135 | 136 | 엔터프라이즈 시스템 개발이 너무 복잡했다. 137 | - 비즈니스 로직 이외에도 고려할 사항이 많았다 138 | - 개발이 진행도미에 따라 로직이 복잡해지고, 잦은 변경 요구가 있었기 때문이다 139 | - 스프링은 복잡함을 해결하기 위해 DI,IoC,AOP,PSA의 특징을 가지고있다 140 | - IoC - 결합도 낮춰준다 141 | - AOP - 응집도 높혀준다 142 | 143 | >[참고](https://galid1.tistory.com/493) 144 | 145 | **POJO(Plain Old Java Object)** 146 | - __객체지향의 원리에 충실하면서__ 147 | - __환경과 기술에 종속되지 않고__ 148 | - 필요에 따라 재활용될수있는 방식으로 설계된 오브젝트 149 | - ex) Servlet 클래스는 POJO가 아니다. 150 | - 왜냐하면, 우리마음대로 만들수 없고 , 규칙에 맞게 만들어야하기 때문. 151 | 152 | ## 스프링 버전 몇 사용하셨나요? (버전별 차이) 153 | - springBootVersion 2.1.7 버전 사용해봤습니다. 154 | 155 | ### 2.3이전에는 156 | 스프링 부트 앱 만들면서 -> 웹이라는 모듈 추가하면 -> 웹이 vaildation 모듈 같이 가져왔다 157 | ###2.3부터 158 | 스프링 부트 앱 만들면서 -> 웹 추가해도 벨리데이션 모듈 가져오지 않는다 159 | 160 | ``` 161 | spring-boot-starter-validation은 기본적으로 가져오지 않는다 162 | -> 객체가 빈값인지 확인해주는 것 , 빈값이면 badRequest나오게 test 163 | @NotEmpty 추가 못한다 164 | 사용하고 싶다면 직접 모듈 가져올것 165 | ``` 166 | 167 | > [백기선님 유튜브 설명](https://www.youtube.com/watch?v=cP8TwMV4LjE) 168 | 169 | 170 | * 스프링 security 사용해봤나요? 171 | -------------------------------------------------------------------------------- /README.md: -------------------------------------------------------------------------------- 1 | # Tech Interview 2 | 3 | **기술 면접 대비를 위한 기본 개념을 정리하는 Repository 입니다.** 4 | 5 | > 자세한 내용은 contents 폴더에서 확인 가능하며 6 | 모든 문제에 대한 정리 & 짧은 답변은 [이곳](https://docs.google.com/spreadsheets/d/1gi9yQ_wlg2utcs15mkkktFG-0xgycFhgZvOb9KIqHH0/edit?usp=sharing)에서 확인 가능합니다. 7 | 8 | 9 |
10 |
11 | [](https://github.com/devham76)
12 | [](http://hits.dwyl.io/devham76/tech-interview-study)
13 |
14 |
15 |
16 |
17 | **:book: Contents**
18 | 1. [Data Structure](#1-data-structure)
19 | 2. [Network](#2-network)
20 | 3. [Operating System](#3-operating-system)
21 | 4. [Database](#4-database)
22 | 5. [Design Pattern](#5-design-pattern)
23 | 6. [Algorithm](#6-algorithm)
24 | 7. [Java](#7-java)
25 | 8. [Spring](#8-spring)
26 | 9. [Software Engineering](#9-software-engineering)
27 | 10. [ETC](#11-etc)
28 |
29 | ---
30 |
31 | ## 1. Data Structure
32 | :arrow_forward: [답변 내용](/contents/datastructure.md)
33 |
34 | ## 2. Network
35 | :arrow_forward: [답변 내용](/contents/network.md)
36 | * tcp/udp의 차이점을 설명하라
37 | * 흐름제어기법중 슬라이딩 윈도우 방식에대해 설명하라]
38 | * 브라우저에 네이버홈페이지 url을 입력했을때 일어나는 과정을 설명해라
39 | * OSI 7계층에대해 설명하여라
40 | * Restful API란?
41 |
42 | * 3-way handshaking이란?
43 | * HTTP와 HTTPS의 차이는?
44 | * GET과 POST의 차이는?
45 | * TCP/IP 프로토콜 스택 4계층으로 구분짓고 설명하라
46 | * Session과 Cookie 차이는?
47 |
48 | * iocp
49 | * http keep alive / tcp keep alive
50 | * ssl
51 | * tcp udp 패킷구조 차이점
52 | * 리피터, 허브, 브릿지, 라우터와 L2, L3, L4, L7 스위치 차이점
53 |
54 | * HTTP 자세히 설명해주세요
55 |
56 | ## 3. Operating System
57 | :arrow_forward: [답변 내용](/contents/os.md)
58 |
59 | - OS란 무엇이며, 핵심 기능은?
60 | - 부팅이 되는 과정을 설명하시오.
61 | - 프로세스의 5가지 상태에 대해 설명하시오.
62 | - 메모리 계층 구조를 설명하시오.
63 | - 캐시와 버퍼의 차이점은?
64 |
65 | * 세마포어와 뮤텍스란? 차이점은 무엇인가?
66 | * 메모리 단편화란? / 페이징과 세그멘테이션?
67 | * 선점스케줄링과 비선점스케줄링, 그리고 해당하는 알고리즘 한개씩 말하시오
68 | * 문맥교환이란?
69 | * PCB란?
70 |
71 | * 가상메모리란?
72 | * Deadlock이란?
73 | * 프로세스의 메모리구조?
74 | * thrashing이란?
75 | * 프로세스간 통신하는 방법은?
76 | * Thread 가 3개 생성 되었을 때 t1, t2, t3의 순서가 보장 되는 코드를 짜 보세요.
77 |
78 | ## 4. Database
79 | :arrow_forward: [답변 내용](/contents/db.md)
80 | * Primary Key, Foreign Key, ER 모델이란?
81 | * 정규화에 대해서 말해보시오, 정규화의 목적은?
82 | * 무결성에 대해 말해보시오
83 | * 조인이 무엇인지?(inner, left, right, outer)
84 | * NoSQL이란? 기존RDBMS와 다른점은?
85 |
86 | 87 | 88 | * 트랜잭션이란?(+트랜잭션의 성질) 89 | * 2단계 락킹이란? 90 | * 공유락, 배타락이란? 91 | * 색인이란? 색인을 사용했을때 장단점? 92 | * 역정규화를 하는 이유는 무엇인가? 93 | 94 | * view관련 95 | * 어떤 이상현상 생길수있을지 96 | 97 | * MySQL을 사용하셨다면, 어떤 엔진을 사용했나요? 왜 사용했나요? 98 | 99 | ## 5. Algorithm 100 | ### :pushpin: [알고리즘 ps](https://github.com/devham76/AlgorithmPS) 101 | :arrow_forward: [답변 내용](/contents/algorithm.md) 102 | 103 | * quick sort가 일어나는 과정을 설명해주세요 104 | * insertion sort가 일어나는 과정을 설명해주세요 105 | * DFS와 BFS의 차이를 말해주세요 106 | * 이분 탐색 알고리즘에 대해 설명해주세요 107 | * 알고있는 정렬 알고리즘과 그 중 좋아하는 정렬알고리즘 설명해주세요 108 | 109 | * 두개의 stack을 이용해 queue를 구현하라 110 | * LinkedList의 원소를 역순으로 출력하는 방법은? 111 | * tree와 graph를 설명하라 112 | * 해싱의 충돌을 해결하는 방법들을 설명하라 113 | * huffman encoding에 대해 설명하라 114 | 115 | * 벨만포드 알고리즘과 다익스트라 알고리즘의 차이점? 116 | * MST 알고리즘(Spanning Tree란?) 117 | * 프림 118 | * 크루스칼 119 | * Floyd-Warshall 알고리즘 120 | 121 | * 프라이어리티 큐의 구조 설명 122 | * heap에서 delete 과정을 그려라 123 | * 16진수 수를 10진수로 변경하는 코드를 작성해보세요 124 | * 이진트리, 이진 검색트리, 힙이 각각 무엇인지 설명해주세요 125 | * 해시테이블과 이진 검색트리를 비교하고 장단점을 이야기해주세요 126 | * 메모리가 제한된 모바일 기기용 주소록에 사용할 자료구조를 설계한다면 어느쪽을 쓰는것이 좋을까요? 127 | 128 | * 해쉬 테이블/큐/스택을 구현해주세요 129 | * 트리/링크드리스트 구현해주세요 130 | 131 | ## 6. Java 132 | :arrow_forward: [답변 내용](/contents/java.md) 133 | 134 | * 자바 컴파일 과정을 설명하라 135 | * String, StringBuffer, StringBuilder의 차이점에 대해 설명하라 136 | * OOP의 4가지 특징 137 | * 오버로딩과 오버라이딩의 차이 138 | * HashMap과 TreeMap의 차이 139 | 140 | * GC에 대해 설명하라 141 | * 자바의 메모리구조는? 142 | * 동등성(equals)과 동일성(==)에 대해 설명하라 143 | * 제네릭과 와일드카드에 대해 설명하라 144 | * 멀티스레딩환경에서 동기화문제를 해결하는 방법에대해 설명하라 (syncronized, atomic, volatile) 145 | 146 |
147 | 148 | * java의 접근 제어자의 종류와 특징 설명해주세요 149 | * non-static 멤버와 static멤버의 차이 설명해주세요 150 | * final 키워드 (final/finally/finalize) 설명해주세요 151 | * 인터페이스와 추상 클래스의 차이(Interface vs Abstract Class) 설명해주세요 152 | * set, list, map의 차이와 각각의 인터페이스 구현체의 종류를 설명해주세요 153 | 154 |
155 | 156 | * java8을 써보셨나요? java7에서 8로 올라오면서 어떤게 달라졌나요? 157 | * this 키워드 158 | * 자바에서 tcp udp 소켓 생성 방법 159 | * 리틀엔디안 빅엔디안 160 | * Reflection 161 | * oop 5대 원칙 162 | 163 | ## 7. Spring 164 | :arrow_forward: [답변 내용](/contents/spring.md) 165 | * IOC 란? 166 | * DI 란? 167 | * AOP 란? 168 | * 흐름(웹브라우저에서 Spring MVC로 요청했을 떄) 169 | * Bean 객체란? 170 | * 스프링 디스패처 서블릿이란 171 | * MVC1과 MVC2 패턴의 차이 172 | * Bean 생성 원리 173 | * Spring에서 AOP를 구현하는 3가지 방법. 174 | * Spring을 쓰는 이유 175 | 176 | 177 | * 스프링 버전 몇 사용하셨나요? (버전별 차이) 178 | * 스프링 security 사용해봤나요? 179 | 180 | ## 8. Software Engineering 181 | :arrow_forward: [답변 내용](/contents/software-engineering.md) 182 | * sw공학이란? 필요한 이유? 좋은 설계란? 183 | * 형상관리란? 184 | * Singleton, Adapter, Template패턴은 어떤 것인가? 왜 사용하는지? 코드 구현해보시오 185 | * 코드 결합도와 응집도란? 186 | * 블랙박스/화이트박스 테스트란? 187 | 188 | * Agile 방법론이 무엇인지 설명해주세요 189 | * 소프트웨어 생명 주기 모델은 무엇이고 어떤 모델이 있는지 설명해주세요 190 | * CVS, SVN, GIT에 대해서 아는대로 설명해 보시오. 191 | * 형상 관리를 잘못하면 어떤 문제가 발생하나요? 192 | * 객체지향과 절차지향 차이 설명해주세요 193 | 194 |
195 | 196 | * MVP패턴, MVVM패턴이란? 197 | * TDD란? 198 | * Java에서 Builder 패턴을 사용하는이유는? 199 | * Observer 패턴은? 200 | * Java에서 팩토리 메서드 패턴을 사용하는 이유는? 201 | 202 | 203 | ## 9. ETC 204 | :arrow_forward: [답변 내용](/contents/etc.md) 205 | 206 | * sass lass pass 207 | * Docker란 무엇인가요? 왜 사용하나요? 208 | * AWS를 사용해 본 경험이 있나요? 209 | * XML, json 차이 210 | * 최근 관심 있는 인터넷 이슈는 무엇인가요? 211 | * HTTP와 HTTP2의 차이 + HTTP3 212 | * apache와 nginx차이 213 | 214 | ## 10. 기술 외의 질문 215 | * 어떤 역할을 맡았고, 무슨 기술을 썼으며, 어떤 어려움이 있었고 어떻게 해결했는지 216 | * 작성한 프로젝트의 보안은 어떻게 신경썼나요? 217 | * 코딩테스트문제에서 뭐가 인상깊거나 아쉬웠는지 간단히 218 | * 어떤 실패를 했고 어떻게 극복했고 어떤것을 얻었는지 219 | * 대용량 데이터 처리를 위한 서비스 아키텍처에 대해 설명해 주세요. 그에 대한 기술도 함께 말씀해 주세요. 220 | * 무슨과목좋아하는지 221 | * 챗봇은 어떤엔진으로 구축햇는지 222 | * 우리회사에서 뭐하고싶은지 223 | * 알림톡데몬 유지보수 224 | * 개발이좋은지 유지하는게좋은지? 225 | * 전산이 적성에맞는지 226 | 227 | * 저희 회사에 대해 궁금한건 질문 해보세요 228 | 229 | :arrow_forward: [답변 내용](/contents/experience.md) 230 | 231 | --- 232 | 233 | # Reference 234 | -------------------------------------------------------------------------------- /contents/db.md: -------------------------------------------------------------------------------- 1 | # 4. Database 2 | **:book: Contents** 3 | * [Primary Key, Foreign Key, ER 모델이란?](#Primary-Key,-Foreign-Key,-ER-모델) 4 | * [정규화에 대해서 말해보시오, 정규화의 목적은?](#정규화에-대해서-말해보시오,-정규화의-목적은?) 5 | * [무결성에 대해 말해보시오](#무결성에-대해-말해보시오) 6 | * [조인이 무엇인지?(inner, left, right, outer)](#조인이-무엇인지?) 7 | * [NoSQL이란? 기존RDBMS와 다른점은?](#NoSQL이란?-기존RDBMS와-다른점은?) 8 | 9 |
10 | 11 | * [트랜잭션이란?(+트랜잭션의 성질)](#트랜잭션이란?(+트랜잭션의-성질)) 12 | * [2단계 락킹이란?](#2단계-락킹이란?) 13 | * [공유락, 배타락이란?](#공유락,-배타락이란?) 14 | * [색인이란? 색인을 사용했을때 장단점?](#색인이란?-색인을-사용했을때-장단점?) 15 | * [역정규화를 하는 이유는 무엇인가?](#역정규화를-하는-이유는-무엇인가?) 16 | 17 | * MySQL을 사용하셨다면, 어떤 엔진을 사용했나요? 왜 사용했나요? 18 | 19 | --- 20 | ## Primary Key, Foreign Key, ER 모델 21 | 22 | **Key 종류** 23 |
 24 |
25 | - Super key : 유일성 O, 최소성 X
26 | - Candidate key : 유일성 O, 최소성 O (키의 집합에서 하나라도 삭제하면 유일성 만족하지 못하는 성질)
27 | - Primary key : 후보 키 중에서 선정된 키. 유일성 O, 최소성 O / Null값 가질수 없다
28 | - Alternate Key : 후보 키에서 기본키를 뺀 모든 후보 키
29 | - Foreign Key : 다른 테이블의 Primary key를 참조하는 컬럼
30 |
31 | **ER 모델**
32 | - Entity Relation Model
33 | 
34 | - 개체(Entity), 애트리뷰트(Attribute), 관계성(Relation)으로 기술하는 데이터 모델을 말한다.
35 |
36 | > [참고](https://victorydntmd.tistory.com/126)
37 |
38 | ## 정규화에 대해서 말해보시오, 정규화의 목적은?
39 |
40 | **DB 정규화란 ?**
41 | - RDBMS의 설계에서 중복을 최소화하여 데이터를 구조화하는 프로세스
42 | - 연관성 있는 속성들을 분류하여, 각 릴레이션들에 이상현상이 생기지 않도록 하는 과정
43 | - 정규형에는 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, 6NF 까지 있다 (보통 3정규형 까지 되어있으면 정규화 되었다고 한다)
44 |
45 | **정규화 종료**
46 | - 1NF
47 | - 2NF
48 | - 3NF
49 |
50 |
51 | **DB 정규화가 필요한 이유?**
52 | - DB설계를 잘못 하면 불필요한 데이터 중복으로 인해 공간이 낭비되고 부작용을 초래할수있다.
53 | - 이러한 부작용을 이상(Anomaly)이라고 한다.
54 | - 삽입이상, 갱신이상, 삭제이상이 있다.
55 |
56 | **이상 예제**
57 | - 기본키 : student_id, course_id
58 | 
59 |
60 | **삽입 이상**
61 | - 세 데이터를 삽입하기 위해 불필요한 데이터도 함께 삽입해야 하는 문제
62 | - ex ) 아직 수업을 하나도 수강하지 않은 학생이 있다고 가정하자. 현재 KEY 를 학번과 과목코드로 지정해 놓았고 기본키로 쓰이는 컬럼은 NULL 이 될 수 없으므로 그 학생은 이 테이블에 추가 될 수가 없다. 굳이 삽입하려면 ‘미수강’ 같은 과목코드를 새로 만들어서 삽입해야 한다.
63 |
64 | **갱신 이상**
65 | - 중복 튜플 중 일부만 변경하여 데이터가 불일치하게 되는 모순
66 | - ex ) 야붕이 컴퓨터공학이 싫어서 음악학부로 옮기게 되는경우 ‘컴퓨터공학부’ 의 갯수는 과목코드의 갯수만큼 있으므로 모두 ‘음악학부’ 로 변경해주어야 한다. 이때 모두 변경하지 않고 두개만 바꾸는 경우 야붕은 컴퓨터공학부인지 음악학부인지 알 수 없게 된다.
67 |
68 | **삭제 이상**
69 | - 튜플을 삭제하면 꼭 필요한 데이터까지 함께 삭제되는 데이터 손실의 문제
70 | - ex ) 모찌가 수강정정기간에 MEC011101 라는 수업을 듣기 싫어져서 드랍하는 경우, 위 테이블에 반영하기 위해서는 모찌에 대한 행을 모두 삭제하게 된다. 수강취소를 반영하기 위해 학생등록정보를 모두 날리게 되는 것이다.
71 |
72 |
73 | > [참고] (https://yaboong.github.io/database/2018/03/09/database-normalization-1/)
74 |
75 | ## 무결성에 대해 말해보시오
76 |
77 | **무결성이란**
78 | - 데이터의 __정확성과 일관성을 유지하고 보증하는__ 것
79 |
80 | **개체 무결성**
81 | - 기본키로 설정된 컬럼은 고유한 값을 가지며 NULL허용X
82 |
83 | **참조 무결성**
84 | - 외래키 값은 NULL이거나 참조 릴레이션의 기본키 값과 동일해야 합니다.
85 | - 즉 릴레이션은 참조할 수 없는 외래키 값을 가질 수 없습니다.
86 | - 참조 관계에 있는 두 테이블의 데이터가 항상 일관된 값을 갖도록 유지하는것
87 |
88 | **도메인 무결성**
89 | - 특정 속성의 값이 그 속성이 정의된 도메인에 속한 값이어야 한다는 규정
90 | - ex) 주민등록번호에 알파벳입력되면 도메인 무결성 깨진것
91 |
92 | **고유 무결성**
93 | - 특정 속성에 대해 고유한 값을 가지도록 조건이 주어진 경우, 그 속성값은 모두 달라야 하는 제약조건을 말합니다.
94 | - ex)학생 릴레이션(테이블)에서 테이블 정의시 '이름' 속성에는 중복된 값이 없도록 제한했다면, '이름' 속성에는 중복된 이름이 있어서는 안됩니다.
95 |
96 | **NULL 무결성**
97 | - 특정 속성값에 NULL 이 올 수 없다는 조건이 주어진 경우, 그 속성값은 NULL 값이 올 수 없다는 제약조건을 말합니다.
98 |
99 | **키 무결성**
100 | - 한 릴레이션(테이블)에는 최소한 하나의 키가 존재해야 한다는 제약조건을 뜻합니다.
