├── .gitignore
├── Chapter1.md
├── Chapter10-1.md
├── Chapter10-2.md
├── Chapter10-3.md
├── Chapter2.md
├── Chapter3.md
├── Chapter4.md
├── Chapter5.md
├── Chapter6.md
├── Chapter7-1.md
├── Chapter7-2.md
├── Chapter8-1.md
├── Chapter8-2.md
├── Chapter9-1.md
├── Chapter9-2.md
├── Chapter9-3.md
└── README.md
/.gitignore:
--------------------------------------------------------------------------------
1 |
2 | # Created by https://www.toptal.com/developers/gitignore/api/macos,windows,kotlin,java,gradle,intellij,jetbrains
3 | # Edit at https://www.toptal.com/developers/gitignore?templates=macos,windows,kotlin,java,gradle,intellij,jetbrains
4 |
5 | ### Intellij ###
6 | # Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio, WebStorm and Rider
7 | # Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
8 |
9 | # User-specific stuff
10 | .idea/**/workspace.xml
11 | .idea/**/tasks.xml
12 | .idea/**/usage.statistics.xml
13 | .idea/**/dictionaries
14 | .idea/**/shelf
15 |
16 | # AWS User-specific
17 | .idea/**/aws.xml
18 |
19 | # Generated files
20 | .idea/**/contentModel.xml
21 |
22 | # Sensitive or high-churn files
23 | .idea/**/dataSources/
24 | .idea/**/dataSources.ids
25 | .idea/**/dataSources.local.xml
26 | .idea/**/sqlDataSources.xml
27 | .idea/**/dynamic.xml
28 | .idea/**/uiDesigner.xml
29 | .idea/**/dbnavigator.xml
30 |
31 | # Gradle
32 | .idea/**/gradle.xml
33 | .idea/**/libraries
34 |
35 | # Gradle and Maven with auto-import
36 | # When using Gradle or Maven with auto-import, you should exclude module files,
37 | # since they will be recreated, and may cause churn. Uncomment if using
38 | # auto-import.
39 | # .idea/artifacts
40 | # .idea/compiler.xml
41 | # .idea/jarRepositories.xml
42 | # .idea/modules.xml
43 | # .idea/*.iml
44 | # .idea/modules
45 | # *.iml
46 | # *.ipr
47 |
48 | # CMake
49 | cmake-build-*/
50 |
51 | # Mongo Explorer plugin
52 | .idea/**/mongoSettings.xml
53 |
54 | # File-based project format
55 | *.iws
56 |
57 | # IntelliJ
58 | out/
59 |
60 | # mpeltonen/sbt-idea plugin
61 | .idea_modules/
62 |
63 | # JIRA plugin
64 | atlassian-ide-plugin.xml
65 |
66 | # Cursive Clojure plugin
67 | .idea/replstate.xml
68 |
69 | # Crashlytics plugin (for Android Studio and IntelliJ)
70 | com_crashlytics_export_strings.xml
71 | crashlytics.properties
72 | crashlytics-build.properties
73 | fabric.properties
74 |
75 | # Editor-based Rest Client
76 | .idea/httpRequests
77 |
78 | # Android studio 3.1+ serialized cache file
79 | .idea/caches/build_file_checksums.ser
80 |
81 | ### Intellij Patch ###
82 | # Comment Reason: https://github.com/joeblau/gitignore.io/issues/186#issuecomment-215987721
83 |
84 | # *.iml
85 | # modules.xml
86 | # .idea/misc.xml
87 | # *.ipr
88 |
89 | # Sonarlint plugin
90 | # https://plugins.jetbrains.com/plugin/7973-sonarlint
91 | .idea/**/sonarlint/
92 |
93 | # SonarQube Plugin
94 | # https://plugins.jetbrains.com/plugin/7238-sonarqube-community-plugin
95 | .idea/**/sonarIssues.xml
96 |
97 | # Markdown Navigator plugin
98 | # https://plugins.jetbrains.com/plugin/7896-markdown-navigator-enhanced
99 | .idea/**/markdown-navigator.xml
100 | .idea/**/markdown-navigator-enh.xml
101 | .idea/**/markdown-navigator/
102 |
103 | # Cache file creation bug
104 | # See https://youtrack.jetbrains.com/issue/JBR-2257
105 | .idea/$CACHE_FILE$
106 |
107 | # CodeStream plugin
108 | # https://plugins.jetbrains.com/plugin/12206-codestream
109 | .idea/codestream.xml
110 |
111 | ### Java ###
112 | # Compiled class file
113 | *.class
114 |
115 | # Log file
116 | *.log
117 |
118 | # BlueJ files
119 | *.ctxt
120 |
121 | # Mobile Tools for Java (J2ME)
122 | .mtj.tmp/
123 |
124 | # Package Files #
125 | *.jar
126 | *.war
127 | *.nar
128 | *.ear
129 | *.zip
130 | *.tar.gz
131 | *.rar
132 |
133 | # virtual machine crash logs, see http://www.java.com/en/download/help/error_hotspot.xml
134 | hs_err_pid*
135 |
136 | ### JetBrains ###
137 | # Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio, WebStorm and Rider
138 | # Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
139 |
140 | # User-specific stuff
141 |
142 | # AWS User-specific
143 |
144 | # Generated files
145 |
146 | # Sensitive or high-churn files
147 |
148 | # Gradle
149 |
150 | # Gradle and Maven with auto-import
151 | # When using Gradle or Maven with auto-import, you should exclude module files,
152 | # since they will be recreated, and may cause churn. Uncomment if using
153 | # auto-import.
154 | # .idea/artifacts
155 | # .idea/compiler.xml
156 | # .idea/jarRepositories.xml
157 | # .idea/modules.xml
158 | # .idea/*.iml
159 | # .idea/modules
160 | # *.iml
161 | # *.ipr
162 |
163 | # CMake
164 |
165 | # Mongo Explorer plugin
166 |
167 | # File-based project format
168 |
169 | # IntelliJ
170 |
171 | # mpeltonen/sbt-idea plugin
172 |
173 | # JIRA plugin
174 |
175 | # Cursive Clojure plugin
176 |
177 | # Crashlytics plugin (for Android Studio and IntelliJ)
178 |
179 | # Editor-based Rest Client
180 |
181 | # Android studio 3.1+ serialized cache file
182 |
183 | ### JetBrains Patch ###
184 | # Comment Reason: https://github.com/joeblau/gitignore.io/issues/186#issuecomment-215987721
185 |
186 | # *.iml
187 | # modules.xml
188 | # .idea/misc.xml
189 | # *.ipr
190 |
191 | # Sonarlint plugin
192 | # https://plugins.jetbrains.com/plugin/7973-sonarlint
193 |
194 | # SonarQube Plugin
195 | # https://plugins.jetbrains.com/plugin/7238-sonarqube-community-plugin
196 |
197 | # Markdown Navigator plugin
198 | # https://plugins.jetbrains.com/plugin/7896-markdown-navigator-enhanced
199 |
200 | # Cache file creation bug
201 | # See https://youtrack.jetbrains.com/issue/JBR-2257
202 |
203 | # CodeStream plugin
204 | # https://plugins.jetbrains.com/plugin/12206-codestream
205 |
206 | ### Kotlin ###
207 | # Compiled class file
208 |
209 | # Log file
210 |
211 | # BlueJ files
212 |
213 | # Mobile Tools for Java (J2ME)
214 |
215 | # Package Files #
216 |
217 | # virtual machine crash logs, see http://www.java.com/en/download/help/error_hotspot.xml
218 |
219 | ### macOS ###
220 | # General
221 | .DS_Store
222 | .AppleDouble
223 | .LSOverride
224 |
225 | # Icon must end with two \r
226 | Icon
227 |
228 |
229 | # Thumbnails
230 | ._*
231 |
232 | # Files that might appear in the root of a volume
233 | .DocumentRevisions-V100
234 | .fseventsd
235 | .Spotlight-V100
236 | .TemporaryItems
237 | .Trashes
238 | .VolumeIcon.icns
239 | .com.apple.timemachine.donotpresent
240 |
241 | # Directories potentially created on remote AFP share
242 | .AppleDB
243 | .AppleDesktop
244 | Network Trash Folder
245 | Temporary Items
246 | .apdisk
247 |
248 | ### Windows ###
249 | # Windows thumbnail cache files
250 | Thumbs.db
251 | Thumbs.db:encryptable
252 | ehthumbs.db
253 | ehthumbs_vista.db
254 |
255 | # Dump file
256 | *.stackdump
257 |
258 | # Folder config file
259 | [Dd]esktop.ini
260 |
261 | # Recycle Bin used on file shares
262 | $RECYCLE.BIN/
263 |
264 | # Windows Installer files
265 | *.cab
266 | *.msi
267 | *.msix
268 | *.msm
269 | *.msp
270 |
271 | # Windows shortcuts
272 | *.lnk
273 |
274 | ### Gradle ###
275 | .gradle
276 | build/
277 |
278 | # Ignore Gradle GUI config
279 | gradle-app.setting
280 |
281 | # Avoid ignoring Gradle wrapper jar file (.jar files are usually ignored)
282 | !gradle-wrapper.jar
283 |
284 | # Cache of project
285 | .gradletasknamecache
286 |
287 | # # Work around https://youtrack.jetbrains.com/issue/IDEA-116898
288 | # gradle/wrapper/gradle-wrapper.properties
289 |
290 | ### Gradle Patch ###
291 | **/build/
292 |
293 | # Eclipse Gradle plugin generated files
294 | # Eclipse Core
295 | .project
296 | # JDT-specific (Eclipse Java Development Tools)
297 | .classpath
298 |
299 | # End of https://www.toptal.com/developers/gitignore/api/macos,windows,kotlin,java,gradle,intellij,jetbrains
300 |
--------------------------------------------------------------------------------
/Chapter1.md:
--------------------------------------------------------------------------------
1 | # 1장 - 코틀린이란 무엇이며 왜 필요한가?
2 |
3 | 코틀린은 자바 플랫폼에서 돌아가는 새로운 프로그래밍 언어입니다. 간결하고 실용적이며, 자바 코드와의 상호 운용성을 중시합니다.
4 |
5 |
6 |
7 | ## 1.1 코틀린 맛보기
8 |
9 | 다음 코드를 살펴봅시다.
10 |
11 | ```kotlin
12 | data class Person(
13 | val name: String,
14 | val age: Int? = null
15 | )
16 |
17 | fun main(args: Array) {
18 | val persons = listOf(
19 | Person("영희"),
20 | Person("철수", age = 29)
21 | )
22 |
23 | val oldest = persons.maxBy { it.age ?: 0 }
24 | println("나이가 가장 많은 사람: $oldest")
25 | }
26 | ```
27 |
28 |
29 |
30 | ## 1.2 코틀린의 주요 특성
31 |
32 | - 대상 플랫폼 : 서버, 안드로이드 등 자바가 실행되는 모든 곳. 자바 뿐 아니라 자바스크립트로도 코틀린을 컴파일할 수 있습니다.
33 |
34 |
35 |
36 | - 정적 타입 지정 언어 : 모든 프로그램 구성 요소의 타입을 컴파일 시점에 알 수 있고 컴파일러가 타입을 검증해준다는 뜻입니다. 그루비나 JRuby 같은 동적 타입 지정 언어와 다릅니다.
37 |
38 | 자바와 달리 코틀린에서는 모든 변수의 타입을 프로그래머가 직접 명시할 필요가 없습니다. 대부분의 경우 컴파일러가 자동으로 유추할 수 있기 때문에 타입 선언을 생략해도 됩니다.
39 |
40 | ```kotlin
41 | var x = 1
42 | ```
43 |
44 | 정적 타입 지정의 장점은 다음과 같습니다.
45 |
46 | - **성능** : 실행 시점에 어떤 메소드를 호출할지 알아내는 과정이 필요 없으므로 메소드 호출이 더 빠릅니다.
47 | - **신뢰성** : 컴파일러가 프로그램의 정확성을 검증하기 때문에 실행 시 오류로 중단될 가능성이 더 적어집니다.
48 | - **유지 보수성** : 코드에서 다루는 객체가 어떤 타입에 속하는지 알 수 있기 때문에 처음 보는 코드를 다룰 때도 더 쉽습니다.
49 | - **도구 지원** : 정적 타입 지정을 활용하면 더 안전하게 리팩토링 할 수 있고, 도구는 더 정확한 코드 완성 기능을 제공해줍니다.
50 |
51 | 가장 중요한 특성은 **코틀린은 nullable 타입을 지원한다**는 점입니다.
52 |
53 |
54 |
55 | - 함수형 프로그래밍과 객체형 프로그래밍
56 |
57 | 함수형 프로그래밍의 핵심 개념은 다음과 같습니다.
58 |
59 | - **일급 시민인 함수** : 함수를 일반 값처럼 다룰 수 있습니다. 함수를 변수에 저장할 수 있고, 함수를 인자로 다른 함수에 전달할 수 있으며, 함수에서 새로운 함수를 만들어서 반환할 수 있습니다.
60 |
61 | ```kotlin
62 | val func: () -> String = { "Hello" }
63 |
64 | fun invokeFunc(func: () -> String)
65 |
66 | fun returnFunc(): () -> String {
67 | return func
68 | }
69 | ```
70 |
71 | - **불변성** : 함수형 프로그래밍에서는 일단 만들어지고 나면 내부 상태가 절대로 바뀌지 않는 불편 객체를 사용해 프로그램을 작성합니다.
72 |
73 | - **부수 효과 없음** : 함수형 프로그래밍에서는 입력이 같으면 항상 같은 출력을 내놓고 다른 객체의 상태를 변경하지 않으며, 함수 외부나 다른 바깥 환경과 상호작용하지 않는 순수 함수를 사용합니다.
74 |
75 |
76 |
77 | ### 함수형 프로그래밍의 이점
78 |
79 | - **간결성** : 명령형 코드에 비해 더 간결하며 우아합니다. 함수를 값처럼 활용할 수 있으면 더 강력한 추상화를 할 수 있습니다.
80 |
81 | 비슷한 작업을 수행하는 비슷한 두 개의 코드 조각이 있다고 가정해봅시다. 하지만 두 코드 조각은 일부 세부 사항에서 차이가 납니다. 이때 로직에서 공통부분을 따로 함수로 뽑아내고 서로 다른 세부 사항을 인자로 전달할 수 있습니다.
82 |
83 | ```kotlin
84 | fun findAlice() = findPerson { it.name == "Alice" }
85 | fun findBob() = findPerson { it.name = "Bob" }
86 | ```
87 |
88 | - **다중 스레드에서 안전함** : 적절한 동기화 없이 같은 데이터를 여러 스레드가 변경하는 경우 많은 문제가 생깁니다. 불변 데이터 구조를 사용하고 순수 함수를 그 데이터 구조에 적용한다면 다중 스레드 환경에서 같은 데이터를 여러 스레드가 변경할 수 없습니다. 따라서 복잡한 동기화를 적용하지 않아도 됩니다.
89 |
90 | - **테스트 용이성** : 부수 효과가 있는 함수는 그 함수를 실행할 때 전체 환경을 구성하는 준비 코드가 따로 필요하지만 순수 함수는 그런 준비 코드 없이 독립적으로 테스트 할 수 있습니다.
91 |
92 |
93 |
94 | 물론 자바에서도 함수형 프로그래밍이 가능하지만 편하게 사용하기에 충분한 라이브러리와 문법을 지원하지 않습니다. 코틀린은 처음부터 함수형 프로그래밍을 다음처럼 지원해왔습니다.
95 |
96 | - 함수 타입을 지원함에 따라 어떤 함수가 다른 함수를 파라미터로 받거나 함수가 새로운 함수를 반환할 수 있습니다.
97 | - 람다식을 지원함에 따라 번거로운 준비 코드를 작성하지 않아도 코드 블록을 쉽게 정의하고 여기저기 전달할 수 있습니다.
98 | - 데이터 클래스는 불변적인 값 객체를 간편하게 만들 수 있는 구문을 제공합니다.
99 | - 코틀린 표준 라이브러리는 객체와 컬렉션을 함수형 스타일로 다룰 수 있는 API를 제공합니다.
100 |
101 | - 무료 오픈소스 : 코틀린 언어와 컴파일러, 라이브러리 및 도구는 모두 오픈소스이다.
102 |
103 |
104 |
105 | ## 1.3 코틀린 응용
106 |
107 | 코틀린이 각 분야에 적합한 언어인 이유를 살펴봅시다.
108 |
109 | - 코틀린 서버 프로그래밍 - 자바 코드와 매끄럽게 상호운용할 수 있는 코틀린을 사용하면 몇 가지 새로운 기술을 활용하여 서버 시스템을 개발할 수 있습니다. 예를 들면 코틀린이 제공하는 깔끔하고 간결한 DSL 기능을 활용하여 영속성 프레임워크인 `Exposed` 프레임워크(SQL 데이터 베이스의 구조를 기술할 수 있는 읽기 쉬운 DSL. 코틀린 코드만을 사용하여 완전한 타입 검사를 지원하며 질의를 실행할 수 있습니다.)가 있습니다.
110 |
111 | ```kotlin
112 | // 테이블
113 | object CountryTable: IdTable() {
114 | val name = varchar("name", 250).uniqueIndex()
115 | val iso = varchar("iso", 2).uniqueIndex()
116 | }
117 |
118 | // 엔티티
119 | class Country(id: EntityID): Entity(id) {
120 | var name: String by CountryTable.name
121 | var iso: String by CountryTable.iso
122 | }
123 |
124 | // 코틀린 코드만으로 쿼리 날리기
125 | val russia = Country.find {
126 | CountryTable.iso.eq("ru")
127 | }.first()
128 | println(russia.name)
129 | ```
130 |
131 | - 코틀린 안드로이드 프로그래밍 - 안드로이드 스튜디오에서 지원하는 1순위 언어는 코틀린입니다. 책의 예시로 나와있는 `Anko` 라이브러리는 더 이상 사용되지 않으므로 작성하지 않겠습니다.
132 |
133 |
134 |
135 | ## 1.4 코틀린의 철학
136 |
137 | 코틀린의 실용성, 간결성, 안정성, 상호운용성이 왜 장점으로 꼽히는지 알아보겠습니다.
138 |
139 | - **실용성** : 코틀린은 다른 언어가 채택한 이미 성공적으로 검증된 해법과 기능에 의존합니다. 또한 특정 프로그래밍 스타일이나 패러다임을 사용할 것을 강제로 요구하지 않습니다. 마지막으로 코틀린은 인텔리제이 IDE의 개발과 컴파일러의 개발이 맞물려 이뤄져왔기 때문에 도구를 강조합니다.
140 |
141 | - **간결성** : 코틀린은 프로그래머가 작성하는 코드에서 의미 없는 부분을 줄이고 언어가 요구하는 구조를 만족시키기 위한 많은 노력들이 모여 만들어졌습니다. `getter`, `setter`, 생성자 파라미터를 필드에 대입하기 위한 로직 등 자바에 존재하는 여러 가지 번거로운 준비 코드를 묵시적으로 제공합니다.
142 |
143 | 컬렉션에서 원소를 찾는 것과 같은 작업을 수행하는 코드는 라이브러리 함수 호출로 쉽게 대치할 수 있으며 연산자 오버로딩을 지원하지만, 언어가 제공하지 않는 연산자를 정의할 수 있게 허용하지는 않습니다.
144 |
145 | - **안정성** : JVM을 사용하면 메모리 안정성을 보장하고, 버퍼 오버플로를 방지하며, 동적으로 할당한 메모리를 잘못 사용함으로 인해 발생할 수 있는 다양한 문제를 예방할 수 있습니다. JVM 위에서 실행되는 코틀린은 자바보다 더 적은 비용으로 타입 안정성을 사용할 수 있습니다. 타입 추론을 제공해주며, 컴파일 시점 검사를 통해 실행 시점 오류를 더 많이 방지해줍니다. 코틀린의 타입 시스템은 null이 될 수 없는 값을 추적하며, 실행 시점에 NPE(`NullPointerException`)이 발생할 수 있는 연산을 금지합니다.
146 |
147 | ```kotlin
148 | val s: String? = null // null 가능 타입
149 | val s2: String = "" // null 불가능 타입
150 | ```
151 |
152 | 방지해주는 또 다른 예외로는 `ClassCastException`이 있습니다. 어떤 객체를 다른 타입으로 cast하기 전에 타입을 미리 검사하지 않으면 해당 익셉션이 발생할 수 있는데 코틀린에서는 타입 검사와 cast가 한 연산자에 의해 이뤄집니다.
153 |
154 | ```kotlin
155 | if (value is String) // 타입 검사
156 | println(value.toUpperCase()) // 해당 타입의 메소드 사용
157 | ```
158 |
159 | - **상호운용성** : 코틀린의 경우 자바에서 쓰던 기존 라이브러리를 그대로 사용할 수 있습니다. 자바 메소드 호출, 상속 인터페이스 구현, 자바 어노테이션을 적용하는 등의 일이 모두 가능합니다. 다른 일부 JVM 언어와 달리 코틀린은 자바 코드에서 코틀린 코드를 호출할 때도 아무런 노력이 필요 없습니다. 이에 따라 자바 프로젝트에 코틀린을 도입하는 경우 자바를 코틀린으로 변환하는 도구를 자바 클래스에 대해 실행하여 변환할 수도 있습니다.
160 |
161 | 또 다른 방향으로는 기존 자바 라이브러리를 가능하면 최대한 활용한다는 점입니다. 코틀린은 자체 컬렉션 라이브러리를 제공하지 않으며 자바 표준 라이브러리 클래스에 의존하고, 더 쉽게 활용할 수 있는 몇 가지 기능을 더 제공합니다. 이는 코틀린에서 자바 API를 호출할 때 객체를 감싸거나 변환할 필요가 없고, 자바에서 코틀린 API를 호출할 때도 마찬가지로 아무런 변환이 필요없다는 뜻입니다.
162 |
163 | 코틀린이 제공하는 도구도 다중 언어 프로젝트를 완전히 지원하는데 따라서 다음과 같은 동작이 가능합니다.
164 |
165 | - 자바와 코틀린 소스 파일을 자유롭게 네비게이션 할 수 있습니다.
166 | - 여러 언어로 이뤄진 프로젝트를 디버깅하고 서로 다른 언어로 작성된 코드를 언어와 관계없이 한 단계씩 실행할 수 있습니다.
167 | - 자바 메소드를 리팩토링해도 그 메소드와 관련 있는 코틀린 코드까지 제대로 변경됩니다. 역으로 코틀린 메소드를 리팩토링해도 자바 코드까지 모두 자동으로 변경됩니다.
168 |
169 |
170 |
171 | ## 1.5 코틀린 도구 사용
172 |
173 | 컴파일 과정이 어떻게 이뤄지며 그 과정에서 어떤 도구가 쓰이는지 알아봅시다.
174 |
175 | - **코틀린 코드 컴파일** - 코틀린 소스코드를 저장할 때는 보통 `.kt`라는 확장자를 파일에 붙입니다. 코틀린 컴파일러는 코드를 분석하여 `.class` 파일을 만들어내고 만들어진 `.class` 파일은 개발 중인 애플리케이션의 유형에 맞는 표준 패키징 과정을 거쳐 실행될 수 있습니다.
176 |
177 | 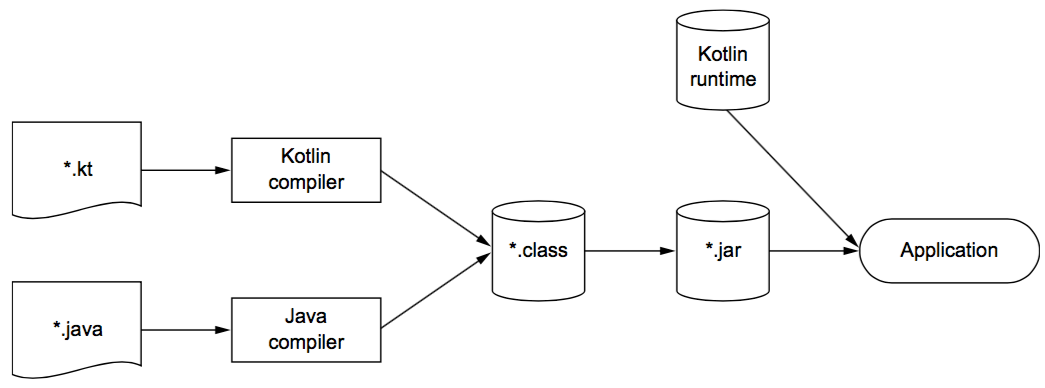
178 |
179 | 코틀린 컴파일러로 컴파일한 코드는 코틀린 런타임 라이브러리에 의존합니다. 런타임 라이브러리에는 코틀린 자체 표준 라이브러리 클래스와 코틀린에서 자바 API의 기능을 확장한 내용이 들어있습니다. 코틀린으로 컴파일한 애플리케이션을 배포할 때는 런타임 라이브러리도 함께 배포해야 합니다.
180 |
181 | - **인텔리제이 IDE와 안드로이드 스튜디오의 코틀린 플러그인**
182 |
183 | - **대화형 셸** - kotlinc 명령을 실행하거나 인텔리제이 IDE 플러그인의 메뉴(툴 > 코틀린> 코틀린 REPL)를 사용하면 됩니다.
184 |
185 | - **이클립스 플러그인** - 코틀린 플러그인을 설치하여 사용할 수 있습니다.
186 |
187 | - **온라인 플레이그라운드** - https://play.kotlinlang.org/ 에 접속하면 온라인으로 코드를 작성하고 컴파일 해볼 수 있습니다.
188 |
189 | - **자바-코틀린 변환기** - 인텔리제이 메뉴에서 코드 > 자바 파일을 코틀린 파일로 변환을 선택하여 변환할 수 있습니다.
190 |
191 |
--------------------------------------------------------------------------------
/Chapter10-1.md:
--------------------------------------------------------------------------------
1 | # 10. 애노테이션과 리플렉션
2 |
3 | - 지금까지는 함수나 클래스 이름을 소스코드에서 정확하게 알고 있어야만 사용할 수 있었다.
4 | - 애노테이션과 리플렉션을 사용하면 그런 제약을 벗어나서 미리 알지 못하는 임의의 클래스를 다룰 수 있다.
5 | - 애노테이션을 사용하면 실행 시점에 컴파일러 내부 구조를 분석할 수 있다.
6 | - 애노테이션과 리플렉션의 사용법을 보여주는 예제로 이 장에서는 JSON 직렬화와 역질렬화 라이브러리인 제이키드를 구현한다.
7 | - 이 라이브러리는 실행 시점에 코틀린 객체의 프로퍼티를 읽거나 JSON 파일에서 읽은 데이터를 코틀린 객체로 만들기 위해 리플렉션을 사용한다.
8 | - 그리고 애노테이션을 통해 제이키드 라이브러리가 클래스와 프로퍼티를 직렬화하고 역직렬화하는 방식을 변경한다.
9 |
10 | ## 애노테이션 선언과 적용
11 |
12 | - 코틀린 애노테이션도 자바 개념과 동일하게 메타데이터를 선언에 추가하면 애노테이션을 처리하는 도구가 컴파일 시점이나 실행 시점에 적절한 처리를 해준다.
13 |
14 | ### 애노테이션 적용
15 |
16 | - 애노테이션은 @과 애노테이션 이름으로 이뤄진다. 함수나 클래스 등 여러 다른 코드 구성 요소에 애노테이션을 붙일 수 있다.
17 | - 예를 들어 제이유닛(JUnit) 프레임워크를 사용한다면 테스트 메소드 앞에 `@Test` 애노테이션을 붙여야 한다.
18 |
19 | ```kotlin
20 | import org.junit.*
21 |
22 | class MyTest {
23 | // @Test 애노테이션을 사용해 제이유닛 프레임워크에게 이 메소드를 테스트로 호출하라고 지시
24 | @Test fun testTrue() {
25 | Assert.assertTrue(true)
26 | }
27 | ```
28 |
29 | - `@Deprecated` 을 코틀린에서는 replaceWith 파라미터를 통해 옛 버전을 대신할 수 있는 패턴을 제시할 수 있다.
30 |
31 | ```kotlin
32 | @Deprecated("Use removeAt(index) instead.", **ReplaceWith**("removeAt (index)"))
33 | fun remove(index: Int) {...}
34 | // ReplaceWith는 애노테이션의 인자로 사용하기 때문에 @를 붙이지 않는다.
35 | ```
36 |
37 | - 애노테이션에 인자를 넘길 때는 일반 함수와 마찬가지로 괄호 안에 인자를 넣는다. 애노테이션의 인자로는 원시 타입의 값, 문자열, enum, 클래스 참조, 다른 애노테이션 클래스, 이 요소들의 배열이 들어갈 수 있다. 애노테이션 인자를 지정하는 문법은 자바와 약간 다르다.
38 | - 클래스를 애노테이션 인자로 지정할 때는 `@MyAnnotation(MyClass::class)` 처럼 ::class를 클래스 이름 뒤에 넣어야 한다.
39 | - 다른 애노테이션을 인자로 지정할 때는 인자로 들어가는 애노테이션의 이름 앞에 @를 넣지 않아야 한다.
40 | - 배열을 인자로 지정하려면 `@RequestMapping(path=arrayOf(”/foo”,”/bar”))` 처럼 arrayOf 함수를 사용한다.
41 | - 자바에서 선언한 애노테이션의 경우 value라는 이름의 파라미터가 필요에 따라 자동으로 가변 길이 인자로 변환된다. 따라서 그럼 경우 `@JavaAnootationWithArrayValue(”abc”,”foo”,”bar”)` 처럼 arrayOf 함수를 쓰지 않아도 된다.
42 | - 애노테이션 인자를 컴파일 시점에 알 수 있어야 한다. 따라서 임의의 프로퍼티를 인자로 지정할 수는 없다. 프로퍼티를 애노테이션 인자로 사용하려면 그 앞에 const 변경자를 붙여야 한다. (컴파일러는 const가 붙은 프로퍼티를 컴파일 시점 상수로 취급한다)
43 |
44 | `const val TEST_TIMEOUT = 100L`
45 |
46 | `@Test(timeout = TEST_TIMEOUT) fun testMethod() {...}`
47 |
48 | - const가 붙은 프로퍼티는 파일의 맨 위에 object 안에 선언해야 하며, 원시 타입이나 String으로 초기화해야 한다. 일반 프로퍼티를 애노테이션 인자로 사용하려하면 오류 발생 `(”Only const val can be used in constant expressions”)`
49 |
50 | ### 애노테이션 대상
51 |
52 | - 애노테이션을 붙일 때 어떤 요소에 애노테이션을 붙일지 표시할 필요가 있다.
53 | - 사용 지점 대상(use-site target) 선언으로 애노테이션을 붙일 요소를 정할 수 있다. 사용 지점 대상은 @기호화 애노테이션 이름 사이에 붙으며, 애노테이션 이름과는 콜론(:)으로 분리된다. 그림 10.1의 get은 `@Rule` 애노테이션을 프로퍼티 게터에 적용하라는 뜻이다.
54 |
55 | 
56 |
57 | - Rule 애노테이션 사용 예 → 제이유닛에서 각 테스트 메소드 앞에 해당 메소드를 실행하기 위한 규칙 지정
58 | - 예를 들어 TemporaryFolder라는 규칙을 사용하면 메소드가 끝나면 삭제될 임시 파일과 폴더를 만들 수 있다.
59 | - 규칙을 지정하려면 공개 필드(public(나 메소드 앞에 `@Rule` 를 붙여야 하지만 코틀린 필드는 기본적으로 비공개 이기 때문에 예외가 발생한다 따라서 정확한 대상에 적용하려면 `@get:Rule`을 사용해야 한다.
60 |
61 | 
62 |
63 | - 자바에 선언된 애노테이션을 사용해 프로퍼티에 애노테이션을 붙이는 경우 기본적으로 프로퍼티의 필드에 그 애노테이션이 붙는다. 하지만 코틀린은 프로퍼티 대상을 직접 적용해서 애노테이션을 만들 수 있다.
64 | - 사용 지점 대상을 지정할 때 지원하는 대상 목록
65 | - property → 프로퍼티 전체, 자바에서 선언된 애노테이션에는 이 사용 지점 대상을 사용할 수 없다.
66 | - field → 프로퍼티에 의해 생성되는 필드
67 | - get → 프로퍼티 게터
68 | - set → 프로퍼티 세터
69 | - receiver → 확장 함수나 프로퍼티의 수신 객체 파라미터
70 | - param → 생성자 파라미터
71 | - setparam → 세터 파라미터
72 | - delegate → 위임 프로퍼티의 위임 인스턴스를 담아둔 필드
73 | - file → 파일 안에 선언된 최상위 함수와 프로퍼티를 담아두는 클래스
74 | - file 대상을 사용하는 애노테이션은 package 선언 앞에서 파일의 최상위 수준에만 적용할 수 있다.
75 | - example `@file:JvmName("StringFunctions")` → 파일에 있는 최상위 선언을 담는 클래스의 이름을 바꿔주는 기능
76 | - 자바와 달리 코틀린에서는 애노테이션 인자로 클래스나 함수 선언이나 타입 외에 임의의 식을 허용한다. (컴파일러 경고를 무시한기 위한 `@Supress` 애노테이션)
77 |
78 | ```kotlin
79 | fun test(list: List<*>( {
80 | @Supress("UNCHECKED_CAST")
81 | val strings = list as List
82 | // ...
83 | }
84 | ```
85 |
86 |
87 | ### 애노테이션을 활용한 JSON 직렬화 제어
88 |
89 | - 애노테이션을 사용하는 고전적인 예제로 객체 직렬화 제어를 들 수 있다.
90 | - 잭슨(jackson), 지슨(GSON), **제이키드**
91 | - **직렬화(serialization)**는 객체를 저장장치에 저장하거나 네트워크를 통해 전송하기 위해 텍스트나 이진 형식으로 변환하는 것이다.
92 | - 반대 과정인 **역직렬화(deserialization)**는 텍스트나 이진 형식으로 저장된 데이터로부터 원래의 객체를 만들어낸다.
93 |
94 | ```kotlin
95 | fun main() {
96 | val person = Person("Alice", 29)
97 | println(serialize(person))
98 |
99 | val json = """{"name":"Alice", "age": 29}"""
100 | println(deserialize(json))
101 | }
102 |
103 | >>> {"age": 29, "name": "Alice"}
104 | >>> Person(name=Alice, age=29)
105 | ```
106 |
107 | 
108 |
109 | - 애노테이션을 활용해 객체를 직렬화하거나 역직렬화하는 방법을 제어할 수 있다.
110 | - `@JsonExclude` 애노테이션을 사용하면 직렬화나 역직렬화 시 그 프로퍼티를 무시할 수 있다.
111 | - `@JsonName` 애노테이션을 사용하면 프로퍼티를 표현하는 키/값 쌍의 키로 프로퍼티 이름 대신 애노테이션이 지정한 이름을 쓰게 할 수 있다.
112 |
113 | ```kotlin
114 | data class Person(
115 | @JsonName("alias") val firstName: String,
116 | @JsonExclude val age: Int
117 | )
118 |
119 | fun main() {
120 | val person = Person("test", 20)
121 | println(serialize(person))
122 |
123 | val json = """{"alias": "test", "age":20}"""
124 | println(deserialize(json))
125 | }
126 |
127 | >>> {"alias": "test"}
128 | >>> Person(firstName=test, age=20)
129 | ```
130 |
131 |
132 | ### 애노테이션 선언
133 |
134 | - 애노테이션 선언의 예: `@annotation class JsonExclude` → 아무 파라미터도 없는 가장 단순한 애노테이션, 일반 클래스와의 차이는 class 앞에 annotation이 붙는다.
135 | - 하지만 애노테이션 클래스는 오직 선언이나 식과 관련 있는 메타데이터의 구조를 정의하기 때문에 내부에 코드가 존재할 수 없다. (컴파일러에서 본문 정의못하도록 막음)
136 | - 파라미터가 있는 애노테이션을 정의하려면 주 생성자에 파라미터를 선언해야 한다. → `annotation class JsonName(val name: String)` (모든 파라미터 앞에 val만 사용할 수 있다.)
137 | - 자바에는 value라는 메소드가 있다. value는 특별하다. 어떤 애노테이션을 적용할 때 value를 제외한 모든 애트리뷰트에는 이름을 명시해야 한다. 반면 코틀린의 애노테이션 적용 문법은 일반적인 생성자 호출과 같다. → `@JsonName(name = “first_name”) = @JsonName(”first_name")`
138 |
139 | ### 메타애노테이션: 애노테이션을 처리하는 방법 제어
140 |
141 | - 자바와 마찬가지로 코틀린 애노테이션에도 애노테이션을 붙일 수 있다. 애노테이션 클래스에 적용할 수 있는 애노테이션을 **메타애노테이션(meta-annotation)**이라고 부른다.
142 | - 메타애노테이션들은 컴파일러가 애노테이션을 처리하는 방법을 제어한다.
143 | - `@Target` → 애노테이션을 적용할 수 있는 요소의 유형을 정의한다. (지정하지 않으면 모든 선언에 적용가능)
144 |
145 | ```kotlin
146 | // @Target(AnnotationTarget.PROPERTY, AnnotationTarget.CLASS)
147 | @Target(AnnotationTarget.PROPERTY) // 대상 지정
148 | annotation class JsonExclude
149 | ```
150 |
151 | - `@Retention` → 정의 중인 애노테이션 클래스를 소스 수준에서만 유지할지, .class 파일에 저장할지, 실행 시점에 리플렉션을 사용해 접근할 수 있게 할지를 지정하는 메타애노테이션이다. 자바 컴파일러는 기본적으로 애노테이션을 .class 파일에는 저장하지만 런타임에는 사용할 수 없게 한다. 하지만 대부분의 애노테이션은 런타임에도 사용할 수 있어야 하므로 코틀린에서는 RUNTIME으로 지정한다.
152 |
153 | ### 애노테이션 파라미터로 클래스 사용
154 |
155 | - 어떤 클래스를 선언 메타데이터로 참조할 수 있는 기능이 필요할 때도 있다.
156 | - 클래스 참조를 파라미터로 하는 애노테이션 클래스를 선언하면 그런 기능을 사용할 수 있다.
157 |
158 | ```kotlin
159 | @Target(AnnotationTarget.PROPERTY)
160 | annotation class DeserializeInterface(val targetClass: KClass)
161 |
162 | data class Person(
163 | val name: String,
164 | @DeserializeInterface(CompanyImpl::class) val company: Company
165 | // 일반적으로 클래스를 가리키려면 클래승 이름 뒤에 ::class 키워드를 붙여야 한다.
166 | )
167 |
168 | interface Company {
169 | val name: String
170 | }
171 |
172 | data class CompanyImpl(override val name: String) : Company
173 | ```
174 |
175 | - KClass는 자바 java.lang.Class 타입과 같은 역할을 하는 코틀린 타입이다. 코틀린 클래스에 대한 참조를 저장할 때 KClass 타입을 사용한다.
176 | - CompanyImpl::classd의 타입은 KClass이며 이는 KClass의 하위 타입이다. out 키워드가 있으면 모든 코틀린 타입 T에 대해 KClass가 KClass의 하위 타입이 된다(공변성)
177 |
178 | 
179 |
180 |
181 | ### 애노테이션 파라미터로 제네릭 클래스 받기
182 |
183 | - 기본적으로 제이키드는 원시 타입이 아닌 프로퍼티를 중첩된 객체로 직렬화 한다. 이런 기본 동작을 변경하고 싶으면 값을 직렬화하는 로직을 직접 제공하면 된다.
184 |
185 | ```kotlin
186 | @Target(AnnotationTarget.PROPERTY)
187 | // ValueSerializer 타입을 참조하려면 항상 타입 인자를 제공해야 한다. 하지만 이 애노테이션이
188 | // 어떤 타입에 대해 쓰일지 전혀 알 수 없으므로 스타 프로젝을 사용한다.
189 | annotation class CustomSerializer(val serializerClass: KClass>)
190 |
191 | data class Person(
192 | val name: String,
193 | @CustomSerializer(DateSerializer::class) val birthData: Date
194 | )
195 |
196 | // ValueSerializer 클래스는 제네릭 클래스라서 타입 파라미터가 있다.
197 | interface ValueSerializer {
198 | fun toJsonValue(value: T): Any?
199 | fun fromJsonValue(jsonValue: Any?): T
200 | }
201 |
202 | object DateSerializer : ValueSerializer {
203 | private val dateFormat = SimpleDateFormat("dd-mm-yyyy")
204 |
205 | override fun toJsonValue(value: Date): Any? {
206 | return dateFormat.format(value)
207 | }
208 |
209 | override fun fromJsonValue(jsonValue: Any?): Date {
210 | return dateFormat.parse(jsonValue as String)
211 | }
212 | }
213 |
214 | fun main() {
215 | val person = Person("test", SimpleDateFormat("dd-mm-yyyy").parse("13-02-1987"))
216 | println(serialize(person))
217 |
218 | val json = """{"birthData": "13-02-1987", "name": "test"}"""
219 | println(deserialize(json))
220 | }
221 |
222 | >>> {"birthData": "13-02-1987", "name": "test"}
223 | >>> Person(name=test, birthData=Tue Jan 13 00:02:00 KST 1987)
224 | ```
225 |
226 | - 클래스를 인자로 받아야 하면 애노테이션 파라미터 타입에 KClass을 쓴다. 제네릭 클래스를 인자로 받아야 하면 KClass> 처럼 허용할 클래스의 이름 뒤에 스타 프로젝션을 덧붙인다.
--------------------------------------------------------------------------------
/Chapter10-2.md:
--------------------------------------------------------------------------------
1 | # Chapter 10 : 애노테이션과 리플렉션
2 |
3 | ## 10. 2 : 리플렉션 : 실행 시점에 코틀린 객체 내부 관찰
4 |
5 | 리플렉션은 실행 시점에 동적으로 객체의 프로퍼티와 메소드에 접근할 수 있게 해주는 방법입니다. 타입과 관계없이 객체를 다뤄야 하거나 객체가 제공하는 메소드나 프로퍼티 이름을 오직 실행 시점에만 알 수 있는 경우가 있습니다. JSON 직렬화 라이브러리를 사용하는 경우입니다.
6 |
7 | 코틀린에서 리플렉션을 사용하려면 두 가지 서로 다른 리플렉션 API를 다뤄야 합니다.
8 |
9 | - `java.lang.reflect`
10 | - `kotlin.reflect` : 자바에는 없는 프로퍼티나 널이 될 수 있는 타입과 같은 코틀린 고유 개념에 대한 리플렉션 제공
11 |
12 |
13 |
14 | ### 10.2.1 코틀린 리플렉션 API : KClass, KCallable, KFunction, KProperty
15 |
16 | `java.lang.Class`에 해당하는 `KClass`를 사용하면 클래스 안에 존재하는 모든 선언을 열거하고 접근하거나 상위 클래스를 얻는 등의 작업이 가능해집니다. `MyClass::class`라는 식을 써서 인스턴스를 얻을 수 있으며, 실행 시점에 객체의 클래스를 얻으려면 javaClass 프로퍼티를 사용하여 객체의 자바 클래스를 얻어야 합니다. 이 클래스를 얻었으면, `.kotlin` 확장 프로퍼티를 통해 자바에서 코틀린 리플렉션 API로 옮겨올 수 있습니다.
17 |
18 | ```kotlin
19 | class Person(val name: String, val age: Int)
20 |
21 | val person = Person("Hongbeom", 28)
22 | val kClass = person.javaClass.kotlin
23 | println(kClass.simpleName) // Person
24 | kClass.memberProperties.forEach { println(it.name) } // age, name
25 | ```
26 |
27 |
28 |
29 | `KClass` 인터페이스를 살펴보면, 클래스의 모든 멤버 목록이 `KCallable` 인스턴스의 컬렉션이라는 것을 알 수 있습니다. `KCallable`은 함수와 프로퍼티를 아우르는 공통 상위 인터페이스이며, 내부에 `call`이라는 메소드가 들어있어서 `call`을 사용하면 함수나 프로퍼티의 게터를 호출할 수 있습니다.
30 |
31 | ```kotlin
32 | interface KClass {
33 | val simpleName: String?
34 | val qualifiedName: String?
35 | val members: Collection>
36 | val constructors: Collection>
37 | val nestedClasses: Collection>
38 | }
39 | ```
40 |
41 | ```kotlin
42 | interface KCallable {
43 | fun call(vararg args: Any?): R
44 | }
45 | ```
46 |
47 |
48 |
49 | 다음 코드는 리플렉션이 제공하는 `call`을 사용하여 함수를 호출할 수 있음을 보여줍니다.
50 |
51 | ```kotlin
52 | fun foo(x: Int) = println(x)
53 | val kFunction = ::foo
54 | kFunction.call(42) // 42
55 | ```
56 |
57 |
58 |
59 | 하지만 여기서 함수를 호출하기 위해 더 구체적인 메소드를 사용할 수도 있습니다. (call은 인자가 `vararg`라서 인자의 개수를 올바르게 맞춰주지 않아도 컴파일 에러가 안남) `::foo`의 타입 `KFunction1`에는 파라미터와 리턴값 정보가 들어있습니다. 1은 파라미터가 1개라는 뜻입니다. 우리는 `kFunction`의 함수를 직접 호출할 수 있습니다.
60 |
61 | ```kotlin
62 | fun sum(x: Int, y: Int) = x + y
63 | val kFunction: KFunction2 = ::sum
64 | println(kFunction.invoke(1, 2) + kFunction(3, 4)) // 10
65 |
66 | kFunction(1) // ERROR : No value passed for parameter p2
67 | ```
68 |
69 | 
70 |
71 | - https://t1.daumcdn.net/cfile/tistory/99178A33599A8FFB37 참조 이미지
72 |
73 |
74 |
75 | ## Quiz
76 |
77 | `var`로 선언한 프로퍼티를 `KProperty`로 접근하여 값을 `set`하고 `get`을 통해 해당 프로퍼티를 출력해봅시다
78 |
79 | `name`과 `age`를 가지는 `Person` 클래스를 정의하고 `KProperty` 리플렉션을 통해 `age`에 접근한 후 접근한 `KProperty`를 사용하여 `age`를 출력해봅시다.
