├── README.md
├── assets
├── OpenSans-Regular.ttf
├── character_sheet_default_ref.jpg
├── characters_parts
│ ├── part_a.jpg
│ ├── part_b.jpg
│ └── part_c.jpg
├── openimages_classes.txt
├── plush_parts
│ ├── part_a.jpg
│ ├── part_b.jpg
│ └── part_c.jpg
└── product_parts
│ ├── part_a.jpg
│ ├── part_b.jpg
│ └── part_c.jpg
├── configs
├── infer
│ ├── infer_characters.yaml
│ ├── infer_plush.yaml
│ └── infer_products.yaml
└── train
│ └── train_characters.yaml
├── demo
├── app.py
└── pit.py
├── ip_adapter
├── __init__.py
├── attention_processor.py
├── attention_processor_faceid.py
├── custom_pipelines.py
├── ip_adapter.py
├── ip_adapter_faceid.py
├── ip_adapter_faceid_separate.py
├── resampler.py
├── sd3_attention_processor.py
├── test_resampler.py
└── utils.py
├── ip_lora_inference
├── download_ip_adapter.sh
├── download_loras.sh
└── inference_ip_lora.py
├── ip_lora_train
├── ip_adapter_for_lora.py
├── ip_lora_dataset.py
├── run_example.sh
├── sdxl_ip_lora_pipeline.py
└── train_ip_lora.py
├── ip_plus_space_exploration
├── download_directions.sh
├── download_ip_adapter.sh
├── edit_by_direction.py
├── find_direction.py
└── ip_model_utils.py
├── model
├── __init__.py
├── dit.py
└── pipeline_pit.py
├── pyproject.toml
├── scripts
├── generate_characters.py
├── generate_products.py
├── infer.py
└── train.py
├── training
├── __init__.py
├── coach.py
├── dataset.py
└── train_config.py
└── utils
├── __init__.py
├── bezier_utils.py
├── vis_utils.py
└── words_bank.py
/README.md:
--------------------------------------------------------------------------------
1 | # Piece it Together: Part-Based Concepting with IP-Priors
2 | > Elad Richardson, Kfir Goldberg, Yuval Alaluf, Daniel Cohen-Or
3 | > Tel Aviv University, Bria AI
4 | >
5 | > Advanced generative models excel at synthesizing images but often rely on text-based conditioning. Visual designers, however, often work beyond language, directly drawing inspiration from existing visual elements. In many cases, these elements represent only fragments of a potential concept-such as an uniquely structured wing, or a specific hairstyle-serving as inspiration for the artist to explore how they can come together creatively into a coherent whole. Recognizing this need, we introduce a generative framework that seamlessly integrates a partial set of user-provided visual components into a coherent composition while simultaneously sampling the missing parts needed to generate a plausible and complete concept. Our approach builds on a strong and underexplored representation space, extracted from IP-Adapter+, on which we train IP-Prior, a lightweight flow-matching model that synthesizes coherent compositions based on domain-specific priors, enabling diverse and context-aware generations. Additionally, we present a LoRA-based fine-tuning strategy that significantly improves prompt adherence in IP-Adapter+ for a given task, addressing its common trade-off between reconstruction quality and prompt adherence.
6 |
7 |  8 |
8 |  9 |
10 |
11 |
12 |
13 |
9 |
10 |
11 |
12 |
13 |
14 | 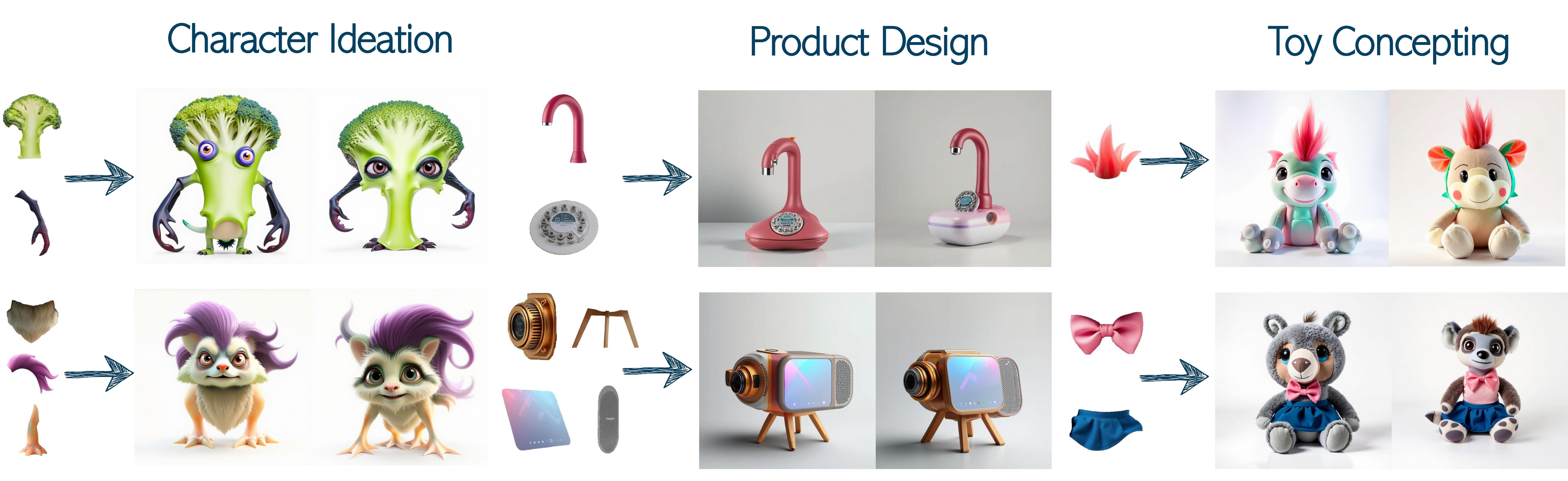 15 |
15 |
16 | Using a dedicated prior for the target domain, our method, Piece it Together (PiT), effectively completes missing information by seamlessly integrating given elements into a coherent composition while adding the necessary missing pieces needed for the complete concept to reside in the prior domain.
17 |
18 |
19 | ## Description :scroll:
20 | Official implementation of the paper "Piece it Together: Part-Based Concepting with IP-Priors"
21 |
22 |
23 | ## Table of contents
24 | - [Piece it Together: Part-Based Concepting with IP-Priors](#piece-it-together-part-based-concepting-with-ip-priors)
25 | - [Description :scroll:](#description-scroll)
26 | - [Table of contents](#table-of-contents)
27 | - [Getting started with PiT :rocket:](#getting-started-with-pit-rocket)
28 | - [Setup your environment](#setup-your-environment)
29 | - [Inference with PiT](#inference-with-pit)
30 | - [Training PiT](#training-pit)
31 | - [Inference with IP-LoRA](#inference-with-ip-lora)
32 | - [Training IP-LoRA](#training-ip-lora)
33 | - [Preparing your data](#preparing-your-data)
34 | - [Running the training script](#running-the-training-script)
35 | - [Exploring the IP+ space](#exploring-the-ip-space)
36 | - [Finding new directions](#finding-new-directions)
37 | - [Editing images with found directions](#editing-images-with-found-directions)
38 | - [Acknowledgments](#acknowledgments)
39 | - [Citation](#citation)
40 |
41 |
42 |
43 | ## Getting started with PiT :rocket:
44 |
45 | ### Setup your environment
46 |
47 | 1. Clone the repo:
48 |
49 | ```bash
50 | git clone https://github.com/eladrich/PiT
51 | cd PiT
52 | ```
53 |
54 | 2. Install `uv`:
55 |
56 | Instructions taken from [here](https://docs.astral.sh/uv/getting-started/installation/).
57 |
58 | For linux systems this should be:
59 | ```bash
60 | curl -LsSf https://astral.sh/uv/install.sh | sh
61 | source $HOME/.local/bin/env
62 | ```
63 |
64 | 3. Install the dependencies:
65 |
66 | ```bash
67 | uv sync
68 | ```
69 |
70 | 4. Activate your `.venv` and set the Python env:
71 |
72 | ```bash
73 | source .venv/bin/activate
74 | export PYTHONPATH=${PYTHONPATH}:${PWD}
75 | ```
76 |
77 |
78 |
79 | ## Inference with PiT
80 | | Domain | Examples | Link |
81 | |--------|--------------|----------------------------------------------------------------------------------------------|
82 | | Characters |  | [Here](https://huggingface.co/kfirgold99/Piece-it-Together/tree/main/models/characters_ckpt) |
83 | | Products |
| [Here](https://huggingface.co/kfirgold99/Piece-it-Together/tree/main/models/characters_ckpt) |
83 | | Products |  | [Here](https://huggingface.co/kfirgold99/Piece-it-Together/tree/main/models/products_ckpt) |
84 | | Toys |
| [Here](https://huggingface.co/kfirgold99/Piece-it-Together/tree/main/models/products_ckpt) |
84 | | Toys |  | [Here](https://huggingface.co/kfirgold99/Piece-it-Together/tree/main/models/plush_ckpt) |
85 |
86 |
87 | ## Training PiT
88 |
89 | ### Data Generation
90 | PiT assumes that the data is structured so that the the target images and part images are in the same directory with the naming convention being `image_name.jpg` for hte base image and `image_name_i.jpg` for the parts.
91 |
92 | To use a generated data see the sample scripts
93 | ```bash
94 | python -m scripts.generate_characters
95 | ```
96 |
97 | ```bash
98 | python -m scripts.generate_products
99 | ```
100 |
101 | ### Training
102 |
103 | For training see the `training/coach.py` file and the example below
104 |
105 | ``bash
106 | python -m scripts.train --config_path=configs/train/train_characters.yaml
107 | ``
108 |
109 | ## PiT Inference
110 |
111 | For inference see `scripts.infer.py` with the corresponding configs under `configs/infer`
112 |
113 | ```bash
114 | python -m scripts.infer --config_path=configs/infer/infer_characters.yaml
115 | ```
116 |
117 |
118 | ## Inference with IP-LoRA
119 |
120 | 1. Download the IP checkpoint and the LoRAs
121 |
122 | ```bash
123 | ip_lora_inference/download_ip_adapter.sh
124 | ip_lora_inference/download_loras.sh
125 | ```
126 |
127 | 2. Run inference with your preferred model
128 |
129 | example for running the styled-generation LoRA
130 |
131 | ```bash
132 | python ip_lora_inference/inference_ip_lora.py --lora_type "character_sheet" --lora_path "weights/character_sheet/pytorch_lora_weights.safetensors" --prompt "a character sheet displaying a creature, from several angles with 1 large front view in the middle, clean white background. In the background we can see half-completed, partially colored, sketches of different parts of the object" --output_dir "ip_lora_inference/character_sheet/" --ref_images_paths "assets/character_sheet_default_ref.jpg"
133 | --ip_adapter_path "weights/ip_adapter/sdxl_models/ip-adapter-plus_sdxl_vit-h.bin"
134 | ```
135 |
136 | ## Training IP-LoRA
137 |
138 | ### Preparing your data
139 |
140 | The expected data format for the training script is as follows:
141 |
142 | ```
143 | --base_dir/
144 | ----targets/
145 | ------img1.jpg
146 | ------img1.txt
147 | ------img2.jpg
148 | ------img2.txt
149 | ------img3.jpg
150 | ------img3.txt
151 | .
152 | .
153 | .
154 | ----refs/
155 | ------img1_ref.jpg
156 | ------img2_ref.jpg
157 | ------img3_ref.jpg
158 | .
159 | .
160 | .
161 | ```
162 |
163 | Where `imgX.jpg` is the target image for the input reference image `imgX_ref.jpg` with the prompt `imgX.txt`
164 |
165 | ### Running the training script
166 |
167 | For training a character-sheet styled generation LoRA, run the following command:
168 |
169 | ```bash
170 | python ./ip_lora_train/train_ip_lora.py \
171 | --rank 64 \
172 | --resolution 1024 \
173 | --validation_epochs 1 \
174 | --num_train_epochs 100 \
175 | --checkpointing_steps 50 \
176 | --train_batch_size 2 \
177 | --learning_rate 1e-4 \
178 | --dataloader_num_workers 1 \
179 | --gradient_accumulation_steps 8 \
180 | --dataset_base_dir \
181 | --prompt_mode character_sheet \
182 | --output_dir ./output/train_ip_lora/character_sheet
183 |
184 | ```
185 |
186 | and for the text adherence LoRA, run the following command:
187 |
188 | ```bash
189 | python ./ip_lora_train/train_ip_lora.py \
190 | --rank 64 \
191 | --resolution 1024 \
192 | --validation_epochs 1 \
193 | --num_train_epochs 100 \
194 | --checkpointing_steps 50 \
195 | --train_batch_size 2 \
196 | --learning_rate 1e-4 \
197 | --dataloader_num_workers 1 \
198 | --gradient_accumulation_steps 8 \
199 | --dataset_base_dir \
200 | --prompt_mode creature_in_scene \
201 | --output_dir ./output/train_ip_lora/creature_in_scene
202 | ```
203 |
204 | ## Exploring the IP+ space
205 |
206 | Start by downloading the needed IP+ checkpoint and the directions presented in the paper:
207 |
208 | ```bash
209 | ip_plus_space_exploration/download_directions.sh
210 | ip_plus_space_exploration/download_ip_adapter.sh
211 | ```
212 |
213 | ### Finding new directions
214 |
215 | To find a direction in the IP+ space from "class1" (e.g. "scrawny") to "class2" (e.g. "muscular"):
216 |
217 | 1. Create `class1_dir` and `class2_dir` containing images of the source and target classes respectively
218 |
219 | 2. Run the `find_direction` script:
220 |
221 | ```bash
222 | python ip_plus_space_exploration/find_direction.py --class1_dir --class2_dir --output_dir ./ip_directions --ip_model_type "plus"
223 | ```
224 |
225 | ### Editing images with found directions
226 |
227 | Use the direction found in the previous stage, or one downloaded from [HuggingFace](https://huggingface.co/kfirgold99/Piece-it-Together) in the previous stage.
228 |
229 | ```bash
230 | python ip_plus_space_exploration/edit_by_direction.py --ip_model_type "plus" --image_path --direction_path --direction_type "ip" --output_dir "./edit_by_direction/"
231 | ```
232 |
233 | ## Acknowledgments
234 |
235 | Code is based on
236 | - https://github.com/pOpsPaper/pOps
237 | - https://github.com/cloneofsimo/minRF by the great [@cloneofsimo](https://github.com/cloneofsimo)
238 |
239 | ## Citation
240 |
241 | If you use this code for your research, please cite the following paper:
242 |
243 | ```
244 | @misc{richardson2025piece,
245 | title={Piece it Together: Part-Based Concepting with IP-Priors},
246 | author={Richardson, Elad and Goldberg, Kfir and Alaluf, Yuval and Cohen-Or, Daniel},
247 | year={2025},
248 | eprint={2503.10365},
249 | archivePrefix={arXiv},
250 | primaryClass={cs.CV},
251 | url={https://arxiv.org/abs/2503.10365},
252 | }
253 | ```
--------------------------------------------------------------------------------
/assets/OpenSans-Regular.ttf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/OpenSans-Regular.ttf
--------------------------------------------------------------------------------
/assets/character_sheet_default_ref.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/character_sheet_default_ref.jpg
--------------------------------------------------------------------------------
/assets/characters_parts/part_a.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/characters_parts/part_a.jpg
--------------------------------------------------------------------------------
/assets/characters_parts/part_b.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/characters_parts/part_b.jpg
--------------------------------------------------------------------------------
/assets/characters_parts/part_c.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/characters_parts/part_c.jpg
--------------------------------------------------------------------------------
/assets/plush_parts/part_a.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/plush_parts/part_a.jpg
--------------------------------------------------------------------------------
/assets/plush_parts/part_b.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/plush_parts/part_b.jpg
--------------------------------------------------------------------------------
/assets/plush_parts/part_c.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/plush_parts/part_c.jpg
--------------------------------------------------------------------------------
/assets/product_parts/part_a.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/product_parts/part_a.jpg
--------------------------------------------------------------------------------
/assets/product_parts/part_b.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/product_parts/part_b.jpg
--------------------------------------------------------------------------------
/assets/product_parts/part_c.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/product_parts/part_c.jpg
--------------------------------------------------------------------------------
/configs/infer/infer_characters.yaml:
--------------------------------------------------------------------------------
1 | prior_path: models/characters_ckpt/prior.ckpt
2 | prior_repo: kfirgold99/Piece-it-Together
3 | crops_dir: assets/characters_parts
4 | output_dir: inference/characters
--------------------------------------------------------------------------------
/configs/infer/infer_plush.yaml:
--------------------------------------------------------------------------------
1 | prior_path: models/plush_ckpt/prior.ckpt
2 | prior_repo: kfirgold99/Piece-it-Together
3 | crops_dir: assets/plush_parts
4 | output_dir: inference/plush
--------------------------------------------------------------------------------
/configs/infer/infer_products.yaml:
--------------------------------------------------------------------------------
1 | prior_path: models/products_ckpt/prior.ckpt
2 | prior_repo: kfirgold99/Piece-it-Together
3 | crops_dir: assets/product_parts
4 | output_dir: inference/products
--------------------------------------------------------------------------------
/configs/train/train_characters.yaml:
--------------------------------------------------------------------------------
1 | dataset_path: 'datasets/generated/characters'
2 | val_dataset_path: 'datasets/generated/characters'
3 | output_dir: 'training_results/train_characters'
4 | train_batch_size: 64
5 | num_layers: 4
6 | max_crops: 7
7 |
8 |
9 |
10 |
--------------------------------------------------------------------------------
/demo/app.py:
--------------------------------------------------------------------------------
1 | import gradio as gr
2 | import spaces
3 | from pit import PiTDemoPipeline
4 |
5 | BLOCK_WIDTH = 300
6 | BLOCK_HEIGHT = 360
7 | FONT_SIZE = 3.5
8 |
9 | pit_pipeline = PiTDemoPipeline(
10 | prior_repo="kfirgold99/Piece-it-Together", prior_path="models/characters_ckpt/prior.ckpt"
11 | )
12 |
13 |
14 | @spaces.GPU
15 | def run_character_generation(part_1, part_2, part_3, seed=None):
16 | crops_paths = [part_1, part_2, part_3]
17 | image = pit_pipeline.run(crops_paths=crops_paths, seed=seed, n_images=1)[0]
18 | return image
19 |
20 |
21 | with gr.Blocks(css="style.css") as demo:
22 | gr.HTML(
23 | """
| [Here](https://huggingface.co/kfirgold99/Piece-it-Together/tree/main/models/plush_ckpt) |
85 |
86 |
87 | ## Training PiT
88 |
89 | ### Data Generation
90 | PiT assumes that the data is structured so that the the target images and part images are in the same directory with the naming convention being `image_name.jpg` for hte base image and `image_name_i.jpg` for the parts.
91 |
92 | To use a generated data see the sample scripts
93 | ```bash
94 | python -m scripts.generate_characters
95 | ```
96 |
97 | ```bash
98 | python -m scripts.generate_products
99 | ```
100 |
101 | ### Training
102 |
103 | For training see the `training/coach.py` file and the example below
104 |
105 | ``bash
106 | python -m scripts.train --config_path=configs/train/train_characters.yaml
107 | ``
108 |
109 | ## PiT Inference
110 |
111 | For inference see `scripts.infer.py` with the corresponding configs under `configs/infer`
112 |
113 | ```bash
114 | python -m scripts.infer --config_path=configs/infer/infer_characters.yaml
115 | ```
116 |
117 |
118 | ## Inference with IP-LoRA
119 |
120 | 1. Download the IP checkpoint and the LoRAs
121 |
122 | ```bash
123 | ip_lora_inference/download_ip_adapter.sh
124 | ip_lora_inference/download_loras.sh
125 | ```
126 |
127 | 2. Run inference with your preferred model
128 |
129 | example for running the styled-generation LoRA
130 |
131 | ```bash
132 | python ip_lora_inference/inference_ip_lora.py --lora_type "character_sheet" --lora_path "weights/character_sheet/pytorch_lora_weights.safetensors" --prompt "a character sheet displaying a creature, from several angles with 1 large front view in the middle, clean white background. In the background we can see half-completed, partially colored, sketches of different parts of the object" --output_dir "ip_lora_inference/character_sheet/" --ref_images_paths "assets/character_sheet_default_ref.jpg"
133 | --ip_adapter_path "weights/ip_adapter/sdxl_models/ip-adapter-plus_sdxl_vit-h.bin"
134 | ```
135 |
136 | ## Training IP-LoRA
137 |
138 | ### Preparing your data
139 |
140 | The expected data format for the training script is as follows:
141 |
142 | ```
143 | --base_dir/
144 | ----targets/
145 | ------img1.jpg
146 | ------img1.txt
147 | ------img2.jpg
148 | ------img2.txt
149 | ------img3.jpg
150 | ------img3.txt
151 | .
152 | .
153 | .
154 | ----refs/
155 | ------img1_ref.jpg
156 | ------img2_ref.jpg
157 | ------img3_ref.jpg
158 | .
159 | .
160 | .
161 | ```
162 |
163 | Where `imgX.jpg` is the target image for the input reference image `imgX_ref.jpg` with the prompt `imgX.txt`
164 |
165 | ### Running the training script
166 |
167 | For training a character-sheet styled generation LoRA, run the following command:
168 |
169 | ```bash
170 | python ./ip_lora_train/train_ip_lora.py \
171 | --rank 64 \
172 | --resolution 1024 \
173 | --validation_epochs 1 \
174 | --num_train_epochs 100 \
175 | --checkpointing_steps 50 \
176 | --train_batch_size 2 \
177 | --learning_rate 1e-4 \
178 | --dataloader_num_workers 1 \
179 | --gradient_accumulation_steps 8 \
180 | --dataset_base_dir \
181 | --prompt_mode character_sheet \
182 | --output_dir ./output/train_ip_lora/character_sheet
183 |
184 | ```
185 |
186 | and for the text adherence LoRA, run the following command:
187 |
188 | ```bash
189 | python ./ip_lora_train/train_ip_lora.py \
190 | --rank 64 \
191 | --resolution 1024 \
192 | --validation_epochs 1 \
193 | --num_train_epochs 100 \
194 | --checkpointing_steps 50 \
195 | --train_batch_size 2 \
196 | --learning_rate 1e-4 \
197 | --dataloader_num_workers 1 \
198 | --gradient_accumulation_steps 8 \
199 | --dataset_base_dir \
200 | --prompt_mode creature_in_scene \
201 | --output_dir ./output/train_ip_lora/creature_in_scene
202 | ```
203 |
204 | ## Exploring the IP+ space
205 |
206 | Start by downloading the needed IP+ checkpoint and the directions presented in the paper:
207 |
208 | ```bash
209 | ip_plus_space_exploration/download_directions.sh
210 | ip_plus_space_exploration/download_ip_adapter.sh
211 | ```
212 |
213 | ### Finding new directions
214 |
215 | To find a direction in the IP+ space from "class1" (e.g. "scrawny") to "class2" (e.g. "muscular"):
216 |
217 | 1. Create `class1_dir` and `class2_dir` containing images of the source and target classes respectively
218 |
219 | 2. Run the `find_direction` script:
220 |
221 | ```bash
222 | python ip_plus_space_exploration/find_direction.py --class1_dir --class2_dir --output_dir ./ip_directions --ip_model_type "plus"
223 | ```
224 |
225 | ### Editing images with found directions
226 |
227 | Use the direction found in the previous stage, or one downloaded from [HuggingFace](https://huggingface.co/kfirgold99/Piece-it-Together) in the previous stage.
228 |
229 | ```bash
230 | python ip_plus_space_exploration/edit_by_direction.py --ip_model_type "plus" --image_path --direction_path --direction_type "ip" --output_dir "./edit_by_direction/"
231 | ```
232 |
233 | ## Acknowledgments
234 |
235 | Code is based on
236 | - https://github.com/pOpsPaper/pOps
237 | - https://github.com/cloneofsimo/minRF by the great [@cloneofsimo](https://github.com/cloneofsimo)
238 |
239 | ## Citation
240 |
241 | If you use this code for your research, please cite the following paper:
242 |
243 | ```
244 | @misc{richardson2025piece,
245 | title={Piece it Together: Part-Based Concepting with IP-Priors},
246 | author={Richardson, Elad and Goldberg, Kfir and Alaluf, Yuval and Cohen-Or, Daniel},
247 | year={2025},
248 | eprint={2503.10365},
249 | archivePrefix={arXiv},
250 | primaryClass={cs.CV},
251 | url={https://arxiv.org/abs/2503.10365},
252 | }
253 | ```
--------------------------------------------------------------------------------
/assets/OpenSans-Regular.ttf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/OpenSans-Regular.ttf
--------------------------------------------------------------------------------
/assets/character_sheet_default_ref.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/character_sheet_default_ref.jpg
--------------------------------------------------------------------------------
/assets/characters_parts/part_a.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/characters_parts/part_a.jpg
--------------------------------------------------------------------------------
/assets/characters_parts/part_b.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/characters_parts/part_b.jpg
--------------------------------------------------------------------------------
/assets/characters_parts/part_c.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/characters_parts/part_c.jpg
--------------------------------------------------------------------------------
/assets/plush_parts/part_a.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/plush_parts/part_a.jpg
--------------------------------------------------------------------------------
/assets/plush_parts/part_b.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/plush_parts/part_b.jpg
--------------------------------------------------------------------------------
/assets/plush_parts/part_c.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/plush_parts/part_c.jpg
--------------------------------------------------------------------------------
/assets/product_parts/part_a.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/product_parts/part_a.jpg
--------------------------------------------------------------------------------
/assets/product_parts/part_b.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/product_parts/part_b.jpg
--------------------------------------------------------------------------------
/assets/product_parts/part_c.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/assets/product_parts/part_c.jpg
--------------------------------------------------------------------------------
/configs/infer/infer_characters.yaml:
--------------------------------------------------------------------------------
1 | prior_path: models/characters_ckpt/prior.ckpt
2 | prior_repo: kfirgold99/Piece-it-Together
3 | crops_dir: assets/characters_parts
4 | output_dir: inference/characters
--------------------------------------------------------------------------------
/configs/infer/infer_plush.yaml:
--------------------------------------------------------------------------------
1 | prior_path: models/plush_ckpt/prior.ckpt
2 | prior_repo: kfirgold99/Piece-it-Together
3 | crops_dir: assets/plush_parts
4 | output_dir: inference/plush
--------------------------------------------------------------------------------
/configs/infer/infer_products.yaml:
--------------------------------------------------------------------------------
1 | prior_path: models/products_ckpt/prior.ckpt
2 | prior_repo: kfirgold99/Piece-it-Together
3 | crops_dir: assets/product_parts
4 | output_dir: inference/products
--------------------------------------------------------------------------------
/configs/train/train_characters.yaml:
--------------------------------------------------------------------------------
1 | dataset_path: 'datasets/generated/characters'
2 | val_dataset_path: 'datasets/generated/characters'
3 | output_dir: 'training_results/train_characters'
4 | train_batch_size: 64
5 | num_layers: 4
6 | max_crops: 7
7 |
8 |
9 |
10 |
--------------------------------------------------------------------------------
/demo/app.py:
--------------------------------------------------------------------------------
1 | import gradio as gr
2 | import spaces
3 | from pit import PiTDemoPipeline
4 |
5 | BLOCK_WIDTH = 300
6 | BLOCK_HEIGHT = 360
7 | FONT_SIZE = 3.5
8 |
9 | pit_pipeline = PiTDemoPipeline(
10 | prior_repo="kfirgold99/Piece-it-Together", prior_path="models/characters_ckpt/prior.ckpt"
11 | )
12 |
13 |
14 | @spaces.GPU
15 | def run_character_generation(part_1, part_2, part_3, seed=None):
16 | crops_paths = [part_1, part_2, part_3]
17 | image = pit_pipeline.run(crops_paths=crops_paths, seed=seed, n_images=1)[0]
18 | return image
19 |
20 |
21 | with gr.Blocks(css="style.css") as demo:
22 | gr.HTML(
23 | """Piece it Together: Part-Based Concepting with IP-Priors
"""
24 | )
25 | gr.HTML(
26 | ''
27 | )
28 | gr.HTML(
29 | 'Piece it Together (PiT) combines different input parts to generate a complete concept in a prior domain.
