├── .coveragerc
├── .gitignore
├── .style.yapf
├── CONTRIBUTING.md
├── LICENSE
├── README.md
├── bin
├── __init__.py
├── data
│ ├── cnn_daily_mail_summarization
│ │ ├── process_data.sh
│ │ └── process_story.py
│ ├── toy.sh
│ └── wmt16_en_de.sh
├── infer.py
├── tools
│ ├── beam_search_viz
│ │ ├── tree.css
│ │ └── tree.js
│ ├── generate_beam_viz.py
│ ├── generate_toy_data.py
│ ├── generate_vocab.py
│ ├── multi-bleu.perl
│ └── profile.py
└── train.py
├── circle.yml
├── docs
├── concepts.md
├── contributing.md
├── data.md
├── decoders.md
├── encoders.md
├── extra.css
├── getting_started.md
├── help.md
├── image_captioning.md
├── images
│ ├── nmt_tutorial_bleu.png
│ └── nmt_tutorial_ppl.png
├── index.md
├── inference.md
├── license.md
├── models.md
├── nmt.md
├── results.md
├── summarization.md
├── tools.md
└── training.md
├── example_configs
├── nmt_conv.yml
├── nmt_conv_small.yml
├── nmt_large.yml
├── nmt_medium.yml
├── nmt_small.yml
├── text_metrics_bpe.yml
├── text_metrics_sp.yml
├── train_seq2seq.yml
└── train_seq2seq_delay_start.yml
├── mkdocs.yml
├── pylintrc
├── seq2seq
├── __init__.py
├── configurable.py
├── contrib
│ ├── __init__.py
│ ├── experiment.py
│ ├── rnn_cell.py
│ └── seq2seq
│ │ ├── __init__.py
│ │ ├── decoder.py
│ │ └── helper.py
├── data
│ ├── __init__.py
│ ├── input_pipeline.py
│ ├── parallel_data_provider.py
│ ├── postproc.py
│ ├── sequence_example_decoder.py
│ ├── split_tokens_decoder.py
│ └── vocab.py
├── decoders
│ ├── __init__.py
│ ├── attention.py
│ ├── attention_decoder.py
│ ├── basic_decoder.py
│ ├── beam_search_decoder.py
│ └── rnn_decoder.py
├── encoders
│ ├── __init__.py
│ ├── conv_encoder.py
│ ├── encoder.py
│ ├── image_encoder.py
│ ├── pooling_encoder.py
│ └── rnn_encoder.py
├── global_vars.py
├── graph_module.py
├── graph_utils.py
├── inference
│ ├── __init__.py
│ ├── beam_search.py
│ └── inference.py
├── losses.py
├── metrics
│ ├── __init__.py
│ ├── bleu.py
│ ├── metric_specs.py
│ └── rouge.py
├── models
│ ├── __init__.py
│ ├── attention_seq2seq.py
│ ├── basic_seq2seq.py
│ ├── bridges.py
│ ├── image2seq.py
│ ├── model_base.py
│ └── seq2seq_model.py
├── tasks
│ ├── __init__.py
│ ├── decode_text.py
│ ├── dump_attention.py
│ ├── dump_beams.py
│ └── inference_task.py
├── test
│ ├── __init__.py
│ ├── attention_test.py
│ ├── beam_search_test.py
│ ├── bridges_test.py
│ ├── conv_encoder_test.py
│ ├── data_test.py
│ ├── decoder_test.py
│ ├── example_config_test.py
│ ├── hooks_test.py
│ ├── input_pipeline_test.py
│ ├── losses_test.py
│ ├── metrics_test.py
│ ├── models_test.py
│ ├── pipeline_test.py
│ ├── pooling_encoder_test.py
│ ├── rnn_cell_test.py
│ ├── rnn_encoder_test.py
│ ├── train_utils_test.py
│ ├── utils.py
│ └── vocab_test.py
└── training
│ ├── __init__.py
│ ├── hooks.py
│ └── utils.py
├── setup.py
└── tox.ini
/.coveragerc:
--------------------------------------------------------------------------------
1 | [run]
2 | source =
3 | seq2seq
4 |
5 | include =
6 | seq2seq/*
7 | seq2seq/data/*
8 | seq2seq/decoders/*
9 | seq2seq/encoders/*
10 | seq2seq/inference/*
11 | seq2seq/metrics/*
12 | seq2seq/models/*
13 | seq2seq/tasks/*
14 | seq2seq/training/*
15 |
16 | omit =
17 | seq2seq/contrib/*
18 | seq2seq/test/*
19 | seq2seq/scripts/*
20 |
21 | [report]
22 | show_missing=True
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Created by https://www.gitignore.io/api/python
2 |
3 | notebooks/WIP
4 |
5 | ### Python ###
6 | # Byte-compiled / optimized / DLL files
7 | __pycache__/
8 | *.py[cod]
9 | *$py.class
10 |
11 | # C extensions
12 | *.so
13 |
14 | # Distribution / packaging
15 | .Python
16 | env/
17 | build/
18 | develop-eggs/
19 | dist/
20 | downloads/
21 | eggs/
22 | .eggs/
23 | lib/
24 | lib64/
25 | parts/
26 | sdist/
27 | var/
28 | *.egg-info/
29 | .installed.cfg
30 | *.egg
31 |
32 | # PyInstaller
33 | # Usually these files are written by a python script from a template
34 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
35 | *.manifest
36 | *.spec
37 |
38 | # Installer logs
39 | pip-log.txt
40 | pip-delete-this-directory.txt
41 |
42 | # Unit test / coverage reports
43 | htmlcov/
44 | .tox/
45 | .coverage
46 | .coverage.*
47 | .cache
48 | nosetests.xml
49 | coverage.xml
50 | *,cover
51 | .hypothesis/
52 |
53 | # Translations
54 | *.mo
55 | *.pot
56 |
57 | # Django stuff:
58 | *.log
59 | local_settings.py
60 |
61 | # Flask stuff:
62 | instance/
63 | .webassets-cache
64 |
65 | # Scrapy stuff:
66 | .scrapy
67 |
68 | # Sphinx documentation
69 | docs/_build/
70 |
71 | # PyBuilder
72 | target/
73 |
74 | # Jupyter Notebook
75 | .ipynb_checkpoints
76 |
77 | # pyenv
78 | .python-version
79 |
80 | # celery beat schedule file
81 | celerybeat-schedule
82 |
83 | # dotenv
84 | .env
85 |
86 | # virtualenv
87 | .venv/
88 | venv/
89 | ENV/
90 |
91 | # Spyder project settings
92 | .spyderproject
93 |
94 | # Rope project settings
95 | .ropeproject
96 |
97 | # Sublime
98 | .sublimelinterrc
99 |
100 | # Tensorflow
101 | .tfprof_history.txt
102 |
103 | # Mac OS X
104 | .DS_Store
105 |
106 | # MkDocs
107 | site/
108 |
109 | ### Emacs ###
110 | # -*- mode: gitignore; -*-
111 | *~
112 | \#*\#
113 | /.emacs.desktop
114 | /.emacs.desktop.lock
115 | *.elc
116 | auto-save-list
117 | tramp
118 | .\#*
119 |
120 | # Org-mode
121 | .org-id-locations
122 | *_archive
123 |
124 | # flymake-mode
125 | *_flymake.*
126 |
127 | # eshell files
128 | /eshell/history
129 | /eshell/lastdir
130 |
131 | # elpa packages
132 | /elpa/
133 |
134 | # reftex files
135 | *.rel
136 |
137 | # AUCTeX auto folder
138 | /auto/
139 |
140 | # cask packages
141 | .cask/
142 | dist/
143 |
144 | # Flycheck
145 | flycheck_*.el
146 |
147 | # server auth directory
148 | /server/
149 |
150 | # projectiles files
151 | .projectile
152 |
153 | # directory configuration
154 | .dir-locals.el
155 |
156 | # End of https://www.gitignore.io/api/emacs
--------------------------------------------------------------------------------
/.style.yapf:
--------------------------------------------------------------------------------
1 | [style]
2 | based_on_style = google
3 | indent_width = 2
4 | column_limit = 80
--------------------------------------------------------------------------------
/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | # How to contribute
2 |
3 | We'd love to accept your patches and contributions to this project. There are
4 | just a few small guidelines you need to follow.
5 |
6 | ## Contributor License Agreement
7 |
8 | Contributions to this project must be accompanied by a Contributor License
9 | Agreement. You (or your employer) retain the copyright to your contribution,
10 | this simply gives us permission to use and redistribute your contributions as
11 | part of the project. Head over to to see
12 | your current agreements on file or to sign a new one.
13 |
14 | You generally only need to submit a CLA once, so if you've already submitted one
15 | (even if it was for a different project), you probably don't need to do it
16 | again.
17 |
18 | ## Code reviews
19 |
20 | All submissions, including submissions by project members, require review. We
21 | use GitHub pull requests for this purpose. Consult [GitHub Help] for more
22 | information on using pull requests.
23 |
24 | [GitHub Help]: https://help.github.com/articles/about-pull-requests/
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | [](https://circleci.com/gh/google/seq2seq)
2 |
3 | ---
4 |
5 | **[READ THE DOCUMENTATION](https://google.github.io/seq2seq)**
6 |
7 | **[CONTRIBUTING](https://google.github.io/seq2seq/contributing/)**
8 |
9 | ---
10 |
11 | A general-purpose encoder-decoder framework for Tensorflow that can be used for Machine Translation, Text Summarization, Conversational Modeling, Image Captioning, and more.
12 |
13 | 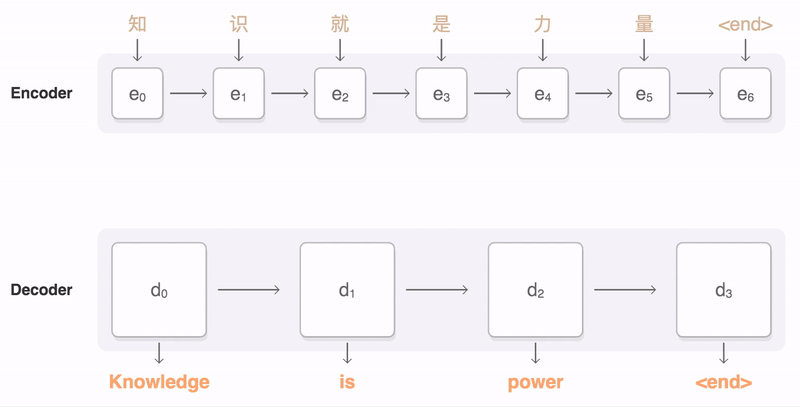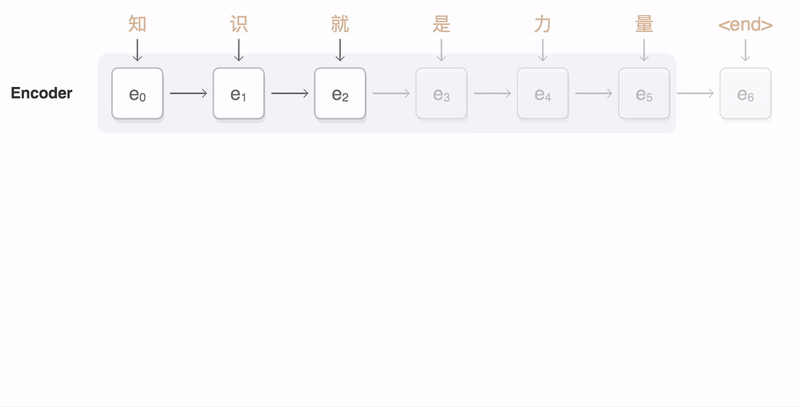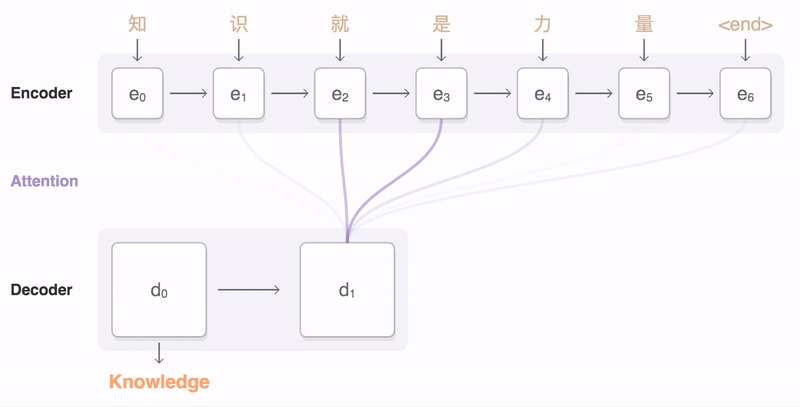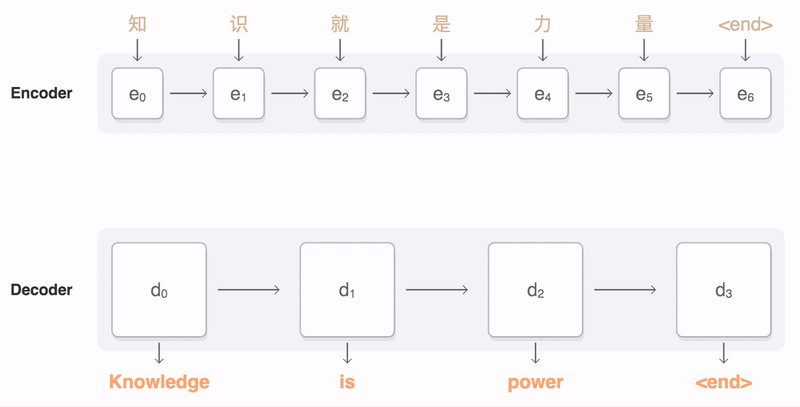
14 |
15 | ---
16 |
17 | The official code used for the [Massive Exploration of Neural Machine Translation Architectures](https://arxiv.org/abs/1703.03906) paper.
18 |
19 | If you use this code for academic purposes, please cite it as:
20 |
21 | ```
22 | @ARTICLE{Britz:2017,
23 | author = {{Britz}, Denny and {Goldie}, Anna and {Luong}, Thang and {Le}, Quoc},
24 | title = "{Massive Exploration of Neural Machine Translation Architectures}",
25 | journal = {ArXiv e-prints},
26 | archivePrefix = "arXiv",
27 | eprinttype = {arxiv},
28 | eprint = {1703.03906},
29 | primaryClass = "cs.CL",
30 | keywords = {Computer Science - Computation and Language},
31 | year = 2017,
32 | month = mar,
33 | }
34 | ```
35 |
36 | This is not an official Google product.
37 |
--------------------------------------------------------------------------------
/bin/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/google/seq2seq/7f485894d412e8d81ce0e07977831865e44309ce/bin/__init__.py
--------------------------------------------------------------------------------
/bin/data/cnn_daily_mail_summarization/process_data.sh:
--------------------------------------------------------------------------------
1 | #! /usr/bin/env bash
2 |
3 | # Copyright 2017 Google Inc.
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 |
17 | # The argument is the dat directory with all story files
18 | # Downloaded from http://cs.nyu.edu/~kcho/DMQA/
19 | DATA_DIR=$1
20 |
21 | # Directory to write processed dataset to
22 | OUTPUT_DIR=$2
23 |
24 | # seq2seq root directory
25 | BASE_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )/../../.." && pwd )"
26 |
27 | mkdir -p $OUTPUT_DIR
28 | echo "Writing to $OUTPUT_DIR"
29 |
30 | for story in $(find $DATA_DIR/ -name *.story); do
31 | $BASE_DIR/bin/data/cnn_daily_mail_summarization/process_story.py \
32 | < $story \
33 | >> ${OUTPUT_DIR}/stories_and_summaries.txt
34 | done
35 |
36 | # Split processed files into stories and summaries
37 | cut -f 1 ${OUTPUT_DIR}/stories_and_summaries.txt > ${OUTPUT_DIR}/data.stories
38 | cut -f 2 ${OUTPUT_DIR}/stories_and_summaries.txt > ${OUTPUT_DIR}/data.summaries
39 |
40 | # Split into train/dev/test
41 | # First 1000 lines are dev, next 1000 lines are test, the rest is train
42 | tail -n +2000 ${OUTPUT_DIR}/data.stories > ${OUTPUT_DIR}/train.stories
43 | tail -n +2000 ${OUTPUT_DIR}/data.summaries > ${OUTPUT_DIR}/train.summaries
44 | head -n 1000 ${OUTPUT_DIR}/data.stories > ${OUTPUT_DIR}/dev.stories
45 | head -n 1000 ${OUTPUT_DIR}/data.summaries > ${OUTPUT_DIR}/dev.summaries
46 | head -n 2000 ${OUTPUT_DIR}/data.stories | tail -n +1000 > ${OUTPUT_DIR}/test.stories
47 | head -n 2000 ${OUTPUT_DIR}/data.summaries | tail -n +1000 > ${OUTPUT_DIR}/test.summaries
48 |
49 | # Use google/sentencepiece to learn vocabulary
50 | # Follow installation instructions at https://github.com/google/sentencepiece
51 | spm_train \
52 | --input=${OUTPUT_DIR}/train.stories,${OUTPUT_DIR}/train.summaries \
53 | --model_prefix=${OUTPUT_DIR}/bpe \
54 | --vocab_size=32000 \
55 | --model_type=bpe
56 |
57 | for data in train dev test; do
58 | spm_encode --model=${OUTPUT_DIR}/bpe.model --output_format=piece \
59 | < ${OUTPUT_DIR}/${data}.summaries \
60 | > ${OUTPUT_DIR}/${data}.bpe.summaries
61 | spm_encode --model=${OUTPUT_DIR}/bpe.model --output_format=piece \
62 | < ${OUTPUT_DIR}/${data}.stories \
63 | > ${OUTPUT_DIR}/${data}.bpe.stories
64 | done
65 |
--------------------------------------------------------------------------------
/bin/data/cnn_daily_mail_summarization/process_story.py:
--------------------------------------------------------------------------------
1 | #! /usr/bin/env python
2 |
3 | # -*- coding: utf-8 -*-
4 | # Copyright 2017 Google Inc.
5 | #
6 | # Licensed under the Apache License, Version 2.0 (the "License");
7 | # you may not use this file except in compliance with the License.
8 | # You may obtain a copy of the License at
9 | #
10 | # http://www.apache.org/licenses/LICENSE-2.0
11 | #
12 | # Unless required by applicable law or agreed to in writing, software
13 | # distributed under the License is distributed on an "AS IS" BASIS,
14 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 | # See the License for the specific language governing permissions and
16 | # limitations under the License.
17 |
18 |
19 | """
20 | Processes a CNN/Daily Mail story file into a format that can
21 | be used for summarization.
22 | """
23 |
24 | import fileinput
25 | import re
26 |
27 | def process_story(text):
28 | """Processed a story text into an (article, summary) tuple.
29 | """
30 | # Split by highlights
31 | elements = text.split("@highlight")
32 | elements = [_.strip() for _ in elements]
33 |
34 | story_text = elements[0]
35 | highlights = elements[1:]
36 |
37 | # Join all highlights into a single blob
38 | highlights_joined = "; ".join(highlights)
39 | highlights_joined = re.sub(r"\s+", " ", highlights_joined)
40 | highlights_joined = highlights_joined.strip()
41 |
42 | # Remove newlines from story
43 | # story_text = story_text.replace("\n", " ")
44 | story_text = re.sub(r"\s+", " ", story_text)
45 | story_text = story_text.strip()
46 |
47 | return story_text, highlights_joined
48 |
49 | def main(*args, **kwargs):
50 | """Program entry point"""
51 | story_text = "\n".join(list(fileinput.input()))
52 | story, highlights = process_story(story_text)
53 |
54 | if story and highlights:
55 | print("{}\t{}".format(story, highlights))
56 |
57 | if __name__ == '__main__':
58 | main()
59 |
--------------------------------------------------------------------------------
/bin/data/toy.sh:
--------------------------------------------------------------------------------
1 | #! /usr/bin/env bash
2 | # Copyright 2017 Google Inc.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 |
16 | set -e
17 |
18 | BASE_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )/../.." && pwd )"
19 |
20 | DATA_TYPE=${DATA_TYPE:-copy}
21 | echo "Using type=${DATA_TYPE}. To change this set DATA_TYPE to 'copy' or 'reverse'"
22 |
23 | OUTPUT_DIR=${OUTPUT_DIR:-$HOME/nmt_data/toy_${DATA_TYPE}}
24 | echo "Writing to ${OUTPUT_DIR}. To change this, set the OUTPUT_DIR environment variable."
25 |
26 | OUTPUT_DIR_TRAIN="${OUTPUT_DIR}/train"
27 | OUTPUT_DIR_DEV="${OUTPUT_DIR}/dev"
28 | OUTPUT_DIR_TEST="${OUTPUT_DIR}/test"
29 |
30 | mkdir -p $OUTPUT_DIR
31 |
32 | # Write train, dev and test data
33 | ${BASE_DIR}/bin/tools/generate_toy_data.py \
34 | --type ${DATA_TYPE} \
35 | --num_examples 10000 \
36 | --vocab_size 20 \
37 | --max_len 20 \
38 | --output_dir ${OUTPUT_DIR_TRAIN}
39 |
40 | ${BASE_DIR}/bin/tools/generate_toy_data.py \
41 | --type ${DATA_TYPE} \
42 | --num_examples 1000 \
43 | --vocab_size 20 \
44 | --max_len 20 \
45 | --output_dir ${OUTPUT_DIR_DEV}
46 |
47 | ${BASE_DIR}/bin/tools/generate_toy_data.py \
48 | --type ${DATA_TYPE} \
49 | --num_examples 1000 \
50 | --vocab_size 20 \
51 | --max_len 20 \
52 | --output_dir ${OUTPUT_DIR_TEST}
53 |
54 | # Create Vocabulary
55 | ${BASE_DIR}/bin/tools/generate_vocab.py \
56 | < ${OUTPUT_DIR_TRAIN}/sources.txt \
57 | > ${OUTPUT_DIR_TRAIN}/vocab.sources.txt
58 | echo "Wrote ${OUTPUT_DIR_TRAIN}/vocab.sources.txt"
59 |
60 | ${BASE_DIR}/bin/tools/generate_vocab.py \
61 | < ${OUTPUT_DIR_TRAIN}/targets.txt \
62 | > ${OUTPUT_DIR_TRAIN}/vocab.targets.txt
63 | echo "Wrote ${OUTPUT_DIR_TRAIN}/vocab.targets.txt"
64 |
65 | # Optionally encode data with google/sentencepice
66 | # Useful for testing
67 | if [ "$SENTENCEPIECE" = true ]; then
68 | spm_train \
69 | --input=${OUTPUT_DIR_TRAIN}/sources.txt,${OUTPUT_DIR_TRAIN}/targets.txt \
70 | --model_prefix=${OUTPUT_DIR}/bpe \
71 | --vocab_size=20 \
72 | --model_type=bpe
73 | for dir in ${OUTPUT_DIR_TRAIN} ${OUTPUT_DIR_DEV} ${OUTPUT_DIR_TEST}; do
74 | spm_encode --model=${OUTPUT_DIR}/bpe.model --output_format=piece \
75 | < ${dir}/sources.txt \
76 | > ${dir}/sources.bpe.txt
77 | spm_encode --model=${OUTPUT_DIR}/bpe.model --output_format=piece \
78 | < ${dir}/targets.txt \
79 | > ${dir}/targets.bpe.txt
80 | done
81 | fi
82 |
--------------------------------------------------------------------------------
/bin/infer.py:
--------------------------------------------------------------------------------
1 | #! /usr/bin/env python
2 | # Copyright 2017 Google Inc.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 |
16 | """ Generates model predictions.
17 | """
18 |
19 | from __future__ import absolute_import
20 | from __future__ import division
21 | from __future__ import print_function
22 | from __future__ import unicode_literals
23 |
24 | from pydoc import locate
25 |
26 | import yaml
27 | from six import string_types
28 |
29 | import tensorflow as tf
30 | from tensorflow import gfile
31 |
32 | from seq2seq import tasks, models
33 | from seq2seq.configurable import _maybe_load_yaml, _deep_merge_dict
34 | from seq2seq.data import input_pipeline
35 | from seq2seq.inference import create_inference_graph
36 | from seq2seq.training import utils as training_utils
37 |
38 | tf.flags.DEFINE_string("tasks", "{}", "List of inference tasks to run.")
39 | tf.flags.DEFINE_string("model_params", "{}", """Optionally overwrite model
40 | parameters for inference""")
41 |
42 | tf.flags.DEFINE_string("config_path", None,
43 | """Path to a YAML configuration file defining FLAG
44 | values and hyperparameters. Refer to the documentation
45 | for more details.""")
46 |
47 | tf.flags.DEFINE_string("input_pipeline", None,
48 | """Defines how input data should be loaded.
49 | A YAML string.""")
50 |
51 | tf.flags.DEFINE_string("model_dir", None, "directory to load model from")
52 | tf.flags.DEFINE_string("checkpoint_path", None,
53 | """Full path to the checkpoint to be loaded. If None,
54 | the latest checkpoint in the model dir is used.""")
55 | tf.flags.DEFINE_integer("batch_size", 32, "the train/dev batch size")
56 |
57 | FLAGS = tf.flags.FLAGS
58 |
59 | def main(_argv):
60 | """Program entry point.
