├── README.md
├── 信息安全
├── README.md
├── 信息安全(一)——概述.md
├── 信息安全(三)——对称密码体制.md
├── 信息安全(二)——密码学.md
├── 信息安全(五)——消息认证、数字签名及PGP.md
└── 信息安全(四)——公私钥密码体制.md
├── 操作系统
├── 第一章 操作系统引论
│ ├── 第一章 操作系统引论.md
│ ├── 第一章 操作系统引论.png
│ └── 第一章操作系统引论.xmind
├── 第七章 文件管理
│ ├── 第七章 文件管理.md
│ ├── 第七章 文件管理.png
│ └── 第七章文件管理.xmind
├── 第三章 处理机调度与死锁
│ ├── 第三章 处理机调度与死锁.md
│ ├── 第三章 处理机调度与死锁.png
│ └── 第三章处理机调度与死锁.xmind
├── 第二章 进程的描述与控制
│ ├── 第二章 进程的描述与控制.md
│ ├── 第二章 进程的描述与控制.png
│ └── 第二章进程的描述与控制.xmind
├── 第五章 虚拟存储器
│ ├── 第五章 虚拟存储器.md
│ ├── 第五章 虚拟存储器.png
│ └── 第五章虚拟存储器.xmind
├── 第六章 输入输出系统
│ ├── 第六章 输入输出系统.md
│ ├── 第六章 输入输出系统.png
│ └── 第六章输入输出系统.xmind
├── 第四章 存储器管理
│ ├── 第四章 存储器管理.md
│ ├── 第四章 存储器管理.png
│ └── 第四章存储器管理.xmind
├── 计算机操作系统.md
├── 计算机操作系统.png
└── 计算机操作系统.xmind
├── 数据库
├── 关系代数
│ ├── 关系代数.md
│ ├── 关系代数.png
│ └── 关系代数.xmind
├── 关系数据库设计理论
│ ├── 关系数据库设计理论.md
│ ├── 关系数据库设计理论.png
│ └── 关系数据库设计理论.xmind
├── 关系模型
│ ├── 关系模型.md
│ ├── 关系模型.png
│ └── 关系模型.xmind
├── 完整性约束
│ ├── 完整性约束.md
│ ├── 完整性约束.png
│ └── 完整性约束.xmind
├── 并发控制
│ ├── 并发控制.md
│ ├── 并发控制.png
│ └── 并发控制.xmind
├── 数据库.md
├── 数据库.xmind
├── 数据库恢复技术
│ ├── 数据库恢复技术.md
│ ├── 数据库恢复技术.png
│ └── 数据库恢复技术.xmind
├── 数据库绪论
│ ├── 数据库绪论.md
│ └── 数据库绪论.xmind
├── 数据库设计
│ ├── 数据库设计.md
│ ├── 数据库设计.png
│ └── 数据库设计.xmind
├── 数据库语言SQL
│ ├── 数据库语言SQL.md
│ ├── 数据库语言SQL.png
│ └── 数据库语言SQL.xmind
└── 查询优化
│ ├── 查询优化.md
│ ├── 查询优化.png
│ └── 查询优化.xmind
├── 数据结构
├── 数据结构.md
├── 数据结构.png
└── 数据结构.xmind
├── 计算机组成原理
├── 计算机组成.md
├── 计算机组成.png
└── 计算机组成.xmind
└── 计算机网络
├── README.md
├── 第 1 章 概述
├── 第 1 章 概述.md
├── 第 1 章 概述.png
└── 第 1 章 概述.xmind
├── 第 2 章 物理层
├── 第 2 章 物理层.md
├── 第 2 章 物理层.png
└── 第 2 章 物理层.xmind
├── 第 3 章 数据链路层
├── 第 3 章 数据链路层.md
├── 第 3 章 数据链路层.png
└── 第 3 章 数据链路层.xmind
├── 第 4 章 网络层
├── 第 4 章 网络层.md
├── 第 4 章 网络层.png
└── 第 4 章 网络层.xmind
├── 第 5 章 运输层
├── 第 5 章 运输层.md
├── 第 5 章 运输层.png
└── 第 5 章 运输层.xmind
└── 第 6 章 应用层
├── 第 6 章 应用层.md
├── 第 6 章 应用层.png
└── 第 6 章 应用层.xmind
/README.md:
--------------------------------------------------------------------------------
1 | # 专业课目录
2 |
3 | - [计算机组成原理思维导图](https://github.com/SSHeRun/CS-Xmind-Note/blob/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BB%84%E6%88%90.md)
4 |
5 | - [计算机操作系统思维导图](https://github.com/SSHeRun/CS-Xmind-Note/blob/master/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F/%E8%AE%A1%E7%AE%97%E6%9C%BA%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F.md)
6 |
7 | - [计算机数据结构思维导图](https://github.com/SSHeRun/CS-Xmind-Note/blob/master/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84.md)
8 |
9 | - [计算机网络思维导图](https://github.com/SSHeRun/CS-Xmind-Note/blob/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/README.md)
10 |
11 | # 其他专业课程笔记
12 |
13 | - [数据库](https://github.com/SSHeRun/CS-Xmind-Note/blob/master/%E6%95%B0%E6%8D%AE%E5%BA%93/%E6%95%B0%E6%8D%AE%E5%BA%93.md)
14 |
15 | - [信息安全](https://github.com/SSHeRun/CS-Xmind-Note/blob/master/%E4%BF%A1%E6%81%AF%E5%AE%89%E5%85%A8/README.md)
16 |
17 | # 每个文件夹内都有Xmind格式文件,以及png格式图片。
18 |
19 | # 可能排版设计做的不是很好,有一些内容也有问题,大家可以去fork下,根据自己想法去改,欢迎大家提交合并请求。
20 |
21 | # 目前只上传了专业课方面的思维导图,有空的话还会上传其他课程做的导图。大家如果也有用xmind做的导图的话,也可以相互交流一下。
22 |
--------------------------------------------------------------------------------
/信息安全/README.md:
--------------------------------------------------------------------------------
1 | - [第 1 章 概述](https://github.com/SSHeRun/CS-Xmind-Note/blob/master/%E4%BF%A1%E6%81%AF%E5%AE%89%E5%85%A8/%E4%BF%A1%E6%81%AF%E5%AE%89%E5%85%A8%EF%BC%88%E4%B8%80%EF%BC%89%E2%80%94%E2%80%94%E6%A6%82%E8%BF%B0.md)
2 | - [第 2 章 密码学](https://github.com/SSHeRun/CS-Xmind-Note/blob/master/%E4%BF%A1%E6%81%AF%E5%AE%89%E5%85%A8/%E4%BF%A1%E6%81%AF%E5%AE%89%E5%85%A8%EF%BC%88%E4%BA%8C%EF%BC%89%E2%80%94%E2%80%94%E5%AF%86%E7%A0%81%E5%AD%A6.md)
3 | - [第 3 章 对称密码体制](https://github.com/SSHeRun/CS-Xmind-Note/blob/master/%E4%BF%A1%E6%81%AF%E5%AE%89%E5%85%A8/%E4%BF%A1%E6%81%AF%E5%AE%89%E5%85%A8%EF%BC%88%E4%B8%89%EF%BC%89%E2%80%94%E2%80%94%E5%AF%B9%E7%A7%B0%E5%AF%86%E7%A0%81%E4%BD%93%E5%88%B6.md)
4 | - [第 4 章 公私钥密码体制](https://github.com/SSHeRun/CS-Xmind-Note/blob/master/%E4%BF%A1%E6%81%AF%E5%AE%89%E5%85%A8/%E4%BF%A1%E6%81%AF%E5%AE%89%E5%85%A8%EF%BC%88%E5%9B%9B%EF%BC%89%E2%80%94%E2%80%94%E5%85%AC%E7%A7%81%E9%92%A5%E5%AF%86%E7%A0%81%E4%BD%93%E5%88%B6.md)
5 | - [第 5 章 消息认证、数字签名及PGP](https://github.com/SSHeRun/CS-Xmind-Note/blob/master/%E4%BF%A1%E6%81%AF%E5%AE%89%E5%85%A8/%E4%BF%A1%E6%81%AF%E5%AE%89%E5%85%A8%EF%BC%88%E4%BA%94%EF%BC%89%E2%80%94%E2%80%94%E6%B6%88%E6%81%AF%E8%AE%A4%E8%AF%81%E3%80%81%E6%95%B0%E5%AD%97%E7%AD%BE%E5%90%8D%E5%8F%8APGP.md)
6 |
7 | # 信息安全只做大体的笔记,还有一些内容没有完善
8 |
9 |
10 |
--------------------------------------------------------------------------------
/信息安全/信息安全(一)——概述.md:
--------------------------------------------------------------------------------
1 | # 信息安全的目标
2 |
3 | ## 保密性 Confidentiality
4 |
5 | 数据保密性:对于未授权的个体而言,信息不可用
6 | 隐私性:确保个人能控制或确定自身那些信息可以被收集、保存,这些信息可以被谁公开及向谁公开
7 |
8 | ## 完整性 Integrity
9 |
10 | 信息的完整性、一致性,分为
11 | 数据完整性,未被未授权篡改或者损坏;系统完整性,系统未被非法操纵,按既定的目标运行
12 |
13 | ## 可用性 Availability
14 |
15 | 服务连续性,对授权用户不能拒绝服务
16 |
17 | ## 真实性Authenticity
18 |
19 | 能够验证用户是他声称的那个人
20 | 确保系统的输入来源于可信任的源
21 |
22 | ## 可追溯性Accountability
23 |
24 | 实体的行为可以唯一追溯到该实体
25 |
26 | # 安全攻击
27 |
28 | ## 被动攻击:窃听和检测
29 | 信息内容泄露攻击——隐藏信息:加密
30 | 流量分析
31 | 难察觉,关键:预防
32 |
33 | ## 主动攻击:
34 | 伪装:假装别的实体。如:捕获认证信息,进行重播
35 | 重播:将获得的信息再次发送以产生非授权效果
36 | 消息修改:修改合法消息的一部分或者延迟消息,或改变消息的顺序以获得非授权效果
37 | 拒绝服务:阻止或禁止对通信设施的增产使用和管理。
38 |
39 | # 安全服务
40 | ITU-T X.800,安全服务目的在于利用一种或者多种安全机制进行反攻击。
41 |
42 | ## 1)认证
43 |
44 | 同等实体认证
45 | 数据源认证:电子邮件的应用
46 |
47 | ## 2)访问控制:阻止对资源的非授权使用
48 |
49 | ## 3)数据保密性:防止被动攻击
50 |
51 | 数据免于非授权泄露
52 | 流量保密性
53 |
54 | ## 4)数据完整性:
55 | 保证收到的数据没有修改、插入、删除或重播
56 |
57 | ## 5)不可否认性
58 |
59 | 源不可否认
60 | 宿不可否认
61 |
62 | ## 6)可用性服务
63 |
64 | # 安全机制
65 | 1. 加密
66 | 2. 数字签名
67 | 3. 访问控制
68 | 4. 数据完整性
69 | 5. 认证交换
70 | 6. 流量填充
71 | 7. 路由控制
72 | 8. 公证
--------------------------------------------------------------------------------
/信息安全/信息安全(三)——对称密码体制.md:
--------------------------------------------------------------------------------
1 | **单密钥系统的加密密钥和解密密钥相同,或实质上等同,即从一个易于得出另一个,如下图所示。**
2 | 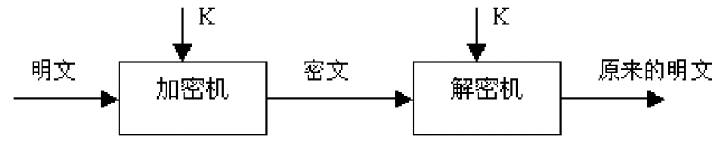
3 |
4 | **对称密码算法(symmetric cipher):**
5 |
6 | - DES(Data Encryption Standard)
7 | - Triple DES
8 | - IDEA
9 | - AES
10 | - RC5
11 | - CAST-128
12 | - 。。。。。。
13 |
14 |
15 | # 分组密码算法(Block Cipher)
16 |
17 | ## 特点
18 |
19 | - 明文被分为固定长度的块,即分组,分组一般为64比特,或者128比特
20 | - 对每个分组用相同的算法和密钥加/解密
21 | - 密文分组和明文分组同样长
22 |
23 | ## 分组密码原理
24 |
25 | 分组密码是将明文消息编码表示后的数字(简称明文数字)序列,划分成长度为n的组(可看成长度为n的矢量),每组分别在密钥的控制下变换成等长的输出数字(简称密文数字)序列。
26 | 
27 |
28 | ## 分组密码的一般设计原理
29 | - 加密函数:V~n~×K→V~n'~,n是n维矢量空间,K为密钥空间。
30 | - 在相同的密钥k的控制下,加密函数可看成是函数E(ο,K): V~n~→V~n'~,这实质上是对字长为n的数字序列的置换。
31 | - 分组加密器本质上就是一个巨大的替换器,在密钥的控制下,能从一个足够大和足够好的置换子集中简单而迅速地选出一个置换,用来对当前输入的明文数字组进行加密变换。
32 | - 采用了乘积加密器的思想,即轮流使用替代和置换
33 | - Shannon提出的设计密码系统的两种基本方法:扩散和混淆。Shannon认为,在理想密码系统中,密文的所有统计特性都应与使用的密钥独立。
34 |
35 | 扩散
36 | >要求明文的统计特征消散在密文中。即让明文的每个比特影响到密文的许多比特的取值。尽可能使明文和密文的统计关系变复杂。
37 |
38 | 混淆
39 | >使密文与密钥之间的统计关系尽量复杂,以阻止攻击者发现密钥。
40 |
41 | - 扩散和混淆的目的都是为了挫败推测出密钥的尝试,从而抗击统计分析。
42 | - 迭代密码是实现混淆和扩散原则的一种有效的方法。
43 | - 迭代密码是实现混淆和扩散原则的一种有效的方法。合理选择的轮函数经过若干次迭代后能够提供必要的混淆和扩散。
44 | - 分组密码由**加密算法、解密算法和密钥扩展算法**三部分组成。解密算法是加密算法的逆,由加密算法惟一确定,因而我们主要讨论加密算法和密钥扩展算法。
45 |
46 | ## 分组密码的一般结构--Feistel网络结构
47 | - Feistel网络是由Horst Feistel在设计Lucifer分组密码时基于扩散和扰乱的思想所发明的,并因被DES采用而流行。
48 | - 现在正在使用的几乎所有重要的对称分组密码都使用这种结构,如FEAL、Blowfish等。
49 | - Feistel密码结构的设计动机
50 | - 分组密码对n比特的明文分组进行操作,产生出一个n比特的密文分组,共有2n个不同的明文分组,每一种都必须产生一个唯一的密文分组,这种变换称为可逆的或非奇异的。
51 | - | 可逆映射 | | | | 不可逆映射|
52 | |---|----|----|---|---|
53 | | 00 | 11 | | 00 | 11 |
54 | | 01 | 10 | | 01 | 10 |
55 | | 10 | 00 | | 10 | ==01== |
56 | | 11 | 01 | | 11 | ==01== |
57 | - n = 4时的一个普通代换密码的结构
58 | 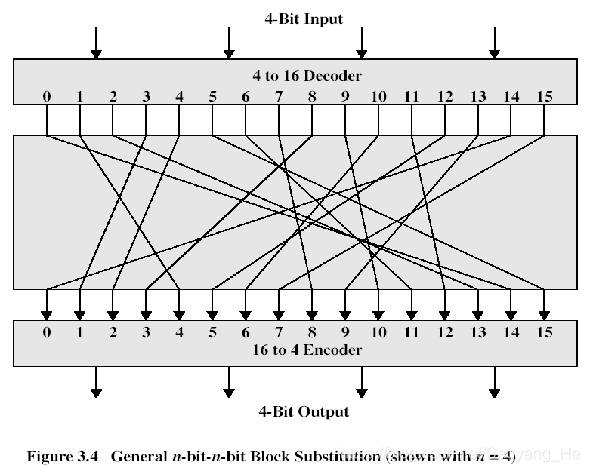
59 |
60 | **Feistel网络结构原理**
61 | 一个分组长度为n (偶数)比特的L轮Feistel网络的加密过程如下:
62 | - 给定明文P,将P分成左边和右边长度相等的两半并分别记为L~0~ 和R~0~,从而P = L~0~R~0~,进行L轮完全类似的迭代运算后,再将左边和右边长度相等的两半合并产生密文分组。
63 | - 每一轮i从以前一轮得到的L~i-1~和R~i-1~为输入,另外的总输入还有从总的密钥K生成的子密钥K~i~。
64 |
65 | 其中L~i~和R~i~的计算规则如下:
66 |
67 | - L~i~ = R~i-1~; R~i~ = L~i-1~ ⊕F(R~i-1~,K~i~)
68 | - 在第L轮迭代运算后,将L~L~和R~L~再进行交换,输出C = R~L~L~L~
69 | - 其中F是轮函数,K~i~是由种子密钥K生成的子密钥
70 | - 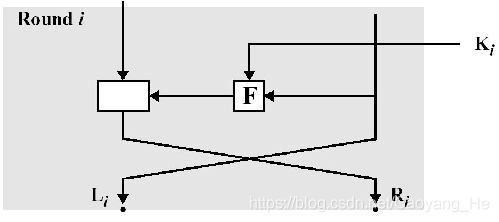
71 | - 一般结构
72 | 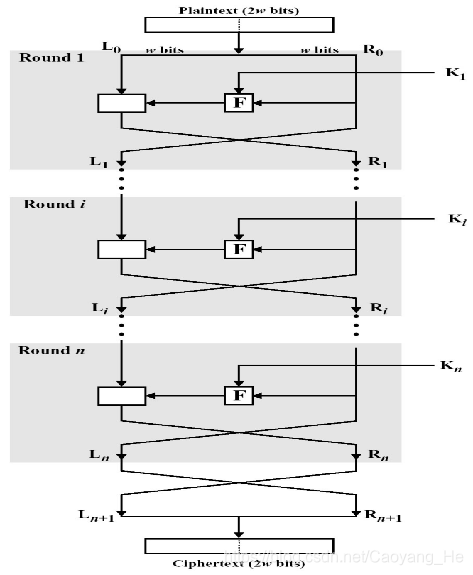
73 |
74 | **Feistel网络的安全性和软、硬件实现速度取决于下列参数:**
75 | - 分组长度:分组长度越大则安全性越高(其他条件相同时),但加、解密速度也越慢。64比特的分组目前也可用,但最好采用128比特。
76 | - 密钥长度:密钥长度越大则安全性越高(其他条件相同时),但加、解密速度也越慢。64比特密钥现在已不安全,128比特是一个折中的选择。
77 | - 循环次数:Feistel网络结构的一个特点是循环次数越多则安全性越高,通常选择16次。
78 |
79 | **Feistel网络的安全性和软、硬件实现速度取决于下列参数:**
80 |
81 | - 子密钥算法:子密钥算法越复杂则安全性越高。
82 | - 轮函数:轮函数越复杂则安全性越高。
83 | - 快速的软件实现:有时候客观条件不允许用硬件实现,算法被镶嵌在应用程序中。此时算法的执行速度是关键。
84 | - 算法简洁:通常希望算法越复杂越好,但采用容易分析的却很有好处。若算法能被简洁地解释清楚,就能容易通过分析算法而知道算法抗各种攻击的能力,也有助于设计高强度的算法。
85 |
86 | **Feistel网络解密过程**
87 | - Feistel网络解密过程与其加密过程实质是相同的。
88 | - 以密文分组作为算法的输入,但以相反的次序使用子密钥,即- 第一轮使用K~L~,第二轮使用K~L-1~,直至第L轮使用K~1~,这意味着可以用同样的算法来进行加、解密。
89 | - 先将密文分组C = R~L~L~L~,分成左边和右边长度相等的两半,分别记为L~0’~和R~0’~,根据下列规则计算 L~i’~ R~i’~
90 | L~i’~ = R~i-1’~ ,R~i’~ = L~i-1’~ ⊕ F (R~i-1’~ ,K~i’~) 1≤i≤L
91 | - 最后输出的分组是R~L’~L~L’~
92 |
93 |
94 | ## 数据加密标准(DES)
95 | 数据加密标准(Data Encryption Standard,DES)是至 今为止使用最为广泛的加密算法。
96 | >1974年8月27日, NBS开始第二次征集,IBM提交了算法LUCIFER,该算法由IBM的工程师在1971~1972年研制。
97 | 1975年3月17日, NBS公开了全部细节1976年,NBS指派了两个小组进行评价。
98 | 1976年11月23日,采纳为联邦标准,批准用于非军事场合的各种政府机构。
99 | 1977年1月15日,“数据加密标准”FIPS PUB 46发布
100 | 规定每隔5年由美国国家保密局(National Security Agency)重新评估它是否继续作为联邦加密标准。
101 | 最近的一次评估是在1994年1月,当时决定1998年12月以后,DES不再作为联邦加密标准。新的美国联邦加密标准被称为高级加密标准AES ( Advanced Encryption Standard )。
102 | DES对推动密码理论的发展和应用起到了重大的作用,学习 和研究它,对于掌握分组密码的基本理论、设计思想和实际应用仍然有着重要的参考价值。
103 |
104 | # DES加密的主要步骤和操作
105 | DES背景
106 | >数据加密标准(Data Encryption Standard,DES)是至 今为止使用最为广泛的加密算法。
107 | 1974年8月27日, NBS开始第二次征集,IBM提交了算法LUCIFER,该算法由IBM的工程师在1971~1972年研制。
108 | 1975年3月17日, NBS公开了全部细节1976年,NBS指派了两个小组进行评价。
109 | 1976年11月23日,采纳为联邦标准,批准用于非军事场合的各种政府机构。
110 | 1977年1月15日,“数据加密标准”FIPS PUB 46发布
111 | 规定每隔5年由美国国家保密局(National Security Agency)重新评估它是否继续作为联邦加密标准。
112 | 最近的一次评估是在1994年1月,当时决定1998年12月以后,DES不再作为联邦加密标准。新的美国联邦加密标准被称为高级加密标准AES ( Advanced Encryption Standard )。
113 | DES对推动密码理论的发展和应用起到了重大的作用,学习 和研究它,对于掌握分组密码的基本理论、设计思想和实际应用仍然有着重要的参考价值。
114 |
115 | ## DES的变形
116 | 双重DES
117 | 最简单的多次加密形式有两个加密阶段和两个密钥,给定一个明文P和两个加密密钥K1和K2,有:
118 | C = E~K2~(E~K1~(/P)) ←→ P = D~K1~(D~K2~(/C))
119 | 对于DES来说,密钥长度56×2=112
120 | 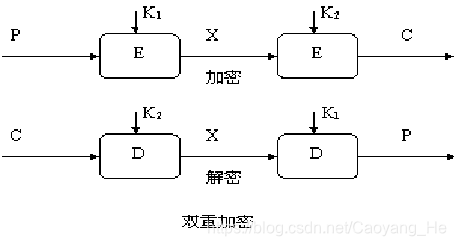
121 | **双密钥的三重DES**
122 | 一个用于对付中途攻击的明显方法是用3个密钥进行三个阶段的加密,这样要求一个56×3=168bit的密钥,这个密钥有点过大。
123 | 作为一种替代方案,Tuchman提出使用两个密钥的三重加密方法。这个加密函数采用一个加密-解密-加密序列:
124 | C=E~K1~(D~K2~(E~K1~(/P))) ←→ P=D~K1~(E~K2~( D~K1~(/C)))。
125 | 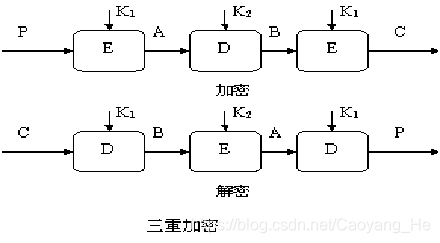
126 |
127 | ## 具体细节
128 | https://blog.csdn.net/Caoyang_He/article/details/88868493
129 | # AES加密的主要步骤和操作
130 | AES背景
131 | >1997年4月15日,美国国家标准技术研究(NIST)发起征集高级加密标准(Advanced Encryption Standard)AES的活动,活动目的是确定一个非保密的、可以公开技术细节的、全球免费使用的分组密码算法,作为新的数据加密标准。
132 | 1997年9月12日,美国联邦登记处公布了正式征集AES候选算法的通告。基本要求是:比三重DES快、至少与三重DES一样安全、数据分组长度为128比特、密钥长度为128/192/256比特。
133 | 1998年8月12日,在首届AES会议上指定了15个候选算法。
134 | 1999年3月22日第二次AES会议上,将候选名单减少为5个,这5个算法是RC6,Rijndael,SERPENT,Twofish和MARS。
135 | 2000年4月13日,第三次AES会议上,对这5个候选算法的各种分析结果进行了讨论。
136 | 2000年10月2日,NIST宣布了获胜者—Rijndael算法,2001年11月出版了最终标准FIPS PUB197
137 |
138 | AES的总体描述
139 | >AES具有128bit的分组长度,三种可选的密钥长度,即128bit、192bit和256bit。AES是一个迭代型密码;轮数Nr依赖于密钥长度。密钥为128bit、192bit、256 bit时,轮数分别为:10、12、14。算法执行过程如下:
140 |
141 | 1. 给定一个明文x,将State初始化为x,并进行AddRoundKey操作,将RoundKey和State异或。
142 | 2. 对前Nr-1轮中的每一轮,用S盒对进行一次代换操作,称为SubBytes;对State做一置换ShiftRows;再对State做一次操作MixColumns;然后进行AddRoundKey操作。
143 | 3. 依次进行SubBytes、 ShiftRows和AddRoundKey操作。
144 | 4. 将State定义为密文。
145 |
146 | AES的参数
147 | 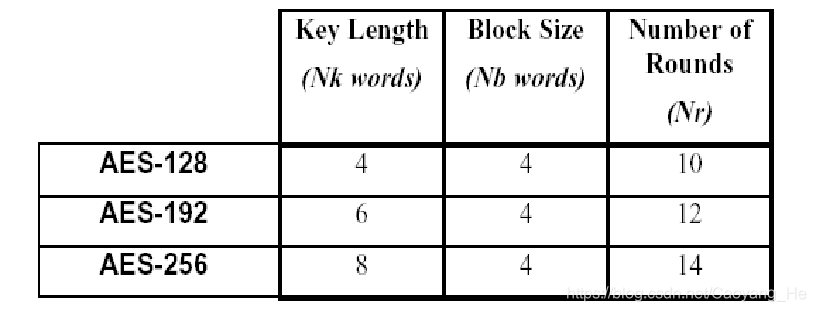
148 |
149 | ## 具体细节
150 | https://blog.csdn.net/Caoyang_He/article/details/88868493
151 | # 分组密码的工作模式
152 |
153 | ## 含义
154 | 分组密码在加密时明文分组的长度是固定的,而实用中待加密消息的数据量是不定的,数据格式可能是多种多样的。为了能在各种应用场合安全地使用分组密码,通常 对不同的使用目的运用不同的工作模式。
155 | 一个分组密 码的工作模式就是以该分组密码为基础构造的一个密码系统。
156 | 目前已提出许多种分组密码的工作模式,如电码本(ECB)、密码分组链接(CBC)、密码反馈(CFB)、输 出反馈(OFB)、级连(CM)、计数器、分组链接(BC)、扩散密码分组链接(PCBC)、明文反馈(PFB) 、非 线性函数输出反馈(OFBNLF)等模式。
157 | **PS:提出分组密码的工作模式就是为了让同一个分组的明文加密后的密文不同,从而避免统计攻击**
158 |
159 | ## ECB(Electronic Codebook)模式
160 | ECB(Electronic Codebook)模式是最简单的运行模式,它一次对一个64比特长的明文分组加密,而且每次的加密密钥都相同
161 |
162 | **概念图**
163 | 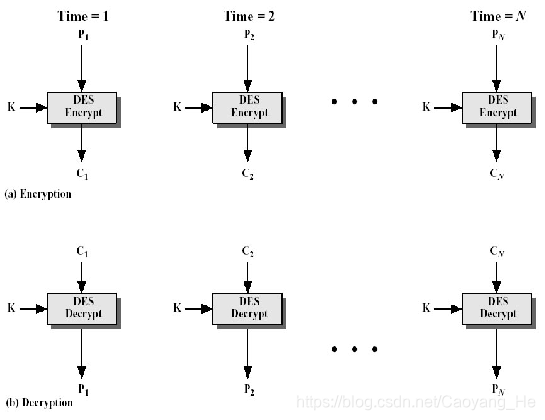
164 | **优点**
165 | 1. 实现简单
166 | 2. 不同明文分组的加密可并行实施,尤其是硬件实现时速度很快
167 |
168 | **缺点**
169 | 不同的明文分组之间的加密独立进行,造成相同明文分组对应相同密文分组,因而不能隐蔽明文分组的统计规律和结构规律,不能抵抗替换攻击。
170 |
171 | **典型应用**
172 | 1. 用于随机数的加密保护;
173 | 2. 用于单分组明文的加密。
174 |
175 | **实例**
176 | 例: 假设银行A和银行B之间的资金转帐系统所使用报文模式如下
177 | 
178 | 敌手C通过截收从A到B的加密消息,只要将第5至第12分组替换为自己的姓名和帐号相对应的密文,即可将别人的存款存入自己的帐号。
179 |
180 | ## 密码分组链接(CBC-Cipher Block Chaining)模式
181 | 每次加密使用同一密钥,加密算法的输入是当前明文前一次密文组的异或。因此加密算法的输入与明文分组之间 不再有固定的关系,所以重复的明文分组不会在密文中暴露。
182 |
183 | **概念图**
184 | 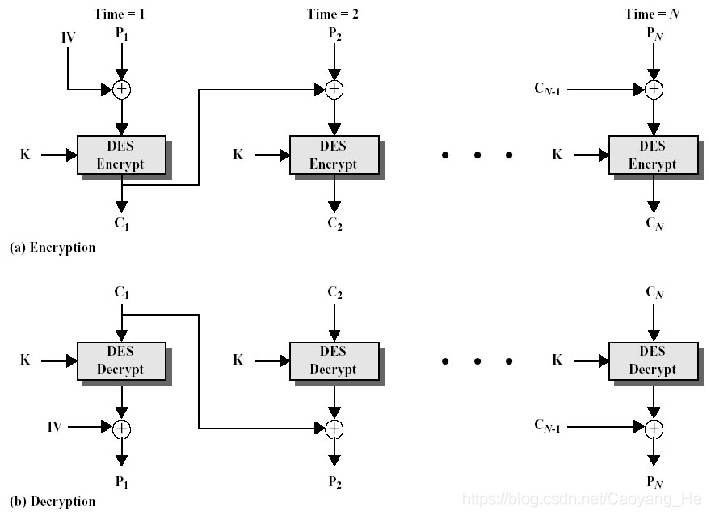
185 | **特点**
186 | 1. 明文块的统计特性得到了隐蔽。
187 | 由于在密文CBC模式中,各密文块不仅与当前明文块有关,而且还与以前的明文块及初始化向量有关,从而使明文的统计规律在密文中得到了较好的隐蔽。
188 | 2. 具有有限的(两步)错误传播特性。
189 | 一个密文块的错误将导致两个密文块不能正确脱密。
190 | 3. 具有自同步功能
191 | 密文出现丢块和错块不影响后续密文块的脱密。若从第t块起密文块正确,则第t+1个明文块就能正确求出。
192 | 4. 明文分组中一位出错,将影响该分组的密文及其以后的所有密文分组
193 |
194 |
195 | **典型应用**
196 |
197 | 1. 数据加密;
198 | 2. 完整性认证和身份认证;
199 |
200 | **完整性认证的含义**
201 | >完整性认证是一个“用户”检验它收到的文件是否遭到第三方有意或无意的篡改。
202 |
203 | **实例**
204 | 例:电脑彩票的防伪技术
205 | 方法:
206 | 1) 选择一个分组密码算法和一个认证密钥,存于售票机内
207 | 2) 将电脑彩票上的重要信息,如彩票期号、彩票号码、彩票股量、售票单位代号等重要信息按某个约定的规则作为彩票资料明文
208 | 3) 对彩票资料明文扩展一个校验码分组后,利用认证密钥和分组密码算法对之加密,并将得到的最后一个分组密文作为认证码打印于彩票上面;
209 |
210 | 认证过程:
211 | 执行3),并将计算出的认证码与彩票上的认证码比较,二者一致时判定该彩票是真彩票,否则判定该彩票是假彩票。
212 |
213 | ## CFB(Cipher Feedback)模式:
214 | 若待加密消息需按字符、字节或比特处理时,可采用CFB模式。并称待加密消息按 j 比特处理的CFB模式为 j 比特CFB模式。
215 |
216 | **适用范围**
217 | 适用于每次处理 j比特明文块的特定需求的加密情形,能灵活适应数据各格式的需要。
218 |
219 | **概念图**
220 | 加密
221 | 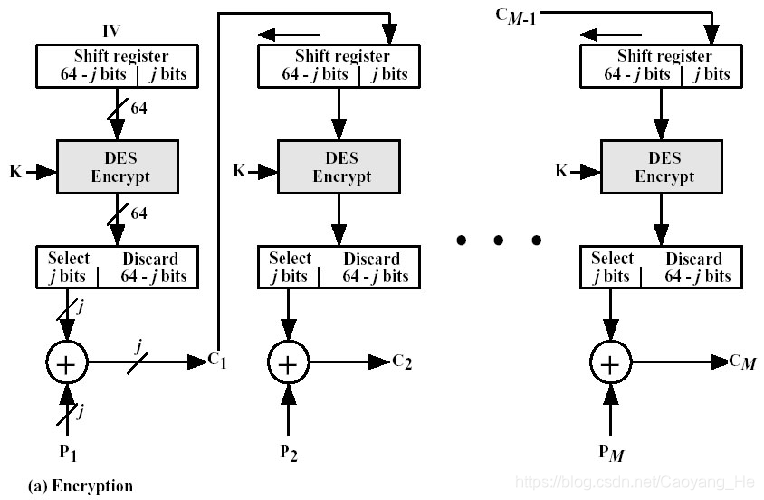
222 | 解密
223 | 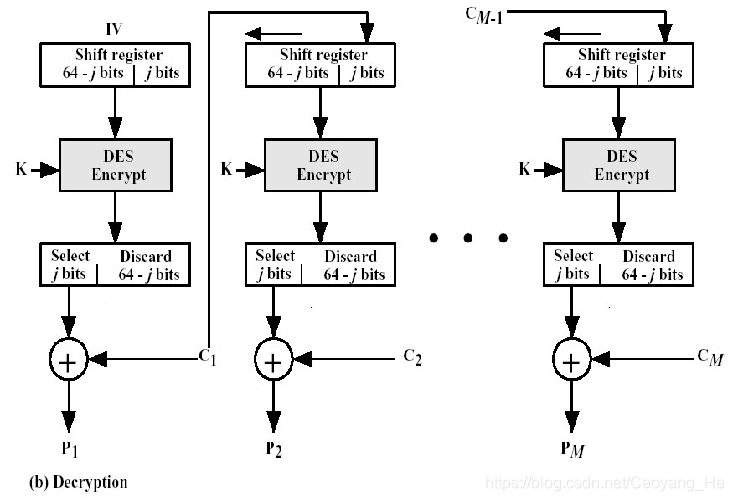
224 | **优点**
225 | 1. 这是将分组密码当作序列密码(数据以位或者字节形式到达)使用的一种方式,
226 | 2. 加密、解密都需要用到分组加密器;
227 | 3. 明文发生错误,错误会传播;
228 | 4. 如果密文发生传输错误,只会影响它出现在移位寄存器期间解密的8个字节的数据得不到正确解密,8个字节一过,后面明文可以得到正确的解密结果。
229 |
230 | **缺点**
231 | 比较浪费,因为每轮加解密中都丢弃了大部分结果,通常只保留了的S为为1个字节。
232 |
233 | ## OFB (Output Feedback)模式
234 | OFB 模式在结构上类似于CFB。不同之处
235 | 1. OFB模式将加密算法的输出反馈到移位寄存器,而CFB模式是将密文单元反馈到移位寄存器。
236 | 2. OFB针对明文和密文分组运算,而CFB仅对S位的子集运算
237 |
238 | **概念图**
239 | 加密
240 | 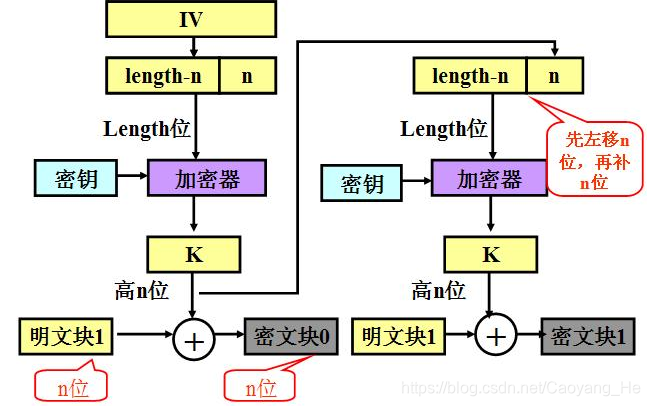
241 | 解密
242 | 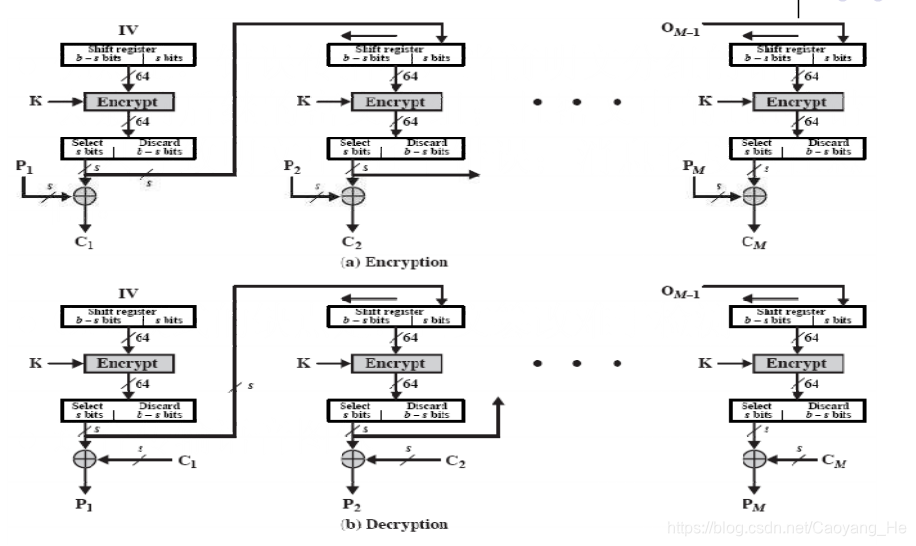
243 | **优点**
244 | 1. 传输过程中的比特错误不会被传播。
245 | 例如C1中出现一比特错误,在解密结果中 只有P1受影响,以后各明文单元则不受影响 。而在CFB中, C1也作为移位寄存器的输入,因此它的一比特错误会影响解 密结果中各明文单元的值。
246 | 解密中密文的1比特也只影响明文的1个错误
247 | 2. 分组密码转化为流模式;
248 | 3. 可以及时加密传送小于分组的数据;
249 |
250 | **缺点**
251 | 难于检测密文是否被篡改。
252 |
253 | **适用于传输语音图像**
254 |
255 | ## 计数器模式CTR(Counter)
256 | 对一系列输入数据块(称为计数)进行加密,产生一系列的输出块,输出块与明文异或得到密文。
257 | 应用于ATM网络安全及IPSec中
258 | 密码算法产生一个16 字节的伪随机码块流,伪随机码块与输入的明文进行异或运算后产生密文输出。密文与同样的伪随机码进行异或运算后可以重产生明文。
259 | **概念图**
260 | 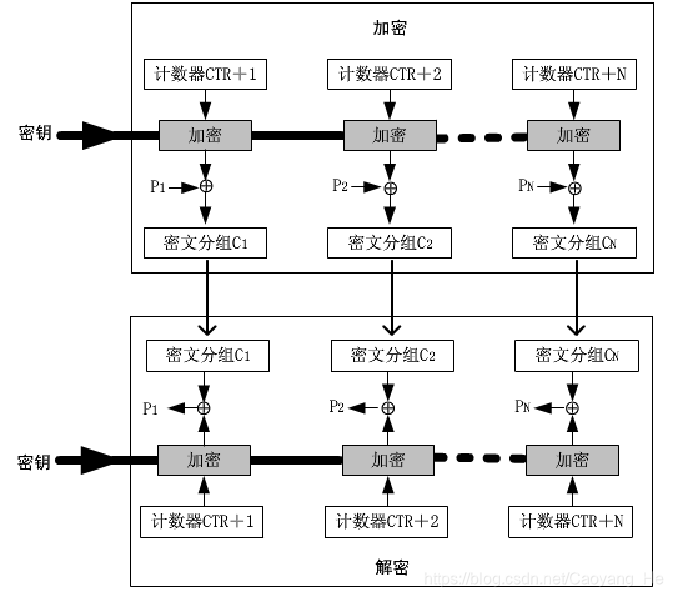
261 | **CTR的特点**
262 | - 使用与明文分组规模相同的计数器长度
263 | - 处理效率高(并行计算)
264 | - 预处理可以极大提高吞吐量:算法和加密盒的输出不依靠明文和密文的输入
265 | - 可以随机对任意一个密文分组进行解密处理,对该密文分组的处理与其他密文无关(第i块解密不依赖第i-1块)
266 | - 实现的简单性,只是异或,且无解密算法
267 | - 适用于实时性和速度要求较高的场合
268 | ## 总结
269 |
270 |
271 | 模式|描述|典型应用
272 | ---|---|----|
273 | 电码本(CBC)|用相同的密钥分别对明文分组独立加密|单个数据的安全传输(如一个加密密钥)
274 | 密文分组链接(CBC)|加密算法的输入是上一个密文组和下一个明文组的异或| 面向分组的通用传播
认证
275 | 密文反馈(CFB)| 一次处理s位,上一块密文作为加密算法的输入,产生的伪随机数输出与明文异或作为下一个单元的密文|面向数据流的通用传播
认证
276 | 输出反馈(OFB)|与CFB类似,只是加密算法的输入是上一次加密的输出,且使用整个分组|噪声信道上的数据流传输(如卫星通信)
277 | 计数器(CTR)|每个明文分组都与一个经过加密的计数器相异或。对每个后续分组计数器递增|面向分组的通用传播
用于高速需求
278 | # 流密码
279 |
280 | - 每次可加密一个比特或一个字节
281 |
282 | - 适合比如远程终端输入加密类的应用
283 |
284 | ## RC4
285 | **简介**
286 | >RC4由RSA三人组中的头号人物Ronald Rivest在1987年设计的密钥长度可变的流加密算法簇。
287 | 和DES算法一样,是一种对称加密算法。
288 | 算法的速度可以达到DES加密的10倍左右,且具有很高级别的非线性 。
289 | 可变密钥长度,可变范围为1-256字节(8-2048比特)
290 | 以随机置换为基础。密钥长度是可变的,RC4起初是用于保护商业机密的。但是在1994年9月,它的算法被发布在互联网上,也就不再有什么商业机密了
291 | 用途广泛,常用于SSL/TLS,IEEE 802.11无线语句网标准的一部分WEP(Wired Equivalent Privacy)协议和新Wifi受保护访问协议(WPA)中。
292 |
293 | **相关概念**
294 | 1. 密钥流:RC4算法的关键是根据明文和密钥生成相应的密钥流,密钥流的长度和明文的长度是对应的,也就是说明文的长度是500字节,那么密钥流也是500字节。当然,加密生成的密文也是500字节,因为密文第i字节=明文第i字节^密钥流第i字节;
295 | 2. 状态向量S:长度为256,S[0],S[1].....S[255]。每个单元都是一个字节,算法运行的任何时候,S都包括0-255的8比特数的排列组合,只不过值的位置发生了变换;
296 | 3. 临时向量T:长度也为256,每个单元也是一个字节。如果密钥的长度是256字节,就直接把密钥的值赋给T,否则,轮转地将密钥的每个字节赋给T;
297 | 4. 密钥K:长度为1-256字节,注意密钥的长度keylen与明文长度、密钥流的长度没有必然关系,通常密钥的长度趣味16字节(128比特)。
298 |
299 | **概念图**
300 | 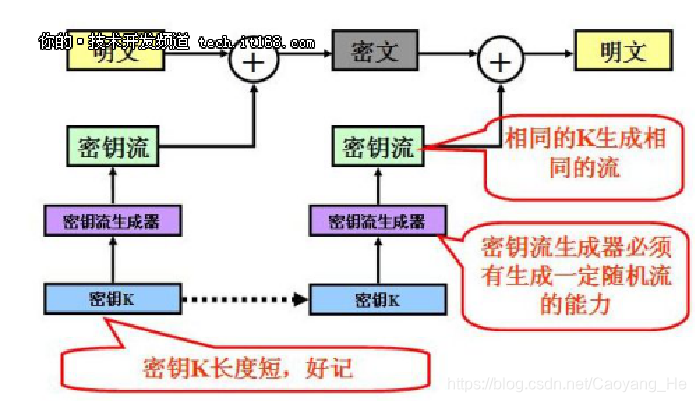
301 | **伪代码**
302 | 第一部分:初始化算法(KSA)
303 | 1. 初始化S和T
304 | for i=0 to 255 do
305 | S[i]=i;
306 | T[i]=K[ i mod keylen ];
307 | 2. 初始排列S
308 | j=0;
309 | for i=0 to 255 do
310 | j= ( j+S[i]+T[i])mod256;
311 | swap(S[i],S[j]);
312 |
313 | 第二部分:伪随机子密钥流生成算法
314 |
315 | 3. 产生密钥流
316 | i,j=0;
317 | for r=0 to len do //r为明文长度,r字节
318 | i=(i+1) mod 256;
319 | j=(j+S[i])mod 256;
320 | swap(S[i],S[j]);
321 | t=(S[i]+S[j])mod 256;
322 | k[r]=S[t];
--------------------------------------------------------------------------------
/信息安全/信息安全(二)——密码学.md:
--------------------------------------------------------------------------------
1 | # 密码学的基本概念
2 | 密码学(Cryptology):
3 | >研究信息系统安全保密的科学。
4 |
5 | 密码编码学(Cryptography):
6 | >研究对信息进行编码,实现对信息的隐蔽。
7 |
8 | 密码分析学(Cryptanalytics) :
9 | >研究加密消息的破译或消息的伪造。
10 |
11 | 消息被称为明文(Plaintext)。
12 | >用某种方法伪装消息以隐藏它的内容的过程称为加密(Encrtption),被加密的消息称为密文(Ciphertext),而把密文转变为明文的过程称为解密(Decryption)。
13 |
14 | 密码算法:
15 | >用于加密和解密的数学函数。
16 | 密码员对明文进行加密操作时所采用的一组规则称作**加密算法(Encryption Algorithm)。**\所传送消息的预定对象称为接收者(Receiver)。接收者对密文解密所采用的一组规则称为\***解密算法(Decryption Algorithm)**。
17 |
18 | **加密过程**
19 | 密码学的目的:Alice和Bob两个人在不安全的信道上进行通信,而破译者Oscar不能理解他们通信的内容。
20 | 
21 | 加密和解密算法的操作通常都是在一组密钥的控制下进行的,分别称为加密密钥(Encryption Key) 和解密密钥(Decryption Key)。
22 | 
23 |
24 | **密码体制**
25 | 一个五元组(P,C,K,E,D)满足条件:
26 | 1) P是可能明文的有限集;(明文空间)
27 | 2) C是可能密文的有限集;(密文空间)
28 | 3) K是一切可能密钥构成的有限集;(密钥空间)
29 | 4) 任意k∈K,有一个加密算法ek∈E和相应的解密算法dk∈D,使得ek : P→C和dk : C→P分别为加密解密函数,满足dk(ek(x))=x,其中 x ∈P。
30 |
31 | **加密算法基本原理**
32 | 代替:明文中的元素映射成另一个元素
33 | 置换 :重新排列
34 | 要求:不允许信息丢失,即算法可逆
35 |
36 | **基于密钥的算法,按照密钥的特点分类:**
37 | ==对称密码算法(symmetric cipher)==:加密密钥和解密密钥相同,或实质上等同,即从一个易于推出另一个。又称秘密密钥算法或单密钥算法。
38 | ==非对称密钥算法(asymmetric cipher)==:加密密钥和解密密钥不相同,从一个很难推出另一个。又称公开密钥算法(public-key cipher) 。
39 |
40 | **密码分析破解类型:**
41 | 1. 唯密文攻击
42 | 密码分析者仅知道有限数量用同一个密钥加密的密文
43 | 2. 已知明文攻击
44 | 密码分析者除了拥有有限数量的密文外,还有数量限定的一些已知“明文—密文”对
45 | 3. 选择明文攻击
46 | 密码分析者除了拥有有限数量的密文外,还有机会使用注入了未知密钥的加密机,通过自由选择明文来获取所希望的“明文—密文”对。
47 | 4. 选择密文攻击
48 | 密码分析者除了拥有有限数量的密文外,还有机会使用注入了未知密钥的解密机,通过自由选择密文来获取所希望的“密文—明文”对。
49 | 5. 选择文本攻击
50 |
51 | **密码的安全性**
52 | ==无条件安全(Unconditionally secure)==
53 | 无论破译者有多少密文,他也无法解出对应的明文,即使他解出了,他也无法验证结果的正确性。**(除一次一密钥,都不是无条件安全)**
54 | ==计算上安全(Computationally secure)==
55 | 破译的代价超出信息本身的价值
56 | 破译的时间超出了信息的有效期
57 |
58 | **现代密码学基本原则**
59 | 设计加密系统时,总假定密码算法是可以公开的,需要保密的是密钥。“**一切秘密在于密钥之中,而加密算法可以公开**” 即Kerckhoff原则。
60 |
61 |
62 | **密码学的起源和发展三个阶段:**
63 | 1949年之前:密码学是一门艺术
64 | >古典密码(classical cryptography)
65 | >**隐写术(steganography):不同于加密。**
66 | 如果把一封信锁在保险柜中,把保险柜藏在纽约的某个地方…,然后告诉你去看这封信。这并不是安全,而是隐藏。
67 |
68 | 1949~1975年:密码学成为科学
69 | >计算机使得基于复杂计算的密码成为可能
70 | 1949年Shannon的“The Communication Theory of Secret Systems”
71 | 1967年David Kahn的《The Codebreakers》
72 | 1971-73年IBM Watson实验室的Horst Feistel等的几篇技术报告
73 | Smith,J.L.,The Design of Lucifer, A Cryptographic Device for Data Communication, 1971
74 | Smith,J.L.,…,An Expremental Application of Cryptogrphy to a remotely Accessed Data System, Aug.1972
75 | Feistel,H.,Cryptography and Computer Privacy, May 1973
76 | 数据的安全基于密钥而不是算法的保密
77 |
78 | 1976年以后:密码学的新方向——公钥密码学
79 | >1976年Diffie & Hellman的“New Directions in Cryptography”提出了不对称密钥密码
80 | 1977年Rivest,Shamir & Adleman提出了RSA公钥算法
81 | 90年代逐步出现椭圆曲线等其他公钥算法
82 | 公钥密码使得发送端和接收端无密钥传输的保密通信成为可能!
