├── .github
├── FUNDING.yml
└── workflows
│ ├── ci.yml
│ └── pypi-publish.yml
├── .gitignore
├── LICENSE
├── Makefile
├── README.md
├── doccano_mini
├── __init__.py
├── cli.py
├── components.py
├── docs
│ └── usage.md
├── examples
│ ├── named_entity_recognition.json
│ ├── paraphrase.json
│ ├── question_answering.json
│ ├── summarization.json
│ ├── task_free.json
│ └── text_classification.json
├── home.py
├── layout.py
├── models
│ ├── entity.py
│ └── stepper.py
├── pages
│ ├── 01_Text_Classification.py
│ ├── 02_Question_Answering.py
│ ├── 03_Summarization.py
│ ├── 04_Paraphrase.py
│ ├── 05_Named_Entity_Recognition.py
│ ├── 06_(Beta)_Evaluation.py
│ └── 09_Task_Free.py
├── prompts.py
├── storages
│ ├── entity.py
│ ├── session_storage.py
│ └── stepper.py
└── utils.py
├── docs
├── CODE_OF_CONDUCT.md
├── CONTRIBUTING.md
└── images
│ ├── annotation.gif
│ ├── copy_and_paste.gif
│ ├── download_config.jpg
│ └── test_new_example.jpg
├── poetry.lock
├── pyproject.toml
└── tests
└── test_prompts.py
/.github/FUNDING.yml:
--------------------------------------------------------------------------------
1 | github: Hironsan
2 |
--------------------------------------------------------------------------------
/.github/workflows/ci.yml:
--------------------------------------------------------------------------------
1 | name: doccano-mini CI
2 |
3 | on: [push, pull_request]
4 |
5 | jobs:
6 | backend:
7 | runs-on: ubuntu-latest
8 | steps:
9 | - uses: actions/checkout@v2
10 | - name: Set up Python 3.10
11 | uses: actions/setup-python@v2
12 | with:
13 | python-version: '3.10'
14 | - name: Install dependencies
15 | run: |
16 | python -m pip install --upgrade pip
17 | pip install poetry
18 | poetry install
19 | - name: Lint with flake8
20 | run: |
21 | poetry run task flake8
22 | - name: Lint with isort
23 | run: |
24 | poetry run task isort
25 | - name: Black
26 | run: |
27 | poetry run task black
28 | - name: mypy
29 | run: |
30 | poetry run task mypy
31 | - name: pytest
32 | run: |
33 | poetry run task test
34 |
--------------------------------------------------------------------------------
/.github/workflows/pypi-publish.yml:
--------------------------------------------------------------------------------
1 | name: Upload Python Package
2 |
3 | on:
4 | release:
5 | types: [created]
6 |
7 | jobs:
8 | deploy:
9 | runs-on: ubuntu-latest
10 |
11 | steps:
12 | - uses: actions/checkout@v2
13 | - name: Setup Python 3.10
14 | uses: actions/setup-python@v2
15 | with:
16 | python-version: '3.10'
17 | - name: Install dependencies
18 | run: |
19 | python -m pip install --upgrade pip
20 | pip install poetry poetry-dynamic-versioning
21 | poetry install
22 | - name: Copy README
23 | run: |
24 | cp README.md doccano_mini/docs/
25 | - name: Build a binary wheel and a source tarball
26 | run: |
27 | poetry build
28 | - name: Publish a Python distribution to PyPI
29 | uses: pypa/gh-action-pypi-publish@master
30 | with:
31 | user: ${{ secrets.PYPI_USERNAME }}
32 | password: ${{ secrets.PYPI_PASSWORD }}
33 | packages_dir: ./dist/
34 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Created by .ignore support plugin (hsz.mobi)
2 | ### macOS template
3 | # General
4 | .DS_Store
5 | .AppleDouble
6 | .LSOverride
7 | .idea
8 |
9 | # Icon must end with two \r
10 | Icon
11 |
12 | # Thumbnails
13 | ._*
14 |
15 | # Files that might appear in the root of a volume
16 | .DocumentRevisions-V100
17 | .fseventsd
18 | .Spotlight-V100
19 | .TemporaryItems
20 | .Trashes
21 | .VolumeIcon.icns
22 | .com.apple.timemachine.donotpresent
23 |
24 | # Directories potentially created on remote AFP share
25 | .AppleDB
26 | .AppleDesktop
27 | Network Trash Folder
28 | Temporary Items
29 | .apdisk
30 | ### Python template
31 | # Byte-compiled / optimized / DLL files
32 | __pycache__/
33 | *.py[cod]
34 | *$py.class
35 |
36 | # C extensions
37 | *.so
38 |
39 | # Distribution / packaging
40 | .Python
41 | build/
42 | develop-eggs/
43 | dist/
44 | downloads/
45 | eggs/
46 | .eggs/
47 | lib/
48 | lib64/
49 | parts/
50 | sdist/
51 | var/
52 | wheels/
53 | *.egg-info/
54 | .installed.cfg
55 | *.egg
56 | MANIFEST
57 |
58 | # PyInstaller
59 | # Usually these files are written by a python script from a template
60 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
61 | *.manifest
62 | *.spec
63 |
64 | # Installer logs
65 | pip-log.txt
66 | pip-delete-this-directory.txt
67 |
68 | # Unit test / coverage reports
69 | htmlcov/
70 | .tox/
71 | .coverage
72 | .coverage.*
73 | .cache
74 | nosetests.xml
75 | coverage.xml
76 | *.cover
77 | .hypothesis/
78 | junitxml/
79 |
80 | # Translations
81 | *.mo
82 | *.pot
83 |
84 | # Django stuff:
85 | *.log
86 | local_settings.py
87 | *.sqlite3
88 | staticfiles/
89 |
90 | # Flask stuff:
91 | instance/
92 | .webassets-cache
93 |
94 | # Scrapy stuff:
95 | .scrapy
96 |
97 | # Sphinx documentation
98 | docs/_build/
99 |
100 | # PyBuilder
101 | target/
102 |
103 | # Jupyter Notebook
104 | .ipynb_checkpoints
105 |
106 | # pyenv
107 | .python-version
108 |
109 | # celery beat schedule file
110 | celerybeat-schedule
111 |
112 | # SageMath parsed files
113 | *.sage.py
114 |
115 | # Environments
116 | .env
117 | .venv
118 | env/
119 | venv/
120 | ENV/
121 | env.bak/
122 | venv.bak/
123 |
124 | # Spyder project settings
125 | .spyderproject
126 | .spyproject
127 |
128 | # Rope project settings
129 | .ropeproject
130 |
131 | # mkdocs documentation
132 | /site
133 |
134 | # mypy
135 | .mypy_cache/
136 | ### JetBrains template
137 | # Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and Webstorm
138 | # Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
139 |
140 | # User-specific stuff:
141 | .idea/**/workspace.xml
142 | .idea/**/tasks.xml
143 | .idea/dictionaries
144 |
145 | # Sensitive or high-churn files:
146 | .idea/**/dataSources/
147 | .idea/**/dataSources.ids
148 | .idea/**/dataSources.xml
149 | .idea/**/dataSources.local.xml
150 | .idea/**/sqlDataSources.xml
151 | .idea/**/dynamic.xml
152 | .idea/**/uiDesigner.xml
153 |
154 | # Gradle:
155 | .idea/**/gradle.xml
156 | .idea/**/libraries
157 |
158 | # CMake
159 | cmake-build-debug/
160 |
161 | # Mongo Explorer plugin:
162 | .idea/**/mongoSettings.xml
163 |
164 | ## File-based project format:
165 | *.iws
166 |
167 | ## Plugin-specific files:
168 |
169 | # IntelliJ
170 | out/
171 |
172 | # mpeltonen/sbt-idea plugin
173 | .idea_modules/
174 |
175 | # JIRA plugin
176 | atlassian-ide-plugin.xml
177 |
178 | # Cursive Clojure plugin
179 | .idea/replstate.xml
180 |
181 | # Crashlytics plugin (for Android Studio and IntelliJ)
182 | com_crashlytics_export_strings.xml
183 | crashlytics.properties
184 | crashlytics-build.properties
185 | fabric.properties
186 | ### VirtualEnv template
187 | # Virtualenv
188 | # http://iamzed.com/2009/05/07/a-primer-on-virtualenv/
189 | [Bb]in
190 | [Ii]nclude
191 | [Ll]ib
192 | [Ll]ib64
193 | [Ll]ocal
194 | [Ss]cripts
195 | pyvenv.cfg
196 | pip-selfcheck.json
197 |
198 | # ignore webpack state
199 | node_modules/
200 | bundle/
201 | webpack-stats.json
202 |
203 | .vscode
204 | config.yaml
205 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2023 Hiroki Nakayama.
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/Makefile:
--------------------------------------------------------------------------------
1 | lint:
2 | poetry run task flake8
3 | poetry run task black
4 | poetry run task isort
5 | poetry run task mypy
6 |
7 | test:
8 | poetry run task test
9 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # doccano-mini
2 |
3 | doccano-mini is a few-shot annotation tool to assist the development of applications with Large language models (LLMs). Once you annotate a few text, you can solve your task (e.g. text classification) with LLMs via [LangChain](https://github.com/hwchase17/langchain).
4 |
5 | At this time, the following tasks are supported:
6 |
7 | - Text classification
8 | - Question answering
9 | - Summarization
10 | - Paraphrasing
11 | - Named Entity Recognition
12 | - Task Free
13 |
14 | Note: This is an experimental project.
15 |
16 | ## Installation
17 |
18 | ```bash
19 | pip install doccano-mini
20 | ```
21 |
22 | ## Usage
23 |
24 | For this example, we will be using OpenAI’s APIs, so we need to set the environment variable in the terminal.
25 |
26 | ```bash
27 | export OPENAI_API_KEY="..."
28 | ```
29 |
30 | Then, we can run the server.
31 |
32 | ```bash
33 | doccano-mini
34 | ```
35 |
36 | Now, we can open the browser and go to `http://localhost:8501/` to see the interface.
37 |
38 | ### Step1: Annotate a few text
39 |
40 | In this step, we will annotate a few text. We can add a new text by clicking the `+` button. Try it out by double-clicking on any cell. You'll notice you can edit all cell values.
41 |
42 | 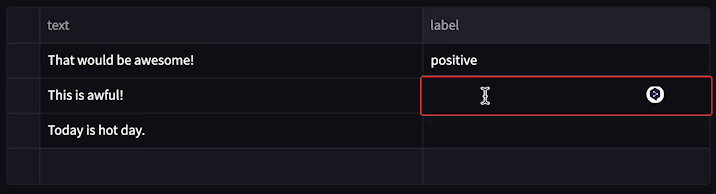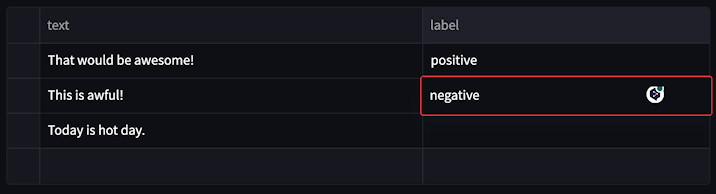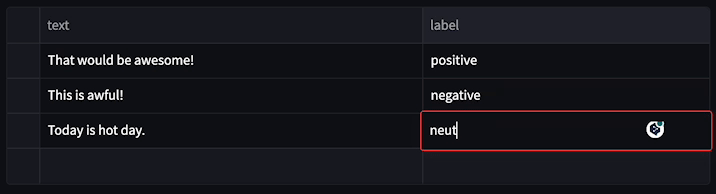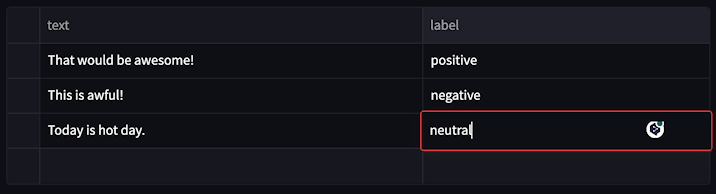
43 |
44 | The editor also supports pasting in tabular data from Google Sheets, Excel, and many other similar tools.
45 |
46 | 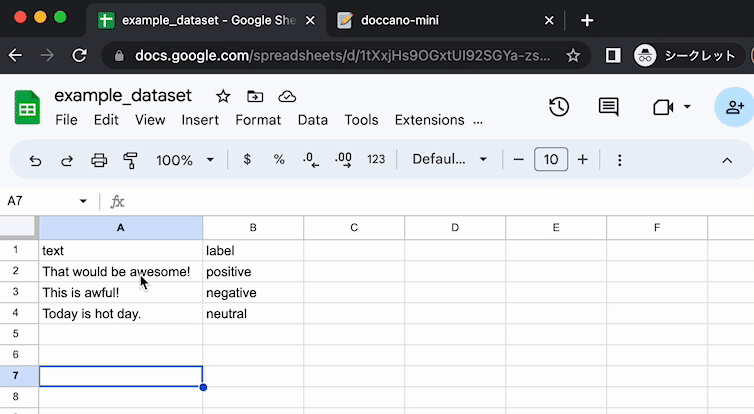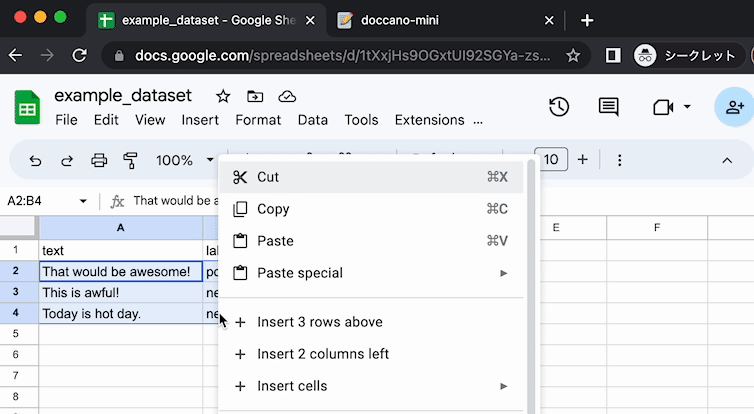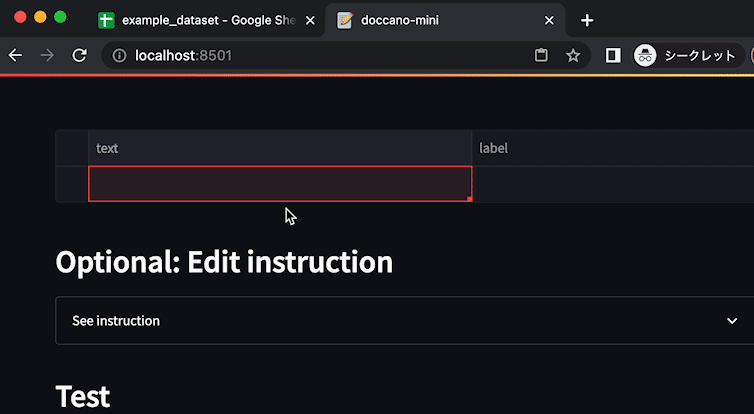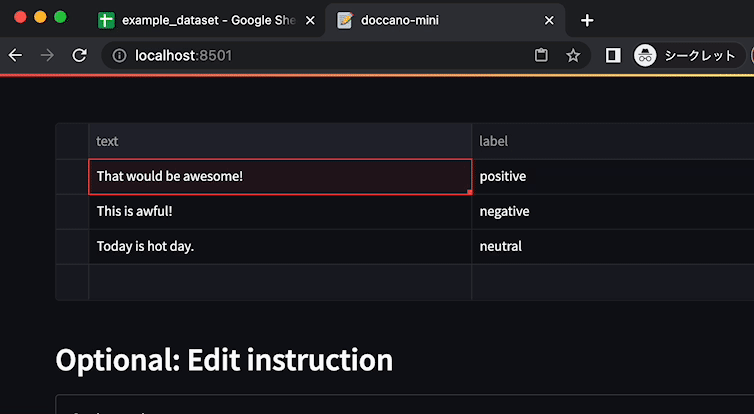
47 |
48 | ### Step2: Test your task
49 |
50 | In this step, we will test your task. We can enter a new test to the text box and click the `Predict` button. Then, we can see the result of the test.
