├── README.md
├── interviewDoc
└── Java
│ ├── base
│ ├── JVM.md
│ ├── Java基础.md
│ ├── Java并发编程.md
│ ├── Java集合&容器.md
│ ├── 字符串&集合.md
│ ├── 数据结构与算法.md
│ └── 网络协议.md
│ ├── database
│ ├── 52条SQL语句性能优化策略.md
│ ├── MongoDB.md
│ ├── MySQL.md
│ ├── Redis.md
│ └── 一千行MySQL命令.md
│ ├── index.md
│ ├── linux
│ ├── Linux常用命令.md
│ └── Linux面试题 .md
│ ├── middleware
│ ├── Dubbo.md
│ ├── ElasticSearch.md
│ ├── Kafka.md
│ ├── Nginx.md
│ ├── RabbitMQ.md
│ └── zookeeper.md
│ ├── other
│ └── Git常用命令.md
│ ├── qr.md
│ └── 框架
│ ├── MyBatis.md
│ ├── Spring.md
│ ├── SpringBoot.md
│ ├── SpringBoot常用注解.md
│ └── SpringCloud.md
└── qr_code.jpg
/interviewDoc/Java/database/52条SQL语句性能优化策略.md:
--------------------------------------------------------------------------------
1 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
2 |
3 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
4 |
5 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
6 |
7 | **1、** 对查询进行优化,应尽量避免全表扫描,首先应考虑在where及order by涉及的列上建立索引。
8 |
9 |
10 |
11 | **2、** 应尽量避免在where子句中对字段进行null值判断,创建表时NULL是默认值,但大多数时候应该使用NOT NULL,或者使用一个特殊的值,如0,-1作为默认值。
12 |
13 |
14 |
15 | **3、** 应尽量避免在where子句中使用!=或<>操作符,MySQL只有对以下操作符才使用索引:<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE。
16 |
17 |
18 |
19 | **4、** 应尽量避免在where子句中使用or来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,可以使用UNION合并查询:select id from t where num=10 union all select id from t where num=20。
20 |
21 |
22 |
23 | **5、** in和not in也要慎用,否则会导致全表扫描,对于连续的数值,能用between就不要用in了:Select id from t where num between 1 and 3。
24 |
25 |
26 |
27 | **6、** 下面的查询也将导致全表扫描:select id from t where name like‘%abc%’或者select id from t where name like‘%abc’若要提高效率,可以考虑全文检索。而select id from t where name like‘abc%’才用到索引。
28 |
29 |
30 |
31 | **7、** 如果在where子句中使用参数,也会导致全表扫描。
32 |
33 |
34 |
35 | **8、** 应尽量避免在where子句中对字段进行表达式操作,应尽量避免在where子句中对字段进行函数操作。
36 |
37 |
38 |
39 | **9、** 很多时候用exists代替in是一个好的选择:
40 |
41 | ```
42 | select num from a where num in(select num from b)
43 | ```
44 |
45 | 用下面的语句替换:
46 |
47 | ```
48 | select num from a where exists(select 1 from b where num=a.num)
49 | ```
50 |
51 |
52 |
53 | **10、** 索引固然可以提高相应的select的效率,但同时也降低了insert及update的效率,因为insert或update时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
54 |
55 |
56 |
57 | **11、** 应尽可能的避免更新clustered索引数据列, 因为clustered索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新clustered索引数据列,那么需要考虑是否应将该索引建为clustered索引。
58 |
59 |
60 |
61 | **12、** 尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
62 |
63 |
64 |
65 | **13、** 尽可能的使用varchar/nvarchar代替char/nchar,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
66 |
67 |
68 |
69 | **14、** 最好不要使用”“返回所有:select from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
70 |
71 |
72 |
73 | **15、** 尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
74 |
75 |
76 |
77 | **16、** 使用表的别名(Alias):当在SQL语句中连接多个表时,请使用表的别名并把别名前缀于每个Column上。这样一来,就可以减少解析的时间并减少那些由Column歧义引起的语法错误。
78 |
79 |
80 |
81 | **17、** 使用“临时表”暂存中间结果 :
82 |
83 | 简化SQL语句的重要方法就是采用临时表暂存中间结果,但是临时表的好处远远不止这些,将临时结果暂存在临时表,后面的查询就在tempdb中了,这可以避免程序中多次扫描主表,也大大减少了程序执行中“共享锁”阻塞“更新锁”,减少了阻塞,提高了并发性能。
84 |
85 |
86 |
87 | **18、** 一些SQL查询语句应加上nolock,读、写是会相互阻塞的,为了提高并发性能,对于一些查询,可以加上nolock,这样读的时候可以允许写,但缺点是可能读到未提交的脏数据。
88 |
89 | 使用nolock有3条原则:
90 |
91 | - 查询的结果用于“插、删、改”的不能加nolock;
92 | - 查询的表属于频繁发生页分裂的,慎用nolock ;
93 | - 使用临时表一样可以保存“数据前影”,起到类似Oracle的undo表空间的功能,能采用临时表提高并发性能的,不要用nolock。
94 |
95 |
96 |
97 | **19、** 常见的简化规则如下:
98 |
99 | 不要有超过5个以上的表连接(JOIN),考虑使用临时表或表变量存放中间结果。少用子查询,视图嵌套不要过深,一般视图嵌套不要超过2个为宜。
100 |
101 |
102 |
103 | **20、 **将需要查询的结果预先计算好放在表中,查询的时候再Select。这在SQL7.0以前是最重要的手段,例如医院的住院费计算。
104 |
105 |
106 |
107 | **21、 **用OR的字句可以分解成多个查询,并且通过UNION 连接多个查询。他们的速度只同是否使用索引有关,如果查询需要用到联合索引,用UNION all执行的效率更高。多个OR的字句没有用到索引,改写成UNION的形式再试图与索引匹配。一个关键的问题是否用到索引。
108 |
109 |
110 |
111 | **22、 **在IN后面值的列表中,将出现最频繁的值放在最前面,出现得最少的放在最后面,减少判断的次数。
112 |
113 |
114 |
115 | **23、** 尽量将数据的处理工作放在服务器上,减少网络的开销,如使用存储过程。
116 |
117 | 存储过程是编译好、优化过、并且被组织到一个执行规划里、且存储在数据库中的SQL语句,是控制流语言的集合,速度当然快。反复执行的动态SQL,可以使用临时存储过程,该过程(临时表)被放在Tempdb中。
118 |
119 |
120 |
121 | **24、** 当服务器的内存够多时,配制线程数量 = 最大连接数+5,这样能发挥最大的效率;否则使用 配制线程数量<最大连接数启用SQL SERVER的线程池来解决,如果还是数量 = 最大连接数+5,严重的损害服务器的性能。
122 |
123 |
124 |
125 | **25、** 查询的关联同写的顺序 :
126 |
127 | ```sql
128 | select a.personMemberID, * from chineseresume a,personmember b where personMemberID = b.referenceid and a.personMemberID = ‘JCNPRH39681’ (A = B ,B = ‘号码’)
129 |
130 |
131 |
132 | select a.personMemberID, * from chineseresume a,personmember b where a.personMemberID = b.referenceid and a.personMemberID = ‘JCNPRH39681’ and b.referenceid = ‘JCNPRH39681’ (A = B ,B = ‘号码’, A = ‘号码’)
133 |
134 |
135 |
136 | select a.personMemberID, * from chineseresume a,personmember b where b.referenceid = ‘JCNPRH39681’ and a.personMemberID = ‘JCNPRH39681’ (B = ‘号码’, A = ‘号码’)
137 |
138 | ```
139 |
140 |
141 |
142 | **26、** 尽量使用exists代替select count(1)来判断是否存在记录,count函数只有在统计表中所有行数时使用,而且count(1)比count(*)更有效率。
143 |
144 |
145 |
146 | **27、** 尽量使用“>=”,不要使用“>”。
147 |
148 |
149 |
150 | **28、** 索引的使用规范:
151 |
152 | - 索引的创建要与应用结合考虑,建议大的OLTP表不要超过6个索引;
153 | - 尽可能的使用索引字段作为查询条件,尤其是聚簇索引,必要时可以通过index index_name来强制指定索引;
154 | - 避免对大表查询时进行table scan,必要时考虑新建索引;
155 | - 在使用索引字段作为条件时,如果该索引是联合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用;
156 | - 要注意索引的维护,周期性重建索引,重新编译存储过程。
157 |
158 |
159 |
160 |
161 |
162 | **29、** 下列SQL条件语句中的列都建有恰当的索引,但执行速度却非常慢:
163 |
164 | ```sql
165 | SELECT * FROM record WHERE substrINg(card_no,1,4)=’5378’ (13秒)
166 |
167 |
168 | SELECT * FROM record WHERE amount/30< 1000 (11秒)
169 |
170 |
171 | SELECT * FROM record WHERE convert(char(10),date,112)=’19991201’ (10秒)
172 | ```
173 |
174 |
175 |
176 | **分析:**
177 |
178 | WHERE子句中对列的任何操作结果都是在SQL运行时逐列计算得到的,因此它不得不进行表搜索,而没有使用该列上面的索引。
179 |
180 |
181 |
182 | 如果这些结果在查询编译时就能得到,那么就可以被SQL优化器优化,使用索引,避免表搜索,因此将SQL重写成下面这样:
183 |
184 | ```sql
185 |
186 | SELECT * FROM record WHERE card_no like ‘5378%’ (< 1秒)
187 |
188 | SELECT * FROM record WHERE amount< 1000*30 (< 1秒)
189 |
190 | SELECT * FROM record WHERE date= ‘1999/12/01’ (< 1秒)
191 | ```
192 |
193 |
194 |
195 | **30、** 当有一批处理的插入或更新时,用批量插入或批量更新,绝不会一条条记录的去更新。
196 |
197 |
198 |
199 | **31、** 在所有的存储过程中,能够用SQL语句的,我绝不会用循环去实现。
200 |
201 | 例如:列出上个月的每一天,我会用connect by去递归查询一下,绝不会去用循环从上个月第一天到最后一天。
202 |
203 |
204 |
205 | **32、** 选择最有效率的表名顺序(只在基于规则的优化器中有效):
206 |
207 | Oracle的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表 driving table)将被最先处理,在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。
208 |
209 | 如果有3个以上的表连接查询,那就需要选择交叉表(intersection table)作为基础表,交叉表是指那个被其他表所引用的表。
210 |
211 |
212 |
213 | **33、** 提高GROUP BY语句的效率,可以通过将不需要的记录在GROUP BY之前过滤掉。下面两个查询返回相同结果,但第二个明显就快了许多。
214 |
215 | **低效:**
216 |
217 | ```sql
218 | SELECT JOB , AVG(SAL)
219 |
220 | FROM EMP
221 |
222 | GROUP BY JOB
223 |
224 | HAVING JOB =’PRESIDENT’
225 |
226 | OR JOB =’MANAGER’
227 | ```
228 |
229 |
230 |
231 | **高效:**
232 |
233 | ```sql
234 | SELECT JOB , AVG(SAL)
235 |
236 | FROM EMP
237 |
238 | WHERE JOB =’PRESIDENT’
239 |
240 | OR JOB =’MANAGER’
241 |
242 | GROUP BY JOB
243 | ```
244 |
245 |
246 |
247 |
248 |
249 | **34、** SQL语句用大写,因为Oracle总是先解析SQL语句,把小写的字母转换成大写的再执行。
250 |
251 |
252 |
253 | **35、** 别名的使用,别名是大型数据库的应用技巧,就是表名、列名在查询中以一个字母为别名,查询速度要比建连接表快1.5倍。
254 |
255 |
256 |
257 | **36、** 避免死锁,在你的存储过程和触发器中访问同一个表时总是以相同的顺序;事务应经可能地缩短,在一个事务中应尽可能减少涉及到的数据量;永远不要在事务中等待用户输入。
258 |
259 |
260 |
261 | **37、** 避免使用临时表,除非却有需要,否则应尽量避免使用临时表,相反,可以使用表变量代替;大多数时候(99%),表变量驻扎在内存中,因此速度比临时表更快,临时表驻扎在TempDb数据库中,因此临时表上的操作需要跨数据库通信,速度自然慢。
262 |
263 |
264 |
265 | **38、** 最好不要使用触发器:
266 |
267 | - 触发一个触发器,执行一个触发器事件本身就是一个耗费资源的过程;
268 | - 如果能够使用约束实现的,尽量不要使用触发器;
269 | - 不要为不同的触发事件(Insert,Update和Delete)使用相同的触发器;
270 | - 不要在触发器中使用事务型代码。
271 |
272 |
273 |
274 | **39、** 索引创建规则:
275 |
276 | - 表的主键、外键必须有索引;
277 | - 数据量超过300的表应该有索引;
278 | - 经常与其他表进行连接的表,在连接字段上应该建立索引;
279 | - 经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
280 | - 索引应该建在选择性高的字段上;
281 | - 索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
282 | - 复合索引的建立需要进行仔细分析,尽量考虑用单字段索引代替;
283 | - 正确选择复合索引中的主列字段,一般是选择性较好的字段;
284 | - 复合索引的几个字段是否经常同时以AND方式出现在Where子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
285 | - 如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引;
286 | - 如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段;
287 | - 如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
288 | - 频繁进行数据操作的表,不要建立太多的索引;
289 | - 删除无用的索引,避免对执行计划造成负面影响;
290 | - 表上建立的每个索引都会增加存储开销,索引对于插入、删除、更新操作也会增加处理上的开销。另外,过多的复合索引,在有单字段索引的情况下,一般都是没有存在价值的;相反,还会降低数据增加删除时的性能,特别是对频繁更新的表来说,负面影响更大。
291 | - 尽量不要对数据库中某个含有大量重复的值的字段建立索引。
292 |
293 |
294 |
295 | **40、** MySQL查询优化总结:
296 |
297 | 使用慢查询日志去发现慢查询,使用执行计划去判断查询是否正常运行,总是去测试你的查询看看是否他们运行在最佳状态下。
298 |
299 | 久而久之性能总会变化,避免在整个表上使用count(*),它可能锁住整张表,使查询保持一致以便后续相似的查询可以使用查询缓存,在适当的情形下使用GROUP BY而不是DISTINCT,在WHERE、GROUP BY和ORDER BY子句中使用有索引的列,保持索引简单,不在多个索引中包含同一个列。
300 |
301 | 有时候MySQL会使用错误的索引,对于这种情况使用USE INDEX,检查使用SQL_MODE=STRICT的问题,对于记录数小于5的索引字段,在UNION的时候使用LIMIT不是是用OR。
302 |
303 | 为了避免在更新前SELECT,使用INSERT ON DUPLICATE KEY或者INSERT IGNORE,不要用UPDATE去实现,不要使用MAX,使用索引字段和ORDER BY子句,LIMIT M,N实际上可以减缓查询在某些情况下,有节制地使用,在WHERE子句中使用UNION代替子查询,在重新启动的MySQL,记得来温暖你的数据库,以确保数据在内存和查询速度快,考虑持久连接,而不是多个连接,以减少开销。
304 |
305 | 基准查询,包括使用服务器上的负载,有时一个简单的查询可以影响其他查询,当负载增加在服务器上,使用SHOW PROCESSLIST查看慢的和有问题的查询,在开发环境中产生的镜像数据中测试的所有可疑的查询。
306 |
307 |
308 |
309 | **41、** MySQL备份过程:
310 |
311 | - 从二级复制服务器上进行备份;
312 | - 在进行备份期间停止复制,以避免在数据依赖和外键约束上出现不一致;
313 | - 彻底停止MySQL,从数据库文件进行备份;
314 | - 如果使用MySQL dump进行备份,请同时备份二进制日志文件 – 确保复制没有中断;
315 | - 不要信任LVM快照,这很可能产生数据不一致,将来会给你带来麻烦;
316 | - 为了更容易进行单表恢复,以表为单位导出数据——如果数据是与其他表隔离的。
317 | - 当使用mysqldump时请使用–opt;
318 | - 在备份之前检查和优化表;
319 | - 为了更快的进行导入,在导入时临时禁用外键约束。;
320 | - 为了更快的进行导入,在导入时临时禁用唯一性检测;
321 | - 在每一次备份后计算数据库,表以及索引的尺寸,以便更够监控数据尺寸的增长;
322 | - 通过自动调度脚本监控复制实例的错误和延迟;
323 | - 定期执行备份。
324 |
325 |
326 |
327 | **42、** 查询缓冲并不自动处理空格,因此,在写SQL语句时,应尽量减少空格的使用,尤其是在SQL首和尾的空格(因为查询缓冲并不自动截取首尾空格)。
328 |
329 |
330 |
331 | **43、** member用mid做标准进行分表方便查询么?一般的业务需求中基本上都是以username为查询依据,正常应当是username做hash取模来分表。
332 |
333 | 而分表的话MySQL的partition功能就是干这个的,对代码是透明的;在代码层面去实现貌似是不合理的。
334 |
335 |
336 |
337 | **44、** 我们应该为数据库里的每张表都设置一个ID做为其主键,而且最好的是一个INT型的(推荐使用UNSIGNED),并设置上自动增加的AUTO_INCREMENT标志。
338 |
339 |
340 |
341 | **45、** 在所有的存储过程和触发器的开始处设置SET NOCOUNT ON,在结束时设置SET NOCOUNT OFF。无需在执行存储过程和触发器的每个语句后向客户端发送DONE_IN_PROC消息。
342 |
343 |
344 |
345 | **46、** MySQL查询可以启用高速查询缓存。这是提高数据库性能的有效MySQL优化方法之一。当同一个查询被执行多次时,从缓存中提取数据和直接从数据库中返回数据快很多。
346 |
347 |
348 |
349 | **47、** EXPLAIN SELECT查询用来跟踪查看效果:
350 |
351 | 使用EXPLAIN关键字可以让你知道MySQL是如何处理你的SQL语句的。这可以帮你分析你的查询语句或是表结构的性能瓶颈。EXPLAIN的查询结果还会告诉你你的索引主键被如何利用的,你的数据表是如何被搜索和排序的。
352 |
353 |
354 |
355 | **48、** 当只要一行数据时使用LIMIT 1 :
356 |
357 |
358 |
359 | 当你查询表的有些时候,你已经知道结果只会有一条结果,但因为你可能需要去fetch游标,或是你也许会去检查返回的记录数。
360 |
361 | 在这种情况下,加上LIMIT 1可以增加性能。这样一来,MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据。
362 |
363 |
364 |
365 | **49、** 选择表合适存储引擎:
366 |
367 | - myisam:应用时以读和插入操作为主,只有少量的更新和删除,并且对事务的完整性,并发性要求不是很高的。
368 |
369 | - InnoDB:事务处理,以及并发条件下要求数据的一致性。除了插入和查询外,包括很多的更新和删除。(InnoDB有效地降低删除和更新导致的锁定)。
370 |
371 | 对于支持事务的InnoDB类型的表来说,影响速度的主要原因是AUTOCOMMIT默认设置是打开的,而且程序没有显式调用BEGIN 开始事务,导致每插入一条都自动提交,严重影响了速度。可以在执行SQL前调用begin,多条SQL形成一个事物(即使autocommit打开也可以),将大大提高性能。
372 |
373 |
374 |
375 | **50、** 优化表的数据类型,选择合适的数据类型:
376 |
377 | 原则:更小通常更好,简单就好,所有字段都得有默认值,尽量避免null。
378 |
379 |
380 |
381 | 例如:数据库表设计时候更小的占磁盘空间尽可能使用更小的整数类型。(mediumint就比int更合适)
382 |
383 |
384 |
385 | 比如时间字段:datetime和timestamp,datetime占用8个字节,而timestamp占用4个字节,只用了一半,而timestamp表示的范围是1970—2037适合做更新时间
386 |
387 |
388 |
389 | MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快。
390 |
391 |
392 |
393 | 因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽可能小。
394 |
395 |
396 |
397 | 例如:在定义邮政编码这个字段时,如果将其设置为CHAR(255),显然给数据库增加了不必要的空间。甚至使用VARCHAR这种类型也是多余的,因为CHAR(6)就可以很好的完成任务了。
398 |
399 |
400 |
401 | 同样的,如果可以的话,我们应该使用MEDIUMINT而不是BIGIN来定义整型字段,应该尽量把字段设置为NOT NULL,这样在将来执行查询的时候,数据库不用去比较NULL值。
402 |
403 |
404 |
405 | 对于某些文本字段,例如“省份”或者“性别”,我们可以将它们定义为ENUM类型。因为在MySQL中,ENUM类型被当作数值型数据来处理,而数值型数据被处理起来的速度要比文本类型快得多。这样,我们又可以提高数据库的性能。
406 |
407 |
408 |
409 | **51、** 字符串数据类型:char,varchar,text选择区别。
410 |
411 |
412 |
413 | **52、** 任何对列的操作都将导致表扫描,它包括数据库函数、计算表达式等等,查询时要尽可能将操作移至等号右边。
--------------------------------------------------------------------------------
/interviewDoc/Java/database/MongoDB.md:
--------------------------------------------------------------------------------
1 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
2 |
3 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
4 |
5 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
6 |
7 |
8 |
9 |
10 | - [Mongodb是什么?](#mongodb是什么)
11 | - [Mongodb有哪些特点?](#mongodb有哪些特点)
12 | - [什么是非关系型数据库](#什么是非关系型数据库)
13 | - [非关系型数据库有哪些类型](#非关系型数据库有哪些类型)
14 | - [Mongodb的结构介绍](#mongodb的结构介绍)
15 | - [MongoDB成为最好NoSQL数据库的原因是什么?](#mongodb成为最好nosql数据库的原因是什么)
16 | - [MongoDB的优势有哪些](#mongodb的优势有哪些)
17 | - [MySQL与MongoDB之间最基本的差别是什么?](#mysql与mongodb之间最基本的差别是什么)
18 | - [什么是集合](#什么是集合)
19 | - [什么是文档](#什么是文档)
20 | - [什么是NoSQL数据库?NoSQL与RDBMS直接有什么区别?为什么要使用和不使用NoSQL数据库?说一说NoSQL数据库的几个优点?](#什么是nosql数据库nosql与rdbms直接有什么区别为什么要使用和不使用nosql数据库说一说nosql数据库的几个优点)
21 | - [NoSQL数据库有哪些类型?](#nosql数据库有哪些类型)
22 | - [分析器在MongoDB中的作用是什么?](#分析器在mongodb中的作用是什么)
23 | - [MySQL与MongoDB之间最基本的差别是什么?](#mysql与mongodb之间最基本的差别是什么)
24 | - [你怎么比较MongoDB、CouchDB及CouchBase?](#你怎么比较mongodbcouchdb及couchbase)
25 | - [MongoDB成为最好NoSQL数据库的原因是什么?](#mongodb成为最好nosql数据库的原因是什么)
26 | - ["ObjectID"有哪些部分组成](#objectid有哪些部分组成)
27 | - [如何使用"AND"或"OR"条件循环查询集合中的文档](#如何使用and或or条件循环查询集合中的文档)
28 | - [在MongoDB中如何排序?](#在mongodb中如何排序)
29 | - [如何执行事务/加锁?](#如何执行事务加锁)
30 | - [journal回放在条目(entry)不完整时(比如恰巧有一个中途故障了)会遇到问题吗?](#journal回放在条目entry不完整时比如恰巧有一个中途故障了会遇到问题吗)
31 | - [分析器在MongoDB中的作用是什么?](#分析器在mongodb中的作用是什么)
32 | - [如果用户移除对象的属性,该属性是否从存储层中删除?](#如果用户移除对象的属性该属性是否从存储层中删除)
33 | - [能否使用日志特征进行安全备份?](#能否使用日志特征进行安全备份)
34 | - [允许空值null吗?](#允许空值null吗)
35 | - [MongoDB更新操作立刻fsync到磁盘?](#mongodb更新操作立刻fsync到磁盘)
36 | - [如何执行事务/加锁?](#如何执行事务加锁)
37 | - [为什么我的数据文件如此庞大?](#为什么我的数据文件如此庞大)
38 | - [启用备份故障恢复需要多久?](#启用备份故障恢复需要多久)
39 | - [什么是master或primary?](#什么是master或primary)
40 | - [什么是secondary或slave?](#什么是secondary或slave)
41 | - [必须调用getLastError来确保写操作生效了么?](#必须调用getlasterror来确保写操作生效了么)
42 | - [MongoDB副本集选举条件有那些?](#mongodb副本集选举条件有那些)
43 | - [简单的描述下MongoDB选举流程](#简单的描述下mongodb选举流程)
44 | - [我应该启动一个集群分片(sharded)还是一个非集群分片的 MongoDB 环境?](#我应该启动一个集群分片sharded还是一个非集群分片的-mongodb-环境)
45 | - [什么是MongoDB分片集群?](#什么是mongodb分片集群)
46 | - [Monogodb中的分片什么意思?](#monogodb中的分片什么意思)
47 | - [MongoDB中为何需要水平分片?](#mongodb中为何需要水平分片)
48 | - [什么情况下需要用到MongoDB的分片?](#什么情况下需要用到mongodb的分片)
49 | - [MongoDB中分片键的意义何在?](#mongodb中分片键的意义何在)
50 | - [分片(sharding)和复制(replication)是怎样工作的?](#分片sharding和复制replication是怎样工作的)
51 | - [构建一个分片集群需要用的那些角色?分别是什么?](#构建一个分片集群需要用的那些角色分别是什么)
52 | - [副本集角色有那些?做是什么?](#副本集角色有那些做是什么)
53 | - [数据在什么时候才会扩展到多个分片(shard)里?](#数据在什么时候才会扩展到多个分片shard里)
54 | - [当我试图更新一个正在被迁移的块(chunk)上的文档时会发生什么?](#当我试图更新一个正在被迁移的块chunk上的文档时会发生什么)
55 | - [如果在一个分片(shard)停止或者很慢的时候,我发起一个查询会怎样?](#如果在一个分片shard停止或者很慢的时候我发起一个查询会怎样)
56 | - [我可以把moveChunk目录里的旧文件删除吗?](#我可以把movechunk目录里的旧文件删除吗)
57 | - [怎么查看 Mongo 正在使用的链接?](#怎么查看-mongo-正在使用的链接)
58 | - [如果块移动操作(moveChunk)失败了,我需要手动清除部分转移的文档吗?](#如果块移动操作movechunk失败了我需要手动清除部分转移的文档吗)
59 | - [如果我在使用复制技术(replication),可以一部分使用日志(journaling)而其他部分则不使用吗?](#如果我在使用复制技术replication可以一部分使用日志journaling而其他部分则不使用吗)
60 | - [MongoDB在A:{B,C}上建立索引,查询A:{B,C}和A:{C,B}都会使用索引吗?](#mongodb在abc上建立索引查询abc和acb都会使用索引吗)
61 | - [如果一个分片(Shard)停止或很慢的时候,发起一个查询会怎样?](#如果一个分片shard停止或很慢的时候发起一个查询会怎样)
62 | - [MongoDB支持存储过程吗?如果支持的话,怎么用?](#mongodb支持存储过程吗如果支持的话怎么用)
63 | - [解释一下什么是MongoDB中的GridFS ?](#解释一下什么是mongodb中的gridfs-)
64 | - [如何理解MongoDB中的GridFS机制,MongoDB为何使用GridFS来存储文件?](#如何理解mongodb中的gridfs机制mongodb为何使用gridfs来存储文件)
65 | - [MongoDB支持存储过程吗?如果支持的话,怎么用?](#mongodb支持存储过程吗如果支持的话怎么用)
66 | - [如何理解MongoDB中的GridFS机制,MongoDB为何使用GridFS来存储文件?](#如何理解mongodb中的gridfs机制mongodb为何使用gridfs来存储文件)
67 | - [为什么MongoDB的数据文件很大?](#为什么mongodb的数据文件很大)
68 | - [MongoDB在A:{B,C}上建立索引,查询A:{B,C}和A:{C,B}都会使用索引吗?](#mongodb在abc上建立索引查询abc和acb都会使用索引吗)
69 | - [如果用户移除对象的属性,该属性是否从存储层中删除?](#如果用户移除对象的属性该属性是否从存储层中删除)
70 | - [能否使用日志特征进行安全备份?](#能否使用日志特征进行安全备份)
71 | - [更新操作立刻fsync到磁盘?](#更新操作立刻fsync到磁盘)
72 | - [如何执行事务/加锁?](#如何执行事务加锁)
73 | - [什么是master或primary?](#什么是master或primary)
74 | - [getLastError的作用](#getlasterror的作用)
75 | - [分片(sharding)和复制(replication)是怎样工作的?](#分片sharding和复制replication是怎样工作的)
76 | - [数据在什么时候才会扩展到多个分片(shard)里?](#数据在什么时候才会扩展到多个分片shard里)
77 | - [什么是”mongod“](#什么是mongod)
78 | - ["mongod"参数有什么](#mongod参数有什么)
79 | - [什么是"mongo"](#什么是mongo)
80 | - [MongoDB哪个命令可以切换数据库](#mongodb哪个命令可以切换数据库)
81 | - [为什么用MOngoDB?](#为什么用mongodb)
82 | - [MongoDB适合应用在那些场景?](#mongodb适合应用在那些场景)
83 | - [在哪些场景使用MongoDB](#在哪些场景使用mongodb)
84 | - [MongoDB中的命名空间是什么意思?](#mongodb中的命名空间是什么意思)
85 | - [哪些语言支持MongoDB?](#哪些语言支持mongodb)
86 | - [在MongoDB中如何创建一个新的数据库](#在mongodb中如何创建一个新的数据库)
87 | - [在MongoDB中如何查看数据库列表](#在mongodb中如何查看数据库列表)
88 | - [MongoDB中的分片是什么意思](#mongodb中的分片是什么意思)
89 | - [如何查看使用MongoDB的连接Sharding - MongoDB Manual21.如何查看使用MongoDB的连接](#如何查看使用mongodb的连接sharding---mongodb-manual21如何查看使用mongodb的连接)
90 | - [什么是复制](#什么是复制)
91 | - [在MongoDB中如何在集合中插入一个文档](#在mongodb中如何在集合中插入一个文档)
92 | - [在MongoDB中如何除去一个数据库Collection Methods24.在MongoDB中如何除去一个数据库](#在mongodb中如何除去一个数据库collection-methods24在mongodb中如何除去一个数据库)
93 | - [在MongoDB中如何查看一个已经创建的集合](#在mongodb中如何查看一个已经创建的集合)
94 | - [在MongoDB中如何删除一个集合](#在mongodb中如何删除一个集合)
95 | - [为什么要在MongoDB中使用分析器](#为什么要在mongodb中使用分析器)
96 | - [分析器在MongoDB中的作用是什么?](#分析器在mongodb中的作用是什么)
97 | - [MongoDB支持主键外键关系吗](#mongodb支持主键外键关系吗)
98 | - [MongoDB支持哪些数据类型](#mongodb支持哪些数据类型)
99 | - [为什么要在MongoDB中用"Code"数据类型](#为什么要在mongodb中用code数据类型)
100 | - [为什么要在MongoDB中用"Regular Expression"数据类型](#为什么要在mongodb中用regular-expression数据类型)
101 | - [为什么在MongoDB中使用"Object ID"数据类型](#为什么在mongodb中使用object-id数据类型)
102 | - ["ObjectID"由哪些部分组成](#objectid由哪些部分组成)
103 | - [在MongoDb中什么是索引](#在mongodb中什么是索引)
104 | - [如何添加索引](#如何添加索引)
105 | - [用什么方法可以格式化输出结果](#用什么方法可以格式化输出结果)
106 | - [如何使用"AND"或"OR"条件循环查询集合中的文档](#如何使用and或or条件循环查询集合中的文档)
107 | - [在MongoDB中如何更新数据](#在mongodb中如何更新数据)
108 | - [如何删除文档](#如何删除文档)
109 | - [在MongoDB中如何排序](#在mongodb中如何排序)
110 | - [什么是聚合](#什么是聚合)
111 | - [在MongoDB中什么是副本集](#在mongodb中什么是副本集)
112 |
113 |
114 |
115 | ### Mongodb是什么?
