├── .dockerignore
├── .github
├── ISSUE_TEMPLATE
│ ├── bug_report.md
│ └── feature_request.md
└── workflows
│ ├── lint_and_format.yml
│ ├── publish_pypi.yml
│ ├── publish_to_ghcr.yml
│ └── pytest.yml
├── .gitignore
├── CONTRIBUTING.md
├── Dockerfile
├── LICENSE
├── Makefile
├── README.md
├── assets
├── bert.gif
├── glass-gif.gif
├── inference.gif
├── llama_images
│ ├── llama-13b-class.png
│ ├── llama-13b-summ.png
│ ├── llama-7b-class.png
│ └── llama-7b-summ.png
├── money.gif
├── overview_diagram.png
├── progress.gif
├── readme_images
│ └── redpajama_results
│ │ ├── RedPajama-3B Classification.png
│ │ ├── RedPajama-3B Summarization.png
│ │ ├── RedPajama-7B Classification.png
│ │ └── RedPajama-7B Summarization.png
├── repo-main.png
├── rocket.gif
├── time.gif
└── toolkit-animation.gif
├── examples
├── ablation_config.yml
├── config.yml
├── llama2_config.yml
├── mistral_config.yml
└── test_suite
│ ├── dot_product_tests.csv
│ └── json_validity_tests.csv
├── llama2
├── README.md
├── baseline_inference.sh
├── llama2_baseline_inference.py
├── llama2_classification.py
├── llama2_classification_inference.py
├── llama2_summarization.py
├── llama2_summarization_inference.py
├── llama_patch.py
├── prompts.py
├── run_lora.sh
└── sample_ablate.sh
├── llmtune
├── __init__.py
├── cli
│ ├── __init__.py
│ └── toolkit.py
├── config.yml
├── constants
│ └── files.py
├── data
│ ├── __init__.py
│ ├── dataset_generator.py
│ └── ingestor.py
├── finetune
│ ├── __init__.py
│ ├── generics.py
│ └── lora.py
├── inference
│ ├── __init__.py
│ ├── generics.py
│ └── lora.py
├── pydantic_models
│ ├── __init__.py
│ └── config_model.py
├── qa
│ ├── __init__.py
│ ├── metric_suite.py
│ ├── qa_metrics.py
│ ├── qa_tests.py
│ └── test_suite.py
├── ui
│ ├── __init__.py
│ ├── generics.py
│ └── rich_ui.py
└── utils
│ ├── __init__.py
│ ├── ablation_utils.py
│ ├── rich_print_utils.py
│ └── save_utils.py
├── mistral
├── README.md
├── baseline_inference.sh
├── mistral_baseline_inference.py
├── mistral_classification.py
├── mistral_classification_inference.py
├── mistral_summarization.py
├── mistral_summarization_inference.py
├── prompts.py
├── run_lora.sh
└── sample_ablate.sh
├── poetry.lock
├── pyproject.toml
├── requirements.txt
├── test_utils
├── __init__.py
└── test_config.py
└── tests
├── data
├── test_dataset_generator.py
└── test_ingestor.py
├── finetune
├── test_finetune_generics.py
└── test_finetune_lora.py
├── inference
├── test_inference_generics.py
└── test_inference_lora.py
├── qa
├── test_metric_suite.py
├── test_qa_metrics.py
├── test_qa_tests.py
└── test_test_suite.py
├── test_ablation_utils.py
├── test_cli.py
├── test_directory_helper.py
└── test_version.py
/.dockerignore:
--------------------------------------------------------------------------------
1 | # .git
2 |
3 | # exlcude temp folder
4 | temp
5 |
6 | # exclude data files
7 | data/ucr/*
8 |
9 | # Jupyter
10 | *.bundle.*
11 | lib/
12 | node_modules/
13 | *.egg-info/
14 | .ipynb_checkpoints
15 | .ipynb_checkpoints/
16 | *.tsbuildinfo
17 |
18 | # IDE
19 | .vscode
20 | .vscode/*
21 |
22 | #Cython
23 | *.pyc
24 |
25 | # Packages
26 | *.egg
27 | !/tests/**/*.egg
28 | /*.egg-info
29 | /dist/*
30 | build
31 | _build
32 | .cache
33 | *.so
34 |
35 | # Installer logs
36 | pip-log.txt
37 |
38 | # Unit test / coverage reports
39 | .coverage
40 | .tox
41 | .pytest_cache
42 |
43 | .DS_Store
44 | .idea/*
45 | .python-version
46 | .vscode/*
47 |
48 | /test.py
49 | /test_*.*
50 |
51 | /setup.cfg
52 | MANIFEST.in
53 | /docs/site/*
54 | /tests/fixtures/simple_project/setup.py
55 | /tests/fixtures/project_with_extras/setup.py
56 | .mypy_cache
57 |
58 | .venv
59 | /releases/*
60 | pip-wheel-metadata
61 | /poetry.toml
62 |
63 | poetry/core/*
64 |
65 | # Logs
66 | log.txt
67 | logs
68 | /logs/*
69 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/bug_report.md:
--------------------------------------------------------------------------------
1 | ---
2 | name: Bug report
3 | about: Create a report to help us improve
4 | title: ''
5 | labels: ''
6 | assignees: ''
7 |
8 | ---
9 |
10 | **Describe the bug**
11 | A clear and concise description of what the bug is.
12 |
13 | **To Reproduce**
14 | Steps to reproduce the behavior:
15 | 1. Go to '...'
16 | 2. Click on '....'
17 | 3. Scroll down to '....'
18 | 4. See error
19 |
20 | **Expected behavior**
21 | A clear and concise description of what you expected to happen.
22 |
23 | **Screenshots**
24 | If applicable, add screenshots to help explain your problem.
25 |
26 | **Environment:**
27 | - OS: [e.g. Ubuntu 22.04]
28 | - GPU model and number [e.g. 1x NVIDIA RTX 3090]
29 | - GPU driver version [e.g. 535.171.04]
30 | - CUDA Driver version [e.g. 12.2]
31 | - Packages Installed
32 |
33 | **Additional context**
34 | Add any other context about the problem here.
35 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/feature_request.md:
--------------------------------------------------------------------------------
1 | ---
2 | name: Feature request
3 | about: Suggest an idea for this project
4 | title: ''
5 | labels: ''
6 | assignees: ''
7 |
8 | ---
9 |
10 | **Is your feature request related to a problem? Please describe.**
11 | A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
12 |
13 | **Describe the solution you'd like**
14 | A clear and concise description of what you want to happen.
15 |
16 | **Describe alternatives you've considered**
17 | A clear and concise description of any alternative solutions or features you've considered.
18 |
19 | **Additional context**
20 | Add any other context or screenshots about the feature request here.
21 |
--------------------------------------------------------------------------------
/.github/workflows/lint_and_format.yml:
--------------------------------------------------------------------------------
1 | name: Ruff
2 | on: pull_request
3 | jobs:
4 | lint:
5 | name: Lint & Format
6 | runs-on: ubuntu-latest
7 | steps:
8 | - uses: actions/checkout@v4
9 | - uses: chartboost/ruff-action@v1
10 | name: Lint
11 | with:
12 | version: 0.3.5
13 | args: "check --output-format=full --statistics"
14 | - uses: chartboost/ruff-action@v1
15 | name: Format
16 | with:
17 | version: 0.3.5
18 | args: "format --check"
19 |
--------------------------------------------------------------------------------
/.github/workflows/publish_pypi.yml:
--------------------------------------------------------------------------------
1 | name: PyPI CD
2 | on:
3 | release:
4 | types: [published]
5 | jobs:
6 | pypi:
7 | name: Build and Upload Release
8 | runs-on: ubuntu-latest
9 | environment:
10 | name: pypi
11 | url: https://pypi.org/p/llm-toolkit
12 | permissions:
13 | id-token: write # IMPORTANT: this permission is mandatory for trusted publishing
14 | steps:
15 | # ----------------
16 | # Set Up
17 | # ----------------
18 | - name: Checkout
19 | uses: actions/checkout@v4
20 | with:
21 | fetch-depth: 0
22 | - name: Setup Python
23 | uses: actions/setup-python@v5
24 | with:
25 | python-version: "3.11"
26 | - name: Install poetry
27 | uses: snok/install-poetry@v1
28 | with:
29 | version: 1.5.1
30 | virtualenvs-create: true
31 | virtualenvs-in-project: true
32 | installer-parallel: true
33 | # ----------------
34 | # Install Deps
35 | # ----------------
36 | - name: Install Dependencies
37 | run: |
38 | poetry install --no-interaction --no-root
39 | poetry self add "poetry-dynamic-versioning[plugin]"
40 | # ----------------
41 | # Build & Publish
42 | # ----------------
43 | - name: Build
44 | run: poetry build
45 | - name: Publish package distributions to PyPI
46 | uses: pypa/gh-action-pypi-publish@release/v1
47 |
--------------------------------------------------------------------------------
/.github/workflows/publish_to_ghcr.yml:
--------------------------------------------------------------------------------
1 | name: Github Packages CD
2 | on:
3 | release:
4 | types: [published]
5 | env:
6 | REGISTRY: ghcr.io
7 | IMAGE_NAME: ${{ github.repository }}
8 | jobs:
9 | build-and-push-image:
10 | name: Build and Push Image
11 | runs-on: ubuntu-latest
12 | permissions:
13 | contents: read
14 | packages: write
15 | steps:
16 | - name: Checkout repository
17 | uses: actions/checkout@v4
18 | - name: Log in to the Container registry
19 | uses: docker/login-action@65b78e6e13532edd9afa3aa52ac7964289d1a9c1
20 | with:
21 | registry: ${{ env.REGISTRY }}
22 | username: ${{ github.actor }}
23 | password: ${{ secrets.GITHUB_TOKEN }}
24 | - name: Extract metadata (tags, labels) for Docker
25 | id: meta
26 | uses: docker/metadata-action@9ec57ed1fcdbf14dcef7dfbe97b2010124a938b7
27 | with:
28 | images: ${{ env.REGISTRY }}/${{ env.IMAGE_NAME }}
29 | - name: Build and push Docker image
30 | uses: docker/build-push-action@f2a1d5e99d037542a71f64918e516c093c6f3fc4
31 | with:
32 | context: .
33 | push: true
34 | tags: ${{ steps.meta.outputs.tags }}
35 | labels: ${{ steps.meta.outputs.labels }}
36 |
--------------------------------------------------------------------------------
/.github/workflows/pytest.yml:
--------------------------------------------------------------------------------
1 | name: pytest CI
2 | on: pull_request
3 | jobs:
4 | pytest:
5 | name: Run pytest and check min coverage threshold (80%)
6 | runs-on: ubuntu-latest
7 | steps:
8 | # ----------------
9 | # Set Up
10 | # ----------------
11 | - name: Checkout
12 | uses: actions/checkout@v4
13 | with:
14 | fetch-depth: 0
15 | - name: Setup Python
16 | uses: actions/setup-python@v5
17 | with:
18 | python-version: "3.11"
19 | - name: Install poetry
20 | uses: snok/install-poetry@v1
21 | with:
22 | version: 1.5.1
23 | virtualenvs-create: true
24 | virtualenvs-in-project: true
25 | installer-parallel: true
26 | # ----------------
27 | # Install Deps
28 | # ----------------
29 | - name: Install Dependencies
30 | run: |
31 | poetry install --no-interaction --no-root
32 | # ----------------
33 | # Run Test
34 | # ----------------
35 | - name: Run pytest
36 | run: poetry run pytest --cov=./ --cov-report=term
37 | - name: Check Coverage
38 | run: poetry run coverage report --fail-under=80
39 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | .DS_Store
2 |
3 | # experiment files
4 | */experiments
5 | */experiment
6 | experiment/*
7 | */archive
8 | */backup
9 | */baseline_results
10 |
11 | # Byte-compiled / optimized / DLL files
12 | __pycache__/
13 | *.py[cod]
14 | *$py.class
15 |
16 | # C extensions
17 | *.so
18 |
19 | # Distribution / packaging
20 | .Python
21 | build/
22 | develop-eggs/
23 | dist/
24 | downloads/
25 | eggs/
26 | .eggs/
27 | lib/
28 | lib64/
29 | parts/
30 | sdist/
31 | var/
32 | wheels/
33 | share/python-wheels/
34 | *.egg-info/
35 | .installed.cfg
36 | *.egg
37 | MANIFEST
38 |
39 | # Jupyter Notebook
40 | .ipynb_checkpoints
41 |
42 | # Environments
43 | .env
44 | .venv
45 | env/
46 | venv/
47 | ENV/
48 | env.bak/
49 | venv.bak/
50 |
51 | # Coverage Report
52 | .coverage
53 | /htmlcov
54 |
--------------------------------------------------------------------------------
/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | ## Contributing
2 |
3 | If you would like to contribute to this project, we recommend following the ["fork-and-pull" Git workflow](https://www.atlassian.com/git/tutorials/comparing-workflows/forking-workflow).
4 |
5 | 1. **Fork** the repo on GitHub
6 | 2. **Clone** the project to your own machine
7 | 3. **Commit** changes to your own branch
8 | 4. **Push** your work back up to your fork
9 | 5. Submit a **Pull request** so that we can review your changes
10 |
11 | NOTE: Be sure to merge the latest from "upstream" before making a pull request!
12 |
13 | ### Set Up Dev Environment
14 |
15 |
16 | 1. Clone Repo
17 |
18 | ```shell
19 | git clone https://github.com/georgian-io/LLM-Finetuning-Toolkit.git
20 | cd LLM-Finetuning-Toolkit/
21 | ```
22 |
23 |
24 |
25 |
26 | 2. Install Dependencies
27 |
28 | Install with Docker [Recommended]
29 |
30 | ```shell
31 | docker build -t llm-toolkit .
32 | ```
33 |
34 | ```shell
35 | # CPU
36 | docker run -it llm-toolkit
37 | # GPU
38 | docker run -it --gpus all llm-toolkit
39 | ```
40 |
41 |
42 |
43 |
44 | Poetry (recommended)
45 |
46 | See poetry documentation page for poetry [installation instructions](https://python-poetry.org/docs/#installation)
47 |
48 | ```shell
49 | poetry install
50 | ```
51 |
52 |
53 |
54 | pip
55 | We recommend using a virtual environment like `venv` or `conda` for installation
56 |
57 | ```shell
58 | pip install -e .
59 | ```
60 |
61 |
62 |
63 |
64 | ### Checklist Before Pull Request (Optional)
65 |
66 | 1. Use `ruff check --fix` to check and fix lint errors
67 | 2. Use `ruff format` to apply formatting
68 | 3. Run `pytest` at the top level directory to run unit tests
69 |
70 | NOTE: Ruff linting and formatting checks are done when PR is raised via Git Action. Before raising a PR, it is a good practice to check and fix lint errors, as well as apply formatting.
71 |
72 | ### Releasing
73 |
74 | To manually release a PyPI package, please run:
75 |
76 | ```shell
77 | make build-release
78 | ```
79 |
80 | Note: Make sure you have a pypi token for this [PyPI repo](https://pypi.org/project/llm-toolkit/).
81 |
--------------------------------------------------------------------------------
/Dockerfile:
--------------------------------------------------------------------------------
1 | FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu20.04
2 | RUN apt-get update && \
3 | DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends git curl software-properties-common && \
4 | add-apt-repository ppa:deadsnakes/ppa && apt-get update && apt install -y python3.10 python3.10-distutils && \
5 | curl -sS https://bootstrap.pypa.io/get-pip.py | python3.10
6 |
7 |
8 | RUN update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.8 1 && \
9 | update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.10 2 && \
10 | update-alternatives --auto python3
11 |
12 | RUN export CUDA_HOME=/usr/local/cuda/
13 |
14 | COPY . /home/llm-finetuning-hub
15 | WORKDIR /home/llm-finetuning-hub
16 | RUN pip3 install --no-cache-dir -r ./requirements.txt
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 |
179 | Copyright 2024 Georgian Partners
180 |
181 | Licensed under the Apache License, Version 2.0 (the "License");
182 | you may not use this file except in compliance with the License.
183 | You may obtain a copy of the License at
184 |
185 | http://www.apache.org/licenses/LICENSE-2.0
186 |
187 | Unless required by applicable law or agreed to in writing, software
188 | distributed under the License is distributed on an "AS IS" BASIS,
189 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
190 | See the License for the specific language governing permissions and
191 | limitations under the License.
192 |
--------------------------------------------------------------------------------
/Makefile:
--------------------------------------------------------------------------------
1 | test-coverage:
2 | pytest --cov=llmtune tests/
3 |
4 | fix-format:
5 | ruff check --fix
6 | ruff format
7 |
8 | build-release:
9 | rm -rf dist
10 | rm -rf build
11 | poetry build
12 | poetry publish
13 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # LLM Finetuning Toolkit
2 |
3 |
4 |  5 |
5 |
6 |
7 | ## Overview
8 |
9 | LLM Finetuning toolkit is a config-based CLI tool for launching a series of LLM fine-tuning experiments on your data and gathering their results. From one single `yaml` config file, control all elements of a typical experimentation pipeline - **prompts**, **open-source LLMs**, **optimization strategy** and **LLM testing**.
10 |
11 |
12 | 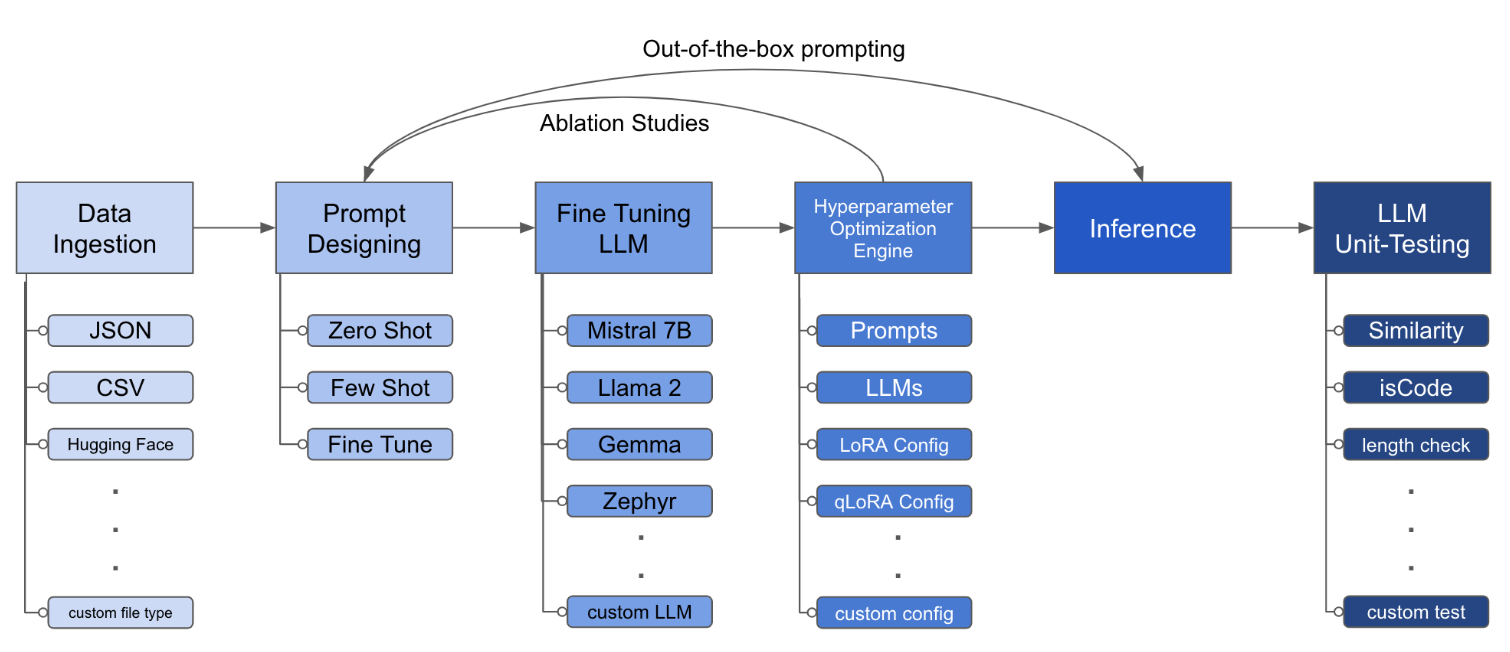 13 |
13 |
14 |
15 | ## Installation
16 |
17 | ### [pipx](https://pipx.pypa.io/stable/) (recommended)
18 |
19 | [pipx](https://pipx.pypa.io/stable/) installs the package and dependencies in a separate virtual environment
20 |
21 | ```shell
22 | pipx install llm-toolkit
23 | ```
24 |
25 | ### pip
26 |
27 | ```shell
28 | pip install llm-toolkit
29 | ```
30 |
31 | ## Quick Start
32 |
33 | This guide contains 3 stages that will enable you to get the most out of this toolkit!
34 |
35 | - **Basic**: Run your first LLM fine-tuning experiment
36 | - **Intermediate**: Run a custom experiment by changing the components of the YAML configuration file
37 | - **Advanced**: Launch series of fine-tuning experiments across different prompt templates, LLMs, optimization techniques -- all through **one** YAML configuration file
38 |
39 | ### Basic
40 |
41 | ```shell
42 | llmtune generate config
43 | llmtune run ./config.yml
44 | ```
45 |
46 | The first command generates a helpful starter `config.yml` file and saves in the current working directory. This is provided to users to quickly get started and as a base for further modification.
47 |
48 | Then the second command initiates the fine-tuning process using the settings specified in the default YAML configuration file `config.yaml`.
49 |
50 | ### Intermediate
51 |
52 | The configuration file is the central piece that defines the behavior of the toolkit. It is written in YAML format and consists of several sections that control different aspects of the process, such as data ingestion, model definition, training, inference, and quality assurance. We highlight some of the critical sections.
53 |
54 | #### Flash Attention 2
55 |
56 | To enable Flash-attention for [supported models](https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-2). First install `flash-attn`:
57 |
58 | **pipx**
59 |
60 | ```shell
61 | pipx inject llm-toolkit flash-attn --pip-args=--no-build-isolation
62 | ```
63 |
64 | **pip**
65 |
66 | ```
67 | pip install flash-attn --no-build-isolation
68 | ```
69 |
70 | Then, add to config file.
71 |
72 | ```yaml
73 | model:
74 | torch_dtype: "bfloat16" # or "float16" if using older GPU
75 | attn_implementation: "flash_attention_2"
76 | ```
77 |
78 | #### Data Ingestion
79 |
80 | An example of what the data ingestion may look like:
81 |
82 | ```yaml
83 | data:
84 | file_type: "huggingface"
85 | path: "yahma/alpaca-cleaned"
86 | prompt:
87 | ### Instruction: {instruction}
88 | ### Input: {input}
89 | ### Output:
90 | prompt_stub: { output }
91 | test_size: 0.1 # Proportion of test as % of total; if integer then # of samples
92 | train_size: 0.9 # Proportion of train as % of total; if integer then # of samples
93 | train_test_split_seed: 42
94 | ```
95 |
96 | - While the above example illustrates using a public dataset from Hugging Face, the config file can also ingest your own data.
97 |
98 | ```yaml
99 | file_type: "json"
100 | path: "
101 | ```
102 |
103 | ```yaml
104 | file_type: "csv"
105 | path: "
106 | ```
107 |
108 | - The prompt fields help create instructions to fine-tune the LLM on. It reads data from specific columns, mentioned in {} brackets, that are present in your dataset. In the example provided, it is expected for the data file to have column names: `instruction`, `input` and `output`.
109 |
110 | - The prompt fields use both `prompt` and `prompt_stub` during fine-tuning. However, during testing, **only** the `prompt` section is used as input to the fine-tuned LLM.
111 |
112 | #### LLM Definition
113 |
114 | ```yaml
115 | model:
116 | hf_model_ckpt: "NousResearch/Llama-2-7b-hf"
117 | quantize: true
118 | bitsandbytes:
119 | load_in_4bit: true
120 | bnb_4bit_compute_dtype: "bf16"
121 | bnb_4bit_quant_type: "nf4"
122 |
123 | # LoRA Params -------------------
124 | lora:
125 | task_type: "CAUSAL_LM"
126 | r: 32
127 | lora_dropout: 0.1
128 | target_modules:
129 | - q_proj
130 | - v_proj
131 | - k_proj
132 | - o_proj
133 | - up_proj
134 | - down_proj
135 | - gate_proj
136 | ```
137 |
138 | - While the above example showcases using Llama2 7B, in theory, any open-source LLM supported by Hugging Face can be used in this toolkit.
139 |
140 | ```yaml
141 | hf_model_ckpt: "mistralai/Mistral-7B-v0.1"
142 | ```
143 |
144 | ```yaml
145 | hf_model_ckpt: "tiiuae/falcon-7b"
146 | ```
147 |
148 | - The parameters for LoRA, such as the rank `r` and dropout, can be altered.
149 |
150 | ```yaml
151 | lora:
152 | r: 64
153 | lora_dropout: 0.25
154 | ```
155 |
156 | #### Quality Assurance
157 |
158 | ```yaml
159 | qa:
160 | llm_metrics:
161 | - length_test
162 | - word_overlap_test
163 | ```
164 |
165 | - To ensure that the fine-tuned LLM behaves as expected, you can add tests that check if the desired behaviour is being attained. Example: for an LLM fine-tuned for a summarization task, we may want to check if the generated summary is indeed smaller in length than the input text. We would also like to learn the overlap between words in the original text and generated summary.
166 |
167 | #### Artifact Outputs
168 |
169 | This config will run fine-tuning and save the results under directory `./experiment/[unique_hash]`. Each unique configuration will generate a unique hash, so that our tool can automatically pick up where it left off. For example, if you need to exit in the middle of the training, by relaunching the script, the program will automatically load the existing dataset that has been generated under the directory, instead of doing it all over again.
170 |
171 | After the script finishes running you will see these distinct artifacts:
172 |
173 | ```shell
174 | /dataset # generated pkl file in hf datasets format
175 | /model # peft model weights in hf format
176 | /results # csv of prompt, ground truth, and predicted values
177 | /qa # csv of test results: e.g. vector similarity between ground truth and prediction
178 | ```
179 |
180 | Once all the changes have been incorporated in the YAML file, you can simply use it to run a custom fine-tuning experiment!
181 |
182 | ```shell
183 | python toolkit.py --config-path
184 | ```
185 |
186 | ### Advanced
187 |
188 | Fine-tuning workflows typically involve running ablation studies across various LLMs, prompt designs and optimization techniques. The configuration file can be altered to support running ablation studies.
189 |
190 | - Specify different prompt templates to experiment with while fine-tuning.
191 |
192 | ```yaml
193 | data:
194 | file_type: "huggingface"
195 | path: "yahma/alpaca-cleaned"
196 | prompt:
197 | - >-
198 | This is the first prompt template to iterate over
199 | ### Input: {input}
200 | ### Output:
201 | - >-
202 | This is the second prompt template
203 | ### Instruction: {instruction}
204 | ### Input: {input}
205 | ### Output:
206 | prompt_stub: { output }
207 | test_size: 0.1 # Proportion of test as % of total; if integer then # of samples
208 | train_size: 0.9 # Proportion of train as % of total; if integer then # of samples
209 | train_test_split_seed: 42
210 | ```
211 |
212 | - Specify various LLMs that you would like to experiment with.
213 |
214 | ```yaml
215 | model:
216 | hf_model_ckpt:
217 | [
218 | "NousResearch/Llama-2-7b-hf",
219 | mistralai/Mistral-7B-v0.1",
220 | "tiiuae/falcon-7b",
221 | ]
222 | quantize: true
223 | bitsandbytes:
224 | load_in_4bit: true
225 | bnb_4bit_compute_dtype: "bf16"
226 | bnb_4bit_quant_type: "nf4"
227 | ```
228 |
229 | - Specify different configurations of LoRA that you would like to ablate over.
230 |
231 | ```yaml
232 | lora:
233 | r: [16, 32, 64]
234 | lora_dropout: [0.25, 0.50]
235 | ```
236 |
237 | ## Extending
238 |
239 | The toolkit provides a modular and extensible architecture that allows developers to customize and enhance its functionality to suit their specific needs. Each component of the toolkit, such as data ingestion, fine-tuning, inference, and quality assurance testing, is designed to be easily extendable.
240 |
241 | ## Contributing
242 |
243 | Open-source contributions to this toolkit are welcome and encouraged.
244 | If you would like to contribute, please see [CONTRIBUTING.md](CONTRIBUTING.md).
245 |
--------------------------------------------------------------------------------
/assets/bert.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/bert.gif
--------------------------------------------------------------------------------
/assets/glass-gif.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/glass-gif.gif
--------------------------------------------------------------------------------
/assets/inference.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/inference.gif
--------------------------------------------------------------------------------
/assets/llama_images/llama-13b-class.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/llama_images/llama-13b-class.png
--------------------------------------------------------------------------------
/assets/llama_images/llama-13b-summ.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/llama_images/llama-13b-summ.png
--------------------------------------------------------------------------------
/assets/llama_images/llama-7b-class.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/llama_images/llama-7b-class.png
--------------------------------------------------------------------------------
/assets/llama_images/llama-7b-summ.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/llama_images/llama-7b-summ.png
--------------------------------------------------------------------------------
/assets/money.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/money.gif
--------------------------------------------------------------------------------
/assets/overview_diagram.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/overview_diagram.png
--------------------------------------------------------------------------------
/assets/progress.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/progress.gif
--------------------------------------------------------------------------------
/assets/readme_images/redpajama_results/RedPajama-3B Classification.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/readme_images/redpajama_results/RedPajama-3B Classification.png
--------------------------------------------------------------------------------
/assets/readme_images/redpajama_results/RedPajama-3B Summarization.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/readme_images/redpajama_results/RedPajama-3B Summarization.png
--------------------------------------------------------------------------------
/assets/readme_images/redpajama_results/RedPajama-7B Classification.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/readme_images/redpajama_results/RedPajama-7B Classification.png
--------------------------------------------------------------------------------
/assets/readme_images/redpajama_results/RedPajama-7B Summarization.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/readme_images/redpajama_results/RedPajama-7B Summarization.png
--------------------------------------------------------------------------------
/assets/repo-main.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/repo-main.png
--------------------------------------------------------------------------------
/assets/rocket.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/rocket.gif
--------------------------------------------------------------------------------
/assets/time.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/time.gif
--------------------------------------------------------------------------------
/assets/toolkit-animation.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/assets/toolkit-animation.gif
--------------------------------------------------------------------------------
/examples/ablation_config.yml:
--------------------------------------------------------------------------------
1 | save_dir: "./experiment/"
2 |
3 | ablation:
4 | use_ablate: false
5 |
6 | # Data Ingestion -------------------
7 | data:
8 | file_type: "huggingface" # one of 'json', 'csv', 'huggingface'
9 | path: "yahma/alpaca-cleaned"
10 | prompt:
11 | >- # prompt, make sure column inputs are enclosed in {} brackets and that they match your data
12 | Below is an instruction that describes a task.
13 | Write a response that appropriately completes the request.
14 | ### Instruction: {instruction}
15 | ### Input: {input}
16 | ### Output:
17 | prompt_stub:
18 | >- # Stub to add for training at the end of prompt, for test set or inference, this is omitted; make sure only one variable is present
19 | {output}
20 | test_size: 0.1 # Proportion of test as % of total; if integer then # of samples
21 | train_size: 0.9 # Proportion of train as % of total; if integer then # of samples
22 | train_test_split_seed: 42
23 |
24 | # Model Definition -------------------
25 | model:
26 | hf_model_ckpt: ["NousResearch/Llama-2-7b-hf", "mistralai/Mistral-7B-v0.1"]
27 | quantize: true
28 | bitsandbytes:
29 | load_in_4bit: true
30 | bnb_4bit_compute_dtype: "bfloat16"
31 | bnb_4bit_quant_type: "nf4"
32 |
33 | # LoRA Params -------------------
34 | lora:
35 | task_type: "CAUSAL_LM"
36 | r: [16, 32, 64]
37 | lora_dropout: [0.1, 0.25]
38 | target_modules:
39 | - q_proj
40 | - v_proj
41 | - k_proj
42 | - o_proj
43 | - up_proj
44 | - down_proj
45 | - gate_proj
46 |
47 | # Training -------------------
48 | training:
49 | training_args:
50 | num_train_epochs: 5
51 | per_device_train_batch_size: 4
52 | gradient_accumulation_steps: 4
53 | gradient_checkpointing: True
54 | optim: "paged_adamw_32bit"
55 | logging_steps: 100
56 | learning_rate: 2.0e-4
57 | bf16: true # Set to true for mixed precision training on Newer GPUs
58 | tf32: true
59 | # fp16: false # Set to true for mixed precision training on Older GPUs
60 | max_grad_norm: 0.3
61 | warmup_ratio: 0.03
62 | lr_scheduler_type: "constant"
63 | sft_args:
64 | max_seq_length: 5000
65 | # neftune_noise_alpha: None
66 |
67 | inference:
68 | max_new_tokens: 1024
69 | use_cache: True
70 | do_sample: True
71 | top_p: 0.9
72 | temperature: 0.8
73 |
--------------------------------------------------------------------------------
/examples/config.yml:
--------------------------------------------------------------------------------
1 | save_dir: "./experiment/"
2 |
3 | ablation:
4 | use_ablate: false
5 |
6 | # Data Ingestion -------------------
7 | data:
8 | file_type: "huggingface" # one of 'json', 'csv', 'huggingface'
9 | path: "yahma/alpaca-cleaned"
10 | prompt:
11 | >- # prompt, make sure column inputs are enclosed in {} brackets and that they match your data
12 | Below is an instruction that describes a task.
13 | Write a response that appropriately completes the request.
14 | ### Instruction: {instruction}
15 | ### Input: {input}
16 | ### Output:
17 | prompt_stub:
18 | >- # Stub to add for training at the end of prompt, for test set or inference, this is omitted; make sure only one variable is present
19 | {output}
20 | test_size: 0.1 # Proportion of test as % of total; if integer then # of samples
21 | train_size: 0.9 # Proportion of train as % of total; if integer then # of samples
22 | train_test_split_seed: 42
23 |
24 | # Model Definition -------------------
25 | model:
26 | hf_model_ckpt: "NousResearch/Llama-2-7b-hf"
27 | quantize: true
28 | bitsandbytes:
29 | load_in_4bit: true
30 | bnb_4bit_compute_dtype: "bfloat16"
31 | bnb_4bit_quant_type: "nf4"
32 |
33 | # LoRA Params -------------------
34 | lora:
35 | task_type: "CAUSAL_LM"
36 | r: 32
37 | lora_dropout: 0.1
38 | target_modules:
39 | - q_proj
40 | - v_proj
41 | - k_proj
42 | - o_proj
43 | - up_proj
44 | - down_proj
45 | - gate_proj
46 |
47 | # Training -------------------
48 | training:
49 | training_args:
50 | num_train_epochs: 5
51 | per_device_train_batch_size: 4
52 | gradient_accumulation_steps: 4
53 | gradient_checkpointing: True
54 | optim: "paged_adamw_32bit"
55 | logging_steps: 100
56 | learning_rate: 2.0e-4
57 | bf16: true # Set to true for mixed precision training on Newer GPUs
58 | tf32: true
59 | # fp16: false # Set to true for mixed precision training on Older GPUs
60 | max_grad_norm: 0.3
61 | warmup_ratio: 0.03
62 | lr_scheduler_type: "constant"
63 | sft_args:
64 | max_seq_length: 5000
65 | # neftune_noise_alpha: None
66 |
67 | inference:
68 | max_new_tokens: 1024
69 | use_cache: True
70 | do_sample: True
71 | top_p: 0.9
72 | temperature: 0.8
--------------------------------------------------------------------------------
/examples/llama2_config.yml:
--------------------------------------------------------------------------------
1 | save_dir: "./experiment/"
2 |
3 | ablation:
4 | use_ablate: false
5 |
6 | # Data Ingestion -------------------
7 | data:
8 | file_type: "huggingface" # one of 'json', 'csv', 'huggingface'
9 | path: "yahma/alpaca-cleaned"
10 | prompt:
11 | >- # prompt, make sure column inputs are enclosed in {} brackets and that they match your data
12 | Below is an instruction that describes a task.
13 | Write a response that appropriately completes the request.
14 | ### Instruction: {instruction}
15 | ### Input: {input}
16 | ### Output:
17 | prompt_stub:
18 | >- # Stub to add for training at the end of prompt, for test set or inference, this is omitted; make sure only one variable is present
19 | {output}
20 | test_size: 0.1 # Proportion of test as % of total; if integer then # of samples
21 | train_size: 0.9 # Proportion of train as % of total; if integer then # of samples
22 | train_test_split_seed: 42
23 |
24 | # Model Definition -------------------
25 | model:
26 | hf_model_ckpt: "NousResearch/Llama-2-7b-hf"
27 | quantize: true
28 | bitsandbytes:
29 | load_in_4bit: true
30 | bnb_4bit_compute_dtype: "bfloat16"
31 | bnb_4bit_quant_type: "nf4"
32 |
33 | # LoRA Params -------------------
34 | lora:
35 | task_type: "CAUSAL_LM"
36 | r: 32
37 | lora_dropout: 0.1
38 | target_modules:
39 | - q_proj
40 | - v_proj
41 | - k_proj
42 | - o_proj
43 | - up_proj
44 | - down_proj
45 | - gate_proj
46 |
47 | # Training -------------------
48 | training:
49 | training_args:
50 | num_train_epochs: 5
51 | per_device_train_batch_size: 4
52 | gradient_accumulation_steps: 4
53 | gradient_checkpointing: True
54 | optim: "paged_adamw_32bit"
55 | logging_steps: 100
56 | learning_rate: 2.0e-4
57 | bf16: true # Set to true for mixed precision training on Newer GPUs
58 | tf32: true
59 | # fp16: false # Set to true for mixed precision training on Older GPUs
60 | max_grad_norm: 0.3
61 | warmup_ratio: 0.03
62 | lr_scheduler_type: "constant"
63 | sft_args:
64 | max_seq_length: 5000
65 | # neftune_noise_alpha: None
66 |
67 | inference:
68 | max_new_tokens: 1024
69 | use_cache: True
70 | do_sample: True
71 | top_p: 0.9
72 | temperature: 0.8
73 |
--------------------------------------------------------------------------------
/examples/mistral_config.yml:
--------------------------------------------------------------------------------
1 | save_dir: "./experiment/"
2 |
3 | ablation:
4 | use_ablate: false
5 |
6 | # Data Ingestion -------------------
7 | data:
8 | file_type: "huggingface" # one of 'json', 'csv', 'huggingface'
9 | path: "yahma/alpaca-cleaned"
10 | prompt:
11 | >- # prompt, make sure column inputs are enclosed in {} brackets and that they match your data
12 | Below is an instruction that describes a task.