80 |
81 |
82 |
83 | ### 10.2.2 리플렉션을 사용한 객체 직렬화 구현
84 |
85 | 직렬화 함수의 기능을 알아봅시다. 기본적으로 직렬화 함수는 객체의 모든 프로퍼티를 직렬화합니다. 아래 코드를 살펴봅시다.
86 |
87 | ```kotlin
88 | private fun StrintBuilder.serializeObject(obj: Any) {
89 | val kClass = obj.javaClass.kotlin
90 | val properties = kClass.memberProperties
91 |
92 | properties.joinToStringBuilder(this, prefix = "{", postfix = "}") { prop ->
93 | serializeString(prop.name) // 프로퍼티 이름 얻기
94 | append(": ")
95 | serializePropertyValue(prop,get(obj)) // 프로퍼티 값 얻기
96 | }
97 | }
98 |
99 | // 결과 json 예시 : { prop1: value1, prop2: value2 }
100 | ```
101 |
102 |
103 |
104 | `joinToStringBuilder` 함수는 프로퍼티를 콤마(,)로 분리해주며, `serializeString` 함수는 `JSON` 명세에 따라 특수 문자를 이스케이프 해줍니다. `serializePropertyValue` 함수는 어떤 값이 원시 타입, 문자열, 컬렉션, 중첩된 객체 중 어떤 것인지 판단하고 그에 따라 값을 적절히 직렬화 합니다.
105 |
106 | 하지만 이 예제 코드에서는 어떤 객체의 클래스에 정의된 모든 프로퍼티를 열거하기 때문에 정확히 각 프로퍼티가 어떤 타입인지 알 수 없는데, 따라서 `prop` 변수의 타입은 `KProperty`이며, `prop.get(obj)` 메소드 호출은 `Any` 타입의 값을 반환합니다. 이 경우 수신 객체 타입을 컴파일 시점에 검사할 방법이 없으나, 어떤 프로퍼티의 `get`에 넘기는 객체가 바로 그 프로퍼티를 가져온 객체(`obj`)이기 때문에 항상 프로퍼티 값이 제대로 리턴됩니다.
107 |
108 |
109 |
110 |
--------------------------------------------------------------------------------
/Chapter10-3.md:
--------------------------------------------------------------------------------
1 | ## 10.2.3 애노테이션을 활용한 직렬화 제어
2 |
3 | 이제 Jkid에서 정의한 `@JsonExclude`, `@JsonName`, `@CustomSerializer` 애노테이션들을 `serializeObject` 함수가 어떻게 처리하는지 알아보자.
4 |
5 | 먼저 `@JsonExclude`부터 보자.
6 |
7 | 어떤 프로퍼티를 직렬화에서 제외하고 싶을 때 이 애노테이션을 쓸 수 있다.
8 |
9 | 클래스의 모든 멤버 프로퍼티를 가져오기 위해 `KClass` 인스턴스의 `memberProperties` 프로퍼티를 사용했었다.
10 |
11 | 하지만 지금은 `@JsonExclude` 애노테이션이 붙은 프로퍼티를 제외해야 한다.
12 |
13 | `KAnnotatedElement` 인터페이스에는 `annotations` 프로퍼티가 있다.
14 |
15 | 이는 소스코드상에서 해당 요소에 적용된 모든 애노테이션 인스턴스의 컬렉션이다.
16 |
17 | `KProperty`는 `KAnnotatedElement`를 확장하므로 `propery.annotations`를 통해 프로퍼티의 모든 애노테이션을 얻을 수 있다.
18 |
19 | 여기서는 모든 애노테이션이 아닌 특정 애노테이션만 찾으면 되므로 `findAnnotation`라는 함수를 사용할 수 있다.
20 |
21 | ```kotlin
22 | inline fun KAnnotatedElement.findAnnotation(): T?
23 | = annotations.filterIsInstance().firstOrNull()
24 | ```
25 |
26 | `findAnnotation` 함수는 인자로 전달받은 타입에 해당하는 애노테이션이 있으면 그 애노테이션을 반환한다.
27 |
28 | 9장에서 배운 타입 실체화를 사용해 타입 파라미터를 `reified`로 만들어 애노테이션 클래스를 타입 인자로 전달한다.
29 |
30 | 이제 `findAnnotation`을 표준 라이브러리 함수인 `filter`와 함께 사용하면 `@JsonExclude` 애노테이션된 프로퍼티를 없앨 수 있다.
31 |
32 | ```kotlin
33 | val properties = obj.javaClass.kotlin.memberProperties
34 | .filter { it.findAnnotation() == null }
35 | ```
36 |
37 | 다음은 `@JsonName`이다.
38 |
39 | 기억을 되살리기 위해 `@JsonName` 선언과 사용법을 다시 보자.
40 |
41 | ```kotlin
42 | @Target(AnnotationTarget.PROPERTY)
43 | annotation class JsonName(val name: String)
44 |
45 | data class Person(
46 | @JsonName("alias") val firstName: String,
47 | val age: Int
48 | )
49 | ```
50 |
51 | 이 경우 애노테이션의 존재 여부뿐 아니라 애노테이션에 전달한 인자도 알아야 한다.
52 |
53 | `@JsonName`의 인자는 프로퍼티를 직렬화해서 JSON에 넣을 때 사용할 이름이다.
54 |
55 | 다행히 이 경우에도 `findAnnotation`을 사용할 수 있다.
56 |
57 | ```kotlin
58 | val jsonNameAnn = prop.findAnnotation() // @JsonName 애노테이션이 있으면 그 인스턴스를 얻는다.
59 | val propName = jsonNameAnn?.name ?: prop.name // 애노테이션에서 "name" 인자를 찾고 그런 인자가 없으면 prop.name을 사용한다.
60 | ```
61 |
62 | 프로퍼티에 `@JsonName` 애노테이션이 없다면 `jsonNameAnn`은 `null`일 것이다.
63 |
64 | 그런 경우 여전히 `prop.name`을 JSON의 프로퍼티 이름으로 사용할 수 있다.
65 |
66 | 프로퍼티에 `@JsonName` 애노테이션이 있다면 애노테이션이 지정하는 이름을 대신 사용한다.
67 |
68 | 앞에서 본 `Person` 클래스 인스턴스를 직렬화하는 과정을 보자.
69 |
70 | `firtName` 프로퍼티를 직렬화하는 동안 `jsonNameAnn`에는 `JsonName` 애노테이션 클래스에 해당하는 인스턴스가 들어있다.
71 |
72 | 따라서 `jsonNameAnn?.name`의 값은 `null`이 아니고 `alias`이며, 직렬화 시 이 이름을 키로 사용한다.
73 |
74 | `age` 프로퍼티를 직렬화할 때는 `@JsonName` 애노테이션이 없으므로 `age`를 키로 사용한다.
75 |
76 | 다음은 지금까지 설명한 내용을 반영한 직렬화 로직이다.
77 |
78 | ```kotlin
79 | private fun StringBuilder.serializeObject(obj: Any) {
80 | obj.javaClass.kotlin.memberProperties
81 | .filter { it.findAnnotation() == null }
82 | .joinToStringBuilder(this, prefix = "{", postfix = "}") {
83 | serializeProperty(it, obj)
84 | }
85 | }
86 | ```
87 |
88 | 위 코드는 `@JsonExclude`로 애노테이션한 프로퍼티를 제외시킨다.
89 |
90 | 또한 프로퍼티 직렬화와 관련된 로직을 `serializeProperty`라는 확장 함수로 분리해 호출한다.
91 |
92 | ```kotlin
93 | private fun StringBuilder.serializeProperty(
94 | prop: KProperty1, obj: Any,
95 | ) {
96 | val jsonNameAnn = prop.findAnnotation()
97 | val propName = jsonNameAnn?.name ?: prop.name
98 | serializeString(propName)
99 | append(": ")
100 |
101 | val value = prop.get(obj)
102 | val jsonValue = prop.getSerializer()?.toJsonValue(value) ?: value
103 | serializePropertyValue(jsonValue)
104 | }
105 | ```
106 |
107 | 앞에서 설명한 것처럼 `@JsonName`에 따라 프로퍼티 이름을 처리한다.
108 |
109 | `out`: 생산할 수 있지만 소비할 수 없음. 공변성
110 |
111 | `in`: 소비할 수 있지만 생산할 수 없음. 반공변성
112 |
113 | 다음으로 나머지 애노테이션인 `@CustomSerializer`를 구현해보자.
114 |
115 | 이 구현은 `getSerializer`라는 함수에 기초한다.
116 |
117 | `getSerializer`는 `@CustomSerializer`를 통해 등록한 `ValueSerializer` 인스턴스를 반환한다.
118 |
119 | 예를 들어 `Person` 클래스를 다음과 같이 정의하고 `birthDate` 프로퍼티를 직렬화하면서 `getSerializer()`를 호출하면 `DateSerializer` 인스턴스를 얻을 수 있다.
120 |
121 | ```kotlin
122 | data class Person(
123 | val name: String,
124 | @CustomSerializer(DateSerializer::class) val birthDate: Date
125 | )
126 | ```
127 |
128 | `getSerializer` 구현을 이해하기 위해 `@CustomSerializer` 선언을 살펴보자.
129 |
130 | ```kotlin
131 | annotation class CustomSerializer(
132 | val serializerClass: KClass>
133 | )
134 | ```
135 |
136 | `getSerializer` 구현은 다음과 같다.
137 |
138 | ```kotlin
139 | fun KProperty<*>.getSerializer(): ValueSerializer? {
140 | val customSerializerAnn = findAnnotation() ?: return null
141 | val serializerClass = customSerializerAnn.serializerClass
142 | val valueSerializer = serializerClass.objectInstance
143 | ?: serializerClass.createInstance()
144 | @Suppress("UNCHECKED_CAST")
145 | return valueSerializer as ValueSerializer
146 | }
147 | ```
148 |
149 | `getSerializer`가 주로 다루는 객체가 `KProperty` 인스턴스이기 때문에 `KProperty`의 확장 함수로 정의한다.
150 |
151 | `getSerializer`는 `findAnnotation` 함수를 호출해서 `@CustomSerializer` 애노테이션이 있는지 찾는다.
152 |
153 | `@CustomSerializer` 애노테이션이 있다면 그 애노테이션의 `serializerClass`가 직렬화기 인스턴스를 얻기 위해 사용해야할 클래스다.
154 |
155 | 여기서 `@CustomSerializer`의 값으로 클래스와 객체(`object`)를 처리하는 방식을 보자.
156 |
157 | 클래스와 객체는 모두 `KClass` 클래스로 표현된다.
158 |
159 | 다만 객체에는 `object` 선언에 의해 생성된 싱글턴을 가리키는 `objectInstance`라는 프로퍼티가 있다는 것이 클래스와 다른 점이다.
160 |
161 | 따라서 그 싱글턴 인스턴스를 사용해 모든 객체를 직렬화하면 되므로 객체를 생성할 필요가 없다.
162 |
163 | 하지만 `KClass`가 일반 클래스를 표현한다면 `createInstance`를 호출해서 새 인스턴스를 만들어야 한다.
164 |
165 | ```kotlin
166 | private fun StringBuilder.serializeProperty(
167 | prop: KProperty1, obj: Any,
168 | ) {
169 | val jsonNameAnn = prop.findAnnotation()
170 | val propName = jsonNameAnn?.name ?: prop.name
171 | serializeString(propName)
172 | append(": ")
173 |
174 | val value = prop.get(obj)
175 | val jsonValue = prop.getSerializer()?.toJsonValue(value) ?: value
176 | // 프로퍼티에 대해 정의된 커스텀 직렬화기가 있으면 그 커스텀 직렬화기를 사용한다.
177 | // 커스텀 직렬화기가 없으면 일반적인 방법을 따라 프로퍼티를 직렬화한다.
178 | serializePropertyValue(jsonValue)
179 | }
180 | ```
181 |
182 | 이제 역직렬화 부분을 보자.
183 |
184 | 역직렬화 부분은 코드가 더 길기 때문에 전체 구조와 리플렉션을 어떻게 사용하는지를 주로 설명한다.
185 |
186 | *4~5절의 역직렬화 부분은 애노테이션과 리플렉션보다도 구현에 관한 내용이 많아 생략한다.*
187 |
188 | *사실 이 책에서 나온 내용만으로 애노테이션과 리플렉션을 완벽하게 사용할 수는 없으므로 사용해야 할 일이 생긴다면 다음의 문서를 참고하도록 하자.*
189 |
190 | [Annotations | Kotlin](https://kotlinlang.org/docs/annotations.html)
191 |
192 | [Reflection | Kotlin](https://kotlinlang.org/docs/reflection.html)
193 |
194 |
195 |
196 | # 10.3 요약
197 |
198 | - 코틀린에서 애노테이션을 적용할 때 사용하는 문법은 자바와 거의 같지만 더 넓은 대상에 애노테이션을 적용할 수 있다.
199 | - 애노테이션 인자로 원시 타입, 문자열, 이넘, 클래스 참조, 다른 애노테이션 클래스의 인스턴스, 배열을 사용할 수 있다.
200 | - @get:Rule와 같은 문법 사용해 애노테이션의 사용 대상을 명시하면 한 코틀린 선언이 여러 가지 바이트코드 요소를 만들어내는 경우 정확히 어떤 부분에 애노테이션을 적용할지 지정할 수 있다.
201 | - 애노테이션 클래스를 정의할 때는 본문이 없고 주 생성자의 모든 파라미터를 val 프로퍼티로 표시한 코틀린 클래스를 사용한다.
202 | - 메타애노테이션을 사용해 대상, 애노테이션 유지 방식 등 여러 애노테이션 특성을 지정할 수 있다.
203 | - 리플렉션 API를 통해 실행 시점에 객체의 메서드와 프로퍼티를 열거하고 접근할 수 있다.
204 | 리플렉션 API에는 클래스(`KClass`), 함수(`KFunction`) 등 여러 종류의 선언을 표현하는 인터페이스가 들어있다.
205 | - 클래스를 컴파일 시점에 알고 있다면 `KClass` 인스턴스를 얻기 위해 `ClassName::class`를 사용한다.
206 | 하지만 실행 시점에 `KClass` 인스턴스를 얻기 위해서는 `obj.javaClass.kotlin`을 사용한다.
207 | - `KFunction`과 `KProperty` 인터페이스는 모두 `KCallable`을 확장한다. `KCallable`은 제네릭 `call` 메서드를 제공한다.
208 | - `KFunction0`, `KFunction1` 등의 인터페이스는 모두 파라미터 수가 다른 함수를 표현하며, `invoke` 메서드를 사용해 함수를 호출할 수 있다.
209 | - `KProperty0`은 최상위 프로퍼티나 변수, `KProperty1`은 수신 객체가 있는 프로퍼티에 접근할 때 쓰는 인터페이스다. 두 인터페이스 모두 `get` 메서드를 사용해 프로퍼티 값을 가져올 수 있다.
210 | - `KMutablePropertyN`(`var`)은 `KPropertyN`을 확장하며, `set` 메서드를 통해 프로퍼티 값을 변경할 수 있게 해준다.
211 |
--------------------------------------------------------------------------------
/Chapter2.md:
--------------------------------------------------------------------------------
1 | # 2장 - 코틀린 기초
2 |
3 | **2장에서 다루는 내용**
4 |
5 | - 함수, 변수, 클래스, enum, 프로퍼티를 선언하는 방법
6 | - 제어 구조
7 | - 스마트 캐스트
8 | - 예외 던지기와 예외 잡기
9 |
10 |
11 |
12 |
13 | ## 2.1 기본 요소: 함수와 변수
14 | ### 2.1.1 Hello, World
15 | ```kotlin
16 | fun main(args: Array) {
17 | println("Hello, World!")
18 | }
19 | ```
20 |
21 | - 함수를 선언할 때 fun 키워드를 사용한다.
22 | - 파라미터 이름 뒤에 타입을 쓴다.
23 | - 클래스 안에 함수를 넣어야 할 필요가 없고, 함수를 최상위 수준에 정의할 수 있다.
24 | - 배열 처리를 위한 문법이 따로 존재하지 않는다.
25 | - 자바의 System.out.println 대신 `println`을 사용한다.
26 |
27 | ### 2.1.2 함수
28 | 아무런 값도 반환하지 않는 함수는 방금 살펴봤지만 의미 있는 결과를 반환하는 함수의 경우 반환 값의 타입을 어디에 지정해야 할까?
29 |
30 | ```kotlin
31 | fun max(a: Int, b: Int): Int {
32 | return if (a > b) a else b
33 | }
34 |
35 | println(max(1, 2))
36 | // 2
37 | ```
38 |
39 | 함수 선언은 fun 키워드로 시작하며, 그 다음에는 함수의 이름이 온다. 함수 이름 뒤에는 괄포 안에 파라미터 목록이 온다. 함수의 반환 타입은 파라미터 목록의 닫는 괄호 다음에 오는데, 괄호와 반환 타입 사이를 콜론으로 구분한다.
40 |
41 |
42 | 🥀`문(statement)`과 `식(expression)`의 구분
43 | **식**은 값을 만들어 내며 다른 식의 하위 요소로 계산에 참여할 수 있다.
44 | **문**은 자신을 둘러싸고 있는 가장 안쪽 블록의 최상위 요소로 존재하며 아무런 값을 만들어내지 않는다.
45 | 자바에서는 모든 제어 구조가 문인 반면, 코틀린에서는 루프를 제외한 대부분의 제어 구조가 식이다.
46 |
47 | ### A. 식이 본문인 함수
48 | 앞에서 살펴본 함수를 더 간결하게 표현할 수도 있다. 앞의 함수 본문은 if 식 하나로만 이뤄져 있는데, 다음과 같이 중괄호를 없애고 return을 제거하면서 등호를 식 앞에 붙이면 더 간결하게 함수를 표현할 수 있다.
49 |
50 | ```kotlin
51 | fun max(a: Int, b: Int): Int = if (a>b) a else b
52 | ```
53 |
54 | 본문이 중괄호로 둘러싸인 함수를 `블록이 본문인 함수`라 부르고, 등호와 식으로 이뤄진 함수를 `식이 본문인 함수`라고 한다.
55 |
56 | 코틀린에서는 식이 본문이 함수가 자주 쓰인다. 그런 함수의 본문 식에는 단순한 산술식이나 함수 호출 식뿐 아니라 if, when, try 등의 더 복잡한 식도 자주 쓰인다.
57 |
58 | 반환 타입을 생략하면 max 함수를 더 간략하게 만들 수 있다.
59 |
60 | ```kotlin
61 | fun max(a: Int, b: Int) = if (a>b) a else b
62 | ```
63 |
64 | 코틀린은 정적 타입 지정 언어이므로 컴파일 시점에 모든 식의 타입을 지정해야 하는데, 여기서 반환 타입을 생략할 수 있는 이유는 무엇일까?
65 |
66 | 실제로 모든 변수나 모든 식에는 타입이 있으며, 모든 함수는 반환 타입이 정해져야 한다. 하지만 **식이 본문인 함수의 경우 굳이 사용자가 반환 타입을 적지 않아도 컴파일러가 함수 본문 식을 분석해서 식의 결과 타입을 함수 반환 타입으로 정해준다.**
67 |
68 | 이렇게 컴파일러가 타입을 분석해 프로그래머 대신 프로그램 구성 요소의 타입을 정해주는 기능을 `타입 추론(type inference)`이라 부른다.
69 |
70 | 식이 본문이 함수의 반환 타입만 생략 가능하다는 점에 유의해야 한다. 블록이 본문인 함수가 값을 반환한다면 반드시 반환 타입을 지정하고 return문을 사용해 반환 값을 명시해야 한다.
71 |
72 |
73 |
74 | ### 2.1.3 변수
75 | 코틀린에서는 키워드로 변수 선언을 시작하는 대신 변수 이름 뒤에 타입을 명시하거나 생략하게 허용한다.
76 |
77 | ```kotlin
78 | val question = "삶이란?"
79 | val answer = 32
80 | ```
81 |
82 | 식이 본문인 함수에서와 마찬가지로 우리가 타입을 지정하지 않으면 컴파일러가 **초기화 식을 분석해서 초기화 식의 타입을 변수 타입으로 지정**한다.
83 | 초기화 식을 사용하지 않고 변수를 선언하려면 변수 타입을 반드시 명시해야 한다.
84 | 초기화 식이 없다면 변수에 저장될 값에 대해 아무 정보가 없기 대문에 컴파일러가 타입을 추론할 수 없다.
85 |
86 | ### A. 변경 가능한 변수와 변경 불가능한 변수
87 | 변수 선언 시 사용하는 키워드는 다음과 같이 2가지가 있다.
88 |
89 | - **`val`** (값을 뜻하는 value에서 따옴)
90 | - 변경 불가능한(immutavle) 참조를 저장하는 변수다. val로 선언된 변수는 일단 초기화하고 나면 재대입이 불가능하다.
91 | (자바의 final 변수에 해당)
92 | - **`var`** (변수를 뜻하는 variable에서 따옴)
93 | - 변경 가능한(mutable) 참조다. 이런 변수의 값은 바뀔 수 있다. (자바의 일반 변수에 해당)
94 |
95 | 기본적으로 모든 변수를 val 키워드를 사용해 불변 변수로 선언하고, 나중에 꼭 필요할 때에만 var로 변경하는 것을 추천한다고 한다.
96 |
97 | val 변수는 블록을 실행할 때 정확히 한 번만 초기화돼야 한다. 하지만 어떤 블록이 실행될 때 오직 한 초기화 문장만 실행됨을 컴파일러가 확인할 수 있다면 조건에 따라 val 값을 다른 여러 값으로 초기화할 수도 있다.
98 |
99 | ```kotlin
100 | val message: String
101 | if (canPerformOperation()) {
102 | message = "Success"
103 | // 연산 수행 ..
104 | } else {
105 | message = "Failed"
106 | }
107 | ```
108 |
109 | val 참조 자체는 불변일지라도 그 참조가 가리키는 객체의 내부 값은 변경될 수 있다는 사실을 기억하라.
110 |
111 | ```kotlin
112 | val languages = arrayListOf("Java") //불변 참조 선언
113 | languages.add("Kotlin") //참조가 가리키는 객체 내부를 변경
114 | ```
115 |
116 | var 키워드를 사용하면 변수의 값을 변경할 수 있지만 변수의 타입은 고정돼 바뀌지 않는다.
117 |
118 | ```kotlin
119 | var answer = 42
120 | answer = "no answer" //"Error: type mismatch" 컴파일 오류 발생
121 | ```
122 |
123 | 문자열 리터럴에서 컴파일 오류가 발생한다. 이유는 String 타입이 컴파일러가 기대하는 타입과 다르기 때문이다. **컴파일러는 변수 선언 시점의 초기화 식으로부터 변수의 타입을 추론하며, 변수 선언 이후 변수 제대입이 이뤄질 때는 이미 추론한 변수의 타입을 염두에 두고 대입문의 타입을 검사**한다.
124 |
125 | 어떤 타입의 변수에 다른 타입의 값을 저장하고 싶다면 변환 함수를 써서 값을 변수의 타입으로 변환하거나, 값을 변수에 대입할 수 있는 타입으로 강제 형 변환해야 한다.
126 |
127 |
128 |
129 | ### 2.1.4 더 쉽게 문자열 형식 지정: 문자열 템플릿
130 | 다음은 Hello,World 예제의 다음 단계로, 사람 이름을 사용해 환영 인사를 출력하는 코틀린 프로그램이다.
131 |
132 | ```kotlin
133 | fun main(args: Array) {
134 | val name = if (args.size > 0) args[0] else "Kotlin"
135 | println("Hello, $name")
136 | }
137 | ```
138 |
139 | 이 예제는 `문자열 템플릿` 이라는 기능을 보여준다. 이 코드는 name이라는 변수를 선언하고 그 다음 줄에 있는 문자열 리터럴 안에서 그 변수를 사용했다. 문자열 리터럴의 필요한 곳에 변수를 넣되 변수 앞에 `$`를 추가해야 한다.
140 | 물론 컴파일러는 각 식을 정적(static)으로 검사하기 때문에 존재하지 않는 변수를 문자열 템플릿 안에서 사용하면 컴파일 오류가 발생한다.
141 |
142 |
143 |
144 | ## 2.2 클래스와 프로퍼티
145 | 이번에는 클래스를 선언하는 기본 문법을 소개한다. 자세한 내용은 뒷 부분에서 다룬다.
146 |
147 | 시작하기 위해 간단한 자바빈(JavaBean) 클래스인 Person을 정의한다. Person에는 name이라는 프로퍼티(property)만 들어있다.
148 |
149 | ```java
150 | public class Person {
151 | private final String name;
152 |
153 | public Person(String name) {
154 | this.name = name;
155 | }
156 |
157 | public String getName() {
158 | return name;
159 | }
160 | }
161 | ```
162 |
163 | 필드가 둘 이상으로 늘어나면 생성자인 `Person(String name)`의 본문에서 파라미터를 이름이 같은 필드에 대입하는 대입문의 수도 늘어난다. 코틀린에서는 그런 필드 대입 로직을 훨씬 더 적은 코드로 작성할 수 있다.
164 |
165 | 자바-코틀린 변환기는 자바 코드를 같은 일을 하는 코틀린 코드로 자동으로 변환해준다. 변환기를 써서 방금 본 Person 클래스를 코틀린으로 변환해보자.
166 |
167 | ```kotlin
168 | class Person(val name: String)
169 | ```
170 |
171 | 이런 유형의 클래스(코드가 없이 데이터만 저장하는 클래스)를 `값 객체(value object)`라 부르며, 다양한 언어가 값 객체를 간결하게 기술할 수 있는 구문을 제공한다.
172 |
173 | 코틀린으로 변환한 결과, public 가시성 변경자가 사라졌음을 확인할 수 있다. **코틀린의 기본 가시성은 public**이므로 생략할 수 있다.
174 |
175 |
176 |
177 | ### 2.2.1 프로퍼티
178 | `클래스`라는 개념의 목적은 데이터를 캡슐화하고 캡슐화한 데이터를 다루는 코드를 한 주체 아래 가두는 것이다. 자바에서는 데이터를 필드에 저장하며, 멤버 필드의 가시성은 보통 비공개이다. 클래스는 자신을 사용하는 클라이언트가 그 데이터에 접근하는 통로로 쓸 수 있는 접근자 메소드를 제공한다. 보통은 필드를 읽기를 위한 게터를 제공하고, 필드를 변경하게 허용해야 할 경우 세터를 추가 제공할 수 있다.
179 |
180 | 자바에서는 필드와 접근자를 묶어 `프로퍼티(property)`라고 부른다. 코틀린은 프로퍼티를 언어 기본 기능으로 제공하며, **코틀린 프로퍼티는 자바의 필드와 접근자 메소드를 완전히 대신**한다.
181 |
182 | 클래스에서 프로퍼티를 선언할 때는 앞에서 살펴본 변수를 선언하는 방법과 마찬가지로 val, var을 사용한다.
183 |
184 | ```kotlin
185 | class Person(
186 | val name: String, //읽기 전용 프로퍼티. 비공개 필드와 단순한 공개 게터를 만든다.
187 | var isMarried: Boolean //쓸 수 있는 프로퍼티. 비공개 필드, 공개 게터, 공개 세터를 만든다.
188 | )
189 | ```
190 |
191 | 기본적으로 코틀린에서 프로퍼티를 선언하는 방식은 프로퍼티와 관련 있는 접근자를 선언하는 것이다.
192 | (읽기 전용 프로퍼티의 경우 게터만 선언하며, 변경할 수 있는 프로퍼티의 경우 게터와 세터를 모두 선언한다.)
193 |
194 | 코틀린은 값을 저장하기 위한 비공개 필드와 그 필드에 값을 저장하기 위한 세터, 필드의 값을 읽기 위한 게터로 이뤄진 간단한 디폴트 접근자 구현을 제공한다.
195 |
196 | 다음은 Person을 자바 코드에서 사용하는 방법을 보여준다.
197 |
198 | ```java
199 | Person person = new Person("Bob", true);
200 | System.out.println(person.getName());
201 | -> Bob
202 | System.out.println(person.isMarried());
203 | -> true
204 | ```
205 |
206 | 게터와 세터의 이름을 정하는 규칙에는 예외가 있다. 이름이 is로 시작하는 프로퍼티의 게터에는 get이 붙지 않고 원래 이름 그대로 사용하며, 세터에는 is를 set으로 바꾼 이름을 사용한다.
207 |
208 | 위 코드를 자바-코틀린 변환기로 변환한 결과는 다음과 같다.
209 |
210 | ```kotlin
211 | val person = Person("Bob", true) //new 키워드를 사용하지 않음
212 | println(person.name)
213 | -> Bob
214 | println(person.isMarried)
215 | -> true
216 | //프로퍼티 이름을 직접 사용해도 자동으로 게터를 호출해줌
217 | ```
218 |
219 | 게터를 호출하는 대신 프로퍼티를 직접 사용했음에 유의하라. 로직은 동일하지만 코드는 더 간결해졌다.
220 |
221 | (🌱자바에서 선언한 클래스에 대해 코틀린 문법을 사용해도 된다. 코틀린에서는 자바 클래스의 게터를 val 프로퍼티처럼 사용할 수 있고, 게터/세터 쌍이 있는 경우에는 var 프로퍼티처럼 사용할 수 있다.)
222 |
223 | 대부분의 프로퍼티에는 그 프로퍼티의 값을 저장하기 위한 필드가 있다. 이를 프로퍼티를 뒷받침하는 필드(backing field)라고 부른다. 하지만 원한다면 그때그때 계산할 수도 있다. 커스텀 게터를 작성하면 그런 프로퍼티를 만들 수 있다.
224 |
225 |
226 |
227 | ### 2.2.2 커스텀 접근자
228 | 이번 절에서는 프로퍼티의 접근자를 직접 작성하는 방법을 보여준다. 직사각형 클래스인 Rectangle을 정의하면서 자신이 정사각형인지 알려주는 기능을 만들어보자. 직사각형이 정사각형인지를 별도의 필드에 저장할 필요가 없다. 사각형의 너비와 높이가 같은지 검사하면 정사각형 여부를 알 수 있다.
229 |
230 | ```kotlin
231 | class Rectangle(val height: Int, val width: Int) {
232 | val isSquare: Boolean
233 | get() {
234 | return height == width
235 | }
236 | }
237 | ```
238 |
239 | isSquare 프로퍼티에는 자체 값을 저장하는 필드가 필요 없다. 이 프로퍼티에는 자체 구현을 제공하는 게터만 존재한다.
240 |
241 | 블록을 본문으로 하는 구문을 꼭 사용하지 않아도 된다. 이런 경우 `get() = height == width`라고 할 수 있다.
242 |
243 | 파라미터가 없는 함수를 정의하는 방식과 커스텀 게터를 정의하는 방식 중 어느 쪽이 더 나은지 궁금할 수 있다. 두 방식 모두 비슷하며, 구현이나 성능상의 차이는 없다. 차이가 나는 부분은 가독성뿐이다. 일반적으로 클래스의 특성을 정의하고 싶다면 프로퍼티로 그 특성(프로퍼티에는 특성이라는 뜻이 있다)을 정의해야 한다.
244 |
245 |
246 |
247 | ### 2.2.3 코틀린 소스코드 구조: 디렉터리와 패키지
248 | 모든 코틀린 파일의 맨 앞에 package 문을 넣을 수 있다. 그러면 그 파일 안에 있는 모든 선언(클래스, 함수, 프로퍼티 등)이 해당 패키지에 들어간다. 같은 패키지에 속해 있다면 다른 파일에서 정의한 선언일지라도 직접 사용할 수 있는 반면 다른 패키지에 정의한 선언을 사용하려면 임포트를 통해 선언을 불러와야 한다. 자바와 마찬가지로 임포트문은 맨 앞에 와야 하며 import 키워드를 사용한다.
249 |
250 | ```kotlin
251 | package geometry.shapes
252 | import java.util.Random
253 |
254 | class Rectangle(val height: Int, val width: Int) {
255 | val isSquare: Boolean
256 | get() = height == width
257 | }
258 |
259 | fun createRandomRectangle(): Rectangle {
260 | val random = Random()
261 | return Rectangle(random.nextInt(), random.nextInt())
262 | }
263 | ```
264 |
265 | 코틀린에서는 클래스 임포트와 함수 임포트에 차이가 없으며, 모든 선언을 import 키워드로 가져올 수 있다.
266 |
267 | ```kotlin
268 | package geometry.example
269 | import geometry.shapes.createRandomRectangle
270 |
271 | fun main(args: Array) {
272 | println(createRandomRectangle().isSquare)
273 | }
274 | ```
275 |
276 | 패키지 이름 뒤에 `*`를 추가하면 패키지 안의 모든 선언을 임포트할 수 있다. 이런 스타 임포트(star import)를 사용하면 패키지 안에 있는 모든 클래스뿐 아니라 최상위에 정의된 함수나 프로퍼티까지 모두 불러온다는 점에 유의해야 한다.
277 |
278 | 코틀린에서는 여러 클래스를 한 파일에 넣을 수 있고, 파일의 이름도 마음대로 정할 수 있다. 디스크상의 어느 디렉터리에 소스코드 파일을 위치시키든 관계없다. 따라서 원하는 대로 소스코드를 구성할 수 있다.
279 |
280 | 하지만 대부분의 경우 자바와 같이 패키지별로 디렉터리를 구성하는 편이 낫다. 특히 자바와 코틀린을 함께 사용하는 프로젝트에서는 자바의 방식을 따르는게 중요하다. 자바 클래스를 코틀린 클래스로 마이그레이션할 때 문제가 생길 수도 있다. 하지만 여러 클래스를 한 파일에 넣는 것을 주저해서는 안 된다. 특히 각 클래스를 정의하는 소스코드 크기가 아주 작은 경우 더욱 그렇다.
281 |
282 |
283 |
284 | ## 2.3 선택 표현과 처리: enum과 when
285 | when은 자바의 switch를 대치하되 훨씬 더 강력하며, 앞으로 더 자주 사용할 프로그래밍 요소이다. when에 대해 설명하는 과정에서 코틀린에서 enum을 선언하는 방법과 스마트 캐스트에 대해서도 살펴본다.
286 |
287 | ### 2.3.1 enum 클래스 정의
288 | 색을 표현하는 enum을 하나 정의한다.
289 |
290 | ```kotlin
291 | enum class Color {
292 | RED, ORANGE, YELLOW, GREEN, BLUE, INDIGO, VIOLET
293 | }
294 | ```
295 |
296 | 코틀린에서 enum은 소프트 키워드(soft keyword)라 부르는 존재다. enum은 class 앞에 있을 때는 특별한 의미를 지니지만 다른 곳에서는 이름에 사용할 수 있다. 반면 class는 키워드이다. 따라서 class라는 이름을 사용할 수 없으므로 클래스를 표현하는 변수 등을 정의할 때는 claaz나 aClass와 같은 이름을 사용해야 한다.
297 |
298 | 자바와 마찬가지로 enum은 단순히 값만 열거하는 존재가 아니다. enum 클래스 안에도 프로퍼티나 메소드를 정의할 수 있다. 다음은 프로퍼티와 메소드를 enum 안에 선언하는 방법을 보여준다.
299 |
300 | ```kotlin
301 | enum class Color (
302 | val r: Int, val g: Int, val b: Int //상수의 프로퍼티 정의
303 | ) {
304 | //각 상수를 생성할 때 그에 대한 프로퍼티 값을 지정
305 | RED(255, 0, 0), ORANGE(255, 165, 0),
306 | YELLOW(255, 255, 0), GREEN(0, 255, 0), BLUE(0, 0, 255),
307 | INDIGO(75, 0, 130), VIOLET(238, 130, 238); //세미콜론 반드시 사용
308 |
309 | fun rgb() = (r * 256 + g) * 256 + b //enum 클래스 안에서 메소드를 정의
310 | }
311 |
312 | println(Color.BLUE.rgb())
313 | -> 255
314 | ```
315 |
316 | enum에서도 일반적인 클래스와 마찬가지로 생성자와 프로퍼티를 선언한다. 각 enum 상수를 정의할 때는 그 상수에 해당하는 프로퍼티 값을 지정해야만 한다. 이 예제에서는 코틀린에서 유일하게 세미콜론이 필수인 부분을 볼 수 있다. enum 클래스 안에 메소드를 정의하는 경우 반드시 enum 상수 목록과 메소드 정의 사이에 세미콜론을 넣어야 한다.
317 |
318 |
319 |
320 | ### 2.3.2 when으로 enum 클래스 다루기
321 | 무지개의 각 색에 대해 그와 상응하는 연상 단어를 짝지어주는 함수가 필요하다고 생각해보자. 그리고 그 연상 단어 정보를 enum안에 저장하지는 않는다고 하자. 자바라면 switch문으로 그런 함수를 작성할 수 있다. switch에 해당하는 코틀린 구성 요소는 `when`이다.
322 |
323 | if와 마찬가지로 when도 값을 만들어내는 식이기에, 식이 본문인 함수에 when을 바로 사용할 수 있다.
324 |
325 | ```kotlin
326 | enum class Color (
327 | val r: Int, val g: Int, val b: Int //상수의 프로퍼티 정의
328 | ) {
329 | //각 상수를 생성할 때 그에 대한 프로퍼티 값을 지정
330 | RED(255, 0, 0), ORANGE(255, 165, 0),
331 | YELLOW(255, 255, 0), GREEN(0, 255, 0), BLUE(0, 0, 255),
332 | INDIGO(75, 0, 130), VIOLET(238, 130, 238); //세미콜론 반드시 사용
333 |
334 | fun rgb() = (r * 256 + g) * 256 + b //enum 클래스 안에서 메소드를 정의
335 |
336 | fun getMnemonic(color: Color) {
337 | when (color) {
338 | Color.RED -> "Richard"
339 | Color.ORANGE -> "Of"
340 | Color.YELLOW -> "York"
341 | Color.GREEN -> "Gave"
342 | Color.BLUE -> "Battle"
343 | Color.INDIGO -> "In"
344 | Color.VIOLET -> "Vain"
345 | }
346 | }
347 | }
348 | ```
349 |
350 | 위 코드는 color로 전달된 값과 같은 분기를 찾는다. 자바와 달리 각 분기의 끝에 break를 넣지 않아도 된다. 성공적으로 매치되는 분기를 찾으면 switch는 그 분기를 실행한다. 한 분기 안에서 여러 값을 매치 패턴으로 사용할 수도 있는데, 이런 경우 값 사이를 콤마로 분리한다.
351 |
352 | ```kotlin
353 | fun getWarmth(color: Color) = when (color) {
354 | Color.RED, Color.ORANGE, Color.YELLOW -> "warm"
355 | Color.GREEN -> "neutral"
356 | Color.BLUE, Color.INDIGO, Color.VIOLET -> "cold"
357 | }
358 | println(getWarmth(Color.ORANGE))
359 | ```
360 |
361 |
362 |
363 | ### 2.3.3 when과 임의의 객체를 함께 사용
364 | 코틀린에서 when은 자바의 switch보다 훨씬 더 강력하다. 분기 조건에 상수(enum 상수나 숫자 리터럴)만을 사용할 수 있는 자바 switch와 달리 코틀린 when의 분기 조건은 임의의 객체를 허용한다. 두 색을 혼합했을 때 미리 정해진 팔레트에 들어있는 색이 될 수 있는지 알려주는 함수를 작성한다.
365 |
366 | ```kotlin
367 | fun mix(c1: Color, c2: Color) =
368 | when (setOf(c1, c2)) {
369 | setOf(RED, YELLOW) -> ORANGE
370 | setOf(YELLOW, BLUE) -> GREEN
371 | setOf(BLUE, VIOLET) -> INDIGO
372 | else -> throw Exception("Dirty color")
373 | }
374 | ```
375 |
376 | c1과 c2가 RED와 YELLOW라면 혹은 그 반대라면 그 둘을 혼합한 결과는 ORANGE이다. 코틀린 표준 라이브러리에는 인자로 전달받은 여러 객체를 그 객체들을 포함하는 집한인 Set 객체로 만드는 setOf라는 함수가있다. 집합(set)은 원소가 모여 있는 컬렉션으로, 각 원소의 순서는 중요하지 않다.
377 |
378 | when 식은 인자 값과 매치하는 조건 값을 찾을 때까지 각 분기를 검사한다. 여기서는 setOf(c1, c2)와 분기 조건에 있는 객체 사이를 매치할 때 동등성(equality)을 사용한다. 그러므로 앞의 코드는 처음에는 setOf(c1, c2)와 setOf(RED, YELLOW)를 비교하고, 그 둘이 같지 않으면 계속 다음 분기의 조건 객체와 setOf(c1, c2)를 차례로 비교하는 식으로 작동한다. 모든 분기 식에서 만족하는 조건을 찾을 수 없다면 else 분기의 문장을 계산한다.
379 |
380 | 다음 예제에서는 임의의 Boolean 식을 조건으로 사용하는 모습을 살펴본다.
381 |
382 |
383 | ### 2.3.4 인자 없는 when 사용
384 | 전 함수는 호출될 때마다 함수 인자로 주어진 두 색이 when의 분기 조건에 있는 다른 두 색과 같은지 비교하기 위해 여러 Set 인스턴스를 생성한다. 보통은 이런 비효율성이 크게 문제가 되지 않는다. 하지만 이 함수가 아주 자주 호출된다면 불필요한 가비지 객체가 늘어나는 것을 방지하기 위해 함수를 고쳐쓰는 편이 낫다. 인자가 없는 when 식을 사용하면 불필요한 객체 생성을 막을 수 있다. 코드는 읽기 약간 어려워지지만 성능을 더 향상시키기 위해 그 정도 비용을 감수해야 하는 경우도 있다.
385 |
386 | ```kotlin
387 | fun mixOptimized(c1: Color, c2: Color) =
388 | when {
389 | (c1 == RED && c2 == YELLOW) ||
390 | (c1 == YELLOW && c2 == RED) -> ORANGE
391 | (c1 == YELLOW && c2 == BLUE) ||
392 | (c1 == BLUE && c2 == YELLOW) -> GREEN
393 | (c1 == BLUE && c2 == VIOLET) ||
394 | (c1 == VIOLET && c2 == BLUE) -> INDIGO
395 | else -> throw Exception("Dirty color")
396 | }
397 | ```
398 |
399 | when에 아무 인자도 없으려면 각 분기의 조건이 불리언 결과를 계산하는 식이어야 한다. mixOptimized 함수는 앞에서 살펴본 mix 함수와 같은 동작을 한다. mixOptimized는 추가 객체를 만들지 않는다는 장점이 있지만 가독성은 더 떨어진다.
400 |
401 |
402 |
403 | ### 2.3.5 스마트 캐스트: 타입 검사와 타입 캐스트를 조합
404 | 이번 절에서 사용할 예제로 (1 + 2) + 4와 같은 간단한 산술식을 계산하는 함수를 만들어보자. 함수가 받을 산술식에서는 오직 두 수를 더하는 연산만 가능하다.
405 |
406 | 우선 식을 인코딩하는 방법을 생각해야 한다. 식을 트리 구조로 저장하자. 노드는 합계(sum)나 수(num) 중 하나다. Num은 항상 말단노드이지만, Sum은 자식이 둘 있는 중간노드로, 두 자식 노드는 덧셈의 두 인자이다.
407 |
408 | 다음 코드는 식을 표현하는 간단한 클래스를 보여준다. 식을 위한 Expr 인터페이스가 있고, Sum과 Num 클래스는 그 Expr 인터페이스를 구현한다. Expr은 아무 메소드도 선언하지 않으며, 단지 여러 타입의 식 객체를 아우르는 공통 타입 역할만 수행한다.
409 |
410 | ```kotlin
411 | interface Expr
412 | class Num(val value: Int): Expr
413 | class Sum(val left: Expr, val right: Expr): Expr
414 | ```
415 |
416 | Sum은 Expr의 왼쪽과 오른쪽 인자에 대한 참조를 left와 right 프로퍼티로 저장한다. 이 예제에서 left와 right는 각각 Num이나 Sum일 수 있다.
417 | (1 + 2) + 4라는 식을 저장하면
418 | Sum( Sum( Num(1), Num(2) ), Num(4) ) 라는 구조의 객체가 생긴다. 다음 그림은 이런 트리 표현을 보여준다.
419 |
420 | Expr 인터페이스에는 두 가지 구현 클래스가 존재한다. 따라서 식을 평가하려면 두 가지 경우를 고려해야 한다.
421 |
422 | - 어떤 식이 수라면 그 값을 반환한다.
423 | - 어떤 식이 합계라면 좌항과 우항의 값을 계산한 다음에 그 두 값을 합한 값을 반환한다.
424 |
425 | 코틀린에서 if를 사용해서 자바 스타일로 함수를 작성해보자.
426 |
427 | ```kotlin
428 | fun eval(e: Expr): Int {
429 | if (e is Num) {
430 | val n = e as Num
431 | return n.value
432 | }
433 | if (e is Sum) {
434 | return eval(e.right) + eval(e.left)
435 | }
436 | throw IllegalArgumentException("Unknown expression")
437 | }
438 | ```
439 |
440 | 코틀린에서는 is를 사용해 변수 타입을 검사한다. is 검사는 자바의 instanceOf와 비슷하다. 하지만 자바에서 어떤 변수의 타입을 instanceOf로 확인한 다음에 그 타입에 속한 멤버에 접근하기 위해서는 명시적으로 변수 타입을 캐스팅해야 한다. 이런 멤버 접근을 여러 번 수행해야 한다면 변수에 따로 캐스팅한 결과를 저장한 후 사용해야 한다. 코틀린에서는 프로그래머 대신 **컴파일러가 캐스팅을 해준다**. 어떤 변수가 원하는 타입인지 일단 is로 검사하고 나면 굳이 변수를 원하는 타입으로 캐스팅하지 않아도 마치 처음부터 그 변수가 원하는 타입으로 선언된 것처럼 사용할 수 있다. 이를 **스마트 캐스트**(smart cast)라고 부른다.