116 |
117 | MongoDB 是由 C++语言编写的,是一个基于分布式文件存储的开源数据库系统。在高负载的情况下,添加更多的节点,可以保证服务器性能。MongoDB 旨在给 WEB 应用提供可扩展的高性能数据存储解决方案。
118 |
119 | MongoDB 将数据存储给一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
120 |
121 | 
122 |
123 | ### Mongodb有哪些特点?
124 |
125 | **1、**MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
126 |
127 | **2、**你可以在 MongoDB 记录中设置任何属性的索引 (如:FirstName="Sameer",Address="8 Gandhi Road")来实现更快的排序。
128 |
129 | **3、**你可以通过本地或者网络创建数据镜像,这使得 MongoDB 有更强的扩展性。
130 |
131 | **4、**如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
132 |
133 | **5、**Mongo 支持丰富的查询表达式。查询指令使用 JSON 形式的标记,可轻易查询文档中内嵌的对象及数组。
134 |
135 | **6、**MongoDb 使用 update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
136 |
137 | **7、**Mongodb 中的 Map/reduce 主要是用来对数据进行批量处理和聚合操作。
138 |
139 | **8、**Map 和 Reduce。Map 函数调用 emit(key,value)遍历集合中所有的记录,将 key 与 value 传给 Reduce 函数进行处理。
140 |
141 | **9、**Map 函数和 Reduce 函数是使用 Javascript 编写的,并可以通过 db.runCommand 或 mapreduce 命令来执行 MapReduce 操作。
142 |
143 | **10、**GridFS 是 MongoDB 中的一个内置功能,可以用于存放大量小文件。
144 |
145 | **11、**MongoDB 允许在服务端执行脚本, 可以用 Javascript 编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
146 |
147 |
148 |
149 | ### 什么是非关系型数据库
150 |
151 | 非关系型数据库是对不同于传统关系型数据库的统称。非关系型数据库的显著特点是不使用SQL作为查询语言,数据存储不需要特定的表格模式。由于简单的设计和非常好的性能所以被用于大数据和Web Apps等
152 |
153 |
154 |
155 | ### 非关系型数据库有哪些类型
156 |
157 | - **-Key-Value 存储:Amazon S3**
158 | - **图表:Neo4J**
159 | - **文档存储:MongoDB**
160 | - **基于列存储:Cassandra**
161 |
162 |
163 |
164 | ### Mongodb的结构介绍
165 |
166 | 数据库中存储的对象设计bson,一种类似json的二进制文件,由键值对组成
167 |
168 |
169 |
170 | ### MongoDB成为最好NoSQL数据库的原因是什么?
171 |
172 | 以下特点使得MongoDB成为最好的NoSQL数据库:
173 |
174 | 面向文件的
175 |
176 | 高性能
177 |
178 | 高可用性
179 |
180 | 易扩展性
181 |
182 | 丰富的查询语言
183 |
184 |
185 |
186 | ### MongoDB的优势有哪些
187 |
188 | - 面向文档的存储:以 JSON 格式的文档保存数据。
189 | - 任何属性都可以建立索引。
190 | - 复制以及高可扩展性。
191 | - 自动分片。
192 | - 丰富的查询功能。
193 | - 快速的即时更新。
194 | - 来自 MongoDB 的专业支持。
195 |
196 |
197 |
198 | ### MySQL与MongoDB之间最基本的差别是什么?
199 |
200 | MySQL和MongoDB两者都是免费开源的数据库。MySQL和MongoDB有许多基本差别包括数据的表示(data representation),查询,关系,事务,schema的设计和定义,标准化(normalization),速度和性能。
201 |
202 | 通过比较MySQL和MongoDB,实际上我们是在比较关系型和非关系型数据库,即数据存储结构不同。详细阅读
203 |
204 |
205 |
206 | ### 什么是集合
207 |
208 | 集合就是一组 MongoDB 文档。它相当于关系型数据库(RDBMS)中的表这种概念。集合位于单独的一个数据库中。一个集合内的多个文档可以有多个不同的字段。一般来说,集合中的文档都有着相同或相关的目的。
209 |
210 |
211 |
212 | ### 什么是文档
213 |
214 | 文档由一组key value组成。文档是动态模式,这意味着同一集合里的文档不需要有相同的字段和结构。在关系型数据库中table中的每一条记录相当于MongoDB中的一个文档。
215 |
216 |
217 |
218 |
219 |
220 | ### 什么是NoSQL数据库?NoSQL与RDBMS直接有什么区别?为什么要使用和不使用NoSQL数据库?说一说NoSQL数据库的几个优点?
221 |
222 | NoSQL是非关系型数据库,NoSQL = Not Only SQL。
223 |
224 | 关系型数据库采用的结构化的数据,NoSQL采用的是键值对的方式存储数据。
225 |
226 | 在处理非结构化/半结构化的大数据时;在水平方向上进行扩展时;随时应对动态增加的数据项时可以优先考虑使用NoSQL数据库。
227 |
228 | 再考虑数据库的成熟度;支持;分析和商业智能;管理及专业性等问题时,应优先考虑关系型数据库。
229 |
230 |
231 |
232 | ### NoSQL数据库有哪些类型?
233 |
234 | NoSQL数据库的类型
235 |
236 | 例如:MongoDB, Cassandra, CouchDB, Hypertable, Redis, Riak, HBASE, Memcache
237 |
238 |
239 |
240 | ### 分析器在MongoDB中的作用是什么?
241 |
242 | MongoDB中包括了一个可以显示数据库中每个操作性能特点的数据库分析器。通过这个分析器你可以找到比预期慢的查询(或写操作);利用这一信息,比如,可以确定是否需要添加索引。
243 |
244 |
245 |
246 | ### MySQL与MongoDB之间最基本的差别是什么?
247 |
248 | MySQL和MongoDB两者都是免费开源的数据库。MySQL和MongoDB有许多基本差别包括数据的表示(data representation),查询,关系,事务,schema的设计和定义,标准化(normalization),速度和性能。
249 |
250 | 通过比较MySQL和MongoDB,实际上我们是在比较关系型和非关系型数据库,即数据存储结构不同。
251 |
252 |
253 |
254 | ### 你怎么比较MongoDB、CouchDB及CouchBase?
255 |
256 | MongoDB和CouchDB都是面向文档的数据库。MongoDB和CouchDB都是开源NoSQL数据库的最典型代表。除了都以文档形式存储外它
257 |
258 | 们没有其他的共同点。
259 |
260 | MongoDB和CouchDB在数据模型实现、接口、对象存储以及复制方法等方面有很多不同。
261 |
262 |
263 |
264 | ### MongoDB成为最好NoSQL数据库的原因是什么?
265 |
266 | 以下特点使得MongoDB成为最好的NoSQL数据库:
267 |
268 | - 面向文件的
269 | - 高性能
270 | - 高可用性
271 | - 易扩展性
272 | - 丰富的查询语言
273 |
274 |
275 |
276 | ### "ObjectID"有哪些部分组成
277 |
278 | 一共有四部分组成:时间戳、客户端ID、客户进程ID、三个字节的增量计数器。
279 | _id是一个 12 字节长的十六进制数,它保证了每一个文档的唯一性。在插入文档时,需要提供_id。如果你不提供,那么 MongoDB 就会为每一文档提供一个唯一的 id。_id的头 4 个字节代表的是当前的时间戳,接着的后 3 个字节表示的是机器 id 号,接着的 2 个字节表示 MongoDB 服务器进程 id,最后的 3 个字节代表递增值。
280 |
281 |
282 |
283 | ### 如何使用"AND"或"OR"条件循环查询集合中的文档
284 |
285 | 在 find() 方法中,如果传入多个键,并用逗号( , )分隔它们,那么 MongoDB 会把它看成是AND条件。
286 |
287 | >db.mycol.find({key1:value1, key2:value2}).pretty()
288 | 若基于OR条件来查询文档,可以使用关键字$or。
289 |
290 | db.mycol.find(
291 | {
292 | $or: [
293 | {key1: value1}, {key2:value2}
294 | ]
295 | }
296 | ).pretty()
297 |
298 |
299 |
300 | ### 在MongoDB中如何排序?
301 |
302 | MongoDB 中的文档排序是通过 sort() 方法来实现的。sort() 方法可以通过一些参数来指定要进行排序的字段,并使用 1 和 -1 来指定排序方式,其中 1 表示升序,而 -1 表示降序。
303 |
304 | > db.connectionName.find({key:value}).sort({columnName:1})
305 |
306 |
307 |
308 | ### 如何执行事务/加锁?
309 |
310 | MongoDB没有使用传统的锁或者复杂的带回滚的事务,因为它设计的宗旨是轻量,快速以及可预计的高性能。可以把它类比成MySQL MylSAM的自动提交模式。通过精简对事务的支持,性能得到了提升,特别是在一个可能会穿过多个服务器的系统里。
311 |
312 |
313 |
314 | ### journal回放在条目(entry)不完整时(比如恰巧有一个中途故障了)会遇到问题吗?
315 |
316 | 每个journal (group)的写操作都是一致的,除非它是完整的否则在恢复过程中它不会回放。
317 |
318 |
319 |
320 | ### 分析器在MongoDB中的作用是什么?
321 |
322 | MongoDB中包括了一个可以显示数据库中每个操作性能特点的数据库分析器。通过这个分析器你可以找到比预期慢的查询(或写操作);
323 |
324 | 利用这一信息,比如,可以确定是否需要添加索引。
325 |
326 |
327 |
328 | ### 如果用户移除对象的属性,该属性是否从存储层中删除?
329 |
330 | 是的,用户移除属性然后对象会重新保存(re-save())。
331 |
332 |
333 |
334 | ### 能否使用日志特征进行安全备份?
335 |
336 | 是的。
337 |
338 |
339 |
340 | ### 允许空值null吗?
341 |
342 | 对于对象成员而言,是的。然而用户不能够添加空值(null)到数据库丛集(collection)因为空值不是对象。然而用户能够添加空对象{}。
343 |
344 |
345 |
346 | ### MongoDB更新操作立刻fsync到磁盘?
347 |
348 | 不会,磁盘写操作默认是延迟执行的。写操作可能在两三秒(默认在60秒内)后到达磁盘。
349 |
350 | 例如,如果一秒内数据库收到一千个对一个对象递增的操作,仅刷新磁盘一次。(注意,尽管fsync选项在命令行和经过getLastError_old是有效的)
351 |
352 |
353 |
354 | ### 如何执行事务/加锁?
355 |
356 | MongoDB没有使用传统的锁或者复杂的带回滚的事务,因为它设计的宗旨是轻量,快速以及可预计的高性能。可以把它类比成MySQLMylSAM的自动提交模式。通过精简对事务的支持,性能得到了提升,特别是在一个可能会穿过多个服务器的系统里。
357 |
358 |
359 |
360 | ### 为什么我的数据文件如此庞大?
361 |
362 | MongoDB会积极的预分配预留空间来防止文件系统碎片。
363 |
364 |
365 |
366 | ### 启用备份故障恢复需要多久?
367 |
368 | 从备份数据库声明主数据库宕机到选出一个备份数据库作为新的主数据库将花费10到30秒时间。
369 |
370 | 这期间在主数据库上的操作将会失败--包括写入和强一致性读取(strong consistent read)操作。
371 |
372 | 然而,你还能在第二数据库上执行最终一致性查询(eventually consistent query)(在slaveOk模式下),即使在这段时间里。
373 |
374 |
375 |
376 | ### 什么是master或primary?
377 |
378 | 它是当前备份集群(replica set)中负责处理所有写入操作的主要节点/成员。
379 |
380 | 在一个备份集群中,当失效备援(failover)事件发生时,一个另外的成员会变成primary。
381 |
382 |
383 |
384 | ### 什么是secondary或slave?
385 |
386 | Seconday从当前的primary上复制相应的操作。它是通过跟踪复制oplog(local.oplog.rs)做到的。
387 |
388 |
389 |
390 | ### 必须调用getLastError来确保写操作生效了么?
391 |
392 | 不用。不管你有没有调用getLastError(又叫"Safe Mode")服务器做的操作都一样。调用getLastError只是为了确认写操作成功提交了。当然,你经常想得到确认,但是写操作的安全性和是否生效不是由这个决定的。
393 |
394 |
395 |
396 | ### MongoDB副本集选举条件有那些?
397 |
398 | 1.复制集初始化。
399 | 2.主节点挂掉。
400 | 3.主节点脱离副本集(可能是网络原因)。
401 | 4.参与选举的节点数量必须大于副本集总节点数量的一半,如果已经小于一半了所有节点保持只读状态。
402 |
403 |
404 |
405 | ### 简单的描述下MongoDB选举流程
406 |
407 | **1、** 副本集中的主节点选举必须满足“大多数”的原则,所谓“大多数”是指副本中一半以上的成员。副本集中成员只有在得到大多数成员投票支持时,才能成为主节点。例如:有N个副本集成员节点,必须有N/2+1个成员投票支持某个节点,此节点才能成为主节点。注意:副本集中若有成员节点处于不可用状态,并不会影响副本集中的“大多数”,“大多数”是以副本集的配置来计算的。
408 |
409 | **2、** 仲裁节点(Arbiter)它并不保存数据,并且不能被选举为主节点,但是具有投票权。仲裁节点使用最小的资源,不能将Arbiter部署在同一个数据集节点中。
410 |
411 | **3、** 副本集中最好是有奇数个成员节点,如果有偶数个节点,最好加一个仲裁节点。若副本集中有偶数个成员节点,如图2所示,IDC1网络连不通IDC2,IDC1和IDC2内的成员节点分别会发生选举主节点的行为,然而选举因都无法满足大多数的原则,都不能选出主节点;加入一个仲裁节点之后,则副本集就能满足大多数原则,从中选出主节点了。
412 |
413 | **4、** 如果副本集成员节点数量是奇数,就不再需要仲裁者。但是如果在成员节点是奇数时,强行使用仲裁者,会导致选举耗时变长。由于添加了仲裁者就可能出现两个成员节点票数相同的情况,从而导致选举耗时变长。
414 |
415 | **5、** 若在一轮投票中,副本集中成员节点被投了反对票,则本轮不能被选为主节点。例如,在一个10个成员节点的副本集,某轮投票中,成员节点A由于数据延迟较大被某个成员节点投了反对票,则A同时收到了9票赞成票,然而A仍然不能被选为主节点。
416 |
417 | **6、** 集群中的优先级为0的节点不能成为主节点,并且不能触发选举,但是具有投票权,并且拥有与主节点一致的数据集。
418 |
419 |
420 |
421 | ### 我应该启动一个集群分片(sharded)还是一个非集群分片的 MongoDB 环境?
422 |
423 | 为开发便捷起见,我们建议以非集群分片(unsharded)方式开始一个 MongoDB 环境,除非一台服务器不足以存放你的初始数据集。从非集群分片升级到集群分片(sharding)是无缝的,所以在你的数据集还不是很大的时候没必要考虑集群分片(sharding)。
424 |
425 |
426 |
427 | ### 什么是MongoDB分片集群?
428 |
429 | Sharding cluster是一种可以水平扩展的模式,在数据量很大时特给力,实际大规模应用一般会采用这种架 构去构建。sharding分片很好的解决了单台服务器磁盘空间、内存、cpu等硬件资源的限制问题,把数据水 平拆分出去,降低单节点的访问压力。每个分片都是一个独立的数据库,所有的分片组合起来构成一个逻辑上 的完整的数据库。因此,分片机制降低了每个分片的数据操作量及需要存储的数据量,达到多台服务器来应对 不断增加的负载和数据的效果。
430 |
431 |
432 |
433 | ### Monogodb中的分片什么意思?
434 |
435 | 分片是将数据水平切分到不同的物理节点,当应用数据越来越大的时候,数据量也会越来越大。当数据量增长时,单台机器有可能无法存储数据或可接受的读取写入吞吐量,利用分片技术可以添加更多的机器来应对数据量增加以及读写操作的要求。
436 |
437 |
438 |
439 | ### MongoDB中为何需要水平分片?
440 |
441 | 1)减少单机请求数,将单机负载,提高总负载
442 |
443 | 2)减少单机的存储空间,提高总存空间
444 |
445 |
446 |
447 | ### 什么情况下需要用到MongoDB的分片?
448 |
449 | **1、** 机器的磁盘不够用了。使用分片解决磁盘空间的问题。
450 |
451 | **2、** 单个mongod已经不能满足写数据的性能要求。通过分片让写压力分散到各个分片上面,使用分片服务器自 身的资源。
452 |
453 | **3、** 想把大量数据放到内存里提高性能。和上面一样,通过分片使用分片服务器自身的资源。
454 |
455 |
456 |
457 | ### MongoDB中分片键的意义何在?
458 |
459 | **1、** 一个好的片键对分片至关重要。片键必须是一个索引 ,通 过 sh.shardCollection 加会自动创建索 引。一个自增的片键对写入和数据均匀分布就不是很好, 因为自增的片键总会在一个分片上写入,后续达到某 个阀值可能会写到别的分片。但是按照片键查询会非常高效。随机片键对数据的均匀分布效果很好。注意尽量 避免在多个分片上进行查询。
460 |
461 | **2、** 在所有分片上查询,mongos 会对结果进行归并排序,提高查询效率和速度
462 |
463 |
464 |
465 | ### 分片(sharding)和复制(replication)是怎样工作的?
466 |
467 | 每一个分片(shard)是一个分区数据的逻辑集合。分片可能由单一服务器或者集群组成,我们推荐为每一个分片(shard)使用集群。
468 |
469 |
470 |
471 | ### 构建一个分片集群需要用的那些角色?分别是什么?
472 |
473 | **1、分片服务器(Shard Server)** mongod 实例,用于存储实际的数据块,实际生产环境中一个 shard server 角色可由几台机器组个一 个 relica set 承担,防止主机单点故障 这是一个独立普通的mongod进程,保存数据信息。可以是一个副本集也可以是单独的一台服务器。
474 |
475 | **2、配置服务器(Config Server)** mongod 实例,存储了整个 Cluster Metadata,其中包括 chunk 信息。 这是一个独立的mongod进程,保存集群和分片的元数据,即各分片包含了哪些数据的信息。最先开始建立, 启用日志功能。像启动普通的 mongod 一样启动 配置服务器,指定configsvr 选项。不需要太多的空间和资源,配置服务器的 1KB 空间相当于真是数据 的 200MB。保存的只是数据的分布表。
476 |
477 | **3、路由服务器(Route Server)** mongos实例,前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用 起到一个路由的功能,供程序连接。本身不保存数据,在启动时从配置服务器加载集群信息,开启 mongos 进程需要知道配置服务器的地址,指定configdb选项。
478 |
479 |
480 |
481 | ### 副本集角色有那些?做是什么?
482 |
483 | **1、主节点(Primary)**
484 |
485 | 接收所有的写请求,然后把修改同步到所有Secondary。一个Replica Set只能有一个Primary节点,当 Primary挂掉后,其他Secondary或者Arbiter节点会重新选举出来一个主节点。默认读请求也是发到Primary节点处理的,可以通过修改客户端连接配置以支持读取Secondary节点。
486 |
487 | **2、副本节点(Secondary)**
488 |
489 | 与主节点保持同样的数据集。当主节点挂掉的时候,参与选主。
490 |
491 | **3、仲裁者(Arbiter)**
492 |
493 | 不保有数据,不参与选主,只进行选主投票。使用Arbiter可以减轻数据存储的硬件需求,Arbiter几乎没什 么大的硬件资源需求,但重要的一点是,在生产环境下它和其他数据节点不要部署在同一台机器上。
494 |
495 |
496 |
497 | ### 数据在什么时候才会扩展到多个分片(shard)里?
498 |
499 | MongoDB 分片是基于区域(range)的。所以一个集合(collection)中的所有的对象都被存放到一个块(chunk)中。只有当存在多余一个块的时候,才会有多个分片获取数据的选项。现在,每个默认块的大小是 64Mb,所以你需要至少 64 Mb 空间才可以实施一个迁移。
500 |
501 |
502 |
503 | ### 当我试图更新一个正在被迁移的块(chunk)上的文档时会发生什么?
504 |
505 | 更新操作会立即发生在旧的分片(shard)上,然后更改才会在所有权转移(ownership transfers)前复制到新的分片上。
506 |
507 |
508 |
509 | ### 如果在一个分片(shard)停止或者很慢的时候,我发起一个查询会怎样?
510 |
511 | 如果一个分片(shard)停止了,除非查询设置了“Partial”选项,否则查询会返回一个错误。如果一个分片(shard)响应很慢,MongoDB则会等待它的响应。
512 |
513 |
514 |
515 | ### 我可以把moveChunk目录里的旧文件删除吗?
516 |
517 | 没问题,这些文件是在分片(shard)进行均衡操作(balancing)的时候产生的临时文件。一旦这些操作已经完成,相关的临时文件也应该被删除掉。但目前清理工作是需要手动的,所以请小心地考虑再释放这些文件的空间。
518 |
519 |
520 |
521 | ### 怎么查看 Mongo 正在使用的链接?
522 |
523 | db._adminCommand("connPoolStats");
524 |
525 |
526 |
527 | ### 如果块移动操作(moveChunk)失败了,我需要手动清除部分转移的文档吗?
528 |
529 | 不需要,移动操作是一致(consistent)并且是确定性的(deterministic);一次失败后,移动操作会不断重试;当完成后,数据只会出现在新的分片里(shard)。
530 |
531 |
532 |
533 | ### 如果我在使用复制技术(replication),可以一部分使用日志(journaling)而其他部分则不使用吗?
534 |
535 | 可以。
536 |
537 |
538 |
539 | ### MongoDB在A:{B,C}上建立索引,查询A:{B,C}和A:{C,B}都会使用索引吗?
540 |
541 | 不会,只会在A:{B,C}上使用索引。
542 |
543 |
544 |
545 | ### 如果一个分片(Shard)停止或很慢的时候,发起一个查询会怎样?
546 |
547 | 如果一个分片停止了,除非查询设置了“Partial”选项,否则查询会返回一个错误。如果一个分片响应很慢,MongoDB会等待它的响应。
548 |
549 |
550 |
551 | ### MongoDB支持存储过程吗?如果支持的话,怎么用?
552 |
553 | MongoDB支持存储过程,它是javascript写的,保存在db.system.js表中。
554 |
555 |
556 |
557 | ### 解释一下什么是MongoDB中的GridFS ?
558 |
559 | 为了存储和检索大文件,例如图像,视频文件和音频文件,使用GridFS。默认情况下,它使用两个文件fs.files和fs.chunks来存储文件的元数据和块。
560 |
561 |
562 |
563 | ### 如何理解MongoDB中的GridFS机制,MongoDB为何使用GridFS来存储文件?
564 |
565 | GridFS是一种将大型文件存储在MongoDB中的文件规范。使用GridFS可以将大文件分隔成多个小文档存放,这样我们能够有效的保存大文档,而且解决了BSON对象有限制的问题。
566 |
567 |
568 |
569 | ### MongoDB支持存储过程吗?如果支持的话,怎么用?
570 |
571 | MongoDB支持存储过程,它是javascript写的,保存在db.system.js表中。
572 |
573 |
574 |
575 | ### 如何理解MongoDB中的GridFS机制,MongoDB为何使用GridFS来存储文件?
576 |
577 | GridFS是一种将大型文件存储在MongoDB中的文件规范。使用GridFS可以将大文件分隔成多个小文档存放,这样我们能够有效的保存大文档,而且解决了BSON对象有限制的问题。
578 |
579 |
580 |
581 | ### 为什么MongoDB的数据文件很大?
582 |
583 | MongoDB采用的预分配空间的方式来防止文件碎片。
584 |
585 |
586 |
587 | ### MongoDB在A:{B,C}上建立索引,查询A:{B,C}和A:{C,B}都会使用索引吗?
588 |
589 | 不会,只会在A:{B,C}上使用索引。
590 |
591 |
592 |
593 | ### 如果用户移除对象的属性,该属性是否从存储层中删除?
594 |
595 | 是的,用户移除属性然后对象会重新保存(re-save())。
596 |
597 |
598 |
599 | ### 能否使用日志特征进行安全备份?
600 |
601 | 是的
602 |
603 |
604 |
605 | ### 更新操作立刻fsync到磁盘?
606 |
607 | 一般磁盘的写操作都是延迟执行的
608 |
609 |
610 |
611 | ### 如何执行事务/加锁?
612 |
613 | MongoDB没有使用传统的锁或者复杂的带回滚的事务,因为它设计的宗旨是轻量,快速以及可预计的高性能。可以把它类比成MySQL MylSAM的自动提交模式。通过精简对事务的支持,性能得到了提升,特别是在一个可 能会穿过多个服务器的系统里。
614 |
615 |
616 |
617 | ### 什么是master或primary?
618 |
619 | 它是当前备份集群(replica set)中负责处理所有写入操作的主要节点/成员。在一个备份集群中,当失效备援(failover)事件发生时,一个另外的成员会变成primary。
620 |
621 | ### getLastError的作用
622 |
623 | 调用getLastError 可以确认当前的写操作是否成功的提交
624 |
625 |
626 |
627 | ### 分片(sharding)和复制(replication)是怎样工作的?
628 |
629 | 分片可能是单一的服务器或者集群组成,推荐使用集群
630 |
631 |
632 |
633 | ### 数据在什么时候才会扩展到多个分片(shard)里?
634 |
635 | mongodb分片是基于区域的,所以一个集合的所有对象都放置在同一个块中,只有当存在多余一个块的时候,才会有多个分片获取数据的选项
636 |
637 |
638 |
639 | ### 什么是”mongod“
640 |
641 | mongod是处理MongoDB系统的主要进程。它处理数据请求,管理数据存储,和执行后台管理操作。当我们运行mongod命令意味着正在启动MongoDB进程,并且在后台运行。
642 |
643 |
644 |
645 | ### "mongod"参数有什么
646 |
647 | - 传递数据库存储路径,默认是"/data/db"
648 | - 端口号 默认是 "27017"
649 |
650 |
651 |
652 | ### 什么是"mongo"
653 |
654 | 它是一个命令行工具用于连接一个特定的mongod实例。当我们没有带参数运行mongo命令它将使用默认的端口号和localhost连接
655 |
656 |
657 |
658 | ### MongoDB哪个命令可以切换数据库
659 |
660 | MongoDB 用 use +数据库名称的方式来创建数据库。use 会创建一个新的数据库,如果该数据库存在,则返回这个数据库。
661 |
662 |
663 |
664 |
665 |
666 | ### 为什么用MOngoDB?
667 |
668 | **1、**架构简单
669 |
670 | **2、**没有复杂的连接
671 |
672 | **3、**深度查询能力,MongoDB支持动态查询。
673 |
674 | **4、**容易调试
675 |
676 | **5、**容易扩展
677 |
678 | **6、**不需要转化/映射应用对象到数据库对象
679 |
680 | **7、**使用内部内存作为存储工作区,以便更快的存取数据。
681 |
682 |
683 |
684 | ### MongoDB适合应用在那些场景?
685 |
686 | 从目前阿里云 MongoDB 云数据库上的用户看,MongoDB 的应用已经渗透到各个领域,比如游戏、物流、电商、内容管理、社交、物联网、视频直播等,以下是几个实际的应用案例。
687 |
688 | 游戏场景,使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、更新
689 |
690 | 物流场景,使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB 内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来。
691 |
692 | 社交场景,使用 MongoDB 存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能
693 |
694 | 物联网场景,使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析
695 |
696 | 视频直播,使用 MongoDB 存储用户信息、礼物信息等
697 |
698 |
699 |
700 | ### 在哪些场景使用MongoDB
701 |
702 | - 大数据
703 | - 内容管理系统
704 | - 移动端Apps
705 | - 数据管理
706 |
707 |
708 |
709 | ### MongoDB中的命名空间是什么意思?
710 |
711 | MongoDB内部有预分配空间的机制,每个预分配的文件都用0进行填充。
712 |
713 | 数据文件每新分配一次,它的大小都是上一个数据文件大小的2倍,每个数据文件最大2G。欢迎关注公种浩:程序员追风,回复003领取一套200页的2020最新的Java面试题手册。
714 |
715 | MongoDB每个集合和每个索引都对应一个命名空间,这些命名空间的元数据集中在16M的*.ns文件中,平均每个命名占用约 628 字节,也即整个数据库的命名空间的上限约为24000。
716 |
717 | 如果每个集合有一个索引(比如默认的_id索引),那么最多可以创建12000个集合。如果索引数更多,则可创建的集合数就更少了。同时,如果集合数太多,一些操作也会变慢。
718 |
719 | 要建立更多的集合的话,MongoDB 也是支持的,只需要在启动时加上“--nssize”参数,这样对应数据库的命名空间文件就可以变得更大以便保存更多的命名。这个命名空间文件(.ns文件)最大可以为 2G。
720 |
721 | 每个命名空间对应的盘区不一定是连续的。与数据文件增长相同,每个命名空间对应的盘区大小都是随分配次数不断增长的。目的是为了平衡命名空间浪费的空间与保持一个命名空间数据的连续性。
722 |
723 | 需要注意的一个命名空间freelist是否有大小合适的盘区可以使用,如果有就回收空闲的磁盘空间。
724 |
725 |
726 |
727 | ### 哪些语言支持MongoDB?
728 |
729 | C、C++、C#、Java、Node.js、Perl、Php 等
730 |
731 |
732 |
733 | ### 在MongoDB中如何创建一个新的数据库
734 |
735 | MongoDB 用 use + 数据库名称 的方式来创建数据库。use 会创建一个新的数据库,如果该数据库存在,则返回这个数据库。
736 |
737 |
738 |
739 | ### 在MongoDB中如何查看数据库列表
740 |
741 | 使用命令"show dbs"
742 |
743 |
744 |
745 | ### MongoDB中的分片是什么意思
746 |
747 | 分片是将数据水平切分到不同的物理节点。当应用数据越来越大的时候,数据量也会越来越大。当数据量增长时,单台机器有可能无法存储数据或可接受的读取写入吞吐量。利用分片技术可以添加更多的机器来应对数据量增加以及读写操作的要求。
748 |
749 |
750 |
751 | ### 如何查看使用MongoDB的连接Sharding - MongoDB Manual21.如何查看使用MongoDB的连接
752 |
753 | 使用命令"db.adminCommand(“connPoolStats”)"
754 |
755 | >db.adminCommand(“connPoolStats”)
756 |
757 |
758 |
759 | ### 什么是复制
760 |
761 | 复制是将数据同步到多个服务器的过程,通过多个数据副本存储到多个服务器上增加数据可用性。复制可以保障数据的安全性,灾难恢复,无需停机维护(如备份,重建索引,压缩),分布式读取数据。
762 |
763 |
764 |
765 | ### 在MongoDB中如何在集合中插入一个文档
766 |
767 | 要想将数据插入 MongoDB 集合中,需要使用 insert() 或 save() 方法。
768 |
769 | ```
770 | db.collectionName.insert({"key":"value"})
771 | db.collectionName.save({"key":"value"})
772 | ```
773 |
774 |
775 |
776 | ### 在MongoDB中如何除去一个数据库Collection Methods24.在MongoDB中如何除去一个数据库
777 |
778 | MongoDB 的 dropDatabase() 命令用于删除已有数据库。
779 |
780 | ```
781 | db.dropDatabase()
782 | ```
783 |
784 |
785 |
786 | ### 在MongoDB中如何查看一个已经创建的集合
787 |
788 | 可以使用show collections 查看当前数据库中的所有集合清单
789 |
790 | ```
791 | show collections
792 | ```
793 |
794 |
795 |
796 | ### 在MongoDB中如何删除一个集合
797 |
798 | MongoDB 利用 db.collection.drop() 来删除数据库中的集合。
799 |
800 | ```
801 | db.CollectionName.drop()
802 | ```
803 |
804 |
805 |
806 | ### 为什么要在MongoDB中使用分析器
807 |
808 | 数据库分析工具(Database Profiler)会针对正在运行的mongod实例收集数据库命令执行的相关信息。包括增删改查的命令以及配置和管理命令。分析器(profiler)会写入所有收集的数据到 system.profile集合,一个capped集合在管理员数据库。分析器默认是关闭的你能通过per数据库或per实例开启。
809 |
810 |
811 |
812 | ### 分析器在MongoDB中的作用是什么?