61 | """
62 |
63 | # Load flags from config file
64 | if FLAGS.config_path:
65 | with gfile.GFile(FLAGS.config_path) as config_file:
66 | config_flags = yaml.load(config_file)
67 | for flag_key, flag_value in config_flags.items():
68 | setattr(FLAGS, flag_key, flag_value)
69 |
70 | if isinstance(FLAGS.tasks, string_types):
71 | FLAGS.tasks = _maybe_load_yaml(FLAGS.tasks)
72 |
73 | if isinstance(FLAGS.input_pipeline, string_types):
74 | FLAGS.input_pipeline = _maybe_load_yaml(FLAGS.input_pipeline)
75 |
76 | input_pipeline_infer = input_pipeline.make_input_pipeline_from_def(
77 | FLAGS.input_pipeline, mode=tf.contrib.learn.ModeKeys.INFER,
78 | shuffle=False, num_epochs=1)
79 |
80 | # Load saved training options
81 | train_options = training_utils.TrainOptions.load(FLAGS.model_dir)
82 |
83 | # Create the model
84 | model_cls = locate(train_options.model_class) or \
85 | getattr(models, train_options.model_class)
86 | model_params = train_options.model_params
87 | model_params = _deep_merge_dict(
88 | model_params, _maybe_load_yaml(FLAGS.model_params))
89 | model = model_cls(
90 | params=model_params,
91 | mode=tf.contrib.learn.ModeKeys.INFER)
92 |
93 | # Load inference tasks
94 | hooks = []
95 | for tdict in FLAGS.tasks:
96 | if not "params" in tdict:
97 | tdict["params"] = {}
98 | task_cls = locate(tdict["class"]) or getattr(tasks, tdict["class"])
99 | task = task_cls(tdict["params"])
100 | hooks.append(task)
101 |
102 | # Create the graph used for inference
103 | predictions, _, _ = create_inference_graph(
104 | model=model,
105 | input_pipeline=input_pipeline_infer,
106 | batch_size=FLAGS.batch_size)
107 |
108 | saver = tf.train.Saver()
109 | checkpoint_path = FLAGS.checkpoint_path
110 | if not checkpoint_path:
111 | checkpoint_path = tf.train.latest_checkpoint(FLAGS.model_dir)
112 |
113 | def session_init_op(_scaffold, sess):
114 | saver.restore(sess, checkpoint_path)
115 | tf.logging.info("Restored model from %s", checkpoint_path)
116 |
117 | scaffold = tf.train.Scaffold(init_fn=session_init_op)
118 | session_creator = tf.train.ChiefSessionCreator(scaffold=scaffold)
119 | with tf.train.MonitoredSession(
120 | session_creator=session_creator,
121 | hooks=hooks) as sess:
122 |
123 | # Run until the inputs are exhausted
124 | while not sess.should_stop():
125 | sess.run([])
126 |
127 | if __name__ == "__main__":
128 | tf.logging.set_verbosity(tf.logging.INFO)
129 | tf.app.run()
130 |
--------------------------------------------------------------------------------
/bin/tools/beam_search_viz/tree.css:
--------------------------------------------------------------------------------
1 | /*
2 | * Copyright 2017 Google Inc.
3 | *
4 | * Licensed under the Apache License, Version 2.0 (the "License");
5 | * you may not use this file except in compliance with the License.
6 | * You may obtain a copy of the License at
7 | *
8 | * http://www.apache.org/licenses/LICENSE-2.0
9 | *
10 | * Unless required by applicable law or agreed to in writing, software
11 | * distributed under the License is distributed on an "AS IS" BASIS,
12 | * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | * See the License for the specific language governing permissions and
14 | * limitations under the License.
15 | */
16 |
17 |
18 | .node {
19 | cursor: pointer;
20 | }
21 |
22 | .node circle {
23 | fill: #fff;
24 | stroke: steelblue;
25 | stroke-width: 3px;
26 | }
27 |
28 | .node text {
29 | font: 11px sans-serif;
30 | }
31 |
32 | .link {
33 | fill: none;
34 | stroke: #ccc;
35 | stroke-width: 2px;
36 | }
37 |
--------------------------------------------------------------------------------
/bin/tools/beam_search_viz/tree.js:
--------------------------------------------------------------------------------
1 | // Copyright 2017 Google Inc.
2 | //
3 | // Licensed under the Apache License, Version 2.0 (the "License");
4 | // you may not use this file except in compliance with the License.
5 | // You may obtain a copy of the License at
6 | //
7 | // http://www.apache.org/licenses/LICENSE-2.0
8 | //
9 | // Unless required by applicable law or agreed to in writing, software
10 | // distributed under the License is distributed on an "AS IS" BASIS,
11 | // WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | // See the License for the specific language governing permissions and
13 | // limitations under the License.
14 |
15 | var margin = { top: 20, right: 120, bottom: 20, left: 120 },
16 | width = 5000 - margin.right - margin.left,
17 | height = 500 - margin.top - margin.bottom;
18 |
19 | var i = 0;
20 | var duration = 750;
21 |
22 | var tree = d3.layout.tree()
23 | .size([height, width]);
24 |
25 | var diagonal = d3.svg.diagonal()
26 | .projection(function(d) { return [d.y, d.x]; });
27 |
28 | var svg = d3.select("body").append("svg")
29 | .attr("width", width + margin.right + margin.left)
30 | .attr("height", height + margin.top + margin.bottom)
31 | .append("g")
32 | .attr("transform", "translate(" + margin.left + "," + margin.top + ")");
33 |
34 | root = treeData;
35 | root.x0 = height / 2;
36 | root.y0 = 0;
37 |
38 | update(root);
39 |
40 | d3.select(self.frameElement).style("height", "500px");
41 |
42 | function update(source) {
43 |
44 | // Compute the new tree layout.
45 | var nodes = tree.nodes(root).reverse(),
46 | links = tree.links(nodes);
47 |
48 | // Normalize for fixed-depth.
49 | nodes.forEach(function(d) { d.y = d.depth * 90; });
50 |
51 | // Update the nodes…
52 | var node = svg.selectAll("g.node")
53 | .data(nodes, function(d) { return d.id || (d.id = ++i); });
54 |
55 | // Enter any new nodes at the parent's previous position.
56 | var nodeEnter = node.enter().append("g")
57 | .attr("class", "node")
58 | .attr("transform", function(d) { return "translate(" + source.y0 + "," + source.x0 + ")"; })
59 | .on("click", click);
60 |
61 | nodeEnter.append("circle")
62 | .attr("r", 1e-6)
63 | .style("fill", function(d) { return d._children ? "lightsteelblue" : "#fff"; });
64 |
65 | nodeEnter.append("text")
66 | .attr("dy", "2.5em")
67 | .attr("text-anchor", "middle")
68 | .text(function(d) { return d.name })
69 |
70 | nodeEnter.append("text")
71 | .attr("dy", "3.5em")
72 | .attr("text-anchor", "middle")
73 | .text(function(d) { return d.score })
74 |
75 | // Transition nodes to their new position.
76 | var nodeUpdate = node.transition()
77 | .duration(duration)
78 | .attr("transform", function(d) { return "translate(" + d.y + "," + d.x + ")"; });
79 |
80 | nodeUpdate.select("circle")
81 | .attr("r", 10)
82 | .style("fill", function(d) { return d._children ? "lightsteelblue" : "#fff"; });
83 |
84 | nodeUpdate.select("text")
85 | .style("fill-opacity", 1);
86 |
87 | // Transition exiting nodes to the parent's new position.
88 | var nodeExit = node.exit().transition()
89 | .duration(duration)
90 | .attr("transform", function(d) { return "translate(" + source.y + "," + source.x + ")"; })
91 | .remove();
92 |
93 | nodeExit.select("circle")
94 | .attr("r", 1e-6);
95 |
96 | nodeExit.select("text")
97 | .style("fill-opacity", 1e-6);
98 |
99 | // Update the links…
100 | var link = svg.selectAll("path.link")
101 | .data(links, function(d) { return d.target.id; });
102 |
103 | // Enter any new links at the parent's previous position.
104 | link.enter().insert("path", "g")
105 | .attr("class", "link")
106 | .attr("d", function(d) {
107 | var o = {x: source.x0, y: source.y0};
108 | return diagonal({source: o, target: o});
109 | });
110 |
111 | // Transition links to their new position.
112 | link.transition()
113 | .duration(duration)
114 | .attr("d", diagonal);
115 |
116 | // Transition exiting nodes to the parent's new position.
117 | link.exit().transition()
118 | .duration(duration)
119 | .attr("d", function(d) {
120 | var o = {x: source.x, y: source.y};
121 | return diagonal({source: o, target: o});
122 | })
123 | .remove();
124 |
125 | // Stash the old positions for transition.
126 | nodes.forEach(function(d) {
127 | d.x0 = d.x;
128 | d.y0 = d.y;
129 | });
130 | }
131 |
132 | // Toggle children on click.
133 | function click(d) {
134 | if (d.children) {
135 | d._children = d.children;
136 | d.children = null;
137 | } else {
138 | d.children = d._children;
139 | d._children = null;
140 | }
141 | update(d);
142 | }
--------------------------------------------------------------------------------
/bin/tools/generate_beam_viz.py:
--------------------------------------------------------------------------------
1 | #! /usr/bin/env python
2 | # Copyright 2017 Google Inc.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 |
16 | """ Generate beam search visualization.
17 | """
18 |
19 | from __future__ import absolute_import
20 | from __future__ import division
21 | from __future__ import print_function
22 | from __future__ import unicode_literals
23 |
24 | import argparse
25 | import os
26 | import json
27 | import shutil
28 | from string import Template
29 | import numpy as np
30 |
31 | import networkx as nx
32 | from networkx.readwrite import json_graph
33 |
34 | PARSER = argparse.ArgumentParser(
35 | description="Generate beam search visualizations")
36 | PARSER.add_argument(
37 | "-d", "--data", type=str, required=True,
38 | help="path to the beam search data file")
39 | PARSER.add_argument(
40 | "-o", "--output_dir", type=str, required=True,
41 | help="path to the output directory")
42 | PARSER.add_argument(
43 | "-v", "--vocab", type=str, required=False,
44 | help="path to the vocabulary file")
45 | ARGS = PARSER.parse_args()
46 |
47 |
48 | HTML_TEMPLATE = Template("""
49 |
50 |
51 |
52 |
53 | Beam Search
54 |
55 |
56 |
57 |
58 |
61 |
62 |
63 | """)
64 |
65 |
66 | def _add_graph_level(graph, level, parent_ids, names, scores):
67 | """Adds a levelto the passed graph"""
68 | for i, parent_id in enumerate(parent_ids):
69 | new_node = (level, i)
70 | parent_node = (level - 1, parent_id)
71 | graph.add_node(new_node)
72 | graph.node[new_node]["name"] = names[i]
73 | graph.node[new_node]["score"] = str(scores[i])
74 | graph.node[new_node]["size"] = 100
75 | # Add an edge to the parent
76 | graph.add_edge(parent_node, new_node)
77 |
78 | def create_graph(predicted_ids, parent_ids, scores, vocab=None):
79 | def get_node_name(pred):
80 | return vocab[pred] if vocab else str(pred)
81 |
82 | seq_length = predicted_ids.shape[0]
83 | graph = nx.DiGraph()
84 | for level in range(seq_length):
85 | names = [get_node_name(pred) for pred in predicted_ids[level]]
86 | _add_graph_level(graph, level + 1, parent_ids[level], names, scores[level])
87 | graph.node[(0, 0)]["name"] = "START"
88 | return graph
89 |
90 |
91 | def main():
92 | beam_data = np.load(ARGS.data)
93 |
94 | # Optionally load vocabulary data
95 | vocab = None
96 | if ARGS.vocab:
97 | with open(ARGS.vocab) as file:
98 | vocab = file.readlines()
99 | vocab = [_.strip() for _ in vocab]
100 | vocab += ["UNK", "SEQUENCE_START", "SEQUENCE_END"]
101 |
102 | if not os.path.exists(ARGS.output_dir):
103 | os.makedirs(ARGS.output_dir)
104 |
105 | # Copy required files
106 | shutil.copy2("./bin/tools/beam_search_viz/tree.css", ARGS.output_dir)
107 | shutil.copy2("./bin/tools/beam_search_viz/tree.js", ARGS.output_dir)
108 |
109 | for idx in range(len(beam_data["predicted_ids"])):
110 | predicted_ids = beam_data["predicted_ids"][idx]
111 | parent_ids = beam_data["beam_parent_ids"][idx]
112 | scores = beam_data["scores"][idx]
113 |
114 | graph = create_graph(
115 | predicted_ids=predicted_ids,
116 | parent_ids=parent_ids,
117 | scores=scores,
118 | vocab=vocab)
119 |
120 | json_str = json.dumps(
121 | json_graph.tree_data(graph, (0, 0)),
122 | ensure_ascii=False)
123 |
124 | html_str = HTML_TEMPLATE.substitute(DATA=json_str)
125 | output_path = os.path.join(ARGS.output_dir, "{:06d}.html".format(idx))
126 | with open(output_path, "w") as file:
127 | file.write(html_str)
128 | print(output_path)
129 |
130 |
131 | if __name__ == "__main__":
132 | main()
--------------------------------------------------------------------------------
/bin/tools/generate_toy_data.py:
--------------------------------------------------------------------------------
1 | #! /usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # Copyright 2017 Google Inc.
5 | #
6 | # Licensed under the Apache License, Version 2.0 (the "License");
7 | # you may not use this file except in compliance with the License.
8 | # You may obtain a copy of the License at
9 | #
10 | # http://www.apache.org/licenses/LICENSE-2.0
11 | #
12 | # Unless required by applicable law or agreed to in writing, software
13 | # distributed under the License is distributed on an "AS IS" BASIS,
14 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 | # See the License for the specific language governing permissions and
16 | # limitations under the License.
17 |
18 | """
19 | Functions to generate various toy datasets.
20 | """
21 |
22 | from __future__ import absolute_import
23 | from __future__ import division
24 | from __future__ import print_function
25 | from __future__ import unicode_literals
26 |
27 | import argparse
28 | import os
29 | import numpy as np
30 | import io
31 |
32 | PARSER = argparse.ArgumentParser(description="Generates toy datasets.")
33 | PARSER.add_argument(
34 | "--vocab_size", type=int, default=100, help="size of the vocabulary")
35 | PARSER.add_argument(
36 | "--num_examples", type=int, default=10000, help="number of examples")
37 | PARSER.add_argument(
38 | "--min_len", type=int, default=5, help="minimum sequence length")
39 | PARSER.add_argument(
40 | "--max_len", type=int, default=40, help="maximum sequence length")
41 | PARSER.add_argument(
42 | "--type",
43 | type=str,
44 | default="copy",
45 | choices=["copy", "reverse"],
46 | help="Type of dataet to generate. One of \"copy\" or \"reverse\"")
47 | PARSER.add_argument(
48 | "--output_dir",
49 | type=str,
50 | help="path to the output directory",
51 | required=True)
52 | ARGS = PARSER.parse_args()
53 |
54 | VOCABULARY = list([str(x) for x in range(ARGS.vocab_size - 1)])
55 | VOCABULARY += ["笑"]
56 |
57 |
58 | def make_copy(num_examples, min_len, max_len):
59 | """
60 | Generates a dataset where the target is equal to the source.
61 | Sequence lengths are chosen randomly from [min_len, max_len].
62 |
63 | Args:
64 | num_examples: Number of examples to generate
65 | min_len: Minimum sequence length
66 | max_len: Maximum sequence length
67 |
68 | Returns:
69 | An iterator of (source, target) string tuples.
70 | """
71 | for _ in range(num_examples):
72 | turn_length = np.random.choice(np.arange(min_len, max_len + 1))
73 | source_tokens = np.random.choice(
74 | list(VOCABULARY), size=turn_length, replace=True)
75 | target_tokens = source_tokens
76 | yield " ".join(source_tokens), " ".join(target_tokens)
77 |
78 |
79 | def make_reverse(num_examples, min_len, max_len):
80 | """
81 | Generates a dataset where the target is equal to the source reversed.
82 | Sequence lengths are chosen randomly from [min_len, max_len].
83 |
84 | Args:
85 | num_examples: Number of examples to generate
86 | min_len: Minimum sequence length
87 | max_len: Maximum sequence length
88 |
89 | Returns:
90 | An iterator of (source, target) string tuples.
91 | """
92 | for _ in range(num_examples):
93 | turn_length = np.random.choice(np.arange(min_len, max_len + 1))
94 | source_tokens = np.random.choice(
95 | list(VOCABULARY), size=turn_length, replace=True)
96 | target_tokens = source_tokens[::-1]
97 | yield " ".join(source_tokens), " ".join(target_tokens)
98 |
99 |
100 | def write_parallel_text(sources, targets, output_prefix):
101 | """
102 | Writes two files where each line corresponds to one example
103 | - [output_prefix].sources.txt
104 | - [output_prefix].targets.txt
105 |
106 | Args:
107 | sources: Iterator of source strings
108 | targets: Iterator of target strings
109 | output_prefix: Prefix for the output file
110 | """
111 | source_filename = os.path.abspath(os.path.join(output_prefix, "sources.txt"))
112 | target_filename = os.path.abspath(os.path.join(output_prefix, "targets.txt"))
113 |
114 | with io.open(source_filename, "w", encoding='utf8') as source_file:
115 | for record in sources:
116 | source_file.write(record + "\n")
117 | print("Wrote {}".format(source_filename))
118 |
119 | with io.open(target_filename, "w", encoding='utf8') as target_file:
120 | for record in targets:
121 | target_file.write(record + "\n")
122 | print("Wrote {}".format(target_filename))
123 |
124 |
125 | def main():
126 | """Main function"""
127 |
128 | if ARGS.type == "copy":
129 | generate_fn = make_copy
130 | elif ARGS.type == "reverse":
131 | generate_fn = make_reverse
132 |
133 | # Generate dataset
134 | examples = list(generate_fn(ARGS.num_examples, ARGS.min_len, ARGS.max_len))
135 | try:
136 | os.makedirs(ARGS.output_dir)
137 | except OSError:
138 | if not os.path.isdir(ARGS.output_dir):
139 | raise
140 |
141 | # Write train data
142 | train_sources, train_targets = zip(*examples)
143 | write_parallel_text(train_sources, train_targets, ARGS.output_dir)
144 |
145 |
146 | if __name__ == "__main__":
147 | main()
148 |
--------------------------------------------------------------------------------
/bin/tools/generate_vocab.py:
--------------------------------------------------------------------------------
1 | #! /usr/bin/env python
2 | # Copyright 2017 Google Inc.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 |
16 | #pylint: disable=invalid-name
17 | """
18 | Generate vocabulary for a tokenized text file.
19 | """
20 |
21 | import sys
22 | import argparse
23 | import collections
24 | import logging
25 |
26 | parser = argparse.ArgumentParser(
27 | description="Generate vocabulary for a tokenized text file.")
28 | parser.add_argument(
29 | "--min_frequency",
30 | dest="min_frequency",
31 | type=int,
32 | default=0,
33 | help="Minimum frequency of a word to be included in the vocabulary.")
34 | parser.add_argument(
35 | "--max_vocab_size",
36 | dest="max_vocab_size",
37 | type=int,
38 | help="Maximum number of tokens in the vocabulary")
39 | parser.add_argument(
40 | "--downcase",
41 | dest="downcase",
42 | type=bool,
43 | help="If set to true, downcase all text before processing.",
44 | default=False)
45 | parser.add_argument(
46 | "infile",
47 | nargs="?",
48 | type=argparse.FileType("r"),
49 | default=sys.stdin,
50 | help="Input tokenized text file to be processed.")
51 | parser.add_argument(
52 | "--delimiter",
53 | dest="delimiter",
54 | type=str,
55 | default=" ",
56 | help="Delimiter character for tokenizing. Use \" \" and \"\" for word and char level respectively."
57 | )
58 | args = parser.parse_args()
59 |
60 | # Counter for all tokens in the vocabulary
61 | cnt = collections.Counter()
62 |
63 | for line in args.infile:
64 | if args.downcase:
65 | line = line.lower()
66 | if args.delimiter == "":
67 | tokens = list(line.strip())
68 | else:
69 | tokens = line.strip().split(args.delimiter)
70 | tokens = [_ for _ in tokens if len(_) > 0]
71 | cnt.update(tokens)
72 |
73 | logging.info("Found %d unique tokens in the vocabulary.", len(cnt))
74 |
75 | # Filter tokens below the frequency threshold
76 | if args.min_frequency > 0:
77 | filtered_tokens = [(w, c) for w, c in cnt.most_common()
78 | if c > args.min_frequency]
79 | cnt = collections.Counter(dict(filtered_tokens))
80 |
81 | logging.info("Found %d unique tokens with frequency > %d.",
82 | len(cnt), args.min_frequency)
83 |
84 | # Sort tokens by 1. frequency 2. lexically to break ties
85 | word_with_counts = cnt.most_common()
86 | word_with_counts = sorted(
87 | word_with_counts, key=lambda x: (x[1], x[0]), reverse=True)
88 |
89 | # Take only max-vocab
90 | if args.max_vocab_size is not None:
91 | word_with_counts = word_with_counts[:args.max_vocab_size]
92 |
93 | for word, count in word_with_counts:
94 | print("{}\t{}".format(word, count))
95 |
--------------------------------------------------------------------------------
/bin/tools/multi-bleu.perl:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env perl
2 | #
3 | # This file is part of moses. Its use is licensed under the GNU Lesser General
4 | # Public License version 2.1 or, at your option, any later version.
5 |
6 | # $Id$
7 | use warnings;
8 | use strict;
9 |
10 | my $lowercase = 0;
11 | if ($ARGV[0] eq "-lc") {
12 | $lowercase = 1;
13 | shift;
14 | }
15 |
16 | my $stem = $ARGV[0];
17 | if (!defined $stem) {
18 | print STDERR "usage: multi-bleu.pl [-lc] reference < hypothesis\n";
19 | print STDERR "Reads the references from reference or reference0, reference1, ...\n";
20 | exit(1);
21 | }
22 |
23 | $stem .= ".ref" if !-e $stem && !-e $stem."0" && -e $stem.".ref0";
24 |
25 | my @REF;
26 | my $ref=0;
27 | while(-e "$stem$ref") {
28 | &add_to_ref("$stem$ref",\@REF);
29 | $ref++;
30 | }
31 | &add_to_ref($stem,\@REF) if -e $stem;
32 | die("ERROR: could not find reference file $stem") unless scalar @REF;
33 |
34 | # add additional references explicitly specified on the command line
35 | shift;
36 | foreach my $stem (@ARGV) {
37 | &add_to_ref($stem,\@REF) if -e $stem;
38 | }
39 |
40 |
41 |
42 | sub add_to_ref {
43 | my ($file,$REF) = @_;
44 | my $s=0;
45 | if ($file =~ /.gz$/) {
46 | open(REF,"gzip -dc $file|") or die "Can't read $file";
47 | } else {
48 | open(REF,$file) or die "Can't read $file";
49 | }
50 | while() {
51 | chop;
52 | push @{$$REF[$s++]}, $_;
53 | }
54 | close(REF);
55 | }
56 |
57 | my(@CORRECT,@TOTAL,$length_translation,$length_reference);
58 | my $s=0;
59 | while() {
60 | chop;
61 | $_ = lc if $lowercase;
62 | my @WORD = split;
63 | my %REF_NGRAM = ();
64 | my $length_translation_this_sentence = scalar(@WORD);
65 | my ($closest_diff,$closest_length) = (9999,9999);
66 | foreach my $reference (@{$REF[$s]}) {
67 | # print "$s $_ <=> $reference\n";
68 | $reference = lc($reference) if $lowercase;
69 | my @WORD = split(' ',$reference);
70 | my $length = scalar(@WORD);
71 | my $diff = abs($length_translation_this_sentence-$length);
72 | if ($diff < $closest_diff) {
73 | $closest_diff = $diff;
74 | $closest_length = $length;
75 | # print STDERR "$s: closest diff ".abs($length_translation_this_sentence-$length)." = abs($length_translation_this_sentence-$length), setting len: $closest_length\n";
76 | } elsif ($diff == $closest_diff) {
77 | $closest_length = $length if $length < $closest_length;
78 | # from two references with the same closeness to me
79 | # take the *shorter* into account, not the "first" one.
