├── Notebooks
├── ...
├── Lesson_1_.ipynb
├── Lesson_2.ipynb
├── Lesson_3.ipynb
├── Lesson_4.ipynb
├── Lesson_5.ipynb
└── Lesson_6.ipynb
└── README.md
/Notebooks/...:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/Notebooks/Lesson_1_.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "name": "Lesson_1.ipynb",
7 | "version": "0.3.2",
8 | "provenance": [],
9 | "collapsed_sections": []
10 | },
11 | "kernelspec": {
12 | "name": "python3",
13 | "display_name": "Python 3"
14 | }
15 | },
16 | "cells": [
17 | {
18 | "metadata": {
19 | "id": "oEmqcrMusfbS",
20 | "colab_type": "text"
21 | },
22 | "cell_type": "markdown",
23 | "source": [
24 | "\n",
25 | "## Breve Introducción\n",
26 | "\n",
27 | "El **análisis de datos** consiste en una serie de etapas y manipulaciones de información que puede provenir de diferentes fuentes. Los objetivos pueden ser diversos, desde el desarrollo de un proceso para integrar y limpiar información, hasta la exploración y desarrollo\n",
28 | "de algún modelo o visualización de resultados.\n",
29 | "\n",
30 | "En si, la tarea de analizar datos puede contar con diversas etapas y diferentes objetivos. Para nuestro caso, el objetivo se centra en revisar los aspectos básicos y generales del ciclo de vida de un proceso hasta un paso antes de la contrucción de modelos.\n",
31 | "\n",
32 | "Tomando una abstracción del proceso de Análisis de Datos, se puede pensar que consiste de una secuencia de transformación sobre los datos y en algunos casos finaliza con algún resumen de resultados o con la transformación de los datos para ser insumo de otro proceso o modelo.\n",
33 | "\n",
34 | "Existen diversas metodologías propuestas para desarrollar un proyecto de Análisis de Datos, un par de ejemplos son las siguientes:\n",
35 | "\n",
36 | "* [CRISP-DM](https://www.ibm.com/support/knowledgecenter/en/SS3RA7_15.0.0/com.ibm.spss.crispdm.help/crisp_overview.htm) : es una metodología estandar y con muchos años de maduración.\n",
37 | "* [Foundational Methodology for Data Science](https://www.ibmbigdatahub.com/blog/why-we-need-methodology-data-science): Esta metodología junto con ASUM-DM son propuestas recientes, pero son muy similares a CRISP-DM.\n",
38 | "\n",
39 | "\n",
40 | "\n",
41 | "Ambas metodologías, si bien cuentan con pasos diferentes o con nombres diferentes. De fondo mapean el cliclo de vida general de un proyecto de Data Mining o Machine Learning. Las sutiles diferencias en la practica reflejan cambios no perceptibles en la implementación de la metodología, pero no con ellos digo que sean los mismo. Así que depende del problema de negocio y del equipo de trabajo la decision de tomar tal o cual metodología. En general la más usada y difundida es CRISP-DM."
42 | ]
43 | },
44 | {
45 | "metadata": {
46 | "id": "2Ai_BBm0x7Ou",
47 | "colab_type": "text"
48 | },
49 | "cell_type": "markdown",
50 | "source": [
51 | "## Mini Curso Python para Data Análisis.\n",
52 | "\n",
53 | "* [Breve Introducción](#Breve Introducción) \n",
54 | "* [Pros y Contras de Python](#Pros y Contras de Python) \n",
55 | "* [Objetivo del Curso](#Objetivo del Curso)\n",
56 | "\n",
57 | "### Programación en Python\n",
58 | "\n",
59 | "[Python](#Python)\n",
60 | "\n",
61 | "* [Variables y expresiones](#Variables y expresiones) \n",
62 | "* [Condicionales](#Condicionales) \n",
63 | "* [Funciones](#Funciones) \n",
64 | "* [Loops](#Loops) \n",
65 | "* [Colecciones Básicas](#Colecciones Básicas) \n",
66 | " * [Listas](#Listas)\n",
67 | " * [Tuplas](#Tuplas)\n",
68 | " * [Conjuntos](#Conjuntos)\n",
69 | " * [Diccionarios](#Diccionarios)\n",
70 | " \n",
71 | "* [Comentarios Extra](#Comentarios Extra) \n",
72 | "\n",
73 | "### Matrices y Arreglos\n",
74 | "\n",
75 | "[Numpy](#Numpy) \n",
76 | "\n",
77 | "* [Arreglos](#Arrays)\n",
78 | "* [Indexado de Matrices](#Indexado)\n",
79 | "* [Tipos de Datos](#Tipos de Datos)\n",
80 | "* [Operaciones con Matrices](#Operaciones)\n",
81 | "* [Brocasting](#Brocasting)\n",
82 | "\n"
83 | ]
84 | },
85 | {
86 | "metadata": {
87 | "id": "7dEkhcdmw_mo",
88 | "colab_type": "text"
89 | },
90 | "cell_type": "markdown",
91 | "source": [
92 | "\n",
93 | "## Pros y Contras de Python\n",
94 | "\n",
95 | "\n",
96 | "Python es un lenguaje de programación multi-paradígma. En sus 28 años de existencia ha sufrido diferentes cambios y evoluciones. En los recientes años se ha posicionado como uno de los lenguajes más [demandados](https://spectrum.ieee.org/static/interactive-the-top-programming-languages-2018), superando hasta cierto modo las expectativas de popularidad nunca imaginadas por los primeros desarrolladores en este lenguaje.\n",
97 | "\n",
98 | "*¿Cuáles son las razones de que sea casi una moda aprender a programar con Python?*No tengo la respuesta....y quizás no hay una única respuesta. Pero para mi es gracias a su comunidad en buena medida.\n",
99 | "\n",
100 | "Como todo lenguaje de programación, cuenta con pros y contras. Algunos ejemplos son:\n",
101 | " * Contras\n",
102 | " * Es lento\n",
103 | " * Problemas con Threading\n",
104 | " * No es nativo para aplicaciones mobiles.\n",
105 | " * Tiene limitaciones con el acceso a Bases de Datos\n",
106 | " \n",
107 | "* Pros\n",
108 | " * Versatil, fácil de usar y desarrollar.\n",
109 | " * Multi paradigma y con soporte en multiples plataformas\n",
110 | " * Cuenta con bibliotecas para todo tipo de desarrollo.\n",
111 | " * Por su facilidad y versatilidad es genial para crear prototipos.\n",
112 | " * Tiene una vibrante e inmensa comunidad.\n",
113 | " \n",
114 | "Este último punto es quizás uno de los más relevantes, debido a que ante cada limitante su comunidad busca como superarla y crear algo que le permite a Python contar con nuevas herramientas.\n",
115 | "\n",
116 | "Hoy día los desarrolladores de Python más longevos, quizás estan más que sorprendidos con el fenómeno que se esta viviendo en su comunidad. El fenómeno cultural al rededor de dicho lenguaje es impresionante. \n",
117 | "\n",
118 | "En Julio de este año (2018), la revista [The Economicst](https://www.economist.com/science-and-technology/2018/07/19/python-has-brought-computer-programming-to-a-vast-new-audience) publico un artículo sobre Python y escribió la siguiente línea: *\"in the past 12 months Google users in America have searched for Python more often than for Kim Kardashian\"*.\n",
119 | "\n",
120 | "\n",
121 | "Mi razón de porqué uno debe aprender Python es simple, *por que uno aprende a programar más rápido que en otros lenguajes.*\n",
122 | "\n",
123 | "\n",
124 | "\n"
125 | ]
126 | },
127 | {
128 | "metadata": {
129 | "id": "8Xw-bMCMLW3L",
130 | "colab_type": "text"
131 | },
132 | "cell_type": "markdown",
133 | "source": [
134 | "\n",
135 | "## Objetivo del Curso\n",
136 | "\n",
137 | "Para el curso solo estan planteados 3 objetivos:\n",
138 | "\n",
139 | "* Aprender lo mínimo necesario para ser capaz de leer y escribir un código en Python.\n",
140 | "* Conocer el entorno mínimo de PyData (bibliotecas para hacer Análisis de Datos con Python)\n",
141 | "* Aprender las etapas básicas de un proyecto de Análisis de Datos y ser capaz de desarrollarlos en Python."
142 | ]
143 | },
144 | {
145 | "metadata": {
146 | "id": "dTcs-EgrMYmC",
147 | "colab_type": "text"
148 | },
149 | "cell_type": "markdown",
150 | "source": [
151 | "## Programación en Python\n",
152 | "\n",
153 | "\n",
154 | "###Python\n",
155 | "\n",
156 | "El entorno donde se desarrollan estas notas del curso es [**Colaboratory **](https://colab.research.google.com/), la plataforma de Google para notebook. Este entorno es una versión de alto nivel que [Jupyter](http://jupyter.org/), en el cual se construyen block de notas con celdas o cuadros ejecutables. El código que se ejecuta en lenguaje Python version 3.6. \n",
157 | "\n",
158 | "Existen mucha documentación respecto a las funciones y comandos de Jupyter que facilitan el trabajo. Como ejemplo de como funciona, se pueden ejecutar los siguientes ejemplos."
159 | ]
160 | },
161 | {
162 | "metadata": {
163 | "id": "Fx74-Ivy0PyU",
164 | "colab_type": "code",
165 | "outputId": "d7922341-d903-416c-ef4d-71f224e0b0c1",
166 | "colab": {
167 | "base_uri": "https://localhost:8080/",
168 | "height": 34
169 | }
170 | },
171 | "cell_type": "code",
172 | "source": [
173 | "#Se visualia la versión de Python que se está utilizando en el entorno.\n",
174 | "!python --version"
175 | ],
176 | "execution_count": 0,
177 | "outputs": [
178 | {
179 | "output_type": "stream",
180 | "text": [
181 | "Python 3.6.7\n"
182 | ],
183 | "name": "stdout"
184 | }
185 | ]
186 | },
187 | {
188 | "metadata": {
189 | "id": "AjXWerz8Niyf",
190 | "colab_type": "text"
191 | },
192 | "cell_type": "markdown",
193 | "source": [
194 | "El anterior código solo muestra la versión de Python usada en el entorno. El siguiente código es un ejemplo mas elaborado. "
195 | ]
196 | },
197 | {
198 | "metadata": {
199 | "id": "clOEKzVkMwXl",
200 | "colab_type": "code",
201 | "outputId": "ca9d9868-3b88-4055-f5d7-b52b52557e76",
202 | "colab": {
203 | "base_uri": "https://localhost:8080/",
204 | "height": 389
205 | }
206 | },
207 | "cell_type": "code",
208 | "source": [
209 | "%matplotlib inline\n",
210 | "\n",
211 | "import matplotlib.pyplot as plt\n",
212 | "\n",
213 | "#configuraciones de tipo de gráficos y de tamaño\n",
214 | "\n",
215 | "plt.rcParams[\"figure.figsize\"] = (12, 5)\n",
216 | "plt.rcParams['figure.titlesize'] = 'large'\n",
217 | "plt.rcParams['font.size'] = 12\n",
218 | "plt.rcParams['axes.titlesize']=15\n",
219 | "\n",
220 | "#Módulos para generar y manipular los datos\n",
221 | "import numpy as np\n",
222 | "import pandas as pd\n",
223 | "from IPython.core.interactiveshell import InteractiveShell\n",
224 | "\n",
225 | "InteractiveShell.ast_node_interactivity = \"all\"\n",
226 | "\n",
227 | "M=np.random.rand(1000,4)\n",
228 | "\n",
229 | "\n",
230 | "pd.DataFrame(M,columns=['Var_1','Var_2','Var_3','Var_4'])\\\n",
231 | " .mean().to_frame().rename({0:\"Media\"},axis=1)\n",
232 | "\n",
233 | "pd.DataFrame(M,columns=['Var_1','Var_2','Var_3','Var_4'])\\\n",
234 | " .mean()\\\n",
235 | " .plot(kind='bar',title='Gráfica de Barras')\n",
236 | "\n"
237 | ],
238 | "execution_count": 0,
239 | "outputs": [
240 | {
241 | "output_type": "execute_result",
242 | "data": {
243 | "text/plain": [
244 | ""
245 | ]
246 | },
247 | "metadata": {
248 | "tags": []
249 | },
250 | "execution_count": 1
251 | },
252 | {
253 | "output_type": "display_data",
254 | "data": {
255 | "image/png": "iVBORw0KGgoAAAANSUhEUgAAAsEAAAFQCAYAAABeY6MPAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDIuMS4yLCBo\ndHRwOi8vbWF0cGxvdGxpYi5vcmcvNQv5yAAAGLVJREFUeJzt3Xu0pXdZH/DvmIGkgSQOMhgCIkjD\ng4BlEZAmBkhMKNUFXoAgllaMhl4kdUUuYpCLAlVRwEgqxdJWEQUVEcLFAKmmiBCtaZTUS/pEkXCb\nqKcwTYIJQZLpH3sf2BzOzOwk58zee36fz1qzZr+X/b7P3us5s77nN7/3fXfs27cvAAAwkq9YdAEA\nAHCoCcEAAAxHCAYAYDhCMAAAwxGCAQAYjhAMAMBwdi66AIBlUVWPTHJpkrO7+y0z609N8oYkJyR5\nQJLfSfKm7n7JIarrV5Pcu7tPPxTnAxiBEAysvKo6Psnzkjwhyb2SfC7Jx5L8ZpJXdPfNcxzj2CT/\nKcnju/v3Nmx+TpK1JA/s7n9IUltY/rarqh9P8mNJ1r+HWzL5PO9Ncn53711QaQALYzoEsNKq6v5J\nPpTkPkmemOSumQTh5yc5O8klVXXEHIc6OsmTNgnASbIryV9NA/Cq+mR3H9XdR2XyHX1rktOS/NJi\nywJYDCPBwKp7bSajvk/p7vVHYN6Y5OKq6kyC8V2SXF9VZyd5ZSajoj+R5Lzu/uWqenqSH05y36r6\nTJK3J3lWd99UVX+e5OuT7KuqszIZBf69JL/a3S9Mkqr6V0nOT3K/JB9J8h+6+9en2yrJzyZ5ZJI7\nJ7kyyQ919x9v9mGq6sgkP5fkyZkMVLwhGwYsquqhSV6R5KQkRyb5/ekxr57nC5t+T1dV1XuTnDFz\n3LsmeVUmI+rHJflokpfNfJYfn27770nOTfLtSU7fuK6731dVz03ybzKZQrJ3+jle2N37qmpHkpcm\neXqS3dPtv5HkR1b8Fw1ghRgJBlZWVd09yWOT/NxMAP6C7v5wd7+yu6+fWf2PMgmP907yhqp6eJLX\nJ3lBkmOTPDrJd2YSatPdD07y/iS/Nh1J/eiGGh6X5HVJnp1JcHx+kl+pqkdPd3lLkk9nMlJ9fCYh\n+a0H+FjPyyQAPy6TEe2PZBI218+3O5N5y3+Q5Gumf/4uyW/POeKdqto5/dzfOf3s634qyaOm389x\nSS6cfpYTZ/a5byYDKLsz+WXgy9ZV1ZMz+SXjX3T3XafneVYmI/NJ8tQkz0hyRncfneSbkzw+yffP\nUz/AVjASDKyy+yfZkaRvw3uOziQ0fyZJqupDSU7o7r+Zbv+rqnp/kn865/F+IMm7u/uS6fI7pyPG\na9Plb0ry+e6+aXq+30jy9Ko6fuacs747yRu7+0PT5f9YVf92ZvvTktzc3T82Xb6pqn4oyacyGZX9\n3f3Uea+q+uz09c4kRyT51UwC/LrnJjmqu6+b1vorSX4hycOT/OV0n12ZjHTfPN1ns3UXZfKdfipJ\nuvuKqvqzTL7TX0rylUluTXLTdPvVVfXAzX6RAdguQjCwytZD05f8W1ZVV+aLF68dkcl/6b90ZpcP\nbzjGOVX1tCT3yOSiseOS/M85azgxyXtmV3T322cWvynJi6vqwUmOyhf/B+6o/RzvPpmM/s768yRf\nPX39wCTHzwTadbdmMiK7P5/s7nsnyXQ6wr2SvCTJn1TVw6fB92uSvKKqHpXJqPj69ztb66fWQ/IB\n1h2Z5CVV9R2ZjA4nk6kgfzF9/WtJnpLkmqr6QCZ323hjJtMvAA4J0yGAVdaZhNaHfMnK7ofOXAT2\nwXz5v3Wfm3n9/EymIPxgknt09/GZzAme1y2bHD9JUlUPSPKOTKYufN20nm87yPGOzCTQzpo9/k1J\n/nT98838uVN3/7d5Cu7ufd39iST/LpMw/NSq+opM7hZxbJJvzCT4HrfJ2z83x7rXZDIX+8lJ7jL9\n3F/4paK7r+vuM5M8LMm7kvzzJFdX1RPmqR9gKwjBwMqajj6+PcmPVNWd97Pbwf6de3SS93X3pdOL\nto5I8ojbUMbVmYzOfkFVfU9VPSaTubV3TvKT3f3p6eaDTbP4eJKv3bDuGzac7x9X1TEz59tRVfe7\nDTWv25fJdJK7ZDIK/nVJXtPd10ynJsw7JWSjU5L8Vnf/UXffMr3g7kEz9R5ZVcd09593989292lJ\n3pzJhXQAh4TpEMCq+8FMRnvfU1XnJ7kik2D3TzK5W8Ejk/zMAd7/10keN73I7ohM7lqwN8k9q2pn\nd3/+IOd/7fTcT0ryzkzm5f6XTC5sW5928aiquiSTUeDTpuvuk+SaTY73jiTfU1W/nOSvMplzfM8k\n6/OH3zSt8eer6tmZjAw/P8kzq+p+Gy4C3K+quluSFyX5+0wu1Pu/Sa5P8k1V9Y5MAvyzk9wwrfW2\n+HCSh1XVXZLcPclPZzLV4WumUzF+PpMg/73d/bGqWn8IyWa3pwPYFkaCgZXW3XsyuXDrj5L8ciZB\n7tOZ3JLr+iQP7u53HeAQP5HkE5mEtD9I8oEk5yW5W5I/neP8lyb5nkyC9vVJXp3knO5+f3dfPj3+\nLya5NpN78z5peo53V9VpmxzyBUkuTvK+JJ/M5LZrb5o53/VJviWT+bsfm+5zcpLHHiQA36uqPrv+\nJ8n/mR77jO7+6DTsf1+Ss5Jcl0lwfU4mF879aFU9/2DfxYwfzmQ6xdr0s7w+k/nH3zhdfm4mvwD8\nr6q6KckfJrk8k1vXARwSO/btczEuAABjMRIMAMBwhGAAAIYjBAMAMBwhGACA4RzyW6Strd3gSrwt\ntGvX0dm798ZFlwFfRm+yzPQny0pvbq3du4/Zsb9tRoJX3M6dRyy6BNiU3mSZ6U+Wld48dIRgAACG\nIwQDADAcIRgAgOEIwQAADEcIBgBgOEIwAADDEYIBABiOEAwAwHCEYAAAhiMEAwAwHCEYAIDh7Jxn\np6q6IMnJSfYlOa+7L5/Zdk2Sjye5ZbrqX3b3J7e2TABWwdXPOHvRJczl6kUXMKcH/NfXL7oEOGwd\nNARX1WlJTuzuU6rq65P8YpJTNuz2rd39me0oEPhS5176vEWXcFh5zRk/s+gSgEPgtS9/36JLOKz8\nwPmnL7qEO2ye6RBnJrkoSbr7qiS7qurYba0KAAC20TzTIY5PcsXM8tp03fUz636hqu6b5ANJnt/d\n+/Z3sF27js7OnUfcjlLZn927j1l0CbCy/PxsrVWZZrAq9CfL6nDozbnmBG+wY8Pyi5O8J8mnMxkx\nfnKSt+zvzXv33ng7Tsn+7N59TNbWblh0GbCy/PywzPQny2pVevNAYX2eELwnk