setIsMobileMenuOpen(false)}
61 | />
62 | )}
63 |
64 | {/* 导航菜单 */}
65 |
101 |
102 | {/* 移动端内容区域 padding */}
103 |
104 |
105 | )
106 | }
--------------------------------------------------------------------------------
/posts/ai/agent/20250214_outsource_agentic_infrastructure_own_cognitive_architecture.mdx:
--------------------------------------------------------------------------------
1 | ---
2 | title: 为什么你应该外包智能体基础设施,但保留自己的认知架构[译]
3 | date: 2025-02-14
4 | description: LangChain 创始人 Harrison Chase 提出:在构建智能体时,应将基础设施(状态管理、任务队列等)交由第三方处理,而专注于开发应用特有的认知架构(决策流程、状态表示)。虽然 OpenAI Assistants API 提供了完善的基础设施,但其通用认知架构限制了复杂应用的开发。开发者应将精力集中在能带来差异化优势的认知架构设计上。
5 | category: ai
6 | tags: AI, Agent, Cognitive Architecture, LLM, LangChain, LangGraph, OpenAI, Assistants API
7 | cover: https://media.ginonotes.com/covers/cover-own-cognitive-architecture.jpeg
8 | slug: outsource-agentic-infrastructure-own-cognitive-architecture
9 | ---
10 |
11 |
12 | 本文是 LangChain 博客上关于智能体 (AI Agent) 的系列文章的第三篇,提出在构建智能体时,应将基础设施(状态管理、任务队列等)交由第三方处理,而专注于开发应用特有的认知架构(决策流程、状态表示)。
13 |
14 |
15 | 当 OpenAI Assistants API 发布时,这标志着 AI 领域向智能体时代迈出了重要一步。它使 OpenAI 从一家提供大型语言模型(LLM)API 的公司,转变为一家提供智能体 API 的企业。
16 |
17 | 我认为 OpenAI Assistants API 在多个方面都表现出色,它引入了许多创新且实用的基础设施,专门用于运行智能体应用。然而,这也在某种程度上限制了开发者在其基础上构建真正复杂(且极具价值!)智能体时所能采用的"[认知架构](https://blog.langchain.dev/what-is-a-cognitive-architecture/)"的灵活性。
18 |
19 | 这凸显了"智能体基础设施"与"[认知架构](https://blog.langchain.dev/what-is-a-cognitive-architecture/)"之间的本质区别。正如亚马逊创始人杰夫·贝索斯那句经典箴言所言:["专注于让你的啤酒更美味"](https://www.acquired.fm/episodes/amazon-com)。如果将这一比喻应用到构建智能体的公司身上,我们可以这样理解:
20 |
21 |
22 | 💡 智能体基础设施本身并不能让你的啤酒更美味。
23 |
24 | 💡 而认知架构则绝对能够提升你啤酒的口感。
25 |
26 |
27 | ## 对智能体基础设施的需求
28 |
29 | OpenAI 准确把握了开发者对更优质基础设施的需求,特别是在运行智能体应用方面。具体表现在:
30 |
31 | - 通过提示词和工具"配置"助手的能力,使创建不同智能体变得便捷
32 | - 支持助手在后台运行,简化了长时间运行工作流程的管理
33 | - 内置的消息持久化功能,便于进行状态管理
34 |
35 | 所有这些功能都是开发者不应该过多考虑的部分。用杰夫·贝索斯的话说,它们不会让你的"啤酒"味道更好,也就是说,它们并不能使你的应用脱颖而出。
36 |
37 | 事实上,还有更多的基础设施可以进一步构建以辅助开发者!例如,在当前的 OpenAI Assistants API 中,你无法在同一对话上运行多个任务,也难以轻松修改对话的状态。尽管如此,Assistants API 无疑朝着正确的方向迈出了重要一步。
38 |
39 | ## 应用专属认知架构的重要性
40 |
41 | Assistants API 的局限性在于,它在支持构建更复杂应用方面显得不够灵活。
42 |
43 | 如果你的目标是开发一个聊天机器人,那么这个 API 确实非常适合!因为对话中的"状态"仅需要一个消息列表就足够了。
44 |
45 | 如果你想构建一个基础的 ReAct 模式智能体,这同样可行,本质上就是在 `while` 循环中反复调用大型语言模型。
46 |
47 | 但智能体应用绝不仅仅是一个不断重复调用相同工具和提示的单一聊天模型。它们需要追踪比消息列表更为复杂的状态,而对应用状态和流程的精细控制正是确保智能体可靠运行的关键所在。
48 |
49 | 通过与数千名开发者的合作,我们发现那些迈向生产化的智能体,各自都具备略有不同的认知架构。应用的认知架构正是让它 **真正卓越** 的关键,各团队正是在这一领域不断创新,力图通过构建独具特色的认知架构来使他们的应用脱颖而出,就像让啤酒更美味一样。
50 |
51 | 这并不是说你无法利用 Assistants API 实现更复杂的功能,理论上可以,但 API 设计上并不鼓励这种做法。OpenAI 押注于一种通用认知架构,这在一定程度上使得构建面向特定应用需求的、能够提升智能体可靠性的专属认知架构变得困难重重。
52 |
53 | ## 我们为何如此关注?
54 |
55 | 为何我对此如此关切?为何要写这么多文字来讨论这个话题?原因在于我坚信 OpenAI 在很多方面做得非常出色,他们早已预见到市场对智能体基础设施的迫切需求,让开发者无需烦恼智能体状态的存储、任务队列的管理等问题,这一点无疑非常振奋人心。
56 |
57 | 在 LangChain,我们的目标是让构建智能体应用变得简单至极,而这正需要这样的基础设施。
58 |
59 | 我们希望将智能体基础设施的优势与 LangGraph 所赋予你对认知架构的掌控力相结合,这正是我们开发 LangGraph Cloud 的初衷。你可以利用 [LangGraph](https://www.langchain.com/langgraph) 设计专属的认知架构,再通过 [LangGraph Cloud](https://blog.langchain.dev/langgraph-cloud/) 进行部署,从而享受智能体基础设施带来的所有优势。
60 |
61 | LangGraph Cloud 提供了容错性极强的可扩展性,专为真实世界的交互场景而优化。我们设计了横向扩展的任务队列和服务器,内置持久化层针对高负载进行了优化,同时支持跨运行的节点缓存配置。这样一来,你就可以掌控应用中那些决定性、具有差异化优势的部分,将其余部分外包处理。
62 |
63 | 总之,专注于让你的"啤酒"味道更美味的关键在于构建优秀的认知架构,而不仅仅是依赖基础设施。
64 |
65 | 原文地址:[Why you should outsource your agentic infrastructure, but own your cognitive architecture](https://blog.langchain.dev/why-you-should-outsource-your-agentic-infrastructure-but-own-your-cognitive-architecture/)
66 |
67 | ---
68 |
69 | LangChain 智能体系列文章:
70 |
71 | - [1. 什么是智能体?](https://www.ginonotes.com/posts/what-is-ai-agents)
72 | - [2. 什么是认知架构?](https://www.ginonotes.com/posts/what-is-a-cognitive-architecture)
73 | - [3. 为什么你应该外包智能体基础设施,但保留自己的认知架构](https://www.ginonotes.com/posts/outsource-agentic-infrastructure-own-cognitive-architecture)
74 | - [4. 智能体的规划能力](https://www.ginonotes.com/posts/planning-for-agents)
75 | - [5. 智能体的交互模式](https://www.ginonotes.com/posts/ux-for-agents)
76 | - [6. 智能体的记忆](https://www.ginonotes.com/posts/memory-for-agents)
77 | - [7. 沟通:你所需要的一切](https://www.ginonotes.com/posts/communication-is-all-you-need)
--------------------------------------------------------------------------------
/scripts/utils.ts:
--------------------------------------------------------------------------------
1 | import * as fs from 'fs';
2 | import * as path from 'path';
3 | import { config } from './config';
4 |
5 | // 显示进度
6 | export function showProgress(current: number, total: number, message: string = '处理进度'): void {
7 | const percentage = Math.round((current / total) * 100);
8 | const bar = '='.repeat(Math.floor(percentage / 2)) + '-'.repeat(50 - Math.floor(percentage / 2));
9 | process.stdout.write(`${message}: [${bar}] ${percentage}% (${current}/${total})\r`);
10 | if (current === total) {
11 | process.stdout.write('\n');
12 | }
13 | }
14 |
15 | // 验证文件
16 | export function validateFile(filePath: string): { valid: boolean; reason?: string } {
17 | const ext = path.extname(filePath).toLowerCase();
18 |
19 | if (!Object.keys(config.mimeTypes).includes(ext)) {
20 | return { valid: false, reason: `不支持的文件类型:${ext}` };
21 | }
22 |
23 | try {
24 | const stats = fs.statSync(filePath);
25 | if (stats.size > config.maxFileSize) {
26 | return {
27 | valid: false,
28 | reason: `文件过大:${(stats.size / 1024 / 1024).toFixed(2)}MB(最大限制:${(config.maxFileSize / 1024 / 1024).toFixed(2)}MB)`
29 | };
30 | }
31 | } catch (error) {
32 | return { valid: false, reason: `无法读取文件:${filePath}` };
33 | }
34 |
35 | return { valid: true };
36 | }
37 |
38 | // 备份文件
39 | export async function backupFile(filePath: string): Promise
{
40 | const date = new Date().toISOString().split('T')[0];
41 | const backupDir = path.join(process.cwd(), config.backup.dir, date);
42 |
43 | // 创建备份目录
44 | await fs.promises.mkdir(backupDir, { recursive: true });
45 |
46 | // 保持原始目录结构
47 | const relativePath = path.relative(process.cwd(), filePath);
48 | const backupPath = path.join(backupDir, relativePath);
49 | const backupFileDir = path.dirname(backupPath);
50 |
51 | // 创建备份文件的目录
52 | await fs.promises.mkdir(backupFileDir, { recursive: true });
53 |
54 | // 复制文件
55 | await fs.promises.copyFile(filePath, backupPath);
56 |
57 | return backupPath;
58 | }
59 |
60 | // 清理旧备份
61 | export async function cleanupOldBackups(): Promise {
62 | const backupDir = path.join(process.cwd(), config.backup.dir);
63 | if (!fs.existsSync(backupDir)) return;
64 |
65 | const now = new Date();
66 | const dirs = await fs.promises.readdir(backupDir);
67 |
68 | for (const dir of dirs) {
69 | const dirPath = path.join(backupDir, dir);
70 | const dirDate = new Date(dir);
71 | const daysDiff = (now.getTime() - dirDate.getTime()) / (1000 * 60 * 60 * 24);
72 |
73 | if (daysDiff > config.backup.keepDays) {
74 | await fs.promises.rm(dirPath, { recursive: true });
75 | console.log(`已删除旧备份:${dir}`);
76 | }
77 | }
78 | }
79 |
80 | // 分块处理数组
81 | export async function processInChunks(
82 | items: T[],
83 | processor: (item: T) => Promise,
84 | options: {
85 | chunkSize?: number;
86 | onProgress?: (current: number, total: number) => void;
87 | } = {}
88 | ): Promise {
89 | const { chunkSize = config.concurrency, onProgress } = options;
90 | const results: R[] = [];
91 |
92 | for (let i = 0; i < items.length; i += chunkSize) {
93 | const chunk = items.slice(i, i + chunkSize);
94 | const chunkResults = await Promise.all(chunk.map(processor));
95 | results.push(...chunkResults);
96 |
97 | if (onProgress) {
98 | onProgress(Math.min(i + chunkSize, items.length), items.length);
99 | }
100 | }
101 |
102 | return results;
103 | }
104 |
105 | // 获取文件的 MIME 类型
106 | export function getMimeType(filePath: string): string {
107 | const ext = path.extname(filePath).toLowerCase();
108 | return config.mimeTypes[ext as keyof typeof config.mimeTypes] || 'application/octet-stream';
109 | }
110 |
