | FP-树构造如下:
39 | 1. 首先,创建树的根结点,用“null”标记。
40 | 2. 二次扫描数据库 D。每个事务中的项按 L 中的次序处理(即,根据递减支持度计数排序)并对每个事务创建一个分枝.
41 | 3. 例如,
42 | 第一个事务“T100: I1, I2, I5”按 L 的次序包含三个项{ I2, I1, I5},导致构造树的第一个分
43 | 枝<(I2:1), (I1:1), (I5:1)>。该分枝具有三个结点,其中,I2 作为根的子女链接,I1 链接到 I2,
44 | I5 链接到 I1。第二个事务 T200 按 L 的次序包含项 I2 和 I4,它导致一个分枝,其中,I2 链接到根,
45 | I4 链接到 I2。然而,该分枝应当与 T100 已存在的路径共享前缀 51 | 5. 根据fp tree得到频繁项集,根据支持度计数依次考虑每一个满足的元素,首先考虑计数最小的ID I5. 从根节点遍历所有到I5的路径,记录这个路径作为条件模式基,之后根据最小支持度得到条件Fp-tree,最后产生频繁项集. 具体的操作表格如下:
52 |
51 | 5. 根据fp tree得到频繁项集,根据支持度计数依次考虑每一个满足的元素,首先考虑计数最小的ID I5. 从根节点遍历所有到I5的路径,记录这个路径作为条件模式基,之后根据最小支持度得到条件Fp-tree,最后产生频繁项集. 具体的操作表格如下:
52 |  53 |
54 | **注:** 详细见数据挖掘概念与技术第6章
55 |
56 | # 核心公式
57 | 1. 如何评估哪些模式是有趣的?
58 | > 相关规则是A=>B[support, confidence]进一步扩充到相关分析A=>B[support, confidence, correlation],
59 | > 常用的相关性度量:
60 | > + 提升度(lift),计算公式如下:
61 | > $$lift(A,b)=\frac{p(A \cup B)}{p(A)p(B)}=\frac{P(B|A)}{p(B)}=\frac{conf(A=>B)}{sup(B)} \tag{3}$$
62 | > + 使用$\chi^2$进行相关分析
63 |
64 | 2. 常用的模式评估度量
65 | > + 全置信度(all_confidence)
66 | > $$all_conf(A,B)=\frac{A \cup B}{max\{sup(A),sup(B)\}}=min\{p(A|B),p(B|A)\} \tag{4}$$
67 | > + 最大置信度(max_confidence)
68 | > $$max_conf(A,B)=max\{P(A|B),p(B|A)\} \tag{5}$$
69 | > + Kulczynski(Kulc)度量
70 | > $$Kulc(A,B)=\frac{1}{2}(P(A|B)+P(B|A)) \tag{6}$$
71 | > + 余弦度量
72 | > $$cosine(A,B)=\frac{P(A\cup B)}{\sqrt{P(A) \times P(B)}}=\frac{sup(A \cup B)}{\sqrt{(sup(A) \times sup(B))}}=\sqrt{P(A|B)\times P(B|A)} \tag{7}$$
73 | 对于指示有趣的模式联系,全置信度、最大置信度、Kulczynsji和余弦哪个最好? 为了回答这个问题,引进不平衡比(Imbalance Ratio, IR)
74 | $$IR(A,B)=\frac{|sup(A)-sup(B)|}{sup(A)+sup(B)-sup(A\cup B)} \tag{8}$$
75 | # 算法十问
76 | 1. 强规则一定是有趣的吗?
77 | > 不一定,规则是否有兴趣可能用主观或客观的标准来衡量。最终,只有用户能够确定规则是否是有趣的,并且这种判断是主观的,因不同用户而异。
78 |
79 | 2. 如何提高Apriori算法的效率?
80 | > + **事务压缩**(压缩进一步迭代扫描的事务数):不包含任何 k-项集的事务不可能包含任何(k+1)-项集。这样,这种事务在其后的考虑时,可以加上标记或删除,因为为产生 j-项集(j > k),扫描数据库时不再需要它们。
81 | > + **基于散列的技术**(散列项集计数):一种基于散列的技术可以用于压缩候选 k-项集 Ck (k >1)。
82 | > **划分**(为找候选项集划分数据):可以使用划分技术,它只需要两次数据库扫描,以挖掘频繁项集。
83 | > + **选样**(在给定数据的一个子集挖掘):选样方法的基本思想是:选取给定数据库 D 的随机样本 S,然后,在 S 而不是在 D 中搜索频繁项集。用这种方法,我们牺牲了一些精度换取了有效性。
84 | > + **动态项集计数**(在扫描的不同点添加候选项集):动态项集计数技术将数据库划分为标记开始点的块。
85 |
86 | 3. Apriori算法的优缺点?
87 | > 1. 优点:
88 | > + 简单、易理解
89 | > + 数据要求低。
90 | > 2. 缺点:
91 | > + 在每一步产生候选项目集时循环产生的组合过多,没有排除不应该参与组合的元素。
92 | > + 每次计算项集的支持度时,都对数据库中的全部记录进行了一遍扫描比较,如果是一个大型的数据库时,这种扫描会大大增加计算机的I/O开销。
93 | > 3. 改进:
94 | > + 利用建立临时数据库的方法来提高Apriori算法的效率。
95 | > + Fp-tree 算法。以树形的形式来展示、表达数据的形态;可以理解为水在不同河流分支的流动过程。
96 | > + 垂直数据分布。相当于把原始数据进行行转列的操作,并且记录每个元素的个数。
97 |
98 | 4. FPtree vs Apriori算法
99 | > FP-tree算法相对于Apriori算法,时间复杂度和空间复杂都有了显著的提高。但是对海量数据集,时空复杂度仍然很高,此时需要用到数据库划分等技术。
100 |
101 |
102 | # 面试真题
103 | 1. 简述Apriori算法的思想,谈谈该算法的应用领域并举例?
104 | 思想:其发现关联规则分两步,第一是通过迭代,检索出数据源中所有烦琐项集,即支持度不低于用户设定的阀值的项即集,第二是利用第一步中检索出的烦琐项集构造出满足用户最小信任度的规则,其中,第一步即挖掘出所有频繁项集是该算法的核心,也占整个算法工作量的大部分。在商务、金融、保险等领域皆有应用。在建筑陶瓷行业中的交叉销售应用,主要采用了Apriori算法.
105 | 2. 简述FPtree的原理和Apriori的不同?
106 |
107 | 3. 豆瓣电影数据集关联规则挖掘?
108 | 如果让你分析电影数据集中的导演和演员信息,从而发现两者之间的频繁项集及关联规则,你会怎么做?
109 |
110 | # 参考
111 | 1. https://saliormoon.github.io/2016/07/01/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E9%9D%A2%E8%AF%95%E9%97%AE%E9%A2%981/
112 | 2. 数据挖掘概念与技术第三版
113 | 3. https://baijiahao.baidu.com/s?id=1607039314145277013&wfr=spider&for=pc
114 | 4.
--------------------------------------------------------------------------------
/AI算法/machine-learning/HMM.md:
--------------------------------------------------------------------------------
1 | # HMM #
2 | #### Author: 李文乐; Email: cocoleYY@outlook.com ####
3 |
4 |
5 | ## 直观理解 ##
6 |
7 | ------------------------------------------------------------
8 | 马尔可夫链(英语:Markov chain),又称离散时间马尔可夫链(discrete-time Markov chain,缩写为DTMC),因俄国数学家安德烈·马尔可夫(俄语:Андрей Андреевич Марков)得名,为状态空间中经过从一个状态到另一个状态的转换的随机过程。
9 | 隐马尔可夫模型包含5个要素:**初始概率分布,状态转移概率分布,观测概率分布,所有可能状态的集合,所有可能观测的集合**。
10 | 隐马尔可夫模型HMM是结构最简单的动态贝叶斯网络,是**有向图模型**。
11 |
12 | ## 核心公式 ##
13 |
14 | ----------
15 | 1. 依据马尔可夫性,所有变量的联合概率分布为:
16 | > 
17 |
18 |
19 | ## 注意要点 ##
20 |
21 | ----------
22 |
23 |
24 | - 统计语言模型[Statistical Language Model]
25 | > 是自然语言处理的重要技术,对于要处理的一段文本,我们可以看做是离散的时间序列,并且具有上下文依存关系;该模型可以应用在语音识别和机器翻译等领域,其模型表达式如下:
26 | > 
27 | > 如果只考虑前n-1个单词的影响,称为n元语法(n-grams),那么语言模型变为:
28 | > 
29 | > 注意:很多时候我们无法考量太久以前的词,一是因为距离太远的词与当前词关系不大,二是因为距离越长模型参数越多,并且成指数级增长,因此4元以上几乎没人使用。当n=2的时候,就是只考虑前一个单词的一阶马尔科夫链模型,大家都知道在NLP任务中,上下文信息相关性的跨度可能非常大,马尔科夫模型无法处理这样的问题,需要新的模型可以解决这种长程依赖性(Long Distance Dependency)。
30 | > 这里可以回忆一下RNN/LSTM网络,通过隐状态传递信息,可以有效解决长程依赖问题,但当处理很长的序列的时候,它们仍然面临着挑战,即梯度消失。
31 |
32 |
33 |
34 | - 两点马尔可夫性质:[可以理解为无记忆性;留意:NLP问题会涉及哦]
35 |
36 |
37 | > (1). 下一个状态的概率分布只与当前状态有关
38 | 
39 |
40 |
41 | > (2). 下一个时刻的观测只与其相对应的状态有关
42 | 
43 |
44 |
45 |
46 | - 最大熵马尔可夫模型为什么会产生标注偏置问题?如何解决?
47 |
48 |
49 |
50 | - HMM为什么是生成模型
51 | > 因为HMM直接对联合概率分布建模;相对而言,条件随机场CRF直接对条件概率建模,所以是判别模型。
52 |
53 |
54 |
55 | - HMM在处理NLP词性标注和实体识别任务中的局限性
56 | > 在序列标注问题中,隐状态(标注)不仅和单个观测状态相关,还 和观察序列的长度、上下文等信息相关。例如词性标注问题中,一个词被标注为 动词还是名词,不仅与它本身以及它前一个词的标注有关,还依赖于上下文中的 其他词
57 | >
58 |
59 |
60 |
61 | - 隐马尔可夫模型包括概率计算问题、预测问题、学习问题三个基本问题
62 | > (1)概率计算问题:已知模型的所有参数,计算观测序列Y出现的概率,可 使用前向和后向算法求解。
63 | > (2)预测问题:已知模型所有参数和观测序列Y,计算最可能的隐状态序 列X,可使用经典的动态规划算法——维特比算法来求解最可能的状态序列。
64 | > (3)学习问题:已知观测序列Y,求解使得该观测序列概率最大的模型参 数,包括隐状态序列、隐状态之间的转移概率分布以及从隐状态到观测状态的概 率分布,可使用Baum-Welch算法进行参数的学习,Baum-Welch算法是最大期望算 法的一个特例。
65 |
66 |
67 |
68 | - 浅谈最大熵模型
69 | >最大熵这个词听起来很玄妙,其实就是保留全部的不确定性,将风险降到最小。
70 | >应用在词性标注,句法分析,机器翻译等NLP任务中。
71 | >
72 | >
73 |
74 |
75 |
76 | ## 面试真题 ##
77 |
78 | ----------
79 | 1. 如何对中文分词问题用HMM模型进行建模的训练?
80 | 
81 | 2. 最大熵HMM模型为什么会产生标注偏置问题,如何解决?
82 | 
83 |
84 |
85 |
86 | ## 参考 ##
87 | 1.隐马尔可夫链定义参考维基百科
88 | 2.统计学 李航
89 | 3.数学之美
90 | 4.百面机器学习
91 |
--------------------------------------------------------------------------------
/AI算法/machine-learning/LightGBM.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 |
4 |
5 | # LightGBM面试题
6 |
7 | ## 1. 简单介绍一下LightGBM?
8 |
9 | LightGBM是一个梯度 boosting 框架,使用基于学习算法的决策树。 它可以说是分布式的,高效的。
10 |
11 | 从 LightGBM 名字我们可以看出其是轻量级(Light)的梯度提升机(GBM),其相对 XGBoost 具有训练速度快、内存占用低的特点。
12 |
13 | LightGBM 是为解决GBDT训练速度慢,内存占用大的缺点,此外还提出了:
14 |
15 | - 基于Histogram的决策树算法
16 |
17 | - 单边梯度采样 Gradient-based One-Side Sampling(GOSS)
18 |
19 | - 互斥特征捆绑 Exclusive Feature Bundling(EFB)
20 |
21 | - 带深度限制的Leaf-wise的叶子生长策略
22 |
23 | - 直接支持类别特征(Categorical Feature)
24 |
25 | - 支持高效并行
26 |
27 | - Cache命中率优化
28 |
29 | ## 2. 介绍一下直方图算法?
30 |
31 | 直方图算法就是使用直方图统计,将大规模的数据放在了直方图中,分别是每个bin中**样本的梯度之和** 还有就是每个bin中**样本数量**
32 |
33 | - 首先确定对于每一个特征需要多少个箱子并为每一个箱子分配一个整数;
34 |
35 | - 将浮点数的范围均分成若干区间,区间个数与箱子个数相等
36 |
37 | - 将属于该箱子的样本数据更新为箱子的值
38 |
39 | - 最后用直方图表示
40 |
41 | 优点:
42 |
43 | **内存占用更小**:相比xgb不需要额外存储预排序,且只保存特征离散化后的值(整型)
44 |
45 | **计算代价更小**: 相比xgb不需要遍历一个特征值就需要计算一次分裂的增益,只需要计算k次(k为箱子的个数)
46 |
47 | **直方图做差加速**:一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到,在速度上可以提升一倍
48 |
49 | ## 3. 介绍一下Leaf-wise和 Level-wise?
50 |
51 | XGBoost 采用 Level-wise,策略遍历一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,实际上很多叶子的分裂增益较低,没必要进行搜索和分裂
52 |
53 | LightGBM采用Leaf-wise的增长策略,该策略每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,Leaf-wise的优点是:在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度;Leaf-wise的缺点是:可能会长出比较深的决策树,产生过拟合。因此LightGBM会在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合
54 |
55 | ## 4. 介绍一下单边梯度采样算法(GOSS)?
56 |
57 | GOSS算法从减少样本的角度出发,排除大部分小梯度的样本,仅用剩下的样本计算信息增益,它是一种在减少数据量和保证精度上平衡的算法。与此同时,未了不改变数据的总体分布,GOSS对要进行分裂的特征按照绝对值大小进行排序,选取最大的a个数据,在剩下梯度小的数据中选取b个,这b个数据乘以权重$\frac{1-a}{b}$,最后使用这a+b个数据计算信息增益。
58 |
59 | ## 5. 介绍互斥特征捆绑算法(EFB)?
60 |
61 | 互斥特征捆绑算法(Exclusive Feature Bundling, EFB)指出如果将一些特征进行融合绑定,则可以降低特征数量。
62 | LightGBM的EFB算法将这个问题转化为图着色的问题来求解,将所有的特征视为图的各个顶点,将不是相互独立的特征用一条边连接起来,边的权重就是两个相连接的特征的总冲突值,这样需要绑定的特征就是在图着色问题中要涂上同一种颜色的那些点(特征)。另外,算法可以允许一小部分的冲突,我们可以得到更少的绑定特征,进一步提高计算效率。
63 |
64 | ## 6. 特征之间如何捆绑?
65 |
66 | 比如,我们在bundle中绑定了两个特征A和B,A特征的原始取值为区间 $[0,10)$,B特征的原始取值为区间$[0,20)$,我们可以在B特征的取值上加一个偏置常量10,将其取值范围变为$[10,30)$,绑定后的特征取值范围为$[0,30)$
67 |
68 | ## 7. LightGBM是怎么支持类别特征?
69 |
70 | * 离散特征建立直方图的过程
71 |
72 | 统计该特征下每一种离散值出现的次数,并从高到低排序,并过滤掉出现次数较少的特征值, 然后为每一个特征值,建立一个bin容器。
73 |
74 | * 计算分裂阈值的过程
75 |
76 | * 先看该特征下划分出的bin容器的个数,如果bin容器的数量小于4,直接使用one vs other方式, 逐个扫描每一个bin容器,找出最佳分裂点;
77 |
78 | * 对于bin容器较多的情况, 先进行过滤,只让子集合较大的bin容器参加划分阈值计算, 对每一个符合条件的bin容器进行公式计算
79 | $$
80 | \frac{该bin容器下所有样本的一阶梯度之和 }{ 该bin容器下所有样本的二阶梯度之和} + 正则项
81 | $$
82 |
83 | * **这里为什么不是label的均值呢?其实"label的均值"只是为了便于理解,只针对了学习一棵树且是回归问题的情况, 这时候一阶导数是Y, 二阶导数是1**),得到一个值,根据该值对bin容器从小到大进行排序,然后分从左到右、从右到左进行搜索,得到最优分裂阈值。但是有一点,没有搜索所有的bin容器,而是设定了一个搜索bin容器数量的上限值,程序中设定是32,即参数max_num_cat。
84 |
85 | * LightGBM中对离散特征实行的是many vs many 策略,这32个bin中最优划分的阈值的左边或者右边所有的bin容器就是一个many集合,而其他的bin容器就是另一个many集合。
86 |
87 | * 对于连续特征,划分阈值只有一个,对于离散值可能会有多个划分阈值,每一个划分阈值对应着一个bin容器编号,当使用离散特征进行分裂时,只要数据样本对应的bin容器编号在这些阈值对应的bin集合之中,这条数据就加入分裂后的左子树,否则加入分裂后的右子树。
88 |
89 | ## 8. LightGBM的优缺点
90 |
91 | 优点:
92 |
93 | - 直方图算法极大的降低了时间复杂度;
94 | - 单边梯度算法过滤掉梯度小的样本,减少了计算量;
95 | - 基于 Leaf-wise 算法的增长策略构建树,减少了计算量;
96 | - 直方图算法将存储特征值转变为存储 bin 值,降低了内存消耗
97 | - 互斥特征捆绑算法减少了特征数量,降低了内存消耗
98 |
99 | 缺点:
100 |
101 | - LightGBM在Leaf-wise可能会长出比较深的决策树,产生过拟合
102 | - LightGBM是基于偏差的算法,所以会对噪点较为敏感;
103 |
104 |
105 |
106 | ## 9. GBDT是如何做回归和分类的
107 |
108 | - **回归**
109 |
110 | 生成每一棵树的时候,第一棵树的一个叶子节点内所有样本的label的均值就是这个棵树的预测值,后面根据残差再预测,最后根据将第一棵树的预测值+权重*(其它树的预测结果)
111 |
112 | 
113 |
114 | * **分类**
115 |
116 | 分类时针对样本有三类的情况,
117 |
118 | * 首先同时训练三颗树。
119 | - 第一棵树针对样本 x 的第一类,输入为(x, 0)。
120 | - 第二棵树输入针对样本 x 的第二类,假设 x 属于第二类,输入为(x, 1)。
121 | - 第三棵树针对样本 x 的第三类,输入为(x, 0)。
122 | - 参照 CART 的生成过程。输出三棵树对 x 类别的预测值 f1(x), f2(x), f3(x)。
123 | * 在后面的训练中,我们仿照多分类的逻辑回归,使用 softmax 来产生概率。
124 | - 针对类别 1 求出残差 f11(x) = 0 − f1(x);
125 | - 类别 2 求出残差 f22(x) = 1 − f2(x);
126 | - 类别 3 求出残差 f33(x) = 0 − f3(x)。
127 | * 然后第二轮训练,
128 | - 第一类输入为(x, f11(x))
129 | - 第二类输入为(x, f22(x))
130 | - 第三类输入为(x, f33(x))。
131 | * 继续训练出三棵树,一直迭代 M 轮,每轮构建 3 棵树。当训练完毕以后,新来一个样本 x1,我们需要预测该样本的类别的时候,便可使用 softmax 计算每个类别的概率。
132 |
133 |
134 |
135 | ## 参考资料
136 |
137 | 深入理解LightGBM https://mp.weixin.qq.com/s/zejkifZnYXAfgTRrkMaEww
138 |
139 | 决策树(下)——XGBoost、LightGBM(非常详细) - 阿泽的文章 - 知乎 https://zhuanlan.zhihu.com/p/87885678
140 |
141 | Lightgbm如何处理类别特征: https://blog.csdn.net/anshuai_aw1/article/details/83275299
142 |
143 | LightGBM 直方图优化算法:https://blog.csdn.net/jasonwang_/article/details/80833001
144 |
--------------------------------------------------------------------------------
/AI算法/machine-learning/NaïveBayes.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # 贝叶斯面试题
4 |
5 | ## 1.简述朴素贝叶斯算法原理和工作流程
6 |
7 | **工作原理**:
8 |
9 | * 假设现在有样本$x=(x_1, x_2, x_3, \dots x_n)$待分类项
10 | * 假设样本有$m$个特征$(a_1,a_2,a_3,\dots a_m)$(特征独立)
11 | * 再假设现在有分类目标$Y=\{ y_1,y_2,y_3,\dots ,y_n\}$
12 | * 那么就$\max ({P}({y}_1 | {x}), {P}({y}_2 | {x}), {P}({y}_3 | {x}) ,{P}({y_n} | {x}))$是最终的分类类别。
13 | * 而$P(y_i | x)=\frac{P(x | y_i) * P(y_i)}{ P(x)} $,因为$x$对于每个分类目标来说都一样,所以就是求$\max({P}({x}|{y_i})*{P}({y_i}))$
14 | * $P(x | y _i) * P(y_i)=P(y_i) * \prod(P(a_j| y_i))$,而具体的$P(a_j|y_i)$和$P(y_i)$都是能从训练样本中统计出来
15 | * ${P}({a_j} | {y_i})$表示该类别下该特征$a_j$出现的概率$P(y_i)$表示全部类别中这个这个类别出现的概率,这样就能找到应该属于的类别了
16 |
17 |
18 |
19 | ## 2. 条件概率、先验概率、后验概率、联合概率、贝叶斯公式的概念
20 |
21 | * 条件概率:
22 |
23 | * $P(X|Y)$含义: 表示$Y$发生的条件下$X$发生的概率。
24 | * 先验概率
25 |
26 | * **表示事件发生前的预判概率。**这个可以是基于历史数据统计,也可以由背景常识得出,也可以是主观观点得出。一般都是单独事件发生的概率,如 $P(X)$
27 | * 后验概率
28 |
29 | * 基于先验概率求得的**反向条件概率**,形式上与条件概率相同(若$P(X|Y)$ 为正向,则$P(Y|X)$ 为反向)
30 | * 联合概率:
31 |
32 | * 事件$X$与事件$Y$同时发生的概率。
33 |
34 | * 贝叶斯公式
35 |
36 | *
37 | $$
38 | P(Y|X) = \frac{P(X|Y) P(Y)}{P(X)} \\
39 | $$
40 |
41 | * $P(Y)$ 叫做**先验概率**:事件$X$发生之前,我们根据以往经验和分析对事件$Y$发生的一个概率的判断
42 |
43 | * $P(Y|X)$ 叫做**后验概率**:事件$X$发生之后,我们对事件$Y$发生的一个概率的重新评估
44 |
45 | * $P(Y,X)$叫做**联合概率**:事件$X$与事件$Y$同时发生的概率。
46 |
47 | * 先验概率和后验概率是相对的。如果以后还有新的信息引入,更新了现在所谓的后验概率,得到了新的概率值,那么这个新的概率值被称为后验概率。
48 |
49 |
50 |
51 | ## 3.为什么朴素贝叶斯如此“朴素”?