51 |
52 | 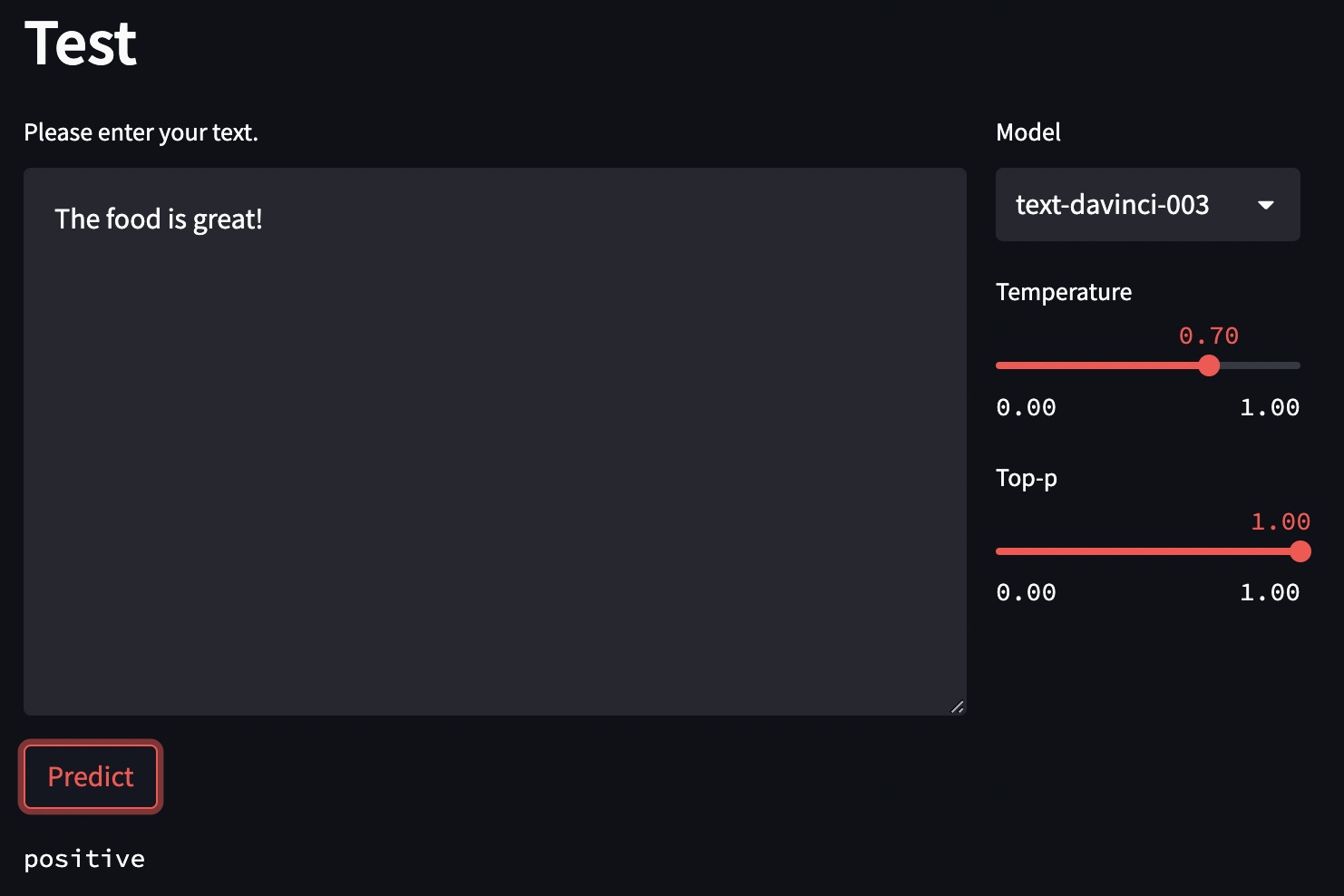 53 |
54 | ### Step3: Download the config
55 |
56 | In this step, we will download the [LangChain](https://github.com/hwchase17/langchain)'s config. We can click the `Download` button to download it. After loading the config file, we can predict a label for the new text.
57 |
58 | ```python
59 | from langchain.chains import load_chain
60 |
61 | chain = load_chain("chain.yaml")
62 | chain.run("YOUR TEXT")
63 | ```
64 |
65 | ## Development
66 |
67 | ```bash
68 | poetry install
69 | streamlit run doccano_mini/home.py
70 | ```
71 |
--------------------------------------------------------------------------------
/doccano_mini/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/doccano/doccano-mini/0ef6c3368499eb172ff5c8c446d61c7f240baf8f/doccano_mini/__init__.py
--------------------------------------------------------------------------------
/doccano_mini/cli.py:
--------------------------------------------------------------------------------
1 | import sys
2 | from pathlib import Path
3 |
4 | import streamlit.web.cli as stcli
5 |
6 |
7 | def main():
8 | filepath = str(Path(__file__).parent.resolve() / "home.py")
9 | sys.argv = ["streamlit", "run", filepath, "--global.developmentMode=false"]
10 | sys.exit(stcli.main())
11 |
12 |
13 | if __name__ == "__main__":
14 | main()
15 |
--------------------------------------------------------------------------------
/doccano_mini/components.py:
--------------------------------------------------------------------------------
1 | import os
2 | from pathlib import Path
3 | from typing import Optional
4 |
5 | import streamlit as st
6 | from langchain.llms import OpenAI
7 | from langchain.prompts.few_shot import FewShotPromptTemplate
8 | from langchain.schema import BaseLanguageModel
9 |
10 |
11 | def display_download_button():
12 | st.header("Download a config file")
13 | with open("config.yaml", "r", encoding="utf-8") as f:
14 | st.download_button(
15 | label="Download",
16 | data=f,
17 | file_name="config.yaml",
18 | )
19 |
20 |
21 | def usage():
22 | st.header("Usage")
23 | filepath = Path(__file__).parent.resolve() / "docs" / "usage.md"
24 | with filepath.open("r", encoding="utf-8") as f:
25 | st.markdown(f.read())
26 |
27 |
28 | def task_instruction_editor(prompt: FewShotPromptTemplate) -> FewShotPromptTemplate:
29 | st.header("Edit instruction")
30 | with st.expander("See instruction"):
31 | prompt.prefix = st.text_area(label="Enter task instruction", value=prompt.prefix, height=200)
32 | return prompt
33 |
34 |
35 | def openai_model_form() -> Optional[BaseLanguageModel]:
36 | # https://platform.openai.com/docs/models/gpt-3-5
37 | AVAILABLE_MODELS = (
38 | "gpt-3.5-turbo",
39 | "gpt-3.5-turbo-0301",
40 | "text-davinci-003",
41 | "text-davinci-002",
42 | "code-davinci-002",
43 | )
44 | api_key = st.text_input("API key", value=os.environ.get("OPENAI_API_KEY", ""), type="password")
45 | model_name = st.selectbox("Model", AVAILABLE_MODELS, index=2)
46 | temperature = st.slider("Temperature", min_value=0.0, max_value=1.0, value=0.7, step=0.01)
47 | top_p = st.slider("Top-p", min_value=0.0, max_value=1.0, value=1.0, step=0.01)
48 | if not api_key:
49 | return None
50 | return OpenAI(model_name=model_name, temperature=temperature, top_p=top_p, openai_api_key=api_key) # type:ignore
51 |
--------------------------------------------------------------------------------
/doccano_mini/docs/usage.md:
--------------------------------------------------------------------------------
1 | ```python
2 | from langchain.chains import load_chain
3 |
4 | chain = load_chain("chain.yaml")
5 | chain.run("YOUR TEXT")
6 | ```
--------------------------------------------------------------------------------
/doccano_mini/examples/named_entity_recognition.json:
--------------------------------------------------------------------------------
1 | [
2 | {"text": "EU rejects German call to boycott British lamb."},
3 | {"text": "Peter Blackburn"},
4 | {"text": "BRUSSELS 1996-08-22"}
5 | ]
--------------------------------------------------------------------------------
/doccano_mini/examples/paraphrase.json:
--------------------------------------------------------------------------------
1 | [
2 | {
3 | "text": "Amrozi accused his brother, whom he called \"the witness\", of deliberately distorting his evidence.",
4 | "paraphrase": "Referring to him as only \"the witness\", Amrozi accused his brother of deliberately distorting his evidence.'"
5 | },
6 | {
7 | "text": "Yucaipa owned Dominick's before selling the chain to Safeway in 1998 for $2.5 billion.",
8 | "paraphrase": "Yucaipa bought Dominick's in 1995 for $693 million and sold it to Safeway for $1.8 billion in 1998."
9 | }
10 | ]
--------------------------------------------------------------------------------
/doccano_mini/examples/question_answering.json:
--------------------------------------------------------------------------------
1 | [
2 | {
3 | "context": "Google was founded by computer scientists Larry Page and Sergey Brin.",
4 | "question": "Who founded Google?",
5 | "answer": "Larry Page and Sergey Brin"
6 | }
7 | ]
--------------------------------------------------------------------------------
/doccano_mini/examples/summarization.json:
--------------------------------------------------------------------------------
1 | [
2 | {
3 | "passage": "WASHINGTON (CNN) -- Vice President Dick Cheney will serve as acting president briefly Saturday while President Bush is anesthetized for a routine colonoscopy, White House spokesman Tony Snow said Friday. Bush is scheduled to have the medical procedure, expected to take about 2 1/2 hours, at the presidential retreat at Camp David, Maryland, Snow said. Bush's last colonoscopy was in June 2002, and no abnormalities were found, Snow said. The president's doctor had recommended a repeat procedure in about five years. The procedure will be supervised by Dr. Richard Tubb and conducted by a multidisciplinary team from the National Naval Medical Center in Bethesda, Maryland, Snow said. A colonoscopy is the most sensitive test for colon cancer, rectal cancer and polyps, small clumps of cells that can become cancerous, according to the Mayo Clinic. Small polyps may be removed during the procedure. Snow said that was the case when Bush had colonoscopies before becoming president. Snow himself is undergoing chemotherapy for cancer that began in his colon and spread to his liver. Snow told reporters he had a chemo session scheduled later Friday. Watch Snow talk about Bush's procedure and his own colon cancer » . \"The president wants to encourage everybody to use surveillance,\" Snow said. The American Cancer Society recommends that people without high-risk factors or symptoms begin getting screened for signs of colorectal cancer at age 50. E-mail to a friend .",
4 | "summary": "President Bush will have a routine colonoscopy Saturday. While he's anesthetized, his powers will be transferred to the vice president. Bush had last colonoscopy in 2002, which found no problems."
5 | },
6 | {
7 | "passage": "LONDON, England (Reuters) -- Harry Potter star Daniel Radcliffe gains access to a reported £20 million ($41.1 million) fortune as he turns 18 on Monday, but he insists the money won't cast a spell on him. Daniel Radcliffe as Harry Potter in \"Harry Potter and the Order of the Phoenix\" To the disappointment of gossip columnists around the world, the young actor says he has no plans to fritter his cash away on fast cars, drink and celebrity parties. \"I don't plan to be one of those people who, as soon as they turn 18, suddenly buy themselves a massive sports car collection or something similar,\" he told an Australian interviewer earlier this month. \"I don't think I'll be particularly extravagant. \"The things I like buying are things that cost about 10 pounds -- books and CDs and DVDs.\" At 18, Radcliffe will be able to gamble in a casino, buy a drink in a pub or see the horror film \"Hostel: Part II,\" currently six places below his number one movie on the UK box office chart. Details of how he'll mark his landmark birthday are under wraps. His agent and publicist had no comment on his plans. \"I'll definitely have some sort of party,\" he said in an interview. \"Hopefully none of you will be reading about it.\" Radcliffe's earnings from the first five Potter films have been held in a trust fund which he has not been able to touch. Despite his growing fame and riches, the actor says he is keeping his feet firmly on the ground. \"People are always looking to say 'kid star goes off the rails,'\" he told reporters last month. \"But I try very hard not to go that way because it would be too easy for them.\" His latest outing as the boy wizard in \"Harry Potter and the Order of the Phoenix\" is breaking records on both sides of the Atlantic and he will reprise the role in the last two films. Watch I-Reporter give her review of Potter's latest » . There is life beyond Potter, however. The Londoner has filmed a TV movie called \"My Boy Jack,\" about author Rudyard Kipling and his son, due for release later this year. He will also appear in \"December Boys,\" an Australian film about four boys who escape an orphanage. Earlier this year, he made his stage debut playing a tortured teenager in Peter Shaffer's \"Equus.\" Meanwhile, he is braced for even closer media scrutiny now that he's legally an adult: \"I just think I'm going to be more sort of fair game,\" he told Reuters. E-mail to a friend . Copyright 2007 Reuters. All rights reserved.This material may not be published, broadcast, rewritten, or redistributed.",
8 | "summary": "Harry Potter star Daniel Radcliffe gets £20M fortune as he turns 18 Monday . Young actor says he has no plans to fritter his cash away . Radcliffe's earnings from first five Potter films have been held in trust fund ."