80 | }
81 | for(my $n=1;$n<=4;$n++) {
82 | my %REF_NGRAM_N = ();
83 | for(my $start=0;$start<=$#WORD-($n-1);$start++) {
84 | my $ngram = "$n";
85 | for(my $w=0;$w<$n;$w++) {
86 | $ngram .= " ".$WORD[$start+$w];
87 | }
88 | $REF_NGRAM_N{$ngram}++;
89 | }
90 | foreach my $ngram (keys %REF_NGRAM_N) {
91 | if (!defined($REF_NGRAM{$ngram}) ||
92 | $REF_NGRAM{$ngram} < $REF_NGRAM_N{$ngram}) {
93 | $REF_NGRAM{$ngram} = $REF_NGRAM_N{$ngram};
94 | # print "$i: REF_NGRAM{$ngram} = $REF_NGRAM{$ngram} \n";
95 | }
96 | }
97 | }
98 | }
99 | $length_translation += $length_translation_this_sentence;
100 | $length_reference += $closest_length;
101 | for(my $n=1;$n<=4;$n++) {
102 | my %T_NGRAM = ();
103 | for(my $start=0;$start<=$#WORD-($n-1);$start++) {
104 | my $ngram = "$n";
105 | for(my $w=0;$w<$n;$w++) {
106 | $ngram .= " ".$WORD[$start+$w];
107 | }
108 | $T_NGRAM{$ngram}++;
109 | }
110 | foreach my $ngram (keys %T_NGRAM) {
111 | $ngram =~ /^(\d+) /;
112 | my $n = $1;
113 | # my $corr = 0;
114 | # print "$i e $ngram $T_NGRAM{$ngram} \n";
115 | $TOTAL[$n] += $T_NGRAM{$ngram};
116 | if (defined($REF_NGRAM{$ngram})) {
117 | if ($REF_NGRAM{$ngram} >= $T_NGRAM{$ngram}) {
118 | $CORRECT[$n] += $T_NGRAM{$ngram};
119 | # $corr = $T_NGRAM{$ngram};
120 | # print "$i e correct1 $T_NGRAM{$ngram} \n";
121 | }
122 | else {
123 | $CORRECT[$n] += $REF_NGRAM{$ngram};
124 | # $corr = $REF_NGRAM{$ngram};
125 | # print "$i e correct2 $REF_NGRAM{$ngram} \n";
126 | }
127 | }
128 | # $REF_NGRAM{$ngram} = 0 if !defined $REF_NGRAM{$ngram};
129 | # print STDERR "$ngram: {$s, $REF_NGRAM{$ngram}, $T_NGRAM{$ngram}, $corr}\n"
130 | }
131 | }
132 | $s++;
133 | }
134 | my $brevity_penalty = 1;
135 | my $bleu = 0;
136 |
137 | my @bleu=();
138 |
139 | for(my $n=1;$n<=4;$n++) {
140 | if (defined ($TOTAL[$n])){
141 | $bleu[$n]=($TOTAL[$n])?$CORRECT[$n]/$TOTAL[$n]:0;
142 | # print STDERR "CORRECT[$n]:$CORRECT[$n] TOTAL[$n]:$TOTAL[$n]\n";
143 | }else{
144 | $bleu[$n]=0;
145 | }
146 | }
147 |
148 | if ($length_reference==0){
149 | printf "BLEU = 0, 0/0/0/0 (BP=0, ratio=0, hyp_len=0, ref_len=0)\n";
150 | exit(1);
151 | }
152 |
153 | if ($length_translation<$length_reference) {
154 | $brevity_penalty = exp(1-$length_reference/$length_translation);
155 | }
156 | $bleu = $brevity_penalty * exp((my_log( $bleu[1] ) +
157 | my_log( $bleu[2] ) +
158 | my_log( $bleu[3] ) +
159 | my_log( $bleu[4] ) ) / 4) ;
160 | printf "BLEU = %.2f, %.1f/%.1f/%.1f/%.1f (BP=%.3f, ratio=%.3f, hyp_len=%d, ref_len=%d)\n",
161 | 100*$bleu,
162 | 100*$bleu[1],
163 | 100*$bleu[2],
164 | 100*$bleu[3],
165 | 100*$bleu[4],
166 | $brevity_penalty,
167 | $length_translation / $length_reference,
168 | $length_translation,
169 | $length_reference;
170 |
171 | sub my_log {
172 | return -9999999999 unless $_[0];
173 | return log($_[0]);
174 | }
175 |
--------------------------------------------------------------------------------
/circle.yml:
--------------------------------------------------------------------------------
1 | general:
2 | branches:
3 | ignore:
4 | - gh-pages
5 |
6 | dependencies:
7 | pre:
8 | - sudo apt-get update; sudo apt-get install python-matplotlib python3-matplotlib python-tk python3-tk libtcmalloc-minimal4
9 | override:
10 | - pip install tox tox-pyenv mkdocs
11 | - pyenv local 2.7.10 3.5.1
12 |
13 | machine:
14 | environment:
15 | LD_PRELOAD: /usr/lib/libtcmalloc_minimal.so.4
16 |
17 | test:
18 | pre:
19 | - mkdir -p $HOME/.config/matplotlib
20 | - "echo 'backend : Agg' >> $HOME/.config/matplotlib/matplotlibrc"
21 | override:
22 | - tox
23 |
--------------------------------------------------------------------------------
/docs/concepts.md:
--------------------------------------------------------------------------------
1 | ## Configuration
2 |
3 | Many objects, including Encoders, Decoders, Models, Input Pipelines, and Inference Tasks, are configured using key-value parameters. These parameters are typically passed as [YAML](https://en.wikipedia.org/wiki/YAML) through configuration files or directly on the command line. For example, you can pass a `model_params` string to the training script configure model. Configurations are often be nested, as in the following example:
4 |
5 | ```yml
6 | model_params:
7 | attention.class: seq2seq.decoders.attention.AttentionLayerBahdanau
8 | attention.params:
9 | num_units: 512
10 | embedding.dim: 1024
11 | encoder.class: seq2seq.encoders.BidirectionalRNNEncoder
12 | encoder.params:
13 | rnn_cell:
14 | cell_class: LSTMCell
15 | cell_params:
16 | num_units: 512
17 | ```
18 |
19 | ## Input Pipeline
20 |
21 | An [`InputPipeline`](https://github.com/google/seq2seq/blob/master/seq2seq/data/input_pipeline.py) defines how data is read, parsed, and separated into features and labels. For example, the `ParallelTextInputPipeline` reads data from two text files, separates tokens by a delimiter, and produces tensors corresponding to the `source_tokens`, `source_length`, `target_tokens`, and `target_length` for each example. If you want to read new data formats you need to implement your own input pipeline.
22 |
23 | ## Encoder
24 |
25 | An encoder reads in "source data", e.g. a sequence of words or an image, and produces a feature representation in continuous space. For example, a Recurrent Neural Network encoder may take as input a sequence of words and produce a fixed-length vector that roughly corresponds to the meaning of the text. An encoder based on a Convolutional Neural Network may take as input an image and generate a new volume that contains higher-level features of the image. The idea is that the representation produced by the encoder can be used by the Decoder to generate new data, e.g. a sentence in another language, or the description of the image. For a list of available encoders, see the [Encoder Reference](encoders/).
26 |
27 |
28 | ## Decoder
29 |
30 | A decoder is a generative model that is conditioned on the representation created by the encoder. For example, a Recurrent Neural Network decoder may learn generate the translation for an encoded sentence in another language. For a list of available decoder, see the [Decoder Reference](decoders/).
31 |
32 |
33 | ## Model
34 |
35 | A model defines how to put together an encoder and decoder, and how to calculate and minize the loss functions. It also handles the necessary preprocessing of data read from an input pipeline. Under the hood, each model is implemented as a [model_fn passed to a tf.contrib.learn Estimator](https://www.tensorflow.org/api_docs/python/tf/contrib/learn/Estimator). For a list of available models, see the [Models Reference](models/).
36 |
37 |
--------------------------------------------------------------------------------
/docs/contributing.md:
--------------------------------------------------------------------------------
1 | ## What to work on
2 |
3 | We are always looking for contributors. If you are interested in contributing but are not sure to what work on, take a look at the open [Github Issues](https://github.com/google/seq2seq/issues) that are unassigned. Those with the `help wanted` label are especially good candidates. If you are working on a larger task and unsure how to approach it, just leave a comment to get feedback on design decisions. We are also always looking for the following:
4 |
5 | - Fix issues with the documentation (typos, outdated docs, ...)
6 | - Improve code quality through refactoring, more tests, better docstrings, etc.
7 | - Implement standard benchmark model found in the literature
8 | - Running benchmarks on standard datasets
9 |
10 | ## Development Setup
11 |
12 | We recommend using Python 3. If you're on a Mac the easiest way to do this is probably using [Homebrew](http://brew.sh/). Then,
13 |
14 | ```bash
15 | # Clone this repository.
16 | git clone https://github.com/google/seq2seq.git
17 | cd seq2seq
18 |
19 | # Create a new virtual environment and activate it.
20 | python3 -m venv ~/tf-venv
21 | source ~/tf-venv/bin/activate
22 |
23 | # Install package dependencies and utilities.
24 | pip install -e .
25 | pip install nose pylint tox yapf mkdocs
26 |
27 | # Make sure the tests are passing.
28 | nosetests
29 |
30 | # Code :)
31 |
32 | # Make sure the tests are passing
33 | nosetests
34 |
35 | # Before submitting a pull request,
36 | # run the full test suite for Python 3 and Python 2.7
37 | tox
38 | ```
39 |
40 | ## Python Style
41 |
42 | We use [pylint](https://www.pylint.org/) to enforce coding style. Before submitting a pull request, make
43 | sure you run:
44 |
45 | ```bash
46 | pylint seq2seq
47 | ```
48 |
49 | CircleCI integration tests will fail if pylint reports any critica errors, preventing use from merging your changes. If you are unsure about code formatting, you can use [yapf](https://github.com/google/yapf) for automated code formatting:
50 |
51 | ```bash
52 | yapf -ir ./seq2seq/some/file/you/changed
53 | ```
54 |
55 | ## Recommended Tensorflow Style
56 |
57 | ### GraphModule
58 |
59 | All classes that modify the Graph should inherit from `seq2seq.graph_module.GraphModule`, which is a wrapper around TensorFlow's [`tf.make_template`](https://www.tensorflow.org/versions/r0.12/api_docs/python/state_ops.html#make_template) function that enables easy variable sharing, allowing you to do something like this:
60 |
61 | ```python
62 | encode_fn = SomeEncoderModule(...)
63 |
64 | # New variables are created in this call.
65 | output1 = encode_fn(input1)
66 |
67 | # No new variables are created here. The variables from the above call are re-used.
68 | # Note how this is different from normal TensorFlow where you would need to use variable scopes.
69 | output2 = encode_fn(input2)
70 |
71 | # Because this is a new instance a second set of variables is created.
72 | encode_fn2 = SomeEncoderModule(...)
73 | output3 = encode_fn2(input3)
74 | ```
75 |
76 | ### Functions vs. Classes
77 |
78 | - Operations that **create new variables** must be implemented as classes and must inherit from `GraphModule`.
79 | - Operations that **do not create new variables** can be implemented as standard python functions, or as classes that inherit from `GraphModule` if they have a lot of logic.
--------------------------------------------------------------------------------
/docs/data.md:
--------------------------------------------------------------------------------
1 | ## Available Datasets
2 |
3 | We provide data generation scripts to generate standard datasets.
4 |
5 | | Dataset | Description | Training/Dev/Test Size | Vocabulary | Download |
6 | | --- | --- | --- | --- | --- |
7 | | WMT'16 EN-DE | Data for the [WMT'16 Translation Task](http://www.statmt.org/wmt16/translation-task.html) English to German. Training data is combined from Europarl v7, Common Crawl, and News Commentary v11. Development data sets include `newstest[2010-2015]`. `newstest2016` should serve as test data. All SGM files were converted to plain text. | 4.56M/3K/2.6K | 32k BPE| [Generate](https://github.com/google/seq2seq/blob/master/bin/data/wmt16_en_de.sh) [Download](https://drive.google.com/open?id=0B_bZck-ksdkpM25jRUN2X2UxMm8) |
8 | | WMT'17 All Pairs | Data for the [WMT'17 Translation Task](http://www.statmt.org/wmt17/translation-task.html). | Coming soon. | Coming soon. | [Coming soon]() |
9 | | Toy Copy | A toy dataset where the target sequence is equal to the source sequence. The model must learn to copy the source sequence. | 10k/1k/1k | 20 | [Generate](https://github.com/google/seq2seq/blob/master/bin/data/toy.sh) |
10 | | Toy Reverse | A toy dataset where the target sequence is equal to the reversed source sequence. The model must learn to reverse the source sequence. | 10k/1k/1k | 20 | [Generate](https://github.com/google/seq2seq/blob/master/bin/data/toy.sh) |
11 |
12 | ## Creating your own data
13 |
14 | To create your own data, we recommend taking a look at the data generation scripts above. A typical data preprocessing pipeline looks as follows:
15 |
16 | 1. Generate data in parallel text format
17 | 2. Tokenize your data
18 | 3. Create fixed vocabularies for your source and target data
19 | 4. Learn and apply subword units to handle rare and unknown words
--------------------------------------------------------------------------------
/docs/decoders.md:
--------------------------------------------------------------------------------
1 | ## Decoder Reference
2 |
3 | The following tables list available decoder classes and parameters.
4 |
5 | ### [`BasicDecoder`](https://github.com/google/seq2seq/blob/master/seq2seq/decoders/basic_decoder.py)
6 | ---
7 |
8 | A Recurrent Neural Network decoder that produces a sequence of output tokens.
9 |
10 | | Name | Default | Description |
11 | | --- | --- | --- |
12 | | `max_decode_length` | `100` | Stop decoding early if a sequence reaches this length threshold. |
13 | | `rnn_cell.cell_class` | `BasicLSTMCell` | The class of the rnn cell. Cell classes can be fully defined (e.g. `tensorflow.contrib.rnn.BasicRNNCell`) or must be in `tf.contrib.rnn` or `seq2seq.contrib.rnn_cell`. |
14 | | `rnn_cell.cell_params` | `{"num_units": 128}` | A dictionary of parameters to pass to the cell class constructor. |
15 | | `rnn_cell.dropout_input_keep_prob` | `1.0` | Apply dropout to the (non-recurrent) inputs of each RNN layer using this keep probability. A value of `1.0` disables dropout. |
16 | | `rnn_cell.dropout_output_keep_prob` | `1.0`| Apply dropout to the (non-recurrent) outputs of each RNN layer using this keep probability. A value of `1.0` disables dropout. |
17 | | `rnn_cell.num_layers` | `1` | Number of RNN layers. |
18 | | `rnn_cell.residual_connections` | `False` | If true, add residual connections between all RNN layers in the encoder. |
19 |
20 | ### [`AttentionDecoder`](https://github.com/google/seq2seq/blob/master/seq2seq/decoders/attention_decoder.py)
21 | ---
22 |
23 | A Recurrent Neural Network decoder that produces a sequence of output tokens using an attention mechanisms over its inputs. Parameters are the same as for `BasicDecoder`.
24 |
--------------------------------------------------------------------------------
/docs/encoders.md:
--------------------------------------------------------------------------------
1 | ## Encoder Reference
2 |
3 | All encoders inherit from the abstract `Encoder` defined in `seq2seq.encoders.encoder` and receive `params`, `mode` arguments at instantiation time. Available hyperparameters vary by encoder class.
4 |
5 | ### [`UnidirectionalRNNEncoder`](https://github.com/google/seq2seq/blob/master/seq2seq/encoders/rnn_encoder.py)
6 |
7 | ---
8 |
9 | | Name | Default | Description |
10 | | --- | --- | --- |
11 | | `rnn_cell.cell_class` | `BasicLSTMCell` | The class of the rnn cell. Cell classes can be fully defined (e.g. `tensorflow.contrib.rnn.BasicRNNCell`) or must be in `tf.contrib.rnn` or `seq2seq.contrib.rnn_cell`. |
12 | | `rnn_cell.cell_params` | `{"num_units": 128}` | A dictionary of parameters to pass to the cell class constructor. |
13 | | `rnn_cell.dropout_input_keep_prob` | `1.0` | Apply dropout to the (non-recurrent) inputs of each RNN layer using this keep probability. A value of `1.0` disables dropout. |
14 | | `rnn_cell.dropout_output_keep_prob` | `1.0`| Apply dropout to the (non-recurrent) outputs of each RNN layer using this keep probability. A value of `1.0` disables dropout. |
15 | | `rnn_cell.num_layers` | `1` | Number of RNN layers. |
16 | | `rnn_cell.residual_connections` | `False` | If true, add residual connections between RNN layers in the encoder. |
17 |
18 | ### [`BidirectionalRNNEncoder`](https://github.com/google/seq2seq/blob/master/seq2seq/encoders/rnn_encoder.py)
19 |
20 | ---
21 |
22 | Same as the `UnidirectionalRNNEncoder`. The same cell is used for forward and backward RNNs.
23 |
24 | ### [`StackBidirectionalRNNEncoder`](https://github.com/google/seq2seq/blob/master/seq2seq/encoders/rnn_encoder.py)
25 |
26 | ---
27 |
28 | Same as the `UnidirectionalRNNEncoder`. The same cell is used for forward and backward RNNs.
29 |
30 |
31 | ### [`PoolingEncoder`](https://github.com/google/seq2seq/blob/master/seq2seq/encoders/pooling_encoder.py)
32 |
33 | ---
34 |
35 | An encoder that pools over embeddings, as described in [https://arxiv.org/abs/1611.02344](https://arxiv.org/abs/1611.02344). The encoder supports optional positions embeddings and a configurable pooling window.
36 |
37 |
38 | | Name | Default | Description |
39 | | --- | --- | --- |
40 | | `pooling_fn` | `tensorflow.layers.average_pooling1d` | The 1-d pooling function to use, e.g. `tensorflow.layers.average_pooling1d`. |
41 | | `pool_size` | `5` | The pooling window, passed as `pool_size` to the pooling function. |
42 | | `strides` | `1` | The stride during pooling, passed as `strides` the pooling function. |
43 | | `position_embeddings.enable` | `True` | If true, add position embeddings to the inputs before pooling. |
44 | | `position_embeddings.combiner_fn` | `tensorflow.add` | Function used to combine the position embeddings with the inputs. For example, `tensorflow.add`. |
45 | | `position_embeddings.num_positions` | `100` | Size of the position embedding matrix. This should be set to the maximum sequence length of the inputs. |
46 |
47 |
48 | ### [`InceptionV3Encoder`](https://github.com/google/seq2seq/blob/master/seq2seq/encoders/image_encoder.py)
49 |
50 | ---
51 |
52 | **This encoder is experimental**. This encoder puts the image through an InceptionV3 network and uses the last
53 | hidden layer before the logits as the feature representation.
54 |
55 | | Name | Default | Description |
56 | | --- | --- | --- |
57 | | `resize_height` | `299` | Resize the image to this height before feeding it into the convolutional network. |
58 | | `resize_width` | `299` | Resize the image to this width before feeding it into the convolutional network. |
59 |
60 |
61 |
--------------------------------------------------------------------------------
/docs/extra.css:
--------------------------------------------------------------------------------
1 | .wy-nav-content {
2 | max-width: 1200px !important;
3 | }
--------------------------------------------------------------------------------
/docs/getting_started.md:
--------------------------------------------------------------------------------
1 | ## Download & Setup
2 |
3 | To use tf-seq2seq you need a working installation of TensorFlow 1.0 with
4 | Python 2.7 or Python 3.5. Follow the [TensorFlow Getting Started](https://www.tensorflow.org/versions/r1.0/get_started/os_setup) guide for detailed setup instructions. With TensorFlow installed, you can clone this repository:
5 |
6 | ```bash
7 | git clone https://github.com/google/seq2seq.git
8 | cd seq2seq
9 |
10 | # Install package and dependencies
11 | pip install -e .
12 | ```
13 |
14 | To make sure everything works as expect you can run a simple pipeline unit test:
15 |
16 | ```bash
17 | python -m unittest seq2seq.test.pipeline_test
18 | ```
19 |
20 | If you see a "OK" message, you are all set. Note that you may need to install pyrouge, pyyaml, and matplotlib, in order for these tests to pass. If you run into other setup issues,
21 | please [file a Github issue](https://github.com/google/seq2seq/issues).
22 |
23 | ## Common Installation Issues
24 |
25 | ### Incorrect matploblib backend
26 |
27 | In order to generate plots using matplotlib you need to have set the correct [backend](http://matplotlib.org/faq/usage_faq.html#what-is-a-backend). Also see this [StackOverflow thread](http://stackoverflow.com/questions/4930524/how-can-i-set-the-backend-in-matplotlib-in-python). To use the `Agg` backend, simply:
28 |
29 | ```
30 | echo "backend : Agg" >> $HOME/.config/matplotlib/matplotlibrc
31 | ```
32 |
33 | ## Next Steps
34 |
35 | - Learn about [concepts and terminology](concepts.md)
36 | - Read through the [Neural Machine Translation Tutorial](nmt.md)
37 | - Use [pre-processed datasets](data.md) or train a model on your own data
38 | - [Contribute!](contributing.md)
39 |
--------------------------------------------------------------------------------
/docs/help.md:
--------------------------------------------------------------------------------
1 | ## Getting Help
2 |
3 | If you run into problems or find bugs in the code, please file a [Github Issue](https://github.com/google/seq2seq/issues).
--------------------------------------------------------------------------------
/docs/image_captioning.md:
--------------------------------------------------------------------------------
1 | ## Coming Soon
2 |
3 | This tutorial is coming soon. It is easy to swap out the RNN encoder with a Convolutional Neural Network to perform image captioning.
--------------------------------------------------------------------------------
/docs/images/nmt_tutorial_bleu.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/google/seq2seq/7f485894d412e8d81ce0e07977831865e44309ce/docs/images/nmt_tutorial_bleu.png
--------------------------------------------------------------------------------
/docs/images/nmt_tutorial_ppl.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/google/seq2seq/7f485894d412e8d81ce0e07977831865e44309ce/docs/images/nmt_tutorial_ppl.png
--------------------------------------------------------------------------------
/docs/index.md:
--------------------------------------------------------------------------------
1 | ## Introduction
2 |
3 | tf-seq2seq is a general-purpose encoder-decoder framework for Tensorflow that can be used for Machine Translation, Text Summarization, Conversational Modeling, Image Captioning, and more.
4 |
5 | 
6 |
7 | ## Design Goals
8 |
9 | We built tf-seq2seq with the following goals in mind:
10 |
11 | - **General Purpose**: We initially built this framework for Machine Translation, but have since used it for a variety of other tasks, including Summarization, Conversational Modeling, and Image Captioning. As long as your problem can be phrased as encoding input data in one format and decoding it into another format, you should be able to use or extend this framework.
12 |
13 | - **Usability**: You can train a model with a single command. Several types of input data are supported, including standard raw text.
14 |
15 | - **Reproducibility**: Training pipelines and models are configured using YAML files. This allows other to run your exact same model configurations.
16 |
17 | - **Extensibility**: Code is structured in a modular way and that easy to build upon. For example, adding a new type of attention mechanism or encoder architecture requires only minimal code changes.
18 |
19 | - **Documentation**: All code is documented using standard Python docstrings, and we have written guides to help you get started with common tasks.
20 |
21 | - **Good Performance**: For the sake of code simplicity, we did not try to squeeze out every last bit of performance, but the implementation is fast enough to cover almost all production and research use cases. tf-seq2seq also supports distributed training to trade off computational power and training time.
22 |
23 |
24 | ## FAQ
25 |
26 | **1. How does this framework compare to the [Google Neural Machine Translation](https://research.googleblog.com/2016/09/a-neural-network-for-machine.html) system? Is this the official open-source implementation?**
27 |
28 | No, this is not an official open-source implementation of the GNMT system. This framework was built from the bottom up to cover a wider range of tasks, Neural Machine Translation being one of them. We have not replicated the exact GNMT architecture in this framework, but we welcome [contributions](contributing.md) in that direction.
29 |
30 |
31 | ## Related Frameworks
32 |
33 | The following frameworks offer functionality similar to that of tf-seq2seq. We hope to collaborate with the authors of these frameworks so that we can learn from each other.
34 |
35 | - [OpenNMT (Torch)](http://opennmt.net/)
36 | - [Neural Monkey (Tensorflow)](https://github.com/ufal/neuralmonkey)
37 | - [NEMATUS (Theano)](https://github.com/rsennrich/nematus)
38 |
--------------------------------------------------------------------------------
/docs/inference.md:
--------------------------------------------------------------------------------
1 | ## Inference Tasks
2 |
3 | When calling the inference script `bin/infer.py`, you must provide a list of tasks to run. The most basic task, `DecodeText`, simply prints out the model predictions. By additing more tasks you can perform additional features, such as storing debugging infromation or visualization attention scores. Under the hood, each `InferenceTask` is implemented as a Tensorflow [SessionRunHook](https://www.tensorflow.org/api_docs/python/tf/train/SessionRunHook) that requests outputs from the model and knows how to process them.
4 |
5 | ## DecodeText
6 |
7 | The `DecodeText` task reads the model predictions and prints the predictions to standard output. It has the following parameters:
8 |
9 | - `delimiter`: String to join the tokens predicted by the model on. Defaults to space.
10 | - `unk_replace`: If set to `True`, perform unknown token replacement based on attention scores. Default is `False`. See below for more details.
11 | - `unk_mapping`: If set to the path of a dictionary file, use the provided mapping to perform unknown token replacement. See below for more details.
12 |
13 | #### UNK token replacement using a Copy Mechanism
14 |
15 | Rare words (such as place and people names) are often absent from the target vocabulary and result in `UNK` tokens in the output predictions. An easy strategy to target sequences is to replace each `UNK` token with the word in the source sequence it is best aligned with. Alignments are typically calculated using an attention mechanism which produces alignment scores for each target token. If you trained a model that generates such attention scores (e.g. `AttentionSeq2Seq`), you can use them to perform UNK token replacement by activating the `unk_replace` parameter.
16 |
17 |
18 | ```bash
19 | mkdir -p ${DATA_PATH}/pred
20 | python -m bin.infer \
21 | --tasks "
22 | - class: DecodeText
23 | params:
24 | unk_replace: True"
25 | ```
26 |
27 | #### UNK token replacement using a mapping
28 |
29 | A more sophisticated approach to UNK token replacement is to use a mapping instead of copying words from the source. For example, the English word "Munich" is usually translated as "München" in German. Simply copying "Munich" from the source you would never result in the right translation even if the words were perfectly aligned using attention scores. One strategy is to use [fast_align](https://github.com/clab/fast_align) to generate a mapping based on the conditional probabilities of target given source.
30 |
31 | ```bash
32 | # Download and build fast_align
33 | git clone https://github.com/clab/fast_align.git
34 | mkdir fast_align/build && cd fast_align/build
35 | cmake ../ && make
36 |
37 | # Convert your data into a format that fast_align understands:
38 | # |||
39 | paste \
40 | $HOME/nmt_data/toy_reverse/train/sources.txt \
41 | $HOME/nmt_data/toy_reverse/train/targets.txt \
42 | | sed "s/$(printf '\t')/ ||| /g" > $HOME/nmt_data/toy_reverse/train/source_targets.fastalign
43 |
44 | # Learn alignments
45 | ./fast_align \
46 | -i $HOME/nmt_data/toy_reverse/train/source_targets.fastalign \
47 | -v -p $HOME/nmt_data/toy_reverse/train/source_targets.cond \
48 | > $HOME/nmt_data/toy_reverse/train/source_targets.align
49 |
50 | # Find the most probable traslation for each word and write them to a file
51 | sort -k1,1 -k3,3gr $HOME/nmt_data/toy_reverse/train/source_targets.cond \
52 | | sort -k1,1 -u \
53 | > $HOME/nmt_data/toy_reverse/train/source_targets.cond.dict
54 |
55 | ```
56 |
57 | The output file specified by the `-p` argument will contain conditional probabilities for `p(target | source)` in the form of `\t\t`. These can be used to do smarter UNK token replacement by passing the `unk_mapping` flag.
58 |
59 | ```bash
60 | mkdir -p ${DATA_PATH}/pred
61 | python -m bin.infer \
62 | --tasks "
63 | - class: DecodeText
64 | params:
65 | unk_replace: True"
66 | unk_mapping: $HOME/nmt_data/toy_reverse/train/source_targets.cond.dict"
67 | ...
68 | ```
69 |
70 |
71 | ## Visualizing Attention
72 |
73 | If you trained a model using the `AttentionDecoder`, you can dump the raw attention scores and generate alignment visualizations during inference using the `DumpAttention` task.
74 |
75 | ```shell
76 | python -m bin.infer \
77 | --tasks "
78 | - class: DecodeText
79 | - class: DumpAttention
80 | params:
81 | output_dir: $HOME/attention" \
82 | ...
83 | ```
84 |
85 | By default, this script generates an `attention_score.npy` array file and one attention plot per example. The array file can be [loaded used numpy](https://docs.scipy.org/doc/numpy/reference/generated/numpy.load.html) and will contain a list of arrays with shape `[target_length, source_length]`. If you only want the raw attention score data without the plots you can enable the `dump_atention_no_plot` parameter.
86 |
87 |
88 |
89 | ## Dumping Beams
90 |
91 | If you are using beam search during decoding, you can use the `DumpBeams` task to write beam search debugging information to disk. You can later inspect the data using numpy, or use the [provided script](tools/) to generate visualizations.