83 | 1977年DES正式成为标准80年代出现“过渡性”的“post DES”算法,如IDEA,RCx,CAST等
84 | 90年代对称密钥密码进一步成熟 Rijndael,RC6, MARS,Twofish,Serpent等出现
85 | 2001年Rijndael成为DES的替代者
86 |
87 | # 经典密码体制
88 |
89 | ## 代替密码(substitution cipher)
90 | 就是明文中的每一个字符被替换成密文中的另一个字符。接收者对密文做反向替换就可以恢复出明文。
91 |
92 | **简单代替密码(simple substitution cipher):**
93 | 又称单字母密码(monoalphabetic cipher),明文的一个字符用相应的一个密文字符代替。
94 |
95 | **多字母密码(ployalphabetic cipher):**
96 | 明文中的字符映射到密文空间的字符还依赖于它在上下文的位置。
97 |
98 | **恺撒密码(Caesar Cipher):**
99 | 已知的最早(也是最简单的方式)的简单替代密码是朱里斯.恺撒所用的密码。恺撒密码是把字母表中的每个字母用该字母后面第3个字母进行代替。例如:
100 | 明文:meet me after the toga party
101 | 密文:PHHW PH DIWHU WKH WRJD SDUWS
102 | 既然字母表是循环的,因此Z后面的字母是A。能够通过列出所以可能性定义如下所示的变换:
103 | 
104 |
105 | **移位密码(Shift cipher)**
106 | 对每个明文字母p,恺撒加密可转化为移位密码,其中加密算法:
107 | C = E(p) = (p+k) mod (26),其中k在1~25之间取值。
108 | 解密算法是:p = D(C) = (C-k) mod (26)
109 | 如果已知密文是恺撒密码,则使用强行攻击密码分析容易取得结果
110 | 直接对所有25个可能的密钥进行尝试。
111 |
112 | **模运算**
113 | a+b mod n = (a mod n+b mod n) mod n
114 | a-b mod n = (a mod n-b mod n) mod n
115 | a×b mod n = (a mod n×b mod n) mod n
116 |
117 | **仿射密码算法:**
118 | P = C = Z~26~
119 | K = (a,b) ∈K = Z~26~×Z~26~
120 | 加密
121 | y = e~K~(x) = (ax+b) mod 26
122 | 要求唯一解的充要条件:gcd(a,26)=1
123 | 解密
124 | d~K~ (y) = (y – b) / a mod 26 = (y – b) a^-1^ mod 26
125 | **仿射密码算法例:**
126 | K = (7,3),则有7~-1~ mod 26 = 15
127 | 因此对任一明文x有:e~k~ (x) = 7x + 3
128 | 解密:
129 | d~k~ (y) = 15 * (y – 3) mod 26 = 15y – 19 mod 26
130 | = 15 * (7x + 3) – 19 = 105*x + 45 – 19
131 | = 105x = x mod 26
132 | 仿射密码算法讨论:
133 | >首先,a = 1时,即是移位密码 (shift)
134 | 其次,如果K随意选择,可能会有问题
135 | 比如取K = (8,5) ,即y=8x+5 mod 26
136 | 明文a和n,记x~1~ = 0 (a),x~2~ = 13 (n),则y~1~= 5,y~2~ = 5 (F)
137 | 不同的明文被加密成相同的密文,这样在解密时就有歧义
138 | 那么,如何避免这种歧义的出现?
139 | 合理选取密钥
140 | 要求a和26互素,即gcd (a, 26) = 1
141 | 如果k = (a,b)中a和26不互素则会有歧义,若a和26有公因子gcd (a, 26)=d>1,则对明文x~1~=0和x~2~ =26/d的就相同密文
142 | 因为ax~1~+b≡b mod 26,而ax~2~+b=a×26/d+b=a/d×26+b≡b mod 26
143 | 即x1和x2被加密成相同的密文,所以解密时会混淆
144 | 这里,是否互素代表了什么性质呢?
145 | 互素才有“逆”
146 | 逆元,讨论在余数集合上进行
147 | 加法逆元:如果a + b≡0 mod n,互为加法逆元
148 | 则Zn中都有:0,0 1,n-1 2,n-2 … n/2,n/2
149 | 乘法逆元:如果a×b≡1 mod n,则a、b互为乘法逆元
150 | 如6×20≡1 mod 119
151 | 定义a的乘法逆元a~-1~,a~-1~a ≡ 1 mod n,显然可交换
152 | 由y = (ax + b) mod 26,
153 | 得x = d~K~ (y) = (y - b) / a = a~-1~ (y - b) /a~-1~a = a~-1~ (y - b)
154 | 即x = a~-1~(ax + b - b) = a~-1~ax = x mod 26,x恢复了
155 | 乘法逆元如何构造?
156 | 3×9 ≡ 1 mod 26
157 | 5×?≡ 1 mod 26
158 | 并不是每个元素都有乘法逆元,概括为解方程 ax≡1 mod n
159 |
160 | **如何求乘法逆元:**
161 | 一次同余方程ax ≡ b (mod m)这个方程有没有解,相当于问有没有那样一个整数x,使得对于某个整数y来说,有ax + my=b
162 | 推论:ax≡1 mod n有解 IFF (a, n) | 1,即a、n互素
163 |
164 | **欧几里德算法(求最大公约数):**
165 | 基于定理:对于任何非负的整数a和非负的整数b:
166 | gcd (a,b) = gcd (b,a mod b)
167 | 例如: gcd (55,22) = gcd (22,55 mod 22) = gcd (22,11) = 11
168 | 扩展欧几里德算法(求乘法逆元)例:
169 | **方式一**
170 | 求7关于96的乘法逆元
171 | |Q |X1| X2| X3| Y1 | Y2 | Y3|
172 | |---|---|---|---|---|---|---|
173 | | | 1 | 0 |96| 0 | 1 | 7|
174 | |13| 0| 1| 7| 1-0*13=1 |0–1*13= -13| 96-7*13=5|
175 | | 1 | 1| -13| 5 |0-1*1= -1 | 1- 1*(-13)= 14 |7-1*5=2|
176 | |2 |-1 | 14| 2 | 1-2*0=1 | -13-2*14= -41 | 5-2*2=1|
177 | 由于Y3=1,所以算法中止,故乘法逆元为-41 mod 96 = 55
178 | 即7×55 ≡1 mod 96
179 | **方式二**
180 | 求22mod31的逆元
181 | |i|r~i~|q~i~|x~i~|y~i~|
182 | |--|--|--|--|--|
183 | -1|31| |1|0|
184 | 0|22| |0|1|
185 | |1| 9| 1| 1 |-1|
186 | |2 |4| 2 |-2 |3|
187 | |3 |1 |2 |5 |-7|
188 | 当r~i~=1,则5x31+(-7)x 22 =1 mod 31
189 | 则逆元为(-7)+ 31 = 24
190 | (PS:第一行为被除数,默认X~i~Y~i~为 1 0 ,第二行为除数,默认X~i~Y~i~为 0 1 个人觉得方式二好理解一些)
191 | 
192 | **任意的单表代替密码算法:**
193 | 设P=C=Z~26~,K是由26个符号0,1,..,25的所有可能置换组成。任意π∈K,定义eπ(x)= π(x)=y 且d~π~(y)=π~-1~(y)=x, π~-1~是π的逆置换。
194 | 注:
195 | 密钥空间K很大,|k|=26! ≈ 4×1026,破译者穷举搜索不行的(每微秒搜索加密一次需要6.4×1012年)。移位密码、乘数密码、仿射密码算法都是替换密码的特例。
196 | **任意的单表代替密码算法可由统计的方式破译**
197 |
198 | **简单代替密码(simple substitution cipher):**
199 | 又称单字母密码(monoalphabetic cipher),明文的一个字符用相应的一个密文字符代替。
200 |
201 | **多字母密码(ployalphabetic cipher):**
202 | 明文中的字符映射到密文空间的字符还依赖于它在上下文的位置。
203 |
204 | **多字母代替密码:Playfair**
205 | Playfair:将明文中的双字母组合作为一个单元对待,并将这些单元转换为密文的双字母组合。
206 | 5×5变换矩阵: I与J视为同一字符
207 | 加密规则:按成对字母加密
208 | 相同对中的字母加分隔符(如x)
209 | 
210 | balloon ->ba lx lo on
211 | 同行取右边: he -> EC
212 | 同列取下边: dm -> MT
213 | 其他取交叉: kt > MQ,OD > TR
214 |
215 | **Hill密码:**
216 | 基于矩阵的线性变换,由数学家Lester Hill于1929年研制
217 | Z26上的线性变换
218 | 例:x=(x1,x2),y=(y1,y2)
219 | 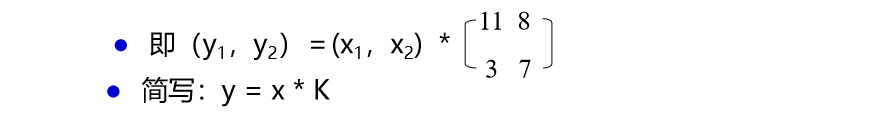定义:y~1~=11x~1~+3x~2~ mod 26,y~2~= 8x~1~+7x~2~ mod 26
220 |
221 | **Vigenére密码:**
222 | 是一种多表移位代替密码
223 | 设d为一固定的正整数,d个移位代换π=(π1,π2,…,πd) 由密钥序列K=(k1,k2,…,kd)给定,第i+td个明文字母由表i决定,即密钥ki决定
224 | ek(xi+td) = (xi+td + ki) mod q = y,dk(yi+td) = (xi+td-ki) mod q = x
225 | 例子:q=26, x=polyalphabetic cipher, K=RADIO
226 | 明文 x= p o lya l phab e t i cc i pher
227 | 密钥 k= R ADIO RADIO RADIO RADIO
228 | 密文 y= GOOGO CPKTP NTLKQ ZPKMF
229 |
230 | **One-Time Pad一次一密:**
231 | Joseph Mauborgne提出使用与消息一样长且无重复的随机密钥来加密消息,密钥只对一个消息加解密,之后弃之不用;每条新消息都需要与其等长的新密钥,这就是一次一密,它是不可攻破的。
232 | 运算基于二进制数据而非字母
233 | 加密:ci = pi ⊕ ki, pi是明文第i个二进制位, ki是密钥第i个二进制位,ci是密文第i个二进制位, ⊕是异或运算
234 | 密文是通过对明文和密钥的逐位异或而成的,根据异或运算的性质,解密过程为pi = ci ⊕ ki,
235 | 给出任何长度与密文一样的明文,都存在着一个密钥产生这个明文。如果用穷举法搜索所有可能的密钥,会得到大量可读、清楚的明文,但是无法确定哪个才是真正所需的,因而这种密码不可破。
236 | **一次一密的两个限制**
237 | 产生大规模随机密钥有实际困难
238 | 密钥的分配和保护无法保证
239 | ## 置换密码(permutation cipher)
240 | 又称换位密码(transposition cipher),明文的字母保持相同,但顺序被打乱了。
241 |
242 | **斯巴达密码棒**
243 | >公元前405年,雅典和斯巴达之间的战争已进入尾声。斯巴达急需摸清波斯帝国的具体行动计划。斯巴达军队捕获了一名从波斯帝国回雅典送信的信使。可他身上除了一条布满希腊字母字样的普通腰带外,什么也没有。
244 | 斯巴达统帅把注意力集中到了那条腰带上,他反复琢磨那些乱码似的文字,却怎么也解不出来。最后当他无意中把腰带呈螺旋形缠绕在手中的剑鞘上时,原来腰带上那些杂乱无章的字母,竟组成了一段文字。它告诉雅典,波斯准备在斯巴达发起最后攻击时,突然对斯巴达军队进行袭击。
245 |
246 | **栅栏技术:**
247 | 在这种密码中最简单的是栅栏技术,在该密码中以对角线顺序写下明文,并以行的顺序读出。
248 | 例如:以深度为2的栅栏密码加密消息“meet me after the toga party”,写出如下形式:
249 | |m | |e| |m| | a| | t| |r| |h| | t| | g | |p | |r| |y|
250 | |--|--|--|--|--|--|--|--|--|--|--|--|--|--|--|--|--|--|--|--|--|--|--|
251 | | | e| |t| | e| | f| | e| | t| | e| | o| | a| | a| | t|
252 | 被加密的消息为:mematrhtgpryetefeteoaat
253 |
254 | **置换密码:**
255 | 更为复杂的方式是以一个矩形逐行写出消息,再逐列读出该消息。
256 | 该方法以行的顺序排列。列的阶则成为该算法的密钥。密钥包含3方面信息::行宽、列高、读出顺序
257 | 例:
258 | |key | 4| 3| 1| 2| 5| 6| 7|
259 | |--|--|--|--|--|--|--|--|--|
260 | |plaintext: |a | t | t | a| c| k| p|
261 | | | o| s | t| p | o | n| e|
262 | | | d| u | n| t| i| l| t|
263 | || w | o | a | m |x | y| z|
264 | ciphertext :TTNAAPTMTSUOAODWCOIXPETZ
265 |
266 | 完全保留字符的统计信息
267 | 使用多轮加密可提高安全性
268 |
269 | **Rotor Machines转轮密码机:**
270 | 在现代密码系统出现之前,转轮密码机是最为广泛使用的多重加密器,尤其是在第二次世界大战中。
271 | 代表:German Enigma, Japanese Purple
272 | 转轮机使用了一组相互独立的旋转圆筒,可以通过电脉冲,每个圆筒有26个输入和26个输出,每个输入仅与一个输出相连,一个圆筒就定义了一个单表代换。
273 | 每按下一个键,圆筒旋转一个位置,内部连线相应改变,就定义了不同的单表代换密码,经过26个明文字母,圆筒回到初始状态,就得到一个周期为26的多表代换密码。
274 | 3个圆筒的转轮机就有263=17576个不同的代换字母表
275 |
276 | Enigma的使用
277 | >发信人首先要调节三个转子的方向,而这个转子的初始方向就是密钥,是收发双方必须预先约定好的,然后依次键入明文,并把显示器上灯泡闪亮的字母依次记下来,最后把记录下的闪亮字母按照顺序用正常的电报方式发送出去。
278 | 收信方收到电文后,只要也使用一台恩尼格玛,按照原来的约定,把转子的方向调整到和发信方相同的初始方向上,然后依次键入收到的密文,显示器上自动闪亮的字母就是明文了。
279 | 加密的关键在于转子的初始方向。如果敌人收到了完整的密文,还是可以通过不断试验转动转子方向来找到这个密匙,特别是如果破译者同时使用许多台机器同时进行这项工作,那么所需要的时间就会大大缩短。对付这样暴力破译法(即一个一个尝试所有可能性的方法),可以通过增加转子的数量来对付,因为只要每增加一个转子,就能使试验的数量乘上26倍!
280 | 由于增加转子就会增加机器的体积和成本,恩尼格玛密码机的三个转子是可以拆卸下来并互相交换位置,这样一来初始方向的可能性一下就增加了六倍。假设三个转子的编号为1、2、3,那么它们可以被放成123-132-213-231-312-321这六种不同位置。
281 | 恩尼格玛还有一道保障安全的关卡,在键盘和第一个转子之间有块连接板。通过这块连接板可以用一根连线把某个字母和另一个字母连接起来,这样这个字母的信号在进入转子之前就会转变为另一个字母的信号。这种连线最多可以有六根,后期的恩尼格玛甚至达到十根连线,这样就可以使6对字母的信号两两互换,其他没有插上连线的字母则保持不变。当然连接板上的连线状况也是收发双方预先约定好的。
282 | 转子的初始方向、转子之间的相互位置以及连接板的连线状况组成了恩尼格玛三道牢不可破的保密防线,其中连接板是一个简单替换密码系统,而不停转动的转子,虽然数量不多,但却使整个系统变成了复式替换系统。
283 |
284 | Enigma的破解
285 | >“暴力破译法”还原明文,需要试验多少种可能性:
286 | 三个转子不同的方向组成了26x26x26=17576种可能性;
287 | 三个转子间不同的相对位置为6种可能性;
288 | 连接板上两两交换6对字母的可能性则是异常庞大,有100391791500种;
289 | 于是一共有17576x6x100391791500,其结果大约为10,000,000,000,000,000!即一亿亿种可能性!
290 |
--------------------------------------------------------------------------------
/信息安全/信息安全(五)——消息认证、数字签名及PGP.md:
--------------------------------------------------------------------------------
1 | # 消息认证
2 | 消息认证 (Message Authentication):是一个证实收到的消息来自可信的源点且未被篡改的过程。
3 | ## 鉴别的目的
4 | 鉴别的主要目的有二:
5 | 第一,验证信息的发送者是真正的,而不是冒充的,此为信源识别;
6 | 第二,验证信息的完整性,在传送或存储过程中未被篡改,重放或延迟等。
7 |
8 | ## 鉴别模型
9 | 一个单纯鉴别系统的模型
10 | 
11 | ## 鉴别系统的组成
12 | 鉴别编码器和鉴别译码器可抽象为鉴别函数。一个安全的鉴别系统,需满足
13 | 1) 接收者能够检验和证实消息的合法性、真实性和完整性
14 | 2) 消息的发送者和接收者不能抵赖
15 | 3) 除了合法的消息发送者,其它人不能伪造合法的消息
16 |
17 | 首先要选好恰当的鉴别函数,该函数产生一个鉴别标识,然后在此基础上,给出合理的鉴别协议(Authentication Protocol),使接收者完成消息的鉴别。
18 |
19 | ## 鉴别函数
20 | 可用来做鉴别的函数分为三类:
21 | 1) 消息加密函数(Message encryption):用完整信息的密文作为对信息的鉴别。
22 | 2) 消息鉴别码MAC(Message Authentication Code):公开函数+密钥产生一个固定长度的值作为鉴别标识
23 | 3) 散列函数(Hash Function):是一个公开的函数,它将任意长的信息映射成一个固定长度的信息。
24 |
25 |
26 | ## 加密认证
27 | 用完整信息的密文作为对信息的鉴别
28 | ### 对称密码体制加密认证
29 | 
30 | ### 公钥密码体制加密认证
31 | 
32 | 
33 | 
34 | 公钥密码体制加密认证
35 | - 使用公开密钥加密信息的明文只能提供保密而不能提供认证。为了提供认证,发送者A用私钥对信息的明文进行加密,任意接收者都可以用A的公钥解密。
36 | - 采用这样的结构既可提供了认证,也可提供数字签名。因为只有A 能够产生该密文,其它任何一方都不能产生该密文。
37 | - 从效果上看A 已经用私钥对信息的明文进行了签名。
38 | - 应当注意只用私钥加密不能提供保密性。因为,任何人只要有A的公开密钥就能够对该密文进行解密。
39 | - 保密性与真实性是两个不同的概念。根本上,信息加密提供的是保密性而非真实性。
40 | - 加密代价大(公钥算法代价更大)。
41 | - 鉴别函数与保密函数的分离能提供功能上的灵活性。
42 | 广播的信息难以使用加密(信息量大)
43 | 某些信息只需要真实性,不需要保密性
44 | ## 消息认证码
45 | 带密钥的hash函数
46 |
47 | 适用于:通信双方基于共享的同一密钥来认证彼此之间交互的信息。
48 |
49 | MAC 函数将密钥和数据块作为输入,产生hash值作为MAC码。
50 |
51 | 设M是变长的消息,K是仅由收发双方共享的密钥,则M的MAC由如下的函数C生成:MAC = C~k~(M )
52 | 这里的C~k~(M )是定长的。发送者每次将MAC附加到消息中,接收者通过重新计算MAC来对消息进行认证。
53 | 如果收到的MAC与计算得出的MAC相同,则接收者可以认为:
54 | - 消息未被更改过
55 | - 消息来自与他共享密钥的发送者
56 |
57 | MAC函数类似于加密函数,主要区别在于MAC 函数不需要可逆性,而加密函数必须是可逆的,因此认证函数比加密函数更不易破解。
58 |
59 | 因为收发双方共享相同的密钥,上述过程只提供认证而不提供保密,也不能提供数字签名
60 | ### MAC的基本用法
61 | 
62 | 
63 | 
64 | #### HMAC简介
65 | ash函数用来构造MAC:HMAC为其中之一
66 | # 散列函数:
67 | ## 概念
68 | 散列函数 (Hash Functions):一个散列函数以一个变长的报文作为输入,并产生一个定长的散列码,有时也称报文摘要,作为输出。
69 |
70 | 散列函数(又称杂凑函数)是对不定长的输入产生定长输出的一种特殊函数:h = H(M)
71 | 其中M是变长的消息
72 | h=H(M)是定长的散列值或称为消息摘要。
73 |
74 | 散列函数H是公开的,散列值在信源处被附加在消息上,接收方通过重新计算散列值来保证消息未被篡改。
75 |
76 | 由于函数本身公开,传送过程中对散列值需要另外的加密保护(如果没有对散列值的保护,篡改者可以在修改消息的同时修改散列值,从而使散列值的认证功能失效)。
77 | ## 散列函数的基本用法:消息认证
78 | 
79 | 
80 | ## 散列函数的基本用法:数字签名
81 | 
82 | 
83 | ## 散列函数的基本用法:其他应用
84 | 单向口令文件
85 |
86 | 入侵检测和病毒检测
87 |
88 | 构建随机函数或伪随机函数
89 |
90 | ## 两个简单的Hash函数
91 | 分组对应位异或
92 | 移位分组对应位异或
93 | ## Hash函数的安全需求(重点)
94 | 散列函数的目的是为文件、消息或其他的分组数据产生“指纹”。用于消息认证的散列函数H必须具有如下性质:
95 | 1. 输入长度可变:H能用于任何大小的数据分组
96 | 2. 输出长度固定:H都能产生定长的输出
97 | 3. 效率:对于任何给定的x,H(x)要相对易于计算
98 | 4. 抗原像攻击:对任何给定的散列码h,寻找x使得H(x)=h在计算上不可行
99 | 5. 抗第二原像攻击:对任何给定的分组x,寻找不等于x的y,使得H(x)=H(y)在计算上不可行(弱抗冲突)
100 | 6. 抗强抗攻击:寻找任何的(x,y),使得H(x)=H(y)在计算上不可行(强抗冲突)
101 | 7. 伪随机性:H的输入输出满足伪随机性测试标准
102 |
103 | ### 散列(Hash)函数的安全性需求
104 | Oscar以一个x开始。首先他计算Z=h(x),并企图找到一个x’满足h(x’)=h(x)。若他做到这一点,x‘也将为有效。为防止这一点,要求函数h具有无碰撞特性。
105 |
106 | - 定义1(弱无碰撞),散列函数h称为是弱无碰撞的,是指对给定消息x∈X,在计算上几乎找不到不等于x的x’∈X,使h(x)=h(x’)。
107 |
108 | - 定义2(强无碰撞),散列函数h被称为是强无碰撞的,是指在计算上几乎不可能找到任意的相异的x,x’,使得h(x)=h(x’)。
109 | 注:强无碰撞自然含弱无碰撞!
110 |
111 | 前两条要求具有实用性
112 | 第2条和第3条是单向性质,即给定消息可以产生一个散列码,而给定散列码不可能产生对应的消息
113 | 第4条性质是保证一个给定的消息的散列码不能找到与之相同的另外的消息,即防止伪造
114 | 第6条是对已知的生日攻击方法的防御能力。
115 |
116 | ### 散列函数的生日攻击
117 | 假定使用64位的散列码,是否安全?
118 |
119 | 如果采用传输加密的散列码和不加密的报文M,对手需要找到M ',使得H(M')=H(M),以便使用替代报文来欺骗接收者。
120 | 一种基于生日悖论的攻击可能做到这一点。
121 |
122 | 生日问题:一个教室中,最少应有多少学生,才使至少有两人具有相同生日的概率不小于1/2?
123 |
124 | 生日问题:
125 | 假定一年按365天计算。每人生日在一年365天中的任何一天是等可能的,即都等于1/365
126 | 他们生日各不相同的概率为:
127 | 365\*364\*363\*…\*(365-n+1)/365~n~
128 | 因而,n个人中至少有两个人生日相同的概率为:
129 | P = 1 - 365\*364\*363\*…*(365-n+1)/365~n~
130 | 若要使P≥0.5,n = 23即可,在64人的班级中,“至少两人生日相同”的概率为0.997(n=46,p>=94.15%)
131 |
132 |
133 | 给定一个散列函数,有n个可能的输出(m位),输出值为H(x),如果H有k个随机输入,k必须为多大才能使至少存在一个输入y使得H(y)=H(x)的概率大于0.5。
134 | 对单个y,H(y) = H(x)的概率为1/n,H(y) ≠ H(x)的概率为1-(1/n)。
135 | 如果产生k个随机值y,他们之间两两不等的概率等于每个个体不匹配概率的乘积,即[1-(1/n)]^k^。
136 | 这样,至少有一个匹配的概率为1-[1-(1/n)]^k^≈1-[1-(k/n)]=k/n。要概率等于0.5,只需k=n/2=2^m-1^。
137 | 对长度为m位的散列码,共有2^m^个可能的散列码,若要使任意的x,y 有H(x)=H(y)的概率为0.5,只需k=2^m/2^。
138 |
139 | ## 散列函数的结构
140 | 由Merkle于1989年提出
141 | Ron Rivest于1990年提出MD4
142 | 几乎被所有hash函数使用
143 |
144 |
145 | 具体做法:
146 | 把原始消息M分成一些固定长度的块Y~i~
147 | 最后一块padding并使其包含消息M长度
148 | 设定初始值CV~0~
149 | 重复使用压缩函数f,CV~i~ = f(CV~i-1~,Y~i-1~)
150 | 最后一个CV~i~为hash值
151 | 
152 | ## MD5算法、SHA算法
153 | ### MD5简介
154 | Merkle于1989年提出hash function模型
155 | Ron Rivest于1990年提出MD4
156 | 1992年, MD5 (RFC 1321) developed by Ron Rivest at MIT
157 | MD5把数据分成512-bit块
158 | MD5的hash值是128-bit
159 | 在最近数年之前,MD5是最主要的hash算法
160 | 美国标准SHA-1以MD5的前身MD4为基础
161 | 该算法以一个任意长度的报文作为输入,产生一个128bit的报文摘要作为输出。输入是按512bit的分组进行处理的。
162 | #### [MD5算法](https://blog.csdn.net/Caoyang_He/article/details/89431923)
163 | #### MD5小结
164 | MD5使用小数在前
165 | Dobbertin在1996年找到了两个不同的512-bit块,它们在MD5计算下产生相同的hash
166 | MD5不是足够安全的
167 | MD5在线查询破解
168 | http://www.md5.org.cn/
169 | http://www.cmd5.com/
170 | http://md5jiami.51240.com/
171 | MD5的32位和16位加密算法
172 | MD5通常是32位的编码,而在不少地方会用到16位的编码。16位就是从32位MD5散列中把中间16位提取出来。
173 | admin 的摘要:
174 | 16位:7a57a5a743894a0e
175 | 32位:21232f297a57a5a743894a0e4a801fc3
176 |
177 | ### SHA简介
178 | 
179 | SHA-512逻辑
180 | 步骤1 附加填充位:消息长为模1024与896同余
181 | 步骤2 附加长度:最后128位:128位无符号整数表明消息的长度
182 | 初始化Hash缓冲区:Hash函数的中间结果和最终结果保存在512位的缓冲区中,缓冲区用8个64位寄存器(a,b,c,d,e,f,g,h)
183 | 以1024位的分组(128个字节)为单位处理消息
184 | 输出
185 |
186 | #### [SHA1算法](https://blog.csdn.net/Caoyang_He/article/details/89431966)
187 |
188 | #### SHA Summary
189 | - Applications of cryptographic hash functions
190 | Message authentication
191 | Digital signatures
192 | Other applications
193 |
194 | - Requirements and security
195 | Security requirements for cryptographic hash functions
196 | Brute-force attacks
197 | Cryptanalysis
198 |
199 | - Hash functions based on cipher block chaining
200 |
201 | - Secure hash algorithm (SHA)
202 | SHA-512 logic
203 | SHA-512 round function
204 |
205 | - SHA-3
206 | The sponge construction
207 | The SHA-3 Iteration Function f
208 | # 数据签名体制
209 | 数字签名(Digital Signature)是一种防止源点或终点抵赖的鉴别技术。
210 |
211 | 消息认证(Message authentication)保护双方之间的数据交换不被第三方侵犯,但它并不保证双方自身的相互欺骗。
212 |
213 | 假定A发送一个认证的信息给B,双方之间的争议可能有多种形式:
214 | B伪造一个不同的消息,但声称是从A收到的。
215 | A可以否认发过该消息,B无法证明A确实发了该消息。
216 |
217 | 例如:股票交易指令亏损后抵赖。
218 |
219 |
220 |
221 | ## 数字签名原理
222 | ### 一个数字签名至少应满足以下几个条件:
223 | 依赖性:数字签名必须是依赖于要签名报文的比特模式(类似于笔迹签名与被签文件的不可分离性)
224 | 唯一性:数字签名必须使用对签名者来说是唯一的信息,以防伪造和否认
225 | 可验证:数字签名必须是在算法上可验证的
226 | 抗伪造:伪造一个数字签名在计算上不可行,无论是通过以后的数字签名来构造新报文,还是对给定的报文构造一个虚假的数字签名(类似笔迹签名不可模仿性)
227 | 可用性:数字签名的产生、识别和证实必须相对简单,并且其备份在存储上是可实现的
228 | ### 数字签名的类别:
229 | 以方式分:
230 | 直接数字签名direct digital signature
231 | 仲裁数字签名arbitrated digital signature
232 |
233 | 以安全性分
234 | 无条件安全的数字签名
235 | 计算上安全的数字签名
236 |
237 | 以可签名次数分
238 | 一次性的数字签名
239 | 多次性的数字签名
240 | ## 数字签名算法
241 | ### 普通数字签名算法
242 | #### RSA
243 | 
244 | A的公钥私钥对{KUa||KRa}
245 | A对消息M签名: SA=EKRa(M)
246 | 问题:
247 | 速度慢
248 | 信息量大
249 | 第三方仲裁时必须暴露明文信息
250 | hash函数的无碰撞性保证了签名的有效性
251 |
252 | ##### 签名与加密
253 | 签名提供真实性(authentication)、加密提供保密性(confidentiality)
254 | “签名+加密”提供“真实性+保密性”
255 | 两种实现方式: (A→B)
256 | 1. 先签名,后加密: E~KUb~{M||Sig~A~(M)}
257 | 2. 先加密,后签名: {E~KUb~(M)||Sig~A~(E~KUb~(M))}
258 |
259 | 方式2的问题:
260 | 发生争议时,B需要向仲裁者提供自己的私钥
261 | 安全漏洞:攻击者E截获消息,把Sig~A~(E~KUb~(M))换成Sig~E~(E~KUb~(M)),让B以为该消息来自E
262 | 保存信息多:除了M,Sig~A~(E~KUb~(M)),还要保存E~KUb~(M)
263 | ∵KUb可能过期
264 | #### EIGamal
265 | EIGamal签名方案由T.ElGamal于1985年提出,其变体用于DSS中,其安全性依赖于有限域上离散对数的困难性上。
266 | 构造参数:
267 | 全局参数,p:一个大素数,g:Z~p~中乘法群Z~p~\*的一个生成元。
268 | 私钥参数,x:用户的私钥,x∈Z~p~\*
269 | 公钥参数,y:用户的公钥,y=g^x^ mod p
270 | 算法中常还使用一个随机数k
271 | ##### EIGamal签名方案签名过程
272 | 给定要签名的明文M:
273 | 生成一个随机数k,k∈Zp\*
274 | 计算r:r = g^k^ mod p
275 | 计算s:s = (H(M) – xr)k^-1^ mod p – 1,到此,签名结果为(r,s)
276 | 把消息和签名结果(M,r,s)发给接收者
277 |
278 | ##### EIGamal签名方案认证过程
279 | 取得发送方的公钥y;
280 | 预查合法性:若1≤r≤p-1,继续;否则,签名不合法
281 | 计算v1:v1=y^r^r^s^ mod p;
282 | 计算v2:v2=g^H(M)^ mod p;
283 | 比较v1和v2 :如果v1=v2,表示签名有效;否则,无效
284 |
285 | ##### EIGamal签名方案证明:
286 | 先对s进行处理,有:
287 | S = (H(M) – xr)k^-1^ mod p – 1
288 | ks = (H(M) – xr)k^-1^k mod p – 1 = (H(M) – xr) mod p – 1
289 | H(M) = xr+ks mod p – 1
290 | 考察认证过程中的等式v2 = gH(M) mod p
291 | v2 = g xr+ks mod ( p-1) mod p = (g x)r(g k)s mod p
292 | v2 = yrrs mod p
293 | 因为v2 = v1所以该算法成立
294 | #### DSS/DSA
295 | 数字签名标准
296 | 美国国家标准与技术研究所(NIST)公布的联邦信息标准FIPS186,称为数字签名算法(DSA)。
297 |
298 | FIPS186-3的最新版本包括三个算法
299 | DSA
300 | 基于RSA的数字签名算法RSA-PSS
301 | 椭圆曲线的数字签名算法ECDSA
302 |
303 | 与RSA不同,DSA算法是一种密钥方案,但不能用于加密或密钥交换。DSA的安全性建立在离散对数的困难性上。
304 | 
305 | 全局公开密钥分量
306 | p:素数,其中2^L-1^盲变换->签名->接收者->逆盲变换
363 |
364 | 盲签名协议:
365 | 采用分割-选择(Cut - and - Choose)技术,可以使签名者B知道他签署的是哪方面的信息,但是还保留盲签名的特征
366 | 例:反间谍人员化名的签名
367 | 反间谍组织的成员身份保密,甚至机构头目也不知道。机构头目还要给每个成员一个签字文件,文件的内容是:持有该文件的**人具有外交豁免权。
368 | 文件中必须使用反间谍组织的成员的化名,另外机构头目也不能对任意的文件签名。假定成员为A,机构头目是签名者B
369 | ## 特殊的数字签名算法
370 |
371 | # PGP
372 | 作者:Phil Zimmermann
373 | 提供可用于电子邮件和文件存储应用的保密与鉴别服务。
374 | 支持版本多。PGP支持各种系统平台和不同商业版本。
375 | 选择众所周知的算法,避免算法的安全性争议。如公钥加密包括RSA、DSS、Diffie-Hellman,对称加密包括CAST-128、IDEA、3DES、AES,以及SHA-1散列算法。
376 | 适用性强,既可用于机构,也可用于个人。
377 | 可自主使用,不由政府或标准化组织所控制。
378 |
379 | ## PGP安全服务
380 | 数字签名:DSS/SHA或RSA/SHA
381 | 消息加密:CAST-128或IDEA或3DES + Diffie-Hellman或RSA
382 | 数据压缩:ZIP
383 | 邮件兼容:Radix 64转换
384 |
385 | ## PGP运行流程
386 | K~s~:session key
387 | K~Ra~、 K~Ua~:用户A的私钥和用户A的公钥
388 | EP、DP:公钥加密和公钥解密
389 | EC、DC:常规加密和常规加密
390 | H:散列函数
391 | Z:用ZIP算法数据压缩
392 | R64:用radix64转换到ASCII格式
393 |
394 | 1. 认证
395 | 
396 | 说明:
397 | 1、 SHA-1生成消息的160的HASH码
398 | 2、SHA-1和RSA结合提供了一个高效的数字签名方案
399 | 3、DSS/SHA-1可选替代方案。
400 |
401 | 3. 加密
402 | 发送方
403 | 生成消息M并为该消息生成一个随机数作为会话密钥。
404 | 用会话密钥加密M( CAST-128、IDEA或3DES )
405 | 用接收者的公钥加密会话密钥(RSA)并与消息M结合
406 | 接收方
407 | 用自己的私钥解密恢复会话密钥
408 | 用会话密钥解密恢复消息M
409 | 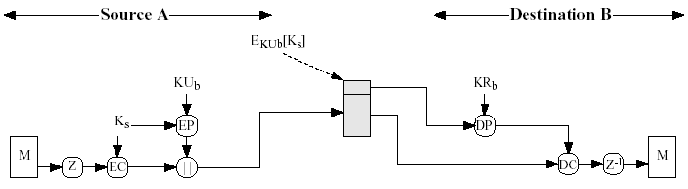
410 | 加密:保密与鉴别同时运用
411 | 
412 |
413 | 3. 数据压缩
414 | 压缩的位置:发生在签名后、加密前。
415 | 压缩之前生成签名:
416 | 验证时无须压缩
417 | 压缩算法的多样性
418 | 在加密前压缩:压缩的报文更难分析
419 | 对邮件传输或存储都有节省空间的好处。
420 |
421 | 4. E-mail兼容性
422 | 加密后是任意的8位字节,很多邮件系统需要ASCII正文组成的块,需要转换到ASCII格式。
423 | Radix64将3字节输入转换到4个ASCII字符,并带CRC校验,属盲目转换(即输入流即使是ASCII,算法也会将其转换)
424 | 5. 分段与重组
425 | Email常常受限制于最大消息长度(一般限制在最大50000字节)
426 | 更长的消息要进行分段,每一段分别邮寄。
427 | PGP自动分段并在接收时自动恢复。
428 | 签名只需一次,在第一段中。
429 |
430 | ## PGP消息的传送与接收
431 | 
432 |
433 | ## 发送消息的格式
434 | 
435 |
436 | ## PGP密钥需求
437 | PGP使用四种类型的密钥:一次性会话的常规密钥,公钥,私钥,基于口令短语的常规密钥。
438 |
439 | 这些密钥存在三种独立需求:
440 | 需要一种生成不可预知的会话密钥的手段
441 | 需要某种手段来标识具体的密钥。
442 | 一个用户拥有多个公钥/私钥对。(更换,分组)
443 |
444 | 每个PGP实体需要维护一个文件保存其公钥私钥对,和一个文件保存通信对方的公钥。
445 |
446 | ## 会话密钥的生成
447 | 以CAST-128为例。
448 |
449 | 128位的随机数是由CAST-128自己生成的。输入包括一个128位的密钥和两个64位的数据块作为加密的输入。使用CFB方式,CAST-128产生两个64位的加密数据块,这两个数据块的结合构成128位的会话密钥。
450 |
451 | 作为明文输入的两个64位数据块,是从一个128位的随机数流中导出的。这些数基于用户的键盘输入的。键盘输入时间和内容用来产生随机流。因此,如果用户以他通常的步调敲击任意键,将会产生合理的随机性。
452 |
453 |
454 | ## 密钥标识符
455 | 一个用户有多个公钥/私钥对时,接收者如何知道发送者是用了哪个公钥来加密会话密钥?