13 | Write a response that appropriately completes the request.
14 | ### Instruction: {instruction}
15 | ### Input: {input}
16 | ### Output:
17 | prompt_stub:
18 | >- # Stub to add for training at the end of prompt, for test set or inference, this is omitted; make sure only one variable is present
19 | {output}
20 | test_size: 0.1 # Proportion of test as % of total; if integer then # of samples
21 | train_size: 0.9 # Proportion of train as % of total; if integer then # of samples
22 | train_test_split_seed: 42
23 |
24 | # Model Definition -------------------
25 | model:
26 | hf_model_ckpt: "mistralai/Mistral-7B-v0.1"
27 | quantize: true
28 | bitsandbytes:
29 | load_in_4bit: true
30 | bnb_4bit_compute_dtype: "bfloat16"
31 | bnb_4bit_quant_type: "nf4"
32 |
33 | # LoRA Params -------------------
34 | lora:
35 | task_type: "CAUSAL_LM"
36 | r: 32
37 | lora_dropout: 0.1
38 | target_modules:
39 | - q_proj
40 | - v_proj
41 | - k_proj
42 | - o_proj
43 | - up_proj
44 | - down_proj
45 | - gate_proj
46 |
47 | # Training -------------------
48 | training:
49 | training_args:
50 | num_train_epochs: 5
51 | per_device_train_batch_size: 4
52 | gradient_accumulation_steps: 4
53 | gradient_checkpointing: True
54 | optim: "paged_adamw_32bit"
55 | logging_steps: 100
56 | learning_rate: 2.0e-4
57 | bf16: true # Set to true for mixed precision training on Newer GPUs
58 | tf32: true
59 | # fp16: false # Set to true for mixed precision training on Older GPUs
60 | max_grad_norm: 0.3
61 | warmup_ratio: 0.03
62 | lr_scheduler_type: "constant"
63 | sft_args:
64 | max_seq_length: 5000
65 | # neftune_noise_alpha: None
66 |
67 | inference:
68 | max_new_tokens: 1024
69 | use_cache: True
70 | do_sample: True
71 | top_p: 0.9
72 | temperature: 0.8
73 |
--------------------------------------------------------------------------------
/examples/test_suite/dot_product_tests.csv:
--------------------------------------------------------------------------------
1 | "Test Type","prompt","ground_truth","threshold"
2 | "cosine_similarity","Output “the dog is brown”, word for word:","the dog is brown",0.95
3 | "cosine_similarity","You are a customer service chatbot, offering polite responses to customer questions. The company has a 30 day cancellation policy. Answer the following customer question. Question: “How long is the cancellation policy? Answer: ","30 days",0.2
4 |
--------------------------------------------------------------------------------
/examples/test_suite/json_validity_tests.csv:
--------------------------------------------------------------------------------
1 | "Test Type","prompt"
2 | "json_valid","Hi my name is John. My age is 30 and I have blue eyes. Here is the same data in json format: "
3 | "json_valid","Here is an example of a simple json object: "
4 |
--------------------------------------------------------------------------------
/llama2/baseline_inference.sh:
--------------------------------------------------------------------------------
1 | python llama2_baseline_inference.py --task_type classification --prompt_type zero-shot & wait
2 | python llama2_baseline_inference.py --task_type classification --prompt_type few-shot & wait
3 | python llama2_baseline_inference.py --task_type summarization --prompt_type zero-shot & wait
4 | python llama2_baseline_inference.py --task_type summarization --prompt_type few-shot
5 |
--------------------------------------------------------------------------------
/llama2/llama2_baseline_inference.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | import evaluate
4 | import warnings
5 | import json
6 | import pandas as pd
7 | import pickle
8 | import torch
9 | import time
10 |
11 | from datasets import load_dataset
12 | from prompts import (
13 | ZERO_SHOT_CLASSIFIER_PROMPT,
14 | FEW_SHOT_CLASSIFIER_PROMPT,
15 | ZERO_SHOT_SUMMARIZATION_PROMPT,
16 | FEW_SHOT_SUMMARIZATION_PROMPT,
17 | get_newsgroup_data,
18 | get_samsum_data,
19 | )
20 | from transformers import (
21 | AutoTokenizer,
22 | AutoModelForCausalLM,
23 | BitsAndBytesConfig,
24 | )
25 | from sklearn.metrics import (
26 | accuracy_score,
27 | f1_score,
28 | precision_score,
29 | recall_score,
30 | )
31 |
32 | metric = evaluate.load("rouge")
33 | warnings.filterwarnings("ignore")
34 |
35 |
36 | def compute_metrics_decoded(decoded_labs, decoded_preds, args):
37 | if args.task_type == "summarization":
38 | rouge = metric.compute(
39 | predictions=decoded_preds, references=decoded_labs, use_stemmer=True
40 | )
41 | metrics = {metric: round(rouge[metric] * 100.0, 3) for metric in rouge.keys()}
42 |
43 | elif args.task_type == "classification":
44 | metrics = {
45 | "micro_f1": f1_score(decoded_labs, decoded_preds, average="micro"),
46 | "macro_f1": f1_score(decoded_labs, decoded_preds, average="macro"),
47 | "precision": precision_score(decoded_labs, decoded_preds, average="micro"),
48 | "recall": recall_score(decoded_labs, decoded_preds, average="micro"),
49 | "accuracy": accuracy_score(decoded_labs, decoded_preds),
50 | }
51 |
52 | return metrics
53 |
54 |
55 | def main(args):
56 | # replace attention with flash attention
57 | if torch.cuda.get_device_capability()[0] >= 8:
58 | from llama_patch import replace_attn_with_flash_attn
59 |
60 | print("Using flash attention")
61 | replace_attn_with_flash_attn()
62 | use_flash_attention = True
63 |
64 | save_dir = os.path.join(
65 | "baseline_results", args.pretrained_ckpt, args.task_type, args.prompt_type
66 | )
67 | if not os.path.exists(save_dir):
68 | os.makedirs(save_dir)
69 |
70 | if args.task_type == "classification":
71 | dataset = load_dataset("rungalileo/20_Newsgroups_Fixed")
72 | test_dataset = dataset["test"]
73 | test_data, test_labels = test_dataset["text"], test_dataset["label"]
74 |
75 | newsgroup_classes, few_shot_samples, _ = get_newsgroup_data()
76 |
77 | elif args.task_type == "summarization":
78 | dataset = load_dataset("samsum")
79 | test_dataset = dataset["test"]
80 | test_data, test_labels = test_dataset["dialogue"], test_dataset["summary"]
81 |
82 | few_shot_samples = get_samsum_data()
83 |
84 | if args.prompt_type == "zero-shot":
85 | if args.task_type == "classification":
86 | prompt = ZERO_SHOT_CLASSIFIER_PROMPT
87 | elif args.task_type == "summarization":
88 | prompt = ZERO_SHOT_SUMMARIZATION_PROMPT
89 |
90 | elif args.prompt_type == "few-shot":
91 | if args.task_type == "classification":
92 | prompt = FEW_SHOT_CLASSIFIER_PROMPT
93 | elif args.task_type == "summarization":
94 | prompt = FEW_SHOT_SUMMARIZATION_PROMPT
95 |
96 | # BitsAndBytesConfig int-4 config
97 | bnb_config = BitsAndBytesConfig(
98 | load_in_4bit=True,
99 | bnb_4bit_use_double_quant=True,
100 | bnb_4bit_quant_type="nf4",
101 | bnb_4bit_compute_dtype=torch.bfloat16,
102 | )
103 |
104 | # Load model and tokenizer
105 | model = AutoModelForCausalLM.from_pretrained(
106 | args.pretrained_ckpt,
107 | quantization_config=bnb_config,
108 | use_cache=False,
109 | device_map="auto",
110 | )
111 | model.config.pretraining_tp = 1
112 |
113 | if use_flash_attention:
114 | from llama_patch import forward
115 |
116 | assert (
117 | model.model.layers[0].self_attn.forward.__doc__ == forward.__doc__
118 | ), "Model is not using flash attention"
119 |
120 | tokenizer = AutoTokenizer.from_pretrained(args.pretrained_ckpt)
121 | tokenizer.pad_token = tokenizer.eos_token
122 | tokenizer.padding_side = "right"
123 |
124 | results = []
125 | good_data, good_labels = [], []
126 | ctr = 0
127 | # for instruct, label in zip(instructions, labels):
128 | for data, label in zip(test_data, test_labels):
129 | if not isinstance(data, str):
130 | continue
131 | if not isinstance(label, str):
132 | continue
133 |
134 | # example = instruct[:-len(label)] # remove the answer from the example
135 | if args.prompt_type == "zero-shot":
136 | if args.task_type == "classification":
137 | example = prompt.format(
138 | newsgroup_classes=newsgroup_classes,
139 | sentence=data,
140 | )
141 | elif args.task_type == "summarization":
142 | example = prompt.format(
143 | dialogue=data,
144 | )
145 |
146 | elif args.prompt_type == "few-shot":
147 | if args.task_type == "classification":
148 | example = prompt.format(
149 | newsgroup_classes=newsgroup_classes,
150 | few_shot_samples=few_shot_samples,
151 | sentence=data,
152 | )
153 | elif args.task_type == "summarization":
154 | example = prompt.format(
155 | few_shot_samples=few_shot_samples,
156 | dialogue=data,
157 | )
158 |
159 | input_ids = tokenizer(
160 | example, return_tensors="pt", truncation=True
161 | ).input_ids.cuda()
162 |
163 | with torch.inference_mode():
164 | outputs = model.generate(
165 | input_ids=input_ids,
166 | max_new_tokens=20 if args.task_type == "classification" else 50,
167 | do_sample=True,
168 | top_p=0.95,
169 | temperature=1e-3,
170 | )
171 | result = tokenizer.batch_decode(
172 | outputs.detach().cpu().numpy(), skip_special_tokens=True
173 | )[0]
174 |
175 | # Extract the generated text, and do basic processing
176 | result = result[len(example) :].replace("\n", "").lstrip().rstrip()
177 | results.append(result)
178 | good_labels.append(label)
179 | good_data.append(data)
180 |
181 | print(f"Example {ctr}/{len(test_data)} | GT: {label} | Pred: {result}")
182 | ctr += 1
183 |
184 | metrics = compute_metrics_decoded(good_labels, results, args)
185 | print(metrics)
186 | metrics["predictions"] = results
187 | metrics["labels"] = good_labels
188 | metrics["data"] = good_data
189 |
190 | with open(os.path.join(save_dir, "metrics.pkl"), "wb") as handle:
191 | pickle.dump(metrics, handle)
192 |
193 | print(f"Completed experiment {save_dir}")
194 | print("----------------------------------------")
195 |
196 |
197 | if __name__ == "__main__":
198 | parser = argparse.ArgumentParser()
199 | parser.add_argument("--pretrained_ckpt", default="NousResearch/Llama-2-7b-hf")
200 | parser.add_argument("--prompt_type", default="zero-shot")
201 | parser.add_argument("--task_type", default="classification")
202 | args = parser.parse_args()
203 |
204 | main(args)
205 |
--------------------------------------------------------------------------------
/llama2/llama2_classification.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import torch
3 | import os
4 | import numpy as np
5 | import pandas as pd
6 | import pickle
7 |
8 |
9 | from peft import (
10 | LoraConfig,
11 | prepare_model_for_kbit_training,
12 | get_peft_model,
13 | )
14 | from transformers import (
15 | AutoTokenizer,
16 | AutoModelForCausalLM,
17 | BitsAndBytesConfig,
18 | TrainingArguments,
19 | )
20 | from trl import SFTTrainer
21 |
22 | from prompts import get_newsgroup_data_for_ft
23 |
24 |
25 | def main(args):
26 | train_dataset, test_dataset = get_newsgroup_data_for_ft(
27 | mode="train", train_sample_fraction=args.train_sample_fraction
28 | )
29 | print(f"Sample fraction:{args.train_sample_fraction}")
30 | print(f"Training samples:{train_dataset.shape}")
31 |
32 | # BitsAndBytesConfig int-4 config
33 | bnb_config = BitsAndBytesConfig(
34 | load_in_4bit=True,
35 | bnb_4bit_use_double_quant=True,
36 | bnb_4bit_quant_type="nf4",
37 | bnb_4bit_compute_dtype=torch.bfloat16,
38 | )
39 |
40 | # Load model and tokenizer
41 | model = AutoModelForCausalLM.from_pretrained(
42 | args.pretrained_ckpt,
43 | quantization_config=bnb_config,
44 | use_cache=False,
45 | device_map="auto",
46 | )
47 | model.config.pretraining_tp = 1
48 |
49 | tokenizer = AutoTokenizer.from_pretrained(args.pretrained_ckpt)
50 | tokenizer.pad_token = tokenizer.eos_token
51 | tokenizer.padding_side = "right"
52 |
53 | # LoRA config based on QLoRA paper
54 | peft_config = LoraConfig(
55 | lora_alpha=16,
56 | lora_dropout=args.dropout,
57 | r=args.lora_r,
58 | bias="none",
59 | task_type="CAUSAL_LM",
60 | )
61 |
62 | # prepare model for training
63 | model = prepare_model_for_kbit_training(model)
64 | model = get_peft_model(model, peft_config)
65 |
66 | results_dir = f"experiments/classification-sampleFraction-{args.train_sample_fraction}_epochs-{args.epochs}_rank-{args.lora_r}_dropout-{args.dropout}"
67 |
68 | training_args = TrainingArguments(
69 | output_dir=results_dir,
70 | logging_dir=f"{results_dir}/logs",
71 | num_train_epochs=args.epochs,
72 | per_device_train_batch_size=6 if use_flash_attention else 4,
73 | gradient_accumulation_steps=2,
74 | gradient_checkpointing=True,
75 | optim="paged_adamw_32bit",
76 | logging_steps=100,
77 | learning_rate=2e-4,
78 | bf16=True,
79 | tf32=True,
80 | max_grad_norm=0.3,
81 | warmup_ratio=0.03,
82 | lr_scheduler_type="constant",
83 | report_to="none",
84 | # disable_tqdm=True # disable tqdm since with packing values are in correct
85 | )
86 |
87 | max_seq_length = 512 # max sequence length for model and packing of the dataset
88 |
89 | trainer = SFTTrainer(
90 | model=model,
91 | train_dataset=train_dataset,
92 | peft_config=peft_config,
93 | max_seq_length=max_seq_length,
94 | tokenizer=tokenizer,
95 | packing=True,
96 | args=training_args,
97 | dataset_text_field="instructions",
98 | )
99 |
100 | trainer_stats = trainer.train()
101 | train_loss = trainer_stats.training_loss
102 | print(f"Training loss:{train_loss}")
103 |
104 | peft_model_id = f"{results_dir}/assets"
105 | trainer.model.save_pretrained(peft_model_id)
106 | tokenizer.save_pretrained(peft_model_id)
107 |
108 | with open(f"{results_dir}/results.pkl", "wb") as handle:
109 | run_result = [
110 | args.epochs,
111 | args.lora_r,
112 | args.dropout,
113 | train_loss,
114 | ]
115 | pickle.dump(run_result, handle)
116 | print("Experiment over")
117 |
118 |
119 | if __name__ == "__main__":
120 | parser = argparse.ArgumentParser()
121 | parser.add_argument("--pretrained_ckpt", default="NousResearch/Llama-2-7b-hf")
122 | parser.add_argument("--lora_r", default=8, type=int)
123 | parser.add_argument("--epochs", default=5, type=int)
124 | parser.add_argument("--dropout", default=0.1, type=float)
125 | parser.add_argument("--train_sample_fraction", default=0.99, type=float)
126 |
127 | args = parser.parse_args()
128 | main(args)
129 |
--------------------------------------------------------------------------------
/llama2/llama2_classification_inference.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import torch
3 | import os
4 | import pandas as pd
5 | import evaluate
6 | import pickle
7 | import warnings
8 | from tqdm import tqdm
9 |
10 | from llama_patch import unplace_flash_attn_with_attn
11 | from peft import AutoPeftModelForCausalLM
12 | from transformers import AutoTokenizer
13 | from sklearn.metrics import (
14 | accuracy_score,
15 | f1_score,
16 | precision_score,
17 | recall_score,
18 | )
19 |
20 | from prompts import get_newsgroup_data_for_ft
21 |
22 | metric = evaluate.load("rouge")
23 | warnings.filterwarnings("ignore")
24 |
25 |
26 | def main(args):
27 | _, test_dataset = get_newsgroup_data_for_ft(mode="inference")
28 |
29 | experiment = args.experiment_dir
30 | peft_model_id = f"{experiment}/assets"
31 |
32 | # unpatch flash attention
33 | unplace_flash_attn_with_attn()
34 |
35 | # load base LLM model and tokenizer
36 | model = AutoPeftModelForCausalLM.from_pretrained(
37 | peft_model_id,
38 | low_cpu_mem_usage=True,
39 | torch_dtype=torch.float16,
40 | load_in_4bit=True,
41 | )
42 | model.eval()
43 |
44 | tokenizer = AutoTokenizer.from_pretrained(peft_model_id)
45 |
46 | results = []
47 | oom_examples = []
48 | instructions, labels = test_dataset["instructions"], test_dataset["labels"]
49 |
50 | for instruct, label in tqdm(zip(instructions, labels)):
51 | input_ids = tokenizer(
52 | instruct, return_tensors="pt", truncation=True
53 | ).input_ids.cuda()
54 |
55 | with torch.inference_mode():
56 | try:
57 | outputs = model.generate(
58 | input_ids=input_ids,
59 | max_new_tokens=20,
60 | do_sample=True,
61 | top_p=0.95,
62 | temperature=1e-3,
63 | )
64 | result = tokenizer.batch_decode(
65 | outputs.detach().cpu().numpy(), skip_special_tokens=True
66 | )[0]
67 | result = result[len(instruct) :]
68 | except:
69 | result = ""
70 | oom_examples.append(input_ids.shape[-1])
71 |
72 | results.append(result)
73 |
74 | metrics = {
75 | "micro_f1": f1_score(labels, results, average="micro"),
76 | "macro_f1": f1_score(labels, results, average="macro"),
77 | "precision": precision_score(labels, results, average="micro"),
78 | "recall": recall_score(labels, results, average="micro"),
79 | "accuracy": accuracy_score(labels, results),
80 | "oom_examples": oom_examples,
81 | }
82 | print(metrics)
83 |
84 | save_dir = os.path.join(experiment, "metrics")
85 | if not os.path.exists(save_dir):
86 | os.makedirs(save_dir)
87 |
88 | with open(os.path.join(save_dir, "metrics.pkl"), "wb") as handle:
89 | pickle.dump(metrics, handle)
90 |
91 | print(f"Completed experiment {peft_model_id}")
92 | print("----------------------------------------")
93 |
94 |
95 | if __name__ == "__main__":
96 | parser = argparse.ArgumentParser()
97 | parser.add_argument(
98 | "--experiment_dir",
99 | default="experiments/classification-sampleFraction-0.1_epochs-5_rank-8_dropout-0.1",
100 | )
101 |
102 | args = parser.parse_args()
103 | main(args)
104 |
--------------------------------------------------------------------------------
/llama2/llama2_summarization.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import torch
3 | import os
4 | import numpy as np
5 | import pandas as pd
6 | import pickle
7 | import datasets
8 | from datasets import Dataset, load_dataset
9 |
10 | from peft import (
11 | LoraConfig,
12 | prepare_model_for_kbit_training,
13 | get_peft_model,
14 | )
15 | from transformers import (
16 | AutoTokenizer,
17 | AutoModelForCausalLM,
18 | BitsAndBytesConfig,
19 | TrainingArguments,
20 | )
21 | from trl import SFTTrainer
22 |
23 | from prompts import TRAINING_SUMMARIZATION_PROMPT_v2
24 |
25 |
26 | def prepare_instructions(dialogues, summaries):
27 | instructions = []
28 |
29 | prompt = TRAINING_SUMMARIZATION_PROMPT_v2
30 |
31 | for dialogue, summary in zip(dialogues, summaries):
32 | example = prompt.format(
33 | dialogue=dialogue,
34 | summary=summary,
35 | )
36 | instructions.append(example)
37 |
38 | return instructions
39 |
40 |
41 | def prepare_samsum_data():
42 | dataset = load_dataset("samsum")
43 | train_dataset = dataset["train"]
44 | val_dataset = dataset["test"]
45 |
46 | dialogues = train_dataset["dialogue"]
47 | summaries = train_dataset["summary"]
48 | train_instructions = prepare_instructions(dialogues, summaries)
49 | train_dataset = datasets.Dataset.from_pandas(
50 | pd.DataFrame(data={"instructions": train_instructions})
51 | )
52 |
53 | return train_dataset
54 |
55 |
56 | def main(args):
57 | train_dataset = prepare_samsum_data()
58 |
59 | # BitsAndBytesConfig int-4 config
60 | bnb_config = BitsAndBytesConfig(
61 | load_in_4bit=True,
62 | bnb_4bit_use_double_quant=True,
63 | bnb_4bit_quant_type="nf4",
64 | bnb_4bit_compute_dtype=torch.bfloat16,
65 | )
66 |
67 | # Load model and tokenizer
68 | model = AutoModelForCausalLM.from_pretrained(
69 | args.pretrained_ckpt,
70 | quantization_config=bnb_config,
71 | use_cache=False,
72 | device_map="auto",
73 | )
74 | model.config.pretraining_tp = 1
75 |
76 | tokenizer = AutoTokenizer.from_pretrained(args.pretrained_ckpt)
77 | tokenizer.pad_token = tokenizer.eos_token
78 | tokenizer.padding_side = "right"
79 |
80 | # LoRA config based on QLoRA paper
81 | peft_config = LoraConfig(
82 | lora_alpha=16,
83 | lora_dropout=args.dropout,
84 | r=args.lora_r,
85 | bias="none",
86 | task_type="CAUSAL_LM",
87 | )
88 |
89 | # prepare model for training
90 | model = prepare_model_for_kbit_training(model)
91 | model = get_peft_model(model, peft_config)
92 |
93 | results_dir = f"experiments/summarization_epochs-{args.epochs}_rank-{args.lora_r}_dropout-{args.dropout}"
94 |
95 | training_args = TrainingArguments(
96 | output_dir=results_dir,
97 | logging_dir=f"{results_dir}/logs",
98 | num_train_epochs=args.epochs,
99 | per_device_train_batch_size=6 if use_flash_attention else 4,
100 | gradient_accumulation_steps=2,
101 | gradient_checkpointing=True,
102 | optim="paged_adamw_32bit",
103 | logging_steps=100,
104 | learning_rate=2e-4,
105 | bf16=True,
106 | tf32=True,
107 | max_grad_norm=0.3,
108 | warmup_ratio=0.03,
109 | lr_scheduler_type="constant",
110 | report_to="none",
111 | # disable_tqdm=True # disable tqdm since with packing values are in correct
112 | )
113 |
114 | max_seq_length = 512 # max sequence length for model and packing of the dataset
115 |
116 | trainer = SFTTrainer(
117 | model=model,
118 | train_dataset=train_dataset,
119 | peft_config=peft_config,
120 | max_seq_length=max_seq_length,
121 | tokenizer=tokenizer,
122 | packing=True,
123 | args=training_args,
124 | dataset_text_field="instructions",
125 | )
126 |
127 | trainer_stats = trainer.train()
128 | train_loss = trainer_stats.training_loss
129 | print(f"Training loss:{train_loss}")
130 |
131 | peft_model_id = f"{results_dir}/assets"
132 | trainer.model.save_pretrained(peft_model_id)
133 | tokenizer.save_pretrained(peft_model_id)
134 |
135 | with open(f"{results_dir}/results.pkl", "wb") as handle:
136 | run_result = [
137 | args.epochs,
138 | args.lora_r,
139 | args.dropout,
140 | train_loss,
141 | ]
142 | pickle.dump(run_result, handle)
143 | print("Experiment over")
144 |
145 |
146 | if __name__ == "__main__":
147 | parser = argparse.ArgumentParser()
148 | parser.add_argument("--pretrained_ckpt", default="NousResearch/Llama-2-7b-hf")
149 | parser.add_argument("--lora_r", default=64, type=int)
150 | parser.add_argument("--epochs", default=1, type=int)
151 | parser.add_argument("--dropout", default=0.1, type=float)
152 |
153 | args = parser.parse_args()
154 | main(args)
155 |
--------------------------------------------------------------------------------
/llama2/llama2_summarization_inference.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import torch
3 | import os
4 | import pandas as pd
5 | import evaluate
6 | from datasets import load_dataset
7 | import pickle
8 | import warnings
9 |
10 | from llama_patch import unplace_flash_attn_with_attn
11 | from peft import AutoPeftModelForCausalLM
12 | from transformers import AutoTokenizer
13 |
14 | from prompts import INFERENCE_SUMMARIZATION_PROMPT_v2
15 |
16 | metric = evaluate.load("rouge")
17 | warnings.filterwarnings("ignore")
18 |
19 |
20 | def prepare_instructions(dialogues, summaries):
21 | instructions = []
22 |
23 | prompt = INFERENCE_SUMMARIZATION_PROMPT_v2
24 |
25 | for dialogue, summary in zip(dialogues, summaries):
26 | example = prompt.format(
27 | dialogue=dialogue,
28 | )
29 | instructions.append(example)
30 |
31 | return instructions
32 |
33 |
34 | def prepare_samsum_data():
35 | dataset = load_dataset("samsum")
36 | val_dataset = dataset["test"]
37 |
38 | dialogues = val_dataset["dialogue"]
39 | summaries = val_dataset["summary"]
40 | val_instructions = prepare_instructions(dialogues, summaries)
41 |
42 | return val_instructions, summaries
43 |
44 |
45 | def main(args):
46 | val_instructions, summaries = prepare_samsum_data()
47 |
48 | experiment = args.experiment_dir
49 | peft_model_id = f"{experiment}/assets"
50 |
51 | # unpatch flash attention
52 | unplace_flash_attn_with_attn()
53 |
54 | # load base LLM model and tokenizer
55 | model = AutoPeftModelForCausalLM.from_pretrained(
56 | peft_model_id,
57 | low_cpu_mem_usage=True,
58 | torch_dtype=torch.float16,
59 | load_in_4bit=True,
60 | )
61 | tokenizer = AutoTokenizer.from_pretrained(peft_model_id)
62 |
63 | results = []
64 | for instruct, summary in zip(val_instructions, summaries):
65 | input_ids = tokenizer(
66 | instruct, return_tensors="pt", truncation=True
67 | ).input_ids.cuda()
68 | with torch.inference_mode():
69 | outputs = model.generate(
70 | input_ids=input_ids,
71 | max_new_tokens=100,
72 | do_sample=True,
73 | top_p=0.9,
74 | temperature=1e-2,
75 | )
76 | result = tokenizer.batch_decode(
77 | outputs.detach().cpu().numpy(), skip_special_tokens=True
78 | )[0]
79 | result = result[len(instruct) :]
80 | results.append(result)
81 | print(f"Instruction:{instruct}")
82 | print(f"Summary:{summary}")
83 | print(f"Generated:{result}")
84 | print("----------------------------------------")
85 |
86 | # compute metric
87 | rouge = metric.compute(predictions=results, references=summaries, use_stemmer=True)
88 |
89 | metrics = {metric: round(rouge[metric] * 100, 2) for metric in rouge.keys()}
90 |
91 | save_dir = os.path.join(experiment, "metrics")
92 | if not os.path.exists(save_dir):
93 | os.makedirs(save_dir)
94 |
95 | with open(os.path.join(save_dir, "metrics.pkl"), "wb") as handle:
96 | pickle.dump(metrics, handle)
97 |
98 | print(f"Completed experiment {peft_model_id}")
99 | print("----------------------------------------")
100 |
101 |
102 | if __name__ == "__main__":
103 | parser = argparse.ArgumentParser()
104 | parser.add_argument(
105 | "--experiment_dir",
106 | default="experiments/summarization_epochs-1_rank-64_dropout-0.1",
107 | )
108 |
109 | args = parser.parse_args()
110 | main(args)
111 |
--------------------------------------------------------------------------------
/llama2/llama_patch.py:
--------------------------------------------------------------------------------
1 | from typing import List, Optional, Tuple
2 |
3 | import torch
4 | from torch import nn
5 | import warnings
6 | import transformers
7 | from transformers.models.llama.modeling_llama import apply_rotary_pos_emb
8 | from peft.tuners.lora import LoraLayer
9 |
10 | try:
11 | from flash_attn.flash_attn_interface import flash_attn_varlen_qkvpacked_func
12 | from flash_attn.bert_padding import unpad_input, pad_input
13 | except Exception:
14 | raise ModuleNotFoundError(
15 | "Please install FlashAttention first, e.g., with pip install flash-attn --no-build-isolation, Learn more at https://github.com/Dao-AILab/flash-attention#installation-and-features"
16 | )
17 |
18 | try:
19 | from einops import rearrange
20 | except Exception:
21 | raise ModuleNotFoundError(
22 | "Please install einops first, e.g., with pip install einops"
23 | )
24 |
25 |
26 | # ADAPTED from https://github.com/allenai/open-instruct/blob/main/open_instruct/llama_flash_attn_monkey_patch.py
27 | # AND https://github.com/lm-sys/FastChat/blob/main/fastchat/train/llama_flash_attn_monkey_patch.py
28 | # AND https://github.com/LAION-AI/Open-Assistant/blob/04fa9a24b2a58c8885b8aa6a2eb02b18de6b4961/model/model_training/models/patching_llama.py
29 | # AND Sourabh https://github.com/huggingface/transformers/commit/ee81bf5aee0d65f005d157c013777e3d27d8d6bf
30 | def forward(
31 | self,
32 | hidden_states: torch.Tensor,
33 | attention_mask: Optional[torch.Tensor] = None,
34 | position_ids: Optional[torch.Tensor] = None,
35 | past_key_value: Optional[Tuple[torch.Tensor]] = None,
36 | output_attentions: bool = False,
37 | use_cache: bool = False,
38 | ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
39 | """Input shape: Batch x Time x Channel
40 |
41 | attention_mask: [bsz, q_len]
42 | """
43 | if output_attentions:
44 | warnings.warn(
45 | "Output attentions is not supported for patched `LlamaAttention`, returning `None` instead."
46 | )
47 |
48 | bsz, q_len, _ = hidden_states.size()
49 |
50 | query_states = (
51 | self.q_proj(hidden_states)
52 | .view(bsz, q_len, self.num_heads, self.head_dim)
53 | .transpose(1, 2)
54 | )
55 | key_states = (
56 | self.k_proj(hidden_states)
57 | .view(bsz, q_len, self.num_heads, self.head_dim)
58 | .transpose(1, 2)
59 | )
60 | value_states = (
61 | self.v_proj(hidden_states)
62 | .view(bsz, q_len, self.num_heads, self.head_dim)
63 | .transpose(1, 2)
64 | )
65 | # [bsz, q_len, nh, hd]
66 | # [bsz, nh, q_len, hd]
67 |
68 | kv_seq_len = key_states.shape[-2]
69 | if past_key_value is not None:
70 | kv_seq_len += past_key_value[0].shape[-2]
71 | cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
72 | query_states, key_states = apply_rotary_pos_emb(
73 | query_states, key_states, cos, sin, position_ids
74 | )
75 |
76 | # Past Key value support
77 | if past_key_value is not None:
78 | # reuse k, v, self_attention
79 | key_states = torch.cat([past_key_value[0], key_states], dim=2)
80 | value_states = torch.cat([past_key_value[1], value_states], dim=2)
81 |
82 | past_key_value = (key_states, value_states) if use_cache else None
83 |
84 | # Flash attention codes from
85 | # https://github.com/HazyResearch/flash-attention/blob/main/flash_attn/flash_attention.py
86 |
87 | # transform the data into the format required by flash attention
88 | qkv = torch.stack(
89 | [query_states, key_states, value_states], dim=2
90 | ) # [bsz, nh, 3, q_len, hd]
91 | qkv = qkv.transpose(1, 3) # [bsz, q_len, 3, nh, hd]
92 | # We have disabled _prepare_decoder_attention_mask in LlamaModel
93 | # the attention_mask should be the same as the key_padding_mask
94 | key_padding_mask = attention_mask
95 |
96 | if key_padding_mask is None:
97 | qkv = rearrange(qkv, "b s ... -> (b s) ...")
98 | max_s = q_len
99 | cu_q_lens = torch.arange(
100 | 0, (bsz + 1) * q_len, step=q_len, dtype=torch.int32, device=qkv.device
101 | )
102 | output = flash_attn_varlen_qkvpacked_func(
103 | qkv, cu_q_lens, max_s, 0.0, softmax_scale=None, causal=True
104 | )
105 | output = rearrange(output, "(b s) ... -> b s ...", b=bsz)
106 | else:
107 | nheads = qkv.shape[-2]
108 | x = rearrange(qkv, "b s three h d -> b s (three h d)")
109 | x_unpad, indices, cu_q_lens, max_s = unpad_input(x, key_padding_mask)
110 | x_unpad = rearrange(
111 | x_unpad, "nnz (three h d) -> nnz three h d", three=3, h=nheads
112 | )
113 | output_unpad = flash_attn_varlen_qkvpacked_func(
114 | x_unpad, cu_q_lens, max_s, 0.0, softmax_scale=None, causal=True
115 | )
116 | output = rearrange(
117 | pad_input(
118 | rearrange(output_unpad, "nnz h d -> nnz (h d)"), indices, bsz, q_len
119 | ),
120 | "b s (h d) -> b s h d",
121 | h=nheads,
122 | )
123 | return self.o_proj(rearrange(output, "b s h d -> b s (h d)")), None, past_key_value
124 |
125 |
126 | # Disable the transformation of the attention mask in LlamaModel as the flash attention
127 | # requires the attention mask to be the same as the key_padding_mask
128 | def _prepare_decoder_attention_mask(
129 | self, attention_mask, input_shape, inputs_embeds, past_key_values_length
130 | ):
131 | # [bsz, seq_len]
132 | return attention_mask
133 |
134 |
135 | def replace_attn_with_flash_attn():
136 | cuda_major, cuda_minor = torch.cuda.get_device_capability()
137 | if cuda_major < 8:
138 | print(
139 | "Flash attention is only supported on Ampere or Hopper GPU during training due to head dim > 64 backward."
140 | "ref: https://github.com/HazyResearch/flash-attention/issues/190#issuecomment-1523359593"
141 | )
142 | transformers.models.llama.modeling_llama.LlamaModel._prepare_decoder_attention_mask = (
143 | _prepare_decoder_attention_mask
144 | )
145 | transformers.models.llama.modeling_llama.LlamaAttention.forward = forward
146 |
147 |
148 | def unplace_flash_attn_with_attn():
149 | import importlib
150 | import transformers
151 |
152 | print("Reloading llama model, unpatching flash attention")
153 | importlib.reload(transformers.models.llama.modeling_llama)
154 |
155 |
156 | # Adapted from https://github.com/tmm1/axolotl/blob/2eda9e02a9d15a7a3f92b41f257d9844d72fc220/src/axolotl/utils/models.py#L338
157 | def upcast_layer_for_flash_attention(model, torch_dtype):
158 | # LlamaRMSNorm layers are in fp32 after kbit_training, so we need to
159 | # convert them back to fp16/bf16 for flash-attn compatibility.
160 | for name, module in model.named_modules():
161 | if isinstance(module, LoraLayer):
162 | module.to(torch_dtype)
163 | if "norm" in name:
164 | module.to(torch_dtype)
165 | if "lm_head" in name or "embed_tokens" in name:
166 | if hasattr(module, "weight"):
167 | module.to(torch_dtype)
168 |
169 | return model
170 |
--------------------------------------------------------------------------------
/llama2/prompts.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | import datasets
3 | from datasets import load_dataset
4 | from sklearn.model_selection import train_test_split
5 |
6 |
7 | ZERO_SHOT_CLASSIFIER_PROMPT = """Classify the sentence into one of 20 classes. The list of classes is provided below, where the classes are separated by commas:
8 |
9 | {newsgroup_classes}
10 |
11 | From the above list of classes, select only one class that the provided sentence can be classified into. The sentence will be delimited with triple backticks. Once again, only predict the class from the given list of classes. Do not predict anything else.
12 |
13 | ### Sentence: ```{sentence}```
14 | ### Class:
15 | """
16 |
17 | FEW_SHOT_CLASSIFIER_PROMPT = """Classify the sentence into one of 20 classes. The list of classes is provided below, where the classes are separated by commas:
18 |
19 | {newsgroup_classes}
20 |
21 | From the above list of classes, select only one class that the provided sentence can be classified into. Once again, only predict the class from the given list of classes. Do not predict anything else. The sentence will be delimited with triple backticks. To help you, examples are provided of sentence and the corresponding class they belong to.
22 |
23 | {few_shot_samples}
24 |
25 | ### Sentence: ```{sentence}```
26 | ### Class:
27 | """
28 |
29 | TRAINING_CLASSIFIER_PROMPT = """Classify the following sentence that is delimited with triple backticks.
30 |
31 | ### Sentence: ```{sentence}```
32 | ### Class: {label}
33 | """
34 |
35 | INFERENCE_CLASSIFIER_PROMPT = """Classify the following sentence that is delimited with triple backticks.
