├── 极客时间
└── 45讲
│ └── 2.md
├── 笔记
├── 1.1Java基础
│ ├── x..md
│ ├── 0.Java基础.md
│ └── 1.概述.md
├── 1.4Jvm 相关
│ ├── 5 文章收集.md
│ └── 4 内存模型.md
├── 2.3 Redis
│ └── Redis.xmind
├── 1.3Java并发
│ ├── archive
│ │ └── assets
│ │ │ ├── CAS.png
│ │ │ ├── aba1.png
│ │ │ ├── aba2.png
│ │ │ ├── aba3.png
│ │ │ ├── aba4.png
│ │ │ ├── aba5.png
│ │ │ ├── aba6.png
│ │ │ ├── 无标题.jpg
│ │ │ ├── 无标题.png
│ │ │ ├── 游泳池.jpg
│ │ │ ├── 线程池原理.bmp
│ │ │ ├── 线程流程图.png
│ │ │ ├── 线程状态图.png
│ │ │ ├── 计时等待.png
│ │ │ ├── 锁阻塞.png
│ │ │ ├── 02-流水线.jpeg
│ │ │ ├── 无限等待(2).png
│ │ │ ├── 栈内存原理图.bmp
│ │ │ ├── 线程安全问题.png
│ │ │ ├── Exchange交换.png
│ │ │ ├── Exchange超时.png
│ │ │ ├── Exchange阻塞.png
│ │ │ ├── HashMap假死.png
│ │ │ ├── HashMap异常.png
│ │ │ ├── 02-Lambda(2).png
│ │ │ ├── 03-Overview.png
│ │ │ ├── HashMap错误结果.png
│ │ │ ├── Semaphore_1.png
│ │ │ ├── aba_version1.png
│ │ │ ├── aba_version3.png
│ │ │ ├── 01-流式思想示意图(2).png
│ │ │ ├── 02-流水线.jpeg.lnk.重命名
│ │ │ ├── 1550281809857.png
│ │ │ ├── 1561042741339.png
│ │ │ ├── 1561303332516.png
│ │ │ ├── 1561386329752.png
│ │ │ ├── 1561389716317.png
│ │ │ ├── 1561516472597.png
│ │ │ ├── 1561517963033.png
│ │ │ ├── 1561524132215.png
│ │ │ ├── 1561550710005.png
│ │ │ ├── 1561550793084.png
│ │ │ ├── 1561550911597.png
│ │ │ ├── 1561551122602.png
│ │ │ ├── 1561551254968.png
│ │ │ ├── 1561551329313.png
│ │ │ ├── 1561551377905.png
│ │ │ ├── 1561647062658.png
│ │ │ ├── 1573352376549.png
│ │ │ ├── 1576207627535.png
│ │ │ ├── CyclicBarrier_1.png
│ │ │ ├── Hashtable执行时间.png
│ │ │ ├── Hashtable锁示意图.png
│ │ │ ├── Semaphore1个线程执行.png
│ │ │ ├── Semaphore2个线程执行.png
│ │ │ ├── aba_version_2.png
│ │ │ ├── 02-Annotation(2).jpeg
│ │ │ ├── ConcurrentHashMap执行时间.png
│ │ │ └── ConcurrentHashMap锁示意图.png
│ ├── 0.总结.md
│ ├── 面试题.md
│ ├── 3并发理论(JMM).md
│ ├── 6 JUC集合-1.md
│ ├── 1.线程理论基础.md
│ └── 2并发关键字.md
├── 3 分布式
│ ├── 4 分布式锁.md
│ ├── 3 分布式解决方案相关.md
│ └── 分布式简单入门.md
├── 2.2 MySQL
│ ├── 0.MySQL.md
│ ├── 1.基础回顾.md
│ └── 2.mysql怎么运行的.md
├── 4 系统设计、场景题
│ └── 1 .md
├── 0.2计算机网络
│ └── 1 .md
├── 2.1 Spring
│ └── 1.基础知识.md
├── 1.2Java容器
│ ├── ArrayList-1.md
│ ├── map分析.md
│ └── 容器源码分析.md
├── 2.5 Zookeeper
│ ├── zk .md
│ └── 1 基础知识.md
├── 0.1操作系统
│ └── 9.24 .md
└── 1.5 Java8
│ └── 1.新特性.md
├── .gitignore
├── .DS_Store
├── 深度学习机器学习
├── 吴恩达笔记5.md
├── 吴恩达笔记6.md
├── 0 总结.md
├── 吴恩达笔记2.md
├── 00 纠错.md
├── 吴恩达笔记4.md
├── 吴恩达笔记3.md
├── 资源汇总.md
└── 吴恩达笔记1.md
├── 2022日常实习面经(2022.11-12
├── .DS_Store
├── 团子面经收集.md
├── 百度后端日常实习二面.md
├── 网易灵犀一面.md
├── 网易灵犀三面(hr面).md
├── 上海公司(云,k8s开源).md
├── 源码佬模拟面.md
├── 网易面经收集.md
├── 美团后端二面.md
├── smartX超融合go后端一面.md
├── vivo后端一面.md
├── 某车厂基础架构部门二面.md
├── 某车厂基础架构部门一面.md
├── 百度后端日常实习一面.md
├── 网易灵犀二面.md
├── 粤港澳后端开发.md
├── 美团后端实习一面.md
├── 百度面经收集.md
├── 上海小厂懂技术的面试官技术面.md
├── 字节面经收集.md
├── 上海小公司面经-复盘版.md
├── 滴滴准实习员工模拟面 .md
└── 整理.md
├── 算法
├── 1 动态规划.md
├── 百度算法.md
└── 字节算法.md
├── shell.sh
├── x 常见智力题
└── 1 赛马问题.md
├── x
└── 面试1 .md
├── README.md
└── 项目
├── Raft.md
├── 理论.md
├── paxos.md
├── 1 笔记.md
└── redis和数据库是如何保持一致性的.md
/极客时间/45讲/2.md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/笔记/1.1Java基础/x..md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | /.idea/
2 |
--------------------------------------------------------------------------------
/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/.DS_Store
--------------------------------------------------------------------------------
/笔记/1.4Jvm 相关/5 文章收集.md:
--------------------------------------------------------------------------------
1 | https://tech.meituan.com/2020/11/12/java-9-cms-gc.html
--------------------------------------------------------------------------------
/深度学习机器学习/吴恩达笔记5.md:
--------------------------------------------------------------------------------
1 | ## 九、神经网络的学习(Neural Networks: Learning)
2 |
3 | ### 9.1 代价函数
4 |
--------------------------------------------------------------------------------
/笔记/2.3 Redis/Redis.xmind:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/2.3 Redis/Redis.xmind
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/2022日常实习面经(2022.11-12/.DS_Store
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/CAS.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/CAS.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/aba1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/aba1.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/aba2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/aba2.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/aba3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/aba3.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/aba4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/aba4.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/aba5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/aba5.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/aba6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/aba6.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/无标题.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/无标题.jpg
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/无标题.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/无标题.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/游泳池.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/游泳池.jpg
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/线程池原理.bmp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/线程池原理.bmp
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/线程流程图.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/线程流程图.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/线程状态图.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/线程状态图.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/计时等待.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/计时等待.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/锁阻塞.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/锁阻塞.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/02-流水线.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/02-流水线.jpeg
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/无限等待(2).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/无限等待(2).png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/栈内存原理图.bmp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/栈内存原理图.bmp
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/线程安全问题.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/线程安全问题.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/Exchange交换.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/Exchange交换.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/Exchange超时.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/Exchange超时.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/Exchange阻塞.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/Exchange阻塞.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/HashMap假死.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/HashMap假死.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/HashMap异常.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/HashMap异常.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/02-Lambda(2).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/02-Lambda(2).png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/03-Overview.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/03-Overview.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/HashMap错误结果.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/HashMap错误结果.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/Semaphore_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/Semaphore_1.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/aba_version1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/aba_version1.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/aba_version3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/aba_version3.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/01-流式思想示意图(2).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/01-流式思想示意图(2).png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/02-流水线.jpeg.lnk.重命名:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/02-流水线.jpeg.lnk.重命名
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1550281809857.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1550281809857.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1561042741339.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1561042741339.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1561303332516.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1561303332516.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1561386329752.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1561386329752.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1561389716317.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1561389716317.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1561516472597.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1561516472597.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1561517963033.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1561517963033.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1561524132215.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1561524132215.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1561550710005.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1561550710005.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1561550793084.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1561550793084.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1561550911597.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1561550911597.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1561551122602.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1561551122602.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1561551254968.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1561551254968.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1561551329313.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1561551329313.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1561551377905.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1561551377905.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1561647062658.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1561647062658.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1573352376549.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1573352376549.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/1576207627535.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/1576207627535.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/CyclicBarrier_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/CyclicBarrier_1.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/Hashtable执行时间.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/Hashtable执行时间.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/Hashtable锁示意图.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/Hashtable锁示意图.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/Semaphore1个线程执行.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/Semaphore1个线程执行.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/Semaphore2个线程执行.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/Semaphore2个线程执行.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/aba_version_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/aba_version_2.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/02-Annotation(2).jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/02-Annotation(2).jpeg
--------------------------------------------------------------------------------
/算法/1 动态规划.md:
--------------------------------------------------------------------------------
1 | ## 设计状态
2 |
3 | ## 写出状态转移方程
4 |
5 |
6 |
7 | ## 设定初始化状态
8 |
9 | 上升子序列中,初始化所有元素为 1
10 |
11 | ## 执行状态转移
12 |
13 | ## 返回解
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/ConcurrentHashMap执行时间.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/ConcurrentHashMap执行时间.png
--------------------------------------------------------------------------------
/笔记/1.3Java并发/archive/assets/ConcurrentHashMap锁示意图.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/erdengk/notes/HEAD/笔记/1.3Java并发/archive/assets/ConcurrentHashMap锁示意图.png
--------------------------------------------------------------------------------
/shell.sh:
--------------------------------------------------------------------------------
1 | now=$(date "+%Y-%m-%d-%H:%M")
2 |
3 | git add ./
4 | git commit -m "$now :update"
5 | git push origin main
6 |
7 | echo "complete,in order to forever free"
--------------------------------------------------------------------------------
/算法/百度算法.md:
--------------------------------------------------------------------------------
1 | 十亿个数据集中选出最大的1000个数,在内存中排序时除了快排之外,还可以用那些排序算法
2 |
3 |
4 |
5 | 把时间戳转换成年月日时分秒
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 | https://www.nowcoder.com/practice/947f6eb80d944a84850b0538bf0ec3a5
--------------------------------------------------------------------------------
/笔记/3 分布式/4 分布式锁.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | 使使用用数数据据库库、、ZZKK、、RReeddiiss实实现现分分布布式式锁锁方方案案https://www.heiz123.com/2022/03/361/#ZK_fen_bu_shi_suo_shi_xian_yuan_li
4 |
5 |
6 |
7 | https://note.dolyw.com/distributed/12-Distributed-Lock.html#_1-redis
--------------------------------------------------------------------------------
/笔记/1.1Java基础/0.Java基础.md:
--------------------------------------------------------------------------------
1 | ## 引用
2 |
3 | 主要~~复制~~参考自
4 |
5 | [Java 入门教学(韩顺平)](https://www.bilibili.com/video/BV1fh411y7R8?share_source=copy_web)
6 |
7 | [Java 概述](https://i-melody.github.io/2021/11/21/Java/入门阶段/1 基础知识/)
8 |
9 | 再加上自己的修改
--------------------------------------------------------------------------------
/笔记/2.2 MySQL/0.MySQL.md:
--------------------------------------------------------------------------------
1 | ## 引用
2 |
3 | 主要~~复制~~参考自
4 |
5 |
6 |
7 | [MySQL 教程](https://www.runoob.com/mysql/mysql-tutorial.html)
8 |
9 | mysql必知必会
10 |
11 | [《MySQL 是怎样运行的:从根儿上理解 MySQL》](https://relph1119.github.io/mysql-learning-notes/)
12 |
13 |
14 |
15 | 再加上自己的理解与修改
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/团子面经收集.md:
--------------------------------------------------------------------------------
1 | https://www.nowcoder.com/discuss/post/419287223318663168
2 |
3 | https://www.nowcoder.com/discuss/post/416883089135153152
4 |
5 | for(int i= 0; i<100; i++) {
6 | redis.asyncpush("key"+i, "value");
7 | redis.expire("key"+i, 100);
8 | }
--------------------------------------------------------------------------------
/深度学习机器学习/吴恩达笔记6.md:
--------------------------------------------------------------------------------
1 | ## 十、应用机器学习的建议(Advice for Applying Machine Learning)
2 |
3 | ==当我们运用训练好了的模型来预测未知数据的时候发现有较大的误差,我们下一步可以做什么?==
4 |
5 | 1. 获得更多的训练样本——通常是有效的,但代价较大,下面的方法也可能有效,可考虑先采用下面的几种方法。
6 | 2. 尝试减少特征的数量
7 | 3. 尝试获得更多的特征
8 | 4. 尝试增加多项式特征
9 | 5. 尝试减少正则化程度
10 | 6. 尝试增加正则化程度
11 |
12 | ### 10.2 评估一个假设
13 |
--------------------------------------------------------------------------------
/x 常见智力题/1 赛马问题.md:
--------------------------------------------------------------------------------
1 | ## 有 25 匹⻢和 5 条赛道,赛⻢过程⽆法进⾏计 时,只能知道相对快慢。问最少需要⼏场赛⻢ 可以知道前3名?
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 | ## 给定两条绳⼦,每条绳⼦烧完正好⼀个⼩时, 并且绳⼦是不均匀的。问要怎么准确测量 15 分钟。
10 |
11 | 点燃第⼀条绳⼦ R1 两头的同时,点燃第⼆条绳⼦ R2 的⼀头;
12 |
13 | 当 R1 烧完,正好过去 30 分钟,⽽ R2 还可以再烧 30 分钟;
14 |
15 | 点燃 R2 的另⼀头,15 分钟后,R2 将全部烧完。
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/百度后端日常实习二面.md:
--------------------------------------------------------------------------------
1 | ## 百度后端日常实习二面
2 |
3 | 自我介绍
4 |
5 | 介绍项目
6 |
7 | 介绍GSoC
8 |
9 | 介绍集成测试
10 |
11 | 介绍Paxos项目
12 |
13 | 为什么做这个项目
14 |
15 | 为什么做微服务的项目
16 |
17 | Redis存了哪些东西
18 |
19 | 双写一致性
20 |
21 | Kafka同步方法
22 |
23 | > 扯了raft和zab
24 |
25 | 算法
26 |
27 | 矩阵,左上到右下,每个格子有权值,求最大
28 |
29 | 什么时候到岗
30 |
31 | 实习多久
32 |
33 | 转go
34 |
35 | …………………………
36 |
37 | 周五忙着下班?(我也急,面试官也急)
38 |
39 | 给我整不会了,不知道他要不要我。。。。
40 |
41 |
--------------------------------------------------------------------------------
/笔记/3 分布式/3 分布式解决方案相关.md:
--------------------------------------------------------------------------------
1 | ## 分布式全局唯一ID
2 |
3 | ####
4 |
5 | ## 分布式锁
6 |
7 |
8 |
9 |
10 |
11 | [https://www.processon.com/view/link/635babc31efad41bb43d2c9d](https://www.processon.com/view/link/635babc31efad41bb43d2c9d)
12 |
13 | ## 分布式事务
14 |
15 | ## 分布式缓存
16 |
17 |
--------------------------------------------------------------------------------
/笔记/1.3Java并发/0.总结.md:
--------------------------------------------------------------------------------
1 | ## 线程理论基础
2 |
3 | ## 并发理论(JMM)
4 |
5 | ## 并发关键字
6 |
7 | ## Lock体系
8 |
9 | ## 并发容器和框架
10 |
11 | ## 原子操作类
12 |
13 | ## 线程池
14 |
15 | ## 并发工具
16 |
17 | ## 并发实践
18 |
19 | [一篇文章,让你彻底弄懂生产者--消费者问题](https://juejin.im/post/5aeec675f265da0b7c072c56)
20 |
21 | ## 参考
22 |
23 | https://pdai.tech/md/java/thread/java-thread-x-overview.html
24 |
25 | https://github.com/CL0610/Java-concurrency
26 |
27 | https://www.cnblogs.com/aspirant/p/8657681.html
28 |
29 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/网易灵犀一面.md:
--------------------------------------------------------------------------------
1 | ## 网易灵犀一面
2 |
3 | 总结:面试官很好,体验非常好
4 |
5 | 面试结束5分钟hr约了下一面
6 |
7 | ………………………………………………………………
8 |
9 | 自我介绍
10 |
11 | 介绍一下项目
12 |
13 | 介绍下开源活动
14 |
15 | 介绍下GSoC
16 |
17 | 介绍下你做的事
18 |
19 | 你知道的所有排序算法 时间复杂 空间复杂 如何实现 稳定性如何
20 |
21 | 讲讲红黑树的实现?
22 |
23 | 操作系统页面置换算法
24 |
25 | https和浏览器之间如何交互的
26 |
27 | 计算机网络的滑动窗口是干嘛的?拥塞控制是怎么样的
28 |
29 | 交换机,路由器分别在哪一层
30 |
31 | redis的底层如何实现的?
32 |
33 | redis的缓存淘汰策略?
34 |
35 | mysql的redo log undo log干嘛的
36 |
37 | CMS
38 |
39 | Threadlocal ?有什么问题
40 |
41 | 智力题: 100个人一个阳性,只测一次,最少几个试管?
42 |
43 | 算法题: pow(n, x)
44 |
45 | 如何判断溢出
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/网易灵犀三面(hr面).md:
--------------------------------------------------------------------------------
1 | ## 网易灵犀三面(hr面)
2 |
3 | 自我介绍
4 |
5 | 介绍项目
6 |
7 | 介绍开源实习
8 |
9 | 介绍GSoC
10 |
11 | 介绍GSoC职责、工作内容
12 |
13 | 项目做了多久
14 |
15 | 怎么申请的
16 |
17 | 全英申请书怎么写的
18 |
19 | 申请书有请国外的同学改吗
20 |
21 | 申请书排名(11/121
22 |
23 | 介绍GLCC
24 |
25 | 介绍GLCC职责、工作内容
26 |
27 | 为什么拒绝那个四段大厂实习的同学的申请
28 |
29 | 研究生课程
30 |
31 | 研究生成绩
32 |
33 | 研究生研究的东西
34 |
35 | 读研体会
36 |
37 | 导师放不放实习
38 |
39 | 学校政策
40 |
41 | 为什么当程序员
42 |
43 | 职业规划
44 |
45 | > 我希望觉得我写的代码是对世界有益的
46 |
47 | 有其他offer吗?
48 |
49 | > 投了paypal、ebay 都挂了
50 |
51 | 为什么挂了
52 |
53 | 哪里人
54 |
55 | 为什么去杭州
56 |
57 | ……………………………………
58 |
59 | 薪资介绍
60 |
61 | 到岗时间
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/上海公司(云,k8s开源).md:
--------------------------------------------------------------------------------
1 | 上海云中小厂,面试官是经常写代码的,code质量要求很高,追着GitHub看。
2 |
3 | 面试的时候,感觉好多时间不在线的样子,复盘的时候发觉是他应该是在看GitHub的pr
4 |
5 |
6 |
7 | 自我介绍
8 |
9 | helmchart 和maven pom.xml 区别
10 |
11 | k8s了解程度
12 |
13 | 讲讲微服务项目
14 |
15 | 项目相关问题
16 |
17 | 将Paxos项目
18 |
19 | cap--base--nwr---paxos
20 |
21 | tcp和ip关系
22 |
23 | pr里的commit不够简洁
24 |
25 | 缓存雪崩、缓存穿透、缓存击穿
26 |
27 | 删除策略
28 |
29 | 你觉得k8s是一个什么样的分布式的云原生的平台
30 |
31 | 为什么k8s之前的编排软件不行?
32 |
33 | docker了解程度
34 |
35 | 开源项目为什么文档类居多,
36 |
37 | Github profies 里变量风格不一致,细节问题
38 |
39 |
40 |
41 | 他讲了讲部门业务(为k8s做贡献,带薪做开源)
42 |
43 |
44 |
45 | 反问:go语法学完,做什么?
46 |
47 | 找个开源项目去参与
48 |
49 |
50 |
51 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/源码佬模拟面.md:
--------------------------------------------------------------------------------
1 | ### 京东源码佬模拟面
2 |
3 | 延时双删举出具体例子
4 |
5 | reids回收策略
6 |
7 | redis 对回收策略的优化
8 |
9 | paxos讲一下
10 |
11 | 讲一下zab
12 |
13 | 开源里最难的工作
14 |
15 | 插件怎么集成进去的
16 |
17 | JVM类加载机制
18 |
19 | 双亲委派机制
20 |
21 | 代码怎么实现双亲委派
22 |
23 | 一致性hash算法、虚拟节点
24 |
25 | 哪种数据结构适合实现一致性hash算法(查找尽可能快
26 |
27 | > 链表--》数组---〉mysql b+树---》TreeMap(提供了最近的下一个的api)
28 |
29 | volitale关键字作用
30 |
31 | 怎么防止指令重排的
32 |
33 | 局部变量存在哪?
34 |
35 | g1回收器、内存布局
36 |
37 | gms回收器
38 |
39 | 流量控制
40 |
41 | 拥塞控制
42 |
43 | ioc、aop
44 |
45 | 死锁
46 |
47 | 怎么解决死锁
48 |
49 | mysql怎么解决死锁(a事务要 1、2资源,b事务要2,1资源)
50 |
51 | >mysql会给事务上一个定时时间,如果一个事务执行的时间很长的话,它可能就是出现死锁了
52 |
53 |
54 |
55 |
--------------------------------------------------------------------------------
/笔记/4 系统设计、场景题/1 .md:
--------------------------------------------------------------------------------
1 | ### 微信扫码登录是怎么实现的
2 |
3 | https://zhuanlan.zhihu.com/p/110997772
4 |
5 | 手机进行扫描二维码,然后手机携带uuid和用户信息向手机的服务器发送请求,手机服务器收到之后携带uuid去redis服务器查询用户,并把uuid与用户信息绑定在一起。 查询用户成功之后返回一个Token给网页服务器,通过解析这个Token可以拿出用户的信息,然后浏览器就成功登录微信了。
6 |
7 |
8 |
9 | https://soulmachine.gitbooks.io/system-design/content/cn/
10 |
11 |
12 |
13 | 智力题:一枚银币,不停地抛,第N次才正面朝上的期望
14 |
15 | 智力题:N个人,每个人手中握有一个数,要得到这些数之和,又不能让别人知道自己手中的数是多少,怎么做到
16 |
17 | N个人成一个圈,0号把手中的数加上一个随机数传给旁边的人,每个人在拿到的数上加上自己的数再传给旁边的人,最后回到0号手中,减去随机数,就是答案了
18 |
19 |
20 |
21 | 场景题:给一个人定位坐标,然后给一个城市的轮廓坐标,你怎么确定这个人在不在这个城市内?(向量叉乘,面试官说这个只能解决凸多边形问题)
22 |
23 | 场景题:统计每日通行车辆最多的前`100`个路口?(`top K`问题,说小根堆,但是并不满意,让从架构角度思考。又说到各地服务器分别`top 100`,然后多路归并)
--------------------------------------------------------------------------------
/x/面试1 .md:
--------------------------------------------------------------------------------
1 | 
2 |
3 |
4 |
5 | 递归遍历数组
6 |
7 | ```java
8 | void traverse(int[] nums, int index) {
9 | if (index == nums.length) {
10 | return;
11 | }
12 | System.out.println(nums[index]);
13 | traverse(nums, index + 1);
14 | }
15 | ```
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 | 进程间最高效的通信方式?
24 |
25 |
26 |
27 | 内存共享是最高效的一种进程间通信的方法,它省去了从用户到内存的复制和从内存到用户的复制,但是它的同步于互斥机制需要用户手动的去实现,总之内存共享给程序员自由发挥的空间更大。
28 |
29 |
30 |
31 |
32 |
33 | 水平触发和边缘触发
34 |
35 | 四层负载和七层负载
36 |
37 | 滑动窗口和拥塞窗口区别
38 |
39 |
40 |
41 |
42 |
43 | 刚百度问了一个,threadlocal内部的map,key是什么,为什么不可以使用thread作为key
44 |
45 |
46 |
47 |
48 |
49 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/网易面经收集.md:
--------------------------------------------------------------------------------
1 | https://www.nowcoder.com/discuss/post/410769850044350464
2 |
3 | https://www.nowcoder.com/discuss/post/411993359819046912
4 |
5 | https://www.nowcoder.com/discuss/post/415542573845020672
6 |
7 |
8 |
9 | https://www.nowcoder.com/discuss/post/417792778371956736
10 |
11 | https://www.nowcoder.com/discuss/post/401424843768451072
12 |
13 | https://www.nowcoder.com/discuss/post/403941840112701440
14 |
15 | https://www.nowcoder.com/discuss/post/401167134800322560
16 |
17 | https://www.nowcoder.com/discuss/post/401167429001297920
18 |
19 | https://www.nowcoder.com/discuss/post/358684171756113920
20 |
21 |
22 |
23 | 慢查询如何定位时间长的
24 |
25 | synchronized得底层实现
26 |
27 | 介绍JVM的GC过程
28 |
29 | 微信扫码登录,如何让电脑端获取用户信息
--------------------------------------------------------------------------------
/深度学习机器学习/0 总结.md:
--------------------------------------------------------------------------------
1 | ### 人工智能、机器学习、深度学习
2 |
3 | 机器学习是不使用显示编程的AI的子集,这意味着它没有使用任何固定的规则,但它需要人类先定义学习特征(规则)
4 |
5 | 深度学习是机器学习的子集,(理论上)不需要人工定义特征,它能够自行决定哪些特征是相关的,并根据给定的数据进行自我训练
6 |
7 |
8 |
9 | ### 神经网络
10 |
11 | 类似于机场
12 |
13 | 从入机场、安检、查证、摆渡车、上具体某班飞机
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 | 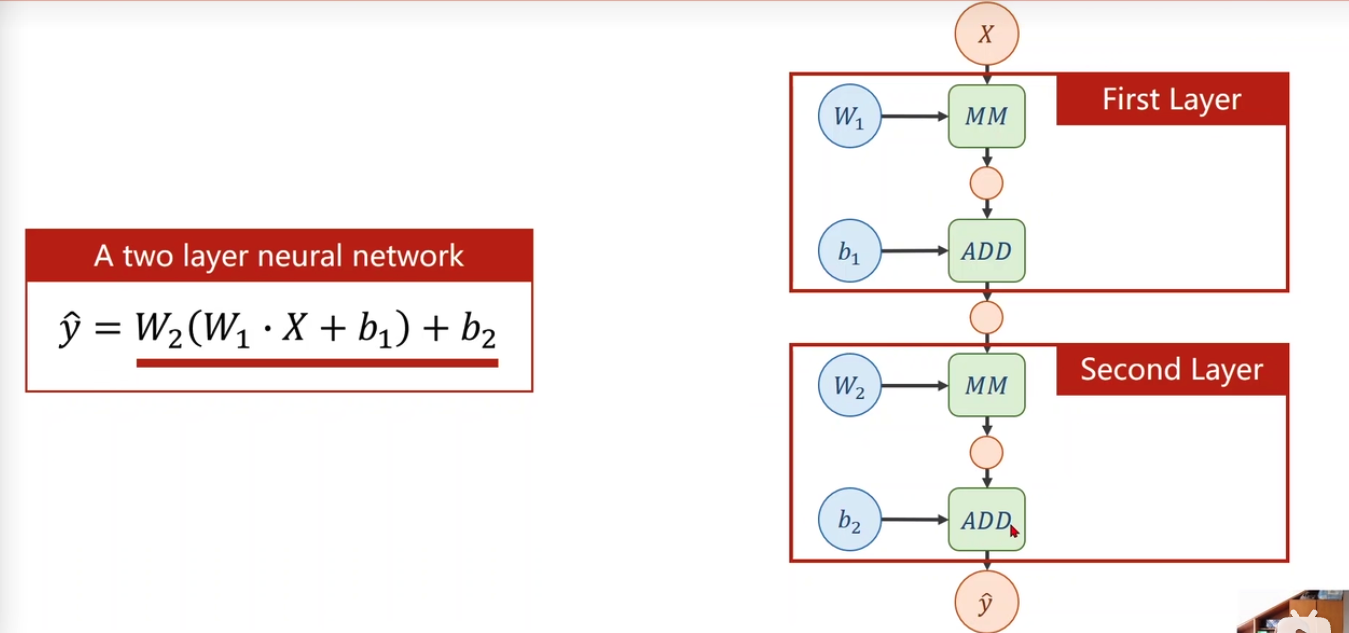
22 |
23 | 前一层是下一层的输入
24 |
25 | [两层神经网络](https://www.bilibili.com/video/BV1Y7411d7Ys?p=4&spm_id_from=pageDriver&vd_source=2de111953f823751c56f32f11f1416a2&t=609.2)
26 |
27 | https://blog.csdn.net/Pin_BOY/article/details/119707344
28 |
29 |
30 |
31 | 步骤
32 |
33 | 
34 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/美团后端二面.md:
--------------------------------------------------------------------------------
1 | ## 美团后端二面
2 |
3 | 面试官全程您,太客气了
4 |
5 | ………………………………
6 |
7 | 两道场景
8 |
9 | 一道 数字转中文读法(1000-》一千)
10 |
11 | 0八股0自我介绍
12 |
13 | 反问 “您觉得我能过吗?”
14 | “这个需要横行对比之后才能有结果”
15 |
16 | ………………………………
17 |
18 | 什么时候到岗
19 |
20 | 场景题 1
21 |
22 | 假设我有一个文本文件。这个文本文件每一行都是一个长度不固定的,由英文字符跟阿拉伯数字组成的字符串。但是它的长度不固定。就是文件也比较大。我现在需要您在内存有限的情况下去统计出这个文本文件当中出现次数最多的5个字符串。
23 |
24 | > 分治
25 | >
26 | > 分小文件hash ,然后每个取top5,然后总的取top5
27 |
28 | ………………………………
29 |
30 | 场景题 2
31 |
32 | 比如说我们现在在搞一个大促对吧?我们现在在卖商品,然后商品卖商品通常都会有一个这样的一个功能,就是榜单。就是说我们每卖一件商品,我往一个文件当中去写一个这个商品的 ID 对吧?然后商品的编码。然后我是进行大促的那一刻开始到当前我们卖的最好的100件商品的一个榜单。啊那这是一个实际的业务场景了。
33 |
34 | > 一开始没答道点子上,面试官引导他没限制内存,
35 | >
36 | > 然后又引导 (在不影响业务的情况下,降低成本)
37 | >
38 | > 排行榜不需要很精准
39 | >
40 | > 排行榜需要尽快返回
41 |
42 | 面试官:其实我想问的是说如何尽量地节约成本
43 |
44 | > 后面又提到pipeline的思想
45 | >
46 | > 不要一次一次传输,累计传输一下
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/smartX超融合go后端一面.md:
--------------------------------------------------------------------------------
1 | 总结:面试体验超级好
2 |
3 | 上来面试官先介绍了接下来会有4部分内容
4 |
5 | 自我介绍、项目及知识问答、算法、反问
6 |
7 | 因为是Go后端岗,也没问Java相关的。。。
8 |
9 | ( 面试官好像姜文,好🆒
10 |
11 | -----------------------------------------
12 |
13 | 你之前java、为什么想转go
14 |
15 | > 兴趣需要,分布式和云原生还是用go多一些
16 | >
17 | > 也读过三驾马车
18 | >
19 | > 也因为想要从事这方面的工作,所以要学go
20 |
21 | paxos
22 |
23 | raft
24 |
25 | 他们的区别
26 |
27 | GSoC算实习么?
28 |
29 | > 官方定义是一段实习,有津贴、有导师、有项目产出
30 |
31 | 讲一下网关
32 |
33 | 它项目活跃度
34 |
35 | 你在里面的贡献
36 |
37 | 你的集测怎么写的,什么流程
38 |
39 | 你提到限流,有了解过限流算法么
40 |
41 | 有看过限流算法的源码么
42 |
43 | Java 写了多久
44 |
45 | linux熟么?
46 |
47 | > 不熟,平时用的少
48 |
49 | 说些你平时用的命令
50 |
51 | docker 命令
52 |
53 | 你 helm chart 将哪些配置抽离出来了
54 |
55 | mysql 索引数据结构
56 |
57 | 聚簇索引和非聚簇索引
58 |
59 | mvcc 隔离机制
60 |
61 | redis 持久化机制
62 |
63 | 分布式锁
64 |
65 | red lock
66 |
67 | zk 分布式锁
68 |
69 |
70 |
71 | 算法
72 |
73 | 判断是否是子树
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/vivo后端一面.md:
--------------------------------------------------------------------------------
1 | ## VIVO后端日常实习一面
2 |
3 | 总结:要干活的,0算法
4 |
5 | 要么面试官水我捡漏了
6 |
7 | 要么 他们公司水。。。
8 |
9 | ---
10 |
11 |
12 |
13 | 自我介绍
14 |
15 | 介绍开源实习
16 |
17 | 介绍GSoC
18 |
19 | 有多少人中选
20 |
21 | 介绍开源工作内容
22 |
23 | 讲集测流程
24 |
25 | 限流插件、可观测性插件、缓存插件测试用例设计
26 |
27 | rocketmq 作用
28 |
29 | 聊ShenYu的插件
30 |
31 | 你自己搭过k8s么
32 |
33 | 你kafka怎么搭的
34 |
35 | 问项目
36 |
37 | 为什么做paxos这个项目?
38 |
39 | 讲下paxos
40 |
41 | > 开始吟唱 cap paxos
42 |
43 | 为什么做微服务这个项目?
44 |
45 | 项目自己做的还是一起做的?
46 |
47 | springboot 和springcloud 关系
48 |
49 | springcloud 和 微服务
50 |
51 | jpa 和 mybatis
52 |
53 | 你还知道哪些消息中间件
54 |
55 | Kafka 作用
56 |
57 | zk 作用
58 |
59 | 消息队列消费异常怎么处理
60 |
61 | 消息积压怎么办
62 |
63 | > 1.非实时,定时任务处理
64 | >
65 | > 2.实时,增加线程去消费
66 |
67 | 分布式和集群有什么区别
68 |
69 |
70 |
71 | ---
72 |
73 | 什么时候到岗
74 |
75 | 实习能实习多久
76 |
77 | 线下实习过没
78 |
79 | ---
80 |
81 | 反问:
82 |
83 | 什么部门
84 |
85 | 实习生工作
--------------------------------------------------------------------------------
/深度学习机器学习/吴恩达笔记2.md:
--------------------------------------------------------------------------------
1 | ## Week2
2 |
3 | ### 梯度下降的线性回归
4 |
5 | ### 梯度下降法实践1-特征缩放
6 |
7 | 很多时候,多个特征的单位不同,梯度下降算法需要非常多次的迭代才能收敛。
8 |
9 | ==解决的方法是尝试将所有特征的尺度都尽量缩放到-1到1之间==
10 |
11 | ### 4.4 梯度下降法实践2-学习率
12 |
13 | 也有一些自动测试是否收敛的方法,例如将代价函数的变化值与某个阀值(例如0.001)进行比较,但通常看上面这样的图表更好。
14 |
15 | ==相当于当误差小于某个值之后停止迭代,但通常选择一个合适的误差值会比较困难,所以推荐看图==
16 |
17 | 梯度下降算法的每次迭代受到学习率的影响,如果学习率过小,则达到收敛所需的迭代次数会非常高;如果学习率过大,每次迭代可能不会减小代价函数,可能会越过局部最小值导致无法收敛。
18 |
19 | ### 4.5 特征和多项式回归
20 |
21 | 通常我们需要先观察数据然后再决定准备尝试怎样的模型
22 |
23 | 注:如果我们采用多项式回归模型,在运行梯度下降算法前,特征缩放非常有必要。
24 |
25 | ### 4.6 正规方程
26 |
27 |  28 |
29 | 总结一下,只要特征变量的数目并不大,标准方程是一个很好的计算参数的替代方法。具体地说,只要特征变量数量小于一万,我通常使用标准方程法,而不使用梯度下降法。
30 |
31 | 随着我们要讲的学习算法越来越复杂,例如,当我们讲到分类算法,==像逻辑回归算法,我们会看到,实际上对于那些算法,并不能使用标准方程法。对于那些更复杂的学习算法,我们将不得不仍然使用梯度下降法。==因此,梯度下降法是一个非常有用的算法,可以用在有大量特征变量的线性回归问题。或者我们以后在课程中,会讲到的一些其他的算法,因为标准方程法不适合或者不能用在它们上。但对于这个特定的线性回归模型,标准方程法是一个比梯度下降法更快的替代算法。所以,根据具体的问题,以及你的特征变量的数量,这两种算法都是值得学习的。
32 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/某车厂基础架构部门二面.md:
--------------------------------------------------------------------------------
1 | ## 某车厂基础架构部门二面
2 |
3 | 自我介绍
4 |
5 | 能实习多久
6 |
7 | 上次面完有复盘么
8 |
9 | java 和 go有什么区别
10 |
11 | 为什么学java
12 |
13 | 了解云原生么,为什么想来做这个
14 |
15 | 你怎么理解云原生
16 |
17 | 你对分布式存储有兴趣么?
18 |
19 | > 提到了三驾马车,然后上了场景题
20 |
21 | 我们数据怎么做成一个可靠的,不丢数据呢?
22 |
23 | raft怎么保证数据一致性?
24 |
25 | follower宕机,集群出现什么问题
26 |
27 | > 有个问题没听清直接跳过了
28 |
29 | 为什么产生脑裂?
30 |
31 | 三节点变成5节点会出现什么问题?
32 |
33 | 介绍下谷歌夏令营
34 |
35 | 介绍下开源活动
36 |
37 | 介绍下你在里面做的事
38 |
39 | 你对go有兴趣么,对它的未来有什么看法
40 |
41 | 你是要完全转go么?
42 |
43 | 存储数据会遇到哪些问题?
44 |
45 | 比如我们要存100亿个文件(文件大小先不讨论),你怎么存下它?
46 |
47 | > 协调(调度),冗余(副本)
48 |
49 | 怎么实现高并发读写?
50 |
51 | 文件元信息存哪?
52 |
53 | > 分布式kv
54 |
55 | 分布式kv会用到哪些技术?
56 |
57 | 拿到元信息之后,你知道了它数据写哪里,你怎么分片它?
58 |
59 | 分片完了,你需要组合,怎么组合它?组合关系放到哪呢?
60 |
61 | > 放元信息里
62 |
63 | 你分成小分片文件,那你是存在文件系统里呢?还是不存文件系统里呢?存在文件系统里会出现什么问题呢?
64 |
65 | 如果存文件系统,那要多少台机器呢?
66 |
67 | 存不下去的话,你怎么解决它?
68 |
69 | 还有个问题,进程和线程,那你觉得这个问题什么时候用到线程和进程?
70 |
71 | 从这个角度来看,进程线程有什么区别?进程怎么通信,线程怎么通信?
72 |
73 | ………………………………………………
74 |
75 | 10亿个数字中找出重复的两个
76 |
77 | 还有些面试官讲的行业现状之类的就不公开发表了,我在 冲友群(小红书链接: http://xhslink.com/k6xqnl ) 等你来交流。
78 |
--------------------------------------------------------------------------------
/深度学习机器学习/00 纠错.md:
--------------------------------------------------------------------------------
1 | 请问,中文文本纠错如何做? - 顾颜兮的回答 - 知乎 https://www.zhihu.com/question/34818800/answer/499306314
2 |
3 |
4 |
5 | 传统的n-gram,贝叶斯,互信息等方法都能实现句子的检错,纠错的模块一般采用计算编辑距离啊,或者根据拼音或者字型或者其他的同义词混淆词,建立一个词典,计算一些概率啊,来找错误和纠正错误。现在检错部分开始有一些序列标注的方法开始使用了,建立BiLSTM+CRF模型,特征可以加入字,词性,依存关系等,似乎能更好的理解上下文。
6 |
7 |
8 |
9 |
10 |
11 | NLP任务最新研究进展(六)——文本纠错
12 |
13 | https://zhuanlan.zhihu.com/p/550699273
14 |
15 |
16 |
17 | 手撕 BiLSTM-CRF - 虎哥的文章 - 知乎 https://zhuanlan.zhihu.com/p/97676647
18 |
19 |
20 |
21 |
22 |
23 | ### N-Gram
24 |
25 | n-gramhttps://paddlepedia.readthedocs.io/en/latest/tutorials/natural_language_processing/N-Gram.html
26 |
27 |
28 |
29 | attention机制
30 |
31 | https://www.bilibili.com/video/BV1xS4y1k7tn/?spm_id_from=pageDriver&vd_source=2de111953f823751c56f32f11f1416a2
32 |
33 |
34 |
35 |
36 |
37 | 语言模型困惑度(Perplexity,PPL),是用来评价语言模型的一个指标,用来预
38 | 测文本的质量如何。通常情况下,PPL 的值越小,表明样本越可靠,也就是越准确,
39 | 模型的效果较好。反之,PPL 的值越大,说明模型的效果越差。
40 | 字粒度:可以用来判断某个字是否为错别字,评判的标准使用 PPL 指标来评价,
41 | 如果 P(某字)< avg P(语句),则认为该字可能为错别字,其中,P 表示概率,avg
42 | 表示语句的平均值。
43 | 词粒度:如果某词为汉语中常见的词语,则认为该词为正确词,如果语句切词后
44 | 发现某词不在词典中,则认为该词疑似错词的概率比较
45 |
46 |
47 |
48 |
49 |
50 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/某车厂基础架构部门一面.md:
--------------------------------------------------------------------------------
1 | ## 某车厂基础架构部门一面
2 |
3 | 总结
4 |
5 | 体验很好,不会问一些偏的八股,不会的还会引导
6 |
7 | 最后也给了些学习建议,非常不错的面试
8 |
9 | ----
10 |
11 | 自我介绍
12 |
13 | 操作系统线程、进程
14 |
15 | 线程、进程的通讯方式
16 |
17 | tcp/udp 区别、应用场景
18 |
19 | 三次/四次
20 |
21 | tcp粘包(不了解,给我讲了是个什么情形)
22 |
23 | 你怎么解决tcp粘包
24 |
25 | 讲一下paxos(因为聊的很开心,我直接说我就开始吟唱了😼
26 |
27 | >从CAP--》PACELC
28 | >
29 | >应该再讲NWR的
30 | >
31 | >然后Paxos
32 | >
33 | >活锁
34 | >
35 | >mutil-paxos
36 |
37 | 你觉得raft和paxos他们有什么本质的区别吗?它为了工程实现丢弃了什么东西?
