扫描下方二维码关注公众号:Datawhale
96 | 97 |
97 | 扫描下方二维码关注公众号:Datawhale
96 |
97 | 扫描下方二维码关注公众号:Datawhale
74 |
75 |  20 |
21 | 传统方法主要集中在图像先验,包含基于重构的方法、基于字 典稀疏表示等。
22 |
23 | 现在很多研究方向都是基于深度学习的超分辨率技术,研究现状主要是集中在CNN。
24 |
25 |
20 |
21 | 传统方法主要集中在图像先验,包含基于重构的方法、基于字 典稀疏表示等。
22 |
23 | 现在很多研究方向都是基于深度学习的超分辨率技术,研究现状主要是集中在CNN。
24 |
25 |  26 |
27 | 参考:Anwar, Saeed, Salman Khan, and Nick Barnes. "A deep journey into super-resolution: A survey." arXiv preprint arXiv:1904.07523 (2019).
28 |
29 |
26 |
27 | 参考:Anwar, Saeed, Salman Khan, and Nick Barnes. "A deep journey into super-resolution: A survey." arXiv preprint arXiv:1904.07523 (2019).
28 |
29 |  30 |
31 | **SRCNN**
32 |
33 | 先将低分辨率图像使用双三次插值放大至目标尺寸(如放大至2倍、 3倍、4倍),此时仍然称放大至目标尺寸后的图像为低分辨率图像 (Low-resolution image),即图中的输入(input)
34 |
35 |
30 |
31 | **SRCNN**
32 |
33 | 先将低分辨率图像使用双三次插值放大至目标尺寸(如放大至2倍、 3倍、4倍),此时仍然称放大至目标尺寸后的图像为低分辨率图像 (Low-resolution image),即图中的输入(input)
34 |
35 |  36 |
37 | - Patch extraction and representation:从低分辨率图像中提取重叠块,将每一个块通过卷积网络表达为高维向量
38 | - Nonlinear Mapping:将每一个块的高维向量经过非线性映射为另外一个高维向量(维度增加)
39 | - Reconstruction:将高维向量累积成高分辨率图像
40 |
41 | 参考:Dong, Chao, Chen Change Loy, Kaiming He, and Xiaoou Tang. "Learning a deep convolutional network for image super-resolution." In *European conference on computer vision*, pp. 184-199. Springer, Cham, 2014.
42 |
43 | **VDSR**
44 |
45 | 上面介绍的SRCNN存在三个问题:
46 |
47 | - 依赖于小图像区域的内容
48 | - 训练收敛太慢
49 | - 网络只对于某一个比例有效
50 |
51 | VDSR的改进:
52 |
53 | - 增加了感受野,在处理大图像上有优势,由SRCNN的 $13\times13$变为 $41\times41$.
54 | - 采用残差图像进行训练,收敛速度变快
55 | - 考虑多个尺度,一个卷积网络可以处理多尺度问题
56 |
57 |
36 |
37 | - Patch extraction and representation:从低分辨率图像中提取重叠块,将每一个块通过卷积网络表达为高维向量
38 | - Nonlinear Mapping:将每一个块的高维向量经过非线性映射为另外一个高维向量(维度增加)
39 | - Reconstruction:将高维向量累积成高分辨率图像
40 |
41 | 参考:Dong, Chao, Chen Change Loy, Kaiming He, and Xiaoou Tang. "Learning a deep convolutional network for image super-resolution." In *European conference on computer vision*, pp. 184-199. Springer, Cham, 2014.
42 |
43 | **VDSR**
44 |
45 | 上面介绍的SRCNN存在三个问题:
46 |
47 | - 依赖于小图像区域的内容
48 | - 训练收敛太慢
49 | - 网络只对于某一个比例有效
50 |
51 | VDSR的改进:
52 |
53 | - 增加了感受野,在处理大图像上有优势,由SRCNN的 $13\times13$变为 $41\times41$.
54 | - 采用残差图像进行训练,收敛速度变快
55 | - 考虑多个尺度,一个卷积网络可以处理多尺度问题
56 |
57 |  58 |
59 | 参考:Kim, Jiwon, Jung Kwon Lee, and Kyoung Mu Lee. "Accurate image super-resolution using very deep convolutional networks." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1646-1654. 2016.
60 |
61 | ### 图像去噪
62 |
63 | 图像在获取、处理和传输过程中都会引入噪声,去噪问题就是从带噪声的实际图像中恢复出原始图像。
64 | $$
65 | \operatorname{argmin}_{\boldsymbol{X}} \| \boldsymbol{X} - \boldsymbol{Y}\|_2^2 + \lambda \|\boldsymbol{T(X)}\| \quad \boldsymbol{Y} = \boldsymbol{X}+\boldsymbol{n}
66 | $$
67 | 去噪方法大概有下面五类,我们主要介绍基于深度学习的图像去噪方法
68 |
69 | - 滤波类
70 | - 稀疏表达类
71 | - 外部先验
72 | - 聚类低秩
73 | - 深度学习
74 |
75 | 基于深度学习的图像去噪的研究现状可以参考下面这篇综述,这篇综述介绍了超过200篇关于深度学习去噪的论文。
76 |
77 |
58 |
59 | 参考:Kim, Jiwon, Jung Kwon Lee, and Kyoung Mu Lee. "Accurate image super-resolution using very deep convolutional networks." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1646-1654. 2016.
60 |
61 | ### 图像去噪
62 |
63 | 图像在获取、处理和传输过程中都会引入噪声,去噪问题就是从带噪声的实际图像中恢复出原始图像。
64 | $$
65 | \operatorname{argmin}_{\boldsymbol{X}} \| \boldsymbol{X} - \boldsymbol{Y}\|_2^2 + \lambda \|\boldsymbol{T(X)}\| \quad \boldsymbol{Y} = \boldsymbol{X}+\boldsymbol{n}
66 | $$
67 | 去噪方法大概有下面五类,我们主要介绍基于深度学习的图像去噪方法
68 |
69 | - 滤波类
70 | - 稀疏表达类
71 | - 外部先验
72 | - 聚类低秩
73 | - 深度学习
74 |
75 | 基于深度学习的图像去噪的研究现状可以参考下面这篇综述,这篇综述介绍了超过200篇关于深度学习去噪的论文。
76 |
77 |  78 |
79 |
78 |
79 |  80 |
81 | 参考:Tian, Chunwei, Lunke Fei, Wenxian Zheng, Yong Xu, Wangmeng Zuo, and Chia-Wen Lin. "Deep Learning on Image Denoising: An overview." arXiv preprint arXiv:1912.13171 (2019).
82 |
83 | **DnCNN**
84 |
85 | DnCNN 是面向高斯噪声的端到端深度卷积去噪网络,它使用residual learning和batch normalization。
86 |
87 | 目标函数:$\ell(\Theta)=\frac{1}{2 N} \sum_{i=1}^{N}\left\|\mathcal{R}\left(\mathbf{y}_{i} ; \Theta\right)-\left(\mathbf{y}_{i}-\mathbf{x}_{i}\right)\right\|_{F}^{2}$
88 |
89 | 复原图像:$ x_i = y_i - \mathcal{R}(y_i)$
90 |
91 | 这里与传统的residuallearning不同,DnCNN并非每隔两层就加一个 shortcut connection,而是将网络的输出直接改成residual image(残差图片)
92 |
93 |
80 |
81 | 参考:Tian, Chunwei, Lunke Fei, Wenxian Zheng, Yong Xu, Wangmeng Zuo, and Chia-Wen Lin. "Deep Learning on Image Denoising: An overview." arXiv preprint arXiv:1912.13171 (2019).
82 |
83 | **DnCNN**
84 |
85 | DnCNN 是面向高斯噪声的端到端深度卷积去噪网络,它使用residual learning和batch normalization。
86 |
87 | 目标函数:$\ell(\Theta)=\frac{1}{2 N} \sum_{i=1}^{N}\left\|\mathcal{R}\left(\mathbf{y}_{i} ; \Theta\right)-\left(\mathbf{y}_{i}-\mathbf{x}_{i}\right)\right\|_{F}^{2}$
88 |
89 | 复原图像:$ x_i = y_i - \mathcal{R}(y_i)$
90 |
91 | 这里与传统的residuallearning不同,DnCNN并非每隔两层就加一个 shortcut connection,而是将网络的输出直接改成residual image(残差图片)
92 |
93 |  94 |
95 | 参考:Zhang, Kai, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang. "Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising." *IEEE Transactions on Image Processing* 26, no. 7 (2017): 3142-3155.
96 |
97 | **CBDNet**
98 |
99 | 为了解决盲去噪的鲁棒性,增加了噪声估计子网络,这里介绍的CBDNet包括噪声估计子网 $CNN_E$ 和非盲去噪子网 $CNN_D$;更加真实的噪声模型,以及引入非对称损失函数。
100 |
101 |
94 |
95 | 参考:Zhang, Kai, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang. "Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising." *IEEE Transactions on Image Processing* 26, no. 7 (2017): 3142-3155.
96 |
97 | **CBDNet**
98 |
99 | 为了解决盲去噪的鲁棒性,增加了噪声估计子网络,这里介绍的CBDNet包括噪声估计子网 $CNN_E$ 和非盲去噪子网 $CNN_D$;更加真实的噪声模型,以及引入非对称损失函数。
100 |
101 |  102 |
103 | 独立同分布的高斯噪声模型不能准确反映实际噪声,因为实际的噪声是通常是复杂且信号依赖的,这里提出了多种噪声混合的模型,更加接近真实图像噪声:
104 |
105 | - 成像过程中的噪声由泊松分布和高斯分布联合构成:$n(L) = n_s(L) + n_c $.
106 | - 图像处理过程中的噪声
107 | - Demosaicing和Gamma校正:$\boldsymbol{y} = f(\boldsymbol{D}\boldsymbol{M}(\boldsymbol{L}+n(\boldsymbol{L})))$.
108 | - JPEG压缩:$\boldsymbol{y} = JPEG(f(\boldsymbol{D}\boldsymbol{M}(\boldsymbol{L}+n(\boldsymbol{L}))))$.
109 |
110 |
102 |
103 | 独立同分布的高斯噪声模型不能准确反映实际噪声,因为实际的噪声是通常是复杂且信号依赖的,这里提出了多种噪声混合的模型,更加接近真实图像噪声:
104 |
105 | - 成像过程中的噪声由泊松分布和高斯分布联合构成:$n(L) = n_s(L) + n_c $.
106 | - 图像处理过程中的噪声
107 | - Demosaicing和Gamma校正:$\boldsymbol{y} = f(\boldsymbol{D}\boldsymbol{M}(\boldsymbol{L}+n(\boldsymbol{L})))$.
108 | - JPEG压缩:$\boldsymbol{y} = JPEG(f(\boldsymbol{D}\boldsymbol{M}(\boldsymbol{L}+n(\boldsymbol{L}))))$.
109 |
110 |  111 |
112 | 非对称损失函数:根据实际效果,当估计的噪声强度高于实际噪声强度时,去噪具有较强的鲁棒性,可以得到较好的图像质量;当估计的噪声强度低于实际噪声强度时,图像中会残留较多噪声,质量不高因此,训练过程中目标函数引入非对称约束:
113 | $$
114 | \mathcal{L}_{a s y m m}=\sum\left|\alpha-\mathbb{I}_{\left(\hat{\sigma}\left(y_{i}\right)-\sigma\left(y_{i}\right)\right)<0}\right| \cdot\left(\hat{\sigma}\left(y_{i}\right)-\sigma\left(y_{i}\right)\right)^{2}
115 | $$
116 | 总的优化目标函数:
117 | $$
118 | \mathcal{L}=\mathcal{L}_{\text {rec }}+\lambda_{\text {asymm }} \mathcal{L}_{\text {asymm }}+\lambda_{T V} \mathcal{L}_{T V} \\ \mathcal{L}_{\text {rec }}=\|\hat{\mathbf{x}}-\mathbf{x}\|_{2}^{2} \quad \mathcal{L}_{T V}=\left\|\nabla_{h} \hat{\sigma}(\mathbf{y})\right\|_{2}^{2}+\left\|\nabla_{v} \hat{\sigma}(\mathbf{y})\right\|_{2}^{2}
119 | $$
120 | 参考:Guo S, Yan Z, Zhang K, et al. Toward convolutional blind denoising of real photographs[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 1712-1722.
121 |
122 | **CBDNet**性能分析:在实际的带噪图像上的结果
123 |
124 |
111 |
112 | 非对称损失函数:根据实际效果,当估计的噪声强度高于实际噪声强度时,去噪具有较强的鲁棒性,可以得到较好的图像质量;当估计的噪声强度低于实际噪声强度时,图像中会残留较多噪声,质量不高因此,训练过程中目标函数引入非对称约束:
113 | $$
114 | \mathcal{L}_{a s y m m}=\sum\left|\alpha-\mathbb{I}_{\left(\hat{\sigma}\left(y_{i}\right)-\sigma\left(y_{i}\right)\right)<0}\right| \cdot\left(\hat{\sigma}\left(y_{i}\right)-\sigma\left(y_{i}\right)\right)^{2}
115 | $$
116 | 总的优化目标函数:
117 | $$
118 | \mathcal{L}=\mathcal{L}_{\text {rec }}+\lambda_{\text {asymm }} \mathcal{L}_{\text {asymm }}+\lambda_{T V} \mathcal{L}_{T V} \\ \mathcal{L}_{\text {rec }}=\|\hat{\mathbf{x}}-\mathbf{x}\|_{2}^{2} \quad \mathcal{L}_{T V}=\left\|\nabla_{h} \hat{\sigma}(\mathbf{y})\right\|_{2}^{2}+\left\|\nabla_{v} \hat{\sigma}(\mathbf{y})\right\|_{2}^{2}
119 | $$
120 | 参考:Guo S, Yan Z, Zhang K, et al. Toward convolutional blind denoising of real photographs[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 1712-1722.
121 |
122 | **CBDNet**性能分析:在实际的带噪图像上的结果
123 |
124 |  125 |
126 | ### 图像增强
127 |
128 | 多种图像增强技术:图像的选帧、图像的降噪、图像的增强、重影 的消除、对比度调整
129 |
130 | ### 弱光照增强
131 |
132 | 问题描述:解决暗光拍照由于光线不足,导致的欠曝光或者对比度不足的问题
133 |
134 | 解决手段:根本上是调整图像的对比度
135 |
136 |
125 |
126 | ### 图像增强
127 |
128 | 多种图像增强技术:图像的选帧、图像的降噪、图像的增强、重影 的消除、对比度调整
129 |
130 | ### 弱光照增强
131 |
132 | 问题描述:解决暗光拍照由于光线不足,导致的欠曝光或者对比度不足的问题
133 |
134 | 解决手段:根本上是调整图像的对比度
135 |
136 |  137 |
138 | ### 夜景增强
139 |
140 | **LLNet (Low-light Net)**
141 |
142 | ...
143 |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 |
152 | # 图像/视频压缩
153 |
154 | ### 编码框架
155 |
156 | **JPEG压缩**
157 |
158 |
137 |
138 | ### 夜景增强
139 |
140 | **LLNet (Low-light Net)**
141 |
142 | ...
143 |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 |
152 | # 图像/视频压缩
153 |
154 | ### 编码框架
155 |
156 | **JPEG压缩**
157 |
158 |  159 |
160 | **视频编码**
161 |
162 |
159 |
160 | **视频编码**
161 |
162 |  163 |
164 |
165 |
166 |
167 |
168 | # 传统的计算机视觉处理
169 |
170 |
171 |
172 | # 图像分类
173 |
174 |
175 |
176 | # 目标检测
177 |
178 |
179 |
180 | # 图像分割
181 |
182 |
183 |
184 | # 图像回归
185 |
186 |
187 |
188 |
189 |
190 |
191 |
192 |
193 |
194 |
195 |
196 |
197 |
198 |
--------------------------------------------------------------------------------
/docs/案例/NLP.md:
--------------------------------------------------------------------------------
1 | NLP自然语言处理
2 |
3 | 1. 语言模型
4 | 2. 机器翻译
5 | 3. 机器阅读理解
6 | 4. 自动摘要
7 | 5. 图像描述
8 |
9 |
10 |
11 | # 语言模型
12 |
13 | **什么是语言模型** 语言模型的核心思想是按照特定的训练方式,从语料中提取所蕴含的语言知识,应用于词序列的预测。语言模型通常可以分为基于规则的语言模型和统计语言模 型。统计语言模型处于主流地位,通过对语料库的统计学习, 归纳出其中的语言知识,获得词与词之间的连接概率,并以词序列的概率为依据来判断其是否合理。
14 |
15 | **为什么需要语言模型** 语言是人类最重要的、最有效的一种信息交流的手段,也 是人类进行观点、思想及情感交流最便捷、最自然的方式 之一,在信息传递中发挥着重要的作用。统计语言模型在语音识别、机器翻译、中文分词、问答系 统等自然语言处理领域中取得了成功地应用,例如:“厨房里食油用完了”和“厨房里石油用完了”。近年来,随着深度学习技术的不断发展,神经网络语言模型已成为目前语言模型领域的主流。
16 |
17 |
163 |
164 |
165 |
166 |
167 |
168 | # 传统的计算机视觉处理
169 |
170 |
171 |
172 | # 图像分类
173 |
174 |
175 |
176 | # 目标检测
177 |
178 |
179 |
180 | # 图像分割
181 |
182 |
183 |
184 | # 图像回归
185 |
186 |
187 |
188 |
189 |
190 |
191 |
192 |
193 |
194 |
195 |
196 |
197 |
198 |
--------------------------------------------------------------------------------
/docs/案例/NLP.md:
--------------------------------------------------------------------------------
1 | NLP自然语言处理
2 |
3 | 1. 语言模型
4 | 2. 机器翻译
5 | 3. 机器阅读理解
6 | 4. 自动摘要
7 | 5. 图像描述
8 |
9 |
10 |
11 | # 语言模型
12 |
13 | **什么是语言模型** 语言模型的核心思想是按照特定的训练方式,从语料中提取所蕴含的语言知识,应用于词序列的预测。语言模型通常可以分为基于规则的语言模型和统计语言模 型。统计语言模型处于主流地位,通过对语料库的统计学习, 归纳出其中的语言知识,获得词与词之间的连接概率,并以词序列的概率为依据来判断其是否合理。
14 |
15 | **为什么需要语言模型** 语言是人类最重要的、最有效的一种信息交流的手段,也 是人类进行观点、思想及情感交流最便捷、最自然的方式 之一,在信息传递中发挥着重要的作用。统计语言模型在语音识别、机器翻译、中文分词、问答系 统等自然语言处理领域中取得了成功地应用,例如:“厨房里食油用完了”和“厨房里石油用完了”。近年来,随着深度学习技术的不断发展,神经网络语言模型已成为目前语言模型领域的主流。
16 |
17 |  18 |
19 | ### 基于文法的语言模型
20 |
21 | 基于文法的语言模型是依据语法规则,由计算机根据这些语法解析文本的含义,其中语法规则来源于语言学家掌握 的语言学知识和领域知识。
22 |
23 | 弊端:不能处理大规模真实文本;需要大量专家知识。
24 |
25 | ### 统计语言模型
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 | ### 神经网络语言模型
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 | # 机器翻译
50 |
51 | 机器翻译 (Machine Translation, MT)是用计算机把一种语 言(源语言, source language)翻译成另一种语言(目标语言, target language)的一门技术。
52 |
53 |
18 |
19 | ### 基于文法的语言模型
20 |
21 | 基于文法的语言模型是依据语法规则,由计算机根据这些语法解析文本的含义,其中语法规则来源于语言学家掌握 的语言学知识和领域知识。
22 |
23 | 弊端:不能处理大规模真实文本;需要大量专家知识。
24 |
25 | ### 统计语言模型
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 | ### 神经网络语言模型
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 | # 机器翻译
50 |
51 | 机器翻译 (Machine Translation, MT)是用计算机把一种语 言(源语言, source language)翻译成另一种语言(目标语言, target language)的一门技术。
52 |
53 |  54 |
55 | ### 机器学习发展史
56 |
57 | - 1949年,W. Weaver正式提出机器翻译问题
58 | - 1954年,Georgetown大学在IBM协助下,用IBM-701计算机实现了世界上第一个MT系统,实现俄译英翻译
59 | - 1990年,IBM提出统计机器翻译模型,机器翻译研究进入了繁荣时期
60 | - 2014年,神经网络机器翻译被提出,机器翻译研究进入了 新的突破时期
61 |
62 | ### Seq2Seq模型
63 |
64 | ### 注意力机制
65 |
66 | ### 对偶学习
67 |
68 | ### 展望
69 |
70 | 在工业界有很多研究机器翻译的机构,国外有Google、Microsoft、IBM、Facebook,国内有百度、华为、阿里巴巴、腾讯、搜狗、有道...
71 |
72 | 神经机器翻译采用编码解码网络,简单有效,已逐渐取代 统计机器翻译,成为主流研究范式,但神经机器翻译仍面临诸多问题:
73 |
74 | - 缺乏可解释性
75 | - 难利用先验知识、语言相关知识
76 | - 训练、测试复杂度高(需GPU、甚至TPU)
77 | - 领域、场景迁移性能差
78 |
79 | 对未来的展望:
80 |
81 | - 神经机器翻译的可解释性研究
82 | - 与专家知识、常识知识的融合研究
83 | - 场景、领域的迁移和定制化研究
84 | - 面向资源稀缺语言的机器翻译建模
85 | - 多模态机器翻译(语音和文本的一体化)研究
86 | - 与硬件的一体化研究
87 |
88 | # 机器阅读理解
89 |
90 | 自然语言处理(Natural Language Processing, NLP)是实 现人类无障碍人机交互愿景的基石,被誉为“人工智能皇冠的明珠”;而机器阅读理解(Machine Read Comprehension, MRC) 是近年来 NLP 领域的研究热点之一,被视为“自然语言处 理皇冠上的明珠之一”。
91 |
92 |
93 |
94 |
95 |
96 |
97 |
98 | # 自动摘要
99 |
100 |
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 | # 图像描述
109 |
110 |
111 |
112 |
--------------------------------------------------------------------------------
/docs/案例/Speech.md:
--------------------------------------------------------------------------------
1 | Speech语音
2 |
3 | 1. 语音技术概述
4 | 2. 语音数据集
5 | 3. 语音识别
6 | 4. 声纹识别
7 | 5. 语音合成
8 |
9 |
10 |
11 | # 语音技术概述
12 |
13 | 语音指的是人们讲话时发出的话语,是组成语言的声音或者带有语言信息的声音,是一种人们进行信息交流产生的声音:语音(Speech) = 声音(Acoustic) + 语言(Language)。
14 |
15 |
16 |
17 | # 常见语音数据集
18 |
19 | ### THCHS30
20 |
21 | - 由清华大学语音与语言技术中心(CSLT)出版的开放式免费中文语音数据库
22 | - 包含了1万余条语音文件,大约40小时的中文语音数据,内容以文 章诗句为主,全部为女声
23 | - 数据库对学术用户完全免费
24 | - https://arxiv.org/abs/1512.01882
25 | - https://www.openslr.org/18/
26 |
27 |
54 |
55 | ### 机器学习发展史
56 |
57 | - 1949年,W. Weaver正式提出机器翻译问题
58 | - 1954年,Georgetown大学在IBM协助下,用IBM-701计算机实现了世界上第一个MT系统,实现俄译英翻译
59 | - 1990年,IBM提出统计机器翻译模型,机器翻译研究进入了繁荣时期
60 | - 2014年,神经网络机器翻译被提出,机器翻译研究进入了 新的突破时期
61 |
62 | ### Seq2Seq模型
63 |
64 | ### 注意力机制
65 |
66 | ### 对偶学习
67 |
68 | ### 展望
69 |
70 | 在工业界有很多研究机器翻译的机构,国外有Google、Microsoft、IBM、Facebook,国内有百度、华为、阿里巴巴、腾讯、搜狗、有道...
71 |
72 | 神经机器翻译采用编码解码网络,简单有效,已逐渐取代 统计机器翻译,成为主流研究范式,但神经机器翻译仍面临诸多问题:
73 |
74 | - 缺乏可解释性
75 | - 难利用先验知识、语言相关知识
76 | - 训练、测试复杂度高(需GPU、甚至TPU)
77 | - 领域、场景迁移性能差
78 |
79 | 对未来的展望:
80 |
81 | - 神经机器翻译的可解释性研究
82 | - 与专家知识、常识知识的融合研究
83 | - 场景、领域的迁移和定制化研究
84 | - 面向资源稀缺语言的机器翻译建模
85 | - 多模态机器翻译(语音和文本的一体化)研究
86 | - 与硬件的一体化研究
87 |
88 | # 机器阅读理解
89 |
90 | 自然语言处理(Natural Language Processing, NLP)是实 现人类无障碍人机交互愿景的基石,被誉为“人工智能皇冠的明珠”;而机器阅读理解(Machine Read Comprehension, MRC) 是近年来 NLP 领域的研究热点之一,被视为“自然语言处 理皇冠上的明珠之一”。
91 |
92 |
93 |
94 |
95 |
96 |
97 |
98 | # 自动摘要
99 |
100 |
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 | # 图像描述
109 |
110 |
111 |
112 |
--------------------------------------------------------------------------------
/docs/案例/Speech.md:
--------------------------------------------------------------------------------
1 | Speech语音
2 |
3 | 1. 语音技术概述
4 | 2. 语音数据集
5 | 3. 语音识别
6 | 4. 声纹识别
7 | 5. 语音合成
8 |
9 |
10 |
11 | # 语音技术概述
12 |
13 | 语音指的是人们讲话时发出的话语,是组成语言的声音或者带有语言信息的声音,是一种人们进行信息交流产生的声音:语音(Speech) = 声音(Acoustic) + 语言(Language)。
14 |
15 |
16 |
17 | # 常见语音数据集
18 |
19 | ### THCHS30
20 |
21 | - 由清华大学语音与语言技术中心(CSLT)出版的开放式免费中文语音数据库
22 | - 包含了1万余条语音文件,大约40小时的中文语音数据,内容以文 章诗句为主,全部为女声
23 | - 数据库对学术用户完全免费
24 | - https://arxiv.org/abs/1512.01882
25 | - https://www.openslr.org/18/
26 |
27 |  28 |
29 | ### AISHELL
30 |
31 | - 由北京希尔公司发布的一个免费中文语音数据集
32 |
33 | - 包含约178小时的开源版数据
34 |
35 | - 该数据集包含400个来自中国不同地区、具有不同的口音的人的语
36 |
37 | 音
38 |
39 | - 该数据免费供学术使用
40 |
41 | - https://arxiv.org/abs/1709.05522
42 |
43 | - https://www.openslr.org/33/
44 |
45 |
28 |
29 | ### AISHELL
30 |
31 | - 由北京希尔公司发布的一个免费中文语音数据集
32 |
33 | - 包含约178小时的开源版数据
34 |
35 | - 该数据集包含400个来自中国不同地区、具有不同的口音的人的语
36 |
37 | 音
38 |
39 | - 该数据免费供学术使用
40 |
41 | - https://arxiv.org/abs/1709.05522
42 |
43 | - https://www.openslr.org/33/
44 |
45 |  46 |
47 | ### ST-CMDS
48 |
49 | - 由一个AI数据公司发布的免费中文语音数据集
50 | - 包含10万余条语音文件,大约100余小时的语音数据
51 | - 数据内容以平时的网上语音聊天和智能语音控制语句为主,855个不同说话者,同时有男声和女声
52 | - https://www.openslr.org/38/
53 |
54 |
46 |
47 | ### ST-CMDS
48 |
49 | - 由一个AI数据公司发布的免费中文语音数据集
50 | - 包含10万余条语音文件,大约100余小时的语音数据
51 | - 数据内容以平时的网上语音聊天和智能语音控制语句为主,855个不同说话者,同时有男声和女声
52 | - https://www.openslr.org/38/
53 |
54 |  55 |
56 | ### Primewords Chinese Corpus Set 1
57 |
58 | - 由上海普力信息技术有限公司发布的免费中文普通话语料库。
59 | - 包含了大约100小时的中文语音数据,语料库由296名母语为中文的智能手机录制。
60 | - 学术用途免费
61 | - https://www.openslr.org/47/
62 |
63 |
55 |
56 | ### Primewords Chinese Corpus Set 1
57 |
58 | - 由上海普力信息技术有限公司发布的免费中文普通话语料库。
59 | - 包含了大约100小时的中文语音数据,语料库由296名母语为中文的智能手机录制。
60 | - 学术用途免费
61 | - https://www.openslr.org/47/
62 |
63 |  64 |
65 | ### TIMIT
66 |
67 | - 由德州仪器、麻省理工学院和SRIInternational合作构建的声学-音素连续语音语料库。
68 | - TIMIT数据集的语音采样频率为16kHz,一共包含6300个句子
69 | - 语音由来自美国八个主要方言地区的630个人每人说出给定的10个 句子,所有的句子都在音素级别(phone level)上进行了手动分割, 标记
70 | - https://catalog.ldc.upenn.edu/LDC93S1
71 |
72 | ### TED-LIUM Corpus
73 |
74 | - 包括TED演讲音频和对应讲稿。其中包括1495段演讲录音和对应的演讲稿,数据获取自TED网站
75 | - https://www.openslr.org/51/
76 |
77 | ### VoxForge
78 |
79 | - 该数据集是带口音的语音清洁数据集,对测试模型在不同重音或语调下的鲁棒性非常有用
80 | - http://www.voxforge.org/
81 |
82 | # 语音识别
83 |
84 | 语音识别(Speech Recognition,SR)是以语音信号为研究对象,让机器通过识别和理解的过程,将语音信号转为相应文字或命令的技术。目的是让机器“听懂”人说话,是人机交互的重要方式之一。
85 |
86 | 先展示语音识别的技术框架:
87 |
88 |
64 |
65 | ### TIMIT
66 |
67 | - 由德州仪器、麻省理工学院和SRIInternational合作构建的声学-音素连续语音语料库。
68 | - TIMIT数据集的语音采样频率为16kHz,一共包含6300个句子
69 | - 语音由来自美国八个主要方言地区的630个人每人说出给定的10个 句子,所有的句子都在音素级别(phone level)上进行了手动分割, 标记
70 | - https://catalog.ldc.upenn.edu/LDC93S1
71 |
72 | ### TED-LIUM Corpus
73 |
74 | - 包括TED演讲音频和对应讲稿。其中包括1495段演讲录音和对应的演讲稿,数据获取自TED网站
75 | - https://www.openslr.org/51/
76 |
77 | ### VoxForge
78 |
79 | - 该数据集是带口音的语音清洁数据集,对测试模型在不同重音或语调下的鲁棒性非常有用
80 | - http://www.voxforge.org/
81 |
82 | # 语音识别
83 |
84 | 语音识别(Speech Recognition,SR)是以语音信号为研究对象,让机器通过识别和理解的过程,将语音信号转为相应文字或命令的技术。目的是让机器“听懂”人说话,是人机交互的重要方式之一。
85 |
86 | 先展示语音识别的技术框架:
87 |
88 |  89 |
90 | ### 声学模型
91 |
92 | 声学模型(AcousticModel,AM)的任务是建模给定文本下产生语音波形的概率,将声学和发音学的知识进行整合,以特征提取模块提取的特征为输入, 生成声学模型得分。声学模型是语音识别系统的重要组成部分,它占据着语音识别大部分的计算开销,决定着语音识别系统的性能。
93 |
94 | **GMM-HMM**
95 |
96 | 高斯混合模型(Gaussian mixture model,GMM)用于对语音信号的声学特征分布进行建模;隐马尔科夫模型(Hidden Markov model,HMM)则用于对语音信号的时序性进行建模。
97 |
98 | 维特比算法(Viterbi):针对篱笆网络的有向图(Lattice)的最短路径问题而提出的动态规划算法。凡是使用隐含马 尔可夫模型描述的问题都可以用维特比算法来解码。
99 |
100 | GMM-HMM语音识别分三步:
101 |
102 | 1. 把帧识别成状态(难点),GMM
103 | 2. 把状态组合成音素,HMM
104 | 3. 把音素组合成单词,HMM
105 |
106 |
89 |
90 | ### 声学模型
91 |
92 | 声学模型(AcousticModel,AM)的任务是建模给定文本下产生语音波形的概率,将声学和发音学的知识进行整合,以特征提取模块提取的特征为输入, 生成声学模型得分。声学模型是语音识别系统的重要组成部分,它占据着语音识别大部分的计算开销,决定着语音识别系统的性能。
93 |
94 | **GMM-HMM**
95 |
96 | 高斯混合模型(Gaussian mixture model,GMM)用于对语音信号的声学特征分布进行建模;隐马尔科夫模型(Hidden Markov model,HMM)则用于对语音信号的时序性进行建模。
97 |
98 | 维特比算法(Viterbi):针对篱笆网络的有向图(Lattice)的最短路径问题而提出的动态规划算法。凡是使用隐含马 尔可夫模型描述的问题都可以用维特比算法来解码。
99 |
100 | GMM-HMM语音识别分三步:
101 |
102 | 1. 把帧识别成状态(难点),GMM
103 | 2. 把状态组合成音素,HMM
104 | 3. 把音素组合成单词,HMM
105 |
106 |  107 |
108 | **DNN-HMM**
109 |
110 | GMM模拟任意函数的功能取决于混合高斯函数的个数,所以具有一定的局限性,属于浅层模型;深度神经网络可以模拟任意的函数,因而表达能力更强;随着深度学习的发展,DNN模型展现出了明显超越GMM 模型的性能,于是替代了GMM进行HMM状态建模。
111 |
112 |
107 |
108 | **DNN-HMM**
109 |
110 | GMM模拟任意函数的功能取决于混合高斯函数的个数,所以具有一定的局限性,属于浅层模型;深度神经网络可以模拟任意的函数,因而表达能力更强;随着深度学习的发展,DNN模型展现出了明显超越GMM 模型的性能,于是替代了GMM进行HMM状态建模。
111 |
112 |  113 |
114 | **BLSTM-CTC**
115 |
116 | 然而在混合DNN/HMM系统的训练过程中,依然需要利用 GMM 来对训练数据进行强制对齐,以获得语音帧层面的 标注信息进一步训练DNN。这样显然不利于针对整句发音 进行全局优化,同时也相应地增加了识别系统的复杂度和 搭建门槛。
117 |
118 | 对于序列标记任务,Graves 等人提出了在循环神经网络训 练中引入联结时序分类(Connectionist Temporal Classification,CTC)目标函数,使得RNN可以自动地完成 序列输入自动对齐任务,进而提出了BLSTM-CTC模型。
119 |
120 |
113 |
114 | **BLSTM-CTC**
115 |
116 | 然而在混合DNN/HMM系统的训练过程中,依然需要利用 GMM 来对训练数据进行强制对齐,以获得语音帧层面的 标注信息进一步训练DNN。这样显然不利于针对整句发音 进行全局优化,同时也相应地增加了识别系统的复杂度和 搭建门槛。
117 |
118 | 对于序列标记任务,Graves 等人提出了在循环神经网络训 练中引入联结时序分类(Connectionist Temporal Classification,CTC)目标函数,使得RNN可以自动地完成 序列输入自动对齐任务,进而提出了BLSTM-CTC模型。
119 |
120 |  121 |
122 | **DFCNN-CTC**
123 |
124 | 深度全序列卷积神经网络(Deep Fully Convolutional Neural Network,DFCNN ):由科大讯飞2016年提出的一 种使用深度卷积神经网络来对语音时频图进行识别的方法。
125 |
126 | 连接时序分类(Connectionist temporal classification,CTC ):CTC不需要标签在时间上一一对齐就可以进行训练,在对输入数据的任一时刻做出的预测不是很关心,而关心的是整体上输出是否与标签一致,从而减少了标签预 划定的冗杂工作。在整个网络结构中把CTC作为损失函数。
127 |
128 |
129 |
130 | DFCNN 比较灵活,可以方便地和其他建模方式融合,比如和连接时序分类模型(CTC)方案结合,以实现整个模型 的端到端声学模型训练。和目前(2016年)业界最好的语音识别框架BLSTM-CTC 系统相比, DFCNN 系统获得了额外15%的性能提升。
131 |
132 | DFCNN 先对时域的语音信号进行傅里叶变换得到语音的语谱图, 直接将 一句语音转化成一张图像作为输入,输出单元则 直接与最终的识别结果(比如音节或者汉字)相对应。
133 |
134 |
121 |
122 | **DFCNN-CTC**
123 |
124 | 深度全序列卷积神经网络(Deep Fully Convolutional Neural Network,DFCNN ):由科大讯飞2016年提出的一 种使用深度卷积神经网络来对语音时频图进行识别的方法。
125 |
126 | 连接时序分类(Connectionist temporal classification,CTC ):CTC不需要标签在时间上一一对齐就可以进行训练,在对输入数据的任一时刻做出的预测不是很关心,而关心的是整体上输出是否与标签一致,从而减少了标签预 划定的冗杂工作。在整个网络结构中把CTC作为损失函数。
127 |
128 |
129 |
130 | DFCNN 比较灵活,可以方便地和其他建模方式融合,比如和连接时序分类模型(CTC)方案结合,以实现整个模型 的端到端声学模型训练。和目前(2016年)业界最好的语音识别框架BLSTM-CTC 系统相比, DFCNN 系统获得了额外15%的性能提升。
131 |
132 | DFCNN 先对时域的语音信号进行傅里叶变换得到语音的语谱图, 直接将 一句语音转化成一张图像作为输入,输出单元则 直接与最终的识别结果(比如音节或者汉字)相对应。
133 |
134 |  135 |
136 | ### 语音识别主要应用
137 |
138 | - 智能家居
139 | - 用语音可以控制电视机、VCD、空调、电扇、窗帘的操作
140 | - 语音搜索
141 | - 搜索内容直接以语音的方式输入,响应速度更快,适用于音乐、电影、小说等内容搜索场景,让搜索内容输入更加便捷,高效
142 | - 人机对话
143 | - 将语音识别为文字,毫秒级响应,可用于聊天机器人、故事机等近场语音识别环境,让人机对话更加流畅自然
144 | - 语音输入
145 | - 通过语音识别将语音转换为文字实现输入,如语音输入法等
146 |
147 | # 声纹识别
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
157 |
158 |
159 |
160 |
161 |
162 |
163 | # 语音合成
164 |
165 |
166 |
167 |
168 |
169 |
170 |
171 |
172 |
173 |
174 |
175 |
176 |
177 |
178 |
179 |
180 |
181 |
--------------------------------------------------------------------------------
/docs/理论入门/01.绪论与深度学习概述.md:
--------------------------------------------------------------------------------
1 | # 绪论与深度学习概述
2 |
3 | 1. 人工智能、机器学习与深度学习
4 | 2. 起源与发展
5 | 3. 重要的研究机构和著名科学家
6 | 4. 定义、理论和方法
7 | 5. 主要应用
8 |
9 |
10 |
11 | ## 人工智能、机器学习与深度学习
12 |
13 | ### 人工智能
14 |
15 | 人工智能是一门新兴学科,关于人工智能的定义,有很多人给出过,比如
16 |
17 | - 约翰·麦卡锡(2007):It is the science and engineering of making intelligent machines, especially intelligent computer programs. It is related to the similar task of using computers to understand human intelligence, but AI does not have to confine itself to methods that are biologically observable.
18 | - $Andreas Kaplan$:A system’s ability to correctly interpret external data, to learn from such data, and to use those learnings to achieve specific goals and tasks through flexible adaptation.
19 |
20 | - 全国信息安全标准化技术委员会:人工智能,是利用数字计算机或者数字计算机控制的机器模拟、延伸 和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理 论、方法、技术及应用系统。
21 |
22 | 人工智能可以分成以下三类:
23 |
24 | - 强人工智能:认为有可能制造出真正能推理和解决问题的智能机器,这样的机器被认为是有自主意识的
25 | - 弱人工智能:认为不可能制造出能真正进行推理和解决问题的智能 机器,这些机器只不过看起来像是智能的,但是并不真正拥有智能, 也不会有自主意识
26 | - 超级人工智能:机器的智能彻底超过了人类,“奇点”2050年到来?
27 |
28 | **人工智能的三次浪潮**
29 |
30 |
135 |
136 | ### 语音识别主要应用
137 |
138 | - 智能家居
139 | - 用语音可以控制电视机、VCD、空调、电扇、窗帘的操作
140 | - 语音搜索
141 | - 搜索内容直接以语音的方式输入,响应速度更快,适用于音乐、电影、小说等内容搜索场景,让搜索内容输入更加便捷,高效
142 | - 人机对话
143 | - 将语音识别为文字,毫秒级响应,可用于聊天机器人、故事机等近场语音识别环境,让人机对话更加流畅自然
144 | - 语音输入
145 | - 通过语音识别将语音转换为文字实现输入,如语音输入法等
146 |
147 | # 声纹识别
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
157 |
158 |
159 |
160 |
161 |
162 |
163 | # 语音合成
164 |
165 |
166 |
167 |
168 |
169 |
170 |
171 |
172 |
173 |
174 |
175 |
176 |
177 |
178 |
179 |
180 |
181 |
--------------------------------------------------------------------------------
/docs/理论入门/01.绪论与深度学习概述.md:
--------------------------------------------------------------------------------
1 | # 绪论与深度学习概述
2 |
3 | 1. 人工智能、机器学习与深度学习
4 | 2. 起源与发展
5 | 3. 重要的研究机构和著名科学家
6 | 4. 定义、理论和方法
7 | 5. 主要应用
8 |
9 |
10 |
11 | ## 人工智能、机器学习与深度学习
12 |
13 | ### 人工智能
14 |
15 | 人工智能是一门新兴学科,关于人工智能的定义,有很多人给出过,比如
16 |
17 | - 约翰·麦卡锡(2007):It is the science and engineering of making intelligent machines, especially intelligent computer programs. It is related to the similar task of using computers to understand human intelligence, but AI does not have to confine itself to methods that are biologically observable.
18 | - $Andreas Kaplan$:A system’s ability to correctly interpret external data, to learn from such data, and to use those learnings to achieve specific goals and tasks through flexible adaptation.
19 |
20 | - 全国信息安全标准化技术委员会:人工智能,是利用数字计算机或者数字计算机控制的机器模拟、延伸 和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理 论、方法、技术及应用系统。
21 |
22 | 人工智能可以分成以下三类:
23 |
24 | - 强人工智能:认为有可能制造出真正能推理和解决问题的智能机器,这样的机器被认为是有自主意识的
25 | - 弱人工智能:认为不可能制造出能真正进行推理和解决问题的智能 机器,这些机器只不过看起来像是智能的,但是并不真正拥有智能, 也不会有自主意识
26 | - 超级人工智能:机器的智能彻底超过了人类,“奇点”2050年到来?
27 |
28 | **人工智能的三次浪潮**
29 |
30 |  31 |
32 | ### 机器学习
33 |
34 | **机器学习定义** 让计算机具有像人一样的学习和思考能力的技术的总称。具体来说是从已知数据中获得规律,并利用规律对未知数据进行预测的技术
35 |
36 | **机器学习分类**
37 |
38 | - 有监督学习( $SupervisedLearning$ ):有老师(环境)的情况下, 学生(计算机)从老师(环境)那里获得对错指示、最终答案的学
39 |
40 | 习方法。跟学师评
41 |
42 | - 无监督学习( $UnsupervisedLearning$ ):没有老师(环境)的情
43 |
44 | 况下,学生(计算机)自学的过程,一般使用一些既定标准进行评价。自学标评
45 |
46 | - 强化学习( $ReinforcementLearning$ ):没有老师(环境)的情况 下,学生(计算机)对问题答案进行自我评价的方法。自学自评
47 |
48 |
31 |
32 | ### 机器学习
33 |
34 | **机器学习定义** 让计算机具有像人一样的学习和思考能力的技术的总称。具体来说是从已知数据中获得规律,并利用规律对未知数据进行预测的技术
35 |
36 | **机器学习分类**
37 |
38 | - 有监督学习( $SupervisedLearning$ ):有老师(环境)的情况下, 学生(计算机)从老师(环境)那里获得对错指示、最终答案的学
39 |
40 | 习方法。跟学师评
41 |
42 | - 无监督学习( $UnsupervisedLearning$ ):没有老师(环境)的情
43 |
44 | 况下,学生(计算机)自学的过程,一般使用一些既定标准进行评价。自学标评
45 |
46 | - 强化学习( $ReinforcementLearning$ ):没有老师(环境)的情况 下,学生(计算机)对问题答案进行自我评价的方法。自学自评
47 |
48 |  49 |
50 | ## 起源与发展
51 |
52 |
49 |
50 | ## 起源与发展
51 |
52 |  53 |
54 | - 第一阶段(1943 -1969)
55 | - 1943年: $Warren McCulloch$ 和 $Walter Pitts$ 提出了`MP`神经元模型
56 | - 1958年: $Frank Rosenblatt$ 提出了感知器( $Perceptron$ )
57 | - 1960年: $Bernard Widrow$ 和 $Ted Hoff$ 提出了`ADLINE`神经网络
58 | - 1969年: $Marvin Minsky$ 和 $Seymour Papert$ 指出感知器只能做简单的线性分类任务,无法解决`XOR`这种简单分类问题
59 | - 第二阶段(1980 -1989)
60 | - 1982年: $John Hopfield$ 提出了`Hopfield`神经网络
61 | - 1986年: $David Rumelhart$ 、 $Geoffrey Hinton$ 和 $Ronald Williams$ 提出了误差反向传播算法(`Error Back Propagation`,`BP`)
62 | - 1989年: $YannLeCun$ 等人提出了卷积神经网络(`Convolutional Neural Networks`,`CNN`)
63 |
64 | - 第三阶段(2006 - )
65 |
66 | - 2006年: $Hinton$ 和他的学生正式提出了深度学习的概念,通过无监督学习方法逐层训练算法,再使用有监督的反向传播算法进行调优
67 |
68 | - 2011年: $Frank Seide$ 在语音识别基准测试数据集上获得压倒性优势
69 |
70 | - 2012年: $AlexKrizhevsky$ 在`CNN`中引入`ReLU`激活函数,在图像识别基准测试中获得压倒性优势。
71 |
72 | - 2012年:吴恩达( $Andrew Ng$ )教授和谷歌首席架构师 $Jeff Dean$ 共同主导著名的 $GoogleBrain$ 项目,采用 $16$ 万个 $CPU$ 来构建一个深层 神经网络——`DNN`,将其应用于图像和语音的识别,大获成功
73 |
74 | - 2014年: $Facebook$ 的 $DeepFace$ 项目,在人脸识别方面的准确率已 经能够达到 $97%$ 以上,跟人类识别的准确率几乎没有差别
75 |
76 | - 2016年:谷歌 $DeepMind$ 开发的 $AlphaGo$ 以 $4:1$ 的比分战胜国际顶尖 围棋高手李世石,证明在围棋领域,基于深度学习技术的机器人已经超越了人类
77 |
78 | ## 重要的研究机构和著名科学家
79 |
80 | ### 深度学习研究机构
81 |
82 | - **$Machine Learning at University of Toronto$**
83 |
84 | 代表人物: $GeoffreyHinton$
85 |
86 |
53 |
54 | - 第一阶段(1943 -1969)
55 | - 1943年: $Warren McCulloch$ 和 $Walter Pitts$ 提出了`MP`神经元模型
56 | - 1958年: $Frank Rosenblatt$ 提出了感知器( $Perceptron$ )
57 | - 1960年: $Bernard Widrow$ 和 $Ted Hoff$ 提出了`ADLINE`神经网络
58 | - 1969年: $Marvin Minsky$ 和 $Seymour Papert$ 指出感知器只能做简单的线性分类任务,无法解决`XOR`这种简单分类问题
59 | - 第二阶段(1980 -1989)
60 | - 1982年: $John Hopfield$ 提出了`Hopfield`神经网络
61 | - 1986年: $David Rumelhart$ 、 $Geoffrey Hinton$ 和 $Ronald Williams$ 提出了误差反向传播算法(`Error Back Propagation`,`BP`)
62 | - 1989年: $YannLeCun$ 等人提出了卷积神经网络(`Convolutional Neural Networks`,`CNN`)
63 |
64 | - 第三阶段(2006 - )
65 |
66 | - 2006年: $Hinton$ 和他的学生正式提出了深度学习的概念,通过无监督学习方法逐层训练算法,再使用有监督的反向传播算法进行调优
67 |
68 | - 2011年: $Frank Seide$ 在语音识别基准测试数据集上获得压倒性优势
69 |
70 | - 2012年: $AlexKrizhevsky$ 在`CNN`中引入`ReLU`激活函数,在图像识别基准测试中获得压倒性优势。
71 |
72 | - 2012年:吴恩达( $Andrew Ng$ )教授和谷歌首席架构师 $Jeff Dean$ 共同主导著名的 $GoogleBrain$ 项目,采用 $16$ 万个 $CPU$ 来构建一个深层 神经网络——`DNN`,将其应用于图像和语音的识别,大获成功
73 |
74 | - 2014年: $Facebook$ 的 $DeepFace$ 项目,在人脸识别方面的准确率已 经能够达到 $97%$ 以上,跟人类识别的准确率几乎没有差别
75 |
76 | - 2016年:谷歌 $DeepMind$ 开发的 $AlphaGo$ 以 $4:1$ 的比分战胜国际顶尖 围棋高手李世石,证明在围棋领域,基于深度学习技术的机器人已经超越了人类
77 |
78 | ## 重要的研究机构和著名科学家
79 |
80 | ### 深度学习研究机构
81 |
82 | - **$Machine Learning at University of Toronto$**
83 |
84 | 代表人物: $GeoffreyHinton$
85 |
86 |  87 |
88 | - **Deepmind at Google**
89 |
90 |
87 |
88 | - **Deepmind at Google**
89 |
90 |  91 |
92 | - **$AI research at Facebook$**
93 | - **清华大学AI研究院**
94 | - **中国科学院自动化所**
95 | - **中国科学院数学与系统科学研究院**
96 | - **$Tencent AI Lab$**
97 | - **华为诺亚方舟实验室**
98 | - **阿里达摩院**
99 | - ...
100 |
101 | ### 深度学习知名科学家
102 |
103 | - **$Geoffrey Hinton$**
104 |
105 | 深度学习之父;多伦多大学杰出教授; $Google$ 副总裁及首席科学顾问;英国皇家科学院院士,美国国家工 程院外籍院士,美国艺术与科学院 外籍院士。
106 |
107 | 在`BP`算法, $Boltzmannmachines$ , $Time-delay neural nets$ , $Variational learning and Deep learning$ 做出杰出文献。
108 |
109 | - **$Yann LeCun$**
110 |
111 | 卷积神经网络之父;纽约大学杰出教授; $Facebook$ 人工智能实验室负责人;纽约大学数据科学实验室创始人。
112 |
113 | 在学习理论与学习算法、卷积神经 网络领域做出杰出文献。
114 |
115 | - **$Yoshua Bengio$**
116 |
117 | 蒙特利尔大学全职教授;加拿大统计学习算法研究主席;加拿大皇家科学院院士; $CIFAR Senior Fellow$ ;创办了 $ICLR$ 国际会议。
118 |
119 | 在 $MachineLearning$ , $Deeplearning$ 领域做出杰出文献。
120 |
121 | - **吴恩达(Andrew Ng)**
122 |
123 | 斯坦福大学计算机科学系和电子工程系副教授;在线教育平台$Coursera$ 的联合创始人( $with Daphne Koller$ );2014年5月16日,吴恩达加入百度,担任百度公司首席科学家;2017年10月,吴恩达出任 $Woebot$ 公司新任董事长。
124 |
125 |
91 |
92 | - **$AI research at Facebook$**
93 | - **清华大学AI研究院**
94 | - **中国科学院自动化所**
95 | - **中国科学院数学与系统科学研究院**
96 | - **$Tencent AI Lab$**
97 | - **华为诺亚方舟实验室**
98 | - **阿里达摩院**
99 | - ...
100 |
101 | ### 深度学习知名科学家
102 |
103 | - **$Geoffrey Hinton$**
104 |
105 | 深度学习之父;多伦多大学杰出教授; $Google$ 副总裁及首席科学顾问;英国皇家科学院院士,美国国家工 程院外籍院士,美国艺术与科学院 外籍院士。
106 |
107 | 在`BP`算法, $Boltzmannmachines$ , $Time-delay neural nets$ , $Variational learning and Deep learning$ 做出杰出文献。
108 |
109 | - **$Yann LeCun$**
110 |
111 | 卷积神经网络之父;纽约大学杰出教授; $Facebook$ 人工智能实验室负责人;纽约大学数据科学实验室创始人。
112 |
113 | 在学习理论与学习算法、卷积神经 网络领域做出杰出文献。
114 |
115 | - **$Yoshua Bengio$**
116 |
117 | 蒙特利尔大学全职教授;加拿大统计学习算法研究主席;加拿大皇家科学院院士; $CIFAR Senior Fellow$ ;创办了 $ICLR$ 国际会议。
118 |
119 | 在 $MachineLearning$ , $Deeplearning$ 领域做出杰出文献。
120 |
121 | - **吴恩达(Andrew Ng)**
122 |
123 | 斯坦福大学计算机科学系和电子工程系副教授;在线教育平台$Coursera$ 的联合创始人( $with Daphne Koller$ );2014年5月16日,吴恩达加入百度,担任百度公司首席科学家;2017年10月,吴恩达出任 $Woebot$ 公司新任董事长。
124 |
125 |  126 |
127 |
128 |
129 | ## 深度学习的定义和主要应用
130 |
131 | ### 定义
132 |
133 | **深度学习定义**:一般是指通过训练多层网络结构对未知数据进行分类或回归
134 |
135 | **深度学习分类**:有监督学习方法——深度前馈网络、卷积神经网络、循环神经网络等;无监督学习方法——深度信念网、深度玻尔兹曼机,深度自编码器等。
136 |
137 | ### 主要应用
138 |
139 | **图像处理领域主要应用**
140 |
141 | - 图像分类(物体识别):整幅图像的分类或识别
142 | - 物体检测:检测图像中物体的位置进而识别物体
143 | - 图像分割:对图像中的特定物体按边缘进行分割
144 | - 图像回归:预测图像中物体组成部分的坐标
145 |
146 | **语音识别领域主要应用**
147 |
148 | - 语音识别:将语音识别为文字
149 | - 声纹识别:识别是哪个人的声音
150 | - 语音合成:根据文字合成特定人的语音
151 |
152 | **自然语言处理领域主要应用**
153 |
154 | - 语言模型:根据之前词预测下一个单词。
155 | - 情感分析:分析文本体现的情感(正负向、正负中或多态度类型)。
156 | - 神经机器翻译:基于统计语言模型的多语种互译。
157 | - 神经自动摘要:根据文本自动生成摘要。
158 | - 机器阅读理解:通过阅读文本回答问题、完成选择题或完型填空。
159 | - 自然语言推理:根据一句话(前提)推理出另一句话(结论)。
160 |
161 | **综合应用**
162 |
163 | - 图像描述:根据图像给出图像的描述句子
164 | - 可视问答:根据图像或视频回答问题
165 | - 图像生成:根据文本描述生成图像
166 | - 视频生成:根据故事自动生成视频
--------------------------------------------------------------------------------
/docs/理论入门/02.数学基础.md:
--------------------------------------------------------------------------------
1 | # 数学基础
2 |
3 | 1. 张量、矩阵运算、矩阵的基础知识、矩阵分解
4 | 2. 概率统计、常见的(多变量)分布
5 | 3. 信息论、熵、互信息、相对熵、交叉熵
6 | 4. 最优化估计方法、最小二乘、线性模型
7 |
8 |
9 |
10 | ## 矩阵论
11 |
12 | ### 矩阵基本知识
13 |
14 | **矩阵**:是一个二维数组,其中的每一个元素一般由两个索引来确定一般用大写变量表示,m行n列的实数矩阵,记做
15 | $A \in R_{m \times n}$.