'
30 | )
31 | with gr.Row(equal_height=True, elem_classes="justified-element"):
32 | with gr.Column(scale=0, min_width=BLOCK_WIDTH):
33 | part_1 = gr.Image(label="Upload part 1 (or keep empty)", type="filepath", width=BLOCK_WIDTH, height=BLOCK_HEIGHT)
34 | with gr.Column(scale=0, min_width=BLOCK_WIDTH):
35 | part_2 = gr.Image(label="Upload part 2 (or keep empty)", type="filepath", width=BLOCK_WIDTH, height=BLOCK_HEIGHT)
36 | with gr.Column(scale=0, min_width=BLOCK_WIDTH):
37 | part_3 = gr.Image(label="Upload part 3 (or keep empty)", type="filepath", width=BLOCK_WIDTH, height=BLOCK_HEIGHT)
38 | with gr.Column(scale=0, min_width=BLOCK_WIDTH):
39 | output_eq_1 = gr.Image(label="Output", width=BLOCK_WIDTH, height=BLOCK_HEIGHT)
40 | with gr.Row(equal_height=True, elem_classes="justified-element"):
41 | run_button = gr.Button("Create your character!", elem_classes="small-elem")
42 | run_button.click(fn=run_character_generation, inputs=[part_1, part_2, part_3], outputs=[output_eq_1])
43 | with gr.Row(equal_height=True, elem_classes="justified-element"):
44 | pass
45 |
46 | with gr.Row(equal_height=True, elem_classes="justified-element"):
47 | with gr.Column(scale=1):
48 | examples = [
49 | [
50 | "assets/characters_parts/part_a.jpg",
51 | "assets/characters_parts/part_b.jpg",
52 | "assets/characters_parts/part_c.jpg",
53 | ]
54 | ]
55 | gr.Examples(
56 | examples=examples,
57 | inputs=[part_1, part_2, part_3],
58 | outputs=[output_eq_1],
59 | fn=run_character_generation,
60 | cache_examples=False,
61 | )
62 |
63 | demo.queue().launch(share=True)
64 |
--------------------------------------------------------------------------------
/demo/pit.py:
--------------------------------------------------------------------------------
1 | import random
2 | from pathlib import Path
3 | from typing import Optional
4 |
5 | import numpy as np
6 | import pyrallis
7 | import torch
8 | from diffusers import (
9 | StableDiffusionXLPipeline,
10 | )
11 | from huggingface_hub import hf_hub_download
12 | from PIL import Image
13 |
14 | from ip_adapter import IPAdapterPlusXL
15 | from model.dit import DiT_Llama
16 | from model.pipeline_pit import PiTPipeline
17 | from training.train_config import TrainConfig
18 |
19 |
20 | def paste_on_background(image, background, min_scale=0.4, max_scale=0.8, scale=None):
21 | # Calculate aspect ratio and determine resizing based on the smaller dimension of the background
22 | aspect_ratio = image.width / image.height
23 | scale = random.uniform(min_scale, max_scale) if scale is None else scale
24 | new_width = int(min(background.width, background.height * aspect_ratio) * scale)
25 | new_height = int(new_width / aspect_ratio)
26 |
27 | # Resize image and calculate position
28 | image = image.resize((new_width, new_height), resample=Image.LANCZOS)
29 | pos_x = random.randint(0, background.width - new_width)
30 | pos_y = random.randint(0, background.height - new_height)
31 |
32 | # Paste the image using its alpha channel as mask if present
33 | background.paste(image, (pos_x, pos_y), image if "A" in image.mode else None)
34 | return background
35 |
36 |
37 | def set_seed(seed: int):
38 | """Ensures reproducibility across multiple libraries."""
39 | random.seed(seed) # Python random module
40 | np.random.seed(seed) # NumPy random module
41 | torch.manual_seed(seed) # PyTorch CPU random seed
42 | torch.cuda.manual_seed_all(seed) # PyTorch GPU random seed
43 | torch.backends.cudnn.deterministic = True # Ensures deterministic behavior
44 | torch.backends.cudnn.benchmark = False # Disable benchmarking to avoid randomness
45 |
46 |
47 | class PiTDemoPipeline:
48 | def __init__(self, prior_repo: str, prior_path: str):
49 | # Download model and config
50 | prior_ckpt_path = hf_hub_download(
51 | repo_id=prior_repo,
52 | filename=str(prior_path),
53 | local_dir="pretrained_models",
54 | )
55 | prior_cfg_path = hf_hub_download(
56 | repo_id=prior_repo, filename=str(Path(prior_path).parent / "cfg.yaml"), local_dir="pretrained_models"
57 | )
58 | self.model_cfg: TrainConfig = pyrallis.load(TrainConfig, open(prior_cfg_path, "r"))
59 |
60 | self.weight_dtype = torch.float32
61 | self.device = "cuda:0"
62 | prior = DiT_Llama(
63 | embedding_dim=2048,
64 | hidden_dim=self.model_cfg.hidden_dim,
65 | n_layers=self.model_cfg.num_layers,
66 | n_heads=self.model_cfg.num_attention_heads,
67 | )
68 | prior.load_state_dict(torch.load(prior_ckpt_path))
69 | image_pipe = StableDiffusionXLPipeline.from_pretrained(
70 | "stabilityai/stable-diffusion-xl-base-1.0",
71 | torch_dtype=torch.float16,
72 | add_watermarker=False,
73 | )
74 | ip_ckpt_path = hf_hub_download(
75 | repo_id="h94/IP-Adapter",
76 | filename="ip-adapter-plus_sdxl_vit-h.bin",
77 | subfolder="sdxl_models",
78 | local_dir="pretrained_models",
79 | )
80 |
81 | self.ip_model = IPAdapterPlusXL(
82 | image_pipe,
83 | "models/image_encoder",
84 | ip_ckpt_path,
85 | self.device,
86 | num_tokens=16,
87 | )
88 | self.image_processor = self.ip_model.clip_image_processor
89 |
90 | empty_image = Image.new("RGB", (256, 256), (255, 255, 255))
91 | zero_image = torch.Tensor(self.image_processor(empty_image)["pixel_values"][0])
92 | self.zero_image_embeds = self.ip_model.get_image_embeds(zero_image.unsqueeze(0), skip_uncond=True)
93 |
94 | prior_pipeline = PiTPipeline(
95 | prior=prior,
96 | )
97 | self.prior_pipeline = prior_pipeline.to(self.device)
98 | set_seed(42)
99 |
100 | def run(self, crops_paths: list[str], scale: float = 2.0, seed: Optional[int] = None, n_images: int = 1):
101 | if seed is not None:
102 | set_seed(seed)
103 | processed_crops = []
104 | input_images = []
105 |
106 | crops_paths = [None] + crops_paths
107 | # Extend to >3 with Nones
108 | while len(crops_paths) < 3:
109 | crops_paths.append(None)
110 |
111 | for path_ind, path in enumerate(crops_paths):
112 | if path is None:
113 | image = Image.new("RGB", (224, 224), (255, 255, 255))
114 | else:
115 | image = Image.open(path).convert("RGB")
116 | if path_ind > 0 or not self.model_cfg.use_ref:
117 | background = Image.new("RGB", (1024, 1024), (255, 255, 255))
118 | image = paste_on_background(image, background, scale=0.92)
119 | else:
120 | image = image.resize((1024, 1024))
121 | input_images.append(image)
122 | # Name should be parent directory name
123 | processed_image = (
124 | torch.Tensor(self.image_processor(image)["pixel_values"][0])
125 | .to(self.device)
126 | .unsqueeze(0)
127 | .to(self.weight_dtype)
128 | )
129 | processed_crops.append(processed_image)
130 |
131 | image_embed_inputs = []
132 | for crop_ind in range(len(processed_crops)):
133 | image_embed_inputs.append(self.ip_model.get_image_embeds(processed_crops[crop_ind], skip_uncond=True))
134 | crops_input_sequence = torch.cat(image_embed_inputs, dim=1)
135 | generated_images = []
136 | for _ in range(n_images):
137 | seed = random.randint(0, 1000000)
138 | for curr_scale in [scale]:
139 | negative_cond_sequence = torch.zeros_like(crops_input_sequence)
140 | embeds_len = self.zero_image_embeds.shape[1]
141 | for i in range(0, negative_cond_sequence.shape[1], embeds_len):
142 | negative_cond_sequence[:, i : i + embeds_len] = self.zero_image_embeds.detach()
143 |
144 | img_emb = self.prior_pipeline(
145 | cond_sequence=crops_input_sequence,
146 | negative_cond_sequence=negative_cond_sequence,
147 | num_inference_steps=25,
148 | num_images_per_prompt=1,
149 | guidance_scale=curr_scale,
150 | generator=torch.Generator(device="cuda").manual_seed(seed),
151 | ).image_embeds
152 |
153 | for seed_2 in range(1):
154 | images = self.ip_model.generate(
155 | image_prompt_embeds=img_emb,
156 | num_samples=1,
157 | num_inference_steps=50,
158 | )
159 | generated_images += images
160 |
161 | return generated_images
162 |
--------------------------------------------------------------------------------
/ip_adapter/__init__.py:
--------------------------------------------------------------------------------
1 | from .ip_adapter import IPAdapter, IPAdapterPlus, IPAdapterPlusXL, IPAdapterXL, IPAdapterFull
2 |
3 | __all__ = [
4 | "IPAdapter",
5 | "IPAdapterPlus",
6 | "IPAdapterPlusXL",
7 | "IPAdapterXL",
8 | "IPAdapterFull",
9 | ]
10 |
--------------------------------------------------------------------------------
/ip_adapter/attention_processor.py:
--------------------------------------------------------------------------------
1 | # modified from https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py
2 | import torch
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 |
6 |
7 | class AttnProcessor(nn.Module):
8 | r"""
9 | Default processor for performing attention-related computations.
10 | """
11 |
12 | def __init__(
13 | self,
14 | hidden_size=None,
15 | cross_attention_dim=None,
16 | ):
17 | super().__init__()
18 |
19 | def __call__(
20 | self,
21 | attn,
22 | hidden_states,
23 | encoder_hidden_states=None,
24 | attention_mask=None,
25 | temb=None,
26 | *args,
27 | **kwargs,
28 | ):
29 | residual = hidden_states
30 |
31 | if attn.spatial_norm is not None:
32 | hidden_states = attn.spatial_norm(hidden_states, temb)
33 |
34 | input_ndim = hidden_states.ndim
35 |
36 | if input_ndim == 4:
37 | batch_size, channel, height, width = hidden_states.shape
38 | hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
39 |
40 | batch_size, sequence_length, _ = (
41 | hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
42 | )
43 | attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
44 |
45 | if attn.group_norm is not None:
46 | hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
47 |
48 | query = attn.to_q(hidden_states)
49 |
50 | if encoder_hidden_states is None:
51 | encoder_hidden_states = hidden_states
52 | elif attn.norm_cross:
53 | encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
54 |
55 | key = attn.to_k(encoder_hidden_states)
56 | value = attn.to_v(encoder_hidden_states)
57 |
58 | query = attn.head_to_batch_dim(query)
59 | key = attn.head_to_batch_dim(key)
60 | value = attn.head_to_batch_dim(value)
61 |
62 | attention_probs = attn.get_attention_scores(query, key, attention_mask)
63 | hidden_states = torch.bmm(attention_probs, value)
64 | hidden_states = attn.batch_to_head_dim(hidden_states)
65 |
66 | # linear proj
67 | hidden_states = attn.to_out[0](hidden_states)
68 | # dropout
69 | hidden_states = attn.to_out[1](hidden_states)
70 |
71 | if input_ndim == 4:
72 | hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
73 |
74 | if attn.residual_connection:
75 | hidden_states = hidden_states + residual
76 |
77 | hidden_states = hidden_states / attn.rescale_output_factor
78 |
79 | return hidden_states
80 |
81 |
82 | class IPAttnProcessor(nn.Module):
83 | r"""
84 | Attention processor for IP-Adapater.
85 | Args:
86 | hidden_size (`int`):
87 | The hidden size of the attention layer.
88 | cross_attention_dim (`int`):
89 | The number of channels in the `encoder_hidden_states`.
90 | scale (`float`, defaults to 1.0):
91 | the weight scale of image prompt.
92 | num_tokens (`int`, defaults to 4 when do ip_adapter_plus it should be 16):
93 | The context length of the image features.
94 | """
95 |
96 | def __init__(self, hidden_size, cross_attention_dim=None, scale=1.0, num_tokens=4):
97 | super().__init__()
98 |
99 | self.hidden_size = hidden_size
100 | self.cross_attention_dim = cross_attention_dim
101 | self.scale = scale
102 | self.num_tokens = num_tokens
103 |
104 | self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
105 | self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
106 |
107 | def __call__(
108 | self,
109 | attn,
110 | hidden_states,
111 | encoder_hidden_states=None,
112 | attention_mask=None,
113 | temb=None,
114 | *args,
115 | **kwargs,
116 | ):
117 | residual = hidden_states
118 |
119 | if attn.spatial_norm is not None:
120 | hidden_states = attn.spatial_norm(hidden_states, temb)
121 |
122 | input_ndim = hidden_states.ndim
123 |
124 | if input_ndim == 4:
125 | batch_size, channel, height, width = hidden_states.shape
126 | hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
127 |
128 | batch_size, sequence_length, _ = (
129 | hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
130 | )
131 | attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
132 |
133 | if attn.group_norm is not None:
134 | hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
135 |
136 | query = attn.to_q(hidden_states)
137 |
138 | if encoder_hidden_states is None:
139 | encoder_hidden_states = hidden_states
140 | else:
141 | # get encoder_hidden_states, ip_hidden_states
142 | end_pos = encoder_hidden_states.shape[1] - self.num_tokens
143 | encoder_hidden_states, ip_hidden_states = (
144 | encoder_hidden_states[:, :end_pos, :],
145 | encoder_hidden_states[:, end_pos:, :],
146 | )
147 | if attn.norm_cross:
148 | encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
149 |
150 | key = attn.to_k(encoder_hidden_states)
151 | value = attn.to_v(encoder_hidden_states)
152 |
153 | query = attn.head_to_batch_dim(query)
154 | key = attn.head_to_batch_dim(key)
155 | value = attn.head_to_batch_dim(value)
156 |
157 | attention_probs = attn.get_attention_scores(query, key, attention_mask)
158 | hidden_states = torch.bmm(attention_probs, value)
159 | hidden_states = attn.batch_to_head_dim(hidden_states)
160 |
161 | # for ip-adapter
162 | ip_key = self.to_k_ip(ip_hidden_states)
163 | ip_value = self.to_v_ip(ip_hidden_states)
164 |
165 | ip_key = attn.head_to_batch_dim(ip_key)
166 | ip_value = attn.head_to_batch_dim(ip_value)
167 |
168 | ip_attention_probs = attn.get_attention_scores(query, ip_key, None)
169 | self.attn_map = ip_attention_probs
170 | ip_hidden_states = torch.bmm(ip_attention_probs, ip_value)
171 | ip_hidden_states = attn.batch_to_head_dim(ip_hidden_states)
172 |
173 | hidden_states = hidden_states + self.scale * ip_hidden_states
174 |
175 | # linear proj
176 | hidden_states = attn.to_out[0](hidden_states)
177 | # dropout
178 | hidden_states = attn.to_out[1](hidden_states)
179 |
180 | if input_ndim == 4:
181 | hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
182 |
183 | if attn.residual_connection:
184 | hidden_states = hidden_states + residual
185 |
186 | hidden_states = hidden_states / attn.rescale_output_factor
187 |
188 | return hidden_states
189 |
190 |
191 | class AttnProcessor2_0(torch.nn.Module):
192 | r"""
193 | Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0).
194 | """
195 |
196 | def __init__(
197 | self,
198 | hidden_size=None,
199 | cross_attention_dim=None,
200 | ):
201 | super().__init__()
202 | if not hasattr(F, "scaled_dot_product_attention"):
203 | raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
204 |
205 | def __call__(
206 | self,
207 | attn,
208 | hidden_states,
209 | encoder_hidden_states=None,
210 | attention_mask=None,
211 | temb=None,
212 | *args,
213 | **kwargs,
214 | ):
215 | residual = hidden_states
216 |
217 | if attn.spatial_norm is not None:
218 | hidden_states = attn.spatial_norm(hidden_states, temb)
219 |
220 | input_ndim = hidden_states.ndim
221 |
222 | if input_ndim == 4:
223 | batch_size, channel, height, width = hidden_states.shape
224 | hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
225 |
226 | batch_size, sequence_length, _ = (
227 | hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
228 | )
229 |
230 | if attention_mask is not None:
231 | attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
232 | # scaled_dot_product_attention expects attention_mask shape to be
233 | # (batch, heads, source_length, target_length)
234 | attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
235 |
236 | if attn.group_norm is not None:
237 | hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
238 |
239 | query = attn.to_q(hidden_states)
240 |
241 | if encoder_hidden_states is None:
242 | encoder_hidden_states = hidden_states
243 | elif attn.norm_cross:
244 | encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
245 |
246 | key = attn.to_k(encoder_hidden_states)
247 | value = attn.to_v(encoder_hidden_states)
248 |
249 | inner_dim = key.shape[-1]
250 | head_dim = inner_dim // attn.heads
251 |
252 | query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
253 |
254 | key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
255 | value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
256 |
257 | # the output of sdp = (batch, num_heads, seq_len, head_dim)
258 | # TODO: add support for attn.scale when we move to Torch 2.1
259 | hidden_states = F.scaled_dot_product_attention(
260 | query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
261 | )
262 |
263 | hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
264 | hidden_states = hidden_states.to(query.dtype)
265 |
266 | # linear proj
267 | hidden_states = attn.to_out[0](hidden_states)
268 | # dropout
269 | hidden_states = attn.to_out[1](hidden_states)
270 |
271 | if input_ndim == 4:
272 | hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
273 |
274 | if attn.residual_connection:
275 | hidden_states = hidden_states + residual
276 |
277 | hidden_states = hidden_states / attn.rescale_output_factor
278 |
279 | return hidden_states
280 |
281 |
282 | class IPAttnProcessor2_0(torch.nn.Module):
283 | r"""
284 | Attention processor for IP-Adapater for PyTorch 2.0.
285 | Args:
286 | hidden_size (`int`):
287 | The hidden size of the attention layer.
288 | cross_attention_dim (`int`):
289 | The number of channels in the `encoder_hidden_states`.
290 | scale (`float`, defaults to 1.0):
291 | the weight scale of image prompt.
292 | num_tokens (`int`, defaults to 4 when do ip_adapter_plus it should be 16):
293 | The context length of the image features.
294 | """
295 |
296 | def __init__(self, hidden_size, cross_attention_dim=None, scale=1.0, num_tokens=4):
297 | super().__init__()
298 |
299 | if not hasattr(F, "scaled_dot_product_attention"):
300 | raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
301 |
302 | self.hidden_size = hidden_size
303 | self.cross_attention_dim = cross_attention_dim
304 | self.scale = scale
305 | self.num_tokens = num_tokens
306 |
307 | self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
308 | self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
309 |
310 | def __call__(
311 | self,
312 | attn,
313 | hidden_states,
314 | encoder_hidden_states=None,
315 | attention_mask=None,
316 | temb=None,
317 | *args,
318 | **kwargs,
319 | ):
320 | residual = hidden_states
321 |
322 | if attn.spatial_norm is not None:
323 | hidden_states = attn.spatial_norm(hidden_states, temb)
324 |
325 | input_ndim = hidden_states.ndim
326 |
327 | if input_ndim == 4:
328 | batch_size, channel, height, width = hidden_states.shape
329 | hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
330 |
331 | batch_size, sequence_length, _ = (
332 | hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
333 | )
334 |
335 | if attention_mask is not None:
336 | attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
337 | # scaled_dot_product_attention expects attention_mask shape to be
338 | # (batch, heads, source_length, target_length)
339 | attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
340 |
341 | if attn.group_norm is not None:
342 | hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
343 |
344 | query = attn.to_q(hidden_states)
345 |
346 | if encoder_hidden_states is None:
347 | encoder_hidden_states = hidden_states
348 | else:
349 | # get encoder_hidden_states, ip_hidden_states
350 | end_pos = encoder_hidden_states.shape[1] - self.num_tokens
351 | encoder_hidden_states, ip_hidden_states = (
352 | encoder_hidden_states[:, :end_pos, :],
353 | encoder_hidden_states[:, end_pos:, :],
354 | )
355 | if attn.norm_cross:
356 | encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
357 |
358 | key = attn.to_k(encoder_hidden_states)
359 | value = attn.to_v(encoder_hidden_states)
360 |
361 | inner_dim = key.shape[-1]
362 | head_dim = inner_dim // attn.heads
363 |
364 | query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
365 |
366 | key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
367 | value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
368 |
369 | # the output of sdp = (batch, num_heads, seq_len, head_dim)
370 | # TODO: add support for attn.scale when we move to Torch 2.1
371 | hidden_states = F.scaled_dot_product_attention(
372 | query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
373 | )
374 |
375 | hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
376 | hidden_states = hidden_states.to(query.dtype)
377 |
378 | # for ip-adapter
379 | ip_key = self.to_k_ip(ip_hidden_states)
380 | ip_value = self.to_v_ip(ip_hidden_states)
381 |
382 | ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
383 | ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
384 |
385 | # the output of sdp = (batch, num_heads, seq_len, head_dim)
386 | # TODO: add support for attn.scale when we move to Torch 2.1
387 | ip_hidden_states = F.scaled_dot_product_attention(
388 | query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
389 | )
390 | with torch.no_grad():
391 | self.attn_map = query @ ip_key.transpose(-2, -1).softmax(dim=-1)
392 | #print(self.attn_map.shape)
393 |
394 | ip_hidden_states = ip_hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
395 | ip_hidden_states = ip_hidden_states.to(query.dtype)
396 |
397 | hidden_states = hidden_states + self.scale * ip_hidden_states
398 |
399 | # linear proj
400 | hidden_states = attn.to_out[0](hidden_states)
401 | # dropout
402 | hidden_states = attn.to_out[1](hidden_states)
403 |
404 | if input_ndim == 4:
405 | hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
406 |
407 | if attn.residual_connection:
408 | hidden_states = hidden_states + residual
409 |
410 | hidden_states = hidden_states / attn.rescale_output_factor
411 |
412 | return hidden_states
413 |
414 |
415 | ## for controlnet
416 | class CNAttnProcessor:
417 | r"""
418 | Default processor for performing attention-related computations.
419 | """
420 |
421 | def __init__(self, num_tokens=4):
422 | self.num_tokens = num_tokens
423 |
424 | def __call__(self, attn, hidden_states, encoder_hidden_states=None, attention_mask=None, temb=None, *args, **kwargs,):
425 | residual = hidden_states
426 |
427 | if attn.spatial_norm is not None:
428 | hidden_states = attn.spatial_norm(hidden_states, temb)
429 |
430 | input_ndim = hidden_states.ndim
431 |
432 | if input_ndim == 4:
433 | batch_size, channel, height, width = hidden_states.shape
434 | hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
435 |
436 | batch_size, sequence_length, _ = (
437 | hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
438 | )
439 | attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
440 |
441 | if attn.group_norm is not None:
442 | hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
443 |
444 | query = attn.to_q(hidden_states)
445 |
446 | if encoder_hidden_states is None:
447 | encoder_hidden_states = hidden_states
448 | else:
449 | end_pos = encoder_hidden_states.shape[1] - self.num_tokens
450 | encoder_hidden_states = encoder_hidden_states[:, :end_pos] # only use text
451 | if attn.norm_cross:
452 | encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
453 |
454 | key = attn.to_k(encoder_hidden_states)
455 | value = attn.to_v(encoder_hidden_states)
456 |
457 | query = attn.head_to_batch_dim(query)
458 | key = attn.head_to_batch_dim(key)
459 | value = attn.head_to_batch_dim(value)
460 |
461 | attention_probs = attn.get_attention_scores(query, key, attention_mask)
462 | hidden_states = torch.bmm(attention_probs, value)
463 | hidden_states = attn.batch_to_head_dim(hidden_states)
464 |
465 | # linear proj
466 | hidden_states = attn.to_out[0](hidden_states)
467 | # dropout
468 | hidden_states = attn.to_out[1](hidden_states)
469 |
470 | if input_ndim == 4:
471 | hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
472 |
473 | if attn.residual_connection:
474 | hidden_states = hidden_states + residual
475 |
476 | hidden_states = hidden_states / attn.rescale_output_factor
477 |
478 | return hidden_states
479 |
480 |
481 | class CNAttnProcessor2_0:
482 | r"""
483 | Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0).
484 | """
485 |
486 | def __init__(self, num_tokens=4):
487 | if not hasattr(F, "scaled_dot_product_attention"):
488 | raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
489 | self.num_tokens = num_tokens
490 |
491 | def __call__(
492 | self,
493 | attn,
494 | hidden_states,
495 | encoder_hidden_states=None,
496 | attention_mask=None,
497 | temb=None,
498 | *args,
499 | **kwargs,
500 | ):
501 | residual = hidden_states
502 |
503 | if attn.spatial_norm is not None:
504 | hidden_states = attn.spatial_norm(hidden_states, temb)
505 |
506 | input_ndim = hidden_states.ndim
507 |
508 | if input_ndim == 4:
509 | batch_size, channel, height, width = hidden_states.shape
510 | hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
511 |
512 | batch_size, sequence_length, _ = (
513 | hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
514 | )
515 |
516 | if attention_mask is not None:
517 | attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
518 | # scaled_dot_product_attention expects attention_mask shape to be
519 | # (batch, heads, source_length, target_length)
520 | attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
521 |
522 | if attn.group_norm is not None:
523 | hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
524 |
525 | query = attn.to_q(hidden_states)
526 |
527 | if encoder_hidden_states is None:
528 | encoder_hidden_states = hidden_states
529 | else:
530 | end_pos = encoder_hidden_states.shape[1] - self.num_tokens
531 | encoder_hidden_states = encoder_hidden_states[:, :end_pos] # only use text
532 | if attn.norm_cross:
533 | encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
534 |
535 | key = attn.to_k(encoder_hidden_states)
536 | value = attn.to_v(encoder_hidden_states)
537 |
538 | inner_dim = key.shape[-1]
539 | head_dim = inner_dim // attn.heads
540 |
541 | query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
542 |
543 | key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
544 | value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
545 |
546 | # the output of sdp = (batch, num_heads, seq_len, head_dim)
547 | # TODO: add support for attn.scale when we move to Torch 2.1
548 | hidden_states = F.scaled_dot_product_attention(
549 | query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
550 | )
551 |
552 | hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
553 | hidden_states = hidden_states.to(query.dtype)
554 |
555 | # linear proj
556 | hidden_states = attn.to_out[0](hidden_states)
557 | # dropout
558 | hidden_states = attn.to_out[1](hidden_states)
559 |
560 | if input_ndim == 4:
561 | hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
562 |
563 | if attn.residual_connection:
564 | hidden_states = hidden_states + residual
565 |
566 | hidden_states = hidden_states / attn.rescale_output_factor
567 |
568 | return hidden_states
569 |
--------------------------------------------------------------------------------
/ip_adapter/attention_processor_faceid.py:
--------------------------------------------------------------------------------
1 | # modified from https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py
2 | import torch
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 |
6 | from diffusers.models.lora import LoRALinearLayer
7 |
8 |
9 | class LoRAAttnProcessor(nn.Module):
10 | r"""
11 | Default processor for performing attention-related computations.