38 |
39 | 讲讲raft的子功能过程
40 |
41 | -----场景题-----
42 |
43 | 如果有个节点落后其他节点很多日志,raft怎么处理?
44 |
45 | > follower强制同步leader日志
46 |
47 | 有个读请求到了follower,raft怎么操作
48 |
49 | > 转发给leader
50 |
51 | 读请求正好打到了刚才那个落后了很多日志的节点上怎么办?
52 |
53 | >如果实现了线性一致性读,是可以从follower读的
54 |
55 | 三节点,有一个节点(可能是leader可能是follower宕机),说下此时集群内部是什么情况
56 |
57 | 宕机节点重新加入集群后发生什么?
58 |
59 | 网络分区时,候选者的term不停+1后,另外两个节点正常服务,网络恢复后,集群发生什么?
60 |
61 | > leader选举规则
62 | >
63 | > 保证被选出来的leader一定包含了之前各任期的所有被提交的日志
64 | >
65 | > 投票rpc有限制:如果投票者自己的日志比candidate的还新,那么它会拒绝掉该投票
66 | >
67 | >
68 |
69 |
70 |
71 | ---
72 |
73 |
74 |
75 | 算法
76 |
77 | 字符串转数字
78 |
79 | poj1852 (默默感谢zju人形题库ACM巨佬
80 |
81 |
82 |
83 |
--------------------------------------------------------------------------------
/算法/字节算法.md:
--------------------------------------------------------------------------------
1 | 1. two sum
2 |
3 | 2. three sum
4 |
5 | 3. 已知 rand3 函数,希望生成一个 rand7 函数
6 |
7 | 4. 求二叉树哪一个点到其他所有点的路径总和最小,树的重心
8 |
9 | 5. `acm` abaaabbbaaab 要求 O(N)算法,求最长子串,包含相同数目的 a 和 b 字符
10 |
11 | 6. 快速排序和归并排序描述一下
12 |
13 | 快速排序:先选定一个基准元素,按照这个基准元素将数组划分,再在被划分的数组上重 复上过程,最后可以得到排序结果。 归并排序:将数组不断细分成最小的单位,然后每个单位分别排序,排序完以后合并,重 复这个过程就得到了排序结果 优缺点:归并排序稳定且最高最低时间复杂度都是 nlogn,但是占用额外空间;不稳定, 最高时间复杂度 n2,最低时间复杂度 nlgn,不占用额外空间
14 |
15 | 7. 算法题:给出一个数字矩阵,寻找一条最长上升路径,每个位置只能向上下左右四个位置 移动。
16 |
17 | 8. 给定数组返回任意满足(当前数大于左右两个数) 要求时间小于 O(n)
18 |
19 | 9. 蛇形打印
20 |
21 | 10. bfs 非递归遍历二叉树
22 |
23 | 11. 数组的中位数(快速选择)
24 |
25 | 12. 反转链表?如何按照步长反转链表,即 1->2->3->4->5,步长为 2,反转为 2->1->4->3->5;
26 |
27 | 13. 合并 n 个有序数组
28 |
29 | 14. 枚举全排列
30 |
31 | 15. 最近公共祖先
32 |
33 | 16. 海量数据 TopK 问题
34 |
35 | 17. leetcode 85
36 |
37 | 18. 岛屿问题
38 |
39 | 19. 交替上升数组
40 |
41 | 20. 合并 K 个排序链表
42 |
43 | 21. 一个由 01 组成的矩阵,问其中由 1 组成的矩形的个数
44 |
45 | 22. 松鼠捡松子(n个格子,每个格子有不同数量的松子,松鼠在第一个格子,每次可以向前跳3-5格,到了一个格子拿走松子,问跳出去后松鼠最少捡多少松子)
46 |
47 | 23. 奇偶位置分别升序和降 序的链表转化为升序链表
48 |
49 | 24. 旋转数组找最小值
50 |
51 | 25. 数据流的中位数。这道题有点吃亏,虽然见过原题,但是没有去网上找过最 优的解法。然后现场面,面试官就硬要让优化,最后才想出来用两个堆实现。
52 |
53 | 26. 有若干个整数,每次输入一个,要求每输入一个就输出当前所有输入的中位 数,时间复杂度尽量小,能想到几种解法(leetcode 原题,好像叫 stream median)
54 |
55 | 27. 二叉树转换成中序链表,不能用额外空间,可以递归。
56 |
57 | 回文串的数量
58 |
59 | 第一个缺失的正数
60 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/百度后端日常实习一面.md:
--------------------------------------------------------------------------------
1 | ## 百度后端日常实习一面
2 |
3 | 总结:非常好的面试体验。1.5h, 算法没想出来面试官给耐心讲思路
4 |
5 | 信号不好,端着电脑站着面完了算法题以外的部门。。。
6 |
7 | 新体验+++
8 |
9 | 整体来看就是八股测试知识边界
10 |
11 | …………………………………………………………
12 |
13 | 自我介绍
14 |
15 | 讲讲项目
16 |
17 | GSoC介绍
18 |
19 | 开源实习介绍
20 |
21 | 集成测试介绍
22 |
23 | ShenYu社区介绍
24 |
25 | 为什么学分布式
26 |
27 | 分布式介绍
28 |
29 | > cap-pacelc-nwr-paxos
30 |
31 | 分布式算法介绍
32 |
33 | 分布式项目介绍
34 |
35 | 项目难点
36 |
37 | 难点怎么解决
38 |
39 | …………………………………………………………
40 |
41 | 十进制怎么转换成二进制呢
42 |
43 | 有一个七进制怎么转三进制呢
44 |
45 | 指令位数有了解过么
46 |
47 | CRC 校验
48 |
49 | 抓包工具用过没
50 |
51 | 从输入一个 URL 告诉我整个显示页面这个过程是一个怎么样
52 |
53 | > 开始吟唱
54 |
55 | 七层模型
56 |
57 | TCP 和 UDP 的区别
58 |
59 | linux命令用过哪些
60 |
61 | 怎么查看开发日志
62 |
63 | mysql 和redis
64 |
65 | mysql 分工分表有用过吗
66 |
67 | MySQL 索引的是 B 加数。 B 加数属于二叉数吗
68 |
69 | 红黑树
70 |
71 | 红黑数和 B 加树的区别可以总结一下吗
72 |
73 | 经典的一些排序算法有了解过吗
74 |
75 | 快排、堆排、冒泡
76 |
77 | 树
78 |
79 | 图
80 |
81 | 队列、栈、链表的区别
82 |
83 | 图和数的区别
84 |
85 | …………………………………………………………
86 |
87 | GitHub上找到了之前我写的爬虫,然后问现在你有什么新方案没
88 |
89 | …………………………………………………………
90 |
91 | 数组旋转90度
92 |
93 | 二叉树后序非递归遍历
94 |
95 | …………………………………………………………
96 |
97 | 反问
98 |
99 | 部门业务
100 |
101 | 实习生工作
102 |
103 |
--------------------------------------------------------------------------------
/笔记/1.3Java并发/面试题.md:
--------------------------------------------------------------------------------
1 | ### Java的线程和操作系统的线程的关系?是通过操作系统来操作的吗?
2 |
3 | 在Java SE 8 API规范的Thread类说明中算是找到了线程调度的有关描述:
4 |
5 | - 每个线程有一个优先级(从1级到10级),较高优先级的线程比低优先级线程先执行。
6 | - 程序员可以通过Thread.setPriority(int)设置线程的优先级,默认的优先级是NORM_PRIORITY。
7 | - Java SE 还声明JVM可以任何方式实现线程的优先级,甚至忽略它的存在。
8 |
9 | 我们是通过Java创建的线程,线程调度的事儿Java是脱不开的。那Java又是如何将线程调度交给底层的操作系统去做呢?下面我们将跟随JVM虚拟机底层平台上的实现,说明Java线程的调度策略。
10 |
11 | 既然Java底层的运行平台提供了强大的线程管理能力,Java就没有理由再自己进行线程的管理和调度了。于是JVM放弃了绿色线程的实现机制
12 |
13 | 将每个Java线程一对一映射到底层平台上的一个本地线程上,并将线程调度交由本地线程的调度程序
14 |
15 | 只有在底层平台不支持线程时,JVM才会自己实现线程的管理和调度,此时Java线程以绿色线程的方式运行。由于目前流行的操作系统都支持线程,所以JVM就没必要管线程调度的事情了。应用程序通过setPriority()方法设置的线程优先级,将映射到内核级线程的优先级,影响内核的线程调度。
16 |
17 | 作者:A_minor
18 | 链接:https://juejin.cn/post/6872588006121816077
19 | 来源:稀土掘金
20 |
21 | 总结来说,**现今 Java 中线程的本质,其实就是操作系统中的线程,其线程库和线程模型很大程度上依赖于操作系统(宿主系统)的具体实现,比如在 Windows 中 Java 就是基于 Win32 线程库来管理线程,且 Windows 采用的是一对一的线程模型。**
22 |
23 | https://zhuanlan.zhihu.com/p/474022823
24 |
25 |
26 |
27 |
28 |
29 | ### final方法可以被重载吗?
30 |
31 | 我们知道父类的final方法是不能够被子类重写的,那么final方法可以被重载吗? 答案是可以的,下面代码是正确的。
32 |
33 | ```java
34 | public class FinalExampleParent {
35 | public final void test() {
36 | }
37 |
38 | public final void test(String str) {
39 | }
40 | }
41 | ```
42 |
43 | 著作权归https://pdai.tech所有。 链接:https://pdai.tech/md/java/thread/java-thread-x-key-final.html
44 |
45 |
--------------------------------------------------------------------------------
/深度学习机器学习/吴恩达笔记4.md:
--------------------------------------------------------------------------------
1 | ## 第八、神经网络:表述(Neural Networks: Representation)
2 |
3 | ### 8.1 非线性假设
4 |
5 | 无论是线性回归还是逻辑回归都有这样一个缺点,即:当特征太多时,计算的负荷会非常大。
6 |
7 | 普通的逻辑回归模型,不能有效地处理这么多的特征,这时候我们需要神经网络。
8 |
9 | ### 8.2 神经元和大脑
10 |
11 | 神经网络是一种很古老的算法,它最初产生的目的是制造能模拟大脑的机器。
12 |
13 | 如果你能把几乎任何传感器接入到大脑中,大脑的学习算法就能找出学习数据的方法,并处理这些数据。从某种意义上来说,如果我们能找出大脑的学习算法,然后在计算机上执行大脑学习算法或与之相似的算法,也许这将是我们向人工智能迈进做出的最好的尝试。人工智能的梦想就是:有一天能制造出真正的智能机器。
14 |
15 | ### 8.3 模型表示1/前向传播
16 |
17 | 每一个神经元都可以被认为是一个处理单元/神经核(**processing unit**/**Nucleus**),它含有许多输入/树突(**input**/**Dendrite**),并且有一个输出/轴突(**output**/**Axon**)。神经网络是大量神经元相互链接并通过电脉冲来交流的一个网络。
18 |
19 | 神经网络模型建立在很多神经元之上,每一个神经元又是一个个学习模型。这些神经元(也叫==激活单元,**activation unit**==)采纳一些特征作为输出,并且根据本身的模型提供一个输出。下图是一个以逻辑回归模型作为自身学习模型的神经元示例,在神经网络中,==参数又可被成为权重(**weight**)==。
20 |
21 | 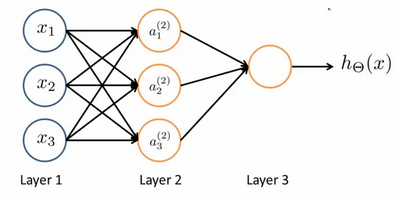
22 |
23 | ==X1 是输入单元(**input units**),====A1 a2 是中间单元==它们负责将数据进行处理,然后呈递到下一层。 最后是输出单元,它负责计算
24 |
25 | 神经网络模型是许多逻辑单元按照不同层级组织起来的网络,每一层的输出变量都是下一层的输入变量。下图为一个3层的神经网络,第一层成为==输入层(**Input Layer**)==,最后一层称为==输出层(**Output Layer**)==,中间一层成为==隐藏层(**Hidden Layers**)==。我们为每一层都增加一个==偏差单位(**bias unit**)==:
26 |
27 | 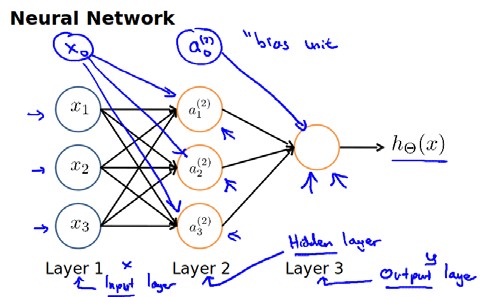
28 |
29 |
30 |
31 | 上图中每一个 a 都是由上一层所有的 x 和 每层对应的 x 所决定的
32 |
33 | 把这样从左到右的算法称为==前向传播算法( **FORWARD PROPAGATION** )==
34 |
35 | ### 8.4 模型表示2
36 |
37 | ### 8.5 特征和直观理解1
38 |
39 |
40 |
41 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/网易灵犀二面.md:
--------------------------------------------------------------------------------
1 | ## 网易灵犀二面
2 |
3 | 总结:全程扣项目细节,算法打家劫舍1
4 |
5 | 信号不好,站着面了一半
6 |
7 | ……………………………………
8 |
9 | 自我介绍
10 |
11 | 你对实习的期望有什么预期吗?有什么实习目的吗?
12 |
13 | 你对实习的动机是?工作内容是倾向于业务/基础研发?
14 |
15 | 讲下GSoC
16 |
17 | 讲下做的工作
18 |
19 | 讲下集成测试流程
20 |
21 | 网关底层了解过吗
22 |
23 | hystrix 底层了解过吗
24 |
25 | 实习遇到的问题
26 |
27 | 讲下分布式的那个项目
28 |
29 | > 他说可以讲cap,我就开始吟唱了
30 | >
31 | > cap-pacelc-nwr-paxos-活锁
32 |
33 | 脑裂
34 |
35 | raft解决脑裂
36 |
37 | 写代码有用到设计模式吗?
38 |
39 | 最近有看什么书么?
40 |
41 | > DDIA 、 吴军博士的软能力
42 |
43 | 读DDIA有什么收获吗?
44 |
45 | 为什么读DDIA?
46 |
47 | 讲讲为什么做这个微服务系统
48 |
49 | 拆分微服务原则是?
50 |
51 | > **2.拆分原则**
52 | >
53 | > - **单一职责原则:** 每个微服务只需关心自己的业务规则,确保职责单一,避免职责交叉,耦合度过高将会造成代码修改重合,不利于后期维护。
54 | > - **服务自治原则:** 每个微服务的开发,必须拥有开发、测试、运维、部署等整个过程,并且拥有自己独立的[数据库](https://cloud.tencent.com/solution/database?from=10680)等,可以完全把其当作一个单独的项目来做,而不牵扯到其他无关业务。
55 | > - **轻量级通信原则:** 微服务间需通过轻量级通信机制进行交互。首先是体量较轻,其次是需要支持跨平台、跨语言的通信协议,再次是需要具备操作性强、易于测试等能力,如:REST通信协议。
56 | > - **接口明确原则:** 明确接口要实现的内容,避免接口依赖,如A接口的改动会导致B接口的改动。
57 | > - **持续演进原则:** 单体架构向微服务架构拆分过程中,无法做到一蹴而就,刚开始不建议拆分太小,过度拆分将会带来架构复杂度的急剧升高,开发、测试、运维等环节很难快速适应,将会导致故障率大幅增加,可用性降低,非必要情况,应逐步拆分细化,持续演进,避免微服务数量的瞬间爆炸性增长。
58 |
59 | 你会有一些场景会你就是某一些场景导致你会在两个服务之间去做一些数据的同时的变更吗?
60 |
61 | 然后这里 Redis 主要是用来缓存什么数据,
62 |
63 | 双写问题
64 |
65 | 怎么优化?
66 |
67 | 项目流程是?
68 |
69 | ……………………………………
70 |
71 | 打家劫舍1
72 |
73 | ……………………………………
74 |
75 | 反问
76 |
77 | 部门工作
78 |
79 | 实习生工作
80 |
81 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 | # notes
3 |
4 | 记录一下找到实习(日常/暑期)之前的笔记
5 |
6 | ## 自动提交
7 |
8 | [github 生成ssh-key ,免用户名密码提交代码](https://blog.csdn.net/qq_33398459/article/details/97397812)
9 |
10 | [git脚本,一键提交代码](https://blog.csdn.net/Jie0817/article/details/121650229)
11 |
12 | [shell.sh](https://github.com/erdengk/notes/blob/main/shell.sh)
13 |
14 | ## 目录
15 |
16 | ```
17 | ├── x
18 | │ └── 面试1 .md
19 | ├── x 常见智力题
20 | │ └── 1 赛马问题.md
21 | ├── 笔记
22 | │ ├── 0.1操作系统
23 | │ │ └── 1基础.md
24 | │ ├── 0.2计算机网络
25 | │ ├── 0.3机组
26 | │ ├── 1.1Java基础
27 | │ │ ├── 0.Java基础.md
28 | │ │ ├── 1.概述.md
29 | │ │ ├── 2.面向对象.md
30 | │ │ ├── 3.常用类.md
31 | │ │ ├── 4.异常-反射-泛型.md
32 | │ │ └── x..md
33 | │ ├── 1.2Java容器
34 | │ │ ├── 1 集合.md
35 | │ │ ├── ArrayList-1.md
36 | │ │ ├── ArrayList.md
37 | │ │ ├── hashmap.md
38 | │ │ ├── map分析.md
39 | │ │ └── 容器源码分析.md
40 | │ ├── 1.3Java并发
41 | │ │ ├── 0.总结.md
42 | │ │ ├── 1.线程理论基础.md
43 | │ │ ├── archive
44 | │ │ ├── 并发关键字.md
45 | │ │ └── 并发理论(JMM).md
46 | │ ├── 1.4Jvm 相关
47 | │ ├── 1.5 Java8
48 | │ │ └── 1.新特性.md
49 | │ ├── MySQL
50 | │ │ ├── 0.MySQL.md
51 | │ │ ├── 1.基础回顾.md
52 | │ │ └── 2.mysql怎么运行的.md
53 | │ ├── Spring相关
54 | │ │ └── 1.基础知识.md
55 | │ └── 技术面试+v2.0.md
56 | ├── 极客时间
57 | │ └── Java核心面试
58 | │ └── 1.md
59 | └── 深度学习机器学习
60 | ├── 0 总结.md
61 | ├── 00 纠错.md
62 | ├── 资源汇总.md
63 | ├── 吴恩达笔记1.md
64 | ├── 吴恩达笔记2.md
65 | ├── 吴恩达笔记3.md
66 | ├── 吴恩达笔记4.md
67 | ├── 吴恩达笔记5.md
68 | └── 吴恩达笔记6.md
69 | ```
70 |
71 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/粤港澳后端开发.md:
--------------------------------------------------------------------------------
1 | ## 粤港澳后端开发
2 |
3 | 自我介绍
4 |
5 | 为什么主动参加开源
6 |
7 | 对实习有什么看法
8 |
9 | 你参加开源不就是在实习么,你觉得他们有什么区别
10 |
11 | springboot 和spring有什么区别
12 |
13 | springboot怎么做到简化开发的
14 |
15 | 约定大于配置(其实面试官想问自动装配的,没反应过来)
16 |
17 | 讲讲cap
18 |
19 | 为什么增高一致性要提高写副本数量
20 |
21 | 讲paxos项目实现了哪些功能
22 |
23 | 你自己觉得项目还有哪些改进地方
24 |
25 | 说下paxos两阶段流程
26 |
27 | 活锁
28 |
29 | Raft在两阶段提交上做了什么优化
30 |
31 | > 引导思考:
32 | >
33 | > 你觉得两阶段提交有什么问题
34 | >
35 | > >**2PC的缺点**
36 | > >
37 | > >1、协调者存在单点问题。如果协调者挂了,整个2PC逻辑就彻底不能运行。
38 | > >
39 | > >2、执行过程是完全同步的。各参与者在等待其他参与者响应的过程中都处于阻塞状态,大并发下有性能问题。
40 | > >
41 | > >3、仍然存在不一致风险。如果由于网络异常等意外导致只有部分参与者收到了commit请求,就会造成部分参与者提交了事务而其他参与者未提交的情况。
42 | > >
43 | > >[链接](https://zhuanlan.zhihu.com/p/35616810)
44 | > >
45 | > >[链接1](https://zhuanlan.zhihu.com/p/111304281)
46 | > >
47 | > >[链接2](https://learn.lianglianglee.com/%E4%B8%93%E6%A0%8F/%E5%88%86%E5%B8%83%E5%BC%8F%E6%8A%80%E6%9C%AF%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E6%88%9845%E8%AE%B2-%E5%AE%8C/08%20%E5%AF%B9%E6%AF%94%E4%B8%A4%E9%98%B6%E6%AE%B5%E6%8F%90%E4%BA%A4%EF%BC%8C%E4%B8%89%E9%98%B6%E6%AE%B5%E5%8D%8F%E8%AE%AE%E6%9C%89%E5%93%AA%E4%BA%9B%E6%94%B9%E8%BF%9B%EF%BC%9F.md)
48 | > >
49 | > >[链接3](https://karellincoln.github.io/2018/04/07/consensus-2pc/)
50 | >
51 | > 如果leader发送心跳发送的慢了,网络阻塞了,follower会发生什么
52 | >
53 | > leader投票规则
54 | >
55 | >
56 |
57 | raft和zab区别
58 |
59 | 讲讲zab
60 |
61 | > 这部分答的不好
62 | >
63 | > 面试官:没事,后面多了解,用的多了就了解了,很正常,没关系
64 | >
65 | > 我:疯狂道歉
66 |
67 | JVM内存模型
68 |
69 | jvm解决可见性、原子性
70 |
71 | 保证可见性
72 |
73 | sync关键字
74 |
75 |
76 |
77 | 写代码
78 |
79 | 输入两个矩阵(输入有效),输出矩阵乘积
80 |
81 |
82 |
83 | 场景题
84 |
85 | 比如刚才的这个过程中,如果中间有的部分加起来大于int,我们该怎么判断他中间是否超过了int
--------------------------------------------------------------------------------
/笔记/0.2计算机网络/1 .md:
--------------------------------------------------------------------------------
1 | https://app.yinxiang.com/fx/743af2df-4651-4097-8479-29b5639dca70
2 |
3 |
4 |
5 | https://www.nowcoder.com/discuss/post/353159080753700864
6 |
7 |
8 |
9 | ### Web页面的请求过程
10 |
11 | #### **简略版**:
12 |
13 | URL 敲下之后,浏览器是想要生成一个 TCP 套接字,以向目标 HTTP 服务器请求资源。
14 | 为了生成 TCP 套接字,我们必须知道域名对应的 IP 地址;
15 | 为了知道域名的 IP 地址,我们必须先向 DNS 服务器发送 DNS 查询报文;
16 | 为了向 DNS 服务器发送 DNS 查询报文,需要知道默认网关的 MAC 地址。
17 | 为了知道其 MAC 地址,必须用 ARP 协议进行解析出下一跳,也就是默认网关的 MAC 地址。
18 |
19 | 拿到默认网关 MAC 地址后,会封装一个 DNS 查询报文,向 DNS 发送 查询请求。
20 | DNS 服务器收到请求后,把查询结果放在 UDP 报文段中,返回给主机。
21 |
22 | 主机现在拿到了域名对应的 IP 地址,可以生成套接字,把套接字用于向 HTTP 服务器发送 HTTP GET 报文了。
23 | 而在生成 TCP 套接字之前,要进行三次握手的连接
24 | 1
25 | 2
26 | 3
27 | 连接之后,把 GET 请求封装在报文中,交付给 HTTP 服务器。
28 | HTTP 服务器拿到请求报文后,返回对应的 Web 资源。
29 | 浏览器收到 HTTP 响应之后,抽取 Web 页面的内容进行渲染。
30 |
31 | #### **巨tm详细版**:
32 |
33 | 应用层:URL 敲下之后,首先浏览器会生成一个 TCP 套接字,以向目标 HTTP 服务器请求资源。为了生成该套接字,需要知道该 URL 域名对应的 IP 地址。
34 | 应用层:而为了向 DNS 服务器发送请求,生成一个 DNS 查询报文,是 53 端口号的。
35 | 网络层:这个 DNS 数据报被放入一个目的地址为 DNS 服务器 IP 地址的 IP 数据报中。
36 | IP 数据报被放入一个帧中,把帧发到默认的网关中,而为了知道网关的 MAC 地址,需要用 ARP 协议来把网关的 IP 解析为 MAC 地址。
37 |
38 | 直到了网关的 MAC 地址后,才可以继续 DNS 的解析过程。
39 | 网关路由器拿到 DNS 查询报文后,会根据报文转发给下一跳,直到到达 DNS 服务器。
40 | 到达 DNS 服务器后,DNS 在数据库中查询待解析的域名。
41 | 找到 DNS 记录后,发送 DNS 回答报文,放入 UDP 报文段中,转发回主机。
42 |
43 | 主机拿到了解析后的域名,也就是 IP 地址后,就能生成套接字,把套接字用于向 Web 服务器发送 HTTP GET 报文。
44 | 在生成 TCP 套接字之前,必须先与 HTTP 服务器进行三次握手来建立连接。
45 | 生成一个具有目的端口 80 的 TCP SYN 报文段,并向 HTTP 服务器发送该报文段。
46 | HTTP 服务器收到该报文段之后,回复 TCP 的 SYN ACK 报文段,发回主机。
47 | 主机接收到 SYN ACK 之后,再次恢复一个 ACK 确认连接报文段到 HTTP 服务器。
48 | 三次连接建立完毕。
49 | 浏览器生成 HTTP GET 报文,并交付给 HTTP 服务器。
50 | HTTP 服务器从 TCP 套接字读取 HTTP GET 报文,生成一个响应报文,把 Web 页面的内容放入报文主体中,返回给主机。
51 | 浏览器拿到响应报文后,抽取 Web 页面内容,渲染页面。
52 |
53 |
--------------------------------------------------------------------------------
/深度学习机器学习/吴恩达笔记3.md:
--------------------------------------------------------------------------------
1 | ## 六、逻辑回归(Logistic Regression)
2 |
3 | 在分类问题中,你要预测的变量`y`是离散的值,我们将学习一种叫做逻辑回归 (**Logistic Regression**) 的算法,这是目前最流行使用最广泛的一种学习算法。
4 |
5 | ==逻辑回归算法,这个算法的性质是:它的输出值永远在0到 1 之间。==
6 |
7 | 逻辑回归算法实际上是一种分类算法,它适用于标签 `y` 取值离散的情况,如:1 0 0 1。
8 |
9 | ### 6.3 判定边界
10 |
11 | 下决策边界(**decision boundary**)的概念。这个概念能更好地帮助我们理解逻辑回归的假设函数在计算什么。
12 |
13 | ### 6.4 代价函数
14 |
15 | 如何拟合逻辑回归模型的参数
16 |
17 | 我要定义用来拟合参数的优化目标或者叫代价函数,这便是监督学习问题中的逻辑回归模型的拟合问题
18 |
19 | 
20 |
21 | 除了梯度下降算法以外,还有一些常被用来令代价函数最小的算法,这些算法更加复杂和优越,而且通常不需要人工选择学习率,通常比梯度下降算法要更加快速。这些算法有:**共轭梯度**(**Conjugate Gradient**),**局部优化法**(**Broyden fletcher goldfarb shann,BFGS**)和**有限内存局部优化法**(**LBFGS**) ,**fminunc**是 **matlab**和**octave** 中都带的一个最小值优化函数,使用时我们需要提供代价函数和每个参数的求导。
22 |
23 | ### 6.5 简化的成本函数和梯度下降
24 |
25 | ==如何运用梯度下降法,来拟合出逻辑回归的参数==
26 |
27 | ### 6.7 多类别分类:一对多
28 |
29 | 如何使用逻辑回归 (**logistic regression**)来解决多类别分类问题,具体来说,我想通过一个叫做"一对多" (**one-vs-all**) 的分类算法。
30 |
31 | "一对余"方法
32 |
33 | abc 三类,拆成 a(bc)、 (ab)c 、(ac)b 三个二元分类问题
34 |
35 | ## 七、正则化(Regularization)
36 |
37 | ### 7.1 过拟合的问题
38 |
39 | 过拟合(**over-fitting**)的问题
40 |
41 | 正则化(**regularization**)的技术,它可以改善或者减少过度拟合问题
42 |
43 | 问题是,如果我们发现了过拟合问题,应该如何处理?
44 |
45 | 1. 丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(例如**PCA**)
46 | 2. 正则化。 保留所有的特征,但是减少参数的大小(**magnitude**)。
47 |
48 |
49 |
50 | ### 7.2 代价函数
51 |
52 | 正是那些高次项导致了过拟合的产生,所以如果我们能让这些高次项的系数接近于0的话,我们就能很好的拟合了
53 |
54 | ==引入惩罚系数,降低高次项系数==
55 |
56 | 假如我们有非常多的特征,我们并不知道其中哪些特征我们要惩罚,我们将对所有的特征进行惩罚,并且让代价函数最优化的软件来选择这些惩罚的程度
57 |
58 | ### 7.3 正则化线性回归
59 |
60 | 正则化线性回归的梯度下降算法的变化在于,每次都在原有算法更新规则的基础上令θ值减少了一个额外的值
61 |
62 | ### 7.4 正则化的逻辑回归模型
63 |
64 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/美团后端实习一面.md:
--------------------------------------------------------------------------------
1 | ## 美团后端实习一面
2 |
3 | 总结:面试官很热情,讲了很多部门相关的东西
4 |
5 | 场景题也给讲了一些东西,学到了
6 |
7 | ……………………………………
8 |
9 | 面试官自我介绍
10 |
11 | 自我介绍
12 |
13 | 讲讲GSoC
14 |
15 | 讲讲开源实习
16 |
17 | 讲讲做的工作
18 |
19 | 我要去怎么样定义我这个插件是成功了,然后是有一些怎么样的测试方式呢?
20 |
21 | 这种测试你们能怎么验证它是能不能用呢?
22 |
23 | 讲讲集成测试流程
24 |
25 | 用例设计
26 |
27 | ……………………………………
28 |
29 | 这个项目中间又遇到过什么问题呢?
30 |
31 | > 讲了设计测试用例以及如何写一份可靠的代码
32 |
33 | 有没有什么你关于项目的一些执行或者是说从项目的开发到落地上面的一些认知呢?
34 |
35 | 那像这种开源的项目,他是他的需求来源点是什么呢?
36 |
37 | 我看你还有一个项目叫那个分布式算法。然后可以。给我介绍一下这个
38 |
39 | > 开始吟唱
40 | >
41 | > cap-pacelc-nwr-paxos-活锁-raft-zab
42 |
43 | 然后你是基于什么的原因会去学习到这些分布式相关的或者说开源的这些东西,自己是怎么有有有的有个什么想法呢?
44 |
45 | ……………………………………
46 |
47 | 讲讲JUC
48 |
49 | redis 数据结构
50 |
51 | 删除策略
52 |
53 | 过期策略
54 |
55 | ……………………………………
56 |
57 | 场景题
58 |
59 | 我异步添加了100个key,然后让他们在指定过期时间上加一部分随机过期时间,最后发现总是有些key没有加随机时间,怎么排除问题?
60 |
61 | ```
62 | //伪代码
63 | for(int i= 0; i<100; i++) {
64 | redis.asyncPush("key"+i, "value");
65 | redis.expire("key"+i, 100);
66 | }
67 | ```
68 |
69 | > 一开始想了key是否会存在,然后没往这方面继续想
70 | >
71 | > 丢包?不会
72 | >
73 | > 面试官:是不是可以从日志去查?
74 | >
75 | > 我:aof 和 rdb日志
76 | >
77 | > 面试官:还有就是我们的api是否用对了?asyncPush、expire 的方法我们是否真的理解了
78 | >
79 | > --------
80 | >
81 | > 对于这个问题,因为是异步添加,因为有些key是不存在的,所以我们的expire可能会失败。
82 |
83 |
84 |
85 | ……………………………………
86 |
87 | 算法
88 |
89 | lc,移动零
90 |
91 | ……………………………………
92 |
93 | 反问
94 |
95 | 部门工作
96 |
97 | 实习生工作
98 |
99 | base
100 |
101 | 几面
102 |
103 | ……………………………………
104 |
105 | 场景题的话,我在 冲友群(小红书链接:https://www.xiaohongshu.com/discovery/item/6373b539000000002203b896 ) 等你来交流。(也可以私信我你的个人介绍,我和群主说了拉你进群
--------------------------------------------------------------------------------
/深度学习机器学习/资源汇总.md:
--------------------------------------------------------------------------------
1 | ## 理论学习
2 |
3 | 【黑马程序员3天快速入门python机器学习】 https://www.bilibili.com/video/BV1nt411r7tj?p=6&share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
4 |
5 | 【(强推)李宏毅2021/2022春机器学习课程】 https://www.bilibili.com/video/BV1Wv411h7kN?share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
6 |
7 | 【[双语字幕]吴恩达深度学习deeplearning.ai】 https://www.bilibili.com/video/BV1FT4y1E74V?share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
8 |
9 | ---
10 |
11 | 【[中英字幕]吴恩达机器学习系列课程】 https://www.bilibili.com/video/BV164411b7dx?share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
12 |
13 | [斯坦福大学2014机器学习教程中文笔记目录](http://www.ai-start.com/ml2014/)
14 |
15 | 动画ai https://space.bilibili.com/1921388479
16 |
17 | 【卷积神经网络】8分钟搞懂CNN,动画讲解喜闻乐见】 https://www.bilibili.com/video/BV1fY411H7g8?share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
18 |
19 | ## 实战
20 |
21 | 【PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】】 https://www.bilibili.com/video/BV1hE411t7RN?share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
22 |
23 | 【04 数据操作 + 数据预处理【动手学深度学习v2】】 https://www.bilibili.com/video/BV1CV411Y7i4?share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
24 |
25 | 【Python+人工智能基础班(通俗易懂版教学)_人工智能基础入门教程_人工智能机器学习】 https://www.bilibili.com/video/BV1ou411U7J4?share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
26 |
27 | ## 目标
28 |
29 | 1. 吴恩达视频你并不需要全看,并且看的时候更多的你只需要关注一些机器学习中的重要概念**(过拟合、欠拟合、损失函数、评价指标等、前向传播、反向传播,能明白在干什么就行)**,至于具体的公式推导(尤其是反向传播具体的推导),没有必要去看,你也不会直接用到)。你看以下几部分就好了:**引言、单变量线性回归、(线性代数回顾)、多变量线性回归、逻辑回归、正则化、神经网络的学习、神经网络:表述、应用、机器学习的建议、机器学习系统的设计**。这里面最最重要的是**线性回归和逻辑回归**,这两个你要搞得比较明白。
30 | 2. 你在看吴恩达视频的时候只需要用到numpy(这是一个python的矩阵运算库)就够了,pytorch之后再学比较好。(pytorch中很大一部分操作和numpy是一样的,只是多了一些用于训练模型的方便的函数)
31 | 3. 这里有一个图文版的吴恩达课程,你可以先看这个,看不懂再看视频,这样可能会快一些http://www.ai-start.com/ml2014/
32 | 3. **你只要能完整地搞明白线性回归和逻辑回归的原理和代码**,你关于吴恩达视频的目标就算完成了
33 | 3. 所以不要耗太多时间在这个上面,感觉差不多的话就可以切换到PyTorch上了
34 | 3. 你就花一个周或者稍微多一点点差不多把这些最基本的东西差不多搞清楚就行
35 |
36 | -----
37 |
38 | pytorch \ transformer 能修改开源的代码就行
39 |
40 | 与原理对应的关系 了解就可以
41 |
42 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/百度面经收集.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | https://www.nowcoder.com/enterprise/139/interview
4 |
5 | ### 实习
6 |
7 | https://www.nowcoder.com/discuss/post/392104028828708864
8 |
9 | https://www.nowcoder.com/discuss/post/422438091262054400
10 |
11 | https://www.nowcoder.com/discuss/post/384102178951110656
12 |
13 | https://www.nowcoder.com/discuss/post/383744565965070336
14 |
15 | https://www.nowcoder.com/discuss/382278026720026624
16 |
17 | https://www.nowcoder.com/discuss/post/424705098825072640
18 |
19 | https://www.nowcoder.com/discuss/post/422438091262054400
20 |
21 | https://www.nowcoder.com/discuss/post/402137855114457088
22 |
23 | https://www.nowcoder.com/discuss/post/409760803471044608
24 |
25 | https://www.nowcoder.com/discuss/post/406119364531941376
26 |
27 | https://www.nowcoder.com/discuss/post/397180832601960448
28 |
29 | ### 提前批/秋招/社招
30 |
31 | https://www.nowcoder.com/discuss/post/416537596492349440
32 |
33 | https://www.nowcoder.com/discuss/post/393075119143366656
34 |
35 | https://www.nowcoder.com/discuss/post/394241237249794048
36 |
37 | https://www.nowcoder.com/discuss/post/390928190703763456
38 |
39 | https://www.nowcoder.com/discuss/post/395953742338592768
40 |
41 | https://www.nowcoder.com/discuss/post/398978026636066816
42 |
43 | https://www.nowcoder.com/discuss/post/414204606991843328
44 |
45 | https://www.nowcoder.com/discuss/post/418048972818837504
46 |
47 | https://www.nowcoder.com/discuss/post/385226120973635584
48 |
49 | https://www.nowcoder.com/discuss/post/384450105879920640
50 |
51 | https://www.nowcoder.com/discuss/post/381172254556659712
52 |
53 | https://www.nowcoder.com/discuss/post/381912595815628800
54 |
55 | https://www.nowcoder.com/discuss/post/383697412597067776
56 |
57 | https://www.nowcoder.com/discuss/383693481930252288
58 |
59 | https://www.nowcoder.com/discuss/382552296046043136
60 |
61 | https://www.nowcoder.com/discuss/post/379732925338738688
62 |
63 | https://www.nowcoder.com/discuss/382184734011547648
64 |
65 | https://www.nowcoder.com/discuss/post/380482995600297984
66 |
67 | https://www.nowcoder.com/discuss/post/381910191615365120
68 |
69 | https://www.nowcoder.com/discuss/post/381753156055707648
70 |
71 | https://www.nowcoder.com/discuss/post/380500761812246528
72 |
73 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/上海小厂懂技术的面试官技术面.md:
--------------------------------------------------------------------------------
1 | ## 11.3 上海小厂懂技术的面试官技术面
2 |
3 | 当时以为录音了,后期发现没录音,哭死。。。
4 |
5 | ### 自我介绍
6 |
7 | 因为他开场说对分布式感兴趣,所以就正常的个人信息结束后,在技能部分补充了对分布式的理解
8 |
9 | ```
10 | 如果面试官和你说他对你某个点感兴趣,在你能讲清楚这个点的前提下,请加大力度阐述
11 | ```
12 |
13 | 然后在个人技术方向部分多说了会分布式和云原生
14 |
15 | ```
16 | 参考模版:
17 |
18 | 姓名,学校,年级,专业
19 | 实习时间
20 |
21 | 主要语言,技术栈,数据库,中间件,目前学习方向
22 | 未来发展方向
23 |
24 | 个人开源经历/核心竞争力阐述
25 | 个人技术分享/校内/竞赛经历
26 |
27 | 个人项目/实习经历
28 |
29 | 希望能一起共事
30 | ```
31 |
32 |
33 |
34 | ### 讲讲你的开源经历
35 |
36 | 从shenyu到glcc
37 |
38 | ### 讲讲paxos项目
39 |
40 | 从CAP开始讲
41 |
42 | (中间可以讲PACELC、BASE、Quorum,我忘了)
43 |
44 | 然后讲Paxos的两阶段提交
45 |
46 | 然后讲活锁
47 |
48 | 然后讲项目里自己怎么解决的(参考raft)
49 |
50 | (他如果没让停,就可以继续说Raft)
51 |
52 | >讲完之后他说,你这个理解不错,本来准备问的问题都被你回答了。算法就免了。
53 | >
54 | >我:算法还是要刷的
55 | >
56 | >面试官:没办法才考算法,你这个可以不用考了
57 |
58 | ### 讲讲网关
59 |
60 | 南北向网关(APISIX),东西向网关(ShenYu)
61 |
62 |
63 |
64 | ### 我看你博客UV 7k,很高了,平时写些什么
65 |
66 | 主要是开源分享、后端技术分享和个人读书推荐
67 |
68 | ### 我看你博客里写了多级页表,讲讲
69 |
70 | [链接](http://erdengk.top/archives/924jiang-jiang-cao-zuo-xi-tong-de-duo-ji-ye-biao--wei-shen-me-duo-ji-ye-biao-hui-sheng-kong-jian-)
71 |
72 |
73 |
74 | ### 我看你写了零拷贝,能讲一下不?