52 |
53 | 因为它**假定所有的特征在数据集中的作用是同样重要和独立的**。正如我们所知,这个假设在现实世界中是很不真实的,因此,说朴素贝叶斯真的很“朴素”。用贝叶斯公式表达如下:
54 | $$
55 | P(Y|X_1, X_2) = \frac{P(X_1|Y) P(X_2|Y) P(Y)}{P(X_1)P(X_2)}
56 | $$
57 | **而在很多情况下,所有变量几乎不可能满足两两之间的条件。**
58 |
59 | 朴素贝叶斯模型(Naive Bayesian Model)的朴素(Naive)的含义是**“很简单很天真”**地假设样本特征彼此独立.这个假设现实中基本上不存在,但特征相关性很小的实际情况还是很多的,所以这个模型仍然能够工作得很好。
60 |
61 | ## 4.什么是贝叶斯决策理论?
62 |
63 | 贝叶斯决策理论是主观贝叶斯派归纳理论的重要组成部分。贝叶斯决策就是在不完全情报下,对部分未知的状态用主观概率估计,然后用贝叶斯公式对发生概率进行修正,最后再利用期望值和修正概率做出最优决策(选择概率最大的类别)。
64 | 贝叶斯决策理论方法是统计模型决策中的一个基本方法,其**基本思想**是:
65 |
66 | * 已知类条件概率密度参数表达式和先验概率
67 | * 利用贝叶斯公式转换成后验概率
68 | * 根据后验概率大小进行决策分类
69 |
70 | ## 5.朴素贝叶斯算法的前提假设是什么?
71 |
72 | * 特征之间相互独立
73 | * 每个特征同等重要
74 |
75 | ## 6.为什么属性独立性假设在实际情况中很难成立,但朴素贝叶斯仍能取得较好的效果?
76 |
77 | * 对于分类任务来说,只要各类别的条件概率排序正确、无需精准概率值即可导致正确分类;
78 | * 如果属性间依赖对所有类别影响相同,或依赖关系的影响能相互抵消,则属性条件独立性假设在降低计算开销的同时不会对性能产生负面影响。
79 |
80 | ## 7.什么是朴素贝叶斯中的零概率问题?如何解决?
81 |
82 | **零概率问题**:在计算实例的概率时,如果某个量$x$,在观察样本库(训练集)中没有出现过,会导致整个实例的概率结果是0。
83 |
84 | **解决办法**:若$P(x)$为零则无法计算。为了解决零概率的问题,法国数学家拉普拉斯最早提出用加1的方法估计没有出现过的现象的概率,所以加法平滑也叫做**拉普拉斯平滑**。
85 |
86 | **举个栗子**:假设在文本分类中,有3个类,$C1、C2、C3$,在指定的训练样本中,某个词语$K1$,在各个类中观测计数分别为0,990,10,$K1$的概率为0,0.99,0.01,对这三个量使用拉普拉斯平滑的计算方法如下:
87 |
88 | ```
89 | 1/1003=0.001,
90 | 991/1003=0.988,
91 | 11/1003=0.011
92 | 在实际的使用中也经常使用加 lambda(1≥lambda≥0)来代替简单加1。如果对N个计数都加上lambda,这时分母也要记得加上N*lambda。
93 | ```
94 |
95 | 将朴素贝叶斯中的所有概率计算**应用拉普拉斯平滑即可以解决零概率问题**。
96 |
97 | ## 8.朴素贝叶斯中概率计算的下溢问题如何解决?
98 |
99 | **下溢问题**:在朴素贝叶斯的计算过程中,需要对特定分类中各个特征出现的**概率进行连乘,小数相乘,越乘越小,这样就造成了下溢出**。
100 | 为了解决这个问题,对乘积结果取自然对数。通过求对数可以避免下溢出或者浮点数舍入导致的错误。
101 | $$
102 | \prod_{i=x}^{n} p\left(x_{i} | y_{j}\right)
103 | $$
104 | **解决办法**:对其**取对数**:
105 | $$
106 | \log \prod_{i=1}^{n} p\left(x_{i} | y_{j}\right)
107 | $$
108 |
109 | $$
110 | =\sum_{i=1}^{n} \log p\left(x_{i} | y_{j}\right)
111 | $$
112 |
113 | 将小数的乘法操作转化为取对数后的加法操作,规避了变为零的风险同时并不影响分类结果。
114 |
115 | ## 9.当数据的属性是连续型变量时,朴素贝叶斯算法如何处理?
116 |
117 | 当朴素贝叶斯算法数据的属性为连续型变量时,有两种方法可以计算属性的类条件概率。
118 |
119 | * 第一种方法:把一个连续的属性离散化,然后用相应的离散区间替换连续属性值。但这种方法不好控制离散区间划分的粒度。如果粒度太细,就会因为每个区间内训练记录太少而不能对$P(X|Y)$
120 | 做出可靠的估计,如果粒度太粗,那么有些区间就会有来自不同类的记录,因此失去了正确的决策边界。
121 | * 第二种方法:假设连续变量服从某种概率分布,然后使用训练数据估计分布的参数,例如可以使用高斯分布来表示连续属性的类条件概率分布。
122 | * 高斯分布有两个参数,均值$\mu$和方差$\sigma 2$,对于每个类$y_i$,属性$X_i$的类条件概率等于:
123 |
124 | $$
125 | P\left(X_{i}=x_{i} | Y=y_{j}\right)=\frac{1}{\sqrt{2 \Pi} \sigma_{i j}^{2}} e^{\frac{\left(x_{i}-\mu_{j}\right)^{2}}{2 \sigma_{i}^{2}}}
126 | $$
127 |
128 | $\mu_{i j}$:类$y_j$的所有训练记录关于$X_i$的样本均值估计
129 |
130 | $\sigma_{i j}^{2}$:类$y_j$的所有训练记录关于$X$的样本方差
131 |
132 | 通过高斯分布估计出类条件概率。
133 |
134 | ## 10.朴素贝叶斯有哪几种常用的分类模型?
135 |
136 | 朴素贝叶斯的三个常用模型:高斯、多项式、伯努利
137 |
138 | * 高斯模型:
139 |
140 | * 处理包含连续型变量的数据,使用高斯分布概率密度来计算类的条件概率密度
141 |
142 | * 多项式模型:
143 |
144 | * 其中$\alpha$为拉普拉斯平滑,加和的是属性出现的总次数,比如文本分类问题里面,不光看词语是否在文本中出现,也得看出现的次数。如果总词数为$n$,出现词数为$m$的话,说起来有点像掷骰子$n$次出现$m$次这个词的场景。
145 | $$
146 | P\left(x_{i} | y_{k}\right)=\frac{N_{y k_{1}}+\alpha}{N_{y_{k}}+\alpha n}
147 | $$
148 |
149 | * 多项式模型适用于离散特征情况,在文本领域应用广泛, 其基本思想是:**我们将重复的词语视为其出现多次**。
150 |
151 | * 伯努利模型:
152 |
153 | * 伯努利模型特征的取值为布尔型,即出现为true没有出现为false,在文本分类中,就是一个单词有没有在一个文档中出现。
154 |
155 | * 伯努利模型适用于离散特征情况,它将重复的词语都视为只出现一次。
156 | $$
157 | P( '代开', '发票', '发票', '我' | S) = P('代开' | S) P( '发票' | S) P('我' | S)
158 | $$
159 | 我们看到,”发票“出现了两次,但是我们只将其算作一次。我们看到,”发票“出现了两次,但是我们只将其算作一次。
160 |
161 | ## 11.为什么说朴素贝叶斯是高偏差低方差?
162 |
163 | 在统计学习框架下,大家刻画模型复杂度的时候,有这么个观点,认为$Error=Bias +Variance$。
164 |
165 | * $Error$反映的是整个模型的准确度,
166 | * $Bias$反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,
167 | * $Variance$反映的是模型每一次输出结果与模型输出期望(平均值)之间的误差,即模型的稳定性,数据是否集中。
168 | * 对于复杂模型,充分拟合了部分数据,使得他们的偏差较小,而由于对部分数据的过度拟合,对于部分数据预测效果不好,整体来看可能引起方差较大。
169 | * 对于朴素贝叶斯了。它简单的假设了各个数据之间是无关的,是一个被严重简化了的模型,简单模型与复杂模型相反,大部分场合偏差部分大于方差部分,也就是说高偏差而低方差。
170 |
171 | ## 12.朴素贝叶斯为什么适合增量计算?
172 |
173 | 因为朴素贝叶斯在训练过程中实际只需要计算出各个类别的概率和各个特征的类条件概率,这些概率值可以快速的根据增量数据进行更新,无需重新全量训练,所以其十分适合增量计算,该特性可以使用在超出内存的大量数据计算和按小时级等获取的数据计算中。
174 |
175 | ## 13.高度相关的特征对朴素贝叶斯有什么影响?
176 |
177 | 假设有两个特征高度相关,相当于该特征在模型中发挥了两次作用(计算两次条件概率),使得朴素贝叶斯获得的结果向该特征所希望的方向进行了偏移,影响了最终结果的准确性,所以朴素贝叶斯算法应先处理特征,把相关特征去掉。
178 |
179 | ## 14.朴素贝叶斯的应用场景有哪些?
180 |
181 | * **文本分类/垃圾文本过滤/情感判别**:
182 | 这大概是朴素贝叶斯应用最多的地方了,即使在现在这种分类器层出不穷的年代,在文本分类场景中,朴素贝叶斯依旧坚挺地占据着一席之地。因为多分类很简单,同时在文本数据中,分布独立这个假设基本是成立的。而垃圾文本过滤(比如垃圾邮件识别)和情感分析(微博上的褒贬情绪)用朴素贝叶斯也通常能取得很好的效果。
183 | * **多分类实时预测**:
184 | 对于文本相关的多分类实时预测,它因为上面提到的优点,被广泛应用,简单又高效。
185 | * **推荐系统**:
186 | 朴素贝叶斯和协同过滤是一对好搭档,协同过滤是强相关性,但是泛化能力略弱,朴素贝叶斯和协同过滤一起,能增强推荐的覆盖度和效果。
187 |
188 | ## 15.朴素贝叶斯有什么优缺点?
189 |
190 | * 优点:
191 | * 对数据的训练快,分类也快
192 | * 对缺失数据不太敏感,算法也比较简单
193 | * 对小规模的数据表现很好,能个处理多分类任务,适合增量式训练,尤其是数据量超出内存时,可以一批批的去增量训练
194 | * 缺点:
195 | * 对输入数据的表达形式很敏感
196 | * 由于朴素贝叶斯的“朴素”特点,所以会带来一些准确率上的损失。
197 | * 需要计算先验概率,分类决策存在错误率。
198 |
199 | ## 16.朴素贝叶斯与 LR 区别?
200 |
201 | - **朴素贝叶斯是生成模型**,根据已有样本进行贝叶斯估计学习出先验概率 $P(Y)$ 和条件概率 $P(X|Y)$,进而求出联合分布概率 $P(X,Y)$,最后利用贝叶斯定理求解$P(Y|X)$, 而**LR是判别模型**,根据极大化对数似然函数直接求出条件概率 $P(Y|X)$
202 | - 朴素贝叶斯是基于很强的**条件独立假设**(在已知分类Y的条件下,各个特征变量取值是相互独立的),而 LR 则对此没有要求
203 | - 朴素贝叶斯适用于数据集少的情景,而LR适用于大规模数据集。
204 |
205 | ## 17. 贝叶斯优化算法(参数调优)
206 |
207 | * 网格搜索和随机搜索:在测试一个新点时,会忽略前一个点的信息;
208 |
209 | * 贝叶斯优化算法:充分利用了之前的信息。贝叶斯优化算法通过对目标函数形式进行学习,找到使目标函数向全局最优值提升的参数。
210 |
211 | * 学习目标函数形式的方法:
212 | * 首先根据先验分布,假设一个搜集函数;
213 | * 每一次使用新的采样点来测试目标函数时,利用这个信息来更新目标函数的先验分布
214 | * 算法测试由后验分布给出的全局最值最可能出现的位置的点。
215 |
216 | 对于贝叶斯优化算法,有一个需要注意的地方,一旦找到了一个局部最优值,它会在该区域不断采样,所以很容易陷入局部最优值。为了弥补这个缺陷,贝叶斯优化算法会在探索和利用之间找到一个平衡点,“探索”就是在还未取样的区域获取采样点;而“利用”则是根据后验分布在最可能出现全局最值的区域进行采样。
217 |
218 | ## 18.朴素贝叶斯分类器对异常值敏感吗?
219 |
220 | 朴素贝叶斯是一种**对异常值不敏感**的分类器,保留数据中的异常值,常常可以保持贝叶斯算法的整体精度,如果对原始数据进行降噪训练,分类器可能会因为失去部分异常值的信息而导致泛化能力下降。
221 |
222 | ## 19.朴素贝叶斯算法对缺失值敏感吗?
223 |
224 | 朴素贝叶斯是一种**对缺失值不敏感**的分类器,朴素贝叶斯算法能够处理缺失的数据,在算法的建模时和预测时数据的属性都是单独处理的。因此**如果一个数据实例缺失了一个属性的数值,在建模时将被忽略**,不影响类条件概率的计算,在预测时,计算数据实例是否属于某类的概率时也将忽略缺失属性,不影响最终结果。
225 |
226 | ## 20. 一句话总结贝叶斯算法
227 |
228 | **贝叶斯分类器直接用贝叶斯公式解决分类问题**。假设样本的特征向量为$x$,类别标签为$y$,根据贝叶斯公式,样本属于每个类的条件概率(后验概率)为:
229 | $$
230 | p(y | \mathbf{x})=\frac{p(\mathbf{x} | y) p(y)}{p(\mathbf{x})}
231 | $$
232 | 分母$p(x)$对所有类都是相同的,**分类的规则是将样本归到后验概率最大的那个类**,不需要计算准确的概率值,只需要知道属于哪个类的概率最大即可,这样可以忽略掉分母。分类器的判别函数为:
233 | $$
234 | \arg \max _{y} p(\mathrm{x} | y) p(y)
235 | $$
236 | 在实现贝叶斯分类器时,**需要知道每个类的条件概率分布$p(x|y)$即先验概率**。一般假设样本服从正态分布。训练时确定先验概率分布的参数,一般用最大似然估计,即最大化对数似然函数。
237 |
238 | **贝叶斯分类器是一种生成模型,可以处理多分类问题,是一种非线性模型。**
239 |
240 | ## 21.朴素贝叶斯与LR的区别?(经典问题)
241 |
242 | 朴素贝叶斯是生成模型,而LR为判别模型.朴素贝叶斯:已知样本求出先验概率与条件概率,进而计算后验概率。**优点:样本容量增加时,收敛更快;隐变量存在时也可适用。缺点:时间长;需要样本多;浪费计算资源**. **Logistic回归**:不关心样本中类别的比例及类别下出现特征的概率,它直接给出预测模型的式子。设每个特征都有一个权重,训练样本数据更新权重w,得出最终表达式。**优点:直接预测往往准确率更高;简化问题;可以反应数据的分布情况,类别的差异特征;适用于较多类别的识别。缺点:收敛慢;不适用于有隐变量的情况。** > + 朴素贝叶斯是基于很强的条件独立假设(在已知分类Y的条件下,各个特征变量取值是相互独立的),而LR则对此没有要求。 > + 朴素贝叶斯适用于数据集少的情景,而LR适用于大规模数据集。
243 |
244 |
245 |
246 |
--------------------------------------------------------------------------------
/AI算法/machine-learning/Prophet.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ## Prophet面试题
4 |
5 | ## 1. 简要介绍Prophet
6 |
7 | 常见的时间序列分解方法:
8 |
9 | 将时间序列分成季节项$S_t$,趋势项$T_t$,剩余项$R_t$,即对所有的$t≥0$
10 | $$
11 | y_{t}=S_{t}+T_{t}+R_{t}
12 | $$
13 |
14 | $$
15 | y_{t}=S_{t} \times T_{t} \times R_{t}
16 | $$
17 |
18 | $$
19 | \ln y_{t}=\ln S_{t}+\ln T_{t}+\ln R_{t}
20 | $$
21 |
22 | fbprophet 的在此基础上,添加了节日项。
23 | $$
24 | y(t)=g(t)+s(t)+h(t)+\epsilon_{t}
25 | $$
26 |
27 | ## 2. 趋势项模型
28 |
29 | * **基于逻辑回归**
30 |
31 | sigmoid 函数为
32 | $$
33 | \sigma(x)=1 /\left(1+e^{-x}\right)
34 | $$
35 | prophet在逻辑回归的基础上添加了随时间变化的参数,那么逻辑回归就可以改写成:
36 | $$
37 | f(x)=\frac{C(t)}{\left(1+e^{-k(t)(x-m(t))}\right)}
38 | $$
39 | 这里的 $C$ 称为曲线的最大渐近值, $k$ 表示曲线的增长率,$m$ 表示曲线的中点。当 $$
40 | C=1, k=1, m=0
41 | $$时,恰好就是大家常见的 sigmoid 函数的形式。
42 |
43 | * **基于分段线性函数**
44 | $$
45 | g(t)=\frac{C(t)}{1+\exp \left(-\left(k+\boldsymbol{a}(t)^{t} \boldsymbol{\delta}\right) \cdot\left(t-\left(m+\boldsymbol{a}(t)^{T} \boldsymbol{\gamma}\right)\right.\right.}
46 | $$
47 | $k$表示变化量
48 |
49 | $a_{j}(t)$表示指示函数:
50 | $$
51 | a_{j}(t)=\left\{\begin{array}{l}1, \text { if } t \geq s_{j} \\ 0, \text { otherwise }\end{array}\right.
52 | $$
53 | $\delta_{j}$表示在时间戳$s_{j}$上的增长率的变化量
54 |
55 | $\gamma_{j}$确定线段边界
56 | $$
57 | \gamma_{j}=\left(s_{j}-m-\sum_{\ell
53 |
54 | **注:** 详细见数据挖掘概念与技术第6章
55 |
56 | # 核心公式
57 | 1. 如何评估哪些模式是有趣的?
58 | > 相关规则是A=>B[support, confidence]进一步扩充到相关分析A=>B[support, confidence, correlation],
59 | > 常用的相关性度量:
60 | > + 提升度(lift),计算公式如下:
61 | > $$lift(A,b)=\frac{p(A \cup B)}{p(A)p(B)}=\frac{P(B|A)}{p(B)}=\frac{conf(A=>B)}{sup(B)} \tag{3}$$
62 | > + 使用$\chi^2$进行相关分析
63 |
64 | 2. 常用的模式评估度量
65 | > + 全置信度(all_confidence)
66 | > $$all_conf(A,B)=\frac{A \cup B}{max\{sup(A),sup(B)\}}=min\{p(A|B),p(B|A)\} \tag{4}$$
67 | > + 最大置信度(max_confidence)
68 | > $$max_conf(A,B)=max\{P(A|B),p(B|A)\} \tag{5}$$
69 | > + Kulczynski(Kulc)度量
70 | > $$Kulc(A,B)=\frac{1}{2}(P(A|B)+P(B|A)) \tag{6}$$
71 | > + 余弦度量
72 | > $$cosine(A,B)=\frac{P(A\cup B)}{\sqrt{P(A) \times P(B)}}=\frac{sup(A \cup B)}{\sqrt{(sup(A) \times sup(B))}}=\sqrt{P(A|B)\times P(B|A)} \tag{7}$$
73 | 对于指示有趣的模式联系,全置信度、最大置信度、Kulczynsji和余弦哪个最好? 为了回答这个问题,引进不平衡比(Imbalance Ratio, IR)
74 | $$IR(A,B)=\frac{|sup(A)-sup(B)|}{sup(A)+sup(B)-sup(A\cup B)} \tag{8}$$
75 | # 算法十问
76 | 1. 强规则一定是有趣的吗?
