(token, 1));
18 | }
19 | }
20 | }
21 | }
22 |
--------------------------------------------------------------------------------
/codes/scala/src/main/scala/ClassDemo.scala:
--------------------------------------------------------------------------------
1 | /**
2 | * 类和对象示例
3 | *
4 | * @author peng.zhang
5 | */
6 | class Point(val xc: Int, val yc: Int) {
7 | var x: Int = xc
8 | var y: Int = yc
9 |
10 | def move(dx: Int, dy: Int) {
11 | x = x + dx
12 | y = y + dy
13 | println("x 的坐标点 : " + x);
14 | println("y 的坐标点 : " + y);
15 | }
16 | }
17 |
18 | class Location(override val xc: Int, override val yc: Int, val zc: Int)
19 | extends Point(xc, yc) {
20 | var z: Int = zc
21 |
22 | def move(dx: Int, dy: Int, dz: Int) {
23 | x = x + dx
24 | y = y + dy
25 | z = z + dz
26 | println("x 的坐标点 : " + x);
27 | println("y 的坐标点 : " + y);
28 | println("z 的坐标点 : " + z);
29 | }
30 | }
31 |
32 | object Test {
33 | def main(args: Array[String]) {
34 | val loc = new Location(10, 20, 15);
35 |
36 | // 移到一个新的位置
37 | loc.move(10, 10, 5);
38 | }
39 | }
40 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/springboot/KafkaProducerController.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.springboot;
2 |
3 | import org.springframework.beans.factory.annotation.Autowired;
4 | import org.springframework.web.bind.annotation.RequestMapping;
5 | import org.springframework.web.bind.annotation.RestController;
6 |
7 | /**
8 | * spring-boot kafka 示例
9 | *
10 | * 此 Controller 作为生产者,接受REST接口传入的消息,并写入到指定 Kafka Topic
11 | *
12 | * 访问方式:http://localhost:8080/kafka/send?topic=xxx&data=xxx
13 | * @author Zhang Peng
14 | */
15 | @RestController
16 | @RequestMapping("kafka")
17 | public class KafkaProducerController {
18 |
19 | @Autowired
20 | private KafkaProducer kafkaProducer;
21 |
22 | @RequestMapping("sendTx")
23 | public void send(String topic, String data) {
24 | kafkaProducer.sendTransactionMsg(topic, data);
25 | }
26 |
27 | }
28 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/resources/application.properties:
--------------------------------------------------------------------------------
1 | server.port = 18080
2 | spring.kafka.bootstrap-servers = localhost:9092
3 | #spring.kafka.bootstrap-servers = tdh60dev01:9092,tdh60dev02:9092,tdh60dev03:9092
4 | spring.kafka.producer.retries = 3
5 | spring.kafka.producer.transaction-id-prefix = bigdata-kafka
6 | # producer
7 | spring.kafka.producer.batch-size = 1000
8 | spring.kafka.producer.key-serializer = org.apache.kafka.common.serialization.StringSerializer
9 | spring.kafka.producer.value-serializer = org.apache.kafka.common.serialization.StringSerializer
10 | # consumer
11 | spring.kafka.consumer.group-id = bigdata
12 | spring.kafka.consumer.enable-auto-commit = true
13 | spring.kafka.consumer.auto-commit-interval = 1000
14 | spring.kafka.consumer.key-deserializer = org.apache.kafka.common.serialization.StringDeserializer
15 | spring.kafka.consumer.value-deserializer = org.apache.kafka.common.serialization.StringDeserializer
16 |
--------------------------------------------------------------------------------
/codes/hbase/pom.xml:
--------------------------------------------------------------------------------
1 |
2 |
4 | 4.0.0
5 |
6 | io.github.dunwu.bigdata
7 | hbase
8 | 大数据 - HBase
9 | 1.0.0
10 | pom
11 |
12 |
13 | UTF-8
14 | UTF-8
15 | 1.8
16 | ${java.version}
17 | ${java.version}
18 |
19 |
20 |
21 | hbase-java-api-1.x
22 | hbase-java-api-2.x
23 |
24 |
25 |
--------------------------------------------------------------------------------
/codes/zookeeper/src/main/java/io/github/dunwu/bigdata/zk/config/ConnectionWatcher.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.zk.config;
2 |
3 | import org.apache.zookeeper.WatchedEvent;
4 | import org.apache.zookeeper.Watcher;
5 | import org.apache.zookeeper.Watcher.Event.KeeperState;
6 | import org.apache.zookeeper.ZooKeeper;
7 |
8 | import java.io.IOException;
9 | import java.util.concurrent.CountDownLatch;
10 |
11 | public class ConnectionWatcher implements Watcher {
12 |
13 | private static final int SESSION_TIMEOUT = 5000;
14 |
15 | protected ZooKeeper zk;
16 | private CountDownLatch connectedSignal = new CountDownLatch(1);
17 |
18 | public void connect(String hosts) throws IOException, InterruptedException {
19 | zk = new ZooKeeper(hosts, SESSION_TIMEOUT, this);
20 | connectedSignal.await();
21 | }
22 |
23 | @Override
24 | public void process(WatchedEvent event) {
25 | if (event.getState() == KeeperState.SyncConnected) {
26 | connectedSignal.countDown();
27 | }
28 | }
29 |
30 | public void close() throws InterruptedException {
31 | zk.close();
32 | }
33 |
34 | }
35 |
--------------------------------------------------------------------------------
/docs/16.大数据/03.hbase/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: HBase 教程
3 | date: 2020-09-09 17:53:08
4 | categories:
5 | - 大数据
6 | - hbase
7 | tags:
8 | - 大数据
9 | - HBase
10 | permalink: /pages/417be6/
11 | hidden: true
12 | ---
13 |
14 | # HBase 教程
15 |
16 | ## 📖 内容
17 |
18 | - [HBase 原理](01.HBase原理.md)
19 | - [HBase 命令](02.HBase命令.md)
20 | - [HBase 运维](03.HBase运维.md)
21 |
22 | ## 📚 资料
23 |
24 | - **官方**
25 | - [HBase 官网](http://hbase.apache.org/)
26 | - [HBase 官方文档](https://hbase.apache.org/book.html)
27 | - [HBase 官方文档中文版](http://abloz.com/hbase/book.html)
28 | - [HBase API](https://hbase.apache.org/apidocs/index.html)
29 | - **教程**
30 | - [BigData-Notes](https://github.com/heibaiying/BigData-Notes)
31 | - **书籍**
32 | - [《Hadoop 权威指南(第四版)》](https://item.jd.com/12109713.html)
33 | - **文章**
34 | - [Bigtable: A Distributed Storage System for Structured Data](https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/bigtable-osdi06.pdf)
35 | - [Intro to HBase](https://www.slideshare.net/alexbaranau/intro-to-hbase)
36 |
37 | ## 🚪 传送
38 |
39 | ◾ 💧 [钝悟的 IT 知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [钝悟的博客](https://dunwu.github.io/blog/) ◾
40 |
--------------------------------------------------------------------------------
/docs/16.大数据/13.flink/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Flink 教程
3 | date: 2022-02-21 09:30:27
4 | categories:
5 | - 大数据
6 | - flink
7 | tags:
8 | - 大数据
9 | - Flink
10 | permalink: /pages/5c85bd/
11 | hidden: true
12 | ---
13 |
14 | # Flink 教程
15 |
16 | > Apache Flink 是一个框架和分布式处理引擎,用于在**无边界**和**有边界**数据流上进行**有状态**的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
17 |
18 | ## 📖 内容
19 |
20 | ### [Flink 入门](01.Flink入门.md)
21 |
22 | ### [Flink 简介](02.Flink简介.md)
23 |
24 | ### [Flink ETL](03.FlinkETL.md)
25 |
26 | ### [Flink 事件驱动](04.Flink事件驱动.md)
27 |
28 | ### [Flink API](05.FlinkApi.md)
29 |
30 | ### [Flink 架构](06.Flink架构.md)
31 |
32 | ### [Flink 运维](07.Flink运维.md)
33 |
34 | ### [Flink Table API & SQL](08.FlinkTableApi.md)
35 |
36 | ## 📚 资料
37 |
38 | - **官方**
39 | - [Flink Github](https://github.com/apache/flink)
40 | - [Flink 官方文档](https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/)
41 | - **教程**
42 | - [flink-learning](https://github.com/zhisheng17/flink-learning)
43 | - [flink-training-course](https://github.com/flink-china/flink-training-course) - Flink 中文视频课程
44 |
45 | ## 🚪 传送
46 |
47 | ◾ 💧 [钝悟的 IT 知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [钝悟的博客](https://dunwu.github.io/blog/) ◾
48 |
--------------------------------------------------------------------------------
/codes/zookeeper/src/main/java/io/github/dunwu/bigdata/zk/config/ConfigUpdater.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.zk.config;
2 |
3 | import org.apache.zookeeper.KeeperException;
4 |
5 | import java.io.IOException;
6 | import java.util.Random;
7 | import java.util.concurrent.TimeUnit;
8 |
9 | public class ConfigUpdater {
10 |
11 | public static final String PATH = "/config";
12 |
13 | private ActiveKeyValueStore store;
14 | private Random random = new Random();
15 |
16 | public ConfigUpdater(String hosts) throws IOException, InterruptedException {
17 | store = new ActiveKeyValueStore();
18 | store.connect(hosts);
19 | }
20 |
21 | public void run() throws InterruptedException, KeeperException {
22 | while (true) {
23 | String value = random.nextInt(100) + "";
24 | store.write(PATH, value);
25 | System.out.printf("Set %s to %s\n", PATH, value);
26 | TimeUnit.SECONDS.sleep(random.nextInt(10));
27 | }
28 | }
29 |
30 | public static void main(String[] args) throws Exception {
31 | ConfigUpdater configUpdater = new ConfigUpdater("localhost");
32 | configUpdater.run();
33 | }
34 |
35 | }
36 |
--------------------------------------------------------------------------------
/codes/zookeeper/src/main/java/io/github/dunwu/bigdata/zk/config/ActiveKeyValueStore.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.zk.config;
2 |
3 | import org.apache.zookeeper.CreateMode;
4 | import org.apache.zookeeper.KeeperException;
5 | import org.apache.zookeeper.Watcher;
6 | import org.apache.zookeeper.ZooDefs.Ids;
7 | import org.apache.zookeeper.data.Stat;
8 |
9 | import java.nio.charset.Charset;
10 |
11 | public class ActiveKeyValueStore extends ConnectionWatcher {
12 |
13 | private static final Charset CHARSET = Charset.forName("UTF-8");
14 |
15 | public void write(String path, String value) throws InterruptedException,
16 | KeeperException {
17 | Stat stat = zk.exists(path, false);
18 | if (stat == null) {
19 | zk.create(path, value.getBytes(CHARSET), Ids.OPEN_ACL_UNSAFE,
20 | CreateMode.PERSISTENT);
21 | } else {
22 | zk.setData(path, value.getBytes(CHARSET), -1);
23 | }
24 | }
25 |
26 | public String read(String path, Watcher watcher) throws InterruptedException,
27 | KeeperException {
28 | byte[] data = zk.getData(path, watcher, null/*stat*/);
29 | return new String(data, CHARSET);
30 | }
31 |
32 | }
33 |
--------------------------------------------------------------------------------
/.gitattributes:
--------------------------------------------------------------------------------
1 | * text=auto eol=lf
2 |
3 | # plan text
4 | *.txt text
5 | *.java text
6 | *.scala text
7 | *.groovy text
8 | *.gradle text
9 | *.xml text
10 | *.xsd text
11 | *.tld text
12 | *.yaml text
13 | *.yml text
14 | *.wsdd text
15 | *.wsdl text
16 | *.jsp text
17 | *.jspf text
18 | *.js text
19 | *.jsx text
20 | *.json text
21 | *.css text
22 | *.less text
23 | *.sql text
24 | *.properties text
25 | *.md text
26 |
27 | # unix style
28 | *.sh text eol=lf
29 |
30 | # win style
31 | *.bat text eol=crlf
32 |
33 | # don't handle
34 | *.der -text
35 | *.jks -text
36 | *.pfx -text
37 | *.map -text
38 | *.patch -text
39 | *.dat -text
40 | *.data -text
41 | *.db -text
42 |
43 | # binary
44 | *.jar binary
45 | *.war binary
46 | *.zip binary
47 | *.tar binary
48 | *.tar.gz binary
49 | *.gz binary
50 | *.apk binary
51 | *.bin binary
52 | *.exe binary
53 |
54 | # images
55 | *.png binary
56 | *.jpg binary
57 | *.ico binary
58 | *.gif binary
59 |
60 | # medias
61 | *.mp3 binary
62 | *.swf binary
63 |
64 | # fonts
65 | *.eot binary
66 | *.svg binary
67 | *.ttf binary
68 | *.woff binary
69 |
70 | # others
71 | *.pdf binary
72 | *.doc binary
73 | *.docx binary
74 | *.ppt binary
75 | *.pptx binary
76 | *.xls binary
77 | *.xlsx binary
78 | *.xmind binary
79 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/springboot/KafkaProducer.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.springboot;
2 |
3 | import org.slf4j.Logger;
4 | import org.slf4j.LoggerFactory;
5 | import org.springframework.beans.factory.annotation.Autowired;
6 | import org.springframework.kafka.core.KafkaTemplate;
7 | import org.springframework.stereotype.Component;
8 | import org.springframework.transaction.annotation.Transactional;
9 |
10 | /**
11 | * Kafka生产者
12 | * @author Zhang Peng
13 | * @since 2018-11-29
14 | */
15 | @Component
16 | public class KafkaProducer {
17 |
18 | private final Logger log = LoggerFactory.getLogger(KafkaProducer.class);
19 |
20 | @Autowired
21 | private KafkaTemplate template;
22 |
23 | @Transactional(rollbackFor = RuntimeException.class)
24 | public void sendTransactionMsg(String topic, String data) {
25 | log.info("向kafka发送数据:[{}]", data);
26 | template.executeInTransaction(t -> {
27 | t.send(topic, "prepare");
28 | if ("error".equals(data)) {
29 | throw new RuntimeException("failed");
30 | }
31 | t.send(topic, "finish");
32 | return true;
33 | });
34 | }
35 |
36 | }
37 |
--------------------------------------------------------------------------------
/scripts/deploy.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 |
3 | # ------------------------------------------------------------------------------
4 | # gh-pages 部署脚本
5 | # @author Zhang Peng
6 | # @since 2020/2/10
7 | # ------------------------------------------------------------------------------
8 |
9 | # 装载其它库
10 | ROOT_DIR=$(
11 | cd $(dirname $0)/..
