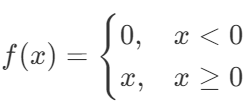 bu fonksiyonun döngü kullanmadan Python'da kodladık.
12 |
13 | Ödev6: Çalışma saati ve saat ücretini alarak kişinin ücretini hesaplayan bir program kodlandı. Eğer ki kişi 40 saatten fazla çalışmışsa, çalıştığı fazladan saat başına normal ücretin bir buçuk katını almasını sağlayacak bir koşul yazıldı.
14 |
15 | Ödev7: Bir metindeki büyük harf sayısını bulan programı for döngüsü ile yazdık daha sonrasında aynı işi tek satırda yapan kodu yazdık.
16 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | ## Türkçe Kitaplar :books:
2 |
3 | :green_book: Ödevler :ledger: Notlar :blue_book: Projeler :orange_book: Ödevler+Projeler
4 |
5 | Bu repo veri bilimi, makine öğrenmesi, programlama, kriptografi vb. alanlarda ilgili Türkçe kaynaklardaki ödev çözümlerini, üretilmiş projeleri ve notları içerir.
6 |
7 |
8 | |:sparkles: Veri Bilimi | :sparkles: Derin Öğrenme | :sparkles: Python | :sparkles: Programlama | :sparkles: Kriptografi |
9 | |---|---|---|---|---|
10 | |:orange_book: [Python ile Veri Bilimi](https://github.com/enesmanan/turkce-kitaplar/tree/main/Python%20ile%20Veri%20Bilimi) | TensorFlow ile Derin Öğrenme | :ledger: [Python](https://github.com/enesmanan/turkce-kitaplar/tree/main/Python) | :blue_book: [Algoritma](https://github.com/enesmanan/turkce-kitaplar/blob/main/Algoritma/README.md) | Kriptografiye Giriş |
11 | |:orange_book: [Uygulamalarla Veri Bilimi](https://github.com/enesmanan/turkce-kitaplar/tree/main/Uygulamalarla%20Veri%20Bilimi) | Yapay Zeka Uygulamaları | :blue_book: [Veri Bilimi İçin Python](https://github.com/enesmanan/turkce-kitaplar/tree/main/Veri%20Bilimi%20%C4%B0%C3%A7in%20Python) | Algoritmalara Giriş | |
12 | |:orange_book: [Projelerle Yapay Zeka](https://github.com/enesmanan/turkce-kitaplar/tree/main/Projelerle%20Yapay%20Zeka) | OpenCV ve Python ile Görüntü İşleme | | | |
13 |
14 |
15 | ### Oluşturan:sparkles:
16 |
17 | [Enes Fehmi Manan](https://github.com/enesmanan)
18 |
19 | [enesmanan768@gmail.com](mailto:enesmanan768@gmail.com)
20 |
21 | [LinkedIn](https://linkedin.com/in/enesfehmimanan/)
22 |
--------------------------------------------------------------------------------
/Python ile Veri Bilimi/Bölüm_8/README.md:
--------------------------------------------------------------------------------
1 | ## 8.4 Alıştırmalar
2 | ### Kod Açıklamaları
3 | Ödev1: Numpy kütüphanesinin zeros metodu ile sıfırlardan ve False değerlerden oluşan 4x4 boyutunda bir numpy array oluşturduk.
4 |
5 | Ödev2: 1'den 1000'e kadar olan sayilardan olusan numpy array olusturduk, bu arraydaki sayıların 18 ile tam bolunenlerini secerek ekrana bastırdık.
6 |
7 | Ödev3: NumPy dizisi içerisinden en büyük 3 sayıyı seçmek için önce `np.sort()` metodu ile diziyi sıralıyoruz, akabinde sıralanmış diziden `[-3:]` ifadesi ile son 3 elemanını seçiyoruz.
8 |
9 | Matriste seçim yapmak için extra bir işlem olarak `flatten()` metodu ile matrisin boyutunu indirgiyoruz akabinde dizi ile aynı işlemler söz konusu.
10 |
11 | Ödev4: Bir dizi içerisindeki sayıları sıralayan fonksiyonu yazdık. Fonksiyonun çalışma prensibi, her iterasyonda en küçük elemanı seçerek o anki konumuna yerleştirmek ve daha sonra işlemi, kalan elemanlar üzerinde tekrarlamaktır.
12 |
13 | Detaylı bakarsak:
14 |
15 | 1. `for` döngüsü ile dizinin eleman uzunluğunca, diziyi eleman eleman gezeriz.
16 | 2. Dizinin belirlenen aralığındaki en küçük sayının indexini `argmin()` metodu ile buluyoruz. En küçük değerin indexini bulmak içinde `np.argmin()` metodunun sonucu, `i` değişkenine eklenir. Bu işlem her iterasyonda kalan bölüm içindeki en küçük sayının index'ini bulmak için tekrarlanır.
17 | 3. Python'daki çoklu atama özelliği ile geçici bir değişken kullanmadan döngü içindeki en küçük sayının bulunduğu index ile döngü değişkeninin değerinin yer değiştirilmesi sağlanıyor.
18 | 4. `return` anahtar kelimesi ile sıralanmış dizi döndürülüyor ve fonksiyon son buluyor.
19 |
--------------------------------------------------------------------------------
/Veri Bilimi İçin Python/rastgele_sifre_olusturucu.py:
--------------------------------------------------------------------------------
1 | import string
2 | import random
3 |
4 | # ozel karakterlerin de eklenmis hali ile
5 | # maksimum 94 haneli bir sifre uretebilir
6 |
7 | def sifre_olustur(uzunluk, ozel_karakterler=True):
8 | kucuk_harfler = string.ascii_lowercase
9 | buyuk_harfler = string.ascii_uppercase
10 | rakamlar = string.digits
11 |
12 | if ozel_karakterler: # printable ile hepsi eklenebilir
13 | ozel_karakterler = string.punctuation
14 | else:
15 | ozel_karakterler = ''
16 |
17 | karakter_listesi = []
18 | karakter_listesi.extend(list(kucuk_harfler))
19 | karakter_listesi.extend(list(buyuk_harfler))
20 | karakter_listesi.extend(list(rakamlar))
21 | karakter_listesi.extend(list(ozel_karakterler))
22 | random.shuffle(karakter_listesi)
23 |
24 | password = ''.join(random.sample(karakter_listesi, uzunluk))
25 | return password
26 |
27 | if __name__ == '__main__':
28 | while True:
29 | try:
30 | password_uzunlugu = int(input('Sifre uzunlugu giriniz: '))
31 | if password_uzunlugu <= 0:
32 | raise ValueError
33 | break
34 | except ValueError:
35 | print('Lutfen pozitif bir tamsayi giriniz.')
36 |
37 | ozel_karakterler = input('Ozel karakterler kullanilsin mi? (E/H): ')
38 |
39 | if ozel_karakterler.lower() == 'e':
40 | ozel_karakterler = True
41 | else:
42 | ozel_karakterler = False
43 |
44 | password = sifre_olustur(password_uzunlugu, ozel_karakterler)
45 | print('Uretilen sifre:', password)
--------------------------------------------------------------------------------
/Algoritma/README.md:
--------------------------------------------------------------------------------
1 | ## Algoritma ve Programlama Mantığı
2 |
3 | #### Repo link: https://github.com/enesmanan/Python_Practices
4 | + **[Genel Uygulamalar](https://github.com/enesmanan/Python_Practices/blob/main/Genel%20Uygulamalar%20I.ipynb)**
5 | + **[Dizi Uygulamaları](https://github.com/enesmanan/Python_Practices/blob/main/Dizi%20Uygulamalar%C4%B1%20II.ipynb)**
6 | + **[Özel Uygulamalar](https://github.com/enesmanan/Python_Practices/blob/main/Ozel%20Uygulamalar%20III.ipynb)**
7 | ----------
8 |
9 |
10 | ### Açıklama
11 | Algoritma ve Programalama Mantığı kitabı, yazılım alanı için ilk aldığım ve bende yeri ayrı bir kitaptır. Bu kitabı 2020 yılında üniversiteye geçtikten sonra yazılıma nasıl giriş yapabilirim derken tüm yollar bir şekilde algoritmaya çıktığında almıştım. İyi ki de almışım, gerçekten çok açıklayıcı bir dilde ve bolca örnekle bezenmiş çok sevdiğim bir kitap.
12 |
13 | 2022'de Python öğrenirken kitabı tekrar baştan sonra bir kez daha okudum. Kitaptaki örnekler Java ve C++ üzerinden verildiğinden dolayı bunları kendimce Python dilinin yapısına uyarlayarak ama kitaptaki mantıktan da uzaklaşmayaraktan tekrar yazdım. O dönem yaptığım bu iş algoritma mantığımı ve problem çözme yeteneklerimi çokça geliştirmişti. Tabii ki o dönemler ChatGPT gibi modeller yoktu, ben de tamamen kendim yapmaya çalışmıştım. Dolayısıyla bana çok faydası dokunmuştu. [Buradaki](https://github.com/enesmanan/python_documentation) eğitimi verirken de çokça o dönemki bilgilerden faydalandım. Kitabın yazarı H. Burak Tungut'a teşekkür ederim.
14 |
15 |
bu fonksiyonun döngü kullanmadan Python'da kodladık.
12 |
13 | Ödev6: Çalışma saati ve saat ücretini alarak kişinin ücretini hesaplayan bir program kodlandı. Eğer ki kişi 40 saatten fazla çalışmışsa, çalıştığı fazladan saat başına normal ücretin bir buçuk katını almasını sağlayacak bir koşul yazıldı.
14 |
15 | Ödev7: Bir metindeki büyük harf sayısını bulan programı for döngüsü ile yazdık daha sonrasında aynı işi tek satırda yapan kodu yazdık.
16 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | ## Türkçe Kitaplar :books:
2 |
3 | :green_book: Ödevler :ledger: Notlar :blue_book: Projeler :orange_book: Ödevler+Projeler
4 |
5 | Bu repo veri bilimi, makine öğrenmesi, programlama, kriptografi vb. alanlarda ilgili Türkçe kaynaklardaki ödev çözümlerini, üretilmiş projeleri ve notları içerir.
6 |
7 |
8 | |:sparkles: Veri Bilimi | :sparkles: Derin Öğrenme | :sparkles: Python | :sparkles: Programlama | :sparkles: Kriptografi |
9 | |---|---|---|---|---|
10 | |:orange_book: [Python ile Veri Bilimi](https://github.com/enesmanan/turkce-kitaplar/tree/main/Python%20ile%20Veri%20Bilimi) | TensorFlow ile Derin Öğrenme | :ledger: [Python](https://github.com/enesmanan/turkce-kitaplar/tree/main/Python) | :blue_book: [Algoritma](https://github.com/enesmanan/turkce-kitaplar/blob/main/Algoritma/README.md) | Kriptografiye Giriş |
11 | |:orange_book: [Uygulamalarla Veri Bilimi](https://github.com/enesmanan/turkce-kitaplar/tree/main/Uygulamalarla%20Veri%20Bilimi) | Yapay Zeka Uygulamaları | :blue_book: [Veri Bilimi İçin Python](https://github.com/enesmanan/turkce-kitaplar/tree/main/Veri%20Bilimi%20%C4%B0%C3%A7in%20Python) | Algoritmalara Giriş | |
12 | |:orange_book: [Projelerle Yapay Zeka](https://github.com/enesmanan/turkce-kitaplar/tree/main/Projelerle%20Yapay%20Zeka) | OpenCV ve Python ile Görüntü İşleme | | | |
13 |
14 |
15 | ### Oluşturan:sparkles:
16 |
17 | [Enes Fehmi Manan](https://github.com/enesmanan)
18 |
19 | [enesmanan768@gmail.com](mailto:enesmanan768@gmail.com)
20 |
21 | [LinkedIn](https://linkedin.com/in/enesfehmimanan/)
22 |
--------------------------------------------------------------------------------
/Python ile Veri Bilimi/Bölüm_8/README.md:
--------------------------------------------------------------------------------
1 | ## 8.4 Alıştırmalar
2 | ### Kod Açıklamaları
3 | Ödev1: Numpy kütüphanesinin zeros metodu ile sıfırlardan ve False değerlerden oluşan 4x4 boyutunda bir numpy array oluşturduk.
4 |
5 | Ödev2: 1'den 1000'e kadar olan sayilardan olusan numpy array olusturduk, bu arraydaki sayıların 18 ile tam bolunenlerini secerek ekrana bastırdık.
6 |
7 | Ödev3: NumPy dizisi içerisinden en büyük 3 sayıyı seçmek için önce `np.sort()` metodu ile diziyi sıralıyoruz, akabinde sıralanmış diziden `[-3:]` ifadesi ile son 3 elemanını seçiyoruz.
8 |
9 | Matriste seçim yapmak için extra bir işlem olarak `flatten()` metodu ile matrisin boyutunu indirgiyoruz akabinde dizi ile aynı işlemler söz konusu.
10 |
11 | Ödev4: Bir dizi içerisindeki sayıları sıralayan fonksiyonu yazdık. Fonksiyonun çalışma prensibi, her iterasyonda en küçük elemanı seçerek o anki konumuna yerleştirmek ve daha sonra işlemi, kalan elemanlar üzerinde tekrarlamaktır.
12 |
13 | Detaylı bakarsak:
14 |
15 | 1. `for` döngüsü ile dizinin eleman uzunluğunca, diziyi eleman eleman gezeriz.
16 | 2. Dizinin belirlenen aralığındaki en küçük sayının indexini `argmin()` metodu ile buluyoruz. En küçük değerin indexini bulmak içinde `np.argmin()` metodunun sonucu, `i` değişkenine eklenir. Bu işlem her iterasyonda kalan bölüm içindeki en küçük sayının index'ini bulmak için tekrarlanır.
17 | 3. Python'daki çoklu atama özelliği ile geçici bir değişken kullanmadan döngü içindeki en küçük sayının bulunduğu index ile döngü değişkeninin değerinin yer değiştirilmesi sağlanıyor.
18 | 4. `return` anahtar kelimesi ile sıralanmış dizi döndürülüyor ve fonksiyon son buluyor.
19 |
--------------------------------------------------------------------------------
/Veri Bilimi İçin Python/rastgele_sifre_olusturucu.py:
--------------------------------------------------------------------------------
1 | import string
2 | import random
3 |
4 | # ozel karakterlerin de eklenmis hali ile
5 | # maksimum 94 haneli bir sifre uretebilir
6 |
7 | def sifre_olustur(uzunluk, ozel_karakterler=True):
8 | kucuk_harfler = string.ascii_lowercase
9 | buyuk_harfler = string.ascii_uppercase
10 | rakamlar = string.digits
11 |
12 | if ozel_karakterler: # printable ile hepsi eklenebilir
13 | ozel_karakterler = string.punctuation
14 | else:
15 | ozel_karakterler = ''
16 |
17 | karakter_listesi = []
18 | karakter_listesi.extend(list(kucuk_harfler))
19 | karakter_listesi.extend(list(buyuk_harfler))
20 | karakter_listesi.extend(list(rakamlar))
21 | karakter_listesi.extend(list(ozel_karakterler))
22 | random.shuffle(karakter_listesi)
23 |
24 | password = ''.join(random.sample(karakter_listesi, uzunluk))
25 | return password
26 |
27 | if __name__ == '__main__':
28 | while True:
29 | try:
30 | password_uzunlugu = int(input('Sifre uzunlugu giriniz: '))
31 | if password_uzunlugu <= 0:
32 | raise ValueError
33 | break
34 | except ValueError:
35 | print('Lutfen pozitif bir tamsayi giriniz.')
36 |
37 | ozel_karakterler = input('Ozel karakterler kullanilsin mi? (E/H): ')
38 |
39 | if ozel_karakterler.lower() == 'e':
40 | ozel_karakterler = True
41 | else:
42 | ozel_karakterler = False
43 |
44 | password = sifre_olustur(password_uzunlugu, ozel_karakterler)
45 | print('Uretilen sifre:', password)
--------------------------------------------------------------------------------
/Algoritma/README.md:
--------------------------------------------------------------------------------
1 | ## Algoritma ve Programlama Mantığı
2 |
3 | #### Repo link: https://github.com/enesmanan/Python_Practices
4 | + **[Genel Uygulamalar](https://github.com/enesmanan/Python_Practices/blob/main/Genel%20Uygulamalar%20I.ipynb)**
5 | + **[Dizi Uygulamaları](https://github.com/enesmanan/Python_Practices/blob/main/Dizi%20Uygulamalar%C4%B1%20II.ipynb)**
6 | + **[Özel Uygulamalar](https://github.com/enesmanan/Python_Practices/blob/main/Ozel%20Uygulamalar%20III.ipynb)**
7 | ----------
8 |
9 |
10 | ### Açıklama
11 | Algoritma ve Programalama Mantığı kitabı, yazılım alanı için ilk aldığım ve bende yeri ayrı bir kitaptır. Bu kitabı 2020 yılında üniversiteye geçtikten sonra yazılıma nasıl giriş yapabilirim derken tüm yollar bir şekilde algoritmaya çıktığında almıştım. İyi ki de almışım, gerçekten çok açıklayıcı bir dilde ve bolca örnekle bezenmiş çok sevdiğim bir kitap.
12 |
13 | 2022'de Python öğrenirken kitabı tekrar baştan sonra bir kez daha okudum. Kitaptaki örnekler Java ve C++ üzerinden verildiğinden dolayı bunları kendimce Python dilinin yapısına uyarlayarak ama kitaptaki mantıktan da uzaklaşmayaraktan tekrar yazdım. O dönem yaptığım bu iş algoritma mantığımı ve problem çözme yeteneklerimi çokça geliştirmişti. Tabii ki o dönemler ChatGPT gibi modeller yoktu, ben de tamamen kendim yapmaya çalışmıştım. Dolayısıyla bana çok faydası dokunmuştu. [Buradaki](https://github.com/enesmanan/python_documentation) eğitimi verirken de çokça o dönemki bilgilerden faydalandım. Kitabın yazarı H. Burak Tungut'a teşekkür ederim.
14 |
15 | | Level | 87 |Puan | 88 |Durum | 89 |
|---|
12 | 13 | ## Vector Space Similarity 14 | + [Vektör Uzay Benzerlik Algoritması](https://github.com/enesmanan/turkce-kitaplar/blob/main/Projelerle%20Yapay%20Zeka/Benzerlik_Algoritmalar%C4%B1/vector_similarity.py) 15 | + [RGB Renk Koduna Göre En Yüksek Benzerlik Oranına Sahip Rengi Bulan Algoritma](https://github.com/enesmanan/turkce-kitaplar/blob/main/Projelerle%20Yapay%20Zeka/Benzerlik_Algoritmalar%C4%B1/rgb_similarity.py) $\to$ **Ödev_2** 16 | + Algoritma, konsoldan rastgele girilen RGB renk koduna göre isimlendirilmiş renklerden en yüksek benzerlik oranına sahip 3 rengi tespit eder ve döndürür. 17 | + Renk kodlarını [buradaki](https://www.rapidtables.com/web/color/RGB_Color.html) siteden aldım ve toplamda 139 adet renk içeriyor. 18 | + Renkleri algoritma her çalıştığında RGB değerlerini normalize etmek algoritmanın time complexity değerini olumsuz etkileyebileceği için ve kullancağım tüm uzay da bu değerlerden oluştuğu için algoritmaya RGB renk kodlarını normalize ederek verdim. 19 | + RGB renk kodları $\to$ [RGBCodes.txt](https://github.com/enesmanan/turkce-kitaplar/blob/main/Projelerle%20Yapay%20Zeka/Benzerlik_Algoritmalar%C4%B1/RGBCodes.txt) 20 | + Normalize edilmiş RGB renk kodları $\to$ [RGBCodes_normalized.txt](https://github.com/enesmanan/turkce-kitaplar/blob/main/Projelerle%20Yapay%20Zeka/Benzerlik_Algoritmalar%C4%B1/RGBCodes_normalized.txt) 21 | 22 |
23 | 24 | ## Cosine Similarity 25 | + [Kosinüs Benzerlik Algoritması](https://github.com/enesmanan/turkce-kitaplar/blob/main/Projelerle%20Yapay%20Zeka/Benzerlik_Algoritmalar%C4%B1/cosine_similarity.py) 26 | + [TF-IDF Nedir?](https://github.com/enesmanan/turkce-kitaplar/blob/main/Projelerle%20Yapay%20Zeka/Benzerlik_Algoritmalar%C4%B1/TF-IDF.ipynb) 27 | + [TF-IDF Algoritması](https://github.com/enesmanan/turkce-kitaplar/blob/main/Projelerle%20Yapay%20Zeka/Benzerlik_Algoritmalar%C4%B1/tf_idf.py) 28 | + [TF-IDF ile Kosinüs Benzerliği](https://github.com/enesmanan/turkce-kitaplar/blob/main/Projelerle%20Yapay%20Zeka/Benzerlik_Algoritmalar%C4%B1/cosine_similarity_tf_idf.py) 29 | + [Standart vs TF-IDF ile Optimize Edilmiş Kosinüs Benzerliği Arasındaki Farklar](https://github.com/enesmanan/turkce-kitaplar/blob/main/Projelerle%20Yapay%20Zeka/Benzerlik_Algoritmalar%C4%B1/kosinusBenzerligiFark.md) $\to$ **Ödev_3** 30 | 31 |
32 | 33 | ## Matrix Similarity 34 | + [Origin Matris Benzerliği](https://github.com/enesmanan/turkce-kitaplar/blob/main/Projelerle%20Yapay%20Zeka/Benzerlik_Algoritmalar%C4%B1/origin_matrix_similarity.py) 35 | + Kitaptaki kodda bazı düzeltmeler yapıldı. (eksik import eklendi ve bazı küçük düzeltmeler yapıldı) 36 | + [Matris Benzerliği Algoritması](https://github.com/enesmanan/turkce-kitaplar/blob/main/Projelerle%20Yapay%20Zeka/Benzerlik_Algoritmalar%C4%B1/matrix_similarity.py) 37 | + Matris benzerliğini hesaplamak için OpenCV kütüphanesinin içerisinde bulunan hazır fonksiyonlar kullanıldı. 38 | + [PIL ile Görsel Fark](https://github.com/enesmanan/turkce-kitaplar/blob/main/Projelerle%20Yapay%20Zeka/Benzerlik_Algoritmalar%C4%B1/gorsel_fark.py) 39 | + PIL (Pillow) kütüphanesindeki hazır fonksiyonlar ile iki görsel arasındaki farkı tespit eder ve image olarak ekrana döndürür. 40 | + [Toleranslı Benzerlik Algoritması](https://github.com/enesmanan/turkce-kitaplar/blob/main/Projelerle%20Yapay%20Zeka/Benzerlik_Algoritmalar%C4%B1/tolerant_similarity.py) $\to$ **Ödev_4** 41 | + Algoritma, tolerans değeri büyüdükçe iki piksel arasındaki renk farkının yüksek olmasına izin verir ve benzerlik oranı artar. 42 | + [Tanimoto Benzerliği Nedir](https://github.com/enesmanan/turkce-kitaplar/blob/main/Projelerle%20Yapay%20Zeka/Benzerlik_Algoritmalar%C4%B1/Tanimoto_Benzerligi.ipynb) $\to$ **Ödev_5** 43 | + [Tanimoto Benzerlik Algoritması](https://github.com/enesmanan/turkce-kitaplar/blob/main/Projelerle%20Yapay%20Zeka/Benzerlik_Algoritmalar%C4%B1/tanimoto_similarity.py) 44 | #### Gorseller 45 | + Kitaptaki görsellere ek aşağıdaki gibi farklı görseller üzerinden de denemeler yapıldı. 46 | + [gorsel1](https://github.com/enesmanan/turkce-kitaplar/blob/main/Projelerle%20Yapay%20Zeka/Benzerlik_Algoritmalar%C4%B1/gorsel1.png), [gorsel2](https://github.com/enesmanan/turkce-kitaplar/blob/main/Projelerle%20Yapay%20Zeka/Benzerlik_Algoritmalar%C4%B1/gorsel2.png) 47 | -------------------------------------------------------------------------------- /Veri Bilimi İçin Python/README.md: -------------------------------------------------------------------------------- 1 | # :blue_book: Veri Bilimi İçin Python 2 | Bu klasör kitaptaki ilgimi çeken örnek programların genişletilmiş ve geliştirilmiş versiyonlarını içerir. 3 | 4 | Kitabın isminde veri bilimi ibaresi olsa da büyük bir kısımda Python temelleri anlatılmış olduğundan dolayı veri bilimi ile doğrudan alakalı program sayısı tatminkar seviyede değil. 5 | 6 | ## :open_book: Programlar 7 | 8 | ### :point_right: [Pascal Üçgeni](https://github.com/enesmanan/turkce-kitaplar/blob/main/Veri%20Bilimi%20%C4%B0%C3%A7in%20Python/pascal_ucgeni.py) 9 | + Kullanıcıdan int tipinde aldığı satır sayısı inputuna göre konsola Pascal Üçgenini basar. Buradaki ana amacım gerçekten konsoldaki görüntünün orantılı bir şekilde gözükmesiydi. 10 | 11 | ### :point_right: [Rastgele Şifre Oluşturucu](https://github.com/enesmanan/turkce-kitaplar/blob/main/Veri%20Bilimi%20%C4%B0%C3%A7in%20Python/rastgele_sifre_olusturucu.py) 12 | + Kullanıcıdan int tipinde aldığı şifre uzunluğu inputuna göre rastgele karakterlerden oluşan bir şifre oluşturur. 13 | 14 | **NOT:** Pascal Üçgeni ve Rastgele Şifre Oluşturucu programlarında hata ayıklama işlemini `if __name__ == '__main__':` yapısı altına yazdığım için modül olarak kullanılırsa hata ayıklama kısımları çalışmayacaktır. Hata ayıklama ksımlarının çalışmasını istiyorsak, bir main fonksiyonu oluşturup içerisinde hata ayıklama yapmak daha doğru bir yaklaşım olacaktır. Nitekim yazdığım diğer programlarda bunu tecrübe ettim. 15 | 16 | ### :point_right: [Sayısal Loto Çekilişi](https://github.com/enesmanan/turkce-kitaplar/blob/main/Veri%20Bilimi%20%C4%B0%C3%A7in%20Python/sayisal_loto.py) 17 | + Program her çalıştırıldığında 1 ile 49 arasındaki (49 dahil) 6 adet unique sayı üretir. 18 | 19 | ### :point_right: [Puanlı Sayı Tahmin Oyunu](https://github.com/enesmanan/turkce-kitaplar/blob/main/Veri%20Bilimi%20%C4%B0%C3%A7in%20Python/sayi_tahmin_oyunu.py) 20 | + Dört adet zorluk seviyesi sunar ve bilgisayarın rastgele olarak tutmuş olduğu sayıyı oyuncu tahmin etmeye çalışır. Buradaki ana amacım oyun scorunu şaşaalı bir şekilde sunabilmekti. Bununu yapmanın yolunuda tarayıcıyı açıp raporu oyuncuya göstermeyi düşündüm. Bunun için [webbrowser](https://docs.python.org/3/library/webbrowser.html) modülünü kullandım. Daha estetik bir sonuç için HTML kısmı geliştirilebilir. 21 | 22 | ### :point_right: [Adam Asmaca](https://github.com/enesmanan/turkce-kitaplar/blob/main/Veri%20Bilimi%20%C4%B0%C3%A7in%20Python/adam_asmaca.py) 23 | + Oyuncu bilgisayarın rastgele bir şekilde tuttuğu Python kütüphanesini tahmin etmeye çalışır. 24 | 25 | ### :point_right: [Ing-Tr Sözlük](https://github.com/enesmanan/turkce-kitaplar/blob/main/Veri%20Bilimi%20%C4%B0%C3%A7in%20Python/ing_tr_sozluk.py) 26 | + Bilmediğiniz bir ingilizce kelimeyi arayabilirsiniz. Eğer kelime [sozluk.txt](https://github.com/enesmanan/turkce-kitaplar/blob/main/Veri%20Bilimi%20%C4%B0%C3%A7in%20Python/sozluk.txt) dosyasının içinde yoksa, olmayan kelimeyi program ilk çalıştırıldığı anda otamatik olarak oluşan yeni_kelimeler.txt dosyasının içerisine, programın 2 numaralı fonksiyonu ile ekleyebilirsiniz. 27 | 28 | **NOT:** Programın çalışabilmesi için sozluk.txt dosyası ile programın kaynak kodlarının aynı dizinde olması gerekiyor. 29 | 30 | ### :point_right: [XOX Oyunu](https://github.com/enesmanan/turkce-kitaplar/blob/main/Veri%20Bilimi%20%C4%B0%C3%A7in%20Python/xox_oyunu.py) 31 | + XOX oyununu konsol üzerinden oynayabilirsiniz. Oyunda herhangi bir algoritma veya yapay zeka eşlik etmiyor, oyuncu sırası ile X ve O harflerini tahtada belirtilen yerlerden birisine koyar. 32 | 33 | ### :point_right: [E-Posta Doğrulama](https://github.com/enesmanan/turkce-kitaplar/blob/main/Veri%20Bilimi%20%C4%B0%C3%A7in%20Python/email_dogrulama.py) 34 | + Regex ile girilen e-postanın doğruluğu kontrol edilir. E-postaların içerisinde "." dışında özel karakterler bulunamayacağı için eğer özel karakter girildiyse onları kaldırarak girilen e-postayı tahmin etmeye çalışır. 35 | 36 | ### :point_right: [Datetime Uygulamaları](https://github.com/enesmanan/turkce-kitaplar/blob/main/Veri%20Bilimi%20%C4%B0%C3%A7in%20Python/datetime_uygulamalar.py) 37 | + Datetime modülünü öğrenebilmek için çeşitli-ufak programların bir araya getirilmesinden oluşur. Program ile iki tarih arasındaki farkı bulmak, doğum gününe kaç gün kaldığını görmek, takvimi görüntülmek, istenilen ülkenin saatini görmek, tatil ve bayram günlerine kaç gün kaldığını öğrenmek gibi şeyler yapılabiliyor. 38 | 39 | **NOT:** Bu programı exe formatına getirdim, dileyenler [buradaki](https://drive.google.com/drive/folders/1t2TfsGxblBPyYrzBzz2RuYUcErF3ksvw?usp=sharing) adresten sağ yukarıdan tümünü indir deyip ***dist*** klasörünün içerisindeki ***run.exe*** dosyasını çalıştırarak, kendi bilgisayarında Python kurulu olmasa bile programı deneyimleyebilirsiniz. 40 | 41 | ### :point_right: [IMDB Top 250](https://github.com/enesmanan/turkce-kitaplar/blob/main/Veri%20Bilimi%20%C4%B0%C3%A7in%20Python/imdb_veri_cekme.py) 42 | + Bu program IMDB sitesinde top 250 olarak gözüken filmlerin bilgilerini çeker akabinde bir csv dosyası oluşturur ve bilgileri içerisine yazar. 43 | 44 | ### :point_right: [Twitter Veri Çekme](https://github.com/enesmanan/turkce-kitaplar/blob/main/Veri%20Bilimi%20%C4%B0%C3%A7in%20Python/twitter_veri_cekme.py) 45 | + Twitter'an veri çekmenin birçok farklı yolu mevcuttur. Bu programı kodlarken ben de kitapta gösterilen [pytwitterscraper](https://github.com/mrwan200/pytwitterscraper) isimli modülü kullandım. Program ile Türkiye'deki ve diğer ülkelerdeki trend konuları görebilmek, kullanıcı adı veya ID'si girilen kişinin profil bilgilerine ulaşmak, bir tweetin bilgilerini veya yorumlarını görmek, girilen kullanıcı adını kullanan diğer kişileri görüntülemek ve kullanıcı adı bilinen bir kişinin ID bilgisine ulaşmak gibi işlemler yapılabilir. 46 | 47 | **NOT:** Maalesef tweet çekme işlemini bu paket ile yapamıyoruz. Tahminimce Elon Musk'ın Twitter'ı satın almasından sonra değişen politikalar ile alakalı. (Tweet çekmek için [Tweepy](https://docs.tweepy.org/en/stable/) kütüphanesi kullanılabilir.) 48 | 49 | ### :point_right: [OpenCV Uygulamaları](https://github.com/enesmanan/turkce-kitaplar/blob/main/Veri%20Bilimi%20%C4%B0%C3%A7in%20Python/opencv_uygulamalari.py) 50 | + Kullanıcının bilgisayarından seçtiği bir resme döndürme, grileştirme ve blur atma gibi işlemler yapılabiliyor. 51 | 52 | **NOT:** Bu programın çalışabilmesi için resmin bulunduğu dosya yolunda Türkçe karakter bulunmaması gerekiyor. Yani bilgisayarınızı Türkçe olarak kullanıyorsanız dosya yolunda Masa Üstü bulunabilir. Bu durumda dosya yolu Türkçe karakter içerdiği için program çalışmayacaktır. 53 | -------------------------------------------------------------------------------- /Uygulamalarla Veri Bilimi/1. Veri Bilimi Uygulamalarına Giriş/calisma_sorulari_1.ipynb: -------------------------------------------------------------------------------- 1 | { 2 | "cells": [ 3 | { 4 | "cell_type": "markdown", 5 | "metadata": {}, 6 | "source": [ 7 | "# 1. Bölüm Çalışma Soruları Cevapları" 8 | ] 9 | }, 10 | { 11 | "cell_type": "markdown", 12 | "metadata": {}, 13 | "source": [ 14 | "## 1. Soru: Regresyon mu, sınıflandırma mı?\n", 15 | "\n", 16 | "Karşımıza gelen bir problemin regresyon mu yoksa sınıflandırma mı olduğunu anlamak için hedef değişkenin yapısını inceleriz. Eğer bağımlı değişkenimiz kategorik verilerden oluşuyorsa sınıflandırma, sürekli verilerden oluşuyosa regresyon problemi olduğunu kabaca anlayabiliriz.\n", 17 | "\n", 18 | "**Kategorik Veriler:** \n", 19 | "+ **İkili sınıflandırma** $\\to$ Kadın/Erkek, Evli/Bekar, Kedi/Köpek vb.\n", 20 | "+ **Çok sınıflı sınıflandırma** $\\to$ Araba markaları, renkler vb.\n", 21 | "\n", 22 | "**Sürekli Veriler:**\n", 23 | "+ Sıcaklık, yaş, maaş, bir şeyin fiyatı vb.\n", 24 | "\n", 25 | "*Burada hangisinin seçileceği iş probleminin tanımına ve eldeki veriye göre değişkenlik gösterebilir.*" 26 | ] 27 | }, 28 | { 29 | "cell_type": "markdown", 30 | "metadata": {}, 31 | "source": [ 32 | "
" 33 | ] 34 | }, 35 | { 36 | "cell_type": "markdown", 37 | "metadata": {}, 38 | "source": [ 39 | "## 2. Soru: Dengesiz bir veri kümesine karşı yaklaşımınız nasıl olur?\n", 40 | "\n", 41 | "**Dengesiz veri kümesi**, sınıflar arası farkın bariz bir şekilde açık olduğu veri kümesidir. Yani, bir gözlem biriminde 100 varken öteki gözlem biriminden 10000 olması gibi. Bir veri kümesindeki dengesizliğin kesin bir tanımı yoktur.\n", 42 | "\n", 43 | "Dengesizliği gidermek için yöntemler:\n", 44 | "1. **Azınlıkta olan sınıf için daha fazla veri toplamak:** Bu yöntem, veriyi biz topladıysak kullanılabilir.\n", 45 | "2. **Çoğunlukta olan sınıfın örneklerini azaltmak:** Eğer bunu uygularsak çoğunlukta olan sınıf için veri kaybına neden olabilriz. Bunun sonucunda algoritma yeterince öğrenemeyebilir.\n", 46 | "3. **Azınlık sınıfın örneklerini kopyalamak:** Aynı veriler tekrarlanacağız için overfitting sorununa neden olabilir.\n", 47 | "4. **Sentetik örnekleme yöntemleri ile sınıflar arası dengesizliği azaltmak:** SMOTE gibi bir yöntem ile azınlık sınıfın örnekleri sentetik olarak artırılabilir." 48 | ] 49 | }, 50 | { 51 | "cell_type": "markdown", 52 | "metadata": {}, 53 | "source": [ 54 | "
" 55 | ] 56 | }, 57 | { 58 | "cell_type": "markdown", 59 | "metadata": {}, 60 | "source": [ 61 | "## 3. Soru: Tasarlanan bir algoritma ve oluşturulan model hangi aralıklarla güncellenmelidir?\n", 62 | "\n", 63 | "Bu sorunun kesin bir cevabı yoktur, iş problemine ve veri kümesindeki performans kriterlerine göre değişkenlik gösterebilir.\n", 64 | "\n", 65 | "Bazı genel prensipler:\n", 66 | "+ **Veri setinde önemli bir değişiklik olduğunda** \n", 67 | "+ **Modelin performansında önemli bir değişiklik olduğunda**\n", 68 | "+ **Yeni çıkan teknolojik gelişmeler olduğunda**\n", 69 | "\n", 70 | "Bu şartlar sağlandığında algoritma ve modelde güncellemeler yapmak gerekebilir.\n", 71 | "\n", 72 | "*Bu işin bir standartı yoktur. Aslolan, algoritma ve modelin düzenli olarak gözlemlenmesi, performanslarının takip edilmesi, değişen gereksinimlere ve koşullara göre güncellenmesidir.*\n" 73 | ] 74 | }, 75 | { 76 | "cell_type": "markdown", 77 | "metadata": {}, 78 | "source": [ 79 | "
" 80 | ] 81 | }, 82 | { 83 | "cell_type": "markdown", 84 | "metadata": {}, 85 | "source": [ 86 | "## 4. Soru: 500 sütun ve 1 milyon satırlık satırlık bir veri seti üzerinde sınıflandırma yaptığımızı düşünelim. Çalıştığımız bilgisayarda da bellek kısıtları olduğunu düşünelim. Hesaplama bellek yetersizliğinden dolayı aşırı zaman alacaktır, hesaplama zamanını kısaltmak için verinin boyutunu hangi yaklaşımlar ile küçültebiliriz?\n", 87 | "\n", 88 | "1. **Özellik Seçimi (Feature Selection):** Her özelliğin hedef değişkeni açıklamaktaki başarısı bir olmadığı için hedef değişkeni en iyi açıklayan özellikler seçilerek hesaplama süresi azaltılabilir.\n", 89 | "2. **Özellik Çıkarımı (Feature Extraction):** Var olan özelliklerden yeni özellikler oluşturarak verinin boyutunu küçültmek için kullanılabilcek bir yöntemdir.\n", 90 | "3. **Boyut İndirgeme:** Veri setindeki sütunlarının sayısını azaltmak için kullanılır. PCA (Temel Bileşen Analizi) en basit ve bilinen yöntemlerden biridir.\n", 91 | "4. **Örneklem Seçimi:** Veri kümesinden rastgele olarak örneklemeler alınabilir. Bu yöntem sonucunda bilgi kaybı oluşabilir. Bilgi kaybını en aza indirgemek için daha fazla örneklem alarak bunların ortak sonucuna bakılabilir. " 92 | ] 93 | }, 94 | { 95 | "cell_type": "markdown", 96 | "metadata": {}, 97 | "source": [ 98 | "
" 99 | ] 100 | }, 101 | { 102 | "cell_type": "markdown", 103 | "metadata": {}, 104 | "source": [ 105 | "## 5. Soru: Modelde düşük bias ve yüksek varyans varsa bu durumu aşmak için hangi algoritma kullanılmalıdır?\n", 106 | "\n", 107 | "Modelde düşük bias ve yüksek varyans gözleniyorsa model overfitting (aşırı uyum) problemi yaşıyordur. Bu durumda modelin eğitim hatası düşük olmasına rağmen test hatası yüksek olabilir.\n", 108 | "\n", 109 | "Modelin genelleme yeteneğini korumak için aşağıdaki yöntemler kullanılabilir:\n", 110 | "+ **Düzenlileştirme (Regularization):** Düzenlileştireme ile modelin karmaşıklığını düşürerek overfitting sorunundan kurtulmaya çalışırız. Modelin ağırlıklarına (weights) bir ceza terimi ekleyerek modelin eğitim verisinde aşırı uymasını engeller.\n", 111 | "+ **Topluluk Modelleri (Ensemble Learning):** Bu modeller birden fazla modeli birleştirerek tek bir modelden daha iyi performans vermeyi amaçlarlar. Ensemble yöntemler, varyansı azaltarak modelin performansını artırabilir. Bunlar arasında Bagging, Boosting ve Random Forest gibi yöntemler yer alır." 112 | ] 113 | }, 114 | { 115 | "cell_type": "markdown", 116 | "metadata": {}, 117 | "source": [ 118 | "
" 119 | ] 120 | } 121 | ], 122 | "metadata": { 123 | "kernelspec": { 124 | "display_name": "Python 3 (ipykernel)", 125 | "language": "python", 126 | "name": "python3" 127 | }, 128 | "language_info": { 129 | "codemirror_mode": { 130 | "name": "ipython", 131 | "version": 3 132 | }, 133 | "file_extension": ".py", 134 | "mimetype": "text/x-python", 135 | "name": "python", 136 | "nbconvert_exporter": "python", 137 | "pygments_lexer": "ipython3", 138 | "version": "3.9.16" 139 | } 140 | }, 141 | "nbformat": 4, 142 | "nbformat_minor": 4 143 | } 144 | -------------------------------------------------------------------------------- /Projelerle Yapay Zeka/Benzerlik_Algoritmaları/Tanimoto_Benzerligi.ipynb: -------------------------------------------------------------------------------- 1 | { 2 | "cells": [ 3 | { 4 | "cell_type": "markdown", 5 | "id": "ae11b079-d826-4322-ba0e-2281e2c3c684", 6 | "metadata": {}, 7 | "source": [ 8 | "# Tanimoto Benzerliği" 9 | ] 10 | }, 11 | { 12 | "cell_type": "markdown", 13 | "id": "8457ef07-94b8-4491-b9b5-eee224fd0ae5", 14 | "metadata": {}, 15 | "source": [ 16 | "### Tanimoto (Jaccard) Benzerliği\n", 17 | "\n", 18 | "Tanimoto benzerliği, Jaccard benzerliğini taban alarak oluşturulmuştur. iki kümenin ne kadar çok elemanı paylaştığını ölçen bir benzerlik metriğidir. İki kümenin kesişimini, birleşimine bölerek benzerlik oranını hesaplar. Formülü aşağıdaki gibidir:" 19 | ] 20 | }, 21 | { 22 | "cell_type": "markdown", 23 | "id": "2485c2e3-f1b9-4f8c-b08b-404f0fbc8216", 24 | "metadata": {}, 25 | "source": [ 26 | "
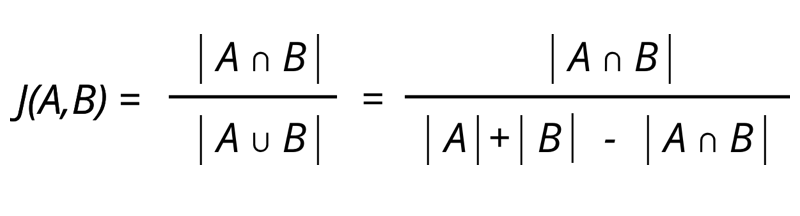 "
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "id": "86a13f11-775e-448b-921d-f0b924881f51",
32 | "metadata": {},
33 | "source": [
34 | "Burada:\n",
35 | "- `A ∩ B` kümelerin kesişimi,\n",
36 | "- `A ∪ B` kümelerin birleşimi."