77 | > 不一定,规则是否有兴趣可能用主观或客观的标准来衡量。最终,只有用户能够确定规则是否是有趣的,并且这种判断是主观的,因不同用户而异。
78 |
79 | 2. 如何提高Apriori算法的效率?
80 | > + **事务压缩**(压缩进一步迭代扫描的事务数):不包含任何 k-项集的事务不可能包含任何(k+1)-项集。这样,这种事务在其后的考虑时,可以加上标记或删除,因为为产生 j-项集(j > k),扫描数据库时不再需要它们。
81 | > + **基于散列的技术**(散列项集计数):一种基于散列的技术可以用于压缩候选 k-项集 Ck (k >1)。
82 | > **划分**(为找候选项集划分数据):可以使用划分技术,它只需要两次数据库扫描,以挖掘频繁项集。
83 | > + **选样**(在给定数据的一个子集挖掘):选样方法的基本思想是:选取给定数据库 D 的随机样本 S,然后,在 S 而不是在 D 中搜索频繁项集。用这种方法,我们牺牲了一些精度换取了有效性。
84 | > + **动态项集计数**(在扫描的不同点添加候选项集):动态项集计数技术将数据库划分为标记开始点的块。
85 |
86 | 3. Apriori算法的优缺点?
87 | > 1. 优点:
88 | > + 简单、易理解
89 | > + 数据要求低。
90 | > 2. 缺点:
91 | > + 在每一步产生候选项目集时循环产生的组合过多,没有排除不应该参与组合的元素。
92 | > + 每次计算项集的支持度时,都对数据库中的全部记录进行了一遍扫描比较,如果是一个大型的数据库时,这种扫描会大大增加计算机的I/O开销。
93 | > 3. 改进:
94 | > + 利用建立临时数据库的方法来提高Apriori算法的效率。
95 | > + Fp-tree 算法。以树形的形式来展示、表达数据的形态;可以理解为水在不同河流分支的流动过程。
96 | > + 垂直数据分布。相当于把原始数据进行行转列的操作,并且记录每个元素的个数。
97 |
98 | 4. FPtree vs Apriori算法
99 | > FP-tree算法相对于Apriori算法,时间复杂度和空间复杂都有了显著的提高。但是对海量数据集,时空复杂度仍然很高,此时需要用到数据库划分等技术。
100 |
101 |
102 | # 面试真题
103 | 1. 简述Apriori算法的思想,谈谈该算法的应用领域并举例?
104 | 思想:其发现关联规则分两步,第一是通过迭代,检索出数据源中所有烦琐项集,即支持度不低于用户设定的阀值的项即集,第二是利用第一步中检索出的烦琐项集构造出满足用户最小信任度的规则,其中,第一步即挖掘出所有频繁项集是该算法的核心,也占整个算法工作量的大部分。在商务、金融、保险等领域皆有应用。在建筑陶瓷行业中的交叉销售应用,主要采用了Apriori算法.
105 | 2. 简述FPtree的原理和Apriori的不同?
106 |
107 | 3. 豆瓣电影数据集关联规则挖掘?
108 | 如果让你分析电影数据集中的导演和演员信息,从而发现两者之间的频繁项集及关联规则,你会怎么做?
109 |
110 | # 参考
111 | 1. https://saliormoon.github.io/2016/07/01/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E9%9D%A2%E8%AF%95%E9%97%AE%E9%A2%981/
112 | 2. 数据挖掘概念与技术第三版
113 | 3. https://baijiahao.baidu.com/s?id=1607039314145277013&wfr=spider&for=pc
114 | 4.
--------------------------------------------------------------------------------
/AI算法/machine-learning/HMM.md:
--------------------------------------------------------------------------------
1 | # HMM #
2 | #### Author: 李文乐; Email: cocoleYY@outlook.com ####
3 |
4 |
5 | ## 直观理解 ##
6 |
7 | ------------------------------------------------------------
8 | 马尔可夫链(英语:Markov chain),又称离散时间马尔可夫链(discrete-time Markov chain,缩写为DTMC),因俄国数学家安德烈·马尔可夫(俄语:Андрей Андреевич Марков)得名,为状态空间中经过从一个状态到另一个状态的转换的随机过程。
9 | 隐马尔可夫模型包含5个要素:**初始概率分布,状态转移概率分布,观测概率分布,所有可能状态的集合,所有可能观测的集合**。
10 | 隐马尔可夫模型HMM是结构最简单的动态贝叶斯网络,是**有向图模型**。
11 |
12 | ## 核心公式 ##
13 |
14 | ----------
15 | 1. 依据马尔可夫性,所有变量的联合概率分布为:
16 | > 
17 |
18 |
19 | ## 注意要点 ##
20 |
21 | ----------
22 |
23 |
24 | - 统计语言模型[Statistical Language Model]
25 | > 是自然语言处理的重要技术,对于要处理的一段文本,我们可以看做是离散的时间序列,并且具有上下文依存关系;该模型可以应用在语音识别和机器翻译等领域,其模型表达式如下:
26 | > 
27 | > 如果只考虑前n-1个单词的影响,称为n元语法(n-grams),那么语言模型变为:
28 | > 
29 | > 注意:很多时候我们无法考量太久以前的词,一是因为距离太远的词与当前词关系不大,二是因为距离越长模型参数越多,并且成指数级增长,因此4元以上几乎没人使用。当n=2的时候,就是只考虑前一个单词的一阶马尔科夫链模型,大家都知道在NLP任务中,上下文信息相关性的跨度可能非常大,马尔科夫模型无法处理这样的问题,需要新的模型可以解决这种长程依赖性(Long Distance Dependency)。
30 | > 这里可以回忆一下RNN/LSTM网络,通过隐状态传递信息,可以有效解决长程依赖问题,但当处理很长的序列的时候,它们仍然面临着挑战,即梯度消失。
31 |
32 |
33 |
34 | - 两点马尔可夫性质:[可以理解为无记忆性;留意:NLP问题会涉及哦]
35 |
36 |
37 | > (1). 下一个状态的概率分布只与当前状态有关
38 | 
39 |
40 |
41 | > (2). 下一个时刻的观测只与其相对应的状态有关
42 | 
43 |
44 |
45 |
46 | - 最大熵马尔可夫模型为什么会产生标注偏置问题?如何解决?
47 |
48 |
49 |
50 | - HMM为什么是生成模型
51 | > 因为HMM直接对联合概率分布建模;相对而言,条件随机场CRF直接对条件概率建模,所以是判别模型。
52 |
53 |
54 |
55 | - HMM在处理NLP词性标注和实体识别任务中的局限性
56 | > 在序列标注问题中,隐状态(标注)不仅和单个观测状态相关,还 和观察序列的长度、上下文等信息相关。例如词性标注问题中,一个词被标注为 动词还是名词,不仅与它本身以及它前一个词的标注有关,还依赖于上下文中的 其他词
57 | >
58 |
59 |
60 |
61 | - 隐马尔可夫模型包括概率计算问题、预测问题、学习问题三个基本问题
62 | > (1)概率计算问题:已知模型的所有参数,计算观测序列Y出现的概率,可 使用前向和后向算法求解。
63 | > (2)预测问题:已知模型所有参数和观测序列Y,计算最可能的隐状态序 列X,可使用经典的动态规划算法——维特比算法来求解最可能的状态序列。
64 | > (3)学习问题:已知观测序列Y,求解使得该观测序列概率最大的模型参 数,包括隐状态序列、隐状态之间的转移概率分布以及从隐状态到观测状态的概 率分布,可使用Baum-Welch算法进行参数的学习,Baum-Welch算法是最大期望算 法的一个特例。
65 |
66 |
67 |
68 | - 浅谈最大熵模型
69 | >最大熵这个词听起来很玄妙,其实就是保留全部的不确定性,将风险降到最小。
70 | >应用在词性标注,句法分析,机器翻译等NLP任务中。
71 | >
72 | >
73 |
74 |
75 |
76 | ## 面试真题 ##
77 |
78 | ----------
79 | 1. 如何对中文分词问题用HMM模型进行建模的训练?
80 | 
81 | 2. 最大熵HMM模型为什么会产生标注偏置问题,如何解决?
82 | 
83 |
84 |
85 |
86 | ## 参考 ##
87 | 1.隐马尔可夫链定义参考维基百科
88 | 2.统计学 李航
89 | 3.数学之美
90 | 4.百面机器学习
91 |
--------------------------------------------------------------------------------
/AI算法/machine-learning/LightGBM.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 |
4 |
5 | # LightGBM面试题
6 |
7 | ## 1. 简单介绍一下LightGBM?
8 |
9 | LightGBM是一个梯度 boosting 框架,使用基于学习算法的决策树。 它可以说是分布式的,高效的。
10 |
11 | 从 LightGBM 名字我们可以看出其是轻量级(Light)的梯度提升机(GBM),其相对 XGBoost 具有训练速度快、内存占用低的特点。
12 |
13 | LightGBM 是为解决GBDT训练速度慢,内存占用大的缺点,此外还提出了:
14 |
15 | - 基于Histogram的决策树算法
16 |
17 | - 单边梯度采样 Gradient-based One-Side Sampling(GOSS)
18 |
19 | - 互斥特征捆绑 Exclusive Feature Bundling(EFB)
20 |
21 | - 带深度限制的Leaf-wise的叶子生长策略
22 |
23 | - 直接支持类别特征(Categorical Feature)
24 |
25 | - 支持高效并行
26 |
27 | - Cache命中率优化
28 |
29 | ## 2. 介绍一下直方图算法?
30 |
31 | 直方图算法就是使用直方图统计,将大规模的数据放在了直方图中,分别是每个bin中**样本的梯度之和** 还有就是每个bin中**样本数量**
32 |
33 | - 首先确定对于每一个特征需要多少个箱子并为每一个箱子分配一个整数;
34 |
35 | - 将浮点数的范围均分成若干区间,区间个数与箱子个数相等
36 |
37 | - 将属于该箱子的样本数据更新为箱子的值
38 |
39 | - 最后用直方图表示
40 |
41 | 优点:
42 |
43 | **内存占用更小**:相比xgb不需要额外存储预排序,且只保存特征离散化后的值(整型)
44 |
45 | **计算代价更小**: 相比xgb不需要遍历一个特征值就需要计算一次分裂的增益,只需要计算k次(k为箱子的个数)
46 |
47 | **直方图做差加速**:一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到,在速度上可以提升一倍
48 |
49 | ## 3. 介绍一下Leaf-wise和 Level-wise?
50 |
51 | XGBoost 采用 Level-wise,策略遍历一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,实际上很多叶子的分裂增益较低,没必要进行搜索和分裂
52 |
53 | LightGBM采用Leaf-wise的增长策略,该策略每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,Leaf-wise的优点是:在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度;Leaf-wise的缺点是:可能会长出比较深的决策树,产生过拟合。因此LightGBM会在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合
54 |
55 | ## 4. 介绍一下单边梯度采样算法(GOSS)?
56 |
57 | GOSS算法从减少样本的角度出发,排除大部分小梯度的样本,仅用剩下的样本计算信息增益,它是一种在减少数据量和保证精度上平衡的算法。与此同时,未了不改变数据的总体分布,GOSS对要进行分裂的特征按照绝对值大小进行排序,选取最大的a个数据,在剩下梯度小的数据中选取b个,这b个数据乘以权重$\frac{1-a}{b}$,最后使用这a+b个数据计算信息增益。
58 |
59 | ## 5. 介绍互斥特征捆绑算法(EFB)?
60 |
61 | 互斥特征捆绑算法(Exclusive Feature Bundling, EFB)指出如果将一些特征进行融合绑定,则可以降低特征数量。
62 | LightGBM的EFB算法将这个问题转化为图着色的问题来求解,将所有的特征视为图的各个顶点,将不是相互独立的特征用一条边连接起来,边的权重就是两个相连接的特征的总冲突值,这样需要绑定的特征就是在图着色问题中要涂上同一种颜色的那些点(特征)。另外,算法可以允许一小部分的冲突,我们可以得到更少的绑定特征,进一步提高计算效率。
63 |
64 | ## 6. 特征之间如何捆绑?
65 |
66 | 比如,我们在bundle中绑定了两个特征A和B,A特征的原始取值为区间 $[0,10)$,B特征的原始取值为区间$[0,20)$,我们可以在B特征的取值上加一个偏置常量10,将其取值范围变为$[10,30)$,绑定后的特征取值范围为$[0,30)$
67 |
68 | ## 7. LightGBM是怎么支持类别特征?
69 |
70 | * 离散特征建立直方图的过程
71 |
72 | 统计该特征下每一种离散值出现的次数,并从高到低排序,并过滤掉出现次数较少的特征值, 然后为每一个特征值,建立一个bin容器。
73 |
74 | * 计算分裂阈值的过程
75 |
76 | * 先看该特征下划分出的bin容器的个数,如果bin容器的数量小于4,直接使用one vs other方式, 逐个扫描每一个bin容器,找出最佳分裂点;
77 |
78 | * 对于bin容器较多的情况, 先进行过滤,只让子集合较大的bin容器参加划分阈值计算, 对每一个符合条件的bin容器进行公式计算
79 | $$
80 | \frac{该bin容器下所有样本的一阶梯度之和 }{ 该bin容器下所有样本的二阶梯度之和} + 正则项
81 | $$
82 |
83 | * **这里为什么不是label的均值呢?其实"label的均值"只是为了便于理解,只针对了学习一棵树且是回归问题的情况, 这时候一阶导数是Y, 二阶导数是1**),得到一个值,根据该值对bin容器从小到大进行排序,然后分从左到右、从右到左进行搜索,得到最优分裂阈值。但是有一点,没有搜索所有的bin容器,而是设定了一个搜索bin容器数量的上限值,程序中设定是32,即参数max_num_cat。
84 |
85 | * LightGBM中对离散特征实行的是many vs many 策略,这32个bin中最优划分的阈值的左边或者右边所有的bin容器就是一个many集合,而其他的bin容器就是另一个many集合。
86 |
87 | * 对于连续特征,划分阈值只有一个,对于离散值可能会有多个划分阈值,每一个划分阈值对应着一个bin容器编号,当使用离散特征进行分裂时,只要数据样本对应的bin容器编号在这些阈值对应的bin集合之中,这条数据就加入分裂后的左子树,否则加入分裂后的右子树。
88 |
89 | ## 8. LightGBM的优缺点
90 |
91 | 优点:
92 |
93 | - 直方图算法极大的降低了时间复杂度;
94 | - 单边梯度算法过滤掉梯度小的样本,减少了计算量;
95 | - 基于 Leaf-wise 算法的增长策略构建树,减少了计算量;
96 | - 直方图算法将存储特征值转变为存储 bin 值,降低了内存消耗
97 | - 互斥特征捆绑算法减少了特征数量,降低了内存消耗
98 |
99 | 缺点:
100 |
101 | - LightGBM在Leaf-wise可能会长出比较深的决策树,产生过拟合
102 | - LightGBM是基于偏差的算法,所以会对噪点较为敏感;
103 |
104 |
105 |
106 | ## 9. GBDT是如何做回归和分类的
107 |
108 | - **回归**
109 |
110 | 生成每一棵树的时候,第一棵树的一个叶子节点内所有样本的label的均值就是这个棵树的预测值,后面根据残差再预测,最后根据将第一棵树的预测值+权重*(其它树的预测结果)
111 |
112 | 
113 |
114 | * **分类**
115 |
116 | 分类时针对样本有三类的情况,
117 |
118 | * 首先同时训练三颗树。
119 | - 第一棵树针对样本 x 的第一类,输入为(x, 0)。
120 | - 第二棵树输入针对样本 x 的第二类,假设 x 属于第二类,输入为(x, 1)。
121 | - 第三棵树针对样本 x 的第三类,输入为(x, 0)。
122 | - 参照 CART 的生成过程。输出三棵树对 x 类别的预测值 f1(x), f2(x), f3(x)。
123 | * 在后面的训练中,我们仿照多分类的逻辑回归,使用 softmax 来产生概率。
124 | - 针对类别 1 求出残差 f11(x) = 0 − f1(x);
125 | - 类别 2 求出残差 f22(x) = 1 − f2(x);
126 | - 类别 3 求出残差 f33(x) = 0 − f3(x)。
127 | * 然后第二轮训练,
128 | - 第一类输入为(x, f11(x))
129 | - 第二类输入为(x, f22(x))
130 | - 第三类输入为(x, f33(x))。
131 | * 继续训练出三棵树,一直迭代 M 轮,每轮构建 3 棵树。当训练完毕以后,新来一个样本 x1,我们需要预测该样本的类别的时候,便可使用 softmax 计算每个类别的概率。
132 |
133 |
134 |
135 | ## 参考资料
136 |
137 | 深入理解LightGBM https://mp.weixin.qq.com/s/zejkifZnYXAfgTRrkMaEww
138 |
139 | 决策树(下)——XGBoost、LightGBM(非常详细) - 阿泽的文章 - 知乎 https://zhuanlan.zhihu.com/p/87885678
140 |
141 | Lightgbm如何处理类别特征: https://blog.csdn.net/anshuai_aw1/article/details/83275299
142 |
143 | LightGBM 直方图优化算法:https://blog.csdn.net/jasonwang_/article/details/80833001
144 |
--------------------------------------------------------------------------------
/AI算法/machine-learning/NaïveBayes.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # 贝叶斯面试题
4 |
5 | ## 1.简述朴素贝叶斯算法原理和工作流程
6 |
7 | **工作原理**:
8 |
9 | * 假设现在有样本$x=(x_1, x_2, x_3, \dots x_n)$待分类项
10 | * 假设样本有$m$个特征$(a_1,a_2,a_3,\dots a_m)$(特征独立)
11 | * 再假设现在有分类目标$Y=\{ y_1,y_2,y_3,\dots ,y_n\}$
12 | * 那么就$\max ({P}({y}_1 | {x}), {P}({y}_2 | {x}), {P}({y}_3 | {x}) ,{P}({y_n} | {x}))$是最终的分类类别。
13 | * 而$P(y_i | x)=\frac{P(x | y_i) * P(y_i)}{ P(x)} $,因为$x$对于每个分类目标来说都一样,所以就是求$\max({P}({x}|{y_i})*{P}({y_i}))$
14 | * $P(x | y _i) * P(y_i)=P(y_i) * \prod(P(a_j| y_i))$,而具体的$P(a_j|y_i)$和$P(y_i)$都是能从训练样本中统计出来
15 | * ${P}({a_j} | {y_i})$表示该类别下该特征$a_j$出现的概率$P(y_i)$表示全部类别中这个这个类别出现的概率,这样就能找到应该属于的类别了
16 |
17 |
18 |
19 | ## 2. 条件概率、先验概率、后验概率、联合概率、贝叶斯公式的概念
20 |
21 | * 条件概率:
22 |
23 | * $P(X|Y)$含义: 表示$Y$发生的条件下$X$发生的概率。
24 | * 先验概率
25 |
26 | * **表示事件发生前的预判概率。**这个可以是基于历史数据统计,也可以由背景常识得出,也可以是主观观点得出。一般都是单独事件发生的概率,如 $P(X)$
27 | * 后验概率
28 |
29 | * 基于先验概率求得的**反向条件概率**,形式上与条件概率相同(若$P(X|Y)$ 为正向,则$P(Y|X)$ 为反向)
30 | * 联合概率:
31 |
32 | * 事件$X$与事件$Y$同时发生的概率。
33 |
34 | * 贝叶斯公式
35 |
36 | *
37 | $$
38 | P(Y|X) = \frac{P(X|Y) P(Y)}{P(X)} \\
39 | $$
40 |
41 | * $P(Y)$ 叫做**先验概率**:事件$X$发生之前,我们根据以往经验和分析对事件$Y$发生的一个概率的判断
42 |
43 | * $P(Y|X)$ 叫做**后验概率**:事件$X$发生之后,我们对事件$Y$发生的一个概率的重新评估
44 |
45 | * $P(Y,X)$叫做**联合概率**:事件$X$与事件$Y$同时发生的概率。
46 |
47 | * 先验概率和后验概率是相对的。如果以后还有新的信息引入,更新了现在所谓的后验概率,得到了新的概率值,那么这个新的概率值被称为后验概率。
48 |
49 |
50 |
51 | ## 3.为什么朴素贝叶斯如此“朴素”?
52 |
53 | 因为它**假定所有的特征在数据集中的作用是同样重要和独立的**。正如我们所知,这个假设在现实世界中是很不真实的,因此,说朴素贝叶斯真的很“朴素”。用贝叶斯公式表达如下:
54 | $$
55 | P(Y|X_1, X_2) = \frac{P(X_1|Y) P(X_2|Y) P(Y)}{P(X_1)P(X_2)}
56 | $$
57 | **而在很多情况下,所有变量几乎不可能满足两两之间的条件。**
58 |
59 | 朴素贝叶斯模型(Naive Bayesian Model)的朴素(Naive)的含义是**“很简单很天真”**地假设样本特征彼此独立.这个假设现实中基本上不存在,但特征相关性很小的实际情况还是很多的,所以这个模型仍然能够工作得很好。
60 |
61 | ## 4.什么是贝叶斯决策理论?
62 |
63 | 贝叶斯决策理论是主观贝叶斯派归纳理论的重要组成部分。贝叶斯决策就是在不完全情报下,对部分未知的状态用主观概率估计,然后用贝叶斯公式对发生概率进行修正,最后再利用期望值和修正概率做出最优决策(选择概率最大的类别)。
64 | 贝叶斯决策理论方法是统计模型决策中的一个基本方法,其**基本思想**是:
65 |
66 | * 已知类条件概率密度参数表达式和先验概率
67 | * 利用贝叶斯公式转换成后验概率
68 | * 根据后验概率大小进行决策分类
69 |
70 | ## 5.朴素贝叶斯算法的前提假设是什么?