101 |
102 | > [참고](https://limkydev.tistory.com/161)
103 |
104 | ## 조인이 무엇인지?
105 | - inner, left, right, outer
106 | - 관련 있는 컬럼을 기준으로 행을 합쳐주는 연산
107 | 
108 |
109 |
110 | ## NoSQL이란? 기존 RDBMS와 다른점은?
111 | - NoSQL = Not Only SQL or Non relational Database
112 |
113 |
114 | **RDBMS**
115 | - 데이터는 엄격한 스키마(데이터 개체, 속성, 관계,제약조건)에 따라 table에 저장된다
116 | - 관계를 통해 연결된 여러개의 테이블에 저장
117 | - 사용
118 | - __데이터 자주 수정되는 애플리케이션 일때_
119 | - __변경될 여지 없고, 명확한 스키마가 중요할경우__
120 |
121 | - __장점__
122 | - 명확한 데이터 구조 보장 (정해진 스키마에 따라 데이터를 저장하기 때문에)
123 | - __데이터 중복을 피해,__ 공간 절약 (각 데이터에 맞게 테이블을 나눠서 저장하기 때문)
124 | - __단점__
125 | - 관계로 인한 시스템 복잡도를 고려하여 구조화 해야한다
126 | - 시스템이 복잡하면, query문 복잡, 성능 저하
127 | - 수평적 확장 어려움, 대부분 수직적 확장, 한계에 직면할 수 있다
128 |
129 | *NoSQL*
130 | - 분산처리 목적으로 나옴
131 | - 스키마X 관계X
132 | - 테이블과 같은 개념으로 컬렉션이라는 형태로 데이터를 관리
133 | - 사용
134 | - 정확한 데이터 구조 알 수 없거나 변경,확장 가능한 경우
135 | - __읽기가 많고, 변경이 적을때__
136 | - __막대한 양의 데이터 다룰때__ (수평적 확장 용이)
137 | - __장점__
138 | - 테이블간의 복잡한 관계를 생각 안해도 된다.
139 | - 스키마가 없어서, 유연하다. 언제든지 저장데이터를 조정하고 새로운 필드 추가 가능
140 | - __자주 변경도지 않는 데이터를 저장하기 유리하다__
141 | - __수평적 확장에 용이__ ,(읽기, 쓰기가 빠르다)
142 | - __단점__
143 | - __데이터 업데이트시, 중복될수__ 있어 저장 __데이터를 똑같이 관리__ 해줘야한다.(자유롭게 데이터 추가가능하여, 중복 저장될수있다)
144 | - 종류 : MongoDB, HBASE, Cassandra등
145 | >[참고](https://kimsangyeon.github.io/sql/nosql/database/2019/08/16/rdbms-nosql.html)
146 |
147 | **Redis**
148 | - Remote DIctionary System
149 | - 메모리 기반의 Key/Value Store
150 | - 빠른처리 (read/write) 속도와 검증괸 s/w 안정성 제공
151 | - 다양한 데이터 구조 저장
152 | - string, hash, lists, sets, sorted set, bitmap등
153 | - 사용하는곳
154 | - 인스타그램, 트위터 등
155 |
156 | **HBase**
157 | - 기존의 Redis NoSQL의 한계
158 | - 많은 Memory 공간을 필요, 분산 저장 시스템이 아님
159 |
160 |
161 | ## 트랜잭션이란?(+트랜잭션의 성질)
162 |
163 | - 의미 : (한 단위를 이루는) __일련의 연관된 DB조작__
164 | - 데이터 __무결성__ 을 위해 가장 좋은 방법
165 |
166 | **1. 원자성**
167 | - 트랜잭션의 연산은 데이터베이스에 __모두 반영 or 전혀 반영되지 않아야 한다.__
168 |
169 | **2. 일관성**
170 | - 트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 변환한다.
171 | - 시스템이 가지고 있는 __고정요소는 트랜잭션 수행 전과 트랜잭션 수행 완료 후의 상태가 같아야 한다.__
172 |
173 | **3. 고립성**
174 | - 둘 이상의 트랜잭션이 동시에 병행 실행되는 경우 어느 하나의 트랜잭션 실행중에 다른 트랜잭션의 연산이 끼어들 수 없다.
175 | - __수행중인 트랜잭션은 완전히 완료될 때까지 다른 트랜잭션에서 수행 결과를 참조할 수 없다.__
176 |
177 | **4. 영속성**
178 | - 성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되어야 한다.
179 | - 일단 커밋이 되면 트랜잭션에 의해 변경된 내용은 영구적이어야한다
180 | - DB시스템은 DB의 현재 상태가 유실되지 않도록 시스템 충돌 등의 문제로부터 복구할 수 있는 방법을 갖춰야 한다.
181 |
182 | > :arrow_double_up:[Top](#4-Database) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#4-Database) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview)
183 |
184 | ## 2단계 락킹이란?
185 | - 데이터가 읽거나 쓰거나 락을 해야하는데
186 | - 동시에 락을 걸수있기때문에 , 단계를 나눠서 생각해야한다
187 | - 확장단계 - 락을 걸수있고
188 | - 수축단계 - 언락
189 | - 공유락, 배타락을 따로 두고 임의로 병행접근못하게한다
190 | - 데드락 발생가능, 확장단계에서 수축단계를 기다릴수있기때문
191 |
192 | > :arrow_double_up:[Top](#4-Database) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#4-Database) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview)
193 |
194 | ## 공유락, 배타락이란?
195 | - 공유락 : 읽기만
196 | - 배타락 : 읽기+쓰기
197 | - 공유락이 걸려있을때 배타락이 허용가능한가요?
198 | - 공유락 일때 공유락은 가능. 배타락 불가능
199 | - 배타락일땐, 공유락 불가능. 배타락 불가능.
200 |
201 | > :arrow_double_up:[Top](#4-Database) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#4-Database) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview)
202 |
203 | ## 색인이란? 색인을 사용했을때 장단점?
204 | - DB에서 검색시, 테이블의 모든 데이터를 검색하면 시간이 오래걸린다
205 | - 컬럼의 값 & 해당 레코드가 저장된 주소를 키&쌍 으로 index로 만들어 관리하는것
206 |
207 | - 특징
208 | - 논리적/물리적으로 테이블과 독립적이다
209 | - 장점 : 검색 시 빠르게 탐색
210 | - 단점 : 새로운 값 추가, 삭제, 수정시 쿼리문 속도 느려진다(인덱스를 수정해야하기때문)
211 |
212 | >[참고](https://lalwr.blogspot.com/2016/02/db-index.html)
213 |
214 | >[인덱스란? Clustered Index/ Non-Clustered Index란?](https://s1107.tistory.com/38?category=242156)
215 |
216 | > :arrow_double_up:[Top](#4-Database) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#4-Database) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview)
217 |
218 | ## 역정규화를 하는 이유는 무엇인가? (★★★)
219 | -
24 |
25 | - Super key : 유일성 O, 최소성 X
26 | - Candidate key : 유일성 O, 최소성 O (키의 집합에서 하나라도 삭제하면 유일성 만족하지 못하는 성질)
27 | - Primary key : 후보 키 중에서 선정된 키. 유일성 O, 최소성 O / Null값 가질수 없다
28 | - Alternate Key : 후보 키에서 기본키를 뺀 모든 후보 키
29 | - Foreign Key : 다른 테이블의 Primary key를 참조하는 컬럼
30 |
31 | **ER 모델**
32 | - Entity Relation Model
33 | 
34 | - 개체(Entity), 애트리뷰트(Attribute), 관계성(Relation)으로 기술하는 데이터 모델을 말한다.
35 |
36 | > [참고](https://victorydntmd.tistory.com/126)
37 |
38 | ## 정규화에 대해서 말해보시오, 정규화의 목적은?
39 |
40 | **DB 정규화란 ?**
41 | - RDBMS의 설계에서 중복을 최소화하여 데이터를 구조화하는 프로세스
42 | - 연관성 있는 속성들을 분류하여, 각 릴레이션들에 이상현상이 생기지 않도록 하는 과정
43 | - 정규형에는 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, 6NF 까지 있다 (보통 3정규형 까지 되어있으면 정규화 되었다고 한다)
44 |
45 | **정규화 종료**
46 | - 1NF
47 | - 2NF
48 | - 3NF
49 |
50 |
51 | **DB 정규화가 필요한 이유?**
52 | - DB설계를 잘못 하면 불필요한 데이터 중복으로 인해 공간이 낭비되고 부작용을 초래할수있다.
53 | - 이러한 부작용을 이상(Anomaly)이라고 한다.
54 | - 삽입이상, 갱신이상, 삭제이상이 있다.
55 |
56 | **이상 예제**
57 | - 기본키 : student_id, course_id
58 | 
59 |
60 | **삽입 이상**
61 | - 세 데이터를 삽입하기 위해 불필요한 데이터도 함께 삽입해야 하는 문제
62 | - ex ) 아직 수업을 하나도 수강하지 않은 학생이 있다고 가정하자. 현재 KEY 를 학번과 과목코드로 지정해 놓았고 기본키로 쓰이는 컬럼은 NULL 이 될 수 없으므로 그 학생은 이 테이블에 추가 될 수가 없다. 굳이 삽입하려면 ‘미수강’ 같은 과목코드를 새로 만들어서 삽입해야 한다.
63 |
64 | **갱신 이상**
65 | - 중복 튜플 중 일부만 변경하여 데이터가 불일치하게 되는 모순
66 | - ex ) 야붕이 컴퓨터공학이 싫어서 음악학부로 옮기게 되는경우 ‘컴퓨터공학부’ 의 갯수는 과목코드의 갯수만큼 있으므로 모두 ‘음악학부’ 로 변경해주어야 한다. 이때 모두 변경하지 않고 두개만 바꾸는 경우 야붕은 컴퓨터공학부인지 음악학부인지 알 수 없게 된다.
67 |
68 | **삭제 이상**
69 | - 튜플을 삭제하면 꼭 필요한 데이터까지 함께 삭제되는 데이터 손실의 문제
70 | - ex ) 모찌가 수강정정기간에 MEC011101 라는 수업을 듣기 싫어져서 드랍하는 경우, 위 테이블에 반영하기 위해서는 모찌에 대한 행을 모두 삭제하게 된다. 수강취소를 반영하기 위해 학생등록정보를 모두 날리게 되는 것이다.
71 |
72 |
73 | > [참고] (https://yaboong.github.io/database/2018/03/09/database-normalization-1/)
74 |
75 | ## 무결성에 대해 말해보시오
76 |
77 | **무결성이란**
78 | - 데이터의 __정확성과 일관성을 유지하고 보증하는__ 것
79 |
80 | **개체 무결성**
81 | - 기본키로 설정된 컬럼은 고유한 값을 가지며 NULL허용X
82 |
83 | **참조 무결성**
84 | - 외래키 값은 NULL이거나 참조 릴레이션의 기본키 값과 동일해야 합니다.
85 | - 즉 릴레이션은 참조할 수 없는 외래키 값을 가질 수 없습니다.
86 | - 참조 관계에 있는 두 테이블의 데이터가 항상 일관된 값을 갖도록 유지하는것
87 |
88 | **도메인 무결성**
89 | - 특정 속성의 값이 그 속성이 정의된 도메인에 속한 값이어야 한다는 규정
90 | - ex) 주민등록번호에 알파벳입력되면 도메인 무결성 깨진것
91 |
92 | **고유 무결성**
93 | - 특정 속성에 대해 고유한 값을 가지도록 조건이 주어진 경우, 그 속성값은 모두 달라야 하는 제약조건을 말합니다.
94 | - ex)학생 릴레이션(테이블)에서 테이블 정의시 '이름' 속성에는 중복된 값이 없도록 제한했다면, '이름' 속성에는 중복된 이름이 있어서는 안됩니다.
95 |
96 | **NULL 무결성**
97 | - 특정 속성값에 NULL 이 올 수 없다는 조건이 주어진 경우, 그 속성값은 NULL 값이 올 수 없다는 제약조건을 말합니다.
98 |
99 | **키 무결성**
100 | - 한 릴레이션(테이블)에는 최소한 하나의 키가 존재해야 한다는 제약조건을 뜻합니다.
101 |
102 | > [참고](https://limkydev.tistory.com/161)
103 |
104 | ## 조인이 무엇인지?
105 | - inner, left, right, outer
106 | - 관련 있는 컬럼을 기준으로 행을 합쳐주는 연산
107 | 
108 |
109 |
110 | ## NoSQL이란? 기존 RDBMS와 다른점은?
111 | - NoSQL = Not Only SQL or Non relational Database
112 |
113 |
114 | **RDBMS**
115 | - 데이터는 엄격한 스키마(데이터 개체, 속성, 관계,제약조건)에 따라 table에 저장된다
116 | - 관계를 통해 연결된 여러개의 테이블에 저장
117 | - 사용
118 | - __데이터 자주 수정되는 애플리케이션 일때_
119 | - __변경될 여지 없고, 명확한 스키마가 중요할경우__
120 |
121 | - __장점__
122 | - 명확한 데이터 구조 보장 (정해진 스키마에 따라 데이터를 저장하기 때문에)
123 | - __데이터 중복을 피해,__ 공간 절약 (각 데이터에 맞게 테이블을 나눠서 저장하기 때문)
124 | - __단점__
125 | - 관계로 인한 시스템 복잡도를 고려하여 구조화 해야한다
126 | - 시스템이 복잡하면, query문 복잡, 성능 저하
127 | - 수평적 확장 어려움, 대부분 수직적 확장, 한계에 직면할 수 있다
128 |
129 | *NoSQL*
130 | - 분산처리 목적으로 나옴
131 | - 스키마X 관계X
132 | - 테이블과 같은 개념으로 컬렉션이라는 형태로 데이터를 관리
133 | - 사용
134 | - 정확한 데이터 구조 알 수 없거나 변경,확장 가능한 경우
135 | - __읽기가 많고, 변경이 적을때__
136 | - __막대한 양의 데이터 다룰때__ (수평적 확장 용이)
137 | - __장점__
138 | - 테이블간의 복잡한 관계를 생각 안해도 된다.
139 | - 스키마가 없어서, 유연하다. 언제든지 저장데이터를 조정하고 새로운 필드 추가 가능
140 | - __자주 변경도지 않는 데이터를 저장하기 유리하다__
141 | - __수평적 확장에 용이__ ,(읽기, 쓰기가 빠르다)
142 | - __단점__
143 | - __데이터 업데이트시, 중복될수__ 있어 저장 __데이터를 똑같이 관리__ 해줘야한다.(자유롭게 데이터 추가가능하여, 중복 저장될수있다)
144 | - 종류 : MongoDB, HBASE, Cassandra등
145 | >[참고](https://kimsangyeon.github.io/sql/nosql/database/2019/08/16/rdbms-nosql.html)
146 |
147 | **Redis**
148 | - Remote DIctionary System
149 | - 메모리 기반의 Key/Value Store
150 | - 빠른처리 (read/write) 속도와 검증괸 s/w 안정성 제공
151 | - 다양한 데이터 구조 저장
152 | - string, hash, lists, sets, sorted set, bitmap등
153 | - 사용하는곳
154 | - 인스타그램, 트위터 등
155 |
156 | **HBase**
157 | - 기존의 Redis NoSQL의 한계
158 | - 많은 Memory 공간을 필요, 분산 저장 시스템이 아님
159 |
160 |
161 | ## 트랜잭션이란?(+트랜잭션의 성질)
162 |
163 | - 의미 : (한 단위를 이루는) __일련의 연관된 DB조작__
164 | - 데이터 __무결성__ 을 위해 가장 좋은 방법
165 |
166 | **1. 원자성**
167 | - 트랜잭션의 연산은 데이터베이스에 __모두 반영 or 전혀 반영되지 않아야 한다.__
168 |
169 | **2. 일관성**
170 | - 트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 변환한다.
171 | - 시스템이 가지고 있는 __고정요소는 트랜잭션 수행 전과 트랜잭션 수행 완료 후의 상태가 같아야 한다.__
172 |
173 | **3. 고립성**
174 | - 둘 이상의 트랜잭션이 동시에 병행 실행되는 경우 어느 하나의 트랜잭션 실행중에 다른 트랜잭션의 연산이 끼어들 수 없다.
175 | - __수행중인 트랜잭션은 완전히 완료될 때까지 다른 트랜잭션에서 수행 결과를 참조할 수 없다.__
176 |
177 | **4. 영속성**
178 | - 성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되어야 한다.
179 | - 일단 커밋이 되면 트랜잭션에 의해 변경된 내용은 영구적이어야한다
180 | - DB시스템은 DB의 현재 상태가 유실되지 않도록 시스템 충돌 등의 문제로부터 복구할 수 있는 방법을 갖춰야 한다.
181 |
182 | > :arrow_double_up:[Top](#4-Database) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#4-Database) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview)
183 |
184 | ## 2단계 락킹이란?
185 | - 데이터가 읽거나 쓰거나 락을 해야하는데
186 | - 동시에 락을 걸수있기때문에 , 단계를 나눠서 생각해야한다
187 | - 확장단계 - 락을 걸수있고
188 | - 수축단계 - 언락
189 | - 공유락, 배타락을 따로 두고 임의로 병행접근못하게한다
190 | - 데드락 발생가능, 확장단계에서 수축단계를 기다릴수있기때문
191 |
192 | > :arrow_double_up:[Top](#4-Database) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#4-Database) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview)
193 |
194 | ## 공유락, 배타락이란?
195 | - 공유락 : 읽기만
196 | - 배타락 : 읽기+쓰기
197 | - 공유락이 걸려있을때 배타락이 허용가능한가요?
198 | - 공유락 일때 공유락은 가능. 배타락 불가능
199 | - 배타락일땐, 공유락 불가능. 배타락 불가능.
200 |
201 | > :arrow_double_up:[Top](#4-Database) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#4-Database) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview)
202 |
203 | ## 색인이란? 색인을 사용했을때 장단점?