37 | ]
38 | },
39 | {
40 | "cell_type": "markdown",
41 | "id": "20e73575-13b2-4975-995c-2f886843b2f5",
42 | "metadata": {},
43 | "source": [
44 | "Tanimoto (Jaccard) benzerliği, ikili veya binarize edilmiş verilerin kullanıldığı bilgisayar bilimi, ekoloji, genomik, kimya gibi alanlarda yaygın olarak kullanılır. 0 ile 1 arasında değer alabilir."
45 | ]
46 | },
47 | {
48 | "cell_type": "markdown",
49 | "id": "3e2bc4be-4f27-44df-94b9-62360932a489",
50 | "metadata": {},
51 | "source": [
52 | "### Matris Benzerliği\n",
53 | "\n",
54 | "Matris benzerliği, genellikle piksel değerlerini kullanarak iki görsel arasındaki farkı matrisler yardımıyla ölçer. Piksel değerleri arasındaki farkı veya benzerliği hesaplamak için farklı metrikler kullanabilir. Örneğin, L1 veya L2 normları veya mutlak fark gibi metrikler kullanılabilir."
55 | ]
56 | },
57 | {
58 | "cell_type": "markdown",
59 | "id": "305056af-da47-4b34-98c1-d2e61a729c9e",
60 | "metadata": {},
61 | "source": [
62 | "### Tanimoto ile Matris Benzerliği Arasındaki Farklar\n",
63 | "\n",
64 | "Bu iki benzerlik algoritması farklı yaklaşımlar kullanıldığından ötürü sonuçlarda farklılaşıyor:\n",
65 | "\n",
66 | "- Tanimoto benzerliği, görüntüleri siyah beyaz matrislere dönüştürüp piksel değerlerini kullanarak benzerlik hesaplar. Bu yaklaşım, renk tonlarından ziyade yalnızca varlık veya yokluğu dikkate alır. Bundan dolayı da benzerlik oranı yüksek çıkma eğilimindedir.\n",
67 | "- Matris benzerliği ise renkli piksel değerlerini kullanarak daha detaylı bir farklılık ve benzerlik değeri elde etmeye çalışır. Bu yaklaşım renk farklarını da içerir.\n",
68 | "\n",
69 | "Sonuçlar arasındaki bu farklılık, iki yöntemin de farklı özellikleri nedeniyle oluşabilir. Bir yöntemin diğerine üstün olduğunu söylemek için, hangi benzerlik metriğinin spesifik senaryoda daha uygun olduğunu anlamak önemlidir. Örneğin, Tanimoto (Jaccard) benzerliği ikili veya ikili hale getirilmiş verilerde kullanılırken matris benzerliği daha genel durumlarda kullanılabilir."
70 | ]
71 | },
72 | {
73 | "cell_type": "markdown",
74 | "id": "0f8f7f6d-f3c5-4682-b173-bb24fa73be47",
75 | "metadata": {},
76 | "source": [
77 | "## Tanimoto Benzerliği"
78 | ]
79 | },
80 | {
81 | "cell_type": "code",
82 | "execution_count": 1,
83 | "id": "50b11d88-77a8-47a1-9f99-061fe2195509",
84 | "metadata": {},
85 | "outputs": [
86 | {
87 | "name": "stdout",
88 | "output_type": "stream",
89 | "text": [
90 | "Benzerlik orani: 0.995361906808377\n"
91 | ]
92 | }
93 | ],
94 | "source": [
95 | "import numpy as np\n",
96 | "from PIL import Image\n",
97 | "\n",
98 | "def jaccard_similarity(matrix1, matrix2):\n",
99 | " intersection = np.logical_and(matrix1, matrix2)\n",
100 | " union = np.logical_or(matrix1, matrix2)\n",
101 | " return intersection.sum() / union.sum()\n",
102 | "\n",
103 | "def png_to_matrix(file_path):\n",
104 | " img = Image.open(file_path).convert('L')\n",
105 | " img_arr = np.array(img)\n",
106 | " return img_arr\n",
107 | "\n",
108 | "file1 = 'gorsel1.png'\n",
109 | "file2 = 'gorsel2.png'\n",
110 | "\n",
111 | "\n",
112 | "matrix1 = png_to_matrix(file1)\n",
113 | "matrix2 = png_to_matrix(file2)\n",
114 | "\n",
115 | "similarity = jaccard_similarity(matrix1, matrix2)\n",
116 | "\n",
117 | "print(f'Benzerlik orani: {similarity}')"
118 | ]
119 | },
120 | {
121 | "cell_type": "markdown",
122 | "id": "0189e343-a21e-42cc-9f67-af152f9e723b",
123 | "metadata": {},
124 | "source": [
125 | "## Matris Benzerliği"
126 | ]
127 | },
128 | {
129 | "cell_type": "code",
130 | "execution_count": 2,
131 | "id": "a108edf6-6b4e-48fe-834d-850fa7d22a18",
132 | "metadata": {},
133 | "outputs": [
134 | {
135 | "name": "stdout",
136 | "output_type": "stream",
137 | "text": [
138 | "Iki gorsel arasindaki farklilik orani :32.44940104341378\n",
139 | "Iki gorsel arasindaki benzerlik orani :67.55059895658621\n",
140 | "Iki gorsel arasindaki farkliliklar, farkMatris.png dosyasi olarak kayit edildi\n"
141 | ]
142 | }
143 | ],
144 | "source": [
145 | "import cv2\n",
146 | "import numpy as np\n",
147 | "\n",
148 | "def matris_benzerligi(gorsel_1, gorsel_2):\n",
149 | " yukseklik = gorsel_1.shape[0]\n",
150 | " genislik = gorsel_1.shape[1]\n",
151 | "\n",
152 | " fark = cv2.absdiff(gorsel_1,gorsel_2)\n",
153 | "\n",
154 | " farklilik_oran = np.mean(fark) * 100 / 255\n",
155 | " print('Iki gorsel arasindaki farklilik orani :' + str(farklilik_oran))\n",
156 | "\n",
157 | " benzerlik_oran = 100 - farklilik_oran\n",
158 | " print('Iki gorsel arasindaki benzerlik orani :' + str(benzerlik_oran))\n",
159 | "\n",
160 | " farkMatris = np.zeros(shape=(yukseklik, genislik, 3), dtype=np.uint8)\n",
161 | " mask = fark <= 0\n",
162 | " farkMatris[mask] = 255\n",
163 | " farkMatris[~mask] = gorsel_2[~mask]\n",
164 | "\n",
165 | " cv2.imwrite('farkMatris.png',farkMatris)\n",
166 | " print('Iki gorsel arasindaki farkliliklar, farkMatris.png dosyasi olarak kayit edildi')\n",
167 | "\n",
168 | "if __name__ == '__main__':\n",
169 | " gorsel_1 = cv2.imread('gorsel1.png')\n",
170 | " gorsel_2 = cv2.imread('gorsel2.png')\n",
171 | " matris_benzerligi(gorsel_1, gorsel_2)"
172 | ]
173 | }
174 | ],
175 | "metadata": {
176 | "kernelspec": {
177 | "display_name": "Python 3 (ipykernel)",
178 | "language": "python",
179 | "name": "python3"
180 | },
181 | "language_info": {
182 | "codemirror_mode": {
183 | "name": "ipython",
184 | "version": 3
185 | },
186 | "file_extension": ".py",
187 | "mimetype": "text/x-python",
188 | "name": "python",
189 | "nbconvert_exporter": "python",
190 | "pygments_lexer": "ipython3",
191 | "version": "3.9.16"
192 | }
193 | },
194 | "nbformat": 4,
195 | "nbformat_minor": 5
196 | }
197 |
--------------------------------------------------------------------------------
/Python/Notebook_2.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "id": "80890a0c-3604-4f2d-8e7c-a7617a203233",
6 | "metadata": {},
7 | "source": [
8 | "# Nesne Tabanlı Programlama (Object Oriented Programming-OOP)\n",
9 | "\n",
10 | "## Sınıf (Class) Yapısı"
11 | ]
12 | },
13 | {
14 | "cell_type": "markdown",
15 | "id": "6faefaa4-f3ed-4151-8039-34b29705e718",
16 | "metadata": {},
17 | "source": [
18 | "**Sınıflar, nesne üretmemizi sağlayan veri tipleridir. Sınıflar, bir 'şablon' veya 'taslak' olarak düşünülebilir ve bu şablonu kullanarak farklı nesneler oluşturulabilir.**\n",
19 | "\n",
20 | "Class kullanmanın avantajları:\n",
21 | "+ Kodun yeniden kullanılabilirliğini artırır.\n",
22 | "+ Kodun okunabilirliğini artırır.\n",
23 | "+ Kodun bakımını kolaylaştırır.\n",
24 | "+ Kodun karmaşıklığını azaltır.\n",
25 | "\n",
26 | "> *Bir programcının görevi yalnızca çalışan kodlar yazmak değildir. Programcı aynı zamanda kodlarının okunaklılığını artırmak ve bakımını kolaylaştırmakla da yükümlüdür.*"
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "id": "018fef65-94be-4863-a1b6-5c6d665db2aa",
32 | "metadata": {},
33 | "source": [
34 | "## Sınıf Metotları:\n",
35 | "### 1. Sınıflar (Classes) \n",
36 | "+ **Büyük harfle tanımlanırlar**"
37 | ]
38 | },
39 | {
40 | "cell_type": "markdown",
41 | "id": "6f3de465-8a8d-4a13-98c8-b348bcce8c4a",
42 | "metadata": {},
43 | "source": [
44 | "### 2. Sınıf Nitelikleri (Class Attribute)\n",
45 | "+ **Sınıf tanımlandıktan sonra sınıf nitelikleri (class attribute) tanımlanabilir ve üzerlerinde değişiklik yapılırsa tüm nesneler için geçerli bir değişim olmuş olur.**\n",
46 | " + Sınıf niteliklerine erişmek için sınıf adını parantezsiz olarak kullanılır. $\\to$ `SuperKahraman.evren` "
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "id": "2abbe3c7-83f0-4331-86a0-cde058150587",
52 | "metadata": {},
53 | "source": [
54 | "### 3. Örnekler (Instances) ve Örnek Nitelikleri (Instances Attributes)\n",
55 | "+ **Sınıflardan yeni nesneler (objects) oluşturabiliriz ve bu nesneler, sınıfın örnekleri (instances) olarak adlandırılırlar.**\n",
56 | " + Sınıfların örneklenmesi, bir sınıfın yapıcı metotu olan `__init__(self):` fonksiyonu ile gerçekleştirilir. \n",
57 | " + Bu fonksiyon, bir sınıftan nesne türetildiğinde otomatik olarak çağrılır ve sınıfın özelliklerine başlangıç değerlerini atar.\n",
58 | " + Örnek niteliği (instance attributes), self kelimesini kullanarak tanımlanır. Örneğin, `self.ad = ad` ifadesi, sınıfın her bir örneğinin ad özniteliğini tanımlar.\n",
59 | " + Örnek nitelikleri sadece fonksiyonlar içerisinde tanımlanabilir. "
60 | ]
61 | },
62 | {
63 | "cell_type": "markdown",
64 | "id": "73173712-e0fd-43ff-af8a-70f8bf680239",
65 | "metadata": {},
66 | "source": [
67 | "### 4. Örnek Metotları (Instance Methods)\n",
68 | "+ **Sınıfların örnekleri tarafından kullanılan örnek metotları (instance methods) olabilir.**\n",
69 | " + Bu metotlar bir sınıfın örnekleri vasıtasıyla çağırılabilen fonksiyonlardır.\n",
70 | " + Bu fonksiyonların ilk parametresi her zaman self kelimesidir.\n",
71 | " + Örneğin, `donusum(self):` ve `saldir(self):`"
72 | ]
73 | },
74 | {
75 | "cell_type": "markdown",
76 | "id": "9abbd027-2efc-453e-93d8-906b1ceff6ba",
77 | "metadata": {},
78 | "source": [
79 | "## Örnek: SuperKahraman Sınıfı"
80 | ]
81 | },
82 | {
83 | "cell_type": "code",
84 | "execution_count": 1,
85 | "id": "5e801ef8-f811-4344-b8bf-9e25b08d7d35",
86 | "metadata": {
87 | "tags": []
88 | },
89 | "outputs": [],
90 | "source": [
91 | "class SuperKahraman:\n",
92 | " evren = 'DC'\n",
93 | " \n",
94 | " def __init__(self, ad, zirh, silahlar, guc):\n",
95 | " self.ad = ad\n",
96 | " self.zirh = zirh\n",
97 | " self.silahlar = silahlar\n",
98 | " self.guc = guc\n",
99 | " self.durum = 'Normal'\n",
100 | "\n",
101 | " def donusum(self):\n",
102 | " if self.durum == 'Normal':\n",
103 | " self.durum = 'Super Kahraman'\n",
104 | " return f'{self.ad}, donusum gerceklestirdi! Artik {self.durum} olarak hareket ediyor.'\n",
105 | " elif self.durum == 'Super Kahraman':\n",
106 | " self.durum = 'Normal'\n",
107 | " return f'{self.ad}, donusum gerceklestirdi! Artik {self.durum} olarak hareket ediyor.'\n",
108 | "\n",
109 | " def saldir(self, hedef):\n",
110 | " return f'{self.ad}, {hedef} uzerine saldiri gerceklestirildi!'\n"
111 | ]
112 | },
113 | {
114 | "cell_type": "markdown",
115 | "id": "62a1c0b0-9456-46b7-98ac-118d9aefcd1b",
116 | "metadata": {},
117 | "source": [
118 | "+ Class $\\to$ SuperKahraman\n",
119 | "+ Class Attributes $\\to$ evren\n",
120 | "+ Instance Attributes $\\to$ ad, zirh, silahlar, guc, durum\n",
121 | "+ Instance Methods $\\to$ donusum(), saldir()"
122 | ]
123 | },
124 | {
125 | "cell_type": "code",
126 | "execution_count": 2,
127 | "id": "2b6ff896-962d-41c4-9d2c-93d83558d8d5",
128 | "metadata": {},
129 | "outputs": [
130 | {
131 | "data": {
132 | "text/plain": [
133 | "'DC'"
134 | ]
135 | },
136 | "execution_count": 2,
137 | "metadata": {},
138 | "output_type": "execute_result"
139 | }
140 | ],
141 | "source": [
142 | "# Sinif niteliklerine erismek icin sinif adini parantezsiz olarak kullandık\n",
143 | "SuperKahraman.evren"
144 | ]
145 | },
146 | {
147 | "cell_type": "code",
148 | "execution_count": 3,
149 | "id": "9a96e26f-74ea-4239-b2a9-eb8fa548c15f",
150 | "metadata": {},
151 | "outputs": [],
152 | "source": [
153 | "# SuperKahraman sinifindan yeni bir örnek olusturalim\n",
154 | "# Batman nesnesi olusturalim\n",
155 | "batman = SuperKahraman('Batman', 'Batsuit', ['Batarang', 'Batmobile'], 'Zeka ve Fiziksel Beceriler')"
156 | ]
157 | },
158 | {
159 | "cell_type": "markdown",
160 | "id": "61661c58-1bc3-48b6-9b9b-fccd204760ab",
161 | "metadata": {},
162 | "source": [
163 | "SuperKahraman sınıfından yeni bir örnek oluşturmak için, sınıfın adını ve parantez içinde sınıfın `__init__` fonksiyonuna gönderilecek parametreleri girerek sınıfı çağırırız."
164 | ]
165 | },
166 | {
167 | "cell_type": "code",
168 | "execution_count": 4,
169 | "id": "76786f82-86ed-4a4e-9ca0-e6653d79d5bd",
170 | "metadata": {},
171 | "outputs": [
172 | {
173 | "name": "stdout",
174 | "output_type": "stream",
175 | "text": [
176 | "Batman, zirh: Batsuit, Silahlar: Batarang, Batmobile, guc: Zeka ve Fiziksel Beceriler\n",
177 | "Batman, donusum gerceklestirdi! Artik Super Kahraman olarak hareket ediyor.\n",
178 | "Batman, Joker uzerine saldiri gerceklestirildi!\n",
179 | "Batman, donusum gerceklestirdi! Artik Normal olarak hareket ediyor.\n"
180 | ]
181 | }
182 | ],
183 | "source": [
184 | "# Batman'in ozelliklerine eriselim ardindan donusum ve saldiri yeteneklerini cagiralim\n",
185 | "print(f'{batman.ad}, zirh: {batman.zirh}, Silahlar: {\", \".join(batman.silahlar)}, guc: {batman.guc}')\n",
186 | "print(batman.donusum())\n",
187 | "print(batman.saldir('Joker'))\n",
188 | "print(batman.donusum())"
189 | ]
190 | }
191 | ],
192 | "metadata": {
193 | "kernelspec": {
194 | "display_name": "Python 3 (ipykernel)",
195 | "language": "python",
196 | "name": "python3"
197 | },
198 | "language_info": {
199 | "codemirror_mode": {
200 | "name": "ipython",
201 | "version": 3
202 | },
203 | "file_extension": ".py",
204 | "mimetype": "text/x-python",
205 | "name": "python",
206 | "nbconvert_exporter": "python",
207 | "pygments_lexer": "ipython3",
208 | "version": "3.9.16"
209 | }
210 | },
211 | "nbformat": 4,
212 | "nbformat_minor": 5
213 | }
214 |
--------------------------------------------------------------------------------
/Projelerle Yapay Zeka/Benzerlik_Algoritmaları/RGBCodes_normalized.txt:
--------------------------------------------------------------------------------
1 | maroon: [50.196078431372555, 0.0, 0.0]
2 | dark red: [54.50980392156863, 0.0, 0.0]
3 | brown: [64.70588235294117, 16.47058823529412, 16.47058823529412]
4 | firebrick: [69.80392156862746, 13.333333333333334, 13.333333333333334]
5 | crimson: [86.27450980392157, 7.843137254901961, 23.529411764705884]
6 | red: [100.0, 0.0, 0.0]
7 | tomato: [100.0, 38.82352941176471, 27.84313725490196]
8 | coral: [100.0, 49.80392156862745, 31.372549019607845]
9 | indian red: [80.3921568627451, 36.07843137254902, 36.07843137254902]
10 | light coral: [94.11764705882354, 50.196078431372555, 50.196078431372555]
11 | dark salmon: [91.37254901960785, 58.82352941176471, 47.84313725490196]
12 | salmon: [98.03921568627452, 50.196078431372555, 44.70588235294118]
13 | light salmon: [100.0, 62.74509803921569, 47.84313725490196]
14 | orange red: [100.0, 27.058823529411768, 0.0]
15 | dark orange: [100.0, 54.90196078431373, 0.0]
16 | orange: [100.0, 64.70588235294117, 0.0]
17 | gold: [100.0, 84.31372549019608, 0.0]
18 | dark golden rod: [72.15686274509804, 52.54901960784314, 4.313725490196079]
19 | golden rod: [85.49019607843138, 64.70588235294117, 12.549019607843139]
20 | pale golden rod: [93.33333333333334, 90.98039215686275, 66.66666666666667]
21 | dark khaki: [74.11764705882354, 71.76470588235294, 41.96078431372549]
22 | khaki: [94.11764705882354, 90.19607843137256, 54.90196078431373]
23 | olive: [50.196078431372555, 50.196078431372555, 0.0]
24 | yellow: [100.0, 100.0, 0.0]
25 | yellow green: [60.392156862745104, 80.3921568627451, 19.607843137254903]
26 | dark olive green: [33.333333333333336, 41.96078431372549, 18.43137254901961]
27 | olive drab: [41.96078431372549, 55.68627450980392, 13.725490196078432]
28 | lawn green: [48.62745098039216, 98.82352941176471, 0.0]
29 | chartreuse: [49.80392156862745, 100.0, 0.0]
30 | green yellow: [67.84313725490196, 100.0, 18.43137254901961]
31 | dark green: [0.0, 39.21568627450981, 0.0]
32 | green: [0.0, 50.196078431372555, 0.0]
33 | forest green: [13.333333333333334, 54.50980392156863, 13.333333333333334]
34 | lime: [0.0, 100.0, 0.0]
35 | lime green: [19.607843137254903, 80.3921568627451, 19.607843137254903]
36 | light green: [56.47058823529412, 93.33333333333334, 56.47058823529412]
37 | pale green: [59.6078431372549, 98.43137254901961, 59.6078431372549]
38 | dark sea green: [56.078431372549026, 73.72549019607844, 56.078431372549026]
39 | medium spring green: [0.0, 98.03921568627452, 60.392156862745104]
40 | spring green: [0.0, 100.0, 49.80392156862745]
41 | sea green: [18.03921568627451, 54.50980392156863, 34.11764705882353]
42 | medium aqua marine: [40.0, 80.3921568627451, 66.66666666666667]
43 | medium sea green: [23.529411764705884, 70.19607843137256, 44.313725490196084]
44 | light sea green: [12.549019607843139, 69.80392156862746, 66.66666666666667]
45 | dark slate gray: [18.43137254901961, 30.98039215686275, 30.98039215686275]
46 | teal: [0.0, 50.196078431372555, 50.196078431372555]
47 | dark cyan: [0.0, 54.50980392156863, 54.50980392156863]
48 | aqua: [0.0, 100.0, 100.0]
49 | cyan: [0.0, 100.0, 100.0]
50 | light cyan: [87.84313725490196, 100.0, 100.0]
51 | dark turquoise: [0.0, 80.78431372549021, 81.9607843137255]
52 | turquoise: [25.098039215686278, 87.84313725490196, 81.5686274509804]
53 | medium turquoise: [28.23529411764706, 81.9607843137255, 80.0]
54 | pale turquoise: [68.62745098039215, 93.33333333333334, 93.33333333333334]
55 | aqua marine: [49.80392156862745, 100.0, 83.13725490196079]
56 | powder blue: [69.01960784313727, 87.84313725490196, 90.19607843137256]
57 | cadet blue: [37.254901960784316, 61.9607843137255, 62.74509803921569]
58 | steel blue: [27.450980392156865, 50.98039215686275, 70.58823529411765]
59 | corn flower blue: [39.21568627450981, 58.43137254901961, 92.94117647058825]
60 | deep sky blue: [0.0, 74.90196078431373, 100.0]
61 | dodger blue: [11.764705882352942, 56.47058823529412, 100.0]
62 | light blue: [67.84313725490196, 84.70588235294119, 90.19607843137256]
63 | sky blue: [52.94117647058824, 80.78431372549021, 92.15686274509804]
64 | light sky blue: [52.94117647058824, 80.78431372549021, 98.03921568627452]
65 | midnight blue: [9.803921568627452, 9.803921568627452, 43.92156862745098]
66 | navy: [0.0, 0.0, 50.196078431372555]
67 | dark blue: [0.0, 0.0, 54.50980392156863]
68 | medium blue: [0.0, 0.0, 80.3921568627451]
69 | blue: [0.0, 0.0, 100.0]
70 | royal blue: [25.490196078431374, 41.1764705882353, 88.23529411764706]
71 | blue violet: [54.117647058823536, 16.862745098039216, 88.62745098039217]
72 | indigo: [29.411764705882355, 0.0, 50.98039215686275]
73 | dark slate blue: [28.23529411764706, 23.92156862745098, 54.50980392156863]
74 | slate blue: [41.568627450980394, 35.294117647058826, 80.3921568627451]
75 | medium slate blue: [48.235294117647065, 40.7843137254902, 93.33333333333334]
76 | medium purple: [57.64705882352941, 43.92156862745098, 85.88235294117648]
77 | dark magenta: [54.50980392156863, 0.0, 54.50980392156863]
78 | dark violet: [58.03921568627452, 0.0, 82.74509803921569]
79 | dark orchid: [60.00000000000001, 19.607843137254903, 80.0]
80 | medium orchid: [72.94117647058825, 33.333333333333336, 82.74509803921569]
81 | purple: [50.196078431372555, 0.0, 50.196078431372555]
82 | thistle: [84.70588235294119, 74.90196078431373, 84.70588235294119]
83 | plum: [86.66666666666667, 62.74509803921569, 86.66666666666667]
84 | violet: [93.33333333333334, 50.98039215686275, 93.33333333333334]
85 | magenta: [100.0, 0.0, 100.0]
86 | orchid: [85.49019607843138, 43.92156862745098, 83.92156862745098]
87 | medium violet red: [78.03921568627452, 8.23529411764706, 52.156862745098046]
88 | pale violet red: [85.88235294117648, 43.92156862745098, 57.64705882352941]
89 | deep pink: [100.0, 7.843137254901961, 57.64705882352941]
90 | hot pink: [100.0, 41.1764705882353, 70.58823529411765]
91 | light pink: [100.0, 71.37254901960785, 75.68627450980392]
92 | pink: [100.0, 75.29411764705883, 79.6078431372549]
93 | antique white: [98.03921568627452, 92.15686274509804, 84.31372549019608]
94 | beige: [96.07843137254902, 96.07843137254902, 86.27450980392157]
95 | bisque: [100.0, 89.41176470588236, 76.86274509803923]
96 | blanched almond: [100.0, 92.15686274509804, 80.3921568627451]
97 | wheat: [96.07843137254902, 87.05882352941177, 70.19607843137256]
98 | corn silk: [100.0, 97.25490196078432, 86.27450980392157]
99 | lemon chiffon: [100.0, 98.03921568627452, 80.3921568627451]
100 | light golden rod yellow: [98.03921568627452, 98.03921568627452, 82.3529411764706]
101 | light yellow: [100.0, 100.0, 87.84313725490196]
102 | saddle brown: [54.50980392156863, 27.058823529411768, 7.450980392156863]
103 | sienna: [62.74509803921569, 32.15686274509804, 17.647058823529413]
104 | chocolate: [82.3529411764706, 41.1764705882353, 11.764705882352942]
105 | peru: [80.3921568627451, 52.156862745098046, 24.705882352941178]
106 | sandy brown: [95.68627450980392, 64.31372549019608, 37.64705882352941]
107 | burly wood: [87.05882352941177, 72.15686274509804, 52.94117647058824]
108 | tan: [82.3529411764706, 70.58823529411765, 54.90196078431373]
109 | rosy brown: [73.72549019607844, 56.078431372549026, 56.078431372549026]
110 | moccasin: [100.0, 89.41176470588236, 70.98039215686275]
111 | navajo white: [100.0, 87.05882352941177, 67.84313725490196]
112 | peach puff: [100.0, 85.49019607843138, 72.54901960784314]
113 | misty rose: [100.0, 89.41176470588236, 88.23529411764706]
114 | lavender blush: [100.0, 94.11764705882354, 96.07843137254902]
115 | linen: [98.03921568627452, 94.11764705882354, 90.19607843137256]
116 | old lace: [99.2156862745098, 96.07843137254902, 90.19607843137256]
117 | papaya whip: [100.0, 93.72549019607844, 83.52941176470588]
118 | sea shell: [100.0, 96.07843137254902, 93.33333333333334]
119 | mint cream: [96.07843137254902, 100.0, 98.03921568627452]
120 | slate gray: [43.92156862745098, 50.196078431372555, 56.47058823529412]
121 | light slate gray: [46.66666666666667, 53.333333333333336, 60.00000000000001]
122 | light steel blue: [69.01960784313727, 76.86274509803923, 87.05882352941177]
123 | lavender: [90.19607843137256, 90.19607843137256, 98.03921568627452]
124 | floral white: [100.0, 98.03921568627452, 94.11764705882354]
125 | alice blue: [94.11764705882354, 97.25490196078432, 100.0]
126 | ghost white: [97.25490196078432, 97.25490196078432, 100.0]
127 | honeydew: [94.11764705882354, 100.0, 94.11764705882354]
128 | ivory: [100.0, 100.0, 94.11764705882354]
129 | azure: [94.11764705882354, 100.0, 100.0]
130 | snow: [100.0, 98.03921568627452, 98.03921568627452]
131 | black: [0.0, 0.0, 0.0]
132 | dim gray: [41.1764705882353, 41.1764705882353, 41.1764705882353]
133 | gray: [50.196078431372555, 50.196078431372555, 50.196078431372555]
134 | dark gray: [66.27450980392157, 66.27450980392157, 66.27450980392157]
135 | silver: [75.29411764705883, 75.29411764705883, 75.29411764705883]
136 | light gray: [82.74509803921569, 82.74509803921569, 82.74509803921569]
137 | gainsboro: [86.27450980392157, 86.27450980392157, 86.27450980392157]
138 | white smoke: [96.07843137254902, 96.07843137254902, 96.07843137254902]
139 | white: [100.0, 100.0, 100.0]
--------------------------------------------------------------------------------
/Python/Notebook_1.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "id": "5c3652dc-07e9-4249-a40e-63dbab046459",
6 | "metadata": {},
7 | "source": [
8 | "## `if __name__ == '__main__'`"
9 | ]
10 | },
11 | {
12 | "cell_type": "markdown",
13 | "id": "cacbe8ae-4b9c-4a37-a9c0-ad1bbbb575a8",
14 | "metadata": {},
15 | "source": [
16 | "Python'da `if __name__ == '__main__'` yapısı, bir Python dosyasının modül olarak mı yoksa ana program olarak mı kullanıldığını kontrol etmek için kullanılır. \n",
17 | "\n",
18 | "**Direkt olarak çalışırdığımızda:**\n",
19 | "+ Eğer .py uzantılı dosyayı direkt olarak çalıştırılırsa `__name__`değeri default olarak `__main__` olduğundan dolayı `if __name__ == '__main__'` yapısının altında bulunan kodlar otomatik olarak çalışacaktır.\n",
20 | "\n",
21 | "**Modül olarak içeri aktardığımızda**\n",
22 | "+ Eğer .py uzantılı dosya import komutu ile içe aktarılırsa modüldeki tüm kodlar çalıştırılmaz, yalnızca tanımlanan sınıflar, fonksiyonlar, değişkenler vb. kullanılabilir hale gelir."