75 |
76 | 零拷贝是一种硬件层面的优化,在这种方法中,并不是拷贝0次,而是减少了拷贝次数,如果不使用0拷贝,需要先将数据放到cpu中,然后再让其他进程读取,这样肯定会影响cpu的性能。
77 |
78 | 如果使用了0拷贝,并不需要将数据放到cpu中,而是让cpu通知具体的模块去做个事,也就降低了cpu的压力。
79 |
80 | ---
81 |
82 | 在正式介绍零拷贝结束(Zero-Copy)之前,我们先简单介绍一下DMA(Direct Memory Access)技术。DMA,又称之为直接内存访问,是零拷贝技术的基石。DMA 传输将数据从一个地址空间复制到另外一个地址空间。当CPU 初始化这个传输动作,传输动作本身是由 DMA 控制器来实行和完成。因此通过DMA,硬件则可以绕过CPU,自己去直接访问系统主内存。很多硬件都支持DMA,其中就包括网卡、声卡、磁盘驱动控制器等。
83 | 有了DMA技术的支持之后,网卡就可以直接区访问内核空间的内存,这样就可以实现内核空间和应用空间之间的零拷贝了,极大地提升传输性能。
84 |
85 | Kafka用到的零拷贝技术,主要是减少了核心态和用户态之间的两次数据拷贝过程,使得数据可以不用经过用户态直接通过网卡发送到接收方,同时通过DMA技术,可以使CPU得到解放,这样实现了数据的高性能传输。
86 |
87 | https://www.jianshu.com/p/0af1b4f1e164
88 |
89 |
90 |
91 | ### 反问:您那边是做什么业务的,我需要做什么?
92 |
93 | 是做知识图谱和图数据库相关的,实习生的话会做一些图数据库相关的
94 |
95 | ```
96 | 记得要问自己做什么,还有他们在做什么
97 | ```
98 |
99 |
100 |
101 | ### 反问:您对我的项目有什么建议吗?
102 |
103 | 这个paxos可以再完善下,现在是非拜占庭问题,考虑怎么解决拜占庭问题。
104 |
105 | 还有PBFT 算法可以了解下
106 |
107 | 处理非拜占庭错误的算法有:paxos、raft和其变种
108 |
109 | 处理拜占庭错误算法有:pbft、pow算法
110 |
111 | ```
112 | 抓住机会,如果面试官懂你的技术栈,必问问题之一
113 | ```
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/字节面经收集.md:
--------------------------------------------------------------------------------
1 | Hashmap 描述。多线程会发生什么问题
2 |
3 | 多线程 put 操作可能发生死循环或者元素丢失
4 |
5 | 加问死循环发生原因: 多个线程执行 put 操作时同时触发了 rehash 方法,可能会生成环形链
6 |
7 |
8 |
9 | select * from tableA whereA.a=?order by A.b 加索引优化
10 |
11 |
12 |
13 |
14 |
15 | tcp/ip 五层架构对应什么协议
16 |
17 | url 访问原理
18 |
19 | dns 的原理,在路由器上找的时候,有哪几种情况
20 |
21 | 写爬虫系统时,如何判定该 url 已经爬过了。这个问题很开 放,而且也挺有意思。
22 |
23 |
24 |
25 | jvm g1 回收器讲一下
26 |
27 |
28 |
29 | mysql的索引用的什么数据结构
30 |
31 | B+树属于二叉树么
32 |
33 | 为什么不用红黑树
34 |
35 | 红黑树和B+树的区别
36 |
37 |
38 |
39 |
40 |
41 | close_wait状态有什么用
42 |
43 | 场景题1:m元分成n个红包,随机分配,需要保证红包的金额均匀分布,每个红包金额大于等于0.01,且是0.01的整数倍
44 |
45 | 场景题2:m*n矩阵,从第一行第一列开始走,每次只能往右或者往下走,求走到最后一行最后一列的位置有多少种走法:dp和数学方法都说一下
46 |
47 |
48 |
49 |
50 |
51 | 交换机,路由器分别在哪一层
52 |
53 | 路由和交换机之间的主要区别就是交换机发生在OSI参考模型第二层(数据链路层),而路由发生在第三层,即网络层。
54 |
55 |
56 |
57 | mysql的redo log undo log干嘛的
58 |
59 |
60 |
61 |
62 |
63 | q
64 |
65 | redis跳表 是不是 空间换时间的思想,在链表上构建索引来减少查询的时间
66 |
67 |
68 |
69 | java的gc机制
70 |
71 | java的类加载机制?好处?
72 |
73 | java堆和栈里存的都是什么
74 |
75 | 被static修饰的成员变量存放在哪里
76 |
77 |
78 |
79 | MySQL事务如何实现回滚
80 |
81 | MySQL的事务隔离级别,每种隔离级别遇到的问题,如何解决
82 |
83 |
84 |
85 | 了解http么?http的长连接
86 |
87 | tcp的keep-alive
88 |
89 | tcp的拥塞控制
90 |
91 |
92 |
93 | 1.Mysql的慢查询如何排查?
94 |
95 | 2.Mysql为什么要使用两阶段提交?
96 |
97 | 3.如何监控redo日志的刷盘频率?
98 |
99 | 4.数据库的四大范式讲一讲?
100 |
101 | 5.redis满足acid吗,仔细讲讲哪些满足哪些不满足?
102 |
103 | 6.http和https的区别?
104 |
105 | mysql为什么用B+树做索引不用B树,为什么不用跳表做索引?
106 |
107 | 2.zookeeper做分布式锁和redis做分布式锁的区别?zookeeper如何实现分布式锁?
108 |
109 | 谈谈AQS?
110 |
111 | 5.并发环境使用原子整形计数会有什么问题?longAddr有了解吗?
112 |
113 | .三次握手第一次握手的报文问丢失会怎么样?有做过实验吗?
114 |
115 | 3.要一次性发送10mb数据,用tcp还是udp?
116 |
117 | 4.软中断和硬中断的区别?
118 |
119 | 5.数据从用户空间到发送出去需要经过哪些步骤?
120 |
121 |
122 |
123 | 如果建立外连接,两张表都太大了咋优化 https://blog.csdn.net/robinson1988/article/details/50756921
124 |
125 |
126 |
127 |
128 |
129 | https://www.nowcoder.com/discuss/post/415582189854752768
130 |
131 | https://www.nowcoder.com/discuss/post/403957055290175488
132 |
133 | https://www.nowcoder.com/discuss/post/405050183480782848
134 |
135 | https://www.nowcoder.com/discuss/post/410116058700324864
136 |
137 | https://www.nowcoder.com/discuss/post/423433825918668800
138 |
139 | https://www.nowcoder.com/discuss/post/422804842957033472
140 |
141 | https://www.nowcoder.com/discuss/post/419502682978729984
142 |
143 | https://www.nowcoder.com/discuss/post/423628210666070016
144 |
--------------------------------------------------------------------------------
/深度学习机器学习/吴恩达笔记1.md:
--------------------------------------------------------------------------------
1 | ## 机器学习是什么?
2 |
3 | 在进行特定编程的情况下,给予计算机学习能力的领域
4 |
5 | 目前存在几种不同类型的学习算法。主要的两种类型被我们称之为监督学习和无监督学习
6 |
7 | 监督学习这个想法是指,我们将教计算机如何去完成任务,
8 |
9 | 无监督学习中,我们打算让它自己进行学习
10 |
11 | ### 监督学习
12 |
13 | 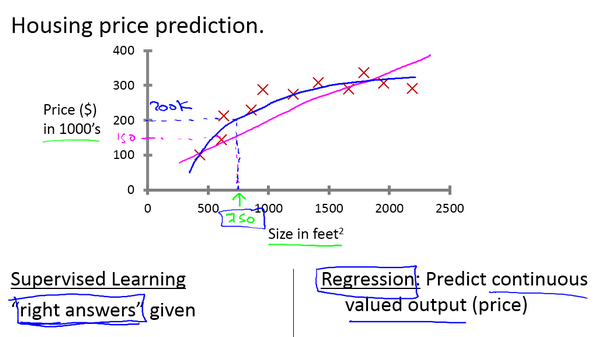
14 |
15 | ==监督学习==指的就是我们给学习算法一个数据集。这个数据集由“正确答案”组成
16 |
17 | 在房价的例子中,我们给了一系列房子的数据,我们给定数据集中每个样本的正确价格,即它们实际的售价然后运用学习算法,算出更多的正确答案。比如你朋友那个新房子的价格。用术语来讲,这叫做回归问题。我们试着推测出一个连续值的结果,即房子的价格
18 |
19 | ==回归==这个词的意思是,我们在试着推测出这一系列连续值属性。
20 |
21 | **支持向量机,里面有一个巧妙的数学技巧,能让计算机处理无限多个特征**
22 |
23 |
24 |
25 | ### 无监督学习
26 |
27 | 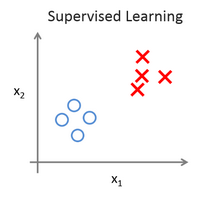
28 |
29 | 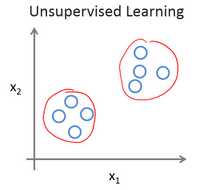
30 |
31 | 不同于监督学习的数据的样子,即无监督学习中没有任何的标签或者是有相同的标签或者就是没标签
32 |
33 | 针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。这是一个,那是另一个,二者不同。是的,无监督学习算法可能会把这些数据分成两个不同的簇。所以叫做聚类算法。事实证明,它能被用在很多地方。
34 |
35 | 这是有一堆数据。我不知道数据里面有什么。我不知道谁是什么类型。我甚至不知道人们有哪些不同的类型,这些类型又是什么
36 |
37 | ## 单变量线性回归(Linear Regression with One Variable)
38 |
39 | ### 线性回归算法
40 |
41 | 在监督学习中我们有一个数据集,这个数据集被称==训练集==
42 |
43 |
28 |
29 | 总结一下,只要特征变量的数目并不大,标准方程是一个很好的计算参数的替代方法。具体地说,只要特征变量数量小于一万,我通常使用标准方程法,而不使用梯度下降法。
30 |
31 | 随着我们要讲的学习算法越来越复杂,例如,当我们讲到分类算法,==像逻辑回归算法,我们会看到,实际上对于那些算法,并不能使用标准方程法。对于那些更复杂的学习算法,我们将不得不仍然使用梯度下降法。==因此,梯度下降法是一个非常有用的算法,可以用在有大量特征变量的线性回归问题。或者我们以后在课程中,会讲到的一些其他的算法,因为标准方程法不适合或者不能用在它们上。但对于这个特定的线性回归模型,标准方程法是一个比梯度下降法更快的替代算法。所以,根据具体的问题,以及你的特征变量的数量,这两种算法都是值得学习的。
32 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/某车厂基础架构部门二面.md:
--------------------------------------------------------------------------------
1 | ## 某车厂基础架构部门二面
2 |
3 | 自我介绍
4 |
5 | 能实习多久
6 |
7 | 上次面完有复盘么
8 |
9 | java 和 go有什么区别
10 |
11 | 为什么学java
12 |
13 | 了解云原生么,为什么想来做这个
14 |
15 | 你怎么理解云原生
16 |
17 | 你对分布式存储有兴趣么?
18 |
19 | > 提到了三驾马车,然后上了场景题
20 |
21 | 我们数据怎么做成一个可靠的,不丢数据呢?
22 |
23 | raft怎么保证数据一致性?
24 |
25 | follower宕机,集群出现什么问题
26 |
27 | > 有个问题没听清直接跳过了
28 |
29 | 为什么产生脑裂?
30 |
31 | 三节点变成5节点会出现什么问题?
32 |
33 | 介绍下谷歌夏令营
34 |
35 | 介绍下开源活动
36 |
37 | 介绍下你在里面做的事
38 |
39 | 你对go有兴趣么,对它的未来有什么看法
40 |
41 | 你是要完全转go么?
42 |
43 | 存储数据会遇到哪些问题?
44 |
45 | 比如我们要存100亿个文件(文件大小先不讨论),你怎么存下它?
46 |
47 | > 协调(调度),冗余(副本)
48 |
49 | 怎么实现高并发读写?
50 |
51 | 文件元信息存哪?
52 |
53 | > 分布式kv
54 |
55 | 分布式kv会用到哪些技术?
56 |
57 | 拿到元信息之后,你知道了它数据写哪里,你怎么分片它?
58 |
59 | 分片完了,你需要组合,怎么组合它?组合关系放到哪呢?
60 |
61 | > 放元信息里
62 |
63 | 你分成小分片文件,那你是存在文件系统里呢?还是不存文件系统里呢?存在文件系统里会出现什么问题呢?
64 |
65 | 如果存文件系统,那要多少台机器呢?
66 |
67 | 存不下去的话,你怎么解决它?
68 |
69 | 还有个问题,进程和线程,那你觉得这个问题什么时候用到线程和进程?
70 |
71 | 从这个角度来看,进程线程有什么区别?进程怎么通信,线程怎么通信?
72 |
73 | ………………………………………………
74 |
75 | 10亿个数字中找出重复的两个
76 |
77 | 还有些面试官讲的行业现状之类的就不公开发表了,我在 冲友群(小红书链接: http://xhslink.com/k6xqnl ) 等你来交流。
78 |
--------------------------------------------------------------------------------
/深度学习机器学习/00 纠错.md:
--------------------------------------------------------------------------------
1 | 请问,中文文本纠错如何做? - 顾颜兮的回答 - 知乎 https://www.zhihu.com/question/34818800/answer/499306314
2 |
3 |
4 |
5 | 传统的n-gram,贝叶斯,互信息等方法都能实现句子的检错,纠错的模块一般采用计算编辑距离啊,或者根据拼音或者字型或者其他的同义词混淆词,建立一个词典,计算一些概率啊,来找错误和纠正错误。现在检错部分开始有一些序列标注的方法开始使用了,建立BiLSTM+CRF模型,特征可以加入字,词性,依存关系等,似乎能更好的理解上下文。
6 |
7 |
8 |
9 |
10 |
11 | NLP任务最新研究进展(六)——文本纠错
12 |
13 | https://zhuanlan.zhihu.com/p/550699273
14 |
15 |
16 |
17 | 手撕 BiLSTM-CRF - 虎哥的文章 - 知乎 https://zhuanlan.zhihu.com/p/97676647
18 |
19 |
20 |
21 |
22 |
23 | ### N-Gram
24 |
25 | n-gramhttps://paddlepedia.readthedocs.io/en/latest/tutorials/natural_language_processing/N-Gram.html
26 |
27 |
28 |
29 | attention机制
30 |
31 | https://www.bilibili.com/video/BV1xS4y1k7tn/?spm_id_from=pageDriver&vd_source=2de111953f823751c56f32f11f1416a2
32 |
33 |
34 |
35 |
36 |
37 | 语言模型困惑度(Perplexity,PPL),是用来评价语言模型的一个指标,用来预
38 | 测文本的质量如何。通常情况下,PPL 的值越小,表明样本越可靠,也就是越准确,
39 | 模型的效果较好。反之,PPL 的值越大,说明模型的效果越差。
40 | 字粒度:可以用来判断某个字是否为错别字,评判的标准使用 PPL 指标来评价,
41 | 如果 P(某字)< avg P(语句),则认为该字可能为错别字,其中,P 表示概率,avg
42 | 表示语句的平均值。
43 | 词粒度:如果某词为汉语中常见的词语,则认为该词为正确词,如果语句切词后
44 | 发现某词不在词典中,则认为该词疑似错词的概率比较
45 |
46 |
47 |
48 |
49 |
50 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/某车厂基础架构部门一面.md:
--------------------------------------------------------------------------------
1 | ## 某车厂基础架构部门一面
2 |
3 | 总结
4 |
5 | 体验很好,不会问一些偏的八股,不会的还会引导
6 |
7 | 最后也给了些学习建议,非常不错的面试
8 |
9 | ----
10 |
11 | 自我介绍
12 |
13 | 操作系统线程、进程
14 |
15 | 线程、进程的通讯方式
16 |
17 | tcp/udp 区别、应用场景
18 |
19 | 三次/四次
20 |
21 | tcp粘包(不了解,给我讲了是个什么情形)
22 |
23 | 你怎么解决tcp粘包
24 |
25 | 讲一下paxos(因为聊的很开心,我直接说我就开始吟唱了😼
26 |
27 | >从CAP--》PACELC
28 | >
29 | >应该再讲NWR的
30 | >
31 | >然后Paxos
32 | >
33 | >活锁
34 | >
35 | >mutil-paxos
36 |
37 | 你觉得raft和paxos他们有什么本质的区别吗?它为了工程实现丢弃了什么东西?
38 |
39 | 讲讲raft的子功能过程
40 |
41 | -----场景题-----
42 |
43 | 如果有个节点落后其他节点很多日志,raft怎么处理?
44 |
45 | > follower强制同步leader日志
46 |
47 | 有个读请求到了follower,raft怎么操作
48 |
49 | > 转发给leader
50 |
51 | 读请求正好打到了刚才那个落后了很多日志的节点上怎么办?
52 |
53 | >如果实现了线性一致性读,是可以从follower读的
54 |
55 | 三节点,有一个节点(可能是leader可能是follower宕机),说下此时集群内部是什么情况
56 |
57 | 宕机节点重新加入集群后发生什么?
58 |
59 | 网络分区时,候选者的term不停+1后,另外两个节点正常服务,网络恢复后,集群发生什么?
60 |
61 | > leader选举规则
62 | >
63 | > 保证被选出来的leader一定包含了之前各任期的所有被提交的日志
64 | >
65 | > 投票rpc有限制:如果投票者自己的日志比candidate的还新,那么它会拒绝掉该投票
66 | >
67 | >
68 |
69 |
70 |
71 | ---
72 |
73 |
74 |
75 | 算法
76 |
77 | 字符串转数字
78 |
79 | poj1852 (默默感谢zju人形题库ACM巨佬
80 |
81 |
82 |
83 |
--------------------------------------------------------------------------------
/算法/字节算法.md:
--------------------------------------------------------------------------------
1 | 1. two sum
2 |
3 | 2. three sum
4 |
5 | 3. 已知 rand3 函数,希望生成一个 rand7 函数
6 |
7 | 4. 求二叉树哪一个点到其他所有点的路径总和最小,树的重心
8 |
9 | 5. `acm` abaaabbbaaab 要求 O(N)算法,求最长子串,包含相同数目的 a 和 b 字符
10 |
11 | 6. 快速排序和归并排序描述一下
12 |
13 | 快速排序:先选定一个基准元素,按照这个基准元素将数组划分,再在被划分的数组上重 复上过程,最后可以得到排序结果。 归并排序:将数组不断细分成最小的单位,然后每个单位分别排序,排序完以后合并,重 复这个过程就得到了排序结果 优缺点:归并排序稳定且最高最低时间复杂度都是 nlogn,但是占用额外空间;不稳定, 最高时间复杂度 n2,最低时间复杂度 nlgn,不占用额外空间
14 |
15 | 7. 算法题:给出一个数字矩阵,寻找一条最长上升路径,每个位置只能向上下左右四个位置 移动。
16 |
17 | 8. 给定数组返回任意满足(当前数大于左右两个数) 要求时间小于 O(n)
18 |
19 | 9. 蛇形打印
20 |
21 | 10. bfs 非递归遍历二叉树
22 |
23 | 11. 数组的中位数(快速选择)
24 |
25 | 12. 反转链表?如何按照步长反转链表,即 1->2->3->4->5,步长为 2,反转为 2->1->4->3->5;
26 |
27 | 13. 合并 n 个有序数组
28 |
29 | 14. 枚举全排列
30 |
31 | 15. 最近公共祖先
32 |
33 | 16. 海量数据 TopK 问题
34 |
35 | 17. leetcode 85
36 |
37 | 18. 岛屿问题
38 |
39 | 19. 交替上升数组
40 |
41 | 20. 合并 K 个排序链表
42 |
43 | 21. 一个由 01 组成的矩阵,问其中由 1 组成的矩形的个数
44 |
45 | 22. 松鼠捡松子(n个格子,每个格子有不同数量的松子,松鼠在第一个格子,每次可以向前跳3-5格,到了一个格子拿走松子,问跳出去后松鼠最少捡多少松子)
46 |
47 | 23. 奇偶位置分别升序和降 序的链表转化为升序链表
48 |
49 | 24. 旋转数组找最小值
50 |
51 | 25. 数据流的中位数。这道题有点吃亏,虽然见过原题,但是没有去网上找过最 优的解法。然后现场面,面试官就硬要让优化,最后才想出来用两个堆实现。
52 |
53 | 26. 有若干个整数,每次输入一个,要求每输入一个就输出当前所有输入的中位 数,时间复杂度尽量小,能想到几种解法(leetcode 原题,好像叫 stream median)
54 |
55 | 27. 二叉树转换成中序链表,不能用额外空间,可以递归。
56 |
57 | 回文串的数量
58 |
59 | 第一个缺失的正数
60 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/百度后端日常实习一面.md:
--------------------------------------------------------------------------------
1 | ## 百度后端日常实习一面
2 |
3 | 总结:非常好的面试体验。1.5h, 算法没想出来面试官给耐心讲思路
4 |
5 | 信号不好,端着电脑站着面完了算法题以外的部门。。。
6 |
7 | 新体验+++
8 |
9 | 整体来看就是八股测试知识边界
10 |
11 | …………………………………………………………
12 |
13 | 自我介绍
14 |
15 | 讲讲项目
16 |
17 | GSoC介绍
18 |
19 | 开源实习介绍
20 |
21 | 集成测试介绍
22 |
23 | ShenYu社区介绍
24 |
25 | 为什么学分布式
26 |
27 | 分布式介绍
28 |
29 | > cap-pacelc-nwr-paxos
30 |
31 | 分布式算法介绍
32 |
33 | 分布式项目介绍
34 |
35 | 项目难点
36 |
37 | 难点怎么解决
38 |
39 | …………………………………………………………
40 |
41 | 十进制怎么转换成二进制呢
42 |
43 | 有一个七进制怎么转三进制呢
44 |
45 | 指令位数有了解过么
46 |
47 | CRC 校验
48 |
49 | 抓包工具用过没
50 |
51 | 从输入一个 URL 告诉我整个显示页面这个过程是一个怎么样
52 |
53 | > 开始吟唱
54 |
55 | 七层模型
56 |
57 | TCP 和 UDP 的区别
58 |
59 | linux命令用过哪些
60 |
61 | 怎么查看开发日志
62 |
63 | mysql 和redis
64 |
65 | mysql 分工分表有用过吗
66 |
67 | MySQL 索引的是 B 加数。 B 加数属于二叉数吗
68 |
69 | 红黑树
70 |
71 | 红黑数和 B 加树的区别可以总结一下吗
72 |
73 | 经典的一些排序算法有了解过吗
74 |
75 | 快排、堆排、冒泡
76 |
77 | 树
78 |
79 | 图
80 |
81 | 队列、栈、链表的区别
82 |
83 | 图和数的区别
84 |
85 | …………………………………………………………
86 |
87 | GitHub上找到了之前我写的爬虫,然后问现在你有什么新方案没
88 |
89 | …………………………………………………………
90 |
91 | 数组旋转90度
92 |
93 | 二叉树后序非递归遍历
94 |
95 | …………………………………………………………
96 |
97 | 反问
98 |
99 | 部门业务
100 |
101 | 实习生工作
102 |
103 |
--------------------------------------------------------------------------------
/笔记/1.3Java并发/面试题.md:
--------------------------------------------------------------------------------
1 | ### Java的线程和操作系统的线程的关系?是通过操作系统来操作的吗?
2 |
3 | 在Java SE 8 API规范的Thread类说明中算是找到了线程调度的有关描述:
4 |
5 | - 每个线程有一个优先级(从1级到10级),较高优先级的线程比低优先级线程先执行。
6 | - 程序员可以通过Thread.setPriority(int)设置线程的优先级,默认的优先级是NORM_PRIORITY。
7 | - Java SE 还声明JVM可以任何方式实现线程的优先级,甚至忽略它的存在。
8 |
9 | 我们是通过Java创建的线程,线程调度的事儿Java是脱不开的。那Java又是如何将线程调度交给底层的操作系统去做呢?下面我们将跟随JVM虚拟机底层平台上的实现,说明Java线程的调度策略。
10 |
11 | 既然Java底层的运行平台提供了强大的线程管理能力,Java就没有理由再自己进行线程的管理和调度了。于是JVM放弃了绿色线程的实现机制
12 |
13 | 将每个Java线程一对一映射到底层平台上的一个本地线程上,并将线程调度交由本地线程的调度程序
14 |
15 | 只有在底层平台不支持线程时,JVM才会自己实现线程的管理和调度,此时Java线程以绿色线程的方式运行。由于目前流行的操作系统都支持线程,所以JVM就没必要管线程调度的事情了。应用程序通过setPriority()方法设置的线程优先级,将映射到内核级线程的优先级,影响内核的线程调度。
16 |
17 | 作者:A_minor
18 | 链接:https://juejin.cn/post/6872588006121816077
19 | 来源:稀土掘金
20 |
21 | 总结来说,**现今 Java 中线程的本质,其实就是操作系统中的线程,其线程库和线程模型很大程度上依赖于操作系统(宿主系统)的具体实现,比如在 Windows 中 Java 就是基于 Win32 线程库来管理线程,且 Windows 采用的是一对一的线程模型。**
22 |
23 | https://zhuanlan.zhihu.com/p/474022823
24 |
25 |
26 |
27 |
28 |
29 | ### final方法可以被重载吗?
30 |
31 | 我们知道父类的final方法是不能够被子类重写的,那么final方法可以被重载吗? 答案是可以的,下面代码是正确的。
32 |
33 | ```java
34 | public class FinalExampleParent {
35 | public final void test() {
36 | }
37 |
38 | public final void test(String str) {
39 | }
40 | }
41 | ```
42 |
43 | 著作权归https://pdai.tech所有。 链接:https://pdai.tech/md/java/thread/java-thread-x-key-final.html
44 |
45 |
--------------------------------------------------------------------------------
/深度学习机器学习/吴恩达笔记4.md:
--------------------------------------------------------------------------------
1 | ## 第八、神经网络:表述(Neural Networks: Representation)
2 |
3 | ### 8.1 非线性假设
4 |
5 | 无论是线性回归还是逻辑回归都有这样一个缺点,即:当特征太多时,计算的负荷会非常大。
6 |
7 | 普通的逻辑回归模型,不能有效地处理这么多的特征,这时候我们需要神经网络。
8 |
9 | ### 8.2 神经元和大脑
10 |
11 | 神经网络是一种很古老的算法,它最初产生的目的是制造能模拟大脑的机器。
12 |
13 | 如果你能把几乎任何传感器接入到大脑中,大脑的学习算法就能找出学习数据的方法,并处理这些数据。从某种意义上来说,如果我们能找出大脑的学习算法,然后在计算机上执行大脑学习算法或与之相似的算法,也许这将是我们向人工智能迈进做出的最好的尝试。人工智能的梦想就是:有一天能制造出真正的智能机器。
14 |
15 | ### 8.3 模型表示1/前向传播
16 |
17 | 每一个神经元都可以被认为是一个处理单元/神经核(**processing unit**/**Nucleus**),它含有许多输入/树突(**input**/**Dendrite**),并且有一个输出/轴突(**output**/**Axon**)。神经网络是大量神经元相互链接并通过电脉冲来交流的一个网络。
18 |
19 | 神经网络模型建立在很多神经元之上,每一个神经元又是一个个学习模型。这些神经元(也叫==激活单元,**activation unit**==)采纳一些特征作为输出,并且根据本身的模型提供一个输出。下图是一个以逻辑回归模型作为自身学习模型的神经元示例,在神经网络中,==参数又可被成为权重(**weight**)==。
20 |
21 | 
22 |
23 | ==X1 是输入单元(**input units**),====A1 a2 是中间单元==它们负责将数据进行处理,然后呈递到下一层。 最后是输出单元,它负责计算
24 |
25 | 神经网络模型是许多逻辑单元按照不同层级组织起来的网络,每一层的输出变量都是下一层的输入变量。下图为一个3层的神经网络,第一层成为==输入层(**Input Layer**)==,最后一层称为==输出层(**Output Layer**)==,中间一层成为==隐藏层(**Hidden Layers**)==。我们为每一层都增加一个==偏差单位(**bias unit**)==:
26 |
27 | 
28 |
29 |
30 |
31 | 上图中每一个 a 都是由上一层所有的 x 和 每层对应的 x 所决定的
32 |
33 | 把这样从左到右的算法称为==前向传播算法( **FORWARD PROPAGATION** )==
34 |
35 | ### 8.4 模型表示2
36 |
37 | ### 8.5 特征和直观理解1
38 |
39 |
40 |
41 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/网易灵犀二面.md:
--------------------------------------------------------------------------------
1 | ## 网易灵犀二面
2 |
3 | 总结:全程扣项目细节,算法打家劫舍1
4 |
5 | 信号不好,站着面了一半
6 |
7 | ……………………………………
8 |
9 | 自我介绍
10 |
11 | 你对实习的期望有什么预期吗?有什么实习目的吗?
12 |
13 | 你对实习的动机是?工作内容是倾向于业务/基础研发?
14 |
15 | 讲下GSoC
16 |
17 | 讲下做的工作
18 |
19 | 讲下集成测试流程
20 |
21 | 网关底层了解过吗
22 |
23 | hystrix 底层了解过吗
24 |
25 | 实习遇到的问题
26 |
27 | 讲下分布式的那个项目
28 |
29 | > 他说可以讲cap,我就开始吟唱了
30 | >
31 | > cap-pacelc-nwr-paxos-活锁
32 |
33 | 脑裂
34 |
35 | raft解决脑裂
36 |
37 | 写代码有用到设计模式吗?
38 |
39 | 最近有看什么书么?
40 |
41 | > DDIA 、 吴军博士的软能力
42 |
43 | 读DDIA有什么收获吗?
44 |
45 | 为什么读DDIA?
46 |
47 | 讲讲为什么做这个微服务系统
48 |
49 | 拆分微服务原则是?
50 |
51 | > **2.拆分原则**
52 | >
53 | > - **单一职责原则:** 每个微服务只需关心自己的业务规则,确保职责单一,避免职责交叉,耦合度过高将会造成代码修改重合,不利于后期维护。
54 | > - **服务自治原则:** 每个微服务的开发,必须拥有开发、测试、运维、部署等整个过程,并且拥有自己独立的[数据库](https://cloud.tencent.com/solution/database?from=10680)等,可以完全把其当作一个单独的项目来做,而不牵扯到其他无关业务。
55 | > - **轻量级通信原则:** 微服务间需通过轻量级通信机制进行交互。首先是体量较轻,其次是需要支持跨平台、跨语言的通信协议,再次是需要具备操作性强、易于测试等能力,如:REST通信协议。
56 | > - **接口明确原则:** 明确接口要实现的内容,避免接口依赖,如A接口的改动会导致B接口的改动。
57 | > - **持续演进原则:** 单体架构向微服务架构拆分过程中,无法做到一蹴而就,刚开始不建议拆分太小,过度拆分将会带来架构复杂度的急剧升高,开发、测试、运维等环节很难快速适应,将会导致故障率大幅增加,可用性降低,非必要情况,应逐步拆分细化,持续演进,避免微服务数量的瞬间爆炸性增长。
58 |
59 | 你会有一些场景会你就是某一些场景导致你会在两个服务之间去做一些数据的同时的变更吗?
60 |
61 | 然后这里 Redis 主要是用来缓存什么数据,
62 |
63 | 双写问题
64 |
65 | 怎么优化?
66 |
67 | 项目流程是?
68 |
69 | ……………………………………
70 |
71 | 打家劫舍1
72 |
73 | ……………………………………
74 |
75 | 反问
76 |
77 | 部门工作
78 |
79 | 实习生工作
80 |
81 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 | # notes
3 |
4 | 记录一下找到实习(日常/暑期)之前的笔记
5 |
6 | ## 自动提交
7 |
8 | [github 生成ssh-key ,免用户名密码提交代码](https://blog.csdn.net/qq_33398459/article/details/97397812)
9 |
10 | [git脚本,一键提交代码](https://blog.csdn.net/Jie0817/article/details/121650229)
11 |
12 | [shell.sh](https://github.com/erdengk/notes/blob/main/shell.sh)
13 |
14 | ## 目录
15 |
16 | ```
17 | ├── x
18 | │ └── 面试1 .md
19 | ├── x 常见智力题
20 | │ └── 1 赛马问题.md
21 | ├── 笔记
22 | │ ├── 0.1操作系统
23 | │ │ └── 1基础.md
24 | │ ├── 0.2计算机网络
25 | │ ├── 0.3机组
26 | │ ├── 1.1Java基础
27 | │ │ ├── 0.Java基础.md
28 | │ │ ├── 1.概述.md
29 | │ │ ├── 2.面向对象.md
30 | │ │ ├── 3.常用类.md
31 | │ │ ├── 4.异常-反射-泛型.md
32 | │ │ └── x..md
33 | │ ├── 1.2Java容器
34 | │ │ ├── 1 集合.md
35 | │ │ ├── ArrayList-1.md
36 | │ │ ├── ArrayList.md
37 | │ │ ├── hashmap.md
38 | │ │ ├── map分析.md
39 | │ │ └── 容器源码分析.md
40 | │ ├── 1.3Java并发
41 | │ │ ├── 0.总结.md
42 | │ │ ├── 1.线程理论基础.md
43 | │ │ ├── archive
44 | │ │ ├── 并发关键字.md
45 | │ │ └── 并发理论(JMM).md
46 | │ ├── 1.4Jvm 相关
47 | │ ├── 1.5 Java8
48 | │ │ └── 1.新特性.md
49 | │ ├── MySQL
50 | │ │ ├── 0.MySQL.md
51 | │ │ ├── 1.基础回顾.md
52 | │ │ └── 2.mysql怎么运行的.md
53 | │ ├── Spring相关
54 | │ │ └── 1.基础知识.md
55 | │ └── 技术面试+v2.0.md
56 | ├── 极客时间
57 | │ └── Java核心面试
58 | │ └── 1.md
59 | └── 深度学习机器学习
60 | ├── 0 总结.md
61 | ├── 00 纠错.md
62 | ├── 资源汇总.md
63 | ├── 吴恩达笔记1.md
64 | ├── 吴恩达笔记2.md
65 | ├── 吴恩达笔记3.md
66 | ├── 吴恩达笔记4.md
67 | ├── 吴恩达笔记5.md
68 | └── 吴恩达笔记6.md
69 | ```
70 |
71 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/粤港澳后端开发.md:
--------------------------------------------------------------------------------
1 | ## 粤港澳后端开发
2 |
3 | 自我介绍
4 |
5 | 为什么主动参加开源
6 |
7 | 对实习有什么看法
8 |
9 | 你参加开源不就是在实习么,你觉得他们有什么区别
10 |
11 | springboot 和spring有什么区别
12 |
13 | springboot怎么做到简化开发的
14 |
15 | 约定大于配置(其实面试官想问自动装配的,没反应过来)
16 |
17 | 讲讲cap
18 |
19 | 为什么增高一致性要提高写副本数量
20 |
21 | 讲paxos项目实现了哪些功能
22 |
23 | 你自己觉得项目还有哪些改进地方
24 |
25 | 说下paxos两阶段流程
26 |
27 | 活锁
28 |
29 | Raft在两阶段提交上做了什么优化
30 |
31 | > 引导思考:
32 | >
33 | > 你觉得两阶段提交有什么问题
34 | >
35 | > >**2PC的缺点**
36 | > >
37 | > >1、协调者存在单点问题。如果协调者挂了,整个2PC逻辑就彻底不能运行。
38 | > >
39 | > >2、执行过程是完全同步的。各参与者在等待其他参与者响应的过程中都处于阻塞状态,大并发下有性能问题。
40 | > >
41 | > >3、仍然存在不一致风险。如果由于网络异常等意外导致只有部分参与者收到了commit请求,就会造成部分参与者提交了事务而其他参与者未提交的情况。
42 | > >
43 | > >[链接](https://zhuanlan.zhihu.com/p/35616810)
44 | > >
45 | > >[链接1](https://zhuanlan.zhihu.com/p/111304281)
46 | > >
47 | > >[链接2](https://learn.lianglianglee.com/%E4%B8%93%E6%A0%8F/%E5%88%86%E5%B8%83%E5%BC%8F%E6%8A%80%E6%9C%AF%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E6%88%9845%E8%AE%B2-%E5%AE%8C/08%20%E5%AF%B9%E6%AF%94%E4%B8%A4%E9%98%B6%E6%AE%B5%E6%8F%90%E4%BA%A4%EF%BC%8C%E4%B8%89%E9%98%B6%E6%AE%B5%E5%8D%8F%E8%AE%AE%E6%9C%89%E5%93%AA%E4%BA%9B%E6%94%B9%E8%BF%9B%EF%BC%9F.md)
48 | > >
49 | > >[链接3](https://karellincoln.github.io/2018/04/07/consensus-2pc/)
50 | >
51 | > 如果leader发送心跳发送的慢了,网络阻塞了,follower会发生什么
52 | >
53 | > leader投票规则
54 | >
55 | >
56 |
57 | raft和zab区别
58 |
59 | 讲讲zab
60 |
61 | > 这部分答的不好
62 | >
63 | > 面试官:没事,后面多了解,用的多了就了解了,很正常,没关系
64 | >
65 | > 我:疯狂道歉
66 |
67 | JVM内存模型
68 |
69 | jvm解决可见性、原子性
70 |
71 | 保证可见性
72 |
73 | sync关键字
74 |
75 |
76 |
77 | 写代码
78 |
79 | 输入两个矩阵(输入有效),输出矩阵乘积
80 |
81 |
82 |
83 | 场景题
84 |
85 | 比如刚才的这个过程中,如果中间有的部分加起来大于int,我们该怎么判断他中间是否超过了int
--------------------------------------------------------------------------------
/笔记/0.2计算机网络/1 .md:
--------------------------------------------------------------------------------
1 | https://app.yinxiang.com/fx/743af2df-4651-4097-8479-29b5639dca70
2 |
3 |
4 |
5 | https://www.nowcoder.com/discuss/post/353159080753700864
6 |
7 |
8 |
9 | ### Web页面的请求过程
10 |
11 | #### **简略版**:
12 |
13 | URL 敲下之后,浏览器是想要生成一个 TCP 套接字,以向目标 HTTP 服务器请求资源。
14 | 为了生成 TCP 套接字,我们必须知道域名对应的 IP 地址;
15 | 为了知道域名的 IP 地址,我们必须先向 DNS 服务器发送 DNS 查询报文;
16 | 为了向 DNS 服务器发送 DNS 查询报文,需要知道默认网关的 MAC 地址。
17 | 为了知道其 MAC 地址,必须用 ARP 协议进行解析出下一跳,也就是默认网关的 MAC 地址。
18 |
19 | 拿到默认网关 MAC 地址后,会封装一个 DNS 查询报文,向 DNS 发送 查询请求。
20 | DNS 服务器收到请求后,把查询结果放在 UDP 报文段中,返回给主机。
21 |
22 | 主机现在拿到了域名对应的 IP 地址,可以生成套接字,把套接字用于向 HTTP 服务器发送 HTTP GET 报文了。
23 | 而在生成 TCP 套接字之前,要进行三次握手的连接
24 | 1
25 | 2
26 | 3
27 | 连接之后,把 GET 请求封装在报文中,交付给 HTTP 服务器。
28 | HTTP 服务器拿到请求报文后,返回对应的 Web 资源。
29 | 浏览器收到 HTTP 响应之后,抽取 Web 页面的内容进行渲染。
30 |
31 | #### **巨tm详细版**:
32 |
33 | 应用层:URL 敲下之后,首先浏览器会生成一个 TCP 套接字,以向目标 HTTP 服务器请求资源。为了生成该套接字,需要知道该 URL 域名对应的 IP 地址。
34 | 应用层:而为了向 DNS 服务器发送请求,生成一个 DNS 查询报文,是 53 端口号的。
35 | 网络层:这个 DNS 数据报被放入一个目的地址为 DNS 服务器 IP 地址的 IP 数据报中。
36 | IP 数据报被放入一个帧中,把帧发到默认的网关中,而为了知道网关的 MAC 地址,需要用 ARP 协议来把网关的 IP 解析为 MAC 地址。
37 |
38 | 直到了网关的 MAC 地址后,才可以继续 DNS 的解析过程。
39 | 网关路由器拿到 DNS 查询报文后,会根据报文转发给下一跳,直到到达 DNS 服务器。
40 | 到达 DNS 服务器后,DNS 在数据库中查询待解析的域名。
41 | 找到 DNS 记录后,发送 DNS 回答报文,放入 UDP 报文段中,转发回主机。
42 |
43 | 主机拿到了解析后的域名,也就是 IP 地址后,就能生成套接字,把套接字用于向 Web 服务器发送 HTTP GET 报文。
44 | 在生成 TCP 套接字之前,必须先与 HTTP 服务器进行三次握手来建立连接。
45 | 生成一个具有目的端口 80 的 TCP SYN 报文段,并向 HTTP 服务器发送该报文段。
46 | HTTP 服务器收到该报文段之后,回复 TCP 的 SYN ACK 报文段,发回主机。
47 | 主机接收到 SYN ACK 之后,再次恢复一个 ACK 确认连接报文段到 HTTP 服务器。
48 | 三次连接建立完毕。
49 | 浏览器生成 HTTP GET 报文,并交付给 HTTP 服务器。
50 | HTTP 服务器从 TCP 套接字读取 HTTP GET 报文,生成一个响应报文,把 Web 页面的内容放入报文主体中,返回给主机。
51 | 浏览器拿到响应报文后,抽取 Web 页面内容,渲染页面。
52 |
53 |
--------------------------------------------------------------------------------
/深度学习机器学习/吴恩达笔记3.md:
--------------------------------------------------------------------------------
1 | ## 六、逻辑回归(Logistic Regression)
2 |
3 | 在分类问题中,你要预测的变量`y`是离散的值,我们将学习一种叫做逻辑回归 (**Logistic Regression**) 的算法,这是目前最流行使用最广泛的一种学习算法。
4 |
5 | ==逻辑回归算法,这个算法的性质是:它的输出值永远在0到 1 之间。==
6 |
7 | 逻辑回归算法实际上是一种分类算法,它适用于标签 `y` 取值离散的情况,如:1 0 0 1。
8 |
9 | ### 6.3 判定边界
10 |
11 | 下决策边界(**decision boundary**)的概念。这个概念能更好地帮助我们理解逻辑回归的假设函数在计算什么。
12 |
13 | ### 6.4 代价函数
14 |
15 | 如何拟合逻辑回归模型的参数
16 |
17 | 我要定义用来拟合参数的优化目标或者叫代价函数,这便是监督学习问题中的逻辑回归模型的拟合问题
18 |
19 | 
20 |
21 | 除了梯度下降算法以外,还有一些常被用来令代价函数最小的算法,这些算法更加复杂和优越,而且通常不需要人工选择学习率,通常比梯度下降算法要更加快速。这些算法有:**共轭梯度**(**Conjugate Gradient**),**局部优化法**(**Broyden fletcher goldfarb shann,BFGS**)和**有限内存局部优化法**(**LBFGS**) ,**fminunc**是 **matlab**和**octave** 中都带的一个最小值优化函数,使用时我们需要提供代价函数和每个参数的求导。
22 |
23 | ### 6.5 简化的成本函数和梯度下降
24 |
25 | ==如何运用梯度下降法,来拟合出逻辑回归的参数==
26 |
27 | ### 6.7 多类别分类:一对多
28 |
29 | 如何使用逻辑回归 (**logistic regression**)来解决多类别分类问题,具体来说,我想通过一个叫做"一对多" (**one-vs-all**) 的分类算法。
30 |
31 | "一对余"方法
32 |
33 | abc 三类,拆成 a(bc)、 (ab)c 、(ac)b 三个二元分类问题
34 |
35 | ## 七、正则化(Regularization)
36 |
37 | ### 7.1 过拟合的问题
38 |
39 | 过拟合(**over-fitting**)的问题
40 |
41 | 正则化(**regularization**)的技术,它可以改善或者减少过度拟合问题
42 |
43 | 问题是,如果我们发现了过拟合问题,应该如何处理?
