├── .env
├── .gitignore
├── README.md
├── app.py
├── data
├── alpha_society.pdf
├── beta_society.pdf
└── gamma_society.pdf
├── embeddings
├── embeddings.py
└── openai_embeddings.py
├── llm
├── llm.py
└── llm_factory.py
├── populate_database.py
├── requirements.txt
├── retrieval
└── rag_retriever.py
├── static
├── admin_settings.js
├── demo_img
│ ├── rag_demo.mp4
│ ├── screenshot_1.jpg
│ ├── screenshot_2.jpg
│ ├── screenshot_3.jpg
│ └── screenshot_4.jpg
└── styles.css
├── templates
├── admin.html
└── index.html
└── test_rag.py
/.env:
--------------------------------------------------------------------------------
1 | VECTOR_DB_OPENAI_PATH='chroma-openai'
2 | VECTOR_DB_OLLAMA_PATH='chroma-ollama'
3 | DATA_PATH='data'
4 | EMBEDDING_MODEL_NAME='openai'
5 | LLM_MODEL_TYPE='gpt'
6 | LLM_MODEL_NAME='gpt-3.5-turbo'
7 | NUM_RELEVANT_DOCS='3'
8 | OPENAI_API_KEY='YOUR_OPENAI_KEY_HERE'
9 | CLAUDE_API_KEY='YOUR_CLAUDE_KEY_HERE'
10 |
11 | # UNCOMMENT FOR LOCAL SETUP:
12 |
13 | #EMBEDDING_MODEL_NAME=ollama
14 | #LLM_MODEL_TYPE=ollama
15 | #LLM_MODEL_NAME=llama3:8b
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | *.pyc
2 | .DS_Store
3 | backup
4 | chroma-ollama
5 | chroma-openai
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | A simple local Retrieval-Augmented Generation (RAG) chatbot that can answer to questions by acquiring information from personal pdf documents.
2 |
3 | (please, if you find this content useful please consider leaving a star ⭐)
4 |
5 | ## What is Retrieval-Augmented Generation (RAG)?
6 |
7 |
8 |
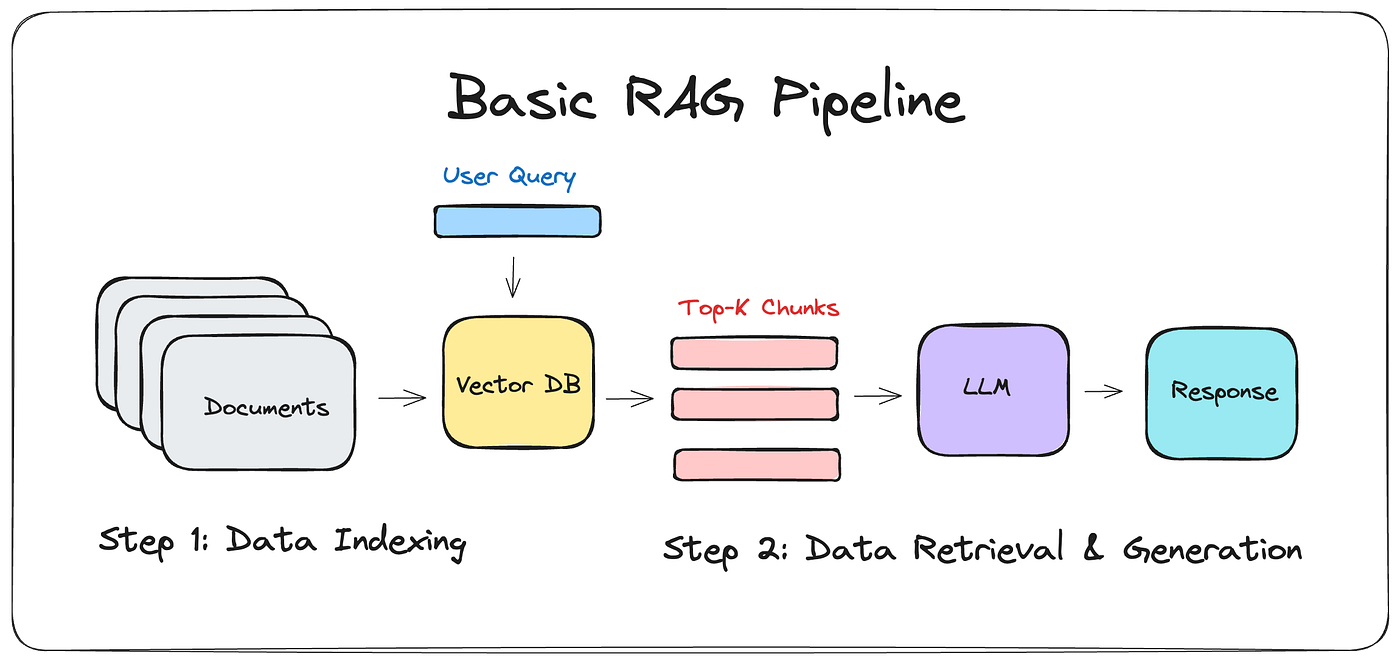
9 | Retrieval-Augmented Generation (RAG) is a technique that combines the strengths of information retrieval and natural language generation. In a RAG system, a retriever fetches relevant documents or text chunks from a database, and then a generator produces a response based on the retrieved context.
10 |
11 | 1. **Data Indexing**
12 | - Documents: This is the starting point where multiple documents are stored.