36 |
37 | ### Sentence: ```{sentence}```
38 | ### Class:
39 | """
40 |
41 | TRAINING_CLASSIFIER_PROMPT_v2 = """### Sentence:{sentence} ### Class:{label}"""
42 | INFERENCE_CLASSIFIER_PROMPT_v2 = """### Sentence:{sentence} ### Class:"""
43 |
44 | ZERO_SHOT_SUMMARIZATION_PROMPT = """Summarize the following dialogue that is delimited with triple backticks.
45 |
46 | ### Dialogue: ```{dialogue}```
47 | ### Summary:
48 | """
49 |
50 | FEW_SHOT_SUMMARIZATION_PROMPT = """Summarize the following dialogue that is delimited with triple backticks. To help you, examples of summarization are provided.
51 |
52 | {few_shot_samples}
53 |
54 | ### Dialogue: ```{dialogue}```
55 | ### Summary:
56 | """
57 |
58 | TRAINING_SUMMARIZATION_PROMPT = """Summarize the following dialogue that is delimited with triple backticks.
59 |
60 | ### Dialogue: ```{dialogue}```
61 | ### Summary: {summary}
62 | """
63 |
64 | TRAINING_SUMMARIZATION_PROMPT_v2 = """### Dialogue:{dialogue} ### Summary:{summary}"""
65 | INFERENCE_SUMMARIZATION_PROMPT_v2 = """### Dialogue:{dialogue} ### Summary:"""
66 |
67 | INFERENCE_SUMMARIZATION_PROMPT = """Summarize the following dialogue that is delimited with triple backticks.
68 |
69 | ### Dialogue: ```{dialogue}```
70 | ### Summary:
71 | """
72 |
73 |
74 | def get_newsgroup_instruction_data(mode, texts, labels):
75 | if mode == "train":
76 | prompt = TRAINING_CLASSIFIER_PROMPT_v2
77 | elif mode == "inference":
78 | prompt = INFERENCE_CLASSIFIER_PROMPT_v2
79 |
80 | instructions = []
81 |
82 | for text, label in zip(texts, labels):
83 | if mode == "train":
84 | example = prompt.format(
85 | sentence=text,
86 | label=label,
87 | )
88 | elif mode == "inference":
89 | example = prompt.format(
90 | sentence=text,
91 | )
92 | instructions.append(example)
93 |
94 | return instructions
95 |
96 |
97 | def clean_newsgroup_data(texts, labels):
98 | label2data = {}
99 | clean_data, clean_labels = [], []
100 | for data, label in zip(texts, labels):
101 | if isinstance(data, str) and isinstance(label, str):
102 | clean_data.append(data)
103 | clean_labels.append(label)
104 |
105 | if label not in label2data:
106 | label2data[label] = data
107 |
108 | return label2data, clean_data, clean_labels
109 |
110 |
111 | def get_newsgroup_data_for_ft(mode="train", train_sample_fraction=0.99):
112 | newsgroup_dataset = load_dataset("rungalileo/20_Newsgroups_Fixed")
113 | train_data = newsgroup_dataset["train"]["text"]
114 | train_labels = newsgroup_dataset["train"]["label"]
115 | label2data, train_data, train_labels = clean_newsgroup_data(
116 | train_data, train_labels
117 | )
118 |
119 | test_data = newsgroup_dataset["test"]["text"]
120 | test_labels = newsgroup_dataset["test"]["label"]
121 | _, test_data, test_labels = clean_newsgroup_data(test_data, test_labels)
122 |
123 | # sample n points from training data
124 | train_df = pd.DataFrame(data={"text": train_data, "label": train_labels})
125 | train_df, _ = train_test_split(
126 | train_df,
127 | train_size=train_sample_fraction,
128 | stratify=train_df["label"],
129 | random_state=42,
130 | )
131 | train_data = train_df["text"]
132 | train_labels = train_df["label"]
133 |
134 | train_instructions = get_newsgroup_instruction_data(mode, train_data, train_labels)
135 | test_instructions = get_newsgroup_instruction_data(mode, test_data, test_labels)
136 |
137 | train_dataset = datasets.Dataset.from_pandas(
138 | pd.DataFrame(
139 | data={
140 | "instructions": train_instructions,
141 | "labels": train_labels,
142 | }
143 | )
144 | )
145 | test_dataset = datasets.Dataset.from_pandas(
146 | pd.DataFrame(
147 | data={
148 | "instructions": test_instructions,
149 | "labels": test_labels,
150 | }
151 | )
152 | )
153 |
154 | return train_dataset, test_dataset
155 |
156 |
157 | def get_newsgroup_data():
158 | newsgroup_dataset = load_dataset("rungalileo/20_Newsgroups_Fixed")
159 | train_data = newsgroup_dataset["train"]["text"]
160 | train_labels = newsgroup_dataset["train"]["label"]
161 |
162 | label2data, clean_data, clean_labels = clean_newsgroup_data(
163 | train_data, train_labels
164 | )
165 | df = pd.DataFrame(data={"text": clean_data, "label": clean_labels})
166 |
167 | newsgroup_classes = df["label"].unique()
168 | newsgroup_classes = ", ".join(newsgroup_classes)
169 |
170 | few_shot_samples = ""
171 | for label, data in label2data.items():
172 | sample = f"Sentence: {data} \n Class: {label} \n\n"
173 | few_shot_samples += sample
174 |
175 | return newsgroup_classes, few_shot_samples, df
176 |
177 |
178 | def get_samsum_data():
179 | samsum_dataset = load_dataset("samsum")
180 | train_dataset = samsum_dataset["train"]
181 | dialogues = train_dataset["dialogue"][:2]
182 | summaries = train_dataset["summary"][:2]
183 |
184 | few_shot_samples = ""
185 | for dialogue, summary in zip(dialogues, summaries):
186 | sample = f"Sentence: {dialogue} \n Summary: {summary} \n\n"
187 | few_shot_samples += sample
188 |
189 | return few_shot_samples
190 |
--------------------------------------------------------------------------------
/llama2/run_lora.sh:
--------------------------------------------------------------------------------
1 | epochs=(2 5 10 20 30 50)
2 | lora_r=(2 4 8 16)
3 | dropout=(0.1 0.2 0.5)
4 |
5 | for (( epoch=0; epoch<6; epoch=epoch+1 )) do
6 | for ((r=0; r<4; r=r+1 )) do
7 | for (( d=0; d<3; d=d+1 )) do
8 | python llama2_summarization.py --lora_r ${lora_r[$r]} --epochs ${epochs[$epoch]} --dropout ${dropout[$d]} & wait
9 | done
10 | done
11 | done
12 |
--------------------------------------------------------------------------------
/llama2/sample_ablate.sh:
--------------------------------------------------------------------------------
1 | sample_fraction=(0.025 0.05 0.1)
2 |
3 | for (( sf=0; sf<3; sf=sf+1 )) do
4 | python llama2_classification.py --train_sample_fraction ${sample_fraction[$sf]} & wait
5 | done
6 |
--------------------------------------------------------------------------------
/llmtune/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2024 Georgian Partners
2 |
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 |
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 |
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | __version__ = "0.0.0"
16 |
--------------------------------------------------------------------------------
/llmtune/cli/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/llmtune/cli/__init__.py
--------------------------------------------------------------------------------
/llmtune/cli/toolkit.py:
--------------------------------------------------------------------------------
1 | import logging
2 | import shutil
3 | from pathlib import Path
4 |
5 | import torch
6 | import transformers
7 | import typer
8 | import yaml
9 | from pydantic import ValidationError
10 | from typing_extensions import Annotated
11 |
12 | import llmtune
13 | from llmtune.constants.files import EXAMPLE_CONFIG_FNAME
14 | from llmtune.data.dataset_generator import DatasetGenerator
15 | from llmtune.finetune.lora import LoRAFinetune
16 | from llmtune.inference.lora import LoRAInference
17 | from llmtune.pydantic_models.config_model import Config
18 | from llmtune.qa.metric_suite import LLMMetricSuite
19 | from llmtune.qa.qa_metrics import QaMetricRegistry
20 | from llmtune.qa.test_suite import LLMTestSuite
21 | from llmtune.ui.rich_ui import RichUI
22 | from llmtune.utils.ablation_utils import generate_permutations
23 | from llmtune.utils.save_utils import DirectoryHelper
24 |
25 |
26 | transformers.logging.set_verbosity(transformers.logging.CRITICAL)
27 | torch._logging.set_logs(all=logging.CRITICAL)
28 | logging.captureWarnings(True)
29 |
30 |
31 | app = typer.Typer()
32 | generate_app = typer.Typer()
33 |
34 | app.add_typer(
35 | generate_app,
36 | name="generate",
37 | help="Generate various artefacts, such as config files",
38 | )
39 |
40 |
41 | def run_one_experiment(config: Config, config_path: Path) -> None:
42 | dir_helper = DirectoryHelper(config_path, config)
43 |
44 | # Loading Data -------------------------------
45 | RichUI.before_dataset_creation()
46 |
47 | with RichUI.during_dataset_creation("Injecting Values into Prompt", "monkey"):
48 | dataset_generator = DatasetGenerator(**config.data.model_dump())
49 |
50 | _ = dataset_generator.train_columns
51 | test_column = dataset_generator.test_column
52 |
53 | dataset_path = dir_helper.save_paths.dataset
54 | if not dataset_path.exists():
55 | train, test = dataset_generator.get_dataset()
56 | dataset_generator.save_dataset(dataset_path)
57 | else:
58 | RichUI.dataset_found(dataset_path)
59 | train, test = dataset_generator.load_dataset_from_pickle(dataset_path)
60 |
61 | RichUI.dataset_display_one_example(train[0], test[0])
62 | RichUI.after_dataset_creation(dataset_path, train, test)
63 |
64 | # Loading Model -------------------------------
65 | RichUI.before_finetune()
66 |
67 | weights_path = dir_helper.save_paths.weights
68 |
69 | # model_loader = ModelLoader(config, console, dir_helper)
70 | if not weights_path.exists() or not any(weights_path.iterdir()):
71 | finetuner = LoRAFinetune(config, dir_helper)
72 | with RichUI.during_finetune():
73 | finetuner.finetune(train)
74 | finetuner.save_model()
75 | RichUI.after_finetune()
76 | else:
77 | RichUI.finetune_found(weights_path)
78 |
79 | # Inference -------------------------------
80 | RichUI.before_inference()
81 | results_path = dir_helper.save_paths.results
82 | results_file_path = dir_helper.save_paths.results_file
83 | if not results_file_path.exists():
84 | inference_runner = LoRAInference(test, test_column, config, dir_helper)
85 | inference_runner.infer_all()
86 | RichUI.after_inference(results_path)
87 | else:
88 | RichUI.results_found(results_path)
89 |
90 | # Quality Assurance -------------------------
91 | RichUI.before_qa()
92 |
93 | qa_folder_path = dir_helper.save_paths.qa
94 | if not qa_folder_path.exists():
95 | # metrics
96 | llm_metrics = config.qa.llm_metrics
97 | metrics = QaMetricRegistry.create_metrics_from_list(llm_metrics)
98 | metric_suite = LLMMetricSuite.from_csv(results_file_path, metrics)
99 | qa_metric_file = dir_helper.save_paths.metric_file
100 | metric_suite.save_metric_results(qa_metric_file)
101 | metric_suite.print_metric_results()
102 |
103 | # testing suites
104 | inference_runner = LoRAInference(test, test_column, config, dir_helper)
105 | test_suite_path = config.qa.test_suite
106 | test_suite = LLMTestSuite.from_dir(test_suite_path)
107 | test_suite.run_inference(inference_runner)
108 | test_suite.save_test_results(dir_helper.save_paths.qa)
109 | test_suite.print_test_results()
110 |
111 |
112 | @app.command("run")
113 | def run(config_path: Annotated[str, typer.Argument(help="Path of the config yaml file")] = "./config.yml") -> None:
114 | """Run the entire exmperiment pipeline"""
115 | # Load YAML config
116 | with Path(config_path).open("r") as file:
117 | config = yaml.safe_load(file)
118 | configs = (
119 | generate_permutations(config, Config) if config.get("ablation", {}).get("use_ablate", False) else [config]
120 | )
121 | for config in configs:
122 | # validate data with pydantic
123 | try:
124 | config = Config(**config)
125 | except ValidationError as e:
126 | print(e.json())
127 |
128 | dir_helper = DirectoryHelper(config_path, config)
129 |
130 | # Reload config from saved config
131 | with dir_helper.save_paths.config_file.open("r") as file:
132 | config = yaml.safe_load(file)
133 | config = Config(**config)
134 |
135 | run_one_experiment(config, config_path)
136 |
137 |
138 | @generate_app.command("config")
139 | def generate_config():
140 | """
141 | Generate an example `config.yml` file in current directory
142 | """
143 | module_path = Path(llmtune.__file__)
144 | example_config_path = module_path.parent / EXAMPLE_CONFIG_FNAME
145 | destination = Path.cwd()
146 | shutil.copy(example_config_path, destination)
147 | RichUI.generate_config(EXAMPLE_CONFIG_FNAME)
148 |
149 |
150 | def cli():
151 | app()
152 |
--------------------------------------------------------------------------------
/llmtune/config.yml:
--------------------------------------------------------------------------------
1 | save_dir: "./experiment/"
2 |
3 | ablation:
4 | use_ablate: false
5 |
6 | # Data Ingestion -------------------
7 | data:
8 | file_type: "huggingface" # one of 'json', 'csv', 'huggingface'
9 | path: "yahma/alpaca-cleaned"
10 | prompt:
11 | >- # prompt, make sure column inputs are enclosed in {} brackets and that they match your data
12 | Below is an instruction that describes a task.
13 | Write a response that appropriately completes the request.
14 | ### Instruction: {instruction}
15 | ### Input: {input}
16 | ### Output:
17 | prompt_stub:
18 | >- # Stub to add for training at the end of prompt, for test set or inference, this is omitted; make sure only one variable is present
19 | {output}
20 | test_size: 25 # Proportion of test as % of total; if integer then # of samples
21 | train_size: 500 # Proportion of train as % of total; if integer then # of samples
22 | train_test_split_seed: 42
23 |
24 | # Model Definition -------------------
25 | model:
26 | hf_model_ckpt: "facebook/opt-125m"
27 | torch_dtype: "bfloat16"
28 | #attn_implementation: "flash_attention_2"
29 | quantize: true
30 | bitsandbytes:
31 | load_in_4bit: true
32 | bnb_4bit_compute_dtype: "bfloat16"
33 | bnb_4bit_quant_type: "nf4"
34 |
35 | # LoRA Params -------------------
36 | lora:
37 | task_type: "CAUSAL_LM"
38 | r: 32
39 | lora_alpha: 64
40 | lora_dropout: 0.1
41 | target_modules: "all-linear"
42 | # to target specific modules
43 | # target_modules:
44 | # - q_proj
45 | # - v_proj
46 | # - k_proj
47 | # - o_proj
48 | # - up_proj
49 | # - down_proj
50 | # - gate_proj
51 |
52 | # Training -------------------
53 | training:
54 | training_args:
55 | num_train_epochs: 1
56 | per_device_train_batch_size: 4
57 | gradient_accumulation_steps: 4
58 | gradient_checkpointing: True
59 | optim: "paged_adamw_32bit"
60 | logging_steps: 1
61 | learning_rate: 2.0e-4
62 | bf16: true # [Ampere+] Set to true for mixed precision training on Newer GPUs
63 | tf32: true # [Ampere+] Set to true for mixed precision training on Newer GPUs
64 | # fp16: false # Set to true for mixed precision training on Older GPUs
65 | max_grad_norm: 0.3
66 | warmup_ratio: 0.03
67 | lr_scheduler_type: "constant"
68 | sft_args:
69 | max_seq_length: 1024
70 | # neftune_noise_alpha: None
71 |
72 | inference:
73 | max_new_tokens: 256
74 | use_cache: True
75 | do_sample: True
76 | top_p: 0.9
77 | temperature: 0.8
78 |
79 | qa:
80 | llm_metrics:
81 | - jaccard_similarity
82 | - dot_product
83 | - rouge_score
84 | - word_overlap
85 | - verb_percent
86 | - adjective_percent
87 | - noun_percent
88 | - summary_length
89 | test_suite: "examples/test_suite"
90 |
--------------------------------------------------------------------------------
/llmtune/constants/files.py:
--------------------------------------------------------------------------------
1 | # Example config file
2 | EXAMPLE_CONFIG_FNAME = "config.yml"
3 |
4 | # DIRECTORY HELPER - HASH SETTING
5 | NUM_MD5_DIGITS_FOR_SQIDS = 2
6 |
7 | # DIRECTORY HELPER - DIRECTORY & FILE NAMES
8 | CONFIG_DIR_NAME = "config"
9 | CONFIG_FILE_NAME = "config.yml"
10 |
11 | DATASET_DIR_NAME = "dataset"
12 |
13 | WEIGHTS_DIR_NAME = "weights"
14 |
15 | RESULTS_DIR_NAME = "results"
16 | RESULTS_FILE_NAME = "results.csv"
17 |
18 | QA_DIR_NAME = "qa"
19 | METRIC_FILE_NAME = "qa_metrics_results.csv"
20 |
--------------------------------------------------------------------------------
/llmtune/data/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/llmtune/data/__init__.py
--------------------------------------------------------------------------------
/llmtune/data/dataset_generator.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pickle
3 | import re
4 | from functools import partial
5 | from os.path import exists, join
6 | from typing import Tuple, Union
7 |
8 | from datasets import Dataset
9 |
10 | from llmtune.data.ingestor import Ingestor, get_ingestor
11 |
12 |
13 | class DatasetGenerator:
14 | def __init__(
15 | self,
16 | file_type: str,
17 | path: str,
18 | prompt: str,
19 | prompt_stub: str,
20 | test_size: Union[float, int],
21 | train_size: Union[float, int],
22 | train_test_split_seed: int,
23 | ):
24 | self.ingestor: Ingestor = get_ingestor(file_type)
25 | self.ingestor: Ingestor = self.ingestor(path)
26 |
27 | self.dataset: Dataset = self.ingestor.to_dataset()
28 | self.prompt: str = prompt
29 | self.prompt_stub: str = prompt_stub
30 | self.test_size = test_size
31 | self.train_size = train_size
32 | self.train_test_split_seed: int = train_test_split_seed
33 |
34 | self.train_columns: list = self._get_train_columns()
35 | self.test_column: str = self._get_test_column()
36 |
37 | def _get_train_columns(self):
38 | pattern = r"\{([^}]*)\}"
39 | return re.findall(pattern, self.prompt)
40 |
41 | def _get_test_column(self):
42 | pattern = r"\{([^}]*)\}"
43 | return re.findall(pattern, self.prompt_stub)[0]
44 |
45 | # TODO: stratify_by_column
46 | def _train_test_split(self):
47 | self.dataset = self.dataset.train_test_split(
48 | test_size=self.test_size,
49 | train_size=self.train_size,
50 | seed=self.train_test_split_seed,
51 | )
52 |
53 | def _format_one_prompt(self, example, is_test: bool = False):
54 | train_mapping = {var_name: example[var_name] for var_name in self.train_columns}
55 | example["formatted_prompt"] = self.prompt.format(**train_mapping)
56 |
57 | if not is_test:
58 | test_mapping = {self.test_column: example[self.test_column]}
59 | example["formatted_prompt"] += self.prompt_stub.format(**test_mapping)
60 |
61 | return example
62 |
63 | def _format_prompts(self):
64 | self.dataset["train"] = self.dataset["train"].map(partial(self._format_one_prompt, is_test=False))
65 | self.dataset["test"] = self.dataset["test"].map(partial(self._format_one_prompt, is_test=True))
66 |
67 | def get_dataset(self) -> Tuple[Dataset, Dataset]:
68 | self._train_test_split()
69 | self._format_prompts()
70 |
71 | return self.dataset["train"], self.dataset["test"]
72 |
73 | def save_dataset(self, save_dir: str):
74 | os.makedirs(save_dir, exist_ok=True)
75 | with open(join(save_dir, "dataset.pkl"), "wb") as f:
76 | pickle.dump(self.dataset, f)
77 |
78 | def load_dataset_from_pickle(self, save_dir: str):
79 | data_path = join(save_dir, "dataset.pkl")
80 |
81 | if not exists(data_path):
82 | raise FileNotFoundError(f"Train set pickle not found at {save_dir}")
83 |
84 | with open(data_path, "rb") as f:
85 | data = pickle.load(f)
86 | self.dataset = data
87 |
88 | return self.dataset["train"], self.dataset["test"]
89 |
--------------------------------------------------------------------------------
/llmtune/data/ingestor.py:
--------------------------------------------------------------------------------
1 | import csv
2 | from abc import ABC, abstractmethod
3 |
4 | import ijson
5 | from datasets import Dataset, concatenate_datasets, load_dataset
6 |
7 |
8 | def get_ingestor(data_type: str):
9 | if data_type == "json":
10 | return JsonIngestor
11 | elif data_type == "jsonl":
12 | return JsonlIngestor
13 | elif data_type == "csv":
14 | return CsvIngestor
15 | elif data_type == "huggingface":
16 | return HuggingfaceIngestor
17 | else:
18 | raise ValueError(f"'type' must be one of 'json', 'jsonl', 'csv', or 'huggingface', you have {data_type}")
19 |
20 |
21 | class Ingestor(ABC):
22 | @abstractmethod
23 | def to_dataset(self) -> Dataset:
24 | pass
25 |
26 |
27 | class JsonIngestor(Ingestor):
28 | def __init__(self, path: str):
29 | self.path = path
30 |
31 | def _json_generator(self):
32 | with open(self.path, "rb") as f:
33 | for item in ijson.items(f, "item"):
34 | yield item
35 |
36 | def to_dataset(self) -> Dataset:
37 | return Dataset.from_generator(self._json_generator)
38 |
39 |
40 | class JsonlIngestor(Ingestor):
41 | def __init__(self, path: str):
42 | self.path = path
43 |
44 | def _jsonl_generator(self):
45 | with open(self.path, "rb") as f:
46 | for item in ijson.items(f, "", multiple_values=True):
47 | yield item
48 |
49 | def to_dataset(self) -> Dataset:
50 | return Dataset.from_generator(self._jsonl_generator)
51 |
52 |
53 | class CsvIngestor(Ingestor):
54 | def __init__(self, path: str):
55 | self.path = path
56 |
57 | def _csv_generator(self):
58 | with open(self.path) as csvfile:
59 | reader = csv.DictReader(csvfile)
60 | for row in reader:
61 | yield row
62 |
63 | def to_dataset(self) -> Dataset:
64 | return Dataset.from_generator(self._csv_generator)
65 |
66 |
67 | class HuggingfaceIngestor(Ingestor):
68 | def __init__(self, path: str):
69 | self.path = path
70 |
71 | def to_dataset(self) -> Dataset:
72 | ds = load_dataset(self.path)
73 | return concatenate_datasets(ds.values())
74 |
--------------------------------------------------------------------------------
/llmtune/finetune/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/llmtune/finetune/__init__.py
--------------------------------------------------------------------------------
/llmtune/finetune/generics.py:
--------------------------------------------------------------------------------
1 | from abc import ABC, abstractmethod
2 |
3 |
4 | class Finetune(ABC):
5 | @abstractmethod
6 | def finetune(self):
7 | pass
8 |
9 | @abstractmethod
10 | def save_model(self):
11 | pass
12 |
--------------------------------------------------------------------------------
/llmtune/finetune/lora.py:
--------------------------------------------------------------------------------
1 | from os.path import join
2 |
3 | from datasets import Dataset
4 | from peft import (
5 | LoraConfig,
6 | get_peft_model,
7 | prepare_model_for_kbit_training,
8 | )
9 | from transformers import (
10 | AutoModelForCausalLM,
11 | AutoTokenizer,
12 | BitsAndBytesConfig,
13 | ProgressCallback,
14 | TrainingArguments,
15 | )
16 | from trl import SFTTrainer
17 |
18 | from llmtune.finetune.generics import Finetune
19 | from llmtune.pydantic_models.config_model import Config
20 | from llmtune.ui.rich_ui import RichUI
21 | from llmtune.utils.save_utils import DirectoryHelper
22 |
23 |
24 | class LoRAFinetune(Finetune):
25 | def __init__(self, config: Config, directory_helper: DirectoryHelper):
26 | self.config = config
27 |
28 | self._model_config = config.model
29 | self._training_args = config.training.training_args
30 | self._sft_args = config.training.sft_args
31 | self._lora_config = LoraConfig(**config.lora.model_dump())
32 | self._directory_helper = directory_helper
33 | self._weights_path = self._directory_helper.save_paths.weights
34 | self._trainer = None
35 |
36 | self.model = None
37 | self.tokenizer = None
38 |
39 | self.device_map = self._model_config.device_map
40 |
41 | self._load_model_and_tokenizer()
42 | self._inject_lora()
43 |
44 | def _load_model_and_tokenizer(self):
45 | ckpt = self._model_config.hf_model_ckpt
46 | RichUI.on_basemodel_load(ckpt)
47 | model = self._get_model()
48 | tokenizer = self._get_tokenizer()
49 | RichUI.after_basemodel_load(ckpt)
50 |
51 | self.model = model
52 | self.tokenizer = tokenizer
53 |
54 | def _get_model(self):
55 | model = AutoModelForCausalLM.from_pretrained(
56 | self._model_config.hf_model_ckpt,
57 | quantization_config=BitsAndBytesConfig(**self._model_config.bitsandbytes.model_dump()),
58 | use_cache=False,
59 | device_map=self.device_map,
60 | torch_dtype=self._model_config.casted_torch_dtype,
61 | attn_implementation=self._model_config.attn_implementation,
62 | )
63 |
64 | model.config.pretraining_tp = 1
65 |
66 | return model
67 |
68 | def _get_tokenizer(self):
69 | tokenizer = AutoTokenizer.from_pretrained(self._model_config.hf_model_ckpt)
70 | tokenizer.pad_token = tokenizer.eos_token
71 | tokenizer.padding_side = "right"
72 |
73 | return tokenizer
74 |
75 | def _inject_lora(self):
76 | self.model.gradient_checkpointing_enable()
77 | self.model = prepare_model_for_kbit_training(self.model)
78 | self.model = get_peft_model(self.model, self._lora_config)
79 |
80 | def finetune(self, train_dataset: Dataset):
81 | logging_dir = join(self._weights_path, "/logs")
82 | training_args = TrainingArguments(
83 | output_dir=self._weights_path,
84 | logging_dir=logging_dir,
85 | report_to="none",
86 | **self._training_args.model_dump(),
87 | )
88 |
89 | progress_callback = ProgressCallback()
90 |
91 | self._trainer = SFTTrainer(
92 | model=self.model,
93 | train_dataset=train_dataset,
94 | peft_config=self._lora_config,
95 | tokenizer=self.tokenizer,
96 | packing=True,
97 | args=training_args,
98 | dataset_text_field="formatted_prompt", # TODO: maybe move consts to a dedicated folder
99 | callbacks=[progress_callback],
100 | **self._sft_args.model_dump(),
101 | )
102 |
103 | self._trainer.train()
104 |
105 | def save_model(self) -> None:
106 | self._trainer.model.save_pretrained(self._weights_path)
107 | self.tokenizer.save_pretrained(self._weights_path)
108 |
--------------------------------------------------------------------------------
/llmtune/inference/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/llmtune/inference/__init__.py
--------------------------------------------------------------------------------
/llmtune/inference/generics.py:
--------------------------------------------------------------------------------
1 | from abc import ABC, abstractmethod
2 |
3 |
4 | class Inference(ABC):
5 | @abstractmethod
6 | def infer_one(self, prompt: str):
7 | pass
8 |
9 | @abstractmethod
10 | def infer_all(self):
11 | pass
12 |
--------------------------------------------------------------------------------
/llmtune/inference/lora.py:
--------------------------------------------------------------------------------
1 | import csv
2 | import os
3 | from os.path import join
4 | from threading import Thread
5 |
6 | import torch
7 | from datasets import Dataset
8 | from peft import AutoPeftModelForCausalLM
9 | from rich.text import Text
10 | from transformers import AutoTokenizer, BitsAndBytesConfig, TextIteratorStreamer
11 |
12 | from llmtune.inference.generics import Inference
13 | from llmtune.pydantic_models.config_model import Config
14 | from llmtune.ui.rich_ui import RichUI
15 | from llmtune.utils.save_utils import DirectoryHelper
16 |
17 |
18 | # TODO: Add type hints please!
19 | class LoRAInference(Inference):
20 | def __init__(
21 | self,
22 | test_dataset: Dataset,
23 | label_column_name: str,
24 | config: Config,
25 | dir_helper: DirectoryHelper,
26 | ):
27 | self.test_dataset = test_dataset
28 | self.label_column = label_column_name
29 | self.config = config
30 |
31 | self.save_dir = dir_helper.save_paths.results
32 | self.save_path = join(self.save_dir, "results.csv")
33 | self.device_map = self.config.model.device_map
34 | self._weights_path = dir_helper.save_paths.weights
35 |
36 | self.model, self.tokenizer = self._get_merged_model(dir_helper.save_paths.weights)
37 |
38 | def _get_merged_model(self, weights_path: str):
39 | # purge VRAM
40 | torch.cuda.empty_cache()
41 |
42 | # Load from path
43 |
44 | self.model = AutoPeftModelForCausalLM.from_pretrained(
45 | weights_path,
46 | torch_dtype=self.config.model.casted_torch_dtype,
47 | quantization_config=BitsAndBytesConfig(**self.config.model.bitsandbytes.model_dump()),
48 | device_map=self.device_map,
49 | attn_implementation=self.config.model.attn_implementation,
50 | )
51 |
52 | model = self.model.merge_and_unload()
53 |
54 | tokenizer = AutoTokenizer.from_pretrained(self._weights_path, device_map=self.device_map)
55 |
56 | return model, tokenizer
57 |
58 | def infer_all(self):
59 | results = []
60 | prompts = self.test_dataset["formatted_prompt"]
61 | labels = self.test_dataset[self.label_column]
62 |
63 | # inference loop
64 | for idx, (prompt, label) in enumerate(zip(prompts, labels)):
65 | RichUI.inference_ground_truth_display(f"Generating on test set: {idx+1}/{len(prompts)}", prompt, label)
66 |
67 | try:
68 | result = self.infer_one(prompt)
69 | except Exception:
70 | continue
71 | results.append((prompt, label, result))
72 |
73 | # TODO: seperate this into another method
74 | header = ["Prompt", "Ground Truth", "Predicted"]
75 | os.makedirs(self.save_dir, exist_ok=True)
76 | with open(self.save_path, "w", newline="") as f:
77 | writer = csv.writer(f)
78 | writer.writerow(header)
79 | for row in results:
80 | writer.writerow(row)
81 |
82 | def infer_one(self, prompt: str) -> str:
83 | input_ids = self.tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.cuda()
84 |
85 | # stream processor
86 | streamer = TextIteratorStreamer(
87 | self.tokenizer,
88 | skip_prompt=True,
89 | decode_kwargs={"skip_special_tokens": True},
90 | timeout=60, # 60 sec timeout for generation; to handle OOM errors
91 | )
92 |
93 | generation_kwargs = dict(input_ids=input_ids, streamer=streamer, **self.config.inference.model_dump())
94 |
95 | thread = Thread(target=self.model.generate, kwargs=generation_kwargs)
96 | thread.start()
97 |
98 | result = Text()
99 | with RichUI.inference_stream_display(result) as live:
100 | for new_text in streamer:
101 | result.append(new_text)
102 | live.update(result)
103 |
104 | return str(result)
105 |
--------------------------------------------------------------------------------
/llmtune/pydantic_models/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/llmtune/pydantic_models/__init__.py
--------------------------------------------------------------------------------
/llmtune/qa/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/llmtune/qa/__init__.py
--------------------------------------------------------------------------------
/llmtune/qa/metric_suite.py:
--------------------------------------------------------------------------------
1 | import statistics
2 | from pathlib import Path
3 | from typing import Dict, List, Union
4 |
5 | import pandas as pd
6 |
7 | from llmtune.qa.qa_metrics import LLMQaMetric
8 | from llmtune.ui.rich_ui import RichUI
9 |
10 |
11 | class LLMMetricSuite:
12 | """
13 | Represents and runs a suite of metrics on a set of prompts,
14 | golden responses, and model predictions.
15 | """
16 |
17 | def __init__(
18 | self,
19 | metrics: List[LLMQaMetric],
20 | prompts: List[str],
21 | ground_truths: List[str],
22 | model_preds: List[str],
23 | ) -> None:
24 | self.metrics = metrics
25 | self.prompts = prompts
26 | self.ground_truths = ground_truths
27 | self.model_preds = model_preds
28 |
29 | self._results: Dict[str, List[Union[float, int]]] = {}
30 |
31 | @staticmethod
32 | def from_csv(
33 | file_path: str,
34 | metrics: List[LLMQaMetric],
35 | prompt_col: str = "Prompt",
36 | gold_col: str = "Ground Truth",
37 | pred_col="Predicted",
38 | ) -> "LLMMetricSuite":
39 | results_df = pd.read_csv(file_path)
40 | prompts = results_df[prompt_col].tolist()
41 | ground_truths = results_df[gold_col].tolist()
42 | model_preds = results_df[pred_col].tolist()
43 | return LLMMetricSuite(metrics, prompts, ground_truths, model_preds)
44 |
45 | def compute_metrics(self) -> Dict[str, List[Union[float, int]]]:
46 | results = {}
47 | for metric in self.metrics:
48 | metric_results = []
49 | for prompt, ground_truth, model_pred in zip(self.prompts, self.ground_truths, self.model_preds):
50 | metric_results.append(metric.get_metric(prompt, ground_truth, model_pred))
51 | results[metric.metric_name] = metric_results
52 |
53 | self._results = results
54 | return results
55 |
56 | @property
57 | def metric_results(self) -> Dict[str, List[Union[float, int]]]:
58 | return self._results if self._results else self.compute_metrics()
59 |
60 | def print_metric_results(self):
61 | result_dictionary = self.metric_results
62 | column_data = {key: list(result_dictionary[key]) for key in result_dictionary}
63 | mean_values = {key: statistics.mean(column_data[key]) for key in column_data}
64 | median_values = {key: statistics.median(column_data[key]) for key in column_data}
65 | stdev_values = {key: statistics.stdev(column_data[key]) for key in column_data}
66 | # Use the RichUI class to display the table
67 | RichUI.qa_display_metric_table(result_dictionary, mean_values, median_values, stdev_values)
68 |
69 | def save_metric_results(self, path: str):
70 | # TODO: save these!
71 | path = Path(path)
72 | dir = path.parent
73 |
74 | if not dir.exists():
75 | dir.mkdir(parents=True, exist_ok=True)
76 |
77 | resultant_dataframe = pd.DataFrame(self.metric_results)
78 | resultant_dataframe.to_csv(path, index=False)
79 |
--------------------------------------------------------------------------------
/llmtune/qa/qa_metrics.py:
--------------------------------------------------------------------------------
1 | from abc import ABC, abstractmethod
2 | from typing import List, Union
3 |
4 | import nltk
5 | import numpy as np
6 | import torch
7 | from langchain.evaluation import JsonValidityEvaluator
8 | from nltk import pos_tag
9 | from nltk.corpus import stopwords
10 | from nltk.tokenize import word_tokenize
11 | from rouge_score import rouge_scorer
12 | from transformers import DistilBertModel, DistilBertTokenizer
13 |
14 |
15 | json_validity_evaluator = JsonValidityEvaluator()
16 |
17 | nltk.download("stopwords")
18 | nltk.download("punkt")
19 | nltk.download("averaged_perceptron_tagger")
20 |
21 |
22 | class LLMQaMetric(ABC):
23 | """
24 | Abstract base class for a metric. A metric can be computed over a single
25 | data instance, and outputs a scalar value (integer or float).
26 | """
27 |
28 | @property
29 | @abstractmethod
30 | def metric_name(self) -> str:
31 | pass
32 |
33 | @abstractmethod
34 | def get_metric(self, prompt: str, grount_truth: str, model_pred: str) -> Union[float, int]:
35 | pass
36 |
37 |
38 | class QaMetricRegistry:
39 | """Provides a registry that maps metric names to metric classes.
40 | A user can provide a list of metrics by name, and the registry will convert
41 | that into a list of metric objects.
42 | """
43 |
44 | registry = {}
45 |
46 | @classmethod
47 | def register(cls, *names):
48 | def inner_wrapper(wrapped_class):
49 | for name in names:
50 | cls.registry[name] = wrapped_class
51 | return wrapped_class
52 |
53 | return inner_wrapper
54 |
55 | @classmethod
56 | def create_metrics_from_list(cls, metric_names: List[str]) -> List[LLMQaMetric]:
57 | return [cls.registry[metric]() for metric in metric_names]
58 |
59 |
60 | @QaMetricRegistry.register("summary_length")
61 | class LengthMetric(LLMQaMetric):
62 | @property
63 | def metric_name(self) -> str:
64 | return "summary_length"
65 |
66 | def get_metric(self, prompt: str, ground_truth: str, model_prediction: str) -> Union[float, int, bool]:
67 | return abs(len(ground_truth) - len(model_prediction))
68 |
69 |
70 | @QaMetricRegistry.register("jaccard_similarity")
71 | class JaccardSimilarityMetric(LLMQaMetric):
72 | @property
73 | def metric_name(self) -> str:
74 | return "jaccard_similarity"
75 |
76 | def get_metric(self, prompt: str, ground_truth: str, model_prediction: str) -> Union[float, int, bool]:
77 | set_ground_truth = set(ground_truth.lower())
78 | set_model_prediction = set(model_prediction.lower())
79 |
80 | intersection_size = len(set_ground_truth.intersection(set_model_prediction))
81 | union_size = len(set_ground_truth.union(set_model_prediction))
82 |
83 | similarity = intersection_size / union_size if union_size != 0 else 0
84 | return float(similarity)
85 |
86 |
87 | @QaMetricRegistry.register("dot_product")
88 | class DotProductSimilarityMetric(LLMQaMetric):
89 | """Encodes both the ground truth and model prediction using DistilBERT, and
90 | computes the dot product similarity between the two embeddings."""