23 | ]
24 | },
25 | {
26 | "cell_type": "markdown",
27 | "id": "5104155d-6d3d-4ae0-b4ab-51004be787ce",
28 | "metadata": {},
29 | "source": [
30 | "> **`if __name__ == '__main__'` Yapısı Olmadan**"
31 | ]
32 | },
33 | {
34 | "cell_type": "markdown",
35 | "id": "6a43b7a6-0e47-4556-8e6a-a52faefd42f2",
36 | "metadata": {},
37 | "source": [
38 | "Bunu daha iyi görmek için aşağıdaki kod parçacığını ele alalım.\n",
39 | "\n",
40 | "Bu kodu direkt olarak çalıştırdığımızda program bize 6 adet unique değer verecektir. "
41 | ]
42 | },
43 | {
44 | "cell_type": "code",
45 | "execution_count": 1,
46 | "id": "19e7899e-5b19-4f81-a058-cc73d653f56f",
47 | "metadata": {},
48 | "outputs": [
49 | {
50 | "name": "stdout",
51 | "output_type": "stream",
52 | "text": [
53 | "Lotoyu kazanan sayilar: [3, 46, 4, 38, 49, 16]\n"
54 | ]
55 | }
56 | ],
57 | "source": [
58 | "from random import sample\n",
59 | "# sample unique degerler uretir\n",
60 | "\n",
61 | "def loto_sayilarini_uret(min_sayi, max_sayi, adet):\n",
62 | " return sample(range(min_sayi, max_sayi + 1), adet)\n",
63 | "\n",
64 | "def main():\n",
65 | " min_sayi = 1\n",
66 | " max_sayi = 49\n",
67 | " adet = 6\n",
68 | " sayilar = loto_sayilarini_uret(min_sayi, max_sayi, adet)\n",
69 | " #sayilar.sort()\n",
70 | " print('Lotoyu kazanan sayilar:', sayilar)\n",
71 | " \n",
72 | "main()"
73 | ]
74 | },
75 | {
76 | "cell_type": "markdown",
77 | "id": "0bca6e9f-96cf-445e-bf1a-adf344ac6c74",
78 | "metadata": {},
79 | "source": [
80 | "Şimdi bu kodu **[sayisal_loto.py](https://github.com/enesmanan/turkce-kitaplar/blob/main/Veri%20Bilimi%20%C4%B0%C3%A7in%20Python/sayisal_loto.py)** isimli bir python dosyasına kaydettiğimizi düşünelim.\n",
81 | "\n",
82 | "Şimdi de bu dosyayı içe aktaralım ve ne olduğuna bakalım."
83 | ]
84 | },
85 | {
86 | "cell_type": "code",
87 | "execution_count": 2,
88 | "id": "195d1b83-1bb2-4be7-92bf-cedce9206a3b",
89 | "metadata": {},
90 | "outputs": [
91 | {
92 | "name": "stdout",
93 | "output_type": "stream",
94 | "text": [
95 | "Lotoyu kazanan sayilar: [47, 1, 5, 42, 26, 16]\n"
96 | ]
97 | }
98 | ],
99 | "source": [
100 | "import sayisal_loto"
101 | ]
102 | },
103 | {
104 | "cell_type": "markdown",
105 | "id": "a3fe654d-266f-472f-b9a9-ab78a44edb96",
106 | "metadata": {},
107 | "source": [
108 | "Görüldüğü gibi program import ettiğimiz gibi baştan aşağı tüm kodları çalıştırdı ve ekrana 6 tane unique değer bastı."
109 | ]
110 | },
111 | {
112 | "cell_type": "markdown",
113 | "id": "9aaa31ed-88ee-4455-80c3-62673e4a3a02",
114 | "metadata": {},
115 | "source": [
116 | "> **`if __name__ == '__main__'` Yapısı İle**"
117 | ]
118 | },
119 | {
120 | "cell_type": "markdown",
121 | "id": "f1851626-189b-4eab-9786-b694931dfe95",
122 | "metadata": {},
123 | "source": [
124 | "Eğer programa `if __name__ == '__main__'` yapısını eklersek ne olduğuna bakalım."
125 | ]
126 | },
127 | {
128 | "cell_type": "code",
129 | "execution_count": 3,
130 | "id": "4e16c8b7-04fa-48f3-892a-744d9f2aa8e2",
131 | "metadata": {},
132 | "outputs": [
133 | {
134 | "name": "stdout",
135 | "output_type": "stream",
136 | "text": [
137 | "Lotoyu kazanan sayilar: [19, 38, 33, 26, 10, 17]\n"
138 | ]
139 | }
140 | ],
141 | "source": [
142 | "from random import sample\n",
143 | "# sample unique degerler uretir\n",
144 | "\n",
145 | "def loto_sayilarini_uret(min_sayi, max_sayi, adet):\n",
146 | " return sample(range(min_sayi, max_sayi + 1), adet)\n",
147 | "\n",
148 | "def main():\n",
149 | " min_sayi = 1\n",
150 | " max_sayi = 49\n",
151 | " adet = 6\n",
152 | " sayilar = loto_sayilarini_uret(min_sayi, max_sayi, adet)\n",
153 | " #sayilar.sort()\n",
154 | " print('Lotoyu kazanan sayilar:', sayilar)\n",
155 | "\n",
156 | "if __name__ == '__main__':\n",
157 | " main()"
158 | ]
159 | },
160 | {
161 | "cell_type": "markdown",
162 | "id": "bcf44fc1-3a54-4550-8705-cab89164c472",
163 | "metadata": {},
164 | "source": [
165 | "Bu kodu direkt olarak çalıştırdığımızda `__name__` değeri default olarak `__main__`'e eşit olduğundan dolayı program bize 6 adet unique değer verecektir. "
166 | ]
167 | },
168 | {
169 | "cell_type": "markdown",
170 | "id": "95685092-652f-4f71-950d-9901b1e895c2",
171 | "metadata": {},
172 | "source": [
173 | "Peki bu kodu **sayisal_loto.py** isimli dosyadan import edersek ne olacak?"
174 | ]
175 | },
176 | {
177 | "cell_type": "code",
178 | "execution_count": 4,
179 | "id": "632cd8d5-2128-4190-b170-25322882df41",
180 | "metadata": {},
181 | "outputs": [],
182 | "source": [
183 | "import sayisal_loto"
184 | ]
185 | },
186 | {
187 | "cell_type": "markdown",
188 | "id": "4a6a78cd-e2d6-4be3-846b-74aaebddf421",
189 | "metadata": {},
190 | "source": [
191 | "Görüldüğü gibi bu sefer dosyayı import ettiğimizde programın `if __name__ == '__main__':` yapısı altında bulunan kodlar çalıştırılmadı. Bunun sebebi artık `__name__` yapısının değerinin `__main__`'e eşit olmamasıdır. `__name__` yapısının yeni değeri import ettiğimiz dosyanın adı olmuştur. Yani bu senaryoda **sayisal_loto** `__name__` değerine eşit olmuştur."
192 | ]
193 | },
194 | {
195 | "cell_type": "markdown",
196 | "id": "e48818e5-dce1-4479-ba94-63e878aa7156",
197 | "metadata": {},
198 | "source": [
199 | "Şuan sadece dosyadaki fonksiyonlar kullanılabilir hale geldi. \n",
200 | "\n",
201 | "Eğer bunları kullanmak istersek çağırmamız gerekecek."
202 | ]
203 | },
204 | {
205 | "cell_type": "code",
206 | "execution_count": 5,
207 | "id": "61ddad00-9f8e-4ae1-8706-7924784c5926",
208 | "metadata": {},
209 | "outputs": [
210 | {
211 | "name": "stdout",
212 | "output_type": "stream",
213 | "text": [
214 | "Lotoyu kazanan sayilar: [14, 10, 20, 41, 45, 44]\n"
215 | ]
216 | }
217 | ],
218 | "source": [
219 | "import sayisal_loto\n",
220 | "\n",
221 | "loto = sayisal_loto.main()\n",
222 | "\n",
223 | "loto"
224 | ]
225 | },
226 | {
227 | "cell_type": "markdown",
228 | "id": "6e84beeb-4d5b-45be-b25f-80cbcf84ec1a",
229 | "metadata": {},
230 | "source": [
231 | "Bu yapıyı kullanarak, bir Python dosyasının hem modül olarak başka bir programda içe aktarıldığında kullanılabilmesini sağlayabilir hem de aynı dosyanın doğrudan çalıştırıldığında farklı bir işlevi yerine getirmesini sağlayabiliriz."
232 | ]
233 | },
234 | {
235 | "cell_type": "markdown",
236 | "id": "547658ef-665d-4cd1-9c8e-ba47eacd0f94",
237 | "metadata": {},
238 | "source": [
239 | "### Avantajları\n",
240 | "+ Modül olarak kullanıldığında, dosyanın kodlarının yanlışlıkla çalıştırılması önlenir. Eğer bir dosya bir modül olarak başka bir dosyada kullanılıyorsa, `if __name__ == '__main__':` bloğu içindeki kodlar çalışmayacaktır. Böylece, modül olarak kullanılan dosyaların yanlışlıkla yan etki oluşturacak kodlar içermesi engellenir.\n",
241 | "+ Ana program olarak kullanıldığında, dosyanın test edilmesini sağlar. `if __name__ == '__main__':` bloğu içindeki kodlar, dosyanın doğrudan çalıştırıldığı zaman çalışacak ek işlemler veya test kodları olarak kullanılabilir. Böylece, dosyanın doğru şekilde çalıştığını test etmek için ayrı bir test dosyası yazmaya gerek kalmaz.\n",
242 | "\n",
243 | "### Dezavantajları\n",
244 | "+ Kodun karmaşıklığını artırabilir ve bazen gereksiz olabilir."
245 | ]
246 | }
247 | ],
248 | "metadata": {
249 | "kernelspec": {
250 | "display_name": "Python 3 (ipykernel)",
251 | "language": "python",
252 | "name": "python3"
253 | },
254 | "language_info": {
255 | "codemirror_mode": {
256 | "name": "ipython",
257 | "version": 3
258 | },
259 | "file_extension": ".py",
260 | "mimetype": "text/x-python",
261 | "name": "python",
262 | "nbconvert_exporter": "python",
263 | "pygments_lexer": "ipython3",
264 | "version": "3.9.16"
265 | }
266 | },
267 | "nbformat": 4,
268 | "nbformat_minor": 5
269 | }
270 |
--------------------------------------------------------------------------------
/Python ile Veri Bilimi/Extra/Wholesale customers data.csv:
--------------------------------------------------------------------------------
1 | Channel,Region,Fresh,Milk,Grocery,Frozen,Detergents_Paper,Delicassen
2 | 2,3,12669,9656,7561,214,2674,1338
3 | 2,3,7057,9810,9568,1762,3293,1776
4 | 2,3,6353,8808,7684,2405,3516,7844
5 | 1,3,13265,1196,4221,6404,507,1788
6 | 2,3,22615,5410,7198,3915,1777,5185
7 | 2,3,9413,8259,5126,666,1795,1451
8 | 2,3,12126,3199,6975,480,3140,545
9 | 2,3,7579,4956,9426,1669,3321,2566
10 | 1,3,5963,3648,6192,425,1716,750
11 | 2,3,6006,11093,18881,1159,7425,2098
12 | 2,3,3366,5403,12974,4400,5977,1744
13 | 2,3,13146,1124,4523,1420,549,497
14 | 2,3,31714,12319,11757,287,3881,2931
15 | 2,3,21217,6208,14982,3095,6707,602
16 | 2,3,24653,9465,12091,294,5058,2168
17 | 1,3,10253,1114,3821,397,964,412
18 | 2,3,1020,8816,12121,134,4508,1080
19 | 1,3,5876,6157,2933,839,370,4478
20 | 2,3,18601,6327,10099,2205,2767,3181
21 | 1,3,7780,2495,9464,669,2518,501
22 | 2,3,17546,4519,4602,1066,2259,2124
23 | 1,3,5567,871,2010,3383,375,569
24 | 1,3,31276,1917,4469,9408,2381,4334
25 | 2,3,26373,36423,22019,5154,4337,16523
26 | 2,3,22647,9776,13792,2915,4482,5778
27 | 2,3,16165,4230,7595,201,4003,57
28 | 1,3,9898,961,2861,3151,242,833
29 | 1,3,14276,803,3045,485,100,518
30 | 2,3,4113,20484,25957,1158,8604,5206
31 | 1,3,43088,2100,2609,1200,1107,823
32 | 1,3,18815,3610,11107,1148,2134,2963
33 | 1,3,2612,4339,3133,2088,820,985
34 | 1,3,21632,1318,2886,266,918,405
35 | 1,3,29729,4786,7326,6130,361,1083
36 | 1,3,1502,1979,2262,425,483,395
37 | 2,3,688,5491,11091,833,4239,436
38 | 1,3,29955,4362,5428,1729,862,4626
39 | 2,3,15168,10556,12477,1920,6506,714
40 | 2,3,4591,15729,16709,33,6956,433
41 | 1,3,56159,555,902,10002,212,2916
42 | 1,3,24025,4332,4757,9510,1145,5864
43 | 1,3,19176,3065,5956,2033,2575,2802
44 | 2,3,10850,7555,14961,188,6899,46
45 | 2,3,630,11095,23998,787,9529,72
46 | 2,3,9670,7027,10471,541,4618,65
47 | 2,3,5181,22044,21531,1740,7353,4985
48 | 2,3,3103,14069,21955,1668,6792,1452
49 | 2,3,44466,54259,55571,7782,24171,6465
50 | 2,3,11519,6152,10868,584,5121,1476
51 | 2,3,4967,21412,28921,1798,13583,1163
52 | 1,3,6269,1095,1980,3860,609,2162
53 | 1,3,3347,4051,6996,239,1538,301
54 | 2,3,40721,3916,5876,532,2587,1278
55 | 2,3,491,10473,11532,744,5611,224
56 | 1,3,27329,1449,1947,2436,204,1333
57 | 1,3,5264,3683,5005,1057,2024,1130
58 | 2,3,4098,29892,26866,2616,17740,1340
59 | 2,3,5417,9933,10487,38,7572,1282
60 | 1,3,13779,1970,1648,596,227,436
61 | 1,3,6137,5360,8040,129,3084,1603
62 | 2,3,8590,3045,7854,96,4095,225
63 | 2,3,35942,38369,59598,3254,26701,2017
64 | 2,3,7823,6245,6544,4154,4074,964
65 | 2,3,9396,11601,15775,2896,7677,1295
66 | 1,3,4760,1227,3250,3724,1247,1145
67 | 2,3,85,20959,45828,36,24231,1423
68 | 1,3,9,1534,7417,175,3468,27
69 | 2,3,19913,6759,13462,1256,5141,834
70 | 1,3,2446,7260,3993,5870,788,3095
71 | 1,3,8352,2820,1293,779,656,144
72 | 1,3,16705,2037,3202,10643,116,1365
73 | 1,3,18291,1266,21042,5373,4173,14472
74 | 1,3,4420,5139,2661,8872,1321,181
75 | 2,3,19899,5332,8713,8132,764,648
76 | 2,3,8190,6343,9794,1285,1901,1780
77 | 1,3,20398,1137,3,4407,3,975
78 | 1,3,717,3587,6532,7530,529,894
79 | 2,3,12205,12697,28540,869,12034,1009
80 | 1,3,10766,1175,2067,2096,301,167
81 | 1,3,1640,3259,3655,868,1202,1653
82 | 1,3,7005,829,3009,430,610,529
83 | 2,3,219,9540,14403,283,7818,156
84 | 2,3,10362,9232,11009,737,3537,2342
85 | 1,3,20874,1563,1783,2320,550,772
86 | 2,3,11867,3327,4814,1178,3837,120
87 | 2,3,16117,46197,92780,1026,40827,2944
88 | 2,3,22925,73498,32114,987,20070,903
89 | 1,3,43265,5025,8117,6312,1579,14351
90 | 1,3,7864,542,4042,9735,165,46
91 | 1,3,24904,3836,5330,3443,454,3178
92 | 1,3,11405,596,1638,3347,69,360
93 | 1,3,12754,2762,2530,8693,627,1117
94 | 2,3,9198,27472,32034,3232,18906,5130
95 | 1,3,11314,3090,2062,35009,71,2698
96 | 2,3,5626,12220,11323,206,5038,244
97 | 1,3,3,2920,6252,440,223,709
98 | 2,3,23,2616,8118,145,3874,217
99 | 1,3,403,254,610,774,54,63
100 | 1,3,503,112,778,895,56,132
101 | 1,3,9658,2182,1909,5639,215,323
102 | 2,3,11594,7779,12144,3252,8035,3029
103 | 2,3,1420,10810,16267,1593,6766,1838
104 | 2,3,2932,6459,7677,2561,4573,1386
105 | 1,3,56082,3504,8906,18028,1480,2498
106 | 1,3,14100,2132,3445,1336,1491,548
107 | 1,3,15587,1014,3970,910,139,1378
108 | 2,3,1454,6337,10704,133,6830,1831
109 | 2,3,8797,10646,14886,2471,8969,1438
110 | 2,3,1531,8397,6981,247,2505,1236
111 | 2,3,1406,16729,28986,673,836,3
112 | 1,3,11818,1648,1694,2276,169,1647
113 | 2,3,12579,11114,17569,805,6457,1519
114 | 1,3,19046,2770,2469,8853,483,2708
115 | 1,3,14438,2295,1733,3220,585,1561
116 | 1,3,18044,1080,2000,2555,118,1266
117 | 1,3,11134,793,2988,2715,276,610
118 | 1,3,11173,2521,3355,1517,310,222
119 | 1,3,6990,3880,5380,1647,319,1160
120 | 1,3,20049,1891,2362,5343,411,933
121 | 1,3,8258,2344,2147,3896,266,635
122 | 1,3,17160,1200,3412,2417,174,1136
123 | 1,3,4020,3234,1498,2395,264,255
124 | 1,3,12212,201,245,1991,25,860
125 | 2,3,11170,10769,8814,2194,1976,143
126 | 1,3,36050,1642,2961,4787,500,1621
127 | 1,3,76237,3473,7102,16538,778,918
128 | 1,3,19219,1840,1658,8195,349,483
129 | 2,3,21465,7243,10685,880,2386,2749
130 | 1,3,140,8847,3823,142,1062,3
131 | 1,3,42312,926,1510,1718,410,1819
132 | 1,3,7149,2428,699,6316,395,911
133 | 1,3,2101,589,314,346,70,310
134 | 1,3,14903,2032,2479,576,955,328
135 | 1,3,9434,1042,1235,436,256,396
136 | 1,3,7388,1882,2174,720,47,537
137 | 1,3,6300,1289,2591,1170,199,326
138 | 1,3,4625,8579,7030,4575,2447,1542
139 | 1,3,3087,8080,8282,661,721,36
140 | 1,3,13537,4257,5034,155,249,3271
141 | 1,3,5387,4979,3343,825,637,929
142 | 1,3,17623,4280,7305,2279,960,2616
143 | 1,3,30379,13252,5189,321,51,1450
144 | 1,3,37036,7152,8253,2995,20,3
145 | 1,3,10405,1596,1096,8425,399,318
146 | 1,3,18827,3677,1988,118,516,201
147 | 2,3,22039,8384,34792,42,12591,4430
148 | 1,3,7769,1936,2177,926,73,520
149 | 1,3,9203,3373,2707,1286,1082,526
150 | 1,3,5924,584,542,4052,283,434
151 | 1,3,31812,1433,1651,800,113,1440
152 | 1,3,16225,1825,1765,853,170,1067
153 | 1,3,1289,3328,2022,531,255,1774
154 | 1,3,18840,1371,3135,3001,352,184
155 | 1,3,3463,9250,2368,779,302,1627
156 | 1,3,622,55,137,75,7,8
157 | 2,3,1989,10690,19460,233,11577,2153
158 | 2,3,3830,5291,14855,317,6694,3182
159 | 1,3,17773,1366,2474,3378,811,418
160 | 2,3,2861,6570,9618,930,4004,1682
161 | 2,3,355,7704,14682,398,8077,303
162 | 2,3,1725,3651,12822,824,4424,2157
163 | 1,3,12434,540,283,1092,3,2233
164 | 1,3,15177,2024,3810,2665,232,610
165 | 2,3,5531,15726,26870,2367,13726,446
166 | 2,3,5224,7603,8584,2540,3674,238
167 | 2,3,15615,12653,19858,4425,7108,2379
168 | 2,3,4822,6721,9170,993,4973,3637
169 | 1,3,2926,3195,3268,405,1680,693
170 | 1,3,5809,735,803,1393,79,429
171 | 1,3,5414,717,2155,2399,69,750
172 | 2,3,260,8675,13430,1116,7015,323
173 | 2,3,200,25862,19816,651,8773,6250
174 | 1,3,955,5479,6536,333,2840,707
175 | 2,3,514,7677,19805,937,9836,716
176 | 1,3,286,1208,5241,2515,153,1442
177 | 2,3,2343,7845,11874,52,4196,1697
178 | 1,3,45640,6958,6536,7368,1532,230
179 | 1,3,12759,7330,4533,1752,20,2631
180 | 1,3,11002,7075,4945,1152,120,395
181 | 1,3,3157,4888,2500,4477,273,2165
182 | 1,3,12356,6036,8887,402,1382,2794
183 | 1,3,112151,29627,18148,16745,4948,8550
184 | 1,3,694,8533,10518,443,6907,156
185 | 1,3,36847,43950,20170,36534,239,47943
186 | 1,3,327,918,4710,74,334,11
187 | 1,3,8170,6448,1139,2181,58,247
188 | 1,3,3009,521,854,3470,949,727
189 | 1,3,2438,8002,9819,6269,3459,3
190 | 2,3,8040,7639,11687,2758,6839,404
191 | 2,3,834,11577,11522,275,4027,1856
192 | 1,3,16936,6250,1981,7332,118,64
193 | 1,3,13624,295,1381,890,43,84
194 | 1,3,5509,1461,2251,547,187,409
195 | 2,3,180,3485,20292,959,5618,666
196 | 1,3,7107,1012,2974,806,355,1142
197 | 1,3,17023,5139,5230,7888,330,1755
198 | 1,1,30624,7209,4897,18711,763,2876
199 | 2,1,2427,7097,10391,1127,4314,1468
200 | 1,1,11686,2154,6824,3527,592,697
201 | 1,1,9670,2280,2112,520,402,347
202 | 2,1,3067,13240,23127,3941,9959,731
203 | 2,1,4484,14399,24708,3549,14235,1681
204 | 1,1,25203,11487,9490,5065,284,6854
205 | 1,1,583,685,2216,469,954,18
206 | 1,1,1956,891,5226,1383,5,1328
207 | 2,1,1107,11711,23596,955,9265,710
208 | 1,1,6373,780,950,878,288,285
209 | 2,1,2541,4737,6089,2946,5316,120
210 | 1,1,1537,3748,5838,1859,3381,806
211 | 2,1,5550,12729,16767,864,12420,797
212 | 1,1,18567,1895,1393,1801,244,2100
213 | 2,1,12119,28326,39694,4736,19410,2870
214 | 1,1,7291,1012,2062,1291,240,1775
215 | 1,1,3317,6602,6861,1329,3961,1215
216 | 2,1,2362,6551,11364,913,5957,791
217 | 1,1,2806,10765,15538,1374,5828,2388
218 | 2,1,2532,16599,36486,179,13308,674
219 | 1,1,18044,1475,2046,2532,130,1158
220 | 2,1,18,7504,15205,1285,4797,6372
221 | 1,1,4155,367,1390,2306,86,130
222 | 1,1,14755,899,1382,1765,56,749
223 | 1,1,5396,7503,10646,91,4167,239
224 | 1,1,5041,1115,2856,7496,256,375
225 | 2,1,2790,2527,5265,5612,788,1360
226 | 1,1,7274,659,1499,784,70,659
227 | 1,1,12680,3243,4157,660,761,786
228 | 2,1,20782,5921,9212,1759,2568,1553
229 | 1,1,4042,2204,1563,2286,263,689
230 | 1,1,1869,577,572,950,4762,203
231 | 1,1,8656,2746,2501,6845,694,980
232 | 2,1,11072,5989,5615,8321,955,2137
233 | 1,1,2344,10678,3828,1439,1566,490
234 | 1,1,25962,1780,3838,638,284,834
235 | 1,1,964,4984,3316,937,409,7
236 | 1,1,15603,2703,3833,4260,325,2563
237 | 1,1,1838,6380,2824,1218,1216,295
238 | 1,1,8635,820,3047,2312,415,225
239 | 1,1,18692,3838,593,4634,28,1215
240 | 1,1,7363,475,585,1112,72,216
241 | 1,1,47493,2567,3779,5243,828,2253
242 | 1,1,22096,3575,7041,11422,343,2564
243 | 1,1,24929,1801,2475,2216,412,1047
244 | 1,1,18226,659,2914,3752,586,578
245 | 1,1,11210,3576,5119,561,1682,2398
246 | 1,1,6202,7775,10817,1183,3143,1970
247 | 2,1,3062,6154,13916,230,8933,2784
248 | 1,1,8885,2428,1777,1777,430,610
249 | 1,1,13569,346,489,2077,44,659
250 | 1,1,15671,5279,2406,559,562,572
251 | 1,1,8040,3795,2070,6340,918,291
252 | 1,1,3191,1993,1799,1730,234,710
253 | 2,1,6134,23133,33586,6746,18594,5121
254 | 1,1,6623,1860,4740,7683,205,1693
255 | 1,1,29526,7961,16966,432,363,1391
256 | 1,1,10379,17972,4748,4686,1547,3265
257 | 1,1,31614,489,1495,3242,111,615
258 | 1,1,11092,5008,5249,453,392,373
259 | 1,1,8475,1931,1883,5004,3593,987
260 | 1,1,56083,4563,2124,6422,730,3321
261 | 1,1,53205,4959,7336,3012,967,818
262 | 1,1,9193,4885,2157,327,780,548
263 | 1,1,7858,1110,1094,6818,49,287
264 | 1,1,23257,1372,1677,982,429,655
265 | 1,1,2153,1115,6684,4324,2894,411
266 | 2,1,1073,9679,15445,61,5980,1265
267 | 1,1,5909,23527,13699,10155,830,3636
268 | 2,1,572,9763,22182,2221,4882,2563
269 | 1,1,20893,1222,2576,3975,737,3628
270 | 2,1,11908,8053,19847,1069,6374,698
271 | 1,1,15218,258,1138,2516,333,204
272 | 1,1,4720,1032,975,5500,197,56
273 | 1,1,2083,5007,1563,1120,147,1550
274 | 1,1,514,8323,6869,529,93,1040
275 | 1,3,36817,3045,1493,4802,210,1824
276 | 1,3,894,1703,1841,744,759,1153
277 | 1,3,680,1610,223,862,96,379
278 | 1,3,27901,3749,6964,4479,603,2503
279 | 1,3,9061,829,683,16919,621,139
280 | 1,3,11693,2317,2543,5845,274,1409
281 | 2,3,17360,6200,9694,1293,3620,1721
282 | 1,3,3366,2884,2431,977,167,1104
283 | 2,3,12238,7108,6235,1093,2328,2079
284 | 1,3,49063,3965,4252,5970,1041,1404
285 | 1,3,25767,3613,2013,10303,314,1384
286 | 1,3,68951,4411,12609,8692,751,2406
287 | 1,3,40254,640,3600,1042,436,18
288 | 1,3,7149,2247,1242,1619,1226,128
289 | 1,3,15354,2102,2828,8366,386,1027
290 | 1,3,16260,594,1296,848,445,258
291 | 1,3,42786,286,471,1388,32,22
292 | 1,3,2708,2160,2642,502,965,1522
293 | 1,3,6022,3354,3261,2507,212,686
294 | 1,3,2838,3086,4329,3838,825,1060
295 | 2,2,3996,11103,12469,902,5952,741
296 | 1,2,21273,2013,6550,909,811,1854
297 | 2,2,7588,1897,5234,417,2208,254
298 | 1,2,19087,1304,3643,3045,710,898
299 | 2,2,8090,3199,6986,1455,3712,531
300 | 2,2,6758,4560,9965,934,4538,1037
301 | 1,2,444,879,2060,264,290,259
302 | 2,2,16448,6243,6360,824,2662,2005
303 | 2,2,5283,13316,20399,1809,8752,172
304 | 2,2,2886,5302,9785,364,6236,555
305 | 2,2,2599,3688,13829,492,10069,59
306 | 2,2,161,7460,24773,617,11783,2410
307 | 2,2,243,12939,8852,799,3909,211
308 | 2,2,6468,12867,21570,1840,7558,1543
309 | 1,2,17327,2374,2842,1149,351,925
310 | 1,2,6987,1020,3007,416,257,656
311 | 2,2,918,20655,13567,1465,6846,806
312 | 1,2,7034,1492,2405,12569,299,1117
313 | 1,2,29635,2335,8280,3046,371,117
314 | 2,2,2137,3737,19172,1274,17120,142
315 | 1,2,9784,925,2405,4447,183,297
316 | 1,2,10617,1795,7647,1483,857,1233
317 | 2,2,1479,14982,11924,662,3891,3508
318 | 1,2,7127,1375,2201,2679,83,1059
319 | 1,2,1182,3088,6114,978,821,1637
320 | 1,2,11800,2713,3558,2121,706,51
321 | 2,2,9759,25071,17645,1128,12408,1625
322 | 1,2,1774,3696,2280,514,275,834
323 | 1,2,9155,1897,5167,2714,228,1113
324 | 1,2,15881,713,3315,3703,1470,229
325 | 1,2,13360,944,11593,915,1679,573
326 | 1,2,25977,3587,2464,2369,140,1092
327 | 1,2,32717,16784,13626,60869,1272,5609
328 | 1,2,4414,1610,1431,3498,387,834
329 | 1,2,542,899,1664,414,88,522
330 | 1,2,16933,2209,3389,7849,210,1534
331 | 1,2,5113,1486,4583,5127,492,739
332 | 1,2,9790,1786,5109,3570,182,1043
333 | 2,2,11223,14881,26839,1234,9606,1102
334 | 1,2,22321,3216,1447,2208,178,2602
335 | 2,2,8565,4980,67298,131,38102,1215
336 | 2,2,16823,928,2743,11559,332,3486
337 | 2,2,27082,6817,10790,1365,4111,2139
338 | 1,2,13970,1511,1330,650,146,778
339 | 1,2,9351,1347,2611,8170,442,868
340 | 1,2,3,333,7021,15601,15,550
341 | 1,2,2617,1188,5332,9584,573,1942
342 | 2,3,381,4025,9670,388,7271,1371
343 | 2,3,2320,5763,11238,767,5162,2158
344 | 1,3,255,5758,5923,349,4595,1328
345 | 2,3,1689,6964,26316,1456,15469,37
346 | 1,3,3043,1172,1763,2234,217,379
347 | 1,3,1198,2602,8335,402,3843,303
348 | 2,3,2771,6939,15541,2693,6600,1115
349 | 2,3,27380,7184,12311,2809,4621,1022
350 | 1,3,3428,2380,2028,1341,1184,665
351 | 2,3,5981,14641,20521,2005,12218,445
352 | 1,3,3521,1099,1997,1796,173,995
353 | 2,3,1210,10044,22294,1741,12638,3137
354 | 1,3,608,1106,1533,830,90,195
355 | 2,3,117,6264,21203,228,8682,1111
356 | 1,3,14039,7393,2548,6386,1333,2341
357 | 1,3,190,727,2012,245,184,127
358 | 1,3,22686,134,218,3157,9,548
359 | 2,3,37,1275,22272,137,6747,110
360 | 1,3,759,18664,1660,6114,536,4100
361 | 1,3,796,5878,2109,340,232,776
362 | 1,3,19746,2872,2006,2601,468,503
363 | 1,3,4734,607,864,1206,159,405
364 | 1,3,2121,1601,2453,560,179,712
365 | 1,3,4627,997,4438,191,1335,314
366 | 1,3,2615,873,1524,1103,514,468
367 | 2,3,4692,6128,8025,1619,4515,3105
368 | 1,3,9561,2217,1664,1173,222,447
369 | 1,3,3477,894,534,1457,252,342
370 | 1,3,22335,1196,2406,2046,101,558
371 | 1,3,6211,337,683,1089,41,296
372 | 2,3,39679,3944,4955,1364,523,2235
373 | 1,3,20105,1887,1939,8164,716,790
374 | 1,3,3884,3801,1641,876,397,4829
375 | 2,3,15076,6257,7398,1504,1916,3113
376 | 1,3,6338,2256,1668,1492,311,686
377 | 1,3,5841,1450,1162,597,476,70
378 | 2,3,3136,8630,13586,5641,4666,1426
379 | 1,3,38793,3154,2648,1034,96,1242
380 | 1,3,3225,3294,1902,282,68,1114
381 | 2,3,4048,5164,10391,130,813,179
382 | 1,3,28257,944,2146,3881,600,270
383 | 1,3,17770,4591,1617,9927,246,532
384 | 1,3,34454,7435,8469,2540,1711,2893
385 | 1,3,1821,1364,3450,4006,397,361
386 | 1,3,10683,21858,15400,3635,282,5120
387 | 1,3,11635,922,1614,2583,192,1068
388 | 1,3,1206,3620,2857,1945,353,967
389 | 1,3,20918,1916,1573,1960,231,961
390 | 1,3,9785,848,1172,1677,200,406
391 | 1,3,9385,1530,1422,3019,227,684
392 | 1,3,3352,1181,1328,5502,311,1000
393 | 1,3,2647,2761,2313,907,95,1827
394 | 1,3,518,4180,3600,659,122,654
395 | 1,3,23632,6730,3842,8620,385,819
396 | 1,3,12377,865,3204,1398,149,452
397 | 1,3,9602,1316,1263,2921,841,290
398 | 2,3,4515,11991,9345,2644,3378,2213
399 | 1,3,11535,1666,1428,6838,64,743
400 | 1,3,11442,1032,582,5390,74,247
401 | 1,3,9612,577,935,1601,469,375
402 | 1,3,4446,906,1238,3576,153,1014
403 | 1,3,27167,2801,2128,13223,92,1902
404 | 1,3,26539,4753,5091,220,10,340
405 | 1,3,25606,11006,4604,127,632,288
406 | 1,3,18073,4613,3444,4324,914,715
407 | 1,3,6884,1046,1167,2069,593,378
408 | 1,3,25066,5010,5026,9806,1092,960
409 | 2,3,7362,12844,18683,2854,7883,553
410 | 2,3,8257,3880,6407,1646,2730,344
411 | 1,3,8708,3634,6100,2349,2123,5137
412 | 1,3,6633,2096,4563,1389,1860,1892
413 | 1,3,2126,3289,3281,1535,235,4365
414 | 1,3,97,3605,12400,98,2970,62
415 | 1,3,4983,4859,6633,17866,912,2435
416 | 1,3,5969,1990,3417,5679,1135,290
417 | 2,3,7842,6046,8552,1691,3540,1874
418 | 2,3,4389,10940,10908,848,6728,993
419 | 1,3,5065,5499,11055,364,3485,1063
420 | 2,3,660,8494,18622,133,6740,776
421 | 1,3,8861,3783,2223,633,1580,1521
422 | 1,3,4456,5266,13227,25,6818,1393
423 | 2,3,17063,4847,9053,1031,3415,1784
424 | 1,3,26400,1377,4172,830,948,1218
425 | 2,3,17565,3686,4657,1059,1803,668
426 | 2,3,16980,2884,12232,874,3213,249
427 | 1,3,11243,2408,2593,15348,108,1886
428 | 1,3,13134,9347,14316,3141,5079,1894
429 | 1,3,31012,16687,5429,15082,439,1163
430 | 1,3,3047,5970,4910,2198,850,317
431 | 1,3,8607,1750,3580,47,84,2501
432 | 1,3,3097,4230,16483,575,241,2080
433 | 1,3,8533,5506,5160,13486,1377,1498
434 | 1,3,21117,1162,4754,269,1328,395
435 | 1,3,1982,3218,1493,1541,356,1449
436 | 1,3,16731,3922,7994,688,2371,838
437 | 1,3,29703,12051,16027,13135,182,2204
438 | 1,3,39228,1431,764,4510,93,2346
439 | 2,3,14531,15488,30243,437,14841,1867
440 | 1,3,10290,1981,2232,1038,168,2125
441 | 1,3,2787,1698,2510,65,477,52
442 |
--------------------------------------------------------------------------------
/Projelerle Yapay Zeka/Benzerlik_Algoritmaları/TF-IDF.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "
"
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "id": "86a13f11-775e-448b-921d-f0b924881f51",
32 | "metadata": {},
33 | "source": [
34 | "Burada:\n",
35 | "- `A ∩ B` kümelerin kesişimi,\n",
36 | "- `A ∪ B` kümelerin birleşimi."