13 | - Vector DB: The documents are processed and indexed into a Vector Database.
14 |
15 | 2. **User Query**
16 | - A user query is input into the system, which interacts with the Vector Database.
17 |
18 | 3. **Data Retrieval & Generation**
19 | - Top-K Chunks: The Vector Database retrieves the top-K relevant chunks based on the user query.
20 | - LLM (Large Language Model): These chunks are then fed into a Large Language Model.
21 | - Response: The LLM generates a response based on the relevant chunks.
22 |
23 | ## 🏗️ Implementation Components
24 | For this project, i exploited the following components to build the RAG architecture:
25 | 1. **Chroma**: A vector database used to store and retrieve document embeddings efficiently.
26 | 2. **Flask**: Framework for rendering web page and handling user interactions.
27 | 3. **Ollama**: Manages the local language model for generating responses.
28 | 4. **LangChain**: A framework for integrating language models and retrieval systems.
29 |
30 | ## 🛠️ Setup and Local Deployment
31 |
32 | 1. **Choose Your Setup**:
33 | - You have three different options for setting up the LLMs:
34 | 1. Local setup using Ollama.
35 | 2. Using the OpenAI API for GPT models.
36 | 3. Using the Anthropic API for Claude models.
37 |
38 | ### Option 1: Local Setup with Ollama
39 |
40 | - **Download and install Ollama on your PC**:
41 | - Visit [Ollama's official website](https://ollama.com/download) to download and install Ollama. Ensure you have sufficient hardware resources to run the local language model.
42 | - Pull a LMM of your choice:
43 | ```sh
44 | ollama pull # e.g. ollama pull llama3:8b
45 |
46 | ### Option 2: Use OpenAI API for GPT Models
47 | - **Set up OpenAI API**: you can sign up and get your API key from [OpenAI's website](https://openai.com/api/).
48 |
49 | ### Option 3: Use Anthropic API for Claude Models
50 | - **Set up Anthropic API**: you can sign up and get your API key from [Anthropic's website](https://www.anthropic.com/api).