92 |
93 | ```shell
94 | python -m bin.infer \
95 | --tasks "
96 | - class: DecodeText
97 | - class: DumpBeams
98 | params:
99 | file: ${TMPDIR:-/tmp}/wmt_16_en_de/newstest2014.pred.beams.npz" \
100 | --model_params "
101 | inference.beam_search.beam_width: 5" \
102 | ...
103 | ```
104 |
--------------------------------------------------------------------------------
/docs/license.md:
--------------------------------------------------------------------------------
1 | ## License
2 |
3 | The code is available under the [Apache License](https://www.apache.org/licenses/LICENSE-2.0).
4 |
5 | ## Citation
6 |
7 | If you use this code for academic purposes, plase cite it as:
8 |
9 | ```
10 | @ARTICLE{Britz:2017,
11 | author = {{Britz}, D. and {Goldie}, A. and {Luong}, T. and {Le}, Q.},
12 | title = "{Massive Exploration of Neural Machine Translation Architectures}",
13 | journal = {ArXiv e-prints},
14 | archivePrefix = "arXiv",
15 | eprinttype = {arxiv},
16 | eprint = {1703.03906},
17 | primaryClass = "cs.CL",
18 | keywords = {Computer Science - Computation and Language},
19 | year = 2017,
20 | month = mar,
21 | }
22 | ```
23 |
--------------------------------------------------------------------------------
/docs/results.md:
--------------------------------------------------------------------------------
1 | ## Machine Translation: WMT'15 English-German
2 |
3 | Single models only, no ensembles. Results are listed in chronological order.
4 |
5 | | Model Name & Reference | Settings / Notes| Training Time | Test Set BLEU |
6 | | --- | --- | --- | --- |
7 | | tf-seq2seq | [Configuration](https://github.com/google/seq2seq/blob/master/example_configs/nmt_large.yml) | ~4 days on 8 NVidia K80 GPUs | newstest2014: **22.19** newstest2015: **25.23** | [Model]() [Data]() |
8 | | [Gehring, et al. (2016-11)](https://arxiv.org/abs/1611.02344) Deep Convolutional 15/5 | | --- | newstest2014: - newstest2015: **24.3** | --- |
9 | | [Wu et al. (2016-09)](https://arxiv.org/abs/1609.08144) GNMT | 8 encoder/decoder layers, 1024 LSTM units, 32k shared wordpieces (similar to BPE); residual between layers connections; lots of other tricks; newstest2012 and newstest2013 as validation sets. | --- | newstest2014: **24.61** newstest2015: -|
10 | | [Zhou et al. (2016-06)](https://arxiv.org/abs/1606.04199) Deep-Att | | --- | newstest2014: **20.6** newstest2015: - | --- |
11 | | [Chung, et al. (2016-03)](https://arxiv.org/abs/1603.06147v4) BPE-Char | **Character-level decoder with BPE encoder.** Based on Bahdanau attention model; Bidirectional encoder with 512 GRU units; 2-layer GRU decoder with 1024 units; Adam; batch size 128; gradient clipping at norm 1; Moses Tokenizer; limit sequences to 50 symbols in source and 100 symbols and 500 characters in target. | --- | newstest2014: **21.5** newstest2015: **23.9** | --- |
12 | | [Sennrich et al. (2015-8)](https://arxiv.org/abs/1508.07909) BPE | **Authors propose BPE for subword unit nsegmentation as a pre/post-processing step to handle open vocabulary**; Base model is based on [Bahndanau's paper](https://arxiv.org/abs/1409.0473). Bidirectional encoder; GRU; 1000 hidden units; 1000 attention units; 620-dimensional word embeddings; single-layer; beam search width 12; Adadelta with batch size 80; Using [Groundhog](https://github.com/sebastien-j/LV_groundhog); | | newstest2014: - newstest2015: **20.5** | --- |
13 | | [Luong et al. (2015-08)](https://arxiv.org/abs/1508.04025) | **Novel local/global attention mechanism;** 50k vocabulary; 4 layers in encoder and decoder; unidirectional encoder; gradient clipping at norm 5; 1028 LSTM units, 1028-dimensional embeddings; (somewhat complicated) SGD decay schedule; dropout 0.2; UNK replace;| --- | newstest2014: **20.9** newstest2015: - | --- |
14 | | [Jean et al. (2014-12)](https://arxiv.org/abs/1412.2007) RNNsearch-LV | **Authors propose a new sampling-based approach to incorporate a larger vocabulary**; Base model is based on [Bahndanau's paper](https://arxiv.org/abs/1409.0473). Bidirectional encoder; GRU; 1000 hidden units; 1000 attention units; 620-dimensional word embeddings; single-layer; beam search width 12; | --- | newstest2014: **19.4** newstest2015: - | --- |
15 |
16 |
17 | ## Machine Translation: WMT'17
18 |
19 | Coming soon.
20 |
21 |
22 | ## Text Summarization: Gigaword
23 |
24 | Coming soon.
25 |
26 |
27 | ## Image Captioning: MSCOCO
28 |
29 | Coming soon.
30 |
31 |
32 | ## Conversational Modeling
33 |
34 | Coming soon.
--------------------------------------------------------------------------------
/docs/summarization.md:
--------------------------------------------------------------------------------
1 | ## Coming Soon
2 |
3 | Training a summarization model is very similar to [training a Neural Machine Translation](nmt/). Please refer to NMT tutorial for the time being while we are working on a summarization-specific tutorial.
--------------------------------------------------------------------------------
/docs/tools.md:
--------------------------------------------------------------------------------
1 | ## Generating Vocabulary
2 |
3 | A vocabulary file is a raw text file that contains one word per line, followed by a tab separator and the word count. The total number of lines is equal to the size of the vocabulary and each token is mapped to its line number. We provide a helper script [`bin/tools/generate_vocab.py`](https://github.com/google/seq2seq/blob/master/bin/tools/generate_vocab.py) that takes in a raw text file of space-delimited tokens and generates a vocabulary file:
4 |
5 | ```shell
6 | ./bin/tools/generate_vocab.py < data.txt > vocab
7 | ```
8 |
9 |
10 | ## Generating Character Vocabulary
11 |
12 | Sometimes you want to run training on characters instead of words or subword units. Using the same script [`bin/tools/generate_vocab.py`](https://github.com/google/seq2seq/blob/master/bin/tools/generate_vocab.py) with `--delimiter ""` can generate a vocabulary file that contains the unique set of characters found in the text:
13 |
14 | ```shell
15 | ./bin/tools/generate_vocab.py --delimiter "" < data.txt > vocab
16 | ```
17 |
18 | To run training on characters you must pass set `source_delimiter` and `target_delimiter` delimiter of the input pipeline to `""`. See the [Training documentation](training.md) for more details.
19 |
20 |
21 | ## Visualizing Beam Search
22 |
23 | If you use the `DumpBeams` inference task (see [Inference](inference/) for more details) you can inspect the beam search data by loading the array using numpy, or generate beam search visualizations using the `generate_beam_viz.py` script. This required the `networkx` module to be installed.
24 |
25 | ```
26 | python -m bin.tools.generate_beam_viz \
27 | -o ${TMPDIR:-/tmp}/beam_visualizations \
28 | -d ${TMPDIR:-/tmp}/beams.npz \
29 | -v $HOME/nmt_data/toy_reverse//train/vocab.targets.txt
30 | ```
31 |
32 | 
33 |
--------------------------------------------------------------------------------
/docs/training.md:
--------------------------------------------------------------------------------
1 | For a concrete of how to run the training script, refer to the [Neural Machine Translation Tutorial](nmt/).
2 |
3 | ## Configuring Training
4 |
5 | Also see [Configuration](concepts/#configuration). The configuration for input data, models, and training parameters is done via [YAML](https://en.wikipedia.org/wiki/YAML). You can pass YAML strings directly to the training script, or create configuration files and pass their paths to the script. These two approaches are technically equivalent. However, large YAML strings can become difficult to manage so we recommend the latter one. For example, the following two are equivalent:
6 |
7 | 1\. Pass FLAGS directly:
8 |
9 | ```shell
10 | python -m bin.train \
11 | --model AttentionSeq2Seq \
12 | --model_params "
13 | embedding.dim: 256
14 | encoder.class: seq2seq.encoders.BidirectionalRNNEncoder
15 | encoder.params:
16 | rnn_cell:
17 | cell_class: GRUCell"
18 | ```
19 |
20 |
21 | 2\. Define `config.yml`
22 |
23 | ```yaml
24 | model: AttentionSeq2Seq
25 | model_params:
26 | embedding.dim: 256
27 | encoder.class: seq2seq.encoders.BidirectionalRNNEncoder
28 | encoder.params:
29 | rnn_cell:
30 | cell_class: GRUCell
31 | ```
32 |
33 | ... and pass FLAGS via config:
34 |
35 | ```shell
36 | python -m bin.train --config_paths config.yml
37 | ```
38 |
39 |
40 | Multiple configuration files are merged recursively, in the order they are passed. This means you can have separate configuration files for model hyperparameters, input data, and training options, and mix and match as needed.
41 |
42 | For a concrete examples of configuration files, refer to the [example configurations](https://github.com/google/seq2seq/tree/master/example_configs) and [Neural Machine Translation Tutorial](NMT/).
43 |
44 |
45 | ## Monitoring Training
46 |
47 | In addition to looking at the output of the training script, Tensorflow write summaries and training logs into the specified `output_dir`. Use [Tensorboard](https://www.tensorflow.org/how_tos/summaries_and_tensorboard/) to visualize training progress.
48 |
49 | ```shell
50 | tensorboard --logdir=/path/to/model/dir
51 | ```
52 |
53 | ## Distributed Training
54 |
55 | Distributed Training is supported out of the box using `tf.learn`. Cluster Configurations can be specified using the `TF_CONFIG` environment variable, which is parsed by the [`RunConfig`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/learn/python/learn/estimators/run_config.py). Refer to the [Distributed Tensorflow](https://www.tensorflow.org/how_tos/distributed/) Guide for more information.
56 |
57 |
58 | ## Training script Reference
59 |
60 | The [train.py](https://github.com/google/seq2seq/blob/master/bin/train.py) script has many more options.
61 |
62 | | Argument | Default | Description |
63 | | --- | --- | --- |
64 | | config_paths | `""` | Path to a YAML configuration file defining FLAG values. Multiple files can be separated by commas. Files are merged recursively. Setting a key in these files is equivalent to setting the FLAG value with the same name. |
65 | | hooks | `"[]"` | YAML configuration string for the training hooks to use. |
66 | | metrics | `"[]"` | YAML configuration string for the training metrics to use. |
67 | | model | `""` | Name of the model class. Can be either a fully-qualified name, or the name of a class defined in `seq2seq.models`. |
68 | | model_params | `"{}"` | YAML configuration string for the model parameters. |
69 | | input_pipeline_train | `"{}"` | YAML configuration string for the training data input pipeline. |
70 | | input_pipeline_dev | `"{}"` | YAML configuration string for the development data input pipeline. |
71 | | buckets | `None` | Buckets input sequences according to these length. A comma-separated list of sequence length buckets, e.g. `"10,20,30"` would result in 4 buckets: `<10, 10-20, 20-30, >30`. `None` disables bucketing. |
72 | | batch_size | `16` | Batch size used for training and evaluation. |
73 | | output_dir | `None` | The directory to write model checkpoints and summaries to. If None, a local temporary directory is created. |
74 | | train_steps | `None` | Maximum number of training steps to run. If None, train forever. |
75 | | eval_every_n_steps | `1000` | Run evaluation on validation data every N steps. |
76 | | tf_random_seed | `None` | Random seed for TensorFlow initializers. Setting this value allows consistency between reruns. |
77 | | save_checkpoints_secs | `600` | Save checkpoints every N seconds. Can not be specified with `save_checkpoints_steps`. |
78 | | save_checkpoints_steps | `None` | Save checkpoints every N steps. Can not be specified with `save_checkpoints_secs`. |
79 | | keep_checkpoint_max | `5` | Maximum number of recent checkpoint files to keep. As new files are created, older files are deleted. If None or 0, all checkpoint files are kept. |
80 | | keep_checkpoint_every_n_hours | `4` | In addition to keeping the most recent checkpoint files, keep one checkpoint file for every N hours of training. |
81 |
82 |
--------------------------------------------------------------------------------
/example_configs/nmt_conv.yml:
--------------------------------------------------------------------------------
1 | model: AttentionSeq2Seq
2 | model_params:
3 | attention.class: seq2seq.decoders.attention.AttentionLayerBahdanau
4 | attention.params:
5 | num_units: 512
6 | bridge.class: seq2seq.models.bridges.ZeroBridge
7 | embedding.dim: 512
8 | encoder.class: seq2seq.encoders.ConvEncoder
9 | encoder.params:
10 | attention_cnn.units: 512
11 | attention_cnn.kernel_size: 3
12 | attention_cnn.layers: 15
13 | output_cnn.units: 256
14 | output_cnn.kernel_size: 3
15 | output_cnn.layers: 5
16 | position_embeddings.enable: true
17 | position_embeddings.combiner_fn: tensorflow.multiply
18 | position_embeddings.num_positions: 52
19 | decoder.class: seq2seq.decoders.AttentionDecoder
20 | decoder.params:
21 | rnn_cell:
22 | cell_class: LSTMCell
23 | cell_params:
24 | num_units: 512
25 | dropout_input_keep_prob: 0.8
26 | dropout_output_keep_prob: 1.0
27 | num_layers: 4
28 | optimizer.name: Adam
29 | optimizer.learning_rate: 0.0001
30 | source.max_seq_len: 50
31 | source.reverse: false
32 | target.max_seq_len: 50
33 |
--------------------------------------------------------------------------------
/example_configs/nmt_conv_small.yml:
--------------------------------------------------------------------------------
1 | model: AttentionSeq2Seq
2 | model_params:
3 | attention.class: seq2seq.decoders.attention.AttentionLayerBahdanau
4 | attention.params:
5 | num_units: 128
6 | bridge.class: seq2seq.models.bridges.ZeroBridge
7 | embedding.dim: 128
8 | encoder.class: seq2seq.encoders.ConvEncoder
9 | encoder.params:
10 | attention_cnn.units: 128
11 | attention_cnn.kernel_size: 3
12 | attention_cnn.layers: 6
13 | output_cnn.units: 128
14 | output_cnn.kernel_size: 3
15 | output_cnn.layers: 3
16 | position_embeddings.enable: true
17 | position_embeddings.combiner_fn: tensorflow.multiply
18 | position_embeddings.num_positions: 52
19 | decoder.class: seq2seq.decoders.AttentionDecoder
20 | decoder.params:
21 | rnn_cell:
22 | cell_class: GRUCell
23 | cell_params:
24 | num_units: 128
25 | dropout_input_keep_prob: 0.8
26 | dropout_output_keep_prob: 1.0
27 | num_layers: 1
28 | optimizer.name: Adam
29 | optimizer.learning_rate: 0.0001
30 | source.max_seq_len: 50
31 | source.reverse: false
32 | target.max_seq_len: 50
33 |
--------------------------------------------------------------------------------
/example_configs/nmt_large.yml:
--------------------------------------------------------------------------------
1 | model: AttentionSeq2Seq
2 | model_params:
3 | attention.class: seq2seq.decoders.attention.AttentionLayerBahdanau
4 | attention.params:
5 | num_units: 512
6 | bridge.class: seq2seq.models.bridges.ZeroBridge
7 | embedding.dim: 512
8 | encoder.class: seq2seq.encoders.BidirectionalRNNEncoder
9 | encoder.params:
10 | rnn_cell:
11 | cell_class: LSTMCell
12 | cell_params:
13 | num_units: 512
14 | dropout_input_keep_prob: 0.8
15 | dropout_output_keep_prob: 1.0
16 | num_layers: 2
17 | decoder.class: seq2seq.decoders.AttentionDecoder
18 | decoder.params:
19 | rnn_cell:
20 | cell_class: LSTMCell
21 | cell_params:
22 | num_units: 512
23 | dropout_input_keep_prob: 0.8
24 | dropout_output_keep_prob: 1.0
25 | num_layers: 4
26 | optimizer.name: Adam
27 | optimizer.params:
28 | epsilon: 0.0000008
29 | optimizer.learning_rate: 0.0001
30 | source.max_seq_len: 50
31 | source.reverse: false
32 | target.max_seq_len: 50
33 |
--------------------------------------------------------------------------------
/example_configs/nmt_medium.yml:
--------------------------------------------------------------------------------
1 | model: AttentionSeq2Seq
2 | model_params:
3 | attention.class: seq2seq.decoders.attention.AttentionLayerBahdanau
4 | attention.params:
5 | num_units: 256
6 | bridge.class: seq2seq.models.bridges.ZeroBridge
7 | embedding.dim: 256
8 | encoder.class: seq2seq.encoders.BidirectionalRNNEncoder
9 | encoder.params:
10 | rnn_cell:
11 | cell_class: GRUCell
12 | cell_params:
13 | num_units: 256
14 | dropout_input_keep_prob: 0.8
15 | dropout_output_keep_prob: 1.0
16 | num_layers: 1
17 | decoder.class: seq2seq.decoders.AttentionDecoder
18 | decoder.params:
19 | rnn_cell:
20 | cell_class: GRUCell
21 | cell_params:
22 | num_units: 256
23 | dropout_input_keep_prob: 0.8
24 | dropout_output_keep_prob: 1.0
25 | num_layers: 2
26 | optimizer.name: Adam
27 | optimizer.params:
28 | epsilon: 0.0000008
29 | optimizer.learning_rate: 0.0001
30 | source.max_seq_len: 50
31 | source.reverse: false
32 | target.max_seq_len: 50
33 |
--------------------------------------------------------------------------------
/example_configs/nmt_small.yml:
--------------------------------------------------------------------------------
1 | model: AttentionSeq2Seq
2 | model_params:
3 | attention.class: seq2seq.decoders.attention.AttentionLayerDot
4 | attention.params:
5 | num_units: 128
6 | bridge.class: seq2seq.models.bridges.ZeroBridge
7 | embedding.dim: 128
8 | encoder.class: seq2seq.encoders.BidirectionalRNNEncoder
9 | encoder.params:
10 | rnn_cell:
11 | cell_class: GRUCell
12 | cell_params:
13 | num_units: 128
14 | dropout_input_keep_prob: 0.8
15 | dropout_output_keep_prob: 1.0
16 | num_layers: 1
17 | decoder.class: seq2seq.decoders.AttentionDecoder
18 | decoder.params:
19 | rnn_cell:
20 | cell_class: GRUCell
21 | cell_params:
22 | num_units: 128
23 | dropout_input_keep_prob: 0.8
24 | dropout_output_keep_prob: 1.0
25 | num_layers: 1
26 | optimizer.name: Adam
27 | optimizer.params:
28 | epsilon: 0.0000008
29 | optimizer.learning_rate: 0.0001
30 | source.max_seq_len: 50
31 | source.reverse: false
32 | target.max_seq_len: 50
--------------------------------------------------------------------------------
/example_configs/text_metrics_bpe.yml:
--------------------------------------------------------------------------------
1 | default_params: &default_params
2 | - separator: " "
3 | - postproc_fn: "seq2seq.data.postproc.strip_bpe"
4 |
5 | metrics:
6 | - class: LogPerplexityMetricSpec
7 | - class: BleuMetricSpec
8 | params:
9 | <<: *default_params
10 | - class: RougeMetricSpec
11 | params:
12 | <<: *default_params
13 | rouge_type: rouge_1/f_score
14 | - class: RougeMetricSpec
15 | params:
16 | <<: *default_params
17 | rouge_type: rouge_1/r_score
18 | - class: RougeMetricSpec
19 | params:
20 | <<: *default_params
21 | rouge_type: rouge_1/p_score
22 | - class: RougeMetricSpec
23 | params:
24 | <<: *default_params
25 | rouge_type: rouge_2/f_score
26 | - class: RougeMetricSpec
27 | params:
28 | <<: *default_params
29 | rouge_type: rouge_2/r_score
30 | - class: RougeMetricSpec
31 | params:
32 | <<: *default_params
33 | rouge_type: rouge_2/p_score
34 | - class: RougeMetricSpec
35 | params:
36 | <<: *default_params
37 | rouge_type: rouge_l/f_score
38 |
--------------------------------------------------------------------------------
/example_configs/text_metrics_sp.yml:
--------------------------------------------------------------------------------
1 | default_params: &default_params
2 | - separator: " "
3 | - postproc_fn: "seq2seq.data.postproc.decode_sentencepiece"
4 |
5 | metrics:
6 | - class: LogPerplexityMetricSpec
7 | - class: BleuMetricSpec
8 | params:
9 | <<: *default_params
10 | - class: RougeMetricSpec
11 | params:
12 | <<: *default_params
13 | rouge_type: rouge_1/f_score
14 | - class: RougeMetricSpec
15 | params:
16 | <<: *default_params
17 | rouge_type: rouge_1/r_score
18 | - class: RougeMetricSpec
19 | params:
20 | <<: *default_params
21 | rouge_type: rouge_1/p_score
22 | - class: RougeMetricSpec
23 | params:
24 | <<: *default_params
25 | rouge_type: rouge_2/f_score
26 | - class: RougeMetricSpec
27 | params:
28 | <<: *default_params
29 | rouge_type: rouge_2/r_score
30 | - class: RougeMetricSpec
31 | params:
32 | <<: *default_params
33 | rouge_type: rouge_2/p_score
34 | - class: RougeMetricSpec
35 | params:
36 | <<: *default_params
37 | rouge_type: rouge_l/f_score
38 |
--------------------------------------------------------------------------------
/example_configs/train_seq2seq.yml:
--------------------------------------------------------------------------------
1 | buckets: 10,20,30,40
2 | hooks:
3 | - class: PrintModelAnalysisHook
4 | - class: MetadataCaptureHook
5 | - class: SyncReplicasOptimizerHook
6 | - class: TrainSampleHook
7 | params:
8 | every_n_steps: 1000
9 |
--------------------------------------------------------------------------------
/example_configs/train_seq2seq_delay_start.yml:
--------------------------------------------------------------------------------
1 | buckets: 10,20,30,40
2 | hooks:
3 | - class: PrintModelAnalysisHook
4 | - class: MetadataCaptureHook
5 | - class: DelayStartHook
6 | - class: TrainSampleHook
7 | params:
8 | every_n_steps: 1000
9 |
--------------------------------------------------------------------------------
/mkdocs.yml:
--------------------------------------------------------------------------------
1 | site_name: seq2seq
2 | theme: readthedocs
3 | extra_css: [extra.css]
4 | markdown_extensions: [fenced_code]
5 | pages:
6 | - Overview: index.md
7 | - Getting Started: getting_started.md
8 | - Concepts: concepts.md
9 | - "Tutorial: Neural Machine Translation": nmt.md
10 | - "Tutorial: Summarization": summarization.md
11 | - "Tutorial: Image Captioning": image_captioning.md
12 | - Data: data.md
13 | - Training: training.md
14 | - Inference: inference.md
15 | - Tools: tools.md
16 | - Results: results.md
17 | - Getting Help: help.md
18 | - Contributing: contributing.md
19 | - License: license.md
20 | - "Reference: Models": models.md
21 | - "Reference: Encoders": encoders.md
22 | - "Reference: Decoders": decoders.md
23 |
--------------------------------------------------------------------------------
/seq2seq/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | seq2seq library base module
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 |
22 | from seq2seq.graph_module import GraphModule
23 |
24 | from seq2seq import contrib
25 | from seq2seq import data
26 | from seq2seq import decoders
27 | from seq2seq import encoders
28 | from seq2seq import global_vars
29 | from seq2seq import graph_utils
30 | from seq2seq import inference
31 | from seq2seq import losses
32 | from seq2seq import metrics
33 | from seq2seq import models
34 | from seq2seq import test
35 | from seq2seq import training
36 |
--------------------------------------------------------------------------------
/seq2seq/configurable.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Abstract base class for objects that are configurable using
16 | a parameters dictionary.
17 | """
18 |
19 | from __future__ import absolute_import
20 | from __future__ import division
21 | from __future__ import print_function
22 |
23 | import abc
24 | import copy
25 | from pydoc import locate
26 |
27 | import six
28 | import yaml
29 |
30 | import tensorflow as tf
31 |
32 |
33 | class abstractstaticmethod(staticmethod): #pylint: disable=C0111,C0103
34 | """Decorates a method as abstract and static"""
35 | __slots__ = ()
36 |
37 | def __init__(self, function):
38 | super(abstractstaticmethod, self).__init__(function)
39 | function.__isabstractmethod__ = True
40 |
41 | __isabstractmethod__ = True
42 |
43 |
44 | def _create_from_dict(dict_, default_module, *args, **kwargs):
45 | """Creates a configurable class from a dictionary. The dictionary must have
46 | "class" and "params" properties. The class can be either fully qualified, or
47 | it is looked up in the modules passed via `default_module`.
48 | """
49 | class_ = locate(dict_["class"]) or getattr(default_module, dict_["class"])
50 | params = {}
51 | if "params" in dict_:
52 | params = dict_["params"]
53 | instance = class_(params, *args, **kwargs)
54 | return instance
55 |
56 |
57 | def _maybe_load_yaml(item):
58 | """Parses `item` only if it is a string. If `item` is a dictionary
59 | it is returned as-is.
60 | """
61 | if isinstance(item, six.string_types):
62 | return yaml.load(item)
63 | elif isinstance(item, dict):
64 | return item
65 | else:
66 | raise ValueError("Got {}, expected YAML string or dict", type(item))
67 |
68 |
69 | def _deep_merge_dict(dict_x, dict_y, path=None):
70 | """Recursively merges dict_y into dict_x.
71 | """
72 | if path is None: path = []
73 | for key in dict_y:
74 | if key in dict_x:
75 | if isinstance(dict_x[key], dict) and isinstance(dict_y[key], dict):
76 | _deep_merge_dict(dict_x[key], dict_y[key], path + [str(key)])
77 | elif dict_x[key] == dict_y[key]:
78 | pass # same leaf value
79 | else:
80 | dict_x[key] = dict_y[key]
81 | else:
82 | dict_x[key] = dict_y[key]
83 | return dict_x
84 |
85 |
86 | def _parse_params(params, default_params):
87 | """Parses parameter values to the types defined by the default parameters.
88 | Default parameters are used for missing values.