204 | - DB에서 검색시, 테이블의 모든 데이터를 검색하면 시간이 오래걸린다
205 | - 컬럼의 값 & 해당 레코드가 저장된 주소를 키&쌍 으로 index로 만들어 관리하는것
206 |
207 | - 특징
208 | - 논리적/물리적으로 테이블과 독립적이다
209 | - 장점 : 검색 시 빠르게 탐색
210 | - 단점 : 새로운 값 추가, 삭제, 수정시 쿼리문 속도 느려진다(인덱스를 수정해야하기때문)
211 |
212 | >[참고](https://lalwr.blogspot.com/2016/02/db-index.html)
213 |
214 | >[인덱스란? Clustered Index/ Non-Clustered Index란?](https://s1107.tistory.com/38?category=242156)
215 |
216 | > :arrow_double_up:[Top](#4-Database) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#4-Database) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview)
217 |
218 | ## 역정규화를 하는 이유는 무엇인가? (★★★)
219 | - 17 | 18 | * [MVP패턴, MVVM패턴이란?](#MVP패턴,-MVVM패턴이란?) 19 | * [TDD란?](#TDD란?) 20 | * [Java에서 Builder 패턴을 사용하는이유는?](#Java에서-Builder-패턴을-사용하는이유는?) 21 | * [Observer 패턴은?](#Observer-패턴은?) 22 | * [Java에서 팩토리 메서드 패턴을 사용하는 이유는?](#Java에서-팩토리-메서드-패턴을-사용하는-이유는?) 23 | 24 | --- 25 | ## sw공학이란? 필요한 이유? 좋은 설계란? 26 | 27 | **sw공학이란?** 28 | - sw의 설계, 개발, 유지보수 등에 대한 체계적인 이론과 기술 29 | 30 | **필요한 이유?** 31 | - 시간이 지날수록 sw의 수요는 늘었지만 sw의 개발은 여전히 어렵고 힘들어 여러 가지 문제점이 나타나기 시작했다 32 | - 유지보수나 확장등의 문제를 해결하기 위해 sw공학이 필요하다. 33 | 34 | **좋은 설계란?** 35 | - 요구사항 명세서의 모든 내용을 포함 36 | - 유지 보수시 변경이 용이 37 | 38 | > :arrow_double_up:[Top](#9-Software-Engineering) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#9-Software-Engineering) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 39 | 40 | ## 형상관리란? 41 | - sw의 변경사항을 체계적으로 추적하고 통제하는 것 42 | - 프로젝트와 관련된 모든 변경사항을 관리한다 43 | - 형상 관리 도구 : CVS, SVN, Git 등이 있다 44 | 45 | > :arrow_double_up:[Top](#9-Software-Engineering) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#9-Software-Engineering) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 46 | 47 | 48 | ## Singleton,Adapter,Template패턴은 어떤 것인가? 왜 사용하는지? 코드 구현해보시오 49 | 50 | **Singleton 패턴** 51 | - 생성자가 여러 차례 호출되더라도 실제 생성되는 객체는 하나이고 52 | 최고 생성 이후 호출된 생성자는 최초 생성자가 생성한 객체를 리턴한다 53 | - DBCPC(DataBase Connetcion Pool)과 같은 상황에서 많이 사용된다 54 | - 왜 사용하나요? 55 | 56 | **구현** 57 | - 생성자를 외부에서 호출할수 없게 private으로 선언한다 58 | - 인스턴스 생성을 내부에서 처리하여 외부에서는 그것을 가져다가 쓰기만 하도록한다 59 | > [참고](https://gmlwjd9405.github.io/2018/07/06/singleton-pattern.html) 60 | 61 | **Adapter 패턴** 62 |  63 | 64 | - 한 클래스의 인터페이스를 사용하고자 하는 다른 인터페이스로 변환한다. 65 | - 어댑터를 이용하면 인터페이스 호환성 문제 때문에 같이 쓸 수 없는 클래스들을 연결해서 쓸수 있다. 66 | 67 | > [참고](https://niceman.tistory.com/141) 68 | 69 | **Template 패턴** 70 | - public final 메소드(HoustTemplate.buildHouse())에서 알고리즘의 골격을 정의한다. 71 | - 알고리즘의 여러 단계 중 일부는 서브 클래스(WoodenHouse.java, GlassHouse.java)에서 구현할 수 있다. 72 | - 템플릿 메소드를 이용하면 알고리즘의 구조는 그대로 유지하면서 서브클래스에서 특정 단계를 재정의 할 수 있다. 73 | 74 |  75 | 76 | > [참고](https://niceman.tistory.com/142?category=940951) 77 | 78 | > :arrow_double_up:[Top](#9-Software-Engineering) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#9-Software-Engineering) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 79 | 80 | 81 | ## 코드 결합도와 응집도란? 82 | **결합도** 83 | 모듈간의 연결되어 상호 의존하는 정도 84 | 결합도가 약할수록 좋은 설계 85 | 86 | **응집도** 87 | 모듈 안의 요소들이 서로 관련되어 있는 정도 88 | 응집도가 강할수록 좋은 설계 89 | 90 | > [참고](https://chayan-memorias.tistory.com/90) 91 | 92 | > :arrow_double_up:[Top](#9-Software-Engineering) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#9-Software-Engineering) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 93 | 94 | 95 | ## 블랙박스/화이트박스 테스트란? 96 | **화이트 박스 검사** 97 | - sw 내부 코드를 테스트 하는 기법 98 | - 개발자 관점의 내부 구조와 동작을 테스트 하는 방법 99 | 100 | **블랙 박스 검사** 101 | - sw내부 구조나 작동 원리를 모르는 상태에서 동작을 검사하는 방법 102 | 103 | > [참고](https://kkhipp.tistory.com/158) 104 | > :arrow_double_up:[Top](#9-Software-Engineering) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#9-Software-Engineering) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 105 | 106 | ## Agile 방법론이 무엇인지 설명해주세요 107 | **애자일 방법론** 108 | 일정한 주기를 가지고 끊임없이 프로토 타입을 만들어 내며, 그때그때 필요한 요구를 더하고 수정하여 하나의 커라단 소프트웨어를 만들어 내는 소프트웨어 개발 방법론인 Agile 개발 방법론 채택 109 |
110 | 일정 주기를 가지고 계속 프로토 타입을 만들면서 요구사항을 필요할때마다 추가하고 수정하면서 큰 프로그램을 만들어 나아가는 겁니다. 111 | 1~2주나 3~4주 단위로 쪼개서 개발합니다. 112 | 이런게 많아지자 이를 지원하는 소프트웨어도 생겨났습니다. 113 | Jira같은 것이 있죠. 하지만 장점만 있는 건 아닙니다. 너무 개발자 중심이고, 수정이 가능하다에서 무한 수정이 될 수 있습니다. 114 | 시너지가 있을 수도 있지만 그에 대한 부작용도 많을 수 있습니다. 115 | > [참고](http://blog.naver.com/PostView.nhn?blogId=potter777777&logNo=220784755910) 116 | 117 | **애자일 방법론의 장점** 118 | - 프로젝트 진행 중간 중간에 필요한 요소들을 바꿀 수 있습니다. 119 | - 시작할 때 프로젝트를 정확하게 규정하지 않아도 됩니다. 120 | - 작은 요소들을 출시 할 때 빠르게 만들 수 있습니다. 121 | - 점진적으로 테스트되기 때문에 초기에 버그를 발견할 수 있습니다. 122 | 123 | 124 | > [참고](https://flearning-blog.tistory.com/233) 125 | 126 | > :arrow_double_up:[Top](#9-Software-Engineering) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#9-Software-Engineering) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 127 | 128 | ## 소프트웨어 생명 주기 모델은 무엇이고 어떤 모델이 있는지 설명해주세요 129 | 130 | **생명 주기 모델** 131 | -소프트웨어를 어떻게 개발할 것인가에 대한 추상적 표현 132 | - 프로젝트 비용 산정과 개발 계획 수립의 기본 골격 133 | - 요구사항 분석(정의) -> 개발(설계, 구현, 테스트) -> 유지보수 134 | 135 | **모델 종류** 136 | 1. 폭포수 모델 137 | - 선형 순차적, 처음부터 사용자들이 요구사항 명확하게 제시해야한다 138 | - 요구사항이 이해하기 쉽고, 시스템 개발 중 급격한 변경이 없는 경우 효과적 139 | 140 | 2. 프로토 타입 모델 141 | - 포르토타입 모델 제시 142 | 143 | 3. 나선형 모델 144 | - 폭포수 개선 + 프로토타입 모델의 반복성 + 위험분석 145 | - 대규모 프로젝트에 적합 146 | - 여러 차례 개발 과정 반복 147 | 148 | > [참고](https://storyofsol.tistory.com/124) 149 | 150 | > :arrow_double_up:[Top](#9-Software-Engineering) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#9-Software-Engineering) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 151 | 152 | ## CVS, SVN, GIT에 대해서 아는대로 설명해 보시오 153 | 154 | - CVS (Concurrent Version System) 155 | - 90년에 출시된 무료 서버-클라이언트 형상관리 시스템. 156 | - 파일 전체를 저장하는 것이 아니라 __변경사항만을 저장함__ 으로 용량을 적게 차지하지만 157 | - 속도가 상대적으로 느리다. 158 | 159 | - SVN (Subversion) 160 | - 형상관리/소스관리 툴의 일종. 161 | - 중앙관리만을 지원. 162 | - 다른 사용자의 커밋과 엉키지 않으며, 커밋 실패 시 롤백 기능을 지원. 163 | - 안정성에 있어 CVS보다 상대적으로 좋지 않다. 164 | 165 | - Git 166 | - 분산형 버전관리 시스템 167 | - Repository의 완전한 복사본을 로컬에 저장할 수 있다. 168 | - 처리속도가 빠르지만 대용량 코드 관리에 부적절하다. 169 | 170 | > [참고](https://velog.io/@rxjw95/SE) 171 | 172 | > :arrow_double_up:[Top](#9-Software-Engineering) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#9-Software-Engineering) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 173 | 174 | ## 형상 관리를 잘못하면 어떤 문제가 발생하나요? 175 | 176 | 대규모 프로젝트는 수십, 수백명의 인원이 소프트웨어를 함께 개발하는데 그에 맞는 표준이 존재하지 않고 서로의 개발 사항을 확인하지 못한다면 프로젝트의 위험이나 혼란이 발생할 수 있음 177 | 178 | ``` 179 | 대규모 프로젝트에서는 발생 가능한 위험이나 혼란을 줄이고 프로젝트를 체계적으로 관리하기 위해 형상관리가 반드시 필요 180 | ``` 181 | 182 | > [참고](https://velog.io/@rxjw95/SE) 183 | 184 | > :arrow_double_up:[Top](#9-Software-Engineering) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#9-Software-Engineering) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 185 | 186 | ## 객체지향과 절차지향 차이 설명해주세요 187 | <<<<<<< HEAD 188 | 189 | **절차지향 프로그래밍** 190 | - 실행하고자 하는 절차를 정하고, 이 절차대로 프로그래밍하는 방법 191 | 목적을 달성하기 위한 일의 흐름에 중점을 둔다. 192 | 193 | - 장점 : 객체지향보다 속도가 빠르다 194 | 195 | **객체지향 프로그래밍** 196 | 197 | - 실세상의 물체를 객체로 표현하고, 이들 사이의 관계, 상호 작용을 프로그램으로 나타낸다. 198 | 199 | - __객체를 추출하고 객체들의 관계를 결정__ 하고 이들의 __상호 작용에__ 필요한 함수(메서드)와 변수(필드)를 설계 및 구현하다. 200 | 201 | - 객체 지향의 행심은 연관되어 있는 변수와 메서드를 하나의 그룹으로 묶어서 그룹핑하는 것이다. 202 | 203 | - 사람의 사고와 가장 비슷하게 프로그래밍을 하기 위해서 생성된 기법 204 | 205 | - 하나의 클래스를 바탕으로 서로 다른 상태를 가진 인스턴스를 만들면 서로 다른 행동을 하게 된다. 즉, 하나의 클래스가 여러 개의 인스턴스가 될 수 있다는 점이 객체 지향이 제공하는 가장 기본적인 재활용성이라고 할 수 있다. 206 | 207 | - 단점 : 설계에 많은 시간 208 | - 장점 : 유지보수에 좋다. 큰 프로젝트에 적합하다 209 | 210 | 211 | **객체지향 프로그래밍과 절차지향 프로그래밍의 차이** 212 | - 절차지향 프로그래밍 213 | 214 | 실행하고자 하는 절차를 정하고, 이 절차대로 프로그래밍하는 방법 215 | 목적을 달성하기 위한 __일의 흐름에 중점을__ 둔다. 216 | 217 | - 객체지향 프로그래밍 218 | 219 | __실세상의 물체를 객체로 표현하고, 이들 사이의 관계, 상호 작용을 프로그램으로 나타낸다.__ 220 | 객체를 추출하고 객체들의 관계를 결정하고 이들의 상호 작용에 필요한 함수(메서드)와 변수(필드)를 설계 및 구현하다. 221 | 객체 지향의 행심은 연관되어 있는 변수와 메서드를 하나의 그룹으로 묶어서 그룹핑하는 것이다. 222 | 사람의 사고와 가장 비슷하게 프로그래밍을 하기 위해서 생성된 기법 223 | 하나의 클래스를 바탕으로 서로 다른 상태를 가진 인스턴스를 만들면 서로 다른 행동을 하게 된다. 즉, 하나의 클래스가 여러 개의 인스턴스가 될 수 있다는 점이 객체 지향이 제공하는 가장 기본적인 재활용성이라고 할 수 있다. 224 | 225 | > [참고1](https://gmlwjd9405.github.io/2017/10/01/basic-concepts-of-development-java.html) 226 | > [참고2](https://gbsb.tistory.com/3) 227 | 228 | > :arrow_double_up:[Top](#9-Software-Engineering) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#9-Software-Engineering) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 229 | 230 | 231 | ## MVP패턴, MVVM패턴이란? 232 | 모바일과 관련된 233 | controller가 사용자 입력 234 | view가 처리. presenter에게 전달 235 | 단점 ; view와 presenter 1:1 대응이여서 코드가많아지고, 의존성이 높아져서 236 | 237 | 보완하기 위해 나온것이 mvvp 238 | 239 | view가 변경되면 변경된 view model을 이용한다 240 | 데이터바인딩을 이용해서 view model을 만든다 241 | 단점 ; view를만들기 어렵다 242 | 243 | >[참고](https://beomy.tistory.com/43) 244 | 245 | > :arrow_double_up:[Top](#9-Software-Engineering) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#9-Software-Engineering) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 246 | 247 | ## TDD란? 248 | - Test Driven Development 249 | - 테스트 주도 개발 : __테스트가 개발을 이끌어 나간다__ 250 | - 개념 251 | - 테스트를 먼저 만들고 테스트를 통과하기 위한 코드를 작성하는 것. 252 | - 레드 그린 사이클 (TDD사이클) 253 | 1. RED 항상 실패하는 테스트를 먼저 작성하고 254 | 2. GREEN 테스트가 통과하는 프로덕션 코드를 작성하고 255 | 3. Refactor 테스트가 통과하면 프로턱션 코드를 리팩토링한다 256 | (리팩토링 : 작동하는것은 그대로 놓고, 내부구현(코드)만 변경한다) 257 | 258 | - TDD를 하는이유 : __테스트와 개발을 같이 진행하여 개발 초기의 오류를 발견하고, 수정하여__ 좋은 소프트웨어를 개발하기 위한 방법 259 | - 단점 : 개발시간이 오래걸린다 260 | 261 | > [참고](https://devham76.github.io/testcode/Spring-testCode/) 262 | 263 | > :arrow_double_up:[Top](#9-Software-Engineering) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#9-Software-Engineering) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 264 | 265 | ## Java에서 Builder패턴을 사용하는이유는? 266 | - .builder 267 | - 생성자 매게변수가 많으면 유리 268 | > :arrow_double_up:[Top](#9-Software-Engineering) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#9-Software-Engineering) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 269 | 270 | ## Observer 패턴은? 271 | - 느슨한 결합도 제공 272 | > :arrow_double_up:[Top](#9-Software-Engineering) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#9-Software-Engineering) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 273 | 274 | ## Java에서 팩토리 메서드 패턴을 사용하는 이유는? 275 | -
76 | - 윈도우는 전송, 수신 스테이션 양쪽에서 만들어진 버퍼의 크기이다. 77 | - 윈도우의 크기 = (가장 최근 ACK로 응답한 프레임의 수) - (이전에 ACK 프레임을 보낸 프레임의 수) 78 | - ACK 프렝임을 수신하지 않아도 여러 개의 프레임을 연속적으로 전송할 수 있다. 79 | 80 | **슬라이딩 윈도우 과정** 81 |  82 | - 데이커 0,1 전송했다고 가정하면 아래 처럼 변경된다 83 | - 윈도우의 크기는 전송한 데이터 프레임 만큼 왼쪽 경계가 줄어든다. 84 | 85 |  86 | - 이때 수신측에서 ACK 프레임을 전송하고 수신하면 되면 전송측은 0과 1데이터를 정상적으로 받았음을 알게되고 87 | - 전송측은 ACK 프레임에 따른 프레임의 수만큼 오른쪽으로 경계가 확장된다. 88 | 89 |  90 | 91 | > -