111 | // 格式化文件大小
112 | export function formatFileSize(bytes: number): string {
113 | const units = ['B', 'KB', 'MB', 'GB'];
114 | let size = bytes;
115 | let unitIndex = 0;
116 |
117 | while (size >= 1024 && unitIndex < units.length - 1) {
118 | size /= 1024;
119 | unitIndex++;
120 | }
121 |
122 | return `${size.toFixed(2)} ${units[unitIndex]}`;
123 | }
--------------------------------------------------------------------------------
/src/components/home/FeaturedPost.tsx:
--------------------------------------------------------------------------------
1 | 'use client'
2 |
3 | import { Post } from 'contentlayer2/generated'
4 | import Link from 'next/link'
5 | import { motion } from 'framer-motion'
6 | import { formatDate } from '@/lib/utils'
7 | import { getCategoryName, CATEGORY_MAP } from '@/lib/images'
8 | import Image from 'next/image'
9 |
10 | interface FeaturedPostProps {
11 | post: Post
12 | }
13 |
14 | export function FeaturedPost({ post }: FeaturedPostProps) {
15 | const categoryName = getCategoryName(post.category as keyof typeof CATEGORY_MAP)
16 |
17 | return (
18 |
22 |
26 |
27 |
28 |
29 |
30 |
34 | {categoryName}
35 |
36 | ·
37 |
38 |
39 |
40 |
41 |
42 | {post.title}
43 |
44 |
45 |
46 |
47 |
48 | {post.description}
49 |
50 |
51 |
52 |
56 | 阅读更多
57 |
70 |
71 |
72 |
73 |
74 |
81 |
82 |
118 | {post && (
119 |
125 | )}
126 |
127 | {children}
128 |
129 |
130 | )
131 | }
--------------------------------------------------------------------------------
/posts/dev/growth/20240409_technical_project_manager.mdx:
--------------------------------------------------------------------------------
1 | ---
2 | title: 聊聊开发人员兼任技术 PM 的心得
3 | date: 2024-04-09
4 | description: 作为一名开发人员,如何平衡好技术和项目管理的角色,在保持技术深度的同时,也能够有效地推进项目进展。
5 | category: dev
6 | tags: Project Management, Technical PM, Personal Growth
7 | cover: https://media.ginonotes.com/covers/cover1.jpeg
8 | slug: technical-project-manager
9 | ---
10 |
11 | 作为一名开发人员,如何平衡好技术和项目管理的角色,在保持技术深度的同时,也能够有效地推进项目进展。
12 |
13 | ## 引言
14 |
15 | 在这个数字化飞速发展的时代,技术人才的角色正在经历一场革命。过去,开发人员只需专注于编码和解决技术难题,项目管理由专职的 PM 承担。但在项目日益复杂、市场需求不断演变的今天,越来越多的开发人员开始兼任技术 PM 的角色。常见的情况是,对于一些中小复杂度的项目,核心开发人员和产品经理兼任 PM 的角色,以更好地推动项目的进展。
16 |
17 | 技术 PM 是项目成功的关键推手,他们不仅需要深厚的技术背景,还要掌握项目管理的精髓,包括需求分析、资源协调、风险控制和市场洞察等。这一角色的转变,对开发人员来说既是机遇也是挑战。机遇在于,技术 PM 能够更全面地影响产品的发展方向,提升用户体验,并为企业创造更大的价值。挑战则在于,从专注于技术细节的开发人员,到需要全面考虑项目各个方面的技术 PM,这一过程中需要克服的心理和技术障碍不容小觑。
18 |
19 | 在过去的几年里,我也承担过一些技术 PM 的角色,从最初的不适应到逐渐适应,再到后来的熟练掌握,这一过程中积累了一些经验和心得。本文将分享一些关于开发人员兼任项目技术 PM 的心得,希望能够对正在转型的开发人员有所帮助。
20 |
21 | ## 技术 PM 的新角色与职责
22 |
23 | 技术 PM 的角色是在技术团队和关键项目目标之间架起桥梁。这一角色要求个人不仅要有深厚的技术背景,还要具备项目管理的能力,以及对市场和用户需求的敏锐洞察。对于从开发岗位转型而来的技术 PM 来说,这是一个全新的挑战。
24 |
25 | ### 核心职责
26 |
27 | 1. **需求理解与转化**:技术 PM 需要深入理解业务需求,将其转化为可执行的产品功能。例如,与业务团队紧密合作,将抽象的业务需求转化为具体的产品特性,并从技术角度对需求进行评估和优化。
28 |
29 | 2. **技术战略规划**:技术 PM 负责制定技术路线图,确保技术发展与产品演进、公司战略相匹配。这包括选择合适的技术栈、架构设计以及技术预研,以支持产品的长期发展。
30 |
31 | 3. **项目管理**:技术 PM 要管理项目的整个生命周期,从项目启动、规划、执行、监控到项目收尾。这涉及到时间线管理、资源分配、预算控制以及风险管理,确保项目按时按质完成。
32 |
33 | 4. **团队协作**:技术 PM 需要在几乎没有职权领导力的情况下领导和激励技术团队,推动团队成员朝着共同的目标努力。同时,技术 PM 还要与其他部门协作,确保项目顺利进行,这可能包括与各个业务部门合作,以确保完成业务目标。
34 |
35 | 5. **沟通协调**:技术 PM 是团队内部、团队与利益相关者之间沟通的关键节点。他们需要确保所有参与者对项目目标、进度和预期结果有清晰的认识,并通过有效沟通解决项目过程中的任何问题。
36 |
37 | ### 角色转变
38 |
39 | 对于习惯了专注于代码和具体技术问题的开发者来说,转型为技术 PM 意味着思维方式和工作重点的转变。技术 PM 不再只是解决技术问题,而是要站在更高的层面,从项目整体出发,考虑如何将技术创新转化为用户价值和商业成功。此外,技术 PM 还需要培养自己的领导力和影响力,以便在没有直接管理权限的情况下,有效地推动项目前进。这通常意味着要通过建立信任、展示专业知识和提供指导来赢得团队成员的尊重和支持。
40 |
41 | 总结而言,技术 PM 的新角色和职责要求他们在保持技术专业性的同时,发展出项目管理和领导能力,以确保项目的成功交付和商业价值的实现。
42 |
43 | ## 转型关键:综合能力与项目管理思维
44 |
45 | 开发人员转型为技术 PM 的过程中,关键在于培养和提升一系列综合能力和项目管理思维。这些能力不仅涵盖了技术知识的应用,还包括了对项目管理的理解和实践。
46 |
47 | ### 技术洞察与业务理解
48 |
49 | 技术 PM 首先需要保持对技术趋势的敏感性,同时深入理解业务流程和市场动态。这种洞察力使他们能够在项目规划阶段做出明智的技术选择,并确保技术解决方案与业务目标保持一致。例如,通过参加行业会议、阅读最新的技术材料,技术 PM 可以预见技术变革对产品和市场的影响,从而引导团队进行必要的技术储备和创新。
50 |
51 | ### 沟通与协调
52 |
53 | 沟通是技术 PM 工作的核心。他们需要与不同背景的团队成员进行有效沟通,包括技术人员、设计师、业务人员甚至高层管理者。技术 PM 必须能够清晰地传达技术概念和项目进度,同时也要能够倾听和理解他人的观点和需求。此外,协调能力使技术 PM 能够在团队内部和跨部门之间建立合作,解决冲突,确保项目资源的最优配置。
54 |
55 | ### 风险管理
56 |
57 | 技术 PM 必须具备识别和应对项目风险的能力。这包括技术风险、资源风险、市场风险等。通过风险评估和管理,技术 PM 能够制定应对策略,减少不确定性对项目的影响。这种能力要求技术 PM 具备前瞻性思维和应急处理能力,以及在面对压力时保持冷静和理性。
58 |
59 | ### 目标导向的决策制定
60 |
61 | 技术 PM 需要具备基于目标的决策制定能力。这意味着他们必须明确项目的目标,制定实现这些目标的策略,并在项目执行过程中不断调整和优化。这种能力要求技术 PM 能够基于数据和直觉做出合理的判断,并能够在面对复杂情况时迅速做出决策。
62 |
63 | ### 持续学习与适应
64 |
65 | 技术 PM 的角色要求持续学习和适应新技术、新方法和新流程。他们需要不断更新自己的技术知识库,同时也要学习项目管理的最佳实践。这种持续学习的态度有助于技术 PM 保持竞争力,并能够适应不断变化的市场和技术环境。例如,通过在线课程、行业交流等,技术 PM 可以不断提升自己的专业技能和项目管理能力。
66 |
67 | 总结来说,开发人员转型为技术 PM 的成功关键在于综合能力的提升和项目管理思维的培养。这不仅要求技术 PM 在技术领域保持专业和前瞻性,还要求他们在项目管理、沟通协调、风险控制和决策制定等方面展现出卓越的能力。
68 |
69 | ## 应对挑战的策略:技术 PM 的实践心得
70 |
71 | 在技术 PM 的角色中,面对项目的各种挑战,采取恰当的策略是确保项目成功的关键。项目管理知识体系十分庞大,有五大过程组和十大知识领域,以下是一些个人在实践中认为比较关键、实用的策略。
72 |
73 | ### 组织关键会议
74 |
75 | 1. **项目启动会议**:项目启动是确立项目基调的重要时刻。在这个阶段,技术 PM 应组织一个包含业务方、团队领导和所有相关利益相关者的会议。这次会议的目的是明确项目目标、期望成果和关键里程碑,确保所有参与者对项目有共同的理解。
76 |
77 | 2. **需求评审会议**:需求评审是确保项目按照正确方向前进的关键环节。技术 PM 应该在评审前邀请核心人员进行预审,确保需求的清晰和可实施性,解决分歧、对齐认知。在正式评审时邀请业务方、产品经理、技术团队和测试团队参与,进一步讨论和细化需求。这有助于提前发现潜在问题,减少返工。
78 |
79 | ### 任务分解与时间点管理
80 |
81 | 3. **明确关键时间点**:技术 PM 应做好任务分解,将项目划分为具体的工作项,一个工作项小于 3 人天的粒度,并明确开发、联调、提测、发布等关键时间点。这不仅有助于团队成员理解自己的任务和责任,也便于技术 PM 监控项目进度和及时调整计划。
82 |
83 | ### 沟通与信息同步
84 |
85 | 4. **建立有效的沟通机制**:技术 PM 应通过定期的晨会、群聊、评审会议等方式,及时对齐团队成员的认知。这包括分享项目进度、讨论技术难题、更新变更请求等。确保信息的透明度和及时性,及时更新文档,知会相关人员,有助于减少误解和提高团队效率。
86 |
87 | ### 功能演示与质量控制
88 |
89 | 5. **组织功能演示**:通过组织功能演示,技术 PM 可以将需求中的典型场景具体化,提前接收来自业务、产品、测试等多方的反馈。这不仅有助于确保提测质量,还能促进团队成员对产品功能的理解,提前发现并解决问题。
90 |
91 | ## 小结
92 |
93 | 最后,我想引用一下雷蓓蓓老师在[《雷蓓蓓的项目管理实战课》](https://time.geekbang.org/column/intro/100038501) 专栏中提到的两句话作为小结。
94 |
95 | > **项目管理的底层思维很简单,就是“对焦”两个字。**
96 |
97 | 这句话很精辟的概况了项目管理的精髓。技术 PM 需要对焦业务目标和技术实现,对焦团队成员和项目进度,对焦需求和交付质量。这种对焦能力是技术 PM 成功的关键,很多项目的失败往往是因为对焦不够,导致目标模糊、分歧严重、进度滞后等问题。
98 |
99 | > **所谓的独当一面,就是从一个人做好自己的事,到带领一群人从头到尾把事做成。而学习项目管理,就是在习得这种“使众人行”的协同能力。**
100 |
101 | 技术 PM 和开发人员最大的区别在于,技术 PM 需要从一个人做好自己的事,转变为带领团队从头到尾把事做成。这需要技术 PM 具备协同能力,能够识别不同参与人的性格特质,能够激励团队成员,推动项目进展,确保项目的成功交付,参与人员得到成长。这种能力和发心是技术 PM 成功的关键,也是开发人员转型为技术 PM 需要培养的核心能力。
102 |
--------------------------------------------------------------------------------
/posts/build/design/20250314_practical_ux_for_startups_surviving.mdx:
--------------------------------------------------------------------------------
1 | ---
2 | title: 初创公司实用 UX 指南:无设计师生存之道[译]
3 | date: 2025-03-14
4 | description: 本文为没有设计师的初创公司提供了实用的用户体验设计指南。核心建议包括借鉴成熟的设计模式和竞争对手经验,避免从零开始;明确设计目标并思考用户可能遇到的极端情况;利用 AI 工具进行快速评估;关注用户体验的可衡量指标;保持设计的简洁和用户友好;以及在非核心功能上遵循已有的用户习惯。文章强调实用性胜过创新性,尤其是在资源有限的情况下,借鉴成熟模式能更快地提升用户体验并降低用户学习成本。
5 | category: build
6 | tags: UX, Design, Startups, AI, User Experience
7 | cover: https://media.ginonotes.com/covers/cover_practical_ux_for_startups_surviving.jpeg
8 | slug: practical-ux-for-startups-surviving
9 | ---
10 |
11 | 在资源有限,尤其是**没有设计师**的情况下,如何确定用户体验的设计方向?本文将提供一些实用的建议,帮助那些**没有时间、预算或设计团队**的初创公司,也能打造出色的用户体验。
12 |
13 | 我曾在两家初创公司工作过,当时虽然都希望能聘请产品设计师,但实际操作上这一愿望始终难以实现,只能算是一种**奢望**。即使我们最终决定需要一位设计师,但从面试、通知离职到正式入职,至少需要 3 个月的时间。因此,即使没有设计师,我们也不得不在这段时间内推进项目进展。
14 |
15 | 
16 |
17 | 一个常见的捷径是使用预制组件库,例如 Google 的 [Material UI](https://m2.material.io/design)。它们为你提供了构建模块,但不会帮你考虑整个用户流程。你仍然需要弄清楚如何将所有东西组合在一起。
18 |
19 | 但很多时候,我们做的都不是什么**新鲜玩意儿**。仔细观察大多数软件产品,会发现它们的用户流程大都存在共通之处,因此对于账户注册或密码重置等基础功能,往往不必**从零开始**设计。
20 |
21 | 既然你的时间应该花在能让你的产品**与众不同**的地方,那么如何才能尽快地定义一个好的用户体验呢?
22 |
23 | ### 避免空白页陷阱
24 |
25 | 不要在一块空白的画布前犹豫不决,而疑惑"电子邮件输入框究竟该如何设计?"
26 |
27 | 
28 |
29 | 那些拥有更大团队、价值数百万美元的公司,早已对此进行了深入研究。你可以借鉴他们的经验,更快地获得出色的用户体验。
30 |
31 | 避免参考以下内容:
32 |
33 | * **设计奖网站**:关注原创,而非实用。
34 | * **Dribbble**:重美观,轻功能。
35 |
36 | 相反,可以参考以下内容:
37 |
38 | * **竞争对手网站**:注册体验,截图记录。
39 | * **聚合网站**:如 [PageFlows](https://pageflows.com/) 或 [Mobbin](https://mobbin.com/),方便快速参考。
40 |
41 | 
42 |
43 | 记录以下内容:
44 |
45 | * 常见的用户界面 (UI) 元素,如电子邮件、密码字段、确认流程。
46 | * 视觉布局惯例:如居中表单、响应式设计、清晰按钮、顶部 Logo。
47 |
48 | 想象一个 **维恩图**。如果你的领域中所有产品都以相同方式处理,那很可能 **事出有因**。如果某家公司做法不同,请自问:这是 **有意为之**,还是仅仅是 **失误**?