441 |
442 | eval 함수에서 e의 타입이 Num인지 검사한 다음 부분에서 컴파일러는 e의 타입을 Num으로 해석한다. 그렇기 때문에 Num의 프로퍼티인 value를 명시적 캐스팅 없이 e.value로 사용할 수 있다. Sum의 프로퍼티인 right와 left도 마찬가지다. IDE를 사용하면 스마트 캐스트 부분의 배경색을 달리 표시해주므로 이런 변환이 자동으로 이뤄졌음을 쉽게 알 수 있다.
443 |
444 | 스마트 캐스트는 is로 변수에 든 값의 타입을 검사한 다음에 그 값이 바뀔 수 없는 경우에만 작동한다. 예를 들어 앞에서 본 예제처럼 클래스의 프로퍼티에 대해 스마트 캐스트를 사용한다면 그 프로퍼티는 반드시 val이어야 하며 커스텀 접근자를 사용한 것이어도 안된다. val이 아니거나 val이지만 커스텀 접근자를 사용하는 경우에는 해당 프로퍼티에 대한 접근이 항상 같은 값을 내놓는다고 확신할 수 없기 때문이다.
445 |
446 | 원하는 타입으로 명시적으로 타입 캐스팅하려면 위 코드처럼 `as` 키워드를 사용한다.
447 |
448 |
449 |
450 | ### 2.3.6 리팩토링: if를 when으로 변경
451 | ```kotlin
452 | fun eval(e: Expr): Int =
453 | when (e) {
454 | is Num -> e.value
455 | is Sum -> eval(e.right) + eval(e.left)
456 | else -> throw IllegalArgumentException("Unknown Exception")
457 | }
458 | ```
459 |
460 | 이 예제는 받은 값의 타입을 검사하는 when 분기를 보여준다. 앞의 if 예제와 마찬가지로 타입을 검사하고 나면 스마트 캐스트가 이루어진다.
461 |
462 | when과 if 식을 사용한 함수를 서로 비교해보고, when으로 if를 대신할 수 있는 경우가 언제인지 생각해보자. if나 when의 각 분기에서 수행해야 하는 로직이 복잡해지면 분기 본문에 블록을 사용할 수 있다.
463 |
464 |
465 |
466 | ### 2.3.7 if와 when의 분기에서 블록 사용
467 | if나 when 모두 분기에 블록을 사용할 수 있다. 그런 경우 블록의 마지막 문장이 블록 전체의 결과가 된다. 예제로 봤던 함수에 로그를 추가하고 싶다면 각 분기를 블록으로 만들고 블록의 맨 마지막에 그 분기의 결과 값을 위치시키면 된다.
468 |
469 | ```kotlin
470 | fun evalWithLogging(e: Expr): Int =
471 | when (e) {
472 | is Num -> {
473 | println("num: ${e.value}")
474 | e.value //e의 타입이 Num이면 e.value 반환
475 | }
476 | is Sum -> {
477 | val left = evalWithLogging(e.left)
478 | val right = evalWithLogging(e.right)
479 | println("sum: $left + $right")
480 | left + right //e의 타입이 Sum이면 left+right 반환
481 | }
482 | else -> throw IllegalArgumentException("Unknown expression")
483 | }
484 | ```
485 |
486 | 블록의 마지막 식이 블록의 결과 라는 규칙은 블록이 값을 만들어내야 하는 경우 항상 성립한다. 앞에서 설명한 대로 이 규칙은 함수에 대해서는 성립하지 않는다. 식이 본문인 함수는 블록을 본문으로 가질 수 없고 블록이 본문인 함수는 내부에 return문이 반드시 있어야 한다.
487 |
488 |
489 |
490 | ## 2.4 대상을 이터레이션: while과 for 루프
491 |
492 | while은 자바와 동일하므로 간략하게 다루고 넘어가며, for는 자바의 for-each 루프에 해당하는 형태만 존재한다.
493 |
494 |
495 |
496 | ### 2.4.1 while 루프
497 | 코틀린에는 while과 do-while 루프가 있다.
498 |
499 | ```kotlin
500 | while(조건) {
501 | //조건이 참인 동안 본문을 반복 실행
502 | }
503 |
504 | do {
505 | //맨 처음에 무조건 본문을 한 번 실행한 다음,
506 | // 조건이 참인 동안 본문을 반복 실행
507 | } while(조건)
508 | ```
509 |
510 |
511 | ### 2.4.2 수에 대한 이터레이션: 범위와 수열
512 |
513 | 앞에서 설명했지만 코틀린에는 자바의 for 루프에 해당하는 요소가 없다. 이런 루프의 가장 흔한 용례인 초깃값, 증가 값, 최종 값을 사용한 루프를 대신하기 위해 코틀린에서는 `범위(range)`를 사용한다.
514 | 범위는 기본적으로 두 값으로 이뤄진 구간이다. 보통 그 두 값은 정수 등의 숫자 타입의 값이며, `..` 연산자로 시작 값과 끝 값을 연결해서 범위를 만든다.
515 | 코틀린의 범위는 폐구간(닫힌 구간) 또는 양끝을 포함하는 구간이다. 이는 1..10 이면 10을 포함하는 뜻이다.
516 | 정수 범위로 수행할 수 있는 가장 단순한 작업은 범위에 속한 모든 값에 대한 이터레이션이다. 이런 식으로 어떤 범위에 속한 값을 일정한 순서로 이터레이션하는 경우를 `수열(progression)`이라고 부른다.
517 | 피즈버즈게임을 위해 정수 범위를 사용해보자. 참가자는 순차적으로 수를 세면서 3으로 나눠떨어지는 수에 대해서는 피즈, 5로 나눠떨어지면 버즈라고 말한다. 3과5로 모두 나눠떨어지면 피즈버즈라고 말해야 한다.
518 |
519 | ```kotlin
520 | fun fizzBuzz(i: Int) = when {
521 | i % 15 == 0 -> "FizzBuzz"
522 | i % 3 == 0 -> "Fizz"
523 | i % 5 == 0 -> "Buzz"
524 | else -> "$i"
525 | }
526 |
527 | for (i in 1..100) {
528 | print(fizzBuzz(i))
529 | }
530 | ```
531 |
532 | 이제는 100부터 거꾸로 세되 짝수만으로 게임을 진행해보자.
533 |
534 | ```kotlin
535 | for (i in 100 downTo 1 step 2) {
536 | print(fizzBuzz(i))
537 | }
538 | ```
539 |
540 | 여기서는 증가 값 step을 갖는 수열에 대해 이터레이션한다. 증가 값을 사용하면 수를 건너 뛸 수 있다. 증가 값을 음수로 만들면 정방향 수열이 아닌 역방향 수열을 만들 수 있다.
541 | 앞에서 언급한 대로 `..`는 항상 범위의 끝 값을 포함한다. 하지만 끝 값을 포함하지 않는 반만 닫힌 범위에 대해 이터레이션하면 편할때가 자주 있다. 그런 범위를 만들고 싶다면 until 함수를 사용한다.
542 |
543 |
544 |
545 | ### 2.4.3 맵에 대한 이터레이션
546 | 이런 for 루프는 자바와 마찬가지로 작동하기 때문에 설명할 내용이 많지 않다. 대신 맵에 대한 이터레이션을 살펴보자.
547 | 문자에 대한 2진 표현을 출력하는 프로그램을 살펴보자. 이대 2진 표현을 맵에 저장하자. 다음 코드는 맵을 만들고, 몇 글자에 대한 2진 표현으로 맵을 채운 다음, 그 맵의 내용을 출력한다.
548 |
549 | ```kotlin
550 | val binaryReps = TreeMap()
551 |
552 | fun binaryFunc() {
553 | for (c in 'A'..'F') {
554 | val binary = Integer.toBinaryString(c.toInt())
555 | binaryReps[c] = binary
556 | }
557 |
558 | for ((letter, binary) in binaryReps) {
559 | println("$letter = $binary")
560 | }
561 | }
562 | ```
563 |
564 | `..` 연산자를 숫자 타입의 값뿐 아니라 문자 타입의 값에도 적용할 수 있다. 위 코드는 for 루프를 사용해 이터레이션하려난 컬렉션의 원소를 푸는 방법을 보여준다. 원소를 풀어서 letter와 binary라는 두 변수에 저장하며, letter에는 키가 들어가고, binary에는 2진 표현이 들어간다.
565 |
566 | 맵에 사용했던 구조 분해 구문을 맵이 아닌 컬렉션에도 활용할 수 있다. 그런 구조 분해 구문을 사용하면 원소의 현재 인덱스를 유지하면서 컬렉션을 이터레이션할 수 있다.
567 |
568 |
569 |
570 | ### 2.4.4 in으로 컬렉션이나 범위의 원소 검사
571 | `in` 연산자를 사용해 어떤 값이 범위에 속하는지 검사할 수 있다. 반대로 `!in`을 사용하면 어떤 값이 범위에 속하지 않는지 검사할 수 있다. 다음은 어떤 문자가 정해진 문자의 범위에 속하는지를 검사하는 방법을 보여준다.
572 |
573 | ```kotlin
574 | fun isLetter(c: Char) = c in 'a'..'z' || c in 'A'..'Z'
575 | fun isNotDigit(c: Char) = c !in '0'..'9'
576 |
577 | println(isLetter('q')) -> true
578 | println(isNotDigit('x')) -> true
579 | ```
580 |
581 | 이렇게 어떤 문자가 글자인지 검사하는 방법은 간단해 보인다. 내부적으로도 교묘한 부분은 전혀 없다. 이렇게 코드를 작성해도 여전히 문자의 코드가 범위의 첫 번째 글자의 코드와 마지막 굴자의 코드 사이에 있는지를 비교한다. 하지만 그런 비교 로직은 표준 라이브러리의 범위 클래스 구현 안에 깔끔하게 감춰져 있다.
582 |
583 | ```kotlin
584 | c in 'a'..'z' // 다음처럼 변환된다.
585 | 'a' <= c && c <= 'z'
586 | ```
587 |
588 | 범위는 문자에만 국한되지 않고, 비교가 가능한 클래스라면 그 클래스의 인스턴스 객체를 사용해 범위를 만들 수 있다. Comparable을 사용하는 범위의 경우 그 범위 내의 모든 객체를 항상 이터레이션하지는 못한다. 예를 들어 'Java'와 'Kotlin' 사이의 모든 문자열을 이터레이션할 수 있을까? 그럴 수 없다. 하지만 in 연산자를 사용하면 값이 범위 안에 속하는지 결정할 수 있다.
589 |
590 |
591 |
592 | ## 2.5 코틀린의 예외 처리
593 |
594 | 코틀린의 예외처리는 자바나 다른 언어와 비슷하다. 함수는 정상적으로 종료할 수 있지만 오류가 발생하면 예외를 던질 수 있다. 함수를 호출하는 쪽에서는 그 예외를 잡아 처리할 수 있다.
595 |
596 | ### 2.5.1 try, catch, finally
597 | 자바와 마찬가지로 예외를 처리하려면 try와 catch, finally 절을 함께 사용한다. 파일에서 각 줄을 읽어 수로 변환하되 그 줄이 올바른 수 형태가 아니면 null을 반환하는 다음 예제에서 그 세 가지 요소를 볼 수 있다.
598 |
599 | ```kotlin
600 | fun readNumber(reader: BufferedReader): Int? {
601 | try {
602 | val line = reader.readLine()
603 | return Integer.parseInt(line)
604 | }
605 | catch(e: NumberFormatException) {
606 | return null
607 | }
608 | finally {
609 | reader.close()
610 | }
611 | }
612 | ```
613 |
614 | 자바 코드와 가장 큰 차이는 throws 절이 코드에 없다는 점이다. 자바에서는 함수를 작성할 때 함수 선언 뒤에 throws IOException을 붙여야 한다. 이유는 IOException이 체크 예외이기 때문이다. 자바에서는 체크 예외를 명시적으로 처리해야 한다. 어떤 함수가 던질 가능성이 있는 예외나 그 함수가 호출한 다른 함수에서 발생할 수 있는 예외를 모두 catch로 처리해야 하며, 처리하지 않은 예외는 throws 절에 명시해야 한다.
615 | 다른 최신 JVM 언어와 마찬가지로 코틀린도 체크 예외와 언체크 예외를 구별하지 않는다. 코틀린에서는 함수가 던지는 예외를 지정하지 않고 발생한 예외를 잡아내도 되고 잡아내지 않아도 된다.
616 | 자바는 체크 예외 처리를 강제하지만 프로그래머들이 의미 없이 예외를 다시 던지거나, 예외를 잡되 처리하지는 않고 그냥 무시하는 코드를 작성하는 경우가 흔하다. 그로 인해 예외 처리 규칙이 실제로는 오류 발생을 방지하지 못하는 경우가 자주 있다.
617 | 자바 7 의 자원을 사용하는 try-with-resource는 어떨까? 코틀린은 그런 경우를 위한 특별한 문법을 제공하지 않는다. 하지만 라이브러리 함수로 같은 기능을 구현하다.
618 |
619 | ### 2.5.2 try를 식으로 사용
620 |
621 | 자바와 코틀린의 중요한 차이를 살펴보기 위해 방금 살펴본 예제를 고쳐보자. finally 절을없애고 파일에서 읽은 수를 출력하는 코드를 추가하자.
622 |
623 | ```kotlin
624 | fun readNumber(reader: BufferedReader) {
625 | val number = try {
626 | Integer.parseInt(reader.readLine())
627 | } catch(e: NumberFormatException) {
628 | return
629 | }
630 | println(number)
631 | }
632 | ```
633 | 코틀린의 try 키워드는 if나 when과 마찬가지로 식이다. 따라서 try의 값을 변수에 대입할 수 있다. if와 달리 try의 본문을 반드시 중괄호로 둘러싸야 한다. 다른 문장과 마찬가지로 try의 본문도 내부에 여러 문장이 있으면 마지막 식의 값이 전체 결과 값이다.
634 | 이 예제는 catch 블록 안에서 return 문을 사용한다. 따라서 예외가 발생할 경우 catch 블록 다음의 코드는 실행되지 않는다. 하지만 계속 진행하고 싶다면 catch 블록도 값을 만들어야 한다. 역시 catch 블록도 그 안의 마지막 식이 블록 전체의 값이 된다. 다음은 그런 동작을 보여준다.
635 |
636 | ```kotlin
637 | fun readNumber(reader: BufferedReader) {
638 | val number = try {
639 | Integer.parseInt(reader.readLine())
640 | } catch(e: NumberFormatException) {
641 | null
642 | }
643 | println(number)
644 | }
645 | ```
646 | try 코드 블록의 실행이 정상적으로 끝나면 그 블록의 마지막 식의 값이 결과다. 예외가 발생하고 잡히면 그 예외에 해당하는 catch 블록의 값이 결과다. 위 코드에서 예외가 발생하면 함수의 결과값이 null이 된다.
647 |
648 |
649 |
650 | ### 2.6 요약
651 |
652 | - 함수를 정의할 때 fun 키워드를 사용한다. val과 var는 각각 읽기 전용 변수와 변경 가능한 변수를 선언할 때 쓰인다.
653 | - 문자열 템플릿을 사용하면 문자열을 연결하지 않아도 되므로 코드가 간결해진다. 변수 이름 앞에 `$`를 붙이거나, 식을 `${식}`처럼 둘러싸면 변수나 식의 값을 문자열 안에 넣을 수 있다.
654 | - 코틀린에서는 값 객체 클래스를 아주 간결하게 표현할 수 있다.
655 | - 다른 언어에도 있는 if는 코틀린에서 식이며, 값을 만들어낸다.
656 | - 코틀린 when은 자바의 switch와 비슷하지만 더 강력하다.
657 | - 어떤 변수의 타입을 검사하고 나면 굳이 그 변수를 캐스팅하지 않아도 검사한 타입의 변수처럼 사용할 수 있다. 그런 경우 컴파일러가 스마트 캐스트를 활용해 자동으로 타입을 바꿔준다.
658 | - for, while, do-while 루프는 자바가 제공하는 같은 키워드의 기능과 비슷하다. 하지만 코틀린의 for는 자바의 for보다 더 편리하다. 특히 맵을 이터레이션하거나 이터레이션하면서 컬렉션의 원소와 인덱스를 함께 사용해야 하는 경우 코틀린의 for가 더 편리하다.
659 | - 1..5와 같은 식은 범위를 만든다. 범위와 수열은 코틀린에서 같은 문법을 사용하며, for 루프에 대해 같은 추상화를 제공한다. 어떤 값이 범위 안에 들어있거나 들어있지 않은지 검사하기 위해서 `in`이나 `!in`을 사용한다.
660 | - 코틀린 예외 처리는 자바와 비슷하지만 코틀린에서는 함수가 던질 수 있는 예외를 선언하지 않아도 된다.
661 |
662 |
--------------------------------------------------------------------------------
/Chapter3.md:
--------------------------------------------------------------------------------
1 | # 03. 함수 정의와 호출
2 |
3 | 이 장에서 다루는 내용
4 |
5 | * 컬렉션, 문자열, 정규식을 다루기 위한 함수
6 | * 이름 붙인 인자, 디폴트 파라미터 값, 중위 호출 문법
7 | * 확장 함수와 확장 프로퍼티
8 | * 최상위 및 로컬 함수와 프로퍼티를 사용해 코드 구조화
9 |
10 |
11 |
12 | # 1. 코틀린에서 컬렉션 만들기
13 |
14 | ### [ HashSet, ArrayList, HashMap 생성 ]
15 |
16 | ```kotlin
17 | fun main() {
18 | // 집합 (Set)
19 | val numberSet = hashSetOf(1, 2, 3)
20 |
21 | // 리스트 (List)
22 | val numberArrayList = arrayListOf(4, 5, 6)
23 |
24 | // 맵 (Map)
25 | val numberMap = hashMapOf(
26 | 1 to "one",
27 | 2 to "two",
28 | 3 to "three"
29 | )
30 |
31 | // [1, 2, 3]
32 | println(numberSet)
33 |
34 | // [4, 5, 6]
35 | println(numberArrayList)
36 |
37 | // {1=one, 2=two, 3=three}
38 | println(numberMap)
39 | }
40 | ```
41 |
42 | * 코틀린에서는 위와 같이 `Set` , `List` , `Map` 을 만들 수 있다.
43 | * Map을 만들 때 사용한 `to` 는 특별한 키워드가 아니라 `일반 함수` 이다. - *to에 대해서는 나중에 다룬다.*
44 |
45 |
46 |
47 | 컬렉션을 만들어봤으니, 컬렉션이 어떤 클래스로 되어있는지 확인한다.
48 |
49 | ### [ Collection 클래스 확인 ]
50 |
51 | ```kotlin
52 | fun main() {
53 | // 집합 (Set)
54 | val numberSet = hashSetOf(1, 2, 3)
55 |
56 | // 리스트 (List)
57 | val numberArrayList = arrayListOf(4, 5, 6)
58 |
59 | // 맵 (Map)
60 | val numberMap = hashMapOf(
61 | 1 to "one",
62 | 2 to "two",
63 | 3 to "three"
64 | )
65 |
66 | // class java.util.HashSet
67 | println(numberSet.javaClass)
68 |
69 | // class java.util.ArrayList
70 | println(numberArrayList.javaClass)
71 |
72 | // class java.util.HashMap
73 | println(numberMap.javaClass)
74 | }
75 | ```
76 |
77 | * `javaClass` : 호출한 객체의 Class 타입을 반환해주는 제네릭 확장 함수
78 |
79 | ```kotlin
80 | /**
81 | * Returns the runtime Java class of this object.
82 | */
83 | public inline val T.javaClass: Class
84 | @Suppress("UsePropertyAccessSyntax")
85 | get() = (this as java.lang.Object).getClass() as Class
86 | ```
87 |
88 | * Set, List, Map이 자바 컬렉션인 것을 확인할 수 있다.
89 |
90 | * 이처럼 코틀린은 표준 자바 컬렉션을 활용함으로써, **자바 코드와 상호작용하기 쉽도록** 만들어져 있다.
91 |
92 | * 하지만 코틀린에서는 자바보다 더 많은 기능을 쓸 수 있다.
93 |
94 | * Java를 활용하여 List에서 max 값 구하기
95 |
96 | ```java
97 | public class CollectionJava {
98 |
99 | public static void main(String[] args) {
100 | final List numberList = List.of(1, 2, 3);
101 | final Integer max = numberList.stream().max(Integer::compareTo).get();
102 | System.out.println(max); // 3
103 | }
104 |
105 | }
106 | ```
107 |
108 | * Kotlin을 활용하여 List에서 max 값 구하기
109 |
110 | ```kotlin
111 | fun main() {
112 | val numberArrayList = arrayListOf(1, 2, 3)
113 | println(numberArrayList.maxOrNull()) // 3
114 | }
115 | ```
116 |
117 |
118 |
119 | > 코틀린으로 컬렉션을 만들고, 최댓값을 구하는 함수에 대해 간단히 살펴봤다.
120 | >
121 | > 이제 함수를 만들고 호출하는 것에 대해 좀 더 자세히 살펴보자.
122 |
123 |
124 |
125 | # 2. 함수를 호출하기 쉽게 만들기
126 |
127 | 컬렉션의 원소들을 내가 원하는 형태로 출력시키는 함수를 작성해보자.
128 |
129 | ### [ 함수를 만들고 사용하는 예시 ]
130 |
131 | ```kotlin
132 | fun joinToString( ... ) { ... }
133 |
134 | fun main() {
135 | val numberList = listOf(1, 2, 3)
136 |
137 | println(numberList)
138 |
139 | val joinToString = joinToString(numberList, " or ", "<", ">")
140 | println(joinToString)
141 | }
142 | ```
143 |
144 | **실행결과**
145 |
146 | ```kotlin
147 | <1 or 2 or 3>
148 | ```
149 |
150 |
151 |
152 | 함수의 요구사항
153 |
154 | * 함수명 : **joinToString**
155 |
156 | * 함수 시그니처
157 |
158 | ```kotlin
159 | fun joinToString(
160 | collection: Collection, // 컬렉션
161 | separator: String, // 구분자
162 | prefix: String, // 접두사
163 | postfix: String, // 접미사
164 | ): String
165 | ```
166 |
167 | * 함수 기능
168 |
169 | * StringBuilder를 활용
170 | * 컬렉션을 출력
171 | * 맨 앞에 접두사( **prefix** ) 출력
172 | * 각 원소 사이에 구분자( **separator** ) 출력
173 | * 맨 뒤에 접미사( **postfix** ) 출력
174 |
175 |
176 |
177 | ### [ `joinToString()` 함수 초기 구현 ]
178 |
179 | ```kotlin
180 | // 컬렉션의 원소들을 내가 원하는 형태로 출력시키는 함수
181 | fun joinToString(
182 | collection: Collection, // 컬렉션
183 | separator: String, // 구분자
184 | prefix: String, // 접두사
185 | postfix: String, // 접미사
186 | ): String {
187 | val result = StringBuilder(prefix)
188 |
189 | for ((index, element) in collection.withIndex()) {
190 | // 첫 원소의 앞에는 구분자를 붙이면 안 되기 때문에
191 | // 1번째 부터 추가
192 | if (index > 0) result.append(separator)
193 | result.append(element)
194 | }
195 |
196 | result.append(postfix)
197 | return result.toString()
198 | }
199 |
200 | fun main() {
201 | val numberList = listOf(1, 2, 3)
202 |
203 | // [1, 2, 3]
204 | println(numberList)
205 |
206 | val joinToString = joinToString(numberList, " or ", "<", ">")
207 |
208 | // <1 or 2 or 3>
209 | println(joinToString)
210 | }
211 | ```
212 |
213 | * 함수 시그니처를 살펴보면 제네릭 함수인 것을 알 수 있다. => *제네릭은 뒤쪽에서 자세히..*
214 | * 즉, 모든 타입의 컬렉션을 처리할 수 있다.
215 |
216 |
217 |
218 | > 함수를 호출할 때, 모든 인자를 전달하지 않고 기본 값을 제공하는 방법에 대해 살펴보자.
219 |
220 |
221 |
222 | ## 2.1 이름 붙인 인자
223 |
224 | 함수의 기본 값을 제공하는 방법을 살펴보기 전에, 함수 호출 부분의 가독성을 향상시켜보자.
225 |
226 |
227 |
228 | `joinToString` 함수를 활용해 컬렉션의 인자들을 이어 붙여서 출력하면 다음과 같이 호출하게 된다.
229 |
230 | ```kotlin
231 | val joinToString = joinToString(numberList, "", "", "")
232 | ```
233 |
234 | * 해당 함수의 시그니처를 모르는 개발자가 이 코드를 봤을 때, 두 번째와 세 번째, 네 번째가 파라미터가 어떤 의미를 갖는지 전혀 알지 못한다.
235 |
236 |
237 |
238 | 이러한 혼동을 막기 위해 코틀린에서는 함수를 호출할 때, **인자에 이름을 명시할 수 있다.**
239 |
240 | ```kotlin
241 | // 인자의 이름을 명시하지 않은 함수 호출 예시
242 | val joinToString = joinToString(
243 | numberList,
244 | "",
245 | "",
246 | ""
247 | )
248 |
249 | // 인자의 이름을 명시한 함수 호출 예시
250 | val joinToString = joinToString(
251 | collection = numberList,
252 | separator = "",
253 | prefix = "",
254 | postfix = ""
255 | )
256 | ```
257 |
258 |
259 |
260 | ## 2.2. 디폴트 파라미터 값
261 |
262 | 함수 호출 부분의 가독성을 향상시키는 것에 대해 살펴봤으니, 함수의 디폴트 파라미터 값(기본값)을 제공하는 방법에 대해 알아보자.
263 |
264 |
265 |
266 | 대부분의 경우 아무 접두사나 접미사 없이 콤마로 원소를 구분하기 때문에, 해당 값 들을 디폴트로 지정해보자.
267 |
268 | ### [ 디폴트 파라미터 값을 사용해 `joinToString()` 정의하기 ]
269 |
270 | ```kotlin
271 | fun joinToString(
272 | collection: Collection,
273 | separator: String = ", ", // 디폴트 값이 지정된 파라미터
274 | prefix: String = "", // 디폴트 값이 지정된 파라미터
275 | postfix: String = "", // 디폴트 값이 지정된 파라미터
276 | ): String {
277 | val result = StringBuilder(prefix)
278 |
279 | for ((index, element) in collection.withIndex()) {
280 | if (index > 0) result.append(separator)
281 | result.append(element)
282 | }
283 |
284 | result.append(postfix)
285 | return result.toString()
286 | }
287 |
288 | fun main() {
289 | val numberList = listOf(1, 2, 3)
290 | val joinToString = joinToString(numberList)
291 |
292 | // 1, 2, 3
293 | println(joinToString)
294 | }
295 | ```
296 |
297 | 이와 같이 **디폴트 값을 지정해놓으면, 모든 인자를 쓸 수도 있고 일부를 생략할 수도 있다.**
298 |
299 | ```kotlin
300 | // 1, 2, 3
301 | println(joinToString(numberList))
302 |
303 | // 1 2 3
304 | println(joinToString(numberList, " "))
305 |
306 | // [1 2 3]
307 | println(joinToString(numberList, " ", "[", "]"))
308 | ```
309 |
310 |
311 |
312 | > 자바에서는 함수를 클래스 안에 선언해야만 사용할 수 있었으나, 지금까지 살펴본 코틀린의 함수들은 클래스를 선언하지 않고
313 | > 함수를 작성했다. 이와 같은 함수를 최상위 함수라고 하는데, 이에 대해 자세히 살펴보자.
314 |
315 |
316 |
317 | ## 2.3. 정적인 유틸리티 클래스 없애기: 최상위 함수와 프로퍼티
318 |
319 | 정적인 유틸리티란 상태(필드)와 인스턴스 메서드를 갖지 않고 오로지 정적 메서드만을 갖는 클래스이다.
320 |
321 | 대표적인 예로 JDK의 *java.util.Collections* 클래스가 있다.
322 |
323 | ### [ `java.util.Collections` 클래스 ]
324 |
325 | ```java
326 | public class Collections {
327 | private Collections() {
328 | }
329 |
330 | public static void reverse(List list) { ... }
331 | public static void shuffle(List list) { ... }
332 | ...
333 | }
334 | ```
335 |
336 | * 위와 같이 자바에서는 모든 코드를 클래스 안에 작성해야 하기 때문에, 정적인 유틸리티가 생겨난다.
337 |
338 |
339 |
340 | 하지만, 코틀린에서는 이런 무의미한 클래스가 필요 없다.
341 | 함수를 클래스에 정의할 필요없이, **소스 파일의 최상위 수준(클래스의 밖)에 위치**시키면 된다.
342 |
343 |
344 |
345 | 파일의 최상위에 구현된 함수는 맨 위에 정의된 패키지(ex. `package io.wisoft` )의 멤버 함수이므로,
346 | 다른 패키지에서 그 함수를 사용하고 싶을 때는 그 함수가 정의된 패키지를 임포트하면 된다.
347 |
348 |
349 |
350 | 컴파일러가 코틀린의 최상위 함수를 어떻게 컴파일하는지 한 번 살펴보자.
351 |
352 | 먼저 `strings` 패키지를 만들고, 해당 패키지에 `Join.kt` 파일을 만든 다음 `joinToString` 함수를 정의해보자.
353 |
354 | ### [ `strings.Join.kt` ]
355 |
356 | ```kotlin
357 | package strings // 패키지 위치
358 |
359 | fun joinToString(
360 | collection: Collection, // 컬렉션
361 | separator: String = ", ", // 구분자
362 | prefix: String = "", // 접두사
363 | postfix: String = "", // 접미사
364 | ): String {
365 | val result = StringBuilder(prefix)
366 |
367 | for ((index, element) in collection.withIndex()) {
368 | if (index > 0) result.append(separator)
369 | result.append(element)
370 | }
371 |
372 | result.append(postfix)
373 | return result.toString()
374 | }
375 | ```
376 |
377 | 위의 코드를 Java 코드로 변환하면 아래와 같이 변환된다.
378 |
379 |
380 |
381 | ### [ Java로 변환된 코드 ]
382 |
383 | ```java
384 | public final class JoinKt {
385 | @NotNull
386 | public static final String joinToString(...) {
387 | ...
388 | }
389 | }
390 |
391 | ```
392 |
393 | 즉, JVM이 클래스 안에 들어 있는 코드만을 실행할 수 있기 때문에, 컴파일러는 `Join.kt` 파일을 컴파일 할 때
394 | 새로운 클래스( `JoinKt` )를 정의해준다.
395 |
396 |
397 |
398 | ### 최상위 프로퍼티
399 |
400 | 함수와 마찬가지로 프로퍼티도 파일의 최상위 수준에 위치시킬 수 있다.
401 |
402 | ```kotlin
403 | const val PI: Double = 3.141592
404 | var result: Double = 0.0
405 |
406 | fun main() {
407 | result = PI * 2
408 | println(result) // 6.283184
409 | }
410 | ```
411 |
412 | * 이런 프로퍼티 값은 정적 필드에 저장된다.
413 |
414 |
415 |
416 | 어떻게 이렇게 구성될 수 있는지 궁금하기 때문에, 코드를 Java 코드로 변환해보자.
417 |
418 | ### [ 최상위 프로퍼티를 사용한 Kotlin 파일을 Java 코드로 변환한 예시 ]
419 |
420 | ```java
421 | public final class SuperPropertyKt {
422 | public static final double PI = 3.141592D;
423 | private static double result;
424 |
425 | public static final double getResult() {
426 | return result;
427 | }
428 |
429 | public static final void setResult(double var0) {
430 | result = var0;
431 | }
432 |
433 | ...
434 | }
435 | ```
436 |
437 | * 보시다시피 `const val` 은 `public static final` 로 변환이 되었으며,
438 | `var` 는 `private static` 으로 변환이 되며 getter와 setter가 구현되었다.
439 |
440 |
441 |
442 | > 지금까지 디폴트 파라미터 값과 최상위 함수와 프로퍼티를 살펴보며 `joinToString` 함수를 개선했다.
443 | > 이제 확장 함수와 확장 프로퍼티를 활용해, 함수를 좀 더 개선해보도록 하자.
444 |
445 |
446 |
447 | # 3. 확장 함수와 확장 프로퍼티
448 |
449 | **확장 함수**는 기존의 클래스를 상속받거나 재작성하지 않고도, **해당 클래스의 멤버 메서드인 것처럼 호출할 수 있도록 한다.**
450 |
451 | 예시를 통해 자세히 살펴보도록 하자.
452 |
453 |
454 |
455 | 어떤 문자열의 마지막 문자를 돌려주는 메소드를 확장 함수로 만들어보자.
456 |
457 | ### [ 문자열의 마지막 문자를 돌려주는 확장 함수 ]
458 |
459 | ```kotlin
460 | // 확장 함수
461 | fun String.lastChar(): Char = this[this.length - 1]
462 |
463 | fun main() {
464 | println("abc".lastChar()) // c
465 | }
466 | ```
467 |
468 | * 확장 함수를 만들려면 추가하려는 함수 이름 앞에 그 함수가 확장할 클래스의 이름을 덧붙이기만 하면 된다.
469 |
470 | * 확장할 클래스 이름을 **수신 객체 타입(receiver type)** 이라 부른다.
471 | -> `fun String.lastChar(): Char` 에서 **`String`**
472 |
473 | * 확장 함수가 호출되는 대상이 되는 값(객체)을 **수신 객체(receiver object)** 라고 부른다.
474 | -> `this[this.length - 1]` 에서 **`this`**
475 | -> `"abc".lastChar()` 에서 **`"abc"`**
476 |
477 | * 현재는 `this` 를 사용해 수신 객체 멤버에 접근하고 있지만, `this` 없이도 접근할 수 있다. 54ㄷ
478 |
479 | *ex) `this` 를 생략한 예시*
480 |
481 | ```kotlin
482 | //fun String.lastChar(): Char = this[this.length - 1]
483 | fun String.lastChar(): Char = get(length - 1)
484 |
485 | fun main() {
486 | println("abc".lastChar()) // c
487 | }
488 | ```
489 |
490 |
491 |
492 | 위와 같이 확장 함수 내부에서는 수신 객체 타입의 메소드나 프로퍼티를 바로 사용할 수 있다.
493 | 하지만, 클래스 내부에서만 사용할 수 있는 `private` 멤버나 `protected` 멤버는 접근할 수 없다.
494 |
495 |
496 |
497 | > 확장 함수가 무엇이고, 어떻게 정의하며 어떻게 사용하는지 간단하게 알아봤고,
498 | > 확장 함수를 임포트 하는 것과 자바에서의 확장 함수 호출, 확장 함수의 제약 사항 등을 살펴보며,
499 | > 확장 함수에 대해 좀 더 자세히 살펴보자.
500 |
501 |
502 |
503 | ## 3.1. 임포트와 확장 함수
504 |
505 | 확장 함수를 사용하기 위해서는 그 함수를 다른 클래스나 함수와 마찬가지로 임포트해야만 한다.
506 |
507 | ### [ `strings.Print.kt` ]
508 |
509 | ```kotlin
510 | package strings
511 |
512 | fun String.print() = println(this)
513 | ```
514 |
515 | ### [ `ImportAndExtension.kt` ]
516 |
517 | ```kotlin
518 | // strings 패키지에 있는 print 확장 함수를 임포트하는 코드
519 | import ch03.strings.print
520 | // *로 모두 임포트 할 수 있다.
521 | import ch03.strings.*
522 | // as 키워드로 함수를 다른 이름으로 부를 수 있다.
523 | import ch03.strings.print as println
524 |
525 | fun main() {
526 | "abc".print() // abc
527 | "abc".println() // abc
528 | }
529 | ```
530 |
531 | * 한 파일 안에서 다른 여러 패키지에 속해있는 이름이 같은 함수를 가져와 사용해야 하는 경우, `as` 키워드로 이름을 바꿔서
532 | 임포트하면 **이름 충돌을 막을 수 있다.**
533 |
534 |
535 |
536 | ## 3.2. 자바에서 확장 함수 호출
537 |
538 | 코틀린의 확장 함수는 수신 객체를 첫 번째 인자로 받는 정적 메소드다.
539 |
540 | 따라서 확장 함수를 `Print.kt` 파일에 정의했다면 다음과 같이 호출할 수 있다.
541 |
542 | ### [ 자바에서 확장 함수를 호출하는 예시 ]
543 |
544 | ```java
545 | import strings.PrintKt;
546 |
547 | public class PrintExam {
548 | public static void main(String[] args) {
549 | PrintKt.print("abc"); // abc
550 | }
551 | }
552 | ```
553 |
554 |
555 |
556 | ## 3.3. 확장 함수로 유틸리티 함수 정의
557 |
558 | 일반 함수 였던 `joinToString` 함수를 확장 함수로 바꿔보자.
559 |
560 | ### [ `joinToString` 함수를 확장 함수로 변환 ]
561 |
562 | ```kotlin
563 | package ch03.strings
564 |
565 | // 기존의 joinToString 함수
566 | //fun joinToString(
567 | // collection: Collection, // 컬렉션
568 | // separator: String = ", ", // 구분자
569 | // prefix: String = "", // 접두사
570 | // postfix: String = "", // 접미사
571 | //): String {
572 | // val result = StringBuilder(prefix)
573 | //
574 | // for ((index, element) in collection.withIndex()) {
575 | // if (index > 0) result.append(separator)
576 | // result.append(element)
577 | // }
578 | //
579 | // result.append(postfix)
580 | // return result.toString()
581 | //}
582 |
583 | // Collection 에 대한 확장 함수 선언
584 | fun Collection.joinToString(
585 | separator: String = ", ", // 구분자
586 | prefix: String = "", // 접두사
587 | postfix: String = "", // 접미사
588 | ): String {
589 | val result = StringBuilder(prefix)
590 |
591 | // "this"는 수신 객체를 의미한다.
592 | for ((index, element) in this.withIndex()) {
593 | if (index > 0) result.append(separator)
594 | result.append(element)
595 | }
596 |
597 | result.append(postfix)
598 | return result.toString()
599 | }
600 |
601 | fun main() {
602 | val joinToString = listOf("a", "b", "c").joinToString()
603 |
604 | // a, b, c
605 | println(joinToString)
606 | }
607 | ```
608 |
609 |
610 |
611 | 현재는 수신 객체인 컬렉션의 타입을 제네릭 타입으로 선언했지만, 더 구체적인 타입으로 지정할 수도 있다.
612 |
613 | ```kotlin
614 | // Collection 에 대한 확장 함수 선언
615 | //fun Collection.joinToString(
616 | // separator: String = ", ", // 구분자
617 | // prefix: String = "", // 접두사
618 | // postfix: String = "", // 접미사
619 | //): String {
620 | // val result = StringBuilder(prefix)
621 | //
622 | // // "this"는 수신 객체를 의미한다.
623 | // for ((index, element) in this.withIndex()) {
624 | // if (index > 0) result.append(separator)
625 | // result.append(element)
626 | // }
627 | //
628 | // result.append(postfix)
629 | // return result.toString()
630 | //}
631 |
632 | fun Collection.join(
633 | separator: String = ", ", // 구분자
634 | prefix: String = "", // 접두사
635 | postfix: String = "", // 접미사
636 | ): String {
637 | val result = StringBuilder(prefix)
638 |
639 | // "this"는 수신 객체를 의미한다.
640 | for ((index, element) in this.withIndex()) {
641 | if (index > 0) result.append(separator)
642 | result.append(element)
643 | }
644 |
645 | result.append(postfix)
646 | return result.toString()
647 | }
648 |
649 | fun main() {
650 | println(listOf("a", "b", "c").join())
651 |
652 | // 타입이 맞지 않기 때문에, 컴파일 에러 발생!
653 | println(listOf(1, 2, 3).join())
654 | }
655 | ```
656 |
657 |
658 |
659 | ## 3.4. 확장 함수는 오버라이드할 수 없다
660 |
661 | 먼저 멤버 함수를 오버라이드하여 사용하는 예시를 살펴보자.
662 |
663 | ### [ 멤버 함수 오버라이드하기 ]
664 |
665 | ```kotlin
666 | open class View {
667 | open fun click() = println("View clicked")
668 | }
669 |
670 | // Button은 View를 확장한다.
671 | class Button : View() {
672 | override fun click() = println("Button clicked")
673 | }
674 |
675 | fun main() {
676 | val view: View = Button()
677 |
678 | // Button clicked
679 | view.click()
680 | }
681 | ```
682 |
683 | * `View` 타입 변수에 대해 `click` 메소드를 호출했는데, `Button` 이 오버라이드한 `click` 이 호출되어
684 | **Button clicked** 라는 결과가 출력된다.
685 |
686 |
687 |
688 | 하지만, 확장 함수는 이처럼 작동하지 않는다. 확장 함수는 클래스의 일부가 아니기 때문이다.
689 |
690 | 확장 함수는 호출될 때, 수신 객체로 지정한 변수의 정적 타입에 의해 어떤 확장 함수가 호출될지 결정된다.
691 |
692 | ### [ 기반 클래스와 하위 클래스에 확장 함수를 정의하고 호출하는 예시 ]
693 |
694 | ```kotlin
695 | open class View {
696 | open fun click() = println("View clicked")
697 | }
698 |
699 | class Button : View() {
700 | override fun click() = println("Button clicked")
701 | }
702 |
703 | fun View.showOff() = println("I'm a view!")
704 | fun Button.showOff() = println("I'm a button!")
705 |
706 | fun main() {
707 | val view: View = Button()
708 |
709 | // I'm a view!
710 | view.showOff()
711 | }
712 | ```
713 |
714 | * 결과를 보시다시피, `view` 가 가리키는 객체의 실제 타입이 `Button` 이지만, 이 경우 `view` 객체의 타입이 `View` 이기 때문에
715 | 무조거 `View` 의 확장 함수가 호출된다.
716 |
717 |
718 |
719 | 어떤 클래스를 확장한 함수와 그 클래스의 멤버 함수의 이름과 시그니처가 같다면 확장 함수가 아닌 멤버 함수가 호출된다.
720 | 즉, 멤버 함수가 확장 함수보다 우선순위가 더 높다.
721 |
722 | ```kotlin
723 | class User() {
724 | fun hello() = "hello"
725 | }
726 |
727 | fun User.hello() = "안녕하세요"
728 |
729 | fun main() {
730 | val user = User()
731 | println(user.hello())
732 | }
733 | ```
734 |
735 | **실행결과**
736 |
737 | ```
738 | hello
739 | ```
740 |
741 |
742 |
743 | 기존 클래스에 새로운 메소드를 추가하는 확장 함수에 대해 살펴봤으니, 이제는 새로운 속성을 추가하는
744 | **확장 프로퍼티**에 대해 살펴보자.
745 |
746 |
747 |
748 | ## 3.5. 확장 프로퍼티
749 |
750 | ### [ 확장 프로퍼티 선언하기 ]
751 |
752 | ```kotlin
753 | val String.lastChar: Char
754 | get() = get(length - 1)
755 |
756 | fun main() {
757 | println("abc".lastChar) // c
758 | }
759 | ```
760 |
761 | * 이처럼 확장 프로퍼티는 기존 클래스 객체에 대한 프로퍼티를 추가할 수 있다.
762 |
763 | * 하지만 확장 프로퍼티는 뒷받침하는 필드가 없어서 **상태를 저장할 수는 없다.**
764 | 그러므로 기본 게터가 제공되지 않아, **커스텀 게터를 꼭 정의해야 한다.**
765 |
766 | * 마찬가지로 초기화 코드도 쓸 수 없다.
767 |
768 | ```kotlin
769 | // 컴파일 에러 발생 !!
770 | // Extension property cannot be initialized because it has no backing field
771 | // 백킹 필드가 없기 때문에 확장 속성을 초기화할 수 없습니다.
772 | val String.defaultChar: Char = "a"
773 | ```
774 |
775 |
776 |
777 | ### [ 변경 가능한 확장 프로퍼티 선언하기 ]
778 |
779 | ```kotlin
780 | var StringBuilder.lastChar: Char
781 | get() = get(length - 1) // 프로퍼티 게터
782 | set(value: Char) {
783 | this.setCharAt(length - 1, value) // 프로퍼티 세터
784 | }
785 |
786 | fun main() {
787 | val stringBuilder = StringBuilder("Kotlin?")
788 | println(stringBuilder) // Kotlin?
789 |
790 | stringBuilder.lastChar = '!'
791 | println(stringBuilder) // Kotlin!
792 | }
793 | ```
794 |
795 | * 확장 프로퍼티를 선언할 때, 커스텀 게터 뿐만 아니라 커스텀 세터 또한 정의할 수 있다.
796 | * 위의 코드와 같이 `var` 로 확장 프로퍼티를 선언한 뒤, 커스텀 세터를 구현하면 된다.
797 |
798 |
799 |
800 | 지금까지 확장에 대해 알아봤다.
801 | 이번에는 컬렉션을 처리할 때 유용한 라이브러리 함수들에 대해 살펴보자.
802 |
803 |
804 |
805 | # 4. 가변 길이 인자, 중위 함수 호출, 라이브러리 지원
806 |
807 | 코틀린 표준 라이브러리에는 수많은 확장 함수가 존재하는데, IDE의 코드 완성 기능을 통해 원하는 함수를 선택하면 되기 때문에 굳이 다 알 필요는 없다.
808 |
809 |
810 |
811 | ## 4.1. 가변 인자 함수: 인자의 개수가 달라질 수 있는 함수 정의
812 |
813 | 가변 길이 인자는 메소드를 호출할 때 원하는 개수만큼 값을 인자로 넘기면 컴파일러가 배열에 그 값들을 넣어주는 기능이다.
814 |
815 |
816 |
817 | ### [ 자바에서의 가변 인자 사용 예시 ]
818 |
819 | ```java
820 | public static List asList(T... a) {
821 | return new ArrayList<>(a);
822 | }
823 |
824 | public static void main(String[] args) {
825 | final List integers = Arrays.asList(1, 2, 3);
826 | }
827 | ```
828 |
829 | * 자바에서는 `...` 문법을 활용해 가변인자를 사용한다.
830 |
831 |
832 |
833 | 코틀린은 자바에서의 `...` 대신 `vararg` 변경자를 사용한다.
834 |
835 | ### [ 코틀린에서의 가변 인자 사용 예시 ]
836 |
837 | ```kotlin
838 | val list: List = listOf(1, 2, 3)
839 | ```
840 |
841 |
842 |
843 | `listOf` 확장 함수 시그니처를 살펴보자.