12 | pwd
13 | )
14 |
15 | # 确保脚本抛出遇到的错误
16 | set -e
17 |
18 | # 生成静态文件
19 | npm run build
20 |
21 | # 进入生成的文件夹
22 | cd ${ROOT_DIR}/docs/.temp
23 |
24 | # 如果是发布到自定义域名
25 | # echo 'www.example.com' > CNAME
26 |
27 | if [[ ${GITHUB_TOKEN} && ${GITEE_TOKEN} ]]; then
28 | msg='自动部署'
29 | GITHUB_URL=https://dunwu:${GITHUB_TOKEN}@github.com/dunwu/bigdata-tutorial.git
30 | GITEE_URL=https://turnon:${GITEE_TOKEN}@gitee.com/turnon/bigdata-tutorial.git
31 | git config --global user.name "dunwu"
32 | git config --global user.email "forbreak@163.com"
33 | else
34 | msg='手动部署'
35 | GITHUB_URL=git@github.com:dunwu/bigdata-tutorial.git
36 | GITEE_URL=git@gitee.com:turnon/bigdata-tutorial.git
37 | fi
38 | git init
39 | git add -A
40 | git commit -m "${msg}"
41 | # 推送到github gh-pages分支
42 | git push -f "${GITHUB_URL}" master:gh-pages
43 | git push -f "${GITEE_URL}" master:gh-pages
44 |
45 | cd -
46 | rm -rf ${ROOT_DIR}/docs/.temp
47 |
--------------------------------------------------------------------------------
/docs/16.大数据/01.hadoop/01.hdfs/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: HDFS 教程
3 | date: 2022-02-21 20:26:47
4 | categories:
5 | - 大数据
6 | - hadoop
7 | - hdfs
8 | tags:
9 | - 大数据
10 | - Hadoop
11 | - HDFS
12 | permalink: /pages/8d798e/
13 | hidden: true
14 | ---
15 |
16 | # HDFS 教程
17 |
18 | > **HDFS** 是 **Hadoop Distributed File System** 的缩写,即 Hadoop 的分布式文件系统。
19 | >
20 | > HDFS 是一种用于存储具有流数据访问模式的超大文件的文件系统,它运行在廉价的机器集群上。
21 | >
22 | > HDFS 的设计目标是管理数以千计的服务器、数以万计的磁盘,将这么大规模的服务器计算资源当作一个单一的存储系统进行管理,对应用程序提供数以 PB 计的存储容量,让应用程序像使用普通文件系统一样存储大规模的文件数据。
23 | >
24 | > HDFS 是在一个大规模分布式服务器集群上,对数据分片后进行并行读写及冗余存储。因为 HDFS 可以部署在一个比较大的服务器集群上,集群中所有服务器的磁盘都可供 HDFS 使用,所以整个 HDFS 的存储空间可以达到 PB 级容量。
25 |
26 | ## 📖 内容
27 |
28 | - [HDFS 入门](01.HDFS入门.md)
29 | - [HDFS 运维](02.HDFS运维.md)
30 | - [HDFS Java API](03.HDFSJavaApi.md)
31 |
32 | ## 📚 资料
33 |
34 | - **官方**
35 | - [HDFS 官方文档](http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html)
36 | - **书籍**
37 | - [《Hadoop 权威指南(第四版)》](https://item.jd.com/12109713.html)
38 | - **文章**
39 | - [翻译经典 HDFS 原理讲解漫画](https://blog.csdn.net/hudiefenmu/article/details/37655491)
40 | - [HDFS 知识点总结](https://www.cnblogs.com/caiyisen/p/7395843.html)
41 |
42 | ## 🚪 传送
43 |
44 | ◾ 💧 [钝悟的 IT 知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [钝悟的博客](https://dunwu.github.io/blog/) ◾
45 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # ---------------------------------------------------------------------
2 | # more gitignore templates see https://github.com/github/gitignore
3 | # ---------------------------------------------------------------------
4 |
5 | # ------------------------------- java -------------------------------
6 | # compiled folders
7 | classes
8 | target
9 | logs
10 | .mtj.tmp/
11 |
12 | # compiled files
13 | *.class
14 |
15 | # bluej files
16 | *.ctxt
17 |
18 | # package files #
19 | *.jar
20 | *.war
21 | *.nar
22 | *.ear
23 | *.zip
24 | *.tar.gz
25 | *.rar
26 |
27 | # virtual machine crash logs
28 | hs_err_pid*
29 |
30 | # maven plugin temp files
31 | .flattened-pom.xml
32 |
33 |
34 | # ------------------------------- javascript -------------------------------
35 | # dependencies
36 | node_modules
37 |
38 | # temp folders
39 | build
40 | dist
41 | _book
42 | _jsdoc
43 | .temp
44 | .deploy*/
45 |
46 | # temp files
47 | *.log
48 | npm-debug.log*
49 | yarn-debug.log*
50 | yarn-error.log*
51 | bundle*.js
52 | .DS_Store
53 | Thumbs.db
54 | db.json
55 | book.pdf
56 | package-lock.json
57 |
58 |
59 | # ------------------------------- intellij -------------------------------
60 | .idea
61 | *.iml
62 |
63 |
64 | # ------------------------------- eclipse -------------------------------
65 | .classpath
66 | .project
67 |
--------------------------------------------------------------------------------
/codes/hbase/hbase-java-api-2.x/pom.xml:
--------------------------------------------------------------------------------
1 |
2 |
4 | 4.0.0
5 |
6 | io.github.dunwu.bigdata
7 | hbase-java-api-2.x
8 | 大数据 - HBase - API - 2.x
9 | 1.0.0
10 | jar
11 |
12 |
13 | UTF-8
14 | UTF-8
15 | 1.8
16 | ${java.version}
17 | ${java.version}
18 |
19 |
20 |
21 |
22 | org.apache.hbase
23 | hbase-client
24 | 2.1.4
25 |
26 |
27 | junit
28 | junit
29 | 4.12
30 | test
31 |
32 |
33 |
34 |
35 |
--------------------------------------------------------------------------------
/codes/flink/src/main/java/io/github/dunwu/bigdata/flink/WordCount.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.flink;
2 |
3 | import org.apache.flink.api.java.DataSet;
4 | import org.apache.flink.api.java.ExecutionEnvironment;
5 | import org.apache.flink.api.java.aggregation.Aggregations;
6 | import org.apache.flink.api.java.tuple.Tuple2;
7 |
8 | public class WordCount {
9 |
10 | public static void main(String[] args) throws Exception {
11 |
12 | // 设置运行环境
13 | final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
14 |
15 | // 配置数据源
16 | // you can also use env.readTextFile(...) to get words
17 | DataSet text = env.fromElements("To be, or not to be,--that is the question:--",
18 | "Whether 'tis nobler in the mind to suffer",
19 | "The slings and arrows of outrageous fortune",
20 | "Or to take arms against a sea of troubles,");
21 |
22 | // 进行一系列转换
23 | DataSet> counts =
24 | // split up the lines in pairs (2-tuples) containing: (word,1)
25 | text.flatMap(new LineSplitter())
26 | // group by the tuple field "0" and sum up tuple field "1"
27 | .groupBy(0).aggregate(Aggregations.SUM, 1);
28 |
29 | // emit result
30 | counts.print();
31 | }
32 |
33 | }
34 |
--------------------------------------------------------------------------------
/utils/modules/readFileList.js:
--------------------------------------------------------------------------------
1 | /**
2 | * 读取所有md文件数据
3 | */
4 | const fs = require('fs'); // 文件模块
5 | const path = require('path'); // 路径模块
6 | const docsRoot = path.join(__dirname, '..', '..', 'docs'); // docs文件路径
7 |
8 | function readFileList(dir = docsRoot, filesList = []) {
9 | const files = fs.readdirSync(dir);
10 | files.forEach( (item, index) => {
11 | let filePath = path.join(dir, item);
12 | const stat = fs.statSync(filePath);
13 | if (stat.isDirectory() && item !== '.vuepress') {
14 | readFileList(path.join(dir, item), filesList); //递归读取文件
15 | } else {
16 | if(path.basename(dir) !== 'docs'){ // 过滤docs目录级下的文件
17 |
18 | const fileNameArr = path.basename(filePath).split('.')
19 | let name = null, type = null;
20 | if (fileNameArr.length === 2) { // 没有序号的文件
21 | name = fileNameArr[0]
22 | type = fileNameArr[1]
23 | } else if (fileNameArr.length === 3) { // 有序号的文件
24 | name = fileNameArr[1]
25 | type = fileNameArr[2]
26 | } else { // 超过两个‘.’的
27 | log(chalk.yellow(`warning: 该文件 "${filePath}" 没有按照约定命名,将忽略生成相应数据。`))
28 | return
29 | }
30 | if(type === 'md'){ // 过滤非md文件
31 | filesList.push({
32 | name,
33 | filePath
34 | });
35 | }
36 |
37 | }
38 | }
39 | });
40 | return filesList;
41 | }
42 |
43 | module.exports = readFileList;
--------------------------------------------------------------------------------
/package.json:
--------------------------------------------------------------------------------
1 | {
2 | "name": "bigdata-tutorial",
3 | "version": "1.0.0",
4 | "private": true,
5 | "scripts": {
6 | "clean": "rimraf docs/.temp",
7 | "start": "vuepress dev docs",
8 | "build": "vuepress build docs",
9 | "deploy": "bash scripts/deploy.sh",
10 | "updateTheme": "yarn remove vuepress-theme-vdoing && rm -rf node_modules && yarn && yarn add vuepress-theme-vdoing -D",
11 | "editFm": "node utils/editFrontmatter.js",
12 | "lint": "markdownlint -r markdownlint-rule-emphasis-style -c docs/.markdownlint.json **/*.md -i node_modules",
13 | "lint:fix": "markdownlint -f -r markdownlint-rule-emphasis-style -c docs/.markdownlint.json **/*.md -i node_modules",
14 | "show-help": "vuepress --help",
15 | "view-info": "vuepress view-info ./ --temp docs/.temp"
16 | },
17 | "devDependencies": {
18 | "dayjs": "^1.11.7",
19 | "inquirer": "^7.1.0",
20 | "json2yaml": "^1.1.0",
21 | "markdownlint-cli": "^0.25.0",
22 | "markdownlint-rule-emphasis-style": "^1.0.1",
23 | "rimraf": "^3.0.1",
24 | "vue-toasted": "^1.1.25",
25 | "vuepress": "^1.9.8",
26 | "vuepress-plugin-baidu-tongji": "^1.0.1",
27 | "vuepress-plugin-comment": "^0.7.3",
28 | "vuepress-plugin-demo-block": "^0.7.2",
29 | "vuepress-plugin-flowchart": "^1.4.2",
30 | "vuepress-plugin-fulltext-search": "^2.2.1",
31 | "vuepress-plugin-one-click-copy": "^1.0.2",
32 | "vuepress-plugin-thirdparty-search": "^1.0.2",
33 | "vuepress-plugin-zooming": "^1.1.7",
34 | "vuepress-theme-vdoing": "^1.12.8",
35 | "yamljs": "^0.3.0"
36 | }
37 | }
38 |
--------------------------------------------------------------------------------
/docs/16.大数据/99.其他/02.sqoop.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: sqoop
3 | date: 2020-09-09 17:53:08
4 | categories:
5 | - 大数据
6 | - 其他
7 | tags:
8 | - 大数据
9 | - Sqoop
10 | permalink: /pages/773408/
11 | ---
12 |
13 | # Sqoop
14 |
15 | > **Sqoop 是一个主要在 Hadoop 和关系数据库之间进行批量数据迁移的工具。**
16 |
17 | ## Sqoop 简介
18 |
19 | **Sqoop 是一个主要在 Hadoop 和关系数据库之间进行批量数据迁移的工具。**
20 |
21 | - Hadoop:HDFS、Hive、HBase、Inceptor、Hyperbase
22 | - 面向大数据集的批量导入导出
23 | - 将输入数据集分为 N 个切片,然后启动 N 个 Map 任务并行传输
24 | - 支持全量、增量两种传输方式
25 |
26 | ### 提供多种 Sqoop 连接器
27 |
28 | #### 内置连接器
29 |
30 | - 经过优化的专用 RDBMS 连接器:MySQL、PostgreSQL、Oracle、DB2、SQL Server、Netzza 等
31 | - 通用的 JDBC 连接器:支持 JDBC 协议的数据库
32 |
33 | #### 第三方连接器
34 |
35 | - 数据仓库:Teradata
36 | - NoSQL 数据库:Couchbase
37 |
38 | ### Sqoop 版本
39 |
40 | #### Sqoop 1 优缺点
41 |
42 | 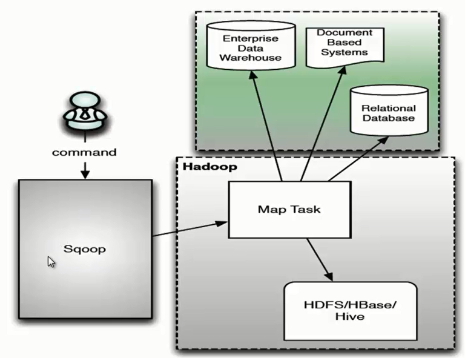
43 |
44 | 优点
45 |
46 | - 架构简单
47 | - 部署简单
48 | - 功能全面
49 | - 稳定性较高
50 | - 速度较快
51 |
52 | 缺点
53 |
54 | - 访问方式单一
55 | - 命令行方式容易出错,格式紧耦合
56 | - 安全机制不够完善,存在密码泄露风险
57 |
58 | #### Sqoop 2 优缺点
59 |
60 | 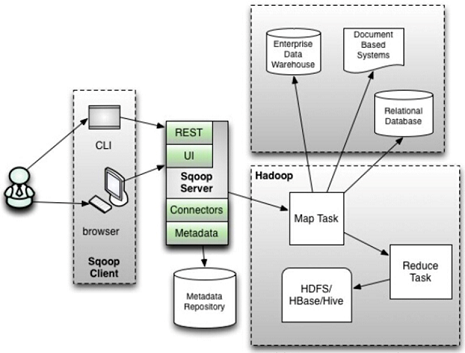
61 |
62 | 优点
63 |
64 | - 访问方式多样
65 | - 集中管理连接器
66 | - 安全机制较完善
67 | - 支持多用户
68 |
69 | 缺点
70 |
71 | - 架构较复杂
72 | - 部署较繁琐
73 | - 稳定性一般
74 | - 速度一般
75 |
76 | ## Sqoop 原理
77 |
78 | ### 导入
79 |
80 | 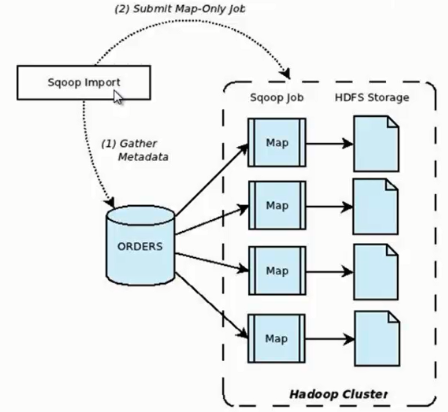
81 |
82 | ### 导出
83 |
84 | 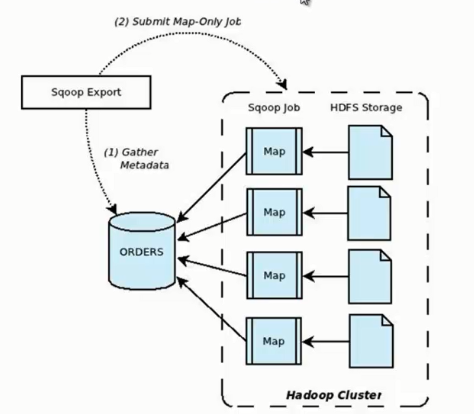
85 |
--------------------------------------------------------------------------------
/codes/zookeeper/src/main/java/io/github/dunwu/bigdata/zk/config/ResilientConfigUpdater.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.zk.config;
2 |
3 | import java.io.IOException;
4 | import java.util.Random;
5 | import java.util.concurrent.TimeUnit;
6 |
7 | import org.apache.zookeeper.KeeperException;
8 |
9 | public class ResilientConfigUpdater {
10 |
11 | public static final String PATH = "/config";
12 |
13 | private ResilientActiveKeyValueStore store;
14 | private Random random = new Random();
15 |
16 | public ResilientConfigUpdater(String hosts) throws IOException,
17 | InterruptedException {
18 | store = new ResilientActiveKeyValueStore();
19 | store.connect(hosts);
20 | }
21 |
22 | public void run() throws InterruptedException, KeeperException {
23 | while (true) {
24 | String value = random.nextInt(100) + "";
25 | store.write(PATH, value);
26 | System.out.printf("Set %s to %s\n", PATH, value);
27 | TimeUnit.SECONDS.sleep(random.nextInt(10));
28 | }
29 | }
30 |
31 | //vv ResilientConfigUpdater
32 | public static void main(String[] args) throws Exception {
33 | /*[*/while (true) {
34 | try {/*]*/
35 | ResilientConfigUpdater configUpdater =
36 | new ResilientConfigUpdater(args[0]);
37 | configUpdater.run();
38 | /*[*/} catch (KeeperException.SessionExpiredException e) {
39 | // start a new session
40 | } catch (KeeperException e) {
41 | // already retried, so exit
42 | e.printStackTrace();
43 | break;
44 | }
45 | }/*]*/
46 | }
47 | //^^ ResilientConfigUpdater
48 | }
49 |
--------------------------------------------------------------------------------
/codes/hbase/hbase-java-api-1.x/pom.xml:
--------------------------------------------------------------------------------
1 |
2 |
4 | 4.0.0
5 |
6 | io.github.dunwu.bigdata
7 | hbase-java-api-1.x
8 | 大数据 - HBase - API - 1.x
9 | 1.0.0
10 | jar
11 |
12 |
13 | UTF-8
14 | UTF-8
15 | 1.8
16 | ${java.version}
17 | ${java.version}
18 |
19 |
20 |
21 |
22 | org.apache.hbase
23 | hbase-client
24 | 1.3.1
25 |
26 |
27 | log4j
28 | log4j
29 | 1.2.17
30 |
31 |
32 | junit
33 | junit
34 | 4.12
35 |
36 |
37 | io.github.dunwu
38 | dunwu-tool-core
39 | 0.5.6
40 |
41 |
42 |
43 |
44 |
--------------------------------------------------------------------------------
/docs/.vuepress/styles/palette.styl:
--------------------------------------------------------------------------------
1 |
2 | // 原主题变量已弃用,以下是vdoing使用的变量,你可以在这个文件内修改它们。
3 |
4 | //***vdoing主题-变量***//
5 |
6 | // // 颜色
7 |
8 | // $bannerTextColor = #fff // 首页banner区(博客标题)文本颜色
9 | // $accentColor = #11A8CD
10 | // $arrowBgColor = #ccc
11 | // $badgeTipColor = #42b983
12 | // $badgeWarningColor = darken(#ffe564, 35%)
13 | // $badgeErrorColor = #DA5961
14 |
15 | // // 布局
16 | // $navbarHeight = 3.6rem
17 | // $sidebarWidth = 18rem
18 | // $contentWidth = 860px
19 | // $homePageWidth = 1100px
20 | // $rightMenuWidth = 230px // 右侧菜单
