├── README.md
├── blog02-Kmeans
└── test01.py
├── blog03-Kmeans-yh
├── data.txt
├── result01.png
├── test01.py
└── test02.py
├── blog04-DTC
├── result.png
├── test01.py
├── test02.py
├── test03.py
└── test04.py
├── blog05-LR
├── res.png
├── res02.png
├── res03.png
├── test01.py
├── test02.py
├── test03.py
└── test04.py
├── blog06-Numpy+Matplotlib
├── data.xls
├── test01.py
├── test02.py
├── test03.py
├── test04.py
├── test05-matplotlib.py
├── test06-matplotlib.py
└── test07-matplotlib.py
├── blog07-pac
├── result01.png
├── result02.png
├── test01.py
├── test02.py
└── test03.py
├── blog08-Apriori
└── test01.py
├── blog09-LinearRegression
├── Index
├── glass.csv
├── glass.data
├── glass.names
├── glass.tag
├── result01.png
├── result02.png
├── result03.png
├── test01.py
└── test02.py
├── blog10-Pandas
├── 41.txt
├── bankloan.png
├── ccc.png
├── data.csv
├── data2.xlsx
├── guiyang.png
├── test01.py
├── test02.py
├── test03.py
├── test04.py
├── test05.py
├── test06-dalian.py
├── test07.py
├── 时序图.png
└── 贵阳自相关图.png
├── blog11-Matplotlib+SQL
├── test01.py
├── test02.py
├── test03.py
└── test04.py
├── blog12-matplotlib+SQL
├── test01.py
├── test02.py
├── test03.py
└── test04.py
├── blog13-wordcloud
├── cloudimg.png
├── mb.png
├── result01.png
├── test.txt
├── test01.py
└── test02.py
├── blog14-curve_fit
├── data.csv
├── result01.png
├── result02.png
├── test01.py
├── test02.py
├── test03.py
├── test04.py
├── test3.png
└── test4.png
├── blog15-imshow
├── result01.png
├── result02.png
├── result03.png
├── test01.py
├── test02.py
├── test03.py
├── test04.py
├── test05.py
├── test06.py
└── test07.py
├── blog16-LR
├── result01.png
├── result02.png
├── result03.png
├── test01.py
├── test02.py
└── test03.py
├── blog17-networkx
├── result01.png
├── test01.py
└── test02.py
├── blog18-Regression
├── blog01-LR.py
├── blog02-LR.py
├── blog03-boston.py
├── blog04-boson.py
├── blog05-random.py
├── blog06-random.py
├── blog07-3Drandom.py
├── blog08-PolynomialFeatures.py
├── blog09-PolynomialFeatures.py
├── result01.png
├── result02.png
├── result03.png
├── result04.png
├── result05.png
└── result06.png
├── blog19-Iris
├── result01.png
├── result02.png
├── result03.png
├── result04.png
├── result05.png
├── result06.png
├── result07.png
├── result08.png
├── result09.png
├── test01.py
├── test02-hist.py
├── test03-plot.py
├── test04-kde.py
├── test05-box.py
├── test06-box.py
├── test07-show.py
├── test08-LR.py
├── test09-Kmeans.py
├── test10-Kmeans.py
└── test11-Kmeans.py
├── blog20-KNN
├── blog01.py
├── blog02.py
├── blog03.py
├── blog04.py
├── result.png
├── result02.png
└── wine.txt
├── blog21-NB
├── blog01.py
├── blog02.py
├── blog03.py
├── blog04-getdata.py
├── blog05-fenci.py
├── blog06-static.py
├── blog07-classifier.py
├── data.csv
├── data_preprocess.py
├── result.png
├── result2.png
├── seed.txt
├── seed_x.csv
└── seed_y.csv
├── blog22-Basemap
├── 001.png
├── 002.png
├── 003.png
├── 004.png
├── 005.png
├── 006.png
├── basemap下载.txt
├── blog-001.py
├── blog-002.py
├── blog-003.py
├── blog-004.py
├── blog-005.py
├── blog-006.py
└── blog-007.py
├── blog23-statsmodels
├── blog01.py
├── blog02.py
├── blog03_show.py
├── blog04_show.py
├── blog05_groupby.py
├── blog06_ARIMA.py
├── blog07_ARIMA.py
├── blog08_statsmodels.py
├── blog09_statsmodels.py
├── result01.png
├── result02.png
├── result03.png
├── result04.png
└── result05.png
├── blog24-Kmeans-Chinese
├── BaiduSpiderSpots.rar
├── HudongSpider_Result.txt
├── blog01_merge.py
├── blog02_spider.py
├── blog03_fenci.py
├── blog04_kmeans.py
└── result.png
├── blog25-Matplotlib
├── allname.txt
├── plot.png
├── test01-show.py
├── test02-show.py
├── test03-kmeans.py
└── test04-kmeans.py
├── blog26-SnowNLP
├── data.txt
├── result01.png
├── result02.png
├── result03.png
├── result04.png
├── result05.png
├── test-douban.csv
├── test01-spider.py
├── test02-wordcloud.py
├── test03-snownlp01.py
├── test04-snownlp02.py
├── test05-snownlp03.py
├── test06-snownlp-show.py
├── test07-snownlp-show.py
└── test08-snownlp-show.py
├── blog27-SVM&WineDataset
├── data intro.txt
├── result01.png
├── result02.png
├── test01-svm.py
├── test02-datapre.py
├── test03-svm.py
├── test04-update.py
└── wine.txt
├── blog28-LDA&pyLDAvis
├── data.csv
├── result.png
├── test01-read.py
├── test02-jieba.py
├── test03-tfidf.py
├── test04-lda.py
└── test05-pyLDAvis.py
└── blog29-DataPreprocessing&KNN
├── kddcup.data_10_percent_corrected
├── kddcup.data_10_percent_corrected-result-minmax.csv
├── kddcup.data_10_percent_corrected-result.csv
├── kddcup.data_10_percent_corrected.csv
├── result01.png
├── result02.png
├── test01-data pre.py
├── test02-zscoreNormalization.py
├── test03-minmax.py
├── test04-knn-roc.py
├── test05-knn-gitHub-roc.py
└── test06-knn.py
/README.md:
--------------------------------------------------------------------------------
1 | # Python-for-Data-Mining
2 | 该资源为作者在CSDN的撰写Python数据挖掘和数据分析文章的支撑,主要是Python实现数据挖掘、机器学习、文本挖掘等算法代码实现,希望该资源对您有所帮助,一起加油。
3 |
4 | > 该部分代码修改成了Python 3.x版本,与Python 2.x略微不同。
5 | > 大家注意其差异即可,这也是为了更好的帮助同学们适应新的版本。
6 |
7 | ---
8 |
9 | 具体内容请参照如下CSDN博客:
10 |
11 | [【Python数据挖掘课程】一.安装Python及爬虫入门介绍](https://blog.csdn.net/eastmount/article/details/52577215)
12 | [【Python数据挖掘课程】二.Kmeans聚类数据分析及Anaconda介绍](https://blog.csdn.net/eastmount/article/details/52777308)
13 | [【Python数据挖掘课程】三.Kmeans聚类代码实现、作业及优化](https://blog.csdn.net/eastmount/article/details/52793549)
14 | [【Python数据挖掘课程】四.决策树DTC数据分析及鸢尾数据集分析](https://blog.csdn.net/eastmount/article/details/52820400)
15 | [【Python数据挖掘课程】五.线性回归知识及预测糖尿病实例](https://blog.csdn.net/eastmount/article/details/52929765)
16 | [【Python数据挖掘课程】六.Numpy、Pandas和Matplotlib包基础知识](https://blog.csdn.net/eastmount/article/details/53144633)
17 | [【Python数据挖掘课程】七.PCA降维操作及subplot子图绘制](https://blog.csdn.net/eastmount/article/details/53285192)
18 | [【Python数据挖掘课程】八.关联规则挖掘及Apriori实现购物推荐](https://blog.csdn.net/eastmount/article/details/53368440)
19 | [【Python数据挖掘课程】九.回归模型LinearRegression简单分析氧化物数据](https://blog.csdn.net/eastmount/article/details/60468818)
20 | [【python数据挖掘课程】十.Pandas、Matplotlib、PCA绘图实用代码补充](https://blog.csdn.net/eastmount/article/details/60675865)
21 | [【python数据挖掘课程】十一.Pandas、Matplotlib结合SQL语句可视化分析](https://blog.csdn.net/eastmount/article/details/62489186)
22 | [【python数据挖掘课程】十二.Pandas、Matplotlib结合SQL语句对比图分析](https://blog.csdn.net/eastmount/article/details/64127445)
23 | [【python数据挖掘课程】十三.WordCloud词云配置过程及词频分析](https://blog.csdn.net/eastmount/article/details/64438407)
24 | [【python数据挖掘课程】十四.Scipy调用curve_fit实现曲线拟合](https://blog.csdn.net/eastmount/article/details/71308373)
25 | [【python数据挖掘课程】十五.Matplotlib调用imshow()函数绘制热图](https://blog.csdn.net/eastmount/article/details/73392106)
26 | [【python数据挖掘课程】十六.逻辑回归LogisticRegression分析鸢尾花数据](https://blog.csdn.net/eastmount/article/details/77920470)
27 | [【python数据挖掘课程】十七.社交网络Networkx库分析人物关系(初识篇)](https://blog.csdn.net/eastmount/article/details/78452581)
28 | [【python数据挖掘课程】十八.线性回归及多项式回归分析四个案例分享](https://blog.csdn.net/eastmount/article/details/78635096)
29 | [【python数据挖掘课程】十九.鸢尾花数据集可视化、线性回归、决策树花样分析](https://blog.csdn.net/eastmount/article/details/78692227)
30 | [【python数据挖掘课程】二十.KNN最近邻分类算法分析详解及平衡秤TXT数据集读取](https://blog.csdn.net/eastmount/article/details/78747128)
31 | [【python数据挖掘课程】二十一.朴素贝叶斯分类器详解及中文文本舆情分析](https://blog.csdn.net/eastmount/article/details/79128235)
32 | [【python数据挖掘课程】二十二.Basemap地图包安装入门及基础知识讲解](https://blog.csdn.net/eastmount/article/details/79188415)
33 | [【python数据挖掘课程】二十三.时间序列金融数据预测及Pandas库详解](https://blog.csdn.net/eastmount/article/details/79188415)
34 | [【python数据挖掘课程】二十四.KMeans文本聚类分析互动百科语料](https://blog.csdn.net/eastmount/article/details/80935427)
35 | [【python数据挖掘课程】二十五.Matplotlib绘制带主题及聚类类标的散点图](https://blog.csdn.net/Eastmount/article/details/81106487)
36 | [【python数据挖掘课程】二十六.基于SnowNLP的豆瓣评论情感分析](https://blog.csdn.net/Eastmount/article/details/85118818)
37 | [【python数据挖掘课程】二十七.基于SVM分类器的红酒数据分析](https://blog.csdn.net/Eastmount/article/details/86512901)
38 | [【python数据挖掘课程】二十八.基于LDA和pyLDAvis的主题挖掘及可视化分析](https://blog.csdn.net/Eastmount/article/details/91380607)
39 | [【python数据挖掘课程】二十九.数据预处理之字符型转换数值型、标准化、归一化处理](https://blog.csdn.net/Eastmount/article/details/103212931)
40 |
41 |
42 | 效果图显示如下:
43 |
44 |
45 |

46 |
48 |
49 |
50 |
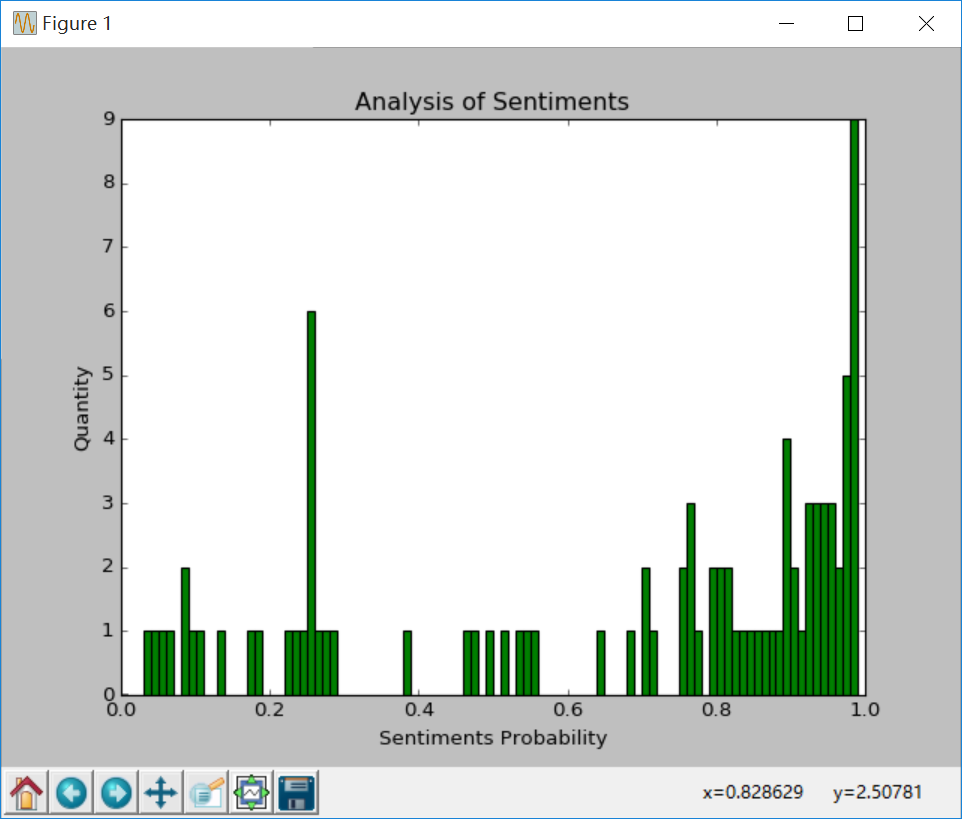
51 |
54 |
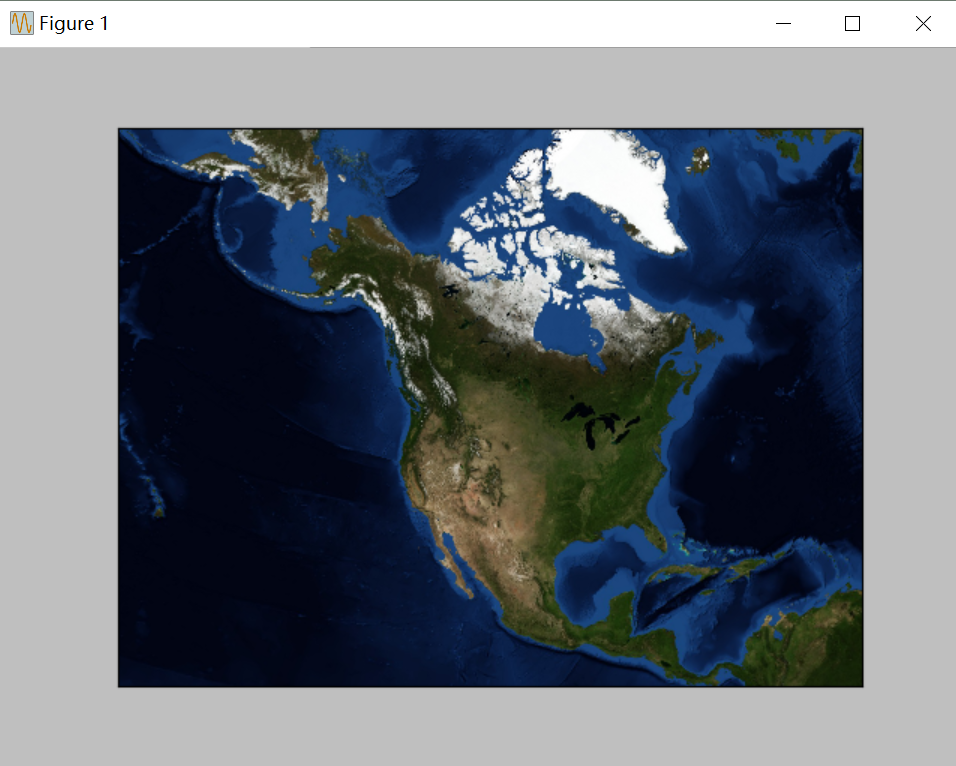
55 |
60 |
61 | ---
62 |
63 | 都是非常基础的文章,如果有错误或不足之处,还请告知及海涵,谢谢您的鼓励与支持,请帮忙点个Star!您的支持是我最大的动力,共勉~
64 |
65 | 数据挖掘相关知识分享。
66 |
67 | By:杨秀璋 Eastmount
68 |
69 | 2021-01-21
70 |
71 |
--------------------------------------------------------------------------------
/blog02-Kmeans/test01.py:
--------------------------------------------------------------------------------
1 | """
2 | 第一部分:导入包
3 | 从sklearn.cluster机器学习聚类包中导入KMeans聚类
4 | """
5 | # coding=utf-8
6 | from sklearn.cluster import Birch
7 | from sklearn.cluster import KMeans
8 |
9 | """
10 | 第二部分:数据集
11 | X表示二维矩阵数据,篮球运动员比赛数据
12 | 总共20行,每行两列数据
13 | 第一列表示球员每分钟助攻数:assists_per_minute
14 | 第二列表示球员每分钟得分数:points_per_minute
15 | """
16 |
17 | X = [[0.0888, 0.5885],
18 | [0.1399, 0.8291],
19 | [0.0747, 0.4974],
20 | [0.0983, 0.5772],
21 | [0.1276, 0.5703],
22 | [0.1671, 0.5835],
23 | [0.1906, 0.5276],
24 | [0.1061, 0.5523],
25 | [0.2446, 0.4007],
26 | [0.1670, 0.4770],
27 | [0.2485, 0.4313],
28 | [0.1227, 0.4909],
29 | [0.1240, 0.5668],
30 | [0.1461, 0.5113],
31 | [0.2315, 0.3788],
32 | [0.0494, 0.5590],
33 | [0.1107, 0.4799],
34 | [0.2521, 0.5735],
35 | [0.1007, 0.6318],
36 | [0.1067, 0.4326],
37 | [0.1956, 0.4280]
38 | ]
39 |
40 | #输出数据集
41 | print(X)
42 |
43 |
44 | """
45 | 第三部分:KMeans聚类
46 | clf = KMeans(n_clusters=3) 表示类簇数为3,聚成3类数据,clf即赋值为KMeans
47 | y_pred = clf.fit_predict(X) 载入数据集X,并且将聚类的结果赋值给y_pred
48 | """
49 |
50 | clf = KMeans(n_clusters=3)
51 | y_pred = clf.fit_predict(X)
52 |
53 | #输出完整Kmeans函数,包括很多省略参数
54 | print(clf)
55 | #输出聚类预测结果,20行数据,每个y_pred对应X一行或一个球员,聚成3类,类标为0、1、2
56 | print(y_pred)
57 |
58 |
59 | """
60 | 第四部分:可视化绘图
61 | Python导入Matplotlib包,专门用于绘图
62 | import matplotlib.pyplot as plt 此处as相当于重命名,plt用于显示图像
63 | """
64 |
65 | import numpy as np
66 | import matplotlib.pyplot as plt
67 |
68 | #获取第一列和第二列数据 使用for循环获取 n[0]表示X第一列
69 | x = [n[0] for n in X]
70 | print(x)
71 | y = [n[1] for n in X]
72 | print(y)
73 |
74 | #绘制散点图 参数:x横轴 y纵轴 c=y_pred聚类预测结果 marker类型 o表示圆点 *表示星型 x表示点
75 | plt.scatter(x, y, c=y_pred, marker='x')
76 |
77 | #绘制标题
78 | plt.title("Kmeans-Basketball Data")
79 |
80 | #绘制x轴和y轴坐标
81 | plt.xlabel("assists_per_minute")
82 | plt.ylabel("points_per_minute")
83 |
84 | #设置右上角图例
85 | plt.legend(["A","B","C"])
86 |
87 | #显示图形
88 | plt.show()
89 |
--------------------------------------------------------------------------------
/blog03-Kmeans-yh/data.txt:
--------------------------------------------------------------------------------
1 | 0.0888 201 36.02 28 0.5885
2 | 0.1399 198 39.32 30 0.8291
3 | 0.0747 198 38.8 26 0.4974
4 | 0.0983 191 40.71 30 0.5772
5 | 0.1276 196 38.4 28 0.5703
6 | 0.1671 201 34.1 31 0.5835
7 | 0.1906 193 36.2 30 0.5276
8 | 0.1061 191 36.75 27 0.5523
9 | 0.2446 185 38.43 29 0.4007
10 | 0.167 203 33.54 24 0.477
11 | 0.2485 188 35.01 27 0.4313
12 | 0.1227 198 36.67 29 0.4909
13 | 0.124 185 33.88 24 0.5668
14 | 0.1461 191 35.59 30 0.5113
15 | 0.2315 191 38.01 28 0.3788
16 | 0.0494 193 32.38 32 0.559
17 | 0.1107 196 35.22 25 0.4799
18 | 0.2521 183 31.73 29 0.5735
19 | 0.1007 193 28.81 34 0.6318
20 | 0.1067 196 35.6 23 0.4326
21 | 0.1956 188 35.28 32 0.428
22 | 0.1828 191 29.54 28 0.4401
23 | 0.1627 196 31.35 28 0.5581
24 | 0.1403 198 33.5 23 0.4866
25 | 0.1563 193 34.56 32 0.5267
26 | 0.2681 183 39.53 27 0.5439
27 | 0.1236 196 26.7 34 0.4419
28 | 0.13 188 30.77 26 0.3998
29 | 0.0896 198 25.67 30 0.4325
30 | 0.2071 178 36.22 30 0.4086
31 | 0.2244 185 36.55 23 0.4624
32 | 0.3437 185 34.91 31 0.4325
33 | 0.1058 191 28.35 28 0.4903
34 | 0.2326 185 33.53 27 0.4802
35 | 0.1577 193 31.07 25 0.4345
36 | 0.2327 185 36.52 32 0.4819
37 | 0.1256 196 27.87 29 0.6244
38 | 0.107 198 24.31 34 0.3991
39 | 0.1343 193 31.26 28 0.4414
40 | 0.0586 196 22.18 23 0.4013
41 | 0.2383 185 35.25 26 0.3801
42 | 0.1006 198 22.87 30 0.3498
43 | 0.2164 193 24.49 32 0.3185
44 | 0.1485 198 23.57 27 0.3097
45 | 0.227 191 31.72 27 0.4319
46 | 0.1649 188 27.9 25 0.3799
47 | 0.1188 191 22.74 24 0.4091
48 | 0.194 193 20.62 27 0.3588
49 | 0.2495 185 30.46 25 0.4727
50 | 0.2378 185 32.38 27 0.3212
51 | 0.1592 191 25.75 31 0.3418
52 | 0.2069 170 33.84 30 0.4285
53 | 0.2084 185 27.83 25 0.3917
54 | 0.0877 193 21.67 26 0.5769
55 | 0.101 193 21.79 24 0.4773
56 | 0.0942 201 20.17 26 0.4512
57 | 0.055 193 29.07 31 0.3096
58 | 0.1071 196 24.28 24 0.3089
59 | 0.0728 193 19.24 27 0.4573
60 | 0.2771 180 27.07 28 0.3214
61 | 0.0528 196 18.95 22 0.5437
62 | 0.213 188 21.59 30 0.4121
63 | 0.1356 193 13.27 31 0.2185
64 | 0.1043 196 16.3 23 0.3313
65 | 0.113 191 23.01 25 0.3302
66 | 0.1477 196 20.31 31 0.4677
67 | 0.1317 188 17.46 33 0.2406
68 | 0.2187 191 21.95 28 0.3007
69 | 0.2127 188 14.57 37 0.2471
70 | 0.2547 160 34.55 28 0.2894
71 | 0.1591 191 22.0 24 0.3682
72 | 0.0898 196 13.37 34 0.389
73 | 0.2146 188 20.51 24 0.512
74 | 0.1871 183 19.78 28 0.4449
75 | 0.1528 191 16.36 33 0.4035
76 | 0.156 191 16.03 23 0.2683
77 | 0.2348 188 24.27 26 0.2719
78 | 0.1623 180 18.49 28 0.3408
79 | 0.1239 180 17.76 26 0.4393
80 | 0.2178 185 13.31 25 0.3004
81 | 0.1608 185 17.41 26 0.3503
82 | 0.0805 193 13.67 25 0.4388
83 | 0.1776 193 17.46 27 0.2578
84 | 0.1668 185 14.38 35 0.2989
85 | 0.1072 188 12.12 31 0.4455
86 | 0.1821 185 12.63 25 0.3087
87 | 0.188 180 12.24 30 0.3678
88 | 0.1167 196 12.0 24 0.3667
89 | 0.2617 185 24.46 27 0.3189
90 | 0.1994 188 20.06 27 0.4187
91 | 0.1706 170 17.0 25 0.5059
92 | 0.1554 183 11.58 24 0.3195
93 | 0.2282 185 10.08 24 0.2381
94 | 0.1778 185 18.56 23 0.2802
95 | 0.1863 185 11.81 23 0.381
96 | 0.1014 193 13.81 32 0.1593
--------------------------------------------------------------------------------
/blog03-Kmeans-yh/result01.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog03-Kmeans-yh/result01.png
--------------------------------------------------------------------------------
/blog03-Kmeans-yh/test01.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | from sklearn.cluster import Birch
4 | from sklearn.cluster import KMeans
5 |
6 | X = [[0.0888, 0.5885],
7 | [0.1399, 0.8291],
8 | [0.0747, 0.4974],
9 | [0.0983, 0.5772],
10 | [0.1276, 0.5703],
11 | [0.1671, 0.5835],
12 | [0.1906, 0.5276],
13 | [0.1061, 0.5523],
14 | [0.2446, 0.4007],
15 | [0.1670, 0.4770],
16 | [0.2485, 0.4313],
17 | [0.1227, 0.4909],
18 | [0.1240, 0.5668],
19 | [0.1461, 0.5113],
20 | [0.2315, 0.3788],