91 |
92 | def __init__(self):
93 | model_name = "distilbert-base-uncased"
94 | self.tokenizer = DistilBertTokenizer.from_pretrained(model_name)
95 | self.model = DistilBertModel.from_pretrained(model_name)
96 |
97 | @property
98 | def metric_name(self) -> str:
99 | return "dot_product"
100 |
101 | def _encode_sentence(self, sentence):
102 | tokens = self.tokenizer(sentence, return_tensors="pt")
103 | with torch.no_grad():
104 | outputs = self.model(**tokens)
105 | return outputs.last_hidden_state.mean(dim=1).squeeze().numpy()
106 |
107 | def get_metric(self, prompt: str, ground_truth: str, model_prediction: str) -> Union[float, int, bool]:
108 | embedding_ground_truth = self._encode_sentence(ground_truth)
109 | embedding_model_prediction = self._encode_sentence(model_prediction)
110 | dot_product_similarity = np.dot(embedding_ground_truth, embedding_model_prediction)
111 | return float(dot_product_similarity)
112 |
113 |
114 | @QaMetricRegistry.register("rouge_score")
115 | class RougeScoreMetric(LLMQaMetric):
116 | @property
117 | def metric_name(self) -> str:
118 | return "rouge_score"
119 |
120 | def get_metric(self, prompt: str, ground_truth: str, model_prediction: str) -> Union[float, int, bool]:
121 | scorer = rouge_scorer.RougeScorer(["rouge1"], use_stemmer=True)
122 | scores = scorer.score(model_prediction, ground_truth)
123 | return float(scores["rouge1"].precision)
124 |
125 |
126 | @QaMetricRegistry.register("word_overlap")
127 | class WordOverlapMetric(LLMQaMetric):
128 | @property
129 | def metric_name(self) -> str:
130 | return "word_overlap"
131 |
132 | def _remove_stopwords(self, text: str) -> str:
133 | stop_words = set(stopwords.words("english"))
134 | word_tokens = word_tokenize(text)
135 | filtered_text = [word for word in word_tokens if word.lower() not in stop_words]
136 | return " ".join(filtered_text)
137 |
138 | def get_metric(self, prompt: str, ground_truth: str, model_prediction: str) -> Union[float, int, bool]:
139 | cleaned_model_prediction = self._remove_stopwords(model_prediction)
140 | cleaned_ground_truth = self._remove_stopwords(ground_truth)
141 |
142 | words_model_prediction = set(cleaned_model_prediction.split())
143 | words_ground_truth = set(cleaned_ground_truth.split())
144 |
145 | common_words = words_model_prediction.intersection(words_ground_truth)
146 | overlap_percentage = (len(common_words) / len(words_ground_truth)) * 100
147 | return float(overlap_percentage)
148 |
149 |
150 | @QaMetricRegistry.register("json_valid")
151 | class JSONValidityMetric(LLMQaMetric):
152 | """
153 | Checks to see if valid json can be parsed from the model output, according
154 | to langchain_core.utils.json.parse_json_markdown
155 | The JSON can be wrapped in markdown and this test will still pass
156 | """
157 |
158 | @property
159 | def metric_name(self) -> str:
160 | return "json_valid"
161 |
162 | def get_metric(self, prompt: str, ground_truth: str, model_prediction: str) -> float:
163 | result = json_validity_evaluator.evaluate_strings(prediction=model_prediction)
164 | binary_res = result["score"]
165 | return float(binary_res)
166 |
167 |
168 | class PosCompositionMetric(LLMQaMetric):
169 | def _get_pos_percent(self, text: str, pos_tags: List[str]) -> float:
170 | words = word_tokenize(text)
171 | tags = pos_tag(words)
172 | pos_words = [word for word, tag in tags if tag in pos_tags]
173 | total_words = len(text.split(" "))
174 | return round(len(pos_words) / total_words, 2)
175 |
176 |
177 | @QaMetricRegistry.register("verb_percent")
178 | class VerbPercentMetric(PosCompositionMetric):
179 | @property
180 | def metric_name(self) -> str:
181 | return "verb_percent"
182 |
183 | def get_metric(self, prompt: str, ground_truth: str, model_prediction: str) -> float:
184 | return self._get_pos_percent(model_prediction, ["VB", "VBD", "VBG", "VBN", "VBP", "VBZ"])
185 |
186 |
187 | @QaMetricRegistry.register("adjective_percent")
188 | class AdjectivePercentMetric(PosCompositionMetric):
189 | @property
190 | def metric_name(self) -> str:
191 | return "adjective_percent"
192 |
193 | def get_metric(self, prompt: str, ground_truth: str, model_prediction: str) -> float:
194 | return self._get_pos_percent(model_prediction, ["JJ", "JJR", "JJS"])
195 |
196 |
197 | @QaMetricRegistry.register("noun_percent")
198 | class NounPercentMetric(PosCompositionMetric):
199 | @property
200 | def metric_name(self) -> str:
201 | return "noun_percent"
202 |
203 | def get_metric(self, prompt: str, ground_truth: str, model_prediction: str) -> float:
204 | return self._get_pos_percent(model_prediction, ["NN", "NNS", "NNP", "NNPS"])
205 |
206 |
207 | # Instantiate tests
208 | # length_test = LengthMetric()
209 | # jaccard_similarity_test = JaccardSimilarityMetric()
210 | # dot_product_similarity_test = DotProductSimilarityMetric()
211 | # rouge_score_test = RougeScoreMetric()
212 | # word_overlap_test = WordOverlapMetric()
213 | # verb_percent_test = VerbPercentMetric()
214 | # adjective_percent_test = AdjectivePercentMetric()
215 | # noun_percent_test = NounPercentMetric()
216 |
--------------------------------------------------------------------------------
/llmtune/qa/qa_tests.py:
--------------------------------------------------------------------------------
1 | from abc import ABC, abstractmethod
2 | from typing import List
3 |
4 | import numpy as np
5 | import torch
6 | from langchain.evaluation import JsonValidityEvaluator
7 | from transformers import DistilBertModel, DistilBertTokenizer
8 |
9 |
10 | class LLMQaTest(ABC):
11 | """
12 | Abstract base class for a test. A test can be computed over a single
13 | data instance/llm response, and outputs a boolean value (pass or fail).
14 | """
15 |
16 | @property
17 | @abstractmethod
18 | def test_name(self) -> str:
19 | pass
20 |
21 | @abstractmethod
22 | def test(self, prompt: str, grount_truth: str, model_pred: str) -> bool:
23 | pass
24 |
25 |
26 | # TODO this is the same as QaMetricRegistry, could be combined?
27 | class QaTestRegistry:
28 | """Provides a registry that maps metric names to metric classes.
29 | A user can provide a list of metrics by name, and the registry will convert
30 | that into a list of metric objects.
31 | """
32 |
33 | registry = {}
34 |
35 | @classmethod
36 | def register(cls, *names):
37 | def inner_wrapper(wrapped_class):
38 | for name in names:
39 | cls.registry[name] = wrapped_class
40 | return wrapped_class
41 |
42 | return inner_wrapper
43 |
44 | @classmethod
45 | def create_tests_from_list(cls, test_names: List[str]) -> List[LLMQaTest]:
46 | return [cls.registry[test]() for test in test_names]
47 |
48 | @classmethod
49 | def from_name(cls, name: str) -> LLMQaTest:
50 | """Return a LLMQaTest object from a given name."""
51 | return cls.registry[name]()
52 |
53 |
54 | @QaTestRegistry.register("json_valid")
55 | class JSONValidityTest(LLMQaTest):
56 | """
57 | Checks to see if valid json can be parsed from the model output, according
58 | to langchain_core.utils.json.parse_json_markdown
59 | The JSON can be wrapped in markdown and this test will still pass
60 | """
61 |
62 | def __init__(self):
63 | self.json_validity_evaluator = JsonValidityEvaluator()
64 |
65 | @property
66 | def test_name(self) -> str:
67 | return "json_valid"
68 |
69 | def test(self, model_pred: str) -> bool:
70 | result = self.json_validity_evaluator.evaluate_strings(prediction=model_pred)
71 | binary_res = result["score"]
72 | return bool(binary_res)
73 |
74 |
75 | @QaTestRegistry.register("cosine_similarity")
76 | class CosineSimilarityTest(LLMQaTest):
77 | """
78 | Checks to see if the response of the LLM is within a certain cosine
79 | similarity to the gold-standard response. Uses a DistilBERT model to encode
80 | the responses into vectors.
81 | """
82 |
83 | def __init__(self):
84 | model_name = "distilbert-base-uncased"
85 | self.tokenizer = DistilBertTokenizer.from_pretrained(model_name)
86 | self.model = DistilBertModel.from_pretrained(model_name)
87 |
88 | @property
89 | def test_name(self) -> str:
90 | return "cosine_similarity"
91 |
92 | def _encode_sentence(self, sentence: str) -> np.ndarray:
93 | """Encode a sentence into a vector using a language model."""
94 | tokens = self.tokenizer(sentence, return_tensors="pt")
95 | with torch.no_grad():
96 | outputs = self.model(**tokens)
97 | return outputs.last_hidden_state.mean(dim=1).squeeze().numpy()
98 |
99 | def test(self, model_pred: str, ground_truth: str, threshold: float = 0.8) -> bool:
100 | embedding_ground_truth = self._encode_sentence(ground_truth)
101 | embedding_model_prediction = self._encode_sentence(model_pred)
102 | dot_product = np.dot(embedding_ground_truth, embedding_model_prediction)
103 | norm_ground_truth = np.linalg.norm(embedding_ground_truth)
104 | norm_model_prediction = np.linalg.norm(embedding_model_prediction)
105 | cosine_similarity = dot_product / (norm_ground_truth * norm_model_prediction)
106 | return cosine_similarity >= threshold
107 |
--------------------------------------------------------------------------------
/llmtune/qa/test_suite.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 | from typing import Any, Dict, List
3 |
4 | import pandas as pd
5 |
6 | from llmtune.inference.lora import LoRAInference
7 | from llmtune.qa.qa_tests import LLMQaTest, QaTestRegistry
8 | from llmtune.ui.rich_ui import RichUI
9 |
10 |
11 | def all_same(items: List[Any]) -> bool:
12 | """Check if all items in a list are the same."""
13 | if len(items) == 0:
14 | return False
15 |
16 | same = True
17 | for item in items:
18 | if item != items[0]:
19 | same = False
20 | break
21 | return same
22 |
23 |
24 | class TestBank:
25 | """A test bank is a collection of test cases for a single test type.
26 | Test banks can be specified using CSV files, and also save their results to CSV files.
27 | """
28 |
29 | def __init__(self, test: LLMQaTest, cases: List[Dict[str, str]], file_name_stem: str) -> None:
30 | self.test = test
31 | self.cases = cases
32 | self.results: List[bool] = []
33 | self.file_name = file_name_stem + "_results.csv"
34 |
35 | def generate_results(self, model: LoRAInference) -> None:
36 | """Generates pass/fail results for each test case, based on the model's predictions."""
37 | self.results = [] # reset results
38 | for case in self.cases:
39 | prompt = case["prompt"]
40 | model_pred = model.infer_one(prompt)
41 | # run the test with the model prediction and additional args
42 | test_args = {k: v for k, v in case.items() if k != "prompt"}
43 | result = self.test.test(model_pred, **test_args)
44 | self.results.append(result)
45 |
46 | def save_test_results(self, output_dir: Path, result_col: str = "result") -> None:
47 | """
48 | Re-saves the test results in a CSV file, with a results column.
49 | """
50 | df = pd.DataFrame(self.cases)
51 | df[result_col] = self.results
52 | df.to_csv(output_dir / self.file_name, index=False)
53 |
54 |
55 | class LLMTestSuite:
56 | """
57 | Represents and runs a suite of different tests for LLMs.
58 | """
59 |
60 | def __init__(
61 | self,
62 | test_banks: List[TestBank],
63 | ) -> None:
64 | self.test_banks = test_banks
65 |
66 | @staticmethod
67 | def from_dir(
68 | dir_path: str,
69 | test_type_col: str = "Test Type",
70 | ) -> "LLMTestSuite":
71 | """Creates an LLMTestSuite from a directory of CSV files.
72 | Each CSV file is a test bank, which encodes test cases for a certain
73 | test type.
74 | """
75 |
76 | csv_files = Path(dir_path).rglob("*.csv")
77 |
78 | test_banks = []
79 | for file_name in csv_files:
80 | df = pd.read_csv(file_name)
81 | test_type_column = df[test_type_col].tolist()
82 | # everything that isn't the test type column is a test parameter
83 | params = list(set(df.columns.tolist()) - set([test_type_col])) # noqa: C405
84 | assert all_same(
85 | test_type_column
86 | ), f"All test cases in a test bank {file_name} must have the same test type."
87 | test_type = test_type_column[0]
88 | test = QaTestRegistry.from_name(test_type)
89 | cases = []
90 | # all rows are a test case, encode them all
91 | for _, row in df.iterrows():
92 | case = {}
93 | for param in params:
94 | case[param] = row[param]
95 | cases.append(case)
96 | # get file name stub without extension or path
97 | test_banks.append(TestBank(test, cases, file_name.stem))
98 | return LLMTestSuite(test_banks)
99 |
100 | def run_inference(self, model: LoRAInference) -> None:
101 | """Runs inference on all test cases in all the test banks."""
102 | for test_bank in self.test_banks:
103 | test_bank.generate_results(model)
104 |
105 | def print_test_results(self) -> None:
106 | """Prints the results of the tests in the suite."""
107 | test_names, num_passed, num_instances = [], [], []
108 | for test_bank in self.test_banks:
109 | test_name = test_bank.test.test_name
110 | test_results = test_bank.results
111 | passed = sum(test_results)
112 | instances = len(test_results)
113 | test_names.append(test_name)
114 | num_passed.append(passed)
115 | num_instances.append(instances)
116 |
117 | RichUI.qa_display_test_table(test_names, num_passed, num_instances)
118 |
119 | def save_test_results(self, output_dir: Path) -> None:
120 | """Saves the results of the tests in a folder of CSV files."""
121 | if not output_dir.exists():
122 | output_dir.mkdir(parents=True, exist_ok=True)
123 | for test_bank in self.test_banks:
124 | test_bank.save_test_results(output_dir)
125 |
--------------------------------------------------------------------------------
/llmtune/ui/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/llmtune/ui/__init__.py
--------------------------------------------------------------------------------
/llmtune/ui/generics.py:
--------------------------------------------------------------------------------
1 | from abc import ABC, abstractstaticmethod
2 |
3 | from datasets import Dataset
4 | from rich.text import Text
5 |
6 |
7 | class UI(ABC):
8 | """
9 | DATASET
10 | """
11 |
12 | # Lifecycle functions
13 | @abstractstaticmethod
14 | def before_dataset_creation():
15 | pass
16 |
17 | @abstractstaticmethod
18 | def during_dataset_creation(message: str, spinner: str):
19 | pass
20 |
21 | @abstractstaticmethod
22 | def after_dataset_creation(save_dir: str, train: Dataset, test: Dataset):
23 | pass
24 |
25 | @abstractstaticmethod
26 | def dataset_found(save_dir: str):
27 | pass
28 |
29 | # Display functions
30 | @abstractstaticmethod
31 | def dataset_display_one_example(train_row: dict, test_row: dict):
32 | pass
33 |
34 | """
35 | FINETUNING
36 | """
37 |
38 | # Lifecycle functions
39 | @abstractstaticmethod
40 | def before_finetune():
41 | pass
42 |
43 | @abstractstaticmethod
44 | def on_basemodel_load(checkpoint: str):
45 | pass
46 |
47 | @abstractstaticmethod
48 | def after_basemodel_load(checkpoint: str):
49 | pass
50 |
51 | @abstractstaticmethod
52 | def during_finetune():
53 | pass
54 |
55 | @abstractstaticmethod
56 | def after_finetune():
57 | pass
58 |
59 | @abstractstaticmethod
60 | def finetune_found(weights_path: str):
61 | pass
62 |
63 | """
64 | INFERENCE
65 | """
66 |
67 | # Lifecycle functions
68 | @abstractstaticmethod
69 | def before_inference():
70 | pass
71 |
72 | @abstractstaticmethod
73 | def during_inference():
74 | pass
75 |
76 | @abstractstaticmethod
77 | def after_inference(results_path: str):
78 | pass
79 |
80 | @abstractstaticmethod
81 | def results_found(results_path: str):
82 | pass
83 |
84 | # Display functions
85 | @abstractstaticmethod
86 | def inference_ground_truth_display(title: str, prompt: str, label: str):
87 | pass
88 |
89 | @abstractstaticmethod
90 | def inference_stream_display(text: Text):
91 | pass
92 |
93 | """
94 | QA
95 | """
96 |
97 | # Lifecycle functions
98 | @abstractstaticmethod
99 | def before_qa(cls):
100 | pass
101 |
102 | @abstractstaticmethod
103 | def during_qa(cls):
104 | pass
105 |
106 | @abstractstaticmethod
107 | def after_qa(cls):
108 | pass
109 |
110 | @abstractstaticmethod
111 | def qa_found(cls):
112 | pass
113 |
114 | @abstractstaticmethod
115 | def qa_display_metric_table(cls):
116 | pass
117 |
--------------------------------------------------------------------------------
/llmtune/ui/rich_ui.py:
--------------------------------------------------------------------------------
1 | from datasets import Dataset
2 | from rich.console import Console
3 | from rich.layout import Layout
4 | from rich.live import Live
5 | from rich.panel import Panel
6 | from rich.table import Table
7 | from rich.text import Text
8 |
9 | from llmtune.ui.generics import UI
10 | from llmtune.utils.rich_print_utils import inject_example_to_rich_layout
11 |
12 |
13 | console = Console()
14 |
15 |
16 | class StatusContext:
17 | def __init__(self, console, message, spinner):
18 | self.console = console
19 | self.message = message
20 | self.spinner = spinner
21 |
22 | def __enter__(self):
23 | self.task = self.console.status(self.message, spinner=self.spinner)
24 | self.task.__enter__() # Manually enter the console status context
25 | return self # This allows you to use variables from this context if needed
26 |
27 | def __exit__(self, exc_type, exc_val, exc_tb):
28 | self.task.__exit__(exc_type, exc_val, exc_tb) # Cleanly exit the console status context
29 |
30 |
31 | class LiveContext:
32 | def __init__(self, text: Text, refresh_per_second=4, vertical_overflow="visible"):
33 | self.console = console
34 | self.text = text
35 | self.refresh_per_second = refresh_per_second
36 | self.vertical_overflow = vertical_overflow
37 |
38 | def __enter__(self):
39 | self.task = Live(
40 | self.text,
41 | refresh_per_second=self.refresh_per_second,
42 | vertical_overflow=self.vertical_overflow,
43 | )
44 | self.task.__enter__() # Manually enter the console status context
45 | return self # This allows you to use variables from this context if needed
46 |
47 | def __exit__(self, exc_type, exc_val, exc_tb):
48 | self.task.__exit__(exc_type, exc_val, exc_tb) # Cleanly exit the console status context
49 |
50 | def update(self, new_text: Text):
51 | self.task.update(new_text)
52 |
53 |
54 | class RichUI(UI):
55 | """
56 | DATASET
57 | """
58 |
59 | # Lifecycle functions
60 | @staticmethod
61 | def before_dataset_creation():
62 | console.rule("[bold green]Loading Data")
63 |
64 | @staticmethod
65 | def during_dataset_creation(message: str, spinner: str):
66 | return StatusContext(console, message, spinner)
67 |
68 | @staticmethod
69 | def after_dataset_creation(save_dir: str, train: Dataset, test: Dataset):
70 | console.print(f"Dataset Saved at {save_dir}")
71 | console.print("Post-Split data size:")
72 | console.print(f"Train: {len(train)}")
73 | console.print(f"Test: {len(test)}")
74 |
75 | @staticmethod
76 | def dataset_found(save_dir: str):
77 | console.print(f"Loading formatted dataset from directory {save_dir}")
78 |
79 | # Display functions
80 | @staticmethod
81 | def dataset_display_one_example(train_row: dict, test_row: dict):
82 | layout = Layout()
83 | layout.split_row(
84 | Layout(Panel("Train Sample"), name="train"),
85 | Layout(
86 | Panel("Inference Sample"),
87 | name="inference",
88 | ),
89 | )
90 |
91 | inject_example_to_rich_layout(layout["train"], "Train Example", train_row)
92 | inject_example_to_rich_layout(layout["inference"], "Inference Example", test_row)
93 |
94 | console.print(layout)
95 |
96 | """
97 | FINETUNING
98 | """
99 |
100 | # Lifecycle functions
101 | @staticmethod
102 | def before_finetune():
103 | console.rule("[bold yellow]:smiley: Finetuning")
104 |
105 | @staticmethod
106 | def on_basemodel_load(checkpoint: str):
107 | console.print(f"Loading {checkpoint}...")
108 |
109 | @staticmethod
110 | def after_basemodel_load(checkpoint: str):
111 | console.print(f"{checkpoint} Loaded :smile:")
112 |
113 | @staticmethod
114 | def during_finetune():
115 | return StatusContext(console, "Finetuning Model...", "runner")
116 |
117 | @staticmethod
118 | def after_finetune():
119 | console.print("Finetuning complete!")
120 |
121 | @staticmethod
122 | def finetune_found(weights_path: str):
123 | console.print(f"Fine-Tuned Model Found at {weights_path}... skipping training")
124 |
125 | """
126 | INFERENCE
127 | """
128 |
129 | # Lifecycle functions
130 | @staticmethod
131 | def before_inference():
132 | console.rule("[bold pink]:face_with_monocle: Running Inference")
133 |
134 | @staticmethod
135 | def during_inference():
136 | pass
137 |
138 | @staticmethod
139 | def after_inference(results_path: str):
140 | console.print(f"Inference Results Saved at {results_path}")
141 |
142 | @staticmethod
143 | def results_found(results_path: str):
144 | console.print(f"Inference Results Found at {results_path}")
145 |
146 | # Display functions
147 | @staticmethod
148 | def inference_ground_truth_display(title: str, prompt: str, label: str):
149 | prompt = prompt.replace("[INST]", "").replace("[/INST]", "")
150 | label = label.replace("[INST]", "").replace("[/INST]", "")
151 |
152 | table = Table(title=title, show_lines=True)
153 | table.add_column("prompt")
154 | table.add_column("ground truth")
155 | table.add_row(prompt, label)
156 | console.print(table)
157 |
158 | @staticmethod
159 | def inference_stream_display(text: Text):
160 | console.print("[bold red]Prediction >")
161 | return LiveContext(text)
162 |
163 | """
164 | QA
165 | """
166 |
167 | # Lifecycle functions
168 | @staticmethod
169 | def before_qa():
170 | pass
171 |
172 | @staticmethod
173 | def during_qa():
174 | pass
175 |
176 | @staticmethod
177 | def after_qa():
178 | pass
179 |
180 | @staticmethod
181 | def qa_found():
182 | pass
183 |
184 | @staticmethod
185 | def qa_display_metric_table(result_dictionary, mean_values, median_values, stdev_values):
186 | # Create a table
187 | table = Table(show_header=True, header_style="bold", title="Test Set Metric Results")
188 |
189 | # Add columns to the table
190 | table.add_column("Metric", style="cyan")
191 | table.add_column("Mean", style="magenta")
192 | table.add_column("Median", style="green")
193 | table.add_column("Standard Deviation", style="yellow")
194 |
195 | # Add data rows to the table
196 | for key in result_dictionary:
197 | table.add_row(
198 | key,
199 | f"{mean_values[key]:.4f}",
200 | f"{median_values[key]:.4f}",
201 | f"{stdev_values[key]:.4f}",
202 | )
203 |
204 | # Print the table
205 | console.print(table)
206 |
207 | @staticmethod
208 | def qa_display_test_table(test_names, num_passed, num_instances):
209 | # Create a table
210 | table = Table(show_header=True, header_style="bold", title="Test Suite Results")
211 |
212 | # Add columns to the table
213 | table.add_column("Test Suite", style="cyan")
214 | table.add_column("Passing", style="magenta")
215 |
216 | # Add data rows to the table
217 | for test_name, passed, total in zip(test_names, num_passed, num_instances):
218 | table.add_row(test_name, f"{passed}/{total}")
219 |
220 | # Print the table
221 | console.print(table)
222 |
223 | """
224 | GENERATE
225 | """
226 |
227 | @staticmethod
228 | def generate_config(file_name: str):
229 | console.print(f"Generated config at [bold green]./{file_name}[/]")
230 |
--------------------------------------------------------------------------------
/llmtune/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/llmtune/utils/__init__.py
--------------------------------------------------------------------------------
/llmtune/utils/ablation_utils.py:
--------------------------------------------------------------------------------
1 | import copy
2 | import itertools
3 | from typing import Dict, Tuple, Union, get_args, get_origin
4 |
5 |
6 | # TODO: organize this a little bit. It's a bit of a mess rn.
7 |
8 | """
9 | Helper functions to create multiple valid configs based on ablation (i.e. list of values)
10 | fron a single config yaml
11 | """
12 |
13 |
14 | def get_types_from_dict(source_dict: dict, root="", type_dict={}) -> Dict[str, Tuple[type, type]]:
15 | for key, val in source_dict.items():
16 | if not isinstance(val, dict):
17 | attr = f"{root}.{key}" if root else key
18 | tp = (type(val), None) if not isinstance(val, list) else (type(val), type(val[0]))
19 | type_dict[attr] = tp
20 | else:
21 | join_array = [root, key] if root else [key]
22 | new_root = ".".join(join_array)
23 | get_types_from_dict(val, new_root, type_dict)
24 |
25 | return type_dict
26 |
27 |
28 | def get_annotation(key: str, base_model):
29 | keys = key.split(".")
30 | model = base_model
31 | for key in keys:
32 | model = model.__annotations__[key]
33 |
34 | return model
35 |
36 |
37 | def get_model_field_type(annotation):
38 | origin = get_origin(annotation)
39 | if not origin:
40 | return annotation
41 | if origin is Union:
42 | annotations = get_args(annotation)[0]
43 | return get_model_field_type(annotations)
44 | if origin is list:
45 | return list
46 |
47 |
48 | def get_data_with_key(key, data):
49 | keys = key.split(".")
50 | for key in keys:
51 | data = data[key]
52 | return data
53 |
54 |
55 | def validate_and_get_ablations(type_dict, data, base_model):
56 | ablations = {}
57 | for key, (tp, subtype) in type_dict.items():
58 | annotation = get_annotation(key, base_model)
59 | model_field_type = get_model_field_type(annotation)
60 | if (model_field_type is list) and (tp is list) and (subtype is list):
61 | # Handle both list and list of lists
62 | ablations[key] = get_data_with_key(key, data)
63 | elif model_field_type is not list and tp is list:
64 | # Handle single-level lists
65 | ablations[key] = get_data_with_key(key, data)
66 |
67 | return ablations
68 |
69 |
70 | def patch_with_permutation(old_dict, permutation_dict):
71 | # Create a deep copy of the old dictionary to avoid modifying the original
72 | updated_dict = copy.deepcopy(old_dict)
73 |
74 | # Iterate over each item in the permutation dictionary
75 | for dot_key, new_value in permutation_dict.items():
76 | # Split the dot-joined key into individual keys
77 | keys = dot_key.split(".")
78 |
79 | # Start from the root of the updated dictionary
80 | current_level = updated_dict
81 |
82 | # Traverse to the second-to-last key in the nested dictionary
83 | for key in keys[:-1]:
84 | current_level = current_level[key]
85 |
86 | # Update the value at the final key
87 | current_level[keys[-1]] = new_value
88 |
89 | return updated_dict
90 |
91 |
92 | def generate_permutations(yaml_dict, model):
93 | type_dict = get_types_from_dict(yaml_dict)
94 |
95 | ablations = validate_and_get_ablations(type_dict, yaml_dict, model)
96 |
97 | # get permutations
98 | lists = list(ablations.values())
99 | permutations = list(itertools.product(*lists))
100 |
101 | permutation_dicts = []
102 | for perm in permutations:
103 | new_dict = dict(zip(ablations.keys(), perm))
104 | permutation_dicts.append(new_dict)
105 |
106 | new_dicts = []
107 | for perm in permutation_dicts:
108 | new_dicts.append(patch_with_permutation(yaml_dict, perm))
109 |
110 | return new_dicts
111 |
--------------------------------------------------------------------------------
/llmtune/utils/rich_print_utils.py:
--------------------------------------------------------------------------------
1 | from rich.layout import Layout
2 | from rich.panel import Panel
3 | from rich.table import Table
4 | from rich.text import Text
5 |
6 |
7 | def inject_example_to_rich_layout(layout: Layout, layout_name: str, example: dict):
8 | example = example.copy()
9 |
10 | # Crate Table
11 | table = Table(expand=True)
12 | colors = [
13 | "navy_blue",
14 | "dark_green",
15 | "spring_green3",
16 | "turquoise2",
17 | "cyan",
18 | "blue_violet",
19 | "royal_blue1",
20 | "steel_blue1",
21 | "chartreuse1",
22 | "deep_pink4",
23 | "plum2",
24 | "red",
25 | ]
26 |
27 | # Crate Formatted Text
28 | formatted = example.pop("formatted_prompt", None)
29 | formatted_text = Text(formatted)
30 |
31 | print(example)
32 | for key, c in zip(example.keys(), colors):
33 | table.add_column(key, style=c)
34 |
35 | tgt_text = str(example[key])
36 | start_idx = formatted.find(tgt_text)
37 | formatted_text.stylize(f"bold {c}", start_idx, start_idx + len(tgt_text))
38 |
39 | table.add_row(*[str(v) for v in example.values()])
40 |
41 | layout.split_column(
42 | Layout(
43 | Panel(
44 | table,
45 | title=f"{layout_name} - Raw",
46 | title_align="left",
47 | )
48 | ),
49 | Layout(
50 | Panel(
51 | formatted_text,
52 | title=f"{layout_name} - Formatted",
53 | title_align="left",
54 | )
55 | ),
56 | )
57 |
--------------------------------------------------------------------------------
/llmtune/utils/save_utils.py:
--------------------------------------------------------------------------------
1 | """
2 | Helper functions to help managing saving and loading of experiments:
3 | 1. Generate save directory name
4 | 2. Check if files are present at various experiment stages
5 | """
6 |
7 | import hashlib
8 | import re
9 | from dataclasses import dataclass
10 | from functools import cached_property
11 | from pathlib import Path
12 |
13 | import yaml
14 | from sqids import Sqids
15 |
16 | from llmtune.constants.files import (
17 | CONFIG_DIR_NAME,
18 | CONFIG_FILE_NAME,
19 | DATASET_DIR_NAME,
20 | METRIC_FILE_NAME,
21 | NUM_MD5_DIGITS_FOR_SQIDS,
22 | QA_DIR_NAME,
23 | RESULTS_DIR_NAME,
24 | RESULTS_FILE_NAME,
25 | WEIGHTS_DIR_NAME,
26 | )
27 | from llmtune.pydantic_models.config_model import Config
28 |
29 |
30 | @dataclass
31 | class DirectoryList:
32 | save_dir: Path
33 | config_hash: str
34 |
35 | @property
36 | def experiment(self) -> Path:
37 | return self.save_dir / self.config_hash
38 |
39 | @property
40 | def config(self) -> Path:
41 | return self.experiment / CONFIG_DIR_NAME
42 |
43 | @property
44 | def config_file(self) -> Path:
45 | return self.config / CONFIG_FILE_NAME
46 |
47 | @property
48 | def dataset(self) -> Path:
49 | return self.experiment / DATASET_DIR_NAME
50 |
51 | @property
52 | def weights(self) -> Path:
53 | return self.experiment / WEIGHTS_DIR_NAME
54 |
55 | @property
56 | def results(self) -> Path:
57 | return self.experiment / RESULTS_DIR_NAME
58 |
59 | @property
60 | def results_file(self) -> Path:
61 | return self.results / RESULTS_FILE_NAME
62 |
63 | @property
64 | def qa(self) -> Path:
65 | return self.experiment / QA_DIR_NAME
66 |
67 | @property
68 | def metric_file(self) -> Path:
69 | return self.qa / METRIC_FILE_NAME
70 |
71 |
72 | class DirectoryHelper:
73 | def __init__(self, config_path: Path, config: Config):
74 | self.config_path: Path = config_path
75 | self.config: Config = config
76 | self.sqids: Sqids = Sqids()
77 | self.save_paths: DirectoryList = self._get_directory_state()
78 |
79 | self.save_paths.experiment.mkdir(parents=True, exist_ok=True)
80 | if not self.save_paths.config.exists():
81 | self.save_config()
82 |
83 | @cached_property
84 | def config_hash(self) -> str:
85 | config_str = self.config.model_dump_json()
86 | config_str = re.sub(r"\s", "", config_str)
87 | hash = hashlib.md5(config_str.encode()).digest()
88 | return self.sqids.encode(hash[:NUM_MD5_DIGITS_FOR_SQIDS])
89 |
90 | def _get_directory_state(self) -> DirectoryList:
91 | save_dir = (
92 | Path(self.config.save_dir)
93 | if not self.config.ablation.use_ablate
94 | else Path(self.config.save_dir) / self.config.ablation.study_name
95 | )
96 | return DirectoryList(save_dir, self.config_hash)
97 |
98 | def save_config(self) -> None:
99 | self.save_paths.config.mkdir(parents=True, exist_ok=True)
100 | model_dict = self.config.model_dump()
101 |
102 | with (self.save_paths.config / "config.yml").open("w") as file:
103 | yaml.dump(model_dict, file)
104 |
--------------------------------------------------------------------------------
/mistral/README.md:
--------------------------------------------------------------------------------
1 | Important: Mistral has the option of using flash attention to speed up inference. In order to use flash attention, please do:
2 |
3 | ```shell
4 | pip install -U flash-attn --no-build-isolation
5 | ```
6 |
7 | ```shell
8 | git clone https://github.com/huggingface/peft
9 | cd peft
10 | pip install .
11 | ```
12 |
13 | # Contents:
14 |
15 | - [Contents:](#contents)
16 | - [What is Mistral?](#what-is-mistral)
17 | - [Variations of Mistral and Parameters](#variations-of-mistral-and-parameters)
18 | - [What does this folder contain?](#what-does-this-folder-contain)
19 | - [Evaluation Framework](#evaluation-framework)
20 | - [ Performance ](#-performance-)
21 | - [Classification](#classification)
22 | - [Summarization](#summarization)
23 |
24 |
25 | ## What is Mistral?
26 |
27 | Mistral-7B-v0.1 is Mistral AI’s first Large Language Model (LLM). Mistral-7B-v0.1 is a decoder-based LM with the following architectural choices: (i) Sliding Window Attention, (ii) GQA (Grouped Query Attention) and (iii) Byte-fallback BPE tokenizer.
28 |
29 |
30 | ## Variations of Mistral and Parameters
31 |
32 | Mistral models come in two sizes, and can be leveraged depending on the task at hand.
33 |
34 | | Mistral variation | Parameters |
35 | |:----------------:|:-----------:|
36 | |Base |7B |
37 | |Instruct |7B |
38 |
39 | In this repository, we have experimented with the Base 7B variation.
40 |
41 | ## What does this folder contain?
42 |
43 | This folder contains ready-to-use scripts, using which you can do the following:
44 |
45 | * Finetuning Mistral using PeFT methodology QLoRA:
46 | * ```mistral_classification.py```: Finetune on News Group classification dataset
47 | * ```mistral_summarization.py```: Finetune on Samsum summarization dataset
48 | * Prompts used:
49 | * ```prompts.py```: Zero-shot, Few-shot and instruction tuning for classification and summarization
50 | * Perform hyperparameter optimization over a well-constrained search space:
51 | * ```run_lora.sh```: Ablation study on LoRA's parameters
52 | * ```sample_ablate.sh```: Ablation study over sample complexities
53 | * Infer Mistral using trained checkpoints:
54 | * ```mistral_baseline_inference.py```: Infer in zero-shot and few-shot settings using Mistral-7B
55 | * ```mistral_classification_inference.py```: Infer on News Group classification dataset
56 | * ```mistral_summarization_inference.py```: Infer on Samsum summarization dataset
57 | * Infer across a different settings:
58 | * ```baseline_inference.sh```: Loop over all settings to perform zero-shot and few-shot prompting across classification and summarization tasks
59 |
60 | ## Evaluation Framework
61 |
62 |
63 | ###  Performance
64 |
65 | We evaluated Mistral under the following conditions:
66 |
67 | * Tasks & Datasets:
68 | * Classification: News Group dataset, which is a 20-way classification task.
69 | * Summarization: Samsum dataset.
70 | * Experiments:
71 | * Sample Efficiency vs Accuracy
72 | * Zero-Shot prompting vs Few-Shot prompting vs PeFT QLoRA (for summarization)
73 | * Training config:
74 | * Epochs: 5 (for classification)
75 | * Epochs: 1 (for summarization)
76 | * Mistral-7B:
77 | * PeFT technique: QLoRA
78 | * Learning rate: 2e-4
79 | * Hardware:
80 | * Cloud provider: AWC EC2
81 | * Instance: g5.2xlarge
82 |
83 | #### Classification ####
84 |
85 | Table 1: Sample Efficiency vs Accuracy
86 |
87 | |Training samples (fraction) | Mistral Base-7B |
88 | |:--------------------------:|:---------------:|
89 | |266 (2.5%) |49.30 |
90 | |533 (5%) |48.14 |
91 | |1066 (10%) |58.41 |
92 | |2666 (25%) |64.89 |
93 | |5332 (50%) |73.10 |
94 | |10664 (100%) |74.36 |
95 |
96 |
97 | The above table shows how performance of Mistral-7B track with the number of training samples. The last row of the table demonstrates the performance when the entire dataset is used.