12 | """
13 |
14 | def __init__(
15 | self,
16 | hidden_size=None,
17 | cross_attention_dim=None,
18 | rank=4,
19 | network_alpha=None,
20 | lora_scale=1.0,
21 | ):
22 | super().__init__()
23 |
24 | self.rank = rank
25 | self.lora_scale = lora_scale
26 |
27 | self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
28 | self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
29 | self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
30 | self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
31 |
32 | def __call__(
33 | self,
34 | attn,
35 | hidden_states,
36 | encoder_hidden_states=None,
37 | attention_mask=None,
38 | temb=None,
39 | *args,
40 | **kwargs,
41 | ):
42 | residual = hidden_states
43 |
44 | if attn.spatial_norm is not None:
45 | hidden_states = attn.spatial_norm(hidden_states, temb)
46 |
47 | input_ndim = hidden_states.ndim
48 |
49 | if input_ndim == 4:
50 | batch_size, channel, height, width = hidden_states.shape
51 | hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
52 |
53 | batch_size, sequence_length, _ = (
54 | hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
55 | )
56 | attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
57 |
58 | if attn.group_norm is not None:
59 | hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
60 |
61 | query = attn.to_q(hidden_states) + self.lora_scale * self.to_q_lora(hidden_states)
62 |
63 | if encoder_hidden_states is None:
64 | encoder_hidden_states = hidden_states
65 | elif attn.norm_cross:
66 | encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
67 |
68 | key = attn.to_k(encoder_hidden_states) + self.lora_scale * self.to_k_lora(encoder_hidden_states)
69 | value = attn.to_v(encoder_hidden_states) + self.lora_scale * self.to_v_lora(encoder_hidden_states)
70 |
71 | query = attn.head_to_batch_dim(query)
72 | key = attn.head_to_batch_dim(key)
73 | value = attn.head_to_batch_dim(value)
74 |
75 | attention_probs = attn.get_attention_scores(query, key, attention_mask)
76 | hidden_states = torch.bmm(attention_probs, value)
77 | hidden_states = attn.batch_to_head_dim(hidden_states)
78 |
79 | # linear proj
80 | hidden_states = attn.to_out[0](hidden_states) + self.lora_scale * self.to_out_lora(hidden_states)
81 | # dropout
82 | hidden_states = attn.to_out[1](hidden_states)
83 |
84 | if input_ndim == 4:
85 | hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
86 |
87 | if attn.residual_connection:
88 | hidden_states = hidden_states + residual
89 |
90 | hidden_states = hidden_states / attn.rescale_output_factor
91 |
92 | return hidden_states
93 |
94 |
95 | class LoRAIPAttnProcessor(nn.Module):
96 | r"""
97 | Attention processor for IP-Adapater.
98 | Args:
99 | hidden_size (`int`):
100 | The hidden size of the attention layer.
101 | cross_attention_dim (`int`):
102 | The number of channels in the `encoder_hidden_states`.
103 | scale (`float`, defaults to 1.0):
104 | the weight scale of image prompt.
105 | num_tokens (`int`, defaults to 4 when do ip_adapter_plus it should be 16):
106 | The context length of the image features.
107 | """
108 |
109 | def __init__(self, hidden_size, cross_attention_dim=None, rank=4, network_alpha=None, lora_scale=1.0, scale=1.0, num_tokens=4):
110 | super().__init__()
111 |
112 | self.rank = rank
113 | self.lora_scale = lora_scale
114 |
115 | self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
116 | self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
117 | self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
118 | self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
119 |
120 | self.hidden_size = hidden_size
121 | self.cross_attention_dim = cross_attention_dim
122 | self.scale = scale
123 | self.num_tokens = num_tokens
124 |
125 | self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
126 | self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
127 |
128 | def __call__(
129 | self,
130 | attn,
131 | hidden_states,
132 | encoder_hidden_states=None,
133 | attention_mask=None,
134 | temb=None,
135 | *args,
136 | **kwargs,
137 | ):
138 | residual = hidden_states
139 |
140 | if attn.spatial_norm is not None:
141 | hidden_states = attn.spatial_norm(hidden_states, temb)
142 |
143 | input_ndim = hidden_states.ndim
144 |
145 | if input_ndim == 4:
146 | batch_size, channel, height, width = hidden_states.shape
147 | hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
148 |
149 | batch_size, sequence_length, _ = (
150 | hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
151 | )
152 | attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
153 |
154 | if attn.group_norm is not None:
155 | hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
156 |
157 | query = attn.to_q(hidden_states) + self.lora_scale * self.to_q_lora(hidden_states)
158 |
159 | if encoder_hidden_states is None:
160 | encoder_hidden_states = hidden_states
161 | else:
162 | # get encoder_hidden_states, ip_hidden_states
163 | end_pos = encoder_hidden_states.shape[1] - self.num_tokens
164 | encoder_hidden_states, ip_hidden_states = (
165 | encoder_hidden_states[:, :end_pos, :],
166 | encoder_hidden_states[:, end_pos:, :],
167 | )
168 | if attn.norm_cross:
169 | encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
170 |
171 | key = attn.to_k(encoder_hidden_states) + self.lora_scale * self.to_k_lora(encoder_hidden_states)
172 | value = attn.to_v(encoder_hidden_states) + self.lora_scale * self.to_v_lora(encoder_hidden_states)
173 |
174 | query = attn.head_to_batch_dim(query)
175 | key = attn.head_to_batch_dim(key)
176 | value = attn.head_to_batch_dim(value)
177 |
178 | attention_probs = attn.get_attention_scores(query, key, attention_mask)
179 | hidden_states = torch.bmm(attention_probs, value)
180 | hidden_states = attn.batch_to_head_dim(hidden_states)
181 |
182 | # for ip-adapter
183 | ip_key = self.to_k_ip(ip_hidden_states)
184 | ip_value = self.to_v_ip(ip_hidden_states)
185 |
186 | ip_key = attn.head_to_batch_dim(ip_key)
187 | ip_value = attn.head_to_batch_dim(ip_value)
188 |
189 | ip_attention_probs = attn.get_attention_scores(query, ip_key, None)
190 | self.attn_map = ip_attention_probs
191 | ip_hidden_states = torch.bmm(ip_attention_probs, ip_value)
192 | ip_hidden_states = attn.batch_to_head_dim(ip_hidden_states)
193 |
194 | hidden_states = hidden_states + self.scale * ip_hidden_states
195 |
196 | # linear proj
197 | hidden_states = attn.to_out[0](hidden_states) + self.lora_scale * self.to_out_lora(hidden_states)
198 | # dropout
199 | hidden_states = attn.to_out[1](hidden_states)
200 |
201 | if input_ndim == 4:
202 | hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
203 |
204 | if attn.residual_connection:
205 | hidden_states = hidden_states + residual
206 |
207 | hidden_states = hidden_states / attn.rescale_output_factor
208 |
209 | return hidden_states
210 |
211 |
212 | class LoRAAttnProcessor2_0(nn.Module):
213 |
214 | r"""
215 | Default processor for performing attention-related computations.
216 | """
217 |
218 | def __init__(
219 | self,
220 | hidden_size=None,
221 | cross_attention_dim=None,
222 | rank=4,
223 | network_alpha=None,
224 | lora_scale=1.0,
225 | ):
226 | super().__init__()
227 |
228 | self.rank = rank
229 | self.lora_scale = lora_scale
230 |
231 | self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
232 | self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
233 | self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
234 | self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
235 |
236 | def __call__(
237 | self,
238 | attn,
239 | hidden_states,
240 | encoder_hidden_states=None,
241 | attention_mask=None,
242 | temb=None,
243 | *args,
244 | **kwargs,
245 | ):
246 | residual = hidden_states
247 |
248 | if attn.spatial_norm is not None:
249 | hidden_states = attn.spatial_norm(hidden_states, temb)
250 |
251 | input_ndim = hidden_states.ndim
252 |
253 | if input_ndim == 4:
254 | batch_size, channel, height, width = hidden_states.shape
255 | hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
256 |
257 | batch_size, sequence_length, _ = (
258 | hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
259 | )
260 | attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
261 |
262 | if attn.group_norm is not None:
263 | hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
264 |
265 | query = attn.to_q(hidden_states) + self.lora_scale * self.to_q_lora(hidden_states)
266 |
267 | if encoder_hidden_states is None:
268 | encoder_hidden_states = hidden_states
269 | elif attn.norm_cross:
270 | encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
271 |
272 | key = attn.to_k(encoder_hidden_states) + self.lora_scale * self.to_k_lora(encoder_hidden_states)
273 | value = attn.to_v(encoder_hidden_states) + self.lora_scale * self.to_v_lora(encoder_hidden_states)
274 |
275 | inner_dim = key.shape[-1]
276 | head_dim = inner_dim // attn.heads
277 |
278 | query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
279 |
280 | key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
281 | value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
282 |
283 | # the output of sdp = (batch, num_heads, seq_len, head_dim)
284 | # TODO: add support for attn.scale when we move to Torch 2.1
285 | hidden_states = F.scaled_dot_product_attention(
286 | query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
287 | )
288 |
289 | hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
290 | hidden_states = hidden_states.to(query.dtype)
291 |
292 | # linear proj
293 | hidden_states = attn.to_out[0](hidden_states) + self.lora_scale * self.to_out_lora(hidden_states)
294 | # dropout
295 | hidden_states = attn.to_out[1](hidden_states)
296 |
297 | if input_ndim == 4:
298 | hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
299 |
300 | if attn.residual_connection:
301 | hidden_states = hidden_states + residual
302 |
303 | hidden_states = hidden_states / attn.rescale_output_factor
304 |
305 | return hidden_states
306 |
307 |
308 | class LoRAIPAttnProcessor2_0(nn.Module):
309 | r"""
310 | Processor for implementing the LoRA attention mechanism.
311 |
312 | Args:
313 | hidden_size (`int`, *optional*):
314 | The hidden size of the attention layer.
315 | cross_attention_dim (`int`, *optional*):
316 | The number of channels in the `encoder_hidden_states`.
317 | rank (`int`, defaults to 4):
318 | The dimension of the LoRA update matrices.
319 | network_alpha (`int`, *optional*):
320 | Equivalent to `alpha` but it's usage is specific to Kohya (A1111) style LoRAs.
321 | """
322 |
323 | def __init__(self, hidden_size, cross_attention_dim=None, rank=4, network_alpha=None, lora_scale=1.0, scale=1.0, num_tokens=4):
324 | super().__init__()
325 |
326 | self.rank = rank
327 | self.lora_scale = lora_scale
328 | self.num_tokens = num_tokens
329 |
330 | self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
331 | self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
332 | self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
333 | self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
334 |
335 |
336 | self.hidden_size = hidden_size
337 | self.cross_attention_dim = cross_attention_dim
338 | self.scale = scale
339 |
340 | self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
341 | self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
342 |
343 | def __call__(
344 | self, attn, hidden_states, encoder_hidden_states=None, attention_mask=None, scale=1.0, temb=None, *args, **kwargs,
345 | ):
346 | residual = hidden_states
347 |
348 | if attn.spatial_norm is not None:
349 | hidden_states = attn.spatial_norm(hidden_states, temb)
350 |
351 | input_ndim = hidden_states.ndim
352 |
353 | if input_ndim == 4:
354 | batch_size, channel, height, width = hidden_states.shape
355 | hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
356 |
357 | batch_size, sequence_length, _ = (
358 | hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
359 | )
360 | attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
361 |
362 | if attn.group_norm is not None:
363 | hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
364 |
365 | query = attn.to_q(hidden_states) + self.lora_scale * self.to_q_lora(hidden_states)
366 | #query = attn.head_to_batch_dim(query)
367 |
368 | if encoder_hidden_states is None:
369 | encoder_hidden_states = hidden_states
370 | else:
371 | # get encoder_hidden_states, ip_hidden_states
372 | end_pos = encoder_hidden_states.shape[1] - self.num_tokens
373 | encoder_hidden_states, ip_hidden_states = (
374 | encoder_hidden_states[:, :end_pos, :],
375 | encoder_hidden_states[:, end_pos:, :],
376 | )
377 | if attn.norm_cross:
378 | encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
379 |
380 | # for text
381 | key = attn.to_k(encoder_hidden_states) + self.lora_scale * self.to_k_lora(encoder_hidden_states)
382 | value = attn.to_v(encoder_hidden_states) + self.lora_scale * self.to_v_lora(encoder_hidden_states)
383 |
384 | inner_dim = key.shape[-1]
385 | head_dim = inner_dim // attn.heads
386 |
387 | query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
388 |
389 | key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
390 | value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
391 |
392 | # the output of sdp = (batch, num_heads, seq_len, head_dim)
393 | # TODO: add support for attn.scale when we move to Torch 2.1
394 | hidden_states = F.scaled_dot_product_attention(
395 | query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
396 | )
397 |
398 | hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
399 | hidden_states = hidden_states.to(query.dtype)
400 |
401 | # for ip
402 | ip_key = self.to_k_ip(ip_hidden_states)
403 | ip_value = self.to_v_ip(ip_hidden_states)
404 |
405 | ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
406 | ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
407 |
408 | # the output of sdp = (batch, num_heads, seq_len, head_dim)
409 | # TODO: add support for attn.scale when we move to Torch 2.1
410 | ip_hidden_states = F.scaled_dot_product_attention(
411 | query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
412 | )
413 |
414 |
415 | ip_hidden_states = ip_hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
416 | ip_hidden_states = ip_hidden_states.to(query.dtype)
417 |
418 | hidden_states = hidden_states + self.scale * ip_hidden_states
419 |
420 | # linear proj
421 | hidden_states = attn.to_out[0](hidden_states) + self.lora_scale * self.to_out_lora(hidden_states)
422 | # dropout
423 | hidden_states = attn.to_out[1](hidden_states)
424 |
425 | if input_ndim == 4:
426 | hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
427 |
428 | if attn.residual_connection:
429 | hidden_states = hidden_states + residual
430 |
431 | hidden_states = hidden_states / attn.rescale_output_factor
432 |
433 | return hidden_states
434 |
--------------------------------------------------------------------------------
/ip_adapter/ip_adapter.py:
--------------------------------------------------------------------------------
1 | import os
2 | from typing import List
3 |
4 | import torch
5 | from diffusers import StableDiffusionPipeline
6 | from diffusers.pipelines.controlnet import MultiControlNetModel
7 | from PIL import Image
8 | from safetensors import safe_open
9 | from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
10 |
11 | from .utils import is_torch2_available, get_generator
12 |
13 | if is_torch2_available():
14 | from .attention_processor import (
15 | AttnProcessor2_0 as AttnProcessor,
16 | )
17 | from .attention_processor import (
18 | CNAttnProcessor2_0 as CNAttnProcessor,
19 | )
20 | from .attention_processor import (
21 | IPAttnProcessor2_0 as IPAttnProcessor,
22 | )
23 | else:
24 | from .attention_processor import AttnProcessor, CNAttnProcessor, IPAttnProcessor
25 | from .resampler import Resampler
26 |
27 |
28 | class ImageProjModel(torch.nn.Module):
29 | """Projection Model"""
30 |
31 | def __init__(self, cross_attention_dim=1024, clip_embeddings_dim=1024, clip_extra_context_tokens=4):
32 | super().__init__()
33 |
34 | self.generator = None
35 | self.cross_attention_dim = cross_attention_dim
36 | self.clip_extra_context_tokens = clip_extra_context_tokens
37 | self.proj = torch.nn.Linear(clip_embeddings_dim, self.clip_extra_context_tokens * cross_attention_dim)
38 | self.norm = torch.nn.LayerNorm(cross_attention_dim)
39 |
40 | def forward(self, image_embeds):
41 | embeds = image_embeds
42 | clip_extra_context_tokens = self.proj(embeds).reshape(
43 | -1, self.clip_extra_context_tokens, self.cross_attention_dim
44 | )
45 | clip_extra_context_tokens = self.norm(clip_extra_context_tokens)
46 | return clip_extra_context_tokens
47 |
48 |
49 | class MLPProjModel(torch.nn.Module):
50 | """SD model with image prompt"""
51 |
52 | def __init__(self, cross_attention_dim=1024, clip_embeddings_dim=1024):
53 | super().__init__()
54 |
55 | self.proj = torch.nn.Sequential(
56 | torch.nn.Linear(clip_embeddings_dim, clip_embeddings_dim),
57 | torch.nn.GELU(),
58 | torch.nn.Linear(clip_embeddings_dim, cross_attention_dim),
59 | torch.nn.LayerNorm(cross_attention_dim),
60 | )
61 |
62 | def forward(self, image_embeds):
63 | clip_extra_context_tokens = self.proj(image_embeds)
64 | return clip_extra_context_tokens
65 |
66 |
67 | class IPAdapter:
68 | def __init__(self, sd_pipe, image_encoder_path, ip_ckpt, device, num_tokens=4):
69 | self.device = device
70 | self.image_encoder_path = image_encoder_path
71 | self.ip_ckpt = ip_ckpt
72 | self.num_tokens = num_tokens
73 |
74 | self.pipe = sd_pipe.to(self.device)
75 | self.set_ip_adapter()
76 |
77 | # load image encoder
78 | # self.image_encoder = CLIPVisionModelWithProjection.from_pretrained("h94/IP-Adapter", subfolder="models/image_encoder").to(
79 | self.image_encoder = CLIPVisionModelWithProjection.from_pretrained(
80 | "h94/IP-Adapter", subfolder=image_encoder_path
81 | ).to(self.device, dtype=torch.float16)
82 | self.clip_image_processor = CLIPImageProcessor()
83 | # image proj model
84 | self.image_proj_model = self.init_proj()
85 |
86 | self.load_ip_adapter()
87 |
88 | def init_proj(self):
89 | image_proj_model = ImageProjModel(
90 | cross_attention_dim=self.pipe.unet.config.cross_attention_dim,
91 | clip_embeddings_dim=self.image_encoder.config.projection_dim,
92 | clip_extra_context_tokens=self.num_tokens,
93 | ).to(self.device, dtype=torch.float16)
94 | return image_proj_model
95 |
96 | def set_ip_adapter(self):
97 | unet = self.pipe.unet
98 | attn_procs = {}
99 | for name in unet.attn_processors.keys():
100 | cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
101 | if name.startswith("mid_block"):
102 | hidden_size = unet.config.block_out_channels[-1]
103 | elif name.startswith("up_blocks"):
104 | block_id = int(name[len("up_blocks.")])
105 | hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
106 | elif name.startswith("down_blocks"):
107 | block_id = int(name[len("down_blocks.")])
108 | hidden_size = unet.config.block_out_channels[block_id]
109 | if cross_attention_dim is None:
110 | attn_procs[name] = AttnProcessor()
111 | else:
112 | attn_procs[name] = IPAttnProcessor(
113 | hidden_size=hidden_size,
114 | cross_attention_dim=cross_attention_dim,
115 | scale=1.0,
116 | num_tokens=self.num_tokens,
117 | ).to(self.device, dtype=torch.float16)
118 | unet.set_attn_processor(attn_procs)
119 | if hasattr(self.pipe, "controlnet"):
120 | if isinstance(self.pipe.controlnet, MultiControlNetModel):
121 | for controlnet in self.pipe.controlnet.nets:
122 | controlnet.set_attn_processor(CNAttnProcessor(num_tokens=self.num_tokens))
123 | else:
124 | self.pipe.controlnet.set_attn_processor(CNAttnProcessor(num_tokens=self.num_tokens))
125 |
126 | def load_ip_adapter(self):
127 | if os.path.splitext(self.ip_ckpt)[-1] == ".safetensors":
128 | state_dict = {"image_proj": {}, "ip_adapter": {}}
129 | with safe_open(self.ip_ckpt, framework="pt", device="cpu") as f:
130 | for key in f.keys():
131 | if key.startswith("image_proj."):
132 | state_dict["image_proj"][key.replace("image_proj.", "")] = f.get_tensor(key)
133 | elif key.startswith("ip_adapter."):
134 | state_dict["ip_adapter"][key.replace("ip_adapter.", "")] = f.get_tensor(key)
135 | else:
136 | state_dict = torch.load(self.ip_ckpt, map_location="cpu")
137 | self.image_proj_model.load_state_dict(state_dict["image_proj"])
138 | ip_layers = torch.nn.ModuleList(self.pipe.unet.attn_processors.values())
139 | ip_layers.load_state_dict(state_dict["ip_adapter"])
140 |
141 | def save_ip_adapter(self, save_path):
142 | state_dict = {
143 | "image_proj": self.image_proj_model.state_dict(),
144 | "ip_adapter": torch.nn.ModuleList(self.pipe.unet.attn_processors.values()).state_dict(),
145 | }
146 | torch.save(state_dict, save_path)
147 |
148 | @torch.inference_mode()
149 | def get_image_embeds(self, pil_image=None, clip_image_embeds=None):
150 | if pil_image is not None:
151 | if isinstance(pil_image, Image.Image):
152 | pil_image = [pil_image]
153 | clip_image = self.clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
154 | clip_image_embeds = self.image_encoder(clip_image.to(self.device, dtype=torch.float16)).image_embeds
155 | else:
156 | clip_image_embeds = clip_image_embeds.to(self.device, dtype=torch.float16)
157 | image_prompt_embeds = self.image_proj_model(clip_image_embeds)
158 | uncond_image_prompt_embeds = self.image_proj_model(torch.zeros_like(clip_image_embeds))
159 | return image_prompt_embeds, uncond_image_prompt_embeds
160 |
161 | def set_scale(self, scale):
162 | for attn_processor in self.pipe.unet.attn_processors.values():
163 | if isinstance(attn_processor, IPAttnProcessor):
164 | attn_processor.scale = scale
165 |
166 | def generate(
167 | self,
168 | pil_image=None,
169 | clip_image_embeds=None,
170 | prompt=None,
171 | negative_prompt=None,
172 | scale=1.0,
173 | num_samples=4,
174 | seed=None,
175 | guidance_scale=7.5,
176 | num_inference_steps=30,
177 | **kwargs,
178 | ):
179 | self.set_scale(scale)
180 |
181 | if pil_image is not None:
182 | num_prompts = 1 if isinstance(pil_image, Image.Image) else len(pil_image)
183 | else:
184 | num_prompts = clip_image_embeds.size(0)
185 |
186 | if prompt is None:
187 | prompt = "best quality, high quality"
188 | if negative_prompt is None:
189 | negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
190 |
191 | if not isinstance(prompt, List):
192 | prompt = [prompt] * num_prompts
193 | if not isinstance(negative_prompt, List):
194 | negative_prompt = [negative_prompt] * num_prompts
195 |
196 | image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(
197 | pil_image=pil_image, clip_image_embeds=clip_image_embeds
198 | )
199 | bs_embed, seq_len, _ = image_prompt_embeds.shape
200 | image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
201 | image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
202 | uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
203 | uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
204 |
205 | with torch.inference_mode():
206 | prompt_embeds_, negative_prompt_embeds_ = self.pipe.encode_prompt(
207 | prompt,
208 | device=self.device,
209 | num_images_per_prompt=num_samples,
210 | do_classifier_free_guidance=True,
211 | negative_prompt=negative_prompt,
212 | )
213 | prompt_embeds = torch.cat([prompt_embeds_, image_prompt_embeds], dim=1)
214 | negative_prompt_embeds = torch.cat([negative_prompt_embeds_, uncond_image_prompt_embeds], dim=1)
215 |
216 | generator = get_generator(seed, self.device)
217 |
218 | images = self.pipe(
219 | prompt_embeds=prompt_embeds,
220 | negative_prompt_embeds=negative_prompt_embeds,
221 | guidance_scale=guidance_scale,
222 | num_inference_steps=num_inference_steps,
223 | generator=generator,
224 | **kwargs,
225 | ).images
226 |
227 | return images
228 |
229 |
230 | class IPAdapterXL(IPAdapter):
231 | """SDXL"""
232 |
233 | def generate(
234 | self,
235 | pil_image,
236 | prompt=None,
237 | negative_prompt=None,
238 | scale=1.0,
239 | num_samples=4,
240 | seed=None,
241 | num_inference_steps=30,
242 | image_prompt_embeds=None,
243 | **kwargs,
244 | ):
245 | self.set_scale(scale)
246 |
247 | if pil_image is not None:
248 | num_prompts = 1 if isinstance(pil_image, Image.Image) else len(pil_image)
249 | else:
250 | num_prompts = 1
251 |
252 | if prompt is None:
253 | prompt = "best quality, high quality"
254 | if negative_prompt is None:
255 | negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
256 |
257 | if not isinstance(prompt, List):
258 | prompt = [prompt] * num_prompts
259 | if not isinstance(negative_prompt, List):
260 | negative_prompt = [negative_prompt] * num_prompts
261 |
262 | if pil_image is None:
263 | assert image_prompt_embeds is not None
264 | clip_image = self.clip_image_processor(
265 | images=[Image.new("RGB", (128, 128))], return_tensors="pt"
266 | ).pixel_values
267 | clip_image = clip_image.to(self.device, dtype=torch.float16)
268 | uncond_clip_image_embeds = self.image_encoder(torch.zeros_like(clip_image)).image_embeds
269 | uncond_image_prompt_embeds = self.image_proj_model(uncond_clip_image_embeds)
270 | else:
271 | image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(pil_image)
272 | bs_embed, seq_len, _ = image_prompt_embeds.shape
273 | image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
274 | image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
275 | uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
276 | uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
277 |
278 | with torch.inference_mode():
279 | (
280 | prompt_embeds,
281 | negative_prompt_embeds,
282 | pooled_prompt_embeds,
283 | negative_pooled_prompt_embeds,
284 | ) = self.pipe.encode_prompt(
285 | prompt,
286 | num_images_per_prompt=num_samples,
287 | do_classifier_free_guidance=True,
288 | negative_prompt=negative_prompt,
289 | )
290 | prompt_embeds = torch.cat([prompt_embeds, image_prompt_embeds], dim=1)
291 | negative_prompt_embeds = torch.cat([negative_prompt_embeds, uncond_image_prompt_embeds], dim=1)
292 |
293 | self.generator = get_generator(seed, self.device)
294 |
295 | images = self.pipe(
296 | prompt_embeds=prompt_embeds,
297 | negative_prompt_embeds=negative_prompt_embeds,
298 | pooled_prompt_embeds=pooled_prompt_embeds,
299 | negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
300 | num_inference_steps=num_inference_steps,
301 | generator=self.generator,
302 | **kwargs,
303 | ).images
304 |
305 | return images
306 |
307 |
308 | class IPAdapterPlus(IPAdapter):
309 | """IP-Adapter with fine-grained features"""
310 |
311 | def init_proj(self):
312 | image_proj_model = Resampler(
313 | dim=self.pipe.unet.config.cross_attention_dim,
314 | depth=4,
315 | dim_head=64,
316 | heads=12,
317 | num_queries=self.num_tokens,
318 | embedding_dim=self.image_encoder.config.hidden_size,
319 | output_dim=self.pipe.unet.config.cross_attention_dim,
320 | ff_mult=4,
321 | ).to(self.device, dtype=torch.float16)
322 | return image_proj_model
323 |
324 | @torch.inference_mode()
325 | def get_image_embeds(self, pil_image=None, clip_image_embeds=None):
326 | if isinstance(pil_image, Image.Image):
327 | pil_image = [pil_image]
328 | clip_image = self.clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
329 | clip_image = clip_image.to(self.device, dtype=torch.float16)
330 | clip_image_embeds = self.image_encoder(clip_image, output_hidden_states=True).hidden_states[-2]
331 | image_prompt_embeds = self.image_proj_model(clip_image_embeds)
332 | uncond_clip_image_embeds = self.image_encoder(
333 | torch.zeros_like(clip_image), output_hidden_states=True
334 | ).hidden_states[-2]
335 | uncond_image_prompt_embeds = self.image_proj_model(uncond_clip_image_embeds)
336 | return image_prompt_embeds, uncond_image_prompt_embeds
337 |
338 |
339 | class IPAdapterFull(IPAdapterPlus):
340 | """IP-Adapter with full features"""
341 |
342 | def init_proj(self):
343 | image_proj_model = MLPProjModel(
344 | cross_attention_dim=self.pipe.unet.config.cross_attention_dim,
345 | clip_embeddings_dim=self.image_encoder.config.hidden_size,
346 | ).to(self.device, dtype=torch.float16)
347 | return image_proj_model
348 |
349 |
350 | class IPAdapterPlusXL(IPAdapter):
351 | """SDXL"""
352 |
353 | def init_proj(self):
354 | image_proj_model = Resampler(
355 | dim=1280,
356 | depth=4,
357 | dim_head=64,
358 | heads=20,
359 | num_queries=self.num_tokens,
360 | embedding_dim=self.image_encoder.config.hidden_size,
361 | output_dim=self.pipe.unet.config.cross_attention_dim,
362 | ff_mult=4,
363 | ).to(self.device, dtype=torch.float16)
364 | return image_proj_model
365 |
366 | @torch.inference_mode()
367 | def get_image_embeds(self, pil_image, skip_uncond=False):
368 | if isinstance(pil_image, Image.Image):
369 | pil_image = [pil_image]
370 | clip_image = self.clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
371 | else:
372 | clip_image = pil_image
373 | clip_image = clip_image.to(self.device, dtype=torch.float16)