44 |
45 | 1. 丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(例如**PCA**)
46 | 2. 正则化。 保留所有的特征,但是减少参数的大小(**magnitude**)。
47 |
48 |
49 |
50 | ### 7.2 代价函数
51 |
52 | 正是那些高次项导致了过拟合的产生,所以如果我们能让这些高次项的系数接近于0的话,我们就能很好的拟合了
53 |
54 | ==引入惩罚系数,降低高次项系数==
55 |
56 | 假如我们有非常多的特征,我们并不知道其中哪些特征我们要惩罚,我们将对所有的特征进行惩罚,并且让代价函数最优化的软件来选择这些惩罚的程度
57 |
58 | ### 7.3 正则化线性回归
59 |
60 | 正则化线性回归的梯度下降算法的变化在于,每次都在原有算法更新规则的基础上令θ值减少了一个额外的值
61 |
62 | ### 7.4 正则化的逻辑回归模型
63 |
64 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/美团后端实习一面.md:
--------------------------------------------------------------------------------
1 | ## 美团后端实习一面
2 |
3 | 总结:面试官很热情,讲了很多部门相关的东西
4 |
5 | 场景题也给讲了一些东西,学到了
6 |
7 | ……………………………………
8 |
9 | 面试官自我介绍
10 |
11 | 自我介绍
12 |
13 | 讲讲GSoC
14 |
15 | 讲讲开源实习
16 |
17 | 讲讲做的工作
18 |
19 | 我要去怎么样定义我这个插件是成功了,然后是有一些怎么样的测试方式呢?
20 |
21 | 这种测试你们能怎么验证它是能不能用呢?
22 |
23 | 讲讲集成测试流程
24 |
25 | 用例设计
26 |
27 | ……………………………………
28 |
29 | 这个项目中间又遇到过什么问题呢?
30 |
31 | > 讲了设计测试用例以及如何写一份可靠的代码
32 |
33 | 有没有什么你关于项目的一些执行或者是说从项目的开发到落地上面的一些认知呢?
34 |
35 | 那像这种开源的项目,他是他的需求来源点是什么呢?
36 |
37 | 我看你还有一个项目叫那个分布式算法。然后可以。给我介绍一下这个
38 |
39 | > 开始吟唱
40 | >
41 | > cap-pacelc-nwr-paxos-活锁-raft-zab
42 |
43 | 然后你是基于什么的原因会去学习到这些分布式相关的或者说开源的这些东西,自己是怎么有有有的有个什么想法呢?
44 |
45 | ……………………………………
46 |
47 | 讲讲JUC
48 |
49 | redis 数据结构
50 |
51 | 删除策略
52 |
53 | 过期策略
54 |
55 | ……………………………………
56 |
57 | 场景题
58 |
59 | 我异步添加了100个key,然后让他们在指定过期时间上加一部分随机过期时间,最后发现总是有些key没有加随机时间,怎么排除问题?
60 |
61 | ```
62 | //伪代码
63 | for(int i= 0; i<100; i++) {
64 | redis.asyncPush("key"+i, "value");
65 | redis.expire("key"+i, 100);
66 | }
67 | ```
68 |
69 | > 一开始想了key是否会存在,然后没往这方面继续想
70 | >
71 | > 丢包?不会
72 | >
73 | > 面试官:是不是可以从日志去查?
74 | >
75 | > 我:aof 和 rdb日志
76 | >
77 | > 面试官:还有就是我们的api是否用对了?asyncPush、expire 的方法我们是否真的理解了
78 | >
79 | > --------
80 | >
81 | > 对于这个问题,因为是异步添加,因为有些key是不存在的,所以我们的expire可能会失败。
82 |
83 |
84 |
85 | ……………………………………
86 |
87 | 算法
88 |
89 | lc,移动零
90 |
91 | ……………………………………
92 |
93 | 反问
94 |
95 | 部门工作
96 |
97 | 实习生工作
98 |
99 | base
100 |
101 | 几面
102 |
103 | ……………………………………
104 |
105 | 场景题的话,我在 冲友群(小红书链接:https://www.xiaohongshu.com/discovery/item/6373b539000000002203b896 ) 等你来交流。(也可以私信我你的个人介绍,我和群主说了拉你进群
--------------------------------------------------------------------------------
/深度学习机器学习/资源汇总.md:
--------------------------------------------------------------------------------
1 | ## 理论学习
2 |
3 | 【黑马程序员3天快速入门python机器学习】 https://www.bilibili.com/video/BV1nt411r7tj?p=6&share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
4 |
5 | 【(强推)李宏毅2021/2022春机器学习课程】 https://www.bilibili.com/video/BV1Wv411h7kN?share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
6 |
7 | 【[双语字幕]吴恩达深度学习deeplearning.ai】 https://www.bilibili.com/video/BV1FT4y1E74V?share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
8 |
9 | ---
10 |
11 | 【[中英字幕]吴恩达机器学习系列课程】 https://www.bilibili.com/video/BV164411b7dx?share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
12 |
13 | [斯坦福大学2014机器学习教程中文笔记目录](http://www.ai-start.com/ml2014/)
14 |
15 | 动画ai https://space.bilibili.com/1921388479
16 |
17 | 【卷积神经网络】8分钟搞懂CNN,动画讲解喜闻乐见】 https://www.bilibili.com/video/BV1fY411H7g8?share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
18 |
19 | ## 实战
20 |
21 | 【PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】】 https://www.bilibili.com/video/BV1hE411t7RN?share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
22 |
23 | 【04 数据操作 + 数据预处理【动手学深度学习v2】】 https://www.bilibili.com/video/BV1CV411Y7i4?share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
24 |
25 | 【Python+人工智能基础班(通俗易懂版教学)_人工智能基础入门教程_人工智能机器学习】 https://www.bilibili.com/video/BV1ou411U7J4?share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
26 |
27 | ## 目标
28 |
29 | 1. 吴恩达视频你并不需要全看,并且看的时候更多的你只需要关注一些机器学习中的重要概念**(过拟合、欠拟合、损失函数、评价指标等、前向传播、反向传播,能明白在干什么就行)**,至于具体的公式推导(尤其是反向传播具体的推导),没有必要去看,你也不会直接用到)。你看以下几部分就好了:**引言、单变量线性回归、(线性代数回顾)、多变量线性回归、逻辑回归、正则化、神经网络的学习、神经网络:表述、应用、机器学习的建议、机器学习系统的设计**。这里面最最重要的是**线性回归和逻辑回归**,这两个你要搞得比较明白。
30 | 2. 你在看吴恩达视频的时候只需要用到numpy(这是一个python的矩阵运算库)就够了,pytorch之后再学比较好。(pytorch中很大一部分操作和numpy是一样的,只是多了一些用于训练模型的方便的函数)
31 | 3. 这里有一个图文版的吴恩达课程,你可以先看这个,看不懂再看视频,这样可能会快一些http://www.ai-start.com/ml2014/
32 | 3. **你只要能完整地搞明白线性回归和逻辑回归的原理和代码**,你关于吴恩达视频的目标就算完成了
33 | 3. 所以不要耗太多时间在这个上面,感觉差不多的话就可以切换到PyTorch上了
34 | 3. 你就花一个周或者稍微多一点点差不多把这些最基本的东西差不多搞清楚就行
35 |
36 | -----
37 |
38 | pytorch \ transformer 能修改开源的代码就行
39 |
40 | 与原理对应的关系 了解就可以
41 |
42 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/百度面经收集.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | https://www.nowcoder.com/enterprise/139/interview
4 |
5 | ### 实习
6 |
7 | https://www.nowcoder.com/discuss/post/392104028828708864
8 |
9 | https://www.nowcoder.com/discuss/post/422438091262054400
10 |
11 | https://www.nowcoder.com/discuss/post/384102178951110656
12 |
13 | https://www.nowcoder.com/discuss/post/383744565965070336
14 |
15 | https://www.nowcoder.com/discuss/382278026720026624
16 |
17 | https://www.nowcoder.com/discuss/post/424705098825072640
18 |
19 | https://www.nowcoder.com/discuss/post/422438091262054400
20 |
21 | https://www.nowcoder.com/discuss/post/402137855114457088
22 |
23 | https://www.nowcoder.com/discuss/post/409760803471044608
24 |
25 | https://www.nowcoder.com/discuss/post/406119364531941376
26 |
27 | https://www.nowcoder.com/discuss/post/397180832601960448
28 |
29 | ### 提前批/秋招/社招
30 |
31 | https://www.nowcoder.com/discuss/post/416537596492349440
32 |
33 | https://www.nowcoder.com/discuss/post/393075119143366656
34 |
35 | https://www.nowcoder.com/discuss/post/394241237249794048
36 |
37 | https://www.nowcoder.com/discuss/post/390928190703763456
38 |
39 | https://www.nowcoder.com/discuss/post/395953742338592768
40 |
41 | https://www.nowcoder.com/discuss/post/398978026636066816
42 |
43 | https://www.nowcoder.com/discuss/post/414204606991843328
44 |
45 | https://www.nowcoder.com/discuss/post/418048972818837504
46 |
47 | https://www.nowcoder.com/discuss/post/385226120973635584
48 |
49 | https://www.nowcoder.com/discuss/post/384450105879920640
50 |
51 | https://www.nowcoder.com/discuss/post/381172254556659712
52 |
53 | https://www.nowcoder.com/discuss/post/381912595815628800
54 |
55 | https://www.nowcoder.com/discuss/post/383697412597067776
56 |
57 | https://www.nowcoder.com/discuss/383693481930252288
58 |
59 | https://www.nowcoder.com/discuss/382552296046043136
60 |
61 | https://www.nowcoder.com/discuss/post/379732925338738688
62 |
63 | https://www.nowcoder.com/discuss/382184734011547648
64 |
65 | https://www.nowcoder.com/discuss/post/380482995600297984
66 |
67 | https://www.nowcoder.com/discuss/post/381910191615365120
68 |
69 | https://www.nowcoder.com/discuss/post/381753156055707648
70 |
71 | https://www.nowcoder.com/discuss/post/380500761812246528
72 |
73 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/上海小厂懂技术的面试官技术面.md:
--------------------------------------------------------------------------------
1 | ## 11.3 上海小厂懂技术的面试官技术面
2 |
3 | 当时以为录音了,后期发现没录音,哭死。。。
4 |
5 | ### 自我介绍
6 |
7 | 因为他开场说对分布式感兴趣,所以就正常的个人信息结束后,在技能部分补充了对分布式的理解
8 |
9 | ```
10 | 如果面试官和你说他对你某个点感兴趣,在你能讲清楚这个点的前提下,请加大力度阐述
11 | ```
12 |
13 | 然后在个人技术方向部分多说了会分布式和云原生
14 |
15 | ```
16 | 参考模版:
17 |
18 | 姓名,学校,年级,专业
19 | 实习时间
20 |
21 | 主要语言,技术栈,数据库,中间件,目前学习方向
22 | 未来发展方向
23 |
24 | 个人开源经历/核心竞争力阐述
25 | 个人技术分享/校内/竞赛经历
26 |
27 | 个人项目/实习经历
28 |
29 | 希望能一起共事
30 | ```
31 |
32 |
33 |
34 | ### 讲讲你的开源经历
35 |
36 | 从shenyu到glcc
37 |
38 | ### 讲讲paxos项目
39 |
40 | 从CAP开始讲
41 |
42 | (中间可以讲PACELC、BASE、Quorum,我忘了)
43 |
44 | 然后讲Paxos的两阶段提交
45 |
46 | 然后讲活锁
47 |
48 | 然后讲项目里自己怎么解决的(参考raft)
49 |
50 | (他如果没让停,就可以继续说Raft)
51 |
52 | >讲完之后他说,你这个理解不错,本来准备问的问题都被你回答了。算法就免了。
53 | >
54 | >我:算法还是要刷的
55 | >
56 | >面试官:没办法才考算法,你这个可以不用考了
57 |
58 | ### 讲讲网关
59 |
60 | 南北向网关(APISIX),东西向网关(ShenYu)
61 |
62 |
63 |
64 | ### 我看你博客UV 7k,很高了,平时写些什么
65 |
66 | 主要是开源分享、后端技术分享和个人读书推荐
67 |
68 | ### 我看你博客里写了多级页表,讲讲
69 |
70 | [链接](http://erdengk.top/archives/924jiang-jiang-cao-zuo-xi-tong-de-duo-ji-ye-biao--wei-shen-me-duo-ji-ye-biao-hui-sheng-kong-jian-)
71 |
72 |
73 |
74 | ### 我看你写了零拷贝,能讲一下不?
75 |
76 | 零拷贝是一种硬件层面的优化,在这种方法中,并不是拷贝0次,而是减少了拷贝次数,如果不使用0拷贝,需要先将数据放到cpu中,然后再让其他进程读取,这样肯定会影响cpu的性能。
77 |
78 | 如果使用了0拷贝,并不需要将数据放到cpu中,而是让cpu通知具体的模块去做个事,也就降低了cpu的压力。
79 |
80 | ---
81 |
82 | 在正式介绍零拷贝结束(Zero-Copy)之前,我们先简单介绍一下DMA(Direct Memory Access)技术。DMA,又称之为直接内存访问,是零拷贝技术的基石。DMA 传输将数据从一个地址空间复制到另外一个地址空间。当CPU 初始化这个传输动作,传输动作本身是由 DMA 控制器来实行和完成。因此通过DMA,硬件则可以绕过CPU,自己去直接访问系统主内存。很多硬件都支持DMA,其中就包括网卡、声卡、磁盘驱动控制器等。
83 | 有了DMA技术的支持之后,网卡就可以直接区访问内核空间的内存,这样就可以实现内核空间和应用空间之间的零拷贝了,极大地提升传输性能。
84 |
85 | Kafka用到的零拷贝技术,主要是减少了核心态和用户态之间的两次数据拷贝过程,使得数据可以不用经过用户态直接通过网卡发送到接收方,同时通过DMA技术,可以使CPU得到解放,这样实现了数据的高性能传输。
86 |
87 | https://www.jianshu.com/p/0af1b4f1e164
88 |
89 |
90 |
91 | ### 反问:您那边是做什么业务的,我需要做什么?
92 |
93 | 是做知识图谱和图数据库相关的,实习生的话会做一些图数据库相关的
94 |
95 | ```
96 | 记得要问自己做什么,还有他们在做什么
97 | ```
98 |
99 |
100 |
101 | ### 反问:您对我的项目有什么建议吗?
102 |
103 | 这个paxos可以再完善下,现在是非拜占庭问题,考虑怎么解决拜占庭问题。
104 |
105 | 还有PBFT 算法可以了解下
106 |
107 | 处理非拜占庭错误的算法有:paxos、raft和其变种
108 |
109 | 处理拜占庭错误算法有:pbft、pow算法
110 |
111 | ```
112 | 抓住机会,如果面试官懂你的技术栈,必问问题之一
113 | ```
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/字节面经收集.md:
--------------------------------------------------------------------------------
1 | Hashmap 描述。多线程会发生什么问题
2 |
3 | 多线程 put 操作可能发生死循环或者元素丢失
4 |
5 | 加问死循环发生原因: 多个线程执行 put 操作时同时触发了 rehash 方法,可能会生成环形链
6 |
7 |
8 |
9 | select * from tableA whereA.a=?order by A.b 加索引优化
10 |
11 |
12 |
13 |
14 |
15 | tcp/ip 五层架构对应什么协议
16 |
17 | url 访问原理
18 |
19 | dns 的原理,在路由器上找的时候,有哪几种情况
20 |
21 | 写爬虫系统时,如何判定该 url 已经爬过了。这个问题很开 放,而且也挺有意思。
22 |
23 |
24 |
25 | jvm g1 回收器讲一下
26 |
27 |
28 |
29 | mysql的索引用的什么数据结构
30 |
31 | B+树属于二叉树么
32 |
33 | 为什么不用红黑树
34 |
35 | 红黑树和B+树的区别
36 |
37 |
38 |
39 |
40 |
41 | close_wait状态有什么用
42 |
43 | 场景题1:m元分成n个红包,随机分配,需要保证红包的金额均匀分布,每个红包金额大于等于0.01,且是0.01的整数倍
44 |
45 | 场景题2:m*n矩阵,从第一行第一列开始走,每次只能往右或者往下走,求走到最后一行最后一列的位置有多少种走法:dp和数学方法都说一下
46 |
47 |
48 |
49 |
50 |
51 | 交换机,路由器分别在哪一层
52 |
53 | 路由和交换机之间的主要区别就是交换机发生在OSI参考模型第二层(数据链路层),而路由发生在第三层,即网络层。
54 |
55 |
56 |
57 | mysql的redo log undo log干嘛的
58 |
59 |
60 |
61 |
62 |
63 | q
64 |
65 | redis跳表 是不是 空间换时间的思想,在链表上构建索引来减少查询的时间
66 |
67 |
68 |
69 | java的gc机制
70 |
71 | java的类加载机制?好处?
72 |
73 | java堆和栈里存的都是什么
74 |
75 | 被static修饰的成员变量存放在哪里
76 |
77 |
78 |
79 | MySQL事务如何实现回滚
80 |
81 | MySQL的事务隔离级别,每种隔离级别遇到的问题,如何解决
82 |
83 |
84 |
85 | 了解http么?http的长连接
86 |
87 | tcp的keep-alive
88 |
89 | tcp的拥塞控制
90 |
91 |
92 |
93 | 1.Mysql的慢查询如何排查?
94 |
95 | 2.Mysql为什么要使用两阶段提交?
96 |
97 | 3.如何监控redo日志的刷盘频率?
98 |
99 | 4.数据库的四大范式讲一讲?
100 |
101 | 5.redis满足acid吗,仔细讲讲哪些满足哪些不满足?
102 |
103 | 6.http和https的区别?
104 |
105 | mysql为什么用B+树做索引不用B树,为什么不用跳表做索引?
106 |
107 | 2.zookeeper做分布式锁和redis做分布式锁的区别?zookeeper如何实现分布式锁?
108 |
109 | 谈谈AQS?
110 |
111 | 5.并发环境使用原子整形计数会有什么问题?longAddr有了解吗?
112 |
113 | .三次握手第一次握手的报文问丢失会怎么样?有做过实验吗?
114 |
115 | 3.要一次性发送10mb数据,用tcp还是udp?
116 |
117 | 4.软中断和硬中断的区别?
118 |
119 | 5.数据从用户空间到发送出去需要经过哪些步骤?
120 |
121 |
122 |
123 | 如果建立外连接,两张表都太大了咋优化 https://blog.csdn.net/robinson1988/article/details/50756921
124 |
125 |
126 |
127 |
128 |
129 | https://www.nowcoder.com/discuss/post/415582189854752768
130 |
131 | https://www.nowcoder.com/discuss/post/403957055290175488
132 |
133 | https://www.nowcoder.com/discuss/post/405050183480782848
134 |
135 | https://www.nowcoder.com/discuss/post/410116058700324864
136 |
137 | https://www.nowcoder.com/discuss/post/423433825918668800
138 |
139 | https://www.nowcoder.com/discuss/post/422804842957033472
140 |
141 | https://www.nowcoder.com/discuss/post/419502682978729984
142 |
143 | https://www.nowcoder.com/discuss/post/423628210666070016
144 |
--------------------------------------------------------------------------------
/深度学习机器学习/吴恩达笔记1.md:
--------------------------------------------------------------------------------
1 | ## 机器学习是什么?
2 |
3 | 在进行特定编程的情况下,给予计算机学习能力的领域
4 |
5 | 目前存在几种不同类型的学习算法。主要的两种类型被我们称之为监督学习和无监督学习
6 |
7 | 监督学习这个想法是指,我们将教计算机如何去完成任务,
8 |
9 | 无监督学习中,我们打算让它自己进行学习
10 |
11 | ### 监督学习
12 |
13 | 
14 |
15 | ==监督学习==指的就是我们给学习算法一个数据集。这个数据集由“正确答案”组成
16 |
17 | 在房价的例子中,我们给了一系列房子的数据,我们给定数据集中每个样本的正确价格,即它们实际的售价然后运用学习算法,算出更多的正确答案。比如你朋友那个新房子的价格。用术语来讲,这叫做回归问题。我们试着推测出一个连续值的结果,即房子的价格
18 |
19 | ==回归==这个词的意思是,我们在试着推测出这一系列连续值属性。
20 |
21 | **支持向量机,里面有一个巧妙的数学技巧,能让计算机处理无限多个特征**
22 |
23 |
24 |
25 | ### 无监督学习
26 |
27 | 
28 |
29 | 
30 |
31 | 不同于监督学习的数据的样子,即无监督学习中没有任何的标签或者是有相同的标签或者就是没标签
32 |
33 | 针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。这是一个,那是另一个,二者不同。是的,无监督学习算法可能会把这些数据分成两个不同的簇。所以叫做聚类算法。事实证明,它能被用在很多地方。
34 |
35 | 这是有一堆数据。我不知道数据里面有什么。我不知道谁是什么类型。我甚至不知道人们有哪些不同的类型,这些类型又是什么
36 |
37 | ## 单变量线性回归(Linear Regression with One Variable)
38 |
39 | ### 线性回归算法
40 |
41 | 在监督学习中我们有一个数据集,这个数据集被称==训练集==
42 |
43 | 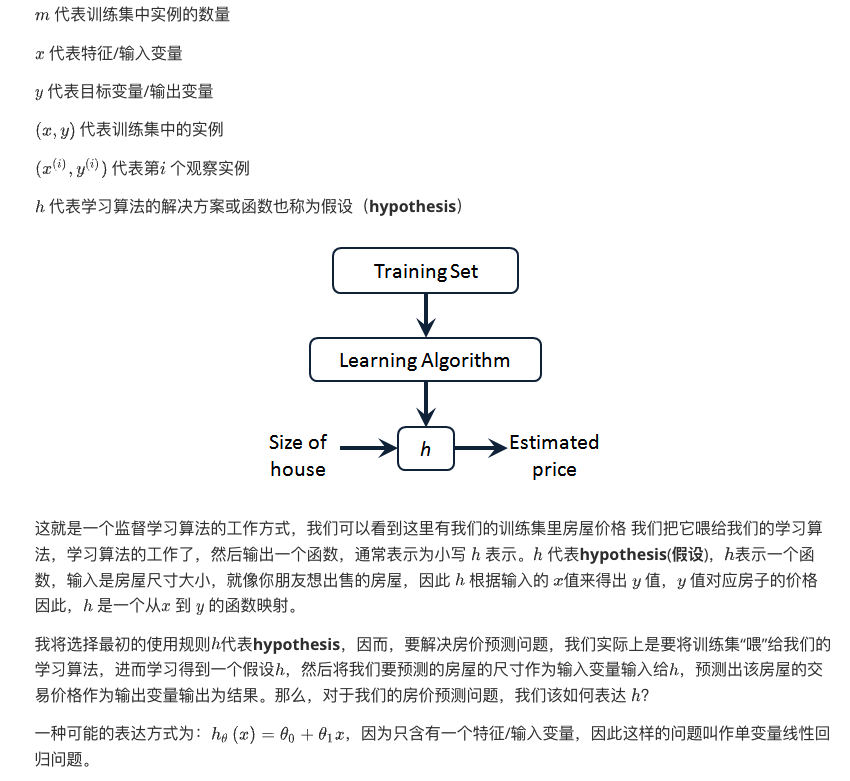 44 |
45 | ### 代价函数
46 |
47 | 代价函数也被称作平方误差函数,有时也被称为平方误差代价函数。我们之所以要求出误差的平方和,是因为误差平方代价函数,对于大多数问题,特别是回归问题,都是一个合理的选择。还有其他的代价函数也能很好地发挥作用,但是平方误差代价函数可能是解决回归问题最常用的手段了。
48 |
49 | 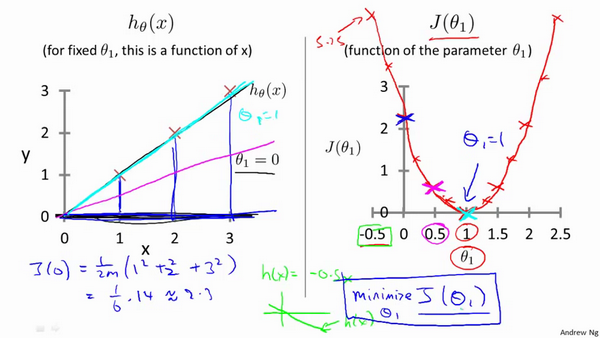
50 |
51 | 通过计算代价函数,可以发现有一点能使得代价最低
52 |
53 | 为了找到函数最小值的算法,引入梯度下降
54 |
55 | ### 梯度下降
56 |
57 | ==梯度下降==是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数的最小值
58 |
59 | 梯度下降背后的思想是:开始时我们随机选择一个参数的组合,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到到到一个局部最小值(**local minimum**),因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(**global minimum**),**选择不同的初始参数组合,可能会找到不同的局部最小值。**
60 |
61 | 想象一下你正站立在山的这一点上,站立在你想象的公园这座红色山上,在梯度下降算法中,我们要做的就是旋转360度,看看我们的周围,并问自己要在某个方向上,用小碎步尽快下山。这些小碎步需要朝什么方向?如果我们站在山坡上的这一点,你看一下周围,你会发现最佳的下山方向,你再看看周围,然后再一次想想,我应该从什么方向迈着小碎步下山?然后你按照自己的判断又迈出一步,重复上面的步骤,从这个新的点,你环顾四周,并决定从什么方向将会最快下山,然后又迈进了一小步,并依此类推,直到你接近局部最低点的位置。
62 |
63 |
64 |
65 | 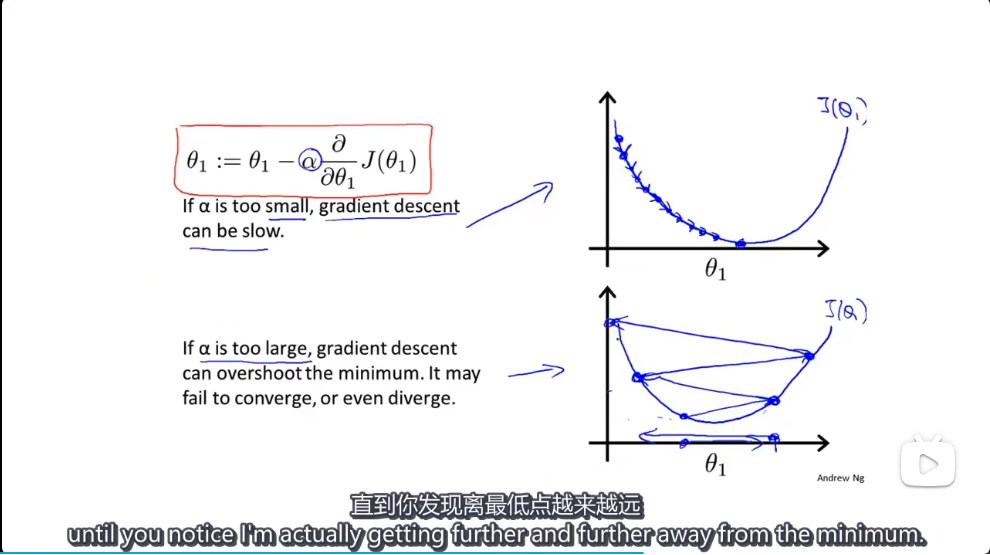
66 |
67 | 阿尔法 如果过大或过小,都会导致梯度下降过慢或者过快。
68 |
69 | 在梯度下降法中,当我们接近局部最低点时,梯度下降法会自动采取更小的幅度,这是因为当我们接近局部最低点时,很显然在局部最低时导数等于零,所以当我们接近局部最低时,导数值会自动变得越来越小,所以梯度下降将自动采取较小的幅度,这就是梯度下降的做法
70 |
71 |
72 |
73 | ## 总结
74 |
75 | 通过不断试错,降低代价函数,也由此引入了梯度下降算法
76 |
77 | 如果下降过快、过慢都会导致错过最小代价
78 |
79 | 可能找到多个局部最优,然后多个局部最优再选出全局最优
80 |
81 |
--------------------------------------------------------------------------------
/笔记/2.1 Spring/1.基础知识.md:
--------------------------------------------------------------------------------
1 | ### 请求处理-常用参数注解使用
2 |
3 | 注解:
4 |
5 | `@PathVariable` 路径变量
6 | `@RequestHeader` 获取请求头
7 | `@RequestParam` 获取请求参数(指问号后的参数,url?a=1&b=2)
8 | `@CookieValue` 获取Cookie值
9 | `@RequestAttribute` 获取request域属性
10 | `@RequestBody` 获取请求体[POST]
11 | `@MatrixVariable` 矩阵变量
12 | `@ModelAttribute`
13 |
14 |
15 |
16 | ### 请求处理-【源码分析】-请求映射原理
17 |
18 |
44 |
45 | ### 代价函数
46 |
47 | 代价函数也被称作平方误差函数,有时也被称为平方误差代价函数。我们之所以要求出误差的平方和,是因为误差平方代价函数,对于大多数问题,特别是回归问题,都是一个合理的选择。还有其他的代价函数也能很好地发挥作用,但是平方误差代价函数可能是解决回归问题最常用的手段了。
48 |
49 | 
50 |
51 | 通过计算代价函数,可以发现有一点能使得代价最低
52 |
53 | 为了找到函数最小值的算法,引入梯度下降
54 |
55 | ### 梯度下降
56 |
57 | ==梯度下降==是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数的最小值
58 |
59 | 梯度下降背后的思想是:开始时我们随机选择一个参数的组合,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到到到一个局部最小值(**local minimum**),因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(**global minimum**),**选择不同的初始参数组合,可能会找到不同的局部最小值。**
60 |
61 | 想象一下你正站立在山的这一点上,站立在你想象的公园这座红色山上,在梯度下降算法中,我们要做的就是旋转360度,看看我们的周围,并问自己要在某个方向上,用小碎步尽快下山。这些小碎步需要朝什么方向?如果我们站在山坡上的这一点,你看一下周围,你会发现最佳的下山方向,你再看看周围,然后再一次想想,我应该从什么方向迈着小碎步下山?然后你按照自己的判断又迈出一步,重复上面的步骤,从这个新的点,你环顾四周,并决定从什么方向将会最快下山,然后又迈进了一小步,并依此类推,直到你接近局部最低点的位置。
62 |
63 |
64 |
65 | 
66 |
67 | 阿尔法 如果过大或过小,都会导致梯度下降过慢或者过快。
68 |
69 | 在梯度下降法中,当我们接近局部最低点时,梯度下降法会自动采取更小的幅度,这是因为当我们接近局部最低点时,很显然在局部最低时导数等于零,所以当我们接近局部最低时,导数值会自动变得越来越小,所以梯度下降将自动采取较小的幅度,这就是梯度下降的做法
70 |
71 |
72 |
73 | ## 总结
74 |
75 | 通过不断试错,降低代价函数,也由此引入了梯度下降算法
76 |
77 | 如果下降过快、过慢都会导致错过最小代价
78 |
79 | 可能找到多个局部最优,然后多个局部最优再选出全局最优
80 |
81 |
--------------------------------------------------------------------------------
/笔记/2.1 Spring/1.基础知识.md:
--------------------------------------------------------------------------------
1 | ### 请求处理-常用参数注解使用
2 |
3 | 注解:
4 |
5 | `@PathVariable` 路径变量
6 | `@RequestHeader` 获取请求头
7 | `@RequestParam` 获取请求参数(指问号后的参数,url?a=1&b=2)
8 | `@CookieValue` 获取Cookie值
9 | `@RequestAttribute` 获取request域属性
10 | `@RequestBody` 获取请求体[POST]
11 | `@MatrixVariable` 矩阵变量
12 | `@ModelAttribute`
13 |
14 |
15 |
16 | ### 请求处理-【源码分析】-请求映射原理
17 |
18 |  19 |
20 | SpringMVC功能分析都从 `org.springframework.web.servlet.DispatcherServlet` -> `doDispatch()`
21 |
22 | ```java
23 | protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
24 | HttpServletRequest processedRequest = request;
25 | HandlerExecutionChain mappedHandler = null;
26 | boolean multipartRequestParsed = false;
27 |
28 | WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request);
29 |
30 | try {
31 | ModelAndView mv = null;
32 | Exception dispatchException = null;
33 |
34 | try {
35 | processedRequest = checkMultipart(request);
36 | multipartRequestParsed = (processedRequest != request);
37 |
38 | // 找到当前请求使用哪个Handler(Controller的方法)处理
39 | mappedHandler = getHandler(processedRequest);
40 |
41 | //HandlerMapping:处理器映射。/xxx->>xxxx
42 | ...
43 | }
44 |
45 | ```
46 |
47 | `getHandler()`方法如下:
48 |
49 | ```java
50 | @Nullable
51 | protected HandlerExecutionChain getHandler(HttpServletRequest request) throws Exception {
52 | if (this.handlerMappings ! = null) {
53 | for (HandlerMapping mapping : this.handlerMappings) {
54 | HandlerExecutionChain handler = mapping.getHandler(request);
55 | if (handler ! = null) {
56 | return handler;
57 | }
58 | }
59 | }
60 | return null;
61 | }
62 |
63 | ```
64 |
65 | 
66 |
67 | 其中,`RequestMappingHandlerMapping`保存了所有`@RequestMapping` 和`handler`的映射规则。
68 |
69 |
19 |
20 | SpringMVC功能分析都从 `org.springframework.web.servlet.DispatcherServlet` -> `doDispatch()`
21 |
22 | ```java
23 | protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
24 | HttpServletRequest processedRequest = request;
25 | HandlerExecutionChain mappedHandler = null;
26 | boolean multipartRequestParsed = false;
27 |
28 | WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request);
29 |
30 | try {
31 | ModelAndView mv = null;
32 | Exception dispatchException = null;
33 |
34 | try {
35 | processedRequest = checkMultipart(request);
36 | multipartRequestParsed = (processedRequest != request);
37 |
38 | // 找到当前请求使用哪个Handler(Controller的方法)处理
39 | mappedHandler = getHandler(processedRequest);
40 |
41 | //HandlerMapping:处理器映射。/xxx->>xxxx
42 | ...
43 | }
44 |
45 | ```
46 |
47 | `getHandler()`方法如下:
48 |
49 | ```java
50 | @Nullable
51 | protected HandlerExecutionChain getHandler(HttpServletRequest request) throws Exception {
52 | if (this.handlerMappings ! = null) {
53 | for (HandlerMapping mapping : this.handlerMappings) {
54 | HandlerExecutionChain handler = mapping.getHandler(request);
55 | if (handler ! = null) {
56 | return handler;
57 | }
58 | }
59 | }
60 | return null;
61 | }
62 |
63 | ```
64 |
65 | 
66 |
67 | 其中,`RequestMappingHandlerMapping`保存了所有`@RequestMapping` 和`handler`的映射规则。
68 |
69 |  70 |
71 | 所有的请求映射都在HandlerMapping中:
72 |
73 | 1. SpringBoot自动配置欢迎页的 WelcomePageHandlerMapping 。访问 /能访问到index.html;
74 |
75 | 2. SpringBoot自动配置了默认 的 RequestMappingHandlerMapping
76 |
77 | 3. 请求进来,挨个尝试所有的HandlerMapping看是否有请求信息。
78 | 1. 如果有就找到这个请求对应的handler
79 | 2. 如果没有就是下一个 HandlerMapping
80 |
81 | 我们需要一些自定义的映射处理,我们也可以自己给容器中放HandlerMapping。自定义 HandlerMapping
82 |
83 |
--------------------------------------------------------------------------------
/笔记/1.2Java容器/ArrayList-1.md:
--------------------------------------------------------------------------------
1 | ### 讲讲深浅拷贝
2 |
3 | 1、浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝
4 |
5 | 2、深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
6 |
7 | https://segmentfault.com/a/1190000010648514
8 |
9 |
10 |
11 | 为什么要准备两个空数组?
12 |
13 |
14 |
15 | 讲讲transient关键字?
16 |
17 |
18 |
19 | Arrays.asList() 的使用场景是?
20 |
21 | ```
22 | // asList 用在固定的多个值的情况,不进行修改的情况下使用。
23 | // 不能删除或者增加,可以修改值
24 | // 确保任何情况下都不能对这个list进行size的修改
25 | ```
26 |
27 |
28 |
29 | Collections.emptyList() 使用场景?
30 |
31 | ```
32 | // 代码中的一个if或者else 需要返回空list时,使用这个
33 | // 如果直接使用 new ArrayList 的话,会有对象的创建
34 | // Collections.emptyList() 无需进行创建
35 | // Arrays.asList() 也会创建对象,浪费一定的空间 不建议使用(不是不能用)
36 | ```
37 |
38 |
39 |
40 |
41 |
42 | removeRange(int fromIndex, int toIndex) 开头和结尾的元素是否被删除?
43 |
44 | ```java
45 |
46 | public class SubArrayList extends ArrayList {
47 |
48 | public static void main(String[] args) {
49 | SubArrayList arrayList = new SubArrayList();
50 | Integer integer = 0;
51 | Integer integer1 = 1;
52 | Integer integer2 = 2;
53 | Integer integer3 = 3;
54 | Object object = null;
55 |
56 | arrayList.add(integer);
57 | arrayList.add(integer1);
58 | arrayList.add(integer2);
59 | arrayList.add(integer3);
60 | arrayList.add(object);
61 |
62 | // 移除下标为1,2的元素
63 | arrayList.removeRange(1, 3);
64 |
65 | // 常规for循环遍历
66 | System.out.println("常规for循环遍历:");
67 | for (int i = 0; i < arrayList.size(); i++) {
68 | System.out.println("object:" + arrayList.get(i));
69 | }
70 | }
71 |
72 | 常规for循环遍历:
73 | object:0
74 | object:3
75 | object:null
76 | ```
77 |
78 | 开头不被删,结尾的会被删
79 |
80 | 这种类似数组下标区间一般都是取下不取上,即[min, max) ,包含min而不包含max。[1]
81 |
82 |
83 |
84 |
85 |
86 | ### 序列化是什么?为什么要序列化?
87 |
88 | 序列化是指把一个Java对象变成二进制内容,本质上就是一个`byte[]`数组。
89 |
90 | 为什么要把Java对象序列化呢?