71 |
72 | * 特征之间相互独立
73 | * 每个特征同等重要
74 |
75 | ## 6.为什么属性独立性假设在实际情况中很难成立,但朴素贝叶斯仍能取得较好的效果?
76 |
77 | * 对于分类任务来说,只要各类别的条件概率排序正确、无需精准概率值即可导致正确分类;
78 | * 如果属性间依赖对所有类别影响相同,或依赖关系的影响能相互抵消,则属性条件独立性假设在降低计算开销的同时不会对性能产生负面影响。
79 |
80 | ## 7.什么是朴素贝叶斯中的零概率问题?如何解决?
81 |
82 | **零概率问题**:在计算实例的概率时,如果某个量$x$,在观察样本库(训练集)中没有出现过,会导致整个实例的概率结果是0。
83 |
84 | **解决办法**:若$P(x)$为零则无法计算。为了解决零概率的问题,法国数学家拉普拉斯最早提出用加1的方法估计没有出现过的现象的概率,所以加法平滑也叫做**拉普拉斯平滑**。
85 |
86 | **举个栗子**:假设在文本分类中,有3个类,$C1、C2、C3$,在指定的训练样本中,某个词语$K1$,在各个类中观测计数分别为0,990,10,$K1$的概率为0,0.99,0.01,对这三个量使用拉普拉斯平滑的计算方法如下:
87 |
88 | ```
89 | 1/1003=0.001,
90 | 991/1003=0.988,
91 | 11/1003=0.011
92 | 在实际的使用中也经常使用加 lambda(1≥lambda≥0)来代替简单加1。如果对N个计数都加上lambda,这时分母也要记得加上N*lambda。
93 | ```
94 |
95 | 将朴素贝叶斯中的所有概率计算**应用拉普拉斯平滑即可以解决零概率问题**。
96 |
97 | ## 8.朴素贝叶斯中概率计算的下溢问题如何解决?
98 |
99 | **下溢问题**:在朴素贝叶斯的计算过程中,需要对特定分类中各个特征出现的**概率进行连乘,小数相乘,越乘越小,这样就造成了下溢出**。
100 | 为了解决这个问题,对乘积结果取自然对数。通过求对数可以避免下溢出或者浮点数舍入导致的错误。
101 | $$
102 | \prod_{i=x}^{n} p\left(x_{i} | y_{j}\right)
103 | $$
104 | **解决办法**:对其**取对数**:
105 | $$
106 | \log \prod_{i=1}^{n} p\left(x_{i} | y_{j}\right)
107 | $$
108 |
109 | $$
110 | =\sum_{i=1}^{n} \log p\left(x_{i} | y_{j}\right)
111 | $$
112 |
113 | 将小数的乘法操作转化为取对数后的加法操作,规避了变为零的风险同时并不影响分类结果。
114 |
115 | ## 9.当数据的属性是连续型变量时,朴素贝叶斯算法如何处理?
116 |
117 | 当朴素贝叶斯算法数据的属性为连续型变量时,有两种方法可以计算属性的类条件概率。
118 |
119 | * 第一种方法:把一个连续的属性离散化,然后用相应的离散区间替换连续属性值。但这种方法不好控制离散区间划分的粒度。如果粒度太细,就会因为每个区间内训练记录太少而不能对$P(X|Y)$
120 | 做出可靠的估计,如果粒度太粗,那么有些区间就会有来自不同类的记录,因此失去了正确的决策边界。
121 | * 第二种方法:假设连续变量服从某种概率分布,然后使用训练数据估计分布的参数,例如可以使用高斯分布来表示连续属性的类条件概率分布。
122 | * 高斯分布有两个参数,均值$\mu$和方差$\sigma 2$,对于每个类$y_i$,属性$X_i$的类条件概率等于:
123 |
124 | $$
125 | P\left(X_{i}=x_{i} | Y=y_{j}\right)=\frac{1}{\sqrt{2 \Pi} \sigma_{i j}^{2}} e^{\frac{\left(x_{i}-\mu_{j}\right)^{2}}{2 \sigma_{i}^{2}}}
126 | $$
127 |
128 | $\mu_{i j}$:类$y_j$的所有训练记录关于$X_i$的样本均值估计
129 |
130 | $\sigma_{i j}^{2}$:类$y_j$的所有训练记录关于$X$的样本方差
131 |
132 | 通过高斯分布估计出类条件概率。
133 |
134 | ## 10.朴素贝叶斯有哪几种常用的分类模型?
135 |
136 | 朴素贝叶斯的三个常用模型:高斯、多项式、伯努利
137 |
138 | * 高斯模型:
139 |
140 | * 处理包含连续型变量的数据,使用高斯分布概率密度来计算类的条件概率密度
141 |
142 | * 多项式模型:
143 |
144 | * 其中$\alpha$为拉普拉斯平滑,加和的是属性出现的总次数,比如文本分类问题里面,不光看词语是否在文本中出现,也得看出现的次数。如果总词数为$n$,出现词数为$m$的话,说起来有点像掷骰子$n$次出现$m$次这个词的场景。
145 | $$
146 | P\left(x_{i} | y_{k}\right)=\frac{N_{y k_{1}}+\alpha}{N_{y_{k}}+\alpha n}
147 | $$
148 |
149 | * 多项式模型适用于离散特征情况,在文本领域应用广泛, 其基本思想是:**我们将重复的词语视为其出现多次**。
150 |
151 | * 伯努利模型:
152 |
153 | * 伯努利模型特征的取值为布尔型,即出现为true没有出现为false,在文本分类中,就是一个单词有没有在一个文档中出现。
154 |
155 | * 伯努利模型适用于离散特征情况,它将重复的词语都视为只出现一次。
156 | $$
157 | P( '代开', '发票', '发票', '我' | S) = P('代开' | S) P( '发票' | S) P('我' | S)
158 | $$
159 | 我们看到,”发票“出现了两次,但是我们只将其算作一次。我们看到,”发票“出现了两次,但是我们只将其算作一次。
160 |
161 | ## 11.为什么说朴素贝叶斯是高偏差低方差?
162 |
163 | 在统计学习框架下,大家刻画模型复杂度的时候,有这么个观点,认为$Error=Bias +Variance$。
164 |
165 | * $Error$反映的是整个模型的准确度,
166 | * $Bias$反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,
167 | * $Variance$反映的是模型每一次输出结果与模型输出期望(平均值)之间的误差,即模型的稳定性,数据是否集中。
168 | * 对于复杂模型,充分拟合了部分数据,使得他们的偏差较小,而由于对部分数据的过度拟合,对于部分数据预测效果不好,整体来看可能引起方差较大。
169 | * 对于朴素贝叶斯了。它简单的假设了各个数据之间是无关的,是一个被严重简化了的模型,简单模型与复杂模型相反,大部分场合偏差部分大于方差部分,也就是说高偏差而低方差。
170 |
171 | ## 12.朴素贝叶斯为什么适合增量计算?
172 |
173 | 因为朴素贝叶斯在训练过程中实际只需要计算出各个类别的概率和各个特征的类条件概率,这些概率值可以快速的根据增量数据进行更新,无需重新全量训练,所以其十分适合增量计算,该特性可以使用在超出内存的大量数据计算和按小时级等获取的数据计算中。
174 |
175 | ## 13.高度相关的特征对朴素贝叶斯有什么影响?
176 |
177 | 假设有两个特征高度相关,相当于该特征在模型中发挥了两次作用(计算两次条件概率),使得朴素贝叶斯获得的结果向该特征所希望的方向进行了偏移,影响了最终结果的准确性,所以朴素贝叶斯算法应先处理特征,把相关特征去掉。
178 |
179 | ## 14.朴素贝叶斯的应用场景有哪些?
180 |
181 | * **文本分类/垃圾文本过滤/情感判别**:
182 | 这大概是朴素贝叶斯应用最多的地方了,即使在现在这种分类器层出不穷的年代,在文本分类场景中,朴素贝叶斯依旧坚挺地占据着一席之地。因为多分类很简单,同时在文本数据中,分布独立这个假设基本是成立的。而垃圾文本过滤(比如垃圾邮件识别)和情感分析(微博上的褒贬情绪)用朴素贝叶斯也通常能取得很好的效果。
183 | * **多分类实时预测**:
184 | 对于文本相关的多分类实时预测,它因为上面提到的优点,被广泛应用,简单又高效。
185 | * **推荐系统**:
186 | 朴素贝叶斯和协同过滤是一对好搭档,协同过滤是强相关性,但是泛化能力略弱,朴素贝叶斯和协同过滤一起,能增强推荐的覆盖度和效果。
187 |
188 | ## 15.朴素贝叶斯有什么优缺点?
189 |
190 | * 优点:
191 | * 对数据的训练快,分类也快
192 | * 对缺失数据不太敏感,算法也比较简单
193 | * 对小规模的数据表现很好,能个处理多分类任务,适合增量式训练,尤其是数据量超出内存时,可以一批批的去增量训练
194 | * 缺点:
195 | * 对输入数据的表达形式很敏感
196 | * 由于朴素贝叶斯的“朴素”特点,所以会带来一些准确率上的损失。
197 | * 需要计算先验概率,分类决策存在错误率。
198 |
199 | ## 16.朴素贝叶斯与 LR 区别?
200 |
201 | - **朴素贝叶斯是生成模型**,根据已有样本进行贝叶斯估计学习出先验概率 $P(Y)$ 和条件概率 $P(X|Y)$,进而求出联合分布概率 $P(X,Y)$,最后利用贝叶斯定理求解$P(Y|X)$, 而**LR是判别模型**,根据极大化对数似然函数直接求出条件概率 $P(Y|X)$
202 | - 朴素贝叶斯是基于很强的**条件独立假设**(在已知分类Y的条件下,各个特征变量取值是相互独立的),而 LR 则对此没有要求
203 | - 朴素贝叶斯适用于数据集少的情景,而LR适用于大规模数据集。
204 |
205 | ## 17. 贝叶斯优化算法(参数调优)
206 |
207 | * 网格搜索和随机搜索:在测试一个新点时,会忽略前一个点的信息;
208 |
209 | * 贝叶斯优化算法:充分利用了之前的信息。贝叶斯优化算法通过对目标函数形式进行学习,找到使目标函数向全局最优值提升的参数。
210 |
211 | * 学习目标函数形式的方法:
212 | * 首先根据先验分布,假设一个搜集函数;
213 | * 每一次使用新的采样点来测试目标函数时,利用这个信息来更新目标函数的先验分布
214 | * 算法测试由后验分布给出的全局最值最可能出现的位置的点。
215 |
216 | 对于贝叶斯优化算法,有一个需要注意的地方,一旦找到了一个局部最优值,它会在该区域不断采样,所以很容易陷入局部最优值。为了弥补这个缺陷,贝叶斯优化算法会在探索和利用之间找到一个平衡点,“探索”就是在还未取样的区域获取采样点;而“利用”则是根据后验分布在最可能出现全局最值的区域进行采样。
217 |
218 | ## 18.朴素贝叶斯分类器对异常值敏感吗?
219 |
220 | 朴素贝叶斯是一种**对异常值不敏感**的分类器,保留数据中的异常值,常常可以保持贝叶斯算法的整体精度,如果对原始数据进行降噪训练,分类器可能会因为失去部分异常值的信息而导致泛化能力下降。
221 |
222 | ## 19.朴素贝叶斯算法对缺失值敏感吗?
223 |
224 | 朴素贝叶斯是一种**对缺失值不敏感**的分类器,朴素贝叶斯算法能够处理缺失的数据,在算法的建模时和预测时数据的属性都是单独处理的。因此**如果一个数据实例缺失了一个属性的数值,在建模时将被忽略**,不影响类条件概率的计算,在预测时,计算数据实例是否属于某类的概率时也将忽略缺失属性,不影响最终结果。
225 |
226 | ## 20. 一句话总结贝叶斯算法
227 |
228 | **贝叶斯分类器直接用贝叶斯公式解决分类问题**。假设样本的特征向量为$x$,类别标签为$y$,根据贝叶斯公式,样本属于每个类的条件概率(后验概率)为:
229 | $$
230 | p(y | \mathbf{x})=\frac{p(\mathbf{x} | y) p(y)}{p(\mathbf{x})}
231 | $$
232 | 分母$p(x)$对所有类都是相同的,**分类的规则是将样本归到后验概率最大的那个类**,不需要计算准确的概率值,只需要知道属于哪个类的概率最大即可,这样可以忽略掉分母。分类器的判别函数为:
233 | $$
234 | \arg \max _{y} p(\mathrm{x} | y) p(y)
235 | $$
236 | 在实现贝叶斯分类器时,**需要知道每个类的条件概率分布$p(x|y)$即先验概率**。一般假设样本服从正态分布。训练时确定先验概率分布的参数,一般用最大似然估计,即最大化对数似然函数。
237 |
238 | **贝叶斯分类器是一种生成模型,可以处理多分类问题,是一种非线性模型。**
239 |
240 | ## 21.朴素贝叶斯与LR的区别?(经典问题)
241 |
242 | 朴素贝叶斯是生成模型,而LR为判别模型.朴素贝叶斯:已知样本求出先验概率与条件概率,进而计算后验概率。**优点:样本容量增加时,收敛更快;隐变量存在时也可适用。缺点:时间长;需要样本多;浪费计算资源**. **Logistic回归**:不关心样本中类别的比例及类别下出现特征的概率,它直接给出预测模型的式子。设每个特征都有一个权重,训练样本数据更新权重w,得出最终表达式。**优点:直接预测往往准确率更高;简化问题;可以反应数据的分布情况,类别的差异特征;适用于较多类别的识别。缺点:收敛慢;不适用于有隐变量的情况。** > + 朴素贝叶斯是基于很强的条件独立假设(在已知分类Y的条件下,各个特征变量取值是相互独立的),而LR则对此没有要求。 > + 朴素贝叶斯适用于数据集少的情景,而LR适用于大规模数据集。
243 |
244 |
245 |
246 |
--------------------------------------------------------------------------------
/AI算法/machine-learning/Prophet.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ## Prophet面试题
4 |
5 | ## 1. 简要介绍Prophet
6 |
7 | 常见的时间序列分解方法:
8 |
9 | 将时间序列分成季节项$S_t$,趋势项$T_t$,剩余项$R_t$,即对所有的$t≥0$
10 | $$
11 | y_{t}=S_{t}+T_{t}+R_{t}
12 | $$
13 |
14 | $$
15 | y_{t}=S_{t} \times T_{t} \times R_{t}
16 | $$
17 |
18 | $$
19 | \ln y_{t}=\ln S_{t}+\ln T_{t}+\ln R_{t}
20 | $$
21 |
22 | fbprophet 的在此基础上,添加了节日项。
23 | $$
24 | y(t)=g(t)+s(t)+h(t)+\epsilon_{t}
25 | $$
26 |
27 | ## 2. 趋势项模型
28 |
29 | * **基于逻辑回归**
30 |
31 | sigmoid 函数为
32 | $$
33 | \sigma(x)=1 /\left(1+e^{-x}\right)
34 | $$
35 | prophet在逻辑回归的基础上添加了随时间变化的参数,那么逻辑回归就可以改写成:
36 | $$
37 | f(x)=\frac{C(t)}{\left(1+e^{-k(t)(x-m(t))}\right)}
38 | $$
39 | 这里的 $C$ 称为曲线的最大渐近值, $k$ 表示曲线的增长率,$m$ 表示曲线的中点。当 $$
40 | C=1, k=1, m=0
41 | $$时,恰好就是大家常见的 sigmoid 函数的形式。
42 |
43 | * **基于分段线性函数**
44 | $$
45 | g(t)=\frac{C(t)}{1+\exp \left(-\left(k+\boldsymbol{a}(t)^{t} \boldsymbol{\delta}\right) \cdot\left(t-\left(m+\boldsymbol{a}(t)^{T} \boldsymbol{\gamma}\right)\right.\right.}
46 | $$
47 | $k$表示变化量
48 |
49 | $a_{j}(t)$表示指示函数:
50 | $$
51 | a_{j}(t)=\left\{\begin{array}{l}1, \text { if } t \geq s_{j} \\ 0, \text { otherwise }\end{array}\right.