16 |
17 | **张量**(Tensor):是矢量概念的推广,可用来表示在一些矢量、标量和其他张量之间的线性关系的多线性函数。标量是0阶张量,矢量是一阶张量,矩阵是二阶张量,三维及以上数组一般称为张量。
18 |
19 |
126 |
127 |
128 |
129 | ## 深度学习的定义和主要应用
130 |
131 | ### 定义
132 |
133 | **深度学习定义**:一般是指通过训练多层网络结构对未知数据进行分类或回归
134 |
135 | **深度学习分类**:有监督学习方法——深度前馈网络、卷积神经网络、循环神经网络等;无监督学习方法——深度信念网、深度玻尔兹曼机,深度自编码器等。
136 |
137 | ### 主要应用
138 |
139 | **图像处理领域主要应用**
140 |
141 | - 图像分类(物体识别):整幅图像的分类或识别
142 | - 物体检测:检测图像中物体的位置进而识别物体
143 | - 图像分割:对图像中的特定物体按边缘进行分割
144 | - 图像回归:预测图像中物体组成部分的坐标
145 |
146 | **语音识别领域主要应用**
147 |
148 | - 语音识别:将语音识别为文字
149 | - 声纹识别:识别是哪个人的声音
150 | - 语音合成:根据文字合成特定人的语音
151 |
152 | **自然语言处理领域主要应用**
153 |
154 | - 语言模型:根据之前词预测下一个单词。
155 | - 情感分析:分析文本体现的情感(正负向、正负中或多态度类型)。
156 | - 神经机器翻译:基于统计语言模型的多语种互译。
157 | - 神经自动摘要:根据文本自动生成摘要。
158 | - 机器阅读理解:通过阅读文本回答问题、完成选择题或完型填空。
159 | - 自然语言推理:根据一句话(前提)推理出另一句话(结论)。
160 |
161 | **综合应用**
162 |
163 | - 图像描述:根据图像给出图像的描述句子
164 | - 可视问答:根据图像或视频回答问题
165 | - 图像生成:根据文本描述生成图像
166 | - 视频生成:根据故事自动生成视频
--------------------------------------------------------------------------------
/docs/理论入门/02.数学基础.md:
--------------------------------------------------------------------------------
1 | # 数学基础
2 |
3 | 1. 张量、矩阵运算、矩阵的基础知识、矩阵分解
4 | 2. 概率统计、常见的(多变量)分布
5 | 3. 信息论、熵、互信息、相对熵、交叉熵
6 | 4. 最优化估计方法、最小二乘、线性模型
7 |
8 |
9 |
10 | ## 矩阵论
11 |
12 | ### 矩阵基本知识
13 |
14 | **矩阵**:是一个二维数组,其中的每一个元素一般由两个索引来确定一般用大写变量表示,m行n列的实数矩阵,记做
15 | $A \in R_{m \times n}$.
16 |
17 | **张量**(Tensor):是矢量概念的推广,可用来表示在一些矢量、标量和其他张量之间的线性关系的多线性函数。标量是0阶张量,矢量是一阶张量,矩阵是二阶张量,三维及以上数组一般称为张量。
18 |
19 |  20 |
21 | **矩阵的秩**(Rank):矩阵列向量中的极大线性无关组的数目,记作矩阵的列秩,同样可以定义行秩。行秩=列秩=矩阵的秩,通常记作rank(A)。
22 |
23 | **矩阵的逆**
24 |
25 | - 若矩阵A为方阵,当 $rank(A_{n×n})\lt n$
26 | 时,称A为奇异矩阵或不可逆矩阵;
27 | - 若矩阵A为方阵,当 $rank(A_{n×n})=n$
28 | 时,称A为非奇异矩阵或可逆矩阵
29 |
30 | 其逆矩阵 $A^{-1}$ 满足以下条件,则称 $A^{-1}$ 为矩阵A的逆矩阵:
31 |
32 | $$
33 | AA^{-1} = A^{-1}A = I_n
34 | $$
35 |
36 | 其中 $I_n$ 是 $n×n$ 的单位阵。
37 |
38 | **矩阵的广义逆矩阵**
39 |
40 | - 如果矩阵不为方阵或者是奇异矩阵,不存在逆矩阵,但是可以计算其广义逆矩阵或者伪逆矩阵;
41 | - 对于矩阵A,如果存在矩阵 $B$ 使得 $ABA=A$,则称 $B$ 为 $A$ 的广义逆矩阵。
42 |
43 | ### 矩阵分解
44 |
45 | 机器学习中常见的矩阵分解有特征分解和奇异值分解。
46 |
47 | 先提一下矩阵的特征值和特征向量的定义
48 |
49 | - 若矩阵 $A$ 为方阵,则存在非零向量 $x$ 和常数 $\lambda$ 满足 $Ax=\lambda x$,则称 $ \lambda$ 为矩阵 $ A$ 的一个特征值,$x$ 为矩阵 $A$ 关于 $\lambda$ 的特征向量。
50 | - $A_{n \times n}$ 的矩阵具有 $n$ 个特征值, $λ_1 ≤ λ_2 ≤ ⋯ ≤ λ_n$ 其对应的*n*个特征向量为 $𝒖_1,𝒖_2, ⋯ ,𝒖_𝑛$
51 | - 矩阵的迹(trace)和行列式(determinant)的值分别为
52 |
53 | $$
54 | \mathrm{tr}(\mathrm{A})=\sum_{i=1}^{n} \lambda_{i} \quad|\mathrm{~A}|=\prod_{i=1}^{n} \lambda_{i}
55 | $$
56 |
57 | **矩阵特征分解**: $A_{n \times n}$ 的矩阵具有 $n$ 个不同的特征值,那么矩阵A可以分解为 $A = U\Sigma U^{T}$.
58 |
59 | 其中
60 |
61 | $$
62 | \Sigma=\left[\begin{array}{cccc}\lambda_{1} & 0 & \cdots & 0 \\ 0 & \lambda_{2} & \cdots & 0 \\ 0 & 0 & \ddots & \vdots \\ 0 & 0 & \cdots & \lambda_{n}\end{array}\right] \quad \mathrm{U}=\left[\boldsymbol{u}_{1}, \boldsymbol{u}_{2}, \cdots, \boldsymbol{u}_{n}\right] \quad \left\|\boldsymbol{u}_{i}\right\|_{2}=1
63 | $$
64 |
65 | **奇异值分解**:对于任意矩阵 $A_{m \times n}$,存在正交矩阵 $U_{m \times m}$ 和 $V_{n \times n}$,使其满足 $A = U \Sigma V^{T} \quad U^T U = V^T V = I$,则称上式为矩阵 $A$ 的特征分解。
66 |
67 |
20 |
21 | **矩阵的秩**(Rank):矩阵列向量中的极大线性无关组的数目,记作矩阵的列秩,同样可以定义行秩。行秩=列秩=矩阵的秩,通常记作rank(A)。
22 |
23 | **矩阵的逆**
24 |
25 | - 若矩阵A为方阵,当 $rank(A_{n×n})\lt n$
26 | 时,称A为奇异矩阵或不可逆矩阵;
27 | - 若矩阵A为方阵,当 $rank(A_{n×n})=n$
28 | 时,称A为非奇异矩阵或可逆矩阵
29 |
30 | 其逆矩阵 $A^{-1}$ 满足以下条件,则称 $A^{-1}$ 为矩阵A的逆矩阵:
31 |
32 | $$
33 | AA^{-1} = A^{-1}A = I_n
34 | $$
35 |
36 | 其中 $I_n$ 是 $n×n$ 的单位阵。
37 |
38 | **矩阵的广义逆矩阵**
39 |
40 | - 如果矩阵不为方阵或者是奇异矩阵,不存在逆矩阵,但是可以计算其广义逆矩阵或者伪逆矩阵;
41 | - 对于矩阵A,如果存在矩阵 $B$ 使得 $ABA=A$,则称 $B$ 为 $A$ 的广义逆矩阵。
42 |
43 | ### 矩阵分解
44 |
45 | 机器学习中常见的矩阵分解有特征分解和奇异值分解。
46 |
47 | 先提一下矩阵的特征值和特征向量的定义
48 |
49 | - 若矩阵 $A$ 为方阵,则存在非零向量 $x$ 和常数 $\lambda$ 满足 $Ax=\lambda x$,则称 $ \lambda$ 为矩阵 $ A$ 的一个特征值,$x$ 为矩阵 $A$ 关于 $\lambda$ 的特征向量。
50 | - $A_{n \times n}$ 的矩阵具有 $n$ 个特征值, $λ_1 ≤ λ_2 ≤ ⋯ ≤ λ_n$ 其对应的*n*个特征向量为 $𝒖_1,𝒖_2, ⋯ ,𝒖_𝑛$
51 | - 矩阵的迹(trace)和行列式(determinant)的值分别为
52 |
53 | $$
54 | \mathrm{tr}(\mathrm{A})=\sum_{i=1}^{n} \lambda_{i} \quad|\mathrm{~A}|=\prod_{i=1}^{n} \lambda_{i}
55 | $$
56 |
57 | **矩阵特征分解**: $A_{n \times n}$ 的矩阵具有 $n$ 个不同的特征值,那么矩阵A可以分解为 $A = U\Sigma U^{T}$.
58 |
59 | 其中
60 |
61 | $$
62 | \Sigma=\left[\begin{array}{cccc}\lambda_{1} & 0 & \cdots & 0 \\ 0 & \lambda_{2} & \cdots & 0 \\ 0 & 0 & \ddots & \vdots \\ 0 & 0 & \cdots & \lambda_{n}\end{array}\right] \quad \mathrm{U}=\left[\boldsymbol{u}_{1}, \boldsymbol{u}_{2}, \cdots, \boldsymbol{u}_{n}\right] \quad \left\|\boldsymbol{u}_{i}\right\|_{2}=1
63 | $$
64 |
65 | **奇异值分解**:对于任意矩阵 $A_{m \times n}$,存在正交矩阵 $U_{m \times m}$ 和 $V_{n \times n}$,使其满足 $A = U \Sigma V^{T} \quad U^T U = V^T V = I$,则称上式为矩阵 $A$ 的特征分解。
66 |
67 |  68 |
69 | # 概率统计
70 |
71 | ### 随机变量
72 |
73 | 随机变量(Random variable)是随机事件的数量表现,随机事件数量化的好处是可以用数学分析的方法来研究随机现象。
74 |
75 | 随机变量可以是离散的或者连续的,离散随机变量是指拥有有限个或者可列无限多个状态的随机变量,连续随机变量是指变量值不可随机列举出来的随机变量,一般取实数值。
76 |
77 | 随机变量通常用概率分布来指定它的每个状态的可能性。
78 |
79 | 举例:
80 |
81 | 1. 投掷一枚硬币为正面是离散型随机事件X,发生概率P(X=1)=0.5
82 | 2. 每次射箭距离靶心的距离X可以认为连续型随机变量,距离靶心小 于1cm的概率P(X<1cm)
83 |
84 | ### 常见的概率分布
85 |
86 | **伯努利分布**
87 |
88 | - 伯努利试验:只可能有两种结果的单次随机实验
89 | - 又称0-1分布,单个二值型离散随机变量的分布
90 | - 其概率分布: $P*(*X=1)=p,P(X=0)=1-p$.
91 |
92 | **二项分布**
93 |
94 | - 二项分布即重复*n*次伯努利试验,各试验之间都相互独立
95 | - 如果每次试验时,事件发生的概率为*p*,不发生的概率为1-p,则*n*次重复独立试验中事件发生*k*次的概率为
96 |
97 | $$
98 | P(X = k) = C_n^kp^k(1-p)^{n-k}
99 | $$
100 |
101 | **均匀分布**
102 |
103 | 均匀分布,又称矩形分布,在给定长度间隔[*a*,*b*]内的分布概率是等可能的,均匀分布由参数*a*,*b*定义,概率密度函数为:
104 |
105 | $$
106 | p(x) = \frac{1}{b-a} \quad a < x < b
107 | $$
108 |
109 |
68 |
69 | # 概率统计
70 |
71 | ### 随机变量
72 |
73 | 随机变量(Random variable)是随机事件的数量表现,随机事件数量化的好处是可以用数学分析的方法来研究随机现象。
74 |
75 | 随机变量可以是离散的或者连续的,离散随机变量是指拥有有限个或者可列无限多个状态的随机变量,连续随机变量是指变量值不可随机列举出来的随机变量,一般取实数值。
76 |
77 | 随机变量通常用概率分布来指定它的每个状态的可能性。
78 |
79 | 举例:
80 |
81 | 1. 投掷一枚硬币为正面是离散型随机事件X,发生概率P(X=1)=0.5
82 | 2. 每次射箭距离靶心的距离X可以认为连续型随机变量,距离靶心小 于1cm的概率P(X<1cm)
83 |
84 | ### 常见的概率分布
85 |
86 | **伯努利分布**
87 |
88 | - 伯努利试验:只可能有两种结果的单次随机实验
89 | - 又称0-1分布,单个二值型离散随机变量的分布
90 | - 其概率分布: $P*(*X=1)=p,P(X=0)=1-p$.
91 |
92 | **二项分布**
93 |
94 | - 二项分布即重复*n*次伯努利试验,各试验之间都相互独立
95 | - 如果每次试验时,事件发生的概率为*p*,不发生的概率为1-p,则*n*次重复独立试验中事件发生*k*次的概率为
96 |
97 | $$
98 | P(X = k) = C_n^kp^k(1-p)^{n-k}
99 | $$
100 |
101 | **均匀分布**
102 |
103 | 均匀分布,又称矩形分布,在给定长度间隔[*a*,*b*]内的分布概率是等可能的,均匀分布由参数*a*,*b*定义,概率密度函数为:
104 |
105 | $$
106 | p(x) = \frac{1}{b-a} \quad a < x < b
107 | $$
108 |
109 |  110 |
111 | **高斯分布**
112 |
113 | 高斯分布,又称正态分布(normal),是实数中最常用的分布,由均值*μ*和标准差*σ*决定其分布,概率密度函数为:
114 |
115 | $$
116 | p(x) = \frac{1}{\sqrt{2 \pi}\sigma}e^{-\frac{(x-\mu)^2}{2 \sigma^2}}
117 | $$
118 |
119 | **指数分布**
120 |
121 | 常用来表示独立随机事件发生的时间间隔,参数为λ>0的指数分布概率密度函数为: $p(x) = \lambda e^{-\lambda x} \quad x \geq 0$. 指数分布重要特征是无记忆性。
122 |
123 | ### 多变量概率分布
124 |
125 | **条件概率**(Conditional probability):事件X在事件Y发生的条件下发生的概率,P(X|Y)
126 |
127 | **联合概率**(Joint probability):表示两个事件X和Y共同发生的概率,P(X,Y)
128 |
129 | 条件概率和联合概率的性质: $P(Y|X) = \frac{P(Y,X)}{P(X)} \quad P(X ) > 0$.
130 |
131 | 推广到 n 个事件,条件概率的链式法则:
132 |
133 | $$
134 | \begin{aligned} P\left(X_{1}, X_{2}, \ldots, X_{n}\right) &=P\left(X_{1} \mid X_{2}, \ldots, X_{n}\right) P\left(X_{2} \mid X_{3}, X_{4}, \ldots, X_{n}\right) \ldots P\left(X_{n-1} \mid X_{n}\right) P\left(X_{n}\right) \\ &=P\left(X_{n}\right) \prod_{i=1}^{n-1} P\left(X_{i} \mid X_{i+1}, \ldots, X_{n}\right) \end{aligned}
135 | $$
136 |
137 | **先验概率**(Prior probability):根据以往经验和分析得到的概率,在事件发生前已知,它往往作为“由因求果”问题中的“因”出现。
138 |
139 | **后验概率**(Posterior probability):指得到“结果”的信息后重新修正的概率,是“执果寻因”问题中 的“因”,后验概率是基于新的信息,修正后来的先验概率所获得 的更接近实际情况的概率估计。
140 |
141 | 举例说明:一口袋里有3只红球、2只白球,采用不放回方式摸取,求:
142 | (1) 第一次摸到红球(记作A)的概率;
143 | (2) 第二次摸到红球(记作B)的概率;
144 | (3) 已知第二次摸到了红球,求第一次摸到的是红球的概率?
145 |
146 | 解:(1) $P(A=1) = 3/5$, 这就是先验概率;
147 |
148 | (2) $P(B=1) = P(A=1) P(B=1|A=1)+ P(A=0)P(B=1|A=0)=\frac{3}{5}\frac{2}{4}+\frac{2}{5}\frac{3}{4} = \frac{3}{5}$
149 |
150 | (3) $P(A=1|B=1) = \frac{P(A = 1)P(B = 1|A = 1)}{P(B = 1)} = \frac{1}{2}$, 这就是后验概率。
151 |
152 | **全概率公式**:设事件 $\{A_i\}$ 是样本空间 $Ω$ 的一个划分,且 $P(A_i)>0(i=1,2,...,n)$ ,那么: $P(B) = \sum_{i = 1}^nP(A_i)P(B|A_i)$ .
153 |
154 | **贝叶斯公式**:全概率公式给我们提供了计算后验概率的途径,即贝叶斯公式
155 |
156 | $$
157 | P\left(\mathrm{~A}_{i} \mid \mathrm{B}\right)=\frac{P\left(\mathrm{~B} \mid \mathrm{A}_{i}\right) P\left(\mathrm{~A}_{i}\right)}{P(\mathrm{~B})}=\frac{P\left(\mathrm{~B} \mid \mathrm{A}_{i}\right) P\left(\mathrm{~A}_{i}\right)}{\sum_{j=1}^{n} P\left(\mathrm{~A}_{j}\right) P\left(\mathrm{~B} \mid \mathrm{A}_{j}\right)}
158 | $$
159 |
160 | ### 常用统计量
161 |
162 | **方差**:用来衡量随机变量与数学期望之间的偏离程度。统计中的方差则为样本方差,是各个样本数据分别与其平均数之差 的平方和的平均数,计算过程为:
163 |
164 | $$
165 | \mathrm{Var}(X) = E\left\{[x-E(x)]^{2}\right\} = E\left(x^{2}\right) - [E(x)]^{2}
166 | $$
167 |
168 | **协方差**:衡量两个随机变量X和Y直接的总体误差,计算过程为:
169 |
170 | $$
171 | \mathrm{Cov}(X,Y) = E\left\{[x-E(x)][y-E(y)]\right\} = E\left(xy\right) - E(x)E(y)
172 | $$
173 |
174 | # 信息论
175 |
176 | ### 熵(Entropy)
177 |
178 | 信息熵,可以看作是样本集合纯度一种指标,也可以认为是样本集合包含的平均信息量。
179 |
180 | 假定当前样本集合X中第*i*类样本 $𝑥_𝑖$ 所占的比例为$P(𝑥_𝑖)(i=1,2,...,n)$,则*X*的信息熵定义为:
181 |
182 | $$
183 | H(X) = -\sum_{i = 1}^n P(x_i)\log_2P(x_i)
184 | $$
185 |
186 | H(X)的值越小,则X的纯度越高,蕴含的不确定性越少
187 |
188 | ### 联合熵
189 |
190 | 两个随机变量X和Y的联合分布可以形成联合熵,度量二维随机变量XY的不确定性:
191 |
192 | $$
193 | H(X, Y) = -\sum_{i = 1}^n \sum_{j = 1}^n P(x_i,y_j)\log_2 P(x_i,y_j)
194 | $$
195 |
196 | ### 条件熵
197 |
198 | 在随机变量X发生的前提下,随机变量Y发生带来的熵,定义为Y的条件熵,用H(Y|X)表示,定义为:
199 |
200 | $$
201 | H(Y|X) = \sum_{i = 1}^n P(x_i)H(Y|X = x_i)
202 | = -\sum_{i = 1}^n P(x_i) \sum_{j = 1}^n P(y_j|x_i)\log_2
203 | P(y_j|x_i)
204 | = -\sum_{i = 1}^n \sum_{j = 1}^n P(x_i,y_j) \log_2
205 | P(y_j|x_i)
206 | $$
207 |
208 | 条件熵用来衡量在已知随机变量X的条件下,随机变量Y的不确定。 熵、联合熵和条件熵之间的关系: $H(Y|X) = H(X,Y)-H(X)$.
209 |
210 | ### 互信息
211 |
212 | $$
213 | I(X;Y) = H(X)+H(Y)-H(X,Y)
214 | $$
215 |
216 |
110 |
111 | **高斯分布**
112 |
113 | 高斯分布,又称正态分布(normal),是实数中最常用的分布,由均值*μ*和标准差*σ*决定其分布,概率密度函数为:
114 |
115 | $$
116 | p(x) = \frac{1}{\sqrt{2 \pi}\sigma}e^{-\frac{(x-\mu)^2}{2 \sigma^2}}
117 | $$
118 |
119 | **指数分布**
120 |
121 | 常用来表示独立随机事件发生的时间间隔,参数为λ>0的指数分布概率密度函数为: $p(x) = \lambda e^{-\lambda x} \quad x \geq 0$. 指数分布重要特征是无记忆性。
122 |
123 | ### 多变量概率分布
124 |
125 | **条件概率**(Conditional probability):事件X在事件Y发生的条件下发生的概率,P(X|Y)
126 |
127 | **联合概率**(Joint probability):表示两个事件X和Y共同发生的概率,P(X,Y)
128 |
129 | 条件概率和联合概率的性质: $P(Y|X) = \frac{P(Y,X)}{P(X)} \quad P(X ) > 0$.
130 |
131 | 推广到 n 个事件,条件概率的链式法则:
132 |
133 | $$
134 | \begin{aligned} P\left(X_{1}, X_{2}, \ldots, X_{n}\right) &=P\left(X_{1} \mid X_{2}, \ldots, X_{n}\right) P\left(X_{2} \mid X_{3}, X_{4}, \ldots, X_{n}\right) \ldots P\left(X_{n-1} \mid X_{n}\right) P\left(X_{n}\right) \\ &=P\left(X_{n}\right) \prod_{i=1}^{n-1} P\left(X_{i} \mid X_{i+1}, \ldots, X_{n}\right) \end{aligned}
135 | $$
136 |
137 | **先验概率**(Prior probability):根据以往经验和分析得到的概率,在事件发生前已知,它往往作为“由因求果”问题中的“因”出现。
138 |
139 | **后验概率**(Posterior probability):指得到“结果”的信息后重新修正的概率,是“执果寻因”问题中 的“因”,后验概率是基于新的信息,修正后来的先验概率所获得 的更接近实际情况的概率估计。
140 |
141 | 举例说明:一口袋里有3只红球、2只白球,采用不放回方式摸取,求:
142 | (1) 第一次摸到红球(记作A)的概率;
143 | (2) 第二次摸到红球(记作B)的概率;
144 | (3) 已知第二次摸到了红球,求第一次摸到的是红球的概率?
145 |
146 | 解:(1) $P(A=1) = 3/5$, 这就是先验概率;
147 |
148 | (2) $P(B=1) = P(A=1) P(B=1|A=1)+ P(A=0)P(B=1|A=0)=\frac{3}{5}\frac{2}{4}+\frac{2}{5}\frac{3}{4} = \frac{3}{5}$
149 |
150 | (3) $P(A=1|B=1) = \frac{P(A = 1)P(B = 1|A = 1)}{P(B = 1)} = \frac{1}{2}$, 这就是后验概率。
151 |
152 | **全概率公式**:设事件 $\{A_i\}$ 是样本空间 $Ω$ 的一个划分,且 $P(A_i)>0(i=1,2,...,n)$ ,那么: $P(B) = \sum_{i = 1}^nP(A_i)P(B|A_i)$ .
153 |
154 | **贝叶斯公式**:全概率公式给我们提供了计算后验概率的途径,即贝叶斯公式
155 |
156 | $$
157 | P\left(\mathrm{~A}_{i} \mid \mathrm{B}\right)=\frac{P\left(\mathrm{~B} \mid \mathrm{A}_{i}\right) P\left(\mathrm{~A}_{i}\right)}{P(\mathrm{~B})}=\frac{P\left(\mathrm{~B} \mid \mathrm{A}_{i}\right) P\left(\mathrm{~A}_{i}\right)}{\sum_{j=1}^{n} P\left(\mathrm{~A}_{j}\right) P\left(\mathrm{~B} \mid \mathrm{A}_{j}\right)}
158 | $$
159 |
160 | ### 常用统计量
161 |
162 | **方差**:用来衡量随机变量与数学期望之间的偏离程度。统计中的方差则为样本方差,是各个样本数据分别与其平均数之差 的平方和的平均数,计算过程为:
163 |
164 | $$
165 | \mathrm{Var}(X) = E\left\{[x-E(x)]^{2}\right\} = E\left(x^{2}\right) - [E(x)]^{2}
166 | $$
167 |
168 | **协方差**:衡量两个随机变量X和Y直接的总体误差,计算过程为:
169 |
170 | $$
171 | \mathrm{Cov}(X,Y) = E\left\{[x-E(x)][y-E(y)]\right\} = E\left(xy\right) - E(x)E(y)
172 | $$
173 |
174 | # 信息论
175 |
176 | ### 熵(Entropy)
177 |
178 | 信息熵,可以看作是样本集合纯度一种指标,也可以认为是样本集合包含的平均信息量。
179 |
180 | 假定当前样本集合X中第*i*类样本 $𝑥_𝑖$ 所占的比例为$P(𝑥_𝑖)(i=1,2,...,n)$,则*X*的信息熵定义为:
181 |
182 | $$
183 | H(X) = -\sum_{i = 1}^n P(x_i)\log_2P(x_i)
184 | $$
185 |
186 | H(X)的值越小,则X的纯度越高,蕴含的不确定性越少
187 |
188 | ### 联合熵
189 |
190 | 两个随机变量X和Y的联合分布可以形成联合熵,度量二维随机变量XY的不确定性:
191 |
192 | $$
193 | H(X, Y) = -\sum_{i = 1}^n \sum_{j = 1}^n P(x_i,y_j)\log_2 P(x_i,y_j)
194 | $$
195 |
196 | ### 条件熵
197 |
198 | 在随机变量X发生的前提下,随机变量Y发生带来的熵,定义为Y的条件熵,用H(Y|X)表示,定义为:
199 |
200 | $$
201 | H(Y|X) = \sum_{i = 1}^n P(x_i)H(Y|X = x_i)
202 | = -\sum_{i = 1}^n P(x_i) \sum_{j = 1}^n P(y_j|x_i)\log_2
203 | P(y_j|x_i)
204 | = -\sum_{i = 1}^n \sum_{j = 1}^n P(x_i,y_j) \log_2
205 | P(y_j|x_i)
206 | $$
207 |
208 | 条件熵用来衡量在已知随机变量X的条件下,随机变量Y的不确定。 熵、联合熵和条件熵之间的关系: $H(Y|X) = H(X,Y)-H(X)$.
209 |
210 | ### 互信息
211 |
212 | $$
213 | I(X;Y) = H(X)+H(Y)-H(X,Y)
214 | $$
215 |
216 |  217 |
218 | ### 相对熵
219 |
220 | 相对熵又称KL散度,是描述两个概率分布P和Q差异的一种方法,记做D(P||Q)。在信息论中,D(P||Q)表示用概率分布Q来拟合真实分布P时,产生的信息表达的损耗,其中P表示信源的真实分布,Q表示P的近似分布。
221 |
222 | - 离散形式: $D(P||Q) = \sum P(x)\log \frac{P(x)}{Q(x)}$.
223 | - 连续形式: $D(P||Q) = \int P(x)\log \frac{P(x)}{Q(x)}$.
224 |
225 | ### 交叉熵
226 |
227 | 一般用来求目标与预测值之间的差距,深度学习中经常用到的一类损失函数度量,比如在对抗生成网络( GAN )中
228 |
229 | $$
230 | D(P||Q) = \sum P(x)\log \frac{P(x)}{Q(x)}
231 | = \sum P(x)\log P(x) - \sum P(x)\log Q(x)
232 | =-H(P(x)) -\sum P(x)\log Q(x)
233 | $$
234 |
235 | 交叉熵: $H(P,Q) = -\sum P(x)\log Q(x)$.
236 |
237 | # 最优化估计
238 |
239 | ### 最小二乘估计
240 |
241 | 最小二乘估计又称最小平方法,是一种数学优化方法。它通过最小化误差的平方和寻找数据的最佳函数匹配。最小二乘法经常应用于回归问题,可以方便地求得未知参数,比如曲线拟合、最小化能量或者最大化熵等问题。
242 |
243 |
217 |
218 | ### 相对熵
219 |
220 | 相对熵又称KL散度,是描述两个概率分布P和Q差异的一种方法,记做D(P||Q)。在信息论中,D(P||Q)表示用概率分布Q来拟合真实分布P时,产生的信息表达的损耗,其中P表示信源的真实分布,Q表示P的近似分布。
221 |
222 | - 离散形式: $D(P||Q) = \sum P(x)\log \frac{P(x)}{Q(x)}$.
223 | - 连续形式: $D(P||Q) = \int P(x)\log \frac{P(x)}{Q(x)}$.
224 |
225 | ### 交叉熵
226 |
227 | 一般用来求目标与预测值之间的差距,深度学习中经常用到的一类损失函数度量,比如在对抗生成网络( GAN )中
228 |
229 | $$
230 | D(P||Q) = \sum P(x)\log \frac{P(x)}{Q(x)}
231 | = \sum P(x)\log P(x) - \sum P(x)\log Q(x)
232 | =-H(P(x)) -\sum P(x)\log Q(x)
233 | $$
234 |
235 | 交叉熵: $H(P,Q) = -\sum P(x)\log Q(x)$.
236 |
237 | # 最优化估计
238 |
239 | ### 最小二乘估计
240 |
241 | 最小二乘估计又称最小平方法,是一种数学优化方法。它通过最小化误差的平方和寻找数据的最佳函数匹配。最小二乘法经常应用于回归问题,可以方便地求得未知参数,比如曲线拟合、最小化能量或者最大化熵等问题。
242 |
243 |  244 |
245 |
246 |
247 |
248 |
249 |
250 |
251 |
252 |
253 |
--------------------------------------------------------------------------------
/docs/理论入门/03.机器学习基础.md:
--------------------------------------------------------------------------------
1 | 机器学习基础
2 |
3 | 1. 数据集
4 | 2. 误差分析
5 | 3. 代表的机器学习方法
6 | 1. 有监督、线性回归、SVM、决策树、RF
7 | 2. 无监督、聚类、降维(PCA)
8 |
9 |
10 |
11 | # 机器学习
12 |
13 | ### 基本概念
14 |
15 | 机器学习是指让计算机具有像人一样的学习和思考能力的技术的总称。具体来说是从已知数据中获得规律,并利用规律对未知数据进行预测的技术。
16 |
17 | 机器学习分类:
18 |
19 | - 有监督学习(SupervisedLearning):有老师(环境)的情况下,学 生(计算机)从老师(环境)那里获得对错指示、最终答案的学习 方法。**跟学师评**
20 | - 无监督学习(UnsupervisedLearning):没有老师(环境)的情况 下,学生(计算机)自学的过程,一般使用一些既定标准进行评价。 **自学标评**
21 | - 强化学习(Reinforcement Learning):没有老师(环境)的情况下, 学生(计算机)对问题答案进行自我评价的方法。自学自评
22 |
23 | 机器学习可以做如下两种分类
24 |
25 | - 有监督学习:代表任务“分类”和“回归”
26 | - 无监督学习:代表任务“聚类”和“降维”
27 |
28 |
244 |
245 |
246 |
247 |
248 |
249 |
250 |
251 |
252 |
253 |
--------------------------------------------------------------------------------
/docs/理论入门/03.机器学习基础.md:
--------------------------------------------------------------------------------
1 | 机器学习基础
2 |
3 | 1. 数据集
4 | 2. 误差分析
5 | 3. 代表的机器学习方法
6 | 1. 有监督、线性回归、SVM、决策树、RF
7 | 2. 无监督、聚类、降维(PCA)
8 |
9 |
10 |
11 | # 机器学习
12 |
13 | ### 基本概念
14 |
15 | 机器学习是指让计算机具有像人一样的学习和思考能力的技术的总称。具体来说是从已知数据中获得规律,并利用规律对未知数据进行预测的技术。
16 |
17 | 机器学习分类:
18 |
19 | - 有监督学习(SupervisedLearning):有老师(环境)的情况下,学 生(计算机)从老师(环境)那里获得对错指示、最终答案的学习 方法。**跟学师评**
20 | - 无监督学习(UnsupervisedLearning):没有老师(环境)的情况 下,学生(计算机)自学的过程,一般使用一些既定标准进行评价。 **自学标评**
21 | - 强化学习(Reinforcement Learning):没有老师(环境)的情况下, 学生(计算机)对问题答案进行自我评价的方法。自学自评
22 |
23 | 机器学习可以做如下两种分类
24 |
25 | - 有监督学习:代表任务“分类”和“回归”
26 | - 无监督学习:代表任务“聚类”和“降维”
27 |
28 |  29 |
30 | ### 数据集
31 |
32 | 数据集:观测样本的集合。具体地,$𝐷={𝑥_1,𝑥_2,⋯,𝑥_𝑛}$ 表示一个包含*n*个样本的数据集,其中 $𝑥_𝑖$ 是一个向量,表示数据集的第𝑖个样本,其维度𝑑称为样本空间的维度。
33 |
34 | 向量 $𝑥_𝑖$ 的元素称为样本的特征,其取值可以是连续的,也可以是离散的。从数据集中学出模型的过程,便称为“学习”或“训练”。
35 |
36 |
29 |
30 | ### 数据集
31 |
32 | 数据集:观测样本的集合。具体地,$𝐷={𝑥_1,𝑥_2,⋯,𝑥_𝑛}$ 表示一个包含*n*个样本的数据集,其中 $𝑥_𝑖$ 是一个向量,表示数据集的第𝑖个样本,其维度𝑑称为样本空间的维度。
33 |
34 | 向量 $𝑥_𝑖$ 的元素称为样本的特征,其取值可以是连续的,也可以是离散的。从数据集中学出模型的过程,便称为“学习”或“训练”。
35 |
36 |  37 |
38 | **数据集分类**
39 |
40 | - 训练集(Trainingset):用于模型拟合的数据样本;
41 | - 验证集(Validation set):是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估;
42 | - 例如SVM中参数 $c$ (控制分类错误的惩罚程度)和核函数的选择, 或者选择网络结构
43 |
44 | - 测试集(Testset):用来评估模最终模型的泛化能力。但不能作为调 参、选择特征等算法相关的选择的依据。
45 |
46 |
37 |
38 | **数据集分类**
39 |
40 | - 训练集(Trainingset):用于模型拟合的数据样本;
41 | - 验证集(Validation set):是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估;
42 | - 例如SVM中参数 $c$ (控制分类错误的惩罚程度)和核函数的选择, 或者选择网络结构
43 |
44 | - 测试集(Testset):用来评估模最终模型的泛化能力。但不能作为调 参、选择特征等算法相关的选择的依据。
45 |
46 |  47 |
48 | **常见数据集**
49 |
50 | - 图像分类
51 | - MNIST(手写数字) http://yann.lecun.com/exdb/mnist/
52 | - CIFAR-10, CIFAR-100, ImageNet
53 | - https://www.cs.toronto.edu/~kriz/cifar.html
54 | - http://www.image-net.org/
55 | - 电影评论情感分类
56 | - Large Movie Review Dataset v1.0
57 | - http://ai.stanford.edu/~amaas/data/sentiment/
58 |
59 | - 图像生成诗歌
60 | - 数据集:https://github.com/researchmm/img2poem
61 |
62 | # 误差分析
63 |
64 | 误差是指算法实际预测输出与样本真实输出之间的差异。
65 |
66 | - 模型在训练集上的误差称为“训练误差”
67 | - 模型在总体样本上的误差称为“泛化误差”
68 | - 模型在测试集上的误差称为“测试误差”
69 |
70 | 由于我们无法知道总体样本会,所以我们只能尽量最小化训练误差, 导致训练误差和泛化误差有可能存在明显差异。
71 |
72 | **过拟合**是指模型能很好地拟合训练样本,而无法很好地拟合测试样本的现象,从而导致泛化性能下降。为防止“过拟合”,可以选择减少参数、降低模型复杂度、正则化等
73 |
74 | **欠拟合**是指模型还没有很好地训练出数据的一般规律,模型拟合程度不高的现象。为防止“欠拟合”,可以选择调整参数、增加迭代深度、换用更加复杂的模型等。
75 |
76 |
47 |
48 | **常见数据集**
49 |
50 | - 图像分类
51 | - MNIST(手写数字) http://yann.lecun.com/exdb/mnist/
52 | - CIFAR-10, CIFAR-100, ImageNet
53 | - https://www.cs.toronto.edu/~kriz/cifar.html
54 | - http://www.image-net.org/
55 | - 电影评论情感分类
56 | - Large Movie Review Dataset v1.0
57 | - http://ai.stanford.edu/~amaas/data/sentiment/
58 |
59 | - 图像生成诗歌
60 | - 数据集:https://github.com/researchmm/img2poem
61 |
62 | # 误差分析
63 |
64 | 误差是指算法实际预测输出与样本真实输出之间的差异。
65 |
66 | - 模型在训练集上的误差称为“训练误差”
67 | - 模型在总体样本上的误差称为“泛化误差”
68 | - 模型在测试集上的误差称为“测试误差”
69 |
70 | 由于我们无法知道总体样本会,所以我们只能尽量最小化训练误差, 导致训练误差和泛化误差有可能存在明显差异。
71 |
72 | **过拟合**是指模型能很好地拟合训练样本,而无法很好地拟合测试样本的现象,从而导致泛化性能下降。为防止“过拟合”,可以选择减少参数、降低模型复杂度、正则化等
73 |
74 | **欠拟合**是指模型还没有很好地训练出数据的一般规律,模型拟合程度不高的现象。为防止“欠拟合”,可以选择调整参数、增加迭代深度、换用更加复杂的模型等。
75 |
76 |  77 |
78 | ### 泛化误差分析
79 |
80 | 假设数据集上需要预测的样本为Y,特征为X,潜在模型为 $Y=f(X)+ε$,其中$ε \sim N(0,σ_ε)$是噪声,估计的模型为$\hat{f}(X)$.
81 |
82 | $$
83 | \begin{array}{l}\operatorname{Err}(\hat{f})=\mathrm{E}\left[(Y-\hat{f}(\mathrm{X}))^{2}\right] \\ \operatorname{Err}(\hat{f})=\mathrm{E}\left[(f(X)+\varepsilon-\hat{f}(\mathrm{X}))^{2}\right] \\ \operatorname{Err}(\hat{f})=\mathrm{E}\left[(f(X)-\hat{f}(\mathrm{X}))^{2}+2 \varepsilon(f(X)-\hat{f}(\mathrm{X}))+\varepsilon^{2}\right] \\ \operatorname{Err}(\hat{f})=\mathrm{E}\left[(E(\hat{f}(\mathrm{X}))-f(X)+\hat{f}(\mathrm{X})-E(\hat{f}(\mathrm{X})))^{2}\right]+\sigma_{\varepsilon}^{2} \\ \operatorname{Err}(\hat{f})=\mathrm{E}[(E(\hat{f}(\mathrm{X}))-f(X))]^{2}+\mathrm{E}\left[(\hat{f}(\mathrm{X})-E(\hat{f}(\mathrm{X})))^{2}\right]+\sigma_{\varepsilon}^{2} \\ \operatorname{Err}(\hat{f})=\operatorname{Bias}^{2}(\hat{f})+\operatorname{Var}(\hat{f})+\sigma_{\varepsilon}^{2}\end{array}
84 | $$
85 |
86 | **偏差**(bias)反映了模型在 样本上的期望输出与真实 标记之间的差距,即模型本身的精准度,反映的是模型本身的拟合能力。
87 |
88 | **方差**(variance)反映了模 型在不同训练数据集下学 得的函数的输出与期望输出之间的误差,即模型的稳定性,反应的是模型的波动情况。
89 |
90 |
77 |
78 | ### 泛化误差分析
79 |
80 | 假设数据集上需要预测的样本为Y,特征为X,潜在模型为 $Y=f(X)+ε$,其中$ε \sim N(0,σ_ε)$是噪声,估计的模型为$\hat{f}(X)$.
81 |
82 | $$
83 | \begin{array}{l}\operatorname{Err}(\hat{f})=\mathrm{E}\left[(Y-\hat{f}(\mathrm{X}))^{2}\right] \\ \operatorname{Err}(\hat{f})=\mathrm{E}\left[(f(X)+\varepsilon-\hat{f}(\mathrm{X}))^{2}\right] \\ \operatorname{Err}(\hat{f})=\mathrm{E}\left[(f(X)-\hat{f}(\mathrm{X}))^{2}+2 \varepsilon(f(X)-\hat{f}(\mathrm{X}))+\varepsilon^{2}\right] \\ \operatorname{Err}(\hat{f})=\mathrm{E}\left[(E(\hat{f}(\mathrm{X}))-f(X)+\hat{f}(\mathrm{X})-E(\hat{f}(\mathrm{X})))^{2}\right]+\sigma_{\varepsilon}^{2} \\ \operatorname{Err}(\hat{f})=\mathrm{E}[(E(\hat{f}(\mathrm{X}))-f(X))]^{2}+\mathrm{E}\left[(\hat{f}(\mathrm{X})-E(\hat{f}(\mathrm{X})))^{2}\right]+\sigma_{\varepsilon}^{2} \\ \operatorname{Err}(\hat{f})=\operatorname{Bias}^{2}(\hat{f})+\operatorname{Var}(\hat{f})+\sigma_{\varepsilon}^{2}\end{array}
84 | $$
85 |
86 | **偏差**(bias)反映了模型在 样本上的期望输出与真实 标记之间的差距,即模型本身的精准度,反映的是模型本身的拟合能力。
87 |
88 | **方差**(variance)反映了模 型在不同训练数据集下学 得的函数的输出与期望输出之间的误差,即模型的稳定性,反应的是模型的波动情况。
89 |
90 |  91 |
92 | 欠拟合:高偏差低方差
93 |
94 | - 寻找更好的特征,提升对数据的刻画能力
95 | - 增加特征数量
96 | - 重新选择更加复杂的模型
97 |
98 | 过拟合:低偏差高方差
99 |
100 | - 增加训练样本数量
101 | - 减少特征维数,高维空间密度小
102 | - 加入正则化项,使得模型更加平滑
103 |
104 |
91 |
92 | 欠拟合:高偏差低方差
93 |
94 | - 寻找更好的特征,提升对数据的刻画能力
95 | - 增加特征数量
96 | - 重新选择更加复杂的模型
97 |
98 | 过拟合:低偏差高方差
99 |
100 | - 增加训练样本数量
101 | - 减少特征维数,高维空间密度小
102 | - 加入正则化项,使得模型更加平滑
103 |
104 |  105 |
106 | ### 交叉验证
107 |
108 | 基本思路:将训练集划分为K份,每次采用其中K-1份作为训练集, 另外一份作为验证集,在训练集上学得函数后,然后在验证集上计 算误差---K折交叉验证
109 |
110 | - K折重复多次,每次重复中产生不同的分割
111 | - 留一交叉验证(Leave-One-Out)
112 |
113 |
105 |
106 | ### 交叉验证
107 |
108 | 基本思路:将训练集划分为K份,每次采用其中K-1份作为训练集, 另外一份作为验证集,在训练集上学得函数后,然后在验证集上计 算误差---K折交叉验证
109 |
110 | - K折重复多次,每次重复中产生不同的分割
111 | - 留一交叉验证(Leave-One-Out)
112 |
113 |  114 |
115 | # 有监督学习
116 |
117 | - 数据集有标记(答案)
118 | - 数据集通常扩展为$(𝑥_𝑖,𝑦_𝑖)$,其中$𝑦_𝑖∈Y$是 $𝑥_𝑖$ 的标记,$Y$ 是所有标记的集合,称为“标记空间”或“输出空间”
119 | - 监督学习的任务是训练出一个模型用于预测 $𝑦$ 的取值,根据 $𝐷=\{(𝑥_1,𝑦_1 ),(𝑥_2,𝑦_2),⋯, (𝑥_𝑛,𝑦_𝑛)\}$,训练出函数𝑓,使得$𝑓(𝑥)≅𝑦$
120 | - 若预测的值是离散值,如年龄,此类学习任务称为“分类”
121 | - 若预测的值是连续值,如房价,此类学习任务称为“回归”
122 |
123 | ### 线性回归
124 |
125 | 线性回归是在样本属性和标签中找到一个线性关系的方法,根据训练数据找到一个线性模型,使得模型产生的预测值与样本标 签的差距最小。
126 |
127 | 若用 $𝑥_𝑖^𝑘$ 表示第𝑘个样本的第𝑖个属性,则线性模型一般形式为:
128 |
129 | $$
130 | f(x^k) = w_1x_1^k+w_2x_2^k+\cdots+w_mx_m^k+b = \sum_{i=1}^m w_ix_i^k+b
131 | $$
132 |
133 | 线性回归学习的对象就是权重向量𝑤和偏置向量𝑏。如果用最小均方 误差来衡量预测值与样本标签的差距,那么线性回归学习的目标可以表示为:
134 |
135 | $$
136 | (w^*,b^*) = argmin_{(w,b)}\sum_{k = 1}^n(f(x^k)-y^k)^2 = argmin_{(w,b)}\sum_{k = 1}^n(w^Tx^k+b-y^k)^2
137 | $$
138 |
139 | ### 逻辑回归
140 |
141 | 逻辑回归是利用𝑠𝑖𝑔𝑚𝑜𝑖𝑑函数,将线性回归产生的预测值压缩到0和1之间。此时将𝑦视作样本为正例的可能性,即
142 |
143 | $$
144 | g(f(x^k))=
145 | \left\{\begin{array}{l}
146 | 1, \frac{1}{1+e^{-(w^Tx^k+b)}}\geq 0.5 \\ 0, otherwise
147 | \end{array}\right.
148 | $$
149 |
150 | 注意,逻辑回归本质上属于分类算法,sigmoid函数的具体表达形式为:$g(x) = \frac{1}{1+e^{-x}}$.
151 |
152 | ### 支持向量机
153 |
154 | 支持向量机是有监督学习中最具有影响力的方法之一,是基于线性判别函数的一种模型。
155 |
156 | SVM基本思想:对于线性可分的数据,能将训练样本划分开的超平 面有很多,于是我们寻找“位于两类训练样本正中心的超平面”, 即margin最大化。从直观上看,这种划分对训练样本局部扰动的承 受性最好。事实上,这种划分的性能也表现较好。
157 |
158 |
114 |
115 | # 有监督学习
116 |
117 | - 数据集有标记(答案)
118 | - 数据集通常扩展为$(𝑥_𝑖,𝑦_𝑖)$,其中$𝑦_𝑖∈Y$是 $𝑥_𝑖$ 的标记,$Y$ 是所有标记的集合,称为“标记空间”或“输出空间”
119 | - 监督学习的任务是训练出一个模型用于预测 $𝑦$ 的取值,根据 $𝐷=\{(𝑥_1,𝑦_1 ),(𝑥_2,𝑦_2),⋯, (𝑥_𝑛,𝑦_𝑛)\}$,训练出函数𝑓,使得$𝑓(𝑥)≅𝑦$
120 | - 若预测的值是离散值,如年龄,此类学习任务称为“分类”
121 | - 若预测的值是连续值,如房价,此类学习任务称为“回归”
122 |
123 | ### 线性回归
124 |
125 | 线性回归是在样本属性和标签中找到一个线性关系的方法,根据训练数据找到一个线性模型,使得模型产生的预测值与样本标 签的差距最小。
126 |
127 | 若用 $𝑥_𝑖^𝑘$ 表示第𝑘个样本的第𝑖个属性,则线性模型一般形式为:
128 |
129 | $$
130 | f(x^k) = w_1x_1^k+w_2x_2^k+\cdots+w_mx_m^k+b = \sum_{i=1}^m w_ix_i^k+b
131 | $$
132 |
133 | 线性回归学习的对象就是权重向量𝑤和偏置向量𝑏。如果用最小均方 误差来衡量预测值与样本标签的差距,那么线性回归学习的目标可以表示为:
134 |
135 | $$
136 | (w^*,b^*) = argmin_{(w,b)}\sum_{k = 1}^n(f(x^k)-y^k)^2 = argmin_{(w,b)}\sum_{k = 1}^n(w^Tx^k+b-y^k)^2
137 | $$
138 |
139 | ### 逻辑回归
140 |
141 | 逻辑回归是利用𝑠𝑖𝑔𝑚𝑜𝑖𝑑函数,将线性回归产生的预测值压缩到0和1之间。此时将𝑦视作样本为正例的可能性,即
142 |
143 | $$
144 | g(f(x^k))=
145 | \left\{\begin{array}{l}
146 | 1, \frac{1}{1+e^{-(w^Tx^k+b)}}\geq 0.5 \\ 0, otherwise
147 | \end{array}\right.
148 | $$
149 |
150 | 注意,逻辑回归本质上属于分类算法,sigmoid函数的具体表达形式为:$g(x) = \frac{1}{1+e^{-x}}$.
151 |
152 | ### 支持向量机
153 |
154 | 支持向量机是有监督学习中最具有影响力的方法之一,是基于线性判别函数的一种模型。
155 |
156 | SVM基本思想:对于线性可分的数据,能将训练样本划分开的超平 面有很多,于是我们寻找“位于两类训练样本正中心的超平面”, 即margin最大化。从直观上看,这种划分对训练样本局部扰动的承 受性最好。事实上,这种划分的性能也表现较好。
157 |
158 |  159 |
160 | 下面我们以**线性分类**为例:二类可分数据集 $𝐷 =\{ (𝑥_1 ,𝑦_1) ,(𝑥_2 ,𝑦_2 ),⋯,(𝑥_n ,𝑦_n )\}$ , 其中 $y=1$ 和 $y= -1$ 分别表示两类样本,定义分类的超平面 $f(x)=w^Tx+b$(决策边界 decision boundary) , “最合适”的分类标准就是使得超平面距离两边数据的间隔最大。
161 |
162 | 记 $\gamma$ 为样本 x 到超平面的距离,那么有
163 |
164 | $$
165 | x = x_0 + \gamma \frac{w}{\|w\|}
166 | \\
167 | \gamma = \frac{w^Tx + b}{\|w\|} = \frac{f(x)}{w}
168 | $$
169 |
170 | 目标函数:
171 |
172 | $$
173 | \arg \max_{w,b} \arg \min_{x_i \in D} \frac{|w^Tx_i+b|}{\sqrt{\sum_{i = 1}^dw_i^2}} \\s.t. \forall x_i \in D,y_i(w^Tx_i+b)\geq 0
174 | $$
175 |
176 | 通常为方便优化,我们选择加强约束条件:$\forall x_i \in D,|w^Tx_i+b| \geq 1$.
177 |
178 | 那么,原问题可以近似为:
179 |
180 | $$
181 | \arg \min_{w,b} \frac{1}{2}\sum_{i = 1}^d w_i^2\\s.t. \forall x_i \in D,|w^Tx_i+b| \geq 1
182 | $$
183 |
184 | 对于线性不可分的数据集,我们可以做下面的操作
185 |
186 | - 特征空间存在超曲面(hypersurface)将正类和负类分开
187 | - 核函数(kernelfunction)
188 | - 使用非线性函数将非线性可分问题从原始的特征空间映射至更高维
189 | - 决策边界的超平面表示为 $w^T \phi(x)+b = 0$.
190 | - 定义映射函数的内积为核函数 $K(X_i,x_j) = \phi(x_i)^T \phi(x_j)$.
191 |
192 |
159 |
160 | 下面我们以**线性分类**为例:二类可分数据集 $𝐷 =\{ (𝑥_1 ,𝑦_1) ,(𝑥_2 ,𝑦_2 ),⋯,(𝑥_n ,𝑦_n )\}$ , 其中 $y=1$ 和 $y= -1$ 分别表示两类样本,定义分类的超平面 $f(x)=w^Tx+b$(决策边界 decision boundary) , “最合适”的分类标准就是使得超平面距离两边数据的间隔最大。
161 |
162 | 记 $\gamma$ 为样本 x 到超平面的距离,那么有
163 |
164 | $$
165 | x = x_0 + \gamma \frac{w}{\|w\|}
166 | \\
167 | \gamma = \frac{w^Tx + b}{\|w\|} = \frac{f(x)}{w}
168 | $$
169 |
170 | 目标函数:
171 |
172 | $$
173 | \arg \max_{w,b} \arg \min_{x_i \in D} \frac{|w^Tx_i+b|}{\sqrt{\sum_{i = 1}^dw_i^2}} \\s.t. \forall x_i \in D,y_i(w^Tx_i+b)\geq 0
174 | $$
175 |
176 | 通常为方便优化,我们选择加强约束条件:$\forall x_i \in D,|w^Tx_i+b| \geq 1$.