91 |
92 | 因为序列化后可以把`byte[]`保存到文件中,或者把`byte[]`通过网络传输到远程,这样,就相当于把Java对象存储到文件或者通过网络传输出去了。
93 |
94 | 为什么要序列化,那就是说一下序列化的好处喽,序列化有什么什么优点,所以我们要序列化。
95 |
96 | 优点:
97 |
98 | **一:对象序列化可以实现分布式对象。**
99 |
100 | 主要应用例如:RMI(即远程调用Remote Method Invocation)要利用对象序列化运行远程主机上的服务,就像在本地机上运行对象时一样。
101 |
102 | **二:java对象序列化不仅保留一个对象的数据,而且递归保存对象引用的每个对象的数据。**
103 |
104 | 可以将整个对象层次写入字节流中,可以保存在文件中或在网络连接上传递。利用对象序列化可以进行对象的"深复制",即复制对象本身及引用的对象本身。序列化一个对象可能得到整个对象序列。
105 |
106 | **三:序列化可以将内存中的类写入文件或数据库中。**
107 |
108 | 比如:将某个类序列化后存为文件,下次读取时只需将文件中的数据反序列化就可以将原先的类还原到内存中。也可以将类序列化为流数据进行传输。
109 |
110 | 总的来说就是将一个已经实例化的类转成文件存储,下次需要实例化的时候只要反序列化即可将类实例化到内存中并保留序列化时类中的所有变量和状态。
111 |
112 | **四:对象、文件、数据,有许多不同的格式,很难统一传输和保存。**
113 |
114 | 序列化以后就都是字节流了,无论原来是什么东西,都能变成一样的东西,就可以进行通用的格式传输或保存,传输结束以后,要再次使用,就进行反序列化还原,这样对象还是对象,文件还是文件。【2】
115 |
116 | [1] : https://blog.csdn.net/weixin_41287260/article/details/95357183
117 |
118 | [2] : https://www.cnblogs.com/javazhiyin/p/11841374.html
--------------------------------------------------------------------------------
/笔记/1.4Jvm 相关/4 内存模型.md:
--------------------------------------------------------------------------------
1 | ## 5.synchronized 优化
2 |
3 | Java HotSpot 虚拟机中,每个对象都有对象头(包括 class 指针和 Mark Word)。Mark Word 平时存储这个对象的哈希码 、 分代年龄 ,当加锁时,这些信息就根据情况被替换为标记位 、 线程锁记录指针 、 重量级锁指针 、 线程ID 等内容
4 |
5 | ### 5-1 轻量级锁
6 |
7 | 如果一个对象虽然有多线程访问,但多线程访问的时间是错开的(也就是没有竞争),那么可以使用轻量级锁来优化。这就好比:
8 |
9 | 学生(线程 A)用课本占座,上了半节课,出门了(CPU时间到),回来一看,发现课本没变,说明有竞争,继续上他的课。 如果这期间有其它学生(线程 B)来了,会告知(线程A)有并发访问,线程A 随即升级为重量级锁,进入重量级锁的流程。
10 |
11 | 而重量级锁就不是那么用课本占座那么简单了,可以想象线程 A 走之前,把座位用一个铁栅栏围起来,假设有两个方法同步块,利用同一个对象加锁
12 |
13 | ```java
14 | static Object obj = new Object();
15 | public static void method1() {
16 | synchronized( obj ) {
17 | // 同步块 A
18 | method2();
19 | }
20 | }
21 | public static void method2() {
22 | synchronized( obj ) {
23 | // 同步块 B
24 | }
25 | }
26 | ```
27 |
28 | 每个线程都的栈帧都会包含一个锁记录的结构,内部可以存储锁定对象的 Mark Word
29 |
30 | 
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 | ### 5-2 锁膨胀
39 |
40 | 如果在尝试加轻量级锁的过程中,CAS 操作无法成功,这时一种情况就是有其它线程为此对象加上了轻量级锁(有竞争),这时需要进行锁膨胀,将轻量级锁变为重量级锁。
41 |
42 |
43 |
44 | 
45 |
46 | ### 5-3 重量锁
47 |
48 | 重量级锁竞争的时候,还可以使用自旋来进行优化,如果当前线程自旋成功(即这时候持锁线程已经退出了同步块,释放了锁),这时当前线程就可以避免阻塞。
49 |
50 | 在 Java 6 之后自旋锁是自适应的,比如对象刚刚的一次自旋操作成功过,那么认为这次自旋成功的可能性会高,就多自旋几次;反之,就少自旋甚至不自旋,总之,比较智能。
51 |
52 | 等红灯时,汽车不熄火相当于自旋转(等待时间短了划算),熄火了相当于阻塞(等待时间长了划算)
53 |
54 |
55 |
56 | 自旋重试成功
57 |
58 | 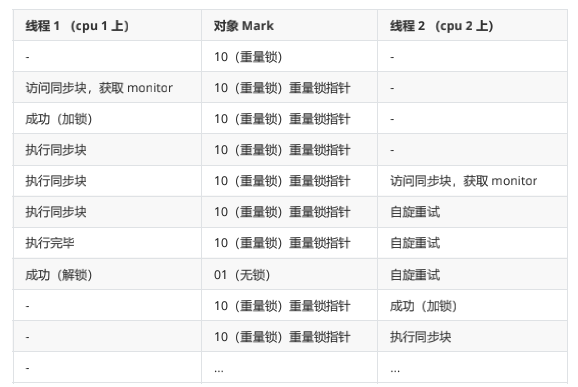
59 |
60 | 自旋重试失败
61 |
62 | 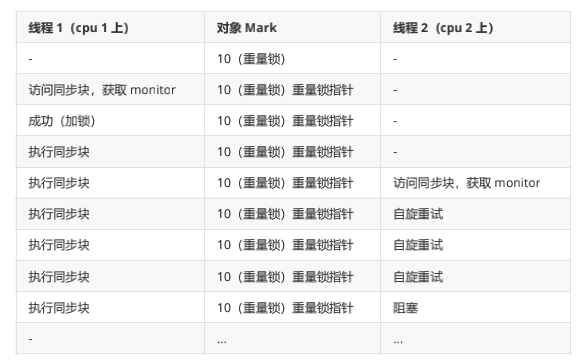
63 |
64 | ### 5-4 偏向锁
65 |
66 | 轻量级锁在没有竞争时(就自己这个线程),每次重入仍然需要执行CAS操作。Java 6中引入了偏向锁来做进一步优化:只有第一次使用CAS将线程ID设置到对象的Mark Word头,之后发现这个线程ID是自己的就表示没有竞争,不用重新CAS
67 |
68 | 撤销偏向需要将持锁线程升级为轻量级锁,这个过程中所有线程需要暂停(STW)
69 | 访问对象的 hashCode 也会撤销偏向锁
70 | 如果对象虽然被多个线程访问,但没有竞争,这时偏向了线程 T1 的对象仍有机会重新偏向 T2,重偏向会重置对象的 Thread ID
71 | 撤销偏向和重偏向都是批量进行的,以类为单位
72 | 如果撤销偏向到达某个阈值,整个类的所有对象都会变为不可偏向的
73 | 可以主动使用 -XX:-UseBiasedLocking 禁用偏向锁
74 |
75 | ####
76 |
77 | ### 5-5 其他优化
78 |
79 | #### (1)减少上锁时间
80 |
81 | 同步代码块中尽量短
82 |
83 | #### (2)减少锁的粒度
84 |
85 | 将一个锁拆分为多个锁提高并发度,例如:
86 |
87 | ConcurrentHashMap
88 | LongAdder 分为 base 和 cells 两部分。没有并发争用的时候或者是 cells 数组正在初始化的时候,会使用 CAS 来累加到base,有并发争用,会初始化 cells 数组,数组有多少个 cell,就允许有多少线程并行修改,最后将数组中每个 cell 累加,再加上 base 就是最终的值
89 | LinkedBlockingQueue 入队和出队使用不同的锁,相对于LinkedBlockingArray只有一个锁效率要高
90 |
91 | #### (3)锁粗化
92 |
93 | 多次循环进入同步块不如同步块内多次循环,另外 JVM 可能会做如下优化,把多次 append 的加锁操作粗化为一次(因为都是对同一个对象加锁,没必要重入多次)
94 |
95 | new StringBuffer().append("a").append("b").append("c");
96 | 1
97 |
98 | #### (4)锁消除
99 |
100 | JVM 会进行代码的逃逸分析,例如某个加锁对象是方法内局部变量,不会被其它线程所访问到,这时候就会被即时编译器忽略掉所有同步操作。
101 |
102 | #### (5)读写分离
103 |
104 | 如果撤销偏向到达某个阈值,整个类的所有对象都会变为不可偏向的
105 |
106 | 可以主动使用 -XX:-UseBiasedLocking 禁用偏向锁
107 |
--------------------------------------------------------------------------------
/项目/Raft.md:
--------------------------------------------------------------------------------
1 | ```
2 | //请求投票的rpc
3 | term //当前任期号
4 | candidateld //自己的id
5 | lastLogIndex // 自己最后一个日志号
6 | lastLogTerm // 自己最后一个日志的任期
7 | ```
8 |
9 | 请求投票的rpc中会包含最后一个日志的信息(安全性子问题)
10 |
11 |
12 |
13 |
14 |
15 | 日志中包含的信息
16 |
17 | 状态机指令
18 |
19 | leader的任期号
20 |
21 | 日志索引
22 |
23 | (任期号和日志索引唯一确定一条日志)
24 |
25 |
26 |
27 |
28 |
29 | ### 日志复制
30 |
31 | 分布式中网络不稳定,需要日志复制来保证状态机的中间态相同
32 |
33 |
34 |
35 | #### follower缓慢
36 |
37 | 如果有follower因为某些原因没有给leader响应,那么leader会不断地重发追加条目请求(AppendEntries RPC),哪怕leader已经回复 了客户端。
38 |
39 | #### follower崩溃恢复
40 |
41 | 如果有follower崩溃后恢复,这时Raft追加条目的一致性检查生效,保证follower能按顺序恢复崩溃后的缺失的日志。
42 |
43 | Raft的一致性检查: leader在 每一 个发往follower的追加条目RPC中,==会放入前一个日志条目的索引位置和任期号==,如果follower在它 的日志中找不到前一个日志,那么它就会拒绝此日志,leader收 到follower的拒绝后,会发送前一个日志条且,从而逐渐向前定位到follower第一个缺失的日志。
44 |
45 |
46 |
47 | #### leader崩溃
48 |
49 | ③如果leader崩溃,那么崩溃的leader可能已经复制了旦志到部分follower 但还没有提交而被选出的新leader又可能不具备这些日志,这样就有部分follower中的日志和新leader的日志不相同。
50 |
51 | Raft在这种情况下,leader通过强制follower复制它的日志来解决不一致的问题,这意味着follower中跟leader冲突的日志条且会被新 leader的旦志条目覆盖(因为没有提交,所以不违背外部一致性)
52 |
53 |
54 |
55 | ●通过这种机制,leader在 当权之后就不需要任何特殊的操作来使日志恢复到一致状态。
56 | ●Leader只需要进行正常的操作,然后日志就能在回复AppendEntries-致 性检查失败的时候自动趋于一致。
57 | ●Leader从来不会覆盖或者删除自己的日志条目。(Append-Only)
58 | ●这样的日志复制机制,就可以保证一 致性特性:
59 | 只要过半的服务器能正常运行,Raft就能够接受、复制并应用新的日志条且;
60 |
61 | 在正常情况下,新的且志条且可以在一个RPC来回中被复制给集群中的过半机器:
62 |
63 | 单个运行慢的follower不会影响整体的性能。
64 |
65 |
66 |
67 |
68 |
69 | ### 安全性
70 |
71 | 领导者选举和日志复制两个子问题实际上已经涵盖了共识算法的全程,但这两点还不能完全保证每一个状态机会按照==相同的顺序==执行相同的命令。
72 |
73 | 所以Raft通过几个补充规则完善整个算法,使算法可以在各类宕机问题下都不出错。
74 |
75 | 这些规则包括(不讨论安全性条件的证明过程):
76 |
77 | 1. Leader宕机处理:选举限制
78 | 2. Leader宕机处理:新leader是 否提交之前任期内的日志条目
79 | 3. Follower和Candidate宕机处理
80 | 4. 时间与可用性限制
81 |
82 |
83 |
84 | #### Leader宕机处理:选举限制
85 |
86 | 现象:
87 |
88 | 一个follower落后了leader若干条日志(但没有漏一整个周期),那么按照leader选举的规则,它依旧有可能当选leader,它在当选leader后就永远无法补上之前缺失的那部分日志,从而造成状态机之间的不一致
89 |
90 | 解决思路:
91 |
92 | 保证被选出来的leader一定包含了之前各任期中所有被提交的日志条目
93 |
94 | 解决方案:
95 |
96 | (比较投票rpc中的日志信息,如果自己的日志号大于投票的日志号,就拒绝,以此来避免出现新选的leader中没有之前提交的日志)
97 |
98 | RequestVote RPC执行了这样的限制: RPC中包含了candidate的日志信息,如果投票者自己的日志比candidate的还新,它会拒绝掉该投票请求。
99 |
100 | Raft通过比较两份日志中最后一条日志条目的索引值和任期号来定义谁的日志比较新。
101 |
102 | 如果两份日志最后条目的任期号不同,那么任期号大的日志更“新”。
103 |
104 | 如果两份日志最后条目的任期号相同,那么日志较长的那个更“新”。
105 |
106 | #### Leader宕机处理:新leader是否提交之前任期内的日志条目
107 |
108 |
109 |
110 | leader提交后,返回给客户端(然后宕机了,没有给follower发送提交信息),这种情况怎么处理?
111 |
112 | >leader提交和follower提交间,必然会间隔一段时间
113 | >
114 | >如果leader提交之后直接返回客户端
115 | >
116 | >在通知follower提交前,也就是一个心跳的时间内,如果leader宕机
117 | >
118 | >就会出现部分提交的问题
119 |
120 | raft 是一种底层的共识算法,本身只是应用实现高可用的一种方式,而与客户端交互本来应该是属于应用端的事情,理论上不是raft该担心的,所以论文中也没有讨论这一点。
121 |
122 | ==原生的raft并没有做处理,是后面自己实现时,设置了集群提交==
123 |
124 |
125 |
126 | > 应用会设置一个集群提交的概念,只有集群中超过半数的节点都完成提交,才认为集群提交完成
127 |
128 |
129 |
130 | raft不是通过计算副本数目的方式来提交之前任期内的日志
131 |
132 | 只有自己任期内的日志才能通过计算副本数目来提交
133 |
134 |
135 |
136 |
137 |
138 | #### Follower和Candidate宕机处理
139 |
140 | raft通过无限的重试来处理这种失败,如果奔溃的机器重启了,这些rpc就能成功
141 |
142 |
143 |
144 | #### 时间与可用性限制
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/上海小公司面经-复盘版.md:
--------------------------------------------------------------------------------
1 | [TOC]
2 |
3 |
4 |
5 | ## 公司介绍
6 |
7 | 上海小厂,200一天,随便面了面发了offer邮件,主要练习了自我介绍和部分项目介绍经验。
8 |
9 | ### 讲讲Java 的抽象类和接口
10 |
11 | `语法层面上的区别:`
12 |
13 | 抽象类可以提供成员方法的实现细节,而接口中只能存在public abstract 方法;
14 |
15 |
16 | 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的;
17 |
18 | 接口中不能含有静态代码块以及静态方法,而抽象类可以有静态代码块和静态方法;
19 |
20 | 一个类只能继承一个抽象类,而一个类却可以实现多个接口。
21 |
22 | `设计层面上的区别:`
23 |
24 | 抽象类是对一种事物的抽象,即对类抽象,而接口是对行为的抽象。
25 |
26 | 抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。
27 |
28 | 设计层面不同,抽象类作为很多子类的父类,它是一种模板式设计。而接口是一种行为规范,它是一种辐射式设计。
29 |
30 | ### @Restcontroller 了解不
31 |
32 | Spring4之后新加入的注解,原来返回json需要@ResponseBody和@Controller配合。
33 |
34 | 即@RestController是@ResponseBody和@Controller的组合注解。
35 |
36 | —》拓展restful 风格---〉自己项目就是restful的
37 |
38 | ### @autowrited 和 @ resource
39 |
40 | 一般没什么区别,用idea的话,autowrited会报警告
41 |
42 | spring建议用set注入和构造器注入,不建议在成员变量上加注解
43 |
44 | autowrited是spring提供的,resource是java jre提供的
45 |
46 | ### IOC 和 AOP
47 |
48 | ioc 基本概念--》ioc 实现(工厂+反射)
49 |
50 | aop 基本概念(面向切面编程,在不修改原代码的基础上对功能坐增强)--〉aop 实现(代理)
51 |
52 | ——〉静态代理、动态代理
53 |
54 | ——〉aop通知、aop在项目的应用(日志收集、鉴权、响应统计)
55 |
56 |
57 |
58 | ### AOF 和 RDB
59 |
60 | #### **AOF(Append Only File)**
61 |
62 | AOF持久化功能,是一种保存写操作命令到日志的持久化方式
63 |
64 | **只会记录写操作命令,读操作命令是不会被记录的**,因为没意义。
65 |
66 | 有三种写回策略
67 |
68 | **Always**,每次写操作命令执行完后,同步将 AOF 日志数据写回硬盘;
69 |
70 | **Everysec**,每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,然后每隔一秒将缓冲区里的内容写回到硬盘;
71 |
72 | **No**,意味着不由 Redis 控制写回硬盘的时机,转交给操作系统控制写回的时机,也就是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,再由操作系统决定何时将缓冲区内容写回硬盘。
73 |
74 | 根据自己的业务场景进行选择:
75 |
76 | - 如果要高性能,就选择 No 策略;
77 | - 如果要高可靠,就选择 Always 策略;
78 | - 如果允许数据丢失一点,但又想性能高,就选择 Everysec 策略。
79 |
80 |
81 |
82 | #### **RDB** 快照
83 |
84 | 也是用日志文件记录信息,RDB 文件的内容是二进制数据
85 |
86 | Redis 提供了两个命令来生成 RDB 文件,分别是 `save` 和 `bgsave`,他们的区别就在于是否在「主线程」里执行:
87 |
88 | - 执行了 save 命令,就会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长,**会阻塞主线程**;
89 | - 执行了 bgsave 命令,会创建一个子进程来生成 RDB 文件,这样可以**避免主线程的阻塞**;
90 |
91 | 执行 bgsave 过程中,Redis 依然**可以继续处理操作命令**的,也就是数据是能被修改的。
92 |
93 | ---》拓展**写时复制技术(Copy-On-Write, COW)**
94 |
95 | #### RDB 和 AOF 合体
96 |
97 | RDB 和 AOF 合体使用,这个方法是在 Redis 4.0 提出的,该方法叫**混合使用 AOF 日志和内存快照**,也叫混合持久化。
98 |
99 | 当开启了混合持久化时,在 AOF 重写日志时,`fork` 出来的重写子进程会先将与主线程共享的内存数据以 RDB 方式写入到 AOF 文件,然后主线程处理的操作命令会被记录在重写缓冲区里,重写缓冲区里的增量命令会以 AOF 方式写入到 AOF 文件,写入完成后通知主进程将新的含有 RDB 格式和 AOF 格式的 AOF 文件替换旧的的 AOF 文件。
100 |
101 | 也就是说,使用了混合持久化,AOF 文件的**前半部分是 RDB 格式的全量数据,后半部分是 AOF 格式的增量数据**。
102 |
103 | 这样的好处在于,重启 Redis 加载数据的时候,由于前半部分是 RDB 内容,这样**加载的时候速度会很快**。
104 |
105 | 加载完 RDB 的内容后,才会加载后半部分的 AOF 内容,这里的内容是 Redis 后台子进程重写 AOF 期间,主线程处理的操作命令,可以使得**数据更少的丢失**。
106 |
107 |
108 |
109 | ### 微服务了解么
110 |
111 |
112 |
113 | 从单体架构的缺点聊到微服务的优点以及缺点
114 |
115 | 然后以自己做的项目为例讲了讲服务的拆分、调用
116 |
117 |
118 |
119 | ### 写个sql
120 |
121 |
122 |
123 | ## 总结
124 |
125 | sql基础薄弱,语法快忘了,要加强
126 |
127 | spring偏业务的忘差不多了,要回忆一下
128 |
129 | redis部分继续融合八股
130 |
131 | 微服务部分
132 |
133 | 从单体优缺点--》微服务架构优缺点
134 |
135 | 然后可以讲服务拆分、服务注册--〉分布式---》共识算法
136 |
137 | 也可以讲网关,从基础的getway--〉南北向网关、东西向网关
--------------------------------------------------------------------------------
/项目/理论.md:
--------------------------------------------------------------------------------
1 | ## 单机二阶段提交
2 |
3 | ## 分布式二阶段提交 2pc
4 |
5 | 场景:分布式事务
6 | 强一致、中心化的原子提交协议
7 | 准备阶段、提交阶段
8 | 协调者(Coordinator)、 参 与者(Participant)
9 |
10 |
11 |
12 | 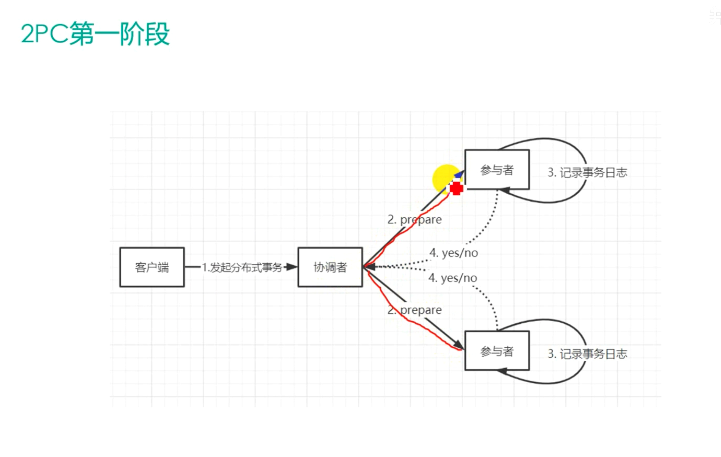
13 |
14 | 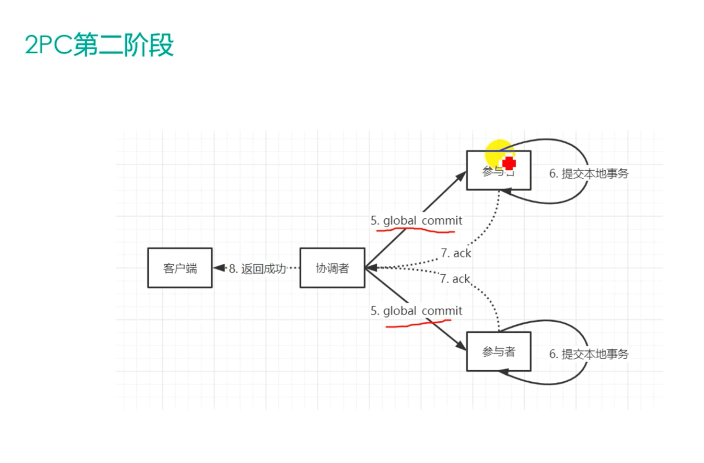
15 |
16 |
17 |
18 | 失败回滚
19 |
20 | 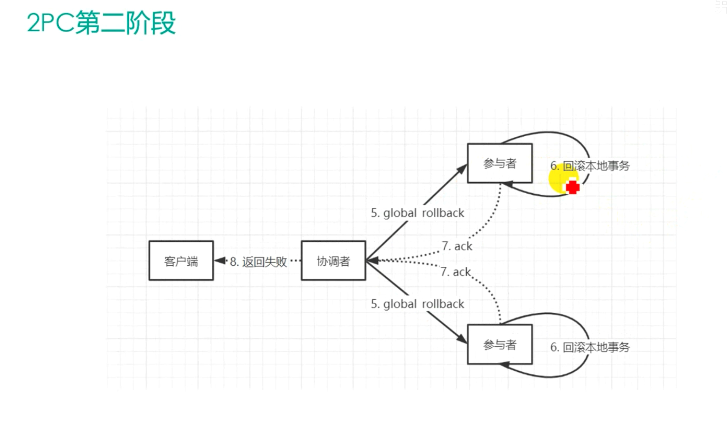
21 |
22 |
23 |
24 | 存在的问题
25 |
26 | 同步阻塞 (等待所有参与者的响应)
27 | 数据不一-致 (一部分参与者回滚事务失败了,一部分参与者回滚事务成功了)
28 | 单点问题/脑裂 (协调者单机问题/ 多个协调者都进行操作,出现脑裂问题)
29 | 太过保守
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 | ----
38 |
39 | ## 三阶段提交 3pc
40 |
41 |
42 |
43 | 3PC简述
44 |
45 | 强一致、中心化的原子提交协议
46 | 协调者(Coordinator) 、参与者(Participant)
47 | 超时机制:
48 | 参与者在等待协调者超时后,允许执行默认操作
49 | 协调者在等待参与者超时后,允许执行默认操作
50 | 降低了事务资源锁定范围
51 | 增加了CanCommit阶段,不会像2PC- -祥,从一开始就锁定所有事务资源,3PC在
52 | 排除掉个别不具备处理事务能力的参与者的前提下,在进入第二阶段的锁定事务
53 | 资源
54 |
55 |
56 |
57 | 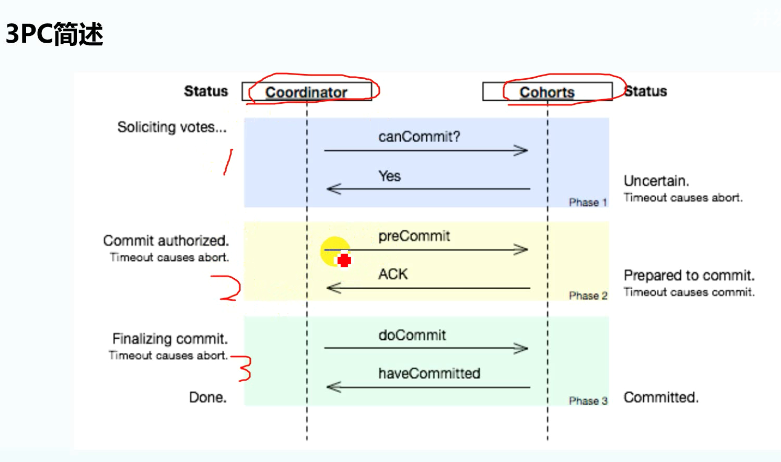
58 |
59 |
60 |
61 | 小结
62 | 减少事务资源锁定范围
63 | ●增 加CanCommit阶段
64 | 降低了同步阻塞
65 | ●超时机制
66 | 增加一-轮消息,增加了复杂度和协商效率。
67 | 数据不一-致
68 |
69 |
70 |
71 | ---
72 |
73 |
74 |
75 | CAP定理,指的是在-一个分布式系统中,一-致性(Consistency) 、可用性
76 | (Availability)、分区容错性(Partition tolerance)。这三个要素最多只能同时实现两
77 | 点,不可能三者兼顾。
78 | ●一致性(C) :这里是指100%强一致性。在分布式系统中的所有数据备份,在同一
79 | 时刻整个系统的制本都拥有的一致的数据。
80 | ●可用性(A) :这里是指100%可用性。客户端无论访问到哪个没有宕机的节点上,
81 | 都能在有限的时间内返回结果,并不是指整个系统处于可用状态。
82 | 分区容错性(P) :网络中允许丢失一个节点发给另一个节点的任意多的消息,即对
83 | 网络分区的容忍。在发生网络分区时,能继续保持可用性或者一致性。如果一个系
84 | 统要求在运行过程中不能发生网络分区,那么这个系统就不具备分区容错性。
85 |
86 |
87 |
88 |
89 |
90 | 当发生网络分区时,你将面临两个选择:
91 | 如果坚持保持各节点之间的数据一致性(选择C),你需要等待网络分区恢复后,将
92 | 数据复制完成,才可以向外部提供服务。期间发生网络分区将不能对外提供服务,
93 | 因为它保证不了数据一致性。
94 | 如果选择可用性(选择A),发生网络分区的节点,依然需要向外提供服务。但是由
95 | 于网络分区,它同步不了最新的数据,所以它返回数据,可能不是最新的(与其他
96 | 节点不一致的)数据。
97 |
98 |
99 |
100 |
101 |
102 | 用户感知的一致性和cap的一致性不是一个一致性
103 |
104 |
105 |
106 | CAP三者不可兼得,仅仅是指在发生网络分区情况下,我们才需要在A和C之间进行抉
107 | 择,选择保证数据一-致还是服务 可用。而集群正常运行时,A和C是都可以保证的。
108 | ,CP架构在当发生网络分区时,为了保证返回给客户端数据准确性,为了不破坏一致
109 | 性,可能会园为无法响应最新数据,而拒绝响应。在网络分区恢复后,完成数据同
110 | 步,才可处理客户端请求。
111 | AP架构在发生网络分区时,发生分区的节点不需要等待数据完成同步,便可处理客
112 | 户端请求,将尽可能的给用户返回相对新的数据。在网络分区恢复后,完成数据同
113 | 步。
114 |
115 |
116 |
117 |
118 |
119 | CAP描述的一致性和可用性,都是100%的强度。
120 |
121 |
122 |
123 | 在生产实践中,我们并不需要100%的- -致性和可用性,因此我们需要对一致性和可用
124 | 性之间进行权衡,选择CP架构或者AP架构。
125 | 我们认为ZooKeeper在关键时刻(少数成员宕机时,仍可以向客户端提供正确的服务,而多数派成员宕机时,zookeeper则选择了一致性,为了保证给客户端响应正确的数据,zookeeper此时不会继续提供服务)选择一致性,但是它仍拥有很高的可用性。
126 |
127 | Brwer指出Spanner系统说是”实际上的CA”(efctivelCA) 系统
128 |
129 | 架构上是cp
130 |
131 | 出现网络分区,会保证一致性,不会对外提供服务
132 |
133 |
134 |
135 |
136 |
137 | 以eureka 为例,eureka 各节点互相独立,平等
138 |
139 | 各节点都提供查询和注册服务(读,写请求)
140 |
141 | 当发生网络分区,eureka 各节点依旧可以接收和注册服务
142 |
143 | 并且当丢失过多客户端时,节点会进入自我保护(接收新服务注册、不删除过期服务)
144 |
145 | 在这种模式下,eureka集群即使受到最后一个节点,也可以向外提供服务
146 |
147 | 尽管向外提供的数据可能是过期的数据
148 |
149 | 考虑选择一致性还是可用性的情况,一定是在发生网络故障,且在关键时间,此时一致性和可用性才是互斥的
150 |
151 | 而网络故障、且非常关键时间,在-一个健壮的系统中,这类情况是
152 | 非常少的,我们大多数情况都能保证-致性和可用性。
153 |
154 | eureka正常运行时,各节点之间可以正常通讯、保持心跳、复制数据、以此保持数据的一致性,但发生网络分区时,eureka 确实选择了可用性,放弃了一致性
155 |
156 | https://www.bilibili.com/video/BV1zS4y1W7hQ
157 |
158 |
159 |
160 | ----
161 |
162 |
--------------------------------------------------------------------------------
/项目/paxos.md:
--------------------------------------------------------------------------------
1 | ### paxos 究竟在解决什么问题 ?
2 |
3 | 用来确定一个不可变变量的取值
4 |
5 |
6 |
7 | ### paxos 如何在分布式存储系统中应用 ?
8 |
9 | 
10 |
11 | 
12 |
13 |
14 |
15 |
16 |
17 | 
18 |
19 |
20 |
21 | 
22 |
23 | 
24 |
25 | 
26 |
27 |
28 |
29 | 
30 |
31 |
32 |
33 | ### paxos 算法的核心思想是什么 ?
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 | 知行学社——paxos和分布式系统https://www.bilibili.com/video/BV1Lt411m7cW
42 |
43 |
44 |
45 |
46 |
47 | ----
48 |
49 | 共识介绍
50 |
51 | 共识Consensus问题:
52 | 在一组允许出现故障的成员中,如何从一组提案中就某一个提案达成共识
53 |
54 | 共识与一致性:
55 |
56 | 共识强调在外部观察者看来,系统数据是一致的
57 | 一致性,是指系统内部真实100%-致
58 |
59 |
60 |
61 | 基本保证:
62 | 已达成共识的提案不会因为任何变故而改变
63 |
64 | 提案编号
65 |
66 | 多数派:
67 | 超过集群一半成员组成集合
68 | l(N)2| +1 (N为成员总数)
69 |
70 |
71 |
72 | 角色
73 |
74 | proposer
75 |
76 | acceptor
77 |
78 | learner
79 |
80 |
81 |
82 | 阶段
83 |
84 | prepare 阶段
85 |
86 | 争取本轮提出提案的所有权
87 |
88 | prpare阶段propose是不会携带提案值的,它只会携带提案编号广播给所有的acceptor,所有的acceptor 根据这个提案编号判断是不是能够接受这个prepare请求
89 |
90 | 当proposer收到集群中大多数acceptor的同意之后,然后它就拥有本轮提出提案的权利,那么它就可以进行accept阶段
91 |
92 | 另一个作用,就是获取上一轮可能达成共识的提案(已经达成共识的值不可改变了)。它会把prepare请求广播给所有的acceptor时,acceptor会把它本地曾接收过的一个提案反馈给 proposer
93 |
94 |
95 |
96 | accept阶段
97 |
98 | 获取上一轮
99 |
100 | learn阶段
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 | 协商约定
109 |
110 | Acceptor:令自己所见过的最大的提案编号为local.n,请求中的提案编号为msg.n
111 |
112 | 收到Prepare请求,msgn> localn,则通过该请求,否则拒绝该请求,直接抛弃该请求。
113 |
114 | 收到Accepl请求,msg.n ≥localn,则通过该请求,否则拒绝该请求,直接抛弃该请求。
115 |
116 | 通过某一Prepare请求时,会在Prepare响应中携带自已所批准过的最大提案编号对应的提案值。
117 |
118 | Proposer:
119 | 收到客户端请求,先发起Prepare请求。
120 | 收到多数派Prepare响应, 才可以进入Accept阶段。 其提案值需要从Prepare响应中获取。
121 | 收到多数派Accepl响应,则该提案达成识。
122 |
123 |
124 |
125 |
126 |
127 | 
128 |
129 |
130 |
131 | 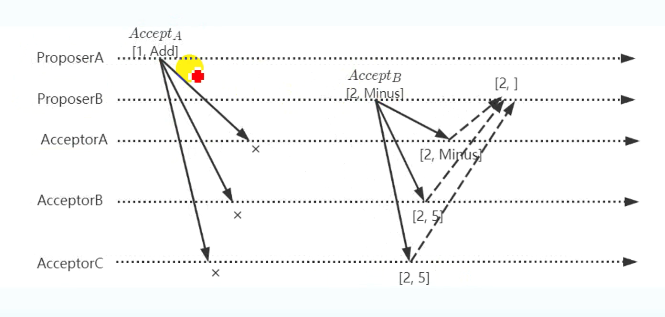
132 |
133 |
134 |
135 |
136 |
137 | 四轮消息响应
138 |
139 | 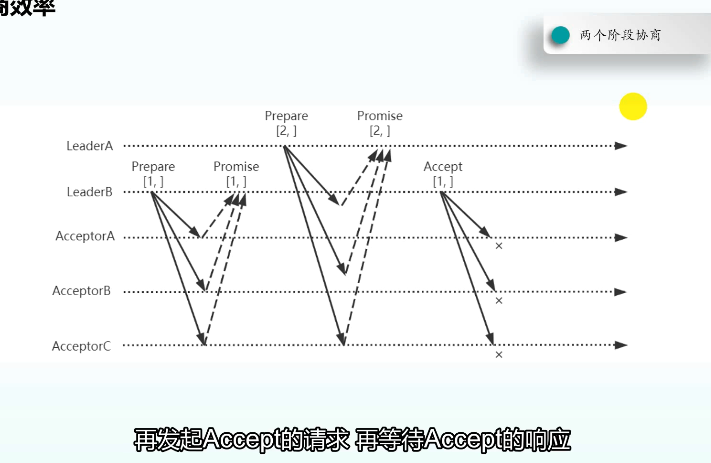
140 |
141 |
142 |
143 |
144 |
145 | 活锁 多个proposer 之间并行提案,它们之间会互相影响
146 |
147 | 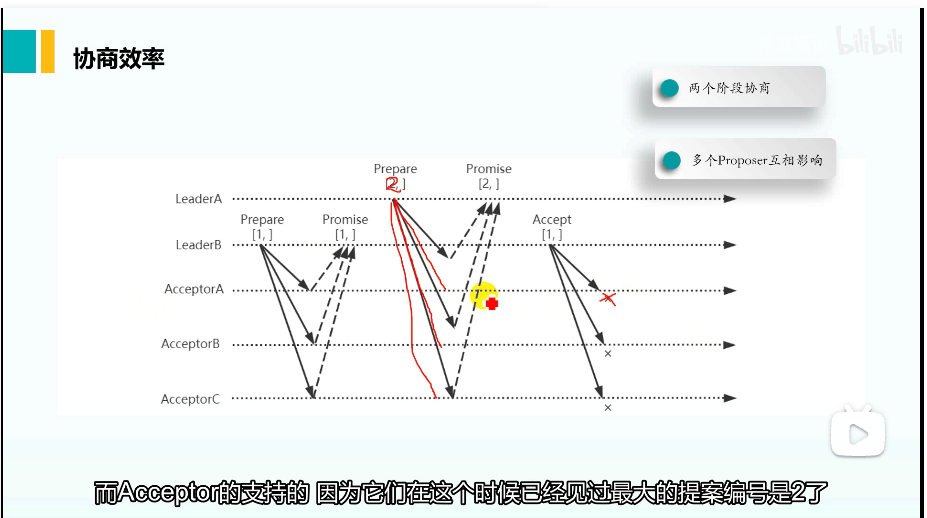
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 | ### Multi paxos
156 |
157 | 引入Leader角色
158 | 只能由Lcaded发起捉案,减少了活锁的概率
159 | 优化Prepare阶段
160 | 在没有提案冲突的情况下,优化Prcpare阶段, 优化成一阶段
161 |
162 |
163 |
164 |
165 |
166 |
167 |
168 | 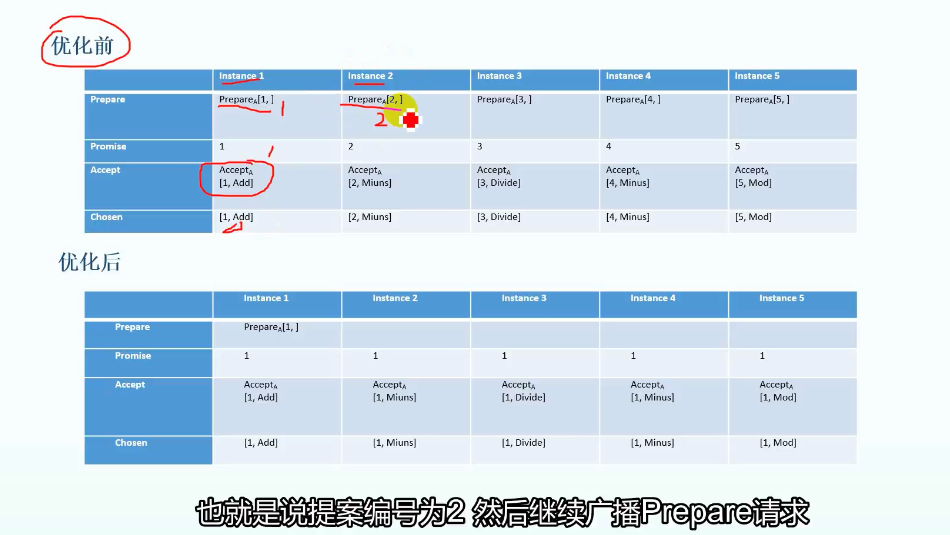
169 |
170 |
171 |
172 | 【分布式一致性/共识算法 - Multi Paxos】 https://www.bilibili.com/video/BV1Y34y1j7b1?share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
173 |
174 |
175 |
176 | 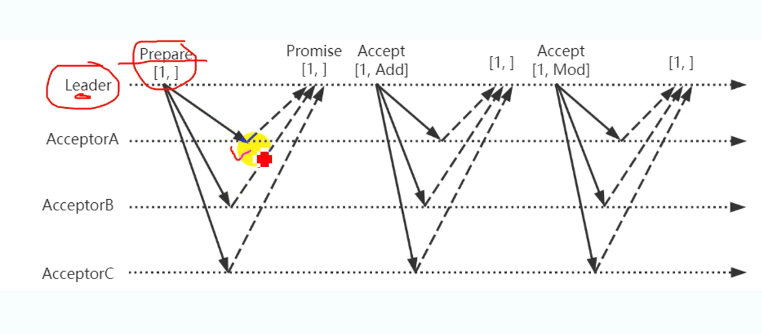
177 |
178 |
179 |
180 |
181 |
182 | https://www.bilibili.com/video/BV1X54y1d7xU
--------------------------------------------------------------------------------
/笔记/1.3Java并发/3并发理论(JMM).md:
--------------------------------------------------------------------------------
1 | # 并发理论(JMM)
2 |
3 | JMM本质上可以理解为,Java 内存模型规范了 JVM 如何提供按需禁用缓存和编译优化的方法。
4 |
5 | 体来说,这些方法包括:
6 |
7 | - volatile、synchronized 和 final 三个关键字
8 | - Happens-Before 规则
9 |
10 | **Java提供了volatile关键字来保证可见性**。
11 |
12 | 当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
13 |
14 | **在Java里面,可以通过volatile关键字来保证一定的“有序性**
15 |
16 | ## Java 内存模型的抽象
17 |
18 | 在 java 中,所有实例域、静态域和数组元素存储在==堆内存==中,==堆内存、和方法区 (JDK1.8 之后的元空间)资源== 在线程之间共享。
19 |
20 | 但是每个线程有自己的程序计数器、虚拟机栈 和 本地方法栈。
21 |
22 | 局部变量(Local variables),方法定义参数(java 语言规范称之为 formal method parameters)和异常处理器参数(exception handler parameters)不会在线程之间共享,它们不会有内存可见性问题,也不受内存模型的影响。
23 |
24 | Java 内存模型的抽象示意图如下:
25 |
26 | 
27 |
28 | 线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读 / 写共享变量的副本。
29 |
30 |
31 |
32 | ## 重排序
33 |
34 | 在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。重排序分三种类型:
35 |
36 | - ==编译器优化的重排序==。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
37 | - ==指令级并行的重排序==。现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
38 | - ==内存系统的重排序==。由于处理器使用缓存和读 / 写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
39 |
40 | 从 java 源代码到最终实际执行的指令序列,会分别经历下面三种重排序:
41 |
42 | 
43 |
44 | 上述的 1 属于编译器重排序,2 和 3 属于处理器重排序。这些重排序都可能会导致多线程程序出现内存可见性问题。
45 |
46 | 对于编译器,JMM 的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。
47 |
48 | 对于处理器重排序,JMM 的处理器重排序规则会要求 java 编译器在生成指令序列时,插入特定类型的内存屏障(memory barriers,intel 称之为 memory fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序(不是所有的处理器重排序都要禁止)。
49 |
50 | ==JMM 属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证==。
51 |
52 | ## happens-before
53 |
54 | 从 JDK5 开始,java 使用新的 JSR -133 内存模型。
55 |
56 | JSR-133 提出了 happens-before 的概念,通过这个概念来阐述操作之间的内存可见性。
57 |
58 | 如==果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在 happens-before 关系。这里提到的两个操作既可以是在一个线程之内,也可以是在不同线程之间。== 与程序员密切相关的 happens-before 规则如下:
59 |
60 | - 程序顺序规则:一个线程中的每个操作,happens- before 于该线程中的任意后续操作。
61 | - 监视器锁规则:对一个监视器锁的解锁,happens- before 于随后对这个监视器锁的加锁。
62 | - ==volatile 变量规则==:对一个 volatile 域的写,happens- before 于任意后续对这个 volatile 域的读。
63 | - 传递性:如果 A happens- before B,且 B happens- before C,那么 A happens- before C。
64 |
65 | ==注意,两个操作之间具有 happens-before 关系,并不意味着前一个操作必须要在后一个操作之前执行!happens-before 仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前==(the first is visible to and ordered before the second)。happens- before 的定义很微妙,后文会具体说明 happens-before 为什么要这么定义。
66 |
67 |
68 |
69 | ## 重排序
70 |
71 | ### 数据依赖性
72 |
73 | 写后读\写后写\读后写
74 |
75 | 只要重排序两个操作的执行顺序,程序的执行结果将会被改变。
76 |
77 | 编译器和处理器可能会对操作做重排序。编译器和处理器在重排序时,会遵守数据依赖性,==编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序==。
78 |
79 | ## ==as-if-serial 语义==
80 |
81 | as-if-serial 语义的意思指:==不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变==。编译器,runtime 和处理器都必须遵守 as-if-serial 语义。
82 |
83 | ```
84 | area = pi * r * r
85 | ```
86 |
87 | 先乘哪个都行
88 |
89 | as-if-serial 语义把单线程程序保护了起来,遵守 as-if-serial 语义的编译器,runtime 和处理器共同为编写单线程程序的程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的。as-if-serial 语义使单线程程序员无需担心重排序会干扰他们,也无需担心内存可见性问题。
90 |
91 |
92 |
93 | ## JMM 的内存可见性保证
94 |
95 | Java 程序的内存可见性保证按程序类型可以分为下列三类:
96 |
97 | - ==单线程程序。单线程程序不会出现内存可见性问题。==编译器,runtime 和处理器会共同确保单线程程序的执行结果与该程序在顺序一致性模型中的执行结果相同。
98 | - ==正确同步的多线程程序。正确同步的多线程程序的执行将具有顺序一致性==(程序的执行结果与该程序在顺序一致性内存模型中的执行结果相同)。这是 JMM 关注的重点,JMM 通过限制编译器和处理器的重排序来为程序员提供内存可见性保证。
99 | - ==未同步 / 未正确同步的多线程程序。==JMM 为它们提供了最小安全性保障:线程执行时读取到的值,要么是之前某个线程写入的值,要么是默认值(0,null,false)。
100 |
101 | 下图展示了这三类程序在 JMM 中与在顺序一致性内存模型中的执行结果的异同:
102 |
103 | 
104 |
105 | 只要多线程程序是正确同步的,JMM 保证该程序在任意的处理器平台上的执行结果,与该程序在顺序一致性内存模型中的执行结果一致。
106 |
107 |
108 |
109 | ## 参考
110 |
111 | https://juejin.cn/post/6844903600318054413
112 |
113 | https://pdai.tech/md/java/thread/java-thread-x-theorty.html
114 |
115 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/滴滴准实习员工模拟面 .md:
--------------------------------------------------------------------------------
1 | ## 11.3 滴滴准实习员工模拟面--简单复盘版
2 |
3 | 滴滴准实习员工模拟面,1h
4 |
5 |
6 |
7 | ### 自我介绍
8 |
9 | 巴拉巴拉
10 |
11 | ```
12 | 继续练,还没特别熟
13 | ```
14 |
15 |
16 |
17 | ### 项目介绍
18 |
19 | ### edis
20 |
21 | > redis过期策略
22 |
23 |
24 |
25 | > 比如说我们数据库当中有 2000 万的数据,然后我 Redis 它只存 20 万的数据,然后让你来设计,你要怎么设计呢?