98 |
99 |
100 |
101 | #### Summarization ####
102 |
103 | Table 2: Zero-Shot prompting vs Few-Shot prompting vs Fine-Tuning QLoRA
104 |
105 | |Method | Mistral-7B Zero-Shot | Mistral-7B Few-Shot | Fine-Tuning + QLoRA |
106 | |:-------------:|:---------------------:|:--------------------:|:-------------------:|
107 | |ROUGE-1 (in %) |32.77 |38.87 |53.61 |
108 | |ROUGE-2 (in %) |10.64 |16.71 |29.28 |
109 |
110 |
111 | Looking at the ROUGE-1 and ROUGE-2 scores, we see that Mistral-7B’s performance increases from zero-shot to few-shot to fine-tuning settings.
112 |
113 |
114 | Table 3: Mistral vs Other LLMs
115 |
116 | |Model | Flan-T5-Base Full Fine-Tune | Flan-T5-Large | Falcon-7B | RP-3B | RP-7B | Llama2-7B | Llama2-13B | Mistral-7B |
117 | |:-------------:|:---------------------------:|:-------------:|:---------:|:-----:|:-----:|:---------:|:----------:|:----------:|
118 | |ROUGE-1 (in %) |47.23 |49.21 |52.18 |47.75 |49.96 |51.71 |52.97 |53.61 |
119 | |ROUGE-2 (in %) |21.01 |23.39 |27.84 |23.53 |25.94 |26.86 |28.32 |29.28 |
120 |
121 |
122 | Mistral-7B achieves the best results, even when compared with Falcon-7B and Llama2-7B. This makes Mistral-7B, in our opinion, the best model to leverage in the 7B parameter space.
123 |
124 |
125 |
--------------------------------------------------------------------------------
/mistral/baseline_inference.sh:
--------------------------------------------------------------------------------
1 | #python mistral_baseline_inference.py --task_type classification --prompt_type zero-shot & wait
2 | #python mistral_baseline_inference.py --task_type classification --prompt_type few-shot & wait
3 | python mistral_baseline_inference.py --task_type summarization --prompt_type zero-shot --use_flash_attention & wait
4 | python mistral_baseline_inference.py --task_type summarization --prompt_type few-shot --use_flash_attention
5 |
--------------------------------------------------------------------------------
/mistral/mistral_baseline_inference.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | import evaluate
4 | import warnings
5 | import json
6 | import pandas as pd
7 | import pickle
8 | import torch
9 | import time
10 |
11 | from datasets import load_dataset
12 | from prompts import (
13 | ZERO_SHOT_CLASSIFIER_PROMPT,
14 | FEW_SHOT_CLASSIFIER_PROMPT,
15 | ZERO_SHOT_SUMMARIZATION_PROMPT,
16 | FEW_SHOT_SUMMARIZATION_PROMPT,
17 | get_newsgroup_data,
18 | get_samsum_data,
19 | )
20 | from transformers import (
21 | AutoTokenizer,
22 | AutoModelForCausalLM,
23 | BitsAndBytesConfig,
24 | )
25 | from sklearn.metrics import (
26 | accuracy_score,
27 | f1_score,
28 | precision_score,
29 | recall_score,
30 | )
31 |
32 | metric = evaluate.load("rouge")
33 | warnings.filterwarnings("ignore")
34 |
35 |
36 | def compute_metrics_decoded(decoded_labs, decoded_preds, args):
37 | if args.task_type == "summarization":
38 | rouge = metric.compute(
39 | predictions=decoded_preds, references=decoded_labs, use_stemmer=True
40 | )
41 | metrics = {metric: round(rouge[metric] * 100.0, 3) for metric in rouge.keys()}
42 |
43 | elif args.task_type == "classification":
44 | metrics = {
45 | "micro_f1": f1_score(decoded_labs, decoded_preds, average="micro"),
46 | "macro_f1": f1_score(decoded_labs, decoded_preds, average="macro"),
47 | "precision": precision_score(decoded_labs, decoded_preds, average="micro"),
48 | "recall": recall_score(decoded_labs, decoded_preds, average="micro"),
49 | "accuracy": accuracy_score(decoded_labs, decoded_preds),
50 | }
51 |
52 | return metrics
53 |
54 |
55 | def main(args):
56 | save_dir = os.path.join(
57 | "baseline_results", args.pretrained_ckpt, args.task_type, args.prompt_type
58 | )
59 | if not os.path.exists(save_dir):
60 | os.makedirs(save_dir)
61 |
62 | if args.task_type == "classification":
63 | dataset = load_dataset("rungalileo/20_Newsgroups_Fixed")
64 | test_dataset = dataset["test"]
65 | test_data, test_labels = test_dataset["text"], test_dataset["label"]
66 |
67 | newsgroup_classes, few_shot_samples, _ = get_newsgroup_data()
68 |
69 | elif args.task_type == "summarization":
70 | dataset = load_dataset("samsum")
71 | test_dataset = dataset["test"]
72 | test_data, test_labels = test_dataset["dialogue"], test_dataset["summary"]
73 |
74 | few_shot_samples = get_samsum_data()
75 |
76 | if args.prompt_type == "zero-shot":
77 | if args.task_type == "classification":
78 | prompt = ZERO_SHOT_CLASSIFIER_PROMPT
79 | elif args.task_type == "summarization":
80 | prompt = ZERO_SHOT_SUMMARIZATION_PROMPT
81 |
82 | elif args.prompt_type == "few-shot":
83 | if args.task_type == "classification":
84 | prompt = FEW_SHOT_CLASSIFIER_PROMPT
85 | elif args.task_type == "summarization":
86 | prompt = FEW_SHOT_SUMMARIZATION_PROMPT
87 |
88 | # BitsAndBytesConfig int-4 config
89 | bnb_config = BitsAndBytesConfig(
90 | load_in_4bit=True,
91 | bnb_4bit_use_double_quant=True,
92 | bnb_4bit_quant_type="nf4",
93 | bnb_4bit_compute_dtype=torch.bfloat16,
94 | )
95 |
96 | # Load model and tokenizer
97 | model = AutoModelForCausalLM.from_pretrained(
98 | args.pretrained_ckpt,
99 | quantization_config=bnb_config,
100 | use_cache=False,
101 | device_map="auto",
102 | use_flash_attention_2=args.use_flash_attention,
103 | )
104 | model.config.pretraining_tp = 1
105 |
106 | tokenizer = AutoTokenizer.from_pretrained(args.pretrained_ckpt)
107 | tokenizer.pad_token = tokenizer.eos_token
108 | tokenizer.padding_side = "right"
109 |
110 | results = []
111 | good_data, good_labels = [], []
112 | ctr = 0
113 | # for instruct, label in zip(instructions, labels):
114 | for data, label in zip(test_data, test_labels):
115 | if not isinstance(data, str):
116 | continue
117 | if not isinstance(label, str):
118 | continue
119 |
120 | # example = instruct[:-len(label)] # remove the answer from the example
121 | if args.prompt_type == "zero-shot":
122 | if args.task_type == "classification":
123 | example = prompt.format(
124 | newsgroup_classes=newsgroup_classes,
125 | sentence=data,
126 | )
127 | elif args.task_type == "summarization":
128 | example = prompt.format(
129 | dialogue=data,
130 | )
131 |
132 | elif args.prompt_type == "few-shot":
133 | if args.task_type == "classification":
134 | example = prompt.format(
135 | newsgroup_classes=newsgroup_classes,
136 | few_shot_samples=few_shot_samples,
137 | sentence=data,
138 | )
139 | elif args.task_type == "summarization":
140 | example = prompt.format(
141 | few_shot_samples=few_shot_samples,
142 | dialogue=data,
143 | )
144 |
145 | input_ids = tokenizer(
146 | example, return_tensors="pt", truncation=True
147 | ).input_ids.cuda()
148 |
149 | with torch.inference_mode():
150 | outputs = model.generate(
151 | input_ids=input_ids,
152 | max_new_tokens=20 if args.task_type == "classification" else 50,
153 | do_sample=True,
154 | top_p=0.95,
155 | temperature=1e-3,
156 | )
157 | result = tokenizer.batch_decode(
158 | outputs.detach().cpu().numpy(), skip_special_tokens=True
159 | )[0]
160 |
161 | # Extract the generated text, and do basic processing
162 | result = result[len(example) :].replace("\n", "").lstrip().rstrip()
163 | results.append(result)
164 | good_labels.append(label)
165 | good_data.append(data)
166 |
167 | print(f"Example {ctr}/{len(test_data)} | GT: {label} | Pred: {result}")
168 | ctr += 1
169 |
170 | metrics = compute_metrics_decoded(good_labels, results, args)
171 | print(metrics)
172 | metrics["predictions"] = results
173 | metrics["labels"] = good_labels
174 | metrics["data"] = good_data
175 |
176 | with open(os.path.join(save_dir, "metrics.pkl"), "wb") as handle:
177 | pickle.dump(metrics, handle)
178 |
179 | print(f"Completed experiment {save_dir}")
180 | print("----------------------------------------")
181 |
182 |
183 | if __name__ == "__main__":
184 | parser = argparse.ArgumentParser()
185 | parser.add_argument("--pretrained_ckpt", default="mistralai/Mistral-7B-v0.1")
186 | parser.add_argument("--prompt_type", default="zero-shot")
187 | parser.add_argument("--task_type", default="classification")
188 | parser.add_argument("--use_flash_attention", action=argparse.BooleanOptionalAction)
189 | args = parser.parse_args()
190 |
191 | main(args)
192 |
--------------------------------------------------------------------------------
/mistral/mistral_classification.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import torch
3 | import os
4 | import numpy as np
5 | import pandas as pd
6 | import pickle
7 |
8 |
9 | from peft import (
10 | LoraConfig,
11 | prepare_model_for_kbit_training,
12 | get_peft_model,
13 | )
14 | from transformers import (
15 | AutoTokenizer,
16 | AutoModelForCausalLM,
17 | BitsAndBytesConfig,
18 | TrainingArguments,
19 | )
20 | from trl import SFTTrainer
21 |
22 | from prompts import get_newsgroup_data_for_ft
23 |
24 |
25 | def main(args):
26 | train_dataset, test_dataset = get_newsgroup_data_for_ft(
27 | mode="train", train_sample_fraction=args.train_sample_fraction
28 | )
29 | print(f"Sample fraction:{args.train_sample_fraction}")
30 | print(f"Training samples:{train_dataset.shape}")
31 |
32 | # BitsAndBytesConfig int-4 config
33 | bnb_config = BitsAndBytesConfig(
34 | load_in_4bit=True,
35 | bnb_4bit_use_double_quant=True,
36 | bnb_4bit_quant_type="nf4",
37 | bnb_4bit_compute_dtype=torch.bfloat16,
38 | )
39 |
40 | # Load model and tokenizer
41 | model = AutoModelForCausalLM.from_pretrained(
42 | args.pretrained_ckpt,
43 | quantization_config=bnb_config,
44 | use_cache=False,
45 | device_map="auto",
46 | )
47 | model.config.pretraining_tp = 1
48 |
49 | tokenizer = AutoTokenizer.from_pretrained(args.pretrained_ckpt)
50 | tokenizer.pad_token = tokenizer.eos_token
51 | tokenizer.padding_side = "right"
52 |
53 | # LoRA config based on QLoRA paper
54 | peft_config = LoraConfig(
55 | lora_alpha=16,
56 | lora_dropout=args.dropout,
57 | r=args.lora_r,
58 | bias="none",
59 | task_type="CAUSAL_LM",
60 | )
61 |
62 | # prepare model for training
63 | model = prepare_model_for_kbit_training(model)
64 | model = get_peft_model(model, peft_config)
65 |
66 | results_dir = f"experiments/classification-sampleFraction-{args.train_sample_fraction}_epochs-{args.epochs}_rank-{args.lora_r}_dropout-{args.dropout}"
67 |
68 | training_args = TrainingArguments(
69 | output_dir=results_dir,
70 | logging_dir=f"{results_dir}/logs",
71 | num_train_epochs=args.epochs,
72 | per_device_train_batch_size=4,
73 | gradient_accumulation_steps=2,
74 | gradient_checkpointing=True,
75 | optim="paged_adamw_32bit",
76 | logging_steps=100,
77 | learning_rate=2e-4,
78 | bf16=True,
79 | tf32=True,
80 | max_grad_norm=0.3,
81 | warmup_ratio=0.03,
82 | lr_scheduler_type="constant",
83 | report_to="none",
84 | # disable_tqdm=True # disable tqdm since with packing values are in correct
85 | )
86 |
87 | max_seq_length = 512 # max sequence length for model and packing of the dataset
88 |
89 | trainer = SFTTrainer(
90 | model=model,
91 | train_dataset=train_dataset,
92 | peft_config=peft_config,
93 | max_seq_length=max_seq_length,
94 | tokenizer=tokenizer,
95 | packing=True,
96 | args=training_args,
97 | dataset_text_field="instructions",
98 | )
99 |
100 | trainer_stats = trainer.train()
101 | train_loss = trainer_stats.training_loss
102 | print(f"Training loss:{train_loss}")
103 |
104 | peft_model_id = f"{results_dir}/assets"
105 | trainer.model.save_pretrained(peft_model_id)
106 | tokenizer.save_pretrained(peft_model_id)
107 |
108 | with open(f"{results_dir}/results.pkl", "wb") as handle:
109 | run_result = [
110 | args.epochs,
111 | args.lora_r,
112 | args.dropout,
113 | train_loss,
114 | ]
115 | pickle.dump(run_result, handle)
116 | print("Experiment over")
117 |
118 |
119 | if __name__ == "__main__":
120 | parser = argparse.ArgumentParser()
121 | parser.add_argument("--pretrained_ckpt", default="mistralai/Mistral-7B-v0.1")
122 | parser.add_argument("--lora_r", default=8, type=int)
123 | parser.add_argument("--epochs", default=5, type=int)
124 | parser.add_argument("--dropout", default=0.1, type=float)
125 | parser.add_argument("--train_sample_fraction", default=0.99, type=float)
126 |
127 | args = parser.parse_args()
128 | main(args)
129 |
--------------------------------------------------------------------------------
/mistral/mistral_classification_inference.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import torch
3 | import os
4 | import pandas as pd
5 | import evaluate
6 | import pickle
7 | import warnings
8 | from tqdm import tqdm
9 |
10 | from peft import AutoPeftModelForCausalLM
11 | from transformers import AutoTokenizer
12 | from sklearn.metrics import (
13 | accuracy_score,
14 | f1_score,
15 | precision_score,
16 | recall_score,
17 | )
18 |
19 | from prompts import get_newsgroup_data_for_ft
20 |
21 | metric = evaluate.load("rouge")
22 | warnings.filterwarnings("ignore")
23 |
24 |
25 | def main(args):
26 | _, test_dataset = get_newsgroup_data_for_ft(mode="inference")
27 |
28 | experiment = args.experiment_dir
29 | peft_model_id = f"{experiment}/assets"
30 |
31 | # load base LLM model and tokenizer
32 | model = AutoPeftModelForCausalLM.from_pretrained(
33 | peft_model_id,
34 | low_cpu_mem_usage=True,
35 | torch_dtype=torch.float16,
36 | load_in_4bit=True,
37 | )
38 |
39 | model.eval()
40 |
41 | tokenizer = AutoTokenizer.from_pretrained(peft_model_id)
42 |
43 | results = []
44 | oom_examples = []
45 | instructions, labels = test_dataset["instructions"], test_dataset["labels"]
46 |
47 | for instruct, label in tqdm(zip(instructions, labels)):
48 | input_ids = tokenizer(
49 | instruct, return_tensors="pt", truncation=True
50 | ).input_ids.cuda()
51 |
52 | with torch.inference_mode():
53 | try:
54 | outputs = model.generate(
55 | input_ids=input_ids,
56 | max_new_tokens=20,
57 | do_sample=True,
58 | top_p=0.95,
59 | temperature=1e-3,
60 | )
61 | result = tokenizer.batch_decode(
62 | outputs.detach().cpu().numpy(), skip_special_tokens=True
63 | )[0]
64 | result = result[len(instruct) :]
65 | print(result)
66 | except:
67 | result = ""
68 | oom_examples.append(input_ids.shape[-1])
69 |
70 | results.append(result)
71 |
72 | metrics = {
73 | "micro_f1": f1_score(labels, results, average="micro"),
74 | "macro_f1": f1_score(labels, results, average="macro"),
75 | "precision": precision_score(labels, results, average="micro"),
76 | "recall": recall_score(labels, results, average="micro"),
77 | "accuracy": accuracy_score(labels, results),
78 | "oom_examples": oom_examples,
79 | }
80 | print(metrics)
81 |
82 | save_dir = os.path.join(experiment, "metrics")
83 | if not os.path.exists(save_dir):
84 | os.makedirs(save_dir)
85 |
86 | with open(os.path.join(save_dir, "metrics.pkl"), "wb") as handle:
87 | pickle.dump(metrics, handle)
88 |
89 | print(f"Completed experiment {peft_model_id}")
90 | print("----------------------------------------")
91 |
92 |
93 | if __name__ == "__main__":
94 | parser = argparse.ArgumentParser()
95 | parser.add_argument(
96 | "--experiment_dir",
97 | default="experiments/classification-sampleFraction-0.1_epochs-5_rank-8_dropout-0.1",
98 | )
99 |
100 | args = parser.parse_args()
101 | main(args)
102 |
--------------------------------------------------------------------------------
/mistral/mistral_summarization.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import torch
3 | import os
4 | import numpy as np
5 | import pandas as pd
6 | import pickle
7 | import datasets
8 | from datasets import Dataset, load_dataset
9 |
10 | from peft import (
11 | LoraConfig,
12 | prepare_model_for_kbit_training,
13 | get_peft_model,
14 | )
15 | from transformers import (
16 | AutoTokenizer,
17 | AutoModelForCausalLM,
18 | BitsAndBytesConfig,
19 | TrainingArguments,
20 | )
21 | from trl import SFTTrainer
22 |
23 | from prompts import TRAINING_SUMMARIZATION_PROMPT_v2
24 |
25 |
26 | def prepare_instructions(dialogues, summaries):
27 | instructions = []
28 |
29 | prompt = TRAINING_SUMMARIZATION_PROMPT_v2
30 |
31 | for dialogue, summary in zip(dialogues, summaries):
32 | example = prompt.format(
33 | dialogue=dialogue,
34 | summary=summary,
35 | )
36 | instructions.append(example)
37 |
38 | return instructions
39 |
40 |
41 | def prepare_samsum_data():
42 | dataset = load_dataset("samsum")
43 | train_dataset = dataset["train"]
44 | val_dataset = dataset["test"]
45 |
46 | dialogues = train_dataset["dialogue"]
47 | summaries = train_dataset["summary"]
48 | train_instructions = prepare_instructions(dialogues, summaries)
49 | train_dataset = datasets.Dataset.from_pandas(
50 | pd.DataFrame(data={"instructions": train_instructions})
51 | )
52 |
53 | return train_dataset
54 |
55 |
56 | def main(args):
57 | train_dataset = prepare_samsum_data()
58 |
59 | # BitsAndBytesConfig int-4 config
60 | bnb_config = BitsAndBytesConfig(
61 | load_in_4bit=True,
62 | bnb_4bit_use_double_quant=True,
63 | bnb_4bit_quant_type="nf4",
64 | bnb_4bit_compute_dtype=torch.bfloat16,
65 | )
66 |
67 | # Load model and tokenizer
68 | model = AutoModelForCausalLM.from_pretrained(
69 | args.pretrained_ckpt,
70 | quantization_config=bnb_config,
71 | use_cache=False,
72 | device_map="auto",
73 | )
74 | model.config.pretraining_tp = 1
75 |
76 | tokenizer = AutoTokenizer.from_pretrained(args.pretrained_ckpt)
77 | tokenizer.pad_token = tokenizer.eos_token
78 | tokenizer.padding_side = "right"
79 |
80 | # LoRA config based on QLoRA paper
81 | peft_config = LoraConfig(
82 | lora_alpha=16,
83 | lora_dropout=args.dropout,
84 | r=args.lora_r,
85 | bias="none",
86 | task_type="CAUSAL_LM",
87 | )
88 |
89 | # prepare model for training
90 | model = prepare_model_for_kbit_training(model)
91 | model = get_peft_model(model, peft_config)
92 |
93 | results_dir = f"experiments/summarization_epochs-{args.epochs}_rank-{args.lora_r}_dropout-{args.dropout}"
94 |
95 | training_args = TrainingArguments(
96 | output_dir=results_dir,
97 | logging_dir=f"{results_dir}/logs",
98 | num_train_epochs=args.epochs,
99 | per_device_train_batch_size=4,
100 | gradient_accumulation_steps=2,
101 | gradient_checkpointing=True,
102 | optim="paged_adamw_32bit",
103 | logging_steps=100,
104 | learning_rate=2e-4,
105 | bf16=True,
106 | tf32=True,
107 | max_grad_norm=0.3,
108 | warmup_ratio=0.03,
109 | lr_scheduler_type="constant",
110 | report_to="none",
111 | # disable_tqdm=True # disable tqdm since with packing values are in correct
112 | )
113 |
114 | max_seq_length = 512 # max sequence length for model and packing of the dataset
115 |
116 | trainer = SFTTrainer(
117 | model=model,
118 | train_dataset=train_dataset,
119 | peft_config=peft_config,
120 | max_seq_length=max_seq_length,
121 | tokenizer=tokenizer,
122 | packing=True,
123 | args=training_args,
124 | dataset_text_field="instructions",
125 | )
126 |
127 | trainer_stats = trainer.train()
128 | train_loss = trainer_stats.training_loss
129 | print(f"Training loss:{train_loss}")
130 |
131 | peft_model_id = f"{results_dir}/assets"
132 | trainer.model.save_pretrained(peft_model_id)
133 | tokenizer.save_pretrained(peft_model_id)
134 |
135 | with open(f"{results_dir}/results.pkl", "wb") as handle:
136 | run_result = [
137 | args.epochs,
138 | args.lora_r,
139 | args.dropout,
140 | train_loss,
141 | ]
142 | pickle.dump(run_result, handle)
143 | print("Experiment over")
144 |
145 |
146 | if __name__ == "__main__":
147 | parser = argparse.ArgumentParser()
148 | parser.add_argument("--pretrained_ckpt", default="mistralai/Mistral-7B-v0.1")
149 | parser.add_argument("--lora_r", default=64, type=int)
150 | parser.add_argument("--epochs", default=1, type=int)
151 | parser.add_argument("--dropout", default=0.1, type=float)
152 |
153 | args = parser.parse_args()
154 | main(args)
155 |
--------------------------------------------------------------------------------
/mistral/mistral_summarization_inference.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import torch
3 | import os
4 | import pandas as pd
5 | import evaluate
6 | from datasets import load_dataset
7 | import pickle
8 | import warnings
9 |
10 | from peft import AutoPeftModelForCausalLM
11 | from transformers import AutoTokenizer
12 |
13 | from prompts import INFERENCE_SUMMARIZATION_PROMPT_v2
14 |
15 | metric = evaluate.load("rouge")
16 | warnings.filterwarnings("ignore")
17 |
18 |
19 | def prepare_instructions(dialogues, summaries):
20 | instructions = []
21 |
22 | prompt = INFERENCE_SUMMARIZATION_PROMPT_v2
23 |
24 | for dialogue, summary in zip(dialogues, summaries):
25 | example = prompt.format(
26 | dialogue=dialogue,
27 | )
28 | instructions.append(example)
29 |
30 | return instructions
31 |
32 |
33 | def prepare_samsum_data():
34 | dataset = load_dataset("samsum")
35 | val_dataset = dataset["test"]
36 |
37 | dialogues = val_dataset["dialogue"]
38 | summaries = val_dataset["summary"]
39 | val_instructions = prepare_instructions(dialogues, summaries)
40 |
41 | return val_instructions, summaries
42 |
43 |
44 | def main(args):
45 | val_instructions, summaries = prepare_samsum_data()
46 |
47 | experiment = args.experiment_dir
48 | peft_model_id = f"{experiment}/assets"
49 |
50 | # load base LLM model and tokenizer
51 | model = AutoPeftModelForCausalLM.from_pretrained(
52 | peft_model_id,
53 | low_cpu_mem_usage=True,
54 | torch_dtype=torch.float16,
55 | load_in_4bit=True,
56 | )
57 | tokenizer = AutoTokenizer.from_pretrained(peft_model_id)
58 |
59 | results = []
60 | for instruct, summary in zip(val_instructions, summaries):
61 | input_ids = tokenizer(
62 | instruct, return_tensors="pt", truncation=True
63 | ).input_ids.cuda()
64 | with torch.inference_mode():
65 | outputs = model.generate(
66 | input_ids=input_ids,
67 | max_new_tokens=100,
68 | do_sample=True,
69 | top_p=0.9,
70 | temperature=1e-2,
71 | )
72 | result = tokenizer.batch_decode(
73 | outputs.detach().cpu().numpy(), skip_special_tokens=True
74 | )[0]
75 | result = result[len(instruct) :]
76 | results.append(result)
77 | print(f"Instruction:{instruct}")
78 | print(f"Summary:{summary}")
79 | print(f"Generated:{result}")
80 | print("----------------------------------------")
81 |
82 | # compute metric
83 | rouge = metric.compute(predictions=results, references=summaries, use_stemmer=True)
84 |
85 | metrics = {metric: round(rouge[metric] * 100, 2) for metric in rouge.keys()}
86 |
87 | save_dir = os.path.join(experiment, "metrics")
88 | if not os.path.exists(save_dir):
89 | os.makedirs(save_dir)
90 |
91 | with open(os.path.join(save_dir, "metrics.pkl"), "wb") as handle:
92 | pickle.dump(metrics, handle)
93 |
94 | print(f"Completed experiment {peft_model_id}")
95 | print("----------------------------------------")
96 |
97 |
98 | if __name__ == "__main__":
99 | parser = argparse.ArgumentParser()
100 | parser.add_argument(
101 | "--experiment_dir",
102 | default="experiments/summarization_epochs-1_rank-64_dropout-0.1",
103 | )
104 |
105 | args = parser.parse_args()
106 | main(args)
107 |
--------------------------------------------------------------------------------
/mistral/prompts.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | import datasets
3 | from datasets import load_dataset
4 | from sklearn.model_selection import train_test_split
5 |
6 |
7 | ZERO_SHOT_CLASSIFIER_PROMPT = """Classify the sentence into one of 20 classes. The list of classes is provided below, where the classes are separated by commas:
8 |
9 | {newsgroup_classes}
10 |
11 | From the above list of classes, select only one class that the provided sentence can be classified into. The sentence will be delimited with triple backticks. Once again, only predict the class from the given list of classes. Do not predict anything else.
12 |
13 | ### Sentence: ```{sentence}```
14 | ### Class:
15 | """
16 |
17 | FEW_SHOT_CLASSIFIER_PROMPT = """Classify the sentence into one of 20 classes. The list of classes is provided below, where the classes are separated by commas:
18 |
19 | {newsgroup_classes}
20 |
21 | From the above list of classes, select only one class that the provided sentence can be classified into. Once again, only predict the class from the given list of classes. Do not predict anything else. The sentence will be delimited with triple backticks. To help you, examples are provided of sentence and the corresponding class they belong to.
22 |
23 | {few_shot_samples}
24 |
25 | ### Sentence: ```{sentence}```
26 | ### Class:
27 | """
28 |
29 | TRAINING_CLASSIFIER_PROMPT = """Classify the following sentence that is delimited with triple backticks.
30 |
31 | ### Sentence: ```{sentence}```
32 | ### Class: {label}
33 | """
34 |
35 | INFERENCE_CLASSIFIER_PROMPT = """Classify the following sentence that is delimited with triple backticks.
36 |
37 | ### Sentence: ```{sentence}```
38 | ### Class:
39 | """
40 |
41 | TRAINING_CLASSIFIER_PROMPT_v2 = """### Sentence:{sentence} ### Class:{label}"""
42 | INFERENCE_CLASSIFIER_PROMPT_v2 = """### Sentence:{sentence} ### Class:"""
43 |
44 | ZERO_SHOT_SUMMARIZATION_PROMPT = """Summarize the following dialogue that is delimited with triple backticks.
45 |
46 | ### Dialogue: ```{dialogue}```
47 | ### Summary:
48 | """
49 |
50 | FEW_SHOT_SUMMARIZATION_PROMPT = """Summarize the following dialogue that is delimited with triple backticks. To help you, examples of summarization are provided.
51 |
52 | {few_shot_samples}
53 |
54 | ### Dialogue: ```{dialogue}```
55 | ### Summary:
56 | """
57 |
58 | TRAINING_SUMMARIZATION_PROMPT = """Summarize the following dialogue that is delimited with triple backticks.
59 |
60 | ### Dialogue: ```{dialogue}```
61 | ### Summary: {summary}
62 | """
63 |
64 | TRAINING_SUMMARIZATION_PROMPT_v2 = """### Dialogue:{dialogue} ### Summary:{summary}"""
65 | INFERENCE_SUMMARIZATION_PROMPT_v2 = """### Dialogue:{dialogue} ### Summary:"""
66 |
67 | INFERENCE_SUMMARIZATION_PROMPT = """Summarize the following dialogue that is delimited with triple backticks.
68 |
69 | ### Dialogue: ```{dialogue}```
70 | ### Summary:
71 | """
72 |
73 |
74 | def get_newsgroup_instruction_data(mode, texts, labels):
75 | if mode == "train":
76 | prompt = TRAINING_CLASSIFIER_PROMPT_v2
77 | elif mode == "inference":
78 | prompt = INFERENCE_CLASSIFIER_PROMPT_v2
79 |
80 | instructions = []
81 |
82 | for text, label in zip(texts, labels):
83 | if mode == "train":
84 | example = prompt.format(
85 | sentence=text,
86 | label=label,
87 | )
88 | elif mode == "inference":
89 | example = prompt.format(
90 | sentence=text,
91 | )
92 | instructions.append(example)
93 |
94 | return instructions
95 |
96 |
97 | def clean_newsgroup_data(texts, labels):
98 | label2data = {}
99 | clean_data, clean_labels = [], []
100 | for data, label in zip(texts, labels):
101 | if isinstance(data, str) and isinstance(label, str):
102 | clean_data.append(data)
103 | clean_labels.append(label)
104 |
105 | if label not in label2data:
106 | label2data[label] = data
107 |
108 | return label2data, clean_data, clean_labels
109 |
110 |
111 | def get_newsgroup_data_for_ft(mode="train", train_sample_fraction=0.99):
112 | newsgroup_dataset = load_dataset("rungalileo/20_Newsgroups_Fixed")
113 | train_data = newsgroup_dataset["train"]["text"]
114 | train_labels = newsgroup_dataset["train"]["label"]
115 | label2data, train_data, train_labels = clean_newsgroup_data(
116 | train_data, train_labels
117 | )
118 |
119 | test_data = newsgroup_dataset["test"]["text"]
120 | test_labels = newsgroup_dataset["test"]["label"]
121 | _, test_data, test_labels = clean_newsgroup_data(test_data, test_labels)
122 |
123 | # sample n points from training data
124 | train_df = pd.DataFrame(data={"text": train_data, "label": train_labels})
125 | train_df, _ = train_test_split(
126 | train_df,
127 | train_size=train_sample_fraction,
128 | stratify=train_df["label"],
129 | random_state=42,
130 | )
131 | train_data = train_df["text"]
132 | train_labels = train_df["label"]
133 |
134 | train_instructions = get_newsgroup_instruction_data(mode, train_data, train_labels)
135 | test_instructions = get_newsgroup_instruction_data(mode, test_data, test_labels)
136 |
137 | train_dataset = datasets.Dataset.from_pandas(
138 | pd.DataFrame(
139 | data={
140 | "instructions": train_instructions,
141 | "labels": train_labels,
142 | }
143 | )
144 | )
145 | test_dataset = datasets.Dataset.from_pandas(
146 | pd.DataFrame(
147 | data={
148 | "instructions": test_instructions,
149 | "labels": test_labels,
150 | }
151 | )
152 | )
153 |
154 | return train_dataset, test_dataset
155 |
156 |
157 | def get_newsgroup_data():
158 | newsgroup_dataset = load_dataset("rungalileo/20_Newsgroups_Fixed")
159 | train_data = newsgroup_dataset["train"]["text"]
160 | train_labels = newsgroup_dataset["train"]["label"]
161 |
162 | label2data, clean_data, clean_labels = clean_newsgroup_data(
163 | train_data, train_labels
164 | )
165 | df = pd.DataFrame(data={"text": clean_data, "label": clean_labels})
166 |
167 | newsgroup_classes = df["label"].unique()
168 | newsgroup_classes = ", ".join(newsgroup_classes)
169 |
170 | few_shot_samples = ""
171 | for label, data in label2data.items():
172 | sample = f"Sentence: {data} \n Class: {label} \n\n"
173 | few_shot_samples += sample
174 |
175 | return newsgroup_classes, few_shot_samples, df
176 |
177 |
178 | def get_samsum_data():
179 | samsum_dataset = load_dataset("samsum")
180 | train_dataset = samsum_dataset["train"]
181 | dialogues = train_dataset["dialogue"][:2]
182 | summaries = train_dataset["summary"][:2]
183 |
184 | few_shot_samples = ""
185 | for dialogue, summary in zip(dialogues, summaries):
186 | sample = f"Sentence: {dialogue} \n Summary: {summary} \n\n"
187 | few_shot_samples += sample
188 |
189 | return few_shot_samples
190 |
--------------------------------------------------------------------------------
/mistral/run_lora.sh:
--------------------------------------------------------------------------------
1 | epochs=(2 5 10 20 30 50)
2 | lora_r=(2 4 8 16)
3 | dropout=(0.1 0.2 0.5)
4 |
5 | for (( epoch=0; epoch<6; epoch=epoch+1 )) do
6 | for ((r=0; r<4; r=r+1 )) do
7 | for (( d=0; d<3; d=d+1 )) do
8 | python mistral_summarization.py --lora_r ${lora_r[$r]} --epochs ${epochs[$epoch]} --dropout ${dropout[$d]} & wait
9 | done
10 | done
11 | done
12 |
--------------------------------------------------------------------------------
/mistral/sample_ablate.sh:
--------------------------------------------------------------------------------
1 | sample_fraction=(0.025 0.05 0.1)
2 |
3 | for (( sf=0; sf<3; sf=sf+1 )) do
4 | python mistral_classification.py --train_sample_fraction ${sample_fraction[$sf]} & wait
5 | done
6 |
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [tool.poetry]
2 | name = "llm-toolkit"
3 | version = "0.0.0"
4 | description = "LLM Finetuning resource hub + toolkit"
5 | authors = ["Benjamin Ye "]
6 | license = "Apache 2.0"
7 | readme = "README.md"
8 | packages = [{include = "llmtune"}]
9 | repository = "https://github.com/georgian-io/LLM-Finetuning-Toolkit"
10 | # homepage = ""
11 | # documentation = ""
12 | keywords = ["llm", "finetuning", "language models", "machine learning", "deep learning"]
13 | classifiers = [
14 | "Intended Audience :: Developers",
15 | "Intended Audience :: Science/Research",
16 | "Topic :: Scientific/Engineering :: Artificial Intelligence",
17 | ]
18 |
19 |
20 | [tool.poetry.scripts]
21 | llmtune = "llmtune.cli.toolkit:cli"
22 |
23 | [tool.poetry-dynamic-versioning]
24 | enable = true
25 | vcs = "git"
26 | style = "semver"
27 |
28 | [tool.poetry-dynamic-versioning.substitution]
29 | folders = [
30 | { path = "llmtune" }
31 | ]
32 |
33 | [tool.poetry.dependencies]
34 | python = ">=3.9, <=3.12"
35 | transformers = "~4.40.2"
36 | datasets = "^2.17.0"
37 | peft = "^0.8.2"
38 | pandas = "^2.2.0"
39 | numpy = "^1.26.4"
40 | ipdb = "^0.13.13"
41 | evaluate = "^0.4.1"
42 | wandb = "^0.16.3"
43 | einops = "^0.7.0"
44 | bitsandbytes = ">=0.43.2"
45 | nltk = "^3.8.1"
46 | accelerate = "^0.27.0"
47 | trl = "~0.8.6"
48 | rouge-score = "^0.1.2"
49 | absl-py = "^2.1.0"
50 | py7zr = "^0.20.8"
51 | tiktoken = "^0.6.0"
52 | ninja = "^1.11.1.1"
53 | packaging = "^23.2"
54 | sentencepiece = "^0.1.99"
55 | protobuf = "^4.25.2"
56 | ai21 = "^2.0.3"
57 | openai = "^1.12.0"
58 | ujson = "^5.9.0"
59 | pyyaml = "^6.0.1"
60 | ijson = "^3.2.3"
61 | rich = "^13.7.0"
62 | sqids = "^0.4.1"
63 | pydantic = "^2.6.1"
64 | typer = "^0.10.0"
65 | shellingham = "^1.5.4"
66 | langchain = "^0.2.5"
67 |
68 |
69 | [tool.poetry.group.dev.dependencies]
70 | ruff = "~0.3.5"
71 | pytest = "^8.1.1"
72 | pytest-cov = "^5.0.0"
73 | pytest-mock = "^3.14.0"
74 |
75 | [build-system]
76 | requires = ["poetry-core", "poetry-dynamic-versioning>=1.0.0,<2.0.0"]
77 | build-backend = "poetry_dynamic_versioning.backend"
78 |
79 | [tool.ruff]
80 | lint.ignore = ["C901", "E501", "E741", "F402", "F823" ]
81 | lint.select = ["C", "E", "F", "I", "W"]
82 | line-length = 119
83 | exclude = [
84 | "llama2",
85 | "mistral",
86 | ]
87 |
88 |
89 | [tool.ruff.lint.isort]
90 | lines-after-imports = 2
91 | known-first-party = ["llmtune"]
92 |
93 | [tool.ruff.format]
94 | quote-style = "double"
95 | indent-style = "space"
96 | skip-magic-trailing-comma = false
97 | line-ending = "auto"
98 |
99 | [tool.coverage.run]
100 | omit = [
101 | # Ignore UI for now as this might change quite often
102 | "llmtune/ui/*",
103 | "llmtune/utils/rich_print_utils.py"
104 | ]
105 |
106 | [tool.coverage.report]
107 | skip_empty = true
108 | exclude_also = [
109 | "pass",
110 | ]
111 |
112 | [tool.pytest.ini_options]
113 | addopts = "--cov=llmtune --cov-report term-missing"
114 |
--------------------------------------------------------------------------------
/test_utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/test_utils/__init__.py
--------------------------------------------------------------------------------
/test_utils/test_config.py:
--------------------------------------------------------------------------------
1 | """
2 | Defines a configuration that can be used for unit testing.