813 |
814 | MongoDB中包括了一个可以显示数据库中每个操作性能特点的数据库分析器。通过这个分析器你可以找到比预期慢的查询(或写操作);利用这一信息,比如,可以确定是否需要添加索引。
815 |
816 |
817 |
818 | ### MongoDB支持主键外键关系吗
819 |
820 | 默认MongoDB不支持主键和外键关系。用Mongodb本身的API需要硬编码才能实现外键关联,不够直观且难度较大。
821 |
822 |
823 |
824 | ### MongoDB支持哪些数据类型
825 |
826 | String、Integer、Double、Boolean、Object、Object ID、Arrays、Min/Max Keys、Datetime、Code、Regular Expression等
827 |
828 |
829 |
830 | ### 为什么要在MongoDB中用"Code"数据类型
831 |
832 | "Code"类型用于在文档中存储 JavaScript 代码。
833 |
834 |
835 |
836 | ### 为什么要在MongoDB中用"Regular Expression"数据类型
837 |
838 | "Regular Expression"类型用于在文档中存储正则表达式
839 |
840 |
841 |
842 | ### 为什么在MongoDB中使用"Object ID"数据类型
843 |
844 | "ObjectID"数据类型用于存储文档id
845 |
846 |
847 |
848 | ### "ObjectID"由哪些部分组成
849 |
850 | 一共有四部分组成:时间戳、客户端ID、客户进程ID、三个字节的增量计数器
851 |
852 | _id是一个 12 字节长的十六进制数,它保证了每一个文档的唯一性。在插入文档时,需要提供 _id 。如果你不提供,那么 MongoDB 就会为每一文档提供一个唯一的 id。_id 的头 4 个字节代表的是当前的时间戳,接着的后 3 个字节表示的是机器 id 号,接着的 2 个字节表示MongoDB 服务器进程 id,最后的 3 个字节代表递增值。
853 |
854 |
855 |
856 | ### 在MongoDb中什么是索引
857 |
858 | 索引用于高效的执行查询.没有索引MongoDB将扫描查询整个集合中的所有文档这种扫描效率很低,需要处理大量数据。索引是一种特殊的数据结构,将一小块数据集保存为容易遍历的形式。索引能够存储某种特殊字段或字段集的值,并按照索引指定的方式将字段值进行排序。
859 |
860 |
861 |
862 | ### 如何添加索引
863 |
864 | 使用 db.collection.createIndex() 在集合中创建一个索引
865 |
866 | ```
867 | db.collectionName.createIndex({columnName:1})
868 | ```
869 |
870 |
871 |
872 | ### 用什么方法可以格式化输出结果
873 |
874 | 使用pretty() 方法可以格式化显示结果
875 |
876 | ```
877 | >db.collectionName.find().pretty()
878 | ```
879 |
880 |
881 |
882 | ### 如何使用"AND"或"OR"条件循环查询集合中的文档
883 |
884 | 在 find() 方法中,如果传入多个键,并用逗号( , )分隔它们,那么 MongoDB 会把它看成是AND条件。
885 |
886 | ```
887 | >db.mycol.find({key1:value1, key2:value2}).pretty()
888 | ```
889 |
890 | 若基于OR条件来查询文档,可以使用关键字$or。
891 |
892 | ```
893 | >db.mycol.find(
894 | {
895 | $or: [
896 | {key1: value1}, {key2:value2}
897 | ]
898 | }
899 | ).pretty()
900 | ```
901 |
902 |
903 |
904 | ### 在MongoDB中如何更新数据
905 |
906 | update() 与 save() 方法都能用于更新集合中的文档。update() 方法更新已有文档中的值,而 save() 方法则是用传入该方法的文档来替换已有文档。
907 |
908 |
909 |
910 | ### 如何删除文档
911 |
912 | MongoDB 利用 remove() 方法 清除集合中的文档。它有 2 个可选参数:
913 |
914 | - deletion criteria:(可选)删除文档的标准。
915 | - justOne:(可选)如果设为 true 或 1,则只删除一个文档。
916 |
917 | ```
918 | >db.collectionName.remove({key:value})
919 | ```
920 |
921 |
922 |
923 | ### 在MongoDB中如何排序
924 |
925 | MongoDB 中的文档排序是通过 sort() 方法来实现的。sort() 方法可以通过一些参数来指定要进行排序的字段,并使用 1 和 -1 来指定排序方式,其中 1 表示升序,而 -1 表示降序。
926 |
927 | ```
928 | >db.connectionName.find({key:value}).sort({columnName:1})
929 | ```
930 |
931 |
932 |
933 | ### 什么是聚合
934 |
935 | 聚合操作能够处理数据记录并返回计算结果。聚合操作能将多个文档中的值组合起来,对成组数据执行各种操作,返回单一的结果。它相当于 SQL 中的 count(*) 组合 group by。对于 MongoDB 中的聚合操作,应该使用 aggregate() 方法。
936 |
937 | ```
938 | >db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
939 | ```
940 |
941 |
942 |
943 | ### 在MongoDB中什么是副本集
944 |
945 | 在MongoDB中副本集由一组MongoDB实例组成,包括一个主节点多个次节点,MongoDB客户端的所有数据都写入主节点(Primary),副节点从主节点同步写入数据,以保持所有复制集内存储相同的数据,提高数据可用性。
--------------------------------------------------------------------------------
/interviewDoc/Java/index.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 |
4 | 
5 |
6 | # 所有面试题完整版,都整理成了高清的PDF。
7 |
8 | 
--------------------------------------------------------------------------------
/interviewDoc/Java/linux/Linux常用命令.md:
--------------------------------------------------------------------------------
1 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
2 |
3 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
4 |
5 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
6 |
7 |
8 | ### 启动网络命令
9 |
10 | ip addr 查看网卡信息
11 |
12 | ```
13 | service network start 启动网卡
14 | service network stop 关闭网卡
15 | service network restart 重启网络
16 | ```
17 |
18 | ### pwd命令
19 |
20 | pwd命令,查看当前目录的路径
21 |
22 | linux下所有的绝对路径都是从根目录"/"开始
23 |
24 | root:是linux下root用户的根目录
25 |
26 | home:是linux下其他用户的默认根目录 (例如:在linux上创建了一个bow用户,那么就会在/home下面生成一个bow目录作为bow用户的根目录)
27 |
28 | etc:是linux下系统配置文件目录
29 |
30 | tmp:临时文件目录,所有用户都可以用
31 |
32 |
33 |
34 | ### ls命令
35 |
36 | ls [参数] 目录路径
37 | ls 表示查看目录下的文件
38 |
39 | ```
40 | ls #表示查看当前目录下的文件
41 | ls -l #表示查看当前目录下的详细信息
42 | ls -a #表示查看当前目录下的所有文件(包含隐藏文件)
43 | ls -la #表示查看当前目录下的所有文件(包含隐藏文件)的详细信息
44 | ls -lh #h是以适当的单位来显示文件的大小 ls -lh表示查看当前目录下的文件的详细信息,并以合适单位显示文件大小
45 |
46 | ls -l / #表示查看根目录"/"下文件的详细信息
47 |
48 | ls /etc #表示查看目录/etc下的文件
49 |
50 | ls --help #查看命令的帮助文档
51 | --help参数:所有linux上的命令都有,但写法上有如下几种:
52 | (1)--help
53 | (2)--h
54 | (3)-help
55 | (4)-h
56 | ll命令:它和ls -l命令功能相同,但是不是所有的linux上都默认安装
57 | ```
58 |
59 |
60 |
61 | ### cd命令
62 |
63 | cd 目录路径 #进入一个目录,目录路径可以是绝对路径(以/开始的路径都是绝对路径),也可以是相对路径
64 | 相对路径:以非/开始的路径,
65 | 注意: "."表示当前目录
66 | "…"表示当前目录的上一级目录,它可以多个一起使用
67 | "~"表示当前用户的根目录 例如:root用户时,~表示/root目录 bow用户时,~表示/home/bow目录
68 |
69 | ```
70 | cd / #表示进入系统根目录
71 | cd usr/ #表示进入当前目录下的usr目录
72 | cd local/ #表示进入当前目录下的local目录
73 | cd ./bin #表示进入当前目录下的bin目录
74 | cd .. #表示进入当前目录的上一级目录
75 | cd ../.. #表示进入当前目录的上级目录的上一级目录
76 | cd /usr/local/bin #进入/usr/local/bin目录
77 | cd ../etc #表示进入和当前目录同级的etc目录 #..表示当前目录的上一级目录 ../etc表示当前目录上级目录下的etc目录(和当前目录同级)
78 | cd ~ #表示进入当前用户的根目录(cd ~ 和直接执行cd后不加目录的效果相同)
79 | #例如:root用户进入/root目录,bow用户进入/home/bow目录
80 |
81 | cd ~/data #表示进入当前用户根目录下的data目录 例如:root用户则进入了/root/data目录
82 | ```
83 |
84 |
85 |
86 | ### mkdir命令
87 |
88 | mkdir 目录路径 #创建一个目录,目录路径可以是绝对路径也可以是相对路径
89 |
90 | ```
91 | mkdir data #在当前目录下创建一个data目录
92 | mkdir ./dir #在当前目录下创建一个dir目录
93 | mkdir /root/tmp #在/root目录下创建一个tmp目录
94 | ```
95 |
96 | mkdir创建目录时,只有在目录的上级目录存在时,才会创建
97 |
98 | mkdir -p 目录#创建目录时,如果没有父目录,会创建父目录,递归地创建目录
99 | mkdir -p a/b/c #在当前目录下创建3级目录
100 |
101 |
102 |
103 | ### rmdir命令
104 |
105 | ```
106 | rmdir [参数] 目录路径 #删除目录命令,rmdir默认只能删除空目录
107 |
108 | rmdir ./dir #删除当前目录下的dir目录
109 |
110 | rmdir -p 目录路径 #表示删除目录和它的父目录(目录要是一个空目录)
111 | rmdir -p a/b/c #删除当前目录下的a/b/c目录
112 | ```
113 |
114 |
115 |
116 | ### touch命令
117 |
118 | touch 命令 #创建文件命令
119 |
120 | touch 文件路径
121 |
122 | ```
123 | touch 1.txt #在当前目录下创建一个1.txt文件
124 | touch /root/2.txt #在/root目录下创建一个2.txt文件
125 | ```
126 |
127 |
128 |
129 | ### rm命令
130 |
131 | rm [参数] 路径 #删除命令
132 |
133 | rm 1.txt #删除当前目录下的1.txt文件,删除时会提示,是否删除如果输入y表示删除,输入n表示不删除
134 |
135 | rm -f /root/2.txt #-f表示强制删除,不会提示,强制删除/root目录下的2.txt
136 |
137 | ```
138 | rm -r a/ #递归的删除当前目录下a目录下的所有内容
139 | [root@bow ~]# rm -r a/
140 | rm:是否进入目录"a/"? y
141 | rm:是否进入目录"a/b"? y
142 | rm:是否进入目录"a/b/c"? y
143 | rm:是否删除普通空文件 "a/b/c/3.txt"?y
144 | rm:是否删除目录 "a/b/c"?y
145 | rm:是否删除普通空文件 "a/b/2.txt"?y
146 | rm:是否删除目录 "a/b"?y
147 | rm:是否删除普通空文件 "a/1.txt"?y
148 | rm:是否删除目录 "a/"?y
149 | rm -rf a/ #强制删除当前目录下a目录及a目录下的所有内容
150 |
151 | rm -rf * #删除当前目录下的所有内容
152 | rm -rf a/* #删除当前目录下a目录下的所有内容
153 | rm -rf *.txt #删除当前目录下的所有txt文件
154 | rm -rf *s* #删除当前目录下所有名字中包含s的文件或文件夹
155 | ```
156 |
157 |
158 |
159 | ### echo命令
160 |
161 | echo #输出命令,可以输入变量,字符串的值
162 |
163 | ```
164 | echo Hello World #打印Hello World
165 | echo $PATH #打印环境变量PATH的值,其中$是取变量值的符号,用法:$变量名 或者 ${变量名}
166 |
167 | echo -n #打印内容但不换行
168 | echo -n Hello World
169 | ```
170 |
171 |
172 |
173 | ### >和>>命令
174 |
175 | 和>>:输出符号,将内容输出到文件中,>表示覆盖(会删除原文件内容) >>表示追加
176 |
177 | ```
178 | echo Hello World > 1.txt #将Hello World输出到当前目录下的1.txt文件
179 | #如果当前目录下没有1.txt文件会创建一个新文件,
180 | #如果当前目录下有1.txt,则会删除原文件内容,写入Hello World
181 | echo 1234 >> 1.txt #将1234追加到当前目录下的1.txt中,如果文件不存在会创建新文件
182 | ```
183 |
184 | 通过>和>>都可以创建文件
185 |
186 |
187 |
188 | ### 文件查看命令
189 |
190 | cat 文件路径 #查看文件的所有内容
191 |
192 | ```
193 | cat 1.txt #查看当前目录下1.txt的内容
194 | cat /root/1.txt #查看/root目录下的1.txt文件内容
195 | ```
196 |
197 | more 文件路径 #分页查看文件内容
198 |
199 | more linux常用命令.txt #分页查看当前目录下linux常用命令.txt文件的内容
200 | \#按空格或回车,会继续加载文件内容,按q退出查看
201 | \#当加载到文件末尾时,会自动退出查看
202 |
203 | less 文件路径 #分页查看文件内容
204 | less linux常用命令.txt #分页查看文件内容,按空格继续加载文件,按q退出查看,不会自动退出查看
205 |
206 | head [参数] 文件路径 #从文件开始查看文件
207 |
208 | ```
209 | head linux常用命令.txt #查看文件的前10行内容
210 |
211 | head -n 文件路径 # n是一个正整数,表示查看文件的前n行数据
212 | head -20 linux常用命令.txt #查看文件的前20行内容
213 | ```
214 |
215 | tail [参数] 文件路径 #从文件的末尾查看文件内容
216 | tail linux常用命令.txt #查看文件的后10行内容
217 |
218 | ```
219 | tail -n 文件路径 # n是一个正整数,表示查看文件的后n行数据
220 | tail -15 linux常用命令.txt #查看文件后15行内容
221 |
222 | tail -f 文件路径 #动态的查看文件的最后几行内容(查看文件时,等待文件更新,如果文件更新了,会显示出新的内容)
223 | ```
224 |
225 | tail -f 1.txt #查看文件1.txt的最新内容,tail -f 一般用来查看日志文件 按CTRL+C或才CTRL+Z退出查看
226 |
227 | ```
228 | CTRL+C:表示暂停进程
229 | CTRL+Z: 表示停止进程
230 | ```
231 |
232 |
233 |
234 | ### 文件编辑命令
235 |
236 | vi/vim命令:这两个命令在使用上几乎完全一样(个人喜欢vim命令)
237 |
238 | 安装vim命令:(安装是需要网络的)
239 |
240 | ```
241 | yum -y install vim
242 | ```
243 |
244 | yum命令是centos和red hat系统上使用官方资源包去安装软件的命令
245 |
246 | ```
247 | yum -y install 软件名
248 | yum -y remove 软件名
249 | ```
250 |
251 | 查看虚拟机能不能上外网:
252 |
253 | ```
254 | ping www.baidu.com
255 | CTRL+C或者CTRL+Z退出
256 | ```
257 |
258 | vim命令总体分为两类
259 |
260 | vim 文件路径 --进入非编辑模式
261 |
262 | 非编辑模式命令:
263 |
264 | ```
265 | yy:复制光标当前行
266 | p:粘贴
267 | dd:删除光标当前行
268 | $:光标跳到当前行的行尾
269 | ^:光标跳到当前行的行首
270 |
271 | :s/原字符串/新字符串/:替换光标当前行内容
272 | :%s/原字符串/新字符串/g:全文替换 #g表示global i表示ignore忽略大小写
273 |
274 | /要查找的内容:从光标当前行向后查找内容
275 | /d #在文件中查找d字母
276 | ?要查找的内容:从光标当前位置向前查找内容
277 | ?d #查找文件中的d字母
278 | CTRL+F:向下翻1页
279 | CTRL+B:向上翻1页
280 |
281 | :set nu:显示文件的行号
282 | :set nonu: 去掉行号显示
283 | u:撤消
284 |
285 | **:set ff :显示文件的格式 #unix表示在unix上的文件 dos表示文件是windows上的文件**
286 | :w :表示保存文件
287 | :q :表示退出vim命令
288 | :wq:保存并退出
289 | :w!:强制保存
290 | :q!:强制退出但不保存
291 | :wq!:强制保存并退出
292 | i:表示进入编辑模式,并且光标在当前行
293 | o:表示进入编辑模式,并且光标出现的当前行的下一行(新行)
294 | ```
295 |
296 | 编辑模式命令:
297 |
298 | 编辑模式下可以能过方向键控制光标的位置,并且可以输入文件到光标当前位置
299 |
300 | ```
301 | ESC:退出编辑模式
302 | ```
303 |
304 |
305 |
306 | ### cp命令
307 |
308 | cp 拷贝命令
309 |
310 | cp [参数] 原文件路径 目标文件路径
311 |
312 | ```
313 | cp 1.txt a/ #将1.txt文件拷贝到a目录下
314 | cp 1.txt 2.txt #将1.txt拷贝到2.txt
315 | cp -r a data #-r参数表示将目录和目录下的文件一起拷贝,将a目录拷贝到data目录
316 | ```
317 |
318 |
319 |
320 | ### scp命令
321 |
322 | scp 远程拷贝命令,它可以将本地文件拷贝到远程服务器,也可以将远程服务器的文件拷贝到本地,也可以将一台服务器文件拷贝到另一台
323 |
324 | ```
325 | scp -r 本地文件路径 用户名@ip[:port]:远程路径 #将本地文件拷贝到远程服务器
326 | scp -r 2.txt root@192.168.5.105:/root/data/ #将本地的2.txt拷贝到192.168.5.105的/root/data目录下
327 |
328 | scp -r 用户名@ip[:port]:远程文件路径 本地路径 #将远程文件拷贝到本地
329 | scp -r root@192.168.5.105:/root/3.bak /root/data #将远程的/root/3.bak文件拷贝到本地的/root/data目录
330 | ```
331 |
332 | scp -r 用户名@ip[:port]:远程文件路径 用户名@ip[:port]:远程文件路径 #将文件从一台服务器拷贝到另一台服务器
333 |
334 | ```
335 | scp -r root@192.168.5.105:/root/tmp root@192.168.5.105:/root/data/ #将/root/tmp拷贝到远程的/root/data目录下
336 | ```
337 |
338 |
339 |
340 | ### mv命令
341 |
342 | mv 移动命令,它可以移动文件,也可以给文件改名
343 |
344 | mv 原文件路径 目标文件路径 #将文件从一个地方拷贝到另一个地方
345 |
346 | ```
347 | mv 1.txt 12.txt #将文件1.txt改名为12.txt
348 | mv tmp tmp #将tmp目录改名为tm
349 | mv 12.txt tm #将文件12.txt移动到tm目录下
350 | ```
351 |
352 |
353 |
354 | ### man命令
355 |
356 | man 命令,查看命令的命令,查看命令帮助文档(显示的信息最详细)
357 |
358 | ```
359 | man mv #查看mv命令的文件
360 |
361 | man命令和命令的 --help参数结果相似(man命令只适用于linux本身的命令)
362 | ```
363 |
364 |
365 |
366 | ### free命令
367 |
368 | free命令,它是用来查看系统内存的命令
369 |
370 | ```
371 | free #查看系统内存使用情况
372 | free -h #查看内存使用情况,并且以合适的单位显示大小
373 | ```
374 |
375 |
376 |
377 | ### df命令
378 |
379 | df命令,它是查看系统硬盘的命令
380 |
381 | ```
382 | df #查看系统硬盘使用情况
383 | df -h #查看硬盘使用,并以合适单位显示大小
384 | ```
385 |
386 |
387 |
388 | ### wc命令
389 |
390 | wc 命令,word count的缩写,它是查看文件的单词个数
391 |
392 | wc [参数] 文件
393 |
394 | ```
395 | wc -l linux常用命令.txt #-l表示line行数 计算文件的行数
396 | wc -w linux常用命令.txt #-w表示word单词个数 计算文件的单词个数
397 | ```
398 |
399 |
400 |
401 | ### ps命令
402 |
403 | ps命令,它是查看系统进程的命令
404 |
405 | ps -aux
406 |
407 | ps -ef
408 |
409 | jps 查看java进程
410 |
411 |
412 |
413 | ### kill命令
414 |
415 | kill 进程id #结束进程
416 |
417 | ```
418 | root 21752 1.6 0.5 158800 5532 ? Ss 08:34 0:00 sshd: root@pts/0
419 | ```
420 |
421 | kill 21752 #结束ssh登陆的进程
422 |
423 | kill -9 进程id #强制结束进程
424 |
425 |
426 |
427 | ### 用户和权限命令
428 |
429 | 创建用户组:
430 |
431 | groupadd 用户组名称 #创建一个用户组
432 |
433 | ```
434 | groupadd bows #创建一个叫bows的用户组
435 | 删除用户组:
436 | groupdel 用户组名称 #删除一个用户组(删除时必须是用户组下没有用户时)
437 | groupdel bows #删除用户组
438 | ```
439 |
440 | 创建用户:
441 |
442 | useradd 用户名 [-g 用户组名 -G 用户组名] #创建一个用户,-g指定用户的主用户组,-G指定用户的其他用户组
443 |
444 | ```
445 | useradd bow -g bows #创建bow用户,并指定它的主用户组是bows
446 | id 用户名 #查看用户的id
447 | id bow #查看用户bow的id
448 | ```
449 |
450 | 删除用户:
451 |
452 | ```
453 | userdel 用户名 #删除用户
454 | userdel bow #删除用户bow
455 | ```
456 |
457 | 切换用户:
458 |
459 | ```
460 | su 用户名 #切换用户,但不加载用户的环境变量
461 | su - 用户名 #切换用户,并加载用户的环境变量(建议使用这种方式切换用户)
462 | su bow #切换到bow用户(root用户切换到其他用户是不需要输入密码的,其他用户切换到root用户是要输入root用户密码的,其他用户之间的切换也是需要密码)
463 | exit #退出当前用户的登陆
464 | ```
465 |
466 | 修改用户密码:
467 |
468 | ```
469 | passwd 用户名 #修改用户密码
470 | passwd bow #修改bow用户的密码
471 | ```
472 |
473 | 权限:
474 |
475 | ```
476 | 文件类型 用户权限 用户组权限 其他用户权限
477 | - rw- r-- r-- . 1 root
478 | root 5890 3月 23 14:11 linux常用命令.txt
479 | d rwx r-x r-x . 4 root
480 | root 81 3月 24 08:06 data
481 | d表示文件夹 u表示用户权限 g表示用户组权限 o表示其他用户权限
482 |
483 | r:表示读权限 数字表示为4
484 | w:表示写权限 数字表示为2
485 | x:表示执行权限 数字表示为1
486 | -:表示没有权限
487 | ```
488 |
489 |
490 |
491 | ### chmod 赋权限命令
492 |
493 | ```
494 | chmod 权限 文件路径
495 | -rw-r--r--. 1 root root 31 3月 24 07:46 2.txt
496 | chmod u+x 2.txt #给用户加上执行权限
497 | -rwxr--r--. 1 root root 31 3月 24 07:46 2.txt
498 | chmod g+w 2.txt #给用户组加写权限
499 | -rwxrw-r--. 1 root root 31 3月 24 07:46 2.txt
500 | chmod o+x 2.txt #给其他用户加执行权限
501 | -rwxrw-r-x. 1 root root 31 3月 24 07:46 2.txt
502 | chmod g-w 2.txt #去掉用户的写权限
503 | -rwxr--r-x. 1 root root 31 3月 24 07:46 2.txt
504 | ```
505 |
506 | 用3个数字来设置文件或目录的权限,第1个数字表示用户权限,第2数字表示用户组权限,第3个数字表示其他用户权限
507 |
508 | ```
509 | chmod 755 2.txt #设置用户的权限为rwx,用户组的权限r-x,其他用户的权限r-x
510 | -rwxr-xr-x. 1 root root 31 3月 24 07:46 2.txt
511 | chmod 766 2.txt #设置用户权限为rwx,用户组权限rw-,其他用户的权限rw-
512 | -rwxrw-rw-. 1 root root 31 3月 24 07:46 2.txt
513 | ```
514 |
515 | 设置目录权限时,要使用-R参数,保证目录下的所有文件和目录的权限相同
516 |
517 | ```
518 | drwxr-xr-x. 4 root root 81 3月 24 08:06 data
519 | chmod -R 777 data #将data目录以及它下面的所有文件的权限设置为rwxrwxrwx
520 | drwxrwxrwx. 4 root root 81 3月 24 08:06 data
521 | ```
522 |
523 | chown 命令,它是更改文件所属用户
524 |
525 | ```
526 | chown -R 用户[:用户组] 目录或文件
527 | -rwxrw-rw-. 1 root root 31 3月 24 07:46 2.txt
528 | chown bow 2.txt #将2.txt的所属用户改为bow
529 | -rwxrw-rw-. 1 bow root 31 3月 24 07:46 2.txt
530 | chown bow:bows 2.txt #将2.txt所属的用户改为bow,用户组改为bows
531 | -rwxrw-rw-. 1 bow bows 31 3月 24 07:46 2.txt
532 | drwxr--r--. 4 root root 81 3月 24 08:06 data
533 | chown -R bow:bows data #将data目录及它子目录文件的所属用户改为bow,用户组改为bows
534 | drwxr--r--. 4 bow bows 81 3月 24 08:06 data
535 | ```
536 |
537 |
538 |
539 | ### 查找命令
540 |
541 | find命令,可以根据文件的时间,名称等查找文件
542 |
543 | ```
544 | find *.txt #查找txt文件
545 | ```
546 |
547 | grep 命令,查找内容
548 |
549 | ```
550 | grep cat linux常用命令.txt #在linux常用命令.txt文件中查询包含cat的行,查找文件内容
551 | ```
552 |
553 | | 通道符号,连接两个命令的,将前一个命令的查询结果传给后一个命令
554 |
555 | ```
556 | ps -ef | grep sshd #查看系统中sshd的进程
557 | ps -ef | grep java #查看所有java进程
558 | grep -v #-v参数表示查询不包含查找条件的行
559 | grep -v cat linux常用命令.txt #查找linux常用命令.txt中不包含cat的行
560 |
561 | ps -ef | grep sshd | grep -v grep #查询sshd的进程,不包括grep的行
562 | ```
563 |
564 | –了解性查询命令
565 |
566 | ```
567 | who命令 #查询系统中的用户(登陆的用户)
568 | whoami命令 #查看系统当前用户名
569 | whereis命令 #查看系统安装的某个软件的路径
570 | whereis python #查看python的安装路径
571 | which 命令 #查找软件的可执行文件路径
572 | which python #查看python可执行文件路径
573 | ```
574 |
575 |
576 |
577 | ### 压缩命令
578 |
579 | 安装zip和unzip命令:
580 |
581 | ```
582 | yum -y install zip unzip
583 | ```
584 |
585 | zip压缩命令
586 |
587 | zip 压缩文件名 要压缩的文件路径
588 |
589 | ```
590 | zip 2.zip 2.txt #将2.txt压缩到2.zip中
591 |
592 | zip data.zip data #只会压缩文件夹,不会压缩文件夹下的内容
593 |
594 | zip da.zip da/* #压缩文件夹和文件夹内的文件(压缩文件夹和它的下一级文件)
595 |
596 | zip -r data.zip date #-r表示递归地将文件夹及它的子目录文件全部压缩
597 | ```
598 |
599 | unzip解压命令
600 |
601 | unzip 压缩文件路径
602 |
603 | ```
604 | unzip 2.zip #将2.zip压缩包解压到当前目录下
605 | unzip -l 压缩文件名 #不解压文件,查看压缩包内的文件
606 | unzip -l da.zip #查看da.zip压缩文件中包含的文件
607 | unzip da.zip -d 目标目录 #将压缩文件解压到指定目录
608 | unzip da.zip -d tm/ #将压缩文件da.zip解压到tm目录下
609 | ```
610 |
611 | tar命令,用来压缩和解压缩.tar和.tar.gz包
612 |
613 | 压缩.tar包:
614 |
615 | ```
616 | tar cvf 压缩文件名 要压缩的文件或目录
617 | tar cvf 2.tar 2.txt #将2.txt压缩为2.tar包
618 | tar cvf data.tar data #将data目录夸张到data.tar包中
619 | ```
620 |
621 | 解压.tar包:
622 |
623 | tar xvf 压缩文件名 [-C 指定解压目录]
624 |
625 | ```
626 | tar xvf 2.tar #将2.tar解压到当前目录
627 | tar xvf 2.tar -C a/ #将2.tar解压到a目录
628 | tar xvf data.tar #解压data.tar到当前目录
629 | ```
630 |
631 | 压缩.tar.gz包:
632 |
633 | ```
634 | tar zcvf 压缩文件名 要压缩的文件
635 | tar zcvf tm.tar.gz tm #将当前目录下的tm目录压缩为tm.tar.gz
636 | ```
637 |
638 | 解压.tar.gz包:
639 |
640 | ```
641 | tar zxvf 压缩文件名
642 | tar zxvf tm.tar.gz #将tm.tar.gz解压到当前目录
643 | gzip命令,将文件压缩为.gz包(可以用来压缩.tar文件)
644 | gzip 要压缩的文件
645 | gzip 2.txt #将2.txt压缩为2.txt.gz
646 | gzip data.tar #将data.tar压缩为data.tar.gz
647 | ```
648 |
649 |
650 |
651 | ### source命令
652 |
653 | source 文件路径 #让配置文件修改结果立即生效,(还可以在shell脚本中引用其他的shell脚本)
654 |
655 | ```
656 | /etc/profile #linux上的系统环境变量配置文件
657 | source /etc/profile #将系统环境变量生效
658 | ```
659 |
660 |
661 |
662 | ### export命令
663 |
664 | ```
665 | export 导入全局变量(环境变量)
666 |
667 | export 变量名=变量值
668 | export 变量名
669 |
670 | 变量的赋值:
671 | 变量名=变量值
672 | ```
673 |
674 | < HELLO
682 | > WORD
683 | > JOB
684 | > SMITH
685 | > EOF
686 | HELLO
687 | WORD
688 | JOB
689 | SMITH
690 | ```
691 |
692 | < 11234
697 | > 1234
698 | > 1234
699 | > 1253
700 | > 1253
701 | > A
702 | 11234
703 | 1234
704 | 1234
705 | 1253
706 | 1253
707 | ```
708 |
709 | 注意:EOF必须顶行写
710 |
711 | ```
712 | [root@bow ~]# cat < ASDF
714 | > EOF
715 | > ASDFASDF
716 | > EOF
717 | ASDF
718 | EOF
719 | ASDFASDF
720 | ```
721 |
722 |
723 |
724 | ### cut命令
725 |
726 | cut 截取命令
727 |
728 | ```
729 | -f 参数,指定列
730 | -d 参数指定列和列之间的分隔符,默认的分隔符是\t(行向制表符)
731 | cut -f 1 1.txt #取1.txt文件中的第1列内容(列分隔符默认为\t)
732 | cut -f 2 1.txt #取1.txt文件中的第2列内容
733 | cut -f 1 -d ',' 3.txt #取3.txt文件中的第1列(列分隔符为,)
734 | cut -f 2 -d ',' 3.txt #取3.txt第2列
735 | ```
736 |
737 | wc -l linux常用命令.txt | cut -f 1 -d ’ ’ #取文件linux常用命令.txt的行数(分隔符是空格)
738 |
739 | ```
740 | [root@bow ~]# cut -f 1 -d ',' < A,B,C
742 | > D,E,F
743 | > EOF
744 | A
745 | D
746 | ```
747 |
748 |
749 |
750 | ### printf命令
751 |
752 | ```
753 | %ns 输出字符串,n是数字,指代输出几个字符
754 | %ni 输出整数。n是数字,指代输出几个数字
755 | %m.nf 位数和小数位数。例如:%8.2f 代表输出8位数,其中2位是小数,6位是整数
756 | ```
757 |
758 | printf 格式字符串 内容
759 |
760 | ```
761 | [root@bow ~]# printf '%s,%s,%s\n' abc def ghj klj klo qer #一行单词第三个打印成一行,单词和单词之间用逗号隔开
762 | abc,def,ghj
763 | klj,klo,qer
764 | [root@bow ~]# printf '%s %s\n' $(cat 4.txt) #将文件4.txt中的一行内容中的单词划分为两个一组打印 cat 合作查看文件内容 $(cat 4.txt)表示取cat命令的执行结果
765 | empno ename
766 | job sal
767 | comm depno
768 | 5.txt内容
769 | A B C D E
770 | F G H
771 | [root@bow ~]# printf '%s,%s\n' $(cat 5.txt)
772 | A,B
773 | C,D
774 | E,F
775 | G,H
776 | [root@bow ~]# printf '%5.2f\n' 12.1 #%5.2f表示输出一个小数,数的长度是5,其中有两个小数
777 | 12.10
778 | [root@bow ~]# printf '%5.2f\n' 121234.116134 #如果输出的值最大长度超出5,那么整数部分不变量,小数部分会按照四舍五入的方法保存两位
779 | 121234.12
780 | [root@bow ~]# printf '%i\n' 1234.5678 #%i只取数字的整数部分
781 | -bash: printf: 1234.5678: 无效数字
782 | 1234
783 | ```
784 |
785 |
786 |
787 | ### awk命令
788 |
789 | awk 命令字符串 要处理的内容
790 |
791 | ```
792 | [root@bow ~]# awk '{printf $1 "\n"}' 1.txt #printf 打印 $n 表示取第几列 $1表示取第1列
793 | Hello
794 | smith
795 | tomcat
796 | ```
797 |
798 | awk ‘{print $2}’ 1.txt #取1.txt的第2列,print和printf功能相同是打印,比printf多一个换行功能
799 |
800 | ```
801 | [root@bow ~]# awk '{printf $1 ","}' 1.txt
802 | Hello,smith,tomcat,[root@bow ~]#
803 | [root@bow ~]# awk '{printf $1}' 1.txt
804 | Hellosmithtomcat
805 | [root@bow ~]# awk '{printf $1 "\v"}' 1.txt
806 | Hello
807 | smith
808 | tomcat
809 | [root@bow ~]# awk '{printf $1 ","}' 1.txt
810 | Hello,smith,tomcat,
811 | ```
812 |
813 |
814 |
815 | ### sed命令
816 |
817 | sed 参数 命令 要处理的内容
818 |
819 | ```
820 | -n 一般sed命令会把所有数据都输出到屏幕。如果加入此选择,则只会把经过sed命令处理的行输出到屏幕。
821 | -e 允许对输入数据应用多条sed命令编辑
822 | -i 用sed的修改结果直接修改读取的数据的文件,而不是修改屏幕输出
823 | [root@bow ~]# sed '2p' 1.txt #查询第2行
824 | Hello world
825 | smith 18
826 | smith 18
827 | tomcat etl
828 | [root@bow ~]# sed -n '2p' 1.txt
829 | smith 18
830 | [root@bow ~]# sed -i 's/18/20/g' 1.txt 使用sed命令修改1.txt内容,将1.txt中18替换为20
831 | [root@bow ~]# cat 1.txt
832 | Hello world
833 | smith 20
834 | tomcat etl
835 | a\ 追加,在当前行后添加一行或多行。添加多行时除最后一行外,每行末尾需要用"\"代表数据未完结。
836 | d 删除,删除指定的
837 | p 打印,输出指定的行
838 | [root@bow ~]# sed -i '2a !' 1.txt #在第2行后面追加一行 !