177 |
178 | 那么,原问题可以近似为:
179 |
180 | $$
181 | \arg \min_{w,b} \frac{1}{2}\sum_{i = 1}^d w_i^2\\s.t. \forall x_i \in D,|w^Tx_i+b| \geq 1
182 | $$
183 |
184 | 对于线性不可分的数据集,我们可以做下面的操作
185 |
186 | - 特征空间存在超曲面(hypersurface)将正类和负类分开
187 | - 核函数(kernelfunction)
188 | - 使用非线性函数将非线性可分问题从原始的特征空间映射至更高维
189 | - 决策边界的超平面表示为 $w^T \phi(x)+b = 0$.
190 | - 定义映射函数的内积为核函数 $K(X_i,x_j) = \phi(x_i)^T \phi(x_j)$.
191 |
192 |  193 |
194 | ### 决策树
195 |
196 | 决策树是一种基于树结构进行决策的机器学习方法,这恰是人类面临决策 时一种很自然的处理机制。
197 |
198 | - 在这些树的结构里,叶子节点给出类标而内部节点代表某个属性;
199 | - 例如,银行在面对是否借贷给客户的问题时,通常会进行一系列的决 策。银行会首先判断:客户的信贷声誉是否良好?良好的话,再判断 客户是否有稳定的工作? 不良好的话,可能直接拒绝,也可能判断客 户是否有可抵押物?......这种思考过程便是决策树的生成过程。
200 |
201 | 决策树的生成过程中,最重要的因素便是根节点的选择,即选择哪种特征作为决策因素:ID3算法使用信息增益作为准则。
202 |
203 | ### 随机森林
204 |
205 | - 集成学习(Ensemblelearning)
206 | - 组合多个弱监督模型以期得到一个更好更全面的强监督模型,集成学 习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分 类器也可以将错误纠正回来。
207 |
208 | - 随机森林用随机的方式建立起一棵棵决策树,然后由这些决策树组成 一个森林,其中每棵决策树之间没有关联,当有一个新的样本输入 时,就让每棵树独立的做出判断,按照多数原则决定该样本的分类 结果。
209 |
210 | **随机森林构建的基本步骤**
211 |
212 | - 随机有放回地从训练集中的抽取*m*个训练样本,训练集 $D_t$.
213 | - 从 $D_t$ 对应的特征属性中随机选择部分特征,构建决策树
214 | - 重复上述步骤构建多个决策树
215 |
216 | **预测步骤**
217 |
218 | - 向建立好的随机森林中输入一个新样本
219 | - 随机森林中的每棵决策树都独立的做出判断
220 | - 将得到票数最多的分类结果作为该样本最终的类别
221 |
222 | # 无监督学习
223 |
224 | - 数据集没有标记信息(自学)
225 | - 聚类:我们可以使用无监督学习来预测各样本之间的关联度,把关 联度大的样本划为同一类,关联度小的样本划为不同类,这便是 “聚类”
226 | - 降维:我们也可以使用无监督学习处理数据,把维度较高、计算复 杂的数据,转化为维度低、易处理、且蕴含的信息不丢失或较少丢 失的数据,这便是“降维”
227 |
228 | ### 聚类
229 |
230 | 聚类的目的是将数据分成多个类别,在同一个类内,对象(实体)之间具 有较高的相似性,在不同类内,对象之间具有较大的差异。
231 |
232 | 对一批没有类别标签的样本集,按照样本之间的相似程度分类,相似的归为一类,不相似的归为其它类。这种分类称为聚类分析,也 称为无监督分类
233 |
234 | 常见方法有K-Means聚类、均值漂移聚类、基于密度的聚类等
235 |
236 | **K-means**聚类是一个反复迭代的过程,算法分为四个步骤:
237 |
238 | 1. 选取数据空间中的K个对象作为初始中心,每个对象代表一个聚 类中心;
239 | 2. 对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离, 按距离最近的准则将它们分到距离它们最近的聚类中心(最相似) 所对应的类;
240 | 3. 更新聚类中心:将每个类别中所有对象所对应的均值作为该类别 的聚类中心,计算目标函数的值;
241 | 4. 判断聚类中心和目标函数的值是否发生改变,若不变,则输出结 果,若改变,则返回2)。
242 |
243 | ### 降维
244 |
245 | 降维的目的就是将原始样本数据的维度𝑑降低到一个更小的数𝑚,且尽量使得样本蕴含信息量损失最小,或还原数据时产生的误差最小。比如主成分分析法...
246 |
247 | 降维的优势:
248 |
249 | - 数据在低维下更容易处理、更容易使用;
250 | - 相关特征,特别是重要特征更能在数据中明确的显示出来;
251 | - 如果只有二维或者三维的话,能够进行可视化展示;
252 | - 去除数据噪声,降低算法开销等。
253 |
254 |
255 |
256 |
--------------------------------------------------------------------------------
/docs/理论入门/04.前馈神经网络.md:
--------------------------------------------------------------------------------
1 | 前馈神经网络
2 |
3 | 1. 神经元模型
4 | 2. 感知器、多层感知器
5 | 3. BP算法
6 | 4. 前馈神经网络
7 |
8 |
9 |
10 | 神经网络是最早作为一种连接主义为主的模型。
11 |
12 | ## 神经元模型
13 |
14 | 神经网络的发展历程
15 |
16 |
193 |
194 | ### 决策树
195 |
196 | 决策树是一种基于树结构进行决策的机器学习方法,这恰是人类面临决策 时一种很自然的处理机制。
197 |
198 | - 在这些树的结构里,叶子节点给出类标而内部节点代表某个属性;
199 | - 例如,银行在面对是否借贷给客户的问题时,通常会进行一系列的决 策。银行会首先判断:客户的信贷声誉是否良好?良好的话,再判断 客户是否有稳定的工作? 不良好的话,可能直接拒绝,也可能判断客 户是否有可抵押物?......这种思考过程便是决策树的生成过程。
200 |
201 | 决策树的生成过程中,最重要的因素便是根节点的选择,即选择哪种特征作为决策因素:ID3算法使用信息增益作为准则。
202 |
203 | ### 随机森林
204 |
205 | - 集成学习(Ensemblelearning)
206 | - 组合多个弱监督模型以期得到一个更好更全面的强监督模型,集成学 习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分 类器也可以将错误纠正回来。
207 |
208 | - 随机森林用随机的方式建立起一棵棵决策树,然后由这些决策树组成 一个森林,其中每棵决策树之间没有关联,当有一个新的样本输入 时,就让每棵树独立的做出判断,按照多数原则决定该样本的分类 结果。
209 |
210 | **随机森林构建的基本步骤**
211 |
212 | - 随机有放回地从训练集中的抽取*m*个训练样本,训练集 $D_t$.
213 | - 从 $D_t$ 对应的特征属性中随机选择部分特征,构建决策树
214 | - 重复上述步骤构建多个决策树
215 |
216 | **预测步骤**
217 |
218 | - 向建立好的随机森林中输入一个新样本
219 | - 随机森林中的每棵决策树都独立的做出判断
220 | - 将得到票数最多的分类结果作为该样本最终的类别
221 |
222 | # 无监督学习
223 |
224 | - 数据集没有标记信息(自学)
225 | - 聚类:我们可以使用无监督学习来预测各样本之间的关联度,把关 联度大的样本划为同一类,关联度小的样本划为不同类,这便是 “聚类”
226 | - 降维:我们也可以使用无监督学习处理数据,把维度较高、计算复 杂的数据,转化为维度低、易处理、且蕴含的信息不丢失或较少丢 失的数据,这便是“降维”
227 |
228 | ### 聚类
229 |
230 | 聚类的目的是将数据分成多个类别,在同一个类内,对象(实体)之间具 有较高的相似性,在不同类内,对象之间具有较大的差异。
231 |
232 | 对一批没有类别标签的样本集,按照样本之间的相似程度分类,相似的归为一类,不相似的归为其它类。这种分类称为聚类分析,也 称为无监督分类
233 |
234 | 常见方法有K-Means聚类、均值漂移聚类、基于密度的聚类等
235 |
236 | **K-means**聚类是一个反复迭代的过程,算法分为四个步骤:
237 |
238 | 1. 选取数据空间中的K个对象作为初始中心,每个对象代表一个聚 类中心;
239 | 2. 对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离, 按距离最近的准则将它们分到距离它们最近的聚类中心(最相似) 所对应的类;
240 | 3. 更新聚类中心:将每个类别中所有对象所对应的均值作为该类别 的聚类中心,计算目标函数的值;
241 | 4. 判断聚类中心和目标函数的值是否发生改变,若不变,则输出结 果,若改变,则返回2)。
242 |
243 | ### 降维
244 |
245 | 降维的目的就是将原始样本数据的维度𝑑降低到一个更小的数𝑚,且尽量使得样本蕴含信息量损失最小,或还原数据时产生的误差最小。比如主成分分析法...
246 |
247 | 降维的优势:
248 |
249 | - 数据在低维下更容易处理、更容易使用;
250 | - 相关特征,特别是重要特征更能在数据中明确的显示出来;
251 | - 如果只有二维或者三维的话,能够进行可视化展示;
252 | - 去除数据噪声,降低算法开销等。
253 |
254 |
255 |
256 |
--------------------------------------------------------------------------------
/docs/理论入门/04.前馈神经网络.md:
--------------------------------------------------------------------------------
1 | 前馈神经网络
2 |
3 | 1. 神经元模型
4 | 2. 感知器、多层感知器
5 | 3. BP算法
6 | 4. 前馈神经网络
7 |
8 |
9 |
10 | 神经网络是最早作为一种连接主义为主的模型。
11 |
12 | ## 神经元模型
13 |
14 | 神经网络的发展历程
15 |
16 |  17 |
18 | ### 神经元(`M-P`)
19 |
20 | 1943 年,美国神经生理学家沃伦·麦卡洛克( $Warren McCulloch$ ) 和数学家沃尔特 ·皮茨( $Walter Pitts$ )对生物神经元进行建模,首次提出了一种形式神经元模型,并命名为`McCulloch-Pitts`模型,即后 来广为人知的`M-P`模型。
21 |
22 |
17 |
18 | ### 神经元(`M-P`)
19 |
20 | 1943 年,美国神经生理学家沃伦·麦卡洛克( $Warren McCulloch$ ) 和数学家沃尔特 ·皮茨( $Walter Pitts$ )对生物神经元进行建模,首次提出了一种形式神经元模型,并命名为`McCulloch-Pitts`模型,即后 来广为人知的`M-P`模型。
21 |
22 |  23 |
24 | 在`M-P`模型中,神经元接受其他 $n$ 个神经元的输入信号( $0$ 或 $1$ ),这些输入信号经过权重加权并求和,将求和结果与阈值( $threshold$ ) *θ* 比较,然后经过激活函数处理,得到神经元的输出。
25 |
26 | $$
27 | y=f\left(\sum_{i=1}^{n} \omega_{i j} x_{i}-\theta\right)
28 | $$
29 |
30 | `M-P` 模型可以表示多种逻辑运算,如取反运算、逻辑或、逻辑与。
31 |
32 | - 取反运算可以用单输入单输出模型表示,即如果输入为 $0$ 则输出 $1$ ,如果输入为 $1$ 则输出 $0$ 。由`M-P`模型的运算规则可得 $w = -2, θ = -1$.
33 |
34 |
35 |
23 |
24 | 在`M-P`模型中,神经元接受其他 $n$ 个神经元的输入信号( $0$ 或 $1$ ),这些输入信号经过权重加权并求和,将求和结果与阈值( $threshold$ ) *θ* 比较,然后经过激活函数处理,得到神经元的输出。
25 |
26 | $$
27 | y=f\left(\sum_{i=1}^{n} \omega_{i j} x_{i}-\theta\right)
28 | $$
29 |
30 | `M-P` 模型可以表示多种逻辑运算,如取反运算、逻辑或、逻辑与。
31 |
32 | - 取反运算可以用单输入单输出模型表示,即如果输入为 $0$ 则输出 $1$ ,如果输入为 $1$ 则输出 $0$ 。由`M-P`模型的运算规则可得 $w = -2, θ = -1$.
33 |
34 |
35 |  36 |
37 | - 逻辑或与逻辑与运算可以用双输入单输出模型表示。以逻辑与运算为例, $w_1=1,w_2=1, θ =1.5$.
38 |
39 |
36 |
37 | - 逻辑或与逻辑与运算可以用双输入单输出模型表示。以逻辑与运算为例, $w_1=1,w_2=1, θ =1.5$.
38 |
39 |  40 |
41 | ### 网络结构
42 |
43 | 人工神经网络由神经元模型构成,这种由许多神经元组成的信息处理网络具有并行分布结构。
44 |
45 |
40 |
41 | ### 网络结构
42 |
43 | 人工神经网络由神经元模型构成,这种由许多神经元组成的信息处理网络具有并行分布结构。
44 |
45 |  46 |
47 | 其中圆形节点表示一个神经元,方形节点表示一组神经元。
48 |
49 | ## 感知器
50 |
51 | ### 单层感知器
52 |
53 | 1958 年,罗森布拉特( $Roseblatt$ )提出了感知器,与 M-P 模型需 要人为确定参数不同,感知器能够通过训练自动确定参数。训练方式为有监督学习,即需要设定训练样本和期望输出,然后调整实际输出和期望输出之差的方式(误差修正学习)。
54 | $$
55 | \begin{aligned} w_{i} & \leftarrow w_{i}+\alpha(r-y) x \\ \theta & \leftarrow \theta-\alpha(r-y) \end{aligned}
56 | $$
57 | 其中,$\alpha$ 是学习率,$r$ 和 $y$ 分别是期望输出和实际输出。
58 |
59 | 感知器权重调整的基本思路:
60 |
61 | - 实际输出 y 与期望输出 r 相等时,w 和 θ 不变
62 | - 实际输出 y 与期望输出 r 不相等时,调整 w 和 θ 的值
63 |
64 | $$
65 | \begin{aligned} w_{i} & \leftarrow w_{i}+\alpha(r-y) x \\ \theta & \leftarrow \theta-\alpha(r-y) \end{aligned}
66 | $$
67 |
68 |
46 |
47 | 其中圆形节点表示一个神经元,方形节点表示一组神经元。
48 |
49 | ## 感知器
50 |
51 | ### 单层感知器
52 |
53 | 1958 年,罗森布拉特( $Roseblatt$ )提出了感知器,与 M-P 模型需 要人为确定参数不同,感知器能够通过训练自动确定参数。训练方式为有监督学习,即需要设定训练样本和期望输出,然后调整实际输出和期望输出之差的方式(误差修正学习)。
54 | $$
55 | \begin{aligned} w_{i} & \leftarrow w_{i}+\alpha(r-y) x \\ \theta & \leftarrow \theta-\alpha(r-y) \end{aligned}
56 | $$
57 | 其中,$\alpha$ 是学习率,$r$ 和 $y$ 分别是期望输出和实际输出。
58 |
59 | 感知器权重调整的基本思路:
60 |
61 | - 实际输出 y 与期望输出 r 相等时,w 和 θ 不变
62 | - 实际输出 y 与期望输出 r 不相等时,调整 w 和 θ 的值
63 |
64 | $$
65 | \begin{aligned} w_{i} & \leftarrow w_{i}+\alpha(r-y) x \\ \theta & \leftarrow \theta-\alpha(r-y) \end{aligned}
66 | $$
67 |
68 |  69 |
70 | 下面给出感知器模型的训练过程
71 |
72 |
69 |
70 | 下面给出感知器模型的训练过程
71 |
72 |  73 |
74 | ### 多层感知器
75 |
76 | 单层感知器只能解决线性可分问题,而不能解决线性不可分问题;为了解决线性不可分问题,我们需要使用多层感知器。
77 |
78 |
73 |
74 | ### 多层感知器
75 |
76 | 单层感知器只能解决线性可分问题,而不能解决线性不可分问题;为了解决线性不可分问题,我们需要使用多层感知器。
77 |
78 |  79 |
80 | 多层感知器指的是由多层结构的感知器递阶组成的输入值向前传播的网络,也被称为前馈网络或正向传播网络。
81 |
82 | 以三层结构的多层感知器为例,它由输入层、中间层及输出层组成
83 |
84 | - 与M-P模型相同,中间层的感知器通过权重与输入层的各单元相连接,通过阈值函数计算中间层各单元的输出值
85 | - 中间层与输出层之间同样是通过权重相连接
86 |
87 |
79 |
80 | 多层感知器指的是由多层结构的感知器递阶组成的输入值向前传播的网络,也被称为前馈网络或正向传播网络。
81 |
82 | 以三层结构的多层感知器为例,它由输入层、中间层及输出层组成
83 |
84 | - 与M-P模型相同,中间层的感知器通过权重与输入层的各单元相连接,通过阈值函数计算中间层各单元的输出值
85 | - 中间层与输出层之间同样是通过权重相连接
86 |
87 |  88 |
89 | # BP算法
90 |
91 | 多层感知器的训练使用误差反向传播算法(Error Back Propagation),即BP算法。BP算法最早有沃博斯于1974年提出,鲁梅尔哈特等人进一步发展了该理论。
92 |
93 | ### BP算法的基本过程
94 |
95 | - 前向传播计算:由输入层经过隐含层向输出层的计算网络输出
96 | - 误差反向逐层传递:网络的期望输出与实际输出之差的误差信号由输出层经过隐含层逐层向输入层传递
97 | - 由“前向传播计算”与“误差反向逐层传递”的反复进行的网络训练 过程
98 |
99 | BP算法就是通过比较实际输出和期望输出得到误差信号,把误差信 号从输出层逐层向前传播得到各层的误差信号,再通过调整各层的连接权重以减小误差。权重的调整主要使用梯度下降法:
100 | $$
101 | \Delta w = -\alpha \frac{\partial E}{\partial w}
102 | $$
103 |
104 | ### 激活函数
105 |
106 | 通过误差反向传播算法调整多层感知器的连接权重时,一个瓶颈问题就是**激活函数**:
107 |
108 | - M-P 模型中使用阶跃函数作为激活函数,只能输出 0或 1,不连续所以 不可导
109 | - 为了使误差能够传播,鲁梅尔哈特等人提出使用可导函数Sigmoid作为激活函数
110 |
111 |
88 |
89 | # BP算法
90 |
91 | 多层感知器的训练使用误差反向传播算法(Error Back Propagation),即BP算法。BP算法最早有沃博斯于1974年提出,鲁梅尔哈特等人进一步发展了该理论。
92 |
93 | ### BP算法的基本过程
94 |
95 | - 前向传播计算:由输入层经过隐含层向输出层的计算网络输出
96 | - 误差反向逐层传递:网络的期望输出与实际输出之差的误差信号由输出层经过隐含层逐层向输入层传递
97 | - 由“前向传播计算”与“误差反向逐层传递”的反复进行的网络训练 过程
98 |
99 | BP算法就是通过比较实际输出和期望输出得到误差信号,把误差信 号从输出层逐层向前传播得到各层的误差信号,再通过调整各层的连接权重以减小误差。权重的调整主要使用梯度下降法:
100 | $$
101 | \Delta w = -\alpha \frac{\partial E}{\partial w}
102 | $$
103 |
104 | ### 激活函数
105 |
106 | 通过误差反向传播算法调整多层感知器的连接权重时,一个瓶颈问题就是**激活函数**:
107 |
108 | - M-P 模型中使用阶跃函数作为激活函数,只能输出 0或 1,不连续所以 不可导
109 | - 为了使误差能够传播,鲁梅尔哈特等人提出使用可导函数Sigmoid作为激活函数
110 |
111 |  112 |
113 | Sigmoid函数的导数:$\frac{df(u)}{du} = f(u)(1-f(u))$
114 |
115 |
112 |
113 | Sigmoid函数的导数:$\frac{df(u)}{du} = f(u)(1-f(u))$
114 |
115 |  116 |
117 | 其他常见的激活函数:ReLU (Rectified Linear Unit,修正线性单元)和tanh等
118 |
119 |
116 |
117 | 其他常见的激活函数:ReLU (Rectified Linear Unit,修正线性单元)和tanh等
118 |
119 |  120 |
121 | ### BP算法示例
122 |
123 | 以包含一个中间层和一个输出单元 $y$ 的多层感知器为例:$w_{1ij}$ 表示输 入层与中间层之间的连接权重,$w_{2j1}$ 表示中间层与输出层之间的连接权重, $i$ 表示输入层单元,$j$ 表示中间层单元。
124 |
125 |
120 |
121 | ### BP算法示例
122 |
123 | 以包含一个中间层和一个输出单元 $y$ 的多层感知器为例:$w_{1ij}$ 表示输 入层与中间层之间的连接权重,$w_{2j1}$ 表示中间层与输出层之间的连接权重, $i$ 表示输入层单元,$j$ 表示中间层单元。
124 |
125 |  126 |
127 | - 首先调整中间层与输出层之间的连接权重,其中 $y=f(u)$, $f$ 是激活函数,$u_{21} = \sum_{j = 1}^{m}w_{2j1}z_j$,把误差函数 E 对连接权重$w_{2j1}$ 的求导展开成复合函数求导:
128 |
129 | $$
130 | \begin{array}{c}\frac{\partial E}{\partial w_{2 j 1}} =\frac{\partial E}{\partial y} \frac{\partial y}{\partial u_{21}} \frac{\partial u_{21}}{\partial w_{2 j 1}} \\ =-(r-y) y(1-y) z_{j}\end{array}
131 | $$
132 |
133 | 这里 $z_j$ 表示的是中间层的值。
134 |
135 | - 第二,中间层到输出层的连接权重调整值如下所示:
136 |
137 | $$
138 | \Delta w_{2 j 1}=\alpha(r-y) y(1-y) z_{j}
139 | $$
140 |
141 | - 第三,调整输入层与中间层之间的连接权重
142 |
143 | $$
144 | \begin{aligned} \frac{\partial E}{\partial w_{1 i j}} &=\frac{\partial E}{\partial y} \frac{\partial y}{\partial u_{21}} \frac{\partial u_{21}}{\partial w_{1 i j}} \\ &=-(r-y) y(1-y) \frac{\partial u_{21}}{\partial w_{1 i j}} \end{aligned}
145 | $$
146 |
147 | **中间层到输出层**
148 |
149 |
126 |
127 | - 首先调整中间层与输出层之间的连接权重,其中 $y=f(u)$, $f$ 是激活函数,$u_{21} = \sum_{j = 1}^{m}w_{2j1}z_j$,把误差函数 E 对连接权重$w_{2j1}$ 的求导展开成复合函数求导:
128 |
129 | $$
130 | \begin{array}{c}\frac{\partial E}{\partial w_{2 j 1}} =\frac{\partial E}{\partial y} \frac{\partial y}{\partial u_{21}} \frac{\partial u_{21}}{\partial w_{2 j 1}} \\ =-(r-y) y(1-y) z_{j}\end{array}
131 | $$
132 |
133 | 这里 $z_j$ 表示的是中间层的值。
134 |
135 | - 第二,中间层到输出层的连接权重调整值如下所示:
136 |
137 | $$
138 | \Delta w_{2 j 1}=\alpha(r-y) y(1-y) z_{j}
139 | $$
140 |
141 | - 第三,调整输入层与中间层之间的连接权重
142 |
143 | $$
144 | \begin{aligned} \frac{\partial E}{\partial w_{1 i j}} &=\frac{\partial E}{\partial y} \frac{\partial y}{\partial u_{21}} \frac{\partial u_{21}}{\partial w_{1 i j}} \\ &=-(r-y) y(1-y) \frac{\partial u_{21}}{\partial w_{1 i j}} \end{aligned}
145 | $$
146 |
147 | **中间层到输出层**
148 |
149 |  150 |
151 | **输入层到中间层**
152 |
153 |
150 |
151 | **输入层到中间层**
152 |
153 |  154 |
155 | # 优化问题
156 |
157 | **难点**
158 |
159 | - 参数过多,影响训练
160 | - 非凸优化问题:即存在局部最优而非全局最优解,影响迭代
161 | - 梯度消失问题,下层参数比较难调
162 | - 参数解释起来比较困难
163 |
164 | **需求**
165 |
166 | - 计算资源要大
167 | - 数据要多
168 | - 算法效率要好:即收敛快
169 |
170 | **非凸优化问题**
171 |
172 |
154 |
155 | # 优化问题
156 |
157 | **难点**
158 |
159 | - 参数过多,影响训练
160 | - 非凸优化问题:即存在局部最优而非全局最优解,影响迭代
161 | - 梯度消失问题,下层参数比较难调
162 | - 参数解释起来比较困难
163 |
164 | **需求**
165 |
166 | - 计算资源要大
167 | - 数据要多
168 | - 算法效率要好:即收敛快
169 |
170 | **非凸优化问题**
171 |
172 |  173 |
174 | **梯度消失问题**
175 |
176 |
173 |
174 | **梯度消失问题**
175 |
176 |  177 |
--------------------------------------------------------------------------------
/docs/理论入门/05.卷积神经网络CNN.md:
--------------------------------------------------------------------------------
1 | 卷积神经网络CNN
2 |
3 | 1. 卷积
4 | 2. CNN基本原理
5 | 3. 经典CNN
6 | 4. CNN主要应用
7 |
8 |
9 |
10 | 之前我们介绍了全连接神经网络,它的权重矩阵的参数非常多。
11 |
12 |
177 |
--------------------------------------------------------------------------------
/docs/理论入门/05.卷积神经网络CNN.md:
--------------------------------------------------------------------------------
1 | 卷积神经网络CNN
2 |
3 | 1. 卷积
4 | 2. CNN基本原理
5 | 3. 经典CNN
6 | 4. CNN主要应用
7 |
8 |
9 |
10 | 之前我们介绍了全连接神经网络,它的权重矩阵的参数非常多。
11 |
12 |  13 |
14 | 而且往往自然图像中的物体都具有局部不变性特征,即尺度缩放、平移、旋转等操作不影响其语义信息,但是全连接前馈网络很难提取这些局部不变特征,这就引出了我们将要介绍的卷积神经网络(Convolutional Neural Networks,CNN)。
15 |
16 | 卷积神经网络也是一种前馈神经网络,是受到生物学上感受野(感受野主要是指听觉系统、本体感觉系统和视觉系统中神经元的一些性质)的机制而提出的(在视觉神经系统中,一个神经元的感受野是指视网膜上的特定区域,只有这个区域内的刺激才能够激活该神经元)。
17 |
18 | # 卷积
19 |
20 | 卷积:(*f***g*)(*n*)成为 $f$ 和 $g$ 的卷积,连续卷积和离散卷积可以表达为如下形式:
21 |
22 | $$
23 | (f * g)(n)=\int_{-\infty}^{\infty} f(\tau) g(n-\tau) d \tau
24 | \\
25 | n = \tau + (n - \tau)
26 | \\
27 | (f * g)(n) = \sum_{\tau = -\infty}^{\infty} f(\tau) g(n-\tau)
28 | $$
29 |
30 | 卷积有很多应用,经常用于处理一个输入,通过系统产生一个适应需求的输出。
31 |
32 |
13 |
14 | 而且往往自然图像中的物体都具有局部不变性特征,即尺度缩放、平移、旋转等操作不影响其语义信息,但是全连接前馈网络很难提取这些局部不变特征,这就引出了我们将要介绍的卷积神经网络(Convolutional Neural Networks,CNN)。
15 |
16 | 卷积神经网络也是一种前馈神经网络,是受到生物学上感受野(感受野主要是指听觉系统、本体感觉系统和视觉系统中神经元的一些性质)的机制而提出的(在视觉神经系统中,一个神经元的感受野是指视网膜上的特定区域,只有这个区域内的刺激才能够激活该神经元)。
17 |
18 | # 卷积
19 |
20 | 卷积:(*f***g*)(*n*)成为 $f$ 和 $g$ 的卷积,连续卷积和离散卷积可以表达为如下形式:
21 |
22 | $$
23 | (f * g)(n)=\int_{-\infty}^{\infty} f(\tau) g(n-\tau) d \tau
24 | \\
25 | n = \tau + (n - \tau)
26 | \\
27 | (f * g)(n) = \sum_{\tau = -\infty}^{\infty} f(\tau) g(n-\tau)
28 | $$
29 |
30 | 卷积有很多应用,经常用于处理一个输入,通过系统产生一个适应需求的输出。
31 |
32 |  33 |
34 | - 统计学中加权平均法
35 | - 概率论中两个独立变量之和概率密度的计算
36 | - 信号处理中的线性系统
37 | - 物理学的线性系统
38 | - 图像处理中的应用(卷积神经网络)
39 |
40 | 卷积经常用在信号处理中,用于计算信号的延迟累积。
41 |
42 | 例如,假设一个信号发生器每个时刻 $t$ 产生一个信号 $x_t$ ,其信息的衰减率为 $w_k$ ,即在 $k−1$ 个时间步长后,信息为原来的 $w_k$ 倍,假设 $w_1 = 1,w_2 = 1/2,w_3 = 1/4$,则时刻 $t$ 收到的信号 $y_t$ 为当前时刻产生的信息和以前时刻延迟信息的叠加,即:
43 |
44 | $$
45 | \begin{aligned} y_{t} &=1 \times x_{t}+1 / 2 \times x_{t-1}+1 / 4 \times x_{t-2} \\ &=w_{1} \times x_{t}+w_{2} \times x_{t-1}+w_{3} \times x_{t-2} \\ &=\sum_{k=1}^{3} w_{k} \cdot x_{t-k+1} \end{aligned}
46 | $$
47 |
48 | 其中 $w_k$ 就是滤波器,也就是常说的卷积核 convolution kernel。
49 |
50 | 给定一个输入信号序列 $x$ 和滤波器 $w$,卷积的输出为:
51 |
52 | $$
53 | y_t = \sum_{k = 1}^{K} w_k x_{t-k+1}
54 | $$
55 |
56 | 不同的滤波器来提取信号序列中的不同特征:
57 |
58 |
33 |
34 | - 统计学中加权平均法
35 | - 概率论中两个独立变量之和概率密度的计算
36 | - 信号处理中的线性系统
37 | - 物理学的线性系统
38 | - 图像处理中的应用(卷积神经网络)
39 |
40 | 卷积经常用在信号处理中,用于计算信号的延迟累积。
41 |
42 | 例如,假设一个信号发生器每个时刻 $t$ 产生一个信号 $x_t$ ,其信息的衰减率为 $w_k$ ,即在 $k−1$ 个时间步长后,信息为原来的 $w_k$ 倍,假设 $w_1 = 1,w_2 = 1/2,w_3 = 1/4$,则时刻 $t$ 收到的信号 $y_t$ 为当前时刻产生的信息和以前时刻延迟信息的叠加,即:
43 |
44 | $$
45 | \begin{aligned} y_{t} &=1 \times x_{t}+1 / 2 \times x_{t-1}+1 / 4 \times x_{t-2} \\ &=w_{1} \times x_{t}+w_{2} \times x_{t-1}+w_{3} \times x_{t-2} \\ &=\sum_{k=1}^{3} w_{k} \cdot x_{t-k+1} \end{aligned}
46 | $$
47 |
48 | 其中 $w_k$ 就是滤波器,也就是常说的卷积核 convolution kernel。
49 |
50 | 给定一个输入信号序列 $x$ 和滤波器 $w$,卷积的输出为:
51 |
52 | $$
53 | y_t = \sum_{k = 1}^{K} w_k x_{t-k+1}
54 | $$
55 |
56 | 不同的滤波器来提取信号序列中的不同特征:
57 |
58 |  59 |
60 | 下面引入滤波器的滑动步长*S*和零填充*P*:
61 |
62 |
59 |
60 | 下面引入滤波器的滑动步长*S*和零填充*P*:
61 |
62 |  63 |
64 | 卷积的结果按输出长度不同可以分为三类:
65 |
66 | 1. 窄卷积:步长 𝑇 = 1 ,两端不补零 𝑃 = 0 ,卷积后输出长度为 𝑀 − 𝐾 + 1
67 | 2. 宽卷积:步长 𝑇 = 1 ,两端补零 𝑃 = 𝐾 − 1 ,卷积后输出长度 𝑀 + 𝐾 − 1
68 | 3. 等宽卷积:步长 𝑇 = 1 ,两端补零 𝑃 =(𝐾 − 1)/2 ,卷积后输出长度 𝑀
69 |
70 | 在早期的文献中,卷积一般默认为窄卷积。而目前的文献中,卷积一般默认为等宽卷积。
71 |
72 | 在图像处理中,图像是以二维矩阵的形式输入到神经网络中,因此我们需要二维卷积。下面给出定义:一个输入信息 $X$ 和滤波器 $W$ 的二维卷积为 $Y = W * X$,即 $y_{ij} = \sum_{u =1}^U \sum_{v = 1}{V}w_{uv}x_{i-u+1,j-v+1}$ .可以参考下面的算例。
73 |
74 |
63 |
64 | 卷积的结果按输出长度不同可以分为三类:
65 |
66 | 1. 窄卷积:步长 𝑇 = 1 ,两端不补零 𝑃 = 0 ,卷积后输出长度为 𝑀 − 𝐾 + 1
67 | 2. 宽卷积:步长 𝑇 = 1 ,两端补零 𝑃 = 𝐾 − 1 ,卷积后输出长度 𝑀 + 𝐾 − 1
68 | 3. 等宽卷积:步长 𝑇 = 1 ,两端补零 𝑃 =(𝐾 − 1)/2 ,卷积后输出长度 𝑀
69 |
70 | 在早期的文献中,卷积一般默认为窄卷积。而目前的文献中,卷积一般默认为等宽卷积。
71 |
72 | 在图像处理中,图像是以二维矩阵的形式输入到神经网络中,因此我们需要二维卷积。下面给出定义:一个输入信息 $X$ 和滤波器 $W$ 的二维卷积为 $Y = W * X$,即 $y_{ij} = \sum_{u =1}^U \sum_{v = 1}{V}w_{uv}x_{i-u+1,j-v+1}$ .可以参考下面的算例。
73 |
74 |  75 |
76 |
75 |
76 |  77 |
78 | 下图直接表示卷积层的映射关系
79 |
80 |
77 |
78 | 下图直接表示卷积层的映射关系
79 |
80 |  81 |
82 | 多个卷积核的情况:下图是表示步长2、filter 3*3 、filter个数6、零填充 1的情形。
83 |
84 |
81 |
82 | 多个卷积核的情况:下图是表示步长2、filter 3*3 、filter个数6、零填充 1的情形。
83 |
84 |  85 |
86 | 几乎很多实际应用都可以对应到这个问题上,都是在做这样一件事
87 |
88 | 1)输入对应着rgb图片
89 |
90 | 2)一旦输入的特征图个数是多个,这个时候每一组filter就应该是多个,而这里有两组filter
91 |
92 | 3)输入是三个特征图,输出为两个特征图,那么我们同样看看每个特征图怎么计算的。
93 |
94 | 典型的卷积层为3维结构
95 |
96 |
85 |
86 | 几乎很多实际应用都可以对应到这个问题上,都是在做这样一件事
87 |
88 | 1)输入对应着rgb图片
89 |
90 | 2)一旦输入的特征图个数是多个,这个时候每一组filter就应该是多个,而这里有两组filter
91 |
92 | 3)输入是三个特征图,输出为两个特征图,那么我们同样看看每个特征图怎么计算的。
93 |
94 | 典型的卷积层为3维结构
95 |
96 |  97 |
98 | ### 其他卷积
99 |
100 | **转置卷积/微步卷积**:低维特征映射到高维特征
101 |
102 |
97 |
98 | ### 其他卷积
99 |
100 | **转置卷积/微步卷积**:低维特征映射到高维特征
101 |
102 |  103 |
104 | **空洞卷积**:为了增加输出单元的感受野,通过给卷积核插入“空洞”来变相地增加其大小。
105 |
106 |
103 |
104 | **空洞卷积**:为了增加输出单元的感受野,通过给卷积核插入“空洞”来变相地增加其大小。
105 |
106 |  107 |
108 | # 卷积神经网络基本原理
109 |
110 | 卷积神经网络的基本结构大致包括:卷积层、激活函数、池化层、全连接层、输出层等。
111 |
112 | ### 卷积层
113 |
114 | 二维卷积运算:给定二维的图像*I*作为输入,二维卷积核*K*,卷积运算可表示为 $S(i, j)=(I * K)(i, j)=\sum_{m} \sum_{n} I(i-m, j-n) K(m, n)$,卷积核需要进行上下翻转和左右反转
115 |
116 | $$
117 | \left.S(i, j)=\operatorname{sum}\left(\begin{array}{ccc}I(i-2, j-2) & I(i-2, j-1) & I(i-2, j) \\ I(i-1, j-2) & I(i-1, j-1) & I(i-1, j) \\ I(i, j-2) & I(i, j-1) & I(i, j)\end{array}\right] . *\left[\begin{array}{rll}K(2,2) & K(2,1) & K(2,0) \\ K(1,2) & K(1,1) & K(1,0) \\ K(0,2) & K(0,1) & K(0,0)\end{array}\right]\right)
118 | $$
119 |
120 | 卷积实际上就是互相关
121 |
122 |
107 |
108 | # 卷积神经网络基本原理
109 |
110 | 卷积神经网络的基本结构大致包括:卷积层、激活函数、池化层、全连接层、输出层等。
111 |
112 | ### 卷积层
113 |
114 | 二维卷积运算:给定二维的图像*I*作为输入,二维卷积核*K*,卷积运算可表示为 $S(i, j)=(I * K)(i, j)=\sum_{m} \sum_{n} I(i-m, j-n) K(m, n)$,卷积核需要进行上下翻转和左右反转
115 |
116 | $$
117 | \left.S(i, j)=\operatorname{sum}\left(\begin{array}{ccc}I(i-2, j-2) & I(i-2, j-1) & I(i-2, j) \\ I(i-1, j-2) & I(i-1, j-1) & I(i-1, j) \\ I(i, j-2) & I(i, j-1) & I(i, j)\end{array}\right] . *\left[\begin{array}{rll}K(2,2) & K(2,1) & K(2,0) \\ K(1,2) & K(1,1) & K(1,0) \\ K(0,2) & K(0,1) & K(0,0)\end{array}\right]\right)
118 | $$
119 |
120 | 卷积实际上就是互相关
121 |
122 |  123 |
124 | **卷积的步长(stride)**:卷积核移动的步长
125 |
126 |
123 |
124 | **卷积的步长(stride)**:卷积核移动的步长
125 |
126 |  127 |
128 | **卷积的模式**:Full**,** Same和Valid
129 |
130 |
127 |
128 | **卷积的模式**:Full**,** Same和Valid
129 |
130 |  131 |
132 | **数据填充**:如果我们有一个 𝑛×𝑛 的图像,使用𝑓×𝑓 的卷积核进行卷积操作,在进行卷积操作之前我们在图像周围填充 𝑝 层数据,输出的维度:
133 |
134 |
131 |
132 | **数据填充**:如果我们有一个 𝑛×𝑛 的图像,使用𝑓×𝑓 的卷积核进行卷积操作,在进行卷积操作之前我们在图像周围填充 𝑝 层数据,输出的维度:
133 |
134 |  135 |
136 | **感受野**:卷积神经网络每一层输出的特征图(featuremap)上的像素点在输 入图片上映射的区域大小,即特征图上的一个点对应输入图上的区 域。
137 |
138 |
135 |
136 | **感受野**:卷积神经网络每一层输出的特征图(featuremap)上的像素点在输 入图片上映射的区域大小,即特征图上的一个点对应输入图上的区 域。
137 |
138 |  139 |
140 | 那么如何计算感受野的大小,可以采用从后往前逐层的计算方法:
141 |
142 | - 第 *i* 层的感受野大小和第 i - 1 层的卷积核大小和步长有关系,同时也与第 (i - 1)层感受野大小有关
143 | - 假设最后一层(卷积层或池化层)输出特征图感受野的大小(相对于其直 接输入而言)等于卷积核的大小
144 |
145 |
139 |
140 | 那么如何计算感受野的大小,可以采用从后往前逐层的计算方法:
141 |
142 | - 第 *i* 层的感受野大小和第 i - 1 层的卷积核大小和步长有关系,同时也与第 (i - 1)层感受野大小有关
143 | - 假设最后一层(卷积层或池化层)输出特征图感受野的大小(相对于其直 接输入而言)等于卷积核的大小
144 |
145 |  146 |
147 | **卷积层的深度(卷积核个数)**:一个卷积层通常包含多个尺寸一致的卷积核
148 |
149 |
146 |
147 | **卷积层的深度(卷积核个数)**:一个卷积层通常包含多个尺寸一致的卷积核
148 |
149 |  150 |
151 | ### 激活函数
152 |
153 | 激活函数是用来加入非线性因素,提高网络表达能力,卷积神经网络中最常用的是ReLU,Sigmoid使用较少。
154 |
155 |
150 |
151 | ### 激活函数
152 |
153 | 激活函数是用来加入非线性因素,提高网络表达能力,卷积神经网络中最常用的是ReLU,Sigmoid使用较少。
154 |
155 |  156 |
157 |
156 |
157 |  158 |
159 | **1. ReLU函数**
160 |
161 | $$
162 | f(x)=\left\{\begin{array}{l}0, x<0 \\ x, x \geq 0\end{array}\right.
163 | $$
164 |
165 | **ReLU**函数的优点:
166 |
167 | - 计算速度快,ReLU函数只有线性关系,比Sigmoid和Tanh要快很多
168 | - 输入为正数的时候,不存在梯度消失问题
169 |
170 | **ReLU**函数的缺点:
171 |
172 | - 强制性把负值置为0,可能丢掉一些特征
173 | - 当输入为负数时,权重无法更新,导致“神经元死亡”(学习率不 要太大)
174 |
175 | **2. Parametric ReLU**
176 |
177 | $$
178 | f(x)=\left\{\begin{array}{l}\alpha x, x<0 \\ x, x \geq 0\end{array}\right.
179 | $$
180 |
181 | - 当 𝛼=0.01 时,称作Leaky ReLU
182 | - 当 𝛼 从高斯分布中随机产生时,称为Randomized ReLU(RReLU)
183 |
184 | **PReLU**函数的优点:
185 |
186 | - 比sigmoid/tanh收敛快
187 | - 解决了ReLU的“神经元死亡”问题
188 |
189 | **PReLU**函数的缺点:需要再学习一个参数,工作量变大
190 |
191 | **3. ELU函数**
192 |
193 | $$
194 | f(x)=\left\{\begin{array}{l}\alpha (e^x-1), x<0 \\ x, x \geq 0\end{array}\right.
195 | $$
196 |
197 | **ELU**函数的优点:
198 |
199 | - 处理含有噪声的数据有优势
200 | - 更容易收敛
201 |
202 | **ELU**函数的缺点:计算量较大,收敛速度较慢
203 |
204 | - CNN在卷积层尽量不要使用Sigmoid和Tanh,将导致梯度消失。
205 | - 首先选用ReLU,使用较小的学习率,以免造成神经元死亡的情况。
206 | - 如果ReLU失效,考虑使用Leaky ReLU、PReLU、ELU或者Maxout,此时一般情况都可以解决
207 |
208 | **特征图**
209 |
210 | - 浅层卷积层:提取的是图像基本特征,如边缘、方向和纹理等特征
211 | - 深层卷积层:提取的是图像高阶特征,出现了高层语义模式,如“车轮”、“人脸”等特征
212 |
213 | ### 池化层
214 |
215 | 池化操作使用某位置相邻输出的总体统计特征作为该位置 的输出,常用最大池化**(max-pooling)**和均值池化**(average- pooling)**。
216 |
217 | 池化层不包含需要训练学习的参数,仅需指定池化操作的核大小、操作步幅以及池化类型。
218 |
219 |
158 |
159 | **1. ReLU函数**
160 |
161 | $$
162 | f(x)=\left\{\begin{array}{l}0, x<0 \\ x, x \geq 0\end{array}\right.
163 | $$
164 |
165 | **ReLU**函数的优点:
166 |
167 | - 计算速度快,ReLU函数只有线性关系,比Sigmoid和Tanh要快很多
168 | - 输入为正数的时候,不存在梯度消失问题
169 |
170 | **ReLU**函数的缺点:
171 |
172 | - 强制性把负值置为0,可能丢掉一些特征
173 | - 当输入为负数时,权重无法更新,导致“神经元死亡”(学习率不 要太大)
174 |
175 | **2. Parametric ReLU**
176 |
177 | $$
178 | f(x)=\left\{\begin{array}{l}\alpha x, x<0 \\ x, x \geq 0\end{array}\right.
179 | $$
180 |
181 | - 当 𝛼=0.01 时,称作Leaky ReLU
182 | - 当 𝛼 从高斯分布中随机产生时,称为Randomized ReLU(RReLU)
183 |
184 | **PReLU**函数的优点:
185 |
186 | - 比sigmoid/tanh收敛快
187 | - 解决了ReLU的“神经元死亡”问题
188 |
189 | **PReLU**函数的缺点:需要再学习一个参数,工作量变大
190 |
191 | **3. ELU函数**
192 |
193 | $$
194 | f(x)=\left\{\begin{array}{l}\alpha (e^x-1), x<0 \\ x, x \geq 0\end{array}\right.
195 | $$
196 |
197 | **ELU**函数的优点:
198 |
199 | - 处理含有噪声的数据有优势
200 | - 更容易收敛
201 |
202 | **ELU**函数的缺点:计算量较大,收敛速度较慢
203 |
204 | - CNN在卷积层尽量不要使用Sigmoid和Tanh,将导致梯度消失。
205 | - 首先选用ReLU,使用较小的学习率,以免造成神经元死亡的情况。
206 | - 如果ReLU失效,考虑使用Leaky ReLU、PReLU、ELU或者Maxout,此时一般情况都可以解决
207 |
208 | **特征图**
209 |
210 | - 浅层卷积层:提取的是图像基本特征,如边缘、方向和纹理等特征
211 | - 深层卷积层:提取的是图像高阶特征,出现了高层语义模式,如“车轮”、“人脸”等特征
212 |
213 | ### 池化层
214 |
215 | 池化操作使用某位置相邻输出的总体统计特征作为该位置 的输出,常用最大池化**(max-pooling)**和均值池化**(average- pooling)**。
216 |
217 | 池化层不包含需要训练学习的参数,仅需指定池化操作的核大小、操作步幅以及池化类型。
218 |
219 |  220 |
221 | 池化的作用:
222 |
223 | - 减少网络中的参数计算量,从而遏制过拟合
224 | - 增强网络对输入图像中的小变形、扭曲、平移的鲁棒性(输入里的微 小扭曲不会改变池化输出——因为我们在局部邻域已经取了最大值/ 平均值)
225 | - 帮助我们获得不因尺寸而改变的等效图片表征。这非常有用,因为 这样我们就可以探测到图片里的物体,不管它在哪个位置
226 |
227 | ### 全连接层
228 |
229 | - 对卷积层和池化层输出的特征图(二维)进行降维
230 | - 将学到的特征表示映射到样本标记空间的作用
231 |
232 | ### 输出层
233 |
234 | 对于分类问题:使用**Softmax**函数
235 |
236 | $$
237 | y_i = \frac{e^{z_i}}{\sum_{i = 1}^{n}e^{z_i}}
238 | $$
239 | 对于回归问题:使用线性函数
240 | $$
241 | y_i = \sum_{m = 1}^{M}w_{im}x_m
242 | $$
243 |
244 | ### 卷积神经网络的训练
245 |
246 | Step 1:用随机数初始化所有的卷积核和参数/权重
247 |
248 | Step 2:将训练图片作为输入,执行前向步骤(卷积, ReLU,池化以及全连接层的前向传播)并计算每个类别的对应输出概率。
249 |
250 | Step 3:计算输出层的总误差
251 |
252 | Step 4:反向传播算法计算误差相对于所有权重的梯度,并用梯度下降法更新所有的卷积核和参数/权重的值,以使输出误差最小化
253 |
254 | 注:卷积核个数、卷积核尺寸、网络架构这些参数,是在 Step 1 之前就已经固定的,且不会在训练过程中改变——只有卷 积核矩阵和神经元权重会更新。
255 |
256 |
220 |
221 | 池化的作用:
222 |
223 | - 减少网络中的参数计算量,从而遏制过拟合
224 | - 增强网络对输入图像中的小变形、扭曲、平移的鲁棒性(输入里的微 小扭曲不会改变池化输出——因为我们在局部邻域已经取了最大值/ 平均值)
225 | - 帮助我们获得不因尺寸而改变的等效图片表征。这非常有用,因为 这样我们就可以探测到图片里的物体,不管它在哪个位置
226 |
227 | ### 全连接层
228 |
229 | - 对卷积层和池化层输出的特征图(二维)进行降维
230 | - 将学到的特征表示映射到样本标记空间的作用
231 |
232 | ### 输出层
233 |
234 | 对于分类问题:使用**Softmax**函数
235 |
236 | $$
237 | y_i = \frac{e^{z_i}}{\sum_{i = 1}^{n}e^{z_i}}
238 | $$
239 | 对于回归问题:使用线性函数
240 | $$
241 | y_i = \sum_{m = 1}^{M}w_{im}x_m
242 | $$
243 |
244 | ### 卷积神经网络的训练
245 |
246 | Step 1:用随机数初始化所有的卷积核和参数/权重
247 |
248 | Step 2:将训练图片作为输入,执行前向步骤(卷积, ReLU,池化以及全连接层的前向传播)并计算每个类别的对应输出概率。
249 |
250 | Step 3:计算输出层的总误差
251 |
252 | Step 4:反向传播算法计算误差相对于所有权重的梯度,并用梯度下降法更新所有的卷积核和参数/权重的值,以使输出误差最小化
253 |
254 | 注:卷积核个数、卷积核尺寸、网络架构这些参数,是在 Step 1 之前就已经固定的,且不会在训练过程中改变——只有卷 积核矩阵和神经元权重会更新。
255 |
256 |  257 |
258 | 和多层神经网络一样,卷积神经网络中的参数训练也是使用误差反向传播算法,关于池化层的训练,需要再提一下,是将池化层改为多层神经网络的形式
259 |
260 |
257 |
258 | 和多层神经网络一样,卷积神经网络中的参数训练也是使用误差反向传播算法,关于池化层的训练,需要再提一下,是将池化层改为多层神经网络的形式
259 |
260 |  261 |
262 |
261 |
262 |  263 |
264 | 将卷积层也改为多层神经网络的形式
265 |
266 |
263 |
264 | 将卷积层也改为多层神经网络的形式
265 |
266 |  267 |
268 | # 经典卷积神经网络
269 |
270 |
267 |
268 | # 经典卷积神经网络
269 |
270 |  271 |
272 | ### 1. LeNet-5
273 |
274 | LeNet-5由LeCun等人提出于1998年提出,主要进行手写数字识别和英文字母识别。经典的卷积神经网络,LeNet虽小,各模块齐全,是学习 CNN的基础。
275 |
276 | 参考:**http://yann.lecun.com/exdb/lenet/**
277 |
278 | Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, November 1998.
279 |
280 | **网络结构**
281 |
282 |
271 |
272 | ### 1. LeNet-5
273 |
274 | LeNet-5由LeCun等人提出于1998年提出,主要进行手写数字识别和英文字母识别。经典的卷积神经网络,LeNet虽小,各模块齐全,是学习 CNN的基础。
275 |
276 | 参考:**http://yann.lecun.com/exdb/lenet/**
277 |
278 | Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, November 1998.