21 | [0.0494, 0.5590],
22 | [0.1107, 0.4799],
23 | [0.2521, 0.5735],
24 | [0.1007, 0.6318],
25 | [0.1067, 0.4326],
26 | [0.1956, 0.4280]
27 | ]
28 | print(X)
29 |
30 | # Kmeans聚类
31 | clf = KMeans(n_clusters=3)
32 | y_pred = clf.fit_predict(X)
33 | print(clf)
34 | print(y_pred)
35 |
36 |
37 | import numpy as np
38 | import matplotlib.pyplot as plt
39 |
40 | x = [n[0] for n in X]
41 | print(x)
42 | y = [n[1] for n in X]
43 | print(y)
44 |
45 | # 可视化操作
46 | plt.scatter(x, y, c=y_pred, marker='x')
47 | plt.title("Kmeans-Basketball Data")
48 | plt.xlabel("assists_per_minute")
49 | plt.ylabel("points_per_minute")
50 | plt.legend(["Rank"])
51 | plt.show()
52 |
--------------------------------------------------------------------------------
/blog03-Kmeans-yh/test02.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | """
4 | By: Eastmount CSDN 2016-10-12
5 | 该部分讲数据集读取,然后赋值给X变量
6 | 读取文件data.txt 保存结果为X
7 | """
8 |
9 | import os
10 |
11 | data = []
12 | for line in open("data.txt", "r").readlines():
13 | line = line.rstrip() #删除换行
14 | #删除多余空格,保存一个空格连接
15 | result = ' '.join(line.split())
16 | #获取每行五个值 '0 0.0888 201 36.02 28 0.5885' 注意:字符串转换为浮点型数
17 | s = [float(x) for x in result.strip().split(' ')]
18 | #输出结果:['0', '0.0888', '201', '36.02', '28', '0.5885']
19 | print(s)
20 | #数据存储至data
21 | data.append(s)
22 |
23 | #输出完整数据集
24 | print('完整数据集')
25 | print(data)
26 | print(type(data))
27 |
28 | '''
29 | 现在输出数据集:
30 | ['0 0.0888 201 36.02 28 0.5885',
31 | '1 0.1399 198 39.32 30 0.8291',
32 | '2 0.0747 198 38.80 26 0.4974',
33 | '3 0.0983 191 40.71 30 0.5772',
34 | '4 0.1276 196 38.40 28 0.5703'
35 | ]
36 | '''
37 |
38 | print('第一列 第五列数据')
39 | L2 = [n[0] for n in data]
40 | print(L2)
41 | L5 = [n[4] for n in data]
42 | print(L5)
43 |
44 | '''
45 | X表示二维矩阵数据,篮球运动员比赛数据
46 | 总共96行,每行获取两列数据
47 | 第一列表示球员每分钟助攻数:assists_per_minute
48 | 第五列表示球员每分钟得分数:points_per_minute
49 | '''
50 |
51 | #两列数据生成二维数据
52 | print('两列数据合并成二维矩阵')
53 | T = dict(zip(L2,L5))
54 | type(T)
55 |
56 | #dict类型转换为list
57 | print('List')
58 | X = list(map(lambda x,y: (x,y), T.keys(),T.values()))
59 | print(X)
60 | print(type(X))
61 |
62 |
63 | """
64 | KMeans聚类
65 | clf = KMeans(n_clusters=3) 表示类簇数为3,聚成3类数据,clf即赋值为KMeans
66 | y_pred = clf.fit_predict(X) 载入数据集X,并且将聚类的结果赋值给y_pred
67 | """
68 |
69 | from sklearn.cluster import Birch
70 | from sklearn.cluster import KMeans
71 |
72 | clf = KMeans(n_clusters=3)
73 | y_pred = clf.fit_predict(X)
74 | print(clf)
75 | #输出聚类预测结果,96行数据,每个y_pred对应X一行或一个球员,聚成3类,类标为0、1、2
76 | print(y_pred)
77 |
78 |
79 | """
80 | 可视化绘图
81 | Python导入Matplotlib包,专门用于绘图
82 | import matplotlib.pyplot as plt 此处as相当于重命名,plt用于显示图像
83 | """
84 |
85 | import numpy as np
86 | import matplotlib.pyplot as plt
87 |
88 |
89 | #获取第一列和第二列数据 使用for循环获取 n[0]表示X第一列
90 | x = [n[0] for n in X]
91 | print(x)
92 | y = [n[1] for n in X]
93 | print(y)
94 |
95 | #绘制散点图 参数:x横轴 y纵轴 c=y_pred聚类预测结果 marker类型 o表示圆点 *表示星型 x表示点
96 | #plt.scatter(x, y, c=y_pred, marker='x')
97 |
98 |
99 | #坐标
100 | x1 = []
101 | y1 = []
102 |
103 | x2 = []
104 | y2 = []
105 |
106 | x3 = []
107 | y3 = []
108 |
109 | #分布获取类标为0、1、2的数据 赋值给(x1,y1) (x2,y2) (x3,y3)
110 | i = 0
111 | while i < len(X):
112 | if y_pred[i]==0:
113 | x1.append(X[i][0])
114 | y1.append(X[i][1])
115 | elif y_pred[i]==1:
116 | x2.append(X[i][0])
117 | y2.append(X[i][1])
118 | elif y_pred[i]==2:
119 | x3.append(X[i][0])
120 | y3.append(X[i][1])
121 |
122 | i = i + 1
123 |
124 |
125 | #四种颜色 红 绿 蓝 黑
126 | plot1, = plt.plot(x1, y1, 'or', marker="x")
127 | plot2, = plt.plot(x2, y2, 'og', marker="o")
128 | plot3, = plt.plot(x3, y3, 'ob', marker="*")
129 |
130 | #绘制标题
131 | plt.title("Kmeans-Basketball Data")
132 |
133 | #绘制x轴和y轴坐标
134 | plt.xlabel("assists_per_minute")
135 | plt.ylabel("points_per_minute")
136 |
137 | #设置右上角图例
138 | plt.legend((plot1, plot2, plot3), ('A', 'B', 'C'), fontsize=10)
139 |
140 | plt.show()
141 |
--------------------------------------------------------------------------------
/blog04-DTC/result.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog04-DTC/result.png
--------------------------------------------------------------------------------
/blog04-DTC/test01.py:
--------------------------------------------------------------------------------
1 | #导入数据集iris
2 | from sklearn.datasets import load_iris
3 |
4 | #载入数据集
5 | iris = load_iris()
6 | #输出数据集
7 | print(iris.data)
8 |
--------------------------------------------------------------------------------
/blog04-DTC/test02.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Fri Oct 14 21:44:19 2016
4 | @author: 杨秀璋
5 | """
6 |
7 | #导入数据集iris
8 | from sklearn.datasets import load_iris
9 |
10 | #载入数据集
11 | iris = load_iris()
12 |
13 | print(iris.data) #输出数据集
14 | print(iris.target) #输出真实标签
15 | print(len(iris.target))
16 | print(iris.data.shape) #150个样本 每个样本4个特征
17 |
18 |
19 | #导入决策树DTC包
20 | from sklearn.tree import DecisionTreeClassifier
21 |
22 | #训练
23 | clf = DecisionTreeClassifier()
24 | clf.fit(iris.data, iris.target)
25 | print(clf)
26 |
27 | #预测
28 | predicted = clf.predict(iris.data)
29 |
30 | #获取花卉两列数据集
31 | X = iris.data
32 | L1 = [x[0] for x in X]
33 | print(L1)
34 | L2 = [x[1] for x in X]
35 | print(L2)
36 |
37 | #绘图
38 | import numpy as np
39 | import matplotlib.pyplot as plt
40 | plt.scatter(L1, L2, c=predicted, marker='x') #cmap=plt.cm.Paired
41 | plt.title("DTC")
42 | plt.show()
43 |
--------------------------------------------------------------------------------
/blog04-DTC/test03.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Fri Oct 14 21:44:19 2016
4 | @author: 杨秀璋
5 | """
6 |
7 | #导入数据集iris
8 | from sklearn.datasets import load_iris
9 | import numpy as np
10 |
11 | #载入数据集
12 | iris = load_iris()
13 |
14 | '''
15 | print iris.data #输出数据集
16 | print iris.target #输出真实标签
17 | print len(iris.target)
18 | print iris.data.shape #150个样本 每个样本4个特征
19 | '''
20 |
21 | '''
22 | 重点:分割数据集 构造训练集/测试集,120/30
23 | 70%训练 0-40 50-90 100-140
24 | 30%预测 40-50 90-100 140-150
25 | '''
26 | #训练集
27 | train_data = np.concatenate((iris.data[0:40, :], iris.data[50:90, :], iris.data[100:140, :]), axis = 0)
28 | #训练集样本类别
29 | train_target = np.concatenate((iris.target[0:40], iris.target[50:90], iris.target[100:140]), axis = 0)
30 | #测试集
31 | test_data = np.concatenate((iris.data[40:50, :], iris.data[90:100, :], iris.data[140:150, :]), axis = 0)
32 | #测试集样本类别
33 | test_target = np.concatenate((iris.target[40:50], iris.target[90:100], iris.target[140:150]), axis = 0)
34 |
35 |
36 | #导入决策树DTC包
37 | from sklearn.tree import DecisionTreeClassifier
38 |
39 | #训练
40 | clf = DecisionTreeClassifier()
41 | #注意均使用训练数据集和样本类标
42 | clf.fit(train_data, train_target)
43 | print(clf)
44 |
45 | #预测结果
46 | predict_target = clf.predict(test_data)
47 | print(predict_target)
48 |
49 | #预测结果与真实结果比对
50 | print(sum(predict_target == test_target))
51 |
52 | #输出准确率 召回率 F值
53 | from sklearn import metrics
54 | print(metrics.classification_report(test_target, predict_target))
55 | print(metrics.confusion_matrix(test_target, predict_target))
56 |
57 |
58 | #获取花卉测试数据集两列数据集
59 | X = test_data
60 | L1 = [n[0] for n in X]
61 | print(L1)
62 | L2 = [n[1] for n in X]
63 | print(L2)
64 |
65 | #绘图
66 | import numpy as np
67 | import matplotlib.pyplot as plt
68 | plt.scatter(L1, L2, c=predict_target, marker='x') #cmap=plt.cm.Paired
69 | plt.title("DecisionTreeClassifier")
70 | plt.show()
71 |
--------------------------------------------------------------------------------
/blog04-DTC/test04.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Wed Oct 12 23:30:34 2016
4 | @author: yxz15
5 | """
6 |
7 | print(__doc__)
8 |
9 | import numpy as np
10 | import matplotlib.pyplot as plt
11 |
12 | from sklearn.datasets import load_iris
13 | from sklearn.tree import DecisionTreeClassifier
14 |
15 | # Parameters
16 | n_classes = 3
17 | plot_colors = "bry"
18 | plot_step = 0.02
19 |
20 | # Load data
21 | iris = load_iris()
22 |
23 | for pairidx, pair in enumerate([[0, 1], [0, 2], [0, 3],
24 | [1, 2], [1, 3], [2, 3]]):
25 | # We only take the two corresponding features
26 | X = iris.data[:, pair]
27 | y = iris.target
28 |
29 | # Train
30 | clf = DecisionTreeClassifier().fit(X, y)
31 |
32 | # Plot the decision boundary
33 | plt.subplot(2, 3, pairidx + 1)
34 |
35 | x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
36 | y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
37 | xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step),
38 | np.arange(y_min, y_max, plot_step))
39 |
40 | Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
41 | Z = Z.reshape(xx.shape)
42 | cs = plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
43 |
44 | plt.xlabel(iris.feature_names[pair[0]])
45 | plt.ylabel(iris.feature_names[pair[1]])
46 | plt.axis("tight")
47 |
48 | # Plot the training points
49 | for i, color in zip(range(n_classes), plot_colors):
50 | idx = np.where(y == i)
51 | plt.scatter(X[idx, 0], X[idx, 1], c=color, label=iris.target_names[i],
52 | cmap=plt.cm.Paired)
53 |
54 | plt.axis("tight")
55 |
56 | plt.suptitle("Decision surface of a decision tree using paired features")
57 | plt.legend()
58 | plt.show()
59 |
--------------------------------------------------------------------------------
/blog05-LR/res.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog05-LR/res.png
--------------------------------------------------------------------------------
/blog05-LR/res02.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog05-LR/res02.png
--------------------------------------------------------------------------------
/blog05-LR/res03.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog05-LR/res03.png
--------------------------------------------------------------------------------
/blog05-LR/test01.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Thu Oct 27 02:37:05 2016
4 | @author: yxz15
5 | """
6 |
7 | from sklearn import datasets
8 | diabetes = datasets.load_diabetes() #载入数据
9 | print(diabetes.data) #数据
10 | print(diabetes.target) #类标
11 | print('总行数: ', len(diabetes.data), len(diabetes.target)) #数据总行数
12 | print('特征数: ', len(diabetes.data[0])) #每行数据集维数
13 | print('数据类型: ', diabetes.data.shape) #类型
14 | print(type(diabetes.data), type(diabetes.target)) #数据集类型
15 |
16 | """
17 | [[ 0.03807591 0.05068012 0.06169621 ..., -0.00259226 0.01990842
18 | -0.01764613]
19 | [-0.00188202 -0.04464164 -0.05147406 ..., -0.03949338 -0.06832974
20 | -0.09220405]
21 | ...
22 | [-0.04547248 -0.04464164 -0.0730303 ..., -0.03949338 -0.00421986
23 | 0.00306441]]
24 | [ 151. 75. 141. 206. 135. 97. 138. 63. 110. 310. 101.
25 | ...
26 | 64. 48. 178. 104. 132. 220. 57.]
27 | 总行数: 442 442
28 | 特征数: 10
29 | 数据类型: (442L, 10L)
30 |
31 | """
32 |
--------------------------------------------------------------------------------
/blog05-LR/test02.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Fri Oct 28 00:44:55 2016
4 | @author: yxz15
5 | """
6 |
7 | from sklearn import linear_model #导入线性模型
8 | import matplotlib.pyplot as plt #绘图
9 | import numpy as np
10 |
11 | #X表示匹萨尺寸 Y表示匹萨价格
12 | X = [[6], [8], [10], [14], [18]]
13 | Y = [[7], [9], [13], [17.5], [18]]
14 |
15 | print('数据集X: ', X)
16 | print('数据集Y: ', Y)
17 |
18 | #回归训练
19 | clf = linear_model.LinearRegression() #使用线性回归
20 | clf.fit(X, Y) #导入数据集
21 | res = clf.predict(np.array([12]).reshape(-1, 1))[0] #预测结果
22 | print('预测一张12英寸匹萨价格:$%.2f' % res)
23 |
24 | #预测结果
25 | X2 = [[0], [10], [14], [25]]
26 | Y2 = clf.predict(X2)
27 |
28 | #绘制线性回归图形
29 | plt.figure()
30 | plt.title(u'diameter-cost curver') #标题
31 | plt.xlabel(u'diameter') #x轴坐标
32 | plt.ylabel(u'cost') #y轴坐标
33 | plt.axis([0, 25, 0, 25]) #区间
34 | plt.grid(True) #显示网格
35 | plt.plot(X, Y, 'k.') #绘制训练数据集散点图
36 | plt.plot(X2, Y2, 'g-') #绘制预测数据集直线
37 | plt.show()
38 |
39 |
--------------------------------------------------------------------------------
/blog05-LR/test03.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Fri Oct 28 01:21:30 2016
4 | @author: yxz15
5 | """
6 |
7 | from sklearn import datasets
8 | import matplotlib.pyplot as plt
9 | import numpy as np
10 | from sklearn import linear_model #导入线性模型
11 |
12 | #数据集
13 | diabetes = datasets.load_diabetes() #载入数据
14 |
15 | #获取一个特征
16 | diabetes_x_temp = diabetes.data[:, np.newaxis, 2]
17 |
18 | diabetes_x_train = diabetes_x_temp[:-20] #训练样本
19 | diabetes_x_test = diabetes_x_temp[-20:] #测试样本 后20行
20 | diabetes_y_train = diabetes.target[:-20] #训练标记
21 | diabetes_y_test = diabetes.target[-20:] #预测对比标记
22 |
23 | #回归训练及预测
24 | clf = linear_model.LinearRegression()
25 | clf.fit(diabetes_x_train, diabetes_y_train) #注: 训练数据集
26 |
27 | #系数 残差平法和 方差得分
28 | print('Coefficients :\n', clf.coef_)
29 | print("Residual sum of square: %.2f" %np.mean((clf.predict(diabetes_x_test) - diabetes_y_test) ** 2))
30 | print("variance score: %.2f" % clf.score(diabetes_x_test, diabetes_y_test))
31 |
32 | #绘图
33 | plt.title(u'LinearRegression Diabetes') #标题
34 | plt.xlabel(u'Attributes') #x轴坐标
35 | plt.ylabel(u'Measure of disease') #y轴坐标
36 | #点的准确位置
37 | plt.scatter(diabetes_x_test, diabetes_y_test, color = 'black')
38 | #预测结果 直线表示
39 | plt.plot(diabetes_x_test, clf.predict(diabetes_x_test), color='blue', linewidth = 3)
40 | plt.show()
41 |
--------------------------------------------------------------------------------
/blog05-LR/test04.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Thu Dec 29 12:47:58 2011
4 | @author: Administrator
5 | """
6 | #第一步 数据集划分
7 | from sklearn import datasets
8 | import numpy as np
9 |
10 | #获取数据 10*442
11 | d = datasets.load_diabetes()
12 | x = d.data
13 | print('获取x特征')
14 | print(len(x), x.shape)
15 | print(x[:4])
16 |
17 | #获取一个特征 第3列数据
18 | x_one = x[:,np.newaxis, 2]
19 | print(x_one[:4])
20 |
21 | #获取的正确结果
22 | y = d.target
23 | print('获取的结果')
24 | print(y[:4])
25 |
26 | #x特征划分
27 | x_train = x_one[:-42]
28 | x_test = x_one[-42:]
29 | print(len(x_train), len(x_test))
30 | y_train = y[:-42]
31 | y_test = y[-42:]
32 | print(len(y_train), len(y_test))
33 |
34 |
35 | #第二步 线性回归实现
36 | from sklearn import linear_model
37 | clf = linear_model.LinearRegression()
38 | print(clf)
39 | clf.fit(x_train, y_train)
40 | pre = clf.predict(x_test)
41 | print('预测结果')
42 | print(pre)
43 | print('真实结果')
44 | print(y_test)
45 |
46 |
47 | #第三步 评价结果
48 | cost = np.mean(y_test-pre)**2
49 | print('次方', 2**5)
50 | print('平方和计算:', cost)
51 | print('系数', clf.coef_)
52 | print('截距', clf.intercept_)
53 | print('方差', clf.score(x_test, y_test))
54 |
55 |
56 | #第四步 绘图
57 | import matplotlib.pyplot as plt
58 | plt.title("diabetes")
59 | plt.xlabel("x")
60 | plt.ylabel("y")
61 | plt.plot(x_test, y_test, 'k.')