5HfdSckuXZ9obvf\nsP66qi5O8g05QAgGAIBFm2dO8CVJzkqSqjopyZ7uvmG6fFxVvbeq7jzd97Qkf7YtlQIAwBY56Ehw\nd19WVVdU1WVJbk1yblWdneS67n7bdPT3D6vqpiR/EqPAAAAsubnmBHf3+RtWXTmz7dVJXr2VRQEA\nwHa6PRfGDeH7X37poks4rPzi+WcsugQAgC/w2GQAAIYjBAMAMBwhGACA4QjBAAAMRwgGAGA4QjAA\nAMMRggEAGI4QDADAcIRgAACGIwQDADAcIRgAgOEIwQAADEcIBgBgOEIwAADDEYIBABiOEAwAwHCE\nYAAAhiMEAwAwHCEYAIDhCMEAAAxHCAYAYDhCMAAAwxGCAQAYjhAMAMBwhGAAAIYjBAMAMBwhGACA\n4QjBAAAMRwgGAGA4QjAAAMMRggEAGI4QDADAcIRgAACGIwQDADAcIRgAgOEIwQAADEcIBgBgOEIw\nAADDEYIBABiOEAwAwHCEYAAAhrNznp2q6oIkJyfZl+S87r58k31+Kskp3X36llYIAABb7KAjwVV1\nWpITu/uUJOckuXCTfR6U5DFbXx4AAGy9eaZDnJnkoiTp7quS7KqqYzfs86okL9ji2gAAYFvMMx3i\n+CRXzCyvTdddnyRVdXaS30tyzTwn3LXr6OzcecRtKpLVt3v3MYsuATalN7fW1Ysu4DCjP1lWh0Nv\nzjUneIMd6y+q6m5Jvi/JY5Pca54379174+04Jatube2GRZcAm9KbLDP9ybJald48UFifZzrEnkxG\nftedkOTa6eszkuxO8vtJ3pbkpOlFdAAAsLTmCcGXJDkrSarqpCR7uvuGJOnut3T3g7r75CRPTPLH\n3f2sbasWAAC2wEFDcHdfluSKqroskztDnFtVZ1fVE7e9OgAA2AZzzQnu7vM3rLpyk32uSXL6HS8J\nAAC2lyfGAQAwHCEYAIDhCMEAAAxHCAYAYDhCMAAAwxGCAQAYjhAMAMBwhGAAAIYjBAMAMBwhGACA\n4QjBAAAMRwgGAGA4QjAAAMMRggEAGI4QDADAcIRgAACGIwQDADAcIRgAgOEIwQAADEcIBgBgOEIw\nAADDEYIBABiOEAwAwHCEYAAAhiMEAwAwHCEYAIDhCMEAAAxHCAYAYDhCMAAAwxGCAQAYjhAMAMBw\nhGAAAIYjBAMAMBwhGACA4QjBAAAMRwgGAGA4QjAAAMMRggEAGI4QDADAcIRgAACGIwQDADAcIRgA\ngOHsnGenqrogyclJ9iU5r7svn9n2r5Ock+SWJFcmObe7921DrQAAsCUOOhJcVaclObG7T8kk7F44\ns+3oJN+d5NHdfWqSByY5ZZtqBQCALTHPdIgzk1yUJN19VZJdVXXsdPnG7j6zu/9hGoiPS/I321Yt\nAABsgXlC8PFJ1maW16brvqCqzk/y4SRv7u6/3rryAABg6801J3iDHRtXdPfLq+rVSS6uqg909wf3\n9+Zdu47Ozp1H3I7Tssp27z5m0SXApvTm1rp60QUcZvQny+pw6M15QvCefOnI7wlJrk2Sqrpbkod0\n9/u7+6aqeneSU5PsNwTv3XvjHSiXVbW2dsOiS4BN6U2Wmf5kWa1Kbx4orM8zHeKSJGclSVWdlGRP\nd69/8jsleX1V3XW6/MgkfftLBQCA7XfQkeDuvqyqrqiqy5LcmuTcqjo7yXXd/baqemmS/1FVn8/k\nFmnv2NaKAQDgDpprTnB3n79h1ZUz216f5PVbVxIAAGwvT4wDAGA4QjAAAMMRggEAGI4QDADAcIRg\nAACGIwQDADAcIRgAgOEIwQAADEcIBgBgOEIwAADDEYIBABiOEAwAwHCEYAAAhiMEAwAwHCEYAIDh\nCMEAAAxHCAYAYDhCMAAAwxGCAQAYjhAMAMBwhGAAAIYjBAMAMBwhGACA4QjBAAAMRwgGAGA4QjAA\nAMMRggEAGI4QDADAcIRgAACGIwQDADAcIRgAgOEIwQAADEcIBgBgOEIwAADDEYIBABiOEAwAwHCE\nYAAAhiMEAwAwHCEYAIDhCMEAAAxHCAYAYDhCMAAAwxGCAQAYzs55dqqqC5KcnGRfkvO6+/KZbd+c\n5KeS3JKkkzyju2/dhloBAGBLHHQkuKpOS3Jid5+S5JwkF27Y5XVJzuruU5Mck+RbtrxKAADYQvNM\nhzgzyUVJ0t1XJdlVVcfObH94d39i+notyVdtbYkAALC15pkOcXySK2aW16brrk+S7r4+Sarqnkke\nl+RFBzrYrl1HZ+fOI25Xsayu3buPWXQJsCm9ubWuXnQBhxn9ybI6HHpzrjnBG+zYuKKq7pHknUme\n2d2fOtCb9+698XacklW3tnbDokuATelNlpn+ZFmtSm8eKKzPE4L3ZDLyu+6EJNeuL0ynRrw7yQu6\n+5LbWSMAABwy88wJviTJWUlSVScl2dPds/H/VUku6O73bEN9AACw5Q46Etzdl1XVFVV1WZJbk5xb\nVWcnuS7Je5M8PcmJVfWM6Vve1N2v266CAQDgjpprTnB3n79h1ZUzr4/cunIAAGD7eWIcAADDEYIB\nABiOEAwAwHCEYAAAhiMEAwAwHCEYAIDhCMEAAAxHCAYAYDhCMAAAwxGCAQAYjhAMAMBwhGAAAIYj\nBAMAMBwhGACA4QjBAAAMRwgGAGA4QjAAAMMRggEAGI4QDADAcIRgAACGIwQDADAcIRgAgOEIwQAA\nDEcIBgBgOEIwAADDEYIBABiOEAwAwHCEYAAAhiMEAwAwHCEYAIDhCMEAAAxHCAYAYDhCMAAAwxGC\nAQAYjhAMAMBwhGAAAIYjBAMAMBwhGACA4QjBAAAMRwgGAGA4QjAAAMMRggEAGM7OeXaqqguSnJxk\nX5LzuvvymW1HJfnPSR7c3Y/YlioBAGALHXQkuKpOS3Jid5+S5JwkF27Y5RVJPrQNtQEAwLaYZzrE\nmUkuSpLuvirJrqo6dmb7jyZ52zbUBgAA22Ke6RDHJ7liZnltuu76JOnuG6rqq+Y94a5dR2fnziNu\nU5Gsvt27j1l0CbApvbm1rl50AYcZ/cmyOhx6c645wRvsuCMn3Lv3xjvydlbU2toNiy4BNqU3WWb6\nk2W1Kr15oLA+z3SIPZmM/K47Icm1d7AmAABYmHlC8CVJzkqSqjopyZ7uXo34DwAAmzhoCO7uy5Jc\nUVWXZXJniHOr6uyqemKSVNVvJvn1yct6X1U9bVsrBgCAO2iuOcHdff6GVVfObHvKllYEAADbzBPj\nAAAYjhAMAMBwhGAAAIYjBAMAMBwhGACA4QjBAAAMRwgGAGA4QjAAAMMRggEAGI4QDADAcIRgAACG\nIwQDADAcIRgAgOEIwQAADEcIBgBgOEIwAADDEYIBABiOEAwAwHCEYAAAhiMEAwAwHCEYAIDhCMEA\nAAxHCAYAYDhCMAAAwxGCAQAYjhAMAMBwhGAAAIYjBAMAMBwhGACA4QjBAAAMRwgGAGA4QjAAAMMR\nggEAGI4QDADAcIRgAACGIwQDADAcIRgAgOEIwQAADEcIBgBgOEIwAADDEYIBABiOEAwAwHB2zrNT\nVV2Q5OQk+5Kc192Xz2x7bJKfTHJLkou7+2XbUSgAAGyVg44EV9VpSU7s7lOSnJPkwg27XJjkyUlO\nTfK4qnrQllcJAABbaJ7pEGcmuShJuvuqJLuq6tgkqaqvS/Lp7v54d9+a5OLp/gAAsLTmmQ5xfJIr\nZpbXpuuun/69NrPt75Lc/0AH2737mB23scaFeOervmPRJcCm3vzU1y66BNiv3W//rUWXAJt68au+\nbdElsGRuz4VxBwqxKxFwAQAY2zwheE8mI77rTkhy7X623Wu6DgAAltY8IfiSJGclSVWdlGRPd9+Q\nJN19TZJjq+q+VbUzyROm+wMAwNLasW/fvoPuVFUvT/KYJLcmOTfJw5Jc191vq6rHJPnp6a6/1d2v\n3K5iAQBgK8wVggEA4HDiiXEAAAxHCAYAYDhCMAAAwxGCAQAYjhB8mKiqr1x0DVBVX/bAnKq69yJq\ngQOpqrsvugbYTFWdsegaRjHPY5NZDW9N4geHhaiqJyb5uSRHV9XFSf79+v3Ek7whepMFqqrHJ/nZ\nJB9P8kNJ3phkZ1XdJckzu/viRdbHuKrq6RtW7Ujywqp6WZJ09xsOfVXjEIJXSFU9cz+bdmTytD5Y\nlPMzuX/4/0vyjCSXVNW3dPd18Th1Fu+FSf5ZkvskeVeS7+juK6vqq5O8M4kQzKK8OMmnkvx2vvhv\n5VFJ7rewigYiBK+WZyf5nXzxsdWz7nSIa4FZt3T3p6evX1dVf5vkvVX1hCRuRs6i3dzdH0vysar6\nZHdfmSTd/bdV9dkF18bYHpLkRUkemuTZ3f3R6QDCSxZc1xCE4NXynUkuTHJed988u6GqTl9IRTDx\ngap6V5KndPdN3f32abj43SRfteDa4G+r6rnd/cruPjX5wlz152QyRQIWors/m+QFVVVJXlNVl8X1\nWoeML3qFdPefJXlCkn/YZPNzkqSqjjykRUGS7n5eklcm+ezMuvcmeXSSlyR6k4U6O8nHNqy7R5KP\nJjkn0Z8sVk88IZNfyj4yu01vbh+PTT7MVNWl3e0iJJaO3mSZ6U+Wld7cPkaCDz8uQmJZ6U2Wmf5k\nWenNbSIEH34M7bOs9CbLTH+yrPTmNhGCAQAYjhB8+PHfJiwrvcky058sK725TYTgFVRVDzvA5r84\nZIXABnqTZaY/WVZ6czHcHWIFVdWlSR7X3Z9fdC0wS2+yzPQny0pvLoaHZaymv0/yl1V1ZZLPra/s\n7u9aXEmQRG+y3PQny0pvLoAQvJpeucm64w95FfDl9CbLTH+yrPTmApgTvJo+mOSuSb52+ufEJD+5\n0IpgQm+yzPQny0pvLoCR4NX05iQ3JDk9yTuSfHOSH19gPbBOb7LM9CfLSm8ugJHg1bSru783yUe6\n+weTPCrJ4xdcEyR6k+WmP1lWenMBhODVdGRVfW2Sz1fVA5LcnKQWXBMkepPlpj9ZVnpzAUyHWCFV\n9awkv57kRUkekeRlSd6d5Ngkr1lgaQxOb7LM9CfLSm8ulhC8WnYneV+STyR5U5Lf6e77L7QimNCb\nLDP9ybLSmwvkYRkrqKpOSvJdSb49SWfyg/OO7r55oYUxPL3JMtOfLCu9uRhC8Iqrqocn+dEkj+3u\n4xZdD6zTmywz/cmy0puHjukQK6qqHpHkqUm+Lcn/TvK9i60IJvQmy0x/sqz05qFnJHiFVNXDMvkB\neVKSDyf5tSRv7e7PLLQwhqc3WWb6k2WlNxfLSPBqeU2SNyY5tbvXFl0MzNCbLDP9ybLSmwtkJBgA\ngOF4WAYAAMMRggEAGI4QDADAcIRgAACG8/8BFtw5kS0xrUoAAAAASUVORK5CYII=\n",
256 | "text/plain": [
257 | ""
258 | ]
259 | },
260 | "metadata": {
261 | "tags": []
262 | }
263 | }
264 | ]
265 | },
266 | {
267 | "metadata": {
268 | "id": "bj9toXrBNx2E",
269 | "colab_type": "text"
270 | },
271 | "cell_type": "markdown",
272 | "source": [
273 | "De momento no se explica muchos detalles del código, pero se muestra que se puede presentar los resultados de estimar un estadístico (la media) y una gráfica de las variables. Del mismo modo, se puede desarrollar código para hacer todo el proceso de limpieza, transformación e integración de datos, aplicar un modelo y evaluar su resultados.\n",
274 | "\n",
275 | "El entorno; las notebook de Jupyter, se ha vuelto un estandar de trabajo para analizar datos y hacer pruebas de modelos. Para conocer más al respecto se pueden consultar las siguientes referencias:\n",
276 | "\n",
277 | "* [Project Jupyter ](http://jupyter.org/)\n",
278 | "* [Colaboratory](https://colab.research.google.com/notebooks/welcome.ipynb#scrollTo=jPJ3JVUui_qQ)\n",
279 | "\n",
280 | "\n",
281 | "La versión de Python que se usará es la 3.6.7, para conocer más respecto al lenguaje la siguientes refencias pueden ser consultadas:\n",
282 | "\n",
283 | "* [https://www.python.org/](https://www.python.org/)\n",
284 | "* [Think Python: How to Think Like a Computer Scientist](http://www.greenteapress.com/thinkpython/html/index.html)\n",
285 | "* [https://www.py4e.com/](https://www.py4e.com/)\n",
286 | "* [Dive into Python](https://www.cmi.ac.in/~madhavan/courses/prog2-2012/docs/diveintopython3/index.html)"
287 | ]
288 | },
289 | {
290 | "metadata": {
291 | "id": "wHK7R_OhQwBo",
292 | "colab_type": "text"
293 | },
294 | "cell_type": "markdown",
295 | "source": [
296 | "*Las siguientes notas son un breve resumen de algunas de las características del leguaje Python, no son notas exhaustivas y se recomienda revisar las referencias para leer y aprender más respecto al tema. Prero ante todo se recomiendo hacer muchos programas para familiarizarse con la sintaxis y el lenguaje.*\n",
297 | "\n",
298 | "\n",
299 | "## Variables y expresiones\n",
300 | "\n",
301 | "El siguiente código define tipos de datos básicos. \n"
302 | ]
303 | },
304 | {
305 | "metadata": {
306 | "id": "3WetyIO2TrcL",
307 | "colab_type": "code",
308 | "outputId": "5af76489-c039-49bd-e19e-f912a35c0f2b",
309 | "colab": {
310 | "base_uri": "https://localhost:8080/",
311 | "height": 120
312 | }
313 | },
314 | "cell_type": "code",
315 | "source": [
316 | "Is_True=False #Booleana\n",
317 | "Entero_Num=12 #Entero\n",
318 | "Float_Num=12.1234 #Floatante\n",
319 | "Frac_Num=1/3 #Racional o Floatante\n",
320 | "Cadena=\"Variable No Numerica\"\n",
321 | "\n",
322 | "print(\"Diferentes Tipos de Variables:\")\n",
323 | "print(Is_True)\n",
324 | "print(Entero_Num)\n",
325 | "print(Float_Num)\n",
326 | "print(Frac_Num)\n",
327 | "print(Cadena)"
328 | ],
329 | "execution_count": 0,
330 | "outputs": [
331 | {
332 | "output_type": "stream",
333 | "text": [
334 | "Diferentes Tipos de Variables:\n",
335 | "False\n",
336 | "12\n",
337 | "12.1234\n",
338 | "0.3333333333333333\n",
339 | "Variable No Numerica\n"
340 | ],
341 | "name": "stdout"
342 | }
343 | ]
344 | },
345 | {
346 | "metadata": {
347 | "id": "RMVnX_GL3tjA",
348 | "colab_type": "text"
349 | },
350 | "cell_type": "markdown",
351 | "source": [
352 | "Los anteriores son los tipos de datos, en orden:\n",
353 | " * Booleans(True/False)\n",
354 | " * Númericas(12,12.1234,1/3)\n",
355 | " * String o Cadenas\n",
356 | " \n",
357 | " *¿Existen otros tipo de datos?* **Si!**\n",
358 | " \n",
359 | "Entre los otros tipos de datos que se pueden encontrar son: bytes arrays, listas, tuplas, diccionarios, conjuntos y números complejos. También se pueden considerar como colecciones de datos. En otras secciones se revisan algunos aspectos de algunos de las colecciones de datos.\n",
360 | " \n",
361 | "En el código se muestra un patrón, se toma un nombre (puede ser una sola letra) y seguido del signo \"=\" se asigna un valor o tipo de dato. Por ejemplo:\n",
362 | " \n",
363 | " ~~~python\n",
364 | "Is_True=True\n",
365 | "~~~\n",
366 | "\n",
367 | "En este caso la variable es *Is_True* y es de tipo Booleans. Así que toda variable tiene un nombre y le es asignado un tipo de dato.\n",
368 | "\n",
369 | "¿Se puede usar cualquier nombre para una variables? **No!**\n",
370 | "\n",
371 | "El siguiente código muestra el tipo de variable de *Is_True* y se definen nuevas variables:\n",
372 | "\n",
373 | " "
374 | ]
375 | },
376 | {
377 | "metadata": {
378 | "id": "r1m9i7RSi9rx",
379 | "colab_type": "code",
380 | "outputId": "c3f990b0-74f6-44dd-a67c-730d75f42677",
381 | "colab": {
382 | "base_uri": "https://localhost:8080/",
383 | "height": 34
384 | }
385 | },
386 | "cell_type": "code",
387 | "source": [
388 | "#Revisamos el tipo de dato con la funcion type()\n",
389 | "type(Is_True)"
390 | ],
391 | "execution_count": 0,
392 | "outputs": [
393 | {
394 | "output_type": "execute_result",
395 | "data": {
396 | "text/plain": [
397 | "bool"
398 | ]
399 | },
400 | "metadata": {
401 | "tags": []
402 | },
403 | "execution_count": 9
404 | }
405 | ]
406 | },
407 | {
408 | "metadata": {
409 | "id": "dBHa2kB37sYL",
410 | "colab_type": "code",
411 | "outputId": "0f97f519-9e2f-4b99-aa23-cd36a12610fe",
412 | "colab": {
413 | "base_uri": "https://localhost:8080/",
414 | "height": 163
415 | }
416 | },
417 | "cell_type": "code",
418 | "source": [
419 | "#Tratamos de definir la nueva variable Is_True@\n",
420 | "Is_True@=False"
421 | ],
422 | "execution_count": 0,
423 | "outputs": [
424 | {
425 | "output_type": "error",
426 | "ename": "TypeError",
427 | "evalue": "ignored",
428 | "traceback": [
429 | "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
430 | "\u001b[0;31mTypeError\u001b[0m Traceback (most recent call last)",
431 | "\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[0;32m----> 1\u001b[0;31m \u001b[0mIs_True\u001b[0m\u001b[0;34m@=\u001b[0m\u001b[0;32mFalse\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
432 | "\u001b[0;31mTypeError\u001b[0m: unsupported operand type(s) for @=: 'bool' and 'bool'"
433 | ]
434 | }
435 | ]
436 | },
437 | {
438 | "metadata": {
439 | "id": "Pnn0a4v67pE7",
440 | "colab_type": "code",
441 | "outputId": "72b4e0e2-0485-41cb-d946-5e4ebdc1761d",
442 | "colab": {
443 | "base_uri": "https://localhost:8080/",
444 | "height": 130
445 | }
446 | },
447 | "cell_type": "code",
448 | "source": [
449 | "#Tratamos de defiir la variable def\n",
450 | "def=2"
451 | ],
452 | "execution_count": 0,
453 | "outputs": [
454 | {
455 | "output_type": "error",
456 | "ename": "SyntaxError",
457 | "evalue": "ignored",
458 | "traceback": [
459 | "\u001b[0;36m File \u001b[0;32m\"\"\u001b[0;36m, line \u001b[0;32m1\u001b[0m\n\u001b[0;31m def=2\u001b[0m\n\u001b[0m ^\u001b[0m\n\u001b[0;31mSyntaxError\u001b[0m\u001b[0;31m:\u001b[0m invalid syntax\n"
460 | ]
461 | }
462 | ]
463 | },
464 | {
465 | "metadata": {
466 | "id": "QORowjEA70NQ",
467 | "colab_type": "text"
468 | },
469 | "cell_type": "markdown",
470 | "source": [
471 | "Las anteriores líneas de código muestran que usando la funcione *type()* se puede conocer el tipo de dato. En otra se observa que no se puede usar *@* en nombre y *def* tampoco. \n",
472 | "\n",
473 | "Con los últimos dos ejemplo se muestra que hay un mínimo de requisitos para ser una variable, por otro lado también exiten alguna palabras que son reservadas por el lenguaje y no se pueden usar , como *def*; para definir una variable. \n",
474 | "\n",
475 | "La lista de palabras reservadas es la siguiente:\n",
476 | "\n",
477 | "~~~python \n",
478 | "and del from None True\n",
479 | "as elif global nonlocal try\n",
480 | "assert else if not while\n",
481 | "break except import or with\n",
482 | "class False in pass yield\n",
483 | "continue finally is raise\n",
484 | "def for lambda return\n",
485 | "~~~\n",
486 | "\n",
487 | "Otros símbolos reservados son : *+,-,\\**,/,%,//.*\n",
488 | "\n",
489 | "Los cuales representan las operaciones que se pueden hacer, son los *operadores*. Una combinación de valores, variables y operadores forma una *expresion*, por ejemplo:\n",
490 | "\n",
491 | "~~~python\n",
492 | "\n",
493 | "x=127\n",
494 | "y=34\n",
495 | "#Se escribe una expresión con x & y\n",
496 | "x+y+(x*y)+(x**3)+10\n",
497 | "~~~\n",
498 | "\n",
499 | "¿Existe un orden entre las operaciones?"