49 |
50 | 有时,设置摩擦是 **刻意的**。有些公司要求提前提供信用卡详细信息,不是非要这么做,而是为了筛选出真正 **有意的用户**。体验不快,但目的明确。
51 |
52 | 如果你正在构建的东西不简单,请在你的行业之外寻找灵感。假设你正在设计一个收集医疗数据以进行处方续订的功能。
53 |
54 | 如果找不到直接对标,不妨 **扩大视野**:还有哪些机构需要收集敏感信息?比如抵押贷款机构、税务部门,他们同样面临高风险的数据处理。观察他们如何建立信任,解释风险,引导用户完成复杂流程。
55 |
56 | ### 明确你的目标
57 |
58 | 如果你正在设计一个注册页面,那么目标不仅仅是"两个文本字段和一个注册按钮"。而应设定更具体的目标,例如:"**让注册流程尽可能轻松便捷**"。
59 |
60 | 进一步提问:"**如何才能让注册流程更简单、更直观?**"
61 |
62 | 一些答案:
63 |
64 | * 在用户点击提交之前显示密码强度。
65 | * 给他们一个注册的理由,而不仅仅是一个要填写的表格。
66 |
67 | 这也提出了新的问题:
68 |
69 | * 用户是立即登录,还是先验证邮箱?
70 | * 他们应该进入确认页面,还是只收到一条细微的成功消息?
71 |
72 | 你不会预先获得所有答案,但提出正确的问题可以让你专注于重要的事情。
73 |
74 | ### 考虑边缘情况
75 |
76 | 真实用户不会 **按套路出牌**:他们会匆忙操作,跳过指示,或者注意力不集中。
77 |
78 | 时刻反思:**哪里可能出错?**
79 |
80 | * 针对每个输入框思考:如果用户在该处操作仓促并出错,会引发怎样的问题?
81 | * 接着再从整体角度审视——整个流程是否存在其他问题?
82 |
83 | 如果能确保那些 **不耐烦、易分心** 的用户也能获得顺畅的体验,其他用户自然不在话下。
84 |
85 | 糟糕的用户体验并不总是关于丑陋的设计——它通常只是一个 **困惑的用户**,不知道哪里出了问题或如何解决它。
86 |
87 | 例如:
88 |
89 | * 如果他们在创建密码时没有注意会怎么样?他们会设置一个糟糕的密码,然后在以后被锁定。
90 | * **修复方案**:增加"确认密码"字段,要求用户再次输入密码以确保准确。
91 | * 如果密码不匹配会怎么样?他们会点击"注册"并收到一个错误。这令人沮丧。
92 | * **修复方案**:在用户输入第二次密码后,立即显示密码不匹配的警告。
93 |
94 | ### 使用 AI 发现盲点
95 |
96 | 利用 [ChatGPT](https://openai.com/blog/chatgpt) 等工具,可以发现你可能忽略的 UX 问题。这是一个快速的理智检查——虽然并非完美方案,但**胜过盲目猜测**。这种方式比单纯依靠直觉要可靠得多。
97 |
98 | 以下是一些可以尝试的提示:
99 |
100 | * **红蓝对抗**:「挑刺:注册流程哪里会让用户卡壳?」vs.「辩护:这个设计的亮点何在?」
101 | * **对标行业**:「头部 SaaS 企业的注册流程是怎样的?」
102 | * **极端情况**:「如果用户输错邮箱地址却未察觉,会发生什么?」
103 |
104 | 
105 |
106 | 
107 |
108 | ### 其他提示
109 |
110 | * 明确衡量标准。「好的用户体验」可能意味着转化率、用户留存率或用户满意度。设计在某种程度上总是主观的,所以尽量将其客观化,这能让你在项目结束时保持理智。
111 | * 保持颜色简单。一种主色、一种辅助色和一种强调色。[Coolors](https://coolors.co/) 是一个很棒的小工具。
112 | * 用用户能理解的语言,而不是开发者能理解的语言。不要说「数据库错误」,而要说「我们无法保存更改」。
113 |
114 | ### 结束语
115 |
116 | 初创公司需要快速迭代,**完美主义**,尤其是在美学方面,往往是**多余的**。
117 |
118 | 如果团队中没有设计师,更应该**注重实用性**,而不是一味追求新颖。**简洁明了的用户流程**胜过**华而不实的设计**。
119 |
120 | 如果确实需要创新,请明确目标:「**我们真正需要差异化的地方在哪里?**」
121 |
122 | 遵循已有的设计模式,实际上是**借助其他公司来教育用户**,降低用户的学习成本。
123 |
124 | 在你的核心价值上创新;对于其他一切,坚持有效的方法。
125 |
126 | ---
127 |
128 | 原文链接:[Practical UX for startups surviving without a designer](https://www.tibinotes.com/p/practical-ux-for-startups-surviving)
--------------------------------------------------------------------------------
/documents/project.md:
--------------------------------------------------------------------------------
1 | # GinoNotes 博客项目文档
2 |
3 | 这是一个基于 Next.js 14 + Tailwind CSS + contentlayer 构建的个人博客项目。
4 |
5 | ## 1. 技术栈
6 |
7 | - **框架**: Next.js 14 (App Router)
8 | - **样式**: Tailwind CSS
9 | - **内容管理**: contentlayer
10 | - **语言**: TypeScript
11 | - **包管理**: pnpm
12 |
13 | ## 2. 项目结构
14 |
15 | ```
16 | src/
17 | ├── app/ # Next.js App Router 目录
18 | │ ├── page.tsx # 首页
19 | │ ├── global.css # 全局样式
20 | │ ├── layout.tsx # 根布局
21 | │ ├── posts/ # 文章页面
22 | │ └── categories/ # 分类页面
23 | ├── components/ # 可复用组件
24 | │ ├── Navigation.tsx # 导航组件
25 | │ ├── ArticleLayout.tsx # 文章布局
26 | │ ├── CategoryLayout.tsx # 分类布局
27 | │ └── TableOfContents.tsx# 文章目录
28 | ├── lib/ # 工具函数
29 | │ ├── utils.ts # 通用工具
30 | │ └── images.ts # 图片处理
31 | └── content/ # 文章内容
32 | └── posts/ # MDX 文章
33 | ```
34 |
35 | ## 3. 主要功能实现
36 |
37 | ### 3.1 导航系统
38 | - 响应式左侧导航
39 | - 移动端抽屉式菜单
40 | - 文章分类导航
41 | - 搜索功能(Command+K 快捷键)
42 |
43 | ### 3.2 文章系统
44 |
45 | ```typescript
46 | // 文章结构
47 | interface Post {
48 | title: string
49 | date: string
50 | category: string
51 | tags?: string[]
52 | description?: string
53 | cover?: string
54 | featured?: boolean
55 | url: string
56 | body: {
57 | raw: string
58 | code: string
59 | }
60 | }
61 | ```
62 |
63 | ### 3.3 样式系统
64 |
65 | ```css
66 | /* Tailwind CSS 层级组织 */
67 | @layer base {
68 | /* 基础样式:颜色、排版等 */
69 | }
70 |
71 | @layer components {
72 | /* 组件样式:导航、卡片等 */
73 | }
74 |
75 | @layer utilities {
76 | /* 工具类:自定义工具类 */
77 | }
78 | ```
79 |
80 | ## 4. 开发规范
81 |
82 | ### 4.1 文章编写规范
83 | - 文件命名:`YYYYMMDD_title.mdx`
84 | - 必填字段:title, date, category
85 | - 图片路径:使用相对路径,存放在 public/images
86 | - 代码块:使用 rehype-pretty-code 语法
87 |
88 | ### 4.2 样式规范
89 | - 优先使用 Tailwind CSS 类
90 | - 遵循移动优先的响应式设计
91 | - 响应式断点:
92 | ```css
93 | sm: 640px - 小屏手机
94 | md: 768px - 大屏手机/平板
95 | lg: 1024px - 桌面
96 | xl: 1280px - 大屏桌面
97 | ```
98 |
99 | ### 4.3 组件开发规范
100 | - 使用 TypeScript 类型定义
101 | - 组件文件使用 PascalCase 命名
102 | - 客户端组件添加 "use client" 指令
103 | - 提取可复用逻辑到 hooks
104 |
105 | ### 4.4 性能优化
106 | - 使用 Next.js Image 组件优化图片
107 | - 实现组件懒加载
108 | - 优化字体加载
109 | - 合理使用缓存策略
110 |
111 | ## 5. 注意事项
112 |
113 | ### 5.1 类型安全
114 | ```typescript
115 | // 总是定义明确的类型
116 | interface Props {
117 | post: Post
118 | prevPost?: Post
119 | nextPost?: Post
120 | }
121 | ```
122 |
123 | ### 5.2 路由处理
124 | ```typescript
125 | // 使用正确的路由类型
126 | href={post.url as `/posts/${string}/${string}`}
127 | ```
128 |
129 | ### 5.3 暗色模式
130 | - 使用 Tailwind 的 dark: 前缀
131 | - 遵循系统主题设置
132 |
133 | ### 5.4 可访问性
134 | - 添加适当的 ARIA 标签
135 | - 确保键盘导航可用
136 | - 保持足够的颜色对比度
137 |
138 | ## 6. 后续开发建议
139 |
140 | ### 6.1 新功能开发
141 | - 评论系统集成
142 | - 文章统计和分析
143 | - 社交分享功能
144 | - 订阅系统
145 |
146 | ### 6.2 性能优化
147 | - 实现增量静态再生成 (ISR)
148 | - 优化大型文章的加载
149 | - 添加预加载策略
150 |
151 | ### 6.3 用户体验
152 | - 添加加载状态反馈
153 | - 优化移动端交互
154 | - 改进搜索体验
155 |
156 | ### 6.4 维护建议
157 | - 定期更新依赖
158 | - 监控性能指标
159 | - 备份文章内容
160 | - 保持代码风格一致
161 |
162 | ## 7. 开发流程
163 |
164 | 1. 克隆项目后,首先安装依赖:
165 | ```bash
166 | pnpm install
167 | ```
168 |
169 | 2. 启动开发服务器:
170 | ```bash
171 | pnpm dev
172 | ```
173 |
174 | 3. 构建生产版本:
175 | ```bash
176 | pnpm build
177 | ```
178 |
179 | 4. 运行生产版本:
180 | ```bash
181 | pnpm start
182 | ```
183 |
184 | ## 8. 写作指南
185 |
186 | ### 8.1 创建新文章
187 | 1. 在 `content/posts` 目录下创建新的 MDX 文件
188 | 2. 文件名格式:`YYYYMMDD_title.mdx`
189 | 3. 添加必要的 frontmatter:
190 | ```mdx
191 | ---
192 | title: 文章标题
193 | date: 2024-01-01
194 | category: dev
195 | tags: Next.js,React,TypeScript
196 | description: 文章描述
197 | cover: /images/cover.jpg
198 | ---
199 | ```
200 |
201 | ### 8.2 文章格式
202 | - 使用 Markdown 语法
203 | - 代码块指定语言
204 | - 图片使用相对路径
205 | - 保持段落间距
206 |
207 | ### 8.3 图片处理
208 | - 图片存放在 `public/images` 目录
209 | - 使用 Next.js Image 组件
210 | - 提供合适的图片尺寸
211 | - 添加 alt 文本
212 |
213 | ## 9. 部署
214 |
215 | ### 9.1 部署前检查
216 | - 运行所有测试
217 | - 检查构建输出
218 | - 验证页面性能
219 | - 确认环境变量
220 |
221 | ### 9.2 部署流程
222 | 1. 提交代码到 GitHub
223 | 2. 触发自动部署
224 | 3. 验证部署结果
225 | 4. 监控性能指标
226 |
227 | ## 10. 贡献指南
228 |
229 | 1. Fork 项目
230 | 2. 创建功能分支
231 | 3. 提交更改
232 | 4. 发起 Pull Request
233 |
234 | ## 11. 问题反馈
235 |
236 | 如果发现问题或有改进建议,请:
237 | 1. 检查是否是已知问题
238 | 2. 创建详细的 Issue
239 | 3. 提供复现步骤
240 | 4. 附上相关日志或截图
241 |
242 | ---
243 |
244 | **注意**:本文档会随项目发展持续更新,请定期查看最新版本。
--------------------------------------------------------------------------------
/posts/ai/mcp/20250311_mcp_fad_or_fixture.mdx:
--------------------------------------------------------------------------------
1 | ---
2 | title: MCP:昙花一现还是未来之选?[译]
3 | date: 2025-03-11
4 | description: LangChain 的 Harrison Chase 认为 MCP 有潜力成为未来标准,尤其在为用户无法控制的智能体便捷扩展工具方面具有重要意义,并能赋能非开发者。他将其比作 AI 领域的 Zapier,看好其在长尾应用场景的潜力。 然而,LangGraph 的 Nuno Campos 对此持怀疑态度,认为 MCP 当前形式复杂、实用性有限,且模型在工具调用方面仍存在挑战。他强调工具与智能体架构深度集成的必要性,并指出 MCP 需要在易用性、服务器部署和质量保证方面做出重大改进才能真正普及。
5 | category: ai
6 | tags: MCP, AI, Agent, LLM, Tools
7 | cover: https://media.ginonotes.com/covers/cover_mcp_fad_or_fixture.jpeg
8 | slug: mcp-fad-or-fixture
9 | ---
10 |
11 | *模型上下文协议 (MCP) 近来在 Twitter 上引发热议,但它究竟是真有价值,还是仅仅是又一次炒作? 在这场辩论中,LangChain 首席执行官 Harrison Chase 和 LangGraph 负责人 Nuno Campos 展开交锋,深入探讨 MCP 的前景与价值。*
12 |
13 | **Harrison:** 我认为 MCP 确实大有可为。最初我对它持保留态度,但现在我逐渐看到了它的潜力。 核心价值在于: **当你需要为你无法直接控制的智能体扩展工具时,MCP 就显得尤为重要。**
14 |
15 | 举例来说,对于像 Claude Desktop、Cursor、Windsurf 这样的应用,作为用户,我们无法触及它们底层的智能体逻辑。 这些智能体只能使用预先集成的少量内置工具。
16 |
17 | 但如果我们希望它们能够使用默认配置之外的工具呢? 这就需要一种协议规范来解决问题,否则智能体如何知晓并调用这些外部工具?
