')
33 | page = data[start:end]
34 | res = r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')"
35 | t1 = re.findall(res, page) #超链接
36 | print(t1[0])
37 | t2 = re.findall(r'
(.*?)', page) #标题
38 | print(t2[0])
39 | t3 = re.findall('
(.*?)
', page, re.M|re.S) #摘要
40 | print(t3[0])
41 |
42 |
43 |
--------------------------------------------------------------------------------
/第3章-正则表达式爬虫/chapter03_17.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 | import urllib.request
3 |
4 | url = 'https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png'
5 | local = 'baidu.png'
6 | urllib.request.urlretrieve(url, local)
7 |
--------------------------------------------------------------------------------
/第3章-正则表达式爬虫/test.html:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Book1-Python-DataCrawl/6d5259371a60a8fa5f4dd1c40673a9704414c8c8/第3章-正则表达式爬虫/test.html
--------------------------------------------------------------------------------
/第4章-BeautifulSoup基础知识/test01.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | from bs4 import BeautifulSoup
3 |
4 | #HTML源码
5 | html = """
6 |
7 |
8 |
BeautifulSoup技术
9 |
10 |
11 |
静夜思
12 |
13 | 窗前明月光,
14 | 疑似地上霜。
15 | 举头望明月,
16 | 低头思故乡。
17 |
18 |
19 | 李白(701年-762年),字太白,号青莲居士,又号“谪仙人”,
20 | 唐代伟大的浪漫主义诗人,被后人誉为“诗仙”,与
21 | 杜甫
22 | 并称为“李杜”,为了与另两位诗人
23 | 李商隐、
24 | 杜牧即“小李杜”区别,杜甫与李白又合称“大李杜”。
25 | 其人爽朗大方,爱饮酒...
26 |
27 |
...
28 | """
29 |
30 | #按照标准的缩进格式的结构输出
31 | soup = BeautifulSoup(html)
32 | print(soup.prettify())
33 |
--------------------------------------------------------------------------------
/第4章-BeautifulSoup基础知识/test02.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | from bs4 import BeautifulSoup
3 |
4 | #创建本地文件soup对象
5 | soup = BeautifulSoup(open('test04_01.html'), "html.parser")
6 |
7 | #获取标题
8 | title = soup.title
9 | print('标题:', title)
10 |
11 | #获取标题
12 | head = soup.head
13 | print('头部:', head)
14 |
15 | #获取a标签
16 | ta = soup.a
17 | print('超链接内容:', ta)
18 |
19 | #获取p标签
20 | tp = soup.p
21 | print('段落内容:', tp)
22 |
23 | #从文档中找到
的所有标签链接
24 | for a in soup.find_all('a'):
25 | print(a)
26 |
27 | #获取的超链接
28 | for link in soup.find_all('a'):
29 | print(link.get('href'))
30 |
31 | print(soup.title)
32 | # BeautifulSoup技术
33 | print(soup.head)
34 | # BeautifulSoup技术
35 | print(soup.p)
36 | # 静夜思
37 | print(soup.a)
38 | # 杜甫
39 |
40 | print(soup.name)
41 | #[document]
42 | print(soup.head.name)
43 | #head
44 | print(soup.title.name)
45 | #title
46 |
--------------------------------------------------------------------------------
/第4章-BeautifulSoup基础知识/test03.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | from bs4 import BeautifulSoup
3 | soup = BeautifulSoup('
Eastmount',"html.parser")
4 | tag = soup.b
5 | print(tag)
6 | print(type(tag))
7 |
8 | #Name
9 | print(tag.name)
10 | print(tag.string)
11 |
12 | #Attributes
13 | print(tag.attrs)
14 | print(tag['class'])
15 | print(tag.get('id'))
16 |
17 | #修改属性 增加属性name
18 | tag['class'] = 'abc'
19 | tag['id'] = '1'
20 | tag['name'] = '2'
21 | print(tag)
22 |
23 | #删除属性
24 | del tag['class']
25 | del tag['name']
26 | print(tag)
27 | print(tag['class'])
28 | #KeyError: 'class'
29 |
--------------------------------------------------------------------------------
/第4章-BeautifulSoup基础知识/test04.py:
--------------------------------------------------------------------------------
1 | from bs4 import BeautifulSoup
2 | soup = BeautifulSoup(open('test04_01.html'), "html.parser")
3 | tag = soup.title
4 | print(type(tag.string))
5 | #
6 |
7 | unicode_string = tag.string
8 | print(unicode_string)
9 | #BeautifulSoup技术
10 | print(type(unicode_string))
11 | #
12 |
13 | markup = ""
14 | soup = BeautifulSoup(markup, "html.parser")
15 | comment = soup.b.string
16 | print(type(comment))
17 | #
18 | print(comment)
19 | # This is a comment code.
20 |
--------------------------------------------------------------------------------
/第4章-BeautifulSoup基础知识/test04_01.html:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Book1-Python-DataCrawl/6d5259371a60a8fa5f4dd1c40673a9704414c8c8/第4章-BeautifulSoup基础知识/test04_01.html
--------------------------------------------------------------------------------
/第4章-BeautifulSoup基础知识/test05.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | from bs4 import BeautifulSoup
3 | soup = BeautifulSoup(open('test04_01.html'), "html.parser")
4 | print(soup.head.contents)
5 | #['\n', BeautifulSoup技术, '\n']
6 |
7 | print(soup.head.contents[1])
8 | #BeautifulSoup技术
9 |
10 | for child in soup.descendants:
11 | print(child)
12 |
13 | for content in soup.stripped_strings:
14 | print(content)
15 |
16 | #搜索文档树
17 | urls = soup.find_all('a')
18 | for u in urls:
19 | print(u)
20 |
--------------------------------------------------------------------------------
/第4章-BeautifulSoup基础知识/test06.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import re
3 | import urllib.request
4 | from bs4 import BeautifulSoup
5 |
6 | url = "http://www.eastmountyxz.com/"
7 | page = urllib.request.urlopen(url)
8 | soup = BeautifulSoup(page, "html.parser")
9 | essay0 = soup.find_all(attrs={"class":"essay"})
10 | for tag in essay0:
11 | print(tag)
12 | print('') #换行
13 | print(tag.a)
14 | print(tag.find("a").get_text())
15 | print(tag.find("a").attrs['href'])
16 | content = tag.find("p").get_text()
17 | print(content.replace(' ',''))
18 | print('--------------------------\n')
19 |
20 | #整理输出
21 | i = 1
22 | while i<=3:
23 | num = "essay" + str(i)
24 | essay = soup.find_all(attrs={"class":num})
25 | for tag in essay:
26 | print(tag.find("a").get_text())
27 | print(tag.find("a").attrs['href'])
28 | content = tag.find("p").get_text()
29 | print(content.replace(' ',''))
30 | i += 1
31 | print('')
32 |
--------------------------------------------------------------------------------
/第5章-BS爬取豆瓣电影/Result_Douban.txt:
--------------------------------------------------------------------------------
1 | 1
2 | [中文名称]肖申克的救赎
3 | [网页链接]https://movie.douban.com/subject/1292052/
4 | [影评]希望让人自由。
5 | 2
6 | [中文名称]霸王别姬
7 | [网页链接]https://movie.douban.com/subject/1291546/
8 | [影评]风华绝代。
9 | 3
10 | [中文名称]阿甘正传
11 | [网页链接]https://movie.douban.com/subject/1292720/
12 | [影评]一部美国近现代史。
13 | 4
14 | [中文名称]这个杀手不太冷
15 | [网页链接]https://movie.douban.com/subject/1295644/
16 | [影评]怪蜀黍和小萝莉不得不说的故事。
17 | 5
18 | [中文名称]泰坦尼克号
19 | [网页链接]https://movie.douban.com/subject/1292722/
20 | [影评]失去的才是永恒的。
21 | 6
22 | [中文名称]美丽人生
23 | [网页链接]https://movie.douban.com/subject/1292063/
24 | [影评]最美的谎言。
25 | 7
26 | [中文名称]千与千寻
27 | [网页链接]https://movie.douban.com/subject/1291561/
28 | [影评]最好的宫崎骏,最好的久石让。
29 | 8
30 | [中文名称]辛德勒的名单
31 | [网页链接]https://movie.douban.com/subject/1295124/