37 | ]
38 | },
39 | {
40 | "cell_type": "markdown",
41 | "id": "20e73575-13b2-4975-995c-2f886843b2f5",
42 | "metadata": {},
43 | "source": [
44 | "Tanimoto (Jaccard) benzerliği, ikili veya binarize edilmiş verilerin kullanıldığı bilgisayar bilimi, ekoloji, genomik, kimya gibi alanlarda yaygın olarak kullanılır. 0 ile 1 arasında değer alabilir."
45 | ]
46 | },
47 | {
48 | "cell_type": "markdown",
49 | "id": "3e2bc4be-4f27-44df-94b9-62360932a489",
50 | "metadata": {},
51 | "source": [
52 | "### Matris Benzerliği\n",
53 | "\n",
54 | "Matris benzerliği, genellikle piksel değerlerini kullanarak iki görsel arasındaki farkı matrisler yardımıyla ölçer. Piksel değerleri arasındaki farkı veya benzerliği hesaplamak için farklı metrikler kullanabilir. Örneğin, L1 veya L2 normları veya mutlak fark gibi metrikler kullanılabilir."
55 | ]
56 | },
57 | {
58 | "cell_type": "markdown",
59 | "id": "305056af-da47-4b34-98c1-d2e61a729c9e",
60 | "metadata": {},
61 | "source": [
62 | "### Tanimoto ile Matris Benzerliği Arasındaki Farklar\n",
63 | "\n",
64 | "Bu iki benzerlik algoritması farklı yaklaşımlar kullanıldığından ötürü sonuçlarda farklılaşıyor:\n",
65 | "\n",
66 | "- Tanimoto benzerliği, görüntüleri siyah beyaz matrislere dönüştürüp piksel değerlerini kullanarak benzerlik hesaplar. Bu yaklaşım, renk tonlarından ziyade yalnızca varlık veya yokluğu dikkate alır. Bundan dolayı da benzerlik oranı yüksek çıkma eğilimindedir.\n",
67 | "- Matris benzerliği ise renkli piksel değerlerini kullanarak daha detaylı bir farklılık ve benzerlik değeri elde etmeye çalışır. Bu yaklaşım renk farklarını da içerir.\n",
68 | "\n",
69 | "Sonuçlar arasındaki bu farklılık, iki yöntemin de farklı özellikleri nedeniyle oluşabilir. Bir yöntemin diğerine üstün olduğunu söylemek için, hangi benzerlik metriğinin spesifik senaryoda daha uygun olduğunu anlamak önemlidir. Örneğin, Tanimoto (Jaccard) benzerliği ikili veya ikili hale getirilmiş verilerde kullanılırken matris benzerliği daha genel durumlarda kullanılabilir."
70 | ]
71 | },
72 | {
73 | "cell_type": "markdown",
74 | "id": "0f8f7f6d-f3c5-4682-b173-bb24fa73be47",
75 | "metadata": {},
76 | "source": [
77 | "## Tanimoto Benzerliği"
78 | ]
79 | },
80 | {
81 | "cell_type": "code",
82 | "execution_count": 1,
83 | "id": "50b11d88-77a8-47a1-9f99-061fe2195509",
84 | "metadata": {},
85 | "outputs": [
86 | {
87 | "name": "stdout",
88 | "output_type": "stream",
89 | "text": [
90 | "Benzerlik orani: 0.995361906808377\n"
91 | ]
92 | }
93 | ],
94 | "source": [
95 | "import numpy as np\n",
96 | "from PIL import Image\n",
97 | "\n",
98 | "def jaccard_similarity(matrix1, matrix2):\n",
99 | " intersection = np.logical_and(matrix1, matrix2)\n",
100 | " union = np.logical_or(matrix1, matrix2)\n",
101 | " return intersection.sum() / union.sum()\n",
102 | "\n",
103 | "def png_to_matrix(file_path):\n",
104 | " img = Image.open(file_path).convert('L')\n",
105 | " img_arr = np.array(img)\n",
106 | " return img_arr\n",
107 | "\n",
108 | "file1 = 'gorsel1.png'\n",
109 | "file2 = 'gorsel2.png'\n",
110 | "\n",
111 | "\n",
112 | "matrix1 = png_to_matrix(file1)\n",
113 | "matrix2 = png_to_matrix(file2)\n",
114 | "\n",
115 | "similarity = jaccard_similarity(matrix1, matrix2)\n",
116 | "\n",
117 | "print(f'Benzerlik orani: {similarity}')"
118 | ]
119 | },
120 | {
121 | "cell_type": "markdown",
122 | "id": "0189e343-a21e-42cc-9f67-af152f9e723b",
123 | "metadata": {},
124 | "source": [
125 | "## Matris Benzerliği"
126 | ]
127 | },
128 | {
129 | "cell_type": "code",
130 | "execution_count": 2,
131 | "id": "a108edf6-6b4e-48fe-834d-850fa7d22a18",
132 | "metadata": {},
133 | "outputs": [
134 | {
135 | "name": "stdout",
136 | "output_type": "stream",
137 | "text": [
138 | "Iki gorsel arasindaki farklilik orani :32.44940104341378\n",
139 | "Iki gorsel arasindaki benzerlik orani :67.55059895658621\n",
140 | "Iki gorsel arasindaki farkliliklar, farkMatris.png dosyasi olarak kayit edildi\n"
141 | ]
142 | }
143 | ],
144 | "source": [
145 | "import cv2\n",
146 | "import numpy as np\n",
147 | "\n",
148 | "def matris_benzerligi(gorsel_1, gorsel_2):\n",
149 | " yukseklik = gorsel_1.shape[0]\n",
150 | " genislik = gorsel_1.shape[1]\n",
151 | "\n",
152 | " fark = cv2.absdiff(gorsel_1,gorsel_2)\n",
153 | "\n",
154 | " farklilik_oran = np.mean(fark) * 100 / 255\n",
155 | " print('Iki gorsel arasindaki farklilik orani :' + str(farklilik_oran))\n",
156 | "\n",
157 | " benzerlik_oran = 100 - farklilik_oran\n",
158 | " print('Iki gorsel arasindaki benzerlik orani :' + str(benzerlik_oran))\n",
159 | "\n",
160 | " farkMatris = np.zeros(shape=(yukseklik, genislik, 3), dtype=np.uint8)\n",
161 | " mask = fark <= 0\n",
162 | " farkMatris[mask] = 255\n",
163 | " farkMatris[~mask] = gorsel_2[~mask]\n",
164 | "\n",
165 | " cv2.imwrite('farkMatris.png',farkMatris)\n",
166 | " print('Iki gorsel arasindaki farkliliklar, farkMatris.png dosyasi olarak kayit edildi')\n",
167 | "\n",
168 | "if __name__ == '__main__':\n",
169 | " gorsel_1 = cv2.imread('gorsel1.png')\n",
170 | " gorsel_2 = cv2.imread('gorsel2.png')\n",
171 | " matris_benzerligi(gorsel_1, gorsel_2)"
172 | ]
173 | }
174 | ],
175 | "metadata": {
176 | "kernelspec": {
177 | "display_name": "Python 3 (ipykernel)",
178 | "language": "python",
179 | "name": "python3"
180 | },
181 | "language_info": {
182 | "codemirror_mode": {
183 | "name": "ipython",
184 | "version": 3
185 | },
186 | "file_extension": ".py",
187 | "mimetype": "text/x-python",
188 | "name": "python",
189 | "nbconvert_exporter": "python",
190 | "pygments_lexer": "ipython3",
191 | "version": "3.9.16"
192 | }
193 | },
194 | "nbformat": 4,
195 | "nbformat_minor": 5
196 | }
197 |
--------------------------------------------------------------------------------
/Python/Notebook_2.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "id": "80890a0c-3604-4f2d-8e7c-a7617a203233",
6 | "metadata": {},
7 | "source": [
8 | "# Nesne Tabanlı Programlama (Object Oriented Programming-OOP)\n",
9 | "\n",
10 | "## Sınıf (Class) Yapısı"
11 | ]
12 | },
13 | {
14 | "cell_type": "markdown",
15 | "id": "6faefaa4-f3ed-4151-8039-34b29705e718",
16 | "metadata": {},
17 | "source": [
18 | "**Sınıflar, nesne üretmemizi sağlayan veri tipleridir. Sınıflar, bir 'şablon' veya 'taslak' olarak düşünülebilir ve bu şablonu kullanarak farklı nesneler oluşturulabilir.**\n",
19 | "\n",
20 | "Class kullanmanın avantajları:\n",
21 | "+ Kodun yeniden kullanılabilirliğini artırır.\n",
22 | "+ Kodun okunabilirliğini artırır.\n",
23 | "+ Kodun bakımını kolaylaştırır.\n",
24 | "+ Kodun karmaşıklığını azaltır.\n",
25 | "\n",
26 | "> *Bir programcının görevi yalnızca çalışan kodlar yazmak değildir. Programcı aynı zamanda kodlarının okunaklılığını artırmak ve bakımını kolaylaştırmakla da yükümlüdür.*"
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "id": "018fef65-94be-4863-a1b6-5c6d665db2aa",
32 | "metadata": {},
33 | "source": [
34 | "## Sınıf Metotları:\n",
35 | "### 1. Sınıflar (Classes) \n",
36 | "+ **Büyük harfle tanımlanırlar**"
37 | ]
38 | },
39 | {
40 | "cell_type": "markdown",
41 | "id": "6f3de465-8a8d-4a13-98c8-b348bcce8c4a",
42 | "metadata": {},
43 | "source": [
44 | "### 2. Sınıf Nitelikleri (Class Attribute)\n",
45 | "+ **Sınıf tanımlandıktan sonra sınıf nitelikleri (class attribute) tanımlanabilir ve üzerlerinde değişiklik yapılırsa tüm nesneler için geçerli bir değişim olmuş olur.**\n",
46 | " + Sınıf niteliklerine erişmek için sınıf adını parantezsiz olarak kullanılır. $\\to$ `SuperKahraman.evren` "
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "id": "2abbe3c7-83f0-4331-86a0-cde058150587",
52 | "metadata": {},
53 | "source": [
54 | "### 3. Örnekler (Instances) ve Örnek Nitelikleri (Instances Attributes)\n",
55 | "+ **Sınıflardan yeni nesneler (objects) oluşturabiliriz ve bu nesneler, sınıfın örnekleri (instances) olarak adlandırılırlar.**\n",
56 | " + Sınıfların örneklenmesi, bir sınıfın yapıcı metotu olan `__init__(self):` fonksiyonu ile gerçekleştirilir. \n",
57 | " + Bu fonksiyon, bir sınıftan nesne türetildiğinde otomatik olarak çağrılır ve sınıfın özelliklerine başlangıç değerlerini atar.\n",
58 | " + Örnek niteliği (instance attributes), self kelimesini kullanarak tanımlanır. Örneğin, `self.ad = ad` ifadesi, sınıfın her bir örneğinin ad özniteliğini tanımlar.\n",
59 | " + Örnek nitelikleri sadece fonksiyonlar içerisinde tanımlanabilir. "
60 | ]
61 | },
62 | {
63 | "cell_type": "markdown",
64 | "id": "73173712-e0fd-43ff-af8a-70f8bf680239",
65 | "metadata": {},
66 | "source": [
67 | "### 4. Örnek Metotları (Instance Methods)\n",
68 | "+ **Sınıfların örnekleri tarafından kullanılan örnek metotları (instance methods) olabilir.**\n",
69 | " + Bu metotlar bir sınıfın örnekleri vasıtasıyla çağırılabilen fonksiyonlardır.\n",
70 | " + Bu fonksiyonların ilk parametresi her zaman self kelimesidir.\n",
71 | " + Örneğin, `donusum(self):` ve `saldir(self):`"
72 | ]
73 | },
74 | {
75 | "cell_type": "markdown",
76 | "id": "9abbd027-2efc-453e-93d8-906b1ceff6ba",
77 | "metadata": {},
78 | "source": [
79 | "## Örnek: SuperKahraman Sınıfı"
80 | ]
81 | },
82 | {
83 | "cell_type": "code",
84 | "execution_count": 1,
85 | "id": "5e801ef8-f811-4344-b8bf-9e25b08d7d35",
86 | "metadata": {
87 | "tags": []
88 | },
89 | "outputs": [],
90 | "source": [
91 | "class SuperKahraman:\n",
92 | " evren = 'DC'\n",
93 | " \n",
94 | " def __init__(self, ad, zirh, silahlar, guc):\n",
95 | " self.ad = ad\n",
96 | " self.zirh = zirh\n",
97 | " self.silahlar = silahlar\n",
98 | " self.guc = guc\n",
99 | " self.durum = 'Normal'\n",
100 | "\n",
101 | " def donusum(self):\n",
102 | " if self.durum == 'Normal':\n",
103 | " self.durum = 'Super Kahraman'\n",
104 | " return f'{self.ad}, donusum gerceklestirdi! Artik {self.durum} olarak hareket ediyor.'\n",
105 | " elif self.durum == 'Super Kahraman':\n",
106 | " self.durum = 'Normal'\n",
107 | " return f'{self.ad}, donusum gerceklestirdi! Artik {self.durum} olarak hareket ediyor.'\n",
108 | "\n",
109 | " def saldir(self, hedef):\n",
110 | " return f'{self.ad}, {hedef} uzerine saldiri gerceklestirildi!'\n"
111 | ]
112 | },
113 | {
114 | "cell_type": "markdown",
115 | "id": "62a1c0b0-9456-46b7-98ac-118d9aefcd1b",
116 | "metadata": {},
117 | "source": [
118 | "+ Class $\\to$ SuperKahraman\n",
119 | "+ Class Attributes $\\to$ evren\n",
120 | "+ Instance Attributes $\\to$ ad, zirh, silahlar, guc, durum\n",
121 | "+ Instance Methods $\\to$ donusum(), saldir()"
122 | ]
123 | },
124 | {
125 | "cell_type": "code",
126 | "execution_count": 2,
127 | "id": "2b6ff896-962d-41c4-9d2c-93d83558d8d5",
128 | "metadata": {},
129 | "outputs": [
130 | {
131 | "data": {
132 | "text/plain": [
133 | "'DC'"
134 | ]
135 | },
136 | "execution_count": 2,
137 | "metadata": {},
138 | "output_type": "execute_result"
139 | }
140 | ],
141 | "source": [
142 | "# Sinif niteliklerine erismek icin sinif adini parantezsiz olarak kullandık\n",
143 | "SuperKahraman.evren"
144 | ]
145 | },
146 | {
147 | "cell_type": "code",
148 | "execution_count": 3,
149 | "id": "9a96e26f-74ea-4239-b2a9-eb8fa548c15f",
150 | "metadata": {},
151 | "outputs": [],
152 | "source": [
153 | "# SuperKahraman sinifindan yeni bir örnek olusturalim\n",
154 | "# Batman nesnesi olusturalim\n",
155 | "batman = SuperKahraman('Batman', 'Batsuit', ['Batarang', 'Batmobile'], 'Zeka ve Fiziksel Beceriler')"
156 | ]
157 | },
158 | {
159 | "cell_type": "markdown",
160 | "id": "61661c58-1bc3-48b6-9b9b-fccd204760ab",
161 | "metadata": {},
162 | "source": [
163 | "SuperKahraman sınıfından yeni bir örnek oluşturmak için, sınıfın adını ve parantez içinde sınıfın `__init__` fonksiyonuna gönderilecek parametreleri girerek sınıfı çağırırız."
164 | ]
165 | },
166 | {
167 | "cell_type": "code",
168 | "execution_count": 4,
169 | "id": "76786f82-86ed-4a4e-9ca0-e6653d79d5bd",
170 | "metadata": {},
171 | "outputs": [
172 | {
173 | "name": "stdout",
174 | "output_type": "stream",
175 | "text": [
176 | "Batman, zirh: Batsuit, Silahlar: Batarang, Batmobile, guc: Zeka ve Fiziksel Beceriler\n",
177 | "Batman, donusum gerceklestirdi! Artik Super Kahraman olarak hareket ediyor.\n",
178 | "Batman, Joker uzerine saldiri gerceklestirildi!\n",
179 | "Batman, donusum gerceklestirdi! Artik Normal olarak hareket ediyor.\n"
180 | ]
181 | }
182 | ],
183 | "source": [
184 | "# Batman'in ozelliklerine eriselim ardindan donusum ve saldiri yeteneklerini cagiralim\n",
185 | "print(f'{batman.ad}, zirh: {batman.zirh}, Silahlar: {\", \".join(batman.silahlar)}, guc: {batman.guc}')\n",
186 | "print(batman.donusum())\n",
187 | "print(batman.saldir('Joker'))\n",
188 | "print(batman.donusum())"
189 | ]
190 | }
191 | ],
192 | "metadata": {
193 | "kernelspec": {
194 | "display_name": "Python 3 (ipykernel)",
195 | "language": "python",
196 | "name": "python3"
197 | },
198 | "language_info": {
199 | "codemirror_mode": {
200 | "name": "ipython",
201 | "version": 3
202 | },
203 | "file_extension": ".py",
204 | "mimetype": "text/x-python",
205 | "name": "python",
206 | "nbconvert_exporter": "python",
207 | "pygments_lexer": "ipython3",
208 | "version": "3.9.16"
209 | }
210 | },
211 | "nbformat": 4,
212 | "nbformat_minor": 5
213 | }
214 |
--------------------------------------------------------------------------------
/Projelerle Yapay Zeka/Benzerlik_Algoritmaları/RGBCodes_normalized.txt:
--------------------------------------------------------------------------------
1 | maroon: [50.196078431372555, 0.0, 0.0]
2 | dark red: [54.50980392156863, 0.0, 0.0]
3 | brown: [64.70588235294117, 16.47058823529412, 16.47058823529412]
4 | firebrick: [69.80392156862746, 13.333333333333334, 13.333333333333334]
5 | crimson: [86.27450980392157, 7.843137254901961, 23.529411764705884]
6 | red: [100.0, 0.0, 0.0]
7 | tomato: [100.0, 38.82352941176471, 27.84313725490196]
8 | coral: [100.0, 49.80392156862745, 31.372549019607845]
9 | indian red: [80.3921568627451, 36.07843137254902, 36.07843137254902]
10 | light coral: [94.11764705882354, 50.196078431372555, 50.196078431372555]
11 | dark salmon: [91.37254901960785, 58.82352941176471, 47.84313725490196]
12 | salmon: [98.03921568627452, 50.196078431372555, 44.70588235294118]
13 | light salmon: [100.0, 62.74509803921569, 47.84313725490196]
14 | orange red: [100.0, 27.058823529411768, 0.0]
15 | dark orange: [100.0, 54.90196078431373, 0.0]
16 | orange: [100.0, 64.70588235294117, 0.0]
17 | gold: [100.0, 84.31372549019608, 0.0]
18 | dark golden rod: [72.15686274509804, 52.54901960784314, 4.313725490196079]
19 | golden rod: [85.49019607843138, 64.70588235294117, 12.549019607843139]
20 | pale golden rod: [93.33333333333334, 90.98039215686275, 66.66666666666667]
21 | dark khaki: [74.11764705882354, 71.76470588235294, 41.96078431372549]
22 | khaki: [94.11764705882354, 90.19607843137256, 54.90196078431373]
23 | olive: [50.196078431372555, 50.196078431372555, 0.0]
24 | yellow: [100.0, 100.0, 0.0]
25 | yellow green: [60.392156862745104, 80.3921568627451, 19.607843137254903]
26 | dark olive green: [33.333333333333336, 41.96078431372549, 18.43137254901961]
27 | olive drab: [41.96078431372549, 55.68627450980392, 13.725490196078432]
28 | lawn green: [48.62745098039216, 98.82352941176471, 0.0]
29 | chartreuse: [49.80392156862745, 100.0, 0.0]
30 | green yellow: [67.84313725490196, 100.0, 18.43137254901961]
31 | dark green: [0.0, 39.21568627450981, 0.0]
32 | green: [0.0, 50.196078431372555, 0.0]
33 | forest green: [13.333333333333334, 54.50980392156863, 13.333333333333334]
34 | lime: [0.0, 100.0, 0.0]
35 | lime green: [19.607843137254903, 80.3921568627451, 19.607843137254903]
36 | light green: [56.47058823529412, 93.33333333333334, 56.47058823529412]
37 | pale green: [59.6078431372549, 98.43137254901961, 59.6078431372549]
38 | dark sea green: [56.078431372549026, 73.72549019607844, 56.078431372549026]
39 | medium spring green: [0.0, 98.03921568627452, 60.392156862745104]
40 | spring green: [0.0, 100.0, 49.80392156862745]
41 | sea green: [18.03921568627451, 54.50980392156863, 34.11764705882353]
42 | medium aqua marine: [40.0, 80.3921568627451, 66.66666666666667]
43 | medium sea green: [23.529411764705884, 70.19607843137256, 44.313725490196084]
44 | light sea green: [12.549019607843139, 69.80392156862746, 66.66666666666667]
45 | dark slate gray: [18.43137254901961, 30.98039215686275, 30.98039215686275]
46 | teal: [0.0, 50.196078431372555, 50.196078431372555]
47 | dark cyan: [0.0, 54.50980392156863, 54.50980392156863]
48 | aqua: [0.0, 100.0, 100.0]
49 | cyan: [0.0, 100.0, 100.0]
50 | light cyan: [87.84313725490196, 100.0, 100.0]
51 | dark turquoise: [0.0, 80.78431372549021, 81.9607843137255]
52 | turquoise: [25.098039215686278, 87.84313725490196, 81.5686274509804]
53 | medium turquoise: [28.23529411764706, 81.9607843137255, 80.0]
54 | pale turquoise: [68.62745098039215, 93.33333333333334, 93.33333333333334]
55 | aqua marine: [49.80392156862745, 100.0, 83.13725490196079]
56 | powder blue: [69.01960784313727, 87.84313725490196, 90.19607843137256]
57 | cadet blue: [37.254901960784316, 61.9607843137255, 62.74509803921569]
58 | steel blue: [27.450980392156865, 50.98039215686275, 70.58823529411765]
59 | corn flower blue: [39.21568627450981, 58.43137254901961, 92.94117647058825]
60 | deep sky blue: [0.0, 74.90196078431373, 100.0]
61 | dodger blue: [11.764705882352942, 56.47058823529412, 100.0]
62 | light blue: [67.84313725490196, 84.70588235294119, 90.19607843137256]
63 | sky blue: [52.94117647058824, 80.78431372549021, 92.15686274509804]
64 | light sky blue: [52.94117647058824, 80.78431372549021, 98.03921568627452]
65 | midnight blue: [9.803921568627452, 9.803921568627452, 43.92156862745098]
66 | navy: [0.0, 0.0, 50.196078431372555]
67 | dark blue: [0.0, 0.0, 54.50980392156863]
68 | medium blue: [0.0, 0.0, 80.3921568627451]
69 | blue: [0.0, 0.0, 100.0]
70 | royal blue: [25.490196078431374, 41.1764705882353, 88.23529411764706]
71 | blue violet: [54.117647058823536, 16.862745098039216, 88.62745098039217]
72 | indigo: [29.411764705882355, 0.0, 50.98039215686275]
73 | dark slate blue: [28.23529411764706, 23.92156862745098, 54.50980392156863]
74 | slate blue: [41.568627450980394, 35.294117647058826, 80.3921568627451]
75 | medium slate blue: [48.235294117647065, 40.7843137254902, 93.33333333333334]
76 | medium purple: [57.64705882352941, 43.92156862745098, 85.88235294117648]
77 | dark magenta: [54.50980392156863, 0.0, 54.50980392156863]
78 | dark violet: [58.03921568627452, 0.0, 82.74509803921569]
79 | dark orchid: [60.00000000000001, 19.607843137254903, 80.0]
80 | medium orchid: [72.94117647058825, 33.333333333333336, 82.74509803921569]
81 | purple: [50.196078431372555, 0.0, 50.196078431372555]
82 | thistle: [84.70588235294119, 74.90196078431373, 84.70588235294119]
83 | plum: [86.66666666666667, 62.74509803921569, 86.66666666666667]
84 | violet: [93.33333333333334, 50.98039215686275, 93.33333333333334]
85 | magenta: [100.0, 0.0, 100.0]
86 | orchid: [85.49019607843138, 43.92156862745098, 83.92156862745098]
87 | medium violet red: [78.03921568627452, 8.23529411764706, 52.156862745098046]
88 | pale violet red: [85.88235294117648, 43.92156862745098, 57.64705882352941]
89 | deep pink: [100.0, 7.843137254901961, 57.64705882352941]
90 | hot pink: [100.0, 41.1764705882353, 70.58823529411765]
91 | light pink: [100.0, 71.37254901960785, 75.68627450980392]
92 | pink: [100.0, 75.29411764705883, 79.6078431372549]
93 | antique white: [98.03921568627452, 92.15686274509804, 84.31372549019608]
94 | beige: [96.07843137254902, 96.07843137254902, 86.27450980392157]
95 | bisque: [100.0, 89.41176470588236, 76.86274509803923]
96 | blanched almond: [100.0, 92.15686274509804, 80.3921568627451]
97 | wheat: [96.07843137254902, 87.05882352941177, 70.19607843137256]
98 | corn silk: [100.0, 97.25490196078432, 86.27450980392157]
99 | lemon chiffon: [100.0, 98.03921568627452, 80.3921568627451]
100 | light golden rod yellow: [98.03921568627452, 98.03921568627452, 82.3529411764706]
101 | light yellow: [100.0, 100.0, 87.84313725490196]
102 | saddle brown: [54.50980392156863, 27.058823529411768, 7.450980392156863]
103 | sienna: [62.74509803921569, 32.15686274509804, 17.647058823529413]
104 | chocolate: [82.3529411764706, 41.1764705882353, 11.764705882352942]
105 | peru: [80.3921568627451, 52.156862745098046, 24.705882352941178]
106 | sandy brown: [95.68627450980392, 64.31372549019608, 37.64705882352941]
107 | burly wood: [87.05882352941177, 72.15686274509804, 52.94117647058824]
108 | tan: [82.3529411764706, 70.58823529411765, 54.90196078431373]
109 | rosy brown: [73.72549019607844, 56.078431372549026, 56.078431372549026]
110 | moccasin: [100.0, 89.41176470588236, 70.98039215686275]
111 | navajo white: [100.0, 87.05882352941177, 67.84313725490196]
112 | peach puff: [100.0, 85.49019607843138, 72.54901960784314]
113 | misty rose: [100.0, 89.41176470588236, 88.23529411764706]
114 | lavender blush: [100.0, 94.11764705882354, 96.07843137254902]
115 | linen: [98.03921568627452, 94.11764705882354, 90.19607843137256]
116 | old lace: [99.2156862745098, 96.07843137254902, 90.19607843137256]
117 | papaya whip: [100.0, 93.72549019607844, 83.52941176470588]
118 | sea shell: [100.0, 96.07843137254902, 93.33333333333334]
119 | mint cream: [96.07843137254902, 100.0, 98.03921568627452]
120 | slate gray: [43.92156862745098, 50.196078431372555, 56.47058823529412]
121 | light slate gray: [46.66666666666667, 53.333333333333336, 60.00000000000001]
122 | light steel blue: [69.01960784313727, 76.86274509803923, 87.05882352941177]
123 | lavender: [90.19607843137256, 90.19607843137256, 98.03921568627452]
124 | floral white: [100.0, 98.03921568627452, 94.11764705882354]
125 | alice blue: [94.11764705882354, 97.25490196078432, 100.0]
126 | ghost white: [97.25490196078432, 97.25490196078432, 100.0]
127 | honeydew: [94.11764705882354, 100.0, 94.11764705882354]
128 | ivory: [100.0, 100.0, 94.11764705882354]
129 | azure: [94.11764705882354, 100.0, 100.0]
130 | snow: [100.0, 98.03921568627452, 98.03921568627452]
131 | black: [0.0, 0.0, 0.0]
132 | dim gray: [41.1764705882353, 41.1764705882353, 41.1764705882353]
133 | gray: [50.196078431372555, 50.196078431372555, 50.196078431372555]
134 | dark gray: [66.27450980392157, 66.27450980392157, 66.27450980392157]
135 | silver: [75.29411764705883, 75.29411764705883, 75.29411764705883]
136 | light gray: [82.74509803921569, 82.74509803921569, 82.74509803921569]
137 | gainsboro: [86.27450980392157, 86.27450980392157, 86.27450980392157]
138 | white smoke: [96.07843137254902, 96.07843137254902, 96.07843137254902]
139 | white: [100.0, 100.0, 100.0]
--------------------------------------------------------------------------------
/Python/Notebook_1.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "id": "5c3652dc-07e9-4249-a40e-63dbab046459",
6 | "metadata": {},
7 | "source": [
8 | "## `if __name__ == '__main__'`"
9 | ]
10 | },
11 | {
12 | "cell_type": "markdown",
13 | "id": "cacbe8ae-4b9c-4a37-a9c0-ad1bbbb575a8",
14 | "metadata": {},
15 | "source": [
16 | "Python'da `if __name__ == '__main__'` yapısı, bir Python dosyasının modül olarak mı yoksa ana program olarak mı kullanıldığını kontrol etmek için kullanılır. \n",
17 | "\n",
18 | "**Direkt olarak çalışırdığımızda:**\n",
19 | "+ Eğer .py uzantılı dosyayı direkt olarak çalıştırılırsa `__name__`değeri default olarak `__main__` olduğundan dolayı `if __name__ == '__main__'` yapısının altında bulunan kodlar otomatik olarak çalışacaktır.\n",
20 | "\n",
21 | "**Modül olarak içeri aktardığımızda**\n",
22 | "+ Eğer .py uzantılı dosya import komutu ile içe aktarılırsa modüldeki tüm kodlar çalıştırılmaz, yalnızca tanımlanan sınıflar, fonksiyonlar, değişkenler vb. kullanılabilir hale gelir."