21 |
22 | // // 代码块
23 | // $lineNumbersWrapperWidth = 2.5rem
24 |
25 | // 浅色模式
26 | .theme-mode-light
27 | --bodyBg: rgba(255,255,255,1)
28 | --mainBg: rgba(255,255,255,1)
29 | --sidebarBg: rgba(255,255,255,.8)
30 | --blurBg: rgba(255,255,255,.9)
31 | --textColor: #004050
32 | --textLightenColor: #0085AD
33 | --borderColor: rgba(0,0,0,.15)
34 | --codeBg: #f6f6f6
35 | --codeColor: #525252
36 | codeThemeLight()
37 |
38 | // 深色模式
39 | .theme-mode-dark
40 | --bodyBg: rgba(30,30,34,1)
41 | --mainBg: rgba(30,30,34,1)
42 | --sidebarBg: rgba(30,30,34,.8)
43 | --blurBg: rgba(30,30,34,.8)
44 | --textColor: rgb(140,140,150)
45 | --textLightenColor: #0085AD
46 | --borderColor: #2C2C3A
47 | --codeBg: #252526
48 | --codeColor: #fff
49 | codeThemeDark()
50 |
51 | // 阅读模式
52 | .theme-mode-read
53 | --bodyBg: rgba(245,245,213,1)
54 | --mainBg: rgba(245,245,213,1)
55 | --sidebarBg: rgba(245,245,213,.8)
56 | --blurBg: rgba(245,245,213,.9)
57 | --textColor: #004050
58 | --textLightenColor: #0085AD
59 | --borderColor: rgba(0,0,0,.15)
60 | --codeBg: #282c34
61 | --codeColor: #fff
62 | codeThemeDark()
63 |
--------------------------------------------------------------------------------
/codes/hbase/hbase-java-api-1.x/src/main/resources/log4j.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
--------------------------------------------------------------------------------
/codes/zookeeper/src/main/java/io/github/dunwu/bigdata/zk/config/ConfigWatcher.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.zk.config;
2 |
3 | import org.apache.zookeeper.KeeperException;
4 | import org.apache.zookeeper.WatchedEvent;
5 | import org.apache.zookeeper.Watcher;
6 | import org.apache.zookeeper.Watcher.Event.EventType;
7 |
8 | import java.io.IOException;
9 |
10 | public class ConfigWatcher implements Watcher {
11 |
12 | private ActiveKeyValueStore store;
13 |
14 | public ConfigWatcher(String hosts) throws IOException, InterruptedException {
15 | store = new ActiveKeyValueStore();
16 | store.connect(hosts);
17 | }
18 |
19 | public void displayConfig() throws InterruptedException, KeeperException {
20 | String value = store.read(ConfigUpdater.PATH, this);
21 | System.out.printf("Read %s as %s\n", ConfigUpdater.PATH, value);
22 | }
23 |
24 | @Override
25 | public void process(WatchedEvent event) {
26 | if (event.getType() == EventType.NodeDataChanged) {
27 | try {
28 | displayConfig();
29 | } catch (InterruptedException e) {
30 | System.err.println("Interrupted. Exiting.");
31 | Thread.currentThread().interrupt();
32 | } catch (KeeperException e) {
33 | System.err.printf("KeeperException: %s. Exiting.\n", e);
34 | }
35 | }
36 | }
37 |
38 | public static void main(String[] args) throws Exception {
39 | ConfigWatcher configWatcher = new ConfigWatcher("localhost");
40 | configWatcher.displayConfig();
41 |
42 | // stay alive until process is killed or thread is interrupted
43 | Thread.sleep(Long.MAX_VALUE);
44 | }
45 |
46 | }
47 |
--------------------------------------------------------------------------------
/docs/16.大数据/99.其他/01.flume.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Flume
3 | date: 2019-05-07 20:19:25
4 | categories:
5 | - 大数据
6 | - 其他
7 | tags:
8 | - 大数据
9 | - Flume
10 | permalink: /pages/ac5a41/
11 | ---
12 |
13 | # Flume
14 |
15 | > **Sqoop 是一个主要在 Hadoop 和关系数据库之间进行批量数据迁移的工具。**
16 |
17 | ## Flume 简介
18 |
19 | ### 什么是 Flume ?
20 |
21 | Flume 是一个分布式海量数据采集、聚合和传输系统。
22 |
23 | 特点
24 |
25 | - 基于事件的海量数据采集
26 | - 数据流模型:Source -> Channel -> Sink
27 | - 事务机制:支持重读重写,保证消息传递的可靠性
28 | - 内置丰富插件:轻松与各种外部系统集成
29 | - 高可用:Agent 主备切换
30 | - Java 实现:开源,优秀的系统设计
31 |
32 | ### 应用场景
33 |
34 | ## Flume 原理
35 |
36 | ### Flume 基本概念
37 |
38 | - Event:事件,最小数据传输单元,由 Header 和 Body 组成。
39 | - Agent:代理,JVM 进程,最小运行单元,由 Source、Channel、Sink 三个基本组件构成,负责将外部数据源产生的数据以 Event 的形式传输到目的地
40 | - Source:负责对接各种外部数据源,将采集到的数据封装成 Event,然后写入 Channel
41 | - Channel:Event 暂存容器,负责保存 Source 发送的 Event,直至被 Sink 成功读取
42 | - Sink:负责从 Channel 读取 Event,然后将其写入外部存储,或传输给下一阶段的 Agent
43 | - 映射关系:1 个 Source -> 多个 Channel,1 个 Channel -> 多个 Sink,1 个 Sink -> 1 个 Channel
44 |
45 | ### Flume 基本组件
46 |
47 | #### Source 组件
48 |
49 | - 对接各种外部数据源,将采集到的数据封装成 Event,然后写入 Channel
50 | - 一个 Source 可向多个 Channel 发送 Event
51 | - Flume 内置类型丰富的 Source,同时用户可自定义 Source
52 |
53 | #### Channel 组件
54 |
55 | - Event 中转暂存区,存储 Source 采集但未被 Sink 读取的 Event
56 | - 为了平衡 Source 采集、Sink 读取的速度,可视为 Flume 内部的消息队列
57 | - 线程安全并具有事务性,支持 Source 写失败重写和 Sink 读失败重读
58 |
59 | #### Sink 组件
60 |
61 | - 从 Channel 读取 Event,将其写入外部存储,或传输到下一阶段的 Agent
62 | - 一个 Sink 只能从一个 Channel 中读取 Event
63 | - Sink 成功读取 Event 后,向 Channel 提交事务,Event 被删除,否则 Channel 会等待 Sink 重新读取
64 |
65 | ### Flume 数据流
66 |
67 | 单层架构
68 |
69 | 优点:架构简单,使用方便,占用资源较少
70 | 缺点
71 | 如果采集的数据源或 Agent 较多,将 Event 写入到 HDFS 会产生很多小文件
72 | 外部存储升级维护或发生故障,需对采集层的所有 Agent 做处理,人力成本较高,系统稳定性较差
73 | 系统安全性较差
74 | 数据源管理较混乱
75 |
--------------------------------------------------------------------------------
/codes/zookeeper/src/main/java/io/github/dunwu/bigdata/zk/dlock/ZkDLockTemplate.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.zk.dlock;
2 |
3 | import org.apache.curator.framework.CuratorFramework;
4 | import org.slf4j.Logger;
5 | import org.slf4j.LoggerFactory;
6 |
7 | import java.util.concurrent.TimeUnit;
8 |
9 | /**
10 | * Created by sunyujia@aliyun.com on 2016/2/26.
11 | */
12 | public class ZkDLockTemplate implements DLockTemplate {
13 |
14 | private static final Logger log = LoggerFactory.getLogger(ZkDLockTemplate.class);
15 |
16 | private final CuratorFramework client;
17 |
18 | public ZkDLockTemplate(CuratorFramework client) {
19 | this.client = client;
20 | }
21 |
22 | @Override
23 | public V execute(String lockId, long timeout, Callback callback) {
24 | ZookeeperReentrantDistributedLock lock = null;
25 | boolean getLock = false;
26 | try {
27 | lock = new ZookeeperReentrantDistributedLock(client, lockId);
28 | if (tryLock(lock, timeout)) {
29 | getLock = true;
30 | return callback.onGetLock();
31 | } else {
32 | return callback.onTimeout();
33 | }
34 | } catch (InterruptedException ex) {
35 | log.error(ex.getMessage(), ex);
36 | Thread.currentThread().interrupt();
37 | } catch (Exception e) {
38 | log.error(e.getMessage(), e);
39 | } finally {
40 | if (getLock) {
41 | lock.unlock();
42 | }
43 | }
44 | return null;
45 | }
46 |
47 | private boolean tryLock(ZookeeperReentrantDistributedLock lock, long timeout) {
48 | return lock.tryLock(timeout, TimeUnit.MILLISECONDS);
49 | }
50 |
51 | }
52 |
--------------------------------------------------------------------------------
/codes/hbase/hbase-java-api-1.x/src/main/java/io/github/dunwu/bigdata/hbase/HBaseTableDTO.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.hbase;
2 |
3 | /**
4 | * @author Zhang Peng
5 | * @since 2019-03-04
6 | */
7 | public class HBaseTableDTO {
8 |
9 | private String tableName;
10 |
11 | private String row;
12 |
13 | private String colFamily;
14 |
15 | private String col;
16 |
17 | private String val;
18 |
19 | public HBaseTableDTO() {}
20 |
21 | public HBaseTableDTO(String row, String colFamily, String col, String val) {
22 | this.row = row;
23 | this.colFamily = colFamily;
24 | this.col = col;
25 | this.val = val;
26 | }
27 |
28 | public HBaseTableDTO(String tableName, String row, String colFamily, String col, String val) {
29 | this.tableName = tableName;
30 | this.row = row;
31 | this.colFamily = colFamily;
32 | this.col = col;
33 | this.val = val;
34 | }
35 |
36 | public String getTableName() {
37 | return tableName;
38 | }
39 |
40 | public void setTableName(String tableName) {
41 | this.tableName = tableName;
42 | }
43 |
44 | public String getRow() {
45 | return row;
46 | }
47 |
48 | public void setRow(String row) {
49 | this.row = row;
50 | }
51 |
52 | public String getColFamily() {
53 | return colFamily;
54 | }
55 |
56 | public void setColFamily(String colFamily) {
57 | this.colFamily = colFamily;
58 | }
59 |
60 | public String getCol() {
61 | return col;
62 | }
63 |
64 | public void setCol(String col) {
65 | this.col = col;
66 | }
67 |
68 | public String getVal() {
69 | return val;
70 | }
71 |
72 | public void setVal(String val) {
73 | this.val = val;
74 | }
75 |
76 | }
77 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/demo/KafkaProducerSendAsyncDemo.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.demo;
2 |
3 | import org.apache.kafka.clients.producer.KafkaProducer;
4 | import org.apache.kafka.clients.producer.Producer;
5 | import org.apache.kafka.clients.producer.ProducerConfig;
6 | import org.apache.kafka.clients.producer.ProducerRecord;
7 |
8 | import java.util.Properties;
9 |
10 | /**
11 | * Kafka 异步发送
12 | *
13 | * 直接发送消息,不关心消息是否到达。
14 | *
15 | * 这种方式吞吐量最高,但有小概率会丢失消息。
16 | *
17 | * 生产者配置参考:https://kafka.apache.org/documentation/#producerconfigs
18 | * @author Zhang Peng
19 | * @since 2020-06-20
20 | */
21 | public class KafkaProducerSendAsyncDemo {
22 |
23 | private static Producer producer;
24 |
25 | static {
26 | // 指定生产者的配置
27 | final Properties properties = new Properties();
28 | properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
29 | properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
30 | "org.apache.kafka.common.serialization.StringSerializer");
31 | properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
32 | "org.apache.kafka.common.serialization.StringSerializer");
33 |
34 | // 使用配置初始化 Kafka 生产者
35 | producer = new KafkaProducer<>(properties);
36 | }
37 |
38 | public static void main(String[] args) {
39 | try {
40 | // 使用 send 方法发送异步消息
41 | for (int i = 0; i < 100; i++) {
42 | String msg = "Message " + i;
43 | producer.send(new ProducerRecord<>("test", msg));
44 | System.out.println("Sent:" + msg);
45 | }
46 | } catch (Exception e) {
47 | e.printStackTrace();
48 | } finally {
49 | // 关闭生产者
50 | producer.close();
51 | }
52 | }
53 |
54 | }
55 |
--------------------------------------------------------------------------------
/codes/zookeeper/src/main/java/io/github/dunwu/bigdata/zk/config/ResilientActiveKeyValueStore.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.zk.config;
2 |
3 | import org.apache.zookeeper.CreateMode;
4 | import org.apache.zookeeper.KeeperException;
5 | import org.apache.zookeeper.Watcher;
6 | import org.apache.zookeeper.ZooDefs.Ids;
7 | import org.apache.zookeeper.data.Stat;
8 |
9 | import java.nio.charset.Charset;
10 | import java.util.concurrent.TimeUnit;
11 |
12 | public class ResilientActiveKeyValueStore extends ConnectionWatcher {
13 |
14 | private static final Charset CHARSET = Charset.forName("UTF-8");
15 | private static final int MAX_RETRIES = 5;
16 | private static final int RETRY_PERIOD_SECONDS = 10;
17 |
18 | public void write(String path, String value) throws InterruptedException,
19 | KeeperException {
20 | int retries = 0;
21 | while (true) {
22 | try {
23 | Stat stat = zk.exists(path, false);
24 | if (stat == null) {
25 | zk.create(path, value.getBytes(CHARSET), Ids.OPEN_ACL_UNSAFE,
26 | CreateMode.PERSISTENT);
27 | } else {
28 | zk.setData(path, value.getBytes(CHARSET), stat.getVersion());
29 | }
30 | return;
31 | } catch (KeeperException.SessionExpiredException e) {
32 | throw e;
33 | } catch (KeeperException e) {
34 | if (retries++ == MAX_RETRIES) {
35 | throw e;
36 | }
37 | // sleep then retry
38 | TimeUnit.SECONDS.sleep(RETRY_PERIOD_SECONDS);
39 | }
40 | }
41 | }
42 |
43 | public String read(String path, Watcher watcher) throws InterruptedException,
44 | KeeperException {
45 | byte[] data = zk.getData(path, watcher, null/*stat*/);
46 | return new String(data, CHARSET);
47 | }
48 |
49 | }
50 |
--------------------------------------------------------------------------------
/codes/kafka/pom.xml:
--------------------------------------------------------------------------------
1 |
2 |
4 | 4.0.0
5 |
6 |
7 | org.springframework.boot
8 | spring-boot-starter-parent
9 | 2.6.3
10 |
11 |
12 | io.github.dunwu.bigdata
13 | kafka
14 | 大数据 - Kafka
15 | 1.0.0
16 | jar
17 |
18 |
19 |
20 | org.springframework.boot
21 | spring-boot-starter-web
22 |
23 |
24 | org.springframework.boot
25 | spring-boot-starter-test
26 | test
27 |
28 |
29 |
30 | org.springframework.kafka
31 | spring-kafka
32 |
33 |
34 | org.apache.kafka
35 | kafka-streams
36 |
37 |
38 | org.springframework.kafka
39 | spring-kafka-test
40 | test
41 |
42 |
43 |
44 |
45 |
46 |
47 | org.springframework.boot
48 | spring-boot-maven-plugin
49 |
50 |
51 |
52 |
53 |
--------------------------------------------------------------------------------
/codes/zookeeper/pom.xml:
--------------------------------------------------------------------------------
1 |
2 |
4 | 4.0.0
5 |
6 |
7 | org.springframework.boot
8 | spring-boot-starter-parent
9 | 2.6.3
10 |
11 |
12 | io.github.dunwu.bigdata
13 | zookeeper
14 | 大数据 - ZooKeeper
15 | 1.0.0
16 | jar
17 |
18 |
19 | UTF-8
20 | UTF-8
21 | 1.8
22 | ${java.version}
23 | ${java.version}
24 |
25 |
26 |
27 |
28 | org.apache.zookeeper
29 | zookeeper
30 | 3.7.0
31 |
32 |
33 | org.apache.curator
34 | curator-recipes
35 | 5.1.0
36 |
37 |
38 | cn.hutool
39 | hutool-all
40 | 5.7.20
41 |
42 |
43 | org.springframework.boot
