├── data
├── multiprocessing
│ ├── main.py
│ └── fineweb.py
├── ray_distributed
│ ├── test_cluster.py
│ └── main.py
├── scripts
│ ├── batch_test.sh
│ └── setup_tpu.sh
├── make_folder.py
├── requirements.txt
└── README.md
├── .env.local
├── public
├── banner.png
├── experts.png
├── loss-load.png
├── loss-val.png
└── banner-light.png
├── .gitignore
├── launcher.sh
├── setupTpu.sh
├── run.sh
├── debug_tpu.sh
├── README.md
├── dataset.py
├── utils.py
├── main.py
└── model.py
/data/multiprocessing/main.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/.env.local:
--------------------------------------------------------------------------------
1 | WANDB_KEY=your_wandb_key
--------------------------------------------------------------------------------
/public/banner.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/divyamakkar0/JAXformer/HEAD/public/banner.png
--------------------------------------------------------------------------------
/public/experts.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/divyamakkar0/JAXformer/HEAD/public/experts.png
--------------------------------------------------------------------------------
/public/loss-load.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/divyamakkar0/JAXformer/HEAD/public/loss-load.png
--------------------------------------------------------------------------------
/public/loss-val.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/divyamakkar0/JAXformer/HEAD/public/loss-val.png
--------------------------------------------------------------------------------
/public/banner-light.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/divyamakkar0/JAXformer/HEAD/public/banner-light.png
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | *.txt
2 | *.npy
3 | *.pyc
4 | trainSet/*
5 | valSet/*
6 | *.tgz
7 | results/*
8 | *.env
9 | wandb/*
10 | .vscode/*
11 | .DS_Store
12 | .env
13 | data_dir/
14 | edu_fineweb10B
15 | checkpoints/
16 | final_data/
17 |
--------------------------------------------------------------------------------
/launcher.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | source .env
3 |
4 | IPS=(
5 | "35.186.25.28"
6 | "35.186.39.76"
7 | "107.167.173.215"
8 | "35.186.132.44"
9 | "35.186.24.134"
10 | "35.186.58.69"
11 | "35.186.134.160"
12 | "35.186.107.62"
13 | )
14 |
15 |
16 | printf "%s\n" "${IPS[@]}" | xargs -n 1 -P 0 -I {} bash run.sh {}
--------------------------------------------------------------------------------
/setupTpu.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # script to run to setup dependencies on TPU
4 |
5 | pip install -U "jax[tpu]"
6 | pip install flax jaxtyping wandb tpu-info einops tiktoken
7 | pip install google-cloud google-cloud-storage gcloud gcsfs
8 |
9 | if [[ -z "~/.config/gcloud/application_default_credentials.json" ]]; then
10 | echo "gcloud storage credentials found "
11 | else
12 | echo "gcloud storage credentials not found "
13 | gcloud auth application-default login
14 | fi
15 |
16 | echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
17 | echo -e "\n\ndone run tpu-info to check"
18 |
--------------------------------------------------------------------------------
/run.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | IP=$1
4 | SESSION="trainingRun"
5 | command="python main.py --checkpoint_steps=75 --n_device_axis 8 2 2 --name moe1B --train_batch_size 32 --use_cache --wandb --eval_steps 10"
6 |
7 | echo "Running on $IP"
8 |
9 | ssh adityamakkar@$IP "
10 |
11 | tmux kill-session -t $SESSION
12 | tmux new-session -d -s $SESSION
13 |
14 | tmux send-keys -t $SESSION:0 'cd ~/Jaxformer && rm -rf samples && mkdir samples' C-m
15 | tmux send-keys -t $SESSION:0 'git fetch origin && git reset --hard origin/main' C-m
16 | tmux send-keys -t $SESSION:0 'bash setupTpu.sh' C-m
17 | tmux send-keys -t $SESSION:0 '$command' C-m
18 | "
19 | echo "done commands"
20 |
--------------------------------------------------------------------------------
/data/ray_distributed/test_cluster.py:
--------------------------------------------------------------------------------
1 | from collections import Counter
2 | import socket
3 | import time
4 |
5 | import ray
6 |
7 | ray.init()
8 |
9 | print('''This cluster consists of
10 | {} nodes in total
11 | {} CPU resources in total
12 | '''.format(len(ray.nodes()), ray.cluster_resources()['CPU']))
13 |
14 | @ray.remote
15 | def f():
16 | time.sleep(0.001)
17 | # Return IP address.
18 | return socket.gethostname()
19 |
20 | object_ids = [f.remote() for _ in range(10000)]
21 | ip_addresses = ray.get(object_ids)
22 | # ip_addresses = [f() for _ in range(10000)]
23 |
24 | print('Tasks executed')
25 | for ip_address, num_tasks in Counter(ip_addresses).items():
26 | print(' {} tasks on {}'.format(num_tasks, ip_address))
--------------------------------------------------------------------------------
/data/scripts/batch_test.sh:
--------------------------------------------------------------------------------
1 | set -euo pipefail
2 |
3 | # TODO: fill in these variables
4 | PY_SCRIPT=""
5 | RUNTIME_S="5"
6 | RESULTS="bs_benchmark_$(date +%Y%m%d_%H%M%S).csv"
7 | EXTRA_ARGS=""
8 |
9 | echo "batch_size,tokens_per_s" > "$RESULTS"
10 |
11 | for bs in $(seq 25 50 750) 750; do
12 | if grep -q "^$bs," "$RESULTS"; then
13 | continue
14 | fi
15 |
16 | echo "Testing BATCH_SIZE=$bs ..."
17 |
18 | LOG="$(BENCHMARK=1 BATCH_SIZE="$bs" timeout --signal=INT "${RUNTIME_S}s" \
19 | python "$PY_SCRIPT" $EXTRA_ARGS 2>&1 || true)"
20 |
21 | RATE="$(printf "%s\n" "$LOG" \
22 | | sed -nE 's/.*([0-9]+(\.[0-9]+)?) ?tokens\/s.*/\1/p' \
23 | | tail -n1)"
24 | [ -z "${RATE:-}" ] && RATE="NA"
25 |
26 |
27 | echo "$LOG"
28 |
29 | if [ -z "${RATE:-}" ]; then
30 | RATE="NA"
31 | fi
32 |
33 | echo "$bs,$RATE" | tee -a "$RESULTS"
34 | done
35 |
36 | echo "Done. Results saved to $RESULTS"
37 |
--------------------------------------------------------------------------------
/data/make_folder.py:
--------------------------------------------------------------------------------
1 | # Before running:
2 | # 1) pip install -r requirements.txt in data dir
3 | # 2) authenticate using gcloud CLI
4 |
5 | from google.cloud import storage_control_v2
6 | from dotenv import load_dotenv
7 | import os
8 |
9 | load_dotenv()
10 |
11 | def create_folder(bucket_name: str, folder_name: str) -> None:
12 | storage_control_client = storage_control_v2.StorageControlClient()
13 | project_path = storage_control_client.common_project_path("_")
14 | bucket_path = f"{project_path}/buckets/{bucket_name}"
15 |
16 | request = storage_control_v2.CreateFolderRequest(
17 | parent=bucket_path,
18 | folder_id=folder_name,
19 | )
20 | response = storage_control_client.create_folder(request=request)
21 |
22 | print(f"Created folder: {response.name}")
23 |
24 | if __name__ == '__main__':
25 | bucket_name = os.getenv("GCP_BUCKET", default="")
26 |
27 | for folder_name in ['train', 'test', 'checkpoints']:
28 | if bucket_name == "":
29 | print("GCP_BUCKET is not set")
30 | raise ValueError("GCP_BUCKET is not set")
31 | else:
32 | create_folder(bucket_name, folder_name)
--------------------------------------------------------------------------------
/data/requirements.txt:
--------------------------------------------------------------------------------
1 | aiohappyeyeballs==2.6.1
2 | aiohttp==3.12.14
3 | aiosignal==1.4.0
4 | async-timeout==5.0.1
5 | attrs==25.3.0
6 | beautifulsoup4==4.13.4
7 | cachetools==5.5.2
8 | certifi==2025.7.14
9 | charset-normalizer==3.4.2
10 | datasets==4.0.0
11 | dill==0.3.8
12 | filelock==3.18.0
13 | frozenlist==1.7.0
14 | fsspec==2025.3.0
15 | gcloud==0.18.3
16 | google==3.0.0
17 | google-api-core==2.25.1
18 | google-auth==2.40.3
19 | google-cloud-core==2.4.3
20 | google-cloud-storage==3.2.0
21 | google-crc32c==1.7.1
22 | google-resumable-media==2.7.2
23 | googleapis-common-protos==1.70.0
24 | hf-xet==1.1.5
25 | httplib2==0.22.0
26 | huggingface-hub==0.33.4
27 | idna==3.10
28 | multidict==6.6.3
29 | multiprocess==0.70.16
30 | numpy==2.2.6
31 | oauth2client==4.1.3
32 | packaging==25.0
33 | pandas==2.3.1
34 | propcache==0.3.2
35 | proto-plus==1.26.1
36 | protobuf==6.31.1
37 | pyarrow==20.0.0
38 | pyasn1==0.6.1
39 | pyasn1_modules==0.4.2
40 | pyparsing==3.2.3
41 | python-dateutil==2.9.0.post0
42 | python-dotenv==1.1.1
43 | pytz==2025.2
44 | PyYAML==6.0.2
45 | regex==2024.11.6
46 | requests==2.32.4
47 | rsa==4.9.1
48 | six==1.17.0
49 | soupsieve==2.7
50 | tiktoken==0.9.0
51 | tqdm==4.67.1
52 | typing_extensions==4.14.1
53 | tzdata==2025.2
54 | urllib3==2.5.0
55 | xxhash==3.5.0
56 | yarl==1.20.1
57 |
--------------------------------------------------------------------------------
/data/README.md:
--------------------------------------------------------------------------------
1 | ## Tokenization
2 |
3 | Collection of scripts to efficiently upload tokenized shards to GCP buckets.
4 |
5 | ### Authentication with GCP
6 |
7 | To get started, follow these steps to prepare your Google Cloud environment and configure the scripts for execution.
8 |
9 | 1. **Initialize `gcloud`**: First, you need to set up the Google Cloud SDK and link it to your project. Run the `gcloud init` command in your terminal and follow the prompts to select your project.
10 |
11 | ```bash
12 | gcloud init
13 | ```
14 |
15 | 2. **Authenticate Credentials**: Authenticate your application-default credentials. This step is crucial as it allows the Python scripts to securely access and interact with your Google Cloud Storage bucket.
16 |
17 | ```bash
18 | gcloud auth application-default login
19 | ```
20 |
21 | 3. **Create a GCP Bucket**: Create a new Google Cloud Storage bucket to store your tokenized data. Although Google Cloud Storage has a flat namespace, you can simulate a hierarchical structure (like folders) by using prefixes in your object names. The scripts will handle this automatically.
22 |
23 | ```bash
24 | gcloud storage buckets create gs://[YOUR_BUCKET_NAME]
25 | ```
26 |
27 | ### Running the Scripts
28 |
29 | 4. **Configure Scripts**: Open the Python scripts and change any placeholder names to match your specific setup, such as the `BUCKET_NAME` and `DATA_CACHE_DIR`.
30 |
31 | 5. **Run `make_folder.py`**: Execute the `make_folder.py` script to create the necessary local directories for temporary data storage.
32 |
33 | ```bash
34 | python make_folder.py
35 | ```
36 |
37 | 6. **Run `main.py`**: Finally, run the main `main.py` script. This will start the data streaming, tokenization, and upload process. Run the script from the folder you wish to use (single VM runs the `multiprocessing` main.py, while distributed runs from `ray_distributed`).
38 |
39 | ```bash
40 | python main.py
41 | ```
--------------------------------------------------------------------------------
/debug_tpu.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | source .env # wandb key from here
4 | SESSION="mysession"
5 | command="python main.py --checkpoint_steps=1 --n_device_axis 8 2 2 --name moe1B --train_batch_size 16 --use_cache --wandb --eval_steps 1"
6 |
7 | IPS=(
8 | "35.186.25.28"
9 | "35.186.39.76"
10 | "107.167.173.215"
11 | "35.186.132.44"
12 | "35.186.24.134"
13 | "35.186.58.69"
14 | "35.186.134.160"
15 | "35.186.107.62"
16 | )
17 |
18 | tmux new-session -d -s "$SESSION" -n "main" \; \
19 | split-window -v \; split-window -v \; split-window -v \; \
20 | select-pane -t "$SESSION":0.0 \; split-window -h \; \
21 | select-pane -t "$SESSION":0.1 \; split-window -h \; \
22 | select-pane -t "$SESSION":0.2 \; split-window -h \; \
23 | select-pane -t "$SESSION":0.3 \; split-window -h \; \
24 | select-layout tiled
25 |
26 | tmux new-window -t "$SESSION" -n "monitor" \; \
27 | split-window -v \; split-window -v \; split-window -v \; \
28 | select-pane -t "$SESSION":1.0\; split-window -h \; \
29 | select-pane -t "$SESSION":1.1 \; split-window -h \; \
30 | select-pane -t "$SESSION":1.2 \; split-window -h \; \
31 | select-pane -t "$SESSION":1.3 \; split-window -h \; \
32 | select-layout tiled
33 |
34 | for i in $(seq 0 7); do
35 | tmux send-keys -t "$SESSION":0.$i "ssh adityamakkar@${IPS[$i]}" C-m
36 | tmux send-keys -t "$SESSION":0.$i "cd ~/Jaxformer && rm -rf samples && mkdir samples" C-m
37 | tmux send-keys -t "$SESSION":0.$i "git fetch origin && git reset --hard origin/main" C-m
38 | tmux send-keys -t "$SESSION":0.$i "bash setupTpu.sh" C-m
39 | tmux send-keys -t "$SESSION":0.$i "wandb login $WANDB_KEY" C-m
40 | tmux send-keys -t "$SESSION":0.$i "$command" C-m
41 | done
42 |
43 | for i in $(seq 0 7); do
44 | tmux send-keys -t "$SESSION":1.$i "ssh adityamakkar@${IPS[$i]}" C-m
45 | tmux send-keys -t "$SESSION":1.$i "watch -n 1 tpu-info" C-m
46 | done
47 |
48 | tmux attach -t "$SESSION"
49 |
--------------------------------------------------------------------------------
/data/scripts/setup_tpu.sh:
--------------------------------------------------------------------------------
1 | set -euo pipefail
2 | source .env 2>/dev/null || true
3 |
4 | IPS=(
5 | "LIST GOES HERE"
6 | )
7 |
8 | HEAD_IP="${HEAD_IP:-${IPS[0]}}"
9 |
10 | SSH_USER="${SSH_USER:-$USER}"
11 | SSH_KEY="${SSH_KEY:-}"
12 |
13 | RAY_PORT="${RAY_PORT:-6379}" # ray head port
14 | WORKDIR="${WORKDIR:-~/jaxformer}" # remote project dir on each node
15 | PYTHON="${PYTHON:-python3}" # python on the remote machines
16 | MAIN_SCRIPT="${MAIN_SCRIPT:-main_distributed.py}"
17 | MAIN_ARGS="${MAIN_ARGS:-}" # optional args for your script
18 |
19 |
20 | export HEAD_IP RAY_PORT WORKDIR PYTHON SSH_USER SSH_KEY
21 |
22 | echo "[1/3] Starting Ray on all nodes (head: $HEAD_IP, port: $RAY_PORT)..."
23 | printf "%s\n" "${IPS[@]}" | xargs -n 1 -P 0 -I {} bash run.sh {}
24 |
25 | echo "[2/3] Waiting for Ray cluster to become ready..."