456 | 将公钥与消息一起传送。(浪费空间)
457 | 将一个标识符与一个公钥关联。对一个用户来说做到一一对应。(管理上带来负担)
458 | PGP给每个公开密钥指定KeyID, KeyID由公开密钥的最低64比特组成, 包括64个有效位:(K~Ua~ mod 2^64^)
459 | PGP数字签名同样也需要KeyID。
460 |
461 | ## 密钥环
462 | KeyID对于PGP非常关键。
463 | 两个keyID包含在任何PGP消息中,提供保密与鉴别功能。
464 | 需要一种系统化的方法存储和组织这些key以保证使用。
465 |
466 | PGP在每一个节点上提供一对数据结构:
467 | 存储该节点拥有的公钥/私钥对;(私钥环)
468 | 存储本节点知道的其他用户的公钥;(公钥环)
469 |
470 | ## 私有密钥环
471 | 时间戳:密钥对生成的日期/时间;
472 | 密钥ID:公开密钥的低64位
473 | 私有密钥:密钥对的私有部分(该字段加密)
474 | 用户ID:该字段的典型值是用户的邮件地址,用户也可为每个密钥对选择不同的名字
475 |
476 | 
477 |
478 | ## 公开密钥环
479 | UserID:公钥的拥有者。多个UserID可以对应一个公钥。
480 | 公钥环可以用UserID或KeyID索引。
481 | 
482 |
483 | ## PGP —报文传输过程
484 | 签名:
485 | 从私钥环中得到私钥,利用userid作为索引
486 | PGP提示输入口令短语,恢复私钥
487 | 构造签名部分
488 |
489 | 加密:
490 | PGP产生一个会话密钥,并加密消息
491 | PGP用接收者userid从公钥环中获取其公钥
492 | 构造消息的会话密钥部分
493 |
494 | 
495 |
496 | ## PGP —报文接收过程
497 | 解密消息
498 | PGP用消息的会话密钥部分中的KeyID作为索引,从私钥环中获取私钥
499 | PGP提示输入口令短语,恢复未加密的私钥
500 | PGP恢复会话密钥,并解密消息
501 |
502 | 验证消息
503 | 用消息的签名部分中的KeyID作为索引,从公钥环中获取发送者的公钥
504 | PGP恢复被传输过来的消息摘要
505 | PGP对于接收到的消息作摘要,并与上一步的结果作比较
506 | 
507 |
508 | ## 公钥管理问题
509 | 由于PGP重在广泛地在正式或非正式环境下应用,没有建立严格的公钥管理模式。
510 | 如果A的公钥环上有一个从BBS上获得B发布的公钥,但已被C替换,这是就存在两条通道。C可以向A发信并冒充B的签名,A以为是来自B;A与B的任何加密消息C都可以读取。
--------------------------------------------------------------------------------
/信息安全/信息安全(四)——公私钥密码体制.md:
--------------------------------------------------------------------------------
1 | # 公钥算法和对称钥算法区别
2 |
3 | ## 对称加密的优点
4 |
5 | 速度快,处理量大,适用于对应用数据的直接加密。
6 | 加密密钥长度相对较短,如40比特~256比特。
7 | 可构造各种加密体制,如产生伪随机数,HASH函数等。
8 |
9 | ## 对称加密的缺点
10 |
11 | 密钥在双方都要一致、保密,传递较难。
12 | 大型网络中密钥量大,难以管理,一般需要TTP(KDC)。
13 | 密钥需要经常更换
14 | 数字签名的问题:传统加密算法无法实现抗抵赖的需求。
15 | ## 公钥加密的优点
16 |
17 | 只有秘密钥保密,公开钥公开。
18 | 密钥生命周期相对较长。
19 | 许多公钥方案可以产生数字签名机制。
20 | 在大型网络上,所需的密钥相对较少。
21 |
22 | ## 公钥加密的缺点
23 |
24 | 速度慢,处理量少,适用于密钥交换。
25 | 密钥长度相对较长。
26 | 安全性没有得到理论证明。
27 |
28 | # 公钥算法的思想
29 |
30 | ## 公钥密码体制的起源
31 |
32 | 1976年,Standford Uni. Diffie博士和其导师Hellman 在IEEE Trans. on IT 上发表划时代的文献:
33 | W.Diffie and M.E.Hellman, New Directrions in Cryptography, IEEE Transaction on Information Theory, V.IT-22.No.6, Nov 1976, PP.644-654
34 | 这一体制的出现为解决计算机信息网中的安全提供了新的理论和技术基础,被公认为现代够公钥密码学诞生的标志。
35 | 1978年,MIT三位数学家R.L.Rivest,A.Shamir和L.Adleman 发明了一种用数论构造双钥体制的方法,称作MIT体制,后来被广泛称之为RSA体制。
36 | 
37 |
38 | ## 公钥密码体制的基本原理
39 | ### 公钥算法基于数学函数而不是基于替换和置换
40 | 使用两个独立的密钥
41 | 公钥密码学的提出是为了解决两个问题:
42 | 密钥的分配
43 | 数字签名
44 |
45 | ### 基本思想和要求
46 | 用户拥有自己的密钥对(K~U~,K~R~),即(公开密钥,私有密钥)
47 | 公钥K~U~公开,私钥K~R~保密 A->B:Y=EKUb(X)
48 | B:DK~Rb~(Y)= DK~Rb~(EK~Ub~(X))=X
49 | 
50 | ### 公钥体制的主要特点
51 | - 加密和解密能力分开
52 | - 多个用户加密的消息只能由一个用户解读,(用于公共网络中实现保密通信)
53 | - 只能由一个用户加密消息而使多个用户可以解读(可用于认证系统中对消息进行数字签字)。
54 | - 无需事先分配密钥
55 | - 密钥持有量大大减少
56 | - 提供了对称密码技术无法或很难提供的服务:如与哈希函数联合运用可生成数字签名,可证明的安全伪随机数发生器的构造,零知识证明等
57 | ### 基本思想和要求
58 | - 涉及到各方:发送方、接收方、攻击者
59 | - 涉及到数据:公钥、私钥、明文、密文
60 | - 公钥算法的条件:
61 | - 产生一对密钥是计算可行的
62 | - 已知公钥和明文,产生密文是计算可行的
63 | - 接收方利用私钥来解密密文是计算可行的
64 | - 对于攻击者,利用公钥来推断私钥是计算不可行的
65 | - 已知公钥和密文,恢复明文是计算不可行的
66 | - (可选)加密和解密的顺序可交换
67 |
68 | ### 如何设计一个公钥算法
69 | - 公钥和私钥必须相关,而且从公钥到私钥不可推断
70 | 必须要找到一个难题,从一个方向走是容易的,从另一个方向走是困难的
71 | 如何把这个难题跟加解密结合起来
72 | - 一个实用的公开密钥方案的发展依赖于找到一个陷阱门单向函数。
73 |
74 | ### 陷门单向函数
75 | - 单向陷门函数是满足下列条件的函数f:
76 | (1)给定x,计算y=fk(x)是容易的;
77 | (2)给定y,计算x使x=fk-1(y)是不可行的。
78 | (3)存在k,已知k时,对给定的任何y,若相应的x存在,则计算x使fk-1(y)是容易的。
79 | ### 非对称密钥加密的原理
80 | - 使用数学上的理论;
81 | - 数学上某些复杂的计算问题:正向计算容易,反向计算困难。计算机不可能在有效的时间内算出反向结果(从而不可能破解密码)。
82 | - 例如:
83 | - 计算两个大数的乘积,非常容易。
84 | - 分解一个很大的数(如200多位)非常困难,假如这个大数只含有两个非常大的素数(各100多位)作为因子。
85 | - 背包问题
86 | - 大整数分解问题(The Integer Factorization Problem, RSA体制)
87 | - 二次剩余问题
88 | - 模n的平方根问题
89 | - 离散对数问题:
90 | - 有限域的乘法群上的离散对数问题(The Discrete Logarithm Problem, ELGamal体制)
91 | - 定义在有限域的椭圆曲线上的离散对数问题(The Elliptic Curve Discrete Logarithm Problem,类比的ELGamal体制)
92 |
93 | ### 公钥密钥的应用范围
94 | 加密/解密
95 | 数字签名(身份鉴别)
96 | 密钥交换
97 | 
98 | # Diffie-Hellman密钥协商协议
99 | ## Diffie-Hellman密钥交换算法
100 | 允许两个用户可以安全地交换一个秘密信息,用于后续的通讯过程
101 |
102 | 算法的安全性依赖于计算离散对数的难度
103 |
104 | ## Diffie-Hellman算法
105 | 1) 双方选择素数p以及p的一个原根a
106 | 2) 用户A选择一个随机数X~a~ < p,计算Y~a~=a^Xa^ mod p
107 | 3) 用户B选择一个随机数X~b~ < p,计算Y~b~=a^Xb^ mod p
108 | 4) 每一方保密X值,而将Y值交换给对方
109 | 5) 用户A计算出 K=Y~b~X~a~ mod p
110 | 6) 用户B计算出 K=Y~a~X~b~ mod p
111 | 7) 双方获得一个共享密钥(a^XaXb^mod p)
112 | 注:素数p以及p的原根a可由一方选择后发给对方
113 | ## Diffie-Hellman算法例:
114 | 密钥交换基于素数q = 97和97的一个原根,在这里是a = 5。A和B分别选择秘密密钥X~a~ = 36和X~b~ = 58。每人计算其公开密钥如下:
115 | Y~a~ = 536 = 50 mod 97
116 | Y~b~ = 558 = 44 mod 97
117 | 在他们交换了公开密钥以后,每人计算共享的秘密密钥如下:
118 | A : K = (Y~b~)X~a~ mod 97 = 4436 = 75 mod 97
119 | B : K = (Y~a~)X~b~ mod 97 = 5058 = 75 mod 97
120 | 从{50,44}出发,攻击者要计算出75很不容易
121 |
122 | # RSA算法的数学原理
123 | ## RSA密码体制的建立:
124 | ### 产生密钥对
125 | 1、选择两个大素数p,q, p ≠q (p、q 私有,选定)
126 | 2、计算n=pq(n<2^1024^ ) (n 公开,计算出)
127 | 3、选择整数e,使得gcd(e,Φ(n))=1 (e公开,选定的)
128 | 4、计算d ≡ e^-1^ mod Φ(n) (d保密,计算得出的)
129 | ### 公钥: KU={e,n}, 私钥: KR={d,n}
130 | ### 使用
131 | 加密: 明文M1)是素数,如果p的因子只有±1,±p。
177 | 若满足下面2个条件,则称c是两个整数a、b的最大公因子,表示为c=gcd(a, b)。
178 | ① c是a的因子也是b的因子,即c是a、b的公因子。
179 | ② a和b的任一公因子,也是c的因子。
180 | 如果gcd(a,b)=1,则称a和b互素。
181 |
182 | ### 模运算:
183 | 设n是一正整数,a是整数,如果用n除a,得商为q,余数为r,用a mod n表示余数r。
184 | 如果(a mod n)=(b mod n),则称两整数a和b模n同余,记为a≡b mod n。
185 | 称与a模n同余的数的全体为a的同余类,记为[a],称a为这个同余类的表示元素。
186 | 注意: 如果a≡0(mod n),则n|a。
187 |
188 | 同余有以下性质:
189 | ① 若n|(a-b),则a≡b mod n。
190 | ② (a mod n)≡(b mod n),则a≡b mod n。
191 | ③ a≡b mod n,则b≡a mod n。
192 | ④ a≡b mod n,b≡c mod n,则a≡c mod n。
193 |
194 | 求余数运算(简称求余运算)a mod n将整数a映射到集合{0,1, …,n-1},称求余运算在这个集合上的算术运算为模运算
195 | 模运算有以下性质:
196 | [(a mod n)+(b mod n)] mod n = (a+b) mod n
197 | [(a mod n)- (b mod n)] mod n = (a-b) mod n
198 | [(a mod n)×(b mod n)] mod n = (a×b) mod n
199 |
200 | 费马(Fermat)定理:
201 | p素数,a是整数且不能被p整除,则:ap-1 ≡ 1 mod p
202 | 例:a = 7,p = 19,则a^p-1^ = 7^18^ ≡ 1 mod p
203 |
204 | 欧拉(Euler)函数Φ(n):
205 | Φ(n)表示小于n且与n互素的正整数个数。例:Φ(6) = 2
206 | p是素数,Φ(p) = p-1 。例:Φ(7) = 6
207 | 若n的因子分解为n=∏Piai, ai>0,Pi互不相同,则Φ(n) = ΦPiaiΦ(1-1/Pi)
208 | 若gcd(m,n) = 1,则Φ(mn) = Φ(m)Φ(n),特别地,若pφq,且都是素数,φ(pq)=(p-1)(q-1)。如: φ(21) = 12 = φ(3)× φ(7) = 2×6
209 |
210 | Euler定理:
211 | 若a与n为互素的正整数,则a^φ(n)^ ≡ 1 mod n
212 | 例:a=3,n=10,φ(10)=4,3^4^=81 ≡ 1 mod 10
213 | Euler定理的等价形式:
214 | a^φ(n)+1^ ≡ a mod n
215 | 推论: 若n=pq, p≠q都是素数, k是任意整数,则
216 | mkφ(n) + 1=mk(p-1)(q-1)+1 ≡ m mod n, 对任意0≤m≤n
217 |
218 | 原根(Primitive root)
219 | Euler定理表明:对两个互素的整数a,n
220 | a^φ(n)^ ≡ 1 mod n
221 | 定义:存在最小正整数m≤φ(n) (m|φ(n)),使得a^m^ ≡ 1 mod n,若对某个a,m=φ(n),则称a是n的一个原根
222 |
223 | #### 离散对数
224 | 若a是素数p的一个原根,则对任意整数b,b≠0 mod p,存在唯一的整数i, 1≤i≤(p-1),使得:b ≡ a^i^ mod p,i称为b以(a mod p)的指数(离散对数),记作ind~a,p~(b)。
225 | 两个性质:
226 | ind~a,p~(xy) = [ind~a,p~(x)+ind~a,p~(y)] mod φ(p)
227 | ind~a,p~(xr) = [r x ind~a,p~(x)] mod φ(p)
228 | 离散对数的计算:y ≡ g^x^ mod p,
229 | 已知g,x,p,计算y是容易的
230 | 已知y,g,p,计算x是困难的
--------------------------------------------------------------------------------
/操作系统/第一章 操作系统引论/第一章 操作系统引论.md:
--------------------------------------------------------------------------------
1 | # 一.操作系统引论
2 | ## 1.操作系统的目标和功能
3 | ### 目标
4 | * 方便性
5 | * 有效性
6 | * 提高系统资源利用率
7 | * 提高系统吞吐量
8 | * 可扩充性
9 | * 开放性
10 | ### 作用
11 | * OS作为用户与计算机硬件系统之间的接口
12 | * 命令方式
13 | * 系统调用方式
14 | * 图标–窗口方式
15 | * OS实现了对计算机资源的抽象
16 | ## 2.操作系统的发展过程
17 | ### 未配置操作系统的计算机系统
18 | * 人工操作方式
19 | * > 用户独占全机 CPU等待人工操作 严重降低了计算机资源的利用率
20 |
21 | * 脱机输入/输出(Off–Line I/O)方式
22 | * > 减少了CPU的空闲时间 提高了I/O速度 效率仍然不理想
23 |
24 | ### 单道批处理系统
25 | ### 多道批处理系统
26 | > 1.资源利用率高
27 | > 2.系统吞吐量大
28 | > 3.平均周转时间长
29 | > 4.无交互能力
30 |
31 | * (宏观并行,微观串行)
32 | ### 分时系统
33 | > 特征:
34 | > 1.多路性
35 | > 2.独立性
36 | > 3.及时性
37 | > 4.交互性
38 |
39 | ### 实时系统
40 | ### 集群系统–超算~云计算
41 | ### 微机操作系统的发展
42 | ## 3.操作系统的基本特征
43 | ### 1.并发concurrence
44 | * 区别并行和并发
45 | * > 并行性是指两个或多个事件在同一时刻发生→宏观并行,微观并行
46 | * > 并发性是指两个或多个事件在同一时间间隔内发生→宏观并行,微观串行
47 |
48 | * 并发是进程宏观一起运行,微观上交替运行,而并行是指同时运行
49 | * 引入进程
50 | * > 进程是指在系统中能独立运行并作为资源分配的基本单位,它是由一组机器指令,数据和堆栈等组成的,是一个能独立运行的活动实体
51 |
52 | ### 2.共享sharing
53 | * 1.互斥共享方式
54 | * 2.同时访问方式
55 | * 并发和共享是多用户(多任务)OS的两个最基本的特征。它们又是互为存在的条件
56 | ### 3.虚拟virtual
57 | * 时分复用技术
58 | * 空分复用技术
59 | ### 4.异步asynchronism
60 | ## 4.操作系统的主要功能
61 | ### 1.处理机管理功能
62 | * 进程控制
63 | * 进程同步
64 | * 进程互斥方式
65 | * 进程同步方式(协同)
66 | * 进程通信
67 | * 调度
68 | * 作业调度
69 | * 进程调度
70 | ### 2.存储器管理功能
71 | * 内存分配
72 | * 静态分配
73 | * 动态分配
74 | * 内存保护
75 | * 地址映射
76 | * 内存扩充
77 | ### 3.设备管理功能
78 | * 缓冲管理
79 | * 设备分配
80 | * 设备处理
81 | * 设备处理程序又称设备驱动程序
82 | ### 4.文件管理功能
83 | * 文件存储空间的管理
84 | * 目录管理
85 | * 文件的读写管理和保护
86 | ### 5.操作系统与用户之间的接口
87 | * 用户接口
88 | * 程序接口
89 | ### 6.现代操作系统的新功能
90 | * 系统安全
91 | * 网络的功能和服务
92 | * 支持多媒体
93 | ## 5.OS结构设计
94 | ### 传统操作系统结构
95 | * 无结构操作系统
96 | * 模块化OS
97 | * 分层式结构OS
98 | ### 微内核os结构
99 | * 客户/服务器模式
100 | * 面对对象的程序设计
101 |
102 | *XMind: ZEN - Trial Version*
--------------------------------------------------------------------------------
/操作系统/第一章 操作系统引论/第一章 操作系统引论.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/操作系统/第一章 操作系统引论/第一章 操作系统引论.png
--------------------------------------------------------------------------------
/操作系统/第一章 操作系统引论/第一章操作系统引论.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/操作系统/第一章 操作系统引论/第一章操作系统引论.xmind
--------------------------------------------------------------------------------
/操作系统/第七章 文件管理/第七章 文件管理.md:
--------------------------------------------------------------------------------
1 | # 第七章:文件管理
2 | ## 数据项
3 | ### 基本数据项
4 | ### 组合数据项
5 | ## 记录
6 | ### 记录是一组相关数据项的集合,用于描述一个对象在某个方面的属性
7 | ## 文件
8 | ### 文件类型
9 | ### 文件长度
10 | ### 文件的物理位置
11 | ### 文件的建立时间
12 | ## 文件操作
13 | ### 创建文件
14 | ### 删除文件
15 | ### 读文件
16 | ### 写文件
17 | ### 设置文件读写的位置
18 | ## 文件的逻辑结构
19 | ### 顺序文件
20 | ### 记录寻址
21 | ### 索引文件
22 | ### 索引顺序文件
23 | ### 直接文件和哈希文件
24 | ## 文件目录
25 | ### 文件控制块(FCB)
26 | * 文件名+inode(属性)
27 | ### 简单的文件目录
28 | * 单级文件目录
29 | * 查找慢
30 | * 不允许重名
31 | * 不便于实现文件共享
32 | * 两级文件目录
33 | * 提高检索速度,从M*N到M+N
34 | ### 树形结构目录
35 | * 路径名
36 | * “..”是父目录
37 | * “/”是根目录
38 | * 区别绝对路径和相对路径(../.../.../1/2/3/)
39 | ## 文件共享
40 | ### 有向无循环图(DAG)
41 | ### 利用符号链接实现文件共享
42 | * 实际上就是“快捷方式”
43 | ## 文件保护
44 |
45 | *XMind: ZEN - Trial Version*
--------------------------------------------------------------------------------
/操作系统/第七章 文件管理/第七章 文件管理.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/操作系统/第七章 文件管理/第七章 文件管理.png
--------------------------------------------------------------------------------
/操作系统/第七章 文件管理/第七章文件管理.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/操作系统/第七章 文件管理/第七章文件管理.xmind
--------------------------------------------------------------------------------
/操作系统/第三章 处理机调度与死锁/第三章 处理机调度与死锁.md:
--------------------------------------------------------------------------------
1 | # 第三章:处理机调度与死锁
2 | ## 处理机调度算法的目标
3 | ### 处理机调度算法的共同目标
4 | * 资源利用率:CPU的利用率=CPU有效工作时间/(CPU有效工作时间+CPU空闲等待时间)
5 | * 公平性
6 | * 平衡性
7 | * 策略强制执行
8 | ### 批处理系统的目标
9 | * 平均周转时间短
10 | * 系统吞吐量高
11 | * 处理机利用率高
12 | ### 分时系统的目标
13 | * 响应时间快
14 | * 均衡性
15 | ### 实时系统目标
16 | * 截止时间的保证
17 | * 可预测性
18 | ### 处理机调度的层次
19 | * 高级调度(作业调度)
20 | * 分时系统无需作业调度,因为需要交互
21 | * 批处理系统需要作业调度
22 | * 中级调度(和挂起有关)
23 | * 低级调度(进程调度)
24 | * 进程调度是最基本的调度,任何操作系统都有进程调度。
25 | * 低级调度的三个基本机制
26 | * 排队器
27 | * 分派器
28 | * 上下文切换
29 | * 进程调度方式
30 | * 非抢占方式
31 | * 抢占方式
32 | * 优先权原则
33 | * 短进程优先原则
34 | * 时间片原则
35 | * 进程调度的任务
36 | * 保存处理机的现场信息
37 | * 按某种算法选取进程
38 | * 把处理器分配给进程
39 | * 进程调度的算法
40 | * 优先级调度算法
41 | * 优先级调度算法的类型
42 | * 非抢占式优先级调度算法
43 | * 等当前进程执行完以后,再执行另一个优先权最高的进程
44 | * 这种调度算法主要用于批处理系统中;也可用于某些对实时性要求不严的实时系统中。
45 | * 抢占式优先级调度算法
46 | * 不等当前进程结束,直接抢处理机
47 | * 常用于要求比较严格的实时系统中, 以及对性能要求较高的批处理和分时系统中。
48 | * 优先级的类型
49 | * 静态优先级
50 | * 优先权是在创建进程时确定的,且在进程的整个运行期间保持不变。一般地,优先权是利用某一范围内的一个整数来表示的,例如,0~7或0~255中的某一整数, 又把该整数称为优先数。
51 | * 可以参考BIOS系统中设置boot的优先级
52 | * 动态优先级
53 | * 在创建进程时所赋予的优先权,是可以随进程的推进或随其等待时间的增加而改变的,以便获得更好的调度性能。
54 | * 轮转调度算法
55 | * 基本原理:在轮转(RR)法中,系统根据FCFS策略,将所有的就绪进程排成一个就绪队列,并可设置每隔一定时间间隔(如30ms)即产生一次中断,激活系统中的进程调度程序,完成一次调度,将CPU分配给队首进程,令其执行
56 | * 进程切换时机
57 | * 时间片未用完,进程完成
58 | * 时间片到,进程未完成
59 | * 时间片大小的确定
60 | * 太小利于短作业,增加系统切换开销
61 | * 太长就退化为FCFS算法
62 | * 一般选择: q略大于一次交互所需要的时间,使大多数进程在一个时间片内完成
63 | * 一般来说,平均周转时间将比SJF长,但是有较好的响应时间
64 | * 多队列调度算法
65 | * 多级反馈队列调度算法
66 | * 调度机制
67 | * 设置多个就绪队列
68 | * 每个队列都采用FCFS算法
69 | * 按照队列优先级调度,在第n队列中采取按时间片轮转的方式运行
70 | * 调度算法的性能
71 | * 对于终端型用户,由于作业小,感觉满意
72 | * 对于短批处理作业用户,周转时间也较小
73 | * 长批处理作业用户,也能够得到执行
74 | * 基于公平原则的调度算法
75 | * 保证调度算法
76 | * 公平分享调度算法
77 | ## 作业与作业调度
78 | ### 作业
79 | * 作业不仅包含程序和数据,还配有一份作业说明书,系统根据说明书对程序的运行进行控制。批处理系统是以作业为单位从外存掉入内存的。
80 | ### 作业控制块JCB
81 | * 为每个作业设置一个JCB,保存了对作业管理调度的全部信息。是作业存在的标志。
82 | ### 作业步
83 | * 作业步,每个作业都必须经过若干相对独立,有相互关联的顺序步骤才能得到结果。每一个步骤就是一个作业步。
84 | ### 作业运行的三个阶段
85 | * 收容阶段
86 | * 运行阶段
87 | * 完成阶段
88 | ### 作业运行的三个状态
89 | * 后备状态
90 | * 运行状态
91 | * 完成状态
92 | ### 作业调度的主要任务
93 | * 接纳多少个作业
94 | * 接纳哪些作业
95 | ### 先来先服务(first–come first–served,FCFS)调度算法
96 | * 比较有利于长作业,而不利于短作业。
97 | * 有利于CPU繁忙的作业,而不利于I/O繁忙的作业。
98 | ### 短作业优先(short job first,SJF)的调度算法
99 | * 优点
100 | * 比FCFS改善平均周转时间和平均带权周转时间,缩短作业的等待时间;
101 | * 提高系统的吞吐量;
102 | * 缺点
103 | * 必须预知作业的运行时间
104 | * 对长作业非常不利,长作业的周转时间会明显地增长
105 | * 在采用SJF算法时,人–机无法实现交互
106 | * 该调度算法完全未考虑作业的紧迫程度,故不能保证紧迫性作业能得到及时处理
107 | ### 优先级调度算法(priority–scheduling algorithm,PSA)
108 | ### 高响应比优先调度算法(Highest Response Ratio Next,HRRN)
109 | * 原理
110 | * 在每次选择作业投入运行时,先计算此时后备作业队列中每个作业的响应比RP然后选择其值最大的作业投入运行
111 | * 优先权=(等待时间+要求服务时间)/要求服务时间=响应时间/要求服务时间=1+等待时间/要求服务时间
112 | * 特点
113 | * 如果作业的等待时间相同,则要求服务的时间愈短,其优先权愈高,因而类似于SJF算法,有利于短作业
114 | * 当要求服务的时间相同时,作业的优先权又决定于其等待时间,因而该算法又类似于FCFS算法
115 | * 对于长时间的优先级,可以为随等待时间的增加而提高,当等待时间足够长时,也可获得处理机
116 | ## 实时调度(HRT和SRT任务)
117 | ### 实现实时调度的基本条件
118 | * 提供必要信息
119 | * 就绪时间
120 | * 开始截止时间和完成截止时间
121 | * 处理时间
122 | * 资源要求
123 | * 优先级
124 | * 系统处理能力强
125 | * ∑(Ci/Pi)≤1
126 | * N个处理机:∑(Ci/Pi)≤N
127 | * 采用抢占式调度机制
128 | * 具有快速切换机制
129 | * 对中断的快速响应能力
130 | * 快速的任务分派能力
131 | ### 实时调度算法的分类
132 | * 非抢占式调度算法
133 | * 非抢占式轮转调度算法
134 | * 非抢占式优先调度算法
135 | * 抢占式调度算法
136 | * 基于时钟中断的抢占式优先级调度算法
137 | * 立即抢占的优先级调度算法
138 | ### 最早截止时间优先EDF(Earliest Deadline First)算法
139 | * 根据任务的开始截至时间来确定任务的优先级
140 | * 截至时间越早,优先级越高
141 | * 非抢占式调度方式用于非周期实时任务
142 | * 抢占式调度方式用于周期实时任务
143 | ### 最低松弛度优先LLF(Least Laxity First)算法
144 | * 类似EDF
145 | * 算法根据任务紧急(或松弛)的程度,来确定任务的优先级。任务的紧急程度愈高,为该任务所赋予的优先级就愈高, 以使之优先执行。
146 | * 松弛度例子
147 | * 例如,一个任务在200ms时必须完成,而它本身所需的运行时间就有100ms,因此,调度程序必须在100 ms之前调度执行,该任务的紧急程度(松弛程度)为100 ms
148 | ### 优先级倒置(Priority inversion problem)
149 | * 优先级倒置的形成
150 | * 高优先级进程被低优先级进程延迟或阻塞。
151 | * 优先级倒置的解决方法
152 | * 简单的:假如进程P3在进入临界区后P3所占用的处理机就不允许被抢占
153 | * 实用的:建立在动态优先级继承基础上的
154 | ## 死锁概述
155 | ### 资源问题
156 | * 可重用性资源
157 | * 计算机外设
158 | * 消耗性资源
159 | * 数据,消息
160 | * 可抢占性资源
161 | * 不引起死锁
162 | * CPU,内存
163 | * 不可抢占性资源
164 | * 光驱,打印机
165 | ### 计算机系统中的死锁
166 | * 竞争不可抢占性资源引起死锁
167 | * 竞争可消耗资源引起死锁
168 | * 进程推进顺序不当引起死锁
169 | ### 死锁的定义,必要条件和处理方法
170 | * 定义:如果一组进程中的每一个进程都在等待仅由该进程中的其他进程才能引发的事件,那么该组进程是死锁的
171 | * 产生死锁的必要条件
172 | * 互斥条件
173 | * 请求和保存条件
174 | * 不可抢占条件
175 | * 循环等待条件
176 | * 如果每个资源只有一个实例,则环路等待条件是死锁存在的充分必要条件
177 | * 处理死锁的方法
178 | * 预防死锁
179 | * 静态方法,在进程执行前采取的措施,通过设置某些限制条件,去破坏产生死锁的四个条件之一,防止发生死锁。
180 | * 预防死锁的策略
181 | * 破坏"请求和保存"条件
182 | * 第一种协议
183 | * 所有进程在开始运行之前,必须一次性地申请其在整个运行过程中所需的全部资源
184 | * 优点:简单,易行,安全
185 | * 缺点
186 | * 资源被严重浪费,严重地恶化了资源的利用率
187 | * 使进程经常会发生饥饿现象
188 | * 第二种协议
189 | * 它允许一个进程只获得运行初期所需的资源后,便开始运行。进程运行过程中再逐步释放已分配给自己的,且已用毕的全部资源,然后再请求新的所需资源
190 | * 破坏"不可抢占"条件
191 | * 当一个已经保存了某些不可被抢占资源的进程,提出新的资源请求而不能得到满足时,它必须释放已经保持的所有资源,待以后需要时再重新申请
192 | * 破坏"循环等待"条件
193 | * 对系统所以资源类型进行线性排序,并赋予不同的序号
194 | * 例如令输入机的序号为1,打印机序号为2,磁盘机序号为3等。所有进程对资源的请求必须严格按资源序号递增的次序提出。
195 | * 避免死锁
196 | * 动态的方法,在进程执行过程中采取的措施,不需事先采取限制措施破坏产生死锁的必要条件,而是在进程申请资源时用某种方法去防止系统进入不安全状态,从而避免发生死锁。如银行家算法
197 | * 避免死锁的策略
198 | * 系统安全状态
199 | * 安全状态
200 | * 某时刻,对于并发执行的n个进程,若系统能够按照某种顺序如来为每个进程分配所需资源,直至最大需求,从而使每个进程都可顺利完成,则认为该时刻系统处于安全状态,这样的序列为安全序列
201 | * 安全状态之例
202 | * 由安全状态向不安全状态的转换
203 | * 利用银行家算法避免死锁
204 | * 含义:每一个新进程在进入系统时,它必须申明在运行过程中,可能需要每种资源类型的最大单元数目,其数目不应超过系统所拥有的资源总量。当进程请求一组资源时,系统必须首先确定是否有足够的资源分配给该进程。若有,再进一步计算在将这些资源分配给进程后,是否会使系统处于不安全状态。如果不会,才将资源分配给它,否则让进程等待
205 | * 银行家算法中的数据结构
206 | * 可用资源向量 Available[m]:m为系统中资源种类数,Available[j]=k表示系统中第j类资源数为k个。
207 | * 最大需求矩阵 Max[n,m]:n为系统中进程数,Max[i,j]=k表示进程i对j类资源的最大需求数为中k。
208 | * 分配矩阵 Allocation[n,m]:它定义了系统中每一类资源当前已分配给每一进程资源数, Allocation[i,j] = k表示进程i已分得j类资源的数目为k个。
209 | * 需求矩阵 Need[n,m]:它表示每个进程尚需的各类资源数,Need[i,j]=k 表示进程i 还需要j类资源k个。Need[i,j]=Max[i,j] - Allocation[i,j]
210 | * 银行家算法
211 | * 安全性算法
212 | * 银行家算法之例
213 | * 解题
214 | * 矩阵
215 | * 列表
216 | * 检测死锁
217 | * 死锁的检测与解除
218 | * 死锁的检测
219 | * 资源分配图
220 | * 简化步骤
221 | * 选择一个没有阻塞的进程p
222 | * 将p移走,包括它的所有请求边和分配边
223 | * 重复步骤1,2,直至不能继续下去
224 | * 死锁定理
225 | * 若一系列简化以后不能使所有的进程节点都成为孤立节点
226 | * 检测时机
227 | * 当进程等待时检测死锁 (其缺点是系统的开销大)
228 | * 定时检测
229 | * 系统资源利用率下降时检测死锁
230 | * 死锁检测中的数据结构
231 | * 死锁的解除
232 | * 抢占资源
233 | * 终止(或撤销)进程
234 | * 终止进程的方法
235 | * 终止所有死锁进程
236 | * 逐个终止进程
237 | * 代价最小
238 | * 进程的优先级的大小
239 | * 进程已执行了多少时间,还需时间
240 | * 进程在运行中已经使用资源的多少,还需多少资源
241 | * 进程的性质是交互式还是批处理的
242 | * 付出代价最小的死锁解除算法
243 | * 是使用一个有效的挂起和解除机构来挂起一些死锁的进程
244 | * 解除死锁
245 |
246 | *XMind: ZEN - Trial Version*
--------------------------------------------------------------------------------
/操作系统/第三章 处理机调度与死锁/第三章 处理机调度与死锁.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/操作系统/第三章 处理机调度与死锁/第三章 处理机调度与死锁.png
--------------------------------------------------------------------------------
/操作系统/第三章 处理机调度与死锁/第三章处理机调度与死锁.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/操作系统/第三章 处理机调度与死锁/第三章处理机调度与死锁.xmind
--------------------------------------------------------------------------------
/操作系统/第二章 进程的描述与控制/第二章 进程的描述与控制.md:
--------------------------------------------------------------------------------
1 | # 第二章进程的描述与控制
2 | ## 前驱图和程序执行
3 | ## 程序并发执行
4 | ### 程序的并发执行
5 | ### 程序并发执行时的特征
6 | * 间断性
7 | * 失去封闭性
8 | * 不可再现性
9 | ## 进程的描述
10 | ### 进程的定义
11 | * 进程是程序的一次执行
12 | * 进程是一个程序及其数据在处理机上顺序执行时所发生的活动
13 | * 进程是具有独立功能的程序在一个数据集合上运行的过程,它是系统进行资源分配和调度的一个独立单位
14 | ### 进程的特征
15 | * 动态性
16 | * 并发性
17 | * 独立性
18 | * 异步性
19 | ### 从操作系统角度分类
20 | * 系统进程
21 | * 用户进程
22 | ### 进程和程序的区别
23 | * 进程是动态概念,而程序则是静态概念
24 | * 程序是指令的有序集合,永远存在;进程强调是程序在数据集上的一次执行,有创建有撤销,存在是暂时的;
25 | * 进程具有并发性,而程序没有
26 | * 进程可创建其他进程,而程序并不能形成新的程序
27 | * 进程是竞争计算机资源的基本单位,程序不是
28 | ### 进程和程序的联系
29 | * 进程是程序在数据集上的一次执行
30 | * 程序是构成进程的组成部分,一个程序可对应多个进程,一个进程可包括多个程序
31 | * 进程的运行目标是执行所对应的程序
32 | * 从静态看,进程由程序、数据和进程控制块(PCB)组成
33 | ### 进程的基本状态及转换
34 | * 进程的三种基本状态
35 | * 就绪状态ready
36 | * 执行状态running
37 | * 阻塞状态block
38 | * 三种基本状态的转换
39 | * 创建状态和终止状态
40 | * 五状态进程模型
41 | * 注意
42 | * 阻塞态->运行态和就绪态->阻塞态这二种状态转换不可能发生
43 | ### 挂起操作和进程状态的转换
44 | * 挂起和阻塞的区别
45 | * 挂起操作的目的
46 | * 终端用户的需要: 修改、检查进程
47 | * 父进程的需要:修改、协调子进程
48 | * 对换的需要:缓和内存
49 | * 负荷调节的需要:保证实时任务的执行
50 | * 关键图
51 | ### 进程管理中的数据结构
52 | * 进程控制块PCB的作用
53 | * 作为独立运行基本单位的标志
54 | * 能实现间断性运行方式
55 | * 提供进程管理所需要的信息
56 | * 提供进程调度所需要的信息
57 | * 实现与其他进程的同步与通信
58 | * 进程控制块的信息
59 | * 进程标识符
60 | * 外部标识符PID
61 | * 内部标识符(端口)
62 | * 处理机状态
63 | * 通用寄存器
64 | * 指令计数器
65 | * 程序状态字PSW
66 | * 用户栈指针
67 | * 进程调度信息
68 | * 进程状态
69 | * 进程优先级
70 | * 进程调度所需的其他信息
71 | * 事件
72 | * 进程控制信息
73 | * 程序和数据的地址
74 | * 进程同步和通信机制
75 | * 资源清单
76 | * 链接指针
77 | * 进程控制块的组织方式
78 | * 线性方式
79 | * 链接方式
80 | * 索引方式
81 | ## 进程控制
82 | ### 操作系统内核
83 | * 两大功能
84 | * 支撑功能
85 | * 中断管理
86 | * 时钟管理
87 | * 原语操作
88 | * 进程的管理,由若干原语(primitive)来执行
89 | * 资源管理功能
90 | * 进程管理
91 | * 存储器管理
92 | * 设备管理
93 | * 状态
94 | * 系统态,管态,内核态
95 | * 用户态,目态
96 | ### 进程的创建
97 | * 进程的层次结构
98 | * 父进程
99 | * 子进程
100 | * 引起创建进程的事件
101 | * 用户登录
102 | * 作业调度
103 | * 提供服务
104 | * 应用请求
105 | * 进程的创建过程
106 | * 1.申请空白PCB
107 | * 2.为新进程分配其运行所需的资源
108 | * 3.初始化进程块PCB
109 | * 4.如果进程就绪队列能够接纳新进程,便将新进程插入就绪队列
110 | * 进程的终止
111 | * 引起进程终止的事件
112 | * 1.正常结束
113 | * 2.异常结束
114 | * 3.外界干预
115 | * 进程的终止过程
116 | * 1.根据被终止进程的标识符
117 | * 进程的阻塞与唤醒
118 | * 引起进程阻塞和唤醒的事件
119 | * 请求系统服务而未满足
120 | * 启动某种操作而阻塞当前进程
121 | * 新数据尚未到达
122 | * 无新工作可做:系统进程
123 | * 进程阻塞过程(自己阻塞自己)
124 | * 进程唤醒过程(系统或其他进程唤醒自己)
125 | * 进程的挂起与激活
126 | * suspend
127 | * active
128 | ### 进程同步
129 | * 基本概念
130 | * 两种形式的制约关系
131 | * 间接相互制约关系
132 | * 互斥——竞争
133 | * 直接相互制约关系
134 | * 同步——协作
135 | * 临界资源
136 | * 分区
137 | * 进入区enter section
138 | * 临界区critical section
139 | * 退出区exit section
140 | * 剩余区remainder section
141 | * 同步机制应遵循的规则
142 | * 1.空闲让进
143 | * 2.忙则等待
144 | * 3.有限等待
145 | * 4.让权等待
146 | * 进程同步机制
147 | * 软件同步机制:都没有解决让权等待,而且部分方法还会产生死锁的情况
148 | * 硬件同步机制
149 | * 关中断
150 | * 利用Test-and-Set指令实现互斥
151 | * 利用swap指令实现进程互斥
152 | * 信号量机制
153 | * 整型信号量
154 | * 记录型信号量
155 | * 由于整型信号量没有遵循让权等待原则,记录型允许负数,即阻塞链表
156 | * AND型信号量
157 | * 信号量集
158 | * 理解:AND型号量的wait和signal仅能对信号施以加1或减1操作,意味着每次只能对某类临界资源进行一个单位的申请或释放。当一次需要N个单位时,便要进行N次wait操作,这显然是低效的,甚至会增加死锁的概率。此外,在有些情况下,为确保系统的安全性,当所申请的资源数量低于某一下限值时,还必须进行管制,不予以分配。因此,当进程申请某类临界资源时,在每次分配前,都必须测试资源数量,判断是否大于可分配的下限值,决定是否予以分配
159 | * 操作
160 | * Swait(S1,t1,d1…Sn,tn,dn)
161 | * Ssignal(S1,d1…Sn,dn)
162 | * 特殊情况
163 | * 经典进程的同步问题
164 | * 生产者–消费者问题
165 | * 哲学家进餐问题
166 | * 读者–写者问题
167 | ## 进程通信
168 | ### 进程通信是指进程之间的信息交换,又称低级进程通信
169 | ### 进程通信的类型
170 | * 共享存储器系统
171 | * 基于共享数据结构的通信方式
172 | * 生产者和消费者
173 | * 基于共享存储区的通信方式
174 | * 高级通信
175 | * 管道通信系统(pipe)
176 | * 高级通信
177 | * 消息传递系统
178 | * 高级通信
179 | * 方式分类
180 | * 直接通信
181 | * 间接通信
182 | * 客服机–服务器系统
183 | ### 消息传递通信的实现方式
184 | * 直接消息传递系统
185 | * 信箱通信
186 | ## 线程的基本概念
187 | ### 线程的引入
188 | * 线程的引入正是为了简化线程间的通信,以小的开销来提高进程内的并发程度
189 | * 多线程并发的不足
190 | * 进程的两个基本属性
191 | * 一个拥有资源的独立单位,可独立分配系统资源
192 | * 一个可独立调度和分派的基本单位,PCB
193 | * 程序并发执行所需付出的时空开销
194 | * 创建进程
195 | * 撤销进程
196 | * 进程切换
197 | * 进程间通信效率低
198 | * 将分配资源和调度两个属性分开
199 | * 线程——作为调度和分派的基本单位
200 | * 进程是系统资源分配的单位,线程是处理器调度的单位
201 | * 线程表示进程的一个控制点,可以执行一系列的指令。通常,和应用程序的一个函数相对应
202 | * 进程分解为线程还可以有效利用多处理器和多核计算机
203 | ### 线程与进程的比较
204 | * 不同点
205 | * 调度的基本单位
206 | * 并发性
207 | * 相似点
208 | * 状态:运行、阻塞、就绪
209 | * 线程具有一定的生命期
210 | * 进程可创建线程,一个线程可创建另一个子线程
211 | * 多个线程并发执行时仍然存在互斥与同步
212 | ### 线程的实现
213 | * 线程的实现方式
214 | * 内核支持线程KST
215 | * 用户级线程ULT
216 | * 组合方式
217 | * 多线程OS中的进程属性
218 | * 进程是一个可拥有资源的基本单位
219 | * 多个线程可并发执行
220 | * 进程已不是可执行的实体
221 | * 线程的状态和线程控制块
222 | * 线程运行的三个状态
223 | * 执行状态
224 | * 就绪状态
225 | * 阻塞状态
226 | * 线程控制块TCB
227 |
228 | *XMind: ZEN - Trial Version*
--------------------------------------------------------------------------------
/操作系统/第二章 进程的描述与控制/第二章 进程的描述与控制.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/操作系统/第二章 进程的描述与控制/第二章 进程的描述与控制.png
--------------------------------------------------------------------------------
/操作系统/第二章 进程的描述与控制/第二章进程的描述与控制.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/操作系统/第二章 进程的描述与控制/第二章进程的描述与控制.xmind
--------------------------------------------------------------------------------
/操作系统/第五章 虚拟存储器/第五章 虚拟存储器.md:
--------------------------------------------------------------------------------
1 | # 第五章:虚拟存储器
2 | ## 常规存储管理方式的特征
3 | ### 一次性
4 | ### 驻留性
5 | ## 局部性原理
6 | ### 程序在执行时将呈现出局部性特征,即在一较短的时间内,程序的执行仅局限于某个部分,相应地,它所访问的存储空间也局限于某个区域
7 | ### 时间局限性
8 | * 如果程序中的某条指令一旦执行, 则不久以后该指令可能再次执行;如果某数据被访问过, 则不久以后该数据可能再次被访问。产生时间局限性的典型原因,是由于在程序中存在着大量的循环操作
9 | ### 空间局限性
10 | * 一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也将被访问,即程序在一段时间内所访问的地址,可能集中在一定的范围之内,其典型情况便是程序的顺序执行。
11 | ## 定义
12 | ### 指具有请求调入功能和置换功能,能从逻辑上对内存容量加以扩充的一种存储器系统
13 | ## 优点
14 | ### 大程序:可在较小的可用内存中执行较大的用户程序;
15 | ### 大的用户空间:提供给用户可用的虚拟内存空间通常大于物理内存(real memory)
16 | ### 并发:可在内存中容纳更多程序并发执行;
17 | ### 易于开发:不必影响编程时的程序结构
18 | ### 以CPU时间和外存空间换取昂贵内存空间,这是操作系统中的资源转换技术
19 | ## 特征
20 | ### 离散性
21 | * 指在内存分配时采用离散的分配方式,它是虚拟存储器的实现的基础
22 | ### 多次性
23 | * 指一个作业被分成多次调入内存运行,即在作业运行时没有必要将其全部装入,只须将当前要运行的那部分程序和数据装入内存即可。多次性是虚拟存储器最重要的特征
24 | ### 对换性
25 | * 指允许在作业的运行过程中在内存和外存的对换区之间换进、换出。
26 | ### 虚拟性
27 | * 指能够从逻辑上扩充内存容量,使用户所看到的内存容量远大于实际内存容量。
28 | ## 虚拟存储器的实现方式
29 | ### 请求分页存储管理方式
30 | * 硬件
31 | * 请求页表机制
32 | * 格式:页号+物理块号+状态位P+访问字段A+修改位M+外存地址
33 | * 缺页中断机构
34 | * 地址变换机构(过程图很关键)
35 | * 请求分页中的内存分配
36 | * 最小物理块数
37 | * 即能保证进程正常运行所需的最小物理块数
38 | * 内存分配策略
39 | * 固定分配局部置换(国王的大儿子)
40 | * 可变分配全局置换(国王的二儿子)
41 | * 可变分配局部置换(国王的小儿子)
42 | * 物理块分配算法
43 | * 平均分配算法
44 | * 按比例分配算法
45 | * 考虑优先权的分配算法
46 | * 页面调入策略
47 | * 系统应在何时调入所需页面
48 | * 预调页策略(不能实现)
49 | * 请求调页策略(需要才给)
50 | * 系统应该从何处调入这些页面
51 | * 对换区
52 | * 文件区
53 | * 页面调入过程
54 | * 缺页率(出计算题)
55 | ### 请求分段系统
56 | * 硬件
57 | * 请求分段的段表机构
58 | * 缺段中断机构
59 | * 地址变换机构
60 | ## 页面置换算法
61 | ### 抖动的概念
62 | * 即刚被换出的页很快又要被访问,需要将它重新调入,此时又需要再选一页调出
63 | ### 最佳置换算法(需要预知后面进程,所以不能实现)
64 | ### 先进先出页面置换算法(FIFO)
65 | * 选择在内存中驻留时间最久的页面予以淘汰
66 | ### 最近最久未使用置换算法(LRU)Recently
67 | * 寄存器支持
68 | * 特殊的栈结构
69 | ### 最少使用置换算法(LFU)Frequently
70 | ### clock置换算法(对访问位A的判断)
71 | * 改进型——增加对修改位M思维判断
72 | ### 页面缓冲算法(PBA,page buffering algorithm)
73 | * 空闲页面链表
74 | * 修改页面链表
75 |
76 | *XMind: ZEN - Trial Version*
--------------------------------------------------------------------------------
/操作系统/第五章 虚拟存储器/第五章 虚拟存储器.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/操作系统/第五章 虚拟存储器/第五章 虚拟存储器.png
--------------------------------------------------------------------------------
/操作系统/第五章 虚拟存储器/第五章虚拟存储器.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/操作系统/第五章 虚拟存储器/第五章虚拟存储器.xmind
--------------------------------------------------------------------------------
/操作系统/第六章 输入输出系统/第六章 输入输出系统.md:
--------------------------------------------------------------------------------
1 | # 第六章:输入输出系统
2 | ## I/O系统的功能,模型和接口
3 | ### I/O系统管理的对象是I/O设备和相应的设备控制器。
4 | ### I/O系统的基本功能
5 | * 隐藏物理设备的细节
6 | * 与设备的无关性
7 | * 提高处理机和I/O设备的利用率
8 | * 对I/O设备进行控制
9 | * 确保对设备的正确共享
10 | * 错误处理
11 | ### I/O软件的层次结构
12 | * 用户层I/O软件
13 | * 设备独立性软件
14 | * 设备驱动程序(厂家开发)
15 | * 中断处理程序
16 | * 硬件
17 | ### I/O系统的分层
18 | * 中断处理程序
19 | * 设备驱动程序
20 | * 设备独立性软件
21 | ### I/O系统接口
22 | * 块设备接口
23 | * 指以数据块为单位来组织和传送数据信息的设备
24 | * 典型的块设备是磁盘、光盘
25 | * 块设备的基本特征
26 | * ①传输速率较高,通常每秒钟为几兆位;
27 | * ②它是可寻址的,即可随机地读/写任意一块;
28 | * ③磁盘设备的I/O采用DMA方式。
29 | * 流设备接口
30 | * 又称字符设备指以单个字符为单位来传送数据信息的设备
31 | * 这类设备一般用于数据的输入和输出,有交互式终端、打印机
32 | * 字符设备的基本特征
33 | * ①传输速率较低;
34 | * ②不可寻址,即不能指定输入时的源地址或输出时的目标地址;
35 | * ③字符设备的I/O常采用中断驱动方式。
36 | * 网络通信接口
37 | * 提供网络接入功能,使计算机能通过网络与其他计算机进行通信或上网浏览。
38 | ## I/O设备和设备控制器
39 | ### 分类
40 | * 使用特性分
41 | * 存储设备
42 | * I/O设备
43 | * 传输速率分
44 | * 低速设备(几字节——几百字节)
45 | * 典型的设备有键盘、鼠标、语音的输入
46 | * 中速设备(数千——数万字节)
47 | * 典型的设备有行式打印机、激光打印机
48 | * 高速设备(数十万——千兆字节)
49 | * 典型的设备有磁带机、磁盘机、光盘机
50 | ### 设备并不是直接与CPU进行通信,而是与设备控制器通信。在设备与设备控制器之间应该有一个接口。
51 | * 数据信号:控制器 ← 设备 ← 控制器
52 | * 传送数据信号,输入、输出bit
53 | * 控制信号: 控制器 → 设备
54 | * 执行读、写操作的信号
55 | * 状态信号:设备当前使用状态
56 | ### 设备控制器
57 | * 主要功能:控制一个或多个I/O设备,以实现I/O设备和计算机之间的数据交换
58 | * 基本功能
59 | * 接收和识别命令
60 | * 控制寄存器、命令译码器
61 | * 数据交换
62 | * 实现CPU与控制器,控制器与设备间的数据交换
63 | * 标识和报告设备的状态
64 | * 地址识别
65 | * 配置地址译码器,识别不同的设备
66 | * 数据缓冲区
67 | * 差错控制
68 | * 设备控制器的组成
69 | * 设备控制器与处理机(CPU)的接口
70 | * 实现CPU与设备控制器之间的通信
71 | * 设备控制器与设备的接口
72 | * 控制器可连接多个设备
73 | * I/O逻辑
74 | * 实现对设备的控制
75 | * CPU利用该逻辑向控制器发送I/O命令
76 | * 命令、地址译码
77 | ### 内存映像I/O
78 | * 驱动程序将抽象I/O命令转换出的一系列具体的命令,参数等数据装入设备控制器的相应寄存器,由控制器来执行这些命令,具体实施对I/O设备的操作
79 | ### I/O通道
80 | * 目的:建立独立的I/O操作(组织, 管理和结束),使由CPU处理的I/O工作转由通道完成(解放CPU,实现并行)
81 |
82 | * 什么是I/O通道?