500 | ]
501 | },
502 | {
503 | "metadata": {
504 | "id": "TA7tCdyRNg47",
505 | "colab_type": "code",
506 | "outputId": "4196e48e-81ac-4a40-fe98-2effb1268f27",
507 | "colab": {
508 | "base_uri": "https://localhost:8080/",
509 | "height": 34
510 | }
511 | },
512 | "cell_type": "code",
513 | "source": [
514 | "#Operacion módulo\n",
515 | "5%3"
516 | ],
517 | "execution_count": 0,
518 | "outputs": [
519 | {
520 | "output_type": "execute_result",
521 | "data": {
522 | "text/plain": [
523 | "2"
524 | ]
525 | },
526 | "metadata": {
527 | "tags": []
528 | },
529 | "execution_count": 16
530 | }
531 | ]
532 | },
533 | {
534 | "metadata": {
535 | "id": "XbA0JgWa7yii",
536 | "colab_type": "code",
537 | "outputId": "adebf338-5994-414c-cf66-5d2d5fe40010",
538 | "colab": {
539 | "base_uri": "https://localhost:8080/",
540 | "height": 51
541 | }
542 | },
543 | "cell_type": "code",
544 | "source": [
545 | "#Ejemplo de ejecución con diferente orden\n",
546 | "x=1\n",
547 | "y=3\n",
548 | "\n",
549 | "print(x-y+2)\n",
550 | "print(x-(y+2))"
551 | ],
552 | "execution_count": 0,
553 | "outputs": [
554 | {
555 | "output_type": "stream",
556 | "text": [
557 | "0\n",
558 | "-4\n"
559 | ],
560 | "name": "stdout"
561 | }
562 | ]
563 | },
564 | {
565 | "metadata": {
566 | "id": "E-9X-RnRzirZ",
567 | "colab_type": "code",
568 | "colab": {}
569 | },
570 | "cell_type": "code",
571 | "source": [
572 | ""
573 | ],
574 | "execution_count": 0,
575 | "outputs": []
576 | },
577 | {
578 | "metadata": {
579 | "id": "nhuIrw6B_e6B",
580 | "colab_type": "text"
581 | },
582 | "cell_type": "markdown",
583 | "source": [
584 | "El orden de las operaciones respetan cierto orden, el acrónimo del orden de prioridad es **PEMDAS**. El significado es:\n",
585 | "\n",
586 | "* Paréntesis, Exponenciales, Multiplicación, División, Addición y Sustracción = PEMDAS\n",
587 | "\n",
588 | "\n",
589 | "### String\n",
590 | "\n",
591 | "Los datos que son considerados cadenas se delimitan por comillas.\n",
592 | "\n",
593 | "~~~python\n",
594 | "x='Variable'\n",
595 | "y=\"variable\"\n",
596 | "~~~"
597 | ]
598 | },
599 | {
600 | "metadata": {
601 | "id": "k1LLAzv_9tqL",
602 | "colab_type": "code",
603 | "outputId": "e4b7fc5b-3bfa-4f18-b748-ec32061c9748",
604 | "colab": {
605 | "base_uri": "https://localhost:8080/",
606 | "height": 86
607 | }
608 | },
609 | "cell_type": "code",
610 | "source": [
611 | "#Definición de Variables con valores String\n",
612 | "x='Variable'\n",
613 | "y=\"variable\"\n",
614 | "\n",
615 | "print(x)\n",
616 | "print(y)\n",
617 | "\n",
618 | "print(x+' '+y)\n",
619 | "print(x*3)\n"
620 | ],
621 | "execution_count": 0,
622 | "outputs": [
623 | {
624 | "output_type": "stream",
625 | "text": [
626 | "Variable\n",
627 | "variable\n",
628 | "Variable variable\n",
629 | "VariableVariableVariable\n"
630 | ],
631 | "name": "stdout"
632 | }
633 | ]
634 | },
635 | {
636 | "metadata": {
637 | "id": "din2ecsACPxE",
638 | "colab_type": "text"
639 | },
640 | "cell_type": "markdown",
641 | "source": [
642 | "El código anterior muestra dos operaciones con cadenas, la suma y la multiplicación por un entero. \n",
643 | "\n",
644 | "Nota: Existen *métodos* para trabajar con las cadenas, estas son acciones que se pueden hacer o ejecutar sobre una cadena. Se veran ejemplos más adelante.\n",
645 | "\n",
646 | " \n",
647 | "### Comentarios y Debugging\n",
648 | "\n",
649 | "Ejecutamos el siguiente código:"
650 | ]
651 | },
652 | {
653 | "metadata": {
654 | "id": "BT72fg7YCL2m",
655 | "colab_type": "code",
656 | "outputId": "887c2fc7-ad70-4e8d-b2a9-deeb940d9d6a",
657 | "colab": {
658 | "base_uri": "https://localhost:8080/",
659 | "height": 199
660 | }
661 | },
662 | "cell_type": "code",
663 | "source": [
664 | "#Definimos dos cadenas\n",
665 | "x=\"Var_1\"\n",
666 | "y=\"Var_2\"\n",
667 | "\n",
668 | "#Tratamos de hacer el producto de las cadenas\n",
669 | "\n",
670 | "print(x*y)"
671 | ],
672 | "execution_count": 0,
673 | "outputs": [
674 | {
675 | "output_type": "error",
676 | "ename": "TypeError",
677 | "evalue": "ignored",
678 | "traceback": [
679 | "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
680 | "\u001b[0;31mTypeError\u001b[0m Traceback (most recent call last)",
681 | "\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[1;32m 4\u001b[0m \u001b[0;31m#Tratamos de hacer el producto de las cadenas\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 5\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 6\u001b[0;31m \u001b[0mprint\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mx\u001b[0m\u001b[0;34m*\u001b[0m\u001b[0my\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
682 | "\u001b[0;31mTypeError\u001b[0m: can't multiply sequence by non-int of type 'str'"
683 | ]
684 | }
685 | ]
686 | },
687 | {
688 | "metadata": {
689 | "id": "MvoIV_iKEL6n",
690 | "colab_type": "text"
691 | },
692 | "cell_type": "markdown",
693 | "source": [
694 | "El código anterior nos muestra que para poner comentarios en el código basta hacer uso de **\"#\"**. Además, se observa que no se puede multiplicar un par de cadenas. Se tiene un error(TypeError) y python nos indica lo siguiente:\n",
695 | "\n",
696 | "~~~python\n",
697 | "\n",
698 | "----> 6 print(x*y)\n",
699 | "\n",
700 | "TypeError: can't multiply sequence by non-int of type 'str'\n",
701 | " \n",
702 | " ~~~\n",
703 | " \n",
704 | " Lo anterior nos indica la línea donde se produce el error y nos regresa el tipo de problema que detecta Python.\n",
705 | " \n",
706 | " Referencias:\n",
707 | " \n",
708 | " * [Capítulo 2 :Variables, Dr. Charles Russell Severance ](https://www.py4e.com/lessons/memory)\n",
709 | " * [Capítulo 2:Variables,Allen B. Downey](http://www.greenteapress.com/thinkpython/html/thinkpython003.html)\n",
710 | " * [Capítulo 2,Mark Pilgrim](https://www.cmi.ac.in/~madhavan/courses/prog2-2012/docs/diveintopython3/native-datatypes.html)"
711 | ]
712 | },
713 | {
714 | "metadata": {
715 | "id": "lzSnLnkTFemD",
716 | "colab_type": "text"
717 | },
718 | "cell_type": "markdown",
719 | "source": [
720 | "\n",
721 | "## Condicionales\n",
722 | "\n",
723 | "Las expresiones son combinación de valores, variables y operaciones. Pero no necesariamente solo se escriben expresiones numéricas, también se pueden escribir expresiones lógicas y operar sobre ellas. Ejemplo el siguiente código:"
724 | ]
725 | },
726 | {
727 | "metadata": {
728 | "id": "-7Np0KQKG0QD",
729 | "colab_type": "code",
730 | "outputId": "6f7d3334-1a6a-4a73-9d2b-e9121a1b501b",
731 | "colab": {
732 | "base_uri": "https://localhost:8080/",
733 | "height": 34
734 | }
735 | },
736 | "cell_type": "code",
737 | "source": [
738 | "#Expresion 1\n",
739 | "5==5"
740 | ],
741 | "execution_count": 0,
742 | "outputs": [
743 | {
744 | "output_type": "execute_result",
745 | "data": {
746 | "text/plain": [
747 | "True"
748 | ]
749 | },
750 | "metadata": {
751 | "tags": []
752 | },
753 | "execution_count": 7
754 | }
755 | ]
756 | },
757 | {
758 | "metadata": {
759 | "id": "i5XgKgzOHdFX",
760 | "colab_type": "code",
761 | "outputId": "135b808e-9d90-4de1-a937-a1f1a879e329",
762 | "colab": {
763 | "base_uri": "https://localhost:8080/",
764 | "height": 34
765 | }
766 | },
767 | "cell_type": "code",
768 | "source": [
769 | "#Expresion 2\n",
770 | "5==6\n"
771 | ],
772 | "execution_count": 0,
773 | "outputs": [
774 | {
775 | "output_type": "execute_result",
776 | "data": {
777 | "text/plain": [
778 | "False"
779 | ]
780 | },
781 | "metadata": {
782 | "tags": []
783 | },
784 | "execution_count": 8
785 | }
786 | ]
787 | },
788 | {
789 | "metadata": {
790 | "id": "nDngfVROHgHf",
791 | "colab_type": "code",
792 | "outputId": "54719173-8ec2-43bd-a83f-69ff7f62fb0a",
793 | "colab": {
794 | "base_uri": "https://localhost:8080/",
795 | "height": 34
796 | }
797 | },
798 | "cell_type": "code",
799 | "source": [
800 | "#Se observa qué tipo de valor es True\n",
801 | "type(\"True\")\n"
802 | ],
803 | "execution_count": 0,
804 | "outputs": [
805 | {
806 | "output_type": "execute_result",
807 | "data": {
808 | "text/plain": [
809 | "bool"
810 | ]
811 | },
812 | "metadata": {
813 | "tags": []
814 | },
815 | "execution_count": 10
816 | }
817 | ]
818 | },
819 | {
820 | "metadata": {
821 | "id": "NJNycf2AHVRX",
822 | "colab_type": "text"
823 | },
824 | "cell_type": "markdown",
825 | "source": [
826 | "Expresiones Booleanas cuentan con sus operaciones de comparación, ejemplos :\n",
827 | "\n",
828 | "~~~python\n",
829 | "x != y # x no es igual a y\n",
830 | "x > y # x es mas grande que y\n",
831 | "x < y # x es menos grande que y\n",
832 | "x >= y # x es mayor o igual a y\n",
833 | "x <= y # x es menor o igual a y\n",
834 | "x is y # x es lo mismo a y\n",
835 | "x is not y # x no es lo mismo a y\n",
836 | "~~~\n",
837 | "\n",
838 | "Existen 3 operaciones lógicas:\n",
839 | "~~~python \n",
840 | "and, or, not\n",
841 | "~~~\n",
842 | "Su definición es la misma que tiene como palabra en ingles."
843 | ]
844 | },
845 | {
846 | "metadata": {
847 | "id": "0-X2zblvEJsU",
848 | "colab_type": "code",
849 | "outputId": "11df9ee3-dffa-41c0-a001-c9c83a491c82",
850 | "colab": {
851 | "base_uri": "https://localhost:8080/",
852 | "height": 34
853 | }
854 | },
855 | "cell_type": "code",
856 | "source": [
857 | "x=5\n",
858 | "\n",
859 | "print(x>4 and x<10)"
860 | ],
861 | "execution_count": 0,
862 | "outputs": [
863 | {
864 | "output_type": "stream",
865 | "text": [
866 | "True\n"
867 | ],
868 | "name": "stdout"
869 | }
870 | ]
871 | },
872 | {
873 | "metadata": {
874 | "id": "OCcTOOQzJl0k",
875 | "colab_type": "text"
876 | },
877 | "cell_type": "markdown",
878 | "source": [
879 | "Por *condicionales* se debe de entender como las partes del programa donde los pasos a seguir dependen de sí se cumplen o no ciertas condiciones lógicas o booleanas. Los siguientes códigos son ejemplos:"
880 | ]
881 | },
882 | {
883 | "metadata": {
884 | "id": "5_hXtdvLJka5",
885 | "colab_type": "code",
886 | "outputId": "2fbda86d-8297-4502-f0da-dd75dd1c0236",
887 | "colab": {
888 | "base_uri": "https://localhost:8080/",
889 | "height": 68
890 | }
891 | },
892 | "cell_type": "code",
893 | "source": [
894 | "#Se define x\n",
895 | "\n",
896 | "x=5\n",
897 | "\n",
898 | "#Primera condicional\n",
899 | "if x > 0 :\n",
900 | " print('x es positivo')\n",
901 | " \n",
902 | "#Segundo condicional\n",
903 | "\n",
904 | "if x> 0 :\n",
905 | " print('x es positivo')\n",
906 | "else :\n",
907 | " print('x no es positivo')\n",
908 | " \n",
909 | "#Tercer condicional\n",
910 | "\n",
911 | "if x > 0:\n",
912 | " print('x es mayor a cero')\n",
913 | "elif x < 0:\n",
914 | " print('x es menor a cero')\n",
915 | "else:\n",
916 | " print('x es igual a cero')"
917 | ],
918 | "execution_count": 0,
919 | "outputs": [
920 | {
921 | "output_type": "stream",
922 | "text": [
923 | "x es positivo\n",
924 | "x es positivo\n",
925 | "x es mayor a cero\n"
926 | ],
927 | "name": "stdout"
928 | }
929 | ]
930 | },
931 | {
932 | "metadata": {
933 | "id": "AkJIQNm2LQ48",
934 | "colab_type": "text"
935 | },
936 | "cell_type": "markdown",
937 | "source": [
938 | "Los 3 ejemplos muestran los condicionales básicos en Python. En el primer caso solo se hace la comparación y se imprime un mensaje. Para las otras dos se hace uso de condiciones y se valida el cumplimiento o no de la condición.\n",
939 | "\n",
940 | "¿Se pueden hacer condicionales más complejos o anidados? **Si!**"
941 | ]
942 | },
943 | {
944 | "metadata": {
945 | "id": "WDMGmdzPLNBE",
946 | "colab_type": "code",
947 | "colab": {}
948 | },
949 | "cell_type": "code",
950 | "source": [
951 | "#Se definen las variables\n",
952 | "x=5\n",
953 | "y=10\n",
954 | "\n",
955 | "if x == y:\n",
956 | " print('Son iguales')\n",
957 | "else:\n",
958 | " if x < y:\n",
959 | " print('x es menor que y')\n",
960 | " else:\n",
961 | " print('x es mayor que y')"
962 | ],
963 | "execution_count": 0,
964 | "outputs": []
965 | },
966 | {
967 | "metadata": {
968 | "id": "gOEYfFCfNI1u",
969 | "colab_type": "text"
970 | },
971 | "cell_type": "markdown",
972 | "source": [
973 | "Como se observa la contrucción de decisiones o condicionales se puede volver extensamente largos y seguidos de diferentes condiones y comparaciones.\n",
974 | "\n",
975 | "Para más detalles se puede consultar en las referencias:\n",
976 | "\n",
977 | "* [Capítulo 3 :Condicionales, Dr. Charles Russell Severance ](https://www.py4e.com/html3/03-conditional)\n",
978 | "* [Capítulo 5: Condicionales y recursividad](http://www.greenteapress.com/thinkpython/html/thinkpython006.html)\n"
979 | ]
980 | },
981 | {
982 | "metadata": {
983 | "id": "xmm5syztNZJg",
984 | "colab_type": "text"
985 | },
986 | "cell_type": "markdown",
987 | "source": [
988 | "\n",
989 | "## Funciones\n",
990 | "\n",
991 | "Similar con el concepto de funcion en matemáticas, las funciones en un lenguaje de programación definen una regla para asignar objetos de un conjunto a otro. Siendo posible que los conjuntos sean formados por tipos de datos de cualqueir tipo definido en el lenguaje.\n",
992 | "\n",
993 | "El siguiente código da unos ejemplos sencillos de funciones."