141 | - Client > Server : TCP SYN 142 | - Client -> SYN_SNET상태 143 | - Client < Server : TCP SYN ACK 144 | - Server -> SYN_RECEIVED 145 | - Client > Server : TCP ACK 146 | - Server -> ESTABBLISHED 147 | 148 | > :arrow_double_up:[Top](#2-network) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#2-network) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 149 | 150 | ## HTTP와 HTTPS의 차이는? 151 | 152 |  153 | 154 | **HTTP** 155 | HTTP는 인터넷에서 웹 서버와 사용자 측의 웹 브라우저 사이에 문서를 전송하기 위한 프로토콜이다 156 | 인터넷에서 HyperText를 전송하기 위해 사용하는 프로토콜이다 157 | 158 | **HTTP의 문제점** 159 | HTTP는 정보를 단순 텍스트로 주고 받기 때문에 (암호화X) N/W상에서 전송 신호를 인터셉트하는 경우 데이터 유출이 발생할수있다. 160 | 161 | **HTTPS** 162 | - SSL이나 TLS 프로토콜을 사용하여 데이터를 암호화한다 163 | - HTTPS는 초기에 C,S가 통신을 하며 암호화 키를 서로 안전하게 주고 받는다.(SSL Handshake) 164 | - 이때 암호화 키값이 노출되지 않도록 안전하게 해주는게 https 서버 인증서이다. 165 |
166 | - SSL(보안 소켓 계층)을 사용함으로써 서버와 브라우저 사이에 안전하게 암호화된 연결을 만든다 167 | - TLS(전송 계층 보안) 프로토콜을 통해서도 보안을 유지한다. 168 | - TLS는 데이터 무결성을 제공하기 때문에 데이터가 전송 중에 수정,손상되는것을 방지한다 169 | 170 | **SSL** 171 |  172 | 173 | > [참고](https://wayhome25.github.io/cs/2018/03/11/ssl-https/) 174 | 175 | > :arrow_double_up:[Top](#2-network) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#2-network) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 176 | 177 | ## GET과 POST의 차이는? 178 | 179 | **GET** 180 | - 주로 조회 할때 사용된다 181 | - 요청데이터를 URL에 파라메터로 담아서 전송한다 182 | - URL에 데이터를 포함해서 전달하므로 전송하는 길이에 제한이있다 183 | - 정적 컨텐츠를 요청하면, 브라우저가 요청을 캐싱해두고 동일 요청이 들어오면 캐싱된 데이터를 전송 184 | 185 | **POST** 186 | - 서버의 상태나 데이터를 생성할때 상용된다 187 | - 요청 정보를 BODY에 담는다 188 | - 요청 BODY는 길이 제한이 없기 때문에 GET과 달리 대용량 데이터 전송 가능 189 | - 요청 헤더의 Content-Type에 요청 데이터의 타입을 표시해야한다 190 | 191 | > :arrow_double_up:[Top](#2-network) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#2-network) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 192 | 193 | ## TCP/IP 프로토콜 스택 4계층으로 구분짓고 설명하라 194 | - LINK 계층(네트워크 인터페이스 계층) 195 | - 물리적인 영역의 표준화에 대한 결과. LAN,WAN,MAN과 같은 NW표준과 관련된 프로토콜을 정의하는 영역 196 | - 물리적 네트워크를 통한 실제 송수신 담당 197 | - 데이터 링크 계층과 물리 계층 198 | 199 | - IP(인터넷 계층) 200 | - 경로검색을 해주는 계층 201 | - IP자체는 비연결지향적이며 신뢰할 수 없는 프로토콜 202 | - 데이터를 전송할 때마다 거쳐야 할 경로를 선택해주지만 그 경로는 일정하지 않다 203 | - 특히 데이터 전송 도중에 경로상의 문제가 발생하면 다른 경로를 선택해주는데, 이 과정에서 데이터가 손실되거나 오류가 발생하는 등의 문제가 발생할수있고 , 이를 해결해주진않는다. 204 | - 즉, 오류발생에 대한 대비가 되어있지 않은 프로토콜이다. 205 |
206 | - 논리 주소인 IP주소를 사용하여 데이터를 목적지 호스트 까지 전달 207 | - 전세계적으로 유일성 보장 208 | 209 | - TCP/UDP(전송) 계층 210 | - 데이터의 실제 송수신을 담당한다 211 | - UDP는 TCP에 비해 상대적으로 간단하다 212 | - TCP는 신뢰성 있는 데이터의 전송을 담당한다 213 | - TCP가 데이터를 보낼 때 기반이 되는 프로토콜은 IP이다. 214 | - IP 계층은 문제 발생시 해결하지않아서 신뢰성이 없다. 215 | - 이 문제를 해결해주는 것이 TCP이다 216 | - 데이터가 순서대로 전송됬는지 확인하며 대화를 주고 받는다 217 | - 확인절차를 걸쳐서 신뢰성 없는 IP에 신뢰성을 부여하는 프로토콜이라고 생각하면 된다 218 | 219 | - APPLICATION 계층 220 | - 이러한 서버와 클라이언트의 프로그램 성격에 때라 데이터 송수신에 대한 규칙이 정해지는데 이를 가리켜 Application 프로토콜이라고 한다 221 | - 어플리케이션 계층, 표현 계층, 세션 층 222 | 223 | --- 224 | 225 | 226 | > :arrow_double_up:[Top](#2-network) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#2-network) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 227 | 228 | ## Session과 Cookie 차이는? 229 | 230 | **쿠키와 세션 사용하는 이유** 231 | - HTTP는 Connectionless(클라이언트가 요청후 응답 받으면 연결 해제), Stateles(통신이 끝나면 상태를 유지하지 않는 특징) 특성이 있다. 232 | - 따라서 Server, Client가 통신할때마다 Server는 Client가 누구인지 인증을 계속해야한다. 233 | - ex) 쿠키와 세션을 사용하지 않으면 쇼핑몰에서 옷을 구매하려고 최초 로그인을 했음에도, 페이지를 이동할 때 마다 계속 로그인을 해야한다. 234 | 왜냐하면, 서버는 클라이언트가 누군지 기억하지 않기 때문 235 | - 쿠키와 세션을 통해 서버는 클라이언트에 대한 인증을 유지한다 (기억하고 있는다) 236 | 237 | **쿠키** 238 | - Client측(브라우저)에서 관리되는 작은 기록정보 파일 239 | - 사용자 인증에 유효한 시간 명시가능, 브라우저 종료되도 인증 유지 240 | 241 | **쿠키 동작** 242 | 1. 클라이언트가 페이지 요청 243 | 2. 서버에서 쿠키 생성 244 | 3. HTTP헤더에 쿠키 포함 시켜 응답 245 | 4. 브라우저가 종료되어도 쿠키 만료 기간이 있다면 __클라이언트에서 보관__ 246 | 5. 쿠기가 존재하면 요청시, HTTP헤더에 쿠키를 함께 보내서 요청 247 | 6. 서버에서 쿠키를 읽어 이전 상태 정보를 변경 할 필요가 있으면, 쿠키를 업데이트하여 변경된 쿠키를 HTTP헤더에 포함시켜 응답 248 | 249 | -> 브라우저 종료시에도 남을수있다 250 | 251 | **쿠키 사용** 252 | - 방문 사이트에서 로그인 시, "아이디, 비밀번호 저장하겠습니까?" 253 | - 쇼핑몰 장바구니 기능 254 | 255 | **세션** 256 | - 사용자 정보 파일을 브라우저에 저장하는 쿠키와 달리 세션은 __서버 측__ 에서 관리 257 | - 서버에서 Client를 구분하기 위해 __세션 ID__ 를 부여 258 | - 웹 브라우저가 서버에 접속해서 브라우저 종료할때 까지인증상태 유지 259 | - __사용자 정보를 서버에 저장하기 때문에 쿠키보다 보안에 좋다__ 260 | - __사용자가 많아질수록 서버 메모리를 많이 차지하게 된다__ 261 | 262 | -> 브라우저가 종료되면 없어진다 263 | 264 | **세션 동작** 265 | 1. 클라이언트가 세버에 접속 시 세션ID 발급 266 | 2. 클라이언트는 세션ID에 대해 쿠키를 사용해서 저장(쿠키 이름 = JSESSIONID) 267 | 3. 클라이언트가 서버에 다시 접속 시 이 쿠키를 이용해서 세션 ID 값을 서버에 전달 268 | 269 | **세션 사용** 270 | - 로그인과 같이 보안상 중요한 작업을 수행할 때 사용 271 | 272 | **둘의 차이** 273 | - __사용자의 기록 정보가 저장되는 위치__ : 쿠키-브라우저, 세션-서버 274 | - __보안__ : 세션이 서버에서 관리 되므로 더 좋다. 275 | - __요청속도__ : 쿠키가 빠르다. 세션은 서버에서 처리가 필요하기 때문이다. 276 | 277 | > [참고](https://victorydntmd.tistory.com/34) 278 | > :arrow_double_up:[Top](#2-network) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#2-network) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 279 | 280 | 281 | ## iocp 282 | 283 | > :arrow_double_up:[Top](#2-network) 284 | :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#2-network) 285 | :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 286 | 287 | ## http keep alive / tcp keep alive 288 | 289 | **TCP keepalive** 290 | - 서버간에 ACK 패킷을 보내 세션 테이블이 지워지지 않고 계속 __세션 정보를 유지__ 291 | - mq, kafka 등 TCP 기반의 서비스들을 대상으로 __지속적 연결을 유지해야 하는 경우__ 사용 292 | - 과정 293 | 1. A – B가 서로 Connection이 Establish된 상태에서 (3-handshake) 294 | 2. 지정된 시간(OS 설정 값 또는 어플리케이션 설정) 동안 서로 패킷 교환(Exchange)이 없을경우 295 | 3. payload가 없는 패킷을 보냅니다. 296 | 4. 패킷에 반응없으면 접속 close 297 | 298 | - 언제사용하지? 299 | - 한쪽만 연결되어있는 상태를 정리하기 위해 사용 300 | 301 | ``` 302 | 1. Checking for dead peers 303 | 304 | A – B가 연결된 경우 B시스템이 장애로 인해서 restart 될 경우 305 | A의 keep-alive 설정에 의해서 probe 패킷을 보내면 306 | B는 RST(Reset)을 응답 합니다. 307 | 308 | 이럴 경우 B 시스템의 커넥션이 끊겼다는 것을 감지 할 수 있습니다. 309 | 310 | ※ TCP 프로토콜 자체에서 장애 감지가 없기 때문에 Keepalive 옵션을 311 | 통해서 감지 312 | ``` 313 | 314 | 315 | **HTTP Keepalive** 316 | - http 는 특성상 커넥션을 유지하지 않는다. 317 | - 따라서 KeepAlive를 사용해서 __커넥션을 유지해서 빠르게 데이터 주고받을__ 수 있다. 318 | - 일정시간이 지나면 __능동적으로 연결을 끊는다.__ 319 | - 너무 많은 연결을 오래 유지하면, 다른 연결에 방해를 줄수있다. 320 |
321 | - Apache, Nginx 등 웹 애플리케이션에서 __설정된 기간까지 최대한 연결을 유지하기 위해__ 사용된다. 322 | 323 | - HTTP 1.1부터 keepalive를 default로 제공한다 324 | 325 | 326 | > :arrow_double_up:[Top](#2-network) 327 | :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#2-network) 328 | :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 329 | 330 | ## ssl 331 | - HTTP의 보안 문제를 해결해준다. SSL이 적용되어 HTTPS라고 칭한다 332 | - http와 tcp사이에 있는 인증서. TLS가 정식명칭이나, SSL이라고 부른다 333 | - 동작 334 | 1. Server측에서 CA(인증기관)에 사이트정보+공개키를 주고 인증서를 요청한다 335 | 2. CA에서 심사완료 후 사이트정보+공개키를 개인키로 암호화 하고 공개키를 브라우저에 등록한다 336 | 3. 브라우저가 서버에 인증서를 요청한다 337 | 4. 인증서가 CA에서 인증받은것인지 브라우저가 확인하고 공개키를 이용해서 서버측 사이트정보+공개키를 획득한다 338 | 5. 클라이언트의 대칭키를 서버측의 공개키로 암호화 해서 서버에게 전송한다 339 | 6. 서버는 자신의 개인키로 복호화하여 클라이언트 측의 대칭키를 획득한다 -> 그러면, 대칭키는 클라이언트,서버만 갖게 된다 340 | 7. 이 대칭키로 암호화,복호화하여 통신한다 341 | >
255 | 256 | **트리의 구성** 257 | 258 | ``` 259 | 1. 하나의 루트 노드를 갖는다 260 | 2. 루트 노드는 0개 이상의 자식 노드를 갖는다. 261 | 3. 그 자식의 노드 또한 0개 이상의 자식을 갖고 이 구조가 반복된다. 262 | ``` 263 | 264 |
265 | 266 | - 트리의 종류 267 | - 이진 트리, 이진 탐색 트리, 균형 트리(AVL 트리, red-black 트리), 이진 힙(최대힙, 최소힙) 268 | - 트리의 탐색 269 | - 중위 순회(in-order traversal): 왼쪽 가지 -> _현재 노드_ -> 오른쪽 가지 270 | - 전위 순회(pre-order traversal): _현재 노드_ -> 왼쪽 가지 -> 오른쪽 가지 271 | - 후위 순회(post-order traversal): 왼쪽 가지 -> 오른쪽 가지 -> _현재 노드_ 272 | - 트리의 구현 : 배열과 연결리스트 모두 사용하여 구현이 가능 273 | 274 | > [참고](https://gmlwjd9405.github.io/2018/08/12/data-structure-tree.html) 275 | 276 | **그래프** 277 | - 노드와 그 노드를 연결하는 간선을 모아 놓은 자료구조 278 | - 연결되어 있는 객체 간의 __관계__ 를 표현할 수 있는 자료구조 279 | 280 | **그래프 특징** 281 | - 네트워크 모델 282 | - 루트 노드라는 개념x 283 | - 부모-자식 관계 개념x 284 | - 순환 혹은 비순환이다 285 | - 방향 그래프와 무방햔 그래프가 있다. 286 | 287 | **그래프 구현** 288 | - 인접리스트 , 인접행렬로 구현가능 289 | 290 | **그래프의 탐색** 291 | - 깊이 우선 탐색(DFS, Depth-First Search) 292 | 루트 노드(혹은 다른 임의의 노드)에서 시작해서 다음 분기(branch)로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방법 293 | - 즉, 넓게(wide) 탐색하기 전에 깊게(deep) 탐색하는 것이다. 294 | - 사용하는 경우: 모든 노드를 방문 하고자 하는 경우에 이 방법을 선택한다. 295 | - 깊이 우선 탐색이 너비 우선 탐색보다 좀 더 간단하다. 296 | - 너비 우선 탐색(BFS, Breadth-First Search) 297 | 루트 노드(혹은 다른 임의의 노드)에서 시작해서 인접한 노드를 먼저 탐색하는 방법 298 | - 즉, 깊게(deep) 탐색하기 전에 넓게(wide) 탐색하는 것이다. 299 | - 사용하는 경우: 두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 이 방법을 선택한다. 300 | - Ex) 지구상에 존재하는 모든 친구 관계를 그래프로 표현한 후 Ash와 Vanessa 사이에 존재하는 경로를 찾는 경우 301 | - 깊이 우선 탐색의 경우 - 모든 친구 관계를 다 살펴봐야 할지도 모른다. 302 | - 너비 우선 탐색의 경우 - Ash와 가까운 관계부터 탐색 303 | 304 | 305 | > :arrow_double_up:[Top](#6-algorithm) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#6-algorithm) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 306 | 307 | ## 해싱의 충돌을 해결하는 방법들을 설명하라 308 | 309 | 310 | **체이닝** 311 |  312 | 313 | - 같은 주소로 해슁되는 원소를 모두 하나의 __연결 리스트__ 에 매달아 관리한다 314 | - 체이닝에서 삽입은 효율성을 위해 연결리스트의 _맨 앞에 삽입_ 한다. 315 | - 맨 뒤에 삽입할 경우 삽입시마다 연결리스트를 따라 맨 끝으로 이동해야 하므로 낭비가 된다 316 | 317 | - 탐색과 삭제를 하려면 원하는 데이터를 찾기 위해 순차 탐색해야한다. 318 | 319 | **개방주소(open address)** 320 | - 체이닝과 같이 __추가 공간을 허용하지 않고__ 주어진 해쉬 테이블 공간 내에서 해결한다 321 | - 해쉬 함수를 계산해서 계산된 주소를 차지하고 있는 다른 원소가 없으면 그 자리에 넣고 322 | - 다른 원소가 있으면 __정해진 규칙__ 에 따라 다음 자리를 찾게 된다. 323 | - 정해진 규칙, 즉 다음 주소를 결정하는 방법은 3가지 이다. : __선형조사, 이차원 조사, 더블해슁__ 324 | 325 | **개방주소 - 선형 조사** 326 |  327 | - 가장 간단한 충돌 해결방법 328 | - 충돌이 일어나면 바로 뒷자리를 확인해서 비어있는 경우 저장한다. 329 | - 단점 : 특정 영역에 원소가 몰리면 성능이떨어진다. (검색시간, 삽입시간 저하) __1차군집화__ 330 | 331 | 332 | **개방주소 - 제곱 탐색(Quadratic Probing)** 333 |  334 | - 이차원 조사는 바로 뒷자리를 보는 선형 조사와 달리 __보폭을 이차함수에 의해 넓혀가면서__ 본다. 335 | - ex) i번째 해쉬 함수를 h(x)로 부터 i^2만큼 떨어진 자리로 삼을 수 있다. 336 | - ex) h(x), h(x)+1, h(x)+4, h(x)+9, h(x)+16... 337 | - 해시충돌 시 제곱만큼 건너뛴 버켓에 데이터를 삽입(1,4,9,16..) 338 | - 장점 : 선형 조사에서처럼 특정 영역에 원소가 몰려도 그 영역을 빨리 벗어날수있다. 339 | - 단점 : __2차 군집화__ 문제발생 340 | 341 | **개방주소 - 더블 해싱** 342 | - 2개의 해시함수를 사용해서, 충돌 발생시 다른 해시함수로 해시값을 만들어 원소를 저장한다. 343 | - 해시충돌 시 다른 해시함수를 한 번 더 적용한 결과를 이용함. 344 | 345 | - 장점 : 군집화 해결 346 | 347 | > [참고 - 더블해싱](https://m.blog.naver.com/beaqon/221300416700) 348 | 349 | > [참고 - 해시 충돌](https://itstory.tk/entry/%ED%95%B4%EC%8A%81%EC%97%90%EC%84%9C%EC%9D%98-%EC%B6%A9%EB%8F%99%ED%95%B4%EA%B2%B0Collision-Resolution) 350 | 351 | > :arrow_double_up:[Top](#6-algorithm) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#6-algorithm) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 352 | 353 | ## huffman encoding에 대해 설명하라 354 | 355 | > [참고](http://www.judgeon.net/problem.php?id=3022) 356 | 357 | > :arrow_double_up:[Top](#6-algorithm) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#6-algorithm) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 358 | 359 | 360 | ## 벨만포드 알고리즘과 다익스트라 알고리즘의 차이점? 361 | 362 | 다익스트라 - 우선순위큐 363 | 벨만코드 - 구현어떻게하는지 364 | 365 | - 최단 경로 : 주어진 두 노드 사이의 경로들 중에서 __최소 비용인 경로__ 를 찾는 것 366 | 367 | **다익스트라** 368 | - 하나의 정점, 다른 모든 정점으로의 최단경로 369 | 370 | - 다익스트라 알고리즘은 다음과 같다. (P[A][B]는 A와 B 사이의 거리라고 가정한다) 371 | 372 | 1. 출발점으로부터의 최단거리를 저장할 배열 d[v]를 만들고, 출발 노드에는 0을, 출발점을 제외한 다른 노드들에는 매우 큰 값 INF를 채워 넣는다. (정말 무한이 아닌, 무한으로 간주될 수 있는 값을 의미한다.) 