26 |
27 | LRU策略
28 |
29 |
30 |
31 | >但是你看我们传统的 LRU 的话,那它造成的这个缓存污染怎么办?比如说有一个热点数据,我刚进去,结果刚进去待了很久,然后但是他已经很久没有使用了,但是他就是比如说我们一开始就是我们热点不是最近访问的。然后然后我们这个 Redis 当中有一个比如说有有一个预读机制,就是比如说 A 和 B 数据都进去了,然后他们的访他们只可能就是最近访问了一两次,但是这样他就会导致以前的那些热点数据给清除了。你能就是你觉得这个要怎么办?就是让你来优化一下 LRU 算法,你要怎么优化一下呢?
32 |
33 | 我们需要一个晋升的阈值,可以参考Linux中优化LRU的算法
34 |
35 | 就是设计了一个 active 链表,还有一个 inactive 链表。
36 |
37 | 访问次数在阈值内的会在inactive链表中,超过次数的会晋升到active链表里
38 |
39 | Linux 操作系统:在内存页被访问**第二次**的时候,才将页从 inactive list 升级到 active list 里。(自己回答的时候可以说设定一个晋级门槛和inactive list和active list)
40 |
41 | **只要我们提高进入到活跃 LRU 链表(或者 young 区域)的门槛,就能有效地保证活跃 LRU 链表(或者 young 区域)里的热点数据不会被轻易替换掉**。
42 |
43 |
44 | ### MySQL
45 |
46 | mysql 索引
47 |
48 | > innodb中,b+树是怎么实现的?
49 | >
50 | > 就是比如说它是它的叶子节点当中是怎么样连接的,然后里面的数据是怎么连接的?
51 |
52 | https://bbs.huaweicloud.com/blogs/317532
53 |
54 |
55 |
56 | > B 加树当中一定要有聚簇索引吗?
57 |
58 |
59 |
60 | >你知道就是 B 加树当中一般是多少层吗?
61 |
62 | InnoDB中页大小一般16KB,一般表的**主键类型为INT**(占用4个字节)或BIGINT(8字节),**指针类型一般也是4-8字节**,也就是一个页中大概存储16KB/(8B+8B)=1K个键值(估算K取10三次方),则一个深度为3的B+Tree索引可以维护10亿条记录(9次方,假定一个数据页也是10三次方行记录数据)实际情况中每个节点可能不能被充满,所以高度一般2-4层,而根节点为常驻节点故只需要1-3次。
63 |
64 |
65 |
66 | >然后那索引的优点和缺点你说说。
67 |
68 |
69 |
70 | >你有了解过那个 MVCC 机制吗?
71 | >
72 | >那它底层是通过什么来实现的?
73 |
74 |
75 |
76 |
77 |
78 | > 它隐藏字段是哪些?你知道吗?
79 |
80 |
81 |
82 | > 你知道读视图主要是包含了哪些重要内容吗?
83 |
84 |
85 |
86 | >它里面就是包含了四个字段,就是包含了四个比较重要的内容,你知道是哪四个吗?
87 |
88 |
89 |
90 | >比如说我读了一条数据,那我们是怎么通过就是我是怎么通过 MVCC 机制来判断我能不能读到这条数据的呢?他的判断规则是什么?
91 |
92 |
93 |
94 | >事物的特性是哪些特性吗?
95 | >
96 | >隔离性它是有哪几个等级呢?
97 |
98 |
99 |
100 | >可重复读不能解决幻读的情况。
101 |
102 | 可重复读解决幻读是快照读利用了MVCC机制的版本号, 而当前读为强制获取当前数据 故不能解决
103 |
104 | 快照读:又叫一致性读,读取的是快照数据。不加锁的简单的 SELECT 都属于快照读,即不加锁的非阻塞读;快照读的实现时基于MVCC的。**快照读基于多版本则可能读到历史数据并不是最新的**。快照读的前提时隔离级别不是串行级别,串行级别快照读退化当前读。
105 |
106 | 当前读:**强制读取记录的最新版本,且上锁。对数据的增删改都会先进行当前读**
107 |
108 |
109 |
110 | ### 网络
111 |
112 | > 三次握手
113 |
114 |
115 |
116 | >那三次握手,他那个 accept 过程发生在钉哪次握手呢?就是发生在什么时候?就是 Linux 当中不是有一个 accept 就是获取到那个 socket 你知道它是发生在什么时候吗?
117 |
118 | 三次握手过程
119 |
120 | - 客户端的协议栈向服务器端发送了 SYN 包,并告诉服务器端当前发送序列号 client_isn,客户端进入 SYN_SENT 状态;
121 | - 服务器端的协议栈收到这个包之后,和客户端进行 ACK 应答,应答的值为 client_isn+1,表示对 SYN 包 client_isn 的确认,同时服务器也发送一个 SYN 包,告诉客户端当前我的发送序列号为 server_isn,服务器端进入 SYN_RCVD 状态;
122 | - 客户端协议栈收到 ACK 之后,使得应用程序从 `connect` 调用返回,表示客户端到服务器端的单向连接建立成功,客户端的状态为 ESTABLISHED,同时客户端协议栈也会对服务器端的 SYN 包进行应答,应答数据为 server_isn+1;
123 | - ACK 应答包到达服务器端后,服务器端的 TCP 连接进入 ESTABLISHED 状态,同时服务器端协议栈使得 `accept` 阻塞调用返回,这个时候服务器端到客户端的单向连接也建立成功。至此,客户端与服务端两个方向的连接都建立成功。
124 |
125 | 从上面的描述过程,我们可以得知**客户端 connect 成功返回是在第二次握手,服务端 accept 成功返回是在三次握手成功之后。**
126 |
127 |
128 |
129 | >拥塞控制,我看你这边写了,就是那你知道拥塞控制那几个算法吗?
130 |
131 |
132 |
133 | >快速恢复,你能给我具体说说它是怎么用的吗?
134 |
135 |
136 |
137 | > 四次挥手的过程
138 |
139 |
140 |
141 | >那你知道这个他四次挥手,他有没有可能变成三次挥手呢?
142 |
143 |
144 |
145 | > TCP 和 UDP 它们的区别吧。
146 |
147 |
148 |
149 | >那咱们平时打视频电话的话,它是通过用什么来连接的?
150 |
151 |
152 |
153 | ### 并发
154 |
155 | > cas原理
156 |
157 |
158 |
159 | > volitale
160 |
161 |
162 |
163 | > 线程和进程
164 |
165 |
166 |
167 |
168 |
169 | > 操作系统当中进程的通信方式有几种吗?你能说有哪些吗?
170 |
171 |
172 |
173 | ### Jvm
174 |
175 | 内存结构
176 |
177 | > 那咱们平常分配内存都是在哪里分配的?大多数情况。
178 |
179 |
180 |
181 | > 逃逸分析
182 |
183 | Java 世界中“几乎”所有的对象都在堆中分配,但是,随着 JIT 编译器的发展与逃逸分析技术逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化,所有的对象都分配到堆上也渐渐变得不那么“绝对”了。**从 JDK 1.7 开始已经默认开启逃逸分析,如果某些方法中的对象引用没有被返回或者未被外面使用(也就是未逃逸出去),那么对象可以直接在栈上分配内存**。
184 |
185 | > 垃圾回收算法
186 |
187 |
188 |
189 | ### 算法
190 |
191 | 手写堆排
192 |
193 | 前序和后序为什么不能重建二叉树,举例
194 |
195 | 手写快排
196 |
197 |
198 |
199 |
200 |
201 |
--------------------------------------------------------------------------------
/笔记/1.1Java基础/1.概述.md:
--------------------------------------------------------------------------------
1 | # 1 Java 概述
2 |
3 | ## 1.1 Java 历史
4 |
5 | - 目前 Java 版权属于甲骨文公司。
6 |
7 | - 长期支持的版本只有 Java8 与 Java11。这两个版本也是最多使用的版本。
8 |
9 | - Java SE:标准版
10 |
11 | Java EE:企业版(重要)
12 |
13 | Java ME:小型版(少)
14 |
15 | ## 1.2 Java 重要特点
16 |
17 | 1. Java 语言是**面向对象的(oop)**
18 |
19 | 简单来说,面向对象是一种程序设计技术。其重点放在数据(对象)和对象的接口上。
20 |
21 | 2. Java 语言是**健壮的**。其强类型机制、异常处理、垃圾自动收集是健壮性的保证。
22 |
23 | Java 强调早期问题检测、后期动态检测,及消除易出错的情况。其编译器能检测很多其他语言仅在运行时才会发现的问题。
24 |
25 | 3. Java 语言是**跨平台性**的:一个编译好的 `.class` 文件可以在多个不同系统下直接运行。
26 |
27 | Java 中没有 “依赖具体实现” 的地方。其基本数据类型大小、有关运算的行为等都有明确说明。其绝大多数库都能很好地支持平台独立性,而不用担心操作系统。
28 |
29 | 4. Java 语言是**解释型**的:解释型语言编译后需要解释器才能运行。相对的,编译型语言可以被直接执行。
30 |
31 | Java 解释器能在任何移植了解释器的机器上直接执行 Java 字节码。
32 |
33 | ## 1.3 Java 的开发工具
34 |
35 | - javac:Java 编译器。将 Java 程序编译成字节码
36 | - java:Java 解释器。执行已经转换为字节码的文件
37 | - jdb:Java 调试器。调试 Java 程序
38 | - javap:反编译。将类文件还原回方法和变量
39 | - javadoc:文档生成器。创建 HTML 文件
40 |
41 | ## 1.4 Java 运行基础
42 |
43 | > JVM:Java 虚拟机
44 |
45 | - JVM 是–跨平台性的基础。被包含在 JDK 中。
46 | - 不同平台有各自对应的不同 JVM
47 | - JVM 屏蔽了底层平台的区别。能做到 ”一次编译,到处运行”
48 |
49 | > JDK 全称:Java Development Kit(Java 开发工具包)
50 |
51 | - JDK = JRE + Java 的开发工具(Java,Javac,Javadoc 等等)
52 | - 给开发人员使用的,包含 JRE
53 |
54 | > JRE:Java Runtime Enviroment(Java 运行环境)
55 |
56 | - JRE = JVM + Java SE 标准类库(Java 的核心类库)
57 | - 运行一个 Java 程序的基本条件
58 |
59 | ## 1.5 Java 执行流程分析
60 |
61 | > `.Java` 文件(源文件) — javac(编译)— `.class` 文件(字节码文件) — java(运行)— 结果
62 |
63 | ### 1.5.1 编译
64 |
65 | ```
66 | javac [选项] 源文件名.java //[] 中是可选项
67 | ```
68 |
69 | - 通过编译器将 Java 源文件编译成 JVM 可识别的字节码文件。字节码文件是二进制格式的,其格式是统一的。在源文件目录下使用 Javac 编译工具对 Java 文件进行编译。
70 | - 如果没有错误将没有提示,当前目录会对应其中每一个类生成对应名称的 `.class` 文件,即字节码文件,也是可执行的 Java 程序。
71 |
72 | ### 1.5.2 运行
73 |
74 | ```
75 | java [选项] 程序名 [参数列表] //[] 中是可选项
76 | ```
77 |
78 | - 有了可执行的 Java 程序(字节码文件)
79 | - 通过运行工具` Java.exe` 对字节码文件进行执行,本质是将 `.class` 文件装载到 JVM 运行。
80 |
81 | # 2 变量
82 |
83 | ## 2.1 Java 数据类型
84 |
85 | #### 基本数据类型(本章)
86 |
87 | - **数值型**
88 | - 整数类型:
89 | - byte:占用 1 字节
90 | - short:占用 2 字节
91 | - int:占用 4 字节
92 | - long:占用 8 字节
93 | - 浮点(小数)类型:
94 | - float:占用 4 字节
95 | - double:占用 8 字节
96 | - **字符型**
97 | - char:存放单个字符,占用 2 字节
98 | - **布尔型**
99 | - boolean:存放 true(真),false(假)。占用 1 字节
100 |
101 | #### 引用数据类型(复合数据类型)
102 |
103 | - **类**:class
104 | - **接口**:interface
105 | - **数组**:`[]`
106 |
107 | ## 2.2 浮点类型
108 |
109 | > 可以表示一个小数
110 |
111 | - `float` 单精度(6 ~ 7 位有效数字),占用 4 字节,范围约 -3.403E38 ~ 3.403E38
112 | - `double` 双精度(15 位有效数字),占用 8 字节,范围约 -1.798E308 ~ 1.798E308
113 |
114 | *浮点数在机器中存放形式为:浮点数 = 符号位 + 指数位 + 尾数位*
115 |
116 | ***因此,尾数部分可能丢失,造成精度损失。换言之,小数都是近似值***
117 |
118 | ## 2.3 基本数据类型转换
119 |
120 | ### 2.3.1 自动类型转换
121 |
122 | > 自动类型转换:Java 在进行赋值或运算时,精度(容量)小的类型自动转换为精度(容量)大的类型。
123 | >
124 | > ```
125 | > char` > `int `> `long` > `float` > `double
126 | > byte` > `short` > `int `> `long` > `float` > `double
127 | > ```
128 | >
129 | > 例子:`int a = 'c'` 或者 `double b = 80`
130 |
131 | #### 2.3.1.1 使用细节
132 |
133 | 1. 有多种类型数据混合运算时,系统会将所有数据转换成容量最大的那种,再进行运算。
134 |
135 | 2. 如若把大精度(容量)数据赋值给小精度(容量)类型,就会报错(小数由于精度原因,大赋小会丢失精度,必不可用。但整数大赋小时:1.赋予具体数值时,判断范围。2.变量赋值时,判断类型。反之进行自动类型转换。
136 |
137 | 3. `byte` `short` `char` 三者不会相互自动转换,但可以计算。计算时首先转化为 `int`。
138 |
139 | > `byte a = 1;`
140 | >
141 | > `byte b = 1;`
142 | >
143 | > `a + b` 结果是 `int` 类型
144 |
145 | 4. `boolean` 类型不参与自动转换
146 |
147 | 5. 自动提升原则:表达式结果的类型自动提升为操作数中最大的类型。
148 |
149 | ### 2.3.2 强制类型转换
150 |
151 | > 强制类型转换:自动类型转换的逆过程,将容量大的数据类型转换为容量小的数据类型。使用时加上强制转换符 `( )` ,但**可能造成精度降低或溢出**,要格外注意。
152 |
153 | #### 2.3.2.1 使用细节
154 |
155 | 1. 当进行数据从大到小转换时,用强制转换。
156 |
157 | 2. 强制转换只能对最近的操作数有效,往往会使用 `( )` 提升优先级。
158 |
159 | ```
160 | int a = (int)(3 * 2.5 + 1.1 * 6);
161 | JAVA
162 | ```
163 |
164 | 3. `char` 可以保留 `int` 的常量值,但不能保存其变量值。此时需要强制类型转换。
165 |
166 | ```
167 | int a = 10;
168 | char b = 10;
169 | char c = (char)a;
170 | JAVA
171 | ```
172 |
173 | 4. `byte` `short` `char` 在进行运算时,当作 `int` 处理。
--------------------------------------------------------------------------------
/笔记/3 分布式/分布式简单入门.md:
--------------------------------------------------------------------------------
1 | ## 分布式简单入门知识
2 |
3 | 学习了这些不一定入门,但不学这些应该不能入门
4 |
5 | 因学业繁忙,所以先写一个大致框架,后期补充相关博客
6 |
7 | 可以使用小标题直接去 **谷歌** 搜索对应知识,标题下会写一些最近面试遇到的问题
8 |
9 | 最后引用部门贴一些之前看到的写的好的博客,暂未分类
10 |
11 | ## 分布式基础理论
12 |
13 | ### CAP理论
14 |
15 | https://tanxinyu.work/cap-theory/
16 |
17 | ### PACELC理论
18 |
19 | 这个好好看,说了CAP记得要说这个
20 |
21 | ### BASE理论
22 |
23 | ### NWR多数派理论
24 |
25 | 说了PACELC可以补充一个这个的例子
26 |
27 | ### 一致性理论
28 |
29 |
30 |
31 | https://tanxinyu.work/consistency-and-consensus/
32 |
33 | ### 一致性hash算法
34 |
35 | 普通一致性hash算法
36 |
37 | 一致性hash算法底层数据结构
38 |
39 | 一致性hash算法的具体实现
40 |
41 | 虚拟节点
42 |
43 | ## 分布式共识算法
44 |
45 | ### 2PC & 3PC
46 |
47 | 说一下2pc、3pc
48 |
49 | https://www.bilibili.com/video/BV1EA411u7gM
50 |
51 | https://www.bilibili.com/video/BV1XT4y1B73Y
52 |
53 | ### Paxos协议
54 |
55 | 将一下paxos协议
56 |
57 | 活锁
58 |
59 | https://www.bilibili.com/video/BV1X54y1d7xU/
60 |
61 | https://www.infoq.cn/article/wechat-paxosstore-paxos-algorithm-protocol/
62 |
63 | ### Raft算法
64 |
65 | raft选举过程
66 |
67 | raft脑裂
68 |
69 | https://www.bilibili.com/video/BV1BZ4y1U774
70 |
71 | https://www.bilibili.com/video/BV1aA4y1R7YH
72 |
73 | https://tanxinyu.work/raft/#%E8%83%8C%E6%99%AF
74 |
75 | ### Zab协议
76 |
77 | zab选举过程
78 |
79 | zab奔溃恢复过程
80 |
81 | 脑裂
82 |
83 | https://www.bilibili.com/video/BV14Y411g7ok
84 |
85 | ### Have we reached consensus on consensus?
86 |
87 | https://tanxinyu.work/have-we-reached-consensus-on-consensus/
88 |
89 | 清华佬的ppt:https://vevotse3pn.feishu.cn/file/boxcnBKfW8q9E61Bfi314R0hOfe
90 |
91 | ## 总结类
92 |
93 | [Replication(上):常见复制模型&分布式系统挑战](https://tech.meituan.com/2022/08/25/replication-in-meituan-01.html)
94 |
95 | [Replication(下):事务,一致性与共识](https://tech.meituan.com/2022/08/25/replication-in-meituan-02.html)
96 |
97 |
98 |
99 | ## Reference
100 |
101 | 分布式理论相关(总):https://github.com/erdengk/notes/blob/main/%E7%AC%94%E8%AE%B0/3%20%E5%88%86%E5%B8%83%E5%BC%8F/1%20%E5%88%86%E5%B8%83%E5%BC%8F%E7%90%86%E8%AE%BA%E7%9B%B8%E5%85%B3.md
102 |
103 | 分布式算法相关(总):https://github.com/erdengk/notes/blob/main/%E7%AC%94%E8%AE%B0/3%20%E5%88%86%E5%B8%83%E5%BC%8F/2%20%20%E5%88%86%E5%B8%83%E5%BC%8F%E7%AE%97%E6%B3%95%E7%9B%B8%E5%85%B3.md
104 |
105 | https://www.nowcoder.com/discuss/post/362412702839451648
106 |
107 | 基础理论:
108 |
109 | http://zhangtielei.com/posts/blog-distributed-strong-weak-consistency.html
110 |
111 | https://cn.pingcap.com/blog/linearizability-and-raft
112 |
113 | http://www.choudan.net/2013/08/07/CAP%E7%90%86%E8%AE%BA%E5%92%8CNWR%E7%AD%96%E7%95%A5.html
114 |
115 | https://blog.csdn.net/m0_68850571/article/details/126140636
116 |
117 | https://www.changping.me/2020/04/10/distributed-theory-cap-pacelc/
118 |
119 | https://pdai.tech/md/dev-spec/spec/dev-microservice-kangwei.html
120 |
121 | https://www.52code.net/a/8xjTPFSabM
122 |
123 | https://pdai.tech/md/arch/arch-z-theory.html
124 |
125 | https://cloud.tencent.com/developer/article/1752382
126 |
127 | 分布式算法:
128 |
129 | https://zhuanlan.zhihu.com/p/112651338
130 |
131 | https://pdai.tech/md/algorithm/alg-domain-distribute-x-zab.html
132 |
133 | https://cloud.tencent.com/developer/article/1525566
134 |
135 | https://pdai.tech/md/algorithm/alg-domain-distribute-x-paxos.html
136 |
137 | https://blog.csdn.net/yzf279533105/article/details/127163022
138 |
139 | https://blog.openacid.com/algo/paxos
140 |
141 | https://blog.csdn.net/Z_Stand/article/details/108547684
142 |
143 | http://www.xuyasong.com/?p=1970
144 |
145 | https://cloud.tencent.com/developer/article/1798049
146 |
147 | https://zhuanlan.zhihu.com/p/68743917
148 |
149 | https://draveness.me/consensus/
150 |
151 | https://pdai.tech/md/algorithm/alg-domain-distribute-x-consistency-hash.html
152 |
153 | https://learn.lianglianglee.com/%E4%B8%93%E6%A0%8F/24%E8%AE%B2%E5%90%83%E9%80%8F%E5%88%86%E5%B8%83%E5%BC%8F%E6%95%B0%E6%8D%AE%E5%BA%93-%E5%AE%8C/20%20%20%E5%85%B1%E8%AF%86%E7%AE%97%E6%B3%95%EF%BC%9A%E4%B8%80%E6%AC%A1%E6%80%A7%E8%AF%B4%E6%B8%85%E6%A5%9A%20Paxos%E3%80%81Raft%20%E7%AD%89%E7%AE%97%E6%B3%95%E7%9A%84%E5%8C%BA%E5%88%AB.md
154 |
155 | https://here2say.com/44/
156 |
157 |
--------------------------------------------------------------------------------
/笔记/2.5 Zookeeper/zk .md:
--------------------------------------------------------------------------------
1 | ## 对zk的理解
2 |
3 | 可以从分布式中三种应用场景来说
4 |
5 | ==集群管理==
6 |
7 | 在多个节点组成的集群中,为了去保证集群的高可用特性
8 |
9 | 每个节点都会去冗余一份数据副本,在这种情况下,需要保证客户端访问集群中任意一个节点都是最新的数据
10 |
11 | ==分布式锁==
12 |
13 | 如何保证跨进厂的共享资源的并发安全性
14 |
15 | 对于分布式系统来说,也是一个比较大的挑战,而为了达到这个目的,必须要使用跨进程的锁,也就是分布式锁来实现
16 |
17 | ==master选举==
18 |
19 | 为了降低集群数据同步的复杂度,一般会存在master和slave两种角色的节点。master去做事务和非事务性的请求处理,slave负责去做非事务的请求处理,但是在分布式系统中如何确定某个节点是master还是slave也是一个需要解决的问题。
20 |
21 | 基于这些需求,所以产生了zk这样的中间件,它是一个分布式协调中间件。它类似一个裁判,专门来负责协调和解决分布式中的各类问题。
22 |
23 | zk实现了cp模型,来保证集群中的每一个节点的数据一致性。zk本身不是一个线性一致性模型,而是一个顺序一致性模型。
24 |
25 | 分布式锁,zk提供了多种不同的节点类型 持久化节点、临时节点、有序节点、容器节点,对于分布式锁来说,zk可以利用有序节点的特性来实现 ,初次之外,还可以用同一级节点的唯一特性来实现分布式锁
26 |
27 | 对于master选举,zk可以利用持久化节点来存储和管理其他集群节点的一些信息,从而去进行master选举。目前Kafka、habase都是通过zk来实现集群中节点的一个主从选举
28 |
29 | zk就是一个分布式数据一致性的解决方案,主要解决分布式应用中一些 高可用的需要严格控制访问顺序的一些场景,实现分布式的协调服务,底层的一致性算法是基于Paxos演化后的ZAB协议。
30 |
31 | ## 讲讲zab协议
32 |
33 | ### 为什么有zab
34 |
35 | paxos并没有给出完整且正确的实现,比如像节点扩容、奔溃恢复这些功能并没有提及,
36 |
37 | 所以zk中实现了zab这个原子广播协议来完成它的需求。基于Fast Paxos算法实现。
38 |
39 | #### 活锁问题
40 |
41 | #### 复杂度问题
42 |
43 | 为了解决活锁问题,出现了multi-paxos;
44 |
45 | 为了解决通信次数较多的问题,出现了fast-paxos;
46 |
47 | 为了尽量减少冲突,出现了epaxos。
48 |
49 | 可以看到,工业级实现需要考虑更多的方面,诸如性能,异常等等。这也是许多分布式的一致性框架并非真正基于paxos来实现的原因。
50 |
51 | #### 全序问题
52 |
53 | 对于paxos算法来说,不能保证两次提交最终的顺序,而zookeeper需要做到这点。(先买了咖啡才能和咖啡,反之不可以)
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 | ### zxid、epoch、xid
62 |
63 | 在 ZAB 中有三个很重要的数据:
64 |
65 | - `zxid`: 一个 `64 位长度的 Long 类型`,其中高 32 位表示纪元 epoch,低 32 位表示事务标识 xid。即 zxid 由两部分构成: epoch 与 xid。
66 | - `epoch`:`抽取自 zxid 中的高 32 位`。每个 Leader 都会具有一个不同的 epoch 值,表示一个时期、时代、年号。每一次新的选举结束后都会生成一个新的 epoch,新的 Leader产生,则会更新所有 zkServer 的 zxid 中的 epoch。
67 | - `xid`:`抽取自 zxid 中的低 32 位`。为 zk 的事务 id,`每一个写操作都是一个事务`,都会有一个 xid。 xid 为一个`依次递增的流水号`。
68 |
69 | ### 三阶段(leader选举、广播阶段、恢复阶段)
70 |
71 | ### 消息广播
72 |
73 | - 类似于一个**二阶段提交**过程。
74 |
75 | - 当过半的follower反馈ack之后就可以提交事务Proposal(提案)了。
76 |
77 | - 但是该模型无法处理leader崩溃退出而带来的数据不一致问题。因此,在ZAB协议中添加了另一模式,即采用**崩溃恢复模式**来解决这个问题。
78 |
79 | - Leader 接收到消息请求后,将消息赋予一个全局唯一的 64 位自增 id,叫做:zxid,通过 zxid 的大小比较即可实现因果有序这一特性。
80 |
81 | - Leader 通过先进先出队列(会给每个follower都创建一个队列,保证发送的顺序性)(通过 TCP 协议来实现,以此实现了全局有序这一特性)将带有 zxid 的消息作为一个提案(proposal)分发给所有 follower。
82 |
83 | - 当 follower 接收到 proposal,先将 proposal 写到本地事务日志,写事务成功后再向 leader 回一个 ACK。
84 |
85 | - 当 leader 接收到过半的 ACKs 后,leader 就向所有 follower 发送 COMMIT 命令,同意会在本地执行该消息
86 |
87 | - 当 follower 收到消息的 COMMIT 命令时,就会执行该消
88 |
89 | - 在消息广播过程中,leader server会为每个follower分配一个单独的**队列**,然后将需要广播的事务proposal依次放入这些队列中,并且根据FIFO策略发送消息。
90 |
91 | 每个follower接收到proposal后,会首先将其**以事务日志形式写入本地磁盘**,并且在成功写入后(ack)反馈给leader。**当leader收到超过半数的ack后,会广播一个commit消息**给所有的follower以通知其进行事务提交,同时leader自身也会完成对事务的提交,follower也会在接收到commit消息后,完成对事务的提交。(提交至内存)
92 |
93 |
94 |
95 | ## 可靠性保证
96 |
97 | 已经被leader提交的事务需要最终被所有的机器提交(已经发出commit了)
98 |
99 | 保证丢弃那些只在leader上提出的事务。(只在leader上提出了proposal,还没有收到回应,还没有进行提交)
100 |
101 |
102 |
103 | ### leader提交的,需要被全局提交
104 |
105 | 当 leader 收到合法数量 follower 的 ACKs 后,就向各个 follower 广播 COMMIT 命令,同时也会在本地执行 COMMIT 并向连接的客户端返回「成功」。
106 |
107 | 但是如果在各个 follower 在收到 COMMIT 命令前 leader 就挂了,导致剩下的服务器并没有执行都这条消息。
108 |
109 | #### 解决方案
110 |
111 | 选举拥有 proposal 最大值(即 zxid 最大) 的节点作为新的 leader:由于所有提案被 COMMIT 之前必须有合法数量的 follower ACK,即必须有合法数量的服务器的事务日志上有该提案的 proposal,因此,只要有合法数量的节点正常工作,就必然有一个节点保存了所有被 COMMIT 消息的 proposal 状态。
112 |
113 | 新的 leader 将自己事务日志中 proposal 但未 COMMIT 的消息处理。
114 |
115 | 新的 leader 与 follower 建立先进先出的队列, 先将自身有而 follower 没有的 proposal 发送给 follower,再将这些 proposal 的 COMMIT 命令发送给 follower,以保证所有的 follower 都保存了所有的 proposal、所有的 follower 都处理了所有的消息。通过以上策略,能保证已经被处理的消息不会丢
116 |
117 | ### 只在leader提交未广播的,需要丢弃
118 |
119 | 当 leader 接收到消息请求生成 proposal 后就挂了,其他 follower 并没有收到此 proposal,因此经过恢复模式重新选了 leader 后,这条消息是被跳过的。 此时,之前挂了的 leader 重新启动并注册成了 follower,他保留了被跳过消息的 proposal 状态,与整个系统的状态是不一致的,需要将其删除。
120 |
121 | #### 解决方案
122 |
123 | Zab 通过巧妙的设计 zxid 来实现这一目的。一个 zxid 是64位,高 32 是纪元(epoch)编号,每经过一次 leader 选举产生一个新的 leader,新 leader 会将 epoch 号 +1。低 32 位是消息计数器,每接收到一条消息这个值 +1,新 leader 选举后这个值重置为 0。
124 |
125 | 这样设计的好处是旧的 leader 挂了后重启,它不会被选举为 leader,因为此时它的 zxid 肯定小于当前的新 leader。当旧的 leader 作为 follower 接入新的 leader 后,新的 leader 会让它将所有的拥有旧的 epoch 号的未被 COMMIT 的 proposal 清除。
126 |
127 | 每次变换一个leader,则epoch加一,可以理解为改朝换代了,新朝代的zxid必然比旧朝代的zxid大,新代的leader可以要求将旧朝代的proposal清除。
128 |
129 |
130 |
131 |
132 |
133 | https://zhuanlan.zhihu.com/p/75720517
134 |
135 | https://www.cnblogs.com/felixzh/p/5869212.html
136 |
137 | https://juejin.cn/post/7099251134333714440
138 |
139 | http://wangwren.com/2019/09/02-Zookeeper%E7%90%86%E8%AE%BA%E7%9B%B8%E5%85%B3%E2%80%94%E2%80%94Paxos%E5%92%8CZAB/#Paxos%E7%AE%97%E6%B3%95
--------------------------------------------------------------------------------
/项目/1 笔记.md:
--------------------------------------------------------------------------------
1 | 根据运营人员设定的条件构建优惠券模版
2 |
3 | 生成优惠券模版的核心思想
4 |
5 | 异步+优惠券码
6 |
7 | 优惠券码(不可以重复、有一定的识别性)
8 |
9 |
10 |
11 | 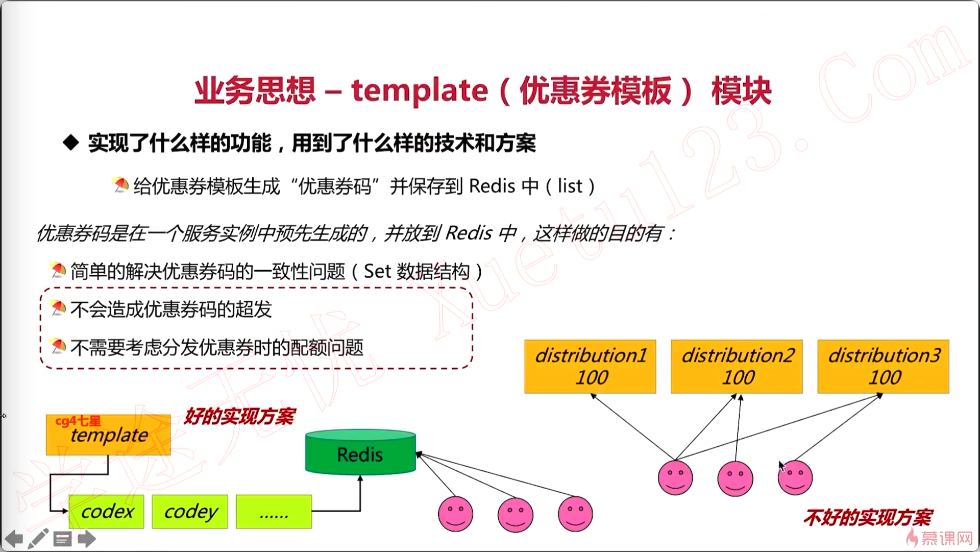
12 |
13 |
14 |
15 | 动态生成优惠券
16 |
17 | 生成时,使用set保证唯一性
18 |
19 | 放到redis中不会超发且保证性能
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 | ```
28 | 实现了统一的异常处理
29 | 统一响应
30 | ```
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 | 借鉴 redis 的过期策略,主动+被动
43 |
44 | 
45 |
46 |
47 |
48 | 优惠券过期清除时
49 |
50 | 使用优惠券模块的定时任务来定期清理(每日将过期的模版清理一次)
51 |
52 | 校验时清理
53 |
54 |
55 |
56 |
57 |
58 | 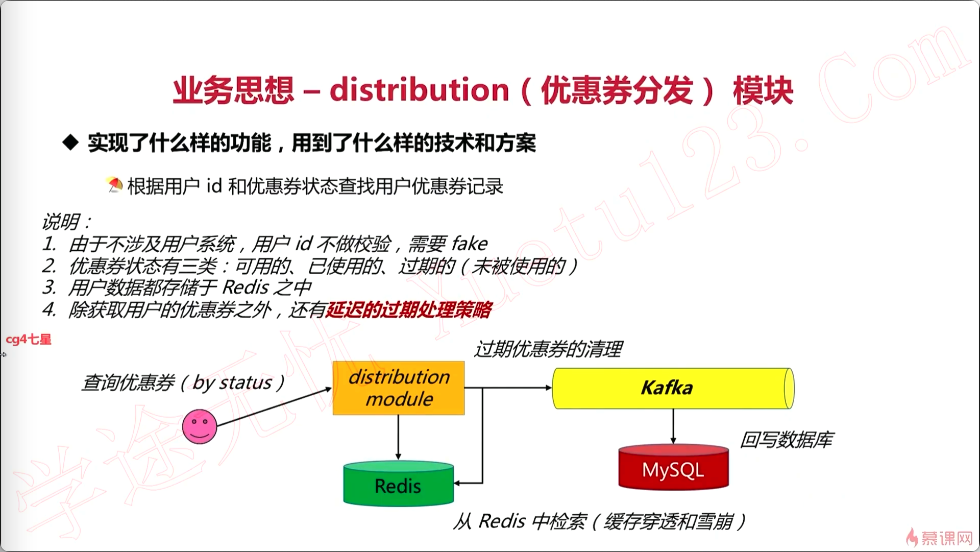
59 |
60 | 查询优惠券时,先去查缓存,在获取用户优惠券之外,交给Kafka异步清理
61 |
62 |
63 |
64 |
65 |
66 | 查找
67 |
68 | 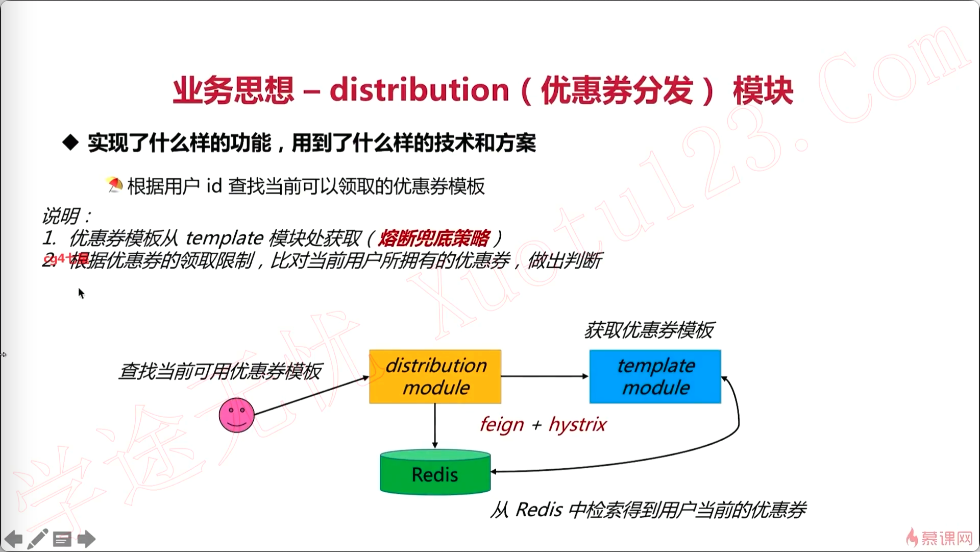
69 |
70 |
71 |
72 | 领取
73 |
74 |
75 |
76 | 根据用户id去查找当前可以领取的模版,然后再用模版去领取redis中的优惠券
77 |
78 | 领取限制 TemplateRule.java
79 |
80 |
81 |
82 | 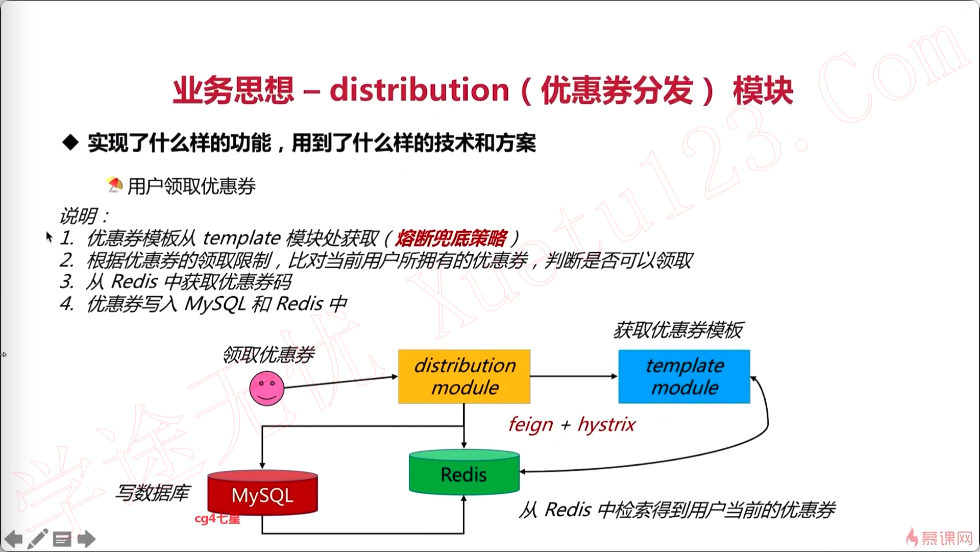
83 |
84 |
85 |
86 |
87 |
88 | 结算/核销
89 |
90 |
91 |
92 | 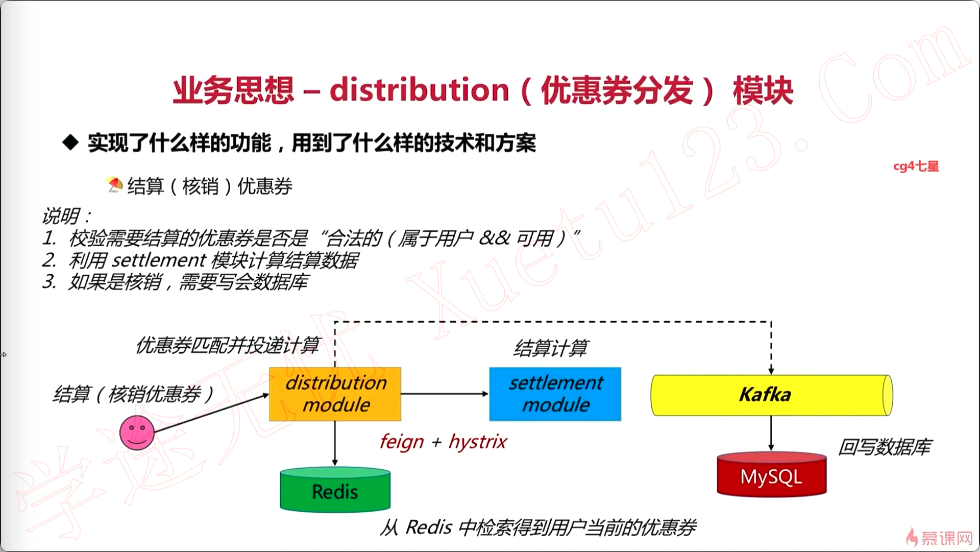
93 |
94 |
95 |
96 | 结算
97 |
98 |
99 |
100 | 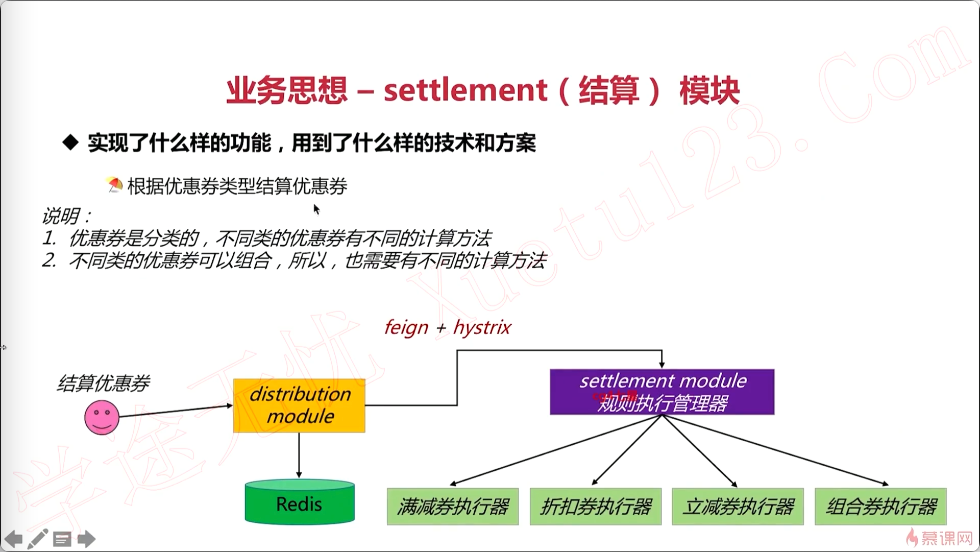
101 |
102 |
103 |
104 | 优惠券码缓存
105 |
106 | 
107 |
108 | 
109 |
110 |
111 |
112 |
113 |
114 | 架构
115 |
116 | 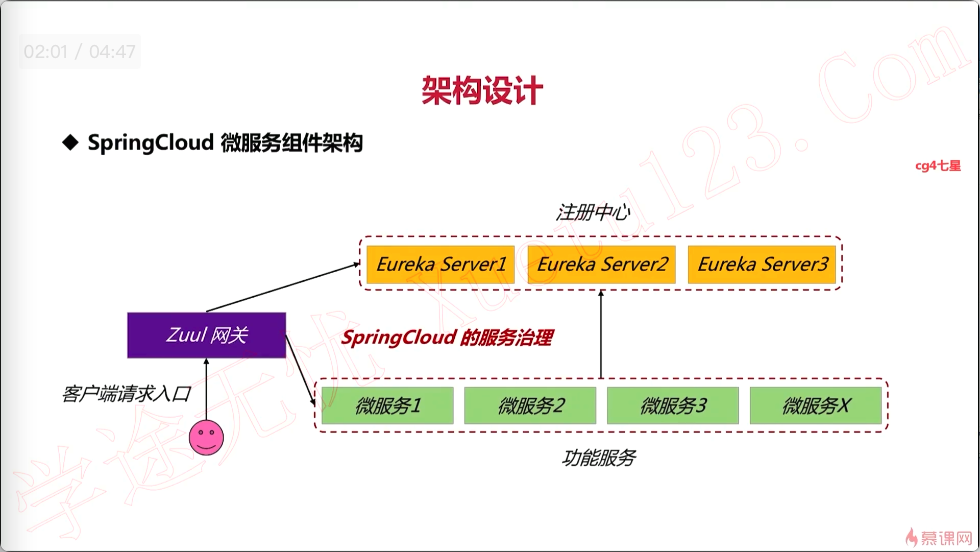
117 |
118 | 功能设计
119 |
120 | 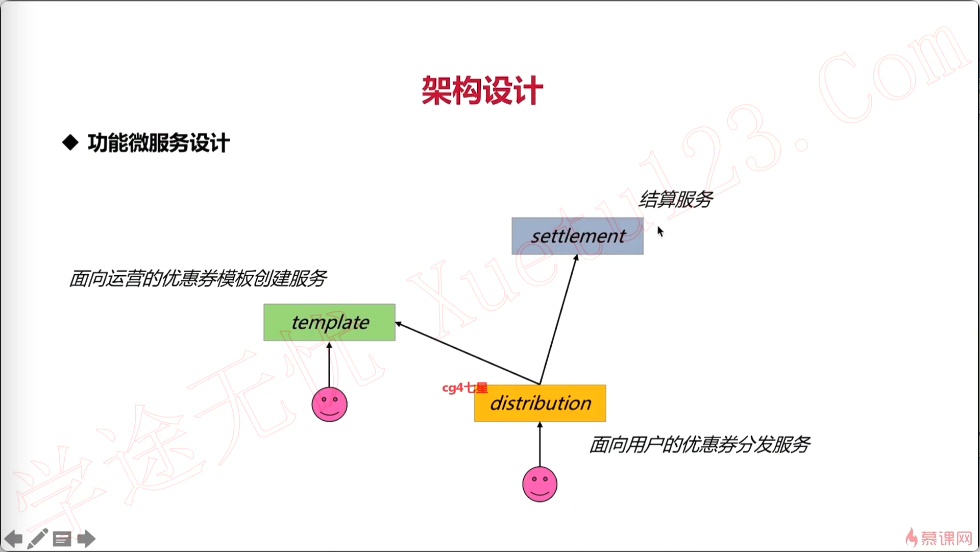
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 | 异步任务是否返回,如果失败怎么处理
131 |
132 | 定时任务相关
133 |
134 |
135 |
136 |
137 |
138 | ```
139 | 使用 SessionCallback 把数据命令放入到 Redis 的 pipeline
140 |
141 | SessionCallback
70 |
71 | 所有的请求映射都在HandlerMapping中:
72 |
73 | 1. SpringBoot自动配置欢迎页的 WelcomePageHandlerMapping 。访问 /能访问到index.html;
74 |
75 | 2. SpringBoot自动配置了默认 的 RequestMappingHandlerMapping
76 |
77 | 3. 请求进来,挨个尝试所有的HandlerMapping看是否有请求信息。
78 | 1. 如果有就找到这个请求对应的handler
79 | 2. 如果没有就是下一个 HandlerMapping
80 |
81 | 我们需要一些自定义的映射处理,我们也可以自己给容器中放HandlerMapping。自定义 HandlerMapping
82 |
83 |
--------------------------------------------------------------------------------
/笔记/1.2Java容器/ArrayList-1.md:
--------------------------------------------------------------------------------
1 | ### 讲讲深浅拷贝
2 |
3 | 1、浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝
4 |
5 | 2、深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
6 |
7 | https://segmentfault.com/a/1190000010648514
8 |
9 |
10 |
11 | 为什么要准备两个空数组?