52 | $$
53 | $\delta_{j}$表示在时间戳$s_{j}$上的增长率的变化量
54 |
55 | $\gamma_{j}$确定线段边界
56 | $$
57 | \gamma_{j}=\left(s_{j}-m-\sum_{\ell$where d(c_i, c_j)=\min_{x \in c_i, x' \in c_j}{\parallel x-x' \parallel}^2 and$
$diam(c_k)=\max_{x, x' \in c_k}{\parallel x-x' \parallel}^2$ |本质上也是簇间距离和簇内距离之比|越大越好| 102 | 103 | 104 | 另一个常见的方法是画图,将不同簇的数据点用不同颜色表示。这么做的好处是最直观,缺点是无法处理高维的数据,它最多能展示三维的数据集。 105 | 如果维数不多也可以做一定的降维处理(PCA)后再画图,但会损失一定的信息量。 106 | 107 | 聚类算法几乎没有统一的评估指标,可能还需要根据聚类目标想评估方式,如对会员作分群以后,我想检查分得的群体之间是否确实有差异,这时候可以用MANOVA计算,当p值小于0.01说明分群合理。 108 | 109 | ## 12. K-means中空聚类的处理 110 | 111 | 112 | 如果所有的点在指派步骤都未分配到某个簇,就会得到空簇。如果这种情况发生,则需要某种策略来选择一个替补质心,否则的话,平方误差将会偏大。一种方法是选择一个距离当前任何质心最远的点。这将消除当前对总平方误差影响最大的点。另一种方法是从具有最大SEE的簇中选择一个替补的质心。这将分裂簇并降低聚类的总SEE。如果有多个空簇,则该过程重复多次。另外编程实现时,要注意空簇可能导致的程序bug。 113 | 114 | 115 | ## 参考资料 116 | 117 | 1. Mann A K, Kaur N. Review paper on clustering techniques[J]. Global Journal of Computer Science and Technology, 2013. 118 | 2. https://blog.csdn.net/hua111hua/article/details/86556322 119 | 3. REZAEI M. Clustering validation[J]. 120 | -------------------------------------------------------------------------------- /AI算法/machine-learning/metrics.md: -------------------------------------------------------------------------------- 1 | 2 | 3 | # 评测指标面试题 4 | 5 | metric主要用来评测机器学习模型的好坏程度,不同的任务应该选择不同的评价指标,分类,回归和排序问题应该选择不同的评价函数. 不同的问题应该不同对待,即使都是分类问题也不应该唯评价函数论,不同问题不同分析. 6 | 7 | ## 回归(Regression) 8 | ### 平均绝对误差(MAE) 9 | 10 | 平均绝对误差MAE(Mean Absolute Error)又被称为 L1范数损失。 11 | $$ 12 | MAE=\frac{1}{n}\sum_{i=1}^{n}|y_i-\hat{y}_i| \tag{1} 13 | $$ 14 | MAE虽能较好衡量回归模型的好坏,但是绝对值的存在导致函数不光滑,在某些点上不能求导,可以考虑将绝对值改为残差的平方,这就是均方误差。 15 | 16 | ### 均方误差(MSE) 17 | 18 | 均方误差MSE(Mean Squared Error)又被称为 L2范数损失 。 19 | $$ 20 | MSE=\frac{1}{n}\sum_{i=1}^{n}(y_i-\hat{y}_i)^2 \tag{2} 21 | $$ 22 | 由于MSE与我们的目标变量的量纲不一致,为了保证量纲一致性,我们需要对MSE进行开方 。 23 | 24 | ### 均方根误差(RMSE) 25 | $$ 26 | RMSE=\sqrt{\frac{1}{n}\sum_{i=1}^{n}(y_i-\hat{y}_i)^2} \tag{3} 27 | $$ 28 | 29 | 30 | 31 | ### R2_score 32 | 33 | $$ 34 | R2_score =1-\frac{\sum^n_{i}\left(y_{i}-\hat{y}\right)^{2} / n}{\sum^n_{i}\left(y_{i}-\bar{y}\right)^{2} / n}=1-\frac{M S E}{\operatorname{Var}} \tag{4} 35 | $$ 36 | 37 | 38 | $R2{_score}$又称决定系数,表示反应因变量的全部变异能通过数学模型被自变量解释的比例, $R2\_{score}$越大,模型准确率越好。 39 | 40 | $y$表示实际值,$\hat{y}$表示预测值,$\bar{y}$表示实际值的均值,$n$表示样本数,$i$表示第$i$个样本。$Var$表示实际值的方差,也就是值的变异情况。 41 | 42 | $MSE$表示均方误差,为残差平方和的均值,该部分不能能被数学模型解释的部分,属于不可解释性变异。 43 | 44 | 因此: 45 | $$ 46 | 可解释性变异占比 = 1-\frac{不可解释性变异}{整体变异}= 1-\frac{M S E}{\operatorname{Var}} = R2\_score \tag{5} 47 | $$ 48 | 49 | 50 | ## 分类(Classification) 51 | ### 准确率和错误率 52 | 53 | 54 | $$ 55 | Acc(y,\hat{y})=\frac{1}{n}\sum_{i=1}^{n}y_i=\hat{y_i} \tag{6} 56 | $$ 57 | 58 | $$ 59 | Error(y, \hat{y})=1-acc(y,\hat{y}) \tag{7} 60 | $$ 61 | Acc与Error平等对待每个类别,即每一个样本判对 (0) 和判错 (1) 的代价都是一样的。使用Acc与Error作为衡量指标时,需要考虑样本不均衡问题以及实际业务中好样本与坏样本的重要程度。 62 | 63 | ### 混淆矩阵 64 | 对于二分类问题,可将样例根据其真是类别与学习器预测类别的组合划分为: 65 | 66 | ``` 67 | 真正例(true positive, TP):预测为 1,预测正确,即实际 1 68 | 假正例(false positive, FP):预测为 1,预测错误,即实际 0 69 | 真反例(ture negative, TN):预测为 0,预测正确,即实际 0 70 | 假反例(false negative, FN):预测为 0,预测错误,即实际 1 71 | ``` 72 | 73 | 则有:TP+FP+TN+FN=样例总数. 分类结果的混淆矩阵(confusion matrix)如下: 74 | 75 |  76 | 77 | ### 精确率(查准率) Precision 78 | 79 | Precision 是分类器预测的正样本中预测正确的比例,取值范围为[0,1],取值越大,模型预测能力越好。 80 | $$ 81 | P=\frac{TP}{TP+FP} \tag{8} 82 | $$ 83 | 84 | ### 召回率(查全率)Recall 85 | 86 | Recall 是分类器所预测正确的正样本占所有正样本的比例,取值范围为[0,1],取值越大,模型预测能力越好。 87 | $$ 88 | R=\frac{TP}{TP+FN} \tag{9} 89 | $$ 90 | 91 | 92 | ### F1 Score 93 | 94 | Precision和Recall 是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下Precision高、Recall 就低, Recall 高、Precision就低。为了均衡两个指标,我们可以采用Precision和Recall的加权调和平均(weighted harmonic mean)来衡量,即F1 Score 95 | $$ 96 | \frac{1}{F_1}=\frac{1}{2} \cdot (\frac{1}{P}+\frac{1}{R}) \tag{10} 97 | $$ 98 | 99 | $$ 100 | F_1=\frac{2*P*R}{P+R} \tag{11} 101 | $$ 102 | 103 | 104 | ### ROC 105 | ROC全称是"受试者工作特征"(Receiver Operating Characteristic)曲线. ROC曲线为 FPR 与 TPR 之间的关系曲线,这个组合以 FPR 对 TPR,即是以代价 (costs) 对收益 (benefits),显然收益越高,代价越低,模型的性能就越好。 其中ROC曲线的横轴是"假正例率"(False Positive Rate, **FPR**), 纵轴是"真正例率"(True Positive Rate, **TPR**), **注意这里不是上文提高的P和R**. 106 | 107 | - y 轴为真阳性率(TPR):在所有的正样本中,分类器预测正确的比例(等于Recall) 108 | 109 | $$ 110 | TPR=\frac{TP}{TP+FN} \tag{12} 111 | $$ 112 | 113 | - x 轴为假阳性率(FPR):在所有的负样本中,**分类器预测错误的比例** 114 | 115 | 116 | $$ 117 | FPR=\frac{FP}{TN+FP} \tag{13} 118 | $$ 119 | 120 | 121 | 现实使用中,一般使用有限个测试样例绘制ROC曲线,此时需要有有限个(真正例率,假正例率)坐标对. 绘图过程如下: 122 | 1. 给定$m^+$个正例和$m^-$个反例,根据学习器预测结果对样例进行排序,然后将分类阈值设为最大,此时真正例率和假正例率都为0,坐标在(0,0)处,标记一个点. 123 | 2. 将分类阈值依次设为每个样本的预测值,即依次将每个样本划分为正例. 124 | 3. 假设前一个坐标点是(x,y),若当前为真正例,则对应坐标为$(x,y+\frac{1}{m^+})$, 若是假正例,则对应坐标为$(x+\frac{1}{m^-}, y)$ 125 | 4. 线段连接相邻的点. 126 | 127 | ROC曲线如下图(其中对角线对应于"随机猜测"模型): 128 | 129 |  130 | 131 | ### AUC 132 | 133 | 对于二分类问题,预测模型会对每一个样本预测一个得分s或者一个概率p。 然后,可以选取一个阈值t,让得分s>t的样本预测为正,而得分s
18 |  19 |
19 |
20 |
21 | 在DeepWalk中使用深度优先的方式生成对象序列,为了丰富对网络中相似结点的含义,也可以尝试用广度优先的方式生成对象序列。Node2Vec 就是一种在生成对象序列时结合深度优先和广度优先的算法。
22 |
23 | ## 2. Node2Vec
24 | ### 2.1 序列生成算法
25 | Node2Vec 在RandomWalk的基础上引入search bias $\alpha$,通过调节超参数$\alpha$,控制对象序列生成过程中广度优先和深度优先的强度。
26 |
27 | RandomWalk的搜索方法比较朴素。在相邻结点之间根据边的权重或者其他业务理解定义转移概率。特别地,DeepWalk 采用等概率的方式搜索下一个结点。转移概率可以有如下的表达形式。
28 |
29 |
19 |
30 | 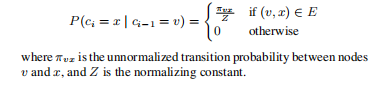 31 |
31 |
32 |
33 | 进一步,Node2Vec在未归一化的转移概率$\pi_{vx}$之前乘以偏置项$\alpha$,来反映序列生成算法对于深度优先和广度优先的偏好。以下是偏置项$\alpha$的具体表达形式。
34 |
35 |
36 | 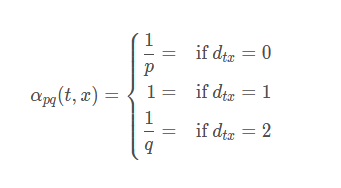 37 |
37 |
38 |
39 | 其中$d_{tx}$为顶点$t$和顶点$x$之间的最短路径长度,$p, q$控制深度优先和广度优先的强度。
40 |
41 | 假设当前随机游走经过边$(t,x)$后达到顶点$v$,以$\pi_{vx}=\alpha_{pq}(t,x)\omega_{vx}$的未归一化概率搜索下一个结点。
42 |
43 |
37 |
44 | 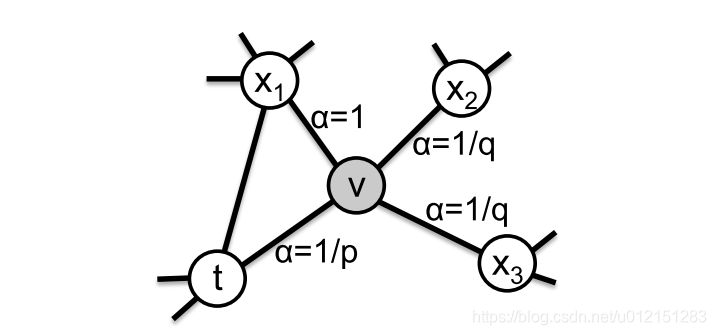 45 |
45 |
46 |
47 | 偏置项$\alpha$受到超参数p和q的控制,具体来说p, q的大小会对搜索策略产生如下影响。
48 |
49 | Return parameter p的影响:
50 | 1. 超参数p影响回到之前结点t的概率大小。如果p越小,则回到之前结点t的概率越大,搜索策略越倾向于在初始结点的附近进行搜索。
51 |
52 | In-out parameter q的影响:
53 | 1. 超参数q控制着搜索算法对于广度优先和深度优先的偏好。从示意图中,我们可以看到q越小,越倾向于搜索远离初始结点t,与倾向于深度优先的方式。
54 |
55 | ### 2.2 Embedding学习
56 | Node2vec 采用和SkipGram类似的想法,学习从节点到embedding的函数$f$,使得给定结点$u$,其近邻结点$N_S(u)$的出现的概率最大。近邻结点的是由序列生成算法获得的一系列点。具体数学表达如下。
57 |
58 |
45 |
59 | 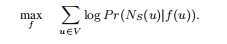 60 |
60 |
61 |
62 | 在原文中使用了条件独立性假设和特征空间独立行假设,并使用softmax函数来表示概率,将上述优化问题化简为容易求解的优化问题。采用SGD算法获得生成Embedding的函数$f$。具体的化简过程可以参考原文。
63 |
64 | 如下是Node2Vec的整个算法过程,其中采用了时间复杂度为O(1)的alias采样方法,具体可以参考[2]。
65 |
66 |
60 |
67 |  68 |
68 |
69 |
70 | ## 面试真题
71 | 1. 请结合业务谈一下怎样在推荐场景中建立网络。
72 | 2. 在Node2Vec建立对象序列的过程中,怎样实现深度优先和广度优先的?
73 |
74 | ## 参考文献
75 | 1. [浅梦的学习笔记——DeepWalk](https://blog.csdn.net/u012151283/article/details/86806922)
76 | 2. [浅梦的学习笔记——Node2Vec](https://blog.csdn.net/u012151283/article/details/87081272)
77 | 3. [《深度学习推荐系统》——王喆著](https://zhuanlan.zhihu.com/p/119248677?utm_source=zhihu&utm_medium=social&utm_oi=26827615633408)
78 | 4. [DeepWalk: Online Learning of Social Representations](http://www.perozzi.net/publications/14_kdd_deepwalk.pdf)
79 | 5. [node2vec: Scalable Feature Learning for Networks](https://arxiv.org/abs/1607.00653)
80 |
--------------------------------------------------------------------------------
/AI算法/推荐/collaborative_filtering.md:
--------------------------------------------------------------------------------
1 | Author: Summer; Email: huangmeihong11@sina.com
2 | # 协同过滤(collaborative filtering)
3 | ## 直观解释
4 | 协同过滤是推荐算法中最常用的算法之一,它根据user与item的交互,发现item之间的相关性,或者发现user之间的相关性,进行推荐。比如你有位朋友看电影的爱好跟你类似,然后最近新上了《调音师》,他觉得不错,就会推荐给你,这是最简单的基于user的协同过滤算法(user-based collaboratIve filtering),还有一种是基于item的协同过滤算法(item-based collaborative filtering),比如你非常喜欢电影《当幸福来敲门的时候》,那么观影系统可能会推荐一些类似的励志片给你,比如《风雨哈佛路》等。如下主要分析user-based,item-based同理。
5 |
6 | ## 导图
7 | 
8 | ## 核心公式
9 | * 符号定义
10 | $r_{u,i}$:user $u$ 对 item $i$ 的评分
11 | $\bar{r}_{u}$:user $u$ 的平均评分
12 | $P_{a,b}$:用户$a,b$都有评价的items集合
13 |
14 | * 核心公式
15 | 1. item-based CF 邻域方法预测公式
16 | $$\operatorname{Pred}(u, i)=\overline{r}_{u}+\frac{\sum_{j \in S_{i}}\left(\operatorname{sim}(i, j) \times r_{u, j}\right)}{\sum_{j \in S_{i}} \operatorname{sim}(i, j)}$$
17 |
18 | 1. 偏差优化目标
19 | $$\min _{b} \sum_{(u, i) \in K}\left(r_{(u, i)}-\mu-b_{u}-b_{i}\right)^{2}$$
20 | 其中$(u,i) \in K$表示所有的评分,$\mu$总评分均值,$b_u$为user $u$的偏差,$b_i$为item $i$ 的偏差。
21 |
22 | 1. - 加入正则项后的Funk SVD 优化公式
23 | $$\min _{u v} \sum_{(u, i) \in k n o w n}\left(r_{u,i}-u_{u} v_{i}\right)+\lambda\left(|u|^{2}+|v|^{2}\right)$$
24 | 其中$u_u$为user $u$的偏好,即为user特征矩阵$U$的第$u$行,$v_i$为item $i$的特征,即为特征矩阵$V$的第$i$列
25 | ## 注意要点
26 | * 相似度与距离之间的关系
27 | 距离越大,相似度越小;距离越小,相似度越高。即在求解最大相似度的时候可以转为求解最小距离。
28 |
29 | * 在协同过滤中,常用的相似度函数有哪些,简要说明
30 | * 杰卡德相似度(Jaccard similarity)
31 | 公式:
32 | $$sim_{jaccard}(u_{1}, u_{2})=\frac{ \text {items} \text { bought by } u_{1}\ and\ u_{2}}{ \text { items bought by } u_{1}\ or\ u_{2}}$$
33 | 适用于二元情况,即定性情况,比如买或者没买,喜欢或者不喜欢,在数据稀疏的情况,可以转为二元应用。
34 | * 余弦相似度
35 | 公式:$$\operatorname{sim}(u_{1}, u_{2})=\frac{r_{u_{1}} \cdot r_{u_{2}}}{\left|r_{u_{1}}\right|_{2}|r_{u_{2}}|_{2}}=\frac{\sum_{i \in P_{u_1,u_2}} r_{u_{1}, i} r_{u_{2}, i}}{\sqrt{\sum_{i \in P_{u_1}} r_{u_{1},i}^{2}} \sqrt{\sum_{i \in P_{u_2}}r_{u_{2},i}^{2}}}$$
36 | 考虑不同用户的评价范围不一样,比如乐天派一般评分范围一般会高于悲观的人,会将评分进行去中心化再进行计算,即
37 | * 修正余弦相似度,公式变为
38 | $$\operatorname{sim}(u_{1}, u_{2})=\frac{r_{u_{1}} \cdot r_{u_{2}}}{\left|r_{u_{1}}\right|_{2}|r_{u_{2}}|_{2}}=\frac{\sum_{i \in P_{u_1,u_2}} (r_{u_{1}, i}-{\bar{r}_{u_{1}}}) (r_{u_{2}, i}-\bar{r}_{u_2})}{\sqrt{\sum_{i \in P_{u_1}} (r_{u_{1},i}-\bar{r}_{u_{1}})^{2}} \sqrt{\sum_{i \in P_{u_2}}(r_{u_{2},i}-\bar{r}_{u_{2}})^{2}}}$$
39 | 适用于定量情况,比如评分场景,要求数据具有一定的稠密度。注意如果计算一个评价很少电影的用户与一个评价很多电影的用户会导致相似度为0.
40 | * 皮尔森相关系数
41 | 公式:
42 | $$\operatorname{sim}(u_1, u_2)=\frac{\sum_{i \in P_{u_1.u_2}}\left(r_{u_1, i}-\overline{r}_{u_1}\right)\left(r_{u_2, i}-\overline{r}_{u_2}\right)}{\sqrt{\sum_{i \in P_{u_1.u_2}}\left(r_{u_1, i}-\overline{r}_{u_1}\right)^{2}} \sqrt{\sum_{i \in P_{u_1.u_2}}\left(r_{u_2, i}-\overline{r}_{u_2}\right)^{2}}}$$
43 | 皮尔森系数跟修正的余弦相似度几乎一致,两者的区别在于分母上,皮尔逊系数的分母采用的评分集是两个用户的共同评分集(就是两个用户都对这个物品有评价),而修正的余弦系数则采用两个用户各自的评分集。
44 | * $L_{p}-norms$
45 | 公式:$$sim(u_1,u_2) =\frac{1}{ \sqrt[p]{| r_{u_1}-r_{u_2} |^p}+1}$$
46 | $p$取不同的值对应不同的距离公式,空间距离公式存在的不足这边也存在。对数值比较敏感。
47 | * 有了相似度测量后,那么基于邻域的推荐思路是怎样的呢?
48 | 过滤掉被评论较少的items以及较少评价的users,然后计算完users之间的相似度后,寻找跟目标user偏好既有大量相同的items,又存在不同的items的近邻几个users(可采用K-top、阈值法、聚类等方式),然后进行推荐。步骤如下:
49 | (1) 选择:选出最相似几个用户,将这些用户所喜欢的物品提取出来并过滤掉目标用户已经喜欢的物品
50 | (2) 评估:对余下的物品进行评分与相似度加权
51 | (3) 排序:根据加权之后的值进行排序
52 | (4) 推荐:由排序结果对目标用户进行推荐
53 |
54 | * 协同过滤算法具有特征学习的特点,试解释原理以及如何学习
55 | 1. 特征学习:把users做为行,items作为列,即得评分矩阵$R_{m,n}=[r_{i,j}]$,通过矩阵分解的方式进行特征学习,即将评分矩阵分解为$R=U_{m,d}V_{d,n}$,其中$U_{m,d}$为用户特征矩阵,$V_{d,n}$表示items特征矩阵,其中$d$表示对items进行$d$个主题划分。举个简单例子,比如看电影的评分矩阵划分后,$U$中每一列表示电影的一种主题成分,比如搞笑、动作等,$V$中每一行表示一个用户的偏好,比如喜欢搞笑的程度,喜欢动作的程度,值越大说明越喜欢。这样,相当于,把电影进行了主题划分,把人物偏好也进行主题划分,主题是评分矩阵潜在特征。
56 | 2. 学习方式
57 | 3. - SVD,分解式为 $$R_{m,n}=U_{m,m}\Sigma_{m,n}V_{n,n}^T$$
58 | 其中$U$为user特征矩阵,$\Sigma$为权重矩阵体现对应特征提供的信息量,$V$为item特征矩阵。同时可通过SVD进行降维处理,如下
59 | 
60 | 奇异值分解的方式,便于处理要目标user(直接添加到用户特征矩阵的尾部即可),然而要求评分矩阵元素不能为空,因此需要事先进行填充处理,同时由于user和item的数量都比较多,矩阵分解的方式计算量大,且矩阵为静态的需要随时更新,因此实际中比较少用。
61 | 4. - Funk SVD, Funk SVD 是去掉SVD的$\Sigma$成分,优化如下目标函数,可通过梯度下降法,得到的$U,V$矩阵
62 | $$J=\min _{u v} \sum_{(u, i) \in k n o w n}\left(r_{u,i}-u_{u} v_{i}\right)+\lambda\left(|u|^{2}+|v|^{2}\right)$$
63 | Funk SVD 只要利用全部有评价的信息,不需要就空置进行处理,同时可以采用梯度下降法,优化较为方便,较为常用。
64 |
65 | 有了user特征信息和item特征信息,就可用$u_{u} v_{i}$对目标用户进行评分预测,如果目标用户包含在所计算的特征矩阵里面的话。针对于新user、新item,协同过滤失效。
66 |
67 | * 如何简单计算user偏差以及item偏差?
68 | $$b_u=\frac{1}{|I_u|}\sum_{i \in I_u}(r_{u,i}-\mu) \
69 | b_i=\frac{1}{|U_i|}\sum_{u \in U_i}(r_{u,i}-b_u-\mu)
70 | $$
71 |
72 | * 如何选择协同过滤算法是基于user还是基于item
73 | 一般,谁的量多就不选谁。然而基于user的会给推荐目标带来惊喜,选择的范围更为宽阔,而不是基于推荐目标当前的相似item。因此如果要给推荐目标意想不到的推荐,就选择基于user的方式。可以两者结合。
74 |
75 |
76 | * 协同过滤的优缺点
77 | 1. 缺点:
78 | (1)稀疏性—— 这是协同过滤中最大的问题,大部分数据不足只能推荐比较流行的items,因为很多人只有对少量items进行评价,而且一般items的量非常多,很难找到近邻。导致大量的user木有数据可推荐(一般推荐比较流行的items),大量的item不会被推荐
79 | (2)孤独用户——孤独user具有非一般的品味,难以找到近邻,所以推荐不准确
80 | (3) 冷启动——只有大量的评分之后,才能协同出较多信息,所以前期数据比较少,推荐相对不准确;而如果没有人进行评分,将无法被推荐
81 | (4)相似性——协同过滤是与内容无关的推荐,只根据用户行为,所以倾向于推荐较为流行的items。
82 |
83 | * 优点:
84 | (1)不需要领域知识,存在users和items的互动,便能进行推荐
85 | (2)简单易于理解
86 | (3)相似度计算可预计算,预测效率高
87 |
88 | * 协同过滤与关联规则的异同
89 | 关联规则是不考虑tems或者使用它们的users情况下分析内容之间的关系,而协同过滤是不考虑内容直接分析items之间的关系或者users之间的关系。两者殊途同归均能用于推荐系统,但是计算方式不同。
90 |
91 | * 实践中的一些注意点
92 | (1) 过滤掉被评价较少的items
93 | (2) 过滤掉评价较少的users
94 | (3) 可用聚类方式缩小搜索空间,但是面临找不到相同偏好的用户(如果用户在分界点,被误分的情况),这种方式通过缩小搜索空间的方式优化协同过滤算法
95 | (4) 使用的时候,可以考虑时间范围,偏好随着时间的改变会改变
96 |
97 | ## 面试真题
98 | 使用协同过滤算法之前,数据应该如何进行预处理?
99 | 协同过滤的方式有哪些?
100 | 如何通过相似度计算设计协同过滤推荐系统?
101 | 请谈谈你对协同过滤中特征学习的理解?
102 | 如何将协同过滤用于推荐系统?
103 | FUNK SVD相对于SVD有哪些优势?
104 | 如何求解FUNK SVD?
105 | 请描述下协同过滤的优缺点?