374 | clip_image_embeds = self.image_encoder(clip_image, output_hidden_states=True).hidden_states[-2]
375 | image_prompt_embeds = self.image_proj_model(clip_image_embeds)
376 | if skip_uncond:
377 | return image_prompt_embeds
378 | uncond_clip_image_embeds = self.image_encoder(
379 | torch.zeros_like(clip_image), output_hidden_states=True
380 | ).hidden_states[-2]
381 | uncond_image_prompt_embeds = self.image_proj_model(uncond_clip_image_embeds)
382 | return image_prompt_embeds, uncond_image_prompt_embeds
383 |
384 | def get_uncond_embeds(self):
385 | clip_image = self.clip_image_processor(images=[Image.new("RGB", (128, 128))], return_tensors="pt").pixel_values
386 | clip_image = clip_image.to(self.device, dtype=torch.float16)
387 | uncond_clip_image_embeds = self.image_encoder(
388 | torch.zeros_like(clip_image), output_hidden_states=True
389 | ).hidden_states[-2]
390 | uncond_image_prompt_embeds = self.image_proj_model(uncond_clip_image_embeds)
391 | return uncond_image_prompt_embeds
392 |
393 | def generate(
394 | self,
395 | pil_image=None,
396 | prompt=None,
397 | negative_prompt=None,
398 | scale=1.0,
399 | num_samples=4,
400 | seed=None,
401 | num_inference_steps=30,
402 | image_prompt_embeds=None,
403 | **kwargs,
404 | ):
405 | self.set_scale(scale)
406 |
407 | num_prompts = 1 # if isinstance(pil_image, Image.Image) else len(pil_image)
408 |
409 | if prompt is None:
410 | prompt = "best quality, high quality"
411 | if negative_prompt is None:
412 | negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
413 |
414 | if not isinstance(prompt, List):
415 | prompt = [prompt] * num_prompts
416 | if not isinstance(negative_prompt, List):
417 | negative_prompt = [negative_prompt] * num_prompts
418 |
419 | if image_prompt_embeds is None:
420 | image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(pil_image)
421 | else:
422 | uncond_image_prompt_embeds = self.get_uncond_embeds()
423 |
424 | bs_embed, seq_len, _ = image_prompt_embeds.shape
425 | image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
426 | image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
427 | uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
428 | uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
429 |
430 | with torch.inference_mode():
431 | (
432 | prompt_embeds,
433 | negative_prompt_embeds,
434 | pooled_prompt_embeds,
435 | negative_pooled_prompt_embeds,
436 | ) = self.pipe.encode_prompt(
437 | prompt,
438 | num_images_per_prompt=num_samples,
439 | do_classifier_free_guidance=True,
440 | negative_prompt=negative_prompt,
441 | )
442 | prompt_embeds = torch.cat([prompt_embeds, image_prompt_embeds], dim=1)
443 | negative_prompt_embeds = torch.cat([negative_prompt_embeds, uncond_image_prompt_embeds], dim=1)
444 |
445 | generator = get_generator(seed, self.device)
446 |
447 | images = self.pipe(
448 | prompt_embeds=prompt_embeds,
449 | negative_prompt_embeds=negative_prompt_embeds,
450 | pooled_prompt_embeds=pooled_prompt_embeds,
451 | negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
452 | num_inference_steps=num_inference_steps,
453 | generator=generator,
454 | **kwargs,
455 | ).images
456 |
457 | return images
458 |
--------------------------------------------------------------------------------
/ip_adapter/resampler.py:
--------------------------------------------------------------------------------
1 | # modified from https://github.com/mlfoundations/open_flamingo/blob/main/open_flamingo/src/helpers.py
2 | # and https://github.com/lucidrains/imagen-pytorch/blob/main/imagen_pytorch/imagen_pytorch.py
3 |
4 | import math
5 |
6 | import torch
7 | import torch.nn as nn
8 | from einops import rearrange
9 | from einops.layers.torch import Rearrange
10 |
11 |
12 | # FFN
13 | def FeedForward(dim, mult=4):
14 | inner_dim = int(dim * mult)
15 | return nn.Sequential(
16 | nn.LayerNorm(dim),
17 | nn.Linear(dim, inner_dim, bias=False),
18 | nn.GELU(),
19 | nn.Linear(inner_dim, dim, bias=False),
20 | )
21 |
22 |
23 | def reshape_tensor(x, heads):
24 | bs, length, width = x.shape
25 | # (bs, length, width) --> (bs, length, n_heads, dim_per_head)
26 | x = x.view(bs, length, heads, -1)
27 | # (bs, length, n_heads, dim_per_head) --> (bs, n_heads, length, dim_per_head)
28 | x = x.transpose(1, 2)
29 | # (bs, n_heads, length, dim_per_head) --> (bs*n_heads, length, dim_per_head)
30 | x = x.reshape(bs, heads, length, -1)
31 | return x
32 |
33 |
34 | class PerceiverAttention(nn.Module):
35 | def __init__(self, *, dim, dim_head=64, heads=8):
36 | super().__init__()
37 | self.scale = dim_head**-0.5
38 | self.dim_head = dim_head
39 | self.heads = heads
40 | inner_dim = dim_head * heads
41 |
42 | self.norm1 = nn.LayerNorm(dim)
43 | self.norm2 = nn.LayerNorm(dim)
44 |
45 | self.to_q = nn.Linear(dim, inner_dim, bias=False)
46 | self.to_kv = nn.Linear(dim, inner_dim * 2, bias=False)
47 | self.to_out = nn.Linear(inner_dim, dim, bias=False)
48 |
49 | def forward(self, x, latents):
50 | """
51 | Args:
52 | x (torch.Tensor): image features
53 | shape (b, n1, D)
54 | latent (torch.Tensor): latent features
55 | shape (b, n2, D)
56 | """
57 | x = self.norm1(x)
58 | latents = self.norm2(latents)
59 |
60 | b, l, _ = latents.shape
61 |
62 | q = self.to_q(latents)
63 | kv_input = torch.cat((x, latents), dim=-2)
64 | k, v = self.to_kv(kv_input).chunk(2, dim=-1)
65 |
66 | q = reshape_tensor(q, self.heads)
67 | k = reshape_tensor(k, self.heads)
68 | v = reshape_tensor(v, self.heads)
69 |
70 | # attention
71 | scale = 1 / math.sqrt(math.sqrt(self.dim_head))
72 | weight = (q * scale) @ (k * scale).transpose(-2, -1) # More stable with f16 than dividing afterwards
73 | weight = torch.softmax(weight.float(), dim=-1).type(weight.dtype)
74 | out = weight @ v
75 |
76 | out = out.permute(0, 2, 1, 3).reshape(b, l, -1)
77 |
78 | return self.to_out(out)
79 |
80 |
81 | class Resampler(nn.Module):
82 | def __init__(
83 | self,
84 | dim=1024,
85 | depth=8,
86 | dim_head=64,
87 | heads=16,
88 | num_queries=8,
89 | embedding_dim=768,
90 | output_dim=1024,
91 | ff_mult=4,
92 | max_seq_len: int = 257, # CLIP tokens + CLS token
93 | apply_pos_emb: bool = False,
94 | num_latents_mean_pooled: int = 0, # number of latents derived from mean pooled representation of the sequence
95 | ):
96 | super().__init__()
97 | self.pos_emb = nn.Embedding(max_seq_len, embedding_dim) if apply_pos_emb else None
98 |
99 | self.latents = nn.Parameter(torch.randn(1, num_queries, dim) / dim**0.5)
100 |
101 | self.proj_in = nn.Linear(embedding_dim, dim)
102 |
103 | self.proj_out = nn.Linear(dim, output_dim)
104 | self.norm_out = nn.LayerNorm(output_dim)
105 |
106 | self.to_latents_from_mean_pooled_seq = (
107 | nn.Sequential(
108 | nn.LayerNorm(dim),
109 | nn.Linear(dim, dim * num_latents_mean_pooled),
110 | Rearrange("b (n d) -> b n d", n=num_latents_mean_pooled),
111 | )
112 | if num_latents_mean_pooled > 0
113 | else None
114 | )
115 |
116 | self.layers = nn.ModuleList([])
117 | for _ in range(depth):
118 | self.layers.append(
119 | nn.ModuleList(
120 | [
121 | PerceiverAttention(dim=dim, dim_head=dim_head, heads=heads),
122 | FeedForward(dim=dim, mult=ff_mult),
123 | ]
124 | )
125 | )
126 |
127 | def forward(self, x):
128 | if self.pos_emb is not None:
129 | n, device = x.shape[1], x.device
130 | pos_emb = self.pos_emb(torch.arange(n, device=device))
131 | x = x + pos_emb
132 |
133 | latents = self.latents.repeat(x.size(0), 1, 1)
134 |
135 | x = self.proj_in(x)
136 |
137 | if self.to_latents_from_mean_pooled_seq:
138 | meanpooled_seq = masked_mean(x, dim=1, mask=torch.ones(x.shape[:2], device=x.device, dtype=torch.bool))
139 | meanpooled_latents = self.to_latents_from_mean_pooled_seq(meanpooled_seq)
140 | latents = torch.cat((meanpooled_latents, latents), dim=-2)
141 |
142 | for attn, ff in self.layers:
143 | latents = attn(x, latents) + latents
144 | latents = ff(latents) + latents
145 |
146 | latents = self.proj_out(latents)
147 | return self.norm_out(latents)
148 |
149 |
150 | def masked_mean(t, *, dim, mask=None):
151 | if mask is None:
152 | return t.mean(dim=dim)
153 |
154 | denom = mask.sum(dim=dim, keepdim=True)
155 | mask = rearrange(mask, "b n -> b n 1")
156 | masked_t = t.masked_fill(~mask, 0.0)
157 |
158 | return masked_t.sum(dim=dim) / denom.clamp(min=1e-5)
159 |
--------------------------------------------------------------------------------
/ip_adapter/sd3_attention_processor.py:
--------------------------------------------------------------------------------
1 | from typing import Callable, List, Optional, Union
2 |
3 | import torch
4 | import torch.nn.functional as F
5 | from torch import nn
6 | from diffusers.models.attention_processor import Attention
7 |
8 |
9 | class JointAttnProcessor2_0:
10 | """Attention processor used typically in processing the SD3-like self-attention projections."""
11 |
12 | def __init__(self):
13 | if not hasattr(F, "scaled_dot_product_attention"):
14 | raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
15 |
16 | def __call__(
17 | self,
18 | attn: Attention,
19 | hidden_states: torch.FloatTensor,
20 | encoder_hidden_states: torch.FloatTensor = None,
21 | attention_mask: Optional[torch.FloatTensor] = None,
22 | *args,
23 | **kwargs,
24 | ) -> torch.FloatTensor:
25 | residual = hidden_states
26 |
27 | input_ndim = hidden_states.ndim
28 | if input_ndim == 4:
29 | batch_size, channel, height, width = hidden_states.shape
30 | hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
31 | context_input_ndim = encoder_hidden_states.ndim
32 | if context_input_ndim == 4:
33 | batch_size, channel, height, width = encoder_hidden_states.shape
34 | encoder_hidden_states = encoder_hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
35 |
36 | batch_size = encoder_hidden_states.shape[0]
37 |
38 | # `sample` projections.
39 | query = attn.to_q(hidden_states)
40 | key = attn.to_k(hidden_states)
41 | value = attn.to_v(hidden_states)
42 |
43 | # `context` projections.
44 | encoder_hidden_states_query_proj = attn.add_q_proj(encoder_hidden_states)
45 | encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
46 | encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
47 |
48 | # attention
49 | query = torch.cat([query, encoder_hidden_states_query_proj], dim=1)
50 | key = torch.cat([key, encoder_hidden_states_key_proj], dim=1)
51 | value = torch.cat([value, encoder_hidden_states_value_proj], dim=1)
52 |
53 | inner_dim = key.shape[-1]
54 | head_dim = inner_dim // attn.heads
55 | query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
56 | key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
57 | value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
58 |
59 | hidden_states = F.scaled_dot_product_attention(query, key, value, dropout_p=0.0, is_causal=False)
60 | hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
61 | hidden_states = hidden_states.to(query.dtype)
62 |
63 | # Split the attention outputs.
64 | hidden_states, encoder_hidden_states = (
65 | hidden_states[:, : residual.shape[1]],
66 | hidden_states[:, residual.shape[1] :],
67 | )
68 |
69 | # linear proj
70 | hidden_states = attn.to_out[0](hidden_states)
71 | # dropout
72 | hidden_states = attn.to_out[1](hidden_states)
73 | if not attn.context_pre_only:
74 | encoder_hidden_states = attn.to_add_out(encoder_hidden_states)
75 |
76 | if input_ndim == 4:
77 | hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
78 | if context_input_ndim == 4:
79 | encoder_hidden_states = encoder_hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
80 |
81 | return hidden_states, encoder_hidden_states
82 |
83 |
84 | class IPJointAttnProcessor2_0(torch.nn.Module):
85 | """Attention processor used typically in processing the SD3-like self-attention projections."""
86 |
87 | def __init__(self, context_dim, hidden_dim, scale=1.0):
88 | if not hasattr(F, "scaled_dot_product_attention"):
89 | raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
90 | super().__init__()
91 | self.scale = scale
92 |
93 | self.add_k_proj_ip = nn.Linear(context_dim, hidden_dim)
94 | self.add_v_proj_ip = nn.Linear(context_dim, hidden_dim)
95 |
96 |
97 | def __call__(
98 | self,
99 | attn: Attention,
100 | hidden_states: torch.FloatTensor,
101 | encoder_hidden_states: torch.FloatTensor = None,
102 | attention_mask: Optional[torch.FloatTensor] = None,
103 | ip_hidden_states: torch.FloatTensor = None,
104 | *args,
105 | **kwargs,
106 | ) -> torch.FloatTensor:
107 | residual = hidden_states
108 |
109 | input_ndim = hidden_states.ndim
110 | if input_ndim == 4:
111 | batch_size, channel, height, width = hidden_states.shape
112 | hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
113 | context_input_ndim = encoder_hidden_states.ndim
114 | if context_input_ndim == 4:
115 | batch_size, channel, height, width = encoder_hidden_states.shape
116 | encoder_hidden_states = encoder_hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
117 |
118 | batch_size = encoder_hidden_states.shape[0]
119 |
120 | # `sample` projections.
121 | query = attn.to_q(hidden_states)
122 | key = attn.to_k(hidden_states)
123 | value = attn.to_v(hidden_states)
124 |
125 | sample_query = query # latent query
126 |
127 | # `context` projections.
128 | encoder_hidden_states_query_proj = attn.add_q_proj(encoder_hidden_states)
129 | encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
130 | encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
131 |
132 | # attention
133 | query = torch.cat([query, encoder_hidden_states_query_proj], dim=1)
134 | key = torch.cat([key, encoder_hidden_states_key_proj], dim=1)
135 | value = torch.cat([value, encoder_hidden_states_value_proj], dim=1)
136 |
137 | inner_dim = key.shape[-1]
138 | head_dim = inner_dim // attn.heads
139 | query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
140 | key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
141 | value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
142 |
143 | hidden_states = F.scaled_dot_product_attention(query, key, value, dropout_p=0.0, is_causal=False)
144 | hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
145 | hidden_states = hidden_states.to(query.dtype)
146 |
147 | # Split the attention outputs.
148 | hidden_states, encoder_hidden_states = (
149 | hidden_states[:, : residual.shape[1]],
150 | hidden_states[:, residual.shape[1] :],
151 | )
152 |
153 | # for ip-adapter
154 | ip_key = self.add_k_proj_ip(ip_hidden_states)
155 | ip_value = self.add_v_proj_ip(ip_hidden_states)
156 | ip_query = sample_query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
157 | ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
158 | ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
159 |
160 | ip_hidden_states = F.scaled_dot_product_attention(ip_query, ip_key, ip_value, dropout_p=0.0, is_causal=False)
161 | ip_hidden_states = ip_hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
162 | ip_hidden_states = ip_hidden_states.to(ip_query.dtype)
163 |
164 | hidden_states = hidden_states + self.scale * ip_hidden_states
165 |
166 | # linear proj
167 | hidden_states = attn.to_out[0](hidden_states)
168 | # dropout
169 | hidden_states = attn.to_out[1](hidden_states)
170 | if not attn.context_pre_only:
171 | encoder_hidden_states = attn.to_add_out(encoder_hidden_states)
172 |
173 | if input_ndim == 4:
174 | hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
175 | if context_input_ndim == 4:
176 | encoder_hidden_states = encoder_hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
177 |
178 | return hidden_states, encoder_hidden_states
179 |
180 |
--------------------------------------------------------------------------------
/ip_adapter/test_resampler.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from resampler import Resampler
3 | from transformers import CLIPVisionModel
4 |
5 | BATCH_SIZE = 2
6 | OUTPUT_DIM = 1280
7 | NUM_QUERIES = 8
8 | NUM_LATENTS_MEAN_POOLED = 4 # 0 for no mean pooling (previous behavior)
9 | APPLY_POS_EMB = True # False for no positional embeddings (previous behavior)
10 | IMAGE_ENCODER_NAME_OR_PATH = "laion/CLIP-ViT-H-14-laion2B-s32B-b79K"
11 |
12 |
13 | def main():
14 | image_encoder = CLIPVisionModel.from_pretrained(IMAGE_ENCODER_NAME_OR_PATH)
15 | embedding_dim = image_encoder.config.hidden_size
16 | print(f"image_encoder hidden size: ", embedding_dim)
17 |
18 | image_proj_model = Resampler(
19 | dim=1024,
20 | depth=2,
21 | dim_head=64,
22 | heads=16,
23 | num_queries=NUM_QUERIES,
24 | embedding_dim=embedding_dim,
25 | output_dim=OUTPUT_DIM,
26 | ff_mult=2,
27 | max_seq_len=257,
28 | apply_pos_emb=APPLY_POS_EMB,
29 | num_latents_mean_pooled=NUM_LATENTS_MEAN_POOLED,
30 | )
31 |
32 | dummy_images = torch.randn(BATCH_SIZE, 3, 224, 224)
33 | with torch.no_grad():
34 | image_embeds = image_encoder(dummy_images, output_hidden_states=True).hidden_states[-2]
35 | print("image_embds shape: ", image_embeds.shape)
36 |
37 | with torch.no_grad():
38 | ip_tokens = image_proj_model(image_embeds)
39 | print("ip_tokens shape:", ip_tokens.shape)
40 | assert ip_tokens.shape == (BATCH_SIZE, NUM_QUERIES + NUM_LATENTS_MEAN_POOLED, OUTPUT_DIM)
41 |
42 |
43 | if __name__ == "__main__":
44 | main()
45 |
--------------------------------------------------------------------------------
/ip_adapter/utils.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 | import numpy as np
4 | from PIL import Image
5 |
6 | attn_maps = {}
7 | def hook_fn(name):
8 | def forward_hook(module, input, output):
9 | if hasattr(module.processor, "attn_map"):
10 | attn_maps[name] = module.processor.attn_map
11 | del module.processor.attn_map
12 |
13 | return forward_hook
14 |
15 | def register_cross_attention_hook(unet):
16 | for name, module in unet.named_modules():
17 | if name.split('.')[-1].startswith('attn2'):
18 | module.register_forward_hook(hook_fn(name))
19 |
20 | return unet
21 |
22 | def upscale(attn_map, target_size):
23 | attn_map = torch.mean(attn_map, dim=0)
24 | attn_map = attn_map.permute(1,0)
25 | temp_size = None
26 |
27 | for i in range(0,5):
28 | scale = 2 ** i
29 | if ( target_size[0] // scale ) * ( target_size[1] // scale) == attn_map.shape[1]*64:
30 | temp_size = (target_size[0]//(scale*8), target_size[1]//(scale*8))
31 | break
32 |
33 | assert temp_size is not None, "temp_size cannot is None"
34 |
35 | attn_map = attn_map.view(attn_map.shape[0], *temp_size)
36 |
37 | attn_map = F.interpolate(
38 | attn_map.unsqueeze(0).to(dtype=torch.float32),
39 | size=target_size,
40 | mode='bilinear',
41 | align_corners=False
42 | )[0]
43 |
44 | attn_map = torch.softmax(attn_map, dim=0)
45 | return attn_map
46 | def get_net_attn_map(image_size, batch_size=2, instance_or_negative=False, detach=True):
47 |
48 | idx = 0 if instance_or_negative else 1
49 | net_attn_maps = []
50 |
51 | for name, attn_map in attn_maps.items():
52 | attn_map = attn_map.cpu() if detach else attn_map
53 | attn_map = torch.chunk(attn_map, batch_size)[idx].squeeze()
54 | attn_map = upscale(attn_map, image_size)
55 | net_attn_maps.append(attn_map)
56 |
57 | net_attn_maps = torch.mean(torch.stack(net_attn_maps,dim=0),dim=0)
58 |
59 | return net_attn_maps
60 |
61 | def attnmaps2images(net_attn_maps):
62 |
63 | #total_attn_scores = 0
64 | images = []
65 |
66 | for attn_map in net_attn_maps:
67 | attn_map = attn_map.cpu().numpy()
68 | #total_attn_scores += attn_map.mean().item()
69 |
70 | normalized_attn_map = (attn_map - np.min(attn_map)) / (np.max(attn_map) - np.min(attn_map)) * 255
71 | normalized_attn_map = normalized_attn_map.astype(np.uint8)
72 | #print("norm: ", normalized_attn_map.shape)
73 | image = Image.fromarray(normalized_attn_map)
74 |
75 | #image = fix_save_attn_map(attn_map)
76 | images.append(image)
77 |
78 | #print(total_attn_scores)
79 | return images
80 | def is_torch2_available():
81 | return hasattr(F, "scaled_dot_product_attention")
82 |
83 | def get_generator(seed, device):
84 |
85 | if seed is not None:
86 | if isinstance(seed, list):
87 | generator = [torch.Generator(device).manual_seed(seed_item) for seed_item in seed]
88 | else:
89 | generator = torch.Generator(device).manual_seed(seed)
90 | else:
91 | generator = None
92 |
93 | return generator
--------------------------------------------------------------------------------
/ip_lora_inference/download_ip_adapter.sh:
--------------------------------------------------------------------------------
1 | huggingface-cli download h94/IP-Adapter --repo-type model --include "sdxl_models/ip-adapter-plus_sdxl_vit-h.bin" --local-dir ./weights/ip_adapter/
2 |
--------------------------------------------------------------------------------
/ip_lora_inference/download_loras.sh:
--------------------------------------------------------------------------------
1 | echo "using HF_API_TOKEN: $HF_API_TOKEN"
2 |
3 | huggingface-cli download kfirgold99/Piece-it-Together --repo-type model --include "background_generation/pytorch_lora_weights.safetensors" --local-dir ./weights/
4 | huggingface-cli download kfirgold99/Piece-it-Together --repo-type model --include "character_sheet/pytorch_lora_weights.safetensors" --local-dir ./weights/
--------------------------------------------------------------------------------
/ip_lora_inference/inference_ip_lora.py:
--------------------------------------------------------------------------------
1 | from dataclasses import dataclass
2 | from pathlib import Path
3 | from typing import Optional, Union
4 |
5 | import matplotlib.pyplot as plt
6 | import pyrallis
7 | import torch
8 | from diffusers import UNet2DConditionModel
9 | from PIL import Image
10 | from torchvision import transforms
11 | from transformers import AutoModelForImageSegmentation
12 |
13 | from ip_lora_train.ip_adapter_for_lora import IPAdapterPlusXLLoRA
14 | from ip_lora_train.sdxl_ip_lora_pipeline import StableDiffusionXLIPLoRAPipeline
15 |
16 |
17 | @dataclass
18 | class ExperimentConfig:
19 | lora_type: str = "character_sheet"
20 | lora_path: Path = Path("weights/character_sheet/pytorch_lora_weights.safetensors")
21 | prompt: str = "a character sheet displaying a creature, from several angles with 1 large front view in the middle, clean white background. In the background we can see half-completed, partially colored, sketches of different parts of the object"
22 | output_dir: Path = Path("ip_lora_inference/character_sheet/")
23 | ref_images_paths: Union[list[Path], Path] = Path("assets/character_sheet_default_ref.jpg")
24 | ip_adapter_path: Path = Path("weights/ip_adapter/sdxl_models/ip-adapter-plus_sdxl_vit-h.bin")
25 | seed: Optional[int] = None
26 | num_inference_steps: int = 50
27 | remove_background: bool = True
28 |
29 | def __post_init__(self):
30 | assert self.lora_type in ["character_sheet", "background_generation"]
31 | assert self.lora_path.exists(), f"Lora path {self.lora_path} does not exist"
32 | assert self.ip_adapter_path.exists(), f"IP adapter path {self.ip_adapter_path} does not exist"
33 | self.output_dir.mkdir(parents=True, exist_ok=True)
34 | if isinstance(self.ref_images_paths, Path):
35 | self.ref_images_paths = [self.ref_images_paths]
36 | for ref_image_path in self.ref_images_paths:
37 | assert ref_image_path.exists(), f"Reference image path {ref_image_path} does not exist"
38 |
39 |
40 | def load_rmbg_model():
41 | model = AutoModelForImageSegmentation.from_pretrained("briaai/RMBG-2.0", trust_remote_code=True)
42 | torch.set_float32_matmul_precision(["high", "highest"][0])
43 | model.to("cuda")
44 | model.eval()
45 | return model
46 |
47 |
48 | def remove_background(model, image: Image.Image) -> Image.Image:
49 | assert image.size == (1024, 1024)
50 | # Data settings
51 | image_size = (1024, 1024)
52 | transform_image = transforms.Compose(
53 | [
54 | transforms.Resize(image_size),
55 | transforms.ToTensor(),
56 | transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
57 | ]
58 | )
59 |
60 | input_images = transform_image(image).unsqueeze(0).to("cuda")
61 |
62 | # Prediction
63 | with torch.no_grad():
64 | preds = model(input_images)[-1].sigmoid().cpu()
65 | pred = preds[0].squeeze()
66 | mask = transforms.ToPILImage()(pred).resize(image_size)
67 |
68 | # Create white background
69 | white_bg = Image.new("RGB", image_size, (255, 255, 255))
70 | # Paste original image using mask
71 | white_bg.paste(image, mask=mask)
72 | return white_bg
73 |
74 |
75 | @torch.inference_mode()
76 | @pyrallis.wrap()
77 | def main(cfg: ExperimentConfig):
78 | pipe_id = "stabilityai/stable-diffusion-xl-base-1.0"
79 | print("loading unet")
80 | unet = UNet2DConditionModel.from_pretrained(pipe_id, subfolder="unet")
81 | print("loading ip model")
82 | ip_model = IPAdapterPlusXLLoRA(
83 | unet=unet,
84 | image_encoder_path="models/image_encoder",
85 | ip_ckpt=cfg.ip_adapter_path,
86 | device="cuda",
87 | num_tokens=16,
88 | )
89 | print("loading pipeline")
90 | pipe = StableDiffusionXLIPLoRAPipeline.from_pretrained(
91 | pipe_id,
92 | unet=unet,
93 | variant=None,
94 | torch_dtype=torch.float32,
95 | )
96 | print("loading lora")
97 | pipe.load_lora_weights(
98 | pretrained_model_name_or_path_or_dict=cfg.lora_path,
99 | adapter_name="lora1",
100 | )
101 | pipe.set_adapters(["lora1"], adapter_weights=[1.0])
102 |
103 | pipe.to("cuda")
104 | print("running inference")
105 | if cfg.remove_background:
106 | rmbg_model = load_rmbg_model()
107 | else:
108 | rmbg_model = None
109 | for ref_image_path in cfg.ref_images_paths:
110 | if cfg.seed is not None:
111 | generator = torch.Generator("cuda").manual_seed(cfg.seed)
112 | else:
113 | generator = None
114 | ref_image = Image.open(ref_image_path).convert("RGB")
115 | if cfg.remove_background:
116 | rmbg_model.cuda()
117 | ref_image = remove_background(model=rmbg_model, image=ref_image)
118 | rmbg_model.cpu()
119 | image_name = ref_image_path.stem
120 | image = pipe(
121 | cfg.prompt,
122 | ip_adapter_image=ref_image,
123 | ip_model=ip_model,
124 | num_inference_steps=cfg.num_inference_steps,
125 | generator=generator,
126 | ).images[0]
127 | image.save(cfg.output_dir / f"{image_name}_pred.jpg")
128 | ref_image.save(cfg.output_dir / f"{image_name}_ref.jpg")
129 |
130 | # Create side-by-side plot
131 | fig, ax = plt.subplots(1, 2, figsize=(20, 10))
132 | ax[0].imshow(ref_image)
133 | ax[0].axis("off")
134 | ax[1].imshow(image)
135 | ax[1].axis("off")
136 | fig.suptitle(cfg.prompt, fontsize=24, wrap=True)
137 | plt.tight_layout()
138 | plt.savefig(cfg.output_dir / f"{image_name}_side_by_side.jpeg", bbox_inches="tight", dpi=300)
139 | plt.close()
140 |
141 |
142 | if __name__ == "__main__":
143 | main()
144 |
--------------------------------------------------------------------------------
/ip_lora_train/ip_adapter_for_lora.py:
--------------------------------------------------------------------------------
1 | import os
2 | from typing import List
3 |
4 | import torch
5 | from PIL import Image
6 | from safetensors import safe_open
7 | from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
8 |
9 | from ip_adapter.ip_adapter import ImageProjModel
10 | from ip_adapter.resampler import Resampler
11 | from ip_adapter.utils import get_generator, is_torch2_available
12 |
13 | if is_torch2_available():
14 | from ip_adapter.attention_processor import (
15 | AttnProcessor2_0 as AttnProcessor,
16 | )
17 | from ip_adapter.attention_processor import (
18 | CNAttnProcessor2_0 as CNAttnProcessor,
19 | )
20 | from ip_adapter.attention_processor import (
21 | IPAttnProcessor2_0 as IPAttnProcessor,
22 | )
23 | else:
24 | from ip_adapter.attention_processor import AttnProcessor, CNAttnProcessor, IPAttnProcessor
25 |
26 | WEIGHT_DTYPE = torch.float32
27 |
28 | class IPAdapterLoRA:
29 | def __init__(self, unet, image_encoder_path, ip_ckpt, device, num_tokens=4):
30 | self.device = device
31 | self.image_encoder_path = image_encoder_path
32 | self.ip_ckpt = ip_ckpt
33 | self.num_tokens = num_tokens
34 |
35 | self.unet = unet
36 | self.set_ip_adapter()
37 |
38 | # load image encoder
39 | self.image_encoder = CLIPVisionModelWithProjection.from_pretrained(
40 | "h94/IP-Adapter", subfolder="models/image_encoder"
41 | ).to(self.device, dtype=WEIGHT_DTYPE)
42 | self.clip_image_processor = CLIPImageProcessor()
43 | # image proj model
44 | self.image_proj_model = self.init_proj()
45 |
46 | self.load_ip_adapter()
47 |
48 | def init_proj(self):
49 | image_proj_model = ImageProjModel(
50 | cross_attention_dim=self.unet.config.cross_attention_dim,
51 | clip_embeddings_dim=self.image_encoder.config.projection_dim,
52 | clip_extra_context_tokens=self.num_tokens,
53 | ).to(self.device, dtype=WEIGHT_DTYPE)
54 | return image_proj_model
55 |
56 | def set_ip_adapter(self):
57 | unet = self.unet
58 | attn_procs = {}
59 | for name in unet.attn_processors.keys():
60 | cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
61 | if name.startswith("mid_block"):
62 | hidden_size = unet.config.block_out_channels[-1]
63 | elif name.startswith("up_blocks"):
64 | block_id = int(name[len("up_blocks.")])