62 | plt.plot(x_test, pre, 'g-')
63 |
64 | for idx, m in enumerate(x_test):
65 | plt.plot([m, m],[y_test[idx],
66 | pre[idx]], 'r-')
67 |
68 | plt.savefig('power.png', dpi=300)
69 |
70 | plt.show()
71 |
72 |
--------------------------------------------------------------------------------
/blog06-Numpy+Matplotlib/data.xls:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog06-Numpy+Matplotlib/data.xls
--------------------------------------------------------------------------------
/blog06-Numpy+Matplotlib/test01.py:
--------------------------------------------------------------------------------
1 | #导入包并重命名
2 | import numpy as np
3 |
4 | #定义一维数组
5 | a = np.array([2, 0, 1, 5, 8, 3])
6 | print('原始数据:', a)
7 |
8 | #输出最大、最小值及形状
9 | print('最小值:', a.min())
10 | print('最大值:', a.max())
11 | print('形状', a.shape)
12 |
13 | #数据切片
14 | print('切片操作:')
15 | print(a[:-2])
16 | print(a[-2:])
17 | print(a[:1])
18 |
19 | #排序
20 | print(type(a))
21 | a.sort()
22 | print('排序后:', a)
23 |
--------------------------------------------------------------------------------
/blog06-Numpy+Matplotlib/test02.py:
--------------------------------------------------------------------------------
1 | #定义二维数组
2 | import numpy as np
3 | c = np.array([[1, 2, 3, 4],[4, 5, 6, 7], [7, 8, 9, 10]])
4 |
5 | #获取值
6 | print('形状:', c.shape)
7 | print('获取值:', c[1][0])
8 | print('获取某行:')
9 | print(c[1][:])
10 | print('获取某行并切片:')
11 | print(c[0][:-1])
12 | print(c[0][-1:])
13 |
14 | #获取具体某列值
15 | print('获取第3列:')
16 | print(c[:,np.newaxis, 2])
17 |
18 | #调用sin函数
19 | print(np.sin(np.pi/6))
20 | print(type(np.sin(0.5)))
21 |
22 | #范围定义
23 | print(np.arange(0,4))
24 | print(type(np.arange(0,4)))
25 |
--------------------------------------------------------------------------------
/blog06-Numpy+Matplotlib/test03.py:
--------------------------------------------------------------------------------
1 | #读取数据 header设置Excel无标题头
2 | import pandas as pd
3 | data = pd.read_excel("data.xls", header=None)
4 | print(data)
5 |
6 | #计算数据长度
7 | print('行数', len(data))
8 |
9 | #计算用户A\B\C用电总和
10 | print(data.sum())
11 |
12 | #计算用户A\B\C用点量算术平均数
13 | mm = data.sum()
14 | print(mm)
15 |
16 | #输出预览前5行数据
17 | print('预览前5行数据')
18 | print(data.head())
19 |
20 | #输出数据基本统计量
21 | print('输出数据基本统计量')
22 | print(data.describe())
23 |
--------------------------------------------------------------------------------
/blog06-Numpy+Matplotlib/test04.py:
--------------------------------------------------------------------------------
1 | from pandas import Series, DataFrame
2 |
3 | #通过传递一个list对象来创建Series,默认创建整型索引;
4 | a = Series([4, 7, -5, 3])
5 | print('创建Series:')
6 | print(a)
7 |
8 | #创建一个带有索引来确定每一个数据点的Series ;
9 | b = Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c'])
10 | print('创建带有索引的Series:')
11 | print(b)
12 |
13 | #如果你有一些数据在一个Python字典中,你可以通过传递字典来创建一个Series;
14 | sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
15 | c = Series(sdata)
16 | print('通过传递字典创建Series:')
17 | print(c)
18 | states = ['California', 'Ohio', 'Oregon', 'Texas']
19 | d = Series(sdata, index=states)
20 | print('California没有字典为空:')
21 | print(d)
22 |
--------------------------------------------------------------------------------
/blog06-Numpy+Matplotlib/test05-matplotlib.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Mon Nov 14 04:06:01 2016
4 | @author: yxz15
5 | """
6 |
7 | #导入数据集
8 | import pandas as pd
9 | data = pd.read_excel("data.xls", header=None)
10 | mm = data.sum()
11 | print('计算用电量总数:')
12 | print(mm)
13 |
14 | #绘制图形
15 | import numpy as np
16 | import matplotlib.pyplot as plt
17 | #中文字体显示
18 | plt.rc('font', family='SimHei', size=13)
19 | N = 3
20 | #3个用户 0 1 2
21 | ind = np.arange(N) # the x locations for the groups
22 | print(ind)
23 | #设置宽度
24 | width = 0.35
25 | x = [u'用户A', u'用户B', u'用户C']
26 | #绘图
27 | plt.bar(ind, mm, width, color='r', label='sum num')
28 | plt.xlabel(u"用户名")
29 | plt.ylabel(u"总耗电量")
30 | plt.title(u'电力窃漏电用户自动识别--总耗电量')
31 | plt.legend()
32 | #设置底部名称
33 | plt.xticks(ind+width/2, x, rotation=40) #旋转40度
34 | plt.show()
35 |
36 |
--------------------------------------------------------------------------------
/blog06-Numpy+Matplotlib/test06-matplotlib.py:
--------------------------------------------------------------------------------
1 | import matplotlib.pyplot as plt
2 |
3 | mm = [45, 30, 25] #每一块占得比例,总和为100
4 | n = mm[0]+mm[1]+mm[2]
5 | a = (mm[0]*1.0*100/n)
6 | b = (mm[1]*1.0*100/n)
7 | c = (mm[2]*1.0*100/n)
8 | print(a, b, c, n)
9 | fracs = [a, b, c]
10 |
11 | explode=(0, 0, 0.08) #离开整体的距离,看效果
12 | labels = 'A', 'B', 'C' #对应每一块的标志
13 |
14 | plt.pie(fracs, explode=explode, labels=labels,
15 | autopct='%1.1f%%', shadow=True, startangle=90, colors = ("g", "r", "y"))
16 | # startangle是开始的角度,默认为0,从这里开始按逆时针方向依次展开
17 |
18 | plt.title('Raining Hogs and Dogs') #标题
19 |
20 | plt.show()
21 |
--------------------------------------------------------------------------------
/blog06-Numpy+Matplotlib/test07-matplotlib.py:
--------------------------------------------------------------------------------
1 | import matplotlib.pyplot as plt
2 | import numpy as np
3 | plt.rc('font', family='SimHei', size=13)
4 |
5 | num = np.array([13325, 9403, 9227, 8651])
6 | ratio = np.array([0.75, 0.76, 0.72, 0.75])
7 | men = num * ratio
8 | women = num * (1-ratio)
9 | x = [u'聊天',u'支付',u'团购\n优惠券',u'在线视频']
10 |
11 | width = 0.5
12 | idx = np.arange(len(x))
13 | plt.bar(idx, men, width, color='red', label=u'男性用户')
14 | plt.bar(idx, women, width, bottom=men, color='yellow', label=u'女性用户')
15 | plt.xlabel(u'应用类别')
16 | plt.ylabel(u'男女分布')
17 | plt.xticks(idx+width/2, x, rotation=40)
18 | plt.legend()
19 | plt.show()
20 |
--------------------------------------------------------------------------------
/blog07-pac/result01.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog07-pac/result01.png
--------------------------------------------------------------------------------
/blog07-pac/result02.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog07-pac/result02.png
--------------------------------------------------------------------------------
/blog07-pac/test01.py:
--------------------------------------------------------------------------------
1 | #载入数据集
2 | from sklearn.datasets import load_boston
3 | d = load_boston()
4 | x = d.data
5 | y = d.target
6 | print(x[:10])
7 | print('形状:', x.shape)
8 |
9 | #降维
10 | import numpy as np
11 | from sklearn.decomposition import PCA
12 | pca = PCA(n_components=2)
13 | newData = pca.fit_transform(x)
14 | print('降维后数据:')
15 | print(newData[:4])
16 | print('形状:', newData.shape)
17 |
--------------------------------------------------------------------------------
/blog07-pac/test02.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import matplotlib.pyplot as plt
3 |
4 | plt.figure(1) # 创建图表1
5 | plt.figure(2) # 创建图表2
6 | ax1 = plt.subplot(211) # 在图表2中创建子图1
7 | ax2 = plt.subplot(212) # 在图表2中创建子图2
8 |
9 | x = np.linspace(0, 3, 100)
10 | for i in range(5):
11 | plt.figure(1) # 选择图表1
12 | plt.plot(x, np.exp(i*x/3))
13 | plt.sca(ax1) # 选择图表2的子图1
14 | plt.plot(x, np.sin(i*x))
15 | plt.sca(ax2) # 选择图表2的子图2
16 | plt.plot(x, np.cos(i*x))
17 |
18 | plt.show()
19 |
--------------------------------------------------------------------------------
/blog07-pac/test03.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | #糖尿病数据集
4 | from sklearn.datasets import load_diabetes
5 | data = load_diabetes()
6 | x = data.data
7 | print(x[:4])
8 | y = data.target
9 | print(y[:4])
10 |
11 | #KMeans聚类算法
12 | from sklearn.cluster import KMeans
13 | #训练
14 | clf = KMeans(n_clusters=2)
15 | print(clf)
16 | clf.fit(x)
17 | #预测
18 | pre = clf.predict(x)
19 | print(pre[:10])
20 |
21 | #使用PCA降维操作
22 | from sklearn.decomposition import PCA
23 | pca = PCA(n_components=2)
24 | newData = pca.fit_transform(x)
25 | print(newData[:4])
26 |
27 | L1 = [n[0] for n in newData]
28 | L2 = [n[1] for n in newData]
29 |
30 | #绘图
31 | import numpy as np
32 | import matplotlib.pyplot as plt
33 |
34 | #用来正常显示中文标签
35 | plt.rc('font', family='SimHei', size=8)
36 | #plt.rcParams['font.sans-serif']=['SimHei']
37 |
38 | #用来正常显示负号
39 | plt.rcParams['axes.unicode_minus']=False
40 |
41 | p1 = plt.subplot(221)
42 | plt.title(u"Kmeans聚类 n=2")
43 | plt.scatter(L1,L2,c=pre,marker="s")
44 | plt.sca(p1)
45 |
46 |
47 | ###################################
48 | # 聚类 类蔟数=3
49 |
50 | clf = KMeans(n_clusters=3)
51 | clf.fit(x)
52 | pre = clf.predict(x)
53 |
54 | p2 = plt.subplot(222)
55 | plt.title("Kmeans n=3")
56 | plt.scatter(L1,L2,c=pre,marker="s")
57 | plt.sca(p2)
58 |
59 |
60 | ###################################
61 | # 聚类 类蔟数=4
62 |
63 | clf = KMeans(n_clusters=4)
64 | clf.fit(x)
65 | pre = clf.predict(x)
66 |
67 | p3 = plt.subplot(223)
68 | plt.title("Kmeans n=4")
69 | plt.scatter(L1,L2,c=pre,marker="+")
70 | plt.sca(p3)
71 |
72 |
73 | ###################################
74 | # 聚类 类蔟数=5
75 |
76 | clf = KMeans(n_clusters=5)
77 | clf.fit(x)
78 | pre = clf.predict(x)
79 |
80 | p4 = plt.subplot(224)
81 | plt.title("Kmeans n=5")
82 | plt.scatter(L1,L2,c=pre,marker="+")
83 | plt.sca(p4)
84 |
85 | #保存图片本地
86 | plt.savefig('power.png', dpi=300)
87 | plt.show()
88 |
89 |
--------------------------------------------------------------------------------
/blog08-Apriori/test01.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Mon Nov 28 03:29:51 2016
4 | 地址:http://blog.csdn.net/u010454729/article/details/49078505
5 | @author: 参考CSDN u010454729
6 | """
7 |
8 | def loadDataSet():
9 | return [[1,3,4],[2,3,5],[1,2,3,5],[2,5]]
10 |
11 | def createC1(dataSet): #构建所有候选项集的集合
12 | C1 = []
13 | for transaction in dataSet:
14 | for item in transaction:
15 | if not [item] in C1:
16 | C1.append([item]) #C1添加的是列表,对于每一项进行添加,{1},{3},{4},{2},{5}
17 | C1.sort()
18 | return map(frozenset, C1) #使用frozenset,被“冰冻”的集合,为后续建立字典key-value使用。
19 |
20 | def scanD(D,Ck,minSupport): #由候选项集生成符合最小支持度的项集L。参数分别为数据集、候选项集列表,最小支持度
21 | ssCnt = {}
22 | for tid in D: #对于数据集里的每一条记录
23 | for can in Ck: #每个候选项集can
24 | if can.issubset(tid): #若是候选集can是作为记录的子集,那么其值+1,对其计数
25 | if can not in ssCnt: #ssCnt[can] = ssCnt.get(can,0)+1一句可破,没有的时候为0,加上1,有的时候用get取出,加1
26 | ssCnt[can] = 1
27 | else:
28 | ssCnt[can] += 1
29 | numItems = float(len(list(D)))
30 | retList = []
31 | supportData = {}
32 | for key in ssCnt:
33 | if numItems > 0: #除以总的记录条数,即为其支持度
34 | support = ssCnt[key] / numItems
35 | else:
36 | support = 0
37 | if support >= minSupport:
38 | retList.insert(0,key) #超过最小支持度的项集,将其记录下来。
39 | supportData[key] = support
40 | return retList, supportData
41 |
42 | def aprioriGen(Lk, k): #创建符合置信度的项集Ck,
43 | retList = []
44 | lenLk = len(Lk)
45 | for i in range(lenLk):
46 | for j in range(i+1, lenLk): #k=3时,[:k-2]即取[0],对{0,1},{0,2},{1,2}这三个项集来说,L1=0,L2=0,将其合并得{0,1,2},当L1=0,L2=1不添加,
47 | L1 = list(Lk[i])[:k-2]
48 | L2 = list(Lk[j])[:k-2]
49 | L1.sort()
50 | L2.sort()
51 | if L1==L2:
52 | retList.append(Lk[i]|Lk[j])
53 | return retList
54 |
55 | def apriori(dataSet, minSupport = 0.5):
56 | C1 = createC1(dataSet)
57 | D = map(set,dataSet)
58 | L1, supportData = scanD(D,C1,minSupport)
59 | L = [L1] #L将包含满足最小支持度,即经过筛选的所有频繁n项集,这里添加频繁1项集
60 | k = 2
61 | while (len(L[k-2])>0): #k=2开始,由频繁1项集生成频繁2项集,直到下一个打的项集为空
62 | Ck = aprioriGen(L[k-2], k)
63 | Lk, supK = scanD(D, Ck, minSupport)
64 | supportData.update(supK) #supportData为字典,存放每个项集的支持度,并以更新的方式加入新的supK
65 | L.append(Lk)
66 | k +=1
67 | return L,supportData
68 |
69 | dataSet = loadDataSet()
70 | C1 = createC1(dataSet)
71 |
72 | print("所有候选1项集C1:\n")
73 | for n in C1:
74 | print(n)
75 |
76 | D = map(set, dataSet)
77 | print("数据集D:\n")
78 | for n in D:
79 | print(n)
80 |
81 | L1, supportData0 = scanD(D,C1, 0.5)
82 | print("符合最小支持度的频繁1项集L1:\n",L1)
83 |
84 | L, suppData = apriori(dataSet)
85 | print("所有符合最小支持度的项集L:\n",L)
86 | print("频繁2项集:\n",aprioriGen(L[0],2))
87 |
88 | L, suppData = apriori(dataSet, minSupport=0.7)
89 | print("所有符合最小支持度为0.7的项集L:\n",L)
90 |
91 |
--------------------------------------------------------------------------------
/blog09-LinearRegression/Index:
--------------------------------------------------------------------------------
1 | Index of glass
2 |
3 | 02 Dec 1996 139 Index
4 | 02 Mar 1993 11903 glass.data
5 | 16 Jul 1992 780 glass.tag
6 | 30 May 1989 3506 glass.names
7 |
--------------------------------------------------------------------------------
/blog09-LinearRegression/glass.names:
--------------------------------------------------------------------------------
1 | 1. Title: Glass Identification Database
2 |
3 | 2. Sources:
4 | (a) Creator: B. German
5 | -- Central Research Establishment
6 | Home Office Forensic Science Service
7 | Aldermaston, Reading, Berkshire RG7 4PN
8 | (b) Donor: Vina Spiehler, Ph.D., DABFT
9 | Diagnostic Products Corporation
10 | (213) 776-0180 (ext 3014)
11 | (c) Date: September, 1987
12 |
13 | 3. Past Usage:
14 | -- Rule Induction in Forensic Science
15 | -- Ian W. Evett and Ernest J. Spiehler
16 | -- Central Research Establishment
17 | Home Office Forensic Science Service
18 | Aldermaston, Reading, Berkshire RG7 4PN
19 | -- Unknown technical note number (sorry, not listed here)
20 | -- General Results: nearest neighbor held its own with respect to the
21 | rule-based system
22 |
23 | 4. Relevant Information:n
24 | Vina conducted a comparison test of her rule-based system, BEAGLE, the
25 | nearest-neighbor algorithm, and discriminant analysis. BEAGLE is
26 | a product available through VRS Consulting, Inc.; 4676 Admiralty Way,
27 | Suite 206; Marina Del Ray, CA 90292 (213) 827-7890 and FAX: -3189.
28 | In determining whether the glass was a type of "float" glass or not,
29 | the following results were obtained (# incorrect answers):
30 |
31 | Type of Sample Beagle NN DA
32 | Windows that were float processed (87) 10 12 21
33 | Windows that were not: (76) 19 16 22
34 |
35 | The study of classification of types of glass was motivated by
36 | criminological investigation. At the scene of the crime, the glass left
37 | can be used as evidence...if it is correctly identified!