보통은 최단거리 저장 배열의 이론상 최대값에 맞게 INF를 정한다. 실무에서는 보통 d의 원소 타입에 대한 최대값으로 설정하는 편. [5][6] 373 | 2. 현재 노드를 나타내는 변수 A에 출발 노드의 번호를 저장한다. 374 | 3. A로부터 갈 수 있는 임의의 노드 B에 대해, d[A] + P[A][B][7]와 d[B][8]의 값을 비교한다. INF와 비교할 경우 무조건 전자가 작다. 375 | 4. 만약 d[A] + P[A][B]의 값이 더 작다면, 즉 더 짧은 경로라면, d[B]의 값을 이 값으로 갱신시킨다. 376 | 5. A의 모든 이웃 노드 B에 대해 이 작업을 수행한다. 377 | 6. A의 상태를 "방문 완료"로 바꾼다. 그러면 이제 더 이상 A는 사용하지 않는다. 378 | 7. "미방문" 상태인 모든 노드들 중, 출발점으로부터의 거리가 제일 짧은 노드 하나를 골라서 그 노드를 A에 저장한다. 379 | 8. 도착 노드가 "방문 완료" 상태가 되거나, 혹은 더 이상 미방문 상태의 노드를 선택할 수 없을 때까지, 3~7의 과정을 반복한다. 380 | 381 | - 이 작업을 마친 뒤, 도착 노드에 저장된 값이 바로 A로부터의 최단 거리이다. 만약 이 값이 INF라면, 중간에 길이 끊긴 것임을 의미한다. 382 | 383 | > [참고](https://namu.wiki/w/%EB%8B%A4%EC%9D%B5%EC%8A%A4%ED%8A%B8%EB%9D%BC%20%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98) 384 | > [코드 확인하기](https://devham76.github.io/datastructure/data_struture-Dijkstra/) 385 | 386 | **벨만 포드** 387 | - dp 관점 388 | - 다익스트라보다 느리다 389 | 390 | | 다익스트라| 벨만 포드| 391 | |--|--| 392 | |greedy 관점| dp관점| 393 | |벨만 포드 보다 빠르다 | 모든 수를 고려하기 때문에 다익스트라 보다 느리다| 394 | |그래프에 음의 가중치를 가진 간선x|그래프에 음의 가중치를 가진 간선o| 395 | 396 | >[참고](http://blog.naver.com/PostView.nhn?blogId=qbxlvnf11&logNo=221377612306&categoryNo=21&parentCategoryNo=0&viewDate=¤tPage=1&postListTopCurrentPage=1&from=postView) 397 | 398 | 399 | ## MST 알고리즘(Spanning Tree란?) 400 | 401 | ``` 402 | ※) 다익스트라 알고리즘 403 | "그래프"에서 출발점에서 목표점까지의 404 | 최단거리를 구할 때 사용하는 알고리즘 405 | ``` 406 | 407 | - 언제 사용하나요 ? 408 | - 통신구축 409 | 410 | **Spanning Tree** 411 | - 그래프 내의 모든 정점을 포함하고 일부 간선을 선택해서 만든 트리 412 | - 사이클 포함 x 413 | - 하나의 크래프에서 많은 신장 트리 존재할수있다 414 | 415 | **MST(Minimum Spanning Tree)** 416 | - 최소 신장 트리 417 | - 그래프에 있는 __모든 정점들을 가장 적은 수의 간선과 비용으로 연결__ 418 | 419 | - 정점 n개이면, 간선은 n-1개 420 | 421 | - MST는 최단거리가 아닐 수 있다. (최단 경로는 다익스트라) 422 | 423 | **MST 종류** 424 | - Kruskal , Prim 425 | 426 | >[참고](https://devham76.github.io/algorithm/mst/) 427 | 428 | ## 프림 429 |  430 | 431 | - __시작 정점에서부터 출발__ 하여 신장 트리 집합을 단계적으로 확장해나가는 방법 432 | - 정점에 연결 된 간선의 가중치 중 __가장 작은 가중치의 간선을 연결해__ 나가는 방식 433 | - __그래프에 간선이 많이 존재 하는 ‘밀집 그래프’의 경우 적합__ 434 | 435 | 436 | - 시간 복잡도 : 437 | 438 | - 구현코드 ? 439 | 440 | ## 크루스칼 441 | 442 |  443 | 444 | 1. 그래프의 간선들을 가중치의 오름차순으로 정렬 한다 445 | 2. 정렬된 간선 리스트에서 순서대로 사이클을 형성하지 않는 간선을 선택한다. 446 | - 즉, 가장 낮은 가중치를 먼저 선택 447 | 448 | - kruskal : 그래프에 간선이 적게 존재 하는 __'희소 그래프'__ 의 경우 적합 449 | 450 | 451 | - 시간복잡도 : 452 | 453 | - 구현 코드 ? 454 | 455 | 456 | ## Floyd-Warshall 알고리즘 457 | - 모든 정점 에서 모든 정점으로 최단 경로 458 | - 거쳐가는 정점을 기준으로 최단 거리를 구한다 459 | - 다익스트라 - 가장 적은 비용을 하나씩 선택 460 | 461 | - https://blog.naver.com/ndb796/221234427842 462 | 463 | 464 | ## 프라이어리티 큐의 구조 설명 465 | - 들어간 순서에 상관없이 우선순위가 높은 데이터가 먼저 나온다 466 | - 구현 방법 467 | - 배열 468 | - 연결리스트 469 | - 힙 470 |
471 | 1. 배열 472 | - 데이터 삽입, 삭제 과정이 비효율적이다. 473 | - 삽입 위치를 찾기 위해 배열에 저장된 모든 데이터와 우선순위를 비교해야한다 474 | 475 | 2. 연결리스트 476 | - 삽입 위치를 찾기 위해 배열에 저장된 모든 데이터와 우선순위를 비교해야한다 477 | 478 | 3. 힙 479 | - 배열과 연결리스트의 단점 때문에 주로 힙으로 구현한다 480 | 481 | 482 | > :arrow_double_up:[Top](#6-algorithm) 483 | :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#6-algorithm) 484 | :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 485 | 486 | ## heap에서 delete 과정을 그려라 487 | - __삽입, 가장 마지막에 삽입 / 삭제, 루트 노드 삭제__ 488 | 489 | 490 | **힙** 491 | - __완진이진트리 + 이진탐색트리의 형태__ 492 | - 최대힙(부모노드>자식노드) / 최소힙(부모노드<자식노드) 493 | - 최댓값, 최솟값을 쉽게 추출할 수 있는 자료구조 494 | 495 | **삭제** 496 | - logN 497 | - __루트만 삭제 가능 , 삭제후 마지막 노드를 루트로 두고 우선순위비교__ 498 | 499 | 1. 루트노드를 삭제 500 | 2. 가장 마지막 원소를 루트 노드의 위치로 옮겨준다. 501 | 3. 자식노드와 우선순위를 비교해서 자신의 자리를 찾는다. 502 | 503 | 504 |  505 | 506 | **삽입** 507 | - 마지막 노드에 삽입 logN 508 |  509 | 510 | 511 | > [참고1](https://hannom.tistory.com/36) 512 | > [참고2](https://gmlwjd9405.github.io/2018/05/10/data-structure-heap.html) 513 | 514 | > :arrow_double_up:[Top](#6-algorithm) 515 | :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#6-algorithm) 516 | :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 517 | 518 | ## 16진수 수를 10진수로 변경하는 코드를 작성해보세요 519 | > :arrow_double_up:[Top](#6-algorithm) 520 | :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#6-algorithm) 521 | :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 522 | 523 | 524 | ## 이진트리, 이진 검색트리, 힙이 각각 무엇인지 설명해주세요 525 | 526 | **이진트리 (Binary Tree)** 527 |  528 | - 노드의 최대 차수가 2인 트리 529 | 530 |
531 | 1. 편향 이진트리 532 | - 한 쪽으로 편향 533 | 534 |  535 | 536 | 2. 포화 이진트리 537 | - 이진트리에서 최대 노드의 수를 만족 538 |  539 | 540 | 3. 완전 이진트리 -> __힙__ (형태만) 541 | - 위에서 아래로, 왼쪽에서 오른쪽으로 __순서대로 채워진 트리__ 542 | 543 |  544 | 545 | 546 | **이진트리 vs 이진탐색 트리** 547 | 548 | - 이진트리 : 노드의 최대차수가 2인 트리 549 | 550 | - 이진탐색 : 정렬된 숫자에서 검색시, 한 숫자 선택, 검색 숫자보다 작으면 오른쪽, 크면 왼쪽 검사 551 | 552 | - 이진탐색트리 : 이진트리 + 조건 553 | - __조건 : 루트노드 > 왼쪽 자식 노드 && 루트노드 < 오른쪽 자식 노드__ 554 | - 트리가 이진탐색을 한다 555 | - __완전 이진트리가 아닐수있다__ 556 | - __탐색 방법__ : 전위, 중위, 후위 검색 방법이 있다 557 | 558 | ### 문제점 : 삽입,삭제를 하다보면 편향이진트리가 될수도있다. 559 | - 삽입,삭제,검색 최악 : O(N) / 평균 : O(logN) 560 | 561 | **이진탐색 트리** 562 | 563 | - 이진탐색트리 검색 564 |  565 | 566 | - 이진탐색 삭제 567 | 568 | ``` 569 | 지우려는 노드에 570 | 1. 자식이 없을 때 571 | - 부모와 연결해제 572 | 2. 자식이 하나만 있을 때 573 | - 자식과 그의 부모노드를 이어준다 574 | 3. 자식이 두개 다 있을 때 575 | - 왼쪽 자식 노드들 중에 가장 큰값 또는 576 | 오른쪽 자식 노드들 중에 가장 작은값으로 교체 577 | ``` 578 | 579 | > [참고](https://zeddios.tistory.com/492) 580 | 581 | - 자식 하나일때 582 |  583 | 584 | - 자식 두개일때 585 |  586 | 587 | > [참고](https://galid1.tistory.com/176?category=746456) 588 | 589 | > :arrow_double_up:[Top](#6-algorithm) 590 | :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#6-algorithm) 591 | :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 592 | 593 | ## 해시테이블과 이진 검색트리를 비교하고 장단점을 이야기해주세요. 그리고 메모리가 제한된 모바일 기기용 주소록에 사용할 자료구조를 설계한다면 어느쪽을 쓰는것이 좋을까요? 594 | 595 | |비교|해시테이블|이진검색트리| 596 | |--|--|--| 597 | |시간복잡도 평균|key,value 충돌 없을때 O(1)| O(logN)| 598 | |시간복잡도 최악 - 선형으로 검색|O(N)|O(N)| 599 | |정렬| x| o| 600 | 601 | - 해시테이블이 이진검색트리보다 빠르다 602 | - 하지만, 정렬이 되지않아 정렬을 위한 메모리를 추가로 필요하다 603 | - 따라서 이진검색트리가 해시테이블 보다는 느리지만 O(logN) 의 속도도 충분히 빠르기 때문에 메모리가 제한된 모바일 기기에서는 더 적절하다. 604 | - 해시트리 ; 해시테이블때문에, 메모리가 추가로 필요할수있다. 605 | - 해시트리 ; 충돌이 많이 일어나면 , 성능이 낮아진다 606 | 607 | > :arrow_double_up:[Top](#6-algorithm) 608 | :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#6-algorithm) 609 | :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 610 | 611 | 612 | ## LinkedList와 ArrayList의 차이 613 | - ArrayList는 검색에 유리한 구조 614 | - 삽입 삭제가 자주 일어나면 LinkedList를 사용하는것이 좋다. 615 | 616 | - 이유 : ArrayList는 내부적으로 데이터를 배열에서 관리하며 데이터의 추가, 삭제를 위해 아래와 같이 __임시 배열을 생성해 데이터를 복사 하는 방법을__ 사용 하고 있기 때문에 삽입 삭제시 많은 복사가 일어나기 때문. 617 | 618 | 619 | > :arrow_double_up:[Top](#6-algorithm) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#6-algorithm) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 620 | -------------------------------------------------------------------------------- /contents/os.md: -------------------------------------------------------------------------------- 1 | ## 3. Operating System 2 | **:book: Contents** 3 | 4 | - [OS란 무엇이며, 핵심 기능은?](#OS개념과-핵심-기능) 5 | - [부팅이 되는 과정을 설명하시오.](#부팅이-되는-과정) 6 | - [프로세스의 5가지 상태에 대해 설명하시오.](#프로세스의-5가지-상태) 7 | - [메모리 계층 구조를 설명하시오.](#메모리-계층-구조) 8 | - [캐시와 버퍼의 차이점은?](#캐시와-버퍼의-차이점) 9 | 10 | * [세마포어와 뮤텍스란? 차이점은 무엇인가?](#세마포어와 뮤텍스란?-차이점은-무엇인가?) 11 | * [메모리 단편화, 페이징, 세그멘테이션](#메모리-단편화,-페이징,-세그멘테이션) 12 | * [선점스케줄링과 비선점스케줄링, 해당하는 알고리즘 한개씩](#선점스케줄링과-비선점스케줄링,-해당하는-알고리즘-한개씩) 13 | * [문맥교환이란?](#문맥교환이란?) 14 | * [PCB란?](#PCB란?) 15 | 16 | 17 | * [가상메모리란?](#가상메모리란?) 18 | * [Deadlock이란?](#Deadlock이란?) 19 | * [프로세스의 메모리구조?](#프로세스의-메모리구조?) 20 | * [thrashing이란?](#thrashing이란?) 21 | * [프로세스간 통신하는 방법은?](#프로세스간-통신하는-방법은?) 22 | 23 | 24 | * 멀티프로세싱, 멀티프로그래밍, 멀티스레딩, 멀티태스킹 25 | * 톰캣은 멀티 프로세스인가 멀티 스레드인가 26 | * 아파치는 멀티 프로세스인가 멀티 스레드인가 27 | * 동기, 비동기, 블로킹, 넌블로킹 차이 28 | * 스레드와 프로세스의 차이 29 | * Thread 가 3개 생성 되었을 때 t1, t2, t3의 순서가 보장 되는 코드를 짜 보세요. 30 | 31 | --- 32 | 33 | ## OS개념과 핵심 기능 34 | **운영체제란** 35 | H/W와 S/W 사이에서 둘을 효율적으로 운영하고 관리하여 36 | 사용자가 컴퓨터를 편리하게 사용할수 있도록 하는 프로그램 37 | 38 | **운영체제 기능** 39 | 1. 자원관리 40 | - 컴퓨터 시스템을 구성하는 cpu, 기억장치, 주변장치, data등 컴퓨터 자원을 관리한다 41 | 42 | 2. 프로세스 관리 43 | - 프로세스와 쓰레드 스케줄링, 프로세스 생성과 제거, 프로세스 시작, 정지, 재수행 44 | - 프로세스 동기화 및 통신, 주기억 장치 관리를 위해 주기억장치 관리자와 협력 45 | 46 | 3. 기억장치 관리 47 | - 메모리 상태 추적, 메모리 할당 및 회수, 가상기억장치 및 페이징 장치 관리, 장치 관리자 또는 파일 관리자와 협력 48 | 49 | 4. 입출력 장치 관리 50 | - 입출력 장시의 스케줄 관리, 각종 주변장치의 스케줄링 및 관리 51 | 52 | 5. 파일 관리 53 | - 파일 생성과 삭제, 변경 유지들의 관리 54 | - 정보의 위치, 사용여부와 상태 등을 추적 관리 55 | 56 | >
128 | - 세마포어 종류 : binary 세마포어(세마포어가 0또는1만허용), counting 세마포어(0또는1이상의수를 가질수있다) 129 | 130 | **뮤텍스** 131 | - 초기값을 1과0으로 가진다 132 | - 임계구역에 들어갈때 락(lock)을 걸어 다른 프로세스(or 쓰레드)가 접근하지 못하도록하고 133 | - 임계구역에서 나올때 해당 락을 해제(unlock)한다. 134 | 135 | **뮤텍스와 세마포어의 차이** 136 | - 세마포어는 공유 자원에 __세마포어의 변수만큼 프로세스(or 쓰레드)가__ 접근할 수 있다 137 | - 반면에 뮤텍스는 __오직 1개만의 프로세스(or 쓰레드)만 접근 가능 138 |
139 | - 현재 수행중인 프로세스가 아닌 __다른 프로세스가 세마포어 해제__ 가능 140 | - 뮤텍스는 __락(lock)을 획득한 프로세스가 반드시 그 락을 해제__ 해야 한다. 141 | 142 | > [참고](https://velog.io/@conatuseus/OS-%EC%84%B8%EB%A7%88%ED%8F%AC%EC%96%B4%EC%99%80-%EB%AE%A4%ED%85%8D%EC%8A%A4) 143 | 144 | > :arrow_double_up:[Top](#3-os) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#3-os) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 145 | 146 | ## 메모리 단편화, 페이징, 세그멘테이션 147 | 148 | 149 | - 세그멘테이션-가변적으로 자른다 / 장점,단점 150 | - 페이지-고정된 크기로 자른다 / 장점, 단점 151 | - 물리메모리- 프레임 152 | - 가상메모리- 페이지 153 | 154 | **메모리 단편화** 155 | - 메모리의 공간이 작은 조각으로 나뉘어져서 __사용가능한 메모리가 충분히 존재하지만 할당(사용)이 불가능한 상태__ 156 | 157 | **외부 단편화** 158 | - 메모리가 할당되고 해제되는 작업이 반복되면서 작은 메모리가 중간중간에 존재 159 | - 이 때 중간에 생긴 사용하지 않은 메모리가 많이 존재해서 총 메모리 공간은 충분하지만 실제로 할당할수 없는 상황 160 | 161 | **내부 단편화** 162 | - __프로세스가 필요한 양보다 더 큰 메모리가 할당 되어서__ 프로세스에서 사용하는 메모리가 낭비되는 상황 163 | 164 | 165 | **페이징 기법** 166 | - 외부 단편화 해결, 내부 단편화 존재 167 | - __가상메모리를__ 같은 크기의 블록으로 나눈것을 __페이지__ 라고한다. 168 | - __물리메모리를__ 같은 크기의 블록으로 나눈것을 __프레임__ 이라고 한다. 169 |