18 |
19 | 我相信 MCP 对于非开发者构建智能体也将大有裨益。 当前的一个趋势是,越来越多的行业专家希望能够参与到智能体的构建中来,无论他们是否具备深厚的技术背景。 这些"智能体构建者"通常不希望,或者说不具备能力,去修改智能体底层的代码逻辑,但他们一定希望能够为智能体赋予特定的工具能力。 而 MCP 正好可以满足这种需求。
20 |
21 | **Nuno:** 我认为你可能低估了工具与智能体其他组件之间深度适配的重要性。 诚然,如果像 Windsurf 这样的应用(天哪!)内置了一个糟糕的网页搜索工具,你想用更好的工具来替换它,这或许可行。 但这并非 MCP 真正有价值的应用场景。
22 |
23 | 真正令人兴奋的应用场景是,用户可以通过注入你"独门秘籍"般的工具,赋予 Cursor 等应用开发者都意想不到的全新能力。 但在实际应用中,这种情况往往难以实现。 我所见过的几乎所有生产级别的智能体,都需要针对所集成的工具进行深度定制,包括调整系统提示,甚至是智能体的整体架构。
24 |
25 | **Harrison:** 话虽如此,这些集成了 MCP 工具的智能体,即使不能达到 99% 的完美可靠,也可能已经足够好用,能够满足一定的需求,不是吗? 工具的描述和使用说明固然重要! 但我们也要看到:
26 |
27 | 1. **MCP 本身就支持工具定义。** 优秀的 MCP 服务器提供的工具描述,很可能比我们临时编写的描述更加完善和有效。
28 | 2. **MCP 允许自定义提示 (Prompts)。** 这意味着我们可以通过提示来引导智能体更好地使用工具。
29 | 3. **随着底层大模型的不断进化,开箱即用的工具调用能力必将显著提升。** 我不认为会有人仅仅依靠 MCP 集成和通用的工具调用智能体,就能打造出媲美 Cursor 的下一代应用。 但 MCP 肯定有其内在价值,尤其是在构建内部或个人智能体方面。
30 |
31 | **Nuno:** 我们自己进行的工具调用基准测试表明,即使是那些架构和提示词都针对特定工具集量身定制的智能体,当前的模型在工具选择上的正确率也只有一半左右。 设想一下,一个工具调用成功率只有一半的个人智能体,其可用性实在令人担忧……
32 |
33 | 诚然,模型会不断进步,但用户的期望也会随之水涨船高。 正如杰夫·贝索斯所说:"我欣赏顾客的一点是,他们天生就'不满'。 他们的期望从不是一成不变的,而是不断攀升的。 这就是人性。"
34 |
35 | 如果你掌控了整个技术栈——从用户界面 (UI) 到提示词,再到智能体架构和工具本身——你或许还能勉力满足这些日益增长的期望。 否则,恐怕只能祝你好运了。
36 |
37 | **Harrison:** 模型性能持续提升是毋庸置疑的大趋势,对此我充满信心。 因此,无论当前智能体的工具调用成功率如何,未来都只会不断提高。
38 |
39 | 我认为,将 MCP 方案构建的智能体,与那些针对特定工具深度优化的成熟智能体直接比较,是不恰当的。 MCP 的真正价值在于其能够实现大量的、个性化的长尾连接和集成。
40 |
41 | 就像 Zapier 那样,它可以将电子邮件与 Google Sheets、Slack 等各种应用和服务无缝连接。 我们可以基于 MCP 构建出数量庞大、种类繁多的定制化工作流,而不可能为每一种工作流都开发一个完美打磨的专属智能体。 借助 MCP,我们就能快速创建满足自身特定需求的"定制版 Zapier"。
42 |
43 | 你觉得用 Zapier 来类比 MCP 恰当吗?
44 |
45 | **Nuno:** 在 LangChain,我们早在两年前就推出了包含 500 多个工具的工具库,但遗憾的是,我并没有看到这些工具在实际生产环境中得到广泛应用。 这些工具都遵循相同的"协议"标准开发,与各种模型兼容,并且支持即插即用。 那么,MCP 的独特之处究竟在哪里呢? 难道仅仅是它那"令人惊叹"的形式——需要在本地终端运行无数个服务器,而且只能在桌面应用中使用? 这怎么看都不像是什么优势。 坦白说,我认为 Zapier 已经是 MCP 能够达到的上限了。
46 |
47 | **Harrison:** 我认为 LangChain 工具和 MCP 工具的核心区别在于,MCP 并非为智能体的开发者而设计。 当你需要为你**无法**自行开发的智能体扩展工具能力时,MCP 的价值才能真正体现。
48 |
49 | 需要明确的是——如果我要开发一个全新的智能体来完成 XYZ 任务,我肯定不会选择 MCP。 因为我并不认为那是 MCP 的目标应用场景。 MCP 的目标是为那些你无法控制的智能体添加工具。 此外,MCP 还能够让非开发者也能轻松为智能体扩展工具能力(而 LangChain 工具主要面向开发者)。 要知道,**非开发者的数量远超**开发者。
50 |
51 | 至于 MCP 目前这种略显笨拙的使用形式? 确实有待改进。 但它一定会变得更好,对吗? 我设想的 MCP 未来形态是: 用户可以一键安装 MCP 应用(无需再在本地终端运行服务器),并且可以在 Web 应用中直接使用。 我相信这才是 MCP 的发展方向。
52 |
53 | 你认为 MCP 需要做出哪些改变,才能让你相信它真的有价值?
54 |
55 | **Nuno:** 好吧,你的意思是 MCP 需要变得更像 OpenAI 的 Custom GPTs,这样当前的这波热潮才算师出有名。 但问题是,Custom GPTs 本身也并不算非常流行。 那么,Custom GPTs 究竟缺了什么,而 MCP 又拥有什么独特的优势呢?
56 |
57 | **Harrison:** 我的意思是,MCP 其实更像是插件 (Plugins),而插件的尝试也并未获得成功,不是吗? 我对插件的体验已经有些模糊了(甚至不确定自己是否真正用过 Plugins),所以我的类比可能不完全准确。 但我认为:
58 |
59 | * **MCP 的生态系统已经远超插件。**
60 | * **如今的模型性能更强大,也更有能力有效地利用这些工具。**
61 |
62 | **Nuno:** 嗯,我不确定 MCP 的生态系统是否真的更大。 我随便在网上搜了一下,找到一个[随机的 MCP 服务器目录](https://glama.ai/mcp/servers),它在撰写本文时只列出了 893 个服务器。 我怀疑你是不是把 Twitter 时间线上提到 MCP 的推文数量,当成了实际基于 MCP 构建的应用数量了? 🙂 言归正传,回到你刚才提出的问题,我认为,如果 MCP 不想仅仅成为人工智能发展史上的一个短暂注脚,它就必须做到以下几点:
63 |
64 | * **降低复杂性。** 为什么一个工具协议需要同时承担提示词处理和 LLM 补全 (completions) 的功能?
65 | * **简化实现难度。** 为什么一个服务于工具的协议需要双向通信? 是的,我读过 MCP 官方列出的种种理由,但恕我直言,仅仅为了从服务器接收日志,并非一个充分合理的理由。
66 | * **支持在服务器端部署。** 无状态协议是实现服务器端部署的关键——不能因为我们现在都在用大语言模型 (LLM) 进行开发,就忘记了那些在 Web 服务规模化扩展方面积累的宝贵经验教训。 一旦支持服务器端部署,一系列新的问题也会浮出水面,例如身份验证 (Auth)(这在分布式环境下并非易事)。
67 | * **解决集成随机工具带来的质量损失问题。** 将未经适配的工具随意接入智能体,势必会影响智能体的整体性能和用户体验。
68 |
69 | **Harrison:** 你说的或许有道理,我最近可能确实因为过于关注 Twitter 上的讨论,而产生了一些认知偏差。 但 Twitter 上对 MCP 的质疑声音也同样不少啊!
70 |
71 | 所以,不如让我们把这个问题抛给大众,听听大家的看法。 参与下面的 Twitter 投票,投出你的一票——你认为 MCP 会是昙花一现,还是会成为未来的行业标准?
72 |
73 | 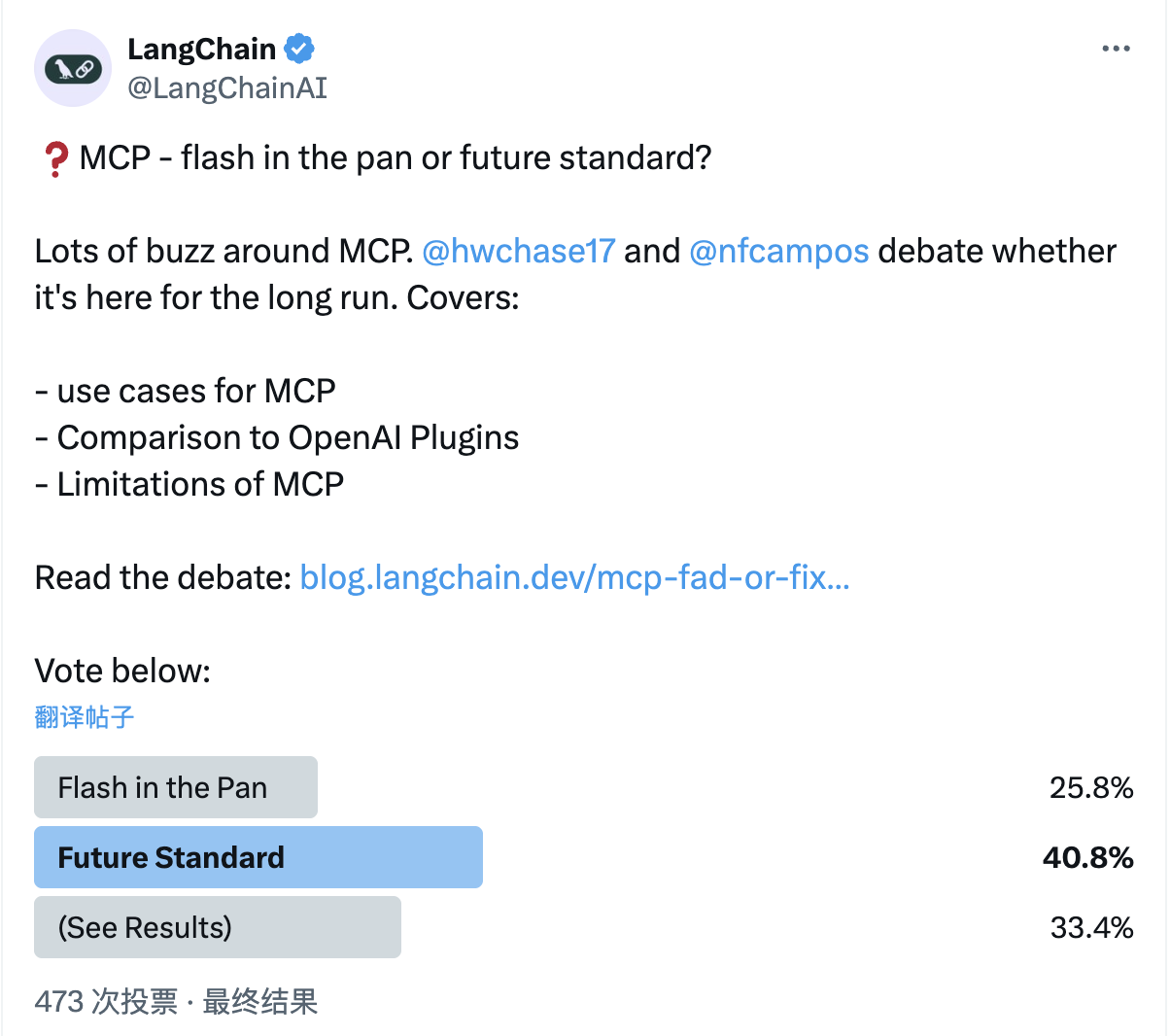
74 |
75 | 原文地址:[MCP: Flash in the Pan or Future Standard?](https://blog.langchain.dev/mcp-fad-or-fixture/)
76 |
77 |
--------------------------------------------------------------------------------
/posts/ai/model/20250312_openai_agents_platform.mdx:
--------------------------------------------------------------------------------
1 | ---
2 | title: OpenAI 全新智能体平台 [译]
3 | date: 2025-03-12
4 | description: OpenAI 发布全新智能体平台,包括 Responses API、Web Search、Computer Use 等工具,以及开源的 Agents SDK,为开发者提供更强大的智能体开发能力。
5 | category: ai
6 | tags: OpenAI, Agents Platform, Responses API, Web Search, Computer Use, Agents SDK
7 | cover: https://media.ginonotes.com/covers/cover_openai_agents_platform.jpeg
8 | slug: openai-agents-platform
9 | ---
10 |
11 | import VideoPlayer from '@/components/common/VideoPlayer'
12 |
13 | 尽管现在业界普遍认为 **[2025 年将是「智能体之年」](https://www.youtube.com/watch?v=5N33E9tC400)**,OpenAI 却在默默发力,为此目标积极布局。今年年初的两个月,他们相继推出了 **Operator** 和 **Deep Research**,堪称目前为止最成功的智能体之一。而今天,他们正在将这些能力中的诸多部分开放到 API 接口。
14 |
15 | * [Responses API](https://platform.openai.com/docs/quickstart?api-mode=responses)(响应 API)
16 | * [Web Search Tool](https://platform.openai.com/docs/guides/tools-web-search)(网页搜索工具)
17 | * [Computer Use Tool](https://platform.openai.com/docs/guides/tools-computer-use)(计算机使用工具)
18 | * [File Search Tool](https://platform.openai.com/docs/guides/tools-file-search)(文件搜索工具)
19 | * 一个全新的开源 [Agents SDK](https://platform.openai.com/docs/guides/agents)(智能体开发工具包),集成了 [Observability Tools](https://platform.openai.com/docs/guides/agents#orchestration)(可观测性工具)
20 |
21 | 我们将在今天的 [YouTube](https://www.youtube.com/watch?v=QU9QLi1-VvU) 闪电播客中介绍所有这些内容以及更多精彩信息!