26 |
27 | TIMEOUT_SEC=120
28 | EXPECTED_NODES=${#IPS[@]}
29 | DEADLINE=$(( $(date +%s) + TIMEOUT_SEC ))
30 |
31 | while :; do
32 | set +e
33 | NODES=$(
34 | ssh -o StrictHostKeyChecking=no ${SSH_KEY:+-i "$SSH_KEY"} "$SSH_USER@$HEAD_IP" \
35 | "bash -lc '$PYTHON - <<\"PY\"
36 | import time, ray
37 | ray.init(address=\"auto\", ignore_reinit_error=True, namespace=\"_probe_\")
38 | print(len(ray.nodes()))
39 | PY
40 | '"
41 | )
42 | STATUS=$?
43 | set -e
44 | if [[ $STATUS -eq 0 && \"$NODES\" =~ ^[0-9]+$ && $NODES -ge $EXPECTED_NODES ]]; then
45 | echo "Ray is up with $NODES/$EXPECTED_NODES nodes."
46 | break
47 | fi
48 | if [[ $(date +%s) -ge $DEADLINE ]]; then
49 | echo "Timed out waiting for Ray cluster. Got $NODES/$EXPECTED_NODES nodes." >&2
50 | exit 1
51 | fi
52 | sleep 3
53 | done
54 |
55 | echo "[3/3] Launching training on the head node..."
56 | ssh -o StrictHostKeyChecking=no ${SSH_KEY:+-i "$SSH_KEY"} "$SSH_USER@$HEAD_IP" "bash -lc '
57 | set -e
58 | cd \"$WORKDIR\"
59 | # If your script needs the Ray address, pass it explicitly:
60 | # $PYTHON -u $MAIN_SCRIPT --address $HEAD_IP:$RAY_PORT $MAIN_ARGS
61 | # Otherwise, if it uses ray.init(\"auto\"), the below is fine:
62 | $PYTHON -u $MAIN_SCRIPT $MAIN_ARGS
63 | '"
64 |
65 | echo "Done."
66 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |  5 |
6 |
7 |
5 |
6 |
7 |
8 |
9 | # JAXformer
10 |
11 | This is a zero-to-one guide on scaling modern transformers with n-dimensional parallelism in JAX. Our blog for [JAXformer](https://jaxformer.com) covers a from-scratch guide to distributed data processing, FSDP, pipeline parallelism, tensor parallelism, weight-sharding, activation-sharding, MoE scaling and much more. Our guide aims to bridge the gap between theory and end-to-end implementation by demonstrating how to scale a modern language model.
12 |
13 | ## Structure
14 |
15 | The model built throughout the blog is defined in `model.py`. The main training script is in `main.py`. `utils.py` and `dataset.py` contain the dataclasses and dataset processing implementations. `debug_tpu.sh` launches a TMUX with 8 panes to SSH into 8 nodes at once running the command in the `command` variable. `launcher.sh` ssh's headlessly into each node and executves `run.sh` creating TMUX terminals inside the ssh to allow for runs to continue even if the ssh connection is broken. `setup_tpu.sh` setups all the dependencies on the TPU. The `data` directory contains all the relevant code for tokenization.
16 |
17 | ## Results
18 |
19 | Results for a 1B model (300M active) trained to 3.28 val loss using 3-D sharding on a cluster of 32 TPU-v4(8 FSDP, 2 Pipeline, 2 Tensor).
20 |
21 | ### Val-Loss
22 |
23 | 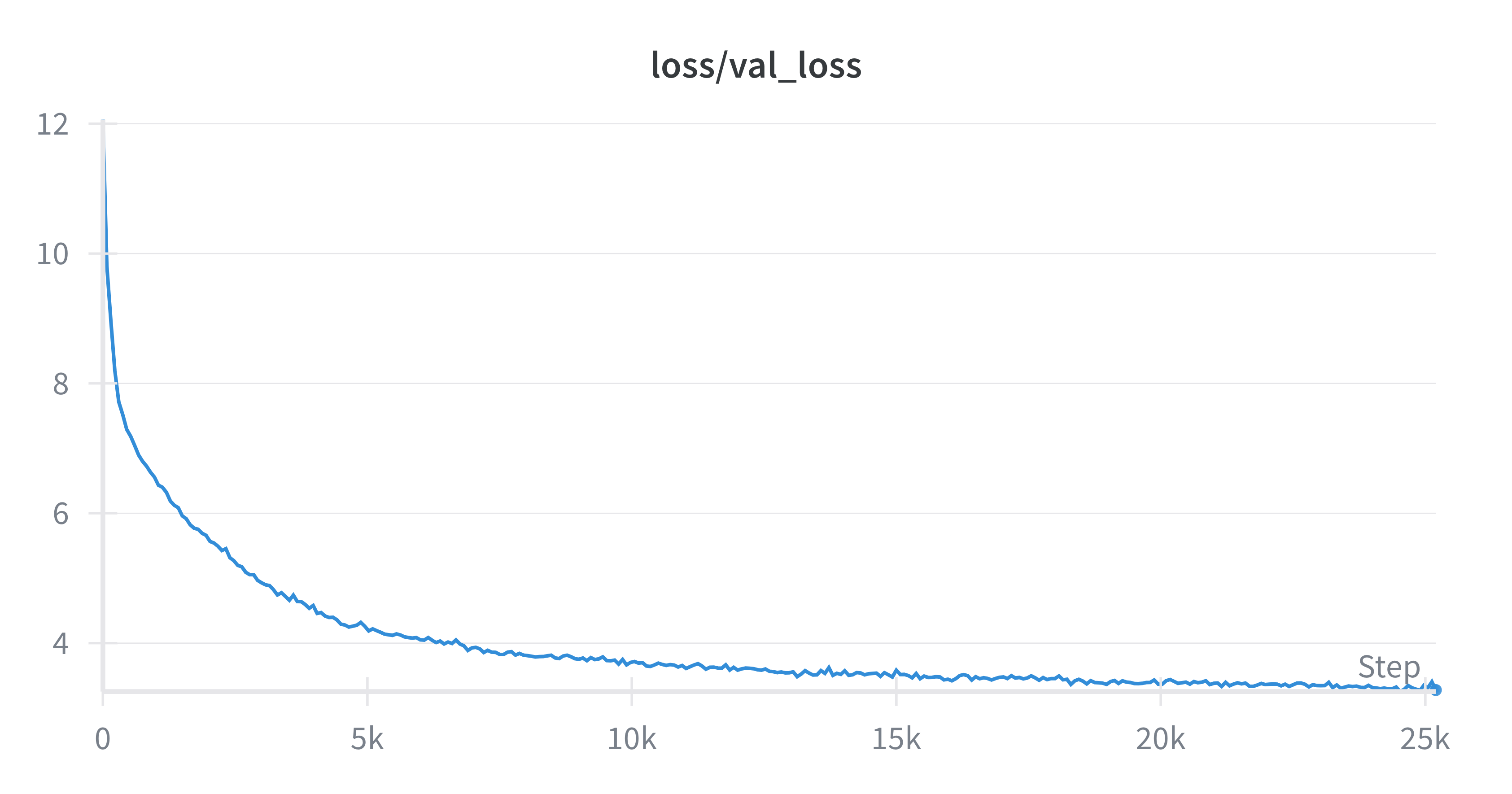 24 |
24 |
25 |
26 | ### Load-Loss
27 |
28 | 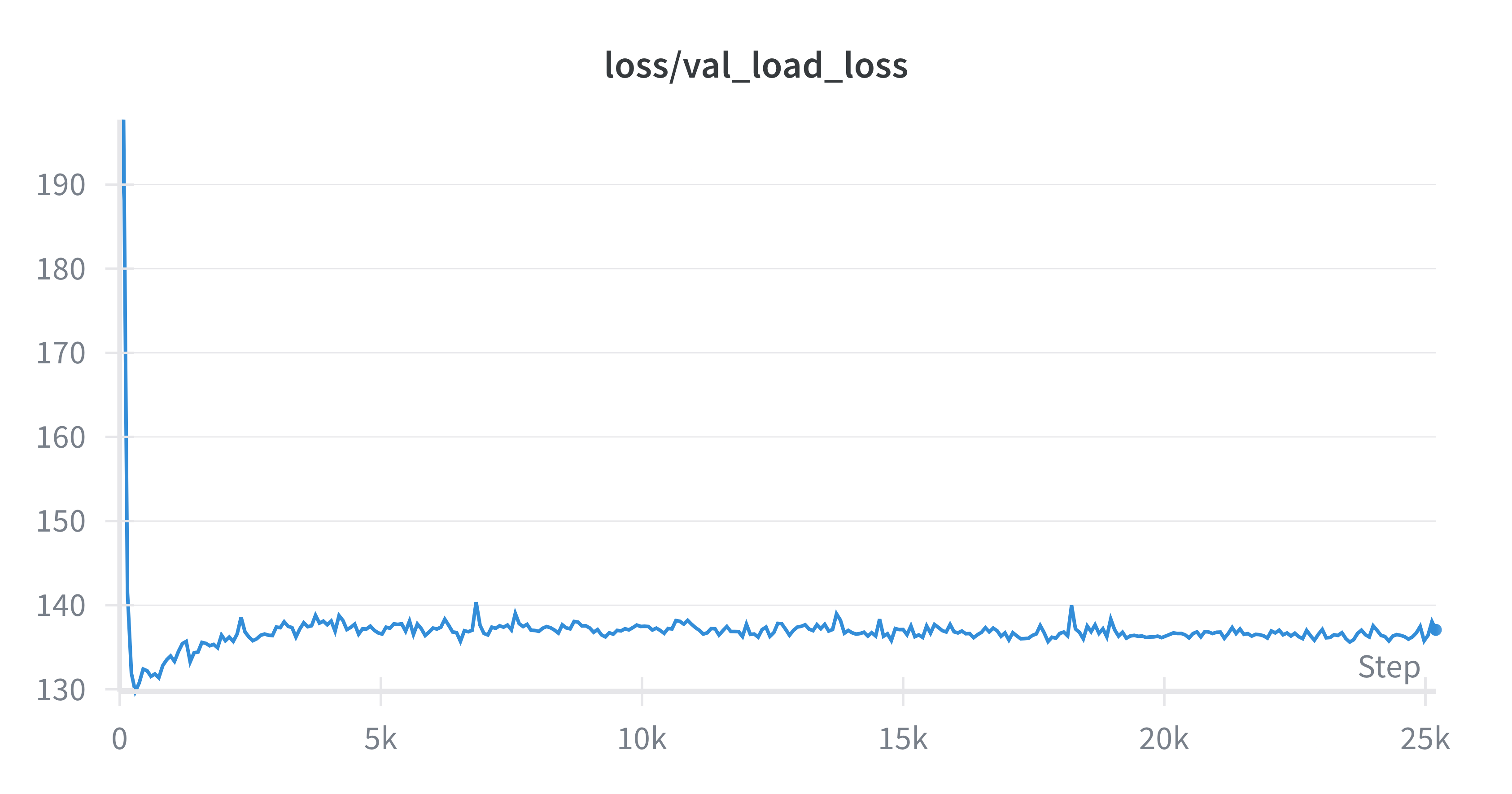 29 |
29 |
30 |
31 | ### Expert-per-Head
32 |
33 | 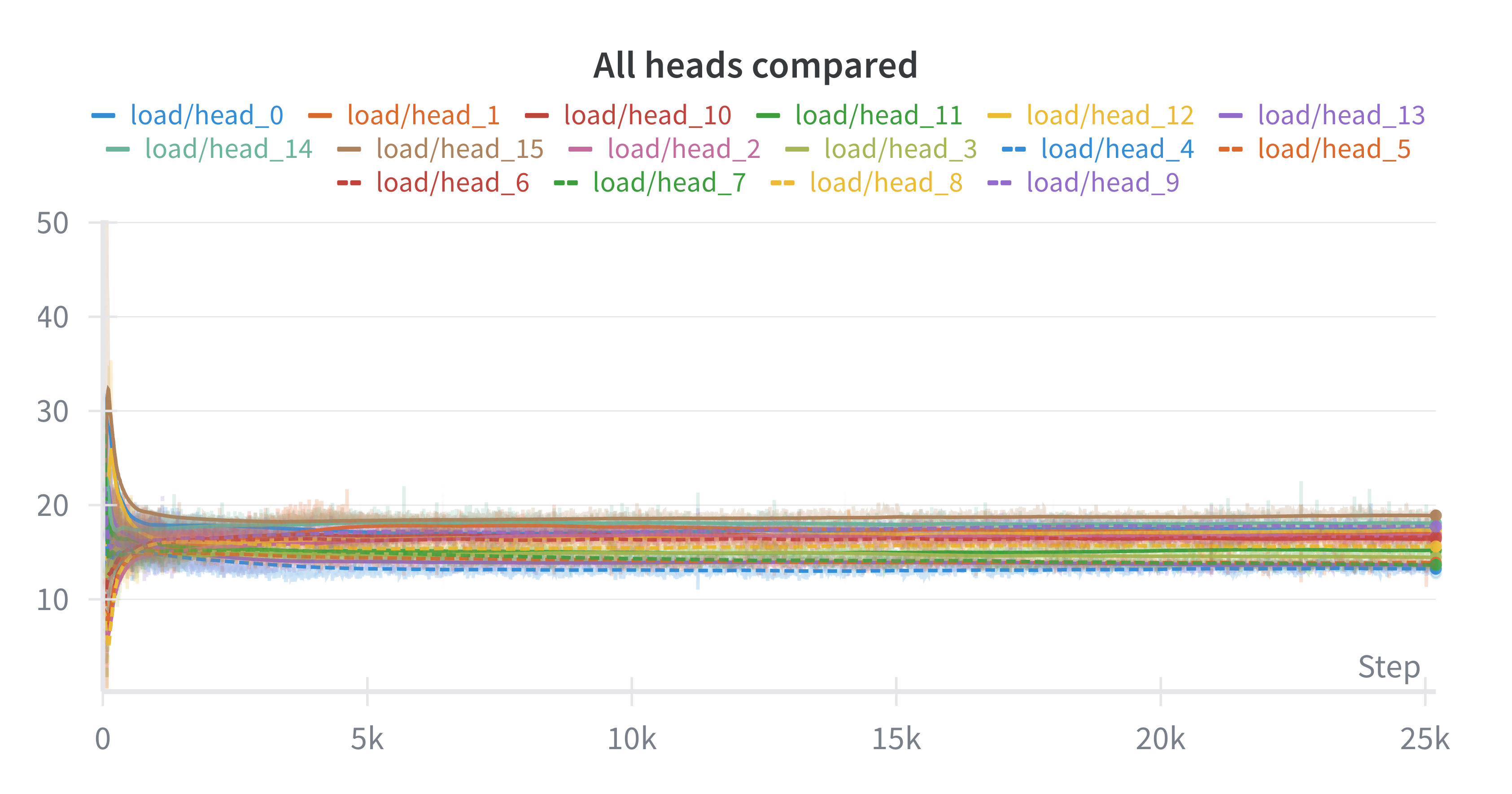 34 |
34 |
35 |
36 | ## Contributing and Contact
37 |
38 | If you see any issues or have questions, open up an issue or send in a PR. You can also leave a comment on the website itself (powered by Giscus) or in the GitHub discussion.
39 |
40 | ## Acknowledgements
41 |
42 | This guide was written by [Aditya Makkar](https://x.com/AdityaMakkar000), [Divya Makkar](https://x.com/_DivyaMakkar), and [Chinmay Jindal](https://x.com/chinmayjindal_). We are all undergraduate students studying Computer Science at the University of Waterloo.