170 | - 방법 171 | - 프로세스를 페이지 단위로 나눈 뒤에, 사용하지 않는 영역을 보조기억장치에 적재한다. 이를 페이징 되었다고 하는데, 만약 이 페이징 된 영역에 접근해야 하면 페이징 폴트를 발생시킨 후 메모리에 적재시킨다(요구 페이징). 페이징된 정보는 페이징테이블에 저장된다. 172 | 173 | - 장점 174 | - 연속적이지 않은 공간도 활용할수 있기 때문에 외부 단편화 문제를 해결 할 수 있다. 175 | - 단점 176 | - 내부 단편화가 발생할 수 있다 177 | 178 | **페이지 테이블이란 ?** 179 | - 페이징 기법에서 사용되는 자료구조로서, __프로세스의 페이지 정보를 저장하고__ 있는 테이블이다. 180 | 181 | **세그멘테이션 기법** 182 | - 내부 단편화 해결, 외부 단편화 존재 183 | - 가상메모리를 __서로 크기가 다른 논리적 단위인 세크멘트로 분할해서 메모리를 할당__ 하여 실제 메모리 주소로 변환을 하게 된다. 184 | - 각 세그먼트는 __연속적인 공간에 저장__ 되어 있다. 185 | - 세그먼트들의 크기가 다르기 때문에 미리 분할해 둘 수 없고 메모리에 적재될 때 빈공간을 찾아 할당하는 기법. 186 | 187 | > [참고](https://jeong-pro.tistory.com/91) 188 | 189 | > :arrow_double_up:[Top](#3-os) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#3-os) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 190 | 191 | ## 선점스케줄링과 비선점스케줄링, 해당하는 알고리즘 한개씩 192 | 193 | - 선점 알고리즘 : 어떤 프로세스가 CPU를 할당 받아 실행 중이더라도 OS가 CPU를 강제로 빼앗을 수 있다. 194 | 195 | **비선점 알고리즘** 196 | - FCFS 197 | - SJF(Shortest Job First, 실생 시간이 가장 짧은 작업부터) 198 | - HRN(Highest Response Ratio Next, 최고 응답률 우선 스케줄링) 199 | 200 | **선점 알고리즘** 201 | - RR(Round Robin) : 할당받은 시간(타임 슬라이스)동안 작업 하다가 작업 미완료시 준비 큐의 맨뒤로 간다. 202 | - SRT(Shortest Remaining Time) : SJF + RR 방식 203 | - 최소 잔류 시간 우선 스케줄링 204 | - 남은 시간이 적은 프로세스에 CPU를 먼저 할당 205 | - 다단계 큐 스케줄링 206 | - 우선순위에 따라 준비 큐가 여러개 207 | - 상단의 큐에 있는 모든 프로세스가 종료되야 다음 우선순위 큐의 작업이 시작된다. 208 | - 다단계 피드백 큐 스케줄링 209 | - __우선순위가 낮은 프로세스에 불리한 다단계 큐 스케줄링__ 을 보완한 방식 210 | - CPU를 사용하고 난 프로세스는 원래 큐로 돌아가지않고, 우선순위가 하나 낮은 큐의 끝으로 들어간다. 211 | - 우선순위를 낮춤으로써, 다단계 큐에서 우선순위가 낮은 프로세스의 실해이 연기되는 문제를 완화한다. 212 | 213 | **둘 다 가능** 214 | - 우선순위 스케줄링 215 | - 프로세스는 중요도에 따라 우선순위를 갖는다. 216 | - 일정 시간마다 우선순위가 변하거나 고정되거나 217 | 218 | > :arrow_double_up:[Top](#3-os) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#3-os) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 219 | 220 | ## 문맥교환이란? 221 | - CPU를 차지하던 프로세스가 나가고 새로운 프로세스를 받아들이는 작업을 말한다. 222 | - 두 프로세스의 PCB를 교환 하는 작업 223 | - 현재까지의 작업 상태를 저장하고 다음 작업에 필요한 각종 상태, 데이터를 읽어오는 작업 224 |
225 | - 멀티 프로세스 환경에서 CPU 스케줄러가 인터럽트 발생 시 현재 프로세스의 상태를 PCB에 저장하고, 새로운 프로세스의 상태를 레지스터에 저장하는 것을 말함. 226 | - 인터럽트의 종류 : 227 | - I/O Request : 입출력 요청 228 | - Time Slice Expired : CPU 사용시간 만료 229 | - Fork Child : 자식 프로세스 생성 230 | - Wait for interrupt : 인터럽트 처리 대기 231 | 232 | - 컨텍스트 스위칭 시 CPU는 아무런 작업을 하지 못한다. 따라서 잦은 컨텍스트 스위칭은 성능 저하를 일으킴. 233 | 234 | > :arrow_double_up:[Top](#3-os) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#3-os) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 235 | 236 | ## PCB란? 237 | - __프로세스를 실행하는 데 필요한 중요한 정보를 보관하는 자료구조__ 238 | - __각 프로세스가 생성될 때마다 고유의 PCB가__ 생성되고, 완료되면 제거된다. 239 |
240 | - 프로세스는 CPU를 할당받아 작업을 처리하다가, CPU를 선점 당하게 되면 진행 중이던 작업 내용을 PCB에 저장하고 CPU를 반환한다. 241 | - 이후에 다시 CPU를 할당받으면 PCB로 부터 진행이 끊겼던 부분에서 다시 작업을 실행한다 242 | - 프로세스 식별자, 상태, PC(프로그램 카운터, 다음 실행할 명령의 주소 가르킴), 메모리 관리 정보 등을 가지고 있다. 243 | 244 | > :arrow_double_up:[Top](#3-os) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#3-os) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 245 | 246 | ## 가상메모리란? 247 | 실제 시스템에 있는 물리적인 메모리의 크기에 상관 없이 가상 공간을 프로세스에게 제공합니다. 이런 가상 메모리는 프로세스 전체가 메모리에 적재되지 않아도 프로세스의 실행이 가능하도록 합니다. 248 | 249 | 250 | > [참고](https://ko.wikipedia.org/wiki/%EA%B0%80%EC%83%81_%EB%A9%94%EB%AA%A8%EB%A6%AC) 251 | 252 | > [참고](https://twinw.tistory.com/106?category=543743) 253 | 254 | - 가상메모리 어떻게 구현하나요 ? - 페이징, 세크멘테이션 255 | 256 | ## Deadlock이란? 257 | 258 | - 교착 상태란 두 개 이상의 작업이 서로 __상대방의 작업이 끝나기 만을 기다리고__ 있기 때문에 결과적으로 아무것도 완료되지 못하는 상태를 가리킨다 259 | 260 | 261 | ## Deadlock이란? 262 | 263 | - 교착 상태란 두 개 이상의 작업이 서로 상대방의 작업이 끝나기 만을 기다리고 있기 때문에 결과적으로 아무것도 완료되지 못하는 상태를 가리킨다 264 | 265 | - 멀티프로세스나 멀티쓰레드 환경에서 __여러 프로세스들이 한정된 자원을__ 사용하기 때문에 발생할 수 있다 266 | 267 | 268 | **데드락 발생 조건** 269 | - 모두 충족해야 발생 270 | 271 | 1. 상호배제 272 | - 자원은 한 번에 한 프로세스만이 사용할수 있다 273 | 2. 점유대기 (Hold and wait) 274 | - 자원을 할당받은 상태에서 다른 자원을 기다리는 상태 275 | 3. 비선점 276 | - 다른 프로세스에 할당된 자원은 사용이 끝날 때까지 강제로 뺏을수 없다 277 | 4. 순환 대기 (Circular wait) 278 | - 점유와 대기를 하는 프로세스 간의 관계가 원을 이룬다. 279 | - 점유와 대기를 하는 프로세스들이 서로 방해하는 방향이 원을 이루면, 프로세스들이 서로 양보하지 않기 때문에 교착상태 발생 280 | 281 | **데드락 처리 - 1.예방** 282 | - 교착 상태 발생 조건 중 하나를 제거함으로써 해결 283 | 1) 상호배제 부정 : 여러 개의 프로세스가 공유 자원 사용가능 (보호해야할 자원을 공유하기힘들다) 284 | 2) 점유대기 부정 : 자원을 점유한상태에서 다른 자원 기다리지 못함. (전부 할당 or 아예할당x) 285 | 3) 비선점 부정 : 자원을 빼앗을 수 있도록 만든다 (우선순위가 낮은 프로세스 기아현상) 286 | 4) 순환대기 부정 : 모든 자원에 숫자를 부여하고 숫자가 큰 방향으로만 자원할당(번호 부여 방식 선정 어려움) 287 | - 문제점 : 288 | - 자원을 보호하기 위해 1.상호배제, 3.비선점을 예방하기 어렵고 289 | - 2.점유대기, 4.순환대기는 프로세스 작업 방식을 제한하고 자원을 낭비한다 290 | 291 | **데드락 처리 - 2.회피** 292 | - 교착 상태가 발생하면 피하는 방법 293 | - 교착 상태가 발생하지 않는 범위 내에서만 자원할당, 교착 상태 발생하는 범위에서 프로세스 대기 294 | - 교착 상태 예방보다 좀 더 유연하다. 295 | 296 | **은행원 알고리즘 (Banker’s Algorithm)** 297 | - 은행이 대출 해주는 방식. 즉, 대출 금액이 대출 가능한 범위이면(안정 상태) 허용, 그렇지 않으면 거부. 298 | - 안정 상태에 있으면 자원을 할당하고, 그렇지 않으면 다른 프로세스들이 자원을 해지할 때까지 대기함 299 |
300 | - 최대 자원 : 자신이 사용할 자원의 최대수 301 | - 할당 자원 : 할당된 자원수 302 | - 기대 자원 : 최대자원 - 할당 자원 303 | - 가용 자원 : 남은 자원의 수 304 |
305 | - 문제점 : 306 | - 모든 프로세스가 __자신이 사용할 모든 자원을 미리 알기 어렵다__ 307 | - 시스템의 전체 자원 수는 유동적이므로 전체 자원 수를 고정하기 어렵다 308 | - 자원 낭비 ; 실제로 교착상태가 발생하지 않았지만 발생할 것이라고 예상하여, _프로세스에 자원 할당하는 것에 제약_ 을 둔다. 309 | 310 | **데드락 처리 - 3.탐지** 311 | - os가 프로세스의 작업을 관찰하면서 데드락 발생 여부를 계속 주시 312 | 313 | **타임아웃** 314 | - __일정 시간 동안 작업이 진행되지 않은 프로세스를__ 데드락 발생한것으로 간주하여 처리 315 | - 자원 할당 그래프를 이용하는것보다 쉽기 때문에 선호한다 316 | 317 | **자원 할당 그래프** 318 | - 자원할당 그래프를 통해 프로세스가 어떤 자원을 사용, 기다리는지 알 수 있다 319 | - 장점 : 프로세스의 작업 방식을 제한하지 않으면서 교착상태를 정확하게 파악 320 | - 단점 : 자원 할당 그래프를 유지, 갱신, 사이클 검수하면서 __오버헤드가 발생__ 321 | - 추가 작업을 줄이기 위해 자원 할당시마다 사이클 검사X, 일정 시간마다 검사하는 방법도 있음 322 | 323 | 324 | 325 | **데드락 처리 - 4.회복** 326 | - 데드락 발생 시킨 프로세스 종료하거나 할당된 자원을 해제 하여 회복하는 것을 의미 327 | 1. 교착상태 발생시킨 프로세스 동시에 종료 328 | 2. 교착상태 발생시킨 프로세스 중 하나를 골라 순서대로 종료 329 | - 우선순위 낮은 프로세스 종료 330 | - 작업 시간 짧은 프로세스 종료 331 | - 자원을 많이 사용하는 프로세스 종료 332 | 333 | > [참고](https://jwprogramming.tistory.com/12) 334 | > [참고 - 쉽게 배우는 운영체제] 335 | 336 | ## 프로세스의 메모리구조? 337 | 338 |  339 | - 메모리 영역은 크게 두가지로 나눌 수 있는데 컴파일시 크기가 고정되는 code, data, bss 영역과 실행시 메모리가 할당되었다 반납되는 heap, stack영역으로 나눌 수 있다. 340 | 341 | 342 | 1. 메모리 할당이 고정되는 영역 (compile시 결정) 343 | 344 | * code영역 345 | - 실행 파일을 구성하는 명령어들이 올라가는 메모리 영역으로 함수, 제어문, 상수 등이 여기에 지정된다. 346 | 347 | * data 영역 & BSS 348 | - data 영역은 BSS와 함께 묶어서 데이터 영역으로 칭하기도 하는데 이는 전역변수와 static변수가 지정되는 영역이다. 349 | - 초기화 되지 않은 전역변수들은 BSS에 지정된다. 350 | - data :초기값 있는 전역밴수, 배열, static으로 선언된 변수 351 | - bss : 초기값 없는 전역변수, 배열, static으로 선언된 변수 352 | 353 | 2. 실행 중에 메모리를 할당하는 영역(할당과 반납이 이루어짐) 354 | - data 영역은 BSS와 함께 묶어서 데이터 영역으로 칭하기도 하는데 이는 전역변수와 Static변수가 지정되는 영역이다. 355 | - 초기화 되지 않은 전역변수들은 BSS에 지정된다. 356 | 357 | 358 | 2. 실행 중에 메모리를 할당하는 영역(할당과 반납이 이루어짐) 359 | 360 | * HEAP 영역 361 | - malloc(), calloc() 등으로 프로그래머가 자율적으로 메모리 크기를 할당할 수 있는 영역이다. 362 | - 위의 함수들은 free()함수로 할당된 영역을 반납해줘야하므로 동적할당 영역에 속한다. 363 | 364 | * STACK 영역 365 | - 지역변수가 할당되는 영역으로 함수가 호출되면 할당되었다 함수의 종료시 반납되는 영역이다. 366 | 367 | 368 | **메모리 오버플로우** 369 | - 위의 HEAP과 STACK영역은 사실 같은 공간을 공유한다. 370 | - HEAP이 메모리 위쪽 주소부터 할당되면 STACK은 아래쪽 부터 할당되는 식이다. 371 | - 그래서 각 영역이 상대 공간을 침범하는 일이 발생할 수 있는데 이를 각각 HEAP OVERFLOW, STACK OVERFLOW라고 칭한다. 372 | 373 |  374 | 375 | > [참고](https://zapiro.tistory.com/entry/%ED%95%A8%EC%88%98%EC%99%80-%EB%A9%94%EB%AA%A8%EB%A6%AC-%EC%98%81%EC%97%AD) 376 | 377 | ## thrashing이란? 378 | 379 | - 가상메모리 크기 = 물리메모리 + 스왑영역 (하드디스크에 존재 or 멤리 관리자가 관리하는 영역) 380 | 381 | **페이지 부재(페이지 폴트)** 382 | - 프로세스가 페이지를 요청했을 때 그 페이지가 메모리에 없는 상황 383 | 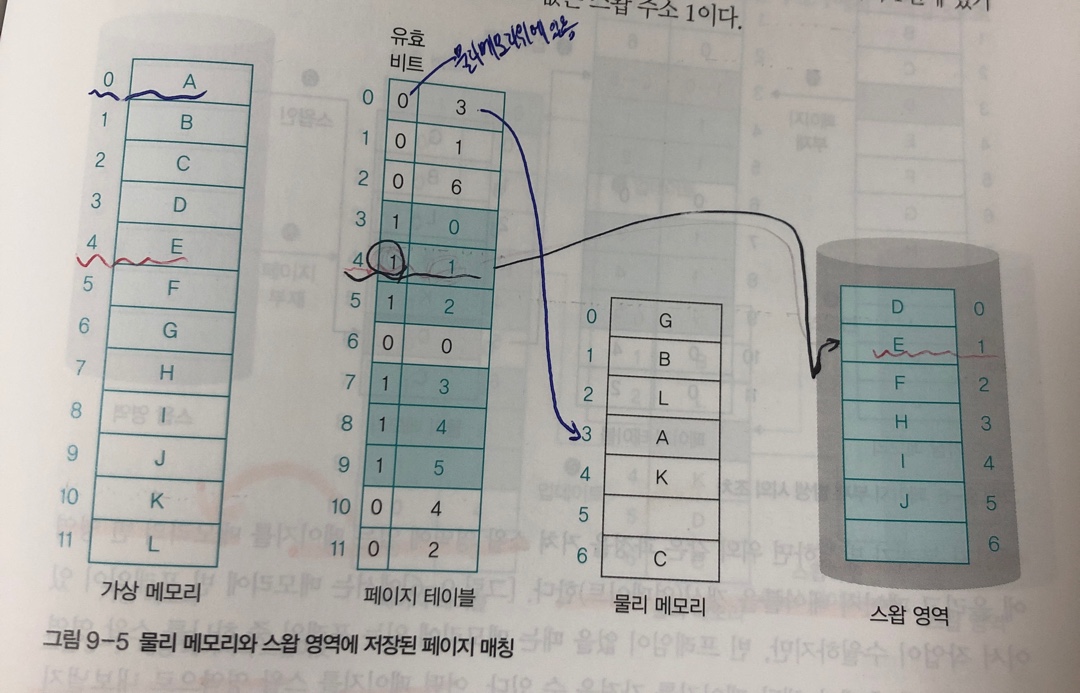 384 | ex) 프로세스가 페이지 4를 요청 했을때, 페이지 테이블에 유효비트1, 주소 필드값 1 이므로 __메모리에 없고 스왑영역__ 에 있다. 이것을 페이지 부재라한다 385 | 386 | - ex) 1,2,3 있을때 실제 메모리에 1,2 할당, 다음에 3할당하려면 빼고...반복 387 | 388 | **Thrashing(쓰레싱)** 389 | - 메모리에 __페이지 부재율이 높은것,__ 심각한 성능 저하를 초래 390 | - 하드디스크의 입출력이 너무 많아져서 잦은 페이지 부재로 작업이 멈춘 것 같은 상태 391 | - 재료를 창고->도마 or 도마->창고 옮기는 작업이 많아, 요리 못하는 상태 392 | 393 | **스레싱과 물리 메모리 크기** 394 | - __멀티프로그래밍 정도__ : 동시에 실행하는 프로그램의 수 395 | - 멀티프로그래밍 정도가 높으면 스레싱 발생 396 | - 메모리가 꽉차면, 397 | - cpu가 작업하는 시간 < 스왑영역으로 페이지 보내고, 새로운 페이지 가져오는 작업 시간 398 | - cpu가 작업할 수 없는 상태 --> __스레싱 발생 지점__ 399 |  400 | 401 | **물리 메모리 크기와 작업 속도** 402 | - 물리 메모리 용량을 512MB->4GB로 늘리면, 스레싱 발생 지점 늦춰져서 성능 향상 403 | - 물리 메모리 용량을 4GB -> 16GB로 늘리면 ? (물리 메모리가 작업하는데 충분한 크기면) 크기를 늘려도 작업 속도에 영향 미치지 X 404 | - 식탁 크기의 도마 -> 방 크기의 도마로 바꾼다해서 요리 시간이 빨라지지 X 405 | 406 | 407 | **스레싱과 프레임 할당** 408 | - 남아 있는 프레임을 실행 중인 프로세스에 적절히 나눠주는 정책 409 | - 프로세스에 너무 적은 프레임 할당시, 페이지 부재 빈번 410 | - 너무 많은 프레임 할당시, 페이지 부재 少, 메모리 낭비 411 | --> 각 프로세스가 필요로 하는 최소한의 프레임 갯수를 보장해줘야 한다. 412 | 413 | - 정적할당 414 | - 동적할당 415 | 416 | > [참고](https://jwprogramming.tistory.com/56) 417 | > [참고 - 쉽게 배우는 운영체제] 418 | 419 | ## 프로세스간 통신하는 방법은? 420 | 421 |  422 | 423 | 프로세스간 통신(IPC, Inter Process Communication) 424 | 425 | - 정의 : 하나의 컴퓨터 안에서 실행중인 서로 다른 프로세스 간 발생하는 통신 426 | - 기능 : 의사 소통 기능 & 동기화를 보장해야 한다. 427 | - 동기화 : 하나의 프로세스가 공유 데이터 값을 변경하는 동안 , 다른 프로세스는 그 데이터에 접근 x 428 | - 종류 : 메시지 전달(message passing) & 공유 메모리(shared memory) / __공유 변수 사용 여부에__ 나뉜다 429 | 430 | **1.메시지 전달** 431 | - 특징 : ipc를 위해 __커널을 통해__ 메세지를 전달하는 방식으로 자원,데이터 주고받는다 432 | - 장점 : 별도의 구축없이 커널을 이용하기 때문에 비교적 구현이 쉽다 433 | - 단점 : 커널을 이용하기 때문에, __시스템 콜__이 필요하며 이로 인해 __오버헤드가__ 발생 434 | - 종류 : __파이프, 메시지 큐, 소켓, 시그널 등__ 435 | 436 | **1-1.메시지 전달 모델 - 파이프** 437 | - 특징 : 하나의 프로세스가 파이프를 통해 다른 프로세스로 메시지를 직접 전달 438 | - 단점 : __단방향 통신__ , 따라서 2개의 프로세스 통신시, 2개 파이프 필요 -> 100개 프로세스 통신시, 100P2 = 9900개 필요하므로 __자원 낭비가 심하다__ 439 | - 종류 : 익명파이프, 네임드 파이프 440 | 441 | **익명파이프** 442 | - 사용에 제한이 있다. 443 | - 이름이 없기 때문에 __외부 프로세스에서 이 파이프 호출불가__ 444 | - 부모, 자식 프로세스 간 통신시 사용 445 | 446 | **네임드파이프** 447 | - 이름이 있기 때문에 __외부 프로세스와 통신 가능__ 448 | 449 | **1-2.메시지 전달 모델 - 메시지 큐** 450 | - 특징 : 고정 크키의 메시지를 연결 리스트를 통해 통신하는 방식 451 | - 메시지 단위의 통신, 메시지 큐id를 통해 통신 452 | 453 | **1-3.메시지 전달 모델 - 소켓** 454 | - 특징 : 네트워크 상에서 프로세스간 통신, local&remote 통신가능 455 | 456 | 457 | **2.공유 메모리** 458 | - 특징 : ipc를 위해 __공유 메모리 영역__ 을 구축하고, 공유 영역을 통해 자원이나 데이터를 주고 받는다. 459 | - 장점 : 커널 의존성이 낮기 때문에 __속도가 빠르다__ , 유저 레벨에서 ipc가 가능하기 때문에, __통신이 자유롭다__ 460 | - 단점 : 자원과 데이터를 __공유하기 때문에 동기화!!!__ 이슈 발생. 461 | 462 | 463 | 464 | ## 32bit CPU와 64bit CPU의 차이 465 | 466 | bit : CPU가 처리하는 데이터의 최소 단위(레지스터)의 크기 467 | - 32bit/64bit CPU는 한 번에 다룰 수 있는 데이터의 최대 크기가 32bit/64bit 468 | - CPU 내부 부품은 비트를 기준으로 제작된다. 469 | - 32bit CPU 내의 레지스터 크기, 산술 논리 연산장치, 버스의 크기, 대역폭 모두 32bit 470 | - 메모리 주소 레지스터(MAR, 메모리 주소를 지정하는 레지스터) 크기가 32bit 이므로 표현 할 수 있는 메모리 주소의 범위가 0~2의32승, 총 크기는 2의32승bit, 약 4GB이다 471 | 472 | **차이점** 473 | - 32bit CPU컴퓨터는 최대 4GB의 메모리까지만 사용 가능하다 474 | - 64bit CPU컴퓨터는 4GB이상의 메인 메모리를 사용가능 475 | 476 | 477 | ## 장기/단기/중기 스케줄러에 대해 설명해라 478 | 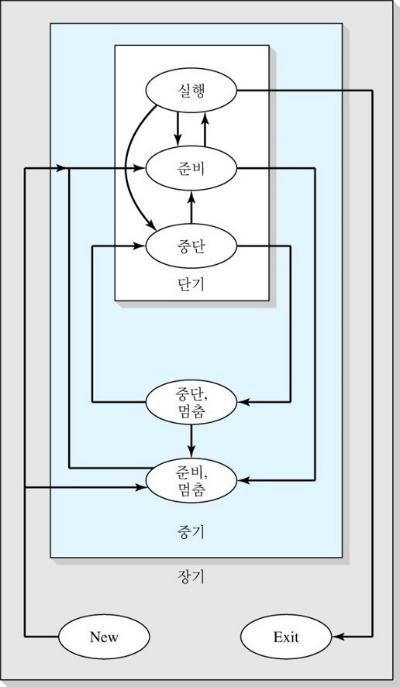 479 | 480 | 481 | **장기 스케줄러(잡 스케줄러)** 482 | - 메모리와 디스크 사이에서 메모리에(Ready Queue)에 어떤 걸 집어넣을지 결정 483 | - 하드디스크에서 메인 메모리로 로드하는것은 꽤 느린 작업이므로, 장기 스케줄러는 신중히 프로세스를 로드해야한다. 484 | - 입/출력을 많이하는 프로세스&cpu연산을 많이 하는 프로세스를 적절히 선택하여 메인 메모리로 로드하는 것이 중요 485 | - 하드디스크 -> 메인 메모리 486 | 487 | **단기 스케줄러(cpu 스케줄러)** 488 | - CPU와 메모리 사이에서 __Ready Queue에 있는 프로세스 중 어떤 것을 CPU 할당을 받게 할지__ 스케줄링 489 | - 메인 메모리 -> CPU 490 | 491 | **중기 스케줄러(Swapper)** 492 | - 여유공간 부족 시 공간을 만들기 위해 메모리에서 쫓아내어 하드 디스크로 옮김, 동시에 메모리가 많이 올라가는 것을 조절 493 | 494 | >[참고1](https://twinw.tistory.com/4) 495 | >[참고2](https://twinjh.tistory.com/18) 496 | 497 | ## 멀티프로세스와 멀티쓰레드는 무엇이고 어떤 차이가 있나요 498 | 499 | - 멀티프로세스 : 여러개의 프로세서를 이용해 여러개의 프로세스로 작업하는것 500 | - __문맥 교환시 오버헤드가 크다__ 501 | - 프로세스간 통신이 어렵다 502 | - 프로세스간 독립적이다 503 | 504 | - 멀티쓰레드 : 하나의 프로세서로 여러개의 쓰레드로 작업하는것 505 | - 스레드간 자원을 공유하기 때문에 506 | - 문맥교환시 __오버헤드가 적고,__ 스레드간 통신이 비교적 쉽고, 중복되는 자원을 줄일수있다. 