844 |
845 | ### [ `kotlin.collections.Collections.kt` ]
846 |
847 | ```kotlin
848 | package kotlin.collections
849 |
850 | ...
851 |
852 | public fun listOf(vararg elements: T): List = ...
853 | ```
854 |
855 | * `vararg` 변경자를 사용해 가변 인자를 전달하는 것을 확인할 수 있다.
856 |
857 |
858 |
859 | 배열에 들어있는 원소를 가변 길이 인자로 넘길 때도 코틀린과 자바 구문이 다르다.
860 |
861 | 자바에서는 배열을 그냥 넘기면 되지만 **코틀린에서는 배열을 명시적으로 풀어서 배열의 각 원소가 인자로 전달되게 해야 한다.**
862 |
863 | 이때, **스프레드(spread) 연산자**를 사용한다.
864 |
865 |
866 |
867 | ### [ 스프레드 연산자(*) 사용 예시 ]
868 |
869 | ```kotlin
870 | fun printIntList(vararg elements: Int) = elements.forEach(System.out::println)
871 |
872 | fun main() {
873 | val intArray = intArrayOf(1, 2, 3)
874 | printIntList(*intArray)
875 | }
876 | ```
877 |
878 | 실행예시
879 |
880 | ```
881 | 1
882 | 2
883 | 3
884 | ```
885 |
886 |
887 |
888 | 이번에는 함수 호출의 가독성을 향상시킬 수 있는 **중위 호출에** 대해 살펴보자.
889 |
890 |
891 |
892 | ## 4.2. 값의 쌍 다루기: 중위 호출과 구조 분해 선언
893 |
894 | 코틀린에서는 Map을 만들 때, `mapOf` 함수를 사용한다.
895 |
896 | ### [ Map 생성 예시 ]
897 |
898 | ```kotlin
899 | fun main() {
900 | val map = mapOf(1 to "one", 2 to "two", 3 to "three")
901 | println(map) // {1=one, 2=two, 3=three}
902 | }
903 | ```
904 |
905 | * 보시다시피 `to` 라는 키워드를 사용하는데, 이는 **중위 호출(infix call)** 이라는 특별한 방식으로 `to` 라는 일반 메소드를
906 | 호출한 것이다.
907 |
908 |
909 |
910 | 중위 호출 시에는 수신 객체와 유일한 메소드 인자 사이에 메소드 이름을 넣는 것이다.
911 |
912 | ### [ 일반 호출 방식과 중위 호출 방식 예시 ]
913 |
914 | ```kotlin
915 | println(5.to("five")) // (5, five) - 일반 호출
916 | println(6 to "six") // (6, six) - 중위 호출
917 | ```
918 |
919 | * 이처럼 인자가 하나뿐인 일반 메소드나 인자가 하나뿐인 확장 함수에 중위 호출을 사용할 수 있다.
920 |
921 |
922 |
923 | `to` 확장 함수의 시그니처를 살펴보자.
924 |
925 | ```kotlin
926 | public infix fun A.to(that: B): Pair = Pair(this, that)
927 | ```
928 |
929 | * 함수를 중위 호출이 가능하도록 허용하고 싶으면 `infix` 변경자를 함수 선언 앞에 추가하면 된다.
930 |
931 |
932 |
933 | `to` 함수는 `Pair` 인스턴스를 반환한다. 이는 두 원소로 이뤄진 순서쌍을 의미한다.
934 |
935 | 이 `Pair` 인스턴스를 활용해 두 변수를 즉시 초기화할 수 있다.
936 |
937 | ```kotlin
938 | val (number, name) = 1 to "one"
939 | println(number) // 1
940 | println(name) // one
941 | ```
942 |
943 | * 이런 기능을 **구조 분해 선언(destructuring declaration)** 이라고 부른다.
944 |
945 |
946 |
947 | 루프에서도 구조 분해 선언을 활용할 수 있다.
948 |
949 | ```kotlin
950 | fun main() {
951 | val list = listOf("a", "b", "c")
952 | for ((index, element) in list.withIndex()) {
953 | println("$index : $element")
954 | }
955 | }
956 | ```
957 |
958 | 실행결과
959 |
960 | ```
961 | 0 : a
962 | 1 : b
963 | 2 : c
964 | ```
965 |
966 |
967 |
968 | 이번에는 확장 함수를 통해 문자열과 정규식을 더 편리하게 다루는 방법에 대해 살펴보자.
969 |
970 |
971 |
972 | # 5. 문자열과 정규식 다루기
973 |
974 | 자바와 코틀린 문자열 처리 API의 차이에 대해 살펴보자.
975 |
976 |
977 |
978 | ## 5.1. 문자열 나누기
979 |
980 | 자바에서의 `split` 메소드를 활용해 `.` 을 기준으로 문자열을 분리하려다 실수하는 개발자들이 많다.
981 |
982 |
983 |
984 | 예시를 통해 자세히 살펴보자.
985 |
986 | ### [ 자바에서의 `split` 메서드로 `.` 을 기준으로 문자열을 분리하는 예시 ]
987 |
988 | ```java
989 | public static void main(String[] args) {
990 | final String[] stringArray = "2021.10.03".split(".");
991 |
992 | System.out.println("원소 출력");
993 | for (String element: stringArray) {
994 | System.out.println(element);
995 | }
996 | }
997 | ```
998 |
999 | 실행결과
1000 |
1001 | ```
1002 | 원소 출력
1003 |
1004 | ```
1005 |
1006 | * 결과를 보면 빈 문자열("")이 출력된 것을 확인할 수 있다.
1007 |
1008 | * 이와 같이 결과가 나오는 이유는 자바의 `split` 메서드는 파라미터로 정규식을 전달받기 때문이다.
1009 |
1010 | * *정규식으로 `.` 은 모든 문자와 대응된다.*
1011 |
1012 | * 꿀팁 : Intellij 에서 입력 커서를 정규식에 두고 `option + enter (Mac 기준)` 를 누르면,
1013 | `Check RegExp` 라는 기능을 사용할 수 있다.
1014 |
1015 | 
1016 |
1017 | 
1018 |
1019 | 
1020 |
1021 |
1022 |
1023 | 하지만, 코틀린에서는 자바의 `split` 대신에 여러 가지 다른 조합의 파라미터를 받는 `split` 확장 함수를 제공한다.
1024 |
1025 | ### [ `kotlin.text.Strings` API ]
1026 |
1027 | ```kotlin
1028 | public inline fun CharSequence.split(
1029 | regex: Regex,
1030 | limit: Int = 0
1031 | ): List {
1032 | ...
1033 | }
1034 |
1035 | public fun CharSequence.split(
1036 | vararg delimiters: String,
1037 | ignoreCase: Boolean = false,
1038 | limit: Int = 0
1039 | ): List {
1040 | ...
1041 | }
1042 | ```
1043 |
1044 | * 첫 번째 함수는 정규식을 파라미터로 받는 함수이고, 두 번째 함수는 나눌 기준의 문자열을 받는 함수이다.
1045 | * 따라서 정규식이나 일반 텍스트 중 어느 것으로 문자열을 분리하는지 쉽게 알 수 있다.
1046 |
1047 |
1048 |
1049 | 대시(-)로 문자열을 분리하는 예시를 통해 살펴보자.
1050 |
1051 | ### [ 문자열을 대시(-)로 분리하는 예시 ]
1052 |
1053 | ```kotlin
1054 | fun main() {
1055 | val strings: List = "010-1234-1234".split("[\\-]".toRegex())
1056 | println(strings) // [010, 1234, 1234]
1057 | }
1058 | ```
1059 |
1060 | * [\\\\-] : 대시(-)를 찾는 정규식 (대시는 특수문자이기 때문에 백슬래시로 찾을 문자로 사용할 것이라고 명시해야 함)
1061 |
1062 | * 자바에서는 `split` 의 기본 파라미터가 정규식이지만, 코틀린은 문자열과 정규식을 각각 받는 함수가 따로 있기 때문에
1063 | 편리하게 사용할 수 있다.
1064 |
1065 |
1066 |
1067 | 코틀린에서는 `split` 확장 함수를 오버로딩한 버전 중에서 구분 문자열을 하나 이상 인자로 받는 함수가 있다.
1068 |
1069 | ```kotlin
1070 | fun main() {
1071 | val telephone: List = "+82 10-1234-1234".split(" ", "-")
1072 | println(telephone) // [+82, 10, 1234, 1234]
1073 | }
1074 | ```
1075 |
1076 | * 공백과 대시로 전화번호 문자열을 나눠 문자열 배열로 변환한 예시이다.
1077 |
1078 |
1079 |
1080 | ## 5.2. 정규식과 3중 따옴표로 묶은 문자열
1081 |
1082 | 이번에는 파일의 전체 경로명을 디렉터리, 파일 이름, 확장자로 구분하는 함수를 구현해보자.
1083 |
1084 | ```java
1085 | "/Users/min/kotlin-book/chapter.md"
1086 | ```
1087 |
1088 | * **"/Users/min/kotlin-book"** : 디렉터리
1089 | * **"chapter"** : 파일 이름
1090 | * **"md"** : 확장자
1091 |
1092 |
1093 |
1094 | 먼저 String 확장 함수를 사용해 경로를 파싱해보자.
1095 |
1096 | ### [ String 확장 함수를 사용해 경로 파싱하기 ]
1097 |
1098 | ```kotlin
1099 | fun parsePath(path: String) {
1100 | val directory = path.substringBeforeLast("/")
1101 | println("directory: $directory")
1102 |
1103 | val fullName = path.substringAfterLast("/")
1104 | println("fullName: $fullName")
1105 |
1106 | val fileName = fullName.substringBeforeLast(".")
1107 | println("fileName: $fileName")
1108 |
1109 | val extension = fullName.substringAfterLast(".")
1110 | println("extension: $extension")
1111 | }
1112 |
1113 | fun main() {
1114 | parsePath("/Users/sangminlee/README.md")
1115 | }
1116 | ```
1117 |
1118 | [ 실행결과 ]
1119 |
1120 | ```
1121 | directory: /Users/sangminlee
1122 | fullName: README.md
1123 | fileName: README
1124 | extension: md
1125 | ```
1126 |
1127 | * 이처럼 코틀린에서는 정규식을 사용하지 않고도 문자열을 쉽게 파싱할 수 있다.
1128 |
1129 |
1130 |
1131 | ### [ 정규식을 사용해 경로 파싱하기 ]
1132 |
1133 | ```kotlin
1134 | fun parsePath(path: String) {
1135 | val regex = """(.+)/(.+)\.(.+)""".toRegex()
1136 | val matchResult = regex.matchEntire(path)
1137 | if (matchResult != null) {
1138 | val (directory, filename, extension) = matchResult.destructured
1139 | println("directory: $directory")
1140 | println("fillName: $filename")
1141 | println("extension: $extension")
1142 | }
1143 | }
1144 |
1145 | fun main() {
1146 | parsePath("/Users/sangminlee/README.md")
1147 | }
1148 | ```
1149 |
1150 | [ 실행결과 ]
1151 |
1152 | ```
1153 | directory: /Users/sangminlee
1154 | fillName: README
1155 | extension: md
1156 | ```
1157 |
1158 | * 3중 따옴표 문자열을 사용해 정규식을 사용했다.
1159 |
1160 | * 3중 따옴표 문자열에서는 역슬래시(\\)를 포함한 어떤 문자도 이스케이프할 필요가 없다.
1161 |
1162 | ```kotlin
1163 | """(.+)/(.+)\.(.+)"""
1164 | "(.+)/(.+)\\.(.+)" // . 을 문자로 나타내기 위해 역슬래시(\)를 2개를 써야함.
1165 | ```
1166 |
1167 | * 이 예제에서 쓴 정규식은 슬래시와 마침표를 기준으로 경로를 세 그룹으로 분리한다.
1168 |
1169 | ```
1170 | (.+)/(.+)\.(.+)
1171 | ```
1172 |
1173 | * **(.+)** : 디렉터리
1174 | * **(.+)** : 파일 이름
1175 | * **(.+)** : 확장자
1176 |
1177 |
1178 |
1179 | ## 5.3. 여러 줄 3중 따옴표 문자열
1180 |
1181 | 3중 따옴표를 쓰면 줄 바꿈이 들어있는 프로그램 텍스트를 쉽게 문자열로 만들 수 있다.
1182 |
1183 | ```kotlin
1184 | fun main() {
1185 | println("""
1186 | *
1187 | **
1188 | ***
1189 | ****
1190 | *****
1191 | """.trimIndent())
1192 | }
1193 | ```
1194 |
1195 | ```
1196 | *
1197 | **
1198 | ***
1199 | ****
1200 | *****
1201 | ```
1202 |
1203 | * `trimIndent()` : 들여쓰기 제거
1204 |
1205 |
1206 |
1207 | 3중 따옴표는 윈도우 파일 경로를 나타낼때도 편리하다.
1208 |
1209 | ```kotlin
1210 | fun main() {
1211 | println("1. C:\\Users\\min\\kotlin")
1212 | println("""2. C:\Users\min\kotlin""")
1213 | }
1214 | ```
1215 |
1216 | ```
1217 | 1. C:\Users\min\kotlin
1218 | 2. C:\Users\min\kotlin
1219 | ```
1220 |
1221 | * 이처럼 3중 따옴표를 사용하면 백슬래시를 나타낼때 편리하다.
1222 |
1223 |
1224 |
1225 | # 6. 코드 다듬기: 로컬 함수와 확장
1226 |
1227 | 코틀린에서는 함수에서 추출한 함수를 원 함수 내부에 중첩시킬 수 있다.
1228 |
1229 | 흔히 발생하는 코드 중복을 **로컬 함수** 를 통해 어떻게 제거할 수 있는지 살펴보자.
1230 |
1231 |
1232 |
1233 | 사용자를 데이터베이스에 저장하는 함수를 작성하는 예시를 살펴보자.
1234 |
1235 | 데이터베이스에 사용자 객체를 저장하기 전에 각 필드를 검증해야 한다고 해보자.
1236 |
1237 | #### [ 코드 중복을 보여주는 예제 ]
1238 |
1239 | ```kotlin
1240 | class User(
1241 | val id: Int,
1242 | val name: String,
1243 | val address: String,
1244 | )
1245 |
1246 | fun saveUser(user: User) {
1247 | // 필드 검증이 중복
1248 | if (user.name.isEmpty()) {
1249 | throw IllegalArgumentException(
1250 | "Can't save user ${user.id}: empty Name"
1251 | )
1252 | }
1253 | // 필드 검증이 중복
1254 | if (user.address.isEmpty()) {
1255 | throw IllegalArgumentException(
1256 | "Can't save user ${user.id}: empty Address"
1257 | )
1258 | }
1259 |
1260 | // user를 데이터베이스에 저장한다.
1261 | println("save")
1262 | }
1263 |
1264 | fun main() {
1265 | val user = User(1, "sangmin", "daejeon")
1266 | saveUser(user)
1267 | }
1268 | ```
1269 |
1270 | * 필드를 검증할 때, 검증 코드를 로컬 함수로 분리하면 중복을 없애는 동시에 코드 구조를 깔끔하게 유지할 수 있다.
1271 |
1272 |
1273 |
1274 | #### [ 로컬 함수를 사용해 코드 중복 줄이기 ]
1275 |
1276 | ```kotlin
1277 | ...
1278 |
1279 | fun saveUser(user: User) {
1280 | // 한 필드를 검증하는 로컬 함수를 정의
1281 | fun validate(
1282 | user: User,
1283 | value: String,
1284 | fieldName: String,
1285 | ) {
1286 | if (value.isEmpty()) {
1287 | throw IllegalArgumentException(
1288 | "Can't save user ${user.id}: empty $fieldName"
1289 | )
1290 | }
1291 | }
1292 |
1293 | // 로컬 함수를 호출해서 각 필드를 검증한다.
1294 | validate(user, user.name, "Name")
1295 | validate(user, user.address, "Address")
1296 |
1297 | ...
1298 | }
1299 |
1300 | ...
1301 | ```
1302 |
1303 | * 검증 로직 중복이 사라졌고, User의 다른 필드에 대한 검증도 쉽게 추가할 수 있다.
1304 | * 하지만, User 객체를 로컬 함수에 매번 전달해야 하고 있는 점이 아쉽다.
1305 | * 이를 개선해보자.
1306 |
1307 |
1308 |
1309 | #### [ 로컬 함수에서 바깥 함수의 파라미터 접근하기 ]
1310 |
1311 | ```kotlin
1312 | ...
1313 |
1314 | fun saveUser(user: User) {
1315 | // User 파라미터를 사용하지 않도록 수정
1316 | fun validate(
1317 | value: String,
1318 | fieldName: String,
1319 | ) {
1320 | if (value.isEmpty()) {
1321 | // 바깥 함수의 파라미터에 직접 접근
1322 | // - ${user.id}
1323 | throw IllegalArgumentException(
1324 | "Can't save user ${user.id}: empty $fieldName"
1325 | )
1326 | }
1327 | }
1328 |
1329 | validate(user.name, "Name")
1330 | validate(user.address, "Address")
1331 |
1332 | ...
1333 | }
1334 |
1335 | ...
1336 | ```
1337 |
1338 |
1339 |
1340 | 위의 코드를 더 개선하고 싶다면 검증 로직을 `User` 클래스를 확장한 함수로 만들어보자.
1341 |
1342 | #### [ 검증 로직을 확장 함수로 추출하기 ]
1343 |
1344 | ```kotlin
1345 | ...
1346 |
1347 | // 확장 함수 선언
1348 | fun User.validateBeforeSave() {
1349 | fun validate(
1350 | value: String,
1351 | fieldName: String,
1352 | ) {
1353 | if (value.isEmpty()) {
1354 | // User의 프로퍼티를 직접 사용
1355 | throw IllegalArgumentException(
1356 | "Can't save user $id: empty $fieldName"
1357 | )
1358 | }
1359 | }
1360 |
1361 | validate(name, "Name")
1362 | validate(address, "Address")
1363 | }
1364 |
1365 | fun saveUser(user: User) {
1366 | // 확장 함수 호출
1367 | user.validateBeforeSave()
1368 |
1369 | // user를 데이터베이스에 저장한다.
1370 | println("save")
1371 | }
1372 |
1373 | ...
1374 | ```
1375 |
1376 | * 이 경우 검증 로직이 `saveUser` 에서 밖에 쓰이지 않기 때문에 `User` 클래스에 포함시키지 않았다.
1377 | * 이처럼 `User` 클래스를 간결하게 유지하면 생각해야 할 내용이 줄어들어서 **더 쉽게 코드를 파악할 수 있다.**
1378 | * 확장 함수를 로컬 함수로 정의할 수도 있지만, 중첩된 함수의 깊이가 깊어지면 코드를 읽기가 상당히 어려워진다.
1379 | 따라서 일반적으로는 **한 단계만 함수를 중첩시키라고 권장한다.**
1380 |
1381 |
1382 |
1383 | # 7. 요약
1384 |
1385 | * 코틀린은 자바 클래스를 확장해서 더 풍부한 API를 제공한다.
1386 | * 함수 파라미터의 디폴트 값을 정의하면 오버로딩한 함수를 정의할 필요성이 줄어든다.
1387 | * 이름 붙인 인자를 사용하면 함수 호출이 가독성을 향상시킬 수 있다.
1388 | * 코틀린은 클래스 멤버가 아닌 최상위 함수와 프로퍼티를 직접 선언할 수 있다.
1389 | * 확장 함수와 프로퍼티를 사용하면 외부 라이브러리의 소스코드를 바꿀 필요 없이 확장할 수 있다.
1390 | * 중위 호출을 통해 메소드나 확장 함수를 더 깔끔한 구문으로 호출할 수 있다.
1391 | * 코틀린은 다양한 문자열 처리 함수를 제공한다.
1392 | * 수많은 이스케이프가 필요한 문자열의 경우 3중 따옴표 문자열을 사용하면 깔끔하게 표현할 수 있다.
1393 |
1394 | ---
1395 |
1396 |
--------------------------------------------------------------------------------
/Chapter4.md:
--------------------------------------------------------------------------------
1 | # 04. 클래스, 객체, 인터페이스
2 |
3 | [노션 링크(노션으로 보는 것이 더 깔끔합니다.)](https://www.notion.so/moochipark/04-dc2a5cff20d24b589f5724c1235fbc58)
4 |
5 | **4장에서 다루는 내용**
6 | • 클래스와 인터페이스
7 | • 뻔하지 않은 생성자와 프로퍼티
8 | • 데이터 클래스
9 | • 클래스 위임
10 | • object 키워드 사용
11 |
12 | 여기선 코틀린 클래스를 다루는 방법을 더 깊이 이해하는 장이다.
13 |
14 | 코틀린의 클래스와 인터페이스는 자바의 것과는 약간 다르다.
15 | 예를 들어, 인터페이스에 프로퍼티 선언이 들어갈 수 있다.
16 |
17 | 자바와 달리 코틀린의 선언은 기본적으로 final이며 public이다.
18 | 게다가 중첩 클래스는 기본적으로는 내부 클래스가 아니다. 즉, 코틀린 중첩 클래스에는 외부 클래스에 대한 참조가 없다.
19 |
20 | 짧은 주 생성자 구문으로도 거의 모든 경우를 잘 처리할 수 있지만, 복잡한 초기화 로직을 수행하는 경우를 대비해 완전한 문법도 있다.
21 | 프로퍼티도 마찬가지로 간결한 구문으로 충분히 제 기능을 하지만, 필요하면 접근자를 직접 정의할 수 있다.
22 |
23 | 코틀린 컴파일러는 번잡스러움을 피하기 위해 유용한 메서드를 자동으로 만들어준다.
24 | 클래스를 data로 선언하면 일부 표준 메서드를 생성해준다.
25 |
26 | 그리고 코틀린 언어가 제공하는 위임(delegation)을 사용하면 위임을 처리하기 위한 준비 메서드를 직접 작성할 필요가 없다.
27 |
28 | 또한 클래스와 인스턴스를 동시에 선언하면서 만들 때 쓰는 object 키워드에 대해 알아본다.
29 | 싱글턴 클래스, 동반 객체(companion object), 객체 식(object expression = java 익명 클래스)을 표현할 때 사용한다.
30 |
31 | 먼저 클래스와 인터페이스에 대해 알아보고 코틀린에서 클래스 계층을 정의할 때 주의해야 할 점을 알아보자.
32 |
33 | # 1. 클래스 계층 정의
34 |
35 |
36 | 코틀린의 가시성/접근 변경자는 자바와 비슷하지만 기본 가시성이 다르다. 또한 클래스 상속을 제한하는 sealed 변경자도 추가되었다.
37 |
38 | ## 1.1 코틀린 인터페이스
39 |
40 | 코틀린 인터페이스는 자바8 인터페이스와 비슷하다.
41 | 코틀린 인터페이스 안에는 추상 메서드뿐 아니라 구현이 있는 메서드(자바8의 디폴트 메서드와 비슷하다)도 정의할 수 있다.
42 |
43 | 다만 인터페이스에는 아무런 상태(필드)도 저장될 수 없다.
44 |
45 | ```kotlin
46 | interface Clickable {
47 | fun click()
48 | }
49 | ```
50 |
51 | 위 코드는 click이라는 추상 메서드가 있는 인터페이스를 정의한다.
52 | 이 인터페이스를 구현하는 모든 비추상 클래스(구현 클래스)는 click에 대한 구현을 제공해야 한다.
53 |
54 | ```kotlin
55 | class Button : Clickable {
56 | override fun click() = println("I was clicked")
57 | }
58 |
59 | >>> Button().click()
60 | I was clicked
61 | ```
62 |
63 | 자바에서는 extends와 implements 키워드를 사용하지만,
64 | 코틀린에서는 클래스 이름 뒤에 콜론을 붙이는 것으로 확장과 구현을 모두 처리한다.
65 |
66 | 자바와 마찬가지로 클래스는 인터페이스를 원하는 만큼 마음대로 구현할 수 있지만, 클래스는 오직 하나만 확장할 수 있다.
67 |
68 | 자바의 @Override 애노테이션과 비슷한 override 변경자는 상위 클래스나 상위 인터페이스에 있는 프로퍼티나 메서드를 재정의 한다는 뜻이다.
69 | **하지만 자바와 달리 코틀린에서는 override 변경자를 반드시 사용해야 한다.**
70 | 이는 실수로 상위 클래스의 메서드를 오버라이드 하는경우를 방지해준다.
71 |
72 | 상위 클래스에 있는 메서드와 시그니처가 같은 메서드를 우연히 하위 클래스에서 선언하는 경우 컴파일이 안되기 때문에
73 | override를 붙이거나 메서드 이름을 바꿔야만 한다.
74 |
75 | 인터페이스 메서드도 디폴트 구현을 제공할 수 있다.
76 | default를 붙여야하는 자바와 달리 그냥 메서드 본문을 추가하면 된다.
77 |
78 | ```kotlin
79 | interface Clickable {
80 | fun click()
81 | fun showOff() = println("I'm clickable!")
82 | }
83 | ```
84 |
85 | 이 인터페이스를 구현하는 클래스는 click에 대한 구현을 제공해야 하는 반면,
86 | showOff 메서드의 경우 재정의할 수도 있고, 디폴트 구현을 사용할 수도 있다.
87 |
88 | 다음의 경우를 보자.
89 |
90 | ```kotlin
91 | interface Focusable {
92 | fun setFocus(b: Boolean) =
93 | println("I ${if (b) "got" else "lost"} focus.")
94 |
95 | fun showOff() = println("I'm focusable!")
96 | }
97 | ```
98 |
99 | 한 클래스에서 이 두 인터페이스를 함께 구현하면 어떻게 될까?
100 | 정답은 어느쪽도 선택되지 않는다.
101 | 클래스가 구현하는 두 상위 인터페이스에 정의된 구현을 대체할 오버라이딩 메서드를 직접 제공하지 않으면 컴파일러 오류가 발생한다.
102 |
103 | ```kotlin
104 | Class 'Button' must override public open fun showOff(): Unit defined
105 | in ch04ClassObjectInterface.`interface`.Clickable because it inherits multiple interface methods of it
106 | ```
107 |
108 | 코틀린 컴파일러는 두 메서드를 아우르는 구현을 하위 클래스에 직접 구현하게 강제한다.
109 |
110 | ```kotlin
111 | class Button : Clickable, Focusable {
112 | override fun click() = println("I was clicked")
113 |
114 | override fun showOff() {
115 | super.showOff()
116 | super.showOff()
117 | }
118 | }
119 | ```
120 |
121 | 상위 타입의 구현을 호출할 때는 자바와 마찬가지로 super를 사용하지만, 구체적으로 타입을 지정하는 문법이 다르다.
122 |
123 | 자바에서는 Clickable.super.showOff() 처럼 기반 타입을 명시하지만,
124 | 코틀린에서는 <> 기호 안에 기반 타입의 이름을 지정한다.
125 |
126 | 이제 이 클래스의 인스턴스를 만들고 구현대로 상속한 모든 메서드를 호출하는지 검증해보자.
127 |
128 | ```kotlin
129 | fun main() {
130 | val button = Button()
131 | button.showOff()
132 | button.setFocus(true)
133 | button.click()
134 | }
135 |
136 | >>>
137 | I'm clickable!
138 | I'm focusable!
139 | I got focus.
140 | I was clicked
141 | ```
142 |
143 | Button 클래스는 Focusable 인터페이스 안에 선언된 setFocus의 구현을 자동으로 상속한다.
144 |
145 | ## 1.2 open, final, abstract 변경자: 기본적으로 final
146 |
147 | 자바처럼 기본적으로 상속이 가능하면 편리한 경우도 많지만 문제가 생기는 경우도 많다.
148 |
149 | 취약한 기반 클래스(fragile base class)라는 문제는 하위 클래스가 기반 클래스를 변경함으로써 깨져버린 경우를 말한다.
150 | 어떤 클래스가 자신을 상속하는 방법에 대한 정확한 규칙(어떤 메서드를 어떻게 오버라이드해야 하는지 등)을 제공하지 않는다면
151 | 그 클래스의 클라이언트는 기반 클래스를 작성한 사람의 의도와 다른 방식으로 오버라이드할 위험이 있다.
152 |
153 | 모든 하위 클래스를 분석하는 것은 불가능하므로 기반 클래스를 변경하는 경우 하위 클래스의 동작이 예기치 않게 바뀔 수 있다는 면에서 기반 클래스는 취약하다.
154 |
155 | 이 문제를 해결하기 위해 프로그래밍 기법에 대한 책 중 가장 유명한 조슈아 블로크(Joshua Block)가 쓴 이펙티브 자바에서는
156 |
157 | > "상속을 위한 설계와 문서를 갖추거나, 그럴 수 없다면 상속을 금지하라" - Josua Block
158 | >
159 |
160 | 고 조언한다. 이는 특별히 하위 클래스에서 오버라이드하게 의도된 메서드가 아니라면 모두 final로 만들라는 뜻이다.
161 |
162 | 코틀린도 마찬가지의 철학을 따른다. 자바의 클래스와 메서드는 기본적으로 상속에 대해 열려있지만 코틀린은 기본적으로 final이다.
163 |
164 | 어떤 클래스의 상속을 허용하려면 클래스 앞에 open 변경자를 붙여야 한다.
165 | 그와 더불어 오버라이드를 허용하고 싶은 메서드나 프로퍼티의 앞에도 open 변경자를 붙여야 한다.
166 |
167 | ```kotlin
168 | open class RichButton : Clickable { // 이 클래스는 열려있다. 다른 클래스가 이 클래스를 상속할 수 있다.
169 | fun disable() {} // 이 함수는 final이다. 하위 클래스가 이 메서드를 override할 수 없다.
170 |
171 | open fun animate() {} // 이 함수는 열려있다. 하위 클래스에서 이 메서드를 override해도 된다.
172 |
173 | override fun click() {} // 이 함수는 (상위 클래스에서 선언된) 열려있는 메서드를 override한다. override한 메서드는 기본적으로 열려있다.
174 | }
175 | ```
176 |
177 | 기반 클래스나 인터페이스의 멤버를 오버라이드하는 경우 그 메서드는 기본적으로 열려있다.
178 |
179 | ```kotlin
180 | open class RichButton : Clickable {
181 |
182 | final override fun click() {} // 여기 있는 final은 쓸데 없이 붙은 중복이 아니다.
183 | // final이 없는 override 메서드나 프로퍼티는 기본적으로 열려있다.
184 | }
185 | ```
186 |
187 | **열린 클래스와 스마트 캐스트**
188 | 클래스의 기본적인 상속 가능 상태를 final로 함으로써 얻을 수 있는 큰 이익은 다양한 경우에 스마트 캐스트가 가능하다는 점이다.
189 | 클래스 프로퍼티의 경우 이는 val이면서 커스텀 접근자가 없는 경우에만 스마트 캐스트를 쓸 수 있다는 것이다.
190 | 이 요구 사항은 또한 프로퍼티가 final이어야만 한다는 뜻이기도 하다.
191 | 프로퍼티가 final이 아니라면 그 프로퍼티를 다른 클래스가 상속하면서 커스텀 접근자를 정의함으로써 스마트 캐스트의 요구 사항을 깰 수 있다.
192 | 코틀린의 경우 프로퍼티가 기본적으로 final이므로 고민할 필요 없이 대부분의 프로퍼티를 스마트 캐스트에 활용할 수 있다.
193 |
194 | 자바처럼 코틀린에서도 클래스를 abstract로 선언할 수 있다.
195 |
196 | - abstract로 선언한 추상 클래스는 인스턴스화할 수 없다.
197 | - 추상 클래스에는 구현이 없는 추상 멤버가 있기 때문에 하위 클래스에서 오버라이드해야만 한다.
198 | - 추상 멤버는 항상 열려있다. 따라서 open 변경자를 명시할 필요가 없다.
199 |
200 | ```kotlin
201 | abstract class Animated { // 이 클래스는 추상클래스다. 이 클래스의 인스턴스를 만들 수 없다.
202 | abstract fun animate() // 이 함수는 추상 함수다. 이 함수에는 구현이 없다. 하위 클래스에서는 이 함수를 반드시 오버라이드해야 한다.
203 |
204 | open fun stopAnimating() {} // 추상 클래스에 속했더라도 비추상 함수는 기본적으로 final이지만 원한다면 open으로 오버라이드를 허용할 수 있다.
205 |
206 | fun animateTwice() {}
207 | }
208 | ```
209 |
210 | [코틀린 클래스 내에서의 상속 제어 변경자(access modifier)](https://www.notion.so/3f7be7bfbb0a4d70be759946146517b4)
211 |
212 | 인터페이스 멤버의 경우는 위의 final, open, abstract를 사용하지 않는다.
213 |
214 | ## 1.3 가시성 변경자: 기본적으로 공개
215 |
216 | 기본적으로 코틀린 가시성 변경자는 자바와 비슷하다.
217 |
218 | 자바와 비슷한 public, protected, private 변경자가 있다.
219 |
220 | 하지만 코틀린의 기본 가시성은 자바와 다르게 public이다.
221 |
222 | 자바의 기본 가시성인 package-private(패키지 전용)은 코틀린에 없다.
223 |
224 | 코틀린은 패키지를 네임스페이스를 관리하기 위한 용도로만 사용하기 때문이다. 따라서 패키지를 가시성 제어에 사용하지 않는다.
225 |
226 | 이를 위한 대안으로 코틀린에는 internal이라는 새로운 가시성 변경자를 도입했다.
227 |
228 | internal은 '모듈 내부에서만 볼 수 있음'이라는 의미다. 여기서의 모듈은 한 번에 같이 컴파일되는 코틀린 파일들을 의미한다.
229 | (예: intelliJ 모듈, maven, gradle 프로젝트 등)
230 |
231 | 모듈 내부 가시성은 모듈의 구현에 대해 진정한 캡슐화를 제공한다는 장점이 있다.
232 |
233 | 자바에서는 패키지가 같은 클래스를 선언하기만 하면 어떤 프로젝트의 외부에 있는 코드라도 패키지 내부에 있는 패키지 전용 선언에 쉽게 접근할 수 있다.
234 |
235 | 그래서 모듈의 캡슐화가 쉽게 깨진다.
236 |
237 | 또 다른 차이는 코틀린에서는 최상위 선언(클래스, 함수, 프로퍼티)에 대해 private 가시성을 허용한다는 점이다.
238 |
239 | 비공개 가시성인 최상위 선언은 그 선언이 포함된 파일 내부에서만 사용할 수 있다.
240 |
241 | 이는 하위 시스템의 자세한 구현 사항을 외부에 감추고 싶을 때 유용한 방법이다.
242 |
243 | [코틀린의 가시성 변경자(visibily modifier)](https://www.notion.so/592d6ef5277942749910158970c81a1b)
244 |
245 | 가시성 규칙을 위반하는 예시를 보자.
246 |
247 | ```kotlin
248 | internal open class TalkativeButton : Focusable {
249 | private fun yell() = println("Hey!")
250 | protected fun whisper() = println("Let's talk!")
251 | }
252 |
253 | fun TalkativeButton.giveSpeech() { // 오류: public 멤버가 자신의 internal 수신 타입인 TalkativeButton을 노출함.
254 | yell() // 오류: yell에 접근할 수 없음. yell은 TalktiveButton의 private 멤버임.
255 | whisper() // 오류: whisper에 접근할 수 없음. whisper는 TalktiveButton의 protected 멤버임.
256 | }
257 | ```
258 |
259 | 코틀린은 public 함수인 giveSpeech 안에서 가시성이 더 낮은(이 경우 internal) 타입인 TalkativeButton을 참조하지 못하게 한다.
260 |
261 | 이는 어떤 클래스의 기반인 타입이거나 타입 파라미터에 들어있는 타입의 가시성보다 높아야 한다는 일반적인 규칙에 해당한다.
262 |
263 | 여기서 컴파일 오류를 없애려면 확장 함수의 가시성을 internal로 바꾸거나 기반 클래스의 가시성을 public으로 바꿔야 한다.
264 |
265 | (private, protected인 멤버는 여전히 접근할 수 없다.)
266 |
267 | 자바의 경우 같은 패키지 안에서 protected 멤버에 접근할 수 있었지만, 코틀린에서는 그렇지 않다.
268 |
269 | 코틀린의 가시성 규칙이 더 단순한데, protected 멤버는 오직 어떤 클래스나 그 클래스를 상속한 클래스 안에서만 보인다.
270 |
271 | 또다른 규칙의 차이로 코틀린에서는 외부 클래스가 내부 클래스, 중첩 클래스의 private 멤버에 접근할 수 없다는 점인데, 다음 절에서 자세히 알아보자.
272 |
273 |
274 | ## 1.4 내부 클래스와 중첩된 클래스: 기본적으로 중첩 클래스
275 |
276 | 자바처럼 코틀린에서도 클래스 안에 다른 클래스를 선언할 수 있다.
277 |
278 | 자바와의 차이는 코틀린의 중첩 클래스(nested class)는 명시하지 않는 한 외부 클래스 인스턴스에 대한 접근 권한이 없다는 점이다.
279 |
280 | 직렬화할 수 있는 View 요소를 예시로 들어보자.
281 |
282 | ```kotlin
283 | interface State : Serializable
284 |
285 | interface View {
286 | fun getCurrentState(): State
287 | fun restoreState(state: State) {}
288 | }
289 | ```
290 |
291 | View의 일종인 Button이 있다고 해보자. Button 클래스의 상태를 저장하는 클래스는 Button 클래스 내부에 선언하면 편리할 것이다.
292 |
293 | 자바에서 이를 어떻게 하는지 보자.
294 |
295 | ```java
296 | public class Button implements View {
297 | @Override
298 | public State getCurrentState() {
299 | return new ButtonState();
300 | }
301 |
302 | @Override
303 | public void restoreState(final State state) { /* ... */ }
304 |
305 | public class ButtonState implements State { /* ... */ }
306 | }
307 | ```
308 |
309 | State 인터페이스를 구현한 ButtonState 클래스를 정의해서 Button에 대한 구체적인 정보를 저장한다.
310 |
311 | 이를 getCurrentState 메서드 안에서 인스턴스를 만들어서 정보를 관리한다.
312 |
313 | 하지만 이 코드는 문제가 있다. 선언한 버튼의 상태를 직렬화하면 NotSerializableException: Button이라는 오류가 발생한다.
314 |
315 | 직렬화하려는 변수는 ButtonState 타입의 인스턴스였는데, 왜 Button을 직렬화할 수 없다는 오류가 발생할까?
316 |
317 | 자바에서 다른 클래스 안에 정의한 클래스는 자동으로 내부 클래스(inner class)가 된다는 사실을 기억한다면 어디가 잘못된 건지 명확히 알 수 있다.
318 |
319 | ButtonState 클래스는 외부의 Button 클래스에 대한 참조를 묵시적으로 포함한다.
320 |
321 | 그 참조로 인해 Button을 직렬화할 수 없으므로 문제가 발생하는 것이다.
322 |
323 | 자바의 경우는 이런 중첩 클래스를 static으로 선언하면 그 클래스를 둘러싼 바깥쪽 클래스에 대한 묵시적인 참조가 사라진다.
324 |
325 | 코틀린의 경우 중첩 클래스가 기본적으로 동작하는 방식이 자바와 정반대이다.
326 |
327 | ```kotlin
328 | class Button : View {
329 | override fun getCurrentState(): State = ButtonState()
330 |
331 | override fun restoreState(state: State) { /*...*/ }
332 |
333 | class ButtonState : State { /*...*/ } // 이 클래스는 자바의 정적 중첩 클래스와 대응한다.
334 | }
335 | ```
336 |
337 | 코틀린 중첩 클래스에 아무런 변경자가 붙지 않으면 자바 static 중첩 클래스와 같다.
338 |
339 | 이를 내부 클래스로 변경해서 바깥쪽 클래스에 대한 참조를 포함하게 만들고 싶다면 inner 변경자를 붙여야 한다.
340 |
341 | [자바와 코틀린의 중첩 클래스와 내부 클래스 관계](https://www.notion.so/3b76c67f28ef4dc4bfce4b34e1f5deb4)
342 |
343 | 
344 |
345 | 중첩 클래스 안에는 바깥쪽 클래스에 대한 참조가 없지만 내부 클래스에는 있다.
346 |
347 | 코틀린에서 바깥쪽 클래스의 인스턴스를 가리키는 참조를 표기하는 방법도 자바와 다르다.
348 |
349 | ```kotlin
350 | class Outer {
351 | inner class Inner {
352 | fun getOuterReference(): Outer = this@Outer
353 | }
354 | }
355 | ```
356 |
357 | ```java
358 | public class OuterJava {
359 | class InnerJava {
360 | public OuterJava getOuterReference() {
361 | return OuterJava.this;
362 | }
363 | }
364 | }
365 | ```
366 |
367 | 이제는 코틀린 중첩 클래스를 유용하게 사용하는 예시를 보자.
368 |
369 | 클래스 계층을 만들되 그 계층에 속한 클래스의 수를 제한하고 싶은 경우 중첩 클래스를 쓰면 편리하다.
370 |
371 | ## 1.5 봉인된 클래스: 클래스 계층 정의 시 계층 확장 제한
372 |
373 | 상위 클래스 혹은 인터페이스 아래로 하위 클래스가 있을 때, 다양한 패턴 매칭으로 처리할 수가 있다.
374 |
375 | ```kotlin
376 | interface Expr
377 |
378 | class Num(val value: Int) : Expr
379 | class Sum(val left: Expr, val right: Expr) : Expr
380 |
381 | fun eval(e: Expr): Int =
382 | when (e) {
383 | is Num -> e.value
384 | is Sum -> eval(e.right) + eval(e.left)
385 | else -> throw IllegalArgumentException("Unknown expression")
386 | }
387 | ```
388 |
389 | 코틀린 컴파일러는 when을 사용해 open 클래스 타입 혹은 인터페이스 타입을 검사할 때 반드시 디폴트 분기인 else 분기를 덧붙이게 강제한다.
390 |
391 | 이 예제의 else 분기에서는 반환할 만한 의미 있는 값이 없어 예외를 던지게 했다.
392 |
393 | 항상 이처럼 디폴트 분기를 추가하는 것이 안전하겠지만 편하지는 않다.
394 |
395 | 디폴트 분기가 있을 경우 클래스 계층에 새로운 하위 클래스를 추가하더라도 컴파일러가 when이 모든 경우를 처리하는지 검사할 수가 없다.
396 |
397 | 혹시나 새로운 클래스 처리를 잊어버렸더라도 디폴트 분기가 선택되기 때문에 심각한 버그가 발생할 수도 있다.
398 |
399 | 코틀린은 이런 문제에 대한 해법으로 sealed 클래스를 내놓았다.
400 |
401 | 상위 클래스에 sealed 변경자를 붙이면 그 상위 클래스를 상속한 하위 클래스 정의를 제한할 수 있다.
402 |
403 | sealed 클래스의 하위 클래스를 정의할 때는 상위 클래스 안에 중첩시켜야 한다 (코틀린 1.1부터는 같은 파일 내에서도 하위 클래스를 정의할 수 있다).
404 |
405 | ```kotlin
406 | **sealed class Expr {
407 | class Num(val value: Int) : Expr()
408 | class Sum(val left: Expr, val right: Expr) : Expr()
409 | }**
410 |
411 | fun eval(e: Expr): Int =
412 | when (e) {
413 | is Expr.Num -> e.value
414 | is Expr.Sum -> eval(e.right) + eval(e.left)
415 | }
416 | ```
417 |
418 | when 식에서 sealed 클래스의 모든 하위 클래스를 처리한다면 디폴트 분기가 필요 없다.
419 |
420 | sealed로 표시된 클래스는 자동으로 open이므로 open 변경자를 붙일 필요가 없다.
421 |
422 | 내부적으로 sealed 클래스는 private 생성자를 가진다. 따라서 그 생성자는 같은 파일, 같은 클래스 내부에서만 호출할 수 있다.
423 |
424 | 즉, 같은 파일 혹은 sealed 클래스 내부에서만 상속을 받을 수 있다는 의미이다.
425 |
426 | # 2. 뻔하지 않은 생성자와 프로퍼티를 갖는 클래스 선언
427 |
428 |
429 | 코틀린도 자바와 비슷하게 생성자를 하나 이상 선언할 수 있다.
430 |
431 | 하지만 코틀린은 주 생성자와 부 생성자를 구분한다.
432 |
433 | 또한 초기화 블록을 통해 초기화 로직을 추가할 수 있다.
434 |
435 | ## 2.1 클래스 초기화: 주 생성자와 초기화 블록
436 |
437 | ```kotlin
438 | class User(val nickname: String)
439 | ```
440 |
441 | 위처럼 클래스 이름 뒤에 오는 괄호로 둘러싸인 코드를 **주 생성자**라고 부른다.
442 |
443 | 위 선언을 같은 목적을 달성하는 가장 명시적인 선언으로 풀어서 실제론 어떤 일이 벌어지는지 보자.
444 |
445 | ```kotlin
446 | class User constructor(nickname: String) {
447 | val nickname: String
448 |
449 | init {
450 | this.nickname = nickname
451 | }
452 | }
453 | ```
454 |
455 | constructor 키워드는 주 생성자나 부 생성자 정의를 시작할 때 사용한다.
456 |
457 | init 키워드는 초기화 블록을 시작한다.
458 |
459 | 초기화 블록에는 클래스의 객체가 만들어질 때 실행될 초기화 코드가 들어간다.
460 |
461 | 초기화 블록은 주 생성자와 함께 사용될 수 있는데, 주 생성자는 별도의 코드를 포함할 수 없으므로 초기화 블록이 필요한 경우가 있다.
462 |
463 | 주 생성자에 별도의 애노테이션이나 가시성 변경자가 없다면 constructor를 생략할 수 있다. 위 코드를 간략화하면 다음과 같다.
464 |
465 | ```kotlin
466 | class User(nickname: String) {
467 | val nickname: String = nickname
468 | }
469 | ```
470 |
471 | 위 세 가지 User 선언은 모두 같은 동작을 수행한다.
472 |
473 | 함수 파라미터와 마찬가지로 생성자 파라미터에도 디폴트 값을 정의할 수 있다.