32 | [影评]拯救一个人,就是拯救整个世界。
33 | 9
34 | [中文名称]盗梦空间
35 | [网页链接]https://movie.douban.com/subject/3541415/
36 | [影评]诺兰给了我们一场无法盗取的梦。
37 | 10
38 | [中文名称]忠犬八公的故事
39 | [网页链接]https://movie.douban.com/subject/3011091/
40 | [影评]永远都不能忘记你所爱的人。
41 | 11
42 | [中文名称]星际穿越
43 | [网页链接]https://movie.douban.com/subject/1889243/
44 | [影评]爱是一种力量,让我们超越时空感知它的存在。
45 | 12
46 | [中文名称]海上钢琴师
47 | [网页链接]https://movie.douban.com/subject/1292001/
48 | [影评]每个人都要走一条自己坚定了的路,就算是粉身碎骨。
49 | 13
50 | [中文名称]楚门的世界
51 | [网页链接]https://movie.douban.com/subject/1292064/
52 | [影评]如果再也不能见到你,祝你早安,午安,晚安。
53 | 14
54 | [中文名称]三傻大闹宝莱坞
55 | [网页链接]https://movie.douban.com/subject/3793023/
56 | [影评]英俊版憨豆,高情商版谢耳朵。
57 | 15
58 | [中文名称]机器人总动员
59 | [网页链接]https://movie.douban.com/subject/2131459/
60 | [影评]小瓦力,大人生。
61 | 16
62 | [中文名称]放牛班的春天
63 | [网页链接]https://movie.douban.com/subject/1291549/
64 | [影评]天籁一般的童声,是最接近上帝的存在。
65 | 17
66 | [中文名称]大话西游之大圣娶亲
67 | [网页链接]https://movie.douban.com/subject/1292213/
68 | [影评]一生所爱。
69 | 18
70 | [中文名称]疯狂动物城
71 | [网页链接]https://movie.douban.com/subject/25662329/
72 | [影评]迪士尼给我们营造的乌托邦就是这样,永远善良勇敢,永远出乎意料。
73 | 19
74 | [中文名称]无间道
75 | [网页链接]https://movie.douban.com/subject/1307914/
76 | [影评]香港电影史上永不过时的杰作。
77 | 20
78 | [中文名称]熔炉
79 | [网页链接]https://movie.douban.com/subject/5912992/
80 | [影评]我们一路奋战不是为了改变世界,而是为了不让世界改变我们。
81 | 21
82 | [中文名称]教父
83 | [网页链接]https://movie.douban.com/subject/1291841/
84 | [影评]千万不要记恨你的对手,这样会让你失去理智。
85 | 22
86 | [中文名称]当幸福来敲门
87 | [网页链接]https://movie.douban.com/subject/1849031/
88 | [影评]平民励志片。
89 | 23
90 | [中文名称]龙猫
91 | [网页链接]https://movie.douban.com/subject/1291560/
92 | [影评]人人心中都有个龙猫,童年就永远不会消失。
93 | 24
94 | [中文名称]怦然心动
95 | [网页链接]https://movie.douban.com/subject/3319755/
96 | [影评]真正的幸福是来自内心深处。
97 | 25
98 | [中文名称]控方证人
99 | [网页链接]https://movie.douban.com/subject/1296141/
100 | [影评]比利·怀德满分作品。
101 |
102 |
103 | 26
104 | [中文名称]触不可及
105 | [网页链接]https://movie.douban.com/subject/6786002/
106 | [影评]满满温情的高雅喜剧。
107 | 27
108 | [中文名称]蝙蝠侠:黑暗骑士
109 | [网页链接]https://movie.douban.com/subject/1851857/
110 | [影评]无尽的黑暗。
111 | 28
112 | [中文名称]末代皇帝
113 | [网页链接]https://movie.douban.com/subject/1293172/
114 | [影评]“不要跟我比惨,我比你更惨”再适合这部电影不过了。
115 | 29
116 | [中文名称]活着
117 | [网页链接]https://movie.douban.com/subject/1292365/
118 | [影评]张艺谋最好的电影。
119 | 30
120 | [中文名称]寻梦环游记
121 | [网页链接]https://movie.douban.com/subject/20495023/
122 | [影评]死亡不是真的逝去,遗忘才是永恒的消亡。
123 | 31
124 | [中文名称]何以为家
125 | [网页链接]https://movie.douban.com/subject/30170448/
126 | [影评]凝视卑弱生命,用电影改变命运。
127 | 32
128 | [中文名称]乱世佳人
129 | [网页链接]https://movie.douban.com/subject/1300267/
130 | [影评]Tomorrow is another day.
131 | 33
132 | [中文名称]指环王3:王者无敌
133 | [网页链接]https://movie.douban.com/subject/1291552/
134 | [影评]史诗的终章。
135 | 34
136 | [中文名称]哈利·波特与魔法石
137 | [网页链接]https://movie.douban.com/subject/1295038/
138 | [影评]童话世界的开端。
139 | 35
140 | [中文名称]飞屋环游记
141 | [网页链接]https://movie.douban.com/subject/2129039/
142 | [影评]最后那些最无聊的事情,才是最值得怀念的。
143 | 36
144 | [中文名称]摔跤吧!爸爸
145 | [网页链接]https://movie.douban.com/subject/26387939/
146 | [影评]你不是在为你一个人战斗,你要让千千万万的女性看到女生并不是只能相夫教子。
147 | 37
148 | [中文名称]素媛
149 | [网页链接]https://movie.douban.com/subject/21937452/
150 | [影评]受过伤害的人总是笑得最开心,因为他们不愿意让身边的人承受一样的痛苦。
151 | 38
152 | [中文名称]少年派的奇幻漂流
153 | [网页链接]https://movie.douban.com/subject/1929463/
154 | [影评]瑰丽壮观、无人能及的冒险之旅。
155 | 39
156 | [中文名称]十二怒汉
157 | [网页链接]https://movie.douban.com/subject/1293182/
158 | [影评]1957年的理想主义。
159 | 40
160 | [中文名称]哈尔的移动城堡
161 | [网页链接]https://movie.douban.com/subject/1308807/
162 | [影评]带着心爱的人在天空飞翔。
163 | 41
164 | [中文名称]鬼子来了
165 | [网页链接]https://movie.douban.com/subject/1291858/
166 | [影评]对敌人的仁慈,就是对自己残忍。
167 | 42
168 | [中文名称]天空之城
169 | [网页链接]https://movie.douban.com/subject/1291583/
170 | [影评]对天空的追逐,永不停止。
171 | 43
172 | [中文名称]大话西游之月光宝盒
173 | [网页链接]https://movie.douban.com/subject/1299398/
174 | [影评]旷古烁今。
175 | 44
176 | [中文名称]我不是药神
177 | [网页链接]https://movie.douban.com/subject/26752088/
178 | [影评]对我们国家而言,这样的电影多一部是一部。
179 | 45
180 | [中文名称]闻香识女人
181 | [网页链接]https://movie.douban.com/subject/1298624/
182 | [影评]史上最美的探戈。
183 | 46
184 | [中文名称]罗马假日
185 | [网页链接]https://movie.douban.com/subject/1293839/
186 | [影评]爱情哪怕只有一天。
187 | 47
188 | [中文名称]天堂电影院
189 | [网页链接]https://movie.douban.com/subject/1291828/
190 | [影评]那些吻戏,那些青春,都在影院的黑暗里被泪水冲刷得无比清晰。
191 | 48
192 | [中文名称]辩护人
193 | [网页链接]https://movie.douban.com/subject/21937445/
194 | [影评]电影的现实意义大过电影本身。
195 | 49
196 | [中文名称]猫鼠游戏
197 | [网页链接]https://movie.douban.com/subject/1305487/
198 | [影评]骗子大师和执著警探的你追我跑故事。
199 | 50
200 | [中文名称]大闹天宫
201 | [网页链接]https://movie.douban.com/subject/1418019/
202 | [影评]经典之作,历久弥新。
203 |
204 |
205 | 51
206 | [中文名称]搏击俱乐部
207 | [网页链接]https://movie.douban.com/subject/1292000/
208 | [影评]邪恶与平庸蛰伏于同一个母体,在特定的时间互相对峙。
209 | 52
210 | [中文名称]教父2
211 | [网页链接]https://movie.douban.com/subject/1299131/
212 | [影评]优雅的孤独。
213 | 53
214 | [中文名称]狮子王
215 | [网页链接]https://movie.douban.com/subject/1301753/
216 | [影评]动物版《哈姆雷特》。
217 | 54
218 | [中文名称]指环王2:双塔奇兵
219 | [网页链接]https://movie.douban.com/subject/1291572/
220 | [影评]承前启后的史诗篇章。
221 | 55
222 | [中文名称]死亡诗社
223 | [网页链接]https://movie.douban.com/subject/1291548/
224 | [影评]当一个死水般的体制内出现一个活跃的变数时,所有的腐臭都站在了光明的对面。
225 | 56
226 | [中文名称]钢琴家
227 | [网页链接]https://movie.douban.com/subject/1296736/
228 | [影评]音乐能化解仇恨。
229 | 57
230 | [中文名称]黑客帝国
231 | [网页链接]https://movie.douban.com/subject/1291843/
232 | [影评]视觉革命。
233 | 58
234 | [中文名称]指环王1:魔戒再现
235 | [网页链接]https://movie.douban.com/subject/1291571/
236 | [影评]传说的开始。
237 | 59
238 | [中文名称]饮食男女
239 | [网页链接]https://movie.douban.com/subject/1291818/
240 | [影评]人生不能像做菜,把所有的料都准备好了才下锅。
241 | 60
242 | [中文名称]窃听风暴
243 | [网页链接]https://movie.douban.com/subject/1900841/
244 | [影评]别样人生。
245 | 61
246 | [中文名称]美丽心灵
247 | [网页链接]https://movie.douban.com/subject/1306029/
248 | [影评]爱是一切逻辑和原由。
249 | 62
250 | [中文名称]让子弹飞
251 | [网页链接]https://movie.douban.com/subject/3742360/
252 | [影评]你给我翻译翻译,神马叫做TMD的惊喜。
253 | 63
254 | [中文名称]绿皮书
255 | [网页链接]https://movie.douban.com/subject/27060077/
256 | [影评]去除成见,需要勇气。
257 | 64
258 | [中文名称]两杆大烟枪
259 | [网页链接]https://movie.douban.com/subject/1293350/
260 | [影评]4个臭皮匠顶个诸葛亮,盖·里奇果然不是盖的。
261 | 65
262 | [中文名称]本杰明·巴顿奇事
263 | [网页链接]https://movie.douban.com/subject/1485260/
264 | [影评]在时间之河里感受溺水之苦。
265 | 66
266 | [中文名称]海蒂和爷爷
267 | [网页链接]https://movie.douban.com/subject/25958717/
268 | [影评]如果生活中有什么使你感到快乐,那就去做吧!不要管别人说什么。
269 | 67
270 | [中文名称]飞越疯人院
271 | [网页链接]https://movie.douban.com/subject/1292224/
272 | [影评]自由万岁。
273 | 68
274 | [中文名称]看不见的客人
275 | [网页链接]https://movie.douban.com/subject/26580232/
276 | [影评]你以为你以为的就是你以为的。
277 | 69
278 | [中文名称]西西里的美丽传说
279 | [网页链接]https://movie.douban.com/subject/1292402/
280 | [影评]美丽无罪。
281 | 70
282 | [中文名称]拯救大兵瑞恩
283 | [网页链接]https://movie.douban.com/subject/1292849/
284 | [影评]美利坚精神输出大片No1.