51 |
52 | ## Common Steps
53 |
54 | 2. **Clone the repository and navigate to the project directory**:
55 | ```sh
56 | git clone https://github.com/enricollen/rag-conversational-agent.git
57 | cd rag-conversational-agent
58 | ```
59 |
60 | 3. **Create a virtual environment**:
61 | ```sh
62 | python -m venv venv
63 | source venv/bin/activate # On Windows, use `venv\Scripts\activate`
64 | ```
65 |
66 | 4. **Install the required libraries**:
67 | ```sh
68 | pip install -r requirements.txt
69 | ```
70 |
71 | 5. **Insert you own PDFs in /data folder**
72 |
73 | 6. **Run once the populate_database script to index the pdf files into the vector db:**
74 | ```sh
75 | python populate_database.py
76 | ```
77 |
78 | 7. **Run the application:**
79 | ```sh
80 | python app.py
81 | ```
82 |
83 | 8. **Navigate to `http://localhost:5000/`**
84 |
85 | 9. **If needed, click on ⚙️ icon to access the admin panel and adjust app parameters**
86 |
87 | 10. **Perform a query**
88 |
89 | ## 🚀 Future Improvements
90 | Here are some ideas for future improvements:
91 | - [x] Add OpenAI LLM GPT models compatibility (3.5 turbo, 4, 4-o)
92 | - [x] Add Anthropic Claude LLM models compatibility (Claude 3.5 Sonnet, Claude 3 Sonnet, Claude 3 Opus, Claude 3 Haiku)
93 | - [x] Add unit testing to validate the responses given by the LLM
94 | - [x] Add an admin user interface in web UI to choose interactively the parameters like LLMs, embedding models etc.
95 | - [ ] Add Langchain Tools compatibility, allowing users to define custom Python functions that can be utilized by the LLMs.
96 | - [ ] Add web scraping in case none of the personal documents contain relevant info w.r.t. the query
97 |
98 | ## 📹 Demo Video
99 | Watch the demo video below to see the RAG Chatbot in action:
100 |
101 | [](https://www.youtube.com/watch?v=_JVt5gwwZq0)
102 |
103 | The demo was run on my PC with the following specifications:
104 | - **Processor**: Intel(R) Core(TM) i7-14700K 3.40 GHz
105 | - **RAM**: 32.0 GB
106 | - **GPU**: NVIDIA GeForce RTX 3090 FE 24 GB
107 |
--------------------------------------------------------------------------------
/app.py:
--------------------------------------------------------------------------------
1 | from flask import Flask, request, render_template, jsonify, redirect, url_for
2 | from llm.llm_factory import LLMFactory
3 | from retrieval.rag_retriever import RAGRetriever
4 | from dotenv import load_dotenv, set_key
5 | import os
6 |
7 | load_dotenv()
8 |
9 | VECTOR_DB_OPENAI_PATH = os.getenv('VECTOR_DB_OPENAI_PATH')
10 | VECTOR_DB_OLLAMA_PATH = os.getenv('VECTOR_DB_OLLAMA_PATH')
11 | LLM_MODEL_NAME = os.getenv('LLM_MODEL_NAME') # 'gpt-3.5-turbo', 'GPT-4o' or local LLM like 'llama3:8b', 'gemma2', 'mistral:7b' etc.