38 |
39 | 5. Number of Instances: 214
40 |
41 | 6. Number of Attributes: 10 (including an Id#) plus the class attribute
42 | -- all attributes are continuously valued
43 |
44 | 7. Attribute Information:
45 | 1. Id number: 1 to 214
46 | 2. RI: refractive index
47 | 3. Na: Sodium (unit measurement: weight percent in corresponding oxide, as
48 | are attributes 4-10)
49 | 4. Mg: Magnesium
50 | 5. Al: Aluminum
51 | 6. Si: Silicon
52 | 7. K: Potassium
53 | 8. Ca: Calcium
54 | 9. Ba: Barium
55 | 10. Fe: Iron
56 | 11. Type of glass: (class attribute)
57 | -- 1 building_windows_float_processed
58 | -- 2 building_windows_non_float_processed
59 | -- 3 vehicle_windows_float_processed
60 | -- 4 vehicle_windows_non_float_processed (none in this database)
61 | -- 5 containers
62 | -- 6 tableware
63 | -- 7 headlamps
64 |
65 | 8. Missing Attribute Values: None
66 |
67 | Summary Statistics:
68 | Attribute: Min Max Mean SD Correlation with class
69 | 2. RI: 1.5112 1.5339 1.5184 0.0030 -0.1642
70 | 3. Na: 10.73 17.38 13.4079 0.8166 0.5030
71 | 4. Mg: 0 4.49 2.6845 1.4424 -0.7447
72 | 5. Al: 0.29 3.5 1.4449 0.4993 0.5988
73 | 6. Si: 69.81 75.41 72.6509 0.7745 0.1515
74 | 7. K: 0 6.21 0.4971 0.6522 -0.0100
75 | 8. Ca: 5.43 16.19 8.9570 1.4232 0.0007
76 | 9. Ba: 0 3.15 0.1750 0.4972 0.5751
77 | 10. Fe: 0 0.51 0.0570 0.0974 -0.1879
78 |
79 | 9. Class Distribution: (out of 214 total instances)
80 | -- 163 Window glass (building windows and vehicle windows)
81 | -- 87 float processed
82 | -- 70 building windows
83 | -- 17 vehicle windows
84 | -- 76 non-float processed
85 | -- 76 building windows
86 | -- 0 vehicle windows
87 | -- 51 Non-window glass
88 | -- 13 containers
89 | -- 9 tableware
90 | -- 29 headlamps
91 |
92 |
93 |
94 |
95 |
--------------------------------------------------------------------------------
/blog09-LinearRegression/glass.tag:
--------------------------------------------------------------------------------
1 | An original file donated by Vina Speihler
2 |
3 | ID, N -- numeric identifier of the instance
4 | RI, N -- refractive index
5 | NA2O, N -- Sodium oxide
6 | MGO, N -- magnesium oxide
7 | AL2O3, N -- aluminum oxide
8 | SIO2, N -- silcon oxide
9 | K2O, N -- potassium oxide
10 | CAO, N -- calcium oxide
11 | BAO, N -- barium oxide
12 | FE2O3, N -- iron oxide
13 | TYPE, N -- An unknown, but must correspond to the types in the paper
14 | CAMG, N -- Unsure
15 |
16 | Types include:
17 | 1. WF (Float Window)
18 | 2. WNF (Non-float Window)
19 | 3. C (Container)
20 | 4. T (Tableware)
21 | 5. H (Headlamp) 214 2568 14127 glass.dat
22 | 19 92 518 glass.tag
23 | 62 742 4775 glassx.dat
24 | 51 610 3928 nonwindo.dat
25 | 6 14 120 phones
26 | 163 1955 12552 window.dat
27 | 515 5981 36020 total
28 |
--------------------------------------------------------------------------------
/blog09-LinearRegression/result01.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog09-LinearRegression/result01.png
--------------------------------------------------------------------------------
/blog09-LinearRegression/result02.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog09-LinearRegression/result02.png
--------------------------------------------------------------------------------
/blog09-LinearRegression/result03.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog09-LinearRegression/result03.png
--------------------------------------------------------------------------------
/blog09-LinearRegression/test01.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Sun Mar 05 18:10:07 2017
4 | @author: eastmount & zj
5 | """
6 |
7 | #导入玻璃识别数据集
8 | import pandas as pd
9 | glass=pd.read_csv("glass.csv")
10 | #显示前6行数据
11 | print(glass.shape)
12 | print(glass.head(6))
13 |
14 | import seaborn as sns
15 | import matplotlib.pyplot as plt
16 | sns.set(font_scale=1.5)
17 | sns.lmplot(x='al', y='ri', data=glass, ci=None)
18 | #利用Pandas画散点图
19 | glass.plot(kind='scatter', x='al', y='ri')
20 | plt.show()
21 |
22 | #利用matplotlib做等效的散点图
23 | plt.scatter(glass.al, glass.ri)
24 | plt.xlabel('al')
25 | plt.ylabel('ri')
26 |
27 | #拟合线性回归模型
28 | from sklearn.linear_model import LinearRegression
29 | linreg = LinearRegression()
30 | feature_cols = ['al']
31 | X = glass[feature_cols]
32 | y = glass.ri
33 | linreg.fit(X, y)
34 | plt.show()
35 |
36 | #对于所有的x值做出预测
37 | glass['ri_pred'] = linreg.predict(X)
38 | print("预测的前六行:")
39 | print(glass.head(6))
40 |
41 | #用直线表示预测结果
42 | plt.plot(glass.al, glass.ri_pred, color='red')
43 | plt.xlabel('al')
44 | plt.ylabel('Predicted ri')
45 | plt.show()
46 |
47 | #将直线结果和散点图同时显示出来
48 | plt.scatter(glass.al, glass.ri)
49 | plt.plot(glass.al, glass.ri_pred, color='red')
50 | plt.xlabel('al')
51 | plt.ylabel('ri')
52 | plt.show()
53 |
54 | #利用相关方法线性预测
55 | linreg.intercept_ + linreg.coef_ * 2
56 | #使用预测方法计算Al = 2的预测
57 | linreg.predict(2)
58 |
59 | #铝检验系数
60 | ai=zip(feature_cols, linreg.coef_)
61 | print(ai)
62 |
63 | #使用预测方法计算Al = 3的预测
64 | pre=linreg.predict(3)
65 | print(pre)
66 |
67 | #检查glass_type
68 | sort=glass.glass_type.value_counts().sort_index()
69 | print(sort)
70 |
71 | #类型1、2、3的窗户玻璃
72 | #类型5,6,7是家用玻璃
73 | glass['household'] = glass.glass_type.map({1:0, 2:0, 3:0, 5:1, 6:1, 7:1})
74 | print(glass.head())
75 |
76 | plt.scatter(glass.al, glass.household)
77 | plt.xlabel('al')
78 | plt.ylabel('household')
79 | plt.show()
80 |
81 | #拟合线性回归模型并存储预测
82 | feature_cols = ['al']
83 | X = glass[feature_cols]
84 | y = glass.household
85 | linreg.fit(X, y)
86 | glass['household_pred'] = linreg.predict(X)
87 | plt.show()
88 |
89 | #包括回归线的散点图
90 | plt.scatter(glass.al, glass.household)
91 | plt.plot(glass.al, glass.household_pred, color='red')
92 | plt.xlabel('al')
93 | plt.ylabel('household')
94 | plt.show()
95 |
96 |
--------------------------------------------------------------------------------
/blog09-LinearRegression/test02.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Sun Mar 05 18:28:56 2017
4 | @author: eastmount & zj
5 | """
6 | #导入玻璃识别数据集
7 | import pandas as pd
8 | glass=pd.read_csv("glass.csv")
9 | print(glass.shape)
10 | print(glass.head(6))
11 |
12 | #拟合Logistic回归模型 存储类预测
13 | import numpy as np
14 | nums = np.array([5, 15, 8])
15 | np.where(nums > 10, 'big', 'small')
16 | #将household_pred转换为 1或0
17 | glass['household_pred_class'] = np.where(glass.household_pred >= 0.5, 1, 0)
18 | print(glass.head(6))
19 |
20 | from sklearn.linear_model import LogisticRegression
21 | logreg = LogisticRegression(C=1e9)
22 | feature_cols = ['al']
23 | X = glass[feature_cols]
24 | y = glass.household
25 | logreg.fit(X, y)
26 | glass['household_pred_class'] = logreg.predict(X)
27 |
28 |
29 | #绘图-显示预测结果
30 | plt.scatter(glass.al, glass.household)
31 | plt.plot(glass.al, glass.household_pred_class, color='red')
32 | plt.xlabel('al')
33 | plt.ylabel('household')
34 | plt.show()
35 |
36 | glass['household_pred_prob'] = logreg.predict_proba(X)[:, 1]
37 | #绘图 绘制预测概率
38 |
39 | plt.scatter(glass.al, glass.household)
40 | plt.plot(glass.al, glass.household_pred_prob, color='red')
41 | plt.xlabel('al')
42 | plt.ylabel('household')
43 | plt.show()
44 |
45 | #检查一些例子的预测
46 | print (logreg.predict_proba (1))
47 | print (logreg.predict_proba(2))
48 | print (logreg. predict_proba (3))
49 |
--------------------------------------------------------------------------------
/blog10-Pandas/41.txt:
--------------------------------------------------------------------------------
1 | 61.5 55
2 | 59.8 61
3 | 56.9 65
4 | 62.4 58
5 | 63.3 58
6 | 62.8 57
7 | 62.3 57
8 | 61.9 55
9 | 65.1 61
10 | 59.4 61
11 | 64 55
12 | 62.8 56
13 | 60.4 61
14 | 62.2 54
15 | 60.2 62
16 | 60.9 58
17 | 62 54
18 | 63.4 54
19 | 63.8 56
20 | 62.7 59
21 | 63.3 56
22 | 63.8 55
23 | 61 57
24 | 59.4 62
25 | 58.1 62
26 | 60.4 58
27 | 62.5 57
28 | 62.2 57
29 | 60.5 61
30 | 60.9 57
31 | 60 57
32 | 59.8 57
33 | 60.7 59
34 | 59.5 58
35 | 61.9 58
36 | 58.2 59
37 | 64.1 59
38 | 64 54
39 | 60.8 59
40 | 61.8 55
41 | 61.2 56
42 | 61.1 56
43 | 65.2 56
44 | 58.4 63
45 | 63.1 56
46 | 62.4 58
47 | 61.8 55
48 | 63.8 56
49 | 63.3 60
50 | 60.7 60
51 | 60.9 61
52 | 61.9 54
53 | 60.9 55
54 | 61.6 58
55 | 59.3 62
56 | 61 59
57 | 59.3 61
58 | 62.6 57
59 | 63 57
60 | 63.2 55
61 | 60.9 57
62 | 62.6 59
63 | 62.5 57
64 | 62.1 56
65 | 61.5 59
66 | 61.4 56
67 | 62 55.3
68 | 63.3 57
69 | 61.8 58
70 | 60.7 58
71 | 61.5 60
72 | 63.1 56
73 | 62.9 59
74 | 62.5 57
75 | 63.7 57
76 | 59.2 60
77 | 59.9 58
78 | 62.4 54
79 | 62.8 60
80 | 62.6 59
81 | 63.4 59
82 | 62.1 60
83 | 62.9 58
84 | 61.6 56
85 | 57.9 60
86 | 62.3 59
87 | 61.2 58
88 | 60.8 59
89 | 60.7 58
90 | 62.9 58
91 | 62.5 57
92 | 55.1 69
93 | 61.6 56
94 | 62.4 57
95 | 63.8 56
96 | 57.5 58
97 | 59.4 62
98 | 66.3 62
99 | 61.6 59
100 | 61.5 58
101 | 63.2 56
102 | 59.9 54
103 | 61.6 55
104 | 61.7 58
105 | 62.9 56
106 | 62.2 55
107 | 63 59
108 | 62.3 55
109 | 58.8 57
110 | 62 55
111 | 61.4 57
112 | 62.2 56
113 | 63 58
114 | 62.2 59
115 | 62.6 56
116 | 62.7 53
117 | 61.7 58
118 | 62.4 54
119 | 60.7 58
120 | 59.9 59
121 | 62.3 56
122 | 62.3 54
123 | 61.7 63
124 | 64.5 57
125 | 65.3 55
126 | 61.6 60
127 | 61.4 56
128 | 59.6 57
129 | 64.4 57
130 | 65.7 60
131 | 62 56
132 | 63.6 58
133 | 61.9 59
134 | 62.6 60
135 | 61.3 60
136 | 60.9 60
137 | 60.1 62
138 | 61.8 59
139 | 61.2 57
140 | 61.9 56
141 | 60.9 57
142 | 59.8 56
143 | 61.8 55
144 | 60 57
145 | 61.6 55
146 | 62.1 64
147 | 63.3 59
148 | 60.2 56
149 | 61.1 58
150 | 60.9 57
151 | 61.7 59
152 | 61.3 56
153 | 62.5 60
154 | 61.4 59
155 | 62.9 57
156 | 62.4 57
157 | 60.7 56
158 | 60.7 58
159 | 61.5 58
160 | 59.9 57
161 | 59.2 59
162 | 60.3 56
163 | 61.7 60
164 | 61.9 57
165 | 61.9 55
166 | 60.4 59
167 | 61 57
168 | 61.5 55
169 | 61.7 56
170 | 59.2 61
171 | 61.3 56
172 | 58 62
173 | 60.2 61
174 | 61.7 55
175 | 62.7 55
176 | 64.6 54
177 | 61.3 61
178 | 63.7 56.4
179 | 62.7 58
180 | 62.2 57
181 | 61.6 56
182 | 61.5 57
183 | 61.8 56
184 | 60.7 56
185 | 59.7 60.5
186 | 60.5 56
187 | 62.7 58
188 | 62.1 58
189 | 62.8 57
190 | 63.8 58
191 | 57.8 60
192 | 62.1 55
193 | 61.1 60
194 | 60 59
195 | 61.2 57
196 | 62.7 59
197 | 61 57
198 | 61 58
199 | 61.4 57
200 | 61.8 61
201 | 59.9 63
202 | 61.3 58
203 | 60.5 58
204 | 64.1 59
205 | 67.9 60
206 | 62.4 58
207 | 63.2 60
208 | 61.3 55
209 | 60.8 56
210 | 61.7 56
211 | 63.6 57
212 | 61.2 58
213 | 62.1 54
214 | 61.5 55
215 | 61.4 59
216 | 61.8 60
217 | 62.2 56
218 | 61.2 56
219 | 60.6 63
220 | 57.5 64
221 | 61.3 56
222 | 57.2 62
223 | 62.9 60
224 | 63.1 58
225 | 60.8 57
226 | 62.7 59
227 | 62.8 60
228 | 55.1 67
229 | 61.4 59
230 | 62.2 55
231 | 63 54
232 | 63.7 56
233 | 63.6 58
234 | 62 57
235 | 61.5 56
236 | 60.5 60
237 | 61.1 60
238 | 61.8 56
239 | 63.3 56
240 | 59.4 64
241 | 62.5 55
242 | 64.5 58
243 | 62.7 59
244 | 64.2 52
245 | 63.7 54
246 | 60.4 58
247 | 61.8 58
248 | 63.2 56
249 | 61.6 56
250 | 61.6 56
251 | 60.9 57
252 | 61 61
253 | 62.1 57
254 | 60.9 60
255 | 61.3 60
256 | 65.8 59
257 | 61.3 56
258 | 58.8 59
259 | 62.3 55
260 | 60.1 62
261 | 61.8 59
262 | 63.6 55.8
263 | 62.2 56
264 | 59.2 59
265 | 61.8 59
266 | 61.3 55
267 | 62.1 60
268 | 60.7 60
269 | 59.6 57
270 | 62.2 56
271 | 60.6 57
272 | 62.9 57
273 | 64.1 55
274 | 61.3 56
275 | 62.7 55
276 | 63.2 56
277 | 60.7 56
278 | 61.9 60
279 | 62.6 55
280 | 60.7 60
281 | 62 60
282 | 63 57
283 | 58 59
284 | 62.9 57
285 | 58.2 60
286 | 63.2 58
287 | 61.3 59
288 | 60.3 60
289 | 62.7 60
290 | 61.3 58
291 | 61.6 60
292 | 61.9 55
293 | 61.7 56
294 | 61.9 58
295 | 61.8 58
296 | 61.6 56
297 | 58.8 66
298 | 61 57
299 | 67.4 60
300 | 63.4 60
301 | 61.5 59
302 | 58 62
303 | 62.4 54
304 | 61.9 57
305 | 61.6 56
306 | 62.2 59
307 | 62.2 58
308 | 61.3 56
309 | 62.3 57
310 | 61.8 57
311 | 62.5 59
312 | 62.9 60
313 | 61.8 59
314 | 62.3 56
315 | 59 70
316 | 60.7 55
317 | 62.5 55
318 | 62.7 58
319 | 60.4 57
320 | 62.1 58
321 | 57.8 60
322 | 63.8 58
323 | 62.8 57
324 | 62.2 58
325 | 62.3 58
326 | 59.9 58
327 | 61.9 54
328 | 63 55
329 | 62.4 58
330 | 62.9 58
331 | 63.5 56
332 | 61.3 56
333 | 60.6 54
334 | 65.1 58
335 | 62.6 58
336 | 58 62
337 | 62.4 61
338 | 61.3 57
339 | 59.9 60
340 | 60.8 58
341 | 63.5 55
342 | 62.2 57
343 | 63.8 58
344 | 64 57
345 | 62.5 56
346 | 62.3 58
347 | 61.7 57
348 | 62.2 58
349 | 61.5 56
350 | 61 59
351 | 62.2 56
352 | 61.5 54
353 | 67.3 59
354 | 61.7 58
355 | 61.9 56
356 | 61.8 58
357 | 58.7 66
358 | 62.5 57
359 | 62.8 56
360 | 61.1 68
361 | 64 57
362 | 62.5 60
363 | 60.6 58
364 | 61.6 55
365 | 62.2 58
366 | 60 57
367 | 61.9 57
368 | 62.8 57
369 | 62 57
370 | 66.4 59
371 | 63.4 56
372 | 60.9 56
373 | 63.1 57
374 | 63.1 59
375 | 59.2 57
376 | 60.7 54
377 | 64.6 56
378 | 61.8 56
379 | 59.9 60
380 | 61.7 55
381 | 62.8 61
382 | 62.7 57
383 | 63.4 58
384 | 63.5 54
385 | 65.7 59
386 | 68.1 56
387 | 63 60
388 | 59.5 58
389 | 63.5 59
390 | 61.7 58
391 | 62.7 58
392 | 62.8 58
393 | 62.4 57
394 | 61 59
395 | 63.1 56
396 | 60.7 57
397 | 60.9 59
398 | 60.1 55
399 | 62.9 58
400 | 63.3 56
401 | 63.8 55
402 | 62.9 57
403 | 63.4 60
404 | 63.9 55
405 | 61.4 56
406 | 61.9 55
407 | 62.4 55
408 | 61.8 58
409 | 61.5 56
410 | 60.4 57
411 | 61.8 55
412 | 62 56
413 | 62.3 56
414 | 61.6 56
415 | 60.6 56
416 | 58.4 62
417 | 61.4 58
418 | 61.9 56
419 | 62 56
420 | 61.5 57
421 | 62.3 58
422 | 60.9 61
423 | 62.4 57
424 | 55 61
425 | 58.6 60
426 | 62 57
427 | 59.8 58
428 | 63.4 55
429 | 64.3 58
430 | 62.2 59
431 | 61.7 57
432 | 61.1 59
433 | 61.5 56
434 | 58.5 62
435 | 61.7 58
436 | 60.4 56
437 | 61.4 56
438 | 61.5 55
439 | 61.4 56
440 | 65 56
441 | 56 60
442 | 60.2 59
443 | 58.3 58
444 | 53.1 63
445 | 60.3 58
446 | 61.4 56
447 | 60.1 57
448 | 63.4 55
449 | 61.5 59
450 | 62.7 56
451 | 62.5 55
452 | 61.3 56
453 | 60.2 56
454 | 62.7 57
455 | 62.3 58
456 | 61.5 56
457 | 59.2 59
458 | 61.8 59
459 | 61.3 55
460 | 61.4 58
461 | 62.8 55
462 | 62.8 64
463 | 62.4 61
464 | 59.3 60
465 | 63 60
466 | 61.3 60
467 | 59.3 62
468 | 61 57
469 | 62.9 57
470 | 59.6 57
471 | 61.8 60
472 | 62.7 57
473 | 65.3 62
474 | 63.8 58
475 | 62.3 56
476 | 59.7 63
477 | 64.3 60
478 | 62.9 58
479 | 62 57
480 | 61.6 59
481 | 61.9 55
482 | 61.3 58
483 | 63.6 57
484 | 59.6 61
485 | 62.2 59
486 | 61.7 55
487 | 63.2 58
488 | 60.8 60
489 | 60.3 59
490 | 60.9 60
491 | 62.4 59
492 | 60.2 60
493 | 62 55
494 | 60.8 57
495 | 62.1 55
496 | 62.7 60
497 | 61.3 58
498 | 60.2 60
499 | 60.7 56
--------------------------------------------------------------------------------
/blog10-Pandas/bankloan.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog10-Pandas/bankloan.png
--------------------------------------------------------------------------------
/blog10-Pandas/ccc.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog10-Pandas/ccc.png
--------------------------------------------------------------------------------
/blog10-Pandas/data.csv:
--------------------------------------------------------------------------------
1 | year,Beijing,Chongqing,Shenzhen,Guiyang,Kunming,Shanghai,Wuhai,Changsha
2 | 2002,4764,1556,5802,1643,2276,4134,1928,1802
3 | 2003,4737,1596,6256,1949,2233,5118,2072,2040
4 | 2004,5020.93,1766.24,6756.24,1801.68,2473.78,5855,2516.32,2039.09
5 | 2005,6788.09,2134.99,7582.27,2168.9,2639.72,6842,3061.77,2313.73
6 | 2006,8279.51,2269.21,9385.34,2372.66,2903.32,7196,3689.64,2644.15
7 | 2007,11553.26,2722.58,14049.69,2901.63,3108.12,8361,4664.03,3304.74
8 | 2008,12418,2785,12665,3149,3750,8195,4781,3288
9 | 2009,13799,3442,14615,3762,3807,12840,5329,3648
10 | 2010,17782,4281,19170,4410,3660,14464,5746,4418
11 | 2011,16851.95,4733.84,21350.13,5069.52,4715.23,14603.24,7192.9,5862.39
12 | 2012,17021.63,5079.93,19589.82,4846.14,5744.68,14061.37,7344.05,6100.87
13 | 2013,18553,5569,24402,5025,5795,16420,7717,6292
14 | 2014,18833,5519,24723,5608,6384,16787,7951,6116
15 |
--------------------------------------------------------------------------------
/blog10-Pandas/data2.xlsx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog10-Pandas/data2.xlsx
--------------------------------------------------------------------------------
/blog10-Pandas/guiyang.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog10-Pandas/guiyang.png
--------------------------------------------------------------------------------
/blog10-Pandas/test01.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Mon Mar 06 10:55:17 2017
4 | @author: eastmount
5 | """
6 |
7 | import pandas as pd
8 | data = pd.read_csv("data.csv",index_col='year') #index_col用作行索引的列名
9 | #显示前6行数据
10 | print(data.shape)
11 | print(data.head(6))
12 |
13 | import matplotlib.pyplot as plt
14 | plt.rcParams['font.sans-serif'] = ['simHei'] #用来正常显示中文标签
15 | plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
16 | data.plot()
17 | plt.savefig(u'时序图.png', dpi=500)
18 | plt.show()
