├── .gitignore
├── Neural Image Caption Generator.ipynb
├── README.md
└── requirements.txt
/.gitignore:
--------------------------------------------------------------------------------
1 | data/
2 | checkpoint/
3 | .ipynb_checkpoints/
4 | Image-Captioning.html
5 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Neural Image Caption Generator
2 |
3 |
4 |  5 |
5 |
6 |
7 | The purpose of image captioning is to automatically generate text describing a picture. In the past few years, it has become a topic of increasing interest in machine learning, and advances in this field have resulted in models (depending on which assessment) can score even higher than humans.
8 |
9 |
10 | ## 1. Requirements
11 |
12 | ### 1.1. Recommended system
13 |
14 | I used free gradient notebook of [paperspace](https://www.paperspace.com/)
15 |
16 | - 8 CPUs
17 | - 16 GBs of GPU
18 | - 32 GBs of RAM
19 |
20 | ### 1.2. Required librairies
21 |
22 | ```shell
23 | $ pip install -r requirements.txt
24 | $ python -m spacy download en
25 | $ python -m spacy download en_core_web_lg
26 | ```
27 |
28 | ## 2. Data
29 |
30 | **Flickr8k dataset** It consists of pairs of images and their corresponding captions (there's five captions fo each image).
31 |
32 | Can be downloaded directy using links below:
33 | - [images](https://github.com/jbrownlee/Datasets/releases/download/Flickr8k/Flickr8k_Dataset.zip)
34 | - [captions](https://github.com/jbrownlee/Datasets/releases/download/Flickr8k/Flickr8k_text.zip)
35 |
36 | ## 3. Model structure
37 |
38 | We used the **encoder-decoder architecture** combined with **attention mechanism**. The encoder consists in extracting image representations and the decoder consists in generating image captions.
39 |
40 |
41 |  42 |
42 |
43 |
44 | ### 3.1. Encoder - Convolutional Neural Network
45 |
46 | CNN is a class of deep, feed-forward artificial neural networks that has successfully been applied to analyzing visual imagery. A CNN consists of an input layer and an output layer, as well as multiple hidden layers. The hidden layers of a CNN typically consist of convolutional layers, pooling layers, fully connected layers, and normalization layers. CNN also has many applications such as image and video recognition, recommender systems, and natural language processing.
47 |
48 | We fine tuned the pretrained ResNet model without the last two layers.
49 |
50 |
51 |  52 |
52 |
53 |
54 | ### 3.2. Decoder - Long Short-Term Memory
55 |
56 | LSTM is a basic deep learning model and capable of learning long-term dependencies. A LSTM internal unit is composed of a cell, an input gate, an output gate, and a forget gate. LSTM internal units have hidden state augmented with nonlinear mechanisms to allow state to propagate without modification, be updated, or be reset, using simple learned gating functions. LSTM work tremendously well on various problems, such as natural language text compression, handwriting recognition, and electric load forecasting.
57 |
58 |
59 |  60 |
60 |
61 |
62 | ### 3.3. Attention Mechanism - Badhanau style
63 |
64 | As the name suggests, the attention module on each step of the decoder, uses direct connection to the encoder to focus on a particular part of the source image.