839 | [root@bow ~]# cat 1.txt
840 | Hello world
841 | smith 20
842 | !
843 | tomcat etl
844 | [root@bow ~]# sed -i '3d' 1.txt #删除文件的第3行内容
845 | [root@bow ~]# cat 1.txt
846 | Hello world
847 | smith 20
848 | tomcat etl
849 | [root@bow ~]# vim 6.txt
850 | [root@bow ~]# cat 6.txt
851 | abcd/home/bow
852 | if ad
853 | -e /home/bow
854 | abcd/home/bow
855 | if ad
856 | -e /home/bow
857 | abcd/home/bow
858 | if ad
859 | -e /home/bow
860 | #将6.txt文件中的/home/bow修改为/user/bw
861 | #注意:替换时,的符号是根据/来判断 s/原字符串/目标字符串/g 如果原字符串或新的字符串中有/时,需要使用\来转义
862 | # 错误写法:s//home/bow//user/bw/g 正确写法 s/\/home\/bow/\/user\/bw/g
863 | [root@bow ~]# sed -i 's/\/home\/bow/\/user\/bw/g' 6.txt
864 | [root@bow ~]# cat 6.txt
865 | abcd/user/bw
866 | if ad
867 | -e /user/bw
868 | abcd/user/bw
869 | if ad
870 | -e /user/bw
871 | abcd/user/bw
872 | if ad
873 | -e /user/bw
874 | ```
875 |
876 | 注意:linux中字符串的下标是从0开始的
877 |
878 |
879 |
880 | ### service命令
881 |
882 | service服务命令
883 |
884 | ```
885 | ervice 服务名 [命令]
886 | 命令:enable|disable|start|stop|restart|status
887 | start:启动服务
888 | stop:关闭服务
889 | restart:重启服务
890 | status:查看服务状态
891 | service network start #遍历网络
892 | service network stop #关闭网络
893 | service network restart #重启网络
894 | service network status #查看网络状态
895 | service iptables start #centos6及6以下版本,启动防火墙的命令
896 | service iptables stop #centos6及6以下版本,关闭防火墙(注意,关闭防火墙,只是临时关闭,下次重启之后防火墙依然会启动)
897 | service iptables restart #重启防火墙
898 | service mysqld start #启动mysql数据库
899 | service mysqld restart #启动mysql数据库
900 | service mysqld stop #关闭mysql数据库
901 | ```
902 |
903 |
904 |
905 | ### chkconfig命令
906 |
907 | chkconfig命令检查,设置系统的各种服务
908 |
909 | ```
910 | chkconfig 服务名 on|off #on表示打开服务 off表示关闭服务 通过chkconfig设置的服务是永久生效
911 | centos6及以下版本永久关闭或打开防火墙
912 | chkconfig iptables on #打开防火墙
913 | chkconfig iptables off #永久地关闭防火墙
914 | ```
915 |
916 | 防火墙:
917 |
918 | centos7以上:
919 |
920 | ```
921 | systemctl start firewalld #启动防火墙
922 | systemctl stop firewalld #关闭防火墙(临时关闭)
923 | systemctl status firewalld #查看防火墙状态
924 | systemctl disable firewalld #永久关闭防火墙
925 | systemctl enable firewalld #打开防火墙(不是启动防火墙)
926 | 通过firewall-cmd来配置防火墙
927 | ```
928 |
929 | centos6及以下:
930 |
931 | 防火墙配置文件:/etc/iptables,这个文件可以详细的配置防火墙,如果没有/etc/iptables文件可以使用iptables save可以生成该文件
932 |
933 | iptables 命令配置防火墙
934 |
935 | ```
936 | service iptables start #centos6及6以下版本,启动防火墙的命令
937 | service iptables stop #centos6及6以下版本,关闭防火墙(注意,关闭防火墙,只是临时关闭,下次重启之后防火墙依然会启动)
938 | service iptables restart #重启防火墙
939 | ```
940 |
941 | 环境变量配置文件
942 |
943 | /etc/profile是linux系统上配置系统环境变量的一个文件(针对所有用户的配置)
944 | 用户根目录下的.bash_profile:是用户环境变量的配置(针对当前用户有效)
945 |
946 | ```
947 | su - 用户名 #切换用户时,会加载用户根目录下的.bash_profile环境变量配置文件
948 | su 用户名 #不会加载.bash_profile
949 | ```
950 |
951 | 网络配置文件
952 |
953 | 网卡配置文件目录:/etc/sysconfig/network-scripts
954 |
955 | 网卡配置文件名都是以ifcfg-开头,其中ifcfg-lo是本地网卡,是不需要配置的
956 |
957 | ```
958 | vim /etc/sysconfig/network-scripts/ifcfg-enp0s3
959 | #网卡类型
960 | TYPE="Ethernet"
961 | #协议 dhcp表示:ip地址是自动分配的,static表示静态ip(手动配置ip地址),none表示没有协议(也是需要手动配置ip地址)
962 | BOOTPROTO="dhcp"
963 | DEFROUTE="yes"
964 | #网卡名称
965 | NAME="enp0s3"
966 | UUID="deed3fd2-bd67-459b-8a49-ef0dd6e575a2"
967 | DEVICE="enp0s3"
968 | #配置网卡是否随机启动,yes:表示随机启动,no:表示需要手动启动
969 | ONBOOT="yes"
970 | #配置静态ip,BOOTPROTO必须是static或none
971 | #ip地址配置
972 | IPADDR=192.168.1.106
973 | #配置子网掩码
974 | NETMASTER=255.255.255.0
975 | #配置网关
976 | GATEWAY=192.168.1.1
977 | #配置dns:域名解析服务器可以配置多个
978 | DNS1=192.168.1.1
979 | DNS2=192.168.5.1
980 | ```
981 |
982 | 修改完网卡文件之后,*重启网络*即可
983 |
984 |
985 |
986 | ### sudo命令
987 |
988 | sudo命令,它在非root用户下,去调用一些root用户的命令,或者修改一些文件
989 | sudo命令是需要配置的,sudo的配置文件是/etc/sudoers
990 |
991 | ```
992 | #给bow用户配置sudo权限
993 | [root@bow ~]# vim /etc/sudoers
994 | ##
995 | ## Allow root to run any commands anywhere
996 | root ALL=(ALL) ALL
997 | #给bow用户设置sudo命令权限
998 | bow ALL=(ALL) ALL
999 | ```
1000 |
1001 | sudo命令的使用:
1002 |
1003 | sudo 命令
1004 |
1005 | ```
1006 | [root@bow ~]# su - bow
1007 | 上一次登录:四 3月 26 07:30:53 CST 2020pts/0 上
1008 | [bow@bow ~]$ sudo vim /etc/profile
1009 | ```
1010 |
1011 |
1012 |
1013 | ### ping命令
1014 |
1015 | ping命令查看网络连通性的命令和windows上的功能一样
1016 |
1017 | ```
1018 | ping ip(0.0.0.100)
1019 | ```
1020 |
1021 |
1022 |
1023 | ### ifconfig命令
1024 |
1025 | ifconfig命令属于net-tools软件包,使用前需要安装net-tools
1026 |
1027 | net-tools的安装:
1028 |
1029 | ```
1030 | yum -y install net-tools
1031 | ifconfig查看ip地址
1032 | ```
1033 |
1034 |
1035 |
1036 | ### netstat命令
1037 |
1038 | netstat命令也属于net-tools软件包
1039 |
1040 | ```
1041 | netstat -tulp | grep 1521 #查看oracle监听器程序是否正常启动
1042 | ```
1043 |
1044 |
1045 |
1046 | ### rpm命令
1047 |
1048 | rpm是linux上的安装命令,用来安装.rpm格式的安装包
1049 |
1050 | ```
1051 | rpm -ivh .rpm文件的路径 #表示安装软件包
1052 |
1053 | rpm -qa #查看已安装的软件
1054 | rpm -qa | grep mysql #查看已经安装的mysql软件包
1055 |
1056 | rpm -e --nodeps 安装包名 #卸载软件包 -e表示卸载 --nodeps表示不理会的依赖关系
1057 | OK,本文就这样。
1058 | ```
--------------------------------------------------------------------------------
/interviewDoc/Java/linux/Linux面试题 .md:
--------------------------------------------------------------------------------
1 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
2 |
3 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
4 |
5 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
6 |
7 |
8 |
9 |
10 | - [什么是Linux](#什么是linux)
11 | - [绝对路径用什么符号表示?当前目录、上层目录用什么表示?主目录用什么表示? 切换目录用什么命令?](#绝对路径用什么符号表示当前目录上层目录用什么表示主目录用什么表示-切换目录用什么命令)
12 | - [怎么查看当前进程?怎么执行退出?怎么查看当前路径?](#怎么查看当前进程怎么执行退出怎么查看当前路径)
13 | - [怎么清屏?怎么退出当前命令?怎么执行睡眠?怎么查看当前用户 id?查看指定帮助用什么命令?](#怎么清屏怎么退出当前命令怎么执行睡眠怎么查看当前用户-id查看指定帮助用什么命令)
14 | - [Ls 命令执行什么功能?可以带哪些参数,有什么区别?](#ls-命令执行什么功能可以带哪些参数有什么区别)
15 | - [建立软链接(快捷方式),以及硬链接的命令。](#建立软链接快捷方式以及硬链接的命令)
16 | - [目录创建用什么命令?创建文件用什么命令?复制文件用什么命令?](#目录创建用什么命令创建文件用什么命令复制文件用什么命令)
17 | - [查看文件内容有哪些命令可以使用?](#查看文件内容有哪些命令可以使用)
18 | - [随意写文件命令?怎么向屏幕输出带空格的字符串,比如”hello world”?](#随意写文件命令怎么向屏幕输出带空格的字符串比如hello-world)
19 | - [终端是哪个文件夹下的哪个文件?黑洞文件是哪个文件夹下的哪个命令?](#终端是哪个文件夹下的哪个文件黑洞文件是哪个文件夹下的哪个命令)
20 | - [移动文件用哪个命令?改名用哪个命令?](#移动文件用哪个命令改名用哪个命令)
21 | - [Linux 下命令有哪几种可使用的通配符?分别代表什么含义?](#linux-下命令有哪几种可使用的通配符分别代表什么含义)
22 | - [用什么命令对一个文件的内容进行统计?(行号、单词数、字节数)](#用什么命令对一个文件的内容进行统计行号单词数字节数)
23 | - [Grep 命令有什么用?如何忽略大小写?如何查找不含该串的行?](#grep-命令有什么用如何忽略大小写如何查找不含该串的行)
24 | - [Linux 中进程有哪几种状态?在 ps 显示出来的信息中,分别用什么符号表示的?](#linux-中进程有哪几种状态在-ps-显示出来的信息中分别用什么符号表示的)
25 | - [利用 ps 怎么显示所有的进程? 怎么利用 ps 查看指定进程的信息?](#利用-ps-怎么显示所有的进程-怎么利用-ps-查看指定进程的信息)
26 | - [哪个命令专门用来查看后台任务?](#哪个命令专门用来查看后台任务)
27 | - [终止进程用什么命令? 带什么参数?](#终止进程用什么命令-带什么参数)
28 | - [搜索文件用什么命令? 格式是怎么样的?](#搜索文件用什么命令-格式是怎么样的)
29 | - [查看当前谁在使用该主机用什么命令? 查找自己所在的终端信息用什么命令?](#查看当前谁在使用该主机用什么命令-查找自己所在的终端信息用什么命令)
30 | - [使用什么命令查看用过的命令列表?](#使用什么命令查看用过的命令列表)
31 | - [使用什么命令查看磁盘使用空间?空闲空间呢?](#使用什么命令查看磁盘使用空间空闲空间呢)
32 | - [使用什么命令查看 ip 地址及接口信息?](#使用什么命令查看-ip-地址及接口信息)
33 | - [通过什么命令查找执行命令?](#通过什么命令查找执行命令)
34 | - [du 和 df 的定义,以及区别?](#du-和-df-的定义以及区别)
35 | - [**Unix和Linux有什么区别?**](#unix和linux有什么区别)
36 | - [**什么是 Linux 内核?**](#什么是-linux-内核)
37 | - [**Linux的基本组件是什么?**](#linux的基本组件是什么)
38 | - [简单 Linux 文件系统?](#简单-linux-文件系统)
39 | - [绝对路径用什么符号表示?当前目录、上层目录用什么表示?主目录用什么表示? 切换目录用什么命令?](#绝对路径用什么符号表示当前目录上层目录用什么表示主目录用什么表示-切换目录用什么命令)
40 | - [怎么查看当前进程?怎么执行退出?怎么查看当前路径?](#怎么查看当前进程怎么执行退出怎么查看当前路径)
41 | - [怎么清屏?怎么退出当前命令?怎么执行睡眠?怎么查看当前用户 id?查看指定帮助用什么命令?](#怎么清屏怎么退出当前命令怎么执行睡眠怎么查看当前用户-id查看指定帮助用什么命令)
42 | - [**Ls 命令执行什么功能? 可以带哪些参数,有什么区别?**](#ls-命令执行什么功能-可以带哪些参数有什么区别)
43 | - [建立软链接(快捷方式),以及硬链接的命令。](#建立软链接快捷方式以及硬链接的命令)
44 | - [目录创建用什么命令?创建文件用什么命令?复制文件用什么命令?](#目录创建用什么命令创建文件用什么命令复制文件用什么命令)
45 | - [文件权限修改用什么命令?格式是怎么样的?](#文件权限修改用什么命令格式是怎么样的)
46 | - [查看文件内容有哪些命令可以使用?](#查看文件内容有哪些命令可以使用)
47 | - [随意写文件命令?怎么向屏幕输出带空格的字符串,比如”hello world”?](#随意写文件命令怎么向屏幕输出带空格的字符串比如hello-world)
48 | - [终端是哪个文件夹下的哪个文件?黑洞文件是哪个文件夹下的哪个命令?](#终端是哪个文件夹下的哪个文件黑洞文件是哪个文件夹下的哪个命令)
49 |
50 |
51 |
52 | ### 什么是Linux
53 |
54 | Linux是一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX和Unix的多用户、多任务、支持多线程和多CPU的操作系统。它能运行主要的Unix工具软件、应用程序和网络协议。它支持32位和64位硬件。Linux继承了Unix以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。
55 |
56 |
57 |
58 | ### 绝对路径用什么符号表示?当前目录、上层目录用什么表示?主目录用什么表示? 切换目录用什么命令?
59 |
60 | 绝对路径:如 `/etc/init.d`
61 | 当前目录和上层目录:`./ ../`
62 | 主目录:`~/`
63 | 切换目录:`cd`
64 |
65 |
66 |
67 | ### 怎么查看当前进程?怎么执行退出?怎么查看当前路径?
68 |
69 | 查看当前进程:`ps`
70 | 执行退出:`exit`
71 | 查看当前路径:`pwd`
72 |
73 |
74 |
75 | ### 怎么清屏?怎么退出当前命令?怎么执行睡眠?怎么查看当前用户 id?查看指定帮助用什么命令?
76 |
77 | 清屏:`clear`
78 | 退出当前命令:`ctrl+c` 彻底退出
79 | 执行睡眠 :`ctrl+z` 挂起当前进程fg 恢复后台
80 | 查看当前用户 id:”id“:查看显示目前登陆账户的 uid 和 gid 及所属分组及用户名
81 | 查看指定帮助:如 man adduser 这个很全 而且有例子;adduser --help 这个告诉你一些常用参数;info adduesr;
82 |
83 |
84 |
85 | ### Ls 命令执行什么功能?可以带哪些参数,有什么区别?
86 |
87 | ls 执行的功能:列出指定目录中的目录,以及文件
88 | 哪些参数以及区别:a 所有文件l 详细信息,包括大小字节数,可读可写可执行的权限等
89 |
90 |
91 |
92 | ### 建立软链接(快捷方式),以及硬链接的命令。
93 |
94 | 软链接:`ln -s slink source`
95 | 硬链接:`ln link source`
96 |
97 |
98 |
99 | ### 目录创建用什么命令?创建文件用什么命令?复制文件用什么命令?
100 |
101 | 创建目录:`mkdir`
102 | 创建文件:典型的如 `touch`,`vi` 也可以创建文件,其实只要向一个不存在的文件输出,都会创建文件
103 | 复制文件:cp 7. 文件权限修改用什么命令?格式是怎么样的?
104 | 文件权限修改:`chmod`
105 | 格式如下:
106 |
107 | > $ chmod u+x file 给 file 的属主增加执行权限
108 | > $ chmod 751 file 给 file 的属主分配读、写、执行(7)的权限,给 file 的所在组分配读、执行(5)的权限,给其他用户分配执行(1)的权限
109 | > $ chmod u=rwx,g=rx,o=x file 上例的另一种形式
110 | > $ chmod =r file 为所有用户分配读权限
111 | > $ chmod 444 file 同上例
112 | > $ chmod a-wx,a+r file同上例
113 | > $ chmod -R u+r directory 递归地给 directory 目录下所有文件和子目录的属主分配读的权限
114 |
115 |
116 |
117 | ### 查看文件内容有哪些命令可以使用?
118 |
119 | `vi 文件名` # 编辑方式查看,可修改
120 | `cat 文件名` # 显示全部文件内容
121 | `more 文件名` # 分页显示文件内容
122 | `less 文件名` # 与 more 相似,更好的是可以往前翻页
123 | `tail 文件名` # 仅查看尾部,还可以指定行数
124 | `head 文件名` # 仅查看头部,还可以指定行数
125 |
126 |
127 |
128 | ### 随意写文件命令?怎么向屏幕输出带空格的字符串,比如”hello world”?
129 |
130 | 写文件命令:`vi`
131 |
132 | 向屏幕输出带空格的字符串:`echo hello world`
133 |
134 |
135 |
136 | ### 终端是哪个文件夹下的哪个文件?黑洞文件是哪个文件夹下的哪个命令?
137 |
138 | 终端 `/dev/tty`
139 |
140 | 黑洞文件 `/dev/null`
141 |
142 |
143 |
144 | ### 移动文件用哪个命令?改名用哪个命令?
145 |
146 | mv mv
147 |
148 |
149 |
150 | ### Linux 下命令有哪几种可使用的通配符?分别代表什么含义?
151 |
152 | “?”可替代单个字符。
153 |
154 | “*”可替代任意多个字符。
155 |
156 | 方括号“[charset]”可替代 charset 集中的任何单个字符,如[a-z],[abABC]
157 |
158 |
159 |
160 | ### 用什么命令对一个文件的内容进行统计?(行号、单词数、字节数)
161 |
162 | wc 命令 - c 统计字节数 - l 统计行数 - w 统计字数。
163 |
164 |
165 |
166 | ### Grep 命令有什么用?如何忽略大小写?如何查找不含该串的行?
167 |
168 | 是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。
169 | grep [stringSTRING] filename grep \[^string\] filename
170 |
171 |
172 |
173 | ### Linux 中进程有哪几种状态?在 ps 显示出来的信息中,分别用什么符号表示的?
174 |
175 | **1、** 不可中断状态:进程处于睡眠状态,但是此刻进程是不可中断的。不可中断, 指进程不响应异步信号。
176 | **2、** 暂停状态/跟踪状态:向进程发送一个 SIGSTOP 信号,它就会因响应该信号 而进入 TASK_STOPPED 状态;当进程正在被跟踪时,它处于 TASK_TRACED 这个特殊的状态。
177 | “正在被跟踪”指的是进程暂停下来,等待跟踪它的进程对它进行操作。
178 |
179 | **3、** 就绪状态:在 run_queue 队列里的状态
180 |
181 | **4、** 运行状态:在 run_queue 队列里的状态
182 | **5、** 可中断睡眠状态:处于这个状态的进程因为等待某某事件的发生(比如等待 socket 连接、等待信号量),而被挂起
183 | **6、** zombie 状态(僵尸):父亲没有通过 wait 系列的系统调用会顺便将子进程的尸体(task_struct)也释放掉
184 | **7、** 退出状态
185 |
186 | > D 不可中断 Uninterruptible(usually IO)
187 | > R 正在运行,或在队列中的进程
188 | > S 处于休眠状态
189 | > T 停止或被追踪
190 | > Z 僵尸进程
191 | > W 进入内存交换(从内核 2.6 开始无效)
192 | > X 死掉的进程
193 |
194 |
195 |
196 | ### 利用 ps 怎么显示所有的进程? 怎么利用 ps 查看指定进程的信息?
197 |
198 | ps -ef (system v 输出)
199 |
200 | ps -aux bsd 格式输出
201 |
202 | ps -ef | grep pid
203 |
204 |
205 |
206 | ### 哪个命令专门用来查看后台任务?
207 |
208 | job -l
209 |
210 |
211 |
212 | ### 终止进程用什么命令? 带什么参数?
213 |
214 | kill \[-s <信息名称或编号>][程序] 或 kill [-l <信息编号>\]
215 |
216 | kill-9 pid
217 |
218 |
219 |
220 | ### 搜索文件用什么命令? 格式是怎么样的?
221 |
222 | find <指定目录> <指定条件> <指定动作>
223 |
224 | whereis 加参数与文件名
225 |
226 | locate 只加文件名
227 |
228 | find 直接搜索磁盘,较慢。
229 |
230 | find / -name "string*"
231 |
232 |
233 |
234 | ### 查看当前谁在使用该主机用什么命令? 查找自己所在的终端信息用什么命令?
235 |
236 | 查找自己所在的终端信息:who am i
237 |
238 | 查看当前谁在使用该主机:who
239 |
240 |
241 |
242 | ### 使用什么命令查看用过的命令列表?
243 |
244 | history
245 |
246 |
247 |
248 | ### 使用什么命令查看磁盘使用空间?空闲空间呢?
249 |
250 | df -hl
251 | 文件系统 容量 已用 可用 已用% 挂载点
252 | Filesystem Size Used Avail Use% Mounted on /dev/hda2 45G 19G 24G 44% /
253 | /dev/hda1 494M 19M 450M 4% /boot
254 |
255 |
256 |
257 | ### 使用什么命令查看 ip 地址及接口信息?
258 |
259 | ifconfig
260 |
261 |
262 |
263 | ### 通过什么命令查找执行命令?
264 |
265 | which 只能查可执行文件
266 |
267 | whereis 只能查二进制文件、说明文档,源文件等
268 |
269 |
270 |
271 | ### du 和 df 的定义,以及区别?
272 |
273 | du 显示目录或文件的大小
274 |
275 | df 显示每个<文件>所在的文件系统的信息,默认是显示所有文件系统。
276 | (文件系统分配其中的一些磁盘块用来记录它自身的一些数据,如 i 节点,磁盘分布图,间接块,超级块等。这些数据对大多数用户级的程序来说是不可见的,通常称为 Meta Data。) du 命令是用户级的程序,它不考虑 Meta Data,而 df 命令则查看文件系统的磁盘分配图并考虑 Meta Data。
277 |
278 | df 命令获得真正的文件系统数据,而 du 命令只查看文件系统的部分情况。
279 |
280 |
281 |
282 | ### **Unix和Linux有什么区别?**
283 |
284 | Linux和Unix都是功能强大的操作系统,都是应用广泛的服务器操作系统,有很多相似之处,甚至有一部分人错误地认为Unix和Linux操作系统是一样的,然而,事实并非如此,以下是两者的区别。
285 |
286 | **1、开源性**
287 | Linux是一款开源操作系统,不需要付费,即可使用;Unix是一款对源码实行知识产权保护的传统商业软件,使用需要付费授权使用。
288 |
289 | **2、跨平台性**
290 | Linux操作系统具有良好的跨平台性能,可运行在多种硬件平台上;Unix操作系统跨平台性能较弱,大多需与硬件配套使用。
291 |
292 | **3、可视化界面**
293 | Linux除了进行命令行操作,还有窗体管理系统;Unix只是命令行下的系统。
294 |
295 | **4、硬件环境**
296 | Linux操作系统对硬件的要求较低,安装方法更易掌握;Unix对硬件要求比较苛刻,安装难度较大。
297 |
298 | **5、用户群体**
299 | Linux的用户群体很广泛,个人和企业均可使用;Unix的用户群体比较窄,多是安全性要求高的大型企业使用,如银行、电信部门等,或者Unix硬件厂商使用,如Sun等。
300 |
301 |
302 |
303 | 相比于Unix操作系统,Linux操作系统更受广大计算机爱好者的喜爱,主要原因是Linux操作系统具有Unix操作系统的全部功能,并且能够在普通PC计算机上实现全部的Unix特性,开源免费的特性,更容易普及使用!
304 |
305 |
306 |
307 | ### **什么是 Linux 内核?**
308 |
309 | Linux 系统的核心是内核。内核控制着计算机系统上的所有硬件和软件,在必要时分配硬件,并根据需要执行软件。
310 |
311 | 系统内存管理
312 | 应用程序管理
313 | 硬件设备管理
314 | 文件系统管理
315 |
316 |
317 |
318 | ### **Linux的基本组件是什么?**
319 |
320 | 就像任何其他典型的操作系统一样,Linux拥有所有这些组件:内核,shell和GUI,系统实用程序和应用程序。Linux比其他操作系统更具优势的是每个方面都附带其他功能,所有代码都可以免费下载。.
321 |
322 |
323 |
324 | ### 简单 Linux 文件系统?