19 |
--------------------------------------------------------------------------------
/blog10-Pandas/test02.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Mon Mar 06 10:55:17 2017
4 | @author: eastmount
5 | """
6 |
7 | import pandas as pd
8 | data = pd.read_csv("data.csv",index_col='year') #index_col用作行索引的列名
9 | #显示前6行数据
10 | print(data.shape)
11 | print(data.head(6))
12 |
13 | import matplotlib.pyplot as plt
14 | plt.rcParams['font.sans-serif'] = ['simHei'] #用来正常显示中文标签
15 | plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
16 | data.plot()
17 | plt.savefig(u'时序图.png', dpi=500)
18 | plt.show()
19 |
20 | #获取贵阳数据集并绘图
21 | gy = data['Guiyang']
22 | print('输出贵阳数据')
23 | print(gy)
24 | gy.plot()
25 | plt.show()
26 |
--------------------------------------------------------------------------------
/blog10-Pandas/test03.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Mon Mar 06 10:55:17 2017
4 | @author: eastmount
5 | """
6 | import matplotlib.pyplot as plt
7 | import pandas as pd
8 | data = pd.read_csv("data.csv",index_col='year') #index_col用作行索引的列名
9 | #显示前6行数据
10 | print(data.shape)
11 | print(data.head(6))
12 | #获取贵阳数据集并绘图
13 | gy = data['Guiyang']
14 | print('输出贵阳数据')
15 | print(gy)
16 |
17 | import numpy as np
18 | x = ['2002','2003','2004','2005','2006','2007','2008',
19 | '2009','2010','2011','2012','2013','2014']
20 | N = 13
21 | ind = np.arange(N) #赋值0-13
22 | width=0.35
23 | plt.bar(ind, gy, width, color='r', label='sum num')
24 | #设置底部名称
25 | plt.xticks(ind+width/2, x, rotation=40) #旋转40度
26 | plt.title('The price of Guiyang')
27 | plt.xlabel('year')
28 | plt.ylabel('price')
29 | plt.savefig('guiyang.png',dpi=400)
30 | plt.show()
31 |
--------------------------------------------------------------------------------
/blog10-Pandas/test04.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import pylab as pl
3 | # make an array of random numbers with a gaussian distribution with
4 | # mean = 5.0
5 | # rms = 3.0
6 | # number of points = 1000
7 | data = np.random.normal(5.0, 3.0, 1000)
8 | # make a histogram of the data array
9 | pl.hist(data, histtype='stepfilled') #去掉黑色轮廓
10 | # make plot labels
11 | pl.xlabel('data')
12 | pl.show()
13 |
--------------------------------------------------------------------------------
/blog10-Pandas/test05.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Mon Mar 06 10:55:17 2017
4 | @author: yxz15
5 | """
6 |
7 | import pandas as pd
8 | data = pd.read_csv("data.csv",index_col='year')
9 | #显示前6行数据
10 | print(data.shape)
11 | print(data.head(6))
12 |
13 | import matplotlib.pyplot as plt
14 | plt.rcParams['font.sans-serif'] = ['simHei']
15 | plt.rcParams['axes.unicode_minus'] = False
16 | data.plot()
17 | plt.savefig(u'时序图.png', dpi=500)
18 | plt.show()
19 |
20 | from statsmodels.graphics.tsaplots import plot_acf
21 | gy = data['Guiyang']
22 | print(gy)
23 | plot_acf(gy).show()
24 | plt.savefig(u'贵阳自相关图',dpi=300)
25 |
26 | from statsmodels.tsa.stattools import adfuller as ADF
27 | print('ADF:',ADF(gy))
28 |
--------------------------------------------------------------------------------
/blog10-Pandas/test06-dalian.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Mon Mar 06 10:19:15 2017
4 | @author: yxz15
5 | """
6 |
7 | #第一部分:导入数据集
8 | import pandas as pd
9 | Coke1 =pd.read_csv("data2.csv")
10 | print(Coke1 [:4])
11 |
12 | #第二部分:聚类
13 | from sklearn.cluster import KMeans
14 | clf=KMeans(n_clusters=3)
15 | pre=clf.fit_predict(Coke1)
16 | print(pre[:4])
17 |
18 | #第三部分:降维
19 | from sklearn.decomposition import PCA
20 | pca=PCA(n_components=2)
21 | newData=pca.fit_transform(Coke1)
22 | print(newData[:4])
23 | x1=[n[0] for n in newData]
24 | x2=[n[1] for n in newData]
25 |
26 | #第四部分:用matplotlib包画图
27 | import matplotlib.pyplot as plt
28 | plt.title
29 | plt.xlabel("x feature")
30 | plt.ylabel("y feature")
31 | plt.scatter(x1,x2,c=pre, marker='x')
32 | plt.savefig("bankloan.png",dpi=400)
33 | plt.show()
34 |
--------------------------------------------------------------------------------
/blog10-Pandas/test07.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Mon Mar 06 21:47:46 2017
4 | @author: yxz
5 | """
6 |
7 | from numpy import *
8 | import matplotlib
9 | import matplotlib.pyplot as plt
10 |
11 | #-----------------------------------------------------------------------
12 | #载入数据
13 | def loadDataSet(fileName,delim='\t'):
14 | fr=open(fileName)
15 | stringArr=[line.strip().split(delim) for line in fr.readlines()]
16 | datArr=[list(map(float,line)) for line in stringArr]
17 | return mat(datArr)
18 |
19 | def pca(dataMat,topNfeat=9999999):
20 | meanVals=mean(dataMat,axis=0)
21 | meanRemoved=dataMat-meanVals
22 | covMat=cov(meanRemoved,rowvar=0)
23 | eigVals,eigVets=linalg.eig(mat(covMat))
24 | eigValInd=argsort(eigVals)
25 | eigValInd=eigValInd[:-(topNfeat+1):-1]
26 | redEigVects=eigVets[:,eigValInd]
27 | print(meanRemoved)
28 | print(redEigVects)
29 | lowDDatMat=meanRemoved*redEigVects
30 | reconMat=(lowDDatMat*redEigVects.T)+meanVals
31 | return lowDDatMat,reconMat
32 |
33 | dataMat=loadDataSet('41.txt')
34 | lowDMat,reconMat=pca(dataMat,1)
35 |
36 | #-----------------------------------------------------------------------
37 | #绘制图像
38 | def plotPCA(dataMat,reconMat):
39 | datArr=array(dataMat)
40 | reconArr=array(reconMat)
41 | n1=shape(datArr)[0]
42 | n2=shape(reconArr)[0]
43 | xcord1=[];ycord1=[]
44 | xcord2=[];ycord2=[]
45 | for i in range(n1):
46 | xcord1.append(datArr[i,0])
47 | ycord1.append(datArr[i,1])
48 | for i in range(n2):
49 | xcord2.append(reconArr[i,0])
50 | ycord2.append(reconArr[i,1])
51 | fig=plt.figure()
52 | ax=fig.add_subplot(111)
53 | ax.scatter(xcord1,ycord1,s=90,c='red',marker='^')
54 | ax.scatter(xcord2,ycord2,s=50,c='yellow',marker='o')
55 | plt.title('PCA')
56 | plt.savefig('ccc.png',dpi=400)
57 | plt.show()
58 |
59 | plotPCA(dataMat,reconMat)
60 |
--------------------------------------------------------------------------------
/blog10-Pandas/时序图.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog10-Pandas/时序图.png
--------------------------------------------------------------------------------
/blog10-Pandas/贵阳自相关图.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog10-Pandas/贵阳自相关图.png
--------------------------------------------------------------------------------
/blog11-Matplotlib+SQL/test01.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | '''
3 | ' 这篇代码主要讲述获取MySQL中数据,再进行简单的统计
4 | ' 统计采用SQL语句进行 By:Eastmount CSDN
5 | '''
6 |
7 | import matplotlib.pyplot as plt
8 | import matplotlib
9 | import pandas as pd
10 | import numpy as np
11 | import pylab
12 | import MySQLdb
13 | from pylab import *
14 |
15 |
16 | # 根据SQL语句输出24小时的柱状图
17 | try:
18 | conn = MySQLdb.connect(host='localhost',user='root',
19 | passwd='123456',port=3306, db='test01')
20 | cur = conn.cursor() #数据库游标
21 |
22 | #防止报错:UnicodeEncodeError: 'latin-1' codec can't encode character
23 | conn.set_character_set('utf8')
24 | cur.execute('SET NAMES utf8;')
25 | cur.execute('SET CHARACTER SET utf8;')
26 | cur.execute('SET character_set_connection=utf8;')
27 | sql = "select HOUR(FBTime) as hh, count(*) as cnt from csdn group by hh;"
28 | cur.execute(sql)
29 | result = cur.fetchall() #获取结果复合纸给result
30 | hour1 = [n[0] for n in result]
31 | print hour1
32 | num1 = [n[1] for n in result]
33 | print num1
34 |
35 | N = 23
36 | ind = np.arange(N) #赋值0-23
37 | width=0.35
38 | plt.bar(ind, num1, width, color='r', label='sum num')
39 | #设置底部名称
40 | plt.xticks(ind+width/2, hour1, rotation=40) #旋转40度
41 | for i in range(23): #中心底部翻转90度
42 | plt.text(i, num1[i], str(num1[i]),
43 | ha='center', va='bottom', rotation=45)
44 | plt.title('Number-24Hour')
45 | plt.xlabel('hours')
46 | plt.ylabel('The number of blog')
47 | plt.legend()
48 | plt.savefig('08csdn.png',dpi=400)
49 | plt.show()
50 |
51 |
52 | #异常处理
53 | except MySQLdb.Error,e:
54 | print "Mysql Error %d: %s" % (e.args[0], e.args[1])
55 | finally:
56 | cur.close()
57 | conn.commit()
58 | conn.close()
59 |
60 |
61 |
--------------------------------------------------------------------------------
/blog11-Matplotlib+SQL/test02.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | '''
3 | ' 这篇代码主要讲述获取MySQL中数据,再进行简单的统计
4 | ' 统计采用SQL语句进行 By:Eastmount
5 | '''
6 |
7 | import matplotlib.pyplot as plt
8 | import matplotlib
9 | import pandas as pd
10 | import numpy as np
11 | import pylab
12 | import MySQLdb
13 | from pylab import *
14 | import matplotlib.pyplot as plt
15 |
16 | #根据SQL语句输出散点
17 | try:
18 | conn = MySQLdb.connect(host='localhost',user='root',
19 | passwd='123456',port=3306, db='test01')
20 | cur = conn.cursor() #数据库游标
21 |
22 | #防止报错:UnicodeEncodeError: 'latin-1' codec can't encode character
23 | conn.set_character_set('utf8')
24 | cur.execute('SET NAMES utf8;')
25 | cur.execute('SET CHARACTER SET utf8;')
26 | cur.execute('SET character_set_connection=utf8;')
27 | sql = '''select DATE_FORMAT(FBTime,'%Y%m'), count(*) from csdn
28 | group by DATE_FORMAT(FBTime,'%Y%m');'''
29 | cur.execute(sql)
30 | result = cur.fetchall() #获取结果复合纸给result
31 | date1 = [n[0] for n in result]
32 | print date1
33 | num1 = [n[1] for n in result]
34 | print num1
35 | print type(date1)
36 | plt.scatter(date1,num1,25,color='white',marker='o',
37 | edgecolors='#0D8ECF',linewidth=3,alpha=0.8)
38 | plt.title('Number-12Month')
39 | plt.xlabel('Time')
40 | plt.ylabel('The number of blog')
41 | plt.savefig('02csdn.png',dpi=400)
42 | plt.show()
43 |
44 |
45 | #异常处理
46 | except MySQLdb.Error,e:
47 | print "Mysql Error %d: %s" % (e.args[0], e.args[1])
48 | finally:
49 | cur.close()
50 | conn.commit()
51 | conn.close()
52 |
53 |
--------------------------------------------------------------------------------
/blog11-Matplotlib+SQL/test03.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | '''
3 | ' 这篇代码主要讲述获取MySQL中数据,再进行简单的统计
4 | ' 统计采用SQL语句进行 By:Eastmount
5 | '''
6 |
7 | import matplotlib.pyplot as plt
8 | import matplotlib
9 | import pandas as pd
10 | import numpy as np
11 | import pylab
12 | import MySQLdb
13 | from pylab import *
14 | from pandas import *
15 |
16 |
17 | # 根据SQL语句输出24小时的柱状图
18 | try:
19 | conn = MySQLdb.connect(host='localhost',user='root',
20 | passwd='123456',port=3306, db='test01')
21 | cur = conn.cursor() #数据库游标
22 |
23 | #防止报错:UnicodeEncodeError: 'latin-1' codec can't encode character
24 | conn.set_character_set('utf8')
25 | cur.execute('SET NAMES utf8;')
26 | cur.execute('SET CHARACTER SET utf8;')
27 | cur.execute('SET character_set_connection=utf8;')
28 | sql = '''select DATE_FORMAT(FBTime,'%Y'), Count(*) from csdn
29 | group by DATE_FORMAT(FBTime,'%Y');'''
30 | cur.execute(sql)
31 | result = cur.fetchall() #获取结果复合纸给result
32 | day1 = [n[0] for n in result]
33 | print len(day1)
34 | num1 = [n[1] for n in result]
35 | print len(num1),type(num1)
36 | matplotlib.style.use('ggplot')
37 | df=DataFrame(num1, index=day1,columns=['Nums'])
38 | plt.show(df.plot(kind='bar'))
39 | plt.savefig('05csdn.png',dpi=400)
40 |
41 |
42 | #异常处理
43 | except MySQLdb.Error,e:
44 | print "Mysql Error %d: %s" % (e.args[0], e.args[1])
45 | finally:
46 | cur.close()
47 | conn.commit()
48 | conn.close()
49 |
50 |
51 |
--------------------------------------------------------------------------------
/blog11-Matplotlib+SQL/test04.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | '''
3 | ' 这篇代码主要讲述获取MySQL中数据,再进行简单的统计
4 | ' 统计采用SQL语句进行 By:Eastmount CSDN
5 | '''
6 |
7 | import matplotlib.pyplot as plt
8 | import matplotlib
9 | import pandas as pd
10 | import numpy as np
11 | import pylab
12 | import MySQLdb
13 | from pylab import *
14 |
15 |
16 | # 根据SQL语句输出24小时的柱状图
17 | try:
18 | conn = MySQLdb.connect(host='localhost',user='root',
19 | passwd='123456',port=3306, db='test01')
20 | cur = conn.cursor() #数据库游标
21 |
22 | #防止报错:UnicodeEncodeError: 'latin-1' codec can't encode character
23 | conn.set_character_set('utf8')
24 | cur.execute('SET NAMES utf8;')
25 | cur.execute('SET CHARACTER SET utf8;')
26 | cur.execute('SET character_set_connection=utf8;')
27 | sql = '''select DATE_FORMAT(FBTime,'%Y-%m-%d'), Count(*) from csdn
28 | group by DATE_FORMAT(FBTime,'%Y-%m-%d');'''
29 | cur.execute(sql)
30 | result = cur.fetchall() #获取结果复合纸给result
31 | day1 = [n[0] for n in result]
32 | print len(day1)
33 | num1 = [n[1] for n in result]
34 | print len(num1),type(num1)
35 | matplotlib.style.use('ggplot')
36 | #获取第一天
37 | start = min(day1)
38 | print start
39 | #np.random.randn(len(num1)) 生成正确图形 正态分布随机数
40 | ts = pd.Series(np.random.randn(len(num1)),
41 | index=pd.date_range(start, periods=len(num1)))
42 | ts = ts.cumsum()
43 | ts.plot()
44 | plt.title('Number-365Day')
45 | plt.xlabel('Time')
46 | plt.ylabel('The number of blog')
47 | plt.savefig('04csdn.png',dpi=400)
48 | plt.show()
49 |
50 |
51 | #异常处理
52 | except MySQLdb.Error,e:
53 | print "Mysql Error %d: %s" % (e.args[0], e.args[1])
54 | finally:
55 | cur.close()
56 | conn.commit()
57 | conn.close()
58 |
59 |
--------------------------------------------------------------------------------
/blog12-matplotlib+SQL/test01.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | '''
3 | ' 这篇代码主要讲述获取MySQL中数据,再进行简单的统计
4 | ' 统计采用SQL语句进行
5 | '''
6 |
7 | import matplotlib.pyplot as plt
8 | import matplotlib
9 | import pandas as pd
10 | import numpy as np
11 | import pylab
12 | import MySQLdb
13 | from pylab import *
14 |
15 | # 根据SQL语句输出24小时的柱状图
16 | try:
17 | conn = MySQLdb.connect(host='localhost',user='root',
18 | passwd='123456',port=3306, db='test01')
19 | cur = conn.cursor() #数据库游标
20 |
21 | #防止报错:UnicodeEncodeError: 'latin-1' codec can't encode character
22 | conn.set_character_set('utf8')
23 | cur.execute('SET NAMES utf8;')
24 | cur.execute('SET CHARACTER SET utf8;')
25 | cur.execute('SET character_set_connection=utf8;')
26 |
27 |
28 | #################################################
29 | # 2014年
30 | #################################################
31 | sql = '''select MONTH(FBTime) as mm, count(*) as cnt from csdn_blog
32 | where DATE_FORMAT(FBTime,'%Y')='2014' group by mm;'''
33 | cur.execute(sql)
34 | result = cur.fetchall() #获取结果复制给result
35 | hour1 = [n[0] for n in result]
36 | print hour1
37 | num1 = [n[1] for n in result]
38 | print num1
39 |
40 | N = 12
41 | ind = np.arange(N) #赋值0-11
42 | width=0.35
43 | p1 = plt.subplot(221)
44 | plt.bar(ind, num1, width, color='b', label='sum num')
45 | #设置底部名称
46 | plt.xticks(ind+width/2, hour1, rotation=40) #旋转40度
47 | for i in range(12): #中心底部翻转90度
48 | plt.text(i, num1[i], str(num1[i]),
49 | ha='center', va='bottom', rotation=45)
50 | plt.title('2014 Number-12Month')
51 | plt.sca(p1)
52 |
53 |
54 | #################################################
55 | # 2015年
56 | #################################################
57 | sql = '''select MONTH(FBTime) as mm, count(*) as cnt from csdn_blog
58 | where DATE_FORMAT(FBTime,'%Y')='2015' group by mm;'''
59 | cur.execute(sql)
60 | result = cur.fetchall()
61 | hour1 = [n[0] for n in result]
62 | print hour1
63 | num1 = [n[1] for n in result]
64 | print num1
65 |
66 | N = 12
67 | ind = np.arange(N) #赋值0-11
68 | width=0.35
69 | p2 = plt.subplot(222)
70 | plt.bar(ind, num1, width, color='r', label='sum num')
71 | #设置底部名称
72 | plt.xticks(ind+width/2, hour1, rotation=40) #旋转40度
73 | for i in range(12): #中心底部翻转90度
74 | plt.text(i, num1[i], str(num1[i]),
75 | ha='center', va='bottom', rotation=45)
76 | plt.title('2015 Number-12Month')
77 | plt.sca(p2)
78 |
79 |
80 | #################################################
81 | # 2016年
82 | #################################################
83 | sql = '''select MONTH(FBTime) as mm, count(*) as cnt from csdn_blog
84 | where DATE_FORMAT(FBTime,'%Y')='2016' group by mm;'''
85 | cur.execute(sql)
86 | result = cur.fetchall()
87 | hour1 = [n[0] for n in result]
88 | print hour1
89 | num1 = [n[1] for n in result]
90 | print num1
91 |
92 | N = 12
93 | ind = np.arange(N) #赋值0-11
94 | width=0.35
95 | p3 = plt.subplot(223)
96 | plt.bar(ind, num1, width, color='g', label='sum num')
97 | #设置底部名称
98 | plt.xticks(ind+width/2, hour1, rotation=40) #旋转40度
99 | for i in range(12): #中心底部翻转90度
100 | plt.text(i, num1[i], str(num1[i]),
101 | ha='center', va='bottom', rotation=45)
102 | plt.title('2016 Number-12Month')
103 | plt.sca(p3)
104 |
105 |
106 | #################################################
107 | # 所有年份数据对比
108 | #################################################
109 | sql = '''select MONTH(FBTime) as mm, count(*) as cnt from csdn_blog group by mm;'''
110 | cur.execute(sql)
111 | result = cur.fetchall()
112 | hour1 = [n[0] for n in result]
113 | print hour1
114 | num1 = [n[1] for n in result]
115 | print num1
116 |