65 | hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
66 | elif name.startswith("down_blocks"):
67 | block_id = int(name[len("down_blocks.")])
68 | hidden_size = unet.config.block_out_channels[block_id]
69 | if cross_attention_dim is None:
70 | attn_procs[name] = AttnProcessor()
71 | else:
72 | attn_procs[name] = IPAttnProcessor(
73 | hidden_size=hidden_size,
74 | cross_attention_dim=cross_attention_dim,
75 | scale=1.0,
76 | num_tokens=self.num_tokens,
77 | ).to(self.device, dtype=WEIGHT_DTYPE)
78 | unet.set_attn_processor(attn_procs)
79 |
80 | def load_ip_adapter(self):
81 | if os.path.splitext(self.ip_ckpt)[-1] == ".safetensors":
82 | state_dict = {"image_proj": {}, "ip_adapter": {}}
83 | with safe_open(self.ip_ckpt, framework="pt", device="cpu") as f:
84 | for key in f.keys():
85 | if key.startswith("image_proj."):
86 | state_dict["image_proj"][key.replace("image_proj.", "")] = f.get_tensor(key)
87 | elif key.startswith("ip_adapter."):
88 | state_dict["ip_adapter"][key.replace("ip_adapter.", "")] = f.get_tensor(key)
89 | else:
90 | state_dict = torch.load(self.ip_ckpt, map_location="cpu")
91 | self.image_proj_model.load_state_dict(state_dict["image_proj"])
92 | ip_layers = torch.nn.ModuleList(self.unet.attn_processors.values())
93 | ip_layers.load_state_dict(state_dict["ip_adapter"])
94 |
95 | def save_ip_adapter(self, save_path):
96 | state_dict = {
97 | "image_proj": self.image_proj_model.state_dict(),
98 | "ip_adapter": torch.nn.ModuleList(self.unet.attn_processors.values()).state_dict(),
99 | }
100 | torch.save(state_dict, save_path)
101 |
102 | @torch.inference_mode()
103 | def get_image_embeds(self, pil_image=None, clip_image_embeds=None):
104 | if pil_image is not None:
105 | if isinstance(pil_image, Image.Image):
106 | pil_image = [pil_image]
107 | clip_image = self.clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
108 | clip_image_embeds = self.image_encoder(clip_image.to(self.device, dtype=WEIGHT_DTYPE)).image_embeds
109 | else:
110 | clip_image_embeds = clip_image_embeds.to(self.device, dtype=WEIGHT_DTYPE)
111 | image_prompt_embeds = self.image_proj_model(clip_image_embeds)
112 | uncond_image_prompt_embeds = self.image_proj_model(torch.zeros_like(clip_image_embeds))
113 | return image_prompt_embeds, uncond_image_prompt_embeds
114 |
115 | def set_scale(self, scale):
116 | for attn_processor in self.unet.attn_processors.values():
117 | if isinstance(attn_processor, IPAttnProcessor):
118 | attn_processor.scale = scale
119 |
120 | def generate(
121 | self,
122 | pil_image=None,
123 | clip_image_embeds=None,
124 | prompt=None,
125 | negative_prompt=None,
126 | scale=1.0,
127 | num_samples=4,
128 | seed=None,
129 | guidance_scale=7.5,
130 | num_inference_steps=30,
131 | **kwargs,
132 | ):
133 | self.set_scale(scale)
134 |
135 | if pil_image is not None:
136 | num_prompts = 1 if isinstance(pil_image, Image.Image) else len(pil_image)
137 | else:
138 | num_prompts = clip_image_embeds.size(0)
139 |
140 | if prompt is None:
141 | prompt = "best quality, high quality"
142 | if negative_prompt is None:
143 | negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
144 |
145 | if not isinstance(prompt, List):
146 | prompt = [prompt] * num_prompts
147 | if not isinstance(negative_prompt, List):
148 | negative_prompt = [negative_prompt] * num_prompts
149 |
150 | image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(
151 | pil_image=pil_image, clip_image_embeds=clip_image_embeds
152 | )
153 | bs_embed, seq_len, _ = image_prompt_embeds.shape
154 | image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
155 | image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
156 | uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
157 | uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
158 |
159 | with torch.inference_mode():
160 | prompt_embeds_, negative_prompt_embeds_ = self.pipe.encode_prompt(
161 | prompt,
162 | device=self.device,
163 | num_images_per_prompt=num_samples,
164 | do_classifier_free_guidance=True,
165 | negative_prompt=negative_prompt,
166 | )
167 | prompt_embeds = torch.cat([prompt_embeds_, image_prompt_embeds], dim=1)
168 | negative_prompt_embeds = torch.cat([negative_prompt_embeds_, uncond_image_prompt_embeds], dim=1)
169 |
170 | generator = get_generator(seed, self.device)
171 |
172 | images = self.pipe(
173 | prompt_embeds=prompt_embeds,
174 | negative_prompt_embeds=negative_prompt_embeds,
175 | guidance_scale=guidance_scale,
176 | num_inference_steps=num_inference_steps,
177 | generator=generator,
178 | **kwargs,
179 | ).images
180 |
181 | return images
182 |
183 |
184 | class IPAdapterPlusXLLoRA(IPAdapterLoRA):
185 | """SDXL"""
186 |
187 | def init_proj(self):
188 | image_proj_model = Resampler(
189 | dim=1280,
190 | depth=4,
191 | dim_head=64,
192 | heads=20,
193 | num_queries=self.num_tokens,
194 | embedding_dim=self.image_encoder.config.hidden_size,
195 | output_dim=self.unet.config.cross_attention_dim,
196 | ff_mult=4,
197 | ).to(self.device, dtype=WEIGHT_DTYPE)
198 | return image_proj_model
199 |
200 | @torch.inference_mode()
201 | def get_image_embeds(self, pil_image, skip_uncond=False):
202 | if isinstance(pil_image, Image.Image):
203 | pil_image = [pil_image]
204 | clip_image = self.clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
205 | else:
206 | clip_image = pil_image
207 | clip_image = clip_image.to(self.device, dtype=WEIGHT_DTYPE)
208 | clip_image_embeds = self.image_encoder(clip_image, output_hidden_states=True).hidden_states[-2]
209 | image_prompt_embeds = self.image_proj_model(clip_image_embeds)
210 | if skip_uncond:
211 | return image_prompt_embeds
212 | uncond_clip_image_embeds = self.image_encoder(
213 | torch.zeros_like(clip_image), output_hidden_states=True
214 | ).hidden_states[-2]
215 | uncond_image_prompt_embeds = self.image_proj_model(uncond_clip_image_embeds)
216 | return image_prompt_embeds, uncond_image_prompt_embeds
217 |
218 | def get_uncond_embeds(self):
219 | clip_image = self.clip_image_processor(images=[Image.new("RGB", (128, 128))], return_tensors="pt").pixel_values
220 | clip_image = clip_image.to(self.device, dtype=WEIGHT_DTYPE)
221 | uncond_clip_image_embeds = self.image_encoder(
222 | torch.zeros_like(clip_image), output_hidden_states=True
223 | ).hidden_states[-2]
224 | uncond_image_prompt_embeds = self.image_proj_model(uncond_clip_image_embeds)
225 | return uncond_image_prompt_embeds
226 |
227 | def generate(
228 | self,
229 | pil_image=None,
230 | prompt=None,
231 | negative_prompt=None,
232 | scale=1.0,
233 | num_samples=4,
234 | seed=None,
235 | num_inference_steps=30,
236 | image_prompt_embeds=None,
237 | **kwargs,
238 | ):
239 | self.set_scale(scale)
240 |
241 | num_prompts = 1 # if isinstance(pil_image, Image.Image) else len(pil_image)
242 |
243 | if prompt is None:
244 | prompt = "best quality, high quality"
245 | if negative_prompt is None:
246 | negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
247 |
248 | if not isinstance(prompt, List):
249 | prompt = [prompt] * num_prompts
250 | if not isinstance(negative_prompt, List):
251 | negative_prompt = [negative_prompt] * num_prompts
252 |
253 | if image_prompt_embeds is None:
254 | image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(pil_image)
255 | else:
256 | uncond_image_prompt_embeds = self.get_uncond_embeds()
257 |
258 | bs_embed, seq_len, _ = image_prompt_embeds.shape
259 | image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
260 | image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
261 | uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
262 | uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
263 |
264 | with torch.inference_mode():
265 | (
266 | prompt_embeds,
267 | negative_prompt_embeds,
268 | pooled_prompt_embeds,
269 | negative_pooled_prompt_embeds,
270 | ) = self.pipe.encode_prompt(
271 | prompt,
272 | num_images_per_prompt=num_samples,
273 | do_classifier_free_guidance=True,
274 | negative_prompt=negative_prompt,
275 | )
276 | prompt_embeds = torch.cat([prompt_embeds, image_prompt_embeds], dim=1)
277 | negative_prompt_embeds = torch.cat([negative_prompt_embeds, uncond_image_prompt_embeds], dim=1)
278 |
279 | generator = get_generator(seed, self.device)
280 |
281 | images = self.pipe(
282 | prompt_embeds=prompt_embeds,
283 | negative_prompt_embeds=negative_prompt_embeds,
284 | pooled_prompt_embeds=pooled_prompt_embeds,
285 | negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
286 | num_inference_steps=num_inference_steps,
287 | generator=generator,
288 | **kwargs,
289 | ).images
290 |
291 | return images
292 |
--------------------------------------------------------------------------------
/ip_lora_train/ip_lora_dataset.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 |
3 | import torch
4 | from PIL import Image
5 | from torch.utils.data import Dataset
6 | from torchvision.transforms import Compose, Normalize, ToTensor
7 |
8 | try:
9 | from torchvision.transforms import InterpolationMode
10 |
11 | BICUBIC = InterpolationMode.BICUBIC
12 | except ImportError:
13 | BICUBIC = Image.BICUBIC
14 |
15 | CHARACTER_SHEET_PROMPT = "a character sheet displaying a creature, from several angles with 1 large front view in the middle, clean white background. In the background we can see half-completed, partially colored, sketches of different parts of the object"
16 |
17 |
18 | def _transform():
19 | return Compose(
20 | [
21 | ToTensor(),
22 | Normalize(
23 | [0.5],
24 | [0.5],
25 | ),
26 | ]
27 | )
28 |
29 |
30 | class IPLoraDataset(Dataset):
31 | def __init__(
32 | self,
33 | tokenizer1,
34 | tokenizer2,
35 | image_processor,
36 | target_resolution: int = 1024,
37 | base_dir: Path = Path("dataset/"),
38 | prompt_mode: str = "character_sheet",
39 | ):
40 | super().__init__()
41 | self.base_dir = base_dir
42 | self.samples = self.init_samples(base_dir)
43 | self.tokenizer1 = tokenizer1
44 | self.tokenizer2 = tokenizer2
45 | self.image_processor = image_processor
46 | self.target_resolution = target_resolution
47 | self.prompt_mode = prompt_mode
48 |
49 | def init_samples(self, base_dir):
50 | ref_dir = base_dir / "refs"
51 | targets_dir = base_dir / "targets"
52 | prompt_dir = base_dir / "targets"
53 | ref_files = list(ref_dir.glob("*.png")) + list(ref_dir.glob("*.jpg"))
54 | targets_files = list(targets_dir.glob("*.png")) + list(targets_dir.glob("*.jpg"))
55 | prompt_files = list(prompt_dir.glob("*.txt"))
56 | ref_prefixes = [f.stem.split("_ref")[0] for f in ref_files]
57 | targets_prefixes = [f.stem for f in targets_files]
58 | prompt_prefixes = [f.stem for f in prompt_files]
59 | valid_prefixes = list(set(ref_prefixes) & set(targets_prefixes) & set(prompt_prefixes))
60 | ref_png_paths = [ref_dir / f"{prefix}_ref.png" for prefix in valid_prefixes]
61 | ref_jpg_paths = [ref_dir / f"{prefix}_ref.jpg" for prefix in valid_prefixes]
62 | targets_png_paths = [targets_dir / f"{prefix}.png" for prefix in valid_prefixes]
63 | targets_jpg_paths = [targets_dir / f"{prefix}.jpg" for prefix in valid_prefixes]
64 | prompt_paths = [prompt_dir / f"{prefix}.txt" for prefix in valid_prefixes]
65 | samples = [
66 | {
67 | "ref": ref_png_paths[i] if ref_png_paths[i].exists() else ref_jpg_paths[i],
68 | "sheet": targets_png_paths[i] if targets_png_paths[i].exists() else targets_jpg_paths[i],
69 | "prompt": prompt_paths[i],
70 | }
71 | for i in range(len(valid_prefixes))
72 | ]
73 | print(f"lora_dataset.py:: found {len(samples)} samples")
74 | return samples
75 |
76 | def __len__(self):
77 | return len(self.samples)
78 |
79 | def get_prompt(self, prompt_text):
80 | if self.prompt_mode == "character_sheet":
81 | return CHARACTER_SHEET_PROMPT
82 | elif self.prompt_mode == "creature_in_scene":
83 | return prompt_text.split(",")[0] + " an imaginary fantasy creature in" + prompt_text.split("in a")[1]
84 | else:
85 | raise ValueError(f"Prompt mode {self.prompt_mode} is not supported.")
86 |
87 | def __getitem__(self, i: int):
88 | sample = self.samples[i]
89 | ref_path = sample["ref"]
90 | sheet_path = sample["sheet"]
91 | prompt_path = sample["prompt"]
92 | ref_image = Image.open(ref_path)
93 | sheet_image = Image.open(sheet_path)
94 | prompt_text = open(prompt_path, "r").read()
95 | sample_prompt = self.get_prompt(prompt_text)
96 | out_dict = {}
97 | input_ids1 = self.tokenizer1(
98 | [sample_prompt],
99 | max_length=self.tokenizer1.model_max_length,
100 | padding="max_length",
101 | truncation=True,
102 | return_tensors="pt",
103 | ).input_ids
104 | input_ids2 = self.tokenizer2(
105 | [sample_prompt],
106 | max_length=self.tokenizer2.model_max_length,
107 | padding="max_length",
108 | truncation=True,
109 | return_tensors="pt",
110 | ).input_ids
111 | out_dict["input_ids1"] = input_ids1
112 | out_dict["input_ids2"] = input_ids2
113 |
114 | out_dict["text"] = prompt_text
115 |
116 | processed_image_prompt = self.image_processor(images=[ref_image], return_tensors="pt").pixel_values
117 | out_dict["image_prompt"] = processed_image_prompt
118 | target_image_torch = _transform()(sheet_image)
119 | out_dict["target_image"] = target_image_torch
120 | out_dict["original_sizes"] = (self.target_resolution, self.target_resolution)
121 | out_dict["crop_top_lefts"] = (0, 0)
122 | return out_dict
123 |
124 |
125 | def ip_lora_collate_fn(batch):
126 | return_batch = {}
127 | return_batch["input_ids_one"] = torch.stack([item["input_ids1"] for item in batch])
128 | return_batch["input_ids_two"] = torch.stack([item["input_ids2"] for item in batch])
129 | return_batch["text"] = [item["text"] for item in batch]
130 | image_prompt = torch.stack([item["image_prompt"] for item in batch])
131 | image_prompt = image_prompt.to(memory_format=torch.contiguous_format).float()
132 | return_batch["image_prompt"] = image_prompt
133 | target_image = torch.stack([item["target_image"] for item in batch])
134 | target_image = target_image.to(memory_format=torch.contiguous_format).float()
135 |
136 | return_batch["target_image"] = target_image
137 | original_sizes = [item["original_sizes"] for item in batch]
138 | crop_top_lefts = [item["crop_top_lefts"] for item in batch]
139 | return_batch["original_sizes"] = original_sizes
140 | return_batch["crop_top_lefts"] = crop_top_lefts
141 | return return_batch
142 |
--------------------------------------------------------------------------------
/ip_lora_train/run_example.sh:
--------------------------------------------------------------------------------
1 | python ./ip_lora_train/train_ip_lora.py \
2 | --rank 64 \
3 | --resolution 1024 \
4 | --validation_epochs 1 \
5 | --num_train_epochs 100 \
6 | --checkpointing_steps 50 \
7 | --train_batch_size 2 \
8 | --learning_rate 1e-4 \
9 | --dataloader_num_workers 1 \
10 | --gradient_accumulation_steps 8 \
11 | --dataset_base_dir \
12 | --prompt_mode character_sheet \
13 | --output_dir ./output/train_ip_lora/character_sheet
14 |
--------------------------------------------------------------------------------
/ip_plus_space_exploration/download_directions.sh:
--------------------------------------------------------------------------------
1 | huggingface-cli download kfirgold99/Piece-it-Together --repo-type model --include "ip_space_edit_directions/*" --local-dir ./weights/
--------------------------------------------------------------------------------
/ip_plus_space_exploration/download_ip_adapter.sh:
--------------------------------------------------------------------------------
1 | huggingface-cli download h94/IP-Adapter --repo-type model --include "sdxl_models/ip-adapter-plus_sdxl_vit-h.bin" --local-dir ./weights/ip_adapter/
2 | huggingface-cli download h94/IP-Adapter --repo-type model --include "sdxl_models/ip-adapter_sdxl.bin" --local-dir ./weights/ip_adapter/
3 |
--------------------------------------------------------------------------------
/ip_plus_space_exploration/edit_by_direction.py:
--------------------------------------------------------------------------------
1 | from dataclasses import dataclass
2 | from pathlib import Path
3 | from typing import Optional
4 |
5 | import matplotlib.pyplot as plt
6 | import pyrallis
7 | import torch
8 | from PIL import Image
9 |
10 | from ip_plus_space_exploration.ip_model_utils import get_image_ip_base_tokens, get_image_ip_plus_tokens, load_ip
11 |
12 |
13 | def get_images_with_ip_direction(ip_model, img_tokens, ip_direction, seed):
14 | scales_images = {k: [] for k in [-1, -0.5, 0, 0.5, 1]}
15 |
16 | for step_size in scales_images.keys():
17 | new_ip_tokens = img_tokens + step_size * ip_direction
18 | image = ip_model.generate(
19 | pil_image=None,
20 | scale=1.0,
21 | image_prompt_embeds=new_ip_tokens.cuda(),
22 | num_samples=1,
23 | num_inference_steps=50,
24 | seed=seed,
25 | )
26 | scales_images[step_size] = image
27 | return scales_images
28 |
29 |
30 | def get_images_with_clip_direction(ip_model, clip_features, clip_direction, seed):
31 | scales_images = {k: [] for k in [-1, -0.5, 0, 0.5, 1]}
32 |
33 | for step_size in scales_images.keys():
34 | new_clip_features = clip_features + step_size * clip_direction
35 | new_ip_tokens = ip_model.image_proj_model(new_clip_features.cuda())
36 | image = ip_model.generate(
37 | pil_image=None,
38 | scale=1.0,
39 | image_prompt_embeds=new_ip_tokens.cuda(),
40 | num_samples=1,
41 | num_inference_steps=50,
42 | seed=seed,
43 | )
44 | scales_images[step_size] = image
45 | return scales_images
46 |
47 |
48 | @dataclass
49 | class EditByDirectionConfig:
50 | ip_model_type: str
51 | image_path: Path
52 | direction_path: Path
53 | direction_type: str
54 | output_dir: Path
55 | seed: Optional[int] = None
56 |
57 | def __post_init__(self):
58 | self.output_dir.mkdir(parents=True, exist_ok=True)
59 | assert self.direction_type.lower() in ["ip", "clip"]
60 |
61 |
62 | @torch.inference_mode()
63 | @pyrallis.wrap()
64 | def main(cfg: EditByDirectionConfig):
65 | ip_model = load_ip(cfg.ip_model_type)
66 | edit_direction = torch.load(cfg.direction_path)
67 | if cfg.image_path.is_dir():
68 | image_paths = list(cfg.image_path.glob("*.jpg")) + list(cfg.image_path.glob("*.png"))
69 | else:
70 | image_paths = [cfg.image_path]
71 | for img in image_paths:
72 | if cfg.ip_model_type == "plus":
73 | img_tokens, img_clip_embeds = get_image_ip_plus_tokens(ip_model, Image.open(img))
74 | elif cfg.ip_model_type == "base":
75 | img_tokens, img_clip_embeds = get_image_ip_base_tokens(ip_model, Image.open(img))
76 | if cfg.direction_type.upper() == "IP":
77 | scales_images = get_images_with_ip_direction(
78 | ip_model=ip_model, img_tokens=img_tokens, ip_direction=edit_direction, seed=cfg.seed
79 | )
80 | elif cfg.direction_type.upper() == "CLIP":
81 | scales_images = get_images_with_clip_direction(
82 | ip_model=ip_model, clip_features=img_clip_embeds, clip_direction=edit_direction, seed=cfg.seed
83 | )
84 | # Plot all images in a single row
85 | fig, axes = plt.subplots(1, len(scales_images) + 1, figsize=(20, 5)) # Increased height from 4 to 5
86 |
87 | # Sort the scales for consistent left-to-right ordering
88 | sorted_scales = sorted(scales_images.keys())
89 |
90 | axes[0].imshow(Image.open(img))
91 | axes[0].set_title(f"original", pad=15) # Added padding to the title
92 | axes[0].axis("off")
93 |
94 | for i, scale in enumerate(sorted_scales):
95 | axes[i + 1].imshow(scales_images[scale][0])
96 | axes[i + 1].set_title(f"dist from boundary={scale}", pad=15) # Added padding to the title
97 | axes[i + 1].axis("off")
98 |
99 | plt.tight_layout(rect=[0, 0, 1, 0.95]) # Added rect parameter to leave more room at the top
100 |
101 | plt.savefig(cfg.output_dir / f"{img.stem}_{cfg.direction_type}.png")
102 | for scale in scales_images.keys():
103 | scales_images[scale][0].save(str(cfg.output_dir / f"{img.stem}_{cfg.direction_type}_{scale}.jpg"))
104 | plt.close()
105 |
106 |
107 | if __name__ == "__main__":
108 | main()
109 |
--------------------------------------------------------------------------------
/ip_plus_space_exploration/find_direction.py:
--------------------------------------------------------------------------------
1 | from dataclasses import dataclass
2 | from pathlib import Path
3 |
4 | import pyrallis
5 | import torch
6 | from PIL import Image
7 | from tqdm import tqdm
8 |
9 | from ip_plus_space_exploration.ip_model_utils import get_image_ip_base_tokens, get_image_ip_plus_tokens, load_ip
10 |
11 |
12 | def get_class_tokens(ip_model, class_dir, ip_model_type: str = "plus"):
13 | image_prompt_embeds_list = []
14 | clip_image_embeds_list = []
15 | images = list(class_dir.glob("*.jpg")) + list(class_dir.glob("*.png"))
16 | for _, image in tqdm(enumerate(images), total=len(images)):
17 | pil_image = Image.open(image)
18 | if ip_model_type == "plus":
19 | image_prompt_embeds, clip_image_embeds = get_image_ip_plus_tokens(ip_model, pil_image)
20 | elif ip_model_type == "base":
21 | image_prompt_embeds, clip_image_embeds = get_image_ip_base_tokens(ip_model, pil_image)
22 | image_prompt_embeds_list.append(image_prompt_embeds.detach().cpu())
23 | clip_image_embeds_list.append(clip_image_embeds.detach().cpu())
24 | return torch.cat(image_prompt_embeds_list), torch.cat(clip_image_embeds_list)
25 |
26 |
27 | @dataclass
28 | class FindDirectionConfig:
29 | class1_dir: Path
30 | class2_dir: Path
31 | output_dir: Path
32 | ip_model_type: str
33 |
34 | def __post_init__(self):
35 | self.output_dir.mkdir(parents=True, exist_ok=True)
36 | assert self.ip_model_type in ["plus", "base"]
37 |
38 |
39 | @torch.inference_mode()
40 | @pyrallis.wrap()
41 | def main(cfg: FindDirectionConfig):
42 | ip_model = load_ip(cfg.ip_model_type)
43 | class_1_image_prompt_embeds, class_1_clip_image_embeds = get_class_tokens(
44 | ip_model=ip_model, class_dir=cfg.class1_dir, ip_model_type=cfg.ip_model_type
45 | )
46 | class_2_image_prompt_embeds, class_2_clip_image_embeds = get_class_tokens(
47 | ip_model=ip_model, class_dir=cfg.class2_dir, ip_model_type=cfg.ip_model_type
48 | )
49 | clip_direction = class_2_clip_image_embeds.mean(dim=0) - class_1_clip_image_embeds.mean(dim=0)
50 | ip_direction = class_2_image_prompt_embeds.mean(dim=0) - class_1_image_prompt_embeds.mean(dim=0)
51 | torch.save(clip_direction, cfg.output_dir / "clip_direction.pt")
52 | torch.save(ip_direction, cfg.output_dir / "ip_direction.pt")
53 |
54 |
55 | if __name__ == "__main__":
56 | main()
57 |
--------------------------------------------------------------------------------
/ip_plus_space_exploration/ip_model_utils.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from diffusers import StableDiffusionXLPipeline
3 |
4 | from ip_adapter.ip_adapter import IPAdapterPlusXL, IPAdapterXL
5 |
6 |
7 | def load_ip(type: str = "plus"):
8 | sdxl_pipeline = StableDiffusionXLPipeline.from_pretrained(
9 | "stabilityai/stable-diffusion-xl-base-1.0",
10 | ).to(dtype=torch.float16)
11 | if type == "plus":
12 | ip_model = IPAdapterPlusXL(
13 | sd_pipe=sdxl_pipeline,
14 | image_encoder_path="models/image_encoder",
15 | ip_ckpt="weights/ip_adapter/sdxl_models/ip-adapter-plus_sdxl_vit-h.bin",
16 | device="cuda",
17 | num_tokens=16,
18 | )
19 | elif type == "base":
20 | ip_model = IPAdapterXL(
21 | sd_pipe=sdxl_pipeline,
22 | image_encoder_path="sdxl_models/image_encoder",
23 | ip_ckpt="weights/ip_adapter/sdxl_models/ip-adapter_sdxl.bin",
24 | device="cuda",
25 | )
26 |
27 | return ip_model
28 |
29 |
30 | def get_image_ip_plus_tokens(ip_model, pil_image):
31 | image_processed = ip_model.clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
32 | clip_image = image_processed.to("cuda", dtype=torch.float32)
33 | clip_image_embeds = ip_model.image_encoder(clip_image, output_hidden_states=True).hidden_states[-2]
34 | image_prompt_embeds = ip_model.image_proj_model(clip_image_embeds)
35 | return image_prompt_embeds.cpu().detach(), clip_image_embeds.cpu().detach()
36 |
37 |
38 | def get_image_ip_base_tokens(ip_model, pil_image):
39 | image_processed = ip_model.clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
40 | clip_image = image_processed.to("cuda", dtype=torch.float32)
41 | clip_image_embeds = ip_model.image_encoder(clip_image).image_embeds
42 | image_prompt_embeds = ip_model.image_proj_model(clip_image_embeds)
43 | return image_prompt_embeds.cpu().detach(), clip_image_embeds.cpu().detach()
44 |
--------------------------------------------------------------------------------
/model/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/model/__init__.py
--------------------------------------------------------------------------------
/model/dit.py:
--------------------------------------------------------------------------------
1 | # From the great https://github.com/cloneofsimo/minRF/blob/main/dit.py
2 | # Code heavily based on https://github.com/Alpha-VLLM/LLaMA2-Accessory
3 | # this is modeling code for DiT-LLaMA model
4 |
5 | import math
6 |
7 | import torch
8 | import torch.nn as nn
9 | import torch.nn.functional as F
10 | from diffusers import ModelMixin, ConfigMixin
11 | from diffusers.configuration_utils import register_to_config
12 |
13 |
14 | def modulate(x, shift, scale):
15 | return x * (1 + scale.unsqueeze(1)) + shift.unsqueeze(1)
16 |
17 |
18 | class TimestepEmbedder(nn.Module):
19 | def __init__(self, hidden_size, frequency_embedding_size=256):
20 | super().__init__()
21 | self.mlp = nn.Sequential(
22 | nn.Linear(frequency_embedding_size, hidden_size),
23 | nn.SiLU(),
24 | nn.Linear(hidden_size, hidden_size),
25 | )
26 | self.frequency_embedding_size = frequency_embedding_size