12 | LLM_MODEL_TYPE = os.getenv('LLM_MODEL_TYPE') # 'ollama', 'gpt' or 'claude'
13 | EMBEDDING_MODEL_NAME = os.getenv('EMBEDDING_MODEL_NAME') # 'ollama' or 'openai'
14 | NUM_RELEVANT_DOCS = int(os.getenv('NUM_RELEVANT_DOCS'))
15 | OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
16 | CLAUDE_API_KEY = os.getenv('CLAUDE_API_KEY')
17 | ENV_PATH = '.env'
18 |
19 | app = Flask(__name__)
20 |
21 | # Initialize the retriever and LLM
22 | retriever = None
23 | llm_model = None
24 |
25 | def get_vector_db_path(embedding_model_name):
26 | if embedding_model_name == "openai":
27 | return VECTOR_DB_OPENAI_PATH
28 | elif embedding_model_name == "ollama":
29 | return VECTOR_DB_OLLAMA_PATH
30 | else:
31 | raise ValueError(f"Unsupported embedding model: {embedding_model_name}")
32 |
33 | def initialize_components():
34 | """ Initialize the retriever and LLM components based on the current settings. """
35 | global retriever, llm_model
36 | vector_db_path = get_vector_db_path(EMBEDDING_MODEL_NAME)
37 |
38 | # Select the appropriate API key based on the embedding model
39 | if EMBEDDING_MODEL_NAME == "openai":
40 | api_key = OPENAI_API_KEY
41 | else:
42 | api_key = CLAUDE_API_KEY
43 |
44 | retriever = RAGRetriever(vector_db_path=vector_db_path, embedding_model_name=EMBEDDING_MODEL_NAME, api_key=api_key)
45 | llm_model = LLMFactory.create_llm(model_type=LLM_MODEL_TYPE, model_name=LLM_MODEL_NAME, api_key=api_key)
46 | print(f"Instantiating model type: {LLM_MODEL_TYPE} | model name: {LLM_MODEL_NAME} | embedding model: {EMBEDDING_MODEL_NAME}")
47 |
48 | initialize_components()
49 |
50 | @app.route('/')
51 | def index():
52 | return render_template('index.html')
53 |
54 | @app.route('/admin')
55 | def admin():
56 | return render_template('admin.html',
57 | llm_model_name=LLM_MODEL_NAME,
58 | llm_model_type=LLM_MODEL_TYPE,
59 | embedding_model_name=EMBEDDING_MODEL_NAME,
60 | num_relevant_docs=NUM_RELEVANT_DOCS,
61 | openai_api_key=OPENAI_API_KEY)
62 |
63 | @app.route('/update_settings', methods=['POST'])
64 | def update_settings():
65 | global LLM_MODEL_NAME, LLM_MODEL_TYPE, EMBEDDING_MODEL_NAME, NUM_RELEVANT_DOCS, OPENAI_API_KEY
66 | LLM_MODEL_NAME = request.form['llm_model_name']
67 | LLM_MODEL_TYPE = request.form['llm_model_type']
68 | EMBEDDING_MODEL_NAME = request.form['embedding_model_name']
69 | NUM_RELEVANT_DOCS = int(request.form['num_relevant_docs'])
70 | OPENAI_API_KEY = request.form['openai_api_key']
71 |
72 | # Update the .env file
73 | set_key(ENV_PATH, 'LLM_MODEL_NAME', LLM_MODEL_NAME)
74 | set_key(ENV_PATH, 'LLM_MODEL_TYPE', LLM_MODEL_TYPE)
75 | set_key(ENV_PATH, 'EMBEDDING_MODEL_NAME', EMBEDDING_MODEL_NAME)
76 | set_key(ENV_PATH, 'NUM_RELEVANT_DOCS', str(NUM_RELEVANT_DOCS))
77 | set_key(ENV_PATH, 'OPENAI_API_KEY', OPENAI_API_KEY)
78 |
79 | # Reinitialize the components (llm and retriever objects)
80 | initialize_components()
81 | print(f"Updating model type: {LLM_MODEL_TYPE} | model name: {LLM_MODEL_NAME} | embedding model: {EMBEDDING_MODEL_NAME}")
82 | return redirect(url_for('admin'))
83 |
84 | @app.route('/query', methods=['POST'])
85 | def query():
86 | query_text = request.json['query_text']
87 | # Retrieve and format results
88 | results = retriever.query(query_text, k=NUM_RELEVANT_DOCS)
89 | enhanced_context_text, sources = retriever.format_results(results)
90 | # Generate response from LLM
91 | llm_response = llm_model.generate_response(context=enhanced_context_text, question=query_text)
92 | sources_html = " ".join(sources)
93 | response_text = f"{llm_response}
 8 |
8 |