474 |
475 | ```kotlin
476 | class User(
477 | val nickname: String,
478 | val isSubscribed: Boolean = true,
479 | )
480 | ```
481 |
482 | 클래스에 기반 클래스가 있다면 주 생성자에서 기반 클래스의 생성자를 호출해야 할 필요가 있다.
483 |
484 | 기반 클래스를 초기화하려면 기반 클래스 이름 뒤에 생성자 인자를 넘기면 된다.
485 |
486 | ```kotlin
487 | open class User(val nickname: String) { }
488 |
489 | class TwitterUser(nickname: String) : User(nickname) {
490 | ```
491 |
492 | 코틀린에서는 기반 클래스를 상속을 받는 하위 클래스는 기반 클래스의 생성자를 호출해야 한다.
493 |
494 | ```kotlin
495 | class RadioButton : Button()
496 | ```
497 |
498 | 이 규칙으로 인해 기반 클래스의 이름 뒤에는 꼭 빈 괄호가 들어간다. 물론 생성자 인자가 있다면 괄호 안에 인자가 들어간다.
499 |
500 | 반면 인터페이스는 생성자가 없기 때문에 어떤 클래스가 인터페이스를 구현하는 경우 인터페이스 이름 뒤에 아무 괄호도 없다.
501 |
502 | 이를 통해 기반 클래스와 인터페이스를 쉽게 구별할 수 있다.
503 |
504 | 어떤 클래스를 외부에서 인스턴스화하지 못하게 막고 싶다면 모든 생성자를 private으로 만들면 된다.
505 |
506 | ```kotlin
507 | class Secretive private constructor() { }
508 | ```
509 |
510 | 실제로 대부분의 경우 클래스의 생성자는 코틀린의 주 생성자 구문만으로 충분할 만큼 단순하다.
511 |
512 | 하지만 복잡한 생성자가 생기는 경우를 대비해 코틀린은 다양한 생성자를 정의할 수 있게 해준다.
513 |
514 | ## 2.2 부 생성자: 상위 클래스를 다른 방식으로 초기화
515 |
516 | 일반적으로 코틀린에서 생성자가 여럿 있는 경우는 자바보다 훨씬 적다.
517 |
518 | 자바에서 오버로드한 생성자가 필요한 상황 중 상당수는 코틀린의 디폴트 파라미터 값과 이름 붙인 인자 문법을 사용해 해결할 수 있다.
519 |
520 | 그래도 생성자가 여럿 필요한 경우가 가끔 있다.
521 |
522 | 예를 들어 자바에서 생성자가 2개인 View 클래스를 코틀린으로 정의해보자.
523 |
524 | ```kotlin
525 | open class View {
526 | constructor(ctx: Context) { }
527 | constructor(ctx: Context, attr: AttributeSet) { }
528 | }
529 | ```
530 |
531 | 이 클래스는 주 생성자를 선언하지 않고, 부 생성자만 2가지 선언한다.
532 |
533 | 필요에 따라 얼마든지 부 생성자를 많이 선언해도 된다.
534 |
535 | 이 클래스를 확장하면서 똑같이 부 생성자를 정의해보자.
536 |
537 | ```kotlin
538 | class MyButton : View {
539 | constructor(ctx: Context) : super(ctx) { }
540 | constructor(ctx: Context, attr: AttributeSet) : super(ctx, attr) { }
541 | }
542 | ```
543 |
544 | 여기서 두 부 생성자는 super() 키워드를 통해 자신에 대응하는 상위 클래스 생성자를 호출한다.
545 |
546 | 
547 |
548 | 상위 클래스의 여러 생성자에게 객체 생성 위임하기
549 |
550 | 그림에서 생성자가 상위 클래스의 생성자에게 객체 생성을 위임한다는 것을 나타낸다.
551 |
552 | 자바와 마찬가지로 생성자에서 this()를 통해 클래스 자신의 다른 생성자를 호출할 수 있다.
553 |
554 | ```kotlin
555 | class MyButton : View {
556 | constructor(ctx: Context) : this(ctx, MY_STYLE) { }
557 | constructor(ctx: Context, attr: AttributeSet) : super(ctx, attr) { }
558 | }
559 | ```
560 |
561 | 생성자 중 하나가 파라미터의 디폴트 값을 넘겨서 같은 생성자에게 생성을 위임한다.
562 |
563 | 
564 |
565 | 두 번째 생성자는 여전히 super()를 호출하여 상위 클래스에게 생성을 위임한다.
566 |
567 | 결국 각 부 생성자들에서 객체 생성을 따라가다보면 그 끝에는 상위 클래스 생성자를 호출해야 한다는 의미다.
568 |
569 | 부 생성자가 필요한 주된 이유는 주로 자바와의 상호 운용성이다.
570 |
571 | 물론 인스턴스를 생성할 때 파라미터 목록이 다른 생성 방법이 여럿 존재하는 경우 부 생성자를 사용할 수밖에 없다.
572 |
573 | 이는 뒤의 동반 객체에서 다시 알아보자.
574 |
575 | ## 2.3 인터페이스에 선언된 프로퍼티 구현
576 |
577 | 코틀린에서는 인터페이스에 추상 프로퍼티 선언을 넣을 수 있다.
578 |
579 | ```kotlin
580 | interface User {
581 | val nickname: String
582 | }
583 | ```
584 |
585 | 이는 User 인터페이스의 구현 클래스가 nickname의 값을 얻을 수 있는 방법을 제공해야 한다는 것이다.
586 |
587 | 인터페이스에 있는 프로퍼티 선언에는 뒷받침하는 필드(백킹 필드)나 게터 등의 정보가 들어있지 않다.
588 |
589 | 사실 인터페이스는 아무 상태도 포함할 수 없으므로 상태를 저장할 필요가 있다면 인터페이스를 구현한 하위 클래스에서 상태 저장을 위한 프로퍼티를 만들어야 한다.
590 |
591 | 위 인터페이스를 구현 가능한 몇 가지 방법을 알아보자.
592 |
593 | ```kotlin
594 | class PrivateUser(override val nickname: String) : User // 주 생성자에 있는 프로퍼티
595 |
596 | class SubscribingUser(val email: String) : User {
597 | override val nickname: String
598 | get() = email.substringBefore('@') // 커스텀 게터
599 |
600 | class FacebookUser(val accountId: Int) : User {
601 | override val nickname = getFacebookName(accountId) // 프로퍼티 초기화 식
602 | ```
603 |
604 | PrivateUser는 주 생성자 안에 프로퍼티를 직접 선언하는 간결한 구문을 사용했다.
605 |
606 | 이 프로퍼티는 User의 추상 프로퍼티를 구현하고 있으므로 override를 표시해야 한다.
607 |
608 | SubscribingUser는 커스텀 게터로 nickname 프로퍼티를 설정한다.
609 |
610 | 이 프로퍼티는 뒷받침하는 필드에 값을 저장하지 않고 매번 이메일 주소에서 별명을 계산해 반환한다.
611 |
612 | FacebookUser에서는 초기화 식으로 nickname 값을 초기화한다.
613 |
614 | getFacebookName이라는 함수가 비용이 많이 들 수 있어서 객체를 초기화하는 단계에 한 번만 호출하도록 되어있다.
615 |
616 | 두 번째와 세 번째 방식은 비슷해보이지만 커스텀 게터는 매번 호출될 때마다 값을 계산하고,
617 |
618 | 객체 초기화 식은 객체 초기화 시에 계산한 데이터를 뒷받침하는 필드에 저장했다가 불러오는 방식을 사용한다.
619 |
620 | 인터페이스에 뒷받침하는 필드가 없다고 했지만, 이를 통해 알 수 있는 것은 커스텀 게터, 세터는 선언이 가능하다는 것이다.
621 |
622 | 당연하게도 이런 게터와 세터는 뒷받침하는 필드를 참조할 수 없다.
623 |
624 | 뒷받침하는 필드가 있다면 인터페이스에 상태를 추가하는 셈이다. 인터페이스는 상태를 저장할 수 없다.
625 |
626 | ```kotlin
627 | interface User {
628 | val email: String,
629 | val nickname: String
630 | get() = email.substringBefore('@') // 프로퍼티에 뒷받침하는 필드가 없다. 대신 매번 결과를 계산해 돌려준다.
631 | }
632 | ```
633 |
634 | 이 인터페이스에는 추상 프로퍼티인 email과 커스텀 게터가 있는 nickname 프로퍼티가 함께 있다.
635 |
636 | 하위 클래스는 추상 프로퍼티인 email을 반드시 오버라이드해야 하지만, nickname은 오버라이드하지 않고 상속할 수 있다.
637 |
638 | 인터페이스에 선언된 프로퍼티와 달리 클래스에 구현된 프로퍼티는 뒷받침하는 필드에 원하는 대로 접근할 수 있다.
639 |
640 | 접근자에서 뒷받침하는 필드를 가리키는 방법을 보자.
641 |
642 | ## 2.4 게터와 세터에서 뒷받침하는 필드에 접근
643 |
644 | 값을 저장하는 동시에 특정 로직이 수행되어야 한다면 접근자 안에서 백킹 필드에 접근할 수 있어야 한다.
645 |
646 | ```kotlin
647 | class User(val name: String) {
648 | var address: String = "unspecified"
649 | set(value: String) {
650 | println("""
651 | Address was changed for $name:
652 | "$field" -> "$value".""".trimIndent()) // 백킹 필드 값 읽기
653 | field = value
654 | }
655 | }
656 | ```
657 |
658 | 코틀린에서 프로퍼티의 값을 바꿀 때는 user.address = "new value"처럼 필드 설정 구문을 사용한다.
659 |
660 | 이 구문은 내부적으로 address의 세터를 호출한다.
661 |
662 | 접근자의 본문에서는 field라는 특별한 식별자를 통해 백킹 필드에 접근할 수 있다.
663 |
664 | 게터에서는 field 값을 읽을 수만 있고, 세터에서는 읽거나 쓸 수 있다.
665 |
666 | 변경 가능 프로퍼티의 게터와 세터 중 한쪽만 직접 정의할 수 있다는 점을 기억하자.
667 |
668 | 클래스의 프러퍼티를 사용하는 쪽에서 프로퍼티를 읽는 방법이나 쓰는 방법은 백킹 필드의 유무와는 관계가 없다.
669 |
670 | 컴파일러는 디폴트 접근자 구현을 사용하건, 커스텀 접근자를 사용하건 관계없이 게터나 세터에서 field를 사용하는 프로퍼티에 대해 백킹 필드를 생성해준다.
671 |
672 | 다만 field를 사용하지 않는 커스텀 접근자 구현을 정의한다면 백킹 필드는 존재하지 않는다.
673 | (프로퍼티가 val인 경우 게터에 field가 없으면 되지만, var인 경우에는 게터나 세터 모두에 field가 없어야 한다.)
674 |
675 | 때로 접근자의 기본 구현을 바꿀 필요는 없지만 가시성을 바꿀 때가 있다. 이를 어떻게 하는지 보자.
676 |
677 | ## 2.5 접근자의 가시성 변경
678 |
679 | 접근자의 가시성은 기본적으로 프로퍼티의 가시성과 같다.
680 |
681 | 하지만 원한다면 가시성 변경자를 추가하여 접근자의 가시성을 변경할 수 있다.
682 |
683 | ```kotlin
684 | class LengthCounter {
685 | var counter: Int = 0
686 | private set // 이 클래스 밖에서 이 프로퍼티의 값을 바꿀 수 없다.
687 |
688 | fun addWord(word: String) {
689 | counter += word.length
690 | }
691 | }
692 | ```
693 |
694 | ### 프로퍼티에 대해 나중에 다룰 내용
695 |
696 | - lateinit 변경자를 null이 될 수 없는 프로퍼티에 지정하면 프로퍼티를 생성자가 호출된 다음에 초기화한다는 의미다. (6장)
697 | - 요청이 들어올 때 초기화되는 지연 초기화 프로퍼티는 위임 프로퍼티(delegated property)의 일종이다. (7장)
698 | - 자바와의 호환성을 위해 자바의 특징을 코틀린에서 에뮬레이션하는 애노테이션을 활용할 수 있다. (10장)
--------------------------------------------------------------------------------
/Chapter5.md:
--------------------------------------------------------------------------------
1 | # 05. 람다로 프로그래밍
2 |
3 | [노션링크](https://wsminyoung.notion.site/05-f1cec23725a94c11810cb0e2b5e56d46)
4 |
5 | ### 5장에서 다루는 내용
6 |
7 | • 람다 식과 멤버 참조
8 | • 함수형 스타일로 컬렉션 다루기
9 | • 시퀀스: 지연 컬랙션 연산
10 | • 수신 객체 지정 람다 사용
11 |
12 | 람다 식(lambda expression) 또는 람다는 기본적으로 다른 함수에 넘길 수 있는 작은 코드 조각을 뜻한다.
13 |
14 | 람다를 사용하면 쉽게 공통 코드 구조를 라이브러리 함수로 뽑아낼 수 있다.
15 |
16 | 5장에서는 컬렉션을 처리하는 패턴을 표준 라이브러리 함수에 람다를 넘기는 방식으로 대치하는 예제를 다수 살펴본다.
17 |
18 | 마지막으로 수신 객체 지정 람다(lambda with receiver)에 대해 살펴본다. 수신 객체 지정 람다는 특별한 람다로, 람다 선언을 둘러싸고 있는 환경과는 다른 상황에서 람다 본문을 실행할 수 있다.
19 |
20 | # 5.1 람다 식과 멤버 참조
21 |
22 | 이번 절에서는 람다의 유용성을 보여주고 코틀린 람다 식 구문이 어떻게 생겼는지 알아본다.
23 |
24 | ## 5.1.1 람다 소개: 코드 블록을 함수 인자로 넘기기
25 |
26 | "이벤트가 발생하면 이 핸들러를 실행하자"나 "데이터 구조의 모든 원소에 이 연산을 적용하자"와 같은 생각을 코드로 표현하기 위해 일련의 동작을 변수에 저장하거나 다른 함수에 넘겨야 하는 경우가 자주 있다.
27 |
28 | 함수형 프로그래밍에서는 함수를 값처럼 다루는 접근 방법을 택함으로써 이 문제를 해결한다. 클래스를 선언하고 그 클래스의 인스턴스를 함수에 넘기는 대신 함수형 언어에서는 함수를 직접 다른 함수에 전달할 수 있다.
29 |
30 | 람다 식을 사용하면 코드가 더욱 더 간결해진다. 람다 식은 함수를 선언할 필요가 없고 코드 블록을 직접 함수의 인자로 전달 할 수 있다.
31 |
32 | 예를 들어 버튼 클릭에 따른 동작을 정의하고 싶다.
33 |
34 | 5.1 *무명 내부 클래스로 리스너 구현하기*
35 |
36 | ```java
37 | /* 자바 */
38 | button.setOnClickListener(new OnClickListener() {
39 | @Override
40 | public void onClick(View view) {
41 | /* 클릭 시 수행할 동작 */
42 | }
43 | });
44 | ```
45 |
46 | 위 코드는 무명 내부 클래스를 선언하느라 코드가 번잡스럽다. 클릭 시 벌어질 동작을 간단히 기술할 수 있는 표기법이 있다면 이런 불필요한 코드를 제거할 수 있을 것이다.
47 |
48 | 5.2 *람다로 리스너 구현하기*
49 |
50 | ```kotlin
51 | /* 코틀린 */
52 | button.setOnClickListener { /* 클릭 시 수행할 동작 */ }
53 | ```
54 |
55 | 이 코틀린 코드는 앞에서 살펴본 자바 무명 내부 클래스와 같은 역할을 하지만 훨씬 더 간결하고 읽기 쉽다.
56 |
57 | ## 5.1.2 람다와 컬렉션
58 |
59 | 코드에서 중복을 제거하는 것은 프로그래밍 스타일을 개선하는 중요한 방법 중 하나다.
60 |
61 | 컬렉션을 다룰 때 수행하는 대부분의 작업은 몇 가지 일반적인 패턴에 속한다. 따라서 그런 패턴은 라이브러리 안에 있어야 한다. 하지만 람다가 없다면 컬렉션을 편리하게 처리할 수 있는 좋은 라이브러리를 제공하기 힘들다.
62 |
63 | 그에 따라 자바에서 쓰기 편한 컬렉션 라이브러리가 적었으며, 그에 따라 자바 개발자들은 필요한 컬렉션 기능을 직접 작성하곤 했다.
64 |
65 | 코틀린에서는 이런 습관을 버려야 한다.
66 |
67 | 예제를 하나 살펴보자. 사람의 이름과 나이를 저장하는 Person 클래스를 사용한다.
68 |
69 | ```kotlin
70 | data class Person(val name: String, val age: Int)
71 | ```
72 |
73 | 사람들로 이뤄진 리스트가 있고 그중에 가장 연장자를 찾고 싶다. 람다를 사용해본 경험이 없는 개발자라면 루프를 써서 직접 검색을 구현할 것이다.
74 |
75 | *5.3 컬렉션을 직접 검색하기*
76 |
77 | ```kotlin
78 | fun findTheOldest(people: List) {
79 | var maxAge = 0 // 가장 많은 나이를 저장한다.
80 | var theOldest: Person? = null // 가장 연장자인 사람을 저장한다.
81 | for (person in people) {
82 | if (person.age > maxAge) { // 현재까지 발견한 최연장자보다 더 나이가 많은
83 | maxAge - person.age // 사람을 찾으면 최댓값을 바꾼다.
84 | theOldest = person
85 | }
86 | }
87 |
88 | println(theOldest)
89 |
90 | }
91 |
92 | >>> val people = listOf(Person("Alice", 29), Person("Bob", 31))
93 | >>> findTheOldest(people)
94 | Person(name=Bob, age=31)
95 | ```
96 |
97 | 코틀린에서는 더 좋은 방법이 있다. 라이브러리 함수를 쓰면 된다.
98 |
99 | *5.4 람다를 사용해 컬렉션 검색하기*
100 |
101 | ```kotlin
102 | >>> val people = listOf(Person("Alice", 29), Person("Bob", 31))
103 | >>> println(people.maxBy { it.age }) // 나이 프로퍼티를 비교해서 값이 가장 큰 원소 찾기
104 | Person(name=Bob, age=31)
105 | ```
106 |
107 | maxBy → 가장 큰 원소를 찾기 위해 비교에 사용할 값을 돌려주는 함수
108 |
109 | { it.age } → 바로 비교에 사용할 값을 돌려주는 함수 (it이 그 인자를 가리킨다.)
110 |
111 | 이 예제에서는 컬렉션의 원소가 Person 객체였으므로 이 함수가 반환하는 값은 Person 객체의 age 필드에 저장된 나이 정보다.
112 |
113 | *5.5 멤버 참조를 사용해 컬렉션 검색하기*
114 |
115 | ```kotlin
116 | people.maxBy(Person::age)
117 | ```
118 |
119 | 이 코드는 리스트 5.4와 같은일을 한다. 이에 대해 5.1.5절에서 더 자세히 다룬다.
120 |
121 | ## 5.1.3 람다 식의 문법
122 |
123 | 람다 식 문법
124 |
125 | ```kotlin
126 | { x: Int, y: Int -> x + y }
127 | ```
128 |
129 | 코틀린 람다 식은 항상 중괄호로 둘러싸여 있다. 화살표(→) 가 인자 목록과 람다 본문을 구분해준다.
130 |
131 | 람다 식은 변수에 저장할 수 있다. 람다가 저장된 변수를 다른 일반 함수와 마찬가지로 다룰 수 있다.
132 |
133 | ```kotlin
134 | >>> val sum = { x: Int, y: Int -> x + y }
135 | >>> println(sum(1, 2))
136 | 3
137 | ```
138 |
139 | 원한다면 람다 식을 직접 호출해도 된다.
140 |
141 | ```kotlin
142 | >>> { println(42) } ()
143 | 42
144 | ```
145 |
146 | 하지만 이런 코드는 그다지 쓸모가 없다. 만약 이렇게 코드의 일부분을 블록으로 둘러싸 실행할 필요가 있다면 run을 사용한다. run은 인자로 받은 람다를 실행해주는 라이브러리 함수이다.
147 |
148 | ```kotlin
149 | >>> run { println(42) } // 람다 본문에 있는 코드를 실행한다.
150 | 42
151 | ```
152 |
153 | 다시 사람 목록에서 가장 연장자를 찾은 예제인 5.4로 되돌아가자.
154 |
155 | ```kotlin
156 | >>> val people = listOf(Person("Alice", 29), Person("Bob", 31))
157 | >>> println(people.maxBy { it.age }) // 나이 프로퍼티를 비교해서 값이 가장 큰 원소 찾기
158 | Person(name=Bob, age=31)
159 | ```
160 |
161 | 이 예제에서 코틀린이 코드를 줄여 쓸 수 있게 제공했던 기능을 제거하고 정식으로 람다를 작성하면 다음과 같다.
162 |
163 | ```kotlin
164 | people.maxBy({p: Person -> p.age})
165 | ```
166 |
167 | 하지만 이 코드는 번잡하다. 우선 구분자가 너무 많이 쓰여서 가독성이 떨어진다. 그리고 컴파일러가 문맥으로부터 유추할 수 있는 인자 타입을 굳이 적을 필요는 없다. 마지막으로 인자가 단 하나뿐인 경우 인자에 이름을 붙이지 않아도 된다.
168 |
169 | 이런 개선을 적용해보자. 먼저 중괄호부터 시작하면 코틀린에는 함수 호출 시 맨 뒤에 있는 인자가 람다 식이라면 그 람다를 괄호 밖으로 빼낼 수 있다는 문법 관습이 있다. 이 예제에서는 람다가 유일한 인자이므로 마지막 인자이기도 하다. 따라서 괄호 뒤에 람다를 둘 수 있다.
170 |
171 | ```kotlin
172 | people.maxBy() { p: Person -> p.age }
173 | ```
174 |
175 | 이 코드처럼 람다가 어떤 함수의 유일한 인자이고 괄호 뒤에 람다를 썼다면 호출 시 빈 괄호를 없애도 된다.
176 |
177 | ```kotlin
178 | people.maxBy { p: Person -> p.age }
179 | ```
180 |
181 | 이제 구문을 더 간단하게 다듬고 파라미터 타입을 없애자.
182 |
183 | ```kotlin
184 | people.maxBy { p: Person -> p.age } // 파라미터 타입을 명시
185 | people.maxBy { p -> p.age } // 파라미터 타입을 생략(컴파일러가 추론)
186 | ```
187 |
188 | 로컬 변수처럼 컴파일러는 람다 파라미터의 타입도 추론할 수 있다. 따라서 파라미터 타입을 명시할 필요가 없다. maxBy 함수의 경우 파라미터의 타입은 항상 컬렉션 원소타입과 같다.
189 |
190 | 마지막으로 람다의 파라미터 이름을 디폴트 이름인 it으로 바꾸면 람다 식을 더 간단하게 만들 수 있다. 람다의 파라미터가 하나뿐이고 그 타입을 컴파일러가 추론할 수 있는 경우 it을 바로 쓸 수 있다.
191 |
192 | *5.6 디폴트 파라미터 이름 it 사용하기*
193 |
194 | ```kotlin
195 | people.maxBy { it.age } // "it"은 자동 생성된 파라미터 이름
196 | ```
197 |
198 | ### 노트
199 |
200 | > it을 사용하는 관습은 코드를 아주 간단하게 만들어준다. 하지만 이를 남용하면 안된다. 특히 람다 안에 람다가 중첩되는 경우 각 람다의 파라미터를 명시하는 편이 낫다. 파라미터를 명시하지 않으면 각각의 it이 가리키는 파라미터가 어떤 람다에 속했는지 파악하기 어려울 수 있다
201 | >
202 |
203 | 람다를 변수에 저장할 때는 파라미터의 타입을 추론할 문맥이 존재하지 않는다. 따라서 파라미터 타입을 명시해야 한다.
204 |
205 | ```kotlin
206 | >>> val getAge = { p: Person -> p.age }
207 | >>> people.maxBy(getAge)
208 | ```
209 |
210 | ## 5.1.4 현재 영역에 있는 변수에 접근
211 |
212 | 자바 메소드 안에서 무명 내부 클래스를 정의할 때 메소드의 로컬 변수를 무명 내부 클래스에서 사용할 수 있다. 람다 안에서도 같은 일을 할 수 있다. 람다를 함수 안에 정의하면 함수의 파라미터뿐 아니라 람다 정의의 앞에 선언된 로컬 변수까지 람다에서 모두 사용할 수 있다.
213 |
214 | *5.7 함수 파라미터를 람다 안에서 사용하기*
215 |
216 | ```kotlin
217 | fun printMessageWithPrefix(messages: Collection, prefix: String) {
218 | messages.forEach { // 각 원소에 대해 수행할 작업을 람다로 받는다.
219 | println("$prefix $it") // 람다 안에서 함수의 "prefix" 파라미터를 사용한다.
220 | }
221 | }
222 |
223 | >>> val errors = listOf("403 Forbidden", "404 Not Found")
224 | >>> printMessagesWithPrefix(errors, "Error:")
225 | Error: 403 Forbidden
226 | Error: 404 Not Found
227 | ```
228 |
229 | 자바와 다른 점 중 중요한 한 가지는 코틀린 람다 안에서는 파이널 변수가 아닌 변수에 접근할 수 있다는 점이다. 또한 람다 안에서 바깥으 변수를 변경해도 된다. 다음 리스트는 전달받은 상태 코드 목록에 있는 클라이언트와 서버 오류의 횟수를 센다.
230 |
231 | *5.8 람다 안에서 바깥 함수의 로컬 변수 변경하기*
232 |
233 | ```kotlin
234 | fun printProblemCounts(responses: Collection) {
235 | var clientError = 0
236 | var servererror = 0
237 | responses.forEach {
238 | if (it.startsWith("4")) {
239 | clientErrors++
240 | } else if (it.startsWith("5")) {
241 | serverErrors++
242 | }
243 | }
244 |
245 | println("$clientErrors client errors, $serverErrors server errors")
246 | }
247 |
248 | >>> val responses = listOf("200 OK", "418 I'm a teapot",
249 | "500 Internal Server Error")
250 | ...
251 | >>> printProblemCounts(response)
252 | 1 client errors, 1 server errors
253 | ```
254 |
255 | 코틀린에서는 자바와 달리 람다에서 람다 밖 함수에 있는 파이널이 아닌 변수에 접근할 수 있고, 그 변수를 변경할 수도 있다. 이 예제의 prefix, clientErrors, serverErrors와 같이 람다 안에서 사용하는 외부 변수를 '람다가 포획(capture)한 변수'라고 부른다.
256 |
257 | 포획한 변수가 있는 람다를 저장해서 함수가 끝난 뒤에 실행해도 람다의 본문 코드는 여전히 포획한 변수를 읽거나 쓸 수 있다.
258 |
259 | ### **어떻게 가능할까?**
260 |
261 | 1. 파이널 변수를 포획한 경우에는 람다 코드를 변수 값과 함께 저장한다.
262 | 2. 파이널이 아닌 변수를 포획한 경우에는 변수를 특별한 래퍼로 감싸서 나중에 변경하거나 읽을 수 있게 한 다음, 래퍼에 대한 참조를 코드와 함께 저장한다.
263 |
264 | ```kotlin
265 | class Ref(var value: T) // 변경 가능한 변수를 포획하는 방법을 보여주기 위한 클래스
266 | >>> val counter = Ref(0)
267 | >>> val inc = { counter.value++ } // 공식적으로는 변경 불가능한 변수를 포획했지만
268 | // 그 변수가 가리키는 객체의 필드 값을 바꿀 수 있다.
269 |
270 | // 실제 코드에서는 이런 래퍼를 만들지 않아도 된다. 대신, 변수를 직접 바꾼다.
271 | var counter = 0
272 | val inc = { counnter ++ }
273 |
274 | ```
275 |
276 | ## 5.1.5 멤버 참조
277 |
278 | 람다를 사용해 코드 블록을 다른 함수에게 인자로 넘기는 방법을 살펴봤다. 하지만 넘기려는 코드가 이미 함수로 선언된 경우는 어떻게 할까?
279 |
280 | 코틀린에서는 자바 8과 마찬가지로 함수를 값으로 바꿀 수 있다. 이때 이중 콜론(::)을 사용한다.
281 |
282 | ```kotlin
283 | val getAge = Person::age
284 | ```
285 |
286 | ::를 사용하는 식을 멤버 참조(member reference)라고 부른다. 멤버 참조는 프로퍼티나 메소드를 단 하나만 호출하는 함수 값을 만들어준다.
287 |
288 | 멤버 참조는 그 멤버를 호출하는 람다와 같은 타입이다. 따라서 다음 예처럼 그둘을 자유롭게 바꿔 쓸 수 있다.
289 |
290 | ```kotlin
291 | people.maxBy(Person::age)
292 | people.maxBy { p -> p.age }
293 | people.maxBy { it.age }
294 | ```
295 |
296 | 최상위에 선언된(그리고 다른 클래스의 멤버가 아닌) 함수나 프로퍼티를 참조할 수도 있다.
297 |
298 | ```kotlin
299 | fun salute() = println("Salute!")
300 |
301 | >>> run(::salute) // 최상위 함수를 참조한다.
302 | Salute!
303 | ```
304 |
305 | 람다가 인자가 여럿인 다른 함수한테 작업을 위임하는 경우 람다를 정의하지 않고 직접 위임 함수에 대한 참조를 제공하면 편리하다.
306 |
307 | ```kotlin
308 | val action = { person: Person, message: String -> // 이 람다는 sendEmail 함수에게 작업을
309 | sendEmail(person, message) // 위임한다.
310 | }
311 |
312 | val nextAction = :: sendEmail // 람다 대신 멤버 참조를 쓸 수 있다.
313 | ```
314 |
315 | 생성자 참조(constructor reference)를 사용하면 클래스 생성 작업을 연기하거나 저장해둘 수 있다.
316 |
317 | :: 뒤에 클래스 이름을 넣으면 생성자 참조를 만들 수 있다.
318 |
319 | ```kotlin
320 | >>> val createPerson = ::Person
321 | >>> val p = createPerson("Alice", 29)
322 | >>> println(p)
323 | Person(name=Alice, age=29)
324 | ```
325 |
326 | *바운드 멤버참조*
327 |
328 | 바운드 멤버 참조를 사용하면 멤버 참조를 생성할 때 클래스 인스턴스를 함께 저장한 다음 나중에 그 인스턴스에 대해 멤버를 호출해준다. 따라서 호출 시 수신 대상 객체를 별도로 지정해 줄 필요가 없다,
329 |
330 | ```kotlin
331 | >>> val p = Person("Dmitry", 34)
332 | >>> val personAgeFunction = Person:age
333 | >>> println(personsAgeFunction(p))
334 | 34
335 |
336 | >>> val ditrysAgeFunction = p::age // 코틀린 1.1부터 사용할 수 있는 바운드 멤버 참조
337 | >>> println(dmitrysAgeFunction())
338 | 34
339 | ```
340 |
341 | # 5.2 컬렉션 함수 API
342 |
343 | 함수형 프로그래밍 스타일을 사용하면 컬렉션을 다룰 때 편리하다. 대부분의 작업에 라이브러리 함수를 활용할 수 있고 그로 인해 코드를 아주 간결하게 만들 수 있다.
344 |
345 | 이번절에서는 컬렉션을 다루는 코틀린 표준 라이브러리를 몇 가지 살펴본다.
346 |
347 | ## 5.2.1 필수적인 함수: filter와 map
348 |
349 | filter와 map은 컬렉션을 활용할 때 기반이 되는 함수다. 대부분의 컬렉션 연산을 이 두개의 함수를 통해 표현할 수 있다.
350 |
351 | 숫자를 사용한 예제와 Person을 사용한 예제를 통해 이 두 함수를 자세히 살펴보자.
352 |
353 | ### filter 함수
354 |
355 | filter 함수(필터 함수 또는 걸러내는 함수라고 부름)는 컬렉션을 이터레이션하면서 주어진 람다에 각 원소를 넘겨서 람다가 true를 반환하는 원소만 모은다.
356 |
357 | ```kotlin
358 | >>> val list = listOf(1, 2, 3, 4)
359 | >>> println(list.filter { it % 2 == 0 }) // 짝수만 남는다.
360 | [2, 4]
361 | ```
362 |
363 | 결과는 입력 컬렉션의 원소 중에서 주어진 술어(참/거짓을 반환하는 함수를 술어(predicate)라고 한다)를 만족하는 원소만으로 이뤄진 새로운 컬렉션이다.
364 |
365 | ### map 함수
366 |
367 | filter 함수는 컬렉션에서 원치 않는 원소를 제거한다. 하지만 filter는 원소를 변환할 수는 없다, 원소를 변환하려면 map 함수를 사용해야 한다.
368 |
369 | map 함수는 주어진 람다를 컬렉션의 각 원소에 적용한 결과를 모아서 새 컬렉션을 만든다. 다음과 같이 하면 숫자로 이뤄진 리스트를 각 숫자의 제곱이 모인 리스트로 바꿀 수 있다.
370 |
371 | ```kotlin
372 | >>> val list = listOf(1, 2, 3, 4)
373 | >>> println(list.map { it * it })
374 | [1, 4, 9, 16]
375 | ```
376 |
377 | 사람의 리스트가 아니라 이름의 리스트를 출력하고 싶다면 map으로 사람의 리스트를 이름의 리스트로 변환하면 된다.
378 |
379 | ```kotlin
380 | >>> val people = listOf(Person("Alice", 29), Person("Bob", 31))
381 | >>> println(people.map { it.name })
382 | [Alice, Bob]
383 | ```
384 |
385 | 멤버 참조를 사용해보자.
386 |
387 | ```kotlin
388 | people.map(Person::name)
389 | ```
390 |
391 | 이런 호출을 쉽게 연쇄시킬 수 있다. 예를 들어 30살 이상인 사람의 이름을 출력해보자.
392 |
393 | ```kotlin
394 | >>> people.filter{ it.age > 30 }.map(Person::name)
395 | [Bob]
396 | ```
397 |
398 | 필터와 변환 함수를 맵에 적용할 수도 있다.
399 |
400 | ```kotlin
401 | >>> val numbers = mapOf(0 to "zero", 1 to "one")
402 | >>> println(numbers.mapValues{ it.value.toUpperCase() })
403 | { 0=ZERO, 1=ONE }
404 | ```
405 |
406 | ## 5.2.2 all, any, count, find: 컬렉션에 술어 적용
407 |
408 | 컬렉션에 대해 자주 수행하는 연산으로 컬렉션의 모든 원소가 어떤 조건을 만족하는지 판단하는 연산이 있다.
409 |
410 | 코틀린에서는 all과 any가 이런 연산이다.
411 |
412 | 이런 함수를 살펴보기 위해 어떤 사람의 나이가 27살 이하인지 판단하는 술어 함수 canBeInClub27를 만들자.
413 |
414 | ```kotlin
415 | val canBeInClub27 - { p: Person -> p.age <= 27 }
416 | ```
417 |
418 | 모든 원소가 이 술어를 만족하는지 궁금하다면 all 함수를 쓴다.
419 |
420 | ```kotlin
421 | >>> val people = listOf(Person("Alice", 27), Person("Bob", 31))
422 | >>> println(people.all(canBeInClub27)
423 | false
424 | ```
425 |
426 | 술어를 만족하는 원소가 하나라도 있는지 궁금하면 any를 쓴다.
427 |
428 | ```kotlin
429 | >>> println(people.any(canBeInClub27)
430 | true
431 | ```
432 |
433 | 가독성을 높이려면 any와 all 앞에 !를 붙이지 않는 편이 낫다.
434 |
435 | ```kotlin
436 | >>> val list = listOf(1, 2, 3)
437 | >>> println(!list.all { it == 3 }) // !를 눈치 못채는 경우가 자주 있다.
438 | true
439 | >>> println(list.any { it != 3 })
440 | true
441 | ```
442 |
443 | 술어를 만족하는 원소의 개수를 구하려면 count를 사용한다.
444 |
445 | ```kotlin
446 | >>> val people = listOf(Person("Alice", 27), Person("Bob", 31))
447 | >>> println(people.count(canBeInClub27))
448 | 1
449 | ```
450 |
451 | ### 노트
452 |
453 | > **함수를 적재적소에 사용하라: count와 size**
454 | count가 있다는 사실을 잊어버리고, 컬렉션을 필터링한 결과의 크기를 가져오는 경우가 있다.
455 |
456 | >println(people.filter(canBeInClub27).size)
457 | >
458 | >1
459 | >
460 | >하지만 이렇게 처리하면 조건을 만족하는 모든 원소가 들어가는 중간 컬렉션이 생긴다. 반면 count는 조건을 만족하는 원소의 개수만을 추적하지 조건을 만족하는 원소를 따로 저장하지 않는다.
461 | >따라서 count가 훨씬 더 효울적이다.
462 |
463 |
464 |
465 | 술어를 만족하는 원소를 하나 찾고 싶으면 find 함수를 사용한다.
466 |
467 | ```kotlin
468 | >>> val people = listOf(Person("Alice", 27), Person("Bob", 31))
469 | >>> println(people.find(canBeInClub27))
470 | Person(name=Alice, age=27)
471 | ```
472 |
473 | 이 식은 조건을 만족하는 원소가 하나라도 있는 경우 가장 먼저 조건을 만족한다고 확인된 원소를 반환하며, 만족하는 원소가 전혀 없는 경우 null을 반환한다. (find는 firstOrNull과 같다.)
474 |
475 | ## 5.2.3 groupBy: 리스트를 여러 그룹으로 이뤄진 맵으로 변경
476 |
477 | 컬렉션의 모든 원소를 어떤 특성에 따라 여러 그룹으로 나누고 싶다고 하자. 예를 들어 사람을 나이에 따라 분류해보자. 특성을 파라미터로 전달하면 컬렉션을 자동으로 구분해주는 함수가 있다면 편리할 것이다.
478 |
479 | groupBy 함수가 그런 역할을 한다.
480 |
481 | ```kotlin
482 | >>> val people = listOf(Person("Alice", 31),
483 | ... Person("Bob", 29), Person("Carol", 31))
484 | >>> println(people.groupBy { it.age })
485 |
486 | {29=[Person(name=Bob, age=29)],
487 | 31=[Person(name=Alice, age=31), Person(name=Carol, age=31)]}
488 | ```
489 |
490 | 각 그룹은 리스트다. 따라서 groupBy의 결과 타입은 Map>이다.
491 |
492 | 다른 예로 멤버 참조를 활용해 문자열을 첫 글자에 따라 분류하는 코드를 보자.
493 |
494 | ```kotlin
495 | >>> val list = listOf("a", "ab", "b")
496 | >>> println(list.groupBy(String::first))
497 | {a=[a, ab], b=[b]}
498 | ```
499 |
500 | ## 5.2.4 flatMap과 flatten: 중첩된 컬렉션 안의 원소 처리
501 |
502 | 이제 사람에 대한 관심을 책으로 돌려보자. Book으로 표현한 책에 대한 정보를 저장하는 도서관이 있다고 가정하자.
503 |
504 | ```kotlin
505 | class Book(val title: String, val authors: List
506 | ```
507 |
508 | 책마다 저자가 한 명 또는 여러 명 있다. 도서관에 있는 책의 저자를 모두 모은 집합을 다음과 같이 가져올 수 있다.
509 |
510 | ```kotlin
511 | books.flatMap { it.authors }.toSet() // books 컬렉션에 있는 책을 쓴 모든 저자의 집합
512 | ```
513 |
514 | 1. flatMap 함수는 인자로 주어진 람다를 컬렉션의 모든 객체에 적용(map)
515 | 2. 람다를 적용한 결과 얻어지는 여러 리스트를 한 리스트로 한데 모은다.
516 |
517 | # 5.3 지연 계산(lazy) 컬렉션 연산
518 |
519 | 앞 절에서 map이나 filter 같은 몇가지 컬렉션은 컬렉션을 즉시(eaagerly) 생성한다. 이는 컬렉션 함수를 연쇄하면 매 단계마다 계산 중간 결과를 새로운 컬렉션에 임시로 담는다.
520 |
521 | 시퀀스(sequence)를 사용하면 중간 임시 컬렉션을 사용하지 않고도 컬렉션 연산을 연쇄할 수 있다.
522 |
523 | ```kotlin
524 | people.map(Person::name).filter {it.startsWith("A") }
525 | ```
526 |
527 | filter와 map을 호출할때 리스트를 반환한다.
528 |
529 | 결국 한 리스트는 filter의 결과를 담고 다른 하나는 map의 결과를 담는다.
530 |
531 | 이를 더 효율적으로 만들기 위해 시퀀스를 사용해보자.
532 |
533 | ```kotlin
534 | people.asSequence() // 원본 컬렉션을 시퀀스로 변환한다.
535 | .map(Person::name) // 시퀀스도 컬렉션과 똑같은 API를 제공한다.
536 | .filter{ it.startsWith("A) }
537 | .toList() // 결과 시퀀스를 다시 리스트로 변환한다.
538 | ```
539 |
540 | ### 시퀀스를 사용할 때 toList()를 사용하는 이유
541 |
542 | - 원소를 차례로 이터레이션해야 한다면 시퀀스를 직접 써도 된다.
543 | - 하지만 시퀀스 원소를 인덱스를 사용해 접근하는 등의 다른 API 메소드가 필요하다면 시퀀스를 리스트로 변환해야한다.
544 |
545 |
546 |
547 | ## 5.3.1 시퀀스 연산 실행: 중간 연산과 최종 연산
548 |
549 | 시퀀스에 대한 연산은 중간(intermediate) 연산과 최종(terminal) 연산으로 나뉜다. 중간 연산은 다른 시퀀스를 반환한다. 그 시퀀스는 최초 시퀀스의 원소를 변환하는 방법을 안다.
550 |
551 | 중간 연산은 항상 지연 계산된다. 최종 연산이 없는 예제를 살펴보자.
552 |
553 | ```kotlin
554 | >>> listOf(1, 2, 3, 4).asSequence()
555 | ... .map { print("map($it) "); it * it}
556 | ... .filter { print("filter($it) "); it % 2 == 0 }
557 | ```
558 |
559 | 이 코드를 실행하면 아무 내용도 출력되지 않는다. 이는 map과 filter변환이 늦춰져서 결과를 얻을 필요가 있을 때 (즉 최종 연산이 호출될 때 ) 적용된다는 뜻이다.
560 |
561 | ```kotlin
562 | >>> listOf(1, 2, 3, 4).asSequence()
563 | ... .map { print("map($it) "); it * it}
564 | ... .filter { print("filter($it) "); it % 2 == 0 }
565 | ... .toList()
566 | map(1) filter(1) map(2) filter(4) map(3) filter(9) map(4) filter(16)
567 | ```
568 |
569 | kotlin의 시퀀스는 자바 스트림과 동일하게 동작한다.
570 |
571 | map으로 리스트의 각 숫자를 제곱하고 제곱한 숫자 중에서 find로 3보다 큰 첫 번째 원소를 찾아보자.
572 |
573 | ```kotlin
574 | >>> println(listOf(1, 2, 3, 4).asSequence()
575 | .map { it * it }.find { it > 3 })
576 | 4
577 |
578 | map(1) filter(1) map(2) filter(4)
579 | ```
580 |
581 | ## 5.3.2 시퀀스 만들기
582 |
583 | 지금까지는 모두 컬렉션에 대해 assequence()를 호출해 시퀀스를 만들었다. 시퀀스를 만드는 다른 방법으로 generateSequence 함수를 사용할 수 있다.
584 |
585 | ```kotlin
586 | >>> val naturalNumbers = generateSequnce(0) { it + 1 }
587 | >>> val numbersTo100 = naturalNumbers.taskWhile { it <= 100 }
588 | >>> println(numbersTo100.sum()) // 모든 지연 연산은 "sum"의 결과를 계산할 때 수행된다.
589 | 5050
590 | ```
591 |
592 | # 5.4 수신 객체 지정 람다: with와 apply
593 |
594 | 이번 절은 자바의 람다에는 없는 코틀린 람다의 독특한 가능을 설명한다. 그 기능은 수신 객체를 명시하지 않고 람다의 본문 안에서 다른 객체의 메소드를 호출할 수 있게하는 것이다.
595 |
596 | 그런 람다를 수신 객체 지정 람다(lambda with receiver)라고 부른다.
597 |
598 | ## 5.4.1 with 함수
599 |
600 | with의 유용성 알기 위해 먼저 다음 예제를 살펴보고 이를 with를 사용해 리팩토링해보자.
601 |
602 | ```kotlin
603 | fun alphabet (): String {
604 | val result = StringBuilder()
605 | for (letter in 'A'..'Z') {
606 | result.append(letter)
607 | }
608 | result.append("\nNoew I konw the aplhabet!")
609 | return result.toString()
610 | }
611 | >>> println(alphabet())
612 | ABCDEFGHIJKLMNOPQRSTUVWXYZ
613 | Now I know the alphabet!
614 | ```
615 |
616 | 이제 앞에 예제를 with로 다시 작성한 결과를 살펴보자.
617 |
618 | ```kotlin
619 | fun alphabet (): String {
620 | val stringBuilder = StringBuilder()
621 | return with(stringBuilder) { // 메소드를 호출하려는 수신 객체를 지정한다.
622 | for (letter in 'A'..'Z') {
623 | this.append(letter) // "this"를 명시해서 앞에서 지정한 수신 객체의 메소드를 호출한다.
624 | }
625 | append("\nNoew I konw the aplhabet!") // "this"를 생략하고 메소드를 호출한다.
626 | return this.toString() //람다에서 값을 반환한다.
627 | }
628 | }
629 | ```
630 |
631 | with 함수는 첫 번째 인자로 받은 객체를 두 번째 인자로 받은 람다의 수신 객체로 만든다. 인자로 받은 람다 본문에서는 this를 사용해 그 수신 객체에 접근 할 수 있다.
632 |
633 | 앞에 alphabet 함수를 더 리팩터링해서 불필요한 stringBuilder 변수를 없앨 수도 있다.
634 |
635 | ```kotlin
636 | fun alphabet () = with(StringBuilder()) {
637 | for (letter in 'A'..'Z') {
638 | append(letter)
639 | }
640 | append("\nNoew I konw the aplhabet!")