43 |
44 | The website uses a Distill-style Jekyll theme called [Al-Folio](https://github.com/alshedivat/al-folio). The idea of the blog and front-end structure is inspired by Google DeepMind's [How to Scale Your Model](https://jax-ml.github.io/scaling-book/) guide. [Google's TRC](https://sites.research.google/trc/about/) was used to provide the compute needed. Thanks!
45 |
--------------------------------------------------------------------------------
/data/multiprocessing/fineweb.py:
--------------------------------------------------------------------------------
1 | """
2 | Adapted from Andrej's Karpathy tokenizer script in GPT-2 reproduction
3 | Changes: GPT-4 embeddings with uint32, multiprocessing main guards (macOS), checkpoint marking
4 | """
5 |
6 | import os
7 | import multiprocessing as mp
8 | import numpy as np
9 | import tiktoken
10 | from datasets import load_dataset # pip install datasets
11 | from tqdm import tqdm # pip install tqdm
12 |
13 | BLUE = "\033[34m"
14 | RESET = "\033[0m"
15 |
16 | # ------------------------------------------
17 | local_dir = "edu_fineweb10B"
18 | remote_name = "sample-10BT"
19 | shard_size = int(1e8) # 100M tokens per shard, total of 100 shards
20 |
21 | # create the cache the local directory if it doesn't exist yet
22 | DATA_CACHE_DIR = os.path.join(os.path.dirname(__file__), local_dir)
23 | os.makedirs(DATA_CACHE_DIR, exist_ok=True)
24 |
25 | # download the dataset
26 | fw = load_dataset("HuggingFaceFW/fineweb-edu", name=remote_name, split="train")
27 |
28 | # init the tokenizer
29 | enc = tiktoken.encoding_for_model("gpt-4") # 'cl100k_base'
30 |
31 | eot = enc._special_tokens["<|endoftext|>"] # end of text token
32 |
33 |
34 | def tokenize(doc):
35 | # tokenizes a single document and returns a numpy array of uint32 tokens
36 | tokens = [eot] # the special <|endoftext|> token delimits all documents
37 | tokens.extend(enc.encode_ordinary(doc["text"]))
38 | tokens_np = np.array(tokens)
39 | assert (0 <= tokens_np).all() and (tokens_np < 2**32).all(), (
40 | "token dictionary too large for uint32"
41 | )
42 | tokens_np_uint32 = tokens_np.astype(np.uint32)
43 | return tokens_np_uint32
44 |
45 |
46 | def write_datafile(filename, tokens_np):
47 | np.save(filename, tokens_np)
48 |
49 |
50 | print(f"{BLUE}hf dataset has been downloaded{RESET}")
51 |
52 |
53 | # tokenize all documents and write output shards, each of shard_size tokens (last shard has remainder)
54 | cpu_count = os.cpu_count()
55 | nprocs = max(1, cpu_count // 2)
56 |
57 |
58 | def main():
59 | with mp.Pool(nprocs) as pool:
60 | shard_index = 0
61 | # preallocate buffer to hold current shard
62 | all_tokens_np = np.empty((shard_size,), dtype=np.uint32)
63 | token_count = 0
64 | progress_bar = None
65 | for tokens in pool.imap(tokenize, fw, chunksize=16):
66 | # print(tokens)
67 | # break
68 |
69 | # is there enough space in the current shard for the new tokens?
70 | if token_count + len(tokens) < shard_size:
71 | # simply append tokens to current shard
72 | all_tokens_np[token_count : token_count + len(tokens)] = tokens
73 | token_count += len(tokens)
74 | # update progress bar
75 | if progress_bar is None:
76 | progress_bar = tqdm(
77 | total=shard_size, unit="tokens", desc=f"Shard {shard_index}"
78 | )
79 | progress_bar.update(len(tokens))
80 | else:
81 | # write the current shard and start a new one
82 | split = "val" if shard_index == 0 else "train"
83 | filename = os.path.join(
84 | DATA_CACHE_DIR, f"edufineweb_{split}_{shard_index:06d}"
85 | )
86 | # split the document into whatever fits in this shard; the remainder goes to next one
87 | remainder = shard_size - token_count
88 | progress_bar.update(remainder)
89 | all_tokens_np[token_count : token_count + remainder] = tokens[
90 | :remainder
91 | ]
92 | write_datafile(filename, all_tokens_np)
93 | shard_index += 1
94 | progress_bar = None
95 | # populate the next shard with the leftovers of the current doc
96 | all_tokens_np[0 : len(tokens) - remainder] = tokens[remainder:]
97 | token_count = len(tokens) - remainder
98 |
99 | # write any remaining tokens as the last shard
100 | if token_count != 0:
101 | split = "val" if shard_index == 0 else "train"
102 | filename = os.path.join(
103 | DATA_CACHE_DIR, f"edufineweb_{split}_{shard_index:06d}"
104 | )
105 | write_datafile(filename, all_tokens_np[:token_count])
106 |
107 |
108 | if __name__ == "__main__":
109 | main()
110 |
--------------------------------------------------------------------------------
/dataset.py:
--------------------------------------------------------------------------------
1 | import os
2 | import jax
3 | from jax.sharding import NamedSharding
4 | import numpy as np
5 | from typing import Optional, Tuple
6 | from utils import dataConfig
7 | from google.cloud import storage
8 | import time
9 |
10 |
11 | def log(out: str):
12 | if jax.process_index() == 0:
13 | print(out)
14 |
15 |
16 | class Dataset:
17 | def __init__(
18 | self,
19 | process_path: str,
20 | T: int,
21 | batch_size: int,
22 | microbatch: int,
23 | dp: int,
24 | pp: int,
25 | bucket_name: str,
26 | id: str,
27 | partition: Optional[NamedSharding] = None,
28 | ):
29 | assert (batch_size % microbatch) == 0, (
30 | "microbatch should divide batch size per data axis"
31 | )
32 | assert (microbatch % pp) == 0, "pp should divide microbatch size"
33 |
34 | self.T = T
35 | self.batch_size = batch_size
36 | self.dp = dp
37 | self.microbatch = microbatch
38 |
39 | self.step_idx = 0
40 | self.shard_idx = 0
41 | self.partition = partition
42 |
43 | self.bucket_name = bucket_name
44 | self.base_process_path = process_path
45 | self.process_path = process_path
46 | self.id = id
47 | self.data = self.return_blobs(bucket_name, self.id)
48 | self.dir_name = "bucket_downloads"
49 | try:
50 | os.mkdir(self.dir_name)
51 | except OSError as e:
52 | log(f"{self.dir_name} already exists")
53 |
54 | self.load_next_shard()
55 |
56 | def return_blobs(self, bucket_name, prefix, delimiter=None):
57 | res = []
58 | storage_client = storage.Client()
59 | blobs = storage_client.list_blobs(
60 | bucket_name, prefix=prefix, delimiter=delimiter
61 | )
62 | for blob in blobs:
63 | res.append(blob.name)
64 |
65 | return res[1:]
66 |
67 | def download_blob_to_stream(self, bucket_name, source_blob_name, file_obj):
68 | storage_client = storage.Client()
69 | bucket = storage_client.bucket(bucket_name)
70 |
71 | blob = bucket.blob(source_blob_name)
72 | blob.download_to_file(file_obj)
73 | log(f"Downloaded blob {source_blob_name} to file-like object.")
74 |
75 | return file_obj
76 |
77 | def download_bucket(self, bucket_name, source_name, f):
78 | while True:
79 | try:
80 | result = self.download_blob_to_stream(bucket_name, source_name, f)
81 | return result
82 | except Exception as e:
83 | log("Failed to download due to exception")
84 | time.sleep(5)
85 |
86 | def download_next(self):
87 | log("Started downloading")
88 | source_name = self.data[self.shard_idx % len(self.data)]
89 | self.shard_idx += 1
90 | log(f" Downloading: {source_name} | Shard_idx: {self.shard_idx}")
91 |
92 | self.process_path = f"{self.base_process_path}_{self.id}_{self.shard_idx}"
93 | with open(self.process_path, "wb") as f:
94 | result = self.download_bucket(self.bucket_name, source_name, f)
95 | log(f"Done downloading {result}")
96 |
97 | def load_next_shard(self):
98 | self.download_next()
99 |
100 | def process_prev():
101 | log(f"Processing shard at {self.process_path}\n\n")
102 | try:
103 | data = np.load(self.process_path)
104 | except:
105 | log(f"couldn't load data\n\n")
106 | self.dataset = data[:-1]
107 | self.labels = data[1:]
108 |
109 | len_dataset = self.dataset.shape[0]
110 | max_batches = len_dataset // (self.batch_size * self.T * self.dp)
111 |
112 | self.dataset = self.dataset[
113 | : max_batches * self.batch_size * self.T * self.dp
114 | ].reshape(
115 | max_batches,
116 | self.microbatch,
117 | (self.dp * self.batch_size) // self.microbatch,
118 | self.T,
119 | )
120 | self.labels = self.labels[
121 | : max_batches * self.batch_size * self.T * self.dp
122 | ].reshape(
123 | max_batches,
124 | self.microbatch,
125 | (self.dp * self.batch_size) // self.microbatch,
126 | self.T,
127 | )
128 |
129 | self.dataset = jax.device_put(self.dataset, self.partition)
130 | self.labels = jax.device_put(self.labels, self.partition)
131 |
132 | process_prev()
133 |
134 | os.remove(self.process_path)
135 |
136 | def __len__(self):
137 | return self.dataset.shape[0]
138 |
139 | def __call__(self, step=1):
140 | if self.step_idx + step > self.dataset.shape[0]:
141 | self.step_idx = 0
142 | self.load_next_shard()
143 |
144 | x = self.dataset[self.step_idx : self.step_idx + step]
145 | y = self.labels[self.step_idx : self.step_idx + step]
146 | self.step_idx += step
147 |
148 | return x, y
149 |
150 | @classmethod
151 | def getDataset(
152 | cls,
153 | cfg: dataConfig,
154 | partition: Optional[NamedSharding] = None,
155 | dp: int = 1,
156 | pp: int = 1,
157 | tp: int = 1,
158 | ) -> Tuple["Dataset", "Dataset"]:
159 | assert (cfg.T % tp) == 0, "T should be divisible by tensor parallelism"
160 | train_dataset = cls(
161 | cfg.process_path,
162 | cfg.T,
163 | cfg.train_batch_size,
164 | cfg.micro_batch_size,
165 | partition=partition,
166 | dp=dp,
167 | pp=pp,
168 | bucket_name=cfg.bucket_name,
169 | id=cfg.train_folder_name,
170 | )
171 | val_dataset = cls(
172 | cfg.process_path,
173 | cfg.T,
174 | cfg.val_batch_size,
175 | cfg.micro_batch_size,
176 | partition=partition,
177 | dp=dp,
178 | pp=pp,
179 | bucket_name=cfg.bucket_name,
180 | id=cfg.val_folder_name,
181 | )
182 |
183 | return train_dataset, val_dataset
184 |
185 | @property
186 | def tokens_per_step(self):
187 | return self.dp * self.batch_size * self.T
188 |
--------------------------------------------------------------------------------
/utils.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | from dataclasses import dataclass, field
3 | from typing import List, Optional
4 | import jax.numpy as jnp
5 | from jax.numpy import dtype
6 | import json
7 |
8 |
9 | @dataclass
10 | class modelConfig:
11 | """model config class"""
12 |
13 | model_dimension: int
14 | vocab_size: int
15 | n_head: int
16 | blocks: int
17 | layers_per_block: int
18 | T: int
19 | latent_dim: int
20 | dhR: int
21 | dropout_rate: float = 0.1
22 | model_dtype: str = "bfloat16"
23 | k: int = 0
24 | n_experts: int = 0
25 | n_shared: int = 0
26 | capacity_factor: float = 1.0
27 |
28 |
29 | @dataclass
30 | class dataConfig:
31 | bucket_name: str
32 | process_path: str = "./bucket_downloads/processShard"
33 | train_folder_name: str = "train"
34 | val_folder_name: str = "val"
35 | T: int = 6
36 | train_batch_size: int = 3
37 | val_batch_size: int = 3
38 | micro_batch_size: int = 1
39 |
40 |
41 | @dataclass
42 | class LRConfig:
43 | max_lr: float
44 | min_lr: float
45 | end_lr: float
46 | warmup_steps: int
47 | end_steps: int
48 |
49 |
50 | @dataclass
51 | class deviceConfig:
52 | n_device_axis: List[int]
53 |
54 |
55 | @dataclass
56 | class inferenceConfig:
57 | prompt: Optional[str] = None
58 | batch_size: int = 1
59 | top_k: int = 10000
60 | temperature: float = 1.0
61 | n_devices: int = 1
62 | max_tokens: int = 256
63 | use_cache: bool = True
64 |
65 |
66 | @dataclass
67 | class config:
68 | model_config: modelConfig
69 | data_config: dataConfig
70 | lr: LRConfig
71 | device_config: deviceConfig
72 | inference_config: inferenceConfig
73 | output_dir: str
74 | training_steps: int
75 | name: str
76 | grad_step: int = 1
77 | alpha: float = 0.001
78 | checkpoint_steps: int = 10
79 | eval_steps: int = 25
80 | seed: int = 0
81 | wandb: bool = True
82 | grad_clip_norm: float = 1.0
83 |
84 |
85 | def parse_args():
86 | parser = argparse.ArgumentParser(description="model training")
87 |
88 | parser.add_argument("--model_dimension", type=int, default=768)
89 | parser.add_argument("--vocab_size", type=int, default=100277)
90 | parser.add_argument("--n_head", type=int, default=12)
91 | parser.add_argument("--blocks", type=int, default=8)
92 | parser.add_argument("--layers_per_block", type=int, default=6)
93 | parser.add_argument("--T", type=int, default=1024)
94 | parser.add_argument("--latent_dim", type=int, default=128)
95 | parser.add_argument("--dhR", type=int, default=128)
96 | parser.add_argument("--dropout_rate", type=float, default=0.2)
97 | parser.add_argument("--model_dtype", type=str, default="bfloat16")
98 | parser.add_argument("--k", type=int, default=2)
99 | parser.add_argument("--n_experts", type=int, default=16)
100 | parser.add_argument("--n_shared", type=int, default=2)
101 | parser.add_argument("--capacity_factor", type=float, default=1.5)
102 |
103 | parser.add_argument(
104 | "--bucket_name",
105 | type=str,
106 | default="350bt_gpt4",
107 | )
108 | parser.add_argument(
109 | "--process_path", type=str, default="./bucket_downloads/processShard"
110 | )
111 | parser.add_argument("--train_folder_name", type=str, default="train")
112 | parser.add_argument("--val_folder_name", type=str, default="val")
113 | parser.add_argument("--train_batch_size", type=int, default=16)
114 | parser.add_argument("--val_batch_size", type=int, default=16)
115 | parser.add_argument("--micro_batch_size", type=int, default=4)
116 |
117 | parser.add_argument("--max_lr", type=float, default=6e-4)
118 | parser.add_argument("--min_lr", type=float, default=0)
119 | parser.add_argument("--end_lr", type=float, default=6e-5)
120 | parser.add_argument("--warmup_steps", type=int, default=5000)
121 | parser.add_argument("--end_steps", type=int, default=75000)
122 |
123 | parser.add_argument("--alpha", type=float, default=0.0001)
124 | parser.add_argument("--name", type=str, default=None, required=True)
125 | parser.add_argument("--output_dir", type=str, default="gs://results_jaxformer/")