994 | ]
995 | },
996 | {
997 | "metadata": {
998 | "id": "UkI72KRhMDlq",
999 | "colab_type": "code",
1000 | "outputId": "23a0ce52-493e-4dcc-98fc-76ac415bfa18",
1001 | "colab": {
1002 | "base_uri": "https://localhost:8080/",
1003 | "height": 34
1004 | }
1005 | },
1006 | "cell_type": "code",
1007 | "source": [
1008 | "from math import sin,pi\n",
1009 | "\n",
1010 | "print(\"Valor de Seno de Pi:\",sin(pi))"
1011 | ],
1012 | "execution_count": 0,
1013 | "outputs": [
1014 | {
1015 | "output_type": "stream",
1016 | "text": [
1017 | "Valor de Seno de Pi: 1.2246467991473532e-16\n"
1018 | ],
1019 | "name": "stdout"
1020 | }
1021 | ]
1022 | },
1023 | {
1024 | "metadata": {
1025 | "id": "Ghy70kvbPW2L",
1026 | "colab_type": "text"
1027 | },
1028 | "cell_type": "markdown",
1029 | "source": [
1030 | "El código anterior hace uso de una función y una constante que está definida en Python. Como ejemplo se define una funcion y se ejecuta."
1031 | ]
1032 | },
1033 | {
1034 | "metadata": {
1035 | "id": "s0oPbjaUPMPL",
1036 | "colab_type": "code",
1037 | "outputId": "836b4300-d1d3-4dbc-e290-e6c0c0546e7f",
1038 | "colab": {
1039 | "base_uri": "https://localhost:8080/",
1040 | "height": 34
1041 | }
1042 | },
1043 | "cell_type": "code",
1044 | "source": [
1045 | "def Mul_de_Cadenas(Cadena,Num_Repeticiones):\n",
1046 | " if type(Cadena)==str and type(Num_Repeticiones)==int:\n",
1047 | " return Cadena*Num_Repeticiones\n",
1048 | " \n",
1049 | "Valor=Mul_de_Cadenas(\"Python\",2) \n",
1050 | "\n",
1051 | "print(Valor)"
1052 | ],
1053 | "execution_count": 0,
1054 | "outputs": [
1055 | {
1056 | "output_type": "stream",
1057 | "text": [
1058 | "PythonPython\n"
1059 | ],
1060 | "name": "stdout"
1061 | }
1062 | ]
1063 | },
1064 | {
1065 | "metadata": {
1066 | "id": "b0BoucXfP7OQ",
1067 | "colab_type": "code",
1068 | "outputId": "77cd5c4e-1554-4476-84df-4564b36a4b5e",
1069 | "colab": {
1070 | "base_uri": "https://localhost:8080/",
1071 | "height": 34
1072 | }
1073 | },
1074 | "cell_type": "code",
1075 | "source": [
1076 | "print(Mul_de_Cadenas(\"Python \",10))"
1077 | ],
1078 | "execution_count": 0,
1079 | "outputs": [
1080 | {
1081 | "output_type": "stream",
1082 | "text": [
1083 | "Python Python Python Python Python Python Python Python Python Python \n"
1084 | ],
1085 | "name": "stdout"
1086 | }
1087 | ]
1088 | },
1089 | {
1090 | "metadata": {
1091 | "id": "oa-dMvcKQkMs",
1092 | "colab_type": "text"
1093 | },
1094 | "cell_type": "markdown",
1095 | "source": [
1096 | "En general una función va contar un *nombre* y *parametros y/o argumentos*. El proceso o el contenido de la funcion es el cuerpo y concentra lo que deseamos que haga nuestra función."
1097 | ]
1098 | },
1099 | {
1100 | "metadata": {
1101 | "id": "ltLExx-ZQIyH",
1102 | "colab_type": "code",
1103 | "outputId": "11ab05a9-dbf8-47db-8cb8-bff44d214647",
1104 | "colab": {
1105 | "base_uri": "https://localhost:8080/",
1106 | "height": 34
1107 | }
1108 | },
1109 | "cell_type": "code",
1110 | "source": [
1111 | "#Podemos ver qué tipo de dato es para Python una funcion\n",
1112 | "type(Mul_de_Cadenas)"
1113 | ],
1114 | "execution_count": 0,
1115 | "outputs": [
1116 | {
1117 | "output_type": "execute_result",
1118 | "data": {
1119 | "text/plain": [
1120 | "function"
1121 | ]
1122 | },
1123 | "metadata": {
1124 | "tags": []
1125 | },
1126 | "execution_count": 19
1127 | }
1128 | ]
1129 | },
1130 | {
1131 | "metadata": {
1132 | "id": "b5Mn0qe_Q-tY",
1133 | "colab_type": "text"
1134 | },
1135 | "cell_type": "markdown",
1136 | "source": [
1137 | "Algunas razones para pensar en escribir funciones son las siguientes:\n",
1138 | " * Ayuda hacer más facil de leer y reparar un programa\n",
1139 | " * Ayuda a elimiar la repetición de código.\n",
1140 | " * Dividir el programa en funciones, permite tener már organizado el código.\n",
1141 | " * Un buen diseño de una función puede ayudar a desarrollar herramientas de uso general.\n",
1142 | " \n",
1143 | " \n",
1144 | "La siguiente función hace uso de un concepto fundamental en programación, ¿qué hace esta función?"
1145 | ]
1146 | },
1147 | {
1148 | "metadata": {
1149 | "id": "pGTDJRnUQ5kD",
1150 | "colab_type": "code",
1151 | "outputId": "30cc3e16-7461-4600-ee82-4546ca4795ca",
1152 | "colab": {
1153 | "base_uri": "https://localhost:8080/",
1154 | "height": 103
1155 | }
1156 | },
1157 | "cell_type": "code",
1158 | "source": [
1159 | "def print_n(s, n):\n",
1160 | " if n <= 0:\n",
1161 | " return\n",
1162 | " print(s)\n",
1163 | " print_n(s, n-1)\n",
1164 | " \n",
1165 | "print_n(10,5) \n"
1166 | ],
1167 | "execution_count": 0,
1168 | "outputs": [
1169 | {
1170 | "output_type": "stream",
1171 | "text": [
1172 | "10\n",
1173 | "10\n",
1174 | "10\n",
1175 | "10\n",
1176 | "10\n"
1177 | ],
1178 | "name": "stdout"
1179 | }
1180 | ]
1181 | },
1182 | {
1183 | "metadata": {
1184 | "id": "z2bKmBofSe4i",
1185 | "colab_type": "text"
1186 | },
1187 | "cell_type": "markdown",
1188 | "source": [
1189 | "La anterior función hace uso de **la recursividad**, esto es que la función hace uso de si misma para trabajar. En la definición de la funcion se pide a si misma hacer algo.\n",
1190 | "\n",
1191 | "Para conocer más detalles sobre funciones y recursividad se pueden consultar las referencias:\n",
1192 | "\n",
1193 | "* [Capítulo 5 :Funciones, Dr. Charles Russell Severance ](https://www.py4e.com/lessons/functions)\n",
1194 | "* [Capítulo 3:Funciones,Allen B. Downey](http://www.greenteapress.com/thinkpython/html/thinkpython004.html)\n",
1195 | "* \n",
1196 | "[Capítulo 6: Closures y Generadores](https://www.cmi.ac.in/~madhavan/courses/prog2-2012/docs/diveintopython3/generators.html#generators)\n",
1197 | "\n",
1198 | "Nota: Existen un tipo de funciones relevantes en el análisis de datos, las funciones anónimas o funciones lambda. Para saber respecto a ellas en Python se puede consultar la siguiente liga:\n",
1199 | "\n",
1200 | "* [Funciones Lambda](https://docs.python.org/3/tutorial/controlflow.html#lambda-expressions)"
1201 | ]
1202 | },
1203 | {
1204 | "metadata": {
1205 | "id": "e6DEbCp_UdyA",
1206 | "colab_type": "text"
1207 | },
1208 | "cell_type": "markdown",
1209 | "source": [
1210 | "\n",
1211 | "## Loops\n",
1212 | "\n",
1213 | "En el caso en que se desea hacer un test o prueba de una condicion lógica o numérica por cierta cantidad de veces se pueden usar Loops o ciclos. El siguiente código es un ejemplo:\n"
1214 | ]
1215 | },
1216 | {
1217 | "metadata": {
1218 | "id": "VcMa0Wt3WlIO",
1219 | "colab_type": "code",
1220 | "outputId": "2dac7dab-f4a9-40bb-8467-3a3955107427",
1221 | "colab": {
1222 | "base_uri": "https://localhost:8080/",
1223 | "height": 120
1224 | }
1225 | },
1226 | "cell_type": "code",
1227 | "source": [
1228 | "n = 5\n",
1229 | "while n > 0:\n",
1230 | " print(n)\n",
1231 | " n = n - 1\n",
1232 | "print('Blastoff!')"
1233 | ],
1234 | "execution_count": 0,
1235 | "outputs": [
1236 | {
1237 | "output_type": "stream",
1238 | "text": [
1239 | "5\n",
1240 | "4\n",
1241 | "3\n",
1242 | "2\n",
1243 | "1\n",
1244 | "Blastoff!\n"
1245 | ],
1246 | "name": "stdout"
1247 | }
1248 | ]
1249 | },
1250 | {
1251 | "metadata": {
1252 | "id": "2K9_oAgfUdhG",
1253 | "colab_type": "text"
1254 | },
1255 | "cell_type": "markdown",
1256 | "source": [
1257 | "Lo que se hace en el código anterios es validar si el valor de *n* satisface la condición y mientras sea cierta la condición se ejecutan las acciones seguidas. En otro caso, se puede ejecutar una acción sobre un conjunto o colección de objetos. El siguiente código es un ejemplo:"
1258 | ]
1259 | },
1260 | {
1261 | "metadata": {
1262 | "id": "vPfdVNe7W6py",
1263 | "colab_type": "code",
1264 | "outputId": "36f883ff-9a37-40b7-bf51-a5642bf98cc2",
1265 | "colab": {
1266 | "base_uri": "https://localhost:8080/",
1267 | "height": 86
1268 | }
1269 | },
1270 | "cell_type": "code",
1271 | "source": [
1272 | "friends = ['Joseph', 'Glenn', 'Sally']\n",
1273 | "for friend in friends:\n",
1274 | " print('Happy New Year:', friend)\n",
1275 | "print('Done!')"
1276 | ],
1277 | "execution_count": 0,
1278 | "outputs": [
1279 | {
1280 | "output_type": "stream",
1281 | "text": [
1282 | "Happy New Year: Joseph\n",
1283 | "Happy New Year: Glenn\n",
1284 | "Happy New Year: Sally\n",
1285 | "Done!\n"
1286 | ],
1287 | "name": "stdout"
1288 | }
1289 | ]
1290 | },
1291 | {
1292 | "metadata": {
1293 | "id": "81EguGuaXO5X",
1294 | "colab_type": "text"
1295 | },
1296 | "cell_type": "markdown",
1297 | "source": [
1298 | "En general los ciclos o loops se forman de 3 partes:\n",
1299 | "* Se inicializa una o más variables antes del ciclo\n",
1300 | "* Se valida el complimiento de la condición y se ejecuta el cuerpo del Loop\n",
1301 | "* Se visualiza el resultado de ejecutar el ciclo o loop completo.\n",
1302 | "\n",
1303 | "Para más detalles sobre Loops o cíclos, se pueden consultar las referencias:\n",
1304 | "\n",
1305 | "* [Capítulo 5: Interadores](https://www.py4e.com/html3/05-iterations)\n",
1306 | "* [Capítulo 7: Interadores](http://www.greenteapress.com/thinkpython/html/thinkpython008.html)\n"
1307 | ]
1308 | },
1309 | {
1310 | "metadata": {
1311 | "id": "H8Iuk-RcXwM8",
1312 | "colab_type": "text"
1313 | },
1314 | "cell_type": "markdown",
1315 | "source": [
1316 | "\n",
1317 | "## Colecciones Básicas\n",
1318 | "\n",
1319 | "Las colecciones en Python, igual que en cualquier otro lenguaje, son la parte fundamental para poder desarrollar algoritmos y programas elaborados y funcionales. Conocer sus operaciones y usos es fundamental.\n",
1320 | "\n",
1321 | "En Python los tipos de colecciones son: Listas, Diccionarios, Tuplas y Conjuntos."
1322 | ]
1323 | },
1324 | {
1325 | "metadata": {
1326 | "id": "xXosawG6UdOE",
1327 | "colab_type": "text"
1328 | },
1329 | "cell_type": "markdown",
1330 | "source": [
1331 | "\n",
1332 | "### Listas\n",
1333 | "\n",
1334 | "Una lista en Python es equivalente a un array, pero puede modificarse su tamaño y puede contener elementos de diferentes tipos de datos.\n",
1335 | "\n",
1336 | "\n"
1337 | ]
1338 | },
1339 | {
1340 | "metadata": {
1341 | "id": "6_kKdueeY0WQ",
1342 | "colab_type": "code",
1343 | "outputId": "5a8c50e3-7c9f-465e-8d59-c10a3cc30d9f",
1344 | "colab": {
1345 | "base_uri": "https://localhost:8080/",
1346 | "height": 103
1347 | }
1348 | },
1349 | "cell_type": "code",
1350 | "source": [
1351 | "xs = [3, 1, 2] # Se crea una lista\n",
1352 | "print(xs, xs[2]) # Se imprime \"[3, 1, 2] 2\"\n",
1353 | "print(xs[-1]) # Los indices negativos son posiciones desde el final de la lista; imprime \"2\"\n",
1354 | "xs[2] = 'foo' # Las listas pueden contener elementos de diferentes tipos de datos\n",
1355 | "print(xs) # Imprime \"[3, 1, 'foo']\"\n",
1356 | "xs.append('bar') # Agrega un nuevo elementos al final de la lista\n",
1357 | "print(xs) # Imprime \"[3, 1, 'foo', 'bar']\"\n",
1358 | "x = xs.pop() # Quita el último elemento de la lista\n",
1359 | "print(x, xs) "
1360 | ],
1361 | "execution_count": 0,
1362 | "outputs": [
1363 | {
1364 | "output_type": "stream",
1365 | "text": [
1366 | "[3, 1, 2] 2\n",
1367 | "2\n",
1368 | "[3, 1, 'foo']\n",
1369 | "[3, 1, 'foo', 'bar']\n",
1370 | "bar [3, 1, 'foo']\n"
1371 | ],
1372 | "name": "stdout"
1373 | }
1374 | ]
1375 | },
1376 | {
1377 | "metadata": {
1378 | "id": "W-sHl0vzCx0c",
1379 | "colab_type": "code",
1380 | "colab": {}
1381 | },
1382 | "cell_type": "code",
1383 | "source": [
1384 | "?xs.append"
1385 | ],
1386 | "execution_count": 0,
1387 | "outputs": []
1388 | },
1389 | {
1390 | "metadata": {
1391 | "id": "LvvKsN1DY2no",
1392 | "colab_type": "text"
1393 | },
1394 | "cell_type": "markdown",
1395 | "source": [
1396 | "La información sobre las listas en Python se encuentra [aquí](https://docs.python.org/3/tutorial/datastructures.html).\n",
1397 | "\n",
1398 | "**Nota:** Los arrays en si tienen aspectos diferetnes a las listas en cuanto al alojamiento en memoria, para los ejemplos arriba mencionados solo me refiero a su visualización en general no sobre su alojamiento en memoria. \n",
1399 | "\n",
1400 | "**Slicing:** seleccionar o acceder a elemetos de una listas. En python se tiene una sintaxis amigable para tomar sublistas o elementos.\n",
1401 | "\n",
1402 | "*Nota:* Las posiciones en Python inician en 0, no con el indice 1. Ejemplo comparado con Octave y R.\n",
1403 | "\n",
1404 | "``` bash\n",
1405 | "#En R\n",
1406 | "a=c(1,2,3)\n",
1407 | "a[1]\n",
1408 | "#Imprime 1\n",
1409 | "1\n",
1410 | "\n",
1411 | "#En Octave\n",
1412 | "a=[1 2 3]\n",
1413 | "a(1)\n",
1414 | "#Imprime\n",
1415 | "1\n",
1416 | "\n",
1417 | "#En Python\n",
1418 | "a=[1,2,3]\n",
1419 | "a[1]\n",
1420 | "#Imprime\n",
1421 | "2\n",
1422 | "```"
1423 | ]
1424 | },
1425 | {
1426 | "metadata": {
1427 | "id": "mxksh5dMSEV-",
1428 | "colab_type": "code",
1429 | "outputId": "9779dfb7-71d9-46c3-e2c0-3632f7dc2c65",
1430 | "colab": {
1431 | "base_uri": "https://localhost:8080/",
1432 | "height": 137
1433 | }
1434 | },
1435 | "cell_type": "code",
1436 | "source": [
1437 | "nums = list(range(5)) # Se crea una rango de enteros hasta antes del número 5 \n",
1438 | "print(nums) # Se imprime \"[0, 1, 2, 3, 4]\"\n",
1439 | "print(nums[2:4]) # Se eligen desde la posición 2 hasta antes del 4;se imprime \"[2, 3]\"\n",
1440 | "print(nums[2:]) # Se elige desde la posicion 2 hasta el final de la lista; se imprime \"[2, 3, 4]\"\n",
1441 | "print(nums[:2]) # Se elige hasta antes de la posición 2; se imprime \"[0, 1]\"\n",
1442 | "print(nums[:]) # Se elige toda la lista; se imprime [\"0, 1, 2, 3, 4]\"\n",
1443 | "print(nums[:-1]) # Se elige hasta antes de la última posición; se imprime [\"0, 1, 2, 3]\"\n",
1444 | "nums[2:4] = [8, 9] # Nueva sublista\n",
1445 | "print(nums) "
1446 | ],
1447 | "execution_count": 0,
1448 | "outputs": [
1449 | {
1450 | "output_type": "stream",
1451 | "text": [
1452 | "[0, 1, 2, 3, 4]\n",
1453 | "[2, 3]\n",
1454 | "[2, 3, 4]\n",
1455 | "[0, 1]\n",
1456 | "[0, 1, 2, 3, 4]\n",
1457 | "[0, 1, 2, 3]\n",
1458 | "[0, 1, 8, 9, 4]\n"
1459 | ],
1460 | "name": "stdout"
1461 | }
1462 | ]
1463 | },
1464 | {
1465 | "metadata": {
1466 | "id": "NpnCycu8ZIha",
1467 | "colab_type": "text"
1468 | },
1469 | "cell_type": "markdown",
1470 | "source": [
1471 | "La selección de elementos o el uso de sciling es sumamente útil para el manejo de arrays en NumPy y guardan similitud con el uso de las listas.\n",
1472 | "\n",
1473 | "**Loops sobre listas**\n",
1474 | "\n",
1475 | "Se puede hacer ciclos o Loops sobre los elementos de la lista.\n"
1476 | ]
1477 | },
1478 | {
1479 | "metadata": {
1480 | "id": "pqKfmimGZOd3",
1481 | "colab_type": "code",
1482 | "outputId": "054a71c8-af81-45bc-eeb1-96c2f42e83ae",
1483 | "colab": {
1484 | "base_uri": "https://localhost:8080/",
1485 | "height": 68
1486 | }
1487 | },
1488 | "cell_type": "code",
1489 | "source": [
1490 | "#Se contruye una lista con cadenas\n",
1491 | "animals = ['cat', 'dog', 'monkey']\n",
1492 | "\n",
1493 | "#Se realiza el ciclo\n",
1494 | "for animal in animals:\n",
1495 | " print(animal)"
1496 | ],
1497 | "execution_count": 0,
1498 | "outputs": [
1499 | {
1500 | "output_type": "stream",
1501 | "text": [
1502 | "cat\n",
1503 | "dog\n",
1504 | "monkey\n"
1505 | ],
1506 | "name": "stdout"
1507 | }
1508 | ]
1509 | },
1510 | {
1511 | "metadata": {
1512 | "id": "CHJ2ZIN9ZWLS",
1513 | "colab_type": "text"
1514 | },
1515 | "cell_type": "markdown",
1516 | "source": [
1517 | "Si se desea tener acceso a los índices de cada elemento en el ciclo, se puede usar la función **enumerate**:"
1518 | ]
1519 | },
1520 | {
1521 | "metadata": {
1522 | "id": "jvLDEfZ5ZRlk",
1523 | "colab_type": "code",
1524 | "outputId": "e425969b-b0df-4e59-c837-717ae22b4495",
1525 | "colab": {
1526 | "base_uri": "https://localhost:8080/",
1527 | "height": 68
1528 | }
1529 | },
1530 | "cell_type": "code",
1531 | "source": [
1532 | "animals = ['cat', 'dog', 'monkey']\n",
1533 | "for idx, animal in enumerate(animals):\n",
1534 | " print('#%d: %s' % (idx + 1, animal))\n",
1535 | "# Se imprime \"#1: cat\", \"#2: dog\", \"#3: monkey\""
1536 | ],
1537 | "execution_count": 0,
1538 | "outputs": [
1539 | {
1540 | "output_type": "stream",
1541 | "text": [
1542 | "#1: cat\n",
1543 | "#2: dog\n",
1544 | "#3: monkey\n"
1545 | ],
1546 | "name": "stdout"
1547 | }
1548 | ]
1549 | },
1550 | {
1551 | "metadata": {
1552 | "id": "tPmCb-KMZhZK",
1553 | "colab_type": "text"
1554 | },
1555 | "cell_type": "markdown",
1556 | "source": [
1557 | "Listas por comprensión: facilitan la generación de listas desde otra lista. En situaciones donde se desea transformar, filtrar u operar sobre los elementos de una lista y dejarlos en otra lista puede ser últil en lugar de hacer un cíclo. \n",
1558 | "\n",
1559 | "Ejemplo, se desea crear una lista donde los elementos sean los números elevados al cuadrado que se encuentran en otra lista."