44 | spring-boot-starter-test
45 | test
46 |
47 |
48 |
49 |
--------------------------------------------------------------------------------
/codes/zookeeper/src/test/java/io/github/dunwu/bigdata/zk/id/ZkDistributedIdTest.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.zk.id;
2 |
3 | import java.util.Set;
4 | import java.util.concurrent.*;
5 |
6 | /**
7 | * 并发测试生成分布式ID
8 | *
9 | * @author Zhang Peng
10 | * @since 2020-06-03
11 | */
12 | public class ZkDistributedIdTest {
13 |
14 | public static void main(String[] args) throws ExecutionException, InterruptedException {
15 | DistributedId distributedId = new ZkDistributedId("localhost:2181");
16 |
17 | final CountDownLatch latch = new CountDownLatch(10000);
18 | final ExecutorService executorService = Executors.newFixedThreadPool(20);
19 | long begin = System.nanoTime();
20 |
21 | Set set = new ConcurrentSkipListSet<>();
22 | for (int i = 0; i < 10000; i++) {
23 | Future future = executorService.submit(new MyThread(latch, distributedId));
24 | set.add(future.get());
25 | }
26 |
27 | try {
28 | latch.await();
29 | executorService.shutdown();
30 |
31 | long end = System.nanoTime();
32 | long time = end - begin;
33 | System.out.println("ID 数:" + set.size());
34 | System.out.println("耗时:" + TimeUnit.NANOSECONDS.toSeconds(time) + " 秒");
35 | } catch (Exception e) {
36 | e.printStackTrace();
37 | }
38 | }
39 |
40 | static class MyThread implements Callable {
41 |
42 | private final CountDownLatch latch;
43 | private final DistributedId distributedId;
44 |
45 | MyThread(CountDownLatch latch, DistributedId distributedId) {
46 | this.latch = latch;
47 | this.distributedId = distributedId;
48 | }
49 |
50 | @Override
51 | public Long call() {
52 | Long id = distributedId.generate();
53 | latch.countDown();
54 | return id;
55 | }
56 |
57 | }
58 |
59 | }
60 |
--------------------------------------------------------------------------------
/docs/16.大数据/11.spark/01.Spark简介.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Spark 简介
3 | date: 2019-05-07 20:19:25
4 | categories:
5 | - 大数据
6 | - spark
7 | tags:
8 | - 大数据
9 | - Spark
10 | permalink: /pages/80d4a7/
11 | ---
12 |
13 | # Spark
14 |
15 | ## Spark 简介
16 |
17 | ### Spark 概念
18 |
19 | - 大规模分布式通用计算引擎
20 | - Spark Core:核心计算框架
21 | - Spark SQL:结构化数据查询
22 | - Spark Streaming:实时流处理
23 | - Spark MLib:机器学习
24 | - Spark GraphX:图计算
25 | - 具有高吞吐、低延时、通用易扩展、高容错等特点
26 | - 采用 Scala 语言开发
27 | - 提供多种运行模式
28 |
29 | ### Spark 特点
30 |
31 | - 计算高效
32 | - 利用内存计算、Cache 缓存机制,支持迭代计算和数据共享,减少数据读取的 IO 开销
33 | - 利用 DAG 引擎,减少中间计算结果写入 HDFS 的开销
34 | - 利用多线程池模型,减少任务启动开销,避免 Shuffle 中不必要的排序和磁盘 IO 操作
35 | - 通用易用
36 | - 适用于批处理、流处理、交互式计算、机器学习算法等场景
37 | - 提供了丰富的开发 API,支持 Scala、Java、Python、R 等
38 | - 运行模式多样
39 | - Local 模式
40 | - Standalone 模式
41 | - YARN/Mesos 模式
42 | - 计算高效
43 | - 利用内存计算、Cache 缓存机制,支持迭代计算和数据共享,减少数据读取的 IO 开销
44 | - 利用 DAG 引擎,减少中间计算结果写入 HDFS 的开销
45 | - 利用多线程池模型,减少任务启动开销,避免 Shuffle 中不必要的排序和磁盘 IO 操作
46 | - 通用易用
47 | - 适用于批处理、流处理、交互式计算、机器学习等场景
48 | - 提供了丰富的开发 API,支持 Scala、Java、Python、R 等
49 |
50 | ## Spark 原理
51 |
52 | ### 编程模型
53 |
54 | #### RDD
55 |
56 | - 弹性分布式数据集(Resilient Distributed Datesets)
57 | - 分布在集群中的只读对象集合
58 | - 由多个 Partition 组成
59 | - 通过转换操作构造
60 | - 失效后自动重构(弹性)
61 | - 存储在内存或磁盘中
62 | - Spark 基于 RDD 进行计算
63 |
64 | #### RDD 操作(Operator)
65 |
66 | - Transformation(转换)
67 | - 将 Scala 集合或 Hadoop 输入数据构造成一个新 RDD
68 | - 通过已有的 RDD 产生新 RDD
69 | - 惰性执行:只记录转换关系,不触发计算
70 | - 例如:map、filter、flatmap、union、distinct、sortbykey
71 | - Action(动作)
72 | - 通过 RDD 计算得到一个值或一组值
73 | - 真正触发计算
74 | - 例如:first、count、collect、foreach、saveAsTextFile
75 |
76 | #### RDD 依赖(Dependency)
77 |
78 | - 窄依赖(Narrow Dependency)
79 | - 父 RDD 中的分区最多只能被一个子 RDD 的一个分区使用
80 | - 子 RDD 如果有部分分区数据丢失或损坏,只需从对应的父 RDD 重新计算恢复
81 | - 例如:map、filter、union
82 | - 宽依赖(Shuffle/Wide Dependency )
83 | - 子 RDD 分区依赖父 RDD 的所有分区
84 | - 子 RDD 如果部分或全部分区数据丢失或损坏,必须从所有父 RDD 分区重新计算
85 | - 相对于窄依赖,宽依赖付出的代价要高很多,尽量避免使用
86 | - 例如:groupByKey、reduceByKey、sortByKey
87 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/demo/KafkaProducerSendSyncDemo.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.demo;
2 |
3 | import org.apache.kafka.clients.producer.*;
4 |
5 | import java.util.Properties;
6 |
7 | /**
8 | * Kafka 同步发送
9 | *
10 | * 返回一个 Future 对象,调用 get() 方法,会一直阻塞等待 Broker 返回结果。
11 | *
12 | * 这是一种可靠传输方式,但吞吐量最差。
13 | *
14 | * 生产者配置参考:https://kafka.apache.org/documentation/#producerconfigs
15 | * @author Zhang Peng
16 | * @since 2020-06-20
17 | */
18 | public class KafkaProducerSendSyncDemo {
19 |
20 | private static Producer producer;
21 |
22 | static {
23 | // 指定生产者的配置
24 | final Properties properties = new Properties();
25 | properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
26 | properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
27 | "org.apache.kafka.common.serialization.StringSerializer");
28 | properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
29 | "org.apache.kafka.common.serialization.StringSerializer");
30 |
31 | // 使用配置初始化 Kafka 生产者
32 | producer = new KafkaProducer<>(properties);
33 | }
34 |
35 | public static void main(String[] args) {
36 | try {
37 | // 使用 send 方法发送异步消息
38 | for (int i = 0; i < 100; i++) {
39 | String msg = "Message " + i;
40 | RecordMetadata metadata = producer.send(new ProducerRecord<>("test", msg)).get();
41 | System.out.println("Sent:" + msg);
42 | System.out.printf("Sent success, topic = %s, partition = %s, offset = %d, timestamp = %s\n ",
43 | metadata.topic(), metadata.partition(), metadata.offset(), metadata.timestamp());
44 | }
45 | } catch (Exception e) {
46 | e.printStackTrace();
47 | } finally {
48 | // 关闭生产者
49 | producer.close();
50 | }
51 | }
52 |
53 | }
54 |
--------------------------------------------------------------------------------
/codes/zookeeper/src/main/java/io/github/dunwu/bigdata/zk/id/ZkDistributedId.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.zk.id;
2 |
3 | import org.apache.curator.RetryPolicy;
4 | import org.apache.curator.framework.CuratorFramework;
5 | import org.apache.curator.framework.CuratorFrameworkFactory;
6 | import org.apache.curator.retry.ExponentialBackoffRetry;
7 | import org.slf4j.Logger;
8 | import org.slf4j.LoggerFactory;
9 |
10 | /**
11 | * ZooKeeper 实现的分布式ID生成器
12 | *
13 | * @author Zhang Peng
14 | * @since 2020-06-03
15 | */
16 | public class ZkDistributedId implements DistributedId {
17 |
18 | private static final Logger log = LoggerFactory.getLogger(ZkDistributedId.class);
19 |
20 | private CuratorFramework client;
21 |
22 | /**
23 | * 最大尝试次数
24 | */
25 | private final int MAX_RETRIES = 3;
26 |
27 | /**
28 | * 等待时间,单位:毫秒
29 | */
30 | private final int BASE_SLEEP_TIME = 1000;
31 |
32 | /**
33 | * 默认 ID 存储目录
34 | */
35 | public static final String DEFAULT_ID_PATH = "/dunwu:id";
36 |
37 | public ZkDistributedId(String connectionString) {
38 | this(connectionString, DEFAULT_ID_PATH);
39 | }
40 |
41 | public ZkDistributedId(String connectionString, String path) {
42 | try {
43 | RetryPolicy retryPolicy = new ExponentialBackoffRetry(BASE_SLEEP_TIME, MAX_RETRIES);
44 | client = CuratorFrameworkFactory.newClient(connectionString, retryPolicy);
45 | client.start();
46 | // 自动创建 ID 存储目录
47 | client.create().forPath(path);
48 | } catch (Exception e) {
49 | log.error(e.getMessage(), e);
50 | }
51 | }
52 |
53 | @Override
54 | public Long generate() {
55 | try {
56 | int value = client.setData().withVersion(-1).forPath(DEFAULT_ID_PATH, "".getBytes()).getVersion();
57 | return (long) value;
58 | } catch (Exception e) {
59 | e.printStackTrace();
60 | }
61 | return null;
62 | }
63 |
64 | }
65 |
--------------------------------------------------------------------------------
/codes/flink/src/main/java/io/github/dunwu/bigdata/flink/WordCountStreaming.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.flink;
2 |
3 | import org.apache.flink.api.java.tuple.Tuple2;
4 | import org.apache.flink.api.java.typeutils.TupleTypeInfo;
5 | import org.apache.flink.streaming.api.datastream.DataStreamSource;
6 | import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
7 | import org.apache.flink.util.Collector;
8 |
9 | public class WordCountStreaming {
10 |
11 | public static void main(String[] args) throws Exception {
12 |
13 | // 设置运行环境
14 | StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
15 |
16 | // 配置数据源
17 | DataStreamSource source = env.fromElements("To be, or not to be,--that is the question:--",
18 | "Whether 'tis nobler in the mind to suffer",
19 | "The slings and arrows of outrageous fortune",
20 | "Or to take arms against a sea of troubles");
21 |
22 | // 进行一系列转换
23 | source
24 | // split up the lines in pairs (2-tuples) containing: (word,1)
25 | .flatMap((String value, Collector> out) -> {
26 | // emit the pairs
27 | for (String token : value.toLowerCase().split("\\W+")) {
28 | if (token.length() > 0) {
29 | out.collect(new Tuple2<>(token, 1));
30 | }
31 | }
32 | })
33 | // due to type erasure, we need to specify the return type
34 | .returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class, Integer.class))
35 | // group by the tuple field "0"
36 | .keyBy(0)
37 | // sum up tuple on field "1"
38 | .sum(1)
39 | // print the result
40 | .print();
41 |
42 | // 提交执行
43 | env.execute();
44 | }
45 | }
46 |
--------------------------------------------------------------------------------
/docs/.vuepress/public/markmap/01.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 | Markmap
8 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/demo/KafkaStreamDemo.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.demo;
2 |
3 | import org.apache.kafka.common.serialization.Serdes;
4 | import org.apache.kafka.common.utils.Bytes;
5 | import org.apache.kafka.streams.KafkaStreams;
6 | import org.apache.kafka.streams.StreamsBuilder;
7 | import org.apache.kafka.streams.StreamsConfig;
8 | import org.apache.kafka.streams.kstream.KStream;
9 | import org.apache.kafka.streams.kstream.KTable;
10 | import org.apache.kafka.streams.kstream.Materialized;
11 | import org.apache.kafka.streams.kstream.Produced;
12 | import org.apache.kafka.streams.state.KeyValueStore;
13 |
14 | import java.util.Arrays;
15 | import java.util.Properties;
16 |
17 | /**
18 | * Kafka 流示例
19 | *
20 | * 消费者配置参考:https://kafka.apache.org/documentation/#streamsconfigs
21 | */
22 | public class KafkaStreamDemo {
23 |
24 | private static Properties properties;
25 |
26 | static {
27 | properties = new Properties();
28 | properties.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");
29 | properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
30 | properties.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
31 | properties.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
32 | }
33 |
34 | public static void main(String[] args) {
35 | // 设置流构造器
36 | StreamsBuilder builder = new StreamsBuilder();
37 | KStream textLines = builder.stream("TextLinesTopic");
38 | KTable wordCounts =
39 | textLines.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+")))
40 | .groupBy((key, word) -> word)
41 | .count(Materialized.>as("counts-store"));
42 | wordCounts.toStream().to("WordsWithCountsTopic", Produced.with(Serdes.String(), Serdes.Long()));
43 |
44 | // 根据流构造器和流配置初始化 Kafka 流
45 | KafkaStreams streams = new KafkaStreams(builder.build(), properties);
46 | streams.start();
47 | }
48 |
49 | }
50 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/demo/KafkaConsumerManualPartitionDemo.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.demo;
2 |
3 | import org.apache.kafka.clients.consumer.*;
4 | import org.apache.kafka.common.TopicPartition;
5 |
6 | import java.util.Arrays;
7 | import java.util.Collections;
8 | import java.util.List;
9 | import java.util.Properties;
10 |
11 | /**
12 | * @author Zhang Peng
13 | * @since 2018/7/12
14 | */
15 | public class KafkaConsumerManualPartitionDemo {
16 |
17 | private static final String HOST = "localhost:9092";
18 |
19 | public static void main(String[] args) {
20 | Properties props = new Properties();
21 | props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, HOST);
22 | props.put(ConsumerConfig.GROUP_ID_CONFIG, "test2");
23 | props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
24 | props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
25 | "org.apache.kafka.common.serialization.StringDeserializer");
26 | props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
27 | "org.apache.kafka.common.serialization.StringDeserializer");
28 |
29 | KafkaConsumer consumer = new KafkaConsumer<>(props);
30 | consumer.subscribe(Arrays.asList("t1"));
31 |
32 | try {
33 | while (true) {
34 | ConsumerRecords records = consumer.poll(Long.MAX_VALUE);
35 | for (TopicPartition partition : records.partitions()) {
36 | List> partitionRecords = records.records(partition);
37 | for (ConsumerRecord record : partitionRecords) {
38 | System.out.println(partition.partition() + ": " + record.offset() + ": " + record.value());
39 | }
40 | long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
41 | consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
42 | }
43 | }
44 | } finally {
45 | consumer.close();