106 |
--------------------------------------------------------------------------------
/AI算法/推荐/deepfm.md:
--------------------------------------------------------------------------------
1 | # DeepFM
2 |
3 |
4 |
5 |
6 |
7 | DeepFM模型是2017年由哈工大与华为联合提出的模型,是对Wide&Deep模型的改进。与DCN不同的是,DeepFM模型是将Wide部分替换为了FM模型,增强了模型的低阶特征交互的能力。关于低阶特征交互,文章的Introduction中也提到了其重要性,例如:
8 |
9 | 1、用户经常在饭点下载送餐APP,故存在一个2阶交互:app种类与时间戳;
10 |
11 | 2、青少年喜欢射击游戏和RPG游戏,存在一个3阶交互:app种类、用户性别和年龄;
12 |
13 | 用户背后的特征交互非常的复杂,低阶和高阶的特征交互都是很重要的,这也证明了Wide&Deep这种模型架构的有效性。DeepFM是一种**端到端的模型**,强调了包括低阶和高阶的特征交互接下来直接对DeepFM模型架构进行介绍,并与其他之前提到过的模型进行简单的对比。
14 |
15 |
16 |
17 | ## 模型结构
18 |
19 | DeepFM的模型结构非常简单,由Wide部分与Deep部分共同组成,如下图所示:
20 |
21 |
68 |  22 |
23 | 在论文中模型的目标是**共同学习低阶和高阶特征交互**,应用场景依旧是CTR预估,因此是一个二分类任务($y=1$表示用户点击物品,$y=0$则表示用户未点击物品)
24 |
25 | ### Input与Embedding层
26 |
27 | 关于输入,包括离散的分类特征域(如性别、地区等)和连续的数值特征域(如年龄等)。分类特征域一般通过one-hot或者multi-hot(如用户的浏览历史)进行处理后作为输入特征;数值特征域可以直接作为输入特征,也可以进行离散化进行one-hot编码后作为输入特征。
28 |
29 | 对于每一个特征域,需要单独的进行Embedding操作,因为每个特征域几乎没有任何的关联,如性别和地区。而数值特征无需进行Embedding。
30 |
31 | Embedding结构如下:
32 |
33 |
22 |
23 | 在论文中模型的目标是**共同学习低阶和高阶特征交互**,应用场景依旧是CTR预估,因此是一个二分类任务($y=1$表示用户点击物品,$y=0$则表示用户未点击物品)
24 |
25 | ### Input与Embedding层
26 |
27 | 关于输入,包括离散的分类特征域(如性别、地区等)和连续的数值特征域(如年龄等)。分类特征域一般通过one-hot或者multi-hot(如用户的浏览历史)进行处理后作为输入特征;数值特征域可以直接作为输入特征,也可以进行离散化进行one-hot编码后作为输入特征。
28 |
29 | 对于每一个特征域,需要单独的进行Embedding操作,因为每个特征域几乎没有任何的关联,如性别和地区。而数值特征无需进行Embedding。
30 |
31 | Embedding结构如下:
32 |
33 |  34 |
35 |
36 |
37 | 文章中指出每个特征域使用的Embedding维度$k$都是相同的。
38 |
39 | 【注】与Wide&Deep不同的是,DeepFM中的**Wide部分与Deep部分共享了输入特征**,即Embedding向量。
40 |
41 |
42 |
43 | #### Wide部分---FM
44 |
45 |
34 |
35 |
36 |
37 | 文章中指出每个特征域使用的Embedding维度$k$都是相同的。
38 |
39 | 【注】与Wide&Deep不同的是,DeepFM中的**Wide部分与Deep部分共享了输入特征**,即Embedding向量。
40 |
41 |
42 |
43 | #### Wide部分---FM
44 |
45 |  46 |
47 |
48 |
49 | FM模型[^4]是2010年Rendle提出的一个强大的**非线性分类模型**,除了特征间的线性(1阶)相互作用外,FM还将特征间的(2阶)相互作用作为各自特征潜向量的内积进行j建模。通过隐向量的引入使得FM模型更好的去处理数据稀疏行的问题,想具体了解的可以看一下原文。DeepFM模型的Wide部分就直接使用了FM,Embedding向量作为FM的输入。
50 |
51 | $$
52 | y_{F M}=\langle w, x\rangle+\sum_{j_{1}=1}^{d} \sum_{j_{2}=j_{1}+1}^{d}\left\langle V_{i}, V_{j}\right\rangle x_{j_{1}} \cdot x_{j_{2}}
53 | $$
54 | 其中$w \in \mathbf{R}^d$,$\langle w, x\rangle$表示1阶特征,$V_i \in \mathbf{R}^k$表示第$i$个隐向量,$k$表示隐向量的维度,$$\displaystyle\sum_{j_{1}=1}^{d} \sum_{j_{2}=j_{1}+1}^{d}\left\langle V_{i}, V_{j}\right\rangle x_{j_{1}} \cdot x_{j_{2}}$$表示2阶特征。
55 |
56 | 具体的对于2阶特征,FM论文中有下述计算(采取原文的描述形式),为线性复杂复杂度$O(kn)$:
57 | $$
58 | \begin{aligned} & \sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j} \\=& \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j}-\frac{1}{2} \sum_{i=1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{i}\right\rangle x_{i} x_{i} \\=& \frac{1}{2}\left(\sum_{i=1}^{n} \sum_{j=1}^{n} \sum_{f=1}^{k} v_{i, f} v_{j, f} x_{i} x_{j}-\sum_{i=1}^{n} \sum_{f=1}^{n} v_{i, f} v_{i, f} x_{i} x_{i}\right) \\=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)\left(\sum_{j=1}^{n} v_{j, f} x_{j}\right)-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right) \\=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{2}-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right) \end{aligned}
59 | $$
60 |
61 | #### Deep部分
62 |
63 |
46 |
47 |
48 |
49 | FM模型[^4]是2010年Rendle提出的一个强大的**非线性分类模型**,除了特征间的线性(1阶)相互作用外,FM还将特征间的(2阶)相互作用作为各自特征潜向量的内积进行j建模。通过隐向量的引入使得FM模型更好的去处理数据稀疏行的问题,想具体了解的可以看一下原文。DeepFM模型的Wide部分就直接使用了FM,Embedding向量作为FM的输入。
50 |
51 | $$
52 | y_{F M}=\langle w, x\rangle+\sum_{j_{1}=1}^{d} \sum_{j_{2}=j_{1}+1}^{d}\left\langle V_{i}, V_{j}\right\rangle x_{j_{1}} \cdot x_{j_{2}}
53 | $$
54 | 其中$w \in \mathbf{R}^d$,$\langle w, x\rangle$表示1阶特征,$V_i \in \mathbf{R}^k$表示第$i$个隐向量,$k$表示隐向量的维度,$$\displaystyle\sum_{j_{1}=1}^{d} \sum_{j_{2}=j_{1}+1}^{d}\left\langle V_{i}, V_{j}\right\rangle x_{j_{1}} \cdot x_{j_{2}}$$表示2阶特征。
55 |
56 | 具体的对于2阶特征,FM论文中有下述计算(采取原文的描述形式),为线性复杂复杂度$O(kn)$:
57 | $$
58 | \begin{aligned} & \sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j} \\=& \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j}-\frac{1}{2} \sum_{i=1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{i}\right\rangle x_{i} x_{i} \\=& \frac{1}{2}\left(\sum_{i=1}^{n} \sum_{j=1}^{n} \sum_{f=1}^{k} v_{i, f} v_{j, f} x_{i} x_{j}-\sum_{i=1}^{n} \sum_{f=1}^{n} v_{i, f} v_{i, f} x_{i} x_{i}\right) \\=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)\left(\sum_{j=1}^{n} v_{j, f} x_{j}\right)-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right) \\=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{2}-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right) \end{aligned}
59 | $$
60 |
61 | #### Deep部分
62 |
63 |  64 |
65 | Deep部分是一个前向传播的神经网络,用来学习高阶特征交互。
66 |
67 |
68 |
69 | ### Output层
70 |
71 | FM层与Deep层的输出相拼接,最后通过一个逻辑回归返回最终的预测结果:
72 | $$
73 | \hat y=sigmoid(y_{FM}+y_{DNN})
74 | $$
75 |
76 |
77 |
78 | ## 面试相关
79 |
80 | 1、Wide&Deep与DeepFM的区别?
81 |
82 | Wide&Deep模型,Wide部分采用人工特征+LR的形式,而DeepFM的Wide部分采用FM模型,包含了1阶特征与二阶特征的交叉,且是端到端的,无需人工的特征工程。
83 |
84 |
85 |
86 | 2、DeepFM的Wide部分与Deep部分分别是什么?Embedding内容是否共享
87 |
88 | Wide:FM,Deep:DNN;
89 |
90 | Embedding内容是共享的,在FM的应用是二阶特征交叉时的表征。
91 |
92 |
--------------------------------------------------------------------------------
/AI算法/推荐/gbdt_lr.md:
--------------------------------------------------------------------------------
1 | # gbdt lr
2 | gbdt+lr是facebook提出在线广告模型,我们知道LR之前在广告和推荐系统由于其快速的计算
3 | 而被广泛使用,使用由于lr是线性模型,其模型表现能力不强,需要做大量的特征工程。
4 | facebook提出提出使用决策树进行特征embedding。
5 | 为了提升线性分类器的准确度,有两种方法进行特征变换:
6 | 1. 对于连续特征。先进行离散化bin,然后把bin的编号作为离散型特征。这样的话,线性模型可以分段的学习到一个非线性的映射,在每一段内的映射是不变的。另外,对于bin边界的学习非常重要
7 | 2. 对于离散特征。做笛卡尔积,生成的是tuple input features。笛卡尔积穷举了所有的特征组合,其中也包含部分没用的组合特征,不过可以筛选出来。
8 | 提升决策树(boosted decision tree)就可以很方便很好的实现上面我们说的这种非线性和tuple特征变换。对于一个样本,针对每一颗树得到一个类别型特征。该特征取值为样本在树中落入的叶节点的编号。举例来说:
9 |
64 |
65 | Deep部分是一个前向传播的神经网络,用来学习高阶特征交互。
66 |
67 |
68 |
69 | ### Output层
70 |
71 | FM层与Deep层的输出相拼接,最后通过一个逻辑回归返回最终的预测结果:
72 | $$
73 | \hat y=sigmoid(y_{FM}+y_{DNN})
74 | $$
75 |
76 |
77 |
78 | ## 面试相关
79 |
80 | 1、Wide&Deep与DeepFM的区别?
81 |
82 | Wide&Deep模型,Wide部分采用人工特征+LR的形式,而DeepFM的Wide部分采用FM模型,包含了1阶特征与二阶特征的交叉,且是端到端的,无需人工的特征工程。
83 |
84 |
85 |
86 | 2、DeepFM的Wide部分与Deep部分分别是什么?Embedding内容是否共享
87 |
88 | Wide:FM,Deep:DNN;
89 |
90 | Embedding内容是共享的,在FM的应用是二阶特征交叉时的表征。
91 |
92 |
--------------------------------------------------------------------------------
/AI算法/推荐/gbdt_lr.md:
--------------------------------------------------------------------------------
1 | # gbdt lr
2 | gbdt+lr是facebook提出在线广告模型,我们知道LR之前在广告和推荐系统由于其快速的计算
3 | 而被广泛使用,使用由于lr是线性模型,其模型表现能力不强,需要做大量的特征工程。
4 | facebook提出提出使用决策树进行特征embedding。
5 | 为了提升线性分类器的准确度,有两种方法进行特征变换:
6 | 1. 对于连续特征。先进行离散化bin,然后把bin的编号作为离散型特征。这样的话,线性模型可以分段的学习到一个非线性的映射,在每一段内的映射是不变的。另外,对于bin边界的学习非常重要
7 | 2. 对于离散特征。做笛卡尔积,生成的是tuple input features。笛卡尔积穷举了所有的特征组合,其中也包含部分没用的组合特征,不过可以筛选出来。
8 | 提升决策树(boosted decision tree)就可以很方便很好的实现上面我们说的这种非线性和tuple特征变换。对于一个样本,针对每一颗树得到一个类别型特征。该特征取值为样本在树中落入的叶节点的编号。举例来说:
9 |  10 | 上图中的提升决策树包含两棵子树,第一棵树包含3个叶节点,第二棵树包含2个叶节点。输入样本x,在两棵树种分别落入叶子节点2和叶子节点1。那么特征转换就得到特征向量[0 1 0 1 0]。也就是说,把叶节点编号进行one-hot编码。
11 | 那么, 怎么样直观的理解这种特征变化:
12 | + 看做是一种有监督的特征编码。把实值的vector转换成紧凑的二值的vector。
13 | + 从根节点到叶节点的一条路径,表示的是在特征上的一个特定的规则。所以,叶节点的编号代表了这种规则。表征了样本中的信息,而且进行了非线性的组合变换。
14 | + 最后再对叶节点编号组合,相当于学习这些规则的权重。
15 |
16 | # 核心思想
17 | 1. 数据更新
18 | > 由于推荐和广告等相关的问题,是一个动态的环境,需要对模型进行实时更新,所有对于lr进行在线学习和更新,gbdt可以每天或者几天更新一次。
19 | 2. 在线学习的学习率如何设置
20 | > 一般情况有很多学习率更新的方法,可以根据当前系统进行实验得到最好的学习率设置策略。论文中给出一下几种方法:
21 | + Per-coordinate learning rate:
22 | $$\eta_{t,i}=\frac{\alpha}{\beta+\sqrt{\sum_{j=1}^{t}}\bigtriangledown_{j,i}^2}$$
23 | 其中,$\alpha, \beta$是两个超参数.
24 | + Per-weight square root learning rate:
25 | $$\eta_{t,i}=\frac{\alpha}{\sqrt{n_{t,i}}}$$
26 | 其中,$n_{t,i}$是特征i所有实例的前t次的总和。
27 | + Per-weight learning rate:
28 | $$\eta_{t,i}=\frac{\alpha}{n_{t,i}}$$
29 | + Global learning rate:
30 | $$\eta_{t,i}=\frac{\alpha}{\sqrt{t}}$$
31 | + Constant learning rate:
32 | $$\eta_{t,i}=\alpha$$
33 | 3. 为了保证数据的新鲜性,需要进行在线数据加入,所有的曝光的实例,设置时间t,在时间t内被点击设置为label=1,否则设置label=0,注意时间t不能太大也不能太小,根据现实业务进行设置.
34 |
35 | 4. 样本的均匀采样和负样本数据的下采样,由于负样本太多需要对负样本进行下采样。
36 |
37 | 5. Model Re-Calibration
38 | > 负样本欠采样可以加快训练速度并提升模型性能。但是同样带来了问题:改变了训练数据分布。所以需要进行校准。
39 | $$q=\frac{p}{p+(1-p)/w}$$
40 | 其中:
41 | + w是采样率
42 | + p是在采样后空间中给出的CTR预估值
43 | + 计算得到的q就是修正后的结果
44 |
45 | # 面试十问
46 | 1. lr的权重个数和gbdt的什么有关?
47 | > lr的权重个数,等于gbdt所有叶子节点的个数.
48 |
49 | 2. 负样本欠采样之后会对模型有什么影响,怎么解决?
50 | > 负样本欠采样可以加快训练速度并提升模型性能。但是同样带来了问题:改变了训练数据分布。所以需要进行校准。
51 | > $$q=\frac{p}{p+(1-p)/w}$$
52 |
53 | 3. GBDT特征的重要性是如何评估的?
54 | > 特征j的全局重要度通过特征j在单颗树中的重要度的平均值来衡量:
55 | > $$\hat J_j^2=\frac{1}{M}\sum_{m=1}^{M}\hat J_j^2(T_m)$$
56 | > 其中,M是树的数量,特征j在单棵树中的重要度如下:
57 | > $$\hat J_j^2(T)=\sum_{t=1}^{L-1}\hat i_j^2 I(v_t=j)$$
58 |
59 | 4. gbdt+lr如何训练
60 | > 一般是先训练gbdt在训练lr,首先将数据data分成两部分a和b,a用来训练gbdt,b用来训练lr。其中用a训练gbdt的时候,需要将a分成train_a, valid_a, test_a, 得到gbdt之后。将b通过gbdt得到所有对应叶子节点的下标进行one-hot编码.
61 | > 继续训练b,将b通过gbdt得到update_b, 将update_b分成训练、验证和测试集,训练得到LR.
62 |
63 | 5. 为什么建树采用ensemble决策树?
64 | > 一棵树的表达能力很弱,不足以表达多个有区分性的特征组合,多棵树的表达能力更强一些。GBDT每棵树都在学习前面棵树尚存的不足,迭代多少次就会生成多少颗树。按paper以及Kaggle竞赛中的GBDT+LR融合方式,多棵树正好满足LR每条训练样本可以通过GBDT映射成多个特征的需求。
65 |
66 | 6. 为什么建树采用GBDT而非RF?
67 | > RF也是多棵树,但从效果上有实践证明不如GBDT。且GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理,这应该也是用GBDT的原因。
68 |
69 | 7. GBDT与LR融合方案
70 | > AD ID类特征在CTR预估中是非常重要的特征,直接将AD ID作为feature进行建树不可行,故考虑为每个AD ID建GBDT树。但互联网时代长尾数据现象非常显著,广告也存在长尾现象,为了提升广告整体投放效果,不得不考虑长尾广告。在GBDT建树方案中,对于曝光充分训练样本充足的广告,可以单独建树,发掘对单个广告有区分度的特征,但对于曝光不充分样本不充足的长尾广告,无法单独建树,需要一种方案来解决长尾广告的问题。
71 |
72 | > 综合考虑方案如下,使用GBDT建两类树,非ID建一类树,ID建一类树。
73 |
74 | > 1)非ID类树:不以细粒度的ID建树,此类树作为base,即便曝光少的广告、广告主,仍可以通过此类树得到有区分性的特征、特征组合。
75 |
76 | > 2)ID类树:以细粒度 的ID建一类树,用于发现曝光充分的ID对应有区分性的特征、特征组合。如何根据GBDT建的两类树,对原始特征进行映射?以如下图3为例,当一条样本x进来之后,遍历两类树到叶子节点,得到的特征作为LR的输入。当AD曝光不充分不足以训练树时,其它树恰好作为补充。
77 |
78 |
79 | # 面试真题
80 | 1. 为什么建树采用GBDT而非RF?
81 |
82 | # 参考
83 | 1. https://blog.csdn.net/u010352603/article/details/80681100
84 | 2. http://www.cbdio.com/BigData/2015-08/27/content_3750170.htm
85 | 3. https://blog.csdn.net/u014297722/article/details/89420421
--------------------------------------------------------------------------------
/AI算法/推荐/向量化搜索.md:
--------------------------------------------------------------------------------
1 | # 向量化搜索
2 |
3 | 在高维空间内快速搜索最近邻(Approximate Nearest Neighbor)。召回中,Embedding向量的搜索。
4 |
5 | FAISS、kd-tree、局部敏感哈希、【Amnoy、HNSW】
6 |
7 |
8 |
9 | ## FAISS
10 |
11 | faiss是Facebook的AI团队开源的一套用于做聚类或者相似性搜索的软件库,底层是用C++实现。Faiss因为超级优越的性能,被广泛应用于推荐相关的业务当中。
12 |
13 | faiss工具包一般使用在推荐系统中的向量召回部分。在做向量召回的时候要么是u2u,u2i或者i2i,这里的u和i指的是user和item。我们知道在实际的场景中user和item的数量都是海量的,最容易想到的基于向量相似度的召回就是使用两层循环遍历user列表或者item列表计算两个向量的相似度,但是这样做在面对海量数据是不切实际的,faiss就是用来加速计算某个查询向量最相似的topk个索引向量。
14 |
15 | **faiss查询的原理:**
16 |
17 | faiss使用了PCA和PQ(Product quantization乘积量化)两种技术进行向量压缩和编码,当然还使用了其他的技术进行优化,但是PCA和PQ是其中最核心部分。
18 |
19 | ### **主要流程**
20 |
21 | - 构建索引`index`
22 | - 根据不同索引的特性,对索引进行训练(`train`)
23 | - `add` 添加`xb`数据到索引
24 | - 针对`xq`进行搜索`search`操作
25 |
26 | ### Example
27 |
28 | 1、数据集
29 |
30 | ```python
31 | d = 64 # dimension
32 | nb = 100000 # 完整数据集
33 | nq = 10000 # 查询数据
34 | np.random.seed(1234)
35 | xb = np.random.random((nb, d)).astype('float32')
36 | xb[:, 0] += np.arange(nb) / 1000.
37 | xq = np.random.random((nq, d)).astype('float32')
38 | xq[:, 0] += np.arange(nq) / 1000.