117 | N = 12
118 | ind = np.arange(N) #赋值0-11
119 | width=0.35
120 | p4 = plt.subplot(224)
121 | plt.bar(ind, num1, width, color='y', label='sum num')
122 | #设置底部名称
123 | plt.xticks(ind+width/2, hour1, rotation=40) #旋转40度
124 | for i in range(12): #中心底部翻转90度
125 | plt.text(i, num1[i], str(num1[i]),
126 | ha='center', va='bottom', rotation=45)
127 | plt.title('All Year Number-12Month')
128 | plt.sca(p4)
129 |
130 | plt.savefig('ttt.png',dpi=400)
131 | plt.show()
132 |
133 | #异常处理
134 | except MySQLdb.Error,e:
135 | print "Mysql Error %d: %s" % (e.args[0], e.args[1])
136 | finally:
137 | cur.close()
138 | conn.commit()
139 | conn.close()
140 |
141 |
142 |
--------------------------------------------------------------------------------
/blog12-matplotlib+SQL/test02.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | '''
3 | ' 这篇代码主要讲述获取MySQL中数据,再进行简单的统计
4 | ' 统计采用SQL语句进行 By:Eastmount CSDN
5 | '''
6 |
7 | import matplotlib.pyplot as plt
8 | import matplotlib
9 | import pandas as pd
10 | import numpy as np
11 | import MySQLdb
12 | from pandas import *
13 |
14 | try:
15 | conn = MySQLdb.connect(host='localhost',user='root',
16 | passwd='123456',port=3306, db='test01')
17 | cur = conn.cursor() #数据库游标
18 |
19 | #防止报错:UnicodeEncodeError: 'latin-1' codec can't encode character
20 | conn.set_character_set('utf8')
21 | cur.execute('SET NAMES utf8;')
22 | cur.execute('SET CHARACTER SET utf8;')
23 | cur.execute('SET character_set_connection=utf8;')
24 |
25 | #所有博客数
26 | sql = '''select MONTH(FBTime) as mm, count(*) as cnt from csdn_blog
27 | group by mm;'''
28 | cur.execute(sql)
29 | result = cur.fetchall() #获取结果复制给result
30 | hour1 = [n[0] for n in result]
31 | print hour1
32 | num1 = [n[1] for n in result]
33 | print num1
34 |
35 | #2014年博客数
36 | sql = '''select MONTH(FBTime) as mm, count(*) as cnt from csdn_blog
37 | where DATE_FORMAT(FBTime,'%Y')='2014' group by mm;'''
38 | cur.execute(sql)
39 | result = cur.fetchall()
40 | num2 = [n[1] for n in result]
41 | print num2
42 |
43 | #2015年博客数
44 | sql = '''select MONTH(FBTime) as mm, count(*) as cnt from csdn_blog
45 | where DATE_FORMAT(FBTime,'%Y')='2015' group by mm;'''
46 | cur.execute(sql)
47 | result = cur.fetchall()
48 | num3 = [n[1] for n in result]
49 | print num3
50 |
51 | #2016年博客数
52 | sql = '''select MONTH(FBTime) as mm, count(*) as cnt from csdn_blog
53 | where DATE_FORMAT(FBTime,'%Y')='2016' group by mm;'''
54 | cur.execute(sql)
55 | result = cur.fetchall()
56 | num4 = [n[1] for n in result]
57 | print num4
58 |
59 | #重点: 数据整合 [12,4]
60 | data = np.array([num1, num2, num3, num4])
61 | print data
62 | d = data.T #转置
63 | print d
64 | df = DataFrame(d, index=hour1, columns=['All','2014', '2015', '2016'])
65 | df.plot(kind='area', alpha=0.2) #设置颜色 透明度
66 | plt.title('Arae Plot Blog-Month')
67 | plt.savefig('csdn.png',dpi=400)
68 | plt.show()
69 |
70 | #异常处理
71 | except MySQLdb.Error,e:
72 | print "Mysql Error %d: %s" % (e.args[0], e.args[1])
73 | finally:
74 | cur.close()
75 | conn.commit()
76 | conn.close()
77 |
78 |
--------------------------------------------------------------------------------
/blog12-matplotlib+SQL/test03.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | '''
3 | ' 这篇代码主要讲述获取MySQL中数据,再进行简单的统计
4 | ' 统计采用SQL语句进行 By:Eastmount CSDN
5 | '''
6 |
7 | import matplotlib.pyplot as plt
8 | import matplotlib
9 | import pandas as pd
10 | import numpy as np
11 | import MySQLdb
12 | from pandas import *
13 |
14 | try:
15 | conn = MySQLdb.connect(host='localhost',user='root',
16 | passwd='123456',port=3306, db='test01')
17 | cur = conn.cursor() #数据库游标
18 |
19 | #防止报错:UnicodeEncodeError: 'latin-1' codec can't encode character
20 | conn.set_character_set('utf8')
21 | cur.execute('SET NAMES utf8;')
22 | cur.execute('SET CHARACTER SET utf8;')
23 | cur.execute('SET character_set_connection=utf8;')
24 | sql = '''select
25 | COUNT(case dayofweek(FBTime) when 1 then 1 end) AS '星期日',
26 | COUNT(case dayofweek(FBTime) when 2 then 1 end) AS '星期一',
27 | COUNT(case dayofweek(FBTime) when 3 then 1 end) AS '星期二',
28 | COUNT(case dayofweek(FBTime) when 4 then 1 end) AS '星期三',
29 | COUNT(case dayofweek(FBTime) when 5 then 1 end) AS '星期四',
30 | COUNT(case dayofweek(FBTime) when 6 then 1 end) AS '星期五',
31 | COUNT(case dayofweek(FBTime) when 7 then 1 end) AS '星期六'
32 | from csdn_blog;
33 | '''
34 | cur.execute(sql)
35 | result = cur.fetchall()
36 | print result
37 | #((31704L, 43081L, 42670L, 43550L, 41270L, 39164L, 29931L),)
38 | name = ['Sunday','Monday','Tuesday','Wednesday','Thursday','Friday','Saturday']
39 | #转换为numpy数组
40 | data = np.array(result)
41 | print data
42 | d = data.T #转置
43 | print d
44 |
45 | matplotlib.style.use('ggplot')
46 | df=DataFrame(d, index=name,columns=['Nums'])
47 | df.plot(kind='bar')
48 | plt.title('All Year Blog-Week')
49 | plt.xlabel('Week')
50 | plt.ylabel('The number of blog')
51 | plt.savefig('01csdn.png',dpi=400)
52 | plt.show()
53 |
54 | #异常处理
55 | except MySQLdb.Error,e:
56 | print "Mysql Error %d: %s" % (e.args[0], e.args[1])
57 | finally:
58 | cur.close()
59 | conn.commit()
60 | conn.close()
61 |
62 |
--------------------------------------------------------------------------------
/blog12-matplotlib+SQL/test04.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | '''
3 | ' 这篇代码主要讲述获取MySQL中数据,再进行简单的统计
4 | ' 统计采用SQL语句进行 By:Eastmount CSDN 杨秀璋
5 | '''
6 |
7 | import matplotlib.pyplot as plt
8 | import matplotlib
9 | import pandas as pd
10 | import numpy as np
11 | import MySQLdb
12 | from pandas import *
13 |
14 | try:
15 | conn = MySQLdb.connect(host='localhost',user='root',
16 | passwd='123456',port=3306, db='test01')
17 | cur = conn.cursor() #数据库游标
18 |
19 | #防止报错:UnicodeEncodeError: 'latin-1' codec can't encode character
20 | conn.set_character_set('utf8')
21 | cur.execute('SET NAMES utf8;')
22 | cur.execute('SET CHARACTER SET utf8;')
23 | cur.execute('SET character_set_connection=utf8;')
24 | sql = '''select
25 | COUNT(case dayofweek(FBTime) when 1 then 1 end) AS '星期日',
26 | COUNT(case dayofweek(FBTime) when 2 then 1 end) AS '星期一',
27 | COUNT(case dayofweek(FBTime) when 3 then 1 end) AS '星期二',
28 | COUNT(case dayofweek(FBTime) when 4 then 1 end) AS '星期三',
29 | COUNT(case dayofweek(FBTime) when 5 then 1 end) AS '星期四',
30 | COUNT(case dayofweek(FBTime) when 6 then 1 end) AS '星期五',
31 | COUNT(case dayofweek(FBTime) when 7 then 1 end) AS '星期六'
32 | from csdn_blog where DATE_FORMAT(FBTime,'%Y')='2008';
33 | '''
34 | cur.execute(sql)
35 | result1 = cur.fetchall()
36 | print result1
37 | name = ['Sunday','Monday','Tuesday','Wednesday','Thursday','Friday','Saturday']
38 | data = np.array(result1)
39 | d1 = data.T #转置
40 | print d1
41 |
42 |
43 | sql = '''select
44 | COUNT(case dayofweek(FBTime) when 1 then 1 end) AS '星期日',
45 | COUNT(case dayofweek(FBTime) when 2 then 1 end) AS '星期一',
46 | COUNT(case dayofweek(FBTime) when 3 then 1 end) AS '星期二',
47 | COUNT(case dayofweek(FBTime) when 4 then 1 end) AS '星期三',
48 | COUNT(case dayofweek(FBTime) when 5 then 1 end) AS '星期四',
49 | COUNT(case dayofweek(FBTime) when 6 then 1 end) AS '星期五',
50 | COUNT(case dayofweek(FBTime) when 7 then 1 end) AS '星期六'
51 | from csdn_blog where DATE_FORMAT(FBTime,'%Y')='2011';
52 | '''
53 | cur.execute(sql)
54 | result2 = cur.fetchall()
55 | data = np.array(result2)
56 | d2 = data.T #转置
57 | print d2
58 |
59 |
60 | sql = '''select
61 | COUNT(case dayofweek(FBTime) when 1 then 1 end) AS '星期日',
62 | COUNT(case dayofweek(FBTime) when 2 then 1 end) AS '星期一',
63 | COUNT(case dayofweek(FBTime) when 3 then 1 end) AS '星期二',
64 | COUNT(case dayofweek(FBTime) when 4 then 1 end) AS '星期三',
65 | COUNT(case dayofweek(FBTime) when 5 then 1 end) AS '星期四',
66 | COUNT(case dayofweek(FBTime) when 6 then 1 end) AS '星期五',
67 | COUNT(case dayofweek(FBTime) when 7 then 1 end) AS '星期六'
68 | from csdn_blog where DATE_FORMAT(FBTime,'%Y')='2016';
69 | '''
70 | cur.execute(sql)
71 | result3 = cur.fetchall()
72 | data = np.array(result3)
73 | print type(result3),type(data)
74 | d3 = data.T #转置
75 | print d3
76 |
77 |
78 | #SQL语句获取3个数组,采用循环复制到一个[7][3]的二维数组中
79 | data = np.random.rand(7,3)
80 | print data
81 | i = 0
82 | while i<7:
83 | data[i][0] = d1[i]
84 | data[i][1] = d2[i]
85 | data[i][2] = d3[i]
86 | i = i + 1
87 |
88 | print data
89 | print type(data)
90 |
91 | #绘图
92 | matplotlib.style.use('ggplot')
93 | #数据[7,3]数组 name为星期 columns对应年份
94 | df=DataFrame(data, index=name, columns=['2008','2011','2016'])
95 | df.plot(kind='bar')
96 | plt.title('Comparison Chart Blog-Week')
97 | plt.xlabel('Week')
98 | plt.ylabel('The number of blog')
99 | plt.savefig('03csdn.png', dpi=400)
100 | plt.show()
101 |
102 |
103 |
104 | #异常处理
105 | except MySQLdb.Error,e:
106 | print "Mysql Error %d: %s" % (e.args[0], e.args[1])
107 | finally:
108 | cur.close()
109 | conn.commit()
110 | conn.close()
111 |
112 |
--------------------------------------------------------------------------------
/blog13-wordcloud/cloudimg.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog13-wordcloud/cloudimg.png
--------------------------------------------------------------------------------
/blog13-wordcloud/mb.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog13-wordcloud/mb.png
--------------------------------------------------------------------------------
/blog13-wordcloud/result01.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog13-wordcloud/result01.png
--------------------------------------------------------------------------------
/blog13-wordcloud/test.txt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog13-wordcloud/test.txt
--------------------------------------------------------------------------------
/blog13-wordcloud/test01.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # By:Eastmount CSDN
3 | import jieba
4 | import sys
5 | import matplotlib.pyplot as plt
6 | from wordcloud import WordCloud
7 |
8 | #打开本体TXT文件
9 | text = open('test.txt').read()
10 | print(type(text))
11 |
12 | #结巴分词 cut_all=True 设置为全模式
13 | wordlist = jieba.cut(text, cut_all = True)
14 |
15 | #使用空格连接 进行中文分词
16 | wl_space_split = " ".join(wordlist)
17 | print(wl_space_split)
18 |
19 | #对分词后的文本生成词云
20 | my_wordcloud = WordCloud().generate(wl_space_split)
21 |
22 | #显示词云图
23 | plt.imshow(my_wordcloud)
24 | #是否显示x轴、y轴下标
25 | plt.axis("off")
26 | plt.show()
27 |
--------------------------------------------------------------------------------
/blog13-wordcloud/test02.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # By:Eastmount CSDN
3 | from os import path
4 | from scipy.misc import imread
5 | import jieba
6 | import sys
7 | import matplotlib.pyplot as plt
8 | from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
9 |
10 | # 打开本体TXT文件
11 | text = open('test.txt').read()
12 |
13 | # 结巴分词 cut_all=True 设置为全模式
14 | wordlist = jieba.cut(text) #cut_all = True
15 |
16 | # 使用空格连接 进行中文分词
17 | wl_space_split = " ".join(wordlist)
18 | print(wl_space_split)
19 |
20 | # 读取mask/color图片
21 | d = path.dirname(__file__)
22 | nana_coloring = imread(path.join(d, "mb.png"))
23 |
24 | # 对分词后的文本生成词云
25 | my_wordcloud = WordCloud( background_color = 'white', # 设置背景颜色
26 | mask = nana_coloring, # 设置背景图片
27 | max_words = 2000, # 设置最大现实的字数
28 | stopwords = STOPWORDS, # 设置停用词
29 | max_font_size = 50, # 设置字体最大值
30 | random_state = 30, # 设置有多少种随机生成状态,即有多少种配色方案
31 | )
32 |
33 | # generate word cloud
34 | my_wordcloud.generate(wl_space_split)
35 |
36 | # create coloring from image
37 | image_colors = ImageColorGenerator(nana_coloring)
38 |
39 | # recolor wordcloud and show
40 | my_wordcloud.recolor(color_func=image_colors)
41 |
42 | plt.imshow(my_wordcloud) # 显示词云图
43 | plt.axis("off") # 是否显示x轴、y轴下标
44 | plt.show()
45 |
46 | # save img
47 | my_wordcloud.to_file(path.join(d, "cloudimg.png"))
48 |
49 |
50 |
--------------------------------------------------------------------------------
/blog14-curve_fit/data.csv:
--------------------------------------------------------------------------------
1 | x,y
2 | 0,4
3 | 1,5.2
4 | 2,5.9
5 | 3,6.8
6 | 4,7.34
7 | 5,8.57
8 | 6,9.86
9 | 7,10.12
10 | 8,12.56
11 | 9,14.32
12 | 10,15.42
13 | 11,16.50
14 | 12,18.92
15 | 13,19.58
16 |
--------------------------------------------------------------------------------
/blog14-curve_fit/result01.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog14-curve_fit/result01.png
--------------------------------------------------------------------------------
/blog14-curve_fit/result02.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog14-curve_fit/result02.png
--------------------------------------------------------------------------------
/blog14-curve_fit/test01.py:
--------------------------------------------------------------------------------
1 | #encoding=utf-8
2 | #By:Eastmount CSDN
3 | import numpy as np
4 | import matplotlib.pyplot as plt
5 |
6 | #定义x、y散点坐标
7 | x = np.arange(1, 16, 1)
8 | num = [4.00, 5.20, 5.900, 6.80, 7.34,
9 | 8.57, 9.86, 10.12, 12.56, 14.32,
10 | 15.42, 16.50, 18.92, 19.58, 20.00]
11 | y = np.array(num)
12 |
13 | #用3次多项式拟合
14 | f1 = np.polyfit(x, y, 3)
15 | p1 = np.poly1d(f1)
16 | print(p1)
17 |
18 | #也可使用yvals=np.polyval(f1, x)
19 | yvals = p1(x) #拟合y值
20 |
21 | #绘图
22 | plot1 = plt.plot(x, y, 's',label='original values')
23 | plot2 = plt.plot(x, yvals, 'r',label='polyfit values')
24 | plt.xlabel('x')
25 | plt.ylabel('y')
26 | plt.legend(loc=4) #指定legend的位置右下角
27 | plt.title('polyfitting')
28 | plt.show()
29 | plt.savefig('test.png')
30 |
--------------------------------------------------------------------------------
/blog14-curve_fit/test02.py:
--------------------------------------------------------------------------------
1 | #encoding=utf-8
2 | #By:Eastmount CSDN
3 | import numpy as np
4 | import matplotlib.pyplot as plt
5 | from scipy.optimize import curve_fit
6 |
7 | #自定义函数 e指数形式
8 | def func(x, a, b):
9 | return a*np.exp(b/x)
10 |
11 | #定义x、y散点坐标
12 | x = np.arange(1, 16, 1)
13 | num = [4.00, 5.20, 5.900, 6.80, 7.34,
14 | 8.57, 9.86, 10.12, 12.56, 14.32,
15 | 15.42, 16.50, 18.92, 19.58, 20.00]
16 | y = np.array(num)
17 |
18 | #非线性最小二乘法拟合
19 | popt, pcov = curve_fit(func, x, y)
20 | #获取popt里面是拟合系数
21 | a = popt[0]
22 | b = popt[1]
23 | yvals = func(x,a,b) #拟合y值
24 | print('系数a:', a)
25 | print('系数b:', b)
26 |
27 | #绘图
28 | plot1 = plt.plot(x, y, 's',label='original values')
29 | plot2 = plt.plot(x, yvals, 'r',label='polyfit values')
30 | plt.xlabel('x')
31 | plt.ylabel('y')
32 | plt.legend(loc=4) #指定legend的位置右下角
33 | plt.title('curve_fit')
34 | plt.show()
35 | plt.savefig('test2.png')
36 |
--------------------------------------------------------------------------------
/blog14-curve_fit/test03.py:
--------------------------------------------------------------------------------
1 | #encoding=utf-8
2 | #By:Eastmount CSDN
3 | import numpy as np
4 | import matplotlib.pyplot as plt
5 | from scipy.optimize import curve_fit
6 | import pandas as pd
7 |
8 | #自定义函数 e指数形式
9 | def func(x, a, b):
10 | return a*pow(x,b)
11 |
12 | #导入数据及x、y散点坐标
13 | data = pd.read_csv("data.csv")
14 | print(data)
15 | print(data.shape)
16 | print(data.head(5)) #显示前5行数据
17 | x = data['x']
18 | y = data['y']
19 | print(x)
20 | print(y)
21 |
22 | #非线性最小二乘法拟合
23 | popt, pcov = curve_fit(func, x, y)
24 | #获取popt里面是拟合系数
25 | a = popt[0]
26 | b = popt[1]
27 | yvals = func(x,a,b) #拟合y值
28 | print('系数a:', a)
29 | print('系数b:', b)
30 |
31 | #绘图
32 | plot1 = plt.plot(x, y, 's',label='original values')
33 | plot2 = plt.plot(x, yvals, 'r',label='polyfit values')
34 | plt.xlabel('x')
35 | plt.ylabel('y')
36 | plt.legend(loc=4) #指定legend的位置右下角
37 | plt.title('curve_fit')
38 | plt.savefig('test3.png')
39 | plt.show()
40 |
41 |
--------------------------------------------------------------------------------
/blog14-curve_fit/test04.py:
--------------------------------------------------------------------------------
1 | #encoding:utf-8
2 | #By:Eastmount CSDN
3 | import numpy as np
4 | import matplotlib.pyplot as plt
5 | from scipy.optimize import curve_fit
6 |
7 | def func(x, a, b, c):
8 | return a * np.exp(-b * x) + c
9 |
10 | # define the data to be fit with some noise
11 | xdata = np.linspace(0, 4, 50)
12 | y = func(xdata, 2.5, 1.3, 0.5)
13 | y_noise = 0.2 * np.random.normal(size=xdata.size)
14 | ydata = y + y_noise
15 | plt.plot(xdata, ydata, 'b-', label='data')
16 |
17 | # Fit for the parameters a, b, c of the function `func`
18 | popt, pcov = curve_fit(func, xdata, ydata)
19 | plt.plot(xdata, func(xdata, *popt), 'r-', label='fit')
20 |
21 | # Constrain the optimization to the region of ``0 < a < 3``, ``0 < b < 2``
22 | # and ``0 < c < 1``:
23 | popt, pcov = curve_fit(func, xdata, ydata, bounds=(0, [3., 2., 1.]))