22 |
23 |
24 |
25 | 下面是细节部分。
26 |
27 | ### Responses API(响应 API)
28 |
29 | 
30 |
31 | 在我们的 [Michelle Pokrass 那期节目](https://www.latent.space/p/openai-api-and-o1) 中,我们讨论过 Assistants API(助手 API)需要重新设计。今天,OpenAI 推出了 Responses API,这是一个更灵活的基础,供开发者构建智能体应用。它不仅是 Chat Completion API 的超集,更是开发者探索 OpenAI 模型的理想起点。
32 |
33 | 其中一个重要的升级是为响应 API 提供了一套新的内置工具:网页搜索、计算机使用和文件搜索。
34 |
35 | ### Web Search Tool(网页搜索工具)
36 |
37 | 之前我们曾在播客中邀请了 [Exa AI](https://www.latent.space/p/exa) 来讨论 AI 的网页搜索。现在 OpenAI 也加入了这场网页搜索的竞争;Web Search API(网页搜索 API)实际上是一个新的"模型",它公开了两个 4o 微调模型:`gpt-4o-search-preview` 和 `gpt-4o-mini-search-preview`。这些模型与 ChatGPT Search 使用的模型相同,价格分别为每 1000 次查询 30 美元和 25 美元。
38 |
39 | 其强大的功能是内联引用:你不仅可以获得指向相关页面的链接,更能直接定位到结果页面中精准解答你疑问的具体位置。
40 |
41 | 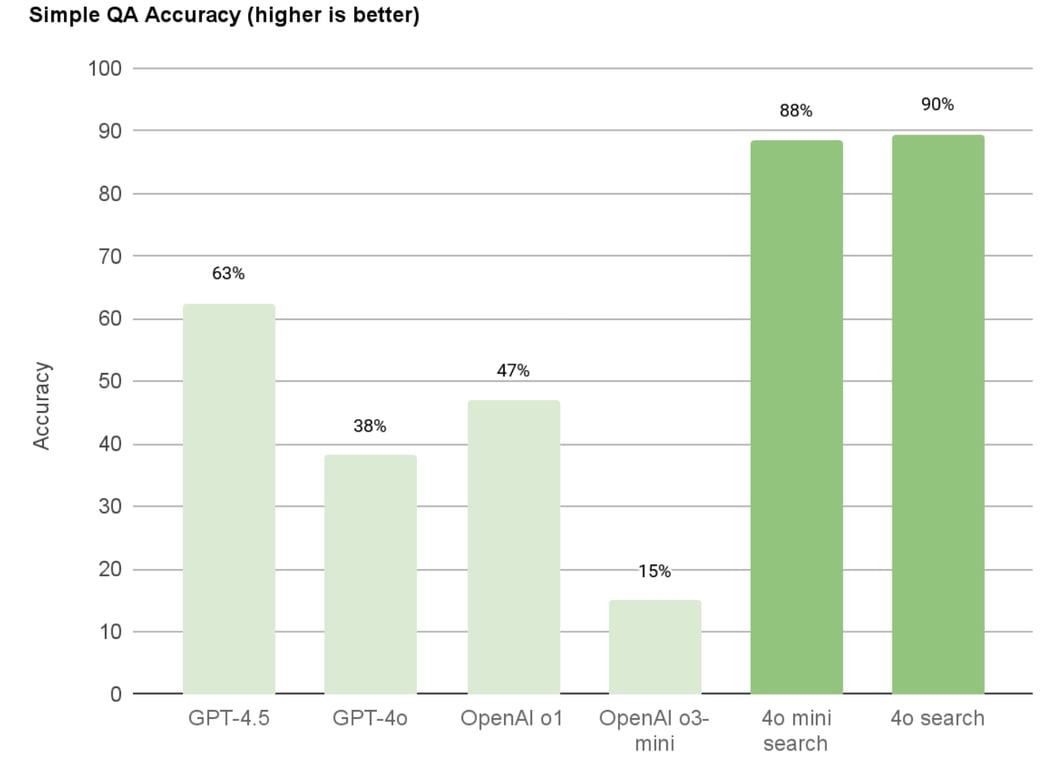
42 |
43 | ### Computer Use Tool(计算机使用工具)
44 |
45 | 驱动 Operator 的模型名为 Computer-Using-Agent (CUA,计算机使用智能体),现在也可在 API 中使用。`computer-use-preview` 模型在大多数基准测试中都处于领先地位,在 OSWorld 上实现了 38.1% 的完整计算机使用任务成功率,在 WebArena 上实现了 58.1% 的成功率,在 WebVoyager 上实现了 87% 的基于 Web 的交互成功率。
46 |
47 | 正如文档所示,`computer-use-preview` 不仅是一个模型,还是一个允许你自定义运行环境的强大工具。
48 |
49 | 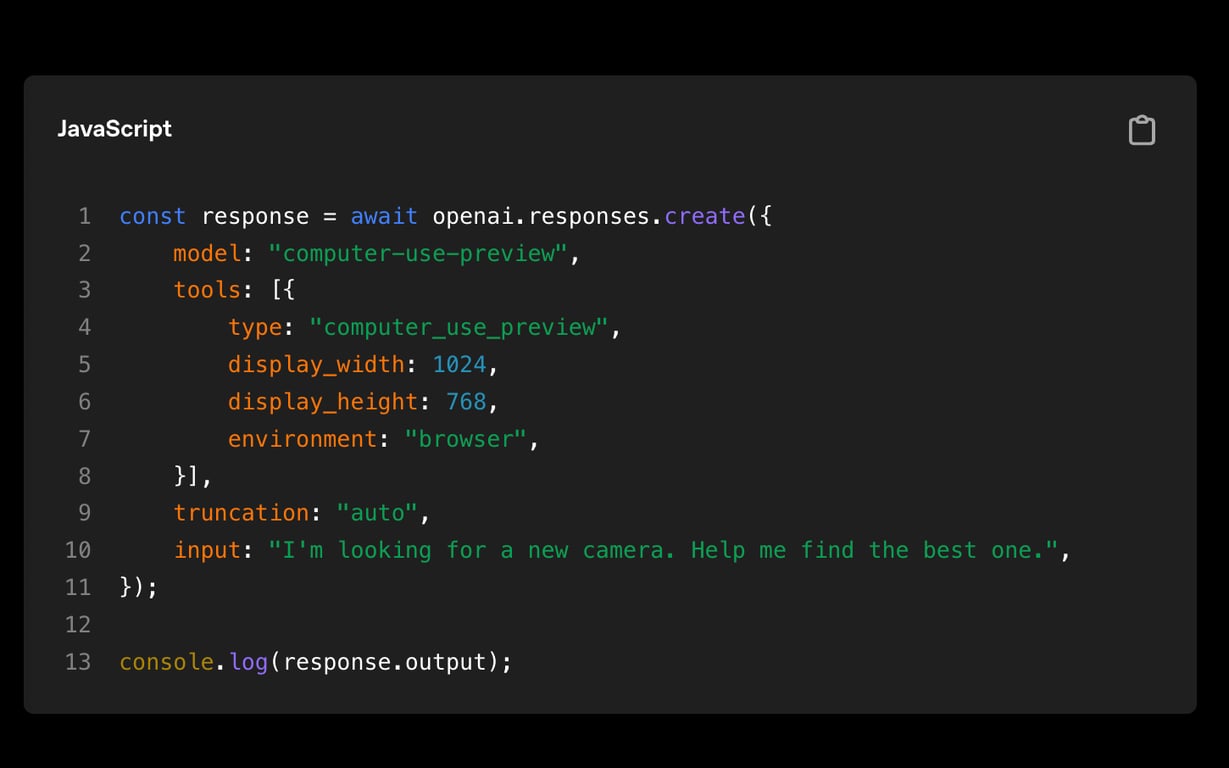
50 |
51 | 使用价格为每 100 万个输入 tokens 3 美元,每 100 万个输出 tokens 12 美元,目前仅对第 3-5 层的用户开放。
52 |
53 | ### File Search Tool(文件搜索工具)
54 |
55 | 文件搜索也可在 Assistants API(助手 API)中使用,现在也已加入 Responses API。OpenAI 正在将搜索和 RAG(检索增强生成)技术集成到一个统一的平台中,我们肯定会看到更多人尝试在 OpenAI 上找到构建一体化应用的新方法。
56 |
57 | 使用价格为每千次查询 2.50 美元,文件存储价格为每天每 GB 0.10 美元,首 GB 免费。
58 |
59 | 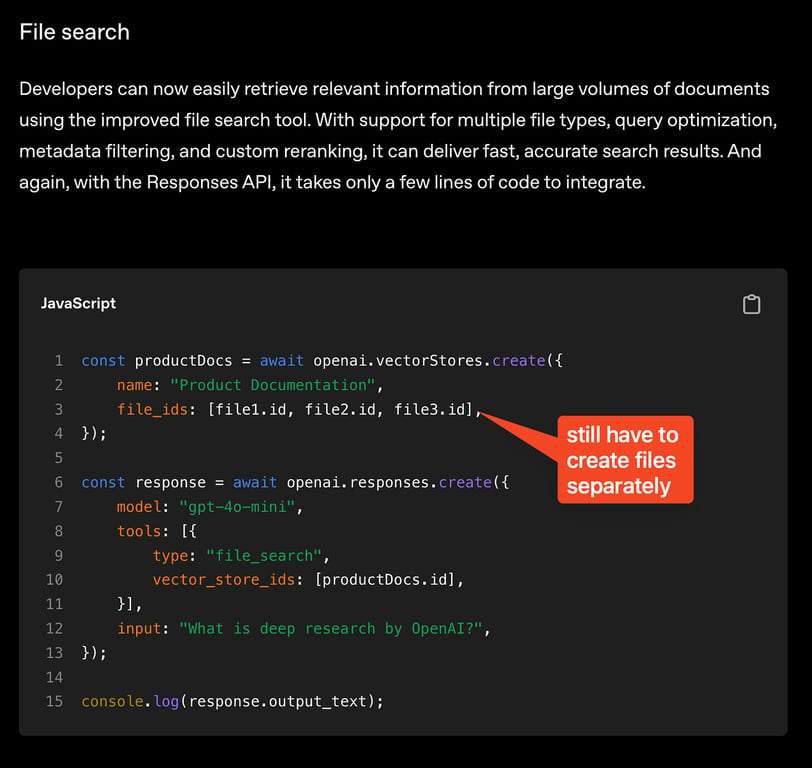
60 |
61 | ### Agent SDK(智能体 SDK):Swarms++!
62 |
63 | https://github.com/openai/openai-agents-python
64 |
65 | 
66 |
67 | 为了实现更强大的整合,在 [Swarm](https://github.com/openai/swarm/) 广受欢迎之后,OpenAI 正式发布官方支持的智能体框架,该框架在 [我们的 AI Engineer Summit 上进行了预览](https://www.youtube.com/watch?v=joHR2pmxDQE),包含4 个核心部分:
68 |
69 | * **智能体(Agents)**:可轻松配置的 LLM,具备明确的指令和内置工具。
70 | * **移交(Handoffs)**:智能地实现智能体之间的控制权转移。
71 | * **安全护栏(Guardrails)**:可配置的安全检查机制,用于输入和输出的有效性验证。
72 | * **追踪与可观测性(Tracing & Observability)**:将智能体执行的轨迹可视化呈现,用于调试和性能优化。
73 |
74 | 多智能体工作流程将长期存在!