39 | ```
40 |
41 | 2、构建索引
42 |
43 | Faiss围绕`Index`对象构建。它封装了数据库向量集,并可选地对其进行预处理以提高搜索效率。索引的类型很多,我们将使用最简单的索引,它们仅对它们执行暴力L2距离搜索:`IndexFlatL2`。
44 |
45 | `d`在我们的例子中,所有索引都需要知道何时建立索引,即它们所操作的向量的维数
46 |
47 | ```python
48 | index = faiss.IndexFlatL2(d) # build the index
49 | ```
50 |
51 | 3、对索引进行训练
52 |
53 | 然后,大多数索引还需要训练阶段,以分析向量的分布。对于`IndexFlatL2`,我们可以跳过此操作。
54 |
55 | 4、添加数据到索引
56 |
57 | 构建和训练索引后,可以对索引执行两项操作:`add`和`search`。
58 |
59 | 将元素添加到索引,我们称之为`add`上`xb`。我们还可以显示索引的两个状态变量:`is_trained`,指示是否需要训练的布尔值,以及`ntotal`索引向量的数量。
60 |
61 | 一些索引还可以存储与每个向量相对应的整数ID(但不能存储`IndexFlatL2`)。如果未提供ID,则`add`只需将向量序号用作ID,即。第一个向量为0,第二个为1,依此类推。
62 |
63 | ```python
64 | index.add(xb) # add vectors to the index
65 | ```
66 |
67 | 5、对查询数据进行搜索操作
68 |
69 | 可以对索引执行的基本搜索操作是`k`-最近邻搜索,即。对于每个查询向量,`k`在数据库中找到其最近的邻居。
70 |
71 | 该操作的结果可以方便地存储在一个大小为`nq`-by-的整数矩阵中`k`,其中第i行包含查询向量i的邻居ID(按距离递增排序)。除此矩阵外,该`search`操作还返回一个具有相应平方距离的`nq`按`k`浮点矩阵。
72 |
73 | ```python
74 | k = 4 # we want to see 4 nearest neighbors
75 | D, I = index.search(xb[:5], k) # sanity check, 首先搜索一些数据库向量,以确保最近的邻居确实是向量本身
76 | print(I)
77 | print(D)
78 | D, I = index.search(xq, k) # actual search
79 | print(I[:5]) # neighbors of the 5 first queries
80 | print(I[-5:]) # neighbors of the 5 last queries
81 | ```
82 |
83 | ### 索引方式
84 |
85 | Faiss中的稠密向量各种索引都是基于 `Index`实现的,主要的索引方法包括: `IndexFlatL2`、`IndexFlatIP`、`IndexHNSWFlat`、`IndexIVFFlat`、`IndexLSH`、`IndexScalarQuantizer`、`IndexPQ`、`IndexIVFScalarQuantizer`、`IndexIVFPQ`、`IndexIVFPQR`等,[每个方法的具体介绍](https://github.com/facebookresearch/faiss/wiki/Faiss-indexes#summary-of-methods)。
86 |
87 | `IndexFlatL2`:
88 |
89 | - 基于L2距离的暴力全量搜索,速度较慢,不需要训练过程。
90 |
91 | `IndexIVFFlat`:
92 |
93 | - 先聚类再搜索,可以加快检索速度;
94 | - 先将`xb`中的数据进行聚类(聚类的数目是超参),`nlist`: 聚类的数目
95 | - `nprobe`: 在多少个聚类中进行搜索,默认为`1`, `nprobe`越大,结果越精确,但是速度越慢
96 |
97 | ```python
98 | def IndexIVFFlat(nlist):
99 | quantizer = faiss.IndexFlatL2(d)
100 | index = faiss.IndexIVFFlat(quantizer, d, nlist)
101 | print(index.is_trained)
102 | index.train(xb)
103 | print(index.is_trained)
104 | index.add(xb)
105 | return index
106 | ```
107 |
108 | `IndexIFVPQ`
109 |
110 | - 基于乘积量化(product quantizers)对存储向量进行压缩,节省存储空间
111 | - `m`:乘积量化中,将原来的向量维度平均分成多少份,`d`必须为`m`的整数倍
112 | - `bits`: 每个子向量用多少个`bits`表示
113 |
114 | ```python
115 | def IndexIVFPQ(nlist, m, bits):
116 | quantizer = faiss.IndexFlatL2(d)
117 | index = faiss.IndexIVFPQ(quantizer, d, nlist, m, bits)
118 | index.train(xb)
119 | index.add(xb)
120 | return index
121 | ```
122 |
123 |
124 |
125 | ## kd树
126 |
127 | kd树是一种对k维空间中的实例点进行**存储**以便对其进行**快速检索**的树形数据结构。kd树是**二叉树**,表示对k维空间的一个划分(partition)。**构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分,构成一系列的k维超矩形区域**。kd树的每个结点对应于一个k维超矩形区域。
128 |
129 | ### kd树的结构
130 |
131 | kd树是一个二叉树结构,它的每一个节点记载了【特征坐标,切分轴,指向左枝的指针,指向右枝的指针】。
132 |
133 | 其中,特征坐标是线性空间$\mathbf{R}^n$的一个点$(x_1,...,x_n)$。
134 |
135 | 切分轴由一个整数$r$表示,这里$1\leq r\leq n$,是我们在$n$ 维空间中沿第$n$维进行一次分割。
136 |
137 | 节点的左枝和右枝分别都是 kd 树,并且满足:如果 y 是左枝的一个特征坐标,那么$y_r \leq x_r$并且如果 z 是右枝的一个特征坐标,那么$x_r \leq z_r $。
138 |
139 | ### kd树的构造
140 |
141 | 通过数据集来构造kd树存储空间,在推荐系统中即用物品Embedding池进行构建。
142 |
143 | - 输入:k维空间数据集$T=\left\{x_{1}, x_{2}, \cdots, x_{N}\right\}$,其中$x_{i}=\left(x_{i}^{(1)}, x_{i}^{(2)}, \cdots, x_{i}^{(k)}\right)^{\mathrm{T}},i=1,2,...,N$;
144 |
145 | - 输出:kd树;
146 |
147 | - (1)开始:构造根结点,根结点对应于包含$T$的$k$维空间的超矩形区域。
148 |
149 | 选择$x^{(1)}$为坐标轴,以$T$中所有实例的$x^{(1)}$坐标的**中位数为切分点**【若超平面上没有切分点,可以适当移动位置,使得超平面上有点】,将根结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴$x^{(1)}$垂直的超平面实现。
150 |
151 | 由根结点生成深度为1的左、右子结点:左子结点对应坐标$x^{(1)}$小于切分点的子区域,右子结点对应于坐标$x^{(1)}$大于切分点的子区域。
152 | 将**落在切分超平面上的实例点保存在根结点**。
153 |
154 | - (2)重复:对深度为$j$的结点,选择$x^{(l)}$为切分的坐标轴,$l=j(\bmod k)+1$,以该结点的区域中所有实例的$x^{(l)}$坐标的中位数为切分点,将该结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴$x^{(l)}$垂直的超平面实现。
155 | 由该结点生成深度为$j+1$的左、右子结点:左子结点对应坐标$x^{(l)}$小于切分点的子区域,右子结点对应坐标$x^{(l)}$大于切分点的子区域
156 | 将落在切分超平面上的实例点保存在该结点。
157 |
158 | - (3)直到两个子区域没有实例存在时停止。从而形成kd树的区域划分。
159 |
160 | 最后每一部分都只剩一个点,将他们记在最底部的节点中。因为不再有未被记录的点,所以不再进行切分。
161 |
162 | 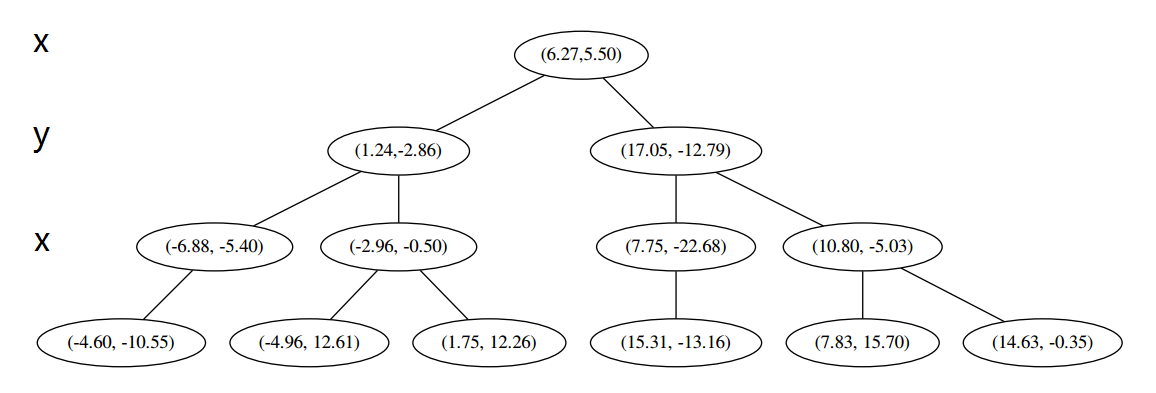
163 |
164 | 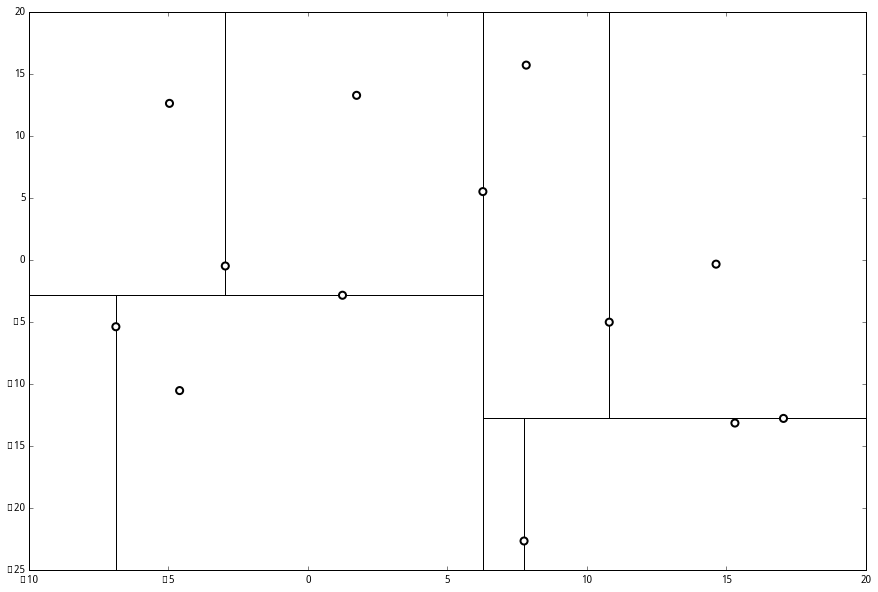
165 |
166 | ### 搜索kd树
167 |
168 | 在推荐系统中,即通过用户的Embedding向量来查找与其近邻的$K$个物品Embedding向量。
169 |
170 | - 输入:已构造的kd树;目标点$x$;
171 | - 输出:$x$的$k$近邻;
172 | - 设有一个$ k$个空位的列表,用于保存已搜寻到的最近点。
173 |
174 | - (1)在kd树中找出包含目标点$x$的叶结点:从根结点出发,递归地向下访问树。若目标点$x$当前维的坐标小于切分点的坐标,则移动到左子结点,否则移动到右子结点,直到子结点为叶结点为止;
175 | - (2)如果**“当前k近邻点集”元素数量小于$k$**或者**叶节点距离小于“当前k近邻点集”中最远点距离**,那么将叶节点插入“当前k近邻点集”;
176 | - (3)递归地向上回退,在每个结点进行以下操作:
177 | - 如果“当前k近邻点集”元素数量小于k或者当前节点距离小于“当前k近邻点集”中最远点距离,那么将该节点插入“当前k近邻点集”。
178 | - 检查该子结点的父结点的另一子结点对应的区域是否与以目标点为球心、以目标点与于“当前k近邻点集”中最远点间的距离为半径的超球体相交。如果相交,可能在另一个子结点对应的区域内存在距目标点更近的点,移动到另一个子结点,接着,递归地进行最近邻搜索;如果不相交,向上回退;
179 | - 当回退到根结点时,搜索结束,最后的“当前k近邻点集”即为$x$的k近邻点。
180 |
181 | kd树的平均计算复杂度是$log(N)$。
182 |
183 | 参考资料:[kd 树算法之详细篇](https://zhuanlan.zhihu.com/p/23966698)
184 |
185 |
186 |
187 | ## 局部敏感哈希
188 |
189 | 局部敏感哈希的基本思想:
190 |
191 | > 让相邻对的点落入同一个“桶”,这样在进行最近邻搜索时,仅需要在一个桶内,或相邻的几个桶内的元素中进行搜索即可。如果保持每个桶中的元素个数在一个常数附近,就可以把最近邻搜索的时间复杂度降低到常数级别。
192 |
193 | 首先需要明确一个概念,
194 |
195 | > 在欧式空间中,将高维空间的点映射到低维空间,原本相近的点在低维空间中肯定依然相近,但原本远离的点则有一定概率变成相近的点。
196 |
197 | 所以**利用低维空间可以保留高维空间相近距离关系的性质**,就可以构造局部敏感哈希的桶。
198 |
199 | 对于Embedding向量,可以用内积操作构建局部敏感哈希桶。假设$\mathbf{v}$是高维空间中的$k$维Embedding向量,$\mathbf{x}$是随机生成的$k$维向量。内积操作可以将$\mathbf{v}$映射到1维空间,成为一个数值:
200 | $$
201 | h(\mathbf{v})=\mathbf{v}\cdot \mathbf{x}
202 | $$
203 | 因此,可以使用哈希函数$h(v)$进行分桶:
204 | $$
205 | h^{x,b}(\mathbf{v})=\lfloor x \frac{\mathbf{x}\cdot \mathbf{v}+ b}{w}\rfloor x
206 | $$
207 | 其中$\lfloor \rfloor$是向下取整,$w$是分桶宽度,$b$是0到$w$间的一个均匀分布随机变量,避免分桶边界固化。
208 |
209 | 如果仅采用一个哈希函数进行分桶,则必然存在相近点误判的情况。有效的解决方法是采用$m$个哈希函数同时进行分桶。同时掉进$m$个哈希函数的同一个桶的两点,是相似点的概率大大增加。找到相邻点集合后,取$K$近邻个。
210 |
211 | 采用多个哈希函数进行分桶,存在一个待解决的问题,到底通过“与”还是“或”:
212 |
213 | - 与:候选集规模减小,计算量降低,但可能会漏掉一些近邻点;
214 | - 或:候选集中近邻点的召回率提高,但候选集的规模变大,计算开销变大;
215 |
216 | 以上是将欧式空间中内积操作的局部敏感哈希使用方法;还有余弦相似度、曼哈顿距离、切比雪夫距离、汉明距离等。
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Daily Interview
2 |
3 | ## 背景
4 |
5 | 牛客网,知乎等众多网站上包含了数以百万计的面经,但往往大而散,面试者在准备面试时候去翻阅不但浪费时间,翻阅材料越多,越觉得自己很多知识点都没有掌握,造成心理上极大的压力,导致面试中不能发挥正常水平甚至面试失败。
6 | 其实,每一位求职者都应该有自己的一份面试笔记,记录笔试中常涉及到的知识点和项目中常被问到的问题。每次面试之前看一遍,做到举一反三,融会贯通,熟捻于心,方能在每次面试中汲取经验,最后从容应对。我个人就有自己的面试笔记,每次面试之前都会翻一遍,边看边想,但求好运。
7 |
8 | ## 宗旨
9 | 不需要大而全,涵盖所有内容,因为知识在不断更新迭代,我们也做不到涵盖所有。
10 | 不提供查漏补缺,因为每个人的短板不尽相同,需要面试者根据自己知识体系,多加思考,自己完善。
11 | 这是一份每一个面试者面试之前必看一遍的小面经。面试之前的半天时间,温故而知新。
12 |
13 | ## 内容
14 |
15 |
10 | 上图中的提升决策树包含两棵子树,第一棵树包含3个叶节点,第二棵树包含2个叶节点。输入样本x,在两棵树种分别落入叶子节点2和叶子节点1。那么特征转换就得到特征向量[0 1 0 1 0]。也就是说,把叶节点编号进行one-hot编码。
11 | 那么, 怎么样直观的理解这种特征变化:
12 | + 看做是一种有监督的特征编码。把实值的vector转换成紧凑的二值的vector。
13 | + 从根节点到叶节点的一条路径,表示的是在特征上的一个特定的规则。所以,叶节点的编号代表了这种规则。表征了样本中的信息,而且进行了非线性的组合变换。
14 | + 最后再对叶节点编号组合,相当于学习这些规则的权重。
15 |
16 | # 核心思想
17 | 1. 数据更新
18 | > 由于推荐和广告等相关的问题,是一个动态的环境,需要对模型进行实时更新,所有对于lr进行在线学习和更新,gbdt可以每天或者几天更新一次。
19 | 2. 在线学习的学习率如何设置
20 | > 一般情况有很多学习率更新的方法,可以根据当前系统进行实验得到最好的学习率设置策略。论文中给出一下几种方法:
21 | + Per-coordinate learning rate:
22 | $$\eta_{t,i}=\frac{\alpha}{\beta+\sqrt{\sum_{j=1}^{t}}\bigtriangledown_{j,i}^2}$$
23 | 其中,$\alpha, \beta$是两个超参数.
24 | + Per-weight square root learning rate:
25 | $$\eta_{t,i}=\frac{\alpha}{\sqrt{n_{t,i}}}$$
26 | 其中,$n_{t,i}$是特征i所有实例的前t次的总和。
27 | + Per-weight learning rate:
28 | $$\eta_{t,i}=\frac{\alpha}{n_{t,i}}$$
29 | + Global learning rate:
30 | $$\eta_{t,i}=\frac{\alpha}{\sqrt{t}}$$
31 | + Constant learning rate:
32 | $$\eta_{t,i}=\alpha$$
33 | 3. 为了保证数据的新鲜性,需要进行在线数据加入,所有的曝光的实例,设置时间t,在时间t内被点击设置为label=1,否则设置label=0,注意时间t不能太大也不能太小,根据现实业务进行设置.
34 |
35 | 4. 样本的均匀采样和负样本数据的下采样,由于负样本太多需要对负样本进行下采样。
36 |
37 | 5. Model Re-Calibration
38 | > 负样本欠采样可以加快训练速度并提升模型性能。但是同样带来了问题:改变了训练数据分布。所以需要进行校准。
39 | $$q=\frac{p}{p+(1-p)/w}$$
40 | 其中:
41 | + w是采样率
42 | + p是在采样后空间中给出的CTR预估值
43 | + 计算得到的q就是修正后的结果
44 |
45 | # 面试十问
46 | 1. lr的权重个数和gbdt的什么有关?
47 | > lr的权重个数,等于gbdt所有叶子节点的个数.
48 |
49 | 2. 负样本欠采样之后会对模型有什么影响,怎么解决?
50 | > 负样本欠采样可以加快训练速度并提升模型性能。但是同样带来了问题:改变了训练数据分布。所以需要进行校准。
51 | > $$q=\frac{p}{p+(1-p)/w}$$
52 |
53 | 3. GBDT特征的重要性是如何评估的?
54 | > 特征j的全局重要度通过特征j在单颗树中的重要度的平均值来衡量:
55 | > $$\hat J_j^2=\frac{1}{M}\sum_{m=1}^{M}\hat J_j^2(T_m)$$
56 | > 其中,M是树的数量,特征j在单棵树中的重要度如下:
57 | > $$\hat J_j^2(T)=\sum_{t=1}^{L-1}\hat i_j^2 I(v_t=j)$$
58 |
59 | 4. gbdt+lr如何训练
60 | > 一般是先训练gbdt在训练lr,首先将数据data分成两部分a和b,a用来训练gbdt,b用来训练lr。其中用a训练gbdt的时候,需要将a分成train_a, valid_a, test_a, 得到gbdt之后。将b通过gbdt得到所有对应叶子节点的下标进行one-hot编码.
61 | > 继续训练b,将b通过gbdt得到update_b, 将update_b分成训练、验证和测试集,训练得到LR.
62 |
63 | 5. 为什么建树采用ensemble决策树?
64 | > 一棵树的表达能力很弱,不足以表达多个有区分性的特征组合,多棵树的表达能力更强一些。GBDT每棵树都在学习前面棵树尚存的不足,迭代多少次就会生成多少颗树。按paper以及Kaggle竞赛中的GBDT+LR融合方式,多棵树正好满足LR每条训练样本可以通过GBDT映射成多个特征的需求。
65 |
66 | 6. 为什么建树采用GBDT而非RF?
67 | > RF也是多棵树,但从效果上有实践证明不如GBDT。且GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理,这应该也是用GBDT的原因。
68 |
69 | 7. GBDT与LR融合方案
70 | > AD ID类特征在CTR预估中是非常重要的特征,直接将AD ID作为feature进行建树不可行,故考虑为每个AD ID建GBDT树。但互联网时代长尾数据现象非常显著,广告也存在长尾现象,为了提升广告整体投放效果,不得不考虑长尾广告。在GBDT建树方案中,对于曝光充分训练样本充足的广告,可以单独建树,发掘对单个广告有区分度的特征,但对于曝光不充分样本不充足的长尾广告,无法单独建树,需要一种方案来解决长尾广告的问题。
71 |
72 | > 综合考虑方案如下,使用GBDT建两类树,非ID建一类树,ID建一类树。
73 |
74 | > 1)非ID类树:不以细粒度的ID建树,此类树作为base,即便曝光少的广告、广告主,仍可以通过此类树得到有区分性的特征、特征组合。
75 |
76 | > 2)ID类树:以细粒度 的ID建一类树,用于发现曝光充分的ID对应有区分性的特征、特征组合。如何根据GBDT建的两类树,对原始特征进行映射?以如下图3为例,当一条样本x进来之后,遍历两类树到叶子节点,得到的特征作为LR的输入。当AD曝光不充分不足以训练树时,其它树恰好作为补充。
77 |
78 |
79 | # 面试真题
80 | 1. 为什么建树采用GBDT而非RF?
81 |
82 | # 参考
83 | 1. https://blog.csdn.net/u010352603/article/details/80681100
84 | 2. http://www.cbdio.com/BigData/2015-08/27/content_3750170.htm
85 | 3. https://blog.csdn.net/u014297722/article/details/89420421
--------------------------------------------------------------------------------
/AI算法/推荐/向量化搜索.md:
--------------------------------------------------------------------------------
1 | # 向量化搜索
2 |
3 | 在高维空间内快速搜索最近邻(Approximate Nearest Neighbor)。召回中,Embedding向量的搜索。
4 |
5 | FAISS、kd-tree、局部敏感哈希、【Amnoy、HNSW】
6 |
7 |
8 |
9 | ## FAISS
10 |
11 | faiss是Facebook的AI团队开源的一套用于做聚类或者相似性搜索的软件库,底层是用C++实现。Faiss因为超级优越的性能,被广泛应用于推荐相关的业务当中。
12 |
13 | faiss工具包一般使用在推荐系统中的向量召回部分。在做向量召回的时候要么是u2u,u2i或者i2i,这里的u和i指的是user和item。我们知道在实际的场景中user和item的数量都是海量的,最容易想到的基于向量相似度的召回就是使用两层循环遍历user列表或者item列表计算两个向量的相似度,但是这样做在面对海量数据是不切实际的,faiss就是用来加速计算某个查询向量最相似的topk个索引向量。
14 |
15 | **faiss查询的原理:**
16 |
17 | faiss使用了PCA和PQ(Product quantization乘积量化)两种技术进行向量压缩和编码,当然还使用了其他的技术进行优化,但是PCA和PQ是其中最核心部分。
18 |
19 | ### **主要流程**
20 |
21 | - 构建索引`index`
22 | - 根据不同索引的特性,对索引进行训练(`train`)
23 | - `add` 添加`xb`数据到索引
24 | - 针对`xq`进行搜索`search`操作
25 |
26 | ### Example
27 |
28 | 1、数据集
29 |
30 | ```python
31 | d = 64 # dimension
32 | nb = 100000 # 完整数据集
33 | nq = 10000 # 查询数据
34 | np.random.seed(1234)
35 | xb = np.random.random((nb, d)).astype('float32')
36 | xb[:, 0] += np.arange(nb) / 1000.