285 | 71
286 | [中文名称]穿条纹睡衣的男孩
287 | [网页链接]https://movie.douban.com/subject/3008247/
288 | [影评]尽管有些不切实际的幻想,这部电影依旧是一部感人肺腑的佳作。
289 | 72
290 | [中文名称]小鞋子
291 | [网页链接]https://movie.douban.com/subject/1303021/
292 | [影评]奔跑的孩子是天使。
293 | 73
294 | [中文名称]音乐之声
295 | [网页链接]https://movie.douban.com/subject/1294408/
296 | [影评]用音乐化解仇恨,让歌声串起美好。
297 | 74
298 | [中文名称]情书
299 | [网页链接]https://movie.douban.com/subject/1292220/
300 | [影评]暗恋的极致。
301 | 75
302 | [中文名称]海豚湾
303 | [网页链接]https://movie.douban.com/subject/3442220/
304 | [影评]海豚的微笑,是世界上最高明的伪装。
305 |
306 |
307 | 76
308 | [中文名称]美国往事
309 | [网页链接]https://movie.douban.com/subject/1292262/
310 | [影评]往事如烟,无处祭奠。
311 | 77
312 | [中文名称]致命魔术
313 | [网页链接]https://movie.douban.com/subject/1780330/
314 | [影评]孪生蝙蝠侠大战克隆金刚狼。
315 | 78
316 | [中文名称]沉默的羔羊
317 | [网页链接]https://movie.douban.com/subject/1293544/
318 | [影评]安东尼·霍普金斯的顶级表演。
319 | 79
320 | [中文名称]禁闭岛
321 | [网页链接]https://movie.douban.com/subject/2334904/
322 | [影评]昔日翩翩少年,今日大腹便便。
323 | 80
324 | [中文名称]低俗小说
325 | [网页链接]https://movie.douban.com/subject/1291832/
326 | [影评]故事的高级讲法。
327 | 81
328 | [中文名称]蝴蝶效应
329 | [网页链接]https://movie.douban.com/subject/1292343/
330 | [影评]人的命运被自己瞬间的抉择改变。
331 | 82
332 | [中文名称]七宗罪
333 | [网页链接]https://movie.douban.com/subject/1292223/
334 | [影评]警察抓小偷,老鼠玩死猫。
335 | 83
336 | [中文名称]心灵捕手
337 | [网页链接]https://movie.douban.com/subject/1292656/
338 | [影评]人生中应该拥有这样的一段豁然开朗。
339 | 84
340 | [中文名称]布达佩斯大饭店
341 | [网页链接]https://movie.douban.com/subject/11525673/
342 | [影评]小清新的故事里注入了大历史的情怀。
343 | 85
344 | [中文名称]春光乍泄
345 | [网页链接]https://movie.douban.com/subject/1292679/
346 | [影评]爱情纠缠,男女一致。
347 | 86
348 | [中文名称]摩登时代
349 | [网页链接]https://movie.douban.com/subject/1294371/
350 | [影评]大时代中的人生,小人物的悲喜。
351 | 87
352 | [中文名称]哈利·波特与死亡圣器(下)
353 | [网页链接]https://movie.douban.com/subject/3011235/
354 | [影评]10年的完美句点。
355 | 88
356 | [中文名称]被嫌弃的松子的一生
357 | [网页链接]https://movie.douban.com/subject/1787291/
358 | [影评]以戏谑来戏谑戏谑。
359 | 89
360 | [中文名称]阿凡达
361 | [网页链接]https://movie.douban.com/subject/1652587/
362 | [影评]绝对意义上的美轮美奂。
363 | 90
364 | [中文名称]喜剧之王
365 | [网页链接]https://movie.douban.com/subject/1302425/
366 | [影评]我是一个演员。
367 | 91
368 | [中文名称]致命ID
369 | [网页链接]https://movie.douban.com/subject/1297192/
370 | [影评]最不可能的那个人永远是最可能的。
371 | 92
372 | [中文名称]剪刀手爱德华
373 | [网页链接]https://movie.douban.com/subject/1292370/
374 | [影评]浪漫忧郁的成人童话。
375 | 93
376 | [中文名称]勇敢的心
377 | [网页链接]https://movie.douban.com/subject/1294639/
378 | [影评]史诗大片的典范。
379 | 94
380 | [中文名称]杀人回忆
381 | [网页链接]https://movie.douban.com/subject/1300299/
382 | [影评]关于连环杀人悬案的集体回忆。
383 | 95
384 | [中文名称]加勒比海盗
385 | [网页链接]https://movie.douban.com/subject/1298070/
386 | [影评]约翰尼·德普的独角戏。
387 | 96
388 | [中文名称]狩猎
389 | [网页链接]https://movie.douban.com/subject/6985810/
390 | [影评]人言可畏。
391 | 97
392 | [中文名称]请以你的名字呼唤我
393 | [网页链接]https://movie.douban.com/subject/26799731/
394 | [影评]沉醉在电影的情感和视听氛围中无法自拔。
395 | 98
396 | [中文名称]天使爱美丽
397 | [网页链接]https://movie.douban.com/subject/1292215/
398 | [影评]法式小清新。
399 | 99
400 | [中文名称]断背山
401 | [网页链接]https://movie.douban.com/subject/1418834/
402 | [影评]每个人心中都有一座断背山。
403 | 100
404 | [中文名称]红辣椒
405 | [网页链接]https://movie.douban.com/subject/1865703/
406 | [影评]梦的勾结。
407 |
408 |
409 | 101
410 | [中文名称]7号房的礼物
411 | [网页链接]https://movie.douban.com/subject/10777687/
412 | [影评]《我是山姆》的《美丽人生》。
413 | 102
414 | [中文名称]幽灵公主
415 | [网页链接]https://movie.douban.com/subject/1297359/
416 | [影评]人与自然的战争史诗。
417 | 103
418 | [中文名称]小森林 夏秋篇
419 | [网页链接]https://movie.douban.com/subject/25814705/
420 | [影评]那些静得只能听见呼吸的日子里,你明白孤独即生活。
421 | 104
422 | [中文名称]阳光灿烂的日子
423 | [网页链接]https://movie.douban.com/subject/1291875/
424 | [影评]一场华丽的意淫。
425 | 105
426 | [中文名称]第六感
427 | [网页链接]https://movie.douban.com/subject/1297630/
428 | [影评]深入内心的恐怖,出人意料的结局。
429 | 106
430 | [中文名称]重庆森林
431 | [网页链接]https://movie.douban.com/subject/1291999/
432 | [影评]寂寞没有期限。
433 | 107
434 | [中文名称]唐伯虎点秋香
435 | [网页链接]https://movie.douban.com/subject/1306249/
436 | [影评]华太师是黄霑,吴镇宇四大才子之一。
437 | 108
438 | [中文名称]小森林 冬春篇
439 | [网页链接]https://movie.douban.com/subject/25814707/
440 | [影评]尊敬他人,尊敬你生活的这片土地,明白孤独是人生的常态。
441 | 109
442 | [中文名称]入殓师
443 | [网页链接]https://movie.douban.com/subject/2149806/
444 | [影评]死可能是一道门,逝去并不是终结,而是超越,走向下一程。
445 | 110
446 | [中文名称]超脱
447 | [网页链接]https://movie.douban.com/subject/5322596/
448 | [影评]穷尽一生,我们要学会的,不过是彼此拥抱。
449 | 111
450 | [中文名称]爱在黎明破晓前
451 | [网页链接]https://movie.douban.com/subject/1296339/
452 | [影评]缘分是个连绵词,最美不过一瞬。
453 | 112
454 | [中文名称]消失的爱人
455 | [网页链接]https://movie.douban.com/subject/21318488/
456 | [影评]年度最佳date movie。
457 | 113
458 | [中文名称]一一
459 | [网页链接]https://movie.douban.com/subject/1292434/
460 | [影评]我们都曾经是一一。
461 | 114
462 | [中文名称]菊次郎的夏天
463 | [网页链接]https://movie.douban.com/subject/1293359/
464 | [影评]从没见过那么流氓的温柔,从没见过那么温柔的流氓。
465 | 115
466 | [中文名称]蝙蝠侠:黑暗骑士崛起
467 | [网页链接]https://movie.douban.com/subject/3395373/
468 | [影评]诺兰就是保证。
469 | 116
470 | [中文名称]侧耳倾听
471 | [网页链接]https://movie.douban.com/subject/1297052/
472 | [影评]少女情怀总是诗。
473 | 117
474 | [中文名称]功夫
475 | [网页链接]https://movie.douban.com/subject/1291543/
476 | [影评]警恶惩奸,维护世界和平这个任务就交给你了,好吗?