27 |
28 | @staticmethod
29 | def timestep_embedding(t, dim, max_period=10000):
30 | half = dim // 2
31 | freqs = torch.exp(-math.log(max_period) * torch.arange(start=0, end=half) / half).to(t.device)
32 | args = t[:, None] * freqs[None]
33 | embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
34 | if dim % 2:
35 | embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
36 | return embedding
37 |
38 | def forward(self, t):
39 | t_freq = self.timestep_embedding(t, self.frequency_embedding_size).to(dtype=next(self.parameters()).dtype)
40 | t_emb = self.mlp(t_freq)
41 | return t_emb
42 |
43 |
44 | class LabelEmbedder(nn.Module):
45 | def __init__(self, num_classes, hidden_size, dropout_prob):
46 | super().__init__()
47 | use_cfg_embedding = int(dropout_prob > 0)
48 | self.embedding_table = nn.Embedding(num_classes + use_cfg_embedding, hidden_size)
49 | self.num_classes = num_classes
50 | self.dropout_prob = dropout_prob
51 |
52 | def token_drop(self, labels, force_drop_ids=None):
53 | if force_drop_ids is None:
54 | drop_ids = torch.rand(labels.shape[0]) < self.dropout_prob
55 | drop_ids = drop_ids.cuda()
56 | drop_ids = drop_ids.to(labels.device)
57 | else:
58 | drop_ids = force_drop_ids == 1
59 | labels = torch.where(drop_ids, self.num_classes, labels)
60 | return labels
61 |
62 | def forward(self, labels, train, force_drop_ids=None):
63 | use_dropout = self.dropout_prob > 0
64 | if (train and use_dropout) or (force_drop_ids is not None):
65 | labels = self.token_drop(labels, force_drop_ids)
66 | embeddings = self.embedding_table(labels)
67 | return embeddings
68 |
69 |
70 | class Attention(nn.Module):
71 | def __init__(self, dim, n_heads):
72 | super().__init__()
73 |
74 | self.n_heads = n_heads
75 | self.n_rep = 1
76 | self.head_dim = dim // n_heads
77 |
78 | self.wq = nn.Linear(dim, n_heads * self.head_dim, bias=False)
79 | self.wk = nn.Linear(dim, self.n_heads * self.head_dim, bias=False)
80 | self.wv = nn.Linear(dim, self.n_heads * self.head_dim, bias=False)
81 | self.wo = nn.Linear(n_heads * self.head_dim, dim, bias=False)
82 |
83 | self.q_norm = nn.LayerNorm(self.n_heads * self.head_dim)
84 | self.k_norm = nn.LayerNorm(self.n_heads * self.head_dim)
85 |
86 | @staticmethod
87 | def reshape_for_broadcast(freqs_cis, x):
88 | ndim = x.ndim
89 | assert 0 <= 1 < ndim
90 | # assert freqs_cis.shape == (x.shape[1], x.shape[-1])
91 | _freqs_cis = freqs_cis[: x.shape[1]]
92 | shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
93 | return _freqs_cis.view(*shape)
94 |
95 | @staticmethod
96 | def apply_rotary_emb(xq, xk, freqs_cis):
97 | xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
98 | xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
99 | freqs_cis_xq = Attention.reshape_for_broadcast(freqs_cis, xq_)
100 | freqs_cis_xk = Attention.reshape_for_broadcast(freqs_cis, xk_)
101 |
102 | xq_out = torch.view_as_real(xq_ * freqs_cis_xq).flatten(3)
103 | xk_out = torch.view_as_real(xk_ * freqs_cis_xk).flatten(3)
104 | return xq_out, xk_out
105 |
106 | def forward(self, x, freqs_cis):
107 | bsz, seqlen, _ = x.shape
108 |
109 | xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
110 |
111 | dtype = xq.dtype
112 |
113 | xq = self.q_norm(xq)
114 | xk = self.k_norm(xk)
115 |
116 | xq = xq.view(bsz, seqlen, self.n_heads, self.head_dim)
117 | xk = xk.view(bsz, seqlen, self.n_heads, self.head_dim)
118 | xv = xv.view(bsz, seqlen, self.n_heads, self.head_dim)
119 |
120 | xq, xk = self.apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
121 | xq, xk = xq.to(dtype), xk.to(dtype)
122 |
123 | output = F.scaled_dot_product_attention(
124 | xq.permute(0, 2, 1, 3),
125 | xk.permute(0, 2, 1, 3),
126 | xv.permute(0, 2, 1, 3),
127 | dropout_p=0.0,
128 | is_causal=False,
129 | ).permute(0, 2, 1, 3)
130 | output = output.flatten(-2)
131 |
132 | return self.wo(output)
133 |
134 |
135 | class FeedForward(nn.Module):
136 | def __init__(self, dim, hidden_dim, multiple_of, ffn_dim_multiplier=None):
137 | super().__init__()
138 | hidden_dim = int(2 * hidden_dim / 3)
139 | if ffn_dim_multiplier:
140 | hidden_dim = int(ffn_dim_multiplier * hidden_dim)
141 | hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
142 |
143 | self.w1 = nn.Linear(dim, hidden_dim, bias=False)
144 | self.w2 = nn.Linear(hidden_dim, dim, bias=False)
145 | self.w3 = nn.Linear(dim, hidden_dim, bias=False)
146 |
147 | def _forward_silu_gating(self, x1, x3):
148 | return F.silu(x1) * x3
149 |
150 | def forward(self, x):
151 | return self.w2(self._forward_silu_gating(self.w1(x), self.w3(x)))
152 |
153 |
154 | class TransformerBlock(nn.Module):
155 | def __init__(
156 | self,
157 | layer_id,
158 | dim,
159 | n_heads,
160 | multiple_of,
161 | ffn_dim_multiplier,
162 | norm_eps,
163 | ):
164 | super().__init__()
165 | self.dim = dim
166 | self.head_dim = dim // n_heads
167 | self.attention = Attention(dim, n_heads)
168 | self.feed_forward = FeedForward(
169 | dim=dim,
170 | hidden_dim=4 * dim,
171 | multiple_of=multiple_of,
172 | ffn_dim_multiplier=ffn_dim_multiplier,
173 | )
174 | self.layer_id = layer_id
175 | self.attention_norm = nn.LayerNorm(dim, eps=norm_eps)
176 | self.ffn_norm = nn.LayerNorm(dim, eps=norm_eps)
177 |
178 | self.adaLN_modulation = nn.Sequential(
179 | nn.SiLU(),
180 | nn.Linear(min(dim, 1024), 6 * dim, bias=True),
181 | )
182 |
183 | def forward(self, x, freqs_cis, adaln_input=None):
184 | if adaln_input is not None:
185 | shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(adaln_input).chunk(
186 | 6, dim=1
187 | )
188 |
189 | x = x + gate_msa.unsqueeze(1) * self.attention(
190 | modulate(self.attention_norm(x), shift_msa, scale_msa), freqs_cis
191 | )
192 | x = x + gate_mlp.unsqueeze(1) * self.feed_forward(modulate(self.ffn_norm(x), shift_mlp, scale_mlp))
193 | else:
194 | x = x + self.attention(self.attention_norm(x), freqs_cis)
195 | x = x + self.feed_forward(self.ffn_norm(x))
196 |
197 | return x
198 |
199 |
200 | class FinalLayer(nn.Module):
201 | def __init__(self, hidden_size, out_channels):
202 | super().__init__()
203 | self.norm_final = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
204 | self.linear = nn.Linear(hidden_size, out_channels, bias=True)
205 | self.adaLN_modulation = nn.Sequential(
206 | nn.SiLU(),
207 | nn.Linear(min(hidden_size, 1024), 2 * hidden_size, bias=True),
208 | )
209 | # # init zero
210 | nn.init.constant_(self.linear.weight, 0)
211 | nn.init.constant_(self.linear.bias, 0)
212 |
213 | def forward(self, x, c):
214 | shift, scale = self.adaLN_modulation(c).chunk(2, dim=1)
215 | x = modulate(self.norm_final(x), shift, scale)
216 | x = self.linear(x)
217 | return x
218 |
219 |
220 | class DiT_Llama(ModelMixin, ConfigMixin):
221 |
222 | @register_to_config
223 | def __init__(
224 | self,
225 | embedding_dim=3,
226 | hidden_dim=512,
227 | n_layers=5,
228 | n_heads=16,
229 | multiple_of=256,
230 | ffn_dim_multiplier=None,
231 | norm_eps=1e-5,
232 | ):
233 | super().__init__()
234 |
235 | self.in_channels = embedding_dim
236 | self.out_channels = embedding_dim
237 |
238 | self.x_embedder = nn.Linear(embedding_dim, hidden_dim, bias=True)
239 | nn.init.constant_(self.x_embedder.bias, 0)
240 |
241 | self.t_embedder = TimestepEmbedder(min(hidden_dim, 1024))
242 | # self.y_embedder = LabelEmbedder(num_classes, min(dim, 1024), class_dropout_prob)
243 |
244 | self.layers = nn.ModuleList(
245 | [
246 | TransformerBlock(
247 | layer_id,
248 | hidden_dim,
249 | n_heads,
250 | multiple_of,
251 | ffn_dim_multiplier,
252 | norm_eps,
253 | )
254 | for layer_id in range(n_layers)
255 | ]
256 | )
257 | self.final_layer = FinalLayer(hidden_dim, self.out_channels)
258 |
259 | self.freqs_cis = DiT_Llama.precompute_freqs_cis(hidden_dim // n_heads, 4096)
260 |
261 | def forward(self, x, t, cond):
262 | self.freqs_cis = self.freqs_cis.to(x.device)
263 |
264 | x = torch.cat([x, cond], dim=1)
265 |
266 | x = self.x_embedder(x)
267 |
268 | t = self.t_embedder(t) # (N, D)
269 | adaln_input = t.to(x.dtype)
270 |
271 | for layer in self.layers:
272 | x = layer(x, self.freqs_cis[: x.size(1)], adaln_input=adaln_input)
273 |
274 | x = self.final_layer(x, adaln_input)
275 | # Drop the cond part
276 | x = x[:, : -cond.size(1)]
277 | return x
278 |
279 | def forward_with_cfg(self, x, t, cond, cfg_scale):
280 | half = x[: len(x) // 2]
281 | combined = torch.cat([half, half], dim=0)
282 | model_out = self.forward(combined, t, cond)
283 | eps, rest = model_out[:, : self.in_channels], model_out[:, self.in_channels :]
284 | cond_eps, uncond_eps = torch.split(eps, len(eps) // 2, dim=0)
285 | half_eps = uncond_eps + cfg_scale * (cond_eps - uncond_eps)
286 | eps = torch.cat([half_eps, half_eps], dim=0)
287 | return torch.cat([eps, rest], dim=1)
288 |
289 | @staticmethod
290 | def precompute_freqs_cis(dim, end, theta=10000.0):
291 | freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
292 | t = torch.arange(end)
293 | freqs = torch.outer(t, freqs).float()
294 | freqs_cis = torch.polar(torch.ones_like(freqs), freqs)
295 | return freqs_cis
296 |
297 |
298 | def DiT_base(**kwargs):
299 | return DiT_Llama(in_dim=2048, hidden_dim=2048, n_layers=8, n_heads=32, **kwargs)
300 |
301 |
302 | if __name__ == "__main__":
303 | model = DiT_Llama_600M_patch2()
304 | model.eval()
305 | x = torch.randn(2, 3, 32, 32)
306 | t = torch.randint(0, 100, (2,))
307 | y = torch.randint(0, 10, (2,))
308 |
309 | with torch.no_grad():
310 | out = model(x, t, y)
311 | print(out.shape)
312 | out = model.forward_with_cfg(x, t, y, 0.5)
313 | print(out.shape)
314 |
--------------------------------------------------------------------------------
/model/pipeline_pit.py:
--------------------------------------------------------------------------------
1 | import math
2 | from typing import List, Optional, Union
3 |
4 | import torch
5 | from diffusers.pipelines.pipeline_utils import DiffusionPipeline
6 | from diffusers.utils import BaseOutput
7 | from diffusers.utils import (
8 | logging,
9 | )
10 | from diffusers.utils.torch_utils import randn_tensor
11 | from dataclasses import dataclass
12 | from model.dit import DiT_Llama
13 |
14 | logger = logging.get_logger(__name__) # pylint: disable=invalid-name
15 |
16 |
17 | @dataclass
18 | class PiTPipelineOutput(BaseOutput):
19 | image_embeds: torch.Tensor
20 |
21 |
22 | class PiTPipeline(DiffusionPipeline):
23 |
24 | def __init__(self, prior: DiT_Llama):
25 | super().__init__()
26 |
27 | self.register_modules(
28 | prior=prior,
29 | )
30 |
31 | def prepare_latents(self, shape, dtype, device, generator, latents):
32 | if latents is None:
33 | latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
34 | else:
35 | if latents.shape != shape:
36 | raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
37 | latents = latents.to(device)
38 |
39 | return latents
40 |
41 | @torch.no_grad()
42 | def __call__(
43 | self,
44 | cond_sequence: torch.FloatTensor,
45 | negative_cond_sequence: torch.FloatTensor,
46 | num_images_per_prompt: int = 1,
47 | num_inference_steps: int = 25,
48 | generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
49 | latents: Optional[torch.FloatTensor] = None,
50 | init_latents: Optional[torch.FloatTensor] = None,
51 | strength: Optional[float] = None,
52 | guidance_scale: float = 1.0,
53 | output_type: Optional[str] = "pt", # pt only
54 | return_dict: bool = True,
55 | ):
56 |
57 | do_classifier_free_guidance = guidance_scale > 1.0
58 |
59 | device = self._execution_device
60 |
61 | batch_size = cond_sequence.shape[0]
62 | batch_size = batch_size * num_images_per_prompt
63 |
64 | embedding_dim = self.prior.config.embedding_dim
65 |
66 | latents = self.prepare_latents(
67 | (batch_size, 16, embedding_dim),
68 | self.prior.dtype,
69 | device,
70 | generator,
71 | latents,
72 | )
73 |
74 | if init_latents is not None:
75 | init_latents = init_latents.to(latents.device)
76 | latents = (strength) * latents + (1 - strength) * init_latents
77 |
78 | # Rectified Flow
79 | dt = 1.0 / num_inference_steps
80 | dt = torch.tensor([dt] * batch_size).to(latents.device).view([batch_size, *([1] * len(latents.shape[1:]))])
81 | start_inference_step = (
82 | math.ceil(num_inference_steps * (strength)) if strength is not None else num_inference_steps
83 | )
84 | for i in range(start_inference_step, 0, -1):
85 | t = i / num_inference_steps
86 | t = torch.tensor([t] * batch_size).to(latents.device)
87 |
88 | vc = self.prior(latents, t, cond_sequence)
89 | if do_classifier_free_guidance:
90 | vu = self.prior(latents, t, negative_cond_sequence)
91 | vc = vu + guidance_scale * (vc - vu)
92 |
93 | latents = latents - dt * vc
94 |
95 | image_embeddings = latents
96 |
97 | if output_type not in ["pt", "np"]:
98 | raise ValueError(f"Only the output types `pt` and `np` are supported not output_type={output_type}")
99 |
100 | if output_type == "np":
101 | image_embeddings = image_embeddings.cpu().numpy()
102 |
103 | if not return_dict:
104 | return image_embeddings
105 |
106 | return PiTPipelineOutput(image_embeds=image_embeddings)
107 |
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [project]
2 | name = "PiT"
3 | version = "1.0"
4 | requires-python = ">=3.12"
5 | dependencies = [
6 | "accelerate>=1.2.1",
7 | "diffusers>=0.32.1",
8 | "einops>=0.8.0",
9 | "kornia>=0.8.0",
10 | "matplotlib>=3.10.0",
11 | "opencv-python>=4.10.0.84",
12 | "pandas>=2.2.3",
13 | "peft>=0.14.0",
14 | "protobuf>=5.29.2",
15 | "pyrallis>=0.3.1",
16 | "scikit-learn>=1.6.1",
17 | "scipy>=1.15.0",
18 | "sentencepiece>=0.2.0",
19 | "supervision>=0.25.1",
20 | "tensorboard>=2.18.0",
21 | "timm>=1.0.12",
22 | "torch>=2.5.1",
23 | "torchvision>=0.20.0",
24 | "transformers>=4.47.1",
25 | "wandb>=0.19.1",
26 | ]
27 |
28 |
29 | [tool.black]
30 | line-length = 120
--------------------------------------------------------------------------------
/scripts/generate_characters.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import einops
3 | import math
4 | import matplotlib.pyplot as plt
5 | import numpy as np
6 | import pyrallis
7 | import random
8 | import supervision as sv
9 | import torch
10 | from PIL import Image
11 | from utils import words_bank
12 | from dataclasses import dataclass
13 | from diffusers import StableDiffusionXLPipeline, FluxPipeline
14 | from pathlib import Path
15 | from scipy import ndimage
16 | from transformers import SamModel, SamProcessor, AutoProcessor, AutoModelForCausalLM
17 | from transformers import pipeline
18 | from typing import Tuple, Dict
19 |
20 |
21 | @dataclass
22 | class RunConfig:
23 | # Generation mode, should be either 'objects' or 'scenes'
24 | out_dir: Path = Path("datasets/generated/monsters/")
25 | n_images: int = 1000000
26 | vis_data: bool = False
27 | n_samples_in_dir: int = 1000
28 |
29 |
30 | def crop_from_mask(image, mask: np.ndarray):
31 | # Apply mask and crop a tight box
32 | mask = mask.astype(np.uint8)
33 | mask = mask * 255
34 | mask = Image.fromarray(mask)
35 | bbox = mask.getbbox()
36 |
37 | # Create a new image with a white background
38 | white_background = Image.new("RGB", image.size, (255, 255, 255))
39 |
40 | # Apply the mask to the original image
41 | masked_image = Image.composite(image, white_background, mask)
42 |
43 | # Crop the image to the bounding box
44 | cropped_image = masked_image.crop(bbox)
45 |
46 | return cropped_image
47 |
48 |
49 | def show_mask(mask, ax, random_color=False):
50 | if random_color:
51 | color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
52 | else:
53 | color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
54 | h, w = mask.shape[-2:]
55 | mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
56 | ax.imshow(mask_image)
57 |
58 |
59 | def show_masks_on_image(raw_image, masks, caption=None):
60 | plt.imshow(np.array(raw_image))
61 | ax = plt.gca()
62 | ax.set_autoscale_on(False)
63 | for mask in masks:
64 | show_mask(mask, ax=ax, random_color=True)
65 | plt.axis("off")
66 | if caption:
67 | plt.title(caption)
68 | plt.show()
69 |
70 |
71 | def show_box(box, ax):
72 | x0, y0 = box[0], box[1]
73 | w, h = box[2] - box[0], box[3] - box[1]
74 | facecolor = [random.random(), random.random(), random.random(), 0.3]
75 | edgecolor = facecolor.copy()
76 | edgecolor[3] = 1
77 | ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor=edgecolor, facecolor=facecolor, lw=2))
78 |
79 |
80 | def show_boxes_on_image(raw_image, boxes):
81 | plt.figure(figsize=(10, 10))
82 | plt.imshow(raw_image)
83 | for box in boxes:
84 | show_box(box, plt.gca())
85 | plt.axis("on")
86 | plt.show()
87 |
88 |
89 | @pyrallis.wrap()
90 | def generate(cfg: RunConfig):
91 | cfg.out_dir.mkdir(exist_ok=True, parents=True)
92 |
93 | flux_pipe = FluxPipeline.from_pretrained("black-forest-labs/FLUX.1-schnell", torch_dtype=torch.bfloat16).to("cuda")
94 |
95 | device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
96 | model = SamModel.from_pretrained("facebook/sam-vit-huge").to(device)
97 | processor = SamProcessor.from_pretrained("facebook/sam-vit-huge")
98 |
99 | checkpoint = "microsoft/Florence-2-large"
100 | florence_processor = AutoProcessor.from_pretrained(checkpoint, trust_remote_code=True)
101 | florence_model = AutoModelForCausalLM.from_pretrained(checkpoint, trust_remote_code=True).to(device).eval()
102 |
103 | def run_florence_inference(
104 | image: Image, task: str = "", text: str = ""
105 | ) -> Tuple[str, Dict]:
106 | prompt = task + text
107 | inputs = florence_processor(text=prompt, images=image, return_tensors="pt").to(device)
108 | generated_ids = florence_model.generate(
109 | input_ids=inputs["input_ids"],
110 | pixel_values=inputs["pixel_values"],
111 | max_new_tokens=1024,
112 | num_beams=3,
113 | output_scores=True,
114 | )
115 | generated_text = florence_processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
116 | response = florence_processor.post_process_generation(generated_text, task=task, image_size=image.size)
117 |
118 | detections = sv.Detections.from_lmm(lmm=sv.LMM.FLORENCE_2, result=response, resolution_wh=image.size)
119 | input_boxes = detections.xyxy
120 | return input_boxes
121 |
122 | with open("assets/openimages_classes.txt", "r") as f:
123 | objects = f.read().splitlines()
124 | objects = ["".join(char if char.isalnum() else " " for char in object_name) for object_name in objects]
125 | # Duplicate creatures to match the same size as objects
126 | creatures = words_bank.creatures * (len(objects) // len(words_bank.creatures) + 1) + objects * 10
127 |
128 | tot_generated = 0
129 | for _ in range(cfg.n_images):
130 | try:
131 | new_dir_name = f"set_{tot_generated}_{random.randint(0, 1000000)}"
132 | out_dir = cfg.out_dir / new_dir_name
133 | out_dir.mkdir(exist_ok=True, parents=True)
134 | monster_grid = []
135 |
136 | for _ in range(cfg.n_samples_in_dir):
137 |
138 | adjective_count = random.randint(2, 6)
139 | adjectives = random.sample(words_bank.adjectives, adjective_count)
140 | if len(adjectives) > 0:
141 | adjectives_txt = " ".join(adjectives) + " "
142 |
143 | character_count = random.randint(1, 3)
144 | characters = random.sample(creatures, character_count)
145 | characters = [f"{c}-like" for c in characters]
146 | character_txt = " ".join(characters)
147 |
148 | prompt = f"studio photo pixar style concept art, An imaginary fantasy {adjectives_txt} {character_txt} creature with eyes arms legs mouth , white background studio photo pixar style asset"
149 | seed = random.randint(0, 1000000)
150 |
151 | print(prompt)
152 | base_image = flux_pipe(
153 | prompt,
154 | guidance_scale=0.0,
155 | num_inference_steps=4,
156 | max_sequence_length=256,
157 | ).images[0]
158 |
159 | input_boxes = []
160 | keywords = words_bank.keywords
161 | for keyword in keywords:
162 | current_boxes = list(run_florence_inference(base_image, text=keyword))
163 | # Randomly choose one
164 | if len(current_boxes) > 0:
165 | input_boxes.extend(random.sample(current_boxes, 1))
166 |
167 | # convert to ints
168 | input_boxes = [[int(x) for x in box] for box in input_boxes]
169 |
170 | inputs = processor(base_image, input_boxes=[input_boxes], return_tensors="pt").to(device)
171 | with torch.no_grad():
172 | outputs = model(**inputs)
173 | masks = processor.image_processor.post_process_masks(
174 | outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu()
175 | )[0]
176 | #
177 | masks = [mask[0].cpu().detach().numpy() for mask in masks]
178 |
179 | masks = sorted(masks, key=lambda mask: mask.sum(), reverse=False)
180 |
181 | # Filter the masks
182 | masks = [mask for mask in masks if 0.015 < mask.sum() / mask.flatten().shape[0] < 0.3]
183 |
184 | for m_ind in range(len(masks)):
185 | # Apply dilate and erode to the mask
186 | mask = masks[m_ind].astype(np.uint8)
187 | mask = cv2.dilate(mask, np.ones((15, 15), np.uint8), iterations=1)
188 | mask = cv2.erode(mask, np.ones((15, 15), np.uint8), iterations=1)
189 | # Now do the reverse to get rid of the small holes
190 | mask = cv2.erode(mask, np.ones((15, 15), np.uint8), iterations=1)
191 | mask = cv2.dilate(mask, np.ones((15, 15), np.uint8), iterations=1)
192 | if True or random.random() < 0.5:
193 | # Close mask
194 | mask = ndimage.binary_fill_holes(mask.astype(int))
195 | masks[m_ind] = mask == 1
196 |
197 | masks = [mask for mask in masks if 0.015 < mask.sum() / mask.flatten().shape[0] < 0.3]
198 |
199 | if cfg.vis_data:
200 | plt.imshow(base_image)
201 | plt.show()
202 | show_masks_on_image(base_image, masks)
203 |
204 | visited_area = np.zeros_like(masks[0])
205 | prompt_hash = str(abs(hash(prompt)))
206 |
207 | for i, mask in enumerate(masks):
208 | # Check if overlaps with visited_area
209 | if (visited_area * mask).sum() > 0:
210 | continue
211 | visited_area += mask
212 |
213 | cropped_image = crop_from_mask(base_image, mask)
214 | out_path = out_dir / f"{prompt_hash}_{seed}_{i}.jpg"
215 | cropped_image.save(out_path)
216 | if cfg.vis_data:
217 | plt.imshow(cropped_image)
218 | plt.show()
219 |
220 | out_path = out_dir / f"{prompt_hash}_{seed}.jpg"
221 | tot_generated += 1
222 | base_image.save(out_path)
223 | monster_grid.append(base_image)
224 |
225 | except Exception as e:
226 | print(e)
227 |
228 |
229 | if __name__ == "__main__":
230 | # Use to generate objects or backgrounds
231 | generate()
232 |
--------------------------------------------------------------------------------
/scripts/generate_products.py:
--------------------------------------------------------------------------------
1 | import random
2 | from pathlib import Path
3 |
4 | import random
5 | from dataclasses import dataclass
6 | from pathlib import Path
7 |
8 | import cv2
9 | import matplotlib.pyplot as plt
10 | import numpy as np
11 | import pyrallis
12 | import torch
13 | from PIL import Image
14 | from diffusers import FluxPipeline
15 | from scipy import ndimage
16 | from transformers import pipeline
17 |
18 | from utils import words_bank
19 |
20 |
21 | @dataclass
22 | class RunConfig:
23 | out_dir: Path = Path("datasets/generated/products")
24 | n_images: int = 1000000
25 | vis_data: bool = False
26 | n_samples_in_dir: int = 1000
27 |
28 |
29 | def crop_from_mask(image, mask: np.ndarray):
30 | # Apply mask and crop a tight box
31 | mask = mask.astype(np.uint8)
32 | mask = mask * 255
33 | mask = Image.fromarray(mask)
34 | bbox = mask.getbbox()
35 |
36 | # Create a new image with a white background
37 | white_background = Image.new("RGB", image.size, (255, 255, 255))
38 |
39 | # Apply the mask to the original image
40 | masked_image = Image.composite(image, white_background, mask)
41 |
42 | # Crop the image to the bounding box
43 | cropped_image = masked_image.crop(bbox)
44 |
45 | return cropped_image
46 |
47 |
48 | def show_mask(mask, ax, random_color=False):
49 | if random_color:
50 | color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
51 | else:
52 | color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
53 | h, w = mask.shape[-2:]
54 | mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
55 | ax.imshow(mask_image)
56 |
57 |
58 | def show_masks_on_image(raw_image, masks, caption=None):
59 | plt.imshow(np.array(raw_image))
60 | ax = plt.gca()
61 | ax.set_autoscale_on(False)
62 | for mask in masks:
63 | show_mask(mask, ax=ax, random_color=True)
64 | plt.axis("off")
65 | if caption:
66 | plt.title(caption)
67 | plt.show()
68 |
69 |
70 | @pyrallis.wrap()
71 | def generate(cfg: RunConfig):
72 | cfg.out_dir.mkdir(exist_ok=True, parents=True)
73 |
74 | flux_pipe = FluxPipeline.from_pretrained("black-forest-labs/FLUX.1-schnell", torch_dtype=torch.bfloat16).to("cuda")
75 |
76 | device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
77 | segmentor = pipeline("mask-generation", model="facebook/sam-vit-base", device=device)
78 |
79 | with open("assets/openimages_classes.txt", "r") as f:
80 | objects = f.read().splitlines()
81 | objects = ["".join(char if char.isalnum() else " " for char in object_name) for object_name in objects]
82 |
83 | tot_generated = 0
84 | for _ in range(cfg.n_images):
85 | new_dir_name = f"set_{tot_generated}_{random.randint(0, 1000000)}"
86 | out_dir = cfg.out_dir / new_dir_name
87 | out_dir.mkdir(exist_ok=True, parents=True)
88 | monster_grid = []
89 |
90 | for _ in range(1000):
91 | try:
92 | character_count = random.randint(0, 3)
93 | if character_count == 0:
94 | character_txt = ""
95 | else:
96 | characters = random.sample(objects, character_count)
97 | # For each character text take only one random word
98 | characters = [random.choice(character.split()) for character in characters]