12 |
13 |
14 |
15 | 讲讲transient关键字?
16 |
17 |
18 |
19 | Arrays.asList() 的使用场景是?
20 |
21 | ```
22 | // asList 用在固定的多个值的情况,不进行修改的情况下使用。
23 | // 不能删除或者增加,可以修改值
24 | // 确保任何情况下都不能对这个list进行size的修改
25 | ```
26 |
27 |
28 |
29 | Collections.emptyList() 使用场景?
30 |
31 | ```
32 | // 代码中的一个if或者else 需要返回空list时,使用这个
33 | // 如果直接使用 new ArrayList 的话,会有对象的创建
34 | // Collections.emptyList() 无需进行创建
35 | // Arrays.asList() 也会创建对象,浪费一定的空间 不建议使用(不是不能用)
36 | ```
37 |
38 |
39 |
40 |
41 |
42 | removeRange(int fromIndex, int toIndex) 开头和结尾的元素是否被删除?
43 |
44 | ```java
45 |
46 | public class SubArrayList extends ArrayList {
47 |
48 | public static void main(String[] args) {
49 | SubArrayList arrayList = new SubArrayList();
50 | Integer integer = 0;
51 | Integer integer1 = 1;
52 | Integer integer2 = 2;
53 | Integer integer3 = 3;
54 | Object object = null;
55 |
56 | arrayList.add(integer);
57 | arrayList.add(integer1);
58 | arrayList.add(integer2);
59 | arrayList.add(integer3);
60 | arrayList.add(object);
61 |
62 | // 移除下标为1,2的元素
63 | arrayList.removeRange(1, 3);
64 |
65 | // 常规for循环遍历
66 | System.out.println("常规for循环遍历:");
67 | for (int i = 0; i < arrayList.size(); i++) {
68 | System.out.println("object:" + arrayList.get(i));
69 | }
70 | }
71 |
72 | 常规for循环遍历:
73 | object:0
74 | object:3
75 | object:null
76 | ```
77 |
78 | 开头不被删,结尾的会被删
79 |
80 | 这种类似数组下标区间一般都是取下不取上,即[min, max) ,包含min而不包含max。[1]
81 |
82 |
83 |
84 |
85 |
86 | ### 序列化是什么?为什么要序列化?
87 |
88 | 序列化是指把一个Java对象变成二进制内容,本质上就是一个`byte[]`数组。
89 |
90 | 为什么要把Java对象序列化呢?
91 |
92 | 因为序列化后可以把`byte[]`保存到文件中,或者把`byte[]`通过网络传输到远程,这样,就相当于把Java对象存储到文件或者通过网络传输出去了。
93 |
94 | 为什么要序列化,那就是说一下序列化的好处喽,序列化有什么什么优点,所以我们要序列化。
95 |
96 | 优点:
97 |
98 | **一:对象序列化可以实现分布式对象。**
99 |
100 | 主要应用例如:RMI(即远程调用Remote Method Invocation)要利用对象序列化运行远程主机上的服务,就像在本地机上运行对象时一样。
101 |
102 | **二:java对象序列化不仅保留一个对象的数据,而且递归保存对象引用的每个对象的数据。**
103 |
104 | 可以将整个对象层次写入字节流中,可以保存在文件中或在网络连接上传递。利用对象序列化可以进行对象的"深复制",即复制对象本身及引用的对象本身。序列化一个对象可能得到整个对象序列。
105 |
106 | **三:序列化可以将内存中的类写入文件或数据库中。**
107 |
108 | 比如:将某个类序列化后存为文件,下次读取时只需将文件中的数据反序列化就可以将原先的类还原到内存中。也可以将类序列化为流数据进行传输。
109 |
110 | 总的来说就是将一个已经实例化的类转成文件存储,下次需要实例化的时候只要反序列化即可将类实例化到内存中并保留序列化时类中的所有变量和状态。
111 |
112 | **四:对象、文件、数据,有许多不同的格式,很难统一传输和保存。**
113 |
114 | 序列化以后就都是字节流了,无论原来是什么东西,都能变成一样的东西,就可以进行通用的格式传输或保存,传输结束以后,要再次使用,就进行反序列化还原,这样对象还是对象,文件还是文件。【2】
115 |
116 | [1] : https://blog.csdn.net/weixin_41287260/article/details/95357183
117 |
118 | [2] : https://www.cnblogs.com/javazhiyin/p/11841374.html
--------------------------------------------------------------------------------
/笔记/1.4Jvm 相关/4 内存模型.md:
--------------------------------------------------------------------------------
1 | ## 5.synchronized 优化
2 |
3 | Java HotSpot 虚拟机中,每个对象都有对象头(包括 class 指针和 Mark Word)。Mark Word 平时存储这个对象的哈希码 、 分代年龄 ,当加锁时,这些信息就根据情况被替换为标记位 、 线程锁记录指针 、 重量级锁指针 、 线程ID 等内容
4 |
5 | ### 5-1 轻量级锁
6 |
7 | 如果一个对象虽然有多线程访问,但多线程访问的时间是错开的(也就是没有竞争),那么可以使用轻量级锁来优化。这就好比:
8 |
9 | 学生(线程 A)用课本占座,上了半节课,出门了(CPU时间到),回来一看,发现课本没变,说明有竞争,继续上他的课。 如果这期间有其它学生(线程 B)来了,会告知(线程A)有并发访问,线程A 随即升级为重量级锁,进入重量级锁的流程。
10 |
11 | 而重量级锁就不是那么用课本占座那么简单了,可以想象线程 A 走之前,把座位用一个铁栅栏围起来,假设有两个方法同步块,利用同一个对象加锁
12 |
13 | ```java
14 | static Object obj = new Object();
15 | public static void method1() {
16 | synchronized( obj ) {
17 | // 同步块 A
18 | method2();
19 | }
20 | }
21 | public static void method2() {
22 | synchronized( obj ) {
23 | // 同步块 B
24 | }
25 | }
26 | ```
27 |
28 | 每个线程都的栈帧都会包含一个锁记录的结构,内部可以存储锁定对象的 Mark Word
29 |
30 | 
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 | ### 5-2 锁膨胀
39 |
40 | 如果在尝试加轻量级锁的过程中,CAS 操作无法成功,这时一种情况就是有其它线程为此对象加上了轻量级锁(有竞争),这时需要进行锁膨胀,将轻量级锁变为重量级锁。
41 |
42 |
43 |
44 | 
45 |
46 | ### 5-3 重量锁
47 |
48 | 重量级锁竞争的时候,还可以使用自旋来进行优化,如果当前线程自旋成功(即这时候持锁线程已经退出了同步块,释放了锁),这时当前线程就可以避免阻塞。
49 |
50 | 在 Java 6 之后自旋锁是自适应的,比如对象刚刚的一次自旋操作成功过,那么认为这次自旋成功的可能性会高,就多自旋几次;反之,就少自旋甚至不自旋,总之,比较智能。
51 |
52 | 等红灯时,汽车不熄火相当于自旋转(等待时间短了划算),熄火了相当于阻塞(等待时间长了划算)
53 |
54 |
55 |
56 | 自旋重试成功
57 |
58 | 
59 |
60 | 自旋重试失败
61 |
62 | 
63 |
64 | ### 5-4 偏向锁
65 |
66 | 轻量级锁在没有竞争时(就自己这个线程),每次重入仍然需要执行CAS操作。Java 6中引入了偏向锁来做进一步优化:只有第一次使用CAS将线程ID设置到对象的Mark Word头,之后发现这个线程ID是自己的就表示没有竞争,不用重新CAS
67 |
68 | 撤销偏向需要将持锁线程升级为轻量级锁,这个过程中所有线程需要暂停(STW)
69 | 访问对象的 hashCode 也会撤销偏向锁
70 | 如果对象虽然被多个线程访问,但没有竞争,这时偏向了线程 T1 的对象仍有机会重新偏向 T2,重偏向会重置对象的 Thread ID
71 | 撤销偏向和重偏向都是批量进行的,以类为单位
72 | 如果撤销偏向到达某个阈值,整个类的所有对象都会变为不可偏向的
73 | 可以主动使用 -XX:-UseBiasedLocking 禁用偏向锁
74 |
75 | ####
76 |
77 | ### 5-5 其他优化
78 |
79 | #### (1)减少上锁时间
80 |
81 | 同步代码块中尽量短
82 |
83 | #### (2)减少锁的粒度
84 |
85 | 将一个锁拆分为多个锁提高并发度,例如:
86 |
87 | ConcurrentHashMap
88 | LongAdder 分为 base 和 cells 两部分。没有并发争用的时候或者是 cells 数组正在初始化的时候,会使用 CAS 来累加到base,有并发争用,会初始化 cells 数组,数组有多少个 cell,就允许有多少线程并行修改,最后将数组中每个 cell 累加,再加上 base 就是最终的值
89 | LinkedBlockingQueue 入队和出队使用不同的锁,相对于LinkedBlockingArray只有一个锁效率要高
90 |
91 | #### (3)锁粗化
92 |
93 | 多次循环进入同步块不如同步块内多次循环,另外 JVM 可能会做如下优化,把多次 append 的加锁操作粗化为一次(因为都是对同一个对象加锁,没必要重入多次)
94 |
95 | new StringBuffer().append("a").append("b").append("c");
96 | 1
97 |
98 | #### (4)锁消除
99 |
100 | JVM 会进行代码的逃逸分析,例如某个加锁对象是方法内局部变量,不会被其它线程所访问到,这时候就会被即时编译器忽略掉所有同步操作。
101 |
102 | #### (5)读写分离
103 |
104 | 如果撤销偏向到达某个阈值,整个类的所有对象都会变为不可偏向的
105 |
106 | 可以主动使用 -XX:-UseBiasedLocking 禁用偏向锁
107 |
--------------------------------------------------------------------------------
/项目/Raft.md:
--------------------------------------------------------------------------------
1 | ```
2 | //请求投票的rpc
3 | term //当前任期号
4 | candidateld //自己的id
5 | lastLogIndex // 自己最后一个日志号
6 | lastLogTerm // 自己最后一个日志的任期
7 | ```
8 |
9 | 请求投票的rpc中会包含最后一个日志的信息(安全性子问题)
10 |
11 |
12 |
13 |
14 |
15 | 日志中包含的信息
16 |
17 | 状态机指令
18 |
19 | leader的任期号
20 |
21 | 日志索引
22 |
23 | (任期号和日志索引唯一确定一条日志)
24 |
25 |
26 |
27 |
28 |
29 | ### 日志复制
30 |
31 | 分布式中网络不稳定,需要日志复制来保证状态机的中间态相同
32 |
33 |
34 |
35 | #### follower缓慢
36 |
37 | 如果有follower因为某些原因没有给leader响应,那么leader会不断地重发追加条目请求(AppendEntries RPC),哪怕leader已经回复 了客户端。
38 |
39 | #### follower崩溃恢复
40 |
41 | 如果有follower崩溃后恢复,这时Raft追加条目的一致性检查生效,保证follower能按顺序恢复崩溃后的缺失的日志。
42 |
43 | Raft的一致性检查: leader在 每一 个发往follower的追加条目RPC中,==会放入前一个日志条目的索引位置和任期号==,如果follower在它 的日志中找不到前一个日志,那么它就会拒绝此日志,leader收 到follower的拒绝后,会发送前一个日志条且,从而逐渐向前定位到follower第一个缺失的日志。
44 |
45 |
46 |
47 | #### leader崩溃
48 |
49 | ③如果leader崩溃,那么崩溃的leader可能已经复制了旦志到部分follower 但还没有提交而被选出的新leader又可能不具备这些日志,这样就有部分follower中的日志和新leader的日志不相同。
50 |
51 | Raft在这种情况下,leader通过强制follower复制它的日志来解决不一致的问题,这意味着follower中跟leader冲突的日志条且会被新 leader的旦志条目覆盖(因为没有提交,所以不违背外部一致性)
52 |
53 |
54 |
55 | ●通过这种机制,leader在 当权之后就不需要任何特殊的操作来使日志恢复到一致状态。
56 | ●Leader只需要进行正常的操作,然后日志就能在回复AppendEntries-致 性检查失败的时候自动趋于一致。
57 | ●Leader从来不会覆盖或者删除自己的日志条目。(Append-Only)
58 | ●这样的日志复制机制,就可以保证一 致性特性:
59 | 只要过半的服务器能正常运行,Raft就能够接受、复制并应用新的日志条且;
60 |
61 | 在正常情况下,新的且志条且可以在一个RPC来回中被复制给集群中的过半机器:
62 |
63 | 单个运行慢的follower不会影响整体的性能。
64 |
65 |
66 |
67 |
68 |
69 | ### 安全性
70 |
71 | 领导者选举和日志复制两个子问题实际上已经涵盖了共识算法的全程,但这两点还不能完全保证每一个状态机会按照==相同的顺序==执行相同的命令。
72 |
73 | 所以Raft通过几个补充规则完善整个算法,使算法可以在各类宕机问题下都不出错。
74 |
75 | 这些规则包括(不讨论安全性条件的证明过程):
76 |
77 | 1. Leader宕机处理:选举限制
78 | 2. Leader宕机处理:新leader是 否提交之前任期内的日志条目
79 | 3. Follower和Candidate宕机处理
80 | 4. 时间与可用性限制
81 |
82 |
83 |
84 | #### Leader宕机处理:选举限制
85 |
86 | 现象:
87 |
88 | 一个follower落后了leader若干条日志(但没有漏一整个周期),那么按照leader选举的规则,它依旧有可能当选leader,它在当选leader后就永远无法补上之前缺失的那部分日志,从而造成状态机之间的不一致
89 |
90 | 解决思路:
91 |
92 | 保证被选出来的leader一定包含了之前各任期中所有被提交的日志条目
93 |
94 | 解决方案:
95 |
96 | (比较投票rpc中的日志信息,如果自己的日志号大于投票的日志号,就拒绝,以此来避免出现新选的leader中没有之前提交的日志)
97 |
98 | RequestVote RPC执行了这样的限制: RPC中包含了candidate的日志信息,如果投票者自己的日志比candidate的还新,它会拒绝掉该投票请求。
99 |
100 | Raft通过比较两份日志中最后一条日志条目的索引值和任期号来定义谁的日志比较新。
101 |
102 | 如果两份日志最后条目的任期号不同,那么任期号大的日志更“新”。
103 |
104 | 如果两份日志最后条目的任期号相同,那么日志较长的那个更“新”。
105 |
106 | #### Leader宕机处理:新leader是否提交之前任期内的日志条目
107 |
108 |
109 |
110 | leader提交后,返回给客户端(然后宕机了,没有给follower发送提交信息),这种情况怎么处理?
111 |
112 | >leader提交和follower提交间,必然会间隔一段时间
113 | >
114 | >如果leader提交之后直接返回客户端
115 | >
116 | >在通知follower提交前,也就是一个心跳的时间内,如果leader宕机
117 | >
118 | >就会出现部分提交的问题
119 |
120 | raft 是一种底层的共识算法,本身只是应用实现高可用的一种方式,而与客户端交互本来应该是属于应用端的事情,理论上不是raft该担心的,所以论文中也没有讨论这一点。
121 |
122 | ==原生的raft并没有做处理,是后面自己实现时,设置了集群提交==
123 |
124 |
125 |
126 | > 应用会设置一个集群提交的概念,只有集群中超过半数的节点都完成提交,才认为集群提交完成
127 |
128 |
129 |
130 | raft不是通过计算副本数目的方式来提交之前任期内的日志
131 |
132 | 只有自己任期内的日志才能通过计算副本数目来提交
133 |
134 |
135 |
136 |
137 |
138 | #### Follower和Candidate宕机处理
139 |
140 | raft通过无限的重试来处理这种失败,如果奔溃的机器重启了,这些rpc就能成功
141 |
142 |
143 |
144 | #### 时间与可用性限制
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/上海小公司面经-复盘版.md:
--------------------------------------------------------------------------------
1 | [TOC]
2 |
3 |
4 |
5 | ## 公司介绍
6 |
7 | 上海小厂,200一天,随便面了面发了offer邮件,主要练习了自我介绍和部分项目介绍经验。
8 |
9 | ### 讲讲Java 的抽象类和接口
10 |
11 | `语法层面上的区别:`
12 |
13 | 抽象类可以提供成员方法的实现细节,而接口中只能存在public abstract 方法;
14 |
15 |
16 | 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的;
17 |
18 | 接口中不能含有静态代码块以及静态方法,而抽象类可以有静态代码块和静态方法;
19 |
20 | 一个类只能继承一个抽象类,而一个类却可以实现多个接口。
21 |
22 | `设计层面上的区别:`
23 |
24 | 抽象类是对一种事物的抽象,即对类抽象,而接口是对行为的抽象。
25 |
26 | 抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。
27 |
28 | 设计层面不同,抽象类作为很多子类的父类,它是一种模板式设计。而接口是一种行为规范,它是一种辐射式设计。
29 |
30 | ### @Restcontroller 了解不
31 |
32 | Spring4之后新加入的注解,原来返回json需要@ResponseBody和@Controller配合。
33 |
34 | 即@RestController是@ResponseBody和@Controller的组合注解。
35 |
36 | —》拓展restful 风格---〉自己项目就是restful的
37 |
38 | ### @autowrited 和 @ resource
39 |
40 | 一般没什么区别,用idea的话,autowrited会报警告
41 |
42 | spring建议用set注入和构造器注入,不建议在成员变量上加注解
43 |
44 | autowrited是spring提供的,resource是java jre提供的
45 |
46 | ### IOC 和 AOP
47 |
48 | ioc 基本概念--》ioc 实现(工厂+反射)
49 |
50 | aop 基本概念(面向切面编程,在不修改原代码的基础上对功能坐增强)--〉aop 实现(代理)
51 |
52 | ——〉静态代理、动态代理
53 |
54 | ——〉aop通知、aop在项目的应用(日志收集、鉴权、响应统计)
55 |
56 |
57 |
58 | ### AOF 和 RDB
59 |
60 | #### **AOF(Append Only File)**
61 |
62 | AOF持久化功能,是一种保存写操作命令到日志的持久化方式
63 |
64 | **只会记录写操作命令,读操作命令是不会被记录的**,因为没意义。
65 |
66 | 有三种写回策略
67 |
68 | **Always**,每次写操作命令执行完后,同步将 AOF 日志数据写回硬盘;
69 |
70 | **Everysec**,每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,然后每隔一秒将缓冲区里的内容写回到硬盘;
71 |
72 | **No**,意味着不由 Redis 控制写回硬盘的时机,转交给操作系统控制写回的时机,也就是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,再由操作系统决定何时将缓冲区内容写回硬盘。
73 |
74 | 根据自己的业务场景进行选择:
75 |
76 | - 如果要高性能,就选择 No 策略;
77 | - 如果要高可靠,就选择 Always 策略;
78 | - 如果允许数据丢失一点,但又想性能高,就选择 Everysec 策略。
79 |
80 |
81 |
82 | #### **RDB** 快照
83 |
84 | 也是用日志文件记录信息,RDB 文件的内容是二进制数据
85 |
86 | Redis 提供了两个命令来生成 RDB 文件,分别是 `save` 和 `bgsave`,他们的区别就在于是否在「主线程」里执行:
87 |
88 | - 执行了 save 命令,就会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长,**会阻塞主线程**;
89 | - 执行了 bgsave 命令,会创建一个子进程来生成 RDB 文件,这样可以**避免主线程的阻塞**;
90 |
91 | 执行 bgsave 过程中,Redis 依然**可以继续处理操作命令**的,也就是数据是能被修改的。
92 |
93 | ---》拓展**写时复制技术(Copy-On-Write, COW)**
94 |
95 | #### RDB 和 AOF 合体
96 |
97 | RDB 和 AOF 合体使用,这个方法是在 Redis 4.0 提出的,该方法叫**混合使用 AOF 日志和内存快照**,也叫混合持久化。
98 |
99 | 当开启了混合持久化时,在 AOF 重写日志时,`fork` 出来的重写子进程会先将与主线程共享的内存数据以 RDB 方式写入到 AOF 文件,然后主线程处理的操作命令会被记录在重写缓冲区里,重写缓冲区里的增量命令会以 AOF 方式写入到 AOF 文件,写入完成后通知主进程将新的含有 RDB 格式和 AOF 格式的 AOF 文件替换旧的的 AOF 文件。
100 |
101 | 也就是说,使用了混合持久化,AOF 文件的**前半部分是 RDB 格式的全量数据,后半部分是 AOF 格式的增量数据**。
102 |
103 | 这样的好处在于,重启 Redis 加载数据的时候,由于前半部分是 RDB 内容,这样**加载的时候速度会很快**。
104 |
105 | 加载完 RDB 的内容后,才会加载后半部分的 AOF 内容,这里的内容是 Redis 后台子进程重写 AOF 期间,主线程处理的操作命令,可以使得**数据更少的丢失**。
106 |
107 |
108 |
109 | ### 微服务了解么
110 |
111 |
112 |
113 | 从单体架构的缺点聊到微服务的优点以及缺点
114 |
115 | 然后以自己做的项目为例讲了讲服务的拆分、调用
116 |
117 |
118 |
119 | ### 写个sql
120 |
121 |
122 |
123 | ## 总结
124 |
125 | sql基础薄弱,语法快忘了,要加强
126 |
127 | spring偏业务的忘差不多了,要回忆一下
128 |
129 | redis部分继续融合八股
130 |
131 | 微服务部分
132 |
133 | 从单体优缺点--》微服务架构优缺点
134 |
135 | 然后可以讲服务拆分、服务注册--〉分布式---》共识算法
136 |
137 | 也可以讲网关,从基础的getway--〉南北向网关、东西向网关
--------------------------------------------------------------------------------
/项目/理论.md:
--------------------------------------------------------------------------------
1 | ## 单机二阶段提交
2 |
3 | ## 分布式二阶段提交 2pc
4 |
5 | 场景:分布式事务
6 | 强一致、中心化的原子提交协议
7 | 准备阶段、提交阶段
8 | 协调者(Coordinator)、 参 与者(Participant)
9 |
10 |
11 |
12 | 
13 |
14 | 
15 |
16 |
17 |
18 | 失败回滚
19 |
20 | 
21 |
22 |
23 |
24 | 存在的问题
25 |
26 | 同步阻塞 (等待所有参与者的响应)
27 | 数据不一-致 (一部分参与者回滚事务失败了,一部分参与者回滚事务成功了)
28 | 单点问题/脑裂 (协调者单机问题/ 多个协调者都进行操作,出现脑裂问题)
29 | 太过保守
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 | ----
38 |
39 | ## 三阶段提交 3pc
40 |
41 |
42 |
43 | 3PC简述
44 |
45 | 强一致、中心化的原子提交协议
46 | 协调者(Coordinator) 、参与者(Participant)
47 | 超时机制:
48 | 参与者在等待协调者超时后,允许执行默认操作
49 | 协调者在等待参与者超时后,允许执行默认操作
50 | 降低了事务资源锁定范围
51 | 增加了CanCommit阶段,不会像2PC- -祥,从一开始就锁定所有事务资源,3PC在
52 | 排除掉个别不具备处理事务能力的参与者的前提下,在进入第二阶段的锁定事务
53 | 资源
54 |
55 |
56 |
57 | 
58 |
59 |
60 |
61 | 小结
62 | 减少事务资源锁定范围
63 | ●增 加CanCommit阶段
64 | 降低了同步阻塞
65 | ●超时机制
66 | 增加一-轮消息,增加了复杂度和协商效率。
67 | 数据不一-致
68 |
69 |
70 |
71 | ---
72 |
73 |
74 |
75 | CAP定理,指的是在-一个分布式系统中,一-致性(Consistency) 、可用性
76 | (Availability)、分区容错性(Partition tolerance)。这三个要素最多只能同时实现两
77 | 点,不可能三者兼顾。
78 | ●一致性(C) :这里是指100%强一致性。在分布式系统中的所有数据备份,在同一
79 | 时刻整个系统的制本都拥有的一致的数据。
80 | ●可用性(A) :这里是指100%可用性。客户端无论访问到哪个没有宕机的节点上,
81 | 都能在有限的时间内返回结果,并不是指整个系统处于可用状态。
82 | 分区容错性(P) :网络中允许丢失一个节点发给另一个节点的任意多的消息,即对
83 | 网络分区的容忍。在发生网络分区时,能继续保持可用性或者一致性。如果一个系
84 | 统要求在运行过程中不能发生网络分区,那么这个系统就不具备分区容错性。
85 |
86 |
87 |
88 |
89 |
90 | 当发生网络分区时,你将面临两个选择:
91 | 如果坚持保持各节点之间的数据一致性(选择C),你需要等待网络分区恢复后,将
92 | 数据复制完成,才可以向外部提供服务。期间发生网络分区将不能对外提供服务,
93 | 因为它保证不了数据一致性。
94 | 如果选择可用性(选择A),发生网络分区的节点,依然需要向外提供服务。但是由
95 | 于网络分区,它同步不了最新的数据,所以它返回数据,可能不是最新的(与其他
96 | 节点不一致的)数据。
97 |
98 |
99 |
100 |
101 |
102 | 用户感知的一致性和cap的一致性不是一个一致性
103 |
104 |
105 |
106 | CAP三者不可兼得,仅仅是指在发生网络分区情况下,我们才需要在A和C之间进行抉
107 | 择,选择保证数据一-致还是服务 可用。而集群正常运行时,A和C是都可以保证的。
108 | ,CP架构在当发生网络分区时,为了保证返回给客户端数据准确性,为了不破坏一致
109 | 性,可能会园为无法响应最新数据,而拒绝响应。在网络分区恢复后,完成数据同
110 | 步,才可处理客户端请求。
111 | AP架构在发生网络分区时,发生分区的节点不需要等待数据完成同步,便可处理客
112 | 户端请求,将尽可能的给用户返回相对新的数据。在网络分区恢复后,完成数据同
113 | 步。
114 |
115 |
116 |
117 |
118 |
119 | CAP描述的一致性和可用性,都是100%的强度。
120 |
121 |
122 |
123 | 在生产实践中,我们并不需要100%的- -致性和可用性,因此我们需要对一致性和可用
124 | 性之间进行权衡,选择CP架构或者AP架构。
125 | 我们认为ZooKeeper在关键时刻(少数成员宕机时,仍可以向客户端提供正确的服务,而多数派成员宕机时,zookeeper则选择了一致性,为了保证给客户端响应正确的数据,zookeeper此时不会继续提供服务)选择一致性,但是它仍拥有很高的可用性。
126 |
127 | Brwer指出Spanner系统说是”实际上的CA”(efctivelCA) 系统
128 |
129 | 架构上是cp
130 |
131 | 出现网络分区,会保证一致性,不会对外提供服务
132 |
133 |
134 |
135 |
136 |
137 | 以eureka 为例,eureka 各节点互相独立,平等
138 |
139 | 各节点都提供查询和注册服务(读,写请求)
140 |
141 | 当发生网络分区,eureka 各节点依旧可以接收和注册服务
142 |
143 | 并且当丢失过多客户端时,节点会进入自我保护(接收新服务注册、不删除过期服务)
144 |
145 | 在这种模式下,eureka集群即使受到最后一个节点,也可以向外提供服务
146 |
147 | 尽管向外提供的数据可能是过期的数据
148 |
149 | 考虑选择一致性还是可用性的情况,一定是在发生网络故障,且在关键时间,此时一致性和可用性才是互斥的
150 |
151 | 而网络故障、且非常关键时间,在-一个健壮的系统中,这类情况是
152 | 非常少的,我们大多数情况都能保证-致性和可用性。
153 |
154 | eureka正常运行时,各节点之间可以正常通讯、保持心跳、复制数据、以此保持数据的一致性,但发生网络分区时,eureka 确实选择了可用性,放弃了一致性
155 |
156 | https://www.bilibili.com/video/BV1zS4y1W7hQ
157 |
158 |
159 |
160 | ----
161 |
162 |
--------------------------------------------------------------------------------
/项目/paxos.md:
--------------------------------------------------------------------------------
1 | ### paxos 究竟在解决什么问题 ?
2 |
3 | 用来确定一个不可变变量的取值
4 |
5 |
6 |
7 | ### paxos 如何在分布式存储系统中应用 ?
8 |
9 | 
10 |
11 | 
12 |
13 |
14 |
15 |
16 |
17 | 
18 |
19 |
20 |
21 | 
22 |
23 | 
24 |
25 | 
26 |
27 |
28 |
29 | 
30 |
31 |
32 |
33 | ### paxos 算法的核心思想是什么 ?