1560 | ]
1561 | },
1562 | {
1563 | "metadata": {
1564 | "id": "CqD8pLWeZcJc",
1565 | "colab_type": "code",
1566 | "outputId": "c9fc82f9-8bad-4a0c-a2f3-1f2e5e2980b7",
1567 | "colab": {
1568 | "base_uri": "https://localhost:8080/",
1569 | "height": 34
1570 | }
1571 | },
1572 | "cell_type": "code",
1573 | "source": [
1574 | "#Se crea una lista con los números originales\n",
1575 | "nums = [0, 1, 2, 3, 4]\n",
1576 | "\n",
1577 | "#List auxiliar\n",
1578 | "squares = []\n",
1579 | "\n",
1580 | "#Ciclo para operar sobre la lista\n",
1581 | "for x in nums:\n",
1582 | " squares.append(x ** 2)\n",
1583 | " \n",
1584 | "print(squares) # Se imprime [0, 1, 4, 9, 16]\n"
1585 | ],
1586 | "execution_count": 0,
1587 | "outputs": [
1588 | {
1589 | "output_type": "stream",
1590 | "text": [
1591 | "[0, 1, 4, 9, 16]\n"
1592 | ],
1593 | "name": "stdout"
1594 | }
1595 | ]
1596 | },
1597 | {
1598 | "metadata": {
1599 | "id": "pHdeRvDeZqwE",
1600 | "colab_type": "text"
1601 | },
1602 | "cell_type": "markdown",
1603 | "source": [
1604 | "Usando listas por comprensión el programa queda así:"
1605 | ]
1606 | },
1607 | {
1608 | "metadata": {
1609 | "id": "BL_1iQpZZr2R",
1610 | "colab_type": "code",
1611 | "outputId": "bc9fe780-aa07-4b95-c417-632838ec2973",
1612 | "colab": {
1613 | "base_uri": "https://localhost:8080/",
1614 | "height": 34
1615 | }
1616 | },
1617 | "cell_type": "code",
1618 | "source": [
1619 | "#Se crea una lista con los números originales\n",
1620 | "nums = [0, 1, 2, 3, 4]\n",
1621 | "\n",
1622 | "#Lista con los cuadrados\n",
1623 | "squares=[i**2 for i in nums]\n",
1624 | "\n",
1625 | "print(squares)"
1626 | ],
1627 | "execution_count": 0,
1628 | "outputs": [
1629 | {
1630 | "output_type": "stream",
1631 | "text": [
1632 | "[0, 1, 4, 9, 16]\n"
1633 | ],
1634 | "name": "stdout"
1635 | }
1636 | ]
1637 | },
1638 | {
1639 | "metadata": {
1640 | "id": "-mHajE7eZzLA",
1641 | "colab_type": "text"
1642 | },
1643 | "cell_type": "markdown",
1644 | "source": [
1645 | "Se pueden agregar condiciones de decisiones en las listas por comprensión. Los siguientes ejemplos muestran como se haría por ciclos y despúes en listas por comprensión."
1646 | ]
1647 | },
1648 | {
1649 | "metadata": {
1650 | "id": "t5OfOonsZ8Tq",
1651 | "colab_type": "code",
1652 | "colab": {}
1653 | },
1654 | "cell_type": "code",
1655 | "source": [
1656 | "#Realizado por un Cíclo\n",
1657 | "\n",
1658 | "#Se crea una lista con los números originales\n",
1659 | "nums = [0, 1, 2, 3, 4]\n",
1660 | "\n",
1661 | "#List auxiliar\n",
1662 | "squares = []\n",
1663 | "\n",
1664 | "#Ciclo para operar sobre la lista\n",
1665 | "for x in nums:\n",
1666 | " if(x%2==0):\n",
1667 | " squares.append(x ** 2)\n",
1668 | " \n",
1669 | "print(squares) # Se imprime [0, 1, 4, 9, 16]\n"
1670 | ],
1671 | "execution_count": 0,
1672 | "outputs": []
1673 | },
1674 | {
1675 | "metadata": {
1676 | "id": "tEqHO_oVaCVx",
1677 | "colab_type": "code",
1678 | "colab": {}
1679 | },
1680 | "cell_type": "code",
1681 | "source": [
1682 | "#Por listas por comprensión\n",
1683 | "\n",
1684 | "#Se crea una lista con los números originales\n",
1685 | "nums = [0, 1, 2, 3, 4]\n",
1686 | "\n",
1687 | "#Lista con los cuadrados\n",
1688 | "squares=[i**2 for i in nums if i%2==0]\n",
1689 | "\n",
1690 | "print(squares)"
1691 | ],
1692 | "execution_count": 0,
1693 | "outputs": []
1694 | },
1695 | {
1696 | "metadata": {
1697 | "id": "EpbuXBBeZ95h",
1698 | "colab_type": "text"
1699 | },
1700 | "cell_type": "markdown",
1701 | "source": [
1702 | "\n",
1703 | "### Diccionarios\n",
1704 | "\n",
1705 | "Un diccionario son tipos de datos que tienen para cada elemento una tupla (clave,valor). Estos son similares a los Map() de Java, Scala o JavaScript."
1706 | ]
1707 | },
1708 | {
1709 | "metadata": {
1710 | "id": "161N5AUGaLOi",
1711 | "colab_type": "code",
1712 | "outputId": "a01387b0-abc7-49a5-fee2-d0d68dd8a4d1",
1713 | "colab": {
1714 | "base_uri": "https://localhost:8080/",
1715 | "height": 120
1716 | }
1717 | },
1718 | "cell_type": "code",
1719 | "source": [
1720 | "d = {'cat': 'cute', 'dog': 'furry'} # Se crea un diccionario con algunos datos\n",
1721 | "print(d['cat']) # Se toma el valor que está asociado a la clave 'cat'; imprime \"cute\"\n",
1722 | "print('cat' in d) # Se valida si una clave está en el diccionario; se imprime \"True\"\n",
1723 | "d['fish'] = 'wet' # Se agrega una nueva clave y con su valor\n",
1724 | "print(d['fish']) # Se imprime \"wet\"\n",
1725 | "# print(d['monkey']) # Al ejecutarse Python regresa un error por que no existe esa clave\n",
1726 | "print(d.get('monkey', 'N/A')) # Se da un valor por default; Se imprime \"N/A\"\n",
1727 | "print(d.get('fish', 'N/A')) # Se imprime un elemento con un valor por default; se imprime \"wet\"\n",
1728 | "del(d['fish']) # Se remueve la clave y el valor del diccionario\n",
1729 | "print(d.get('fish', 'N/A')) #Ya no hay una clave 'fish'; prints \"N/A\""
1730 | ],
1731 | "execution_count": 0,
1732 | "outputs": [
1733 | {
1734 | "output_type": "stream",
1735 | "text": [
1736 | "cute\n",
1737 | "True\n",
1738 | "wet\n",
1739 | "N/A\n",
1740 | "wet\n",
1741 | "N/A\n"
1742 | ],
1743 | "name": "stdout"
1744 | }
1745 | ]
1746 | },
1747 | {
1748 | "metadata": {
1749 | "id": "4w996hIVEVLR",
1750 | "colab_type": "code",
1751 | "outputId": "e2935e47-ae85-43bd-deb6-ac248046f2e1",
1752 | "colab": {
1753 | "base_uri": "https://localhost:8080/",
1754 | "height": 34
1755 | }
1756 | },
1757 | "cell_type": "code",
1758 | "source": [
1759 | "d.keys()"
1760 | ],
1761 | "execution_count": 0,
1762 | "outputs": [
1763 | {
1764 | "output_type": "execute_result",
1765 | "data": {
1766 | "text/plain": [
1767 | "dict_keys(['cat', 'dog'])"
1768 | ]
1769 | },
1770 | "metadata": {
1771 | "tags": []
1772 | },
1773 | "execution_count": 8
1774 | }
1775 | ]
1776 | },
1777 | {
1778 | "metadata": {
1779 | "id": "Zv0L3AvQaTOF",
1780 | "colab_type": "text"
1781 | },
1782 | "cell_type": "markdown",
1783 | "source": [
1784 | "La información sobre diccionario en Python se encuentra [aquí.](https://docs.python.org/3/tutorial/datastructures.html#dictionaries)\n",
1785 | "\n",
1786 | "**Loops**: se puede iterar sobre los diccionarios de manera sencilla."
1787 | ]
1788 | },
1789 | {
1790 | "metadata": {
1791 | "id": "Ky0AdJtQaYu3",
1792 | "colab_type": "code",
1793 | "colab": {}
1794 | },
1795 | "cell_type": "code",
1796 | "source": [
1797 | "#Se crea un diccionario\n",
1798 | "d = {'person': 2, 'cat': 4, 'spider': 8}\n",
1799 | "\n",
1800 | "#Se hace un cíclo sobre las claves del diccionario\n",
1801 | "for animal in d:\n",
1802 | " legs = d[animal]\n",
1803 | " print('A %s has %d legs' % (animal, legs))\n",
1804 | "# Se imprime \"A person has 2 legs\", \"A spider has 8 legs\", \"A cat has 4 legs\""
1805 | ],
1806 | "execution_count": 0,
1807 | "outputs": []
1808 | },
1809 | {
1810 | "metadata": {
1811 | "id": "nW-QOmefahQ2",
1812 | "colab_type": "text"
1813 | },
1814 | "cell_type": "markdown",
1815 | "source": [
1816 | "Si se desea iterar sobre las claves y valores del diccionario se puede hacer uso del método **items**."
1817 | ]
1818 | },
1819 | {
1820 | "metadata": {
1821 | "id": "mCuAQmSGacbj",
1822 | "colab_type": "code",
1823 | "outputId": "1cc26a6f-f2f9-4a68-a123-c94dbf3cc1a6",
1824 | "colab": {
1825 | "base_uri": "https://localhost:8080/",
1826 | "height": 68
1827 | }
1828 | },
1829 | "cell_type": "code",
1830 | "source": [
1831 | "#Se crea el diccionario\n",
1832 | "d = {'person': 2, 'cat': 4, 'spider': 8}\n",
1833 | "\n",
1834 | "#Ciclo sobre la clave y el valor del diccionario\n",
1835 | "for animal, legs in d.items():\n",
1836 | " print('A %s has %d legs' % (animal, legs))\n",
1837 | "# Se imprime \"A person has 2 legs\", \"A spider has 8 legs\", \"A cat has 4 legs\""
1838 | ],
1839 | "execution_count": 0,
1840 | "outputs": [
1841 | {
1842 | "output_type": "stream",
1843 | "text": [
1844 | "A person has 2 legs\n",
1845 | "A cat has 4 legs\n",
1846 | "A spider has 8 legs\n"
1847 | ],
1848 | "name": "stdout"
1849 | }
1850 | ]
1851 | },
1852 | {
1853 | "metadata": {
1854 | "id": "bjjFyCtPaqM_",
1855 | "colab_type": "text"
1856 | },
1857 | "cell_type": "markdown",
1858 | "source": [
1859 | "Diccionarios por comprensión, al igual que las listas se puede hacer uso de estas capacidades de Python"
1860 | ]
1861 | },
1862 | {
1863 | "metadata": {
1864 | "id": "gCCYofM4ak5S",
1865 | "colab_type": "code",
1866 | "outputId": "eaebc76b-ce95-4bb4-cd86-9b3fcc2543ad",
1867 | "colab": {
1868 | "base_uri": "https://localhost:8080/",
1869 | "height": 34
1870 | }
1871 | },
1872 | "cell_type": "code",
1873 | "source": [
1874 | "#Se crea una lista\n",
1875 | "nums = [0, 1, 2, 3, 4]\n",
1876 | "\n",
1877 | "#Se crea desde la lista un diccionario\n",
1878 | "even_num_to_square = {x: x ** 2 for x in nums if x % 2 == 0}\n",
1879 | "\n",
1880 | "print(even_num_to_square) # Se imprime \"{0: 0, 2: 4, 4: 16}\""
1881 | ],
1882 | "execution_count": 0,
1883 | "outputs": [
1884 | {
1885 | "output_type": "stream",
1886 | "text": [
1887 | "{0: 0, 2: 4, 4: 16}\n"
1888 | ],
1889 | "name": "stdout"
1890 | }
1891 | ]
1892 | },
1893 | {
1894 | "metadata": {
1895 | "id": "ElRtHjuEayLf",
1896 | "colab_type": "text"
1897 | },
1898 | "cell_type": "markdown",
1899 | "source": [
1900 | "Ejemplo de creación de otro diccionario desde un dicionario usando su clave y valor"
1901 | ]
1902 | },
1903 | {
1904 | "metadata": {
1905 | "id": "-Yi1ur6taxM9",
1906 | "colab_type": "code",
1907 | "colab": {}
1908 | },
1909 | "cell_type": "code",
1910 | "source": [
1911 | "#Se usa el diccionario creado anteriormente\n",
1912 | "{clave:valor+100 for clave, valor in even_num_to_square.items()}"
1913 | ],
1914 | "execution_count": 0,
1915 | "outputs": []
1916 | },
1917 | {
1918 | "metadata": {
1919 | "id": "mrcG6P0ga-4k",
1920 | "colab_type": "text"
1921 | },
1922 | "cell_type": "markdown",
1923 | "source": [
1924 | "\n",
1925 | "### Conjuntos\n",
1926 | "\n",
1927 | "Un conjunto es una colección de elementos no ordenada. El siguiente código es un ejemplo."
1928 | ]
1929 | },
1930 | {
1931 | "metadata": {
1932 | "id": "VLCXiJiMcyQI",
1933 | "colab_type": "code",
1934 | "outputId": "ae4a90a5-c8b3-4db8-fce6-37a2a368f727",
1935 | "colab": {
1936 | "base_uri": "https://localhost:8080/",
1937 | "height": 120
1938 | }
1939 | },
1940 | "cell_type": "code",
1941 | "source": [
1942 | "animals = {'cat', 'dog'}\n",
1943 | "print('cat' in animals) # Checa si el elemento esta en el conjunto;imprime \"True\"\n",
1944 | "print('fish' in animals) # Imprime \"False\"\n",
1945 | "animals.add('fish') # Agrega un elemento al conjunto\n",
1946 | "print('fish' in animals) # Imprime \"True\"\n",
1947 | "print(len(animals)) # Cantidad de elementos en el conjunto;imprime \"3\"\n",
1948 | "animals.add('cat') # Si se agrega un elemento que ya está en el conjunto, no lo modifica el conjunto\n",
1949 | "print(len(animals)) # Imprime \"3\"\n",
1950 | "animals.remove('cat') # Quita un elemento del conjunto\n",
1951 | "print(len(animals)) # Imprime \"2\""
1952 | ],
1953 | "execution_count": 0,
1954 | "outputs": [
1955 | {
1956 | "output_type": "stream",
1957 | "text": [
1958 | "True\n",
1959 | "False\n",
1960 | "True\n",
1961 | "3\n",
1962 | "3\n",
1963 | "2\n"
1964 | ],
1965 | "name": "stdout"
1966 | }
1967 | ]
1968 | },
1969 | {
1970 | "metadata": {
1971 | "id": "pph54AbhFBdd",
1972 | "colab_type": "code",
1973 | "colab": {}
1974 | },
1975 | "cell_type": "code",
1976 | "source": [
1977 | ""
1978 | ],
1979 | "execution_count": 0,
1980 | "outputs": []
1981 | },
1982 | {
1983 | "metadata": {
1984 | "id": "6J9488Rec6Wh",
1985 | "colab_type": "text"
1986 | },
1987 | "cell_type": "markdown",
1988 | "source": [
1989 | "La documentación sobre conjuntos en Pyhton se puede consultar [aquí.](https://docs.python.org/3/tutorial/datastructures.html)\n",
1990 | "\n",
1991 | "**Loops o ciclos:** se pueden hacer sobre los conjuntos similarmente a como se procesan sobre listas, lo único a tomar en cuenta es que los conjuntos no son ordenados. Pero para mostrar los elementos enumerados se puede usar la función **enumerate**."
1992 | ]
1993 | },
1994 | {
1995 | "metadata": {
1996 | "id": "AibGoiXBa75L",
1997 | "colab_type": "code",
1998 | "outputId": "8a386bab-b873-4dcd-d751-79b53937fb7b",
1999 | "colab": {
2000 | "base_uri": "https://localhost:8080/",
2001 | "height": 66
2002 | }
2003 | },
2004 | "cell_type": "code",
2005 | "source": [
2006 | "animals = {'cat', 'dog', 'fish'}\n",
2007 | "for idx, animal in enumerate(animals):\n",
2008 | " print('#%d: %s' % (idx + 1, animal))\n",
2009 | "# Imprime \"#1: fish\", \"#2: dog\", \"#3: cat\""
2010 | ],
2011 | "execution_count": 0,
2012 | "outputs": [
2013 | {
2014 | "output_type": "stream",
2015 | "text": [
2016 | "#1: fish\n",
2017 | "#2: dog\n",
2018 | "#3: cat\n"
2019 | ],
2020 | "name": "stdout"
2021 | }
2022 | ]
2023 | },
2024 | {
2025 | "metadata": {
2026 | "id": "elgXOhtVdBEB",
2027 | "colab_type": "text"
2028 | },
2029 | "cell_type": "markdown",
2030 | "source": [
2031 | "**Conjuntos por comprensión:** se contruyen con la misma notación que los dicionarios, con la diferencia de las condición sobre las claves y valores."