3 | """
4 |
5 | from llmtune.pydantic_models.config_model import (
6 | AblationConfig,
7 | BitsAndBytesConfig,
8 | Config,
9 | DataConfig,
10 | InferenceConfig,
11 | LoraConfig,
12 | ModelConfig,
13 | QaConfig,
14 | SftArgs,
15 | TrainingArgs,
16 | TrainingConfig,
17 | )
18 |
19 |
20 | def get_sample_config():
21 | """Function to return a comprehensive Config object for testing."""
22 | return Config(
23 | save_dir="./test",
24 | ablation=AblationConfig(
25 | use_ablate=False,
26 | ),
27 | model=ModelConfig(
28 | hf_model_ckpt="NousResearch/Llama-2-7b-hf",
29 | device_map="auto",
30 | torch_dtype="auto",
31 | quantize=False,
32 | bitsandbytes=BitsAndBytesConfig(
33 | load_in_8bit=False,
34 | load_in_4bit=False,
35 | bnb_4bit_compute_dtype="float32",
36 | bnb_4bit_quant_type="nf4",
37 | bnb_4bit_use_double_quant=True,
38 | ),
39 | ),
40 | lora=LoraConfig(
41 | r=8,
42 | task_type="CAUSAL_LM",
43 | lora_alpha=16,
44 | bias="none",
45 | lora_dropout=0.1,
46 | target_modules=None,
47 | fan_in_fan_out=False,
48 | ),
49 | training=TrainingConfig(
50 | training_args=TrainingArgs(
51 | num_train_epochs=1,
52 | per_device_train_batch_size=1,
53 | gradient_accumulation_steps=1,
54 | optim="adamw_8bit",
55 | learning_rate=2.0e-4,
56 | logging_steps=100,
57 | ),
58 | sft_args=SftArgs(max_seq_length=512, neftune_noise_alpha=None),
59 | ),
60 | inference=InferenceConfig(
61 | max_length=128,
62 | do_sample=False,
63 | num_beams=5,
64 | temperature=1.0,
65 | top_k=50,
66 | top_p=1.0,
67 | use_cache=True,
68 | ),
69 | data=DataConfig(
70 | file_type="json",
71 | path="path/to/dataset.json",
72 | prompt="Your prompt here {column_name}",
73 | prompt_stub="Stub for prompt {column_name}",
74 | train_size=0.9,
75 | test_size=0.1,
76 | train_test_split_seed=42,
77 | ),
78 | qa=QaConfig(
79 | llm_metrics=[
80 | "jaccard_similarity",
81 | "dot_product",
82 | "rouge_score",
83 | "word_overlap",
84 | "verb_percent",
85 | "adjective_percent",
86 | "noun_percent",
87 | "summary_length",
88 | ]
89 | ),
90 | )
91 |
--------------------------------------------------------------------------------
/tests/data/test_dataset_generator.py:
--------------------------------------------------------------------------------
1 | # TODO
2 |
--------------------------------------------------------------------------------
/tests/data/test_ingestor.py:
--------------------------------------------------------------------------------
1 | from unittest.mock import MagicMock, mock_open
2 |
3 | import pytest
4 | from datasets import Dataset
5 |
6 | from llmtune.data.ingestor import (
7 | CsvIngestor,
8 | HuggingfaceIngestor,
9 | JsonIngestor,
10 | JsonlIngestor,
11 | get_ingestor,
12 | )
13 |
14 |
15 | def test_get_ingestor():
16 | assert isinstance(get_ingestor("json")(""), JsonIngestor)
17 | assert isinstance(get_ingestor("jsonl")(""), JsonlIngestor)
18 | assert isinstance(get_ingestor("csv")(""), CsvIngestor)
19 | assert isinstance(get_ingestor("huggingface")(""), HuggingfaceIngestor)
20 |
21 | with pytest.raises(ValueError):
22 | get_ingestor("unsupported_type")
23 |
24 |
25 | def test_json_ingestor_to_dataset(mocker):
26 | mock_generator = mocker.patch("llmtune.data.ingestor.JsonIngestor._json_generator")
27 | mock_dataset = mocker.patch("llmtune.data.ingestor.Dataset")
28 | JsonIngestor("").to_dataset()
29 |
30 | mock_dataset.from_generator.assert_called_once_with(mock_generator)
31 |
32 |
33 | def test_jsonl_ingestor_to_dataset(mocker):
34 | mock_generator = mocker.patch("llmtune.data.ingestor.JsonlIngestor._jsonl_generator")
35 | mock_dataset = mocker.patch("llmtune.data.ingestor.Dataset")
36 | JsonlIngestor("").to_dataset()
37 |
38 | mock_dataset.from_generator.assert_called_once_with(mock_generator)
39 |
40 |
41 | def test_csv_ingestor_to_dataset(mocker):
42 | mock_generator = mocker.patch("llmtune.data.ingestor.CsvIngestor._csv_generator")
43 | mock_dataset = mocker.patch("llmtune.data.ingestor.Dataset")
44 | CsvIngestor("").to_dataset()
45 |
46 | mock_dataset.from_generator.assert_called_once_with(mock_generator)
47 |
48 |
49 | def test_huggingface_to_dataset(mocker):
50 | # Setup
51 | path = "some_path"
52 | ingestor = HuggingfaceIngestor(path)
53 | mock_concatenate_datasets = mocker.patch("llmtune.data.ingestor.concatenate_datasets")
54 | mock_load_dataset = mocker.patch("llmtune.data.ingestor.load_dataset")
55 | mock_dataset = mocker.patch("llmtune.data.ingestor.Dataset")
56 |
57 | # Configure the mock objects
58 | mock_dataset = MagicMock(spec=Dataset)
59 | mock_load_dataset.return_value = {"train": mock_dataset, "test": mock_dataset}
60 | mock_concatenate_datasets.return_value = mock_dataset
61 |
62 | # Execute
63 | result = ingestor.to_dataset()
64 |
65 | # Assert
66 | assert isinstance(result, Dataset)
67 | mock_load_dataset.assert_called_once_with(path)
68 | mock_concatenate_datasets.assert_called_once()
69 |
70 |
71 | @pytest.mark.parametrize(
72 | "file_content,expected_output",
73 | [
74 | (
75 | '[{"column1": "value1", "column2": "value2"}, {"column1": "value3", "column2": "value4"}]',
76 | [
77 | {"column1": "value1", "column2": "value2"},
78 | {"column1": "value3", "column2": "value4"},
79 | ],
80 | )
81 | ],
82 | )
83 | def test_json_ingestor_generator(file_content, expected_output, mocker):
84 | mocker.patch("builtins.open", mock_open(read_data=file_content))
85 | mocker.patch("ijson.items", side_effect=lambda f, prefix: iter(expected_output))
86 | ingestor = JsonIngestor("dummy_path.json")
87 |
88 | assert list(ingestor._json_generator()) == expected_output
89 |
90 |
91 | @pytest.mark.parametrize(
92 | "file_content,expected_output",
93 | [
94 | (
95 | '{"column1": "value1", "column2": "value2"}\n{"column1": "value3", "column2": "value4"}',
96 | [
97 | {"column1": "value1", "column2": "value2"},
98 | {"column1": "value3", "column2": "value4"},
99 | ],
100 | )
101 | ],
102 | )
103 | def test_jsonl_ingestor_generator(file_content, expected_output, mocker):
104 | mocker.patch("builtins.open", mock_open(read_data=file_content))
105 | mocker.patch(
106 | "ijson.items",
107 | side_effect=lambda f, prefix, multiple_values: (iter(expected_output) if multiple_values else iter([])),
108 | )
109 | ingestor = JsonlIngestor("dummy_path.jsonl")
110 |
111 | assert list(ingestor._jsonl_generator()) == expected_output
112 |
113 |
114 | @pytest.mark.parametrize(
115 | "file_content,expected_output",
116 | [
117 | (
118 | "column1,column2\nvalue1,value2\nvalue3,value4",
119 | [
120 | {"column1": "value1", "column2": "value2"},
121 | {"column1": "value3", "column2": "value4"},
122 | ],
123 | )
124 | ],
125 | )
126 | def test_csv_ingestor_generator(file_content, expected_output, mocker):
127 | mocker.patch("builtins.open", mock_open(read_data=file_content))
128 | ingestor = CsvIngestor("dummy_path.csv")
129 |
130 | assert list(ingestor._csv_generator()) == expected_output
131 |
--------------------------------------------------------------------------------
/tests/finetune/test_finetune_generics.py:
--------------------------------------------------------------------------------
1 | import pytest
2 |
3 | from llmtune.finetune.generics import Finetune
4 |
5 |
6 | class MockFinetune(Finetune):
7 | def finetune(self):
8 | return "finetuning complete"
9 |
10 | def save_model(self):
11 | return "model saved"
12 |
13 |
14 | def test_finetune_method():
15 | mock_finetuner = MockFinetune()
16 | result = mock_finetuner.finetune()
17 | assert result == "finetuning complete"
18 |
19 |
20 | def test_save_model_method():
21 | mock_finetuner = MockFinetune()
22 | result = mock_finetuner.save_model()
23 | assert result == "model saved"
24 |
25 |
26 | def test_finetune_abstract_class_instantiation():
27 | with pytest.raises(TypeError):
28 | _ = Finetune()
29 |
--------------------------------------------------------------------------------
/tests/finetune/test_finetune_lora.py:
--------------------------------------------------------------------------------
1 | from unittest.mock import MagicMock
2 |
3 | from transformers import BitsAndBytesConfig
4 |
5 | from llmtune.finetune.lora import LoRAFinetune
6 | from test_utils.test_config import get_sample_config
7 |
8 |
9 | def test_lora_finetune_initialization(mocker):
10 | """Test the initialization of LoRAFinetune with a sample configuration."""
11 | # Mock dependencies that LoRAFinetune might call during initialization
12 | mocker.patch("llmtune.finetune.lora.AutoModelForCausalLM.from_pretrained")
13 | mocker.patch("llmtune.finetune.lora.AutoTokenizer.from_pretrained")
14 | mock_lora_config = mocker.patch("llmtune.finetune.lora.LoraConfig")
15 | mocker.patch(
16 | "llmtune.finetune.lora.LoRAFinetune._inject_lora",
17 | return_value=None, # _inject_lora doesn't return a value
18 | )
19 |
20 | # Initialize LoRAFinetune with the sample configuration
21 | lora_finetune = LoRAFinetune(config=get_sample_config(), directory_helper=MagicMock())
22 | # Assertions to ensure that LoRAFinetune is initialized as expected
23 | mock_lora_config.assert_called_once_with(**get_sample_config().lora.model_dump())
24 |
25 | assert lora_finetune.config == get_sample_config(), "Configuration should match the input configuration"
26 |
27 |
28 | def test_model_and_tokenizer_loading(mocker):
29 | # Prepare the configuration
30 | sample_config = get_sample_config()
31 |
32 | mock_model = mocker.patch(
33 | "llmtune.finetune.lora.AutoModelForCausalLM.from_pretrained",
34 | return_value=MagicMock(),
35 | )
36 | mock_tokenizer = mocker.patch("llmtune.finetune.lora.AutoTokenizer.from_pretrained", return_value=MagicMock())
37 | mock_inject_lora = mocker.patch(
38 | "llmtune.finetune.lora.LoRAFinetune._inject_lora",
39 | return_value=None, # _inject_lora doesn't return a value
40 | )
41 | directory_helper = MagicMock()
42 | LoRAFinetune(config=sample_config, directory_helper=directory_helper)
43 |
44 | mock_model.assert_called_once_with(
45 | sample_config.model.hf_model_ckpt,
46 | quantization_config=BitsAndBytesConfig(),
47 | use_cache=False,
48 | device_map=sample_config.model.device_map,
49 | torch_dtype=sample_config.model.casted_torch_dtype,
50 | attn_implementation=sample_config.model.attn_implementation,
51 | )
52 |
53 | mock_tokenizer.assert_called_once_with(sample_config.model.hf_model_ckpt)
54 | mock_inject_lora.assert_called_once()
55 |
56 |
57 | def test_lora_injection(mocker):
58 | """Test the initialization of LoRAFinetune with a sample configuration."""
59 | # Mock dependencies that LoRAFinetune might call during initialization
60 | mocker.patch(
61 | "llmtune.finetune.lora.AutoModelForCausalLM.from_pretrained",
62 | return_value=MagicMock(),
63 | )
64 | mocker.patch(
65 | "llmtune.finetune.lora.AutoTokenizer.from_pretrained",
66 | return_value=MagicMock(),
67 | )
68 |
69 | mock_kbit = mocker.patch("llmtune.finetune.lora.prepare_model_for_kbit_training")
70 | mock_get_peft = mocker.patch("llmtune.finetune.lora.get_peft_model")
71 |
72 | # Initialize LoRAFinetune with the sample configuration
73 | LoRAFinetune(config=get_sample_config(), directory_helper=MagicMock())
74 |
75 | mock_kbit.assert_called_once()
76 | mock_get_peft.assert_called_once()
77 |
78 |
79 | def test_model_finetune(mocker):
80 | sample_config = get_sample_config()
81 |
82 | mocker.patch(
83 | "llmtune.finetune.lora.AutoModelForCausalLM.from_pretrained",
84 | return_value=MagicMock(),
85 | )
86 | mocker.patch("llmtune.finetune.lora.AutoTokenizer.from_pretrained", return_value=MagicMock())
87 | mocker.patch(
88 | "llmtune.finetune.lora.LoRAFinetune._inject_lora",
89 | return_value=None, # _inject_lora doesn't return a value
90 | )
91 |
92 | mock_trainer = mocker.MagicMock()
93 | mock_sft_trainer = mocker.patch("llmtune.finetune.lora.SFTTrainer", return_value=mock_trainer)
94 |
95 | directory_helper = MagicMock()
96 |
97 | mock_training_args = mocker.patch(
98 | "llmtune.finetune.lora.TrainingArguments",
99 | return_value=MagicMock(),
100 | )
101 |
102 | ft = LoRAFinetune(config=sample_config, directory_helper=directory_helper)
103 |
104 | mock_dataset = MagicMock()
105 | ft.finetune(mock_dataset)
106 |
107 | mock_training_args.assert_called_once_with(
108 | logging_dir="/logs",
109 | output_dir=ft._weights_path,
110 | report_to="none",
111 | **sample_config.training.training_args.model_dump(),
112 | )
113 |
114 | mock_sft_trainer.assert_called_once_with(
115 | model=ft.model,
116 | train_dataset=mock_dataset,
117 | peft_config=ft._lora_config,
118 | tokenizer=ft.tokenizer,
119 | packing=True,
120 | args=mocker.ANY, # You can replace this with the expected TrainingArguments if needed
121 | dataset_text_field="formatted_prompt",
122 | callbacks=mocker.ANY, # You can replace this with the expected callbacks if needed
123 | **sample_config.training.sft_args.model_dump(),
124 | )
125 |
126 | mock_trainer.train.assert_called_once()
127 |
128 |
129 | def test_save_model(mocker):
130 | # Prepare the configuration and directory helper
131 | sample_config = get_sample_config()
132 |
133 | # Mock dependencies that LoRAFinetune might call during initialization
134 | mocker.patch("llmtune.finetune.lora.AutoModelForCausalLM.from_pretrained")
135 |
136 | mock_tok = mocker.MagicMock()
137 | mocker.patch("llmtune.finetune.lora.AutoTokenizer.from_pretrained", return_value=mock_tok)
138 | mocker.patch(
139 | "llmtune.finetune.lora.LoRAFinetune._inject_lora",
140 | return_value=None,
141 | )
142 |
143 | directory_helper = MagicMock()
144 | directory_helper.save_paths.weights = "/path/to/weights"
145 |
146 | mock_trainer = mocker.MagicMock()
147 | mocker.patch("llmtune.finetune.lora.SFTTrainer", return_value=mock_trainer)
148 |
149 | ft = LoRAFinetune(config=sample_config, directory_helper=directory_helper)
150 |
151 | mock_dataset = MagicMock()
152 | ft.finetune(mock_dataset)
153 | ft.save_model()
154 |
155 | mock_tok.save_pretrained.assert_called_once_with("/path/to/weights")
156 | mock_trainer.model.save_pretrained.assert_called_once_with("/path/to/weights")
157 |
--------------------------------------------------------------------------------
/tests/inference/test_inference_generics.py:
--------------------------------------------------------------------------------
1 | import pytest
2 |
3 | from llmtune.inference.generics import Inference
4 |
5 |
6 | class MockInference(Inference):
7 | def infer_one(self, prompt: str):
8 | return "inferred one"
9 |
10 | def infer_all(self):
11 | return "inferred all"
12 |
13 |
14 | def test_infer_one():
15 | mock_inference = MockInference()
16 | result = mock_inference.infer_one("")
17 | assert result == "inferred one"
18 |
19 |
20 | def test_infer_all():
21 | mock_inference = MockInference()
22 | result = mock_inference.infer_all()
23 | assert result == "inferred all"
24 |
25 |
26 | def test_inference_abstract_class_instantiation():
27 | with pytest.raises(TypeError):
28 | _ = Inference()
29 |
--------------------------------------------------------------------------------
/tests/inference/test_inference_lora.py:
--------------------------------------------------------------------------------
1 | from unittest.mock import MagicMock
2 |
3 | from datasets import Dataset
4 | from transformers import BitsAndBytesConfig
5 |
6 | from llmtune.inference.lora import LoRAInference
7 | from test_utils.test_config import get_sample_config # Adjust import path as needed
8 |
9 |
10 | def test_lora_inference_initialization(mocker):
11 | # Mock dependencies
12 | mock_model = mocker.patch(
13 | "llmtune.inference.lora.AutoPeftModelForCausalLM.from_pretrained",
14 | return_value=MagicMock(),
15 | )
16 | mock_tokenizer = mocker.patch("llmtune.inference.lora.AutoTokenizer.from_pretrained", return_value=MagicMock())
17 |
18 | # Mock configuration and directory helper
19 | config = get_sample_config()
20 | dir_helper = MagicMock(save_paths=MagicMock(results="results_dir", weights="weights_dir"))
21 | test_dataset = Dataset.from_dict(
22 | {
23 | "formatted_prompt": ["prompt1", "prompt2"],
24 | "label_column_name": ["label1", "label2"],
25 | }
26 | )
27 |
28 | _ = LoRAInference(
29 | test_dataset=test_dataset,
30 | label_column_name="label_column_name",
31 | config=config,
32 | dir_helper=dir_helper,
33 | )
34 |
35 | mock_model.assert_called_once_with(
36 | "weights_dir",
37 | torch_dtype=config.model.casted_torch_dtype,
38 | quantization_config=BitsAndBytesConfig(),
39 | device_map=config.model.device_map,
40 | attn_implementation=config.model.attn_implementation,
41 | )
42 | mock_tokenizer.assert_called_once_with("weights_dir", device_map=config.model.device_map)
43 |
44 |
45 | def test_infer_all(mocker):
46 | mocker.patch(
47 | "llmtune.inference.lora.AutoPeftModelForCausalLM.from_pretrained",
48 | return_value=MagicMock(),
49 | )
50 | mocker.patch("llmtune.inference.lora.AutoTokenizer.from_pretrained", return_value=MagicMock())
51 | mocker.patch("os.makedirs")
52 | mock_open = mocker.patch("builtins.open", mocker.mock_open())
53 | mock_csv_writer = mocker.patch("csv.writer")
54 |
55 | mock_infer_one = mocker.patch.object(LoRAInference, "infer_one", return_value="predicted")
56 |
57 | config = get_sample_config()
58 | dir_helper = MagicMock(save_paths=MagicMock(results="results_dir", weights="weights_dir"))
59 | test_dataset = Dataset.from_dict({"formatted_prompt": ["prompt1"], "label_column_name": ["label1"]})
60 |
61 | inference = LoRAInference(
62 | test_dataset=test_dataset,
63 | label_column_name="label_column_name",
64 | config=config,
65 | dir_helper=dir_helper,
66 | )
67 | inference.infer_all()
68 |
69 | mock_infer_one.assert_called_once_with("prompt1")
70 | mock_open.assert_called_once_with("results_dir/results.csv", "w", newline="")
71 | mock_csv_writer.assert_called() # You might want to add more specific assertions based on your CSV structure
72 |
--------------------------------------------------------------------------------
/tests/qa/test_metric_suite.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from pandas import DataFrame
3 |
4 | from llmtune.qa.metric_suite import LLMMetricSuite
5 | from llmtune.qa.qa_metrics import LLMQaMetric
6 |
7 |
8 | @pytest.fixture
9 | def mock_rich_ui(mocker):
10 | return mocker.patch("llmtune.ui.rich_ui.RichUI")
11 |
12 |
13 | @pytest.fixture
14 | def example_data():
15 | data = {
16 | "Prompt": ["What is 2+2?", "What is the capital of France?"],
17 | "Ground Truth": ["4", "Paris"],
18 | "Predicted": ["3", "Paris"],
19 | }
20 | return DataFrame(data)
21 |
22 |
23 | @pytest.fixture
24 | def mock_csv(mocker, example_data):
25 | mocker.patch("pandas.read_csv", return_value=example_data)
26 |
27 |
28 | class MockQaMetric(LLMQaMetric):
29 | @property
30 | def metric_name(self):
31 | return "Mock Accuracy"
32 |
33 | def get_metric(self, prompt, ground_truth, model_pred) -> int:
34 | return int(ground_truth == model_pred)
35 |
36 |
37 | @pytest.fixture
38 | def mock_metrics():
39 | return [MockQaMetric()]
40 |
41 |
42 | def test_from_csv(mock_metrics, mock_csv):
43 | suite = LLMMetricSuite.from_csv("dummy_path.csv", mock_metrics)
44 | assert len(suite.metrics) == 1
45 | assert suite.prompts[0] == "What is 2+2?"
46 |
47 |
48 | def test_compute_metrics(mock_metrics, mock_csv):
49 | suite = LLMMetricSuite.from_csv("dummy_path.csv", mock_metrics)
50 | results = suite.compute_metrics()
51 | assert results["Mock Accuracy"] == [0, 1] # Expected results from the mock test
52 |
53 |
54 | def test_save_metric_results(mock_metrics, mocker, mock_csv):
55 | mocker.patch("pandas.DataFrame.to_csv")
56 | test_suite = LLMMetricSuite.from_csv("dummy_path.csv", mock_metrics)
57 | test_suite.save_metric_results("dummy_save_path.csv")
58 | assert DataFrame.to_csv.called # Check if pandas DataFrame to_csv was called
59 |
60 |
61 | def test_print_metric_results(capfd, example_data):
62 | metrics = [MockQaMetric()]
63 | suite = LLMMetricSuite(metrics, example_data["Prompt"], example_data["Ground Truth"], example_data["Predicted"])
64 | suite.print_metric_results()
65 | out, err = capfd.readouterr()
66 |
67 | assert "0.5000" in out
68 | assert "0.5000" in out
69 | assert "0.7071" in out
70 |
--------------------------------------------------------------------------------
/tests/qa/test_qa_metrics.py:
--------------------------------------------------------------------------------
1 | import pytest
2 |
3 | from llmtune.qa.qa_metrics import (
4 | AdjectivePercentMetric,
5 | DotProductSimilarityMetric,
6 | JaccardSimilarityMetric,
7 | JSONValidityMetric,
8 | LengthMetric,
9 | NounPercentMetric,
10 | RougeScoreMetric,
11 | VerbPercentMetric,
12 | WordOverlapMetric,
13 | )
14 |
15 |
16 | @pytest.mark.parametrize(
17 | "test_class,expected_type",
18 | [
19 | (LengthMetric, int),
20 | (JaccardSimilarityMetric, float),
21 | (DotProductSimilarityMetric, float),
22 | (RougeScoreMetric, float),
23 | (WordOverlapMetric, float),
24 | (VerbPercentMetric, float),
25 | (AdjectivePercentMetric, float),
26 | (NounPercentMetric, float),
27 | (JSONValidityMetric, float),
28 | ],
29 | )
30 | def test_metric_return_type(test_class, expected_type):
31 | test_instance = test_class()
32 | prompt = "This is a test prompt."
33 | ground_truth = "This is a ground truth sentence."
34 | model_prediction = "This is a model predicted sentence."
35 |
36 | # Depending on the test class, the output could be different.
37 | metric_result = test_instance.get_metric(prompt, ground_truth, model_prediction)
38 | assert isinstance(
39 | metric_result, expected_type
40 | ), f"Expected return type {expected_type}, but got {type(metric_result)}."
41 |
42 |
43 | def test_length_metric():
44 | test = LengthMetric()
45 | result = test.get_metric("prompt", "short text", "longer text")
46 | assert result == 1, "Length difference should be 1."
47 |
48 |
49 | def test_jaccard_similarity_metric():
50 | test = JaccardSimilarityMetric()
51 | result = test.get_metric("prompt", "hello world", "world hello")
52 | assert result == 1.0, "Jaccard similarity should be 1.0 for the same words in different orders."
53 |
54 |
55 | def test_dot_product_similarity_metric():
56 | test = DotProductSimilarityMetric()
57 | result = test.get_metric("prompt", "data", "data")
58 | assert result >= 0, "Dot product similarity should be non-negative."
59 |
60 |
61 | def test_rouge_score_metric():
62 | test = RougeScoreMetric()
63 | result = test.get_metric("prompt", "the quick brown fox", "the quick brown fox jumps over the lazy dog")
64 | assert result >= 0, "ROUGE precision should be non-negative."
65 |
66 |
67 | def test_word_overlap_metric():
68 | test = WordOverlapMetric()
69 | result = test.get_metric("prompt", "jump over the moon", "jump around the sun")
70 | assert result >= 0, "Word overlap percentage should be non-negative."
71 |
72 |
73 | def test_verb_percent_metric():
74 | test = VerbPercentMetric()
75 | result = test.get_metric("prompt", "He eats", "He is eating")
76 | assert result >= 0, "Verb percentage should be non-negative."
77 |
78 |
79 | def test_adjective_percent_metric():
80 | test = AdjectivePercentMetric()
81 | result = test.get_metric("prompt", "It is beautiful", "It is extremely beautiful")
82 | assert result >= 0, "Adjective percentage should be non-negative."
83 |
84 |
85 | def test_noun_percent_metric():
86 | test = NounPercentMetric()
87 | result = test.get_metric("prompt", "The cat", "The cat and the dog")
88 | assert result >= 0, "Noun percentage should be non-negative."
89 |
90 |
91 | @pytest.mark.parametrize(
92 | "input_string,expected_value",
93 | [
94 | ('{"Answer": "The cat"}', 1),
95 | ("{'Answer': 'The cat'}", 0), # Double quotes are required in json
96 | ('{"Answer": "The cat",}', 0),
97 | ('{"Answer": "The cat", "test": "case"}', 1),
98 | ('```json\n{"Answer": "The cat"}\n```', 1), # this json block can still be processed
99 | ('Here is an example of a JSON block: {"Answer": "The cat"}', 0),
100 | ],
101 | )
102 | def test_json_valid_metric(input_string: str, expected_value: float):
103 | test = JSONValidityMetric()
104 | result = test.get_metric("prompt", "The cat", input_string)
105 | assert result == expected_value, f"JSON validity should be {expected_value} but got {result}."
106 |
--------------------------------------------------------------------------------
/tests/qa/test_qa_tests.py:
--------------------------------------------------------------------------------
1 | import pytest
2 |
3 | from llmtune.qa.qa_tests import (
4 | JSONValidityTest,
5 | )
6 |
7 |
8 | @pytest.mark.parametrize(
9 | "test_class",
10 | [
11 | JSONValidityTest,
12 | ],
13 | )
14 | def test_test_return_bool(test_class):
15 | """Test to ensure that all tests return pass/fail boolean value."""
16 | test_instance = test_class()
17 | model_prediction = "This is a model predicted sentence."
18 |
19 | metric_result = test_instance.test(model_prediction)
20 | assert isinstance(metric_result, bool), f"Expected return type bool, but got {type(metric_result)}."
21 |
22 |
23 | @pytest.mark.parametrize(
24 | "input_string,expected_value",
25 | [
26 | ('{"Answer": "The cat"}', True),
27 | ("{'Answer': 'The cat'}", False), # Double quotes are required in json
28 | ('{"Answer": "The cat",}', False), # Trailing comma is not allowed
29 | ('{"Answer": "The cat", "test": "case"}', True),
30 | ('```json\n{"Answer": "The cat"}\n```', True), # this json block can still be processed
31 | ('Here is an example of a JSON block: {"Answer": "The cat"}', False),
32 | ],
33 | )
34 | def test_json_valid_metric(input_string: str, expected_value: bool):
35 | test = JSONValidityTest()
36 | result = test.test(input_string)
37 | assert result == expected_value, f"JSON validity should be {expected_value} but got {result}."
38 |
--------------------------------------------------------------------------------
/tests/qa/test_test_suite.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 |
3 | import pytest
4 | from pandas import DataFrame
5 |
6 | from llmtune.qa.qa_tests import LLMQaTest
7 | from llmtune.qa.test_suite import LLMTestSuite, TestBank, all_same
8 |
9 |
10 | @pytest.fixture
11 | def mock_rich_ui(mocker):
12 | return mocker.patch("llmtune.ui.rich_ui.RichUI")
13 |
14 |
15 | @pytest.fixture
16 | def example_data():
17 | data = {
18 | "Prompt": ["What is 2+2?", "What is the capital of France?"],
19 | "Ground Truth": ["4", "Paris"],
20 | "Predicted": ["3", "Paris"],
21 | }
22 | return DataFrame(data)
23 |
24 |
25 | @pytest.fixture
26 | def mock_csv(mocker, example_data):
27 | mocker.patch("pandas.read_csv", return_value=example_data)
28 |
29 |
30 | # mock a LoRAInference object that returns a value when .infer_one() is called
31 | class MockLoRAInference:
32 | def infer_one(self, prompt: str) -> str:
33 | return "Paris"
34 |
35 |
36 | @pytest.mark.parametrize(
37 | "data, expected",
38 | [
39 | (["a", "a", "a"], True),
40 | (["a", "b", "a"], False),
41 | ([], False),
42 | ],
43 | )
44 | def test_all_same(data, expected):
45 | assert all_same(data) == expected
46 |
47 |
48 | @pytest.fixture
49 | def mock_cases():
50 | return [
51 | {"prompt": "What is the capital of France?"},
52 | {"prompt": "What is the capital of Germany?"},
53 | ]
54 |
55 |
56 | class MockQaTest(LLMQaTest):
57 | @property
58 | def test_name(self):
59 | return "Mock Accuracy"
60 |
61 | def test(self, model_pred) -> bool:
62 | return model_pred == "Paris"
63 |
64 |
65 | @pytest.fixture
66 | def mock_test_banks(mock_cases):
67 | return [
68 | TestBank(MockQaTest(), mock_cases, "mock_file_name_stem"),
69 | TestBank(MockQaTest(), mock_cases, "mock_file_name_stem"),
70 | ]
71 |
72 |
73 | def test_test_bank_save_test_results(mocker, mock_cases):
74 | mocker.patch("pandas.DataFrame.to_csv")
75 | test_bank = TestBank(MockQaTest(), mock_cases, "mock_file_name_stem")
76 | test_bank.generate_results(MockLoRAInference())
77 | test_bank.save_test_results(Path("mock/dir/path"))
78 | assert DataFrame.to_csv.called # Check if pandas DataFrame to_csv was called
79 |
80 |
81 | def test_test_suite_save_test_results(mocker, mock_test_banks):
82 | mocker.patch("pandas.DataFrame.to_csv")
83 | ts = LLMTestSuite(mock_test_banks)
84 | ts.run_inference(MockLoRAInference())
85 | ts.save_test_results(Path("mock/dir/path/doesnt/exist"))
86 | assert DataFrame.to_csv.called # Check if pandas DataFrame to_csv was called
87 |
88 |
89 | def test_test_suite_from_dir():
90 | ts = LLMTestSuite.from_dir("examples/test_suite")
91 | ts.run_inference(MockLoRAInference())
92 |
93 |
94 | def test_test_suite_print_results(capfd, mock_test_banks):
95 | ts = LLMTestSuite(mock_test_banks)
96 | ts.run_inference(MockLoRAInference())
97 | ts.print_test_results()
98 | out, _ = capfd.readouterr()
99 | assert "Mock Accuracy" in out
100 |
--------------------------------------------------------------------------------
/tests/test_ablation_utils.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from pydantic import BaseModel
3 |
4 | from llmtune.utils.ablation_utils import (
5 | generate_permutations,
6 | get_annotation,
7 | get_model_field_type,
8 | get_types_from_dict,
9 | patch_with_permutation,
10 | )
11 |
12 |
13 | # Mocks or fixtures for models and data if necessary
14 | class BarModel(BaseModel):
15 | baz: list
16 | qux: str
17 |
18 |
19 | class ConfigModel(BaseModel):
20 | foo: int
21 | bar: BarModel
22 |
23 |
24 | @pytest.fixture
25 | def example_yaml():
26 | return {"foo": 10, "bar": {"baz": [[1, 2, 3], [4, 5]], "qux": ["hello", "world"]}}
27 |
28 |
29 | def test_get_types_from_dict(example_yaml):
30 | expected = {"foo": (int, None), "bar.baz": (list, list), "bar.qux": (list, str)}
31 | assert get_types_from_dict(example_yaml) == expected
32 |
33 |
34 | def test_get_annotation():
35 | key = "foo"
36 | assert get_annotation(key, ConfigModel) == int
37 |
38 | key_nested = "bar.qux"
39 | # Assuming you adjust your FakeModel or real implementation for nested annotations correctly
40 | assert get_annotation(key_nested, ConfigModel) == str
41 |
42 |
43 | def test_get_model_field_type_from_typing_list():
44 | from typing import List
45 |
46 | annotation = List[int]
47 | assert get_model_field_type(annotation) == list
48 |
49 |
50 | def test_get_model_field_type_from_union():
51 | from typing import Union
52 |
53 | annotation = Union[int, str]
54 | # Assuming the first type is picked from Union for simplicity
55 | assert get_model_field_type(annotation) == int
56 |
57 |
58 | def test_patch_with_permutation():
59 | old_dict = {"foo": {"bar": 10, "baz": 20}}
60 | permutation_dict = {"foo.bar": 100}
61 | expected = {"foo": {"bar": 100, "baz": 20}}
62 | assert patch_with_permutation(old_dict, permutation_dict) == expected
63 |
64 |
65 | def test_generate_permutations(example_yaml):
66 | results = generate_permutations(example_yaml, ConfigModel)
67 | assert isinstance(results, list)
68 |
69 | # Calculate expected permutations
70 | expected_permutation_count = len(example_yaml["bar"]["baz"]) * len(example_yaml["bar"]["qux"])
71 | assert len(results) == expected_permutation_count
72 |
73 | for _, result_dict in enumerate(results):
74 | assert result_dict["foo"] == example_yaml["foo"] # 'foo' should remain unchanged
75 | assert result_dict["bar"]["baz"] in example_yaml["bar"]["baz"]
76 | assert result_dict["bar"]["qux"] in example_yaml["bar"]["qux"]
77 |
--------------------------------------------------------------------------------
/tests/test_cli.py:
--------------------------------------------------------------------------------
1 | from unittest.mock import patch
2 |
3 | from typer.testing import CliRunner
4 |
5 | from llmtune.cli.toolkit import app, cli
6 |
7 |
8 | runner = CliRunner()
9 |
10 |
11 | def test_run_command():
12 | # Test the `run` command
13 | with patch("llmtune.cli.toolkit.run_one_experiment") as mock_run_one_experiment:
14 | result = runner.invoke(app, ["run", "./llmtune/config.yml"])
15 | assert result.exit_code == 0
16 | mock_run_one_experiment.assert_called_once()
17 |
18 |
19 | def test_generate_config_command():
20 | # Test the `generate config` command
21 | with patch("llmtune.cli.toolkit.shutil.copy") as mock_copy:
22 | result = runner.invoke(app, ["generate", "config"])
23 | assert result.exit_code == 0
24 | mock_copy.assert_called_once()
25 |
26 |
27 | def test_cli():
28 | # Test the `cli` function
29 | with patch("llmtune.cli.toolkit.app") as mock_app:
30 | cli()
31 | mock_app.assert_called_once()
32 |
--------------------------------------------------------------------------------
/tests/test_directory_helper.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/tests/test_directory_helper.py
--------------------------------------------------------------------------------
/tests/test_version.py:
--------------------------------------------------------------------------------
1 | from llmtune import __version__
2 |
3 |
4 | def test_version():
5 | assert __version__ == "0.0.0"
6 |
--------------------------------------------------------------------------------
Performance
64 |
65 | We evaluated Mistral under the following conditions:
66 |
67 | * Tasks & Datasets:
68 | * Classification: News Group dataset, which is a 20-way classification task.
69 | * Summarization: Samsum dataset.