89 | """
90 | # Cast parameters to correct types
91 | if params is None:
92 | params = {}
93 | result = copy.deepcopy(default_params)
94 | for key, value in params.items():
95 | # If param is unknown, drop it to stay compatible with past versions
96 | if key not in default_params:
97 | raise ValueError("%s is not a valid model parameter" % key)
98 | # Param is a dictionary
99 | if isinstance(value, dict):
100 | default_dict = default_params[key]
101 | if not isinstance(default_dict, dict):
102 | raise ValueError("%s should not be a dictionary", key)
103 | if default_dict:
104 | value = _parse_params(value, default_dict)
105 | else:
106 | # If the default is an empty dict we do not typecheck it
107 | # and assume it's done downstream
108 | pass
109 | if value is None:
110 | continue
111 | if default_params[key] is None:
112 | result[key] = value
113 | else:
114 | result[key] = type(default_params[key])(value)
115 | return result
116 |
117 |
118 | @six.add_metaclass(abc.ABCMeta)
119 | class Configurable(object):
120 | """Interface for all classes that are configurable
121 | via a parameters dictionary.
122 |
123 | Args:
124 | params: A dictionary of parameters.
125 | mode: A value in tf.contrib.learn.ModeKeys
126 | """
127 |
128 | def __init__(self, params, mode):
129 | self._params = _parse_params(params, self.default_params())
130 | self._mode = mode
131 | self._print_params()
132 |
133 | def _print_params(self):
134 | """Logs parameter values"""
135 | classname = self.__class__.__name__
136 | tf.logging.info("Creating %s in mode=%s", classname, self._mode)
137 | tf.logging.info("\n%s", yaml.dump({classname: self._params}))
138 |
139 | @property
140 | def mode(self):
141 | """Returns a value in tf.contrib.learn.ModeKeys.
142 | """
143 | return self._mode
144 |
145 | @property
146 | def params(self):
147 | """Returns a dictionary of parsed parameters.
148 | """
149 | return self._params
150 |
151 | @abstractstaticmethod
152 | def default_params():
153 | """Returns a dictionary of default parameters. The default parameters
154 | are used to define the expected type of passed parameters. Missing
155 | parameter values are replaced with the defaults returned by this method.
156 | """
157 | raise NotImplementedError
158 |
--------------------------------------------------------------------------------
/seq2seq/contrib/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
--------------------------------------------------------------------------------
/seq2seq/contrib/experiment.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """A patched tf.learn Experiment class to handle GPU memory
16 | sharing issues.
17 | """
18 |
19 | import tensorflow as tf
20 |
21 | class Experiment(tf.contrib.learn.Experiment):
22 | """A patched tf.learn Experiment class to handle GPU memory
23 | sharing issues."""
24 |
25 | def __init__(self, train_steps_per_iteration=None, *args, **kwargs):
26 | super(Experiment, self).__init__(*args, **kwargs)
27 | self._train_steps_per_iteration = train_steps_per_iteration
28 |
29 | def _has_training_stopped(self, eval_result):
30 | """Determines whether the training has stopped."""
31 | if not eval_result:
32 | return False
33 |
34 | global_step = eval_result.get(tf.GraphKeys.GLOBAL_STEP)
35 | return global_step and self._train_steps and (
36 | global_step >= self._train_steps)
37 |
38 | def continuous_train_and_eval(self,
39 | continuous_eval_predicate_fn=None):
40 | """Interleaves training and evaluation.
41 |
42 | The frequency of evaluation is controlled by the `train_steps_per_iteration`
43 | (via constructor). The model will be first trained for
44 | `train_steps_per_iteration`, and then be evaluated in turns.
45 |
46 | This differs from `train_and_evaluate` as follows:
47 | 1. The procedure will have train and evaluation in turns. The model
48 | will be trained for a number of steps (usuallly smaller than `train_steps`
49 | if provided) and then be evaluated. `train_and_evaluate` will train the
50 | model for `train_steps` (no small training iteraions).
51 |
52 | 2. Due to the different approach this schedule takes, it leads to two
53 | differences in resource control. First, the resources (e.g., memory) used
54 | by training will be released before evaluation (`train_and_evaluate` takes
55 | double resources). Second, more checkpoints will be saved as a checkpoint
56 | is generated at the end of each small trainning iteration.
57 |
58 | Args:
59 | continuous_eval_predicate_fn: A predicate function determining whether to
60 | continue after each iteration. `predicate_fn` takes the evaluation
61 | results as its arguments. At the beginning of evaluation, the passed
62 | eval results will be None so it's expected that the predicate function
63 | handles that gracefully. When `predicate_fn` is not specified, this will
64 | run in an infinite loop or exit when global_step reaches `train_steps`.
65 |
66 | Returns:
67 | A tuple of the result of the `evaluate` call to the `Estimator` and the
68 | export results using the specified `ExportStrategy`.
69 |
70 | Raises:
71 | ValueError: if `continuous_eval_predicate_fn` is neither None nor
72 | callable.
73 | """
74 |
75 | if (continuous_eval_predicate_fn is not None and
76 | not callable(continuous_eval_predicate_fn)):
77 | raise ValueError(
78 | "`continuous_eval_predicate_fn` must be a callable, or None.")
79 |
80 | eval_result = None
81 |
82 | # Set the default value for train_steps_per_iteration, which will be
83 | # overriden by other settings.
84 | train_steps_per_iteration = 1000
85 | if self._train_steps_per_iteration is not None:
86 | train_steps_per_iteration = self._train_steps_per_iteration
87 | elif self._train_steps is not None:
88 | # train_steps_per_iteration = int(self._train_steps / 10)
89 | train_steps_per_iteration = min(
90 | self._min_eval_frequency, self._train_steps)
91 |
92 | while (not continuous_eval_predicate_fn or
93 | continuous_eval_predicate_fn(eval_result)):
94 |
95 | if self._has_training_stopped(eval_result):
96 | # Exits once max steps of training is satisfied.
97 | tf.logging.info("Stop training model as max steps reached")
98 | break
99 |
100 | tf.logging.info("Training model for %s steps", train_steps_per_iteration)
101 | self._estimator.fit(
102 | input_fn=self._train_input_fn,
103 | steps=train_steps_per_iteration,
104 | monitors=self._train_monitors)
105 |
106 | tf.logging.info("Evaluating model now.")
107 | eval_result = self._estimator.evaluate(
108 | input_fn=self._eval_input_fn,
109 | steps=self._eval_steps,
110 | metrics=self._eval_metrics,
111 | name="one_pass",
112 | hooks=self._eval_hooks)
113 |
114 | return eval_result, self._maybe_export(eval_result)
115 |
--------------------------------------------------------------------------------
/seq2seq/contrib/rnn_cell.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Collection of RNN Cells
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 | from __future__ import unicode_literals
21 |
22 | import sys
23 | import inspect
24 |
25 | import tensorflow as tf
26 | from tensorflow.python.ops import array_ops # pylint: disable=E0611
27 | from tensorflow.python.util import nest # pylint: disable=E0611
28 | from tensorflow.contrib.rnn import MultiRNNCell # pylint: disable=E0611
29 |
30 | # Import all cell classes from Tensorflow
31 | TF_CELL_CLASSES = [
32 | x for x in tf.contrib.rnn.__dict__.values()
33 | if inspect.isclass(x) and issubclass(x, tf.contrib.rnn.RNNCell)
34 | ]
35 | for cell_class in TF_CELL_CLASSES:
36 | setattr(sys.modules[__name__], cell_class.__name__, cell_class)
37 |
38 |
39 | class ExtendedMultiRNNCell(MultiRNNCell):
40 | """Extends the Tensorflow MultiRNNCell with residual connections"""
41 |
42 | def __init__(self,
43 | cells,
44 | residual_connections=False,
45 | residual_combiner="add",
46 | residual_dense=False):
47 | """Create a RNN cell composed sequentially of a number of RNNCells.
48 |
49 | Args:
50 | cells: list of RNNCells that will be composed in this order.
51 | state_is_tuple: If True, accepted and returned states are n-tuples, where
52 | `n = len(cells)`. If False, the states are all
53 | concatenated along the column axis. This latter behavior will soon be
54 | deprecated.
55 | residual_connections: If true, add residual connections between all cells.
56 | This requires all cells to have the same output_size. Also, iff the
57 | input size is not equal to the cell output size, a linear transform
58 | is added before the first layer.
59 | residual_combiner: One of "add" or "concat". To create inputs for layer
60 | t+1 either "add" the inputs from the prev layer or concat them.
61 | residual_dense: Densely connect each layer to all other layers
62 |
63 | Raises:
64 | ValueError: if cells is empty (not allowed), or at least one of the cells
65 | returns a state tuple but the flag `state_is_tuple` is `False`.
66 | """
67 | super(ExtendedMultiRNNCell, self).__init__(cells, state_is_tuple=True)
68 | assert residual_combiner in ["add", "concat", "mean"]
69 |
70 | self._residual_connections = residual_connections
71 | self._residual_combiner = residual_combiner
72 | self._residual_dense = residual_dense
73 |
74 | def __call__(self, inputs, state, scope=None):
75 | """Run this multi-layer cell on inputs, starting from state."""
76 | if not self._residual_connections:
77 | return super(ExtendedMultiRNNCell, self).__call__(
78 | inputs, state, (scope or "extended_multi_rnn_cell"))
79 |
80 | with tf.variable_scope(scope or "extended_multi_rnn_cell"):
81 | # Adding Residual connections are only possible when input and output
82 | # sizes are equal. Optionally transform the initial inputs to
83 | # `cell[0].output_size`
84 | if self._cells[0].output_size != inputs.get_shape().as_list()[1] and \
85 | (self._residual_combiner in ["add", "mean"]):
86 | inputs = tf.contrib.layers.fully_connected(
87 | inputs=inputs,
88 | num_outputs=self._cells[0].output_size,
89 | activation_fn=None,
90 | scope="input_transform")
91 |
92 | # Iterate through all layers (code from MultiRNNCell)
93 | cur_inp = inputs
94 | prev_inputs = [cur_inp]
95 | new_states = []
96 | for i, cell in enumerate(self._cells):
97 | with tf.variable_scope("cell_%d" % i):
98 | if not nest.is_sequence(state):
99 | raise ValueError(
100 | "Expected state to be a tuple of length %d, but received: %s" %
101 | (len(self.state_size), state))
102 | cur_state = state[i]
103 | next_input, new_state = cell(cur_inp, cur_state)
104 |
105 | # Either combine all previous inputs or only the current input
106 | input_to_combine = prev_inputs[-1:]
107 | if self._residual_dense:
108 | input_to_combine = prev_inputs
109 |
110 | # Add Residual connection
111 | if self._residual_combiner == "add":
112 | next_input = next_input + sum(input_to_combine)
113 | if self._residual_combiner == "mean":
114 | combined_mean = tf.reduce_mean(tf.stack(input_to_combine), 0)
115 | next_input = next_input + combined_mean
116 | elif self._residual_combiner == "concat":
117 | next_input = tf.concat([next_input] + input_to_combine, 1)
118 | cur_inp = next_input
119 | prev_inputs.append(cur_inp)
120 |
121 | new_states.append(new_state)
122 | new_states = (tuple(new_states)
123 | if self._state_is_tuple else array_ops.concat(new_states, 1))
124 | return cur_inp, new_states
125 |
--------------------------------------------------------------------------------
/seq2seq/contrib/seq2seq/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
--------------------------------------------------------------------------------
/seq2seq/data/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Collection of input-related utlities.
15 | """
16 |
17 | from seq2seq.data import input_pipeline
18 | from seq2seq.data import parallel_data_provider
19 | from seq2seq.data import postproc
20 | from seq2seq.data import split_tokens_decoder
21 | from seq2seq.data import vocab
22 |
--------------------------------------------------------------------------------
/seq2seq/data/postproc.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # Copyright 2017 Google Inc.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 |
16 | """
17 | A collection of commonly used post-processing functions.
18 | """
19 |
20 | from __future__ import absolute_import
21 | from __future__ import division
22 | from __future__ import print_function
23 | from __future__ import unicode_literals
24 |
25 | def strip_bpe(text):
26 | """Deodes text that was processed using BPE from
27 | https://github.com/rsennrich/subword-nmt"""
28 | return text.replace("@@ ", "").strip()
29 |
30 | def decode_sentencepiece(text):
31 | """Decodes text that uses https://github.com/google/sentencepiece encoding.
32 | Assumes that pieces are separated by a space"""
33 | return "".join(text.split(" ")).replace("▁", " ").strip()
34 |
35 | def slice_text(text,
36 | eos_token="SEQUENCE_END",
37 | sos_token="SEQUENCE_START"):
38 | """Slices text from SEQUENCE_START to SEQUENCE_END, not including
39 | these special tokens.
40 | """
41 | eos_index = text.find(eos_token)
42 | text = text[:eos_index] if eos_index > -1 else text
43 | sos_index = text.find(sos_token)
44 | text = text[sos_index+len(sos_token):] if sos_index > -1 else text
45 | return text.strip()
46 |
--------------------------------------------------------------------------------
/seq2seq/data/sequence_example_decoder.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """A decoder for tf.SequenceExample"""
15 |
16 | import tensorflow as tf
17 | from tensorflow.contrib.slim.python.slim.data import data_decoder
18 |
19 |
20 | class TFSEquenceExampleDecoder(data_decoder.DataDecoder):
21 | """A decoder for TensorFlow Examples.
22 | Decoding Example proto buffers is comprised of two stages: (1) Example parsing
23 | and (2) tensor manipulation.
24 | In the first stage, the tf.parse_example function is called with a list of
25 | FixedLenFeatures and SparseLenFeatures. These instances tell TF how to parse
26 | the example. The output of this stage is a set of tensors.
27 | In the second stage, the resulting tensors are manipulated to provide the
28 | requested 'item' tensors.
29 | To perform this decoding operation, an ExampleDecoder is given a list of
30 | ItemHandlers. Each ItemHandler indicates the set of features for stage 1 and
31 | contains the instructions for post_processing its tensors for stage 2.
32 | """
33 |
34 | def __init__(self, context_keys_to_features, sequence_keys_to_features,
35 | items_to_handlers):
36 | """Constructs the decoder.
37 | Args:
38 | keys_to_features: a dictionary from TF-Example keys to either
39 | tf.VarLenFeature or tf.FixedLenFeature instances. See tensorflow's
40 | parsing_ops.py.
41 | items_to_handlers: a dictionary from items (strings) to ItemHandler
42 | instances. Note that the ItemHandler's are provided the keys that they
43 | use to return the final item Tensors.
44 | """
45 | self._context_keys_to_features = context_keys_to_features
46 | self._sequence_keys_to_features = sequence_keys_to_features
47 | self._items_to_handlers = items_to_handlers
48 |
49 | def list_items(self):
50 | """See base class."""
51 | return list(self._items_to_handlers.keys())
52 |
53 | def decode(self, serialized_example, items=None):
54 | """Decodes the given serialized TF-example.
55 | Args:
56 | serialized_example: a serialized TF-example tensor.
57 | items: the list of items to decode. These must be a subset of the item
58 | keys in self._items_to_handlers. If `items` is left as None, then all
59 | of the items in self._items_to_handlers are decoded.
60 | Returns:
61 | the decoded items, a list of tensor.
62 | """
63 | context, sequence = tf.parse_single_sequence_example(
64 | serialized_example, self._context_keys_to_features,
65 | self._sequence_keys_to_features)
66 |
67 | # Merge context and sequence features
68 | example = {}
69 | example.update(context)
70 | example.update(sequence)
71 |
72 | all_features = {}
73 | all_features.update(self._context_keys_to_features)
74 | all_features.update(self._sequence_keys_to_features)
75 |
76 | # Reshape non-sparse elements just once:
77 | for k, value in all_features.items():
78 | if isinstance(value, tf.FixedLenFeature):
79 | example[k] = tf.reshape(example[k], value.shape)
80 |
81 | if not items:
82 | items = self._items_to_handlers.keys()
83 |
84 | outputs = []
85 | for item in items:
86 | handler = self._items_to_handlers[item]
87 | keys_to_tensors = {key: example[key] for key in handler.keys}
88 | outputs.append(handler.tensors_to_item(keys_to_tensors))
89 | return outputs
90 |
--------------------------------------------------------------------------------
/seq2seq/data/split_tokens_decoder.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """A decoder that splits a string into tokens and returns the
15 | individual tokens and the length.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import tensorflow as tf
24 | from tensorflow.contrib.slim.python.slim.data import data_decoder
25 |
26 |
27 | class SplitTokensDecoder(data_decoder.DataDecoder):
28 | """A DataProvider that splits a string tensor into individual tokens and
29 | returns the tokens and the length.
30 | Optionally prepends or appends special tokens.
31 |
32 | Args:
33 | delimiter: Delimiter to split on. Must be a single character.
34 | tokens_feature_name: A descriptive feature name for the token values
35 | length_feature_name: A descriptive feature name for the length value
36 | """
37 |
38 | def __init__(self,
39 | delimiter=" ",
40 | tokens_feature_name="tokens",
41 | length_feature_name="length",
42 | prepend_token=None,
43 | append_token=None):
44 | self.delimiter = delimiter
45 | self.tokens_feature_name = tokens_feature_name
46 | self.length_feature_name = length_feature_name
47 | self.prepend_token = prepend_token
48 | self.append_token = append_token
49 |
50 | def decode(self, data, items):
51 | decoded_items = {}
52 |
53 | # Split tokens
54 | tokens = tf.string_split([data], delimiter=self.delimiter).values
55 |
56 | # Optionally prepend a special token
57 | if self.prepend_token is not None:
58 | tokens = tf.concat([[self.prepend_token], tokens], 0)
59 |
60 | # Optionally append a special token
61 | if self.append_token is not None:
62 | tokens = tf.concat([tokens, [self.append_token]], 0)
63 |
64 | decoded_items[self.length_feature_name] = tf.size(tokens)
65 | decoded_items[self.tokens_feature_name] = tokens
66 | return [decoded_items[_] for _ in items]
67 |
68 | def list_items(self):
69 | return [self.tokens_feature_name, self.length_feature_name]
70 |
--------------------------------------------------------------------------------
/seq2seq/data/vocab.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Vocabulary related functions.
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 |
21 | import collections
22 | import tensorflow as tf
23 | from tensorflow import gfile
24 |
25 | SpecialVocab = collections.namedtuple("SpecialVocab",
26 | ["UNK", "SEQUENCE_START", "SEQUENCE_END"])
27 |
28 |
29 | class VocabInfo(
30 | collections.namedtuple("VocbabInfo",
31 | ["path", "vocab_size", "special_vocab"])):
32 | """Convenience structure for vocabulary information.
33 | """
34 |
35 | @property
36 | def total_size(self):
37 | """Returns size the the base vocabulary plus the size of extra vocabulary"""
38 | return self.vocab_size + len(self.special_vocab)
39 |
40 |
41 | def get_vocab_info(vocab_path):
42 | """Creates a `VocabInfo` instance that contains the vocabulary size and
43 | the special vocabulary for the given file.
44 |
45 | Args:
46 | vocab_path: Path to a vocabulary file with one word per line.
47 |
48 | Returns:
49 | A VocabInfo tuple.
50 | """
51 | with gfile.GFile(vocab_path) as file:
52 | vocab_size = sum(1 for _ in file)
53 | special_vocab = get_special_vocab(vocab_size)
54 | return VocabInfo(vocab_path, vocab_size, special_vocab)
55 |
56 |
57 | def get_special_vocab(vocabulary_size):
58 | """Returns the `SpecialVocab` instance for a given vocabulary size.
59 | """
60 | return SpecialVocab(*range(vocabulary_size, vocabulary_size + 3))
61 |
62 |
63 | def create_vocabulary_lookup_table(filename, default_value=None):
64 | """Creates a lookup table for a vocabulary file.
65 |
66 | Args:
67 | filename: Path to a vocabulary file containg one word per line.
68 | Each word is mapped to its line number.
69 | default_value: UNK tokens will be mapped to this id.
70 | If None, UNK tokens will be mapped to [vocab_size]
71 |
72 | Returns:
73 | A tuple (vocab_to_id_table, id_to_vocab_table,
74 | word_to_count_table, vocab_size). The vocab size does not include
75 | the UNK token.
76 | """
77 | if not gfile.Exists(filename):
78 | raise ValueError("File does not exist: {}".format(filename))
79 |
80 | # Load vocabulary into memory
81 | with gfile.GFile(filename) as file:
82 | vocab = list(line.strip("\n") for line in file)
83 | vocab_size = len(vocab)
84 |
85 | has_counts = len(vocab[0].split("\t")) == 2
86 | if has_counts:
87 | vocab, counts = zip(*[_.split("\t") for _ in vocab])
88 | counts = [float(_) for _ in counts]
89 | vocab = list(vocab)
90 | else:
91 | counts = [-1. for _ in vocab]
92 |
93 | # Add special vocabulary items
94 | special_vocab = get_special_vocab(vocab_size)
95 | vocab += list(special_vocab._fields)
96 | vocab_size += len(special_vocab)
97 | counts += [-1. for _ in list(special_vocab._fields)]
98 |
99 | if default_value is None:
100 | default_value = special_vocab.UNK
101 |
102 | tf.logging.info("Creating vocabulary lookup table of size %d", vocab_size)
103 |
104 | vocab_tensor = tf.constant(vocab)
105 | count_tensor = tf.constant(counts, dtype=tf.float32)
106 | vocab_idx_tensor = tf.range(vocab_size, dtype=tf.int64)
107 |
108 | # Create ID -> word mapping
109 | id_to_vocab_init = tf.contrib.lookup.KeyValueTensorInitializer(
110 | vocab_idx_tensor, vocab_tensor, tf.int64, tf.string)
111 | id_to_vocab_table = tf.contrib.lookup.HashTable(id_to_vocab_init, "UNK")
112 |
113 | # Create word -> id mapping
114 | vocab_to_id_init = tf.contrib.lookup.KeyValueTensorInitializer(
115 | vocab_tensor, vocab_idx_tensor, tf.string, tf.int64)
116 | vocab_to_id_table = tf.contrib.lookup.HashTable(vocab_to_id_init,
117 | default_value)
118 |
119 | # Create word -> count mapping
120 | word_to_count_init = tf.contrib.lookup.KeyValueTensorInitializer(
121 | vocab_tensor, count_tensor, tf.string, tf.float32)
122 | word_to_count_table = tf.contrib.lookup.HashTable(word_to_count_init, -1)
123 |
124 | return vocab_to_id_table, id_to_vocab_table, word_to_count_table, vocab_size
125 |
--------------------------------------------------------------------------------
/seq2seq/decoders/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Collection of decoders and decoder-related functions.
15 | """
16 |
17 | from seq2seq.decoders.rnn_decoder import *
18 | from seq2seq.decoders.attention import *
19 | from seq2seq.decoders.basic_decoder import *
20 | from seq2seq.decoders.attention_decoder import *
21 |
--------------------------------------------------------------------------------
/seq2seq/decoders/attention.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """ Implementations of attention layers.
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 | from __future__ import unicode_literals
21 |
22 | import abc
23 | import six
24 |
25 | import tensorflow as tf
26 | from tensorflow.python.framework import function # pylint: disable=E0611
27 |
28 | from seq2seq.graph_module import GraphModule
29 | from seq2seq.configurable import Configurable
30 |
31 |
32 | @function.Defun(
33 | tf.float32,
34 | tf.float32,
35 | tf.float32,
36 | func_name="att_sum_bahdanau",
37 | noinline=True)
38 | def att_sum_bahdanau(v_att, keys, query):
39 | """Calculates a batch- and timweise dot product with a variable"""
40 | return tf.reduce_sum(v_att * tf.tanh(keys + tf.expand_dims(query, 1)), [2])
41 |
42 |
43 | @function.Defun(tf.float32, tf.float32, func_name="att_sum_dot", noinline=True)
44 | def att_sum_dot(keys, query):
45 | """Calculates a batch- and timweise dot product"""
46 | return tf.reduce_sum(keys * tf.expand_dims(query, 1), [2])
47 |
48 |
49 | @six.add_metaclass(abc.ABCMeta)
50 | class AttentionLayer(GraphModule, Configurable):
51 | """
52 | Attention layer according to https://arxiv.org/abs/1409.0473.
53 |
54 | Params:
55 | num_units: Number of units used in the attention layer
56 | """
57 |
58 | def __init__(self, params, mode, name="attention"):
59 | GraphModule.__init__(self, name)
60 | Configurable.__init__(self, params, mode)
61 |
62 | @staticmethod
63 | def default_params():
64 | return {"num_units": 128}
65 |
66 | @abc.abstractmethod
67 | def score_fn(self, keys, query):
68 | """Computes the attention score"""
69 | raise NotImplementedError
70 |
71 | def _build(self, query, keys, values, values_length):
72 | """Computes attention scores and outputs.
73 |
74 | Args:
75 | query: The query used to calculate attention scores.
76 | In seq2seq this is typically the current state of the decoder.
77 | A tensor of shape `[B, ...]`
78 | keys: The keys used to calculate attention scores. In seq2seq, these
79 | are typically the outputs of the encoder and equivalent to `values`.
80 | A tensor of shape `[B, T, ...]` where each element in the `T`
81 | dimension corresponds to the key for that value.
82 | values: The elements to compute attention over. In seq2seq, this is
83 | typically the sequence of encoder outputs.
84 | A tensor of shape `[B, T, input_dim]`.
85 | values_length: An int32 tensor of shape `[B]` defining the sequence
86 | length of the attention values.
87 |
88 | Returns:
89 | A tuple `(scores, context)`.
90 | `scores` is vector of length `T` where each element is the
91 | normalized "score" of the corresponding `inputs` element.
92 | `context` is the final attention layer output corresponding to
93 | the weighted inputs.
94 | A tensor fo shape `[B, input_dim]`.