641 | toString()
642 | }
643 | }
644 | ```
645 |
646 | ### 메소드 이름 충돌
647 |
648 | with에게 인자로 넘긴 객체의 클래스와 with를 사용하는 코드가 들어있는 클래스 안에 이름이 같은 메소드가 있다면 무슨 일이 생길까? 그런 경우 this 참조 앞에 레이블을 붙이면 호출하고 싶은 메소드를 명확하게 정할 수 있다.
649 |
650 | 만약 alphabet 함수가 OuterClass의 메소드라고 하면 StringBuilder가 아닌 바깥쪽 클래스 toString을 호출하고 싶다면 다음과 같은 문구를 사용하면 된다.
651 |
652 | ```kotlin
653 | this@OuterClass.toString()
654 | ```
655 |
656 | 때로는 람다의 결과 대신 수신 객체가 필요한 경우도 있다. 그럴 때는 apply 라이브러리 함수를 사용할 수 있다.
657 |
658 | ## 5.4.2 apply 함수
659 |
660 | apply 함수는 with와 유일한 차이점은 apply는 항상 자신에게 전달된 객체를 반환한다는 점이다.
661 |
662 | apply를 써서 alphabet 함수를 다시 리팩터링해보자.
663 |
664 | ```kotlin
665 | fun alphabet() = StringBuilder().apply {
666 | for (letter in 'A'..'Z') {
667 | append(letter)
668 | {
669 | append("\nNow I know the alphabet!")
670 | }.toString
671 | ```
672 |
673 | apply는 확장 함수로 정의돼 있다. 이런 apply 함수는 객체의 인스턴스를 만들면서 즉시 프로퍼티 중 일부를 초기화해야 하는 경우 유용하다. ex) 자바의 Builder
674 |
675 | apply를 객체 초기화에 활용하는 예로 안드로이드 TextView 컴포넌트를 만들면서 특성 중 일부를 설정해보자.
676 |
677 | ```kotlin
678 | fun createViewWithCustomAttributes(context: Context) =
679 | TextView(context).apply {
680 | text = "sample Text"
681 | textSize = 20.0
682 | setPadding(10, 0, 0, 0)
683 | ```
684 |
685 | with와 apply는 수신 객체 지정 람다를 사용하는 일반적인 예제 중 하나다. 더 구체적인 함수를 비슷한 패턴으로 활용할 수 있다. 예를 들어 표준 라이브러리의 buildString 함수를 사용하면 alphabet 함수를 더 단순화 할 수 있다.
686 |
687 | ```kotlin
688 | fun alphabet() = buildString { // buildString은 StringBuilder 객체를 만드는 일과
689 | for (letter in 'A'..'Z') { // toString을 호출해주는 일을 알아서 해준다.
690 | append(letter)
691 | {
692 | append("\nNow I know the alphabet!")
693 | }
694 | ```
695 |
696 | # 5.5 요약
697 |
698 | - 람다를 사용하면 코드 조각을 다른 함수에게 인자로 넘길 수 있다.
699 | - 코틀린에서는 람다가 함수 인자인 경우 괄호 밖으로 람다를 빼낼 수 있고, 람다의 인자가 단 하나뿐인 경우 인자 이름을 지정하지 않고 it이라는 디폴트 이름으로 부를 수 있다.
700 | - 람다 안에 있는 코드는 그 람다가 들어있는 바깥 함수의 변수를 읽거나 쓸 수 있다.
701 | - 메소드, 생성자, 프로퍼티의 이름 앞에 ::을 붙이면 각각에 대한 참조를 만들 수 있다. 그런 참조를 람다 대신 다른 함수에게 넘길 수 있다.
702 | - filter, map, all, any 등의 함수를 활용하면 컬렉션에 대한 대부분의 연산을 직접 원소를 이터레이션하지 않고 수행할 수 있다.
703 | - 시퀀스를 사용하면 중간 결과를 담는 컬렉션을 생성하지 않고도 컬렉션에 대한 여러 연산을 조합할 수 있다.
704 | - 함수형 인터페이스(추상 메소드가 단 하나뿐인 SAM 인터페이스)를 인자로 받는 자바 함수를 호출할 경우 람다를 함수형 인터페이스 인자 대신 넘길 수 있다.
705 | - 수신 객체 지정 람다를 사용하면 람다 안에서 미리 정해둔 수신 객체의 메소드를 직접 호출할 수 있다.
706 | - 표준 라이브러리의 with 함수를 사용하면 어떤 객체에 대한 참조를 반복해서 언급하지 않으면서 그 객체의 메소드를 호출할 수 있다. apply를 사용하면 어떤 객체라도 빌더 스타일의 API를 사용해 생성하고 초기화할 수 있다.
--------------------------------------------------------------------------------
/Chapter6.md:
--------------------------------------------------------------------------------
1 | # 코틀린 타입 시스템
2 |
3 | 코틀린의 타입 시스템은 코드의 가독성을 향상시키는데 도움이 되는 몇 가지 특성을 제공합니다. 이 특성으로는 nullable 타입과 읽기 전용 컬렉션이 있습니다. 이번 장에서는 이런 내용들에 대해 자세히 살펴보겠습니다.
4 |
5 |
6 |
7 | ## Null이 될 수 있는 타입
8 |
9 | 먼저 다음 자바 함수를 살펴보겠습니다.
10 |
11 | ``` java
12 | int strLen(String s) {
13 | return s.length();
14 | }
15 | ```
16 |
17 |
18 |
19 | 이 함수에 `null`을 넘기면 NPE가 발생합니다. 위 함수를 코틀린으로 다시 작성해보겠습니다.
20 |
21 | ``` kotlin
22 | fun strLen(s: String) = s.length
23 | ```
24 |
25 |
26 |
27 | 코틀린에서는 위와 같은 방식으로 파라미터 타입을 지정했을 때 null을 넘길 수 없습니다. 혹시라도 `null`을 넘길 경우 컴파일 에러가 발생합니다.
28 |
29 | ``` kotlin
30 | strLen(null) // ERROR
31 | ```
32 |
33 |
34 |
35 | 이 함수가 null과 문자열을 인자로 받을 수 있게 하려면 타입 이름 뒤에 물음표(?)를 명시해야 합니다.
36 |
37 | ``` kotlin
38 | fun strLenSafe(s: String?) = ...
39 | ```
40 |
41 |
42 |
43 | 이처럼 `String?`, `Int?` 등 어떤 타입이든 이름 뒤에 물음표를 붙이면 그 타입의 변수나 프로퍼티에 `null` 참조를 저장할 수 있다는 의미가 됩니다. `null`이 될 수 있는 타입의 변수가 있다면 그에 대해 수행할 수 있는 연산이 제한됩니다. 예를 들어 `null`이 될 수 있는 타입인 변수에 대해 **변수.메소드()** 처럼 메소드를 직접 호출할 수는 없습니다.
44 |
45 | ``` kotlin
46 | fun strLenSafe(s: String?) = s.length() // ERROR
47 | ```
48 |
49 |
50 |
51 | 그렇기에 우리는 단순하게 `if` 검사를 통해 `null` 값을 다룰 수 있습니다.
52 |
53 | ``` kotlin
54 | fun strLenSafe(s: String?): Int {
55 | return if (s != null) s.length else 0
56 | }
57 | ```
58 |
59 |
60 |
61 | 하지만 nullable을 다루기 위해 사용할 수 있는 도구가 `if` 검사뿐이라면 코드가 매우 번잡해질 것입니다. 그렇기에 코틀린은 nullable을 다루기 위해 사용할 수 있는 여러 도구를 제공합니다.
62 |
63 |
64 |
65 | ## 안전한 호출 연산자 : ?.
66 |
67 | 코틀린이 제공하는 가장 유용한 도구 중 하나는 안전한 호출 연산자인 `?.` 입니다. `?.`은 `null` 검사와 메소드 호출을 한 번의 연산으로 수행합니다. 예를 들어 `s?.toUpperCase()`는 훨씬 복잡한 `if (s != null) s.toUpperCase() else null`가 같습니다. 하지만 안전한 호출의 결과 타입도 nullable 타입이라는 사실에 유의하여야 합니다.
68 |
69 | ``` kotlin
70 | fun printAllCaps(s: String): String? {
71 | return s?.toUpperCase() // nullable
72 | }
73 | ```
74 |
75 |
76 |
77 | ## 엘비스 연산자 : ?:
78 |
79 | 코틀린은 `null` 대신 사용할 디폴트 값을 지정할 때 편리하게 사용할 수 있는 연산자를 제공합니다. 그 연산자를 엘비스 연산자라고 합니다. 다음은 엘비스 연산자를 사용하는 예시입니다.
80 |
81 | ``` kotlin
82 | fun foo(s: String?): String {
83 | return s ?: "" // null일 경우 "" 리턴
84 | }
85 | ```
86 |
87 |
88 |
89 | 물론 `throw` 키워드에도 함께 사용할 수 있습니다.
90 |
91 | ``` kotlin
92 | fun foo(s: String?): String {
93 | return s ?: throw NullPointerException() // null일 경우 NPE!
94 | }
95 | ```
96 |
97 |
98 |
99 | ## 안전한 캐스트 : as?
100 |
101 | 2장에서 우리는 코틀린 타입 캐스트 연산자인 `as`에 대해 살펴봤습니다. 자바 타입 캐스트와 마찬가지로 대상 값을 형변환 할 수 없으면 `ClassCastException`이 발생합니다. 물론 `as` 를 사용할 때마다 `is` 를 통해 일일이 검사해볼수도 있습니다. 하지만 안전하면서 간결한 언어를 지향하는 코틀린은 더 나은 해법을 제공합니다.
102 |
103 | ``` kotlin
104 | fun foo(o: Any?): String {
105 | return (o as? String) ?: "" // String으로 형변환을 시도했는데 실패하여 null이 떨어질 경우 "" 리턴
106 | }
107 | ```
108 |
109 |
110 |
111 | ### Quiz
112 |
113 | 다음 요구사항을 만족하는 메소드를 작성해봅시다.
114 |
115 | - `Any?` 타입을 파라미터로 받아서 문자열 타입으로 형변환 후 길이를 리턴하는 함수. 형변환에 실패할 경우엔 0을 리턴합니다.
116 |
117 |
118 |
119 | ## Null 아님을 단언 : !!
120 |
121 | 느낌표를 이중으로 사용하면 어떤 값이든 널이 될 수 없는 타입으로 강제로 바꿀 수 있습니다. 하지만 실제로 `null`인 값에 대해 `!!`를 적용하면 NPE가 발생합니다.
122 |
123 |
124 |
125 | ```kotlin
126 | fun foo(s: String?): Int {
127 | val sNotNull: String = s!!
128 | return sNotNull.length
129 | }
130 | ```
131 |
132 | `null`이 아니라고 단언했으므로 `null`일 경우 처리를 따로 해주지 않아서 작성할 때는 편할 수 있지만 `null`이 인자로 들어올 경우 에러를 초래하므로 실제로는 엘비스 연산자 등을 사용하여 핸들링을 해주는 것이 좋습니다.
133 |
134 |
135 |
136 | ## 나중에 초기화할 프로퍼티
137 |
138 | 코틀린에서 클래스 안의 `null`이 될 수 없는 프로퍼티를 생성자 안에서 초기화하지 않고 특별한 메소드 안에서 초기화할 수 는 없습니다. 일반적으로 생성자에서 모든 프로퍼티를 초기화해야하고 프로퍼티 타입이 `null`이 될 수 없는 타입이라면 반드시 `null`이 아닌 값으로 그 프로퍼티를 초기화해야 합니다.
139 |
140 | 이를 해결하기 위해 `lateinit` 변경자를 사용할 수 있습니다. (혹은 `Lazy`)
141 |
142 | ``` kotlin
143 | class MyService {
144 | fun performAction(): String = "foo"
145 | }
146 |
147 | class MyTest {
148 |
149 | private lateinit var myService: MyService
150 |
151 | @Before fun setUp() {
152 | myService = MyService()
153 | }
154 |
155 | @Test fun testAction() {
156 | Assert.assertEquals("foo", myService.performAction())
157 | }
158 |
159 | }
160 | ```
161 |
162 |
163 |
164 | 위 변경자를 사용하여 초기화하는 프로퍼티는 항상 `var` 이어야 합니다. `val` 프로퍼티는 `final` 필드로 컴파일되며, 생성자 안에서 반드시 초기화해야 합니다. 하지만 위 변경자를 사용하여 초기화하는 프로퍼티는 초기화되기 전에 프로퍼티에 접근하면 `"lateinit property ~ has not been initialized"`라는 예외가 발생합니다. 이런 예외를 방어하기 위해 다음과 같은 방법을 사용할 수 있습니다. (필요하다면)
165 |
166 | ``` kotlin
167 | class Foo {
168 |
169 | private lateinit var str: String
170 |
171 | fun action() {
172 | if (this::str.isInitialized) {
173 | println(str)
174 | }
175 | }
176 |
177 | }
178 | ```
179 |
180 |
181 |
182 | ## Null이 될 수 있는 타입 확장
183 |
184 | `null`이 될 수 있는 타입에 대한 확장 함수를 정의하면 `nullable` 타입에 대한 도구로 활용할 수 있습니다. 어떤 메소드를 호출하기 전에 수신 객체 역할을 하는 변수가 `null`이 될 수 없다고 보장하는 대신, 직접 변수에 대해 메소드를 호출해도 확장 함수인 메소드가 알아서 `null`을 처리해줍니다.
185 |
186 | 코틀린의 `isNullOrBlank()` 함수를 살펴봅시다.
187 |
188 | ```kotlin
189 | fun verifyUserInput(input: String?) {
190 | if (input.isNullOrBlank()) { // ?. 호출을 하지 않아도 됨.
191 | println("success")
192 | }
193 | }
194 | ```
195 |
196 |
197 |
198 | `isNullOrBlank` 함수는 `null`을 명시적으로 검사하여 `null`인 경우 `true`를 리턴하고 반대의 경우 `false`를 리턴합니다.
199 |
200 | ```kotlin
201 | fun String?.isNullOrBlank(): Boolean = this == null || this.isBlank() // 뒤의 this는 스마트 캐스트가 적용됨.
202 | ```
203 |
204 |
205 |
206 | ## 타입 파라미터의 Null 가능성
207 |
208 | `null` 가능성은 제네릭 타입에서도 유효합니다. 타입 파라미터 T를 클래스나 함수 안에서 타입 이름으로 사용하면 이름 끝에 물음표가 없더라도 T는 nullable한 타입입니다.
209 |
210 | ```kotlin
211 | fun printHashCode(t: T) {
212 | println(t?.hashCode()) // t가 null이 될 수 있으므로 ?.로 호출해야한다.
213 | }
214 | ```
215 |
216 |
217 |
218 | 타입 파라미터가 `null`이 아님을 확실하게 하려면 타입 상한을 지정해야 합니다. 아래 예시를 보겠습니다.
219 |
220 | ```kotlin
221 | fun printHashCode(t: T) {
222 | println(t.hashCode())
223 | }
224 | ```
225 |
226 |
227 |
228 | 타입 파라미터는 nullable한 타입을 표시하려면 반드시 물음표를 타입 이름 뒤에 붙여야 한다는 규칙의 예외입니다. 이는 9장(제네릭)에서 더 자세히 살펴보겠습니다.
229 |
230 |
231 |
232 | ## 코틀린의 원시 타입
233 |
234 | 코틀린은 자바와 달리 원시 타입과 래퍼 타입을 구분하지 않습니다. 코틀린은 내부에서 원시 타입을 래핑하여 사용하는데, 어떻게 작동하는지, `Object`, `Void` 등의 자바 타입을 어떻게 대응하는지에 대해서 살펴보겠습니다.
235 |
236 |
237 |
238 | ### 원시 타입
239 |
240 | 코틀린은 원시 타입과 래퍼 타입을 구분하지 않으므로 항상 같은 타입을 사용합니다.
241 |
242 | ``` kotlin
243 | val i : Int = 1
244 | val list: List = listOf(1, 2, 3)
245 | ```
246 |
247 | 원시 타입과 참조(래퍼) 타입이 같다면 코틀린은 이것들을 항상 객체로 표현하는 건가라는 의문이 들 수 있습니다. 항상 객체로 표현한다면 이는 상당히 비효율적이겠지만 코틀린은 그렇지 않습니다.
248 |
249 | 대부분의 경우 (변수, 파라미터, 리턴 타입 등등) 코틀린의 `Int` 타입은 자바 `int` 타입으로 컴파일 됩니다. 하지만 컬렉션 같은 제네릭 클래스를 사용하는 경우엔 `Int` 의 래퍼 타입에 해당하는 `java.lang.Integer` 객체가 들어가게 됩니다.
250 |
251 | 코틀린의 원시 타입에는 널 참조가 들어갈 수 없기 때문에 그에 상응하는 자바 원시 타입으로 컴파일 할 수 있습니다. 마찬가지로 반대로 자바 원시 타입도 코틀린에서 사용할 경우 널이 될 수 없는 타입으로 취급할 수 있습니다.
252 |
253 |
254 |
255 | ### 널이 될 수 있는 원시 타입 : Int?, Boolean? 등
256 |
257 | `null` 참조를 자바의 참조 타입 변수에만 대입할 수 있기 때문에 널이 될 수 있는 코틀린 타입은 자바 원시 타입으로 표현할 수 없습니다. 따라서 nullable한 원시 타입을 코틀린에서 사용하면 그 타입은 자바의 래퍼 타입으로 컴파일 됩니다.
258 |
259 | 먼저 nullable한 타입을 사용하는 예시를 살펴보겠습니다.
260 |
261 | ```kotlin
262 | data class Person(
263 | val name: String,
264 | val age: Int? = null
265 | ) {
266 |
267 | fun isOlderThan(other: Person) : Boolean? {
268 | if (age == null || other.age == null) {
269 | return null
270 | }
271 | return age > other.age
272 | }
273 |
274 | }
275 |
276 | println(Person("Sam, 35").isOlderThan("Amy, 32")) // false
277 | println(Person("Sam, 35").isOlderThan(Person("Jane"))) // null
278 |
279 | ```
280 |
281 |
282 |
283 | 여기서 나이를 비교하는 함수를 살펴보면 `age` 는 nullable한 타입이기 때문에 먼저 두 값이 널이 아닌지 검사해야만 합니다. 컴파일러는 널 검사를 마친 다음에야 두 값을 일반적인 값처럼 다루게 허용합니다.
284 |
285 | `Person` 클래스에 선언된 `age` 프로퍼티의 값은 `java.lang.Integer` 로 저장됩니다. 하지만 이런 자세한 사항들은 자바에서 가져온 클래스를 다룰 때만 문제가 됩니다.
286 |
287 | 앞에서 이야기한 대로 제네릭 클래스의 경우 래퍼 타입을 사용하는데, 어떤 클래스의 타입 인자로 원시 타입을 넘기면 코틀린은 그 타입에 대한 박스 타입을 허용하게 됩니다. 예를 들어 아래 코드에서는 `null` 값이나 널이 될 수 있는 타입을 전혀 사용하지 않았지만 만들어지는 리스트는 래퍼인 `Integer` 타입으로 이루어진 리스트입니다.
288 |
289 | ```kotlin
290 | val listOfInts = listOf(1, 2, 3)
291 | ```
292 |
293 |
294 |
295 | 이렇게 컴파일하는 이유는 JVM에서 제네릭을 구현하는 방법 때문입니다. JVM은 타입 인자로 원시 타입을 허용하지 않기에, 자바나 코틀린 모두 제네릭 클래스는 항상 박스 타입을 사용해야 합니다.
296 |
297 |
298 |
299 | ### Any, Any? : 최상위 타입
300 |
301 | 자바에서 `Object` 가 최상위 타입이듯 코틀린에서는 `Any` 타입이 모든 널이 될 수 없는 타입의 조상 타입입니다. 자바와는 다르게 코틀린에서는 `Any`가 `Int` 등의 원시 타입을 포함한 모든 타입의 조상 타입이 됩니다.
302 |
303 | 자바와 마찬가지로 코틀린에서도 원시 타입 값은 `Any` 타입의 변수에 대입하면 자동으로 값을 객체로 감싸게 됩니다.
304 |
305 | ```kotlin
306 | val answer: Any = 42
307 | ```
308 |
309 |
310 |
311 | `Any` 는 널이 될 수 없는 타입이며, 위 변수에는 `null` 이 들어갈 수 가 없습니다. 널을 포함하는 모든 값을 대입할 변수를 선언하려면 `Any?` 타입을 사용해야 합니다. 내부에서 `Any` 타입은 `java.lang.Object` 에 대응하며, 자바 메소드에서 `Object` 를 인자로 받거나 반환하면 코틀린에서는 `Any`로 그 타입을 취급합니다.
312 |
313 |
314 |
315 | ### Unit 타입 : 코틀린의 Void
316 |
317 | 코틀린 `Unit` 타입은 자바 `void` 와 같은 기능을 가지고 있습니다. 아무것도 반환하지 않는 함수의 리턴 타입으로 `Unit` 을 사용할 수 있습니다.
318 |
319 | ```kotlin
320 | fun foo(): Unit { }
321 | ```
322 |
323 |
324 |
325 | 이는 리턴 타입 없이 정의한 블록이 본문인 함수와 같습니다.
326 |
327 | ```kotlin
328 | fun foo() { }
329 | ```
330 |
331 |
332 |
333 | 대부분의 경우 `void`와 `Unit` 의 차이를 알기는 어렵습니다. 코틀린의 `Unit` 과 자바의 `void`와의 차이점은 무엇일까요? `Unit`은 모든 기능을 가지는 일반적인 타입이며, `void`와 달리 `Unit`을 타입 인자로 사용할 수 있습니다.
334 |
335 | ```kotlin
336 | interface Processor {
337 | fun process(): T
338 | }
339 |
340 | class NoResultProcessor: Processor {
341 | override fun process(): {
342 | // process logic
343 | }
344 | }
345 | ```
346 |
347 |
348 |
349 |
350 |
351 |
352 |
353 |
354 |
355 |
356 |
357 | 인터페이스의 시그니처는 `process`가 어떤 값을 리턴하라고 요구합니다. `Unit` 타입도 `Unit` 값을 제공하기 때문에 메소드에서 `Unit` 값을 리턴하는 데는 아무 문제가 없습니다. 하지만 `NoResultProcessor` 에서 명시적으로 `Unit` 을 리턴할 필요 없이 컴파일러가 묵시적으로 `return Unit`을 넣어줍니다.
358 |
359 |
360 |
361 | ### Nothing 타입 : 이 함수는 결코 정상적으로 끝나지 않는다.
362 |
363 | 코틀린에는 결코 성공적으로 값을 돌려주는 일이 없어서 리턴 값이라는 개념 자체가 의미 없는 함수가 일부 존재합니다. 예를 들어 테스트 라이브러리들은 `fail` 이라는 함수를 제공하는 경우가 많은데, `fail`은 특별한 메시지가 들어있는 예외를 던져서 현재 테스트를 실패시킵니다. 다른 예시로 무한 루프를 도는 함수도 결코 값을 리턴하며 정상적으로 끝나지 않습니다. 이런 경우를 표현하기 위해 코틀린에는 `Nothing` 이라는 특별한 리턴 타입이 존재합니다.
364 |
365 | ```kotlin
366 | fun fail(message: String): Nothing {
367 | throw IllegalStateException(message)
368 | }
369 |
370 | fun fail("Error occurred")
371 | // java.lang.IllegalStateException: Error occurred
372 | ```
373 |
374 |
375 |
376 | `Nothing` 타입은 아무 값도 포함하지 않으며 함수의 리턴타입이나 리턴 타입으로 쓰일 타입 파라미터로만 사용할 수 있습니다. 그 외의 다른 용도로 사용하는 경우 `Nothing` 타입의 변수를 선언하더라도 그 변수에 아무 값도 저장할 수 없으므로 아무 의미도 없습니다.
377 |
378 | `Nothing` 을 리턴하는 함수를 엘비스 연산자의 우항에 사용해서 전제 조건을 검사할 수 있습니다.
379 |
380 | ```kotlin
381 | val address = company.address ?: fail("No address")
382 | println(address.city)
383 | ```
384 |
385 |
386 |
387 | ## 컬렉션과 배열
388 |
389 | 우리는 코틀린 컬렉션이 자바 라이브러리를 바탕으로 만들어졌고 확장 함수를 통해 기능을 추가할 수 있다는 사실을 배웠습니다. 이제 코틀린의 컬렉션 지원과 자바와 코틀린 컬렉션 간에 관계에 대해 살펴보겠습니다.
390 |
391 |
392 |
393 | ### 널 가능성과 컬렉션
394 |
395 | 변수 타입뒤에 ?를 붙이며 그 변수에 널을 저장할 수 있다는 뜻인 것처럼 타입 인자로 쓰인 타입에도 같은 표시를 사용할 수 있습니다. 아래 예시를 보겠습니다.
396 |
397 | ```kotlin
398 | val list1: ArrayList = ArrayList() // 리스트 원소의 타입은 Int 타입이다.
399 | val list2: ArrayList? = ArrayList() // 리스트 원소의 타입은 Int 타입이고 리스트 자체가 null일 수도 있다.
400 | val list3: ArrayList? = ArrayList() // 리스트 원소의 타입은 Int? 타입이고 리스트 자체도 null일 수도 있다.
401 | ```
402 |
403 |
404 |
405 | 널이 될 수 있는 값으로 이뤄진 컬렉션으로 널 값을 걸러내는 경우가 자주 있어서 코틀린 표준 API에선 `filterNotNull` 이라는 함수를 제공합니다.
406 |
407 | ``` kotlin
408 | val nullableList: List = listOf(1, 2, null)
409 | val notNullableList: List = nullableList.filterNotNull()
410 | ```
411 |
412 |
413 |
414 | ### 읽기 전용과 변경 가능한 컬렉션
415 |
416 | 코틀린 컬렉션과 자바 컬렉션을 나누는 가장 중요한 특성 중 하나는 코틀린에선 컬렉션 안의 데이터에 접근하는 인터페이스와 컬렉션 안의 데이터를 변경하는 인터페이스를 분리했다는 점입니다. 코틀린의 컬렉션을 다룰 때 사용하는 가장 기초적인 인터페이스인 `kotlin.collections.Collection` 에는 원소에 대한 이터레이션, 컬렉션의 크기, 어떤 값이 들어있는지 검사, 데이터를 읽는 등의 연산을 수행하는 메소드들이 존재합니다. 하지만 추가하거나 제거하는 메소드는 존재하지 않습니다.
417 |
418 | 컬렉션의 데이터를 수정하려면 `kotlin.collection.MutableCollection` 인터페이스를 사용해야 합니다. 해당 인터페이스는 `kotlin.collection.Collection` 을 확장하며 원소를 추가하거나, 삭제하거나, 모두 지우는 등의 메소드를 더 제공합니다.
419 |
420 | `val`과 `var` 의 구별과 마찬가지로 컬렉션의 읽기 전용 인터페이스와 변경 가능 인터페이스를 구별한 이유는 프로그램에서 데이터에 어떤 일이 벌어지는지를 더 쉽게 이해하기 위함입니다. 어떤 메소드의 인자로 `MutableCollection` 이 타입으로 주어진다면 해당 메소드 내부에서 해당 인자의 원소를 변경할 수도 있습니다. 그러므로 `MutableCollection`을 사용할 경우 원소가 어디서든 변경될 수 있다는 점에 유의해야 합니다.
421 |
422 | 물론 읽기 전용 컬렉션을 사용한다고 무조건 안전하진 않습니다. 아래와 같은 코드 처럼 같은 객체를 읽기 전용 / 변경 가능 컬렉션에서 참조하고, 읽기 전용 컬렉션에서 해당 객체를 사용할 때 병렬적으로 변경 가능 컬렉션에서 객체에 대한 수정이 이루어진다면 `ConcurrentModificationException` 이나 다른 예외가 발생할 수 있습니다.
423 |
424 | ```kotlin
425 | val source = listOf(1, 2, 3)
426 | val target1: List = source
427 | val target2: MutableList = source
428 | ```
429 |
430 |
431 |
432 | ### 배열
433 |
434 | 코틀린에서는 Array 타입으로 배열을 정의합니다.
435 |
436 | ```kotlin
437 | fun main(args: Array) { ... }
438 | ```
439 |
440 |
441 |
442 | 배열의 생성 방법은 아래 코드와 같습니다.
443 |
444 | ```kotlin
445 | val num: Array = arrayOf﴾1, 2, 3, 4﴿
446 | val nulls = arrayOfNulls﴾10﴿ // Array
447 | val nulls2 = Array﴾20﴿ { i ‐> ﴾i + 1﴿.toString﴾﴿ }
448 | ```
449 |
450 | 그렇다면 원시 타입 배열은 어떻게 정의할까요? 아래 절에서 확인해보겠습니다.
451 |
452 |
453 |
454 | ### 원시 타입 배열
455 |
456 | 코틀린에선 원시 타입은 `IntArray` , `CharArray`, 등 원시 타입 전용 배열을 사용하여 배열로 나타낼 수 있으며, 자바 원시 타입 배열로 컴파일 되어 성능에서 이점을 취합니다. 배열 생성 방법은 다양하며 다음과 같은 방법들이 존재합니다.
457 |
458 | ```kotlin
459 | IntArray(5) // ?
460 | intArrayOf(1, 2, 3, 4) // ?
461 | IntArray(5) { i -> i * i } // ?
462 | ```
463 |
464 | 또 `Array`와 같은 타입은 `toIntArray` 등의 함수를 사용하여 `IntArray`로 변환이 가능합니다.
465 |
466 |
467 |
468 |
469 |
470 |
471 |
472 |
473 |
474 |
475 |
476 |
--------------------------------------------------------------------------------
/Chapter7-1.md:
--------------------------------------------------------------------------------
1 | # 07. 연산자 오버로딩과 기타 관계
2 |
3 | 자바에는 표준 라이브러리와 연관된 언어 기능이 몇 가지 있다.
4 |
5 | 예로 for ... in 루프에 Iterable을 구현한 객체를 사용하거나,
6 |
7 | try-with-resource 문에 Autoclosable을 구현한 객체를 사용할 수 있다.
8 |
9 | 코틀린에서는 이런 언어 기능이 어떤 타입과 연괸되기 보다는 함수와 연결된다.
10 |
11 | 예를 들어 어떤 클래스 안에 `plus`라는 이름의 메서드를 정의하면 그 클래스의 인스턴스에 대해 `+` 연산자를 사용할 수 있다.
12 |
13 | 이런 식으로 어떤 언어 기능과 미리 정해진 이름의 함수를 연결해주는 기법을 코틀린에서 관례(convention)라고 부른다.
14 |
15 | 이러한 관례들에 대해 알아보도록 하자.
16 |
17 | # 1. 산술 연산자 오버로딩
18 |
19 | 자바에서는 원시 타입과 String에 대해서만 산술 연산자를 사용할 수 있었다.
20 |
21 | 하지만 산술 연산자가 유용한 경우가 많다.
22 |
23 | 예를 들어 BigInteger 클래스를 `add`로 더하는 것보단 `+` 연산을 사용하는 것이 나을 것이다.
24 |
25 | 이런 산술 연산자를 어떻게 정의할 수 있는지 보자.
26 |
27 |
28 | ## 1.1 이항 산술 연산 오버로딩
29 |
30 | ```kotlin
31 | data class Point(val x: Int, val y: Int) {
32 | **operator** fun plus(other: Point): Point {
33 | return Point(x + other.x, y + other.y)
34 | }
35 | }
36 |
37 | >>> val p1 = Point(10, 20)
38 | >>> val p2 = Point(30, 40)
39 | >>> println(p1 + p2)
40 | Point(x=40, y=60)
41 | ```
42 |
43 | 연산자를 오버로딩하는 함수 앞에는 꼭 `operator` 키워드를 붙여야 한다.
44 |
45 | 이를 통해 어떤 함수가 관례를 따르는 함수임을 명확히 할 수 있다.
46 |
47 | 내부적으론 다음과 같이 호출된다.
48 |
49 | 
50 |
51 | 연산자를 확장 함수로 정의할 수도 있다.
52 |
53 | ```kotlin
54 | operator fun Point.plus(other: Point): Point {
55 | return Point(x + other.x, y + other.y)
56 | }
57 | ```
58 |
59 | 다음은 코틀린에서 정의할 수 있는 이항 연산자와 연산자의 함수 이름이다.
60 |
61 | 
62 |
63 | 연산자를 직접 정의한 함수를 통해 구현하더라도 연산자 우선순위는 언제나 숫자 타입에 대한 연산자 우선순위와 같다.
64 |
65 | 예를 들어 a + b * c라는 식에선 언제나 곱셈이 덧셈보다 먼저 수행된다.
66 |
67 | 연산자를 정의할 때 두 피연산자가 같은 타입일 필요는 없다.
68 |
69 | ```kotlin
70 | operator fun Point.times(**scale: Double**): Point {
71 | return Point((x * scale).toInt(), (y * scale).toInt())
72 | }
73 |
74 | >>> val p = Point(10, 20)
75 | >>> println(p * 1.5)
76 | Point(x=15, y=30)
77 | ```
78 |
79 | 두 피연산자의 타입이 다를 때, 코틀린 연산자가 자동으로 교환 법칙을 지원하지 않는다는 것을 명심해야 한다.
80 |
81 | 예를 들어 p * 1.5가 아닌 1.5 * p라고도 쓸 수 있어야 한다면
82 |
83 | ```kotlin
84 | operator fun Double.times(p: Point): Point
85 | ```
86 |
87 | 와 같은 연산자 함수를 정의해주어야 한다.
88 |
89 | 또한 연산자 함수의 반환 타입이 꼭 두 피연산자 중 하나와 일치해야만 하는 것도 아니다.
90 |
91 | ```kotlin
92 | operator fun Char.times(count: Int): String {
93 | return toString().repeat(count)
94 | }
95 |
96 | >>> print('a' * 3)
97 | aaa
98 | ```
99 |
100 | ## 1.2 복합 대입 연산자 오버로딩
101 |
102 | `plus`와 같은 연산자를 오버로딩하면 코틀린은 `+` 연산자뿐 아니라 그와 관련 있는 연산자인 `+=`도 자동으로 함께 지원한다.
103 |
104 | `+=`, `-=` 등의 연산자는 복합 대입(compound assignment) 연산자라 불린다.
105 |
106 | ```kotlin
107 | >>> var point = Point(1, 2)
108 | >>> point += Point(3, 4)
109 | >>> println(point)
110 | Point(x=4, y=6)
111 | ```
112 |
113 | `point += Point(3, 4)`는 `point = point + Point(3, 4)`라고 쓴 식과 같다.
114 |
115 | 물론 변수가 변경 가능한 경우에만 복합 대입 연산자를 사용할 수 있다.
116 |
117 | 경우에 따라 `+=` 연산이 객체에 대한 참조를 다른 참조로 바꾸기 보다 원래 객체의 내부 상태를 변경해야 하는 경우도 있다.
118 |
119 | 이런 경우 반환 타입이 `Unit`인 `plusAssign` 함수를 정의하면 코틀린은 `+=` 연산자에 그 함수를 사용한다.
120 |
121 | 다른 복압 대입 연산자 함수도 비슷하게 `minusAssign`, `timesAssign` 등의 이름을 사용한다.
122 |
123 | 코틀린 표준 라이브러리는 변경 가능한 컬렉션에 대해 이 함수들을 정의하고 있다.
124 |
125 | ```kotlin
126 | operator fun MutableCollection.plusAssign(element: T) {
127 | this.add(element)
128 | }
129 | ```
130 |
131 | 하지만 어떤 클래스가 `plus`와 `plusAssign` 함수 모드를 정의하고 `+=`를 사용하는 경우 컴파일러는 오류를 발생시킨다.
132 |
133 | 물론 복합 대입 연산자 대신 일반 연산자를 사용하면 되지만, 클래스 설계의 일관성이 떨어진다.
134 |
135 | 예를 들어, Point처럼 변경이 불가능하다면 새로운 값을 반환하는 연산만을 추가해야 한다.
136 |
137 | 따라서 둘 중 하나의 방법으로만 설계를 하는 것이 좋다.
138 |
139 | 지금까지 이항(binary) 연산자에 대해 설명했으니, `-a`와 같은 단항(unary) 연산자를 알아보자.
140 |
141 | ## 1.3 단항 연산자 오버로딩
142 |
143 | 단항 연산자를 오버로딩하는 절차도 이항 연산자와 같다.
144 |
145 | ```kotlin
146 | operator fun Point.unaryMinus(): Point {
147 | return Point(-x, -y)
148 | }
149 |
150 | >>> val p = Point(10, 20)
151 | >>> println(-p)
152 | Point(-10, -20)
153 | ```
154 |
155 | 
156 |
157 | 코틀린에서 오버로딩할 수 있는 모든 단항 연산자를 보자.
158 |
159 | 
161 |
162 | inc나 dec 함수를 정의해 증감 연산자를 오버로딩하는 경우 컴파일러는 일반적인 전위와 후위 증감 연산자와 같은 의미를 제공한다.
163 |
164 | ```kotlin
165 | operator fun BigDecimal.inc() = this + BigDecimal.ONE
166 |
167 | >>> var bd = BigDecimal.ZERO
168 |
169 | >>> println(bd++)
170 | 0
171 | >>> println(++bd)
172 | 2
173 | ```
174 |
175 | 후위 증가 연산자는 println이 실행된 다음에 값을 증가시킨다.
176 |
177 | 전위 증가 연산자는 println이 실행되기 전에 값을 증가시킨다.
178 |
179 | 이처럼 별다른 처리를 해주지 않아도 제대로 증감 연산자가 작동한다.
180 |
181 | # 2. 비교 연산자 오버로딩
182 |
183 | `equals`나 `compareTo`를 호출해야 하는 자바와 달리 코틀린에서는 `==` 비교 연산자를 직접 사용할 수 있어서 코드가 더 간결하며 이해하기 쉽다.
184 |
185 | ## 2.1 동등성 연산자: equals
186 |
187 | 코틀린은 `==` 연산잘 호출을 `equals` 메서드 호출로 컴파일한다는 것을 이미 배웠다.
188 |
189 | 이것도 사실은 이전에 살펴봤던 경우와 동일하다.
190 |
191 | `==`와 `≠`는 내부에서 인자가 null인지 검사하므로 다른 연산과 달리 null이 될 수 있는 값에도 사용할 수 있다.
192 |
193 | 
194 |
195 | `a == b`라는 비교를 처리할 때 `a`가 null인지 판단해서 null이 아닌 경우에만 `equals`를 호출한다.
196 |
197 | `a`가 null이라면 `b`도 null인 경우에만 결과가 `true`이다.
198 |
199 | `equals`는 다른 연산자 오버로딩 관례와 달리 `Any`에 정의된 메서드이므로 `operator` 대신 `override`가 필요하다.
200 |
201 | `Any`의 `equals`에 `operator`가 붙어있다.
202 |
203 | 이처럼 상위 클래스의 메서드에 `operator`가 붙어있다면 하위 클래스의 메서드에서 붙이지 않아도 적용된다.
204 |
205 | ## 2.2 순서비교 연산자: compareTo
206 |
207 | 자바에서 정렬이나 최댓값, 최솟값 등 값을 비교해야 하는 알고리즘에 사용할 클래스는 Comparable 인터페이스를 구현해야 한다.
208 |
209 | Comparable 인터페이스에 들어있는 `compareTo` 메서드는 한 객체와 다른 객체의 크기를 비교해 정수로 나타내준다.
210 |
211 | 자바에서는 이 메서드를 짧게 호출할 수 있는 방법이 없지만 코틀린은 Comparable 인터페이스 안에 있는 `compareTo` 메서드를 호출하는 관례를 제공한다.
212 |
213 | 
214 |
215 | 두 객체를 비교하는 식은 compareTo의 결과를 0과 비교하는 코드로 컴파일된다.
216 |
217 | 따라서 위처럼 비교 연산자(`<`, `>`, `≤`, `≥`)는 `compareTo` 호출로 컴파일 된다.
218 |
219 | 예시를 통해 알아보자.
220 |
221 | ```kotlin
222 | class Person {
223 | val firstName: Strimg, val lastName: String
224 | ) : Comparable {
225 | override fun compareTo(other: Person): Int {
226 | // 인자로 받은 함수를 차례로 호출하면서 값을 비교한다. (코틀린 표준 라이브러리임)
227 | return compareValueBy(this, other, Person::lastName, Person::firstName)
228 | }
229 | }
230 |
231 | >>> val p1 = Person("Alice", "Smith")
232 | >>> val p2 = Person("Bob", "Johnson")
233 | >>> println(p1 < p2)
234 | false
235 | ```
236 |
237 | 이렇게 하면 코드는 간결해지지만 필드를 직접 비교하는 것이 훨씬 더 빠르다는 것을 명심하자.
238 |
239 | 언제나 처음에는 이해하기 쉽고 간결한 코드를 작성하고, 나중에 그 코드가 자주 호출됨에 따라 성능이 문제가 된다면 개선하자.
240 |
241 | # 3. 컬렉션과 범위에 대해 쓸 수 있는 관례
242 |
243 | 컬렉션을 다룰 때 가장 많이 쓰는 인덱스 연산과 속해있는지 검사하는 연산을 연산자 구문으로 사용할 수 있다.
244 |
245 | 이런 연산을 지원하기 위해 어떤 관례를 사용하는지 알아보자.
246 |
247 | ## 3.1 인덱스로 원소에 접근: get과 set
248 |
249 | 코틀린에서 맵의 원소에 접근할 때나 자바에서 배열 원소에 접근할 때 일반적으로 `[]`를 사용한다.
250 |
251 | ```kotlin
252 | val value = map[key]
253 | mutableMap[key] = newValue
254 | ```
255 |
256 | 코틀린에서는 인덱스 연산자도 관례를 따른다.
257 |
258 | 인덱스 연산자를 사용해 원소를 읽을 때는 `get` 연산자 메서드로 변환되고, 쓰는 연산은 `set` 연산자 메서드로로 변환된다.
259 |
260 | Map과 MutableMap 인터페이스에는 그 두 메서드가 이미 들어있다.
261 |
262 | 예제를 통해 알아보자.
263 |
264 | ```kotlin
265 | operator fun Point.get(index: Int): Int {
266 | return when(index) {
267 | 0 -> x
268 | 1 -> y
269 | else -> throw IndexOutOfBoundsException("Invalid coordinate $index")
270 | }
271 | }
272 |
273 | val p = Point(10, 20)
274 | >>> println(p[1])
275 | 20
276 | ```
277 |
278 | `get`이라는 메서드를 만들고 `operator` 변경자를 붙이기만 하면 된다.
279 |
280 | 그러면 다음처럼 변환된다.
281 |
282 | 
283 |
284 | `get` 메서드의 파라미터로 Int가 아닌 타입도 사용할 수 있다.
285 |
286 | 예를 들어 맵 인덱스 연산의 경우 파라미터 타입이 맵의 키 타입과 같은 임의의 타입이 될 수 있다.
287 |
288 | 또한 여러 파라미터를 사용하는 get을 정의할 수도 있는데, `operator fun get(rowIndex: Int, colIndex: Int)`를 `matrix[row, col]`로 호출할 수 있다.
289 |
290 | 컬렉션 클래스가 다양한 키 타입을 지원해야 한다면 오버로딩한 `get` 메서드를 여럿 정의할 수도 있다.
291 |
292 | 이제 `set`을 알아보자. (Point는 불변 클래스이므로 set이 의미가 없다.)
293 |
294 | ```kotlin
295 | data class MutablePoint(var x: Int, var y: Int)
296 |
297 | operator fun MutablePoint.set(index: Int, value: Int) {
298 | when(index) {
299 | 0 -> x = value
300 | 1 -> y = value
301 | else -> throw IndexOutOfBoundsException("Invalid coordinate $index")
302 | }
303 | }
304 |
305 | >>> val p = MutablePoint(10, 20)
306 | >>> p[1] = 42
307 | >>> println(p)
308 | MutablePoint(x=10, y=42)
309 | ```
310 |
311 | ![각괄호([])를 사용한 대입문은 set 함수 호출로 컴파일된다.](https://s3.us-west-2.amazonaws.com/secure.notion-static.com/e6f42450-fe88-4c9a-b927-31b536b2b1b9/Untitled.png?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=AKIAT73L2G45EIPT3X45%2F20211213%2Fus-west-2%2Fs3%2Faws4_request&X-Amz-Date=20211213T045112Z&X-Amz-Expires=86400&X-Amz-Signature=88f7cbb0b1e488a4ff09db8695de16b1201043d9fe0996623efa9c939c20aa97&X-Amz-SignedHeaders=host&response-content-disposition=filename%20%3D%22Untitled.png%22&x-id=GetObject)
312 |
313 | 각괄호([])를 사용한 대입문은 set 함수 호출로 컴파일된다.
314 |
315 | ## 3.2 in 관례
316 |
317 | 컬렉션이 지원하는 다른 연산자로 객체가 컬렉션에 들어가 있는지 검사(멤버십 검사)하는 `in`이 있다.
318 |
319 | 이런 경우 `in` 연산자와 대응하는 함수는 `contains`다.
320 |
321 | 예제를 통해 알아보자.
322 |
323 | ```kotlin
324 | data class Rectangle(val upperLeft: Point, val lowerRight: Point)
325 |
326 | operator fun Rectangle.contains(p: Point): Boolean {
327 | return p.x in upperLeft.x until lowerRight.x && // 범위를 만들고 x 좌표가 그 범위 안에 있는지 검사한다.
328 | p.y in upperLeft.y until lowerRight.y
329 | }
330 |
331 | >>> val rect = Rectangle(Point(10, 20), Point(50, 50))
332 | >>> println(Point(20, 30) in rect)
333 | true
334 |
335 | >>> println(Point(5, 5) in rect)
336 | false
337 | ```
338 |
339 | `in`의 우항에 있는 객체는 `contains` 메서드의 수신 객체가 되고, in의 좌항에 있는 객체는 메서드의 인자로 전달된다.
340 |
341 | 
342 |
343 | ## 3.3 rangeTo 관례
344 |
345 | 범위를 만들 때 `..` 구문을 사용할 수 있다. (`1..10`은 1부터 10까지 모든 수가 들어있는 범위이다.)