477 | 118
478 | [中文名称]倩女幽魂
479 | [网页链接]https://movie.douban.com/subject/1297447/
480 | [影评]两张绝世的脸。
481 | 119
482 | [中文名称]无人知晓
483 | [网页链接]https://movie.douban.com/subject/1292337/
484 | [影评]我的平常生活就是他人的幸福。
485 | 120
486 | [中文名称]超能陆战队
487 | [网页链接]https://movie.douban.com/subject/11026735/
488 | [影评]Balalala~~~
489 | 121
490 | [中文名称]人生果实
491 | [网页链接]https://movie.douban.com/subject/26874505/
492 | [影评]土壤没有落叶不会肥沃,没有了你就不算人生。
493 | 122
494 | [中文名称]萤火之森
495 | [网页链接]https://movie.douban.com/subject/5989818/
496 | [影评]触不到的恋人。
497 | 123
498 | [中文名称]甜蜜蜜
499 | [网页链接]https://movie.douban.com/subject/1305164/
500 | [影评]相逢只要一瞬间,等待却像是一辈子。
501 | 124
502 | [中文名称]借东西的小人阿莉埃蒂
503 | [网页链接]https://movie.douban.com/subject/4202302/
504 | [影评]曾经的那段美好会沉淀为一辈子的记忆。
505 | 125
506 | [中文名称]玛丽和马克思
507 | [网页链接]https://movie.douban.com/subject/3072124/
508 | [影评]你是我最好的朋友,你是我唯一的朋友 。
509 |
510 |
511 | 126
512 | [中文名称]爱在日落黄昏时
513 | [网页链接]https://movie.douban.com/subject/1291990/
514 | [影评]九年后的重逢是世俗和责任的交叠,没了悸动和青涩,沧桑而温暖。
515 | 127
516 | [中文名称]驯龙高手
517 | [网页链接]https://movie.douban.com/subject/2353023/
518 | [影评]和谐的生活离不开摸头与被摸头。
519 | 128
520 | [中文名称]完美的世界
521 | [网页链接]https://movie.douban.com/subject/1300992/
522 | [影评]坏人的好总是比好人的好来得更感人。
523 | 129
524 | [中文名称]幸福终点站
525 | [网页链接]https://movie.douban.com/subject/1292274/
526 | [影评]有时候幸福需要等一等。
527 | 130
528 | [中文名称]告白
529 | [网页链接]https://movie.douban.com/subject/4268598/
530 | [影评]没有一人完全善,也没有一人完全恶。
531 | 131
532 | [中文名称]哈利·波特与阿兹卡班的囚徒
533 | [网页链接]https://movie.douban.com/subject/1291544/
534 | [影评]不一样的导演,不一样的哈利·波特。
535 | 132
536 | [中文名称]大鱼
537 | [网页链接]https://movie.douban.com/subject/1291545/
538 | [影评]抱着梦想而活着的人是幸福的,怀抱梦想而死去的人是不朽的。
539 | 133
540 | [中文名称]阳光姐妹淘
541 | [网页链接]https://movie.douban.com/subject/4917726/
542 | [影评]再多各自牛逼的时光,也比不上一起傻逼的岁月。
543 | 134
544 | [中文名称]射雕英雄传之东成西就
545 | [网页链接]https://movie.douban.com/subject/1316510/
546 | [影评]百看不厌。
547 | 135
548 | [中文名称]恐怖直播
549 | [网页链接]https://movie.douban.com/subject/21360417/
550 | [影评]恐怖分子的“秋菊打官司”。
551 | 136
552 | [中文名称]天书奇谭
553 | [网页链接]https://movie.douban.com/subject/1428581/
554 | [影评]传奇的年代,醉人的童话。
555 | 137
556 | [中文名称]怪兽电力公司
557 | [网页链接]https://movie.douban.com/subject/1291579/
558 | [影评]不要给它起名字,起了名字就有感情了。
559 | 138
560 | [中文名称]神偷奶爸
561 | [网页链接]https://movie.douban.com/subject/3287562/
562 | [影评]Mr. I Don't Care其实也有Care的时候。
563 | 139
564 | [中文名称]玩具总动员3
565 | [网页链接]https://movie.douban.com/subject/1858711/
566 | [影评]跨度十五年的欢乐与泪水。
567 | 140
568 | [中文名称]傲慢与偏见
569 | [网页链接]https://movie.douban.com/subject/1418200/
570 | [影评]爱是摈弃傲慢与偏见之后的曙光。
571 | 141
572 | [中文名称]哈利·波特与密室
573 | [网页链接]https://movie.douban.com/subject/1296996/
574 | [影评]魔法的密室之门已打开...