24 | plt.plot(xdata, func(xdata, *popt), 'g--', label='fit-with-bounds')
25 |
26 | plt.xlabel('x')
27 | plt.ylabel('y')
28 | plt.legend()
29 | plt.show()
30 |
--------------------------------------------------------------------------------
/blog14-curve_fit/test3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog14-curve_fit/test3.png
--------------------------------------------------------------------------------
/blog14-curve_fit/test4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog14-curve_fit/test4.png
--------------------------------------------------------------------------------
/blog15-imshow/result01.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog15-imshow/result01.png
--------------------------------------------------------------------------------
/blog15-imshow/result02.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog15-imshow/result02.png
--------------------------------------------------------------------------------
/blog15-imshow/result03.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog15-imshow/result03.png
--------------------------------------------------------------------------------
/blog15-imshow/test01.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | # By:Eastmount CSDN
3 | from matplotlib import pyplot as plt
4 |
5 | fig = plt.figure()
6 | ax1 = fig.add_subplot(231)
7 | ax2 = fig.add_subplot(232)
8 | ax3 = fig.add_subplot(233)
9 | ax4 = fig.add_subplot(234)
10 | ax5 = fig.add_subplot(235)
11 | ax6 = fig.add_subplot(236)
12 | plt.grid(True)
13 | plt.show()
14 |
--------------------------------------------------------------------------------
/blog15-imshow/test02.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | # By:Eastmount CSDN
3 | import numpy as np
4 | from pylab import *
5 | from matplotlib import pyplot as plt
6 |
7 | x = [1, 2, 3, 4]
8 | y = [3, 5, 10, 25]
9 |
10 | #创建Figure
11 | fig = plt.figure()
12 |
13 | #创建一个或多个子图(subplot绘图区才能绘图)
14 | ax1 = fig.add_subplot(231)
15 | plt.plot(x, y, marker='D') #绘图及选择子图
16 | plt.sca(ax1)
17 |
18 | ax2 = fig.add_subplot(232)
19 | plt.scatter(x, y, marker='s', color='r')
20 | plt.sca(ax2)
21 | plt.grid(True)
22 |
23 | ax3 = fig.add_subplot(233)
24 | plt.bar(x, y, 0.5, color='c') #柱状图 width=0.5间距
25 | plt.sca(ax3)
26 |
27 | ax4 = fig.add_subplot(234)
28 | #高斯分布
29 | mean = 0 #均值为0
30 | sigma = 1 #标准差为1 (反应数据集中还是分散的值)
31 | data = mean+sigma*np.random.randn(10000)
32 | plt.hist(data,40,normed=1,histtype='bar',facecolor='yellowgreen',alpha=0.75)
33 | plt.sca(ax4)
34 |
35 | m = np.arange(-5.0, 5.0, 0.02)
36 | n = np.sin(m)
37 | ax5 = fig.add_subplot(235)
38 | plt.plot(m, n)
39 | plt.sca(ax5)
40 |
41 | ax6 = fig.add_subplot(236)
42 | xlim(-2.5, 2.5) #设置x轴范围
43 | ylim(-1, 1) #设置y轴范围
44 | plt.plot(m, n)
45 | plt.sca(ax6)
46 | plt.grid(True)
47 |
48 | plt.show()
49 |
--------------------------------------------------------------------------------
/blog15-imshow/test03.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | # By:Eastmount CSDN
3 | from matplotlib import pyplot as plt
4 |
5 | X = [[1,2],[3,4],[5,6]]
6 | plt.imshow(X)
7 | plt.show()
8 |
--------------------------------------------------------------------------------
/blog15-imshow/test04.py:
--------------------------------------------------------------------------------
1 | #coding=utf-8
2 | # By:Eastmount CSDN
3 | from matplotlib import pyplot as plt
4 |
5 | X = [[1,2],[3,4],[5,6]]
6 | plt.imshow(X)
7 | plt.colorbar()
8 | plt.show()
9 |
--------------------------------------------------------------------------------
/blog15-imshow/test05.py:
--------------------------------------------------------------------------------
1 | #coding=utf-8
2 | #By:Eastmount CSDN
3 | from matplotlib import pyplot as plt
4 |
5 | X = [[1,2],[3,4]]
6 |
7 | fig = plt.figure()
8 | ax = fig.add_subplot(231)
9 | ax.imshow(X)
10 |
11 | ax = fig.add_subplot(232)
12 | ax.imshow(X, cmap=plt.cm.gray) #灰度
13 |
14 | ax = fig.add_subplot(233)
15 | im = ax.imshow(X, cmap=plt.cm.spring) #春
16 | plt.colorbar(im)
17 |
18 | ax = fig.add_subplot(234)
19 | im = ax.imshow(X, cmap=plt.cm.summer)
20 | plt.colorbar(im, cax=None, ax=None, shrink=0.5) #长度为半
21 |
22 | ax = fig.add_subplot(235)
23 | im = ax.imshow(X, cmap=plt.cm.autumn)
24 | plt.colorbar(im, shrink=0.5, ticks=[-1,0,1])
25 |
26 | ax = fig.add_subplot(236)
27 | im = ax.imshow(X, cmap=plt.cm.winter)
28 | plt.colorbar(im, shrink=0.5)
29 |
30 | plt.show()
31 |
--------------------------------------------------------------------------------
/blog15-imshow/test06.py:
--------------------------------------------------------------------------------
1 | #coding=utf-8
2 | #By:Eastmount CSDN
3 | from matplotlib import pyplot as plt
4 |
5 | X = [[0, 0.25], [0.5, 0.75]]
6 |
7 |
8 | fig = plt.figure()
9 | ax = fig.add_subplot(121)
10 | im = ax.imshow(X, cmap=plt.get_cmap('hot'))
11 | plt.colorbar(im, shrink=0.5)
12 |
13 | ax = fig.add_subplot(122)
14 | im = ax.imshow(X, cmap=plt.get_cmap('hot'), interpolation='nearest',
15 | vmin=0, vmax=1)
16 | plt.colorbar(im, shrink=0.2)
17 | plt.show()
18 |
19 |
--------------------------------------------------------------------------------
/blog15-imshow/test07.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | # By:Eastmount CSDN
3 | import numpy as np
4 | from matplotlib import pyplot as plt
5 | from matplotlib import cm
6 | from matplotlib import axes
7 |
8 | def draw_heatmap(data,xlabels,ylabels):
9 | #cmap=cm.Blues
10 | cmap=cm.get_cmap('rainbow',1000)
11 | figure=plt.figure(facecolor='w')
12 | ax=figure.add_subplot(1,1,1,position=[0.1,0.15,0.8,0.8])
13 | ax.set_yticks(range(len(ylabels)))
14 | ax.set_yticklabels(ylabels)
15 | ax.set_xticks(range(len(xlabels)))
16 | ax.set_xticklabels(xlabels)
17 | vmax=data[0][0]
18 | vmin=data[0][0]
19 | for i in data:
20 | for j in i:
21 | if j>vmax:
22 | vmax=j
23 | if j0:
75 | words.write(student1 + " " + student2 + " "
76 | + str(word_vector[i][j]) + "\r\n")
77 | j = j + 1
78 | i = i + 1
79 | words.close()
80 |
81 |
82 | """ 第四步:图形生成 """
83 | a = []
84 | f = codecs.open('word_node.txt','r','utf-8')
85 | line = f.readline()
86 | print line
87 | i = 0
88 | A = []
89 | B = []
90 | while line!="":
91 | a.append(line.split()) #保存文件是以空格分离的
92 | print a[i][0],a[i][1]
93 | A.append(a[i][0])
94 | B.append(a[i][1])
95 | i = i + 1
96 | line = f.readline()
97 | elem_dic = tuple(zip(A,B))
98 | print type(elem_dic)
99 | print list(elem_dic)
100 | f.close()
101 |
102 | import matplotlib
103 | matplotlib.rcParams['font.sans-serif'] = ['SimHei']
104 | matplotlib.rcParams['font.family']='sans-serif'
105 |
106 | colors = ["red","green","blue","yellow"]
107 | G = nx.Graph()
108 | G.add_edges_from(list(elem_dic))
109 | #nx.draw(G,with_labels=True,pos=nx.random_layout(G),font_size=12,node_size=2000,node_color=colors) #alpha=0.3
110 | #pos=nx.spring_layout(G,iterations=50)
111 | pos=nx.random_layout(G)
112 | nx.draw_networkx_nodes(G, pos, alpha=0.2,node_size=1200,node_color=colors)
113 | nx.draw_networkx_edges(G, pos, node_color='r', alpha=0.3) #style='dashed'
114 | nx.draw_networkx_labels(G, pos, font_family='sans-serif', alpha=0.5) #font_size=5
115 | plt.show()
116 |
--------------------------------------------------------------------------------
/blog18-Regression/blog01-LR.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | from sklearn.linear_model import LinearRegression
3 |
4 | #数据集 直径、价格
5 | x = [[5],[6],[7],[8],[10],[11],[13],[14],[16],[18]]
6 | y = [[6],[7.5],[8.6],[9],[12],[13.6],[15.8],[18.5],[19.2],[20]]
7 | print(x)
8 | print(y)
9 |
10 | clf = LinearRegression()
11 | clf.fit(x,y)
12 | pre = clf.predict([[12]])[0]
13 | print(u'预测直径为12英寸的价格: $%.2f' % pre)
14 |
--------------------------------------------------------------------------------
/blog18-Regression/blog02-LR.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | from sklearn.linear_model import LinearRegression
3 |
4 | #数据集 直径、价格
5 | x = [[5],[6],[7],[8],[10],[11],[13],[14],[16],[18]]
6 | y = [[6],[7.5],[8.6],[9],[12],[13.6],[15.8],[18.5],[19.2],[20]]
7 | print(x)
8 | print(y)
9 |
10 | clf = LinearRegression()
11 | clf.fit(x,y)
12 | pre = clf.predict([[12]])[0]
13 | print('预测直径为12英寸的价格: $%.2f' % pre)
14 | x2 = [[0],[12],[15],[25]]
15 | y2 = clf.predict(x2)
16 |
17 | import matplotlib.pyplot as plt
18 | plt.figure()
19 | plt.rcParams['font.sans-serif'] = ['SimHei'] #指定默认字体
20 | plt.title(u"线性回归预测Pizza直径和价格")
21 | plt.xlabel(u"x")
22 | plt.ylabel(u"price")
23 | plt.axis([0,25,0,25])
24 | plt.scatter(x,y,marker="s",s=20)
25 | plt.plot(x2,y2,"g-")
26 | plt.show()
27 |
--------------------------------------------------------------------------------
/blog18-Regression/blog03-boston.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | #导入数据集boston
3 | from sklearn.datasets import load_boston
4 | import numpy as np
5 | boston = load_boston()
6 | print(boston.data.shape, boston.target.shape)
7 | print(boston.data[0])
8 | print(boston.target)
9 |
10 | #划分数据集
11 | boston_temp = boston.data[:, np.newaxis, 5]
12 | x_train = boston_temp[:-100] #训练样本
13 | x_test = boston_temp[-100:] #测试样本 后100行
14 | y_train = boston.target[:-100] #训练标记
15 | y_test = boston.target[-100:] #预测对比标记
16 |
--------------------------------------------------------------------------------
/blog18-Regression/blog04-boson.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | from sklearn.datasets import load_boston
3 | import numpy as np
4 | boston = load_boston()
5 | print(boston.data.shape, boston.target.shape)
6 |
7 | #划分数据集
8 | boston_temp = boston.data[:, np.newaxis, 5]
9 | x_train = boston_temp[:-100] #训练样本
10 | x_test = boston_temp[-100:] #测试样本 后100行
11 | y_train = boston.target[:-100] #训练标记
12 | y_test = boston.target[-100:] #预测对比标记
13 |
14 | #回归分析
15 | from sklearn.linear_model import LinearRegression
16 | clf = LinearRegression()
17 | clf.fit(x_train, y_train)
18 |
19 | #算法评估
20 | pre = clf.predict(x_test)
21 | print("预测结果", pre)
22 | print("真实结果", y_test)
23 | cost = np.mean(y_test-pre)**2
24 | print('平方和计算:', cost)
25 | print('系数', clf.coef_)
26 | print('截距', clf.intercept_)
27 | print('方差', clf.score(x_test, y_test))
28 |
29 | #绘图分析
30 | import matplotlib.pyplot as plt
31 | plt.title(u'LinearRegression Boston')
32 | plt.xlabel(u'x')
33 | plt.ylabel(u'price')
34 | plt.scatter(x_test, y_test, color = 'black')
35 | plt.plot(x_test, clf.predict(x_test), color='blue', linewidth = 3)
36 | for idx, m in enumerate(x_test):
37 | plt.plot([m, m],[y_test[idx],pre[idx]], 'r-')
38 | plt.show()
39 |
--------------------------------------------------------------------------------
/blog18-Regression/blog05-random.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import math
3 | X = np.arange(0,50,0.2)
4 | print(X)
5 | xArr = []
6 | yArr = []
7 | for n in X:
8 | xArr.append(n)
9 | y = 0.7*n + np.random.uniform(0,1)*math.sin(n)*2 - 3
10 | yArr.append(y)
11 |
12 | import matplotlib.pyplot as plt
13 | plt.plot(X, yArr, 'go')
14 | plt.show()
15 |
--------------------------------------------------------------------------------
/blog18-Regression/blog06-random.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import numpy as np
3 | import math
4 |
5 | #随机数生成
6 | X = np.arange(0,50,0.2)
7 | print(X)
8 | xArr = []
9 | yArr = []
10 | for n in X:
11 | xArr.append(n)
12 | y = 0.7*n + np.random.uniform(0,1)*math.sin(n)*2 - 3
13 | yArr.append(y)
14 |
15 | #线性回归分析
16 | from sklearn.linear_model import LinearRegression
17 | clf = LinearRegression()
18 | print(clf)
19 | X = np.array(X).reshape((len(X),1)) #list转化为数组
20 | yArr = np.array(yArr).reshape((len(X),1))
21 | clf.fit(X,yArr)
22 | pre = clf.predict(X)
23 |
24 | import matplotlib.pyplot as plt
25 | plt.plot(X, yArr, 'go')
26 | plt.plot(X, pre, 'r', linewidth=3)
27 | plt.show()
28 |
--------------------------------------------------------------------------------
/blog18-Regression/blog07-3Drandom.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import numpy as np
3 | from sklearn import linear_model
4 | from mpl_toolkits.mplot3d import Axes3D
5 | import matplotlib.pyplot as plt
6 | import math
7 |
8 | #linspace:开始值、终值和元素个数创建表示等差数列的一维数组
9 | xx, yy = np.meshgrid(np.linspace(0,10,20), np.linspace(0,100,20))
10 | zz = 2.4 * xx + 4.5 * yy + np.random.randint(0,100,(20,20))
11 |
12 | #构建成特征、值的形式
13 | X, Z = np.column_stack((xx.flatten(),yy.flatten())), zz.flatten()
14 |
15 | #线性回归分析
16 | regr = linear_model.LinearRegression()
17 | regr.fit(X, Z)
18 |
19 | #预测的一个特征
20 | x_test = np.array([[15.7, 91.6]])
21 | print(regr.predict(x_test))
22 |
23 | #画图可视化分析
24 | fig = plt.figure()
25 | ax = fig.gca(projection='3d')
26 | ax.scatter(xx, yy, zz) #真实点
27 |
28 | #拟合的平面
29 | ax.plot_wireframe(xx, yy, regr.predict(X).reshape(20,20))
30 | ax.plot_surface(xx, yy, regr.predict(X).reshape(20,20), alpha=0.3)
31 | plt.show()
32 |
--------------------------------------------------------------------------------
/blog18-Regression/blog08-PolynomialFeatures.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Sun Nov 26 23:31:16 2017
4 | @author: yxz15
5 | """
6 |
7 | # -*- coding: utf-8 -*-
8 | from sklearn.linear_model import LinearRegression
9 |
10 | #数据集 直径、价格
11 | x = [[5],[6],[7],[8],[10],[11],[13],[14],[16],[18]]
12 | y = [[6],[7.5],[8.6],[9],[12],[13.6],[15.8],[18.5],[19.2],[20]]
13 | print(x)
14 | print(y)
15 |
16 | clf = LinearRegression()
17 | clf.fit(x,y)
18 | pre = clf.predict([[12]])[0]
19 | print(u'预测直径为12英寸的价格: $%.2f' % pre)
20 | x2 = [[0],[12],[15],[25]]
21 | y2 = clf.predict(x2)
22 |
23 | import matplotlib.pyplot as plt
24 | import numpy as np
25 |
26 | plt.figure()
27 | plt.axis([0,25,0,25])
28 | plt.scatter(x,y,marker="s",s=20)
29 | plt.plot(x2,y2,"g-")
30 |
31 | #导入多项式回归模型
32 | from sklearn.preprocessing import PolynomialFeatures
33 | xx = np.linspace(0,25,100) #0到25等差数列
34 | quadratic_featurizer = PolynomialFeatures(degree = 2) #实例化一个二次多项式
35 | x_train_quadratic = quadratic_featurizer.fit_transform(x) #用二次多项式多样本x做变换
36 | X_test_quadratic = quadratic_featurizer.transform(x2)
37 | regressor_quadratic = LinearRegression()
38 | regressor_quadratic.fit(x_train_quadratic, y)
39 | xx_quadratic = quadratic_featurizer.transform(xx.reshape(xx.shape[0], 1))# 把训练好X值的多项式特征实例应用到一系列点上,形成矩阵
40 |
41 | plt.plot(xx, regressor_quadratic.predict(xx_quadratic),
42 | label="$y = ax^2 + bx + c$",linewidth=2,color="r")
43 | plt.legend()
44 | plt.show()
45 |
--------------------------------------------------------------------------------
/blog18-Regression/blog09-PolynomialFeatures.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Sun Nov 26 23:31:16 2017
4 | @author: yxz15
5 | """
6 |
7 | # -*- coding: utf-8 -*-
8 | from sklearn.linear_model import LinearRegression
9 |
10 | #数据集 直径、价格
11 | x = [[5],[6],[7],[8],[10],[11],[13],[14],[16],[18]]
12 | y = [[6],[7.5],[8.6],[9],[12],[13.6],[15.8],[18.5],[19.2],[20]]
13 | print(x)
14 | print(y)
15 |
16 | clf = LinearRegression()
17 | clf.fit(x,y)
18 | pre = clf.predict([[12]])[0]
19 | print(u'预测直径为12英寸的价格: $%.2f' % pre)
20 | x2 = [[0],[12],[15],[25]]
21 | y2 = clf.predict(x2)
22 |
23 | import matplotlib.pyplot as plt
24 | import numpy as np
25 |
26 | plt.figure()
27 | plt.axis([0,25,0,25])
28 | plt.scatter(x,y,marker="s",s=20)
29 | plt.plot(x2,y2,"g-")
30 |
31 | #导入多项式回归模型
32 | from sklearn.preprocessing import PolynomialFeatures
33 | xx = np.linspace(0,25,100) #0到25等差数列
34 | quadratic_featurizer = PolynomialFeatures(degree = 4) #实例化一个二次多项式
35 | x_train_quadratic = quadratic_featurizer.fit_transform(x) #用二次多项式多样本x做变换
36 | X_test_quadratic = quadratic_featurizer.transform(x2)
37 | regressor_quadratic = LinearRegression()
38 | regressor_quadratic.fit(x_train_quadratic, y)
39 | xx_quadratic = quadratic_featurizer.transform(xx.reshape(xx.shape[0], 1))# 把训练好X值的多项式特征实例应用到一系列点上,形成矩阵
40 |
41 | plt.plot(xx, regressor_quadratic.predict(xx_quadratic),
42 | label="$y = ax^4 + bx + c$",linewidth=2,color="r")
43 | plt.legend()
44 | plt.show()
45 |
--------------------------------------------------------------------------------
/blog18-Regression/result01.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog18-Regression/result01.png
--------------------------------------------------------------------------------
/blog18-Regression/result02.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog18-Regression/result02.png
--------------------------------------------------------------------------------
/blog18-Regression/result03.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog18-Regression/result03.png
--------------------------------------------------------------------------------
/blog18-Regression/result04.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog18-Regression/result04.png
--------------------------------------------------------------------------------
/blog18-Regression/result05.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog18-Regression/result05.png
--------------------------------------------------------------------------------
/blog18-Regression/result06.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog18-Regression/result06.png
--------------------------------------------------------------------------------
/blog19-Iris/result01.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog19-Iris/result01.png
--------------------------------------------------------------------------------
/blog19-Iris/result02.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog19-Iris/result02.png
--------------------------------------------------------------------------------
/blog19-Iris/result03.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog19-Iris/result03.png
--------------------------------------------------------------------------------
/blog19-Iris/result04.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog19-Iris/result04.png
--------------------------------------------------------------------------------
/blog19-Iris/result05.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog19-Iris/result05.png
--------------------------------------------------------------------------------
/blog19-Iris/result06.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog19-Iris/result06.png
--------------------------------------------------------------------------------
/blog19-Iris/result07.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog19-Iris/result07.png
--------------------------------------------------------------------------------
/blog19-Iris/result08.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog19-Iris/result08.png
--------------------------------------------------------------------------------
/blog19-Iris/result09.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eastmountyxz/Python-for-Data-Mining/f2dd0b8f3c4f5f51a10613dff99041bca4fd64c5/blog19-Iris/result09.png
--------------------------------------------------------------------------------
/blog19-Iris/test01.py:
--------------------------------------------------------------------------------
1 | #导入数据集iris
2 | from sklearn.datasets import load_iris
3 |
4 | #载入数据集
5 | iris = load_iris()
6 |
7 | #输出数据集
8 | print(iris.data)
9 |
10 | #输出真实标签
11 | print(iris.target)
12 | print(len(iris.target))
13 |
14 | #150个样本 每个样本4个特征
15 | print(iris.data.shape)
16 |
--------------------------------------------------------------------------------
/blog19-Iris/test02-hist.py:
--------------------------------------------------------------------------------
1 | import pandas
2 | import matplotlib.pyplot as plt
3 |
4 | #导入数据集iris
5 | url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
6 | names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
7 |
8 | #读取csv数据
9 | dataset = pandas.read_csv(url, names=names)
10 | print(dataset.describe())
11 |
12 | #直方图 histograms
13 | dataset.hist()
14 | plt.show()
15 |
16 |
--------------------------------------------------------------------------------
/blog19-Iris/test03-plot.py:
--------------------------------------------------------------------------------
1 | import pandas
2 | import matplotlib.pyplot as plt
3 |
4 | #导入数据集iris
5 | url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
6 | names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
7 |
8 | #读取csv数据
9 | dataset = pandas.read_csv(url, names=names)
10 | print(dataset.describe())
11 |
12 | dataset.plot(x='sepal-length', y='sepal-width', kind='scatter')
13 | plt.show()
14 |
--------------------------------------------------------------------------------
/blog19-Iris/test04-kde.py:
--------------------------------------------------------------------------------
1 | import pandas
2 | import matplotlib.pyplot as plt
3 |
4 | #导入数据集iris
5 | url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
6 | names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
7 |
8 | #读取csv数据
9 | dataset = pandas.read_csv(url, names=names)
10 | print(dataset.describe())
11 |
12 | dataset.plot(kind='kde')
13 | plt.show()
14 |
--------------------------------------------------------------------------------
/blog19-Iris/test05-box.py:
--------------------------------------------------------------------------------
1 | import pandas
2 | import matplotlib.pyplot as plt
3 |
4 | url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
5 | names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
6 |
7 | #读取csv数据
8 | dataset = pandas.read_csv(url, names=names)
9 | print(dataset.describe())
10 |
11 | dataset.plot(kind='kde')
12 | dataset.plot(kind='box', subplots=True, layout=(2,2),
13 | sharex=False, sharey=False)
14 | plt.show()
15 |
--------------------------------------------------------------------------------
/blog19-Iris/test06-box.py:
--------------------------------------------------------------------------------
1 | import pandas
2 | import matplotlib.pyplot as plt
3 |
4 | url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
5 | names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
6 | dataset = pandas.read_csv(url, names=names)
7 |
8 | from pandas.plotting import radviz
9 | radviz(dataset, 'class')
10 |
11 | from pandas.plotting import andrews_curves
12 | andrews_curves(dataset, 'class')
13 |
14 | from pandas.plotting import parallel_coordinates
15 | parallel_coordinates(dataset, 'class')
16 | plt.show()
17 |
--------------------------------------------------------------------------------
/blog19-Iris/test07-show.py:
--------------------------------------------------------------------------------
1 | import pandas
2 | import matplotlib.pyplot as plt
3 |
4 | url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
5 | names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
6 | dataset = pandas.read_csv(url, names=names)
7 |
8 | from pandas.plotting import scatter_matrix
9 | scatter_matrix(dataset, alpha=0.2, figsize=(6, 6), diagonal='kde')
10 | plt.show()
11 |
--------------------------------------------------------------------------------
/blog19-Iris/test08-LR.py:
--------------------------------------------------------------------------------
1 | from sklearn.datasets import load_iris
2 | hua = load_iris()
3 | #获取花瓣的长和宽
4 | x = [n[0] for n in hua.data]
5 | y = [n[1] for n in hua.data]
6 |
7 | import numpy as np #转换成数组
8 | x = np.array(x).reshape(len(x),1)
9 | y = np.array(y).reshape(len(y),1)
10 |
11 | from sklearn.linear_model import LinearRegression
12 | clf = LinearRegression()
13 | clf.fit(x,y)
14 | pre = clf.predict(x)
15 |
16 | #第三步 画图
17 | import matplotlib.pyplot as plt
18 | plt.scatter(x,y,s=100)
19 | plt.plot(x,pre,"r-",linewidth=4)
20 | for idx, m in enumerate(x):
21 | plt.plot([m,m],[y[idx],pre[idx]], 'g-')
22 | plt.show()
23 |
--------------------------------------------------------------------------------
/blog19-Iris/test09-Kmeans.py:
--------------------------------------------------------------------------------
1 | from sklearn.datasets import load_iris
2 | from sklearn.tree import DecisionTreeClassifier
3 | iris = load_iris()
4 | clf = DecisionTreeClassifier()
5 | clf.fit(iris.data, iris.target)
6 | print(clf)
7 | predicted = clf.predict(iris.data)
8 |
9 | #获取花卉两列数据集
10 | X = iris.data
11 | L1 = [x[0] for x in X]
12 | print(L1)
13 | L2 = [x[1] for x in X]
14 | print(L2)
15 |
16 | import numpy as np
17 | import matplotlib.pyplot as plt
18 | plt.scatter(L1, L2, c=predicted, marker='x') #cmap=plt.cm.Paired
19 | plt.title("DTC")
20 | plt.show()
21 |
--------------------------------------------------------------------------------
/blog19-Iris/test10-Kmeans.py:
--------------------------------------------------------------------------------
1 | from sklearn.datasets import load_iris
2 | from sklearn.tree import DecisionTreeClassifier
3 | import numpy as np
4 |
5 | iris = load_iris()
6 | #训练集
7 | train_data = np.concatenate((iris.data[0:40, :], iris.data[50:90, :], iris.data[100:140, :]), axis = 0)
8 | train_target = np.concatenate((iris.target[0:40], iris.target[50:90], iris.target[100:140]), axis = 0)
9 | #测试集
10 | test_data = np.concatenate((iris.data[40:50, :], iris.data[90:100, :], iris.data[140:150, :]), axis = 0)
11 | test_target = np.concatenate((iris.target[40:50], iris.target[90:100], iris.target[140:150]), axis = 0)
12 |
13 | #训练
14 | clf = DecisionTreeClassifier()
15 | clf.fit(train_data, train_target)
16 | predict_target = clf.predict(test_data)
17 | print(predict_target)
18 |
19 | #预测结果与真实结果比对
20 | print(sum(predict_target == test_target))
21 |
22 | #输出准确率 召回率 F值
23 | from sklearn import metrics
24 | print(metrics.classification_report(test_target,predict_target))
25 | print(metrics.confusion_matrix(test_target,predict_target))
26 | X = test_data
27 | L1 = [n[0] for n in X]
28 | print(L1)
29 | L2 = [n[1] for n in X]
30 | print(L2)
31 |
32 | import matplotlib.pyplot as plt
33 | plt.scatter(L1, L2, c=predict_target, marker='x') #cmap=plt.cm.Paired
34 | plt.title("DecisionTreeClassifier")
35 | plt.show()
36 |
--------------------------------------------------------------------------------
/blog19-Iris/test11-Kmeans.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | from sklearn.datasets import load_iris
3 | from sklearn.cluster import KMeans
4 | iris = load_iris()
5 | clf = KMeans()
6 | clf.fit(iris.data, iris.target)
7 | print(clf)
8 | predicted = clf.predict(iris.data)
9 |
10 | #获取花卉两列数据集
11 | X = iris.data
12 | L1 = [x[0] for x in X]
13 | print(L1)
14 | L2 = [x[1] for x in X]
15 | print(L2)
16 |
17 | import numpy as np
18 | import matplotlib.pyplot as plt
19 | plt.scatter(L1, L2, c=predicted, marker='s',s=200,cmap=plt.cm.Paired)
20 | plt.title("Iris")
21 | plt.show()
22 |
--------------------------------------------------------------------------------
/blog20-KNN/blog01.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import numpy as np
3 | from sklearn.neighbors import KNeighborsClassifier
4 |
5 | X = np.array([[-1,-1],[-2,-2],[1,2], [1,1],[-3,-4],[3,2]])
6 | Y = [0,0,1,1,0,1]
7 | x = [[4,5],[-4,-3],[2,6]]
8 | knn = KNeighborsClassifier(n_neighbors=3, algorithm="ball_tree")
9 | knn.fit(X,Y)
10 | pre = knn.predict(x)
11 | print(pre)
12 |
--------------------------------------------------------------------------------
/blog20-KNN/blog02.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import os
3 | import numpy as np
4 | data = np.loadtxt("wine.txt",dtype=str,delimiter=",")
5 | print(data)
6 |
7 | yy, x = np.split(data, (1,), axis=1)
8 | print(yy.shape, x.shape)
9 | print(x)
10 | print(yy[:5])
11 |
--------------------------------------------------------------------------------
/blog20-KNN/blog03.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import os
3 | import numpy as np
4 | data = np.loadtxt("wine.txt",dtype=str,delimiter=",")
5 | print(data)
6 | print(type(data))
7 |
8 | yy, x = np.split(data, (1,), axis=1)
9 | print(yy.shape, x.shape)
10 | print(x)
11 | print(yy[:5])
12 |
13 | #从字符型转换为Int整型
14 | X = x.astype(int)
15 | print(X)
16 | #字母转换为数字
17 | y = []
18 | i = 0
19 | print(len(yy))
20 | while i0:
16 | # print(x_mat[i][n])
17 | i = i + 1
18 | print("The ", n , "feature is normal.")