279 |
280 | **网络结构**
281 |
282 |  283 |
284 | **输入层**:$32*32$ 的图片,也就是相当于1024个神经元
285 |
286 | **C1层(卷积层)**:选择6个 $5*5$ 的卷积核,得到6个大小为32-5+1=28的特征图,也就是神经元的个数为 $6*28*28=4704$
287 |
288 | **S2层(下采样层)**:每个下抽样节点的4个输入节点求和后取平均(平均池化),均值 乘上一个权重参数加上一个偏置参数作为激活函数的输入,激活函数的输出即是下一层节点的值。池化核大小选择 $2*2$,得到6个 $14*14$ 大小特征图
289 |
290 | **C3层(卷积层)**:用 $5*5$的卷积核对S2层输出的特征图进行卷积后,得到6张$10*10$ 新 图片,然后将这6张图片相加在一起,然后加一个偏置项b,然后用 激活函数进行映射,就可以得到1张 $10*10$ 的特征图。我们希望得到 16 张 $10*10$ 的 特 征 图 , 因 此 我 们 就 需 要 参 数 个 数 为 $16*(6*(5*5))=16*6*(5*5)$ 个参数
291 |
292 | **S4层(下采样层)**:对C3的16张 $10*10$ 特征图进行最大池化,池化核大小为$2*2$,得到16张大小为 $5*5$ 的特征图。神经元个数已经减少为:$16*5*5=400$
293 |
294 | **C5层(卷积层)**:用 $5*5$ 的卷积核进行卷积,然后我们希望得到120个特征图,特征图 大小为5-5+1=1。神经元个数为120(这里实际上是全连接,但是原文还是称之为了卷积层)
295 |
296 | **F6层(全连接层)**:有84个节点,该层的训练参数和连接数都$(120+1)* 84=10164$
297 |
298 | **Output层**:共有10个节点,分别代表数字0到9,如果节点*i*的输出值为0,则网络识别的结果是数字*i*。采用的是径向基函数(RBF)的网络连接方式:
299 |
300 | $$
301 | y_i = \sum_j(x-j - w_{ij})^2
302 | $$
303 |
304 | **总结**:卷积核大小、卷积核个数(特征图需要多少个)、池化核大小(采样率多少)这些参数都是变化的,这就是所谓的CNN调参,需要学会根据需要进行不同的选择。
305 |
306 | ### 2. AlexNet
307 |
308 | AlexNet由Hinton的学生Alex Krizhevsky于2012年提出,获得ImageNet LSVRC-2012(物体识别挑战赛)的冠军,1000个类别120万幅高清图像(Error: 26.2%(2011) →15.3%(2012)),通过AlexNet确定了CNN在计算机视觉领域的王者地位。
309 |
310 | 参考:A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
311 |
312 | - 首次成功应用ReLU作为CNN的激活函数
313 | - 使用Dropout丢弃部分神元,避免了过拟合
314 | - 使用重叠MaxPooling(让池化层的步长小于池化核的大小), 一定程度上提升了特征的丰富性
315 | - 使用CUDA加速训练过程
316 | - 进行数据增强,原始图像大小为256×256的原始图像中重 复截取224×224大小的区域,大幅增加了数据量,大大减 轻了过拟合,提升了模型的泛化能力
317 |
318 | **网络结构**
319 |
320 |
283 |
284 | **输入层**:$32*32$ 的图片,也就是相当于1024个神经元
285 |
286 | **C1层(卷积层)**:选择6个 $5*5$ 的卷积核,得到6个大小为32-5+1=28的特征图,也就是神经元的个数为 $6*28*28=4704$
287 |
288 | **S2层(下采样层)**:每个下抽样节点的4个输入节点求和后取平均(平均池化),均值 乘上一个权重参数加上一个偏置参数作为激活函数的输入,激活函数的输出即是下一层节点的值。池化核大小选择 $2*2$,得到6个 $14*14$ 大小特征图
289 |
290 | **C3层(卷积层)**:用 $5*5$的卷积核对S2层输出的特征图进行卷积后,得到6张$10*10$ 新 图片,然后将这6张图片相加在一起,然后加一个偏置项b,然后用 激活函数进行映射,就可以得到1张 $10*10$ 的特征图。我们希望得到 16 张 $10*10$ 的 特 征 图 , 因 此 我 们 就 需 要 参 数 个 数 为 $16*(6*(5*5))=16*6*(5*5)$ 个参数
291 |
292 | **S4层(下采样层)**:对C3的16张 $10*10$ 特征图进行最大池化,池化核大小为$2*2$,得到16张大小为 $5*5$ 的特征图。神经元个数已经减少为:$16*5*5=400$
293 |
294 | **C5层(卷积层)**:用 $5*5$ 的卷积核进行卷积,然后我们希望得到120个特征图,特征图 大小为5-5+1=1。神经元个数为120(这里实际上是全连接,但是原文还是称之为了卷积层)
295 |
296 | **F6层(全连接层)**:有84个节点,该层的训练参数和连接数都$(120+1)* 84=10164$
297 |
298 | **Output层**:共有10个节点,分别代表数字0到9,如果节点*i*的输出值为0,则网络识别的结果是数字*i*。采用的是径向基函数(RBF)的网络连接方式:
299 |
300 | $$
301 | y_i = \sum_j(x-j - w_{ij})^2
302 | $$
303 |
304 | **总结**:卷积核大小、卷积核个数(特征图需要多少个)、池化核大小(采样率多少)这些参数都是变化的,这就是所谓的CNN调参,需要学会根据需要进行不同的选择。
305 |
306 | ### 2. AlexNet
307 |
308 | AlexNet由Hinton的学生Alex Krizhevsky于2012年提出,获得ImageNet LSVRC-2012(物体识别挑战赛)的冠军,1000个类别120万幅高清图像(Error: 26.2%(2011) →15.3%(2012)),通过AlexNet确定了CNN在计算机视觉领域的王者地位。
309 |
310 | 参考:A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
311 |
312 | - 首次成功应用ReLU作为CNN的激活函数
313 | - 使用Dropout丢弃部分神元,避免了过拟合
314 | - 使用重叠MaxPooling(让池化层的步长小于池化核的大小), 一定程度上提升了特征的丰富性
315 | - 使用CUDA加速训练过程
316 | - 进行数据增强,原始图像大小为256×256的原始图像中重 复截取224×224大小的区域,大幅增加了数据量,大大减 轻了过拟合,提升了模型的泛化能力
317 |
318 | **网络结构**
319 |
320 |  321 |
322 | AlexNet可分为8层(池化层未单独算作一层),包括5个卷 积层以及3个全连接层
323 |
324 | **输入层**:AlexNet首先使用大小为224×224×3图像作为输入(后改为227×227×3)
325 |
326 | **第一层(卷积层)**:包含96个大小为11×11的卷积核,卷积步长为4,因此第一层输出大小为55×55×96;然后构建一个核大小为3×3、步长为2的最大池化层进行数据降采样,进而输出大小为27×27×96
327 |
328 | **第二层(卷积层)**:包含256个大小为5×5卷积核,卷积步长为1,同时利用padding保证 输出尺寸不变,因此该层输出大小为27×27×256;然后再次通过 核大小为3×3、步长为2的最大池化层进行数据降采样,进而输出大小为13×13×256
329 |
330 | **第三层与第四层(卷积层)**:均为卷积核大小为3×3、步长为1的same卷积,共包含384个卷积核,因此两层的输出大小为13×13×384
331 |
332 | **第五层(卷积层)**:同样为卷积核大小为3×3、步长为1的same卷积,但包含256个卷积 核,进而输出大小为13×13×256;在数据进入全连接层之前再次 通过一个核大小为3×3、步长为2的最大池化层进行数据降采样, 数据大小降为6×6×256,并将数据扁平化处理展开为9216个单元
333 |
334 | **第六层、第七层和第八层(全连接层)**:全连接加上Softmax分类器输出1000类的分类结果,有将近6千万个参数
335 |
336 | ### 3. VGGNet
337 |
338 | VGGNet由牛津大学和DeepMind公司提出
339 |
340 | - Visual Geometry Group:https://www.robots.ox.ac.uk/~vgg/
341 | - DeepMind:https://deepmind.com/
342 |
343 | 参考:K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
344 |
345 | - 比较常用的是VGG-16,结构规整,具有很强的拓展性
346 | - 相较于AlexNet,VGG-16网络模型中的卷积层均使用 $3*3$ 的 卷积核,且均为步长为1的same卷积,池化层均使用 $2*2$ 的 池化核,步长为2
347 |
348 | **网络结构**
349 |
350 |
321 |
322 | AlexNet可分为8层(池化层未单独算作一层),包括5个卷 积层以及3个全连接层
323 |
324 | **输入层**:AlexNet首先使用大小为224×224×3图像作为输入(后改为227×227×3)
325 |
326 | **第一层(卷积层)**:包含96个大小为11×11的卷积核,卷积步长为4,因此第一层输出大小为55×55×96;然后构建一个核大小为3×3、步长为2的最大池化层进行数据降采样,进而输出大小为27×27×96
327 |
328 | **第二层(卷积层)**:包含256个大小为5×5卷积核,卷积步长为1,同时利用padding保证 输出尺寸不变,因此该层输出大小为27×27×256;然后再次通过 核大小为3×3、步长为2的最大池化层进行数据降采样,进而输出大小为13×13×256
329 |
330 | **第三层与第四层(卷积层)**:均为卷积核大小为3×3、步长为1的same卷积,共包含384个卷积核,因此两层的输出大小为13×13×384
331 |
332 | **第五层(卷积层)**:同样为卷积核大小为3×3、步长为1的same卷积,但包含256个卷积 核,进而输出大小为13×13×256;在数据进入全连接层之前再次 通过一个核大小为3×3、步长为2的最大池化层进行数据降采样, 数据大小降为6×6×256,并将数据扁平化处理展开为9216个单元
333 |
334 | **第六层、第七层和第八层(全连接层)**:全连接加上Softmax分类器输出1000类的分类结果,有将近6千万个参数
335 |
336 | ### 3. VGGNet
337 |
338 | VGGNet由牛津大学和DeepMind公司提出
339 |
340 | - Visual Geometry Group:https://www.robots.ox.ac.uk/~vgg/
341 | - DeepMind:https://deepmind.com/
342 |
343 | 参考:K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
344 |
345 | - 比较常用的是VGG-16,结构规整,具有很强的拓展性
346 | - 相较于AlexNet,VGG-16网络模型中的卷积层均使用 $3*3$ 的 卷积核,且均为步长为1的same卷积,池化层均使用 $2*2$ 的 池化核,步长为2
347 |
348 | **网络结构**
349 |
350 |  351 |
352 | - 两个卷积核大小为 $3*3$ 的卷积层串联后的感受野尺寸为 $5*5$, 相当于单个卷积核大小为 $5*5$ 的卷积层
353 | - 两者参数数量比值为$(2*3*3)/(5*5)=72\%$ ,前者参数量更少
354 | - 此外,两个的卷积层串联可使用两次ReLU激活函数,而一个卷积层只使用一次
355 |
356 | ### 4. Inception Net
357 |
358 | Inception Net 是Google公司2014年提出,获得ImageNet LSVRC-2014冠军。文章提出获得高质量模型最保险的做法就是增加模型的深度(层数)或者是其宽度(层核或者神经元数),采用了22层网络。
359 |
360 | **Inception四个版本**所对应的论文及ILSVRC中的Top-5错误率:
361 |
362 | - [v1] Going Deeper with Convolutions: 6.67%
363 |
364 | - [v2] Batch Normalization: Accelerating Deep Network Training byReducing Internal Covariate Shift: 4.8%
365 |
366 | - [v3]RethinkingtheInceptionArchitectureforComputerVision:3.5%
367 |
368 | - [v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning: 3.08%
369 |
370 | **Inception Module**
371 |
372 | - 深度:层数更深,采用了22层,在不同深度处增加了两个 loss来避免上述提到的梯度消失问题
373 | - 宽度:Inception Module包含4个分支,在卷积核3x3、5x5 之前、max pooling之后分别加上了1x1的卷积核,起到了降低特征图厚度的作用
374 | - 1×1的卷积的作用:可以跨通道组织信息,来提高网络的表达能力;可以对输出通道进行升维和降维。
375 |
376 |
351 |
352 | - 两个卷积核大小为 $3*3$ 的卷积层串联后的感受野尺寸为 $5*5$, 相当于单个卷积核大小为 $5*5$ 的卷积层
353 | - 两者参数数量比值为$(2*3*3)/(5*5)=72\%$ ,前者参数量更少
354 | - 此外,两个的卷积层串联可使用两次ReLU激活函数,而一个卷积层只使用一次
355 |
356 | ### 4. Inception Net
357 |
358 | Inception Net 是Google公司2014年提出,获得ImageNet LSVRC-2014冠军。文章提出获得高质量模型最保险的做法就是增加模型的深度(层数)或者是其宽度(层核或者神经元数),采用了22层网络。
359 |
360 | **Inception四个版本**所对应的论文及ILSVRC中的Top-5错误率:
361 |
362 | - [v1] Going Deeper with Convolutions: 6.67%
363 |
364 | - [v2] Batch Normalization: Accelerating Deep Network Training byReducing Internal Covariate Shift: 4.8%
365 |
366 | - [v3]RethinkingtheInceptionArchitectureforComputerVision:3.5%
367 |
368 | - [v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning: 3.08%
369 |
370 | **Inception Module**
371 |
372 | - 深度:层数更深,采用了22层,在不同深度处增加了两个 loss来避免上述提到的梯度消失问题
373 | - 宽度:Inception Module包含4个分支,在卷积核3x3、5x5 之前、max pooling之后分别加上了1x1的卷积核,起到了降低特征图厚度的作用
374 | - 1×1的卷积的作用:可以跨通道组织信息,来提高网络的表达能力;可以对输出通道进行升维和降维。
375 |
376 |  377 |
378 | ### 5. ResNet
379 |
380 | ResNet(Residual Neural Network),又叫做残差神经网 络,是由微软研究院的何凯明等人2015年提出,获得ImageNet ILSVRC 2015比赛冠军,获得CVPR2016最佳论文奖。
381 |
382 | 随着卷积网络层数的增加,误差的逆传播过程中存在的梯 度消失和梯度爆炸问题同样也会导致模型的训练难以进行,甚至会出现随着网络深度的加深,模型在训练集上的训练误差会出现先降低再升高的现象。残差网络的引入则有助于解决梯度消失和梯度爆炸问题。
383 |
384 | **残差块**
385 |
386 | ResNet的核心是叫做残差块(Residual block)的小单元, 残差块可以视作在标准神经网络基础上加入了跳跃连接(Skip connection)
387 |
388 | - 原连接
389 |
390 | $$
391 | a_{l+1} = \sigma(W_{l+1}a_l+b_{l+1})
392 | \\
393 | a_{l+2} = \sigma(W_{l+2}a_{l+1}+b_{l+2})
394 | $$
395 |
396 |
377 |
378 | ### 5. ResNet
379 |
380 | ResNet(Residual Neural Network),又叫做残差神经网 络,是由微软研究院的何凯明等人2015年提出,获得ImageNet ILSVRC 2015比赛冠军,获得CVPR2016最佳论文奖。
381 |
382 | 随着卷积网络层数的增加,误差的逆传播过程中存在的梯 度消失和梯度爆炸问题同样也会导致模型的训练难以进行,甚至会出现随着网络深度的加深,模型在训练集上的训练误差会出现先降低再升高的现象。残差网络的引入则有助于解决梯度消失和梯度爆炸问题。
383 |
384 | **残差块**
385 |
386 | ResNet的核心是叫做残差块(Residual block)的小单元, 残差块可以视作在标准神经网络基础上加入了跳跃连接(Skip connection)
387 |
388 | - 原连接
389 |
390 | $$
391 | a_{l+1} = \sigma(W_{l+1}a_l+b_{l+1})
392 | \\
393 | a_{l+2} = \sigma(W_{l+2}a_{l+1}+b_{l+2})
394 | $$
395 |
396 |  397 |
398 | - 跳跃连接
399 |
400 | $$
401 | a_{l+1} = \sigma(W_{l+1}a_l+b_{l+1})
402 | \\
403 | a_{l+2} = \sigma(W_{l+2}a_{l+1}+b_{l+2}+a_l)
404 | $$
405 |
406 |
397 |
398 | - 跳跃连接
399 |
400 | $$
401 | a_{l+1} = \sigma(W_{l+1}a_l+b_{l+1})
402 | \\
403 | a_{l+2} = \sigma(W_{l+2}a_{l+1}+b_{l+2}+a_l)
404 | $$
405 |
406 |  407 |
408 | **Skip connection的作用**
409 |
410 | 记 $u_{l+1} = W_{l+1}a_l+b_{l+1},u_{l+2} = W_{l+2}a_{l+1}+b_{l+2}+a_l = \hat{u}_{l+2} + a_l$
411 |
412 | 我们有:
413 |
414 | $$
415 | \begin{align}
416 | \frac{\partial E}{\partial w_l} &=
417 | \frac{\partial E}{\partial a_{l+2}}
418 | \frac{\partial a_{l+2}}{\partial u_{l+2}}
419 | \frac{\partial u_{l+2}}{\partial w_l}
420 | \\
421 | &=
422 | \frac{\partial E}{\partial a_{l+2}}
423 | \frac{\partial a_{l+2}}{\partial u_{l+2}}
424 | \frac{\partial \hat{u}_{l+2}}{\partial w_l}
425 | +
426 | \frac{\partial E}{\partial a_{l+2}}
427 | \frac{\partial a_{l+2}}{\partial u_{l+2}}
428 | \frac{\partial a_l}{\partial w_l}
429 | \\
430 | &=
431 | \cdots + \frac{\partial E}{\partial a_{l+2}}
432 | \frac{\partial a_{l+2}}{\partial u_{l+2}}
433 | \frac{\partial a_l}{\partial u_l}
434 | \frac{\partial u_{l}}{\partial w_l}
435 | \end{align}
436 | $$
437 |
438 | ### 6. Densenet
439 |
440 | DenseNet中,两个层之间都有直接的连接,因此该网络的直接连接个数为L(L+1)/2。
441 |
442 | 对于每一层,使用前面所有层的特征映射作为输入,并且使用其自身的特征映射作为所有后续层的输入
443 |
444 |
407 |
408 | **Skip connection的作用**
409 |
410 | 记 $u_{l+1} = W_{l+1}a_l+b_{l+1},u_{l+2} = W_{l+2}a_{l+1}+b_{l+2}+a_l = \hat{u}_{l+2} + a_l$
411 |
412 | 我们有:
413 |
414 | $$
415 | \begin{align}
416 | \frac{\partial E}{\partial w_l} &=
417 | \frac{\partial E}{\partial a_{l+2}}
418 | \frac{\partial a_{l+2}}{\partial u_{l+2}}
419 | \frac{\partial u_{l+2}}{\partial w_l}
420 | \\
421 | &=
422 | \frac{\partial E}{\partial a_{l+2}}
423 | \frac{\partial a_{l+2}}{\partial u_{l+2}}
424 | \frac{\partial \hat{u}_{l+2}}{\partial w_l}
425 | +
426 | \frac{\partial E}{\partial a_{l+2}}
427 | \frac{\partial a_{l+2}}{\partial u_{l+2}}
428 | \frac{\partial a_l}{\partial w_l}
429 | \\
430 | &=
431 | \cdots + \frac{\partial E}{\partial a_{l+2}}
432 | \frac{\partial a_{l+2}}{\partial u_{l+2}}
433 | \frac{\partial a_l}{\partial u_l}
434 | \frac{\partial u_{l}}{\partial w_l}
435 | \end{align}
436 | $$
437 |
438 | ### 6. Densenet
439 |
440 | DenseNet中,两个层之间都有直接的连接,因此该网络的直接连接个数为L(L+1)/2。
441 |
442 | 对于每一层,使用前面所有层的特征映射作为输入,并且使用其自身的特征映射作为所有后续层的输入
443 |
444 |  445 |
446 | 参考:Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. (2017). Densely connected convolutional networks. In *Proceedings of the IEEE conference on computer vision and pattern recognition* (pp. 4700- 4708).
447 |
448 | **5层的稠密块示意图**
449 |
450 |
445 |
446 | 参考:Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. (2017). Densely connected convolutional networks. In *Proceedings of the IEEE conference on computer vision and pattern recognition* (pp. 4700- 4708).
447 |
448 | **5层的稠密块示意图**
449 |
450 |  451 |
452 | DenseNets可以自然地扩展到数百个层,而没有表现出优化困难。在实验中,DenseNets随着参数数量的增加,在精度上产生一致的提高,而没有任何性能下降或过拟合的迹象。
453 |
454 | **优点**:
455 |
456 | - 缓解了消失梯度问题
457 | - 加强了特征传播,鼓励特征重用
458 | - 一定程度上减少了参数的数量
459 |
460 | # 主要应用
461 |
462 | **图像处理领域主要应用**
463 |
464 | - 图像分类(物体识别):整幅图像的分类或识别
465 | - 物体检测:检测图像中物体的位置进而识别物体
466 | - 图像分割:对图像中的特定物体按边缘进行分割
467 | - 图像回归:预测图像中物体组成部分的坐标
468 |
469 |
451 |
452 | DenseNets可以自然地扩展到数百个层,而没有表现出优化困难。在实验中,DenseNets随着参数数量的增加,在精度上产生一致的提高,而没有任何性能下降或过拟合的迹象。
453 |
454 | **优点**:
455 |
456 | - 缓解了消失梯度问题
457 | - 加强了特征传播,鼓励特征重用
458 | - 一定程度上减少了参数的数量
459 |
460 | # 主要应用
461 |
462 | **图像处理领域主要应用**
463 |
464 | - 图像分类(物体识别):整幅图像的分类或识别
465 | - 物体检测:检测图像中物体的位置进而识别物体
466 | - 图像分割:对图像中的特定物体按边缘进行分割
467 | - 图像回归:预测图像中物体组成部分的坐标
468 |
469 |  470 |
471 | **语音识别领域主要应用**
472 |
473 |
470 |
471 | **语音识别领域主要应用**
472 |
473 |  474 |
475 | **自然语言处理领域主要应用**
476 |
477 | 情感分析:分析文本体现的情感(正负向、正负中或多态度类型)
478 |
479 | 参考:(Yoon Kim)Convolutional Neural Networks for Sentence https://arxiv.org/abs/1408.5882
480 |
481 |
474 |
475 | **自然语言处理领域主要应用**
476 |
477 | 情感分析:分析文本体现的情感(正负向、正负中或多态度类型)
478 |
479 | 参考:(Yoon Kim)Convolutional Neural Networks for Sentence https://arxiv.org/abs/1408.5882
480 |
481 |  482 |
483 |
--------------------------------------------------------------------------------
/docs/理论入门/06.循环神经网络RNN.md:
--------------------------------------------------------------------------------
1 | 循环神经网络RNN
2 |
3 | 1. 计算图
4 | 2. RNN
5 | 3. 长短时记忆网络
6 | 4. 其他RNN
7 | 5. RNN主要应用
8 |
9 |
10 |
11 | # 计算图
12 |
13 | 计算图的引入是为了后面更方便的表示网络,计算图是描述计算结构的一种图,它的元素包括节点(node)和边(edge),节点表示变量,可以是标量、矢量、张量等,而边表示的是某个操作,即函数。
14 |
15 | 
16 |
17 | 下面这个计算图表示复合函数
18 |
19 | 
20 |
21 | 关于计算图的求导,我们可以用链式法则表示,有下面两种情况。
22 |
23 | - 情况1
24 |
25 | 
26 |
27 | - 情况2
28 |
29 | 
30 |
31 | 求导举例:
32 |
33 | 例1
34 |
35 |
482 |
483 |
--------------------------------------------------------------------------------
/docs/理论入门/06.循环神经网络RNN.md:
--------------------------------------------------------------------------------
1 | 循环神经网络RNN
2 |
3 | 1. 计算图
4 | 2. RNN
5 | 3. 长短时记忆网络
6 | 4. 其他RNN
7 | 5. RNN主要应用
8 |
9 |
10 |
11 | # 计算图
12 |
13 | 计算图的引入是为了后面更方便的表示网络,计算图是描述计算结构的一种图,它的元素包括节点(node)和边(edge),节点表示变量,可以是标量、矢量、张量等,而边表示的是某个操作,即函数。
14 |
15 | 
16 |
17 | 下面这个计算图表示复合函数
18 |
19 | 
20 |
21 | 关于计算图的求导,我们可以用链式法则表示,有下面两种情况。
22 |
23 | - 情况1
24 |
25 | 
26 |
27 | - 情况2
28 |
29 | 
30 |
31 | 求导举例:
32 |
33 | 例1
34 |
35 |  36 |
37 | - a = 3, b = 1 可以得到 c = 4, d = 2, e = 6
38 |
39 | - $\frac{\partial e}{\partial a} = \frac{\partial e}{\partial c}\frac{\partial c}{\partial a} = d = b + 1 = 2$
40 | - $\frac{\partial e}{\partial b} = \frac{\partial e}{\partial c}\frac{\partial c}{\partial b}+\frac{\partial e}{\partial d}\frac{\partial d}{\partial b} = d + c=b+1+a+b = 5$
41 |
42 | 例2
43 |
44 |
36 |
37 | - a = 3, b = 1 可以得到 c = 4, d = 2, e = 6
38 |
39 | - $\frac{\partial e}{\partial a} = \frac{\partial e}{\partial c}\frac{\partial c}{\partial a} = d = b + 1 = 2$
40 | - $\frac{\partial e}{\partial b} = \frac{\partial e}{\partial c}\frac{\partial c}{\partial b}+\frac{\partial e}{\partial d}\frac{\partial d}{\partial b} = d + c=b+1+a+b = 5$
41 |
42 | 例2
43 |
44 |  45 |
46 | $\frac{\partial Z}{\partial X}=\alpha \delta+\alpha \epsilon+\alpha \zeta+\beta \delta+\beta \epsilon+\beta \zeta+\gamma \delta+\gamma \epsilon+\gamma \zeta = (\alpha +\beta+\gamma)(\delta+\epsilon+\zeta) $
47 |
48 | 计算图可以很好的表示导数的前向传递和后向传递的过程,比如上面例2,前向传递了$\frac{\partial }{\partial X}$ ,反向传递$\frac{\partial }{\partial Z}$ 。
49 |
50 |
45 |
46 | $\frac{\partial Z}{\partial X}=\alpha \delta+\alpha \epsilon+\alpha \zeta+\beta \delta+\beta \epsilon+\beta \zeta+\gamma \delta+\gamma \epsilon+\gamma \zeta = (\alpha +\beta+\gamma)(\delta+\epsilon+\zeta) $
47 |
48 | 计算图可以很好的表示导数的前向传递和后向传递的过程,比如上面例2,前向传递了$\frac{\partial }{\partial X}$ ,反向传递$\frac{\partial }{\partial Z}$ 。
49 |
50 |  51 |
52 |
51 |
52 |  53 |
54 | # 循环神经网络(Recurrent Neural Network)
55 |
56 | 上一章我们已经介绍了CNN,可能我们会想这里为什么还需要构建一种新的网络RNN呢?因为现实生活中存在很多序列化结构,我们需要建立一种更优秀的序列数据模型。
57 |
58 | - 文本:字母和词汇的序列
59 | - 语音:音节的序列
60 | - 视频:图像帧的序列
61 | - 时态数据:气象观测数据,股票交易数据、房价数据等
62 |
63 | RNN的发展历程:
64 |
65 | 
66 |
67 | 循环神经网络是一种人工神经网络,它的节点间的连接形成一个遵循时间序列的有向图,它的核心思想是,样本间存在顺序关系,每个样本和它之前的样本存在关联。通过神经网络在时序上的展开,我们能够找到样本之间的序列相关性。
68 |
69 | 下面给出RNN的一般结构:
70 |
71 | 
72 |
73 | 其中各个符号的表示:$x_t,s_t,o_t$分别表示的是$t$时刻的输入、记忆和输出,$U,V,W$是RNN的连接权重,$b_s,b_o$是RNN的偏置,$\sigma,\varphi$是激活函数,$\sigma$通常选tanh或sigmoid,$\varphi$通常选用softmax。
74 |
75 | 其中 softmax 函数,用于分类问题的概率计算。本质上是将一个K维的任意实数向量压缩 (映射)成另一个K维的实数向量,其中向量中的每个元素取值都介于(0,1)之间。
76 |
77 | $$
78 | \sigma(\vec{z})_{i}=\frac{e^{z_{i}}}{\sum_{j=1}^{K} e^{z_{j}}}
79 | $$
80 |
81 | ### RNN案例
82 |
83 | 比如词性标注,
84 |
85 | - 我/n,爱/v购物/n,
86 | - 我/n在/pre华联/n购物/v
87 |
88 | Word Embedding:自然语言处理(NLP)中的 一组语言建模和特征学习技术的统称,其中来自词汇表的单词或短语被映射到实数的向量。比如这里映射到三个向量然后输入:
89 |
90 |
53 |
54 | # 循环神经网络(Recurrent Neural Network)
55 |
56 | 上一章我们已经介绍了CNN,可能我们会想这里为什么还需要构建一种新的网络RNN呢?因为现实生活中存在很多序列化结构,我们需要建立一种更优秀的序列数据模型。
57 |
58 | - 文本:字母和词汇的序列
59 | - 语音:音节的序列
60 | - 视频:图像帧的序列
61 | - 时态数据:气象观测数据,股票交易数据、房价数据等
62 |
63 | RNN的发展历程:
64 |
65 | 
66 |
67 | 循环神经网络是一种人工神经网络,它的节点间的连接形成一个遵循时间序列的有向图,它的核心思想是,样本间存在顺序关系,每个样本和它之前的样本存在关联。通过神经网络在时序上的展开,我们能够找到样本之间的序列相关性。
68 |
69 | 下面给出RNN的一般结构:
70 |
71 | 
72 |
73 | 其中各个符号的表示:$x_t,s_t,o_t$分别表示的是$t$时刻的输入、记忆和输出,$U,V,W$是RNN的连接权重,$b_s,b_o$是RNN的偏置,$\sigma,\varphi$是激活函数,$\sigma$通常选tanh或sigmoid,$\varphi$通常选用softmax。
74 |
75 | 其中 softmax 函数,用于分类问题的概率计算。本质上是将一个K维的任意实数向量压缩 (映射)成另一个K维的实数向量,其中向量中的每个元素取值都介于(0,1)之间。
76 |
77 | $$
78 | \sigma(\vec{z})_{i}=\frac{e^{z_{i}}}{\sum_{j=1}^{K} e^{z_{j}}}
79 | $$
80 |
81 | ### RNN案例
82 |
83 | 比如词性标注,
84 |
85 | - 我/n,爱/v购物/n,
86 | - 我/n在/pre华联/n购物/v
87 |
88 | Word Embedding:自然语言处理(NLP)中的 一组语言建模和特征学习技术的统称,其中来自词汇表的单词或短语被映射到实数的向量。比如这里映射到三个向量然后输入:
89 |
90 |  91 |
92 | 将神经元的输出存到memory中,memory中值会作为下一时刻的输入。在最开始时刻,给定 memory初始值,然后逐次更新memory中的值。
93 |
94 | 
95 |
96 | 
97 |
98 | ### RNN的一般结构
99 |
100 | - Elman Network
101 |
102 |
91 |
92 | 将神经元的输出存到memory中,memory中值会作为下一时刻的输入。在最开始时刻,给定 memory初始值,然后逐次更新memory中的值。
93 |
94 | 
95 |
96 | 
97 |
98 | ### RNN的一般结构
99 |
100 | - Elman Network
101 |
102 |  103 |
104 | - Jordan Network
105 |
106 |
103 |
104 | - Jordan Network
105 |
106 |  107 |
108 | 各种不同的RNN结构
109 |
110 | 
111 |
112 | ### RNN训练算法 - BPTT
113 |
114 | 我们先来回顾一下BP算法,就是定义损失函数 Loss 来表示输出 $\hat{y}$ 和真实标签 y 的误差,通过链式法则自顶向下求得 Loss 对网络权重的偏导。沿梯度的反方向更新权重的值, 直到 Loss 收敛。而这里的 BPTT 算法就是加上了时序演化,后面的两个字母 TT 就是 Through Time。
115 |
116 |
107 |
108 | 各种不同的RNN结构
109 |
110 | 
111 |
112 | ### RNN训练算法 - BPTT
113 |
114 | 我们先来回顾一下BP算法,就是定义损失函数 Loss 来表示输出 $\hat{y}$ 和真实标签 y 的误差,通过链式法则自顶向下求得 Loss 对网络权重的偏导。沿梯度的反方向更新权重的值, 直到 Loss 收敛。而这里的 BPTT 算法就是加上了时序演化,后面的两个字母 TT 就是 Through Time。
115 |
116 |  117 |
118 | 我们先定义输出函数:
119 |
120 | $$
121 | \begin{array}{l}s_{t}=\tanh \left(U x_{t}+W s_{t-1}\right) \\ \hat{y}_{t}=\operatorname{softmax}\left(V s_{t}\right)\end{array}
122 | $$
123 |
124 | 再定义损失函数:
125 |
126 | $$
127 | \begin{aligned} E_{t}\left(y_{t}, \hat{y}_{t}\right) =-y_{t} \log \hat{y}_{t} \\ E(y, \hat{y}) =\sum_{t} E_{t}\left(y_{t}, \hat{y}_{t}\right) \\ =-\sum_{t} y_{t} \log \hat{y}_{t}\end{aligned}
128 | $$
129 |
130 |
117 |
118 | 我们先定义输出函数:
119 |
120 | $$
121 | \begin{array}{l}s_{t}=\tanh \left(U x_{t}+W s_{t-1}\right) \\ \hat{y}_{t}=\operatorname{softmax}\left(V s_{t}\right)\end{array}
122 | $$
123 |
124 | 再定义损失函数:
125 |
126 | $$
127 | \begin{aligned} E_{t}\left(y_{t}, \hat{y}_{t}\right) =-y_{t} \log \hat{y}_{t} \\ E(y, \hat{y}) =\sum_{t} E_{t}\left(y_{t}, \hat{y}_{t}\right) \\ =-\sum_{t} y_{t} \log \hat{y}_{t}\end{aligned}
128 | $$
129 |
130 |  131 |
132 | 我们分别求损失函数 E 对 U、V、W的梯度:
133 |
134 | $$
135 | \begin{array}{l}\frac{\partial E}{\partial V}=\sum_{t} \frac{\partial E_{t}}{\partial V} \\ \frac{\partial E}{\partial W}=\sum_{t} \frac{\partial E_{t}}{\partial W} \\ \frac{\partial E}{\partial U}=\sum_{t} \frac{\partial E_{t}}{\partial U}\end{array}
136 | $$
137 |
138 | - 求 E 对 V 的梯度,先求 $E_3$ 对 V 的梯度
139 |
140 | $$
141 | \begin{aligned} \frac{\partial E_{3}}{\partial V} &=\frac{\partial E_{3}}{\partial \hat{y}_{3}} \frac{\partial \hat{y}_{3}}{\partial V} \\ &=\frac{\partial E_{3}}{\partial \hat{y}_{3}} \frac{\partial \hat{y}_{3}}{\partial z_{3}} \frac{\partial z_{3}}{\partial V} \end{aligned}
142 | $$
143 |
144 | 其中 $z_3 = V s_3$,然后求和即可。
145 |
146 | - 求 E 对 W 的梯度,先求 $E_3$ 对 W 的梯度
147 |
148 | $$
149 | \begin{array}{c}\frac{\partial E_{3}}{\partial W}=\frac{\partial E_{3}}{\partial \hat{y}_{3}} \frac{\partial \hat{y}_{3}}{\partial s_{3}} \frac{\partial s_{3}}{\partial W} \\ s_{3}=\tanh \left(U x_{3}+W s_{2}\right) \\ \frac{\partial E_{3}}{\partial W}=\sum_{k=0}^{3} \frac{\partial E_{3}}{\partial \hat{y}_{3}} \frac{\partial \hat{y}_{3}}{\partial s_{3}} \frac{\partial s_{3}}{\partial s_{k}} \frac{\partial s_{k}}{\partial W} \\ \frac{\partial E_{3}}{\partial W}=\sum_{k=0}^{3} \frac{\partial E_{3}}{\partial \hat{y}_{3}} \frac{\partial \hat{y}_{3}}{\partial s_{3}}\left(\prod_{j=k+1}^{3} \frac{\partial s_{j}}{\partial s_{j-1}}\right) \frac{\partial s_{k}}{\partial W}\end{array}
150 | $$
151 |
152 | 其中: $s_3$ 依赖于 $s_2$,而 $s_2$ 又依赖于 $s_1 $ 和 W ,依赖关系 一直传递到 t = 0 的时刻。因此,当我们计算对于 W 的偏导数时,不能把 $s_2$ 看作是常数项!
153 |
154 | - 求 E 对 U 的梯度,先求 $E_3$ 对 U 的梯度
155 |
156 | $$
157 | \begin{array}{c}\frac{\partial E_{3}}{\partial U}=\frac{\partial E_{3}}{\partial \hat{y}_{3}} \frac{\partial \hat{y}_{3}}{\partial s_{3}} \frac{\partial s_{3}}{\partial U} \\ s_{3}=\tanh \left(U x_{3}+W s_{2}\right) \\ \frac{\partial E_{3}}{\partial U}=\sum_{k=0}^{3} \frac{\partial E_{3}}{\partial \hat{y}_{3}} \frac{\partial \hat{y}_{3}}{\partial s_{3}} \frac{\partial s_{3}}{\partial s_{k}} \frac{\partial s_{k}}{\partial U}\end{array}
158 | $$
159 |
160 | # 长短时记忆网络
161 |
162 | 在RNN中,存在一个很重要的问题,就是梯度消失问题,一开始我们不能有效的解决长时依赖问题,其中梯度消失的原因有两个:BPTT算法和激活函数Tanh
163 |
164 | $$
165 | \frac{\partial E_{3}}{\partial W}=\sum_{k=0}^{3} \frac{\partial E_{3}}{\partial \hat{y}_{3}} \frac{\partial \hat{y}_{3}}{\partial s_{3}}\left(\prod_{j=k+1}^{3} \frac{\partial s_{j}}{\partial s_{j-1}}\right) \frac{\partial s_{k}}{\partial W}
166 | $$
167 |
168 | 有两种解决方案,分别是ReLU函数和门控RNN(LSTM).
169 |
170 | ### LSTM
171 |
172 | LSTM,即长短时记忆网络,于1997年被Sepp Hochreiter 和Jürgen Schmidhuber提出来,LSTM是一种用于深度学习领域的人工循环神经网络(RNN)结构。一个LSTM单元由输入门、输出门和遗忘门组成,三个门控制信息进出单元。
173 |
174 | 
175 |
176 | - LSTM依靠贯穿隐藏层的细胞状态实现隐藏单元之间的信息传递,其中只有少量的线性操作
177 | - LSTM引入了“门”机制对细胞状态信息进行添加或删除,由此实现长程记忆
178 | - “门”机制由一个Sigmoid激活函数层和一个向量点乘操作组成,Sigmoid层的输出控制了信息传递的比例
179 |
180 | **遗忘门**:LSTM通过遗忘门(forget gate)实现对细胞状态信息遗忘程度的控制,输出当前状态的遗忘权重,取决于 $h_{t−1}$ 和 $x_t$.
181 |
182 | $$
183 | f_{t}=\sigma\left(W_{f} \cdot\left[h_{t-1}, x_{t}\right]+b_{f}\right)
184 | $$
185 |
186 |
131 |
132 | 我们分别求损失函数 E 对 U、V、W的梯度:
133 |
134 | $$
135 | \begin{array}{l}\frac{\partial E}{\partial V}=\sum_{t} \frac{\partial E_{t}}{\partial V} \\ \frac{\partial E}{\partial W}=\sum_{t} \frac{\partial E_{t}}{\partial W} \\ \frac{\partial E}{\partial U}=\sum_{t} \frac{\partial E_{t}}{\partial U}\end{array}
136 | $$
137 |
138 | - 求 E 对 V 的梯度,先求 $E_3$ 对 V 的梯度
139 |
140 | $$
141 | \begin{aligned} \frac{\partial E_{3}}{\partial V} &=\frac{\partial E_{3}}{\partial \hat{y}_{3}} \frac{\partial \hat{y}_{3}}{\partial V} \\ &=\frac{\partial E_{3}}{\partial \hat{y}_{3}} \frac{\partial \hat{y}_{3}}{\partial z_{3}} \frac{\partial z_{3}}{\partial V} \end{aligned}
142 | $$
143 |
144 | 其中 $z_3 = V s_3$,然后求和即可。
145 |
146 | - 求 E 对 W 的梯度,先求 $E_3$ 对 W 的梯度
147 |
148 | $$
149 | \begin{array}{c}\frac{\partial E_{3}}{\partial W}=\frac{\partial E_{3}}{\partial \hat{y}_{3}} \frac{\partial \hat{y}_{3}}{\partial s_{3}} \frac{\partial s_{3}}{\partial W} \\ s_{3}=\tanh \left(U x_{3}+W s_{2}\right) \\ \frac{\partial E_{3}}{\partial W}=\sum_{k=0}^{3} \frac{\partial E_{3}}{\partial \hat{y}_{3}} \frac{\partial \hat{y}_{3}}{\partial s_{3}} \frac{\partial s_{3}}{\partial s_{k}} \frac{\partial s_{k}}{\partial W} \\ \frac{\partial E_{3}}{\partial W}=\sum_{k=0}^{3} \frac{\partial E_{3}}{\partial \hat{y}_{3}} \frac{\partial \hat{y}_{3}}{\partial s_{3}}\left(\prod_{j=k+1}^{3} \frac{\partial s_{j}}{\partial s_{j-1}}\right) \frac{\partial s_{k}}{\partial W}\end{array}
150 | $$
151 |
152 | 其中: $s_3$ 依赖于 $s_2$,而 $s_2$ 又依赖于 $s_1 $ 和 W ,依赖关系 一直传递到 t = 0 的时刻。因此,当我们计算对于 W 的偏导数时,不能把 $s_2$ 看作是常数项!
153 |
154 | - 求 E 对 U 的梯度,先求 $E_3$ 对 U 的梯度
155 |
156 | $$
157 | \begin{array}{c}\frac{\partial E_{3}}{\partial U}=\frac{\partial E_{3}}{\partial \hat{y}_{3}} \frac{\partial \hat{y}_{3}}{\partial s_{3}} \frac{\partial s_{3}}{\partial U} \\ s_{3}=\tanh \left(U x_{3}+W s_{2}\right) \\ \frac{\partial E_{3}}{\partial U}=\sum_{k=0}^{3} \frac{\partial E_{3}}{\partial \hat{y}_{3}} \frac{\partial \hat{y}_{3}}{\partial s_{3}} \frac{\partial s_{3}}{\partial s_{k}} \frac{\partial s_{k}}{\partial U}\end{array}
158 | $$
159 |
160 | # 长短时记忆网络
161 |
162 | 在RNN中,存在一个很重要的问题,就是梯度消失问题,一开始我们不能有效的解决长时依赖问题,其中梯度消失的原因有两个:BPTT算法和激活函数Tanh
163 |
164 | $$
165 | \frac{\partial E_{3}}{\partial W}=\sum_{k=0}^{3} \frac{\partial E_{3}}{\partial \hat{y}_{3}} \frac{\partial \hat{y}_{3}}{\partial s_{3}}\left(\prod_{j=k+1}^{3} \frac{\partial s_{j}}{\partial s_{j-1}}\right) \frac{\partial s_{k}}{\partial W}
166 | $$
167 |
168 | 有两种解决方案,分别是ReLU函数和门控RNN(LSTM).
169 |
170 | ### LSTM
171 |
172 | LSTM,即长短时记忆网络,于1997年被Sepp Hochreiter 和Jürgen Schmidhuber提出来,LSTM是一种用于深度学习领域的人工循环神经网络(RNN)结构。一个LSTM单元由输入门、输出门和遗忘门组成,三个门控制信息进出单元。
173 |
174 | 
175 |
176 | - LSTM依靠贯穿隐藏层的细胞状态实现隐藏单元之间的信息传递,其中只有少量的线性操作
177 | - LSTM引入了“门”机制对细胞状态信息进行添加或删除,由此实现长程记忆
178 | - “门”机制由一个Sigmoid激活函数层和一个向量点乘操作组成,Sigmoid层的输出控制了信息传递的比例
179 |
180 | **遗忘门**:LSTM通过遗忘门(forget gate)实现对细胞状态信息遗忘程度的控制,输出当前状态的遗忘权重,取决于 $h_{t−1}$ 和 $x_t$.
181 |
182 | $$
183 | f_{t}=\sigma\left(W_{f} \cdot\left[h_{t-1}, x_{t}\right]+b_{f}\right)
184 | $$
185 |
186 |  187 |
188 | **输入门**:LSTM通过输入门(input gate)实现对细胞状态输入接收程度的控制,输出当前输入信息的接受权重,取决于 $h_{t−1}$ 和 $x_t$.
189 |
190 | $$
191 | \begin{array}{c}i_{t}=\sigma\left(W_{i} \cdot\left[h_{t-1}, x_{t}\right]+b_{i}\right) \\ \tilde{C}_{t}=\tanh \left(W_{C} \cdot\left[h_{t-1}, x_{t}\right]+b_{C}\right)\end{array}
192 | $$
193 |
194 |
187 |
188 | **输入门**:LSTM通过输入门(input gate)实现对细胞状态输入接收程度的控制,输出当前输入信息的接受权重,取决于 $h_{t−1}$ 和 $x_t$.
189 |
190 | $$
191 | \begin{array}{c}i_{t}=\sigma\left(W_{i} \cdot\left[h_{t-1}, x_{t}\right]+b_{i}\right) \\ \tilde{C}_{t}=\tanh \left(W_{C} \cdot\left[h_{t-1}, x_{t}\right]+b_{C}\right)\end{array}
192 | $$
193 |
194 |  195 |
196 | **输出门**:LSTM通过输出门(output gate)实现对细胞状态输出认可程度的控制,输出当前输出信息的认可权重,取决于 $h_{t−1}$ 和 $x_t$.
197 |
198 | $$
199 | o_{t}=\sigma\left(W_{o} \cdot\left[h_{t-1}, x_{t}\right]+b_{o}\right)
200 | $$
201 |
202 |
195 |
196 | **输出门**:LSTM通过输出门(output gate)实现对细胞状态输出认可程度的控制,输出当前输出信息的认可权重,取决于 $h_{t−1}$ 和 $x_t$.
197 |
198 | $$
199 | o_{t}=\sigma\left(W_{o} \cdot\left[h_{t-1}, x_{t}\right]+b_{o}\right)
200 | $$
201 |
202 |  203 |
204 | **状态更新**:“门”机制对细胞状态信息进行添加或删除,由此实现长程记忆。
205 |
206 | $$
207 | \begin{array}{c}C_{t}=f_{t} * C_{t-1}+i_{t} * \tilde{C}_{t} \\ h_{t}=o_{t} * \tanh \left(C_{t}\right)\end{array}
208 | $$
209 |
210 |
203 |
204 | **状态更新**:“门”机制对细胞状态信息进行添加或删除,由此实现长程记忆。
205 |
206 | $$
207 | \begin{array}{c}C_{t}=f_{t} * C_{t-1}+i_{t} * \tilde{C}_{t} \\ h_{t}=o_{t} * \tanh \left(C_{t}\right)\end{array}
208 | $$
209 |
210 |  211 |
212 | 下面给出一个标准化的RNN例子
213 |
214 | ```python
215 | #构造RNN网络,x的维度5,隐层的维度10,网络的层数2
216 | rnn_ seq = nn.RNN(5, 10,2)
217 | #构造一个输入序列,长为6,batch是3,特征是5
218 | X =V(torch. randn(6, 3,5))
219 | #out,ht = rnn_ seq(x, h0) # h0可以指定或者不指定
220 | out,ht = rnn_ seq(x)
221 | # q1:这里out、ht的size是多少呢? out:6*3*10, ht:2*3*10
222 |
223 | #输入维度50,隐层100维,两层
224 | Lstm_ seq = nn.LSTM(50, 100,num layers=2 )
225 | #输入序列seq= 10,batch =3,输入维度=50
226 | lstm input = torch. randn(10,3,50)
227 | out, (h, c) = lstm_ seq(lstm_ _input) #使用默认的全0隐藏状态
228 | ```
229 |
230 | # 其他经典的循环神经网络
231 |
232 | ### Gated Recurrent Unit(GRU)
233 |
234 | Gated Recurrent Unit (GRU),是在2014年提出的,可认为是LSTM 的变种,它的细胞状态与隐状态合并,在计算当前时刻新信息的方法和LSTM有 所不同;GRU只包含重置门和更新门;在音乐建模与语音信号建模领域与LSTM具有相似的性能,但是参数更少,只有两个门控。
235 |
236 | 
237 |
238 | ### Peephole LSTM
239 |
240 | 让门层也接受细胞状态的输入,同时考虑隐层信息的输入。
241 |
242 |
211 |
212 | 下面给出一个标准化的RNN例子
213 |
214 | ```python
215 | #构造RNN网络,x的维度5,隐层的维度10,网络的层数2
216 | rnn_ seq = nn.RNN(5, 10,2)
217 | #构造一个输入序列,长为6,batch是3,特征是5
218 | X =V(torch. randn(6, 3,5))
219 | #out,ht = rnn_ seq(x, h0) # h0可以指定或者不指定
220 | out,ht = rnn_ seq(x)
221 | # q1:这里out、ht的size是多少呢? out:6*3*10, ht:2*3*10
222 |
223 | #输入维度50,隐层100维,两层
224 | Lstm_ seq = nn.LSTM(50, 100,num layers=2 )
225 | #输入序列seq= 10,batch =3,输入维度=50
226 | lstm input = torch. randn(10,3,50)
227 | out, (h, c) = lstm_ seq(lstm_ _input) #使用默认的全0隐藏状态
228 | ```
229 |
230 | # 其他经典的循环神经网络
231 |
232 | ### Gated Recurrent Unit(GRU)
233 |
234 | Gated Recurrent Unit (GRU),是在2014年提出的,可认为是LSTM 的变种,它的细胞状态与隐状态合并,在计算当前时刻新信息的方法和LSTM有 所不同;GRU只包含重置门和更新门;在音乐建模与语音信号建模领域与LSTM具有相似的性能,但是参数更少,只有两个门控。
235 |
236 | 
237 |
238 | ### Peephole LSTM
239 |
240 | 让门层也接受细胞状态的输入,同时考虑隐层信息的输入。
241 |
242 |  243 |
244 | ### Bi-directional RNN(双向RNN)
245 |
246 | Bi-directional RNN(双向RNN)假设当前t的输出不仅仅和之前的序列有关,并且还与之后的序列有关,例如:完形填空,它由两个RNNs上下叠加在一起组成,输出由这两个RNNs的隐藏层的状态决定。
247 |
248 |
243 |
244 | ### Bi-directional RNN(双向RNN)
245 |
246 | Bi-directional RNN(双向RNN)假设当前t的输出不仅仅和之前的序列有关,并且还与之后的序列有关,例如:完形填空,它由两个RNNs上下叠加在一起组成,输出由这两个RNNs的隐藏层的状态决定。
247 |
248 |  249 |
250 |
249 |
250 |  251 |
252 | ### Continuous time RNN(CTRNN)
253 |
254 | CTRNN利用常微分方程系统对输入脉冲序列神经元的影响 进行建模。CTRNN被应用到进化机器人中,用于解决视觉、协作和最 小认知行为等问题。
255 |
256 |
251 |
252 | ### Continuous time RNN(CTRNN)
253 |
254 | CTRNN利用常微分方程系统对输入脉冲序列神经元的影响 进行建模。CTRNN被应用到进化机器人中,用于解决视觉、协作和最 小认知行为等问题。
255 |
256 |  257 |
258 | # 循环神经网络的主要应用
259 |
260 | ### 语言模型
261 |
262 | 根据之前和当前词预测下一个单词或者字母
263 |
264 |
257 |
258 | # 循环神经网络的主要应用
259 |
260 | ### 语言模型
261 |
262 | 根据之前和当前词预测下一个单词或者字母
263 |
264 |  265 |
266 | 问答系统
267 |
268 |
265 |
266 | 问答系统
267 |
268 |  269 |
270 | ### 自动作曲
271 |
272 |
269 |
270 | ### 自动作曲
271 |
272 |  273 |
274 | 参考:Hang Chu, Raquel Urtasun, Sanja Fidler. Song From PI: A Musically Plausible Network for Pop Music Generation. CoRR abs/1611.03477 (2016)
275 |
276 | Music AI Lab: **https://musicai.citi.sinica.edu.tw/**
277 |
278 |
273 |
274 | 参考:Hang Chu, Raquel Urtasun, Sanja Fidler. Song From PI: A Musically Plausible Network for Pop Music Generation. CoRR abs/1611.03477 (2016)
275 |
276 | Music AI Lab: **https://musicai.citi.sinica.edu.tw/**
277 |
278 |  279 |
280 | ### 机器翻译
281 |
282 | 将一种语言自动翻译成另一种语言
283 |
284 |
279 |
280 | ### 机器翻译
281 |
282 | 将一种语言自动翻译成另一种语言
283 |
284 |  285 |
286 | ### 自动写作
287 |
288 | 根据现有资料自动写作,当前主要包括新闻写作和诗歌创作。主要是基于RNN&LSTM的文本生成技术来实现,需要训练大量同 类文本,结合模板技术。
289 |
290 | 目前主要产品有:腾讯 $Dreamwriter$ 写稿机器人、今日头条xiaomingbot、第一财经DT稿王(背后是阿里巴巴) 、百度Writing-bots...
291 |
292 | ### 图像描述
293 |
294 | 根据图像形成语言描述
295 |
296 |
285 |
286 | ### 自动写作
287 |
288 | 根据现有资料自动写作,当前主要包括新闻写作和诗歌创作。主要是基于RNN&LSTM的文本生成技术来实现,需要训练大量同 类文本,结合模板技术。
289 |
290 | 目前主要产品有:腾讯 $Dreamwriter$ 写稿机器人、今日头条xiaomingbot、第一财经DT稿王(背后是阿里巴巴) 、百度Writing-bots...