83 | * 是一种特殊的处理机,具有通过执行通道程序完成I/O操作的指令
84 | * 特点:指令单一(局限于与I/O操作相关的指令),与CPU共享内存
85 | * 基本过程:
86 | * CPU向通道发出I/O指令->通道接收指令->从内存取出通道程序处理I/O->向CPU发出中断
87 | * 通道类型
88 | * 字节多路通道
89 | * 低中速连接子通道时间片轮转方式共享主通道
90 | * 字节多路通道不适于连接高速设备,这推动了按数组方式进行数据传送的数组选择通道的形成。
91 | * 数组选择通道
92 | * 这种通道可以连接多台高速设备,但只含有一个分配型子通道,在一段时间内只能执行一道通道程序, 控制一台设备进行数据传送, 直至该设备传送完毕释放该通道。这种通道的利用率很低。
93 | * 数组多路通道
94 | * 含有多个非分配型子通道,前两种通道的组合,通道利用率较好
95 | * 瓶颈问题
96 | * 原因;通道不足
97 | * 解决办法:增加设备到主机间的通路,而不增加通道(结果类似RS触发器)
98 | ## 中断机构和中断处理程序
99 | ### 中断
100 | * 分类
101 | * 中断(外部触发)
102 | * 对外部I/O设备发出的中断信号的响应
103 | * 陷入(内部原因:除0)
104 | * 由CPU内部事件引起的中断
105 | * 中断向量表(类比51单片机)
106 | * 中断程序的入口地址表
107 | * 中断优先级
108 | * 对紧急程度不同的中断处理方式
109 | * 对多中断源的处理方式
110 | * 屏蔽中断
111 | * 嵌套中断
112 | ### 中断处理程序
113 | * 测定是否有未响应的中断信号
114 | * 保护被中断进程的CPU环境
115 | * 转入相应的设备处理程序
116 | * 中断处理
117 | * 恢复CPU 的现场并退出中断
118 | ## 设备驱动程序
119 | ### 是I/O进程与设备控制器之间的通信程序,又由于它常以进程的形式存在,故以后就简称为设备驱动进程
120 | ### 主要任务是接受来自它上一层的与设备无关软件的抽象请求,并执行这个请求。
121 | ### 功能
122 | * 1) 接收由I/O进程发来的命令和参数, 并将命令中的抽象要求转换为具体要求。例如,将磁盘块号转换为磁盘的盘面、 磁道号及扇区号。
123 | * 2) 检查用户I/O请求的合法性,了解I/O设备的状态,传递有关参数,设置设备的工作方式。
124 | * 3) 发出I/O命令,如果设备空闲,便立即启动I/O设备去完成指定的I/O操作;如果设备处于忙碌状态,则将请求者的请求块挂在设备队列上等待。
125 | * 4) 及时响应由控制器或通道发来的中断请求,并根据其中断类型调用相应的中断处理程序进行处理。
126 | * 5) 对于设置有通道的计算机系统,驱动程序还应能够根据用户的I/O请求,自动地构成通道程序。
127 | ### 设备驱动程序的处理过程
128 | * 将用户和上层软件对设备控制的抽象要求转换成对设备的具体要求,如对抽象要求的盘块号转换为磁盘的盘面、磁道及扇区。
129 | * 检查I/O请求的合理性。
130 | * 读出和检查设备的状态,确保设备处于就绪态。
131 | * 传送必要的参数,如传送的字节数,数据在主存的首址等。
132 | * 工作方式的设置。
133 | * 启动I/O设备,并检查启动是否成功,如成功则将控制返回给I/O控制系统,在I/O设备忙于传送数据时,该用户进程把自己阻塞,直至中断到来才将它唤醒,而CPU可干别的事。
134 | ### 对I/O设备的控制方式
135 | * I/O控制的宗旨
136 | * 减少CPU对I/O控制的干预
137 | * 充分利用CPU完成数据处理工作
138 | * I/O 控制方式
139 | * 轮询的可编程I/O方式
140 | * 中断驱动I/O方式
141 | * DMA控制方式
142 | * I/O通道控制方式
143 | ### DMA控制器组成
144 | * 主机与DMA控制器的接口
145 | * DMA控制器与块设备的接口
146 | * I/O控制逻辑
147 | ## 与设备无关的I/O软件
148 | ### 基本概念
149 | * 含义: 应用程序独立于具体使用的物理设备。
150 | * 驱动程序是一个与硬件(或设备)紧密相关的软件。为实现设备独立性,须在驱动程序上设置一层软件,称为设备独立性软件。
151 | * 设备独立性(Device Independence)的优点
152 | * 以物理设备名使用设备
153 | * 引入了逻辑设备名
154 | * 逻辑设备名称到物理设备名称的转换(易于实现I/O重定向)
155 | ### 与设备无关的软件
156 | * 设备驱动程序的统一接口
157 | * 缓存管理
158 | * 差错控制
159 | * 对独立设备的分配与回收
160 | * 独立于设备的逻辑数据块
161 | ### 设备分配中的数据结构
162 | * 设备控制表DCT
163 | * 控制器控制表COCT
164 | * 通道控制表CHCT
165 | * 显然,在有通道的系统中,一个进程只有获得了通道,控制器和所需设备三者之后,才具备了进行I/O操作的物理条件
166 | * 系统设备表SDT
167 | * 逻辑设备表LUT
168 | * 分配的流程,从资源多的到资源紧张的:LUT->SDT->DCT->COCT->CHCT
169 | * 在申请设备的过程中,根据用户请求的I/O设备的逻辑名,查找逻辑设备和物理设备的映射表;以物理设备为索引,查找SDT,找到该设备所连接的DCT;继续查找与该设备连接的COCT和CHCT,就找到了一条通路。
170 | ## 用户层的I/O软件
171 | ### 系统调用与库函数
172 | * OS向用户提供的所有功能,用户进程都必须通过系统调用来获取
173 | * 在C语言以及UNIX系统中,系统调用(如read)与各系统调用所使用的库函数(如read)之间几乎是一一对应的。而微软的叫Win32API
174 | ### 假脱机系统(spooling)
175 | * spooling技术是对脱机输入/输出系统的模拟
176 | * 主要组成
177 | * 输入/输出井
178 | * 输入/输出缓冲区
179 | * 输入/输出进程
180 | * 井管理程序
181 | * 特点(体现操作系统的虚拟性)
182 | * 提高了I/O的速度
183 | * 对数据所进行的I/O操作,已从对低速设备演变为对输入井或输出井中的数据存取。
184 | * 将独占设备改造为共享设备
185 | * 实际分给用户进程的不是打印设备,而是共享输出井中的存储区域
186 | * 实现了虚拟设备功能
187 | * 将独占设备变成多台独占的虚拟设备。
188 | ## 缓冲区管理
189 | ### 缓冲的引入(原因)
190 | * 缓和CPU与I/O设备间速度不匹配的矛盾
191 | * 减少对CPU的中断频率,放宽对CPU中断响应时间的限制
192 | * 提高CPU和I/O设备之间的并行性
193 | * 解决数据粒度不匹配的问题
194 | ### 单缓冲区
195 | * 即在CPU计算的时候,将数据数据输入到缓冲区(大小取决与T和C的大小)
196 | ### 双缓冲区
197 | * 即允许CPU连续工作(T不断)
198 | ### 环形缓冲区(专为生产者和消费者打造)
199 | * 组成
200 | * 多个缓冲区
201 | * 多个指针
202 | * 使用
203 | * Getbuf过程
204 | * Releasebuf过程
205 | * 同步问题
206 | ### 缓冲池(理解为更大的缓冲区)
207 | * 组成
208 | * 空白缓冲队列(emq)
209 | * 由空缓冲区链接而成F(emq),L(emq)分别指向该队列首尾缓冲区
210 | * 输入队列(inq)
211 | * 由装满输入数据的缓冲区链接而成F(inq),L(inq)分别指向该队列首尾缓冲区
212 | * 输出队列(outq)
213 | * 由装满输出数据的缓冲区链接而成F(outq), L(outq)分别指向该队列首尾缓冲
214 | * Getbuf和Putbuf过程
215 | * 收容:缓冲池接收外界数据
216 | * 提取:外界从缓冲池获得数据
217 | * 缓冲区工作方式(从缓冲区的角度来看)
218 | * 收容输入
219 | * 提取输入
220 | * 收容输出
221 | * 提取输出
222 | ## 磁盘存储器的性能和调度
223 | ### 数据的组织和格式
224 | ### 磁盘的类型
225 | * 固定头磁盘(贵)
226 | * 移动头磁盘
227 | ### 磁盘访问的时间(关键)
228 | * 寻道时间Ts=m*n+s
229 | * 旋转延迟时间Tr
230 | * 传输时间Tt=b/rN
231 | * 总时间Ta=Ts+1/2r+b/rN
232 | ### 磁盘的调度算法(掌握图表)
233 | * 先来先服务(FCFS)
234 | * 优点:公平,简单
235 | * 缺点:可能导致某些进程的请求长期得不到满足
236 | * 最短寻道时间优先(SSTF)
237 | * 说明:要求访问的磁道和当前磁头所在的磁道距离最近,以使每次的寻道时间最短
238 | * 扫描算法(SCAN)
239 | * 扫描算法不仅考虑到欲访问的磁道与当前磁道间的距离,更优先考虑的是磁道当前的移动方向
240 | * 联想电梯的运行
241 | * 可防止低优先级进程出现“饥饿”的现象
242 | * 循环扫描算法(CSCAN)
243 | * 算法规定磁头单向移动,例如,只是自里向外移动,当磁头移到最外的磁道并访问后,磁头立即返回到最里的欲访问磁道,亦即将最小磁道号紧接着最大磁道号构成循环,进行循环扫描
244 | * NStepScan算法
245 | * N步SCAN算法是将磁盘请求队列分成若干个长度为N的子队列,磁盘调度将按FCFS算法依次这些子队列。
246 | * FSCAN算法
247 | * 是Nstepscan算法的简化,将磁盘请求队列分成两个子队列
248 |
249 | *XMind: ZEN - Trial Version*
--------------------------------------------------------------------------------
/操作系统/第六章 输入输出系统/第六章 输入输出系统.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/操作系统/第六章 输入输出系统/第六章 输入输出系统.png
--------------------------------------------------------------------------------
/操作系统/第六章 输入输出系统/第六章输入输出系统.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/操作系统/第六章 输入输出系统/第六章输入输出系统.xmind
--------------------------------------------------------------------------------
/操作系统/第四章 存储器管理/第四章 存储器管理.md:
--------------------------------------------------------------------------------
1 | # 第四章:存储器管理
2 | ## 存储器的层次结构
3 | ### 多层结构的存储系统
4 | * 存储器的多层结构
5 | * CPU寄存器
6 | * 主存
7 | * 辅存
8 | * 可执行存储器
9 | * 寄存器和主存的总称
10 | * 访问速度快,进程可以在很少的时钟周期内用一条load或store指令完成存取。
11 | ### 主存储器与寄存器
12 | ### 高速缓存和磁盘缓存
13 | ## 程序的装入和链接
14 | ### 步骤
15 | * 编译
16 | * 源程序 ->目标模块(Object modules)--------Compiler
17 | * 由编译程序对用户源程序进行编译,形成若干个目标模块
18 | * 链接
19 | * 一组目标模块 ->装入模块 (Load Module)----------Linker
20 | * 由链接程序将编译后形成的一组目标模板以及它们所需要的库函数链接在一起,形成一个完整的装入模块
21 | * 装入
22 | * 装入模块 ->内存 --------Loader
23 | * 由装入程序将装入模块装入内存
24 | ### 程序的装入
25 | * 绝对装入方式
26 | * 在编译时,如果知道程序将驻留在内存中指定的位置。编译程序将产生绝对地址的目标代码。
27 | * 可重定位装入方式
28 | * 在可执行文件中,列出各个需要重定位的地址单元和相对地址值。当用户程序被装入内存时,一次性实现逻辑地址到物理地址的转换,以后不再转换(一般在装入内存时由软件完成)。
29 | * 优点:不需硬件支持,可以装入有限多道程序。
30 | * 缺点:一个程序通常需要占用连续的内存空间,程序装入内存后不能移动。不易实现共享。
31 | * 动态运行时的装入方式
32 | * 动态运行时的装入程序在把装入模块装入内存后,并不立即把装入模块中的逻辑地址转换为物理地址,而是把这种地址转换推迟到程序真正要执行时才进行
33 | * 优点:
34 | * OS可以将一个程序分散存放于不连续的内存空间,可以移动程序,有利用实现共享。
35 | * 能够支持程序执行中产生的地址引用,如指针变量(而不仅是生成可执行文件时的地址引用)。
36 | * 缺点:需要硬件支持,OS实现较复杂。
37 | * 它是虚拟存储的基础。
38 | ### 程序的链接
39 | * 静态链接方式(lib)
40 | * 装入时动态链接
41 | * 运行时动态链接(dll)
42 | ## 连续分配存储管理方式
43 | ### 连续分配
44 | * 单一连续分配(DOS)
45 | * 固定分区分配(浪费很多空间)
46 | * 动态分区分配
47 | ### 地址映射和存储保护措施
48 | * 基址寄存器:程序的最小物理地址
49 | * 界限寄存器:程序的逻辑地址范围
50 | * 物理地址 = 逻辑地址 + 基址
51 | ### 内碎片:占用分区之内未被利用的空间
52 | ### 外碎片:占用分区之间难以利用的空闲分区(通常是小空闲分区)
53 | ### 把内存划分为若干个固定大小的连续分区。固定式分区又称为静态分区。
54 | * 分区大小相等:只适合于多个相同程序的并发执行(处理多个类型相同的对象)。
55 | * 分区大小不等:多个小分区、适量的中等分区、少量的大分区。根据程序的大小,分配当前空闲的、适当大小的分区。
56 | * 优点:无外碎片、易实现、开销小。
57 | * 缺点:
58 | * 存在内碎片,造成浪费
59 | * 分区总数固定,限制了并发执行的程序数目。
60 | * 通用Os很少采用,部分控制系统中采用
61 | ### 动态创建分区:指在作业装入内存时,从可用的内存中划出一块连续的区域分配给它,且分区大小正好等于该作业的大小。可变式分区中分区的大小和分区的个数都是可变的,而且是根据作业的大小和多少动态地划分。
62 | * 基于顺序搜索的动态分区分配算法
63 | * 首次适应算法(first fit,FF)
64 | * 顺序找,找到一个满足的就分配,但是可能存在浪费
65 | * 这种方法目的在于减少查找时间。
66 | * 空闲分区表(空闲区链)中的空闲分区要按地址由低到高进行排序
67 | * 循环首次适应算法(next fit,NF)
68 | * 相对上面那种,不是顺序,类似哈希算法中左右交叉排序
69 | * 空闲分区分布得更均匀,查找开销小
70 | * 从上次找到的空闲区的下一个空闲区开始查找,直到找到第一个能满足要求的的空闲区为止,并从中划出一块与请求大小相等的内存空间分配给作业。
71 | * 最佳适应算法(best fit,BF)
72 | * 找到最合适的,但是大区域的访问次数减少
73 | * 这种方法能使外碎片尽量小。
74 | * 空闲分区表(空闲区链)中的空闲分区要按大小从小到大进行排序,自表头开始查找到第一个满足要求的自由分区分配。
75 | * 最坏适应算法(worst fit,WF)
76 | * 相对于最好而言,找最大的区域下手,导致最大的区域可能很少,也造成许多碎片
77 | * 空闲分区按大小由大到小排序
78 | * 基于索引搜索的动态分区分配算法
79 | * 快速适应算法(quick fit)
80 | * 伙伴系统(buddy system)
81 | * 哈希算法
82 | * 动态可重定位分区分配
83 | * 紧凑
84 | * 动态重定位
85 | * 动态运行时装入,地址转化在指令执行时进行,需获得硬件地址变换机制的支持
86 | * 内存地址=相对地址+起始地址
87 | * 动态重定位分区分配算法
88 | * 1、在某个分区被释放后立即进行紧凑,系统总是只有一个连续的分区而无碎片,此法很花费机时。
89 | * 2、当“请求分配模块”找不到足够大的自由分区分给用户时再进行紧凑,这样紧缩的次数比上种方法少得多,但管理复杂。采用此法的动态重定位分区分配算法框图如下:
90 | * 优点:没有内碎片。
91 | * 缺点:外碎片。
92 | ## 对换(了解)
93 | ### 系统把所有的作业放在外存,每次只调用一个作业进入内存运行,当时间片用完时,将它调至外存后备队列上等待,在从后备队列调入另一个作业进入内存运行。
94 | ## 基本分页存储管理方式
95 | ### 分页存储管理的基本方式
96 | * 页面
97 | * 将一个进程的逻辑地址空间分成若干个大小相等的片
98 | * 页框(frame)
99 | * 内存空间分成与页面相同大小的存储块
100 | * 由于进程的最后一页经常装不满一块而形成了不可利用的碎片,称之为“页内碎片”
101 | * 地址结构
102 | * 页号P+位移量W(0-31)
103 | * 页表
104 | * 在分页系统中,允许将进程的各个页离散地存储在内存在内存的任一物理块中,为保证进程仍然能够正确地运行,即能在内存中找到每一个页面所对应的物理块,系统又为每个进程建立了一张页面映像表,简称页表
105 | * 页表的作用是实现从页面号到物理块号的地址映射
106 | ### 地址变换机构
107 | * 基本的地址变换机构
108 | * 要访问两次内存
109 | * 页表大都驻留在内存中
110 | * 为了实现地址变换功能,在系统中设置页表寄存器(PTR),用来存放页表的始址和页表的长度。
111 | * 在进程未执行时,每个进程对应的页表的始址和长度存放在进程的PCB中,当该进程被调度时,就将它们装入页表寄存器。
112 | * 具有快表的地址变换机构
113 | * 提高了效率,此处会有计算题
114 | * 如果页表存放在内存中,则每次访问内存时,都要先访问内存中的页表,然后根据所形成的物理地址再访问内存。这样CPU存一个数据必须访问两次内存,从而使计算机的处理速度降低了1/2。
115 | * 为了提高地址变换的速度,在地址变换机构中增设了一个具有并行查询功能的特殊的高速缓冲存储器,称为“联想存储器”或“快表”,用以存放当前访问的那些页表项。
116 | * 地址变换过程为:
117 | * 1、CPU给出有效地址
118 | * 2、地址变换机构自动地将页号送入高速缓存,确定所需要的页是否在快表中。
119 | * 3、若是,则直接读出该页所对应的物理块号,送入物理地址寄存器;
120 | * 4、若快表中未找到对应的页表项,则需再访问内存中的页表
121 | * 5、找到后,把从页表中读出的页表项存入快表中的一个寄存器单元中,以取代一个旧的页表项。
122 | ### 两级和多级页表
123 | * 主要是有的时候页表太多了,要化简
124 | * 格式:外层页号P1+外层页内地址P2+页内地址d
125 | * 基本方法:将页表进行分页,每个页面的大小与内存物理块的大小相同,并为它们进行编号,可以离散地将各个页面分别存放在不同的物理块中。
126 | ### 反置页表
127 | * 反置页表为每一个物理块(页框)设置一个页表项,并按物理块排序,其内容则是页号和其所属进程的标识。
128 | ### 优点:
129 | * 没有外碎片,每个内碎片不超过页大小。
130 | * 一个程序不必连续存放。
131 | * 便于改变程序占用空间的大小。即随着程序运行而动态生成的数据增多,地址空间可相应增长。
132 | ### 缺点:程序全部装入内存。
133 | ## 分段存储管理方式
134 | ### 引入
135 | * 方便编程
136 | * 信息共享
137 | * 动态增长
138 | * 动态链接
139 | ### 在分段存储管理方式中,作业的地址空间被划分为若干个段,每个段是一组完整的逻辑信息,每个段都有自己的名字,都是从零开始编址的一段连续的地址空间,各段长度是不等的。
140 | ### 内存空间被动态的划分为若干个长度不相同的区域,称为物理段,每个物理段由起始地址和长度确定
141 | ### 分段系统的基本原理
142 | * 分段
143 | * 格式:段号+段内地址
144 | * 段表
145 | * 段表实现了从逻辑段到物理内存区的映射。
146 | * 地址变换机构
147 | ### 和分页的区别
148 | * 页是信息的物理单位
149 | * 页的大小固定且由系统固定
150 | * 分页的用户程序地址空间是一维的
151 | * 通常段比页大,因而段表比页表短,可以缩短查找时间,提高访问速度。
152 | * 分页是系统管理的需要,分段是用户应用的需要。一条指令或一个操作数可能会跨越两个页的分界处,而不会跨越两个段的分界处。
153 | ### 信息共享
154 | * 这是分段最重要的优点
155 | ### 段页式存储管理方式
156 | * 基本原理
157 | * 格式:段号(S)+段内页号(P)+页内地址(W)
158 | * 地址变换过程
159 | * 需要三次访问过程
160 | * 在段页式系统中,为了获得一条指令或数据,需三次访问内存:第一次访问内存中的段表,从中取得页表始址;第二次访问内存中的页表,从中取出该页所在的物理块号,并将该块号与页内地址一起形成指令或数据的物理地址;第三次访问才是真正根据所得的物理地址取出指令或数据。
161 |
162 | *XMind: ZEN - Trial Version*
--------------------------------------------------------------------------------
/操作系统/第四章 存储器管理/第四章 存储器管理.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/操作系统/第四章 存储器管理/第四章 存储器管理.png
--------------------------------------------------------------------------------
/操作系统/第四章 存储器管理/第四章存储器管理.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/操作系统/第四章 存储器管理/第四章存储器管理.xmind
--------------------------------------------------------------------------------
/操作系统/计算机操作系统.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/操作系统/计算机操作系统.png
--------------------------------------------------------------------------------
/操作系统/计算机操作系统.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/操作系统/计算机操作系统.xmind
--------------------------------------------------------------------------------
/数据库/关系代数/关系代数.md:
--------------------------------------------------------------------------------
1 | # 关系代数
2 | ## 概述
3 | ### 关系代数是一种抽象的查询语言,用对关系的运算来表达查询,作为研究关系数据语言的数学工具。
4 | ### 关系代数的运算对象是关系,运算结果亦为关系。
5 | ## 关系代数的运算
6 | ### 普通的集合运算
7 | * 并、交、差
8 | ### 删除部分关系的运算
9 | * 选择、投影
10 | ### 合并两个关系元组的运算
11 | * 连接、积
12 | ### 改名运算
13 | ## 关系代数
14 | ### 并Union (∪)
15 | * R和S的并,R∪S,是在R或S或两者中的元素的集合
16 | * 一个元素在并集中只出现一次
17 | * R和S必须同类型(属性集相同、次序相同,但属性名可以不同)
18 | ### 交Intersect (∩)
19 | * R和S的交,R∩S,是在R和S中都存在的元素的集合
20 | * 一个元素在交集中只出现一次
21 | * R和S必须同类型(属性集相同、次序相同,但属性名可以不同)
22 | ### 差Minus (-)
23 | * R和S的差,R-S,是在R中而不在S中的元素的集合
24 | * R和S必须同类型(属性集相同、次序相同,但属性名可以不同)
25 | ### 投影Projection(π)
26 | * 从关系R中选择若干属性组成新的关系
27 | * πA1,A2,…,An(R),表示从R中选择属性集A1,A2,…,An组成新的关系
28 | * 列的运算
29 | * 投影运算的结果中,也要去除可能的重复元组
30 | ### 广义笛卡儿积(×)
31 | * 关系R、S的广义笛卡儿积是两个关系的元组对的集合所组成的新关系
32 | * R×S:
33 | * 属性是R和S的组合(有重复)
34 | * 元组是R和S所有元组的可能组合
35 | * 是R、S的无条件连接,使任意两个关系的信息能组合在一起
36 | ### 选择Selection(σ)
37 | * 从关系R中选择符合条件的元组构成新的关系
38 | * σC(R),表示从R中选择满足条件(使逻辑表达式C为真)的元组
39 | * 行的运算
40 | ### 条件连接(θ)
41 | * 从R×S的结果集中,选取在指定的属性集上满足AθB条件的元组,组成新的关系
42 | * θ是一个关于属性集的比较运算符
43 | * θ为“=”的连接运算称为等值连接。
44 | ### 自然连接
45 | * 从R×S的结果集中,选取在某些公共属性上具有相同值的元组,组成新的关系
46 | * R、S的公共属性
47 | * 属性集的交集(名称及类型相同)
48 | * 公共属性在结果中只出现一次
49 | * 等值连接
50 | ### 关系代数—除( ÷ )
51 | * 给定关系R(X,Y)和S(Y,Z),其中X, Y, Z为属性组。R中的Y与S中的Y可以有不同的属性名,但必须出自相同的域集。R与S的除运算得到一个新的关系P(X),P是R中满足下列条件的元组在X属性列上的投影:元组在X上分量值x的象集Yx包含S在Y上投影的集合。
52 | * R÷S = {tr[X]| tr∈R∧πy (S)Yx}
53 | * 其中Yx为x在R中的象集,x=tr[X]。
54 | * 例子
55 | ## 总图
56 | *XMind: ZEN - Trial Version*
--------------------------------------------------------------------------------
/数据库/关系代数/关系代数.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/关系代数/关系代数.png
--------------------------------------------------------------------------------
/数据库/关系代数/关系代数.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/关系代数/关系代数.xmind
--------------------------------------------------------------------------------
/数据库/关系数据库设计理论/关系数据库设计理论.md:
--------------------------------------------------------------------------------
1 | # 关系数据库设计理论
2 | ## 设计一个好的关系数据库系统,关键是要设计一个好的数据库模式(数据库逻辑设计问题)
3 | ## 数据库逻辑设计主要解决的问题
4 | ### 关系数据库应该组织成几个关系模式
5 | ### 关系模式中包括哪些属性
6 | ## “不好”的数据库设计
7 | ### 举例:为学校设计一个关系数据库
8 | ### 关系模式: UN(Sno,Cno,G,Sdept,MN)
9 | * Sno:描述学生
10 | * Sdept:描述系名
11 | * MN:描述系主任
12 | * Cno:描述课程
13 | * G:描述学习成绩
14 | * 根据对现实世界的分析,可得出:Sno,Cno是码
15 | * 按照关系模式UN装入部分数据
16 | ###
17 | ### 对数据库操作时,会出现以下问题
18 | * 1. 数据冗余(系主任名的存储次数)
19 | * 数据重复存储:浪费存储空间,数据库维护困难(更新异常)
20 | * 2. 插入异常(一个系刚成立)
21 | * 主码为空的记录不能存在与数据库,导致不能进行插入操作
22 | * 3. 删除异常(一个系的学生全部毕业)
23 | * 删除操作后,一些相关信息无法保存在数据库中
24 | ### 要消除以上的“弊病”,把上面的关系数据库模式分解为三个关系模式
25 | * S(Sno,Sdept)
26 | * SG(Sno,Cno,G)
27 | * Dept(Sdept,MN)
28 | ## 函数依赖
29 | ### 类似于变量之间的单值函数关系
30 | ### Y=F(X),其中自变量X的值,决定一个唯一的函数值Y
31 | ### 在一个关系模式里的属性,由于它在不同元组里属性值可能不同,由此可以把关系中的属性看作变量
32 | ### 一个属性与另一个属性在取值上可能存在制约关系
33 | ### 函数依赖就是属性间的逻辑依赖关系
34 | ### 定义1 设R(U)是一个关系模式,U是R的属性集合,X和Y是U的子集.对于R(U)的任何一个可能的关系r,如果r中不存在两个元组,它们在X上的属性值相同,而在Y上的属性值不同,则称X函数决定Y,或Y函数依赖于X,记作:X Y.
35 | ### X通常称为“决定因素”
36 | ### 几点说明
37 | * 1. 函数依赖是语义范畴的概念.它反映了一种语义完整性约束,只能根据语义来确定一个函数依赖.
38 | * 2. 函数依赖是指关系R模式的所有关系元组均应满足的约束条件,而不是关系模式中的某个或某些元组满足的约束条件
39 | * 3. 函数依赖与属性间的联系类型有关
40 | * (1)若属性X和Y之间有“一对一”的联系,
41 | * (2)若属性X和Y之间有“多对一”的联系,
42 | * (3)若属性X和Y之间有“多对多”的联系,
43 | * 4. 如果X Y,并且Y不是X的子集,则称X Y是非平凡的函数依赖;如果Y是X的子集,则称X Y是平凡的函数依赖;
44 | ## 完全函数依赖与部分函数依赖
45 | ### 完全函数依赖
46 | ### 部分函数依赖
47 | ## 码的形式定义
48 | ### 候选码的两个性质
49 | * 1. 标识的唯一性: 对于R(U)中的每一元组,K的值确定后,该元组就相应确定了.
50 | * 2. 无冗余性: K是属性组的情况下,K的任何一部分都不能唯一标识该元组(定义中的完全函数依赖的意义)
51 | ## 规范化
52 | ### 简介
53 | * 用几个简单的关系去取代原来结构复杂的关系的过程叫做关系规范化.
54 | * 规范化理论是研究如何把一个不好的关系模式转化为好的关系模式的理论
55 | * 规范化理论是E.E.Codd在1971年首先提出的
56 | * 规范化理论是数据库设计过程中的一个非常有用的辅助工具
57 | ### 范式
58 | * 简介
59 | * 规范化理论是围绕着范式建立的.
60 | * 满足不同程度要求的约束集则称为不同的范式.
61 | * 如果一个关系满足某个指定的约束集,则称它属于某个特定的范式.
62 | * 较高层次的范式比较低层次的范式具有“更合乎要求的性质”
63 | * 一个低一级范式的关系模式,通过投影运算可以转化为若干个高一级范式的关系模式的集合,这个过程叫做规范化.
64 | * 如果一个关系满足某个范式要求,则它也会满足较其级别低的所有范式的要求
65 | * 范式层次
66 | * 第一范式(1NF)
67 | * 定义5: 在关系模式R中的每一个具体关系r中,如果每个属性值都是不可再分的最小数据单位,则称R是第一范式的关系,记作R∈1NF.
68 | * 数据库理论研究的是规范化关系.
69 | * 1NF规范化: 把非规范化关系规范提高到1NF关系模式的集合.
70 | * 第二范式(2NF)
71 | * 定义6: 若关系模式R∈1NF,且每个非主属性都完全依赖于R的任意候选码,则关系模式R属于第二范式,记作R ∈2NF.
72 | * 2NF规范化是把1NF关系模式规范提高到变成2NF关系模式的集合.
73 | * 从1NF中消除非主属性对候选码的部分函数依赖,则获得2NF关系.
74 | * 举例:UN(Sno,Cno,G,SDN,MN)
75 | * 第三范式(3NF)
76 | * 定义7: 若关系模式R∈2NF,且每个非主属性都不传递依赖于R的任意候选码,则R∈3NF.
77 | * 从2NF关系中,消除非主属性对码的传递依赖函数而获得3NF关系
78 | * R∈3NF,则每个非主属性既不部分依赖,也不传递依赖于R的任何候选码.
79 | * 3NF的规范化
80 | * BCNF范式
81 | * 3NF的不完善性
82 | * 定义8: 若R∈1NF,且R中每个决定因素都是候选码,则R ∈BCNF.
83 | * 满足BCNF的关系将消除任何属性对候选码的部分依赖与传递依赖
84 | * 应用BCNF定义时,可直接判断1NF是否属于BCNF
85 | * BCNF规范化
86 | *XMind: ZEN - Trial Version*
--------------------------------------------------------------------------------
/数据库/关系数据库设计理论/关系数据库设计理论.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/关系数据库设计理论/关系数据库设计理论.png
--------------------------------------------------------------------------------
/数据库/关系数据库设计理论/关系数据库设计理论.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/关系数据库设计理论/关系数据库设计理论.xmind
--------------------------------------------------------------------------------
/数据库/关系模型/关系模型.md:
--------------------------------------------------------------------------------
1 | # 关系模型
2 | ## 关系模型组成的三要素
3 | ### 关系数据结构
4 | * 基本概念
5 | * 关系
6 | * 关系模式
7 | * 什么是关系模式
8 | * 关系模式(Relation Schema)是型
9 | * 关系是值
10 | * 关系模式是对关系的描述
11 | * 关系数据库
12 | ### 关系操作集合
13 | ### 关系完整性约束
14 | * 关系模型的完整性规则是对关系的某种约束条件
15 | * 实体完整性和参照完整性是关系模型必须满足的完整性约束条件,被称作是关系的两个不变性,应该由关系系统自动支持。
16 | ## 基本关系的六大性质
17 | ### ① 列是同质的(Homogeneous)
18 | * 每一列中的分量是同一类型的数据,来自同一个域
19 | ### ② 不同的列可出自同一个域
20 | * 其中的每一列称为一个属性
21 | * 不同的属性要给予不同的属性名
22 | ### ③ 列的顺序无所谓
23 | * 列的次序可以任意交换
24 | * 遵循这一性质的数据库产品(如ORACLE),增加新属性时,永远是插至最后一列。但也有许多关系数据库产品没有遵循这一性质,例如FoxPro仍然区分了属性顺序
25 | ### ④ 任意两个元组的候选码不能完全相同
26 | * 候选码是可以惟一标识一个元组的属性或属性组。若一个关系中的候选码有多个,则选择一个作为主码
27 | ### ⑤ 行的顺序无所谓
28 | * 行的次序可以任意交换
29 | * 遵循这一性质的数据库产品(如ORACLE),插入一个元组时永远插至最后一行。但也有许多关系数据库产品没有遵循这一性质,例如FoxPro仍然区分了元组的顺序
30 |
31 | ### ⑥ 分量必须取原子值
32 | * 每一个分量都必须是不可分的数据项。
33 | ## 关系模型中的三类完整性约束
34 | ### 实体完整性
35 | ### 参照完整性
36 | * 外码(Foreign Key)
37 | ### 用户定义的完整性
38 | *XMind: ZEN - Trial Version*
--------------------------------------------------------------------------------
/数据库/关系模型/关系模型.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/关系模型/关系模型.png
--------------------------------------------------------------------------------
/数据库/关系模型/关系模型.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/关系模型/关系模型.xmind
--------------------------------------------------------------------------------
/数据库/完整性约束/完整性约束.md:
--------------------------------------------------------------------------------
1 | # 完整性约束
2 | ## 静态列级约束
3 | ### 1. 对数据类型的约束,包括数据的类型、长度单位、精度等
4 | ### 2. 对数据格式的约束
5 | ### 3. 对取值范围或取值集合的约束
6 | ### 4. 对空值的约束
7 | ### 5. 其他约束
8 | ## 静态元组约束
9 | ### 一个元组是由若干个列值组成的,静态元组约束就是规定元组的各个列之间的约束关系
10 | ## 静态关系约束
11 | ### 在一个关系的各个元组之间或者若干关系之间常常存在各种联系或约束。 (参照完整性-外码约束)
12 | ## 动态列级约束
13 | ### 1. 修改列定义时的约束
14 | ### 2. 修改列值时的约束
15 | ## 动态元组约束
16 | ### 动态元组约束是指修改元组的值时元组中各个字段间需要满足某种约束条件
17 | ## 动态关系约束
18 | ### 动态关系约束是加在关系变化前后状态上的限制条件,例如事务一致性、原子性等约束条件
19 | *XMind: ZEN - Trial Version*
--------------------------------------------------------------------------------
/数据库/完整性约束/完整性约束.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/完整性约束/完整性约束.png
--------------------------------------------------------------------------------
/数据库/完整性约束/完整性约束.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/完整性约束/完整性约束.xmind
--------------------------------------------------------------------------------
/数据库/并发控制/并发控制.md:
--------------------------------------------------------------------------------
1 | # 并发控制
2 | ## 多事务执行方式
3 | ### (1)事务串行执行
4 | * 每个时刻只有一个事务运行,其他事务必须等到这个事务结束以后方能运行
5 | * 不能充分利用系统资源,发挥数据库共享资源的特点
6 | ### (2)交叉并发方式(interleaved concurrency)
7 | * 事务的并行执行是这些并行事务的并行操作轮流交叉运行
8 | * 是单处理机系统中的并发方式,能够减少处理机的空闲时间,提高系统的效率
9 | ### (3)同时并发方式(simultaneous concurrency)
10 | * 多处理机系统中,每个处理机可以运行一个事务,多个处理机可以同时运行多个事务,实现多个事务真正的并行运行
11 | * 最理想的并发方式,但受制于硬件环境
12 | * 更复杂的并发方式机制
13 | ## 事务并发执行带来的问题
14 | ### 可能会存取和存储不正确的数据,破坏事务的隔离性和数据库的一致性
15 | ### DBMS必须提供并发控制机制
16 | ### 并发控制机制是衡量一个DBMS性能的重要标志之一
17 | ## 并发控制机制的任务
18 | ### 对并发操作进行正确调度
19 | ### 保证事务的隔离性
20 | ### 保证数据库的一致性
21 | ## 并发操作带来的数据不一致性
22 | ### 丢失修改(lost update)
23 | * 丢失修改是指事务1与事务2从数据库中读入同一数据并修改
24 | * 事务2的提交结果破坏了事务1提交的结果,导致事务1的修改被丢失。
25 | ### 不可重复读(non-repeatable read)
26 | * 不可重复读是指事务1读取数据后,事务2执行更新操作,使事务1无法再现前一次读取结果。
27 | ### 读“脏”数据(dirty read)
28 | * 事务1修改某一数据,并将其写回磁盘
29 | * 事务2读取同一数据后
30 | * 事务1由于某种原因被撤消,这时事务1已修改过的数据恢复原值
31 | * 事务2读到的数据就与数据库中的数据不一致,
32 | * 是不正确的数据,又称为“脏”数据。
33 | ## 封锁
34 | ### 什么是封锁
35 | * 封锁就是事务T在对某个数据对象(例如表、记录等)操作之前,先向系统发出请求,对其加锁
36 | * 加锁后事务T就对该数据对象有了一定的控制,在事务T释放它的锁之前,其它的事务不能更新此数据对象。
37 | * 封锁是实现并发控制的一个非常重要的技术
38 | ### 基本封锁类型
39 | * 排它锁(eXclusive lock,简记为X锁)
40 | * 排它锁又称为写锁
41 | * 若事务T对数据对象A加上X锁,则只允许T读取和修改A,其它任何事务都不能再对A加任何类型的锁,直到T释放A上的锁
42 | * 共享锁(Share lock,简记为S锁)
43 | * 共享锁又称为读锁
44 | * 若事务T对数据对象A加上S锁,则其它事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁
45 | ### 基本锁的相容矩阵
46 | ### 封锁协议
47 | * 1级封锁协议
48 | * 事务T在修改数据R之前必须先对其加X锁,直到事务结束才释放
49 | * 1级封锁协议可防止丢失修改
50 | * 在1级封锁协议中,如果是读数据,不需要加锁的,所以它不能保证可重复读和不读“脏”数据。
51 | * 读“脏”数据
52 | * 不可重复读
53 | * 2级封锁协议
54 | * 1级封锁协议+事务T在读取数据R前必须先加S锁,读完后即可释放S锁
55 | * 2级封锁协议可以防止丢失修改和读“脏”数据。
56 | * 在2级封锁协议中,由于读完数据后即可释放S锁,所以它不能保证可重复读。
57 | * 3级封锁协议
58 | * 1级封锁协议 + 事务T在读取数据R之前必须先对其加S锁,直到事务结束才释放
59 | * 3级封锁协议可防止丢失修改、读脏数据和不可重复读。
60 | * 三级协议的主要区别
61 | *XMind: ZEN - Trial Version*
--------------------------------------------------------------------------------
/数据库/并发控制/并发控制.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/并发控制/并发控制.png
--------------------------------------------------------------------------------
/数据库/并发控制/并发控制.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/并发控制/并发控制.xmind
--------------------------------------------------------------------------------
/数据库/数据库.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/数据库.xmind
--------------------------------------------------------------------------------
/数据库/数据库恢复技术/数据库恢复技术.md:
--------------------------------------------------------------------------------
1 | # 数据库恢复技术
2 | ## 什么是事务
3 | ### 事务(Transaction)是用户定义的一个数据库操作序列,这些操作要么全做,要么全不做,是一个不可分割的工作单位
4 | ### 事务和程序是两个概念
5 | * 在关系数据库中,一个事务可以是一条SQL语句,一组SQL语句或整个程序
6 | * 一个应用程序通常包含多个事务
7 | ### 事务是恢复和并发控制的基本单位
8 | ## 事务结束
9 | ### COMMIT
10 | * 事务正常结束
11 | * 提交事务的所有操作(读+更新)
12 | * 事务中所有对数据库的更新永久生效
13 | ### ROLLBACK
14 | * 事务异常终止
15 | * 事务运行的过程中发生了故障,不能继续执行
16 | * 回滚事务的所有更新操作
17 | * 事务滚回到开始时的状态
18 | ## 事务的特性(ACID特性)
19 | ### 原子性(Atomicity)
20 | * 事务是数据库的逻辑工作单位
21 | * 事务中包括的诸操作要么都做,要么都不做
22 | ### 一致性(Consistency)
23 | * 事务执行的结果必须是使数据库从一个 一致性状态变到另一个一致性状态
24 | * 一致性状态:
25 | * 数据库中只包含成功事务提交的结果
26 | * 不一致状态:
27 | * 数据库中包含失败事务的结果
28 | ### 隔离性(Isolation)
29 | * 对并发执行而言一个事务的执行不能被其他事务干扰
30 |
31 | * 一个事务内部的操作及使用的数据对其他并发事务是隔离的
32 | * 并发执行的各个事务之间不能互相干扰
33 | ### 持续性(Durability )
34 | * 持续性也称永久性(Permanence)
35 | * 一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。
36 | * 接下来的其他操作或故障不应该对其执行结果有任何影响。
37 | ## 故障
38 | ### 故障原因
39 | * 计算机硬件故障
40 | * 系统软件和应用软件的错误
41 | * 操作员的失误
42 | * 恶意的破坏
43 | ### 故障的影响
44 | * 运行事务非正常中断
45 | * 破坏数据库
46 | ### 故障的种类
47 | * 事务故障
48 | * 系统故障
49 | * 介质故障
50 | * 计算机病毒
51 | ## 恢复操作的基本原理
52 | ### 恢复操作的基本原理:冗余
53 | ### 利用存储在系统其它地方的冗余数据来重建数据库中已被破坏或不正确的那部分数据
54 | ## 恢复的实现技术
55 | ### 数据转储(backup)
56 | ### 登录日志文件(logging)
57 | *XMind: ZEN - Trial Version*
--------------------------------------------------------------------------------
/数据库/数据库恢复技术/数据库恢复技术.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/数据库恢复技术/数据库恢复技术.png
--------------------------------------------------------------------------------
/数据库/数据库恢复技术/数据库恢复技术.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/数据库恢复技术/数据库恢复技术.xmind
--------------------------------------------------------------------------------
/数据库/数据库绪论/数据库绪论.md:
--------------------------------------------------------------------------------
1 | # 数据库绪论
2 | ## 数据管理的三个阶段
3 | ### 人工管理阶段
4 | ### 文件系统阶段
5 | ### 数据库系统阶段
6 | ## 基本术语
7 | ### 数据(Data)
8 | * 计算机用来描述事物的记录(文字.图形.图像.声音)
9 | * 数据的形式本身并不能完全表达其内容,需要经过语义解释。数据与其语义是不可分的
10 | ### 数据库(Database,简称DB)
11 | * 数据库是长期存储在计算机内有结构的大量的共享的数据集合。
12 | ### 数据库管理系统(DBMS)
13 | * 数据库管理系统是位于用户与操作系统之间的一层数据管理软件。
14 | * 数据库在建立、运用和维护时由数据库管理系统统一管理、统一控制。
15 | * 数据库系统(DBS)
16 | * 数据库系统是指在计算机系统中引入数据库后的系统构成,一般由数据库、数据库管理系统(及其开发工具)、应用系统、数据库管理员和用户构成。
17 | ### 数据冗余度:
18 | * 指同一数据重复存储时的重复程度。
19 | ### 数据的安全性(Security)
20 | * 数据的安全性是指保护数据,防止不合法使用数据造成数据的泄密和破坏,使每个用户只能按规定,对某些数据以某些方式进行访问和处理。
21 | ### 数据的完整性(Integrity)
22 | * 数据的完整性指数据的正确性、有效性和相容性。即将数据控制在有效的范围内,或要求数据之间满足一定的关系。
23 | ### 并发(Concurrency)控制
24 | * 当多个用户的并发进程同时存取、修改数据库时,可能会发生相互干扰而得到错误的结果并使得数据库的完整性遭到破坏,因此必须对多用户的并发操作加以控制和协调。
25 | ### 数据库恢复(Recovery)
26 | * 计算机系统的硬件故障、软件故障、操作员的失误以及故意的破坏也会影响数据库中数据的正确性,甚至造成数据库部分或全部数据的丢失。DBMS必须具有将数据库从错误状态恢复到某一已知的正确状态(亦称为完整状态或一致状态)的功能。
27 | ## 数据库的三要素
28 | ### 数据(描述事物的符号记录,数据库里面存储的内容)
29 | ### 存储器(外存,一般是硬盘,数据库的载体)
30 | ### 数据库管理系统(DBMS,数据库的管理软件)
31 | ## 数据模型
32 | ### 模型
33 | * 是现实世界特征的模拟和抽象
34 | ### 数据模型
35 | * 也是一种模型,它是现实世界数据特征的抽象,表示实体以及实体间的联系
36 | * 一个用于描述数据、数据间关系、数据语义和数据约束的概念工具的集合
37 | ### 两级模型的抽象
38 | * 一是概念模型
39 | * (也称信息模型,用于信息世界的建模),它是按用户的观点来对数据和信息建模,主要用于数据库设计。这类模型强调其语义表达能力,要能够较方便、直接地表达应用中的各种语义知识,这类模型应为概念简单、清晰、易于用户理解,是用户和数据库设计人员之间进行交流的语言。
40 | * 二是数据模型
41 | * (如层次、网状、关系模型,用于机器世界),它是按计算机系统的观点对数据建模,主要用于DBMS的实现。这类模型通常需要有严格的形式化定义,而且常常会加上一些限制或规定,以便于机器上的实现。还通常有一组严格定义了语法和语义的语言,人们可以使用它来定义、操纵数据库中的数据。
42 | ### 数据模型的三要素
43 | * (1) 数据结构
44 | * 数据结构是所研究的对象类型(Object Type)的集合。这些对象是数据库的组成部分。一般可分为两类:一类是与数据类型、内容、性质有关的对象,如网状模型中的数据项、记录,关系模型中的属性、关系等;一类是与数据之间联系有关的对象,如网状模型中的系型(Set Type)等。
45 | * (2) 数据操作
46 | * 数据操作是指对数据库中各种对象(型)的实例(值)允许执行的操作的集合。数据库主要有检索和更新(插入、删除、修改)两大类操作。
47 | * 数据结构是对系统静态特性的描述,数据操作是对系统动态特性的描述。
48 | * (3) 数据的约束条件
49 | * 数据的约束条件是完整性规则的集合。完整性规则是给定的数据模型中数据及其联系所具有的制约和依存规则,用以限定符合数据模型的数据状态以及状态的变化,以保证数据的正确、有效、相容。
50 | ### 概念模型
51 | * 实体(Entity)
52 | * 客观存在并可相互区别的事物称为实体。实体可以是具体的人、事、物,也可以是抽象的概念或联系,如学生、部门、课程、银行帐户、选课、订货、演出、比赛等。
53 | * 属性(Attribute)
54 | * 实体所具有的某一特性称为属性。如学生实体可以由学号、姓名、性别、出生年月、系、入学时间等属性组成
55 | * 码(关键字,Key)
56 | * 唯一标识实体的(最小的)属性集称为码。例如学号学生实体的码
57 | * 域(Domain)
58 | * 属性的取值范围称为该属性的域。例如学号的域为8位整数,姓名的域为字符串集合,,性别的域为(男,女)。
59 | * 实体型(Entity Type)
60 | * 具有相同属性的实体必然具有共同的特征和性质。用实体名及其属性名集合来抽象和刻划同类实体,称为实体型。例如:学生(学号,姓名,性别,出生年月,系,入学时间)
61 | * 实体集(Entity Set)
62 | * 同型实体的集合称为实体集。例如,全体学生就是一个实体集。
63 | * 联系(Relationship)
64 | * 在现实世界中,事物内部以及事物之间是有联系的,这些联系在信息世界中反映为实体(型)内部的联系和实体(型)之间的联系。〖组成实体的各属性之间以及不同实体集之间的联系〗
65 | ## 联系的种类
66 | ### 1对1联系
67 | * 定义:若对于实体集A中的每一个实体,实体集B中至多有一个实体与之联系,反之亦然,则称实体集A与实体集B具有一对一联系,记为1:1。
68 | ### 1对多联系
69 | * 定义:若对于实体集A中的每一个实体,实体集B中有n个实体(n≥0)与之联系,反之,对于对于实体集B中的每一个实体,实体集A中至多只有一个实体与之联系,则称实体集A与实体集B具有一对多联系,记为1:n
70 | ### 多对多联系
71 | * 定义:若对于实体集A中的每一个实体,实体集B中有n个实体(n≥0)与之联系,反之,对于对于实体集B中的每一个实体,实体集A中也有m个实体(m≥0)与之联系,则称实体集A与实体集B具有多对多联系,记为m:n
72 | ## 概念模型的表示方法
73 | ### E-R图
74 | * 使用长方形来表示实体型,框内写上实体名
75 | * 椭圆型表示实体的属性,并用无向边把实体和属性连接起来
76 | * 用菱形表示实体间的联系,菱形框内写上联系名,用无向边把菱形分别与有关实体相连接,在无向边旁标上联系的类型,若实体之间联系也具有属性,则把属性和菱形也用无向边连接上
77 | *
78 | ## 基本数据模型
79 | ### 层次模型(Hierarchical Model)
80 | * 最早使用的一种模型
81 | * 数据结构是一棵有向树
82 | * 特点
83 | * (1) 有且仅有一个结点无双亲,该结点称为根结点。�
84 | * (2) 其他结点有且只有一个双亲
85 | ### 网状模型(Network Model)
86 | * 数据结构是一个有向图
87 | * 特点
88 | * (1)有一个以上的结点没有双亲�
89 | * (2)结点可以有多于一个的双亲
90 | * 能表示实体之间的多种复杂联系
91 | ### 关系模型(Relational Model)
92 | * 关系模型是用二维表格结构来表示实体及实体之间的联系的模型
93 | * 数据结构是一个“二维表框架”组成的集合
94 | * 关系模型概念简单,清晰,用户易懂易用,有严格的数学基础
95 | * 大多数数据库系统都是关系型的
96 | * 主要术语
97 | * 关系:一个关系对应于我们平常讲的一张表