19 |
20 | #-------------------------------------读取文件划分数据集-----------------------------------------
21 | fr = open("kddcup.data_10_percent_corrected.csv")
22 | data_file = open("kddcup.data_10_percent_corrected-result.csv",'wb+')
23 | lines = fr.readlines()
24 | line_nums = len(lines)
25 | print(line_nums)
26 |
27 | #创建line_nums行 para_num列的矩阵
28 | x_mat = np.zeros((line_nums, 42))
29 |
30 | #划分数据集
31 | for i in range(line_nums):
32 | line = lines[i].strip()
33 | item_mat = line.split(',')
34 | x_mat[i, :] = item_mat[0:42] #获取42个特征
35 | fr.close()
36 | print(x_mat.shape)
37 |
38 | #--------------------------------获取某列特征并依次标准化并赋值-----------------------------
39 | print(len(x_mat[:, 0])) #获取某列数据 494021
40 | print(len(x_mat[0, :])) #获取某行数据 42
41 |
42 | #标准化处理
43 | ZscoreNormalization(x_mat[:, 0], 0) #duration
44 | ZscoreNormalization(x_mat[:, 0], 4) #src_bytes
45 | ZscoreNormalization(x_mat[:, 0], 5) #dst_bytes
46 | ZscoreNormalization(x_mat[:, 0], 7) #wrong_fragment
47 | ZscoreNormalization(x_mat[:, 0], 8) #urgent
48 |
49 | ZscoreNormalization(x_mat[:, 0], 9) #hot
50 | ZscoreNormalization(x_mat[:, 0], 10) #num_failed_logins
51 | ZscoreNormalization(x_mat[:, 0], 12) #num_compromised
52 | ZscoreNormalization(x_mat[:, 0], 14) #su_attempte
53 | ZscoreNormalization(x_mat[:, 0], 15) #num_root
54 | ZscoreNormalization(x_mat[:, 0], 16) #num_file_creations
55 | ZscoreNormalization(x_mat[:, 0], 17) #num_shells
56 | ZscoreNormalization(x_mat[:, 0], 18) #num_access_files
57 | ZscoreNormalization(x_mat[:, 0], 19) #num_outbound_cmds
58 |
59 | ZscoreNormalization(x_mat[:, 0], 22) #count
60 | ZscoreNormalization(x_mat[:, 0], 23) #srv_count
61 | ZscoreNormalization(x_mat[:, 0], 24) #serror_rate
62 | ZscoreNormalization(x_mat[:, 0], 25) #srv_serror_rate
63 | ZscoreNormalization(x_mat[:, 0], 26) #rerror_rate
64 | ZscoreNormalization(x_mat[:, 0], 27) #srv_rerror_rate
65 | ZscoreNormalization(x_mat[:, 0], 28) #same_srv_rate
66 | ZscoreNormalization(x_mat[:, 0], 29) #diff_srv_rate
67 | ZscoreNormalization(x_mat[:, 0], 30) #srv_diff_host_rate
68 |
69 | ZscoreNormalization(x_mat[:, 0], 31) #dst_host_count
70 | ZscoreNormalization(x_mat[:, 0], 32) #dst_host_srv_count
71 | ZscoreNormalization(x_mat[:, 0], 33) #dst_host_same_srv_rate
72 | ZscoreNormalization(x_mat[:, 0], 34) #dst_host_diff_srv_rate
73 | ZscoreNormalization(x_mat[:, 0], 35) #dst_host_same_src_port_rate
74 | ZscoreNormalization(x_mat[:, 0], 36) #dst_host_srv_diff_host_rate
75 | ZscoreNormalization(x_mat[:, 0], 37) #dst_host_serror_rate
76 | ZscoreNormalization(x_mat[:, 0], 38) #dst_host_srv_serror_rate
77 | ZscoreNormalization(x_mat[:, 0], 39) #dst_host_rerror_rate
78 | ZscoreNormalization(x_mat[:, 0], 40) #dst_host_srv_rerror_rate
79 |
80 | #文件写入操作
81 | csv_writer = csv.writer(data_file)
82 | i = 0
83 | while i0:
16 | # print(x_mat[i][n])
17 | i = i + 1
18 | print("The ", n , "feature is normal.")
19 |
20 | #-------------------------------------读取文件划分数据集-----------------------------------------
21 | fr = open("kddcup.data_10_percent_corrected-result.csv")
22 | data_file = open("kddcup.data_10_percent_corrected-result-minmax.csv",'wb+')
23 | lines = fr.readlines()
24 | line_nums = len(lines)
25 | print(line_nums)
26 |
27 | #创建line_nums行 para_num列的矩阵
28 | x_mat = np.zeros((line_nums, 42))
29 |
30 | #划分数据集
31 | for i in range(line_nums):
32 | line = lines[i].strip()
33 | item_mat = line.split(',')
34 | x_mat[i, :] = item_mat[0:42] #获取42个特征
35 | fr.close()
36 | print(x_mat.shape)
37 |
38 | #--------------------------------获取某列特征并依次标准化并赋值-----------------------------
39 | print(len(x_mat[:, 0])) #获取某列数据 494021
40 | print(len(x_mat[0, :])) #获取某行数据 42
41 |
42 | #归一化处理
43 | MinmaxNormalization(x_mat[:, 0], 0) #duration
44 | MinmaxNormalization(x_mat[:, 0], 4) #src_bytes
45 | MinmaxNormalization(x_mat[:, 0], 5) #dst_bytes
46 | MinmaxNormalization(x_mat[:, 0], 7) #wrong_fragment
47 | MinmaxNormalization(x_mat[:, 0], 8) #urgent
48 |
49 | MinmaxNormalization(x_mat[:, 0], 9) #hot
50 | MinmaxNormalization(x_mat[:, 0], 10) #num_failed_logins
51 | MinmaxNormalization(x_mat[:, 0], 12) #num_compromised
52 | MinmaxNormalization(x_mat[:, 0], 14) #su_attempte
53 | MinmaxNormalization(x_mat[:, 0], 15) #num_root
54 | MinmaxNormalization(x_mat[:, 0], 16) #num_file_creations
55 | MinmaxNormalization(x_mat[:, 0], 17) #num_shells
56 | MinmaxNormalization(x_mat[:, 0], 18) #num_access_files
57 | MinmaxNormalization(x_mat[:, 0], 19) #num_outbound_cmds
58 |
59 | MinmaxNormalization(x_mat[:, 0], 22) #count
60 | MinmaxNormalization(x_mat[:, 0], 23) #srv_count
61 | MinmaxNormalization(x_mat[:, 0], 24) #serror_rate
62 | MinmaxNormalization(x_mat[:, 0], 25) #srv_serror_rate
63 | MinmaxNormalization(x_mat[:, 0], 26) #rerror_rate
64 | MinmaxNormalization(x_mat[:, 0], 27) #srv_rerror_rate
65 | MinmaxNormalization(x_mat[:, 0], 28) #same_srv_rate
66 | MinmaxNormalization(x_mat[:, 0], 29) #diff_srv_rate
67 | MinmaxNormalization(x_mat[:, 0], 30) #srv_diff_host_rate
68 |
69 | MinmaxNormalization(x_mat[:, 0], 31) #dst_host_count
70 | MinmaxNormalization(x_mat[:, 0], 32) #dst_host_srv_count
71 | MinmaxNormalization(x_mat[:, 0], 33) #dst_host_same_srv_rate
72 | MinmaxNormalization(x_mat[:, 0], 34) #dst_host_diff_srv_rate
73 | MinmaxNormalization(x_mat[:, 0], 35) #dst_host_same_src_port_rate
74 | MinmaxNormalization(x_mat[:, 0], 36) #dst_host_srv_diff_host_rate
75 | MinmaxNormalization(x_mat[:, 0], 37) #dst_host_serror_rate
76 | MinmaxNormalization(x_mat[:, 0], 38) #dst_host_srv_serror_rate
77 | MinmaxNormalization(x_mat[:, 0], 39) #dst_host_rerror_rate
78 | MinmaxNormalization(x_mat[:, 0], 40) #dst_host_srv_rerror_rate
79 |
80 | #文件写入操作
81 | csv_writer = csv.writer(data_file)
82 | i = 0
83 | while i threshold and data_set[2][k] == 1:
79 | normal1 += 1
80 | if data_set[1][k] > threshold and data_set[2][k] != 1:
81 | abnormal1 += 1
82 | roc_rate[0][j] = normal1 / normal # 阈值以上正常点/全体正常的点
83 | roc_rate[1][j] = abnormal1 / abnormal # 阈值以上异常点/全体异常点
84 | return roc_rate
85 |
86 | #图1 散点图
87 | #横轴为序号 纵轴为最小欧氏距离
88 | #点中心颜色根据测试集数据类别而定 点外围无颜色 点大小为最小1 灰度为最大1
89 | plt.figure(1)
90 | plt.scatter(result[0], result[1], c=result[2], edgecolors='None', s=2, alpha=1)
91 |
92 | #图2 ROC曲线
93 | #横轴误报率:即阈值以上正常点/全体正常的点
94 | #纵轴检测率:即阈值以上异常点/全体异常点
95 | roc_rate = roc(result)
96 | plt.figure(2)
97 | plt.scatter(roc_rate[0], roc_rate[1], edgecolors='None', s=1, alpha=1)
98 | plt.show()
99 |
100 |
101 |
102 |
--------------------------------------------------------------------------------
/blog29-DataPreprocessing&KNN/test05-knn-gitHub-roc.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import os
3 | import csv
4 | import numpy as np
5 | from sklearn.svm import SVC
6 | from sklearn import metrics
7 | import matplotlib.pyplot as plt
8 | from matplotlib.colors import ListedColormap
9 | from sklearn.model_selection import train_test_split
10 | from sklearn.decomposition import PCA
11 | from sklearn import neighbors
12 |
13 | #-----------------------------------------第一步 加载数据集-----------------------------------------
14 | fr= open("kddcup.data_10_yxz-result-minmax.csv")
15 | lines = fr.readlines()
16 | line_nums = len(lines)
17 | print(line_nums)
18 |
19 | #创建line_nums行 para_num列的矩阵
20 | x_mat = np.zeros((line_nums, 31))
21 | y_label = []
22 |
23 | #划分数据集
24 | for i in range(line_nums):
25 | line = lines[i].strip()
26 | item_mat = line.split(',')
27 | x_mat[i, :] = item_mat[0:31] #前41个特征
28 | y_label.append(item_mat[-1]) #类标
29 | fr.close()
30 | print(x_mat.shape)
31 | print(len(y_label))
32 |
33 | #-----------------------------------------第二步 划分数据集-----------------------------------------
34 | y = []
35 | for n in y_label:
36 | y.append(int(float(n)))
37 | y = np.array(y, dtype = int) #list转换数组
38 |
39 | #划分数据集 测试集40%
40 | train_data, test_data, train_target, test_target = train_test_split(x_mat, y, test_size=0.4, random_state=42)
41 | print(train_data.shape, train_target.shape)
42 | print(test_data.shape, test_target.shape)
43 |
44 |
45 | #-----------------------------------------第三步 KNN训练-----------------------------------------
46 | def classify(input_vct, data_set):
47 | data_set_size = data_set.shape[0]
48 | #扩充input_vct到与data_set同型并相减
49 | diff_mat = np.tile(input_vct, (data_set_size, 1)) - data_set
50 | sq_diff_mat = diff_mat**2 #矩阵中每个元素都平方
51 | distance = sq_diff_mat.sum(axis=1)**0.5 #每行相加求和并开平方根
52 | return distance.min(axis=0) #返回最小距离
53 |
54 | test_size = len(test_target)
55 | result = np.zeros((test_size, 3))
56 | for i in range(test_size):
57 | #序号 最小欧氏距离 测试集数据类别
58 | result[i] = i + 1, classify(test_data[i], train_data), test_target[i]
59 | #矩阵转置
60 | result = np.transpose(result)
61 |
62 | #-----------------------------------------第四步 评价及可视化-----------------------------------------
63 | def roc(data_set):
64 | normal = 0
65 | data_set_size = data_set.shape[1]
66 | roc_rate = np.zeros((2, data_set_size)) #输出ROC曲线 二维矩阵
67 | #计算正常请求数量
68 | for i in range(data_set_size):
69 | if data_set[2][i] == 1:
70 | normal += 1
71 | abnormal = data_set_size - normal
72 | max_dis = data_set[1].max() #欧式距离最大值
73 | for j in range(1000):
74 | threshold = max_dis / 1000 * j
75 | normal1 = 0
76 | abnormal1 = 0
77 | for k in range(data_set_size):
78 | if data_set[1][k] > threshold and data_set[2][k] == 1:
79 | normal1 += 1
80 | if data_set[1][k] > threshold and data_set[2][k] != 1:
81 | abnormal1 += 1
82 | roc_rate[0][j] = normal1 / normal # 阈值以上正常点/全体正常的点
83 | roc_rate[1][j] = abnormal1 / abnormal # 阈值以上异常点/全体异常点
84 | return roc_rate
85 |
86 | #图1 散点图
87 | #横轴为序号 纵轴为最小欧氏距离
88 | #点中心颜色根据测试集数据类别而定 点外围无颜色 点大小为最小1 灰度为最大1
89 | plt.figure(1)
90 | plt.scatter(result[0], result[1], c=result[2], edgecolors='None', s=2, alpha=1)
91 |
92 | #图2 ROC曲线
93 | #横轴误报率:即阈值以上正常点/全体正常的点
94 | #纵轴检测率:即阈值以上异常点/全体异常点
95 | roc_rate = roc(result)
96 | plt.figure(2)
97 | plt.scatter(roc_rate[0], roc_rate[1], edgecolors='None', s=1, alpha=1)
98 | plt.show()
99 |
100 |
101 |
102 |
--------------------------------------------------------------------------------
/blog29-DataPreprocessing&KNN/test06-knn.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import os
3 | import csv
4 | import numpy as np
5 | import pandas as pd
6 | from sklearn import metrics
7 | import matplotlib.pyplot as plt
8 | from matplotlib.colors import ListedColormap
9 | from sklearn.model_selection import train_test_split
10 | from sklearn.decomposition import PCA
11 | from sklearn import neighbors
12 |
13 | #-----------------------------------------第一步 加载数据集-----------------------------------------
14 | fr= open("kddcup.data_10_percent_corrected-result-minmax.csv")
15 | lines = fr.readlines()
16 | line_nums = len(lines)
17 | print(line_nums)
18 |
19 | #创建line_nums行 para_num列的矩阵
20 | x_mat = np.zeros((line_nums, 41))
21 | y_label = []
22 |
23 | #划分数据集
24 | for i in range(line_nums):
25 | line = lines[i].strip()
26 | item_mat = line.split(',')
27 | x_mat[i, :] = item_mat[0:41] #前41个特征
28 | y_label.append(item_mat[-1]) #类标
29 | fr.close()
30 | print x_mat.shape
31 | print len(y_label)
32 |
33 |
34 | #-----------------------------------------第二步 划分数据集-----------------------------------------
35 | y = []
36 | for n in y_label:
37 | y.append(int(float(n)))
38 | y = np.array(y, dtype = int) #list转换数组
39 |
40 | #划分数据集 测试集40%
41 | train_data, test_data, train_target, test_target = train_test_split(x_mat, y, test_size=0.4, random_state=42)
42 | print train_data.shape, train_target.shape
43 | print test_data.shape, test_target.shape
44 |
45 |
46 | #-----------------------------------------第三步 KNN训练-----------------------------------------
47 | clf = neighbors.KNeighborsClassifier()
48 | clf.fit(train_data, train_target)
49 | print clf
50 | result = clf.predict(test_data)
51 | print result
52 | print test_target
53 |
54 |
55 | #-----------------------------------------第四步 评价算法-----------------------------------------
56 | print sum(result==test_target) #预测结果与真实结果比对
57 | print(metrics.classification_report(test_target, result)) #准确率 召回率 F值
58 |
59 |
60 | #----------------------------------------第五步 降维可视化---------------------------------------
61 | pca = PCA(n_components=2)
62 | newData = pca.fit_transform(test_data)
63 | plt.figure()
64 | plt.scatter(newData[:,0], newData[:,1], c=test_target, s=50)
65 | plt.show()
66 |
--------------------------------------------------------------------------------