95 | """
96 | values_depth = values.get_shape().as_list()[-1]
97 |
98 | # Fully connected layers to transform both keys and query
99 | # into a tensor with `num_units` units
100 | att_keys = tf.contrib.layers.fully_connected(
101 | inputs=keys,
102 | num_outputs=self.params["num_units"],
103 | activation_fn=None,
104 | scope="att_keys")
105 | att_query = tf.contrib.layers.fully_connected(
106 | inputs=query,
107 | num_outputs=self.params["num_units"],
108 | activation_fn=None,
109 | scope="att_query")
110 |
111 | scores = self.score_fn(att_keys, att_query)
112 |
113 | # Replace all scores for padded inputs with tf.float32.min
114 | num_scores = tf.shape(scores)[1]
115 | scores_mask = tf.sequence_mask(
116 | lengths=tf.to_int32(values_length),
117 | maxlen=tf.to_int32(num_scores),
118 | dtype=tf.float32)
119 | scores = scores * scores_mask + ((1.0 - scores_mask) * tf.float32.min)
120 |
121 | # Normalize the scores
122 | scores_normalized = tf.nn.softmax(scores, name="scores_normalized")
123 |
124 | # Calculate the weighted average of the attention inputs
125 | # according to the scores
126 | context = tf.expand_dims(scores_normalized, 2) * values
127 | context = tf.reduce_sum(context, 1, name="context")
128 | context.set_shape([None, values_depth])
129 |
130 |
131 | return (scores_normalized, context)
132 |
133 |
134 | class AttentionLayerDot(AttentionLayer):
135 | """An attention layer that calculates attention scores using
136 | a dot product.
137 | """
138 |
139 | def score_fn(self, keys, query):
140 | return att_sum_dot(keys, query)
141 |
142 |
143 | class AttentionLayerBahdanau(AttentionLayer):
144 | """An attention layer that calculates attention scores using
145 | a parameterized multiplication."""
146 |
147 | def score_fn(self, keys, query):
148 | v_att = tf.get_variable(
149 | "v_att", shape=[self.params["num_units"]], dtype=tf.float32)
150 | return att_sum_bahdanau(v_att, keys, query)
151 |
--------------------------------------------------------------------------------
/seq2seq/decoders/basic_decoder.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | A basic sequence decoder that performs a softmax based on the RNN state.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import tensorflow as tf
24 | from seq2seq.decoders.rnn_decoder import RNNDecoder, DecoderOutput
25 |
26 |
27 | class BasicDecoder(RNNDecoder):
28 | """Simple RNN decoder that performed a softmax operations on the cell output.
29 | """
30 |
31 | def __init__(self, params, mode, vocab_size, name="basic_decoder"):
32 | super(BasicDecoder, self).__init__(params, mode, name)
33 | self.vocab_size = vocab_size
34 |
35 | def compute_output(self, cell_output):
36 | """Computes the decoder outputs."""
37 | return tf.contrib.layers.fully_connected(
38 | inputs=cell_output, num_outputs=self.vocab_size, activation_fn=None)
39 |
40 | @property
41 | def output_size(self):
42 | return DecoderOutput(
43 | logits=self.vocab_size,
44 | predicted_ids=tf.TensorShape([]),
45 | cell_output=self.cell.output_size)
46 |
47 | @property
48 | def output_dtype(self):
49 | return DecoderOutput(
50 | logits=tf.float32, predicted_ids=tf.int32, cell_output=tf.float32)
51 |
52 | def initialize(self, name=None):
53 | finished, first_inputs = self.helper.initialize()
54 | return finished, first_inputs, self.initial_state
55 |
56 | def step(self, time_, inputs, state, name=None):
57 | cell_output, cell_state = self.cell(inputs, state)
58 | logits = self.compute_output(cell_output)
59 | sample_ids = self.helper.sample(
60 | time=time_, outputs=logits, state=cell_state)
61 | outputs = DecoderOutput(
62 | logits=logits, predicted_ids=sample_ids, cell_output=cell_output)
63 | finished, next_inputs, next_state = self.helper.next_inputs(
64 | time=time_, outputs=outputs, state=cell_state, sample_ids=sample_ids)
65 | return (outputs, next_state, next_inputs, finished)
66 |
--------------------------------------------------------------------------------
/seq2seq/decoders/rnn_decoder.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Base class for sequence decoders.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import abc
24 | from collections import namedtuple
25 |
26 | import six
27 | import tensorflow as tf
28 | from tensorflow.python.util import nest # pylint: disable=E0611
29 |
30 | from seq2seq.graph_module import GraphModule
31 | from seq2seq.configurable import Configurable
32 | from seq2seq.contrib.seq2seq.decoder import Decoder, dynamic_decode
33 | from seq2seq.encoders.rnn_encoder import _default_rnn_cell_params
34 | from seq2seq.encoders.rnn_encoder import _toggle_dropout
35 | from seq2seq.training import utils as training_utils
36 |
37 |
38 | class DecoderOutput(
39 | namedtuple("DecoderOutput", ["logits", "predicted_ids", "cell_output"])):
40 | """Output of an RNN decoder.
41 |
42 | Note that we output both the logits and predictions because during
43 | dynamic decoding the predictions may not correspond to max(logits).
44 | For example, we may be sampling from the logits instead.
45 | """
46 | pass
47 |
48 |
49 | @six.add_metaclass(abc.ABCMeta)
50 | class RNNDecoder(Decoder, GraphModule, Configurable):
51 | """Base class for RNN decoders.
52 |
53 | Args:
54 | cell: An instance of ` tf.contrib.rnn.RNNCell`
55 | helper: An instance of `tf.contrib.seq2seq.Helper` to assist decoding
56 | initial_state: A tensor or tuple of tensors used as the initial cell
57 | state.
58 | name: A name for this module
59 | """
60 |
61 | def __init__(self, params, mode, name):
62 | GraphModule.__init__(self, name)
63 | Configurable.__init__(self, params, mode)
64 | self.params["rnn_cell"] = _toggle_dropout(self.params["rnn_cell"], mode)
65 | self.cell = training_utils.get_rnn_cell(**self.params["rnn_cell"])
66 | # Not initialized yet
67 | self.initial_state = None
68 | self.helper = None
69 |
70 | @abc.abstractmethod
71 | def initialize(self, name=None):
72 | raise NotImplementedError
73 |
74 | @abc.abstractmethod
75 | def step(self, name=None):
76 | raise NotImplementedError
77 |
78 | @property
79 | def batch_size(self):
80 | return tf.shape(nest.flatten([self.initial_state])[0])[0]
81 |
82 | def _setup(self, initial_state, helper):
83 | """Sets the initial state and helper for the decoder.
84 | """
85 | self.initial_state = initial_state
86 | self.helper = helper
87 |
88 | def finalize(self, outputs, final_state):
89 | """Applies final transformation to the decoder output once decoding is
90 | finished.
91 | """
92 | #pylint: disable=R0201
93 | return (outputs, final_state)
94 |
95 | @staticmethod
96 | def default_params():
97 | return {
98 | "max_decode_length": 100,
99 | "rnn_cell": _default_rnn_cell_params(),
100 | "init_scale": 0.04,
101 | }
102 |
103 | def _build(self, initial_state, helper):
104 | if not self.initial_state:
105 | self._setup(initial_state, helper)
106 |
107 | scope = tf.get_variable_scope()
108 | scope.set_initializer(tf.random_uniform_initializer(
109 | -self.params["init_scale"],
110 | self.params["init_scale"]))
111 |
112 | maximum_iterations = None
113 | if self.mode == tf.contrib.learn.ModeKeys.INFER:
114 | maximum_iterations = self.params["max_decode_length"]
115 |
116 | outputs, final_state = dynamic_decode(
117 | decoder=self,
118 | output_time_major=True,
119 | impute_finished=False,
120 | maximum_iterations=maximum_iterations)
121 | return self.finalize(outputs, final_state)
122 |
--------------------------------------------------------------------------------
/seq2seq/encoders/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Collection of encoders"""
15 |
16 | import seq2seq.encoders.encoder
17 | import seq2seq.encoders.rnn_encoder
18 |
19 | from seq2seq.encoders.rnn_encoder import *
20 | from seq2seq.encoders.image_encoder import *
21 | from seq2seq.encoders.pooling_encoder import PoolingEncoder
22 | from seq2seq.encoders.conv_encoder import ConvEncoder
23 |
--------------------------------------------------------------------------------
/seq2seq/encoders/conv_encoder.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | An encoder that pools over embeddings, as described in
16 | https://arxiv.org/abs/1611.02344.
17 | """
18 |
19 | from __future__ import absolute_import
20 | from __future__ import division
21 | from __future__ import print_function
22 |
23 | from pydoc import locate
24 |
25 | import tensorflow as tf
26 |
27 | from seq2seq.encoders.encoder import Encoder, EncoderOutput
28 | from seq2seq.encoders.pooling_encoder import _create_position_embedding
29 |
30 |
31 | class ConvEncoder(Encoder):
32 | """A deep convolutional encoder, as described in
33 | https://arxiv.org/abs/1611.02344. The encoder supports optional positions
34 | embeddings.
35 |
36 | Params:
37 | attention_cnn.units: Number of units in `cnn_a`. Same in each layer.
38 | attention_cnn.kernel_size: Kernel size for `cnn_a`.
39 | attention_cnn.layers: Number of layers in `cnn_a`.
40 | embedding_dropout_keep_prob: Dropout keep probability
41 | applied to the embeddings.
42 | output_cnn.units: Number of units in `cnn_c`. Same in each layer.
43 | output_cnn.kernel_size: Kernel size for `cnn_c`.
44 | output_cnn.layers: Number of layers in `cnn_c`.
45 | position_embeddings.enable: If true, add position embeddings to the
46 | inputs before pooling.
47 | position_embeddings.combiner_fn: Function used to combine the
48 | position embeddings with the inputs. For example, `tensorflow.add`.
49 | position_embeddings.num_positions: Size of the position embedding matrix.
50 | This should be set to the maximum sequence length of the inputs.
51 | """
52 |
53 | def __init__(self, params, mode, name="conv_encoder"):
54 | super(ConvEncoder, self).__init__(params, mode, name)
55 | self._combiner_fn = locate(self.params["position_embeddings.combiner_fn"])
56 |
57 | @staticmethod
58 | def default_params():
59 | return {
60 | "attention_cnn.units": 512,
61 | "attention_cnn.kernel_size": 3,
62 | "attention_cnn.layers": 15,
63 | "embedding_dropout_keep_prob": 0.8,
64 | "output_cnn.units": 256,
65 | "output_cnn.kernel_size": 3,
66 | "output_cnn.layers": 5,
67 | "position_embeddings.enable": True,
68 | "position_embeddings.combiner_fn": "tensorflow.multiply",
69 | "position_embeddings.num_positions": 100,
70 | }
71 |
72 | def encode(self, inputs, sequence_length):
73 | if self.params["position_embeddings.enable"]:
74 | positions_embed = _create_position_embedding(
75 | embedding_dim=inputs.get_shape().as_list()[-1],
76 | num_positions=self.params["position_embeddings.num_positions"],
77 | lengths=sequence_length,
78 | maxlen=tf.shape(inputs)[1])
79 | inputs = self._combiner_fn(inputs, positions_embed)
80 |
81 | # Apply dropout to embeddings
82 | inputs = tf.contrib.layers.dropout(
83 | inputs=inputs,
84 | keep_prob=self.params["embedding_dropout_keep_prob"],
85 | is_training=self.mode == tf.contrib.learn.ModeKeys.TRAIN)
86 |
87 | with tf.variable_scope("cnn_a"):
88 | cnn_a_output = inputs
89 | for layer_idx in range(self.params["attention_cnn.layers"]):
90 | next_layer = tf.contrib.layers.conv2d(
91 | inputs=cnn_a_output,
92 | num_outputs=self.params["attention_cnn.units"],
93 | kernel_size=self.params["attention_cnn.kernel_size"],
94 | padding="SAME",
95 | activation_fn=None)
96 | # Add a residual connection, except for the first layer
97 | if layer_idx > 0:
98 | next_layer += cnn_a_output
99 | cnn_a_output = tf.tanh(next_layer)
100 |
101 | with tf.variable_scope("cnn_c"):
102 | cnn_c_output = inputs
103 | for layer_idx in range(self.params["output_cnn.layers"]):
104 | next_layer = tf.contrib.layers.conv2d(
105 | inputs=cnn_c_output,
106 | num_outputs=self.params["output_cnn.units"],
107 | kernel_size=self.params["output_cnn.kernel_size"],
108 | padding="SAME",
109 | activation_fn=None)
110 | # Add a residual connection, except for the first layer
111 | if layer_idx > 0:
112 | next_layer += cnn_c_output
113 | cnn_c_output = tf.tanh(next_layer)
114 |
115 | final_state = tf.reduce_mean(cnn_c_output, 1)
116 |
117 | return EncoderOutput(
118 | outputs=cnn_a_output,
119 | final_state=final_state,
120 | attention_values=cnn_c_output,
121 | attention_values_length=sequence_length)
122 |
--------------------------------------------------------------------------------
/seq2seq/encoders/encoder.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Abstract base class for encoders.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 |
22 | import abc
23 | from collections import namedtuple
24 |
25 | import six
26 |
27 | from seq2seq.configurable import Configurable
28 | from seq2seq.graph_module import GraphModule
29 |
30 | EncoderOutput = namedtuple(
31 | "EncoderOutput",
32 | "outputs final_state attention_values attention_values_length")
33 |
34 |
35 | @six.add_metaclass(abc.ABCMeta)
36 | class Encoder(GraphModule, Configurable):
37 | """Abstract encoder class. All encoders should inherit from this.
38 |
39 | Args:
40 | params: A dictionary of hyperparameters for the encoder.
41 | name: A variable scope for the encoder graph.
42 | """
43 |
44 | def __init__(self, params, mode, name):
45 | GraphModule.__init__(self, name)
46 | Configurable.__init__(self, params, mode)
47 |
48 | def _build(self, inputs, *args, **kwargs):
49 | return self.encode(inputs, *args, **kwargs)
50 |
51 | @abc.abstractmethod
52 | def encode(self, *args, **kwargs):
53 | """
54 | Encodes an input sequence.
55 |
56 | Args:
57 | inputs: The inputs to encode. A float32 tensor of shape [B, T, ...].
58 | sequence_length: The length of each input. An int32 tensor of shape [T].
59 |
60 | Returns:
61 | An `EncoderOutput` tuple containing the outputs and final state.
62 | """
63 | raise NotImplementedError
64 |
--------------------------------------------------------------------------------
/seq2seq/encoders/image_encoder.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Image encoder classes
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 |
22 | import tensorflow as tf
23 | from tensorflow.contrib.slim.python.slim.nets.inception_v3 \
24 | import inception_v3_base
25 |
26 | from seq2seq.encoders.encoder import Encoder, EncoderOutput
27 |
28 |
29 | class InceptionV3Encoder(Encoder):
30 | """
31 | A unidirectional RNN encoder. Stacking should be performed as
32 | part of the cell.
33 |
34 | Params:
35 | resize_height: Resize the image to this height before feeding it
36 | into the convolutional network.
37 | resize_width: Resize the image to this width before feeding it
38 | into the convolutional network.
39 | """
40 |
41 | def __init__(self, params, mode, name="image_encoder"):
42 | super(InceptionV3Encoder, self).__init__(params, mode, name)
43 |
44 | @staticmethod
45 | def default_params():
46 | return {
47 | "resize_height": 299,
48 | "resize_width": 299,
49 | }
50 |
51 | def encode(self, inputs):
52 | inputs = tf.image.resize_images(
53 | images=inputs,
54 | size=[self.params["resize_height"], self.params["resize_width"]],
55 | method=tf.image.ResizeMethod.BILINEAR)
56 |
57 | outputs, _ = inception_v3_base(tf.to_float(inputs))
58 | output_shape = outputs.get_shape() #pylint: disable=E1101
59 | shape_list = output_shape.as_list()
60 |
61 | # Take attentin over output elemnts in width and height dimension:
62 | # Shape: [B, W*H, ...]
63 | outputs_flat = tf.reshape(outputs, [shape_list[0], -1, shape_list[-1]])
64 |
65 | # Final state is the pooled output
66 | # Shape: [B, W*H*...]
67 | final_state = tf.contrib.slim.avg_pool2d(
68 | outputs, output_shape[1:3], padding="VALID", scope="pool")
69 | final_state = tf.contrib.slim.flatten(outputs, scope="flatten")
70 |
71 | return EncoderOutput(
72 | outputs=outputs_flat,
73 | final_state=final_state,
74 | attention_values=outputs_flat,
75 | attention_values_length=tf.shape(outputs_flat)[1])
76 |
--------------------------------------------------------------------------------
/seq2seq/global_vars.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Collection of global variables.
16 | """
17 |
18 | SYNC_REPLICAS_OPTIMIZER = None
19 |
--------------------------------------------------------------------------------
/seq2seq/graph_module.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | All graph components that create Variables should inherit from this
16 | base class defined in this file.
17 | """
18 |
19 | from __future__ import absolute_import
20 | from __future__ import division
21 | from __future__ import print_function
22 |
23 | import tensorflow as tf
24 |
25 |
26 | class GraphModule(object):
27 | """
28 | Convenience class that makes it easy to share variables.
29 | Each insance of this class creates its own set of variables, but
30 | each subsequent execution of an instance will re-use its variables.
31 |
32 | Graph components that define variables should inherit from this class
33 | and implement their logic in the `_build` method.
34 | """
35 |
36 | def __init__(self, name):
37 | """
38 | Initialize the module. Each subclass must call this constructor with a name.
39 |
40 | Args:
41 | name: Name of this module. Used for `tf.make_template`.
42 | """
43 | self.name = name
44 | self._template = tf.make_template(name, self._build, create_scope_now_=True)
45 | # Docstrings for the class should be the docstring for the _build method
46 | self.__doc__ = self._build.__doc__
47 | # pylint: disable=E1101
48 | self.__call__.__func__.__doc__ = self._build.__doc__
49 |
50 | def _build(self, *args, **kwargs):
51 | """Subclasses should implement their logic here.
52 | """
53 | raise NotImplementedError
54 |
55 | def __call__(self, *args, **kwargs):
56 | # pylint: disable=missing-docstring
57 | return self._template(*args, **kwargs)
58 |
59 | def variable_scope(self):
60 | """Returns the proper variable scope for this module.
61 | """
62 | return tf.variable_scope(self._template.variable_scope)
63 |
--------------------------------------------------------------------------------
/seq2seq/graph_utils.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Miscellaneous utility function.
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 |
21 | import tensorflow as tf
22 |
23 |
24 | def templatemethod(name_):
25 | """This decorator wraps a method with `tf.make_template`. For example,
26 |
27 | @templatemethod
28 | def my_method():
29 | # Create variables
30 | """
31 |
32 | def template_decorator(func):
33 | """Inner decorator function"""
34 |
35 | def func_wrapper(*args, **kwargs):
36 | """Inner wrapper function"""
37 | templated_func = tf.make_template(name_, func)
38 | return templated_func(*args, **kwargs)
39 |
40 | return func_wrapper
41 |
42 | return template_decorator
43 |
44 |
45 | def add_dict_to_collection(dict_, collection_name):
46 | """Adds a dictionary to a graph collection.
47 |
48 | Args:
49 | dict_: A dictionary of string keys to tensor values
50 | collection_name: The name of the collection to add the dictionary to
51 | """
52 | key_collection = collection_name + "_keys"
53 | value_collection = collection_name + "_values"
54 | for key, value in dict_.items():
55 | tf.add_to_collection(key_collection, key)
56 | tf.add_to_collection(value_collection, value)
57 |
58 |
59 | def get_dict_from_collection(collection_name):
60 | """Gets a dictionary from a graph collection.
61 |
62 | Args:
63 | collection_name: A collection name to read a dictionary from
64 |
65 | Returns:
66 | A dictionary with string keys and tensor values
67 | """
68 | key_collection = collection_name + "_keys"
69 | value_collection = collection_name + "_values"
70 | keys = tf.get_collection(key_collection)
71 | values = tf.get_collection(value_collection)
72 | return dict(zip(keys, values))
73 |
--------------------------------------------------------------------------------
/seq2seq/inference/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Modules related to running model inference.
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 |
21 | from seq2seq.inference.inference import *
22 | import seq2seq.inference.beam_search
23 |
--------------------------------------------------------------------------------
/seq2seq/inference/inference.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """ Generates model predictions.
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 |
21 | import tensorflow as tf
22 |
23 | from seq2seq.training import utils as training_utils
24 |
25 |
26 | def create_inference_graph(model, input_pipeline, batch_size=32):
27 | """Creates a graph to perform inference.
28 |
29 | Args:
30 | task: An `InferenceTask` instance.
31 | input_pipeline: An instance of `InputPipeline` that defines
32 | how to read and parse data.
33 | batch_size: The batch size used for inference
34 |
35 | Returns:
36 | The return value of the model function, typically a tuple of
37 | (predictions, loss, train_op).
38 | """
39 |
40 | # TODO: This doesn't really belong here.
41 | # How to get rid of this?
42 | if hasattr(model, "use_beam_search"):
43 | if model.use_beam_search:
44 | tf.logging.info("Setting batch size to 1 for beam search.")
45 | batch_size = 1
46 |
47 | input_fn = training_utils.create_input_fn(
48 | pipeline=input_pipeline,
49 | batch_size=batch_size,
50 | allow_smaller_final_batch=True)
51 |
52 | # Build the graph
53 | features, labels = input_fn()
54 | return model(features=features, labels=labels, params=None)
55 |
--------------------------------------------------------------------------------
/seq2seq/losses.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Operations related to calculating sequence losses.
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 |
21 | import tensorflow as tf
22 |
23 |
24 | def cross_entropy_sequence_loss(logits, targets, sequence_length):
25 | """Calculates the per-example cross-entropy loss for a sequence of logits and
26 | masks out all losses passed the sequence length.
27 |
28 | Args:
29 | logits: Logits of shape `[T, B, vocab_size]`
30 | targets: Target classes of shape `[T, B]`
31 | sequence_length: An int32 tensor of shape `[B]` corresponding
32 | to the length of each input
33 |
34 | Returns:
35 | A tensor of shape [T, B] that contains the loss per example, per time step.
36 | """
37 | with tf.name_scope("cross_entropy_sequence_loss"):
38 | losses = tf.nn.sparse_softmax_cross_entropy_with_logits(
39 | logits=logits, labels=targets)
40 |
41 | # Mask out the losses we don't care about
42 | loss_mask = tf.sequence_mask(
43 | tf.to_int32(sequence_length), tf.to_int32(tf.shape(targets)[0]))
44 | losses = losses * tf.transpose(tf.to_float(loss_mask), [1, 0])
45 |
46 | return losses
47 |
--------------------------------------------------------------------------------
/seq2seq/metrics/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """ Collection of metric-related functions
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 |
--------------------------------------------------------------------------------
/seq2seq/metrics/bleu.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # Copyright 2017 Google Inc.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | """BLEU metric implementation.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import os
24 | import re
25 | import subprocess
26 | import tempfile
27 | import numpy as np
28 |
29 | from six.moves import urllib
30 | import tensorflow as tf
31 |
32 |
33 | def moses_multi_bleu(hypotheses, references, lowercase=False):
34 | """Calculate the bleu score for hypotheses and references
35 | using the MOSES ulti-bleu.perl script.
36 |
37 | Args:
38 | hypotheses: A numpy array of strings where each string is a single example.
39 | references: A numpy array of strings where each string is a single example.
40 | lowercase: If true, pass the "-lc" flag to the multi-bleu script
41 |
42 | Returns:
43 | The BLEU score as a float32 value.
44 | """
45 |
46 | if np.size(hypotheses) == 0:
47 | return np.float32(0.0)
48 |
49 | # Get MOSES multi-bleu script
50 | try:
51 | multi_bleu_path, _ = urllib.request.urlretrieve(
52 | "https://raw.githubusercontent.com/moses-smt/mosesdecoder/"
53 | "master/scripts/generic/multi-bleu.perl")
54 | os.chmod(multi_bleu_path, 0o755)
55 | except: #pylint: disable=W0702
56 | tf.logging.info("Unable to fetch multi-bleu.perl script, using local.")
57 | metrics_dir = os.path.dirname(os.path.realpath(__file__))
58 | bin_dir = os.path.abspath(os.path.join(metrics_dir, "..", "..", "bin"))
59 | multi_bleu_path = os.path.join(bin_dir, "tools/multi-bleu.perl")
60 |
61 | # Dump hypotheses and references to tempfiles
62 | hypothesis_file = tempfile.NamedTemporaryFile()
63 | hypothesis_file.write("\n".join(hypotheses).encode("utf-8"))
64 | hypothesis_file.write(b"\n")
65 | hypothesis_file.flush()
66 | reference_file = tempfile.NamedTemporaryFile()
67 | reference_file.write("\n".join(references).encode("utf-8"))
68 | reference_file.write(b"\n")
69 | reference_file.flush()
70 |
71 | # Calculate BLEU using multi-bleu script
72 | with open(hypothesis_file.name, "r") as read_pred:
73 | bleu_cmd = [multi_bleu_path]
74 | if lowercase:
75 | bleu_cmd += ["-lc"]
76 | bleu_cmd += [reference_file.name]
77 | try:
78 | bleu_out = subprocess.check_output(
79 | bleu_cmd, stdin=read_pred, stderr=subprocess.STDOUT)
80 | bleu_out = bleu_out.decode("utf-8")
81 | bleu_score = re.search(r"BLEU = (.+?),", bleu_out).group(1)
82 | bleu_score = float(bleu_score)
83 | except subprocess.CalledProcessError as error:
84 | if error.output is not None:
85 | tf.logging.warning("multi-bleu.perl script returned non-zero exit code")
86 | tf.logging.warning(error.output)
87 | bleu_score = np.float32(0.0)
88 |
89 | # Close temp files
90 | hypothesis_file.close()
91 | reference_file.close()
92 |
93 | return np.float32(bleu_score)
94 |
--------------------------------------------------------------------------------
/seq2seq/models/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """This module contains various Encoder-Decoder models
15 | """
16 |
17 | from seq2seq.models.basic_seq2seq import BasicSeq2Seq
18 | from seq2seq.models.attention_seq2seq import AttentionSeq2Seq
19 | from seq2seq.models.image2seq import Image2Seq
20 |
21 | import seq2seq.models.bridges
22 | import seq2seq.models.model_base
23 |
--------------------------------------------------------------------------------
/seq2seq/models/attention_seq2seq.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Sequence to Sequence model with attention
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | from pydoc import locate
24 |
25 | import tensorflow as tf
26 |
27 | from seq2seq import decoders
28 | from seq2seq.models.basic_seq2seq import BasicSeq2Seq
29 |
30 |
31 | class AttentionSeq2Seq(BasicSeq2Seq):
32 | """Sequence2Sequence model with attention mechanism.