9 | }
10 | ]
--------------------------------------------------------------------------------
/doccano_mini/examples/task_free.json:
--------------------------------------------------------------------------------
1 | [{"Column 1": "", "Column 2": ""}]
--------------------------------------------------------------------------------
/doccano_mini/examples/text_classification.json:
--------------------------------------------------------------------------------
1 | [
2 | {"text": "That would be awesome!", "label": "positive"},
3 | {"text": "This is awful!", "label": "negative"},
4 | {"text": "Today is hot day.", "label": "neutral"}
5 | ]
--------------------------------------------------------------------------------
/doccano_mini/home.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 |
3 | import streamlit as st
4 |
5 |
6 | def main():
7 | st.set_page_config(page_title="doccano-mini", page_icon=":memo:")
8 | filepath = Path(__file__).parent.resolve() / "docs" / "README.md"
9 |
10 | # Development
11 | if not filepath.exists():
12 | filepath = Path(__file__).parent.parent.resolve() / "README.md"
13 |
14 | with filepath.open("r", encoding="utf-8") as f:
15 | st.markdown(f.read(), unsafe_allow_html=True)
16 |
17 |
18 | if __name__ == "__main__":
19 | main()
20 |
--------------------------------------------------------------------------------
/doccano_mini/layout.py:
--------------------------------------------------------------------------------
1 | from abc import ABC, abstractmethod
2 | from pathlib import Path
3 | from typing import Dict, List
4 |
5 | import pandas as pd
6 | import streamlit as st
7 | from langchain.chains import LLMChain
8 | from langchain.prompts.few_shot import FewShotPromptTemplate
9 |
10 | from doccano_mini.components import (
11 | display_download_button,
12 | openai_model_form,
13 | task_instruction_editor,
14 | usage,
15 | )
16 | from doccano_mini.utils import escape_markdown
17 |
18 |
19 | class BasePage(ABC):
20 | example_path: str = ""
21 |
22 | def __init__(self, title: str) -> None:
23 | self.title = title
24 |
25 | @property
26 | def columns(self) -> List[str]:
27 | return []
28 |
29 | def load_examples(self, filename: str) -> pd.DataFrame:
30 | filepath = Path(__file__).parent.resolve().joinpath("examples", filename)
31 | return pd.read_json(filepath)
32 |
33 | def make_examples(self, columns: List[str]) -> List[Dict]:
34 | df = self.load_examples(self.example_path)
35 | edited_df = st.experimental_data_editor(df, num_rows="dynamic", width=1000)
36 | examples = edited_df.to_dict(orient="records")
37 | return examples
38 |
39 | @abstractmethod
40 | def make_prompt(self, examples: List[Dict]) -> FewShotPromptTemplate:
41 | raise NotImplementedError()
42 |
43 | @abstractmethod
44 | def prepare_inputs(self, columns: List[str]) -> Dict:
45 | raise NotImplementedError()
46 |
47 | def annotate(self, examples: List[Dict]) -> List[Dict]:
48 | return examples
49 |
50 | def render(self) -> None:
51 | st.title(self.title)
52 | st.header("Annotate your data")
53 | columns = self.columns
54 | examples = self.make_examples(columns)
55 | examples = self.annotate(examples)
56 |
57 | prompt = self.make_prompt(examples)
58 | prompt = task_instruction_editor(prompt)
59 |
60 | st.header("Test")
61 | col1, col2 = st.columns([3, 1])
62 |
63 | with col1:
64 | inputs = self.prepare_inputs(columns)
65 |
66 | with col2:
67 | llm = openai_model_form()
68 |
69 | with st.expander("See your prompt"):
70 | st.markdown(f"```\n{prompt.format(**inputs)}\n```")
71 |
72 | if llm is None:
73 | st.error("Enter your API key.")
74 |
75 | if st.button("Predict", disabled=llm is None):
76 | chain = LLMChain(llm=llm, prompt=prompt) # type:ignore
77 | response = chain.run(**inputs)
78 | st.markdown(escape_markdown(response).replace("\n", " \n"))
79 |
80 | chain.save("config.yaml")
81 | display_download_button()
82 | usage()
83 |
--------------------------------------------------------------------------------
/doccano_mini/models/entity.py:
--------------------------------------------------------------------------------
1 | from typing import TypedDict
2 |
3 |
4 | class Entity(TypedDict):
5 | start: int
6 | end: int
7 | label: str
8 |
--------------------------------------------------------------------------------
/doccano_mini/models/stepper.py:
--------------------------------------------------------------------------------
1 | class Stepper:
2 | def __init__(self, step=0):
3 | self._step = step
4 |
5 | @property
6 | def step(self) -> int:
7 | return self._step
8 |
9 | def fit(self, total: int):
10 | if self._step >= total:
11 | self._step = total - 1
12 |
13 | def at(self, step: int, total: int):
14 | if step >= total:
15 | raise ValueError(f"step must be less than {total}")
16 | if step < 0:
17 | raise ValueError("step must be greater than 0")
18 | self._step = step
19 |
20 | def increment(self, total: int):
21 | self._step += 1
22 | if self._step >= total:
23 | self._step = 0
24 |
25 | def decrement(self, total: int):
26 | self._step -= 1
27 | if self._step < 0:
28 | self._step = total - 1
29 |
--------------------------------------------------------------------------------
/doccano_mini/pages/01_Text_Classification.py:
--------------------------------------------------------------------------------
1 | from typing import Dict, List
2 |
3 | import streamlit as st
4 |
5 | from doccano_mini.layout import BasePage
6 | from doccano_mini.prompts import make_classification_prompt
7 |
8 |
9 | class TextClassificationPage(BasePage):
10 | example_path = "text_classification.json"
11 |
12 | def make_prompt(self, examples: List[Dict]):
13 | return make_classification_prompt(examples)
14 |
15 | def prepare_inputs(self, columns: List[str]):
16 | return {"input": st.text_area(label="Please enter your text.", value="", height=300)}
17 |
18 |
19 | page = TextClassificationPage(title="Text Classification")
20 | page.render()
21 |
--------------------------------------------------------------------------------
/doccano_mini/pages/02_Question_Answering.py:
--------------------------------------------------------------------------------
1 | from typing import Dict, List
2 |
3 | import streamlit as st
4 |
5 | from doccano_mini.layout import BasePage
6 | from doccano_mini.prompts import make_question_answering_prompt
7 |
8 |
9 | class QuestionAnsweringPage(BasePage):
10 | example_path = "question_answering.json"
11 |
12 | def make_prompt(self, examples: List[Dict]):
13 | return make_question_answering_prompt(examples)
14 |
15 | def prepare_inputs(self, columns: List[str]):
16 | return {
17 | "context": st.text_area(label="Context.", value="", height=300),
18 | "question": st.text_input(label="Question.", value=""),
19 | }
20 |
21 |
22 | page = QuestionAnsweringPage(title="Question Answering")
23 | page.render()
24 |
--------------------------------------------------------------------------------
/doccano_mini/pages/03_Summarization.py:
--------------------------------------------------------------------------------
1 | from typing import Dict, List
2 |
3 | import streamlit as st
4 |
5 | from doccano_mini.layout import BasePage
6 | from doccano_mini.prompts import make_summarization_prompt
7 |
8 |
9 | class SummarizationPage(BasePage):
10 | example_path = "summarization.json"
11 |
12 | def make_prompt(self, examples: List[Dict]):
13 | return make_summarization_prompt(examples)
14 |
15 | def prepare_inputs(self, columns: List[str]):
16 | return {
17 | "passage": st.text_area(label="Passage.", value="", height=300),
18 | }
19 |
20 |
21 | page = SummarizationPage(title="Summarization")
22 | page.render()
23 |
--------------------------------------------------------------------------------
/doccano_mini/pages/04_Paraphrase.py:
--------------------------------------------------------------------------------
1 | from typing import Dict, List
2 |
3 | import streamlit as st
4 |
5 | from doccano_mini.layout import BasePage
6 | from doccano_mini.prompts import make_paraphrase_prompt
7 |
8 |
9 | class ParaphrasePage(BasePage):
10 | example_path = "paraphrase.json"
11 |
12 | def make_prompt(self, examples: List[Dict]):
13 | return make_paraphrase_prompt(examples)
14 |
15 | def prepare_inputs(self, columns: List[str]):
16 | return {
17 | "text": st.text_area(label="Text.", value="", height=300),
18 | }
19 |
20 |
21 | page = ParaphrasePage(title="Paraphrase")
22 | page.render()
23 |
--------------------------------------------------------------------------------
/doccano_mini/pages/05_Named_Entity_Recognition.py:
--------------------------------------------------------------------------------
1 | from typing import Dict, List
2 |
3 | import pandas as pd
4 | import streamlit as st
5 | from st_ner_annotate import st_ner_annotate
6 |
7 | from doccano_mini.layout import BasePage
8 | from doccano_mini.prompts import make_named_entity_recognition_prompt
9 | from doccano_mini.storages.entity import EntitySessionStorage
10 | from doccano_mini.storages.stepper import StepperSessionStorage
11 |
12 |
13 | class NamedEntityRecognitionPage(BasePage):
14 | example_path = "named_entity_recognition.json"
15 |
16 | def __init__(self, title: str) -> None:
17 | super().__init__(title)
18 | self.types: List[str] = []
19 | self.entity_repository = EntitySessionStorage()
20 | self.stepper_repository = StepperSessionStorage()
21 |
22 | def define_entity_types(self):
23 | st.subheader("Define entity types")
24 | default_types = pd.DataFrame([{"type": entity_type} for entity_type in ["ORG", "LOC", "PER"]])
25 | edited_df = st.experimental_data_editor(default_types, num_rows="dynamic", width=1000)
26 | types = edited_df["type"].values
27 | self.types = types
28 | return types
29 |
30 | def annotate(self, examples: List[Dict]) -> List[Dict]:
31 | if len(examples) == 0:
32 | return []
33 |
34 | types = self.define_entity_types()
35 | selected_type = st.selectbox("Select an entity type", types)
36 |
37 | col1, col2, _ = st.columns([1, 1, 8])
38 | col1.button("Prev", on_click=self.stepper_repository.decrement, args=(len(examples),))
39 | col2.button("Next", on_click=self.stepper_repository.increment, args=(len(examples),))
40 |
41 | self.stepper_repository.fit(len(examples))
42 | step = self.stepper_repository.get_step()
43 | text = examples[step]["text"]
44 | entities = self.entity_repository.find_by_text(text)
45 | entities = st_ner_annotate(selected_type, text, entities, key=text)
46 | self.entity_repository.store_by_text(text, entities)
47 | return examples
48 |
49 | def make_prompt(self, examples: List[Dict]):
50 | examples = [
51 | {**example, "entities": self.entity_repository.find_by_text(example["text"])} for example in examples
52 | ]
53 | return make_named_entity_recognition_prompt(examples, types=self.types)
54 |
55 | def prepare_inputs(self, columns: List[str]):
56 | return {"text": st.text_area(label="Please enter your text.", value="", height=300)}
57 |
58 |
59 | page = NamedEntityRecognitionPage(title="Named Entity Recognition")
60 | page.render()
61 |
--------------------------------------------------------------------------------
/doccano_mini/pages/06_(Beta)_Evaluation.py:
--------------------------------------------------------------------------------
1 | from collections import defaultdict
2 |
3 | import pandas as pd
4 | import streamlit as st
5 | from datasets import load_dataset
6 | from langchain.chains import LLMChain
7 | from more_itertools import interleave_longest
8 | from sklearn.metrics import classification_report
9 |
10 | from doccano_mini.components import openai_model_form, task_instruction_editor
11 | from doccano_mini.prompts import make_classification_prompt
12 | from doccano_mini.utils import escape_markdown
13 |
14 | AVAILABLE_DATASETS = ("imdb", "ag_news", "rotten_tomatoes")
15 |
16 |
17 | @st.cache_resource
18 | def prepare_dataset(dataset_id):
19 | # Loading dataset
20 | dataset = load_dataset(dataset_id, split="train")
21 | # Splitting dataset
22 | dataset = dataset.train_test_split(test_size=0.2, stratify_by_column="label", shuffle=True)
23 |
24 | # Preparing indices
25 | indices_by_label = defaultdict(list)
26 | for i, x in enumerate(dataset["train"]):
27 | indices_by_label[x["label"]].append(i)
28 |
29 | return dataset, list(interleave_longest(*indices_by_label.values()))
30 |
31 |
32 | st.title("Text Classification Evaluation on 🤗 datasets")
33 |
34 | st.header("Setup your data")
35 |
36 | dataset_id = st.selectbox("Select a dataset", options=AVAILABLE_DATASETS)
37 |
38 | dataset, train_indices = prepare_dataset(dataset_id)
39 |
40 | train_dataset = dataset["train"]
41 | validation_dataset = dataset["test"]
42 |
43 | label_info = train_dataset.features["label"]
44 | num_classes = label_info.num_classes
45 | few_shot_example_size = int(
46 | st.number_input("Number of examples", min_value=num_classes, max_value=num_classes * 5, value=num_classes)
47 | )
48 |
49 | subset = []
50 | for i in range(few_shot_example_size):
51 | example = train_dataset[train_indices[i]]
52 | subset.append({"text": example["text"], "label": label_info.int2str(example["label"])})
53 |
54 |
55 | df = pd.DataFrame(subset)
56 |
57 | st.write(df)
58 |
59 | prompt = make_classification_prompt(df.to_dict("records"))
60 | prompt = task_instruction_editor(prompt)
61 |
62 |
63 | st.header("Test")
64 | col1, col2 = st.columns([3, 1])
65 |
66 | with col1:
67 | inputs = {"input": st.text_area(label="Please enter your text.", value="", height=300)}
68 |
69 | with col2:
70 | llm = openai_model_form()
71 |
72 | with st.expander("See your prompt"):
73 | st.markdown(f"```\n{prompt.format(**inputs)}\n```")
74 |
75 | if llm is None:
76 | st.error("Enter your API key.")
77 |
78 | if st.button("Predict", disabled=llm is None):
79 | chain = LLMChain(llm=llm, prompt=prompt) # type:ignore
80 | response = chain.run(**inputs)
81 | st.markdown(escape_markdown(response).replace("\n", " \n"))
82 |
83 | st.subheader("Evaluation")
84 |
85 | evaluation_size = int(st.number_input("Number of examples", min_value=5, max_value=validation_dataset.dataset_size))
86 |
87 | if llm is None:
88 | st.error("Enter your API key.")