98 | * 元组:表中的一行称为一个元组
99 | * 属性:表中的一列称为属性,每列的名称为属性名
100 | * 主码:表中的某个属性组,它们的值唯一的标识一个元组
101 | * 域:属性的取值范围
102 | * 分量:元组中的一个属性值
103 | * 关系模式:对关系的描述,用关系名(属性名1,属性名2,…,属性名n)来表示
104 | * 特点
105 | * 1. 概念单一:
106 | * 实体或实体之间的联系都用关系表示
107 | * 用户的观点里,数据的逻辑结构就是表
108 | * 2. 关系必须是规范化的关系
109 | * 指在关系模型中,每一个关系模式要满足一定的要求或者称为规范条件
110 | * 其最基本的要求是每一个分量是一个不可分的数据项,也就是说,不允许表中还有表。
111 | * 3. 用户对数据的检索操作不过是从原来的表中得到一张新的表
112 | * 在用户眼中,无论是原始数据还是结果数据,都是同一种数据结构——二维表。
113 | * 数据操作是集合操作,即操作对象和操作结果都是若干元组的集合,而不象非关系模型中那样单记录的操作方式。
114 | * 把存取路径向用户隐藏起来,提高了数据的独立性。
115 | ## 数据库系统的体系结构
116 | ### 三层模式:外模式、模式、内模式
117 | * 外模式
118 | * 又称为用户模式,是数据库用户和数据库系统的接口,是数据库用户的数据视图,是数据库用户可以看见和使用的局部数据的逻辑结构和特征的描述
119 | * 一个数据库通常都有多个外模式。一个应用程序只能使用一个外模式,但同一外模式可为多个应用程序所用
120 | * 模式
121 | * 可细分为概念模式和逻辑模式,是所有数据库用户的公共数据视图,是数据库中全部数据的逻辑结构和特征的描述。
122 | * •一个数据库只有一个模式。模式不但要描述数据的逻辑结构,还要描述数据之间的联系、数据的完整性、安全性要求。
123 | * 内模式
124 | * 又称为存储模式,是数据库物理结构和存储方式的描述,是数据在数据库内部的表示方式。
125 | * •一个数据库只有一个内模式。内模式并不涉及物理记录,也不涉及硬件设备。
126 | ### •二层映象功能:外模式/模式映象和模式/内模式映象
127 | * 三层模式关系
128 | * 数据库模式是数据库的核心和关键,外模式通常是模式的子集。数据按外模式的描述提供给用户,按内模式的描述存储在硬盘上,而模式介于外、内模式之间,既不涉及外部的访问,也不涉及内部的存储,从而起到隔离作用,有利于保持数据的独立性,内模式依赖于全局逻辑结构,但可以独立于具体的存储设备
129 | * 映象
130 | * 是一种对应规则,说明映象双方如何进行转换。
131 | * 外模式/模式映象
132 | * 作用:把描述局部逻辑结构的外模式与描述全局逻辑结构的模式联系趣来
133 | * 当模式改变时,只要对外模式/模式映象做相应的改变,使外模式保持不变,则以外模式为依据的应用程序不受影响,从而保证了数据与程序之间的逻辑独立性,也就是数据的逻辑独立性
134 | * 模式/内模式映象
135 | * 作用:把描述全局逻辑结构的模式与描述物理结构的内模式联系起来
136 | * 当内模式改变时,比如存储设备或存储方式有所改变,只要模式/内模式映象做相应的改变,使模式保持不变,则应用程序就不受影响,从而保证了数据与程序之的物理独立性。
137 | *XMind: ZEN - Trial Version*
--------------------------------------------------------------------------------
/数据库/数据库绪论/数据库绪论.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/数据库绪论/数据库绪论.xmind
--------------------------------------------------------------------------------
/数据库/数据库设计/数据库设计.md:
--------------------------------------------------------------------------------
1 | # 数据库设计
2 | ## 概述
3 | ### 数据库技术是信息资源管理最有效的手段。数据库设计是指对于一个给定的应用环境,构造最优的数据库模式,建立数据库极其应用系统,有效存储数据,满足用户信息要求和处理要求。
4 | ## 数据库设计的步骤
5 | ### ⒈需求分析阶段
6 | * 收集和分析用户需求,结果得到数据字典描述的数据需求。
7 | * 常用的调查方法
8 | * ⑴跟班作业
9 | * ⑵开调查会
10 | * ⑶请专人介绍
11 | * ⑷询问对某些调查中的问题,可以找专人询问。
12 | * ⑸设计调查表请用户填写
13 | * ⑹查阅记录
14 | ### ⒉概念结构设计阶段
15 | * 通过对用户需求进行综合、归纳与抽象,形成一个独立于具体DBMS的概念模型,可以用E-R图表示。这是数据库设计的关键
16 | ### ⒊逻辑结构设计阶段
17 | * 将概念结构转换为某个DBMS所支持的数据模型(例如关系模型),并对其进行优化(例如使用范式理论)
18 | ### ⒋数据库物理设计阶段
19 | * 为逻辑数据模型选取一个最适合应用环境的物理结构(包括存储结构和存取方法)。
20 | ### ⒌数据库实施阶段
21 | * 运用DBMS提供的数据语言(例如SQL)及其宿主语言(例如C),根据逻辑设计和物理设计的结果建立数据库,编制与调试应用程序,组织数据入库,并进行试运行
22 | ### ⒍数据库运行和维护阶段
23 | * 数据库应用系统经过试运行后即可投入正式运行。在数据库系统运行过程中必须不断地对其进行评价、调整与修改
24 | ## 数据字典
25 | ### 对数据库设计来讲,数据字典是进行数据收集和数据分析所获得的主要成果。数据字典是各类数据描述的集合。
26 | ### 数据字典通常包括数据项、数据结构、数据流、数据存储和处理过程五个部分。
27 | * 数据项是不可再分的数据单位
28 | * 数据结构反映了数据之间的组合关系。一个数据结构可以由若干个数据项组成,也可以由若干个数据结构组成,或由若干个数据项和数据结构混合组成
29 | * 数据流是数据结构在系统内传输的路径
30 | * 数据存储是数据结构停留或保存的地方,也是数据流的来源和去向之一
31 | * 处理过程描述={处理过程名,说明,输入:{数据流},输出:{数据流}, 处理:{简要说明}}
32 | ## 设计概念结构通常有四类方法
33 | ### 自顶向下
34 | * 即首先定义全局概念结构的框架,然后逐步细化。
35 | ### 自底向上
36 | * 即首先定义各局部应用的概念结构,然后将它们集成起来,得到全局概念结构。这是最经常采用的策略。即自顶向下地进行需求分析,然后再自底向上地设计概念结构
37 | ### 逐步扩张
38 | * 首先定义最重要的核心概念结构,然后向外扩充,以滚雪球的方式逐步生成其他概念结构,直至总体概念结构
39 | ### 混合策略
40 | * 即将自顶向下和自底向上相结合,用自顶向下策略设计一个全局概念结构的框架,以它为骨架集成由自底向上策略中设计的各局部概念结构
41 | ## E-R图
42 | ### E-R方法是抽象和描述现实世界的有力工具
43 | ### 要点
44 | * 使用长方形来表示实体型,框内写上实体名
45 | * 椭圆型表示实体的属性,并用无向边把实体和属性连接起来。
46 | * 用菱形表示实体间的联系,菱形框内写上联系名,用无向边把菱形分别与有关实体相连接,在无向边旁标上联系的类型,若实体之间联系也具有属性,则把属性和菱形也用无向边连接上。
47 | ### E-R图之间的冲突主要有三类
48 | * 属性冲突
49 | * (1) 属性域冲突,即属性值的类型、取值范围或取值集合不同。
50 | * (2) 属性取值单位冲突
51 | * 命名冲突
52 | * (1) 同名异义
53 | * (2) 异名同义(一义多名)
54 | * 结构冲突
55 | * (1) 同一对象在不同应用中具有不同的抽象。例如“教材”在某一局部应用中被当作实体,而在另一局部应用中则被当作属性
56 | * (2) 同一实体在不同局部视图中所包含的属性不完全相同,或者属性的排列次序不完全相同
57 | * (3) 实体之间的联系在不同局部视图中呈现不同的类型。例如实体E1与E2在局部应用A中是多对多联系,而在局部应用B中是一对多联系;又如在局部应用X中E1与E2发生联系,而在局部应用Y中E1、E2、E3三者之间有联系
58 | ## 逻辑结构设计阶段
59 | ### ⒈一个实体型转换为一个关系模式。实体的属性就是关系的属性。实体的码就是关系的码。
60 | ### ⒉一个m:n联系转换为一个关系模式。与该联系相连的各实体的码以及联系本身的属性均转换为关系的属性。而关系的码为各实体码的组合。
61 | ### ⒊一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的关系模式合并。如果转换为一个独立的关系模式,则与该联系相连的各实体的码以及联系本身的属性均转换为关系的属性,而关系的码为n端实体的码。
62 | ### ⒋一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应的关系模式合并。如果转换为一个独立的关系模式,则与该联系相连的各实体的码以及联系本身的属性均转换为关系的属性,每个实体的码均是该关系的候选码。如果与某一端对应的关系模式合并,则需要在该关系模式的属性中加入另一个关系模式的码和联系本身的属性。
63 | ### ⒌三个或三个以上实体间的一个多元联系转换为一个关系模式。与该多元联系相连的各实体的码以及联系本身的属性均转换为关系的属性。而关系的码为各实体码的组合。
64 | ### 6. 具有相同码的关系模式可合并。
65 | ## 数据模型的优化
66 | ### 确定数据依赖
67 | ### 对于各个关系模式之间的数据依赖进行极小化处理,消除冗余的联系。
68 | ### 按照数据依赖的理论对关系模式逐一进行分析,考查是否存在部分函数依赖、传递函数依赖、多值依赖等,确定各关系模式分别属于第几范式。
69 | ### 按照需求分析阶段得到的各种应用对数据处理的要求,分析对于这样的应用环境这些模式是否合适,确定是否要对它们进行合并或分解。
70 | ### 对关系模式进行必要的分解。
71 | ## 设计用户子模式
72 | ### (1) 使用更符合用户习惯的别名
73 | ### (2) 针对不同级别的用户定义不同的视图,以满足系统对安全性的要求
74 | ### (3) 简化用户对系统的使用
75 | ## 数据库物理设计
76 | ### 确定数据库存储结构时要综合考虑存取时间、存储空间利用率和维护代价三方面的因素。这三个方面常常是相互矛盾的。
77 | ### 为了提高系统性能,数据应该根据应用情况将易变部分与稳定部分、经常存取部分和存取频率较低部分分开存放
78 | *XMind: ZEN - Trial Version*
--------------------------------------------------------------------------------
/数据库/数据库设计/数据库设计.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/数据库设计/数据库设计.png
--------------------------------------------------------------------------------
/数据库/数据库设计/数据库设计.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/数据库设计/数据库设计.xmind
--------------------------------------------------------------------------------
/数据库/数据库语言SQL/数据库语言SQL.md:
--------------------------------------------------------------------------------
1 | # 数据库语言SQL
2 | ## SQL的发展
3 | ### 1974年,由Boyce和Chamberlin提出
4 | ### 1975~1979,IBM San Jose Research Lab的关系数据库管理系统原型System R实施了这种语言
5 | ### SQL-86是第一个SQL标准
6 | ### SQL-89、SQL-92(SQL2)、SQL-99(SQL3)
7 | ## 非过程化语言
8 | ### SQL语言进行数据库操作时,只需要提出“做什么”,不需要指明“怎么做”。“怎么做”是由DBMS来完成
9 | ## SQL的形式
10 | ### 交互式SQL
11 | * 一般DBMS都提供联机交互工具
12 | * 用户可直接键入SQL命令对数据库进行操作
13 | * 由DBMS来进行解释
14 | ### 嵌入式SQL
15 | * 能将SQL语句嵌入到高级语言(宿主语言)
16 | * 使应用程序充分利用SQL访问数据库的能力、宿主语言的过程处理能力
17 | * 一般需要预编译,将嵌入的SQL语句转化为宿主语言编译器能处理的语句
18 | ## SQL语言主要组成部分
19 | ### 数据定义语言(DDL,Data Definition Language)
20 | * 数据定义语言是指用来定义和管理数据库以及数据库中的各种对象的语句,这些语句包括CREATE、ALTER和DROP等语句。在SQL Server中,数据库对象包括表、视图、触发器、存储过程、规则、缺省、用户自定义的数据类型等。这些对象的创建、修改和删除等都可以通过使用CREATE、ALTER、DROP等语句来完成。
21 | * 常见的数据类型
22 | * 字符型:
23 | * 定长字符型 char(n) 由于是定长,所以速度快
24 | * 变长字符型 varchar(n)
25 | * 数值型:
26 | * 整型 int(或integer) -231~+231
27 | * 短整型 smallint -215~+215的
28 | * 浮点型 real、float、double
29 | * 数值型 numeric (p [,d])
30 | * 日期/时间型:
31 | * DateTime
32 | * 文本和图像型
33 | * Text:存放大量文本数据。在SQLServer中,Text对象实际为一指针
34 | * Image:存放图形数据
35 | ### 数据操纵语言(DML,Data Manipulation Language)
36 | * 数据操纵语言是指用来查询、添加、修改和删除数据库中数据的语句,这些语句包括SELECT、INSERT、UPDATE、DELETE等。在默认情况下,只有sysadmin、dbcreator、db_owner或db_datawriter等角色的成员才有权利执行数据操纵语言。
37 | ### 数据控制语言(DCL,Data Control Language)
38 | * 数据控制语言(DCL)是用来设置或者更改数据库用户或角色权限的语句,这些语句包括GRANT、REVOKE 、DENY等语句,在默认状态下,只有sysadmin、dbcreator、db_owner或db_securityadmin等角色的成员才有权利执行数据控制语言。
39 | ## SQL语句
40 | ### 建立表结构 Create
41 | * 定义基本表的语句格式:
42 | * CREATE TABLE <表名>(<列定义>[{,<列定义>,<表约束>}])
43 | * 表名:
44 | * 列定义:列名、列数据类型、长度、是否允许空值等。
45 | * 定义完整性约束:列约束和表约束
46 | * [CONSTRAINT<约束名>] <约束定义>
47 | ### 删除表结构 Drop
48 | * 用SQL删除关系(表)
49 | * 将整个关系模式(表结构)彻底删除
50 | * 表中的数据也将被删除
51 | ### 修改表结构 Alter
52 | * 增加表中的属性
53 | * 向已经存在的表中添加属性
54 | * allow null (新添加的属性要允许为空)
55 | * 已有的元组中该属性的值被置为Null
56 | * 修改表中的某属性(某列)
57 | * 修改属性类型或精度
58 | * 删除表中的某属性(某列)
59 | * 去除属性及相应的数据
60 | ### 向表中添加数据(Insert)
61 | * 数据添加
62 | * 用SQL的插入语句,向数据库表中添加数据
63 | * 按关系模式的属性顺序
64 | * 按指定的属性顺序,也可以只添加部分属性(非Null属性为必需)
65 | ### 数据删除(Delete)
66 | * 只能对整个元组操作,不能只删除某些属性上的值
67 | * 只能对一个关系起作用,若要从多个关系中删除元组,则必须对每个关系分别执行删除命令
68 | * 删除单个元组
69 | * 删除多个元组
70 | * 删除整个关系中的所有数据
71 | ### 数据更新(Update)
72 | * 改变符合条件的某个(某些)元组的属性值
73 | ## 视 图 (VIEW)
74 | ### 视图是从一个或者多个表或视图中导出的表,其结构和数据是建立在对表的查询基础上的。和真实的表一样,视图也包括几个被定义的数据列和多个数据行,但从本质上讲,这些数据列和数据行来源于其所引用的表。因此,视图不是真实存在的基础表而是一个虚拟表,视图所对应的数据并不实际地以视图结构存储在数据库中,而是存储在视图所引用的表中。
75 | ### 创建视图
76 | ### 视图的更新
77 | ## 数据查询(Select)
78 | ### 数据查询是数据库应用的核心功能
79 | ### Select子句——重复元组
80 | * SQL具有包的特性
81 | * Select 子句的缺省情况是保留重复元组( ALL ),可用 Distinct 去除重复元组
82 | * 去除重复元组:费时
83 | * 需要临时表的支持
84 | ### Select子句—— *与属性列表
85 | * 星号 * 表示所有属性
86 | * 星号 * :按关系模式中属性的顺序排列
87 | * 显式列出属性名:按用户顺序排列
88 | ### Select子句——更名
89 | * 为结果集中的某个属性改名
90 | * 使结果集更具可读性
91 | ### Where 子句
92 | * 查询满足指定条件的元组可以通过Where子句来实现
93 | * 使where子句中的逻辑表达式返回True值的元组,是符合要求的元组,将被选择出来
94 | * Where 子句——运算符
95 | * 比较:<、<=、>、>=、=、<> 等
96 | * 确定范围:
97 | * Between A and B、Not Between A and B
98 | * 确定集合:IN、NOT IN
99 | * 字符匹配:LIKE,NOT LIKE
100 | * 空值:IS NULL、IS NOT NULL
101 | * 多重条件:AND、OR、NOT
102 | * Where 子句——Like
103 | * 字符匹配:Like、Not Like
104 | * 通配符
105 | * % —— 匹配任意字符串
106 | * _ —— 匹配任意一个字符
107 | * 大小写敏感
108 | * Where 子句——转义符 escape
109 | ### From 子句
110 | * 列出将被查询的关系(表)
111 | * From 子句——元组变量
112 | * 为 From 子句中的关系定义元组变量
113 | * 方便关系名的引用
114 | * 连接子句
115 | * 内连接
116 | * 内连接是指包括符合条件的每个表的记录,也称之为全记录操作。
117 | * 外连接
118 | * 外连接是指把两个表分为左右两个表。右外连接是指连接满足条件右侧表的全部记录。左外连接是指连接满足条件左侧表的全部记录。全外连接是指连接满足条件表的全部记录。
119 | * 左外连接
120 | * 右外连接
121 | * 全外连接
122 | ### Order By子句
123 | * 指定结果集中元组的排列次序
124 | * 耗时
125 | * ASC升序(缺省)、DESC降序
126 | ### 子查询(Subquery )
127 | * 子查询是嵌套在另一查询中的 Select-From-Where 表达式(Where/Having)
128 | * SQL允许多层嵌套,由内而外地进行分析,子查询的结果作为父查询的查找条件
129 | * 可以用多个简单查询来构成复杂查询,以增强SQL的查询能力
130 | * 子查询中不使用 Order By 子句,Order By子句只能对最终查询结果进行排序
131 | * 子查询——单值比较
132 | * 返回单值的子查询,只返回一行一列
133 | * 父查询与单值子查询之间用比较运算符进行连接
134 | * 运算符:>、>=、=、<=、<、 <>
135 | * 子查询——多值
136 | * 子查询返回多行一列
137 | * 运算符:In、All、Some(或Any)、Exists
138 | * 子查询——多值成员In
139 | * 若值与子查询返回集中的某一个相等,则返回true
140 | * IN 被用来测试多值中的成员
141 | * 子查询——多值比较 ALL
142 | * 父查询与多值子查询之间的比较用All来连接
143 | * 值s比子查询返回集R中的每个都大时,s>All R 为True
144 | * All表示所有
145 | * > all、< all、<=all、>=all、<> all
146 | * <> all 等价于 not in
147 | * 子查询——多值比较Some/Any
148 | * 父查询与多值子查询之间的比较需用Some/Any来连接
149 | * 值s比子查询返回集R中的某一个都大时返回 Ture
150 | * s > Some R为True 或
151 | * s > Any R为True
152 | * Some(早期用Any)表示某一个(任意一个)
153 | * > some、< some、<=some、>=some、<> some
154 | * = some 等价于 in、<> some 不等价于 not in
155 | * 子查询——存在判断Exists
156 | * Exists + 子查询用来判断该子查询是否返回元组
157 | * 当子查询的结果集非空时,Exists为True
158 | * 当子查询的结果集为空时,Exists为False
159 | * 不关心子查询的具体内容,因此用 Select *
160 | * 具有外部引用的子查询,称为相关子查询(Correlated Queries)
161 | * 外层元组的属性作为内层子查询的条件
162 | ### 聚合函数
163 | * 把一列中的值进行聚合运算,返回单值的函数
164 | * 五个预定义的聚合函数
165 | * 平均值:Avg( )
166 | * 总和: Sum( )
167 | * 最小值:Min( )
168 | * 最大值:Max( )
169 | * 计数: Count( ) 返回所选列中不为NULL的数
170 | * Group By
171 | * 将查询结果集按某一列或多列的值分组,值相等的为一组,一个分组以一个元组的形式出现
172 | * 只有出现在Group By子句中的属性,才可出现在Select子句中
173 | * Having
174 | * 针对聚合函数的结果值进行筛选(选择),它作用于分组计算结果集
175 | * 跟在Group By子句的后面。
176 | * Having 与 Where的区别
177 | * Where 决定哪些元组被选择参加运算,作用于关系中的元组
178 | * Having 决定哪些分组符合要求,作用于分组
179 | * 聚合函数的条件关系必须用Having,Where中不应出现聚合函数
180 | * 聚合函数对Null的处理
181 | * Count:不计
182 | * Sum:不将其计入
183 | * Avg:具有 Null 的元组不参与
184 | * Max / Min:不参与
185 | ## 索引
186 | ### 数据库中的索引与书籍中的索引类似,在一本书中,利用索引可以快速查找所需信息,无须阅读整本书。在数据库中,索引使数据库程序无须对整个表进行扫描,就可以在其中找到所需数据。书中的索引是一个词语列表,其中注明了包含各个词的页码。而数据库中的索引是某个表中一列或者若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单
187 | ### 索引的作用
188 | * 通过创建唯一索引,可以保证数据记录的唯一性。
189 | * 可以大大加快数据检索速度。
190 | * 可以加速表与表之间的连接,这一点在实现数据的参照完整性方面有特别的意义。
191 | * 在使用ORDER BY和GROUP BY子句中进行检索数据时,可以显著减少查询中分组和排序的时间。
192 | * 使用索引可以在检索数据的过程中使用优化隐藏器,提高系统性能
193 | ### 聚集索引与非聚集索引
194 | * 聚集索引对表的物理数据页中的数据按列进行排序,然后再重新存储到磁盘上,即聚集索引与数据是混为一体的,它的叶节点中存储的是实际的数据
195 | * 非聚集索引具有完全独立于数据行的结构,使用非聚集索引不用将物理数据页中的数据按列排序。非聚集索引的叶节点存储了组成非聚集索引的关键字值和行定位器
196 | ### 创建索引
197 | ## 约束
198 | ### 主键约束(primary key constraint)
199 | ### 唯一性约束(unique constraint)
200 | ### 检查约束(check constraint)
201 | ### 缺省约束(default constraint)
202 | ### 外部键约束(foreign key constraint)
203 | ## SQL SERVER权限管理
204 | ### SQL Server权限管理策略
205 | * 安全帐户认证
206 | * 安全帐户认证是用来确认登录SQL Server的用户的登录帐号和密码的正确性,由此来验证其是否具有连接SQL Server的权限。 SQL Server 2000提供了两种确认用户的认证模式:
207 | * (一)Windows NT认证模式。
208 | * SQL Server数据库系统通常运行在Windows NT服务器平台上,而NT作为网络操作系统,本身就具备管理登录、验证用户合法性的能力,因此Windows NT认证模式正是利用了这一用户安全性和帐号管理的机制,允许SQL Server也可以使用NT的用户名和口令。在这种模式下,用户只需要通过Windows NT的认证,就可以连接到SQL Server,而SQL Server本身也就不需要管理一套登录数据。
209 | * (二)混合认证模式。
210 | * 混合认证模式允许用户使用Windows NT安全性或SQL Server安全性连接到SQL Server,这就意味着用户可以使用他的帐号登录到Windows NT,或者使用他的登录名登录到SQL Server系统。NT的用户既可以使用NT认证,也可以使用SQL Server认证
211 | * 访问许可确认
212 | * 但是通过认证阶段并不代表用户能够访问SQL Server中的数据,同时他还必须通过许可确认。用户只有在具有访问数据库的权限之后,才能够对服务器上的数据库进行权限许可下的各种操作,这种用户访问数据库权限的设置是通过用户帐号来实现的。
213 | ### 用户权限管理
214 | * 服务器登录帐号和用户帐号管理
215 | * 1.利用企业管理器创建、管理SQL Server登录帐号
216 | * (1)打开企业管理器,单击需要登录的服务器左边的“+”号,然后展开安全性文件夹。
217 | * (2)用右键单击登录(login)图标,从快捷菜单中选择新建登录(new login)选项,则出现SQL Server登录属性—新建登录对话框,如图6-2所示。
218 | * (3)在名称编辑框中输入登录名,在身份验证选项栏中选择新建的用户帐号是Windows NT认证模式,还是SQL Server认证模式。
219 | * (4)选择服务器角色页框。在服务器角色列表框中,列出了系统的固定服务器角色。
220 | * (5)选择用户映射页框。上面的列表框列出了该帐号可以访问的数据库,单击数据库左边的复选框,表示该用户可以访问相应的数据库以及该帐号在数据库中的用户名。
221 | * (6)设置完成后,单击“确定”按钮即可完成登录帐号的创建。
222 | * 使用SQL 语句创建登录帐号
223 | * 2.用户帐号管理
224 | * 在数据库中,一个用户或工作组取得合法的登录帐号,只表明该帐号通过了Windows NT认证或者SQL Server认证,但不能表明其可以对数据库数据和数据库对象进行某种或者某些操作,只有当他同时拥有了用户权限后,才能够访问数据库。
225 | * 利用企业管理器可以授予SQL Server登录访问数据库的许可权限。使用它可创建一个新数据库用户帐号
226 | * 许可(权限)管理
227 | * 许可用来指定授权用户可以使用的数据库对象和这些授权用户可以对这些数据库对象执行的操作。用户在登录到SQL Server之后,其用户帐号所归属的NT组或角色所被赋予的许可(权限)决定了该用户能够对哪些数据库对象执行哪种操作以及能够访问、修改哪些数据。在每个数据库中用户的许可独立于用户帐号和用户在数据库中的角色,每个数据库都有自己独立的许可系统,在SQL Server中包括三种类型的许可:即对象许可、语句许可和预定义许可。
228 | * 三种许可类型
229 | * 1、对象许可
230 | * 表示对特定的数据库对象,即表、视图、字段和存储过程的操作许可,它决定了能对表、视图等数据库对象执行哪些操作。
231 | * 2、语句许可
232 | * 表示对数据库的操作许可,也就是说,创建数据库或者创建数据库中的其它内容所需要的许可类型称为语句许可。
233 | * 3、预定义许可
234 | * 是指系统安装以后有些用户和角色不必授权就有的许可。
235 | * 角色管理
236 | * 角色是SQL Server 7.0版本引进的新概念,它代替了以前版本中组的概念。利用角色,SQL Server管理者可以将某些用户设置为某一角色,这样只对角色进行权限设置便可以实现对所有用户权限的设置,大大减少了管理员的工作量。SQL Server提供了用户通常管理工作的预定义服务器角色和数据库角色。
237 | * 1、服务器角色
238 | * 服务器角色是指根据SQL Server的管理任务,以及这些任务相对的重要性等级来把具有SQL Server管理职能的用户划分为不同的用户组,每一组所具有的管理SQL Server的权限都是SQL Server内置的,即不能对其进行添加、修改和删除,只能向其中加入用户或者其他角色。
239 | * 几种常用的固定服务器角色
240 | * 系统管理员:拥有SQL Server所有的权限许可。
241 | * 服务器管理员:管理SQL Server服务器端的设置。
242 | * 磁盘管理员:管理磁盘文件。
243 | * 进程管理员:管理SQL Server系统进程。
244 | * 安全管理员:管理和审核SQL Server系统登录。
245 | * 安装管理员:增加、删除连接服务器,建立数据库复制以及管理扩展存储过程。
246 | * 数据库创建者:创建数据库,并对数据库进行修改。
247 | * 2、数据库角色
248 | * 数据库角色是为某一用户或某一组用户授予不同级别的管理或访问数据库以及数据库对象的权限,这些权限是数据库专有的,并且还可以使一个用户具有属于同一数据库的多个角色。SQL Server提供了两种类型的数据库角色:即固定的数据库角色和用户自定义的数据库角色。
249 | * (1)固定的数据库角色
250 | * public:维护全部默认许可。
251 | * db_owner:数据库的所有者,可以对所拥有的数据库执行任何操作。
252 | * db_accessadmin:可以增加或者删除数据库用户、工作组和角色。
253 | * db_addladmin:可以增加、删除和修改数据库中的任何对象。
254 | * db_securityadmin:执行语句许可和对象许可。
255 | * db_backupoperator:可以备份和恢复数据库。
256 | * db_datareader:能且仅能对数据库中的任何表执行select操作,从而读取所有表的信息。
257 | * db_datawriter:能够增加、修改和删除表中的数据,但不能进行select操作。
258 | * db_denydatareader:不能读取数据库中任何表中的数据。
259 | * db_denydatawriter:不能对数据库中的任何表执行增加、修改和删除数据操作。
260 | * (2)用户自定义角色
261 | * 创建用户定义的数据库角色就是创建一组用户,这些用户具有相同的一组许可。如果一组用户需要执行在SQL Server中指定的一组操作并且不存在对应的Windows NT组,或者没有管理Windows NT用户帐号的许可,就可以在数据库中建立一个用户自定义的数据库角色。用户自定义的数据库角色有两种类型:即标准角色和应用程序角色。
262 | ### Transaction_SQL 语句
263 | * 赋权语句——Grant
264 | * 收回权限——Revoke
265 | * 收回权限——Deny
266 | *XMind: ZEN - Trial Version*
--------------------------------------------------------------------------------
/数据库/数据库语言SQL/数据库语言SQL.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/数据库语言SQL/数据库语言SQL.png
--------------------------------------------------------------------------------
/数据库/数据库语言SQL/数据库语言SQL.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/数据库语言SQL/数据库语言SQL.xmind
--------------------------------------------------------------------------------
/数据库/查询优化/查询优化.md:
--------------------------------------------------------------------------------
1 | # 查询优化
2 | ## 概述
3 | ### 关系系统和关系模型是两个密切相关而有不同的概念。支持关系模型的数据库管理系统称为关系系统。但是关系模型中并非每一部分都是同等重要的,所以我们不苛求完全支持关系模型的系统才能称为关系系统。因此,我们给出一个关系系统的最小要求以及分类的定义。
4 | ### 关系系统的定义
5 | * 1.支持关系数据库(关系数据结构)
6 | * 从用户观点看,数据库由表构成,并且只有表这一种结构。
7 | * 2.支持选择、投影和(自然)连接运算,对这些运算不必要求定义任何物理存取路径
8 | * 当然并不要求关系系统的选择、投影、连接运算和关系代数的相应运算完全一样,而只要求有等价的这三种运算功能就行。
9 | ## 查询优化
10 | ### 查询优化:对于给定的查询选择代价最小的操作序列,使查询过程既省时间,具有较高的效率,这就是所谓的查询优化。对于关系数据库系统,用户只要提出“做什么”,而由系统解决“怎么做”的问题。具体来说,是数据库管理系统中的查询处理程序自动实现查询优化。
11 | ### 关系查询优化是影响RDBMS性能的关键因素。关系系统的查询优化既是RDBMS实现的关键技术又是关系系统的优点所在。
12 | ### 查询优化的优点不仅在于用户不必考虑如何最好地表达查询以获得较好的效率,而且在于系统可以比用户程序的“优化”做得更好。
13 | ### 查询优化的一般准则
14 | * 1.选择运算应尽可能先做。在优化策略中这是最重要、最基本的一条。它常常可使执行时节约几个数量级,因为选择运算一般使计算的中间结果大大变小
15 | * 2.在执行连接前对关系适当地预处理。预处理方法主要有两种,在连接属性上建立索引和对关系排序 。
16 | * 3.把投影运算和选择运算同时进行。如有若干投影和选择运算,并且它们都对同一个关系操作,则可以在扫描此关系的同时完成所有的这些运算以避免重复扫描关系。
17 | * 4.把投影同其前或其后的双目运算结合起来,没有必要为了去掉某些字段而扫描一遍关系
18 | * 5.杷某些选择同在它前面要执行的笛卡尔积结合起来成为一个连接运算,连接特别是等值连接运算要比同样关系上的笛卡尔积省很多时间
19 | * 6.找出公共子表达式。
20 | *XMind: ZEN - Trial Version*
--------------------------------------------------------------------------------
/数据库/查询优化/查询优化.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/查询优化/查询优化.png
--------------------------------------------------------------------------------
/数据库/查询优化/查询优化.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据库/查询优化/查询优化.xmind
--------------------------------------------------------------------------------
/数据结构/数据结构.md:
--------------------------------------------------------------------------------
1 | # 数据结构
2 | ## 第一章:数据结构的
3 | 基本概念
4 | ### 定义
5 | * 在任何问题中,数据元素都不是孤立存在的,而是在它们之间存在着某种关系,这种数据元素相互之间的关系称为结构(Structure)。数据结构是相互之间存在一种或多种特定关系的数据元素的集合。数据结构包括三方面的内容:逻辑结构、存储结构和数据的运算。数据的逻辑结构和存储结构是密不可分的两个方面,一个算法的设计取决于所选定的逻辑结构,而算法的实现依赖于所采用的存储结构。
6 | ### 逻辑结构
7 | * 逻辑结构是指数据元素之间的逻辑关系,即从逻辑关系上描述数据。它与数据的存储无关,是独立于计算机的
8 | * 数据的逻辑结构分为线性结构和非线性结构
9 | * 集合 结构中的数据元素之间除了“同属于一个集合”的关系外,别无其他关系。 类似于数学上的集合
10 | * 线性结构 结构中的数据元素之间只存在一对一的关系。比如排队
11 | * 树形结构 结构中的数据元素之间存在一对多的关系。比如家族族谱
12 | * 图状结构或网状结构 结构中的数据元素之间存在多对多的关系。 比如地图
13 | ### 物理结构
14 | * 存储结构是指数据结构在计算机中的表示(又称映像),也称物理结构。它包括数据元素的表示和关系的表示。数据的存储结构是逻辑结构用计算机语言的实现,它依赖于计算机语言。数据的存储结构主要有:顺序存储、链式存储、索引存储和散列存储。
15 | * 顺序存储:存储的物理位置相邻。(p.s. 物理位置即信息在计算机中的位置。)
16 | * 链接存储:存储的物理位置未必相邻,通过记录相邻元素的物理位置来找到相邻元素。
17 | * 索引存储:类似于目录,以后可以联系操作系统的文件系统章节来理解。
18 | * 散列存储:通过关键字直接计算出元素的物理地址(以后详解)。
19 | ### 算法的五个特征
20 | * 1,有穷性:有限步之后结束
21 | * 2,确定性:不存在二义性,即没有歧义
22 | * 3,可行性:比如受限于计算机的计算能力,有些算法虽然理论上可行,但实际上无法完成。
23 | * 4,输入:能被计算机处理的各种类型数据,如数字,音频,图像等等。
24 | * 5,输出:一至多个程序输出结果。
25 | ### 算法的复杂度
26 | * 时间复杂度:
27 | * • 它用来衡量算法随着问题规模增大,算法执行时间增长的快慢;
28 | * • 是问题规模的函数:T(n)是时间规模函数 时间复杂度主要分析T(n)的数量级
29 | * • T(n)=O(f(n)) f(n)是算法中基本运算的频度 一般我们考虑最坏情况下的时间复杂度
30 | * 空间复杂度:
31 | * • 它用来衡量算法随着问题规模增大,算法所需空间的快慢;
32 | * • 是问题规模的函数:S(n)=O(g(n)) ;算法所需空间的增长率和g(n)的增长率相同。
33 | ### 概要: 复杂度计算为重点
34 | * 常用的时间复杂度大小关系:
35 | * 复杂度如何计算
36 | * 时间复杂度计算(单个循环体)
37 | * 直接关注循环体的执行次数,设为k
38 | * 时间复杂度计算(多个循环体)
39 | * 两个运算规则:乘法规则,加法规则。
40 | ## 第二章:线性表
41 | ### 线性表的逻辑结构
42 | * 定义:线性表是具有相同数据类型的n(n≥0)个数据元素的有限序列。其中n为表长。当n=0时 线性表是一个空表
43 | * 特点:线性表中第一个元素称为表头元素;最后一个元素称为表尾元素。
44 | 除第一个元素外,每个元素有且仅有一个直接前驱。
45 | 除最后一个元素外,每个元素有且仅有一个直接后继。
46 | ### 线性表的顺序存储结构
47 | * 线性表的顺序存储又称为顺序表。
48 | 它是用一组地址连续的存储单元(比如C语言里面的数组),依次存储线性表中的数据元素,从而使得逻
49 | 辑上相邻的两个元素在物理位置上也相邻。
50 | * 建立顺序表的三个属性:
51 | 1.存储空间的起始位置(数组名data)
52 | 2.顺序表最大存储容量(MaxSize)
53 | 3.顺序表当前的长度(length)
54 | * 其实数组还可以动态分配空间,存储数组的空间是在程序执行过程中通过动态存储分配语句分配
55 | * 总结:
56 | * 1.顺序表最主要的特点是随机访问(C语言中基于数组),即通过首地址和元素序号可以在O(1)的时间内找到指定的元素。
57 | * 2.顺序表的存储密度高,每个结点只存储数据元素。无需给表中元素花费空间建立它们之间的逻辑关系(因为物理位置相邻特性决定)
58 | * 3.顺序表逻辑上相邻的元素物理上也相邻,所以插入和删除操作需要移动大量元素。
59 | ### 顺序表的操作
60 | * 1.插入
61 | * 算法思路:
62 | * 1.判断i的值是否正确
63 | * 2.判断表长是否超过数组长度
64 | * 3.从后向前到第i个位置,分别将这些元素都向后移动一位
65 | * 4.将该元素插入位置i 并修改表长
66 | * 代码
67 | * 分析:
68 | * 最好情况:在表尾插入(即i=n+1),元素后移语句将不执行,时间复杂度为O(1)。
69 | * 最坏情况:在表头插入(即i=1),元素后移语句将执行
70 | n次,时间复杂度为O(n)。
71 | * 平均情况:假设pi(pi=1/(n+1) )是在第i个位置上插入
72 | 一个结点的概率,则在长度为n的线性表中插入一个结
73 | 点时所需移动结点的平均次数为
74 | * 2.删除
75 | * 算法思路:
76 | * 1.判断i的值是否正确
77 | * 2.取删除的元素
78 | * 3.将被删元素后面的所有元素都依次向前移动一位
79 | * 4.修改表长
80 | * 代码
81 | * 分析
82 | * 最好情况:删除表尾元素(即i=n),无须移动元素,时间复杂度为O(1)。
83 | * 最坏情况:删除表头元素(即i=1),需要移动除第一个元素外的所有元素,时间复杂度为O(n)。
84 | * 平均情况:假设pi(pi=1/n)是删除第i个位置上结点的概率,则在长度为n的线性表中删除一个结点时所需移动结点的平均次数为
85 | ### 线性表的链式存储结构
86 | * 线性表的链式存储是指通过一组任意的存储单元来存储线性表中的数据元素。
87 | * 头结点和头指针的区别?
88 | * 不管带不带头结点,头指针始终指向链表的第一个结点,而头结点是带头结点链表中的第一个结点,结点内通常不存储信息
89 | * 为什么要设置头结点?
90 | * 1.处理操作起来方便 例如:对在第一元素结点前插入结点和删除第一结点起操作与其它结点的操作就统一了
91 | * 2.无论链表是否为空,其头指针是指向头结点的非空指针,因此空表和非空表的处理也就统一了。
92 | ### 单链表的操作
93 | * 1.头插法建立单链表:
94 | * 建立新的结点分配内存空间,将新结点插入到当前链表的表头
95 | * 代码
96 | * 2.尾插法建立单链表:
97 | * 建立新的结点分配内存空间,将新结点插入到当前链表的表尾
98 | * 代码
99 | * 3.按序号查找结点
100 | * 在单链表中从第一个结点出发,顺指针next域逐个往下搜索,直到找到第i个结点为止,否则返回最后一个结点指针域NULL。
101 | * 代码
102 | * 4.按值查找结点
103 | * 从单链表第一个结点开始,由前往后依次比较表中各结点数据域的值,若某结点数据域的值等于给定值e,则返回该结点的指针;若整个单链表中没有这样的结点,则返回NULL。
104 | * 代码
105 | * 5.插入
106 | * 插入操作是将值为x的新结点插入到单链表的第i个位置上。先检查插入位置的合法性,然后找到待插入位置的前驱结点,即第i−1个结点,再在其后插入新结点。
107 | * 算法思路:
108 | 1.取指向插入位置的前驱结点的指针
109 | ① p=GetElem(L,i-1);
110 | 2.令新结点*s的指针域指向*p的后继结点
111 | ② s->next=p->next;
112 | 3.令结点*p的指针域指向新插入的结点*s
113 | ③ p->next=s;
114 | * 6.删除
115 | * 删除操作是将单链表的第i个结点删除。先检查删除位置的合法性,然后查找表中第i−1个结点,即被删结点的前驱结点,再将其删除。
116 | * 算法思路:
117 | 1.取指向删除位置的前驱结点的指针 p=GetElem(L,i-1);
118 | 2.取指向删除位置的指针 q=p->next;
119 | 3.p指向结点的后继指向被删除结点的后继 p->next=q->next
120 | 4.释放删除结点 free(q);
121 | ### 双链表
122 | * 定义
123 | * 1.插入:(方法不唯一)
124 | ① s->next=p->next;
125 | ② p->next->prior=s;
126 | ③ s->prior=p;
127 | ④ p->next=s;
128 | * 2.删除:
129 | ① p->next=q->next;
130 | ② q->next->prior=p;
131 | ③ free(q);
132 |
133 | ### 循环链表&&静态链表
134 | * 循环单链表:循环单链表和单链表的区别在于,表中最后一个结点的指针不是NULL,而改为指向头结点,从而整个链表形成一个环
135 | * 循环双链表:类比循环单链表,循环双链表链表区别于双链表就是首尾结点构成环
136 | * 当循环双链表为空表时,其头结点的prior域和next域都等于Head。
137 | * 静态链表:静态链表是用数组来描述线性表的链式存储结构。
138 | * 数组第一个元素不存储数据,它的指针域存储第一个元素所在的数组下标。链表最后一个元素的指针域值为-1。
139 | * 例子
140 | ## 第三章:栈和队列
141 | ### 栈
142 | * 栈(Stack):只允许在一端进行插入或删除操作的线性表。
143 | * 栈顶(Top):线性表允许进行插入和删除的那一端。
144 | * 栈底(Bottom):固定的,不允许进行插入和删除的另一端
145 | * 特点:
146 | 1.栈是受限的线性表,所以自然具有线性关
147 | 系。
148 | 2.栈中元素后进去的必然先出来,即后进先出
149 | LIFO(Last In First Out)
150 | * 栈中元素后进
151 | 去的必然先出
152 | 来,即后进先
153 | 出LIFO(Last In
154 | First Out)
155 | * 顺序栈
156 | * 栈是线性表的特例,那栈的顺序存储也是线性表顺序存储的简化。栈的顺序存储结构也叫作顺序栈。
157 | * 顺序栈的操作
158 | * 1.判空:
159 | * 2.进栈:
160 | * 3.出栈:
161 | * 4.读取栈顶元素:
162 | * 共享栈
163 | * 顺序栈的存储空间大小需要事先开辟好,很多时候对每个栈各自单独开辟存储空间的利用率不如将各个栈的存储空间共享
164 | * 示意图
165 | * 共享栈的结构
166 | * 共享栈的操作:(进栈)
167 | * 链式栈
168 | * 栈是线性表的特例,线性表的存储结构还有链式存储结构,所以也可以用链表的方式来实现栈。栈的链式存储结构也叫作链栈。
169 | * 特点
170 | 1.链栈一般不存在栈满的情况。
171 | 2.空栈的判定条件通常定为top==NULL;
172 | * 结构
173 | * 链式栈的操作
174 | * 1.进栈
175 | * 2.出栈
176 | ### 队列
177 | * 队列是只允许在一端进行插入,而在另一端进行删除的线性表
178 | * 队头(Front):允许删除的一端,又称为队首。
179 | * 队尾(Rear): 允许插入的一端。
180 | * 先进入队列的元素必然先离开队列,即先进先出(First In First Out)简称FIFO
181 | * 顺序队列
182 | * 用数组来实现队列,可以将队首放在数组下标为0的位置。
183 | * 循环队列
184 | * 把数组“掰弯”,形成一个环。Rear指针到了下标为4的位置还能继续指回到下标为0的地方。这样首尾相连的顺序存储的队列就叫循环队列
185 | * 入队:rear=(rear+1)%MaxSize
186 | * 出队:front=(front+1)%MaxSize
187 | * 循环队列的操作
188 | * 1.入队:
189 | * 2.出队:
190 | * 概要: 那如何分辨队列是空还是满呢?
191 | * 方法一:设置标志位flag,当flag=0且rear等于front时为队列空,当flag=1且rear等于front时为队列满。
192 | * 方法二:我们把front=rear仅作为队空的判定条件。当队列满的时候,令数组中仍然保留一个空余单元。我们认为这种情况就是队列满了。
193 | * 链式队列
194 | * 队列的链式存储结构,其实就是线性表的单链表,只不过需要加点限制,只能表尾插入元素,表头删除元素。
195 | * 为了方便操作,我们分别设置队头指针和队尾指针,队头指针指向头结点,队尾指针指向尾结点。
196 | * 链式队列的操作
197 | * 1.入队:我们知道队列只能从队尾插入元素,队头删除元素。于是入队就是在队尾指针进行插入结点操作。链队的插入操作和单链表的插入操作是一致的。
198 |
199 | * 2.出队:出队就是头结点的后继结点出队,然后将头结点的后继改为它后面的结点。
200 | * 双端队列
201 | * 双端队列是指允许两端都可以进行入队和出队操作的队列
202 | ### 栈的应用
203 | * 1、括号匹配:假设有两种括号,一种圆的(),一种方的[],嵌套的顺序是任意的。
204 | * 算法思想:若是左括号,入栈;若是右括号,出栈一个左括号判断是否与之匹配;检验到字符串尾,还要检查栈是否为空。只有栈空,整个字符串才是括号匹配的。
205 |
206 | * 代码
207 | * 2、表达式求值:
208 | *
209 | * 规则:从左到右扫描表达式的每个数字和符号,遇到数字就进栈,遇到符号就将处于栈顶的两个数字出栈然后跟这个符号进行运算,最后将运算结果进栈,直到最终获得结果。
210 | * 3、递归:
211 | * 要理解递归,你要先理解递归,直到你能理解递归。
212 | 如果在一个函数、过程或数据结构的定义中又应用了它自身,那么这个函数、过程或数据结构称为是递归定义的,简称递归。递归最重要的是递归式和递归边界。
213 | * 1.阶乘
214 | * 时间复杂度:O(NlogN)
215 | * 2.斐波那契数列
216 | * 时间复杂度 O(2^n)
217 | * 概要: 如何将中缀表达式转换成后缀表达式?
218 | * 1.按运算符优先级对所有运算符和它的运算数加括号。(原本的括号不用加)
219 | * 2.把运算符移到对应的括号后。
220 | * 3.去掉括号。
221 | * 例子
222 | ## 第四章:树
223 | ### 树的基本概念
224 | * 树是递归定义的结构
225 | * 结点
226 | * 根节点:树只有一个根结点
227 | * 结点的度:结点拥有的子树的数量
228 | * 度为0:叶子结点或者终端结点
229 | * 度不为0:分支结点或者非终端结点
230 | * 分支结点除去根结点也称为内部结点
231 | * 树的度:树中所有结点的度数的最大值
232 | * 结点关系
233 | * 祖先结点
234 | * 根结点到该结点的唯一路径的任意结点
235 | * 子孙结点
236 | * 双亲结点
237 | * 根结点到该结点的唯一路径上最接近该结点的结点
238 | * 孩子结点
239 | * 兄弟结点
240 | * 有相同双亲结点的结点
241 | * 层次,高度,深度,树的高度
242 | * 层次:根为第一层,它的孩子为第二层,以此类推
243 | * 结点的深度:根结点开始自顶向下累加
244 | * 结点的高度:叶节点开始自底向上累加
245 | * 树的高度(深度):树中结点的最大层数
246 | * 树的性质
247 | * 1.树中的结点数等于所有结点的度数加1。
248 | * 证明:不难想象,除根结点以外,每个结点有且仅有一个指向它的前驱结点。也就是说每个结点和指向它的分支一一对应。
249 | 假设树中一共有b个分支,那么除了根结点,整个树就包含有b个结点,所以整个树的结点数就是这b个结点加上根结点,设为n,则n=b+1。而分支数b也就是所有结点的度数,证毕。
250 | * 2.度为m的树中第i层上至多有m^(i−1)个结点(i≥1)。
251 | * 证明:(数学归纳法)
252 | 首先考虑i=1的情况:第一层只有根结点,即一个结点,i=1带入式子满足。
253 | 假设第i-1层满足这个性质,第i-1层最多有m i-2个结点。
254 | ……… ..........
255 | i-1层
256 | ………
257 | 又因为树的度为m,所以对于第i-1层的每个结点,最多
258 | 有m个孩子结点。所以第i层的结点数最多是i-1层的m
259 | 倍,所以第i层上最多有m ^(i-1)个结点。
260 | * 3.高度为h的m叉树至多有(m^h-1)/(m-1)个结点
261 | * 4.具有n个结点的m叉树的最小高度为logm(n(m-1)+1)
262 | ### 树的存储结构
263 | * 顺序存储结构
264 | * 双亲表示法:用一组连续的存储空间存储树的结点,同时在每个结点中,用一个变量存储该结点的双亲结点在数组中的位置。
265 | * 链式存储结构
266 | * 孩子表示法:把每个结点的孩子结点排列起来存储成一个单链表。所以n个结点就有n个链表;
267 | 如果是叶子结点,那这个结点的孩子单链表就是空的;
268 | 然后n个单链表的的头指针又存储在一个顺序表(数组)中。
269 |
270 | * 孩子兄弟表示法:顾名思义就是要存储孩子和孩子结点的兄弟,具体来说,就是设置两个指针,分别指向该结
271 | 点的第一个孩子结点和这个孩子结点的右兄弟结点。
272 | ### 二叉树
273 | * 定义
274 | * 二叉树是n(n≥0)个结点的有限集合:
275 | ① 或者为空二叉树,即n=0。
276 | ② 或者由一个根结点和两个互不相交的被称为根的左子树
277 | 和右子树组成。左子树和右子树又分别是一棵二叉树。
278 | * 1.每个结点最多有两棵子树。
279 | * 2.左右子树有顺序
280 | * 二叉树的五种基本形态:
281 | * 1.空树
282 | * 2.只有一个根结点
283 | * 3.根结点只有左子树
284 | * 4.根结点只有右子树
285 | * 5.根结点既有左子树又有右子树
286 | * 特殊二叉树
287 | * 1.斜树
288 | * 2.满二叉树:
289 | * 3.完全二叉树
290 | * 二叉树的性质
291 | * 1.非空二叉树上叶子结点数等于度为2的结点数加1
292 | * 2.非空二叉树上第K层上至多有2^k−1个结点(K≥1)
293 | * 3.高度为H的二叉树至多有2^H-1个结点(H≥1)
294 | * 4.具有N个(N>0)结点的完全二叉树的高度为 [log2(N+1)]或[log2N] +1。
295 | ### 二叉树的存储结构
296 | * 顺序存储
297 | * 二叉树的顺序存储结构就是用一组地址连续的存储单元依次自上而下、自左至右存储完全二叉树上的结点元素。
298 | * 链式存储
299 | * 二叉树每个结点最多两个孩子,所以设计二叉树的结点结构时考虑两个指针指向该结点的两个孩子。
300 | ### 二叉树的遍历
301 | * 先序遍历:
302 | 1)访问根结点;
303 | 2)先序遍历左子树;
304 | 3)先序遍历右子树。
305 | * 递归
306 | * 非递归
307 | * 中序遍历:
308 | 1)中序遍历左子树;
309 | 2)访问根结点;
310 | 3)中序遍历右子树。
311 | * 递归
312 | * 非递归
313 | * 后序遍历:
314 | 1)后序遍历左子树;
315 | 2)后序遍历右子树;
316 | 3)访问根结点。
317 | * 递归
318 | * 非递归
319 | * 层次遍历:
320 | 若树为空,则什么都不做直接返回。
321 | 否则从树的第一层开始访问,从上而下逐层遍历,在同一层中,按从左到右的顺序对结点逐个访问。
322 |
323 | ### 线索二叉树
324 | * N个结点的二叉链表,每个结点都有指向左右孩子的
325 | 结点指针,所以一共有2N个指针,而N个结点的二叉
326 | 树一共有N-1条分支,也就是说存在2N-(N-1)=N+1个空指针。比如左图二叉树中有6个结点,那么就有7个空
327 | 指针。
328 |
329 | * 大量的空余指针能否利用起来?