23 | ]
24 | },
25 | {
26 | "cell_type": "markdown",
27 | "id": "5104155d-6d3d-4ae0-b4ab-51004be787ce",
28 | "metadata": {},
29 | "source": [
30 | "> **`if __name__ == '__main__'` Yapısı Olmadan**"
31 | ]
32 | },
33 | {
34 | "cell_type": "markdown",
35 | "id": "6a43b7a6-0e47-4556-8e6a-a52faefd42f2",
36 | "metadata": {},
37 | "source": [
38 | "Bunu daha iyi görmek için aşağıdaki kod parçacığını ele alalım.\n",
39 | "\n",
40 | "Bu kodu direkt olarak çalıştırdığımızda program bize 6 adet unique değer verecektir. "
41 | ]
42 | },
43 | {
44 | "cell_type": "code",
45 | "execution_count": 1,
46 | "id": "19e7899e-5b19-4f81-a058-cc73d653f56f",
47 | "metadata": {},
48 | "outputs": [
49 | {
50 | "name": "stdout",
51 | "output_type": "stream",
52 | "text": [
53 | "Lotoyu kazanan sayilar: [3, 46, 4, 38, 49, 16]\n"
54 | ]
55 | }
56 | ],
57 | "source": [
58 | "from random import sample\n",
59 | "# sample unique degerler uretir\n",
60 | "\n",
61 | "def loto_sayilarini_uret(min_sayi, max_sayi, adet):\n",
62 | " return sample(range(min_sayi, max_sayi + 1), adet)\n",
63 | "\n",
64 | "def main():\n",
65 | " min_sayi = 1\n",
66 | " max_sayi = 49\n",
67 | " adet = 6\n",
68 | " sayilar = loto_sayilarini_uret(min_sayi, max_sayi, adet)\n",
69 | " #sayilar.sort()\n",
70 | " print('Lotoyu kazanan sayilar:', sayilar)\n",
71 | " \n",
72 | "main()"
73 | ]
74 | },
75 | {
76 | "cell_type": "markdown",
77 | "id": "0bca6e9f-96cf-445e-bf1a-adf344ac6c74",
78 | "metadata": {},
79 | "source": [
80 | "Şimdi bu kodu **[sayisal_loto.py](https://github.com/enesmanan/turkce-kitaplar/blob/main/Veri%20Bilimi%20%C4%B0%C3%A7in%20Python/sayisal_loto.py)** isimli bir python dosyasına kaydettiğimizi düşünelim.\n",
81 | "\n",
82 | "Şimdi de bu dosyayı içe aktaralım ve ne olduğuna bakalım."
83 | ]
84 | },
85 | {
86 | "cell_type": "code",
87 | "execution_count": 2,
88 | "id": "195d1b83-1bb2-4be7-92bf-cedce9206a3b",
89 | "metadata": {},
90 | "outputs": [
91 | {
92 | "name": "stdout",
93 | "output_type": "stream",
94 | "text": [
95 | "Lotoyu kazanan sayilar: [47, 1, 5, 42, 26, 16]\n"
96 | ]
97 | }
98 | ],
99 | "source": [
100 | "import sayisal_loto"
101 | ]
102 | },
103 | {
104 | "cell_type": "markdown",
105 | "id": "a3fe654d-266f-472f-b9a9-ab78a44edb96",
106 | "metadata": {},
107 | "source": [
108 | "Görüldüğü gibi program import ettiğimiz gibi baştan aşağı tüm kodları çalıştırdı ve ekrana 6 tane unique değer bastı."
109 | ]
110 | },
111 | {
112 | "cell_type": "markdown",
113 | "id": "9aaa31ed-88ee-4455-80c3-62673e4a3a02",
114 | "metadata": {},
115 | "source": [
116 | "> **`if __name__ == '__main__'` Yapısı İle**"
117 | ]
118 | },
119 | {
120 | "cell_type": "markdown",
121 | "id": "f1851626-189b-4eab-9786-b694931dfe95",
122 | "metadata": {},
123 | "source": [
124 | "Eğer programa `if __name__ == '__main__'` yapısını eklersek ne olduğuna bakalım."
125 | ]
126 | },
127 | {
128 | "cell_type": "code",
129 | "execution_count": 3,
130 | "id": "4e16c8b7-04fa-48f3-892a-744d9f2aa8e2",
131 | "metadata": {},
132 | "outputs": [
133 | {
134 | "name": "stdout",
135 | "output_type": "stream",
136 | "text": [
137 | "Lotoyu kazanan sayilar: [19, 38, 33, 26, 10, 17]\n"
138 | ]
139 | }
140 | ],
141 | "source": [
142 | "from random import sample\n",
143 | "# sample unique degerler uretir\n",
144 | "\n",
145 | "def loto_sayilarini_uret(min_sayi, max_sayi, adet):\n",
146 | " return sample(range(min_sayi, max_sayi + 1), adet)\n",
147 | "\n",
148 | "def main():\n",
149 | " min_sayi = 1\n",
150 | " max_sayi = 49\n",
151 | " adet = 6\n",
152 | " sayilar = loto_sayilarini_uret(min_sayi, max_sayi, adet)\n",
153 | " #sayilar.sort()\n",
154 | " print('Lotoyu kazanan sayilar:', sayilar)\n",
155 | "\n",
156 | "if __name__ == '__main__':\n",
157 | " main()"
158 | ]
159 | },
160 | {
161 | "cell_type": "markdown",
162 | "id": "bcf44fc1-3a54-4550-8705-cab89164c472",
163 | "metadata": {},
164 | "source": [
165 | "Bu kodu direkt olarak çalıştırdığımızda `__name__` değeri default olarak `__main__`'e eşit olduğundan dolayı program bize 6 adet unique değer verecektir. "
166 | ]
167 | },
168 | {
169 | "cell_type": "markdown",
170 | "id": "95685092-652f-4f71-950d-9901b1e895c2",
171 | "metadata": {},
172 | "source": [
173 | "Peki bu kodu **sayisal_loto.py** isimli dosyadan import edersek ne olacak?"
174 | ]
175 | },
176 | {
177 | "cell_type": "code",
178 | "execution_count": 4,
179 | "id": "632cd8d5-2128-4190-b170-25322882df41",
180 | "metadata": {},
181 | "outputs": [],
182 | "source": [
183 | "import sayisal_loto"
184 | ]
185 | },
186 | {
187 | "cell_type": "markdown",
188 | "id": "4a6a78cd-e2d6-4be3-846b-74aaebddf421",
189 | "metadata": {},
190 | "source": [
191 | "Görüldüğü gibi bu sefer dosyayı import ettiğimizde programın `if __name__ == '__main__':` yapısı altında bulunan kodlar çalıştırılmadı. Bunun sebebi artık `__name__` yapısının değerinin `__main__`'e eşit olmamasıdır. `__name__` yapısının yeni değeri import ettiğimiz dosyanın adı olmuştur. Yani bu senaryoda **sayisal_loto** `__name__` değerine eşit olmuştur."
192 | ]
193 | },
194 | {
195 | "cell_type": "markdown",
196 | "id": "e48818e5-dce1-4479-ba94-63e878aa7156",
197 | "metadata": {},
198 | "source": [
199 | "Şuan sadece dosyadaki fonksiyonlar kullanılabilir hale geldi. \n",
200 | "\n",
201 | "Eğer bunları kullanmak istersek çağırmamız gerekecek."
202 | ]
203 | },
204 | {
205 | "cell_type": "code",
206 | "execution_count": 5,
207 | "id": "61ddad00-9f8e-4ae1-8706-7924784c5926",
208 | "metadata": {},
209 | "outputs": [
210 | {
211 | "name": "stdout",
212 | "output_type": "stream",
213 | "text": [
214 | "Lotoyu kazanan sayilar: [14, 10, 20, 41, 45, 44]\n"
215 | ]
216 | }
217 | ],
218 | "source": [
219 | "import sayisal_loto\n",
220 | "\n",
221 | "loto = sayisal_loto.main()\n",
222 | "\n",
223 | "loto"
224 | ]
225 | },
226 | {
227 | "cell_type": "markdown",
228 | "id": "6e84beeb-4d5b-45be-b25f-80cbcf84ec1a",
229 | "metadata": {},
230 | "source": [
231 | "Bu yapıyı kullanarak, bir Python dosyasının hem modül olarak başka bir programda içe aktarıldığında kullanılabilmesini sağlayabilir hem de aynı dosyanın doğrudan çalıştırıldığında farklı bir işlevi yerine getirmesini sağlayabiliriz."
232 | ]
233 | },
234 | {
235 | "cell_type": "markdown",
236 | "id": "547658ef-665d-4cd1-9c8e-ba47eacd0f94",
237 | "metadata": {},
238 | "source": [
239 | "### Avantajları\n",
240 | "+ Modül olarak kullanıldığında, dosyanın kodlarının yanlışlıkla çalıştırılması önlenir. Eğer bir dosya bir modül olarak başka bir dosyada kullanılıyorsa, `if __name__ == '__main__':` bloğu içindeki kodlar çalışmayacaktır. Böylece, modül olarak kullanılan dosyaların yanlışlıkla yan etki oluşturacak kodlar içermesi engellenir.\n",
241 | "+ Ana program olarak kullanıldığında, dosyanın test edilmesini sağlar. `if __name__ == '__main__':` bloğu içindeki kodlar, dosyanın doğrudan çalıştırıldığı zaman çalışacak ek işlemler veya test kodları olarak kullanılabilir. Böylece, dosyanın doğru şekilde çalıştığını test etmek için ayrı bir test dosyası yazmaya gerek kalmaz.\n",
242 | "\n",
243 | "### Dezavantajları\n",
244 | "+ Kodun karmaşıklığını artırabilir ve bazen gereksiz olabilir."
245 | ]
246 | }
247 | ],
248 | "metadata": {
249 | "kernelspec": {
250 | "display_name": "Python 3 (ipykernel)",
251 | "language": "python",
252 | "name": "python3"
253 | },
254 | "language_info": {
255 | "codemirror_mode": {
256 | "name": "ipython",
257 | "version": 3
258 | },
259 | "file_extension": ".py",
260 | "mimetype": "text/x-python",
261 | "name": "python",
262 | "nbconvert_exporter": "python",
263 | "pygments_lexer": "ipython3",
264 | "version": "3.9.16"
265 | }
266 | },
267 | "nbformat": 4,
268 | "nbformat_minor": 5
269 | }
270 |
--------------------------------------------------------------------------------
/Python ile Veri Bilimi/Extra/Wholesale customers data.csv:
--------------------------------------------------------------------------------
1 | Channel,Region,Fresh,Milk,Grocery,Frozen,Detergents_Paper,Delicassen
2 | 2,3,12669,9656,7561,214,2674,1338
3 | 2,3,7057,9810,9568,1762,3293,1776
4 | 2,3,6353,8808,7684,2405,3516,7844
5 | 1,3,13265,1196,4221,6404,507,1788
6 | 2,3,22615,5410,7198,3915,1777,5185
7 | 2,3,9413,8259,5126,666,1795,1451
8 | 2,3,12126,3199,6975,480,3140,545
9 | 2,3,7579,4956,9426,1669,3321,2566
10 | 1,3,5963,3648,6192,425,1716,750
11 | 2,3,6006,11093,18881,1159,7425,2098
12 | 2,3,3366,5403,12974,4400,5977,1744
13 | 2,3,13146,1124,4523,1420,549,497
14 | 2,3,31714,12319,11757,287,3881,2931
15 | 2,3,21217,6208,14982,3095,6707,602
16 | 2,3,24653,9465,12091,294,5058,2168
17 | 1,3,10253,1114,3821,397,964,412
18 | 2,3,1020,8816,12121,134,4508,1080
19 | 1,3,5876,6157,2933,839,370,4478
20 | 2,3,18601,6327,10099,2205,2767,3181
21 | 1,3,7780,2495,9464,669,2518,501
22 | 2,3,17546,4519,4602,1066,2259,2124
23 | 1,3,5567,871,2010,3383,375,569
24 | 1,3,31276,1917,4469,9408,2381,4334
25 | 2,3,26373,36423,22019,5154,4337,16523
26 | 2,3,22647,9776,13792,2915,4482,5778
27 | 2,3,16165,4230,7595,201,4003,57
28 | 1,3,9898,961,2861,3151,242,833
29 | 1,3,14276,803,3045,485,100,518
30 | 2,3,4113,20484,25957,1158,8604,5206
31 | 1,3,43088,2100,2609,1200,1107,823
32 | 1,3,18815,3610,11107,1148,2134,2963
33 | 1,3,2612,4339,3133,2088,820,985
34 | 1,3,21632,1318,2886,266,918,405
35 | 1,3,29729,4786,7326,6130,361,1083
36 | 1,3,1502,1979,2262,425,483,395
37 | 2,3,688,5491,11091,833,4239,436
38 | 1,3,29955,4362,5428,1729,862,4626
39 | 2,3,15168,10556,12477,1920,6506,714
40 | 2,3,4591,15729,16709,33,6956,433
41 | 1,3,56159,555,902,10002,212,2916
42 | 1,3,24025,4332,4757,9510,1145,5864
43 | 1,3,19176,3065,5956,2033,2575,2802
44 | 2,3,10850,7555,14961,188,6899,46
45 | 2,3,630,11095,23998,787,9529,72
46 | 2,3,9670,7027,10471,541,4618,65
47 | 2,3,5181,22044,21531,1740,7353,4985
48 | 2,3,3103,14069,21955,1668,6792,1452
49 | 2,3,44466,54259,55571,7782,24171,6465
50 | 2,3,11519,6152,10868,584,5121,1476
51 | 2,3,4967,21412,28921,1798,13583,1163
52 | 1,3,6269,1095,1980,3860,609,2162
53 | 1,3,3347,4051,6996,239,1538,301
54 | 2,3,40721,3916,5876,532,2587,1278
55 | 2,3,491,10473,11532,744,5611,224
56 | 1,3,27329,1449,1947,2436,204,1333
57 | 1,3,5264,3683,5005,1057,2024,1130
58 | 2,3,4098,29892,26866,2616,17740,1340
59 | 2,3,5417,9933,10487,38,7572,1282
60 | 1,3,13779,1970,1648,596,227,436
61 | 1,3,6137,5360,8040,129,3084,1603
62 | 2,3,8590,3045,7854,96,4095,225
63 | 2,3,35942,38369,59598,3254,26701,2017
64 | 2,3,7823,6245,6544,4154,4074,964
65 | 2,3,9396,11601,15775,2896,7677,1295
66 | 1,3,4760,1227,3250,3724,1247,1145
67 | 2,3,85,20959,45828,36,24231,1423
68 | 1,3,9,1534,7417,175,3468,27
69 | 2,3,19913,6759,13462,1256,5141,834
70 | 1,3,2446,7260,3993,5870,788,3095
71 | 1,3,8352,2820,1293,779,656,144
72 | 1,3,16705,2037,3202,10643,116,1365
73 | 1,3,18291,1266,21042,5373,4173,14472
74 | 1,3,4420,5139,2661,8872,1321,181
75 | 2,3,19899,5332,8713,8132,764,648
76 | 2,3,8190,6343,9794,1285,1901,1780
77 | 1,3,20398,1137,3,4407,3,975
78 | 1,3,717,3587,6532,7530,529,894
79 | 2,3,12205,12697,28540,869,12034,1009
80 | 1,3,10766,1175,2067,2096,301,167
81 | 1,3,1640,3259,3655,868,1202,1653
82 | 1,3,7005,829,3009,430,610,529
83 | 2,3,219,9540,14403,283,7818,156
84 | 2,3,10362,9232,11009,737,3537,2342
85 | 1,3,20874,1563,1783,2320,550,772
86 | 2,3,11867,3327,4814,1178,3837,120
87 | 2,3,16117,46197,92780,1026,40827,2944
88 | 2,3,22925,73498,32114,987,20070,903
89 | 1,3,43265,5025,8117,6312,1579,14351
90 | 1,3,7864,542,4042,9735,165,46
91 | 1,3,24904,3836,5330,3443,454,3178
92 | 1,3,11405,596,1638,3347,69,360
93 | 1,3,12754,2762,2530,8693,627,1117
94 | 2,3,9198,27472,32034,3232,18906,5130
95 | 1,3,11314,3090,2062,35009,71,2698
96 | 2,3,5626,12220,11323,206,5038,244
97 | 1,3,3,2920,6252,440,223,709
98 | 2,3,23,2616,8118,145,3874,217
99 | 1,3,403,254,610,774,54,63
100 | 1,3,503,112,778,895,56,132
101 | 1,3,9658,2182,1909,5639,215,323
102 | 2,3,11594,7779,12144,3252,8035,3029
103 | 2,3,1420,10810,16267,1593,6766,1838
104 | 2,3,2932,6459,7677,2561,4573,1386
105 | 1,3,56082,3504,8906,18028,1480,2498
106 | 1,3,14100,2132,3445,1336,1491,548
107 | 1,3,15587,1014,3970,910,139,1378
108 | 2,3,1454,6337,10704,133,6830,1831
109 | 2,3,8797,10646,14886,2471,8969,1438
110 | 2,3,1531,8397,6981,247,2505,1236
111 | 2,3,1406,16729,28986,673,836,3
112 | 1,3,11818,1648,1694,2276,169,1647
113 | 2,3,12579,11114,17569,805,6457,1519
114 | 1,3,19046,2770,2469,8853,483,2708
115 | 1,3,14438,2295,1733,3220,585,1561
116 | 1,3,18044,1080,2000,2555,118,1266
117 | 1,3,11134,793,2988,2715,276,610
118 | 1,3,11173,2521,3355,1517,310,222
119 | 1,3,6990,3880,5380,1647,319,1160
120 | 1,3,20049,1891,2362,5343,411,933
121 | 1,3,8258,2344,2147,3896,266,635
122 | 1,3,17160,1200,3412,2417,174,1136
123 | 1,3,4020,3234,1498,2395,264,255
124 | 1,3,12212,201,245,1991,25,860
125 | 2,3,11170,10769,8814,2194,1976,143
126 | 1,3,36050,1642,2961,4787,500,1621
127 | 1,3,76237,3473,7102,16538,778,918
128 | 1,3,19219,1840,1658,8195,349,483
129 | 2,3,21465,7243,10685,880,2386,2749
130 | 1,3,140,8847,3823,142,1062,3
131 | 1,3,42312,926,1510,1718,410,1819
132 | 1,3,7149,2428,699,6316,395,911
133 | 1,3,2101,589,314,346,70,310
134 | 1,3,14903,2032,2479,576,955,328
135 | 1,3,9434,1042,1235,436,256,396
136 | 1,3,7388,1882,2174,720,47,537
137 | 1,3,6300,1289,2591,1170,199,326
138 | 1,3,4625,8579,7030,4575,2447,1542
139 | 1,3,3087,8080,8282,661,721,36
140 | 1,3,13537,4257,5034,155,249,3271
141 | 1,3,5387,4979,3343,825,637,929
142 | 1,3,17623,4280,7305,2279,960,2616
143 | 1,3,30379,13252,5189,321,51,1450
144 | 1,3,37036,7152,8253,2995,20,3
145 | 1,3,10405,1596,1096,8425,399,318
146 | 1,3,18827,3677,1988,118,516,201
147 | 2,3,22039,8384,34792,42,12591,4430
148 | 1,3,7769,1936,2177,926,73,520
149 | 1,3,9203,3373,2707,1286,1082,526
150 | 1,3,5924,584,542,4052,283,434
151 | 1,3,31812,1433,1651,800,113,1440
152 | 1,3,16225,1825,1765,853,170,1067
153 | 1,3,1289,3328,2022,531,255,1774
154 | 1,3,18840,1371,3135,3001,352,184
155 | 1,3,3463,9250,2368,779,302,1627
156 | 1,3,622,55,137,75,7,8
157 | 2,3,1989,10690,19460,233,11577,2153
158 | 2,3,3830,5291,14855,317,6694,3182
159 | 1,3,17773,1366,2474,3378,811,418
160 | 2,3,2861,6570,9618,930,4004,1682
161 | 2,3,355,7704,14682,398,8077,303
162 | 2,3,1725,3651,12822,824,4424,2157
163 | 1,3,12434,540,283,1092,3,2233
164 | 1,3,15177,2024,3810,2665,232,610
165 | 2,3,5531,15726,26870,2367,13726,446
166 | 2,3,5224,7603,8584,2540,3674,238
167 | 2,3,15615,12653,19858,4425,7108,2379
168 | 2,3,4822,6721,9170,993,4973,3637
169 | 1,3,2926,3195,3268,405,1680,693
170 | 1,3,5809,735,803,1393,79,429
171 | 1,3,5414,717,2155,2399,69,750
172 | 2,3,260,8675,13430,1116,7015,323
173 | 2,3,200,25862,19816,651,8773,6250
174 | 1,3,955,5479,6536,333,2840,707
175 | 2,3,514,7677,19805,937,9836,716
176 | 1,3,286,1208,5241,2515,153,1442
177 | 2,3,2343,7845,11874,52,4196,1697
178 | 1,3,45640,6958,6536,7368,1532,230
179 | 1,3,12759,7330,4533,1752,20,2631
180 | 1,3,11002,7075,4945,1152,120,395
181 | 1,3,3157,4888,2500,4477,273,2165
182 | 1,3,12356,6036,8887,402,1382,2794
183 | 1,3,112151,29627,18148,16745,4948,8550
184 | 1,3,694,8533,10518,443,6907,156
185 | 1,3,36847,43950,20170,36534,239,47943
186 | 1,3,327,918,4710,74,334,11
187 | 1,3,8170,6448,1139,2181,58,247
188 | 1,3,3009,521,854,3470,949,727
189 | 1,3,2438,8002,9819,6269,3459,3
190 | 2,3,8040,7639,11687,2758,6839,404
191 | 2,3,834,11577,11522,275,4027,1856
192 | 1,3,16936,6250,1981,7332,118,64
193 | 1,3,13624,295,1381,890,43,84
194 | 1,3,5509,1461,2251,547,187,409
195 | 2,3,180,3485,20292,959,5618,666
196 | 1,3,7107,1012,2974,806,355,1142
197 | 1,3,17023,5139,5230,7888,330,1755
198 | 1,1,30624,7209,4897,18711,763,2876
199 | 2,1,2427,7097,10391,1127,4314,1468
200 | 1,1,11686,2154,6824,3527,592,697
201 | 1,1,9670,2280,2112,520,402,347
202 | 2,1,3067,13240,23127,3941,9959,731
203 | 2,1,4484,14399,24708,3549,14235,1681
204 | 1,1,25203,11487,9490,5065,284,6854
205 | 1,1,583,685,2216,469,954,18
206 | 1,1,1956,891,5226,1383,5,1328
207 | 2,1,1107,11711,23596,955,9265,710
208 | 1,1,6373,780,950,878,288,285
209 | 2,1,2541,4737,6089,2946,5316,120
210 | 1,1,1537,3748,5838,1859,3381,806
211 | 2,1,5550,12729,16767,864,12420,797
212 | 1,1,18567,1895,1393,1801,244,2100
213 | 2,1,12119,28326,39694,4736,19410,2870
214 | 1,1,7291,1012,2062,1291,240,1775
215 | 1,1,3317,6602,6861,1329,3961,1215
216 | 2,1,2362,6551,11364,913,5957,791
217 | 1,1,2806,10765,15538,1374,5828,2388
218 | 2,1,2532,16599,36486,179,13308,674
219 | 1,1,18044,1475,2046,2532,130,1158
220 | 2,1,18,7504,15205,1285,4797,6372
221 | 1,1,4155,367,1390,2306,86,130
222 | 1,1,14755,899,1382,1765,56,749
223 | 1,1,5396,7503,10646,91,4167,239
224 | 1,1,5041,1115,2856,7496,256,375
225 | 2,1,2790,2527,5265,5612,788,1360
226 | 1,1,7274,659,1499,784,70,659
227 | 1,1,12680,3243,4157,660,761,786
228 | 2,1,20782,5921,9212,1759,2568,1553
229 | 1,1,4042,2204,1563,2286,263,689
230 | 1,1,1869,577,572,950,4762,203
231 | 1,1,8656,2746,2501,6845,694,980
232 | 2,1,11072,5989,5615,8321,955,2137
233 | 1,1,2344,10678,3828,1439,1566,490
234 | 1,1,25962,1780,3838,638,284,834
235 | 1,1,964,4984,3316,937,409,7
236 | 1,1,15603,2703,3833,4260,325,2563
237 | 1,1,1838,6380,2824,1218,1216,295
238 | 1,1,8635,820,3047,2312,415,225
239 | 1,1,18692,3838,593,4634,28,1215
240 | 1,1,7363,475,585,1112,72,216
241 | 1,1,47493,2567,3779,5243,828,2253
242 | 1,1,22096,3575,7041,11422,343,2564
243 | 1,1,24929,1801,2475,2216,412,1047
244 | 1,1,18226,659,2914,3752,586,578
245 | 1,1,11210,3576,5119,561,1682,2398
246 | 1,1,6202,7775,10817,1183,3143,1970
247 | 2,1,3062,6154,13916,230,8933,2784
248 | 1,1,8885,2428,1777,1777,430,610
249 | 1,1,13569,346,489,2077,44,659
250 | 1,1,15671,5279,2406,559,562,572
251 | 1,1,8040,3795,2070,6340,918,291
252 | 1,1,3191,1993,1799,1730,234,710
253 | 2,1,6134,23133,33586,6746,18594,5121
254 | 1,1,6623,1860,4740,7683,205,1693
255 | 1,1,29526,7961,16966,432,363,1391
256 | 1,1,10379,17972,4748,4686,1547,3265
257 | 1,1,31614,489,1495,3242,111,615
258 | 1,1,11092,5008,5249,453,392,373
259 | 1,1,8475,1931,1883,5004,3593,987
260 | 1,1,56083,4563,2124,6422,730,3321
261 | 1,1,53205,4959,7336,3012,967,818
262 | 1,1,9193,4885,2157,327,780,548
263 | 1,1,7858,1110,1094,6818,49,287
264 | 1,1,23257,1372,1677,982,429,655
265 | 1,1,2153,1115,6684,4324,2894,411
266 | 2,1,1073,9679,15445,61,5980,1265
267 | 1,1,5909,23527,13699,10155,830,3636
268 | 2,1,572,9763,22182,2221,4882,2563
269 | 1,1,20893,1222,2576,3975,737,3628
270 | 2,1,11908,8053,19847,1069,6374,698
271 | 1,1,15218,258,1138,2516,333,204
272 | 1,1,4720,1032,975,5500,197,56
273 | 1,1,2083,5007,1563,1120,147,1550
274 | 1,1,514,8323,6869,529,93,1040
275 | 1,3,36817,3045,1493,4802,210,1824
276 | 1,3,894,1703,1841,744,759,1153
277 | 1,3,680,1610,223,862,96,379
278 | 1,3,27901,3749,6964,4479,603,2503
279 | 1,3,9061,829,683,16919,621,139
280 | 1,3,11693,2317,2543,5845,274,1409
281 | 2,3,17360,6200,9694,1293,3620,1721
282 | 1,3,3366,2884,2431,977,167,1104
283 | 2,3,12238,7108,6235,1093,2328,2079
284 | 1,3,49063,3965,4252,5970,1041,1404
285 | 1,3,25767,3613,2013,10303,314,1384
286 | 1,3,68951,4411,12609,8692,751,2406
287 | 1,3,40254,640,3600,1042,436,18
288 | 1,3,7149,2247,1242,1619,1226,128
289 | 1,3,15354,2102,2828,8366,386,1027
290 | 1,3,16260,594,1296,848,445,258
291 | 1,3,42786,286,471,1388,32,22
292 | 1,3,2708,2160,2642,502,965,1522
293 | 1,3,6022,3354,3261,2507,212,686
294 | 1,3,2838,3086,4329,3838,825,1060
295 | 2,2,3996,11103,12469,902,5952,741
296 | 1,2,21273,2013,6550,909,811,1854
297 | 2,2,7588,1897,5234,417,2208,254
298 | 1,2,19087,1304,3643,3045,710,898
299 | 2,2,8090,3199,6986,1455,3712,531
300 | 2,2,6758,4560,9965,934,4538,1037
301 | 1,2,444,879,2060,264,290,259
302 | 2,2,16448,6243,6360,824,2662,2005
303 | 2,2,5283,13316,20399,1809,8752,172
304 | 2,2,2886,5302,9785,364,6236,555
305 | 2,2,2599,3688,13829,492,10069,59
306 | 2,2,161,7460,24773,617,11783,2410
307 | 2,2,243,12939,8852,799,3909,211
308 | 2,2,6468,12867,21570,1840,7558,1543
309 | 1,2,17327,2374,2842,1149,351,925
310 | 1,2,6987,1020,3007,416,257,656
311 | 2,2,918,20655,13567,1465,6846,806
312 | 1,2,7034,1492,2405,12569,299,1117
313 | 1,2,29635,2335,8280,3046,371,117
314 | 2,2,2137,3737,19172,1274,17120,142
315 | 1,2,9784,925,2405,4447,183,297
316 | 1,2,10617,1795,7647,1483,857,1233
317 | 2,2,1479,14982,11924,662,3891,3508
318 | 1,2,7127,1375,2201,2679,83,1059
319 | 1,2,1182,3088,6114,978,821,1637
320 | 1,2,11800,2713,3558,2121,706,51
321 | 2,2,9759,25071,17645,1128,12408,1625
322 | 1,2,1774,3696,2280,514,275,834
323 | 1,2,9155,1897,5167,2714,228,1113
324 | 1,2,15881,713,3315,3703,1470,229
325 | 1,2,13360,944,11593,915,1679,573
326 | 1,2,25977,3587,2464,2369,140,1092
327 | 1,2,32717,16784,13626,60869,1272,5609
328 | 1,2,4414,1610,1431,3498,387,834
329 | 1,2,542,899,1664,414,88,522
330 | 1,2,16933,2209,3389,7849,210,1534
331 | 1,2,5113,1486,4583,5127,492,739
332 | 1,2,9790,1786,5109,3570,182,1043
333 | 2,2,11223,14881,26839,1234,9606,1102
334 | 1,2,22321,3216,1447,2208,178,2602
335 | 2,2,8565,4980,67298,131,38102,1215
336 | 2,2,16823,928,2743,11559,332,3486
337 | 2,2,27082,6817,10790,1365,4111,2139
338 | 1,2,13970,1511,1330,650,146,778
339 | 1,2,9351,1347,2611,8170,442,868
340 | 1,2,3,333,7021,15601,15,550
341 | 1,2,2617,1188,5332,9584,573,1942
342 | 2,3,381,4025,9670,388,7271,1371
343 | 2,3,2320,5763,11238,767,5162,2158
344 | 1,3,255,5758,5923,349,4595,1328
345 | 2,3,1689,6964,26316,1456,15469,37
346 | 1,3,3043,1172,1763,2234,217,379
347 | 1,3,1198,2602,8335,402,3843,303
348 | 2,3,2771,6939,15541,2693,6600,1115
349 | 2,3,27380,7184,12311,2809,4621,1022
350 | 1,3,3428,2380,2028,1341,1184,665
351 | 2,3,5981,14641,20521,2005,12218,445
352 | 1,3,3521,1099,1997,1796,173,995
353 | 2,3,1210,10044,22294,1741,12638,3137
354 | 1,3,608,1106,1533,830,90,195
355 | 2,3,117,6264,21203,228,8682,1111
356 | 1,3,14039,7393,2548,6386,1333,2341
357 | 1,3,190,727,2012,245,184,127
358 | 1,3,22686,134,218,3157,9,548
359 | 2,3,37,1275,22272,137,6747,110
360 | 1,3,759,18664,1660,6114,536,4100
361 | 1,3,796,5878,2109,340,232,776
362 | 1,3,19746,2872,2006,2601,468,503
363 | 1,3,4734,607,864,1206,159,405
364 | 1,3,2121,1601,2453,560,179,712
365 | 1,3,4627,997,4438,191,1335,314
366 | 1,3,2615,873,1524,1103,514,468
367 | 2,3,4692,6128,8025,1619,4515,3105
368 | 1,3,9561,2217,1664,1173,222,447
369 | 1,3,3477,894,534,1457,252,342
370 | 1,3,22335,1196,2406,2046,101,558
371 | 1,3,6211,337,683,1089,41,296
372 | 2,3,39679,3944,4955,1364,523,2235
373 | 1,3,20105,1887,1939,8164,716,790
374 | 1,3,3884,3801,1641,876,397,4829
375 | 2,3,15076,6257,7398,1504,1916,3113
376 | 1,3,6338,2256,1668,1492,311,686
377 | 1,3,5841,1450,1162,597,476,70
378 | 2,3,3136,8630,13586,5641,4666,1426
379 | 1,3,38793,3154,2648,1034,96,1242
380 | 1,3,3225,3294,1902,282,68,1114
381 | 2,3,4048,5164,10391,130,813,179
382 | 1,3,28257,944,2146,3881,600,270
383 | 1,3,17770,4591,1617,9927,246,532
384 | 1,3,34454,7435,8469,2540,1711,2893
385 | 1,3,1821,1364,3450,4006,397,361
386 | 1,3,10683,21858,15400,3635,282,5120
387 | 1,3,11635,922,1614,2583,192,1068
388 | 1,3,1206,3620,2857,1945,353,967
389 | 1,3,20918,1916,1573,1960,231,961
390 | 1,3,9785,848,1172,1677,200,406
391 | 1,3,9385,1530,1422,3019,227,684
392 | 1,3,3352,1181,1328,5502,311,1000
393 | 1,3,2647,2761,2313,907,95,1827
394 | 1,3,518,4180,3600,659,122,654
395 | 1,3,23632,6730,3842,8620,385,819
396 | 1,3,12377,865,3204,1398,149,452
397 | 1,3,9602,1316,1263,2921,841,290
398 | 2,3,4515,11991,9345,2644,3378,2213
399 | 1,3,11535,1666,1428,6838,64,743
400 | 1,3,11442,1032,582,5390,74,247
401 | 1,3,9612,577,935,1601,469,375
402 | 1,3,4446,906,1238,3576,153,1014
403 | 1,3,27167,2801,2128,13223,92,1902
404 | 1,3,26539,4753,5091,220,10,340
405 | 1,3,25606,11006,4604,127,632,288
406 | 1,3,18073,4613,3444,4324,914,715
407 | 1,3,6884,1046,1167,2069,593,378
408 | 1,3,25066,5010,5026,9806,1092,960
409 | 2,3,7362,12844,18683,2854,7883,553
410 | 2,3,8257,3880,6407,1646,2730,344
411 | 1,3,8708,3634,6100,2349,2123,5137
412 | 1,3,6633,2096,4563,1389,1860,1892
413 | 1,3,2126,3289,3281,1535,235,4365
414 | 1,3,97,3605,12400,98,2970,62
415 | 1,3,4983,4859,6633,17866,912,2435
416 | 1,3,5969,1990,3417,5679,1135,290
417 | 2,3,7842,6046,8552,1691,3540,1874
418 | 2,3,4389,10940,10908,848,6728,993
419 | 1,3,5065,5499,11055,364,3485,1063
420 | 2,3,660,8494,18622,133,6740,776
421 | 1,3,8861,3783,2223,633,1580,1521
422 | 1,3,4456,5266,13227,25,6818,1393
423 | 2,3,17063,4847,9053,1031,3415,1784
424 | 1,3,26400,1377,4172,830,948,1218
425 | 2,3,17565,3686,4657,1059,1803,668
426 | 2,3,16980,2884,12232,874,3213,249
427 | 1,3,11243,2408,2593,15348,108,1886
428 | 1,3,13134,9347,14316,3141,5079,1894
429 | 1,3,31012,16687,5429,15082,439,1163
430 | 1,3,3047,5970,4910,2198,850,317
431 | 1,3,8607,1750,3580,47,84,2501
432 | 1,3,3097,4230,16483,575,241,2080
433 | 1,3,8533,5506,5160,13486,1377,1498
434 | 1,3,21117,1162,4754,269,1328,395
435 | 1,3,1982,3218,1493,1541,356,1449
436 | 1,3,16731,3922,7994,688,2371,838
437 | 1,3,29703,12051,16027,13135,182,2204
438 | 1,3,39228,1431,764,4510,93,2346
439 | 2,3,14531,15488,30243,437,14841,1867
440 | 1,3,10290,1981,2232,1038,168,2125
441 | 1,3,2787,1698,2510,65,477,52
442 |
--------------------------------------------------------------------------------
/Projelerle Yapay Zeka/Benzerlik_Algoritmaları/TF-IDF.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | " [Görsel kaynağı](https://towardsdatascience.com/tf-term-frequency-idf-inverse-document-frequency-from-scratch-in-python-6c2b61b78558)"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## TF-IDF Nedir\n",
15 | "\n",
16 | "**Term Frequency – Inverse Document Frequency**\n",
17 | "\n",
18 | "TF-IDF, bir kelimenin doküman içerisindeki anlam yoğunluğunu istatistiksel yöntemlerle tespit ederek belirli bir ağırlık değeri bulmayı amaçlar. Ortaya çıkan bu TF-IDF değeri, terimin dokümanda ne kadar sık geçtiği ve doküman kümesinde ne kadar nadir olduğu ile orantılıdır. Böylece, dokümanların içeriğini yansıtan ve ayırt edici kelimeleri tespit etmek mümkün olur."