99 | characters = [f"{c}-like" for c in characters]
100 | character_txt = " ".join(characters)
101 |
102 | attributes_count = random.randint(1, 3)
103 | material_count = random.randint(1, 2)
104 | attributes = random.sample(words_bank.object_attributes, attributes_count)
105 | materials = random.sample(words_bank.product_materials, material_count)
106 | features = random.sample(words_bank.product_defining_attributes, 1)
107 | attributes_and_materials_txt = " ".join(attributes + materials + features)
108 |
109 | prompt = f"A product design photo of a {attributes_and_materials_txt}product with {character_txt} attributes, integrated together to create one seamless product. It is set against a light gray background with a soft gradient, creating a neutral and elegant backdrop that emphasizes the contemporary design. The soft, even lighting highlights the contours and textures, lending a professional, polished quality to the composition"
110 | seed = random.randint(0, 1000000)
111 |
112 | print(prompt)
113 | base_image = flux_pipe(
114 | prompt,
115 | guidance_scale=0.0,
116 | num_inference_steps=4,
117 | max_sequence_length=256,
118 | ).images[0]
119 |
120 | if cfg.vis_data:
121 | plt.imshow(base_image)
122 | plt.title(f"{attributes_and_materials_txt} {character_txt}")
123 | plt.show()
124 | # continue
125 | all_masks = segmentor(base_image, points_per_batch=64)["masks"]
126 |
127 | if len(all_masks) == 0:
128 | continue
129 |
130 | # Sort by area
131 | all_masks = sorted(all_masks, key=lambda mask: mask.sum(), reverse=False)
132 | # Remove the last item
133 | masks = all_masks[:-1]
134 |
135 | if len(all_masks) < 3:
136 | # For now take only things with at least 3 parts to keep the data interesting
137 | continue
138 |
139 | # Remove masks that intersect with image boundary
140 | mask_boundary = np.zeros_like(masks[0])
141 | mask_boundary[0, :] = 1
142 | mask_boundary[-1, :] = 1
143 | mask_boundary[:, 0] = 1
144 | mask_boundary[:, -1] = 1
145 |
146 | masks = [mask for mask in masks if (mask * mask_boundary).sum() == 0]
147 |
148 | masks = [mask for mask in masks if 0.015 < mask.sum() / mask.flatten().shape[0] < 0.3]
149 |
150 | for m_ind in range(len(masks)):
151 | # Apply dilate and erode to the mask
152 | mask = masks[m_ind].astype(np.uint8)
153 | mask = cv2.dilate(mask, np.ones((15, 15), np.uint8), iterations=1)
154 | mask = cv2.erode(mask, np.ones((15, 15), np.uint8), iterations=1)
155 | # Now do the reverse to get rid of the small holes
156 | mask = cv2.erode(mask, np.ones((15, 15), np.uint8), iterations=1)
157 | mask = cv2.dilate(mask, np.ones((15, 15), np.uint8), iterations=1)
158 | if True or random.random() < 0.5:
159 | # Close mask
160 | mask = ndimage.binary_fill_holes(mask.astype(int))
161 | masks[m_ind] = mask == 1
162 |
163 | masks = [mask for mask in masks if 0.015 < mask.sum() / mask.flatten().shape[0] < 0.3]
164 |
165 | if len(masks) == 0:
166 | print(f"No masks found for {character_txt}")
167 | continue
168 |
169 | # Restrict to 8
170 | masks = masks[:8]
171 |
172 | if cfg.vis_data:
173 | show_masks_on_image(base_image, masks)
174 |
175 | visited_area = np.zeros_like(masks[0])
176 | prompt_hash = str(abs(hash(prompt)))
177 |
178 | for i, mask in enumerate(masks):
179 | # Check if overlaps with visited_area
180 | if (visited_area * mask).sum() > 0:
181 | continue
182 | visited_area += mask
183 |
184 | cropped_image = crop_from_mask(base_image, mask)
185 | cropped_image.thumbnail((256, 256))
186 | out_path = out_dir / f"{prompt_hash}_{seed}_{i}.jpg"
187 | cropped_image.save(out_path)
188 | if cfg.vis_data:
189 | plt.imshow(cropped_image)
190 | plt.show()
191 |
192 | out_path = out_dir / f"{prompt_hash}_{seed}.jpg"
193 | base_image.thumbnail((512, 512))
194 | tot_generated += 1
195 | base_image.save(out_path)
196 | if len(monster_grid) < 9:
197 | monster_grid.append(base_image)
198 | except Exception as e:
199 | print(e)
200 | continue
201 |
202 |
203 | if __name__ == "__main__":
204 | # Use to generate objects or backgrounds
205 | generate()
206 |
--------------------------------------------------------------------------------
/scripts/infer.py:
--------------------------------------------------------------------------------
1 | import random
2 | from dataclasses import dataclass
3 | from pathlib import Path
4 | from typing import Optional
5 |
6 | import numpy as np
7 | import pyrallis
8 | import torch
9 | from PIL import Image
10 | from diffusers import (
11 | StableDiffusionXLPipeline,
12 | )
13 | from huggingface_hub import hf_hub_download
14 | from tqdm import tqdm
15 |
16 | from ip_adapter import IPAdapterPlusXL
17 | from model.dit import DiT_Llama
18 | from model.pipeline_pit import PiTPipeline
19 | from training.train_config import TrainConfig
20 | from utils import vis_utils, bezier_utils
21 |
22 |
23 | def paste_on_background(image, background, min_scale=0.4, max_scale=0.8, scale=None):
24 | # Calculate aspect ratio and determine resizing based on the smaller dimension of the background
25 | aspect_ratio = image.width / image.height
26 | scale = random.uniform(min_scale, max_scale) if scale is None else scale
27 | new_width = int(min(background.width, background.height * aspect_ratio) * scale)
28 | new_height = int(new_width / aspect_ratio)
29 |
30 | # Resize image and calculate position
31 | image = image.resize((new_width, new_height), resample=Image.LANCZOS)
32 | pos_x = random.randint(0, background.width - new_width)
33 | pos_y = random.randint(0, background.height - new_height)
34 |
35 | # Paste the image using its alpha channel as mask if present
36 | background.paste(image, (pos_x, pos_y), image if "A" in image.mode else None)
37 | return background
38 |
39 |
40 | def set_seed(seed: int):
41 | """Ensures reproducibility across multiple libraries."""
42 | random.seed(seed) # Python random module
43 | np.random.seed(seed) # NumPy random module
44 | torch.manual_seed(seed) # PyTorch CPU random seed
45 | torch.cuda.manual_seed_all(seed) # PyTorch GPU random seed
46 | torch.backends.cudnn.deterministic = True # Ensures deterministic behavior
47 | torch.backends.cudnn.benchmark = False # Disable benchmarking to avoid randomness
48 |
49 |
50 | # Inside main():
51 |
52 |
53 | @dataclass
54 | class RunConfig:
55 | prior_path: Path
56 | crops_dir: Path
57 | output_dir: Path
58 | prior_repo: Optional[str] = None
59 | prior_guidance_scale: float = 1.0
60 | drop_cond: bool = True
61 | n_randoms: int = 10
62 | as_sketch: bool = False
63 | scale: float = 2.0
64 | use_empty_ref: bool = True
65 |
66 |
67 | @pyrallis.wrap()
68 | def main(cfg: RunConfig):
69 | output_dir = cfg.output_dir
70 | output_dir.mkdir(parents=True, exist_ok=True)
71 |
72 | # Download model and config
73 | if cfg.prior_repo is not None:
74 | prior_ckpt_path = hf_hub_download(
75 | repo_id=cfg.prior_repo,
76 | filename=str(cfg.prior_path),
77 | local_dir="pretrained_models",
78 | )
79 | prior_cfg_path = hf_hub_download(
80 | repo_id=cfg.prior_repo, filename=str(cfg.prior_path.parent / "cfg.yaml"), local_dir="pretrained_models"
81 | )
82 | else:
83 | prior_ckpt_path = cfg.prior_path
84 | prior_cfg_path = cfg.prior_path.parent / "cfg.yaml"
85 |
86 | # Load model_cfg from file
87 | model_cfg: TrainConfig = pyrallis.load(TrainConfig, open(prior_cfg_path, "r"))
88 |
89 | weight_dtype = torch.float32
90 | device = "cuda:0"
91 | prior = DiT_Llama(
92 | embedding_dim=2048,
93 | hidden_dim=model_cfg.hidden_dim,
94 | n_layers=model_cfg.num_layers,
95 | n_heads=model_cfg.num_attention_heads,
96 | )
97 | prior.load_state_dict(torch.load(prior_ckpt_path))
98 |
99 | image_pipe = StableDiffusionXLPipeline.from_pretrained(
100 | "stabilityai/stable-diffusion-xl-base-1.0",
101 | torch_dtype=torch.float16,
102 | add_watermarker=False,
103 | )
104 |
105 | ip_ckpt_path = hf_hub_download(
106 | repo_id="h94/IP-Adapter",
107 | filename="ip-adapter-plus_sdxl_vit-h.bin",
108 | subfolder="sdxl_models",
109 | local_dir="pretrained_models",
110 | )
111 |
112 | ip_model = IPAdapterPlusXL(
113 | image_pipe,
114 | "models/image_encoder",
115 | ip_ckpt_path,
116 | device,
117 | num_tokens=16,
118 | )
119 |
120 | image_processor = ip_model.clip_image_processor
121 |
122 | empty_image = Image.new("RGB", (256, 256), (255, 255, 255))
123 | zero_image = torch.Tensor(image_processor(empty_image)["pixel_values"][0])
124 | zero_image_embeds = ip_model.get_image_embeds(zero_image.unsqueeze(0), skip_uncond=True)
125 |
126 | prior_pipeline = PiTPipeline(
127 | prior=prior,
128 | )
129 | prior_pipeline = prior_pipeline.to(device)
130 |
131 | set_seed(42)
132 |
133 | # Read all crops from the dir
134 | crop_sets = []
135 | unordered_crops = []
136 | for crop_dir_path in cfg.crops_dir.iterdir():
137 | unordered_crops.append(crop_dir_path)
138 | unordered_crops = sorted(unordered_crops, key=lambda x: x.stem)
139 |
140 | if len(unordered_crops) > 0:
141 | for _ in range(cfg.n_randoms):
142 | n_crops = random.randint(1, min(3, len(unordered_crops)))
143 | crop_paths = random.sample(unordered_crops, n_crops)
144 | # Some of the paths might be dirs, if it is a dir, take a random file from it
145 | crop_paths = [c if c.is_file() else random.choice([f for f in c.iterdir()]) for c in crop_paths]
146 | crop_sets.append(crop_paths)
147 |
148 | if model_cfg.use_ref:
149 | if cfg.use_empty_ref:
150 | print(f"----- USING EMPTY GRIDS -----")
151 | augmented_crop_sets = [[None] + crop_set for crop_set in crop_sets]
152 | else:
153 | print(f"----- USING REFERENCE GRIDS -----")
154 | augmented_crop_sets = []
155 | refs_dir = Path("assets/ref_grids")
156 | refs = [f for f in refs_dir.iterdir()]
157 | for crop_set in crop_sets:
158 | # Choose a subset of refs
159 | chosen_refs = random.sample(refs, 1) # [None] # + random.sample(refs, 5)
160 | for ref in chosen_refs:
161 | augmented_crop_sets.append([ref] + crop_set)
162 |
163 | crop_sets = augmented_crop_sets
164 |
165 | random.shuffle(crop_sets)
166 |
167 | for crop_paths in tqdm(crop_sets):
168 | out_name = f"{random.randint(0, 1000000)}"
169 |
170 | processed_crops = []
171 | input_images = []
172 | captions = []
173 |
174 | # Extend to >3 with Nones
175 | while len(crop_paths) < 3:
176 | crop_paths.append(None)
177 |
178 | for path_ind, path in enumerate(crop_paths):
179 | if path is None:
180 | image = Image.new("RGB", (224, 224), (255, 255, 255))
181 | else:
182 | image = Image.open(path).convert("RGB")
183 | if path_ind > 0 or not model_cfg.use_ref:
184 | background = Image.new("RGB", (1024, 1024), (255, 255, 255))
185 | image = paste_on_background(image, background, scale=0.92)
186 | else:
187 | image = image.resize((1024, 1024))
188 | if cfg.as_sketch and random.random() < 0.5:
189 | num_lines = random.randint(8, 15)
190 | image = bezier_utils.get_sketch(image, total_curves=num_lines, drop_line_prob=0.1)
191 | input_images.append(image)
192 | # Name should be parent directory name
193 | captions.append(path.parent.stem)
194 | processed_image = (
195 | torch.Tensor(image_processor(image)["pixel_values"][0]).to(device).unsqueeze(0).to(weight_dtype)
196 | )
197 | processed_crops.append(processed_image)
198 |
199 | image_embed_inputs = []
200 | for crop_ind in range(len(processed_crops)):
201 | image_embed_inputs.append(ip_model.get_image_embeds(processed_crops[crop_ind], skip_uncond=True))
202 | crops_input_sequence = torch.cat(image_embed_inputs, dim=1)
203 |
204 | for _ in range(4):
205 | seed = random.randint(0, 1000000)
206 | for scale in [cfg.scale]:
207 | negative_cond_sequence = torch.zeros_like(crops_input_sequence)
208 | embeds_len = zero_image_embeds.shape[1]
209 | for i in range(0, negative_cond_sequence.shape[1], embeds_len):
210 | negative_cond_sequence[:, i : i + embeds_len] = zero_image_embeds.detach()
211 |
212 | img_emb = prior_pipeline(
213 | cond_sequence=crops_input_sequence,
214 | negative_cond_sequence=negative_cond_sequence,
215 | num_inference_steps=25,
216 | num_images_per_prompt=1,
217 | guidance_scale=scale,
218 | generator=torch.Generator(device="cuda").manual_seed(seed),
219 | ).image_embeds
220 |
221 | for seed_2 in range(1):
222 | images = ip_model.generate(
223 | image_prompt_embeds=img_emb,
224 | num_samples=1,
225 | num_inference_steps=50,
226 | )
227 | input_images += images
228 | captions.append(f"prior_s {seed}, cfg {scale}") # , unet_s {seed_2}")
229 | # The rest of the results will just be in the dir
230 | gen_images = vis_utils.create_table_plot(images=input_images, captions=captions)
231 |
232 | gen_images.save(output_dir / f"{out_name}.jpg")
233 |
234 | # Also save the divided images in a separate folder whose name is the same as the output image
235 | divided_images_dir = output_dir / f"{out_name}_divided"
236 | divided_images_dir.mkdir(parents=True, exist_ok=True)
237 | for i, img in enumerate(input_images):
238 | img.save(divided_images_dir / f"{i}.jpg")
239 | print("Done!")
240 |
241 |
242 | if __name__ == "__main__":
243 | main()
244 |
--------------------------------------------------------------------------------
/scripts/train.py:
--------------------------------------------------------------------------------
1 | import pyrallis
2 |
3 | from training.coach import Coach
4 | from training.train_config import TrainConfig
5 |
6 |
7 | @pyrallis.wrap()
8 | def main(cfg: TrainConfig):
9 | coach = Coach(cfg)
10 | coach.train()
11 |
12 |
13 | if __name__ == "__main__":
14 | main()
15 |
--------------------------------------------------------------------------------
/training/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/training/__init__.py
--------------------------------------------------------------------------------
/training/coach.py:
--------------------------------------------------------------------------------
1 | import random
2 | import sys
3 | from pathlib import Path
4 |
5 | import diffusers
6 | import pyrallis
7 | import torch
8 | import torch.utils.checkpoint
9 | import transformers
10 | from PIL import Image
11 | from accelerate import Accelerator
12 | from accelerate.logging import get_logger
13 | from accelerate.utils import ProjectConfiguration, set_seed
14 | from diffusers import StableDiffusionXLPipeline
15 | from huggingface_hub import hf_hub_download
16 | from torchvision import transforms
17 | from tqdm import tqdm
18 |
19 | from ip_adapter import IPAdapterPlusXL
20 | from model.dit import DiT_Llama
21 | from model.pipeline_pit import PiTPipeline
22 | from training.dataset import (
23 | PartsDataset,
24 | )
25 | from training.train_config import TrainConfig
26 | from utils import vis_utils
27 |
28 | logger = get_logger(__name__, log_level="INFO")
29 |
30 |
31 | class Coach:
32 | def __init__(self, config: TrainConfig):
33 | self.cfg = config
34 | self.cfg.output_dir.mkdir(exist_ok=True, parents=True)
35 | (self.cfg.output_dir / "cfg.yaml").write_text(pyrallis.dump(self.cfg))
36 | (self.cfg.output_dir / "run.sh").write_text(f'python {Path(__file__).name} {" ".join(sys.argv)}')
37 |
38 | self.logging_dir = self.cfg.output_dir / "logs"
39 | accelerator_project_config = ProjectConfiguration(
40 | total_limit=2, project_dir=self.cfg.output_dir, logging_dir=self.logging_dir
41 | )
42 | self.accelerator = Accelerator(
43 | gradient_accumulation_steps=self.cfg.gradient_accumulation_steps,
44 | mixed_precision=self.cfg.mixed_precision,
45 | log_with=self.cfg.report_to,
46 | project_config=accelerator_project_config,
47 | )
48 |
49 | self.device = "cuda"
50 |
51 | logger.info(self.accelerator.state, main_process_only=False)
52 | if self.accelerator.is_local_main_process:
53 | transformers.utils.logging.set_verbosity_warning()
54 | diffusers.utils.logging.set_verbosity_info()
55 | else:
56 | transformers.utils.logging.set_verbosity_error()
57 | diffusers.utils.logging.set_verbosity_error()
58 |
59 | if self.cfg.seed is not None:
60 | set_seed(self.cfg.seed)
61 |
62 | if self.accelerator.is_main_process:
63 | self.logging_dir.mkdir(exist_ok=True, parents=True)
64 |
65 | self.weight_dtype = torch.float32
66 | if self.accelerator.mixed_precision == "fp16":
67 | self.weight_dtype = torch.float16
68 | elif self.accelerator.mixed_precision == "bf16":
69 | self.weight_dtype = torch.bfloat16
70 |
71 | self.prior = DiT_Llama(
72 | embedding_dim=2048,
73 | hidden_dim=self.cfg.hidden_dim,
74 | n_layers=self.cfg.num_layers,
75 | n_heads=self.cfg.num_attention_heads,
76 | )
77 | # pretty print total number of parameters in Billions
78 | num_params = sum(p.numel() for p in self.prior.parameters())
79 | print(f"Number of parameters: {num_params / 1e9:.2f}B")
80 |
81 | self.image_pipe = StableDiffusionXLPipeline.from_pretrained(
82 | "stabilityai/stable-diffusion-xl-base-1.0",
83 | torch_dtype=torch.float16,
84 | add_watermarker=False,
85 | ).to(self.device)
86 |
87 | ip_ckpt_path = hf_hub_download(
88 | repo_id="h94/IP-Adapter",
89 | filename="ip-adapter-plus_sdxl_vit-h.bin",
90 | subfolder="sdxl_models",
91 | local_dir="pretrained_models",
92 | )
93 |
94 | self.ip_model = IPAdapterPlusXL(
95 | self.image_pipe,
96 | "models/image_encoder",
97 | ip_ckpt_path,
98 | self.device,
99 | num_tokens=16,
100 | )
101 |
102 | self.image_processor = self.ip_model.clip_image_processor
103 |
104 | empty_image = Image.new("RGB", (256, 256), (255, 255, 255))
105 | zero_image = torch.Tensor(self.image_processor(empty_image)["pixel_values"][0])
106 | self.zero_image_embeds = self.ip_model.get_image_embeds(zero_image.unsqueeze(0), skip_uncond=True)
107 |
108 | self.prior_pipeline = PiTPipeline(prior=self.prior)
109 | self.prior_pipeline = self.prior_pipeline.to(self.accelerator.device)
110 |
111 | params_to_optimize = list(self.prior.parameters())
112 |
113 | self.optimizer = torch.optim.AdamW(
114 | params_to_optimize,
115 | lr=self.cfg.lr,
116 | betas=(self.cfg.adam_beta1, self.cfg.adam_beta2),
117 | weight_decay=self.cfg.adam_weight_decay,
118 | eps=self.cfg.adam_epsilon,
119 | )
120 |
121 | self.train_dataloader, self.validation_dataloader = self.get_dataloaders()
122 |
123 | self.prior, self.optimizer, self.train_dataloader = self.accelerator.prepare(
124 | self.prior, self.optimizer, self.train_dataloader
125 | )
126 |
127 | self.train_step = 0 if self.cfg.resume_from_step is None else self.cfg.resume_from_step
128 | print(self.train_step)
129 |
130 | if self.cfg.resume_from_path is not None:
131 | prior_state_dict = torch.load(self.cfg.resume_from_path, map_location=self.device)
132 | msg = self.prior.load_state_dict(prior_state_dict, strict=False)
133 | print(msg)
134 |
135 | def save_model(self, save_path):
136 | save_path.mkdir(exist_ok=True, parents=True)
137 | prior_state_dict = self.prior.state_dict()
138 | torch.save(prior_state_dict, save_path / "prior.ckpt")
139 |
140 | def unnormalize_and_pil(self, tensor):
141 | unnormed = tensor * torch.tensor(self.image_processor.image_std).view(3, 1, 1).to(tensor.device) + torch.tensor(
142 | self.image_processor.image_mean
143 | ).view(3, 1, 1).to(tensor.device)
144 | return transforms.ToPILImage()(unnormed)
145 |
146 | def save_images(self, image, conds, cond_sequence, target_embeds, label="", save_path=""):
147 | self.prior.eval()
148 | input_images = []
149 | captions = []
150 | for i in range(len(conds)):
151 | pil_image = self.unnormalize_and_pil(conds[i]).resize((self.cfg.img_size, self.cfg.img_size))
152 | input_images.append(pil_image)
153 | captions.append("Condition")
154 | if image is not None:
155 | input_images.append(self.unnormalize_and_pil(image).resize((self.cfg.img_size, self.cfg.img_size)))
156 | captions.append(f"Target {label}")
157 |
158 | seeds = range(2)
159 | output_images = []
160 | embebds_to_vis = []
161 | embeds_captions = []
162 | embebds_to_vis += [target_embeds]
163 | embeds_captions += ["Target Reconstruct" if image is not None else "Source Reconstruct"]
164 | if self.cfg.use_ref:
165 | embebds_to_vis += [cond_sequence[:, :16]]
166 | embeds_captions += ["Grid Reconstruct"]
167 | for embs in embebds_to_vis:
168 | direct_from_emb = self.ip_model.generate(image_prompt_embeds=embs, num_samples=1, num_inference_steps=50)
169 | output_images = output_images + direct_from_emb
170 | captions += embeds_captions
171 |
172 | for seed in seeds:
173 | for scale in [1, 4]:
174 | negative_cond_sequence = torch.zeros_like(cond_sequence)
175 | embeds_len = self.zero_image_embeds.shape[1]
176 | for i in range(0, negative_cond_sequence.shape[1], embeds_len):
177 | negative_cond_sequence[:, i : i + embeds_len] = self.zero_image_embeds.detach()
178 | img_emb = self.prior_pipeline(
179 | cond_sequence=cond_sequence,
180 | negative_cond_sequence=negative_cond_sequence,
181 | num_inference_steps=25,
182 | num_images_per_prompt=1,
183 | guidance_scale=scale,
184 | generator=torch.Generator(device="cuda").manual_seed(seed),
185 | ).image_embeds
186 |
187 | for seed_2 in range(1):
188 | images = self.ip_model.generate(
189 | image_prompt_embeds=img_emb,
190 | num_samples=1,
191 | num_inference_steps=50,
192 | )
193 | output_images += images
194 | captions.append(f"prior_s {seed}, cfg {scale}, unet_s {seed_2}")
195 |
196 | all_images = input_images + output_images
197 | gen_images = vis_utils.create_table_plot(images=all_images, captions=captions)
198 | gen_images.save(save_path)
199 | self.prior.train()
200 |
201 | def get_dataloaders(self) -> torch.utils.data.DataLoader:
202 | dataset_path = self.cfg.dataset_path
203 | if not isinstance(self.cfg.dataset_path, list):
204 | dataset_path = [self.cfg.dataset_path]
205 | datasets = []
206 | for path in dataset_path:
207 | datasets.append(
208 | PartsDataset(
209 | dataset_dir=path,
210 | image_processor=self.image_processor,
211 | use_ref=self.cfg.use_ref,
212 | max_crops=self.cfg.max_crops,
213 | sketch_prob=self.cfg.sketch_prob,
214 | )
215 | )
216 | dataset = torch.utils.data.ConcatDataset(datasets)
217 | print(f"Total number of samples: {len(dataset)}")
218 | dataset_weights = []
219 | for single_dataset in datasets:
220 | dataset_weights.extend([len(dataset) / len(single_dataset)] * len(single_dataset))
221 | sampler_train = torch.utils.data.WeightedRandomSampler(
222 | weights=dataset_weights, num_samples=len(dataset_weights)
223 | )
224 |
225 | validation_dataset = PartsDataset(
226 | dataset_dir=self.cfg.val_dataset_path,
227 | image_processor=self.image_processor,
228 | use_ref=self.cfg.use_ref,
229 | max_crops=self.cfg.max_crops,
230 | sketch_prob=self.cfg.sketch_prob,
231 | )
232 | train_dataloader = torch.utils.data.DataLoader(
233 | dataset,
234 | batch_size=self.cfg.train_batch_size,
235 | shuffle=sampler_train is None,
236 | num_workers=self.cfg.num_workers,
237 | sampler=sampler_train,
238 | )
239 |
240 | validation_dataloader = torch.utils.data.DataLoader(
241 | validation_dataset,
242 | batch_size=1,
243 | shuffle=True,
244 | num_workers=self.cfg.num_workers,
245 | )
246 | return train_dataloader, validation_dataloader
247 |
248 | def train(self):
249 | pbar = tqdm(range(self.train_step, self.cfg.max_train_steps + 1))
250 | # self.log_validation()
251 |
252 | while self.train_step < self.cfg.max_train_steps:
253 | train_loss = 0.0
254 | self.prior.train()
255 | lossbin = {i: 0 for i in range(10)}
256 | losscnt = {i: 1e-6 for i in range(10)}
257 |
258 | for sample_idx, batch in enumerate(self.train_dataloader):
259 | with self.accelerator.accumulate(self.prior):
260 | image, cond = batch
261 |
262 | image = image.to(self.weight_dtype).to(self.accelerator.device)
263 | if "crops" in cond:
264 | for crop_ind in range(len(cond["crops"])):
265 | cond["crops"][crop_ind] = (
266 | cond["crops"][crop_ind].to(self.weight_dtype).to(self.accelerator.device)
267 | )
268 | for key in cond.keys():
269 | if isinstance(cond[key], torch.Tensor):
270 | cond[key] = cond[key].to(self.accelerator.device)
271 |
272 | with torch.no_grad():
273 | image_embeds = self.ip_model.get_image_embeds(image, skip_uncond=True)
274 |
275 | b = image_embeds.size(0)
276 | nt = torch.randn((b,)).to(image_embeds.device)
277 | t = torch.sigmoid(nt)
278 | texp = t.view([b, *([1] * len(image_embeds.shape[1:]))])
279 | z_1 = torch.randn_like(image_embeds)
280 | noisy_latents = (1 - texp) * image_embeds + texp * z_1
281 |
282 | target = image_embeds
283 |
284 | # At some prob uniformly sample across the entire batch so the model also learns to work with unpadded inputs
285 | if random.random() < 0.5:
286 | crops_to_keep = random.randint(1, len(cond["crops"]))
287 | cond["crops"] = cond["crops"][:crops_to_keep]
288 | cond_crops = cond["crops"]
289 |
290 | image_embed_inputs = []
291 | for crop_ind in range(len(cond_crops)):
292 | image_embed_inputs.append(
293 | self.ip_model.get_image_embeds(cond_crops[crop_ind], skip_uncond=True)
294 | )
295 | input_sequence = torch.cat(image_embed_inputs, dim=1)
296 |
297 | loss = 0
298 | image_feat_seq = input_sequence
299 |
300 | model_pred = self.prior(
301 | noisy_latents,
302 | t=t,
303 | cond=image_feat_seq,
304 | )
305 |
306 | batchwise_prior_loss = ((z_1 - target.float() - model_pred.float()) ** 2).mean(
307 | dim=list(range(1, len(target.shape)))
308 | )
309 | tlist = batchwise_prior_loss.detach().cpu().reshape(-1).tolist()
310 | ttloss = [(tv, tloss) for tv, tloss in zip(t, tlist)]
311 |
312 | # count based on t
313 | for t, l in ttloss:
314 | lossbin[int(t * 10)] += l
315 | losscnt[int(t * 10)] += 1
316 |
317 | loss += batchwise_prior_loss.mean()
318 | # Gather the losses across all processes for logging (if we use distributed training).