575 | 142
576 | [中文名称]时空恋旅人
577 | [网页链接]https://movie.douban.com/subject/10577869/
578 | [影评]把每天当作最后一天般珍惜度过,积极拥抱生活,就是幸福。
579 | 143
580 | [中文名称]教父3
581 | [网页链接]https://movie.douban.com/subject/1294240/
582 | [影评]任何信念的力量,都无法改变命运。
583 | 144
584 | [中文名称]釜山行
585 | [网页链接]https://movie.douban.com/subject/25986180/
586 | [影评]揭露人性的丧尸题材力作。
587 | 145
588 | [中文名称]血战钢锯岭
589 | [网页链接]https://movie.douban.com/subject/26325320/
590 | [影评]优秀的战争片不会美化战场,不会粉饰死亡,不会矮化敌人,不会无视常识,最重要的,不会宣扬战争。
591 | 146
592 | [中文名称]哪吒闹海
593 | [网页链接]https://movie.douban.com/subject/1307315/
594 | [影评]想你时你在闹海。
595 | 147
596 | [中文名称]被解救的姜戈
597 | [网页链接]https://movie.douban.com/subject/6307447/
598 | [影评]热血沸腾,那个低俗、性感的无耻混蛋又来了。
599 | 148
600 | [中文名称]七武士
601 | [网页链接]https://movie.douban.com/subject/1295399/
602 | [影评]时代悲歌。
603 | 149
604 | [中文名称]一个叫欧维的男人决定去死
605 | [网页链接]https://movie.douban.com/subject/26628357/
606 | [影评]惠及一生的美丽。
607 | 150
608 | [中文名称]喜宴
609 | [网页链接]https://movie.douban.com/subject/1303037/
610 | [影评]中国家庭的喜怒哀乐忍。
611 |
612 |
613 | 151
614 | [中文名称]电锯惊魂
615 | [网页链接]https://movie.douban.com/subject/1417598/
616 | [影评]真相就在眼前。
617 | 152
618 | [中文名称]风之谷
619 | [网页链接]https://movie.douban.com/subject/1291585/
620 | [影评]动画片的圣经。
621 | 153
622 | [中文名称]我是山姆
623 | [网页链接]https://movie.douban.com/subject/1306861/
624 | [影评]爱并不需要智商 。
625 | 154
626 | [中文名称]头号玩家
627 | [网页链接]https://movie.douban.com/subject/4920389/
628 | [影评]写给影迷,动漫迷和游戏迷的一封情书。
629 | 155
630 | [中文名称]英雄本色
631 | [网页链接]https://movie.douban.com/subject/1297574/
632 | [影评]英雄泪短,兄弟情长。
633 | 156
634 | [中文名称]上帝之城
635 | [网页链接]https://movie.douban.com/subject/1292208/
636 | [影评]被上帝抛弃了的上帝之城。
637 | 157
638 | [中文名称]谍影重重3
639 | [网页链接]https://movie.douban.com/subject/1578507/
640 | [影评]像吃了苏打饼一样干脆的电影。
641 | 158
642 | [中文名称]疯狂原始人
643 | [网页链接]https://movie.douban.com/subject/1907966/
644 | [影评]老少皆宜,这就是好莱坞动画的魅力。
645 | 159
646 | [中文名称]未麻的部屋
647 | [网页链接]https://movie.douban.com/subject/1395091/
648 | [影评]好的剧本是,就算你猜到了结局也猜不到全部。
649 | 160
650 | [中文名称]卢旺达饭店
651 | [网页链接]https://movie.douban.com/subject/1291822/
652 | [影评]当这个世界闭上双眼,他却敞开了怀抱。
653 | 161
654 | [中文名称]纵横四海
655 | [网页链接]https://movie.douban.com/subject/1295409/
656 | [影评]香港浪漫主义警匪动作片的巅峰之作。
657 | 162
658 | [中文名称]三块广告牌
659 | [网页链接]https://movie.douban.com/subject/26611804/
660 | [影评]怼天怼地,你走后,她与世界为敌。
661 | 163
662 | [中文名称]岁月神偷
663 | [网页链接]https://movie.douban.com/subject/3792799/
664 | [影评]岁月流逝,来日可追。
665 | 164
666 | [中文名称]花样年华
667 | [网页链接]https://movie.douban.com/subject/1291557/
668 | [影评]偷情本没有这样美。
669 | 165
670 | [中文名称]达拉斯买家俱乐部
671 | [网页链接]https://movie.douban.com/subject/1793929/
672 | [影评]Jared Leto的腿比女人还美!
673 | 166
674 | [中文名称]心迷宫
675 | [网页链接]https://movie.douban.com/subject/25917973/
676 | [影评]荒诞讽刺,千奇百巧,抽丝剥茧,百转千回。
677 | 167
678 | [中文名称]模仿游戏
679 | [网页链接]https://movie.douban.com/subject/10463953/
680 | [影评]他给机器起名“克里斯托弗”,因为这是他初恋的名字。
681 | 168
682 | [中文名称]黑客帝国3:矩阵革命
683 | [网页链接]https://movie.douban.com/subject/1302467/
684 | [影评]不得不说,《黑客帝国》系列是商业片与科幻、哲学完美结合的典范。
685 | 169
686 | [中文名称]记忆碎片
687 | [网页链接]https://movie.douban.com/subject/1304447/
688 | [影评]一个针管引发的血案。
689 | 170
690 | [中文名称]新世界
691 | [网页链接]https://movie.douban.com/subject/10437779/
692 | [影评]要做就做得狠一点,这样才能活下去。
693 | 171
694 | [中文名称]头脑特工队
695 | [网页链接]https://movie.douban.com/subject/10533913/
696 | [影评]愿我们都不用长大,每一座城堡都能永远存在。
697 | 172
698 | [中文名称]你的名字。
699 | [网页链接]https://movie.douban.com/subject/26683290/
700 | [影评]穿越错位的时空,仰望陨落的星辰,你没留下你的名字,我却无法忘记那句“我爱你”。
701 | 173
702 | [中文名称]荒蛮故事
703 | [网页链接]https://movie.douban.com/subject/24750126/
704 | [影评]始于荒诞,止于更荒诞。
705 | 174
706 | [中文名称]忠犬八公物语
707 | [网页链接]https://movie.douban.com/subject/1959195/
708 | [影评]养狗三日,便会对你终其一生。
709 | 175
710 | [中文名称]真爱至上
711 | [网页链接]https://movie.douban.com/subject/1292401/
712 | [影评]爱,是个动词。
713 |
714 |
715 | 176
716 | [中文名称]爆裂鼓手
717 | [网页链接]https://movie.douban.com/subject/25773932/
718 | [影评]这个世界从不善待努力的人,努力了也不一定会成功,但是知道自己在努力,就是活下去的动力。
719 | 177
720 | [中文名称]贫民窟的百万富翁
721 | [网页链接]https://movie.douban.com/subject/2209573/
722 | [影评]上帝之城+猜火车+阿甘正传+开心辞典=山寨富翁
723 | 178
724 | [中文名称]萤火虫之墓
725 | [网页链接]https://movie.douban.com/subject/1293318/
726 | [影评]幸福是生生不息,却难以触及的远。
727 | 179
728 | [中文名称]东邪西毒
729 | [网页链接]https://movie.douban.com/subject/1292328/
730 | [影评]电影诗。
731 | 180
732 | [中文名称]海街日记
733 | [网页链接]https://movie.douban.com/subject/25895901/
734 | [影评]是枝裕和的家庭习作。
735 | 181
736 | [中文名称]黑天鹅
737 | [网页链接]https://movie.douban.com/subject/1978709/
738 | [影评]黑暗之美。
739 | 182
740 | [中文名称]惊魂记
741 | [网页链接]https://movie.douban.com/subject/1293181/
742 | [影评]故事的反转与反转,分裂电影的始祖。
743 | 183
744 | [中文名称]无敌破坏王
745 | [网页链接]https://movie.douban.com/subject/6534248/
746 | [影评]迪士尼和皮克斯拿错剧本的产物。
747 | 184
748 | [中文名称]你看起来好像很好吃
749 | [网页链接]https://movie.douban.com/subject/4848115/
750 | [影评]感情不分食草或者食肉。
751 | 185
752 | [中文名称]冰川时代
753 | [网页链接]https://movie.douban.com/subject/1291578/
754 | [影评]松鼠才是角儿。
755 | 186
756 | [中文名称]小偷家族
757 | [网页链接]https://movie.douban.com/subject/27622447/
758 | [影评]我们组成了家。
759 | 187
760 | [中文名称]雨人
761 | [网页链接]https://movie.douban.com/subject/1291870/
762 | [影评]生活在自己的世界里,也可以让周围的人显得可笑和渺小。
763 | 188
764 | [中文名称]绿里奇迹
765 | [网页链接]https://movie.douban.com/subject/1300374/
766 | [影评]天使暂时离开。
767 | 189
768 | [中文名称]恋恋笔记本
769 | [网页链接]https://movie.douban.com/subject/1309163/
770 | [影评]爱情没有那么多借口,如果不能圆满,只能说明爱的不够。
771 | 190
772 | [中文名称]寄生虫
773 | [网页链接]https://movie.douban.com/subject/27010768/
774 | 191