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {},
24 | "source": [
25 | "### TF (Term Frequency)\n",
26 | "**TF = (Belirli bir kelimenin belgedeki tekrar sayısı) / (Dokümandaki toplam kelime sayısı)**\n",
27 | "\n",
28 | "Örnek olarak, bir dokümanda *filhakika* kelimesisnin 10 kere geçtiğini varsayalım ve dokümanın tamamı da 500 kelime olsun. Bu durumda, filhakika kelimesinin terim frekansı $10/500 = 0.02$ olarak bulunmuş olur.\n",
29 | "\n",
30 | "Bir terimin sık kullanılması, genellikle o terimin önemli bir bilgi içerdiğini gösterirken, tüm doküman kümesinde nadir bulunması, terimin diğerlerinden farklı ve özgün olduğu anlamına gelebilir. \n",
31 | "\n",
32 | "Ayrıca burada şöyle bir handikap vardır, **Stop Words**. Bunun ne ifade ettiğini anlamak için Türkçe dilindeki stop words sayılan kelimelere baktığımızda *ama, bu, şu, ve, gibi* vs. sözcükler görürüz. Bu sözcükler doküman içerisinde çokça geçebilir olmasına rağmen bun kelimelerin temsil ettiği büyük bir anlam yoktur ve sıklıklarından dolayı TF işleminde gereksiz bir ağırlık kazanabilirler. Dolayısıyla stop words olarak adlandırılan bu kelimlerin işlemin daha anlamlı olabilmesi için, kelime vektörleri oluşturulmadan önce dokumandan ayıklanmalıdırlar. (İngilizce Stop Words örnekleri: *is, on, the, in, of, it* etc.)"
33 | ]
34 | },
35 | {
36 | "cell_type": "markdown",
37 | "metadata": {},
38 | "source": [
39 | "### IDF (Inverse Document Frequency)\n",
40 | "\n",
41 | "**IDF = log((Toplam doküman sayısı) / (Belirli kelime içeren doküman sayısı))**\n",
42 | "\n",
43 | "$IDF(t) = log(N / (1 + DF(t)))$\n",
44 | "\n",
45 | "$IDF = \\log\\left(\\frac{\\text{Toplam Dokuman Sayisi}}{\\text{Kelimenin Essiz Dokuman Sayisi}}\\right)$\n",
46 | "\n",
47 | "\n",
48 | "Burada:\n",
49 | " - N: Toplam doküman sayısı.\n",
50 | " - DF(t): Belirli bir kelimenin geçtiği doküman sayısı.\n",
51 | " \n",
52 | "IDF, bir kelimenin doküman kümesi içerisindeki nadirliğini gösterir. Bu sayede kelimenin doküman içerisindeki önemini belirlemeye yardımcı olur. IDF değeri, tüm dokümanlar üzerinden hesaplanır.\n",
53 | "\n",
54 | "IDF, logaritmik bir ölçeğe sahip olduğundan dolayı nadir kelimelerin büyük değerler almasını engeller ve daha dengeli bir ölçüm değeri sunar. Eğer bir kelime doküman kümesi içerisinde sıkça geçiyorsa, IDF değeri düşük olacaktır ve bu kelime, muhtemelen genel bilgi taşıyan ve metinler arasında ayrımcılık yapmayan yaygın bir kelimeye tekabul edecektir. Tüm dokümanlar içerisinde az geçen bir kelimenin IDF değeri ise büyük olacaktır."
55 | ]
56 | },
57 | {
58 | "cell_type": "markdown",
59 | "metadata": {},
60 | "source": [
61 | "### TF-IDF\n",
62 | "TF-IDF, her terimin doküman içerisindeki sıklığını (TF) ve tüm doküman koleksiyonu içerisinde o terimin ne kadar yaygın olduğunu (IDF) birleştirerek (çarparak) hesaplanır. \n",
63 | "\n",
64 | "$TF-IDF(d, t) = TF(d, t) * IDF(t)$\n",
65 | "\n",
66 | "Burada:\n",
67 | "- $TF(d, t)$ : Belirli bir dokümandaki (d) terimin (t) geçme sıklığı. Yani, dokümandaki terimin tekrar sayısı.\n",
68 | "- $IDF(t$) : Tüm dokümanlardaki (corpus) terimin (t) geçme sıklığının tersi. \n",
69 | "\n",
70 | "Sonuç olarak en yüksek ağırlık değeri, bir kelimenin az sayıda dokümanda birçok kez geçtiği zaman ortaya çıkar."
71 | ]
72 | },
73 | {
74 | "cell_type": "markdown",
75 | "metadata": {},
76 | "source": [
77 | "## Python ile Uygulama"
78 | ]
79 | },
80 | {
81 | "cell_type": "markdown",
82 | "metadata": {},
83 | "source": [
84 | "### Stop Words"
85 | ]
86 | },
87 | {
88 | "cell_type": "code",
89 | "execution_count": 1,
90 | "metadata": {},
91 | "outputs": [],
92 | "source": [
93 | "stop_words = ['acaba', 'ama', 'ancak', 'artık', 'asla', 'aslında', 'az', 'bana', 'bazen', 'bazı', 'belki',\n",
94 | " 'ben','beni', 'bu','benim', 'beri', 'bile', 'bir', 'biri', 'birkaç', 'birçok', 'şey', 'daha',\n",
95 | " 'az', 'gene','gibi', 'da', 'de', 'en', 'daha','diğer', 'diğeri' , 'diye', 'dolayı', 'fakat',\n",
96 | " 'falan', 'filan', 'gibi', 'hala', 'hatta', 'ise', 'kim', 'kime', 'niye', 'oysa', 'pek',\n",
97 | " 'rağmen', 'sanki', 'şayet', 'sen', 'siz', 'tabii', 've', 'veya', 'zira']"
98 | ]
99 | },
100 | {
101 | "cell_type": "markdown",
102 | "metadata": {},
103 | "source": [
104 | "### TF işlemi"
105 | ]
106 | },
107 | {
108 | "cell_type": "code",
109 | "execution_count": 2,
110 | "metadata": {},
111 | "outputs": [
112 | {
113 | "name": "stdout",
114 | "output_type": "stream",
115 | "text": [
116 | "örnek: 0.2857142857142857\n",
117 | "dokümandır: 0.14285714285714285\n",
118 | "dokümanda: 0.14285714285714285\n",
119 | "tf: 0.14285714285714285\n",
120 | "işlemi: 0.14285714285714285\n",
121 | "yapacağız: 0.14285714285714285\n"
122 | ]
123 | }
124 | ],
125 | "source": [
126 | "import re\n",
127 | "\n",
128 | "def kelime_listesi(dokuman):\n",
129 | " liste = []\n",
130 | " for kelime in dokuman: \n",
131 | " kelimeler = kelime.split(' ') \n",
132 | " for kelime in kelimeler: \n",
133 | " kelime = re.sub(r'[^\\w\\s]', '', kelime) \n",
134 | " if kelime.lower() not in stop_words:\n",
135 | " liste.append(kelime.lower())\n",
136 | " return liste\n",
137 | "\n",
138 | "def dokuman_boyutu(liste):\n",
139 | " return len(liste)\n",
140 | "\n",
141 | "def frekans(liste):\n",
142 | " frekans = {}\n",
143 | " for kelime in liste:\n",
144 | " if kelime in frekans:\n",
145 | " frekans[kelime] += 1\n",
146 | " else:\n",
147 | " frekans[kelime] = 1\n",
148 | " return frekans\n",
149 | "\n",
150 | "def tf_degeri(frekans, boyut):\n",
151 | " for anahtar, deger in frekans.items():\n",
152 | " tf = deger/boyut\n",
153 | " print(f'{anahtar}: {tf}')\n",
154 | " \n",
155 | "def main(dokuman):\n",
156 | " degerler = kelime_listesi(dokuman)\n",
157 | " boyut = dokuman_boyutu(degerler)\n",
158 | " frekans_degerleri = frekans(degerler)\n",
159 | " tf = tf_degeri(frekans_degerleri, boyut)\n",
160 | " \n",
161 | "if __name__ == '__main__':\n",
162 | " dokuman = ['Bu bir örnek dokümandır.', 'Bu örnek dokümanda TF işlemi yapacağız.']\n",
163 | " main(dokuman) "
164 | ]
165 | },
166 | {
167 | "cell_type": "markdown",
168 | "metadata": {},
169 | "source": [
170 | "### TF-IDF işlemi"
171 | ]
172 | },
173 | {
174 | "cell_type": "code",
175 | "execution_count": 3,
176 | "metadata": {},
177 | "outputs": [
178 | {
179 | "name": "stdout",
180 | "output_type": "stream",
181 | "text": [
182 | "\n",
183 | " TF degerleri: \n",
184 | "\n",
185 | "platonun: 0.08695652173913043\n",
186 | "devletinde: 0.043478260869565216\n",
187 | "kişinin: 0.043478260869565216\n",
188 | "başkasına: 0.043478260869565216\n",
189 | "değil: 0.043478260869565216\n",
190 | "kendisine: 0.08695652173913043\n",
191 | "köle: 0.13043478260869565\n",
192 | "olma: 0.08695652173913043\n",
193 | "düşüncesi: 0.08695652173913043\n",
194 | "vardır: 0.08695652173913043\n",
195 | "devlet: 0.043478260869565216\n",
196 | "eserinde: 0.043478260869565216\n",
197 | "başka: 0.043478260869565216\n",
198 | "birisine: 0.043478260869565216\n",
199 | "olmaktansa: 0.043478260869565216\n",
200 | "insanın: 0.043478260869565216\n",
201 | "\n",
202 | "---------------------------\n",
203 | "\n",
204 | " IDF degerleri: \n",
205 | "\n",
206 | "platonun: 0.6931471805599453\n",
207 | "devletinde: 1.0986122886681098\n",
208 | "kişinin: 1.0986122886681098\n",
209 | "başkasına: 1.0986122886681098\n",
210 | "değil: 1.0986122886681098\n",
211 | "kendisine: 0.6931471805599453\n",
212 | "köle: 0.5108256237659906\n",
213 | "olma: 0.6931471805599453\n",
214 | "düşüncesi: 0.6931471805599453\n",
215 | "vardır: 0.6931471805599453\n",
216 | "devlet: 1.0986122886681098\n",
217 | "eserinde: 1.0986122886681098\n",
218 | "başka: 1.0986122886681098\n",
219 | "birisine: 1.0986122886681098\n",
220 | "olmaktansa: 1.0986122886681098\n",
221 | "insanın: 1.0986122886681098\n"
222 | ]
223 | }
224 | ],
225 | "source": [
226 | "import re\n",
227 | "import math \n",
228 | "\n",
229 | "def kelime_listesi(dokuman):\n",
230 | " liste = []\n",
231 | " for kelime in dokuman: \n",
232 | " kelimeler = kelime.split(' ') \n",
233 | " for kelime in kelimeler: \n",
234 | " kelime = re.sub(r'[^\\w\\s]', '', kelime) \n",
235 | " if kelime.lower() not in stop_words:\n",
236 | " liste.append(kelime.lower())\n",
237 | " return liste\n",
238 | "\n",
239 | "def dokuman_boyutu(liste):\n",
240 | " return len(liste)\n",
241 | "\n",
242 | "def frekans(liste):\n",
243 | " frekans = {}\n",
244 | " for kelime in liste:\n",
245 | " if kelime in frekans:\n",
246 | " frekans[kelime] += 1\n",
247 | " else:\n",
248 | " frekans[kelime] = 1\n",
249 | " return frekans\n",
250 | "\n",
251 | "def tf_degeri(frekans, boyut):\n",
252 | " for anahtar, deger in frekans.items():\n",
253 | " tf = deger/boyut\n",
254 | " print(f'{anahtar}: {tf}')\n",
255 | "\n",
256 | "\n",
257 | "def idf_degeri(frekans_degerleri): \n",
258 | " idf_boyut = dokuman_boyutu(dokuman)\n",
259 | " for anahtar, deger in frekans_degerleri.items():\n",
260 | " idf = math.log(idf_boyut / deger)\n",
261 | " print(f'{anahtar}: {idf}')\n",
262 | " \n",
263 | " \n",
264 | " \n",
265 | "def main(dokuman):\n",
266 | " \n",
267 | " degerler = kelime_listesi(dokuman)\n",
268 | " boyut = dokuman_boyutu(degerler)\n",
269 | " \n",
270 | " frekans_degerleri = frekans(degerler)\n",
271 | " \n",
272 | " print('\\n TF degerleri: \\n')\n",
273 | " tf = tf_degeri(frekans_degerleri, boyut)\n",
274 | " print('\\n---------------------------')\n",
275 | " print('\\n IDF degerleri: \\n')\n",
276 | " idf = idf_degeri(frekans_degerleri)\n",
277 | " \n",
278 | "if __name__ == '__main__':\n",
279 | " dokuman = ['Platon\\'un devletinde kişinin başkasına değil, kendisine köle olma düşüncesi vardır.',\n",
280 | " 'Platon\\'un devlet eserinde başka birisine köle olmaktansa insanın kendisine köle olma düşüncesi vardır.']\n",
281 | " main(dokuman) "
282 | ]
283 | },
284 | {
285 | "cell_type": "markdown",
286 | "metadata": {},
287 | "source": [
288 | "### TF-IDF Değerleri"
289 | ]
290 | },
291 | {
292 | "cell_type": "code",
293 | "execution_count": 4,
294 | "metadata": {},
295 | "outputs": [
296 | {
297 | "name": "stdout",
298 | "output_type": "stream",
299 | "text": [
300 | "\n",
301 | "TF degerleri:\n",
302 | "\n",
303 | "platonun: 0.08695652173913043\n",
304 | "devletinde: 0.043478260869565216\n",
305 | "kişinin: 0.043478260869565216\n",
306 | "başkasına: 0.043478260869565216\n",
307 | "değil: 0.043478260869565216\n",
308 | "kendisine: 0.08695652173913043\n",
309 | "köle: 0.13043478260869565\n",
310 | "olma: 0.08695652173913043\n",
311 | "düşüncesi: 0.08695652173913043\n",
312 | "vardır: 0.08695652173913043\n",
313 | "devlet: 0.043478260869565216\n",
314 | "eserinde: 0.043478260869565216\n",
315 | "başka: 0.043478260869565216\n",
316 | "birisine: 0.043478260869565216\n",
317 | "olmaktansa: 0.043478260869565216\n",
318 | "insanın: 0.043478260869565216\n",
319 | "\n",
320 | "---------------------------\n",
321 | "\n",
322 | "IDF degerleri:\n",
323 | "\n",
324 | "platonun: 0.6931471805599453\n",
325 | "devletinde: 1.0986122886681098\n",
326 | "kişinin: 1.0986122886681098\n",
327 | "başkasına: 1.0986122886681098\n",
328 | "değil: 1.0986122886681098\n",
329 | "kendisine: 0.6931471805599453\n",
330 | "köle: 0.5108256237659906\n",
331 | "olma: 0.6931471805599453\n",
332 | "düşüncesi: 0.6931471805599453\n",
333 | "vardır: 0.6931471805599453\n",
334 | "devlet: 1.0986122886681098\n",
335 | "eserinde: 1.0986122886681098\n",
336 | "başka: 1.0986122886681098\n",
337 | "birisine: 1.0986122886681098\n",
338 | "olmaktansa: 1.0986122886681098\n",
339 | "insanın: 1.0986122886681098\n",
340 | "\n",
341 | "---------------------------\n",
342 | "\n",
343 | "TF-IDF degerleri:\n",
344 | "\n",
345 | "platonun: 0.06027366787477785\n",
346 | "devletinde: 0.047765751681222164\n",
347 | "kişinin: 0.047765751681222164\n",
348 | "başkasına: 0.047765751681222164\n",
349 | "değil: 0.047765751681222164\n",
350 | "kendisine: 0.06027366787477785\n",
351 | "köle: 0.06662942918686834\n",
352 | "olma: 0.06027366787477785\n",
353 | "düşüncesi: 0.06027366787477785\n",
354 | "vardır: 0.06027366787477785\n",
355 | "devlet: 0.047765751681222164\n",
356 | "eserinde: 0.047765751681222164\n",
357 | "başka: 0.047765751681222164\n",
358 | "birisine: 0.047765751681222164\n",
359 | "olmaktansa: 0.047765751681222164\n",
360 | "insanın: 0.047765751681222164\n"
361 | ]
362 | }
363 | ],
364 | "source": [
365 | "import re\n",
366 | "import math \n",
367 | "\n",
368 | "stop_words = ['acaba', 'ama', 'ancak', 'artık', 'asla', 'aslında', 'az', 'bana', 'bazen', 'bazı', 'belki',\n",
369 | " 'ben','beni', 'bu','benim', 'beri', 'bile', 'bir', 'biri', 'birkaç', 'birçok', 'şey', 'daha',\n",
370 | " 'az', 'gene','gibi', 'da', 'de', 'en', 'daha','diğer', 'diğeri' , 'diye', 'dolayı', 'fakat',\n",
371 | " 'falan', 'filan', 'gibi', 'hala', 'hatta', 'ise', 'kim', 'kime', 'niye', 'oysa', 'pek',\n",
372 | " 'rağmen', 'sanki', 'şayet', 'sen', 'siz', 'tabii', 've', 'veya', 'zira']\n",
373 | "\n",
374 | "def kelime_listesi(dokuman):\n",
375 | " liste = []\n",
376 | " for kelime in dokuman: \n",
377 | " kelimeler = kelime.split(' ')\n",
378 | " for kelime in kelimeler:\n",
379 | " kelime = re.sub(r'[^\\w\\s]', '', kelime)\n",
380 | " if kelime.lower() not in stop_words:\n",
381 | " liste.append(kelime.lower())\n",
382 | " return liste\n",
383 | "\n",
384 | "def dokuman_boyutu(liste):\n",
385 | " return len(liste)\n",
386 | "\n",
387 | "def frekans(liste):\n",
388 | " frekans = {}\n",
389 | " for kelime in liste:\n",
390 | " if kelime in frekans:\n",
391 | " frekans[kelime] += 1\n",
392 | " else:\n",
393 | " frekans[kelime] = 1\n",
394 | " return frekans\n",
395 | "\n",
396 | "def tf_degeri(frekans, boyut):\n",
397 | " tf_values = {}\n",
398 | " for anahtar, deger in frekans.items():\n",
399 | " tf = deger / boyut\n",
400 | " tf_values[anahtar] = tf\n",
401 | " return tf_values\n",
402 | "\n",
403 | "def idf_degeri(frekans_degerleri, idf_boyut):\n",
404 | " idf_values = {}\n",
405 | " for anahtar, deger in frekans_degerleri.items():\n",
406 | " idf = math.log(idf_boyut / deger)\n",
407 | " idf_values[anahtar] = idf\n",
408 | " return idf_values\n",
409 | "\n",
410 | "def main(dokuman):\n",
411 | " degerler = kelime_listesi(dokuman)\n",
412 | " boyut = dokuman_boyutu(degerler)\n",
413 | " \n",
414 | " frekans_degerleri = frekans(degerler)\n",
415 | " \n",
416 | " print('\\nTF degerleri:\\n')\n",
417 | " tf_values = tf_degeri(frekans_degerleri, boyut)\n",
418 | " for kelime, tf in tf_values.items():\n",
419 | " print(f'{kelime}: {tf}')\n",
420 | " \n",
421 | " print('\\n---------------------------\\n')\n",
422 | " print('IDF degerleri:\\n')\n",
423 | " idf_boyut = len(dokuman)\n",
424 | " idf_values = idf_degeri(frekans_degerleri, idf_boyut)\n",
425 | " for kelime, idf in idf_values.items():\n",
426 | " print(f'{kelime}: {idf}')\n",
427 | "\n",
428 | " print('\\n---------------------------\\n')\n",
429 | " print('TF-IDF degerleri:\\n')\n",
430 | " for kelime in frekans_degerleri:\n",
431 | " tf_idf = tf_values[kelime] * idf_values[kelime]\n",
432 | " print(f'{kelime}: {tf_idf}')\n",
433 | "\n",
434 | "if __name__ == '__main__':\n",
435 | " dokuman = ['Platon\\'un devletinde kişinin başkasına değil, kendisine köle olma düşüncesi vardır.',\n",
436 | " 'Platon\\'un devlet eserinde başka birisine köle olmaktansa insanın kendisine köle olma düşüncesi vardır.']\n",
437 | " main(dokuman)"
438 | ]
439 | }
440 | ],
441 | "metadata": {
442 | "kernelspec": {
443 | "display_name": "Python 3 (ipykernel)",
444 | "language": "python",
445 | "name": "python3"
446 | },
447 | "language_info": {
448 | "codemirror_mode": {
449 | "name": "ipython",
450 | "version": 3
451 | },
452 | "file_extension": ".py",
453 | "mimetype": "text/x-python",
454 | "name": "python",
455 | "nbconvert_exporter": "python",
456 | "pygments_lexer": "ipython3",
457 | "version": "3.9.16"
458 | }
459 | },
460 | "nbformat": 4,
461 | "nbformat_minor": 4
462 | }
463 |
--------------------------------------------------------------------------------
/Veri Bilimi İçin Python/sozluk.txt:
--------------------------------------------------------------------------------
1 | a: bir
2 | ability: yetenek
3 | able: yapabilen
4 | about: hakkında
5 | above: yukarıda
6 | accept: kabul etmek
7 | according: göre
8 | account: hesap
9 | across: karşıdan karşıya
10 | act: hareket etmek
11 | action: hareket
12 | activity: aktivite
13 | actually: aslında
14 | add: eklemek
15 | address: adres
16 | administration: yönetim
17 | admit: kabul etmek
18 | adult: yetişkin
19 | affect: etkilemek
20 | after: sonra
21 | again: tekrar
22 | against: karşı
23 | age: yaş
24 | agency: ajans
25 | agent: ajan
26 | ago: önce
27 | agree: katılmak
28 | agreement: anlaşma
29 | ahead: önde
30 | air: hava
31 | all: tümü
32 | allow: izin vermek
33 | almost: neredeyse
34 | alone: yalnız
35 | along: boyunca
36 | already: zaten
37 | also: ayrıca
38 | although: rağmen
39 | always: her zaman
40 | American: Amerikan
41 | among: arasında
42 | amount: miktar
43 | analysis: analiz
44 | and: ve
45 | animal: hayvan
46 | another: başka
47 | answer: cevap
48 | any: herhangi bir
49 | anyone: herhangi birisi
50 | anything: herhangi bir şey
51 | appear: görünmek
52 | apply: uygulamak
53 | approach: yaklaşım
54 | area: bölge
55 | argue: tartışmak
56 | arm: kol
57 | around: etrafında
58 | arrive: varmak
59 | art: sanat
60 | article: makale
61 | artist: sanatçı
62 | as: olarak
63 | ask: sormak
64 | assume: varsaymak
65 | at: de
66 | attack: saldırı
67 | attention: dikkat
68 | attorney: avukat
69 | audience: seyirci
70 | author: yazar
71 | authority: otorite
72 | available: müsait
73 | avoid: kaçınmak
74 | away: uzakta
75 | baby: bebek
76 | back: geri
77 | bad: kötü
78 | bag: çanta
79 | ball: top
80 | bank: banka
81 | bar: bar
82 | base: temel
83 | be: ol
84 | beat: yenmek
85 | beautiful: güzel
86 | because: çünkü
87 | become: olmak
88 | bed: yatak
89 | before: önce
90 | begin: başlamak
91 | behavior: davranış
92 | behind: arkasında
93 | believe: inanmak
94 | benefit: fayda
95 | best: en iyi
96 | better: daha iyi
97 | between: arasında
98 | beyond: ötesinde
99 | big: büyük
100 | bill: fatura
101 | billion: milyar
102 | bit: parça
103 | black: siyah
104 | blood: kan
105 | blue: mavi
106 | board: tahta
107 | body: vücut
108 | book: kitap
109 | born: doğmak
110 | both: her ikisi
111 | box: kutu
112 | boy: erkek çocuk
113 | break: kırmak
114 | bring: getirmek
115 | brother: erkek kardeş
116 | budget: bütçe
117 | build: inşa etmek
118 | building: bina
119 | business: iş
120 | but: ama
121 | buy: satın almak
122 | by: tarafından
123 | call: aramak
124 | camera: kamera
125 | campaign: kampanya
126 | can: yapabilir
127 | cancer: kanser
128 | candidate: aday
129 | capital: sermaye
130 | car: araba
131 | card: kart
132 | care: ilgi
133 | career: kariyer
134 | carry: taşımak
135 | case: durum
136 | catch: yakalamak
137 | cause: neden olmak
138 | cell: hücre
139 | center: merkez
140 | central: merkezi
141 | century: yüzyıl
142 | certain: belli
143 | certainly: kesinlikle
144 | chair: sandalye
145 | challenge: meydan okuma
146 | chance: şans
147 | change: değişiklik
148 | character: karakter
149 | charge: ücretlendirme
150 | check: kontrol etmek
151 | child: çocuk
152 | choice: seçim
153 | choose: seçmek
154 | church: kilise
155 | citizen: vatandaş
156 | city: şehir
157 | civil: sivil
158 | claim: iddia etmek
159 | class: sınıf
160 | clear: açık
161 | clearly: açıkça
162 | close: kapatmak
163 | coach: antrenör
164 | cold: soğuk
165 | collection: koleksiyon
166 | college: üniversite
167 | color: renk
168 | come: gelmek
169 | commercial: ticari
170 | common: ortak
171 | community: topluluk
172 | company: şirket
173 | compare: karşılaştırmak
174 | computer: bilgisayar
175 | concern: endişe
176 | condition: durum
177 | conference: konferans
178 | Congress: Kongre
179 | consider: düşünmek
180 | consumer: tüketici
181 | contain: içermek
182 | continue: devam etmek
183 | control: kontrol
184 | cost: maliyet
185 | could: olabilirdi
186 | country: ülke
187 | couple: çift
188 | course: tabii ki
189 | court: mahkeme
190 | cover: kaplamak
191 | create: yaratmak
192 | crime: suç
193 | cultural: kültürel
194 | culture: kültür
195 | cup: fincan
196 | current: güncel
197 | customer: müşteri
198 | cut: kesmek
199 | dark: karanlık
200 | data: veri
201 | daughter: kız
202 | day: gün
203 | dead: ölü
204 | deal: anlaşma
205 | death: ölüm
206 | debate: tartışma
207 | decade: on yıl
208 | decide: karar vermek
209 | decision: karar
210 | deep: derin
211 | defense: savunma
212 | degree: derece
213 | Democrat: Demokrat
214 | democratic: demokratik
215 | describe: tanımlamak
216 | design: tasarlamak
217 | despite: rağmen
218 | detail: detay
219 | determine: belirlemek