126 | parser.add_argument("--checkpoint_steps", type=int, default=100)
127 | parser.add_argument("--seed", type=int, default=0)
128 | parser.add_argument("--wandb", action="store_true")
129 |
130 | parser.add_argument("--training_steps", type=int, default=100000)
131 | parser.add_argument("--grad_step", type=int, default=1)
132 | parser.add_argument("--eval_steps", type=int, default=25)
133 | parser.add_argument("--grad_clip_norm", type=float, default=1.0)
134 |
135 | parser.add_argument(
136 | "--n_device_axis",
137 | type=int,
138 | nargs="*",
139 | default=[1],
140 | )
141 |
142 | parser.add_argument("--inference_batch", type=int, default=1)
143 | parser.add_argument("--top_k", type=int, default=10000)
144 | parser.add_argument("--temperature", type=float, default=1.0)
145 | parser.add_argument("--use_cache", action="store_true")
146 | parser.add_argument("--max_tokens", type=int, default=10)
147 | parser.add_argument("--prompt", type=str, default="hello world")
148 | parser.add_argument("--n_devices", type=int, default=1)
149 |
150 | args = parser.parse_args()
151 |
152 | model_cfg = modelConfig(
153 | model_dimension=args.model_dimension,
154 | vocab_size=args.vocab_size,
155 | n_head=args.n_head,
156 | blocks=args.blocks,
157 | layers_per_block=args.layers_per_block,
158 | T=args.T,
159 | latent_dim=args.latent_dim,
160 | dhR=args.dhR,
161 | dropout_rate=args.dropout_rate,
162 | model_dtype=args.model_dtype,
163 | k=args.k,
164 | n_experts=args.n_experts,
165 | n_shared=args.n_shared,
166 | capacity_factor=args.capacity_factor,
167 | )
168 |
169 | data_cfg = dataConfig(
170 | bucket_name=args.bucket_name,
171 | process_path=args.process_path,
172 | train_folder_name=args.train_folder_name,
173 | val_folder_name=args.val_folder_name,
174 | T=args.T,
175 | train_batch_size=args.train_batch_size,
176 | val_batch_size=args.val_batch_size,
177 | micro_batch_size=args.micro_batch_size,
178 | )
179 |
180 | lr_cfg = LRConfig(
181 | max_lr=args.max_lr,
182 | min_lr=args.min_lr,
183 | end_lr=args.end_lr,
184 | warmup_steps=args.warmup_steps,
185 | end_steps=args.end_steps,
186 | )
187 |
188 | device_cfg = deviceConfig(
189 | n_device_axis=args.n_device_axis,
190 | )
191 |
192 | inference_cfg = inferenceConfig(
193 | prompt=args.prompt,
194 | batch_size=args.inference_batch,
195 | top_k=args.top_k,
196 | temperature=args.temperature,
197 | n_devices=args.n_devices,
198 | max_tokens=args.max_tokens,
199 | use_cache=args.use_cache,
200 | )
201 |
202 | cfg = config(
203 | model_config=model_cfg,
204 | data_config=data_cfg,
205 | lr=lr_cfg,
206 | name=args.name,
207 | output_dir=args.output_dir,
208 | device_config=device_cfg,
209 | checkpoint_steps=args.checkpoint_steps,
210 | inference_config=inference_cfg,
211 | seed=args.seed,
212 | training_steps=args.training_steps,
213 | grad_step=args.grad_step,
214 | eval_steps=args.eval_steps,
215 | alpha=args.alpha,
216 | wandb=args.wandb,
217 | grad_clip_norm=args.grad_clip_norm,
218 | )
219 |
220 | return cfg
221 |
--------------------------------------------------------------------------------
/data/ray_distributed/main.py:
--------------------------------------------------------------------------------
1 | import os
2 | import shutil
3 | import multiprocessing as mp
4 | import numpy as np
5 | import tiktoken
6 | from datasets import load_dataset
7 | from tqdm import tqdm
8 | from google.cloud.storage import Client, transfer_manager
9 | import argparse
10 | import ray
11 |
12 | # init ray in the cluster mode
13 | ray.init(address="auto")
14 |
15 | # constants for splits and multiprocessing
16 | TEST_SPLIT = 350
17 | BUCKET_NAME = "ray_jaxformer"
18 | BATCH_SIZE = 512
19 | WORKERS = int(os.cpu_count())
20 | nprocs = max(1, int(os.cpu_count() / 1.5))
21 |
22 | # other constants for dataset processing
23 | local_dir = "data_dir"
24 | remote_name = "sample-350BT"
25 | shard_size = int(1e8)
26 |
27 | # gcp storage client and bucket
28 | storage_client = Client()
29 | bucket = storage_client.bucket(BUCKET_NAME)
30 |
31 | # create the cache the local directory if it doesn't exist yet
32 | DATA_CACHE_DIR = os.path.join(os.path.dirname(__file__), local_dir)
33 | checkpoint_dir = os.path.join(os.path.dirname(__file__), 'checkpoints')
34 | os.makedirs(DATA_CACHE_DIR, exist_ok=True)
35 | os.makedirs(checkpoint_dir, exist_ok=True)
36 |
37 | # set up argument parser to check if --continue flag is given
38 | def setup_argument_parser():
39 | parser = argparse.ArgumentParser(description='Process the 350BT dataset')
40 | parser.add_argument('--continue', dest='continue_processing', action='store_true',
41 | help='Continue processing from a checkpoint')
42 | parser.set_defaults(continue_processing=False)
43 | return parser
44 |
45 | parser = setup_argument_parser()
46 | args = parser.parse_args()
47 | continue_processing = args.continue_processing
48 | checkpoint_to_resume = None
49 | shard_to_resume = 0
50 | skip_number = 0
51 |
52 | # if a --continue flag is given, pull latest checkpoint name from gcp bucket called checkpoints
53 | if continue_processing:
54 | # pull latest checkpoint name from gcp bucket called checkpoints
55 | blobs = bucket.list_blobs(prefix="checkpoints/")
56 | checkpoint_blobs = [b for b in blobs if str(b.name).endswith(".txt")]
57 | if not checkpoint_blobs:
58 | continue_processing = False
59 | else:
60 | latest_checkpoint = max(checkpoint_blobs, key=lambda b: b.updated)
61 | checkpoint_to_resume = latest_checkpoint.name[len("checkpoints/"):-4] # remove 'checkpoints/' prefix and '.txt' suffix
62 | shard_to_resume, skip_number = map(int, (latest_checkpoint.download_as_bytes().decode('utf-8')).split(':'))
63 |
64 | # ------------------------------------------
65 |
66 | fw = load_dataset("HuggingFaceFW/fineweb-edu", name=remote_name, split="train", streaming=True)
67 |
68 | # init the tokenizer
69 | enc = tiktoken.encoding_for_model("gpt-4") # 'cl100k_base'
70 | eot = enc._special_tokens['<|endoftext|>'] # end of text token
71 |
72 | # tokenize function with ray remote decorator
73 | @ray.remote
74 | def tokenize(doc):
75 | doc_id_return = doc['id']
76 | tokens = [eot]
77 | tokens.extend(enc.encode_ordinary(doc["text"]))
78 | tokens_np = np.array(tokens)
79 | assert (0 <= tokens_np).all() and (tokens_np < 2**32).all(), "token dictionary too large for uint32"
80 | tokens_np_uint32 = tokens_np.astype(np.uint32)
81 | return tokens_np_uint32, doc_id_return
82 |
83 | def write_datafile(filename, tokens_np):
84 | np.save(filename, tokens_np)
85 |
86 | # function to upload files to gcp bucket using transfer manager
87 | def upload_file(split):
88 | def upload_many_blobs_with_transfer_manager(split, filenames, source_directory="", workers=8):
89 |
90 | blob_names = [split + name for name in filenames]
91 |
92 | blob_file_pairs = [(os.path.join(source_directory, f), bucket.blob(b)) for f, b in zip(filenames, blob_names)]
93 |
94 | results = transfer_manager.upload_many(
95 | blob_file_pairs, skip_if_exists=True, max_workers=workers, worker_type=transfer_manager.THREAD
96 | )
97 |
98 | FILE_NAMES = os.listdir(DATA_CACHE_DIR)
99 | upload_many_blobs_with_transfer_manager(split, FILE_NAMES, DATA_CACHE_DIR, WORKERS)
100 | for file in FILE_NAMES:
101 | full_path = DATA_CACHE_DIR + '/' + file
102 | os.remove(full_path)
103 |
104 | # function to upload checkpoints to gcp bucket and remove local copies
105 | def upload_checkpoint():
106 | checkpoint_files = os.listdir(checkpoint_dir)
107 | for filename in checkpoint_files:
108 | blob = bucket.blob(f"checkpoints/{filename}")
109 | blob.upload_from_filename(os.path.join(checkpoint_dir, filename))
110 | for filename in checkpoint_files:
111 | os.remove(os.path.join(checkpoint_dir, filename))
112 |
113 | # skip to the previous checkpoint (zero by default)
114 | fw.skip(skip_number)
115 | shard_index = shard_to_resume + 1 if continue_processing else 0
116 |
117 | # variables to keep track of tokens in the current shard
118 | all_tokens_np = np.empty((shard_size,), dtype=np.uint32)
119 | token_count = 0
120 | progress_bar = None
121 | doc_iter = iter(fw)
122 |
123 | while True:
124 | batch = []
125 | try:
126 | for _ in range(BATCH_SIZE):
127 | batch.append(next(doc_iter))
128 | except StopIteration:
129 | pass
130 |
131 | if not batch:
132 | break
133 |
134 | # get the tokenized results from ray
135 | futures = [tokenize.remote(doc) for doc in batch]
136 | results = ray.get(futures)
137 |
138 | for tokens, doc_id in results:
139 | skip_number += 1
140 |
141 | # if the current document fits in the current shard
142 | if token_count + len(tokens) < shard_size:
143 |
144 | # simply append tokens to current shard
145 | all_tokens_np[token_count:token_count+len(tokens)] = tokens
146 | token_count += len(tokens)
147 |
148 | # update progress bar
149 | if progress_bar is None:
150 | progress_bar = tqdm(total=shard_size, unit="tokens", desc=f"Shard {shard_index}", dynamic_ncols=True)
151 | progress_bar.update(len(tokens))
152 |
153 | else:
154 |
155 | # save a checkpoint for resuming later
156 | checkpoint_filename = os.path.join(checkpoint_dir, f"{doc_id}.txt")
157 | with open(checkpoint_filename, "w") as f:
158 | f.write(str(shard_index) + ':' + str(skip_number))
159 |
160 | # write the current shard and start a new one
161 | if shard_index >= 0 and shard_index < TEST_SPLIT:
162 | split = 'test/'
163 | shard_index_number = shard_index
164 | else:
165 | split = 'train/'
166 | shard_index_number = shard_index - TEST_SPLIT
167 | split_name = split[:-1]
168 |
169 | filename = os.path.join(DATA_CACHE_DIR, f"{split_name}_{shard_index_number:04d}")
170 |
171 | # split the document into whatever fits in this shard; the remainder goes to next one
172 | remainder = shard_size - token_count
173 | progress_bar.update(remainder)
174 | all_tokens_np[token_count:token_count+remainder] = tokens[:remainder]
175 |
176 | write_datafile(filename, all_tokens_np)
177 | upload_file(split)
178 | upload_checkpoint()
179 |
180 | # update shard index and reset progress bar
181 | shard_index += 1
182 | progress_bar = None
183 |
184 | # populate the next shard with the leftovers of the current doc
185 | all_tokens_np[0:len(tokens)-remainder] = tokens[remainder:]
186 | token_count = len(tokens)-remainder
187 |
188 | # write any remaining tokens as the last shard
189 | if token_count != 0:
190 | if shard_index >= 0 and shard_index < TEST_SPLIT:
191 | split = 'test/'
192 | shard_index_number = shard_index
193 | else:
194 | split = 'train/'
195 | shard_index_number = shard_index - TEST_SPLIT
196 | split_name = split[:-1]
197 |
198 | filename = os.path.join(DATA_CACHE_DIR, f"{split_name}_{shard_index_number:04d}")
199 |
200 | write_datafile(filename, all_tokens_np[:token_count])
201 | upload_file(split)
202 | upload_checkpoint()
203 |
204 |
205 | # clean up directory after function terminates
206 | if os.path.exists(DATA_CACHE_DIR):
207 | shutil.rmtree(DATA_CACHE_DIR)
208 |
--------------------------------------------------------------------------------
/main.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | os.environ["XLA_FLAGS"] = (
4 | "--xla_gpu_triton_gemm_any=True --xla_gpu_enable_latency_hiding_scheduler=true "
5 | )
6 |
7 | import jax
8 | import jax.numpy as jnp
9 |
10 | jax.config.update("jax_compilation_cache_dir", "gs://jaxformer-cache/")
11 | jax.config.update("jax_persistent_cache_min_entry_size_bytes", -1)
12 | jax.config.update("jax_persistent_cache_min_compile_time_secs", 0)
13 | jax.config.update(
14 | "jax_persistent_cache_enable_xla_caches", "xla_gpu_per_fusion_autotune_cache_dir"
15 | )
16 |
17 | import optax
18 | import numpy as np
19 | import time
20 | import json
21 | import wandb
22 | import orbax.checkpoint as ocp
23 |
24 | from dataclasses import asdict
25 | from jax.sharding import PartitionSpec as P
26 | from functools import partial
27 | from typing import Tuple
28 | from model import shardedModel
29 | from dataset import Dataset
30 | from utils import parse_args, config
31 |
32 |
33 | def log(msg: str):
34 | if jax.process_index() == 0:
35 | print(msg)
36 |
37 |
38 | def init_devices(
39 | axes: Tuple[int, ...], axes_name: Tuple[str, ...]
40 | ) -> jax.sharding.Mesh:
41 | devices = np.array(jax.devices())
42 | for idx in np.ndindex(devices.shape):
43 | d = devices[idx]
44 | log(
45 | f" {idx} ID: {d.id}, Process: {d.process_index}, "
46 | f"Coords: {d.coords}, Core: {d.core_on_chip}"
47 | )
48 |
49 | assert devices.size == np.prod(axes), (
50 | f"Expected {np.prod(axes)} devices, got {devices.shape[0]}"
51 | )
52 | try:
53 | mesh = jax.make_mesh(axes, axes_name)
54 | except:
55 | log("Failed to create mesh with make_mesh, falling back to sharding.Mesh")
56 | mesh = jax.sharding.Mesh(devices.reshape(axes), axes_name)
57 | return mesh
58 |
59 |
60 | def main(cfg: config):
61 | key = jax.random.PRNGKey(cfg.seed)
62 | DATA_PARALLEL, LAYER_PARALLEL, TENSOR_PARALLEL = cfg.device_config.n_device_axis
63 |
64 | axes = (*cfg.device_config.n_device_axis,)
65 | axes_name = ("dp", "pp", "tp")
66 |
67 | mesh = init_devices(axes, axes_name)
68 | log(mesh)
69 |
70 | checkpoint_dir = cfg.output_dir + cfg.name
71 | options = ocp.CheckpointManagerOptions(max_to_keep=1)
72 | checkpoint_manager = ocp.CheckpointManager(checkpoint_dir, options=options)
73 | load = checkpoint_manager.latest_step() is not None
74 |
75 | data_spec = P(None, "pp", "dp", "tp")
76 | data_partition = jax.sharding.NamedSharding(mesh, data_spec)
77 |
78 | train_dataset, val_dataset = Dataset.getDataset(
79 | cfg.data_config,
80 | partition=data_partition,
81 | dp=DATA_PARALLEL,
82 | pp=LAYER_PARALLEL,
83 | tp=TENSOR_PARALLEL,
84 | )
85 |
86 | model = shardedModel(cfg.model_config)
87 |
88 | log("creating sharded model ...")