65 |
66 |
67 | 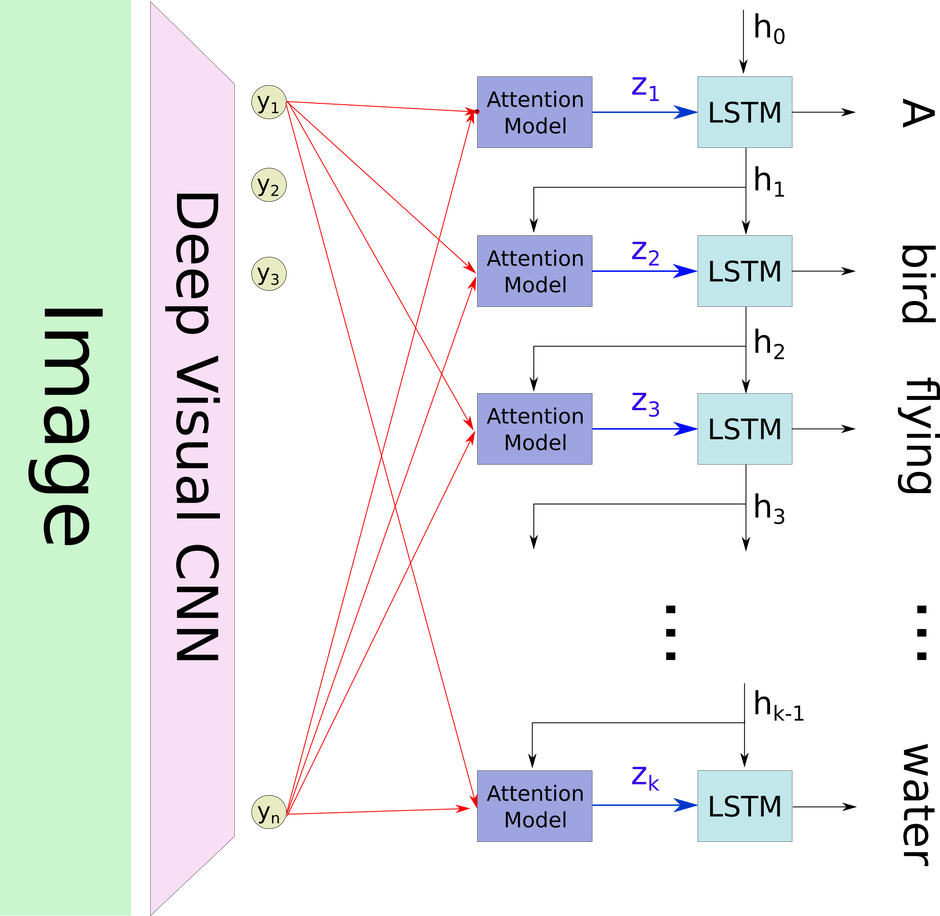 68 |
68 |
69 |
70 |
71 | ## 4. Training
72 |
73 | - Number of training parameters: 136,587,749
74 | - Learning rate: 3e-5
75 | - Teacher forcing ratio: 0. This means we don't train using true captions but the previous generated caption.
76 | - Number of epochs: 15
77 | - Batch size: 32
78 | - Loss function: Crossentropy
79 | - Optimizer: RMSProp
80 | - Metrics: Top5 accuracy & BLEU (more below)
81 |
82 | ## 5. Evaluation - BLEU (Bilingual Evaluation Understudy)
83 |
84 | It compares the machine-generated captions to one or several human-written caption(s), and computes a similarity score based on:
85 | - N-gram precision (we use 4-grams here)
86 | - Plus a penalty for too-short system translations
87 |
88 | ## 6. Inference - Beam Search
89 | While training, we use greedy decoding by taking the argmax. But the problem with this method is that there's no way to undo decision. Instead, we use in inference mode the beam search technique. On each step of decoder, we keep track of the k most probable partial captions (which we call hypotheses); k is the beam size (here 5). Neverthless, using beam search does not guaranteed finding optimal solution.
90 |
91 | # References
92 | - Olah, C., & Carter, S. (2016). Attention and Augmented Recurrent Neural Networks.
93 | - Papineni, K., Roukos, S., Ward, T., & Zhu, W. (2002). Bleu: a Method for Automatic Evaluation of Machine Translation. ACL.
94 | - Jay Alammar - Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention) - [link](http://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/)
95 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | joblib==0.13.2
2 | numpy==1.22.0
3 | Pillow==10.0.1
4 | spacy==2.2.4
5 | torch==1.13.1
6 | torchtext==0.6.0
7 | torchvision==0.4.0a0+d31eafa
8 | tqdm==4.46.1
9 |
--------------------------------------------------------------------------------