46 | }
47 | }
48 |
49 | }
50 |
--------------------------------------------------------------------------------
/docs/.vuepress/config/htmlModules.js:
--------------------------------------------------------------------------------
1 | /** 插入自定义html模块 (可用于插入广告模块等)
2 | * {
3 | * homeSidebarB: htmlString, 首页侧边栏底部
4 | *
5 | * sidebarT: htmlString, 全局左侧边栏顶部
6 | * sidebarB: htmlString, 全局左侧边栏底部
7 | *
8 | * pageT: htmlString, 全局页面顶部
9 | * pageB: htmlString, 全局页面底部
10 | * pageTshowMode: string, 页面顶部-显示方式:未配置默认全局;'article' => 仅文章页①; 'custom' => 仅自定义页①
11 | * pageBshowMode: string, 页面底部-显示方式:未配置默认全局;'article' => 仅文章页①; 'custom' => 仅自定义页①
12 | *
13 | * windowLB: htmlString, 全局左下角②
14 | * windowRB: htmlString, 全局右下角②
15 | * }
16 | *
17 | * ①注:在.md文件front matter配置`article: false`的页面是自定义页,未配置的默认是文章页(首页除外)。
18 | * ②注:windowLB 和 windowRB:1.展示区块最大宽高200px*400px。2.请给自定义元素定一个不超过200px*400px的宽高。3.在屏幕宽度小于960px时无论如何都不会显示。
19 | */
20 |
21 | module.exports = {
22 | // 万维广告
23 | pageB: `
24 |
25 |
29 | `,
30 | windowRB: `
31 |
33 |
41 | `,
42 | }
43 |
44 | // module.exports = {
45 | // homeSidebarB: `自定义模块测试
`,
46 | // sidebarT: `自定义模块测试
`,
47 | // sidebarB: `自定义模块测试
`,
48 | // pageT: `自定义模块测试
`,
49 | // pageB: `自定义模块测试
`,
50 | // windowLB: `自定义模块测试
`,
51 | // windowRB: `自定义模块测试
`,
52 | // }
53 |
--------------------------------------------------------------------------------
/docs/16.大数据/03.hbase/03.HBase运维.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: HBase 运维
3 | date: 2019-05-07 20:19:25
4 | categories:
5 | - 大数据
6 | - hbase
7 | tags:
8 | - 大数据
9 | - HBase
10 | - 运维
11 | permalink: /pages/f808fc/
12 | ---
13 |
14 | # HBase 运维
15 |
16 | ## 配置文件
17 |
18 | - `backup-masters` - 默认情况下不存在。列出主服务器应在其上启动备份主进程的主机,每行一个主机。
19 | - `hadoop-metrics2-hbase.properties` - 用于连接 HBase Hadoop 的 Metrics2 框架。
20 | - `hbase-env.cmd` and hbase-env.sh - 用于 Windows 和 Linux / Unix 环境的脚本,用于设置 HBase 的工作环境,包括 Java,Java 选项和其他环境变量的位置。
21 | - `hbase-policy.xml` - RPC 服务器用于对客户端请求进行授权决策的默认策略配置文件。仅在启用 HBase 安全性时使用。
22 | - `hbase-site.xml` - 主要的 HBase 配置文件。此文件指定覆盖 HBase 默认配置的配置选项。您可以在 docs / hbase-default.xml 中查看(但不要编辑)默认配置文件。您还可以在 HBase Web UI 的 HBase 配置选项卡中查看群集的整个有效配置(默认值和覆盖)。
23 | - `log4j.properties` - log4j 日志配置。
24 | - `regionservers` - 包含应在 HBase 集群中运行 RegionServer 的主机列表。默认情况下,此文件包含单个条目 localhost。它应包含主机名或 IP 地址列表,每行一个,并且如果群集中的每个节点将在其 localhost 接口上运行 RegionServer,则应仅包含 localhost。
25 |
26 | ## 环境要求
27 |
28 | - Java
29 | - HBase 2.0+ 要求 JDK8+
30 | - HBase 1.2+ 要求 JDK7+
31 | - SSH - 环境要支持 SSH
32 | - DNS - 环境中要在 hosts 配置本机 hostname 和本机 IP
33 | - NTP - HBase 集群的时间要同步,可以配置统一的 NTP
34 | - 平台 - 生产环境不推荐部署在 Windows 系统中
35 | - Hadoop - 依赖 Hadoop 配套版本
36 | - Zookeeper - 依赖 Zookeeper 配套版本
37 |
38 | ## 运行模式
39 |
40 | ### 单点
41 |
42 | hbase-site.xml 配置如下:
43 |
44 | ```xml
45 |
46 |
47 | hbase.rootdir
48 | hdfs://namenode.example.org:8020/hbase
49 |
50 |
51 | hbase.cluster.distributed
52 | false
53 |
54 |
55 | ```
56 |
57 | ### 分布式
58 |
59 | hbase-site.xm 配置如下:
60 |
61 | ```xml
62 |
63 |
64 | hbase.rootdir
65 | hdfs://namenode.example.org:8020/hbase
66 |
67 |
68 | hbase.cluster.distributed
69 | true
70 |
71 |
72 | hbase.zookeeper.quorum
73 | node-a.example.com,node-b.example.com,node-c.example.com
74 |
75 |
76 | ```
77 |
78 | ## 引用和引申
79 |
80 | ### 扩展阅读
81 |
82 | - [Apache HBase Configuration](http://hbase.apache.org/book.html#configuration)
83 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/demo/KafkaProducerIdempotencyDemo.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.demo;
2 |
3 | import org.apache.kafka.clients.producer.*;
4 |
5 | import java.util.Properties;
6 |
7 | /**
8 | * Kafka 生产者幂等性
9 | *
10 | * 生产者配置参考:https://kafka.apache.org/documentation/#producerconfigs
11 | * @author Zhang Peng
12 | * @since 2020-06-20
13 | */
14 | public class KafkaProducerIdempotencyDemo {
15 |
16 | private static Producer producer;
17 |
18 | static {
19 | // 指定生产者的配置
20 | final Properties properties = new Properties();
21 | properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
22 | // 设置 key 的序列化器
23 | properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
24 | // 设置 value 的序列化器
25 | properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
26 |
27 | // 开启幂等性
28 | properties.put("enable.idempotence", true);
29 | // 设置重试次数
30 | properties.put("retries", 3);
31 | //Reduce the no of requests less than 0
32 | properties.put("linger.ms", 1);
33 | // buffer.memory 控制生产者可用于缓冲的内存总量
34 | properties.put("buffer.memory", 33554432);
35 |
36 | // 使用配置初始化 Kafka 生产者
37 | producer = new KafkaProducer<>(properties);
38 | }
39 |
40 | public static void main(String[] args) {
41 | try {
42 | // 使用 send 方法发送异步消息
43 | for (int i = 0; i < 100; i++) {
44 | String msg = "Message " + i;
45 | RecordMetadata metadata = producer.send(new ProducerRecord<>("test", msg)).get();
46 | System.out.println("Sent:" + msg);
47 | System.out.printf("Sent success, topic = %s, partition = %s, offset = %d, timestamp = %s\n ",
48 | metadata.topic(), metadata.partition(), metadata.offset(), metadata.timestamp());
49 | }
50 | producer.flush();
51 | } catch (Exception e) {
52 | e.printStackTrace();
53 | } finally {
54 | // 关闭生产者
55 | producer.close();
56 | }
57 | }
58 |
59 | }
60 |
--------------------------------------------------------------------------------
/docs/16.大数据/04.zookeeper/README.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: ZooKeeper 教程
3 | date: 2020-09-09 17:53:08
4 | categories:
5 | - 大数据
6 | - zookeeper
7 | tags:
8 | - 分布式
9 | - 大数据
10 | - ZooKeeper
11 | permalink: /pages/1b41b6/
12 | hidden: true
13 | ---
14 |
15 | # ZooKeeper 教程
16 |
17 | > ZooKeeper 是 Apache 的顶级项目。**ZooKeeper 为分布式应用提供了高效且可靠的分布式协调服务,提供了诸如统一命名服务、配置管理和分布式锁等分布式的基础服务。在解决分布式数据一致性方面,ZooKeeper 并没有直接采用 Paxos 算法,而是采用了名为 ZAB 的一致性协议**。
18 | >
19 | > ZooKeeper 主要用来解决分布式集群中应用系统的一致性问题,它能提供基于类似于文件系统的目录节点树方式的数据存储。但是 ZooKeeper 并不是用来专门存储数据的,它的作用主要是用来**维护和监控存储数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理**。
20 | >
21 | > 很多大名鼎鼎的框架都基于 ZooKeeper 来实现分布式高可用,如:Dubbo、Kafka 等。
22 | >
23 | > ZooKeeper 官方支持 Java 和 C 的 Client API。ZooKeeper 社区为大多数语言(.NET,python 等)提供非官方 API。
24 |
25 | ## 📖 内容
26 |
27 | ### [ZooKeeper 原理](01.ZooKeeper原理.md)
28 |
29 | ### [ZooKeeper 命令](02.ZooKeeper命令.md)
30 |
31 | ### [ZooKeeper 运维](03.ZooKeeper运维.md)
32 |
33 | ### [ZooKeeper Java API](04.ZooKeeperJavaApi.md)
34 |
35 | ### [ZooKeeper ACL](05.ZooKeeperAcl.md)
36 |
37 | ## 📚 资料
38 |
39 | - **官方**
40 | - [ZooKeeper 官网](http://zookeeper.apache.org/)
41 | - [ZooKeeper 官方文档](https://cwiki.apache.org/confluence/display/ZOOKEEPER)
42 | - [ZooKeeper Github](https://github.com/apache/zookeeper)
43 | - [Apache Curator 官网](http://curator.apache.org/)
44 | - **书籍**
45 | - [《Hadoop 权威指南(第四版)》](https://item.jd.com/12109713.html)
46 | - [《从 Paxos 到 Zookeeper 分布式一致性原理与实践》](https://item.jd.com/11622772.html)
47 | - **文章**
48 | - [分布式服务框架 ZooKeeper -- 管理分布式环境中的数据](https://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/index.html)
49 | - [ZooKeeper 的功能以及工作原理](https://www.cnblogs.com/felixzh/p/5869212.html)
50 | - [ZooKeeper 简介及核心概念](https://github.com/heibaiying/BigData-Notes/blob/master/notes/ZooKeeper%E7%AE%80%E4%BB%8B%E5%8F%8A%E6%A0%B8%E5%BF%83%E6%A6%82%E5%BF%B5.md)
51 | - [详解分布式协调服务 ZooKeeper](https://draveness.me/zookeeper-chubby)
52 | - [深入浅出 Zookeeper(一) Zookeeper 架构及 FastLeaderElection 机制](http://www.jasongj.com/zookeeper/fastleaderelection/)
53 | - [Introduction to Apache ZooKeeper](https://www.slideshare.net/sauravhaloi/introduction-to-apache-zookeeper)
54 | - [Zookeeper 的优缺点](https://blog.csdn.net/wwwsq/article/details/7644445)
55 |
56 | ## 🚪 传送
57 |
58 | ◾ 💧 [钝悟的 IT 知识图谱](https://dunwu.github.io/waterdrop/) ◾ 🎯 [钝悟的博客](https://dunwu.github.io/blog/) ◾
59 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/demo/KafkaConsumerManualDemo.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.demo;
2 |
3 | import org.apache.kafka.clients.consumer.ConsumerConfig;
4 | import org.apache.kafka.clients.consumer.ConsumerRecord;
5 | import org.apache.kafka.clients.consumer.ConsumerRecords;
6 | import org.apache.kafka.clients.consumer.KafkaConsumer;
7 | import org.slf4j.Logger;
8 | import org.slf4j.LoggerFactory;
9 |
10 | import java.time.Duration;
11 | import java.util.ArrayList;
12 | import java.util.Arrays;
13 | import java.util.List;
14 | import java.util.Properties;
15 |
16 | /**
17 | * @author Zhang Peng
18 | * @since 2018/7/12
19 | */
20 | public class KafkaConsumerManualDemo {
21 |
22 | private static final String HOST = "localhost:9092";
23 | private final Logger log = LoggerFactory.getLogger(this.getClass());
24 |
25 | public static void main(String[] args) {
26 | // 创建消费者
27 | Properties props = new Properties();
28 | props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, HOST);
29 | props.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
30 | props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
31 | props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
32 | "org.apache.kafka.common.serialization.StringDeserializer");
33 | props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
34 | "org.apache.kafka.common.serialization.StringDeserializer");
35 | KafkaConsumer consumer = new KafkaConsumer<>(props);
36 |
37 | // 订阅主题
38 | consumer.subscribe(Arrays.asList("t1", "t2"));
39 | final int minBatchSize = 200;
40 | List> buffer = new ArrayList<>();
41 |
42 | // 轮询
43 | try {
44 | while (true) {
45 | ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
46 | for (ConsumerRecord record : records) {
47 | buffer.add(record);
48 | }
49 | if (buffer.size() >= minBatchSize) {
50 | // 逻辑处理,例如保存到数据库
51 | consumer.commitSync();
52 | buffer.clear();
53 | }
54 | }
55 | } finally {
56 | // 退出前,关闭消费者
57 | consumer.close();
58 | }
59 | }
60 |
61 | }
62 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/springboot/config/KafkaProducerConfig.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.springboot.config;
2 |
3 | import org.apache.kafka.clients.producer.ProducerConfig;
4 | import org.apache.kafka.common.serialization.StringSerializer;
5 | import org.springframework.beans.factory.annotation.Value;
6 | import org.springframework.context.annotation.Bean;
7 | import org.springframework.context.annotation.Configuration;
8 | import org.springframework.kafka.annotation.EnableKafka;
9 | import org.springframework.kafka.core.DefaultKafkaProducerFactory;
10 | import org.springframework.kafka.core.KafkaTemplate;
11 | import org.springframework.kafka.core.ProducerFactory;
12 | import org.springframework.kafka.transaction.KafkaTransactionManager;
13 |
14 | import java.util.HashMap;
15 | import java.util.Map;
16 |
17 | @Configuration
18 | @EnableKafka
19 | public class KafkaProducerConfig {
20 |
21 | @Value("${spring.kafka.bootstrap-servers}")
22 | private String bootstrapServers;
23 |
24 | @Value("${spring.kafka.producer.retries}")
25 | private Integer retries;
26 |
27 | @Value("${spring.kafka.producer.batch-size}")
28 | private Integer batchSize;
29 |
30 | @Bean
31 | public KafkaTransactionManager transactionManager() {
32 | KafkaTransactionManager manager = new KafkaTransactionManager(producerFactory());
33 | return manager;
34 | }
35 |
36 | @Bean
37 | public ProducerFactory producerFactory() {
38 | DefaultKafkaProducerFactory producerFactory =
39 | new DefaultKafkaProducerFactory<>(producerConfigs());
40 | producerFactory.transactionCapable();
41 | producerFactory.setTransactionIdPrefix("hous-");
42 | return producerFactory;
43 | }
44 |
45 | @Bean
46 | public Map producerConfigs() {
47 | Map props = new HashMap<>(7);
48 | props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
49 | props.put(ProducerConfig.RETRIES_CONFIG, retries);
50 | props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize);
51 | props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
52 | props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
53 | return props;
54 | }
55 |
56 | @Bean
57 | public KafkaTemplate kafkaTemplate() {
58 | return new KafkaTemplate<>(producerFactory());
59 | }
60 |
61 | }
62 |
--------------------------------------------------------------------------------
/docs/.vuepress/styles/index.styl:
--------------------------------------------------------------------------------
1 | .home-wrapper .banner .banner-conent .hero h1{
2 | font-size 2.8rem!important
3 | }
4 | // 文档中适配
5 | table
6 | width auto
7 | .page >*:not(.footer),.card-box
8 | box-shadow: none!important
9 |
10 | .page
11 | @media (min-width $contentWidth + 80)
12 | padding-top $navbarHeight!important
13 | .home-wrapper .banner .banner-conent
14 | padding 0 2.9rem
15 | box-sizing border-box
16 | .home-wrapper .banner .slide-banner .slide-banner-wrapper .slide-item a
17 | h2
18 | margin-top 2rem
19 | font-size 1.2rem!important
20 | p
21 | padding 0 1rem
22 |
23 | // 评论区颜色重置
24 | .gt-container
25 | .gt-ico-tip
26 | &::after
27 | content: '。( Win + . ) or ( ⌃ + ⌘ + ␣ ) open Emoji'
28 | color: #999
29 | .gt-meta
30 | border-color var(--borderColor)!important
31 | .gt-comments-null
32 | color var(--textColor)
33 | opacity .5
34 | .gt-header-textarea
35 | color var(--textColor)