89 | key, init_key = jax.random.split(key, 2)
90 | params = model.init_weights(init_key, mesh)
91 |
92 | lr_scheduler = optax.warmup_cosine_decay_schedule(
93 | init_value=cfg.lr.min_lr,
94 | peak_value=cfg.lr.max_lr,
95 | warmup_steps=cfg.lr.warmup_steps,
96 | decay_steps=cfg.lr.end_steps,
97 | end_value=cfg.lr.end_lr,
98 | )
99 |
100 | tx = optax.chain(
101 | optax.clip_by_global_norm(config.grad_clip_norm),
102 | optax.inject_hyperparams(optax.adamw)(learning_rate=lr_scheduler),
103 | )
104 |
105 | default_sharding = jax.sharding.NamedSharding(mesh, P())
106 | opt_state = jax.tree.map(
107 | lambda x: x if jnp.ndim(x) != 0 else jax.device_put(x, default_sharding),
108 | tx.init(params),
109 | )
110 |
111 | init_step = 0
112 | use_wandb = cfg.wandb is True and jax.process_index() == 0
113 | wandb_id = None
114 |
115 | def make_save_tree(step):
116 | model_state = {
117 | "params": params,
118 | "opt_state": opt_state,
119 | }
120 | save_tree = {
121 | "state": model_state,
122 | "key": jax.device_get(key),
123 | "train_step_idx": train_dataset.step_idx,
124 | "train_shard_idx": (train_dataset.shard_idx - 1) % len(train_dataset.data),
125 | "val_step_idx": val_dataset.step_idx,
126 | "val_shard_idx": (val_dataset.shard_idx - 1) % len(val_dataset.data),
127 | "step": step,
128 | }
129 | metadata = {"wandb_id": wandb_id}
130 | return save_tree, metadata
131 |
132 | def save_checkpoint(
133 | step,
134 | ):
135 | save_tree, metadata = make_save_tree(step)
136 | checkpoint_manager.save(
137 | step,
138 | args=ocp.args.Composite(
139 | state=ocp.args.StandardSave(save_tree),
140 | metadata=ocp.args.JsonSave(metadata),
141 | ),
142 | )
143 |
144 | if load:
145 | abstract_tree_state = jax.tree.map(
146 | ocp.utils.to_shape_dtype_struct, make_save_tree(init_step)[0]
147 | )
148 | tree = checkpoint_manager.restore(
149 | checkpoint_manager.latest_step(),
150 | args=ocp.args.Composite(
151 | state=ocp.args.StandardRestore(abstract_tree_state),
152 | metadata=ocp.args.JsonRestore(),
153 | ),
154 | )
155 |
156 | tree_state, tree_metadata = tree.state, tree.metadata
157 |
158 | init_step = tree_state["step"]
159 | log(f"loading checkpoint @ step {init_step}")
160 |
161 | key.key = tree_state["key"]
162 | params = tree_state["state"]["params"]
163 | opt_state = tree_state["state"]["opt_state"]
164 |
165 | train_dataset.step_idx = tree_state["train_step_idx"]
166 | train_dataset.shard_idx = tree_state["train_shard_idx"]
167 | train_dataset.load_next_shard()
168 |
169 | val_dataset.step_idx = tree_state["val_step_idx"]
170 | val_dataset.shard_idx = tree_state["val_shard_idx"]
171 | val_dataset.load_next_shard()
172 |
173 | wandb_id = tree_metadata["wandb_id"]
174 | if use_wandb:
175 | assert wandb_id is not None, "wandb_id is None"
176 | wandb.init(
177 | entity="waterloo2",
178 | project="jaxformer",
179 | name=cfg.name,
180 | resume="must",
181 | id=wandb_id,
182 | config=asdict(cfg),
183 | )
184 |
185 | else:
186 | log("no checkpoint found, saving init copy")
187 | if use_wandb:
188 | wandb.init(
189 | entity="waterloo2",
190 | project="jaxformer",
191 | name=cfg.name,
192 | resume="allow",
193 | config=asdict(cfg),
194 | )
195 | wandb_id = wandb.run.id
196 | save_checkpoint(init_step)
197 |
198 | if use_wandb:
199 | table = wandb.Table(
200 | columns=["step"]
201 | + [
202 | f"tokens_{i}"
203 | for i in range(
204 | cfg.inference_config.batch_size
205 | * cfg.inference_config.n_devices
206 | * jax.process_count()
207 | )
208 | ],
209 | log_mode="INCREMENTAL",
210 | )
211 |
212 | param_count, active_param_count = model.param_count(params)
213 | log(f"Total parameters: {param_count:,} with {active_param_count:,} active")
214 |
215 | def step(params, x, y, key, train):
216 | def loss_fn(params, x, y, key):
217 | logits, (_, moe_stat) = model.pipe_step(
218 | params,
219 | x,
220 | key=key,
221 | train=train,
222 | )
223 | log_probs = jax.nn.log_softmax(logits, axis=-1)
224 |
225 | M, B, T, V = logits.shape
226 | y = y.reshape(-1)
227 | log_probs = log_probs.reshape(M * B * T, V)
228 |
229 | loss_idx = lambda x, idx: jax.lax.dynamic_slice(x, (idx,), (1,))
230 | loss_cross = -(jax.vmap(loss_idx, in_axes=(0, 0))(log_probs, y)).mean()
231 |
232 | loss_cross = jax.lax.pmean(loss_cross, axis_name="dp")
233 | loss_cross = jax.lax.pmean(loss_cross, axis_name="tp")
234 | loss_cross = jax.lax.pmean(loss_cross, axis_name="pp")
235 |
236 | loss_balance = 0.0
237 |
238 | moe_stat = jax.tree.map(lambda x: jax.lax.psum(x, axis_name="dp"), moe_stat)
239 | moe_stat = jax.tree.map(lambda x: jax.lax.psum(x, axis_name="tp"), moe_stat)
240 | moe_stat = jax.tree.map(lambda x: jax.lax.psum(x, axis_name="pp"), moe_stat)
241 |
242 | loss_balance = (cfg.model_config.n_experts / cfg.model_config.k) * moe_stat[
243 | "aux_loss"
244 | ].sum()
245 |
246 | loss = loss_cross + cfg.alpha * loss_balance
247 |
248 | metrics = {
249 | "loss": loss,
250 | "loss_cross": loss_cross,
251 | "loss_balance": loss_balance,
252 | "load_expert": moe_stat["tokens_per_expert"],
253 | }
254 |
255 | return loss, metrics
256 |
257 | return loss_fn(params, x, y, key)
258 |
259 | param_spec = shardedModel.get_p_spec(
260 | [model.embedding, model.block], mesh, cfg.model_config
261 | )
262 | opt_spec = jax.tree.map(lambda x: x.sharding.spec, opt_state)
263 | key_spec = P("dp", "pp", "tp")
264 |
265 | @jax.jit
266 | @partial(
267 | jax.shard_map,
268 | mesh=mesh,
269 | in_specs=(param_spec, opt_spec, data_spec, data_spec, key_spec),
270 | out_specs=(param_spec, opt_spec, P()),
271 | check_vma=False,
272 | )
273 | def train_step(params, opt_state, x, y, key):
274 | step_fn = jax.value_and_grad(step, has_aux=True)
275 |
276 | def single_step(grads, batch):
277 | (_, metrics), grads_current = step_fn(params, *batch, train=True)
278 | grads = jax.tree.map(lambda x, y: x + y, grads, grads_current)
279 | return grads, metrics
280 |
281 | grads = jax.tree.map(lambda x: jnp.zeros_like(x), params)
282 | key = key.reshape(cfg.grad_step, 2)
283 |
284 | grads, metrics = jax.lax.scan(
285 | single_step,
286 | grads,
287 | (x, y, key),
288 | )
289 |
290 | grads = jax.tree.map(lambda x: x / cfg.grad_step, grads)
291 |
292 | metrics = jax.tree.map(lambda x: x.mean(axis=0), metrics)
293 |
294 | updates, opt_state = tx.update(grads, opt_state, params)
295 | params = optax.apply_updates(params, updates)
296 |
297 | return params, opt_state, metrics
298 |
299 | @jax.jit
300 | @partial(
301 | jax.shard_map,
302 | mesh=mesh,
303 | in_specs=(param_spec, data_spec, data_spec),
304 | out_specs=P(),
305 | check_vma=False,
306 | )
307 | def eval_step(params, x, y):
308 | def single_step(_, batch):
309 | loss, metrics = step(
310 | params, *batch, key=jax.random.PRNGKey(0), train=False
311 | ) # Key does not matter
312 | return loss, metrics
313 |
314 | _, metrics = jax.lax.scan(single_step, 0, (x, y))
315 | metrics = jax.tree.map(lambda x: x.mean(axis=0), metrics)
316 | return metrics
317 |
318 | total_steps = cfg.training_steps
319 | total_tokens = train_dataset.tokens_per_step * cfg.grad_step
320 |
321 | jax.experimental.multihost_utils.sync_global_devices("sync")
322 | log(f"Total steps: {total_steps}")
323 | log(f"Total tokens per step: {total_tokens:,}")
324 |
325 | key, sample_key = jax.random.split(key, 2)
326 | start = time.time()
327 | train_loss = []
328 | wandb_log_array = []
329 |
330 | @partial(jax.jit, static_argnames=["steps"])
331 | def make_sharded_key(key, steps=1):
332 | key = jax.random.split(
333 | key, DATA_PARALLEL * LAYER_PARALLEL * TENSOR_PARALLEL * steps
334 | )
335 | key = jnp.asarray(key).reshape(
336 | (DATA_PARALLEL, LAYER_PARALLEL, TENSOR_PARALLEL, steps, 2)
337 | )
338 | return key
339 |
340 | for current_step in range(init_step, total_steps):
341 | key, train_key = jax.random.split(key)
342 | train_key = make_sharded_key(train_key, steps=cfg.grad_step)
343 |
344 | x, y = train_dataset(step=cfg.grad_step)
345 |
346 | params, opt_state, metrics = train_step(params, opt_state, x, y, train_key)
347 | train_loss.append(metrics["loss"])
348 |
349 | if use_wandb:
350 | wandb_log = {
351 | "step": current_step,
352 | "loss/train_loss": metrics["loss"],
353 | "loss/train_cross_entropy_loss": metrics["loss_cross"],
354 | "lr": opt_state[1].hyperparams["learning_rate"],
355 | }
356 | wandb_log["loss/load_loss"] = metrics["loss_balance"]
357 | for h in range(cfg.model_config.n_experts):
358 | wandb_log[f"load/head_{h}"] = jax.device_get(metrics[f"load_expert"])[h]
359 |
360 | if current_step % cfg.checkpoint_steps == 0:
361 | time_per_batch = time.time() - start
362 | eval_x, eval_y = val_dataset(step=cfg.eval_steps)
363 | val_metrics = eval_step(params, eval_x, eval_y)
364 |
365 | if use_wandb:
366 | wandb_log["loss/val_loss"] = val_metrics["loss"]
367 | wandb_log["loss/val_cross_entropy_loss"] = val_metrics["loss_cross"]
368 | wandb_log["loss/val_load_loss"] = val_metrics["loss_balance"]
369 | for h in range(cfg.model_config.n_experts):
370 | wandb_log[f"load/head_{h}"] = jax.device_get(
371 | val_metrics[f"load_expert"]
372 | )[h]
373 |
374 | jax.experimental.multihost_utils.sync_global_devices("sync")
375 |
376 | tokens_per_second = cfg.checkpoint_steps * total_tokens / time_per_batch
377 | train_loss = jnp.array(train_loss).mean().item()
378 | eval_loss = val_metrics["loss"].item()
379 | log_string = f"Step {current_step + 1}, Loss: {train_loss:.4f}, Eval Loss: {eval_loss:.4f}, tk/s: {tokens_per_second:,.2f}"
380 | log(log_string)
381 |
382 | start = time.time()
383 | train_loss = []
384 |
385 | if current_step % (10 * cfg.checkpoint_steps) == 0:
386 | outputs = model.generate(
387 | params,
388 | cfg.model_config,
389 | key=sample_key,
390 | x=cfg.inference_config.prompt,
391 | B=cfg.inference_config.batch_size,
392 | k=cfg.inference_config.top_k,
393 | temperature=cfg.inference_config.temperature,
394 | n_devices=cfg.inference_config.n_devices,
395 | use_cache=cfg.inference_config.use_cache,
396 | )
397 |
398 | log("Generated outputs:")
399 | for output in outputs:
400 | log(f"\t{output}")
401 |
402 | if jax.process_index() == 0:
403 | save_path = os.path.join(os.path.abspath("./samples"), cfg.name)
404 | if not os.path.exists(save_path):
405 | os.makedirs(save_path)
406 | with open(
407 | os.path.join(save_path, "tokens.txt"),
408 | "a",
409 | ) as f:
410 | f.write(f"{current_step} | {outputs}\n")
411 |
412 | if use_wandb:
413 | table.add_data(current_step, *outputs)
414 | wandb_log["inference_tokens"] = table
415 |
416 | save_checkpoint(current_step)
417 | gen_time = time.time() - start
418 | log(f"Generation time: {gen_time:.4f} seconds")
419 | start = time.time()
420 |
421 | if use_wandb:
422 | wandb_log_array.append({"data": wandb_log, "step": current_step})
423 | if current_step % (10 * cfg.checkpoint_steps) == 0:
424 | for log_entry in wandb_log_array:
425 | wandb.log(data=log_entry["data"], step=log_entry["step"])
426 | wandb_log_array = []
427 |
428 | if use_wandb:
429 | wandb.finish()
430 |
431 |
432 | if __name__ == "__main__":
433 | jax.distributed.initialize()
434 | cfg = parse_args()
435 | print(json.dumps(cfg.__dict__, indent=4, default=lambda o: o.__dict__))
436 | main(cfg)
437 |
--------------------------------------------------------------------------------
/model.py:
--------------------------------------------------------------------------------
1 | import jax
2 | import jax.numpy as jnp
3 | from jax.sharding import PartitionSpec as P
4 | from flax import linen as nn
5 | from einops import rearrange
6 |
7 | import tiktoken
8 | from utils import modelConfig
9 | import numpy as np
10 | from typing import Optional, Tuple, List
11 | from jaxtyping import Array, PyTree
12 | from functools import partial
13 |
14 | import time
15 |
16 | cache_type = Tuple[Optional[Array], Optional[Array]]
17 | dtype_map = {
18 | "bfloat16": jnp.bfloat16,
19 | "float32": jnp.float32,
20 | "float16": jnp.float16,
21 | "int32": jnp.int32,
22 | "int64": jnp.int64,
23 | }
24 |
25 |
26 | def convert_dtype(dtype_str):
27 | if dtype_str in dtype_map:
28 | return dtype_map[dtype_str]
29 | else:
30 | raise ValueError(f"Unsupported dtype: {dtype_str}")
31 |
32 |
33 | class Dense(nn.Module):
34 | features: int
35 | dtype: jnp.dtype = jnp.float32
36 |
37 | @nn.compact
38 | def __call__(self, x: Array) -> Array:
39 | if self.is_mutable_collection("params"):
40 | kernel = self.param(
41 | "kernel",
42 | nn.initializers.lecun_normal(),
43 | (x.shape[-1], self.features),
44 | jnp.float32,
45 | )
46 | else:
47 | kernel = self.scope.get_variable("params", "kernel")
48 | kernel = jax.lax.all_gather(kernel, "dp", axis=-1, tiled=True)
49 |
50 | bias = self.param("bias", nn.initializers.zeros, (self.features,), jnp.float32)
51 | x, kernel, bias = jax.tree.map(
52 | lambda x: x.astype(self.dtype), (x, kernel, bias)
53 | )
54 |
55 | x = jnp.einsum("...d,df->...f", x, kernel)
56 | tensor_size = jax.lax.psum(1, axis_name="tp")
57 | x = x + (1 / tensor_size) * bias
58 | x = jax.lax.psum_scatter(x, "tp", scatter_dimension=x.ndim - 1, tiled=True)
59 |
60 | return x
61 |
62 |
63 | class FeedForward(nn.Module):
64 | model_dimension: int
65 | dropout_rate: float = 0.1
66 | model_dtype: jnp.dtype = jnp.bfloat16
67 |
68 | @nn.compact
69 | def __call__(self, x: Array, train=True) -> Array:
70 | x = Dense(features=self.model_dimension * 4, dtype=self.model_dtype)(x)
71 | x = nn.gelu(x)
72 | x = Dense(features=self.model_dimension, dtype=self.model_dtype)(x)
73 | x = nn.Dropout(rate=self.dropout_rate)(x, deterministic=not train)
74 | return x
75 |
76 |
77 | class RMSNorm(nn.Module):
78 | model_dtype: jnp.dtype = jnp.float32
79 |
80 | @nn.compact
81 | def __call__(self, x: Array) -> Array:
82 | x_type = x.dtype
83 | x = x.astype(jnp.float32)
84 |
85 | rms = jnp.sum(jnp.square(x), axis=-1, keepdims=True)
86 | rms = jax.lax.psum(rms, axis_name="tp")
87 | rms = rms / jax.lax.psum(x.shape[-1], axis_name="tp")
88 |
89 | x = x / jnp.sqrt(rms + 1e-6)
90 | x = x.astype(x_type)
91 |
92 | gamma = self.param(
93 | "gamma", nn.initializers.ones, (1, 1, x.shape[-1]), jnp.float32
94 | )
95 | beta = self.param(
96 | "beta", nn.initializers.zeros, (1, 1, x.shape[-1]), jnp.float32
97 | )
98 |
99 | x, gamma, beta = jax.tree.map(
100 | lambda x: x.astype(self.model_dtype), (x, gamma, beta)
101 | )
102 |
103 | x = x * gamma + beta
104 |
105 | return x
106 |
107 |
108 | class NoisyKGate(nn.Module):
109 | n_experts: int
110 | k: int
111 | model_dtype: jnp.dtype
112 |
113 | def setup(self):
114 | self.centroids = Dense(features=self.n_experts, dtype=self.model_dtype)
115 |
116 | def top(self, x: Array) -> Tuple[Array, Array]:
117 | assert x.shape[0] == self.n_experts, "x must be of shape (n_experts, )"
118 | g_i, i = jax.lax.top_k(x, self.k)
119 | g = g_i / jnp.sum(g_i, axis=-1)
120 |
121 | return g, i
122 |
123 | def __call__(self, x: Array) -> Tuple[Array, Array, Array]:
124 | local_scores = nn.sigmoid(self.centroids(x))
125 |
126 | scores = jax.lax.all_gather(
127 | local_scores,
128 | "tp",
129 | axis=x.ndim - 1,
130 | tiled=True,
131 | ) # ( B, T, C) fully collected
132 | g_scores, indices = jnp.apply_along_axis(func1d=self.top, axis=-1, arr=scores)
133 |
134 | return g_scores, indices, scores
135 |
136 |
137 | class MoE(nn.Module):
138 | model_dimension: int
139 | n_shared: int
140 | n_experts: int
141 | k: int
142 | dropout_rate: float
143 | capacity_factor: float = 1.0
144 | model_dtype: jnp.dtype = jnp.float32
145 |
146 | @nn.compact
147 | def __call__(self, x, train=True):
148 | B, T, C = x.shape
149 |
150 | shared = Dense(
151 | features=self.model_dimension * self.n_shared,
152 | dtype=self.model_dtype,
153 | )
154 |
155 | res_shared = shared(x)
156 | res_shared = rearrange(res_shared, "B T (n d) -> B T n d", n=self.n_shared)
157 | res_shared = jnp.sum(res_shared, axis=2) # (B, T, n, d) -> (B, T, d)
158 |
159 | router = NoisyKGate(
160 | n_experts=self.n_experts,
161 | k=self.k,
162 | model_dtype=self.model_dtype,
163 | )
164 | g_scores, indices, scores = router(x) # (B, T, k), (B, T, k), (B, T, n_experts)
165 |
166 | capacity = B * T
167 | if train:
168 | capacity = int(capacity * self.capacity_factor / self.n_experts)
169 |
170 | expert_inputs, score_mask, tokens_per_expert = self.scatter(
171 | x, g_scores, indices, capacity
172 | ) # (e, c, d) , (B * T, e, c), (e,)
173 |
174 | expert = FeedForward(
175 | model_dimension=self.model_dimension,
176 | dropout_rate=self.dropout_rate,
177 | model_dtype=self.model_dtype,
178 | )
179 |
180 | expert_outputs = nn.vmap(
181 | lambda expert, inp: expert(inp, train=train),
182 | in_axes=(0),
183 | out_axes=(0),
184 | variable_axes={"params": 0},
185 | split_rngs={"params": True, "dropout": True},
186 | )(expert, expert_inputs)
187 |
188 | # sum the out by the weighted dim
189 | expert_outputs = jnp.einsum("ecd,tec->td", expert_outputs, score_mask)
190 | expert_outputs = expert_outputs.reshape(B, T, C)
191 |
192 | f, p = self.auxiliary_loss(scores, indices)
193 |
194 | aux = {"tokens_per_expert": tokens_per_expert, "f": f, "p": p}
195 |
196 | x = res_shared + expert_outputs
197 |
198 | return x, aux
199 |
200 | def scatter(
201 | self, x: Array, scores: Array, indices: Array, capacity: int
202 | ) -> Tuple[Array, Array]:
203 | B, T, C = x.shape
204 | x = x.reshape(B * T, C)
205 | scores = scores.reshape(B * T, self.k)
206 | indices = indices.reshape(B * T, self.k)
207 |
208 | # sort to arrange in order of expert scores for each batch by
209 | # the highest scored expert
210 | sorted_token_idx = jnp.argsort(-scores[:, 0], axis=0)
211 | sorted_indices = jnp.take_along_axis(indices, sorted_token_idx[:, None], axis=0)
212 | sorted_scores = jnp.take_along_axis(scores, sorted_token_idx[:, None], axis=0)
213 |
214 | # swapping gives you the highest highest score across the batch
215 | # expert_1: [b_1, b_2, .. b_{B * T }], expert_2: [b_1, b_2, .. b_{B * T }], ...
216 | # flatten then to get expert indices in order
217 | flat_indices = jnp.swapaxes(sorted_indices, 0, 1).reshape(-1)
218 | flat_scores = jnp.swapaxes(sorted_scores, 0, 1).reshape(-1)
219 |
220 | # convert to one hot encoding
221 | # then multiply to get the score for each instead of 1
222 | expert_onehot = jax.nn.one_hot(
223 | flat_indices, self.n_experts, dtype=jnp.int32
224 | ) # (B*T*k, n_experts)
225 | expert_scores = flat_scores[:, None] * expert_onehot # (B*T*k, n_experts)
226 |
227 | position_in_expert = (
228 | jnp.cumsum(expert_onehot, axis=0) * expert_onehot
229 | ) # get which position it is in the expert
230 | # find max position across all batches since that is the total sum from cumsum
231 | tokens_per_expert = jnp.max(position_in_expert, axis=0) / (
232 | B * T
233 | ) # take average across batch
234 |
235 | # reshape it back to get for
236 | # expert_i: [b_1, b_2, .. b_{B * T }] where b_i is the one hot for which position it is in
237 | # same for expert scores
238 | position_in_expert = position_in_expert.reshape(self.k, B * T, self.n_experts)
239 | expert_scores = expert_scores.reshape(self.k, B * T, self.n_experts)
240 |
241 | # go back to orginal shape
242 | position_in_expert = jnp.swapaxes(
243 | position_in_expert, 0, 1
244 | ) # (B*T, k, n_experts)
245 | expert_scores = jnp.swapaxes(expert_scores, 0, 1) # (B*T, k, n_experts)
246 |
247 | # for every batch in each expert find the non-zero expert position
248 | # as for every expert we only have one non-zero value
249 | final_pos = jnp.max(position_in_expert, axis=1) - 1 # make it 0 indexed
250 | final_scores = jnp.max(expert_scores, axis=1) # do the same for the score
251 |
252 | # unsort the indices
253 | unsorted_indices = jnp.argsort(sorted_token_idx)
254 | final_pos = jnp.take_along_axis(final_pos, unsorted_indices[:, None], axis=0)
255 | final_scores = jnp.take_along_axis(
256 | final_scores, unsorted_indices[:, None], axis=0
257 | )
258 | # final pos is now the orginal order where each index is the position in the expert
259 | # if it is greater than or less than the capcity / 0 (hence -1) the row will be 0 in the capcity
260 | # hence we have for each positoin and expert the one hot tells us which position it is in
261 | # if it is in
262 | dispatch_mask = jax.nn.one_hot(
263 | final_pos, capacity, dtype=jnp.int32
264 | ) # (B*T, n_experts, capacity)
265 | # multiply out all the values in the capcity by final score
266 | # we can replicate since at most 1 value will be non zero
267 | scores_mask = (
268 | dispatch_mask * final_scores[..., None]
269 | ) # (B*T, n_experts, capacity)
270 |
271 | # since only one expert at every position in capactiy at most
272 | # we can sum to get rid of batch dim and get the exepect capacity dimension indicies
273 | expert_inputs = jnp.einsum("bd,bec->ecd", x, dispatch_mask)
274 |
275 | return expert_inputs, scores_mask, tokens_per_expert
276 |
277 | def auxiliary_loss(self, scores: Array, indices: Array) -> Array:
278 | B, T, n_experts = scores.shape
279 |
280 | scores = scores / jnp.sum(scores, axis=-1, keepdims=True)
281 | scores = scores.reshape(B * T, n_experts)
282 | p = jnp.sum(scores, axis=0) / (B * T)
283 |
284 | total_batch = B * T * self.k
285 | indices = indices.reshape(total_batch)
286 | f = jax.nn.one_hot(indices, n_experts, dtype=jnp.float32)
287 | f = jnp.sum(f, axis=0) / (B * T)
288 |
289 | return f, p
290 |
291 |
292 | class Embedding(nn.Module):
293 | model_dimension: int
294 | vocab_size: int
295 | model_dtype: jnp.dtype
296 |
297 | def setup(self):
298 | self.embedding = nn.Embed(
299 | num_embeddings=self.vocab_size,
300 | features=self.model_dimension,
301 | dtype=self.model_dtype,
302 | )
303 | self.norm = RMSNorm(model_dtype=self.model_dtype)
304 |
305 | def __call__(self, x: Array, out: bool = False) -> Array:
306 | if not out:
307 | *_, T = x.shape
308 | x = self.embedding(x)
309 | x = jax.lax.all_to_all(
310 | x, "tp", split_axis=x.ndim - 1, concat_axis=x.ndim - 2, tiled=True
311 | )
312 | if self.is_mutable_collection("params"):
313 | _ = self.norm(x)
314 | else:
315 | x = self.norm(x)
316 | x = jax.lax.all_to_all(
317 | x, "tp", split_axis=x.ndim - 2, concat_axis=x.ndim - 1, tiled=True
318 | )
319 | x = self.embedding.attend(x)
320 |
321 | return x
322 |
323 |
324 | class RoPE(nn.Module):
325 | T: int
326 | model_dim: int
327 |
328 | def setup(self):
329 | assert self.model_dim % 2 == 0, "model_dim must be even"
330 |
331 | freq = jnp.arange(self.T, dtype=jnp.float32)[:, None] + 1
332 |
333 | pos = jnp.arange(self.model_dim // 2, dtype=jnp.float32)[:, None]
334 | pos = pos.repeat(2, axis=-1).reshape(1, -1)
335 | log_theta_base = jnp.log(10000.0)
336 | theta = jnp.exp(-2 * pos / self.model_dim * log_theta_base)
337 |
338 | idx = jax.lax.axis_index("tp")
339 | tensor_size = jax.lax.psum(1, axis_name="tp")
340 | slice_factor = self.model_dim // tensor_size
341 |
342 | cos = jnp.cos(freq * theta)
343 | sin = jnp.sin(freq * theta)
344 |
345 | self.cos = jax.lax.dynamic_slice_in_dim(
346 | cos, slice_factor * idx, slice_factor, axis=-1
347 | )
348 | self.sin = jax.lax.dynamic_slice_in_dim(
349 | sin, slice_factor * idx, slice_factor, axis=-1
350 | )
351 |
352 | def __call__(
353 | self,
354 | x: Array,
355 | t_start: int,
356 | ) -> Array:
357 | B, T, C = x.shape
358 | x_dtype = x.dtype
359 | x = x.astype(jnp.float32)
360 |
361 | cos_rope = x * self.cos[t_start : t_start + T, :]
362 |
363 | x_inter = x.reshape((B, T, C // 2, 2))
364 | x_inter_one = x_inter[..., 0]
365 | x_inter_two = -1 * x_inter[..., 1]
366 | x_inter = jnp.stack([x_inter_two, x_inter_one], axis=-1).reshape((B, T, C))
367 |
368 | x_inter = x_inter.reshape((B, T, C))
369 | sin_rope = x_inter * self.sin[t_start : t_start + T, :]
370 |
371 | x = cos_rope + sin_rope
372 | x = x.astype(x_dtype)
373 |
374 | return x
375 |
376 |
377 | class MLA(nn.Module):
378 | model_dimension: int
379 | n_heads: int
380 | T: int
381 | latent_dim: int
382 | dhR: int
383 | model_dtype: jnp.dtype
384 | dropout: float = 0.0
385 |
386 | @nn.compact
387 | def __call__(
388 | self,
389 | x: Array,
390 | *,
391 | KV_cache: Optional[Array] = None,
392 | KR_cache: Optional[Array] = None,
393 | train=True,
394 | ) -> Tuple[Array, Tuple[Optional[Array], Optional[Array]]]:
395 | use_rope = self.dhR > 0
396 |
397 | B, T, C = x.shape
398 |
399 | x = Dense(features=2 * self.latent_dim, dtype=self.model_dtype)(x)
400 | kv_latent, q_latent = jnp.split(x, 2, axis=-1)
401 |
402 | if use_rope:
403 | t_start = KV_cache.shape[1] if KV_cache is not None else 0
404 | x_k_r = Dense(features=self.dhR, dtype=self.model_dtype)(x)
405 | x_q_r = Dense(features=self.dhR * self.n_heads, dtype=self.model_dtype)(x)
406 |
407 | rope_k = RoPE(model_dim=self.dhR, T=self.T)
408 | rope_q = RoPE(
409 | model_dim=self.dhR * self.n_heads,
410 | T=self.T,
411 | )
412 |
413 | kRt = rope_k(x_k_r, t_start)
414 |
415 | qRt = rope_q(x_q_r, t_start)
416 | qRt = rearrange(qRt, "B T (nh d) -> B nh T d", nh=self.n_heads)
417 |
418 | if not train:
419 | if KV_cache is not None:
420 | kv_latent = jnp.concatenate([KV_cache, kv_latent], axis=1)