220 | develop: geliştirmek
221 | development: gelişme
222 | die: ölmek
223 | difference: fark
224 | different: farklı
225 | difficult: zor
226 | dinner: akşam yemeği
227 | direction: yön
228 | director: yönetmen
229 | discover: keşfetmek
230 | discuss: tartışmak
231 | discussion: tartışma
232 | disease: hastalık
233 | do: yapmak
234 | doctor: doktor
235 | dog: köpek
236 | door: kapı
237 | down: aşağı
238 | draw: çizmek
239 | dream: rüya
240 | drive: sürmek
241 | drop: düşürmek
242 | drug: ilaç
243 | during: sırasında
244 | each: her biri
245 | early: erken
246 | east: doğu
247 | easy: kolay
248 | eat: yemek
249 | economic: ekonomik
250 | economy : ekonomi
251 | edge: kenar
252 | education: eğitim
253 | effect: etki
254 | effort: çaba
255 | eight: sekiz
256 | either: her ikisi de
257 | election: seçim
258 | else: başka
259 | employee: çalışan
260 | end: son
261 | energy: enerji
262 | enjoy: zevk almak
263 | enough: yeterli
264 | enter: girmek
265 | entire: tüm
266 | environment: çevre
267 | environmental: çevresel
268 | especially: özellikle
269 | establish: kurmak
270 | even: hatta
271 | evening: akşam
272 | event: olay
273 | ever: hiç
274 | every: her
275 | everybody: herkes
276 | everyone: herkes
277 | everything: her şey
278 | evidence: kanıt
279 | exactly: tam olarak
280 | example: örnek
281 | executive: yönetici
282 | exist: var olmak
283 | expect: beklemek
284 | experience: deneyim
285 | expert: uzman
286 | explain: açıklamak
287 | eye: göz
288 | face: yüzleşmek
289 | fact: gerçek
290 | factor: faktör
291 | fail: başarısız olmak
292 | fall: düşmek
293 | family: aile
294 | far: uzak
295 | fast: hızlı
296 | father: baba
297 | fear: korku
298 | federal: federal
299 | feel: hissetmek
300 | feeling: hiss
301 | few: birkaç
302 | field: alan
303 | fight: savaşmak
304 | figure: şekil
305 | fill: doldurmak
306 | film: film
307 | final: son
308 | finally: sonunda
309 | financial: finansal
310 | find: bulmak
311 | fine: iyi
312 | finger: parmak
313 | finish: bitirmek
314 | fire: yangın
315 | firm: firma
316 | first: ilk
317 | fish: balık
318 | five: beş
319 | floor: zemin
320 | fly: uçmak
321 | focus: odaklanmak
322 | follow: izlemek
323 | food: yiyecek
324 | foot: ayak
325 | for: için
326 | force: zorlamak
327 | foreign: yabancı
328 | forget: unutmak
329 | form: biçim
330 | former: eski
331 | forward: ileri
332 | four: dört
333 | free: ücretsiz
334 | friend: arkadaş
335 | from: dan
336 | front: ön
337 | full: tam
338 | fully: tamamen
339 | fun: eğlence
340 | function: fonksiyon
341 | fund: fon
342 | future: gelecek
343 | game: oyun
344 | garden: bahçe
345 | gas: gaz
346 | general: genel
347 | generation: nesil
348 | get: almak
349 | girl: kız
350 | give: vermek
351 | glass: cam
352 | go: gitmek
353 | goal: amaç
354 | good: iyi
355 | government: hükümet
356 | great: harika
357 | green: yeşil
358 | ground: yer
359 | group: grup
360 | grow: büyümek
361 | growth: büyüme
362 | guess: tahmin etmek
363 | gun: silah
364 | guy: adam
365 | hair: saç
366 | half: yarım
367 | hand: el
368 | hang: asmak
369 | happen: olmak
370 | happy: mutlu
371 | hard: zor
372 | have: sahip olmak
373 | he: o
374 | head: baş
375 | health: sağlık
376 | hear: duymak
377 | heart: kalp
378 | heat: ısı
379 | heavy: ağır
380 | help: yardım etmek
381 | her: onun
382 | here: burada
383 | herself: kendisi
384 | high: yüksek
385 | him: onu
386 | himself: kendisi
387 | his: onun
388 | history: tarih
389 | hit: vurmak
390 | hold: tutmak
391 | home: ev
392 | hope: umut
393 | hospital: hastane
394 | hot: sıcak
395 | hotel: otel
396 | hour: saat
397 | house: ev
398 | how: nasıl
399 | however: ancak
400 | huge: büyük
401 | human: insan
402 | hundred: yüz
403 | husband: eş
404 | I: ben
405 | idea: fikir
406 | identify: tanımlamak
407 | if: eğer
408 | image: görüntü
409 | imagine: hayal etmek
410 | impact: etki
411 | important: önemli
412 | improve: geliştirmek
413 | in: içinde
414 | include: dahil etmek
415 | including: dahil olmak üzere
416 | income: gelir
417 | increase: artış
418 | indeed: gerçekten
419 | indicate: belirtmek
420 | individual: bireysel
421 | industry: sanayi
422 | information: bilgi
423 | inside: içinde
424 | instead: yerine
425 | institution: kurum
426 | interest: ilgi
427 | interesting: ilginç
428 | international: uluslararası
429 | into: içine
430 | investment: yatırım
431 | involve: içermek
432 | issue: sorun
433 | it: o
434 | item: madde
435 | its: onun
436 | itself: kendisi
437 | job: iş
438 | join: katılmak
439 | just: sadece
440 | keep: saklamak
441 | key: anahtar
442 | kid: çocuk
443 | kill: öldürmek
444 | kind: çeşit
445 | kitchen: mutfak
446 | know: bilmek
447 | knowledge: bilgi
448 | land: arazi
449 | language: dil
450 | large: büyük
451 | last: son
452 | late: geç
453 | later: daha sonra
454 | laugh: gülmek
455 | law: kanun
456 | lay: yerleştirmek
457 | lead: yönetmek
458 | leader: lider
459 | learn: öğrenmek
460 | least: en az
461 | leave: ayrılmak
462 | left: sol
463 | leg: bacak
464 | legal: yasal
465 | less: daha az
466 | let: izin vermek
467 | letter: mektup
468 | level: seviye
469 | lie: yalan söylemek
470 | life: hayat
471 | light: ışık
472 | like: gibi
473 | likely: muhtemelen
474 | limit: sınır
475 | line: hat
476 | link: bağlantı
477 | list: liste
478 | listen: dinlemek
479 | little: az
480 | live: yaşamak
481 | local: yerel
482 | long: uzun
483 | look: bakmak
484 | lose: kaybetmek
485 | loss: kayıp
486 | lot: çok
487 | love: aşk
488 | low: düşük
489 | machine: makine
490 | magazine: dergi
491 | main: ana
492 | maintain: sürdürmek
493 | major: büyük
494 | majority: çoğunluk
495 | make: yapmak
496 | man: adam
497 | manage: yönetmek
498 | management: yönetim
499 | manager: yönetici
500 | many: birçok
501 | market: pazar
502 | marriage: evlilik
503 | material: malzeme
504 | matter: mesele
505 | may: olabilir
506 | maybe: belki
507 | me: beni
508 | mean: anlamına gelmek
509 | measure: ölçmek
510 | media: medya
511 | medical: tıbbi
512 | meet: tanışmak
513 | meeting: toplantı
514 | member: üye
515 | memory: bellek
516 | mention: bahsetmek
517 | message: mesaj
518 | method: yöntem
519 | middle: orta
520 | might: belki
521 | military: askeri
522 | million: milyon
523 | mind: akıl
524 | minute: dakika
525 | miss: kaçırmak
526 | mission: görev
527 | mistake: hata
528 | mix: karıştırmak
529 | model: model
530 | modern: modern
531 | moment: an
532 | money: para
533 | month: ay
534 | more: daha fazla
535 | morning: sabah
536 | most: en çok
537 | mother: anne
538 | mouth: ağız
539 | move: hareket etmek
540 | movement: hareket
541 | movie: film
542 | much: çok
543 | music: müzik
544 | must: meli
545 | my: benim
546 | myself: kendim
547 | name: isim
548 | nation: ulus
549 | national: ulusal
550 | natural: doğal
551 | nature: doğa
552 | near: yakın
553 | nearly: neredeyse
554 | necessary: gerekli
555 | need: ihtiyaç
556 | network: ağ
557 | never: asla
558 | new: yeni
559 | news: haber
560 | newspaper: gazete
561 | next: sonraki
562 | nice: güzel
563 | night: gece
564 | no: hayır
565 | none: hiçbiri
566 | nor: ne de
567 | north: kuzey
568 | not: değil
569 | note: not
570 | nothing: hiçbir şey
571 | notice: fark etmek
572 | now: şimdi
573 | nuclear: nükleer
574 | number: numara
575 | occur: meydana gelmek
576 | of: nin
577 | off: kapalı
578 | offer: teklif
579 | office: ofis
580 | officer: subay
581 | official: resmi
582 | often: sık sık
583 | oh: ah
584 | oil: yağ
585 | ok: tamam
586 | old: eski
587 | on: üzerinde
588 | once: bir kez
589 | one: bir
590 | only: sadece
591 | onto: üstüne
592 | open: açık
593 | operation: işlem
594 | opportunity: fırsat
595 | option: seçenek
596 | or: veya
597 | order: sipariş
598 | ordinary: sıradan
599 | origin: köken
600 | original: özgün
601 | other: diğer
602 | others: diğerleri
603 | otherwise: aksi takdirde
604 | ought: gerekli
605 | our: bizim
606 | ourselves: kendimizi
607 | out: dışarı
608 | over: üzerinde
609 | overall: genel
610 | own: kendi
611 | owner: sahip
612 | page: sayfa
613 | pain: acı
614 | paint: boya
615 | painting: resim
616 | paper: kağıt
617 | parent: ebeveyn
618 | part: parça
619 | participant: katılımcı
620 | particular: belirli
621 | particularly: özellikle
622 | partner: ortak
623 | party: parti
624 | pass: geçmek
625 | past: geçmiş
626 | path: yol
627 | patient: hasta
628 | pattern: desen
629 | pay: ödeme
630 | peace: barış
631 | people: insanlar
632 | per: her
633 | perform: yapmak
634 | performance: performans
635 | perhaps: belki
636 | period: dönem
637 | person: kişi
638 | personal: kişisel
639 | phone: telefon
640 | physical: fiziksel
641 | pick: toplamak
642 | picture: resim
643 | piece: parça
644 | place: yer
645 | plan: planlamak
646 | plant: bitki
647 | play: oynamak
648 | player: oyuncu
649 | PM: öğleden sonra
650 | point: nokta
651 | police: polis
652 | policy: politika
653 | political: siyasi
654 | politics: siyaset
655 | poor: fakir
656 | popular: popüler
657 | population: nüfus
658 | position: pozisyon
659 | positive: pozitif
660 | possible: mümkün
661 | post: gönderi
662 | potential: potansiyel
663 | power: güç
664 | practice: uygulama
665 | prefer: tercih etmek
666 | preparation: hazırlık
667 | prepare: hazırlamak
668 | present: şimdiki
669 | president: başkan
670 | press: basın
671 | pressure: baskı
672 | pretty: oldukça
673 | prevent: önlemek
674 | price: fiyat
675 | principle: ilke
676 | private: özel
677 | probably: muhtemelen
678 | problem: sorun
679 | process: süreç
680 | produce: üretmek
681 | product: ürün
682 | production: üretim
683 | professional: profesyonel
684 | professor: profesör
685 | program: program
686 | project: proje
687 | property: özellik
688 | protect: koruma
689 | prove: kanıtlamak
690 | provide: sağlamak
691 | public: halka açık
692 | pull: çekmek
693 | purpose: amaç
694 | push: itmek
695 | put: koymak
696 | quality: kalite
697 | question: soru
698 | quick: hızlı
699 | quickly: hızlıca
700 | quiet: sessiz
701 | quite: oldukça
702 | race: yarış
703 | radio: radyo
704 | raise: artırmak
705 | range: menzil
706 | rate: oran
707 | rather: oldukça
708 | reach: ulaşmak
709 | read: okumak
710 | ready: hazır
711 | real: gerçek
712 | reality: gerçeklik
713 | realize: farkına varmak
714 | really: gerçekten
715 | reason: neden
716 | receive: almak
717 | recent: son
718 | recently: son zamanlarda
719 | recognize: tanımak
720 | record: kayıt
721 | red: kırmızı
722 | reduce: azaltmak
723 | reflect: yansıtmak
724 | region: bölge
725 | relate: ilişkili
726 | relationship: ilişki
727 | religious: dini
728 | remain: kalmak
729 | remember: hatırlamak
730 | remove: kaldırmak
731 | report: rapor
732 | represent: temsil etmek
733 | Republican: Cumhuriyetçi
734 | require: gerektirmek
735 | research: araştırma
736 | resource: kaynak
737 | respond: yanıtlamak
738 | response: yanıt
739 | responsibility: sorumluluk
740 | rest: dinlenmek
741 | result: sonuç
742 | return: dönmek
743 | reveal: açığa çıkarmak
744 | rich: zengin
745 | right: doğru
746 | rise: yükselmek
747 | risk: risk
748 | road: yol
749 | rock: kaya
750 | role: rol
751 | room: oda
752 | rule: kural
753 | run: koşmak
754 | safe: güvenli
755 | same: aynı
756 | save: kurtarmak
757 | say: demek
758 | scene: sahne
759 | school: okul
760 | science: bilim
761 | scientist: bilim adamı
762 | score: puan
763 | sea: deniz
764 | season: mevsim
765 | seat: koltuk
766 | second: ikinci
767 | secretary: sekreter
768 | section: bölüm
769 | security: güvenlik
770 | see: görmek
771 | seek: aramak
772 | seem: gibi görünmek
773 | sell: satmak
774 | send: göndermek
775 | senior: kıdemli
776 | sense: anlam
777 | series: dizi
778 | serious: ciddi
779 | serve: hizmet etmek
780 | service: hizmet
781 | set: ayarlamak
782 | seven: yedi
783 | several: birkaç
784 | sex: cinsiyet
785 | sexual: cinsel
786 | shake: sarsılmak
787 | share: paylaşmak
788 | she: o (kadın)
789 | shoot: ateş etmek
790 | short: kısa
791 | should: malı
792 | shoulder: omuz
793 | show: göstermek
794 | side: yan
795 | sign: imzalamak
796 | significant: önemli
797 | similar: benzer
798 | simple: basit
799 | simply: basitçe
800 | since: beri
801 | sing: şarkı söylemek
802 | single: yalnız
803 | sister: kız kardeş
804 | sit: oturmak
805 | site: site
806 | situation: durum
807 | six: altı
808 | size: boyut
809 | skill: beceri
810 | skin: cilt
811 | small: küçük
812 | smile: gülümseme
813 | so: öyle
814 | social: sosyal
815 | society: toplum
816 | soldier: asker
817 | some: bazı
818 | somebody: birisi
819 | someone: birisi
820 | something: bir şey
821 | sometimes: bazen
822 | son: oğul
823 | song: şarkı
824 | soon: yakında
825 | sorry: üzgün
826 | sort: çeşit
827 | sound: ses
828 | source: kaynak
829 | south: güney
830 | southern: güneyli
831 | space: uzay
832 | speak: konuşmak
833 | special: özel
834 | specific: belirli
835 | speech: konuşma
836 | spend: harcamak
837 | sport: spor
838 | spring: bahar
839 | staff: personel
840 | stage: sahne
841 | stand: durmak
842 | standard: standart
843 | star: yıldız
844 | start: başlamak
845 | state: durum
846 | statement: ifade
847 | station: istasyon
848 | stay: kalmak
849 | step: adım
850 | still: hala
851 | stomach: mide
852 | stop: durmak
853 | store: mağaza
854 | story: hikaye
855 | strategy: strateji
856 | street: sokak
857 | strength: güç
858 | strong: güçlü
859 | structure: yapı
860 | student: öğrenci
861 | study: çalışmak
862 | stuff: şeyler
863 | style: tarz
864 | subject: konu
865 | substance: madde
866 | succeed: başarılı olmak
867 | success: başarı
868 | successful: başarılı
869 | such: böyle
870 | sudden: aniden
871 | suffer: acı çekmek
872 | suggest: önermek
873 | summer: yaz
874 | support: destek
875 | suppose: zannetmek
876 | sure: emin
877 | surface: yüzey
878 | system: sistem
879 | table: masa
880 | take: almak
881 | talk: konuşmak
882 | task: görev
883 | tax: vergi
884 | teach: öğretmek
885 | teacher: öğretmen
886 | team: takım
887 | technology: teknoloji
888 | telephone: telefon
889 | television: televizyon
890 | tell: söylemek
891 | ten: on
892 | tend: eğilimli olmak
893 | term: dönem
894 | test: test
895 | than: daha
896 | thank: teşekkür etmek
897 | that: o
898 | the: bu
899 | their: onların
900 | them: onları
901 | themselves: kendileri
902 | then: o zaman
903 | theory: teori
904 | there: orada
905 | these: bu
906 | they: onlar
907 | thing: şey
908 | think: düşünmek
909 | third: üçüncü
910 | this: bu
911 | those: şunlar
912 | though: rağmen
913 | thought: düşünce
914 | thousand: bin
915 | threat: tehdit
916 | three: üç
917 | through: vasıtasıyla
918 | throughout: boyunca
919 | throw: atmak
920 | thus: böylece
921 | time: zaman
922 | to: için
923 | today: bugün
924 | together: birlikte
925 | tonight: bu gece
926 | too: çok
927 | top: üst
928 | total: toplam
929 | tough: zorlu
930 | toward: e doğru
931 | town: kasaba
932 | trade: ticaret
933 | traditional: geleneksel
934 | traffic: trafik
935 | training: eğitim
936 | transfer: aktarmak
937 | travel: seyahat etmek
938 | treat: tedavi etmek
939 | treatment: tedavi
940 | tree: ağaç
941 | trial: deneme
942 | trip: seyahat
943 | trouble: sorun
944 | true: doğru
945 | truth: gerçek
946 | try: denemek
947 | turn: dönmek
948 | TV: TV
949 | two: iki
950 | type: tip
951 | under: altında
952 | understand: anlamak
953 | unit: birim
954 | until: kadar
955 | up: yukarı
956 | upon: üzerine
957 | us: biz
958 | use: kullanmak
959 | usually: genellikle
960 | value: değer
961 | various: çeşitli
962 | very: çok
963 | victim: kurban
964 | view: görünüm
965 | violence: şiddet
966 | visit: ziyaret etmek
967 | voice: ses
968 | vote: oy
969 | wait: beklemek
970 | walk: yürümek
971 | wall: duvar
972 | want: istemek
973 | war: savaş
974 | watch: izlemek
975 | water: su
976 | way: yol
977 | we: biz
978 | weak: zayıf
979 | weapon: silah
980 | wear: giymek
981 | week: hafta
982 | weight: ağırlık
983 | well: iyi
984 | west: batı
985 | western: batı
986 | what: ne
987 | whatever: her neyse
988 | when: ne zaman
989 | where: nerede
990 | whether: olup olmadığı
991 | which: hangisi
992 | while: iken
993 | white: beyaz
994 | who: kim
995 | whole: tüm
996 | whom: kimi
997 | whose: kimi
998 | why: neden
999 | wide: geniş
1000 | wife: eş
1001 | will: istemek
1002 | win: kazanmak
1003 | wind: rüzgar
1004 | window: pencere
1005 | wish: dilemek
1006 | with: ile
1007 | within: içinde
1008 | without: olmadan
1009 | woman: kadın
1010 | wonder: merak etmek
1011 | word: kelime
1012 | work: çalışmak
1013 | worker: işçi
1014 | world: dünya
1015 | worry: endişelenmek
1016 | would: olurdu
1017 | write: yazmak
1018 | writer: yazar
1019 | wrong: yanlış
1020 | yard: avlu
1021 | yeah: evet
1022 | year: yıl
1023 | yes: evet
1024 | yet: henüz
1025 | you: sen
1026 | young: genç
1027 | your: senin
1028 | yourself: kendin
1029 | youth: gençlik
1030 | zone: bölge
--------------------------------------------------------------------------------
[Görsel kaynağı](https://towardsdatascience.com/tf-term-frequency-idf-inverse-document-frequency-from-scratch-in-python-6c2b61b78558)"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## TF-IDF Nedir\n",
15 | "\n",
16 | "**Term Frequency – Inverse Document Frequency**\n",
17 | "\n",
18 | "TF-IDF, bir kelimenin doküman içerisindeki anlam yoğunluğunu istatistiksel yöntemlerle tespit ederek belirli bir ağırlık değeri bulmayı amaçlar. Ortaya çıkan bu TF-IDF değeri, terimin dokümanda ne kadar sık geçtiği ve doküman kümesinde ne kadar nadir olduğu ile orantılıdır. Böylece, dokümanların içeriğini yansıtan ve ayırt edici kelimeleri tespit etmek mümkün olur."
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {},
24 | "source": [
25 | "### TF (Term Frequency)\n",
26 | "**TF = (Belirli bir kelimenin belgedeki tekrar sayısı) / (Dokümandaki toplam kelime sayısı)**\n",
27 | "\n",
28 | "Örnek olarak, bir dokümanda *filhakika* kelimesisnin 10 kere geçtiğini varsayalım ve dokümanın tamamı da 500 kelime olsun. Bu durumda, filhakika kelimesinin terim frekansı $10/500 = 0.02$ olarak bulunmuş olur.\n",
29 | "\n",
30 | "Bir terimin sık kullanılması, genellikle o terimin önemli bir bilgi içerdiğini gösterirken, tüm doküman kümesinde nadir bulunması, terimin diğerlerinden farklı ve özgün olduğu anlamına gelebilir. \n",
31 | "\n",
32 | "Ayrıca burada şöyle bir handikap vardır, **Stop Words**. Bunun ne ifade ettiğini anlamak için Türkçe dilindeki stop words sayılan kelimelere baktığımızda *ama, bu, şu, ve, gibi* vs. sözcükler görürüz. Bu sözcükler doküman içerisinde çokça geçebilir olmasına rağmen bun kelimelerin temsil ettiği büyük bir anlam yoktur ve sıklıklarından dolayı TF işleminde gereksiz bir ağırlık kazanabilirler. Dolayısıyla stop words olarak adlandırılan bu kelimlerin işlemin daha anlamlı olabilmesi için, kelime vektörleri oluşturulmadan önce dokumandan ayıklanmalıdırlar. (İngilizce Stop Words örnekleri: *is, on, the, in, of, it* etc.)"
33 | ]
34 | },
35 | {
36 | "cell_type": "markdown",
37 | "metadata": {},
38 | "source": [
39 | "### IDF (Inverse Document Frequency)\n",
40 | "\n",
41 | "**IDF = log((Toplam doküman sayısı) / (Belirli kelime içeren doküman sayısı))**\n",
42 | "\n",
43 | "$IDF(t) = log(N / (1 + DF(t)))$\n",
44 | "\n",
45 | "$IDF = \\log\\left(\\frac{\\text{Toplam Dokuman Sayisi}}{\\text{Kelimenin Essiz Dokuman Sayisi}}\\right)$\n",
46 | "\n",
47 | "\n",
48 | "Burada:\n",
49 | " - N: Toplam doküman sayısı.\n",
50 | " - DF(t): Belirli bir kelimenin geçtiği doküman sayısı.\n",
51 | " \n",
52 | "IDF, bir kelimenin doküman kümesi içerisindeki nadirliğini gösterir. Bu sayede kelimenin doküman içerisindeki önemini belirlemeye yardımcı olur. IDF değeri, tüm dokümanlar üzerinden hesaplanır.\n",
53 | "\n",
54 | "IDF, logaritmik bir ölçeğe sahip olduğundan dolayı nadir kelimelerin büyük değerler almasını engeller ve daha dengeli bir ölçüm değeri sunar. Eğer bir kelime doküman kümesi içerisinde sıkça geçiyorsa, IDF değeri düşük olacaktır ve bu kelime, muhtemelen genel bilgi taşıyan ve metinler arasında ayrımcılık yapmayan yaygın bir kelimeye tekabul edecektir. Tüm dokümanlar içerisinde az geçen bir kelimenin IDF değeri ise büyük olacaktır."
55 | ]
56 | },
57 | {
58 | "cell_type": "markdown",
59 | "metadata": {},
60 | "source": [
61 | "### TF-IDF\n",
62 | "TF-IDF, her terimin doküman içerisindeki sıklığını (TF) ve tüm doküman koleksiyonu içerisinde o terimin ne kadar yaygın olduğunu (IDF) birleştirerek (çarparak) hesaplanır. \n",
63 | "\n",
64 | "$TF-IDF(d, t) = TF(d, t) * IDF(t)$\n",
65 | "\n",
66 | "Burada:\n",
67 | "- $TF(d, t)$ : Belirli bir dokümandaki (d) terimin (t) geçme sıklığı. Yani, dokümandaki terimin tekrar sayısı.\n",
68 | "- $IDF(t$) : Tüm dokümanlardaki (corpus) terimin (t) geçme sıklığının tersi. \n",
69 | "\n",
70 | "Sonuç olarak en yüksek ağırlık değeri, bir kelimenin az sayıda dokümanda birçok kez geçtiği zaman ortaya çıkar."