36 | background rgba(180,180,180,0.1)!important
37 | .gt-btn
38 | border-color $accentColor!important
39 | background-color $accentColor!important
40 | .gt-btn-preview
41 | background-color rgba(255,255,255,0)!important
42 | color $accentColor!important
43 | a
44 | color $accentColor!important
45 | .gt-svg svg
46 | fill $accentColor!important
47 | .gt-comment-content,.gt-comment-admin .gt-comment-content
48 | background-color rgba(150,150,150,0.1)!important
49 | &:hover
50 | box-shadow 0 0 25px rgba(150,150,150,.5)!important
51 | .gt-comment-body
52 | color var(--textColor)!important
53 |
54 |
55 | // qq徽章
56 | .qq
57 | position: relative;
58 | .qq::after
59 | content: "可撩";
60 | background: $accentColor;
61 | color:#fff;
62 | padding: 0 5px;
63 | border-radius: 10px;
64 | font-size:12px;
65 | position: absolute;
66 | top: -4px;
67 | right: -35px;
68 | transform:scale(0.85);
69 |
70 | // demo模块图标颜色
71 | body .vuepress-plugin-demo-block__wrapper
72 | &,.vuepress-plugin-demo-block__display
73 | border-color rgba(160,160,160,.3)
74 | .vuepress-plugin-demo-block__footer:hover
75 | .vuepress-plugin-demo-block__expand::before
76 | border-top-color: $accentColor !important;
77 | border-bottom-color: $accentColor !important;
78 | svg
79 | fill: $accentColor !important;
80 |
81 |
82 | // 全文搜索框
83 | .suggestions
84 | overflow: auto
85 | max-height: calc(100vh - 6rem)
86 | @media (max-width: 719px) {
87 | width: 90vw;
88 | min-width: 90vw!important;
89 | margin-right: -20px;
90 | }
91 | .highlight
92 | color: $accentColor
93 | font-weight: bold
94 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/demo/KafkaProducerSendAsyncCallbackDemo.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.demo;
2 |
3 | import org.apache.kafka.clients.producer.*;
4 |
5 | import java.util.Properties;
6 |
7 | /**
8 | * Kafka 异步回调发送
9 | *
10 | * 返回一个 Future 对象,调用 get() 方法,会一直阻塞等待 Broker 返回结果。
11 | *
12 | * 这是一种可靠传输方式,但吞吐量最差。
13 | *
14 | * 生产者配置参考:https://kafka.apache.org/documentation/#producerconfigs
15 | * @author Zhang Peng
16 | * @since 2020-06-20
17 | */
18 | public class KafkaProducerSendAsyncCallbackDemo {
19 |
20 | private static Producer producer;
21 |
22 | static {
23 | // 指定生产者的配置
24 | final Properties properties = new Properties();
25 | properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
26 | properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
27 | "org.apache.kafka.common.serialization.StringSerializer");
28 | properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
29 | "org.apache.kafka.common.serialization.StringSerializer");
30 | properties.put(ProducerConfig.ACKS_CONFIG, "all");
31 | properties.put(ProducerConfig.RETRIES_CONFIG, 2);
32 | properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
33 | properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 2000);
34 |
35 | // 使用配置初始化 Kafka 生产者
36 | producer = new KafkaProducer<>(properties);
37 | }
38 |
39 |
40 | private static class DemoProducerCallback implements Callback {
41 |
42 | @Override
43 | public void onCompletion(RecordMetadata metadata, Exception e) {
44 | if (e != null) {
45 | e.printStackTrace();
46 | } else {
47 | System.out.printf("Sent success, topic = %s, partition = %s, offset = %d, timestamp = %s\n ",
48 | metadata.topic(), metadata.partition(), metadata.offset(), metadata.timestamp());
49 | }
50 | }
51 |
52 | }
53 |
54 | public static void main(String[] args) {
55 | try {
56 | // 使用 send 方法发送异步消息并设置回调,一旦发送请求得到响应(无论成败),就会进入回调处理
57 | for (int i = 0; i < 10000; i++) {
58 | String msg = "Message " + i;
59 | producer.send(new ProducerRecord<>("test", msg), new DemoProducerCallback());
60 | }
61 | } catch (Exception e) {
62 | e.printStackTrace();
63 | } finally {
64 | // 关闭生产者
65 | producer.close();
66 | }
67 | }
68 |
69 | }
70 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/demo/KafkaConsumerCommitSyncDemo.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.demo;
2 |
3 | import org.apache.kafka.clients.consumer.*;
4 | import org.slf4j.Logger;
5 | import org.slf4j.LoggerFactory;
6 |
7 | import java.time.Duration;
8 | import java.util.Collections;
9 | import java.util.Properties;
10 |
11 | /**
12 | * Kafka 消费者同步提交
13 | *
14 | * 使用 commitSync() 提交偏移量最简单也最可靠。这个 API 会提交由 poll() 方法返回的最新偏移量,提交成功后马上返回,如果提交失败就抛出异常。
15 | *
16 | * 同步提交方式会一直阻塞,直到接收到 Broker 的响应请求,这会大大限制吞吐量。
17 | *
18 | * 消费者配置参考:https://kafka.apache.org/documentation/#consumerconfigs
19 | * @author Zhang Peng
20 | * @since 2020-06-20
21 | */
22 | public class KafkaConsumerCommitSyncDemo {
23 |
24 | private static final Logger log = LoggerFactory.getLogger(KafkaConsumerCommitSyncDemo.class);
25 | private static KafkaConsumer consumer;
26 |
27 | static {
28 | // 指定消费者的配置
29 | final Properties properties = new Properties();
30 | properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
31 | properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
32 | properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
33 | properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
34 | properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
35 | "org.apache.kafka.common.serialization.StringDeserializer");
36 | properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
37 | "org.apache.kafka.common.serialization.StringDeserializer");
38 |
39 | // 使用配置初始化 Kafka 消费者
40 | consumer = new KafkaConsumer<>(properties);
41 | }
42 |
43 | public static void main(String[] args) {
44 |
45 | // 订阅 Topic
46 | consumer.subscribe(Collections.singletonList("test"));
47 |
48 | // 轮询
49 | while (true) {
50 | ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
51 | for (ConsumerRecord record : records) {
52 | System.out.printf("topic = %s, partition = %s, offset = %d, key = %s, value = %s\n ", record.topic(),
53 | record.partition(), record.offset(), record.key(), record.value());
54 | }
55 | try {
56 | // 同步提交
57 | consumer.commitSync();
58 | } catch (CommitFailedException e) {
59 | log.error("commit failed", e);
60 | }
61 | }
62 | }
63 |
64 | }
65 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/demo/KafkaConsumerCommitAsyncDemo.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.demo;
2 |
3 | import org.apache.kafka.clients.consumer.ConsumerConfig;
4 | import org.apache.kafka.clients.consumer.ConsumerRecord;
5 | import org.apache.kafka.clients.consumer.ConsumerRecords;
6 | import org.apache.kafka.clients.consumer.KafkaConsumer;
7 | import org.apache.kafka.clients.producer.ProducerConfig;
8 | import org.slf4j.Logger;
9 | import org.slf4j.LoggerFactory;
10 |
11 | import java.time.Duration;
12 | import java.util.Collections;
13 | import java.util.Properties;
14 |
15 | /**
16 | * Kafka 消费者异步提交
17 | *
18 | * 在成功提交或碰到无法恢复的错误之前,commitSync() 会一直重试,但是 commitAsync() 不会。
19 | *
20 | * 它之所以不进行重试,是因为在它收到服务器响应的时候,可能有一个更大的偏移量已经提交成功。
21 | *
22 | * 消费者配置参考:https://kafka.apache.org/documentation/#consumerconfigs
23 | * @author Zhang Peng
24 | * @since 2020-06-20
25 | */
26 | public class KafkaConsumerCommitAsyncDemo {
27 |
28 | private static final Logger log = LoggerFactory.getLogger(KafkaConsumerCommitAsyncDemo.class);
29 | private static KafkaConsumer consumer;
30 |
31 | static {
32 | // 指定消费者的配置
33 | final Properties properties = new Properties();
34 | properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
35 | properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
36 | properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
37 | properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
38 | properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
39 | "org.apache.kafka.common.serialization.StringDeserializer");
40 | properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
41 | "org.apache.kafka.common.serialization.StringDeserializer");
42 |
43 | // 使用配置初始化 Kafka 消费者
44 | consumer = new KafkaConsumer<>(properties);
45 | }
46 |
47 | public static void main(String[] args) {
48 |
49 | // 订阅 Topic
50 | consumer.subscribe(Collections.singletonList("test"));
51 |
52 | // 轮询
53 | while (true) {
54 | ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
55 | for (ConsumerRecord record : records) {
56 | System.out.printf("topic = %s, partition = %s, offset = %d, key = %s, value = %s\n ", record.topic(),
57 | record.partition(), record.offset(), record.key(), record.value());
58 | }
59 |
60 | // 异步提交
61 | consumer.commitAsync();
62 | }
63 | }
64 |
65 | }
66 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/demo/KafkaOnlyOneConsumer.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.demo;
2 |
3 | import org.apache.kafka.clients.consumer.ConsumerConfig;
4 | import org.apache.kafka.clients.consumer.ConsumerRecord;
5 | import org.apache.kafka.clients.consumer.ConsumerRecords;
6 | import org.apache.kafka.clients.consumer.KafkaConsumer;
7 | import org.apache.kafka.common.PartitionInfo;
8 | import org.apache.kafka.common.TopicPartition;
9 |
10 | import java.util.ArrayList;
11 | import java.util.Collection;
12 | import java.util.List;
13 | import java.util.Properties;
14 |
15 | /**
16 | * Kafka 独立消费者示例
17 | * @author Zhang Peng
18 | * @since 2020-06-20
19 | */
20 | public class KafkaOnlyOneConsumer {
21 |
22 | private static KafkaConsumer consumer;
23 |
24 | static {
25 | // 指定消费者的配置
26 | final Properties properties = new Properties();
27 | properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
28 | properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
29 | properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
30 | properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
31 | properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
32 | "org.apache.kafka.common.serialization.StringDeserializer");
33 | properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
34 | "org.apache.kafka.common.serialization.StringDeserializer");
35 |
36 | // 使用配置初始化 Kafka 消费者
37 | consumer = new KafkaConsumer<>(properties);
38 | }
39 |
40 | public static void main(String[] args) {
41 | Collection partitions = new ArrayList<>();
42 | List partitionInfos = consumer.partitionsFor("test");
43 | if (partitionInfos != null) {
44 | for (PartitionInfo partition : partitionInfos) {
45 | partitions.add(new TopicPartition(partition.topic(), partition.partition()));
46 | }
47 | consumer.assign(partitions);
48 |
49 | while (true) {
50 | ConsumerRecords records = consumer.poll(1000);
51 |
52 | for (ConsumerRecord record : records) {
53 | System.out.printf("topic = %s, partition = %s, offset = %d, key = %s, value = %s\n ",
54 | record.topic(), record.partition(), record.offset(), record.key(),
55 | record.value());
56 | }
57 | consumer.commitSync();
58 | }
59 | }
60 | }
61 |
62 | }
63 |
--------------------------------------------------------------------------------
/codes/zookeeper/src/main/java/io/github/dunwu/bigdata/zk/dlock/ZkReentrantLockCleanerTask.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.zk.dlock;
2 |
3 | import org.apache.curator.RetryPolicy;
4 | import org.apache.curator.framework.CuratorFramework;
5 | import org.apache.curator.framework.CuratorFrameworkFactory;
6 | import org.apache.curator.retry.ExponentialBackoffRetry;
7 | import org.slf4j.LoggerFactory;
8 |
9 | import java.util.List;
10 | import java.util.TimerTask;
11 | import java.util.concurrent.Executors;
12 | import java.util.concurrent.ScheduledExecutorService;
13 |
14 | /**
15 | * Created by sunyujia@aliyun.com on 2016/2/25.
16 | */
17 | public class ZkReentrantLockCleanerTask extends TimerTask {
18 |
19 | private static final org.slf4j.Logger log = LoggerFactory.getLogger(ZkReentrantLockCleanerTask.class);
20 |
21 | private CuratorFramework client;
22 |
23 | private ScheduledExecutorService executorService = Executors.newScheduledThreadPool(3);
24 |
25 | /**
26 | * 检查周期
27 | */
28 | private long period = 5000;
29 |
30 | /**
31 | * Curator RetryPolicy maxRetries
32 | */
33 | private int maxRetries = 3;
34 |
35 | /**
36 | * Curator RetryPolicy baseSleepTimeMs
37 | */
38 | private final int baseSleepTimeMs = 1000;
39 |
40 | public ZkReentrantLockCleanerTask(String zookeeperAddress) {
41 | try {
42 | RetryPolicy retryPolicy = new ExponentialBackoffRetry(baseSleepTimeMs, maxRetries);
43 | client = CuratorFrameworkFactory.newClient(zookeeperAddress, retryPolicy);
44 | client.start();
45 | } catch (Exception e) {
46 | log.error(e.getMessage(), e);
47 | } catch (Throwable ex) {
48 | ex.printStackTrace();
49 | log.error(ex.getMessage(), ex);
50 | }
51 | }
52 |
53 | public void start() {
54 | executorService.execute(this);
55 | }
56 |
57 | private boolean isEmpty(List list) {
58 | return list == null || list.isEmpty();
59 | }
60 |
61 | @Override
62 | public void run() {
63 | try {
64 | List childrenPaths = this.client.getChildren().forPath(ZookeeperReentrantDistributedLock.ROOT_PATH);
65 | for (String path : childrenPaths) {
66 | cleanNode(path);
67 | }
68 | } catch (Exception e) {
69 | e.printStackTrace();
70 | }
71 | }
72 |
73 | private void cleanNode(String path) {
74 | try {
75 | if (isEmpty(this.client.getChildren().forPath(path))) {
76 | this.client.delete().forPath(path);//利用存在子节点无法删除和zk的原子性这两个特性.