75 |
76 | 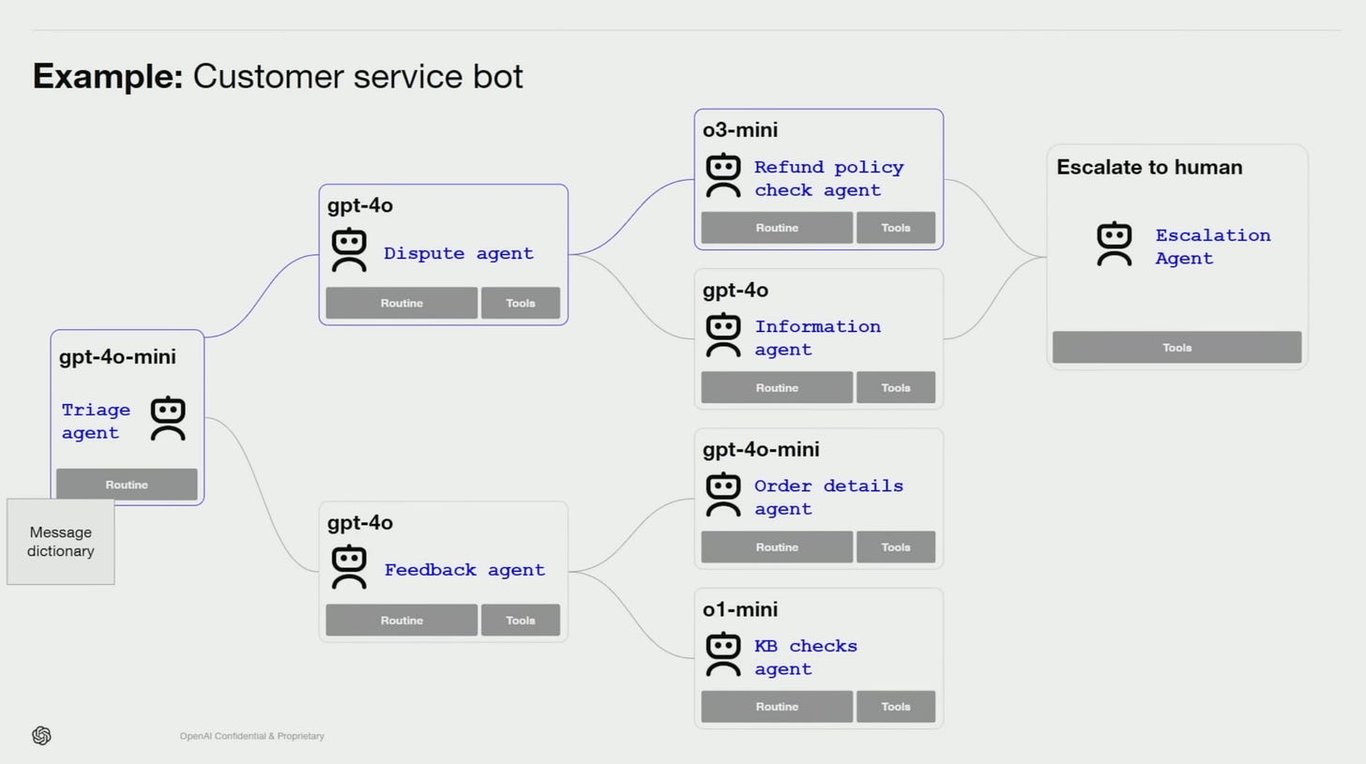
77 |
78 | 为了实现更完善的智能体应用,OpenAI 目前正在设计一系列 [常见的智能体应用模式](https://github.com/openai/openai-agents-python/tree/main/examples/agent_patterns) ,这些模式包括:工作流、移交、智能体即工具、大语言模型即裁判、并行化和安全护栏。OpenAI 在纽约演讲的第二部分中透露了这一点:
79 |
80 |
81 |
82 | 当然,也可以在观看以下发布会的直播内容:
83 |
84 |
85 |
86 | 原文链接:[⚡️ The new OpenAI Agents Platform](https://www.latent.space/p/openai-agents-platform)
87 |
--------------------------------------------------------------------------------
/documents/chinese-copywriting-guidelines.md:
--------------------------------------------------------------------------------
1 | # 中文文案排版指北
2 |
3 | 统一中文文案、排版的相关用法,降低团队成员之间的沟通成本,增强网站气质。
4 |
5 | * * *
6 |
7 | ## 空格
8 |
9 | > 「有研究显示,打字的时候不喜欢在中文和英文之间加空格的人,感情路都走得很辛苦,有七成的比例会在 34 岁的时候跟自己不爱的人结婚,而其余三成的人最后只能把遗产留给自己的猫。毕竟爱情跟书写都需要适时地留白。
10 | >
11 | > 与大家共勉之。」——[vinta/paranoid-auto-spacing](https://github.com/vinta/pangu.js)
12 |
13 | ### 中英文之间需要增加空格
14 |
15 | 正确:
16 |
17 | > 在 LeanCloud 上,数据存储是围绕 `AVObject` 进行的。
18 |
19 | 错误:
20 |
21 | > 在LeanCloud上,数据存储是围绕`AVObject`进行的。
22 | >
23 | > 在 LeanCloud上,数据存储是围绕`AVObject` 进行的。
24 |
25 | 完整的正确用法:
26 |
27 | > 在 LeanCloud 上,数据存储是围绕 `AVObject` 进行的。每个 `AVObject` 都包含了与 JSON 兼容的 key-value 对应的数据。数据是 schema-free 的,你不需要在每个 `AVObject` 上提前指定存在哪些键,只要直接设定对应的 key-value 即可。
28 |
29 | 例外:「豆瓣FM」等产品名词,按照官方所定义的格式书写。
30 |
31 | ### 中文与数字之间需要增加空格
32 |
33 | 正确:
34 |
35 | > 今天出去买菜花了 5000 元。
36 |
37 | 错误:
38 |
39 | > 今天出去买菜花了 5000元。
40 | >
41 | > 今天出去买菜花了5000元。
42 |
43 | ### 数字与单位之间需要增加空格
44 |
45 | 正确:
46 |
47 | > 我家的光纤入屋宽带有 10 Gbps,SSD 一共有 20 TB
48 |
49 | 错误:
50 |
51 | > 我家的光纤入屋宽带有 10Gbps,SSD 一共有 20TB
52 |
53 | 例外:度数/百分比与数字之间不需要增加空格:
54 |
55 | 正确:
56 |
57 | > 角度为 90° 的角,就是直角。
58 | >
59 | > 新 MacBook Pro 有 15% 的 CPU 性能提升。
60 |
61 | 错误:
62 |
63 | > 角度为 90 ° 的角,就是直角。
64 | >
65 | > 新 MacBook Pro 有 15 % 的 CPU 性能提升。
66 |
67 | ### 全角标点与其他字符之间不加空格
68 |
69 | 正确:
70 |
71 | > 刚刚买了一部 iPhone,好开心!
72 |
73 | 错误:
74 |
75 | > 刚刚买了一部 iPhone ,好开心!
76 | >
77 | > 刚刚买了一部 iPhone, 好开心!
78 |
79 | ### 用 `text-spacing` 来挽救?
80 |
81 | CSS Text Module Level 4 的 [`text-spacing`](https://www.w3.org/TR/css-text-4/#text-spacing-property) 和 Microsoft 的 [`-ms-text-autospace`](https://msdn.microsoft.com/library/ms531164(v=vs.85).aspx) 可以实现自动为中英文之间增加空白。不过目前并未普及,另外在其他应用场景,例如 macOS、iOS、Windows 等用户界面目前并不存在这个特性,所以请继续保持随手加空格的习惯。
82 |
83 | ## 标点符号
84 |
85 | ### 不重复使用标点符号
86 |
87 | 虽然中国大陆的标点符号用法允许重复使用标点符号,但是这么做会破坏句子的美观性。
88 |
89 | 正确:
90 |
91 | > 德国队竟然战胜了巴西队!
92 | >
93 | > 她竟然对你说「喵」?!
94 |
95 | 错误:
96 |
97 | > 德国队竟然战胜了巴西队!!
98 | >
99 | > 德国队竟然战胜了巴西队!!!!!!!!
100 | >
101 | > 她竟然对你说「喵」??!!
102 | >
103 | > 她竟然对你说「喵」?!?!??!!
104 |
105 | ## 全角和半角
106 |
107 | 不明白什么是全角(全形)与半角(半形)符号?请查看维基百科条目『[全角和半角](https://zh.wikipedia.org/wiki/%E5%85%A8%E5%BD%A2%E5%92%8C%E5%8D%8A%E5%BD%A2)』。
108 |
109 | ### 使用全角中文标点
110 |
111 | 正确:
112 |
113 | > 嗨!你知道嘛?今天前台的小妹跟我说「喵」了哎!
114 | >
115 | > 核磁共振成像(NMRI)是什么原理都不知道?JFGI!
116 |
117 | 错误:
118 |
119 | > 嗨! 你知道嘛? 今天前台的小妹跟我说 "喵" 了哎!
120 | >
121 | > 嗨!你知道嘛?今天前台的小妹跟我说"喵"了哎!
122 | >
123 | > 核磁共振成像 (NMRI) 是什么原理都不知道? JFGI!
124 | >
125 | > 核磁共振成像(NMRI)是什么原理都不知道?JFGI!
126 |
127 | 例外:中文句子内夹有英文书籍名、报刊名时,不应借用中文书名号,应以英文斜体表示。
128 |
129 | ### 数字使用半角字符
130 |
131 | 正确:
132 |
133 | > 这个蛋糕只卖 1000 元。
134 |
135 | 错误:
136 |
137 | > 这个蛋糕只卖 1000 元。
138 |
139 | 例外:在设计稿、宣传海报中如出现极少量数字的情形时,为方便文字对齐,是可以使用全角数字的。
140 |
141 | ### 遇到完整的英文整句、特殊名词,其内容使用半角标点
142 |
143 | 正确:
144 |
145 | > 乔布斯那句话是怎么说的?「Stay hungry, stay foolish.」
146 | >
147 | > 推荐你阅读 *Hackers & Painters: Big Ideas from the Computer Age*,非常地有趣。
148 |
149 | 错误:
150 |
151 | > 乔布斯那句话是怎么说的?「Stay hungry,stay foolish。」
152 | >
153 | > 推荐你阅读《Hackers&Painters:Big Ideas from the Computer Age》,非常的有趣。
154 |
155 | ## 名词
156 |
157 | ### 专有名词使用正确的大小写
158 |
159 | 大小写相关用法原属于英文书写范畴,不属于本 wiki 讨论内容,在这里只对部分易错用法进行简述。
160 |
161 | 正确:
162 |
163 | > 使用 GitHub 登录
164 | >
165 | > 我们的客户有 GitHub、Foursquare、Microsoft Corporation、Google、Facebook, Inc.。
166 |
167 | 错误:
168 |
169 | > 使用 github 登录
170 | >
171 | > 使用 GITHUB 登录
172 | >
173 | > 使用 Github 登录
174 | >
175 | > 使用 gitHub 登录
176 | >
177 | > 使用 gイんĤЦ8 登录
178 | >
179 | > 我们的客户有 github、foursquare、microsoft corporation、google、facebook, inc.。
180 | >
181 | > 我们的客户有 GITHUB、FOURSQUARE、MICROSOFT CORPORATION、GOOGLE、FACEBOOK, INC.。
182 | >
183 | > 我们的客户有 Github、FourSquare、MicroSoft Corporation、Google、FaceBook, Inc.。
184 | >
185 | > 我们的客户有 gitHub、fourSquare、microSoft Corporation、google、faceBook, Inc.。
186 | >
187 | > 我们的客户有 gイんĤЦ8、キouЯƧquムгє、๓เςг๏ร๏Ŧt ς๏гק๏гคtเ๏ภn、900913、ƒ4ᄃëв๏๏к, IПᄃ.。
188 |
189 | 注意:当网页中需要配合整体视觉风格而出现全部大写/小写的情形,HTML 中请使用标淮的大小写规范进行书写;并通过 `text-transform: uppercase;`/`text-transform: lowercase;` 对表现形式进行定义。
190 |
191 | ### 不要使用不地道的缩写
192 |
193 | 正确:
194 |
195 | > 我们需要一位熟悉 TypeScript、HTML5,至少理解一种框架(如 React、Next.js)的前端开发者。
196 |
197 | 错误:
198 |
199 | > 我们需要一位熟悉 Ts、h5,至少理解一种框架(如 RJS、nextjs)的 FED。
200 |
201 | ## 争议
202 |
203 | 以下用法略带有个人色彩,即:无论是否遵循下述规则,从语法的角度来讲都是**正确**的。
204 |
205 | ### 链接之间增加空格
206 |
207 | 用法:
208 |
209 | > 请 [提交一个 issue](#) 并分配给相关同事。
210 | >
211 | > 访问我们网站的最新动态,请 [点击这里](#) 进行订阅!
212 |
213 | 对比用法:
214 |
215 | > 请[提交一个 issue](#)并分配给相关同事。
216 | >
217 | > 访问我们网站的最新动态,请[点击这里](#)进行订阅!
218 |
219 | ### 简体中文使用直角引号
220 |
221 | 用法:
222 |
223 | > 「老师,『有条不紊』的『紊』是什么意思?」
224 |
225 | 对比用法:
226 |
227 | > “老师,‘有条不紊’的‘紊’是什么意思?”