346 |
347 | `..` 연산자는 `rangeTo` 함수를 간략하게 표현하는 방법이다.
348 |
349 | 
350 |
351 | 이 연산자를 아무 클래스에나 정의할 수 있지만 어떤 클래스가 Comparable 인터페이스를 구현하면 `rangeTo`를 정의할 필요가 없다.
352 |
353 | 코틀린 표준 라이브러리에는 모든 Comparable 객체에 대해 적용 가능한 `rangeTo` 함수가 들어있다.
354 |
355 | ```kotlin
356 | operator fun > T.rangeTo(that: T): ClosedRange
357 | ```
358 |
359 | 예를 들어 LocalDate 클래스를 사용해 날짜의 범위를 만들어보자.
360 |
361 | ```kotlin
362 | >>> val now = LocalDate.now()
363 | >>> val vacation = now..now.plusDays(10)
364 | >>> println(now.plusWeeks(1) in vacation)
365 | true
366 | ```
367 |
368 | `rangeTo` 함수는 `LocalDate`의 멤버는 아니고, 앞에서 본대로 `Comparable`에 대한 확장 함수다.
369 |
370 | `rangeTo` 연산자는 다른 산술 연산자보다 우선순위가 낮지만, 혼동을 피하기 위해 괄호로 인자를 감싸주는 것이 좋다.
371 |
372 | ```kotlin
373 | >>> val n = 9
374 | >>> println(0..(n + 1)) // == 0..n + 1
375 | 0..10
376 |
377 | >>> (0..n).forEach { print(it) } // 0..n.forEach 는 컴파일 불가
378 | 0123456789
379 | ```
380 |
381 | ## 3.4 for 루프를 위한 iterator 관례
382 |
383 | 코틀린의 for 루프는 범위 검사와 똑같이 `in` 연산자를 사용한다.
384 |
385 | 하지만 이 경우 in의 의미는 다르다.
386 |
387 | `for (x in list) { ... }` 와 같은 문장은 `list.iterator()`를 호출해서 이터레이터를 얻은 다음,
388 |
389 | 자바와 마찬가지로 그 이터레이터에 대해 `hasNext`와 `next` 호출을 반복하는 식으로 변환된다.
390 |
391 | 하지만 코틀린에선 이 또한 관례이므로 `iterator` 메서드를 확장 함수로 정의할 수 있다.
392 |
393 | 이런 성질로 인해 자바 문자열에 대한 `for` 루프가 가능하다.
394 |
395 | 코틀린 표준 라이브러리는 `String`의 상위 클래스인 `CharSequence`에 대한 `iterator` 확장 함수를 제공한다.
396 |
397 | ```kotlin
398 | operator fun CharSequence.iterator(): CharIterator
399 |
400 | >>> for (c in "abc") { ... }
401 | ```
402 |
403 | 클래스 안에 직접 iterator 메서드를 구현할 수도 있다.
404 |
405 | ```kotlin
406 | operator fun ClosedRange.iterator(): Iterator =
407 | object : Iterator {
408 | var current = start
409 |
410 | override fun hasNext() = current <= endInclusive
411 |
412 | override fun next() = current.apply { current = plusDays(1) }
413 | ```
414 |
415 | 코드에서 `ClosedRange`에 대한 확장 함수 `iterator`를 정의했기 때문에 `LocalDate`의 범위 객체를 `for` 루프에 사용할 수 있다.
416 |
--------------------------------------------------------------------------------
/Chapter7-2.md:
--------------------------------------------------------------------------------
1 | # 연산자 오버로딩과 기타 관례
2 |
3 | ### 구조 분해 선언과 component 함수
4 |
5 | 구조 분해를 사용하면 복합적인 값을 분해해서 여러 다른 변수를 한꺼번에 초기화할 수 있습니다. 아래 코드를 살펴보겠습니다.
6 |
7 | ```kotlin
8 | val p = Point(10, 20)
9 | val (x, y) = p
10 | println(x) // 10
11 | println(y) // 20
12 | ```
13 |
14 |
15 |
16 | 구조 분해 선언은 일반 변수 선언과 비슷해 보이지만 =의 좌변에 여러 변수를 괄호로 묶었다는 점이 다릅니다. 내부에서 구조 분해 선언은 다시 관례를 사용하는데, 구조 분해 선언의 각 변수를 초기화하기 위해 `componentN`이라는 함수를 호출합니다. 여기서 N은 구조 분해 선언에 있는 변수의 위치에 따라 붙는 번호를 의미합니다.
17 |
18 | ```kotlin
19 | val (x, y) = p
20 | val x = p.component1()
21 | val y = p.component2()
22 | ```
23 |
24 |
25 |
26 | 데이터 클래스의 주 생성자에 들어있는 프로퍼티에 대해서는 컴파일러가 자동으로 `componentN` 함수를 만들어줍니다. 구조 분해 선언은 함수에서 여러 값을 반환할 때 유용합니다. 물론 무한하게 컴포넌트 함수를 선언할 수는 없으므로 이런 구문을 무한정 사용할 수는 없습니다. 코틀린 표준 라이브러리에서는 맨 앞의 다섯 원소에 대한 `componentN` 함수를 제공합니다.
27 |
28 | 또한 표준 라이브러리의 `Pair`나 `Tripple` 클래스를 사용하면 함수에서 여러 값을 더 간단하게 반환할 수 있습니다.
29 |
30 | ```kotlin
31 | val pair: Pair = 1 to "one"
32 | val (index, str) = pair
33 | println(index) // 1
34 | println(str) // one
35 | ```
36 |
37 |
38 |
39 | 위 특징으로 인해 컬렉션의 크기가 5보다 크거나 컬렉션의 크기를 벗어나는 위치의 원소에 대한 구조 분해 선언을 사용하면 에러가 발생합니다.
40 |
41 | ```kotlin
42 | val x = listOf(1, 2)
43 | val (a, b, c) = x // 런타임 에러, ArrayIndexOutOfBoundsException 발생!
44 | val (a, b, c, d, e, f) = x // 컴파일 에러, component6() 함수를 가질 수 없음!
45 | ```
46 |
47 |
48 |
49 | ### 구조 분해 선언과 루프
50 |
51 | 함수 본문 내의 선언뿐 아니라 변수 선언이 들어갈 수 있는 장소라면 어디든 구조 분해 선언을 사용할 수 있습니다. 예를 들어 루프 안에서도 구조 분해 선언을 사용할 수 있습니다.
52 |
53 | ```kotlin
54 | fun printEntries(map: Map) {
55 | for ((key, value) in map) {
56 | println("$key -> $value")
57 | }
58 | }
59 | ```
60 |
61 |
62 |
63 | ### 프로퍼티 접근자 로직 재활용 : 위임 프로퍼티
64 |
65 | 코틀린의 강력한 기능중 하나인 위임 프로퍼티를 사용하면 값을 backing 필드에 단순히 저장하는 것보다 더 복잡한 방식으로 작동하는 프로퍼티를 쉽게 구현할 수 있습니다. 또한 이 과정에서 접근자 로직을 매번 재구현할 필요도 없습니다.
66 |
67 | 위임(delegate)은 객체가 직접 작업을 수행하지 않고 다른 도우미 객체가 그 작업을 처리하게 맡기는 디자인 패턴을 말합니다. 이때 작업을 처리하는 도우미 객체를 위임 객체라고 부릅니다.
68 |
69 |
70 |
71 | ### by lazy를 사용한 프로퍼티 초기화 지연
72 |
73 | 지연 초기화는 객체의 일부분을 초기화하지 않고 남겨뒀다가 실제로 그 부분의 값이 필요한 경우 초기화할 때 흔히 쓰이는 패턴이다. 초기화 과정에 자원을 많이 사용하거나 객체를 사용할 때마다 꼭 초기화하지 않아도 되는 프로퍼티에 대해 지연 초기화 패턴을 사용할 수 있다.
74 |
75 | 에를 들어 `person` 클래스가 자신이 작성한 이메일의 목록을 제공한다고 가정해봅시다. 이메일은 DB에 들어있고 불러오려면 시간이 오래 걸립니다. 그래서 이메일 프로퍼티의 값을 최초로 사용할 때 단 한번만 이메일을 DB에서 가져오고 싶습니다. 이제 DB에서 이메일을 가져오는 `loadEmails` 함수가 있다고 해봅시다.
76 |
77 | ```kotlin
78 | class Email {
79 | // ...
80 | }
81 |
82 | fun loadEmails(person: Person): List {
83 | println("${person.name}의 이메일을 가져옵니다.")
84 | return listOf(
85 | //...
86 | )
87 | }
88 | ```
89 |
90 |
91 |
92 | 다음은 이메일을 불러오기 전에는 `null`을 저장하고 불러온 다음에는 이메일 리스트를 저장하는 `_emails` 프로퍼티를 추가해서 지연 초기화를 구현한 클래스를 보여줍니다.
93 |
94 | ```kotlin
95 | class Person(val name: String) {
96 |
97 | private var _emails: List? = null
98 | val emails: List
99 | get() {
100 | if (_emails == null) {
101 | _emails = loadEmails(this)
102 | }
103 | return _emails!!
104 | }
105 |
106 | }
107 | ```
108 |
109 |
110 |
111 | 여기선 backing 프로퍼티라는 기법을 사용했습니다. 하지만 이런 코드를 작성하는 일은 굉장히 성가십니다. 지연 초기화해야하는 프로퍼티가 많아지면 코드가 굉장히 지저분해 질 것입니다. 게다가 이 방식은 thread-safe 하지 않아서 언제나 제대로 작동한다고 말할 수도 없습니다.
112 |
113 | 위임 프로퍼티를 사용하면 이 코드는 훨씬 더 간단해집니다.
114 |
115 | ```kotlin
116 | class Person(val name : String) {
117 | val emails by lazy { loadEmails(this) }
118 | }
119 | ```
120 |
121 |
122 |
123 | `lazy` 함수는 코틀린 관례에 맞는 시그니처의 `getValue` 메소드가 들어있는 객체를 반환합니다. 또 `lazy` 함수는 기본적으로 thread-safe합니다. 하지만 필요에 따라 동기화에 사용할 락을 `lazy` 함수에 전달할 수도 있고, 다중 스레드 환경에서 사용하지 않을 프로퍼티를 위해 `lazy` 함수가 동기화를 하지 못하게 사용할 수도 있습니다.
124 |
125 | 그렇다면 과연 어떻게 이런 동작이 가능할까요? 그것은 아래 블로그에서 확인해보겠습니다.
126 |
127 | https://medium.com/hongbeomi-dev/%EB%B2%88%EC%97%AD-kotlin%EC%9D%98-delegates%EB%A1%9C-%EC%9C%84%EC%9E%84%ED%95%98%EA%B8%B0-1%ED%8E%B8-87391a2f0645
128 |
129 | https://medium.com/hongbeomi-dev/%EB%B2%88%EC%97%AD-%EB%82%B4%EC%9E%A5%EB%90%9C-delegates-2%ED%8E%B8-bc4a23cb6f10
--------------------------------------------------------------------------------
/Chapter8-1.md:
--------------------------------------------------------------------------------
1 | # 08. 고차 함수: 파라미터와 반환 값으로 람다 사용
2 |
3 | ## 고차 함수 정의
4 |
5 | - 고차 함수로 코드를 간결하게 다듬고 코드 중복을 없애고 더 나은 추상화를 구축하는 방법
6 | - 람다를 사용함에 따라 발생할 수 있는 성능상 부가 비용을 없애고 람다 안에서 더 유연하게 흐름을 제어할 수 있는 **인라인 함수**
7 |
8 | ### 함수 타입
9 |
10 | - 고차 함수를 정의하려면 함수 타입에 대해 먼저 알아야 한다.
11 | - 람다를 인자로 받는 함수를 정의하려면 먼저 람다 인자의 타입을 어떻게 선언할 수 있는지 알아야 한다.
12 | - 람다 인자의 타입 선언 방식 → 로컬 변수에 대입하는 경우
13 |
14 | ```kotlin
15 | // 컴파일러가 타입을 추론한다.
16 | val sum = {x: Int, y: Int -> x + y}
17 | val action = { println(42) }
18 |
19 | // 각 변수에 구체적인 타입 선언 추가
20 | val sum: (Int, Int) -> Int = { x, y -> x + y }
21 | val action: () -> Unit = { println(42) }
22 | ```
23 |
24 | 
25 |
26 | - 함수 타입에도 반환 타입을 널이 될 수 있는 타입으로 지정할 수 있다.
27 |
28 | ```kotlin
29 | var canReturnNull: (Int, Int) -> Int? = {x,y -> null}
30 | ```
31 |
32 | - 널이 될 수 있는 함수 타입 변수를 정의할 수도 있다.
33 |
34 | ```kotlin
35 | var funOrNull: ((Int, Int) -> Int)? = null
36 | ```
37 |
38 | - 함수 타입에서 파라미터 이름을 지정할 수도 있다.
39 |
40 | ```kotlin
41 | fun performRequest(
42 | url: Stirng,
43 | callback: (code: Int, content: String) -> Unit
44 | ) {}
45 | ```
46 |
47 |
48 | ### 인자로 받은 함수 호출
49 |
50 | **고차 함수 구현 방법**
51 |
52 | `리스트 8.1 간단한 고차 함수 정의하기`
53 |
54 | ```kotlin
55 | fun twoAndThree(operation: (Int, Int) -> Int) {
56 | val result = operation(2, 3)
57 | println("The result is $result")
58 | }
59 |
60 | >>> twoAndThree { a, b -> a + b }
61 | The result is 5
62 | >>> twoAndThree { a, b -> a * b }
63 | The result is 6
64 | ```
65 |
66 | `그림 8.2 고차 함수를 파라미터로 받는 filter 함수 정의`
67 |
68 | 
69 |
70 | `리스트 8.2 filter 함수를 단순하게 만든 버전 구현하기`
71 |
72 | ```kotlin
73 | fun String.filter(predicate: (Char) -> Boolean): String {
74 | val sb = StringBuilder()
75 | for (index in 0 until length) {
76 | val element = get(index)
77 | if (predicate(element)) sb.append(element)
78 | }
79 | return sb.toString()
80 | }
81 |
82 | >>> println("ab1c".filter {it in 'a'..'z'})
83 | ```
84 |
85 | ### 자바에서 코틀린 함수 타입 사용
86 |
87 | - 컴파일된 코드 안에서 함수 타입은 일반 인터페이스로 바뀐다. 즉 함수 타입의 변수는 FunctionN 인터페이스를 구현하는 객체를 저장한다.
88 | - 함수 인자의 개수에 따라 `Function0`(인자가 없는 함수), `Function1`(인자가 하나인 함수) 등의 인터페이스를 제공 → 각 인터페이스의 invoke를 호출하여 함수를 실행할 수 있다.
89 | - 함수 타입인 변수는 인자 개수에 따라 적당한 FunctionN 인터페이스를 구현하는 클래스의 인스턴스를 저장하며, 그 클래스의 invoke 메소드 본문에는 람다의 본문이 들어간다.
90 | - 자바 8 람다를 넘기면 자동으로 함수 타입의 값으로 반환된다.
91 |
92 | ```kotlin
93 | // 코틀린 선언
94 | fun processTheAnswer(f: (Int) -> Int) {
95 | println(f(42))
96 | }
97 |
98 | // 자바 코드에서 호출
99 | >>> processTheAnswer(number -> number + 1);
100 | 43
101 | ```
102 |
103 | - 자바 8이전 에서는 필요한 FunctionN 인터페이스의 invoke 메소드를 구현하는 익명 클래스를 넘기면 된다.
104 |
105 | ```kotlin
106 | processTheAnswer(
107 | new Function1() {
108 | @Override
109 | public Integer invoke(Integer number) {
110 | System.out.println(number);
111 | return number + 1;
112 | }
113 | });
114 | ```
115 |
116 |
117 | ### 디폴트 값을 지정한 함수 타입 파라미터나 널이 될 수 있는 함수 타입 파라미터
118 |
119 | - 함수 타입의 파라미터에 대한 디폴트 값을 지정할 수 있다.
120 |
121 | `리스트 8.4 함수 타입의 파라미터에 대한 디폴트 값 지정하기`
122 |
123 | ```kotlin
124 | fun Collection.joinToString(
125 | separator: String = ", ",
126 | prefix: String = "",
127 | postfix: String = "",
128 | // 함수 타입 파라미터를 선언하면서 람다를 디폴트 값으로 지정한다.
129 | transform: (T) -> String = { it.toString() }
130 | ): String {
131 | val result = StringBuilder(prefix)
132 | for ((index, element) in this.withIndex()) {
133 | if (index > 0) result.append(separator)
134 | result.append(transform(element))
135 | }
136 | result.append(postfix)
137 | return result.toString()
138 | }
139 | >>> println(letters.joinToString { it.toLowerCase() })
140 | alpha, beta
141 | >>> println(letters.joinToString(separator = "! ", postfix = "! ", transform = { it.toUpperCase() }))
142 | ALPHA! BETA!
143 | ```
144 |
145 | - 널이 될 수 있는 함수 타입을 사용할 수도 있다.
146 |
147 | `리스트 8.5 널이 될 수 있는 함수 타입 파라미터를 사용하기`
148 |
149 | ```kotlin
150 | fun Collection.joinToString(
151 | separator: String = ", ",
152 | prefix: String = "",
153 | postfix: String = "",
154 | transform: ((T) -> String)? = null
155 | ): String {
156 | val result = StringBuilder(prefix)
157 | for ((index, element) in this.withIndex()) {
158 | if (index > 0) result.append(separator)
159 | val str = transform?.invoke(element) **?:** element.toString()
160 | result.append(str)
161 | }
162 | result.append(postfix)
163 | return result.toString()
164 | }
165 | ```
166 |
167 |
168 | ⇒ 지금까지의 내용은 함수를 인자로 받는 함수를 만드는 방법에 대한 설명
169 |
170 | ### 함수를 함수에서 반환
171 |
172 | - 프로그램의 상태나 조건에 따라 달라질 수 있는 로직이 있을 경우
173 | - 함수가 함수를 반환할 필요가 있는 경우보다는 함수가 함수를 인자로 받아야할 필요가 있는 경우가 훨씬 많으나 함수를 반환하는 함수도 유용하다.
174 |
175 | `리스트 8.6 함수를 반환하는 함수 정의하기`
176 |
177 | ```kotlin
178 | enum class Delivery { STANDARD, EXPEDITED }
179 | class Order(val itemCount: Int)
180 |
181 | // 반환 타입에 고차 함수 정의
182 | fun getShippingCostCalculator(
183 | delivery: Delivery
184 | ): (Order) -> Double {
185 | if (delivery == Delivery.EXPEDITED) {
186 | return { order -> 6 + 2.1 * order.itemCount }
187 | }
188 | return { order -> 1.2 * order.itemCount }
189 | }
190 |
191 | >>> calculator = getShippingCostCalculator(Delivery.EXPEDITED)
192 | >>> println("Shipping costs ${calculator(Order(3))}")
193 | Shipping costs 12.3
194 |
195 | >>> calculator = getShippingCostCalculator(Delivery.STANDARD)
196 | >>> println("Shipping costs ${calculator(Order(3))}")
197 | Shipping costs 3.5999999999999996
198 | ```
199 |
200 | - 함수를 반환하려면 return 식에 람다나 멤버 참조나 함수 타입의 값을 계산하는 식 등을 넣으면 된다.
201 |
202 | ### 람다를 활용한 중복 제거
203 |
204 | - 함수 타입과 람다 식은 재활용하기 좋은 코드를 만들 때 쓸 수 있는 훌륭한 도구다.
205 | - 람다를 사용할 수 없는 환경에서는 아주 복잡한 구조를 만들어야만 피할 수 있는 코드 중복도 람다를 활용하면 간결하고 쉽게 제거할 수 있다.
206 |
207 | `리스트 8.8 사이트 방문 데이터 정의`
208 |
209 | `리스트 8.9 사이트 방문 데이터를 하드 코딩한 필터를 사용해 분석하기`
210 |
211 | ```kotlin
212 | data class SiteVisit(
213 | val path: String,
214 | val duration: Double,
215 | val os: OS
216 | )
217 |
218 | enum class OS { WINDOWS, LINUX, MAC, IOS, ANDROID }
219 |
220 | val log = listOf(
221 | SiteVisit("/", 34.0, OS.WINDOWS),
222 | SiteVisit("/", 22.0, OS.MAC),
223 | SiteVisit("/login", 12.0, OS.WINDOWS),
224 | SiteVisit("/signup", 8.0, OS.IOS),
225 | SiteVisit("/", 16.3, OS.ANDROID)
226 | )
227 |
228 | fun main() {
229 | val averageWindowsDuration = log
230 | .filter { it.os == OS.WINDOWS }
231 | .map(SiteVisit::duration)
232 | .average()
233 | println(averageWindowsDuration)
234 |
235 | val averageWindowsDuration = log
236 | .filter { it.os == OS.MAC }
237 | .map(SiteVisit::duration)
238 | .average()
239 | println(averageWindowsDuration)
240 | }
241 |
242 | 23.0
243 |
244 | // 만약 MAC의 평균 방문 시간을 출력하고 싶다면 -> 동일한 로직 중복
245 | ```
246 |
247 | `리스트 8.10 일반 함수를 통해 중복 제거하기`
248 |
249 | ```kotlin
250 | fun List.averageDurationFor(os: OS) =
251 | filter {it.os == os}.map(SiteVisit::duration).average()
252 |
253 | >>> println(log.averageDurationFor(OS.WINDOWS))
254 | 23.0
255 | >>> println(log.averageDurationFor(OS.MAC))
256 | 22.0
257 | ```
258 |
259 | - 모바일 사용자의 평균 방문 시간 구하기
260 |
261 | `리스트 8.11 복잡하게 하드코딩한 필터를 사용해 방문 데이터 분석하기`
262 |
263 | ```kotlin
264 | val averageMobileDuration = log
265 | .filter { it.os in setOf(OS.ANDROID, OS.IOS) }
266 | .map(SiteVisit::duration)
267 | .average()
268 |
269 | println(averageMobileDuration)
270 | ```
271 |
272 | - 함수 타입을 사용하면 필요한 조건을 파라미터로 뽑아낼 수 있다.
273 |
274 | `리스트 8.12 고차 함수를 사용해 중복 제거하기`
275 |
276 | ```kotlin
277 | // 특정 조건을 통과하는 고차함수를 매개변수로 받음
278 | fun List.averageDurationFor(predicate: (SiteVisit) -> Boolean) =
279 | filter(predicate).map(SiteVisit::duration).average()
280 |
281 | println(log.averageDurationFor { it.os in setOf(OS.ANDROID, OS.IOS) })
282 | ```
283 |
284 | ## 인라인 함수: 람다의 부가 비용 없애기
285 |
286 | - 코틀린에서는 보통 람다를 익명 클래스로 컴파일하지만 그렇다고 람다 식을 사용할 때마다 새로운 클래스가 만들어지지는 않는다.
287 | - 하지만 람다가 변수를 포획하면 람다가 생성되는 시점마다 새로운 익명 클래스 객체가 생긴다. 이 경우 실행 시점에 익명 클래스 생성에 따른 부가 비용이 든다.
288 | - 따라서 람다를 사용하는 구현은 똑같은 작업을 수행하는 일반 함수를 사용한 구현보다 덜 효율적이다.
289 | - inline 변경자를 함수에 붙이면 컴파일러는 그 함수를 호출하는 모든 문장을 함수 본문에 해당하는 바이트코드로 바꿔치기 해준다.
290 |
291 | ### 인라이닝이 작동하는 방식
292 |
293 | - inline으로 선언하면 그 함수의 본문이 인라인된다. 다른 말로 하면 함수를 호출하는 코드를 함수를 호출하는 바이트코드 대신에 함수 본문을 번역한 바이트 코드로 컴파일한다.
294 |
295 | ```kotlin
296 | inline fun calculator(a: Int, b: Int, op: (Int, Int) -> Int): Int {
297 | println("calculator body")
298 | return op(a, b)
299 | }
300 |
301 | fun main() {
302 | val result = calculator(1, 2) { a, b -> a + b }
303 | println(result)
304 | }
305 | ```
306 |
307 | ### 인라인 함수의 한계
308 |
309 | - 인라이닝을 하는 방식으로 인해 람다를 사용하는 모든 함수를 인라이닝할 수는 없다.
310 | - 함수가 인라이닝될 때 그 함수에 인자로 전달된 람다 식의 본문은 결과 코드에 직접 들어갈 수 있다. 하지만 이렇게 람다가 본문에 직접 펼쳐지기 때문에 함수가 파라미터로 전달받은 람다를 본문에 사용하는 방식이 한정될 수밖에 없다.
311 | - 함수 본문에서 파라미터로 받은 람다를 호출한다면 쉽게 람다 본문으로 바꿀 수 있다. 하지만 파라미터로 받은 람다를 다른 변수에 저장하고 나중에 그 변수를 사용한다면 람다를 표현하는 객체가 어딘가는 존재해야 하기 때문에 람다를 인라이닝할 수 없다.
312 | - 이 경우 컴파일러는 `“Illegal usage of inline-parameter”` 라는 메시지와 함께 인라이닝을 금지시킨다.
313 |
314 | `example`
315 |
316 | ```kotlin
317 | fun Sequence.map(transform: (T) -> R): Sequence {
318 | return TransformingSequence(this, transform)
319 | }
320 | ```
321 |
322 | ### 컬렉션 연산 인라이닝
323 |
324 | - kotlin의 filter 함수는 inline 함수다. 따라서 filter 함수의 바이트코드는 그 함수에 전달된 람다 본문의 바이트코드와 함께 filter를 호출한 위치에 들어간다.
325 |
326 | ```kotlin
327 | data class Person(val name: String, val age: Int)
328 |
329 | fun main() {
330 | val people = listOf(Person("Alice", 29), Person("Bob", 31))
331 | println(people.filter { it.age < 30 })
332 |
333 | val result = mutableListOf()
334 | for (person in people) {
335 | if (person.age < 30) result.add(person)
336 | }
337 | println(result)
338 | }
339 | ```
340 |
341 | - filter와 map은 인라인 함수다. 따라서 추가 객체나 클래스 생성은 없다.
342 | - 하지만 리스트를 걸러낸 결과를 저장하는 중간 리스트를 만든다. filter 함수에서 만들어진 코드는 원소를 중간 리스트에 저장하고 map 함수에서 만들어진 코드는 그 중간 리스트를 읽어서 사용한다.
343 | - asSequence를 사용하면 중간 리스트로 인한 부가 비용은 줄어든다. 중간 시퀀스는 람다를 필드에 저장하는 객체로 표현되며, 최종 연산은 중간 시퀀스에 있는 여러 람다를 연쇄 호출한다. 시퀀스 연산에는 람다가 인라이닝되지 않기 때문에 크기가 작은 컬렉션은 오히려 일반 컬렉션보다 성능이 안좋을 수 있다. 시퀀스를 통해 성능을 향상시킬 수 있는 경우는 컬렉션 크기가 큰 경우뿐이다.
344 |
345 | ```kotlin
346 | println(people.filter { it.age > 30 }.map(Person::name))
347 | ```
348 |
349 | ### 함수를 인라인으로 선언해야 하는 이유
350 |
351 | - 람다를 인자로 받는 함수만 성능이 좋아질 가능성이 높기 때문에 다른 경우에는 주의 깊에 성능을 측정하고 조사해봐야 한다.
352 |
353 | **일반 함수 호출**
354 |
355 | - 일반 함수 호출의 경우 JVM은 이미 강력하게 인라이닝을 지원한다. JVM은 코드 실행을 분석해서 가장 이익이 되는 방향으로 호출을 인라이닝한다. 이런 과정은 바이트코드를 실제 기계어 코드로 번역하는 과정(JIT)에서 일어난다.
356 | - JVM 최적화를 활용한다면 바이트코드에서는 각 함수 구현이 한 번만 있으면 되고 함수 호출 부분에서 따로 중복 코드가 필요 없다. 반면 인라인 함수는 바이트 코드에서 각 함수 호출 지점을 함수 본문으로 대치하기 때문에 코드 중복이 생긴다.
357 |
358 | **람다를 인자로 받는 함수 호출**
359 |
360 | - 함수 호출 비용을 줄일 수 있을 뿐 아니라 클래스와 객체를 만들 필요가 없어진다.
361 | - 현재의 JVM은 함수 호출과 람다를 인라이닝해 줄 정도로 똑똑하지 못하다.
362 |
363 | inline 변경자를 붙일 때는 코드 크기에 주의를 기울여야 한다. 인라이닝하는 함수가 큰 경우 본문에 해당하는 바이트코드를 모든 호출 지점에 복사해 바이트코드가 전체적으로 아주 커질 수 있다. 그런 경우 람다 인자와 무관한 코드는 비인라인 함수로 빼는 것이 좋다.
--------------------------------------------------------------------------------
/Chapter8-2.md:
--------------------------------------------------------------------------------
1 | # 고차 함수 : 파라미터와 반환 값으로 람다 사용
2 |
3 | ## 8.3 고차 함수 안에서 흐름 제어
4 |
5 | 루프 같은 명령형 코드를 람다로 바꾸게 되면 우리는 곧 return 문제에 부딫힐 것입니다. 루프의 중간에 있는 `return` 문의 의미를 이해하기는 쉬운데, 이 루프를 `filter`와 같이 람다를 호출하는 함수로 바꾸고 인자로 전달하는 람다 안에서 `return`을 사용한다면 어떤 일이 벌어질까요?
6 |
7 |
8 |
9 | ### 8.3.1 람다 안의 return 문: 람다를 둘러싼 함수로부터 리턴
10 |
11 | 아래 예시를 살펴봅시다.
12 |
13 | ```kotlin
14 | fun lookForAlice(people: List) {
15 | people.forEach {
16 | if (it.name == "Alice") {
17 | println("Found!")
18 | return
19 | }
20 | }
21 | println("Alice is not found")
22 | }
23 | ```
24 |
25 |
26 |
27 | `forEach`에 넘긴 람다 안에서 `return`을 사용하면 람다로부터만 반환되는게 아니라 그 람다를 호출하는 함수가 실행을 끝내고 리턴됩니다. 이렇게 자신을 둘러싸고 있는 블록보다 더 바깥에 있는 다른 블록을 리턴하게 만드는 `return` 문을 non-local `return`이라고 부릅니다.
28 |
29 | 이렇게 `return`이 바깥쪽 함수를 리턴시킬 수 있는 때는 람다를 인자로 받는 함수가 인라인 함수인 경우뿐입니다. 따라서 `return`식이 바깥쪽 함수(여기선 `lookForAlice`)를 리턴시키도록 컴파일 됩니다. 하지만 인라이닝되지 않는 함수에 전달되는 람다 안에서 `return`을 사용할 수는 없습니다.
30 |
31 |
32 |
33 | ### 8.3.2 람다로부터 반환 : 레이블을 사용한 return
34 |
35 | 람다 식에서도 로컬 `return`을 할 수 있습니다. 로컬 `return`은 람다의 실행을 끝내고 람다를 호출했던 코드의 실행을 계속 이어갑니다. 이 때 로컬 `return`과 non-local `return`을 구분하기 위해 레이블을 사용해야 합니다. 아래 예시를 살펴보겠습니다.
36 |
37 | ```kotlin
38 | fun lookForAlice(people: List) {
39 | people.forEach label@ {
40 | if (it.name == "Alice") return@label
41 | }
42 | println("Alice might be somewhere")
43 | }
44 | ```
45 |
46 |
47 |
48 | 물론 람다에 레이블을 붙여서 사용하는 대신 람다를 인자로 받는 인라인 함수의 이름을 `return` 뒤에 레이블로 사용해도 됩니다.
49 |
50 | ```kotlin
51 | fun lookForAlice(people: List) {
52 | people.forEach {
53 | if (it.name == "Alice") return@forEach
54 | }
55 | println("Alice might be somewhere")
56 | }
57 | ```
58 |
59 |
60 |
61 | 람다 식의 레이블을 명시하면 함수 이름을 레이블로 사용할 수 없다는 점에 유의하여야 합니다.
62 |
63 | 하지만 non-local 리턴문은 장황하고, 람다 안의 여러 위치에 `return` 식이 들어가야 하는 경우 사용하기 불편합니다. 이런 경우, 무명 함수를 통해 이 불편함을 해소할 수 있습니다.
64 |
65 |
66 |
67 | ### 8.3.3 무명 함수 : 기본적으로 로컬 return
68 |
69 | 무명 함수는 일반 함수와 비슷해 보이지만 함수 이름이나 파라미터 타입을 생략할 수 있습니다.
70 |
71 | ```kotlin
72 | fun lookForAlice(people: List) {
73 | people.forEach(fun (person) {
74 | if (it.name == "Alice") return
75 | println("${person.name} is not Alice")
76 | })
77 | }
78 | ```
79 |
80 |
81 |
82 | 무명 함수 안에서 레이블이 붙지 않은 `return` 식은 무명 함수 자체를 리턴시킬 뿐 무명 함수를 둘러싼 다른 함수를 리턴시키지 않습니다. 사실 `return`에 적용되는 규칙은 단순히 `return`은 `fun` 키워드를 이용해 정의된 가장 안쪽 함수를 리턴시킨다는 것입니다.
83 |
84 |
85 |
86 | ### Quiz
87 |
88 | 아래 클래스를 참고합시다.
89 |
90 | ```kotlin
91 | data class Person(
92 | val name : String,
93 | val age: Int
94 | )
95 | ```
96 |
97 | - 결과가 참/거짓인 조건을 파라미터로 받아서 해당 조건으로 필터링된 `List`을 리턴하는 `List`에 대한 확장 함수를 만들어봅시다.
98 |
99 | - `Person`을 인자로 사용하는 람다 파라미터를 받아서 이름이 "john"이고 나이가 20살인 `Person`을 만들어 해당 파라미터의 인자로 넘긴 후 출력시키는 코드를 작성해봅시다.
100 |
101 | - `Person`을 리턴하는 람다 파라미터를 받아서 해당 `Person`을 출력하는 함수를 만들어봅시다.
102 |
103 | - 수신 객체가 `Person`인 스코프를 가지는(`apply`처럼 동작) `person` 함수를 만들어봅시다.
104 |
105 | - 아래 함수를 요구사항대로 실행시키는 코드를 작성해봅시다. (hint: 함수를 리턴함)
106 |
107 | 요구사항 : 우리는 `name`을 첫 번째 람다식의 인자로 넘기고 `age`를 두 번째 람다식의 인자로 넘겨서 `name`과 `age`를 출력하려고 합니다.
108 |
109 | ```kotlin
110 | fun testMethod(action: (String) -> (Int) -> Unit): (String) -> (Int) -> Unit =
111 | { s -> { i -> action(s)(i) } }
112 | ```
113 |
114 |
115 |
--------------------------------------------------------------------------------
/Chapter9-1.md:
--------------------------------------------------------------------------------
1 | # Chapter 9 : 제네릭
2 |
3 |
4 |
5 | ## 9.1 제네릭 타입 파라미터
6 |
7 | 제네릭을 사용하면 타입 파라미터를 받는 타입을 정의할 수 있는데, 제네릭 타입의 인스턴스를 만드려면 타입 파라미터를 구체적인 타입 인자로 치환해야 합니다. 예를 들어 `List`라는 타입이 있다면 그 안에 들어가는 원소의 타입을 알아야 쓸모가 있을 것입니다. 이 때 타입 파라미터를 사용하면 "이 변수는 리스트다" 대신 "이 변수는 문자열을 담는 리스트다" 라고 말할 수 있습니다.
8 |
9 | 코틀린에서 제네릭은 자바의 제네릭과 매우 비슷합니다. 하지만 자바와 달리 코틀린에서는 제네렉 타입의 타입 인자를 프로그래머가 명시하거나 컴파일러가 추론할 수 있어야 합니다.
10 |
11 |
12 |
13 | ### 9.1.1 제네릭 함수와 프로퍼티
14 |
15 | 어떤 특정 타입을 타겟하는 함수가 아닌 모든 타입에 대한 함수를 원할 때 제네릭 타입을 활용하여 함수를 작성할 수 있습니다. 제네릭 함수를 호출할 때는 반드시 구체적 타입으로 타입 인자를 넘겨야만 합니다.
16 |
17 | ```kotlin
18 | fun printValue(value: T): T {
19 | println(value.toString())
20 | return value
21 | }
22 | ```
23 |
24 | 위 함수에서 `` 부분은 타입 파라미터 선언에 해당합니다. 물론 이 타입 파라미터는 파라미터의 타입으로 사용할 수 도 있고, 리턴 타입에 사용할 수도 있습니다. 이제 함수를 사용해보겠습니다.
25 |
26 |
27 |
28 | ```kotlin
29 | val str = "hi"
30 | printValue(str) // hi
31 |
32 | val num = 2
33 | printValue(num) // 2
34 | ```
35 |
36 | 우리가 따로 타입 인자를 명시적으로 지정할 필요없이 컴파일러가 `T`를 추론하여 함수를 실행시키는 것을 알 수 있습니다.
37 |
38 |
39 |
40 | 이번엔 제네릭 고차 함수를 호출해보겠습니다. 람다 파라미터에 대해서 자동으로 만들어진 변수 `it` 의 타입은 `T` 라는 제네릭 타입입니다.
41 |
42 | ```kotlin
43 | val peoples = listOf("Hongbeom", "Dmitry", "Svetlana")
44 |
45 | fun List.filter(predicate: (T) -> Boolean): List
46 |
47 | peoples.filter { it == "Hongbeom" } // [Hongbeom]
48 | ```
49 |
50 |
51 |
52 | 또한 클래스나 인터페이스 안에 정의된 메소드, 확장 함수 또는 최상위 함수에서 타입 파라미터를 선언할 수 있습니다. 제네릭 함수를 정의할 때와 마찬가지 방법으로 제네릭 확장 프로퍼티를 선언할 수 있습니다. 예를 들어 다음은 리스트의 마지막 원소 바로 앞에 있는 원소를 반환하는 확장 프로퍼티입니다.
53 |
54 | ```kotlin
55 | val List.penultimate: T
56 | get() {
57 | check(size > 1) {
58 | "Size must be greater than one"
59 | }
60 | return this[size - 2]
61 | }
62 |
63 | println(listOf(1, 2, 3, 4).penultimate)
64 | // 3
65 | ```
66 |
67 |
68 |
69 | ### 9.1.2 제네릭 클래스 선언
70 |
71 | 자바와 마찬가지로 코틀린에서도 타입 파라미터를 넣은 꺾쇠 기호를 클래스(또는 인터페이스) 뒤에 붙이면 클래스를 제네릭하게 만들 수 있습니다. 타입 파라미터를 이름 뒤에 붙이면 클래스 본문 안에서 타입 파라미터를 다른 일반 타입처럼 사용할 수 있다. 표준 자바 인터페이스인 `List`를 코틀린으로 정의해봅시다. 설명을 위해 `get` 메소드 하나만 남기고 전부 생략하겠습니다.
72 |
73 | ```kotlin
74 | interface List {
75 | operator fun get(index: Int): T
76 | }
77 | ```
78 |
79 |
80 |
81 | 이제 구체적인 타입을 하위 클래스에서 상위 클래스로 넘길 수도 있고 타입 파라미터로 받은 타입을 넘길 수도 있습니다.
82 |
83 | ```kotlin
84 | class StringList: List {
85 | override fun get(index: Int): String = // ... //
86 | }
87 |
88 | class ArrayList : List {
89 | override fun get(index: Int): T = // ... //
90 | }
91 | ```
92 |
93 |
94 |
95 | 하위클래스에서 상위 클래스에 정의된 함수를 오버라이드하거나 사용하려면 타입 인자 `T`를 구체적 타입으로 치환해야 합니다. 따라서 `StringList`에서는 `fun get(index: Int): T` 가 아니라 `fun get(index: Int): String` 이라는 시그니처를 사용합니다.
96 |
97 | `ArrayList` 클래스는 자신만의 타입 파라미터 `AT`를 정의하면서 그 `AT`를 상위 클래스의 타입 인자로 사용합니다. 여기서의 `AT` 타입과 위에서 본 `List` 의 `T`는 같지 않습니다.
98 |
99 | 심지어 클래스가 자기 자신을 타입 인자로 참조할 수도 있습니다. `Comparable` 인터페이스를 구현하는 클래스가 이런 패턴의 예시입니다. 비교 가능한 모든 값은 자신을 같은 타입의 다른 값과 비교하는 방법을 제공해야만 합니다.
100 |
101 | ```kotlin
102 | interface Comparable {
103 | fun compareTo(other: T): Int
104 | }
105 |
106 | class People: Comparable {
107 | override fun compareTo(other : People) : Int = /* ... */
108 | }
109 | ```
110 |
111 |
112 |
113 | 지금까지 살펴본 코틀린의 제네릭은 자바의 제네릭과 비슷했습니다. 이제 자바와 비슷한 다른 개념을 살펴보겠습니다. 이 개념을 사용하면 비교 가능한 원소를 다룰 때 쓸모 있는 함수를 작성할 수 있습니다.
114 |
115 |
116 |
117 | ### 9.1.3 타입 파라미터 제약
118 |
119 | 타입 파라미터 제약은 클래스나 함수에 사용할 수 있는 타입 인자를 제한하는 기능입니다. 어떤 타입을 제네릭 타입의 타입 파라미터에 대한 상한으로 지정하면 그 제네릭 타입을 인스턴스화할 때 사용하는 타입 인자는 반드시 그 상한 타입이거나 그 상한 타입의 하위 타입이어야 합니다.
120 |
121 | 제약을 가하려면 타입 파라미터 이름 뒤에 콜론(:)을 표시하고 그 뒤에 상한 타입을 적으면 됩니다.
122 |
123 | ```kotlin
124 | fun List.sum(): T // kotlin
125 | ```
126 |
127 | ```java
128 | T sum(List list) // java
129 | ```
130 |
131 |
132 |
133 | 타입 파라미터 `T`에 대한 상한을 정하고 나면 `T` 타입의 값을 그 상한 타입의 값으로 취급할 수 있습니다.
134 |
135 | ```kotlin
136 | fun oneHalf(value : T): Double {
137 | return value.toDouble() / 2.0 // Number 클래스에 정의된 메소드 호출
138 | }
139 |
140 | println(oneHalf(3)) // 1.5
141 | ```
142 |
143 |
144 |
145 | 이제 두 파라미터 사이에서 더 큰 값을 찾는 제네릭 함수를 작성해보겠습니다. 서로를 비교할 수 있어야 최댓값을 찾을 수 있으므로 시그니처에도 두 인자를 서로 비교할 수 있어야 한다는 사실을 지정해야 합니다.
146 |
147 | ```kotlin
148 | fun > max (first: T, second: T): T {
149 | return if (first > second) first else second
150 | }
151 |
152 | println(max("kotlin", "java"))
153 | // kotlin
154 | // 문자열은 알파벳순으로 비교
155 | ```
156 |
157 |
158 |
159 | 아주 드물지만 타입 파라미터에 대해 둘 이상의 제약을 가해야 하는 경우도 있습니다. 그런 경우에는 약간 다른 구문을 사용합니다. 예를 들어 아래 리스트는 `CharSequence`의 맨 끝에 마침표(.)가 있는지 검사하는 제네릭 함수입니다.
160 |
161 | ```kotlin
162 | fun ensureTrailingPeriod(seq: T) where T: CharSequence, T: Appendable {
163 | if (!seq.endsWith('.')) {
164 | seq.append('.')
165 | }
166 | }
167 |
168 | val helloWorld = StringBuilder("Hello World")
169 | ensureTrailingPeriod(helloWorld)
170 | println(helloWorld)
171 | // Hello World.
172 | ```
173 |
174 |
175 |
176 | ### 9.1.4 타입 파라미터를 널이 될 수 없는 타입으로 한정
177 |
178 | 제네릭 클래스나 함수를 정의하고 그 타입을 인스턴스화할 때는 널이 될 수 있는 타입을 포함하는 어떤 타입으로 타입 인자를 지정해도 타입 파라미터를 치활할 수 있습니다. 아무런 상한을 정하지 않은 타입 파라미터는 결과적으로 `Any?` 를 상한으로 정한 파라미터와 같습니다.
179 |
180 | 그러므로 항상 널이 될 수 없는 타입만 타입 인자로 받게 만드려면 타입 파리미터에 제약을 가해야합니다.
181 |
182 | ```kotlin
183 | class Processor {
184 | fun process(value: T) {
185 | value.hashCode()
186 | }
187 | }
188 | ```
189 |
190 |
191 |
192 | 타입 파라미터를 널이 될 수 없는 타입으로 제약을 걸면 타입 인자로 널이 될 수 있는 타입이 들어오는 일을 막을 수 있기에, `Any`를 사용하지 않고 다른 널이 될 수 없는 타입을 사용하여 상한을 정해도 됩니다.
193 |
194 |
195 |
196 |
--------------------------------------------------------------------------------
/Chapter9-2.md:
--------------------------------------------------------------------------------
1 | # 09. 제네릭스
2 |
3 | #
4 |
5 | ## 9.2 실행 시 제네릭스의 동작: 소거된 타입 파라미터와 실체화된 타입 파라미터
6 |
7 |
8 |
9 | 자바 개발자라면 알고 있듯이 JVM의 제네릭스는 보통 **타입 소거**(type erasure)를 사용해 구현된다.
10 |
11 | 즉, 실행 시점에 제네릭 클래스의 인스턴스에 타입 인자 정보가 들어있지 않다는 것이다.
12 |
13 |
14 |
15 | 이번에는 코틀린에서 타입 소거가 실용적인 면에서 어떤 영향을 끼치는지 살펴보고,
16 |
17 | 함수를 `inline`으로 선언함으로써 이런 제약을 어떻게 우회할 수 있는지 알아본다.
18 |
19 | 함수를 `inline`으로 만들면 타입 인자가 지워지지 않게 할 수 있다. 이를 코틀린에선 **실체화**(reify)라 부른다.
20 |
21 |
22 |
23 | 실체화된 타입 파라미터에 대해 자세히 다루고 실체화한 타입 파라미터가 유용한 이유를 알아보자.
24 |
25 |
26 |
27 |
28 |
29 | ### 9.2.1 실행 시점의 제네릭: 타입 검사와 캐스트
30 |
31 |
32 |
33 | 자바와 마찬가지로 코틀린 제네릭 타입 인자 정보는 런타임에서 지워진다.