291 |
292 | ### 图像描述
293 |
294 | 根据图像形成语言描述
295 |
296 |  297 |
298 |
297 |
298 |  299 |
--------------------------------------------------------------------------------
/docs/理论入门/07.RCNN&YOLO.md:
--------------------------------------------------------------------------------
1 | # R-CNN系列
2 |
3 | - Region-CNN的缩写,主要用于目标检测。
4 | - 来自 2014 年 CVPR 论文“Rich feature hierarchies for accurate object detection and semantic segmentation”
5 | - 在 Pascal VOC 2012 的数据集上,能够将目标检测的验证指标 mAP 提升到 53.3%,这相对于之前最好的结果提升了整整 30%
6 | - 采用在ImageNet上已经训练好的模型,然后在PASCAL VOC数据集上进行 fine-tune
7 |
8 |
299 |
--------------------------------------------------------------------------------
/docs/理论入门/07.RCNN&YOLO.md:
--------------------------------------------------------------------------------
1 | # R-CNN系列
2 |
3 | - Region-CNN的缩写,主要用于目标检测。
4 | - 来自 2014 年 CVPR 论文“Rich feature hierarchies for accurate object detection and semantic segmentation”
5 | - 在 Pascal VOC 2012 的数据集上,能够将目标检测的验证指标 mAP 提升到 53.3%,这相对于之前最好的结果提升了整整 30%
6 | - 采用在ImageNet上已经训练好的模型,然后在PASCAL VOC数据集上进行 fine-tune
7 |
8 |  9 |
10 | 参考:Ross B. Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. CVPR 2014: 580-587
11 |
12 | ### 实现过程
13 |
14 | - 区域划分:给定一张输入图片,从图片中提取2000个类别独立的候选区域,R-CNN 采用的是 Selective Search 算法
15 |
16 | - 特征提取:对于每个区域利用CNN抽取一个固定长度的特征向量, R-CNN 使用的是 Alexnet
17 |
18 | - 目标分类:再对每个区域利用SVM进行目标分类
19 |
20 | - 边框回归:BoundingboxRegression(Bbox回归)进行边框坐标偏移
21 |
22 | 优化和调整
23 |
24 |
9 |
10 | 参考:Ross B. Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. CVPR 2014: 580-587
11 |
12 | ### 实现过程
13 |
14 | - 区域划分:给定一张输入图片,从图片中提取2000个类别独立的候选区域,R-CNN 采用的是 Selective Search 算法
15 |
16 | - 特征提取:对于每个区域利用CNN抽取一个固定长度的特征向量, R-CNN 使用的是 Alexnet
17 |
18 | - 目标分类:再对每个区域利用SVM进行目标分类
19 |
20 | - 边框回归:BoundingboxRegression(Bbox回归)进行边框坐标偏移
21 |
22 | 优化和调整
23 |
24 |  25 |
26 | - Crop就是从一个大图扣出网络输入大小的patch,比如227×227
27 | - Warp把一个边界框bounding box的内容resize成227×227
28 |
29 | ### Selective Search 算法
30 |
31 | 核心思想:图像中物体可能存在的区域应该有某些相似性或者连续性的,选择搜索基于上面这一想法采用子区域合并的方法提取 bounding boxes候选边界框。
32 |
33 | - 首先,通过图像分割算法将输入图像分割成许多小的子区域
34 | - 其次,根据这些子区域之间的相似性(主要考虑颜色、纹理、尺寸和 空间交叠4个相似) 进行区域迭代合并。每次迭代过程中对这些合并 的子区域做bounding boxes(外切矩形),这些子区域的外切矩形就是 通常所说的候选框
35 |
36 | **算法步骤**:
37 |
38 | 1. 生成区域集R,参见论文《Efficient Graph-Based Image Segmentation》
39 | 2. 计算区域集R里每个相邻区域的相似度$S=\{s1,s2,...\}$
40 | 3. 找出相似度最高的两个区域,将其合并为新集,添加进R
41 | 4. 从S中移除所有与step2中有关的子集
42 | 5. 计算新集与所有子集的相似度
43 | 6. 跳至step2,直至S为空
44 |
45 |
25 |
26 | - Crop就是从一个大图扣出网络输入大小的patch,比如227×227
27 | - Warp把一个边界框bounding box的内容resize成227×227
28 |
29 | ### Selective Search 算法
30 |
31 | 核心思想:图像中物体可能存在的区域应该有某些相似性或者连续性的,选择搜索基于上面这一想法采用子区域合并的方法提取 bounding boxes候选边界框。
32 |
33 | - 首先,通过图像分割算法将输入图像分割成许多小的子区域
34 | - 其次,根据这些子区域之间的相似性(主要考虑颜色、纹理、尺寸和 空间交叠4个相似) 进行区域迭代合并。每次迭代过程中对这些合并 的子区域做bounding boxes(外切矩形),这些子区域的外切矩形就是 通常所说的候选框
35 |
36 | **算法步骤**:
37 |
38 | 1. 生成区域集R,参见论文《Efficient Graph-Based Image Segmentation》
39 | 2. 计算区域集R里每个相邻区域的相似度$S=\{s1,s2,...\}$
40 | 3. 找出相似度最高的两个区域,将其合并为新集,添加进R
41 | 4. 从S中移除所有与step2中有关的子集
42 | 5. 计算新集与所有子集的相似度
43 | 6. 跳至step2,直至S为空
44 |
45 |  46 |
47 |
46 |
47 |  48 |
49 | ### Bbox回归
50 |
51 | 核心思想:通过平移和缩放方法对物体边框进行调整和修正。
52 |
53 |
48 |
49 | ### Bbox回归
50 |
51 | 核心思想:通过平移和缩放方法对物体边框进行调整和修正。
52 |
53 |  54 |
55 | - bounding box的表示为$(x,y,w,h)$,即窗口的中心点坐标和宽高
56 | - Bbox回归就是找到函数 $f$,将$(P_x,P_y, P_w,P_h)$映射为更接近 $(G_x,G_y, G_w,G_h)$ 的 $(\hat{G}_x,\hat{G}_y, \hat{G}_w,\hat{G}_h)$
57 |
58 |
54 |
55 | - bounding box的表示为$(x,y,w,h)$,即窗口的中心点坐标和宽高
56 | - Bbox回归就是找到函数 $f$,将$(P_x,P_y, P_w,P_h)$映射为更接近 $(G_x,G_y, G_w,G_h)$ 的 $(\hat{G}_x,\hat{G}_y, \hat{G}_w,\hat{G}_h)$
57 |
58 |  59 |
60 |
59 |
60 |  61 |
62 | $$
63 | \begin{align}
64 | \hat{G}_x &= P_wd_x(P) + P_x
65 | \\
66 | \hat{G}_y &= P_hd_y(P) + P_y
67 | \\
68 | \hat{G}_w &= P_w \exp(d_w(P))
69 | \\
70 | \hat{G}_h &= P_h \exp(d_h(P))
71 | \end{align}
72 | $$
73 |
74 |
61 |
62 | $$
63 | \begin{align}
64 | \hat{G}_x &= P_wd_x(P) + P_x
65 | \\
66 | \hat{G}_y &= P_hd_y(P) + P_y
67 | \\
68 | \hat{G}_w &= P_w \exp(d_w(P))
69 | \\
70 | \hat{G}_h &= P_h \exp(d_h(P))
71 | \end{align}
72 | $$
73 |
74 |  75 |
76 | mAP:mean Average Precision,是多标签图像分类任务中的评价指标。AP衡量的是学出来的模型在给定类别上的好坏,而mAP衡量的是学出的模型在所有类别上的好坏。
77 |
78 | ### SPPnet
79 |
80 | SPPnet (Spatial Pyramid Pooling):空间金字塔网络,R-CNN主要问题:每个Proposal独立提取CNN features,分步训练。
81 |
82 |
75 |
76 | mAP:mean Average Precision,是多标签图像分类任务中的评价指标。AP衡量的是学出来的模型在给定类别上的好坏,而mAP衡量的是学出的模型在所有类别上的好坏。
77 |
78 | ### SPPnet
79 |
80 | SPPnet (Spatial Pyramid Pooling):空间金字塔网络,R-CNN主要问题:每个Proposal独立提取CNN features,分步训练。
81 |
82 |  83 |
84 |
83 |
84 |  85 |
86 | 参考:Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 37(9): 1904-1916 (2015)
87 |
88 | ### Fast R-CNN
89 |
90 | - R-CNN和SPPnet问题:训练步骤过多,需要训练SVM分类器,需要 额外的回归器, 特征也是保存在磁盘上。
91 | - 联合学习(jointtraining):把SVM、Bbox回归和CNN阶段一起训 练,最后一层的Softmax换成两个:一个是对区域的分类Softmax, 另一个是对Bounding box的微调。训练时所有的特征不再存到硬盘上,提升了速度。
92 | - ROI Pooling层:实现了单尺度的区域特征图的Pooling。
93 |
94 |
85 |
86 | 参考:Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 37(9): 1904-1916 (2015)
87 |
88 | ### Fast R-CNN
89 |
90 | - R-CNN和SPPnet问题:训练步骤过多,需要训练SVM分类器,需要 额外的回归器, 特征也是保存在磁盘上。
91 | - 联合学习(jointtraining):把SVM、Bbox回归和CNN阶段一起训 练,最后一层的Softmax换成两个:一个是对区域的分类Softmax, 另一个是对Bounding box的微调。训练时所有的特征不再存到硬盘上,提升了速度。
92 | - ROI Pooling层:实现了单尺度的区域特征图的Pooling。
93 |
94 |  95 |
96 | **ROI Pooling层**:将每个候选区域均匀分成M×N块,对每块进行max pooling,将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层。
97 |
98 |
95 |
96 | **ROI Pooling层**:将每个候选区域均匀分成M×N块,对每块进行max pooling,将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层。
97 |
98 |  99 |
100 | **性能对比**
101 |
102 |
99 |
100 | **性能对比**
101 |
102 |  103 |
104 | **效率对比**
105 |
106 | - Fast R-CNN trains the very deep VGG16 network 9× faster than R- CNN, is 213× faster at test-time, and achieves a higher mAP on PASCAL VOC 2012.
107 | - Compared to SPPnet, Fast R-CNN trains VGG16 3×faster, tests 10× faster, and is more accurate.
108 |
109 | **RPN(Region Proposal Network)**:使用全卷积神经网络来生成区域建议(Region proposal),替代之前的Selective search。
110 |
111 |
103 |
104 | **效率对比**
105 |
106 | - Fast R-CNN trains the very deep VGG16 network 9× faster than R- CNN, is 213× faster at test-time, and achieves a higher mAP on PASCAL VOC 2012.
107 | - Compared to SPPnet, Fast R-CNN trains VGG16 3×faster, tests 10× faster, and is more accurate.
108 |
109 | **RPN(Region Proposal Network)**:使用全卷积神经网络来生成区域建议(Region proposal),替代之前的Selective search。
110 |
111 |  112 |
113 | 参考:Shaoqing Ren, Kaiming He, Ross B. Girshick, Jian Sun. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 39(6): 1137-1149 (2017)
114 |
115 |
112 |
113 | 参考:Shaoqing Ren, Kaiming He, Ross B. Girshick, Jian Sun. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 39(6): 1137-1149 (2017)
114 |
115 |  116 |
117 | **Faster R-CNN训练方式**
118 |
119 | - Alternating training
120 |
121 | - Approximate joint training
122 |
123 |
116 |
117 | **Faster R-CNN训练方式**
118 |
119 | - Alternating training
120 |
121 | - Approximate joint training
122 |
123 |  124 |
125 | # YOLO系列
126 |
127 | - 与R-CNN系列最大的区别是用一个卷积神经网络结构就可以从输入 图像直接预测bounding box和类别概率,实现了End2End训练
128 | - 速度非常快,实时性好
129 | - 可以学到物体的全局信息,背景误检率比R-CNN降低一半,泛化能力强
130 | - 准确率还不如R-CNN高,小物体检测效果较差
131 |
132 | 参考:Joseph Redmon, Santosh Kumar Divvala, Ross B. Girshick, Ali Farhadi. You Only Look Once: Unified, Real-Time Object Detection. CVPR 2016: 779-788
133 |
134 | ### 目标检测和识别
135 |
136 |
124 |
125 | # YOLO系列
126 |
127 | - 与R-CNN系列最大的区别是用一个卷积神经网络结构就可以从输入 图像直接预测bounding box和类别概率,实现了End2End训练
128 | - 速度非常快,实时性好
129 | - 可以学到物体的全局信息,背景误检率比R-CNN降低一半,泛化能力强
130 | - 准确率还不如R-CNN高,小物体检测效果较差
131 |
132 | 参考:Joseph Redmon, Santosh Kumar Divvala, Ross B. Girshick, Ali Farhadi. You Only Look Once: Unified, Real-Time Object Detection. CVPR 2016: 779-788
133 |
134 | ### 目标检测和识别
135 |
136 |  137 |
138 | **The YOLO Detection System.** Processing images with YOLO is simple and straightforward. Our system (1) resizes the input image to 448 ×448, (2) runs a single convolutional network on the image, and (3) thresholds the resulting detections by the model’s confidence.
139 |
140 |
137 |
138 | **The YOLO Detection System.** Processing images with YOLO is simple and straightforward. Our system (1) resizes the input image to 448 ×448, (2) runs a single convolutional network on the image, and (3) thresholds the resulting detections by the model’s confidence.
139 |
140 |  141 |
142 | **The Model.** Our system models detection as a regression problem. It divides the image into an S×S grid and for each grid cell predicts B bounding boxes, confidence for those boxes, and C class probabilities. These predictions are encoded as an S×S×(B∗5+ C) tensor.
143 |
144 |
141 |
142 | **The Model.** Our system models detection as a regression problem. It divides the image into an S×S grid and for each grid cell predicts B bounding boxes, confidence for those boxes, and C class probabilities. These predictions are encoded as an S×S×(B∗5+ C) tensor.
143 |
144 |  145 |
146 | **网络结构**:24个卷积层和2个全连接层
147 |
148 |
145 |
146 | **网络结构**:24个卷积层和2个全连接层
147 |
148 |  149 |
150 | **The Architecture.** Our detection network has 24 convolutional layers followed by 2 fully connected layers. Alternating 1×1 convolutional layers reduce the features space from preceding layers. We pretrain the convolutional layers on the ImageNet classification task at half the resolution (224 ×224 input image) and then double the resolution for detection.
151 |
152 | ### YOLO2和YOLO9000
153 |
154 |
149 |
150 | **The Architecture.** Our detection network has 24 convolutional layers followed by 2 fully connected layers. Alternating 1×1 convolutional layers reduce the features space from preceding layers. We pretrain the convolutional layers on the ImageNet classification task at half the resolution (224 ×224 input image) and then double the resolution for detection.
151 |
152 | ### YOLO2和YOLO9000
153 |
154 |  155 |
156 | 参考:Joseph Redmon, Ali Farhadi. YOLO9000: Better, Faster, Stronger. CVPR 2017: 6517-6525
157 |
158 | **性能分析**
159 |
160 |
155 |
156 | 参考:Joseph Redmon, Ali Farhadi. YOLO9000: Better, Faster, Stronger. CVPR 2017: 6517-6525
157 |
158 | **性能分析**
159 |
160 |  161 |
--------------------------------------------------------------------------------
/docs/理论进阶/08.网络优化算法.md:
--------------------------------------------------------------------------------
1 | 网络优化
2 |
3 |
4 |
5 | # 深度学习中的优化算法
6 |
7 | 在这里建立了基于梯度的优化算法的基本分析框架,并讨论了它如何应用在深度学习中。
8 |
9 | 1. Gradient descent
10 | 2. 1. Formalizing the Taylor Expansion
11 | 2. Descent lemma for gradient descent
12 | 3. Stochastic gradient descent
13 | 4. Accelerated Gradient Descent
14 | 5. Local Runtime Analysis of GD
15 | 6. Pre-conditioners
16 |
17 | ------
18 |
19 | ### 梯度下降(GD)
20 |
21 | 假设我们现在想要找出一个多元连续函数 ![[公式]](https://www.zhihu.com/equation?tex=f%28%5Comega%29) 的最小值 ![[公式]](https://www.zhihu.com/equation?tex=%5Cmin+_%7Bw+%5Cin+%5Cmathbb%7BR%7D%5E%7Bd%7D%7D+f%28w%29)
22 |
23 | 梯度下降算法是这样的: ![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Baligned%7D+w_%7B0%7D+%26%3D%5Ctext+%7B+initializaiton+%7D+%5C%5C+w_%7Bt%2B1%7D+%26%3Dw_%7Bt%7D-%5Ceta+%5Cnabla+f%5Cleft%28w_%7Bt%7D%5Cright%29+%5Cend%7Baligned%7D) ,其中 ![[公式]](https://www.zhihu.com/equation?tex=%5Ceta) 称为步长或学习率。
24 |
25 | 设计出GD算法的一个核心思想就是找出局部最陡的梯度下降方向 ![[公式]](https://www.zhihu.com/equation?tex=-%5Cnabla+f%5Cleft%28w_%7Bt%7D%5Cright%29)
26 |
27 | 我们来考虑该点的泰勒展开式: ![[公式]](https://www.zhihu.com/equation?tex=f%28w%29%3Df%5Cleft%28w_%7Bt%7D%5Cright%29%2B%5Cunderbrace%7B%5Cleft%5Clangle%5Cnabla+f%5Cleft%28w_%7Bt%7D%5Cright%29%2C+w-w_%7Bt%7D%5Cright%5Crangle%7D_%7B%5Ctext+%7Blinear+in+%7D+w%7D%2B%5Ccdots)
28 |
29 | 假设我们去掉高阶项,只在 ![[公式]](https://www.zhihu.com/equation?tex=w_%7Bt%7D) 的一个邻域内优化一阶近似式,即 ![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Barray%7D%7Bc%7D%5Cunderset%7Bw+%5Cin+%5Cmathbb%7BR%7D%5E%7Bd%7D%7D%7B%5Carg+%5Cmin+%7D+f%5Cleft%28w_%7Bt%7D%5Cright%29%2B%5Cleft%5Clangle%5Cnabla+f%5Cleft%28w_%7Bt%7D%5Cright%29%2C+w-w_%7Bt%7D%5Cright%5Crangle+%5C%5C+%5Ctext+%7B+s.t.+%7D%5Cleft%5C%7Cw-w_%7Bt%7D%5Cright%5C%7C_%7B2%7D+%5Cleq+%5Cepsilon%5Cend%7Barray%7D) ,它的最优解是 ![[公式]](https://www.zhihu.com/equation?tex=w%2B%5Cdelta) ,其中 ![[公式]](https://www.zhihu.com/equation?tex=%5Cdelta%3D-%5Calpha+%5Cnabla+f%5Cleft%28w_%7Bt%7D%5Cright%29)
30 |
31 | **泰勒展开的形式化**
32 |
33 | 我们下面来陈述一个引理,它刻画了GD算法下函数值的下降。我们先假设函数 ![[公式]](https://www.zhihu.com/equation?tex=f%28w%29) 的二阶梯度是有界的,即 ![[公式]](https://www.zhihu.com/equation?tex=%5Cnabla%5E%7B2%7D+f%28w%29+%5Cin+%5B-L%2CL%5D+++%5C%2C%5C%2C%5C%2C%5C%2C%5Cforall+w) ,我们称满足这个条件的函数为L-光滑函数。
34 |
35 | ![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Barray%7D%7Bl%7D%5Ctext+%7B+Definition%7D%5Cleft%28L+%5Ctext+%7B+-smoothness%29.+%7D+%5Ctext+%7B+A+function+%7D+f%3A+%5Cmathbb%7BR%7D%5E%7Bn%7D+%5Crightarrow+%5Cmathbb%7BR%7D+%5Ctext+%7B+is+called+%7D+L+%5Ctext+%7B+-smooth+iffor+all+%7D+x%2C+y+%5Cin+%5Cmathbb%7BR%7D%5E%7Bn%7D%5Cright.+%5Ctext+%7B+%2C+the+following+inequality+%7D+%5C%5C+%5Ctext+%7B+holds%3A+%7D+%5C%5C+%5Cqquad%5C%7C%5Cnabla+f%28x%29-%5Cnabla+f%28y%29%5C%7C+%5Cleq+L%5C%7Cx-y%5C%7C+.+%5C%5C+%5Ctext+%7B+If+the+function+%7D+f+%5Ctext+%7B+is+%7D+L+%5Ctext+%7B+-smooth%2C+then+for+all+%7D+x%2C+y+%5Cin+%5Cmathbb%7BR%7D%5E%7Bn%7D+%5C%5C+%5Cqquad+f%28y%29+%5Cleq+f%28x%29%2B%5Clangle%5Cnabla+f%28x%29%2C+y-x%5Crangle%2B%5Cfrac%7BL%7D%7B2%7D%5C%7Cy-x%5C%7C%5E%7B2%7D+.+%5C%5C+%5Ctext+%7B+Next%2C+if+%7D+f+%5Ctext+%7B+is+additionally+convex+and+%7D+x%5E%7B%2A%7D+%5Ctext+%7B+is+its+minimizer%2C+then+for+all+%7D+x+%5Cin+%5Cmathbb%7BR%7D%5E%7Bd%7D+%5C%5C+%5Cqquad%5C%7C%5Cnabla+f%28x%29%5C%7C%5E%7B2%7D+%5Cleq+2+L%5Cleft%28f%28x%29-f%5Cleft%28x%5E%7B%2A%7D%5Cright%29%5Cright%29%5Cend%7Barray%7D)
36 |
37 | 这使我们能够在下面这个意义上使用泰勒展开精确的近似函数: ![[公式]](https://www.zhihu.com/equation?tex=f%28w%29+%5Cleq+f%5Cleft%28w_%7Bt%7D%5Cright%29%2B%5Cleft%5Clangle%5Cnabla+f%5Cleft%28w_%7Bt%7D%5Cright%29%2C+w-w_%7Bt%7D%5Cright%5Crangle%2B%5Cfrac%7BL%7D%7B2%7D%5Cleft%5C%7Cw-w_%7Bt%7D%5Cright%5C%7C_%7B2%7D%5E%7B2%7D)
38 |
39 | **GD的下降引理**
40 |
41 | 下面我们将说明,在下降梯度和足够小的学习率下,函数值总是减小,除非迭代处的梯度为零。
42 |
43 | ![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Barray%7D%7Bl%7D%5Ctext+%7B+Lemma+%28Descent+Lemma%29.+Suppose+%7D+f+%5Ctext+%7B+is+%7D+L+%5Ctext+%7B+-smooth.+Then%2C+if+%7D+%5Ceta%3C+%5C%5C+1+%2F%282+L%29%2C+%5Ctext+%7B+we+have+%7D+%5C%5C+%5Cqquad+f%5Cleft%28w_%7Bt%2B1%7D%5Cright%29+%5Cleq+f%5Cleft%28w_%7Bt%7D%5Cright%29-%5Cfrac%7B%5Ceta%7D%7B2%7D+%5Ccdot%5Cleft%5C%7C%5Cnabla+f%5Cleft%28w_%7Bt%7D%5Cright%29%5Cright%5C%7C_%7B2%7D%5E%7B2%7D%5Cend%7Barray%7D)
44 |
45 | 证明:
46 |
47 | 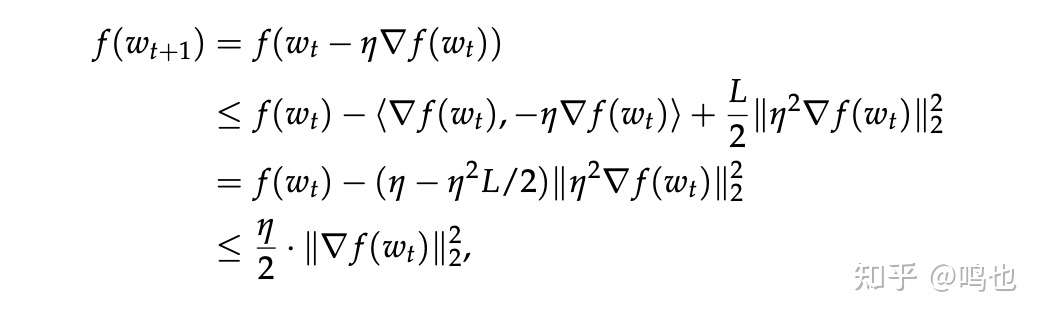
48 |
49 | ### 随机梯度下降(SGD)
50 |
51 | Motivation:损失函数的梯度的计算代价可能很大。
52 |
53 | 在深度学习里,目标函数通常是训练数据集中有关各个样本的损失函数的平均。设 ![[公式]](https://www.zhihu.com/equation?tex=f_i%28%5Cboldsymbol%7Bx%7D%29) 是有关索引为i的训练数据样本的损失函数,n是训练数据样本数, ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bx%7D) 是模型的参数向量,那么目标函数定义为
54 |
55 | ![[公式]](https://www.zhihu.com/equation?tex=f%28%5Cboldsymbol%7Bx%7D%29+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi+%3D+1%7D%5En+f_i%28%5Cboldsymbol%7Bx%7D%29.)
56 |
57 | 目标函数在 ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bx%7D) 处的梯度计算为
58 |
59 | ![[公式]](https://www.zhihu.com/equation?tex=%5Cnabla+f%28%5Cboldsymbol%7Bx%7D%29+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi+%3D+1%7D%5En+%5Cnabla+f_i%28%5Cboldsymbol%7Bx%7D%29.)
60 |
61 | 如果使用梯度下降,每次自变量迭代的计算开销为 ![[公式]](https://www.zhihu.com/equation?tex=%5Cmathcal%7BO%7D%28n%29) ,它随着n线性增长。因此,当训练数据样本数很大时,梯度下降每次迭代的计算开销很高。
62 |
63 | 随机梯度下降(stochastic gradient descent,SGD)减少了每次迭代的计算开销。在随机梯度下降的每次迭代中,我们随机均匀采样的一个样本索引 ![[公式]](https://www.zhihu.com/equation?tex=i%5Cin%5C%7B1%2C%5Cldots%2Cn%5C%7D) ,并计算梯度 ![[公式]](https://www.zhihu.com/equation?tex=%5Cnabla+f_i%28%5Cboldsymbol%7Bx%7D%29) 来迭代 ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bx%7D) :
64 |
65 | ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bx%7D+%5Cleftarrow+%5Cboldsymbol%7Bx%7D+-+%5Ceta+%5Cnabla+f_i%28%5Cboldsymbol%7Bx%7D%29.)
66 |
67 | 这里 ![[公式]](https://www.zhihu.com/equation?tex=%5Ceta) 同样是学习率。可以看到,每次迭代的计算开销从梯度下降的 ![[公式]](https://www.zhihu.com/equation?tex=%5Cmathcal%7BO%7D%28n%29) 降到了常数 ![[公式]](https://www.zhihu.com/equation?tex=%5Cmathcal%7BO%7D%281%29)。值得强调的是,随机梯度 ![[公式]](https://www.zhihu.com/equation?tex=%5Cnabla+f_i%28%5Cboldsymbol%7Bx%7D%29) 是对梯度 ![[公式]](https://www.zhihu.com/equation?tex=%5Cnabla+f%28%5Cboldsymbol%7Bx%7D%29) 的无偏估计:
68 |
69 | ![[公式]](https://www.zhihu.com/equation?tex=E_i+%5Cnabla+f_i%28%5Cboldsymbol%7Bx%7D%29+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi+%3D+1%7D%5En+%5Cnabla+f_i%28%5Cboldsymbol%7Bx%7D%29+%3D+%5Cnabla+f%28%5Cboldsymbol%7Bx%7D%29.)
70 |
71 | 这意味着,平均来说,随机梯度是对梯度的一个良好的估计。
72 |
73 | ### 加速梯度下降(AGD)
74 |
75 | 让我们考虑一个输入和输出分别为二维向量 ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bx%7D+%3D+%5Bx_1%2C+x_2%5D%5E%5Ctop) 和标量的目标函数 ![[公式]](https://www.zhihu.com/equation?tex=f%28%5Cboldsymbol%7Bx%7D%29%3D0.1x_1%5E2%2B2x_2%5E2) 。
76 |
77 | 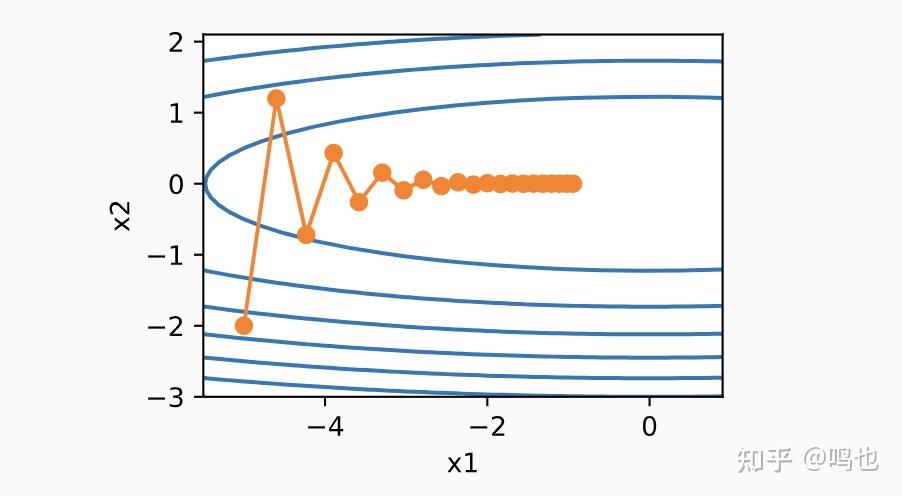
78 |
79 | 可以看到,同一位置上,目标函数在竖直方向( ![[公式]](https://www.zhihu.com/equation?tex=x_2) 轴方向)比在水平方向( ![[公式]](https://www.zhihu.com/equation?tex=x_1) 轴方向)的斜率的绝对值更大。因此,给定学习率,梯度下降迭代自变量时会使自变量在竖直方向比在水平方向移动幅度更大。那么,我们需要一个较小的学习率从而避免自变量在竖直方向上越过目标函数最优解。然而,这会造成自变量在水平方向上朝最优解移动变慢。
80 |
81 | 学习率调得稍大一点,此时自变量在竖直方向不断越过最优解并逐渐发散。
82 |
83 | 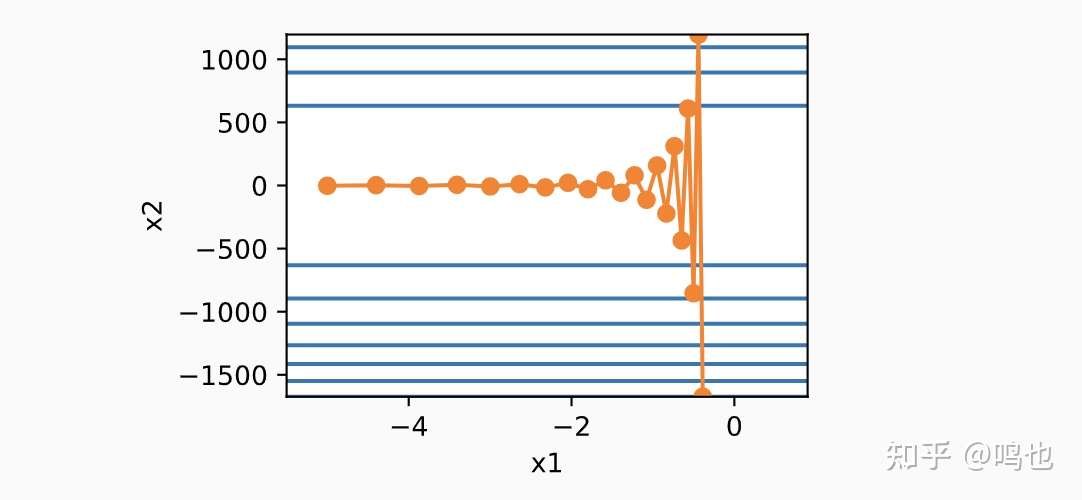
84 |
85 | 动量法的提出是为了解决梯度下降的上述问题。设时间步t的自变量为 ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bx%7D_t) ,学习率为 ![[公式]](https://www.zhihu.com/equation?tex=%5Ceta_t) 。 在时间步0,动量法创建速度变量 ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bv%7D_0) ,并将其元素初始化成0。在时间步t>0,动量法对每次迭代的步骤做如下修改:
86 |
87 | ![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Bsplit%7D%5Cbegin%7Baligned%7D+%5Cboldsymbol%7Bv%7D_t+%26%5Cleftarrow+%5Cgamma+%5Cboldsymbol%7Bv%7D_%7Bt-1%7D+%2B+%5Ceta_t+%5Cboldsymbol%7Bg%7D_t%2C+%5C%5C+%5Cboldsymbol%7Bx%7D_t+%26%5Cleftarrow+%5Cboldsymbol%7Bx%7D_%7Bt-1%7D+-+%5Cboldsymbol%7Bv%7D_t%2C+%5Cend%7Baligned%7D%5Cend%7Bsplit%7D)
88 |
89 | 其中,动量超参数 ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma) 满足 ![[公式]](https://www.zhihu.com/equation?tex=0+%5Cleq+%5Cgamma+%3C+1) 。当 ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma%3D0) 时,动量法等价于小批量随机梯度下降。
90 |
91 | 指数加权移动平均:为了从数学上理解动量法,让我们先解释一下指数加权移动平均(exponentially weighted moving average)。给定超参数 ![[公式]](https://www.zhihu.com/equation?tex=0+%5Cleq+%5Cgamma+%3C+1) ,当前时间步t的变量 ![[公式]](https://www.zhihu.com/equation?tex=y_t)是上一时间步t-1的变量 ![[公式]](https://www.zhihu.com/equation?tex=y_%7Bt-1%7D) 和当前时间步另一变量 ![[公式]](https://www.zhihu.com/equation?tex=x_t) 的线性组合:
92 |
93 | ![[公式]](https://www.zhihu.com/equation?tex=y_t+%3D+%5Cgamma+y_%7Bt-1%7D+%2B+%281-%5Cgamma%29+x_t.)
94 |
95 | 我们可以对 ![[公式]](https://www.zhihu.com/equation?tex=y_t) 展开:
96 |
97 | ![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Bsplit%7D%5Cbegin%7Baligned%7D+y_t+%26%3D+%281-%5Cgamma%29+x_t+%2B+%5Cgamma+y_%7Bt-1%7D%5C%5C+%26%3D+%281-%5Cgamma%29x_t+%2B+%281-%5Cgamma%29+%5Ccdot+%5Cgamma+x_%7Bt-1%7D+%2B+%5Cgamma%5E2y_%7Bt-2%7D%5C%5C+%26%3D+%281-%5Cgamma%29x_t+%2B+%281-%5Cgamma%29+%5Ccdot+%5Cgamma+x_%7Bt-1%7D+%2B+%281-%5Cgamma%29+%5Ccdot+%5Cgamma%5E2x_%7Bt-2%7D+%2B+%5Cgamma%5E3y_%7Bt-3%7D%5C%5C+%26%5Cldots+%5Cend%7Baligned%7D%5Cend%7Bsplit%7D)
98 |
99 | 令 ![[公式]](https://www.zhihu.com/equation?tex=n+%3D+1%2F%281-%5Cgamma%29) ,那么 ![[公式]](https://www.zhihu.com/equation?tex=%5Cleft%281-1%2Fn%5Cright%29%5En+%3D+%5Cgamma%5E%7B1%2F%281-%5Cgamma%29%7D) 。因为
100 |
101 | ![[公式]](https://www.zhihu.com/equation?tex=%5Clim_%7Bn+%5Crightarrow+%5Cinfty%7D+%5Cleft%281-%5Cfrac%7B1%7D%7Bn%7D%5Cright%29%5En+%3D+%5Cexp%28-1%29+%5Capprox+0.3679%2C)
102 |
103 | 所以当 ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma+%5Crightarrow+1) 时, ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma%5E%7B1%2F%281-%5Cgamma%29%7D%3D%5Cexp%28-1%29) ,如 ![[公式]](https://www.zhihu.com/equation?tex=0.95%5E%7B20%7D+%5Capprox+%5Cexp%28-1%29) 。如果把 ![[公式]](https://www.zhihu.com/equation?tex=%5Cexp%28-1%29) 当作一个比较小的数,我们可以在近似中忽略所有含 ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma%5E%7B1%2F%281-%5Cgamma%29%7D) 和比 ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma%5E%7B1%2F%281-%5Cgamma%29%7D) 更高阶的系数的项。例如,当 ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma%3D0.95) 时,
104 |
105 | ![[公式]](https://www.zhihu.com/equation?tex=y_t+%5Capprox+0.05+%5Csum_%7Bi%3D0%7D%5E%7B19%7D+0.95%5Ei+x_%7Bt-i%7D.)
106 |
107 | 因此,在实际中,我们常常将 ![[公式]](https://www.zhihu.com/equation?tex=y_t) 看作是对最近 ![[公式]](https://www.zhihu.com/equation?tex=1%2F%281-%5Cgamma%29) 个时间步的 ![[公式]](https://www.zhihu.com/equation?tex=x_t) 值的加权平均。例如,当 ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma+%3D+0.95) 时, ![[公式]](https://www.zhihu.com/equation?tex=y_t) 可以被看作对最近20个时间步的 ![[公式]](https://www.zhihu.com/equation?tex=x_t) 值的加权平均;当 ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma+%3D+0.9) 时, ![[公式]](https://www.zhihu.com/equation?tex=y_t) 可以看作是对最近10个时间步的 ![[公式]](https://www.zhihu.com/equation?tex=x_t) 值的加权平均。而且,离当前时间步t越近的 ![[公式]](https://www.zhihu.com/equation?tex=x_t) 值获得的权重越大(越接近1)。
108 |
109 | 现在,我们对动量法的速度变量做变形:
110 | ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bv%7D_t+%5Cleftarrow+%5Cgamma+%5Cboldsymbol%7Bv%7D_%7Bt-1%7D+%2B+%281+-+%5Cgamma%29+%5Cleft%28%5Cfrac%7B%5Ceta_t%7D%7B1+-+%5Cgamma%7D+%5Cboldsymbol%7Bg%7D_t%5Cright%29.)
111 | 由指数加权移动平均的形式可得,速度变量 ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bv%7D_t) 实际上对序列 ![[公式]](https://www.zhihu.com/equation?tex=%5C%7B%5Ceta_%7Bt-i%7D%5Cboldsymbol%7Bg%7D_%7Bt-i%7D+%2F%281-%5Cgamma%29%3Ai%3D0%2C%5Cldots%2C1%2F%281-%5Cgamma%29-1%5C%7D) 做了指数加权移动平均。换句话说,相比于小批量随机梯度下降,动量法在每个时间步的自变量更新量近似于将前者对应的最近 ![[公式]](https://www.zhihu.com/equation?tex=1%2F%281-%5Cgamma%29) 个时间步的更新量做了指数加权移动平均后再除以 ![[公式]](https://www.zhihu.com/equation?tex=1-%5Cgamma) 。所以,在动量法中,自变量在各个方向上的移动幅度不仅取决于当前梯度,还取决于过去的各个梯度在各个方向上是否一致。
112 |
113 | ### 本地运行时间分析
114 |
115 | 当迭代接近局部极小值时,梯度下降行为更为明显,因为该函数可以用二次函数进行局部逼近。因此这里为了简单起见,我们假设我们正在优化一个凸二次函数,并了解函数的曲率如何影响算法的收敛性。
116 |
117 | 我们用梯度下降方法来优化 ![[公式]](https://www.zhihu.com/equation?tex=%5Cmin+_%7Bw%7D+%5Cfrac%7B1%7D%7B2%7D+w%5E%7B%5Ctop%7D+A+w) ,其中 ![[公式]](https://www.zhihu.com/equation?tex=w+%5Cin+R%5Ed) ,![[公式]](https://www.zhihu.com/equation?tex=A%5Cin+R%5E%7Bd+%5Ctimes+d%7D) 是半正定矩阵。
118 | 注:w.l.o.g,我们可以假设A是对角矩阵(对角化是线性代数中的一个基本idea)。假设A的SVD分解: ![[公式]](https://www.zhihu.com/equation?tex=A+%3D+U%5CSigma+U%5E%7BT%7D) ,其中 ![[公式]](https://www.zhihu.com/equation?tex=%5CSigma) 是个对角矩阵。我们可以简单的验证得到 ![[公式]](https://www.zhihu.com/equation?tex=w%5E%7BT%7DAw+%3D+%5Chat%7Bw%7D%5E%7BT%7D%5CSigma+%5Chat%7Bw%7D) ,其中 ![[公式]](https://www.zhihu.com/equation?tex=%5Chat%7Bw%7D+%3D+U%5E%7BT%7Dw) 。换句话说,在由U定义的一个不同的坐标系中,我们处理的是一个以对角矩阵 ![[公式]](https://www.zhihu.com/equation?tex=%5CSigma) 为系数的二次型。注意这里的对角化技术仅用于分析。
119 |
120 | 因此我们假设 ![[公式]](https://www.zhihu.com/equation?tex=A+%3D+diag%28%5Clambda_%7B1%7D%2C%5Ccdots%2C%5Clambda_d%29) ,其中 ![[公式]](https://www.zhihu.com/equation?tex=%5Clambda_1%5Cgeq+%5Clambda_2%5Cgeq+%5Ccdots+%5Cgeq+%5Clambda_d) ,这样该函数就可以化简为 ![[公式]](https://www.zhihu.com/equation?tex=f%28w%29+%3D+%5Cfrac%7B1%7D%7B2%7D+%5Csum%5E%7Bd%7D_%7Bi+%3D+1%7D%5Clambda_i+w_i%5E%7B2%7D) ,这样梯度下降更新可以写成: ![[公式]](https://www.zhihu.com/equation?tex=x+%5Cleftarrow+w+-+%5Ceta+%5Cnabla+f%28w%29+%3D+w-%5Ceta%5CSigma+w)
121 |
122 | ### **Pre-conditioners**
123 |
124 | 从上面的二次型例子中,我们可以看到如果我们在不同的坐标系中使用不同的学习率,这将是得到优化。换句话说,如果我们对每个坐标引入一个学习率 ![[公式]](https://www.zhihu.com/equation?tex=%5Ceta_i+%3D+1%2F%5Clambda_i) ,那么我们可以实现更快的收敛。
125 |
126 | 在A不是对角阵这样的更一般的情况下,我们事先不知道坐标系,算法对应于 ![[公式]](https://www.zhihu.com/equation?tex=w%5Cleftarrow+w-A%5E%7B-1%7D+%5Cnabla+f%28w%29)
127 |
128 | 在更一般的情况下,f不是二次函数,这与牛顿算法相对应 ![[公式]](https://www.zhihu.com/equation?tex=w+%5Cleftarrow+w-%5Cnabla%5E2+f%28w%29%5E%7B-1%7D%5Cnabla+f%28w%29)
129 |
130 | 计算Hessian矩阵可能是非常困难的,因为它scale quadratically in d(在实践中可能超过100万)。因此,使用hessian函数及其逆函数的近似值。
--------------------------------------------------------------------------------
/docs/理论进阶/09.正则化方法.md:
--------------------------------------------------------------------------------
1 | 1. 正则化方法概述
2 | 2. 参数范数正则化
3 |
4 |
5 |
6 | # 正则化方法概述
7 |
8 | ### 数据集
9 |
10 | 训练集(Trainingset):用于模型拟合的数据样本
11 |
12 | 验证集(Validation set):是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估,例如SVM中参数c和核函数的选择,或者选择网络结构
13 |
14 | 测试集(Testset):用来评估模最终模型的泛化能力,但不能作为调参、选择特征等算法相关的选择的依据
15 |
16 | ### 过拟合
17 |
18 | 过拟合是指模型能很好地拟合训练样本,而无法很好地拟合测试样本的现象,从而导致泛化性能下降;为防止“过拟合”,可以选择减少参数、降低模型复杂度、正则化等。
19 |
20 | ### 欠拟合
21 |
22 | 欠拟合是指模型还没有很好地训练出数据的一般规律,模型拟合程度不高的现象;为防止“欠拟合”,可以选择调整参数、增加迭代深度、换用更加复杂的模型等。
23 |
24 |
161 |
--------------------------------------------------------------------------------
/docs/理论进阶/08.网络优化算法.md:
--------------------------------------------------------------------------------
1 | 网络优化
2 |
3 |
4 |
5 | # 深度学习中的优化算法
6 |
7 | 在这里建立了基于梯度的优化算法的基本分析框架,并讨论了它如何应用在深度学习中。
8 |
9 | 1. Gradient descent
10 | 2. 1. Formalizing the Taylor Expansion
11 | 2. Descent lemma for gradient descent
12 | 3. Stochastic gradient descent
13 | 4. Accelerated Gradient Descent
14 | 5. Local Runtime Analysis of GD
15 | 6. Pre-conditioners
16 |
17 | ------
18 |
19 | ### 梯度下降(GD)
20 |
21 | 假设我们现在想要找出一个多元连续函数 ![[公式]](https://www.zhihu.com/equation?tex=f%28%5Comega%29) 的最小值 ![[公式]](https://www.zhihu.com/equation?tex=%5Cmin+_%7Bw+%5Cin+%5Cmathbb%7BR%7D%5E%7Bd%7D%7D+f%28w%29)
22 |
23 | 梯度下降算法是这样的: ![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Baligned%7D+w_%7B0%7D+%26%3D%5Ctext+%7B+initializaiton+%7D+%5C%5C+w_%7Bt%2B1%7D+%26%3Dw_%7Bt%7D-%5Ceta+%5Cnabla+f%5Cleft%28w_%7Bt%7D%5Cright%29+%5Cend%7Baligned%7D) ,其中 ![[公式]](https://www.zhihu.com/equation?tex=%5Ceta) 称为步长或学习率。
24 |
25 | 设计出GD算法的一个核心思想就是找出局部最陡的梯度下降方向 ![[公式]](https://www.zhihu.com/equation?tex=-%5Cnabla+f%5Cleft%28w_%7Bt%7D%5Cright%29)
26 |
27 | 我们来考虑该点的泰勒展开式: ![[公式]](https://www.zhihu.com/equation?tex=f%28w%29%3Df%5Cleft%28w_%7Bt%7D%5Cright%29%2B%5Cunderbrace%7B%5Cleft%5Clangle%5Cnabla+f%5Cleft%28w_%7Bt%7D%5Cright%29%2C+w-w_%7Bt%7D%5Cright%5Crangle%7D_%7B%5Ctext+%7Blinear+in+%7D+w%7D%2B%5Ccdots)
28 |
29 | 假设我们去掉高阶项,只在 ![[公式]](https://www.zhihu.com/equation?tex=w_%7Bt%7D) 的一个邻域内优化一阶近似式,即 ![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Barray%7D%7Bc%7D%5Cunderset%7Bw+%5Cin+%5Cmathbb%7BR%7D%5E%7Bd%7D%7D%7B%5Carg+%5Cmin+%7D+f%5Cleft%28w_%7Bt%7D%5Cright%29%2B%5Cleft%5Clangle%5Cnabla+f%5Cleft%28w_%7Bt%7D%5Cright%29%2C+w-w_%7Bt%7D%5Cright%5Crangle+%5C%5C+%5Ctext+%7B+s.t.+%7D%5Cleft%5C%7Cw-w_%7Bt%7D%5Cright%5C%7C_%7B2%7D+%5Cleq+%5Cepsilon%5Cend%7Barray%7D) ,它的最优解是 ![[公式]](https://www.zhihu.com/equation?tex=w%2B%5Cdelta) ,其中 ![[公式]](https://www.zhihu.com/equation?tex=%5Cdelta%3D-%5Calpha+%5Cnabla+f%5Cleft%28w_%7Bt%7D%5Cright%29)
30 |
31 | **泰勒展开的形式化**
32 |
33 | 我们下面来陈述一个引理,它刻画了GD算法下函数值的下降。我们先假设函数 ![[公式]](https://www.zhihu.com/equation?tex=f%28w%29) 的二阶梯度是有界的,即 ![[公式]](https://www.zhihu.com/equation?tex=%5Cnabla%5E%7B2%7D+f%28w%29+%5Cin+%5B-L%2CL%5D+++%5C%2C%5C%2C%5C%2C%5C%2C%5Cforall+w) ,我们称满足这个条件的函数为L-光滑函数。
34 |
35 | ![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Barray%7D%7Bl%7D%5Ctext+%7B+Definition%7D%5Cleft%28L+%5Ctext+%7B+-smoothness%29.+%7D+%5Ctext+%7B+A+function+%7D+f%3A+%5Cmathbb%7BR%7D%5E%7Bn%7D+%5Crightarrow+%5Cmathbb%7BR%7D+%5Ctext+%7B+is+called+%7D+L+%5Ctext+%7B+-smooth+iffor+all+%7D+x%2C+y+%5Cin+%5Cmathbb%7BR%7D%5E%7Bn%7D%5Cright.+%5Ctext+%7B+%2C+the+following+inequality+%7D+%5C%5C+%5Ctext+%7B+holds%3A+%7D+%5C%5C+%5Cqquad%5C%7C%5Cnabla+f%28x%29-%5Cnabla+f%28y%29%5C%7C+%5Cleq+L%5C%7Cx-y%5C%7C+.+%5C%5C+%5Ctext+%7B+If+the+function+%7D+f+%5Ctext+%7B+is+%7D+L+%5Ctext+%7B+-smooth%2C+then+for+all+%7D+x%2C+y+%5Cin+%5Cmathbb%7BR%7D%5E%7Bn%7D+%5C%5C+%5Cqquad+f%28y%29+%5Cleq+f%28x%29%2B%5Clangle%5Cnabla+f%28x%29%2C+y-x%5Crangle%2B%5Cfrac%7BL%7D%7B2%7D%5C%7Cy-x%5C%7C%5E%7B2%7D+.+%5C%5C+%5Ctext+%7B+Next%2C+if+%7D+f+%5Ctext+%7B+is+additionally+convex+and+%7D+x%5E%7B%2A%7D+%5Ctext+%7B+is+its+minimizer%2C+then+for+all+%7D+x+%5Cin+%5Cmathbb%7BR%7D%5E%7Bd%7D+%5C%5C+%5Cqquad%5C%7C%5Cnabla+f%28x%29%5C%7C%5E%7B2%7D+%5Cleq+2+L%5Cleft%28f%28x%29-f%5Cleft%28x%5E%7B%2A%7D%5Cright%29%5Cright%29%5Cend%7Barray%7D)
36 |
37 | 这使我们能够在下面这个意义上使用泰勒展开精确的近似函数: ![[公式]](https://www.zhihu.com/equation?tex=f%28w%29+%5Cleq+f%5Cleft%28w_%7Bt%7D%5Cright%29%2B%5Cleft%5Clangle%5Cnabla+f%5Cleft%28w_%7Bt%7D%5Cright%29%2C+w-w_%7Bt%7D%5Cright%5Crangle%2B%5Cfrac%7BL%7D%7B2%7D%5Cleft%5C%7Cw-w_%7Bt%7D%5Cright%5C%7C_%7B2%7D%5E%7B2%7D)
38 |
39 | **GD的下降引理**
40 |
41 | 下面我们将说明,在下降梯度和足够小的学习率下,函数值总是减小,除非迭代处的梯度为零。
42 |
43 | ![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Barray%7D%7Bl%7D%5Ctext+%7B+Lemma+%28Descent+Lemma%29.+Suppose+%7D+f+%5Ctext+%7B+is+%7D+L+%5Ctext+%7B+-smooth.+Then%2C+if+%7D+%5Ceta%3C+%5C%5C+1+%2F%282+L%29%2C+%5Ctext+%7B+we+have+%7D+%5C%5C+%5Cqquad+f%5Cleft%28w_%7Bt%2B1%7D%5Cright%29+%5Cleq+f%5Cleft%28w_%7Bt%7D%5Cright%29-%5Cfrac%7B%5Ceta%7D%7B2%7D+%5Ccdot%5Cleft%5C%7C%5Cnabla+f%5Cleft%28w_%7Bt%7D%5Cright%29%5Cright%5C%7C_%7B2%7D%5E%7B2%7D%5Cend%7Barray%7D)
44 |
45 | 证明:
46 |
47 | 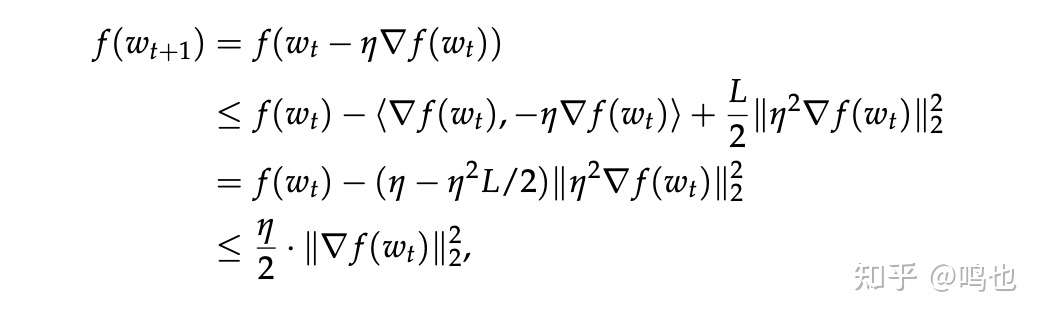
48 |
49 | ### 随机梯度下降(SGD)
50 |
51 | Motivation:损失函数的梯度的计算代价可能很大。
52 |
53 | 在深度学习里,目标函数通常是训练数据集中有关各个样本的损失函数的平均。设 ![[公式]](https://www.zhihu.com/equation?tex=f_i%28%5Cboldsymbol%7Bx%7D%29) 是有关索引为i的训练数据样本的损失函数,n是训练数据样本数, ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bx%7D) 是模型的参数向量,那么目标函数定义为
54 |
55 | ![[公式]](https://www.zhihu.com/equation?tex=f%28%5Cboldsymbol%7Bx%7D%29+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi+%3D+1%7D%5En+f_i%28%5Cboldsymbol%7Bx%7D%29.)
56 |
57 | 目标函数在 ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bx%7D) 处的梯度计算为
58 |
59 | ![[公式]](https://www.zhihu.com/equation?tex=%5Cnabla+f%28%5Cboldsymbol%7Bx%7D%29+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi+%3D+1%7D%5En+%5Cnabla+f_i%28%5Cboldsymbol%7Bx%7D%29.)
60 |
61 | 如果使用梯度下降,每次自变量迭代的计算开销为 ![[公式]](https://www.zhihu.com/equation?tex=%5Cmathcal%7BO%7D%28n%29) ,它随着n线性增长。因此,当训练数据样本数很大时,梯度下降每次迭代的计算开销很高。
62 |
63 | 随机梯度下降(stochastic gradient descent,SGD)减少了每次迭代的计算开销。在随机梯度下降的每次迭代中,我们随机均匀采样的一个样本索引 ![[公式]](https://www.zhihu.com/equation?tex=i%5Cin%5C%7B1%2C%5Cldots%2Cn%5C%7D) ,并计算梯度 ![[公式]](https://www.zhihu.com/equation?tex=%5Cnabla+f_i%28%5Cboldsymbol%7Bx%7D%29) 来迭代 ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bx%7D) :
64 |
65 | ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bx%7D+%5Cleftarrow+%5Cboldsymbol%7Bx%7D+-+%5Ceta+%5Cnabla+f_i%28%5Cboldsymbol%7Bx%7D%29.)
66 |
67 | 这里 ![[公式]](https://www.zhihu.com/equation?tex=%5Ceta) 同样是学习率。可以看到,每次迭代的计算开销从梯度下降的 ![[公式]](https://www.zhihu.com/equation?tex=%5Cmathcal%7BO%7D%28n%29) 降到了常数 ![[公式]](https://www.zhihu.com/equation?tex=%5Cmathcal%7BO%7D%281%29)。值得强调的是,随机梯度 ![[公式]](https://www.zhihu.com/equation?tex=%5Cnabla+f_i%28%5Cboldsymbol%7Bx%7D%29) 是对梯度 ![[公式]](https://www.zhihu.com/equation?tex=%5Cnabla+f%28%5Cboldsymbol%7Bx%7D%29) 的无偏估计:
68 |
69 | ![[公式]](https://www.zhihu.com/equation?tex=E_i+%5Cnabla+f_i%28%5Cboldsymbol%7Bx%7D%29+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi+%3D+1%7D%5En+%5Cnabla+f_i%28%5Cboldsymbol%7Bx%7D%29+%3D+%5Cnabla+f%28%5Cboldsymbol%7Bx%7D%29.)