33 |
34 | Args:
35 | source_vocab_info: An instance of `VocabInfo`
36 | for the source vocabulary
37 | target_vocab_info: An instance of `VocabInfo`
38 | for the target vocabulary
39 | params: A dictionary of hyperparameters
40 | """
41 |
42 | def __init__(self, params, mode, name="att_seq2seq"):
43 | super(AttentionSeq2Seq, self).__init__(params, mode, name)
44 |
45 | @staticmethod
46 | def default_params():
47 | params = BasicSeq2Seq.default_params().copy()
48 | params.update({
49 | "attention.class": "AttentionLayerBahdanau",
50 | "attention.params": {}, # Arbitrary attention layer parameters
51 | "bridge.class": "seq2seq.models.bridges.ZeroBridge",
52 | "encoder.class": "seq2seq.encoders.BidirectionalRNNEncoder",
53 | "encoder.params": {}, # Arbitrary parameters for the encoder
54 | "decoder.class": "seq2seq.decoders.AttentionDecoder",
55 | "decoder.params": {} # Arbitrary parameters for the decoder
56 | })
57 | return params
58 |
59 | def _create_decoder(self, encoder_output, features, _labels):
60 | attention_class = locate(self.params["attention.class"]) or \
61 | getattr(decoders.attention, self.params["attention.class"])
62 | attention_layer = attention_class(
63 | params=self.params["attention.params"], mode=self.mode)
64 |
65 | # If the input sequence is reversed we also need to reverse
66 | # the attention scores.
67 | reverse_scores_lengths = None
68 | if self.params["source.reverse"]:
69 | reverse_scores_lengths = features["source_len"]
70 | if self.use_beam_search:
71 | reverse_scores_lengths = tf.tile(
72 | input=reverse_scores_lengths,
73 | multiples=[self.params["inference.beam_search.beam_width"]])
74 |
75 | return self.decoder_class(
76 | params=self.params["decoder.params"],
77 | mode=self.mode,
78 | vocab_size=self.target_vocab_info.total_size,
79 | attention_values=encoder_output.attention_values,
80 | attention_values_length=encoder_output.attention_values_length,
81 | attention_keys=encoder_output.outputs,
82 | attention_fn=attention_layer,
83 | reverse_scores_lengths=reverse_scores_lengths)
84 |
--------------------------------------------------------------------------------
/seq2seq/models/basic_seq2seq.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Definition of a basic seq2seq model
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | from pydoc import locate
24 | import tensorflow as tf
25 | from seq2seq.contrib.seq2seq import helper as tf_decode_helper
26 |
27 | from seq2seq.models.seq2seq_model import Seq2SeqModel
28 | from seq2seq.graph_utils import templatemethod
29 | from seq2seq.models import bridges
30 |
31 |
32 | class BasicSeq2Seq(Seq2SeqModel):
33 | """Basic Sequence2Sequence model with a unidirectional encoder and decoder.
34 | The last encoder state is used to initialize the decoder and thus both
35 | must share the same type of RNN cell.
36 |
37 | Args:
38 | source_vocab_info: An instance of `VocabInfo`
39 | for the source vocabulary
40 | target_vocab_info: An instance of `VocabInfo`
41 | for the target vocabulary
42 | params: A dictionary of hyperparameters
43 | """
44 |
45 | def __init__(self, params, mode, name="basic_seq2seq"):
46 | super(BasicSeq2Seq, self).__init__(params, mode, name)
47 | self.encoder_class = locate(self.params["encoder.class"])
48 | self.decoder_class = locate(self.params["decoder.class"])
49 |
50 | @staticmethod
51 | def default_params():
52 | params = Seq2SeqModel.default_params().copy()
53 | params.update({
54 | "bridge.class": "seq2seq.models.bridges.InitialStateBridge",
55 | "bridge.params": {},
56 | "encoder.class": "seq2seq.encoders.UnidirectionalRNNEncoder",
57 | "encoder.params": {}, # Arbitrary parameters for the encoder
58 | "decoder.class": "seq2seq.decoders.BasicDecoder",
59 | "decoder.params": {} # Arbitrary parameters for the decoder
60 | })
61 | return params
62 |
63 | def _create_bridge(self, encoder_outputs, decoder_state_size):
64 | """Creates the bridge to be used between encoder and decoder"""
65 | bridge_class = locate(self.params["bridge.class"]) or \
66 | getattr(bridges, self.params["bridge.class"])
67 | return bridge_class(
68 | encoder_outputs=encoder_outputs,
69 | decoder_state_size=decoder_state_size,
70 | params=self.params["bridge.params"],
71 | mode=self.mode)
72 |
73 | def _create_decoder(self, _encoder_output, _features, _labels):
74 | """Creates a decoder instance based on the passed parameters."""
75 | return self.decoder_class(
76 | params=self.params["decoder.params"],
77 | mode=self.mode,
78 | vocab_size=self.target_vocab_info.total_size)
79 |
80 | def _decode_train(self, decoder, bridge, _encoder_output, _features, labels):
81 | """Runs decoding in training mode"""
82 | target_embedded = tf.nn.embedding_lookup(self.target_embedding,
83 | labels["target_ids"])
84 | helper_train = tf_decode_helper.TrainingHelper(
85 | inputs=target_embedded[:, :-1],
86 | sequence_length=labels["target_len"] - 1)
87 | decoder_initial_state = bridge()
88 | return decoder(decoder_initial_state, helper_train)
89 |
90 | def _decode_infer(self, decoder, bridge, _encoder_output, features, labels):
91 | """Runs decoding in inference mode"""
92 | batch_size = self.batch_size(features, labels)
93 | if self.use_beam_search:
94 | batch_size = self.params["inference.beam_search.beam_width"]
95 |
96 | target_start_id = self.target_vocab_info.special_vocab.SEQUENCE_START
97 | helper_infer = tf_decode_helper.GreedyEmbeddingHelper(
98 | embedding=self.target_embedding,
99 | start_tokens=tf.fill([batch_size], target_start_id),
100 | end_token=self.target_vocab_info.special_vocab.SEQUENCE_END)
101 | decoder_initial_state = bridge()
102 | return decoder(decoder_initial_state, helper_infer)
103 |
104 | @templatemethod("encode")
105 | def encode(self, features, labels):
106 | source_embedded = tf.nn.embedding_lookup(self.source_embedding,
107 | features["source_ids"])
108 | encoder_fn = self.encoder_class(self.params["encoder.params"], self.mode)
109 | return encoder_fn(source_embedded, features["source_len"])
110 |
111 | @templatemethod("decode")
112 | def decode(self, encoder_output, features, labels):
113 | decoder = self._create_decoder(encoder_output, features, labels)
114 | if self.use_beam_search:
115 | decoder = self._get_beam_search_decoder(decoder)
116 |
117 | bridge = self._create_bridge(
118 | encoder_outputs=encoder_output,
119 | decoder_state_size=decoder.cell.state_size)
120 | if self.mode == tf.contrib.learn.ModeKeys.INFER:
121 | return self._decode_infer(decoder, bridge, encoder_output, features,
122 | labels)
123 | else:
124 | return self._decode_train(decoder, bridge, encoder_output, features,
125 | labels)
126 |
--------------------------------------------------------------------------------
/seq2seq/models/image2seq.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Definition of a basic seq2seq model
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import tensorflow as tf
24 |
25 | from seq2seq import graph_utils
26 | from seq2seq.data import vocab
27 | from seq2seq.graph_utils import templatemethod
28 | from seq2seq.models.model_base import ModelBase
29 | from seq2seq.models.attention_seq2seq import AttentionSeq2Seq
30 |
31 |
32 | class Image2Seq(AttentionSeq2Seq):
33 | """A model that encodes an image and produces a sequence
34 | of tokens.
35 | """
36 |
37 | def __init__(self, params, mode, name="image_seq2seq"):
38 | super(Image2Seq, self).__init__(params, mode, name)
39 | self.params["source.reverse"] = False
40 | self.params["embedding.share"] = False
41 |
42 | @staticmethod
43 | def default_params():
44 | params = ModelBase.default_params()
45 | params.update({
46 | "attention.class": "AttentionLayerBahdanau",
47 | "attention.params": {
48 | "num_units": 128
49 | },
50 | "bridge.class": "seq2seq.models.bridges.ZeroBridge",
51 | "bridge.params": {},
52 | "encoder.class": "seq2seq.encoders.InceptionV3Encoder",
53 | "encoder.params": {}, # Arbitrary parameters for the encoder
54 | "decoder.class": "seq2seq.decoders.AttentionDecoder",
55 | "decoder.params": {}, # Arbitrary parameters for the decoder
56 | "target.max_seq_len": 50,
57 | "embedding.dim": 100,
58 | "inference.beam_search.beam_width": 0,
59 | "inference.beam_search.length_penalty_weight": 0.0,
60 | "inference.beam_search.choose_successors_fn": "choose_top_k",
61 | "vocab_target": "",
62 | })
63 | return params
64 |
65 | @templatemethod("encode")
66 | def encode(self, features, _labels):
67 | encoder_fn = self.encoder_class(self.params["encoder.params"], self.mode)
68 | return encoder_fn(features["image"])
69 |
70 | def batch_size(self, features, _labels):
71 | return tf.shape(features["image"])[0]
72 |
73 | def _preprocess(self, features, labels):
74 | """Model-specific preprocessing for features and labels:
75 |
76 | - Creates vocabulary lookup tables for target vocab
77 | - Converts tokens into vocabulary ids
78 | - Prepends a speical "SEQUENCE_START" token to the target
79 | - Appends a speical "SEQUENCE_END" token to the target
80 | """
81 |
82 | # Create vocabulary look for target
83 | target_vocab_to_id, target_id_to_vocab, target_word_to_count, _ = \
84 | vocab.create_vocabulary_lookup_table(self.target_vocab_info.path)
85 |
86 | # Add vocab tables to graph colection so that we can access them in
87 | # other places.
88 | graph_utils.add_dict_to_collection({
89 | "target_vocab_to_id": target_vocab_to_id,
90 | "target_id_to_vocab": target_id_to_vocab,
91 | "target_word_to_count": target_word_to_count
92 | }, "vocab_tables")
93 |
94 | if labels is None:
95 | return features, None
96 |
97 | labels = labels.copy()
98 |
99 | # Slices targets to max length
100 | if self.params["target.max_seq_len"] is not None:
101 | labels["target_tokens"] = labels["target_tokens"][:, :self.params[
102 | "target.max_seq_len"]]
103 | labels["target_len"] = tf.minimum(labels["target_len"],
104 | self.params["target.max_seq_len"])
105 |
106 | # Look up the target ids in the vocabulary
107 | labels["target_ids"] = target_vocab_to_id.lookup(labels["target_tokens"])
108 |
109 | labels["target_len"] = tf.to_int32(labels["target_len"])
110 | tf.summary.histogram("target_len", tf.to_float(labels["target_len"]))
111 |
112 | # Add to graph collection for later use
113 | graph_utils.add_dict_to_collection(features, "features")
114 | if labels:
115 | graph_utils.add_dict_to_collection(labels, "labels")
116 |
117 | return features, labels
118 |
--------------------------------------------------------------------------------
/seq2seq/tasks/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Collection of task types.
16 | """
17 |
18 | from seq2seq.tasks.inference_task import InferenceTask
19 | from seq2seq.tasks.decode_text import DecodeText
20 | from seq2seq.tasks.dump_attention import DumpAttention
21 | from seq2seq.tasks.dump_beams import DumpBeams
22 |
--------------------------------------------------------------------------------
/seq2seq/tasks/dump_attention.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Task where both the input and output sequence are plain text.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import os
24 |
25 | import numpy as np
26 | from matplotlib import pyplot as plt
27 |
28 | import tensorflow as tf
29 | from tensorflow import gfile
30 |
31 | from seq2seq.tasks.decode_text import _get_prediction_length
32 | from seq2seq.tasks.inference_task import InferenceTask, unbatch_dict
33 |
34 |
35 | def _get_scores(predictions_dict):
36 | """Returns the attention scores, sliced by source and target length.
37 | """
38 | prediction_len = _get_prediction_length(predictions_dict)
39 | source_len = predictions_dict["features.source_len"]
40 | return predictions_dict["attention_scores"][:prediction_len, :source_len]
41 |
42 |
43 | def _create_figure(predictions_dict):
44 | """Creates and returns a new figure that visualizes
45 | attention scores for for a single model predictions.
46 | """
47 |
48 | # Find out how long the predicted sequence is
49 | target_words = list(predictions_dict["predicted_tokens"])
50 |
51 | prediction_len = _get_prediction_length(predictions_dict)
52 |
53 | # Get source words
54 | source_len = predictions_dict["features.source_len"]
55 | source_words = predictions_dict["features.source_tokens"][:source_len]
56 |
57 | # Plot
58 | fig = plt.figure(figsize=(8, 8))
59 | plt.imshow(
60 | X=predictions_dict["attention_scores"][:prediction_len, :source_len],
61 | interpolation="nearest",
62 | cmap=plt.cm.Blues)
63 | plt.xticks(np.arange(source_len), source_words, rotation=45)
64 | plt.yticks(np.arange(prediction_len), target_words, rotation=-45)
65 | fig.tight_layout()
66 |
67 | return fig
68 |
69 |
70 | class DumpAttention(InferenceTask):
71 | """Defines inference for tasks where both the input and output sequences
72 | are plain text.
73 |
74 | Params:
75 | delimiter: Character by which tokens are delimited. Defaults to space.
76 | unk_replace: If true, enable unknown token replacement based on attention
77 | scores.
78 | unk_mapping: If `unk_replace` is true, this can be the path to a file
79 | defining a dictionary to improve UNK token replacement. Refer to the
80 | documentation for more details.
81 | dump_attention_dir: Save attention scores and plots to this directory.
82 | dump_attention_no_plot: If true, only save attention scores, not
83 | attention plots.
84 | dump_beams: Write beam search debugging information to this file.
85 | """
86 |
87 | def __init__(self, params):
88 | super(DumpAttention, self).__init__(params)
89 | self._attention_scores_accum = []
90 | self._idx = 0
91 |
92 | if not self.params["output_dir"]:
93 | raise ValueError("Must specify output_dir for DumpAttention")
94 |
95 | @staticmethod
96 | def default_params():
97 | params = {}
98 | params.update({"output_dir": "", "dump_plots": True})
99 | return params
100 |
101 | def begin(self):
102 | super(DumpAttention, self).begin()
103 | gfile.MakeDirs(self.params["output_dir"])
104 |
105 | def before_run(self, _run_context):
106 | fetches = {}
107 | fetches["predicted_tokens"] = self._predictions["predicted_tokens"]
108 | fetches["features.source_len"] = self._predictions["features.source_len"]
109 | fetches["features.source_tokens"] = self._predictions[
110 | "features.source_tokens"]
111 | fetches["attention_scores"] = self._predictions["attention_scores"]
112 | return tf.train.SessionRunArgs(fetches)
113 |
114 | def after_run(self, _run_context, run_values):
115 | fetches_batch = run_values.results
116 | for fetches in unbatch_dict(fetches_batch):
117 | # Convert to unicode
118 | fetches["predicted_tokens"] = np.char.decode(
119 | fetches["predicted_tokens"].astype("S"), "utf-8")
120 | fetches["features.source_tokens"] = np.char.decode(
121 | fetches["features.source_tokens"].astype("S"), "utf-8")
122 |
123 | if self.params["dump_plots"]:
124 | output_path = os.path.join(self.params["output_dir"],
125 | "{:05d}.png".format(self._idx))
126 | _create_figure(fetches)
127 | plt.savefig(output_path)
128 | plt.close()
129 | tf.logging.info("Wrote %s", output_path)
130 | self._idx += 1
131 | self._attention_scores_accum.append(_get_scores(fetches))
132 |
133 | def end(self, _session):
134 | scores_path = os.path.join(self.params["output_dir"],
135 | "attention_scores.npz")
136 | np.savez(scores_path, *self._attention_scores_accum)
137 | tf.logging.info("Wrote %s", scores_path)
138 |
--------------------------------------------------------------------------------
/seq2seq/tasks/dump_beams.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Task where both the input and output sequence are plain text.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import numpy as np
24 |
25 | import tensorflow as tf
26 |
27 | from seq2seq.tasks.inference_task import InferenceTask, unbatch_dict
28 |
29 |
30 | class DumpBeams(InferenceTask):
31 | """Defines inference for tasks where both the input and output sequences
32 | are plain text.
33 |
34 | Params:
35 | file: File to write beam search information to.
36 | """
37 |
38 | def __init__(self, params):
39 | super(DumpBeams, self).__init__(params)
40 | self._beam_accum = {
41 | "predicted_ids": [],
42 | "beam_parent_ids": [],
43 | "scores": [],
44 | "log_probs": []
45 | }
46 |
47 | if not self.params["file"]:
48 | raise ValueError("Must specify file for DumpBeams")
49 |
50 | @staticmethod
51 | def default_params():
52 | params = {}
53 | params.update({"file": "",})
54 | return params
55 |
56 | def before_run(self, _run_context):
57 | fetches = {}
58 | fetches["beam_search_output.predicted_ids"] = self._predictions[
59 | "beam_search_output.predicted_ids"]
60 | fetches["beam_search_output.beam_parent_ids"] = self._predictions[
61 | "beam_search_output.beam_parent_ids"]
62 | fetches["beam_search_output.scores"] = self._predictions[
63 | "beam_search_output.scores"]
64 | fetches["beam_search_output.log_probs"] = self._predictions[
65 | "beam_search_output.log_probs"]
66 | return tf.train.SessionRunArgs(fetches)
67 |
68 | def after_run(self, _run_context, run_values):
69 | fetches_batch = run_values.results
70 | for fetches in unbatch_dict(fetches_batch):
71 | self._beam_accum["predicted_ids"].append(fetches[
72 | "beam_search_output.predicted_ids"])
73 | self._beam_accum["beam_parent_ids"].append(fetches[
74 | "beam_search_output.beam_parent_ids"])
75 | self._beam_accum["scores"].append(fetches["beam_search_output.scores"])
76 | self._beam_accum["log_probs"].append(fetches[
77 | "beam_search_output.log_probs"])
78 |
79 | def end(self, _session):
80 | np.savez(self.params["file"], **self._beam_accum)
81 |
--------------------------------------------------------------------------------
/seq2seq/tasks/inference_task.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Abstract base class for inference tasks.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import abc
24 |
25 | import six
26 | import tensorflow as tf
27 |
28 | from seq2seq import graph_utils
29 | from seq2seq.configurable import Configurable, abstractstaticmethod
30 |
31 |
32 | def unbatch_dict(dict_):
33 | """Converts a dictionary of batch items to a batch/list of
34 | dictionary items.
35 | """
36 | batch_size = list(dict_.values())[0].shape[0]
37 | for i in range(batch_size):
38 | yield {key: value[i] for key, value in dict_.items()}
39 |
40 |
41 | @six.add_metaclass(abc.ABCMeta)
42 | class InferenceTask(tf.train.SessionRunHook, Configurable):
43 | """
44 | Abstract base class for inference tasks. Defines the logic used to make
45 | predictions for a specific type of task.
46 |
47 | Params:
48 | model_class: The model class to instantiate. If undefined,
49 | re-uses the class used during training.
50 | model_params: Model hyperparameters. Specified hyperparameters will
51 | overwrite those used during training.
52 |
53 | Args:
54 | params: See Params above.
55 | """
56 |
57 | def __init__(self, params):
58 | Configurable.__init__(self, params, tf.contrib.learn.ModeKeys.INFER)
59 | self._predictions = None
60 |
61 | def begin(self):
62 | self._predictions = graph_utils.get_dict_from_collection("predictions")
63 |
64 | @abstractstaticmethod
65 | def default_params():
66 | raise NotImplementedError()
67 |
--------------------------------------------------------------------------------
/seq2seq/test/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Tests and testing utilities
15 | """
16 |
17 | from seq2seq.test import utils
18 |
--------------------------------------------------------------------------------
/seq2seq/test/attention_test.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Unit tests for attention functions.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import tensorflow as tf
24 | import numpy as np
25 |
26 | from seq2seq.decoders.attention import AttentionLayerDot
27 | from seq2seq.decoders.attention import AttentionLayerBahdanau
28 |
29 |
30 | class AttentionLayerTest(tf.test.TestCase):
31 | """
32 | Tests the AttentionLayer module.
33 | """
34 |
35 | def setUp(self):
36 | super(AttentionLayerTest, self).setUp()
37 | tf.logging.set_verbosity(tf.logging.INFO)
38 | self.batch_size = 8
39 | self.attention_dim = 128
40 | self.input_dim = 16
41 | self.seq_len = 10
42 | self.state_dim = 32
43 |
44 | def _create_layer(self):
45 | """Creates the attention layer. Should be implemented by child classes"""
46 | raise NotImplementedError
47 |
48 | def _test_layer(self):
49 | """Tests Attention layer with a given score type"""
50 | inputs_pl = tf.placeholder(tf.float32, (None, None, self.input_dim))
51 | inputs_length_pl = tf.placeholder(tf.int32, [None])
52 | state_pl = tf.placeholder(tf.float32, (None, self.state_dim))
53 | attention_fn = self._create_layer()
54 | scores, context = attention_fn(
55 | query=state_pl,
56 | keys=inputs_pl,
57 | values=inputs_pl,
58 | values_length=inputs_length_pl)
59 |
60 | with self.test_session() as sess:
61 | sess.run(tf.global_variables_initializer())
62 | feed_dict = {}
63 | feed_dict[inputs_pl] = np.random.randn(self.batch_size, self.seq_len,
64 | self.input_dim)
65 | feed_dict[state_pl] = np.random.randn(self.batch_size, self.state_dim)
66 | feed_dict[inputs_length_pl] = np.arange(self.batch_size) + 1
67 | scores_, context_ = sess.run([scores, context], feed_dict)
68 |
69 | np.testing.assert_array_equal(scores_.shape,
70 | [self.batch_size, self.seq_len])
71 | np.testing.assert_array_equal(context_.shape,
72 | [self.batch_size, self.input_dim])
73 |
74 | for idx, batch in enumerate(scores_, 1):
75 | # All scores that are padded should be zero
76 | np.testing.assert_array_equal(batch[idx:], np.zeros_like(batch[idx:]))
77 |
78 | # Scores should sum to 1
79 | scores_sum = np.sum(scores_, axis=1)
80 | np.testing.assert_array_almost_equal(scores_sum, np.ones([self.batch_size]))
81 |
82 |
83 | class AttentionLayerDotTest(AttentionLayerTest):
84 | """Tests the AttentionLayerDot class"""
85 |
86 | def _create_layer(self):
87 | return AttentionLayerDot(
88 | params={"num_units": self.attention_dim},
89 | mode=tf.contrib.learn.ModeKeys.TRAIN)
90 |
91 | def test_layer(self):
92 | self._test_layer()
93 |
94 |
95 | class AttentionLayerBahdanauTest(AttentionLayerTest):
96 | """Tests the AttentionLayerBahdanau class"""
97 |
98 | def _create_layer(self):
99 | return AttentionLayerBahdanau(
100 | params={"num_units": self.attention_dim},
101 | mode=tf.contrib.learn.ModeKeys.TRAIN)
102 |
103 | def test_layer(self):
104 | self._test_layer()
105 |
106 |
107 | if __name__ == "__main__":
108 | tf.test.main()
109 |
--------------------------------------------------------------------------------
/seq2seq/test/bridges_test.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Tests for Encoder-Decoder bridges.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | from collections import namedtuple
24 | import numpy as np
25 |
26 | import tensorflow as tf
27 | from tensorflow.python.util import nest # pylint: disable=E0611
28 |
29 | from seq2seq.encoders.encoder import EncoderOutput
30 | from seq2seq.models.bridges import ZeroBridge, InitialStateBridge
31 | from seq2seq.models.bridges import PassThroughBridge
32 |
33 | DecoderOutput = namedtuple("DecoderOutput", ["predicted_ids"])
34 |
35 |
36 | class BridgeTest(tf.test.TestCase):
37 | """Abstract class for bridge tests"""
38 |
39 | def setUp(self):
40 | super(BridgeTest, self).setUp()
41 | self.batch_size = 4
42 | self.encoder_cell = tf.contrib.rnn.MultiRNNCell(
43 | [tf.contrib.rnn.GRUCell(4), tf.contrib.rnn.GRUCell(8)])
44 | self.decoder_cell = tf.contrib.rnn.MultiRNNCell(
45 | [tf.contrib.rnn.LSTMCell(16), tf.contrib.rnn.GRUCell(8)])
46 | final_encoder_state = nest.map_structure(
47 | lambda x: tf.convert_to_tensor(
48 | value=np.random.randn(self.batch_size, x),
49 | dtype=tf.float32),
50 | self.encoder_cell.state_size)
51 | self.encoder_outputs = EncoderOutput(
52 | outputs=tf.convert_to_tensor(
53 | value=np.random.randn(self.batch_size, 10, 16), dtype=tf.float32),
54 | attention_values=tf.convert_to_tensor(
55 | value=np.random.randn(self.batch_size, 10, 16), dtype=tf.float32),
56 | attention_values_length=np.full([self.batch_size], 10),
57 | final_state=final_encoder_state)
58 |
59 | def _create_bridge(self):
60 | """Creates the bridge class to be tests. Must be implemented by
61 | child classes"""
62 | raise NotImplementedError()
63 |
64 | def _assert_correct_outputs(self):
65 | """Asserts bridge outputs are correct. Must be implemented by
66 | child classes"""
67 | raise NotImplementedError()
68 |
69 | def _run(self, scope=None, **kwargs):
70 | """Runs the bridge with the given arguments
71 | """
72 |
73 | with tf.variable_scope(scope or "bridge"):
74 | bridge = self._create_bridge(**kwargs)
75 | initial_state = bridge()
76 |
77 | with self.test_session() as sess:
78 | sess.run(tf.global_variables_initializer())
79 | initial_state_ = sess.run(initial_state)
80 |
81 | return initial_state_
82 |
83 |
84 | class TestZeroBridge(BridgeTest):
85 | """Tests for the ZeroBridge class"""
86 |
87 | def _create_bridge(self, **kwargs):
88 | return ZeroBridge(
89 | encoder_outputs=self.encoder_outputs,
90 | decoder_state_size=self.decoder_cell.state_size,
91 | params=kwargs,
92 | mode=tf.contrib.learn.ModeKeys.TRAIN)
93 |
94 | def _assert_correct_outputs(self, initial_state_):
95 | initial_state_flat_ = nest.flatten(initial_state_)
96 | for element in initial_state_flat_:
97 | np.testing.assert_array_equal(element, np.zeros_like(element))
98 |
99 | def test_zero_bridge(self):
100 | self._assert_correct_outputs(self._run())
101 |
102 |
103 | class TestPassThroughBridge(BridgeTest):
104 | """Tests for the ZeroBridge class"""
105 |
106 | def _create_bridge(self, **kwargs):
107 | return PassThroughBridge(
108 | encoder_outputs=self.encoder_outputs,
109 | decoder_state_size=self.decoder_cell.state_size,
110 | params=kwargs,
111 | mode=tf.contrib.learn.ModeKeys.TRAIN)
112 |
113 | def _assert_correct_outputs(self, initial_state_):
114 | nest.assert_same_structure(initial_state_, self.decoder_cell.state_size)
115 | nest.assert_same_structure(initial_state_, self.encoder_outputs.final_state)
116 |
117 | encoder_state_flat = nest.flatten(self.encoder_outputs.final_state)
118 | with self.test_session() as sess:
119 | encoder_state_flat_ = sess.run(encoder_state_flat)
120 |
121 | initial_state_flat_ = nest.flatten(initial_state_)
122 | for e_dec, e_enc in zip(initial_state_flat_, encoder_state_flat_):
123 | np.testing.assert_array_equal(e_dec, e_enc)
124 |
125 | def test_passthrough_bridge(self):
126 | self.decoder_cell = self.encoder_cell
127 | self._assert_correct_outputs(self._run())
128 |
129 |
130 | class TestInitialStateBridge(BridgeTest):
131 | """Tests for the InitialStateBridge class"""
132 |
133 | def _create_bridge(self, **kwargs):
134 | return InitialStateBridge(
135 | encoder_outputs=self.encoder_outputs,
136 | decoder_state_size=self.decoder_cell.state_size,
137 | params=kwargs,
138 | mode=tf.contrib.learn.ModeKeys.TRAIN)
139 |
140 | def _assert_correct_outputs(self, initial_state_):
141 | nest.assert_same_structure(initial_state_, self.decoder_cell.state_size)
142 |
143 | def test_with_final_state(self):
144 | self._assert_correct_outputs(self._run(bridge_input="final_state"))
145 |
146 | def test_with_outputs(self):
147 | self._assert_correct_outputs(self._run(bridge_input="outputs"))
148 |
149 | def test_with_activation_fn(self):
150 | self._assert_correct_outputs(
151 | self._run(
152 | bridge_input="final_state", activation_fn="tanh"))
153 |
154 |
155 | if __name__ == "__main__":
156 | tf.test.main()
157 |
--------------------------------------------------------------------------------
/seq2seq/test/conv_encoder_test.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Test Cases for PoolingEncoder.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import tensorflow as tf
24 | import numpy as np
25 |
26 | from seq2seq.encoders import ConvEncoder
27 |
28 |
29 | class ConvEncoderTest(tf.test.TestCase):
30 | """
31 | Tests the ConvEncoder class.