325 |
326 | 在 Linux 操作系统中,所有被操作系统管理的资源,例如网络接口卡、磁盘驱动器、打印机、输入输出设备、普通文件或是目录都被看作是一个文件。也就是说在 Linux 系统中有一个重要的概念**:一切都是文件**。其实这是 Unix 哲学的一个体现,而 Linux 是重写 Unix 而来,所以这个概念也就传承了下来。在 Unix 系统中,把一切资源都看作是文件,包括硬件设备。UNIX系统把每个硬件都看成是一个文件,通常称为设备文件,这样用户就可以用读写文件的方式实现对硬件的访问。Linux 支持 5 种文件类型,
327 |
328 | 如下图所示:
329 |
330 | 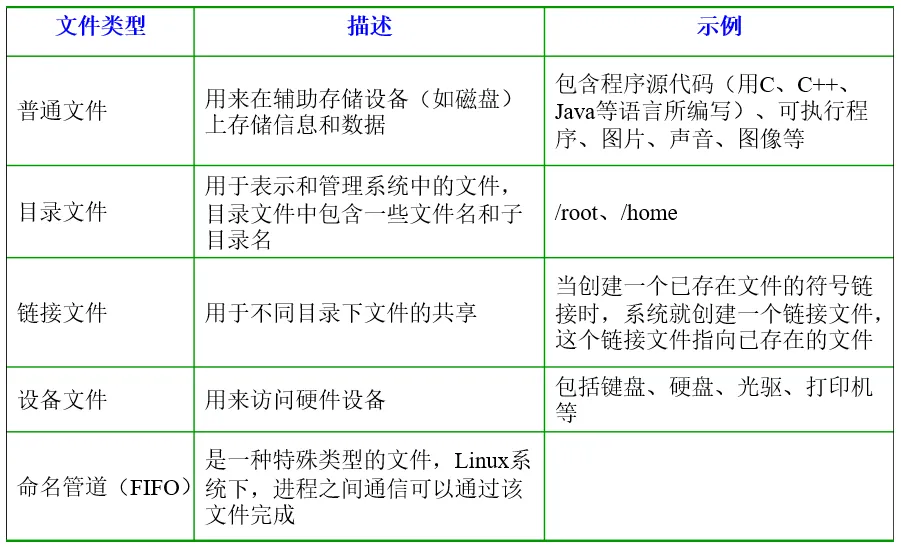
331 |
332 |
333 |
334 |
335 |
336 | ### 绝对路径用什么符号表示?当前目录、上层目录用什么表示?主目录用什么表示? 切换目录用什么命令?
337 |
338 | **绝对路径:**如/etc/init.d
339 | **当前目录和上层目录:**./ ../
340 | **主目录:**~/
341 | **切换目录:**cd
342 |
343 |
344 |
345 | ### 怎么查看当前进程?怎么执行退出?怎么查看当前路径?
346 |
347 | **查看当前进程:**ps
348 | **执行退出:**exit
349 | **查看当前路径:**pwd
350 |
351 |
352 |
353 | ### 怎么清屏?怎么退出当前命令?怎么执行睡眠?怎么查看当前用户 id?查看指定帮助用什么命令?
354 |
355 | **清屏:**clear
356 | **退出当前命令:**ctrl+c 彻底退出
357 | **执行睡眠 :**ctrl+z 挂起当前进程fg 恢复后台
358 | **查看当前用户 id:**”id“:查看显示目前登陆账户的 uid 和 gid 及所属分组及用户名
359 | **查看指定帮助:**如 man adduser 这个很全 而且有例子;adduser --help 这个告诉你一些常用参数;info adduesr;
360 |
361 |
362 |
363 | ### **Ls 命令执行什么功能? 可以带哪些参数,有什么区别?**
364 |
365 | ls 执行的功能: 列出指定目录中的目录,以及文件
366 |
367 | 哪些参数以及区别: a 所有文件 l 详细信息,包括大小字节数,可读可写可执行的权限等
368 |
369 |
370 |
371 | ### 建立软链接(快捷方式),以及硬链接的命令。
372 |
373 | **软链接:** ln -s slink source
374 |
375 | **硬链接:** ln link source
376 |
377 |
378 |
379 | ### 目录创建用什么命令?创建文件用什么命令?复制文件用什么命令?
380 |
381 | **创建目录:** mkdir
382 |
383 | **创建文件:**典型的如 touch,vi 也可以创建文件,其实只要向一个不存在的文件输出,都会创建文件
384 |
385 | **复制文件:** cp
386 |
387 |
388 |
389 | ### 文件权限修改用什么命令?格式是怎么样的?
390 |
391 | **文件权限修改:** chmod
392 |
393 | 格式如下:
394 |
395 | chmodu+xfile 给 file 的属主增加执行权限 chmod 751 file 给 file 的属主分配读、写、执行(7)的权限,给 file 的所在组分配读、执行(5)的权限,给其他用户分配执行(1)的权限
396 |
397 | chmodu=rwx,g=rx,o=xfile 上例的另一种形式 chmod =r file 为所有用户分配读权限
398 |
399 | chmod444file 同上例 chmod a-wx,a+r file 同上例
400 |
401 | $ chmod -R u+r directory 递归地给 directory 目录下所有文件和子目录的属主分配读的权限
402 |
403 |
404 |
405 | ### 查看文件内容有哪些命令可以使用?
406 |
407 | ```
408 | vi 文件名 #编辑方式查看,可修改
409 |
410 | cat 文件名 #显示全部文件内容
411 |
412 | more 文件名 #分页显示文件内容
413 |
414 | less 文件名 #与 more 相似,更好的是可以往前翻页
415 |
416 | tail 文件名 #仅查看尾部,还可以指定行数
417 |
418 | head 文件名 #仅查看头部,还可以指定行数
419 | ```
420 |
421 |
422 |
423 | ### 随意写文件命令?怎么向屏幕输出带空格的字符串,比如”hello world”?
424 |
425 | 写文件命令:vi
426 |
427 | 向屏幕输出带空格的字符串:echo hello world
428 |
429 |
430 |
431 | ### 终端是哪个文件夹下的哪个文件?黑洞文件是哪个文件夹下的哪个命令?
432 |
433 | 终端 /dev/tty
434 |
435 | 黑洞文件 /dev/null
436 |
437 |
438 |
439 |
440 |
441 |
442 |
443 |
--------------------------------------------------------------------------------
/interviewDoc/Java/middleware/Dubbo.md:
--------------------------------------------------------------------------------
1 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
2 |
3 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
4 |
5 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
6 |
7 |
8 |
9 |
10 | - [Dubbo是什么?](#dubbo是什么)
11 | - [为什么要用Dubbo?](#为什么要用dubbo)
12 | - [Dubbo 和 Spring Cloud 有什么区别?](#dubbo-和-spring-cloud-有什么区别)
13 | - [dubbo都支持什么协议,推荐用哪种?](#dubbo都支持什么协议推荐用哪种)
14 | - [Dubbo推荐用什么协议?使用该协议有哪些优缺点?](#dubbo推荐用什么协议使用该协议有哪些优缺点)
15 | - [说说Dubbo的分层?](#说说dubbo的分层)
16 | - [Dubbo核心组件是?](#dubbo核心组件是)
17 | - [Dubbo核心配置有哪些?](#dubbo核心配置有哪些)
18 | - [能说下Dubbo的工作原理吗?](#能说下dubbo的工作原理吗)
19 | - [介绍一下Dubbo框架分层?](#介绍一下dubbo框架分层)
20 | - [注册中心挂了可以继续通信吗?](#注册中心挂了可以继续通信吗)
21 | - [Dubbo需要 Web 容器吗?](#dubbo需要-web-容器吗)
22 | - [Dubbo的执行流程](#dubbo的执行流程)
23 | - [Dubbo内置了哪几种服务容器?](#dubbo内置了哪几种服务容器)
24 | - [Dubbo有哪些注册中心?](#dubbo有哪些注册中心)
25 | - [Dubbo里面有哪几种节点角色?](#dubbo里面有哪几种节点角色)
26 | - [Dubbo中zookeeper做注册中心,如果注册中心集群都挂掉,发布者和订阅者之间还能通信么?](#dubbo中zookeeper做注册中心如果注册中心集群都挂掉发布者和订阅者之间还能通信么)
27 | - [注册中心宕机,服务间是否可以继续通信](#注册中心宕机服务间是否可以继续通信)
28 | - [Dubbo服务负载均衡策略?](#dubbo服务负载均衡策略)
29 | - [Dubbo在安全机制方面是如何解决的](#dubbo在安全机制方面是如何解决的)
30 | - [Dubbo超时时间的设置](#dubbo超时时间的设置)
31 | - [画一画服务注册与发现的流程图](#画一画服务注册与发现的流程图)
32 | - [Dubbo默认使用什么注册中心,还有别的选择吗?](#dubbo默认使用什么注册中心还有别的选择吗)
33 | - [Dubbo有哪几种配置方式?](#dubbo有哪几种配置方式)
34 | - [Dubbo 核心的配置有哪些?](#dubbo-核心的配置有哪些)
35 | - [在 Provider 上可以配置的 Consumer 端的属性有哪些?](#在-provider-上可以配置的-consumer-端的属性有哪些)
36 | - [Dubbo启动时如果依赖的服务不可用会怎样?](#dubbo启动时如果依赖的服务不可用会怎样)
37 | - [Dubbo支持哪些序列化方式?](#dubbo支持哪些序列化方式)
38 | - [Dubbo推荐使用什么序列化框架,你知道的还有哪些?](#dubbo推荐使用什么序列化框架你知道的还有哪些)
39 | - [Dubbo默认使用的是什么通信框架,还有别的选择吗?](#dubbo默认使用的是什么通信框架还有别的选择吗)
40 | - [Dubbo有哪几种集群容错方案,哪几种负载均衡策略?](#dubbo有哪几种集群容错方案哪几种负载均衡策略)
41 | - [Dubbo用到哪些设计模式,简要介绍?](#dubbo用到哪些设计模式简要介绍)
42 | - [注册了多个同一样的服务,如果测试指定的某一个服务呢?](#注册了多个同一样的服务如果测试指定的某一个服务呢)
43 | - [Dubbo支持服务多协议吗?](#dubbo支持服务多协议吗)
44 | - [Dubbo 支持哪些协议,每种协议的应用场景,优缺点?](#dubbo-支持哪些协议每种协议的应用场景优缺点)
45 | - [Dubbo 集群的负载均衡有哪些策略](#dubbo-集群的负载均衡有哪些策略)
46 | - [当一个服务接口有多种实现时怎么做?](#当一个服务接口有多种实现时怎么做)
47 | - [服务调用超时问题怎么解决](#服务调用超时问题怎么解决)
48 | - [服务上线怎么兼容旧版本?](#服务上线怎么兼容旧版本)
49 | - [Dubbo可以对结果进行缓存吗?](#dubbo可以对结果进行缓存吗)
50 | - [Dubbo服务之间的调用是阻塞的吗?](#dubbo服务之间的调用是阻塞的吗)
51 | - [Dubbo支持分布式事务吗?](#dubbo支持分布式事务吗)
52 | - [Dubbo的心跳机制](#dubbo的心跳机制)
53 | - [Dubbo的zookeeper做注册中心,如果注册中心全部挂掉,发布者和订阅者还能通信吗?](#dubbo的zookeeper做注册中心如果注册中心全部挂掉发布者和订阅者还能通信吗)
54 | - [Dubbo telnet 命令能做什么?](#dubbo-telnet-命令能做什么)
55 | - [说说服务暴露的流程?](#说说服务暴露的流程)
56 | - [说说服务引用的流程?](#说说服务引用的流程)
57 | - [有哪些负载均衡策略?](#有哪些负载均衡策略)
58 | - [Dubbo如何优雅停机?](#dubbo如何优雅停机)
59 | - [了解Dubbo SPI机制吗?](#了解dubbo-spi机制吗)
60 | - [如果让你实现一个RPC框架怎么设计?](#如果让你实现一个rpc框架怎么设计)
61 | - [服务提供者能实现失效踢出是什么原理?](#服务提供者能实现失效踢出是什么原理)
62 | - [如何解决服务调用链过长的问题?](#如何解决服务调用链过长的问题)
63 | - [服务读写推荐的容错策略是怎样的?](#服务读写推荐的容错策略是怎样的)
64 | - [Dubbo必须依赖的包有哪些?](#dubbo必须依赖的包有哪些)
65 | - [Dubbo的管理控制台能做什么?](#dubbo的管理控制台能做什么)
66 | - [说说 Dubbo 服务暴露的过程。](#说说-dubbo-服务暴露的过程)
67 | - [Dubbo 停止维护了吗?](#dubbo-停止维护了吗)
68 | - [Dubbo 和 Dubbox 有什么区别?](#dubbo-和-dubbox-有什么区别)
69 | - [在使用过程中都遇到了些什么问题?如何解决的?](#在使用过程中都遇到了些什么问题如何解决的)
70 | - [你还了解别的分布式框架吗?](#你还了解别的分布式框架吗)
71 |
72 |
73 |
74 | ### Dubbo是什么?
75 |
76 | Dubbo是阿里巴巴开源的基于 Java 的高性能 RPC 分布式服务框架,现已成为 Apache 基金会孵化项目。
77 |
78 | 面试官问你如果这个都不清楚,那下面的就没必要问了。
79 |
80 | 官网:http://dubbo.apache.org
81 |
82 |
83 |
84 | ### 为什么要用Dubbo?
85 |
86 | 因为是阿里开源项目,国内很多互联网公司都在用,已经经过很多线上考验。内部使用了 Netty、Zookeeper,保证了高性能高可用性。
87 |
88 | 使用 Dubbo 可以将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,可用于提高业务复用灵活扩展,使前端应用能更快速的响应多变的市场需求。
89 |
90 | 下面这张图可以很清楚的诠释,最重要的一点是,分布式架构可以承受更大规模的并发流量。
91 |
92 | 
93 |
94 | 下面是 Dubbo 的服务治理图。
95 |
96 | 
97 |
98 | ### Dubbo 和 Spring Cloud 有什么区别?
99 |
100 | 两个没关联,如果硬要说区别,有以下几点。
101 |
102 | **1、**通信方式不同
103 |
104 | Dubbo 使用的是 RPC 通信,而 Spring Cloud 使用的是 HTTP RESTFul 方式。
105 |
106 | **2、**组成部分不同
107 |
108 | 
109 |
110 |
111 |
112 | ### dubbo都支持什么协议,推荐用哪种?
113 |
114 | **1、**dubbo://(推荐)
115 |
116 | **2、**rmi://
117 |
118 | **3、**hessian://
119 |
120 | **4、**http://
121 |
122 | **5、**webservice://
123 |
124 | **6、**thrift://
125 |
126 | **7、**memcached://
127 |
128 | **8、**redis://
129 |
130 | **9、**rest://
131 |
132 |
133 |
134 | ### Dubbo推荐用什么协议?使用该协议有哪些优缺点?
135 |
136 | 传入传出参数数据包较小(建议小于100K),消费者比提供者个数多,单一消费者无法压满提供者,尽量不要用dubbo协议传输大文件或超大字符串。
137 |
138 |
139 |
140 | ### 说说Dubbo的分层?
141 |
142 | 从大的范围来说,dubbo分为三层,business业务逻辑层由我们自己来提供接口和实现还有一些配置信息,RPC层就是真正的RPC调用的核心层,封装整个RPC的调用过程、负载均衡、集群容错、代理,remoting则是对网络传输协议和数据转换的封装。
143 |
144 | 划分到更细的层面,就是图中的10层模式,整个分层依赖由上至下,除开business业务逻辑之外,其他的几层都是SPI机制。
145 |
146 | | 层级 | 功能 |
147 | | --------- | -------------- |
148 | | service | 服务实现层 |
149 | | config | 配置相关 |
150 | | proxy | 代理层 |
151 | | register | 服务注册机制 |
152 | | cluster | 多个服务的治理 |
153 | | monitor | 单个服务监控 |
154 | | protocol | 协议层 |
155 | | exchange | 信息交换层 |
156 | | transport | 传输层 |
157 | | serialize | 持久化层 |
158 |
159 |
160 |
161 | ### Dubbo核心组件是?
162 |
163 | - 生产者(Provider):暴露服务的提供方,可以通过jar或者容器的方式启动服务;
164 | - 消费者(Consumer):调用远程服务的服务消费方;
165 | - 注册中心(Registry):服务注册中心和发现中心;
166 | - 监控中心(Monitor):统计服务和调用次数,调用时间监控中心;
167 | - 服务容器(Container):服务运行的容器,负责启动、加载,运行服务;
168 |
169 | 流程:首先`生产者`将服务注册到`注册中心`(zk),使用zk持久节点进行存储,消费订阅zk节点,一旦有节点变更,zk通过事件通知传递给`消费者`,消费可以调用生产者服务。服务与服务之间进行调用,都会在`监控中心`中,存储一个记录。
170 |
171 | 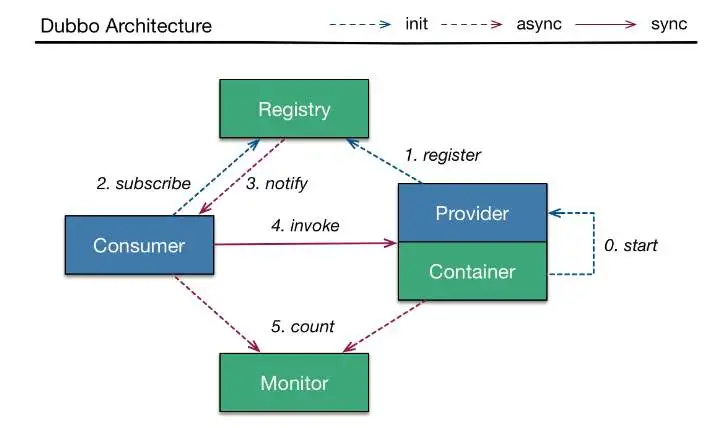
172 |
173 |
174 |
175 | ### Dubbo核心配置有哪些?
176 |
177 | 核心配置有:
178 |
179 | | **配置** | **说明** |
180 | | ------------------ | ------------ |
181 | | dubbo:service/ | 服务配置 |
182 | | dubbo:reference/ | 引用配置 |
183 | | dubbo:argument/ | 参数配置 |
184 | | dubbo:protocol/ | 协议配置 |
185 | | dubbo:registry/ | 注册中心配置 |
186 | | dubbo:application/ | 应用配置 |
187 | | dubbo:provider/ | 提供方配置 |
188 | | dubbo:consumer/ | 消费方配置 |
189 | | dubbo:method/ | 方法配置 |
190 | | dubbo:module/ | 模块配置 |
191 | | dubbo:monitor/ | 监控中心配置 |
192 |
193 |
194 |
195 | ### 能说下Dubbo的工作原理吗?
196 |
197 | **1、** 服务启动的时候,provider和consumer根据配置信息,连接到注册中心register,分别向注册中心注册和订阅服务
198 |
199 | **2、** register根据服务订阅关系,返回provider信息到consumer,同时consumer会把provider信息缓存到本地。如果信息有变更,consumer会收到来自register的推送
200 |
201 | **3、** consumer生成代理对象,同时根据负载均衡策略,选择一台provider,同时定时向monitor记录接口的调用次数和时间信息
202 |
203 | **4、** 拿到代理对象之后,consumer通过代理对象发起接口调用
204 |
205 | **5、** provider收到请求后对数据进行反序列化,然后通过代理调用具体的接口实现
206 |
207 |
208 |
209 | 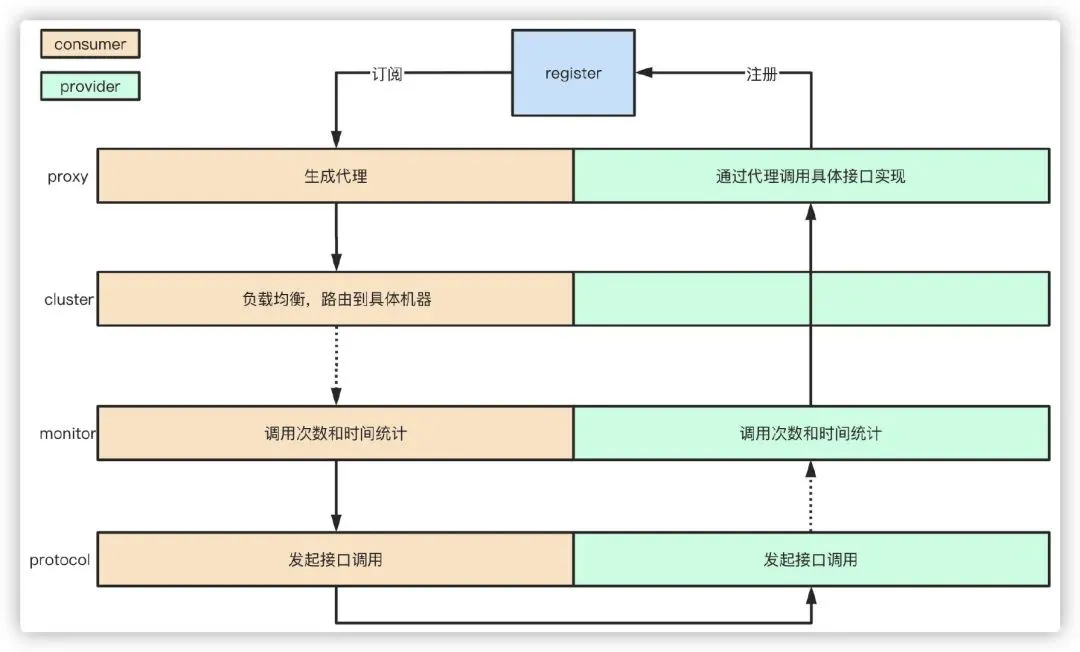
210 |
211 | 
212 |
213 |
214 |
215 | ### 介绍一下Dubbo框架分层?
216 |
217 | 从大的范围来说,Dubbo分为**3**层:`Business业务逻辑层`由我们自己来提供接口和实现还有一些配置信息,`RPC层`就是真正的RPC调用的核心层,封装整个RPC的调用过程、负载均衡、集群容错、代理,`Remoting层`则是对网络传输协议和数据转换的封装。
218 |
219 | 划分到更细的层面,就是**10**层模式,整个分层依赖由上至下,除开business业务逻辑之外,其他的几层都是SPI机制。10层模式如下:
220 |
221 | - **`服务接口层`(Service):** 与实际业务逻辑相关的,根据服务提供方和服务消费方的业务设计对应的接口和实现。
222 | - **`配置层`(Config):** 对外配置接口,以ServiceConfig和ReferenceConfig为中心,可以直接new配置类,也可以通过Spring解析配置生成配置类。
223 | - **`服务代理层`(Proxy):** 服务接口透明代理,生成服务的客户端Stub和服务器端Skeleton,以ServiceProxy为中心,扩展接口为ProxyFactory。
224 | - **`服务注册层`(Registry):** 封装服务地址的注册与发现,以服务URL为中心,扩展接口为RegistryFactory、Registry和RegistryService。可能没有服务注册中心,此时服务提供方直接暴露服务。
225 | - **`集群层`(Cluster):** 封装多个提供者的路由及负载均衡,并桥接注册中心,以Invoker为中心,扩展接口为Cluster、Directory、Router和LoadBalance。将多个服务提供方组合为一个服务提供方,实现对服务消费方来透明,只需要与一个服务提供方进行交互。
226 | - **`监控层`(Monitor):** RPC调用次数和调用时间监控,以Statistics为中心,扩展接口为MonitorFactory、Monitor和MonitorService。
227 | - **`远程调用层`(Protocol): **封将RPC调用,以Invocation和Result为中心,扩展接口为Protocol、Invoker和Exporter。Protocol是服务域,它是Invoker暴露和引用的主功能入口,它负责Invoker的生命周期管理。Invoker是实体域,它是Dubbo的核心模型,其它模型都向它靠扰,或转换成它,它代表一个可执行体,可向它发起invoke调用,它有可能是一个本地的实现,也可能是一个远程的实现,也可能一个集群实现。
228 | - **`信息交换层`(Exchange):** 封装请求响应模式,同步转异步,以Request和Response为中心,扩展接口为Exchanger、ExchangeChannel、ExchangeClient和ExchangeServer。
229 | - **`网络传输层`(Transport):** 抽象mina和netty为统一接口,以Message为中心,扩展接口为Channel、Transporter、Client、Server和Codec。
230 | - **`数据序列化层`(Serialize):** 可复用的一些工具,扩展接口为Serialization、 ObjectInput、ObjectOutput和ThreadPool。
231 |
232 | 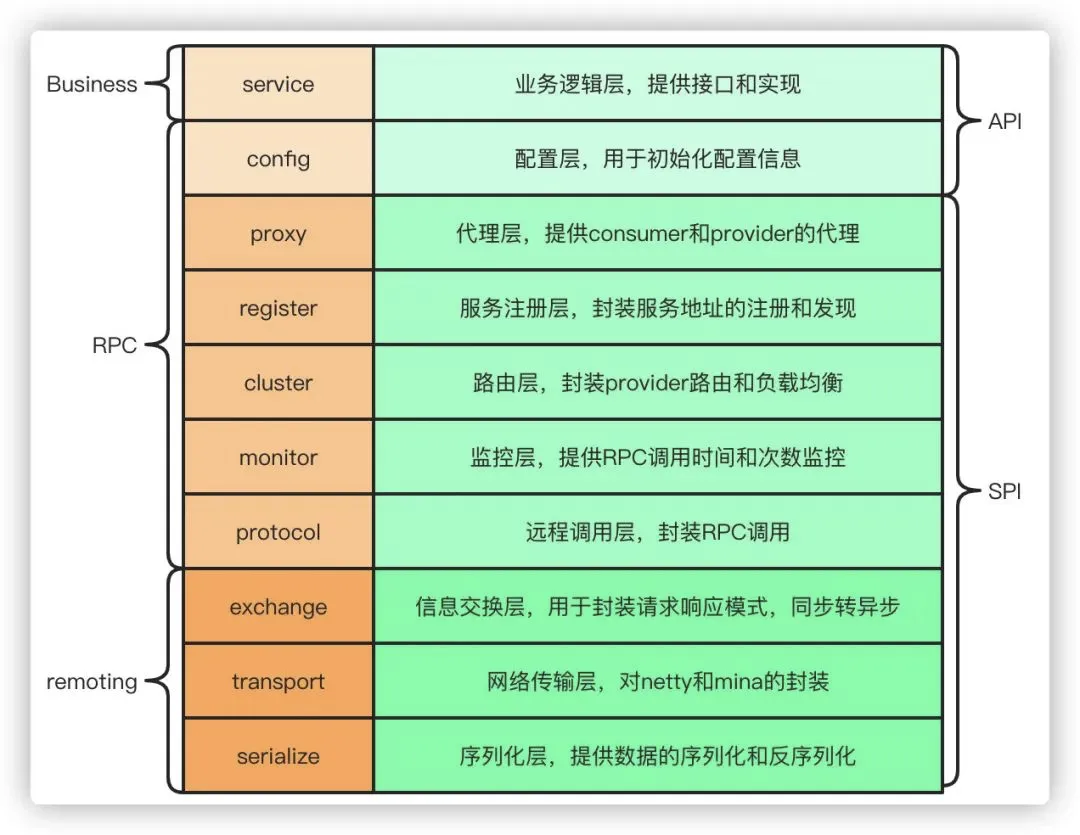
233 |
234 |
235 |
236 |
237 |
238 | ### 注册中心挂了可以继续通信吗?
239 |
240 | 可以,因为刚开始初始化的时候,消费者会将提供者的地址等信息拉取到本地缓存,所以注册中心挂了可以继续通信。
241 |
242 |
243 |
244 | ### Dubbo需要 Web 容器吗?
245 |
246 | 不需要,如果硬要用 Web 容器,只会增加复杂性,也浪费资源。
247 |
248 |
249 |
250 | ### Dubbo的执行流程
251 |
252 | 项目一启动,加载配置文件的时候,就会初始化,服务的提供方ServiceProvider就会向注册中心注册自己提供的服务,当消费者在启动时,就会向注册中心订阅自己所需要的服务,如果服务提供方有数据变更等,注册中心将基于长连接的形式推送变更数据给消费者。
253 | 默认使用Dubbo协议:
254 | 连接个数:单连接
255 | 连接方式:长连接
256 | 传输协议:TCP
257 | 传输方式:NIO异步传输
258 | 序列化:Hessian二进制序列化
259 | 适用范围:传入传出参数数据包较小(建议小于100K),消费者比提供者个数多,单一消费者无法压满提供者,尽量不要使用dubbo协议传输大文件或超大字符串
260 | 使用场景:常规远程服务方法调用
261 | 从上面的适用范围总结,dubbo适合小数据量大并发的服务调用,以及消费者机器远大于生产者机器数的情况,不适合传输大数据量的服务比如文件、视频等,除非请求量很低。
262 |
263 |
264 |
265 | ### Dubbo内置了哪几种服务容器?
266 |
267 | - Spring Container
268 | - Jetty Container
269 | - Log4j Container
270 |
271 | Dubbo 的服务容器只是一个简单的 Main 方法,并加载一个简单的 Spring 容器,用于暴露服务。
272 |
273 |
274 |
275 | ### Dubbo有哪些注册中心?
276 |
277 | - **Multicast 注册中心:** Multicast 注册中心不需要任何中心节点,只要广播地址,就能进行服务注册和发现,基于网络中组播传输实现。
278 | - **Zookeeper 注册中心:** 基于分布式协调系统 Zookeeper 实现,采用 Zookeeper 的 watch 机制实现数据变更。
279 | - **Redis 注册中心:** 基于 Redis 实现,采用 key/map 存储,key 存储服务名和类型,map 中 key 存储服务 url,value 服务过期时间。基于 Redis 的发布/订阅模式通知数据变更。
280 | - **Simple 注册中心:** Simple 注册中心本身就是一个普通的 Dubbo 服务,可以减少第三方依赖,使整体通讯方式一致。
281 |
282 |
283 |
284 | ### Dubbo里面有哪几种节点角色?
285 |
286 | 
287 |
288 |
289 |
290 | ### Dubbo中zookeeper做注册中心,如果注册中心集群都挂掉,发布者和订阅者之间还能通信么?
291 |
292 | 可以通信的,启动 dubbo 时,消费者会从 zk 拉取注册的生产者的地址接口等数据,缓存在本地。每次调用时,按照本地存储的地址进行调用;
293 |
294 | 注册中心对等集群,任意一台宕机后,将会切换到另一台;注册中心全部宕机后,服务的提供者和消费者仍能通过本地缓存通讯。服务提供者无状态,任一台 宕机后,不影响使用;服务提供者全部宕机,服务消费者会无法使用,并无限次重连等待服务者恢复;
295 |
296 | 挂掉是不要紧的,但前提是你没有增加新的服务,如果你要调用新的服务,则是不能办到的。
297 |
298 |
299 |
300 | ### 注册中心宕机,服务间是否可以继续通信
301 |
302 | 可以通信的,启动dubbo时,消费者会从zk拉取注册的生产者的地址接口等数据,缓存在本地。每次调用时,按照本地存储的地址进行调用;但前提是你没有增加新的服务,如果你要调用新的服务,则是不能办到的。另外如果服务的提供者全部宕机,服务消费者会无法使用,并无限次重连等待服务者恢复。
303 |
304 |
305 |
306 | ### Dubbo服务负载均衡策略?
307 |
308 | **l Random LoadBalance**
309 |
310 | 随机,按权重设置随机概率。在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。(权重可以在 dubbo 管控台配置)
311 |
312 | **l RoundRobin LoadBalance**
313 |
314 | 轮循,按公约后的权重设置轮循比率。存在慢的提供者累积请求问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
315 |
316 | **l LeastActive LoadBalance**
317 |
318 | 最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
319 |
320 | **l ConsistentHash LoadBalance**
321 |
322 | 一致性 Hash,相同参数的请求总是发到同一提供者。当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。缺省只对第一个参数 Hash,如果要修改,请配置
323 |
324 | ```
325 |
326 | ```
327 |
328 | 缺省用 160 份虚拟节点,如果要修改,请配置
329 |
330 | ```
331 |
332 | ```
333 |
334 |
335 |
336 | ### Dubbo在安全机制方面是如何解决的
337 |
338 | Dubbo 通过 Token 令牌防止用户绕过注册中心直连,然后在注册中心上管理授权。Dubbo 还提供服务黑白名单,来控制服务所允许的调用方。
339 |
340 |
341 |
342 | ### Dubbo超时时间的设置
343 |
344 | 通过timeout属性配置超时时间,服务的提供者和消费者都可以配置,尽量在服务提供者中配置,因为服务的提供者会对自己提供的服务情况更清楚超时时间不要设置太大(1~5S),会影响并发性能问题。
345 |
346 |
347 |
348 |
349 |
350 | ### 画一画服务注册与发现的流程图
351 |
352 | 
353 |
354 | 该图来自 Dubbo 官网,供你参考,如果你说你熟悉 Dubbo, 面试官经常会让你画这个图,记好了。
355 |
356 |
357 |
358 | ### Dubbo默认使用什么注册中心,还有别的选择吗?