89 |
90 | if st.button("Evaluate", disabled=llm is None):
91 | chain = LLMChain(llm=llm, prompt=prompt) # type:ignore
92 | y_true = []
93 | y_pred = []
94 | for i in range(evaluation_size):
95 | example = validation_dataset[i]
96 | response = chain.run(input=example["text"])
97 | y_true.append(label_info.int2str(example["label"]))
98 | y_pred.append(response.split(":")[-1].strip())
99 |
100 | st.text(classification_report(y_true, y_pred, digits=3))
101 |
--------------------------------------------------------------------------------
/doccano_mini/pages/09_Task_Free.py:
--------------------------------------------------------------------------------
1 | from typing import Dict, List
2 |
3 | import streamlit as st
4 |
5 | from doccano_mini.layout import BasePage
6 | from doccano_mini.prompts import make_task_free_prompt
7 |
8 |
9 | class TaskFreePage(BasePage):
10 | @property
11 | def columns(self) -> List[str]:
12 | num_cols = st.number_input("Set the number of columns", min_value=2, max_value=10)
13 | columns = [st.text_input(f"Column {i + 1}:", value=f"column {i + 1}") for i in range(int(num_cols))]
14 | return columns
15 |
16 | def make_examples(self, columns: List[str]):
17 | df = self.load_examples("task_free.json")
18 | df = df.reindex(columns, axis="columns", fill_value="")
19 | edited_df = st.experimental_data_editor(df, num_rows="dynamic", width=1000)
20 | examples = edited_df.to_dict(orient="records")
21 | return examples
22 |
23 | def make_prompt(self, examples: List[Dict]):
24 | return make_task_free_prompt(examples)
25 |
26 | def prepare_inputs(self, columns: List[str]):
27 | return {column: st.text_area(label=f"Input for {column}:", value="", height=300) for column in columns[:-1]}
28 |
29 |
30 | page = TaskFreePage(title="Task Free")
31 | page.render()
32 |
--------------------------------------------------------------------------------
/doccano_mini/prompts.py:
--------------------------------------------------------------------------------
1 | import json
2 | from typing import List
3 |
4 | from langchain.prompts.few_shot import FewShotPromptTemplate
5 | from langchain.prompts.prompt import PromptTemplate
6 |
7 |
8 | def make_classification_prompt(examples: List[dict]) -> FewShotPromptTemplate:
9 | unique_labels = set([example["label"] for example in examples])
10 |
11 | task_instruction = "Classify the text into one of the following labels:\n"
12 | # Sorting to make label order deterministic
13 | for label in sorted(unique_labels):
14 | task_instruction += f"- {label}\n"
15 |
16 | example_prompt = PromptTemplate(input_variables=["text", "label"], template="text: {text}\nlabel: {label}")
17 | prompt = FewShotPromptTemplate(
18 | examples=examples,
19 | example_prompt=example_prompt,
20 | prefix=task_instruction,
21 | suffix="text: {input}",
22 | input_variables=["input"],
23 | )
24 | return prompt
25 |
26 |
27 | def make_question_answering_prompt(examples: List[dict]) -> FewShotPromptTemplate:
28 | task_instruction = (
29 | "You are a highly intelligent question answering bot. "
30 | "You take context and question as input and return the answer from the context. "
31 | "Retain as much information as needed to answer the question at a later time. "
32 | "If you don't know the answer, you should return N/A."
33 | )
34 |
35 | example_prompt = PromptTemplate(
36 | input_variables=["context", "question", "answer"],
37 | template="context: {context}\nquestion: {question}\nanswer: {answer}",
38 | )
39 | prompt = FewShotPromptTemplate(
40 | examples=examples,
41 | example_prompt=example_prompt,
42 | prefix=task_instruction,
43 | suffix="context: {context}\nquestion: {question}",
44 | input_variables=["context", "question"],
45 | )
46 | return prompt
47 |
48 |
49 | def make_summarization_prompt(examples: List[dict]) -> FewShotPromptTemplate:
50 | task_instruction = (
51 | "You are a highly intelligent Summarization system. "
52 | "You take Passage as input and summarize the passage as an expert."
53 | )
54 | example_prompt = PromptTemplate(
55 | input_variables=["passage", "summary"], template="passage: {passage}\nsummary: {summary}"
56 | )
57 | prompt = FewShotPromptTemplate(
58 | examples=examples,
59 | example_prompt=example_prompt,
60 | prefix=task_instruction,
61 | suffix="passage: {passage}",
62 | input_variables=["passage"],
63 | )
64 | return prompt
65 |
66 |
67 | def make_paraphrase_prompt(examples: List[dict]) -> FewShotPromptTemplate:
68 | task_instruction = (
69 | "You are a highly intelligent paraphrasing system. You take text as input and paraphrase it as an expert."
70 | )
71 | example_prompt = PromptTemplate(
72 | input_variables=["text", "paraphrase"], template="text: {text}\nparaphrase: {paraphrase}"
73 | )
74 | prompt = FewShotPromptTemplate(
75 | examples=examples,
76 | example_prompt=example_prompt,
77 | prefix=task_instruction,
78 | suffix="text: {text}",
79 | input_variables=["text"],
80 | )
81 | return prompt
82 |
83 |
84 | def make_task_free_prompt(examples: List[dict]) -> FewShotPromptTemplate:
85 | columns = list(examples[0])
86 |
87 | task_instruction = f"Predict {columns[-1]} based on {', '.join(columns[:-1])}."
88 | example_prompt = PromptTemplate(
89 | input_variables=columns, template="\n".join([f"{column}: {{{column}}}" for column in columns])
90 | )
91 |
92 | prompt = FewShotPromptTemplate(
93 | examples=examples,
94 | example_prompt=example_prompt,
95 | prefix=task_instruction,
96 | suffix="\n".join([f"{column}: {{{column}}}" for column in columns[:-1]]),
97 | input_variables=columns[:-1],
98 | )
99 | return prompt
100 |
101 |
102 | def make_named_entity_recognition_prompt(examples: List[dict], **kwargs) -> FewShotPromptTemplate:
103 | task_instruction = (
104 | "You are a highly intelligent and accurate Named-entity recognition(NER) system. "
105 | "You take Passage as input and your task is to recognize and extract specific types of "
106 | "named entities in that given passage and classify into a set of entity types.\n"
107 | )
108 | types = kwargs.get("types", [])
109 | task_instruction += "The following entity types are allowed:\n"
110 | for type in types:
111 | task_instruction += f"- {type}\n"
112 |
113 | for example in examples:
114 | entities = [
115 | {"mention": example["text"][entity["start"] : entity["end"]], "type": entity["label"]}
116 | for entity in example["entities"]
117 | ]
118 | example["entities"] = json.dumps(entities)
119 |
120 | example_prompt = PromptTemplate(
121 | input_variables=["text", "entities"],
122 | template="text: {text}\nentities: {entities}",
123 | )
124 | prompt = FewShotPromptTemplate(
125 | examples=examples,
126 | example_prompt=example_prompt,
127 | prefix=task_instruction,
128 | suffix="text: {{text}}",
129 | input_variables=["text"],
130 | template_format="jinja2",
131 | )
132 | return prompt
133 |
--------------------------------------------------------------------------------
/doccano_mini/storages/entity.py:
--------------------------------------------------------------------------------
1 | from collections import defaultdict
2 | from typing import List
3 |
4 | import streamlit as st
5 |
6 | from doccano_mini.models.entity import Entity
7 | from doccano_mini.storages.session_storage import SessionStorage
8 |
9 |
10 | class EntitySessionStorage:
11 | def __init__(self) -> None:
12 | self.storage = SessionStorage(state=st.session_state)
13 | self.storage.init_state("entities", defaultdict(list))
14 |
15 | def find_by_text(self, text: str) -> List[Entity]:
16 | entities = self.storage.get_state("entities")
17 | return entities.get(text, [])
18 |
19 | def store_by_text(self, text: str, entities: List[Entity]) -> None:
20 | current_entities = self.storage.get_state("entities")
21 | current_entities[text] = entities
22 | self.storage.set_state("entities", current_entities)
23 |
--------------------------------------------------------------------------------
/doccano_mini/storages/session_storage.py:
--------------------------------------------------------------------------------
1 | from typing import Any
2 |
3 | from streamlit.runtime.state import SessionStateProxy
4 |
5 |
6 | class SessionStorage:
7 | def __init__(self, state: SessionStateProxy) -> None:
8 | self.state = state
9 |
10 | def init_state(self, key: str, value: Any) -> None:
11 | if key not in self.state:
12 | self.state[key] = value
13 |
14 | def set_state(self, key: str, value: Any, *, do_init: bool = False) -> None:
15 | if do_init:
16 | self.init_state(key, value)
17 |
18 | self.state[key] = value
19 |
20 | def get_state(self, key: str) -> Any:
21 | return self.state.get(key, None)
22 |
--------------------------------------------------------------------------------
/doccano_mini/storages/stepper.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 |
3 | from doccano_mini.models.stepper import Stepper
4 | from doccano_mini.storages.session_storage import SessionStorage
5 |
6 |
7 | class StepperSessionStorage:
8 | def __init__(self) -> None:
9 | self.storage = SessionStorage(state=st.session_state)
10 | self.storage.init_state("step", 0)
11 |
12 | def get_step(self) -> int:
13 | return self.storage.get_state("step")
14 |
15 | def fit(self, total: int) -> None:
16 | step = self.storage.get_state("step")
17 | stepper = Stepper(step)
18 | stepper.fit(total)
19 | self.storage.set_state("step", stepper.step)
20 |
21 | def increment(self, total: int) -> None:
22 | step = self.storage.get_state("step")
23 | stepper = Stepper(step)
24 | stepper.increment(total)
25 | self.storage.set_state("step", stepper.step)
26 |
27 | def decrement(self, total: int) -> None:
28 | step = self.storage.get_state("step")
29 | stepper = Stepper(step)
30 | stepper.decrement(total)
31 | self.storage.set_state("step", stepper.step)
32 |
--------------------------------------------------------------------------------
/doccano_mini/utils.py:
--------------------------------------------------------------------------------
1 | import re
2 |
3 |
4 | def escape_markdown(text: str) -> str:
5 | # Brought from https://github.com/python-telegram-bot/python-telegram-bot/blob/v20.2/telegram/helpers.py#L66
6 | escape_chars = r"\_*[]()~`>#+-=|{}.!$"
7 | return re.sub(f"([{re.escape(escape_chars)}])", r"\\\1", text)
8 |
--------------------------------------------------------------------------------
/docs/CODE_OF_CONDUCT.md:
--------------------------------------------------------------------------------
1 | # Contributor Covenant Code of Conduct
2 |
3 | ## Our Pledge
4 |
5 | In the interest of fostering an open and welcoming environment, we as contributors and maintainers pledge to making participation in our project and our community a harassment-free experience for everyone, regardless of age, body size, disability, ethnicity, sex characteristics, gender identity and expression, level of experience, education, socio-economic status, nationality, personal appearance, race, religion, or sexual identity and orientation.
6 |
7 | ## Our Standards
8 |
9 | Examples of behavior that contributes to creating a positive environment
10 | include:
11 |
12 | * Using welcoming and inclusive language
13 | * Being respectful of differing viewpoints and experiences
14 | * Gracefully accepting constructive criticism
15 | * Focusing on what is best for the community
16 | * Showing empathy towards other community members
17 |
18 | Examples of unacceptable behavior by participants include:
19 |
20 | * The use of sexualized language or imagery and unwelcome sexual attention or advances
21 | * Trolling, insulting/derogatory comments, and personal or political attacks
22 | * Public or private harassment
23 | * Publishing others' private information, such as a physical or electronic address, without explicit permission
24 | * Other conduct which could reasonably be considered inappropriate in a professional setting
25 |
26 | ## Our Responsibilities
27 |
28 | Project maintainers are responsible for clarifying the standards of acceptable behavior and are expected to take appropriate and fair corrective action in response to any instances of unacceptable behavior.
29 |
30 | Project maintainers have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, or to ban temporarily or permanently any contributor for other behaviors that they deem inappropriate, threatening, offensive, or harmful.
31 |
32 | ## Scope
33 |
34 | This Code of Conduct applies both within project spaces and in public spaces when an individual is representing the project or its community. Examples of representing a project or community include using an official project e-mail address, posting via an official social media account, or acting as an appointed representative at an online or offline event. Representation of a project may be further defined and clarified by project maintainers.
35 |
36 | ## Enforcement
37 |
38 | Instances of abusive, harassing, or otherwise unacceptable behavior may be reported by contacting the project team at hiroki.nakayama.py@gmail.com. All complaints will be reviewed and investigated and will result in a response that is deemed necessary and appropriate to the circumstances. The project team is obligated to maintain confidentiality with regard to the reporter of an incident. Further details of specific enforcement policies may be posted separately.
39 |
40 | Project maintainers who do not follow or enforce the Code of Conduct in good faith may face temporary or permanent repercussions as determined by other members of the project's leadership.
41 |
42 | ## Attribution
43 |
44 | This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4, available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
45 |
46 | [homepage]: https://www.contributor-covenant.org
47 |
48 | For answers to common questions about this code of conduct, see https://www.contributor-covenant.org/faq
49 |
--------------------------------------------------------------------------------
/docs/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | # Contributing
2 |
3 | When contributing to this repository, please first discuss the change you wish to make via issue with the owners of this repository before making a change.
4 |
5 | Please note we have a code of conduct, please follow it in all your interactions with the project.
6 |
7 | ## How to contribute
8 |
9 | ### Reporting Bugs
10 |
11 | #### Before submitting a bug report
12 |
13 | * Ensure the bug was not already reported by searching on GitHub under [Issues](https://github.com/doccano/doccano-mini/issues).
14 | * [Open a new issue](https://github.com/doccano/doccano-mini/issues/new/choose) if you're unable to find an open one addressing the problem.
15 | * Use the relevant bug report templates to create the issue.
16 |
17 | #### How do I submit a good bug report?
18 |
19 | Explain the problem and include additional details to help maintainers reproduce the problem:
20 |
21 | * Use a clear and descriptive title for the issue to identify the problem.
22 | * Describe the exact steps which reproduce the problem in as many details as possible.
23 | * Provide specific examples to demonstrate the steps.
24 | * Describe the behavior you observed after following the steps and point out what exactly is the problem with that behavior.
25 | * Explain which behavior you expected to see instead and why.
26 | * Include screenshots and animated GIFs which show you following the described steps and clearly demonstrate the problem.
27 | * If the problem is related to performance or memory, include a CPU profile capture with your report.