71 | ]
72 | },
73 | {
74 | "cell_type": "markdown",
75 | "metadata": {},
76 | "source": [
77 | "## Python ile Uygulama"
78 | ]
79 | },
80 | {
81 | "cell_type": "markdown",
82 | "metadata": {},
83 | "source": [
84 | "### Stop Words"
85 | ]
86 | },
87 | {
88 | "cell_type": "code",
89 | "execution_count": 1,
90 | "metadata": {},
91 | "outputs": [],
92 | "source": [
93 | "stop_words = ['acaba', 'ama', 'ancak', 'artık', 'asla', 'aslında', 'az', 'bana', 'bazen', 'bazı', 'belki',\n",
94 | " 'ben','beni', 'bu','benim', 'beri', 'bile', 'bir', 'biri', 'birkaç', 'birçok', 'şey', 'daha',\n",
95 | " 'az', 'gene','gibi', 'da', 'de', 'en', 'daha','diğer', 'diğeri' , 'diye', 'dolayı', 'fakat',\n",
96 | " 'falan', 'filan', 'gibi', 'hala', 'hatta', 'ise', 'kim', 'kime', 'niye', 'oysa', 'pek',\n",
97 | " 'rağmen', 'sanki', 'şayet', 'sen', 'siz', 'tabii', 've', 'veya', 'zira']"
98 | ]
99 | },
100 | {
101 | "cell_type": "markdown",
102 | "metadata": {},
103 | "source": [
104 | "### TF işlemi"
105 | ]
106 | },
107 | {
108 | "cell_type": "code",
109 | "execution_count": 2,
110 | "metadata": {},
111 | "outputs": [
112 | {
113 | "name": "stdout",
114 | "output_type": "stream",
115 | "text": [
116 | "örnek: 0.2857142857142857\n",
117 | "dokümandır: 0.14285714285714285\n",
118 | "dokümanda: 0.14285714285714285\n",
119 | "tf: 0.14285714285714285\n",
120 | "işlemi: 0.14285714285714285\n",
121 | "yapacağız: 0.14285714285714285\n"
122 | ]
123 | }
124 | ],
125 | "source": [
126 | "import re\n",
127 | "\n",
128 | "def kelime_listesi(dokuman):\n",
129 | " liste = []\n",
130 | " for kelime in dokuman: \n",
131 | " kelimeler = kelime.split(' ') \n",
132 | " for kelime in kelimeler: \n",
133 | " kelime = re.sub(r'[^\\w\\s]', '', kelime) \n",
134 | " if kelime.lower() not in stop_words:\n",
135 | " liste.append(kelime.lower())\n",
136 | " return liste\n",
137 | "\n",
138 | "def dokuman_boyutu(liste):\n",
139 | " return len(liste)\n",
140 | "\n",
141 | "def frekans(liste):\n",
142 | " frekans = {}\n",
143 | " for kelime in liste:\n",
144 | " if kelime in frekans:\n",
145 | " frekans[kelime] += 1\n",
146 | " else:\n",
147 | " frekans[kelime] = 1\n",
148 | " return frekans\n",
149 | "\n",
150 | "def tf_degeri(frekans, boyut):\n",
151 | " for anahtar, deger in frekans.items():\n",
152 | " tf = deger/boyut\n",
153 | " print(f'{anahtar}: {tf}')\n",
154 | " \n",
155 | "def main(dokuman):\n",
156 | " degerler = kelime_listesi(dokuman)\n",
157 | " boyut = dokuman_boyutu(degerler)\n",
158 | " frekans_degerleri = frekans(degerler)\n",
159 | " tf = tf_degeri(frekans_degerleri, boyut)\n",
160 | " \n",
161 | "if __name__ == '__main__':\n",
162 | " dokuman = ['Bu bir örnek dokümandır.', 'Bu örnek dokümanda TF işlemi yapacağız.']\n",
163 | " main(dokuman) "
164 | ]
165 | },
166 | {
167 | "cell_type": "markdown",
168 | "metadata": {},
169 | "source": [
170 | "### TF-IDF işlemi"
171 | ]
172 | },
173 | {
174 | "cell_type": "code",
175 | "execution_count": 3,
176 | "metadata": {},
177 | "outputs": [
178 | {
179 | "name": "stdout",
180 | "output_type": "stream",
181 | "text": [
182 | "\n",
183 | " TF degerleri: \n",
184 | "\n",
185 | "platonun: 0.08695652173913043\n",
186 | "devletinde: 0.043478260869565216\n",
187 | "kişinin: 0.043478260869565216\n",
188 | "başkasına: 0.043478260869565216\n",
189 | "değil: 0.043478260869565216\n",
190 | "kendisine: 0.08695652173913043\n",
191 | "köle: 0.13043478260869565\n",
192 | "olma: 0.08695652173913043\n",
193 | "düşüncesi: 0.08695652173913043\n",
194 | "vardır: 0.08695652173913043\n",
195 | "devlet: 0.043478260869565216\n",
196 | "eserinde: 0.043478260869565216\n",
197 | "başka: 0.043478260869565216\n",
198 | "birisine: 0.043478260869565216\n",
199 | "olmaktansa: 0.043478260869565216\n",
200 | "insanın: 0.043478260869565216\n",
201 | "\n",
202 | "---------------------------\n",
203 | "\n",
204 | " IDF degerleri: \n",
205 | "\n",
206 | "platonun: 0.6931471805599453\n",
207 | "devletinde: 1.0986122886681098\n",
208 | "kişinin: 1.0986122886681098\n",
209 | "başkasına: 1.0986122886681098\n",
210 | "değil: 1.0986122886681098\n",
211 | "kendisine: 0.6931471805599453\n",
212 | "köle: 0.5108256237659906\n",
213 | "olma: 0.6931471805599453\n",
214 | "düşüncesi: 0.6931471805599453\n",
215 | "vardır: 0.6931471805599453\n",
216 | "devlet: 1.0986122886681098\n",
217 | "eserinde: 1.0986122886681098\n",
218 | "başka: 1.0986122886681098\n",
219 | "birisine: 1.0986122886681098\n",
220 | "olmaktansa: 1.0986122886681098\n",
221 | "insanın: 1.0986122886681098\n"
222 | ]
223 | }
224 | ],
225 | "source": [
226 | "import re\n",
227 | "import math \n",
228 | "\n",
229 | "def kelime_listesi(dokuman):\n",
230 | " liste = []\n",
231 | " for kelime in dokuman: \n",
232 | " kelimeler = kelime.split(' ') \n",
233 | " for kelime in kelimeler: \n",
234 | " kelime = re.sub(r'[^\\w\\s]', '', kelime) \n",
235 | " if kelime.lower() not in stop_words:\n",
236 | " liste.append(kelime.lower())\n",
237 | " return liste\n",
238 | "\n",
239 | "def dokuman_boyutu(liste):\n",
240 | " return len(liste)\n",
241 | "\n",
242 | "def frekans(liste):\n",
243 | " frekans = {}\n",
244 | " for kelime in liste:\n",
245 | " if kelime in frekans:\n",
246 | " frekans[kelime] += 1\n",
247 | " else:\n",
248 | " frekans[kelime] = 1\n",
249 | " return frekans\n",
250 | "\n",
251 | "def tf_degeri(frekans, boyut):\n",
252 | " for anahtar, deger in frekans.items():\n",
253 | " tf = deger/boyut\n",
254 | " print(f'{anahtar}: {tf}')\n",
255 | "\n",
256 | "\n",
257 | "def idf_degeri(frekans_degerleri): \n",
258 | " idf_boyut = dokuman_boyutu(dokuman)\n",
259 | " for anahtar, deger in frekans_degerleri.items():\n",
260 | " idf = math.log(idf_boyut / deger)\n",
261 | " print(f'{anahtar}: {idf}')\n",
262 | " \n",
263 | " \n",
264 | " \n",
265 | "def main(dokuman):\n",
266 | " \n",
267 | " degerler = kelime_listesi(dokuman)\n",
268 | " boyut = dokuman_boyutu(degerler)\n",
269 | " \n",
270 | " frekans_degerleri = frekans(degerler)\n",
271 | " \n",
272 | " print('\\n TF degerleri: \\n')\n",
273 | " tf = tf_degeri(frekans_degerleri, boyut)\n",
274 | " print('\\n---------------------------')\n",
275 | " print('\\n IDF degerleri: \\n')\n",
276 | " idf = idf_degeri(frekans_degerleri)\n",
277 | " \n",
278 | "if __name__ == '__main__':\n",
279 | " dokuman = ['Platon\\'un devletinde kişinin başkasına değil, kendisine köle olma düşüncesi vardır.',\n",
280 | " 'Platon\\'un devlet eserinde başka birisine köle olmaktansa insanın kendisine köle olma düşüncesi vardır.']\n",
281 | " main(dokuman) "
282 | ]
283 | },
284 | {
285 | "cell_type": "markdown",
286 | "metadata": {},
287 | "source": [
288 | "### TF-IDF Değerleri"
289 | ]
290 | },
291 | {
292 | "cell_type": "code",
293 | "execution_count": 4,
294 | "metadata": {},
295 | "outputs": [
296 | {
297 | "name": "stdout",
298 | "output_type": "stream",
299 | "text": [
300 | "\n",
301 | "TF degerleri:\n",
302 | "\n",
303 | "platonun: 0.08695652173913043\n",
304 | "devletinde: 0.043478260869565216\n",
305 | "kişinin: 0.043478260869565216\n",
306 | "başkasına: 0.043478260869565216\n",
307 | "değil: 0.043478260869565216\n",
308 | "kendisine: 0.08695652173913043\n",
309 | "köle: 0.13043478260869565\n",
310 | "olma: 0.08695652173913043\n",
311 | "düşüncesi: 0.08695652173913043\n",
312 | "vardır: 0.08695652173913043\n",
313 | "devlet: 0.043478260869565216\n",
314 | "eserinde: 0.043478260869565216\n",
315 | "başka: 0.043478260869565216\n",
316 | "birisine: 0.043478260869565216\n",
317 | "olmaktansa: 0.043478260869565216\n",
318 | "insanın: 0.043478260869565216\n",
319 | "\n",
320 | "---------------------------\n",
321 | "\n",
322 | "IDF degerleri:\n",
323 | "\n",
324 | "platonun: 0.6931471805599453\n",
325 | "devletinde: 1.0986122886681098\n",
326 | "kişinin: 1.0986122886681098\n",
327 | "başkasına: 1.0986122886681098\n",
328 | "değil: 1.0986122886681098\n",
329 | "kendisine: 0.6931471805599453\n",
330 | "köle: 0.5108256237659906\n",
331 | "olma: 0.6931471805599453\n",
332 | "düşüncesi: 0.6931471805599453\n",
333 | "vardır: 0.6931471805599453\n",
334 | "devlet: 1.0986122886681098\n",
335 | "eserinde: 1.0986122886681098\n",
336 | "başka: 1.0986122886681098\n",
337 | "birisine: 1.0986122886681098\n",
338 | "olmaktansa: 1.0986122886681098\n",
339 | "insanın: 1.0986122886681098\n",
340 | "\n",
341 | "---------------------------\n",
342 | "\n",
343 | "TF-IDF degerleri:\n",
344 | "\n",
345 | "platonun: 0.06027366787477785\n",
346 | "devletinde: 0.047765751681222164\n",
347 | "kişinin: 0.047765751681222164\n",
348 | "başkasına: 0.047765751681222164\n",
349 | "değil: 0.047765751681222164\n",
350 | "kendisine: 0.06027366787477785\n",
351 | "köle: 0.06662942918686834\n",
352 | "olma: 0.06027366787477785\n",
353 | "düşüncesi: 0.06027366787477785\n",
354 | "vardır: 0.06027366787477785\n",
355 | "devlet: 0.047765751681222164\n",
356 | "eserinde: 0.047765751681222164\n",
357 | "başka: 0.047765751681222164\n",
358 | "birisine: 0.047765751681222164\n",
359 | "olmaktansa: 0.047765751681222164\n",
360 | "insanın: 0.047765751681222164\n"
361 | ]
362 | }
363 | ],
364 | "source": [
365 | "import re\n",
366 | "import math \n",
367 | "\n",
368 | "stop_words = ['acaba', 'ama', 'ancak', 'artık', 'asla', 'aslında', 'az', 'bana', 'bazen', 'bazı', 'belki',\n",
369 | " 'ben','beni', 'bu','benim', 'beri', 'bile', 'bir', 'biri', 'birkaç', 'birçok', 'şey', 'daha',\n",
370 | " 'az', 'gene','gibi', 'da', 'de', 'en', 'daha','diğer', 'diğeri' , 'diye', 'dolayı', 'fakat',\n",
371 | " 'falan', 'filan', 'gibi', 'hala', 'hatta', 'ise', 'kim', 'kime', 'niye', 'oysa', 'pek',\n",
372 | " 'rağmen', 'sanki', 'şayet', 'sen', 'siz', 'tabii', 've', 'veya', 'zira']\n",
373 | "\n",
374 | "def kelime_listesi(dokuman):\n",
375 | " liste = []\n",
376 | " for kelime in dokuman: \n",
377 | " kelimeler = kelime.split(' ')\n",
378 | " for kelime in kelimeler:\n",
379 | " kelime = re.sub(r'[^\\w\\s]', '', kelime)\n",
380 | " if kelime.lower() not in stop_words:\n",
381 | " liste.append(kelime.lower())\n",
382 | " return liste\n",
383 | "\n",
384 | "def dokuman_boyutu(liste):\n",
385 | " return len(liste)\n",
386 | "\n",
387 | "def frekans(liste):\n",
388 | " frekans = {}\n",
389 | " for kelime in liste:\n",
390 | " if kelime in frekans:\n",
391 | " frekans[kelime] += 1\n",
392 | " else:\n",
393 | " frekans[kelime] = 1\n",
394 | " return frekans\n",
395 | "\n",
396 | "def tf_degeri(frekans, boyut):\n",
397 | " tf_values = {}\n",
398 | " for anahtar, deger in frekans.items():\n",
399 | " tf = deger / boyut\n",
400 | " tf_values[anahtar] = tf\n",
401 | " return tf_values\n",
402 | "\n",
403 | "def idf_degeri(frekans_degerleri, idf_boyut):\n",
404 | " idf_values = {}\n",
405 | " for anahtar, deger in frekans_degerleri.items():\n",
406 | " idf = math.log(idf_boyut / deger)\n",
407 | " idf_values[anahtar] = idf\n",
408 | " return idf_values\n",
409 | "\n",
410 | "def main(dokuman):\n",
411 | " degerler = kelime_listesi(dokuman)\n",
412 | " boyut = dokuman_boyutu(degerler)\n",
413 | " \n",
414 | " frekans_degerleri = frekans(degerler)\n",
415 | " \n",
416 | " print('\\nTF degerleri:\\n')\n",
417 | " tf_values = tf_degeri(frekans_degerleri, boyut)\n",
418 | " for kelime, tf in tf_values.items():\n",
419 | " print(f'{kelime}: {tf}')\n",
420 | " \n",
421 | " print('\\n---------------------------\\n')\n",
422 | " print('IDF degerleri:\\n')\n",
423 | " idf_boyut = len(dokuman)\n",
424 | " idf_values = idf_degeri(frekans_degerleri, idf_boyut)\n",
425 | " for kelime, idf in idf_values.items():\n",
426 | " print(f'{kelime}: {idf}')\n",
427 | "\n",
428 | " print('\\n---------------------------\\n')\n",
429 | " print('TF-IDF degerleri:\\n')\n",
430 | " for kelime in frekans_degerleri:\n",
431 | " tf_idf = tf_values[kelime] * idf_values[kelime]\n",
432 | " print(f'{kelime}: {tf_idf}')\n",
433 | "\n",
434 | "if __name__ == '__main__':\n",
435 | " dokuman = ['Platon\\'un devletinde kişinin başkasına değil, kendisine köle olma düşüncesi vardır.',\n",
436 | " 'Platon\\'un devlet eserinde başka birisine köle olmaktansa insanın kendisine köle olma düşüncesi vardır.']\n",
437 | " main(dokuman)"
438 | ]
439 | }
440 | ],
441 | "metadata": {
442 | "kernelspec": {
443 | "display_name": "Python 3 (ipykernel)",
444 | "language": "python",
445 | "name": "python3"
446 | },
447 | "language_info": {
448 | "codemirror_mode": {
449 | "name": "ipython",
450 | "version": 3
451 | },
452 | "file_extension": ".py",
453 | "mimetype": "text/x-python",
454 | "name": "python",
455 | "nbconvert_exporter": "python",
456 | "pygments_lexer": "ipython3",
457 | "version": "3.9.16"
458 | }
459 | },
460 | "nbformat": 4,
461 | "nbformat_minor": 4
462 | }
463 |
--------------------------------------------------------------------------------
/Veri Bilimi İçin Python/sozluk.txt:
--------------------------------------------------------------------------------
1 | a: bir
2 | ability: yetenek
3 | able: yapabilen
4 | about: hakkında
5 | above: yukarıda
6 | accept: kabul etmek
7 | according: göre
8 | account: hesap
9 | across: karşıdan karşıya
10 | act: hareket etmek
11 | action: hareket
12 | activity: aktivite
13 | actually: aslında
14 | add: eklemek
15 | address: adres
16 | administration: yönetim
17 | admit: kabul etmek
18 | adult: yetişkin
19 | affect: etkilemek
20 | after: sonra
21 | again: tekrar
22 | against: karşı
23 | age: yaş
24 | agency: ajans
25 | agent: ajan
26 | ago: önce
27 | agree: katılmak
28 | agreement: anlaşma
29 | ahead: önde
30 | air: hava
31 | all: tümü
32 | allow: izin vermek
33 | almost: neredeyse
34 | alone: yalnız
35 | along: boyunca
36 | already: zaten
37 | also: ayrıca
38 | although: rağmen
39 | always: her zaman
40 | American: Amerikan
41 | among: arasında
42 | amount: miktar
43 | analysis: analiz
44 | and: ve
45 | animal: hayvan
46 | another: başka
47 | answer: cevap
48 | any: herhangi bir
49 | anyone: herhangi birisi
50 | anything: herhangi bir şey
51 | appear: görünmek
52 | apply: uygulamak
53 | approach: yaklaşım
54 | area: bölge
55 | argue: tartışmak
56 | arm: kol
57 | around: etrafında
58 | arrive: varmak
59 | art: sanat
60 | article: makale
61 | artist: sanatçı
62 | as: olarak
63 | ask: sormak
64 | assume: varsaymak
65 | at: de
66 | attack: saldırı
67 | attention: dikkat
68 | attorney: avukat
69 | audience: seyirci
70 | author: yazar
71 | authority: otorite
72 | available: müsait
73 | avoid: kaçınmak
74 | away: uzakta
75 | baby: bebek
76 | back: geri
77 | bad: kötü
78 | bag: çanta
79 | ball: top
80 | bank: banka
81 | bar: bar
82 | base: temel
83 | be: ol
84 | beat: yenmek
85 | beautiful: güzel
86 | because: çünkü
87 | become: olmak
88 | bed: yatak
89 | before: önce
90 | begin: başlamak
91 | behavior: davranış
92 | behind: arkasında
93 | believe: inanmak
94 | benefit: fayda
95 | best: en iyi
96 | better: daha iyi
97 | between: arasında
98 | beyond: ötesinde
99 | big: büyük
100 | bill: fatura
101 | billion: milyar
102 | bit: parça
103 | black: siyah
104 | blood: kan
105 | blue: mavi
106 | board: tahta
107 | body: vücut
108 | book: kitap
109 | born: doğmak
110 | both: her ikisi
111 | box: kutu
112 | boy: erkek çocuk
113 | break: kırmak
114 | bring: getirmek
115 | brother: erkek kardeş
116 | budget: bütçe
117 | build: inşa etmek
118 | building: bina
119 | business: iş
120 | but: ama
121 | buy: satın almak
122 | by: tarafından
123 | call: aramak
124 | camera: kamera
125 | campaign: kampanya
126 | can: yapabilir
127 | cancer: kanser
128 | candidate: aday
129 | capital: sermaye
130 | car: araba
131 | card: kart
132 | care: ilgi
133 | career: kariyer
134 | carry: taşımak
135 | case: durum
136 | catch: yakalamak
137 | cause: neden olmak
138 | cell: hücre
139 | center: merkez
140 | central: merkezi
141 | century: yüzyıl
142 | certain: belli
143 | certainly: kesinlikle
144 | chair: sandalye
145 | challenge: meydan okuma
146 | chance: şans
147 | change: değişiklik
148 | character: karakter
149 | charge: ücretlendirme
150 | check: kontrol etmek
151 | child: çocuk
152 | choice: seçim
153 | choose: seçmek
154 | church: kilise
155 | citizen: vatandaş
156 | city: şehir
157 | civil: sivil
158 | claim: iddia etmek
159 | class: sınıf
160 | clear: açık
161 | clearly: açıkça
162 | close: kapatmak
163 | coach: antrenör
164 | cold: soğuk
165 | collection: koleksiyon
166 | college: üniversite
167 | color: renk
168 | come: gelmek
169 | commercial: ticari
170 | common: ortak
171 | community: topluluk
172 | company: şirket
173 | compare: karşılaştırmak
174 | computer: bilgisayar
175 | concern: endişe
176 | condition: durum
177 | conference: konferans
178 | Congress: Kongre
179 | consider: düşünmek
180 | consumer: tüketici
181 | contain: içermek
182 | continue: devam etmek
183 | control: kontrol
184 | cost: maliyet
185 | could: olabilirdi
186 | country: ülke
187 | couple: çift
188 | course: tabii ki
189 | court: mahkeme
190 | cover: kaplamak
191 | create: yaratmak
192 | crime: suç
193 | cultural: kültürel
194 | culture: kültür
195 | cup: fincan
196 | current: güncel
197 | customer: müşteri
198 | cut: kesmek
199 | dark: karanlık
200 | data: veri
201 | daughter: kız
202 | day: gün
203 | dead: ölü
204 | deal: anlaşma
205 | death: ölüm
206 | debate: tartışma
207 | decade: on yıl
208 | decide: karar vermek
209 | decision: karar
210 | deep: derin
211 | defense: savunma
212 | degree: derece
213 | Democrat: Demokrat
214 | democratic: demokratik
215 | describe: tanımlamak
216 | design: tasarlamak
217 | despite: rağmen
218 | detail: detay
219 | determine: belirlemek
220 | develop: geliştirmek
221 | development: gelişme
222 | die: ölmek
223 | difference: fark
224 | different: farklı
225 | difficult: zor
226 | dinner: akşam yemeği
227 | direction: yön
228 | director: yönetmen
229 | discover: keşfetmek
230 | discuss: tartışmak
231 | discussion: tartışma
232 | disease: hastalık
233 | do: yapmak
234 | doctor: doktor
235 | dog: köpek
236 | door: kapı
237 | down: aşağı
238 | draw: çizmek
239 | dream: rüya
240 | drive: sürmek
241 | drop: düşürmek
242 | drug: ilaç
243 | during: sırasında
244 | each: her biri
245 | early: erken
246 | east: doğu
247 | easy: kolay
248 | eat: yemek
249 | economic: ekonomik
250 | economy : ekonomi
251 | edge: kenar
252 | education: eğitim
253 | effect: etki
254 | effort: çaba
255 | eight: sekiz
256 | either: her ikisi de
257 | election: seçim
258 | else: başka
259 | employee: çalışan
260 | end: son
261 | energy: enerji
262 | enjoy: zevk almak
263 | enough: yeterli
264 | enter: girmek
265 | entire: tüm
266 | environment: çevre
267 | environmental: çevresel
268 | especially: özellikle
269 | establish: kurmak
270 | even: hatta
271 | evening: akşam
272 | event: olay
273 | ever: hiç
274 | every: her
275 | everybody: herkes
276 | everyone: herkes
277 | everything: her şey
278 | evidence: kanıt
279 | exactly: tam olarak
280 | example: örnek
281 | executive: yönetici
282 | exist: var olmak
283 | expect: beklemek
284 | experience: deneyim
285 | expert: uzman
286 | explain: açıklamak
287 | eye: göz
288 | face: yüzleşmek
289 | fact: gerçek
290 | factor: faktör
291 | fail: başarısız olmak
292 | fall: düşmek
293 | family: aile
294 | far: uzak
295 | fast: hızlı
296 | father: baba
297 | fear: korku
298 | federal: federal
299 | feel: hissetmek
300 | feeling: hiss
301 | few: birkaç
302 | field: alan
303 | fight: savaşmak
304 | figure: şekil
305 | fill: doldurmak
306 | film: film
307 | final: son
308 | finally: sonunda
309 | financial: finansal
310 | find: bulmak
311 | fine: iyi
312 | finger: parmak
313 | finish: bitirmek
314 | fire: yangın
315 | firm: firma
316 | first: ilk
317 | fish: balık
318 | five: beş
319 | floor: zemin
320 | fly: uçmak
321 | focus: odaklanmak
322 | follow: izlemek
323 | food: yiyecek
324 | foot: ayak
325 | for: için
326 | force: zorlamak
327 | foreign: yabancı
328 | forget: unutmak
329 | form: biçim
330 | former: eski
331 | forward: ileri
332 | four: dört
333 | free: ücretsiz
334 | friend: arkadaş
335 | from: dan
336 | front: ön
337 | full: tam
338 | fully: tamamen
339 | fun: eğlence
340 | function: fonksiyon
341 | fund: fon
342 | future: gelecek
343 | game: oyun
344 | garden: bahçe
345 | gas: gaz
346 | general: genel
347 | generation: nesil
348 | get: almak
349 | girl: kız
350 | give: vermek
351 | glass: cam
352 | go: gitmek
353 | goal: amaç
354 | good: iyi
355 | government: hükümet
356 | great: harika
357 | green: yeşil
358 | ground: yer
359 | group: grup
360 | grow: büyümek
361 | growth: büyüme
362 | guess: tahmin etmek
363 | gun: silah
364 | guy: adam
365 | hair: saç
366 | half: yarım
367 | hand: el
368 | hang: asmak
369 | happen: olmak
370 | happy: mutlu
371 | hard: zor
372 | have: sahip olmak
373 | he: o
374 | head: baş
375 | health: sağlık
376 | hear: duymak
377 | heart: kalp
378 | heat: ısı
379 | heavy: ağır
380 | help: yardım etmek
381 | her: onun
382 | here: burada
383 | herself: kendisi
384 | high: yüksek
385 | him: onu
386 | himself: kendisi
387 | his: onun
388 | history: tarih
389 | hit: vurmak
390 | hold: tutmak
391 | home: ev
392 | hope: umut
393 | hospital: hastane
394 | hot: sıcak
395 | hotel: otel
396 | hour: saat
397 | house: ev
398 | how: nasıl
399 | however: ancak
400 | huge: büyük
401 | human: insan
402 | hundred: yüz
403 | husband: eş
404 | I: ben
405 | idea: fikir
406 | identify: tanımlamak
407 | if: eğer
408 | image: görüntü
409 | imagine: hayal etmek
410 | impact: etki
411 | important: önemli
412 | improve: geliştirmek
413 | in: içinde
414 | include: dahil etmek
415 | including: dahil olmak üzere
416 | income: gelir
417 | increase: artış
418 | indeed: gerçekten
419 | indicate: belirtmek
420 | individual: bireysel
421 | industry: sanayi
422 | information: bilgi
423 | inside: içinde
424 | instead: yerine
425 | institution: kurum
426 | interest: ilgi
427 | interesting: ilginç
428 | international: uluslararası
429 | into: içine
430 | investment: yatırım
431 | involve: içermek
432 | issue: sorun
433 | it: o
434 | item: madde
435 | its: onun
436 | itself: kendisi
437 | job: iş
438 | join: katılmak
439 | just: sadece
440 | keep: saklamak
441 | key: anahtar
442 | kid: çocuk
443 | kill: öldürmek
444 | kind: çeşit
445 | kitchen: mutfak
446 | know: bilmek
447 | knowledge: bilgi
448 | land: arazi
449 | language: dil
450 | large: büyük
451 | last: son
452 | late: geç
453 | later: daha sonra
454 | laugh: gülmek
455 | law: kanun
456 | lay: yerleştirmek
457 | lead: yönetmek
458 | leader: lider
459 | learn: öğrenmek
460 | least: en az
461 | leave: ayrılmak
462 | left: sol
463 | leg: bacak
464 | legal: yasal
465 | less: daha az
466 | let: izin vermek
467 | letter: mektup
468 | level: seviye
469 | lie: yalan söylemek
470 | life: hayat
471 | light: ışık
472 | like: gibi
473 | likely: muhtemelen
474 | limit: sınır
475 | line: hat
476 | link: bağlantı
477 | list: liste
478 | listen: dinlemek
479 | little: az
480 | live: yaşamak
481 | local: yerel
482 | long: uzun
483 | look: bakmak
484 | lose: kaybetmek
485 | loss: kayıp
486 | lot: çok
487 | love: aşk
488 | low: düşük
489 | machine: makine
490 | magazine: dergi
491 | main: ana
492 | maintain: sürdürmek
493 | major: büyük
494 | majority: çoğunluk
495 | make: yapmak
496 | man: adam
497 | manage: yönetmek
498 | management: yönetim
499 | manager: yönetici
500 | many: birçok
501 | market: pazar
502 | marriage: evlilik
503 | material: malzeme
504 | matter: mesele
505 | may: olabilir
506 | maybe: belki
507 | me: beni
508 | mean: anlamına gelmek
509 | measure: ölçmek
510 | media: medya
511 | medical: tıbbi
512 | meet: tanışmak
513 | meeting: toplantı
514 | member: üye
515 | memory: bellek
516 | mention: bahsetmek
517 | message: mesaj
518 | method: yöntem
519 | middle: orta
520 | might: belki
521 | military: askeri
522 | million: milyon
523 | mind: akıl
524 | minute: dakika
525 | miss: kaçırmak
526 | mission: görev
527 | mistake: hata
528 | mix: karıştırmak
529 | model: model
530 | modern: modern
531 | moment: an
532 | money: para
533 | month: ay
534 | more: daha fazla
535 | morning: sabah
536 | most: en çok
537 | mother: anne
538 | mouth: ağız
539 | move: hareket etmek
540 | movement: hareket
541 | movie: film
542 | much: çok
543 | music: müzik
544 | must: meli
545 | my: benim
546 | myself: kendim
547 | name: isim
548 | nation: ulus
549 | national: ulusal
550 | natural: doğal
551 | nature: doğa
552 | near: yakın
553 | nearly: neredeyse
554 | necessary: gerekli
555 | need: ihtiyaç
556 | network: ağ
557 | never: asla
558 | new: yeni
559 | news: haber
560 | newspaper: gazete
561 | next: sonraki
562 | nice: güzel
563 | night: gece
564 | no: hayır
565 | none: hiçbiri
566 | nor: ne de
567 | north: kuzey
568 | not: değil
569 | note: not
570 | nothing: hiçbir şey
571 | notice: fark etmek
572 | now: şimdi
573 | nuclear: nükleer
574 | number: numara
575 | occur: meydana gelmek
576 | of: nin
577 | off: kapalı
578 | offer: teklif
579 | office: ofis
580 | officer: subay
581 | official: resmi
582 | often: sık sık
583 | oh: ah
584 | oil: yağ
585 | ok: tamam
586 | old: eski
587 | on: üzerinde
588 | once: bir kez
589 | one: bir
590 | only: sadece
591 | onto: üstüne
592 | open: açık
593 | operation: işlem
594 | opportunity: fırsat
595 | option: seçenek
596 | or: veya
597 | order: sipariş
598 | ordinary: sıradan
599 | origin: köken
600 | original: özgün
601 | other: diğer
602 | others: diğerleri
603 | otherwise: aksi takdirde
604 | ought: gerekli
605 | our: bizim
606 | ourselves: kendimizi
607 | out: dışarı
608 | over: üzerinde
609 | overall: genel
610 | own: kendi
611 | owner: sahip
612 | page: sayfa
613 | pain: acı
614 | paint: boya
615 | painting: resim
616 | paper: kağıt
617 | parent: ebeveyn
618 | part: parça
619 | participant: katılımcı
620 | particular: belirli
621 | particularly: özellikle
622 | partner: ortak
623 | party: parti
624 | pass: geçmek
625 | past: geçmiş
626 | path: yol
627 | patient: hasta
628 | pattern: desen
629 | pay: ödeme
630 | peace: barış
631 | people: insanlar
632 | per: her
633 | perform: yapmak
634 | performance: performans
635 | perhaps: belki
636 | period: dönem
637 | person: kişi
638 | personal: kişisel
639 | phone: telefon
640 | physical: fiziksel
641 | pick: toplamak
642 | picture: resim
643 | piece: parça
644 | place: yer
645 | plan: planlamak
646 | plant: bitki
647 | play: oynamak
648 | player: oyuncu
649 | PM: öğleden sonra
650 | point: nokta
651 | police: polis
652 | policy: politika
653 | political: siyasi
654 | politics: siyaset
655 | poor: fakir
656 | popular: popüler
657 | population: nüfus
658 | position: pozisyon
659 | positive: pozitif
660 | possible: mümkün
661 | post: gönderi
662 | potential: potansiyel
663 | power: güç
664 | practice: uygulama
665 | prefer: tercih etmek
666 | preparation: hazırlık
667 | prepare: hazırlamak
668 | present: şimdiki
669 | president: başkan
670 | press: basın
671 | pressure: baskı
672 | pretty: oldukça
673 | prevent: önlemek
674 | price: fiyat
675 | principle: ilke
676 | private: özel
677 | probably: muhtemelen
678 | problem: sorun
679 | process: süreç
680 | produce: üretmek
681 | product: ürün
682 | production: üretim
683 | professional: profesyonel
684 | professor: profesör
685 | program: program
686 | project: proje
687 | property: özellik
688 | protect: koruma
689 | prove: kanıtlamak
690 | provide: sağlamak
691 | public: halka açık
692 | pull: çekmek
693 | purpose: amaç
694 | push: itmek
695 | put: koymak
696 | quality: kalite
697 | question: soru
698 | quick: hızlı
699 | quickly: hızlıca
700 | quiet: sessiz
701 | quite: oldukça
702 | race: yarış
703 | radio: radyo
704 | raise: artırmak
705 | range: menzil
706 | rate: oran
707 | rather: oldukça
708 | reach: ulaşmak
709 | read: okumak
710 | ready: hazır
711 | real: gerçek
712 | reality: gerçeklik
713 | realize: farkına varmak
714 | really: gerçekten
715 | reason: neden
716 | receive: almak
717 | recent: son
718 | recently: son zamanlarda
719 | recognize: tanımak
720 | record: kayıt
721 | red: kırmızı
722 | reduce: azaltmak
723 | reflect: yansıtmak
724 | region: bölge
725 | relate: ilişkili
726 | relationship: ilişki
727 | religious: dini
728 | remain: kalmak
729 | remember: hatırlamak
730 | remove: kaldırmak
731 | report: rapor
732 | represent: temsil etmek
733 | Republican: Cumhuriyetçi
734 | require: gerektirmek
735 | research: araştırma
736 | resource: kaynak
737 | respond: yanıtlamak
738 | response: yanıt
739 | responsibility: sorumluluk
740 | rest: dinlenmek
741 | result: sonuç
742 | return: dönmek
743 | reveal: açığa çıkarmak
744 | rich: zengin
745 | right: doğru
746 | rise: yükselmek
747 | risk: risk
748 | road: yol
749 | rock: kaya
750 | role: rol
751 | room: oda
752 | rule: kural
753 | run: koşmak
754 | safe: güvenli
755 | same: aynı
756 | save: kurtarmak
757 | say: demek
758 | scene: sahne
759 | school: okul
760 | science: bilim
761 | scientist: bilim adamı
762 | score: puan
763 | sea: deniz
764 | season: mevsim
765 | seat: koltuk
766 | second: ikinci
767 | secretary: sekreter
768 | section: bölüm
769 | security: güvenlik
770 | see: görmek
771 | seek: aramak
772 | seem: gibi görünmek
773 | sell: satmak
774 | send: göndermek
775 | senior: kıdemli
776 | sense: anlam
777 | series: dizi
778 | serious: ciddi
779 | serve: hizmet etmek
780 | service: hizmet
781 | set: ayarlamak
782 | seven: yedi
783 | several: birkaç
784 | sex: cinsiyet
785 | sexual: cinsel
786 | shake: sarsılmak
787 | share: paylaşmak
788 | she: o (kadın)
789 | shoot: ateş etmek
790 | short: kısa
791 | should: malı
792 | shoulder: omuz
793 | show: göstermek
794 | side: yan
795 | sign: imzalamak
796 | significant: önemli
797 | similar: benzer
798 | simple: basit
799 | simply: basitçe
800 | since: beri
801 | sing: şarkı söylemek
802 | single: yalnız
803 | sister: kız kardeş
804 | sit: oturmak
805 | site: site
806 | situation: durum
807 | six: altı
808 | size: boyut
809 | skill: beceri
810 | skin: cilt
811 | small: küçük
812 | smile: gülümseme
813 | so: öyle
814 | social: sosyal
815 | society: toplum
816 | soldier: asker
817 | some: bazı
818 | somebody: birisi
819 | someone: birisi
820 | something: bir şey
821 | sometimes: bazen
822 | son: oğul
823 | song: şarkı
824 | soon: yakında
825 | sorry: üzgün
826 | sort: çeşit
827 | sound: ses
828 | source: kaynak
829 | south: güney
830 | southern: güneyli
831 | space: uzay
832 | speak: konuşmak
833 | special: özel
834 | specific: belirli
835 | speech: konuşma
836 | spend: harcamak
837 | sport: spor
838 | spring: bahar
839 | staff: personel
840 | stage: sahne
841 | stand: durmak
842 | standard: standart
843 | star: yıldız
844 | start: başlamak
845 | state: durum
846 | statement: ifade
847 | station: istasyon
848 | stay: kalmak
849 | step: adım
850 | still: hala
851 | stomach: mide
852 | stop: durmak
853 | store: mağaza
854 | story: hikaye
855 | strategy: strateji
856 | street: sokak
857 | strength: güç
858 | strong: güçlü
859 | structure: yapı
860 | student: öğrenci
861 | study: çalışmak
862 | stuff: şeyler
863 | style: tarz
864 | subject: konu
865 | substance: madde
866 | succeed: başarılı olmak
867 | success: başarı
868 | successful: başarılı
869 | such: böyle
870 | sudden: aniden
871 | suffer: acı çekmek
872 | suggest: önermek
873 | summer: yaz
874 | support: destek
875 | suppose: zannetmek
876 | sure: emin
877 | surface: yüzey
878 | system: sistem
879 | table: masa
880 | take: almak
881 | talk: konuşmak
882 | task: görev
883 | tax: vergi
884 | teach: öğretmek
885 | teacher: öğretmen
886 | team: takım
887 | technology: teknoloji
888 | telephone: telefon
889 | television: televizyon
890 | tell: söylemek
891 | ten: on
892 | tend: eğilimli olmak
893 | term: dönem
894 | test: test
895 | than: daha
896 | thank: teşekkür etmek
897 | that: o
898 | the: bu
899 | their: onların
900 | them: onları
901 | themselves: kendileri
902 | then: o zaman
903 | theory: teori
904 | there: orada
905 | these: bu
906 | they: onlar
907 | thing: şey
908 | think: düşünmek
909 | third: üçüncü
910 | this: bu
911 | those: şunlar
912 | though: rağmen
913 | thought: düşünce
914 | thousand: bin
915 | threat: tehdit
916 | three: üç
917 | through: vasıtasıyla
918 | throughout: boyunca
919 | throw: atmak
920 | thus: böylece
921 | time: zaman
922 | to: için
923 | today: bugün
924 | together: birlikte
925 | tonight: bu gece
926 | too: çok
927 | top: üst
928 | total: toplam
929 | tough: zorlu
930 | toward: e doğru
931 | town: kasaba
932 | trade: ticaret
933 | traditional: geleneksel
934 | traffic: trafik
935 | training: eğitim
936 | transfer: aktarmak
937 | travel: seyahat etmek
938 | treat: tedavi etmek
939 | treatment: tedavi
940 | tree: ağaç
941 | trial: deneme
942 | trip: seyahat
943 | trouble: sorun
944 | true: doğru
945 | truth: gerçek
946 | try: denemek
947 | turn: dönmek
948 | TV: TV
949 | two: iki
950 | type: tip
951 | under: altında
952 | understand: anlamak
953 | unit: birim
954 | until: kadar
955 | up: yukarı
956 | upon: üzerine
957 | us: biz
958 | use: kullanmak
959 | usually: genellikle
960 | value: değer
961 | various: çeşitli
962 | very: çok
963 | victim: kurban
964 | view: görünüm
965 | violence: şiddet
966 | visit: ziyaret etmek
967 | voice: ses
968 | vote: oy
969 | wait: beklemek
970 | walk: yürümek
971 | wall: duvar
972 | want: istemek
973 | war: savaş
974 | watch: izlemek
975 | water: su
976 | way: yol
977 | we: biz
978 | weak: zayıf
979 | weapon: silah
980 | wear: giymek
981 | week: hafta
982 | weight: ağırlık
983 | well: iyi
984 | west: batı
985 | western: batı
986 | what: ne
987 | whatever: her neyse
988 | when: ne zaman
989 | where: nerede
990 | whether: olup olmadığı
991 | which: hangisi
992 | while: iken
993 | white: beyaz
994 | who: kim
995 | whole: tüm
996 | whom: kimi
997 | whose: kimi
998 | why: neden
999 | wide: geniş
1000 | wife: eş
1001 | will: istemek
1002 | win: kazanmak
1003 | wind: rüzgar
1004 | window: pencere
1005 | wish: dilemek
1006 | with: ile
1007 | within: içinde
1008 | without: olmadan
1009 | woman: kadın
1010 | wonder: merak etmek
1011 | word: kelime
1012 | work: çalışmak
1013 | worker: işçi
1014 | world: dünya
1015 | worry: endişelenmek
1016 | would: olurdu
1017 | write: yazmak
1018 | writer: yazar
1019 | wrong: yanlış
1020 | yard: avlu
1021 | yeah: evet
1022 | year: yıl
1023 | yes: evet
1024 | yet: henüz
1025 | you: sen
1026 | young: genç
1027 | your: senin
1028 | yourself: kendin
1029 | youth: gençlik
1030 | zone: bölge
--------------------------------------------------------------------------------