330 | * 指向前驱和后继的指针称为线索,加上线索的二叉链表就称为线索链表,相应的二叉树就称为线索二叉树
331 | * 对二叉树以某种次序遍历使其变为线索二叉树的过程就叫做线索化
332 | ### 哈夫曼树和哈夫曼编码
333 | * 算法的描述如下:
334 | 1)将这N个结点分别作为N棵仅含一个结点的二叉树,构成森林F。
335 | 2)构造一个新结点,并从F中选取两棵根结点权值最小的树作为新结点的左、右子树,并且将新结点的权值
336 | 置为左、右子树上根结点的权值之和。
337 | 3)从F中删除刚才选出的两棵树,同时将新得到的树加入F中。
338 | 4)重复步骤2)和3),直至F中只剩下一棵树为止。
339 |
340 | ## 第五章:图
341 | ### 图的基本概念
342 | * 定义:
343 | 树是N(N≥0)个结点的有限集合,N=0时,称为空树,这是一种特殊情况。在任意一棵非空树中应满足:
344 | 1)有且仅有一个特定的称为根的结点。
345 | 2)当N>1时,其余结点可分为m(m>0)个互不相交的有限集合T1,T2,…,Tm,其中每一个集合本身又是一棵树,并且称为根结点的子树。
346 | * 图G由顶点集V和边集E组成,记为G=(V,E)
347 | * V(G)表示图G中顶点的有限非空集。
348 | 用|V|表示图G中顶点的个数,也称为图G的阶
349 | * E(G)表示图G中顶点之间的关系(边)集合。
350 | 用|E|表示图G中边的条数。
351 | * 分类
352 | * 有向图
353 | * 有向边(弧)的有限集合
354 | * 弧是顶点的有序对
355 | *
356 | * v是弧尾,w是弧头
357 | * v邻接到w或w邻接自v
358 | * 无向图
359 | * 无向边的有限集合
360 | * 边是顶点的无序对
361 | * (v,w)
362 | * (v,w)=(w,v)
363 | * w,v互为邻接点
364 | * 简单图
365 | * 1.不存在顶点到自身的边
366 | * 2.同一条边不重复出现
367 | * 多重图
368 | * 若图G中某两个结点之间的边数多于一条,又允许顶点通过通过同一个边和自己关联
369 | * 完全图
370 | * 无向完全图
371 | * 如果任意两个顶点之间都存在边
372 | * 有向完全图
373 | * 如果任意两个顶点之间都存在方向相反的两条弧
374 | * 子图
375 | * 连通图:图中任意两个顶点都是连通的
376 | * 连通分量:无向图中的极大连通子图
377 | * 连通
378 | * 顶点A到顶点B有路径
379 | * 极大
380 | * 1.顶点足够多
381 | * 2.极大连通子图包含这些依附这些顶点的所有边
382 | * 结论1:如果一个图有n个顶点,并且有小于n-1条边,则此图必是非连通图。
383 | * 概要: 找连通分量的方法:
384 | 从选取一个顶点开始,以这个顶点作为一个子图,然后逐个添加与这个子图相连的顶点和边直到所有相连的顶点都加入该子图
385 | * 强连通:顶点V到顶点W和顶点W到顶点V都有路径
386 | * 强连通图:图中任一对顶点都是强连通的
387 | * 连通图的生成树:包含图中全部n个顶点,但是只有n-1条边的极小连通子图
388 | * 结论2:生成树去掉一条边则变成非连通图,加上一条边就会形成回路。
389 | * 度:以该顶点为一个端点的边数目
390 | * 无向图中顶点V的度是指依附于该顶点的边的条数,记为TD(v)
391 | * 有向图中顶点V的度分为出度和入度
392 | * 入度(ID)是以顶点v为终点的有向边的数目
393 | * 出度(OD)是以顶点V为起点的有向边的数目
394 | * 简单路径和简单回路:顶点不重复出现的路径称为简单路径。对于回路,除了第一个和最后一个顶点其余顶点不重复出现的回路称为简单回路
395 | * 权和网:图中每条边考研赋予一定意义的数值,这个数值叫做这条边的权,有权值得图称为带权图,也叫做网
396 | * 路径和路径长度:顶点p到q之间的路径是指顶点序列怕保存的,p,a,b,c,d,……q。路径上边的数目就是路径长度
397 | * 回路(环):第一个和最后一个顶点相同的路径称为回路或者环
398 | * 距离:从顶点u到v的最短路径长度。不存在路径则为无穷
399 | ### 图的存储结构
400 | * 邻接矩阵(顺序存储)
401 | * 邻接表(链式存储)
402 | * 十字链表(有向图)
403 | * 邻接多重表(无向图)
404 | ### 图的遍历
405 | * 深度优先遍历
406 | * 深度优先搜索(DFS:Depth-First-Search):深度优先搜索类似于树的先序遍历算法
407 | * 空间复杂度:由于DFS是一个递归算法,递归是需要一个工作栈来辅助工作,最多需要图中所有顶点进栈,所以时间复杂度为O(|V|)
408 | * 时间复杂度:1)邻接表:遍历过程的主要操作是对顶点遍历它的邻接点,由于通过访问边表来查找邻接点,所以时间复杂度为O(|E|),访问顶点时间为O(|V|),所以总的时间复杂度为O(|V|+|E|)
409 | 2)邻接矩阵:查找每个顶点的邻接点时间复杂度为O(|V|),对每个顶点都进行查找,所以总的时间复杂度为O(|V|2)
410 | * 广度优先遍历
411 | * 广度优先搜索(BFS:Breadth-First-Search):广度优先搜索类似于树的层序遍历算法
412 | * 空间复杂度:BFS需要借助一个队列,n个顶点均需要入队一次,所以最坏情况下n个顶点在队列,那么则需要O(|V|)的空间复杂度。
413 | * 时间复杂度:
414 | 1)邻接表:每个顶点入队一次,时间复杂度为O(|V|),对于每个顶点,搜索它的邻接点,就需要访问这个顶点的所有边,所以时间复杂度为O(|E|)。所以总的时间复杂度为O(|V|+|E|)
415 | 2)邻接矩阵:每个顶点入队一次,时间复杂度为O(|V|),对于每个顶点,搜索它的邻接点,需要遍历一遍矩阵的一行,所以时间复杂度为O(|V|),所以总的时间复杂度为O(|V|2)
416 |
417 | ### 图的应用
418 | * 最小生成树
419 | * 普利姆(Prlm)
420 | * ①从图中找第一个起始顶点v0,作为生成树的第一个顶点,然后从这个顶点到其他顶点的所有边中选一条权值最小的边。然后把这条边的另一个顶点v和这条边加入到生成树中。
421 | * ②对剩下的其他所有顶点,分别检查这些顶点与顶点v的权值是否比这些顶点在lowcost数组中对应的权值小,如果更小,则用较小的权值更新lowcost数组。
422 | * ③从更新后的lowcost数组中继续挑选权值最小而且不在生成树中的边,然后加入到生成树。
423 | * ④反复执行②③直到所有所有顶点都加入到生成树中。
424 | * 概要:
425 | * 双重循环,外层循环次数为n-1,内层并列的两个循环次数都是n。故普利姆算法时间复杂度为O(n2)
426 | 而且时间复杂度只和n有关,所以适合稠密图
427 | * 克鲁斯卡尔(Kruskal)
428 | * 将图中边按照权值从小到大排列,然后从最小的边开始扫描,设置一个边的集合来记录,如果该边并入不构成回路的话,则将该边并入当前生成树。直到所有的边都检测完为止。
429 | * 概要:
430 | *
431 | *
432 | * 概要: 克鲁斯卡尔算法操作分为对边的权值排序部分和一个单重for循环,它们是并列关系,由于排序耗费时间大于单重循环,所以克鲁斯卡尔算法的主要时间耗费在排序上。排序和图中边的数量有关系,所以适合稀疏图
433 | * 最短路径
434 | * 迪杰斯特拉
435 | * 一个源点到其余顶点的最短路径
436 | * 该算法设置一个集合S记录已求得的最短路径的顶点,可用一个数组s[]来实现,初始化为0,当s[vi]=1时表示将顶点vi放入S中,初始时把源点v0放入S中。此外,在构造过程中还设置了两个辅助数组:
437 | dist[]:记录了从源点v0到其他各顶点当前的最短路径长度,dist[i]初值为arcs[v0][i]。
438 | path[]:path[i]表示从源点到顶点i之间的最短路径的前驱结点,在算法结束时,可根据其值追溯得到源点v0到顶点vi的最短路径。
439 |
440 | 假设从顶点0出发,也就是顶点0为源点,集合S最初只包含顶点0,邻接矩阵arcs表示带权有向图,arcs[i][j]表示有向边的权值,若不存在有向边,则arcs[i][j]为∞。Dijkstra算法的步骤如下:
441 | 1)初始化:集合S初始为{0},dist[]的初始值dist[i]=arcs[0][i],i=1,2,…,n-1。
442 | 2)找出dist[]中的最小值dist[j],将顶点j加入集合S,即修改s[vj]=1。
443 | 3)修改从v0出发到集合V-S上任一顶点vk可达的最短路径长度:如果dist[j] + arcs[j][k]< dist[k],则令dist[k]=dist[j] + arcs[j][k]。另外更新path[k]=j(也就是顶点j加入集合之后如果有新的路径使得到顶点k路径变短的话就将到顶点k的路径长度修改成较短的)
444 | 4)重复2)~3)操作共n-1次,直到所有的顶点都包含在S中。
445 | * 弗洛伊德
446 | * 所有顶点到所有顶点的最短路径
447 | * 算法思想:
448 | 递推产生一个n阶方阵序列A(−1),A(0),…,A(k),…,A(n−1)
449 | 其中A(k)[i][j]表示从顶点vi到顶点vj的路径长度,k表示绕行第k个顶点的运算步骤。初始时,对于任意两个顶点vi和vj,若它们之间存在边,则以此边上的权值作为它们之间的最短路径长度;若它们之间不存在有向边,则以∞作为它们之间的最短路径长度。以后逐步尝试在原路径中加入顶点k(k=0,1,…,n-1)作为中间顶点。如果增加中间顶点后,得到的路径比原来的路径长度减少了,则以此新路径代替原路径
450 | * 非带权图
451 | * 两点之间经过边数最少的路径
452 | * 带权图
453 | * 两点之间经过的边上权值之和最小的路径
454 | * 拓扑排序
455 | * AOV
456 | * 如果我们把每个环节看成图中一个顶点,在这样一个有向图中,用顶点表示活动,用弧表示活动之间的优先关系,那么这样的有向图称为AOV网(Activity On Vertex)
457 |
458 | * 拓扑排序就是对一个有向图构造拓扑序列的过程,构造会有两种结果:
459 | 如果此图全部顶点都被输出了,说明它是不存在回路的AOV网;
460 | 如果没有输出全部顶点,则说明这个图存在回路,不是AOV网。
461 | * 拓扑排序算法:
462 | 从AOV网中选择一个入度为0的顶点输出,然后删去此顶点,并删除以此顶点为弧尾的弧。重复这个步骤直到输出图中全部顶点,或者找不到入度为0的顶点为止。
463 |
464 | * 关键路径
465 | * AOE(Activity On Edge):在一个表示工程的带权有向图中,用顶点表示事件,用有向边表示活动,用边上的权值表示活动的持续时间,这种有向图的边表示活动的网称为AOE网。
466 |
467 | ## 第六章:查找
468 | ### 查找的基本概念和顺序查找
469 | * 查找定义:在数据集合中寻找满足某种条件的数据元素的过程称为查找
470 | * 关键字:数据元素中某个可以以唯一标识该元素的数据项
471 | * 平均查找长度(ASL:Average Search Length):在查找的过程中,一次查找的长度是指需要比较的关键字次数,而平均查找长度则是所有查找过程中进行关键字的比较次数的平均值
472 | * 顺序查找(线性查找),主要用于在线性表中进行查找。从查找表的一端开始,顺序扫描查找表,依次将扫描到的关键字和待查找的值key进行比较。如果相等,则查找成功。如果扫描结束仍然没有发现相等的数据元素,则查找失败。
473 | * 1
474 | * 2
475 | * 3
476 | * 4
477 | * 时间复杂度为O(n)
478 | ### 折半查找
479 | * 算法思路:
480 | * 首先将给定值key与表中中间位置元素的关键字比较,若相等,则查找成功,返回该元素的存储位置;若不等,则所需查找的元素只能在中间元素以外的前半部分或后半部分中。然后在缩小的范围内继续进行同样的查找,如此重复直到找到为止,或者确定表中没有所需要查找的元素,则查找不成功,返回查找失败的信息。
481 | * 折半查找分析
482 | * 折半查找判定树
483 | * 对于折半查找,查找的比较次数就是从根结点到该结点经历的结点数
484 | * 时间复杂度为O(logn)
485 | * 概要: 具有N个(N>0)结点的完全二叉树的高度为 [log2(N+1)] 或 [log2N] +1。
486 |
487 | ### 分块查找
488 | * 分块查找又称为索引顺序查找
489 | * 分块查找思想:
490 | * ①确定待查找值在哪个块(折半查找)
491 |
492 | ②在确定的块中查找待查找值(顺序查找)
493 | * 分块查找分析
494 | * 由于分块查找实际是进行两次查找,所以整个算法的平均查找长度是两次查找的平均查找长度之和。
495 | 即ASL分块=ASL折半+ASL顺序
496 | *
497 | ### 二叉排序树
498 | * 二叉排序树(Binary Search Tree 也叫二叉搜索树)或者是一棵空树,或者是具有以下性质的二叉树
499 | ①若左子树不空,则左子树上所有结点的值均小于它的根结点的值。
500 | ②若右子树不空,则右子树上所有结点的值均大于它的根结点的值。
501 | ③它的左右子树也是一棵二叉排序树。
502 | * 算法思想
503 | * 由于二叉排序树的特点(左子树<根结点<右子树),所以每次查找一个关键字,需要先和根结点进行比较:
504 | 如果这个关键字小于根结点的值,则再到这个根结点的左子树进行同样的比较操作一直进行下去直到找到该关键字,表示查找成功,或者是空指针,表示查找失败。
505 | 如果这个关键字大于根结点的值,则再到这个根结点的右子树进行同样的比较操作一直进行下去直到找到该关键字,表示查找成功,或者是空指针,表示查找失败。
506 | * 查找关键字代码
507 | * 1
508 | * 2
509 | * 插入关键字代码
510 | * 1)空树:直接插入新结点返回成功
511 | 2)树不空:检查是否存在关键字重复的结点:
512 | ①存在:返回插入失败
513 | ②不存在:检查根结点的值和待插入关键字值的大小关系递归插入左右子树
514 | *
515 | * 构造代码
516 | *
517 | * 删除结点
518 | * ①删除的是叶子结点
519 | * 方法:直接删去该结点即可
520 | * ②删除的是仅有左子树或者右子树的结点
521 | * 方法:“子承父业”
522 | * ③删除的是左右子树都有的结点
523 | * 仿照②类型,先将一个孩子“继承父业”,另一个孩子“归顺”于这个孩子
524 | 方法:找到待删除结点的直接前驱或者直接后继结点,用该结点来替换待删除结点,再删除该结点。
525 | * 二叉排序树分析
526 | * 查找时间复杂度是O(n)
527 | * 概要: “左小右大”
528 | ### 平衡二叉树(AVL树)
529 | * 平衡二叉树(AVL树)是特殊的二叉排序树,特殊的地方在于左右子树的高度之差绝对值不超过1,而且左右子树又是一棵平衡二叉树。
530 | * 平衡因子
531 | * 定义结点左子树与右子树的高度差为该结点的平衡因子,则平衡二叉树结点的平衡因子的值只可能是−1、0或1。
532 | * 平衡调整
533 | * 平衡二叉树的建立过程和二叉排序树的建立过程是相似的,都是从一棵空树开始陆续插入结点。不同的地方在于对于平衡二叉树的建立过程中,由于插入结点可能会破坏结点的平衡性,所以需要进行平衡调整。
534 |
535 | * LL调整(左孩子的左子树上插入结点导致)
536 | * 最小不平衡子树根结点的平衡因子为2>0
537 | 它的左孩子结点平衡因子为1>0
538 | 两个都大于0,所以直接右旋就可以调整
539 | * 概要: “正则右旋”
540 | * RR调整(右孩子的右子树上插入结点导致)
541 | * 最小不平衡子树根结点的平衡因子为-2<0
542 | 它的右孩子结点平衡因子为-1<0
543 | 两个都小于0,所以直接左旋就可以调整
544 | * 概要: “负则左旋”
545 | * LR调整(左孩子的右子树上插入结点导致)
546 | * RL调整(右孩子的左子树上插入结点导致)
547 | * 概要: 先局部转换为LL或RR,最后进行调整
548 | * 分析
549 | * 含有n个结点平衡二叉树的最大深度为O(log2n),因此,平衡二叉树的平均查找长度为O(log2n)
550 | ### B树和B+树
551 | * 2-3树
552 | * 2-3树是一种多路查找树:2和3的意思就是2-3树包含两种结点
553 | * 1)2结点包含一个元素和两个孩子(或者没有孩子)。
554 | ①左子树包含的元素小于该结点的元素值,右子树包含的元素大于该结点的元素值
555 | ②2结点要不有两个孩子,要不就没有孩子,不允许有一个孩子
556 | * 2)3结点包含一大一小两个元素和三个孩子(或者没有孩子)。(两个元素按大小顺序排列好)
557 | ①左子树包含的元素小于该结点较小的元素值,右子树包含的元素大于该结点较大的元素值,中间子树包含的元素介于这两个元素值之间。
558 | ②3结点要不有三个孩子,要不就没有孩子,不允许有一个或两个孩子
559 | * 3)2-3树所有叶子结点都在同一层次
560 | * 2-3-4树
561 | * 2-3-4树也是一种多路查找树:2和3和4的意思就是2-3-4树包含三种结点
562 | * 1)2结点包含一个元素和两个孩子(或者没有孩子)。
563 | ①左子树包含的元素小于该结点的元素值,右子树包含的元素大于该结点的元素值
564 | ②2结点要不有两个孩子,要不就没有孩子,不允许有一个孩子
565 | * 2)3结点包含一大一小两个元素和三个孩子(或者没有孩子)。
566 | ①左子树包含的元素小于该结点较小的元素值,右子树包含的元素大于该结点较大的元素值,中间子树包含的元素介于这两个元素值之间。
567 | ②3结点要不有三个孩子,要不就没有孩子,不允许有一个或两个孩子
568 | * 3)4结点包含小中大三个元素和四个孩子(或者没有孩子)。
569 | ①左子树包含的元素小于该结点最小的元素值,第二个子树包含大于最小的元素值小于中间元素值的元素,第三个子树包含大于中间元素值小于最大元素值的元素,右子树包含的元素大于该结点最大的元素值。
570 | ②4结点要不有四个孩子,要不就没有孩子,不允许有一个或两个或三个孩子
571 | * 4)2-3-4树所有叶子结点都在同一层次
572 | * B树
573 | * B树也是一种平衡的多路查找树,2-3树和2-3-4树都是B树的特例,我们把树中结点最大的孩子数目称为B树的阶。通常记为m。
574 | 一棵m阶B树或为空树,或为满足如下特性的m叉树:
575 | * 1)树中每个结点至多有m棵子树。(即至多含有m-1个关键字) ("两棵子树指针夹着一个关键字")
576 | * 2)若根结点不是终端结点,则至少有两棵子树。(至少一个关键字)
577 | * 3)除根结点外的所有非叶结点至少有 ⌈m/2⌉棵子树。(即至少含有⌈m/2⌉-1个关键字)
578 | * 4)所有非叶结点的结构如下:
579 | * 5)所有的叶子结点出现在同一层次上,不带信息。(就像是折半查找判断树中查找失败的结点)
580 | * 1.B树的查找操作
581 | * 查找过程:①先让待查找关键字key和结点的中的关键字比较,如果等于其中某个关键字,则查找成功。
582 | ②如果和所有关键字都不相等,则看key处在哪个范围内,然后去对应的指针所指向的子树中查找。
583 | Eg:如果Key比第一个关键字K1还小,则去P0指针所指向的子树中查找,如果比最后一个关键字Kn还大,则去Pn指针所指向的子树中查找。
584 |
585 | * 2.B树的插入操作
586 | * 分裂的方法:取这个关键字数组中的中间关键字(⌈n/2⌉)作为新的结点,然后其他关键字形成两个结点作为新结点的左右孩子。
587 | * 3.B树的删除操作
588 | * B树中的删除操作与插入操作类似,但要稍微复杂些,要使得删除后的结点中的关键字个数≥⌈m/2⌉-1 ,因此将涉及结点的“合并”问题。由于删除的关键字位置不同,可以分为关键字在终端结点和不在终端结点上两种情况。
589 | * 1)如果删除的关键字在终端结点上(最底层非叶子结点):
590 | ①结点内关键字数量大于⌈m/2⌉-1 ,这时删除这个关键字不会破坏B树的定义要求。所以直接删除。
591 | ②结点内关键字数量等于⌈m/2⌉-1 ,并且其左右兄弟结点中存在关键字数量大于⌈m/2⌉-1 的结点,则去兄弟阶段中借关键字。
592 | ③结点内关键字数量等于⌈m/2⌉-1 ,并且其左右兄弟结点中不存在关键字数量大于⌈m/2⌉-1 的结点,则需要进行结点合并。
593 |
594 | * 2)如果删除的关键字不在终端结点上(最底层非叶子结点):需要先转换成在终端结点上,再按照在终端结点 上的情况来分别考虑对应的方法。
595 | * 相邻关键字:对于不在终端结点上的关键字,它的相邻关键字是其左子树中值最大的关键字或者右子树中值最小的关键字。
596 | * 第一种情况:存在关键字数量大于⌈m/2⌉-1 的左子树或者右子树,在对应子树上找到该关键字的相邻关键字,然后将相邻关键字替换待删除的关键字。
597 | * 第二种情况:左右子树的关键字数量均等于⌈m/2⌉-1 ,则将这两个左右子树结点合并,然后删除待删除关键字。
598 | * B+树
599 | * B+树是常用于数据库和操作系统的文件系统中的一种用于查找的数据结构
600 | * m阶的B+树与m阶的B树的主要差异在于:
601 | 1)在B+树中,具有n个关键字的结点只含有n棵子树,即每个关键字对应一棵子树;而在B树中,具有n个关键字的结点含有(n+1)棵子树。
602 | 2)在B+树中,每个结点(非根内部结点)关键字个数n的范围是 ⌈m/2⌉≤n≤m(根结点1≤n≤m),在B树中,每个结点(非根内部结点)关键字个数n的范围是⌈m/2⌉ -1≤n≤m-1(根结点:1≤n≤m-1)。
603 | 3)在B+树中,叶结点包含信息,所有非叶结点仅起到索引作用,非叶结点中的每个索引项只含有对应子树的最大关键字和指向该子树的指针,不含有该关键字对应记录的存储地址。
604 | 4)在B+树中,叶结点包含了全部关键字,即在非叶结点中出现的关键字也会出现在叶结点中;而在B树中,叶结点包含的关键字和其他结点包含的关键字是不重复的。
605 | ### 散列表
606 | * 散列表:根据给定的关键字来计算出关键字在表中的地址的数据结构。也就是说,散列表建立了关键字和存储地址之间的一种直接映射关系。
607 | * 散列函数:一个把查找表中的关键字映射成该关键字对应的地址的函数,记为Hash(key)=Addr。
608 | * 散列函数可能会把两个或两个以上的不同关键字映射到同一地址,称这种情况为“冲突”,这些发生碰撞的不同关键字称为同义词。
609 | * 构造散列函数的tips:
610 | * 1)散列函数的定义域必须包含全部需要存储的关键字,而值域的范围则依赖于散列表的大小或地址范围。
611 | * 2)散列函数计算出来的地址应该能等概率、均匀地分布在整个地址空间,从而减少冲突的发生。
612 | * 3)散列函数应尽量简单,能够在较短的时间内就计算出任一关键字对应的散列地址。
613 | * 1.常用Hash函数的构造方法:
614 | * 1.开放定址法:直接取关键字的某个线性函数值为散列地址,散列函数为H(key)=a×key+b。式中,a和b是常数。这种方法计算最简单,并且不会产生冲突
615 | * 2.除留余数法:假定散列表表长为m,取一个不大于m但最接近或等于m的质数p,利用以下公式把关键字转换成散列地址。散列函数为H(key)=key % p
616 | 除留余数法的关键是选好p,使得每一个关键字通过该函数转换后等概率地映射到散列空间上的任一地址,从而尽可能减少冲突的可能性
617 | * 3.数字分析法:设关键字是r进制数(如十进制数),而r个数码在各位上出现的频率不一定相同,可能在某些位上分布均匀些,每种数码出现的机会均等;而在某些位上分布不均匀,只有某几种数码经常出现,则应选取数码分布较为均匀的若干位作为散列地址。这种方法适合于已知的关键字集合
618 | * 4.平方取中法:顾名思义,取关键字的平方值的中间几位作为散列地址。具体取多少位要看实际情况而定。这种方法得到的散列地址与关键字的每一位都有关系,使得散列地址分布比较均匀。
619 | * 5.折叠法:将关键字分割成位数相同的几部分(最后一部分的位数可以短一些),然后取这几部分的叠加和作为散列地址,这种方法称为折叠法。关键字位数很多,而且关键字中每一位上数字分布大致均匀时,可以采用折叠法得到散列地址。
620 |
621 | * 2.常用Hash函数的冲突处理办法:
622 | * 1.开放定址法:将产生冲突的Hash地址作为自变量,通过某种冲突解决函数得到一个新的空闲的Hash地址。
623 | * 1)线性探测法:冲突发生时,顺序查看表中下一个单元(当探测到表尾地址m-1时,下一个探测地址是表首地址0),直到找出一个空闲单元(当表未填满时一定能找到一个空闲单元)或查遍全表。
624 | * 2)平方探测法:设发生冲突的地址为d,平方探测法得到的新的地址序列为d+12,d-12,d+22,d-22......
625 | 平方探测法是一种较好的处理冲突的方法,可以避免出现“堆积”问题,它的缺点是不能探测到散列表上的所有单元,但至少能探测到一半单元。
626 | * 3)再散列法:又称为双散列法。需要使用两个散列函数,当通过第一个散列函数H(Key)得到的地址发生冲突时,则利用第二个散列函数Hash2(Key)计算该关键字的地址增量。
627 | * 4)伪随机序列法:当发生地址冲突时,地址增量为伪随机数序列,称为伪随机序列法。
628 | * 2.拉链法:对于不同的关键字可能会通过散列函数映射到同一地址,为了避免非同义词发生冲突,可以把所有的同义词存储在一个线性链表中,这个线性链表由其散列地址唯一标识。拉链法适用于经常进行插入和删除的情况。
629 | * 3.散列表的查找过程:类似于构造散列表,给定一个关键字Key。
630 | 先根据散列函数计算出其散列地址。然后检查散列地址位置有没有关键字。
631 | 1)如果没有,表明该关键字不存在,返回查找失败。
632 | 2)如果有,则检查该记录是否等于关键字。
633 | ①如果等于关键字,返回查找成功。
634 | ②如果不等于,则按照给定的冲突处理办法来计算下一个散列地址,再用该地址去执行上述过程。
635 | * 4.散列表的查找性能:和装填因子有关。
636 | *
637 | * α越大,表示装填的记录越“满”,发生冲突的可能性就越大,反之发生冲突的可能性越小
638 | ## 第七章:排序
639 | ### 排序的基本知识
640 | * 定义:排序就是将原本无序的序列重新排列成有序的序列。
641 | * 排序的稳定性
642 | * 如果待排序表中有两个元素Ri、Rj,其对应的关键字keyi=keyj,且在排序前Ri在Rj前面,如果使用某一排序算法排序后,Ri仍然在Rj的前面,则称这个排序算法是稳定的,否则称排序算法是不稳定的。
643 | ### 插入类排序
644 | * 直接插入排序
645 | * 直接插入排序:首先以一个元素为有序的序列,然后将后面的元素依次插入到有序的序列中合适的位置直到所有元素都插入有序序列。
646 | * 时间复杂度为O(n)
647 | * 直接插入排序是稳定性是稳定的。
648 | * 折半插入排序
649 | * 折半插入排序将比较和移动这两个操作分离出来,也就是先利用折半查找找到插入的位置,然后一次性移动元素,再插入该元素。
650 | * 折半插入排序的时间复杂度为O(n^2)
651 | * 稳定性:和直接插入排序稳定性相同,是稳定的。
652 | * 希尔排序
653 | * 希尔排序的基本思想:希尔排序本质上还是插入排序,只不过是把待排序序列分成几个子序列,再分别对这几个子序列进行直接插入排序。
654 | * ①先以增量5来分割序列,也就是下标为0,5,10,15...的关键字分成一组,下标为1,6,11,16..分成一组,然后对这些组分别进行直接插入排序,这就完成了一轮希尔排序。
655 | * ②缩小增量(d1=n/2,di+1= [di/2],比如10个数据序列,第一次增量d1=10/2=5,第二次增量d2= [d1/2]= [5/2]=2,并且最后一个增量等于1),所以第二轮以增量为2进行类似的排序过程。
656 | * ③接下来的第三轮,第四轮...都是类似的过程,直到最后一轮以增量为1。此时就是前面所说的直接插入排序。
657 | * 概要:
658 | * 时间复杂度:... 希尔排序的时间复杂度约为O(n^1.3) 在最坏情况下希尔排序的时间复杂度为O(n^2)
659 | * 空间复杂度:希尔排序的空间复杂度为O(1)
660 | * 稳定性:不稳定,由于不同的增量可能就会把相等的关键字划分到两个直接插入排序中进行排序, 可能就会造成相对顺序变化。
661 | ### 交换类排序
662 | * 冒泡排序
663 | * 假设待排序表长为n,从后往前(或从前往后)两两比较相邻元素的值,若为逆序(即A[i-1]>A[i]),则交换它们,直到序列比较完。我们称它为一趟冒泡,结果将最小的元素交换到待排序列的第一个位置。下一趟冒泡时,前一趟确定的最小元素不再参与比较,待排序列减少一个元素,每趟冒泡的结果把序列中的最小元素放到了序列的最终位置,……,这样最多做n-1趟冒泡就能把所有元素排好序。
664 | * 空间复杂度:交换时开辟了存储空间来存储中间变量,所以空间复杂度为O(1)
665 | * 时间复杂度
666 | * 稳定性:当两个关键字相等,if判断条件不成立,所以不会发生数据移动。所以是稳定的。
667 | * 快速排序
668 | * 快速排序是一种基于分治法的排序方法。
669 | 每一趟快排选择序列中任一个元素作为枢轴(pivot)(通常选第一个元素),将序列中比枢轴小的元素都移到枢轴前边,比枢轴大的元素都移到枢轴后边。
670 | * 1
671 | * 2
672 | * 时间复杂度:
673 | 最好情况下时间复杂度为O(nlogn) ,待排序序列越无序,算法效率越高。
674 | 最坏情况下时间复杂度为O(n^2),待排序序列越有序,算法效率越低。
675 | * 空间复杂度:
676 | 由于快速排序是递归的,需要借助一个递归工作栈来保存每一层递归调用的必要信息,其容量应与递归调用的最大深度一致。
677 | 最好情况下为 ⌈log2(n+1)⌉(每次partition都很均匀)递归树的深度O(logn)
678 | 最坏情况下,因为要进行n-1次递归调用,所以栈的深度为O(n);
679 | * 稳定性:快速排序是不稳定的,是因为存在交换关键字。
680 | ### 选择类排序
681 | * 简单选择排序
682 | *
683 | * 空间复杂度:需要额外的存储空间仅为交换元素时借助的中间变量,所以空间复杂度是O(1)
684 | * 时间复杂度:
685 | 关键操作在于交换元素操作,整个算法由双重循环组成,外层循环从0到n-2一共n-2+1=n-1次,
686 | 对于第i层外层循环,内层循环执行n-1-(i+1)+1=n-i-1次。
687 | 当i=0,内层循环执行n-1次,当i=n-2,内层循环执行1次,所以是一个等差数列求和,一共为(1+n-1)(n-1)/2=n(n-1)/2 ,所以时间复杂度为O(n^2)
688 | * 稳定性:不稳定 原因就在于交换部分会打破相对顺序
689 | * 堆排序
690 | * 什么是堆?
691 | * 堆是一棵完全二叉树,而且满足任何一个非叶结点的值都不大于(或不小于)其左右孩子结点的值。
692 | * 如果是每个结点的值都不小于它的左右孩子结点的值,则称为大顶堆。
693 | * 如果是每个结点的值都不大于它的左右孩子结点的值,则称为小顶堆。
694 | * 什么是堆排序?
695 | * 我们知道对于一个堆来说,它的根结点是整个堆中所有结点的值的最大值(大顶堆)或者最小值(小顶堆)。所以堆排序的思想就是每次将无序序列调节成一个堆,然后从堆中选择堆顶元素的值,这个值加入有序序列,无序序列减少一个,再反复调节无序序列,直到所有关键字都加入到有序序列。
696 | *
697 | *
698 | * 时间复杂度:
699 | 堆排序的总时间可以分为①建堆部分+②n-1次向下调整堆
700 |
701 | 堆排序的时间复杂度为O(n)+O(nlog2n)=O(nlog2n)
702 | * 堆排序不稳定
703 | ### 归并排序
704 | * 假定待排序表含有n个记录,则可以看成是n个有序的子表,每个子表长度为1,然后两两归并,得到 ⌈n/2⌉个长度为2或1的有序表;再两两归并,……如此重复,直到合并成一个长度为n的有序表为止,这种排序方法称为2-路归并排序。
705 | *
706 | *
707 | * 例如:49 38 65 97 76 13 27
708 | * ①首先将整个序列的每个关键字看成一个单独的有序的子序列
709 | * ②两两归并,49和38归并成{38 49} ,65和97归并成{65 97},76和13归并成{13 76},27没有归并对象
710 | * ③两两归并,{38 49}和{65 97}归并成{38 49 65 97},{13,76}和27归并成{13 27 76}
711 | * ④两两归并,{38 49 65 97}和{13 27 76}归并成{13 27 38 49 65 76 97}
712 | * 时间复杂度:O(nlog2n)
713 | * 空间复杂度:因为需要将这个待排序序列转存到一个数组,所以需要额外开辟大小为n的存储空间,即空间复杂度为O(n)
714 | * 稳定性:稳定
715 | ### 基数排序
716 | * 基数排序(也叫桶排序)是一种很特别的排序方法,它不是基于比较进行排序的,而是采用多关键字排序思想(即基于关键字各位的大小进行排序的),借助“分配”和“收集”两种操作对单逻辑关键字进行排序。基数排序又分为最高位优先(MSD)排序和最低位优先(LSD)排序。
717 | * 例子:53, 3, 542, 748, 14, 214, 154, 63, 616
718 | * 补充位数:053, 003, 542, 748, 014, 214, 154, 063, 616
719 | * 桶实际是一个队列,先进先出(从桶的上面进,下面出)
720 | * 关键字数量为n,关键字的位数为d,比如748 d=3,r为关键字的基的个数,就是组成关键字的数据的种类,比如十进制数字一共有0至9一共10个数字,即r=10
721 | * 空间复杂度:需要开辟关键字基的个数个队列,所以空间复杂度为O(r)
722 | * 时间复杂度:需要进行关键字位数d次"分配"和"收集",一次"分配"需要将n个关键字放进各个队列中,一次"收集"需要将r个桶都收集一遍。所以一次"分配"和一次"收集"时间复杂度为O(n+r)。d次就需要O(d(n+r))的时间复杂度。
723 | * 稳定性:由于是队列,先进先出的性质,所以在分配的时候是按照先后顺序分配,也就是稳定的,所以收集的时候也是保持稳定的。即基数排序是稳定的排序算法。
724 | ### 外部排序
725 | * 需要将待排序的记录存储在外存上,排序时再把数据一部分一部分的调入内存进行排序。在排序过程中需要多次进行内存和外存之间的交换,对外存文件中的记录进行排序后的结果仍然被放到原有文件中。这种排序的方法就叫做外部排序。
726 | * 如何得到初始的归并段
727 | * 置换选择排序:解决排序段放入内存的问题
728 | * 如何减少多个归并段的归并次数
729 | * 最佳归并树:最少的归并次数(I/O次数)
730 | * 如何每次m路归并快速得到最小的关键字
731 | * 败者树:减少比较次数
732 | * 概要: 内存容量无法容纳大量数据
733 | ## 二叉树与树与森林
734 | ### 树与二叉树
735 | * 如何将一棵树转化成二叉树?
736 | * 树的孩子兄弟表示法与二叉树的二叉链表表示法都是用到两个指针
737 | * 将孩子兄弟表示法理解成二叉链表
738 | * 树转换成二叉树的手动模拟方法:
739 | * ①将同一结点的各个孩子用线串连起来
740 | * ②将每个结点的子树分支,从左往右,除了第一个以外全部删除
741 | * 概要: 例子
742 | * 如何将一棵二叉树转化成树?
743 | * 二叉树转换成树的手动模拟方法:
744 | * ①将二叉树从上到下分层,并调节成水平方向。
745 | (分层方法:每遇到左孩子则为一层)
746 | * ②找到每一层的双亲结点,方法为它的上一层相连的那个结点就是双亲结点。
747 | 例如bcd这一层,与它相连的上一层结点即为a,所以bcd这三个结点的双亲结点都是a.
748 | * ③将每一层结点和其双亲结点相连,同时删除该双亲结点各个孩子结点之间的联系。
749 | * 概要: 例子
750 | ### 森林与二叉树
751 | * 森林:森林是m(m≥0)棵互不相交的树的集合
752 | * 如何将森林转换成二叉树?
753 | * 森林转换成树的手动模拟方法:
754 | * ①将森林中每棵树都转换成二叉树
755 | * ②将第二棵树作为第一棵树的根结点的右子树,将第三棵树作为第二棵树的根结点的右子树..依次类推
756 | * 概要: 例子
757 | * 如何将二叉树转换成森林?
758 | * 二叉树转换成森林的手动模拟方法:
759 | * 反复断开二叉树根结点的右孩子的右子树指针,直到不存在根结点有右孩子的二叉树为止。
760 | * 概要: 例子
761 | ### 树与森林的遍历
762 | * 先序:先访问根结点,再访问根结点的每棵子树。 访问子树也是按照先序的要求
763 | * 后序:先访问根结点的每棵子树,再访问根结点。 访问子树也是按照先序的要求
764 | * 树的先序遍历等于它对应二叉树的先序遍历,后序遍历等于它对应的二叉树的中序遍历
765 | * 概要: 例子
766 |
767 | 
768 |
--------------------------------------------------------------------------------
/数据结构/数据结构.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据结构/数据结构.png
--------------------------------------------------------------------------------
/数据结构/数据结构.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/数据结构/数据结构.xmind
--------------------------------------------------------------------------------
/计算机组成原理/计算机组成.md:
--------------------------------------------------------------------------------
1 | # Principle-of-Computer-Composition
2 | 计算机组成原理思维导图
3 | # 计算机组成
4 | ## 第一章 计算机系统概论
5 | ### 冯诺依曼型计算机特点
6 | * 1.计算机由运算器,控制器,存储器,输入和输出设备5部分组成
7 | * 2.采用存储程序的方式,程序和数据放在同一个存储器中,并以二进制表示。
8 | * 3.指令由操作码和地址码组成
9 | * 4.指令在存储器中按执行顺序存放,由指令计数器(即程序计数器PC)指明要执行的指令所在的储存单元地址,一般按顺序递增,但可按运算结果或外界条件而改变
10 | * 5.机器以运算器为中心,输入输出设备与存储器间的数据传送都通过运算器
11 | ### 区别以运算器为中心的计算机还是存储器的方法
12 | * 看输入设备能否直接与存储器相连,是的话就是以存储器为中心
13 | ### 计算机系统
14 | * 硬件
15 | * 结构
16 | * 主机
17 | * cpu
18 | * ALU运算器
19 | * CU控制器
20 | * 存储器
21 | * 主存
22 | * 辅存
23 | * I/O
24 | * 输入设备
25 | * 输出设备
26 | * 主要技术指标
27 | * 机器字长
28 | * CPU一次能处理的数据位数
29 | * 存储容量
30 | * 存储容量=存储单元个数×存储字长
31 | * 运算速度
32 | * 单位时间执行指令的平均条数,MIPS
33 | * 软件
34 | * 系统软件
35 | * 用来管理整个计算机系统
36 | * 语言处理程序
37 | * 操作系统
38 | * 服务性程序
39 | * 数据库管理系统
40 | * 网络软件
41 | * 应用软件
42 | * 按任务需要编制成的各种程序
43 | ## 第三章 运算方法和运算部件
44 | ### 数据的表示方法和转换
45 | * 机器数正0负1
46 | * 符号数值化的带符号二进制数,称为机器数。
47 | * 真值:符号位加绝对值
48 | * 余三码:在8421码的基础上,把每个编码都加上0011
49 | * 当两个余三码想加不产生进位时,应从结果中减去0011;产生进位时,应将进位信号送入高位,本位加0011
50 | * 格雷码:任何两个相邻编码只有1个二进制位不同,而其余3个二进制位相同
51 | * 8421码
52 | * 权值从高到低为8、4、2、1
53 | * 算术运算时,需对运算结果进行修正。� 方法:如果小于、等于(1001)2,不需要修正;否则加6修正
54 | ### 带符号的二进制数据在计算机中的表示方法及加减法运算
55 | * 原码
56 | * 定义
57 | * 最高位为符号位0/1+数值的绝对值形式
58 | * 特点
59 | * (1)值+0,-0的原码分别为00000、10000,形式不唯一;
60 | * (2)正数的原码码值随着真值增长而增长
61 | * 负数的原码码值随着真值增长而减少
62 | * (3)n+1位原码表示定点整数范围-(2n-1)——2n-1
63 | * n+1位原码表示定点小数范围 -(1-2-n)——1-2-n
64 | * 运算
65 | * 绝对值相加减,由数值大小决定运算结果符号
66 | * 补码
67 | * 定义,特点和运算
68 | * 运算:
69 | 结果不超过机器所能表示范围时,[X+Y]补=[X]补+[Y]补
70 | 减法运算:
71 | [X–Y]补=[X+(–Y)]补=[X]补+[–Y]补
72 | * 结论
73 | * 负数的补数=模+负数
74 | * 互为补数的绝对值相加=模
75 | * 在补数中,减法运算即加法运算
76 | * 定义
77 | * 定义法,即[X]补=2·符号位+X (MOD 2)
78 | * X为正数,则符号0+X的绝对值;X为负数,则X的绝对值取反+1。
79 | * 特点
80 | * 数值零的补码表示唯一
81 | * 正数补码码值随着真值增大而增大,负数补码码值随着真值增大而增大
82 | * n+1位补码所表示定点整数范围- 2n——2n-1,n+1位补码所表示定点小数范围-1——1-2-n
83 | * 加法运算逻辑事例
84 | * 过程
85 | * 加减法运算的溢出处理
86 | * 溢出定义
87 | * 当运算结果超出机器数所能表示的范围
88 | * 加减中,可能产生溢出的情况
89 | * 可能出现溢出
90 | * 同号数相加
91 | * 异号数相减
92 | * 不可能出现溢出
93 | * 异号数相加
94 | * 同号数相减
95 | * 判断溢出的方法
96 | * 法一:当符号相同两数相加,结果符号和加数(或被加数)不相同,则溢出
97 | * fa,fb表示两操作数(A,B)的符号位,fs为结果的符号位
98 | * 法二:任意符号相加,如果C=Cf,则结果正确,否则溢出;
99 | * C为数值最高位的进位,Cf为符号位的进位
100 | * 法三:采用双符号相加,如果fs1=fs2,则结果正确,否则溢出;
101 | * 运算结果的符号位为fs2;
102 | * 多符号位的补码,叫做变形补码;
103 | * 如果采用双符号位,当数为小数时,模m=4;当数为整数时,模m=2的n+2次方
104 | * 反码
105 | * 定义
106 | * a.定义法,即[X]反=(2-2-n)·符号位+X (MOD 2-2-n)
107 | * b.X是正数,[X]反=[X]原;X是负数,符号+数值取反。
108 | * 特点
109 | * 数值零的反码表示不唯一
110 | * 正数反码码值随着真值增大而增大,负数反码码值随着真值增大而增大
111 | * n+1位反码所表示定点整数范围- (2n-1)——2n-1,n+1位反码所表示定点小数范围-(1-2-n)——1-2-n
112 | * 加减运算特点
113 | * 在机器数范围内,反码运算满足[X+Y]反=[X]反+[Y]反
114 | ,[X-Y]反=[X]反+[-Y]反
115 | * 反码运算在最高位有进位时,要在最低位+1,此时要多进行一次加法运算,增加了复杂性,又影响了速度,因此很少采用
116 | * 由于反码运算是以2-2的-次方为模,所以,当最高位有进位而丢掉进位(即2)时,要在最低位+/-1
117 | * 移码
118 | * 由来及窍门
119 | * 为了从码值直接判断对应真值的大小,所以引进移码
120 | * [X]补的符号位取反,即得[X]移
121 | * 特点
122 | * 最高位是符号位,1表示正,0表示负
123 | * 数据0有唯一的编码
124 | * 移码码值随着真值增大而增大
125 | * n+1位移码所表示定点整数范围- 2n——2n-1, n+1位移码所表示定点小数范围-1——1-2-n
126 | * 计算机中,移码常用于表示阶码,故只执行加、减运算
127 | * 计算机中,移码运算公式需要对结果进行修正
128 | * 浮点数的阶码运算
129 | * 移码定义:[X]移=2的n次方+X
130 | * 补码定义:[X]补=2的n+1次方+Y
131 | * 阶码求和公式
132 | * [X]移+[Y]补=[X+Y]移 mod2的n+1次方
133 | * [X]移+[-Y]补=[X-Y]移
134 | * 判溢方法
135 | * 双符号位参加运算,最高符号位恒置0
136 | * 当结果最高符号位=1则溢出
137 | * 低位符号=0,则上溢;低位符号=1,则下溢;
138 | * 当结果最高符号位=0则未溢出
139 | * 低位符号=0,负数;低位符号=1,正数
140 | * 说明:如果阶码运算的结果溢出,上述条件不成立。此时,使用双符号位的阶码加法器,并规定移码的第二个符号位,即最高符号位恒用0参加加减运算,则溢出条件是结果的最高符号位为1。此时低位符号为0时,表明结果上溢;为1时,表明结果下溢。当最高符号位为0时,表明没有溢出,低位符号位为1,表明结果为正;为0时表明结果为负。
141 | * 补,反,原,移码的相互转换
142 | * 反码-》原码
143 | * 方法:符号位不变,正数不变,负数数值部分取反。
144 | * 补码-》原码
145 | * 方法1:正数不变,负数数值部分求反加1。
146 | * 方法2:串行转换
147 | * 从最后开始数,遇到第一个“1”,除第一个“1”不变,前面数字分别取反
148 | * 移码-》原码
149 | * 方法:移码转换为补码,再转换为原码
150 | * 数据从补码和反码表示形式转换成原码
151 | * 自低位开始转换,从低位向高位,在遇到第一个1之前,保存各位的0不变,第一个1也不变,以后得各位按位取反,最后保持符号位不变,经历一遍后,即可得到补码
152 | * 定点数和浮点数
153 | * 定点数
154 | * 小数点固定在某个位置上的数据
155 | * 32位定点小数、定点整数补码的范围
156 | * 32位定点小数-1~1-2-31
157 | * 32位定点整数-231~231-1
158 | * 浮点数
159 | * 根据IEEE754国际标准,常用的浮点数有两种格式
160 | * Nmax=Mmax*2的Emax
161 | Nmin=Mmin*2的Emax
162 | * 单精度(32位)=8位阶码+24位尾数
163 | * 单精度浮点数(32位),阶码8位(含一位符号位),尾数24(含一位符号位),取值范围:-2的127次方~(1-2的-23次方)*2的127次方
164 | * 双精度(64位)=11位阶码+53位尾数
165 | * 双精度浮点数(64位),阶码11位(含一位符号位),尾数53位(含一位符号位),取值范围:-2的1023次方~(1-2的-52次方)*2的1023次方
166 | * 为了保证数据精度,尾数通常用规格化形式表示:当R=2,且尾数值不为0时,其绝对值应大于或等于(0.5)10
167 | * 左规
168 | * 右规
169 | * 小数点位置可以浮动的数据。
170 | * 表示形式:N = M · RE
171 | * 计算机中存储形式
172 | * Ms+Es+E(n位)+M(m位)
173 | * 阶码E,一般为整数,用补码或者移码表示;
174 | * 尾数M,一般为规格化的定点小数,用补码表示;
175 | ### 二进制乘法运算
176 | * 定点原码一位乘法
177 | * 两个原码数相乘,其乘积的符号为相乘两数符号的异或值,数值则为两数绝对值之积
178 | * [X·Y]原=[X]原·[Y]原=(X0⊕Y0)|(X1X2..Xn) · (Y1Y2..Yn)
179 | * 几点结论
180 | * 从低到高根据乘数每位0、1决定相加被乘数还是0;
181 | * 相加数每次左移,最后一起求积;
182 | * 符号由异或决定
183 | * 表达式
184 | * 电路框架
185 | * 修正
186 | * 1.在机器内多个数据一般不能同时相加,一次加法操作只能求出两数之和,因此每每求得一个相加数,就与上次部分积相加
187 | * 2.人工计算时,相加数逐次向左偏移一位,由于最后的乘积位数是乘数(或被乘数)的两倍,如按此算法在机器中运算,加法器也需增到两倍。观察计算过程很容易发现,在求本次部分积时,前一次部分积的最低位不再参与运算,因此可将其右移一位,相加数可直送而不必偏移,于是用N位加法器就可实现两个N位数相乘
188 | * 部分积右移时,乘数寄存器同时右移一位,这样可以用乘数寄存器的最低位来控制相加数(取被乘数或零),同时乘数寄存器的最高位可接受部分积右移出来的一位,因此,完成乘法运算后,A寄存器中保存乘积的高位部分,乘数寄存器中保存乘积低位部分
189 | * 例题
190 | * 控制流程图
191 | * 定点补码一位乘法
192 | * 表达式
193 | * [X·Y]补=[X]补·(-Y0+Y1·2-1+….Yn·2-n)
194 | * 注意:此处为双符号位,当最后乘积高位为负数时,需要补充加上[-|x|]补的操作
195 | ### 二进制除法
196 | * 加减交替法
197 | * 当余数为正时,商上1,求下一位商的办法是,余数左移一位,再减去除数;当余数为负时,商上0,求下一位商的办法是,余数左移一位,再加上除数。此方法不用恢复余数,所以又叫不恢复余数法。但若最后一次上商为0而又需得到正确余数,则在这最后扔需恢复余数
198 | ### 浮点数的运算方法
199 | * 浮点数的加减法运算
200 | * 1.对阶操作
201 | * 求出△E,再对小的进行移位
202 | * 2.尾数的加减运算
203 | * 3.规格化操作
204 | * 规则简化是符号位和数值最高位不同,即00.1xxxx或11.0xxxx
205 | * 4.舍入
206 | * 超出表示范围的高位为1舍入
207 | * 5.检查阶码是否溢出
208 | * 浮点数的乘除法运算
209 | * 1.浮点数阶码运算(移码)
210 | * 牢记公式
211 | * [X+Y]移=[X]移+[Y]补
212 | * [X–Y]移=[X]移+[–Y]补
213 | * 2.按照一位乘或加减交替除运算
214 | * 先确定符号,在列式子计算
215 | ### 运算部件
216 | * ABC寄存器作业
217 | * 定点运算部件
218 | * 浮点运算部件
219 | * 由阶码运算部件和尾数运算部件组成
220 | ### 数据校验码
221 | * 码距
222 | * 任意两个合法码之间不相同的二进制位数的最小值
223 | * 要具有差错能力,则码距>1
224 | * 合理增大码距,就能提高发现错误的能力
225 | * 鉴定方法
226 | * 有无差错能力
227 | * 是否能合理增大码距
228 | * 奇偶校验码
229 | * 能发现数据代码中一位或奇数个位出错情况的编码
230 | * 实现原理是使码距由1增加到2
231 | * 步骤1:在字节高位补充一位,即校验位
232 | * 步骤2:依据图3.10电路形成原始数据D8..D1的校验位值
233 | * 步骤3:将9位数据写入主存
234 | * 步骤4:读出该数据时,读取数据D8..D1通过图3.10判定合法性
235 | * 电路图
236 | * 结论
237 | * (1)奇偶校验码只能发现一位或奇位错,且不能确定出错位置
238 | * (2)奇偶校验码的码距=2
239 | * 海明校验码
240 | * 海明码位号和校验位位号的关系
241 | * Pi的位置在2的i-1次方,但是除了最高位
242 | * 笔记
243 | * 3,5,7||3,6,7||5,6,7
244 | * 电路图
245 | * 海明码码距为4
246 | * 纠一位错,查一位错
247 | * 2∧r≥k+r+1
248 | * 纠一位错,查两位错
249 | * 2∧(r–1)≥k+r
250 | * 循环冗余校验码(CRC)
251 | * CRC码可以发现并纠正信息存储或传送过程中连续出现的多位错误
252 | * CRC码一般是指k位信息码之后拼接r位校验码
253 | * 模2运算
254 | * 模2加减
255 | * 模2乘除
256 | * 异或逻辑
257 | * CRC的译码与纠错
258 | * 更换不同的待测码字可以证明:余数与出错位的对应关系是不变,只与码制和生成多项式有关
259 | * 图
260 | ## 第四章 主存储器
261 | ### 主存储器处于全机中心低位
262 | ### 辅助存储器或称为外存储器,通常用来存放主存的副本和当前不在运行的程序和数据
263 | ### 主存储器的类型
264 | * 随机存储器RAM
265 | * 非易失性存储器
266 | ### 主存储器的主要技术指标
267 | * 主存容量
268 | * 64×8等等
269 | * 计算机可寻址的最小信息单元是一个存储字
270 | * 主存储器存储单元的总数
271 | * 存取速度
272 | * 由存储器存取时间和存储周期表示
273 | * 存储器存取时间
274 | * 启动一次存储器操作(读/写)到完成该操作所经历的时间
275 | * 存储周期
276 | * 连续启动两次独立的存储器操作所间隔的最小时间
277 | ### 主存储器的基本操作
278 | * CPU通过使用AR(地址寄存器)和DR(数据寄存器)和主存进行数据传送
279 | * 若AR为K位字长,DR为n位字长,则允许主存包含2∧k个可寻址单元
280 | * CPU与主存采取异步工作方式,以ready信号表示一次访存操作的结束
281 | ### 读/写存储器
282 | * 随机存储器(RAM)按存储元件在运行中能否长时间保存信息分为静态存储器和动态存储器
283 | * 静态存储器,利用触发器保存信息,只要不断电,信息就不会丢失
284 | * 电路简图
285 | * MOS静态存储结构图
286 | * 动态存储器,利用MOS电容存储电荷来保存信息,需要不断给电容充电才能使信息来保存信息
287 | * 电路简图
288 | * 16K×1位动态存储器框图
289 | * 再生
290 | * 集中式
291 | * 分散式
292 | * 时间小于或等于2ms
293 | * 行读出再生
294 | ### 非易失性半导体存储器
295 | * 只读存储器ROM
296 | * 只读不能写
297 | * 可编程序的只读存储器PROM
298 | * 一次性写入
299 | * 可擦可编程序的只读存储器EPROM
300 | * 可多次写入、读出
301 | * 可电擦可编程序只读存储器E2PROM
302 | * 可多次读出但写入次数有限
303 | * 快擦除读写存储器Flash Memory
304 | * 重复写入、读出
305 | ### 存储器的组成与控制
306 | * 存储器容量扩展
307 | * 位扩展:用多个存储器芯片对字长进行扩充
308 | * 字扩展:增加存储器中字的数量,提高存储器的寻址范围
309 | * 字位扩展,假设一个存储器的容量为M×N位,若使用L×K位存储器芯片,那么,这个存储器共需要(M/L)×(N/K)个存储器芯片
310 | ### 多体交叉存储器
311 | * 提高访存速度的方式
312 | * 采用高速器件
313 | * 采用层次结构
314 | * 调整主存结构
315 | * 计算机中大容量的主存可由多个存储体组成,每个存储体都具有自己的读写线路,地址寄存器和数据寄存器,称为"存储模块"。这种多模块存储器可以实现重叠与交叉存取
316 | * 第i个模块M的地址编号应按下式给出:M×j+i