28 | * If the problem is related to network, include a network activity in Chrome/Firefox/Safari DevTools.
29 | * If the problem wasn't triggered by a specific action, describe what you were doing before the problem happened and share more information using the guidelines below.
30 |
31 | ### Suggesting Enhancements
32 |
33 | #### Before submitting an enhancement suggestion
34 |
35 | * Ensure the suggestion was not already reported by searching on GitHub under [Issues](https://github.com/doccano/doccano-mini/issues).
36 | * [Open a new issue](https://github.com/doccano/doccano-mini/issues/new/choose) if you're unable to find an open one addressing the suggestion.
37 | * Use the relevant issue templates to create one.
38 |
39 | #### How do I submit a good enhancement suggestion?
40 |
41 | Explain the suggestion and include additional details to help developers understand it:
42 |
43 | * Use a clear and descriptive title for the issue to identify the suggestion.
44 | * Provide a step-by-step description of the suggested enhancement in as many details as possible.
45 | * Provide specific examples to demonstrate the steps.
46 | * Describe the current behavior and explain which behavior you expected to see instead and why.
47 | * Include screenshots and animated GIFs which help you demonstrate the steps or point out the part of doccano-mini which the suggestion is related to.
48 | * Explain why this enhancement would be useful to most users.
49 | * List some other annotation tools or applications where this enhancement exists.
50 | * Specify which version you're using.
51 | * Specify the name and version of the OS you're using.
52 |
53 | ## development workflow
54 |
55 | 1. **Fork the project & clone it locally:** Click the "Fork" button in the header of the [GitHub repository](https://github.com/doccano/doccano-mini), creating a copy of `doccano-mini` in your GitHub account. To get a working copy on your local machine, you have to clone your fork. Click the "Clone or Download" button in the right-hand side bar, then append its output to the `git clone` command.
56 |
57 | $ git clone https://github.com/YOUR_USERNAME/doccano-mini.git
58 |
59 | 1. **Create an upstream remote and sync your local copy:** Connect your local copy to the original "upstream" repository by adding it as a remote.
60 |
61 | $ cd doccano-mini
62 | $ git remote add upstream https://github.com:doccano/doccano-mini.git
63 |
64 | You should now have two remotes: read/write-able `origin` points to your GitHub fork, and a read-only `upstream` points to the original repo. Be sure to [keep your fork in sync](https://help.github.com/en/articles/syncing-a-fork) with the original, reducing the likelihood of merge conflicts later on.
65 |
66 | 1. **Create a branch for each piece of work:** Branch off `develop` for each bugfix or feature that you're working on. Give your branch a descriptive, meaningful name like `bugfix-for-issue-1234` or `improve-io-performance`, so others know at a glance what you're working on.
67 |
68 | $ git checkout develop
69 | $ git pull develop master && git push origin develop
70 | $ git checkout -b my-descriptive-branch-name
71 |
72 | At this point, you may want to install your version. It's usually best to do this within a dedicated virtual environment; We recomment to use `poetry`:
73 |
74 | $ poetry install
75 | $ poetry shell
76 |
77 | Then run the `streamlit` command to serve:
78 |
79 | $ streamlit run doccano_mini/app.py
80 |
81 | Now, you can access to the frontend at .
82 |
83 | 2. **Implement your changes:** Use your preferred text editor to modify the source code. Be sure to keep your changes focused and in scope, and follow the coding conventions described below! Document your code as you write it. Run your changes against any existing tests and add new ones as needed to validate your changes; make sure you don’t accidentally break existing functionality! Several common commands can be accessed via the `make`:
84 |
85 | $ make lint
86 |
87 | 3. **Push commits to your forked repository:** Group changes into atomic git commits, then push them to your `origin` repository. There's no need to wait until all changes are final before pushing — it's always good to have a backup, in case something goes wrong in your local copy.
88 |
89 | $ git push origin my-descriptive-branch-name
90 |
91 | 4. **Open a new Pull Request in GitHub:** When you're ready to submit your changes to the main repo, navigate to your forked repository on GitHub. Switch to your working branch then click "New pull request"; alternatively, if you recently pushed, you may see a banner at the top of the repo with a "Compare & pull request" button, which you can click on to initiate the same process. Fill out the PR template completely and clearly, confirm that the code "diff" is as expected, then submit the PR. A number of processes will run automatically via GitHub Workflows (see `.github/workflows/`); we'll want to make sure everything passes before the PR gets merged.
92 |
93 | 5. **Respond to any code review feedback:** At this point, @Hironsan will review your work and either request additional changes/clarification or approve your work. There may be some necessary back-and-forth; please do your best to be responsive. If you haven’t gotten a response in a week or so, please politely nudge him in the same thread — thanks in advance for your patience!
94 |
95 | ## Styleguides
96 |
97 | ### Git Commit Messages
98 |
99 | * Use the present tense ("Add feature" not "Added feature")
100 | * Use the imperative mood ("Move cursor to..." not "Moves cursor to...")
101 | * Limit the first line to 72 characters or less
102 | * Reference issues and pull requests liberally after the first line
103 |
--------------------------------------------------------------------------------
/docs/images/annotation.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/doccano/doccano-mini/0ef6c3368499eb172ff5c8c446d61c7f240baf8f/docs/images/annotation.gif
--------------------------------------------------------------------------------
/docs/images/copy_and_paste.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/doccano/doccano-mini/0ef6c3368499eb172ff5c8c446d61c7f240baf8f/docs/images/copy_and_paste.gif
--------------------------------------------------------------------------------
/docs/images/download_config.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/doccano/doccano-mini/0ef6c3368499eb172ff5c8c446d61c7f240baf8f/docs/images/download_config.jpg
--------------------------------------------------------------------------------
/docs/images/test_new_example.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/doccano/doccano-mini/0ef6c3368499eb172ff5c8c446d61c7f240baf8f/docs/images/test_new_example.jpg
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [tool.poetry]
2 | name = "doccano-mini"
3 | version = "0.0.10"
4 | description = "Annotation meets Large Language Models."
5 | authors = ["Hironsan "]
6 | license = "MIT"
7 | readme = "README.md"
8 | homepage = "https://github.com/doccano/doccano-mini"
9 | repository = "https://github.com/doccano/doccano-mini"
10 | classifiers = [
11 | "Programming Language :: Python",
12 | "Programming Language :: Python :: 3.8",
13 | "Programming Language :: Python :: 3.9",
14 | "Programming Language :: Python :: 3.10",
15 | ]
16 |
17 | [tool.poetry.scripts]
18 | doccano-mini = 'doccano_mini.cli:main'
19 |
20 | [tool.poetry.dependencies]
21 | python = ">=3.8.1,<3.9.7 || >3.9.7,<4.0"
22 | streamlit = "^1.20.0"
23 | langchain = "^0.0.113"
24 | openai = "^0.27.2"
25 | st-ner-annotate = "^0.1.0"
26 | scikit-learn = "^1.2.2"
27 | datasets = "^2.11.0"
28 | more-itertools = "^9.1.0"
29 |
30 | [tool.poetry.dev-dependencies]
31 | taskipy = "^1.10.3"
32 | black = "^23.1.0"
33 | isort = "^5.12.0"
34 | mypy = "^1.1.1"
35 | pyproject-flake8 = "^6.0.0"
36 | pytest = "^7.2.2"
37 | pytest-cov = "^4.0.0"
38 |
39 | [build-system]
40 | requires = ["poetry-core>=1.0.0"]
41 | build-backend = "poetry.core.masonry.api"
42 |
43 | [tool.black]
44 | line-length = 120
45 | target-version = ['py38', 'py39']
46 | include = '\.pyi?$'
47 |
48 | [tool.flake8]
49 | max-line-length = 120
50 | max-complexity = 18
51 | ignore = "E203,E266,W503,"
52 | filename = "*.py"
53 |
54 | [tool.mypy]
55 | python_version = "3.8"
56 | ignore_missing_imports = true
57 | show_error_codes = true
58 |
59 | [tool.isort]
60 | profile = "black"
61 | include_trailing_comma = true
62 | multi_line_output = 3
63 |
64 | [tool.pytest.ini_options]
65 | testpaths = [
66 | "tests",
67 | ]
68 |
69 | [tool.taskipy.tasks]
70 | isort = "isort . -c --skip migrations"
71 | flake8 = "pflake8 --filename \"*.py\""
72 | black = "black --check ."
73 | mypy = "mypy ."
74 | test = "pytest --cov=doccano_mini --cov-report=term-missing -vv"
75 |
--------------------------------------------------------------------------------
/tests/test_prompts.py:
--------------------------------------------------------------------------------
1 | from doccano_mini.prompts import make_classification_prompt, make_task_free_prompt
2 |
3 |
4 | def test_make_classification_prompt():
5 | examples = [
6 | {"text": "That would be awesome!", "label": "positive"},
7 | {"text": "This is awful!", "label": "negative"},
8 | ]
9 |
10 | expected = """\
11 | Classify the text into one of the following labels:
12 | - negative
13 | - positive
14 |
15 |
16 | text: That would be awesome!
17 | label: positive
18 |
19 | text: This is awful!
20 | label: negative
21 |
22 | text: It's very hot."""
23 |
24 | input_text = "It's very hot."
25 |
26 | prompt = make_classification_prompt(examples)
27 |
28 | assert prompt.format(input=input_text) == expected
29 |
30 |
31 | def test_make_task_free_prompt():
32 | examples = [
33 | {"English": "I like sushi.", "Japanese": "寿司が好きです。"},
34 | {"English": "I live in Japan.", "Japanese": "日本に住んでいます。"},
35 | ]
36 |
37 | expected = """\
38 | Predict Japanese based on English.
39 |
40 | English: I like sushi.
41 | Japanese: 寿司が好きです。
42 |
43 | English: I live in Japan.
44 | Japanese: 日本に住んでいます。
45 |
46 | English: I'm developing doccano-mini."""
47 |
48 | english_text = "I'm developing doccano-mini."
49 |
50 | prompt = make_task_free_prompt(examples)
51 |
52 | assert prompt.format(English=english_text) == expected
53 |
--------------------------------------------------------------------------------
53 |
54 | ### Step3: Download the config
55 |
56 | In this step, we will download the [LangChain](https://github.com/hwchase17/langchain)'s config. We can click the `Download` button to download it. After loading the config file, we can predict a label for the new text.
57 |
58 | ```python
59 | from langchain.chains import load_chain
60 |
61 | chain = load_chain("chain.yaml")
62 | chain.run("YOUR TEXT")
63 | ```
64 |
65 | ## Development
66 |
67 | ```bash
68 | poetry install
69 | streamlit run doccano_mini/home.py
70 | ```
71 |
--------------------------------------------------------------------------------
/doccano_mini/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/doccano/doccano-mini/0ef6c3368499eb172ff5c8c446d61c7f240baf8f/doccano_mini/__init__.py
--------------------------------------------------------------------------------
/doccano_mini/cli.py:
--------------------------------------------------------------------------------
1 | import sys
2 | from pathlib import Path
3 |
4 | import streamlit.web.cli as stcli
5 |
6 |
7 | def main():
8 | filepath = str(Path(__file__).parent.resolve() / "home.py")
9 | sys.argv = ["streamlit", "run", filepath, "--global.developmentMode=false"]
10 | sys.exit(stcli.main())
11 |
12 |
13 | if __name__ == "__main__":
14 | main()
15 |
--------------------------------------------------------------------------------
/doccano_mini/components.py:
--------------------------------------------------------------------------------
1 | import os
2 | from pathlib import Path
3 | from typing import Optional
4 |
5 | import streamlit as st
6 | from langchain.llms import OpenAI
7 | from langchain.prompts.few_shot import FewShotPromptTemplate
8 | from langchain.schema import BaseLanguageModel
9 |
10 |
11 | def display_download_button():
12 | st.header("Download a config file")
13 | with open("config.yaml", "r", encoding="utf-8") as f:
14 | st.download_button(
15 | label="Download",
16 | data=f,
17 | file_name="config.yaml",
18 | )
19 |
20 |
21 | def usage():
22 | st.header("Usage")
23 | filepath = Path(__file__).parent.resolve() / "docs" / "usage.md"
24 | with filepath.open("r", encoding="utf-8") as f:
25 | st.markdown(f.read())
26 |
27 |
28 | def task_instruction_editor(prompt: FewShotPromptTemplate) -> FewShotPromptTemplate:
29 | st.header("Edit instruction")
30 | with st.expander("See instruction"):
31 | prompt.prefix = st.text_area(label="Enter task instruction", value=prompt.prefix, height=200)
32 | return prompt
33 |
34 |
35 | def openai_model_form() -> Optional[BaseLanguageModel]:
36 | # https://platform.openai.com/docs/models/gpt-3-5
37 | AVAILABLE_MODELS = (
38 | "gpt-3.5-turbo",
39 | "gpt-3.5-turbo-0301",
40 | "text-davinci-003",
41 | "text-davinci-002",
42 | "code-davinci-002",
43 | )
44 | api_key = st.text_input("API key", value=os.environ.get("OPENAI_API_KEY", ""), type="password")
45 | model_name = st.selectbox("Model", AVAILABLE_MODELS, index=2)
46 | temperature = st.slider("Temperature", min_value=0.0, max_value=1.0, value=0.7, step=0.01)
47 | top_p = st.slider("Top-p", min_value=0.0, max_value=1.0, value=1.0, step=0.01)
48 | if not api_key:
49 | return None
50 | return OpenAI(model_name=model_name, temperature=temperature, top_p=top_p, openai_api_key=api_key) # type:ignore
51 |
--------------------------------------------------------------------------------
/doccano_mini/docs/usage.md:
--------------------------------------------------------------------------------
1 | ```python
2 | from langchain.chains import load_chain
3 |
4 | chain = load_chain("chain.yaml")
5 | chain.run("YOUR TEXT")
6 | ```
--------------------------------------------------------------------------------
/doccano_mini/examples/named_entity_recognition.json:
--------------------------------------------------------------------------------
1 | [
2 | {"text": "EU rejects German call to boycott British lamb."},
3 | {"text": "Peter Blackburn"},
4 | {"text": "BRUSSELS 1996-08-22"}
5 | ]
--------------------------------------------------------------------------------
/doccano_mini/examples/paraphrase.json:
--------------------------------------------------------------------------------
1 | [
2 | {
3 | "text": "Amrozi accused his brother, whom he called \"the witness\", of deliberately distorting his evidence.",
4 | "paraphrase": "Referring to him as only \"the witness\", Amrozi accused his brother of deliberately distorting his evidence.'"