319 | avg_loss = self.accelerator.gather(loss.repeat(self.cfg.train_batch_size)).mean()
320 | train_loss += avg_loss.item() / self.cfg.gradient_accumulation_steps
321 |
322 | # Backprop
323 | self.accelerator.backward(loss)
324 | if self.accelerator.sync_gradients:
325 | self.accelerator.clip_grad_norm_(self.prior.parameters(), self.cfg.max_grad_norm)
326 | self.optimizer.step()
327 | self.optimizer.zero_grad()
328 |
329 | # Checks if the accelerator has performed an optimization step behind the scenes
330 | if self.accelerator.sync_gradients:
331 | pbar.update(1)
332 | self.train_step += 1
333 | train_loss = 0.0
334 |
335 | if self.accelerator.is_main_process:
336 |
337 | if self.train_step % self.cfg.checkpointing_steps == 1:
338 | if self.accelerator.is_main_process:
339 | save_path = self.cfg.output_dir # / f"learned_prior.pth"
340 | self.save_model(save_path)
341 | logger.info(f"Saved state to {save_path}")
342 | pbar.set_postfix(**{"loss": loss.cpu().detach().item()})
343 |
344 | if self.cfg.log_image_frequency > 0 and (self.train_step % self.cfg.log_image_frequency == 1):
345 | image_save_path = self.cfg.output_dir / "images" / f"{self.train_step}_step_images.jpg"
346 | image_save_path.parent.mkdir(exist_ok=True, parents=True)
347 | # Apply the full diffusion process
348 | conds_list = []
349 | for crop_ind in range(len(cond["crops"])):
350 | conds_list.append(cond["crops"][crop_ind][0])
351 |
352 | self.save_images(
353 | image=image[0],
354 | conds=conds_list,
355 | cond_sequence=image_feat_seq[:1],
356 | target_embeds=target[:1],
357 | save_path=image_save_path,
358 | )
359 |
360 | if self.cfg.log_validation > 0 and (self.train_step % self.cfg.log_validation == 0):
361 | # Run validation
362 | self.log_validation()
363 |
364 | if self.train_step >= self.cfg.max_train_steps:
365 | break
366 |
367 | self.train_dataloader, self.validation_dataloader = self.get_dataloaders()
368 | pbar.close()
369 |
370 | def log_validation(self):
371 | for sample_idx, batch in tqdm(enumerate(self.validation_dataloader)):
372 | image, cond = batch
373 | image = image.to(self.weight_dtype).to(self.accelerator.device)
374 | if "crops" in cond:
375 | for crop_ind in range(len(cond["crops"])):
376 | cond["crops"][crop_ind] = cond["crops"][crop_ind].to(self.weight_dtype).to(self.accelerator.device)
377 | for key in cond.keys():
378 | if isinstance(cond[key], torch.Tensor):
379 | cond[key] = cond[key].to(self.accelerator.device)
380 |
381 | with torch.no_grad():
382 | target_embeds = self.ip_model.get_image_embeds(image, skip_uncond=True)
383 | crops_to_keep = random.randint(1, len(cond["crops"]))
384 | cond["crops"] = cond["crops"][:crops_to_keep]
385 | cond_crops = cond["crops"]
386 | image_embed_inputs = []
387 | for crop_ind in range(len(cond_crops)):
388 | image_embed_inputs.append(self.ip_model.get_image_embeds(cond_crops[crop_ind], skip_uncond=True))
389 | input_sequence = torch.cat(image_embed_inputs, dim=1)
390 |
391 | image_save_path = self.cfg.output_dir / "val_images" / f"{self.train_step}_step_{sample_idx}_images.jpg"
392 | image_save_path.parent.mkdir(exist_ok=True, parents=True)
393 |
394 | save_target_image = image[0]
395 | conds_list = []
396 | for crop_ind in range(len(cond["crops"])):
397 | conds_list.append(cond["crops"][crop_ind][0])
398 |
399 | # Apply the full diffusion process
400 | self.save_images(
401 | image=save_target_image,
402 | conds=conds_list,
403 | cond_sequence=input_sequence[:1],
404 | target_embeds=target_embeds[:1],
405 | save_path=image_save_path,
406 | )
407 |
408 | if sample_idx == self.cfg.n_val_images:
409 | break
410 |
--------------------------------------------------------------------------------
/training/dataset.py:
--------------------------------------------------------------------------------
1 | import random
2 | import traceback
3 | from pathlib import Path
4 |
5 | import einops
6 | import numpy as np
7 | import torchvision.transforms as T
8 | from PIL import Image
9 | from torch.utils.data import Dataset
10 | from tqdm import tqdm
11 |
12 | from utils import bezier_utils
13 |
14 |
15 | class PartsDataset(Dataset):
16 | def __init__(
17 | self,
18 | dataset_dir: Path,
19 | clip_image_size: int = 224,
20 | image_processor=None,
21 | max_crops=3,
22 | use_ref: bool = True,
23 | ref_as_grid: bool = True,
24 | grid_size: int = 2,
25 | sketch_prob: float = 0.0,
26 | ):
27 | subdirs = [d for d in dataset_dir.iterdir() if d.is_dir()]
28 |
29 | all_paths = []
30 | self.subdir_dict = {}
31 | for subdir in tqdm(subdirs):
32 | current_paths = list(subdir.glob("*.jpg"))
33 | current_target_paths = [p for p in current_paths if len(str(p.name).split("_")) == 2]
34 | if use_ref and len(current_target_paths) < 9:
35 | # Skip if not enough target images
36 | continue
37 | all_paths.extend(current_paths)
38 | self.subdir_dict[subdir] = current_target_paths
39 |
40 | print(f"Percentile of valid subdirs: {len(self.subdir_dict) / len(subdirs)}")
41 | self.target_paths = [p for p in all_paths if len(str(p.name).split("_")) == 2]
42 | source_paths = [p for p in all_paths if len(str(p.name).split("_")) == 3]
43 | self.source_target_mappings = {path: [] for path in self.target_paths}
44 | for source_path in source_paths:
45 | # Remove last part of the path
46 | target_path = Path("_".join(str(source_path).split("_")[:-1]) + ".jpg")
47 | if target_path in self.source_target_mappings:
48 | self.source_target_mappings[target_path].append(source_path)
49 | print(f"Loaded {len(self.target_paths)} target images")
50 |
51 | self.clip_image_size = clip_image_size
52 |
53 | self.image_processor = image_processor
54 |
55 | self.max_crops = max_crops
56 |
57 | self.use_ref = use_ref
58 |
59 | self.ref_as_grid = ref_as_grid
60 |
61 | self.grid_size = grid_size
62 |
63 | self.sketch_prob = sketch_prob
64 |
65 | def __len__(self):
66 | return len(self.target_paths)
67 |
68 | def paste_on_background(self, image, background, min_scale=0.4, max_scale=0.8):
69 | # Calculate aspect ratio and determine resizing based on the smaller dimension of the background
70 | aspect_ratio = image.width / image.height
71 | scale = random.uniform(min_scale, max_scale)
72 | new_width = int(min(background.width, background.height * aspect_ratio) * scale)
73 | new_height = int(new_width / aspect_ratio)
74 |
75 | # Resize image and calculate position
76 | image = image.resize((new_width, new_height), resample=Image.LANCZOS)
77 | pos_x = random.randint(0, background.width - new_width)
78 | pos_y = random.randint(0, background.height - new_height)
79 |
80 | # Paste the image using its alpha channel as mask if present
81 | background.paste(image, (pos_x, pos_y), image if "A" in image.mode else None)
82 | return background
83 |
84 | def get_random_crop(self, image):
85 | crop_percent_x = random.uniform(0.8, 1.0)
86 | crop_percent_y = random.uniform(0.8, 1.0)
87 | # crop_percent_y = random.uniform(0.1, 0.7)
88 | crop_x = int(image.width * crop_percent_x)
89 | crop_y = int(image.height * crop_percent_y)
90 | x = random.randint(0, image.width - crop_x)
91 | y = random.randint(0, image.height - crop_y)
92 | return image.crop((x, y, x + crop_x, y + crop_y))
93 |
94 | def get_empty_image(self):
95 | empty_image = Image.new("RGB", (self.clip_image_size, self.clip_image_size), (255, 255, 255))
96 | return self.image_processor(empty_image)["pixel_values"][0]
97 |
98 | def __getitem__(self, i: int):
99 |
100 | out_dict = {}
101 |
102 | try:
103 | target_path = self.target_paths[i]
104 | image = Image.open(target_path).convert("RGB")
105 |
106 | input_parts = []
107 |
108 | source_paths = self.source_target_mappings[target_path]
109 | n_samples = random.randint(1, len(source_paths))
110 |
111 | n_samples = min(n_samples, self.max_crops)
112 | source_paths = random.sample(source_paths, n_samples)
113 |
114 | if random.random() < 0.1:
115 | # Use empty image, but maybe still pass reference
116 | source_paths = []
117 |
118 | if self.use_ref:
119 | subdir = target_path.parent
120 | # Take something from same dir
121 | potential_refs = list(set(self.subdir_dict[subdir]) - {target_path})
122 | # Choose 4 refs
123 | reference_paths = random.sample(potential_refs, self.grid_size**2)
124 | reference_images = [
125 | np.array(Image.open(reference_path).convert("RGB")) for reference_path in reference_paths
126 | ]
127 | # Concat all images as grid of 2x2
128 | reference_grid = np.stack(reference_images)
129 | grid_image = einops.rearrange(
130 | reference_grid,
131 | "(h w) h1 w1 c -> (h h1) (w w1) c",
132 | h=self.grid_size,
133 | )
134 | reference_image = Image.fromarray(grid_image).resize((512, 512))
135 |
136 | # Always add the reference image
137 | input_parts.append(reference_image)
138 |
139 | # Sample a subset
140 | for source_path in source_paths:
141 | source_image = Image.open(source_path).convert("RGB")
142 | if random.random() < 0.2:
143 | # Instead of using the source image, use a random crop from the target
144 | source_image = self.get_random_crop(source_image)
145 | if random.random() < 0.2:
146 | source_image = T.v2.RandomRotation(degrees=30, expand=True, fill=255)(source_image)
147 | object_with_background = Image.new("RGB", image.size, (255, 255, 255))
148 | self.paste_on_background(source_image, object_with_background, min_scale=0.8, max_scale=0.95)
149 | if self.sketch_prob > 0 and random.random() < self.sketch_prob:
150 | num_lines = random.randint(8, 15)
151 | object_with_background = bezier_utils.get_sketch(
152 | object_with_background,
153 | total_curves=num_lines,
154 | drop_line_prob=0.1,
155 | )
156 | input_parts.append(object_with_background)
157 |
158 | # Always pad to three parts for now
159 | actual_max_crops = self.max_crops + 1 if self.use_ref else self.max_crops
160 | while len(input_parts) < actual_max_crops:
161 | input_parts.append(
162 | Image.new(
163 | "RGB",
164 | (self.clip_image_size, self.clip_image_size),
165 | (255, 255, 255),
166 | )
167 | )
168 |
169 | except Exception as e:
170 | print(f"Error processing image: {e}")
171 | traceback.print_exc()
172 | empty_image = Image.new("RGB", (self.clip_image_size, self.clip_image_size), (255, 255, 255))
173 | image = empty_image
174 | actual_max_crops = self.max_crops + 1 if self.use_ref else self.max_crops
175 | input_parts = [empty_image] * (actual_max_crops)
176 |
177 | clip_target_image = self.image_processor(image)["pixel_values"][0]
178 | clip_parts = [self.image_processor(part)["pixel_values"][0] for part in input_parts]
179 |
180 | out_dict["crops"] = clip_parts
181 |
182 | return clip_target_image, out_dict
183 |
--------------------------------------------------------------------------------
/training/train_config.py:
--------------------------------------------------------------------------------
1 | from dataclasses import dataclass, field
2 | from pathlib import Path
3 | from typing import List, Optional, Union
4 |
5 |
6 | @dataclass
7 | class TrainConfig:
8 | # Dataset path
9 | dataset_path: Union[Path, List[Path]] = Path("datasets/generated/generated_things")
10 | # Validation dataset path
11 | val_dataset_path: Path = Path("datasets/generated/generated_things_val")
12 | # The output directory where the model predictions and checkpoints will be written.
13 | output_dir: Path = Path("results/my_pit_model")
14 | # GPU device
15 | device: str = "cuda:0"
16 | # The resolution for input images, all the images will be resized to this size
17 | img_size: int = 1024
18 | # Batch size (per device) for the training dataloader
19 | train_batch_size: int = 1
20 | # Initial learning rate (after the potential warmup period) to use
21 | lr: float = 1e-5
22 | # Dataloader num workers.
23 | num_workers: int = 8
24 | # The beta1 parameter for the Adam optimizer.
25 | adam_beta1: float = 0.9
26 | # The beta2 parameter for the Adam optimizer
27 | adam_beta2: float = 0.999
28 | # Weight decay to use
29 | adam_weight_decay: float = 0.0 # 1e-2
30 | # Epsilon value for the Adam optimizer
31 | adam_epsilon: float = 1e-08
32 | # How often save images. Values less zero - disable saving
33 | log_image_frequency: int = 500
34 | # How often to run validation
35 | log_validation: int = 5000
36 | # The number of images to save during each validation
37 | n_val_images: int = 10
38 | # A seed for reproducible training
39 | seed: Optional[int] = None
40 | # The number of accumulation steps to use
41 | gradient_accumulation_steps: int = 1
42 | # Whether to use mixed precision training
43 | mixed_precision: Optional[str] = "fp16"
44 | # Log to wandb
45 | report_to: Optional[str] = "wandb"
46 | # The number of training steps to run
47 | max_train_steps: int = 1000000
48 | # Max grad for clipping
49 | max_grad_norm: float = 1.0
50 | # How often to save checkpoints
51 | checkpointing_steps: int = 5000
52 | # The path to resume from
53 | resume_from_path: Optional[Path] = None
54 | # The step to resume from, mainly for logging
55 | resume_from_step: Optional[int] = None
56 | # DiT number of layers
57 | num_layers: int = 8
58 | # DiT hidden dimensionality
59 | hidden_dim: int = 2048
60 | # DiT number of attention heads
61 | num_attention_heads: int = 32
62 | # Whether to use a reference grid
63 | use_ref: bool = False
64 | # Max number of crops
65 | max_crops: int = 3
66 | # Probability of converting to sketch
67 | sketch_prob: float = 0.0
68 |
--------------------------------------------------------------------------------
/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/eladrich/PiT/73d26b0a4ab627e3f26c50763178bd75d0408cc2/utils/__init__.py
--------------------------------------------------------------------------------
/utils/bezier_utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import cv2
3 | from PIL import Image
4 | import random
5 | from scipy.optimize import minimize
6 |
7 |
8 | def draw_contours(image, contours):
9 | """Draw contours on a blank image with random colors."""
10 | output = np.zeros((image.shape[0], image.shape[1], 3), dtype=np.uint8)
11 | for contour in contours:
12 | color = [random.randint(0, 255) for _ in range(3)]
13 | cv2.drawContours(output, [contour], -1, color, thickness=2)
14 | return output
15 |
16 |
17 | def contour_to_bezier(contour):
18 | """Convert an OpenCV contour to a cubic Bézier curve with 4 control points."""
19 | points = contour.reshape(-1, 2)
20 | P0 = points[0]
21 | P3 = points[-1]
22 |
23 | def bezier_point(t, control_points):
24 | P0, P1, P2, P3 = control_points
25 | return (1 - t) ** 3 * P0 + 3 * (1 - t) ** 2 * t * P1 + 3 * (1 - t) * t**2 * P2 + t**3 * P3
26 |
27 | def objective_function(params):
28 | P1 = np.array([params[0], params[1]])
29 | P2 = np.array([params[2], params[3]])
30 | control_points = [P0, P1, P2, P3]
31 | t_values = np.linspace(0, 1, len(points))
32 | bezier_points = np.array([bezier_point(t, control_points) for t in t_values])
33 | distances = np.sum((points - bezier_points) ** 2)
34 | return distances
35 |
36 | initial_P1 = P0 + (P3 - P0) / 3
37 | initial_P2 = P0 + 2 * (P3 - P0) / 3
38 | initial_guess = np.concatenate([initial_P1, initial_P2])
39 | result = minimize(objective_function, initial_guess, method="Nelder-Mead")
40 |
41 | P1 = np.array([result.x[0], result.x[1]])
42 | P2 = np.array([result.x[2], result.x[3]])
43 | return np.array([P0, P1, P2, P3])
44 |
45 |
46 | def visualize_result(img, control_points, num_points=100):
47 | """Draw a Bézier curve defined by control points."""
48 | t_values = np.linspace(0, 1, num_points)
49 | curve_points = []
50 | for t in t_values:
51 | x = (
52 | (1 - t) ** 3 * control_points[0][0]
53 | + 3 * (1 - t) ** 2 * t * control_points[1][0]
54 | + 3 * (1 - t) * t**2 * control_points[2][0]
55 | + t**3 * control_points[3][0]
56 | )
57 | y = (
58 | (1 - t) ** 3 * control_points[0][1]
59 | + 3 * (1 - t) ** 2 * t * control_points[1][1]
60 | + 3 * (1 - t) * t**2 * control_points[2][1]
61 | + t**3 * control_points[3][1]
62 | )
63 | curve_points.append([int(x), int(y)])
64 |
65 | curve_points = np.array(curve_points, dtype=np.int32)
66 | for i in range(len(curve_points) - 1):
67 | cv2.line(img, tuple(curve_points[i]), tuple(curve_points[i + 1]), (0, 0, 0), 2)
68 | return img
69 |
70 |
71 | def get_sketch(image, total_curves=10, drop_line_prob=0.0, pad=False):
72 | """
73 | Convert an image to a sketch made of Bézier curves.
74 |
75 | Args:
76 | image_path: Path to the input image
77 | total_curves: Total number of Bézier curves to use (default: 10)
78 |
79 | Returns:
80 | numpy.ndarray: Image with Bézier curves sketch
81 | """
82 | # Load and preprocess image
83 | image = np.array(image)
84 |
85 | # Pad image to square
86 | height, width, _ = image.shape
87 | if pad:
88 | max_side = max(height, width) + 20
89 | pad_h = (max_side - height) // 2
90 | pad_w = (max_side - width) // 2
91 |
92 | image = np.pad(
93 | image,
94 | ((pad_h, max_side - height - pad_h), (pad_w, max_side - width - pad_w), (0, 0)),
95 | mode="constant",
96 | constant_values=255,
97 | )
98 |
99 | # Convert to binary
100 | gray_image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
101 | binary = np.where(gray_image < 255, 255, 0).astype(np.uint8)
102 |
103 | # Clean up binary image
104 | kernel = np.ones((5, 5), np.uint8)
105 | binary = cv2.erode(binary, kernel, iterations=4)
106 |
107 | # Get contours
108 | contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
109 |
110 | # Calculate curve allocation
111 | contour_lengths = [cv2.arcLength(contour, closed=True) for contour in contours]
112 | total_length = sum(contour_lengths)
113 | curve_allocation = [round((length / total_length) * total_curves) for length in contour_lengths]
114 |
115 | # Adjust allocation to match total_curves
116 | curve_allocation = np.clip(curve_allocation, 1, total_curves)
117 | while sum(curve_allocation) > total_curves:
118 | curve_allocation[np.argmax(curve_allocation)] -= 1
119 | while sum(curve_allocation) < total_curves:
120 | curve_allocation[np.argmin(curve_allocation)] += 1
121 |
122 | # Fit Bézier curves
123 | fitted_curves = []
124 | for contour, n_curves in zip(contours, curve_allocation):
125 | segment_length = len(contour) // n_curves
126 | if segment_length == 0:
127 | continue
128 | segments = [contour[i : i + segment_length] for i in range(0, len(contour), segment_length)]
129 |
130 | for segment in segments:
131 | control_points = contour_to_bezier(segment)
132 | fitted_curves.append(control_points)
133 |
134 | # Create final image
135 | curves_image = np.ones_like(image, dtype=np.uint8) * 255
136 | for curve in fitted_curves:
137 | if random.random() < drop_line_prob:
138 | continue
139 | curves_image = visualize_result(curves_image, curve)
140 | curves_image = Image.fromarray(curves_image)
141 | return curves_image
142 |
--------------------------------------------------------------------------------
/utils/vis_utils.py:
--------------------------------------------------------------------------------
1 | import textwrap
2 | from typing import List, Tuple, Optional
3 |
4 | import numpy as np
5 | from PIL import Image, ImageDraw, ImageFont
6 |
7 | LINE_WIDTH = 20
8 |
9 |
10 | def add_text_to_image(image: np.ndarray, text: str, text_color: Tuple[int, int, int] = (0, 0, 0),
11 | min_lines: Optional[int] = None, add_below: bool = True):
12 | import textwrap
13 | lines = textwrap.wrap(text, width=LINE_WIDTH)
14 | if min_lines is not None and len(lines) < min_lines:
15 | if add_below:
16 | lines += [''] * (min_lines - len(lines))
17 | else:
18 | lines = [''] * (min_lines - len(lines)) + lines
19 | h, w, c = image.shape
20 | offset = int(h * .12)
21 | img = np.ones((h + offset * len(lines), w, c), dtype=np.uint8) * 255
22 | font_size = int(offset * .8)
23 |
24 | try:
25 | font = ImageFont.truetype("assets/OpenSans-Regular.ttf", font_size)
26 | textsize = font.getbbox(text)
27 | y_offset = (offset - textsize[3]) // 2
28 | except:
29 | font = ImageFont.load_default()
30 | y_offset = offset // 2
31 |
32 | if add_below:
33 | img[:h] = image
34 | else:
35 | img[-h:] = image
36 | img = Image.fromarray(img)
37 | draw = ImageDraw.Draw(img)
38 | for i, line in enumerate(lines):
39 | line_size = font.getbbox(line)
40 | text_x = (w - line_size[2]) // 2
41 | if add_below:
42 | draw.text((text_x, h + y_offset + offset * i), line, font=font, fill=text_color)
43 | else:
44 | draw.text((text_x, 0 + y_offset + offset * i), line, font=font, fill=text_color)
45 | return np.array(img)
46 |
47 |
48 | def create_table_plot(images: List[Image.Image], titles: List[str]=None, captions: List[str]=None) -> Image.Image:
49 | title_max_lines = np.max([len(textwrap.wrap(text, width=LINE_WIDTH)) for text in titles]) if titles is not None else 0
50 | caption_max_lines = np.max([len(textwrap.wrap(text, width=LINE_WIDTH)) for text in captions]) if captions is not None else 0
51 | out_images = []
52 | for i in range(len(images)):
53 | im = np.array(images[i])
54 | if titles is not None:
55 | im = add_text_to_image(im, titles[i], add_below=False, min_lines=title_max_lines)
56 | if captions is not None:
57 | im = add_text_to_image(im, captions[i], add_below=True, min_lines=caption_max_lines)
58 | out_images.append(im)
59 | image = Image.fromarray(np.concatenate(out_images, axis=1))
60 | return image
61 |
--------------------------------------------------------------------------------