775 | [中文名称]爱在午夜降临前
776 | [网页链接]https://movie.douban.com/subject/10808442/
777 | [影评]所谓爱情,就是话唠一路,都不会心生腻烦,彼此嫌弃。
778 | 192
779 | [中文名称]哈利·波特与火焰杯
780 | [网页链接]https://movie.douban.com/subject/1309055/
781 | 193
782 | [中文名称]疯狂的石头
783 | [网页链接]https://movie.douban.com/subject/1862151/
784 | [影评]中国版《两杆大烟枪》。
785 | 194
786 | [中文名称]恐怖游轮
787 | [网页链接]https://movie.douban.com/subject/3011051/
788 | [影评]不要企图在重复中寻找已经失去的爱。
789 | 195
790 | [中文名称]奇迹男孩
791 | [网页链接]https://movie.douban.com/subject/26787574/
792 | [影评]世界不完美,爱会有奇迹。
793 | 196
794 | [中文名称]雨中曲
795 | [网页链接]https://movie.douban.com/subject/1293460/
796 | [影评]骨灰级歌舞片。
797 | 197
798 | [中文名称]魔女宅急便
799 | [网页链接]https://movie.douban.com/subject/1307811/
800 | [影评]宫崎骏的电影总让人感觉世界是美好的,阳光明媚的。
801 | 198
802 | [中文名称]二十二
803 | [网页链接]https://movie.douban.com/subject/26430107/
804 | [影评]有一些东西不应该被遗忘。
805 | 199
806 | [中文名称]海边的曼彻斯特
807 | [网页链接]https://movie.douban.com/subject/25980443/
808 | [影评]我们都有权利不与自己的过去和解。
809 | 200
810 | [中文名称]房间
811 | [网页链接]https://movie.douban.com/subject/25724855/
812 | [影评]被偷走的岁月,被伤害的生命,被禁锢的灵魂,终将被希望和善意救赎。
813 |
814 |
815 | 201
816 | [中文名称]虎口脱险
817 | [网页链接]https://movie.douban.com/subject/1296909/
818 | [影评]永远看不腻的喜剧。
819 | 202
820 | [中文名称]九品芝麻官
821 | [网页链接]https://movie.douban.com/subject/1297518/
822 | 203
823 | [中文名称]人工智能
824 | [网页链接]https://movie.douban.com/subject/1302827/
825 | [影评]对爱的执着,可以超越一切。
826 | 204
827 | [中文名称]2001太空漫游
828 | [网页链接]https://movie.douban.com/subject/1292226/
829 | [影评]现代科幻电影的开山之作,最伟大导演的最伟大影片。
830 | 205
831 | [中文名称]可可西里
832 | [网页链接]https://movie.douban.com/subject/1308857/
833 | [影评]坚硬的信仰。
834 | 206
835 | [中文名称]色,戒
836 | [网页链接]https://movie.douban.com/subject/1828115/
837 | [影评]假戏真情,爱欲深海
838 | 207
839 | [中文名称]罗生门
840 | [网页链接]https://movie.douban.com/subject/1291879/
841 | [影评]人生的N种可能性。
842 | 208
843 | [中文名称]城市之光
844 | [网页链接]https://movie.douban.com/subject/1293908/
845 | [影评]永远的小人物,伟大的卓别林。
846 | 209
847 | [中文名称]终结者2:审判日
848 | [网页链接]https://movie.douban.com/subject/1291844/
849 | [影评]少见的超越首部的续集,动作片中的经典。
850 | 210
851 | [中文名称]初恋这件小事
852 | [网页链接]https://movie.douban.com/subject/4739952/
853 | [影评]黑小鸭速效美白记。
854 | 211
855 | [中文名称]魂断蓝桥
856 | [网页链接]https://movie.douban.com/subject/1293964/
857 | [影评]中国式内在的美国电影。
858 | 212
859 | [中文名称]牯岭街少年杀人事件
860 | [网页链接]https://movie.douban.com/subject/1292329/
861 | [影评]弱者送给弱者的一刀。
862 | 213
863 | [中文名称]遗愿清单
864 | [网页链接]https://movie.douban.com/subject/1867345/
865 | [影评]用剩余不多的时间,去燃烧整个生命。
866 | 214
867 | [中文名称]大佛普拉斯
868 | [网页链接]https://movie.douban.com/subject/27059130/
869 | [影评]人们可以登上月球,却永远无法探索人们内心的宇宙。
870 | 215
871 | [中文名称]波西米亚狂想曲
872 | [网页链接]https://movie.douban.com/subject/5300054/
873 | 216
874 | [中文名称]新龙门客栈
875 | [网页链接]https://movie.douban.com/subject/1292287/
876 | [影评]嬉笑怒骂,调风动月。
877 | 217
878 | [中文名称]源代码
879 | [网页链接]https://movie.douban.com/subject/3075287/
880 | [影评]邓肯·琼斯继《月球》之后再度奉献出一部精彩绝伦的科幻佳作。
881 | 218
882 | [中文名称]青蛇
883 | [网页链接]https://movie.douban.com/subject/1303394/
884 | [影评]人生如此,浮生如斯。谁人言,花彼岸,此生情长意短。谁都是不懂爱的罢了。
885 | 219
886 | [中文名称]海洋
887 | [网页链接]https://movie.douban.com/subject/3443389/
888 | [影评]大海啊,不全是水。
889 | 220
890 | [中文名称]燃情岁月
891 | [网页链接]https://movie.douban.com/subject/1295865/
892 | [影评]传奇,不是每个人都可以拥有。
893 | 221
894 | [中文名称]无耻混蛋
895 | [网页链接]https://movie.douban.com/subject/1438652/
896 | [影评]昆汀同学越来越变态了,比北野武还杜琪峰。
897 | 222
898 | [中文名称]疯狂的麦克斯4:狂暴之路
899 | [网页链接]https://movie.douban.com/subject/3592854/
900 | [影评]“多么美好的一天!”轰轰轰砰咚,啪哒哒哒轰隆隆,磅~
901 | 223
902 | [中文名称]血钻
903 | [网页链接]https://movie.douban.com/subject/1428175/
904 | [影评]每个美丽事物背后都是滴血的现实。
905 | 224
906 | [中文名称]步履不停
907 | [网页链接]https://movie.douban.com/subject/2222996/
908 | [影评]日本的家庭电影已经是世界巅峰了,步履不停是巅峰中的佳作。
909 | 225
910 | [中文名称]穿越时空的少女
911 | [网页链接]https://movie.douban.com/subject/1937946/
912 | [影评]爱上未来的你。
913 |
914 |
915 | 226
916 | [中文名称]谍影重重2
917 | [网页链接]https://movie.douban.com/subject/1308767/
918 | [影评]谁说王家卫镜头很晃?
919 | 227
920 | [中文名称]阿飞正传
921 | [网页链接]https://movie.douban.com/subject/1305690/
922 | [影评]王家卫是一种风格,张国荣是一个代表。
923 | 228
924 | [中文名称]彗星来的那一夜
925 | [网页链接]https://movie.douban.com/subject/25807345/
926 | [影评]小成本大魅力。
927 | 229
928 | [中文名称]地球上的星星
929 | [网页链接]https://movie.douban.com/subject/2363506/
930 | [影评]天使保护事件始末。
931 | 230
932 | [中文名称]完美陌生人
933 | [网页链接]https://movie.douban.com/subject/26614893/
934 | [影评]来啊,互相伤害啊!
935 | 231
936 | [中文名称]战争之王
937 | [网页链接]https://movie.douban.com/subject/1419936/
938 | [影评]做一颗让别人需要你的棋子。
939 | 232
940 | [中文名称]谍影重重
941 | [网页链接]https://movie.douban.com/subject/1304102/
942 | [影评]哗啦啦啦啦,天在下雨,哗啦啦啦啦,云在哭泣……找自己。
943 | 233
944 | [中文名称]香水
945 | [网页链接]https://movie.douban.com/subject/1760622/
946 | [影评]一个单凭体香达到高潮的男人。
947 | 234
948 | [中文名称]东京教父
949 | [网页链接]https://movie.douban.com/subject/1310177/
950 | 235
951 | [中文名称]东京物语
952 | [网页链接]https://movie.douban.com/subject/1291568/
953 | [影评]东京那么大,如果有一天走失了,恐怕一辈子不能再相见。
954 | 236
955 | [中文名称]千钧一发
956 | [网页链接]https://movie.douban.com/subject/1300117/
957 | [影评]一部能引人思考的科幻励志片。
958 | 237
959 | [中文名称]朗读者
960 | [网页链接]https://movie.douban.com/subject/2213597/
961 | [影评]当爱情跨越年龄的界限,它似乎能变得更久远一点,成为一种责任,一种水到渠成的相濡以沫。
962 | 238
963 | [中文名称]无间道2
964 | [网页链接]https://movie.douban.com/subject/1307106/
965 | 239
966 | [中文名称]再次出发之纽约遇见你
967 | [网页链接]https://movie.douban.com/subject/6874403/
968 | [影评]爱我就给我看你的播放列表。
969 | 240
970 | [中文名称]驴得水
971 | [网页链接]https://movie.douban.com/subject/25921812/
972 | [影评]过去的如果就让它过去了,未来只会越来越糟!