5 | },
6 | {
7 | "text": "Yucaipa owned Dominick's before selling the chain to Safeway in 1998 for $2.5 billion.",
8 | "paraphrase": "Yucaipa bought Dominick's in 1995 for $693 million and sold it to Safeway for $1.8 billion in 1998."
9 | }
10 | ]
--------------------------------------------------------------------------------
/doccano_mini/examples/question_answering.json:
--------------------------------------------------------------------------------
1 | [
2 | {
3 | "context": "Google was founded by computer scientists Larry Page and Sergey Brin.",
4 | "question": "Who founded Google?",
5 | "answer": "Larry Page and Sergey Brin"
6 | }
7 | ]
--------------------------------------------------------------------------------
/doccano_mini/examples/summarization.json:
--------------------------------------------------------------------------------
1 | [
2 | {
3 | "passage": "WASHINGTON (CNN) -- Vice President Dick Cheney will serve as acting president briefly Saturday while President Bush is anesthetized for a routine colonoscopy, White House spokesman Tony Snow said Friday. Bush is scheduled to have the medical procedure, expected to take about 2 1/2 hours, at the presidential retreat at Camp David, Maryland, Snow said. Bush's last colonoscopy was in June 2002, and no abnormalities were found, Snow said. The president's doctor had recommended a repeat procedure in about five years. The procedure will be supervised by Dr. Richard Tubb and conducted by a multidisciplinary team from the National Naval Medical Center in Bethesda, Maryland, Snow said. A colonoscopy is the most sensitive test for colon cancer, rectal cancer and polyps, small clumps of cells that can become cancerous, according to the Mayo Clinic. Small polyps may be removed during the procedure. Snow said that was the case when Bush had colonoscopies before becoming president. Snow himself is undergoing chemotherapy for cancer that began in his colon and spread to his liver. Snow told reporters he had a chemo session scheduled later Friday. Watch Snow talk about Bush's procedure and his own colon cancer » . \"The president wants to encourage everybody to use surveillance,\" Snow said. The American Cancer Society recommends that people without high-risk factors or symptoms begin getting screened for signs of colorectal cancer at age 50. E-mail to a friend .",
4 | "summary": "President Bush will have a routine colonoscopy Saturday. While he's anesthetized, his powers will be transferred to the vice president. Bush had last colonoscopy in 2002, which found no problems."
5 | },
6 | {
7 | "passage": "LONDON, England (Reuters) -- Harry Potter star Daniel Radcliffe gains access to a reported £20 million ($41.1 million) fortune as he turns 18 on Monday, but he insists the money won't cast a spell on him. Daniel Radcliffe as Harry Potter in \"Harry Potter and the Order of the Phoenix\" To the disappointment of gossip columnists around the world, the young actor says he has no plans to fritter his cash away on fast cars, drink and celebrity parties. \"I don't plan to be one of those people who, as soon as they turn 18, suddenly buy themselves a massive sports car collection or something similar,\" he told an Australian interviewer earlier this month. \"I don't think I'll be particularly extravagant. \"The things I like buying are things that cost about 10 pounds -- books and CDs and DVDs.\" At 18, Radcliffe will be able to gamble in a casino, buy a drink in a pub or see the horror film \"Hostel: Part II,\" currently six places below his number one movie on the UK box office chart. Details of how he'll mark his landmark birthday are under wraps. His agent and publicist had no comment on his plans. \"I'll definitely have some sort of party,\" he said in an interview. \"Hopefully none of you will be reading about it.\" Radcliffe's earnings from the first five Potter films have been held in a trust fund which he has not been able to touch. Despite his growing fame and riches, the actor says he is keeping his feet firmly on the ground. \"People are always looking to say 'kid star goes off the rails,'\" he told reporters last month. \"But I try very hard not to go that way because it would be too easy for them.\" His latest outing as the boy wizard in \"Harry Potter and the Order of the Phoenix\" is breaking records on both sides of the Atlantic and he will reprise the role in the last two films. Watch I-Reporter give her review of Potter's latest » . There is life beyond Potter, however. The Londoner has filmed a TV movie called \"My Boy Jack,\" about author Rudyard Kipling and his son, due for release later this year. He will also appear in \"December Boys,\" an Australian film about four boys who escape an orphanage. Earlier this year, he made his stage debut playing a tortured teenager in Peter Shaffer's \"Equus.\" Meanwhile, he is braced for even closer media scrutiny now that he's legally an adult: \"I just think I'm going to be more sort of fair game,\" he told Reuters. E-mail to a friend . Copyright 2007 Reuters. All rights reserved.This material may not be published, broadcast, rewritten, or redistributed.",
8 | "summary": "Harry Potter star Daniel Radcliffe gets £20M fortune as he turns 18 Monday . Young actor says he has no plans to fritter his cash away . Radcliffe's earnings from first five Potter films have been held in trust fund ."
9 | }
10 | ]
--------------------------------------------------------------------------------
/doccano_mini/examples/task_free.json:
--------------------------------------------------------------------------------
1 | [{"Column 1": "", "Column 2": ""}]
--------------------------------------------------------------------------------
/doccano_mini/examples/text_classification.json:
--------------------------------------------------------------------------------
1 | [
2 | {"text": "That would be awesome!", "label": "positive"},
3 | {"text": "This is awful!", "label": "negative"},
4 | {"text": "Today is hot day.", "label": "neutral"}
5 | ]
--------------------------------------------------------------------------------
/doccano_mini/home.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 |
3 | import streamlit as st
4 |
5 |
6 | def main():
7 | st.set_page_config(page_title="doccano-mini", page_icon=":memo:")
8 | filepath = Path(__file__).parent.resolve() / "docs" / "README.md"
9 |
10 | # Development
11 | if not filepath.exists():
12 | filepath = Path(__file__).parent.parent.resolve() / "README.md"
13 |
14 | with filepath.open("r", encoding="utf-8") as f:
15 | st.markdown(f.read(), unsafe_allow_html=True)
16 |
17 |
18 | if __name__ == "__main__":
19 | main()
20 |
--------------------------------------------------------------------------------
/doccano_mini/layout.py:
--------------------------------------------------------------------------------
1 | from abc import ABC, abstractmethod
2 | from pathlib import Path
3 | from typing import Dict, List
4 |
5 | import pandas as pd
6 | import streamlit as st
7 | from langchain.chains import LLMChain
8 | from langchain.prompts.few_shot import FewShotPromptTemplate
9 |
10 | from doccano_mini.components import (
11 | display_download_button,
12 | openai_model_form,
13 | task_instruction_editor,
14 | usage,
15 | )
16 | from doccano_mini.utils import escape_markdown
17 |
18 |
19 | class BasePage(ABC):
20 | example_path: str = ""
21 |
22 | def __init__(self, title: str) -> None:
23 | self.title = title
24 |
25 | @property
26 | def columns(self) -> List[str]:
27 | return []
28 |
29 | def load_examples(self, filename: str) -> pd.DataFrame:
30 | filepath = Path(__file__).parent.resolve().joinpath("examples", filename)
31 | return pd.read_json(filepath)
32 |
33 | def make_examples(self, columns: List[str]) -> List[Dict]:
34 | df = self.load_examples(self.example_path)
35 | edited_df = st.experimental_data_editor(df, num_rows="dynamic", width=1000)
36 | examples = edited_df.to_dict(orient="records")
37 | return examples
38 |
39 | @abstractmethod
40 | def make_prompt(self, examples: List[Dict]) -> FewShotPromptTemplate:
41 | raise NotImplementedError()
42 |
43 | @abstractmethod
44 | def prepare_inputs(self, columns: List[str]) -> Dict:
45 | raise NotImplementedError()
46 |
47 | def annotate(self, examples: List[Dict]) -> List[Dict]:
48 | return examples
49 |
50 | def render(self) -> None:
51 | st.title(self.title)
52 | st.header("Annotate your data")
53 | columns = self.columns
54 | examples = self.make_examples(columns)
55 | examples = self.annotate(examples)
56 |
57 | prompt = self.make_prompt(examples)
58 | prompt = task_instruction_editor(prompt)
59 |
60 | st.header("Test")
61 | col1, col2 = st.columns([3, 1])
62 |
63 | with col1:
64 | inputs = self.prepare_inputs(columns)
65 |
66 | with col2:
67 | llm = openai_model_form()
68 |
69 | with st.expander("See your prompt"):
70 | st.markdown(f"```\n{prompt.format(**inputs)}\n```")
71 |
72 | if llm is None:
73 | st.error("Enter your API key.")
74 |
75 | if st.button("Predict", disabled=llm is None):
76 | chain = LLMChain(llm=llm, prompt=prompt) # type:ignore
77 | response = chain.run(**inputs)
78 | st.markdown(escape_markdown(response).replace("\n", " \n"))
79 |
80 | chain.save("config.yaml")
81 | display_download_button()
82 | usage()
83 |
--------------------------------------------------------------------------------
/doccano_mini/models/entity.py:
--------------------------------------------------------------------------------
1 | from typing import TypedDict
2 |
3 |
4 | class Entity(TypedDict):
5 | start: int
6 | end: int
7 | label: str
8 |
--------------------------------------------------------------------------------
/doccano_mini/models/stepper.py:
--------------------------------------------------------------------------------
1 | class Stepper:
2 | def __init__(self, step=0):
3 | self._step = step
4 |
5 | @property
6 | def step(self) -> int:
7 | return self._step
8 |
9 | def fit(self, total: int):
10 | if self._step >= total:
11 | self._step = total - 1
12 |
13 | def at(self, step: int, total: int):
14 | if step >= total:
15 | raise ValueError(f"step must be less than {total}")
16 | if step < 0:
17 | raise ValueError("step must be greater than 0")
18 | self._step = step
19 |
20 | def increment(self, total: int):
21 | self._step += 1
22 | if self._step >= total:
23 | self._step = 0
24 |
25 | def decrement(self, total: int):
26 | self._step -= 1
27 | if self._step < 0:
28 | self._step = total - 1
29 |
--------------------------------------------------------------------------------
/doccano_mini/pages/01_Text_Classification.py:
--------------------------------------------------------------------------------
1 | from typing import Dict, List
2 |
3 | import streamlit as st
4 |
5 | from doccano_mini.layout import BasePage
6 | from doccano_mini.prompts import make_classification_prompt
7 |
8 |
9 | class TextClassificationPage(BasePage):
10 | example_path = "text_classification.json"
11 |
12 | def make_prompt(self, examples: List[Dict]):
13 | return make_classification_prompt(examples)
14 |
15 | def prepare_inputs(self, columns: List[str]):
16 | return {"input": st.text_area(label="Please enter your text.", value="", height=300)}
17 |
18 |
19 | page = TextClassificationPage(title="Text Classification")
20 | page.render()
21 |
--------------------------------------------------------------------------------
/doccano_mini/pages/02_Question_Answering.py:
--------------------------------------------------------------------------------
1 | from typing import Dict, List
2 |
3 | import streamlit as st
4 |
5 | from doccano_mini.layout import BasePage
6 | from doccano_mini.prompts import make_question_answering_prompt
7 |
8 |
9 | class QuestionAnsweringPage(BasePage):
10 | example_path = "question_answering.json"
11 |
12 | def make_prompt(self, examples: List[Dict]):
13 | return make_question_answering_prompt(examples)
14 |
15 | def prepare_inputs(self, columns: List[str]):
16 | return {
17 | "context": st.text_area(label="Context.", value="", height=300),
18 | "question": st.text_input(label="Question.", value=""),
19 | }
20 |
21 |
22 | page = QuestionAnsweringPage(title="Question Answering")
23 | page.render()
24 |
--------------------------------------------------------------------------------
/doccano_mini/pages/03_Summarization.py:
--------------------------------------------------------------------------------
1 | from typing import Dict, List
2 |
3 | import streamlit as st
4 |
5 | from doccano_mini.layout import BasePage
6 | from doccano_mini.prompts import make_summarization_prompt
7 |
8 |
9 | class SummarizationPage(BasePage):
10 | example_path = "summarization.json"
11 |
12 | def make_prompt(self, examples: List[Dict]):
13 | return make_summarization_prompt(examples)
14 |
15 | def prepare_inputs(self, columns: List[str]):
16 | return {
17 | "passage": st.text_area(label="Passage.", value="", height=300),
18 | }
19 |
20 |
21 | page = SummarizationPage(title="Summarization")
22 | page.render()
23 |
--------------------------------------------------------------------------------
/doccano_mini/pages/04_Paraphrase.py:
--------------------------------------------------------------------------------
1 | from typing import Dict, List
2 |
3 | import streamlit as st
4 |
5 | from doccano_mini.layout import BasePage
6 | from doccano_mini.prompts import make_paraphrase_prompt
7 |
8 |
9 | class ParaphrasePage(BasePage):
10 | example_path = "paraphrase.json"
11 |
12 | def make_prompt(self, examples: List[Dict]):
13 | return make_paraphrase_prompt(examples)
14 |
15 | def prepare_inputs(self, columns: List[str]):
16 | return {
17 | "text": st.text_area(label="Text.", value="", height=300),
18 | }
19 |
20 |
21 | page = ParaphrasePage(title="Paraphrase")
22 | page.render()
23 |
--------------------------------------------------------------------------------
/doccano_mini/pages/05_Named_Entity_Recognition.py:
--------------------------------------------------------------------------------
1 | from typing import Dict, List
2 |
3 | import pandas as pd
4 | import streamlit as st
5 | from st_ner_annotate import st_ner_annotate
6 |
7 | from doccano_mini.layout import BasePage
8 | from doccano_mini.prompts import make_named_entity_recognition_prompt
9 | from doccano_mini.storages.entity import EntitySessionStorage
10 | from doccano_mini.storages.stepper import StepperSessionStorage
11 |
12 |
13 | class NamedEntityRecognitionPage(BasePage):
14 | example_path = "named_entity_recognition.json"
15 |
16 | def __init__(self, title: str) -> None:
17 | super().__init__(title)
18 | self.types: List[str] = []
19 | self.entity_repository = EntitySessionStorage()
20 | self.stepper_repository = StepperSessionStorage()
21 |
22 | def define_entity_types(self):
23 | st.subheader("Define entity types")
24 | default_types = pd.DataFrame([{"type": entity_type} for entity_type in ["ORG", "LOC", "PER"]])
25 | edited_df = st.experimental_data_editor(default_types, num_rows="dynamic", width=1000)
26 | types = edited_df["type"].values
27 | self.types = types
28 | return types
29 |
30 | def annotate(self, examples: List[Dict]) -> List[Dict]:
31 | if len(examples) == 0:
32 | return []
33 |
34 | types = self.define_entity_types()
35 | selected_type = st.selectbox("Select an entity type", types)
36 |
37 | col1, col2, _ = st.columns([1, 1, 8])
38 | col1.button("Prev", on_click=self.stepper_repository.decrement, args=(len(examples),))
39 | col2.button("Next", on_click=self.stepper_repository.increment, args=(len(examples),))
40 |
41 | self.stepper_repository.fit(len(examples))
42 | step = self.stepper_repository.get_step()
43 | text = examples[step]["text"]
44 | entities = self.entity_repository.find_by_text(text)
45 | entities = st_ner_annotate(selected_type, text, entities, key=text)
46 | self.entity_repository.store_by_text(text, entities)
47 | return examples
48 |
49 | def make_prompt(self, examples: List[Dict]):
50 | examples = [
51 | {**example, "entities": self.entity_repository.find_by_text(example["text"])} for example in examples
52 | ]
53 | return make_named_entity_recognition_prompt(examples, types=self.types)
54 |
55 | def prepare_inputs(self, columns: List[str]):
56 | return {"text": st.text_area(label="Please enter your text.", value="", height=300)}
57 |
58 |
59 | page = NamedEntityRecognitionPage(title="Named Entity Recognition")
60 | page.render()
61 |
--------------------------------------------------------------------------------
/doccano_mini/pages/06_(Beta)_Evaluation.py:
--------------------------------------------------------------------------------
1 | from collections import defaultdict
2 |
3 | import pandas as pd
4 | import streamlit as st
5 | from datasets import load_dataset
6 | from langchain.chains import LLMChain
7 | from more_itertools import interleave_longest
8 | from sklearn.metrics import classification_report
9 |
10 | from doccano_mini.components import openai_model_form, task_instruction_editor
11 | from doccano_mini.prompts import make_classification_prompt
12 | from doccano_mini.utils import escape_markdown
13 |
14 | AVAILABLE_DATASETS = ("imdb", "ag_news", "rotten_tomatoes")
15 |
16 |
17 | @st.cache_resource
18 | def prepare_dataset(dataset_id):
19 | # Loading dataset
20 | dataset = load_dataset(dataset_id, split="train")
21 | # Splitting dataset
22 | dataset = dataset.train_test_split(test_size=0.2, stratify_by_column="label", shuffle=True)
23 |
24 | # Preparing indices
25 | indices_by_label = defaultdict(list)
26 | for i, x in enumerate(dataset["train"]):
27 | indices_by_label[x["label"]].append(i)
28 |
29 | return dataset, list(interleave_longest(*indices_by_label.values()))
30 |
31 |
32 | st.title("Text Classification Evaluation on 🤗 datasets")
33 |
34 | st.header("Setup your data")
35 |
36 | dataset_id = st.selectbox("Select a dataset", options=AVAILABLE_DATASETS)
37 |
38 | dataset, train_indices = prepare_dataset(dataset_id)
39 |
40 | train_dataset = dataset["train"]
41 | validation_dataset = dataset["test"]
42 |
43 | label_info = train_dataset.features["label"]
44 | num_classes = label_info.num_classes
45 | few_shot_example_size = int(
46 | st.number_input("Number of examples", min_value=num_classes, max_value=num_classes * 5, value=num_classes)
47 | )
48 |
49 | subset = []
50 | for i in range(few_shot_example_size):
51 | example = train_dataset[train_indices[i]]
52 | subset.append({"text": example["text"], "label": label_info.int2str(example["label"])})
53 |
54 |
55 | df = pd.DataFrame(subset)
56 |
57 | st.write(df)
58 |
59 | prompt = make_classification_prompt(df.to_dict("records"))
60 | prompt = task_instruction_editor(prompt)
61 |
62 |
63 | st.header("Test")
64 | col1, col2 = st.columns([3, 1])
65 |
66 | with col1:
67 | inputs = {"input": st.text_area(label="Please enter your text.", value="", height=300)}
68 |
69 | with col2:
70 | llm = openai_model_form()
71 |
72 | with st.expander("See your prompt"):
73 | st.markdown(f"```\n{prompt.format(**inputs)}\n```")
74 |
75 | if llm is None:
76 | st.error("Enter your API key.")