70 |
71 | 这意味着,平均来说,随机梯度是对梯度的一个良好的估计。
72 |
73 | ### 加速梯度下降(AGD)
74 |
75 | 让我们考虑一个输入和输出分别为二维向量 ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bx%7D+%3D+%5Bx_1%2C+x_2%5D%5E%5Ctop) 和标量的目标函数 ![[公式]](https://www.zhihu.com/equation?tex=f%28%5Cboldsymbol%7Bx%7D%29%3D0.1x_1%5E2%2B2x_2%5E2) 。
76 |
77 | 
78 |
79 | 可以看到,同一位置上,目标函数在竖直方向( ![[公式]](https://www.zhihu.com/equation?tex=x_2) 轴方向)比在水平方向( ![[公式]](https://www.zhihu.com/equation?tex=x_1) 轴方向)的斜率的绝对值更大。因此,给定学习率,梯度下降迭代自变量时会使自变量在竖直方向比在水平方向移动幅度更大。那么,我们需要一个较小的学习率从而避免自变量在竖直方向上越过目标函数最优解。然而,这会造成自变量在水平方向上朝最优解移动变慢。
80 |
81 | 学习率调得稍大一点,此时自变量在竖直方向不断越过最优解并逐渐发散。
82 |
83 | 
84 |
85 | 动量法的提出是为了解决梯度下降的上述问题。设时间步t的自变量为 ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bx%7D_t) ,学习率为 ![[公式]](https://www.zhihu.com/equation?tex=%5Ceta_t) 。 在时间步0,动量法创建速度变量 ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bv%7D_0) ,并将其元素初始化成0。在时间步t>0,动量法对每次迭代的步骤做如下修改:
86 |
87 | ![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Bsplit%7D%5Cbegin%7Baligned%7D+%5Cboldsymbol%7Bv%7D_t+%26%5Cleftarrow+%5Cgamma+%5Cboldsymbol%7Bv%7D_%7Bt-1%7D+%2B+%5Ceta_t+%5Cboldsymbol%7Bg%7D_t%2C+%5C%5C+%5Cboldsymbol%7Bx%7D_t+%26%5Cleftarrow+%5Cboldsymbol%7Bx%7D_%7Bt-1%7D+-+%5Cboldsymbol%7Bv%7D_t%2C+%5Cend%7Baligned%7D%5Cend%7Bsplit%7D)
88 |
89 | 其中,动量超参数 ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma) 满足 ![[公式]](https://www.zhihu.com/equation?tex=0+%5Cleq+%5Cgamma+%3C+1) 。当 ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma%3D0) 时,动量法等价于小批量随机梯度下降。
90 |
91 | 指数加权移动平均:为了从数学上理解动量法,让我们先解释一下指数加权移动平均(exponentially weighted moving average)。给定超参数 ![[公式]](https://www.zhihu.com/equation?tex=0+%5Cleq+%5Cgamma+%3C+1) ,当前时间步t的变量 ![[公式]](https://www.zhihu.com/equation?tex=y_t)是上一时间步t-1的变量 ![[公式]](https://www.zhihu.com/equation?tex=y_%7Bt-1%7D) 和当前时间步另一变量 ![[公式]](https://www.zhihu.com/equation?tex=x_t) 的线性组合:
92 |
93 | ![[公式]](https://www.zhihu.com/equation?tex=y_t+%3D+%5Cgamma+y_%7Bt-1%7D+%2B+%281-%5Cgamma%29+x_t.)
94 |
95 | 我们可以对 ![[公式]](https://www.zhihu.com/equation?tex=y_t) 展开:
96 |
97 | ![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Bsplit%7D%5Cbegin%7Baligned%7D+y_t+%26%3D+%281-%5Cgamma%29+x_t+%2B+%5Cgamma+y_%7Bt-1%7D%5C%5C+%26%3D+%281-%5Cgamma%29x_t+%2B+%281-%5Cgamma%29+%5Ccdot+%5Cgamma+x_%7Bt-1%7D+%2B+%5Cgamma%5E2y_%7Bt-2%7D%5C%5C+%26%3D+%281-%5Cgamma%29x_t+%2B+%281-%5Cgamma%29+%5Ccdot+%5Cgamma+x_%7Bt-1%7D+%2B+%281-%5Cgamma%29+%5Ccdot+%5Cgamma%5E2x_%7Bt-2%7D+%2B+%5Cgamma%5E3y_%7Bt-3%7D%5C%5C+%26%5Cldots+%5Cend%7Baligned%7D%5Cend%7Bsplit%7D)
98 |
99 | 令 ![[公式]](https://www.zhihu.com/equation?tex=n+%3D+1%2F%281-%5Cgamma%29) ,那么 ![[公式]](https://www.zhihu.com/equation?tex=%5Cleft%281-1%2Fn%5Cright%29%5En+%3D+%5Cgamma%5E%7B1%2F%281-%5Cgamma%29%7D) 。因为
100 |
101 | ![[公式]](https://www.zhihu.com/equation?tex=%5Clim_%7Bn+%5Crightarrow+%5Cinfty%7D+%5Cleft%281-%5Cfrac%7B1%7D%7Bn%7D%5Cright%29%5En+%3D+%5Cexp%28-1%29+%5Capprox+0.3679%2C)
102 |
103 | 所以当 ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma+%5Crightarrow+1) 时, ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma%5E%7B1%2F%281-%5Cgamma%29%7D%3D%5Cexp%28-1%29) ,如 ![[公式]](https://www.zhihu.com/equation?tex=0.95%5E%7B20%7D+%5Capprox+%5Cexp%28-1%29) 。如果把 ![[公式]](https://www.zhihu.com/equation?tex=%5Cexp%28-1%29) 当作一个比较小的数,我们可以在近似中忽略所有含 ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma%5E%7B1%2F%281-%5Cgamma%29%7D) 和比 ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma%5E%7B1%2F%281-%5Cgamma%29%7D) 更高阶的系数的项。例如,当 ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma%3D0.95) 时,
104 |
105 | ![[公式]](https://www.zhihu.com/equation?tex=y_t+%5Capprox+0.05+%5Csum_%7Bi%3D0%7D%5E%7B19%7D+0.95%5Ei+x_%7Bt-i%7D.)
106 |
107 | 因此,在实际中,我们常常将 ![[公式]](https://www.zhihu.com/equation?tex=y_t) 看作是对最近 ![[公式]](https://www.zhihu.com/equation?tex=1%2F%281-%5Cgamma%29) 个时间步的 ![[公式]](https://www.zhihu.com/equation?tex=x_t) 值的加权平均。例如,当 ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma+%3D+0.95) 时, ![[公式]](https://www.zhihu.com/equation?tex=y_t) 可以被看作对最近20个时间步的 ![[公式]](https://www.zhihu.com/equation?tex=x_t) 值的加权平均;当 ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma+%3D+0.9) 时, ![[公式]](https://www.zhihu.com/equation?tex=y_t) 可以看作是对最近10个时间步的 ![[公式]](https://www.zhihu.com/equation?tex=x_t) 值的加权平均。而且,离当前时间步t越近的 ![[公式]](https://www.zhihu.com/equation?tex=x_t) 值获得的权重越大(越接近1)。
108 |
109 | 现在,我们对动量法的速度变量做变形:
110 | ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bv%7D_t+%5Cleftarrow+%5Cgamma+%5Cboldsymbol%7Bv%7D_%7Bt-1%7D+%2B+%281+-+%5Cgamma%29+%5Cleft%28%5Cfrac%7B%5Ceta_t%7D%7B1+-+%5Cgamma%7D+%5Cboldsymbol%7Bg%7D_t%5Cright%29.)
111 | 由指数加权移动平均的形式可得,速度变量 ![[公式]](https://www.zhihu.com/equation?tex=%5Cboldsymbol%7Bv%7D_t) 实际上对序列 ![[公式]](https://www.zhihu.com/equation?tex=%5C%7B%5Ceta_%7Bt-i%7D%5Cboldsymbol%7Bg%7D_%7Bt-i%7D+%2F%281-%5Cgamma%29%3Ai%3D0%2C%5Cldots%2C1%2F%281-%5Cgamma%29-1%5C%7D) 做了指数加权移动平均。换句话说,相比于小批量随机梯度下降,动量法在每个时间步的自变量更新量近似于将前者对应的最近 ![[公式]](https://www.zhihu.com/equation?tex=1%2F%281-%5Cgamma%29) 个时间步的更新量做了指数加权移动平均后再除以 ![[公式]](https://www.zhihu.com/equation?tex=1-%5Cgamma) 。所以,在动量法中,自变量在各个方向上的移动幅度不仅取决于当前梯度,还取决于过去的各个梯度在各个方向上是否一致。
112 |
113 | ### 本地运行时间分析
114 |
115 | 当迭代接近局部极小值时,梯度下降行为更为明显,因为该函数可以用二次函数进行局部逼近。因此这里为了简单起见,我们假设我们正在优化一个凸二次函数,并了解函数的曲率如何影响算法的收敛性。
116 |
117 | 我们用梯度下降方法来优化 ![[公式]](https://www.zhihu.com/equation?tex=%5Cmin+_%7Bw%7D+%5Cfrac%7B1%7D%7B2%7D+w%5E%7B%5Ctop%7D+A+w) ,其中 ![[公式]](https://www.zhihu.com/equation?tex=w+%5Cin+R%5Ed) ,![[公式]](https://www.zhihu.com/equation?tex=A%5Cin+R%5E%7Bd+%5Ctimes+d%7D) 是半正定矩阵。
118 | 注:w.l.o.g,我们可以假设A是对角矩阵(对角化是线性代数中的一个基本idea)。假设A的SVD分解: ![[公式]](https://www.zhihu.com/equation?tex=A+%3D+U%5CSigma+U%5E%7BT%7D) ,其中 ![[公式]](https://www.zhihu.com/equation?tex=%5CSigma) 是个对角矩阵。我们可以简单的验证得到 ![[公式]](https://www.zhihu.com/equation?tex=w%5E%7BT%7DAw+%3D+%5Chat%7Bw%7D%5E%7BT%7D%5CSigma+%5Chat%7Bw%7D) ,其中 ![[公式]](https://www.zhihu.com/equation?tex=%5Chat%7Bw%7D+%3D+U%5E%7BT%7Dw) 。换句话说,在由U定义的一个不同的坐标系中,我们处理的是一个以对角矩阵 ![[公式]](https://www.zhihu.com/equation?tex=%5CSigma) 为系数的二次型。注意这里的对角化技术仅用于分析。
119 |
120 | 因此我们假设 ![[公式]](https://www.zhihu.com/equation?tex=A+%3D+diag%28%5Clambda_%7B1%7D%2C%5Ccdots%2C%5Clambda_d%29) ,其中 ![[公式]](https://www.zhihu.com/equation?tex=%5Clambda_1%5Cgeq+%5Clambda_2%5Cgeq+%5Ccdots+%5Cgeq+%5Clambda_d) ,这样该函数就可以化简为 ![[公式]](https://www.zhihu.com/equation?tex=f%28w%29+%3D+%5Cfrac%7B1%7D%7B2%7D+%5Csum%5E%7Bd%7D_%7Bi+%3D+1%7D%5Clambda_i+w_i%5E%7B2%7D) ,这样梯度下降更新可以写成: ![[公式]](https://www.zhihu.com/equation?tex=x+%5Cleftarrow+w+-+%5Ceta+%5Cnabla+f%28w%29+%3D+w-%5Ceta%5CSigma+w)
121 |
122 | ### **Pre-conditioners**
123 |
124 | 从上面的二次型例子中,我们可以看到如果我们在不同的坐标系中使用不同的学习率,这将是得到优化。换句话说,如果我们对每个坐标引入一个学习率 ![[公式]](https://www.zhihu.com/equation?tex=%5Ceta_i+%3D+1%2F%5Clambda_i) ,那么我们可以实现更快的收敛。
125 |
126 | 在A不是对角阵这样的更一般的情况下,我们事先不知道坐标系,算法对应于 ![[公式]](https://www.zhihu.com/equation?tex=w%5Cleftarrow+w-A%5E%7B-1%7D+%5Cnabla+f%28w%29)
127 |
128 | 在更一般的情况下,f不是二次函数,这与牛顿算法相对应 ![[公式]](https://www.zhihu.com/equation?tex=w+%5Cleftarrow+w-%5Cnabla%5E2+f%28w%29%5E%7B-1%7D%5Cnabla+f%28w%29)
129 |
130 | 计算Hessian矩阵可能是非常困难的,因为它scale quadratically in d(在实践中可能超过100万)。因此,使用hessian函数及其逆函数的近似值。
--------------------------------------------------------------------------------
/docs/理论进阶/09.正则化方法.md:
--------------------------------------------------------------------------------
1 | 1. 正则化方法概述
2 | 2. 参数范数正则化
3 |
4 |
5 |
6 | # 正则化方法概述
7 |
8 | ### 数据集
9 |
10 | 训练集(Trainingset):用于模型拟合的数据样本
11 |
12 | 验证集(Validation set):是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估,例如SVM中参数c和核函数的选择,或者选择网络结构
13 |
14 | 测试集(Testset):用来评估模最终模型的泛化能力,但不能作为调参、选择特征等算法相关的选择的依据
15 |
16 | ### 过拟合
17 |
18 | 过拟合是指模型能很好地拟合训练样本,而无法很好地拟合测试样本的现象,从而导致泛化性能下降;为防止“过拟合”,可以选择减少参数、降低模型复杂度、正则化等。
19 |
20 | ### 欠拟合
21 |
22 | 欠拟合是指模型还没有很好地训练出数据的一般规律,模型拟合程度不高的现象;为防止“欠拟合”,可以选择调整参数、增加迭代深度、换用更加复杂的模型等。
23 |
24 |  25 |
26 | ### 误差分析
27 |
28 | **偏差(bias)**:反映了模型在样本上的期望输出与真实标记之间的差距,即模型本身的精准度,反映的是模型本身的拟合能力。
29 |
30 |
25 |
26 | ### 误差分析
27 |
28 | **偏差(bias)**:反映了模型在样本上的期望输出与真实标记之间的差距,即模型本身的精准度,反映的是模型本身的拟合能力。
29 |
30 |  31 |
32 | **方差(variance)**:反映了模型在不同训练数据集下学得的函数的输出与期望输出之间的误差,即模型的稳定性,反应的是模型的波动情况。
33 |
34 |
31 |
32 | **方差(variance)**:反映了模型在不同训练数据集下学得的函数的输出与期望输出之间的误差,即模型的稳定性,反应的是模型的波动情况。
33 |
34 |  35 |
36 | **泛化误差(Generalization Error)**:度量训练所得模型在总体数据上得到的预估值和标签值偏离程度的期望。
37 |
38 |
35 |
36 | **泛化误差(Generalization Error)**:度量训练所得模型在总体数据上得到的预估值和标签值偏离程度的期望。
37 |
38 |  39 |
40 | **举例说明**
41 |
42 |
39 |
40 | **举例说明**
41 |
42 |  43 |
44 | **深度学习一般步骤**
45 |
46 |
43 |
44 | **深度学习一般步骤**
45 |
46 |  47 |
48 | 下面我们引出正则化的概念,首先我们要明白什么是一个好的模型,基本要求就是在训练数据上表现好,但往往我们也希望它能在其他数据上也有很好的表现,也就是泛化性。
49 |
50 | - 广义正则化:通过某种手段使学习算法在训练误差变化不大的情况下,使得泛化误差显著降低的方法
51 | - 狭义正则化:不减少网络参数,只进行参数范围调整的方法
52 |
53 | # 参数范数正则化
54 |
55 | ### 范数基本知识
56 |
57 | 机器学习中,很多时候都需要衡量一个向量的大小,此时便需要用到范数的知识。
58 |
59 | 范数是将向量映射到非负值的函数,它满足三条性质:
60 |
61 | - 非负性 $f(x) \geq 0(f(x)=0 \Leftrightarrow x=0)$
62 | - 齐次性 $\forall \alpha \in R, f(\alpha x)=|\alpha| f(x)$
63 | - 三角不等式 $f(x+y) \leq f(x)+f(y)$
64 |
65 | $L_p$ 范数是使用最为广泛的一种范数,定义为 $\|\boldsymbol{x}\|_{\boldsymbol{p}}=(\sum_i |x_i|^p)^{1/p}$,当 $p = 2$ 时该范数等价于向量和原点的欧几里得距离。有时候也需要衡量矩阵的大小,在深度学习中,最常见的做法便是使用Frobenius范数(F范数),即 $\|\boldsymbol{x}\|_{\boldsymbol{F}} = \sqrt{\sum_{i, j} A_{i j}^{2}}$.
66 |
67 | ### 参数范数正则化
68 |
69 | 通过简单地在损失函数 $J()$ 后添加一个参数范数正则化项 $\Omega(\theta)$,来限制模型的学习能力,正则化后的损失函数可表示为 $\tilde{J}$:
70 |
71 | $$
72 | \tilde{J}(\boldsymbol{\theta} ; \mathbf{X}, \mathbf{y})=\mathrm{J}(\boldsymbol{\theta} ; \mathbf{X}, \mathbf{y})+\alpha \Omega(\boldsymbol{\theta})
73 | $$
74 |
75 | 其中,$ \alpha $是正则项系数,它是一个超参,用来权衡惩罚项 $Ω$ 对损失函数的贡献。若 $α$ 为0,表示无正则化;$α$ 越大,正则化惩罚越大。
76 |
77 | 我们希望正则化后的训练误差(第一项)最小,又希望模型尽量简单(第二项)。
78 |
79 | 当最小化正则化后的损失函数时候,同时降低原有损失函数 $J()$和正则化项 $\Omega(\theta)$ 的值,一定程度减少了过拟合的程度。通俗来说,正则化就是让参数,如权重w多几个等于0,或 者接近于0,说明该节点影响很小,如果是神经网络相当于 在神经网络中删掉了一些节点,这样模型就变简单了。
80 |
81 | - $L_0$ 范数:$\|\boldsymbol{W}\|_{\boldsymbol{0}}$,指向量中非0的元素的个数,越小说明0元素越多
82 | - $L_1$ 范数:$\|\boldsymbol{W}\|_{\boldsymbol{1}}$,指向量中各个元素绝对值之和
83 | - $L_2$ 范数:$\|\boldsymbol{W}\|_{\boldsymbol{2}}$,即各元素的平方和再开方
84 |
85 | ### $L_2$ 正则化
86 |
87 | L2正则化主要用于线性回归,又称为岭回归(Ridge Regression) 或权重衰减(Weight decay),添加的正则化项形式如下:
88 |
89 | $$
90 | \Omega(\mathbf{w})=\frac{1}{2}\|\mathbf{w}\|_{2}^{2}
91 | $$
92 |
93 | 损失函数:
94 |
95 | $$
96 | \tilde{J}(\boldsymbol{\theta} ; \mathbf{X}, \mathbf{y})=\mathrm{J}(\boldsymbol{\theta} ; \mathbf{X}, \mathbf{y})+ \frac{\alpha}{2}\|\mathbf{w}\|_{2}^{2}
97 | $$
98 |
99 | **L2参数正则化分析(单步)**
100 |
101 | 对于某一模型,假设要对其所有的参数进行参数正则化,则正则化后的整体损失函数 $\tilde{J}$ 为 $\tilde{J}(\boldsymbol{\theta} ; \mathbf{X}, \mathbf{y})=\mathrm{J}(\boldsymbol{\theta} ; \mathbf{X}, \mathbf{y})+ \frac{\alpha}{2}\|\mathbf{w}\|_{2}^{2}$.
102 | 计算梯度得 $\nabla_{\mathbf{w}} \tilde{J}(\boldsymbol{w} ; \boldsymbol{X}, \boldsymbol{y})=\nabla_{\mathbf{w}} J(\boldsymbol{w} ; \boldsymbol{X}, \boldsymbol{y})+\alpha w$.
103 |
104 | 使用单步梯度下降更新权重:
105 |
106 | $$
107 | \begin{aligned} \mathbf{w} & \leftarrow \mathbf{w}-\lambda\left(\nabla_{\mathbf{w}} J(\boldsymbol{w} ; \boldsymbol{X}, \boldsymbol{y})+\alpha \boldsymbol{w}\right) \\ &=(1-\lambda \alpha) \mathbf{w}-\lambda \nabla_{\mathbf{w}} J(\boldsymbol{w} ; \boldsymbol{X}, \boldsymbol{y}) \end{aligned}
108 | $$
109 |
110 | 在进行每步梯度更新前,先对参数 w 进行了缩放。因此,这也是权重衰减名称的来源。
111 |
112 | **L2参数正则化分析(整个训练过程)**
113 |
114 | 我们先记未正则化的损失函数 $𝐽$ 得到的最小损失权重向量为 $\mathbf{w}^{*}=\operatorname{argmin}_{\boldsymbol{w}} J(\boldsymbol{w})$. 在 $w^*$ 附近对损失函数做二次近似,近似的 $\tilde{J}(w)$ 如下:
115 |
116 | $$
117 | \hat{J}(\mathbf{w})=J\left(\mathbf{w}^{*}\right)+\left(\mathbf{w}-\mathbf{w}^{*}\right)^{T} \nabla J\left(\mathbf{w}^{*}\right)+\frac{1}{2}\left(\mathbf{w}-\mathbf{w}^{*}\right)^{T} \boldsymbol{H}\left(\mathbf{w}-\mathbf{w}^{*}\right)
118 | $$
119 |
120 | $𝐻$ 是 $𝐽$ 在 $𝐰$ 处计算的*Hessian*矩阵。当 $\hat{J}(w)$ 取得最小值时,其梯度应为0,即 $\nabla_{\mathbf{w}} \hat{J}(\boldsymbol{w})=\boldsymbol{H}\left(\boldsymbol{w}-\boldsymbol{w}^{*}\right)=0$.
121 |
122 | 引入L2正则化项的梯度,设变量 $\tilde{w}$ 使得 $\tilde{J}(w)$ 最小
123 |
124 | $$
125 | \nabla_{\mathbf{w}} \hat{J}(\boldsymbol{w})= \alpha
126 | \tilde{w}+
127 | \boldsymbol{H}\left(\tilde{\boldsymbol{w}}-\boldsymbol{w}^{*}\right)=0
128 | $$
129 |
130 | 求得
131 |
132 | $$
133 | \tilde{w} = (H + \alpha I)^{-1}Hw^*
134 | $$
135 |
136 | 因为 H 是对称矩阵,可分解为 $𝐻=𝑄Λ𝑄^T$,所以
137 |
138 | $$
139 | \tilde{\mathbf{w}}=Q(\Lambda+\alpha I)^{-1} \Lambda Q^{T} \mathbf{w}^{*}
140 | $$
141 |
142 | $$
143 | (\Lambda+\alpha I)^{-1} \Lambda=\left[\begin{array}{cccc}\frac{\lambda_{1}}{\lambda_{1}+\alpha} & 0 & \cdots & 0 \\ 0 & \frac{\lambda_{2}}{\lambda_{2}+\alpha} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \frac{\lambda_{n}}{\lambda_{n}+\alpha}\end{array}\right]
144 | $$
145 |
146 | 举例:$\begin{array}{r}\frac{w_{1}^{2}}{a^{2}}+\frac{w_{2}^{2}}{b^{2}}=1 , \lambda_{1}=\frac{2}{a^{2}}, \lambda_{2}=\frac{2}{b^{2}}\end{array}$
147 |
148 |
47 |
48 | 下面我们引出正则化的概念,首先我们要明白什么是一个好的模型,基本要求就是在训练数据上表现好,但往往我们也希望它能在其他数据上也有很好的表现,也就是泛化性。
49 |
50 | - 广义正则化:通过某种手段使学习算法在训练误差变化不大的情况下,使得泛化误差显著降低的方法
51 | - 狭义正则化:不减少网络参数,只进行参数范围调整的方法
52 |
53 | # 参数范数正则化
54 |
55 | ### 范数基本知识
56 |
57 | 机器学习中,很多时候都需要衡量一个向量的大小,此时便需要用到范数的知识。
58 |
59 | 范数是将向量映射到非负值的函数,它满足三条性质:
60 |
61 | - 非负性 $f(x) \geq 0(f(x)=0 \Leftrightarrow x=0)$
62 | - 齐次性 $\forall \alpha \in R, f(\alpha x)=|\alpha| f(x)$
63 | - 三角不等式 $f(x+y) \leq f(x)+f(y)$
64 |
65 | $L_p$ 范数是使用最为广泛的一种范数,定义为 $\|\boldsymbol{x}\|_{\boldsymbol{p}}=(\sum_i |x_i|^p)^{1/p}$,当 $p = 2$ 时该范数等价于向量和原点的欧几里得距离。有时候也需要衡量矩阵的大小,在深度学习中,最常见的做法便是使用Frobenius范数(F范数),即 $\|\boldsymbol{x}\|_{\boldsymbol{F}} = \sqrt{\sum_{i, j} A_{i j}^{2}}$.
66 |
67 | ### 参数范数正则化
68 |
69 | 通过简单地在损失函数 $J()$ 后添加一个参数范数正则化项 $\Omega(\theta)$,来限制模型的学习能力,正则化后的损失函数可表示为 $\tilde{J}$:
70 |
71 | $$
72 | \tilde{J}(\boldsymbol{\theta} ; \mathbf{X}, \mathbf{y})=\mathrm{J}(\boldsymbol{\theta} ; \mathbf{X}, \mathbf{y})+\alpha \Omega(\boldsymbol{\theta})
73 | $$
74 |
75 | 其中,$ \alpha $是正则项系数,它是一个超参,用来权衡惩罚项 $Ω$ 对损失函数的贡献。若 $α$ 为0,表示无正则化;$α$ 越大,正则化惩罚越大。
76 |
77 | 我们希望正则化后的训练误差(第一项)最小,又希望模型尽量简单(第二项)。
78 |
79 | 当最小化正则化后的损失函数时候,同时降低原有损失函数 $J()$和正则化项 $\Omega(\theta)$ 的值,一定程度减少了过拟合的程度。通俗来说,正则化就是让参数,如权重w多几个等于0,或 者接近于0,说明该节点影响很小,如果是神经网络相当于 在神经网络中删掉了一些节点,这样模型就变简单了。
80 |
81 | - $L_0$ 范数:$\|\boldsymbol{W}\|_{\boldsymbol{0}}$,指向量中非0的元素的个数,越小说明0元素越多
82 | - $L_1$ 范数:$\|\boldsymbol{W}\|_{\boldsymbol{1}}$,指向量中各个元素绝对值之和
83 | - $L_2$ 范数:$\|\boldsymbol{W}\|_{\boldsymbol{2}}$,即各元素的平方和再开方
84 |
85 | ### $L_2$ 正则化
86 |
87 | L2正则化主要用于线性回归,又称为岭回归(Ridge Regression) 或权重衰减(Weight decay),添加的正则化项形式如下:
88 |
89 | $$
90 | \Omega(\mathbf{w})=\frac{1}{2}\|\mathbf{w}\|_{2}^{2}
91 | $$
92 |
93 | 损失函数:
94 |
95 | $$
96 | \tilde{J}(\boldsymbol{\theta} ; \mathbf{X}, \mathbf{y})=\mathrm{J}(\boldsymbol{\theta} ; \mathbf{X}, \mathbf{y})+ \frac{\alpha}{2}\|\mathbf{w}\|_{2}^{2}
97 | $$
98 |
99 | **L2参数正则化分析(单步)**
100 |
101 | 对于某一模型,假设要对其所有的参数进行参数正则化,则正则化后的整体损失函数 $\tilde{J}$ 为 $\tilde{J}(\boldsymbol{\theta} ; \mathbf{X}, \mathbf{y})=\mathrm{J}(\boldsymbol{\theta} ; \mathbf{X}, \mathbf{y})+ \frac{\alpha}{2}\|\mathbf{w}\|_{2}^{2}$.
102 | 计算梯度得 $\nabla_{\mathbf{w}} \tilde{J}(\boldsymbol{w} ; \boldsymbol{X}, \boldsymbol{y})=\nabla_{\mathbf{w}} J(\boldsymbol{w} ; \boldsymbol{X}, \boldsymbol{y})+\alpha w$.
103 |
104 | 使用单步梯度下降更新权重:
105 |
106 | $$
107 | \begin{aligned} \mathbf{w} & \leftarrow \mathbf{w}-\lambda\left(\nabla_{\mathbf{w}} J(\boldsymbol{w} ; \boldsymbol{X}, \boldsymbol{y})+\alpha \boldsymbol{w}\right) \\ &=(1-\lambda \alpha) \mathbf{w}-\lambda \nabla_{\mathbf{w}} J(\boldsymbol{w} ; \boldsymbol{X}, \boldsymbol{y}) \end{aligned}
108 | $$
109 |
110 | 在进行每步梯度更新前,先对参数 w 进行了缩放。因此,这也是权重衰减名称的来源。
111 |
112 | **L2参数正则化分析(整个训练过程)**
113 |
114 | 我们先记未正则化的损失函数 $𝐽$ 得到的最小损失权重向量为 $\mathbf{w}^{*}=\operatorname{argmin}_{\boldsymbol{w}} J(\boldsymbol{w})$. 在 $w^*$ 附近对损失函数做二次近似,近似的 $\tilde{J}(w)$ 如下:
115 |
116 | $$
117 | \hat{J}(\mathbf{w})=J\left(\mathbf{w}^{*}\right)+\left(\mathbf{w}-\mathbf{w}^{*}\right)^{T} \nabla J\left(\mathbf{w}^{*}\right)+\frac{1}{2}\left(\mathbf{w}-\mathbf{w}^{*}\right)^{T} \boldsymbol{H}\left(\mathbf{w}-\mathbf{w}^{*}\right)
118 | $$
119 |
120 | $𝐻$ 是 $𝐽$ 在 $𝐰$ 处计算的*Hessian*矩阵。当 $\hat{J}(w)$ 取得最小值时,其梯度应为0,即 $\nabla_{\mathbf{w}} \hat{J}(\boldsymbol{w})=\boldsymbol{H}\left(\boldsymbol{w}-\boldsymbol{w}^{*}\right)=0$.
121 |
122 | 引入L2正则化项的梯度,设变量 $\tilde{w}$ 使得 $\tilde{J}(w)$ 最小
123 |
124 | $$
125 | \nabla_{\mathbf{w}} \hat{J}(\boldsymbol{w})= \alpha
126 | \tilde{w}+
127 | \boldsymbol{H}\left(\tilde{\boldsymbol{w}}-\boldsymbol{w}^{*}\right)=0
128 | $$
129 |
130 | 求得
131 |
132 | $$
133 | \tilde{w} = (H + \alpha I)^{-1}Hw^*
134 | $$
135 |
136 | 因为 H 是对称矩阵,可分解为 $𝐻=𝑄Λ𝑄^T$,所以
137 |
138 | $$
139 | \tilde{\mathbf{w}}=Q(\Lambda+\alpha I)^{-1} \Lambda Q^{T} \mathbf{w}^{*}
140 | $$
141 |
142 | $$
143 | (\Lambda+\alpha I)^{-1} \Lambda=\left[\begin{array}{cccc}\frac{\lambda_{1}}{\lambda_{1}+\alpha} & 0 & \cdots & 0 \\ 0 & \frac{\lambda_{2}}{\lambda_{2}+\alpha} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \frac{\lambda_{n}}{\lambda_{n}+\alpha}\end{array}\right]
144 | $$
145 |
146 | 举例:$\begin{array}{r}\frac{w_{1}^{2}}{a^{2}}+\frac{w_{2}^{2}}{b^{2}}=1 , \lambda_{1}=\frac{2}{a^{2}}, \lambda_{2}=\frac{2}{b^{2}}\end{array}$
147 |
148 |  149 |
150 | 可见,权重衰减是沿着H的特征向量的标准正交基所定义的轴缩放 $𝒘^∗$。当原损失函数在特征值大的方向进行下降时, 正则化项对其影响较小;在特征值小的方向进行下降时,正则化项会对其进行限制。也就是说,保证了原损失函数沿着损失下降最大的方向下降。
151 |
152 | **稀疏问题**:
153 |
154 | 1. 特征选择: $x_i$ 的大部分元素(也就是特征)都是和最终的输出$ y_i$ 没有关系;但在预测新的样本时,这些没用的信息反而会被考虑,从而干扰了对正确 $y_i$ 的预测。稀疏规则化算子的引入就是为了完成特征自动选择,它会学习地去掉 这些没有作用的特征,也就是把这些特征对应的权重置为0。
155 | 2. 可解释性:患病回归模型 $y=w_1x_1+w_2x_2+\cdots+w_{1000}x_{1000}+b$, 通过学习,如果最后学习到的 $w^*$ 就只有很少的非零元素, 例如只有5个非零的 $w_i$,也就是说,患不患这种病只和这5个因素有关,那医生就好分析多了。
156 |
157 | ### $L_1$ 正则化
158 |
159 | L1正则化又称为Lasso回归(Lasso Regression),在损失函数中添加待正则化参数w的L1-范数(即w所有参数绝对 值之和)作为正则化项:$\Omega(w) = \|w\|_1$.
160 |
161 | 损失函数:
162 |
163 | $$
164 | \tilde{J}(\boldsymbol{\theta} ; \mathbf{X}, \mathbf{y})=\mathrm{J}(\boldsymbol{\theta} ; \mathbf{X}, \mathbf{y})+ \alpha \|w\|_1
165 | $$
166 |
167 | 计算梯度:
168 |
169 | $$
170 | \nabla_{\mathbf{w}} \tilde{J}(\boldsymbol{w} ; \boldsymbol{X}, \boldsymbol{y})=\nabla_{\mathbf{w}} J(\boldsymbol{w} ; \boldsymbol{X}, \boldsymbol{y})+\alpha \cdot \operatorname{sign}(\boldsymbol{w})
171 | $$
172 |
173 | 其中,sign(w)只是简单的取w各个元素的正负号。L1正则化与L2不 大一样,不一定能得到$J(w;X,y)$二次近似的直接算术解。
174 |
175 | **L1参数正则化分析**
176 |
177 | $w^\star$ 是未正则化的损失函数𝐽得到的最小损失权重向量,即
178 |
179 | $$
180 | \mathbf{w}^{\star}=\operatorname{argmin}_{w} J(\boldsymbol{w})
181 | $$
182 |
183 | 在 $w^*$ 处对正则化后的损失函数进行二次泰勒展开
184 |
185 | $$
186 | \hat{J}(\mathbf{w})=J\left(\mathbf{w}^{*}\right)+\frac{1}{2}\left(\mathbf{w}-\mathbf{w}^{*}\right)^{T} \boldsymbol{H}\left(\mathbf{w}-\mathbf{w}^{*}\right)
187 | $$
188 |
189 | $𝐻$ 是 $𝐽$ 在 $w^*$ 处计算的*Hessian*矩阵。当 $\hat{J}(\boldsymbol{w})$ 取得最小值时,其梯度应为0
190 |
191 | $$
192 | \nabla_{\mathbf{w}} \hat{J}(\boldsymbol{w})=
193 | \boldsymbol{H}\left(\boldsymbol{w}-\boldsymbol{w}^{*}\right)=0
194 | $$
195 |
196 | L1正则项在完全一般化的Hessian矩阵无法得到清晰的代数表达式, 进一步假设Hessian为对角矩阵,即 $H = diag([H_{1,1},\cdots, H_{n,n}]) $,且 $H_{i,i} > 0$ 。(如果线性回归问题中的数据已被预处理,去除输入特征 之间的相关性,那么这一假设成立)。
197 |
198 | 可将目标函数二次近似分解为关于参数的总和
199 |
200 | $$
201 | \tilde{J}(\boldsymbol{w})=J\left(\boldsymbol{w}^{*}\right)+\sum_{i}\left[\frac{1}{2} H_{i, i}\left(w_{i}-w_{i}^{*}\right)^{2}+\alpha\left|w_{i}\right|\right]
202 | $$
203 |
204 | 最小化这个近似损失函数可得
205 |
206 | $$
207 | \widetilde{w_{i}}=\operatorname{sign}\left(w_{i}^{*}\right) \max \left\{\left|w_{i}^{*}\right|-\frac{\alpha}{H_{i, i}}, 0\right\}
208 | $$
209 |
210 | 得到的参数 $\tilde{w}$ 的各个元素可能为0。因此,与L2正则化相比,得到的参数更加稀疏。
211 |
212 |
149 |
150 | 可见,权重衰减是沿着H的特征向量的标准正交基所定义的轴缩放 $𝒘^∗$。当原损失函数在特征值大的方向进行下降时, 正则化项对其影响较小;在特征值小的方向进行下降时,正则化项会对其进行限制。也就是说,保证了原损失函数沿着损失下降最大的方向下降。
151 |
152 | **稀疏问题**:
153 |
154 | 1. 特征选择: $x_i$ 的大部分元素(也就是特征)都是和最终的输出$ y_i$ 没有关系;但在预测新的样本时,这些没用的信息反而会被考虑,从而干扰了对正确 $y_i$ 的预测。稀疏规则化算子的引入就是为了完成特征自动选择,它会学习地去掉 这些没有作用的特征,也就是把这些特征对应的权重置为0。
155 | 2. 可解释性:患病回归模型 $y=w_1x_1+w_2x_2+\cdots+w_{1000}x_{1000}+b$, 通过学习,如果最后学习到的 $w^*$ 就只有很少的非零元素, 例如只有5个非零的 $w_i$,也就是说,患不患这种病只和这5个因素有关,那医生就好分析多了。
156 |
157 | ### $L_1$ 正则化
158 |
159 | L1正则化又称为Lasso回归(Lasso Regression),在损失函数中添加待正则化参数w的L1-范数(即w所有参数绝对 值之和)作为正则化项:$\Omega(w) = \|w\|_1$.
160 |
161 | 损失函数:
162 |
163 | $$
164 | \tilde{J}(\boldsymbol{\theta} ; \mathbf{X}, \mathbf{y})=\mathrm{J}(\boldsymbol{\theta} ; \mathbf{X}, \mathbf{y})+ \alpha \|w\|_1
165 | $$
166 |
167 | 计算梯度:
168 |
169 | $$
170 | \nabla_{\mathbf{w}} \tilde{J}(\boldsymbol{w} ; \boldsymbol{X}, \boldsymbol{y})=\nabla_{\mathbf{w}} J(\boldsymbol{w} ; \boldsymbol{X}, \boldsymbol{y})+\alpha \cdot \operatorname{sign}(\boldsymbol{w})
171 | $$
172 |
173 | 其中,sign(w)只是简单的取w各个元素的正负号。L1正则化与L2不 大一样,不一定能得到$J(w;X,y)$二次近似的直接算术解。
174 |
175 | **L1参数正则化分析**
176 |
177 | $w^\star$ 是未正则化的损失函数𝐽得到的最小损失权重向量,即
178 |
179 | $$
180 | \mathbf{w}^{\star}=\operatorname{argmin}_{w} J(\boldsymbol{w})
181 | $$
182 |
183 | 在 $w^*$ 处对正则化后的损失函数进行二次泰勒展开
184 |
185 | $$
186 | \hat{J}(\mathbf{w})=J\left(\mathbf{w}^{*}\right)+\frac{1}{2}\left(\mathbf{w}-\mathbf{w}^{*}\right)^{T} \boldsymbol{H}\left(\mathbf{w}-\mathbf{w}^{*}\right)
187 | $$
188 |
189 | $𝐻$ 是 $𝐽$ 在 $w^*$ 处计算的*Hessian*矩阵。当 $\hat{J}(\boldsymbol{w})$ 取得最小值时,其梯度应为0
190 |
191 | $$
192 | \nabla_{\mathbf{w}} \hat{J}(\boldsymbol{w})=
193 | \boldsymbol{H}\left(\boldsymbol{w}-\boldsymbol{w}^{*}\right)=0
194 | $$
195 |
196 | L1正则项在完全一般化的Hessian矩阵无法得到清晰的代数表达式, 进一步假设Hessian为对角矩阵,即 $H = diag([H_{1,1},\cdots, H_{n,n}]) $,且 $H_{i,i} > 0$ 。(如果线性回归问题中的数据已被预处理,去除输入特征 之间的相关性,那么这一假设成立)。
197 |
198 | 可将目标函数二次近似分解为关于参数的总和
199 |
200 | $$
201 | \tilde{J}(\boldsymbol{w})=J\left(\boldsymbol{w}^{*}\right)+\sum_{i}\left[\frac{1}{2} H_{i, i}\left(w_{i}-w_{i}^{*}\right)^{2}+\alpha\left|w_{i}\right|\right]
202 | $$
203 |
204 | 最小化这个近似损失函数可得
205 |
206 | $$
207 | \widetilde{w_{i}}=\operatorname{sign}\left(w_{i}^{*}\right) \max \left\{\left|w_{i}^{*}\right|-\frac{\alpha}{H_{i, i}}, 0\right\}
208 | $$
209 |
210 | 得到的参数 $\tilde{w}$ 的各个元素可能为0。因此,与L2正则化相比,得到的参数更加稀疏。
211 |
212 |  213 |
214 | ### $L_1$和$L_2$的对比
215 |
216 | - L2范数更有助于计算病态的问题
217 |
218 | - L1相对于L2能够产生更加稀疏的模型
219 |
220 | - 从概率角度进行分析,很多范数约束相当于对参数添加先 验分布,其中L2范数相当于参数服从高斯先验分布;L1范数相当于拉普拉斯分布
221 |
222 | $$
223 | \begin{array}{l}\underset{\boldsymbol{w}}{\operatorname{argmax}} p(\boldsymbol{w} \mid X)=\underset{\boldsymbol{w}}{\operatorname{argmax}} \frac{p(X \mid \boldsymbol{w}) p(\boldsymbol{w})}{p(X)}=\underset{\boldsymbol{w}}{\operatorname{argmax}} p(X \mid \boldsymbol{w}) p(\boldsymbol{w}) =\underset{\boldsymbol{w}}{\operatorname{argmax}}\left(\prod_{i=1}^{n} p\left(x_{i} \mid \boldsymbol{w}\right)\right) p(\boldsymbol{w}) \\ \operatorname{argmax}_{\boldsymbol{w}} L(\boldsymbol{w})=\prod_{i=1}^{n} \frac{1}{\sigma \sqrt{2 \pi}} \exp \left(\frac{\left(\boldsymbol{y}_{i}-\boldsymbol{w}^{T} \boldsymbol{x}_{i}\right)^{2}}{2 \sigma^{2}}\right) \prod_{j=1}^{d} \frac{1}{\tau \sqrt{2 \pi}} \exp \left(\frac{\left(\boldsymbol{w}_{j}\right)^{2}}{2 \tau^{2}}\right) \\ \operatorname{argmax}_{\boldsymbol{w}} L^{\prime}(\boldsymbol{w})=\ln \prod_{i=1}^{n} \frac{1}{\sigma \sqrt{2 \pi}} \exp \left(-\frac{\left(\boldsymbol{y}_{i}-\boldsymbol{w}^{T} \boldsymbol{x}_{i}\right)^{2}}{2 \sigma^{2}}\right) \prod_{j=1}^{d} \frac{1}{\tau \sqrt{2 \pi}} \exp \left(-\frac{\left(\boldsymbol{w}_{j}\right)^{2}}{2 \tau^{2}}\right) \\ =-\frac{1}{2 \sigma^{2}} \sum_{i=1}^{n}\left(\boldsymbol{y}_{i}-\boldsymbol{w}^{T} \boldsymbol{x}_{i}\right)^{2}-\frac{1}{2 \tau^{2}} \sum_{i=1}^{d}\left(\boldsymbol{w}_{j}\right)^{2}+\cdots\end{array}
224 | $$
225 |
226 | # 稀疏表示
227 |
228 | 数据集可视为矩阵𝑆,其中矩阵的行数表示样本的数量,矩阵的列数则表示对应的特征。在很多应用中,矩阵𝑆中存在 很多零元素,但这些零元素并不是以整列、整行形式存在。
229 |
230 | - 如在文档分类领域,我们将每一篇文档作为一个样本,那么数据集可表示为每一行表示为一个文档,每一列为一个字(词),行列交汇处就是某字(词)在某文档中出现的频率。
231 |
232 | 如果矩阵𝑆是普通的非稀疏矩阵,稀疏表示目的是为这个普 通稠密表达的样本𝑆找到一个合适的字典,将样本转换为稀 疏表示(Sparse Representation)形式,从而在学习训练的 任务上得到简化,降低模型的复杂度。亦被称作字典学习 (Dictionary Learning)
233 |
234 | - 稀疏表示的本质是使用尽可能少的数据表示尽可能多的特征,并且 同时也能带来计算效率的提升。
235 |
236 |
237 | ### 稀疏表示学习
238 |
239 | 给定数据集为 $\{x_1,x_2,\cdots,x_𝑛\} $字典学习可表示为
240 |
241 | $$
242 | \min _{B, \alpha_{i}} \sum_{i=1}^{m}\left\|x_{i}-B \alpha_{i}\right\|_{2}^{2}+\lambda \sum_{i=1}^{m}\left\|\alpha_{i}\right\|_{1}
243 | $$
244 |
245 | 其中$B \in R^{d \times k},\alpha_i \in R^k$ ,k 为字典的词汇量,$\alpha_i$ 是样本的稀疏表示。第一项保证能够通过字典𝐵由稀疏表示 $\alpha_i$ 重构样本数据 $x_i$ , 第二项保证 $\alpha_i$ 尽可能稀疏。学习任务则是求解字典𝐵,以及 $x_i$ 的稀疏表示 $\alpha_i$ ,可采用变量交替优化的策略进行学习。
246 |
--------------------------------------------------------------------------------
/docs/理论进阶/10.注意力机制.md:
--------------------------------------------------------------------------------
1 | # 注意力机制
2 |
3 | ### 人类的注意力机制
4 |
5 |
213 |
214 | ### $L_1$和$L_2$的对比
215 |
216 | - L2范数更有助于计算病态的问题
217 |
218 | - L1相对于L2能够产生更加稀疏的模型
219 |
220 | - 从概率角度进行分析,很多范数约束相当于对参数添加先 验分布,其中L2范数相当于参数服从高斯先验分布;L1范数相当于拉普拉斯分布
221 |
222 | $$
223 | \begin{array}{l}\underset{\boldsymbol{w}}{\operatorname{argmax}} p(\boldsymbol{w} \mid X)=\underset{\boldsymbol{w}}{\operatorname{argmax}} \frac{p(X \mid \boldsymbol{w}) p(\boldsymbol{w})}{p(X)}=\underset{\boldsymbol{w}}{\operatorname{argmax}} p(X \mid \boldsymbol{w}) p(\boldsymbol{w}) =\underset{\boldsymbol{w}}{\operatorname{argmax}}\left(\prod_{i=1}^{n} p\left(x_{i} \mid \boldsymbol{w}\right)\right) p(\boldsymbol{w}) \\ \operatorname{argmax}_{\boldsymbol{w}} L(\boldsymbol{w})=\prod_{i=1}^{n} \frac{1}{\sigma \sqrt{2 \pi}} \exp \left(\frac{\left(\boldsymbol{y}_{i}-\boldsymbol{w}^{T} \boldsymbol{x}_{i}\right)^{2}}{2 \sigma^{2}}\right) \prod_{j=1}^{d} \frac{1}{\tau \sqrt{2 \pi}} \exp \left(\frac{\left(\boldsymbol{w}_{j}\right)^{2}}{2 \tau^{2}}\right) \\ \operatorname{argmax}_{\boldsymbol{w}} L^{\prime}(\boldsymbol{w})=\ln \prod_{i=1}^{n} \frac{1}{\sigma \sqrt{2 \pi}} \exp \left(-\frac{\left(\boldsymbol{y}_{i}-\boldsymbol{w}^{T} \boldsymbol{x}_{i}\right)^{2}}{2 \sigma^{2}}\right) \prod_{j=1}^{d} \frac{1}{\tau \sqrt{2 \pi}} \exp \left(-\frac{\left(\boldsymbol{w}_{j}\right)^{2}}{2 \tau^{2}}\right) \\ =-\frac{1}{2 \sigma^{2}} \sum_{i=1}^{n}\left(\boldsymbol{y}_{i}-\boldsymbol{w}^{T} \boldsymbol{x}_{i}\right)^{2}-\frac{1}{2 \tau^{2}} \sum_{i=1}^{d}\left(\boldsymbol{w}_{j}\right)^{2}+\cdots\end{array}
224 | $$
225 |
226 | # 稀疏表示
227 |
228 | 数据集可视为矩阵𝑆,其中矩阵的行数表示样本的数量,矩阵的列数则表示对应的特征。在很多应用中,矩阵𝑆中存在 很多零元素,但这些零元素并不是以整列、整行形式存在。
229 |
230 | - 如在文档分类领域,我们将每一篇文档作为一个样本,那么数据集可表示为每一行表示为一个文档,每一列为一个字(词),行列交汇处就是某字(词)在某文档中出现的频率。
231 |
232 | 如果矩阵𝑆是普通的非稀疏矩阵,稀疏表示目的是为这个普 通稠密表达的样本𝑆找到一个合适的字典,将样本转换为稀 疏表示(Sparse Representation)形式,从而在学习训练的 任务上得到简化,降低模型的复杂度。亦被称作字典学习 (Dictionary Learning)
233 |
234 | - 稀疏表示的本质是使用尽可能少的数据表示尽可能多的特征,并且 同时也能带来计算效率的提升。
235 |
236 |
237 | ### 稀疏表示学习
238 |
239 | 给定数据集为 $\{x_1,x_2,\cdots,x_𝑛\} $字典学习可表示为
240 |
241 | $$
242 | \min _{B, \alpha_{i}} \sum_{i=1}^{m}\left\|x_{i}-B \alpha_{i}\right\|_{2}^{2}+\lambda \sum_{i=1}^{m}\left\|\alpha_{i}\right\|_{1}
243 | $$
244 |
245 | 其中$B \in R^{d \times k},\alpha_i \in R^k$ ,k 为字典的词汇量,$\alpha_i$ 是样本的稀疏表示。第一项保证能够通过字典𝐵由稀疏表示 $\alpha_i$ 重构样本数据 $x_i$ , 第二项保证 $\alpha_i$ 尽可能稀疏。学习任务则是求解字典𝐵,以及 $x_i$ 的稀疏表示 $\alpha_i$ ,可采用变量交替优化的策略进行学习。
246 |
--------------------------------------------------------------------------------
/docs/理论进阶/10.注意力机制.md:
--------------------------------------------------------------------------------
1 | # 注意力机制
2 |
3 | ### 人类的注意力机制
4 |
5 |  6 |
7 | 在深度学习中注意力机制的研究:
8 |
9 |
6 |
7 | 在深度学习中注意力机制的研究:
8 |
9 |  10 |
11 | 参考:
12 | [1] Recurrent Models of Visual Attention. NIPS 2014: 2204- 2212
13 | [2] Neural machine translation by jointly learning to align and translate, ICLR 2015
14 | [3] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention,ICML 2015
15 | [4] Attention is all you need,NIPS 2017
16 |
17 | ### 注意力机制在在神经机器翻译领域的应用
18 |
19 | - 神经机器翻译主要以Encoder-Decoder模型为基础结构
20 |
21 |
10 |
11 | 参考:
12 | [1] Recurrent Models of Visual Attention. NIPS 2014: 2204- 2212
13 | [2] Neural machine translation by jointly learning to align and translate, ICLR 2015
14 | [3] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention,ICML 2015
15 | [4] Attention is all you need,NIPS 2017
16 |
17 | ### 注意力机制在在神经机器翻译领域的应用
18 |
19 | - 神经机器翻译主要以Encoder-Decoder模型为基础结构
20 |
21 |  22 |
23 | - 在神经机器翻译中,Encoder一般采用RNN或者LSTM实现
24 | - 从统计角度,翻译相当于寻找译句 $y$,使得给定原句 $x$ 时条件概率最大:$\arg\max_{y} p(\boldsymbol{y} | \boldsymbol{x})$
25 | - 得到上下文向量 $c$ 的方法有很多,可以直接将最后一个隐状态作为上下文变量,也可对最后的隐状态进行一个非线性变换 $\sigma(\cdot)$,或对所有的隐状态进行非线性变换 $\sigma(\cdot)$.
26 |
27 | $$
28 | c =h_{T} \\ \,\,\,\ c =\sigma\left(h_{T}\right) \\ c =\sigma\left(h_{1}, h_{2}, \cdots, h_{T}\right)
29 | $$
30 |
31 | ### 解码器
32 |
33 | - 用给定的上下文向量 $c$ 和之前已经预测的词 $\{y_1,\cdots,y_{t-1}\}$
34 |
35 |
22 |
23 | - 在神经机器翻译中,Encoder一般采用RNN或者LSTM实现
24 | - 从统计角度,翻译相当于寻找译句 $y$,使得给定原句 $x$ 时条件概率最大:$\arg\max_{y} p(\boldsymbol{y} | \boldsymbol{x})$
25 | - 得到上下文向量 $c$ 的方法有很多,可以直接将最后一个隐状态作为上下文变量,也可对最后的隐状态进行一个非线性变换 $\sigma(\cdot)$,或对所有的隐状态进行非线性变换 $\sigma(\cdot)$.
26 |
27 | $$
28 | c =h_{T} \\ \,\,\,\ c =\sigma\left(h_{T}\right) \\ c =\sigma\left(h_{1}, h_{2}, \cdots, h_{T}\right)
29 | $$
30 |
31 | ### 解码器
32 |
33 | - 用给定的上下文向量 $c$ 和之前已经预测的词 $\{y_1,\cdots,y_{t-1}\}$
34 |
35 |  36 |
37 | ### 现存问题
38 |
39 | - 输入序列不论长短都会被编码成一个固定长度的向量表示,而解码则受限于该固定长度的向量表示
40 | - 这个问题限制了模型的性能,尤其是当输入序列比较长时,模型的性能会变得很差
41 |
42 | ### 神经网络模型注意力机制
43 |
44 |
36 |
37 | ### 现存问题
38 |
39 | - 输入序列不论长短都会被编码成一个固定长度的向量表示,而解码则受限于该固定长度的向量表示
40 | - 这个问题限制了模型的性能,尤其是当输入序列比较长时,模型的性能会变得很差
41 |
42 | ### 神经网络模型注意力机制
43 |
44 |  45 |
46 | - 在这个新结构中,定义每个输出的条件概率为: $p\left(y_{i} \mid y_{1}, \cdots, y_{i-1}, \boldsymbol{x}\right)=g\left(y_{i-1}, x_{i}, c_{i}\right)$.