507 | - 하지만, 동기화에 신경써야 하고, 하나의 스레드에 문제가 생기면 전체 스레드에 문제가 발생한다. 508 | 509 | ## 사용자 수준 쓰레드와 커널 수준 쓰레드란 무엇인가요 510 | 511 | **사용자 수준 스레드** 512 | - 스레드 교환에 커널이 개입하지않는다 513 | - 쓰레드와 관련된 행위를 유저쪽에서 한다 514 | - 장점 515 | - 스레드 전환 시 커널 스케줄러를 호출할 필요가 없기 때문에 516 | - 사용자 수준 스레드는 context swith가 비교적 적다 517 | - 따라서 커널 수준 스레드 보다 오버헤드가 작다 518 | - 스레드 스케줄러가 사용자 모드에만 존재한다 519 | - 단점 520 | - 프로세스 내의 한 스레드가 __(I/O요청)커널로 진입하는 순간 나머지 스레드는 전부 정지된다__ 521 | - 이는 커널이 스레드의 존재를 알지 못하기 때문에 발생하는 현상 522 | 523 | **커널 수준 스레드** 524 | 525 | -장점 526 | - 사용자 수준 스레드 보다 효율적이다 527 | - 커널 스레드를 쓰면 멀티프로세서를 활용할 수 잇는 장점이있다. 528 | - 사용자 스레드 cpu가 아무리 암ㅎ더라도 커널 모드의 스케줄이 되지 않으므로 cpu에 효율적으로 스레드를 배당할 수 없다 529 | -단점 530 | - 커널 스케줄러를 통해 context swith가 발생한다 531 | - 이 과정에서 프로세서 모드가 사용자 모드와 커널 모드 사이를 움직이기 때문에 빈번할 수록 성능 하락 532 | - 오버헤드가 많이 일어난다. 커널이 개입하기 때문에 533 | 534 | >[참고](https://geekhub.tistory.com/58) 535 | 536 | ## 동기화란 무엇이며 어떤 해결방법이 있나요 537 | - 동기화 538 | - __공유 자원에 대하여 동시에 접근하는 프로세스/스레드들로 인해 발생하는 문제를 해결하기 위해 행하는 방식__ 539 | 540 | - 경쟁 상태 (Race Condition) : 541 | 경쟁 상태란 두 개 이상의 프로세스 혹은 스레드가 공유 자원을 동시에 사용할 때 그 순서에 따라 결과가 달라지는 문제. 542 | 은행 잔고를 예제로 들면 은행 잔고라는 공유 데이터를 읽어와서 입금 연산과 출금 연산을 하는데, 동시에 접근해서 연산해버리면 한 쪽 연산이 반영이 안되는 문제 543 | 544 | - 임계영역과 크리티컬 섹션 : 545 | 사전상으로는 같은 말이지만, 의미하는 바가 다를 수 있다. 546 | 임계영역은 프로세스간 자원이 공유될 수 있는 코드 블록을 의미하며, 크리티컬 섹션은 하나의 동기화 방법을 말한다. 임계 영역을 프로세스들이 같이 쓸 수 있는 전제 조건은 다음과 같다. 547 | 548 | - 상호 배제 (Mutal Exculsion) : 프로세스가 크리티컬 섹션에 들어가 있다면, 다른 프로세스는 크리티컬 섹션에 들어갈 수 없다. 549 | - 진행 (Progress) : 크리티컬 섹션에 들어가 있는 프로세스가 없다면 다른 후보 프로세스가 진입할 수 있다. 550 | - 한정된 대기 (Bounded Waiting) : 프로세스가 진입 가능한 횟수에는 제한이 있다(특정한 한 프로세스만 계속 진입하는 것을 방지). 551 | 552 | - Lock : 553 | 하드웨어 기반 처리로, 임계 영역에 진입하기 위해서는 Lock이 필요하다. 임계 영역에 들어가는 프로세스는 Lock을 획득하고, 빠져나올때 Lock을 반납한다. 다중 처리기 환경에서 성능을 보장할 수 없다. 554 |
555 | 556 | **세마포어** 557 | 558 | - 바쁜대기 해결 559 | - 연산 방법 : 560 | 561 | ``` 562 | - P : 검사(Proberen), 프로세스를 대기시키는 'wait 동작'으로 임계영역에 진입하기 위한 연산 563 | - P(S) : while S <= O do no-op; 564 | 565 | - S := S - ; 566 | 567 | - V : 증가(Verhogen), 대기 중인 프로세스를 '깨우는 신호를' 보내는 signal 동작으로 임계영역에 나오기 위한 연산 568 | - V(S) : S := S + 1; 569 | ``` 570 | 571 | - 문제점 : 572 | - 1. p나v 실행 안되면 , 데드락 발생 573 | - 2. v실행후 2개이상의 프로세스 동시 접근시, 상호배제 보장x 574 | 575 | - 종류 : OS는 카운팅/이진 세마포어를 구분한다. 576 | - 카운팅 세마포어 : 동시에 사용가능한 자원에 대해 사용되며, 임계영역 안에 스레드나 프로세스가 들어오면 카운트를 증가시켜, 일정 숫자만큼의 스레드만 사용하게 하는 것 577 | - 이진 세마포어 : 0과 1로만 된 세마포어로, 임계영역 안에 하나의 프로세스만 들어갈 수 있다. 뮤텍스라고도 함. 578 | 579 | 580 | **모니터** 581 | - 락을 얻고 해제하는 부분이 자동으로 된다는 점만 빼고는 거의 세마포어와 비슷하다. 582 | 583 | 584 | **Busy Waiting** 585 | - 멀티 쓰레드 환경에서, 공유자원을 사용할때 기다리는 쓰레드가 __공유 자원을 사용할수 있는지 계속해서 무한 루프를 돌면서 조건문을 체크하는__ 방식 586 | - 임계 영역에 진입하려는 프로세스는 계속해서 진입하는 코드를 실행해야 한다. 따라서 성능의 저하가 발생할 수 있음. 587 | - 세마포어에서도 데드락이 발생할 수 있다. 588 | 589 | ## 멀티프로세싱, 멀티프로그래밍, 멀티스레딩, 멀티태스킹 590 | - CPU 코어의 관점에서 생각 591 | 592 | **멀티 프로세싱** 593 | - CPU N 프로세스 N 수행 (멀티 프로세스X, 멀티 프로세서O) 594 | 595 | **멀티 쓰레딩** 596 | - CPU 1, 쓰레드 N 수행 597 | 598 | **멀티 프로그래밍** 599 | - CPU 1 프로세스 N 수행 600 | - 프로세스 A에 대해서 프로세서가 작업(ex io작업)을 처리할때 낭비되는 시간동안 다른 프로세스를 처리하도록 하는 것 입니다. 601 | - __CPU의 자원이 낭비되는 것을 최소화__ 602 | 603 | **멀티 태스킹** 604 | - 다수의 TASK(프로세스보다 조금더 확장된 개념)를 운영체제의 스케줄링에 의해 번갈아가면서 수행하는것 605 | - __일정하게 정해진 시간동안 번갈아가면서 각각의 Task를 처리하는 것__ 606 | - job > task > thread, 여러 스레드가 모인것이 태스크 607 | 608 | 609 | ## 톰캣은 멀티 프로세스인가 멀티 스레드인가 610 | - WAS 611 | 612 | ## 아파치는 멀티 프로세스인가 멀티 스레드인가 613 | - WS 614 | - 멀티프로세스, 스레드 둘다있다 615 | 616 | ## 동기, 비동기, 블로킹, 넌블로킹 차이 617 | 618 | **동기** 619 | - 어떤 일에 대한 요청과 응답(혹은 입출력)이 __동시에 이루어져야__ 하는 것 620 | - call하고 응답이 올 때까지 기다렸다가 다음 로직을 실행한다. 621 | * 장점 : 안전성이 보장된다. 순서가 보장된다. 622 | * 단점 : 느리다. 623 | 624 | **비동기** 625 | - 어떤 일에 대한 요청과 응답이 __동시에 이루어질 필요 없이__ 따로 이루어지는 것. 626 | - call하고 응답이 오지 않아도 다음 로직을 실행한다. 627 | * 장점 : 빠르다 628 | * 단점 : 처리 하기가 까다롭다. 순서가 보장이 되지 않는다. 629 | 630 | 631 | **블로킹** 632 | - 어떤 요청에 대한 __응답이 올 때까지 대기__ 하는 것. 633 | - 즉 동기를 위해서는 블로킹 되어야 함 634 | 635 | **넌블로킹** 636 | - 어떤 요청에 대해서 응답을 대기하지 않고 계속 루틴을 수행하는 것. 637 | - 비동기를 위해서는 넌블로킹 되어야 하지만, 넌블로킹이 비동기는 아니다(포함관계라고 생각하면 될 듯) 638 | - 예를 들어 넌블로킹이면서, 요청에 대한 응답을 계속해서 요구하는 폴링 방식의 경우, 비동기라 보기는 힘들다. 639 | - 이벤트 핸들러나 인터럽트를 통해 응답을 받는 것이 비동기 모델. 640 | 641 | ### 스레드와 프로세스의 차이 642 | 643 | |프로세스|스레드| 644 | |--|--| 645 | |요리작업전체 | 각각의 조리| 646 | |os입장에서 작업단위 | cpu입장에서 작업단위| 647 | | 프로세스간 약하게 연결 | 스레드간 강하게 연결| 648 | | 프로세스간 독립적 | 코드, 데이터, 힙 영역 공유| 649 | 650 | **프로세스** 651 |  652 | 653 | - 프로그램이 메모리에 올라와 OS로부터 자원을 할당받은 것 654 | - 다른 프로세스 __메모리에 직접 접근 불가__ (공유메모리나 커널을이용해서 메시지전달 ) 655 | 656 | - __문맥교환__ : cpu에서 여러 프로세스를 돌아가면서 작업을 처리하는 과정(현재 프로세스상태 보관, 다음 프로세스상태 복구하는 작업) 657 | 658 | **스레드** 659 |  660 | - 프로세스 내에서 실행되는 흐름의 단위를 말한다 661 | - 프로세스 내에서 스레드끼리 주소공간이나 자원들을 공유하면서 실행 (code, data, heap 공유) 662 | - 장점 : 663 | - 불필요한 __자원 중복 없앤다__ : 시스템 효율 향상 664 | - 프로세스간 통신보다 스레드간 __통신이 쉽다__ 665 | - 자원을 공유하므로 문맥교환시 오버헤드가 적다 666 | 667 | - 단점 668 | - 자원을 공유하므로 __동기화__ 에 유의해야한다. 669 | - 한 스레드에 문제가 생기면 전체 프로세스에 영향(익스플로러는 문제 생기면 모두종료 / 크롬은 멀티프로세스여서 모두 종료x) 670 | 671 | >[참고](https://gmlwjd9405.github.io/2018/09/14/process-vs-thread.html) 672 | -------------------------------------------------------------------------------- /contents/java.md: -------------------------------------------------------------------------------- 1 | # 7. Java 2 | **:book: Contents** 3 | * [자바 컴파일 과정을 설명하라](#자바-컴파일-과정을-설명하라) 4 | * [String, StringBuffer, StringBuilder의 차이점에 대해 설명하라](#String,StringBuffer,StringBuilder) 5 | * [OOP의 4가지 특징](#OOP의-4가지-특징) 6 | * [오버로딩과 오버라이딩의 차이](#오버로딩과-오버라이딩의-차이) 7 | * [HashMap과 TreeMap의 차이](#HashMap과-TreeMap의-차이) 8 | --- 9 | * [GC에 대해 설명하라](#GC에-대해-설명하라) 10 | * [자바의 메모리구조](#자바의-메모리구조) 11 | * [동등성(equals)과 동일성(==)](#equals,==) 12 | * [제네릭과 와일드카드](#제네릭과-와일드카드) 13 | * [멀티스레딩환경에서 동기화문제를 해결하는 방법에대해 설명하라 (syncronized, atomic, volatile)](#멀티스레딩환경에서-동기화문제를-해결하는-방법) 14 | 15 | --- 16 | * java의 접근 제어자의 종류와 특징 설명해주세요 17 | * 멤버 변수 & 지역 변수 18 | * non-static 멤버와 static멤버의 차이 설명해주세요 19 | * final 키워드 (final/finally/finalize) 설명해주세요 20 | * 인터페이스와 추상 클래스의 차이(Interface vs Abstract Class) 설명해주세요 21 | * set, list, map의 차이와 각각의 인터페이스 구현체의 종류를 설명해주세요 22 | 23 | * Comparable, Comparator 차이 24 | 25 | --- 26 | * [java8을 써보셨나요? java7에서 8로 올라오면서 어떤게 달라졌나요?](#java8을-써보셨나요?-java7에서-8로-올라오면서-어떤게-달라졌나요?) 27 | * [this 키워드](#this-키워드) 28 | * [자바에서 tcp udp 소켓 생성 방법](#자바에서-tcp-udp-소켓-생성-방법) 29 | * [리틀엔디안 빅엔디안](#리틀엔디안-빅엔디안) 30 | * [Reflection](#Reflection) 31 | * [oop 5대 원칙](#oop-5대-원칙) 32 | * [직렬화란?](#직렬화란?) 33 | 34 | --- 35 | --- 36 | ## 자바 컴파일 과정을 설명하라 37 |  38 | 39 | 1. .java 파일을 build하면 Java Compiler의 javac라는 명령어를 사용해서 .class파일을 생성한다 40 | (.class파일은 byte code로 아직 컴퓨터가 읽을 수 없는 반기계어 이다.) 41 | 3. .class파일은 Class Loader에 의해서 JVM내로 로드 된다. 42 | 4. 실행엔진(인터프리터 또는 JIt)을 이용해서 byte code-> binary code로 변환한다. 43 | 5. 변환된 binary code(기계어)는 메모리에(Runtime Data Area) 배치된다. 44 | 6. Runtime Data Area에 올라간 파일은 실행엔진(Execution Engine)에 의해 실행 45 | - 이와 같은 과정을 통해 Java파일이 컴파일되고, JVM에 의해 해당 OS에 맞게 변환시커 컴퓨터가 읽을 수 있도록 만들어준다. 46 | 47 | **실행 엔진 종류** 48 | - Interpreter : 자바 byte code를 한줄 씩 실행. 속도 느림 49 | - JIT Compiler : (Just In Time)Interpreter의 단점을 보완. 50 | 전체 byte code를 컴파일, 속도가 느리지만 캐시를 사용해서 51 | 한번 컴파일 하면 다음에는 빠르게 수행된다. 52 | 53 | 54 | > -
(put,get과 같은 주요 메서드에 syncronized 키워드가 선언되어있다)| X | O (map전체에 lock을걸지않는다 부분적으로 걸기 때문에 더 효율이 좋다)| 190 | 191 | **참고) vector vs arrayList** 192 | - vector는 무조건 동기화를 지원하기 때문에 멀티프로세싱이 아닌 프로그램에서 사용하면 효율이 떨어진다 193 | 194 | >[참고](https://jdm.kr/blog/197) 195 | 196 | 197 | 198 | | HashMap| TreeMap| 199 | |--|--| 200 | | 순서 유지 x | key값에 따라 정렬| 201 | | Hashing으로 내부 구현 | Red-Black 트리로 내부 구현| 202 | |key: null 1개 허용, value:허용 | key: null 허용x, value:허용| 203 | | O(1) get,put 같은 기본 연산에 일정한 시간 성능 | O(log n) 시간 204 | | treemap보다 빠르다 | hashmap보다 느리다| 205 | |Map 인터페이스 구현| NavigableMap 인터페이스 구현| 206 | 207 | >
229 | 230 | **Heap영역은 GC의 주요 대상** 231 | - 구현원리 , 객체들이 한번 참조되면 232 | - 처음에 에덴에 생성이 되고, .....(조사할것) 233 | - __Young Generation__ 234 | - 이 영역은 자바 객체가 생성되자마자 저장되고, 생긴지 얼마 안되는 객체가 저장되는 공간이다. 시간이 지나 우선순위가 낮아지면 Old 영역으로 옮겨진다. 이 영역에서 객체가 사라질 때 Minor GC가 발생한다. 235 | - __Old(Tenured) Generation__ 236 | - Young Generation 영역에서 저장되었던 객체 중에 오래된 객체가 이동되어 저장되는 영역이다. 이 영역에서 객체가 사라질 때 Major GC(Full GC)가 발생한다. 237 | 238 | 239 | >
244 | **GC** 245 | - C++에서 new나 delete를 통해 메모리를 명시적으로 해제했지만 Java에서는 개발자가 프로그램 코드로 메모리를 명시적으로 해제하지 않고 가비지 컬렉터(Garbage Collector)가 이 역할을 대신한다. 더 이상 사용하지 않는 객체를 찾아서 지우는 역할을 하는것이 GC 이다. 246 |
247 | Garbage Collection을 실행하면 JVM이 일시적으로 어플리케이션 실행을 멈추는데 이를 stop-the-world 라 한다. 248 |
249 | stop-the-world가 발생하면 GC를 실행하는 쓰레드를 제외한 나머지 쓰레드는 모두 작업을 멈춘다. GC 작업을 완료한 이후에야 중단했던 작업을 다시 시작한다. 어떤 GC 알고리즘을 사용하더라도 stop-the-world는 발생한다. 대개의 경우 GC 튜닝이란 이 stop-the-world 시간을 줄이는 것이다. 250 |
251 | GC는 아래의 두가지 가설을 토대로 만들어졌다. 252 |
253 | 대부분의 객체는 금방 접근 불가능 상태(unreachable)가 된다. 254 | 오래된 객체에서 젊은 객체로의 참조는 아주 적게 존재한다. 255 | 이러한 가설을 ‘weak generational hypothesis’라 한다. 이 가설의 장점을 최대한 살리기 위해서 HotSpot VM에서는 크게 2개로 물리적 공간을 나누었다. 둘로 나눈 공간이 Young 영역과 Old 영역이다. 256 |
257 | 영역별 데이터 흐름은 아래와 같다. 258 | 259 |  260 | 261 |
262 | 위의 Permanenet Generation 영역은 Method 영역에 포함된 부분이고.. Java 8부터 MetaSpace 영역으로 바뀌었다고 한다(PermGen 영역에서 일어나는 GC도 Major GC에 포함된다.) 263 |
264 | 265 | **Young 영역** 266 | - 새롭게 생성된 데이터 대부분이 Young Generation에 위치하며 여기서 객체가 할당 해제되는 경우 __Minor GC가__ 발생했다고 한다. 267 | - Eden 영역 268 | - Survivor 영역(2개) 269 | - 으로 나뉘며, Eden에서 살아남은 객체는 Survivor 으로 보내고, Survivor영역이 가득 차면 다른 Survivor 영역으로 보낸다. 이 과정에서 살아남은 객체는 Old 영역으로 이동하게 된다. 270 | 271 | 272 | **Old 영역** 273 | 접근 불가능 상태로 되지 않아 Young 영역에서 살아남은 객체가 여기로 복사된다. 대부분 Young 영역보다 크게 할당하며, 크기가 큰 만큼 Young 영역보다 GC는 적게 발생한다. 여기서 객체가 할당 해제되는 경우 __Major GC가__ 발생했다고 한다. 274 |
275 | Old 영역은 기본적으로 데이터가 가득 차면 GC를 실행한다. 276 |
277 | Major GC는 아래와 같은 방식에 따라 동작한다. GC 방식에 따라 처리가 달라진다. 278 | - Serial GC 279 | - Parallel GC 280 | - Parallel Old GC(Parallel Compacting GC) 281 | - Concurrent Mark & Sweep GC(이하 CMS) Java 9 부터 삭제. 282 | - G1(Garbage First) GC 283 | 284 | >[참고](https://tramyu.github.io/etc/interview/) 285 | 286 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#7-java) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 287 | 288 | ## 자바의 메모리구조 289 |  290 | 291 | **Method area(메소드 or 스테틱 영역)** 292 | - __모든 스레드가 공유하는 영역으로 JVM이 시작될 때 생성, 프로그램 종료시 해제.__ 293 | - __static변수, final class변수__ 등이 생성 294 | - JVM이 읽어 들인 각각의 클래스와 인터페이스에 대한 런타임 상수 풀, 필드와 메서드 정보, static 변수, 메서드의 바이트코드 등을 보관한다. 295 | - class의 구조 정보가 들어간다. 296 | 297 | - 멤버변수(static), 데이터 타입, 접근제어자 같은 필드 정보 298 | - 메소드 이름, 리턴 타입, 파라메터, 접근 제어자 같은 __메소드 정보__ 299 | - type정보 (interface or class), Constant Pool(상수 풀: 문자 상수, 타입, 필드, 객체참조) 300 | 301 | **Runtime Constant Pool** 302 | - 각 클래스와 인터페이스의 상수뿐만 아니라, 메서드와 필드에 대한 모든 레퍼런스까지 담고 있는 테이블이다. 303 | - 즉, 어떤 메서드나 필드를 참조할 때 JVM은 런타임 상수 풀을 통해 해당 메서드나 필드의 실제 메모리상 주소를 찾아서 참조한다. 304 | 305 | **Heap area** 306 | - __new 키워드로 생성된 객체와 배열을__ 저장 307 | - 메소드 영역에 로드된 클래스만 생성가능하다 308 | - 데이터가 동적으로 생성, 소멸 309 | - 참조하는 변수나 필드가 없으면 의미 없는 객체가 되어 __GC의 대상이 된다__ 310 | 311 | 312 | **Perm 영역** 313 |  314 | - JDK __8부터 Permanent Heap 영역이 제거되었다.__ 315 | - 대신 Metaspace 영역이 추가되었다. 316 | - __Perm은 JVM에 의해 크기가 강제되던__ 영역이다. 317 | - __Metaspace는 Native memory 영역으로, OS가 자동으로 크기를 조절한다.__ 318 | - 옵션으로 Metaspace의 크기를 줄일 수도 있다. 319 | - 그 결과 기존과 비교해 __큰 메모리 영역을 사용할 수__ 있게 되었다. 320 | - Perm 영역 크기로 인한 __java.lang.OutOfMemoryError를 더 보기 힘들어진다__ 321 | - 저장 정보 : Class의 Meta 정보, Method의 Meta 정보, Static 변수와 상수 정보들이 저장 -> java8 ( Static Object는 Heap 영역으로 옮겨져서 GC의 대상) 322 | 323 | 324 | >