2032 | ]
2033 | },
2034 | {
2035 | "metadata": {
2036 | "id": "AvLofRnZc9Pv",
2037 | "colab_type": "code",
2038 | "colab": {}
2039 | },
2040 | "cell_type": "code",
2041 | "source": [
2042 | "from math import sqrt\n",
2043 | "nums = {int(sqrt(x)) for x in range(30)}\n",
2044 | "print(nums) # Imprime \"set([0, 1, 2, 3, 4, 5])\""
2045 | ],
2046 | "execution_count": 0,
2047 | "outputs": []
2048 | },
2049 | {
2050 | "metadata": {
2051 | "id": "P2L0FckLdUNG",
2052 | "colab_type": "text"
2053 | },
2054 | "cell_type": "markdown",
2055 | "source": [
2056 | "\n",
2057 | "### Tuplas\n",
2058 | "\n",
2059 | "Las **tuplas** son similares a las listas, solo que no son [inmutables](https://es.wikipedia.org/wiki/Objeto_inmutable). Esa propiedad de permite que se pueden considerar como conjunto de claves para un diccionario o elementos de un conjunto, comparado con las listas. El código siguiente son ejemplos sencillos del manejo de tuplas. "
2060 | ]
2061 | },
2062 | {
2063 | "metadata": {
2064 | "id": "F6RRdteddVP8",
2065 | "colab_type": "code",
2066 | "outputId": "543d2c99-a28d-4199-9c6e-e013893eff8b",
2067 | "colab": {
2068 | "base_uri": "https://localhost:8080/",
2069 | "height": 86
2070 | }
2071 | },
2072 | "cell_type": "code",
2073 | "source": [
2074 | "d = {(x, x + 1): x for x in range(10)} #Crea un diccionario con elementos de una tupla\n",
2075 | "print(d) # Imprime el diccionario\n",
2076 | "t = (5, 6) # Crea una tupla\n",
2077 | "print(type(t)) # Imprime \"\"\n",
2078 | "print(d[t]) # Imprime \"5\"\n",
2079 | "print(d[(1, 2)]) # Imprime \"1\""
2080 | ],
2081 | "execution_count": 0,
2082 | "outputs": [
2083 | {
2084 | "output_type": "stream",
2085 | "text": [
2086 | "{(0, 1): 0, (1, 2): 1, (2, 3): 2, (3, 4): 3, (4, 5): 4, (5, 6): 5, (6, 7): 6, (7, 8): 7, (8, 9): 8, (9, 10): 9}\n",
2087 | "\n",
2088 | "5\n",
2089 | "1\n"
2090 | ],
2091 | "name": "stdout"
2092 | }
2093 | ]
2094 | },
2095 | {
2096 | "metadata": {
2097 | "id": "Vnsx5VnvFXx5",
2098 | "colab_type": "code",
2099 | "colab": {}
2100 | },
2101 | "cell_type": "code",
2102 | "source": [
2103 | "t=(1,2,3,4)"
2104 | ],
2105 | "execution_count": 0,
2106 | "outputs": []
2107 | },
2108 | {
2109 | "metadata": {
2110 | "id": "XOO3XBKEFb9N",
2111 | "colab_type": "code",
2112 | "colab": {}
2113 | },
2114 | "cell_type": "code",
2115 | "source": [
2116 | "t2=[1,2,3,4]"
2117 | ],
2118 | "execution_count": 0,
2119 | "outputs": []
2120 | },
2121 | {
2122 | "metadata": {
2123 | "id": "zdMNOFWKdhQV",
2124 | "colab_type": "text"
2125 | },
2126 | "cell_type": "markdown",
2127 | "source": [
2128 | "La documentación correspondiente a las tuplas se puede consultar [aquí.](https://docs.python.org/3/library/stdtypes.html#tuple)\n",
2129 | "\n",
2130 | "\n",
2131 | "## Comentarios Extra\n",
2132 | "\n",
2133 | "Lo revisado sobre el lenguaje es incompleto, en el sentido de que todas las piezas se presentan con lo mínimo requerido para conocer algunos aspectos del Lenguaje.\n",
2134 | "\n",
2135 | "Algunos conceptos que son importantes sobre Pythons son:\n",
2136 | "\n",
2137 | "* Es un lenguaje Interpretado.\n",
2138 | "* La Indentation es fundamental para el código.\n",
2139 | "* Todo en Python es un objeto.\n",
2140 | "* Es modulable.\n",
2141 | "\n",
2142 | "El ecosistema de bibliotecas de Python es inmenso y cambia constantemente. Es decir, se mejoran bibliotecas nuevas que fortalecen al Lenguaje ante cierto tipo de problemas o dificultades.\n",
2143 | "\n",
2144 | "Las siguientes ligas son referencias para conocer las comunidades o información del ecosistema alderredor de Python:\n",
2145 | "\n",
2146 | "* [Página Oficial de Python](https://www.python.org/)\n",
2147 | "* [PyData](https://pydata.org/)\n",
2148 | "* [PyCon](https://us.pycon.org/2019/)\n",
2149 | "* [SciPy](http://conference.scipy.org/)\n",
2150 | "\n",
2151 | "\n",
2152 | "## Numpy\n",
2153 | "\n",
2154 | "Numpy es una de las principales bibliotecas para computo científico en Python. Tienen un capacidades para la manipulación de de arrays multidimensionales y operar con esos objectos. La manipulación de los objetos en Numpy pueden ser vistas como las realizadas con Matlab y Octave.\n",
2155 | "\n",
2156 | "\n",
2157 | "## Arreglos\n",
2158 | "\n",
2159 | "Una matriz o array (arreglo) en Numpy es un \"grid\" o cuadrícula de valores, todos del mismo tipo, y con una tupla de enteros no negativos como índices. El número de dimensiones es la cantidad de filas o rango del arreglo; la forma (shape) del arreglo es la dada por una tupla de enteros lo cuales indican la dimensión del arreglo.\n",
2160 | "\n",
2161 | "Se accede a los elementos del arreglo por medio de los paréntesis cuadrados:"
2162 | ]
2163 | },
2164 | {
2165 | "metadata": {
2166 | "id": "JXVBO_v0dMvd",
2167 | "colab_type": "code",
2168 | "outputId": "bd583ab6-6bf4-46c1-a489-d65a38132d4b",
2169 | "colab": {
2170 | "base_uri": "https://localhost:8080/",
2171 | "height": 119
2172 | }
2173 | },
2174 | "cell_type": "code",
2175 | "source": [
2176 | "import numpy as np\n",
2177 | "\n",
2178 | "a = np.array([1, 2, 3]) # Crea un array de rango 1\n",
2179 | "print(type(a)) # Se imprime \"\"\n",
2180 | "print(a.shape) # Se imprime \"(3,)\"\n",
2181 | "print(a[0],a[1],a[2]) # Se imprime \"1 2 3\"\n",
2182 | "a[0] = 5 # Se cambia un elemento del arreglo\n",
2183 | "print(a) # Se imprime \"[5, 2, 3]\"\n",
2184 | "\n",
2185 | "b = np.array([[1,2,3],[4,5,6]]) # Se crea un arreglo de rango 2\n",
2186 | "print(b.shape) # Se imprime \"(2, 3)\"\n",
2187 | "print(b[0, 0], b[0, 1], b[1, 0]) # Se imprime \"1 2 4\""
2188 | ],
2189 | "execution_count": 0,
2190 | "outputs": [
2191 | {
2192 | "output_type": "stream",
2193 | "text": [
2194 | "\n",
2195 | "(3,)\n",
2196 | "1 2 3\n",
2197 | "[5 2 3]\n",
2198 | "(2, 3)\n",
2199 | "1 2 4\n"
2200 | ],
2201 | "name": "stdout"
2202 | }
2203 | ]
2204 | },
2205 | {
2206 | "metadata": {
2207 | "id": "6W6_1x4Ad3rR",
2208 | "colab_type": "text"
2209 | },
2210 | "cell_type": "markdown",
2211 | "source": [
2212 | "En Numpy se cuentan con muchas funciones para la creación de arreglos:"
2213 | ]
2214 | },
2215 | {
2216 | "metadata": {
2217 | "id": "nRalakl4ddds",
2218 | "colab_type": "code",
2219 | "outputId": "10780272-9f50-4063-e28f-64f73425d19c",
2220 | "colab": {
2221 | "base_uri": "https://localhost:8080/",
2222 | "height": 255
2223 | }
2224 | },
2225 | "cell_type": "code",
2226 | "source": [
2227 | "import numpy as np\n",
2228 | "\n",
2229 | "a = np.zeros((2,2)) # crea un arreglo de puros ceros\n",
2230 | "print(a) # Imprime \"[[ 0. 0.]\n",
2231 | "print() # [ 0. 0.]]\"\n",
2232 | " \n",
2233 | "b = np.ones((1,2)) # Crea un arreglo con puros unos\n",
2234 | "print(b) # Imprime \"[[ 1. 1.]]\"\n",
2235 | "print()\n",
2236 | "\n",
2237 | "c = np.full((2,2), 7) # Crea un arreglo constante\n",
2238 | "print(c) # Imprime \"[[ 7. 7.]\n",
2239 | "print() # [ 7. 7.]]\"\n",
2240 | "\n",
2241 | "d = np.eye(2) # Crea una matriz indentidad 2x2\n",
2242 | "print(d) # Imprime \"[[ 1. 0.]\n",
2243 | "print() # [ 0. 1.]]\"\n",
2244 | " \n",
2245 | "e = np.random.random((2,2)) # Crea una arreglo con números aleatorios\n",
2246 | "print(e) # Imprime \"[[ 0.91940167 0.08143941]\n",
2247 | "print() # [ 0.68744134 0.87236687]]\""
2248 | ],
2249 | "execution_count": 0,
2250 | "outputs": [
2251 | {
2252 | "output_type": "stream",
2253 | "text": [
2254 | "[[0. 0.]\n",
2255 | " [0. 0.]]\n",
2256 | "\n",
2257 | "[[1. 1.]]\n",
2258 | "\n",
2259 | "[[7 7]\n",
2260 | " [7 7]]\n",
2261 | "\n",
2262 | "[[1. 0.]\n",
2263 | " [0. 1.]]\n",
2264 | "\n",
2265 | "[[0.35340401 0.86264678]\n",
2266 | " [0.0475683 0.85805436]]\n",
2267 | "\n"
2268 | ],
2269 | "name": "stdout"
2270 | }
2271 | ]
2272 | },
2273 | {
2274 | "metadata": {
2275 | "id": "9v6xgcPEd-2e",
2276 | "colab_type": "text"
2277 | },
2278 | "cell_type": "markdown",
2279 | "source": [
2280 | "Para consultar más información sobre la creación y manipulación de arregos (arrays), se puede consultar [aquí.]()\n",
2281 | "\n",
2282 | "\n",
2283 | "## Indexado de Matrices\n",
2284 | "\n",
2285 | "Numpy ofrece varios modos de manipular los arreglos por su indexado.\n",
2286 | "\n",
2287 | "**Sciling**: es similar a como se manejan las lista de Python. Como el arreglo puede ser multidimensional, la manipulación debe ser más especifica para cada dimensión:"
2288 | ]
2289 | },
2290 | {
2291 | "metadata": {
2292 | "id": "ifCR-Zhwd64Q",
2293 | "colab_type": "code",
2294 | "outputId": "1045a7e7-bcdd-47e2-aefe-3a3ee00ef3be",
2295 | "colab": {
2296 | "base_uri": "https://localhost:8080/",
2297 | "height": 86
2298 | }
2299 | },
2300 | "cell_type": "code",
2301 | "source": [
2302 | "import numpy as np\n",
2303 | "\n",
2304 | "# Se crea un arreglo de rango 2 y con forma (3,4)\n",
2305 | "# [[ 1 2 3 4]\n",
2306 | "# [ 5 6 7 8]\n",
2307 | "# [ 9 10 11 12]]\n",
2308 | "a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])\n",
2309 | "\n",
2310 | "# Usando slicing se elige el subarreglo que consiste de las primeras 2 filas \n",
2311 | "# y la columna 1 y 2; b es un arreglo de la forma (2,2)\n",
2312 | "# [[2 3]\n",
2313 | "# [6 7]]\n",
2314 | "b = a[:2, 1:3]\n",
2315 | "print(b)\n",
2316 | "# A slice of an array is a view into the same data, so modifying it\n",
2317 | "# will modify the original array.\n",
2318 | "print(a[0, 1]) # Prints \"2\"\n",
2319 | "b[0, 0] = 77 # b[0, 0] is the same piece of data as a[0, 1]\n",
2320 | "print(a[0, 1]) # Prints \"77\""
2321 | ],
2322 | "execution_count": 0,
2323 | "outputs": [
2324 | {
2325 | "output_type": "stream",
2326 | "text": [
2327 | "[[2 3]\n",
2328 | " [6 7]]\n",
2329 | "2\n",
2330 | "77\n"
2331 | ],
2332 | "name": "stdout"
2333 | }
2334 | ]
2335 | },
2336 | {
2337 | "metadata": {
2338 | "id": "yVSiySeAeG0Y",
2339 | "colab_type": "text"
2340 | },
2341 | "cell_type": "markdown",
2342 | "source": [
2343 | "Para hacer selecciones de submatriz se combina el manejo de los indices, los ejemplos siguentes muestran como se hace la selección de una fila y todas las columnas."
2344 | ]
2345 | },
2346 | {
2347 | "metadata": {
2348 | "id": "OLXixumOeCoY",
2349 | "colab_type": "code",
2350 | "outputId": "8a8adde8-68f8-42ec-e166-400828a6c7ab",
2351 | "colab": {
2352 | "base_uri": "https://localhost:8080/",
2353 | "height": 119
2354 | }
2355 | },
2356 | "cell_type": "code",
2357 | "source": [
2358 | "import numpy as np\n",
2359 | "\n",
2360 | "# Crea un arreglo de rango 2 y forma (3, 4)\n",
2361 | "# [[ 1 2 3 4]\n",
2362 | "# [ 5 6 7 8]\n",
2363 | "# [ 9 10 11 12]]\n",
2364 | "a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])\n",
2365 | "\n",
2366 | "# Dos ejemplos de como extraer los datos de una fila.\n",
2367 | "\n",
2368 | "row_r1 = a[1, :] # Se elige la segunda fila del arreglo \n",
2369 | "row_r2 = a[1:2, :] # Segunda selección de la segunda fila del arreglo\n",
2370 | "print(row_r1, row_r1.shape) # Se imprime \"[5 6 7 8] (4,)\"\n",
2371 | "print(row_r2, row_r2.shape) # Se imprime \"[[5 6 7 8]] (1, 4)\"\n",
2372 | "\n",
2373 | "# Se puede hacer lo mismo para manipular las columnas del arreglo:\n",
2374 | "col_r1 = a[:, 1]\n",
2375 | "col_r2 = a[:, 1:2]\n",
2376 | "print(col_r1, col_r1.shape) # Se imprime \"[ 2 6 10] (3,)\"\n",
2377 | "print(col_r2, col_r2.shape) # Se imprime \"[[ 2]\n",
2378 | " # [ 6]\n",
2379 | " # [10]] (3, 1)\""
2380 | ],
2381 | "execution_count": 0,
2382 | "outputs": [
2383 | {
2384 | "output_type": "stream",
2385 | "text": [
2386 | "[5 6 7 8] (4,)\n",
2387 | "[[5 6 7 8]] (1, 4)\n",
2388 | "[ 2 6 10] (3,)\n",
2389 | "[[ 2]\n",
2390 | " [ 6]\n",
2391 | " [10]] (3, 1)\n"
2392 | ],
2393 | "name": "stdout"
2394 | }
2395 | ]
2396 | },
2397 | {
2398 | "metadata": {
2399 | "id": "m7KlsSbZeO4V",
2400 | "colab_type": "text"
2401 | },
2402 | "cell_type": "markdown",
2403 | "source": [
2404 | "**Selección por posición:** \n",
2405 | "\n",
2406 | "Indexación Entera en el Array: Cuando indexa en matrices numpy utilizando la segmentación(slicing), la vista de matriz resultante siempre será una subarreglo de la matriz original.\n",
2407 | "\n",
2408 | "En contraste, la indexación de matrices enteras le permite construir matrices arbitrarias utilizando los datos de otra matriz. Aquí hay un ejemplo:\n"
2409 | ]
2410 | },
2411 | {
2412 | "metadata": {
2413 | "id": "MkGZDjOYeKMk",
2414 | "colab_type": "code",
2415 | "outputId": "9c8a2a47-8f39-4d4d-ac28-52f145ac5cfe",
2416 | "colab": {
2417 | "base_uri": "https://localhost:8080/",
2418 | "height": 204
2419 | }
2420 | },
2421 | "cell_type": "code",
2422 | "source": [
2423 | "import numpy as np\n",
2424 | "\n",
2425 | "a = np.array([[1,2], [3, 4], [5, 6]])\n",
2426 | "\n",
2427 | "print(\"Arreglo inicial\")\n",
2428 | "print(a)#Se imprime el arreglo\n",
2429 | "print(\"Forma del arreglo\")\n",
2430 | "print(a.shape)\n",
2431 | "print()\n",
2432 | "\n",
2433 | "# Ejemplo del manejo de los arreglos por sus índices enteros \n",
2434 | "print(a[[0, 1, 2], [0, 1, 0]]) # Se imprime \"[1 4 5]\"\n",
2435 | "\n",
2436 | "# Un modo equivalente al elegir por indices cada elemento del arreglo:\n",
2437 | "print(np.array([a[0, 0], a[1, 1], a[2, 0]])) # Prints \"[1 4 5]\"\n",
2438 | "\n",
2439 | "#Se puede elegir del arreglo un subarreglo y luego de ese subarreglo elegir \n",
2440 | "# la fila o columna que se desea\n",
2441 | "#para que sea más clara la siguiente selección se puede ejecurar primero las dos lineas comentadas abajo\n",
2442 | "#print(a[[0, 0]) #Imprime [[1 2] \n",
2443 | " # [1 2]]\n",
2444 | "print(a[[0, 0], [1, 1]]) # Imprime \"[2 2]\"\n",
2445 | "\n",
2446 | "# Equivalente a la seleccion previa pero haciendo doble selección \n",
2447 | "print(np.array([a[0, 1], a[0, 1]])) # Imprime \"[2 2]\""
2448 | ],
2449 | "execution_count": 0,
2450 | "outputs": [
2451 | {
2452 | "output_type": "stream",
2453 | "text": [
2454 | "Arreglo inicial\n",
2455 | "[[1 2]\n",
2456 | " [3 4]\n",
2457 | " [5 6]]\n",
2458 | "Forma del arreglo\n",
2459 | "(3, 2)\n",
2460 | "\n",
2461 | "[1 4 5]\n",
2462 | "[1 4 5]\n",
2463 | "[2 2]\n",
2464 | "[2 2]\n"
2465 | ],
2466 | "name": "stdout"
2467 | }
2468 | ]
2469 | },
2470 | {
2471 | "metadata": {
2472 | "id": "5yDPGFRreWar",
2473 | "colab_type": "text"
2474 | },
2475 | "cell_type": "markdown",
2476 | "source": [
2477 | "Otra opción que permite la selección por índices enteros es la mutación o selección de elementos por cada fila de la matriz."