359 |
360 | 推荐使用 Zookeeper 作为注册中心,还有 Redis、Multicast、Simple 注册中心,但不推荐。
361 |
362 |
363 |
364 | ### Dubbo有哪几种配置方式?
365 |
366 | - XML 配置文件方式;
367 | - properties 配置文件方式;
368 | - annotation 配置方式;
369 | - API 配置方式;
370 |
371 |
372 |
373 | ### Dubbo 核心的配置有哪些?
374 |
375 | 我曾经面试就遇到过面试官让你写这些配置,我也是蒙逼。。
376 |
377 | 
378 |
379 | 配置之间的关系见下图。
380 |
381 | 
382 |
383 |
384 |
385 | ### 在 Provider 上可以配置的 Consumer 端的属性有哪些?
386 |
387 | **1、** timeout:方法调用超时
388 | **2、** retries:失败重试次数,默认重试 2 次
389 | **3、** loadbalance:负载均衡算法,默认随机
390 | **4、** actives 消费者端,最大并发调用限制
391 |
392 |
393 |
394 | ### Dubbo启动时如果依赖的服务不可用会怎样?
395 |
396 | Dubbo 缺省会在启动时检查依赖的服务是否可用,不可用时会抛出异常,阻止 Spring 初始化完成,默认 check="true",可以通过 check="false" 关闭检查。
397 |
398 |
399 |
400 | ### Dubbo支持哪些序列化方式?
401 |
402 | **dubbo序列化:** 阿里尚未开发成熟的高效java序列化实现,阿里不建议在生产环境使用它。
403 |
404 | **hessian2序列化(默认推荐):** hessian是一种跨语言的高效二进制序列化方式。但这里实际不是原生的hessian2序列化,而是阿里修改过的hessian lite,它是dubbo RPC默认启用的序列化方式。
405 |
406 | **json序列化:** 目前有两种实现,一种是采用的阿里的fastjson库,另一种是采用dubbo中自己实现的简单json库,但其实现都不是特别成熟,而且json这种文本序列化性能一般不如上面两种二进制序列化。
407 |
408 | **java序列化:** 主要是采用JDK自带的Java序列化实现,性能很不理想。
409 |
410 |
411 |
412 | ### Dubbo推荐使用什么序列化框架,你知道的还有哪些?
413 |
414 | 默认使用 Hessian 序列化,还有 Duddo、FastJson、Java 自带序列化。hessian是一个采用二进制格式传输的服务框架,相对传统soap web service,更轻量,更快速。
415 |
416 | Hessian原理与协议简析:
417 |
418 | http的协议约定了数据传输的方式,hessian也无法改变太多:
419 |
420 | **1、** hessian中client与server的交互,基于http-post方式。
421 |
422 | **2、** hessian将辅助信息,封装在http header中,比如“授权token”等,我们可以基于http-header来封装关于“安全校验”“meta数据”等。hessian提供了简单的”校验”机制。
423 |
424 | **3、 **对于hessian的交互核心数据,比如“调用的方法”和参数列表信息,将通过post请求的body体直接发送,格式为字节流。
425 |
426 | **4、** 对于hessian的server端响应数据,将在response中通过字节流的方式直接输出。
427 |
428 | hessian的协议本身并不复杂,在此不再赘言;所谓协议(protocol)就是约束数据的格式,client按照协议将请求信息序列化成字节序列发送给server端,server端根据协议,将数据反序列化成“对象”,然后执行指定的方法,并将方法的返回值再次按照协议序列化成字节流,响应给client,client按照协议将字节流反序列话成”对象”。
429 |
430 |
431 |
432 | ### Dubbo默认使用的是什么通信框架,还有别的选择吗?
433 |
434 | Dubbo 默认使用 Netty 框架,也是推荐的选择,另外内容还集成有Mina、Grizzly。
435 |
436 |
437 |
438 | ### Dubbo有哪几种集群容错方案,哪几种负载均衡策略?
439 |
440 | 在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。具体的集群容错方案有:
441 |
442 | | **集群容错方案** | **说明** |
443 | | ----------------- | ------------------------------------------ |
444 | | Failover Cluster | 失败自动切换,自动重试其他服务器(默认) |
445 | | Failfast Cluster | 快速失败,立即报错,只发起一次调用 |
446 | | Failsafe Cluster | 失败安全,出现异常时,直接忽略 |
447 | | Failback Cluster | 失败自动恢复,记录失败请求,定时重发 |
448 | | Forking Cluster | 并行调用多个服务器,只要一个成功即返回 |
449 | | Broadcast Cluster | 广播逐个调用所有提供者,任意一个报错则报错 |
450 |
451 |
452 |
453 | Dubbo内置了4种负载均衡策略:
454 |
455 | | **负载均衡策略** | **说明** |
456 | | ------------------------- | ------------------------------------------------------ |
457 | | RandomLoadBalance | 随机负载均衡,按权重设置随机概率(默认) |
458 | | RoundRobinLoadBalance | 轮询负载均衡,按公约后的权重设置轮询比率 |
459 | | LeastActiveLoadBalance | 最少活跃调用数,相同活跃数的随机 |
460 | | ConsistentHashLoadBalance | 一致性Hash负载均衡,相同参数的请求总是发到同一个提供者 |
461 |
462 |
463 |
464 | ### Dubbo用到哪些设计模式,简要介绍?
465 |
466 | - **工厂模式:** Provider在export服务时,会调用ServiceConfig的export方法,实现类的获取采用了JDK SPI的机制,想要扩展实现,只需要在classpath下增加文件即可,代码零侵入;
467 | - **装饰器模式:** Dubbo在启动和调用阶段都大量使用了装饰器模式,如ClassLoaderFilter在主功能上添加功能,更改当前线程的ClassLoader是典型的装饰器模式;
468 | - **观察者模式:** Dubbo的Provider启动时,需要与注册中心交互,先注册自己的服务,再订阅自己的服务,订阅时,采用了观察者模式;
469 | - **动态代理模式:** Dubbo扩展JDK SPI的类ExtensionLoader的Adaptive实现是典型的动态代理实现,Dubbo需要灵活地控制实现类,即在调用阶段动态地根据参数决定调用哪个实现类,所以采用先生成代理类的方法,做到灵活的调用。
470 |
471 |
472 |
473 | ### 注册了多个同一样的服务,如果测试指定的某一个服务呢?
474 |
475 | 可以配置环境点对点直连,绕过注册中心,将以服务接口为单位,忽略注册中心的提供者列表。
476 |
477 |
478 |
479 | ### Dubbo支持服务多协议吗?
480 |
481 | Dubbo 允许配置多协议,在不同服务上支持不同协议或者同一服务上同时支持多种协议。
482 |
483 |
484 |
485 | ### Dubbo 支持哪些协议,每种协议的应用场景,优缺点?
486 |
487 | **1.dubbo默认协议:**
488 |
489 | - 单一 TCP 长连接,Hessian 二进制序列化和 NIO 异步通讯;
490 | - 适合于小数据包大并发的服务调用和服务消费者数远大于服务提供者数的情况;
491 | - 不适合传送大数据包的服务;
492 |
493 |
494 |
495 | **2.rmi协议:**
496 |
497 | - 采用 JDK 标准的 java.rmi.* 实现,阻塞式短连接和 JDK 标准序列化方式;
498 | - 如果服务接口继承了 java.rmi.Remote 接口,可以和原生 RMI 互操作;
499 | - 因反序列化漏洞,需升级 commons-collections3 到 3.2.2版本或 commons-collections4 到 4.1 版本;
500 | - 对传输数据包不限,消费者和传输者个数相当;
501 |
502 |
503 |
504 | **3.hessian协议:**
505 |
506 | - 底层 Http 通讯,Servlet 暴露服务,Dubbo 缺省内嵌 Jetty 作为服务器实现;
507 | - 可与原生 Hessian 服务互操作;
508 | - 通讯效率高于 WebService 和 Java 自带的序列化;
509 | - 参数及返回值需实现 Serializable 接口,自定义实现 List、Map、Number、Date、Calendar 等接口;
510 | - 适用于传输数据包较大,提供者比消费者个数多,提供者压力较大;
511 |
512 |
513 |
514 | **4.http协议:**
515 |
516 | - 基于 http 表单的远程调用协议,短连接,json 序列化;
517 | - 对传输数据包不限,不支持传文件;
518 | - 适用于同时给应用程序和浏览器 JS 使用的服务;
519 |
520 |
521 |
522 | **5.webservice协议:**
523 |
524 | - 基于Apache CXF 的frontend-simple和transports-http 实现,短连接,SOAP文本序列化;
525 | - 可与原生WebService服务互操作;
526 | - 适用于系统集成、跨语言调用;
527 |
528 |
529 |
530 | **6.thrift协议:**
531 |
532 | - 对 thrift 原生协议的扩展添加了额外的头信息;
533 | - 使用较少,不支持传 null 值;
534 |
535 |
536 |
537 | **7.redis协议:**
538 |
539 | - redis在TCP端口6379上监听到来的连接,客户端连接到来时,Redis服务器为此创建一个TCP连接 ;
540 | - redis接收由不同参数组成的命令。一旦收到命令,将会立刻被处理,并回复给客户端;
541 |
542 |
543 |
544 | **8.memcached协议:**
545 |
546 | - 客户端使用TCP链接与服务器通讯,一个运行中的memcached服务器监视一些端口,客户端连接这些端口,发送命令到服务器,读取回应,最后关闭连接;
547 | - memcached协议中发送的数据分为文本行和自由数据两种;
548 |
549 |
550 |
551 | ### Dubbo 集群的负载均衡有哪些策略
552 |
553 | Dubbo 提供了常见的集群策略实现,并预扩展点予以自行实现。
554 |
555 | **Random LoadBalance:** 随机选取提供者策略,有利于动态调整提供者权重。截面碰撞率高,调用次数越多,分布越均匀;
556 |
557 | **RoundRobin LoadBalance:** 轮循选取提供者策略,平均分布,但是存在请求累积的问题;
558 |
559 | **LeastActive LoadBalance:** 最少活跃调用策略,解决慢提供者接收更少的请求;ConstantHash LoadBalance: 一致性 Hash 策略,使相同参数请求总是发到同一提供者,一台机器宕机,可以基于虚拟节点,分摊至其他提供者,避免引起提供者的剧烈变动;
560 |
561 |
562 |
563 | ### 当一个服务接口有多种实现时怎么做?
564 |
565 | 当一个接口有多种实现时,可以用 group 属性来分组,服务提供方和消费方都指定同一个 group 即可。
566 |
567 |
568 |
569 | ### 服务调用超时问题怎么解决
570 |
571 | dubbo在调用服务不成功时,默认是会重试两次的。这样在服务端的处理时间超过了设定的超时时间时,就会有重复请求,比如在发邮件时,可能就会发出多份重复邮件,执行注册请求时,就会插入多条重复的注册数据,那么怎么解决超时问题呢?如下对于核心的服务中心,去除dubbo超时重试机制,并重新评估设置超时时间。业务处理代码必须放在服务端,客户端只做参数验证和服务调用,不涉及业务流程处理 全局配置实例
572 |
573 | ```
574 |
575 | ```
576 |
577 | 当然Dubbo的重试机制其实是非常好的QOS保证,它的路由机制,是会帮你把超时的请求路由到其他机器上,而不是本机尝试,所以 dubbo的重试机器也能一定程度的保证服务的质量。但是请一定要综合线上的访问情况,给出综合的评估。
578 |
579 |
580 |
581 | ### 服务上线怎么兼容旧版本?
582 |
583 | 可以用版本号(version)过渡,多个不同版本的服务注册到注册中心,版本号不同的服务相互间不引用。这个和服务分组的概念有一点类似。
584 |
585 |
586 |
587 | ### Dubbo可以对结果进行缓存吗?
588 |
589 | 可以,Dubbo 提供了声明式缓存,用于加速热门数据的访问速度,以减少用户加缓存的工作量。
590 |
591 |
592 |
593 | ### Dubbo服务之间的调用是阻塞的吗?
594 |
595 | 默认是同步等待结果阻塞的,支持异步调用。
596 |
597 | Dubbo 是基于 NIO 的非阻塞实现并行调用,客户端不需要启动多线程即可完成并行调用多个远程服务,相对多线程开销较小,异步调用会返回一个 Future 对象。
598 |
599 | 异步调用流程图如下。
600 |
601 | 
602 |
603 |
604 |
605 | ### Dubbo支持分布式事务吗?
606 |
607 | 目前暂时不支持,后续可能采用基于 JTA/XA 规范实现,如以图所示。
608 |
609 | 
610 |
611 |
612 |
613 | ### Dubbo的心跳机制
614 |
615 | **目的:**
616 | 维持provider和consumer之间的长连接
617 |
618 | **实现:**
619 | dubbo心跳时间heartbeat默认是1s,超过heartbeat时间没有收到消息,就发送心跳消 息(provider,consumer一样),如果连着3次(heartbeatTimeout为heartbeat*3)没有收到心跳响应,provider会关闭channel,而consumer会进行重连;不论是provider还是consumer的心跳检测都是通过启动定时任务的方式实现;
620 |
621 |
622 |
623 | ### Dubbo的zookeeper做注册中心,如果注册中心全部挂掉,发布者和订阅者还能通信吗?
624 | 可以通信的,启动dubbo时,消费者会从zk拉取注册的生产者的地址接口等数据,缓存在本地。每次调用时,按照本地存储的地址进行调用;
625 | 注册中心对等集群,任意一台宕机后,将会切换到另一台;注册中心全部宕机后,服务的提供者和消费者仍能通过本地缓存通讯。服务提供者无状态,任一台 宕机后,不影响使用;服务提供者全部宕机,服务消费者会无法使用,并无限次重连等待服务者恢复;
626 | 挂掉是不要紧的,但前提是你没有增加新的服务,如果你要调用新的服务,则是不能办到的。
627 |
628 |
629 |
630 | ### Dubbo telnet 命令能做什么?
631 |
632 | dubbo 通过 telnet 命令来进行服务治理
633 |
634 | ```
635 | telnet localhost 8090
636 | ```
637 |
638 |
639 |
640 | ### 说说服务暴露的流程?
641 |
642 | **1、** 在容器启动的时候,通过ServiceConfig解析标签,创建dubbo标签解析器来解析dubbo的标签,容器创建完成之后,触发ContextRefreshEvent事件回调开始暴露服务
643 |
644 | **2、** 通过ProxyFactory获取到invoker,invoker包含了需要执行的方法的对象信息和具体的URL地址
645 |
646 | **3、** 再通过DubboProtocol的实现把包装后的invoker转换成exporter,然后启动服务器server,监听端口
647 |
648 | **4、** 最后RegistryProtocol保存URL地址和invoker的映射关系,同时注册到服务中心
649 |
650 |
651 |
652 | 
653 |
654 |
655 |
656 | ### 说说服务引用的流程?
657 |
658 | 服务暴露之后,客户端就要引用服务,然后才是调用的过程。
659 |
660 | **1、** 首先客户端根据配置文件信息从注册中心订阅服务
661 |
662 | **2、** 之后DubboProtocol根据订阅的得到provider地址和接口信息连接到服务端server,开启客户端client,然后创建invoker
663 |
664 | **3、** invoker创建完成之后,通过invoker为服务接口生成代理对象,这个代理对象用于远程调用provider,服务的引用就完成了
665 |
666 |
667 |
668 | 
669 |
670 |
671 |
672 | ### 有哪些负载均衡策略?
673 |
674 | **1、加权随机:** 假设我们有一组服务器 servers = [A, B, C],他们对应的权重为 weights = [5, 3, 2],权重总和为10。现在把这些权重值平铺在一维坐标值上,[0, 5) 区间属于服务器 A,[5, 8) 区间属于服务器 B,[8, 10) 区间属于服务器 C。接下来通过随机数生成器生成一个范围在 [0, 10) 之间的随机数,然后计算这个随机数会落到哪个区间上就可以了。
675 |
676 | **2、最小活跃数:** 每个服务提供者对应一个活跃数 active,初始情况下,所有服务提供者活跃数均为0。每收到一个请求,活跃数加1,完成请求后则将活跃数减1。在服务运行一段时间后,性能好的服务提供者处理请求的速度更快,因此活跃数下降的也越快,此时这样的服务提供者能够优先获取到新的服务请求。
677 |
678 | **3、一致性hash:** 通过hash算法,把provider的invoke和随机节点生成hash,并将这个 hash 投射到 [0, 2^32 - 1] 的圆环上,查询的时候根据key进行md5然后进行hash,得到第一个节点的值大于等于当前hash的invoker。
679 |
680 |
681 |
682 | ### Dubbo如何优雅停机?
683 |
684 | Dubbo 是通过 JDK 的 ShutdownHook 来完成优雅停机的,所以如果使用 kill -9 PID 等强制关闭指令,是不会执行优雅停机的,只有通过 kill PID 时,才会执行。
685 |
686 |
687 |
688 | ### 了解Dubbo SPI机制吗?
689 |
690 | SPI 全称为 Service Provider Interface,是一种服务发现机制,本质是将接口实现类的全限定名配置在文件中,并由服务加载器读取配置文件,加载实现类,这样可以在运行时,动态为接口替换实现类。
691 |
692 | Dubbo也正是通过SPI机制实现了众多的扩展功能,而且dubbo没有使用java原生的SPI机制,而是对齐进行了增强和改进。
693 |
694 | SPI在dubbo应用很多,包括协议扩展、集群扩展、路由扩展、序列化扩展等等。
695 |
696 | 使用方式可以在META-INF/dubbo目录下配置:
697 |
698 | key=com.xxx.value
699 |
700 | 然后通过dubbo的Extensier按照指定的key加载对应的实现类,这样做的好处就是可以按需加载,性能上得到优化。
701 |
702 |
703 |
704 | ### 如果让你实现一个RPC框架怎么设计?
705 |
706 | **1、** 首先需要一个服务注册中心,这样consumer和provider才能去注册和订阅服务
707 |
708 | **2、** 需要负载均衡的机制来决定consumer如何调用客户端,这其中还当然要包含容错和重试的机制
709 |
710 | **3、** 需要通信协议和工具框架,比如通过http或者rmi的协议通信,然后再根据协议选择使用什么框架和工具来进行通信,当然,数据的传输序列化要考虑
711 |
712 | **4、** 除了基本的要素之外,像一些监控、配置管理页面、日志是额外的优化考虑因素。
713 |
714 | 那么,本质上,只要熟悉一两个RPC框架,就很容易想明白我们自己要怎么实现一个RPC框架。
715 |
716 |
717 |
718 | ### 服务提供者能实现失效踢出是什么原理?
719 |
720 | 服务失效踢出基于 Zookeeper 的临时节点原理。
721 |
722 |
723 |
724 | ### 如何解决服务调用链过长的问题?
725 |
726 | Dubbo 可以使用 Pinpoint 和 Apache Skywalking(Incubator) 实现分布式服务追踪,当然还有其他很多方案。
727 |
728 |
729 |
730 | ### 服务读写推荐的容错策略是怎样的?
731 |
732 | 读操作建议使用 Failover 失败自动切换,默认重试两次其他服务器。
733 |
734 | 写操作建议使用 Failfast 快速失败,发一次调用失败就立即报错。
735 |
736 |
737 |
738 | ### Dubbo必须依赖的包有哪些?
739 |
740 | Dubbo 必须依赖 JDK,其他为可选。
741 |
742 |
743 |
744 | ### Dubbo的管理控制台能做什么?
745 |
746 | 管理控制台主要包含:路由规则,动态配置,服务降级,访问控制,权重调整,负载均衡,等管理功能。
747 |
748 |
749 |
750 | ### 说说 Dubbo 服务暴露的过程。
751 |
752 | Dubbo 会在 Spring 实例化完 bean 之后,在刷新容器最后一步发布 ContextRefreshEvent 事件的时候,通知实现了 ApplicationListener 的 ServiceBean 类进行回调 onApplicationEvent 事件方法,Dubbo 会在这个方法中调用 ServiceBean 父类 ServiceConfig 的 export 方法,而该方法真正实现了服务的(异步或者非异步)发布。
753 |
754 |
755 |
756 | ### Dubbo 停止维护了吗?
757 |
758 | 2014 年开始停止维护过几年,17 年开始重新维护,并进入了 Apache 项目。
759 |
760 |
761 |
762 | ### Dubbo 和 Dubbox 有什么区别?
763 |
764 | Dubbox 是继 Dubbo 停止维护后,当当网基于 Dubbo 做的一个扩展项目,如加了服务可 Restful 调用,更新了开源组件等。
765 |
766 |
767 |
768 | ### 在使用过程中都遇到了些什么问题?如何解决的?
769 |
770 | **1、** 同时配置了 XML 和 properties 文件,则 properties 中的配置无效只有 XML 没有配置时,properties 才生效。
771 |
772 | **2、** dubbo 缺省会在启动时检查依赖是否可用,不可用就抛出异常,阻止 spring 初始化完成,check 属性默认为 true。测试时有些服务不关心或者出现了循环依赖,将 check 设置为 false
773 |
774 | **3、** 为了方便开发测试,线下有一个所有服务可用的注册中心,这时,如果有一个正在开发中的服务提供者注册,可能会影响消费者不能正常运行。
775 |
776 | 解决:让服务提供者开发方,只订阅服务,而不注册正在开发的服务,通过直连测试正在开发的服务。设置 dubbo:registry 标签的 register 属性为 false。
777 |
778 | **4、** spring 2.x 初始化死锁问题。在 spring 解析到 dubbo:service 时,就已经向外暴露了服务,而 spring 还在接着初始化其他 bean,如果这时有请求进来,并且服务的实现类里有调用 applicationContext.getBean() 的用法。getBean 线程和 spring 初始化线程的锁的顺序不一样,导致了线程死锁,不能提供服务,启动不了。
779 |
780 | 解决:不要在服务的实现类中使用 applicationContext.getBean(); 如果不想依赖配置顺序,可以将 dubbo:provider 的 deplay 属性设置为 - 1,使 dubbo 在容器初始化完成后再暴露服务。
781 |
782 | **5、** 服务注册不上
783 |
784 | 检查 dubbo 的 jar 包有没有在 classpath 中,以及有没有重复的 jar 包
785 |
786 | 检查暴露服务的 spring 配置有没有加载
787 |
788 | 在服务提供者机器上测试与注册中心的网络是否通
789 |
790 | **6、** 出现 RpcException: No provider available for remote service 异常
791 |
792 | 表示没有可用的服务提供者,
793 |
794 | - 检查连接的注册中心是否正确
795 |
796 | - 到注册中心查看相应的服务提供者是否存在
797 |
798 | - 检查服务提供者是否正常运行
799 |
800 | **7、** 出现” 消息发送失败” 异常
801 |
802 | 通常是接口方法的传入传出参数未实现 Serializable 接口。
803 |
804 |
805 |
806 | ### 你还了解别的分布式框架吗?
807 |
808 | 别的还有 Spring cloud、Facebook 的 Thrift、Twitter 的 Finagle 等。
809 |
810 |
--------------------------------------------------------------------------------
/interviewDoc/Java/middleware/ElasticSearch.md:
--------------------------------------------------------------------------------
1 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
2 |
3 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
4 |
5 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
6 |
7 |
8 |
9 |
10 | - [简要介绍一下Elasticsearch?](#简要介绍一下elasticsearch)
11 | - [什么是Elasticsearch?](#什么是elasticsearch)
12 | - [安装 Elasticsearch 需要依赖什么组件吗?](#安装-elasticsearch-需要依赖什么组件吗)
13 | - [如何启动 Elasticsearch 服务器?](#如何启动-elasticsearch-服务器)
14 | - [ElasticSearch中的集群、节点、索引、文档、类型是什么?](#elasticsearch中的集群节点索引文档类型是什么)
15 | - [Elasticsearch 支持哪些类型的查询?](#elasticsearch-支持哪些类型的查询)
16 | - [精准匹配检索和全文检索匹配检索的不同?](#精准匹配检索和全文检索匹配检索的不同)
17 | - [ElasticSearch中的分片是什么?](#elasticsearch中的分片是什么)
18 | - [elasticsearch了解多少,说说你们公司es的集群架构,索引数据大小,分片有多少,以及一些调优手段 。](#elasticsearch了解多少说说你们公司es的集群架构索引数据大小分片有多少以及一些调优手段-)
19 | - [1.1 、设计阶段调优](#11-设计阶段调优)
20 | - [1.2 、写入调优](#12-写入调优)
21 | - [1.3 、查询调优](#13-查询调优)
22 | - [1.4 、其他调优](#14-其他调优)
23 | - [elasticsearch 索引数据多了怎么办,如何调优,部署](#elasticsearch-索引数据多了怎么办如何调优部署)
24 | - [请解释一下 Elasticsearch 中聚合?](#请解释一下-elasticsearch-中聚合)
25 | - [解释一下Elasticsearch Cluster?](#解释一下elasticsearch-cluster)
26 | - [解释一下 Elasticsearch Node?](#解释一下-elasticsearch-node)
27 | - [我们可以在 Elasticsearch 中执行搜索的各种可能方式有哪些?](#我们可以在-elasticsearch-中执行搜索的各种可能方式有哪些)
28 | - [解释一下 Elasticsearch 集群中的 Type 的概念 ?](#解释一下-elasticsearch-集群中的-type-的概念-)
29 | - [解释一下 Elasticsearch 的 分片?](#解释一下-elasticsearch-的-分片)
30 | - [定义副本、创建副本的好处是什么?](#定义副本创建副本的好处是什么)
31 | - [Elasticsearch Analyzer 中的字符过滤器如何利用?](#elasticsearch-analyzer-中的字符过滤器如何利用)
32 | - [REST API在 Elasticsearch 方面有哪些优势?](#rest-api在-elasticsearch-方面有哪些优势)
33 | - [Elasticsearch 中常用的 cat命令有哪些?](#elasticsearch-中常用的-cat命令有哪些)
34 | - [你能否列出与 Elasticsearch 有关的主要可用字段数据类型?](#你能否列出与-elasticsearch-有关的主要可用字段数据类型)
35 | - [Elasticsearch了解多少,说说你们公司es的集群架构,索引数据大小,分片有多少,以及一些调优手段 。](#elasticsearch了解多少说说你们公司es的集群架构索引数据大小分片有多少以及一些调优手段-)
36 | - [解释一下 Elasticsearch集群中的 索引的概念 ?](#解释一下-elasticsearch集群中的-索引的概念-)
37 | - [Elasticsearch 索引数据多了怎么办,如何调优,部署](#elasticsearch-索引数据多了怎么办如何调优部署)
38 | - [我们可以在 Elasticsearch 中执行搜索的各种可能方式有哪些?](#我们可以在-elasticsearch-中执行搜索的各种可能方式有哪些)
39 | - [在 Elasticsearch 中删除索引的语法是什么?](#在-elasticsearch-中删除索引的语法是什么)
40 | - [在 Elasticsearch 中列出集群的所有索引的语法是什么?](#在-elasticsearch-中列出集群的所有索引的语法是什么)
41 | - [在索引中更新 Mapping 的语法?](#在索引中更新-mapping-的语法)
42 | - [ES 写数据过程](#es-写数据过程)
43 | - [ES 读数据过程](#es-读数据过程)
44 | - [底层 lucene](#底层-lucene)
45 | - [ES中的倒排索引是什么?](#es中的倒排索引是什么)
46 | - [请解释在 Elasticsearch 集群中添加或创建索引的过程?](#请解释在-elasticsearch-集群中添加或创建索引的过程)
47 | - [详细描述一下Elasticsearch索引文档的过程](#详细描述一下elasticsearch索引文档的过程)
48 | - [详细描述一下Elasticsearch更新和删除文档的过程](#详细描述一下elasticsearch更新和删除文档的过程)
49 | - [详细描述一下Elasticsearch搜索的过程](#详细描述一下elasticsearch搜索的过程)
50 | - [Elasticsearch对于大数据量(上亿量级)的聚合如何实现?](#elasticsearch对于大数据量上亿量级的聚合如何实现)
51 | - [你可以列出 Elasticsearch 各种类型的分析器吗?](#你可以列出-elasticsearch-各种类型的分析器吗)
52 | - [ElaticSearch是如何实现master选举的?](#elaticsearch是如何实现master选举的)
53 | - [Master 节点和 候选 Master节点有什么区别?](#master-节点和-候选-master节点有什么区别)
54 | - [Elasticsearch中的属性 enabled, index 和 store 的功能是什么?](#elasticsearch中的属性-enabled-index-和-store-的功能是什么)
55 | - [Elasticsearch中的节点(比如共20个),其中的10个选了一个master,另外10个选了另一个master,怎么办?](#elasticsearch中的节点比如共20个其中的10个选了一个master另外10个选了另一个master怎么办)
56 | - [如何解决ES集群的脑裂问题](#如何解决es集群的脑裂问题)
57 | - [详细描述一下ES索引文档的过程?](#详细描述一下es索引文档的过程)
58 | - [详细描述一下ES更新和删除文档的过程?](#详细描述一下es更新和删除文档的过程)
59 | - [详细描述一下ES搜索的过程?](#详细描述一下es搜索的过程)
60 | - [在并发情况下,ES如果保证读写一致?](#在并发情况下es如果保证读写一致)
61 | - [ES对于大数据量(上亿量级)的聚合如何实现?](#es对于大数据量上亿量级的聚合如何实现)
62 | - [对于GC方面,在使用ES时要注意什么?](#对于gc方面在使用es时要注意什么)
63 | - [说说你们公司ES的集群架构,索引数据大小,分片有多少,以及一些调优手段?](#说说你们公司es的集群架构索引数据大小分片有多少以及一些调优手段)
64 | - [在并发情况下,Elasticsearch如果保证读写一致?](#在并发情况下elasticsearch如果保证读写一致)
65 |
66 |
67 |
68 | ### 简要介绍一下Elasticsearch?
69 |
70 | Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
71 |
72 | ElasticSearch 是基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。
73 |
74 | 核心特点如下:
75 |
76 | - 分布式的实时文件存储,每个字段都被索引且可用于搜索。
77 | - 分布式的实时分析搜索引擎,海量数据下近实时秒级响应。
78 | - 简单的restful api,天生的兼容多语言开发。
79 | - 易扩展,处理PB级结构化或非结构化数据。
80 |
81 |
82 |
83 | ### 什么是Elasticsearch?
84 |
85 | Elasticsearch 是一个基于 Lucene 的搜索引擎。它提供了具有 HTTP Web 界面和无架构 JSON 文档的分布式,多租户能力的全文搜索引擎。
86 | Elasticsearch 是用 Java 开发的,根据 Apache 许可条款作为开源发布。
87 |
88 |
89 |
90 | ### 安装 Elasticsearch 需要依赖什么组件吗?
91 |
92 | ES 早期版本需要JDK,在7.X版本后已经集成了 JDK,已无需第三方依赖。
93 |
94 |
95 |
96 | ### 如何启动 Elasticsearch 服务器?