77 | }
78 | } catch (Exception e) {
79 | e.printStackTrace();
80 | }
81 | }
82 |
83 | }
84 |
--------------------------------------------------------------------------------
/codes/zookeeper/src/test/resources/logback.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 | ${LOG_MSG}
9 |
10 |
11 |
12 |
13 | DEBUG
14 |
15 | ${USER_HOME}/debug.log
16 |
17 | ${LOG_DIR}/debug%i.log
18 |
19 | 20MB
20 |
21 |
22 |
23 | ${LOG_MSG}
24 |
25 |
26 |
27 | ${USER_HOME}/info.log
28 |
29 | INFO
30 |
31 |
32 | ${LOG_DIR}/info%i.log
33 |
34 | 20MB
35 |
36 |
37 |
38 | ${LOG_MSG}
39 |
40 |
41 |
42 | ${USER_HOME}/error.log
43 |
44 | ERROR
45 |
46 |
47 | ${LOG_DIR}/error%i.log
48 |
49 | 20MB
50 |
51 |
52 |
53 | ${LOG_MSG}
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
--------------------------------------------------------------------------------
/codes/flink/pom.xml:
--------------------------------------------------------------------------------
1 |
2 |
4 | 4.0.0
5 |
6 |
7 | org.springframework.boot
8 | spring-boot-starter-parent
9 | 2.6.3
10 |
11 |
12 | io.github.dunwu.bigdata
13 | flink
14 | 大数据 - Flink
15 | 1.0.0
16 | jar
17 |
18 |
19 | 1.14.3
20 |
21 |
22 |
23 |
24 | org.apache.flink
25 | flink-java
26 | ${flink.version}
27 |
28 |
29 | org.apache.flink
30 | flink-core
31 | ${flink.version}
32 |
33 |
34 | org.apache.flink
35 | flink-clients_2.12
36 | ${flink.version}
37 |
38 |
39 | org.apache.flink
40 | flink-streaming-java_2.12
41 | ${flink.version}
42 |
43 |
44 | org.apache.flink
45 | flink-table-api-java-bridge_2.12
46 | ${flink.version}
47 |
48 |
49 | org.apache.flink
50 | flink-table-planner_2.12
51 | ${flink.version}
52 |
53 |
54 | org.apache.flink
55 | flink-test-utils_2.12
56 | ${flink.version}
57 | test
58 |
59 |
60 |
61 | org.springframework.boot
62 | spring-boot-starter
63 |
64 |
65 | org.springframework.boot
66 | spring-boot-starter-test
67 | test
68 |
69 |
70 |
71 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/demo/KafkaConsumerCommitAutoDemo.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.demo;
2 |
3 | import org.apache.kafka.clients.consumer.ConsumerConfig;
4 | import org.apache.kafka.clients.consumer.ConsumerRecord;
5 | import org.apache.kafka.clients.consumer.ConsumerRecords;
6 | import org.apache.kafka.clients.consumer.KafkaConsumer;
7 | import org.slf4j.Logger;
8 | import org.slf4j.LoggerFactory;
9 |
10 | import java.time.Duration;
11 | import java.util.Collections;
12 | import java.util.Properties;
13 |
14 | /**
15 | * Kafka 消费者自动提交
16 | *
17 | * 当 enable.auto.commit 属性被设为 true,那么每过 5s,消费者会自动把从 poll() 方法接收到的最大偏移量提交上去。
18 | *
19 | * 提交时间间隔由 auto.commit.interval.ms 控制,默认值是 5s。
20 | *
21 | * 自动提交虽然方便,不过无法避免重复消息问题。
22 | *
23 | * 消费者配置参考:https://kafka.apache.org/documentation/#consumerconfigs
24 | * @author Zhang Peng
25 | * @since 2020-06-20
26 | */
27 | public class KafkaConsumerCommitAutoDemo {
28 |
29 | private static final Logger log = LoggerFactory.getLogger(KafkaConsumerCommitAutoDemo.class);
30 | private static KafkaConsumer consumer;
31 |
32 | static {
33 | // 指定消费者的配置
34 | final Properties properties = new Properties();
35 | properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
36 | properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
37 | properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
38 | properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
39 | properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
40 | "org.apache.kafka.common.serialization.StringDeserializer");
41 | properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
42 | "org.apache.kafka.common.serialization.StringDeserializer");
43 |
44 | // 使用配置初始化 Kafka 消费者
45 | consumer = new KafkaConsumer<>(properties);
46 | }
47 |
48 | public static void main(String[] args) {
49 |
50 | // 订阅 Topic
51 | consumer.subscribe(Collections.singletonList("test"));
52 |
53 | try {
54 | // 轮询
55 | while (true) {
56 | // 消费消息
57 | ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
58 | for (ConsumerRecord record : records) {
59 | log.info("topic = {}, partition = {}, offset = {}, key = {}, value = {}", record.topic(),
60 | record.partition(), record.offset(), record.key(), record.value());
61 | }
62 | }
63 | } finally {
64 | // 关闭消费者
65 | consumer.close();
66 | }
67 | }
68 |
69 | }
70 |
--------------------------------------------------------------------------------
/docs/.vuepress/plugins/love-me/love-me.js:
--------------------------------------------------------------------------------
1 | export default () => {
2 | if (typeof window !== "undefined") {
3 | (function(e, t, a) {
4 | function r() {
5 | for (var e = 0; e < s.length; e++) s[e].alpha <= 0 ? (t.body.removeChild(s[e].el), s.splice(e, 1)) : (s[e].y--, s[e].scale += .004, s[e].alpha -= .013, s[e].el.style.cssText = "left:" + s[e].x + "px;top:" + s[e].y + "px;opacity:" + s[e].alpha + ";transform:scale(" + s[e].scale + "," + s[e].scale + ") rotate(45deg);background:" + s[e].color + ";z-index:99999");
6 | requestAnimationFrame(r)
7 | }
8 | function n() {
9 | var t = "function" == typeof e.onclick && e.onclick;
10 |
11 | e.onclick = function(e) {
12 | // 过滤指定元素
13 | let mark = true;
14 | EXCLUDECLASS && e.path && e.path.forEach((item) =>{
15 | if(item.nodeType === 1) {
16 | typeof item.className === 'string' && item.className.indexOf(EXCLUDECLASS) > -1 ? mark = false : ''
17 | }
18 | })
19 |
20 | if(mark) {
21 | t && t(),
22 | o(e)
23 | }
24 | }
25 | }
26 | function o(e) {
27 | var a = t.createElement("div");
28 | a.className = "heart",
29 | s.push({
30 | el: a,
31 | x: e.clientX - 5,
32 | y: e.clientY - 5,
33 | scale: 1,
34 | alpha: 1,
35 | color: COLOR
36 | }),
37 | t.body.appendChild(a)
38 | }
39 | function i(e) {
40 | var a = t.createElement("style");
41 | a.type = "text/css";
42 | try {
43 | a.appendChild(t.createTextNode(e))
44 | } catch(t) {
45 | a.styleSheet.cssText = e
46 | }
47 | t.getElementsByTagName("head")[0].appendChild(a)
48 | }
49 | // function c() {
50 | // return "rgb(" + ~~ (255 * Math.random()) + "," + ~~ (255 * Math.random()) + "," + ~~ (255 * Math.random()) + ")"
51 | // }
52 | var s = [];
53 | e.requestAnimationFrame = e.requestAnimationFrame || e.webkitRequestAnimationFrame || e.mozRequestAnimationFrame || e.oRequestAnimationFrame || e.msRequestAnimationFrame ||
54 | function(e) {
55 | setTimeout(e, 1e3 / 60)
56 | },
57 | i(".heart{width: 10px;height: 10px;position: fixed;background: #f00;transform: rotate(45deg);-webkit-transform: rotate(45deg);-moz-transform: rotate(45deg);}.heart:after,.heart:before{content: '';width: inherit;height: inherit;background: inherit;border-radius: 50%;-webkit-border-radius: 50%;-moz-border-radius: 50%;position: fixed;}.heart:after{top: -5px;}.heart:before{left: -5px;}"),
58 | n(),
59 | r()
60 | })(window, document)
61 | }
62 | }
--------------------------------------------------------------------------------
/utils/editFrontmatter.js:
--------------------------------------------------------------------------------
1 | /**
2 | * 批量添加和修改front matter ,需要配置 ./config.yml 文件。
3 | */
4 | const fs = require('fs'); // 文件模块
5 | const path = require('path'); // 路径模块
6 | const matter = require('gray-matter'); // front matter解析器 https://github.com/jonschlinkert/gray-matter
7 | const jsonToYaml = require('json2yaml')
8 | const yamlToJs = require('yamljs')
9 | const inquirer = require('inquirer') // 命令行操作
10 | const chalk = require('chalk') // 命令行打印美化
11 | const readFileList = require('./modules/readFileList');
12 | const { type, repairDate} = require('./modules/fn');
13 | const log = console.log
14 |
15 | const configPath = path.join(__dirname, 'config.yml') // 配置文件的路径
16 |
17 | main();
18 |
19 | /**
20 | * 主体函数
21 | */
22 | async function main() {
23 |
24 | const promptList = [{
25 | type: "confirm",
26 | message: chalk.yellow('批量操作frontmatter有修改数据的风险,确定要继续吗?'),
27 | name: "edit",
28 | }];
29 | let edit = true;
30 |
31 | await inquirer.prompt(promptList).then(answers => {
32 | edit = answers.edit
33 | })
34 |
35 | if(!edit) { // 退出操作
36 | return
37 | }
38 |
39 | const config = yamlToJs.load(configPath) // 解析配置文件的数据转为js对象
40 |
41 | if (type(config.path) !== 'array') {
42 | log(chalk.red('路径配置有误,path字段应该是一个数组'))
43 | return
44 | }
45 |
46 | if (config.path[0] !== 'docs') {
47 | log(chalk.red("路径配置有误,path数组的第一个成员必须是'docs'"))
48 | return
49 | }
50 |
51 | const filePath = path.join(__dirname, '..', ...config.path); // 要批量修改的文件路径
52 | const files = readFileList(filePath); // 读取所有md文件数据
53 |
54 | files.forEach(file => {
55 | let dataStr = fs.readFileSync(file.filePath, 'utf8');// 读取每个md文件的内容
56 | const fileMatterObj = matter(dataStr) // 解析md文件的front Matter。 fileMatterObj => {content:'剔除frontmatter后的文件内容字符串', data:{}, ...}
57 | let matterData = fileMatterObj.data; // 得到md文件的front Matter
58 |
59 | let mark = false
60 | // 删除操作
61 | if (config.delete) {
62 | if( type(config.delete) !== 'array' ) {
63 | log(chalk.yellow('未能完成删除操作,delete字段的值应该是一个数组!'))
64 | } else {
65 | config.delete.forEach(item => {
66 | if (matterData[item]) {
67 | delete matterData[item]
68 | mark = true
69 | }
70 | })
71 |
72 | }
73 | }
74 |
75 | // 添加、修改操作
76 | if (type(config.data) === 'object') {
77 | Object.assign(matterData, config.data) // 将配置数据合并到front Matter对象
78 | mark = true
79 | }
80 |
81 | // 有操作时才继续
82 | if (mark) {
83 | if(matterData.date && type(matterData.date) === 'date') {
84 | matterData.date = repairDate(matterData.date) // 修复时间格式
85 | }
86 | const newData = jsonToYaml.stringify(matterData).replace(/\n\s{2}/g,"\n").replace(/"/g,"") + '---\r\n' + fileMatterObj.content;
87 | fs.writeFileSync(file.filePath, newData); // 写入
88 | log(chalk.green(`update frontmatter:${file.filePath} `))
89 | }
90 |
91 | })
92 | }
93 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/demo/KafkaProducerTransactionDemo.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.demo;
2 |
3 | import org.apache.kafka.clients.producer.*;
4 |
5 | import java.util.Properties;
6 |
7 | /**
8 | * Kafka 异步回调发送
9 | *
10 | * 返回一个 Future 对象,调用 get() 方法,会一直阻塞等待 Broker 返回结果。
11 | *
12 | * 这是一种可靠传输方式,但吞吐量最差。
13 | *
14 | * 生产者配置参考:https://kafka.apache.org/documentation/#producerconfigs
15 | * @author Zhang Peng
16 | * @since 2020-06-20
17 | */
18 | public class KafkaProducerTransactionDemo {
19 |
20 | private static Producer producer;
21 |
22 | static {
23 | // 指定生产者的配置
24 | final Properties properties = new Properties();
25 | properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
26 | properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
27 | "org.apache.kafka.common.serialization.StringSerializer");
28 | properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
29 | "org.apache.kafka.common.serialization.StringSerializer");
30 | properties.put(ProducerConfig.ACKS_CONFIG, "all");
31 | properties.put(ProducerConfig.RETRIES_CONFIG, 2);
32 | properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
33 | properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 2000);
34 |
35 | // 使用配置初始化 Kafka 生产者
36 | producer = new KafkaProducer<>(properties);
37 | }
38 |
39 |
40 | private static class DemoProducerCallback implements Callback {
41 |
42 | @Override
43 | public void onCompletion(RecordMetadata metadata, Exception e) {
44 | if (e != null) {
45 | e.printStackTrace();
46 | } else {
47 | System.out.printf("Sent success, topic = %s, partition = %s, offset = %d, timestamp = %s\n ",
48 | metadata.topic(), metadata.partition(), metadata.offset(), metadata.timestamp());
49 | }
50 | }
51 |
52 | }
53 |
54 | public static void main(String[] args) {
55 |
56 | // 1.初始化事务
57 | producer.initTransactions();
58 | // 2.开启事务
59 | producer.beginTransaction();
60 |
61 | try {
62 | // 3.kafka写操作集合
63 | // 3.1 do业务逻辑
64 |
65 | // 3.2 发送消息
66 | producer.send(new ProducerRecord("test", "transaction-data-1"));
67 | producer.send(new ProducerRecord("test", "transaction-data-2"));
68 |
69 | // 3.3 do其他业务逻辑,还可以发送其他topic的消息。
70 |
71 | // 4.事务提交
72 | producer.commitTransaction();
73 |
74 | } catch (Exception e) {
75 | e.printStackTrace();
76 | } finally {
77 | // 5.放弃事务
78 | producer.abortTransaction();
79 |
80 | // 关闭生产者
81 | producer.close();
82 | }
83 | }
84 |
85 | }
86 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/springboot/config/KafkaConsumerConfig.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.springboot.config;
2 |
3 | import org.apache.kafka.clients.consumer.ConsumerConfig;
4 | import org.apache.kafka.common.serialization.StringDeserializer;
5 | import org.springframework.beans.factory.annotation.Value;
6 | import org.springframework.context.annotation.Bean;
7 | import org.springframework.context.annotation.Configuration;
8 | import org.springframework.kafka.annotation.EnableKafka;
9 | import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
10 | import org.springframework.kafka.config.KafkaListenerContainerFactory;
11 | import org.springframework.kafka.core.ConsumerFactory;
12 | import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
13 | import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
14 |
15 | import java.util.HashMap;
16 | import java.util.Map;
17 |
18 | @Configuration
19 | @EnableKafka
20 | public class KafkaConsumerConfig {
21 |
22 | @Value("${spring.kafka.bootstrap-servers}")
23 | private String bootstrapServers;
24 |
25 | @Bean(name = "kafkaListenerContainerFactory")
26 | public KafkaListenerContainerFactory> kafkaListenerContainerFactory() {
27 | ConcurrentKafkaListenerContainerFactory factory =
28 | new ConcurrentKafkaListenerContainerFactory<>();
29 | factory.setConsumerFactory(consumerFactory("groupA"));
30 | factory.setConcurrency(3);
31 | factory.getContainerProperties().setPollTimeout(3000);
32 | return factory;
33 | }
34 |
35 | public ConsumerFactory consumerFactory(String consumerGroupId) {
36 | return new DefaultKafkaConsumerFactory<>(consumerConfig(consumerGroupId));
37 | }
38 |
39 | public Map consumerConfig(String consumerGroupId) {
40 | Map props = new HashMap<>();
41 | props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
42 | props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
43 | props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "100");
44 | props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "15000");
45 | props.put(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