503 | 504 | - AtomicInter 클래스는 __CAS(compare-and-swap)__ 기반으로 되어있다. 505 | - CAS는 특정 메모리 위치와 주어진 위치의 value를 비교하여 다르면 대체하지 않는다. 506 | - 이 방법은 저수준의 H/W에서 제공한다. 507 | 508 | ```java 509 | private AtomicInteger c = new AtomicInteger(); 510 | 511 | public int getNextIndex(){ 512 | return c.getAndIncrement(); 513 | } 514 | ``` 515 | 516 | **Volatile** 517 |
518 | - atomic안에 volatile이 구현되어있다 519 | _[자바의 정석 설명]_ 520 | - 멀테 코어 프로세서가 장착된 컴퓨터에서, 코어마다 별도의 캐시를 가질때 문제가 발생할수있다. 521 | - 코어는 메모리에서 읽어온 값을 캐시에 저장하고 캐시에서 값을 읽어 작업한다. 522 | - 다시 같은 값을 읽어올 때는 먼저 캐시에 있는지 확인하고 없을 때만 메모리에서 읽어온다. 523 | - 그러다 보니 도중에 메모리에 저장된 변수의 값이 변경 되었는데도 , 캐시에 저장된 값이 갱신되지 않아 메모리에 저장된 값이 다른 경우가 발생한다. 524 |
525 | - 따라서 변수 앞에 volatile을 붙이면, 코어가 변수의 값을 읽어올때 캐시가 아닌 메모리에서 읽어오기 때문에 캐시와 메모리간의 값의 불일치가 해결된다. 526 |
527 | 528 | _[인터넷 블로그 설명]_ 529 | - 자바 변수에 volatile을 붙이면 volatile 변수를 읽어 들일 때 __cpu캐시가 아니라 컴퓨터의 메인 메모리에서 읽는다___ 530 | - volatile 키워드는 __가시성__ 문제를 해결해준다. 531 | - 가시성 문제란? 멀테 쓰레드 환경에서 메인 메모리로 아직 기록하지 않은 값을 보지 못하여 동기화가 깨진 상황을 말한다 532 | - volatile을 써야 하는 경우는 한 쓰레드에서 변수의 값을 읽고 쓰며, 다른 쓰레드에서 읽기만 하는 경우 항상 value를 보장해줄수있다 533 | - 그러지 않고 멀티 쓰레드가 value를 변경한다면 synchronization을 적용해야 한다 534 | 535 | ```java 536 | public class Foo { 537 | public volatile int c = 0; 538 | } 539 | ``` 540 | 541 | >[참고](https://doll6777.github.io/android/2019/07/10/synchronized/) 542 | 543 | > :arrow_double_up:[Top](#7-java) :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#7-java) :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 544 | 545 | 546 | ## java의 접근 제어자의 종류와 특징 설명해주세요 547 |  548 | 549 | |접근제어자|설명| 550 | |--|--| 551 | |public| 프로젝트 안에서 자유롭게 사용가능하다 (제한이 전혀없다)| 552 | |protected| 같은 패키지 내에서 and 다른 패지키의 자손 클래스에서 접근 가능| 553 | |default| 같은 패키지 내에서만 접근 가능| 554 | |private| 같은 클래스 내에서만 접근 가능| 555 | 556 |  557 | 558 | **Q. 접근 제어자의 조합 퀴즈** 559 | 1. 메소드에 static 과 abstract 를 함께 사용 할 수 없다. why ? static 메소드에는 몸통이 있는 메소드에서만 사용 할 수 있기 때문 560 | 2. 클래스에 abstract 와 final 을 동시에 사용 할 수 없다. why ? 클래스에 사용되는 final은 클래스를 확장 할 수 없다는 의미이고, abstract 는 상속 을 통해서 완성되어야 한다는 의미이므로 서로 모순되기 때문이다. 561 | 3. abstract 메소드의 접근 제어자가 private 일 수는 없다. why ? abstract 메소드는 자손클래스에서 구현하기 위해 접근해야 하기 때문이다. 562 | 4. 메소드에 private 과 final 을 같이 사용 할 필요는 없다. why ? 접근제어자가 private 인 메소드는 오버라이딩 될 수 없기 때문이다. 이 둘중 하나만 사용해도 의미가 충분하다. 563 | 564 | 565 | > [참고](https://csw7432.tistory.com/entry/Java-%EC%A0%91%EA%B7%BC%EC%A0%9C%EC%96%B4%EC%9E%90-Access-Modifier) 566 | 567 | 568 | ## 멤버 변수 & 지역 변수 569 | 570 | **멤버 변수** 571 | - 클래스 블록 영역에 선언되는 변수 572 | 573 | **멤버 변수 - static O** 574 | - 클래스 변수, 공통변수, 정적변수, 전역변수 575 | - 컴파일시에 메모리할당, 프로그램 종료시 메모리 해제 576 | - 클래스 전체에서 사용 가능 577 | - 클래스의 모든 인스턴스가 같은 저장공간을 가리킨다 578 | - 저장공간 : Method 영역 579 | 580 | **멤버 변수 - static X** 581 | - 인스턴스 변수 582 | - 객체 생성시마다 따로 저장되는 변수 583 | - 저장공간 : Heap 영역 584 | - GC가 관리한다 585 | 586 | **지역 변수** 587 | - 메소드 블록 영역 588 | - 저장공간 : Stack 영역 589 | 590 | 591 | 592 | >[참고](https://m.blog.naver.com/PostView.nhn?blogId=turtle0720&logNo=60209489019&proxyReferer=https:%2F%2Fwww.google.com%2F) 593 | 594 | 595 | ## non-static 멤버와 static멤버의 차이 설명해주세요 596 | - static은 메서드 or 변수에 붙을수있다. 597 | 598 | - static 사용의 이점 599 | 600 | **static 멤버** 601 | - 공간적 특성 : __멤버는 클래스당 하나 생성__ 602 | - 객체 내부에 생성되는것 이아니고 컴파일시 method영역에 고정적으로 메모리 할당 603 | - 클래스 멤버 604 | - 시간적 특성: __클래스 로딩 시에 멤버 생성__ 605 | - 컴파일시 생성, 프로그램 종료시 메모리 해제 606 | - 객체 생성 하지 않고도 사용가능 607 | - 객체가 사라져도 멤버는 사라지지않음 608 | - 공유의 특성 : __동일한 클래스의 모든 객체들에 의해 공유된다__ 609 | 610 | **non-static 멤버** 611 | - 공간적 특성 : __멤버는 객체마다 별도로 존재__ 612 | - __인스턴스 멤버__ 라고 부른다 613 | - heap 영역 (클래스 내부에서 선언시) or statck 영역(메소드 내에서 생성시) 에 생성 614 | - 시간적 특성 : __객체 생성시 멤버 생성__ 615 | - 객체 생서 후에 사용 가능 616 | - 객체가 사라지면 메모리에서 해제 617 | - 공유의 특성 : __공유x__ 618 | - 멤버는 객체 내에서 각각의 공간을 유지 619 | 620 | > [참고](https://gmlwjd9405.github.io/2018/08/04/java-static.html) 621 | 622 | ## final 키워드 (final/finally/finalize) 설명해주세요 623 | 624 | **final 키워드** 625 | - 변수나 메서드 또는 클래스가 __‘변경 불가능’__ 하도록 만든다. 626 | 627 | - 원시(Primitive) 변수에 적용 시 628 | - 해당 변수의 값 변경X 629 | - final int number = 1; 630 | - 참조(Reference) 변수에 적용 시 631 | - 참조 변수가 힙(heap) 내의 다른 객체를 가리키도록 변경X 632 | - 메서드에 적용 시 633 | - 해당 메서드를 오버라이딩 X 634 | - 클래스에 적용 시 635 | - 해당 클래스를 __상속받을 수 X__ 636 | 637 | **finally 키워드** 638 | - try/catch 블록이 종료될 때 항상 실행될 코드 블록을 정의하기 위해 사용 639 | - finally는 선택적으로 try 혹은 catch 블록 뒤에 정의할 때 사용 640 | - finally 블록은 예외가 발생하더라도 항상 실행 641 | - 단, JVM이 try 블록 실행 중에 종료되는 경우는 제외 642 | - finally 블록은 종종 뒷마무리 코드를 작성하는 데 사용 643 | finally 블록은 try와 catch 블록 다음과, 통제권이 이전으로 다시 돌아가기 전 사이에 실행된다. 644 | 645 | **finalize() 메서드** 646 | 647 | __쓰레기 수집기(GC, Garbage Collector)가__ 더 이상의 참조가 존재하지 않는 __객체를 메모리에서 삭제하겠다고 결정하는 순간 호출__ 된다. 648 | 649 | 쓰레기 수집기(GC, Garbage Collector)가 더 이상의 참조가 존재하지 않는 객체를 메모리에서 삭제하겠다고 결정하는 순간 호출된다. 650 | 651 | 652 | Object 클래스의 finalize() 메서드를 오버라이드해서 맞춤별 GC를 정의할 수 있다. 653 | ```java 654 | protected void finalize() throws Throwable { 655 | /* 파일 닫기, 자원 반환 등등 */ 656 | } 657 | ``` 658 | 659 | 660 | - 개발자가 마음대로 오버라이딩 하면 안좋다. 661 | 662 |
663 | - Q) final과 abstract는 동시에 사용가능하나요 ? -> 아니요. 불가능합니다. 664 | 665 |
666 | - Q) final 과 abstract는 동시에 사용가능하나요 ? -> 아니요.불가능합니다. 667 | 668 | 669 | >[참고](https://gmlwjd9405.github.io/2018/08/06/java-final.html) 670 | 671 | ## 인터페이스와 추상 클래스의 차이(Interface vs Abstract Class) 설명해주세요 672 | 673 | **추상 메서드** 674 | - abstract 키워드 함께 원형만 선언되고, 코드는 작성되지 않는 메서드 675 | 676 | ```java 677 | public abstract String getName(); // 추상메서드 678 | public abstract int getAge() {return 11; }; // 추상 메서드 x 679 | ``` 680 | 681 | **추상 클래스** 682 | - 개념 : abstract 키워드로 선언된 클래스 683 | 1. __추상 메서드를 최소 한 개 이상__ 가지고 abstract로 선언된 클래스 684 | - 최소 한 개의 추상 메서드를 포함하는 경우 __반드시 추상 클래스로 선언__ 685 | 2. 추상 __메서드가 없어도 abstract로__ 선언된 클래스 686 | - 그러나 추상 메서드가 하나도 없는 경우라도 추상 클래스 선언 가능 687 | - 추상 클래스 구현 688 | - 추상 클래스를 __일반 클래스에서 상속__ 받는다면 슈퍼 클래스의 __모든 추상 메서드를 구현해야한다.__ 689 | - 추상 클래스를 추상 클래스에서 상속 시 , 모든 추상 메서드 구현 안해도 된다. 690 | - 추상 클래스 목적 691 | - 객체를 생성하기 위함X, 상속을 위한 부모 클래스로 활용하기 위한 것 692 | - 여러 클래스들의 __공통된 부분을 추상화(추상 메서드)__ 하여 상속받는 클래스에게 구현을 강제화하기 위함 (메서드의 동작을 구현하는 자식 클래스로 책임을 위임) 693 | - 즉, 추상 클래스의 추상 메서드를 자식 클래스가 구체화하여 __기능을 확장 하는데 목적__ 이 있다. 694 | 695 | 696 | **인터페이스** 697 | - 개념 : 추상 메서드와(public abstract) + 상수만을 포함 (public static final), interface 키워드 사용하여 선언 698 | - 인터페이스 구현 699 | - 일반클래스 : 인터페이스를 상속하고, __추상 메서드 모두 구현__ 700 | - 추상클래스: 일부만 구현하면 abstract사용하여 추상클래스로 구현 701 | - 인터페이스 : 인터페이스를 상속받아 새로운 인터페이스 구현 702 | - implements 키워드 사용 하여 구현 703 | - 인터페이스의 목적 704 | - __목적 : 구현 객체의 같은 동작을 보장__ 705 | - 즉, 서로 관련없는 클래스에게 공통적으로 사용하는 방식이 필요핮만 기능을 각각 구현할 필요가 있는 경우 사용 706 | 707 | 708 | |추상 클래스|인터페이스| 709 | |abstract| interface| 710 | |extends| implements| 711 | |목적:상속을 받아서 __기능을 확장__ 시킨다 | 목적:구현 객체의 __같은 동작을 보장__ 하기 위한 목적| 712 | |다중상속 x | 다중 구현 가능| 713 | |클래스o| 클래스 x| 714 | |abstract class Class| interface Interface| 715 | |일반 변수 가질수있다| 일반변수 x , static이 붙은 변수만 있다| 716 | | is a kind of | cand do this| 717 | |Appliances(Abstract Class) - TV, Refrigerator | Flyable(Interface) - Plane, Bird| 718 | 719 | > [참고1](https://gmlwjd9405.github.io/2017/10/01/basic-concepts-of-development-java.html) 720 | > [참고2](https://loustler.io/languages/oop_interface_and_abstract_class/) 721 | 722 | 723 | ## set, list, map의 차이와 각각의 인터페이스 구현체의 종류를 설명해주세요 724 |  725 | 726 | **Map** 727 | - 검색할 수 있는 인터페이스 728 | - 데이터를 삽입할 때 Key와 Value의 형태로 삽입되며, Key를 이용해서 Value를 얻을 수 있다. 729 | - Map: HashMap, LinkedHashMap, HashTable, TreeMap 730 | 731 | **Collection** 732 | - List 733 | - 순서가 있는 Collection 734 | - 데이터를 중복O 735 | - Map: HashMap, LinkedHashMap, HashTable, TreeMap 736 | - Set 737 | - 집합적인 개념의 Collection 738 | - 순서 x 739 | - 데이터를 중복X 740 | - set : HashSet, LinkedHashSet(순서o), TreeSet(이진 검색트리-레드 블랙트리로 구현) 741 | 742 | 743 | >[참고](https://gmlwjd9405.github.io/2017/10/01/basic-concepts-of-development-java.html) 744 | 745 | 746 | ## 오버플로우 747 | - 오버플로우 748 | 데이터마다 크기가 있는데 최대값이 넘어가면 발생, 음수로 넘어간다 749 | - 언더 플로우 750 | 최소값에서 더 작아지면 반대로 최대값으로 넘어간다 751 | 752 | - 아웃오브메모리 753 | - 힙 오버플로우 754 | - 스택 오버플로우 755 | - 스택에서 스택경계를 넘어설때 756 | - 하나 이상의 메소드가 순환 형식으로 상호 호출하면서 스택 내에 함수 호출 수가 끊임없이 증가할 때 발생한다. 757 | 758 | ## Comparable, Comparator 차이 759 | - Comparable : 기본적으로 정렬할때 사용. compareTo()를 오버라이딩 760 | - Comparator : 기본외에 다른 방법으로 정렬할때 사용. compare()오버라이딩 761 | 762 | ## java8을 써보셨나요? java7에서 8로 올라오면서 어떤게 달라졌나요? 763 | - 네 사용해봤습니다. spring프로젝트 때 사용했습니다. 764 | 765 | 766 | **JAVA 7 부터 지원되는것들** 767 | 1. Diamond Operator 768 | - 제네릭스에서 타입 추론가능 769 | 770 | ```java 771 | // Before Java 7 772 | ArrayList
919 | - 자바 API, getClass ; 코드 작성시점에서 클래스나 메소드가 뭔지 모를때 사용한다. 920 | 921 | > :arrow_double_up:[Top](#7-Java) 922 | :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#7-Java) 923 | :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 924 | 925 | ## oop 5대 원칙 926 | 927 | - SOILD 원칙 928 | - SRP(단일 책임 원칙) - 응집도는 높게, 결합도는 낮은 프로그램 929 | - OCP(개방-폐쇄 원칙) 930 | - LSP(리스코프 치환 원칙) 931 | - DIP(의존 역전 원칙) 932 | - ISP(인터페이스 분리 원칙) 933 | - 유지 보수와 확장을 위한 원칙 934 | 935 | 1. SRP(단일 책임 원칙) - 응집도는 높게, 결합도는 낮은 프로그램 936 | 937 | 2. OCP(개방-폐쇄 원칙, Open-Closed) 938 | - 기존의 코드를 변경하지 않고(closed) 기능을 수정하거나 추가할수있도록(open) 설계 939 | - 설계할때 변경되는 것이 무엇인지에 초점을 맞춘다. 940 | - 이를 위해 interface가 자주 사용된다 941 | 942 | 3. LSP(리스코프 치환 원칙) 943 | - 자식 클래스는 부모클래스에서 가능한 행위를 수행할수있어야한다. 944 | - 틀린 ex) 945 | - class 도형 { 둘레(){}; 각(){};} 946 | - class 사각형 extends 도형 { 둘레(); 각(){}; } (o) 947 | - class 원 extends 도형 { 둘레(); 각(){}; } (x) 948 | 949 | 4. DIP(의존 역전 원칙) 950 | - 의존 관계를 맺을때, 변하기 쉬운것보다 __변하기 어려운것에 의존해야__ 한다. 951 | 952 | 5. ISP(인터페이스 분리 원칙) 953 | - 클래스에서 자신이 사용하지 않는 인터페이스는 구현하지 않아야 한다 954 | - 따라서 하나의 인스턴스보다는 여러개의 구체적인 인터페이스를 설계하는 것이 좋다 955 | 956 | 957 | > [참고](https://dev-momo.tistory.com/entry/SOLID-%EC%9B%90%EC%B9%99) 958 | 959 | > :arrow_double_up:[Top](#7-Java) 960 | :leftwards_arrow_with_hook:[Back](https://github.com/devham76/tech-interview-studyw#7-Java) 961 | :information_source:[Home](https://github.com/devham76/tech-intervie-studyw#tech-interview) 962 | 963 | ## 직렬화란? 964 | - 자바에서 입출력할때는 __스트림이라는 데이터 통로를__ 통해 이동한다 965 | - 하지만 객체는, 그렇지 않아서 스트림을 통해 저장 or N/W로 전송하는것 불가 966 | - 따라서 __객체를 스트림으로 입출력하기 위해 바이트 배열로 변환하는 것__ 967 | - 역직렬화 : 스트림->객체 968 | --------------------------------------------------------------------------------