--------------------------------------------------------------------------------
/posts/ai/model/20250124_openai_introduce_operator.mdx:
--------------------------------------------------------------------------------
1 | ---
2 | title: 介绍 Operator [译]
3 | date: 2025-01-24
4 | description: OpenAI 推出新型 AI 工具「操作员」(Operator),它能像人类一样浏览网页、操作界面完成任务。基于 GPT-4o 和 CUA 技术,它可以自主执行网页操作,目前正在美国地区进行小范围测试。文章详细介绍了其工作原理、使用方法、安全措施和未来发展规划。
5 | category: ai
6 | tags: OpenAI, Operator, AI Agent, GPT-4o, CUA, Web Automation, AI Assistant
7 | cover: https://media.ginonotes.com/images/20250124_openai_introduce_operator/operator.webp
8 | slug: openai-introduce-operator
9 | ---
10 |
11 | import VideoPlayer from '@/components/common/VideoPlayer'
12 |
13 | 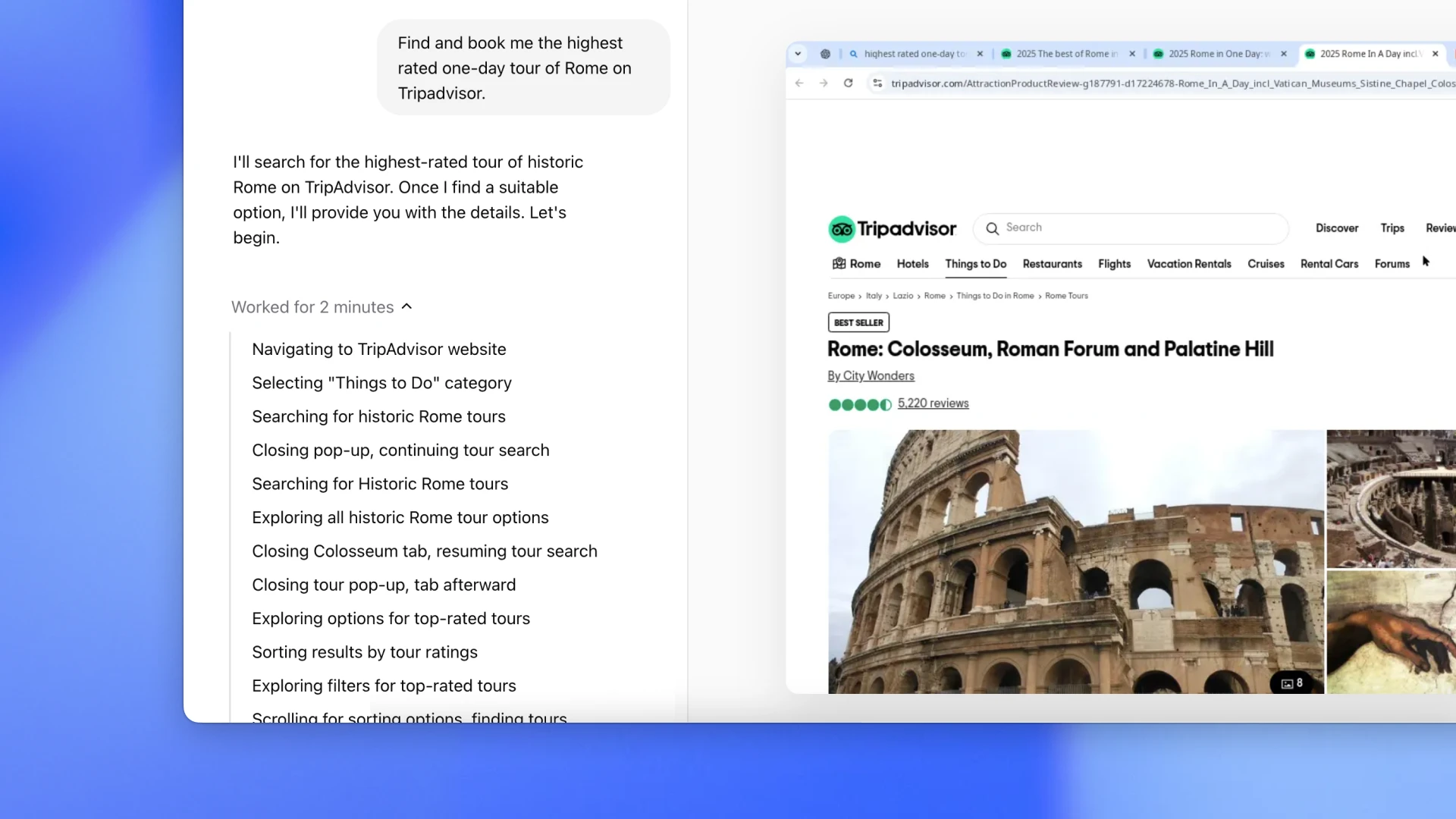
14 |
15 | 我们正在测试一个名为「操作员」(Operator)的 AI 工具,它像一个帮你上网干活的助手。它可以使用自己的浏览器,像你一样浏览网页、输入文字、点击按钮和滚动页面。
16 |
17 | 目前,**「操作员」还处于测试阶段**,功能相对有限,我们会根据大家的使用反馈不断改进它。这是我们推出的首批「智能助手」之一,它能独立完成你交给它的任务。
18 |
19 | 「操作员」可以帮你处理许多重复的网页操作,比如填写表格、订购食品,甚至制作表情包。它能像人一样使用各种网站和工具,这大大扩展了 AI 的应用范围,可以帮助人们节省时间,也为企业提供了新的机会。
20 |
21 | 为了确保安全可靠,我们先进行小范围试用。现在,美国地区的 Pro 用户可以在 [operator.chatgpt.com](https://operator.chatgpt.com) 试用「操作员」。这次测试是为了让我们更好地了解用户需求,并持续改进。我们计划未来将「操作员」推广到 Plus、Team 和 Enterprise 用户,并把它集成到 ChatGPT 中。
22 |
23 |
27 |
28 | ## 操作员的工作原理
29 |
30 | 「操作员」使用一种叫做 [「使用计算机代理」(Computer-Using Agent,简称 CUA)](https://openai.com/index/computer-using-agent/) 的新型 AI 模型。它结合了 GPT-4o 的视觉能力和强大的推理能力,通过学习如何操作我们平时看到的屏幕界面(例如按钮、菜单和文本框)来工作。
31 |
32 | 「操作员」可以通过截图「看到」网页,并像用鼠标和键盘一样「操作」网页。这样,它就能在网上执行任务,而不需要专门为每个网站开发接口。
33 |
34 | 如果遇到困难或犯错,「操作员」会利用自己的推理能力进行自我纠正。如果它实在解决不了,就会把控制权还给用户,确保使用过程顺利协作。
35 |
36 | 虽然 CUA 还处于早期阶段,功能有限,但它在 WebArena 和 WebVoyager 这两个浏览器使用测试中已经取得了很好的成绩。你可以在我们的 [研究博客](https://openai.com/index/computer-using-agent/) 中了解更多关于测试和「操作员」背后的研究内容。
37 |
38 | ## 如何使用操作员
39 |
40 | 你只需要告诉「操作员」你想做什么,它就能帮你完成。你可以随时接管浏览器的控制权。「操作员」也会主动在你需要登录、支付或解决验证码时请求你接管。
41 |
42 | 你还可以自定义「操作员」的工作流程,添加自定义指令。这些指令可以适用于所有网站,也可以针对特定网站,例如在 Booking.com 上设置首选航空公司。你可以在主页上保存常用指令,方便快速执行重复任务,例如在 Instacart 上重新订购食品。就像在浏览器中使用多个标签一样,你可以同时让「操作员」运行多个任务,例如在 Etsy 上订购个性化马克杯,同时在 Hipcamp 上预订露营地。
43 |
44 | ### 使用自定义指令
45 |
46 |
50 |
51 | ### 使用已保存的提示
52 |
53 |
57 |
58 | ## 生态系统和用户
59 |
60 | 「操作员」将 AI 从被动工具转变为数字生态系统中的活跃参与者。它可以简化用户任务,并为希望提供创新客户体验和提高转化率的公司带来好处。我们正在与 DoorDash、Instacart、OpenTable、Priceline、StubHub、Thumbtack、Uber 等公司合作,确保「操作员」能够满足实际需求,并遵守相关规范。我们还认为它在公共部门应用中具有巨大潜力,可以提高某些工作流程的可访问性和效率。例如,我们正在与斯托克顿市合作,让居民更容易注册城市服务和项目。
61 |
62 | 斯托克顿市信息技术主管贾米尔 · 尼亚齐表示:"通过在测试阶段了解更多关于「操作员」的信息,我们将更好地找到 AI 能够为我们的居民提供更便捷的公民参与方式。"
63 |
64 | 通过首先向有限的受众发布「操作员」,我们的目标是从实际反馈中快速学习并改进其功能,从而平衡创新与信任和安全。这种合作方式有助于确保「操作员」为用户、创作者、企业和公共部门组织带来有意义的价值。
65 |
66 | Instacart 首席产品官丹尼尔 · 丹克尔表示:"OpenAI 的「操作员」是一项技术突破,它使订购食品等过程变得非常容易。"
67 |
68 | ## 安全和隐私
69 |
70 | 确保「操作员」的安全使用是我们的首要任务。我们采取了三层保护措施,以防止滥用并确保用户始终处于控制之下。
71 |
72 | 首先,「操作员」经过训练,确保用户始终处于控制之下,并在关键时刻征求用户意见。
73 |
74 | - **接管模式:** 当需要在浏览器中输入敏感信息(例如登录凭据或支付信息)时,「操作员」会要求用户接管。在接管模式下,「操作员」不会收集或截图用户输入的信息。
75 | - **用户确认:** 在完成任何重要操作(例如提交订单或发送电子邮件)之前,「操作员」应请求用户批准。
76 | - **任务限制:** 「操作员」经过训练,会拒绝某些敏感任务,例如银行交易或需要高风险决策的任务(例如决定工作申请)。
77 | - **监视模式:** 在特别敏感的网站(例如电子邮件或金融服务)上,「操作员」需要密切监督其行为,允许用户直接发现任何潜在错误。
78 |
79 | 其次,我们简化了「操作员」中的数据隐私管理。
80 |
81 | - **退出培训:** 在 ChatGPT 设置中关闭"改进每个人的模型"意味着「操作员」中的数据也不会用于训练我们的模型。
82 | - **透明的数据管理:** 用户可以在「操作员」设置的"隐私"部分一键删除所有浏览数据并退出所有网站。也可以一键删除「操作员」中的历史对话。
83 |
84 | 最后,我们构建了针对恶意网站的防御机制,这些网站可能会试图通过隐藏提示、恶意代码或网络钓鱼攻击来误导「操作员」:
85 |
86 | - **谨慎导航:** 「操作员」旨在检测并忽略提示注入。
87 | - **监控:** 专用的"监控模型"会监视可疑行为,如果出现异常情况,可以暂停任务。
88 | - **检测流程:** 自动化和人工审核流程会不断识别新的威胁并快速更新保护措施。
89 |
90 | 我们知道不法分子可能会试图滥用这项技术。这就是为什么我们将「操作员」设计为拒绝有害请求并阻止不允许的内容的原因。我们的审核系统会发出警告,甚至可能会因重复违规而撤销访问权限,并且我们已经集成了额外的审核流程来检测和解决滥用问题。我们还提供了关于如何根据我们的使用政策与「操作员」进行交互的 [指南](https://openai.com/policies/using-operator-in-line-with-our-policies/)。
91 |
92 | 虽然「操作员」的设计考虑了这些保护措施,但没有系统是完美无缺的,这仍然是一个研究预览阶段;我们致力于通过实际反馈和严格测试来持续改进。有关我们方法的更多信息,请访问「操作员」[研究博客](https://openai.com/index/computer-using-agent/) 的安全部分。
93 |
94 | ## 局限性
95 |
96 | 「操作员」目前处于早期研究预览阶段,虽然它已经能够处理各种任务,但它仍在学习、发展,并且可能会犯错。例如,它目前在处理复杂界面(如创建幻灯片或管理日历)时会遇到挑战。早期用户反馈将在提高其准确性、可靠性和安全性方面发挥至关重要的作用,帮助我们为每个人改进「操作员」。
97 |
98 | ## 下一步
99 |
100 | - **API 能力:** 我们计划很快在 API 中公开为「操作员」提供支持的模型 CUA,以便开发人员可以使用它来构建自己的计算机使用代理。
101 | - **增强功能:** 我们将继续提高「操作员」处理更长、更复杂工作流程的能力。
102 | - **更广泛的访问:** 一旦我们对其大规模使用的安全性和可用性充满信心,我们计划将「操作员」(打开新窗口)扩展到 Plus、Team 和 Enterprise 用户,并在未来将其功能直接集成到 ChatGPT 中,从而实现无缝的实时和异步任务执行。
103 |
104 | 原文链接:[https://openai.com/index/introducing-operator/](https://openai.com/index/introducing-operator/)
105 |
--------------------------------------------------------------------------------
/src/app/layout.tsx:
--------------------------------------------------------------------------------
1 | import type { Metadata, Viewport } from 'next'
2 | import { ThemeProvider } from '@/app/providers'
3 | import { Analytics } from "@vercel/analytics/react"
4 | import { SpeedInsights } from "@vercel/speed-insights/next"
5 | import { ErrorBoundary } from '@/components/common/ErrorBoundary'
6 | import { Navigation } from '@/components/navigation/Navigation'
7 | import { jsonLd } from '@/lib/metadata'
8 | import './global.css'
9 | import {
10 | WEBSITE_HOST_URL,
11 | WEBSITE_NAME,
12 | WEBSITE_DESCRIPTION,
13 | WEBSITE_AUTHOR,
14 | WEBSITE_TWITTER,
15 | WEBSITE_LANGUAGE,
16 | WEBSITE_OG_IMAGE
17 | } from '@/lib/constants'
18 |
19 | // 视口配置
20 | export const viewport: Viewport = {
21 | width: 'device-width',
22 | initialScale: 1,
23 | maximumScale: 1,
24 | }
25 |
26 | // Metadata 配置
27 | export const metadata: Metadata = {
28 | metadataBase: new URL(WEBSITE_HOST_URL),
29 | title: {
30 | default: WEBSITE_NAME,
31 | template: `%s - ${WEBSITE_NAME}`,
32 | },
33 | description: WEBSITE_DESCRIPTION,