77 |
78 | if st.button("Predict", disabled=llm is None):
79 | chain = LLMChain(llm=llm, prompt=prompt) # type:ignore
80 | response = chain.run(**inputs)
81 | st.markdown(escape_markdown(response).replace("\n", " \n"))
82 |
83 | st.subheader("Evaluation")
84 |
85 | evaluation_size = int(st.number_input("Number of examples", min_value=5, max_value=validation_dataset.dataset_size))
86 |
87 | if llm is None:
88 | st.error("Enter your API key.")
89 |
90 | if st.button("Evaluate", disabled=llm is None):
91 | chain = LLMChain(llm=llm, prompt=prompt) # type:ignore
92 | y_true = []
93 | y_pred = []
94 | for i in range(evaluation_size):
95 | example = validation_dataset[i]
96 | response = chain.run(input=example["text"])
97 | y_true.append(label_info.int2str(example["label"]))
98 | y_pred.append(response.split(":")[-1].strip())
99 |
100 | st.text(classification_report(y_true, y_pred, digits=3))
101 |
--------------------------------------------------------------------------------
/doccano_mini/pages/09_Task_Free.py:
--------------------------------------------------------------------------------
1 | from typing import Dict, List
2 |
3 | import streamlit as st
4 |
5 | from doccano_mini.layout import BasePage
6 | from doccano_mini.prompts import make_task_free_prompt
7 |
8 |
9 | class TaskFreePage(BasePage):
10 | @property
11 | def columns(self) -> List[str]:
12 | num_cols = st.number_input("Set the number of columns", min_value=2, max_value=10)
13 | columns = [st.text_input(f"Column {i + 1}:", value=f"column {i + 1}") for i in range(int(num_cols))]
14 | return columns
15 |
16 | def make_examples(self, columns: List[str]):
17 | df = self.load_examples("task_free.json")
18 | df = df.reindex(columns, axis="columns", fill_value="")
19 | edited_df = st.experimental_data_editor(df, num_rows="dynamic", width=1000)
20 | examples = edited_df.to_dict(orient="records")
21 | return examples
22 |
23 | def make_prompt(self, examples: List[Dict]):
24 | return make_task_free_prompt(examples)
25 |
26 | def prepare_inputs(self, columns: List[str]):
27 | return {column: st.text_area(label=f"Input for {column}:", value="", height=300) for column in columns[:-1]}
28 |
29 |
30 | page = TaskFreePage(title="Task Free")
31 | page.render()
32 |
--------------------------------------------------------------------------------
/doccano_mini/prompts.py:
--------------------------------------------------------------------------------
1 | import json
2 | from typing import List
3 |
4 | from langchain.prompts.few_shot import FewShotPromptTemplate
5 | from langchain.prompts.prompt import PromptTemplate
6 |
7 |
8 | def make_classification_prompt(examples: List[dict]) -> FewShotPromptTemplate:
9 | unique_labels = set([example["label"] for example in examples])
10 |
11 | task_instruction = "Classify the text into one of the following labels:\n"
12 | # Sorting to make label order deterministic
13 | for label in sorted(unique_labels):
14 | task_instruction += f"- {label}\n"
15 |
16 | example_prompt = PromptTemplate(input_variables=["text", "label"], template="text: {text}\nlabel: {label}")
17 | prompt = FewShotPromptTemplate(
18 | examples=examples,
19 | example_prompt=example_prompt,
20 | prefix=task_instruction,
21 | suffix="text: {input}",
22 | input_variables=["input"],
23 | )
24 | return prompt
25 |
26 |
27 | def make_question_answering_prompt(examples: List[dict]) -> FewShotPromptTemplate:
28 | task_instruction = (
29 | "You are a highly intelligent question answering bot. "
30 | "You take context and question as input and return the answer from the context. "
31 | "Retain as much information as needed to answer the question at a later time. "
32 | "If you don't know the answer, you should return N/A."
33 | )
34 |
35 | example_prompt = PromptTemplate(
36 | input_variables=["context", "question", "answer"],
37 | template="context: {context}\nquestion: {question}\nanswer: {answer}",
38 | )
39 | prompt = FewShotPromptTemplate(
40 | examples=examples,
41 | example_prompt=example_prompt,
42 | prefix=task_instruction,
43 | suffix="context: {context}\nquestion: {question}",
44 | input_variables=["context", "question"],
45 | )
46 | return prompt
47 |
48 |
49 | def make_summarization_prompt(examples: List[dict]) -> FewShotPromptTemplate:
50 | task_instruction = (
51 | "You are a highly intelligent Summarization system. "
52 | "You take Passage as input and summarize the passage as an expert."
53 | )
54 | example_prompt = PromptTemplate(
55 | input_variables=["passage", "summary"], template="passage: {passage}\nsummary: {summary}"
56 | )
57 | prompt = FewShotPromptTemplate(
58 | examples=examples,
59 | example_prompt=example_prompt,
60 | prefix=task_instruction,
61 | suffix="passage: {passage}",
62 | input_variables=["passage"],
63 | )
64 | return prompt
65 |
66 |
67 | def make_paraphrase_prompt(examples: List[dict]) -> FewShotPromptTemplate:
68 | task_instruction = (
69 | "You are a highly intelligent paraphrasing system. You take text as input and paraphrase it as an expert."
70 | )
71 | example_prompt = PromptTemplate(
72 | input_variables=["text", "paraphrase"], template="text: {text}\nparaphrase: {paraphrase}"
73 | )
74 | prompt = FewShotPromptTemplate(
75 | examples=examples,
76 | example_prompt=example_prompt,
77 | prefix=task_instruction,
78 | suffix="text: {text}",
79 | input_variables=["text"],
80 | )
81 | return prompt
82 |
83 |
84 | def make_task_free_prompt(examples: List[dict]) -> FewShotPromptTemplate:
85 | columns = list(examples[0])
86 |
87 | task_instruction = f"Predict {columns[-1]} based on {', '.join(columns[:-1])}."
88 | example_prompt = PromptTemplate(
89 | input_variables=columns, template="\n".join([f"{column}: {{{column}}}" for column in columns])
90 | )
91 |
92 | prompt = FewShotPromptTemplate(
93 | examples=examples,
94 | example_prompt=example_prompt,
95 | prefix=task_instruction,
96 | suffix="\n".join([f"{column}: {{{column}}}" for column in columns[:-1]]),
97 | input_variables=columns[:-1],
98 | )
99 | return prompt
100 |
101 |
102 | def make_named_entity_recognition_prompt(examples: List[dict], **kwargs) -> FewShotPromptTemplate:
103 | task_instruction = (
104 | "You are a highly intelligent and accurate Named-entity recognition(NER) system. "
105 | "You take Passage as input and your task is to recognize and extract specific types of "
106 | "named entities in that given passage and classify into a set of entity types.\n"
107 | )
108 | types = kwargs.get("types", [])
109 | task_instruction += "The following entity types are allowed:\n"
110 | for type in types:
111 | task_instruction += f"- {type}\n"
112 |
113 | for example in examples:
114 | entities = [
115 | {"mention": example["text"][entity["start"] : entity["end"]], "type": entity["label"]}
116 | for entity in example["entities"]
117 | ]
118 | example["entities"] = json.dumps(entities)
119 |
120 | example_prompt = PromptTemplate(
121 | input_variables=["text", "entities"],
122 | template="text: {text}\nentities: {entities}",
123 | )
124 | prompt = FewShotPromptTemplate(
125 | examples=examples,
126 | example_prompt=example_prompt,
127 | prefix=task_instruction,
128 | suffix="text: {{text}}",
129 | input_variables=["text"],
130 | template_format="jinja2",
131 | )
132 | return prompt
133 |
--------------------------------------------------------------------------------
/doccano_mini/storages/entity.py:
--------------------------------------------------------------------------------
1 | from collections import defaultdict
2 | from typing import List
3 |
4 | import streamlit as st
5 |
6 | from doccano_mini.models.entity import Entity
7 | from doccano_mini.storages.session_storage import SessionStorage
8 |
9 |
10 | class EntitySessionStorage:
11 | def __init__(self) -> None:
12 | self.storage = SessionStorage(state=st.session_state)
13 | self.storage.init_state("entities", defaultdict(list))
14 |
15 | def find_by_text(self, text: str) -> List[Entity]:
16 | entities = self.storage.get_state("entities")
17 | return entities.get(text, [])
18 |
19 | def store_by_text(self, text: str, entities: List[Entity]) -> None:
20 | current_entities = self.storage.get_state("entities")
21 | current_entities[text] = entities
22 | self.storage.set_state("entities", current_entities)
23 |
--------------------------------------------------------------------------------
/doccano_mini/storages/session_storage.py:
--------------------------------------------------------------------------------
1 | from typing import Any
2 |
3 | from streamlit.runtime.state import SessionStateProxy
4 |
5 |
6 | class SessionStorage:
7 | def __init__(self, state: SessionStateProxy) -> None:
8 | self.state = state
9 |
10 | def init_state(self, key: str, value: Any) -> None:
11 | if key not in self.state:
12 | self.state[key] = value
13 |
14 | def set_state(self, key: str, value: Any, *, do_init: bool = False) -> None:
15 | if do_init:
16 | self.init_state(key, value)
17 |
18 | self.state[key] = value
19 |
20 | def get_state(self, key: str) -> Any:
21 | return self.state.get(key, None)
22 |
--------------------------------------------------------------------------------
/doccano_mini/storages/stepper.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 |
3 | from doccano_mini.models.stepper import Stepper
4 | from doccano_mini.storages.session_storage import SessionStorage
5 |
6 |
7 | class StepperSessionStorage:
8 | def __init__(self) -> None:
9 | self.storage = SessionStorage(state=st.session_state)
10 | self.storage.init_state("step", 0)
11 |
12 | def get_step(self) -> int:
13 | return self.storage.get_state("step")
14 |
15 | def fit(self, total: int) -> None:
16 | step = self.storage.get_state("step")
17 | stepper = Stepper(step)
18 | stepper.fit(total)
19 | self.storage.set_state("step", stepper.step)
20 |
21 | def increment(self, total: int) -> None:
22 | step = self.storage.get_state("step")
23 | stepper = Stepper(step)
24 | stepper.increment(total)
25 | self.storage.set_state("step", stepper.step)
26 |
27 | def decrement(self, total: int) -> None:
28 | step = self.storage.get_state("step")
29 | stepper = Stepper(step)
30 | stepper.decrement(total)
31 | self.storage.set_state("step", stepper.step)
32 |
--------------------------------------------------------------------------------
/doccano_mini/utils.py:
--------------------------------------------------------------------------------
1 | import re
2 |
3 |
4 | def escape_markdown(text: str) -> str:
5 | # Brought from https://github.com/python-telegram-bot/python-telegram-bot/blob/v20.2/telegram/helpers.py#L66
6 | escape_chars = r"\_*[]()~`>#+-=|{}.!$"
7 | return re.sub(f"([{re.escape(escape_chars)}])", r"\\\1", text)
8 |
--------------------------------------------------------------------------------
/docs/CODE_OF_CONDUCT.md:
--------------------------------------------------------------------------------
1 | # Contributor Covenant Code of Conduct
2 |
3 | ## Our Pledge
4 |
5 | In the interest of fostering an open and welcoming environment, we as contributors and maintainers pledge to making participation in our project and our community a harassment-free experience for everyone, regardless of age, body size, disability, ethnicity, sex characteristics, gender identity and expression, level of experience, education, socio-economic status, nationality, personal appearance, race, religion, or sexual identity and orientation.