37 | xq = np.random.random((nq, d)).astype('float32')
38 | xq[:, 0] += np.arange(nq) / 1000.
39 | ```
40 |
41 | 2、构建索引
42 |
43 | Faiss围绕`Index`对象构建。它封装了数据库向量集,并可选地对其进行预处理以提高搜索效率。索引的类型很多,我们将使用最简单的索引,它们仅对它们执行暴力L2距离搜索:`IndexFlatL2`。
44 |
45 | `d`在我们的例子中,所有索引都需要知道何时建立索引,即它们所操作的向量的维数
46 |
47 | ```python
48 | index = faiss.IndexFlatL2(d) # build the index
49 | ```
50 |
51 | 3、对索引进行训练
52 |
53 | 然后,大多数索引还需要训练阶段,以分析向量的分布。对于`IndexFlatL2`,我们可以跳过此操作。
54 |
55 | 4、添加数据到索引
56 |
57 | 构建和训练索引后,可以对索引执行两项操作:`add`和`search`。
58 |
59 | 将元素添加到索引,我们称之为`add`上`xb`。我们还可以显示索引的两个状态变量:`is_trained`,指示是否需要训练的布尔值,以及`ntotal`索引向量的数量。
60 |
61 | 一些索引还可以存储与每个向量相对应的整数ID(但不能存储`IndexFlatL2`)。如果未提供ID,则`add`只需将向量序号用作ID,即。第一个向量为0,第二个为1,依此类推。
62 |
63 | ```python
64 | index.add(xb) # add vectors to the index
65 | ```
66 |
67 | 5、对查询数据进行搜索操作
68 |
69 | 可以对索引执行的基本搜索操作是`k`-最近邻搜索,即。对于每个查询向量,`k`在数据库中找到其最近的邻居。
70 |
71 | 该操作的结果可以方便地存储在一个大小为`nq`-by-的整数矩阵中`k`,其中第i行包含查询向量i的邻居ID(按距离递增排序)。除此矩阵外,该`search`操作还返回一个具有相应平方距离的`nq`按`k`浮点矩阵。
72 |
73 | ```python
74 | k = 4 # we want to see 4 nearest neighbors
75 | D, I = index.search(xb[:5], k) # sanity check, 首先搜索一些数据库向量,以确保最近的邻居确实是向量本身
76 | print(I)
77 | print(D)
78 | D, I = index.search(xq, k) # actual search
79 | print(I[:5]) # neighbors of the 5 first queries
80 | print(I[-5:]) # neighbors of the 5 last queries
81 | ```
82 |
83 | ### 索引方式
84 |
85 | Faiss中的稠密向量各种索引都是基于 `Index`实现的,主要的索引方法包括: `IndexFlatL2`、`IndexFlatIP`、`IndexHNSWFlat`、`IndexIVFFlat`、`IndexLSH`、`IndexScalarQuantizer`、`IndexPQ`、`IndexIVFScalarQuantizer`、`IndexIVFPQ`、`IndexIVFPQR`等,[每个方法的具体介绍](https://github.com/facebookresearch/faiss/wiki/Faiss-indexes#summary-of-methods)。
86 |
87 | `IndexFlatL2`:
88 |
89 | - 基于L2距离的暴力全量搜索,速度较慢,不需要训练过程。
90 |
91 | `IndexIVFFlat`:
92 |
93 | - 先聚类再搜索,可以加快检索速度;
94 | - 先将`xb`中的数据进行聚类(聚类的数目是超参),`nlist`: 聚类的数目
95 | - `nprobe`: 在多少个聚类中进行搜索,默认为`1`, `nprobe`越大,结果越精确,但是速度越慢
96 |
97 | ```python
98 | def IndexIVFFlat(nlist):
99 | quantizer = faiss.IndexFlatL2(d)
100 | index = faiss.IndexIVFFlat(quantizer, d, nlist)
101 | print(index.is_trained)
102 | index.train(xb)
103 | print(index.is_trained)
104 | index.add(xb)
105 | return index
106 | ```
107 |
108 | `IndexIFVPQ`
109 |
110 | - 基于乘积量化(product quantizers)对存储向量进行压缩,节省存储空间
111 | - `m`:乘积量化中,将原来的向量维度平均分成多少份,`d`必须为`m`的整数倍
112 | - `bits`: 每个子向量用多少个`bits`表示
113 |
114 | ```python
115 | def IndexIVFPQ(nlist, m, bits):
116 | quantizer = faiss.IndexFlatL2(d)
117 | index = faiss.IndexIVFPQ(quantizer, d, nlist, m, bits)
118 | index.train(xb)
119 | index.add(xb)
120 | return index
121 | ```
122 |
123 |
124 |
125 | ## kd树
126 |
127 | kd树是一种对k维空间中的实例点进行**存储**以便对其进行**快速检索**的树形数据结构。kd树是**二叉树**,表示对k维空间的一个划分(partition)。**构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分,构成一系列的k维超矩形区域**。kd树的每个结点对应于一个k维超矩形区域。
128 |
129 | ### kd树的结构
130 |
131 | kd树是一个二叉树结构,它的每一个节点记载了【特征坐标,切分轴,指向左枝的指针,指向右枝的指针】。
132 |
133 | 其中,特征坐标是线性空间$\mathbf{R}^n$的一个点$(x_1,...,x_n)$。
134 |
135 | 切分轴由一个整数$r$表示,这里$1\leq r\leq n$,是我们在$n$ 维空间中沿第$n$维进行一次分割。
136 |
137 | 节点的左枝和右枝分别都是 kd 树,并且满足:如果 y 是左枝的一个特征坐标,那么$y_r \leq x_r$并且如果 z 是右枝的一个特征坐标,那么$x_r \leq z_r $。
138 |
139 | ### kd树的构造
140 |
141 | 通过数据集来构造kd树存储空间,在推荐系统中即用物品Embedding池进行构建。
142 |
143 | - 输入:k维空间数据集$T=\left\{x_{1}, x_{2}, \cdots, x_{N}\right\}$,其中$x_{i}=\left(x_{i}^{(1)}, x_{i}^{(2)}, \cdots, x_{i}^{(k)}\right)^{\mathrm{T}},i=1,2,...,N$;
144 |
145 | - 输出:kd树;
146 |
147 | - (1)开始:构造根结点,根结点对应于包含$T$的$k$维空间的超矩形区域。
148 |
149 | 选择$x^{(1)}$为坐标轴,以$T$中所有实例的$x^{(1)}$坐标的**中位数为切分点**【若超平面上没有切分点,可以适当移动位置,使得超平面上有点】,将根结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴$x^{(1)}$垂直的超平面实现。
150 |
151 | 由根结点生成深度为1的左、右子结点:左子结点对应坐标$x^{(1)}$小于切分点的子区域,右子结点对应于坐标$x^{(1)}$大于切分点的子区域。
152 | 将**落在切分超平面上的实例点保存在根结点**。
153 |
154 | - (2)重复:对深度为$j$的结点,选择$x^{(l)}$为切分的坐标轴,$l=j(\bmod k)+1$,以该结点的区域中所有实例的$x^{(l)}$坐标的中位数为切分点,将该结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴$x^{(l)}$垂直的超平面实现。
155 | 由该结点生成深度为$j+1$的左、右子结点:左子结点对应坐标$x^{(l)}$小于切分点的子区域,右子结点对应坐标$x^{(l)}$大于切分点的子区域
156 | 将落在切分超平面上的实例点保存在该结点。
157 |
158 | - (3)直到两个子区域没有实例存在时停止。从而形成kd树的区域划分。
159 |
160 | 最后每一部分都只剩一个点,将他们记在最底部的节点中。因为不再有未被记录的点,所以不再进行切分。
161 |
162 | 
163 |
164 | 
165 |
166 | ### 搜索kd树
167 |
168 | 在推荐系统中,即通过用户的Embedding向量来查找与其近邻的$K$个物品Embedding向量。
169 |
170 | - 输入:已构造的kd树;目标点$x$;
171 | - 输出:$x$的$k$近邻;
172 | - 设有一个$ k$个空位的列表,用于保存已搜寻到的最近点。
173 |
174 | - (1)在kd树中找出包含目标点$x$的叶结点:从根结点出发,递归地向下访问树。若目标点$x$当前维的坐标小于切分点的坐标,则移动到左子结点,否则移动到右子结点,直到子结点为叶结点为止;
175 | - (2)如果**“当前k近邻点集”元素数量小于$k$**或者**叶节点距离小于“当前k近邻点集”中最远点距离**,那么将叶节点插入“当前k近邻点集”;
176 | - (3)递归地向上回退,在每个结点进行以下操作:
177 | - 如果“当前k近邻点集”元素数量小于k或者当前节点距离小于“当前k近邻点集”中最远点距离,那么将该节点插入“当前k近邻点集”。
178 | - 检查该子结点的父结点的另一子结点对应的区域是否与以目标点为球心、以目标点与于“当前k近邻点集”中最远点间的距离为半径的超球体相交。如果相交,可能在另一个子结点对应的区域内存在距目标点更近的点,移动到另一个子结点,接着,递归地进行最近邻搜索;如果不相交,向上回退;
179 | - 当回退到根结点时,搜索结束,最后的“当前k近邻点集”即为$x$的k近邻点。
180 |
181 | kd树的平均计算复杂度是$log(N)$。
182 |
183 | 参考资料:[kd 树算法之详细篇](https://zhuanlan.zhihu.com/p/23966698)
184 |
185 |
186 |
187 | ## 局部敏感哈希
188 |
189 | 局部敏感哈希的基本思想:
190 |
191 | > 让相邻对的点落入同一个“桶”,这样在进行最近邻搜索时,仅需要在一个桶内,或相邻的几个桶内的元素中进行搜索即可。如果保持每个桶中的元素个数在一个常数附近,就可以把最近邻搜索的时间复杂度降低到常数级别。
192 |
193 | 首先需要明确一个概念,
194 |
195 | > 在欧式空间中,将高维空间的点映射到低维空间,原本相近的点在低维空间中肯定依然相近,但原本远离的点则有一定概率变成相近的点。
196 |
197 | 所以**利用低维空间可以保留高维空间相近距离关系的性质**,就可以构造局部敏感哈希的桶。
198 |
199 | 对于Embedding向量,可以用内积操作构建局部敏感哈希桶。假设$\mathbf{v}$是高维空间中的$k$维Embedding向量,$\mathbf{x}$是随机生成的$k$维向量。内积操作可以将$\mathbf{v}$映射到1维空间,成为一个数值:
200 | $$
201 | h(\mathbf{v})=\mathbf{v}\cdot \mathbf{x}
202 | $$
203 | 因此,可以使用哈希函数$h(v)$进行分桶:
204 | $$
205 | h^{x,b}(\mathbf{v})=\lfloor x \frac{\mathbf{x}\cdot \mathbf{v}+ b}{w}\rfloor x
206 | $$
207 | 其中$\lfloor \rfloor$是向下取整,$w$是分桶宽度,$b$是0到$w$间的一个均匀分布随机变量,避免分桶边界固化。
208 |
209 | 如果仅采用一个哈希函数进行分桶,则必然存在相近点误判的情况。有效的解决方法是采用$m$个哈希函数同时进行分桶。同时掉进$m$个哈希函数的同一个桶的两点,是相似点的概率大大增加。找到相邻点集合后,取$K$近邻个。
210 |
211 | 采用多个哈希函数进行分桶,存在一个待解决的问题,到底通过“与”还是“或”:
212 |
213 | - 与:候选集规模减小,计算量降低,但可能会漏掉一些近邻点;
214 | - 或:候选集中近邻点的召回率提高,但候选集的规模变大,计算开销变大;
215 |
216 | 以上是将欧式空间中内积操作的局部敏感哈希使用方法;还有余弦相似度、曼哈顿距离、切比雪夫距离、汉明距离等。
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Daily Interview
2 |
3 | ## 背景
4 |
5 | 牛客网,知乎等众多网站上包含了数以百万计的面经,但往往大而散,面试者在准备面试时候去翻阅不但浪费时间,翻阅材料越多,越觉得自己很多知识点都没有掌握,造成心理上极大的压力,导致面试中不能发挥正常水平甚至面试失败。
6 | 其实,每一位求职者都应该有自己的一份面试笔记,记录笔试中常涉及到的知识点和项目中常被问到的问题。每次面试之前看一遍,做到举一反三,融会贯通,熟捻于心,方能在每次面试中汲取经验,最后从容应对。我个人就有自己的面试笔记,每次面试之前都会翻一遍,边看边想,但求好运。
7 |
8 | ## 宗旨
9 | 不需要大而全,涵盖所有内容,因为知识在不断更新迭代,我们也做不到涵盖所有。
10 | 不提供查漏补缺,因为每个人的短板不尽相同,需要面试者根据自己知识体系,多加思考,自己完善。
11 | 这是一份每一个面试者面试之前必看一遍的小面经。面试之前的半天时间,温故而知新。
12 |
13 | ## 内容
14 |
15 |
16 |  17 |
17 |
18 |
19 |
20 | ## 使用指南
21 |
22 | 1. 目前大部分成员是做AI算法,所以主要精力在AI算法一块。若有对开发感兴趣的人员参与整理,十分欢迎。
23 |
24 | 2. 数据结构与算法本来属于计算机基础一部分,但是因为不管面试算法岗还是开发岗,都会问到,所以单独提出来。
25 |
26 | 3. 算法岗:重点是AI算法、数据结构与算法;了解数学、计算机基础。
27 |
28 | 开发岗:重点是开发、数据结构与算法、计算机基础。
29 |
30 | 以面试岗位为梳理主线,整理面试之前必看的面试题目,给出高频的面试知识点和面试题。
31 |
32 |
33 | ## 招募
34 |
35 | 如果你也喜欢这个项目,想参与到面经项目中来,可以与我们联系 E-mail:xiongweinie@foxmail.com
36 |
37 | ## 关注我们
38 |
17 |
39 |  41 |
41 |
42 |
43 | ## LICENSE
44 | 扫描下方二维码关注公众号:Datawhale
40 |
41 | 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 45 | -------------------------------------------------------------------------------- /_coverpage.md: -------------------------------------------------------------------------------- 1 | 2 | 3 | # Datawhale面经 4 | 5 | > Datawhale面经 6 | 7 | 8 | 9 | [GitHub](https://github.com/datawhalechina/daily-interview.git) 10 | -------------------------------------------------------------------------------- /_navbar.md: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/_navbar.md -------------------------------------------------------------------------------- /_sidebar.md: -------------------------------------------------------------------------------- 1 | 2 | 3 | - 计算机基础 4 | - [操作系统](./计算机基础/操作系统.md) 5 | - [计算机网络](./计算机基础/计算机网络.md) 6 | - [数据库](./计算机基础/数据库.md) 7 | 8 | - Big data 9 | - [MapReduce](./开发/大数据/mapreduce.md) 10 | - [Technology](./开发/大数据/Technology.md) 11 | - [Questions](./开发/大数据/questions.md) 12 | 13 | - 前端开发 14 | - [基础知识](./开发/前端开发/README.md) 15 | - [JavaScript相关问题](./开发/前端开发/【1】javascript.md) 16 | - [HTML 相关问题](./开发/前端开发/【2】html.md) 17 | - [CSS 相关问题](./开发/前端开发/【3】css.md) 18 | - [网络及浏览器相关问题](./开发/前端开发/【4】网络及浏览器.md) 19 | - [前端框架及打包工具相关问题](./开发/前端开发/【5】前端框架及打包工具.md) 20 | - [NodeJS 相关问题](./开发/前端开发/【6】nodejs.md) 21 | 22 | - Java 后端开发 23 | - [基础知识](./开发/Java后端开发.md) 24 | 25 | - 数学 26 | - [logic题](./数学/统计学/logic.md) 27 | - [probability题](./数学/统计学/logic.md) 28 | 29 | - 数据结构与算法 30 | - [数组](./数据结构与算法/Array.md) 31 | - [排序](./数据结构与算法/sort.md) 32 | - [贪心](./数据结构与算法/greedy.md) 33 | - [字符串](./数据结构与算法/string.md) 34 | - [链表](./数据结构与算法/linklist.md) 35 | - [二叉树](./数据结构与算法/binaryTree.md) 36 | - [图](./数据结构与算法/graph.md) 37 | - [搜索](./数据结构与算法/search.md) 38 | - [动态规划](./数据结构与算法/dp.md) 39 | - 其他 40 | 41 | - 机器学习基础 42 | - [Metrics](./AI算法/machine-learning/metrics.md) 43 | - [过拟合与欠拟合](./AI算法/machine-learning/过拟合与欠拟合.md) 44 | - [梯度下降](./AI算法/machine-learning/梯度下降.md) 45 | - [ABTest](./AI算法/machine-learning/ABTest.md) 46 | 47 | - 机器学习算法 48 | - [线性回归+逻辑回归](./AI算法/machine-learning/线性回归+逻辑回归.md) 49 | - [SVM](./AI算法/machine-learning/SVM.md) 50 | - [Decision Tree](./AI算法/machine-learning/DecisionTree.md) 51 | - [EnsembleLearning](./AI算法/machine-learning/EnsembleLearning.md) 52 | - [Adaboost](./AI算法/machine-learning/Adaboost.md) 53 | - [XGBoost](./AI算法/machine-learning/XGBoost.md) 54 | - [LightGBM](./AI算法/machine-learning/LightGBM.md) 55 | - [Catboost](./AI算法/machine-learning/Catboost.md) 56 | - [KMeans](./AI算法/machine-learning/KMeans.md) 57 | - [KNN](./AI算法/machine-learning/KNN.md) 58 | - [NaïveBayes](./AI算法/machine-learning/NaïveBayes.md) 59 | - [CRF](./AI算法/machine-learning/CRF.md) 60 | - [Apriori](./AI算法/machine-learning/Apriori.md) 61 | - [Prophet](./AI算法/machine-learning/Prophet.md) 62 | 63 | - 图像处理算法 64 | - [CV基础](./AI算法/CV/CV基础.md) 65 | 66 | - 自然语言处理算法 67 | 68 | - [文本结构理解](./AI算法/NLP/文本表示/文本结构理解.md) 69 | - [文本表征方式](./AI算法/NLP/文本表示/文本表征方式.md) 70 | - [特征挖掘-基于深度学习的模型](./AI算法/NLP/特征挖掘/基于深度学习的模型.md) 71 | - [特征挖掘-Bert](./AI算法/NLP/特征挖掘/Bert/Bert面试题.md) 72 | - [NLG应用场景](./AI算法/NLP/应用场景/NLG.md) 73 | 74 | 75 | 76 | -------------------------------------------------------------------------------- /assert/apr.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/apr.png -------------------------------------------------------------------------------- /assert/auc.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/auc.png -------------------------------------------------------------------------------- /assert/big-data1.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/big-data1.png -------------------------------------------------------------------------------- /assert/bigdata2.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/bigdata2.png -------------------------------------------------------------------------------- /assert/conf_matrix.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/conf_matrix.png -------------------------------------------------------------------------------- /assert/d1-1.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/d1-1.png -------------------------------------------------------------------------------- /assert/exm6.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/exm6.png -------------------------------------------------------------------------------- /assert/filter-1.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/filter-1.png -------------------------------------------------------------------------------- /assert/filter-2.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/filter-2.png -------------------------------------------------------------------------------- /assert/formula-word2vec-1.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/formula-word2vec-1.png -------------------------------------------------------------------------------- /assert/formula-word2vec-2.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/formula-word2vec-2.png -------------------------------------------------------------------------------- /assert/fp.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/fp.png -------------------------------------------------------------------------------- /assert/fptree.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/fptree.png -------------------------------------------------------------------------------- /assert/g-1.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/g-1.png -------------------------------------------------------------------------------- /assert/g-2.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/g-2.png -------------------------------------------------------------------------------- /assert/gbdt-1.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/gbdt-1.png -------------------------------------------------------------------------------- /assert/gbdt-2.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/gbdt-2.png -------------------------------------------------------------------------------- /assert/gbdt-3.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/gbdt-3.png -------------------------------------------------------------------------------- /assert/gbdt-4.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/gbdt-4.png -------------------------------------------------------------------------------- /assert/gbdt-lr.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/gbdt-lr.png -------------------------------------------------------------------------------- /assert/mult_gbdt.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/mult_gbdt.png -------------------------------------------------------------------------------- /assert/os1.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/os1.jpg -------------------------------------------------------------------------------- /assert/prb10.gif: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/prb10.gif -------------------------------------------------------------------------------- /assert/r.jpe: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/r.jpe -------------------------------------------------------------------------------- /assert/simain.jpg: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/simain.jpg -------------------------------------------------------------------------------- /assert/word2vec-3.PNG: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/assert/word2vec-3.PNG -------------------------------------------------------------------------------- /content.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/datawhalechina/daily-interview/a46161eb2274bf38fd383e374b7c07ba16b1041e/content.png -------------------------------------------------------------------------------- /index.html: -------------------------------------------------------------------------------- 1 | 2 | 3 | 4 | 5 | 6 |
、-
、
-、、、、、
- 、
- 、
- 、