97 |
98 | 启动方式有很多种,一般 bin 路径下
99 |
100 | ```
101 | ./elasticsearch -d
102 | ```
103 |
104 | 就可以后台启动。
105 |
106 | 打开浏览器输入 http://ES IP:9200 就能知道集群是否启动成功。
107 |
108 | 如果启动报错,日志里会有详细信息,逐条核对解决就可以。
109 |
110 |
111 |
112 | ### ElasticSearch中的集群、节点、索引、文档、类型是什么?
113 |
114 | **群集**是一个或多个节点(服务器)的集合,它们共同保存您的整个数据,并提供跨所有节点的联合索引和搜索功能。群集由唯一名称标识,默认情况下为“elasticsearch”。此名称很重要,因为如果节点设置为按名称加入群集,则该节点只能是群集的一部分。
115 |
116 |
117 |
118 | **节点**是属于集群一部分的单个服务器。它存储数据并参与群集索引和搜索功能。
119 |
120 | **索引**就像关系数据库中的“数据库”。它有一个定义多种类型的映射。索引是逻辑名称空间,映射到一个或多个主分片,并且可以有零个或多个副本分片。 MySQL =>数据库 ElasticSearch =>索引
121 |
122 | **文档**类似于关系数据库中的一行。不同之处在于索引中的每个文档可以具有不同的结构(字段),但是对于通用字段应该具有相同的数据类型。 MySQL => Databases => Tables => Columns / Rows ElasticSearch => Indices => Types =>具有属性的文档
123 |
124 | **类型**是索引的逻辑类别/分区,其语义完全取决于用户。
125 |
126 |
127 |
128 | ### Elasticsearch 支持哪些类型的查询?
129 |
130 | 查询主要分为两种类型:精确匹配、全文检索匹配。
131 |
132 | - 精确匹配,例如 term、exists、term set、 range、prefix、 ids、 wildcard、regexp、 fuzzy等。
133 | - 全文检索,例如match、match_phrase、multi_match、match_phrase_prefix、query_string 等
134 |
135 |
136 |
137 | ### 精准匹配检索和全文检索匹配检索的不同?
138 |
139 | 两者的本质区别:
140 |
141 | - 精确匹配用于:是否完全一致?
142 |
143 | 举例:邮编、身份证号的匹配往往是精准匹配。
144 |
145 | - 全文检索用于:是否相关?
146 |
147 | 举例:类似B站搜索特定关键词如“马保国 视频”往往是模糊匹配,相关的都返回就可以。
148 |
149 |
150 |
151 | ### ElasticSearch中的分片是什么?
152 |
153 | 在大多数环境中,每个节点都在单独的盒子或虚拟机上运行。
154 |
155 | 索引 - 在Elasticsearch中,索引是文档的集合。
156 | 分片 -因为Elasticsearch是一个分布式搜索引擎,所以索引通常被分割成分布在多个节点上的被称为分片的元素。
157 |
158 |
159 |
160 | ### elasticsearch了解多少,说说你们公司es的集群架构,索引数据大小,分片有多少,以及一些调优手段 。
161 |
162 | `面试官`:想了解应聘者之前公司接触的ES使用场景、规模,有没有做过比较大规模的索引设计、规划、调优。
163 | `解答`:
164 | 如实结合自己的实践场景回答即可。
165 | 比如:ES集群架构13个节点,索引根据通道不同共20+索引,根据日期,每日递增20+,索引:10分片,每日递增1亿+数据,
166 | 每个通道每天索引大小控制:150GB之内。
167 |
168 | 仅索引层面调优手段:
169 |
170 | ##### 1.1、设计阶段调优
171 |
172 | - 1)根据业务增量需求,采取基于日期模板创建索引,通过roll over API滚动索引;
173 | - 2)使用别名进行索引管理;
174 | - 3)每天凌晨定时对索引做force_merge操作,以释放空间;
175 | - 4)采取冷热分离机制,热数据存储到SSD,提高检索效率;冷数据定期进行shrink操作,以缩减存储;
176 | - 5)采取curator进行索引的生命周期管理;
177 | - 6)仅针对需要分词的字段,合理的设置分词器;
178 | - 7)Mapping阶段充分结合各个字段的属性,是否需要检索、是否需要存储等。 ……..
179 |
180 | ##### 1.2、写入调优
181 |
182 | - 1)写入前副本数设置为0;
183 | - 2)写入前关闭refresh_interval设置为-1,禁用刷新机制;
184 | - 3)写入过程中:采取bulk批量写入;
185 | - 4)写入后恢复副本数和刷新间隔;
186 | - 5)尽量使用自动生成的id。
187 |
188 | ##### 1.3、查询调优
189 |
190 | - 1)禁用wildcard;
191 | - 2)禁用批量terms(成百上千的场景);
192 | - 3)充分利用倒排索引机制,能keyword类型尽量keyword;
193 | - 4)数据量大时候,可以先基于时间敲定索引再检索;
194 | - 5)设置合理的路由机制。
195 |
196 | ##### 1.4、其他调优
197 |
198 | 部署调优,业务调优等。
199 |
200 | 上面的提及一部分,面试者就基本对你之前的实践或者运维经验有所评估了。
201 |
202 |
203 |
204 | ### elasticsearch 索引数据多了怎么办,如何调优,部署
205 |
206 | `面试官`:想了解大数据量的运维能力。
207 | `解答`:索引数据的规划,应在前期做好规划,正所谓“设计先行,编码在后”,这样才能有效的避免突如其来的数据激增导致集群处理能力不足引发的线上客户检索或者其他业务受到影响。
208 | 如何调优,正如问题1所说,这里细化一下:
209 |
210 | **动态索引层面**
211 |
212 | 基于`模板+时间+rollover api滚动`创建索引,举例:设计阶段定义:blog索引的模板格式为:blog_index_时间戳的形式,每天递增数据。
213 |
214 | 这样做的好处:不至于数据量激增导致单个索引数据量非常大,接近于上线2的32次幂-1,索引存储达到了TB+甚至更大。
215 |
216 | 一旦单个索引很大,存储等各种风险也随之而来,所以要提前考虑+及早避免。
217 |
218 | **存储层面**
219 |
220 | `冷热数据分离存储`,热数据(比如最近3天或者一周的数据),其余为冷数据。
221 | 对于冷数据不会再写入新数据,可以考虑定期force_merge加shrink压缩操作,节省存储空间和检索效率。
222 |
223 | **部署层面**
224 |
225 | 一旦之前没有规划,这里就属于应急策略。
226 | 结合ES自身的支持动态扩展的特点,动态新增机器的方式可以缓解集群压力,注意:如果之前主节点等`规划合理`,不需要重启集群也能完成动态新增的。
227 |
228 |
229 |
230 | ### 请解释一下 Elasticsearch 中聚合?
231 |
232 | 聚合有助于从搜索中使用的查询中收集数据,聚合为各种统计指标,便于统计信息或做其他分析。聚合可帮助回答以下问题:
233 |
234 | - 我的网站平均加载时间是多少?
235 | - 根据交易量,谁是我最有价值的客户?
236 | - 什么会被视为我网络上的大文件?
237 | - 每个产品类别中有多少个产品?
238 |
239 | 聚合的分三类:
240 |
241 | 主要查看7.10 的官方文档,早期是4个分类,别大意啊!
242 |
243 | - 分桶 Bucket 聚合
244 |
245 | 根据字段值,范围或其他条件将文档分组为桶(也称为箱)。
246 |
247 | - 指标 Metric 聚合
248 |
249 | 从字段值计算指标(例如总和或平均值)的指标聚合。
250 |
251 | - 管道 Pipeline 聚合
252 |
253 | 子聚合,从其他聚合(而不是文档或字段)获取输入。
254 |
255 |
256 |
257 | ### 解释一下Elasticsearch Cluster?
258 |
259 | Elasticsearch 集群是一组连接在一起的一个或多个 Elasticsearch 节点实例。
260 |
261 | Elasticsearch 集群的功能在于在集群中的所有节点之间分配任务,进行搜索和建立索引。
262 |
263 |
264 |
265 | ### 解释一下 Elasticsearch Node?
266 |
267 | 节点是 Elasticsearch 的实例。实际业务中,我们会说:ES集群包含3个节点、7个节点。
268 |
269 | 这里节点实际就是:一个独立的 Elasticsearch 进程,一般将一个节点部署到一台独立的服务器或者虚拟机、容器中。
270 |
271 | 不同节点根据角色不同,可以划分为:
272 |
273 | - 主节点
274 |
275 | 帮助配置和管理在整个集群中添加和删除节点。
276 |
277 | - 数据节点
278 |
279 | 存储数据并执行诸如CRUD(创建/读取/更新/删除)操作,对数据进行搜索和聚合的操作。
280 |
281 | - 客户端节点(或者说:协调节点) 将集群请求转发到主节点,将与数据相关的请求转发到数据节点
282 | - 摄取节点
283 |
284 | 用于在索引之前对文档进行预处理。
285 |
286 |
287 |
288 | ### 我们可以在 Elasticsearch 中执行搜索的各种可能方式有哪些?
289 |
290 | 核心方式如下:
291 |
292 | 方式一:基于 DSL 检索(最常用) Elasticsearch提供基于JSON的完整查询DSL来定义查询。
293 |
294 | ```
295 | GET /shirts/_search
296 | {
297 | "query": {
298 | "bool": {
299 | "filter": [
300 | { "term": { "color": "red" }},
301 | { "term": { "brand": "gucci" }}
302 | ]
303 | }
304 | }
305 | }
306 | ```
307 |
308 | 方式二:基于 URL 检索
309 |
310 | ```
311 | GET /my_index/_search?q=user:seina
312 | ```
313 |
314 | 方式三:类SQL 检索
315 |
316 | ```
317 | POST /_sql?format=txt
318 | {
319 | "query": "SELECT * FROM uint-2020-08-17 ORDER BY itemid DESC LIMIT 5"
320 | }
321 | ```
322 |
323 | 功能还不完备,不推荐使用。
324 |
325 |
326 |
327 | ### 解释一下 Elasticsearch 集群中的 Type 的概念 ?
328 |
329 | 5.X 以及之前的 2.X、1.X 版本 ES支持一个索引多个type的,举例 ES 6.X 中的Join 类型在早期版本实际是多 Type 实现的。
330 |
331 | 在6.0.0 或 更高版本中创建的索引只能包含一个 Mapping 类型。
332 |
333 | Type 将在Elasticsearch 7.0.0中的API中弃用,并在8.0.0中完全删除。
334 |
335 |
336 |
337 | ### 解释一下 Elasticsearch 的 分片?
338 |
339 | 当文档数量增加,硬盘容量和处理能力不足时,对客户端请求的响应将延迟。
340 |
341 | 在这种情况下,将索引数据分成小块的过程称为分片,可改善数据搜索结果的获取。
342 |
343 |
344 |
345 | ### 定义副本、创建副本的好处是什么?
346 |
347 | 副本是 分片的对应副本,用在极端负载条件下提高查询吞吐量或实现高可用性。
348 |
349 | 所谓高可用主要指:如果某主分片1出了问题,对应的副本分片1会提升为主分片,保证集群的高可用。
350 |
351 |
352 |
353 | ### Elasticsearch Analyzer 中的字符过滤器如何利用?
354 |
355 | 字符过滤器将原始文本作为字符流接收,并可以通过添加,删除或更改字符来转换字符流。
356 |
357 | 字符过滤分类如下:
358 |
359 | - HTML Strip Character Filter.
360 |
361 | 用途:删除HTML元素,如,并解码HTML实体,如&amp 。
362 |
363 | - Mapping Character Filter
364 |
365 | 用途:替换指定的字符。
366 |
367 | - Pattern Replace Character Filter
368 |
369 | 用途:基于正则表达式替换指定的字符。
370 |
371 |
372 |
373 | ### REST API在 Elasticsearch 方面有哪些优势?
374 |
375 | REST API是使用超文本传输协议的系统之间的通信,该协议以 XML 和 JSON格式传输数据请求。
376 |
377 | REST 协议是无状态的,并且与带有服务器和存储数据的用户界面分开,从而增强了用户界面与任何类型平台的可移植性。它还提高了可伸缩性,允许独立实现组件,因此应用程序变得更加灵活。
378 |
379 | REST API与平台和语言无关,只是用于数据交换的语言是XML或JSON。
380 |
381 | 借助:REST API 查看集群信息或者排查问题都非常方便。
382 |
383 |
384 |
385 | ### Elasticsearch 中常用的 cat命令有哪些?
386 |
387 | 面试时说几个核心的就可以,包含但不限于:
388 |
389 | | 含义 | 命令 |
390 | | :--------- | :----------------------- |
391 | | 别名 | GET _cat/aliases?v |
392 | | 分配相关 | GET _cat/allocation |
393 | | 计数 | GET _cat/count?v |
394 | | 字段数据 | GET _cat/fielddata?v |
395 | | 运行状况 | GET_cat/health? |
396 | | 索引相关 | GET _cat/indices?v |
397 | | 主节点相关 | GET _cat/master?v |
398 | | 节点属性 | GET _cat/nodeattrs?v |
399 | | 节点 | GET _cat/nodes?v |
400 | | 待处理任务 | GET _cat/pending_tasks?v |
401 | | 插件 | GET _cat/plugins?v |
402 | | 恢复 | GET _cat / recovery?v |
403 | | 存储库 | GET _cat /repositories?v |
404 | | 段 | GET _cat /segments?v |
405 | | 分片 | GET _cat/shards?v |
406 | | 快照 | GET _cat/snapshots?v |
407 | | 任务 | GET _cat/tasks?v |
408 | | 模板 | GET _cat/templates?v |
409 | | 线程池 | GET _cat/thread_pool?v |
410 |
411 |
412 |
413 | ### 你能否列出与 Elasticsearch 有关的主要可用字段数据类型?
414 |
415 | - 字符串数据类型,包括支持全文检索的 text 类型 和 精准匹配的 keyword 类型。
416 | - 数值数据类型,例如字节,短整数,长整数,浮点数,双精度数,half_float,scaled_float。
417 | - 日期类型,日期纳秒Date nanoseconds,布尔值,二进制(Base64编码的字符串)等。
418 | - 范围(整数范围 integer_range,长范围 long_range,双精度范围 double_range,浮动范围 float_range,日期范围 date_range)。
419 | - 包含对象的复杂数据类型,nested 、Object。
420 | - GEO 地理位置相关类型。
421 | - 特定类型如:数组(数组中的值应具有相同的数据类型)
422 |
423 |
424 |
425 | ### Elasticsearch了解多少,说说你们公司es的集群架构,索引数据大小,分片有多少,以及一些调优手段 。
426 |
427 | 如实结合自己的实践场景回答即可。
428 | 比如:ES集群架构13个节点,索引根据通道不同共20+索引,根据日期,每日递增20+,索引:10分片,每日递增1亿+数据,
429 | 每个通道每天索引大小控制:150GB之内。
430 |
431 |
432 |
433 | **设计阶段调优**
434 |
435 | 1、根据业务增量需求,采取基于日期模板创建索引,通过roll over API滚动索引;
436 |
437 | 2、使用别名进行索引管理;
438 |
439 | 3、每天凌晨定时对索引做force_merge操作,以释放空间;
440 |
441 | 4、采取冷热分离机制,热数据存储到SSD,提高检索效率;冷数据定期进行shrink操作,以缩减存储;
442 |
443 | 5、采取curator进行索引的生命周期管理;
444 |
445 | 6、仅针对需要分词的字段,合理的设置分词器;
446 |
447 | 7、Mapping阶段充分结合各个字段的属性,是否需要检索、是否需要存储等。……..
448 |
449 |
450 |
451 | **写入调优**
452 |
453 | 1、写入前副本数设置为0;
454 |
455 | 2、写入前关闭refresh_interval设置为-1,禁用刷新机制;
456 |
457 | 3、写入过程中:采取bulk批量写入;
458 |
459 | 4、写入后恢复副本数和刷新间隔;
460 |
461 | 5、尽量使用自动生成的id。
462 |
463 |
464 |
465 | **查询调优**
466 |
467 | 1、禁用wildcard;
468 |
469 | 2、禁用批量terms(成百上千的场景);
470 |
471 | 3、充分利用倒排索引机制,能keyword类型尽量keyword;
472 |
473 | 4、数据量大时候,可以先基于时间敲定索引再检索;
474 |
475 | 5、设置合理的路由机制。
476 |
477 |
478 |
479 | **其他调优**
480 |
481 | 部署调优,业务调优等。
482 |
483 | 上面的提及一部分,面试者就基本对你之前的实践或者运维经验有所评估了。
484 |
485 |
486 |
487 | ### 解释一下 Elasticsearch集群中的 索引的概念 ?
488 |
489 | Elasticsearch 集群可以包含多个索引,与关系数据库相比,它们相当于数据库表
490 |
491 | 其他类别概念,如下表所示,点到为止。
492 |
493 | 
494 |
495 | 
496 |
497 |
498 |
499 |
500 |
501 | ### Elasticsearch 索引数据多了怎么办,如何调优,部署
502 |
503 | 索引数据的规划,应在前期做好规划,正所谓“设计先行,编码在后”,这样才能有效的避免突如其来的数据激增导致集群处理能力不足引发的线上客户检索或者其他业务受到影响。
504 | 如何调优,正如问题1所说,这里细化一下:
505 |
506 | **动态索引层面**
507 |
508 | 基于`模板+时间+rollover api滚动`创建索引,举例:设计阶段定义:blog索引的模板格式为:blog_index_时间戳的形式,每天递增数据。
509 |
510 | 这样做的好处:不至于数据量激增导致单个索引数据量非常大,接近于上线2的32次幂-1,索引存储达到了TB+甚至更大。
511 |
512 | 一旦单个索引很大,存储等各种风险也随之而来,所以要提前考虑+及早避免。
513 |
514 |
515 |
516 | **存储层面**
517 |
518 | `冷热数据分离存储`,热数据(比如最近3天或者一周的数据),其余为冷数据。
519 | 对于冷数据不会再写入新数据,可以考虑定期force_merge加shrink压缩操作,节省存储空间和检索效率。
520 |
521 |
522 |
523 | **部署层面**
524 |
525 | 一旦之前没有规划,这里就属于应急策略。
526 | 结合ES自身的支持动态扩展的特点,动态新增机器的方式可以缓解集群压力,注意:如果之前主节点等`规划合理`,不需要重启集群也能完成动态新增的。
527 |
528 |
529 |
530 | ### 我们可以在 Elasticsearch 中执行搜索的各种可能方式有哪些?
531 |
532 | **方式一:**
533 |
534 | 基于 DSL 检索(最常用) Elasticsearch提供基于JSON的完整查询DSL来定义查询。
535 |
536 | ```
537 | GET /shirts/_search
538 | {
539 | "query": {
540 | "bool": {
541 | "filter": [
542 | { "term": { "color": "red" }},
543 | { "term": { "brand": "gucci" }}
544 | ]
545 | }
546 | }
547 | }
548 | ```
549 |
550 |
551 |
552 | **方式二:**
553 |
554 | 基于 URL 检索
555 |
556 | ```
557 | GET /my_index/_search?q=user:seina
558 | ```
559 |
560 |
561 |
562 | **方式三:**
563 |
564 | 类SQL 检索
565 |
566 | ```
567 | POST /_sql?format=txt
568 | {
569 | "query": "SELECT * FROM uint-2020-08-17 ORDER BY itemid DESC LIMIT 5"
570 | }
571 | ```
572 |
573 | 功能还不完备,不推荐使用。
574 |
575 |
576 |
577 | ### 在 Elasticsearch 中删除索引的语法是什么?
578 |
579 | 可以使用以下语法删除现有索引:
580 |
581 | ```
582 | DELETE
583 | ```
584 |
585 | 支持通配符删除:
586 |
587 | ```
588 | DELETE my_*
589 | ```
590 |
591 |
592 |
593 | ### 在 Elasticsearch 中列出集群的所有索引的语法是什么?
594 |
595 | ```
596 | GET _cat/indices
597 | ```
598 |
599 |
600 |
601 | ### 在索引中更新 Mapping 的语法?
602 |
603 | ```
604 | PUT test_001/_mapping
605 | {
606 | "properties": {
607 | "title":{
608 | "type":"keyword"
609 | }
610 | }
611 | }
612 | ```
613 |
614 |
615 |
616 |
617 |
618 | ### ES 写数据过程
619 |
620 | - 客户端选择一个 node 发送请求过去,这个 node 就是 `coordinating node`(协调节点)。
621 | - `coordinating node` 对 document 进行路由,将请求转发给对应的 node(有 primary shard)。[路由的算法是?]
622 | - 实际的 node 上的 `primary shard` 处理请求,然后将数据同步到 `replica node`。
623 | - `coordinating node` 如果发现 `primary node` 和所有 `replica node` 都搞定之后,就返回响应结果给客户端。
624 |
625 | 
626 |
627 |
628 |
629 | ### ES 读数据过程
630 |
631 | 可以通过 `doc id` 来查询,会根据 `doc id` 进行 hash,判断出来当时把 `doc id` 分配到了哪个 shard 上面去,从那个 shard 去查询。
632 |
633 | - 客户端发送请求到任意一个 node,成为 `coordinate node`。
634 | - `coordinate node` 对 `doc id` 进行哈希路由,将请求转发到对应的 node,此时会使用 `round-robin`随机轮询算法,在 `primary shard` 以及其所有 replica 中随机选择一个,让读请求负载均衡。
635 | - 接收请求的 node 返回 document 给 `coordinate node`。
636 | - `coordinate node` 返回 document 给客户端。
637 |
638 | ***写请求是写入 primary shard,然后同步给所有的 replica shard;读请求可以从 primary shard 或 replica shard 读取,采用的是随机轮询算法。***
639 |
640 |
641 |
642 | ### 底层 lucene
643 |
644 | 简单来说,lucene 就是一个 jar 包,里面包含了封装好的各种建立倒排索引的算法代码。我们用 Java 开发的时候,引入 lucene jar,然后基于 lucene 的 api 去开发就可以了。
645 |
646 | 通过 lucene,我们可以将已有的数据建立索引,lucene 会在本地磁盘上面,给我们组织索引的数据结构。
647 |
648 |
649 |
650 | ### ES中的倒排索引是什么?
651 |
652 | 传统的检索方式是通过文章,逐个遍历找到对应关键词的位置。
653 | 倒排索引,是通过分词策略,形成了词和文章的映射关系表,也称倒排表,这种词典 + 映射表即为**倒排索引**。
654 |
655 | 其中词典中存储词元,倒排表中存储该词元在哪些文中出现的位置。
656 | 有了倒排索引,就能实现 O(1) 时间复杂度的效率检索文章了,极大的提高了检索效率。
657 |
658 | **加分项:**
659 | 倒排索引的底层实现是基于:FST(Finite State Transducer)数据结构。
660 |
661 | Lucene 从 4+ 版本后开始大量使用的数据结构是 FST。FST 有两个优点:
662 | **1、**空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
663 | **2、**查询速度快。O(len(str)) 的查询时间复杂度。
664 |
665 |
666 |
667 | ### 请解释在 Elasticsearch 集群中添加或创建索引的过程?
668 |
669 | 要添加新索引,应使用创建索引 API 选项。创建索引所需的参数是索引的配置Settings,索引中的字段 Mapping 以及索引别名 Alias。
670 |
671 | 也可以通过模板 Template 创建索引。
672 |
673 |
674 |
675 | ### 详细描述一下Elasticsearch索引文档的过程
676 |
677 | 协调节点默认使用文档ID参与计算(也支持通过routing),以便为路由提供合适的分片。
678 |
679 | shard = hash(document_id) % (num_of_primary_shards)
680 |
681 | 当分片所在的节点接收到来自协调节点的请求后,会将请求写入到Memory Buffer,然后定时(默认是每隔1秒)写入到Filesystem Cache,这个从Momery Buffer到Filesystem Cache的过程就叫做refresh;
682 |
683 | 当然在某些情况下,存在Momery Buffer和Filesystem Cache的数据可能会丢失,ES是通过translog的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到translog中,当Filesystem cache中的数据写入到磁盘中时,才会清除掉,这个过程叫做flush;
684 |
685 | 在flush过程中,内存中的缓冲将被清除,内容被写入一个新段,段的fsync将创建一个新的提交点,并将内容刷新到磁盘,旧的translog将被删除并开始一个新的translog。
686 |
687 | flush触发的时机是定时触发(默认30分钟)或者translog变得太大(默认为512M)时;
688 |
689 |
690 |
691 | ### 详细描述一下Elasticsearch更新和删除文档的过程
692 |
693 | 删除和更新也都是写操作,但是Elasticsearch中的文档是不可变的,因此不能被删除或者改动以展示其变更;
694 |
695 | 磁盘上的每个段都有一个相应的.del文件。当删除请求发送后,文档并没有真的被删除,而是在.del文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在.del文件中被标记为删除的文档将不会被写入新段。
696 |
697 | 在新的文档被创建时,Elasticsearch会为该文档指定一个版本号,当执行更新时,旧版本的文档在.del文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
698 |
699 |
700 |
701 | ### 详细描述一下Elasticsearch搜索的过程
702 |
703 | 搜索被执行成一个两阶段过程,我们称之为 Query Then Fetch;
704 |
705 | 在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。PS:在搜索的时候是会查询Filesystem Cache的,但是有部分数据还在Memory Buffer,所以搜索是近实时的。
706 |
707 | 每个分片返回各自优先队列中 所有文档的 ID 和排序值 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
708 |
709 | 接下来就是 取回阶段,协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并 丰富 文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
710 |
711 | 补充:Query Then Fetch的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch增加了一个预查询的处理,询问Term和Document frequency,这个评分更准确,但是性能会变差。
712 |
713 |
714 |
715 | ### Elasticsearch对于大数据量(上亿量级)的聚合如何实现?
716 |
717 | Elasticsearch 提供的首个近似聚合是cardinality 度量。它提供一个字段的基数,即该字段的distinct或者unique值的数目。它是基于HLL算法的。HLL 会先对我们的输入作哈希运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。其特点是:可配置的精度,用来控制内存的使用(更精确 = 更多内存);小的数据集精度是非常高的;我们可以通过配置参数,来设置去重需要的固定内存使用量。无论数千还是数十亿的唯一值,内存使用量只与你配置的精确度相关 .
718 |
719 |
720 |
721 | ### 你可以列出 Elasticsearch 各种类型的分析器吗?
722 |
723 | Elasticsearch Analyzer 的类型为内置分析器和自定义分析器。
724 |
725 | - **Standard Analyzer**
726 |
727 | 标准分析器是默认分词器,如果未指定,则使用该分词器。
728 |
729 | 它基于Unicode文本分割算法,适用于大多数语言。
730 |
731 | - **Whitespace Analyzer**
732 |
733 | 基于空格字符切词。
734 |
735 | - **Stop Analyzer**
736 |
737 | 在simple Analyzer的基础上,移除停用词。
738 |
739 | - **Keyword Analyzer**
740 |
741 | 不切词,将输入的整个串一起返回。
742 |
743 | 自定义分词器的模板
744 |
745 | 自定义分词器的在Mapping的Setting部分设置:
746 |
747 | ```
748 | PUT my_custom_index
749 | {
750 | "settings":{
751 | "analysis":{
752 | "char_filter":{},
753 | "tokenizer":{},
754 | "filter":{},
755 | "analyzer":{}
756 | }
757 | }
758 | }
759 | ```
760 |
761 | 脑海中还是上面的三部分组成的图示。其中:
762 |
763 | “char_filter”:{},——对应字符过滤部分;
764 |
765 | “tokenizer”:{},——对应文本切分为分词部分;
766 |
767 | “filter”:{},——对应分词后再过滤部分;
768 |
769 | “analyzer”:{}——对应分词器组成部分,其中会包含:1. 2. 3。
770 |
771 |
772 |
773 |
774 |
775 | ### ElaticSearch是如何实现master选举的?
776 |
777 | **前置条件:**
778 | **1、**只有是候选主节点(master:true)的节点才能成为主节点。
779 | **2、**最小主节点数(min_master_nodes)的目的是防止脑裂。
780 |
781 | Elasticsearch 的选主是 ZenDiscovery 模块负责的,主要包含 Ping(节点之间通过这个RPC来发现彼此)和 Unicast(单播模块包含一个主机列表以控制哪些节点需要 ping 通)这两部分;
782 | 获取主节点的核心入口为 findMaster,选择主节点成功返回对应 Master,否则返回 null。
783 |
784 | 选举流程大致描述如下:
785 | 第一步:确认候选主节点数达标,elasticsearch.yml 设置的值 discovery.zen.minimum_master_nodes;
786 | 第二步:对所有候选主节点根据nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。
787 | 第三步:如果对某个节点的投票数达到一定的值(候选主节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
788 |
789 | - 补充:
790 | - 这里的 id 为 string 类型。
791 | - master 节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data 节点可以关闭 http 功能。
792 |
793 |
794 |
795 | ### Master 节点和 候选 Master节点有什么区别?
796 |
797 | 主节点负责集群相关的操作,例如创建或删除索引,跟踪哪些节点是集群的一部分,以及决定将哪些分片分配给哪些节点。
798 |
799 | 拥有稳定的主节点是衡量集群健康的重要标志。
800 |
801 | 而候选主节点是被选具备候选资格,可以被选为主节点的那些节点。
802 |
803 |
804 |
805 | ### Elasticsearch中的属性 enabled, index 和 store 的功能是什么?
806 |
807 | - enabled:false,启用的设置仅可应用于顶级映射定义和 Object 对象字段,导致 Elasticsearch 完全跳过对字段内容的解析。
808 |
809 | 仍然可以从_source字段中检索JSON,但是无法搜索或以其他任何方式存储JSON。
810 |
811 | 如果对非全局或者 Object 类型,设置 enable : false 会报错如下:
812 |
813 | ```
814 | "type": "mapper_parsing_exception",
815 | "reason": "Mapping definition for [user_id] has unsupported parameters: [enabled : false]"
816 | ```
817 |
818 | - index:false, 索引选项控制是否对字段值建立索引。它接受true或false,默认为true。未索引的字段不可查询。
819 |
820 | 如果非要检索,报错如下:
821 |
822 | ```
823 | "type": "search_phase_execution_exception",
824 | "reason": "Cannot search on field [user_id] since it is not indexed."
825 | ```
826 |
827 | - store:
828 |
829 | 某些特殊场景下,如果你只想检索单个字段或几个字段的值,而不是整个_source的值,则可以使用源过滤来实现;
830 |
831 | 这个时候, store 就派上用场了。
832 |
833 | 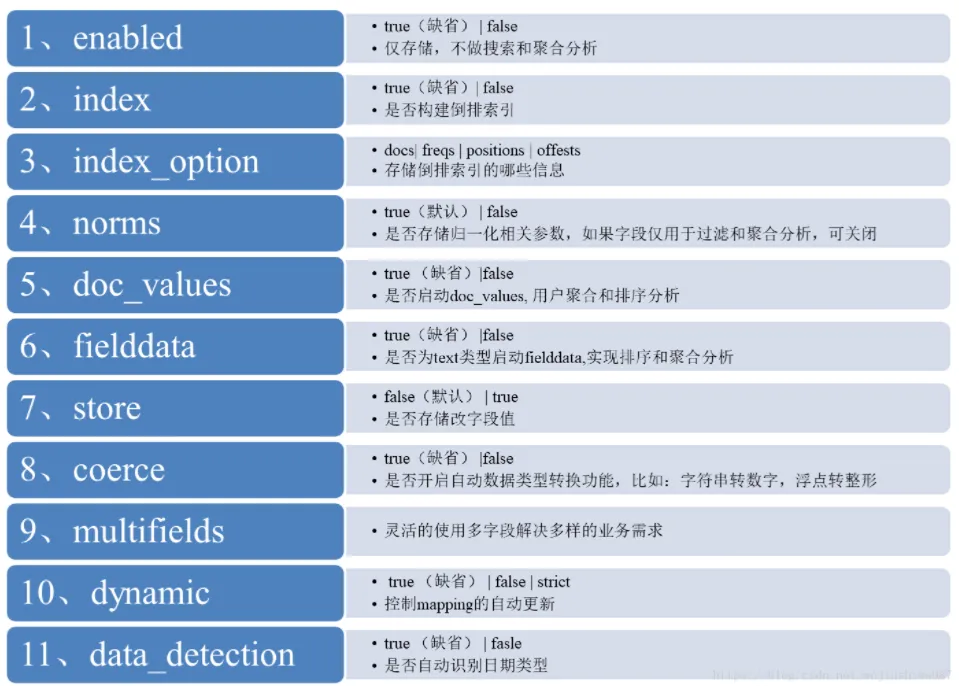
834 |
835 |
836 |
837 | ### Elasticsearch中的节点(比如共20个),其中的10个选了一个master,另外10个选了另一个master,怎么办?