2478 | ]
2479 | },
2480 | {
2481 | "metadata": {
2482 | "id": "sSwSR7X7eSMp",
2483 | "colab_type": "code",
2484 | "outputId": "b8ea8919-15ed-499c-88b3-628cd3cd1f14",
2485 | "colab": {
2486 | "base_uri": "https://localhost:8080/",
2487 | "height": 187
2488 | }
2489 | },
2490 | "cell_type": "code",
2491 | "source": [
2492 | "import numpy as np\n",
2493 | "\n",
2494 | "# Se crea un arreglo\n",
2495 | "a = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])\n",
2496 | "\n",
2497 | "print(\"Visualizacion del arreglo creado\")\n",
2498 | "print(a) # Se imprime \"[[ 1, 2, 3],\n",
2499 | " # [ 4, 5, 6],\n",
2500 | " # [ 7, 8, 9],\n",
2501 | " # [10, 11, 12]]\"\n",
2502 | "\n",
2503 | "# Se crea una arreglo de índices\n",
2504 | "b = np.array([0, 2, 0, 1])\n",
2505 | "\n",
2506 | "# Se elige un elemento de cada fila usando el arreglo de indices que se creo\n",
2507 | "print(a[np.arange(4), b]) # Se imprime \"[ 1 6 7 11]\"\n",
2508 | "\n",
2509 | "# Se cambia cada elemento del arreglo que se elige con el arreglo de índices\n",
2510 | "a[np.arange(4), b] += 10\n",
2511 | "\n",
2512 | "print(a) # Se imprime \"[[11, 2, 3],\n",
2513 | " # [ 4, 5, 16],\n",
2514 | " # [17, 8, 9],\n",
2515 | " # [10, 21, 12]]"
2516 | ],
2517 | "execution_count": 0,
2518 | "outputs": [
2519 | {
2520 | "output_type": "stream",
2521 | "text": [
2522 | "Visualizacion del arreglo creado\n",
2523 | "[[ 1 2 3]\n",
2524 | " [ 4 5 6]\n",
2525 | " [ 7 8 9]\n",
2526 | " [10 11 12]]\n",
2527 | "[ 1 6 7 11]\n",
2528 | "[[11 2 3]\n",
2529 | " [ 4 5 16]\n",
2530 | " [17 8 9]\n",
2531 | " [10 21 12]]\n"
2532 | ],
2533 | "name": "stdout"
2534 | }
2535 | ]
2536 | },
2537 | {
2538 | "metadata": {
2539 | "id": "cvdsAYMlef77",
2540 | "colab_type": "text"
2541 | },
2542 | "cell_type": "markdown",
2543 | "source": [
2544 | "**Selección por índices Booleanos:** La selección de submatrices o arreglos por índices Booleanos se realiza para elegir elementos que cumplen cierta condición.\n",
2545 | "\n",
2546 | "*Nota*: El tipo de selección por condiciones lógicos resulta my útil al analizar datos no solo numéricos, lo cual se realiza con Pandas que hace uso en su base de los arreglos formados en Numpy."
2547 | ]
2548 | },
2549 | {
2550 | "metadata": {
2551 | "id": "GS2r6xMpeagR",
2552 | "colab_type": "code",
2553 | "colab": {}
2554 | },
2555 | "cell_type": "code",
2556 | "source": [
2557 | "import numpy as np\n",
2558 | "\n",
2559 | "a = np.array([[1,2], [3, 4], [5, 6]])\n",
2560 | "\n",
2561 | "bool_idx = (a > 2) # Encontrar todos los elementos del arrego que son mayores a 2;\n",
2562 | " # esto regresa un arreglo booleano de la misma forma(a.shape).\n",
2563 | " \n",
2564 | "print(bool_idx) # Se imprime \"[[False False]\n",
2565 | " # [ True True]\n",
2566 | " # [ True True]]\"\n",
2567 | "\n",
2568 | "# Se puede usar el indice booleano para elegir la submatriz que cumple la condición\n",
2569 | "# los elementos que se obtienen son solo aquellos que tienen en su indice booleano \"True\"\n",
2570 | "\n",
2571 | "print(a[bool_idx]) # Se imprime \"[3 4 5 6]\"\n",
2572 | "\n",
2573 | "# Se puede hacer todo lo anterior en una sola línea de manera más concisa:\n",
2574 | "print(a[a > 2]) # Se imprime \"[3 4 5 6]\"\n"
2575 | ],
2576 | "execution_count": 0,
2577 | "outputs": []
2578 | },
2579 | {
2580 | "metadata": {
2581 | "id": "tHHBfJSgeoFg",
2582 | "colab_type": "text"
2583 | },
2584 | "cell_type": "markdown",
2585 | "source": [
2586 | "**Uniendo temas**: En los dos ejemplos anteriores se vio primero un modo de elegir ciertos indices y modificar el contenido del arreglo. En el segundo ejemplo se vio como elegir bajo ciertas indices booleanos o condición lógica un subarreglo o submatriz. Estas dos operaciones se pueden combinar para cambiar los valores de un arreglo que no cumplen alguna condicíon logica"
2587 | ]
2588 | },
2589 | {
2590 | "metadata": {
2591 | "id": "QXr3IVp2ei-f",
2592 | "colab_type": "code",
2593 | "outputId": "d324e473-8831-4dac-9d62-5576401cda60",
2594 | "colab": {
2595 | "base_uri": "https://localhost:8080/",
2596 | "height": 154
2597 | }
2598 | },
2599 | "cell_type": "code",
2600 | "source": [
2601 | "import numpy as np\n",
2602 | "\n",
2603 | "a = np.array([[1,2], [3, 4], [5, 6]])\n",
2604 | "print(\"El arreglo inicial\")\n",
2605 | "print(a)\n",
2606 | "\n",
2607 | "b=np.where(a>2,a,0)\n",
2608 | "\n",
2609 | "print(\"El arreglo resultado de la condición lógica\")\n",
2610 | "print(b)\n"
2611 | ],
2612 | "execution_count": 0,
2613 | "outputs": [
2614 | {
2615 | "output_type": "stream",
2616 | "text": [
2617 | "El arreglo inicial\n",
2618 | "[[1 2]\n",
2619 | " [3 4]\n",
2620 | " [5 6]]\n",
2621 | "El arreglo resultado de la condición lógica\n",
2622 | "[[0 0]\n",
2623 | " [3 4]\n",
2624 | " [5 6]]\n"
2625 | ],
2626 | "name": "stdout"
2627 | }
2628 | ]
2629 | },
2630 | {
2631 | "metadata": {
2632 | "id": "kPPgla6SevEo",
2633 | "colab_type": "text"
2634 | },
2635 | "cell_type": "markdown",
2636 | "source": [
2637 | "El material anterior es una breve intruducción a NumPy y el manejo de sus índices, para aprender más al respecto se puede consultar la documentación [aquí.](https://docs.scipy.org/doc/numpy-1.12.0/user/quickstart.html#fancy-indexing-and-index-tricks)\n",
2638 | "\n",
2639 | "\n",
2640 | "\n",
2641 | "## Tipo de Datos\n",
2642 | "\n",
2643 | "En general los arreglos de NumPy son numéricos, para ello hay forma de especificar el tipo de dato numérico que se va a manejar, ejemplo:"
2644 | ]
2645 | },
2646 | {
2647 | "metadata": {
2648 | "id": "9td6dP77eq6e",
2649 | "colab_type": "code",
2650 | "outputId": "4ec514d0-dad8-4d0b-a838-74061628fa4a",
2651 | "colab": {
2652 | "base_uri": "https://localhost:8080/",
2653 | "height": 68
2654 | }
2655 | },
2656 | "cell_type": "code",
2657 | "source": [
2658 | "import numpy as np\n",
2659 | "\n",
2660 | "x = np.array([1, 2]) # Se visualiza el tipo de dato que asigno \n",
2661 | "print(x.dtype) # Se imprime \"int64\"\n",
2662 | "\n",
2663 | "x = np.array([1.0, 2.0]) # Se asigna el tipo de dato por inferencia\n",
2664 | "print(x.dtype) # Se imprime \"float64\"\n",
2665 | "\n",
2666 | "x = np.array([1, 2], dtype=np.float64) # Se forza a que el tipo de dato sea definido\n",
2667 | "print(x.dtype) # Se imprime \"int64\""
2668 | ],
2669 | "execution_count": 0,
2670 | "outputs": [
2671 | {
2672 | "output_type": "stream",
2673 | "text": [
2674 | "int64\n",
2675 | "float64\n",
2676 | "float64\n"
2677 | ],
2678 | "name": "stdout"
2679 | }
2680 | ]
2681 | },
2682 | {
2683 | "metadata": {
2684 | "id": "9iSNO0-Me2Jb",
2685 | "colab_type": "text"
2686 | },
2687 | "cell_type": "markdown",
2688 | "source": [
2689 | "Respecto a la asignación de los tipos de datos en numpy se puede leer en la documentación [aquí](https://docs.scipy.org/doc/numpy-1.12.0/user/basics.types.html)\n",
2690 | "\n",
2691 | "\n",
2692 | "\n",
2693 | "## Operaciones con Matrices\n",
2694 | "\n",
2695 | "Las operaciones aritméticas básicas se pueden realizar con las matrices y además se cuenta con operaciones y funciones especificas de Matrices.\n",
2696 | "\n",
2697 | "Las operaciones aritméticas se deben de considerar que Numpy permite el computo \"vectorizado\" lo cual permite hacer u operar sobre todos lo elementos de la matriz."
2698 | ]
2699 | },
2700 | {
2701 | "metadata": {
2702 | "id": "JaD7MJvxezFS",
2703 | "colab_type": "code",
2704 | "outputId": "0f048d59-cd72-438a-caa8-068137e3aaa2",
2705 | "colab": {
2706 | "base_uri": "https://localhost:8080/",
2707 | "height": 326
2708 | }
2709 | },
2710 | "cell_type": "code",
2711 | "source": [
2712 | "import numpy as np\n",
2713 | "\n",
2714 | "x = np.array([[1,2],[3,4]], dtype=np.float64)\n",
2715 | "y = np.array([[5,6],[7,8]], dtype=np.float64)\n",
2716 | "\n",
2717 | "# Se realiza la suma elemento a elemento.Se regresa la matriz:\n",
2718 | "# [[ 6.0 8.0]\n",
2719 | "# [10.0 12.0]]\n",
2720 | "print(x + y)\n",
2721 | "print(np.add(x, y))\n",
2722 | "\n",
2723 | "# Se realiza la diferencia elemento a elemento. Se regresa la matriz:\n",
2724 | "# [[-4.0 -4.0]\n",
2725 | "# [-4.0 -4.0]]\n",
2726 | "print(x - y)\n",
2727 | "print(np.subtract(x, y))\n",
2728 | "\n",
2729 | "# Se realiza la multiplicación elemento a elemento. Se regresa la matriz:\n",
2730 | "# [[ 5.0 12.0]\n",
2731 | "# [21.0 32.0]]\n",
2732 | "print(x * y)\n",
2733 | "print(np.multiply(x, y))\n",
2734 | "\n",
2735 | "# Se realiza la división elemento a elemento. Se regresa la matriz:\n",
2736 | "# [[ 0.2 0.33333333]\n",
2737 | "# [ 0.42857143 0.5 ]]\n",
2738 | "print(x / y)\n",
2739 | "print(np.divide(x, y))\n",
2740 | "\n",
2741 | "# Se realiza la raiz cuadrada elemento a elemento. Se regresa la matriz:\n",
2742 | "# [[ 1. 1.41421356]\n",
2743 | "# [ 1.73205081 2. ]]\n",
2744 | "print(np.sqrt(x))\n"
2745 | ],
2746 | "execution_count": 0,
2747 | "outputs": [
2748 | {
2749 | "output_type": "stream",
2750 | "text": [
2751 | "[[ 6. 8.]\n",
2752 | " [10. 12.]]\n",
2753 | "[[ 6. 8.]\n",
2754 | " [10. 12.]]\n",
2755 | "[[-4. -4.]\n",
2756 | " [-4. -4.]]\n",
2757 | "[[-4. -4.]\n",
2758 | " [-4. -4.]]\n",
2759 | "[[ 5. 12.]\n",
2760 | " [21. 32.]]\n",
2761 | "[[ 5. 12.]\n",
2762 | " [21. 32.]]\n",
2763 | "[[0.2 0.33333333]\n",
2764 | " [0.42857143 0.5 ]]\n",
2765 | "[[0.2 0.33333333]\n",
2766 | " [0.42857143 0.5 ]]\n",
2767 | "[[1. 1.41421356]\n",
2768 | " [1.73205081 2. ]]\n"
2769 | ],
2770 | "name": "stdout"
2771 | }
2772 | ]
2773 | },
2774 | {
2775 | "metadata": {
2776 | "id": "mSo4JH29fD7t",
2777 | "colab_type": "text"
2778 | },
2779 | "cell_type": "markdown",
2780 | "source": [
2781 | "Se observa de las operaciones anteriores que **`*`** es el operados para multiplicar elemento a elemento, pero no para el producto de matrices. Para realizar los productos de matrices, producto interno entre vectores o producto vector/matriz se debe de usar el método **`.dot`**.\n",
2782 | "\n",
2783 | "Los siguientes ejemplos muestran su uso:"
2784 | ]
2785 | },
2786 | {
2787 | "metadata": {
2788 | "id": "03n4_NhWfAC9",
2789 | "colab_type": "code",
2790 | "colab": {}
2791 | },
2792 | "cell_type": "code",
2793 | "source": [
2794 | "import numpy as np\n",
2795 | "\n",
2796 | "x = np.array([[1,2],[3,4]])\n",
2797 | "y = np.array([[5,6],[7,8]])\n",
2798 | "\n",
2799 | "v = np.array([9,10])\n",
2800 | "w = np.array([11, 12])\n",
2801 | "\n",
2802 | "# Producto interno de vectores\n",
2803 | "print(v.dot(w))\n",
2804 | "print(np.dot(v, w))\n",
2805 | "\n",
2806 | "# Producto Matriz / vector\n",
2807 | "print(x.dot(v))\n",
2808 | "print(np.dot(x, v))\n",
2809 | "\n",
2810 | "#Producto Matriz / matriz\n",
2811 | "# [[19 22]\n",
2812 | "# [43 50]]\n",
2813 | "print(x.dot(y))\n",
2814 | "print (np.dot(x, y))"
2815 | ],
2816 | "execution_count": 0,
2817 | "outputs": []
2818 | },
2819 | {
2820 | "metadata": {
2821 | "id": "JalmwhwsfKjP",
2822 | "colab_type": "text"
2823 | },
2824 | "cell_type": "markdown",
2825 | "source": [
2826 | "Numpy cuenta con varias funciones para operar sobre los arreglos, ejemplo realizar la suma sobre columnas o filas, o realizar la suma acumulada de una columna."
2827 | ]
2828 | },
2829 | {
2830 | "metadata": {
2831 | "id": "tOn-K-WdfHA6",
2832 | "colab_type": "code",
2833 | "colab": {}
2834 | },
2835 | "cell_type": "code",
2836 | "source": [
2837 | "import numpy as np\n",
2838 | "\n",
2839 | "x = np.array([[1,2],[3,4]])\n",
2840 | "\n",
2841 | "print(np.sum(x))# Se calcula la suma de todos los elementos; se imprime 10\n",
2842 | "print(np.cumsum(x)) #Se calcula la suma acumulada de cada par de elementos; se imprime [1 3 6 10]\n",
2843 | "print(np.sum(x, axis=0)) # Se calcula la suma de cada columna; se imprime \"[4 6]\"\n",
2844 | "print (np.sum(x, axis=1)) # Se calcula la suma de cada fila; se imprime \"[3 7]\"\n"
2845 | ],
2846 | "execution_count": 0,
2847 | "outputs": []
2848 | },
2849 | {
2850 | "metadata": {
2851 | "id": "aaDXnhOvfSM_",
2852 | "colab_type": "text"
2853 | },
2854 | "cell_type": "markdown",
2855 | "source": [
2856 | "Para aprender más sobre las funciones disponibles en Numpy se puede consultar la documentación [aquí.](https://docs.scipy.org/doc/numpy/reference/routines.math.html)\n",
2857 | "\n",
2858 | "Parte importante de la manipulación de datos no es solo el aplicar alguna función o selección una submatriz; también el hacer algunas transformaciones del arreglo como la transpuesta, cambiar la forma de la matriz, etc. El siguente ejemplo muestra como realizar esto en Numpy."