421 | KV_cache = kv_latent
422 |
423 | if use_rope:
424 | if KR_cache is not None:
425 | kRt = jnp.concatenate([KR_cache, kRt], axis=1)
426 | KR_cache = kRt
427 |
428 | k, v = jnp.split(
429 | Dense(features=2 * self.model_dimension, dtype=self.model_dtype)(kv_latent),
430 | 2,
431 | axis=-1,
432 | )
433 | q = Dense(features=self.model_dimension, dtype=self.model_dtype)(q_latent)
434 |
435 | q, k, v = jax.tree.map(
436 | lambda x: rearrange(x, "B T (nh d) -> B nh T d", nh=self.n_heads), (q, k, v)
437 | )
438 |
439 | q, k, v = jax.tree.map(
440 | lambda x: jax.lax.all_to_all(
441 | x, "tp", split_axis=1, concat_axis=3, tiled=True
442 | ),
443 | (q, k, v),
444 | )
445 |
446 | if use_rope:
447 | qRt = jax.lax.all_to_all(qRt, "tp", split_axis=1, concat_axis=3, tiled=True)
448 | q = jnp.concatenate([q, qRt], axis=-1)
449 |
450 | kRt = jnp.repeat(kRt[:, None, :, :], self.n_heads, axis=1)
451 | kRt = jax.lax.all_to_all(kRt, "tp", split_axis=1, concat_axis=3, tiled=True)
452 | k = jnp.concatenate([k, kRt], axis=-1)
453 |
454 | def scaledDotProd(q, k, v, mask):
455 | input_dtype = q.dtype
456 |
457 | q, k, v = jax.tree.map(lambda x: x.astype(jnp.float32), (q, k, v))
458 | dk = q.shape[-1]
459 |
460 | w = jnp.einsum("B n T d, B n t d -> B n T t", q, k) * (dk**-0.5)
461 | w = jnp.where(mask == 0, -jnp.inf, w)
462 | w = jax.nn.softmax(w, axis=-1)
463 | output = jnp.einsum("B n T t, B n t d -> B n T d", w, v)
464 |
465 | output = output.astype(input_dtype)
466 | return output
467 |
468 | local_n_heads = q.shape[1]
469 | if T == 1:
470 | mask = jnp.ones((B, local_n_heads, 1, k.shape[2]))
471 | else:
472 | mask = jnp.tril(
473 | jnp.ones((B, local_n_heads, q.shape[2], k.shape[2])),
474 | )
475 |
476 | output = scaledDotProd(q, k, v, mask)
477 |
478 | output = jax.lax.all_to_all(
479 | output, "tp", split_axis=3, concat_axis=1, tiled=True
480 | )
481 | output = rearrange(output, "B nh T dk -> B T (nh dk)")
482 |
483 | output = Dense(features=self.model_dimension, dtype=self.model_dtype)(output)
484 | output = nn.Dropout(rate=self.dropout)(output, deterministic=not train)
485 |
486 | return output, (KV_cache, KR_cache)
487 |
488 |
489 | class Layer(nn.Module):
490 | model_dimension: int
491 | n_heads: int
492 | T: int
493 | latent_dim: int
494 | dhR: int
495 | n_experts: int
496 | k: int
497 | n_shared: int
498 | capacity_factor: float
499 | use_moe: bool = False
500 | dropout_rate: float = 0.1
501 | model_dtype: jnp.dtype = jnp.bfloat16
502 |
503 | @nn.compact
504 | def __call__(
505 | self, x, cache: Optional[cache_type] = None, train=True
506 | ) -> Tuple[Array, cache_type]:
507 | x_res = x
508 |
509 | x = RMSNorm(model_dtype=self.model_dtype)(x)
510 | x, cache = MLA(
511 | model_dimension=self.model_dimension,
512 | n_heads=self.n_heads,
513 | T=self.T,
514 | latent_dim=self.latent_dim,
515 | dhR=self.dhR,
516 | model_dtype=self.model_dtype,
517 | dropout=self.dropout_rate,
518 | )(x, KV_cache=cache[0], KR_cache=cache[1], train=train)
519 | x = x + x_res
520 | x_res = x
521 |
522 | x = RMSNorm(model_dtype=self.model_dtype)(x)
523 | if self.use_moe:
524 | x, aux = MoE(
525 | model_dimension=self.model_dimension,
526 | n_experts=self.n_experts,
527 | k=self.k,
528 | n_shared=self.n_shared,
529 | capacity_factor=self.capacity_factor,
530 | dropout_rate=self.dropout_rate,
531 | model_dtype=self.model_dtype,
532 | )(x, train=train)
533 | else:
534 | x, aux = (
535 | FeedForward(
536 | model_dimension=self.model_dimension,
537 | dropout_rate=self.dropout_rate,
538 | model_dtype=self.model_dtype,
539 | )(x, train=train),
540 | None,
541 | )
542 | x = x + x_res
543 |
544 | return x, (cache, aux)
545 |
546 |
547 | class Block(nn.Module):
548 | layers: int
549 | model_dimension: int
550 | n_heads: int
551 | T: int
552 | latent_dim: int
553 | dhR: int
554 | n_experts: int
555 | k: int
556 | n_shared: int
557 | capacity_factor: float
558 | dropout_rate: float = 0.1
559 | model_dtype: jnp.dtype = jnp.bfloat16
560 |
561 | @nn.compact
562 | def __call__(
563 | self, x, cache: Optional[cache_type] = None, train=True
564 | ) -> Tuple[Array, cache_type]:
565 | KV_cache = []
566 | KR_cache = []
567 | moe_stat = None
568 |
569 | for i in range(self.layers):
570 | current_cache = [None, None]
571 | if cache is not None:
572 | current_cache[0] = cache[0][i]
573 | if i < self.layers - 1:
574 | current_cache[1] = cache[1][i]
575 |
576 | x, (cache_out, aux) = Layer(
577 | model_dimension=self.model_dimension,
578 | n_heads=self.n_heads,
579 | T=self.T,
580 | latent_dim=self.latent_dim,
581 | dhR=self.dhR if i < self.layers - 1 else 0,
582 | n_experts=self.n_experts,
583 | k=self.k,
584 | n_shared=self.n_shared,
585 | capacity_factor=self.capacity_factor,
586 | use_moe=(i == self.layers - 1),
587 | dropout_rate=self.dropout_rate,
588 | model_dtype=self.model_dtype,
589 | )(x, current_cache, train=train)
590 |
591 | if aux is not None:
592 | moe_stat = aux
593 |
594 | ckV, kRT = cache_out
595 | if ckV is not None:
596 | KV_cache.append(ckV)
597 | if kRT is not None:
598 | KR_cache.append(kRT)
599 |
600 | KV_cache = jnp.stack(KV_cache, axis=0) if len(KV_cache) > 0 else None
601 | KR_cache = jnp.stack(KR_cache, axis=0) if len(KR_cache) > 0 else None
602 |
603 | out_cache = (KV_cache, KR_cache)
604 |
605 | return x, (out_cache, moe_stat)
606 |
607 |
608 | class Transformer(nn.Module):
609 | model_dimension: int
610 | vocab_size: int
611 | n_head: int
612 | blocks: int
613 | layers_per_block: int
614 | T: int
615 | latent_dim: int
616 | dhR: int
617 | n_experts: int
618 | k: int
619 | n_shared: int
620 | capacity_factor: float
621 | dropout_rate: float = 0.1
622 | model_dtype: jnp.dtype = jnp.bfloat16
623 |
624 | @nn.compact
625 | def __call__(
626 | self, x, cache: Optional[cache_type] = None, train=True
627 | ) -> Tuple[Array, cache_type]:
628 | if cache is not None:
629 | x = x[..., -1:]
630 |
631 | *B, T = x.shape
632 | x = x.reshape(-1, T)
633 |
634 | embedding = Embedding(
635 | vocab_size=self.vocab_size,
636 | model_dimension=self.model_dimension,
637 | model_dtype=self.model_dtype,
638 | )
639 |
640 | x = embedding(x)
641 |
642 | KV_cache = []
643 | ckRT_cache = []
644 | moe_stat = []
645 |
646 | for i in range(self.blocks):
647 | if cache is None:
648 | layer_cache = None
649 | else:
650 | cKV = cache[0][i]
651 | kRT = cache[1][i] if cache[1] is not None else None
652 | layer_cache = (cKV, kRT)
653 |
654 | x, (cache_out, moe_stat_out) = Block(
655 | layers=self.layers_per_block,
656 | model_dimension=self.model_dimension,
657 | n_heads=self.n_head,
658 | T=self.T,
659 | latent_dim=self.latent_dim,
660 | dhR=self.dhR,
661 | n_experts=self.n_experts,
662 | k=self.k,
663 | n_shared=self.n_shared,
664 | capacity_factor=self.capacity_factor,
665 | dropout_rate=self.dropout_rate,
666 | model_dtype=self.model_dtype,
667 | )(x, layer_cache, train=train)
668 |
669 | if cache_out[0] is not None:
670 | KV_cache.append(cache_out[0])
671 | if cache_out[1] is not None:
672 | ckRT_cache.append(cache_out[1])
673 |
674 | moe_stat.append(moe_stat_out)
675 |
676 | if len(KV_cache) > 0:
677 | KV_cache = jnp.stack(KV_cache, axis=0)
678 | else:
679 | KV_cache = None
680 | if len(ckRT_cache) > 0:
681 | ckRT_cache = jnp.stack(ckRT_cache, axis=0)
682 | else:
683 | ckRT_cache = None
684 | out_cache = (KV_cache, ckRT_cache)
685 |
686 | moe_stat = jax.tree.map(lambda *x: jnp.stack(x, axis=0), *moe_stat)
687 |
688 | x_out = embedding(x, out=True)
689 | x_out = x_out.reshape(*B, T, self.vocab_size)
690 |
691 | return x_out, (out_cache, moe_stat)
692 |
693 | def init_weights(self, key: jax.random.key, mesh: jax.sharding.Mesh) -> PyTree:
694 | params = self.init(key, jnp.ones((1, self.T), dtype=jnp.int32), train=False)[
695 | "params"
696 | ]
697 | p_spec = Transformer.get_p_spec(params)
698 | params = jax.tree.map(
699 | lambda x, y: jax.device_put(x, jax.sharding.NamedSharding(mesh, y)),
700 | params,
701 | p_spec,
702 | )
703 | return params
704 |
705 | @classmethod
706 | def get_model(cls, cfg: modelConfig) -> "Transformer":
707 | return cls(
708 | model_dimension=cfg.model_dimension,
709 | vocab_size=cfg.vocab_size,
710 | n_head=cfg.n_head,
711 | blocks=cfg.blocks,
712 | layers_per_block=cfg.layers_per_block,
713 | T=cfg.T,
714 | latent_dim=cfg.latent_dim,
715 | dhR=cfg.dhR,
716 | n_experts=cfg.n_experts,
717 | k=cfg.k,
718 | n_shared=cfg.n_shared,
719 | capacity_factor=cfg.capacity_factor,
720 | dropout_rate=cfg.dropout_rate,
721 | model_dtype=convert_dtype(cfg.model_dtype),
722 | )
723 |
724 | @staticmethod
725 | def get_p_spec(params: PyTree):
726 | return jax.tree.map(
727 | lambda _: P(),
728 | params,
729 | )
730 |
731 | def generate(
732 | self,
733 | params: PyTree,
734 | key: jax.random.key,
735 | x: str = "",
736 | *,
737 | B: int = 1,
738 | k: int = 10000,
739 | temperature: int = 1,
740 | max_tokens: int = 100,
741 | use_cache=True,
742 | ) -> List[str]:
743 | enc = tiktoken.encoding_for_model("gpt-4")
744 | out = jnp.array(
745 | [enc._special_tokens["<|endoftext|>"]] if x == "" else enc.encode(x),
746 | dtype=jnp.int32,
747 | )
748 |
749 | prompt_length = out.shape[0]
750 | generation_length = min(max_tokens, self.T - prompt_length)
751 | out = jnp.repeat(out[None, :], B, axis=0)
752 | cache = None
753 |
754 | @jax.jit
755 | def sample(key, params, inp, cache):
756 | logits, cache = self.apply(
757 | {"params": params}, inp, cache=cache, train=False
758 | )
759 | logits = logits[:, -1, :]
760 | logits, idx = jax.lax.top_k(logits, k=k)
761 | logits /= temperature
762 |
763 | out_next_idx = jax.random.categorical(key, logits, axis=-1, shape=(B,))
764 | out_next = idx[jnp.arange(B, dtype=jnp.int32), out_next_idx][:, None]
765 |
766 | return out_next, (cache, logits)
767 |
768 | for _ in range(generation_length):
769 | start_time = time.time()
770 | if not use_cache:
771 | cache = None
772 | key, sample_key = jax.random.split(key)
773 | out_next, (cache, _logits) = sample(sample_key, params, out, cache)
774 | out = jnp.concatenate([out, out_next], axis=-1)
775 | end_time = time.time()
776 | token_time = end_time - start_time
777 | print(f"Token {_ + 1} generated \t {1 / token_time:.4f} tk/s")
778 |
779 | tokens = jax.device_get(out)
780 | outputs = list(map(lambda x: enc.decode(x), tokens))
781 |
782 | return outputs
783 |
784 |
785 | class shardedModel:
786 | def __init__(self, cfg: modelConfig):
787 | self.dtype = convert_dtype(cfg.model_dtype)
788 | self.embedding = Embedding(
789 | vocab_size=cfg.vocab_size,
790 | model_dimension=cfg.model_dimension,
791 | model_dtype=self.dtype,
792 | )
793 |
794 | self.block = Block(
795 | layers=cfg.layers_per_block,
796 | model_dimension=cfg.model_dimension,
797 | n_heads=cfg.n_head,
798 | T=cfg.T,
799 | latent_dim=cfg.latent_dim,
800 | dhR=cfg.dhR,
801 | n_experts=cfg.n_experts,
802 | k=cfg.k,
803 | n_shared=cfg.n_shared,
804 | capacity_factor=cfg.capacity_factor,
805 | dropout_rate=cfg.dropout_rate,
806 | model_dtype=self.dtype,
807 | )
808 |
809 | self.cfg = cfg
810 |
811 | def init_weights(self, key, mesh):
812 | out_spec = shardedModel.get_p_spec([self.embedding, self.block], mesh, self.cfg)
813 |
814 | def replace_fsdp(p: jax.sharding.PartitionSpec):
815 | if p[-1] == "dp":
816 | p = P(*p[:-1], None)
817 | return p
818 |
819 | out_spec_no_fsdp = jax.tree.map(lambda x: replace_fsdp(x), out_spec)
820 |
821 | x_embed = jnp.ones((1, self.cfg.T), dtype=jnp.int32)
822 | x_layer = jnp.ones((1, self.cfg.T, self.cfg.model_dimension), dtype=self.dtype)
823 |
824 | layer_devices = mesh.devices.shape[1]
825 | tensor_devices = mesh.devices.shape[2]
826 |
827 | assert self.cfg.blocks // layer_devices, (
828 | "Number of blocks must be divisible by number of devices"
829 | )
830 | layers_per_device = self.cfg.blocks // layer_devices
831 |
832 | key, embed_key = jax.random.split(key, 2)
833 | key, *layer_keys = jax.random.split(key, layer_devices * tensor_devices + 1)
834 | layer_keys = jnp.array(layer_keys).reshape(layer_devices, tensor_devices, 2)
835 |
836 | @jax.jit
837 | @partial(
838 | jax.shard_map,
839 | mesh=mesh,
840 | in_specs=(P(None, "tp"), P(None, None, "tp"), P("pp", "tp")),
841 | out_specs=out_spec_no_fsdp,
842 | )
843 | def init_params(x_embed, x_layer, layer_key):
844 | layer_key = layer_key.reshape(
845 | 2,
846 | )
847 | embedding_params = self.embedding.init(embed_key, x_embed, out=False)[
848 | "params"
849 | ]
850 | layer_params = []
851 |
852 | for _ in range(layers_per_device):