317 | * 连续地址分布在相邻的不同模块内,而同一模块内的地址都是不连续的
318 | ## 第五章:指令系统
319 | ### 指令系统的发展
320 | * 20世纪70年代末人们提出了便于VLSI实现的精简指令系统计算机,简称RISC,同时将指令系统越来越复杂的计算机称为复杂指令系统计算机,简称CISC
321 | ### 指令格式
322 | * 结构(操作码+地址码)
323 | * 操作码
324 | * 操作数的地址
325 | * 操作结果的存储地址
326 | * 下一条指令的地址
327 | * 地址码
328 | * 零地址指令
329 | * 一地址指令
330 | * 寻址范围 224 = 16 M
331 | * 2次访存
332 | * 二地址指令
333 | * 寻址范围 212 = 4 K
334 | * 4 次访存
335 | * 三地址指令
336 | * 寻址范围 28 = 256
337 | * 4 次访存
338 | * 多地址指令
339 | * 寻址范围 26 = 64
340 | * 4 次访存
341 | * 指令字长
342 | * 取决因素
343 | * 操作码的长度
344 | * 操作数地址的长度
345 | * 操作数地址的个数
346 | * 指令字长 固定
347 | * 指令字长 = 存储字长
348 | * 指令字长 可变
349 | * 按字节的倍数变化
350 | * 对准边界存放
351 | * 不连续存放数据
352 | * 按字节编址
353 | * a.半字地址最低位恒为0
354 | * b.字地址最低两位恒为0
355 | * c.双字地址的最低三位恒为0
356 | * 减少访存次数,浪费存储空间
357 | * 不 对 准 边 界 存 放
358 | * 连续存放数据
359 | * 节约存储器空间,但增加访存次数,对多字节数据存在调整高 低字节位置的问题
360 | * 寻址方式
361 | * 确定本条指令的数据地址
362 | * 下一条要执行的指令地址的方法
363 | * 指令操作码的扩展技术
364 | * 指令操作码的长度决定了指令系统中完成不同操作的指令数
365 | * 若某机器的操作码长度固定为K位,则它最多只能有2^K条不同指令
366 | * 指令操作码两种格式
367 | * 固定格式
368 | * 优点:对于简化硬件设计,减少指令译码时间非常有利
369 | * 缺点:指令少,浪费地址
370 | * 可变格式(分散地放在字的不同字段)
371 | * 优点:指令多,缩短指令平均长度,减少程序总位数,增加指令字所能表示的操作信息
372 | * 缺点:译码复杂,控制器的设计难度增大
373 | * 拓展方法的一个重要原则
374 | * 使用频度(即指令在程序中出现概率)高的指令应分配短的操作码,使用频度低的指令相应地分配较长的操作码
375 | * 指令系统的兼容性
376 | * 保持系统向上兼容
377 | ### 精简指令系统计算机(RISC)——用于小型机
378 | ### 复杂指令系统计算机(CISC)——用于大型机
379 | ## 第六章:中央处理器
380 | ### 计算机工作过程
381 | * 加电——》产生reset信号——》执行程序——》停机——》停电
382 | * 产生reset信号的任务
383 | * 任务一:使计算机处于初始状态
384 | * 任务二:从PC中取出指令地址
385 | * 控制器作用是协调并控制计算机各部件执行程序的指令序列
386 | ### 控制器的组成
387 | * 控制器的功能
388 | * 取指令
389 | * 发出指令地址,取出指令的内容
390 | * 分析指令
391 | * (1)对操作码译码产生操作相应部件的控制信号
392 | * (2)根据寻址方式形成操作数地址
393 | * 执行指令
394 | * (1)根据分析指令后产生控制信号、操作数地址信号序列,通过CPU及输入输出设备的执行实现每条指令的功能
395 | * (2)结果回送存储器
396 | * (3)形成下条指令的地址
397 | * 控制程序和数据的输入和结果输出
398 | * 对异常情况和某些请求的处理
399 | * 异常情况的处理:例如算术运算的溢出、数据传送奇偶错
400 | * 某些请求的处理
401 | * “中断请求”信号
402 | * DMA请求信号
403 | * 控制器的组成
404 | * 程序计数器(PC)
405 | * 即地址寄存器,用来存放当前正在执行的指令地址或即将要执行的下一条指令地址
406 | * 指令寄存器(IR)
407 | * 用以存放当前正在执行的指令,以便在指令执行过程中控制完成一条指令的全部功能
408 | * 指令译码器或操作码译码器
409 | * 对指令寄存器中的操作码进行分析解释,产生相应的控制信号
410 | * 脉冲源及启停线路
411 | * 脉冲源参数一定评率的脉冲作为整个机器的时钟脉冲,是机器周期和工作脉冲的基准信号,在机器刚加电时,还应产生一个总清信号(reset)
412 | * 时序控制信号形成部件
413 | * 当程序启动后,在CLK时钟作用下,根据当前正在执行的指令的需要,产生相应的时序控制信号,并根据被控制功能部件的反馈信号调整时序控制信号
414 | * 控制存储器
415 | * 微指令寄存器
416 | * 控制字段+下址
417 | * 周期概念
418 | * 指令周期
419 | * 完成一条指令所需的时间,包括取指令、分析指令、执行指令
420 | * 机器周期
421 | * 也称为CPU周期,是CPU从内存中读取一个指令的时间,通常等于取指周期
422 | * 时钟周期
423 | * 称为节拍脉冲或T周期,是基准脉冲信号
424 | * 三条假设
425 | * 程序是存放在主存中的,当执行完一条指令后才从主存中取下一条指令(非流水线)
426 | * 指令的长度是固定的,并限制了寻址方式的多样化
427 | * 在程序运行前,程序和数据都已存在主存中
428 | * 指令执行过程(运算器和控制器配合)
429 | * 组成控制器的基本电路
430 | * 具有记忆功能的触发器以及由它组成的寄存器,计数器和存储单元
431 | * 没有记忆功能的门电路及由它组成的加法器,算术逻辑运算单元(ALU)和各种逻辑电路
432 | * 举例
433 | * 加法
434 | * 取指令——》计算操作数地址——》取操作数——》执行结果并运算送结果
435 | * 要能看懂时序图
436 | * 哪些指令在对应的时间有效
437 | * 条件转移指令
438 | * 取指令——》计算地址
439 | * 控制器的功能就是按每一条指令的要求产生所需的控制信号
440 | * 产生控制信号的方法
441 | * 微程序控制
442 | * 硬布线控制
443 | ### 微程序控制计算机的基本工作原理
444 | * 基本概念
445 | * 微指令
446 | * 在微程序控制的计算机中,将由同时发出的控制信号所执行的一组微操作
447 | * 微命令
448 | * 将指令分为若干条微指令,按次序执行这些微指令。组成微指令的操作即微命令
449 | * 微程序
450 | * 计算机的程序由指令序列构成,而计算机每条指令的功能均由微指令序列解释完成,这些微指令序列的集合就叫做微程序
451 | * 控制存储器
452 | * 微程序一般是存放在专门的存储器中的,由于该存储器主要存放控制命令(信号)与下一条执行的微指令地址(简称下址)
453 | * 存储单元内容
454 | * (1)微指令的控制信号——控制位
455 | * (2)下条微指令的地址——下址字段
456 | * 存储芯片:ROM
457 | * 执行一条指令实际上就是执行一段存放在控制存储器中的微程序
458 | * 实现微程序控制的基本原理
459 | * 控制信号(23条)
460 | * 书上P123页为加法的过程
461 | * 微指令格式:控制字段+下址字段
462 | * 23个控制位,12个下址位——》容量为4K
463 | * 取址微指令的操作对所有指令都是相同的,所以是一条公用的微指令,其下址由操作码译码产生
464 | * 微程序控制器
465 | * 时序信号及工作脉冲的形成
466 | * 停机和停电的区别
467 | * 停机
468 | * 电压:稳定
469 | * 存放内容:保持
470 | * 重启PC内容:断点指令地址
471 | * 停电
472 | * 电压:消失
473 | * 存放内容:RAM的内容消失
474 | * 重启PC内容:第一条指令地址
475 | ### 微程序设计技术
476 | * 如何缩短微指令字长
477 | * 直接控制法(容量太小)
478 | * 编译方法:每一位代表一个控制信号,直接送往相应的控制点
479 | * 优点:控制简单
480 | * 缺点:微指令字长过大
481 | * 字段直接编译法
482 | * 选出互斥的微指令
483 | * 每个字段都要留出一个代码,表示本段不发出任何指令(000)
484 | * 优点:节省微指令的字长
485 | * 缺点:增加了额外的硬件开销
486 | * 字段间接编译法
487 | * 指令之间相互联系的情况
488 | * 举例:A为0-7,B为0-3,如果是直接编译——3+2=5,如果是间接编译——3+1=4
489 | * 编码方法:在字段直接编译法中,译码输出端要兼由另一字段中的某些微命令配合解释
490 | * 优点:减少了微指令长度
491 | * 缺点:可能削弱微指令的并行控制能力,同时增加硬件开销
492 | * 常熟源字段E(了解)
493 | * 如何减少微指令长度
494 | * 现行微指令/微地址
495 | * 现行微指令:当前正在执行的指令
496 | * 现行微地址:存放现行微指令的控制器存储单元
497 | * 后继微指令/微地址
498 | * 后继微指令:下一条要执行的微指令
499 | * 后继微地址:存放后继微指令的控制器存储单元
500 | * 增量与下址字段结合产生后继微指令的方法
501 | * 下址字段分成:转移控制字段BCF和转移地址字段BAF
502 | * BCF:控制微程序的转移情况
503 | * BAF:转移后的微指令所在地址
504 | * BAF有两种情况
505 | * 与uPC的位数相等——转移灵活,但增加微指令长度
506 | * 比uPC短——转移地址收到限制,但可缩短微指令长度
507 | * 优点
508 | * 微指令的下址字段很短,仅用于选择输入uPC计数器的某条线路有效
509 | * 缺点
510 | * 微程序转移不灵活,使得微程序在控存中的物理空间分配有困难
511 | * 多路转移方式
512 | * 一条微指令存在多个转移分支的情况称为多路转移
513 | * 微中断
514 | * 1.微中断请求信号是由程序中断请求信号引起的
515 | * 2.在完成现行指令的微程序后响应该微中断请求
516 | * 3.由硬件产生对应微中断处理程序在控存中的入口地址
517 | * 如何提高微程序的执行速度
518 | * 微指令格式
519 | * 水平型微指令——直接控制,字段编译(直接、间接)
520 | * 特点:在一条微指令中定义并并行执行多个微命令
521 | * 垂直型微指令
522 | * 特点:不强调实现微指令的并行控制功能
523 | * 定义:采用微操作码编译法,由操作码规定微指令的功能
524 | * 微程序控制存储器
525 | * 一般采用ROM存储器
526 | * 也可采用RAM,为防止断电后内容消失,则必须开机后将外存中存放的微程序调入控存RAM,然后才能执行程序。
527 | * 当前为了能不断扩展指令系统,通常采用ROM+RAM
528 | * 动态微程序设计
529 | * 定义:能根据用户要求改变微程序
530 | * 优点:是计算机能更灵活、有效的适应于各种不同的应用目标
531 | * 控制存储器的操作(P136)
532 | * 串行方式
533 | * 并行方式——比串行多了微指令寄存器
534 | * 微周期=max(取微指令时间,执行微指令时间)
535 | * 由于取微指令、执行微指令同时进行,故对于某些后继微地址的产生根据处理结果而定的微指令,则延迟一个微周期再取微指令
536 | ### 硬布线控制的计算机(RISC)——特点快
537 | * 形成操作控制信号的逻辑框图(P141)
538 | * 操作控制信号的产生
539 | * 取值周期cy1所产生的信号对所有指令都是相同的,即与当前执行的指令无关,逻辑式得到最简单的形式
540 | * 通常,同一个控制控制信号在若干条指令的某些周期(或再加上一些条件)中都需要,为此需要把它们组合起来
541 | * 同种类型的指令所需要的控制信号大部分是相同的,仅有少量区别
542 | * 在确定指令的操作码时(即对具体指令赋予二进制操作码),为了便于逻辑表达式的化简以减少逻辑电路数量,往往给予特别关注
543 | * 设计组合逻辑电路从而产生需要的控制信号的步骤
544 | * 1.实际逻辑问题2.真值表3.公式化简4.逻辑电路图
545 | * 设计目标
546 | * 使用最少的电路元件达到最高的操作速度
547 | ### 流水线工作原理
548 | * 几点结论
549 | * 每条指令的执行时间不变
550 | * 每条指令处理结果的时间缩短
551 | * 流水线处理速率最高时=流水线处于满载的稳定状态
552 | * 流水线处理速率最低时=流水线未满载状态
553 | * 为了满足在重叠时间段不同指令的机器周期能够完成指定的操作,将时间段=操作完成的最长时间
554 | * 为了保证一个周期内流水线的输入信号不变,相邻时间段之间必须设置锁存器或寄存器
555 | * 除了指令执行流水线,还有运算操作流水线
556 | * 相关问题
557 | * 流水线阻塞(P163-6.15)
558 | * 数据相关产生
559 | * 假设第二条指令需要的操作数是第一条指令运算的结果,那么出现了数据相关
560 | * 指令执行时间不同产生
561 | * 程序转移的影响
562 | * 异常情况响应中断
563 | ## 第七章:存储系统
564 | ### 存储系统的层次结构
565 | * cache->主存->辅存
566 | ### 高速缓冲存储器
567 | * cache的工作原理
568 | * 局部性原理
569 | * 主存地址和cache地址(P166 图7.2)
570 | * 块长
571 | * 块长一般取一个主存周期所能调出的信息长度(一般为16个字)
572 | * cache的容量和块的大小是影响cache的效率的重要因素
573 | * 命中率
574 | * CPU所要访问的信息是否在cache中的比率,而将所要访问的信息不在cache中的比率称为失败率
575 | * 一致性策略
576 | * 标志交换方式(写回法)
577 | * 通过式写入(写通法)
578 | * 写操作直接对主存进行,而不写入cache
579 | * cache的存取时间
580 | * 平均存取时间=h*tc+(1-h)(tc+tm)
581 | * 最好替换策略
582 | * 按照被替换的字块是下一段时间最少使用的,由替换部件实现
583 | * cache组织
584 | * 地址映像
585 | * 直接映像
586 | * cache中许多空的位置被浪费
587 | * 主存地址:主存字块标记+cache字块地址+字块内地址
588 | * 全相联映像
589 | * 成本太高而不能采用
590 | * 主存地址:主存字块标记+字块内地址
591 | * 优点
592 | * 方式灵活,缩小了块发生冲突的概率
593 | * 缺点
594 | * 增加了标识位位数
595 | * 增加了寻找主存块在cache中对应块的时间
596 | * 组相联映像
597 | * 直接映像和全相联映像的折衷
598 | * 主存地址:主存字块标记+组地址+块内地址
599 | ### 虚拟存储器
600 | * 存储管理部件(MMU)
601 | * 现代计算机一般都有辅助存储器,但具有辅存的存储系统不一定是虚拟存储系统
602 | * 虚拟存储系统的特点
603 | * 允许用户程序用比主存大的多的空间来访问主存
604 | * 每次访存都要进行虚实地址的转换
605 | ## 第八章:辅助存储器
606 | ### 半导体存储器可随机访问任一单元,而辅助存储器一般为串行访问存储器
607 | ### 辅助存储器的种类
608 | * 磁表面存储器
609 | * 数字式磁记录
610 | * 硬盘、软盘和磁带
611 | * 模拟式磁记录
612 | * 录音、录像设备
613 | * 光存储器
614 | * 光盘
615 | ### 串行存储器
616 | * 顺序存取存储器
617 | * 直接存取存储器
618 | ### 辅助存储器的技术指标
619 | * 存储密度
620 | * 定义:单位长度或单位面积磁层表面磁层所存储的二进制信息量
621 | * 道密度
622 | * 沿磁盘半径方向单位长度的磁道数称为道密度,单位为道/英寸tpi或道/毫米tpmm
623 | * 位密度或线密度
624 | * 单位长度磁道所能记录二进制信息的位数叫位密度或线密度,单位为位/英寸bpi或位/毫米bpmm
625 | * 每个磁道所存储的信息量是一样的
626 | * 存储容量
627 | * C = n × k × s
628 | * 寻址时间
629 | * 平均寻址时间Ta=平均找道时间Ts+平均等待时间Tw
630 | * 辅存的速度
631 | * 寻址时间
632 | * 磁头读写时间
633 | * 数据传输率
634 | * Dr = D × V
635 | * 误码率
636 | * 价格
637 | ### 硬磁盘存储器的类型
638 | * (1) 固定磁头和移动磁头
639 | * (2) 可换盘和固定盘
640 | ### 磁盘存储器
641 | * 温彻斯特磁盘简称温盘
642 | * 磁盘存储器由驱动器(HDD),控制器(HDC)和盘片组成
643 | * 最外面的同心圆叫0磁道,最里面的同心圆假设称为n磁道
644 | * 驱动器的定位驱动系统实现快速精准的磁头定位
645 | * 主轴系统的作用是带动盘片按额定转速稳定旋转
646 | * 数据控制系统的作用是控制数据的写入和读出,包括寻址,磁头旋转,写电流控制,读出放大,数据分离
647 | * 磁盘控制器有两个方向的接口
648 | * 与主机的接口
649 | * 与驱动器(设备)的接口
650 | ### 光盘
651 | * 采用光存储技术
652 | * 利用激光写入和读出
653 | * 第一代光存储技术
654 | * 采用非磁性介质
655 | * 不可擦写
656 | * 第二代光存储技术
657 | * 采用磁性介质
658 | * 可擦写
659 | * 光盘的存储原理
660 | * 只读型和只写一次型
661 | * 热作用(物理或化学变化)
662 | * 可擦写光盘
663 | * 热磁效应
664 | ## 第九/十章:输出输出(I/O)设备/系统
665 | ### 设备控制器(I/O)的基本功能
666 | * 实现主机和外部设备之间的数据传送
667 | * 实现数据缓冲,以达到主机同外部设备之间的速度匹配
668 | * 接受主机的命令,提供设备接口的设备,并按照主机的命令控制设备
669 | ### I/O 编址方式
670 | * (1) 统一编址:用取数、存数指令
671 | * (2) 不统一编址:有专门的 I/O 指令
672 | ### I/O 与主机的连接方式
673 | * 辐射式连接
674 | * 每台设备都配有一套
675 | * 控制线路和一组信号线
676 | * 不便于增删设备
677 | * 总线连接
678 | * 便于增删设备
679 | ### I/O设备
680 | * 人机交互设备
681 | * 键盘、鼠标等
682 | * 计算机信息的驻留设备
683 | * 硬盘、光盘等
684 | * 机——机通信设备
685 | * MODEN等
686 | ### 为什么要设置接口?
687 | * 1. 实现设备的选择
688 | * 2. 实现数据缓冲达到速度匹配
689 | * 3. 实现数据串 并格式转换
690 | * 4. 实现电平转换
691 | * 5. 传送控制命令
692 | * 6. 反映设备的状态
693 | * (“忙”、“就绪”、“中断请求”)
694 | ### 中断服务程序的流程
695 | * (1) 保护现场
696 | * 程序断点的保护
697 | * 寄存器内容的保护
698 | * (2) 中断服务
699 | * 对不同的 I/O 设备具有不同内容的设备服务
700 | * (3) 恢复现场
701 | * 出栈指令
702 | * (4) 中断返回
703 | * 中断返回指令
704 | ### 单重中断和多重中断
705 | * 单重 中断
706 | * 不允许中断 现行的 中断服务程序
707 | * 多重 中断
708 | * 允许级别更高 的中断源
709 | * 中断 现行的 中断服务程序
710 | ### DMA 方式
711 | * 主存和 I/O 之间有一条直接数据通道
712 | * CPU 和 I/O 并行工作
713 | * DMA 的三种工作方式
714 | * (1) CPU暂停方式
715 | * (2) CPU周期窃取方式
716 | * (3)直接访问存储器
717 | * DMA 接口功能
718 | * (1) 向 CPU 申请 DMA 传送
719 | * (2) 处理总线 控制权的转交
720 | * (3) 管理 系统总线、控制 数据传送
721 | * (4) 确定 数据传送的 首地址和长度,修正 传送过程中的数据地址和长度
722 | * (5) DMA 传送结束时,给出操作完成信号
723 | * DMA 传送过程
724 | * 预处理、数据传送、后处理
725 | ### 外设接口
726 | * 设备与主机相连时,必须按照规定的物理互连特性、电气特性等进行连接,这些特性的技术规范称为接口标准
727 |
728 | 
729 |
--------------------------------------------------------------------------------
/计算机组成原理/计算机组成.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/计算机组成原理/计算机组成.png
--------------------------------------------------------------------------------
/计算机组成原理/计算机组成.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/计算机组成原理/计算机组成.xmind
--------------------------------------------------------------------------------
/计算机网络/README.md:
--------------------------------------------------------------------------------
1 | - [第 1 章 概述](https://github.com/SSHeRun/CS-Xmind-Note/blob/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/%E7%AC%AC%201%20%E7%AB%A0%20%20%20%E6%A6%82%E8%BF%B0/%E7%AC%AC%201%20%E7%AB%A0%20%20%20%E6%A6%82%E8%BF%B0.md)
2 | - [第 2 章 物理层](https://github.com/SSHeRun/CS-Xmind-Note/blob/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/%E7%AC%AC%202%20%E7%AB%A0%20%20%E7%89%A9%E7%90%86%E5%B1%82/%E7%AC%AC%202%20%E7%AB%A0%20%20%E7%89%A9%E7%90%86%E5%B1%82.md)
3 | - [第 3 章 数据链路层](https://github.com/SSHeRun/CS-Xmind-Note/blob/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/%E7%AC%AC%203%20%E7%AB%A0%20%20%E6%95%B0%E6%8D%AE%E9%93%BE%E8%B7%AF%E5%B1%82/%E7%AC%AC%203%20%E7%AB%A0%20%20%E6%95%B0%E6%8D%AE%E9%93%BE%E8%B7%AF%E5%B1%82.md)
4 | - [第 4 章 网络层](https://github.com/SSHeRun/CS-Xmind-Note/blob/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/%E7%AC%AC%204%20%E7%AB%A0%20%20%E7%BD%91%E7%BB%9C%E5%B1%82/%E7%AC%AC%204%20%E7%AB%A0%20%20%E7%BD%91%E7%BB%9C%E5%B1%82.md)
5 | - [第 5 章 运输层](https://github.com/SSHeRun/CS-Xmind-Note/blob/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/%E7%AC%AC%205%20%E7%AB%A0%20%20%E8%BF%90%E8%BE%93%E5%B1%82/%E7%AC%AC%205%20%E7%AB%A0%20%20%E8%BF%90%E8%BE%93%E5%B1%82.md)
6 | - [第 6 章 应用层](https://github.com/SSHeRun/CS-Xmind-Note/blob/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/%E7%AC%AC%206%20%E7%AB%A0%20%20%E5%BA%94%E7%94%A8%E5%B1%82/%E7%AC%AC%206%20%E7%AB%A0%20%20%E5%BA%94%E7%94%A8%E5%B1%82.md)
7 |
8 |
9 |
10 |
--------------------------------------------------------------------------------
/计算机网络/第 1 章 概述/第 1 章 概述.md:
--------------------------------------------------------------------------------
1 | # 第 1 章 概述
2 | ## 计算机网络在信息时代中的作用
3 | ### 21 世纪的一些重要特征就是数字化、网络化和信息化,它是一个以网络为核心的信息时代。
4 | ### 网络现已成为信息社会的命脉和发展知识经济的重要基础。
5 | ### 网络是指“三网”,即电信网络、有线电视网络和计算机网络。
6 | ### 发展最快的并起到核心作用的是计算机网络。
7 | ### 因特网(Internet)的发展
8 | * 进入 20 世纪 90 年代以后,以因特网为代表的计算机网络得到了飞速的发展。
9 | * 已从最初的教育科研网络逐步发展成为商业网络。
10 | * 已成为仅次于全球电话网的世界第二大网络。
11 | ### 因特网的意义
12 | * 因特网是自印刷术以来人类通信方面最大的变革。
13 | * 现在人们的生活、工作、学习和交往都已离不开因特网。
14 | ## 因特网概述
15 | ### 网络的网络
16 | * 起源于美国的因特网现已发展成为世界上最大的国际性计算机互联网
17 | * 网络(network)由若干结点(node)和连接这些结点的链路(link)组成。
18 | * 互联网是“网络的网络”(network of networks)。
19 | * 连接在因特网上的计算机都称为主机(host)。
20 | * 网络与因特网
21 | * 网络把许多计算机连接在一起。
22 | * 因特网则把许多网络连接在一起。
23 | ### 因特网发展的三个阶段
24 | * 第一阶段是从单个网络 ARPANET 向互联网发展的过程。
25 | * 1983 年 TCP/IP 协议成为 ARPANET 上的标准协议。
26 | * 人们把 1983 年作为因特网的诞生时间。
27 | * 第二阶段的特点是建成了三级结构的因特网。
28 | * 三级计算机网络,分为主干网、地区网和校园网(或企业网)。
29 | * 第三阶段的特点是逐渐形成了多层次 ISP 结构的因特网。
30 | * 出现了因特网服务提供者 ISP (Internet Service Provider)。
31 | * 根据提供服务的覆盖面积大小以及所拥有的IP 地址数目的不同,ISP 也分成为不同的层次。
32 | ### 因特网的标准化工作
33 | * 制订因特网的正式标准要经过以下的四个阶段
34 | * 因特网草案(Internet Draft) ——在这个阶段还不是 RFC 文档。
35 | * 建议标准(Proposed Standard) ——从这个阶段开始就成为 RFC 文档。
36 | * 草案标准(Draft Standard)
37 | * 因特网标准(Internet Standard)
38 | * 各种RFC之间的关系
39 | ### 计算机网络在我国的发展
40 | ## 因特网的组成
41 | ### 因特网的边缘部分
42 | * 由所有连接在因特网上的主机组成。这部分是用户直接使用的,用来进行通信(传送数据、音频或视频)和资源共享。
43 | * 处在因特网边缘的部分就是连接在因特网上的所有的主机。这些主机又称为端系统(end system)。
44 | * “主机 A 和主机 B 进行通信”,实际上是指:“运行在主机 A 上的某个程序和运行在主机 B 上的另一个程序进行通信”。
45 | * 即“主机 A 的某个进程和主机 B 上的另一个进程进行通信”。或简称为“计算机之间通信”
46 | ### 因特网的核心部分
47 | * 由大量网络和连接这些网络的路由器组成。这部分是为边缘部分提供服务的(提供连通性和交换)
48 | * 网络核心部分是因特网中最复杂的部分。
49 | * 网络中的核心部分要向网络边缘中的大量主机提供连通性,使边缘部分中的任何一个主机都能够向其他主机通信(即传送或接收各种形式的数据)。
50 | * 在网络核心部分起特殊作用的是路由器(router)。
51 | * 路由器是实现分组交换(packet switching)的关键构件,其任务是转发收到的分组,这是网络核心部分最重要的功能。
52 | * 在路由器中的输入和输出端口之间没有直接连线。
53 | * 路由器处理分组的过程是:
54 | * 把收到的分组先放入缓存(暂时存储);
55 | * 查找转发表,找出到某个目的地址应从哪个端口转发;
56 | * 把分组送到适当的端口转发出去。
57 | * 路由器是实现分组交换(packet switching)的关键构件,其任务是转发收到的分组,这是网络核心部分最重要的功能。
58 | ## 计算机网络在我国的发展
59 | ### (1) 中国公用计算机互联网 CHINANET
60 | ### (2) 中国教育和科研计算机网 CERNET
61 | ### (3) 中国科学技术网 CSTNET
62 | ### (4) 中国联通互联网 UNINET
63 | ### (5) 中国网通公用互联网 CNCNET
64 | ### (6) 中国国际经济贸易互联网 CIETNET
65 | ### (7) 中国移动互联网 CMNET
66 | ### (8) 中国长城互联网 CGWNET(建设中)
67 | ### (9) 中国卫星集团互联网 CSNET(建设中)
68 | ## 计算机网络的类别
69 | ### 计算机网络的定义
70 | * 最简单的定义:计算机网络是一些互相连接的、自治的计算机的集合。
71 | * 因特网(Internet)是“网络的网络”。
72 | ### 几种不同类别的网络
73 | * 不同作用范围的网络
74 | * 广域网 WAN (Wide Area Network)
75 | * 局域网 LAN (Local Area Network)
76 | * 城域网 MAN (Metropolitan Area Network)
77 | * 个人区域网 PAN (Personal Area Network)
78 | * 从网络的使用者进行分类
79 | * 公用网 (public network)
80 | * 专用网 (private network)
81 | ## 计算机网络的性能
82 | ### 计算机网络的性能指标
83 | * 速率
84 | * 比特(bit)是计算机中数据量的单位,也是信息论中使用的信息量的单位。
85 | * Bit 来源于 binary digit,意思是一个“二进制数字”,因此一个比特就是二进制数字中的一个 1 或 0。
86 | * 速率即数据率(data rate)或比特率(bit rate)是计算机网络中最重要的一个性能指标。速率的单位是 b/s,或kb/s, Mb/s, Gb/s 等
87 | * 速率往往是指额定速率或标称速率。
88 | * 带宽
89 | * “带宽”(bandwidth)本来是指信号具有的频带宽度,单位是赫(或千赫、兆赫、吉赫等)。
90 | * 现在“带宽”是数字信道所能传送的“最高数据率”的同义语,单位是“比特每秒”,或 b/s (bit/s)。
91 | * 常用的带宽单位
92 | * 更常用的带宽单位是
93 | * 千比每秒,即 kb/s (103 b/s)
94 | * 兆比每秒,即 Mb/s(106 b/s)
95 | * 吉比每秒,即 Gb/s(109 b/s)
96 | * 太比每秒,即 Tb/s(1012 b/s)
97 | * 请注意:在计算机界,K = 210 = 1024
98 | * M = 220, G = 230, T = 240。
99 | * 数字信号流随时间的变化
100 | * 在时间轴上信号的宽度随带宽的增大而变窄。
101 | * 吞吐量
102 | * 吞吐量(throughput)表示在单位时间内通过某个网络(或信道、接口)的数据量。
103 | * 吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。
104 | * 吞吐量受网络的带宽或网络的额定速率的限制。
105 | * 时延(delay 或 latency)
106 | * 传输时延(发送时延 ) 发送数据时,数据块从结点进入到传输媒体所需要的时间。
107 | * 也就是从发送数据帧的第一个比特算起,到该帧的最后一个比特发送完毕所需的时间。
108 | * 传播时延 电磁波在信道中需要传播一定的距离而花费的时间。
109 | * 信号传输速率(即发送速率)和信号在信道上的传播速率是完全不同的概念。
110 | * 处理时延 交换结点为存储转发而进行一些必要的处理所花费的时间。
111 | * 排队时延 结点缓存队列中分组排队所经历的时延。
112 | * 排队时延的长短往往取决于网络中当时的通信量。
113 | * 数据经历的总时延就是发送时延、传播时延、处理时延和排队时延之和:
114 | * 时延带宽积
115 | * 链路的时延带宽积又称为以比特为单位的链路长度。
116 | * 利用率
117 | * 信道利用率指出某信道有百分之几的时间是被利用的(有数据通过)。完全空闲的信道的利用率是零。
118 | * 网络利用率则是全网络的信道利用率的加权平均值。
119 | * 信道利用率并非越高越好。
120 | * 时延与网络利用率的关系
121 | * 根据排队论的理论,当某信道的利用率增大时,该信道引起的时延也就迅速增加。
122 | * 若令 D0 表示网络空闲时的时延,D 表示网络当前的时延,则在适当的假定条件下,可以用下面的简单公式表示 D 和 D0之间的关系:
123 | * U 是网络的利用率,数值在 0 到 1 之间。
124 | ### 计算机网络的非性能特征
125 | * 费用
126 | * 质量
127 | * 标准化
128 | * 可靠性
129 | * 可扩展性和可升级性
130 | * 易于管理和维护
131 | ## 计算机网络的体系结构
132 | ### 计算机网络体系结构的形成
133 | * 相互通信的两个计算机系统必须高度协调工作才行,而这种“协调”是相当复杂的。
134 | * “分层”可将庞大而复杂的问题,转化为若干较小的局部问题,而这些较小的局部问题就比较易于研究和处理。
135 | ### 协议与划分层次
136 | * 划分层次的必要性
137 | * 计算机网络中的数据交换必须遵守事先约定好的规则。
138 | * 这些规则明确规定了所交换的数据的格式以及有关的同步问题(同步含有时序的意思)。
139 | * 网络协议(network protocol),简称为协议,是为进行网络中的数据交换而建立的规则、标准或约定。
140 | * 网络协议的组成要素
141 | * 语法 数据与控制信息的结构或格式 。
142 | * 语义 需要发出何种控制信息,完成何种动作以及做出何种响应。
143 | * 同步 事件实现顺序的详细说明。
144 | * 分层的好处
145 | * 各层之间是独立的。
146 | * 灵活性好。
147 | * 结构上可分割开。
148 | * 易于实现和维护。
149 | * 能促进标准化工作。
150 | ### 具有五层协议的体系结构
151 | * TCP/IP 是四层的体系结构:应用层、运输层、网际层和网络接口层。
152 | * 但最下面的网络接口层并没有具体内容。
153 | * 因此往往采取折中的办法,即综合 OSI 和 TCP/IP 的优点,采用一种只有五层协议的体系结构 。
154 | ### 实体、协议、服务和服务访问点
155 | * 实体(entity) 表示任何可发送或接收信息的硬件或软件进程。
156 | * 协议是控制两个对等实体进行通信的规则的集合。
157 | * 在协议的控制下,两个对等实体间的通信使得本层能够向上一层提供服务。
158 | * 要实现本层协议,还需要使用下层所提供的服务。
159 | * 本层的服务用户只能看见服务而无法看见下面的协议。
160 | * 下面的协议对上面的服务用户是透明的。
161 | * 协议是“水平的”,即协议是控制对等实体之间通信的规则。
162 | * 服务是“垂直的”,即服务是由下层向上层通过层间接口提供的。
163 | * 同一系统相邻两层的实体进行交互的地方,称为服务访问点 SAP (Service Access Point)。
164 | * 协议必须把所有不利的条件事先都估计到,而不能假定一切都是正常的和非常理想的。
165 | * 看一个计算机网络协议是否正确,不能光看在正常情况下是否正确,而且还必须非常仔细地检查这个协议能否应付各种异常情况。
166 | ## Internet 和 Internet 的区别
167 | ### 以小写字母 i 开始的 internet(互联网或互连网)是一个通用名词,它泛指由多个计算机网络互连而成的网络。
168 | ### 以大写字母I开始的的 Internet(因特网)则是一个专用名词,它指当前全球最大的、开放的、由众多网络相互连接而成的特定计算机网络,它采用 TCP/IP 协议族作为通信的规则,且其前身是美国的 ARPANET。
169 | ## 万维网 WWW 的问世
170 | ### 因特网已经成为世界上规模最大和增长速率最快的计算机网络,没有人能够准确说出因特网究竟有多大。
171 | ### 因特网的迅猛发展始于 20 世纪 90 年代。由欧洲原子核研究组织 CERN 开发的万维网 WWW (World Wide Web)被广泛使用在因特网上,大大方便了广大非网络专业人员对网络的使用,成为因特网的这种指数级增长的主要驱动力。
172 | ## 客户软件的特点
173 | ### 被用户调用后运行,在打算通信时主动向远地服务器发起通信(请求服务)。因此,客户程序必须知道服务器程序的地址。
174 | ### 不需要特殊的硬件和很复杂的操作系统。
175 | ## 服务器软件的特点
176 | ### 一种专门用来提供某种服务的程序,可同时处理多个远地或本地客户的请求。
177 | ### 系统启动后即自动调用并一直不断地运行着,被动地等待并接受来自各地的客户的通信请求。因此,服务器程序不需要知道客户程序的地址。
178 | ### 一般需要强大的硬件和高级的操作系统支持。
179 | ## 因特网的边缘部分与核心部分
180 | ## 两种国际标准
181 | ### 法律上的(de jure)国际标准 OSI 并没有得到市场的认可。
182 | ### 是非国际标准 TCP/IP 现在获得了最广泛的应用。
183 | ### TCP/IP 常被称为事实上的(de facto) 国际标准。
184 | ## 主机 1 向主机 2 发送数据
185 | ## 主机 1 向主机 2 发送数据
186 | ## 主机 1 向主机 2 发送数据
187 | ## 主机 1 向主机 2 发送数据
188 | ## 主机 1 向主机 2 发送数据
189 | ## 主机 1 向主机 2 发送数据
190 | ## 主机 1 向主机 2 发送数据
191 | ## 主机 1 向主机 2 发送数据
192 | ## 主机 1 向主机 2 发送数据
193 | ## 主机 1 向主机 2 发送数据
194 | ## 主机 1 向主机 2 发送数据
195 | ## 分组交换
196 | ### 在发送端,先把较长的报文划分成较短的、固定长度的数据段。
197 | ### 添加首部构成分组
198 | * 每一个数据段前面添加上首部构成分组
199 | ### 分组交换的传输单元
200 | * 分组交换网以“分组”作为数据传输单元。
201 | * 依次把各分组发送到接收端(假定接收端在左边)
202 | ### 分组首部的重要性
203 | * 每一个分组的首部都含有地址等控制信息。
204 | * 分组交换网中的结点交换机根据收到的分组的首部中的地址信息,把分组转发到下一个结点交换机。
205 | * 用这样的存储转发方式,最后分组就能到达最终目的地。
206 | ### 收到分组后剥去首部
207 | * 接收端收到分组后剥去首部还原成报文
208 | ### 最后还原成原来的报文
209 | ### 分组交换的优点
210 | * 高效 动态分配传输带宽,对通信链路是逐段占用。
211 | * 灵活 以分组为传送单位和查找路由。
212 | * 迅速 不必先建立连接就能向其他主机发送分组。
213 | * 可靠 保证可靠性的网络协议;分布式的路由选择协议使网络有很好的生存性。
214 | ### 分组交换带来的问题
215 | * 分组在各结点存储转发时需要排队,这就会造成一定的时延。
216 | * 分组必须携带的首部(里面有必不可少的控制信息)也造成了一定的开销。
217 | ## 电路交换
218 | ### 两部电话机只需要用一对电线就能够互相连接起来。
219 | ### 更多的电话机互相连通
220 | * 5 部电话机两两相连,需 10 对电线。
221 | * N 部电话机两两相连,需 N(N – 1)/2 对电线。
222 | * 当电话机的数量很大时,这种连接方法需要的电线对的数量与电话机数的平方成正比。
223 | ### 使用交换机
224 | * 当电话机的数量增多时,就要使用交换机来完成全网的交换任务。
225 | ### 电路交换的特点
226 | * 电路交换必定是面向连接的。
227 | * 电路交换的三个阶段:
228 | * 建立连接
229 | * 通信
230 | * 释放连接
231 | * 电路交换传送计算机数据效率低
232 | * 计算机数据具有突发性。
233 | * 这导致通信线路的利用率很低。
234 | ## 三种交换的比较
235 | ## 两种通信方式
236 | ### 客户服务器方式(C/S 方式) 即Client/Server方式
237 | * 客户(client)和服务器(server)都是指通信中所涉及的两个应用进程。
238 | * 客户服务器方式所描述的是进程之间服务和被服务的关系。
239 | * 客户是服务的请求方,服务器是服务的提供方。
240 | ### 对等方式(P2P 方式) 即 Peer-to-Peer方式
241 | * 对等连接(peer-to-peer,简写为 P2P)是指两个主机在通信时并不区分哪一个是服务请求方还是服务提供方。
242 | * 只要两个主机都运行了对等连接软件(P2P 软件),它们就可以进行平等的、对等连接通信。
243 | * 双方都可以下载对方已经存储在硬盘中的共享文档。
244 | * 对等连接方式的特点
245 | * 对等连接方式从本质上看仍然是使用客户服务器方式,只是对等连接中的每一个主机既是客户又同时是服务器。
246 | * 例如主机 C 请求 D 的服务时,C 是客户,D 是服务器。但如果 C 又同时向 F提供服务,那么 C 又同时起着服务器的作用。
247 | ## TCP/IP 的体系结构
248 | ## 关于开放系统互连参考模型OSI/RM
249 | ### 只要遵循 OSI 标准,一个系统就可以和位于世界上任何地方的、也遵循这同一标准的其他任何系统进行通信。
250 | ### 在市场化方面 OSI 却失败了。
251 | * OSI 的专家们在完成 OSI 标准时没有商业驱动力;
252 | * OSI 的协议实现起来过分复杂,且运行效率很低;
253 | * OSI 标准的制定周期太长,因而使得按 OSI 标准生产的设备无法及时进入市场;
254 | * OSI 的层次划分并也不太合理,有些功能在多个层次中重复出现。
255 |
256 | 
257 |
--------------------------------------------------------------------------------
/计算机网络/第 1 章 概述/第 1 章 概述.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/计算机网络/第 1 章 概述/第 1 章 概述.png
--------------------------------------------------------------------------------
/计算机网络/第 1 章 概述/第 1 章 概述.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/计算机网络/第 1 章 概述/第 1 章 概述.xmind
--------------------------------------------------------------------------------
/计算机网络/第 2 章 物理层/第 2 章 物理层.md:
--------------------------------------------------------------------------------
1 | # 第 2 章 物理层
2 | ## 物理层的基本概念
3 | ### 物理层的主要任务描述为确定与传输媒体的接口的一些特性
4 | * 机械特性 指明接口所用接线器的形状和尺寸、引线数目和排列、固定和锁定装置等等。
5 | * 电气特性 指明在接口电缆的各条线上出现的电压的范围。
6 | * 功能特性 指明某条线上出现的某一电平的电压表示何种意义。
7 | * 过程特性 指明对于不同功能的各种可能事件的出现顺序。
8 | ## 数据通信的基础知识
9 | ### 数据通信系统的模型
10 | *
11 | ### 有关信道的几个基本概念
12 | * 单向通信(单工通信)——只能有一个方向的通信而没有反方向的交互。
13 | * 双向交替通信(半双工通信)——通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
14 | * 双向同时通信(全双工通信)——通信的双方可以同时发送和接收信息。
15 | * 几种最基本的调制方法
16 | * 调幅(AM):载波的振幅随基带数字信号而变化。
17 | * 调频(FM):载波的频率随基带数字信号而变化。
18 | * 调相(PM) :载波的初始相位随基带数字信号而变化。
19 | * 概要: 图片
20 | ### 信道的极限容量
21 | * 信道能够通过的频率范围
22 | * 1924 年,奈奎斯特(Nyquist)就推导出了著名的奈氏准则。他给出了在假定的理想条件下,为了避免码间串扰,码元的传输速率的上限值
23 | * 信噪比
24 | * 香农(Shannon)用信息论的理论推导出了带宽受限且有高斯白噪声干扰的信道的极限、无差错的信息传输速率。
25 | 信道的极限信息传输速率 C 可表达为
26 | C = W log2(1+S/N) b/s
27 | W 为信道的带宽(以 Hz 为单位);
28 | S 为信道内所传信号的平均功率;
29 | N 为信道内部的高斯噪声功率。
30 | * 香农公式表明
31 | * 信道的带宽或信道中的信噪比越大,则信息的极限传输速率就越高。
32 | * 只要信息传输速率低于信道的极限信息传输速率,就一定可以找到某种办法来实现无差错的传输。
33 | * 若信道带宽 W 或信噪比 S/N 没有上限(当然实际信道不可能是这样的),则信道的极限信息传输速率 C 也就没有上限。
34 | * 实际信道上能够达到的信息传输速率要比香农的极限传输速率低不少。
35 | ### 信道的极限信息传输速率
36 | ## 物理层下面的传输媒体
37 | ### 导向传输媒体
38 | * 双绞线
39 | * 屏蔽双绞线 STP (Shielded Twisted Pair)
40 | * 无屏蔽双绞线 UTP (Unshielded Twisted Pair)
41 | * 同轴电缆
42 | * 50 Ω同轴电缆
43 | * 75 Ω 同轴电缆
44 | * 光缆
45 | * 光纤的工作原理
46 | * 光线在纤芯中传输的方式是不断地全反射
47 | ### 非导向传输媒体
48 | * 无线传输所使用的频段很广。
49 | * 短波通信主要是靠电离层的反射,但短波信道的通信质量较差。
50 | * 微波在空间主要是直线传播。
51 | * 卫星通信
52 | * 地面微波接力通信
53 | ## 信道复用技术
54 | ### 频分复用、时分复用和统计时分复用
55 | * 频分复用 FDM(Frequency Division Multiplexing)
56 | * 用户在分配到一定的频带后,在通信过程中自始至终都占用这个频带。
57 | * 示意图
58 | * 时分复用TDM(Time Division Multiplexing)
59 | * 时分复用则是将时间划分为一段段等长的时分复用帧(TDM 帧)。每一个时分复用的用户在每一个 TDM 帧中占用固定序号的时隙。
60 | * 示意图
61 | * 统计时分复用 STDM�(Statistic TDM)
62 | * 是对时分复用的一种改进,不固定每个用户在时分复用帧中的位置,只要有数据就集中起来组成统计时分复用帧然后发送。
63 | * 示意图
64 | ### 波分复用
65 | * 波分复用 WDM(Wavelength Division Multiplexing)
66 | * 光的频分复用。由于光的频率很高,因此习惯上用波长而不是频率来表示所使用的光载波。
67 | ### 码分复用
68 | * 码分复用 CDM(Code Division Multiplexing)
69 | * 常用的名词是码分多址 CDMA (Code Division Multiple Access)。
70 | * 各用户使用经过特殊挑选的不同码型,因此彼此不会造成干扰。
71 | * 这种系统发送的信号有很强的抗干扰能力,其频谱类似于白噪声,不易被敌人发现。
72 | * 每一个比特时间划分为 m 个短的间隔,称为码片(chip)。
73 | * 具体内容
74 | * 1.为每个用户分配 m bit 的码片,并且所有的码片正交,对于任意两个码片 S 和 T 有
75 | * 2.为了讨论方便,取 m=8,设码片 s 为 00011011。在拥有该码片的用户发送比特 1 时就发送该码片,发送比特 0 时就发送该码片的反码 11100100。
76 |
77 | 在计算时将 00011011 记作 (-1 -1 -1 +1 +1 -1 +1 +1),可以得到(其中 S' 为 S 的反码。)
78 | * 3.利用上面的式子我们知道,当接收端使用码片 对接收到的数据进行内积运算时,结果为 0 的是其它用户发送的数据,结果为 1 的是用户发送的比特 1,结果为 -1 的是用户发送的比特 0。
79 | * 码分复用需要发送的数据量为原先的 m 倍。
80 | ## 数字传输系统
81 | ### 脉码调制 PCM 体制
82 | ### 同步光纤网 SONET 和同步数字系列 SDH
83 | ## 宽带接入技术
84 | ### xDSL技术
85 | * xDSL 技术就是用数字技术对现有的模拟电话用户线进行改造,使它能够承载宽带业务。把 0~4 kHz 低端频谱留给传统电话使用,而把原来没有被利用的高端频谱留给用户上网使用。
86 | ### 光纤同轴混合网(HFC 网)
87 | * HFC 网是在目前覆盖面很广的有线电视网 CATV 的基础上开发的一种居民宽带接入网。HFC 网除可传送 CATV 外,还提供电话、数据和其他宽带交互型业务。
88 | ### FTTx 技术
89 | * FTTx(光纤到……)也是一种实现宽带居民接入网的方案。这里字母 x 可代表不同意思。
90 | * 光纤到家 FTTH (Fiber To The Home):光纤一直铺设到用户家庭可能是居民接入网最后的解决方法。
91 | * 光纤到大楼 FTTB (Fiber To The Building):光纤进入大楼后就转换为电信号,然后用电缆或双绞线分配到各用户。
92 | * 光纤到路边 FTTC (Fiber To The Curb):从路边到各用户可使用星形结构双绞线作为传输媒体。
93 | 
94 |
--------------------------------------------------------------------------------
/计算机网络/第 2 章 物理层/第 2 章 物理层.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/计算机网络/第 2 章 物理层/第 2 章 物理层.png
--------------------------------------------------------------------------------
/计算机网络/第 2 章 物理层/第 2 章 物理层.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/计算机网络/第 2 章 物理层/第 2 章 物理层.xmind
--------------------------------------------------------------------------------
/计算机网络/第 3 章 数据链路层/第 3 章 数据链路层.md:
--------------------------------------------------------------------------------
1 | # 第 3 章 数据链路层
2 | ## 使用点对点信道的数据链路层
3 | ### 数据链路和帧
4 | * 数据链路层使用的信道主要有以下两种类型:
5 | * 点对点信道。这种信道使用一对一的点对点通信方式。
6 | * 广播信道。这种信道使用一对多的广播通信方式,因此过程比较复杂。广播信道上连接的主机很多,因此必须使用专用的共享信道协议来协调这些主机的数据发
7 | * 数据链路层模型
8 | * 链路(link)是一条无源的点到点的物理线路段,中间没有任何其他的交换结点。
9 | * 数据链路(data link) 除了物理线路外,还必须有通信协议来控制这些数据的传输。若把实现这些协议的硬件和软件加到链路上,就构成了数据链路。
10 | * 数据链路层传送的是帧
11 | ### 三个基本问题
12 | * (1) 封装成帧
13 | * 将网络层传下来的分组添加首部和尾部,用于标记帧的开始和结束。
14 | *
15 | * (2) 透明传输
16 | * 透明表示一个实际存在的事物看起来好像不存在一样。
17 | * 帧使用首部和尾部进行定界,如果帧的数据部分含有和首部尾部相同的内容,那么帧的开始和结束位置就会被错误的判定。需要在数据部分出现首部尾部相同的内容前面插入转义字符。如果数据部分出现转义字符,那么就在转义字符前面再加个转义字符。在接收端进行处理之后可以还原出原始数据。这个过程透明传输的内容是转义字符,用户察觉不到转义字符的存在。
18 | *
19 | * (3) 差错控制
20 | * 循环冗余检验 CRC
21 | 目前数据链路层广泛使用了循环冗余检验(CRC)来检查比特差错。
22 | * 帧检验序列 FCS
23 | 在数据后面添加上的冗余码称为帧检验序列 FCS (Frame Check Sequence)。
24 | * 冗余码的计算
25 | * 例子:
26 | 现在 k = 6, M = 101001。
27 | 设 n = 3, 除数 P = 1101,
28 | 被除数是 2^nM = 101001000。