34 |
35 | 이는 제네릭 클래스 인스턴스가 그 인스턴스를 생성할 때 쓰인 타입 인자에 대한 정보를 유지하지 않는다는 것이다.
36 |
37 | 예를 들어, `List` 객체를 만들고 그 안에 문자열을 넣더라도 실행 시점에는 이 객체는 오직 `List`로만 볼 수 있다.
38 |
39 | 그 `List` 객체가 어떤 타입의 원소를 저장하는지 실행 시점에는 알 수 없다.
40 |
41 | 실제로 코드를 실행할 때 어떤 일이 벌어지는지 알아보자.
42 |
43 |
44 |
45 | 컴파일러는 두 리스트를 서로 다른 타입으로 인식하지만 실행 시점에 이 둘은 완전히 같은 타입의 객체다.
46 |
47 | 하지만 컴파일러가 타입 인자를 알고 올바른 타입의 값만 각 리스트에 넣도록 보장해주므로 각각 문자열과 정수만 들어있다고 보통은 가정할 수 있다.
48 |
49 |
50 |
51 | 이젠 타입 소거로 인해 생기는 한계에 대해 알아보자.
52 |
53 | 먼저, 타입 인자를 따로 저장하지 않기 때문에 실행 시점에 타입 인자를 검사할 수 없다.
54 |
55 | 예를 들어 어떤 리스트가 문자열로 이뤄진 리스트인지 다른 객체로 이뤄졌는지 실행 시점에 검사할 수 없다.
56 |
57 | 일반적으로 발하면 `is` 검사에서 타입 인자로 지정한 타입을 검사할 수는 없다.
58 |
59 | ```kotlin
60 | >>> if (value is List) { ... }
61 | ERROR: Cannot check for instance of erased type
62 | ```
63 |
64 | 실행 시점에 어떤 값이 `List`인지 여부는 알아낼 수 있지만 그 리스트가 `String`의 리스트인지 `Person`의 리스트인지는 알 수가 없다.
65 |
66 |
67 |
68 | 하지만, 코틀린 컴파일러는 컴파일 시점에 타입 정보가 주어진 경우에는 `is` 검사를 수행하게 해준다.
69 |
70 | ```kotlin
71 | fun printSum(c: Collection) {
72 | if (c is List) {
73 | println(c.sum())
74 | }
75 | }
76 |
77 | >>> printSum(listOf(1, 2, 3))
78 | 6
79 | ```
80 |
81 | `c` 컬렉션이 `Int` 값을 저장한다는 사실이 알려져 있으므로 `c`가 `List`인지 검사할 수 있다.
82 |
83 |
84 |
85 | 다만 타입 소거는 저장해야 하는 타입 정보의 크기가 줄어들어 메모리 사용량이 줄어든다는 나름의 장점이 있긴하다.
86 |
87 |
88 |
89 | 9.1에서 말한 대로 코틀린에서는 타입 인자를 명시하지 않고 제네릭을 사용할 순 없다.
90 |
91 | 그렇다면 어떤 값이 단지 집합이나 맵이 아니라 리스트라는 사실만 알고싶을 땐 어떻게 확인할까?
92 |
93 | 바로 **스타 프로젝션**(star projection)을 사용하면 된다.
94 |
95 | ```kotlin
96 | if (value is List<*>) { ... }
97 | ```
98 |
99 | 스타 프로젝션에 대해서는 뒤에서 더 알아보고, 지금은 인자를 알 수 없는 제네릭 타입을 표현할 때 사용한다고 알아두자. *(자바의 List와 비슷함)*
100 |
101 | ### 9.2.2 실체화된 타입 파라미터를 사용한 함수 선언
102 |
103 |
104 |
105 | 코틀린 제네릭 타입의 타입 인자 정보는 실행 시점에 지워진다고 했다.
106 |
107 | 따라서 제네릭 클래스의 인스턴스가 있어도 그 인스턴스를 만들 때 사용한 타입 인자를 알아낼 수 없다. 이것은 제네릭 함수의 타입 인자도 마찬가지이다.
108 |
109 | 제네릭 함수가 호출되도 그 함수의 본문에서 호출 시 쓰인 타입 인자를 알아낼 수 없다.
110 |
111 | ```kotlin
112 | >>> fun isA(value: Any) = value is T
113 | Error: Cannot check for instance of erased type: T
114 | ```
115 |
116 | 하지만 인라인 함수의 타입 파라미터는 실체화되므로 실행 시점에 타입 인자를 알 수 있다.
117 |
118 |
119 |
120 | 8.2절에서 `inline` 함수에 대해 알아봤다.
121 |
122 | 어떤 함수에 `inline` 키워드를 붙이면 컴파일러는 그 함수를 호출한 식을 모두 함수 본문으로 바꾼다.
123 |
124 | 함수가 람다를 인자로 사용하는 경우 그 함수를 인라인 함수로 만들면 람다 코드도 함께 인라이닝되고, 그에 따라 무명 클래스와 객체가 생성되지 않아 성능이 향상될 수 있다.
125 |
126 |
127 |
128 | 이번에는 인라인 함수가 유용한 다른 이유인 타입 인자 실체화에 대해 알아보자.
129 |
130 | 위의 `isA` 함수를 인라인 함수로 만들고 타입 파라미터를 `reified`로 지정하면 `value`의 타입이 `T`의 인스턴스인지를 실행 시점에 검사할 수 있다.
131 |
132 | ```kotlin
133 | inline fun isA(value: Any) = value is T
134 |
135 | >>> println(isA("abc"))
136 | true
137 | >>> println(isA(123))
138 | false
139 | ```
140 |
141 | 실체화된 타입 파라미터를 사용하는 예를 알아보자.
142 |
143 | 가장 간단한 예제 중 하나로 표준 라이브러리 함수인 `filterIsInstance`가 있다.
144 |
145 | ```kotlin
146 | >>> val items = listOf("one", 2, "three")
147 | >>> println(items.filterIsInstance())
148 | [one, three]
149 | ```
150 |
151 | `filterIsInstance`의 타입인자로 `String`을 지정함으로써 문자열만 필요하다는 사실을 기술한다.
152 |
153 | > 인라인 함수에서만 실체화한 타입 인자를 쓸 수 있는 이유
154 |
155 | 실체화한 타입 인자는 어떻게 작동하는 걸까?
156 |
157 | 왜 일반 함수에서는 `element is T`를 사용할 수 없고 인라인 함수에서만 쓸 수 있는가?
158 |
159 | 이전에 설명했던 것처럼 컴파일러는 인라인 함수의 본문을 구현한 바이트코드를 그 함수가 호출되는 모든 지점에 삽입한다.
160 |
161 | 컴파일러는 실체화한 타입 인자를 사용해 인라인 함수를 호출하는 각 부분의 정확한 타입 인자를 알 수 있다.
162 |
163 | 따라서 컴파일러는 타입 인자로 쓰인 구체적인 클래스를 참조하는 바이트코드를 생성해 삽입할 수 있다.
164 |
165 | 결과적으로 위의 예제는 아래와 같은 코드를 만들어낸다.
166 |
167 | ```kotlin
168 | for (element in this) {
169 | if (element is String) {
170 | destination.add(element)
171 | }
172 | }
173 | ```
174 |
175 | 타입 파라미터가 아니라 구체적 타입을 사용하므로 만들어진 바이트코드는 실행 시점에 벌어지는 타입 소거의 영향을 받지 않는 것이다.
176 |
177 | ### 9.2.3 실체화한 타입 파라미터의 제약
178 |
179 |
180 |
181 | 실체화한 타입 파라미터는 유용한 도구지만 몇 가지 제약이 있다.
182 |
183 | 일부는 실체화의 개념으로 인해 생기는 제약이며, 나머지는 코틀린이 실체화를 구현하는 방식에 의해 생기는 제약이다.
184 |
185 |
186 |
187 | 다음과 같은 경우에는 실체화한 타입 파라미터를 사용할 수 있다.
188 |
189 | - 타입 검사와 캐스팅(`is`, `!is`, `as`, `as?`)
190 |
191 | - 10장에서 설명할 코틀린 리플랙션 API(`::class`)
192 |
193 | - 코틀린 타입에 대응하는 `java.lang.Class`를 얻기(`::class.java`)
194 |
195 | ```kotlin
196 | inline fun
197 | Context.startActivity() {
198 | val intent = Intent(this, T::class.java)
199 | startActivity(intent)
200 | }
201 |
202 | startActivity()
203 | ```
204 |
205 | - 다른 함수를 호출할 때 타입 인자로 사용
206 |
207 |
208 |
209 | 하지만 다음과 같은 일은 할 수 없다.
210 |
211 | - 타입 파라미터 클래스의 인스턴스 생성하기
212 | - 타입 파라미터 클래스의 동반 객체 메서드 호출하기
213 | - 실체화한 타입 파라미터를 요구하는 함수를 호출하면서 실체화하지 않은 타입 파라미터로 받은 타입을 타입 인자로 넘기기
214 | - 클래스, 프로퍼티, 인라인 함수가 아닌 함수의 타입 파라미터를 `reified`로 지정하기
215 |
216 |
217 |
218 | 마지막으로, 인라인 함수는 자신에게 전달되는 모든 람다와 함께 인라이닝된다.
219 |
220 | 따라서 인라이닝을 파급하고 싶지 않은 경우에 8장에서 배운 `noinline` 변경자를 함수 타입 파라미터에 붙여서 인라이닝을 금지할 수도 있다.
--------------------------------------------------------------------------------
/Chapter9-3.md:
--------------------------------------------------------------------------------
1 | # 09. 제네릭스
2 |
3 | - 이전 장에서 이미 살펴본 제네릭 설명
4 | - 실체화한 타입 파라미터나 선언 지점 변성 등의 새로운 내용 설명
5 | - 실체화한 타입 파라미터를 사용하면 인라인 함수 호출에서 타입 인자로 쓰인 구체적인 타입을 실행 시점에 알 수 있다.
6 | - 선언 지점 변성을 사용하면 기저 타입은 같지만 타입 인자가 다른 두 제네릭 타입 Type와 Type가 있을 때 타입 인자 A와 B의 상위/하위 타입 관계에 따라 두 제네릭 타입의 상위/하위 타입 관계가 어떻게 되는지 지정할 수 있다.
7 |
8 | ## 제네릭 타입 파라미터
9 |
10 | - 제네릭스를 사용하면 타입 파라미터를 받는 타입을 정의할 수 있다.
11 | - 제네릭 타입의 인스턴스를 만들려면 타입 파라미터를 구체적인 타입 인자로 치환해야 한다.
12 | - 타입 파라미터를 사용하면 “이 변수는 문자열을 담는 리스트다” 라고 말할 수 있다. → `List`
13 | - 코틀린 컴파일러는 보통 타입과 마찬가지로 타입 파라미터도 추론할 수 있다.
14 | - `val authors = listOf(”Dmitry”, “Svetlana”)` → `List` 임을 추론
15 | - 하지만 빈 리스트를 만들 때는 타입 인자를 추론할 근거가 없기 때문에 직접 타입 인자를 명시해야 한다. 변수의 타입을 지정해도 되고 변수를 만드는 함수의 타입 인자를 지정해도 된다.
16 | - `val readers: MutableList = mutableListOf()`
17 | - `val readers: mutableListOf()`
18 |
19 | **note**
20 |
21 |
28 |
29 | ### 제네릭 함수와 프로퍼티
30 |
31 | - 리스트를 다루는 함수를 작성한다면 모든 리스트를 다룰 수 있는 함수를 원할 것이다. 이때 제네릭 함수를 작성해야 한다.
32 | - 컬렉션을 다루는 라이브러리 함수는 대부분 제네릭 함수다.
33 |
34 | `Example`
35 |
36 | 
37 |
38 | - 이런 함수를 포함할 때 타입 인자를 명시적으로 지정할 수 있으나 대부분 컴파일러가 타입 인자를 추론할 수 있다.
39 |
40 | `리스트 9.1 제네릭 함수 호출하기`
41 |
42 | ```kotlin
43 | >>> val letters = ('a'..'z').toList()
44 | >>> println(letters.slice(0..2)) //타입 인자를 명시적으로 지정한다.
45 | [a,b,c]
46 |
47 | >>> println(letters.slice(10..13)) // T가 Char라는 사실을 추론한다.
48 | [k, l, m, n]
49 | ```
50 |
51 |
52 | `리스트 9.2 제네릭 고차 함수 호출하기`
53 |
54 | ```kotlin
55 | val authors = listOf("Dmitry", "Svetlana")
56 | val readers = mutalbleListOf(/* ... */)
57 |
58 | fun List.filter(predicate: (T) -> Boolean): List
59 | >>> readers.filter {it !in authors}
60 | ```
61 |
62 | - filter를 호출하는 readers의 타입이 List이라는 것을 알고 이후로 T가 String이라는 사실을 추론한다.
63 | - 클래스나 인터페이스 안에 정의된 메소드, 확장 함수 또는 최상위 함수에서 타입 파라미터를 선언할 수 있다.
64 |
65 | **note**
66 |
67 |
78 |
79 | ### 제네릭 클래스 선언
80 |
81 | - 자바와 마찬가지로 코틀린에서도 타입 파라미터를 넣은 꺽쇠 기호(<>)를 클래스 이름 뒤에 붙이면 클래스를 제네릭하게 만들 수 있다.
82 | - 타입 파라미터를 이름 뒤에 붙이고 나면 클래스 본문 안에서 타입 파라미터를 다른 일반 타입처럼 사용할 수 있다.
83 | - 제네릭 클래스를 확장하는 클래스를 정의하려면 기반 타입의 제네릭 파라미터에 대해 타입 인자를 지정해야 한다. → 구체적인 타입 or 타입 파라미터로 받은 타입 가능
84 |
85 | ```kotlin
86 | class stringList: List {
87 | override fun get(index: Int): String = ...
88 | }
89 |
90 | // ArrayList의 제네릭 타입 파라미터 T를 List의 타입 인자로 사용한다.
91 | class ArrayList: List {
92 | override fun get(index: Int): T =...
93 | }
94 | ```
95 |
96 | - ArrayList 클래스는 자신만의 타입 파라미터 T를 정의하면서 그 T를 기반 클래스의 타입 인자로 사용한다.
97 | - ArrayList에서 T는 List의 T와 전혀 다른 타입 파라미터이며, 실제로는 T가 아니라 다른 이름을 사용해도 의미에는 차이가 없다.
98 | - StringList 클래스는 String 타입의 원소만을 포함한다. 따라서 String을 기반 타입의 타입 인자로 지정한다. 하위 클래스에서 상위 클래스에 정의된 함수를 오버라이드하거나 사용하려면 타입 인자 T를 구체적 타입 String으로 치환해야 한다.
99 |
100 | ```kotlin
101 | override fun get(index: Int): String {
102 | TODO("Not yet implemented")
103 | }
104 | ```
105 |
106 | - 클래스가 자기 자신을 타입 인자로 참조할 수도 있다.
107 |
108 | ```kotlin
109 | interface Comparable {
110 | fun compareTo(other: T): Int
111 | }
112 |
113 | class String: Comparable {
114 | override fun compareTo(other: String): Int = /* ... */
115 | }
116 | ```
117 |
118 | - String 클래스는 제네릭 Comparable 인터페이스를 구현하면서 그 인터페이스의 타입 파라미터 T로 String 자신을 지정한다.
119 |
120 | 지금까지의 제네릭스는 자바 제네릭스와 비슷하나 이후에는 자바와 다른 점에 대해 설명한다.
121 |
122 | ### 타입 파라미터 제약
123 |
124 | - 타입 파라미터 제약은 클래스나 함수에 사용할 수 있는 타입 인자를 제한하는 기능이다.
125 | - List나 List에 sum함수를 적용할 수 있지만 List에는 적용할 수 없다.
126 | - 어떤 타입을 제네릭 타입의 타입 파라미터에 대한 상한으로 지정하면 그 제네릭 타입을 인스턴스화할 때 사용하는 타입 인자는 반드시 그 상한 타입이거나 그 상한 타입의 하위 타입이어야 한다.
127 | - 제약을 가하려면 타입 파라미터 이름 뒤에 콜론(:)을 표시하고 그 뒤에 상한 타입을 적으면 된다.
128 |
129 | `fun **** List.sum() : T`
130 |
131 | - 타입 파라미터 T에 대한 상한을 정하고 나면 T타입의 값을 그 상한 타입의 값으로 취급 가능하다.
132 |
133 | ```kotlin
134 | fun oneHalf(value: T): Double {
135 | return value.toDouble() / 2.0
136 | }
137 | ```
138 |
139 | - 타입 파라미터에 둘 이상의 제약을 가해야 하는 경우도 있다.
140 |
141 | ```kotlin
142 | fun ensureTrailingPeriod(seq: T)
143 | where T : CharSequence, T : Appendable {
144 | if (!seq.endsWith('.')) {
145 | seq.append('.')
146 | }
147 | }
148 |
149 | >>> val helloWorld = StringBuilder("Hello World")
150 | >>> ensureTrailingPeriod(helloWorld)
151 | >>> println(helloWorld)
152 | Hello World.
153 |
154 | ```
155 |
156 |
157 | ### 타입 파라미터를 널이 될 수 없는 타입으로 한정
158 |
159 | - 제네릭 클래스나 함수를 정의하고 그 타입을 인스턴스화할 때는 널이 될 수 있는 타입을 포함하는 어떤 타입으로 타입 인자를 지정해도 타입 파라미터를 치환할 수 있다.
160 | - 라는 제약은 T 타입이 항상 널이 될 수 없는 타입이 되게 보장한다.
161 |
162 | ```kotlin
163 | class Processor {
164 | fun process(value: T) {
165 | value.hashCode()
166 | }
167 | }
168 |
169 | // 해당 코드 사용 가능, 즉 null이 될 수 있음
170 | val nullableStringProcessor = Processor()
171 | nullableStringProcessor.process(null)
172 |
173 | class Processor {
174 | fun process(value: T) {
175 | value.hashCode()
176 | }
177 | }
178 |
179 | // 해당 코드 사용 불가
180 | val nullableStringProcessor = Processor()
181 | nullableStringProcessor.process(null)
182 |
183 | // 컴파일 오류
184 | Error: Type argument is not within its bounds: should be subtype of 'Any'
185 | ```
186 |
187 | - 타입 파라미터를 널이 될 수 없는 타입으로 제약하기만 하면 타입 파라미터는 널이 될 수 없다. 즉 Any가 아니더라도 다른 타입을 사용해도 된다.
188 |
189 | ## 실행 시 제네릭스의 동작: 소거된 타입 파라미터와 실체화된 타입 파라미터
190 |
191 | - JVM의 제네릭스는 보통 타입 소거(type erasure)를 사용해 구현된다. 이는 실행 시점에 제네릭 클래스의 인스턴스에 타입 인자 정보가 들어있지 않다는 뜻이다.
192 | - 이 절에서는 코틀린 타입 소거가 실용적인 면에서 어떤 영향을 끼치는지 살펴보고 함수를 inline으로 선언함으로써 이런 제약을 어떻게 우회하는지 살펴본다. (inline으로 선언 시 타입 인자자 지워지지 않게 함 → **실체화**)
193 |
194 | ### 실행 시점의 제네릭: 타입 검사와 캐스트
195 |
196 | - 자바와 마찬가지로 코틀린 제네릭 타입 인자 정보는 런타임에 지워진다. 즉 인스턴스를 생성할 때 쓰인 타입 인자에 대한 정보를 유지하지 않는다.
197 | - List 객체를 만들고 그 안에 문자열을 넣더라도 실행 시점에 오직 List로만 볼 수 있다.
198 | - List 객체가 어떤 타입의 원소를 저장하는지 실행 시점에는 알 수 없다.
199 |
200 | 
201 |
202 |
203 | **타입 소거의 한계**
204 |
205 | - 실행 시점에 타입 인자를 검사할 수 없다, 단 List인지 까지는 알아낼 수 있다. (문자열 인지, 다른 객체 인지는 x)
206 |
207 | ```kotlin
208 | if (value is List) {...}
209 |
210 | ERROR: Cannot check for instance of erased type
211 | ```
212 |
213 | - 저장해야 하는 타입 정보의 크기가 줄어들어서 전반적인 메모리 사용량이 줄어든다는 장점이 있다.
214 | - 리스트인지 맵인지 등의 정보는 스타 프로젝션(start projection)을 사용하면 된다. 타입 파라미터가 2개 이상이면 모든 타입 파라미터에 * 포함
215 |
216 | `if (value is List<*>) {...}`
217 |
218 | - as나 as? 캐스팅에도 제네릭 타입을 사용할 수 있다. 하지만 다른 타입으로 캐스팅해도 캐스팅에 성공한다. 하지만 List 으로 만들경우 String을 Number 사용하려고 하면 ClassCastException이 발생한다.
219 |
220 | ```kotlin
221 | fun printSum(c: Collection<*>) {
222 | val intList = c as? List
223 | ?: throw IllegalArgumentException("List is expected")
224 | println(intList.sum())
225 | }
226 | ```
227 |
228 | - 코틀린 컴파일러는 컴파일 시점에 타입 정보가 주어진 경우에는 is 검사를 수행하게 허용한다.
229 |
230 | ```kotlin
231 | fun printSum(c: Collection) {
232 | if (c is List) {
233 | println(c.sum())
234 | }
235 | }
236 | ```
237 |
238 | - c 컬렉션이 Int 값을 저장한다는 사실이 알려져 있으므로 c가 List인지 검사할 수 있다.
239 |
240 | 코틀린은 제네릭 함수의 본문에서 그 함수의 타입 인자를 가리킬 수 있는 특별한 기능은 없지만 inline 함수 안에서는 타입 인자를 사용할 수 있다.
241 |
242 | ### 실체화한 타입 파라미터를 사용한 함수 선언
243 |
244 | - 코틀린 제네릭 타입의 타입 인자 정보는 실행 시점에 지워지므로 제네릭 함수가 호출되도 그 함수의 본문에서는 호출 시 쓰인 타입 인자를 알 수 없다.
245 |
246 | `fun isA(value: Any) value is T`
247 |
248 | - 하지만 inline 키워드를 붙이면 컴파일러는 그 함수를 호출한 식을 모두 함수 본문으로 바꾼다. 이로써 실행 시점에 타입이 T의 인스턴스인지를 검사할 수 있다.
249 |
250 | ```kotlin
251 | // reified 키드는 이 타입 파라미터가 실행 시점에 지워지지 않음을 표시한다.
252 | inline fun isA(value: Any) = value is T
253 | ```
254 |
255 |
256 | `리스트 9.9 filterIsInstance를 간단하게 정리한 버전`
257 |
258 | ```kotlin
259 | inline fun Iterable<*>.filterIsInstance(): List {
260 | val destination = mutableListOf()
261 | for (element in this) {
262 | if (element is T) {
263 | destination.add(element)
264 | }
265 | }
266 | return destination
267 | }
268 | ```
269 |
270 |
279 |
280 | ```kotlin
281 | for (element in this) {
282 | if (element is String) {
283 | destination.add(element)
284 | }
285 | }
286 | ```
287 |
288 | ### 실체화한 타입 파라미터로 클래스 참조 대신
289 |
290 | - java.lang.Class 타입 인자를 파라미터로 받는 API에 대한 코틀린 어댑터를 구축하는 경우 실체화한 타입 파라미터를 자주 사용한다.
291 | - ServiceLoader는 어떤 추상 클래스나 인터페이스를 표현하는 java.lang.Class를 받아서 그 클래스나 인스턴스를 구현한 인스턴스를 반환한다.
292 |
293 | `val serviceImpl = ServiceLoader.load(Service::class.java)`
294 |
295 | - loadService 함수 정의
296 |
297 | ```kotlin
298 | inline fun loadService() {
299 | return ServiceLoader.load(T::class.java)
300 | }
301 | ```
302 |
303 |
304 | ### 실체화한 타입 파라미터의 제약
305 |
306 | 다음과 같은 경우에 실체화한 타입 파라미터를 사용할 수 있다.
307 |
308 | - 타입 검사와 캐스팅(is, !is, as, as?)
309 | - 10장에서 설명할 코틀린 리플렉션 API(::class)
310 | - 코틀린 타입에 대응는 java.lang.Class를 얻디(::class.java)
311 | - 다른 함수를 호출할 때 타입 인자로 사용
312 |
313 | 하지만 다음과 같은 일은 할 수 없다.
314 |
315 | - 타입 파라미터 클래스의 인스턴스 생성하기
316 | - 타입 파라미터 클래스의 동반 객체 메소드 호출하기
317 | - 실체화한 타입 파라미터를 요구하는 함수를 호출하면서 실체화하지 않은 타입 파라미터로 받은 타입을 타입 인자로 넘기기
318 | - 클래스, 프로퍼티, 인라인 함수가 아닌 함수의 타입 파라미터를 reified로 지정하기
319 |
320 | ## 변성: 제네릭과 하위 타입
321 |
322 | - 변성 개념은 List와 List와 같이 기저 타입이 같고 타입 인자가 다른 여러 타입이 서로 어떤 관계가 있는지 설명하는 개념이다.
323 | - 일반적으로 이런 관계가 왜 중요한지 먼저 설명한 다음에 코틀린에서 변성을 어떻게 표시하는지 살펴본다.
324 | - 직접 제네릭 클래스나 함수를 정의하는 경우 변성을 꼭 이해해야 한다.
325 | - 변성을 잘 활용하면 사용에 불편하지 않으면서 타입 안전성을 보장하는 API를 만들 수 있다.
326 |
327 | ### 변성이 있는 이유: 인자를 함수에 넘기기
328 |
329 | - List 타입의 파라미터를 받는 함수에 List을 넘기면 안전할까?
330 | - 원소 추가나 변경이 없는 경우에는 List을 List 대신 넘겨도 안전하다.
331 | - 하지만 어떤 함수가 리스트의 원소를 추가하거나 변경한다면 타입 불일치가 생길 수 있다.
332 | - 코틀린에서는 리스트의 변경 가능성에 따라 적절한 인터페이스를 선택하면 안전하지 못한 함수 호출을 막을 수 있다. 함수가 읽기 전용 리스트를 받는다면 더 구체적인 타입의 원소를 갖는 리스트를 그 함수에 넘길 수 있다. 하지만 리스트가 변경 가능하다면 그럴 수 없다.
333 |
334 | ```kotlin
335 | fun main() {
336 | printContents(listOf("abc", "bac"))
337 | val strings = mutableListOf("abc", "bac")
338 | addAnswer(strings)
339 | }
340 |
341 | // 변경 가능 리스트를 받기 위해서는 특정 타입으로 지정해야 한다.
342 | // list: MutableList
343 | fun addAnswer(list: MutableList) {
344 | list.add(42)
345 | }
346 | ```
347 |
348 | - 이후에 List와 MutableList의 변성이 왜 다른지 살펴본다. 그 내용을 이해하기 위해 **타입**과 **하위 타입**이라는 개념을 알아야 한다.
349 |
350 | ### 클래스, 타입, 하위 타입
351 |
352 | - 변수의 타입은 그 변수에 담을 수 있는 값의 집합을 지정한다.
353 | - 클래스와 타입은 같지 않다.
354 | - 하나의 클래스는 적어도 둘 이상의 타입을 구성할 수 있다. → `var x: String, var x: String?`
355 | - 제네릭은 더 복잡하다. List는 타입이 아니라 클래스다. 하지만 타입 인자를 치환한 List, List List> 등은 모두 타입이다.
356 | - 타입 사이의 관계를 논하기 위해 하윕 타입을 알아야 한다. 어떤 타입 A의 값이 필요한 모든 장소에 어떤 타입 B의 값을 넣어도 아무 문제가 없다면 타입 B는 타입 A의 하위 타입이다.
357 |
358 | 
359 |
360 | - 하위 타입인지는 컴파일러가 변수 대입이나 함수 인자 전달 시 하위 타입 검사를 매번 수행하기 때문에 중요하다.
361 | - **하위 타입**과 **하위 클래스**는 근본적으로 같다. Int 클래스는 Number의 하위 클래스이므로 Int는 Number의 하위 타입이다. 동일하게 어떤 인터페이스를 구현하는 클래스의 타입은 그 인터페이스 타입의 하위 타입이다.
362 | - 널이 될 수 없는 타입은 널이 될 수 있는 타입의 하위 타입이다. 하지만 두 타입 모두 같은 클래스에 해당한다.
363 |
364 | 
365 |
366 | - 제네릭 타입을 다룰 때 하위 클래스와 하위 타입의 차이는 더욱 중요해진다. 제네릭 타입을 인스턴스화할 때 타입 인자가 서로 다른 타입이 들어가면 인스턴스 타입 사이의 하위 타입 관계가 성립하지 않으면 그 제네릭 타입을 **무공변(invariant)**이라고 말한다.
367 | - 즉 MutableList는 항상 MutableList의 하위 타입이 아니다.
368 | - `Example` → MutableList MutableList은 서로 하위 타입이 아니다.
369 | - 하지만 코틀린의 List 인터페이스는 읽기 전용 컬렉션을 표현한다. 즉 A가 B의 하위 타입이면 List는 List의 하위 타입이다. 그런 클래스나 인터페이스를 **공변적(covariant)**이라고 말한다.
370 | - 자바에서는 읽기 전용 타입이 존재하지 않기 때문에 모든 클래스가 무공변이다.
371 |
372 | ### 공변성: 하위 타입 관계를 유지
373 |
374 | - 코틀린에서 제네릭 클래스가 타입 파라미터에 대해 공변적임을 표시하려면 타입 파라미터 이름 앞에 out을 넣어야 한다.
375 |
376 | ```kotlin
377 | interface Producer { // 클래스가 T에 대해 공변적이라고 선언한다.
378 | fun produce(): T
379 | }
380 | ```
381 |
382 | - 클래스의 타입 파라미터를 공변적으로 만들면 함수 정의에 사용한 파라미터 타입과 타입 인자의 타입이 정확히 일치하지 않더라도 그 클래스의 인스턴스를 함수 인자나 반환 값으로 사용할 수 있다.
383 |
384 | `리스트 9.11 무공변 컬렉션 역할을 하는 클래스 정의하기`
385 |
386 | ```kotlin
387 | open class Animal {
388 | fun feed() {}
389 | }
390 |
391 | class Herd {
392 | val size: Int get() = ...
393 | operator fun get(i: Int): T {
394 | ...
395 | }
396 | }
397 |
398 | fun feedAll(animals: Herd) {
399 | for(i in 0 until animals.size) {
400 | animals[i].feed()
401 | }
402 | }
403 | ```
404 |
405 | `리스트 9.12 무공변 컬렉션 역할을 하는 클래스 사용하기`
406 |
407 | ```kotlin
408 | class Cat: Animal() {
409 | fun cleanLitter() {}
410 | }
411 |
412 | fun takeCareOfCats(cats: Herd) {
413 | for (i in 0 until cats.size) {
414 | cats[i].cleanLitter()
415 | // feedAll(cats)
416 | // Error: inferred type is Herd, but Herd
417 | // was expected 라는 오류가 발생한다.
418 | }
419 | }
420 | ```
421 |
422 | - Herd 클래스의 T 타입 파라미터에 대해 아무 변성도 지정하지 않았기 때문에 고양이 무리는 동물 무리의 하위 클래스가 아니다.
423 | - 명시적으로 타입 캐스팅을 할 수 있긴 하지만 코드가 장황해지고 실수 하기 쉽다. 또한 강제 캐스팅은 올바른 방법이 아니다.
424 | - 이를 해결하기 위해 Herd를 공변적인 클래스로 만들 수 있다.
425 |
426 | `리스트 9.13 공변적 컬렉션 역할을 하는 클래스 사용하기`
427 |
428 | ```kotlin
429 | class Herd {}
430 | fun takeCareOfCats(cats: Herd) {
431 | for (i in 0 until cats.size) {
432 | cats[i].cleanLitter()
433 | feedAll(cats)
434 | }
435 | ```
436 |
437 | - 타입 파라미터를 공변적으로 지정하면 클래스 내부에서 그 파라미터를 사용하는 방법을 제한한다.
438 | - 즉, 타입 안전성을 보장하기 위해 공변적 파라미터는 항상 아웃 위치에만 있어야 한다. 이는 클래스가 T 타입의 값을 생산할 수는 있지만 T 타입의 값을 소비할 수는 없다는 뜻이다.
439 | - 함수 파라미터 타입은 인 위치, 반환 타입은 아웃 위치에 해당한다.
440 |
441 | 
442 |
443 | - 코틀린의 List는 읽기 전용이다. 따라서 그 안에는 T 타입의 원소를 반환하는 get 메소드는 있지만 리스트에 T 타입의 값을 추가하거나 리스트에 있는 기존 값을 변경하는 메소드는 없다. 따라서 List는 T에 대해 공변적이다.
444 |
445 | ```kotlin
446 | interface List : Collection {
447 | operator fun get(index: Int): T // T는 항상 아웃 위치에 쓰인다.
448 |
449 | // public abstract fun indexOf(element: E): kotlin.Int 이것은 무엇??
450 | }
451 | ```
452 |
453 | - 이런 위치 규칙은 오직 외부에서 볼 수 있는 (public, protected, internal) 클래스 API에만 적용할 수 있다. 비공개(private) 메소드의 파라미터는 인도 아니고 아웃도 아닌 위치다.
454 |
455 | ### 반공변성: 뒤집힌 하위 타입 관계
456 |
457 | - 반공변성은 공변성의 반대라 할 수 있다. 반공변 클래스의 하위 타입 관계는 공변 클래스의 경우와 반대다.
458 |
459 | ```kotlin
460 | interface Comparator {
461 | fun compare(e1: T, e2: T): Int {...}
462 | }
463 | ```
464 |
465 | - 이 인터페이스의 메소드는 T 타입의 값을 소비하기만 한다. 이는 T가 인 위치에서만 쓰인다는 뜻이다. 따라서 T 앞에는 in 키워드를 붙여야만 한다.
466 |
467 | ### 사용 지점 변성: 타입이 언급되는 지점에서 변성 지정
468 |
469 | ### 스타 프로젝션: 타입 인자 대신 * 사용
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 | # Kotlin-in-Action-Study
4 |
5 | Kotlin in Action 스터디 자료 저장소입니다.
6 |
7 |
8 |
9 | ## Wiki
10 |
11 | 1. [규칙](https://github.com/develop-playground/Kotlin-in-Action-Study/wiki/Rule)
12 | 2. [진행 방식](https://github.com/develop-playground/Kotlin-in-Action-Study/wiki/%EC%A7%84%ED%96%89-%EB%B0%A9%EC%8B%9D)
13 |
14 |
15 |
16 | ## Project
17 |
18 | ### 편의점 포스기 구현하기
19 |
20 | - 무엇을 구현하면 좋을까? : 메뉴 CRUD, 한 주문에 고른 메뉴의 가격 합, 하루 매출 중에 카드 결제, 현금 결제 구분하여 가격 합 출력, `enum`으로 현금/카드를 구분해서 출력, 시작, 종료, 프로세스 선택하기, 결제 방식이나 상태 고르는 기능
21 |
22 | ### 저장소
23 |
24 | https://github.com/ByeongSoon/kotlin-in-action-pos - Byeongsoon
25 |
26 | https://github.com/hongbeomi/POS - Hongbeom
27 |
28 | https://github.com/MoochiPark/kotlin-in-action-pos - Daewon
29 |
30 | https://github.com/junhyung0927/Kotlin-InAction - Junhyeong
31 |
32 | https://github.com/qkrcksduf/pos - Chanyeol
33 |
34 | https://github.com/isoono/Kotlin-in-Action - Soonho
35 |
36 | https://github.com/wisoftMY/kotlin-study - Minyoung
37 |
38 | https://github.com/LeeSM0518/kotlin-tutorial-project - Sangmin
39 |
40 |
41 |
42 | ## Contents
43 |
44 | - [Chapter1. 코틀린이란 무엇이며, 왜 필요한가?](https://github.com/develop-playground/Kotlin-in-Action-Study/blob/main/Chapter1.md)
45 | - [Chapter2. 코틀린 기초](https://github.com/develop-playground/Kotlin-in-Action-Study/blob/main/Chapter2.md)
46 | - [Chapter3. 함수 정의와 호출](https://github.com/develop-playground/Kotlin-in-Action-Study/blob/main/Chapter3.md)
47 | - [Chapter4. 클래스, 객체, 인터페이스](https://github.com/develop-playground/Kotlin-in-Action-Study/blob/main/Chapter4.md)
48 | - [Chapter5. 람다로 프로그래밍](https://github.com/develop-playground/Kotlin-in-Action-Study/blob/main/Chapter5.md)
49 | - [Chapter6. 코틀린 타입 시스템](https://github.com/develop-playground/Kotlin-in-Action-Study/blob/main/Chapter6.md)
50 | - [Chapter7(1). 연산자 오버로딩과 기타 관계](https://github.com/develop-playground/Kotlin-in-Action-Study/blob/main/Chapter7-1.md)
51 | - [Chapter7(2). 연산자 오버로딩과 기타 관계](https://github.com/develop-playground/Kotlin-in-Action-Study/blob/main/Chapter7-2.md)
52 | - [Chapter8(1). 고차함수 : 파라미터와 반환 값으로 람다 사용](https://github.com/develop-playground/Kotlin-in-Action-Study/blob/main/Chapter8-1.md)
53 | - [Chapter8(2). 고차함수 : 파라미터와 반환 값으로 람다 사용](https://github.com/develop-playground/Kotlin-in-Action-Study/blob/main/Chapter8-2.md)
54 | - [Chapter9 (1). 제네릭](https://github.com/develop-playground/Kotlin-in-Action-Study/blob/main/Chapter9-1.md)
55 | - [Chapter9 (2). 제네릭](https://github.com/develop-playground/Kotlin-in-Action-Study/blob/main/Chapter9-2.md)
56 | - [Chapter9 (3). 제네릭](https://github.com/develop-playground/Kotlin-in-Action-Study/blob/main/Chapter9-3.md)
57 |
--------------------------------------------------------------------------------
 41 |
42 | 🥀`문(statement)`과 `식(expression)`의 구분
41 |
42 | 🥀`문(statement)`과 `식(expression)`의 구분  420 | Expr 인터페이스에는 두 가지 구현 클래스가 존재한다. 따라서 식을 평가하려면 두 가지 경우를 고려해야 한다.
421 |
422 | - 어떤 식이 수라면 그 값을 반환한다.
423 | - 어떤 식이 합계라면 좌항과 우항의 값을 계산한 다음에 그 두 값을 합한 값을 반환한다.
424 |
425 | 코틀린에서 if를 사용해서 자바 스타일로 함수를 작성해보자.
426 |
427 | ```kotlin
428 | fun eval(e: Expr): Int {
429 | if (e is Num) {
430 | val n = e as Num
431 | return n.value
432 | }
433 | if (e is Sum) {
434 | return eval(e.right) + eval(e.left)
435 | }
436 | throw IllegalArgumentException("Unknown expression")
437 | }
438 | ```
439 |
440 | 코틀린에서는 is를 사용해 변수 타입을 검사한다. is 검사는 자바의 instanceOf와 비슷하다. 하지만 자바에서 어떤 변수의 타입을 instanceOf로 확인한 다음에 그 타입에 속한 멤버에 접근하기 위해서는 명시적으로 변수 타입을 캐스팅해야 한다. 이런 멤버 접근을 여러 번 수행해야 한다면 변수에 따로 캐스팅한 결과를 저장한 후 사용해야 한다. 코틀린에서는 프로그래머 대신 **컴파일러가 캐스팅을 해준다**. 어떤 변수가 원하는 타입인지 일단 is로 검사하고 나면 굳이 변수를 원하는 타입으로 캐스팅하지 않아도 마치 처음부터 그 변수가 원하는 타입으로 선언된 것처럼 사용할 수 있다. 이를 **스마트 캐스트**(smart cast)라고 부른다.
441 |
442 | eval 함수에서 e의 타입이 Num인지 검사한 다음 부분에서 컴파일러는 e의 타입을 Num으로 해석한다. 그렇기 때문에 Num의 프로퍼티인 value를 명시적 캐스팅 없이 e.value로 사용할 수 있다. Sum의 프로퍼티인 right와 left도 마찬가지다. IDE를 사용하면 스마트 캐스트 부분의 배경색을 달리 표시해주므로 이런 변환이 자동으로 이뤄졌음을 쉽게 알 수 있다.
443 |
444 | 스마트 캐스트는 is로 변수에 든 값의 타입을 검사한 다음에 그 값이 바뀔 수 없는 경우에만 작동한다. 예를 들어 앞에서 본 예제처럼 클래스의 프로퍼티에 대해 스마트 캐스트를 사용한다면 그 프로퍼티는 반드시 val이어야 하며 커스텀 접근자를 사용한 것이어도 안된다. val이 아니거나 val이지만 커스텀 접근자를 사용하는 경우에는 해당 프로퍼티에 대한 접근이 항상 같은 값을 내놓는다고 확신할 수 없기 때문이다.
445 |
446 | 원하는 타입으로 명시적으로 타입 캐스팅하려면 위 코드처럼 `as` 키워드를 사용한다.
447 |
448 |
420 | Expr 인터페이스에는 두 가지 구현 클래스가 존재한다. 따라서 식을 평가하려면 두 가지 경우를 고려해야 한다.
421 |
422 | - 어떤 식이 수라면 그 값을 반환한다.
423 | - 어떤 식이 합계라면 좌항과 우항의 값을 계산한 다음에 그 두 값을 합한 값을 반환한다.
424 |
425 | 코틀린에서 if를 사용해서 자바 스타일로 함수를 작성해보자.
426 |
427 | ```kotlin
428 | fun eval(e: Expr): Int {
429 | if (e is Num) {
430 | val n = e as Num
431 | return n.value
432 | }
433 | if (e is Sum) {
434 | return eval(e.right) + eval(e.left)
435 | }
436 | throw IllegalArgumentException("Unknown expression")
437 | }
438 | ```
439 |
440 | 코틀린에서는 is를 사용해 변수 타입을 검사한다. is 검사는 자바의 instanceOf와 비슷하다. 하지만 자바에서 어떤 변수의 타입을 instanceOf로 확인한 다음에 그 타입에 속한 멤버에 접근하기 위해서는 명시적으로 변수 타입을 캐스팅해야 한다. 이런 멤버 접근을 여러 번 수행해야 한다면 변수에 따로 캐스팅한 결과를 저장한 후 사용해야 한다. 코틀린에서는 프로그래머 대신 **컴파일러가 캐스팅을 해준다**. 어떤 변수가 원하는 타입인지 일단 is로 검사하고 나면 굳이 변수를 원하는 타입으로 캐스팅하지 않아도 마치 처음부터 그 변수가 원하는 타입으로 선언된 것처럼 사용할 수 있다. 이를 **스마트 캐스트**(smart cast)라고 부른다.
441 |
442 | eval 함수에서 e의 타입이 Num인지 검사한 다음 부분에서 컴파일러는 e의 타입을 Num으로 해석한다. 그렇기 때문에 Num의 프로퍼티인 value를 명시적 캐스팅 없이 e.value로 사용할 수 있다. Sum의 프로퍼티인 right와 left도 마찬가지다. IDE를 사용하면 스마트 캐스트 부분의 배경색을 달리 표시해주므로 이런 변환이 자동으로 이뤄졌음을 쉽게 알 수 있다.
443 |
444 | 스마트 캐스트는 is로 변수에 든 값의 타입을 검사한 다음에 그 값이 바뀔 수 없는 경우에만 작동한다. 예를 들어 앞에서 본 예제처럼 클래스의 프로퍼티에 대해 스마트 캐스트를 사용한다면 그 프로퍼티는 반드시 val이어야 하며 커스텀 접근자를 사용한 것이어도 안된다. val이 아니거나 val이지만 커스텀 접근자를 사용하는 경우에는 해당 프로퍼티에 대한 접근이 항상 같은 값을 내놓는다고 확신할 수 없기 때문이다.
445 |
446 | 원하는 타입으로 명시적으로 타입 캐스팅하려면 위 코드처럼 `as` 키워드를 사용한다.
447 |
448 |  44 |
45 | 컴파일러는 두 리스트를 서로 다른 타입으로 인식하지만 실행 시점에 이 둘은 완전히 같은 타입의 객체다.
46 |
47 | 하지만 컴파일러가 타입 인자를 알고 올바른 타입의 값만 각 리스트에 넣도록 보장해주므로 각각 문자열과 정수만 들어있다고 보통은 가정할 수 있다.
48 |
49 |
50 |
51 | 이젠 타입 소거로 인해 생기는 한계에 대해 알아보자.
52 |
53 | 먼저, 타입 인자를 따로 저장하지 않기 때문에 실행 시점에 타입 인자를 검사할 수 없다.
54 |
55 | 예를 들어 어떤 리스트가 문자열로 이뤄진 리스트인지 다른 객체로 이뤄졌는지 실행 시점에 검사할 수 없다.
56 |
57 | 일반적으로 발하면 `is` 검사에서 타입 인자로 지정한 타입을 검사할 수는 없다.
58 |
59 | ```kotlin
60 | >>> if (value is List
44 |
45 | 컴파일러는 두 리스트를 서로 다른 타입으로 인식하지만 실행 시점에 이 둘은 완전히 같은 타입의 객체다.
46 |
47 | 하지만 컴파일러가 타입 인자를 알고 올바른 타입의 값만 각 리스트에 넣도록 보장해주므로 각각 문자열과 정수만 들어있다고 보통은 가정할 수 있다.
48 |
49 |
50 |
51 | 이젠 타입 소거로 인해 생기는 한계에 대해 알아보자.
52 |
53 | 먼저, 타입 인자를 따로 저장하지 않기 때문에 실행 시점에 타입 인자를 검사할 수 없다.
54 |
55 | 예를 들어 어떤 리스트가 문자열로 이뤄진 리스트인지 다른 객체로 이뤄졌는지 실행 시점에 검사할 수 없다.
56 |
57 | 일반적으로 발하면 `is` 검사에서 타입 인자로 지정한 타입을 검사할 수는 없다.
58 |
59 | ```kotlin
60 | >>> if (value is List