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 | 知行学社——paxos和分布式系统https://www.bilibili.com/video/BV1Lt411m7cW
42 |
43 |
44 |
45 |
46 |
47 | ----
48 |
49 | 共识介绍
50 |
51 | 共识Consensus问题:
52 | 在一组允许出现故障的成员中,如何从一组提案中就某一个提案达成共识
53 |
54 | 共识与一致性:
55 |
56 | 共识强调在外部观察者看来,系统数据是一致的
57 | 一致性,是指系统内部真实100%-致
58 |
59 |
60 |
61 | 基本保证:
62 | 已达成共识的提案不会因为任何变故而改变
63 |
64 | 提案编号
65 |
66 | 多数派:
67 | 超过集群一半成员组成集合
68 | l(N)2| +1 (N为成员总数)
69 |
70 |
71 |
72 | 角色
73 |
74 | proposer
75 |
76 | acceptor
77 |
78 | learner
79 |
80 |
81 |
82 | 阶段
83 |
84 | prepare 阶段
85 |
86 | 争取本轮提出提案的所有权
87 |
88 | prpare阶段propose是不会携带提案值的,它只会携带提案编号广播给所有的acceptor,所有的acceptor 根据这个提案编号判断是不是能够接受这个prepare请求
89 |
90 | 当proposer收到集群中大多数acceptor的同意之后,然后它就拥有本轮提出提案的权利,那么它就可以进行accept阶段
91 |
92 | 另一个作用,就是获取上一轮可能达成共识的提案(已经达成共识的值不可改变了)。它会把prepare请求广播给所有的acceptor时,acceptor会把它本地曾接收过的一个提案反馈给 proposer
93 |
94 |
95 |
96 | accept阶段
97 |
98 | 获取上一轮
99 |
100 | learn阶段
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 | 协商约定
109 |
110 | Acceptor:令自己所见过的最大的提案编号为local.n,请求中的提案编号为msg.n
111 |
112 | 收到Prepare请求,msgn> localn,则通过该请求,否则拒绝该请求,直接抛弃该请求。
113 |
114 | 收到Accepl请求,msg.n ≥localn,则通过该请求,否则拒绝该请求,直接抛弃该请求。
115 |
116 | 通过某一Prepare请求时,会在Prepare响应中携带自已所批准过的最大提案编号对应的提案值。
117 |
118 | Proposer:
119 | 收到客户端请求,先发起Prepare请求。
120 | 收到多数派Prepare响应, 才可以进入Accept阶段。 其提案值需要从Prepare响应中获取。
121 | 收到多数派Accepl响应,则该提案达成识。
122 |
123 |
124 |
125 |
126 |
127 | 
128 |
129 |
130 |
131 | 
132 |
133 |
134 |
135 |
136 |
137 | 四轮消息响应
138 |
139 | 
140 |
141 |
142 |
143 |
144 |
145 | 活锁 多个proposer 之间并行提案,它们之间会互相影响
146 |
147 | 
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 | ### Multi paxos
156 |
157 | 引入Leader角色
158 | 只能由Lcaded发起捉案,减少了活锁的概率
159 | 优化Prepare阶段
160 | 在没有提案冲突的情况下,优化Prcpare阶段, 优化成一阶段
161 |
162 |
163 |
164 |
165 |
166 |
167 |
168 | 
169 |
170 |
171 |
172 | 【分布式一致性/共识算法 - Multi Paxos】 https://www.bilibili.com/video/BV1Y34y1j7b1?share_source=copy_web&vd_source=4d050090b394b684b27865dbb93eb184
173 |
174 |
175 |
176 | 
177 |
178 |
179 |
180 |
181 |
182 | https://www.bilibili.com/video/BV1X54y1d7xU
--------------------------------------------------------------------------------
/笔记/1.3Java并发/3并发理论(JMM).md:
--------------------------------------------------------------------------------
1 | # 并发理论(JMM)
2 |
3 | JMM本质上可以理解为,Java 内存模型规范了 JVM 如何提供按需禁用缓存和编译优化的方法。
4 |
5 | 体来说,这些方法包括:
6 |
7 | - volatile、synchronized 和 final 三个关键字
8 | - Happens-Before 规则
9 |
10 | **Java提供了volatile关键字来保证可见性**。
11 |
12 | 当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
13 |
14 | **在Java里面,可以通过volatile关键字来保证一定的“有序性**
15 |
16 | ## Java 内存模型的抽象
17 |
18 | 在 java 中,所有实例域、静态域和数组元素存储在==堆内存==中,==堆内存、和方法区 (JDK1.8 之后的元空间)资源== 在线程之间共享。
19 |
20 | 但是每个线程有自己的程序计数器、虚拟机栈 和 本地方法栈。
21 |
22 | 局部变量(Local variables),方法定义参数(java 语言规范称之为 formal method parameters)和异常处理器参数(exception handler parameters)不会在线程之间共享,它们不会有内存可见性问题,也不受内存模型的影响。
23 |
24 | Java 内存模型的抽象示意图如下:
25 |
26 | 
27 |
28 | 线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读 / 写共享变量的副本。
29 |
30 |
31 |
32 | ## 重排序
33 |
34 | 在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。重排序分三种类型:
35 |
36 | - ==编译器优化的重排序==。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
37 | - ==指令级并行的重排序==。现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
38 | - ==内存系统的重排序==。由于处理器使用缓存和读 / 写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
39 |
40 | 从 java 源代码到最终实际执行的指令序列,会分别经历下面三种重排序:
41 |
42 | 
43 |
44 | 上述的 1 属于编译器重排序,2 和 3 属于处理器重排序。这些重排序都可能会导致多线程程序出现内存可见性问题。
45 |
46 | 对于编译器,JMM 的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。
47 |
48 | 对于处理器重排序,JMM 的处理器重排序规则会要求 java 编译器在生成指令序列时,插入特定类型的内存屏障(memory barriers,intel 称之为 memory fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序(不是所有的处理器重排序都要禁止)。
49 |
50 | ==JMM 属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证==。
51 |
52 | ## happens-before
53 |
54 | 从 JDK5 开始,java 使用新的 JSR -133 内存模型。
55 |
56 | JSR-133 提出了 happens-before 的概念,通过这个概念来阐述操作之间的内存可见性。
57 |
58 | 如==果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在 happens-before 关系。这里提到的两个操作既可以是在一个线程之内,也可以是在不同线程之间。== 与程序员密切相关的 happens-before 规则如下:
59 |
60 | - 程序顺序规则:一个线程中的每个操作,happens- before 于该线程中的任意后续操作。
61 | - 监视器锁规则:对一个监视器锁的解锁,happens- before 于随后对这个监视器锁的加锁。
62 | - ==volatile 变量规则==:对一个 volatile 域的写,happens- before 于任意后续对这个 volatile 域的读。
63 | - 传递性:如果 A happens- before B,且 B happens- before C,那么 A happens- before C。
64 |
65 | ==注意,两个操作之间具有 happens-before 关系,并不意味着前一个操作必须要在后一个操作之前执行!happens-before 仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前==(the first is visible to and ordered before the second)。happens- before 的定义很微妙,后文会具体说明 happens-before 为什么要这么定义。
66 |
67 |
68 |
69 | ## 重排序
70 |
71 | ### 数据依赖性
72 |
73 | 写后读\写后写\读后写
74 |
75 | 只要重排序两个操作的执行顺序,程序的执行结果将会被改变。
76 |
77 | 编译器和处理器可能会对操作做重排序。编译器和处理器在重排序时,会遵守数据依赖性,==编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序==。
78 |
79 | ## ==as-if-serial 语义==
80 |
81 | as-if-serial 语义的意思指:==不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变==。编译器,runtime 和处理器都必须遵守 as-if-serial 语义。
82 |
83 | ```
84 | area = pi * r * r
85 | ```
86 |
87 | 先乘哪个都行
88 |
89 | as-if-serial 语义把单线程程序保护了起来,遵守 as-if-serial 语义的编译器,runtime 和处理器共同为编写单线程程序的程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的。as-if-serial 语义使单线程程序员无需担心重排序会干扰他们,也无需担心内存可见性问题。
90 |
91 |
92 |
93 | ## JMM 的内存可见性保证
94 |
95 | Java 程序的内存可见性保证按程序类型可以分为下列三类:
96 |
97 | - ==单线程程序。单线程程序不会出现内存可见性问题。==编译器,runtime 和处理器会共同确保单线程程序的执行结果与该程序在顺序一致性模型中的执行结果相同。
98 | - ==正确同步的多线程程序。正确同步的多线程程序的执行将具有顺序一致性==(程序的执行结果与该程序在顺序一致性内存模型中的执行结果相同)。这是 JMM 关注的重点,JMM 通过限制编译器和处理器的重排序来为程序员提供内存可见性保证。
99 | - ==未同步 / 未正确同步的多线程程序。==JMM 为它们提供了最小安全性保障:线程执行时读取到的值,要么是之前某个线程写入的值,要么是默认值(0,null,false)。
100 |
101 | 下图展示了这三类程序在 JMM 中与在顺序一致性内存模型中的执行结果的异同:
102 |
103 | 
104 |
105 | 只要多线程程序是正确同步的,JMM 保证该程序在任意的处理器平台上的执行结果,与该程序在顺序一致性内存模型中的执行结果一致。
106 |
107 |
108 |
109 | ## 参考
110 |
111 | https://juejin.cn/post/6844903600318054413
112 |
113 | https://pdai.tech/md/java/thread/java-thread-x-theorty.html
114 |
115 |
--------------------------------------------------------------------------------
/2022日常实习面经(2022.11-12/滴滴准实习员工模拟面 .md:
--------------------------------------------------------------------------------
1 | ## 11.3 滴滴准实习员工模拟面--简单复盘版
2 |
3 | 滴滴准实习员工模拟面,1h
4 |
5 |
6 |
7 | ### 自我介绍
8 |
9 | 巴拉巴拉
10 |
11 | ```
12 | 继续练,还没特别熟
13 | ```
14 |
15 |
16 |
17 | ### 项目介绍
18 |
19 | ### edis
20 |
21 | > redis过期策略
22 |
23 |
24 |
25 | > 比如说我们数据库当中有 2000 万的数据,然后我 Redis 它只存 20 万的数据,然后让你来设计,你要怎么设计呢?
26 |
27 | LRU策略
28 |
29 |
30 |
31 | >但是你看我们传统的 LRU 的话,那它造成的这个缓存污染怎么办?比如说有一个热点数据,我刚进去,结果刚进去待了很久,然后但是他已经很久没有使用了,但是他就是比如说我们一开始就是我们热点不是最近访问的。然后然后我们这个 Redis 当中有一个比如说有有一个预读机制,就是比如说 A 和 B 数据都进去了,然后他们的访他们只可能就是最近访问了一两次,但是这样他就会导致以前的那些热点数据给清除了。你能就是你觉得这个要怎么办?就是让你来优化一下 LRU 算法,你要怎么优化一下呢?
32 |
33 | 我们需要一个晋升的阈值,可以参考Linux中优化LRU的算法
34 |
35 | 就是设计了一个 active 链表,还有一个 inactive 链表。
36 |
37 | 访问次数在阈值内的会在inactive链表中,超过次数的会晋升到active链表里
38 |
39 | Linux 操作系统:在内存页被访问**第二次**的时候,才将页从 inactive list 升级到 active list 里。(自己回答的时候可以说设定一个晋级门槛和inactive list和active list)
40 |
41 | **只要我们提高进入到活跃 LRU 链表(或者 young 区域)的门槛,就能有效地保证活跃 LRU 链表(或者 young 区域)里的热点数据不会被轻易替换掉**。
42 |
43 |
44 | ### MySQL
45 |
46 | mysql 索引
47 |
48 | > innodb中,b+树是怎么实现的?
49 | >
50 | > 就是比如说它是它的叶子节点当中是怎么样连接的,然后里面的数据是怎么连接的?
51 |
52 | https://bbs.huaweicloud.com/blogs/317532
53 |
54 |
55 |
56 | > B 加树当中一定要有聚簇索引吗?
57 |
58 |
59 |
60 | >你知道就是 B 加树当中一般是多少层吗?
61 |
62 | InnoDB中页大小一般16KB,一般表的**主键类型为INT**(占用4个字节)或BIGINT(8字节),**指针类型一般也是4-8字节**,也就是一个页中大概存储16KB/(8B+8B)=1K个键值(估算K取10三次方),则一个深度为3的B+Tree索引可以维护10亿条记录(9次方,假定一个数据页也是10三次方行记录数据)实际情况中每个节点可能不能被充满,所以高度一般2-4层,而根节点为常驻节点故只需要1-3次。
63 |
64 |
65 |
66 | >然后那索引的优点和缺点你说说。
67 |
68 |
69 |
70 | >你有了解过那个 MVCC 机制吗?
71 | >
72 | >那它底层是通过什么来实现的?
73 |
74 |
75 |
76 |
77 |
78 | > 它隐藏字段是哪些?你知道吗?
79 |
80 |
81 |
82 | > 你知道读视图主要是包含了哪些重要内容吗?
83 |
84 |
85 |
86 | >它里面就是包含了四个字段,就是包含了四个比较重要的内容,你知道是哪四个吗?
87 |
88 |
89 |
90 | >比如说我读了一条数据,那我们是怎么通过就是我是怎么通过 MVCC 机制来判断我能不能读到这条数据的呢?他的判断规则是什么?
91 |
92 |
93 |
94 | >事物的特性是哪些特性吗?
95 | >
96 | >隔离性它是有哪几个等级呢?
97 |
98 |
99 |
100 | >可重复读不能解决幻读的情况。
101 |
102 | 可重复读解决幻读是快照读利用了MVCC机制的版本号, 而当前读为强制获取当前数据 故不能解决
103 |
104 | 快照读:又叫一致性读,读取的是快照数据。不加锁的简单的 SELECT 都属于快照读,即不加锁的非阻塞读;快照读的实现时基于MVCC的。**快照读基于多版本则可能读到历史数据并不是最新的**。快照读的前提时隔离级别不是串行级别,串行级别快照读退化当前读。
105 |
106 | 当前读:**强制读取记录的最新版本,且上锁。对数据的增删改都会先进行当前读**
107 |
108 |
109 |
110 | ### 网络
111 |
112 | > 三次握手
113 |
114 |
115 |
116 | >那三次握手,他那个 accept 过程发生在钉哪次握手呢?就是发生在什么时候?就是 Linux 当中不是有一个 accept 就是获取到那个 socket 你知道它是发生在什么时候吗?
117 |
118 | 三次握手过程
119 |
120 | - 客户端的协议栈向服务器端发送了 SYN 包,并告诉服务器端当前发送序列号 client_isn,客户端进入 SYN_SENT 状态;
121 | - 服务器端的协议栈收到这个包之后,和客户端进行 ACK 应答,应答的值为 client_isn+1,表示对 SYN 包 client_isn 的确认,同时服务器也发送一个 SYN 包,告诉客户端当前我的发送序列号为 server_isn,服务器端进入 SYN_RCVD 状态;
122 | - 客户端协议栈收到 ACK 之后,使得应用程序从 `connect` 调用返回,表示客户端到服务器端的单向连接建立成功,客户端的状态为 ESTABLISHED,同时客户端协议栈也会对服务器端的 SYN 包进行应答,应答数据为 server_isn+1;
123 | - ACK 应答包到达服务器端后,服务器端的 TCP 连接进入 ESTABLISHED 状态,同时服务器端协议栈使得 `accept` 阻塞调用返回,这个时候服务器端到客户端的单向连接也建立成功。至此,客户端与服务端两个方向的连接都建立成功。
124 |
125 | 从上面的描述过程,我们可以得知**客户端 connect 成功返回是在第二次握手,服务端 accept 成功返回是在三次握手成功之后。**
126 |
127 |
128 |
129 | >拥塞控制,我看你这边写了,就是那你知道拥塞控制那几个算法吗?
130 |
131 |
132 |
133 | >快速恢复,你能给我具体说说它是怎么用的吗?
134 |
135 |
136 |
137 | > 四次挥手的过程
138 |
139 |
140 |
141 | >那你知道这个他四次挥手,他有没有可能变成三次挥手呢?
142 |
143 |
144 |
145 | > TCP 和 UDP 它们的区别吧。
146 |
147 |
148 |
149 | >那咱们平时打视频电话的话,它是通过用什么来连接的?
150 |
151 |
152 |
153 | ### 并发
154 |
155 | > cas原理
156 |
157 |
158 |
159 | > volitale
160 |
161 |
162 |
163 | > 线程和进程
164 |
165 |
166 |
167 |
168 |
169 | > 操作系统当中进程的通信方式有几种吗?你能说有哪些吗?
170 |
171 |
172 |
173 | ### Jvm
174 |
175 | 内存结构
176 |
177 | > 那咱们平常分配内存都是在哪里分配的?大多数情况。
178 |
179 |
180 |
181 | > 逃逸分析
182 |
183 | Java 世界中“几乎”所有的对象都在堆中分配,但是,随着 JIT 编译器的发展与逃逸分析技术逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化,所有的对象都分配到堆上也渐渐变得不那么“绝对”了。**从 JDK 1.7 开始已经默认开启逃逸分析,如果某些方法中的对象引用没有被返回或者未被外面使用(也就是未逃逸出去),那么对象可以直接在栈上分配内存**。
184 |
185 | > 垃圾回收算法
186 |
187 |
188 |
189 | ### 算法
190 |
191 | 手写堆排
192 |
193 | 前序和后序为什么不能重建二叉树,举例
194 |
195 | 手写快排
196 |
197 |
198 |
199 |
200 |
201 |
--------------------------------------------------------------------------------
/笔记/1.1Java基础/1.概述.md:
--------------------------------------------------------------------------------
1 | # 1 Java 概述
2 |
3 | ## 1.1 Java 历史
4 |
5 | - 目前 Java 版权属于甲骨文公司。
6 |
7 | - 长期支持的版本只有 Java8 与 Java11。这两个版本也是最多使用的版本。
8 |
9 | - Java SE:标准版
10 |
11 | Java EE:企业版(重要)
12 |
13 | Java ME:小型版(少)
14 |
15 | ## 1.2 Java 重要特点
16 |
17 | 1. Java 语言是**面向对象的(oop)**
18 |
19 | 简单来说,面向对象是一种程序设计技术。其重点放在数据(对象)和对象的接口上。
20 |
21 | 2. Java 语言是**健壮的**。其强类型机制、异常处理、垃圾自动收集是健壮性的保证。
22 |
23 | Java 强调早期问题检测、后期动态检测,及消除易出错的情况。其编译器能检测很多其他语言仅在运行时才会发现的问题。
24 |
25 | 3. Java 语言是**跨平台性**的:一个编译好的 `.class` 文件可以在多个不同系统下直接运行。
26 |
27 | Java 中没有 “依赖具体实现” 的地方。其基本数据类型大小、有关运算的行为等都有明确说明。其绝大多数库都能很好地支持平台独立性,而不用担心操作系统。
28 |
29 | 4. Java 语言是**解释型**的:解释型语言编译后需要解释器才能运行。相对的,编译型语言可以被直接执行。
30 |
31 | Java 解释器能在任何移植了解释器的机器上直接执行 Java 字节码。
32 |
33 | ## 1.3 Java 的开发工具
34 |
35 | - javac:Java 编译器。将 Java 程序编译成字节码
36 | - java:Java 解释器。执行已经转换为字节码的文件
37 | - jdb:Java 调试器。调试 Java 程序
38 | - javap:反编译。将类文件还原回方法和变量
39 | - javadoc:文档生成器。创建 HTML 文件
40 |
41 | ## 1.4 Java 运行基础
42 |
43 | > JVM:Java 虚拟机
44 |
45 | - JVM 是–跨平台性的基础。被包含在 JDK 中。
46 | - 不同平台有各自对应的不同 JVM
47 | - JVM 屏蔽了底层平台的区别。能做到 ”一次编译,到处运行”
48 |
49 | > JDK 全称:Java Development Kit(Java 开发工具包)
50 |
51 | - JDK = JRE + Java 的开发工具(Java,Javac,Javadoc 等等)
52 | - 给开发人员使用的,包含 JRE
53 |
54 | > JRE:Java Runtime Enviroment(Java 运行环境)
55 |
56 | - JRE = JVM + Java SE 标准类库(Java 的核心类库)
57 | - 运行一个 Java 程序的基本条件
58 |
59 | ## 1.5 Java 执行流程分析
60 |
61 | > `.Java` 文件(源文件) — javac(编译)— `.class` 文件(字节码文件) — java(运行)— 结果
62 |
63 | ### 1.5.1 编译
64 |
65 | ```
66 | javac [选项] 源文件名.java //[] 中是可选项
67 | ```
68 |
69 | - 通过编译器将 Java 源文件编译成 JVM 可识别的字节码文件。字节码文件是二进制格式的,其格式是统一的。在源文件目录下使用 Javac 编译工具对 Java 文件进行编译。
70 | - 如果没有错误将没有提示,当前目录会对应其中每一个类生成对应名称的 `.class` 文件,即字节码文件,也是可执行的 Java 程序。
71 |
72 | ### 1.5.2 运行
73 |
74 | ```
75 | java [选项] 程序名 [参数列表] //[] 中是可选项
76 | ```
77 |
78 | - 有了可执行的 Java 程序(字节码文件)
79 | - 通过运行工具` Java.exe` 对字节码文件进行执行,本质是将 `.class` 文件装载到 JVM 运行。
80 |
81 | # 2 变量
82 |
83 | ## 2.1 Java 数据类型
84 |
85 | #### 基本数据类型(本章)
86 |
87 | - **数值型**
88 | - 整数类型:
89 | - byte:占用 1 字节
90 | - short:占用 2 字节
91 | - int:占用 4 字节
92 | - long:占用 8 字节
93 | - 浮点(小数)类型:
94 | - float:占用 4 字节
95 | - double:占用 8 字节
96 | - **字符型**
97 | - char:存放单个字符,占用 2 字节
98 | - **布尔型**
99 | - boolean:存放 true(真),false(假)。占用 1 字节
100 |
101 | #### 引用数据类型(复合数据类型)
102 |
103 | - **类**:class
104 | - **接口**:interface
105 | - **数组**:`[]`
106 |
107 | ## 2.2 浮点类型
108 |
109 | > 可以表示一个小数
110 |
111 | - `float` 单精度(6 ~ 7 位有效数字),占用 4 字节,范围约 -3.403E38 ~ 3.403E38
112 | - `double` 双精度(15 位有效数字),占用 8 字节,范围约 -1.798E308 ~ 1.798E308
113 |
114 | *浮点数在机器中存放形式为:浮点数 = 符号位 + 指数位 + 尾数位*
115 |
116 | ***因此,尾数部分可能丢失,造成精度损失。换言之,小数都是近似值***
117 |
118 | ## 2.3 基本数据类型转换
119 |
120 | ### 2.3.1 自动类型转换
121 |
122 | > 自动类型转换:Java 在进行赋值或运算时,精度(容量)小的类型自动转换为精度(容量)大的类型。
123 | >
124 | > ```
125 | > char` > `int `> `long` > `float` > `double
126 | > byte` > `short` > `int `> `long` > `float` > `double
127 | > ```
128 | >
129 | > 例子:`int a = 'c'` 或者 `double b = 80`
130 |
131 | #### 2.3.1.1 使用细节
132 |
133 | 1. 有多种类型数据混合运算时,系统会将所有数据转换成容量最大的那种,再进行运算。
134 |
135 | 2. 如若把大精度(容量)数据赋值给小精度(容量)类型,就会报错(小数由于精度原因,大赋小会丢失精度,必不可用。但整数大赋小时:1.赋予具体数值时,判断范围。2.变量赋值时,判断类型。反之进行自动类型转换。
136 |
137 | 3. `byte` `short` `char` 三者不会相互自动转换,但可以计算。计算时首先转化为 `int`。
138 |
139 | > `byte a = 1;`
140 | >
141 | > `byte b = 1;`
142 | >
143 | > `a + b` 结果是 `int` 类型
144 |
145 | 4. `boolean` 类型不参与自动转换
146 |
147 | 5. 自动提升原则:表达式结果的类型自动提升为操作数中最大的类型。
148 |
149 | ### 2.3.2 强制类型转换
150 |
151 | > 强制类型转换:自动类型转换的逆过程,将容量大的数据类型转换为容量小的数据类型。使用时加上强制转换符 `( )` ,但**可能造成精度降低或溢出**,要格外注意。
152 |
153 | #### 2.3.2.1 使用细节
154 |
155 | 1. 当进行数据从大到小转换时,用强制转换。
156 |
157 | 2. 强制转换只能对最近的操作数有效,往往会使用 `( )` 提升优先级。
158 |
159 | ```
160 | int a = (int)(3 * 2.5 + 1.1 * 6);
161 | JAVA
162 | ```
163 |
164 | 3. `char` 可以保留 `int` 的常量值,但不能保存其变量值。此时需要强制类型转换。
165 |
166 | ```
167 | int a = 10;
168 | char b = 10;
169 | char c = (char)a;
170 | JAVA
171 | ```
172 |
173 | 4. `byte` `short` `char` 在进行运算时,当作 `int` 处理。
--------------------------------------------------------------------------------
/笔记/3 分布式/分布式简单入门.md:
--------------------------------------------------------------------------------
1 | ## 分布式简单入门知识
2 |
3 | 学习了这些不一定入门,但不学这些应该不能入门
4 |
5 | 因学业繁忙,所以先写一个大致框架,后期补充相关博客
6 |
7 | 可以使用小标题直接去 **谷歌** 搜索对应知识,标题下会写一些最近面试遇到的问题
8 |
9 | 最后引用部门贴一些之前看到的写的好的博客,暂未分类
10 |
11 | ## 分布式基础理论
12 |
13 | ### CAP理论
14 |
15 | https://tanxinyu.work/cap-theory/
16 |
17 | ### PACELC理论
18 |
19 | 这个好好看,说了CAP记得要说这个
20 |
21 | ### BASE理论
22 |
23 | ### NWR多数派理论
24 |
25 | 说了PACELC可以补充一个这个的例子
26 |
27 | ### 一致性理论
28 |
29 |
30 |
31 | https://tanxinyu.work/consistency-and-consensus/
32 |
33 | ### 一致性hash算法
34 |
35 | 普通一致性hash算法
36 |
37 | 一致性hash算法底层数据结构
38 |
39 | 一致性hash算法的具体实现
40 |
41 | 虚拟节点
42 |
43 | ## 分布式共识算法
44 |
45 | ### 2PC & 3PC
46 |
47 | 说一下2pc、3pc
48 |
49 | https://www.bilibili.com/video/BV1EA411u7gM
50 |
51 | https://www.bilibili.com/video/BV1XT4y1B73Y
52 |
53 | ### Paxos协议
54 |
55 | 将一下paxos协议
56 |
57 | 活锁
58 |
59 | https://www.bilibili.com/video/BV1X54y1d7xU/
60 |
61 | https://www.infoq.cn/article/wechat-paxosstore-paxos-algorithm-protocol/
62 |
63 | ### Raft算法
64 |
65 | raft选举过程
66 |
67 | raft脑裂
68 |
69 | https://www.bilibili.com/video/BV1BZ4y1U774
70 |
71 | https://www.bilibili.com/video/BV1aA4y1R7YH
72 |
73 | https://tanxinyu.work/raft/#%E8%83%8C%E6%99%AF
74 |
75 | ### Zab协议
76 |
77 | zab选举过程
78 |
79 | zab奔溃恢复过程
80 |
81 | 脑裂
82 |
83 | https://www.bilibili.com/video/BV14Y411g7ok
84 |
85 | ### Have we reached consensus on consensus?
86 |
87 | https://tanxinyu.work/have-we-reached-consensus-on-consensus/
88 |
89 | 清华佬的ppt:https://vevotse3pn.feishu.cn/file/boxcnBKfW8q9E61Bfi314R0hOfe
90 |
91 | ## 总结类
92 |
93 | [Replication(上):常见复制模型&分布式系统挑战](https://tech.meituan.com/2022/08/25/replication-in-meituan-01.html)
94 |
95 | [Replication(下):事务,一致性与共识](https://tech.meituan.com/2022/08/25/replication-in-meituan-02.html)
96 |
97 |
98 |
99 | ## Reference
100 |
101 | 分布式理论相关(总):https://github.com/erdengk/notes/blob/main/%E7%AC%94%E8%AE%B0/3%20%E5%88%86%E5%B8%83%E5%BC%8F/1%20%E5%88%86%E5%B8%83%E5%BC%8F%E7%90%86%E8%AE%BA%E7%9B%B8%E5%85%B3.md
102 |
103 | 分布式算法相关(总):https://github.com/erdengk/notes/blob/main/%E7%AC%94%E8%AE%B0/3%20%E5%88%86%E5%B8%83%E5%BC%8F/2%20%20%E5%88%86%E5%B8%83%E5%BC%8F%E7%AE%97%E6%B3%95%E7%9B%B8%E5%85%B3.md
104 |
105 | https://www.nowcoder.com/discuss/post/362412702839451648
106 |
107 | 基础理论:
108 |
109 | http://zhangtielei.com/posts/blog-distributed-strong-weak-consistency.html
110 |
111 | https://cn.pingcap.com/blog/linearizability-and-raft
112 |
113 | http://www.choudan.net/2013/08/07/CAP%E7%90%86%E8%AE%BA%E5%92%8CNWR%E7%AD%96%E7%95%A5.html
114 |
115 | https://blog.csdn.net/m0_68850571/article/details/126140636
116 |
117 | https://www.changping.me/2020/04/10/distributed-theory-cap-pacelc/
118 |
119 | https://pdai.tech/md/dev-spec/spec/dev-microservice-kangwei.html
120 |
121 | https://www.52code.net/a/8xjTPFSabM
122 |
123 | https://pdai.tech/md/arch/arch-z-theory.html
124 |
125 | https://cloud.tencent.com/developer/article/1752382
126 |
127 | 分布式算法:
128 |
129 | https://zhuanlan.zhihu.com/p/112651338
130 |
131 | https://pdai.tech/md/algorithm/alg-domain-distribute-x-zab.html
132 |
133 | https://cloud.tencent.com/developer/article/1525566
134 |
135 | https://pdai.tech/md/algorithm/alg-domain-distribute-x-paxos.html
136 |
137 | https://blog.csdn.net/yzf279533105/article/details/127163022
138 |
139 | https://blog.openacid.com/algo/paxos
140 |
141 | https://blog.csdn.net/Z_Stand/article/details/108547684
142 |
143 | http://www.xuyasong.com/?p=1970
144 |
145 | https://cloud.tencent.com/developer/article/1798049
146 |
147 | https://zhuanlan.zhihu.com/p/68743917
148 |
149 | https://draveness.me/consensus/
150 |
151 | https://pdai.tech/md/algorithm/alg-domain-distribute-x-consistency-hash.html
152 |
153 | https://learn.lianglianglee.com/%E4%B8%93%E6%A0%8F/24%E8%AE%B2%E5%90%83%E9%80%8F%E5%88%86%E5%B8%83%E5%BC%8F%E6%95%B0%E6%8D%AE%E5%BA%93-%E5%AE%8C/20%20%20%E5%85%B1%E8%AF%86%E7%AE%97%E6%B3%95%EF%BC%9A%E4%B8%80%E6%AC%A1%E6%80%A7%E8%AF%B4%E6%B8%85%E6%A5%9A%20Paxos%E3%80%81Raft%20%E7%AD%89%E7%AE%97%E6%B3%95%E7%9A%84%E5%8C%BA%E5%88%AB.md
154 |
155 | https://here2say.com/44/
156 |
157 |
--------------------------------------------------------------------------------
/笔记/2.5 Zookeeper/zk .md:
--------------------------------------------------------------------------------
1 | ## 对zk的理解
2 |
3 | 可以从分布式中三种应用场景来说
4 |
5 | ==集群管理==
6 |
7 | 在多个节点组成的集群中,为了去保证集群的高可用特性
8 |
9 | 每个节点都会去冗余一份数据副本,在这种情况下,需要保证客户端访问集群中任意一个节点都是最新的数据
10 |
11 | ==分布式锁==
12 |
13 | 如何保证跨进厂的共享资源的并发安全性
14 |
15 | 对于分布式系统来说,也是一个比较大的挑战,而为了达到这个目的,必须要使用跨进程的锁,也就是分布式锁来实现
16 |
17 | ==master选举==
18 |
19 | 为了降低集群数据同步的复杂度,一般会存在master和slave两种角色的节点。master去做事务和非事务性的请求处理,slave负责去做非事务的请求处理,但是在分布式系统中如何确定某个节点是master还是slave也是一个需要解决的问题。
20 |
21 | 基于这些需求,所以产生了zk这样的中间件,它是一个分布式协调中间件。它类似一个裁判,专门来负责协调和解决分布式中的各类问题。
22 |
23 | zk实现了cp模型,来保证集群中的每一个节点的数据一致性。zk本身不是一个线性一致性模型,而是一个顺序一致性模型。
24 |
25 | 分布式锁,zk提供了多种不同的节点类型 持久化节点、临时节点、有序节点、容器节点,对于分布式锁来说,zk可以利用有序节点的特性来实现 ,初次之外,还可以用同一级节点的唯一特性来实现分布式锁
26 |
27 | 对于master选举,zk可以利用持久化节点来存储和管理其他集群节点的一些信息,从而去进行master选举。目前Kafka、habase都是通过zk来实现集群中节点的一个主从选举
28 |
29 | zk就是一个分布式数据一致性的解决方案,主要解决分布式应用中一些 高可用的需要严格控制访问顺序的一些场景,实现分布式的协调服务,底层的一致性算法是基于Paxos演化后的ZAB协议。
30 |
31 | ## 讲讲zab协议
32 |
33 | ### 为什么有zab
34 |
35 | paxos并没有给出完整且正确的实现,比如像节点扩容、奔溃恢复这些功能并没有提及,
36 |
37 | 所以zk中实现了zab这个原子广播协议来完成它的需求。基于Fast Paxos算法实现。
38 |
39 | #### 活锁问题
40 |
41 | #### 复杂度问题
42 |
43 | 为了解决活锁问题,出现了multi-paxos;
44 |
45 | 为了解决通信次数较多的问题,出现了fast-paxos;
46 |
47 | 为了尽量减少冲突,出现了epaxos。
48 |
49 | 可以看到,工业级实现需要考虑更多的方面,诸如性能,异常等等。这也是许多分布式的一致性框架并非真正基于paxos来实现的原因。
50 |
51 | #### 全序问题
52 |
53 | 对于paxos算法来说,不能保证两次提交最终的顺序,而zookeeper需要做到这点。(先买了咖啡才能和咖啡,反之不可以)
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 | ### zxid、epoch、xid
62 |
63 | 在 ZAB 中有三个很重要的数据:
64 |
65 | - `zxid`: 一个 `64 位长度的 Long 类型`,其中高 32 位表示纪元 epoch,低 32 位表示事务标识 xid。即 zxid 由两部分构成: epoch 与 xid。
66 | - `epoch`:`抽取自 zxid 中的高 32 位`。每个 Leader 都会具有一个不同的 epoch 值,表示一个时期、时代、年号。每一次新的选举结束后都会生成一个新的 epoch,新的 Leader产生,则会更新所有 zkServer 的 zxid 中的 epoch。
67 | - `xid`:`抽取自 zxid 中的低 32 位`。为 zk 的事务 id,`每一个写操作都是一个事务`,都会有一个 xid。 xid 为一个`依次递增的流水号`。
68 |
69 | ### 三阶段(leader选举、广播阶段、恢复阶段)
70 |
71 | ### 消息广播
72 |
73 | - 类似于一个**二阶段提交**过程。
74 |
75 | - 当过半的follower反馈ack之后就可以提交事务Proposal(提案)了。
76 |
77 | - 但是该模型无法处理leader崩溃退出而带来的数据不一致问题。因此,在ZAB协议中添加了另一模式,即采用**崩溃恢复模式**来解决这个问题。
78 |
79 | - Leader 接收到消息请求后,将消息赋予一个全局唯一的 64 位自增 id,叫做:zxid,通过 zxid 的大小比较即可实现因果有序这一特性。
80 |
81 | - Leader 通过先进先出队列(会给每个follower都创建一个队列,保证发送的顺序性)(通过 TCP 协议来实现,以此实现了全局有序这一特性)将带有 zxid 的消息作为一个提案(proposal)分发给所有 follower。
82 |
83 | - 当 follower 接收到 proposal,先将 proposal 写到本地事务日志,写事务成功后再向 leader 回一个 ACK。
84 |
85 | - 当 leader 接收到过半的 ACKs 后,leader 就向所有 follower 发送 COMMIT 命令,同意会在本地执行该消息
86 |
87 | - 当 follower 收到消息的 COMMIT 命令时,就会执行该消
88 |
89 | - 在消息广播过程中,leader server会为每个follower分配一个单独的**队列**,然后将需要广播的事务proposal依次放入这些队列中,并且根据FIFO策略发送消息。
90 |
91 | 每个follower接收到proposal后,会首先将其**以事务日志形式写入本地磁盘**,并且在成功写入后(ack)反馈给leader。**当leader收到超过半数的ack后,会广播一个commit消息**给所有的follower以通知其进行事务提交,同时leader自身也会完成对事务的提交,follower也会在接收到commit消息后,完成对事务的提交。(提交至内存)
92 |
93 |
94 |
95 | ## 可靠性保证
96 |
97 | 已经被leader提交的事务需要最终被所有的机器提交(已经发出commit了)
98 |
99 | 保证丢弃那些只在leader上提出的事务。(只在leader上提出了proposal,还没有收到回应,还没有进行提交)
100 |
101 |
102 |
103 | ### leader提交的,需要被全局提交
104 |
105 | 当 leader 收到合法数量 follower 的 ACKs 后,就向各个 follower 广播 COMMIT 命令,同时也会在本地执行 COMMIT 并向连接的客户端返回「成功」。
106 |
107 | 但是如果在各个 follower 在收到 COMMIT 命令前 leader 就挂了,导致剩下的服务器并没有执行都这条消息。
108 |
109 | #### 解决方案
110 |
111 | 选举拥有 proposal 最大值(即 zxid 最大) 的节点作为新的 leader:由于所有提案被 COMMIT 之前必须有合法数量的 follower ACK,即必须有合法数量的服务器的事务日志上有该提案的 proposal,因此,只要有合法数量的节点正常工作,就必然有一个节点保存了所有被 COMMIT 消息的 proposal 状态。
112 |
113 | 新的 leader 将自己事务日志中 proposal 但未 COMMIT 的消息处理。
114 |
115 | 新的 leader 与 follower 建立先进先出的队列, 先将自身有而 follower 没有的 proposal 发送给 follower,再将这些 proposal 的 COMMIT 命令发送给 follower,以保证所有的 follower 都保存了所有的 proposal、所有的 follower 都处理了所有的消息。通过以上策略,能保证已经被处理的消息不会丢
116 |
117 | ### 只在leader提交未广播的,需要丢弃
118 |
119 | 当 leader 接收到消息请求生成 proposal 后就挂了,其他 follower 并没有收到此 proposal,因此经过恢复模式重新选了 leader 后,这条消息是被跳过的。 此时,之前挂了的 leader 重新启动并注册成了 follower,他保留了被跳过消息的 proposal 状态,与整个系统的状态是不一致的,需要将其删除。
120 |
121 | #### 解决方案
122 |
123 | Zab 通过巧妙的设计 zxid 来实现这一目的。一个 zxid 是64位,高 32 是纪元(epoch)编号,每经过一次 leader 选举产生一个新的 leader,新 leader 会将 epoch 号 +1。低 32 位是消息计数器,每接收到一条消息这个值 +1,新 leader 选举后这个值重置为 0。
124 |
125 | 这样设计的好处是旧的 leader 挂了后重启,它不会被选举为 leader,因为此时它的 zxid 肯定小于当前的新 leader。当旧的 leader 作为 follower 接入新的 leader 后,新的 leader 会让它将所有的拥有旧的 epoch 号的未被 COMMIT 的 proposal 清除。
126 |
127 | 每次变换一个leader,则epoch加一,可以理解为改朝换代了,新朝代的zxid必然比旧朝代的zxid大,新代的leader可以要求将旧朝代的proposal清除。
128 |
129 |
130 |
131 |
132 |
133 | https://zhuanlan.zhihu.com/p/75720517
134 |
135 | https://www.cnblogs.com/felixzh/p/5869212.html
136 |
137 | https://juejin.cn/post/7099251134333714440
138 |
139 | http://wangwren.com/2019/09/02-Zookeeper%E7%90%86%E8%AE%BA%E7%9B%B8%E5%85%B3%E2%80%94%E2%80%94Paxos%E5%92%8CZAB/#Paxos%E7%AE%97%E6%B3%95
--------------------------------------------------------------------------------
/项目/1 笔记.md:
--------------------------------------------------------------------------------
1 | 根据运营人员设定的条件构建优惠券模版
2 |
3 | 生成优惠券模版的核心思想
4 |
5 | 异步+优惠券码
6 |
7 | 优惠券码(不可以重复、有一定的识别性)
8 |
9 |
10 |
11 | 
12 |
13 |
14 |
15 | 动态生成优惠券
16 |
17 | 生成时,使用set保证唯一性
18 |
19 | 放到redis中不会超发且保证性能
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 | ```
28 | 实现了统一的异常处理
29 | 统一响应
30 | ```
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 | 借鉴 redis 的过期策略,主动+被动
43 |
44 | 
45 |
46 |
47 |
48 | 优惠券过期清除时
49 |
50 | 使用优惠券模块的定时任务来定期清理(每日将过期的模版清理一次)
51 |
52 | 校验时清理
53 |
54 |
55 |
56 |
57 |
58 | 
59 |
60 | 查询优惠券时,先去查缓存,在获取用户优惠券之外,交给Kafka异步清理
61 |
62 |
63 |
64 |
65 |
66 | 查找
67 |
68 | 
69 |
70 |
71 |
72 | 领取
73 |
74 |
75 |
76 | 根据用户id去查找当前可以领取的模版,然后再用模版去领取redis中的优惠券
77 |
78 | 领取限制 TemplateRule.java
79 |
80 |
81 |
82 | 
83 |
84 |
85 |
86 |
87 |
88 | 结算/核销
89 |
90 |
91 |
92 | 
93 |
94 |
95 |
96 | 结算
97 |
98 |
99 |
100 | 
101 |
102 |
103 |
104 | 优惠券码缓存
105 |
106 | 
107 |
108 | 
109 |
110 |
111 |
112 |
113 |
114 | 架构
115 |
116 | 
117 |
118 | 功能设计
119 |
120 | 
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 | 异步任务是否返回,如果失败怎么处理
131 |
132 | 定时任务相关
133 |
134 |
135 |
136 |
137 |
138 | ```
139 | 使用 SessionCallback 把数据命令放入到 Redis 的 pipeline
140 |
141 | SessionCallback