├── .gitignore
├── LICENSE
├── README.md
├── app.py
├── index.html
├── main.css
├── main.js
└── requirements.txt
/.gitignore:
--------------------------------------------------------------------------------
1 | discovered_links.csv
2 | external_links.json
3 | settings.json
4 | venv/
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2025 Bret Bernhoft
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Mapping A Website's External Links
2 |
3 | 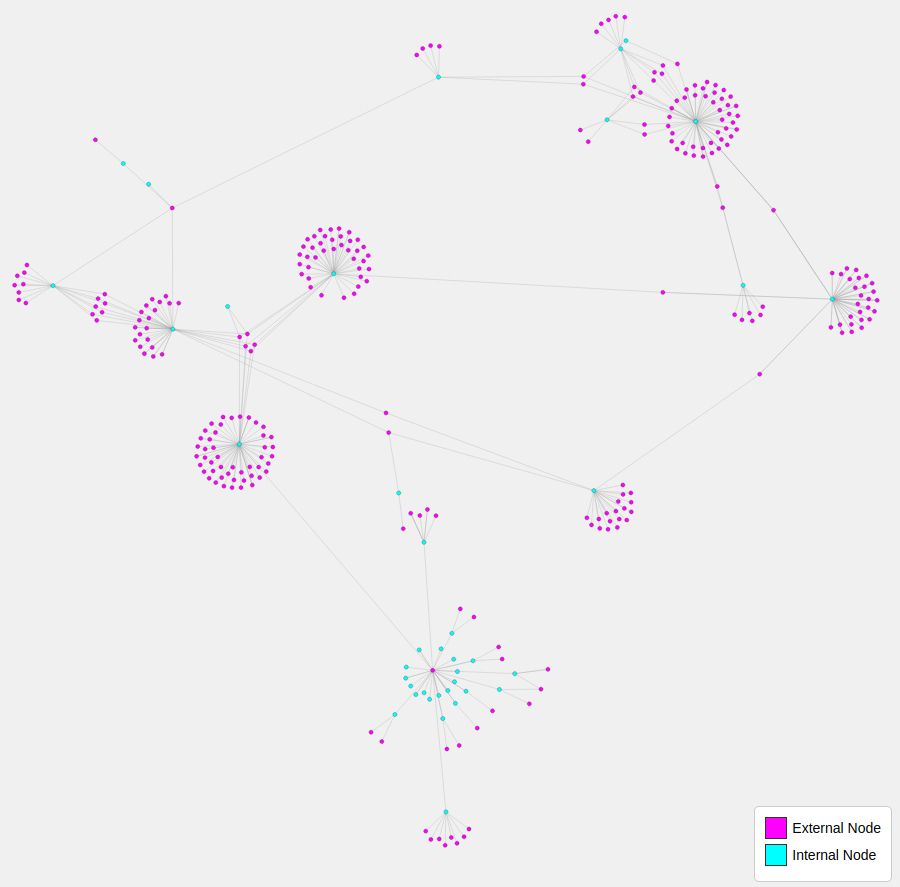
4 |
5 | Use Python to map a website's external facing links. And then apply D3 to visualize those outbound connections as a network graph.
6 |
7 | ## Set Up
8 |
9 | ### Programs Needed
10 |
11 | - [Git](https://git-scm.com/downloads)
12 | - [Python](https://www.python.org/downloads/) (When installing on Windows, make sure you check the ["Add python 3.xx to PATH"](https://hosting.photobucket.com/images/i/bernhoftbret/python.png) box.)
13 |
14 | ### Steps
15 |
16 | 1. Install the above programs.
17 | 2. Open a shell window (For Windows open PowerShell, for MacOS open Terminal & for Linux open your distro's terminal emulator).
18 | 3. Clone this repository using `git` by running the following command; `git clone git@github.com:devbret/website-external-links.git`.
19 | 4. Navigate to the repo's directory by running; `cd website-external-links`.
20 | 5. Install the needed dependencies for running the script by running; `pip install -r requirements.txt`.
21 | 6. Edit the app.py file on line 51, to include the website that you would like to visualize. You can also change the maximum number of URLs that this program will visit at a given domain, by editing the "max_links" value on line 11 in the app.py file; which is set to 50 by default.
22 | 7. Run the script with the command `python3 app.py`.
23 | 8. To view the website's connections in the index.html file you will need to run a local web server. To do this run `python3 -m http.server`.
24 |
--------------------------------------------------------------------------------
/app.py:
--------------------------------------------------------------------------------
1 | import requests
2 | from bs4 import BeautifulSoup
3 | from urllib.parse import urljoin, urlparse
4 | import json
5 | import csv
6 | from datetime import datetime
7 |
8 | def is_external(url, base):
9 | return urlparse(url).netloc != urlparse(base).netloc
10 |
11 | def crawl_site(start_url, max_links=50, csv_filename='discovered_links.csv'):
12 | visited = set()
13 | external_links = {}
14 |
15 | with open(csv_filename, mode='w', newline='') as csvfile:
16 | csv_writer = csv.writer(csvfile)
17 | csv_writer.writerow(['URL', 'Type', 'Timestamp'])
18 |
19 | def crawl(url):
20 | if len(visited) >= max_links:
21 | return
22 | visited.add(url)
23 | timestamp = datetime.now().isoformat()
24 | csv_writer.writerow([url, 'internal', timestamp])
25 | print(f"Crawling: {url}")
26 | try:
27 | response = requests.get(url, timeout=5)
28 | soup = BeautifulSoup(response.text, 'html.parser')
29 | except requests.exceptions.RequestException as e:
30 | print(f"Failed to crawl {url}: {e}")
31 | return
32 |
33 | for link in soup.find_all('a', href=True):
34 | href = urljoin(url, link.get('href'))
35 | if is_external(href, start_url):
36 | if href not in external_links:
37 | external_links[href] = []
38 | external_links[href].append(url)
39 | csv_writer.writerow([href, 'external', timestamp])
40 | elif href not in visited:
41 | crawl(href)
42 |
43 | crawl(start_url)
44 |
45 | return external_links
46 |
47 | def save_links_as_json(external_links, filename='external_links.json'):
48 | with open(filename, 'w') as file:
49 | json.dump(external_links, file, indent=2)
50 |
51 | external_links = crawl_site('https://www.example.com/')
52 | save_links_as_json(external_links)
53 |
--------------------------------------------------------------------------------
/index.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | External Links Network Graph
6 |
7 |
8 |
9 |
10 |