46 | props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
47 | props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
48 | props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
49 | return props;
50 | }
51 |
52 | @Bean(name = "kafkaListenerContainerFactory1")
53 | public KafkaListenerContainerFactory> kafkaListenerContainerFactory1() {
54 | ConcurrentKafkaListenerContainerFactory factory =
55 | new ConcurrentKafkaListenerContainerFactory<>();
56 | factory.setConsumerFactory(consumerFactory("groupB"));
57 | factory.setConcurrency(3);
58 | factory.getContainerProperties().setPollTimeout(3000);
59 | return factory;
60 | }
61 |
62 | }
63 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/demo/KafkaConsumerCommitAsyncCallbackDemo.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.demo;
2 |
3 | import org.apache.kafka.clients.consumer.*;
4 | import org.apache.kafka.clients.producer.ProducerConfig;
5 | import org.apache.kafka.common.TopicPartition;
6 | import org.slf4j.Logger;
7 | import org.slf4j.LoggerFactory;
8 |
9 | import java.time.Duration;
10 | import java.util.Collections;
11 | import java.util.Map;
12 | import java.util.Properties;
13 |
14 | /**
15 | * Kafka 消费者异步提交2
16 | *
17 | * 在成功提交或碰到无法恢复的错误之前,commitSync() 会一直重试,但是 commitAsync() 不会。
18 | *
19 | * 它之所以不进行重试,是因为在它收到服务器响应的时候,可能有一个更大的偏移量已经提交成功。
20 | *
21 | * 消费者配置参考:https://kafka.apache.org/documentation/#consumerconfigs
22 | * @author Zhang Peng
23 | * @since 2020-06-20
24 | */
25 | public class KafkaConsumerCommitAsyncCallbackDemo {
26 |
27 | private static final Logger log = LoggerFactory.getLogger(KafkaConsumerCommitAsyncCallbackDemo.class);
28 | private static KafkaConsumer consumer;
29 |
30 | static {
31 | // 指定消费者的配置
32 | final Properties properties = new Properties();
33 | properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
34 | properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
35 | properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
36 | properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
37 | properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
38 | "org.apache.kafka.common.serialization.StringDeserializer");
39 | properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
40 | "org.apache.kafka.common.serialization.StringDeserializer");
41 |
42 | // 使用配置初始化 Kafka 消费者
43 | consumer = new KafkaConsumer<>(properties);
44 | }
45 |
46 | public static void main(String[] args) {
47 |
48 | // 订阅 Topic
49 | consumer.subscribe(Collections.singletonList("test"));
50 |
51 | // 轮询
52 | while (true) {
53 | ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
54 | for (ConsumerRecord record : records) {
55 | System.out.printf("topic = %s, partition = %s, offset = %d, key = %s, value = %s\n ", record.topic(),
56 | record.partition(), record.offset(), record.key(), record.value());
57 | }
58 | consumer.commitAsync(new OffsetCommitCallback() {
59 | @Override
60 | public void onComplete(Map offsets, Exception e) {
61 | if (e != null) {
62 | log.error("recv failed.", e);
63 | } else {
64 | offsets.forEach((k, v) -> {
65 | System.out.printf("recv success, topic = %s, partition = %s, offset = %d\n ", k.topic(),
66 | k.partition(), v.offset());
67 | });
68 | }
69 | }
70 | });
71 | }
72 | }
73 |
74 | }
75 |
--------------------------------------------------------------------------------
/docs/16.大数据/01.hadoop/02.yarn.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: YARN
3 | date: 2019-05-07 20:19:25
4 | categories:
5 | - 大数据
6 | - hadoop
7 | tags:
8 | - 大数据
9 | - Hadoop
10 | - YARN
11 | permalink: /pages/406588/
12 | ---
13 |
14 | # YARN
15 |
16 | > YARN 的目标是解决 MapReduce 的缺陷。
17 |
18 | ## MapReduce 的缺陷(Hadoop 1.x)
19 |
20 | - 身兼两职:计算框架 + 资源管理框架
21 | - JobTracker
22 | - 既做资源管理,又做任务调度
23 | - 任务太重,开销过大
24 | - 存在单点故障
25 | - 资源描述模型过于简单,资源利用率较低
26 | - 仅把 Task 数量看作资源,没有考虑 CPU 和内存
27 | - 强制把资源分成 Map Task Slot 和 Reduce Task Slot
28 | - 扩展性较差,集群规模上限 4K
29 | - 源码难于理解,升级维护困难
30 |
31 | ## YARN 简介
32 |
33 | YARN(Yet Another Resource Negotiator,另一种资源管理器)是一个**分布式通用资源管理系统**。
34 |
35 | 设计目标:聚焦资源管理、通用(适用各种计算框架)、高可用、高扩展。
36 |
37 | ## YARN 系统架构
38 |
39 | - 主从结构(master/slave)
40 | - 将 JobTracker 的资源管理、任务调度功能分离
41 | - 三种角色:
42 | - ResourceManager(Master) - 集群资源的统一管理和分配
43 | - NodeManager(Slave) - 管理节点资源,以及容器的生命周期
44 | - ApplicationMaster(新角色) - 管理应用程序实例,包括任务调度和资源申请
45 |
46 | ### ResourceManager(RM)
47 |
48 | **主要功能**
49 |
50 | - 统一管理集群的所有资源
51 | - 将资源按照一定策略分配给各个应用(ApplicationMaster)
52 | - 接收 NodeManager 的资源上报信息
53 |
54 | **核心组件**
55 |
56 | - 用户交互服务(User Service)
57 | - NodeManager 管理
58 | - ApplicationMaster 管理
59 | - Application 管理
60 | - 安全管理
61 | - 资源管理
62 |
63 | ### NodeManager(NM)
64 |
65 | **主要功能**
66 |
67 | - 管理单个节点的资源
68 | - 向 ResourceManager 汇报节点资源使用情况
69 | - 管理 Container 的生命周期
70 |
71 | **核心组件**
72 |
73 | - NodeStatusUpdater
74 | - ContainerManager
75 | - ContainerExecutor
76 | - NodeHealthCheckerService
77 | - Security
78 | - WebServer
79 |
80 | ### ApplicationMaster(AM)
81 |
82 | **主要功能**
83 |
84 | - 管理应用程序实例
85 | - 向 ResourceManager 申请任务执行所需的资源
86 | - 任务调度和监管
87 |
88 | **实现方式**
89 |
90 | - 需要为每个应用开发一个 AM 组件
91 | - YARN 提供 MapReduce 的 ApplicationMaster 实现
92 | - 采用基于事件驱动的异步编程模型,由中央事件调度器统一管理所有事件
93 | - 每种组件都是一种事件处理器,在中央事件调度器中注册
94 |
95 | ### Container
96 |
97 | - 概念:Container 封装了节点上进程的相关资源,是 YARN 中资源的抽象
98 | - 分类:运行 ApplicationMaster 的 Container 、运行应用任务的 Container
99 |
100 | ## YARN 高可用
101 |
102 | ResourceManager 高可用
103 |
104 | - 1 个 Active RM、多个 Standby RM
105 | - 宕机后自动实现主备切换
106 | - ZooKeeper 的核心作用
107 | - Active 节点选举
108 | - 恢复 Active RM 的原有状态信息
109 | - 重启 AM,杀死所有运行中的 Container
110 | - 切换方式:手动、自动
111 |
112 | ## YARN 资源调度策略
113 |
114 | ### FIFO Scheduler(先进先出调度器)
115 |
116 | **调度策略**
117 |
118 | 将所有任务放入一个队列,先进队列的先获得资源,排在后面的任务只有等待
119 |
120 | **缺点**
121 |
122 | - 资源利用率低,无法交叉运行任务
123 | - 灵活性差,如:紧急任务无法插队,耗时长的任务拖慢耗时短的任务
124 |
125 | ### Capacity Scheduler(容量调度器)
126 |
127 | **核心思想** - 提前**做预算**,在预算指导下分享集群资源。
128 |
129 | **调度策略**
130 |
131 | - 集群资源由多个队列分享
132 | - 每个队列都要预设资源分配的比例(提前做预算)
133 | - 空闲资源优先分配给“实际资源/预算资源”比值最低的队列
134 | - 队列内部采用 FIFO 调度策略
135 |
136 | **特点**
137 |
138 | - 层次化的队列设计:子队列可使用父队列资源
139 | - 容量保证:每个队列都要预设资源占比,防止资源独占
140 | - 弹性分配:空闲资源可以分配给任何队列,当多个队列争用时,会按比例进行平衡
141 | - 支持动态管理:可以动态调整队列的容量、权限等参数,也可动态增加、暂停队列
142 | - 访问控制:用户只能向自己的队列中提交任务,不能访问其他队列
143 | - 多租户:多用户共享集群资源
144 |
145 | ### Fair Scheduler(公平调度器)
146 |
147 | **调度策略**
148 |
149 | - 多队列公平共享集群资源
150 | - 通过平分的方式,动态分配资源,无需预先设定资源分配比例
151 | - 队列内部可配置调度策略:FIFO、Fair(默认)
152 |
153 | **资源抢占**
154 |
155 | - 终止其他队列的任务,使其让出所占资源,然后将资源分配给占用资源量少于最小资源量限制的队列
156 |
157 | **队列权重**
158 |
159 | - 当队列中有任务等待,并且集群中有空闲资源时,每个队列可以根据权重获得不同比例的空闲资源
160 |
161 | ## 资源
162 |
--------------------------------------------------------------------------------
/codes/kafka/src/main/java/io/github/dunwu/bigdata/kafka/demo/KafkaConsumerCommitSyncAndAsyncDemo.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.kafka.demo;
2 |
3 | import org.apache.kafka.clients.consumer.ConsumerConfig;
4 | import org.apache.kafka.clients.consumer.ConsumerRecord;
5 | import org.apache.kafka.clients.consumer.ConsumerRecords;
6 | import org.apache.kafka.clients.consumer.KafkaConsumer;
7 | import org.apache.kafka.clients.producer.ProducerConfig;
8 | import org.slf4j.Logger;
9 | import org.slf4j.LoggerFactory;
10 |
11 | import java.time.Duration;
12 | import java.util.Collections;
13 | import java.util.Properties;
14 |
15 | /**
16 | * Kafka 消费者同步异步提交
17 | *
18 | * 针对偶尔出现的提交失败,不进行重试不会有太大问题,因为如果提交失败是因为临时问题导致的,那么后续的提交总会有成功的。
19 | *
20 | * 但如果这是发生在关闭消费者或再均衡前的最后一次提交,就要确保能够提交成功。
21 | *
22 | * 因此,在消费者关闭前一般会组合使用 commitSync() 和 commitAsync()。
23 | *
24 | * 消费者配置参考:https://kafka.apache.org/documentation/#consumerconfigs
25 | * @author Zhang Peng
26 | * @since 2020-06-20
27 | */
28 | public class KafkaConsumerCommitSyncAndAsyncDemo {
29 |
30 | private static final Logger log = LoggerFactory.getLogger(KafkaConsumerCommitSyncAndAsyncDemo.class);
31 | private static KafkaConsumer consumer;
32 |
33 | static {
34 | // 指定消费者的配置
35 | final Properties properties = new Properties();
36 | properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
37 | properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
38 | properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
39 | properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
40 | properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
41 | "org.apache.kafka.common.serialization.StringDeserializer");
42 | properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
43 | "org.apache.kafka.common.serialization.StringDeserializer");
44 |
45 | // 使用配置初始化 Kafka 消费者
46 | consumer = new KafkaConsumer<>(properties);
47 | }
48 |
49 | public static void main(String[] args) {
50 |
51 | // 订阅 Topic
52 | consumer.subscribe(Collections.singletonList("test"));
53 |
54 | try {
55 | // 轮询
56 | while (true) {
57 | ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
58 | for (ConsumerRecord record : records) {
59 | System.out.printf("topic = %s, partition = %s, offset = %d, key = %s, value = %s\n ",
60 | record.topic(), record.partition(), record.offset(), record.key(),
61 | record.value());
62 | }
63 | // 如果一切正常,使用 commitAsync() 来提交,这样吞吐量高。并且即使这次提交失败,下一次提交很可能会成功。
64 | consumer.commitAsync();
65 | }
66 | } catch (Exception e) {
67 | log.error("Unexpected error", e);
68 | } finally {
69 | try {
70 | // 如果直接关闭消费者,就没有下一次提交了。这种情况,使用 commitSync() 方法一直重试,直到提交成功或发生无法恢复的错误
71 | consumer.commitSync();
72 | } finally {
73 | consumer.close();
74 | }
75 | }
76 | }
77 |
78 | }
79 |
--------------------------------------------------------------------------------
/codes/zookeeper/src/main/java/io/github/dunwu/bigdata/zk/dlock/ZookeeperReentrantDistributedLock.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.zk.dlock;
2 |
3 | import cn.hutool.core.collection.CollectionUtil;
4 | import org.apache.curator.framework.CuratorFramework;
5 | import org.apache.curator.framework.recipes.locks.InterProcessMutex;
6 | import org.slf4j.Logger;
7 | import org.slf4j.LoggerFactory;
8 |
9 | import java.util.List;
10 | import java.util.concurrent.Executors;
11 | import java.util.concurrent.ScheduledExecutorService;
12 | import java.util.concurrent.TimeUnit;
13 |
14 | /**
15 | * 基于Zookeeper的可重入互斥锁(关于重入:仅限于持有zk锁的jvm内重入) Created by sunyujia@aliyun.com on 2016/2/24.
16 | */
17 | public class ZookeeperReentrantDistributedLock implements DistributedLock {
18 |
19 | private static final Logger log = LoggerFactory.getLogger(ZookeeperReentrantDistributedLock.class);
20 |
21 | /**
22 | * 线程池
23 | */
24 | private static final ScheduledExecutorService executorService = Executors.newScheduledThreadPool(3);
25 |
26 | /**
27 | * 所有PERSISTENT锁节点的根位置
28 | */
29 | public static final String ROOT_PATH = "/distributed_lock/";
30 |
31 | /**
32 | * 每次延迟清理PERSISTENT节点的时间 Unit:MILLISECONDS
33 | */
34 | private static final long DELAY_TIME_FOR_CLEAN = 1000;
35 |
36 | /**
37 | * zk 共享锁实现
38 | */
39 | private InterProcessMutex interProcessMutex;
40 |
41 | /**
42 | * 锁的ID,对应zk一个PERSISTENT节点,下挂EPHEMERAL节点.
43 | */
44 | private String path;
45 |
46 | /**
47 | * zk的客户端
48 | */
49 | private CuratorFramework client;
50 |
51 | public ZookeeperReentrantDistributedLock(CuratorFramework client, String lockId) {
52 | this.client = client;
53 | this.path = ROOT_PATH + lockId;
54 | interProcessMutex = new InterProcessMutex(this.client, this.path);
55 | }
56 |
57 | @Override
58 | public void lock() {
59 | try {
60 | interProcessMutex.acquire();
61 | } catch (Exception e) {
62 | log.error(e.getMessage(), e);
63 | }
64 | }
65 |
66 | @Override
67 | public boolean tryLock(long timeout, TimeUnit unit) {
68 | try {
69 | return interProcessMutex.acquire(timeout, unit);
70 | } catch (Exception e) {
71 | log.error(e.getMessage(), e);
72 | return false;
73 | }
74 | }
75 |
76 | @Override
77 | public void unlock() {
78 | try {
79 | interProcessMutex.release();
80 | } catch (Throwable e) {
81 | log.error(e.getMessage(), e);
82 | } finally {
83 | executorService.schedule(new Cleaner(client, path), DELAY_TIME_FOR_CLEAN, TimeUnit.MILLISECONDS);
84 | }
85 | }
86 |
87 | static class Cleaner implements Runnable {
88 |
89 | private String path;
90 |
91 | private CuratorFramework client;
92 |
93 | public Cleaner(CuratorFramework client, String path) {
94 | this.path = path;
95 | this.client = client;
96 | }
97 |
98 | @Override
99 | public void run() {
100 | try {
101 | List list = client.getChildren().forPath(path);
102 | if (CollectionUtil.isEmpty(list)) {
103 | client.delete().forPath(path);
104 | }
105 | } catch (Exception e) {
106 | log.error(e.getMessage(), e);
107 | }
108 | }
109 |
110 | }
111 |
112 | }
113 |
--------------------------------------------------------------------------------
/codes/zookeeper/src/test/java/io/github/dunwu/bigdata/zk/dlock/ZkReentrantLockTemplateTest.java:
--------------------------------------------------------------------------------
1 | package io.github.dunwu.bigdata.zk.dlock;
2 |
3 | import org.apache.curator.RetryPolicy;
4 | import org.apache.curator.framework.CuratorFramework;
5 | import org.apache.curator.framework.CuratorFrameworkFactory;
6 | import org.apache.curator.retry.ExponentialBackoffRetry;
7 | import org.junit.jupiter.api.Test;
8 |
9 | import java.util.concurrent.CountDownLatch;
10 | import java.util.concurrent.ThreadLocalRandom;
11 |
12 | /**
13 | * Created by sunyujia@aliyun.com on 2016/2/24.
14 | */
15 |
16 | public class ZkReentrantLockTemplateTest {
17 |
18 | @Test
19 | public void testTry() throws InterruptedException {
20 | RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
21 | CuratorFramework client = CuratorFrameworkFactory.newClient("localhost:2181", retryPolicy);
22 | client.start();
23 |
24 | final ZkDLockTemplate template = new ZkDLockTemplate(client);
25 | int size = 100;
26 | final CountDownLatch startCountDownLatch = new CountDownLatch(1);
27 | final CountDownLatch endDownLatch = new CountDownLatch(size);
28 | for (int i = 0; i < size; i++) {
29 | new Thread(() -> {
30 | try {
31 | startCountDownLatch.await();
32 | } catch (InterruptedException e) {
33 | Thread.currentThread().interrupt();
34 | }
35 | final int sleepTime = ThreadLocalRandom.current().nextInt(3) * 1000;
36 |
37 | template.execute("test", 3000, new Callback