32 | """
33 |
34 | def setUp(self):
35 | super(ConvEncoderTest, self).setUp()
36 | self.batch_size = 4
37 | self.sequence_length = 16
38 | self.input_depth = 10
39 | self.mode = tf.contrib.learn.ModeKeys.TRAIN
40 |
41 | def _test_with_params(self, params):
42 | """Tests the encoder with a given parameter configuration"""
43 | inputs = tf.random_normal(
44 | [self.batch_size, self.sequence_length, self.input_depth])
45 | example_length = tf.ones(
46 | self.batch_size, dtype=tf.int32) * self.sequence_length
47 |
48 | encode_fn = ConvEncoder(params, self.mode)
49 | encoder_output = encode_fn(inputs, example_length)
50 |
51 | with self.test_session() as sess:
52 | sess.run(tf.global_variables_initializer())
53 | encoder_output_ = sess.run(encoder_output)
54 |
55 | att_value_units = encode_fn.params["attention_cnn.units"]
56 | output_units = encode_fn.params["output_cnn.units"]
57 |
58 | np.testing.assert_array_equal(
59 | encoder_output_.outputs.shape,
60 | [self.batch_size, self.sequence_length, att_value_units])
61 | np.testing.assert_array_equal(
62 | encoder_output_.attention_values.shape,
63 | [self.batch_size, self.sequence_length, output_units])
64 | np.testing.assert_array_equal(
65 | encoder_output_.final_state.shape,
66 | [self.batch_size, output_units])
67 |
68 | def test_encode_with_pos(self):
69 | self._test_with_params({
70 | "position_embeddings.enable": True,
71 | "position_embeddings.num_positions": self.sequence_length,
72 | "attention_cnn.units": 5,
73 | "output_cnn.units": 6
74 | })
75 |
76 | if __name__ == "__main__":
77 | tf.test.main()
78 |
--------------------------------------------------------------------------------
/seq2seq/test/example_config_test.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # Copyright 2017 Google Inc.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | """
16 | Test Cases for example configuration files.
17 | """
18 |
19 | from __future__ import absolute_import
20 | from __future__ import division
21 | from __future__ import print_function
22 | from __future__ import unicode_literals
23 |
24 | import os
25 | from pydoc import locate
26 |
27 | import yaml
28 |
29 | import tensorflow as tf
30 | from tensorflow import gfile
31 |
32 | from seq2seq.test.models_test import EncoderDecoderTests
33 | from seq2seq import models
34 |
35 | EXAMPLE_CONFIG_DIR = os.path.abspath(
36 | os.path.join(os.path.dirname(__file__), "../../example_configs"))
37 |
38 |
39 | def _load_model_from_config(config_path, hparam_overrides, vocab_file, mode):
40 | """Loads model from a configuration file"""
41 | with gfile.GFile(config_path) as config_file:
42 | config = yaml.load(config_file)
43 | model_cls = locate(config["model"]) or getattr(models, config["model"])
44 | model_params = config["model_params"]
45 | if hparam_overrides:
46 | model_params.update(hparam_overrides)
47 | # Change the max decode length to make the test run faster
48 | model_params["decoder.params"]["max_decode_length"] = 5
49 | model_params["vocab_source"] = vocab_file
50 | model_params["vocab_target"] = vocab_file
51 | return model_cls(params=model_params, mode=mode)
52 |
53 |
54 | class ExampleConfigTest(object):
55 | """Interface for configuration-based tests"""
56 |
57 | def __init__(self, *args, **kwargs):
58 | super(ExampleConfigTest, self).__init__(*args, **kwargs)
59 | self.vocab_file = None
60 |
61 | def _config_path(self):
62 | """Returns the path to the configuration to be tested"""
63 | raise NotImplementedError()
64 |
65 | def create_model(self, mode, params=None):
66 | """Creates the model"""
67 | return _load_model_from_config(
68 | config_path=self._config_path(),
69 | hparam_overrides=params,
70 | vocab_file=self.vocab_file.name,
71 | mode=mode)
72 |
73 |
74 | class TestNMTLarge(ExampleConfigTest, EncoderDecoderTests):
75 | """Tests nmt_large.yml"""
76 |
77 | def _config_path(self):
78 | return os.path.join(EXAMPLE_CONFIG_DIR, "nmt_large.yml")
79 |
80 |
81 | class TestNMTMedium(ExampleConfigTest, EncoderDecoderTests):
82 | """Tests nmt_medium.yml"""
83 |
84 | def _config_path(self):
85 | return os.path.join(EXAMPLE_CONFIG_DIR, "nmt_medium.yml")
86 |
87 |
88 | class TestNMTSmall(ExampleConfigTest, EncoderDecoderTests):
89 | """Tests nmt_small.yml"""
90 |
91 | def _config_path(self):
92 | return os.path.join(EXAMPLE_CONFIG_DIR, "nmt_small.yml")
93 |
94 | class TestNMTConv(ExampleConfigTest, EncoderDecoderTests):
95 | """Tests nmt_small.yml"""
96 |
97 | def _config_path(self):
98 | return os.path.join(EXAMPLE_CONFIG_DIR, "nmt_conv.yml")
99 |
100 |
101 | if __name__ == "__main__":
102 | tf.test.main()
103 |
--------------------------------------------------------------------------------
/seq2seq/test/hooks_test.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # Copyright 2017 Google Inc.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | """Tests for SessionRunHooks.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import os
24 | import tempfile
25 | import shutil
26 | import time
27 |
28 | import tensorflow as tf
29 | from tensorflow.python.training import monitored_session # pylint: disable=E0611
30 | from tensorflow import gfile
31 |
32 | from seq2seq import graph_utils
33 | from seq2seq.training import hooks
34 |
35 |
36 | class TestPrintModelAnalysisHook(tf.test.TestCase):
37 | """Tests the `PrintModelAnalysisHook` hook"""
38 |
39 | def test_begin(self):
40 | model_dir = tempfile.mkdtemp()
41 | outfile = tempfile.NamedTemporaryFile()
42 | tf.get_variable("weigths", [128, 128])
43 | hook = hooks.PrintModelAnalysisHook(
44 | params={}, model_dir=model_dir, run_config=tf.contrib.learn.RunConfig())
45 | hook.begin()
46 |
47 | with gfile.GFile(os.path.join(model_dir, "model_analysis.txt")) as file:
48 | file_contents = file.read().strip()
49 |
50 | self.assertEqual(file_contents.decode(), "_TFProfRoot (--/16.38k params)\n"
51 | " weigths (128x128, 16.38k/16.38k params)")
52 | outfile.close()
53 |
54 |
55 | class TestTrainSampleHook(tf.test.TestCase):
56 | """Tests `TrainSampleHook` class.
57 | """
58 |
59 | def setUp(self):
60 | super(TestTrainSampleHook, self).setUp()
61 | self.model_dir = tempfile.mkdtemp()
62 | self.sample_dir = os.path.join(self.model_dir, "samples")
63 |
64 | # The hook expects these collections to be in the graph
65 | pred_dict = {}
66 | pred_dict["predicted_tokens"] = tf.constant([["Hello", "World", "笑w"]])
67 | pred_dict["labels.target_tokens"] = tf.constant([["Hello", "World", "笑w"]])
68 | pred_dict["labels.target_len"] = tf.constant(2),
69 | graph_utils.add_dict_to_collection(pred_dict, "predictions")
70 |
71 | def tearDown(self):
72 | super(TestTrainSampleHook, self).tearDown()
73 | shutil.rmtree(self.model_dir)
74 |
75 | def test_sampling(self):
76 | hook = hooks.TrainSampleHook(
77 | params={"every_n_steps": 10}, model_dir=self.model_dir,
78 | run_config=tf.contrib.learn.RunConfig())
79 |
80 | global_step = tf.contrib.framework.get_or_create_global_step()
81 | no_op = tf.no_op()
82 | hook.begin()
83 | with self.test_session() as sess:
84 | sess.run(tf.global_variables_initializer())
85 | sess.run(tf.local_variables_initializer())
86 | sess.run(tf.tables_initializer())
87 |
88 | #pylint: disable=W0212
89 | mon_sess = monitored_session._HookedSession(sess, [hook])
90 | # Should trigger for step 0
91 | sess.run(tf.assign(global_step, 0))
92 | mon_sess.run(no_op)
93 |
94 | outfile = os.path.join(self.sample_dir, "samples_000000.txt")
95 | with open(outfile, "rb") as readfile:
96 | self.assertIn("Prediction followed by Target @ Step 0",
97 | readfile.read().decode("utf-8"))
98 |
99 | # Should not trigger for step 9
100 | sess.run(tf.assign(global_step, 9))
101 | mon_sess.run(no_op)
102 | outfile = os.path.join(self.sample_dir, "samples_000009.txt")
103 | self.assertFalse(os.path.exists(outfile))
104 |
105 | # Should trigger for step 10
106 | sess.run(tf.assign(global_step, 10))
107 | mon_sess.run(no_op)
108 | outfile = os.path.join(self.sample_dir, "samples_000010.txt")
109 | with open(outfile, "rb") as readfile:
110 | self.assertIn("Prediction followed by Target @ Step 10",
111 | readfile.read().decode("utf-8"))
112 |
113 |
114 | class TestMetadataCaptureHook(tf.test.TestCase):
115 | """Test for the MetadataCaptureHook"""
116 |
117 | def setUp(self):
118 | super(TestMetadataCaptureHook, self).setUp()
119 | self.model_dir = tempfile.mkdtemp()
120 |
121 | def tearDown(self):
122 | super(TestMetadataCaptureHook, self).tearDown()
123 | shutil.rmtree(self.model_dir)
124 |
125 | def test_capture(self):
126 | global_step = tf.contrib.framework.get_or_create_global_step()
127 | # Some test computation
128 | some_weights = tf.get_variable("weigths", [2, 128])
129 | computation = tf.nn.softmax(some_weights)
130 |
131 | hook = hooks.MetadataCaptureHook(
132 | params={"step": 5}, model_dir=self.model_dir,
133 | run_config=tf.contrib.learn.RunConfig())
134 | hook.begin()
135 |
136 | with self.test_session() as sess:
137 | sess.run(tf.global_variables_initializer())
138 | #pylint: disable=W0212
139 | mon_sess = monitored_session._HookedSession(sess, [hook])
140 | # Should not trigger for step 0
141 | sess.run(tf.assign(global_step, 0))
142 | mon_sess.run(computation)
143 | self.assertEqual(gfile.ListDirectory(self.model_dir), [])
144 | # Should trigger *after* step 5
145 | sess.run(tf.assign(global_step, 5))
146 | mon_sess.run(computation)
147 | self.assertEqual(gfile.ListDirectory(self.model_dir), [])
148 | mon_sess.run(computation)
149 | self.assertEqual(
150 | set(gfile.ListDirectory(self.model_dir)),
151 | set(["run_meta", "tfprof_log", "timeline.json"]))
152 |
153 | if __name__ == "__main__":
154 | tf.test.main()
155 |
--------------------------------------------------------------------------------
/seq2seq/test/losses_test.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Unit tests for loss-related operations.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | from seq2seq import losses as seq2seq_losses
24 | import tensorflow as tf
25 | import numpy as np
26 |
27 |
28 | class CrossEntropySequenceLossTest(tf.test.TestCase):
29 | """
30 | Test for `sqe2seq.losses.sequence_mask`.
31 | """
32 |
33 | def setUp(self):
34 | super(CrossEntropySequenceLossTest, self).setUp()
35 | tf.logging.set_verbosity(tf.logging.INFO)
36 | self.batch_size = 4
37 | self.sequence_length = 10
38 | self.vocab_size = 50
39 |
40 | def test_op(self):
41 | logits = np.random.randn(self.sequence_length, self.batch_size,
42 | self.vocab_size)
43 | logits = logits.astype(np.float32)
44 | sequence_length = np.array([1, 2, 3, 4])
45 | targets = np.random.randint(0, self.vocab_size,
46 | [self.sequence_length, self.batch_size])
47 | losses = seq2seq_losses.cross_entropy_sequence_loss(logits, targets,
48 | sequence_length)
49 |
50 | with self.test_session() as sess:
51 | losses_ = sess.run(losses)
52 |
53 | # Make sure all losses not past the sequence length are > 0
54 | np.testing.assert_array_less(np.zeros_like(losses_[:1, 0]), losses_[:1, 0])
55 | np.testing.assert_array_less(np.zeros_like(losses_[:2, 1]), losses_[:2, 1])
56 | np.testing.assert_array_less(np.zeros_like(losses_[:3, 2]), losses_[:3, 2])
57 |
58 | # Make sure all losses past the sequence length are 0
59 | np.testing.assert_array_equal(losses_[1:, 0], np.zeros_like(losses_[1:, 0]))
60 | np.testing.assert_array_equal(losses_[2:, 1], np.zeros_like(losses_[2:, 1]))
61 | np.testing.assert_array_equal(losses_[3:, 2], np.zeros_like(losses_[3:, 2]))
62 |
63 |
64 | if __name__ == "__main__":
65 | tf.test.main()
66 |
--------------------------------------------------------------------------------
/seq2seq/test/pooling_encoder_test.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Test Cases for PoolingEncoder.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import tensorflow as tf
24 | import numpy as np
25 |
26 | from seq2seq.encoders import PoolingEncoder
27 |
28 |
29 | class PoolingEncoderTest(tf.test.TestCase):
30 | """
31 | Tests the PoolingEncoder class.
32 | """
33 |
34 | def setUp(self):
35 | super(PoolingEncoderTest, self).setUp()
36 | self.batch_size = 4
37 | self.sequence_length = 16
38 | self.input_depth = 10
39 | self.mode = tf.contrib.learn.ModeKeys.TRAIN
40 |
41 | def _test_with_params(self, params):
42 | """Tests the encoder with a given parameter configuration"""
43 | inputs = tf.random_normal(
44 | [self.batch_size, self.sequence_length, self.input_depth])
45 | example_length = tf.ones(
46 | self.batch_size, dtype=tf.int32) * self.sequence_length
47 |
48 | encode_fn = PoolingEncoder(params, self.mode)
49 | encoder_output = encode_fn(inputs, example_length)
50 |
51 | with self.test_session() as sess:
52 | sess.run(tf.global_variables_initializer())
53 | encoder_output_ = sess.run(encoder_output)
54 |
55 | np.testing.assert_array_equal(
56 | encoder_output_.outputs.shape,
57 | [self.batch_size, self.sequence_length, self.input_depth])
58 | np.testing.assert_array_equal(
59 | encoder_output_.attention_values.shape,
60 | [self.batch_size, self.sequence_length, self.input_depth])
61 | np.testing.assert_array_equal(encoder_output_.final_state.shape,
62 | [self.batch_size, self.input_depth])
63 |
64 | def test_encode_with_pos(self):
65 | self._test_with_params({
66 | "position_embeddings.enable": True,
67 | "position_embeddings.num_positions": self.sequence_length
68 | })
69 |
70 | def test_encode_without_pos(self):
71 | self._test_with_params({
72 | "position_embeddings.enable": False,
73 | "position_embeddings.num_positions": 0
74 | })
75 |
76 | if __name__ == "__main__":
77 | tf.test.main()
--------------------------------------------------------------------------------
/seq2seq/test/utils.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Various testing utilities
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 | from __future__ import unicode_literals
21 |
22 | import tempfile
23 | import tensorflow as tf
24 |
25 |
26 | def create_temp_parallel_data(sources, targets):
27 | """
28 | Creates a temporary TFRecords file.
29 |
30 | Args:
31 | source: List of source sentences
32 | target: List of target sentences
33 |
34 | Returns:
35 | A tuple (sources_file, targets_file).
36 | """
37 | file_source = tempfile.NamedTemporaryFile()
38 | file_target = tempfile.NamedTemporaryFile()
39 | file_source.write("\n".join(sources).encode("utf-8"))
40 | file_source.flush()
41 | file_target.write("\n".join(targets).encode("utf-8"))
42 | file_target.flush()
43 | return file_source, file_target
44 |
45 |
46 | def create_temp_tfrecords(sources, targets):
47 | """
48 | Creates a temporary TFRecords file.
49 |
50 | Args:
51 | source: List of source sentences
52 | target: List of target sentences
53 |
54 | Returns:
55 | A tuple (sources_file, targets_file).
56 | """
57 |
58 | output_file = tempfile.NamedTemporaryFile()
59 | writer = tf.python_io.TFRecordWriter(output_file.name)
60 | for source, target in zip(sources, targets):
61 | ex = tf.train.Example()
62 | #pylint: disable=E1101
63 | ex.features.feature["source"].bytes_list.value.extend(
64 | [source.encode("utf-8")])
65 | ex.features.feature["target"].bytes_list.value.extend(
66 | [target.encode("utf-8")])
67 | writer.write(ex.SerializeToString())
68 | writer.close()
69 |
70 | return output_file
71 |
72 |
73 | def create_temporary_vocab_file(words, counts=None):
74 | """
75 | Creates a temporary vocabulary file.
76 |
77 | Args:
78 | words: List of words in the vocabulary
79 |
80 | Returns:
81 | A temporary file object with one word per line
82 | """
83 | vocab_file = tempfile.NamedTemporaryFile()
84 | if counts is None:
85 | for token in words:
86 | vocab_file.write((token + "\n").encode("utf-8"))
87 | else:
88 | for token, count in zip(words, counts):
89 | vocab_file.write("{}\t{}\n".format(token, count).encode("utf-8"))
90 | vocab_file.flush()
91 | return vocab_file
92 |
--------------------------------------------------------------------------------
/seq2seq/test/vocab_test.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # Copyright 2017 Google Inc.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | """
16 | Unit tests for input-related operations.
17 | """
18 |
19 | from __future__ import absolute_import
20 | from __future__ import division
21 | from __future__ import print_function
22 | from __future__ import unicode_literals
23 |
24 | import tensorflow as tf
25 | import numpy as np
26 |
27 | from seq2seq.data import vocab
28 | from seq2seq.test import utils as test_utils
29 |
30 |
31 | class VocabInfoTest(tf.test.TestCase):
32 | """Tests VocabInfo class"""
33 |
34 | def setUp(self):
35 | super(VocabInfoTest, self).setUp()
36 | tf.logging.set_verbosity(tf.logging.INFO)
37 | self.vocab_list = ["Hello", ".", "Bye"]
38 | self.vocab_file = test_utils.create_temporary_vocab_file(self.vocab_list)
39 |
40 | def tearDown(self):
41 | super(VocabInfoTest, self).tearDown()
42 | self.vocab_file.close()
43 |
44 | def test_vocab_info(self):
45 | vocab_info = vocab.get_vocab_info(self.vocab_file.name)
46 | self.assertEqual(vocab_info.vocab_size, 3)
47 | self.assertEqual(vocab_info.path, self.vocab_file.name)
48 | self.assertEqual(vocab_info.special_vocab.UNK, 3)
49 | self.assertEqual(vocab_info.special_vocab.SEQUENCE_START, 4)
50 | self.assertEqual(vocab_info.special_vocab.SEQUENCE_END, 5)
51 | self.assertEqual(vocab_info.total_size, 6)
52 |
53 |
54 | class CreateVocabularyLookupTableTest(tf.test.TestCase):
55 | """
56 | Tests Vocabulary lookup table operations.
57 | """
58 |
59 | def test_without_counts(self):
60 | vocab_list = ["Hello", ".", "笑"]
61 | vocab_file = test_utils.create_temporary_vocab_file(vocab_list)
62 |
63 | vocab_to_id_table, id_to_vocab_table, _, vocab_size = \
64 | vocab.create_vocabulary_lookup_table(vocab_file.name)
65 |
66 | self.assertEqual(vocab_size, 6)
67 |
68 | with self.test_session() as sess:
69 | sess.run(tf.global_variables_initializer())
70 | sess.run(tf.local_variables_initializer())
71 | sess.run(tf.tables_initializer())
72 |
73 | ids = vocab_to_id_table.lookup(
74 | tf.convert_to_tensor(["Hello", ".", "笑", "??", "xxx"]))
75 | ids = sess.run(ids)
76 | np.testing.assert_array_equal(ids, [0, 1, 2, 3, 3])
77 |
78 | words = id_to_vocab_table.lookup(
79 | tf.convert_to_tensor(
80 | [0, 1, 2, 3], dtype=tf.int64))
81 | words = sess.run(words)
82 | np.testing.assert_array_equal(
83 | np.char.decode(words.astype("S"), "utf-8"),
84 | ["Hello", ".", "笑", "UNK"])
85 |
86 | def test_with_counts(self):
87 | vocab_list = ["Hello", ".", "笑"]
88 | vocab_counts = [100, 200, 300]
89 | vocab_file = test_utils.create_temporary_vocab_file(vocab_list,
90 | vocab_counts)
91 |
92 | vocab_to_id_table, id_to_vocab_table, word_to_count_table, vocab_size = \
93 | vocab.create_vocabulary_lookup_table(vocab_file.name)
94 |
95 | self.assertEqual(vocab_size, 6)
96 |
97 | with self.test_session() as sess:
98 | sess.run(tf.global_variables_initializer())
99 | sess.run(tf.local_variables_initializer())
100 | sess.run(tf.tables_initializer())
101 |
102 | ids = vocab_to_id_table.lookup(
103 | tf.convert_to_tensor(["Hello", ".", "笑", "??", "xxx"]))
104 | ids = sess.run(ids)
105 | np.testing.assert_array_equal(ids, [0, 1, 2, 3, 3])
106 |
107 | words = id_to_vocab_table.lookup(
108 | tf.convert_to_tensor(
109 | [0, 1, 2, 3], dtype=tf.int64))
110 | words = sess.run(words)
111 | np.testing.assert_array_equal(
112 | np.char.decode(words.astype("S"), "utf-8"),
113 | ["Hello", ".", "笑", "UNK"])
114 |
115 | counts = word_to_count_table.lookup(
116 | tf.convert_to_tensor(["Hello", ".", "笑", "??", "xxx"]))
117 | counts = sess.run(counts)
118 | np.testing.assert_array_equal(counts, [100, 200, 300, -1, -1])
119 |
120 |
121 | if __name__ == "__main__":
122 | tf.test.main()
123 |
--------------------------------------------------------------------------------
/seq2seq/training/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Operatations and wrappers to help with model training.
15 | """
16 |
17 | from seq2seq.training import hooks
18 | from seq2seq.training import utils
19 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """
16 | Python package setup file.
17 | """
18 |
19 | from setuptools import setup
20 |
21 | setup(
22 | name="seq2seq",
23 | version="0.1",
24 | install_requires=[
25 | "numpy",
26 | "matplotlib",
27 | "pyyaml",
28 | "pyrouge"
29 | ],
30 | extras_require={'tensorflow': ['tensorflow'],
31 | 'tensorflow with gpu': ['tensorflow-gpu']},
32 | )
33 |
--------------------------------------------------------------------------------
/tox.ini:
--------------------------------------------------------------------------------
1 | [tox]
2 | envlist = py27,py35,pylint
3 |
4 | [testenv]
5 | passenv=CIRCLE_ARTIFACTS LD_PRELOAD
6 | deps=
7 | nose
8 | coverage
9 | tensorflow
10 | commands=
11 | coverage run {envbindir}/nosetests
12 | coverage report -m
13 | coverage html -d {env:CIRCLE_ARTIFACTS:/tmp/tox}/{envname}_coverage
14 |
15 | [testenv:pylint]
16 | basepython=python3.5
17 | deps=
18 | tensorflow
19 | pylint
20 | commands=pylint -E seq2seq
21 |
22 | [testenv:py35]
23 | deps=
24 | nose
25 | coverage
26 | tensorflow
27 |
28 | [testenv:py27]
29 | deps=
30 | nose
31 | coverage
32 | tensorflow
33 |
--------------------------------------------------------------------------------