47 | - 其中 $s_i$ 为解码器RNN中的隐层状态: $s_{i}=f \left(s_{i-1}, y_{i-1}, c_{i}\right)$.
48 | - 这里的上下文向量 $c_i$ 取决于注释向量序列 (encoder转化得到),通过使用注意力系数 $\alpha_{ij}$ 对 $h_j$ 加权求得:
49 |
50 | $$
51 | c_{i}=\sum_{j=1}^{T} \alpha_{i j} h_{j}
52 | $$
53 |
54 |
45 |
46 | - 在这个新结构中,定义每个输出的条件概率为: $p\left(y_{i} \mid y_{1}, \cdots, y_{i-1}, \boldsymbol{x}\right)=g\left(y_{i-1}, x_{i}, c_{i}\right)$.
47 | - 其中 $s_i$ 为解码器RNN中的隐层状态: $s_{i}=f \left(s_{i-1}, y_{i-1}, c_{i}\right)$.
48 | - 这里的上下文向量 $c_i$ 取决于注释向量序列 (encoder转化得到),通过使用注意力系数 $\alpha_{ij}$ 对 $h_j$ 加权求得:
49 |
50 | $$
51 | c_{i}=\sum_{j=1}^{T} \alpha_{i j} h_{j}
52 | $$
53 |
54 |  55 |
56 | ### 注意力机制的计算
57 |
58 | 注意力系数计算:
59 |
60 | $$
61 | \alpha_{i j}=\frac{\exp \left(e_{i j}\right)}{\sum_{k=1}^{T_{x}} \exp \left(e_{i k}\right)} \quad e_{i j}=a\left(s_{i-1}, h_{j}\right)
62 | $$
63 |
64 | 后一个公式中的 $a(\cdot)$ 表示alignment mode,反映 $i$ 位置的输入和 $j$ 位置输出的匹配程度。
65 |
66 | 计算注意力系数的相似函数(alignment model)有以下几种:
67 |
68 | $$
69 | a\left(s_{i-1}, h_{j}\right) =
70 | h_{j}^{T} \cdot s_{i-1} \\
71 | a\left(s_{i-1}, h_{j}\right) =
72 | \frac{h_{j}^{T} \cdot W_{\alpha} \cdot s_{i-1}}{W_{\alpha} \cdot\left[h_{j}^{T}, s_{i-1}^{T}\right]^{T}} \\
73 | a\left(s_{i-1}, h_{j}\right) =
74 | v_{\alpha} \tanh \left(U_{\alpha} h_{j}+W_{\alpha} s_{i-1}\right)
75 | $$
76 |
77 | ### 几种主流的注意力机制
78 |
79 |
55 |
56 | ### 注意力机制的计算
57 |
58 | 注意力系数计算:
59 |
60 | $$
61 | \alpha_{i j}=\frac{\exp \left(e_{i j}\right)}{\sum_{k=1}^{T_{x}} \exp \left(e_{i k}\right)} \quad e_{i j}=a\left(s_{i-1}, h_{j}\right)
62 | $$
63 |
64 | 后一个公式中的 $a(\cdot)$ 表示alignment mode,反映 $i$ 位置的输入和 $j$ 位置输出的匹配程度。
65 |
66 | 计算注意力系数的相似函数(alignment model)有以下几种:
67 |
68 | $$
69 | a\left(s_{i-1}, h_{j}\right) =
70 | h_{j}^{T} \cdot s_{i-1} \\
71 | a\left(s_{i-1}, h_{j}\right) =
72 | \frac{h_{j}^{T} \cdot W_{\alpha} \cdot s_{i-1}}{W_{\alpha} \cdot\left[h_{j}^{T}, s_{i-1}^{T}\right]^{T}} \\
73 | a\left(s_{i-1}, h_{j}\right) =
74 | v_{\alpha} \tanh \left(U_{\alpha} h_{j}+W_{\alpha} s_{i-1}\right)
75 | $$
76 |
77 | ### 几种主流的注意力机制
78 |
79 |  80 |
81 | ### 注意力机制的理解
82 |
83 | - Attention函数的本质可以被描述为一个查询(query)到一系列(键key-值value)对的映射
84 |
85 |
80 |
81 | ### 注意力机制的理解
82 |
83 | - Attention函数的本质可以被描述为一个查询(query)到一系列(键key-值value)对的映射
84 |
85 |  86 |
87 | $$
88 | \text { Attention(Query, Source })=\sum_{i=1}^{L_{x}} \text { similarity }\left(\text { Query }, \mathrm{Key}_{i}\right){\times} \text { Value }_{i}
89 | $$
90 |
91 | 参考文献:Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]. Advances in Neural Information Processing Systems. 2017: 6000-6010.
92 |
93 | 注意力系数计算
94 |
95 | - 阶段1:根据Query和Key计算两者的相似性或者相关性
96 | - 阶段2:对第一阶段的原始分值进 行归一化处理
97 | - 阶段3:根据权重系数对Value进行加权求和,得到Attention Value
98 |
99 |
86 |
87 | $$
88 | \text { Attention(Query, Source })=\sum_{i=1}^{L_{x}} \text { similarity }\left(\text { Query }, \mathrm{Key}_{i}\right){\times} \text { Value }_{i}
89 | $$
90 |
91 | 参考文献:Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]. Advances in Neural Information Processing Systems. 2017: 6000-6010.
92 |
93 | 注意力系数计算
94 |
95 | - 阶段1:根据Query和Key计算两者的相似性或者相关性
96 | - 阶段2:对第一阶段的原始分值进 行归一化处理
97 | - 阶段3:根据权重系数对Value进行加权求和,得到Attention Value
98 |
99 |  100 |
101 | Self-attention layer in “Attention is all you need”
102 |
103 |
100 |
101 | Self-attention layer in “Attention is all you need”
102 |
103 |  104 |
105 |
104 |
105 |  106 |
107 |
106 |
107 |  108 |
109 |
108 |
109 |  110 |
111 | ### 注意力机制的应用
112 |
113 | - GPT/GPT-2
114 | - BERT
115 |
116 |
110 |
111 | ### 注意力机制的应用
112 |
113 | - GPT/GPT-2
114 | - BERT
115 |
116 |  117 |
118 |
119 | # 记忆网络
120 |
121 | ### 产生背景
122 |
123 | 现代计算机的一个巨大优势就是可以对信息进行存储。但 是,大多数机器学习模型缺少这种可以读取、写入的长期 记忆的内存结构。RNN、LSTM这样的神经网络原则上可以实现记忆存储, 但是,它们由隐藏状态和权重编码包含的记忆太小了,不能记忆足够信息。基于此,Facebook AI Research提出了一种用于问答任务的记忆网络,实现了记忆的存储。广义上讲,循环神经网络也是记忆网络的一种
124 |
125 | ### 代表工作
126 |
127 | - **Memory Networks**. ICLR 2015
128 |
129 | - **End-To-End Memory Networks**. NIPS 2015: 2440-2448
130 |
131 | - **Key-Value Memory Networks for Directly Reading Documents**. EMNLP 2016: 1400-1409
132 |
133 | - **Tracking the World State with Recurrent Entity Networks**. ICLR 2017
134 |
135 | ### 结构
136 |
137 | 结构示意图: I, G, O, R四个模块
138 |
139 |
117 |
118 |
119 | # 记忆网络
120 |
121 | ### 产生背景
122 |
123 | 现代计算机的一个巨大优势就是可以对信息进行存储。但 是,大多数机器学习模型缺少这种可以读取、写入的长期 记忆的内存结构。RNN、LSTM这样的神经网络原则上可以实现记忆存储, 但是,它们由隐藏状态和权重编码包含的记忆太小了,不能记忆足够信息。基于此,Facebook AI Research提出了一种用于问答任务的记忆网络,实现了记忆的存储。广义上讲,循环神经网络也是记忆网络的一种
124 |
125 | ### 代表工作
126 |
127 | - **Memory Networks**. ICLR 2015
128 |
129 | - **End-To-End Memory Networks**. NIPS 2015: 2440-2448
130 |
131 | - **Key-Value Memory Networks for Directly Reading Documents**. EMNLP 2016: 1400-1409
132 |
133 | - **Tracking the World State with Recurrent Entity Networks**. ICLR 2017
134 |
135 | ### 结构
136 |
137 | 结构示意图: I, G, O, R四个模块
138 |
139 |  140 |
141 | 参考:Weston, Jason, Sumit Chopra, and Antoine Bordes. "Memory networks." arXiv preprint arXiv:1410.3916 (2014).
142 |
143 | - Input vector:将输入 $x$ (字符、单词、句子等不同的粒度)转成内部特征向量的表示 $I(x)$
144 | - Generalization:根据新的输入更新记忆单元中的memory slot $m_i$,$\boldsymbol{m}_{\boldsymbol{i}}=G\left(\boldsymbol{m}_{\boldsymbol{i}}, \boldsymbol{I}(\boldsymbol{x}), \boldsymbol{m}\right), \forall i$.
145 |
146 | - Output feature map:根据记忆单元和新的输入,输出特征 $o = O(x', m)$
147 |
148 | - Response:最后,解码输出特征 $o$,并给出对应的响应 $r = R(o)$,R可以是一个RNN网络生成回答的句子,更简单的话可以计算相关分数,比如 $W$ 是一个单词集合(dictionary)
149 |
150 | ### 端到端的记忆网络
151 |
152 | **单层和三层网络**
153 |
154 | 参考:Sukhbaatar, Sainbayar, Arthur Szlam, Jason Weston, and Rob Fergus. "End-to-end memory networks." arXiv preprint arXiv:1503.08895(2015).
155 |
156 |
140 |
141 | 参考:Weston, Jason, Sumit Chopra, and Antoine Bordes. "Memory networks." arXiv preprint arXiv:1410.3916 (2014).
142 |
143 | - Input vector:将输入 $x$ (字符、单词、句子等不同的粒度)转成内部特征向量的表示 $I(x)$
144 | - Generalization:根据新的输入更新记忆单元中的memory slot $m_i$,$\boldsymbol{m}_{\boldsymbol{i}}=G\left(\boldsymbol{m}_{\boldsymbol{i}}, \boldsymbol{I}(\boldsymbol{x}), \boldsymbol{m}\right), \forall i$.
145 |
146 | - Output feature map:根据记忆单元和新的输入,输出特征 $o = O(x', m)$
147 |
148 | - Response:最后,解码输出特征 $o$,并给出对应的响应 $r = R(o)$,R可以是一个RNN网络生成回答的句子,更简单的话可以计算相关分数,比如 $W$ 是一个单词集合(dictionary)
149 |
150 | ### 端到端的记忆网络
151 |
152 | **单层和三层网络**
153 |
154 | 参考:Sukhbaatar, Sainbayar, Arthur Szlam, Jason Weston, and Rob Fergus. "End-to-end memory networks." arXiv preprint arXiv:1503.08895(2015).
155 |
156 |  157 |
158 | **训练参数**
159 |
160 | - A:inputembeddingmatrix
161 | - C: output embedding matrix
162 | - W: answer prediction matrix
163 | - B: question embedding matrix
164 |
165 | **损失函数**:交叉熵
166 |
167 | ### **Key-Value**记忆网络
168 |
169 | 面向**QA**的**Key-Value**网络结构
170 |
171 | - 高效的知识存储和检索
172 | - key负责寻址lookup,也就是对memory与Question的相关程度进行评分,
173 | - value则负责reading,也就是对记忆的值进行加权求和得到输出
174 |
175 |
157 |
158 | **训练参数**
159 |
160 | - A:inputembeddingmatrix
161 | - C: output embedding matrix
162 | - W: answer prediction matrix
163 | - B: question embedding matrix
164 |
165 | **损失函数**:交叉熵
166 |
167 | ### **Key-Value**记忆网络
168 |
169 | 面向**QA**的**Key-Value**网络结构
170 |
171 | - 高效的知识存储和检索
172 | - key负责寻址lookup,也就是对memory与Question的相关程度进行评分,
173 | - value则负责reading,也就是对记忆的值进行加权求和得到输出
174 |
175 |  176 |
177 | ### 其它记忆网络
178 |
179 | - **2017**年,**Facebook AI Research**提出了一种新的基于记忆网 络的循环实体网络,其使用固定长度的记忆单元来存储世 界上的实体,主要存储该实体相关的属性,且该记忆会随着输入内容实时更新
180 |
181 | - **Google DeepMind**也提出了多种记忆网络,如:**Neural Turing Machines**、**Neural Random Access Machines**以及使用像栈或(双端)队列结构的连续版本等
182 |
183 | - 利用外部存储形式的机器学习方式已经成为机器学习领域中一个热点方向
184 |
--------------------------------------------------------------------------------
/docs/理论进阶/11.Transformer.md:
--------------------------------------------------------------------------------
1 | # Transformer 模型
2 |
3 | 谷歌2017年文章《All you need is attention》提出Transformer模型,文章链接:http://arxiv.org/abs/1706.03762。下面对几个基于Transformer的主要的模型进行简单总结。
4 |
5 | # Bert
6 |
7 | 来自文章《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》。
8 | 整个模型可以划分为embedding、transformer、output三部分。
9 |
10 | 1. embedding部分由word embedding、position embedding、token type embedding三个模型组成,三个embedding相加形成最终的embedding输入。
11 | 2. transformer部分使用的是标准的Transformer模型encorder部分。
12 | 3. output部分由具体的任务决定。对于token级别的任务,可以使用最后一层Transformer层的输出;对于sentence级别的任务,可以使用最后一层Transformer层的第一位输出,即[CLS]对应的输出。
13 | 文章链接:https://arxiv.org/abs/1810.04805
14 |
15 | # GPT
16 |
17 | 来自文章《Improving Language Understanding by Generative Pre-Training》和《Language Models are Unsupervised Multitask Learners》。
18 | GPT为生成式模型。如果说BERT使用了Transformer模型中的encoder部分,那GPT就相当于使用了Transformer模型中的deconder部分。
19 |
20 | 文章链接:
21 | GPT:
22 | https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
23 | GPT-2:
24 | https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
25 |
26 | # Transformer XL
27 |
28 | 来自文章《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》。
29 | 相比于传统的transformer模型,主要有以下两点修改:
30 |
31 | 每个transformer节点除了使用本帧上层节点的数据外,还使用了上一帧上层节点的数据;
32 | 在做position embedding的时候,使用相对位置编码代替绝对位置编码。
33 | 文章链接:
34 | http://arxiv.org/abs/1901.02860
35 |
36 | # ALBERT
37 |
38 | 来自文章《ALBERT: A Lite BERT for Self-supervised Learning of Language Representations》。
39 | ALBERT(A Lite BERT)即轻量级的BERT,轻量级主要体现在减少传统BERT的参数数量,提高模型的泛化能力。相比于传统BERT有以下三点区别:
40 |
41 | 1. 降低embedding层的维度,在embedding层与初始隐藏层之间增加一个全连接层,将低纬的embedding提高至高维的隐藏层纬度,相当于对原embedding层通过因式分解降维;
42 | 2. 在transformer层之间进行参数共享;
43 | 3. 使用SOP(sentence order prediction)代替NSP(next sentence prediction)对模型进行训练,ALBERT参数规模比BERT比传统BERT小18倍,但性能却超越了传统BERT。
44 |
45 | ### 模型大小对比
46 |
47 | | | BERT | RoBERTa | DistilBERT | XLNet | ALBERT |
48 | | ------ | ------------------ | ------------------ | ---------- | ------------------ | ---------------- |
49 | | Size/M | Base 110 Large 340 | Base 110 Large 340 | 66 | Base 110 Large 340 | Base 12 Large 18 |
50 |
--------------------------------------------------------------------------------
/docs/理论进阶/12.深度生成模型.md:
--------------------------------------------------------------------------------
1 | 1. 深度生成模型概述
2 | 2. Hopfield神经网络
3 | 3. 玻尔兹曼机和受限玻尔兹曼机
4 | 4. 深度玻尔兹曼机和深度信念网络
5 | 5. 自编码器及其变种
6 |
7 |
8 |
9 | # 深度生成模型概述
10 |
11 |
176 |
177 | ### 其它记忆网络
178 |
179 | - **2017**年,**Facebook AI Research**提出了一种新的基于记忆网 络的循环实体网络,其使用固定长度的记忆单元来存储世 界上的实体,主要存储该实体相关的属性,且该记忆会随着输入内容实时更新
180 |
181 | - **Google DeepMind**也提出了多种记忆网络,如:**Neural Turing Machines**、**Neural Random Access Machines**以及使用像栈或(双端)队列结构的连续版本等
182 |
183 | - 利用外部存储形式的机器学习方式已经成为机器学习领域中一个热点方向
184 |
--------------------------------------------------------------------------------
/docs/理论进阶/11.Transformer.md:
--------------------------------------------------------------------------------
1 | # Transformer 模型
2 |
3 | 谷歌2017年文章《All you need is attention》提出Transformer模型,文章链接:http://arxiv.org/abs/1706.03762。下面对几个基于Transformer的主要的模型进行简单总结。
4 |
5 | # Bert
6 |
7 | 来自文章《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》。
8 | 整个模型可以划分为embedding、transformer、output三部分。
9 |
10 | 1. embedding部分由word embedding、position embedding、token type embedding三个模型组成,三个embedding相加形成最终的embedding输入。
11 | 2. transformer部分使用的是标准的Transformer模型encorder部分。
12 | 3. output部分由具体的任务决定。对于token级别的任务,可以使用最后一层Transformer层的输出;对于sentence级别的任务,可以使用最后一层Transformer层的第一位输出,即[CLS]对应的输出。
13 | 文章链接:https://arxiv.org/abs/1810.04805
14 |
15 | # GPT
16 |
17 | 来自文章《Improving Language Understanding by Generative Pre-Training》和《Language Models are Unsupervised Multitask Learners》。
18 | GPT为生成式模型。如果说BERT使用了Transformer模型中的encoder部分,那GPT就相当于使用了Transformer模型中的deconder部分。
19 |
20 | 文章链接:
21 | GPT:
22 | https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
23 | GPT-2:
24 | https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
25 |
26 | # Transformer XL
27 |
28 | 来自文章《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》。
29 | 相比于传统的transformer模型,主要有以下两点修改:
30 |
31 | 每个transformer节点除了使用本帧上层节点的数据外,还使用了上一帧上层节点的数据;
32 | 在做position embedding的时候,使用相对位置编码代替绝对位置编码。
33 | 文章链接:
34 | http://arxiv.org/abs/1901.02860
35 |
36 | # ALBERT
37 |
38 | 来自文章《ALBERT: A Lite BERT for Self-supervised Learning of Language Representations》。
39 | ALBERT(A Lite BERT)即轻量级的BERT,轻量级主要体现在减少传统BERT的参数数量,提高模型的泛化能力。相比于传统BERT有以下三点区别:
40 |
41 | 1. 降低embedding层的维度,在embedding层与初始隐藏层之间增加一个全连接层,将低纬的embedding提高至高维的隐藏层纬度,相当于对原embedding层通过因式分解降维;
42 | 2. 在transformer层之间进行参数共享;
43 | 3. 使用SOP(sentence order prediction)代替NSP(next sentence prediction)对模型进行训练,ALBERT参数规模比BERT比传统BERT小18倍,但性能却超越了传统BERT。
44 |
45 | ### 模型大小对比
46 |
47 | | | BERT | RoBERTa | DistilBERT | XLNet | ALBERT |
48 | | ------ | ------------------ | ------------------ | ---------- | ------------------ | ---------------- |
49 | | Size/M | Base 110 Large 340 | Base 110 Large 340 | 66 | Base 110 Large 340 | Base 12 Large 18 |
50 |
--------------------------------------------------------------------------------
/docs/理论进阶/12.深度生成模型.md:
--------------------------------------------------------------------------------
1 | 1. 深度生成模型概述
2 | 2. Hopfield神经网络
3 | 3. 玻尔兹曼机和受限玻尔兹曼机
4 | 4. 深度玻尔兹曼机和深度信念网络
5 | 5. 自编码器及其变种
6 |
7 |
8 |
9 | # 深度生成模型概述
10 |
11 |  12 |
13 |
12 |
13 |  14 |
15 | | 年份 | 事件 | 相关论文 |
16 | | :--: | :----------------------------------------------------------- | ------------------------------------------------------------ |
17 | | 1982 | Hopfield网络提出 | J. J . Hopfield . Neural networks and physical systems with emergent collective computational abilities. Proceedings of the National Academy of Sciences, Vol. 79 , No. 8, pp. 2554-2558, 1982 |
18 | | 1983 | 玻尔兹曼机生成模型被提出 | Fahlman, S. E., Hinton, G. E., & Sejnowski, T. J. (1983). Massively parallel architectures for Al: NETL, Thistle, and Boltzmann machines. Proceedings of AAAI-83109, 113 |
19 | | 1992 | Neal提出了sigmoid信念网 络 | Neal, R. M. (1992). Connectionist learning of belief networks. Artificial intelligence, 56(1), 71- 113 |
20 | | 2006 | Hinton提出深度信念网络 | Hinton, G. E., Osindero, S., & Teh, Y. W. (2006). A fast learning algorithm for deep belief nets. Neural computation, 18(7), 1527-1554 |
21 | | 2008 | 采用DBNs来完成回归任务 | Hinton, G. E., & Salakhutdinov, R. R. (2008). Using deep belief nets to learn covariance kernels for Gaussian processes. In Advances in neural information processing systems (pp. 1249-1256) |
22 | | 2009 | 将卷积深度信念网络用于可视物体识别 | Lee, H., Grosse, R., Ranganath, R., & Ng, A. Y. (2009, June). Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In Proceedings of the 26th annual international conference on machine learning (pp. 609-616). ACM |
23 | | 2012 | DBNs应用在语音识别领域 | Mohamed, A. R., Dahl, G. E., & Hinton, G. (2012). Acoustic modeling using deep belief networks. IEEE Transactions on Audio, Speech, and Language Processing, 20(1), 14-22 |
24 | | 2014 | Goodfellow提出生成对抗网络 | Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., ... & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672-2680) |
25 | | 2016 | Deepmind创建了一个深度 生成模型Wavenet,可用来 生成具有自然人声的语音 | Van Den Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., ... & Kavukcuoglu, K. (2016). Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499 |
26 |
27 | # Hopfield神经网络
28 |
29 | 神经网络可以分为,多层神经网络和相互连接型网络。
30 |
31 | - 多层神经网络:模式识别
32 | - 相互连接型网络:通过联想记忆去除数据中的噪声
33 |
34 |
14 |
15 | | 年份 | 事件 | 相关论文 |
16 | | :--: | :----------------------------------------------------------- | ------------------------------------------------------------ |
17 | | 1982 | Hopfield网络提出 | J. J . Hopfield . Neural networks and physical systems with emergent collective computational abilities. Proceedings of the National Academy of Sciences, Vol. 79 , No. 8, pp. 2554-2558, 1982 |
18 | | 1983 | 玻尔兹曼机生成模型被提出 | Fahlman, S. E., Hinton, G. E., & Sejnowski, T. J. (1983). Massively parallel architectures for Al: NETL, Thistle, and Boltzmann machines. Proceedings of AAAI-83109, 113 |
19 | | 1992 | Neal提出了sigmoid信念网 络 | Neal, R. M. (1992). Connectionist learning of belief networks. Artificial intelligence, 56(1), 71- 113 |
20 | | 2006 | Hinton提出深度信念网络 | Hinton, G. E., Osindero, S., & Teh, Y. W. (2006). A fast learning algorithm for deep belief nets. Neural computation, 18(7), 1527-1554 |
21 | | 2008 | 采用DBNs来完成回归任务 | Hinton, G. E., & Salakhutdinov, R. R. (2008). Using deep belief nets to learn covariance kernels for Gaussian processes. In Advances in neural information processing systems (pp. 1249-1256) |
22 | | 2009 | 将卷积深度信念网络用于可视物体识别 | Lee, H., Grosse, R., Ranganath, R., & Ng, A. Y. (2009, June). Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In Proceedings of the 26th annual international conference on machine learning (pp. 609-616). ACM |
23 | | 2012 | DBNs应用在语音识别领域 | Mohamed, A. R., Dahl, G. E., & Hinton, G. (2012). Acoustic modeling using deep belief networks. IEEE Transactions on Audio, Speech, and Language Processing, 20(1), 14-22 |
24 | | 2014 | Goodfellow提出生成对抗网络 | Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., ... & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672-2680) |
25 | | 2016 | Deepmind创建了一个深度 生成模型Wavenet,可用来 生成具有自然人声的语音 | Van Den Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., ... & Kavukcuoglu, K. (2016). Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499 |
26 |
27 | # Hopfield神经网络
28 |
29 | 神经网络可以分为,多层神经网络和相互连接型网络。
30 |
31 | - 多层神经网络:模式识别
32 | - 相互连接型网络:通过联想记忆去除数据中的噪声
33 |
34 |  35 |
36 | 1982年提出的 Hopfield 神经网络是最典型的相互连结型网络。
37 |
38 | 联想记忆就是当输入模式为某种状态时,输出端要给出与之相应的输出模式。如果输入模式与输出模式一致,称为自联想记忆,否则称为异联想记忆。
39 |
40 |
35 |
36 | 1982年提出的 Hopfield 神经网络是最典型的相互连结型网络。
37 |
38 | 联想记忆就是当输入模式为某种状态时,输出端要给出与之相应的输出模式。如果输入模式与输出模式一致,称为自联想记忆,否则称为异联想记忆。
39 |
40 |  41 |
42 | # 玻尔兹曼机和受限玻尔兹曼机
43 |
44 | ### 玻尔兹曼机
45 |
46 | - 玻尔兹曼机也是相互连接型网络
47 | - 如果发生串扰或陷入局部最优解,Hopfield神经网络就不能正确的 辨别模式。而玻尔兹曼机(Boltzmann Machine)则可以通过让每个单 元按照一定的概率分布发生状态变化,来避免陷入局部最优解
48 | - 玻尔兹曼机保持了**Hopfield**神经网络的假设:
49 | - 权重对称
50 | - 自身无连接
51 | - 二值输出
52 |
53 |
41 |
42 | # 玻尔兹曼机和受限玻尔兹曼机
43 |
44 | ### 玻尔兹曼机
45 |
46 | - 玻尔兹曼机也是相互连接型网络
47 | - 如果发生串扰或陷入局部最优解,Hopfield神经网络就不能正确的 辨别模式。而玻尔兹曼机(Boltzmann Machine)则可以通过让每个单 元按照一定的概率分布发生状态变化,来避免陷入局部最优解
48 | - 玻尔兹曼机保持了**Hopfield**神经网络的假设:
49 | - 权重对称
50 | - 自身无连接
51 | - 二值输出
52 |
53 |  54 |
55 | 玻尔兹曼机的输出是按照某种概率分布决定的:
56 |
57 | $$
58 | \left\{\begin{array}{l}p\left(x_{i}=1 \mid u_{i}\right)=\frac{\exp \left(\frac{x}{k T}\right)}{1+\exp \left(\frac{x}{k T}\right)} \\ p\left(x_{i}=0 \mid u_{i}\right)=\frac{1}{1+\exp \left(\frac{x}{k T}\right)}\end{array}\right.
59 | $$
60 |
61 | - $𝑇(>0)$表示温度系数,当 $𝑇$ 趋近于无穷时,无论 $𝑢_𝑖$ 取值如何,$𝑥_𝑖$ 等于1 或 0 的概率都是1/2,这种状态称为稳定状态(k是玻尔兹曼常数)。
62 |
63 | 附Hopfield网络的输出:
64 |
65 | $$
66 | x_{i}(t+1)=\left\{\begin{array}{ll}1, & u_{i}(t)>0 \\ x_{i}(t), & u_{i}(t)=0 \\ 0, & u_{i}(t)<0\end{array}\right.
67 | $$
68 |
69 | - 玻尔兹曼机选择模拟退火算法,可以先采用较大的温度系 数及进行粗调,然后逐渐减小温度系数进行微调
70 | - 温度系数越大,跳出局部最优解的概率越高。但是温度系数增大时, 获得能量函数极小值的概率就会降低
71 | - 反之,温度系数减小时,虽然获得能量函数极小值的概率增加了, 但是玻尔兹曼机需要经历较长时间才能达到稳定状态
72 |
73 | **模拟退火算法**
74 |
75 | 模拟退火是一种贪心算法,但是它的搜索过程引入了随机因素,以一定的概率来接受一个比当前解要差的解,因此有可能会跳出这个局部的最优解, 达到全局的最优解, 而且这个概率随 着时间推移逐渐降低(逐渐降低才能趋向稳定)
76 |
77 | **玻尔兹曼机的训练过程**
78 |
79 | 1. 训练准备:初始化连接权重 $𝑤_{𝑖𝑗}$ 和偏置 $𝑏_𝑖$
80 |
81 | 2. 调整参数
82 | 2.1 选取一个单元 $𝑖$, 求 $𝑢_𝑖$
83 | 2.2 根据$𝑢_𝑖$ 的值,计算输出 $𝑥_𝑖$
84 | 2.3 根据输出 $𝑥_𝑖$ 和 $𝑥_𝑗$ 的值,调整连接权重 $𝑤_{𝑖𝑗}$ 和偏置 $𝑏_𝑖$
85 |
86 | 重复步骤2,直到满足终止判断条件
87 |
88 | 通常,使用对数似然函数求解
89 |
90 | $$
91 | \ln L(\theta)=\sum_{n=1}^{N} \ln p\left(x_{n} \mid \theta\right)
92 | $$
93 |
94 | 当对数似然函数的梯度为0时,就可以得到最大似然估计量,即通 过求连接权重 $w_{ij}$ 和偏置 $b_i$ 的相关梯度,可以求出调整值。
95 |
96 | **求解困难**:似然函数是基于所有单元组合来计算的,所以单元数过多将导致组 合数异常庞大,无法进行实时计算。为了解决这个问题,人们提出 了一种近似算法,**对比散度算法**(后面有介绍)。
97 |
98 | ### 受限玻尔兹曼机
99 |
100 | - 前面介绍的玻尔兹曼机默认了所有单元都为可见单元,在 实际应用上,玻尔兹曼机还可以由可见单元和隐藏单元共同构成。
101 | - 隐藏单元与输入数据没有直接联系,但会影响可见单元的概率。假 设可见单元为可见变量 𝑣 ,隐藏单元为隐藏变量 h 。玻尔兹曼机含 有隐藏变量时,概率分布仍然与前面计算的结果相同
102 |
103 |
54 |
55 | 玻尔兹曼机的输出是按照某种概率分布决定的:
56 |
57 | $$
58 | \left\{\begin{array}{l}p\left(x_{i}=1 \mid u_{i}\right)=\frac{\exp \left(\frac{x}{k T}\right)}{1+\exp \left(\frac{x}{k T}\right)} \\ p\left(x_{i}=0 \mid u_{i}\right)=\frac{1}{1+\exp \left(\frac{x}{k T}\right)}\end{array}\right.
59 | $$
60 |
61 | - $𝑇(>0)$表示温度系数,当 $𝑇$ 趋近于无穷时,无论 $𝑢_𝑖$ 取值如何,$𝑥_𝑖$ 等于1 或 0 的概率都是1/2,这种状态称为稳定状态(k是玻尔兹曼常数)。
62 |
63 | 附Hopfield网络的输出:
64 |
65 | $$
66 | x_{i}(t+1)=\left\{\begin{array}{ll}1, & u_{i}(t)>0 \\ x_{i}(t), & u_{i}(t)=0 \\ 0, & u_{i}(t)<0\end{array}\right.
67 | $$
68 |
69 | - 玻尔兹曼机选择模拟退火算法,可以先采用较大的温度系 数及进行粗调,然后逐渐减小温度系数进行微调
70 | - 温度系数越大,跳出局部最优解的概率越高。但是温度系数增大时, 获得能量函数极小值的概率就会降低
71 | - 反之,温度系数减小时,虽然获得能量函数极小值的概率增加了, 但是玻尔兹曼机需要经历较长时间才能达到稳定状态
72 |
73 | **模拟退火算法**
74 |
75 | 模拟退火是一种贪心算法,但是它的搜索过程引入了随机因素,以一定的概率来接受一个比当前解要差的解,因此有可能会跳出这个局部的最优解, 达到全局的最优解, 而且这个概率随 着时间推移逐渐降低(逐渐降低才能趋向稳定)
76 |
77 | **玻尔兹曼机的训练过程**
78 |
79 | 1. 训练准备:初始化连接权重 $𝑤_{𝑖𝑗}$ 和偏置 $𝑏_𝑖$
80 |
81 | 2. 调整参数
82 | 2.1 选取一个单元 $𝑖$, 求 $𝑢_𝑖$
83 | 2.2 根据$𝑢_𝑖$ 的值,计算输出 $𝑥_𝑖$
84 | 2.3 根据输出 $𝑥_𝑖$ 和 $𝑥_𝑗$ 的值,调整连接权重 $𝑤_{𝑖𝑗}$ 和偏置 $𝑏_𝑖$
85 |
86 | 重复步骤2,直到满足终止判断条件
87 |
88 | 通常,使用对数似然函数求解
89 |
90 | $$
91 | \ln L(\theta)=\sum_{n=1}^{N} \ln p\left(x_{n} \mid \theta\right)
92 | $$
93 |
94 | 当对数似然函数的梯度为0时,就可以得到最大似然估计量,即通 过求连接权重 $w_{ij}$ 和偏置 $b_i$ 的相关梯度,可以求出调整值。
95 |
96 | **求解困难**:似然函数是基于所有单元组合来计算的,所以单元数过多将导致组 合数异常庞大,无法进行实时计算。为了解决这个问题,人们提出 了一种近似算法,**对比散度算法**(后面有介绍)。
97 |
98 | ### 受限玻尔兹曼机
99 |
100 | - 前面介绍的玻尔兹曼机默认了所有单元都为可见单元,在 实际应用上,玻尔兹曼机还可以由可见单元和隐藏单元共同构成。
101 | - 隐藏单元与输入数据没有直接联系,但会影响可见单元的概率。假 设可见单元为可见变量 𝑣 ,隐藏单元为隐藏变量 h 。玻尔兹曼机含 有隐藏变量时,概率分布仍然与前面计算的结果相同
102 |
103 |  104 |
105 | 含有隐藏变量的波尔兹曼机训练非常困难,所以Hinton等人提出了受限玻尔兹曼机(Restricted Boltzmann Machine)
106 |
107 | - 由可见层和隐藏层构成
108 | - 层内单元之间无连接
109 | - 信息可双向流动
110 |
111 | 下面是受限玻尔兹曼机的能量函数:
112 |
113 | $$
114 | \begin{gathered}
115 | E(\mathbf{v}, \mathbf{h}, \theta)=-\sum_{i=1}^{n_{v}} a_{i} v_{i}-\sum_{j=1}^{n_{h}} b_{j} h_{j}-\sum_{i=1}^{n_{v}} \sum_{j=1}^{n_{h}} w_{i j} v_{i} h_{j} \\
116 | E(\mathbf{v}, \mathbf{h}, \theta)=-\mathbf{a}^{T} \mathbf{v}-\mathbf{b}^{T} \mathbf{h}-\mathbf{h}^{T} W \mathbf{v}
117 | \end{gathered}
118 | $$
119 |
120 | 其中,$a_i$ 是可见变量的偏置,$b_j$ 是隐藏变量的偏置,$w_{ij}$ 是连接权重,$\theta = (W,a,b)$ 表示参数集合。
121 |
122 | # 深度玻尔兹曼机和深度信念网络
123 |
124 | 深度玻尔兹曼机(Deep Boltzmann Machine, DBM) 是由受限玻尔兹曼机堆叠组成。
125 |
126 | 深度信念网络(Deep Belief Network, DBN):最上面的两层之间有无方向的对称连接,形成联想记忆。下层从上层接收自上而下的定向连接。最底层单元的状态表示一个数据向量。
127 |
128 |
104 |
105 | 含有隐藏变量的波尔兹曼机训练非常困难,所以Hinton等人提出了受限玻尔兹曼机(Restricted Boltzmann Machine)
106 |
107 | - 由可见层和隐藏层构成
108 | - 层内单元之间无连接
109 | - 信息可双向流动
110 |
111 | 下面是受限玻尔兹曼机的能量函数:
112 |
113 | $$
114 | \begin{gathered}
115 | E(\mathbf{v}, \mathbf{h}, \theta)=-\sum_{i=1}^{n_{v}} a_{i} v_{i}-\sum_{j=1}^{n_{h}} b_{j} h_{j}-\sum_{i=1}^{n_{v}} \sum_{j=1}^{n_{h}} w_{i j} v_{i} h_{j} \\
116 | E(\mathbf{v}, \mathbf{h}, \theta)=-\mathbf{a}^{T} \mathbf{v}-\mathbf{b}^{T} \mathbf{h}-\mathbf{h}^{T} W \mathbf{v}
117 | \end{gathered}
118 | $$
119 |
120 | 其中,$a_i$ 是可见变量的偏置,$b_j$ 是隐藏变量的偏置,$w_{ij}$ 是连接权重,$\theta = (W,a,b)$ 表示参数集合。
121 |
122 | # 深度玻尔兹曼机和深度信念网络
123 |
124 | 深度玻尔兹曼机(Deep Boltzmann Machine, DBM) 是由受限玻尔兹曼机堆叠组成。
125 |
126 | 深度信念网络(Deep Belief Network, DBN):最上面的两层之间有无方向的对称连接,形成联想记忆。下层从上层接收自上而下的定向连接。最底层单元的状态表示一个数据向量。
127 |
128 |  129 |
130 | 参考论文:
131 |
132 | [1] Hinton, Geoffrey E., Simon Osindero, and Yee-Whye Teh. "A fast learning algorithm for deep belief nets." Neural computation 18, no. 7 (2006): 1527-1554.
133 | [2] Hinton GE. Deep belief networks. Scholarpedia. 2009 May 31;4(5):5947.
134 |
135 | 深度玻尔兹曼机采用与多层神经网络不同的训练方法,在训练时采用对比散度算法,逐层来调整连接权重和偏置。
136 |
137 | 具体做法:
138 |
139 | - 首先训练输入层和隐藏层之间的参数,把训练后得到的参数作为下一层的输入
140 | - 再调整该层与下一个隐藏层之间的参数
141 | - 然后逐次迭代,完成多层网络的训练
142 |
143 |
129 |
130 | 参考论文:
131 |
132 | [1] Hinton, Geoffrey E., Simon Osindero, and Yee-Whye Teh. "A fast learning algorithm for deep belief nets." Neural computation 18, no. 7 (2006): 1527-1554.
133 | [2] Hinton GE. Deep belief networks. Scholarpedia. 2009 May 31;4(5):5947.
134 |
135 | 深度玻尔兹曼机采用与多层神经网络不同的训练方法,在训练时采用对比散度算法,逐层来调整连接权重和偏置。
136 |
137 | 具体做法:
138 |
139 | - 首先训练输入层和隐藏层之间的参数,把训练后得到的参数作为下一层的输入
140 | - 再调整该层与下一个隐藏层之间的参数
141 | - 然后逐次迭代,完成多层网络的训练
142 |
143 |  144 |
145 | 深度玻尔兹曼机既可以当作生成模型,也可以当作判别模型
146 |
147 | - 作为生成模型使用时,网络会按照某种概率分布生成训练数据。概 率分布可根据训练样本导出,但是覆盖全部数据模式的概率分布很难导出,所以通常选择最大似然估计法训练参数,得到最能覆盖训练样本的概率分布
148 |
149 | 这种生成模型能够:去除输入数据中含有的噪声,得到新的数据, 对输入数据压缩和特征表达
150 |
151 | - 作为判别模型使用时,需要在模型顶层添加一层Softmax实现分类
152 |
153 | 进行分类时,需要同时提供训练样本和期望输出,在最顶层级联一 个𝑆𝑜𝑓𝑡𝑚𝑎𝑥层
154 |
155 | 训练方法:
156 |
157 | - 除最顶层外,其他各层都可以使用无监督学习进行训练。
158 | - 把训练得到的参数作为初始值,使用误差反向传播算法对包含最顶 层的神经网络进行训练
159 | - 最顶层的参数使用随机数进行初始化
160 |
161 | # 自编码器
162 |
163 | 自编码器(Autoencoder):是一种有效的数据维度压缩算法, 主要应用在以下两个方面:
164 |
165 | - 构建一种能够重构输入样本并进行特征表达的神经网络
166 | - 特征表达:是指对于分类会发生变动的不稳定模式,例如手写字体识 别中由于不同人的书写习惯和风格的不同造成字符模式不稳定,或者输入样本中包含噪声等情况,神经网络也能将其转换成可以准确识别的特征。
167 |
168 | - 训练多层神经网络时,通过自编码器训练样本得到参数初始值
169 |
170 |
144 |
145 | 深度玻尔兹曼机既可以当作生成模型,也可以当作判别模型
146 |
147 | - 作为生成模型使用时,网络会按照某种概率分布生成训练数据。概 率分布可根据训练样本导出,但是覆盖全部数据模式的概率分布很难导出,所以通常选择最大似然估计法训练参数,得到最能覆盖训练样本的概率分布
148 |
149 | 这种生成模型能够:去除输入数据中含有的噪声,得到新的数据, 对输入数据压缩和特征表达
150 |
151 | - 作为判别模型使用时,需要在模型顶层添加一层Softmax实现分类
152 |
153 | 进行分类时,需要同时提供训练样本和期望输出,在最顶层级联一 个𝑆𝑜𝑓𝑡𝑚𝑎𝑥层
154 |
155 | 训练方法:
156 |
157 | - 除最顶层外,其他各层都可以使用无监督学习进行训练。
158 | - 把训练得到的参数作为初始值,使用误差反向传播算法对包含最顶 层的神经网络进行训练
159 | - 最顶层的参数使用随机数进行初始化
160 |
161 | # 自编码器
162 |
163 | 自编码器(Autoencoder):是一种有效的数据维度压缩算法, 主要应用在以下两个方面:
164 |
165 | - 构建一种能够重构输入样本并进行特征表达的神经网络
166 | - 特征表达:是指对于分类会发生变动的不稳定模式,例如手写字体识 别中由于不同人的书写习惯和风格的不同造成字符模式不稳定,或者输入样本中包含噪声等情况,神经网络也能将其转换成可以准确识别的特征。
167 |
168 | - 训练多层神经网络时,通过自编码器训练样本得到参数初始值
169 |
170 |  171 |
172 | - 自编码器是一种基于无监督学习的神经网络,目的在于通过不断调整参数, 重构经过维度压缩的输入样本
173 |
174 |
171 |
172 | - 自编码器是一种基于无监督学习的神经网络,目的在于通过不断调整参数, 重构经过维度压缩的输入样本
173 |
174 |  175 |
176 | 当样本中包含噪声时,如果神经网络能够消除噪声,则被称为降噪自编码器(**Denoising Autoencoder**),还有一种称为稀疏自编码器**( Sparse Autoencoder )**的网络, 它在自编码器中引入了正则化项,以去除冗余信息。
177 |
--------------------------------------------------------------------------------
/docs/理论进阶/13.深度学习平台.md:
--------------------------------------------------------------------------------
1 | # 深度学习平台概况
2 |
3 | 这一章为大家介绍五种非常有用的深度学习框架,并介绍他们各自的优缺点。
4 |
5 | 很多人不喜欢造轮子的过程,喜欢实用主义,将轮子拼接起来
6 |
7 | 但是当需要为现实世界的数据集构建深度学习模型时,这还是一个不错的主意吗?如果你需要几天或几周的时间来建立起模型,这是完全不可能的。
8 |
9 | 值得庆幸的是,我们现在已经有了易于使用的开源深度学习框架,旨在简化复杂和大规模深度学习模型的实现。使用这些神奇的框架,我们可以实现诸如卷积神经网络这样复杂的模型。
10 |
11 | > A deep learning framework is an interface, library or a tool which allows us to build deep learning models more easily and quickly , without getting into the details of underlying algorithms . They provide a clear and concise way for defining models using a collection of pre-built and optimized components.
12 |
13 | 什么是深度学习框架:深度学习框架是一种界面、库或工具,它使我们在无需深入了解底层算法的细节的情况下,能够更容易、更快速地构建深度学习模型。深度学习框架利用预先构建和优化好的组件集合定义模型,为模型的实现提供了一种清晰而简洁的方法。
14 |
15 | 利用恰当的框架来快速构建模型,而无需编写数百行代码,一个良好的深度学习框架具备以下关键特征:
16 |
17 | - 优化的性能
18 | - 易于理解和编码
19 | - 良好的社区支持
20 | - 并行化的进程,以减少计算
21 | - 自动计算梯度
22 |
23 | 这五点也是我用来挑选顶级深度学习框架的标准。
24 |
25 | 深度学习框架对照
26 |
27 |
175 |
176 | 当样本中包含噪声时,如果神经网络能够消除噪声,则被称为降噪自编码器(**Denoising Autoencoder**),还有一种称为稀疏自编码器**( Sparse Autoencoder )**的网络, 它在自编码器中引入了正则化项,以去除冗余信息。
177 |
--------------------------------------------------------------------------------
/docs/理论进阶/13.深度学习平台.md:
--------------------------------------------------------------------------------
1 | # 深度学习平台概况
2 |
3 | 这一章为大家介绍五种非常有用的深度学习框架,并介绍他们各自的优缺点。
4 |
5 | 很多人不喜欢造轮子的过程,喜欢实用主义,将轮子拼接起来
6 |
7 | 但是当需要为现实世界的数据集构建深度学习模型时,这还是一个不错的主意吗?如果你需要几天或几周的时间来建立起模型,这是完全不可能的。
8 |
9 | 值得庆幸的是,我们现在已经有了易于使用的开源深度学习框架,旨在简化复杂和大规模深度学习模型的实现。使用这些神奇的框架,我们可以实现诸如卷积神经网络这样复杂的模型。
10 |
11 | > A deep learning framework is an interface, library or a tool which allows us to build deep learning models more easily and quickly , without getting into the details of underlying algorithms . They provide a clear and concise way for defining models using a collection of pre-built and optimized components.
12 |
13 | 什么是深度学习框架:深度学习框架是一种界面、库或工具,它使我们在无需深入了解底层算法的细节的情况下,能够更容易、更快速地构建深度学习模型。深度学习框架利用预先构建和优化好的组件集合定义模型,为模型的实现提供了一种清晰而简洁的方法。
14 |
15 | 利用恰当的框架来快速构建模型,而无需编写数百行代码,一个良好的深度学习框架具备以下关键特征:
16 |
17 | - 优化的性能
18 | - 易于理解和编码
19 | - 良好的社区支持
20 | - 并行化的进程,以减少计算
21 | - 自动计算梯度
22 |
23 | 这五点也是我用来挑选顶级深度学习框架的标准。
24 |
25 | 深度学习框架对照
26 |
27 |  28 |
29 | 2018年GitHub统计
30 |
31 |
28 |
29 | 2018年GitHub统计
30 |
31 |  32 |
33 | 2019年GitHub统计
34 |
35 |
32 |
33 | 2019年GitHub统计
34 |
35 |  36 |
37 | # Tensorflow
38 |
39 | TensorFlow是由谷歌大脑团队的研究人员和工程师开发的,它是深度学习领域中最常用的软件库(尽管其他软件正在迅速崛起)。
40 |
41 | > The two things I really like about TensorFlow - it's completely open source and has excellent community support. TensorFlow has pre-written codes for most of the complex deep learning models you'll come across, such as RNN and CNN.
42 |
43 | TensorFlow有两大特点:它完全是开源的,并且有出色的社区支持。TensorFlow为大多数复杂的深度学习模型预先编写好了代码,比如循环神经网络和卷积神经网络。
44 |
45 | TensorFlow如此流行的最大原因之一是支持多种语言来创建深度学习模型,比如Python、C和R,并且有不错的文档和指南。
46 |
47 | TensorFlow有许多组件,其中最为突出的是:
48 |
49 | - **Tensorboard:**帮助使用数据流图进行有效的数据可视化
50 | - **TensorFlow:**用于快速部署新算法/试验
51 |
52 | TensorFlow的灵活架构使我们能够在一个或多个CPU(以及GPU)上部署深度学习模型。下面是一些典型的TensorFlow用例:
53 |
54 | - 基于文本的应用:语言检测、文本摘要
55 | - 图像识别:图像字幕、人脸识别、目标检测
56 | - 声音识别
57 | - 时间序列分析
58 | - 视频分析
59 | - ...
60 |
61 |
62 |
63 |
64 |
65 | # PyTorch
66 |
67 | 在我所研究过的框架中,PyTorch最富灵活性。
68 |
69 | PyTorch是Torch深度学习框架的一个接口,可用于建立深度神经网络和执行张量计算。Torch是一个基于Lua的框架,而PyTorch则运行在Python上。
70 |
71 | PyTorch是一个Python包,它提供张量计算。张量是多维数组,就像numpy的ndarray一样,它也可以在GPU上运行。PyTorch使用动态计算图,PyTorch的Autograd软件包从张量生成计算图,并自动计算梯度。与特定功能的预定义的图表不同,PyTorch提供了一个框架,用于在运行时构建计算图形,甚至在运行时也可以对这些图形进行更改。当不知道创建神经网络需要多少内存的情况下,这个功能便很有价值。
72 |
73 | 可以使用PyTorch处理各种来自深度学习的挑战,包括:
74 |
75 | - 影像(检测、分类等)
76 | - 文本(NLP)
77 | - 增强学习
78 |
79 |
80 |
81 | # Keras
82 |
83 | 如果你习惯使用python,那么可以立即上手到Keras。这是一个非常适合你的深度学习之旅的完美的框架。
84 |
85 | Keras用Python编写,可以在TensorFlow(以及CNTK和Theano)之上运行。TensorFlow的接口具备挑战性,因为它是一个低级库,新用户可能会很难理解某些实现。而Keras是一个高层的API,它为快速实验而开发。因此,如果希望获得快速结果,Keras会自动处理核心任务并生成输出。Keras支持卷积神经网络和递归神经网络,可以在CPU和GPU上无缝运行。
86 |
87 | 深度学习的初学者经常会抱怨:无法正确理解复杂的模型。如果你是这样的用户,Keras便是你的正确选择!它的目标是最小化用户操作,并使其模型真正容易理解。
88 |
89 | 可以将Keras中的模型大致分为两类:
90 |
91 | **1. 序列化**
92 | 模型的层是按顺序定义的。这意味着当我们训练深度学习模型时,这些层次是按顺序实现的。下面是一个顺序模型的示例:
93 | from keras.models import Sequential from keras.layers import Dense model = Sequential() # we can add multiple layers to the model using .add() model.add(Dense(units=64, activation='relu', input_dim=100)) model.add(Dense(units=10, activation='softmax'))
94 | **2. Keras 函数API**
95 | 用于定义复杂模型,例如多输出模型或具有共享层的模型。请查看下面的代码来理解这一点:
96 | from keras.layers import Input, Dense from keras.models import Model inputs = Input(shape=(100,)) # specify the input shape x = Dense(64, activation='relu')(inputs) predictions = Dense(10, activation='softmax')(x) model = Model(inputs=inputs, outputs=predictions)
97 |
98 | # PaddlePaddle
99 |
100 | **PaddlePaddle**是百度提供的开源深度学习框架,致力于为开发者和企业提供最好的深度学习研发体验,框架本身具有易学、易用、安全、高效四大特性,是最适合中国开发者和企业的深度学习工具。
101 |
102 | - 网址:http://www.paddlepaddle.org/zh
103 |
104 |
36 |
37 | # Tensorflow
38 |
39 | TensorFlow是由谷歌大脑团队的研究人员和工程师开发的,它是深度学习领域中最常用的软件库(尽管其他软件正在迅速崛起)。
40 |
41 | > The two things I really like about TensorFlow - it's completely open source and has excellent community support. TensorFlow has pre-written codes for most of the complex deep learning models you'll come across, such as RNN and CNN.
42 |
43 | TensorFlow有两大特点:它完全是开源的,并且有出色的社区支持。TensorFlow为大多数复杂的深度学习模型预先编写好了代码,比如循环神经网络和卷积神经网络。
44 |
45 | TensorFlow如此流行的最大原因之一是支持多种语言来创建深度学习模型,比如Python、C和R,并且有不错的文档和指南。
46 |
47 | TensorFlow有许多组件,其中最为突出的是:
48 |
49 | - **Tensorboard:**帮助使用数据流图进行有效的数据可视化
50 | - **TensorFlow:**用于快速部署新算法/试验
51 |
52 | TensorFlow的灵活架构使我们能够在一个或多个CPU(以及GPU)上部署深度学习模型。下面是一些典型的TensorFlow用例:
53 |
54 | - 基于文本的应用:语言检测、文本摘要
55 | - 图像识别:图像字幕、人脸识别、目标检测
56 | - 声音识别
57 | - 时间序列分析
58 | - 视频分析
59 | - ...