34 | applicationName: WEBSITE_NAME,
35 | authors: [{ name: WEBSITE_AUTHOR, url: WEBSITE_HOST_URL }],
36 | generator: 'Next.js',
37 | keywords: ['博客', '技术', '人工智能', '产品设计', '编程', 'Java', 'Workflow', 'Agent'],
38 | referrer: 'origin-when-cross-origin',
39 | creator: WEBSITE_AUTHOR,
40 | publisher: WEBSITE_AUTHOR,
41 | formatDetection: {
42 | email: true,
43 | address: true,
44 | telephone: true,
45 | },
46 | openGraph: {
47 | title: {
48 | default: WEBSITE_NAME,
49 | template: `%s - ${WEBSITE_NAME}`,
50 | },
51 | description: WEBSITE_DESCRIPTION,
52 | siteName: WEBSITE_NAME,
53 | locale: WEBSITE_LANGUAGE,
54 | type: 'website',
55 | url: WEBSITE_HOST_URL,
56 | images: [{
57 | url: `${WEBSITE_HOST_URL}/images/og.png`,
58 | width: 1200,
59 | height: 630,
60 | alt: WEBSITE_NAME,
61 | }],
62 | },
63 | twitter: {
64 | card: 'summary_large_image',
65 | title: {
66 | default: WEBSITE_NAME,
67 | template: `%s - ${WEBSITE_NAME}`,
68 | },
69 | description: WEBSITE_DESCRIPTION,
70 | site: WEBSITE_TWITTER,
71 | creator: WEBSITE_TWITTER,
72 | images: [`${WEBSITE_HOST_URL}/images/og.png`],
73 | },
74 | robots: {
75 | index: true,
76 | follow: true,
77 | googleBot: {
78 | index: true,
79 | follow: true,
80 | 'max-video-preview': -1,
81 | 'max-image-preview': 'large',
82 | 'max-snippet': -1,
83 | },
84 | },
85 | alternates: {
86 | canonical: WEBSITE_HOST_URL,
87 | types: {
88 | 'application/rss+xml': `${WEBSITE_HOST_URL}/feed.xml`,
89 | },
90 | },
91 | icons: {
92 | icon: [
93 | { url: `${WEBSITE_HOST_URL}/icon`, type: 'image/png', sizes: '32x32' }
94 | ],
95 | apple: `${WEBSITE_HOST_URL}/apple-icon`,
96 | },
97 | manifest: '/manifest.webmanifest',
98 | }
99 |
100 | export default function RootLayout({
101 | children,
102 | }: {
103 | children: React.ReactNode
104 | }) {
105 | return (
106 |
107 |
108 |
109 |
113 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 | {children}
128 |
129 |
130 |
131 |
30 | 💡 与我们对待智能体的方法非常相似:我们的目标是让用户能够对记忆进行底层控制,并能够根据自己的需要进行定制。
31 |
32 |
33 | 这种理念引导了我们上周在 LangGraph 中推出 [Memory Store](https://blog.langchain.dev/launching-long-term-memory-support-in-langgraph/) 时的大部分设计和开发工作。
34 |
35 | ## 记忆的类型
36 |
37 | 虽然你的智能体拥有的记忆 **形式** 可能因应用而异,但我们确实可以看到一些 **常见的** 记忆类型。这些记忆类型并不新鲜 -- 它们模仿了 [人类的记忆类型](https://www.psychologytoday.com/us/basics/memory/types-of-memory)。
38 |
39 | 已经有一些出色的研究将这些人类记忆类型**对应到**智能体记忆。我最喜欢的是 [CoALA 论文](https://arxiv.org/pdf/2309.02427)。以下是我对每种类型的粗略、通俗易懂的解释,以及当今智能体可能使用和更新这种记忆类型的 **实际方法**。
40 |
41 | 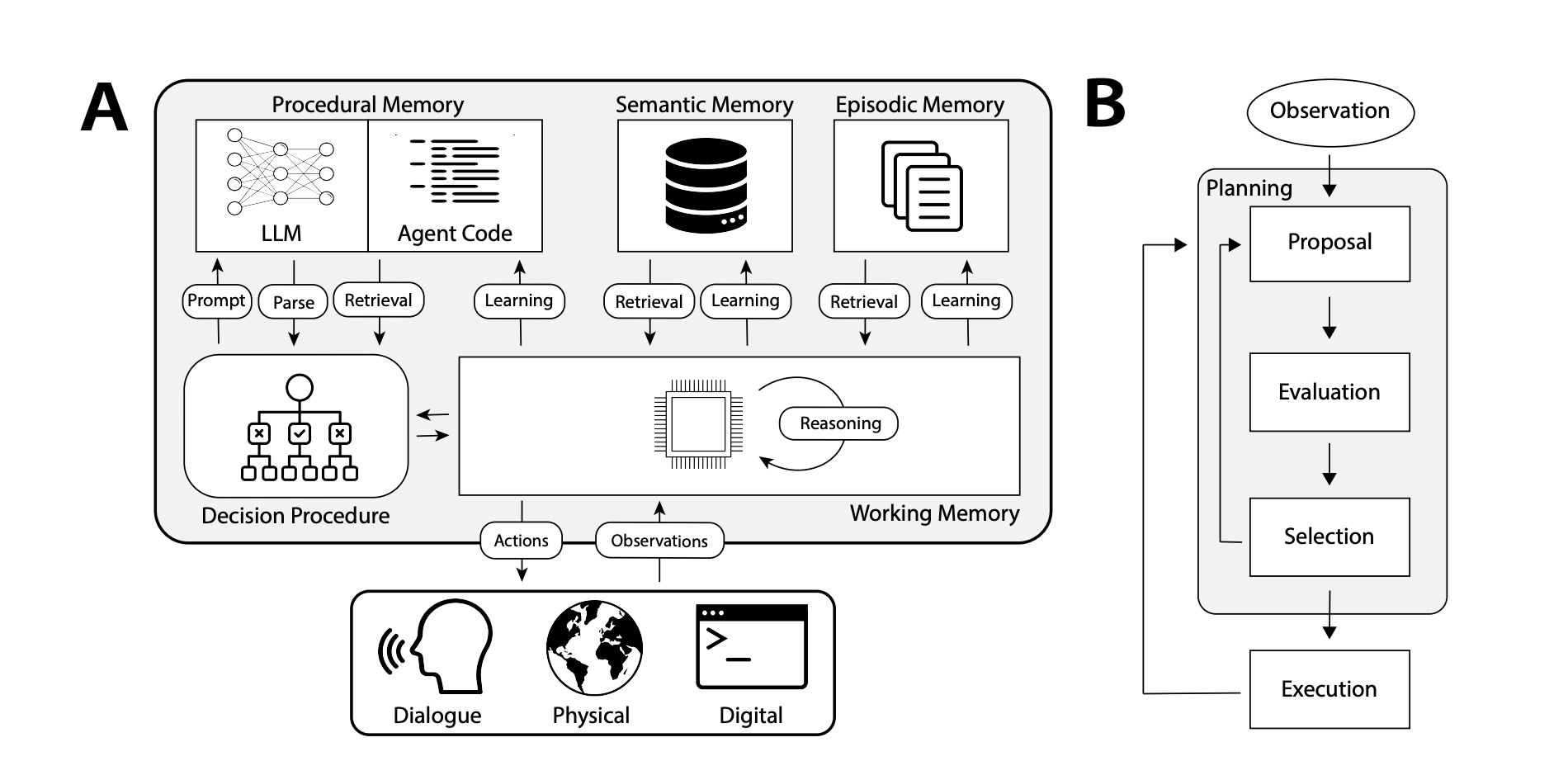
42 |
43 | CoALA 论文中的决策程序图(Sumers, Yao, Narasimhan, Griffiths 2024)
44 |
45 | ### 程序性记忆 (Procedural Memory)
46 |
47 | 这个术语指的是长期记忆中关于如何执行任务的部分,类似于大脑的核心指令集。
48 |
49 | 人类的程序性记忆:记住如何骑自行车。
50 |
51 | 智能体中的程序性记忆:CoALA 论文将程序性记忆描述为大语言模型权重和智能体代码的结合,从根本上决定了智能体的工作方式。
52 |
53 | 在实践中,我们几乎没有见到能够自动更新其大语言模型权重或重写代码的智能体系统。然而,我们确实看到一些智能体更新自身系统提示的例子。虽然这是最接近的实际例子,但仍然相对少见。
54 |
55 | ### 语义记忆 (Semantic Memory)
56 |
57 | 这是一个人长期存储的知识库。
58 |
59 | 人类的语义记忆:它由各种信息片段组成,例如在学校学到的事实、概念的含义以及它们之间的关系。
60 |
61 | 智能体中的语义记忆:CoALA 论文将语义记忆描述为关于世界的各种事实的存储库。
62 |
63 | 如今,智能体最常使用语义记忆来实现应用的个性化定制。
64 |
65 | 在实践中,我们看到这种做法通常是通过使用大语言模型从智能体进行的对话或交互中提取信息来实现的。这些信息的具体形式通常是特定于应用的。然后在未来的对话中检索这些信息,并将其插入到系统提示中,以影响智能体的响应。
66 |
67 | ### 情节记忆 (Episodic Memory)
68 |
69 | 这指的是回想起过去发生的特定事件(亦称情景记忆)。
70 |
71 | 人类的情节记忆:当一个人回忆起过去经历的特定事件(或"情节")时。
72 |
73 | 智能体中的情节记忆:CoALA 论文将情节记忆定义为存储智能体过去动作的序列。
74 |
75 | 情节记忆主要用于确保智能体能够按照预定方式执行任务。
76 |
77 | 在实践中,情节记忆是通过少样本示例提示来实现的。如果你收集了足够多的这类序列,那么就可以通过动态少样本提示来完成。如果对于之前执行过的特定操作存在 **正确** 的执行方式,那么这通常非常适合引导智能体。相比之下,如果并非必须存在正确的做事方式,或者如果智能体不断地做新的事情,以至于之前的例子没有太大帮助,那么语义记忆就更相关。
78 |
79 | ## 如何更新记忆
80 |
81 | 除了思考在智能体中更新哪种类型的记忆之外,我们还看到开发者也在思考 **更新智能体记忆的方式**。
82 |
83 | 更新智能体记忆的一种方法是 ["在热路径中(in the hot path)"](https://langchain-ai.github.io/langgraph/concepts/memory/#writing-memories-in-the-hot-path)。在这种方法中,智能体系统在响应之前显式地决定记住事实(通常通过工具调用)。ChatGPT 就采用了这种方法。
84 |
85 | 另一种更新记忆的方法是 ["在后台(in the background)"](https://langchain-ai.github.io/langgraph/concepts/memory/#writing-memories-in-the-background)。在这种情况下,后台进程在对话期间或之后运行,以更新记忆。
86 |
87 | 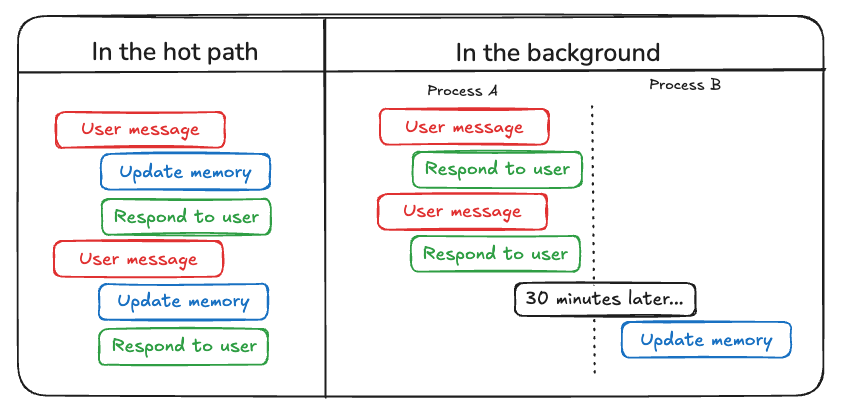
88 |
89 | 比较这两种方法,"在热路径中"的方法的缺点是会在交付任何响应之前引入一些额外的延迟。它还需要将记忆逻辑与智能体逻辑相结合。
90 |
91 | 然而,在后台运行避免了这些问题 -- 不会增加延迟,并且记忆逻辑保持独立。但是"在后台"运行也有其自身的缺点:记忆不会立即更新,并且需要额外的逻辑来确定何时启动后台进程。
92 |
93 | 另一种更新记忆的方法涉及用户反馈,这与情节记忆尤其相关。例如,如果用户将某次交互标记为积极,你可以保存该反馈,供将来参考。
94 |
95 | ## 为什么我们关心智能体的记忆?
96 |
97 | 记忆极大地影响了智能体系统的实用性,因此我们非常有兴趣尽可能轻松地为应用程序利用记忆。
98 |
99 | 为此,我们在我们的产品中构建了许多与此相关的功能。这包括:
100 |
101 | - LangGraph 中 [用于记忆存储的底层抽象](https://blog.langchain.dev/launching-long-term-memory-support-in-langgraph/),使你能够完全控制智能体的记忆
102 | - 用于在 LangGraph 中"在热路径中"和"在后台"运行记忆的 [模板](https://github.com/langchain-ai/memory-template)
103 | - LangSmith 中用于快速迭代的 [动态少样本示例选择](https://blog.langchain.dev/dynamic-few-shot-examples-langsmith-datasets/)
104 |
105 | 我们甚至构建了 [我们自己的一些应用程序](https://github.com/langchain-ai/open-canvas) 来利用记忆!虽然现在还处于早期阶段,但我们将继续学习关于智能体记忆以及它可以有效应用的领域 🙂
106 |
107 | 原文地址:[Memory for agents](https://blog.langchain.dev/memory-for-agents/)
108 |
109 | ---
110 |
111 | LangChain 智能体系列文章:
112 |
113 | - [1. 什么是智能体?](https://www.ginonotes.com/posts/what-is-ai-agents)
114 | - [2. 什么是认知架构?](https://www.ginonotes.com/posts/what-is-a-cognitive-architecture)
115 | - [3. 为什么你应该外包智能体基础设施,但保留自己的认知架构](https://www.ginonotes.com/posts/outsource-agentic-infrastructure-own-cognitive-architecture)
116 | - [4. 智能体的规划能力](https://www.ginonotes.com/posts/planning-for-agents)
117 | - [5. 智能体的交互模式](https://www.ginonotes.com/posts/ux-for-agents)
118 | - [6. 智能体的记忆](https://www.ginonotes.com/posts/memory-for-agents)
119 | - [7. 沟通:你所需要的一切](https://www.ginonotes.com/posts/communication-is-all-you-need)
--------------------------------------------------------------------------------