973 | 241
974 | [中文名称]黑客帝国2:重装上阵
975 | [网页链接]https://movie.douban.com/subject/1304141/
976 | [影评]一个精彩的世界观正在缓缓建立。
977 | 242
978 | [中文名称]崖上的波妞
979 | [网页链接]https://movie.douban.com/subject/1959877/
980 | 243
981 | [中文名称]猜火车
982 | [网页链接]https://movie.douban.com/subject/1292528/
983 | [影评]不可猜的青春迷笛。
984 | 244
985 | [中文名称]我爱你
986 | [网页链接]https://movie.douban.com/subject/5908478/
987 | [影评]你要相信,这世上真的有爱存在,不管在什么年纪
988 | 245
989 | [中文名称]浪潮
990 | [网页链接]https://movie.douban.com/subject/2297265/
991 | [影评]世界离独裁只有五天。
992 | 246
993 | [中文名称]聚焦
994 | [网页链接]https://movie.douban.com/subject/25954475/
995 | [影评]新闻人的理性求真。
996 | 247
997 | [中文名称]小萝莉的猴神大叔
998 | [网页链接]https://movie.douban.com/subject/26393561/
999 | [影评]宝莱坞的萝莉与大叔。
1000 | 248
1001 | [中文名称]追随
1002 | [网页链接]https://movie.douban.com/subject/1397546/
1003 | [影评]诺兰的牛逼来源于内心散发出的恐惧。
1004 | 249
1005 | [中文名称]黑鹰坠落
1006 | [网页链接]https://movie.douban.com/subject/1291824/
1007 | [影评]还原真实而残酷的战争。
1008 | 250
1009 | [中文名称]网络谜踪
1010 | [网页链接]https://movie.douban.com/subject/27615441/
1011 |
1012 |
1013 |
--------------------------------------------------------------------------------
/第5章-BS爬取豆瓣电影/chapter05_01.py:
--------------------------------------------------------------------------------
1 | # -*- coding:utf-8 -*-
2 | # By:Eastmount CSDN
3 | import urllib.request
4 | import re
5 | from bs4 import BeautifulSoup
6 |
7 | # 爬虫函数
8 | def crawl(url, headers):
9 | page = urllib.request.Request(url, headers=headers)
10 | page = urllib.request.urlopen(page)
11 | contents = page.read()
12 | #print(contents)
13 |
14 | soup = BeautifulSoup(contents, "html.parser")
15 | print('豆瓣电影250: 序号 \t影片名\t 评分 \t评价人数')
16 | for tag in soup.find_all(attrs={"class":"item"}):
17 | content = tag.get_text()
18 | content = content.replace('\n','') #删除多余换行
19 | #print(content, '\n')
20 |
21 | for tag in soup.find_all(attrs={"class":"item"}):
22 | title = tag.find_all(attrs={"class":"title"}) #电影名称
23 | info = tag.find(attrs={"class":"star"}).get_text() #爬取评分和评论数
24 | print(title[0])
25 | print(info.replace('\n',''))
26 |
27 | # 主函数
28 | if __name__ == '__main__':
29 | url = 'http://movie.douban.com/top250?format=text'
30 | headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
31 | AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
32 | crawl(url, headers)
33 |
--------------------------------------------------------------------------------
/第5章-BS爬取豆瓣电影/chapter05_02.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # By:Eastmount CSDN
3 | import urllib.request
4 | import re
5 | from bs4 import BeautifulSoup
6 | import codecs
7 |
8 | #-------------------------------------爬虫函数-------------------------------------
9 | def crawl(url, headers):
10 | page = urllib.request.Request(url, headers=headers)
11 | page = urllib.request.urlopen(page)
12 | contents = page.read()
13 |
14 | soup = BeautifulSoup(contents, "html.parser")
15 | infofile.write("")
16 | print('爬取豆瓣电影250: \n')
17 |
18 | for tag in soup.find_all(attrs={"class":"item"}):
19 | #爬取序号
20 | num = tag.find('em').get_text()
21 | print(num)
22 | infofile.write(num + "\r\n")
23 |
24 | #电影名称
25 | name = tag.find_all(attrs={"class":"title"})
26 | zwname = name[0].get_text()
27 | print('[中文名称]', zwname)
28 | infofile.write("[中文名称]" + zwname + "\r\n")
29 |
30 | #网页链接
31 | url_movie = tag.find(attrs={"class":"hd"}).a
32 | urls = url_movie.attrs['href']
33 | print('[网页链接]', urls)
34 | infofile.write("[网页链接]" + urls + "\r\n")
35 |
36 | #爬取评分和评论数
37 | info = tag.find(attrs={"class":"star"}).get_text()
38 | info = info.replace('\n',' ')
39 | info = info.lstrip()
40 | print('[评分评论]', info)
41 |
42 | #获取评语
43 | info = tag.find(attrs={"class":"inq"})
44 | if(info): #避免没有影评调用get_text()报错
45 | content = info.get_text()
46 | print('[影评]', content)
47 | infofile.write(u"[影评]" + content + "\r\n")
48 | print('')
49 |
50 | #-------------------------------------主函数-------------------------------------
51 | if __name__ == '__main__':
52 | #存储文件
53 | infofile = codecs.open("Result_Douban.txt", 'a', 'utf-8')
54 |
55 | #消息头
56 | headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
57 | AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
58 |
59 | #翻页
60 | i = 0
61 | while i<10:
62 | print('页码', (i+1))
63 | num = i*25 #每次显示25部 URL序号按25增加
64 | url = 'https://movie.douban.com/top250?start=' + str(num) + '&filter='
65 | crawl(url, headers)
66 | infofile.write("\r\n\r\n")
67 | i = i + 1
68 | infofile.close()
69 |
--------------------------------------------------------------------------------
/第5章-BS爬取豆瓣电影/chapter05_03.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # By:Eastmount CSDN
3 | import urllib.request
4 | import re
5 | from bs4 import BeautifulSoup
6 | import codecs
7 |
8 | #-----------------------------------爬取详细信息-------------------------------------
9 | def getInfo(url, headers):
10 | page = urllib.request.Request(url, headers=headers)
11 | page = urllib.request.urlopen(page)
12 | content = page.read()
13 | soup = BeautifulSoup(content, "html.parser")
14 |
15 | #电影简介
16 | print('电影简介:')
17 | info = soup.find(attrs={"id":"info"})
18 | print(info.get_text())
19 | other = soup.find(attrs={"class":"related-info"}).get_text()
20 | print(other.replace('\n','').replace(' ',''))
21 |
22 | #评论
23 | print('\n评论信息:')
24 | for tag in soup.find_all(attrs={"id":"hot-comments"}):
25 | for comment in tag.find_all(attrs={"class":"comment-item"}):
26 | com = comment.find("p").get_text()
27 | print(com.replace('\n','').replace(' ',''))
28 | print("\n\n\n----------------------------------------------------------------")
29 |
30 | #-------------------------------------爬虫函数-------------------------------------
31 | def crawl(url, headers):
32 | page = urllib.request.Request(url, headers=headers)
33 | page = urllib.request.urlopen(page)
34 | contents = page.read()
35 | soup = BeautifulSoup(contents, "html.parser")
36 |
37 | for tag in soup.find_all(attrs={"class":"item"}):
38 | #爬取序号
39 | num = tag.find('em').get_text()
40 | print(num)
41 |
42 | #电影名称
43 | name = tag.find_all(attrs={"class":"title"})
44 | zwname = name[0].get_text()
45 | print('[中文名称]', zwname)
46 |
47 | #网页链接
48 | url_movie = tag.find(attrs={"class":"hd"}).a
49 | urls = url_movie.attrs['href']
50 | print('[网页链接]', urls)
51 |
52 | #爬取评分和评论数
53 | info = tag.find(attrs={"class":"star"}).get_text()
54 | info = info.replace('\n',' ')
55 | info = info.lstrip()
56 |
57 | #正则表达式获取数字
58 | mode = re.compile(r'\d+\.?\d*')
59 | i = 0
60 | for n in mode.findall(info):
61 | if i==0:
62 | print('[电影分数]', n)
63 | elif i==1:
64 | print('[电影评论]', n)
65 | i = i + 1
66 |
67 | #获取评语
68 | getInfo(urls, headers)
69 |
70 | #-------------------------------------主函数-------------------------------------
71 | if __name__ == '__main__':
72 | #消息头
73 | headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