2859 | ]
2860 | },
2861 | {
2862 | "metadata": {
2863 | "id": "Iaj4uL-ifNTK",
2864 | "colab_type": "code",
2865 | "colab": {}
2866 | },
2867 | "cell_type": "code",
2868 | "source": [
2869 | "import numpy as np\n",
2870 | "\n",
2871 | "x = np.array([[1,2], [3,4]])\n",
2872 | "print(x) # Se imprime \"[[1 2]\n",
2873 | " # [3 4]]\"\n",
2874 | "print(x.T) # Se imprime \"[[1 3]\n",
2875 | " # [2 4]]\"\n",
2876 | "\n",
2877 | "#Se toma un vector y se muestra después ese vector pero transpuesto.\n",
2878 | "v = np.array([1,2,3])\n",
2879 | "print(v) # Se imprime \"[1 2 3]\"\n",
2880 | "print(v.T) # Se imprime \"[1 2 3]\"\n",
2881 | "\n",
2882 | "#Se cambia la forma de la matriz x por un vector\n",
2883 | "print(x.reshape([1,4]))"
2884 | ],
2885 | "execution_count": 0,
2886 | "outputs": []
2887 | },
2888 | {
2889 | "metadata": {
2890 | "id": "ubhmbbzhfed6",
2891 | "colab_type": "text"
2892 | },
2893 | "cell_type": "markdown",
2894 | "source": [
2895 | "Para aprender más sobre la manipulación de arreglos se puede cosultar [aquí.](https://docs.scipy.org/doc/numpy/reference/routines.array-manipulation.html)\n",
2896 | "\n",
2897 | "\n",
2898 | "## Brocasting\n",
2899 | "\n",
2900 | "**Broadcasting** es un mecanismo (eficiente) para trabajar con arreglos de diferentes tamaños en operaciones aritméticas en Numpy. Lo importante de este mecanísmo se presenta al operar con dos matrices de tamaños diferentes y como la matriz pequeña es manejada por Numpy para operar sobre la matriz grande.\n",
2901 | "\n",
2902 | "Ejemplo, para agregar un elemento constante en una matriz se puede realizar así:"
2903 | ]
2904 | },
2905 | {
2906 | "metadata": {
2907 | "id": "B75H2mENfXFR",
2908 | "colab_type": "code",
2909 | "outputId": "9e2635ca-918a-4a24-af8e-4ca163268ba5",
2910 | "colab": {
2911 | "base_uri": "https://localhost:8080/",
2912 | "height": 120
2913 | }
2914 | },
2915 | "cell_type": "code",
2916 | "source": [
2917 | "%time\n",
2918 | "import numpy as np\n",
2919 | "\n",
2920 | "# Se agregará el vector v a cada columna de la matriz x,\n",
2921 | "# este resutado se guardará en una nueva matriz.\n",
2922 | "x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])\n",
2923 | "v = np.array([1, 0, 1])\n",
2924 | "y = np.empty_like(x) # Se crea una nueva matriz con la misma forma que x\n",
2925 | "\n",
2926 | "# Se agrega el vectorv a cada fila de la matriz x\n",
2927 | "# Se define un ciclo\n",
2928 | "for i in range(4):\n",
2929 | " y[i, :] = x[i, :] + v\n",
2930 | "\n",
2931 | "# La salida de y ahora tiene los siguiente valores:\n",
2932 | "# [[ 2 2 4]\n",
2933 | "# [ 5 5 7]\n",
2934 | "# [ 8 8 10]\n",
2935 | "# [11 11 13]]\n",
2936 | "print (y)"
2937 | ],
2938 | "execution_count": 0,
2939 | "outputs": [
2940 | {
2941 | "output_type": "stream",
2942 | "text": [
2943 | "CPU times: user 3 µs, sys: 1 µs, total: 4 µs\n",
2944 | "Wall time: 8.58 µs\n",
2945 | "[[ 2 2 4]\n",
2946 | " [ 5 5 7]\n",
2947 | " [ 8 8 10]\n",
2948 | " [11 11 13]]\n"
2949 | ],
2950 | "name": "stdout"
2951 | }
2952 | ]
2953 | },
2954 | {
2955 | "metadata": {
2956 | "id": "9krqKrKHfl5S",
2957 | "colab_type": "text"
2958 | },
2959 | "cell_type": "markdown",
2960 | "source": [
2961 | "Lo anterios funciona, pero cuando se opera con matrices muy largas hacer un ciclo de manera explicita resulta ser una operación lenta. Pero esa operación se puede pensar como una operación de matrices donde se suma a *x* una matriz que cuenta un vector *v* en cada fila y luego sumar a *x*. La operación se vería así:"
2962 | ]
2963 | },
2964 | {
2965 | "metadata": {
2966 | "id": "TcYTr2LDfiJs",
2967 | "colab_type": "code",
2968 | "outputId": "8c79f28a-4a90-45e8-f3b9-4a8e5413cb3e",
2969 | "colab": {
2970 | "base_uri": "https://localhost:8080/",
2971 | "height": 188
2972 | }
2973 | },
2974 | "cell_type": "code",
2975 | "source": [
2976 | "%time\n",
2977 | "\n",
2978 | "import numpy as np\n",
2979 | "\n",
2980 | "# Se agregará el vector v a cada columna de la matriz x,\n",
2981 | "# este resutado se guardará en una nueva matriz.\n",
2982 | "x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])\n",
2983 | "v = np.array([1, 0, 1])\n",
2984 | "vv = np.tile(v, (4, 1)) # Se crean 4 copias del vector y se construye una matriz\n",
2985 | "print(vv) # Se imprime \"[[1 0 1]\n",
2986 | " # [1 0 1]\n",
2987 | " # [1 0 1]\n",
2988 | " # [1 0 1]]\"\n",
2989 | "y = x + vv # Se suman x and vv elemento a elemento\n",
2990 | "print (y) # Se imprime \"[[ 2 2 4\n",
2991 | " # [ 5 5 7]\n",
2992 | " # [ 8 8 10]\n",
2993 | " # [11 11 13]]\""
2994 | ],
2995 | "execution_count": 0,
2996 | "outputs": [
2997 | {
2998 | "output_type": "stream",
2999 | "text": [
3000 | "CPU times: user 3 µs, sys: 1 µs, total: 4 µs\n",
3001 | "Wall time: 8.82 µs\n",
3002 | "[[1 0 1]\n",
3003 | " [1 0 1]\n",
3004 | " [1 0 1]\n",
3005 | " [1 0 1]]\n",
3006 | "[[ 2 2 4]\n",
3007 | " [ 5 5 7]\n",
3008 | " [ 8 8 10]\n",
3009 | " [11 11 13]]\n"
3010 | ],
3011 | "name": "stdout"
3012 | }
3013 | ]
3014 | },
3015 | {
3016 | "metadata": {
3017 | "id": "vOQ1dqaafsUL",
3018 | "colab_type": "text"
3019 | },
3020 | "cell_type": "markdown",
3021 | "source": [
3022 | "El mecanismo broadcasting permite trabajar de manera más eficiente, evita hacer multiples copias de v o hacer el ciclo como el primer ejemplo:"
3023 | ]
3024 | },
3025 | {
3026 | "metadata": {
3027 | "id": "v_N9jBoffosN",
3028 | "colab_type": "code",
3029 | "outputId": "f4356ff7-76a8-4414-8184-e272df020134",
3030 | "colab": {
3031 | "base_uri": "https://localhost:8080/",
3032 | "height": 90
3033 | }
3034 | },
3035 | "cell_type": "code",
3036 | "source": [
3037 | "import numpy as np\n",
3038 | "\n",
3039 | "# Se agregará el vector v a cada columna de la matriz x,\n",
3040 | "# este resutado se guardará en una nueva matriz.\n",
3041 | "x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])\n",
3042 | "v = np.array([1, 0, 1])\n",
3043 | "y = x + v # Se suman x y v usando broadcasting\n",
3044 | "print(y) # Se imprime \"[[ 2 2 4]\n",
3045 | " # [ 5 5 7]\n",
3046 | " # [ 8 8 10]\n",
3047 | " # [11 11 13]]\""
3048 | ],
3049 | "execution_count": 1,
3050 | "outputs": [
3051 | {
3052 | "output_type": "stream",
3053 | "text": [
3054 | "[[ 2 2 4]\n",
3055 | " [ 5 5 7]\n",
3056 | " [ 8 8 10]\n",
3057 | " [11 11 13]]\n"
3058 | ],
3059 | "name": "stdout"
3060 | }
3061 | ]
3062 | },
3063 | {
3064 | "metadata": {
3065 | "id": "JIWeHZTsfymT",
3066 | "colab_type": "text"
3067 | },
3068 | "cell_type": "markdown",
3069 | "source": [
3070 | "La línea `y=x+v` en el código anterior trabaja como si sumaramos dos matrices de tamaño (4,3); lo que sucedió es que en la operación el mecanísmo *broadcasting* interviene para tomar a `v` como una matriz de la forma (4,3) y realizar la suma elemento a elemento.\n",
3071 | "\n",
3072 | "Broadcasting funciona bajo las siguentes reglas:\n",
3073 | "\n",
3074 | "* Si dos matrices o arreglos no tienen el mismo tamaño pero comparten una dimensión y se realizará una operación con ellas, prepara la matriz más pequeña para tener la misma forma que la matriz de mayor tamaño.\n",
3075 | "* Dos matrices son compatibles para operar si tienen la misma dimensión o una de ellas tiene dimensión 1.\n",
3076 | "\n",
3077 | "La documentación del funcionamiento de Broadcasting se puede consultar [aquí]()\n",
3078 | "\n",
3079 | "Para revisar el tema desde un punto de vista más avanzado se puede consultar el capítulo 12 del libro [*Python for Data Analysis*](http://shop.oreilly.com/product/0636920023784.do) explica algunos ejemplos y en este [artículo.](http://scipy.github.io/old-wiki/pages/EricsBroadcastingDoc \"Imagen de Jake VanderPlas\")\n",
3080 | "\n",
3081 | "**Un ejemplo visual de lo que hace broadcasting.**\n",
3082 | "\n",
3083 | "El ejemplo anterior al sumar un vector sobre las filas de una matriz puede ser visualizado del siguiente modo:\n",
3084 | "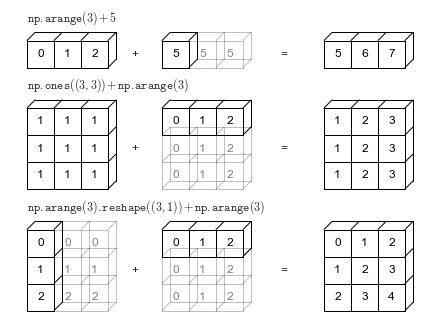\n",
3085 | "\n",
3086 | "\n",
3087 | "Usando el ejemplo anterior al sumar una matriz y un vector usando o no *Broadcasting*, podemos hacer hacer un comparativo del tiempo de ejecución."
3088 | ]
3089 | },
3090 | {
3091 | "metadata": {
3092 | "id": "HydzmIMffu_g",
3093 | "colab_type": "code",
3094 | "outputId": "cab8a2c9-4e74-4c32-e91c-bfcff24ad75c",
3095 | "colab": {
3096 | "base_uri": "https://localhost:8080/",
3097 | "height": 51
3098 | }
3099 | },
3100 | "cell_type": "code",
3101 | "source": [
3102 | "%%time\n",
3103 | "\n",
3104 | "#Eliminar la variables antes de ejcutar con la línea sigueinte\n",
3105 | "#del(x,v,y,i)\n",
3106 | "\n",
3107 | "# este resutado se guardará en una nueva matriz.\n",
3108 | "x = np.ones((1000000,3))\n",
3109 | "v = np.array([1, 0, 1])\n",
3110 | "y = np.empty_like(x) # Se crea una nueva matriz con la misma forma que x\n",
3111 | "\n",
3112 | "# Se agrega el vectorv a cada fila de la matriz x\n",
3113 | "# Se define un ciclo\n",
3114 | "for i in range(1000000):\n",
3115 | " y[i, :] = x[i, :] + v\n",
3116 | "\n",
3117 | "\n",
3118 | "#Se muestra abajo de la celda como el resultado de realizar la operación un con en una matriz \n",
3119 | "# de tamaño (1000000,3)"
3120 | ],
3121 | "execution_count": 0,
3122 | "outputs": [
3123 | {
3124 | "output_type": "stream",
3125 | "text": [
3126 | "CPU times: user 1.97 s, sys: 24.6 ms, total: 2 s\n",
3127 | "Wall time: 2 s\n"
3128 | ],
3129 | "name": "stdout"
3130 | }
3131 | ]
3132 | },
3133 | {
3134 | "metadata": {
3135 | "id": "CeCUWgvKf8Hv",
3136 | "colab_type": "text"
3137 | },
3138 | "cell_type": "markdown",
3139 | "source": [
3140 | "Realizamos la misma operación haciendo uso de *broadcasting*."
3141 | ]
3142 | },
3143 | {
3144 | "metadata": {
3145 | "id": "PQAYT3wwf2aN",
3146 | "colab_type": "code",
3147 | "outputId": "a5ccafa5-f074-4dcd-e5e9-21478e2de964",
3148 | "colab": {
3149 | "base_uri": "https://localhost:8080/",
3150 | "height": 51
3151 | }
3152 | },
3153 | "cell_type": "code",
3154 | "source": [
3155 | "%%time\n",
3156 | "#Se eliman antes de volver a crear las variables\n",
3157 | "#del(x,v,y,i)\n",
3158 | "\n",
3159 | "x = np.ones((1000000,3))\n",
3160 | "v = np.array([1, 0, 1])\n",
3161 | "y = x + v # Se suman x y v usando broadcasting\n",
3162 | "\n",
3163 | "#Se muesta abajo de la celda el tiempo estimado de la operación."
3164 | ],
3165 | "execution_count": 0,
3166 | "outputs": [
3167 | {
3168 | "output_type": "stream",
3169 | "text": [
3170 | "CPU times: user 11.9 ms, sys: 27.6 ms, total: 39.4 ms\n",
3171 | "Wall time: 44.6 ms\n"
3172 | ],
3173 | "name": "stdout"
3174 | }
3175 | ]
3176 | },
3177 | {
3178 | "metadata": {
3179 | "id": "AsqGBaMLgFTc",
3180 | "colab_type": "text"
3181 | },
3182 | "cell_type": "markdown",
3183 | "source": [
3184 | "Algunos ejemplos del uso de *broadcasting* se muestran en el siguiente código."
3185 | ]
3186 | },
3187 | {
3188 | "metadata": {
3189 | "id": "gwiQP0eqf_I9",
3190 | "colab_type": "code",
3191 | "colab": {}
3192 | },
3193 | "cell_type": "code",
3194 | "source": [
3195 | "import numpy as np\n",
3196 | "\n",
3197 | "# Se crean dos vectores para hacer su producto externo\n",
3198 | "v = np.array([1,2,3]) # v tiene la forma (3,)\n",
3199 | "w = np.array([4,5]) # w tiene la forma (2,)\n",
3200 | "\n",
3201 | "print(\"Vectores originales\")\n",
3202 | "print(v)\n",
3203 | "print(w)\n",
3204 | "# Al cualclarse le producto externo de los vectores se transforma el primer vector a \n",
3205 | "# una columna de la forma (3,1); se utiliza broadcasting para generar la salida que es\n",
3206 | "# de la forma:\n",
3207 | "# [[ 4 5]\n",
3208 | "# [ 8 10]\n",
3209 | "# [12 15]]\n",
3210 | "\n",
3211 | "print(\"Producto externo\")\n",
3212 | "print(np.reshape(v, (3, 1)) * w)\n",
3213 | "\n",
3214 | "# Se suman una matriz y un vector\n",
3215 | "x = np.array([[1,2,3], [4,5,6]])\n",
3216 | "# x tiene la forma (2, 3) y v tiene la forma (3,) mediante broadcasting se obtiene una matriz\n",
3217 | "# de la forma (2, 3):\n",
3218 | "# [[2 4 6]\n",
3219 | "# [5 7 9]]\n",
3220 | "print()\n",
3221 | "print(x + v)\n",
3222 | "\n",
3223 | "# Se suma un vector a cada columna de x, donde el vector w tiene la forma (2,),\n",
3224 | "# por las reglas del mecanísmo de broadcasting se tomará w como una matriz adecuada\n",
3225 | "# para la suma, la matriz de salida es la siguiente:\n",
3226 | "# [[ 5 6 7]\n",
3227 | "# [ 9 10 11]]\n",
3228 | "print ((x.T + w).T)\n",
3229 | "# Otra solución es cambiar el vector w de forma por una fila de la forma (2,1)\n",
3230 | "print(x + np.reshape(w, (2, 1)))\n",
3231 | "\n",
3232 | "# Multiplicación de una matriz por una constante:\n",
3233 | "# Se obtiene lo siguente:\n",
3234 | "# [[ 2 4 6]\n",
3235 | "# [ 8 10 12]]\n",
3236 | "print (x * 2)"
3237 | ],
3238 | "execution_count": 0,
3239 | "outputs": []
3240 | },
3241 | {
3242 | "metadata": {
3243 | "id": "WJaxX61ogOBG",
3244 | "colab_type": "text"
3245 | },
3246 | "cell_type": "markdown",
3247 | "source": [
3248 | "Hacer uso del mecanímos de broadcasting, permite tener un código más legible y también se tiene mejor rendimiento, como lo mostramos en el ejemplo. Por lo cual es recomendable hacer uso de ello cuando sea posible.\n",
3249 | "\n",
3250 | "**Documentación de Numpy**\n",
3251 | "\n",
3252 | "Los ejemplos anteriores tratan de mostrar de manera breve los tópicos relevantes de Numpy, pero para nada es un material que cubre todos los detalles. Por lo cual la recomendación es acudir a la documentación oficial la cual es basta y cuenta con código de ejemplos en cada sección.\n",
3253 | "\n",
3254 | "* [Documentación de Numpy](https://docs.scipy.org/doc/numpy/user/index.html)\n"
3255 | ]
3256 | },
3257 | {
3258 | "metadata": {
3259 | "id": "FjwGGvK7kUT6",
3260 | "colab_type": "text"
3261 | },
3262 | "cell_type": "markdown",
3263 | "source": [
3264 | "## Notas finales:\n",
3265 | "\n",
3266 | "Python como lenguaje de programación cuenta con muchas más carácteristicas que las mencionadas en estas notas, pero lo presentado aquí es suficiente para hacer uso de Pandas y bibliotecas relacionadas.\n",
3267 | "\n",
3268 | "Numpy es fundamental para hacer computo científico en Python, si bien cuenta con amplia cantidad de caracteríticas y métodos, lo presentado aquí es lo básico necesario para trabajar con Pandas y Numpy al procesar datos.\n",
3269 | "\n",
3270 | "\n",
3271 | "## Referencias y Créditos:\n",
3272 | "\n",
3273 | "Libros:\n",
3274 | "\n",
3275 | "* [Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython](https://www.amazon.com/Python-Data-Analysis-Wrangling-IPython/dp/1449319793)\n",
3276 | "* [From Python to NumPy](https://www.labri.fr/perso/nrougier/from-python-to-numpy/)\n",
3277 | "* [Guide to NumPy: 2nd Edition](https://www.amazon.com/Guide-NumPy-Travis-Oliphant-PhD/dp/151730007X)\n",
3278 | "\n",
3279 | "El último libro fue escrito por el principal contribuidor de NumPy.\n",
3280 | "\n",
3281 | "Todas las notas sobre Python y Numpy fueron inspiradas e influenciadas por las notas de [Justin Johnson](https://cs.stanford.edu/people/jcjohns/) para el curso [CS231n: Convolutional Neural Networks for Visual Recognition](http://cs231n.github.io/)\n",
3282 | "\n",
3283 | "Sitios Web:\n",
3284 | "\n",
3285 | "* http://cs231n.github.io/python-numpy-tutorial/ \n",
3286 | "\n",
3287 | "Imagen:\n",
3288 | "\n",
3289 | "La imagen sobre Brocasting es del libro de [Jake VanderPlas](https://jakevdp.github.io/PythonDataScienceHandbook/02.05-computation-on-arrays-broadcasting.html)."
3290 | ]
3291 | }
3292 | ]
3293 | }
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Crash Course Pandas
2 |
3 | This repository contains the notebooks of the intensive course that I taught for six weeks in 2018. The intention was to study the "idiomatic Pandas", but first we reviewed topics about Python and Numpy,and then focus on the understanding and preparation of data (following the CRISP-DM methodology).
4 |
5 | Later, I will share more notes on more topics that I consider relevant, unfortunately we could not review them.
6 |
7 | ## Notebook and description:
8 |
9 | * [Basic Programming in Python and Basic topic of Numpy](https://nbviewer.jupyter.org/github/dlegor/Crash_Course_Pandas/blob/master/Notebooks/Lesson_1_.ipynb): We review Python and its collections (dic, list, tuples, sets). About Numpy, we go from introduction (vectors and matrices) to specific operations (Brocasting, Matrix operation, Vectorization, etc.).
10 | * [Pandas and the environment in Jupyter Notebook](https://nbviewer.jupyter.org/github/dlegor/Crash_Course_Pandas/blob/master/Notebooks/Lesson_2.ipynb): In the first part, we examined Pandas and their objects (DataFrames and Series, and their functionalities), we also saw aspects of Jupyter's functionalities, such as the magic commands and the operation of the notebook.
11 | * [DataFrames and Series / Relation between SQL and Pandas 1](https://nbviewer.jupyter.org/github/dlegor/Crash_Course_Pandas/blob/master/Notebooks/Lesson_3.ipynb): We reviewed many ways to create DataFrames and Series, and aspects of the operation with them and each other. With examples, we examined the relationship between basic queries in SQL but using Pandas.
12 | * [Pipeline/Relation between SQL and Pandas 2 / GroupBy and Pivot Tables](https://nbviewer.jupyter.org/github/dlegor/Crash_Course_Pandas/blob/master/Notebooks/Lesson_4.ipynb): We encouraged the use of Pipeline in Pandas step by step with examples. Later, we explored the GropuBy operation on DataFrames and made examples. Finally, we finished reviewing the basic queries in SQL but in Pandas.
13 | * [Methods in Pandas/ Merges and Joins/ Structure of the Data Analysis Project](https://nbviewer.jupyter.org/github/dlegor/Crash_Course_Pandas/blob/master/Notebooks/Lesson_5.ipynb): Previously in other lessons, we used some methods in DataFrames. In this notebook we explored the most useful methods on DataFrames with the intention of working with pipeline. I briefly mentioned something about merge, join, concat and addend, but I showed many examples of how we could work with pipelines and visualizations.
14 | * [Two Data Analysis mini-projects](https://nbviewer.jupyter.org/github/dlegor/Crash_Course_Pandas/blob/master/Notebooks/Lesson_6.ipynb): In this last notebook we made two mini-projects of Data Analysis. We did it using the knowledge from the previous lesson. We also reviewed the topics covered in this course and commented on the omitted topics. For the first mini-project, we estimated some models to see the possible problems in an Machine Learning project.
15 |
16 | ## Next Topics:
17 | * Categories and strings in Pandas.
18 | * Tidy Dataframes.
19 | * Time Series in Pandas.
20 | * Brief introduction in Dask.
21 |
22 | ## Note:
23 | * Unfortunately, this course was taught in *Spanish*, so the comments in the notebooks were done in *Spanish*. But I think if you like and you know Python, you won't have problems with that.
24 | * You can run these notebooks in Colaboraty, on that platform the course was taught.
25 |
26 | ### Comment or suggestion you can write to me.
27 |
28 |
--------------------------------------------------------------------------------