853 | layer_key, init_key = jax.random.split(layer_key)
854 | current_params = self.block.init(init_key, x_layer, train=False)[
855 | "params"
856 | ]
857 | layer_params.append(current_params)
858 | layer_params = jax.tree.map(lambda *x: jnp.stack(x, axis=0), *layer_params)
859 |
860 | return embedding_params, layer_params
861 |
862 | params = init_params(x_embed, x_layer, layer_keys)
863 | params = jax.tree.map(
864 | lambda x, y: jax.device_put(x, jax.sharding.NamedSharding(mesh, y)),
865 | params,
866 | out_spec,
867 | )
868 |
869 | return params
870 |
871 | def pipe_step(self, params, x, key, train, cache=None):
872 | embedding_params, layer_params = params
873 |
874 | if cache is not None:
875 | x = x[..., -1:]
876 |
877 | embeddings = self.embedding.apply({"params": embedding_params}, x, out=False)
878 |
879 | layer_fn = lambda x, params, cache, key: self.block.apply(
880 | {"params": params},
881 | x,
882 | cache=cache,
883 | train=train,
884 | rngs={"dropout": key} if train else None,
885 | )
886 |
887 | @partial(jax.checkpoint, policy=jax.checkpoint_policies.nothing_saveable)
888 | def fwd_fn(state_idx, x, params, cache, key):
889 | def grad_fn(stop_grad):
890 | return (
891 | lambda *args: jax.lax.stop_gradient(layer_fn(*args))
892 | if stop_grad
893 | else layer_fn(*args)
894 | )
895 |
896 | fns = [
897 | grad_fn(stop_grad=True),
898 | grad_fn(stop_grad=False),
899 | ]
900 |
901 | out = jax.lax.switch(
902 | state_idx,
903 | fns,
904 | x,
905 | params,
906 | cache,
907 | key,
908 | )
909 |
910 | return out
911 |
912 | layer_out, (out_cache, moe_stat) = self.pipeline(
913 | fwd_fn, layer_params, embeddings, cache, key
914 | )
915 |
916 | logits = self.embedding.apply({"params": embedding_params}, layer_out, out=True)
917 | return logits, (out_cache, moe_stat)
918 |
919 | def pipeline(
920 | self,
921 | fn,
922 | stage_params: PyTree,
923 | inputs: Array,
924 | cache: Optional[Tuple[Array, Optional[Array]]],
925 | key: jax.random.PRNGKey,
926 | ):
927 | device_idx = jax.lax.axis_index("pp")
928 | n_devices = jax.lax.axis_size("pp")
929 | layers_per_device = stage_params["Layer_0"]["MLA_0"]["Dense_0"]["kernel"].shape[
930 | 0
931 | ]
932 | microbatch_per_device = inputs.shape[0]
933 | microbatches = n_devices * microbatch_per_device
934 | layers = layers_per_device * n_devices
935 | outputs = jnp.zeros_like(inputs) * jnp.nan
936 | state = (
937 | jnp.zeros(
938 | (
939 | layers_per_device,
940 | *inputs.shape[1:],
941 | )
942 | )
943 | * jnp.nan
944 | )
945 |
946 | state_idx = jnp.zeros((layers_per_device,), dtype=jnp.int32)
947 | perm = [(i, (i + 1) % n_devices) for i in range(n_devices)]
948 |
949 | KV_cache = []
950 | KR_cache = []
951 |
952 | moe_stat = []
953 |
954 | for i in range(microbatches + layers - 1):
955 | batch_idx = i % microbatch_per_device
956 | layer_idx = (i - layers + 1) % microbatch_per_device
957 |
958 | state = state.at[0].set(
959 | jnp.where(device_idx == 0, inputs[batch_idx], state[0])
960 | )
961 | state_idx = state_idx.at[0].set(jnp.where(device_idx == 0, 1, state_idx[0]))
962 |
963 | key, *layer_keys = jax.random.split(key, layers_per_device + 1)
964 | layer_keys = jnp.array(layer_keys)
965 |
966 | current_cache = None
967 | if cache is not None:
968 | current_cache = [cache[0][i], None]
969 | if cache[1] is not None:
970 | current_cache[1] = cache[1][i]
971 |
972 | state, (out_cache, out_moe_stat) = jax.vmap(fn)(
973 | state_idx, state, stage_params, current_cache, layer_keys
974 | )
975 |
976 | if out_cache[0] is not None:
977 | KV_cache.append(out_cache[0])
978 | if out_cache[1] is not None:
979 | KR_cache.append(out_cache[1])
980 | moe_stat.append(out_moe_stat)
981 |
982 | outputs = outputs.at[layer_idx].set(
983 | jnp.where(device_idx == n_devices - 1, state[-1], outputs[layer_idx])
984 | )
985 |
986 | state = jnp.concat(
987 | [jax.lax.ppermute(state[-1], "pp", perm)[None, ...], state[:-1]], axis=0
988 | )
989 | state_idx = jnp.concat(
990 | [
991 | jax.lax.ppermute(state_idx[-1], "pp", perm)[None, ...],
992 | state_idx[:-1],
993 | ],
994 | axis=0,
995 | )
996 |
997 | if batch_idx == microbatch_per_device - 1 and i < microbatches:
998 | inputs = jax.lax.ppermute(inputs, axis_name="pp", perm=perm)
999 |
1000 | if layer_idx == microbatch_per_device - 1 and i >= layers - 1:
1001 | outputs = jax.lax.ppermute(outputs, axis_name="pp", perm=perm)
1002 |
1003 | outputs = jax.lax.ppermute(outputs, "pp", perm)
1004 |
1005 | if len(KV_cache) > 0:
1006 | KV_cache = jnp.stack(KV_cache, axis=0)
1007 | else:
1008 | KV_cache = None
1009 |
1010 | if len(KR_cache) > 0:
1011 | KR_cache = jnp.stack(KR_cache, axis=0)
1012 | else:
1013 | KR_cache = None
1014 | out_cache = (KV_cache, KR_cache)
1015 |
1016 | moe_stat = jax.tree.map(lambda *x: jnp.stack(x, axis=0), *moe_stat)
1017 |
1018 | def slice_moe(x: Array) -> Array:
1019 | def each_layer(layer_idx, x):
1020 | return jax.lax.dynamic_slice_in_dim(
1021 | x, layers_per_device * device_idx + layer_idx, microbatches, axis=0
1022 | )
1023 |
1024 | sliced_x = jax.vmap(each_layer, in_axes=(0, -2), out_axes=(-2))(
1025 | jnp.arange(layers_per_device), x
1026 | )
1027 | return sliced_x
1028 |
1029 | moe_stat = jax.tree.map(
1030 | lambda x: slice_moe(x).mean(axis=0), # mean across microbatches
1031 | moe_stat,
1032 | )
1033 |
1034 | moe_stat = {
1035 | "tokens_per_expert": moe_stat["tokens_per_expert"].sum(
1036 | axis=0
1037 | ), # (experts,)
1038 | "aux_loss": moe_stat["f"] * moe_stat["p"], # (layers_per_device, experts)
1039 | }
1040 |
1041 | return outputs, (out_cache, moe_stat)
1042 |
1043 | def generate(
1044 | self,
1045 | params: PyTree,
1046 | cfg: modelConfig,
1047 | key: jax.random.key,
1048 | x: str = "",
1049 | *,
1050 | B: int = 1,
1051 | k: int = 10000,
1052 | temperature: int = 1,
1053 | max_tokens: int = 10,
1054 | n_devices: int = 1,
1055 | use_cache=True,
1056 | ) -> list[str]:
1057 | assert B % n_devices == 0, "Batch size must be divisible by number of devices"
1058 | assert n_devices <= jax.local_device_count(), (
1059 | "Number of devices exceeds available devices"
1060 | )
1061 |
1062 | mesh = jax.make_mesh(
1063 | (1, n_devices, 1),
1064 | axis_names=("dp", "pp", "tp"),
1065 | devices=np.array(jax.local_devices())[:n_devices],
1066 | )
1067 |
1068 | model = shardedModel(cfg)
1069 | out_spec = shardedModel.get_p_spec([model.embedding, model.block], mesh, cfg)
1070 | params = jax.tree.map(
1071 | lambda x, y: jax.device_put(
1072 | jax.experimental.multihost_utils.process_allgather(x, tiled=True),
1073 | jax.sharding.NamedSharding(mesh, y),
1074 | ),
1075 | params,
1076 | out_spec,
1077 | )
1078 | enc = tiktoken.encoding_for_model("gpt-4")
1079 | out = jnp.array(
1080 | [enc._special_tokens["<|endoftext|>"]] if x == "" else enc.encode(x),
1081 | dtype=jnp.int32,
1082 | )
1083 | out = jnp.repeat(out[None, :], B, axis=0).reshape(n_devices, B // n_devices, -1)
1084 |
1085 | prompt_length = out.shape[-1]
1086 | generation_length = min(max_tokens, cfg.T - prompt_length)
1087 |
1088 | generation = jnp.zeros(
1089 | (n_devices, B // n_devices, generation_length + prompt_length),
1090 | dtype=jnp.int32,
1091 | )
1092 | generation = generation.at[:, :, :prompt_length].set(out)
1093 |
1094 | def sample(params, out, cache, sample_key):
1095 | sample_key, pipe_key = jax.random.split(sample_key, 2)
1096 | logits, (cache, _) = shardedModel.pipe_step(
1097 | model, params, out, pipe_key, train=False, cache=cache
1098 | )
1099 |
1100 | logits = logits[:, :, -1, :]
1101 | M, B_sample, _ = logits.shape
1102 | logits = logits.reshape(M * B_sample, -1)
1103 | logits, idx = jax.lax.top_k(logits, k=k)
1104 | logits /= temperature
1105 |
1106 | sample_prob = lambda key, logits, idx: idx[
1107 | jax.random.categorical(key, logits)
1108 | ]
1109 | sample_key = jnp.array(jax.random.split(sample_key, logits.shape[0]))
1110 | out_next = jax.vmap(sample_prob)(sample_key, logits, idx)
1111 | out_next = out_next.reshape(M, B_sample, 1)
1112 |
1113 | return out_next, (cache, logits)
1114 |
1115 | @jax.jit
1116 | @partial(
1117 | jax.shard_map,
1118 | mesh=mesh,
1119 | in_specs=(
1120 | out_spec,
1121 | P(),
1122 | P("dp", "pp", "tp"),
1123 | ),
1124 | out_specs=P("pp", "dp", "tp"),
1125 | )
1126 | def generate_shard(params, generation_buffer, key):
1127 | cache = None
1128 | key = key.reshape(
1129 | 2,
1130 | )
1131 | for idx in range(generation_length):
1132 | if not use_cache:
1133 | cache = None
1134 | key, sample_key = jax.random.split(key)
1135 | current_idx = prompt_length + idx
1136 | out = jax.lax.dynamic_slice_in_dim(
1137 | generation_buffer, 0, current_idx + 1, axis=-1
1138 | )
1139 | out_next, (cache, _logits) = sample(params, out, cache, sample_key)
1140 |
1141 | generation_buffer = generation_buffer.at[
1142 | :, :, current_idx : current_idx + 1
1143 | ].set(out_next)
1144 |
1145 | return generation_buffer[None, None, ...]
1146 |
1147 | key = jax.random.fold_in(key, jax.process_index())
1148 | sample_key = jnp.array(jax.random.split(key, B)).reshape(
1149 | n_devices, B // n_devices, 2
1150 | )
1151 | out = generate_shard(params, generation, sample_key)
1152 |
1153 | tokens = jax.device_get(out)
1154 | tokens = tokens.reshape(-1, tokens.shape[-1])
1155 | tokens = jax.experimental.multihost_utils.process_allgather(tokens, tiled=True)
1156 |
1157 | outputs = [enc.decode(x) for x in tokens]
1158 |
1159 | return outputs
1160 |
1161 | @staticmethod
1162 | def get_p_spec(
1163 | model: Tuple[Embedding, Block], mesh: jax.sharding.Mesh, config: modelConfig
1164 | ) -> Tuple[jax.sharding.NamedSharding, jax.sharding.NamedSharding]:
1165 | T = config.T
1166 | n_devices = mesh.devices.shape[1]
1167 | n_layers = config.blocks
1168 | assert n_layers % n_devices == 0, (
1169 | "Number of layers must be divisible by number of devices"
1170 | )
1171 |
1172 | embed, layer = model
1173 |
1174 | x_embed = jnp.ones((1, T), dtype=jnp.int32)
1175 | x_layer = jnp.ones((1, T, embed.model_dimension), dtype=jnp.float32)
1176 | key = jax.random.PRNGKey(0)
1177 |
1178 | @partial(
1179 | jax.shard_map,
1180 | mesh=mesh,
1181 | in_specs=(P(None, "tp"), P(None, None, "tp")),
1182 | out_specs=(P("pp")),
1183 | )
1184 | def get_var_spec_shard(x_embed, x_layer):
1185 | embed_shape = embed.init(key, x_embed)["params"]
1186 | layer_shape = []
1187 | for _ in range(n_layers // n_devices):
1188 | layer_shape.append(layer.init(key, x_layer, train=False)["params"])
1189 | layer_shape = jax.tree.map(lambda *x: jnp.stack(x, axis=0), *layer_shape)
1190 |
1191 | return embed_shape, layer_shape
1192 |
1193 | eval_shape = jax.eval_shape(
1194 | get_var_spec_shard,
1195 | x_embed,
1196 | x_layer,
1197 | )
1198 |
1199 | join_fn = lambda path: " ".join(i.key for i in path).lower()
1200 |
1201 | def layer_partition(key: Tuple[str, ...], x: Array) -> P:
1202 | path = join_fn(key)
1203 | if "moe" in path and "feedforward" in path:
1204 | if x.ndim == 4:
1205 | return P("pp", None, "tp", "dp")
1206 | if x.ndim == 3:
1207 | return P("pp", None, None)
1208 |
1209 | if "gamma" in path or "beta" in path:
1210 | return P("pp", None, None, "tp")
1211 |
1212 | if x.ndim == 3:
1213 | return P("pp", "tp", "dp")
1214 |
1215 | return P("pp", None)
1216 |
1217 | def embedding_partition(key: Tuple[str, ...], x: Array) -> P:
1218 | path = join_fn(key)
1219 | if "gamma" in path or "beta" in path:
1220 | return P(None, None, "tp")
1221 | return P(*(None for _ in range(x.ndim)))
1222 |
1223 | embed_p_spec = jax.tree.map_with_path(
1224 | embedding_partition,
1225 | eval_shape[0],
1226 | )
1227 |
1228 | layer_p_spec = jax.tree.map_with_path(
1229 | layer_partition,
1230 | eval_shape[1],
1231 | )
1232 |
1233 | return embed_p_spec, layer_p_spec
1234 |
1235 | def param_count(self, params):
1236 | total_params = jax.tree.reduce(
1237 | lambda x, y: x + y.size,
1238 | params,
1239 | 0,
1240 | )
1241 |
1242 | join_fn = lambda path: " ".join(i.key for i in path).lower()
1243 |
1244 | def count_active_params(key, x):
1245 | path = join_fn(key)
1246 | n_elements = x.size
1247 |
1248 | is_expert = "moe" in path and "feedforward" in path
1249 | if is_expert:
1250 | n_elements = n_elements // self.cfg.n_experts * self.cfg.k
1251 |
1252 | return n_elements
1253 |
1254 | active_params_map = jax.tree.map_with_path(count_active_params, params[1])
1255 | active_params = jax.tree.reduce(lambda x, y: x + y, active_params_map, 0)
1256 |
1257 | return total_params, active_params
1258 |
--------------------------------------------------------------------------------