74 | AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
75 |
76 | #翻页
77 | i = 0
78 | while i<10:
79 | print('页码', (i+1))
80 | num = i*25 #每次显示25部 URL序号按25增加
81 | url = 'https://movie.douban.com/top250?start=' + str(num) + '&filter='
82 | crawl(url, headers)
83 | i = i + 1
84 | break
85 |
--------------------------------------------------------------------------------
/第6章-Python数据库知识/MySQL_python-1.2.5-cp27-none-win_amd64.whl:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Book1-Python-DataCrawl/6d5259371a60a8fa5f4dd1c40673a9704414c8c8/第6章-Python数据库知识/MySQL_python-1.2.5-cp27-none-win_amd64.whl
--------------------------------------------------------------------------------
/第6章-Python数据库知识/chapter06_01.py:
--------------------------------------------------------------------------------
1 | import MySQLdb
2 | conn = MySQLdb.connect(host='localhost', db='bookmanage', user='root',
3 | passwd='123456', port=3306, charset='utf8')
4 |
--------------------------------------------------------------------------------
/第6章-Python数据库知识/chapter06_02.py:
--------------------------------------------------------------------------------
1 | import MySQLdb
2 |
3 | try:
4 | conn=MySQLdb.connect(host='localhost',user='root',
5 | passwd='123456',port=3306)
6 | cur=conn.cursor()
7 | res = cur.execute('show databases')
8 | print(res)
9 | for data in cur.fetchall():
10 | print('%s' % data)
11 | cur.close()
12 | conn.close()
13 | except MySQLdb.Error as e:
14 | print("Mysql Error %d: %s" % (e.args[0], e.args[1]))
15 |
--------------------------------------------------------------------------------
/第6章-Python数据库知识/chapter06_03.py:
--------------------------------------------------------------------------------
1 | # coding:utf-8
2 | # By:Eastmount CSDN
3 | import MySQLdb
4 |
5 | try:
6 | conn = MySQLdb.connect(host='localhost',user='root',passwd='123456',
7 | port=3306, db='bookmanage', charset='utf8')
8 | cur = conn.cursor()
9 | res = cur.execute('select * from books')
10 | print('表中包含', res, u'条数据\n')
11 | for data in cur.fetchall():
12 | print('%s %s %s %s' % data)
13 | cur.close()
14 | conn.close()
15 |
16 | except MySQLdb.Error as e:
17 | print("Mysql Error %d: %s" % (e.args[0], e.args[1]))
18 |
--------------------------------------------------------------------------------
/第6章-Python数据库知识/chapter06_04.py:
--------------------------------------------------------------------------------
1 | # coding:utf-8
2 | # By:Eastmount CSDN
3 | import MySQLdb
4 |
5 | try:
6 | conn = MySQLdb.connect(host='localhost',user='root',passwd='123456',
7 | port=3306, db='bookmanage', charset='utf8')
8 | cur = conn.cursor()
9 | sql = '''create table student(id int not null primary key auto_increment,
10 | name char(30) not null,
11 | sex char(20) not null
12 | )'''
13 | cur.execute(sql)
14 |
15 | #查看表
16 | print('插入后包含表:')
17 | cur.execute('show tables')
18 | for data in cur.fetchall():
19 | print('%s' % data)
20 | cur.close()
21 | conn.commit()
22 | conn.close()
23 |
24 | except MySQLdb.Error as e:
25 | print("Mysql Error %d: %s" % (e.args[0], e.args[1]))
26 |
--------------------------------------------------------------------------------
/第6章-Python数据库知识/chapter06_05.py:
--------------------------------------------------------------------------------
1 | # coding:utf-8
2 | # By:Eastmount CSDN
3 | import MySQLdb
4 |
5 | try:
6 | conn=MySQLdb.connect(host='localhost',user='root',passwd='123456',
7 | port=3306, db='bookmanage', charset='utf8')
8 | cur=conn.cursor()
9 |
10 | #插入数据
11 | sql = '''insert into student values(%s, %s, %s)'''
12 | cur.execute(sql, ('3', 'xiaoyang', '男'))
13 |
14 | #查看数据
15 | print('\n插入数据:')
16 | cur.execute('select * from student')
17 | for data in cur.fetchall():
18 | print('%s %s %s' % data)
19 | cur.close()
20 | conn.commit()
21 | conn.close()
22 | except MySQLdb.Error as e:
23 | print("Mysql Error %d: %s" % (e.args[0], e.args[1]))
24 |
--------------------------------------------------------------------------------
/第6章-Python数据库知识/chapter06_06.py:
--------------------------------------------------------------------------------
1 | #-*- coding:utf-8 -*-
2 | # By:Eastmount CSDN
3 | import sqlite3
4 |
5 | #连接数据库:如果数据库不存在则创建
6 | conn = sqlite3.connect('test6.db')
7 | cur = conn.cursor()
8 | print('数据库创建成功.\n')
9 |
10 | #创建表 PEOPLE(编号,姓名,年龄,公司,薪水)
11 | cur.execute('''CREATE TABLE PEOPLE
12 | (ID INT PRIMARY KEY NOT NULL,
13 | NAME TEXT NOT NULL,
14 | AGE INT NOT NULL,
15 | COMPANY CHAR(50),
16 | SALARY REAL);
17 | ''')
18 | print("PEOPLE表创建成功.\n")
19 | conn.commit()
20 |
21 | #插入数据
22 | cur.execute("INSERT INTO PEOPLE (ID,NAME,AGE,COMPANY,SALARY) \
23 | VALUES (1, '小杨', 26, '华为', 10000.00 )");
24 | cur.execute("INSERT INTO PEOPLE (ID,NAME,AGE,COMPANY,SALARY) \
25 | VALUES (2, '小颜', 26, '百度', 8800.00 )");
26 | cur.execute("INSERT INTO PEOPLE (ID,NAME,AGE,COMPANY,SALARY) \
27 | VALUES (3, '小红', 28, '腾讯', 9800.00 )");
28 | conn.commit()
29 | print("数据插入成功.\n")
30 |
31 | #查询操作
32 | cursor = cur.execute("SELECT id, name, age, company, salary from PEOPLE")
33 | print("数据查询成功.")
34 | print("序号", "姓名", "年龄", "公司", "薪水")
35 | for row in cursor:
36 | print(row[0], row[1], row[2], row[3], row[4])
37 | print('')
38 |
39 | #更新操作
40 | cur.execute("UPDATE PEOPLE set COMPANY = '华为' where ID=2")
41 | conn.commit()
42 | print("数据更新成功.")
43 | cursor = cur.execute("SELECT id, name, company from PEOPLE")
44 | for row in cursor:
45 | print(row[0], row[1], row[2])
46 | print('')
47 |
48 | #删除操作
49 | cur.execute("DELETE from PEOPLE where COMPANY='华为';")
50 | conn.commit()
51 | print("数据删除成功.")
52 | cursor = cur.execute("SELECT id, name, company from PEOPLE")
53 | for row in cursor:
54 | print(row[0], row[1], row[2])
55 | print('')
56 |
57 | #关闭连接
58 | conn.close()
59 |
--------------------------------------------------------------------------------
/第6章-Python数据库知识/mysqlclient-1.4.6-cp37-cp37m-win32.whl:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Book1-Python-DataCrawl/6d5259371a60a8fa5f4dd1c40673a9704414c8c8/第6章-Python数据库知识/mysqlclient-1.4.6-cp37-cp37m-win32.whl
--------------------------------------------------------------------------------
/第6章-Python数据库知识/mysqlclient-1.4.6-cp37-cp37m-win_amd64.whl:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Book1-Python-DataCrawl/6d5259371a60a8fa5f4dd1c40673a9704414c8c8/第6章-Python数据库知识/mysqlclient-1.4.6-cp37-cp37m-win_amd64.whl
--------------------------------------------------------------------------------
/第6章-Python数据库知识/test6.db:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Book1-Python-DataCrawl/6d5259371a60a8fa5f4dd1c40673a9704414c8c8/第6章-Python数据库知识/test6.db
--------------------------------------------------------------------------------
 6 |
6 | 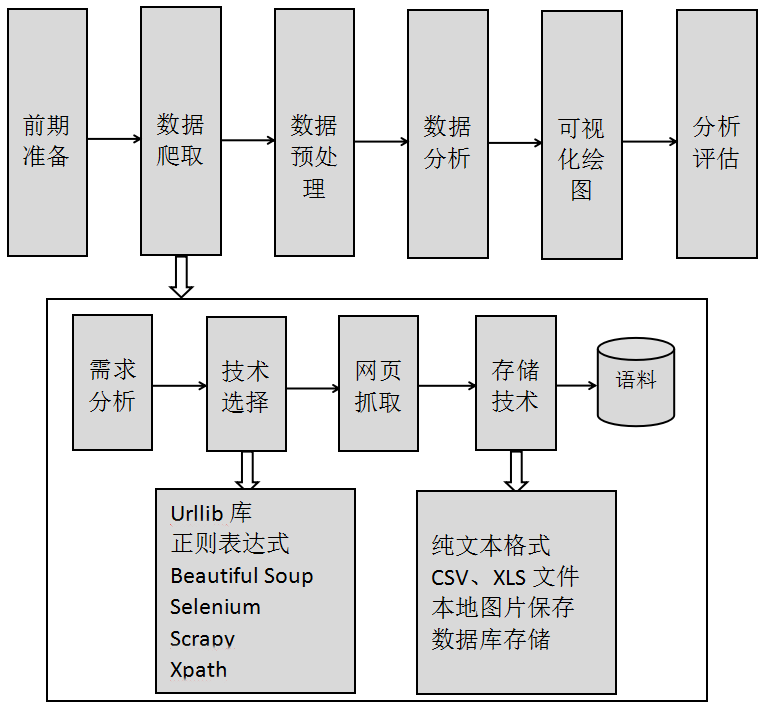 22 |
22 |