70 | * Experiments:
71 | * Sample Efficiency vs Accuracy
72 | * Zero-Shot prompting vs Few-Shot prompting vs PeFT QLoRA (for summarization)
73 | * Training config:
74 | * Epochs: 5 (for classification)
75 | * Epochs: 1 (for summarization)
76 | * Mistral-7B:
77 | * PeFT technique: QLoRA
78 | * Learning rate: 2e-4
79 | * Hardware:
80 | * Cloud provider: AWC EC2
81 | * Instance: g5.2xlarge
82 |
83 | #### Classification ####
84 |
85 | Table 1: Sample Efficiency vs Accuracy
86 |
87 | |Training samples (fraction) | Mistral Base-7B |
88 | |:--------------------------:|:---------------:|
89 | |266 (2.5%) |49.30 |
90 | |533 (5%) |48.14 |
91 | |1066 (10%) |58.41 |
92 | |2666 (25%) |64.89 |
93 | |5332 (50%) |73.10 |
94 | |10664 (100%) |74.36 |
95 |
96 |
97 | The above table shows how performance of Mistral-7B track with the number of training samples. The last row of the table demonstrates the performance when the entire dataset is used.
98 |
99 |
100 |
101 | #### Summarization ####
102 |
103 | Table 2: Zero-Shot prompting vs Few-Shot prompting vs Fine-Tuning QLoRA
104 |
105 | |Method | Mistral-7B Zero-Shot | Mistral-7B Few-Shot | Fine-Tuning + QLoRA |
106 | |:-------------:|:---------------------:|:--------------------:|:-------------------:|
107 | |ROUGE-1 (in %) |32.77 |38.87 |53.61 |
108 | |ROUGE-2 (in %) |10.64 |16.71 |29.28 |
109 |
110 |
111 | Looking at the ROUGE-1 and ROUGE-2 scores, we see that Mistral-7B’s performance increases from zero-shot to few-shot to fine-tuning settings.
112 |
113 |
114 | Table 3: Mistral vs Other LLMs
115 |
116 | |Model | Flan-T5-Base Full Fine-Tune | Flan-T5-Large | Falcon-7B | RP-3B | RP-7B | Llama2-7B | Llama2-13B | Mistral-7B |
117 | |:-------------:|:---------------------------:|:-------------:|:---------:|:-----:|:-----:|:---------:|:----------:|:----------:|
118 | |ROUGE-1 (in %) |47.23 |49.21 |52.18 |47.75 |49.96 |51.71 |52.97 |53.61 |
119 | |ROUGE-2 (in %) |21.01 |23.39 |27.84 |23.53 |25.94 |26.86 |28.32 |29.28 |
120 |
121 |
122 | Mistral-7B achieves the best results, even when compared with Falcon-7B and Llama2-7B. This makes Mistral-7B, in our opinion, the best model to leverage in the 7B parameter space.
123 |
124 |
125 |
--------------------------------------------------------------------------------
/mistral/baseline_inference.sh:
--------------------------------------------------------------------------------
1 | #python mistral_baseline_inference.py --task_type classification --prompt_type zero-shot & wait
2 | #python mistral_baseline_inference.py --task_type classification --prompt_type few-shot & wait
3 | python mistral_baseline_inference.py --task_type summarization --prompt_type zero-shot --use_flash_attention & wait
4 | python mistral_baseline_inference.py --task_type summarization --prompt_type few-shot --use_flash_attention
5 |
--------------------------------------------------------------------------------
/mistral/mistral_baseline_inference.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | import evaluate
4 | import warnings
5 | import json
6 | import pandas as pd
7 | import pickle
8 | import torch
9 | import time
10 |
11 | from datasets import load_dataset
12 | from prompts import (
13 | ZERO_SHOT_CLASSIFIER_PROMPT,
14 | FEW_SHOT_CLASSIFIER_PROMPT,
15 | ZERO_SHOT_SUMMARIZATION_PROMPT,
16 | FEW_SHOT_SUMMARIZATION_PROMPT,
17 | get_newsgroup_data,
18 | get_samsum_data,
19 | )
20 | from transformers import (
21 | AutoTokenizer,
22 | AutoModelForCausalLM,
23 | BitsAndBytesConfig,
24 | )
25 | from sklearn.metrics import (
26 | accuracy_score,
27 | f1_score,
28 | precision_score,
29 | recall_score,
30 | )
31 |
32 | metric = evaluate.load("rouge")
33 | warnings.filterwarnings("ignore")
34 |
35 |
36 | def compute_metrics_decoded(decoded_labs, decoded_preds, args):
37 | if args.task_type == "summarization":
38 | rouge = metric.compute(
39 | predictions=decoded_preds, references=decoded_labs, use_stemmer=True
40 | )
41 | metrics = {metric: round(rouge[metric] * 100.0, 3) for metric in rouge.keys()}
42 |
43 | elif args.task_type == "classification":
44 | metrics = {
45 | "micro_f1": f1_score(decoded_labs, decoded_preds, average="micro"),
46 | "macro_f1": f1_score(decoded_labs, decoded_preds, average="macro"),
47 | "precision": precision_score(decoded_labs, decoded_preds, average="micro"),
48 | "recall": recall_score(decoded_labs, decoded_preds, average="micro"),
49 | "accuracy": accuracy_score(decoded_labs, decoded_preds),
50 | }
51 |
52 | return metrics
53 |
54 |
55 | def main(args):
56 | save_dir = os.path.join(
57 | "baseline_results", args.pretrained_ckpt, args.task_type, args.prompt_type
58 | )
59 | if not os.path.exists(save_dir):
60 | os.makedirs(save_dir)
61 |
62 | if args.task_type == "classification":
63 | dataset = load_dataset("rungalileo/20_Newsgroups_Fixed")
64 | test_dataset = dataset["test"]
65 | test_data, test_labels = test_dataset["text"], test_dataset["label"]
66 |
67 | newsgroup_classes, few_shot_samples, _ = get_newsgroup_data()
68 |
69 | elif args.task_type == "summarization":
70 | dataset = load_dataset("samsum")
71 | test_dataset = dataset["test"]
72 | test_data, test_labels = test_dataset["dialogue"], test_dataset["summary"]
73 |
74 | few_shot_samples = get_samsum_data()
75 |
76 | if args.prompt_type == "zero-shot":
77 | if args.task_type == "classification":
78 | prompt = ZERO_SHOT_CLASSIFIER_PROMPT
79 | elif args.task_type == "summarization":
80 | prompt = ZERO_SHOT_SUMMARIZATION_PROMPT
81 |
82 | elif args.prompt_type == "few-shot":
83 | if args.task_type == "classification":
84 | prompt = FEW_SHOT_CLASSIFIER_PROMPT
85 | elif args.task_type == "summarization":
86 | prompt = FEW_SHOT_SUMMARIZATION_PROMPT
87 |
88 | # BitsAndBytesConfig int-4 config
89 | bnb_config = BitsAndBytesConfig(
90 | load_in_4bit=True,
91 | bnb_4bit_use_double_quant=True,
92 | bnb_4bit_quant_type="nf4",
93 | bnb_4bit_compute_dtype=torch.bfloat16,
94 | )
95 |
96 | # Load model and tokenizer
97 | model = AutoModelForCausalLM.from_pretrained(
98 | args.pretrained_ckpt,
99 | quantization_config=bnb_config,
100 | use_cache=False,
101 | device_map="auto",
102 | use_flash_attention_2=args.use_flash_attention,
103 | )
104 | model.config.pretraining_tp = 1
105 |
106 | tokenizer = AutoTokenizer.from_pretrained(args.pretrained_ckpt)
107 | tokenizer.pad_token = tokenizer.eos_token
108 | tokenizer.padding_side = "right"
109 |
110 | results = []
111 | good_data, good_labels = [], []
112 | ctr = 0
113 | # for instruct, label in zip(instructions, labels):
114 | for data, label in zip(test_data, test_labels):
115 | if not isinstance(data, str):
116 | continue
117 | if not isinstance(label, str):
118 | continue
119 |
120 | # example = instruct[:-len(label)] # remove the answer from the example
121 | if args.prompt_type == "zero-shot":
122 | if args.task_type == "classification":
123 | example = prompt.format(
124 | newsgroup_classes=newsgroup_classes,
125 | sentence=data,
126 | )
127 | elif args.task_type == "summarization":
128 | example = prompt.format(
129 | dialogue=data,
130 | )
131 |
132 | elif args.prompt_type == "few-shot":
133 | if args.task_type == "classification":
134 | example = prompt.format(
135 | newsgroup_classes=newsgroup_classes,
136 | few_shot_samples=few_shot_samples,
137 | sentence=data,
138 | )
139 | elif args.task_type == "summarization":
140 | example = prompt.format(
141 | few_shot_samples=few_shot_samples,
142 | dialogue=data,
143 | )
144 |
145 | input_ids = tokenizer(
146 | example, return_tensors="pt", truncation=True
147 | ).input_ids.cuda()
148 |
149 | with torch.inference_mode():
150 | outputs = model.generate(
151 | input_ids=input_ids,
152 | max_new_tokens=20 if args.task_type == "classification" else 50,
153 | do_sample=True,
154 | top_p=0.95,
155 | temperature=1e-3,
156 | )
157 | result = tokenizer.batch_decode(
158 | outputs.detach().cpu().numpy(), skip_special_tokens=True
159 | )[0]
160 |
161 | # Extract the generated text, and do basic processing
162 | result = result[len(example) :].replace("\n", "").lstrip().rstrip()
163 | results.append(result)
164 | good_labels.append(label)
165 | good_data.append(data)
166 |
167 | print(f"Example {ctr}/{len(test_data)} | GT: {label} | Pred: {result}")
168 | ctr += 1
169 |
170 | metrics = compute_metrics_decoded(good_labels, results, args)
171 | print(metrics)
172 | metrics["predictions"] = results
173 | metrics["labels"] = good_labels
174 | metrics["data"] = good_data
175 |
176 | with open(os.path.join(save_dir, "metrics.pkl"), "wb") as handle:
177 | pickle.dump(metrics, handle)
178 |
179 | print(f"Completed experiment {save_dir}")
180 | print("----------------------------------------")
181 |
182 |
183 | if __name__ == "__main__":
184 | parser = argparse.ArgumentParser()
185 | parser.add_argument("--pretrained_ckpt", default="mistralai/Mistral-7B-v0.1")
186 | parser.add_argument("--prompt_type", default="zero-shot")
187 | parser.add_argument("--task_type", default="classification")
188 | parser.add_argument("--use_flash_attention", action=argparse.BooleanOptionalAction)
189 | args = parser.parse_args()
190 |
191 | main(args)
192 |
--------------------------------------------------------------------------------
/mistral/mistral_classification.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import torch
3 | import os
4 | import numpy as np
5 | import pandas as pd
6 | import pickle
7 |
8 |
9 | from peft import (
10 | LoraConfig,
11 | prepare_model_for_kbit_training,
12 | get_peft_model,
13 | )
14 | from transformers import (
15 | AutoTokenizer,
16 | AutoModelForCausalLM,
17 | BitsAndBytesConfig,
18 | TrainingArguments,
19 | )
20 | from trl import SFTTrainer
21 |
22 | from prompts import get_newsgroup_data_for_ft
23 |
24 |
25 | def main(args):
26 | train_dataset, test_dataset = get_newsgroup_data_for_ft(
27 | mode="train", train_sample_fraction=args.train_sample_fraction
28 | )
29 | print(f"Sample fraction:{args.train_sample_fraction}")
30 | print(f"Training samples:{train_dataset.shape}")
31 |
32 | # BitsAndBytesConfig int-4 config
33 | bnb_config = BitsAndBytesConfig(
34 | load_in_4bit=True,
35 | bnb_4bit_use_double_quant=True,
36 | bnb_4bit_quant_type="nf4",
37 | bnb_4bit_compute_dtype=torch.bfloat16,
38 | )
39 |
40 | # Load model and tokenizer
41 | model = AutoModelForCausalLM.from_pretrained(
42 | args.pretrained_ckpt,
43 | quantization_config=bnb_config,
44 | use_cache=False,
45 | device_map="auto",
46 | )
47 | model.config.pretraining_tp = 1
48 |
49 | tokenizer = AutoTokenizer.from_pretrained(args.pretrained_ckpt)
50 | tokenizer.pad_token = tokenizer.eos_token
51 | tokenizer.padding_side = "right"
52 |
53 | # LoRA config based on QLoRA paper
54 | peft_config = LoraConfig(
55 | lora_alpha=16,
56 | lora_dropout=args.dropout,
57 | r=args.lora_r,
58 | bias="none",
59 | task_type="CAUSAL_LM",
60 | )
61 |
62 | # prepare model for training
63 | model = prepare_model_for_kbit_training(model)
64 | model = get_peft_model(model, peft_config)
65 |
66 | results_dir = f"experiments/classification-sampleFraction-{args.train_sample_fraction}_epochs-{args.epochs}_rank-{args.lora_r}_dropout-{args.dropout}"
67 |
68 | training_args = TrainingArguments(
69 | output_dir=results_dir,
70 | logging_dir=f"{results_dir}/logs",
71 | num_train_epochs=args.epochs,
72 | per_device_train_batch_size=4,
73 | gradient_accumulation_steps=2,
74 | gradient_checkpointing=True,
75 | optim="paged_adamw_32bit",
76 | logging_steps=100,
77 | learning_rate=2e-4,
78 | bf16=True,
79 | tf32=True,
80 | max_grad_norm=0.3,
81 | warmup_ratio=0.03,
82 | lr_scheduler_type="constant",
83 | report_to="none",
84 | # disable_tqdm=True # disable tqdm since with packing values are in correct
85 | )
86 |
87 | max_seq_length = 512 # max sequence length for model and packing of the dataset
88 |
89 | trainer = SFTTrainer(
90 | model=model,
91 | train_dataset=train_dataset,
92 | peft_config=peft_config,
93 | max_seq_length=max_seq_length,
94 | tokenizer=tokenizer,
95 | packing=True,
96 | args=training_args,
97 | dataset_text_field="instructions",
98 | )
99 |
100 | trainer_stats = trainer.train()
101 | train_loss = trainer_stats.training_loss
102 | print(f"Training loss:{train_loss}")
103 |
104 | peft_model_id = f"{results_dir}/assets"
105 | trainer.model.save_pretrained(peft_model_id)
106 | tokenizer.save_pretrained(peft_model_id)
107 |
108 | with open(f"{results_dir}/results.pkl", "wb") as handle:
109 | run_result = [
110 | args.epochs,
111 | args.lora_r,
112 | args.dropout,
113 | train_loss,
114 | ]
115 | pickle.dump(run_result, handle)
116 | print("Experiment over")
117 |
118 |
119 | if __name__ == "__main__":
120 | parser = argparse.ArgumentParser()
121 | parser.add_argument("--pretrained_ckpt", default="mistralai/Mistral-7B-v0.1")
122 | parser.add_argument("--lora_r", default=8, type=int)
123 | parser.add_argument("--epochs", default=5, type=int)
124 | parser.add_argument("--dropout", default=0.1, type=float)
125 | parser.add_argument("--train_sample_fraction", default=0.99, type=float)
126 |
127 | args = parser.parse_args()
128 | main(args)
129 |
--------------------------------------------------------------------------------
/mistral/mistral_classification_inference.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import torch
3 | import os
4 | import pandas as pd
5 | import evaluate
6 | import pickle
7 | import warnings
8 | from tqdm import tqdm
9 |
10 | from peft import AutoPeftModelForCausalLM
11 | from transformers import AutoTokenizer
12 | from sklearn.metrics import (
13 | accuracy_score,
14 | f1_score,
15 | precision_score,
16 | recall_score,
17 | )
18 |
19 | from prompts import get_newsgroup_data_for_ft
20 |
21 | metric = evaluate.load("rouge")
22 | warnings.filterwarnings("ignore")
23 |
24 |
25 | def main(args):
26 | _, test_dataset = get_newsgroup_data_for_ft(mode="inference")
27 |
28 | experiment = args.experiment_dir
29 | peft_model_id = f"{experiment}/assets"
30 |
31 | # load base LLM model and tokenizer
32 | model = AutoPeftModelForCausalLM.from_pretrained(
33 | peft_model_id,
34 | low_cpu_mem_usage=True,
35 | torch_dtype=torch.float16,
36 | load_in_4bit=True,
37 | )
38 |
39 | model.eval()
40 |
41 | tokenizer = AutoTokenizer.from_pretrained(peft_model_id)
42 |
43 | results = []
44 | oom_examples = []
45 | instructions, labels = test_dataset["instructions"], test_dataset["labels"]
46 |
47 | for instruct, label in tqdm(zip(instructions, labels)):
48 | input_ids = tokenizer(
49 | instruct, return_tensors="pt", truncation=True
50 | ).input_ids.cuda()
51 |
52 | with torch.inference_mode():
53 | try:
54 | outputs = model.generate(
55 | input_ids=input_ids,
56 | max_new_tokens=20,
57 | do_sample=True,
58 | top_p=0.95,
59 | temperature=1e-3,
60 | )
61 | result = tokenizer.batch_decode(
62 | outputs.detach().cpu().numpy(), skip_special_tokens=True
63 | )[0]
64 | result = result[len(instruct) :]
65 | print(result)
66 | except:
67 | result = ""
68 | oom_examples.append(input_ids.shape[-1])
69 |
70 | results.append(result)
71 |
72 | metrics = {
73 | "micro_f1": f1_score(labels, results, average="micro"),
74 | "macro_f1": f1_score(labels, results, average="macro"),
75 | "precision": precision_score(labels, results, average="micro"),
76 | "recall": recall_score(labels, results, average="micro"),
77 | "accuracy": accuracy_score(labels, results),
78 | "oom_examples": oom_examples,
79 | }
80 | print(metrics)
81 |
82 | save_dir = os.path.join(experiment, "metrics")
83 | if not os.path.exists(save_dir):
84 | os.makedirs(save_dir)
85 |
86 | with open(os.path.join(save_dir, "metrics.pkl"), "wb") as handle:
87 | pickle.dump(metrics, handle)
88 |
89 | print(f"Completed experiment {peft_model_id}")
90 | print("----------------------------------------")
91 |
92 |
93 | if __name__ == "__main__":
94 | parser = argparse.ArgumentParser()
95 | parser.add_argument(
96 | "--experiment_dir",
97 | default="experiments/classification-sampleFraction-0.1_epochs-5_rank-8_dropout-0.1",
98 | )
99 |
100 | args = parser.parse_args()
101 | main(args)
102 |
--------------------------------------------------------------------------------
/mistral/mistral_summarization.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import torch
3 | import os
4 | import numpy as np
5 | import pandas as pd
6 | import pickle
7 | import datasets
8 | from datasets import Dataset, load_dataset
9 |
10 | from peft import (
11 | LoraConfig,
12 | prepare_model_for_kbit_training,
13 | get_peft_model,
14 | )
15 | from transformers import (
16 | AutoTokenizer,
17 | AutoModelForCausalLM,
18 | BitsAndBytesConfig,
19 | TrainingArguments,
20 | )
21 | from trl import SFTTrainer
22 |
23 | from prompts import TRAINING_SUMMARIZATION_PROMPT_v2
24 |
25 |
26 | def prepare_instructions(dialogues, summaries):
27 | instructions = []
28 |
29 | prompt = TRAINING_SUMMARIZATION_PROMPT_v2
30 |
31 | for dialogue, summary in zip(dialogues, summaries):
32 | example = prompt.format(
33 | dialogue=dialogue,
34 | summary=summary,
35 | )
36 | instructions.append(example)
37 |
38 | return instructions
39 |
40 |
41 | def prepare_samsum_data():
42 | dataset = load_dataset("samsum")
43 | train_dataset = dataset["train"]
44 | val_dataset = dataset["test"]
45 |
46 | dialogues = train_dataset["dialogue"]
47 | summaries = train_dataset["summary"]
48 | train_instructions = prepare_instructions(dialogues, summaries)
49 | train_dataset = datasets.Dataset.from_pandas(
50 | pd.DataFrame(data={"instructions": train_instructions})
51 | )
52 |
53 | return train_dataset
54 |
55 |
56 | def main(args):
57 | train_dataset = prepare_samsum_data()
58 |
59 | # BitsAndBytesConfig int-4 config
60 | bnb_config = BitsAndBytesConfig(
61 | load_in_4bit=True,
62 | bnb_4bit_use_double_quant=True,
63 | bnb_4bit_quant_type="nf4",
64 | bnb_4bit_compute_dtype=torch.bfloat16,
65 | )
66 |
67 | # Load model and tokenizer
68 | model = AutoModelForCausalLM.from_pretrained(
69 | args.pretrained_ckpt,
70 | quantization_config=bnb_config,
71 | use_cache=False,
72 | device_map="auto",
73 | )
74 | model.config.pretraining_tp = 1
75 |
76 | tokenizer = AutoTokenizer.from_pretrained(args.pretrained_ckpt)
77 | tokenizer.pad_token = tokenizer.eos_token
78 | tokenizer.padding_side = "right"
79 |
80 | # LoRA config based on QLoRA paper
81 | peft_config = LoraConfig(
82 | lora_alpha=16,
83 | lora_dropout=args.dropout,
84 | r=args.lora_r,
85 | bias="none",
86 | task_type="CAUSAL_LM",
87 | )
88 |
89 | # prepare model for training
90 | model = prepare_model_for_kbit_training(model)
91 | model = get_peft_model(model, peft_config)
92 |
93 | results_dir = f"experiments/summarization_epochs-{args.epochs}_rank-{args.lora_r}_dropout-{args.dropout}"
94 |
95 | training_args = TrainingArguments(
96 | output_dir=results_dir,
97 | logging_dir=f"{results_dir}/logs",
98 | num_train_epochs=args.epochs,
99 | per_device_train_batch_size=4,
100 | gradient_accumulation_steps=2,
101 | gradient_checkpointing=True,
102 | optim="paged_adamw_32bit",
103 | logging_steps=100,
104 | learning_rate=2e-4,
105 | bf16=True,
106 | tf32=True,
107 | max_grad_norm=0.3,
108 | warmup_ratio=0.03,
109 | lr_scheduler_type="constant",
110 | report_to="none",
111 | # disable_tqdm=True # disable tqdm since with packing values are in correct
112 | )
113 |
114 | max_seq_length = 512 # max sequence length for model and packing of the dataset
115 |
116 | trainer = SFTTrainer(
117 | model=model,
118 | train_dataset=train_dataset,
119 | peft_config=peft_config,
120 | max_seq_length=max_seq_length,
121 | tokenizer=tokenizer,
122 | packing=True,
123 | args=training_args,
124 | dataset_text_field="instructions",
125 | )
126 |
127 | trainer_stats = trainer.train()
128 | train_loss = trainer_stats.training_loss
129 | print(f"Training loss:{train_loss}")
130 |
131 | peft_model_id = f"{results_dir}/assets"
132 | trainer.model.save_pretrained(peft_model_id)
133 | tokenizer.save_pretrained(peft_model_id)
134 |
135 | with open(f"{results_dir}/results.pkl", "wb") as handle:
136 | run_result = [
137 | args.epochs,
138 | args.lora_r,
139 | args.dropout,
140 | train_loss,
141 | ]
142 | pickle.dump(run_result, handle)
143 | print("Experiment over")
144 |
145 |
146 | if __name__ == "__main__":
147 | parser = argparse.ArgumentParser()
148 | parser.add_argument("--pretrained_ckpt", default="mistralai/Mistral-7B-v0.1")
149 | parser.add_argument("--lora_r", default=64, type=int)
150 | parser.add_argument("--epochs", default=1, type=int)
151 | parser.add_argument("--dropout", default=0.1, type=float)
152 |
153 | args = parser.parse_args()
154 | main(args)
155 |
--------------------------------------------------------------------------------
/mistral/mistral_summarization_inference.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import torch
3 | import os
4 | import pandas as pd
5 | import evaluate
6 | from datasets import load_dataset
7 | import pickle
8 | import warnings
9 |
10 | from peft import AutoPeftModelForCausalLM
11 | from transformers import AutoTokenizer
12 |
13 | from prompts import INFERENCE_SUMMARIZATION_PROMPT_v2
14 |
15 | metric = evaluate.load("rouge")
16 | warnings.filterwarnings("ignore")
17 |
18 |
19 | def prepare_instructions(dialogues, summaries):
20 | instructions = []
21 |
22 | prompt = INFERENCE_SUMMARIZATION_PROMPT_v2
23 |
24 | for dialogue, summary in zip(dialogues, summaries):
25 | example = prompt.format(
26 | dialogue=dialogue,
27 | )
28 | instructions.append(example)
29 |
30 | return instructions
31 |
32 |
33 | def prepare_samsum_data():
34 | dataset = load_dataset("samsum")
35 | val_dataset = dataset["test"]
36 |
37 | dialogues = val_dataset["dialogue"]
38 | summaries = val_dataset["summary"]
39 | val_instructions = prepare_instructions(dialogues, summaries)
40 |
41 | return val_instructions, summaries
42 |
43 |
44 | def main(args):
45 | val_instructions, summaries = prepare_samsum_data()
46 |
47 | experiment = args.experiment_dir
48 | peft_model_id = f"{experiment}/assets"
49 |
50 | # load base LLM model and tokenizer
51 | model = AutoPeftModelForCausalLM.from_pretrained(
52 | peft_model_id,
53 | low_cpu_mem_usage=True,
54 | torch_dtype=torch.float16,
55 | load_in_4bit=True,
56 | )
57 | tokenizer = AutoTokenizer.from_pretrained(peft_model_id)
58 |
59 | results = []
60 | for instruct, summary in zip(val_instructions, summaries):
61 | input_ids = tokenizer(
62 | instruct, return_tensors="pt", truncation=True
63 | ).input_ids.cuda()
64 | with torch.inference_mode():
65 | outputs = model.generate(
66 | input_ids=input_ids,
67 | max_new_tokens=100,
68 | do_sample=True,
69 | top_p=0.9,
70 | temperature=1e-2,
71 | )
72 | result = tokenizer.batch_decode(
73 | outputs.detach().cpu().numpy(), skip_special_tokens=True
74 | )[0]
75 | result = result[len(instruct) :]
76 | results.append(result)
77 | print(f"Instruction:{instruct}")
78 | print(f"Summary:{summary}")
79 | print(f"Generated:{result}")
80 | print("----------------------------------------")
81 |
82 | # compute metric
83 | rouge = metric.compute(predictions=results, references=summaries, use_stemmer=True)
84 |
85 | metrics = {metric: round(rouge[metric] * 100, 2) for metric in rouge.keys()}
86 |
87 | save_dir = os.path.join(experiment, "metrics")
88 | if not os.path.exists(save_dir):
89 | os.makedirs(save_dir)
90 |
91 | with open(os.path.join(save_dir, "metrics.pkl"), "wb") as handle:
92 | pickle.dump(metrics, handle)
93 |
94 | print(f"Completed experiment {peft_model_id}")
95 | print("----------------------------------------")
96 |
97 |
98 | if __name__ == "__main__":
99 | parser = argparse.ArgumentParser()
100 | parser.add_argument(
101 | "--experiment_dir",
102 | default="experiments/summarization_epochs-1_rank-64_dropout-0.1",
103 | )
104 |
105 | args = parser.parse_args()
106 | main(args)
107 |
--------------------------------------------------------------------------------
/mistral/prompts.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | import datasets
3 | from datasets import load_dataset
4 | from sklearn.model_selection import train_test_split
5 |
6 |
7 | ZERO_SHOT_CLASSIFIER_PROMPT = """Classify the sentence into one of 20 classes. The list of classes is provided below, where the classes are separated by commas:
8 |
9 | {newsgroup_classes}
10 |
11 | From the above list of classes, select only one class that the provided sentence can be classified into. The sentence will be delimited with triple backticks. Once again, only predict the class from the given list of classes. Do not predict anything else.
12 |
13 | ### Sentence: ```{sentence}```
14 | ### Class:
15 | """
16 |
17 | FEW_SHOT_CLASSIFIER_PROMPT = """Classify the sentence into one of 20 classes. The list of classes is provided below, where the classes are separated by commas:
18 |
19 | {newsgroup_classes}
20 |
21 | From the above list of classes, select only one class that the provided sentence can be classified into. Once again, only predict the class from the given list of classes. Do not predict anything else. The sentence will be delimited with triple backticks. To help you, examples are provided of sentence and the corresponding class they belong to.
22 |
23 | {few_shot_samples}
24 |
25 | ### Sentence: ```{sentence}```
26 | ### Class:
27 | """
28 |
29 | TRAINING_CLASSIFIER_PROMPT = """Classify the following sentence that is delimited with triple backticks.
30 |
31 | ### Sentence: ```{sentence}```
32 | ### Class: {label}
33 | """
34 |
35 | INFERENCE_CLASSIFIER_PROMPT = """Classify the following sentence that is delimited with triple backticks.
36 |
37 | ### Sentence: ```{sentence}```
38 | ### Class:
39 | """
40 |
41 | TRAINING_CLASSIFIER_PROMPT_v2 = """### Sentence:{sentence} ### Class:{label}"""
42 | INFERENCE_CLASSIFIER_PROMPT_v2 = """### Sentence:{sentence} ### Class:"""
43 |
44 | ZERO_SHOT_SUMMARIZATION_PROMPT = """Summarize the following dialogue that is delimited with triple backticks.
45 |
46 | ### Dialogue: ```{dialogue}```
47 | ### Summary:
48 | """
49 |
50 | FEW_SHOT_SUMMARIZATION_PROMPT = """Summarize the following dialogue that is delimited with triple backticks. To help you, examples of summarization are provided.
51 |
52 | {few_shot_samples}
53 |
54 | ### Dialogue: ```{dialogue}```
55 | ### Summary:
56 | """
57 |
58 | TRAINING_SUMMARIZATION_PROMPT = """Summarize the following dialogue that is delimited with triple backticks.
59 |
60 | ### Dialogue: ```{dialogue}```
61 | ### Summary: {summary}
62 | """
63 |
64 | TRAINING_SUMMARIZATION_PROMPT_v2 = """### Dialogue:{dialogue} ### Summary:{summary}"""
65 | INFERENCE_SUMMARIZATION_PROMPT_v2 = """### Dialogue:{dialogue} ### Summary:"""
66 |
67 | INFERENCE_SUMMARIZATION_PROMPT = """Summarize the following dialogue that is delimited with triple backticks.
68 |
69 | ### Dialogue: ```{dialogue}```
70 | ### Summary:
71 | """
72 |
73 |
74 | def get_newsgroup_instruction_data(mode, texts, labels):
75 | if mode == "train":
76 | prompt = TRAINING_CLASSIFIER_PROMPT_v2
77 | elif mode == "inference":
78 | prompt = INFERENCE_CLASSIFIER_PROMPT_v2
79 |
80 | instructions = []
81 |
82 | for text, label in zip(texts, labels):
83 | if mode == "train":
84 | example = prompt.format(
85 | sentence=text,
86 | label=label,
87 | )
88 | elif mode == "inference":
89 | example = prompt.format(
90 | sentence=text,
91 | )
92 | instructions.append(example)
93 |
94 | return instructions
95 |
96 |
97 | def clean_newsgroup_data(texts, labels):
98 | label2data = {}
99 | clean_data, clean_labels = [], []
100 | for data, label in zip(texts, labels):
101 | if isinstance(data, str) and isinstance(label, str):
102 | clean_data.append(data)
103 | clean_labels.append(label)
104 |
105 | if label not in label2data:
106 | label2data[label] = data
107 |
108 | return label2data, clean_data, clean_labels
109 |
110 |
111 | def get_newsgroup_data_for_ft(mode="train", train_sample_fraction=0.99):
112 | newsgroup_dataset = load_dataset("rungalileo/20_Newsgroups_Fixed")
113 | train_data = newsgroup_dataset["train"]["text"]
114 | train_labels = newsgroup_dataset["train"]["label"]
115 | label2data, train_data, train_labels = clean_newsgroup_data(
116 | train_data, train_labels
117 | )
118 |
119 | test_data = newsgroup_dataset["test"]["text"]
120 | test_labels = newsgroup_dataset["test"]["label"]
121 | _, test_data, test_labels = clean_newsgroup_data(test_data, test_labels)
122 |
123 | # sample n points from training data
124 | train_df = pd.DataFrame(data={"text": train_data, "label": train_labels})
125 | train_df, _ = train_test_split(
126 | train_df,
127 | train_size=train_sample_fraction,
128 | stratify=train_df["label"],
129 | random_state=42,
130 | )
131 | train_data = train_df["text"]
132 | train_labels = train_df["label"]
133 |
134 | train_instructions = get_newsgroup_instruction_data(mode, train_data, train_labels)
135 | test_instructions = get_newsgroup_instruction_data(mode, test_data, test_labels)
136 |
137 | train_dataset = datasets.Dataset.from_pandas(
138 | pd.DataFrame(
139 | data={
140 | "instructions": train_instructions,
141 | "labels": train_labels,
142 | }
143 | )
144 | )
145 | test_dataset = datasets.Dataset.from_pandas(
146 | pd.DataFrame(
147 | data={
148 | "instructions": test_instructions,
149 | "labels": test_labels,
150 | }
151 | )
152 | )
153 |
154 | return train_dataset, test_dataset
155 |
156 |
157 | def get_newsgroup_data():
158 | newsgroup_dataset = load_dataset("rungalileo/20_Newsgroups_Fixed")
159 | train_data = newsgroup_dataset["train"]["text"]
160 | train_labels = newsgroup_dataset["train"]["label"]
161 |
162 | label2data, clean_data, clean_labels = clean_newsgroup_data(
163 | train_data, train_labels
164 | )
165 | df = pd.DataFrame(data={"text": clean_data, "label": clean_labels})
166 |
167 | newsgroup_classes = df["label"].unique()
168 | newsgroup_classes = ", ".join(newsgroup_classes)
169 |
170 | few_shot_samples = ""
171 | for label, data in label2data.items():
172 | sample = f"Sentence: {data} \n Class: {label} \n\n"
173 | few_shot_samples += sample
174 |
175 | return newsgroup_classes, few_shot_samples, df
176 |
177 |
178 | def get_samsum_data():
179 | samsum_dataset = load_dataset("samsum")
180 | train_dataset = samsum_dataset["train"]
181 | dialogues = train_dataset["dialogue"][:2]
182 | summaries = train_dataset["summary"][:2]
183 |
184 | few_shot_samples = ""
185 | for dialogue, summary in zip(dialogues, summaries):
186 | sample = f"Sentence: {dialogue} \n Summary: {summary} \n\n"
187 | few_shot_samples += sample
188 |
189 | return few_shot_samples
190 |
--------------------------------------------------------------------------------
/mistral/run_lora.sh:
--------------------------------------------------------------------------------
1 | epochs=(2 5 10 20 30 50)
2 | lora_r=(2 4 8 16)
3 | dropout=(0.1 0.2 0.5)
4 |
5 | for (( epoch=0; epoch<6; epoch=epoch+1 )) do
6 | for ((r=0; r<4; r=r+1 )) do
7 | for (( d=0; d<3; d=d+1 )) do
8 | python mistral_summarization.py --lora_r ${lora_r[$r]} --epochs ${epochs[$epoch]} --dropout ${dropout[$d]} & wait
9 | done
10 | done
11 | done
12 |
--------------------------------------------------------------------------------
/mistral/sample_ablate.sh:
--------------------------------------------------------------------------------
1 | sample_fraction=(0.025 0.05 0.1)
2 |
3 | for (( sf=0; sf<3; sf=sf+1 )) do
4 | python mistral_classification.py --train_sample_fraction ${sample_fraction[$sf]} & wait
5 | done
6 |
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [tool.poetry]
2 | name = "llm-toolkit"
3 | version = "0.0.0"
4 | description = "LLM Finetuning resource hub + toolkit"
5 | authors = ["Benjamin Ye "]
6 | license = "Apache 2.0"
7 | readme = "README.md"
8 | packages = [{include = "llmtune"}]
9 | repository = "https://github.com/georgian-io/LLM-Finetuning-Toolkit"
10 | # homepage = ""
11 | # documentation = ""
12 | keywords = ["llm", "finetuning", "language models", "machine learning", "deep learning"]
13 | classifiers = [
14 | "Intended Audience :: Developers",
15 | "Intended Audience :: Science/Research",
16 | "Topic :: Scientific/Engineering :: Artificial Intelligence",
17 | ]
18 |
19 |
20 | [tool.poetry.scripts]
21 | llmtune = "llmtune.cli.toolkit:cli"
22 |
23 | [tool.poetry-dynamic-versioning]
24 | enable = true
25 | vcs = "git"
26 | style = "semver"
27 |
28 | [tool.poetry-dynamic-versioning.substitution]
29 | folders = [
30 | { path = "llmtune" }
31 | ]
32 |
33 | [tool.poetry.dependencies]
34 | python = ">=3.9, <=3.12"
35 | transformers = "~4.40.2"
36 | datasets = "^2.17.0"
37 | peft = "^0.8.2"
38 | pandas = "^2.2.0"
39 | numpy = "^1.26.4"
40 | ipdb = "^0.13.13"
41 | evaluate = "^0.4.1"
42 | wandb = "^0.16.3"
43 | einops = "^0.7.0"
44 | bitsandbytes = ">=0.43.2"
45 | nltk = "^3.8.1"
46 | accelerate = "^0.27.0"
47 | trl = "~0.8.6"
48 | rouge-score = "^0.1.2"
49 | absl-py = "^2.1.0"
50 | py7zr = "^0.20.8"
51 | tiktoken = "^0.6.0"
52 | ninja = "^1.11.1.1"
53 | packaging = "^23.2"
54 | sentencepiece = "^0.1.99"
55 | protobuf = "^4.25.2"
56 | ai21 = "^2.0.3"
57 | openai = "^1.12.0"
58 | ujson = "^5.9.0"
59 | pyyaml = "^6.0.1"
60 | ijson = "^3.2.3"
61 | rich = "^13.7.0"
62 | sqids = "^0.4.1"
63 | pydantic = "^2.6.1"
64 | typer = "^0.10.0"
65 | shellingham = "^1.5.4"
66 | langchain = "^0.2.5"
67 |
68 |
69 | [tool.poetry.group.dev.dependencies]
70 | ruff = "~0.3.5"
71 | pytest = "^8.1.1"
72 | pytest-cov = "^5.0.0"
73 | pytest-mock = "^3.14.0"
74 |
75 | [build-system]
76 | requires = ["poetry-core", "poetry-dynamic-versioning>=1.0.0,<2.0.0"]
77 | build-backend = "poetry_dynamic_versioning.backend"
78 |
79 | [tool.ruff]
80 | lint.ignore = ["C901", "E501", "E741", "F402", "F823" ]
81 | lint.select = ["C", "E", "F", "I", "W"]
82 | line-length = 119
83 | exclude = [
84 | "llama2",
85 | "mistral",
86 | ]
87 |
88 |
89 | [tool.ruff.lint.isort]
90 | lines-after-imports = 2
91 | known-first-party = ["llmtune"]
92 |
93 | [tool.ruff.format]
94 | quote-style = "double"
95 | indent-style = "space"
96 | skip-magic-trailing-comma = false
97 | line-ending = "auto"
98 |
99 | [tool.coverage.run]
100 | omit = [
101 | # Ignore UI for now as this might change quite often
102 | "llmtune/ui/*",
103 | "llmtune/utils/rich_print_utils.py"
104 | ]
105 |
106 | [tool.coverage.report]
107 | skip_empty = true
108 | exclude_also = [
109 | "pass",
110 | ]
111 |
112 | [tool.pytest.ini_options]
113 | addopts = "--cov=llmtune --cov-report term-missing"
114 |
--------------------------------------------------------------------------------
/test_utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/test_utils/__init__.py
--------------------------------------------------------------------------------
/test_utils/test_config.py:
--------------------------------------------------------------------------------
1 | """
2 | Defines a configuration that can be used for unit testing.