6 |
7 | ## Our Standards
8 |
9 | Examples of behavior that contributes to creating a positive environment
10 | include:
11 |
12 | * Using welcoming and inclusive language
13 | * Being respectful of differing viewpoints and experiences
14 | * Gracefully accepting constructive criticism
15 | * Focusing on what is best for the community
16 | * Showing empathy towards other community members
17 |
18 | Examples of unacceptable behavior by participants include:
19 |
20 | * The use of sexualized language or imagery and unwelcome sexual attention or advances
21 | * Trolling, insulting/derogatory comments, and personal or political attacks
22 | * Public or private harassment
23 | * Publishing others' private information, such as a physical or electronic address, without explicit permission
24 | * Other conduct which could reasonably be considered inappropriate in a professional setting
25 |
26 | ## Our Responsibilities
27 |
28 | Project maintainers are responsible for clarifying the standards of acceptable behavior and are expected to take appropriate and fair corrective action in response to any instances of unacceptable behavior.
29 |
30 | Project maintainers have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, or to ban temporarily or permanently any contributor for other behaviors that they deem inappropriate, threatening, offensive, or harmful.
31 |
32 | ## Scope
33 |
34 | This Code of Conduct applies both within project spaces and in public spaces when an individual is representing the project or its community. Examples of representing a project or community include using an official project e-mail address, posting via an official social media account, or acting as an appointed representative at an online or offline event. Representation of a project may be further defined and clarified by project maintainers.
35 |
36 | ## Enforcement
37 |
38 | Instances of abusive, harassing, or otherwise unacceptable behavior may be reported by contacting the project team at hiroki.nakayama.py@gmail.com. All complaints will be reviewed and investigated and will result in a response that is deemed necessary and appropriate to the circumstances. The project team is obligated to maintain confidentiality with regard to the reporter of an incident. Further details of specific enforcement policies may be posted separately.
39 |
40 | Project maintainers who do not follow or enforce the Code of Conduct in good faith may face temporary or permanent repercussions as determined by other members of the project's leadership.
41 |
42 | ## Attribution
43 |
44 | This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4, available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
45 |
46 | [homepage]: https://www.contributor-covenant.org
47 |
48 | For answers to common questions about this code of conduct, see https://www.contributor-covenant.org/faq
49 |
--------------------------------------------------------------------------------
/docs/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | # Contributing
2 |
3 | When contributing to this repository, please first discuss the change you wish to make via issue with the owners of this repository before making a change.
4 |
5 | Please note we have a code of conduct, please follow it in all your interactions with the project.
6 |
7 | ## How to contribute
8 |
9 | ### Reporting Bugs
10 |
11 | #### Before submitting a bug report
12 |
13 | * Ensure the bug was not already reported by searching on GitHub under [Issues](https://github.com/doccano/doccano-mini/issues).
14 | * [Open a new issue](https://github.com/doccano/doccano-mini/issues/new/choose) if you're unable to find an open one addressing the problem.
15 | * Use the relevant bug report templates to create the issue.
16 |
17 | #### How do I submit a good bug report?
18 |
19 | Explain the problem and include additional details to help maintainers reproduce the problem:
20 |
21 | * Use a clear and descriptive title for the issue to identify the problem.
22 | * Describe the exact steps which reproduce the problem in as many details as possible.
23 | * Provide specific examples to demonstrate the steps.
24 | * Describe the behavior you observed after following the steps and point out what exactly is the problem with that behavior.
25 | * Explain which behavior you expected to see instead and why.
26 | * Include screenshots and animated GIFs which show you following the described steps and clearly demonstrate the problem.
27 | * If the problem is related to performance or memory, include a CPU profile capture with your report.
28 | * If the problem is related to network, include a network activity in Chrome/Firefox/Safari DevTools.
29 | * If the problem wasn't triggered by a specific action, describe what you were doing before the problem happened and share more information using the guidelines below.
30 |
31 | ### Suggesting Enhancements
32 |
33 | #### Before submitting an enhancement suggestion
34 |
35 | * Ensure the suggestion was not already reported by searching on GitHub under [Issues](https://github.com/doccano/doccano-mini/issues).
36 | * [Open a new issue](https://github.com/doccano/doccano-mini/issues/new/choose) if you're unable to find an open one addressing the suggestion.
37 | * Use the relevant issue templates to create one.
38 |
39 | #### How do I submit a good enhancement suggestion?
40 |
41 | Explain the suggestion and include additional details to help developers understand it:
42 |
43 | * Use a clear and descriptive title for the issue to identify the suggestion.
44 | * Provide a step-by-step description of the suggested enhancement in as many details as possible.
45 | * Provide specific examples to demonstrate the steps.
46 | * Describe the current behavior and explain which behavior you expected to see instead and why.
47 | * Include screenshots and animated GIFs which help you demonstrate the steps or point out the part of doccano-mini which the suggestion is related to.
48 | * Explain why this enhancement would be useful to most users.
49 | * List some other annotation tools or applications where this enhancement exists.
50 | * Specify which version you're using.
51 | * Specify the name and version of the OS you're using.
52 |
53 | ## development workflow
54 |
55 | 1. **Fork the project & clone it locally:** Click the "Fork" button in the header of the [GitHub repository](https://github.com/doccano/doccano-mini), creating a copy of `doccano-mini` in your GitHub account. To get a working copy on your local machine, you have to clone your fork. Click the "Clone or Download" button in the right-hand side bar, then append its output to the `git clone` command.
56 |
57 | $ git clone https://github.com/YOUR_USERNAME/doccano-mini.git
58 |
59 | 1. **Create an upstream remote and sync your local copy:** Connect your local copy to the original "upstream" repository by adding it as a remote.
60 |
61 | $ cd doccano-mini
62 | $ git remote add upstream https://github.com:doccano/doccano-mini.git
63 |
64 | You should now have two remotes: read/write-able `origin` points to your GitHub fork, and a read-only `upstream` points to the original repo. Be sure to [keep your fork in sync](https://help.github.com/en/articles/syncing-a-fork) with the original, reducing the likelihood of merge conflicts later on.
65 |
66 | 1. **Create a branch for each piece of work:** Branch off `develop` for each bugfix or feature that you're working on. Give your branch a descriptive, meaningful name like `bugfix-for-issue-1234` or `improve-io-performance`, so others know at a glance what you're working on.
67 |
68 | $ git checkout develop
69 | $ git pull develop master && git push origin develop
70 | $ git checkout -b my-descriptive-branch-name
71 |
72 | At this point, you may want to install your version. It's usually best to do this within a dedicated virtual environment; We recomment to use `poetry`:
73 |
74 | $ poetry install
75 | $ poetry shell
76 |
77 | Then run the `streamlit` command to serve:
78 |
79 | $ streamlit run doccano_mini/app.py
80 |
81 | Now, you can access to the frontend at .
82 |
83 | 2. **Implement your changes:** Use your preferred text editor to modify the source code. Be sure to keep your changes focused and in scope, and follow the coding conventions described below! Document your code as you write it. Run your changes against any existing tests and add new ones as needed to validate your changes; make sure you don’t accidentally break existing functionality! Several common commands can be accessed via the `make`:
84 |
85 | $ make lint
86 |
87 | 3. **Push commits to your forked repository:** Group changes into atomic git commits, then push them to your `origin` repository. There's no need to wait until all changes are final before pushing — it's always good to have a backup, in case something goes wrong in your local copy.
88 |
89 | $ git push origin my-descriptive-branch-name
90 |
91 | 4. **Open a new Pull Request in GitHub:** When you're ready to submit your changes to the main repo, navigate to your forked repository on GitHub. Switch to your working branch then click "New pull request"; alternatively, if you recently pushed, you may see a banner at the top of the repo with a "Compare & pull request" button, which you can click on to initiate the same process. Fill out the PR template completely and clearly, confirm that the code "diff" is as expected, then submit the PR. A number of processes will run automatically via GitHub Workflows (see `.github/workflows/`); we'll want to make sure everything passes before the PR gets merged.
92 |
93 | 5. **Respond to any code review feedback:** At this point, @Hironsan will review your work and either request additional changes/clarification or approve your work. There may be some necessary back-and-forth; please do your best to be responsive. If you haven’t gotten a response in a week or so, please politely nudge him in the same thread — thanks in advance for your patience!
94 |
95 | ## Styleguides
96 |
97 | ### Git Commit Messages
98 |
99 | * Use the present tense ("Add feature" not "Added feature")
100 | * Use the imperative mood ("Move cursor to..." not "Moves cursor to...")
101 | * Limit the first line to 72 characters or less
102 | * Reference issues and pull requests liberally after the first line
103 |
--------------------------------------------------------------------------------
/docs/images/annotation.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/doccano/doccano-mini/0ef6c3368499eb172ff5c8c446d61c7f240baf8f/docs/images/annotation.gif
--------------------------------------------------------------------------------
/docs/images/copy_and_paste.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/doccano/doccano-mini/0ef6c3368499eb172ff5c8c446d61c7f240baf8f/docs/images/copy_and_paste.gif
--------------------------------------------------------------------------------
/docs/images/download_config.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/doccano/doccano-mini/0ef6c3368499eb172ff5c8c446d61c7f240baf8f/docs/images/download_config.jpg
--------------------------------------------------------------------------------
/docs/images/test_new_example.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/doccano/doccano-mini/0ef6c3368499eb172ff5c8c446d61c7f240baf8f/docs/images/test_new_example.jpg
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [tool.poetry]
2 | name = "doccano-mini"
3 | version = "0.0.10"
4 | description = "Annotation meets Large Language Models."
5 | authors = ["Hironsan "]
6 | license = "MIT"
7 | readme = "README.md"
8 | homepage = "https://github.com/doccano/doccano-mini"
9 | repository = "https://github.com/doccano/doccano-mini"
10 | classifiers = [
11 | "Programming Language :: Python",
12 | "Programming Language :: Python :: 3.8",
13 | "Programming Language :: Python :: 3.9",
14 | "Programming Language :: Python :: 3.10",
15 | ]
16 |
17 | [tool.poetry.scripts]
18 | doccano-mini = 'doccano_mini.cli:main'
19 |
20 | [tool.poetry.dependencies]
21 | python = ">=3.8.1,<3.9.7 || >3.9.7,<4.0"
22 | streamlit = "^1.20.0"
23 | langchain = "^0.0.113"
24 | openai = "^0.27.2"
25 | st-ner-annotate = "^0.1.0"
26 | scikit-learn = "^1.2.2"
27 | datasets = "^2.11.0"
28 | more-itertools = "^9.1.0"
29 |
30 | [tool.poetry.dev-dependencies]
31 | taskipy = "^1.10.3"
32 | black = "^23.1.0"
33 | isort = "^5.12.0"
34 | mypy = "^1.1.1"
35 | pyproject-flake8 = "^6.0.0"
36 | pytest = "^7.2.2"
37 | pytest-cov = "^4.0.0"
38 |
39 | [build-system]
40 | requires = ["poetry-core>=1.0.0"]
41 | build-backend = "poetry.core.masonry.api"
42 |
43 | [tool.black]
44 | line-length = 120
45 | target-version = ['py38', 'py39']
46 | include = '\.pyi?$'
47 |
48 | [tool.flake8]
49 | max-line-length = 120
50 | max-complexity = 18
51 | ignore = "E203,E266,W503,"
52 | filename = "*.py"
53 |
54 | [tool.mypy]
55 | python_version = "3.8"
56 | ignore_missing_imports = true
57 | show_error_codes = true
58 |
59 | [tool.isort]
60 | profile = "black"
61 | include_trailing_comma = true
62 | multi_line_output = 3
63 |
64 | [tool.pytest.ini_options]
65 | testpaths = [
66 | "tests",
67 | ]
68 |
69 | [tool.taskipy.tasks]
70 | isort = "isort . -c --skip migrations"
71 | flake8 = "pflake8 --filename \"*.py\""
72 | black = "black --check ."
73 | mypy = "mypy ."
74 | test = "pytest --cov=doccano_mini --cov-report=term-missing -vv"
75 |
--------------------------------------------------------------------------------
/tests/test_prompts.py:
--------------------------------------------------------------------------------
1 | from doccano_mini.prompts import make_classification_prompt, make_task_free_prompt
2 |
3 |
4 | def test_make_classification_prompt():
5 | examples = [
6 | {"text": "That would be awesome!", "label": "positive"},
7 | {"text": "This is awful!", "label": "negative"},
8 | ]
9 |
10 | expected = """\
11 | Classify the text into one of the following labels:
12 | - negative
13 | - positive
14 |
15 |
16 | text: That would be awesome!
17 | label: positive
18 |
19 | text: This is awful!
20 | label: negative
21 |
22 | text: It's very hot."""
23 |
24 | input_text = "It's very hot."
25 |
26 | prompt = make_classification_prompt(examples)
27 |
28 | assert prompt.format(input=input_text) == expected
29 |
30 |
31 | def test_make_task_free_prompt():
32 | examples = [
33 | {"English": "I like sushi.", "Japanese": "寿司が好きです。"},
34 | {"English": "I live in Japan.", "Japanese": "日本に住んでいます。"},
35 | ]
36 |
37 | expected = """\
38 | Predict Japanese based on English.
39 |
40 | English: I like sushi.
41 | Japanese: 寿司が好きです。
42 |
43 | English: I live in Japan.
44 | Japanese: 日本に住んでいます。
45 |
46 | English: I'm developing doccano-mini."""
47 |
48 | english_text = "I'm developing doccano-mini."
49 |
50 | prompt = make_task_free_prompt(examples)
51 |
52 | assert prompt.format(English=english_text) == expected
53 |
--------------------------------------------------------------------------------