29 | 模 2 运算的结果是:商 Q = 110101,
30 | 余数 R = 001。
31 | 把余数 R 作为冗余码添加在数据 M 的后面发送出去。发送的数据是:2^nM + R
32 | 即:101001001,共 (k + n) 位。
33 |
34 | * 概要: CRC 是一种常用的检错方法,而 FCS 是添加在数据后面的冗余码。
35 | FCS 可以用 CRC 这种方法得出,但 CRC 并非用来获得 FCS 的唯一方法。
36 | ## 点对点协议 PPP
37 | ### PPP 协议的特点
38 | * 互联网用户通常需要连接到某个 ISP 之后才能接入到互联网,PPP 协议是用户计算机和 ISP 进行通信时所使用的数据链路层协议。
39 | ### PPP 协议的帧格式
40 | * 示意图:
41 | F 字段为帧的定界符
42 | A 和 C 字段暂时没有意义
43 | FCS 字段是使用 CRC 的检验序列
44 | 信息部分的长度不超过 1500
45 | ### PPP 协议的工作状态
46 | * 过程:
47 | 当用户拨号接入 ISP 时,路由器的调制解调器对拨号做出确认,并建立一条物理连接。
48 | PC 机向路由器发送一系列的 LCP 分组(封装成多个 PPP 帧)。
49 | 这些分组及其响应选择一些 PPP 参数,和进行网络层配置,NCP 给新接入的 PC机分配一个临时的 IP 地址,使 PC 机成为因特网上的一个主机。
50 | 通信完毕时,NCP 释放网络层连接,收回原来分配出去的 IP 地址。接着,LCP 释放数据链路层连接。最后释放的是物理层的连接。
51 | ## 使用广播信道的数据链路层
52 | ### 局域网的数据链路层
53 | * 局域网是一种典型的广播信道,主要特点是网络为一个单位所拥有,且地理范围和站点数目均有限。
54 | * 主要有以太网、令牌环网、FDDI 和 ATM 等局域网技术,目前以太网占领着有线局域网市场。
55 | * 可以按照网络拓扑结构对局域网进行分类:
56 | * 星形网
57 | * 环形网
58 | * 总线网
59 | * 树形网
60 | * 数据链路层的两个子层
61 | * 逻辑链路控制 LLC (Logical Link Control)子层
62 | * 媒体接入控制 MAC (Medium Access Control)子层。
63 | * 概要: 与接入到传输媒体有关的内容都放在 MAC子层,而 LLC 子层则与传输媒体无关,不管采用何种协议的局域网对 LLC 子层来说都是透明的
64 | 所以以后一般不考虑 LLC 子层
65 | * 适配器
66 | * 网络接口板又称为通信适配器(adapter)或网络接口卡 NIC (Network Interface Card),或“网卡”。
67 | * 适配器的重要功能:
68 | * 进行串行/并行转换。
69 | * 对数据进行缓存。
70 | * 在计算机的操作系统安装设备驱动程序。
71 | * 实现以太网协议。
72 | ### CSMA/CD 协议
73 | * CSMA/CD 表示载波监听多点接入 / 碰撞检测。
74 | * 多点接入 :说明这是总线型网络,许多主机以多点的方式连接到总线上。
75 | * 载波监听 :每个主机都必须不停地监听信道。在发送前,如果监听到信道正在使用,就必须等待。
76 | * 碰撞检测 :在发送中,如果监听到信道已有其它主机正在发送数据,就表示发生了碰撞。虽然每个主机在发送数据之前都已经监听到信道为空闲,但是由于电磁波的传播时延的存在,还是有可能会发生碰撞。
77 | * 具体内容
78 | * 记端到端的传播时延为 τ,最先发送的站点最多经过 2τ 就可以知道是否发生了碰撞,称 2τ 为 争用期 。只有经过争用期之后还没有检测到碰撞,才能肯定这次发送不会发生碰撞。
79 | * 当发生碰撞时,站点要停止发送,等待一段时间再发送。这个时间采用 截断二进制指数退避算法 来确定。从离散的整数集合 {0, 1, .., (2k-1)} 中随机取出一个数,记作 r,然后取 r 倍的争用期作为重传等待时间。
80 | * 概要: 示意图
81 | ## 使用广播信道的以太网
82 | ### 使用集线器的星形拓扑
83 | * 传统以太网最初是使用粗同轴电缆,后来演进到使用比较便宜的细同轴电缆,最后发展为使用更便宜和更灵活的双绞线。
84 | 这种以太网采用星形拓扑,在星形的中心则增加了一种可靠性非常高的设备,叫做集线器(hub)
85 | ### 以太网的信道利用率
86 | * 一个帧从开始发送,经可能发生的碰撞后,将再重传数次,到发送成功且信道转为空闲(即再经过时间 τ 使得信道上无信号在传播)时为止,是发送一帧所需的平均时间。
87 | * 发送一帧占用线路的时间是 T0 + τ ,而帧本身的发送时间是 T0。于是我们可计算出理想情况下的极限信道利用率 Smax为:
88 | ### 以太网的 MAC 层
89 | * MAC 地址是链路层地址,长度为 6 字节(48 位),用于唯一标识网络适配器(网卡)。
90 | * 一台主机拥有多少个网络适配器就有多少个 MAC 地址。例如笔记本电脑普遍存在无线网络适配器和有线网络适配器,因此就有两个 MAC 地址。
91 | ### 以太网帧格式:
92 | * 类型 :标记上层使用的协议;
93 | 数据 :长度在 46-1500 之间,如果太小则需要填充;
94 | FCS :帧检验序列,使用的是 CRC 检验方法;
95 | ## 扩展的以太网
96 | ### 在物理层扩展以太网
97 | * 用多个集线器可连成更大的局域网
98 | * 用集线器组成更大的局域网都在一个碰撞域中
99 | * 优点
100 | * 使原来属于不同碰撞域的局域网上的计算机能够进行跨碰撞域的通信。
101 | * 扩大了局域网覆盖的地理范围。
102 | * 缺点
103 | * 碰撞域增大了,但总的吞吐量并未提高。
104 | * 如果不同的碰撞域使用不同的数据率,那么就不能用集线器将它们互连起来。
105 | ### 在数据链路层扩展以太网
106 | * 在数据链路层扩展局域网是使用网桥。
107 | * 网桥工作在数据链路层,它根据 MAC 帧的目的地址对收到的帧进行转发。
108 | 网桥具有过滤帧的功能。当网桥收到一个帧时,并不是向所有的接口转发此帧,而是先检查此帧的目的 MAC 地址,然后再确定将该帧转发到哪一个接口 。
109 | * 优点
110 | * 过滤通信量。
111 | * 扩大了物理范围。
112 | * 提高了可靠性。
113 | * 可互连不同物理层、不同 MAC 子层和不同速率(如10 Mb/s 和 100 Mb/s 以太网)的局域网。
114 | * 缺点
115 | * 存储转发增加了时延。
116 | * 在MAC 子层并没有流量控制功能。
117 | * 具有不同 MAC 子层的网段桥接在一起时时延更大。
118 | * 网桥只适合于用户数不太多(不超过几百个)和通信量不太大的局域网,否则有时还会因传播过多的广播信息而产生网络拥塞。这就是所谓的广播风暴。
119 | * 交换机
120 | * 交换机具有自学习能力,学习的是交换表的内容,交换表中存储着 MAC 地址到接口的映射。
121 | 正是由于这种自学习能力,因此交换机是一种即插即用设备,不需要网络管理员手动配置交换表内容。
122 | * 下图中,交换机有 4 个接口,主机 A 向主机 B 发送数据帧时,交换机把主机 A 到接口 1 的映射写入交换表中。为了发送数据帧到 B,先查交换表,此时没有主机 B 的表项,那么主机 A 就发送广播帧,主机 C 和主机 D 会丢弃该帧,主机 B 回应该帧向主机 A 发送数据包时,交换机查找交换表得到主机 A 映射的接口为 1,就发送数据帧到接口 1,同时交换机添加主机 B 到接口 2 的映射。
123 | ### 虚拟局域网
124 | * 虚拟局域网可以建立与物理位置无关的逻辑组,只有在同一个虚拟局域网中的成员才会收到链路层广播信息。
125 | * 例如下图中 (A1, A2, A3, A4) 属于一个虚拟局域网,A1 发送的广播会被 A2、A3、A4 收到,而其它站点收不到。
126 | * 使用 VLAN 干线连接来建立虚拟局域网,每台交换机上的一个特殊接口被设置为干线接口,以互连 VLAN 交换机。IEEE 定义了一种扩展的以太网帧格式 802.1Q,它在标准以太网帧上加进了 4 字节首部 VLAN 标签,用于表示该帧属于哪一个虚拟局域网。
127 | ## 高速以太网
128 | ### 100BASE-T 以太网
129 | * 速率达到或超过 100 Mb/s 的以太网称为高速以太网
130 | * 可在全双工方式下工作而无冲突发生。因此,不使用 CSMA/CD 协议。
131 | ### 吉比特以太网
132 | * 允许在 1 Gb/s 下全双工和半双工两种方式工作。
133 | * 在半双工方式下使用 CSMA/CD 协议(全双工方式不需要使用 CSMA/CD 协议)。
134 | ### 10 吉比特以太网
135 | * 10 吉比特以太网只工作在全双工方式
136 | * 也不使用 CSMA/CD 协议。
137 | ### 使用高速以太网进行宽带接入
138 | * 以太网接入的重要特点是它可提供双向的宽带通信,并且可根据用户对带宽的需求灵活地进行带宽升级。
139 | * 采用以太网接入可实现端到端的以太网传输,中间不需要再进行帧格式的转换。这就提高了数据的传输效率和降低了传输的成本。
140 | ## 其他类型的高速局域网接口
141 | ## 集线器在转发帧时,不对传输媒体进行检测。
142 | 网桥在转发帧之前必须执行 CSMA/CD 算法。
143 |
144 | 
145 |
--------------------------------------------------------------------------------
/计算机网络/第 3 章 数据链路层/第 3 章 数据链路层.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/计算机网络/第 3 章 数据链路层/第 3 章 数据链路层.png
--------------------------------------------------------------------------------
/计算机网络/第 3 章 数据链路层/第 3 章 数据链路层.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/计算机网络/第 3 章 数据链路层/第 3 章 数据链路层.xmind
--------------------------------------------------------------------------------
/计算机网络/第 4 章 网络层/第 4 章 网络层.md:
--------------------------------------------------------------------------------
1 | # 第 4 章 网络层
2 | ## 网络层提供的两种服务
3 | ### 虚电路服务
4 | ### 数据报服务
5 | ### 概要: 虚电路服务与数据报服务的对比
6 | ## 网际协议 IP
7 | ### 网际协议 IP 是 TCP/IP 体系中两个最主要的协议之一。与 IP 协议配套使用的还有四个协议:
8 | * 地址解析协议 ARP (Address Resolution Protocol)
9 | * 逆地址解析协议 RARP (Reverse Address Resolution Protocol)
10 | * 网际控制报文协议 ICMP (Internet Control Message Protocol)
11 | * 网际组管理协议 IGMP (Internet Group Management Protocol)
12 | * 概要: 示意图
13 | ### 虚拟互连网络
14 | * 网络互相连接起来要使用一些中间设备
15 | * 物理层中继系统:转发器(repeater)。
16 | * 数据链路层中继系统:网桥或桥接器(bridge)。
17 | * 网络层中继系统:路由器(router)。
18 | * 网桥和路由器的混合物:桥路器(brouter)。
19 | * 网络层以上的中继系统:网关(gateway)。
20 | ### IP 数据报的格式
21 | * 版本 : 有 4(IPv4)和 6(IPv6)两个值;
22 | * 首部长度 : 占 4 位,因此最大值为 15。值为 1 表示的是 1 个 32 位字的长度,也就是 4 字节。因为固定部分长度为 20 字节,因此该值最小为 5。如果可选字段的长度不是 4 字节的整数倍,就用尾部的填充部分来填充。
23 | * 区分服务 : 用来获得更好的服务,一般情况下不使用。
24 | * 总长度 : 包括首部长度和数据部分长度。
25 | * 生存时间 :TTL,它的存在是为了防止无法交付的数据报在互联网中不断兜圈子。以路由器跳数为单位,当 TTL 为 0 时就丢弃数据报。
26 | * 协议 :指出携带的数据应该上交给哪个协议进行处理,例如 ICMP、TCP、UDP 等。
27 | * 首部检验和 :因为数据报每经过一个路由器,都要重新计算检验和,因此检验和不包含数据部分可以减少计算的工作量。
28 | * 标识 : 在数据报长度过长从而发生分片的情况下,相同数据报的不同分片具有相同的标识符。
29 | * 片偏移 : 和标识符一起,用于发生分片的情况。片偏移的单位为 8 字节。
30 | * IP数据报分片
31 | * 概要: 示意图
32 | ### 分类的 IP 地址
33 | * IP 地址的编址方式经历了三个历史阶段:
34 | * 分类
35 | * 由两部分组成,网络号和主机号,其中不同分类具有不同的网络号长度,并且是固定的。
36 | IP 地址 ::= {< 网络号 >, < 主机号 >}
37 | * 示意图
38 | * 子网划分
39 | * 通过在主机号字段中拿一部分作为子网号,把两级 IP 地址划分为三级 IP 地址。
40 |
41 | IP 地址 ::= {< 网络号 >, < 子网号 >, < 主机号 >}
42 |
43 | 要使用子网,必须配置子网掩码。一个 B 类地址的默认子网掩码为 255.255.0.0,如果 B 类地址的子网占两个比特,那么子网掩码为 11111111 11111111 11000000 00000000,也就是 255.255.192.0。
44 |
45 | 注意,外部网络看不到子网的存在。
46 | * 无分类
47 | * 无分类编址 CIDR 消除了传统 A 类、B 类和 C 类地址以及划分子网的概念,使用网络前缀和主机号来对 IP 地址进行编码,网络前缀的长度可以根据需要变化。
48 |
49 | IP 地址 ::= {< 网络前缀号 >, < 主机号 >}
50 |
51 | CIDR 的记法上采用在 IP 地址后面加上网络前缀长度的方法,例如 128.14.35.7/20 表示前 20 位为网络前缀。
52 |
53 | CIDR 的地址掩码可以继续称为子网掩码,子网掩码首 1 长度为网络前缀的长度。
54 |
55 | 一个 CIDR 地址块中有很多地址,一个 CIDR 表示的网络就可以表示原来的很多个网络,并且在路由表中只需要一个路由就可以代替原来的多个路由,减少了路由表项的数量。把这种通过使用网络前缀来减少路由表项的方式称为路由聚合,也称为 构成超网 。
56 |
57 | 在路由表中的项目由“网络前缀”和“下一跳地址”组成,在查找时可能会得到不止一个匹配结果,应当采用最长前缀匹配来确定应该匹配哪一个。
58 | ### IP 地址与硬件地址
59 | * IP层抽象的互联网屏蔽了下层很复杂的细节
60 | 在抽象的网络层上讨论问题,就能够使用
61 | 统一的、抽象的 IP 地址
62 | 研究主机和主机或主机和路由器之间的通信
63 | * 示意图
64 | ### 地址解析协议 ARP 与逆地址解析协议RARP
65 | * 缘由
66 | * 网络层实现主机之间的通信,而链路层实现具体每段链路之间的通信。因此在通信过程中,IP 数据报的源地址和目的地址始终不变,而 MAC 地址随着链路的改变而改变。
67 | * 地址解析协议 ARP
68 | * ARP 实现由 IP 地址得到 MAC 地址
69 | * 每个主机都有一个 ARP 高速缓存,里面有本局域网上的各主机和路由器的 IP 地址到 MAC 地址的映射表。
70 |
71 | 如果主机 A 知道主机 B 的 IP 地址,但是 ARP 高速缓存中没有该 IP 地址到 MAC 地址的映射,此时主机 A 通过广播的方式发送 ARP 请求分组,主机 B 收到该请求后会发送 ARP 响应分组给主机 A 告知其 MAC 地址,随后主机 A 向其高速缓存中写入主机 B 的 IP 地址到 MAC 地址的映射。
72 | * 示意图
73 | * 逆地址解析协议 RARP
74 | * 逆地址解析协议 RARP 使只知道自己硬件地址的主机能够知道其 IP 地址。
75 | * 这种主机往往是无盘工作站。 因此 RARP协议目前已很少使用。
76 | ### IP 层转发分组的流程
77 | * 分组转发算法
78 | * (1) 从数据报的首部提取目的主机的 IP 地址 D, 得出目的网络地址为 N。
79 | * (2) 若网络 N 与此路由器直接相连,则把数据报直接交付目的主机 D;否则是间接交付,执行(3)。
80 | * (3) 若路由表中有目的地址为 D 的特定主机路由,则把数据报传送给路由表中所指明的下一跳路由器;否则,执行(4)。
81 | * (4) 若路由表中有到达网络 N 的路由,则把数据报传送给路由表指明的下一跳路由器;否则,执行(5)。
82 | * (5) 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;否则,执行(6)。
83 | * (6) 报告转发分组出错。
84 | * 概要: 示意图
85 | ## 划分子网和构造超网
86 | ### 划分子网
87 | ### 使用子网时分组转发
88 | ### 无分类编址 CIDR(构造超网)
89 | ## 网际控制报文协议 ICMP
90 | ### 简介
91 | * ICMP 是为了更有效地转发 IP 数据报和提高交付成功的机会。它封装在 IP 数据报中,但是不属于高层协议。
92 | ### ICMP 报文的种类
93 | * ICMP 差错报告报文
94 | * 终点不可达
95 | * 源点抑制(Source quench)
96 | * 时间超过
97 | * 参数问题
98 | * 改变路由(重定向)(Redirect)
99 | * ICMP 询问报文
100 | * 回送请求和回答报文
101 | * 时间戳请求和回答报文
102 | * ICMP 报文的前 4 个字节是统一的格式,共有三个字段:即类型、代码和检验和。接着的 4 个字节的内容与 ICMP 的类型有关。
103 | ### ICMP 的应用举例
104 | * 1. Ping
105 | * Ping 是 ICMP 的一个重要应用,主要用来测试两台主机之间的连通性。
106 |
107 | Ping 的原理是通过向目的主机发送 ICMP Echo 请求报文,目的主机收到之后会发送 Echo 回答报文。Ping 会根据时间和成功响应的次数估算出数据包往返时间以及丢包率。
108 | * 2. Traceroute
109 | * Traceroute 是 ICMP 的另一个应用,用来跟踪一个分组从源点到终点的路径。
110 |
111 | Traceroute 发送的 IP 数据报封装的是无法交付的 UDP 用户数据报,并由目的主机发送终点不可达差错报告报文。
112 | * 源主机向目的主机发送一连串的 IP 数据报。第一个数据报 P1 的生存时间 TTL 设置为 1,当 P1 到达路径上的第一个路由器 R1 时,R1 收下它并把 TTL 减 1,此时 TTL 等于 0,R1 就把 P1 丢弃,并向源主机发送一个 ICMP 时间超过差错报告报文;
113 | * 源主机接着发送第二个数据报 P2,并把 TTL 设置为 2。P2 先到达 R1,R1 收下后把 TTL 减 1 再转发给 R2,R2 收下后也把 TTL 减 1,由于此时 TTL 等于 0,R2 就丢弃 P2,并向源主机发送一个 ICMP 时间超过差错报文。
114 | * 不断执行这样的步骤,直到最后一个数据报刚刚到达目的主机,主机不转发数据报,也不把 TTL 值减 1。但是因为数据报封装的是无法交付的 UDP,因此目的主机要向源主机发送 ICMP 终点不可达差错报告报文。
115 | * 之后源主机知道了到达目的主机所经过的路由器 IP 地址以及到达每个路由器的往返时间。
116 | ## 因特网的路由选择协议
117 | ### 有关路由选择协议的几个基本概念
118 | * 静态路由选择策略——即非自适应路由选择,其特点是简单和开销较小,但不能及时适应网络状态的变化。
119 | * 动态路由选择策略——即自适应路由选择,其特点是能较好地适应网络状态的变化,但实现起来较为复杂,开销也比较大。
120 | ### 自治系统 AS(Autonomous System)
121 | * 自治系统 AS 的定义:在单一的技术管理下的一组路由器,而这些路由器使用一种 AS 内部的路由选择协议和共同的度量以确定分组在该 AS 内的路由,同时还使用一种 AS 之间的路由选择协议用以确定分组在 AS之间的路由。
122 | ### 内部网关协议 IGP (Interior Gateway Protocol)
123 | * 即在一个自治系统内部使用的路由选择协议。
124 | * 内部网关协议 RIP
125 | * RIP 是一种基于距离向量的路由选择协议。距离是指跳数,直接相连的路由器跳数为 1。跳数最多为 15,超过 15 表示不可达。
126 |
127 | RIP 按固定的时间间隔仅和相邻路由器交换自己的路由表,经过若干次交换之后,所有路由器最终会知道到达本自治系统中任何一个网络的最短距离和下一跳路由器地址。
128 | * 距离向量算法:
129 | * 对地址为 X 的相邻路由器发来的 RIP 报文,先修改报文中的所有项目,把下一跳字段中的地址改为 X,并把所有的距离字段加 1;
130 | * 对修改后的 RIP 报文中的每一个项目,进行以下步骤:
131 | * 若原来的路由表中没有目的网络 N,则把该项目添加到路由表中;
132 | * 否则:若下一跳路由器地址是 X,则把收到的项目替换原来路由表中的项目;否则:若收到的项目中的距离 d 小于路由表中的距离,则进行更新(例如原始路由表项为 Net2, 5, P,新表项为 Net2, 4, X,则更新);否则什么也不做。
133 | * 若 3 分钟还没有收到相邻路由器的更新路由表,则把该相邻路由器标为不可达,即把距离置为 16。
134 | * RIP 协议实现简单,开销小。但是 RIP 能使用的最大距离为 15,限制了网络的规模。并且当网络出现故障时,要经过比较长的时间才能将此消息传送到所有路由器。
135 | * 内部网关协议 OSPF
136 | * 开放最短路径优先 OSPF,是为了克服 RIP 的缺点而开发出来的。
137 |
138 | 开放表示 OSPF 不受某一家厂商控制,而是公开发表的;最短路径优先表示使用了 Dijkstra 提出的最短路径算法 SPF。
139 | * OSPF 具有以下特点:
140 | * 向本自治系统中的所有路由器发送信息,这种方法是洪泛法。
141 | * 发送的信息就是与相邻路由器的链路状态,链路状态包括与哪些路由器相连以及链路的度量,度量用费用、距离、时延、带宽等来表示。
142 | * 只有当链路状态发生变化时,路由器才会发送信息。
143 | * 所有路由器都具有全网的拓扑结构图,并且是一致的。相比于 RIP,OSPF 的更新过程收敛的很快。
144 | ### 外部网关协议 BGP (External Gateway Protocol)
145 | * 若源站和目的站处在不同的自治系统中,当数据报传到一个自治系统的边界时,就需要使用一种协议将路由选择信息传递到另一个自治系统中。
146 | * AS 之间的路由选择很困难,主要是由于:
147 | * 互联网规模很大;
148 | * 各个 AS 内部使用不同的路由选择协议,无法准确定义路径的度量;
149 | * AS 之间的路由选择必须考虑有关的策略,比如有些 AS 不愿意让其它 AS 经过。
150 | * BGP 只能寻找一条比较好的路由,而不是最佳路由。
151 |
152 | 每个 AS 都必须配置 BGP 发言人,通过在两个相邻 BGP 发言人之间建立 TCP 连接来交换路由信息。
153 | * 示意图
154 | ### 路由器的构成
155 | * 路由器是一种具有多个输入端口和多个输出端口的专用计算机,其任务是转发分组。也就是说,将路由器某个输入端口收到的分组,按照分组要去的目的地(即目的网络),把该分组从路由器的某个合适的输出端口转发给下一跳路由器。
156 | * 路由器从功能上可以划分为
157 | * 路由选择
158 | * 分组转发
159 | * 分组转发结构由三个部分组成
160 | * 交换结构
161 | * 一组输入端口
162 | * 一组输出端口
163 | * 概要: 示意图
164 | ## IP 多播
165 | ### IP 多播的基本概念
166 | * 多播可明显地减少网络中资源的消耗
167 | ### 在局域网上进行硬件多播
168 | *
169 | ### 因特网组管理协议 IGMP 和多播路由选择协议
170 | * IGMP 使多播路由器�知道多播组成员信息
171 | * 多播转发必须动态地适应多播组成员的变化(这时网络拓扑并未发生变化)。请注意,单播路由选择通常是在网络拓扑发生变化时才需要更新路由。
172 | ## 虚拟专用网 VPN 和网络地址转换 NAT
173 | ### 虚拟专用网 VPN
174 | * 由于 IP 地址的紧缺,一个机构能申请到的 IP 地址数往往远小于本机构所拥有的主机数。并且一个机构并不需要把所有的主机接入到外部的互联网中,机构内的计算机可以使用仅在本机构有效的 IP 地址(专用地址)。
175 | * 有三个专用地址块:
176 | * 10.0.0.0 ~ 10.255.255.255
177 | * 172.16.0.0 ~ 172.31.255.255
178 | * 192.168.0.0 ~ 192.168.255.255
179 | * VPN 使用公用的互联网作为本机构各专用网之间的通信载体。专用指机构内的主机只与本机构内的其它主机通信;虚拟指好像是,而实际上并不是,它有经过公用的互联网。
180 | * 下图中,场所 A 和 B 的通信经过互联网,如果场所 A 的主机 X 要和另一个场所 B 的主机 Y 通信,IP 数据报的源地址是 10.1.0.1,目的地址是 10.2.0.3。数据报先发送到与互联网相连的路由器 R1,R1 对内部数据进行加密,然后重新加上数据报的首部,源地址是路由器 R1 的全球地址 125.1.2.3,目的地址是路由器 R2 的全球地址 194.4.5.6。路由器 R2 收到数据报后将数据部分进行解密,恢复原来的数据报,此时目的地址为 10.2.0.3,就交付给 Y。
181 | ### 网络地址转换 NAT
182 | * 专用网内部的主机使用本地 IP 地址又想和互联网上的主机通信时,可以使用 NAT 来将本地 IP 转换为全球 IP。
183 | * 在以前,NAT 将本地 IP 和全球 IP 一一对应,这种方式下拥有 n 个全球 IP 地址的专用网内最多只可以同时有 n 台主机接入互联网。为了更有效地利用全球 IP 地址,现在常用的 NAT 转换表把传输层的端口号也用上了,使得多个专用网内部的主机共用一个全球 IP 地址。使用端口号的 NAT 也叫做网络地址与端口转换 NAPT。
184 | ## 因为网络层是整个互联网的核心,因此应当让网络层尽可能简单。网络层向上只提供简单灵活的、无连接的、尽最大努力交互的数据报服务。
185 | ## 因为网络层是整个互联网的核心,因此应当让网络层尽可能简单。网络层向上只提供简单灵活的、无连接的、尽最大努力交互的数据报服务。
186 |
187 | 
188 |
--------------------------------------------------------------------------------
/计算机网络/第 4 章 网络层/第 4 章 网络层.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/计算机网络/第 4 章 网络层/第 4 章 网络层.png
--------------------------------------------------------------------------------
/计算机网络/第 4 章 网络层/第 4 章 网络层.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/计算机网络/第 4 章 网络层/第 4 章 网络层.xmind
--------------------------------------------------------------------------------
/计算机网络/第 5 章 运输层/第 5 章 运输层.md:
--------------------------------------------------------------------------------
1 | # 第 5 章 运输层
2 | ## 运输层协议概述
3 | ### 进程之间的通信
4 | * 运输层向它上面的应用层提供通信服务,它属于面向通信部分的最高层,同时也是用户功能中的最低层。
5 | * 两个主机进行通信实际上就是两个主机中的应用进程互相通信。
6 | * 应用进程之间的通信又称为端到端的通信。
7 | * 运输层协议和网络层协议的主要区别
8 | ### 运输层的两个主要协议
9 | * (1) 用户数据报协议 UDP(User Datagram Protocol)
10 | * UDP 传送的数据单位协议是 UDP 报文或用户数据报。
11 | * (2) 传输控制协议 TCP(Transmission Control Protocol)
12 | * TCP 传送的数据单位协议是 TCP 报文段(segment)
13 | ### 运输层的端口
14 | * 软件端口与硬件端口
15 | * 在协议栈层间的抽象的协议端口是软件端口。
16 | * 路由器或交换机上的端口是硬件端口。
17 | * 三类端口
18 | * 熟知端口,数值一般为 0~1023。
19 | * 登记端口号,数值为1024~49151,为没有熟知端口号的应用程序使用的。使用这个范围的端口号必须在 IANA 登记,以防止重复。
20 | * 客户端口号或短暂端口号,数值为49152~65535,留给客户进程选择暂时使用。当服务器进程收到客户进程的报文时,就知道了客户进程所使用的动态端口号。通信结束后,这个端口号可供其他客户进程以后使用。
21 | ## 用户数据报协议 UDP
22 | ### UDP 概述
23 | * 用户数据报协议 UDP(User Datagram Protocol)是无连接的,尽最大可能交付,没有拥塞控制,面向报文(对于应用程序传下来的报文不合并也不拆分,只是添加 UDP 首部),支持一对一、一对多、多对一和多对多的交互通信。
24 | ### UDP 的首部格式
25 | ## 传输控制协议 TCP 概述
26 | ### TCP 最主要的特点
27 | * 传输控制协议 TCP(Transmission Control Protocol)是面向连接的,提供可靠交付,有流量控制,拥塞控制,提供全双工通信,面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据块),每一条 TCP 连接只能是点对点的(一对一)。
28 | ### TCP 的连接
29 | * TCP 连接的端点叫做套接字(socket)或插口。
30 | * 套接字 socket = (IP地址: 端口号)
31 | ## 可靠传输的工作原理
32 | ### 停止等待协议
33 | ### 连续 ARQ 协议
34 | ## TCP 报文段的首部格式
35 | ### 序号 :用于对字节流进行编号,例如序号为 301,表示第一个字节的编号为 301,如果携带的数据长度为 100 字节,那么下一个报文段的序号应为 401。
36 | ### 确认号 :期望收到的下一个报文段的序号。例如 B 正确收到 A 发送来的一个报文段,序号为 501,携带的数据长度为 200 字节,因此 B 期望下一个报文段的序号为 701,B 发送给 A 的确认报文段中确认号就为 701。
37 | ### 数据偏移 :指的是数据部分距离报文段起始处的偏移量,实际上指的是首部的长度。
38 | ### 确认 ACK :当 ACK=1 时确认号字段有效,否则无效。TCP 规定,在连接建立后所有传送的报文段都必须把 ACK 置 1。
39 | ### 同步 SYN :在连接建立时用来同步序号。当 SYN=1,ACK=0 时表示这是一个连接请求报文段。若对方同意建立连接,则响应报文中 SYN=1,ACK=1。
40 | ### 终止 FIN :用来释放一个连接,当 FIN=1 时,表示此报文段的发送方的数据已发送完毕,并要求释放连接。
41 | ### 窗口 :窗口值作为接收方让发送方设置其发送窗口的依据。之所以要有这个限制,是因为接收方的数据缓存空间是有限的。
42 | ### 概要: 示意图
43 | ## TCP 可靠传输的实现
44 | ### 以字节为单位的滑动窗口
45 | * 窗口是缓存的一部分,用来暂时存放字节流。发送方和接收方各有一个窗口,接收方通过 TCP 报文段中的窗口字段告诉发送方自己的窗口大小,发送方根据这个值和其它信息设置自己的窗口大小。
46 |
47 | 发送窗口内的字节都允许被发送,接收窗口内的字节都允许被接收。如果发送窗口左部的字节已经发送并且收到了确认,那么就将发送窗口向右滑动一定距离,直到左部第一个字节不是已发送并且已确认的状态;接收窗口的滑动类似,接收窗口左部字节已经发送确认并交付主机,就向右滑动接收窗口。
48 |
49 | 接收窗口只会对窗口内最后一个按序到达的字节进行确认,例如接收窗口已经收到的字节为 {31, 34, 35},其中 {31} 按序到达,而 {34, 35} 就不是,因此只对字节 31 进行确认。发送方得到一个字节的确认之后,就知道这个字节之前的所有字节都已经被接收。
50 | * 1
51 | * 2
52 | * 3
53 | * 4
54 | ### 超时重传时间的选择
55 | * 超时重传
56 | * TCP 使用超时重传来实现可靠传输:如果一个已经发送的报文段在超时时间内没有收到确认,那么就重传这个报文段。
57 |
58 | 一个报文段从发送再到接收到确认所经过的时间称为往返时间 RTT,加权平均往返时间 RTTs 计算如下:
59 | * 其中,0 ≤ a < 1,RTTs 随着 a 的增加更容易受到 RTT 的影响。
60 |
61 | 超时时间 RTO 应该略大于 RTTs,TCP 使用的超时时间计算如下:(其中 RTTd 为偏差的加权平均值)
62 | ### 选择确认 SACK
63 | ## TCP的流量控制
64 | ### 利用滑动窗口实现流量控制
65 | * TCP 流量控制
66 | * 流量控制是为了控制发送方发送速率,保证接收方来得及接收。
67 |
68 | 接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
69 | * 流量控制举例
70 | ### 必须考虑传输效率
71 | ## TCP 的拥塞控制
72 | ### 拥塞控制的一般原理
73 | * 如果网络出现拥塞,分组将会丢失,此时发送方会继续重传,从而导致网络拥塞程度更高。因此当出现拥塞时,应当控制发送方的速率。这一点和流量控制很像,但是出发点不同。流量控制是为了让接收方能来得及接收,而拥塞控制是为了降低整个网络的拥塞程度。
74 | * 拥塞控制所起的作用
75 | ### 几种拥塞控制方法
76 | * TCP 主要通过四个算法来进行拥塞控制:慢开始、拥塞避免、快重传、快恢复。
77 | * 发送方需要维护一个叫做拥塞窗口(cwnd)的状态变量,注意拥塞窗口与发送方窗口的区别:拥塞窗口只是一个状态变量,实际决定发送方能发送多少数据的是发送方窗口。
78 |
79 | 为了便于讨论,做如下假设:
80 |
81 | 接收方有足够大的接收缓存,因此不会发生流量控制;
82 | 虽然 TCP 的窗口基于字节,但是这里设窗口的大小单位为报文段。
83 | * 1. 慢开始与拥塞避免
84 | * 发送的最初执行慢开始,令 cwnd = 1,发送方只能发送 1 个报文段;当收到确认后,将 cwnd 加倍,因此之后发送方能够发送的报文段数量为:2、4、8 ...
85 |
86 | 注意到慢开始每个轮次都将 cwnd 加倍,这样会让 cwnd 增长速度非常快,从而使得发送方发送的速度增长速度过快,网络拥塞的可能性也就更高。设置一个慢开始门限 ssthresh,当 cwnd >= ssthresh 时,进入拥塞避免,每个轮次只将 cwnd 加 1。
87 |
88 | 如果出现了超时,则令 ssthresh = cwnd / 2,然后重新执行慢开始。
89 | * 2. 快重传与快恢复
90 | * 在接收方,要求每次接收到报文段都应该对最后一个已收到的有序报文段进行确认。例如已经接收到 M1 和 M2,此时收到 M4,应当发送对 M2 的确认。
91 |
92 | 在发送方,如果收到三个重复确认,那么可以知道下一个报文段丢失,此时执行快重传,立即重传下一个报文段。例如收到三个 M2,则 M3 丢失,立即重传 M3。
93 |
94 | 在这种情况下,只是丢失个别报文段,而不是网络拥塞。因此执行快恢复,令 ssthresh = cwnd / 2 ,cwnd = ssthresh,注意到此时直接进入拥塞避免。
95 |
96 | 慢开始和快恢复的快慢指的是 cwnd 的设定值,而不是 cwnd 的增长速率。慢开始 cwnd 设定为 1,而快恢复 cwnd 设定为 ssthresh。
97 | ### 随机早期检测 RED
98 | ## TCP 的运输连接管理
99 | ### TCP 的连接建立
100 | * 假设 A 为客户端,B 为服务器端。
101 |
102 | 首先 B 处于 LISTEN(监听)状态,等待客户的连接请求。
103 |
104 | A 向 B 发送连接请求报文,SYN=1,ACK=0,选择一个初始的序号 x。
105 |
106 | B 收到连接请求报文,如果同意建立连接,则向 A 发送连接确认报文,SYN=1,ACK=1,确认号为 x+1,同时也选择一个初始的序号 y。
107 |
108 | A 收到 B 的连接确认报文后,还要向 B 发出确认,确认号为 y+1,序号为 x+1。
109 |
110 | B 收到 A 的确认后,连接建立。
111 | * 三次握手的原因
112 | * 第三次握手是为了防止失效的连接请求到达服务器,让服务器错误打开连接。
113 |
114 | 客户端发送的连接请求如果在网络中滞留,那么就会隔很长一段时间才能收到服务器端发回的连接确认。客户端等待一个超时重传时间之后,就会重新请求连接。但是这个滞留的连接请求最后还是会到达服务器,如果不进行三次握手,那么服务器就会打开两个连接。如果有第三次握手,客户端会忽略服务器之后发送的对滞留连接请求的连接确认,不进行第三次握手,因此就不会再次打开连接。
115 | ### TCP 的连接释放
116 | * 以下描述不讨论序号和确认号,因为序号和确认号的规则比较简单。并且不讨论 ACK,因为 ACK 在连接建立之后都为 1。
117 |
118 | A 发送连接释放报文,FIN=1。
119 |
120 | B 收到之后发出确认,此时 TCP 属于半关闭状态,B 能向 A 发送数据但是 A 不能向 B 发送数据。
121 |
122 | 当 B 不再需要连接时,发送连接释放报文,FIN=1。
123 |
124 | A 收到后发出确认,进入 TIME-WAIT 状态,等待 2 MSL(最大报文存活时间)后释放连接。
125 |
126 | B 收到 A 的确认后释放连接。
127 | * 四次挥手的原因
128 | * 客户端发送了 FIN 连接释放报文之后,服务器收到了这个报文,就进入了 CLOSE-WAIT 状态。这个状态是为了让服务器端发送还未传送完毕的数据,传送完毕之后,服务器会发送 FIN 连接释放报文。
129 | * TIME_WAIT
130 | * 客户端接收到服务器端的 FIN 报文后进入此状态,此时并不是直接进入 CLOSED 状态,还需要等待一个时间计时器设置的时间 2MSL。这么做有两个理由:
131 | * 确保最后一个确认报文能够到达。如果 B 没收到 A 发送来的确认报文,那么就会重新发送连接释放请求报文,A 等待一段时间就是为了处理这种情况的发生。
132 | * 等待一段时间是为了让本连接持续时间内所产生的所有报文都从网络中消失,使得下一个新的连接不会出现旧的连接请求报文。
133 | ### TCP 的有限状态机
134 | * 粗实线箭头表示对客户进程的正常变迁。
135 | 粗虚线箭头表示对服务器进程的正常变迁。
136 | 另一种细线箭头表示异常变迁。
137 |
138 | 
139 |
--------------------------------------------------------------------------------
/计算机网络/第 5 章 运输层/第 5 章 运输层.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/计算机网络/第 5 章 运输层/第 5 章 运输层.png
--------------------------------------------------------------------------------
/计算机网络/第 5 章 运输层/第 5 章 运输层.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/计算机网络/第 5 章 运输层/第 5 章 运输层.xmind
--------------------------------------------------------------------------------
/计算机网络/第 6 章 应用层/第 6 章 应用层.md:
--------------------------------------------------------------------------------
1 | # 第 6 章 应用层
2 | ## 域名系统 DNS
3 | ### 域名系统概述
4 | * DNS 是一个分布式数据库,提供了主机名和 IP 地址之间相互转换的服务。这里的分布式数据库是指,每个站点只保留它自己的那部分数据。
5 | ### 因特网的域名结构
6 | * 域名具有层次结构,从上到下依次为:根域名、顶级域名、二级域名。
7 | ### 域名服务器
8 | * 一个服务器所负责管辖的(或有权限的)范围叫做区(zone)。
9 | * 每一个区设置相应的权限域名服务器,用来保存该区中的所有主机的域名到IP地址的映射。
10 | *
11 | * DNS 可以使用 UDP 或者 TCP 进行传输,使用的端口号都为 53。大多数情况下 DNS 使用 UDP 进行传输,这就要求域名解析器和域名服务器都必须自己处理超时和重传从而保证可靠性。在两种情况下会使用 TCP 进行传输:
12 | * 如果返回的响应超过的 512 字节(UDP 最大只支持 512 字节的数据)。
13 | * 区域传送(区域传送是主域名服务器向辅助域名服务器传送变化的那部分数据)。
14 | ## 文件传送协议
15 | ### FTP 概述
16 | * 文件传送协议 FTP (File Transfer Protocol) 是因特网上使用得最广泛的文件传送协议。
17 | * FTP 提供交互式的访问,允许客户指明文件的类型与格式,并允许文件具有存取权限。
18 | * FTP 屏蔽了各计算机系统的细节,因而适合于在异构网络中任意计算机之间传送文件。
19 | ### FTP 的基本工作原理
20 | * FTP 使用 TCP 进行连接,它需要两个连接来传送一个文件:
21 | * 控制连接:服务器打开端口号 21 等待客户端的连接,客户端主动建立连接后,使用这个连接将客户端的命令传送给服务器,并传回服务器的应答。
22 | * 数据连接:用来传送一个文件数据。
23 | * 根据数据连接是否是服务器端主动建立,FTP 有主动和被动两种模式:
24 | * 主动模式:服务器端主动建立数据连接,其中服务器端的端口号为 20,客户端的端口号随机,但是必须大于 1024,因为 0~1023 是熟知端口号。
25 | * 被动模式:客户端主动建立数据连接,其中客户端的端口号由客户端自己指定,服务器端的端口号随机。
26 | * 主动模式要求客户端开放端口号给服务器端,需要去配置客户端的防火墙。被动模式只需要服务器端开放端口号即可,无需客户端配置防火墙。但是被动模式会导致服务器端的安全性减弱,因为开放了过多的端口号。
27 | ### 简单文件传送协议 TFTP
28 | * TFTP 是一个很小且易于实现的文件传送协议。
29 | * TFTP 使用客户服务器方式和使用 UDP 数据报,因此 TFTP 需要有自己的差错改正措施。
30 | * TFTP 只支持文件传输而不支持交互。
31 | * TFTP 没有一个庞大的命令集,没有列目录的功能,也不能对用户进行身份鉴别。
32 | * TFTP 的主要特点是
33 | * (1) 每次传送的数据 PDU 中有 512 字节的数据,但最后一次可不足 512 字节。
34 | * (2) 数据 PDU 也称为文件块(block),每个块按序编号,从 1 开始。
35 | * (3) 支持 ASCII 码或二进制传送。
36 | * (4) 可对文件进行读或写。
37 | * (5) 使用很简单的首部。
38 | ## 远程终端协议 TELNET
39 | ### 简述
40 | * TELNET 是一个简单的远程终端协议,也是因特网的正式标准。
41 | * 用户用 TELNET 就可在其所在地通过 TCP 连接注册(即登录)到远地的另一个主机上(使用主机名或 IP 地址)。
42 | * TELNET 能将用户的击键传到远地主机,同时也能将远地主机的输出通过 TCP 连接返回到用户屏幕。这种服务是透明的,因为用户感觉到好像键盘和显示器是直接连在远地主机上。
43 | ## 万维网 WWW
44 | ### 概述
45 | * 万维网 WWW (World Wide Web)并非某种特殊的计算机网络。
46 | * 万维网是一个大规模的、联机式的信息储藏所。
47 | * 万维网用链接的方法能非常方便地从因特网上的一个站点访问另一个站点,从而主动地按需获取丰富的信息。
48 | * 这种访问方式称为“链接”。
49 | * 万维网是分布式超媒体(hypermedia)系统,它是超文本(hypertext)系统的扩充。
50 | ### 万维网的工作方式
51 | * 万维网以客户服务器方式工作。
52 | * 浏览器就是在用户计算机上的万维网客户程序。万维网文档所驻留的计算机则运行服务器程序,因此这个计算机也称为万维网服务器。
53 | ### 万维网必须解决的问题
54 | * (1) 怎样标志分布在整个因特网上的万维网文档?
55 | 使用统一资源定位符 URL (Uniform Resource Locator)来标志万维网上的各种文档。
56 | 使每一个文档在整个因特网的范围内具有唯一的标识符 URL。
57 | * (2) 用何协议实现万维网上各种超链的链接?
58 | 在万维网客户程序与万维网服务器程序之间进行交互所使用的协议,是超文本传送协议 HTTP (HyperText Transfer Protocol)。
59 | HTTP 是一个应用层协议,它使用 TCP 连接进行可靠的传送。
60 | * (3) 怎样使各种万维网文档都能在因特网上的各种计算机上显示出来,同时使用户清楚地知道在什么地方存在着超链?
61 | 超文本标记语言 HTML (HyperText Markup Language)使得万维网页面的设计者可以很方便地用一个超链从本页面的某处链接到因特网上的任何一个万维网页面,并且能够在自己的计算机屏幕上将这些页面显示出来。
62 | * (4) 怎样使用户能够很方便地找到所需的信息?
63 | 为了在万维网上方便地查找信息,用户可使用各种的搜索工具(即搜索引擎)。
64 | ### 统一资源定位符 URL
65 | * 统一资源定位符 URL 是对可以从因特网上得到的资源的位置和访问方法的一种简洁的表示。
66 | * URL 的一般形式是:<协议>://<主机>:<端口>/<路径>
67 | ### 超文本传送协议 HTTP
68 | * HTTP 是面向事务的客户服务器协议。
69 | * HTTP 1.0 协议是无状态的(stateless)。
70 | * HTTP 协议本身也是无连接的,虽然它使用了面向连接的 TCP 向上提供的服务。
71 | ### 万维网的文档
72 | * 超文本标记语言 HTML
73 | * 超文本标记语言 HTML 中的 Markup 的意思就是“设置标记”。
74 | * HTML 定义了许多用于排版的命令(即标签)。
75 | * HTML 把各种标签嵌入到万维网的页面中。这样就构成了所谓的 HTML 文档。HTML 文档是一种可以用任何文本编辑器创建的 ASCII 码文件。
76 | * 动态万维网文档
77 | * 静态文档是指该文档创作完毕后就存放在万维网服务器中,在被用户浏览的过程中,内容不会改变。
78 | * 动态文档是指文档的内容是在浏览器访问万维网服务器时才由应用程序动态创建。
79 | * 动态文档和静态文档之间的主要差别体现在服务器一端。这主要是文档内容的生成方法不同。而从浏览器的角度看,这两种文档并没有区别。
80 | ### 万维网的信息检索系统
81 | * 全文检索搜索
82 | * 全文检索搜索引擎是一种纯技术型的检索工具。它的工作原理是通过搜索软件到因特网上的各网站收集信息,找到一个网站后可以从这个网站再链接到另一个网站。然后按照一定的规则建立一个很大的在线数据库供用户查询。
83 | * 分类目录搜索
84 | * 分类目录搜索引擎并不采集网站的任何信息,而是利用各网站向搜索引擎提交的网站信息时填写的关键词和网站描述等信息,经过人工审核编辑后,如果认为符合网站登录的条件,则输入到分类目录的数据库中,供网上用户查询。
85 | ## 电子邮件
86 | ### 电子邮件概述
87 | * 电子邮件(e-mail)是因特网上使用得最多的和最受用户欢迎的一种应用。
88 | * 电子邮件把邮件发送到收件人使用的邮件服务器,并放在其中的收件人邮箱中,收件人可随时上网到自己使用的邮件服务器进行读取。
89 | * 电子邮件不仅使用方便,而且还具有传递迅速和费用低廉的优点。
90 | * 一个电子邮件系统由三部分组成:用户代理、邮件服务器以及邮件协议。
91 | ### 电子邮件的最主要的组成构件
92 | ### 简单邮件传送协议 SMTP
93 | * SMTP 只能发送 ASCII 码,而互联网邮件扩充 MIME 可以发送二进制文件。MIME 并没有改动或者取代 SMTP,而是增加邮件主体的结构,定义了非 ASCII 码的编码规则。
94 | ### 电子邮件的信息格式
95 | * 一个电子邮件分为信封和内容两大部分。
96 | * RFC 822 只规定了邮件内容中的首部(header)格式,而对邮件的主体(body)部分则让用户自由撰写。
97 | * 邮件内容的首部
98 | * “To:”后面填入一个或多个收件人的电子邮件地址。用户只需打开地址簿,点击收件人名字,收件人的电子邮件地址就会自动地填入到合适的位置上。
99 | * “Subject:”是邮件的主题。它反映了邮件的主要内容,便于用户查找邮件。
100 | * 抄送 “Cc:” 表示应给某某人发送一个邮件副本。
101 | * “From” 和 “Date” 表示发信人的电子邮件地址和发信日期。“Reply-To” 是对方回信所用的地址。
102 | ### 邮件读取协议 POP3 和 IMAP
103 | * POP3
104 | * POP3 的特点是只要用户从服务器上读取了邮件,就把该邮件删除。但最新版本的 POP3 可以不删除邮件。
105 | * IMAP
106 | * IMAP 协议中客户端和服务器上的邮件保持同步,如果不手动删除邮件,那么服务器上的邮件也不会被删除。IMAP 这种做法可以让用户随时随地去访问服务器上的邮件。
107 | ### 基于万维网的电子邮件
108 | * 例子
109 | * 电子邮件从 A 发送到网易邮件服务器是使用 HTTP 协议。
110 | * 两个邮件服务器之间的传送使用 SMTP。
111 | * 邮件从新浪邮件服务器传送到 B 是使用 HTTP 协议。
112 | * 概要: 示意图
113 | ### 通用因特网邮件扩充 MIME
114 | * MIME 概述
115 | * MIME 并没有改动 SMTP 或取代它。
116 | * MIME 的意图是继续使用目前的[RFC 822]格式,但增加了邮件主体的结构,并定义了传送非 ASCII 码的编码规则。
117 | ## 动态主机配置协议 DHCP
118 | ### DHCP (Dynamic Host Configuration Protocol) 提供了即插即用的连网方式,用户不再需要手动配置 IP 地址等信息。
119 | ### DHCP 配置的内容不仅是 IP 地址,还包括子网掩码、网关 IP 地址。
120 | ### DHCP 工作过程如下:
121 | * 1.客户端发送 Discover 报文,该报文的目的地址为 255.255.255.255:67,源地址为 0.0.0.0:68,被放入 UDP 中,该报文被广播到同一个子网的所有主机上。如果客户端和 DHCP 服务器不在同一个子网,就需要使用中继代理。
122 | 2.DHCP 服务器收到 Discover 报文之后,发送 Offer 报文给客户端,该报文包含了客户端所需要的信息。因为客户端可能收到多个 DHCP 服务器提供的信息,因此客户端需要进行选择。
123 | 3.如果客户端选择了某个 DHCP 服务器提供的信息,那么就发送 Request 报文给该 DHCP 服务器。
124 | 4.DHCP 服务器发送 Ack 报文,表示客户端此时可以使用提供给它的信息。
125 | ## 简单网络管理协议 SNMP
126 | ### 网络管理的基本概念
127 | * 网络管理包括对硬件、软件和人力的使用、综合与协调,以便对网络资源进行监视、测试、配置、分析、评价和控制,这样就能以合理的价格满足网络的一些需求,如实时运行性能,服务质量等。网络管理常简称为网管。
128 | * SNMP 的网络管理由三个部分组成
129 | * SNMP 本身
130 | * SNMP 定义了管理站和代理之间所交换的分组格式。所交换的分组包含各代理中的对象(变量)名及其状态(值)。
131 | * 管理信息结构 SMI (Structure of Management Information)
132 | * SMI 定义了命名对象和定义对象类型(包括范围和长度)的通用规则,以及把对象和对象的值进行编码的规则。
133 | * 管理信息库 MIB(Management Information Base)。
134 | * MIB 在被管理的实体中创建了命名对象,并规定了其类型。
135 | ### 管理信息结构 SMI
136 | * SMI 的功能:
137 | * (1) 被管对象应怎样命名;
138 | * (2) 用来存储被管对象的数据类型有哪些种;
139 | * (3) 在网络上传送的管理数据应如何编码。
140 | ### 管理信息库 MIB
141 | * 被管对象必须维持可供管理程序读写的若干控制和状态信息。这些信息总称为管理信息库 MIB 。
142 | ### SNMP 的协议数据单元和报文
143 | * SNMP的操作只有两种基本的管理功能,即:
144 | * “读”操作,用 get 报文来检测各被管对象的状况;
145 | * “写”操作,用 set 报文来改变各被管对象的状况。
146 | * SNMP 的报文格式
147 | ## 应用进程跨越网络的通信
148 | ### 系统调用和应用编程接口
149 | ### 几种常用的系统调用
150 |
151 | 
152 |
--------------------------------------------------------------------------------
/计算机网络/第 6 章 应用层/第 6 章 应用层.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/计算机网络/第 6 章 应用层/第 6 章 应用层.png
--------------------------------------------------------------------------------
/计算机网络/第 6 章 应用层/第 6 章 应用层.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/donjy/408/cc8c1022d2e310e6a245521b5777aed0a563d4a6/计算机网络/第 6 章 应用层/第 6 章 应用层.xmind
--------------------------------------------------------------------------------