60 |
61 |
62 |
63 |
64 |
65 | # PyTorch
66 |
67 | 在我所研究过的框架中,PyTorch最富灵活性。
68 |
69 | PyTorch是Torch深度学习框架的一个接口,可用于建立深度神经网络和执行张量计算。Torch是一个基于Lua的框架,而PyTorch则运行在Python上。
70 |
71 | PyTorch是一个Python包,它提供张量计算。张量是多维数组,就像numpy的ndarray一样,它也可以在GPU上运行。PyTorch使用动态计算图,PyTorch的Autograd软件包从张量生成计算图,并自动计算梯度。与特定功能的预定义的图表不同,PyTorch提供了一个框架,用于在运行时构建计算图形,甚至在运行时也可以对这些图形进行更改。当不知道创建神经网络需要多少内存的情况下,这个功能便很有价值。
72 |
73 | 可以使用PyTorch处理各种来自深度学习的挑战,包括:
74 |
75 | - 影像(检测、分类等)
76 | - 文本(NLP)
77 | - 增强学习
78 |
79 |
80 |
81 | # Keras
82 |
83 | 如果你习惯使用python,那么可以立即上手到Keras。这是一个非常适合你的深度学习之旅的完美的框架。
84 |
85 | Keras用Python编写,可以在TensorFlow(以及CNTK和Theano)之上运行。TensorFlow的接口具备挑战性,因为它是一个低级库,新用户可能会很难理解某些实现。而Keras是一个高层的API,它为快速实验而开发。因此,如果希望获得快速结果,Keras会自动处理核心任务并生成输出。Keras支持卷积神经网络和递归神经网络,可以在CPU和GPU上无缝运行。
86 |
87 | 深度学习的初学者经常会抱怨:无法正确理解复杂的模型。如果你是这样的用户,Keras便是你的正确选择!它的目标是最小化用户操作,并使其模型真正容易理解。
88 |
89 | 可以将Keras中的模型大致分为两类:
90 |
91 | **1. 序列化**
92 | 模型的层是按顺序定义的。这意味着当我们训练深度学习模型时,这些层次是按顺序实现的。下面是一个顺序模型的示例:
93 | from keras.models import Sequential from keras.layers import Dense model = Sequential() # we can add multiple layers to the model using .add() model.add(Dense(units=64, activation='relu', input_dim=100)) model.add(Dense(units=10, activation='softmax'))
94 | **2. Keras 函数API**
95 | 用于定义复杂模型,例如多输出模型或具有共享层的模型。请查看下面的代码来理解这一点:
96 | from keras.layers import Input, Dense from keras.models import Model inputs = Input(shape=(100,)) # specify the input shape x = Dense(64, activation='relu')(inputs) predictions = Dense(10, activation='softmax')(x) model = Model(inputs=inputs, outputs=predictions)
97 |
98 | # PaddlePaddle
99 |
100 | **PaddlePaddle**是百度提供的开源深度学习框架,致力于为开发者和企业提供最好的深度学习研发体验,框架本身具有易学、易用、安全、高效四大特性,是最适合中国开发者和企业的深度学习工具。
101 |
102 | - 网址:http://www.paddlepaddle.org/zh
103 |
104 |  105 |
106 | #### 功能特点
107 |
108 | •教程文档友好,提供jupyter文档
109 |
110 | **开源**
111 |
112 | •开源,代码在github上公开
113 | • 社区活跃,合作伙伴支持,有很多的贡献者
114 |
115 | **速度快、方便**
116 |
117 | • 底层C++编写,运行速度快,占用内存少
118 | • 接口Python,使用方便,开发便捷
119 |
120 | **分布式系统**
121 |
122 | • 底层硬件同时支持CPU和GPU
123 | • 分布式系统,支持单机运行和云上运行
124 |
125 | **部署方便**
126 |
127 | • 支持docker部署和原生包部署
128 | • 支持多操作系统windows、 macOS、 Linux
129 |
130 | #### 优势
131 |
132 | 提供搭建私有云的全套解决方案
133 |
134 | - 帮助用户保护数据
135 | - 充分支持分布式系统
136 | - 模型并行和数据并行
137 |
138 | 灵活易用且性能高
139 |
140 | - 支持多种机器学习和优化算法,可定 制
141 | - 全面支持多机、多GPU环境,优化的 通信实现使高吞吐与高性能成为可能
142 |
143 | # MindSpore
144 |
145 | 教育部**-**华为“智能基座” 产教融合协同育人基地
146 |
147 |
105 |
106 | #### 功能特点
107 |
108 | •教程文档友好,提供jupyter文档
109 |
110 | **开源**
111 |
112 | •开源,代码在github上公开
113 | • 社区活跃,合作伙伴支持,有很多的贡献者
114 |
115 | **速度快、方便**
116 |
117 | • 底层C++编写,运行速度快,占用内存少
118 | • 接口Python,使用方便,开发便捷
119 |
120 | **分布式系统**
121 |
122 | • 底层硬件同时支持CPU和GPU
123 | • 分布式系统,支持单机运行和云上运行
124 |
125 | **部署方便**
126 |
127 | • 支持docker部署和原生包部署
128 | • 支持多操作系统windows、 macOS、 Linux
129 |
130 | #### 优势
131 |
132 | 提供搭建私有云的全套解决方案
133 |
134 | - 帮助用户保护数据
135 | - 充分支持分布式系统
136 | - 模型并行和数据并行
137 |
138 | 灵活易用且性能高
139 |
140 | - 支持多种机器学习和优化算法,可定 制
141 | - 全面支持多机、多GPU环境,优化的 通信实现使高吞吐与高性能成为可能
142 |
143 | # MindSpore
144 |
145 | 教育部**-**华为“智能基座” 产教融合协同育人基地
146 |
147 |  148 |
149 | **MindSpore**(**AI**框架):全场景**AI**框架(类似TensorFlow、Pytorch)
150 |
151 | - https://www.mindspore.cn/
152 | - MindSpore提供了Python编程范式
153 | - MindSpore提供了动态图和静态图统一的编码方式
154 | - 能够用串行算法代码,自动实现分布式并行训练
155 | - 具备训练过程静态执行和动态调试能力,开发者通过变更一行代码 即可切换模式,快速在线定位问题
156 | - 最佳匹配昇腾处理器,最大程度地发挥硬件能力,帮助开发者缩短 训练时间,提升推理性能
157 | - 支持云、边缘和手机上的快速部署,实现更好的资源利用和隐私保 护
--------------------------------------------------------------------------------
/docs/理论进阶/14.GAN.md:
--------------------------------------------------------------------------------
1 | 生成对抗网络 Generative Adversarial Networks
2 |
3 | # GAN产生背景
4 |
5 | 机器学习方法有两种,**生成方法**和**判别方法**。
6 |
7 | - 生成方法,所学到到模型称为生成式模型
8 | - 生成方法通过观测数据学习样本与标签的联合概率分布P(X,Y),训练好的模型,即生成模型,能够生成符合样本分布的新数据;
9 | - 生成式模型在无监督深度学习方面占据主要位置,可以用于在没有目标类标签信息的情况下捕捉观测到或可见数据的高阶相关性 – 判别方法,所学到的模型称为判别式模型。
10 |
11 | - 判别方法由数据直接学习决策函数f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型
12 | - 判别模型经常用在有监督学习方面;
13 | - 判别方法关心的是对给定的输入X,应该预测什么样的输出Y。
14 |
15 | 有监督学习经常比无监督学习获得更好的模型,但是有监督学习需 要大量的标注数据,从长远看无监督学习更有发展前景。但是支持无监督学习的生成式模型会遇到下面两大困难:
16 |
17 | - 首先是人们需要大量的先验知识去对真实世界进行建模,而建模的好坏直接影响着我们的生成模型的表现;
18 | - 真实世界的数据往往很复杂,人们要用来拟合模型的计算量往往非常庞大,甚至难以承受。
19 |
20 | # GAN的概况
21 |
22 | **GAN的提出**
23 |
24 | 2014年,生成对抗网络(Generative Adversarial Networks, GAN)由当时还在蒙特利尔读博士的Ian Goodfellow(导师Bengio)提出。
25 |
26 | - 2016年,GAN热潮席卷AI领域顶级会议,从ICLR到NIPS,大量高质量论文被发表和探讨
27 | - 2017年入选MIT评论35岁以下创新人物
28 |
29 | **GAN的基本原理**
30 |
31 | GAN起源于博弈论中的二人零和博弈(获胜1,失败-1)
32 |
33 | - 由两个互为敌手的模型组成
34 | - 生成模型(假币制造者团队)
35 | - 判别模型(警察团队)
36 | - 竞争使得两个团队不断改进他们的方法直到无法区分假币与真币
37 |
38 |
148 |
149 | **MindSpore**(**AI**框架):全场景**AI**框架(类似TensorFlow、Pytorch)
150 |
151 | - https://www.mindspore.cn/
152 | - MindSpore提供了Python编程范式
153 | - MindSpore提供了动态图和静态图统一的编码方式
154 | - 能够用串行算法代码,自动实现分布式并行训练
155 | - 具备训练过程静态执行和动态调试能力,开发者通过变更一行代码 即可切换模式,快速在线定位问题
156 | - 最佳匹配昇腾处理器,最大程度地发挥硬件能力,帮助开发者缩短 训练时间,提升推理性能
157 | - 支持云、边缘和手机上的快速部署,实现更好的资源利用和隐私保 护
--------------------------------------------------------------------------------
/docs/理论进阶/14.GAN.md:
--------------------------------------------------------------------------------
1 | 生成对抗网络 Generative Adversarial Networks
2 |
3 | # GAN产生背景
4 |
5 | 机器学习方法有两种,**生成方法**和**判别方法**。
6 |
7 | - 生成方法,所学到到模型称为生成式模型
8 | - 生成方法通过观测数据学习样本与标签的联合概率分布P(X,Y),训练好的模型,即生成模型,能够生成符合样本分布的新数据;
9 | - 生成式模型在无监督深度学习方面占据主要位置,可以用于在没有目标类标签信息的情况下捕捉观测到或可见数据的高阶相关性 – 判别方法,所学到的模型称为判别式模型。
10 |
11 | - 判别方法由数据直接学习决策函数f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型
12 | - 判别模型经常用在有监督学习方面;
13 | - 判别方法关心的是对给定的输入X,应该预测什么样的输出Y。
14 |
15 | 有监督学习经常比无监督学习获得更好的模型,但是有监督学习需 要大量的标注数据,从长远看无监督学习更有发展前景。但是支持无监督学习的生成式模型会遇到下面两大困难:
16 |
17 | - 首先是人们需要大量的先验知识去对真实世界进行建模,而建模的好坏直接影响着我们的生成模型的表现;
18 | - 真实世界的数据往往很复杂,人们要用来拟合模型的计算量往往非常庞大,甚至难以承受。
19 |
20 | # GAN的概况
21 |
22 | **GAN的提出**
23 |
24 | 2014年,生成对抗网络(Generative Adversarial Networks, GAN)由当时还在蒙特利尔读博士的Ian Goodfellow(导师Bengio)提出。
25 |
26 | - 2016年,GAN热潮席卷AI领域顶级会议,从ICLR到NIPS,大量高质量论文被发表和探讨
27 | - 2017年入选MIT评论35岁以下创新人物
28 |
29 | **GAN的基本原理**
30 |
31 | GAN起源于博弈论中的二人零和博弈(获胜1,失败-1)
32 |
33 | - 由两个互为敌手的模型组成
34 | - 生成模型(假币制造者团队)
35 | - 判别模型(警察团队)
36 | - 竞争使得两个团队不断改进他们的方法直到无法区分假币与真币
37 |
38 |  39 |
40 | 参考:Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, Yoshua Bengio. Generative Adversarial Nets. NIPS 2014: 2672-2680
41 |
42 | **GAN的评价**
43 |
44 | Yann LeCun评价GAN:
45 |
46 | - 我们一直在错过一个关键因素就是无监督/预测学习,这是指:机器给真实环境建模、预测可能的未来、并通过观察和演示来理解世界是如何运行的能力。
47 | - GAN为创建无监督学习提供了强有力的算法框架,有望帮助我们为AI加入常识,我们认为,沿着这条路走下去,有不小的成功的机会能开发出更智慧的AI。
48 |
49 | **The GAN Zoo**
50 |
51 | - https://github.com/hindupuravinash/the-gan-zoo
52 | - ABC-GAN, AC-GAN...
53 | - BAGAN, BCGAN...
54 | - C-GAN, CA-GAN...
55 |
56 |
39 |
40 | 参考:Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, Yoshua Bengio. Generative Adversarial Nets. NIPS 2014: 2672-2680
41 |
42 | **GAN的评价**
43 |
44 | Yann LeCun评价GAN:
45 |
46 | - 我们一直在错过一个关键因素就是无监督/预测学习,这是指:机器给真实环境建模、预测可能的未来、并通过观察和演示来理解世界是如何运行的能力。
47 | - GAN为创建无监督学习提供了强有力的算法框架,有望帮助我们为AI加入常识,我们认为,沿着这条路走下去,有不小的成功的机会能开发出更智慧的AI。
48 |
49 | **The GAN Zoo**
50 |
51 | - https://github.com/hindupuravinash/the-gan-zoo
52 | - ABC-GAN, AC-GAN...
53 | - BAGAN, BCGAN...
54 | - C-GAN, CA-GAN...
55 |
56 |  57 |
58 | # GAN模型
59 |
60 | ### 生成模型中的问题
61 |
62 | **自编码器**
63 |
64 |
57 |
58 | # GAN模型
59 |
60 | ### 生成模型中的问题
61 |
62 | **自编码器**
63 |
64 |  65 |
66 | **概率模型**
67 |
68 | - 按照某种概率分布生成数据,得到最能覆盖训练样本的概率分布
69 | - 需要确定样本的概率模型,即显式地定义概率密度函数
70 |
71 | 对于GAN模型,我们就是改进这些问题,做到估计样本概率分布却不需要显示定义概率分布
72 |
73 |
65 |
66 | **概率模型**
67 |
68 | - 按照某种概率分布生成数据,得到最能覆盖训练样本的概率分布
69 | - 需要确定样本的概率模型,即显式地定义概率密度函数
70 |
71 | 对于GAN模型,我们就是改进这些问题,做到估计样本概率分布却不需要显示定义概率分布
72 |
73 |  74 |
75 | ### GAN模型示例
76 |
77 | **生成模型**
78 |
79 | - 捕捉样本数据的分布,用服从某一分布(均匀分布,高斯分布)的 噪声z生成一个类似真实训练数据的样本,追求效果是越像真实的 数据越好
80 | - $p_{data} (x)$ 表示真实数据的x分布
81 | - $p_z (z)$ 表示输入噪声变量z的分布
82 | - $p_g$ 表示在数据x上学习得到的生成样本的分布
83 | - $𝐺(z;\theta_g)$ 表示生成模型(多层感知器)
84 |
85 | **判别模型**
86 |
87 | - 一个二分类器,估计一个样本来自训练数据(而非生成数据)的概率,如果样本来自真实的训练数据,输出大概率,否则,输出小概率。
88 | - $D(x;\theta_d)$ 表示判别模型(多层感知器)
89 | - $D(x)$ 表示x来自真实数据而非生成数据的概率
90 |
91 | 用网络代替概率模型$P(x;\theta),P_{data}(x)$
92 |
93 |
74 |
75 | ### GAN模型示例
76 |
77 | **生成模型**
78 |
79 | - 捕捉样本数据的分布,用服从某一分布(均匀分布,高斯分布)的 噪声z生成一个类似真实训练数据的样本,追求效果是越像真实的 数据越好
80 | - $p_{data} (x)$ 表示真实数据的x分布
81 | - $p_z (z)$ 表示输入噪声变量z的分布
82 | - $p_g$ 表示在数据x上学习得到的生成样本的分布
83 | - $𝐺(z;\theta_g)$ 表示生成模型(多层感知器)
84 |
85 | **判别模型**
86 |
87 | - 一个二分类器,估计一个样本来自训练数据(而非生成数据)的概率,如果样本来自真实的训练数据,输出大概率,否则,输出小概率。
88 | - $D(x;\theta_d)$ 表示判别模型(多层感知器)
89 | - $D(x)$ 表示x来自真实数据而非生成数据的概率
90 |
91 | 用网络代替概率模型$P(x;\theta),P_{data}(x)$
92 |
93 |  94 |
95 | ### GAN目标函数和损失函数
96 |
97 | $$
98 | \min _{G} \max _{D} V(G, D)=E_{x \sim p_{\text {data }}(x)}[\log D(x)]+E_{z \sim p_{z}(z)}[\log (1-D(G(z)))]
99 | $$
100 |
101 | - 训练GAN的时候,判别模型希望目标函数最大化,也就是使判别模 型判断真实样本为“真”,判断生成样本为“假”的概率最大化, 要尽量最大化自己的判别准确率
102 | - 判别模型也可以写成损失函数的形式:
103 |
104 | $$
105 | L(G, D)=-E_{x \sim p_{\text {data }}(x)}[\log D(x)]-E_{z \sim p_{z}(z)}[\log (1-D(G(z)))]
106 | $$
107 |
108 | - 与之相反,生成模型希望该目标函数最小化,也就是降低 判别模型对数据来源判断正确的概率,要最小化判别模型 的判别准确率
109 |
110 | ### GAN模型训练
111 |
112 | - GAN在训练的过程中固定一方,更新另一方的网络权重
113 | - 交替迭代,在这个过程中,双方都极力优化自己的网络, 从而形成竞争对抗,直到双方达到一个动态的平衡(纳什均衡)
114 | - 此时生成模型的数据分布无限接近训练数据的分布(造出 了和真实数据一模一样的样本),判别模型再也判别不出 来真实数据和生成数据,准确率为50%。
115 |
116 | 固定**G**,训练**D**时,最优的判别器为:
117 |
118 | $$
119 | D_{G}^{*}=\frac{p_{\text {data }}(\boldsymbol{x})}{p_{\text {data }}(\boldsymbol{x})+p_{g}(\boldsymbol{x})}
120 | $$
121 |
122 | 证明:
123 |
124 |
94 |
95 | ### GAN目标函数和损失函数
96 |
97 | $$
98 | \min _{G} \max _{D} V(G, D)=E_{x \sim p_{\text {data }}(x)}[\log D(x)]+E_{z \sim p_{z}(z)}[\log (1-D(G(z)))]
99 | $$
100 |
101 | - 训练GAN的时候,判别模型希望目标函数最大化,也就是使判别模 型判断真实样本为“真”,判断生成样本为“假”的概率最大化, 要尽量最大化自己的判别准确率
102 | - 判别模型也可以写成损失函数的形式:
103 |
104 | $$
105 | L(G, D)=-E_{x \sim p_{\text {data }}(x)}[\log D(x)]-E_{z \sim p_{z}(z)}[\log (1-D(G(z)))]
106 | $$
107 |
108 | - 与之相反,生成模型希望该目标函数最小化,也就是降低 判别模型对数据来源判断正确的概率,要最小化判别模型 的判别准确率
109 |
110 | ### GAN模型训练
111 |
112 | - GAN在训练的过程中固定一方,更新另一方的网络权重
113 | - 交替迭代,在这个过程中,双方都极力优化自己的网络, 从而形成竞争对抗,直到双方达到一个动态的平衡(纳什均衡)
114 | - 此时生成模型的数据分布无限接近训练数据的分布(造出 了和真实数据一模一样的样本),判别模型再也判别不出 来真实数据和生成数据,准确率为50%。
115 |
116 | 固定**G**,训练**D**时,最优的判别器为:
117 |
118 | $$
119 | D_{G}^{*}=\frac{p_{\text {data }}(\boldsymbol{x})}{p_{\text {data }}(\boldsymbol{x})+p_{g}(\boldsymbol{x})}
120 | $$
121 |
122 | 证明:
123 |
124 |  125 |
126 |
125 |
126 |  127 |
128 | 全局最优的生成函数值**-log4**
129 |
130 |
127 |
128 | 全局最优的生成函数值**-log4**
129 |
130 |  131 |
132 |
131 |
132 |  133 |
134 | ### 优势和不足
135 |
136 | **优势**
137 |
138 | - 任何一个可微分函数都可以参数化D和G(如深度神经网络)
139 | - 支持无监督方法实现数据生成,减少了数据标注工作
140 | - 生成模型G的参数更新不是来自于数据样本本身(不是对数据的似然性进行优化),而是来自于判别模型D的一个反传梯度
141 |
142 | **不足**
143 |
144 | - 无需预先建模,数据生成的自由度太大
145 | - 得到的是概率分布,但是没有表达式,可解释性差
146 | - D与G训练无法同步,训练难度大,会产生梯度消失问题
147 |
148 | # GAN的优化和改进
149 |
150 | ### 限定条件优化
151 |
152 | - CGAN:ConditionalGenerativeAdversarialNets
153 | - Generative Adversarial Text to Image Synthesis
154 | - InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
155 | - Improved Techniques for Training GANs
156 | - GP-GAN: Towards Realistic High-Resolution Image Blending
157 |
158 | ### 迭代式生成优化
159 |
160 | - – LAPGAN:Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
161 | - – StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
162 | - – PPGN: “Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space
163 |
164 | ### 结构优化
165 |
166 | - DCGAN:Unsupervised Representation Learning with Deep
167 |
168 | Convolutional Generative Adversarial Networks
169 |
170 | - Pix2Pix: Image-to-Image Translation with Conditional Adversarial Networks
171 |
172 | # GAN的主要应用
173 |
174 | ### 图像转换
175 |
176 | https://affinelayer.com/pixsrv/
177 |
178 |
133 |
134 | ### 优势和不足
135 |
136 | **优势**
137 |
138 | - 任何一个可微分函数都可以参数化D和G(如深度神经网络)
139 | - 支持无监督方法实现数据生成,减少了数据标注工作
140 | - 生成模型G的参数更新不是来自于数据样本本身(不是对数据的似然性进行优化),而是来自于判别模型D的一个反传梯度
141 |
142 | **不足**
143 |
144 | - 无需预先建模,数据生成的自由度太大
145 | - 得到的是概率分布,但是没有表达式,可解释性差
146 | - D与G训练无法同步,训练难度大,会产生梯度消失问题
147 |
148 | # GAN的优化和改进
149 |
150 | ### 限定条件优化
151 |
152 | - CGAN:ConditionalGenerativeAdversarialNets
153 | - Generative Adversarial Text to Image Synthesis
154 | - InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
155 | - Improved Techniques for Training GANs
156 | - GP-GAN: Towards Realistic High-Resolution Image Blending
157 |
158 | ### 迭代式生成优化
159 |
160 | - – LAPGAN:Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
161 | - – StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
162 | - – PPGN: “Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space
163 |
164 | ### 结构优化
165 |
166 | - DCGAN:Unsupervised Representation Learning with Deep
167 |
168 | Convolutional Generative Adversarial Networks
169 |
170 | - Pix2Pix: Image-to-Image Translation with Conditional Adversarial Networks
171 |
172 | # GAN的主要应用
173 |
174 | ### 图像转换
175 |
176 | https://affinelayer.com/pixsrv/
177 |
178 |  179 |
180 | ### 图像迁移
181 |
182 | https://junyanz.github.io/CycleGAN/
183 |
184 |
179 |
180 | ### 图像迁移
181 |
182 | https://junyanz.github.io/CycleGAN/
183 |
184 |  185 |
186 | ### 图像生成
187 |
188 | https://arxiv.org/abs/1606.03498
189 |
190 |
185 |
186 | ### 图像生成
187 |
188 | https://arxiv.org/abs/1606.03498
189 |
190 |  191 |
192 | ### 图像合成
193 |
194 | https://arxiv.org/abs/1704.04086
195 |
196 |
191 |
192 | ### 图像合成
193 |
194 | https://arxiv.org/abs/1704.04086
195 |
196 |  197 |
198 | ### 图像预测
199 |
200 | https://arxiv.org/abs/1702.01983
201 |
202 |
197 |
198 | ### 图像预测
199 |
200 | https://arxiv.org/abs/1702.01983
201 |
202 |  203 |
204 | ### 图像修复
205 |
206 | https://arxiv.org/abs/1604.07379
207 |
208 |
203 |
204 | ### 图像修复
205 |
206 | https://arxiv.org/abs/1604.07379
207 |
208 |  209 |
--------------------------------------------------------------------------------
/docs/理论进阶/15.胶囊网络.md:
--------------------------------------------------------------------------------
1 | **胶囊网络**
2 |
3 |
4 |
5 | # 背景介绍
6 |
7 | **CNN现存的问题**
8 |
9 | 池化操作提供了局部不变性,错误解决了需要解决的等变性问题,从而丢失了位置等信息:
10 |
11 | - 平移等变性:对于一个函数,如果对其输入施加的变换也会同样反应在输出上,那么这个函数就对该变换具有等变性。
12 | - 例如:输入0,3,2,0,0产生结果0,1,0,0,那么输入模式0,0,3,2,0可能会产生 0,0,1,0的输出
13 | - 平移不变性:对于一个函数,如果对其输入施加的某种操作丝毫不会影响到输出,那么这个函数就对该变换具有不变性。
14 |
15 |
209 |
--------------------------------------------------------------------------------
/docs/理论进阶/15.胶囊网络.md:
--------------------------------------------------------------------------------
1 | **胶囊网络**
2 |
3 |
4 |
5 | # 背景介绍
6 |
7 | **CNN现存的问题**
8 |
9 | 池化操作提供了局部不变性,错误解决了需要解决的等变性问题,从而丢失了位置等信息:
10 |
11 | - 平移等变性:对于一个函数,如果对其输入施加的变换也会同样反应在输出上,那么这个函数就对该变换具有等变性。
12 | - 例如:输入0,3,2,0,0产生结果0,1,0,0,那么输入模式0,0,3,2,0可能会产生 0,0,1,0的输出
13 | - 平移不变性:对于一个函数,如果对其输入施加的某种操作丝毫不会影响到输出,那么这个函数就对该变换具有不变性。
14 |
15 |  16 |
17 | 对于CNN而言,两张图片是类似的,因为它们包含相似的部件。
18 |
19 | **胶囊网络的提出**
20 |
21 | 参考:
22 | [1] Hinton, Geoffrey E., Alex Krizhevsky, and Sida D. Wang. "Transforming auto- encoders." In *International conference on artificial neural networks*, pp. 44-51. Springer, Berlin, Heidelberg, 2011.
23 |
24 | [2] Sabour, Sara, Nicholas Frosst, and Geoffrey E. Hinton. "Dynamic routing between capsules." In Advances in neural information processing systems, pp. 3856-3866. 2017.
25 |
26 | Geoffrey Hinton:
27 |
28 | - The pooling operation used in convolutional neural networks is a big
29 |
30 | mistake and the fact that it works so well is a disaster.
31 |
32 | 卷积神经网络中使用的池运算是一个很大的错误,而它工作得如此好的事实是一场灾难。
33 |
34 | - If the pools do not overlap, pooling loses valuable information about where things are. We need this information to detect precise relationships between the parts of an object. Its true that if the pools overlap enough, the positions of features will be accurately preserved by “coarse coding” (see my paper on “distributed representations” in 1986 for an explanation of this effect). But I no longer believe that coarse coding is the best way to represent the poses of objects relative to the viewer (by pose I mean position, orientation, and scale)
35 |
36 | 如果池不重叠,池将丢失有关事物位置的有价值信息。我们需要这些信息来检测对象各部分之间的精确关系。诚然,如果池足够重叠,特征的位置将通过“粗略编码”得到准确保留。但我不再相信粗编码是表示对象相对于观察者的姿势的最佳方式(我所说的姿势是指位置、方向和比例)
37 |
38 | # 胶囊网络模型
39 |
40 | - 使用胶囊作为网络基本单元
41 | - 特征向量表示可视实体,对方位等信息进行编码
42 | - 动态路由算法代替池化操作
43 |
44 |
16 |
17 | 对于CNN而言,两张图片是类似的,因为它们包含相似的部件。
18 |
19 | **胶囊网络的提出**
20 |
21 | 参考:
22 | [1] Hinton, Geoffrey E., Alex Krizhevsky, and Sida D. Wang. "Transforming auto- encoders." In *International conference on artificial neural networks*, pp. 44-51. Springer, Berlin, Heidelberg, 2011.
23 |
24 | [2] Sabour, Sara, Nicholas Frosst, and Geoffrey E. Hinton. "Dynamic routing between capsules." In Advances in neural information processing systems, pp. 3856-3866. 2017.
25 |
26 | Geoffrey Hinton:
27 |
28 | - The pooling operation used in convolutional neural networks is a big
29 |
30 | mistake and the fact that it works so well is a disaster.
31 |
32 | 卷积神经网络中使用的池运算是一个很大的错误,而它工作得如此好的事实是一场灾难。
33 |
34 | - If the pools do not overlap, pooling loses valuable information about where things are. We need this information to detect precise relationships between the parts of an object. Its true that if the pools overlap enough, the positions of features will be accurately preserved by “coarse coding” (see my paper on “distributed representations” in 1986 for an explanation of this effect). But I no longer believe that coarse coding is the best way to represent the poses of objects relative to the viewer (by pose I mean position, orientation, and scale)
35 |
36 | 如果池不重叠,池将丢失有关事物位置的有价值信息。我们需要这些信息来检测对象各部分之间的精确关系。诚然,如果池足够重叠,特征的位置将通过“粗略编码”得到准确保留。但我不再相信粗编码是表示对象相对于观察者的姿势的最佳方式(我所说的姿势是指位置、方向和比例)
37 |
38 | # 胶囊网络模型
39 |
40 | - 使用胶囊作为网络基本单元
41 | - 特征向量表示可视实体,对方位等信息进行编码
42 | - 动态路由算法代替池化操作
43 |
44 |  45 |
46 | ### 特征向量表示可视实体
47 |
48 | ### 胶囊
49 |
50 | ### 动态路由
51 |
52 | # CapsNet
53 |
54 | ### 网络基本结构
55 |
56 | **胶囊网络的单层结构**
57 |
58 |
45 |
46 | ### 特征向量表示可视实体
47 |
48 | ### 胶囊
49 |
50 | ### 动态路由
51 |
52 | # CapsNet
53 |
54 | ### 网络基本结构
55 |
56 | **胶囊网络的单层结构**
57 |
58 |  59 |
60 | - 实现从主胶囊(8D)到数字胶囊(16D)的转换,即:低级特征向量向高级特征向量的转换
61 | - 由于使用特征向量长度来表示对应类别存在概率,所以在最后一层进行分时,需要将输出的特征向量取L2范数
62 |
63 |
59 |
60 | - 实现从主胶囊(8D)到数字胶囊(16D)的转换,即:低级特征向量向高级特征向量的转换
61 | - 由于使用特征向量长度来表示对应类别存在概率,所以在最后一层进行分时,需要将输出的特征向量取L2范数
62 |
63 |  64 |
65 | - 256个步幅为1的9×9的卷积核,完成图像信息到低级特征的转换
66 | - 具有32个通道的8D胶囊卷积层,每个主胶囊具 有8个步幅为2的9×9的卷积核的卷积单元,实现低级特征到胶囊多维实体(低级特征向量) 的转换
67 |
68 | ### 边际损失
69 |
70 | 为了实现同时对多个对象的识别,每类目标对象对应的胶囊应分别使用边际损失函数得到类损失 $L_k$,则总边际损失是所有类损失之和
71 | $$
72 | L_k = T_k \max(0, m^+-\|v_k\|^2)^2 + \lambda(1-T_k)\max(0, \|v_k\|^2-m^-)^2
73 | $$
74 |
75 | - 其中,$T_k$是表示 *k* 类目标对象是否存在,当 *k* 类目标对象存在时为1,不存
76 |
77 | 在时为0
78 |
79 | - 𝑚+是上界,一般取0.9
80 |
81 | - 𝑚−是下界,一般取0.1
82 |
83 | - $\lambda$ 为不存在的对象类别的损失的下调权重,避免最开始从不存在分类对应的胶囊输出的特征向量中学习,一般取0.5
84 |
85 | ### 重构正则化
86 |
87 | 鲁棒性强的模型一定具有很强的重构能力。为了使胶囊对输入图像进行编码并输出对应实例化参数,该网络引入了一个重构损失作为 正则项。重构损失是逻辑单元的输出和像素强度之间的差的平方和:
88 |
89 |
64 |
65 | - 256个步幅为1的9×9的卷积核,完成图像信息到低级特征的转换
66 | - 具有32个通道的8D胶囊卷积层,每个主胶囊具 有8个步幅为2的9×9的卷积核的卷积单元,实现低级特征到胶囊多维实体(低级特征向量) 的转换
67 |
68 | ### 边际损失
69 |
70 | 为了实现同时对多个对象的识别,每类目标对象对应的胶囊应分别使用边际损失函数得到类损失 $L_k$,则总边际损失是所有类损失之和
71 | $$
72 | L_k = T_k \max(0, m^+-\|v_k\|^2)^2 + \lambda(1-T_k)\max(0, \|v_k\|^2-m^-)^2
73 | $$
74 |
75 | - 其中,$T_k$是表示 *k* 类目标对象是否存在,当 *k* 类目标对象存在时为1,不存
76 |
77 | 在时为0
78 |
79 | - 𝑚+是上界,一般取0.9
80 |
81 | - 𝑚−是下界,一般取0.1
82 |
83 | - $\lambda$ 为不存在的对象类别的损失的下调权重,避免最开始从不存在分类对应的胶囊输出的特征向量中学习,一般取0.5
84 |
85 | ### 重构正则化
86 |
87 | 鲁棒性强的模型一定具有很强的重构能力。为了使胶囊对输入图像进行编码并输出对应实例化参数,该网络引入了一个重构损失作为 正则项。重构损失是逻辑单元的输出和像素强度之间的差的平方和:
88 |
89 |  90 |
91 | ### 手写数字识别实验结果
92 |
93 | - 使用3次路由迭代
94 | - (*l*, *p*, *r*)代表label的,预测的和重构的
95 | - 最右边是失败的例子
96 |
97 |
90 |
91 | ### 手写数字识别实验结果
92 |
93 | - 使用3次路由迭代
94 | - (*l*, *p*, *r*)代表label的,预测的和重构的
95 | - 最右边是失败的例子
96 |
97 |  98 |
99 | **特征向量的各个维度表示什么**:每行展示了16D的DigitCaps中某个维度在区间[-0.25,0.25]间调整0.05
100 |
101 |
98 |
99 | **特征向量的各个维度表示什么**:每行展示了16D的DigitCaps中某个维度在区间[-0.25,0.25]间调整0.05
100 |
101 |  102 |
103 | **重叠手写数字识别**
104 |
105 |
102 |
103 | **重叠手写数字识别**
104 |
105 |  106 |
107 | **test error**
108 |
109 |
106 |
107 | **test error**
108 |
109 |  110 |
--------------------------------------------------------------------------------
/docs/理论进阶/16.DRL.md:
--------------------------------------------------------------------------------
1 | # 强化学习
2 |
3 | 网络结构:其中的r: reward、s: state 、a: action
4 |
5 |
110 |
--------------------------------------------------------------------------------
/docs/理论进阶/16.DRL.md:
--------------------------------------------------------------------------------
1 | # 强化学习
2 |
3 | 网络结构:其中的r: reward、s: state 、a: action
4 |
5 |  6 |
7 | 马尔科夫决策过程包含五个元素:
8 |
9 | # 强化学习算法
10 |
11 | ...
12 |
13 | # 深度强化学习
14 |
15 | 深度强化学习是深度学习和强化学习的结合
16 |
17 | - 深度学习具有较强的感知能力,但是缺乏一定的决策能力
18 | - 强化学习具有决策能力,但对感知问题却束手无策
19 | - 深度强化学习(DeepReinforcementLearning,DRL)将深度学习的 感知能力和强化学习的决策能力相结合,可以直接根据输入的状态进行控制,是一种更接近人类思维方式的人工智能方法
20 | - 深度强化学习目前侧重在强化学习上,解决的仍然是决策问题,只 不过是借助神经网络强大的表征能力去拟合Q表或直接拟合策略以 解决状态-动作空间过大或连续状态-动作空间问题
21 |
22 | ### 深度强化学习基本过程
23 |
24 | - 利用深度学习方法来感知状态,以得到具体的状态特征表示
25 | - 基于预期回报来评价各动作的价值函数
26 | - 通过某种策略做出相应的动作,环境对此动作做出反应,并得到下 一个状态与回报
27 | - 通过不断循环以上过程,最终可以得到实现目标的最优策略
28 |
29 |
6 |
7 | 马尔科夫决策过程包含五个元素:
8 |
9 | # 强化学习算法
10 |
11 | ...
12 |
13 | # 深度强化学习
14 |
15 | 深度强化学习是深度学习和强化学习的结合
16 |
17 | - 深度学习具有较强的感知能力,但是缺乏一定的决策能力
18 | - 强化学习具有决策能力,但对感知问题却束手无策
19 | - 深度强化学习(DeepReinforcementLearning,DRL)将深度学习的 感知能力和强化学习的决策能力相结合,可以直接根据输入的状态进行控制,是一种更接近人类思维方式的人工智能方法
20 | - 深度强化学习目前侧重在强化学习上,解决的仍然是决策问题,只 不过是借助神经网络强大的表征能力去拟合Q表或直接拟合策略以 解决状态-动作空间过大或连续状态-动作空间问题
21 |
22 | ### 深度强化学习基本过程
23 |
24 | - 利用深度学习方法来感知状态,以得到具体的状态特征表示
25 | - 基于预期回报来评价各动作的价值函数
26 | - 通过某种策略做出相应的动作,环境对此动作做出反应,并得到下 一个状态与回报
27 | - 通过不断循环以上过程,最终可以得到实现目标的最优策略
28 |
29 |  30 |
31 | ### 深度Q网络(**Deep Q Network**,**DQN**)
32 |
33 | - 这是一个较为典型的DRL算法
34 |
35 | - DQN融合了神经网络和Q learning的方法。
36 | - DQN把Q learning中的价值函数用深度神经网络近似。除此之外,DQN算法还做了经验回放(Experience Replay),即将系统探索环境得到的数据储存起来,然后随机采样样本更新深度神经网络的参数。这是一种离线学习法,它能学习当前经历着的,也能学习过去经历过的,甚至是学习别人的经历。随机采样这种做法打乱了经历之间的相关性,也使得神经网络更新更有效率
37 |
38 | 参考文献:Human-level control through deep reinforcement learning, nature 2015
39 |
40 |
30 |
31 | ### 深度Q网络(**Deep Q Network**,**DQN**)
32 |
33 | - 这是一个较为典型的DRL算法
34 |
35 | - DQN融合了神经网络和Q learning的方法。
36 | - DQN把Q learning中的价值函数用深度神经网络近似。除此之外,DQN算法还做了经验回放(Experience Replay),即将系统探索环境得到的数据储存起来,然后随机采样样本更新深度神经网络的参数。这是一种离线学习法,它能学习当前经历着的,也能学习过去经历过的,甚至是学习别人的经历。随机采样这种做法打乱了经历之间的相关性,也使得神经网络更新更有效率
37 |
38 | 参考文献:Human-level control through deep reinforcement learning, nature 2015
39 |
40 |  41 |
42 | - 算法可以通过观察**Atari 2600**的游戏画面和得分信息,自主的学会玩游戏
43 | - 因为输入是RGB,像素也是高维度,因此,对图像进行初步的图像 处理,变成灰度矩形84*84的图像作为输入,有利于卷积。
44 | - 接下来就是模型的构建问题,毕竟Q(s,a)包含s和a。一种方法就是输 入s和a,输出q值,这样并不方便,每个a都需要forward一遍网络
45 | - Deepmind的做法是神经网络只输入s,输出则是每个a对应的q。这 种做法的优点就是只要输入s,forward前向传播一遍就可以获取所 有a的q值,毕竟a的数量有限
46 |
47 |
41 |
42 | - 算法可以通过观察**Atari 2600**的游戏画面和得分信息,自主的学会玩游戏
43 | - 因为输入是RGB,像素也是高维度,因此,对图像进行初步的图像 处理,变成灰度矩形84*84的图像作为输入,有利于卷积。
44 | - 接下来就是模型的构建问题,毕竟Q(s,a)包含s和a。一种方法就是输 入s和a,输出q值,这样并不方便,每个a都需要forward一遍网络
45 | - Deepmind的做法是神经网络只输入s,输出则是每个a对应的q。这 种做法的优点就是只要输入s,forward前向传播一遍就可以获取所 有a的q值,毕竟a的数量有限
46 |
47 |  48 |
49 | - 双网络结构
50 |
51 | - Main DQN(主网络/当前值网络):通过其最大Q值选择Action,而这个被选定的Action的Q值则由target DQN生成
52 | - Target DQN(目标网络):辅助计算目标Q值,这样做的目的是避免让网络训练陷入目标Q值与预测Q值的反馈循环中
53 |
54 |
48 |
49 | - 双网络结构
50 |
51 | - Main DQN(主网络/当前值网络):通过其最大Q值选择Action,而这个被选定的Action的Q值则由target DQN生成
52 | - Target DQN(目标网络):辅助计算目标Q值,这样做的目的是避免让网络训练陷入目标Q值与预测Q值的反馈循环中
53 |
54 |  55 |
56 | # 其它深度强化学习方法
57 |
58 | - 对于时间序列信息,深度**Q**网络的处理方法是加入经验回 放机制。但是经验回放的记忆能力有限,每个决策点需要获取整个输入画面进行感知记忆
59 | - 将长短时记忆网络与深度Q网络结合,提出深度递归Q网络(Deep Recurrent Q Network,DRQN),在部分可观测马尔科夫决策过程中表现出了更好的鲁棒性,同时在缺失若干帧画面的情况下也能获得 很好的实验结果。
60 | - 受此启发的深度注意力递归Q网络(DeepAttentionRecurrentQ network,DARQN)。它能够选择性地重点关注相关信息区域,减少深度神经网络的参数数量和计算开销。
61 |
62 |
--------------------------------------------------------------------------------
/docs/理论进阶/17.DF.md:
--------------------------------------------------------------------------------
1 | # 决策树
2 |
3 | 决策树(Decision Tree)是一种基于树结构进行决策的机器学习方法,这恰是人类面临决策时一种很自然的处理机制。
4 |
5 | 决策树生成过程:
6 |
7 | - 寻找最适合分割的特征
8 | - 根据纯度判断方法,寻找最优的分割点,基于这一特征把数据分割 成纯度更高的两部分数据
9 | - 判断是否达到要求,若未达到,重复步骤一继续分割,直到达到要 求停止为止
10 | - 剪枝,防止过拟合
11 |
12 | # 随机森林
13 |
14 | 用随机的方式建立起一棵棵决策树,然后由这些决策树组成一个森 林,其中每棵决策树之间没有关联,当有一个新的样本输入时,就 让每棵树独立的做出判断,按照多数原则决定该样本的分类结果。 这是一种典型的集成学习思想
15 |
16 | 集成学习(Ensemblelearning):组合多个弱监督模型以期得到一个更好更全面的强监督模型,集成学 习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来
17 |
18 | # 梯度提升决策树GBDT
19 |
20 | GBDT是一种集成使用多个弱分类器(决策树)来提升分类效果的机器学习算法,所有树的结论累加起来作为最终结果。在很多分类和回归的场景中,表现不错且泛化能力较强。
21 |
22 |
55 |
56 | # 其它深度强化学习方法
57 |
58 | - 对于时间序列信息,深度**Q**网络的处理方法是加入经验回 放机制。但是经验回放的记忆能力有限,每个决策点需要获取整个输入画面进行感知记忆
59 | - 将长短时记忆网络与深度Q网络结合,提出深度递归Q网络(Deep Recurrent Q Network,DRQN),在部分可观测马尔科夫决策过程中表现出了更好的鲁棒性,同时在缺失若干帧画面的情况下也能获得 很好的实验结果。
60 | - 受此启发的深度注意力递归Q网络(DeepAttentionRecurrentQ network,DARQN)。它能够选择性地重点关注相关信息区域,减少深度神经网络的参数数量和计算开销。
61 |
62 |
--------------------------------------------------------------------------------
/docs/理论进阶/17.DF.md:
--------------------------------------------------------------------------------
1 | # 决策树
2 |
3 | 决策树(Decision Tree)是一种基于树结构进行决策的机器学习方法,这恰是人类面临决策时一种很自然的处理机制。
4 |
5 | 决策树生成过程:
6 |
7 | - 寻找最适合分割的特征
8 | - 根据纯度判断方法,寻找最优的分割点,基于这一特征把数据分割 成纯度更高的两部分数据
9 | - 判断是否达到要求,若未达到,重复步骤一继续分割,直到达到要 求停止为止
10 | - 剪枝,防止过拟合
11 |
12 | # 随机森林
13 |
14 | 用随机的方式建立起一棵棵决策树,然后由这些决策树组成一个森 林,其中每棵决策树之间没有关联,当有一个新的样本输入时,就 让每棵树独立的做出判断,按照多数原则决定该样本的分类结果。 这是一种典型的集成学习思想
15 |
16 | 集成学习(Ensemblelearning):组合多个弱监督模型以期得到一个更好更全面的强监督模型,集成学 习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来
17 |
18 | # 梯度提升决策树GBDT
19 |
20 | GBDT是一种集成使用多个弱分类器(决策树)来提升分类效果的机器学习算法,所有树的结论累加起来作为最终结果。在很多分类和回归的场景中,表现不错且泛化能力较强。
21 |
22 |  23 |
24 | # 深度森林
25 |
26 | 神经网络可以堆叠为深度神经网络,并且取得了显著的效果。那我们可以考虑,是不是可以将其他的学习模型堆叠起来,以获取更好的表示性能,深度森林模型就是基于这种想法提出来的一种深度结构。
27 |
28 | 2017年,深度森林由周志华老师提出,基于树模型的方法, 主要使用集成学习思想方法的深度学习框架,也可作为一种在某些任务下替代深度神经网络的方法。
29 |
30 | 参考:Deep Forest: Towards an Alternative to Deep Neural Networks, 2017
31 |
32 | **深度神经网络的问题**
33 |
34 | - 需要使用大量的数据进行训练
35 | - 计算资源消耗大
36 | - 可解释性差
37 | - 超参数多,训练依赖于经验
38 |
39 | **深度森林的优势**
40 |
41 | - 与DNN相比需要的参数更少
42 | - 训练速度快
43 | - 不仅适合大规模数据也适合小规模数据
44 | - 基于树模型解释性比较好
45 |
46 | ### 多粒度级联森林
47 |
48 | GCForest(muti-Grained Cascade Forest,多粒度级联森林),它是基于树的集成方法,通过对树组成的森林来集成并前后串联起来达到表征学习的效果。
49 |
50 |
23 |
24 | # 深度森林
25 |
26 | 神经网络可以堆叠为深度神经网络,并且取得了显著的效果。那我们可以考虑,是不是可以将其他的学习模型堆叠起来,以获取更好的表示性能,深度森林模型就是基于这种想法提出来的一种深度结构。
27 |
28 | 2017年,深度森林由周志华老师提出,基于树模型的方法, 主要使用集成学习思想方法的深度学习框架,也可作为一种在某些任务下替代深度神经网络的方法。
29 |
30 | 参考:Deep Forest: Towards an Alternative to Deep Neural Networks, 2017
31 |
32 | **深度神经网络的问题**
33 |
34 | - 需要使用大量的数据进行训练
35 | - 计算资源消耗大
36 | - 可解释性差
37 | - 超参数多,训练依赖于经验
38 |
39 | **深度森林的优势**
40 |
41 | - 与DNN相比需要的参数更少
42 | - 训练速度快
43 | - 不仅适合大规模数据也适合小规模数据
44 | - 基于树模型解释性比较好
45 |
46 | ### 多粒度级联森林
47 |
48 | GCForest(muti-Grained Cascade Forest,多粒度级联森林),它是基于树的集成方法,通过对树组成的森林来集成并前后串联起来达到表征学习的效果。
49 |
50 |  51 |
52 | 上图每层包含两个随机森林,随机森林和完全随机森林,处理一个三分类的问题。
53 |
54 | - 每个完全随机的森林包含完全随机树,通过随机选择一个 特征在树的每个节点进行分割实现生长,直到叶子节点只包含相同类的实例。
55 | - 类似的,每个随机森林包含的树,通过随机选择 $\sqrt{d}$ 数量的特征作为候选(d是输入特征的数量),然后选择具有 最佳gini值的特征作为分割
56 | - 每个森林中的树的数值是一个超参数
57 |
58 | **GCForest每个森林的类分布向量生成流程**:
59 |
60 | - 对于测试样本,每棵树会根据样本所在的子空间中训练样本的类别 占比生成一个类别的概率分布,然后对森林内所有树的各类比例取 平均,输出整个森林对各类的比例
61 | - 每个森林都会生成长度为C的概率向量,如果一层有N个森林,那 么每个森林生成的C个元素会拼接在一起,组成C*N个元素向量, 这就是一层的输出
62 | - 这基础上把源输入特征向量拼接上去组成了下一层的输入
63 |
64 |
51 |
52 | 上图每层包含两个随机森林,随机森林和完全随机森林,处理一个三分类的问题。
53 |
54 | - 每个完全随机的森林包含完全随机树,通过随机选择一个 特征在树的每个节点进行分割实现生长,直到叶子节点只包含相同类的实例。
55 | - 类似的,每个随机森林包含的树,通过随机选择 $\sqrt{d}$ 数量的特征作为候选(d是输入特征的数量),然后选择具有 最佳gini值的特征作为分割
56 | - 每个森林中的树的数值是一个超参数
57 |
58 | **GCForest每个森林的类分布向量生成流程**:
59 |
60 | - 对于测试样本,每棵树会根据样本所在的子空间中训练样本的类别 占比生成一个类别的概率分布,然后对森林内所有树的各类比例取 平均,输出整个森林对各类的比例
61 | - 每个森林都会生成长度为C的概率向量,如果一层有N个森林,那 么每个森林生成的C个元素会拼接在一起,组成C*N个元素向量, 这就是一层的输出
62 | - 这基础上把源输入特征向量拼接上去组成了下一层的输入
63 |
64 |  65 |
66 | **GCForest的多粒度扫描**:
67 |
68 | - 采用滑动窗口的方法,首先生成若干个实例,其次通过实例生成两 个森林,一个完全随机森林,一个随机森林,接着再把生成的两个 森林生成对应的相同维度的“类向量”,最后把这两大类向量连接在一起。
69 | - 一般来说会采用多个不同大小的窗口做扫描
70 |
71 |
65 |
66 | **GCForest的多粒度扫描**:
67 |
68 | - 采用滑动窗口的方法,首先生成若干个实例,其次通过实例生成两 个森林,一个完全随机森林,一个随机森林,接着再把生成的两个 森林生成对应的相同维度的“类向量”,最后把这两大类向量连接在一起。
69 | - 一般来说会采用多个不同大小的窗口做扫描
70 |
71 |  72 |
73 | **整体结构**
74 |
75 |
72 |
73 | **整体结构**
74 |
75 |  76 |
77 | **相关性能**
78 |
79 |
76 |
77 | **相关性能**
78 |
79 |  80 |
81 | ### 基于森林的自编码器
82 |
83 | **自编码器**(Auto-Encoder)是神经网络的一种,是一种重要的表示学习模型,是深度学习的关键要素之一。自编码器的基本结构是由一个编码器(encoder)和一 个解码器(decoder)组成,其中encoder将输入映射到隐空间,decoder 将隐空间的表示重构为原表示。
84 |
85 | **eForest**(Encoder-Forest):基于森林的自编码器,能够利用决策树的决策路径所定义的等效类 来进行后向重建。利用决策树集成算法进行向前编码和向后解码的操作。
86 |
87 | 参考:AutoEncoder by Forest, AAAI 2017
88 |
89 | **前向编码**
90 |
91 | - 在一个有N个已训练决策树的森林中,前向编码过程接受输入数据并将其发送到集成方法中每棵树的根结点
92 | - 一旦数据遍历(traverse)到所有树的叶结点,该过程将返回T维向 量,T中的每个元素 t 是树 t 中的叶结点的整数索引
93 |
94 |
80 |
81 | ### 基于森林的自编码器
82 |
83 | **自编码器**(Auto-Encoder)是神经网络的一种,是一种重要的表示学习模型,是深度学习的关键要素之一。自编码器的基本结构是由一个编码器(encoder)和一 个解码器(decoder)组成,其中encoder将输入映射到隐空间,decoder 将隐空间的表示重构为原表示。
84 |
85 | **eForest**(Encoder-Forest):基于森林的自编码器,能够利用决策树的决策路径所定义的等效类 来进行后向重建。利用决策树集成算法进行向前编码和向后解码的操作。
86 |
87 | 参考:AutoEncoder by Forest, AAAI 2017
88 |
89 | **前向编码**
90 |
91 | - 在一个有N个已训练决策树的森林中,前向编码过程接受输入数据并将其发送到集成方法中每棵树的根结点
92 | - 一旦数据遍历(traverse)到所有树的叶结点,该过程将返回T维向 量,T中的每个元素 t 是树 t 中的叶结点的整数索引
93 |
94 |  95 |
96 | **后向编码**
97 |
98 | - 利用决策树进行决策时需要将决策的路径记录下来,而每个决策路径对应了一个规则(rule)
99 |
100 |
95 |
96 | **后向编码**
97 |
98 | - 利用决策树进行决策时需要将决策的路径记录下来,而每个决策路径对应了一个规则(rule)
99 |
100 |  101 |
102 | - 在进行解码重构的过程中,利用森林中N个规则,运用最大相容规 则Maximum Compatible Rule(MCR),获取N维编码所对应的更精 确的规则,以此规则进行重构
103 |
104 |
101 |
102 | - 在进行解码重构的过程中,利用森林中N个规则,运用最大相容规 则Maximum Compatible Rule(MCR),获取N维编码所对应的更精 确的规则,以此规则进行重构
103 |
104 |  105 |
106 |
105 |
106 |  107 |
108 | **优势**
109 |
110 | - 训练速度较快:如在MNIST和CIFAR10上的训练速度比基于神经网络的模型快数倍以上
111 |
112 | - 重构误差低:基于规则,而不是计算
113 |
114 | - 容损性:编码规则具有强相关性,因此在部分损坏的情况下也能很 好地工作
115 |
116 | - 可复用性:在一个数据集上训练好的模型能够直接应用于同领域另 外一个数据集
117 |
118 | **不足**
119 |
120 | - 与神经网络相比编码表达力不足
121 |
122 | - 编码、解码速度相对神经网络较慢
123 |
124 | **深度森林的适用条件**
125 |
126 | - 具备逐层处理的任务
127 |
128 | - 参数不可微
129 |
130 | - 一定的模型复杂度
131 |
132 |
133 |
134 |
135 |
136 |
137 |
138 |
139 |
140 |
141 |
142 |
143 |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
--------------------------------------------------------------------------------
107 |
108 | **优势**
109 |
110 | - 训练速度较快:如在MNIST和CIFAR10上的训练速度比基于神经网络的模型快数倍以上
111 |
112 | - 重构误差低:基于规则,而不是计算
113 |
114 | - 容损性:编码规则具有强相关性,因此在部分损坏的情况下也能很 好地工作
115 |
116 | - 可复用性:在一个数据集上训练好的模型能够直接应用于同领域另 外一个数据集
117 |
118 | **不足**
119 |
120 | - 与神经网络相比编码表达力不足
121 |
122 | - 编码、解码速度相对神经网络较慢
123 |
124 | **深度森林的适用条件**
125 |
126 | - 具备逐层处理的任务
127 |
128 | - 参数不可微
129 |
130 | - 一定的模型复杂度
131 |
132 |
133 |
134 |
135 |
136 |
137 |
138 |
139 |
140 |
141 |
142 |
143 |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
--------------------------------------------------------------------------------