3 | """
4 |
5 | from llmtune.pydantic_models.config_model import (
6 | AblationConfig,
7 | BitsAndBytesConfig,
8 | Config,
9 | DataConfig,
10 | InferenceConfig,
11 | LoraConfig,
12 | ModelConfig,
13 | QaConfig,
14 | SftArgs,
15 | TrainingArgs,
16 | TrainingConfig,
17 | )
18 |
19 |
20 | def get_sample_config():
21 | """Function to return a comprehensive Config object for testing."""
22 | return Config(
23 | save_dir="./test",
24 | ablation=AblationConfig(
25 | use_ablate=False,
26 | ),
27 | model=ModelConfig(
28 | hf_model_ckpt="NousResearch/Llama-2-7b-hf",
29 | device_map="auto",
30 | torch_dtype="auto",
31 | quantize=False,
32 | bitsandbytes=BitsAndBytesConfig(
33 | load_in_8bit=False,
34 | load_in_4bit=False,
35 | bnb_4bit_compute_dtype="float32",
36 | bnb_4bit_quant_type="nf4",
37 | bnb_4bit_use_double_quant=True,
38 | ),
39 | ),
40 | lora=LoraConfig(
41 | r=8,
42 | task_type="CAUSAL_LM",
43 | lora_alpha=16,
44 | bias="none",
45 | lora_dropout=0.1,
46 | target_modules=None,
47 | fan_in_fan_out=False,
48 | ),
49 | training=TrainingConfig(
50 | training_args=TrainingArgs(
51 | num_train_epochs=1,
52 | per_device_train_batch_size=1,
53 | gradient_accumulation_steps=1,
54 | optim="adamw_8bit",
55 | learning_rate=2.0e-4,
56 | logging_steps=100,
57 | ),
58 | sft_args=SftArgs(max_seq_length=512, neftune_noise_alpha=None),
59 | ),
60 | inference=InferenceConfig(
61 | max_length=128,
62 | do_sample=False,
63 | num_beams=5,
64 | temperature=1.0,
65 | top_k=50,
66 | top_p=1.0,
67 | use_cache=True,
68 | ),
69 | data=DataConfig(
70 | file_type="json",
71 | path="path/to/dataset.json",
72 | prompt="Your prompt here {column_name}",
73 | prompt_stub="Stub for prompt {column_name}",
74 | train_size=0.9,
75 | test_size=0.1,
76 | train_test_split_seed=42,
77 | ),
78 | qa=QaConfig(
79 | llm_metrics=[
80 | "jaccard_similarity",
81 | "dot_product",
82 | "rouge_score",
83 | "word_overlap",
84 | "verb_percent",
85 | "adjective_percent",
86 | "noun_percent",
87 | "summary_length",
88 | ]
89 | ),
90 | )
91 |
--------------------------------------------------------------------------------
/tests/data/test_dataset_generator.py:
--------------------------------------------------------------------------------
1 | # TODO
2 |
--------------------------------------------------------------------------------
/tests/data/test_ingestor.py:
--------------------------------------------------------------------------------
1 | from unittest.mock import MagicMock, mock_open
2 |
3 | import pytest
4 | from datasets import Dataset
5 |
6 | from llmtune.data.ingestor import (
7 | CsvIngestor,
8 | HuggingfaceIngestor,
9 | JsonIngestor,
10 | JsonlIngestor,
11 | get_ingestor,
12 | )
13 |
14 |
15 | def test_get_ingestor():
16 | assert isinstance(get_ingestor("json")(""), JsonIngestor)
17 | assert isinstance(get_ingestor("jsonl")(""), JsonlIngestor)
18 | assert isinstance(get_ingestor("csv")(""), CsvIngestor)
19 | assert isinstance(get_ingestor("huggingface")(""), HuggingfaceIngestor)
20 |
21 | with pytest.raises(ValueError):
22 | get_ingestor("unsupported_type")
23 |
24 |
25 | def test_json_ingestor_to_dataset(mocker):
26 | mock_generator = mocker.patch("llmtune.data.ingestor.JsonIngestor._json_generator")
27 | mock_dataset = mocker.patch("llmtune.data.ingestor.Dataset")
28 | JsonIngestor("").to_dataset()
29 |
30 | mock_dataset.from_generator.assert_called_once_with(mock_generator)
31 |
32 |
33 | def test_jsonl_ingestor_to_dataset(mocker):
34 | mock_generator = mocker.patch("llmtune.data.ingestor.JsonlIngestor._jsonl_generator")
35 | mock_dataset = mocker.patch("llmtune.data.ingestor.Dataset")
36 | JsonlIngestor("").to_dataset()
37 |
38 | mock_dataset.from_generator.assert_called_once_with(mock_generator)
39 |
40 |
41 | def test_csv_ingestor_to_dataset(mocker):
42 | mock_generator = mocker.patch("llmtune.data.ingestor.CsvIngestor._csv_generator")
43 | mock_dataset = mocker.patch("llmtune.data.ingestor.Dataset")
44 | CsvIngestor("").to_dataset()
45 |
46 | mock_dataset.from_generator.assert_called_once_with(mock_generator)
47 |
48 |
49 | def test_huggingface_to_dataset(mocker):
50 | # Setup
51 | path = "some_path"
52 | ingestor = HuggingfaceIngestor(path)
53 | mock_concatenate_datasets = mocker.patch("llmtune.data.ingestor.concatenate_datasets")
54 | mock_load_dataset = mocker.patch("llmtune.data.ingestor.load_dataset")
55 | mock_dataset = mocker.patch("llmtune.data.ingestor.Dataset")
56 |
57 | # Configure the mock objects
58 | mock_dataset = MagicMock(spec=Dataset)
59 | mock_load_dataset.return_value = {"train": mock_dataset, "test": mock_dataset}
60 | mock_concatenate_datasets.return_value = mock_dataset
61 |
62 | # Execute
63 | result = ingestor.to_dataset()
64 |
65 | # Assert
66 | assert isinstance(result, Dataset)
67 | mock_load_dataset.assert_called_once_with(path)
68 | mock_concatenate_datasets.assert_called_once()
69 |
70 |
71 | @pytest.mark.parametrize(
72 | "file_content,expected_output",
73 | [
74 | (
75 | '[{"column1": "value1", "column2": "value2"}, {"column1": "value3", "column2": "value4"}]',
76 | [
77 | {"column1": "value1", "column2": "value2"},
78 | {"column1": "value3", "column2": "value4"},
79 | ],
80 | )
81 | ],
82 | )
83 | def test_json_ingestor_generator(file_content, expected_output, mocker):
84 | mocker.patch("builtins.open", mock_open(read_data=file_content))
85 | mocker.patch("ijson.items", side_effect=lambda f, prefix: iter(expected_output))
86 | ingestor = JsonIngestor("dummy_path.json")
87 |
88 | assert list(ingestor._json_generator()) == expected_output
89 |
90 |
91 | @pytest.mark.parametrize(
92 | "file_content,expected_output",
93 | [
94 | (
95 | '{"column1": "value1", "column2": "value2"}\n{"column1": "value3", "column2": "value4"}',
96 | [
97 | {"column1": "value1", "column2": "value2"},
98 | {"column1": "value3", "column2": "value4"},
99 | ],
100 | )
101 | ],
102 | )
103 | def test_jsonl_ingestor_generator(file_content, expected_output, mocker):
104 | mocker.patch("builtins.open", mock_open(read_data=file_content))
105 | mocker.patch(
106 | "ijson.items",
107 | side_effect=lambda f, prefix, multiple_values: (iter(expected_output) if multiple_values else iter([])),
108 | )
109 | ingestor = JsonlIngestor("dummy_path.jsonl")
110 |
111 | assert list(ingestor._jsonl_generator()) == expected_output
112 |
113 |
114 | @pytest.mark.parametrize(
115 | "file_content,expected_output",
116 | [
117 | (
118 | "column1,column2\nvalue1,value2\nvalue3,value4",
119 | [
120 | {"column1": "value1", "column2": "value2"},
121 | {"column1": "value3", "column2": "value4"},
122 | ],
123 | )
124 | ],
125 | )
126 | def test_csv_ingestor_generator(file_content, expected_output, mocker):
127 | mocker.patch("builtins.open", mock_open(read_data=file_content))
128 | ingestor = CsvIngestor("dummy_path.csv")
129 |
130 | assert list(ingestor._csv_generator()) == expected_output
131 |
--------------------------------------------------------------------------------
/tests/finetune/test_finetune_generics.py:
--------------------------------------------------------------------------------
1 | import pytest
2 |
3 | from llmtune.finetune.generics import Finetune
4 |
5 |
6 | class MockFinetune(Finetune):
7 | def finetune(self):
8 | return "finetuning complete"
9 |
10 | def save_model(self):
11 | return "model saved"
12 |
13 |
14 | def test_finetune_method():
15 | mock_finetuner = MockFinetune()
16 | result = mock_finetuner.finetune()
17 | assert result == "finetuning complete"
18 |
19 |
20 | def test_save_model_method():
21 | mock_finetuner = MockFinetune()
22 | result = mock_finetuner.save_model()
23 | assert result == "model saved"
24 |
25 |
26 | def test_finetune_abstract_class_instantiation():
27 | with pytest.raises(TypeError):
28 | _ = Finetune()
29 |
--------------------------------------------------------------------------------
/tests/finetune/test_finetune_lora.py:
--------------------------------------------------------------------------------
1 | from unittest.mock import MagicMock
2 |
3 | from transformers import BitsAndBytesConfig
4 |
5 | from llmtune.finetune.lora import LoRAFinetune
6 | from test_utils.test_config import get_sample_config
7 |
8 |
9 | def test_lora_finetune_initialization(mocker):
10 | """Test the initialization of LoRAFinetune with a sample configuration."""
11 | # Mock dependencies that LoRAFinetune might call during initialization
12 | mocker.patch("llmtune.finetune.lora.AutoModelForCausalLM.from_pretrained")
13 | mocker.patch("llmtune.finetune.lora.AutoTokenizer.from_pretrained")
14 | mock_lora_config = mocker.patch("llmtune.finetune.lora.LoraConfig")
15 | mocker.patch(
16 | "llmtune.finetune.lora.LoRAFinetune._inject_lora",
17 | return_value=None, # _inject_lora doesn't return a value
18 | )
19 |
20 | # Initialize LoRAFinetune with the sample configuration
21 | lora_finetune = LoRAFinetune(config=get_sample_config(), directory_helper=MagicMock())
22 | # Assertions to ensure that LoRAFinetune is initialized as expected
23 | mock_lora_config.assert_called_once_with(**get_sample_config().lora.model_dump())
24 |
25 | assert lora_finetune.config == get_sample_config(), "Configuration should match the input configuration"
26 |
27 |
28 | def test_model_and_tokenizer_loading(mocker):
29 | # Prepare the configuration
30 | sample_config = get_sample_config()
31 |
32 | mock_model = mocker.patch(
33 | "llmtune.finetune.lora.AutoModelForCausalLM.from_pretrained",
34 | return_value=MagicMock(),
35 | )
36 | mock_tokenizer = mocker.patch("llmtune.finetune.lora.AutoTokenizer.from_pretrained", return_value=MagicMock())
37 | mock_inject_lora = mocker.patch(
38 | "llmtune.finetune.lora.LoRAFinetune._inject_lora",
39 | return_value=None, # _inject_lora doesn't return a value
40 | )
41 | directory_helper = MagicMock()
42 | LoRAFinetune(config=sample_config, directory_helper=directory_helper)
43 |
44 | mock_model.assert_called_once_with(
45 | sample_config.model.hf_model_ckpt,
46 | quantization_config=BitsAndBytesConfig(),
47 | use_cache=False,
48 | device_map=sample_config.model.device_map,
49 | torch_dtype=sample_config.model.casted_torch_dtype,
50 | attn_implementation=sample_config.model.attn_implementation,
51 | )
52 |
53 | mock_tokenizer.assert_called_once_with(sample_config.model.hf_model_ckpt)
54 | mock_inject_lora.assert_called_once()
55 |
56 |
57 | def test_lora_injection(mocker):
58 | """Test the initialization of LoRAFinetune with a sample configuration."""
59 | # Mock dependencies that LoRAFinetune might call during initialization
60 | mocker.patch(
61 | "llmtune.finetune.lora.AutoModelForCausalLM.from_pretrained",
62 | return_value=MagicMock(),
63 | )
64 | mocker.patch(
65 | "llmtune.finetune.lora.AutoTokenizer.from_pretrained",
66 | return_value=MagicMock(),
67 | )
68 |
69 | mock_kbit = mocker.patch("llmtune.finetune.lora.prepare_model_for_kbit_training")
70 | mock_get_peft = mocker.patch("llmtune.finetune.lora.get_peft_model")
71 |
72 | # Initialize LoRAFinetune with the sample configuration
73 | LoRAFinetune(config=get_sample_config(), directory_helper=MagicMock())
74 |
75 | mock_kbit.assert_called_once()
76 | mock_get_peft.assert_called_once()
77 |
78 |
79 | def test_model_finetune(mocker):
80 | sample_config = get_sample_config()
81 |
82 | mocker.patch(
83 | "llmtune.finetune.lora.AutoModelForCausalLM.from_pretrained",
84 | return_value=MagicMock(),
85 | )
86 | mocker.patch("llmtune.finetune.lora.AutoTokenizer.from_pretrained", return_value=MagicMock())
87 | mocker.patch(
88 | "llmtune.finetune.lora.LoRAFinetune._inject_lora",
89 | return_value=None, # _inject_lora doesn't return a value
90 | )
91 |
92 | mock_trainer = mocker.MagicMock()
93 | mock_sft_trainer = mocker.patch("llmtune.finetune.lora.SFTTrainer", return_value=mock_trainer)
94 |
95 | directory_helper = MagicMock()
96 |
97 | mock_training_args = mocker.patch(
98 | "llmtune.finetune.lora.TrainingArguments",
99 | return_value=MagicMock(),
100 | )
101 |
102 | ft = LoRAFinetune(config=sample_config, directory_helper=directory_helper)
103 |
104 | mock_dataset = MagicMock()
105 | ft.finetune(mock_dataset)
106 |
107 | mock_training_args.assert_called_once_with(
108 | logging_dir="/logs",
109 | output_dir=ft._weights_path,
110 | report_to="none",
111 | **sample_config.training.training_args.model_dump(),
112 | )
113 |
114 | mock_sft_trainer.assert_called_once_with(
115 | model=ft.model,
116 | train_dataset=mock_dataset,
117 | peft_config=ft._lora_config,
118 | tokenizer=ft.tokenizer,
119 | packing=True,
120 | args=mocker.ANY, # You can replace this with the expected TrainingArguments if needed
121 | dataset_text_field="formatted_prompt",
122 | callbacks=mocker.ANY, # You can replace this with the expected callbacks if needed
123 | **sample_config.training.sft_args.model_dump(),
124 | )
125 |
126 | mock_trainer.train.assert_called_once()
127 |
128 |
129 | def test_save_model(mocker):
130 | # Prepare the configuration and directory helper
131 | sample_config = get_sample_config()
132 |
133 | # Mock dependencies that LoRAFinetune might call during initialization
134 | mocker.patch("llmtune.finetune.lora.AutoModelForCausalLM.from_pretrained")
135 |
136 | mock_tok = mocker.MagicMock()
137 | mocker.patch("llmtune.finetune.lora.AutoTokenizer.from_pretrained", return_value=mock_tok)
138 | mocker.patch(
139 | "llmtune.finetune.lora.LoRAFinetune._inject_lora",
140 | return_value=None,
141 | )
142 |
143 | directory_helper = MagicMock()
144 | directory_helper.save_paths.weights = "/path/to/weights"
145 |
146 | mock_trainer = mocker.MagicMock()
147 | mocker.patch("llmtune.finetune.lora.SFTTrainer", return_value=mock_trainer)
148 |
149 | ft = LoRAFinetune(config=sample_config, directory_helper=directory_helper)
150 |
151 | mock_dataset = MagicMock()
152 | ft.finetune(mock_dataset)
153 | ft.save_model()
154 |
155 | mock_tok.save_pretrained.assert_called_once_with("/path/to/weights")
156 | mock_trainer.model.save_pretrained.assert_called_once_with("/path/to/weights")
157 |
--------------------------------------------------------------------------------
/tests/inference/test_inference_generics.py:
--------------------------------------------------------------------------------
1 | import pytest
2 |
3 | from llmtune.inference.generics import Inference
4 |
5 |
6 | class MockInference(Inference):
7 | def infer_one(self, prompt: str):
8 | return "inferred one"
9 |
10 | def infer_all(self):
11 | return "inferred all"
12 |
13 |
14 | def test_infer_one():
15 | mock_inference = MockInference()
16 | result = mock_inference.infer_one("")
17 | assert result == "inferred one"
18 |
19 |
20 | def test_infer_all():
21 | mock_inference = MockInference()
22 | result = mock_inference.infer_all()
23 | assert result == "inferred all"
24 |
25 |
26 | def test_inference_abstract_class_instantiation():
27 | with pytest.raises(TypeError):
28 | _ = Inference()
29 |
--------------------------------------------------------------------------------
/tests/inference/test_inference_lora.py:
--------------------------------------------------------------------------------
1 | from unittest.mock import MagicMock
2 |
3 | from datasets import Dataset
4 | from transformers import BitsAndBytesConfig
5 |
6 | from llmtune.inference.lora import LoRAInference
7 | from test_utils.test_config import get_sample_config # Adjust import path as needed
8 |
9 |
10 | def test_lora_inference_initialization(mocker):
11 | # Mock dependencies
12 | mock_model = mocker.patch(
13 | "llmtune.inference.lora.AutoPeftModelForCausalLM.from_pretrained",
14 | return_value=MagicMock(),
15 | )
16 | mock_tokenizer = mocker.patch("llmtune.inference.lora.AutoTokenizer.from_pretrained", return_value=MagicMock())
17 |
18 | # Mock configuration and directory helper
19 | config = get_sample_config()
20 | dir_helper = MagicMock(save_paths=MagicMock(results="results_dir", weights="weights_dir"))
21 | test_dataset = Dataset.from_dict(
22 | {
23 | "formatted_prompt": ["prompt1", "prompt2"],
24 | "label_column_name": ["label1", "label2"],
25 | }
26 | )
27 |
28 | _ = LoRAInference(
29 | test_dataset=test_dataset,
30 | label_column_name="label_column_name",
31 | config=config,
32 | dir_helper=dir_helper,
33 | )
34 |
35 | mock_model.assert_called_once_with(
36 | "weights_dir",
37 | torch_dtype=config.model.casted_torch_dtype,
38 | quantization_config=BitsAndBytesConfig(),
39 | device_map=config.model.device_map,
40 | attn_implementation=config.model.attn_implementation,
41 | )
42 | mock_tokenizer.assert_called_once_with("weights_dir", device_map=config.model.device_map)
43 |
44 |
45 | def test_infer_all(mocker):
46 | mocker.patch(
47 | "llmtune.inference.lora.AutoPeftModelForCausalLM.from_pretrained",
48 | return_value=MagicMock(),
49 | )
50 | mocker.patch("llmtune.inference.lora.AutoTokenizer.from_pretrained", return_value=MagicMock())
51 | mocker.patch("os.makedirs")
52 | mock_open = mocker.patch("builtins.open", mocker.mock_open())
53 | mock_csv_writer = mocker.patch("csv.writer")
54 |
55 | mock_infer_one = mocker.patch.object(LoRAInference, "infer_one", return_value="predicted")
56 |
57 | config = get_sample_config()
58 | dir_helper = MagicMock(save_paths=MagicMock(results="results_dir", weights="weights_dir"))
59 | test_dataset = Dataset.from_dict({"formatted_prompt": ["prompt1"], "label_column_name": ["label1"]})
60 |
61 | inference = LoRAInference(
62 | test_dataset=test_dataset,
63 | label_column_name="label_column_name",
64 | config=config,
65 | dir_helper=dir_helper,
66 | )
67 | inference.infer_all()
68 |
69 | mock_infer_one.assert_called_once_with("prompt1")
70 | mock_open.assert_called_once_with("results_dir/results.csv", "w", newline="")
71 | mock_csv_writer.assert_called() # You might want to add more specific assertions based on your CSV structure
72 |
--------------------------------------------------------------------------------
/tests/qa/test_metric_suite.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from pandas import DataFrame
3 |
4 | from llmtune.qa.metric_suite import LLMMetricSuite
5 | from llmtune.qa.qa_metrics import LLMQaMetric
6 |
7 |
8 | @pytest.fixture
9 | def mock_rich_ui(mocker):
10 | return mocker.patch("llmtune.ui.rich_ui.RichUI")
11 |
12 |
13 | @pytest.fixture
14 | def example_data():
15 | data = {
16 | "Prompt": ["What is 2+2?", "What is the capital of France?"],
17 | "Ground Truth": ["4", "Paris"],
18 | "Predicted": ["3", "Paris"],
19 | }
20 | return DataFrame(data)
21 |
22 |
23 | @pytest.fixture
24 | def mock_csv(mocker, example_data):
25 | mocker.patch("pandas.read_csv", return_value=example_data)
26 |
27 |
28 | class MockQaMetric(LLMQaMetric):
29 | @property
30 | def metric_name(self):
31 | return "Mock Accuracy"
32 |
33 | def get_metric(self, prompt, ground_truth, model_pred) -> int:
34 | return int(ground_truth == model_pred)
35 |
36 |
37 | @pytest.fixture
38 | def mock_metrics():
39 | return [MockQaMetric()]
40 |
41 |
42 | def test_from_csv(mock_metrics, mock_csv):
43 | suite = LLMMetricSuite.from_csv("dummy_path.csv", mock_metrics)
44 | assert len(suite.metrics) == 1
45 | assert suite.prompts[0] == "What is 2+2?"
46 |
47 |
48 | def test_compute_metrics(mock_metrics, mock_csv):
49 | suite = LLMMetricSuite.from_csv("dummy_path.csv", mock_metrics)
50 | results = suite.compute_metrics()
51 | assert results["Mock Accuracy"] == [0, 1] # Expected results from the mock test
52 |
53 |
54 | def test_save_metric_results(mock_metrics, mocker, mock_csv):
55 | mocker.patch("pandas.DataFrame.to_csv")
56 | test_suite = LLMMetricSuite.from_csv("dummy_path.csv", mock_metrics)
57 | test_suite.save_metric_results("dummy_save_path.csv")
58 | assert DataFrame.to_csv.called # Check if pandas DataFrame to_csv was called
59 |
60 |
61 | def test_print_metric_results(capfd, example_data):
62 | metrics = [MockQaMetric()]
63 | suite = LLMMetricSuite(metrics, example_data["Prompt"], example_data["Ground Truth"], example_data["Predicted"])
64 | suite.print_metric_results()
65 | out, err = capfd.readouterr()
66 |
67 | assert "0.5000" in out
68 | assert "0.5000" in out
69 | assert "0.7071" in out
70 |
--------------------------------------------------------------------------------
/tests/qa/test_qa_metrics.py:
--------------------------------------------------------------------------------
1 | import pytest
2 |
3 | from llmtune.qa.qa_metrics import (
4 | AdjectivePercentMetric,
5 | DotProductSimilarityMetric,
6 | JaccardSimilarityMetric,
7 | JSONValidityMetric,
8 | LengthMetric,
9 | NounPercentMetric,
10 | RougeScoreMetric,
11 | VerbPercentMetric,
12 | WordOverlapMetric,
13 | )
14 |
15 |
16 | @pytest.mark.parametrize(
17 | "test_class,expected_type",
18 | [
19 | (LengthMetric, int),
20 | (JaccardSimilarityMetric, float),
21 | (DotProductSimilarityMetric, float),
22 | (RougeScoreMetric, float),
23 | (WordOverlapMetric, float),
24 | (VerbPercentMetric, float),
25 | (AdjectivePercentMetric, float),
26 | (NounPercentMetric, float),
27 | (JSONValidityMetric, float),
28 | ],
29 | )
30 | def test_metric_return_type(test_class, expected_type):
31 | test_instance = test_class()
32 | prompt = "This is a test prompt."
33 | ground_truth = "This is a ground truth sentence."
34 | model_prediction = "This is a model predicted sentence."
35 |
36 | # Depending on the test class, the output could be different.
37 | metric_result = test_instance.get_metric(prompt, ground_truth, model_prediction)
38 | assert isinstance(
39 | metric_result, expected_type
40 | ), f"Expected return type {expected_type}, but got {type(metric_result)}."
41 |
42 |
43 | def test_length_metric():
44 | test = LengthMetric()
45 | result = test.get_metric("prompt", "short text", "longer text")
46 | assert result == 1, "Length difference should be 1."
47 |
48 |
49 | def test_jaccard_similarity_metric():
50 | test = JaccardSimilarityMetric()
51 | result = test.get_metric("prompt", "hello world", "world hello")
52 | assert result == 1.0, "Jaccard similarity should be 1.0 for the same words in different orders."
53 |
54 |
55 | def test_dot_product_similarity_metric():
56 | test = DotProductSimilarityMetric()
57 | result = test.get_metric("prompt", "data", "data")
58 | assert result >= 0, "Dot product similarity should be non-negative."
59 |
60 |
61 | def test_rouge_score_metric():
62 | test = RougeScoreMetric()
63 | result = test.get_metric("prompt", "the quick brown fox", "the quick brown fox jumps over the lazy dog")
64 | assert result >= 0, "ROUGE precision should be non-negative."
65 |
66 |
67 | def test_word_overlap_metric():
68 | test = WordOverlapMetric()
69 | result = test.get_metric("prompt", "jump over the moon", "jump around the sun")
70 | assert result >= 0, "Word overlap percentage should be non-negative."
71 |
72 |
73 | def test_verb_percent_metric():
74 | test = VerbPercentMetric()
75 | result = test.get_metric("prompt", "He eats", "He is eating")
76 | assert result >= 0, "Verb percentage should be non-negative."
77 |
78 |
79 | def test_adjective_percent_metric():
80 | test = AdjectivePercentMetric()
81 | result = test.get_metric("prompt", "It is beautiful", "It is extremely beautiful")
82 | assert result >= 0, "Adjective percentage should be non-negative."
83 |
84 |
85 | def test_noun_percent_metric():
86 | test = NounPercentMetric()
87 | result = test.get_metric("prompt", "The cat", "The cat and the dog")
88 | assert result >= 0, "Noun percentage should be non-negative."
89 |
90 |
91 | @pytest.mark.parametrize(
92 | "input_string,expected_value",
93 | [
94 | ('{"Answer": "The cat"}', 1),
95 | ("{'Answer': 'The cat'}", 0), # Double quotes are required in json
96 | ('{"Answer": "The cat",}', 0),
97 | ('{"Answer": "The cat", "test": "case"}', 1),
98 | ('```json\n{"Answer": "The cat"}\n```', 1), # this json block can still be processed
99 | ('Here is an example of a JSON block: {"Answer": "The cat"}', 0),
100 | ],
101 | )
102 | def test_json_valid_metric(input_string: str, expected_value: float):
103 | test = JSONValidityMetric()
104 | result = test.get_metric("prompt", "The cat", input_string)
105 | assert result == expected_value, f"JSON validity should be {expected_value} but got {result}."
106 |
--------------------------------------------------------------------------------
/tests/qa/test_qa_tests.py:
--------------------------------------------------------------------------------
1 | import pytest
2 |
3 | from llmtune.qa.qa_tests import (
4 | JSONValidityTest,
5 | )
6 |
7 |
8 | @pytest.mark.parametrize(
9 | "test_class",
10 | [
11 | JSONValidityTest,
12 | ],
13 | )
14 | def test_test_return_bool(test_class):
15 | """Test to ensure that all tests return pass/fail boolean value."""
16 | test_instance = test_class()
17 | model_prediction = "This is a model predicted sentence."
18 |
19 | metric_result = test_instance.test(model_prediction)
20 | assert isinstance(metric_result, bool), f"Expected return type bool, but got {type(metric_result)}."
21 |
22 |
23 | @pytest.mark.parametrize(
24 | "input_string,expected_value",
25 | [
26 | ('{"Answer": "The cat"}', True),
27 | ("{'Answer': 'The cat'}", False), # Double quotes are required in json
28 | ('{"Answer": "The cat",}', False), # Trailing comma is not allowed
29 | ('{"Answer": "The cat", "test": "case"}', True),
30 | ('```json\n{"Answer": "The cat"}\n```', True), # this json block can still be processed
31 | ('Here is an example of a JSON block: {"Answer": "The cat"}', False),
32 | ],
33 | )
34 | def test_json_valid_metric(input_string: str, expected_value: bool):
35 | test = JSONValidityTest()
36 | result = test.test(input_string)
37 | assert result == expected_value, f"JSON validity should be {expected_value} but got {result}."
38 |
--------------------------------------------------------------------------------
/tests/qa/test_test_suite.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 |
3 | import pytest
4 | from pandas import DataFrame
5 |
6 | from llmtune.qa.qa_tests import LLMQaTest
7 | from llmtune.qa.test_suite import LLMTestSuite, TestBank, all_same
8 |
9 |
10 | @pytest.fixture
11 | def mock_rich_ui(mocker):
12 | return mocker.patch("llmtune.ui.rich_ui.RichUI")
13 |
14 |
15 | @pytest.fixture
16 | def example_data():
17 | data = {
18 | "Prompt": ["What is 2+2?", "What is the capital of France?"],
19 | "Ground Truth": ["4", "Paris"],
20 | "Predicted": ["3", "Paris"],
21 | }
22 | return DataFrame(data)
23 |
24 |
25 | @pytest.fixture
26 | def mock_csv(mocker, example_data):
27 | mocker.patch("pandas.read_csv", return_value=example_data)
28 |
29 |
30 | # mock a LoRAInference object that returns a value when .infer_one() is called
31 | class MockLoRAInference:
32 | def infer_one(self, prompt: str) -> str:
33 | return "Paris"
34 |
35 |
36 | @pytest.mark.parametrize(
37 | "data, expected",
38 | [
39 | (["a", "a", "a"], True),
40 | (["a", "b", "a"], False),
41 | ([], False),
42 | ],
43 | )
44 | def test_all_same(data, expected):
45 | assert all_same(data) == expected
46 |
47 |
48 | @pytest.fixture
49 | def mock_cases():
50 | return [
51 | {"prompt": "What is the capital of France?"},
52 | {"prompt": "What is the capital of Germany?"},
53 | ]
54 |
55 |
56 | class MockQaTest(LLMQaTest):
57 | @property
58 | def test_name(self):
59 | return "Mock Accuracy"
60 |
61 | def test(self, model_pred) -> bool:
62 | return model_pred == "Paris"
63 |
64 |
65 | @pytest.fixture
66 | def mock_test_banks(mock_cases):
67 | return [
68 | TestBank(MockQaTest(), mock_cases, "mock_file_name_stem"),
69 | TestBank(MockQaTest(), mock_cases, "mock_file_name_stem"),
70 | ]
71 |
72 |
73 | def test_test_bank_save_test_results(mocker, mock_cases):
74 | mocker.patch("pandas.DataFrame.to_csv")
75 | test_bank = TestBank(MockQaTest(), mock_cases, "mock_file_name_stem")
76 | test_bank.generate_results(MockLoRAInference())
77 | test_bank.save_test_results(Path("mock/dir/path"))
78 | assert DataFrame.to_csv.called # Check if pandas DataFrame to_csv was called
79 |
80 |
81 | def test_test_suite_save_test_results(mocker, mock_test_banks):
82 | mocker.patch("pandas.DataFrame.to_csv")
83 | ts = LLMTestSuite(mock_test_banks)
84 | ts.run_inference(MockLoRAInference())
85 | ts.save_test_results(Path("mock/dir/path/doesnt/exist"))
86 | assert DataFrame.to_csv.called # Check if pandas DataFrame to_csv was called
87 |
88 |
89 | def test_test_suite_from_dir():
90 | ts = LLMTestSuite.from_dir("examples/test_suite")
91 | ts.run_inference(MockLoRAInference())
92 |
93 |
94 | def test_test_suite_print_results(capfd, mock_test_banks):
95 | ts = LLMTestSuite(mock_test_banks)
96 | ts.run_inference(MockLoRAInference())
97 | ts.print_test_results()
98 | out, _ = capfd.readouterr()
99 | assert "Mock Accuracy" in out
100 |
--------------------------------------------------------------------------------
/tests/test_ablation_utils.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from pydantic import BaseModel
3 |
4 | from llmtune.utils.ablation_utils import (
5 | generate_permutations,
6 | get_annotation,
7 | get_model_field_type,
8 | get_types_from_dict,
9 | patch_with_permutation,
10 | )
11 |
12 |
13 | # Mocks or fixtures for models and data if necessary
14 | class BarModel(BaseModel):
15 | baz: list
16 | qux: str
17 |
18 |
19 | class ConfigModel(BaseModel):
20 | foo: int
21 | bar: BarModel
22 |
23 |
24 | @pytest.fixture
25 | def example_yaml():
26 | return {"foo": 10, "bar": {"baz": [[1, 2, 3], [4, 5]], "qux": ["hello", "world"]}}
27 |
28 |
29 | def test_get_types_from_dict(example_yaml):
30 | expected = {"foo": (int, None), "bar.baz": (list, list), "bar.qux": (list, str)}
31 | assert get_types_from_dict(example_yaml) == expected
32 |
33 |
34 | def test_get_annotation():
35 | key = "foo"
36 | assert get_annotation(key, ConfigModel) == int
37 |
38 | key_nested = "bar.qux"
39 | # Assuming you adjust your FakeModel or real implementation for nested annotations correctly
40 | assert get_annotation(key_nested, ConfigModel) == str
41 |
42 |
43 | def test_get_model_field_type_from_typing_list():
44 | from typing import List
45 |
46 | annotation = List[int]
47 | assert get_model_field_type(annotation) == list
48 |
49 |
50 | def test_get_model_field_type_from_union():
51 | from typing import Union
52 |
53 | annotation = Union[int, str]
54 | # Assuming the first type is picked from Union for simplicity
55 | assert get_model_field_type(annotation) == int
56 |
57 |
58 | def test_patch_with_permutation():
59 | old_dict = {"foo": {"bar": 10, "baz": 20}}
60 | permutation_dict = {"foo.bar": 100}
61 | expected = {"foo": {"bar": 100, "baz": 20}}
62 | assert patch_with_permutation(old_dict, permutation_dict) == expected
63 |
64 |
65 | def test_generate_permutations(example_yaml):
66 | results = generate_permutations(example_yaml, ConfigModel)
67 | assert isinstance(results, list)
68 |
69 | # Calculate expected permutations
70 | expected_permutation_count = len(example_yaml["bar"]["baz"]) * len(example_yaml["bar"]["qux"])
71 | assert len(results) == expected_permutation_count
72 |
73 | for _, result_dict in enumerate(results):
74 | assert result_dict["foo"] == example_yaml["foo"] # 'foo' should remain unchanged
75 | assert result_dict["bar"]["baz"] in example_yaml["bar"]["baz"]
76 | assert result_dict["bar"]["qux"] in example_yaml["bar"]["qux"]
77 |
--------------------------------------------------------------------------------
/tests/test_cli.py:
--------------------------------------------------------------------------------
1 | from unittest.mock import patch
2 |
3 | from typer.testing import CliRunner
4 |
5 | from llmtune.cli.toolkit import app, cli
6 |
7 |
8 | runner = CliRunner()
9 |
10 |
11 | def test_run_command():
12 | # Test the `run` command
13 | with patch("llmtune.cli.toolkit.run_one_experiment") as mock_run_one_experiment:
14 | result = runner.invoke(app, ["run", "./llmtune/config.yml"])
15 | assert result.exit_code == 0
16 | mock_run_one_experiment.assert_called_once()
17 |
18 |
19 | def test_generate_config_command():
20 | # Test the `generate config` command
21 | with patch("llmtune.cli.toolkit.shutil.copy") as mock_copy:
22 | result = runner.invoke(app, ["generate", "config"])
23 | assert result.exit_code == 0
24 | mock_copy.assert_called_once()
25 |
26 |
27 | def test_cli():
28 | # Test the `cli` function
29 | with patch("llmtune.cli.toolkit.app") as mock_app:
30 | cli()
31 | mock_app.assert_called_once()
32 |
--------------------------------------------------------------------------------
/tests/test_directory_helper.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/georgian-io/LLM-Finetuning-Toolkit/1593c3ca14a99ba98518c051eb22d80e51b625d7/tests/test_directory_helper.py
--------------------------------------------------------------------------------
/tests/test_version.py:
--------------------------------------------------------------------------------
1 | from llmtune import __version__
2 |
3 |
4 | def test_version():
5 | assert __version__ == "0.0.0"
6 |
--------------------------------------------------------------------------------