838 |
839 | 当集群master候选数量不小于3个时,可以通过设置最少投票通过数量(discovery.zen.minimum_master_nodes)超过所有候选节点一半以上来解决脑裂问题;
840 | 当候选数量为两个时,只能修改为唯一的一个master候选,其他作为data节点,避免脑裂问题。
841 |
842 |
843 |
844 | ### 如何解决ES集群的脑裂问题
845 |
846 | 所谓集群脑裂,是指 Elasticsearch 集群中的节点(比如共 20 个),其中的 10 个选了一个 master,另外 10 个选了另一个 master 的情况。
847 |
848 | 当集群 master 候选数量不小于 3 个时,可以通过设置最少投票通过数量(discovery.zen.minimum_master_nodes)超过所有候选节点一半以上来解决脑裂问题;
849 | 当候选数量为两个时,只能修改为唯一的一个 master 候选,其他作为 data 节点,避免脑裂问题。
850 |
851 |
852 |
853 | ### 详细描述一下ES索引文档的过程?
854 |
855 | 这里的索引文档应该理解为文档写入 ES,创建索引的过程。
856 |
857 | **第一步:**
858 |
859 | 客户端向集群某节点写入数据,发送请求。(如果没有指定路由/协调节点,请求的节点扮演协调节点的角色。)
860 |
861 |
862 |
863 | **第二步:**
864 |
865 | 协调节点接受到请求后,默认使用文档 ID 参与计算(也支持通过 routing),得到该文档属于哪个分片。随后请求会被转到另外的节点。
866 |
867 | ```java
868 | bash# 路由算法:根据文档id或路由计算目标的分片id
869 | shard = hash(document_id) % (num_of_primary_shards)
870 | ```
871 |
872 |
873 |
874 | **第三步:**
875 |
876 | 当分片所在的节点接收到来自协调节点的请求后,会将请求写入到 Memory Buffer,然后定时(默认是每隔 1 秒)写入到F ilesystem Cache,这个从 Momery Buffer 到 Filesystem Cache 的过程就叫做 refresh;
877 |
878 | **第四步:**
879 |
880 | 当然在某些情况下,存在 Memery Buffer 和 Filesystem Cache 的数据可能会丢失,ES 是通过 translog 的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到 translog 中,当 Filesystem cache 中的数据写入到磁盘中时,才会清除掉,这个过程叫做 flush;
881 |
882 | **第五步:**
883 |
884 | 在 flush 过程中,内存中的缓冲将被清除,内容被写入一个新段,段的 fsync 将创建一个新的提交点,并将内容刷新到磁盘,旧的 translog 将被删除并开始一个新的 translog。
885 |
886 | **第六步:**
887 |
888 | flush 触发的时机是定时触发(默认 30 分钟)或者 translog 变得太大(默认为 512 M)时。
889 |
890 | 
891 |
892 |
893 |
894 | - 补充:关于 Lucene 的 Segement
895 | - Lucene 索引是由多个段组成,段本身是一个功能齐全的倒排索引。
896 | - 段是不可变的,允许 Lucene 将新的文档增量地添加到索引中,而不用从头重建索引。
897 | - 对于每一个搜索请求而言,索引中的所有段都会被搜索,并且每个段会消耗 CPU 的时钟周、文件句柄和内存。这意味着段的数量越多,搜索性能会越低。
898 | - 为了解决这个问题,Elasticsearch 会合并小段到一个较大的段,提交新的合并段到磁盘,并删除那些旧的小段。(段合并)
899 |
900 |
901 |
902 | ### 详细描述一下ES更新和删除文档的过程?
903 |
904 | 删除和更新也都是写操作,但是 Elasticsearch 中的文档是不可变的,因此不能被删除或者改动以展示其变更。
905 |
906 | 磁盘上的每个段都有一个相应的 .del 文件。当删除请求发送后,文档并没有真的被删除,而是在 .del 文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在 .del 文件中被标记为删除的文档将不会被写入新段。
907 |
908 | 在新的文档被创建时,Elasticsearch 会为该文档指定一个版本号,当执行更新时,旧版本的文档在 .del 文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
909 |
910 |
911 |
912 | ### 详细描述一下ES搜索的过程?
913 |
914 | 搜索被执行成一个两阶段过程,即 Query Then Fetch;
915 | Query阶段:
916 | 查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。PS:在搜索的时候是会查询Filesystem Cache的,但是有部分数据还在Memory Buffer,所以搜索是近实时的。
917 | 每个分片返回各自优先队列中 **所有文档的 ID 和排序值** 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
918 | Fetch阶段:
919 | 协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并 丰富 文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
920 |
921 | 
922 |
923 |
924 |
925 | ### 在并发情况下,ES如果保证读写一致?
926 |
927 | 可以通过版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
928 | 另外对于写操作,一致性级别支持quorum/one/all,默认为quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。
929 | 对于读操作,可以设置replication为sync(默认),这使得操作在主分片和副本分片都完成后才会返回;如果设置replication为async时,也可以通过设置搜索请求参数_preference为primary来查询主分片,确保文档是最新版本。
930 |
931 | ### ES对于大数据量(上亿量级)的聚合如何实现?
932 |
933 | Elasticsearch 提供的首个近似聚合是cardinality 度量。它提供一个字段的基数,即该字段的distinct或者unique值的数目。它是基于HLL算法的。HLL 会先对我们的输入作哈希运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。其特点是:可配置的精度,用来控制内存的使用(更精确 = 更多内存);小的数据集精度是非常高的;我们可以通过配置参数,来设置去重需要的固定内存使用量。无论数千还是数十亿的唯一值,内存使用量只与你配置的精确度相关。
934 |
935 | ### 对于GC方面,在使用ES时要注意什么?
936 |
937 | 1)倒排词典的索引需要常驻内存,无法GC,需要监控data node上segment memory增长趋势。
938 | 2)各类缓存,field cache, filter cache, indexing cache, bulk queue等等,要设置合理的大小,并且要应该根据最坏的情况来看heap是否够用,也就是各类缓存全部占满的时候,还有heap空间可以分配给其他任务吗?避免采用clear cache等“自欺欺人”的方式来释放内存。
939 | 3)避免返回大量结果集的搜索与聚合。确实需要大量拉取数据的场景,可以采用scan & scroll api来实现。
940 | 4)cluster stats驻留内存并无法水平扩展,超大规模集群可以考虑分拆成多个集群通过tribe node连接。
941 | 5)想知道heap够不够,必须结合实际应用场景,并对集群的heap使用情况做持续的监控。
942 |
943 | ### 说说你们公司ES的集群架构,索引数据大小,分片有多少,以及一些调优手段?
944 |
945 | 根据实际情况回答即可,如果是我的话会这么回答:
946 | 我司有多个ES集群,下面列举其中一个。该集群有20个节点,根据数据类型和日期分库,每个索引根据数据量分片,比如日均1亿+数据的,控制单索引大小在200GB以内。
947 | 下面重点列举一些调优策略,仅是我做过的,不一定全面,如有其它建议或者补充欢迎留言。
948 | 部署层面:
949 | 1)最好是64GB内存的物理机器,但实际上32GB和16GB机器用的比较多,但绝对不能少于8G,除非数据量特别少,这点需要和客户方面沟通并合理说服对方。
950 | 2)多个内核提供的额外并发远胜过稍微快一点点的时钟频率。
951 | 3)尽量使用SSD,因为查询和索引性能将会得到显著提升。
952 | 4)避免集群跨越大的地理距离,一般一个集群的所有节点位于一个数据中心中。
953 | 5)设置堆内存:节点内存/2,不要超过32GB。一般来说设置export ES_HEAP_SIZE=32g环境变量,比直接写-Xmx32g -Xms32g更好一点。
954 | 6)关闭缓存swap。内存交换到磁盘对服务器性能来说是致命的。如果内存交换到磁盘上,一个100微秒的操作可能变成10毫秒。 再想想那么多10微秒的操作时延累加起来。不难看出swapping对于性能是多么可怕。
955 | 7)增加文件描述符,设置一个很大的值,如65535。Lucene使用了大量的文件,同时,Elasticsearch在节点和HTTP客户端之间进行通信也使用了大量的套接字。所有这一切都需要足够的文件描述符。
956 | 8)不要随意修改垃圾回收器(CMS)和各个线程池的大小。
957 | 9)通过设置gateway.recover_after_nodes、gateway.expected_nodes、gateway.recover_after_time可以在集群重启的时候避免过多的分片交换,这可能会让数据恢复从数个小时缩短为几秒钟。
958 | 索引层面:
959 | 1)使用批量请求并调整其大小:每次批量数据 5–15 MB 大是个不错的起始点。
960 | 2)段合并:Elasticsearch默认值是20MB/s,对机械磁盘应该是个不错的设置。如果你用的是SSD,可以考虑提高到100-200MB/s。如果你在做批量导入,完全不在意搜索,你可以彻底关掉合并限流。另外还可以增加 index.translog.flush_threshold_size 设置,从默认的512MB到更大一些的值,比如1GB,这可以在一次清空触发的时候在事务日志里积累出更大的段。
961 | 3)如果你的搜索结果不需要近实时的准确度,考虑把每个索引的index.refresh_interval 改到30s。
962 | 4)如果你在做大批量导入,考虑通过设置index.number_of_replicas: 0 关闭副本。
963 | 5)需要大量拉取数据的场景,可以采用scan & scroll api来实现,而不是from/size一个大范围。
964 | 存储层面:
965 | 1)基于数据+时间滚动创建索引,每天递增数据。控制单个索引的量,一旦单个索引很大,存储等各种风险也随之而来,所以要提前考虑+及早避免。
966 | 2)冷热数据分离存储,热数据(比如最近3天或者一周的数据),其余为冷数据。对于冷数据不会再写入新数据,可以考虑定期force_merge加shrink压缩操作,节省存储空间和检索效率
967 |
968 |
969 |
970 | ### 在并发情况下,Elasticsearch如果保证读写一致?
971 |
972 | 可以通过版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
973 |
974 | 另外对于写操作,一致性级别支持quorum/one/all,默认为quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因
975 |
976 | 导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。
977 |
978 | 对于读操作,可以设置replication为sync(默认),这使得操作在主分片和副本分片都完成后才会返回;如果设置replication为async时,也可以通过设置搜索请求参数_preference为primary来查询主分片,确保文档是最新版本。
--------------------------------------------------------------------------------
/interviewDoc/Java/middleware/Kafka.md:
--------------------------------------------------------------------------------
1 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
2 |
3 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
4 |
5 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
6 |
7 |
8 |
9 |
10 | - [什么是kafka](#什么是kafka)
11 | - [Kafka 都有哪些特点?](#kafka-都有哪些特点)
12 | - [请说明Kafka相对传统技术有什么优势?](#请说明kafka相对传统技术有什么优势)
13 | - [Kafka的优势是什么?](#kafka的优势是什么)
14 | - [Kafka消息传递系统与其他消息传递框架有何不同?](#kafka消息传递系统与其他消息传递框架有何不同)
15 | - [在Kafka中,领导者和追随者是什么意思?](#在kafka中领导者和追随者是什么意思)
16 | - [你知道Kafka的不同组成部分吗?](#你知道kafka的不同组成部分吗)
17 | - [Zookeeper在Kafka的重要性是什么?](#zookeeper在kafka的重要性是什么)
18 | - [Kafka的抵消额是多少?](#kafka的抵消额是多少)
19 | - [请简述下你在哪些场景下会选择 Kafka?](#请简述下你在哪些场景下会选择-kafka)
20 | - [Kafka 缺点?](#kafka-缺点)
21 | - [你们Kafka集群的硬盘一共多大?有多少台机器?日志保存多久?用什么监控的?](#你们kafka集群的硬盘一共多大有多少台机器日志保存多久用什么监控的)
22 | - [Kafka分区数、副本数和topic数量多少比较合适?](#kafka分区数副本数和topic数量多少比较合适)
23 | - [Kafka 可以脱离 zookeeper 单独使用吗?为什么?](#kafka-可以脱离-zookeeper-单独使用吗为什么)
24 | - [Kafka为什么不支持读写分离?](#kafka为什么不支持读写分离)
25 | - [Java Consumer 为什么采用单线程来获取消息?](#java-consumer-为什么采用单线程来获取消息)
26 | - [解释Kafka的Zookeeper是什么?我们可以在没有Zookeeper的情况下使用Kafka吗?](#解释kafka的zookeeper是什么我们可以在没有zookeeper的情况下使用kafka吗)
27 | - [解释一下,在数据制作过程中,你如何能从Kafka得到准确的信息?](#解释一下在数据制作过程中你如何能从kafka得到准确的信息)
28 | - [Consumer与topic关系](#consumer与topic关系)
29 | - [Kafka 的设计架构你知道吗?](#kafka-的设计架构你知道吗)
30 | - [Kafka 分区的目的?](#kafka-分区的目的)
31 | - [Kafka中的消息有序吗?怎么实现的?](#kafka中的消息有序吗怎么实现的)
32 | - [你知道 Kafka 是如何做到消息的有序性?](#你知道-kafka-是如何做到消息的有序性)
33 | - [为什么要使用 kafka,为什么要使用消息队列](#为什么要使用-kafka为什么要使用消息队列)
34 | - [Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么](#kafka中的israr又代表什么isr的伸缩又指什么)
35 | - [LEO、HW、LSO、LW等分别代表什么](#leohwlsolw等分别代表什么)
36 | - [Kafka 消费者是否可以消费指定分区消息?](#kafka-消费者是否可以消费指定分区消息)
37 | - [Kafka消息是采用Pull模式,还是Push模式?](#kafka消息是采用pull模式还是push模式)
38 | - [Kafka 高效文件存储设计特点](#kafka-高效文件存储设计特点)
39 | - [kafka中的broker 是干什么的](#kafka中的broker-是干什么的)
40 | - [Kafka创建Topic时如何将分区放置到不同的Broker中](#kafka创建topic时如何将分区放置到不同的broker中)
41 | - [topic的分区数可以增加或减少吗?为什么?](#topic的分区数可以增加或减少吗为什么)
42 | - [你知道kafka是怎么维护offset的吗?](#你知道kafka是怎么维护offset的吗)
43 | - [你们是怎么对Kafka进行压测的?](#你们是怎么对kafka进行压测的)
44 | - [当Kafka消息数据出现了积压,应该怎么处理?](#当kafka消息数据出现了积压应该怎么处理)
45 | - [聊聊Kafka分区分配策略?](#聊聊kafka分区分配策略)
46 | - [谈谈你对Kafka幂等性的理解?](#谈谈你对kafka幂等性的理解)
47 | - [你对Kafka事务了解多少?](#你对kafka事务了解多少)
48 | - [Kafka怎么实现如此高的读写效率?](#kafka怎么实现如此高的读写效率)
49 | - [Kafka新建的分区会在哪个目录下创建](#kafka新建的分区会在哪个目录下创建)
50 | - [**什么是消费者组?**](#什么是消费者组)
51 | - [**kafka中的 zookeeper 起到什么作用,可以不用zookeeper么**](#kafka中的-zookeeper-起到什么作用可以不用zookeeper么)
52 | - [Kafka 为什么那么快](#kafka-为什么那么快)
53 | - [谈一谈 Kafka 的再均衡](#谈一谈-kafka-的再均衡)
54 | - [Kafka 是如何实现高吞吐率的?](#kafka-是如何实现高吞吐率的)
55 | - [**如何设置Kafka能接收的最大消息的大小?**](#如何设置kafka能接收的最大消息的大小)
56 | - [**监控Kafka的框架都有哪些?**](#监控kafka的框架都有哪些)
57 | - [**如何估算Kafka集群的机器数量?**](#如何估算kafka集群的机器数量)
58 | - [**Kafka能手动删除消息吗?**](#kafka能手动删除消息吗)
59 | - [**consumeroffsets是做什么用的?**](#consumeroffsets是做什么用的)
60 | - [Kafka Stream的一些独特功能是什么?](#kafka-stream的一些独特功能是什么)
61 | - [为什么说Kafka是分布式流媒体平台?](#为什么说kafka是分布式流媒体平台)
62 |
63 |
64 |
65 | ### **什么是kafka**
66 |
67 | Kafka是分布式发布-订阅消息系统,它最初是由LinkedIn公司开发的,之后成为Apache项目的一部分,Kafka是一个分布式,可划分的,冗余备份的持久性的日志服务,它主要用于处理流式数据。
68 |
69 |
70 |
71 | ### Kafka 都有哪些特点?
72 |
73 | - 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
74 | - 可扩展性:kafka集群支持热扩展
75 | - 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
76 | - 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
77 | - 高并发:支持数千个客户端同时读写
78 |
79 |
80 |
81 | ### 请说明Kafka相对传统技术有什么优势?
82 |
83 | Apache Kafka与传统的消息传递技术相比优势之处在于:
84 |
85 | **快速:** 单一的Kafka代理可以处理成千上万的客户端,每秒处理数兆字节的读写操作。
86 |
87 | **可伸缩:** 在一组机器上对数据进行分区和简化,以支持更大的数据
88 |
89 | **持久:** 消息是持久性的,并在集群中进行复制,以防止数据丢失。
90 |
91 | **设计:** 它提供了容错保证和持久性
92 |
93 |
94 |
95 | ### Kafka的优势是什么?
96 |
97 | Kafka的主要优点包括容错,更高的吞吐量,可伸缩性,更低的延迟和耐用性。Kafka不需要任何大型硬件组件,并且在管理高容量和高速数据方面显示出卓越的性能。
98 |
99 | 最重要的是,它可以以每秒数千条消息的速率支持消息吞吐量。Kafka描述了对集群中节点或机器故障的有希望的抵制。Kafka的较低延迟可以帮助在毫秒内轻松管理消息。此外,Kafka还确保消息复制,从而减少了对消息丢失的担忧。Apache Kafka的另一个关键优势是可通过添加更多节点来确保可伸缩性。
100 |
101 |
102 |
103 | ### Kafka消息传递系统与其他消息传递框架有何不同?
104 |
105 | - 该设计遵循公共订购模型。
106 | - 无缝支持Spark和其他大数据技术。
107 | - 支持集群模式操作。
108 | - 容错功能可减少对消息丢失的担忧。
109 | - 支持Scala和Java编程语言。
110 | - 易于编码和配置。
111 | - Web服务体系结构以及大数据体系结构的理想选择。
112 |
113 |
114 |
115 | ### 在Kafka中,领导者和追随者是什么意思?
116 |
117 | Kafka中的每个分区都与一台充当领导者角色的服务器相关联,另一台服务器充当跟随者角色。
118 |
119 | 领导者负责执行有关分区的所有读取和写入请求。另一方面,追随者必须被动地复制领导者。如果领导者失败,则跟随者之一可以担当领导者角色,以确保负载平衡。
120 |
121 |
122 |
123 | ### 你知道Kafka的不同组成部分吗?
124 |
125 | Kafka有四个主要组成部分,例如主题、生产者、经纪人和消费者。Kafka中的主题是同一类型的消息流。
126 |
127 |
128 |
129 | Kafka中的Producer可以帮助你将消息发布到某个主题。代理是一组服务器,用于存储生产者发布的消息。消费者是Kafka组件,它有助于订阅不同的主题并从中间商获取数据。
130 |
131 |
132 |
133 | ### Zookeeper在Kafka的重要性是什么?
134 |
135 |
136 | Zookeeper主要负责开发集群中不同节点之间的协调。Zookeeper可以帮助在节点发生故障时从先前提交的偏移恢复到偏移,因为它可以作为定期提交偏移进行工作。
137 |
138 | 此外,Zookeeper还有助于领导者检测,配置管理,同步以及检测离开或加入集群的任何节点。此外,Kafka将Zookeeper用作存储有关特定主题的已消耗消息的偏移量的存储。Zookeeper还可以帮助根据特定的消费者组对消息的偏移量进行分区。
139 |
140 |
141 |
142 | ### Kafka的抵消额是多少?
143 |
144 | Kafka中的偏移量是分配给分区中消息的顺序ID号。偏移量有助于特定分区中每个消息的唯一标识。
145 |
146 |
147 |
148 | ### 请简述下你在哪些场景下会选择 Kafka?
149 |
150 | - 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、HBase、Solr等。
151 | - 消息系统:解耦和生产者和消费者、缓存消息等。
152 | - 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
153 | - 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
154 | - 流式处理:比如spark streaming和 Flink
155 |
156 |
157 |
158 | ### Kafka 缺点?
159 |
160 | - 由于是批量发送,数据并非真正的实时;
161 | - 对于mqtt协议不支持;
162 | - 不支持物联网传感数据直接接入;
163 | - 仅支持统一分区内消息有序,无法实现全局消息有序;
164 | - 监控不完善,需要安装插件;
165 | - 依赖zookeeper进行元数据管理;
166 |
167 |
168 |
169 | ### 你们Kafka集群的硬盘一共多大?有多少台机器?日志保存多久?用什么监控的?
170 |
171 | 这里考察应试者对kafka实际生产部署的能力,也是为了验证能力的真实程度,如果这个都答不好,那可能就不会再继续下去了。
172 |
173 | 一般企业判断这些指标有一个标准:
174 |
175 | 集群硬盘大小:每天的数据量/70%*日志保存天数;
176 |
177 | 机器数量:Kafka 机器数量=2*(峰值生产速度*副本数/100)+1;
178 |
179 | 日志保存时间:可以回答保存7天;
180 |
181 | 监控Kafka:一般公司有自己开发的监控器,或者cdh配套的监控器,另外还有一些开源的监控器:kafkaeagle、KafkaMonitor、KafkaManager。
182 |
183 |
184 |
185 | ### Kafka分区数、副本数和topic数量多少比较合适?
186 |
187 | 首先要知道**分区数并不是越多越好**,一般分区数不要超过集群机器数量。分区数越多占用内存越大 (ISR 等),一个节点集中的分区也就越多,当它宕机的时候,对系统的影响也就越大。
188 |
189 | 分区数一般设置为:3-10 个。
190 |
191 | 副本数一般设置为:2-3个。
192 |
193 | topic数量需要根据日志类型来定,一般有多少个日志类型就定多少个topic,不过也有对日志类型进行合并的。
194 |
195 |
196 |
197 | ### Kafka 可以脱离 zookeeper 单独使用吗?为什么?
198 |
199 | kafka 不能脱离 zookeeper 单独使用,因为 kafka 使用 zookeeper 管理和协调 kafka 的节点服务器。
200 |
201 |
202 |
203 | ### Kafka为什么不支持读写分离?
204 |
205 | **如果支持了读写分离,就意味着可能的数据不一致,或数据滞后。**这其实是分布式场景下的通用问题,因为我们知道CAP理论下,我们只能保证C(可用性)和A(一致性)取其一,如果支持读写分离,那其实对于一致性的要求可能就会有一定折扣,因为通常的场景下,副本之间都是通过同步来实现副本数据一致的,那同步过程中肯定会有时间的消耗。
206 |
207 |
208 |
209 | Leader/Follower模型并没有规定Follower副本不可以对外提供读服务。很多框架都是允许这么做的,只是 Kafka最初为了避免不一致性的问题,而采用了让Leader统一提供服务的方式。
210 |
211 |
212 |
213 | 不过,自Kafka 2.4之后,Kafka提供了有限度的读写分离,也就是说,Follower副本能够对外提供读服务。
214 |
215 |
216 |
217 | ### Java Consumer 为什么采用单线程来获取消息?
218 |
219 | 首先,Java Consumer是双线程的设计。其中一个线程是用户主线程,负责获取消息;另一个线程是心跳线程,负责向Kafka汇报消费者存活情况。将心跳单独放入专属的线程,能够有效地规避因消息处理速度慢而被视为下线的“假死”情况。
220 |
221 |
222 |
223 | 单线程获取消息的设计能够避免阻塞式的消息获取方式。单线程轮询方式容易实现异步非阻塞式,这样便于将消费者扩展成支持实时流处理的操作算子。因为很多实时流处理操作算子都不能是阻塞式的。
224 |
225 |
226 |
227 | 另外一个可能的好处是,可以简化代码的开发。多线程交互的代码是非常容易出错的。
228 |
229 |
230 |
231 | ### 解释Kafka的Zookeeper是什么?我们可以在没有Zookeeper的情况下使用Kafka吗?
232 |
233 | Zookeeper是一个开放源码的、高性能的协调服务,它用于Kafka的分布式应用。不,不可能越过Zookeeper,直接联系Kafka broker。一旦Zookeeper停止工作,它就不能服务客户端请求。
234 |
235 | Zookeeper主要用于在集群中不同节点之间进行通信
236 |
237 | 在Kafka中,它被用于提交偏移量,因此如果节点在任何情况下都失败了,它都可以从之前提交的偏移量中获取
238 |
239 | 除此之外,它还执行其他活动,如: leader检测、分布式同步、配置管理、识别新节点何时离开或连接、集群、节点实时状态等等。
240 |
241 |
242 |
243 | ### 解释一下,在数据制作过程中,你如何能从Kafka得到准确的信息?
244 |
245 | 在数据中,为了精确地获得Kafka的消息,你必须遵循两件事: 在数据消耗期间避免重复,在数据生产过程中避免重复。
246 |
247 | 这里有两种方法,可以在数据生成时准确地获得一个语义:
248 |
249 | 每个分区使用一个单独的写入器,每当你发现一个网络错误,检查该分区中的最后一条消息,以查看您的最后一次写入是否成功
250 |
251 | 在消息中包含一个主键(UUID或其他),并在用户中进行反复制
252 |
253 |
254 |
255 | ### Consumer与topic关系
256 |
257 | 每个group中可以有多个consumer,每个consumer属于一个consumer group,通常情况下,一个group中会包含多个consumer,这样不仅可以提高topic中消息的并发消费能力,而且还能提高"故障容错"性,如果group中的某个consumer失效那么其消费的partitions将会有其他consumer自动接管。
258 |
259 | 对于Topic中的一条特定的消息,只会被订阅此Topic的每个group中的其中一个consumer消费,此消息不会发送给一个group的多个consumer,不过一个consumer可以同时消费多个partitions中的消息。
260 |
261 |
262 |
263 | ### Kafka 的设计架构你知道吗?
264 |
265 | Kafka 架构分为以下几个部分
266 |
267 | - Producer :消息生产者,就是向 kafka broker 发消息的客户端。
268 | - Consumer :消息消费者,向 kafka broker 取消息的客户端。
269 | - Topic :可以理解为一个队列,一个 Topic 又分为一个或多个分区,
270 | - Consumer Group:这是 kafka 用来实现一个 topic 消息的广播(发给所有的 consumer)和单播(发给任意一个 consumer)的手段。一个 topic 可以有多个 Consumer Group。
271 | - Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
272 | - Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker上,每个 partition 是一个有序的队列。partition 中的每条消息都会被分配一个有序的id(offset)。将消息发给 consumer,kafka 只保证按一个 partition 中的消息的顺序,不保证一个 topic 的整体(多个 partition 间)的顺序。
273 | - Offset:kafka 的存储文件都是按照 offset.kafka 来命名,用 offset 做名字的好处是方便查找。例如你想找位于 2049 的位置,只要找到 2048.kafka 的文件即可。当然 the first offset 就是 00000000000.kafka。
274 |
275 |
276 |
277 | ### Kafka 分区的目的?
278 |
279 | 分区对于 Kafka 集群的好处是:实现负载均衡。分区对于消费者来说,可以提高并发度,提高效率。
280 |
281 |
282 |
283 | ### Kafka中的消息有序吗?怎么实现的?
284 |
285 | kafka无法保证整个topic多个分区有序,但是由于每个分区(partition)内,每条消息都有一个offset,故**可以保证分区内有序**。
286 |
287 |
288 |
289 | ### 你知道 Kafka 是如何做到消息的有序性?
290 |
291 | kafka 中的每个 partition 中的消息在写入时都是有序的,而且单独一个 partition 只能由一个消费者去消费,可以在里面保证消息的顺序性。但是分区之间的消息是不保证有序的。
292 |
293 |
294 |
295 | ### 为什么要使用 kafka,为什么要使用消息队列
296 |
297 | **缓冲和削峰:**上游数据时有突发流量,下游可能扛不住,或者下游没有足够多的机器来保证冗余,kafka在中间可以起到一个缓冲的作用,把消息暂存在kafka中,下游服务就可以按照自己的节奏进行慢慢处理。
298 |
299 | **解耦和扩展性:**项目开始的时候,并不能确定具体需求。消息队列可以作为一个接口层,解耦重要的业务流程。只需要遵守约定,针对数据编程即可获取扩展能力。
300 |
301 | **冗余:**可以采用一对多的方式,一个生产者发布消息,可以被多个订阅topic的服务消费到,供多个毫无关联的业务使用。
302 |
303 | **健壮性:**消息队列可以堆积请求,所以消费端业务即使短时间死掉,也不会影响主要业务的正常进行。
304 |
305 | **异步通信:**很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
306 |
307 |
308 |
309 | ### Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么
310 |
311 | ISR:In-Sync Replicas 副本同步队列
312 | AR:Assigned Replicas 所有副本
313 | ISR是由leader维护,follower从leader同步数据有一些延迟(包括延迟时间replica.lag.time.max.ms和延迟条数replica.lag.max.messages两个维度, 当前最新的版本0.10.x中只支持replica.lag.time.max.ms这个维度),任意一个超过阈值都会把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR。
314 |
315 |
316 |
317 | ### LEO、HW、LSO、LW等分别代表什么
318 |
319 | - LEO:是 LogEndOffset 的简称,代表当前日志文件中下一条
320 | - HW:水位或水印(watermark)一词,也可称为高水位(high watermark),通常被用在流式处理领域(比如Apache Flink、Apache Spark等),以表征元素或事件在基于时间层面上的进度。在Kafka中,水位的概念反而与时间无关,而是与位置信息相关。严格来说,它表示的就是位置信息,即位移(offset)。取 partition 对应的 ISR中 最小的 LEO 作为 HW,consumer 最多只能消费到 HW 所在的位置上一条信息。
321 | - LSO:是 LastStableOffset 的简称,对未完成的事务而言,LSO 的值等于事务中第一条消息的位置(firstUnstableOffset),对已完成的事务而言,它的值同 HW 相同
322 | - LW:Low Watermark 低水位, 代表 AR 集合中最小的 logStartOffset 值。
323 |
324 |
325 |
326 | ### Kafka 消费者是否可以消费指定分区消息?
327 |
328 | Kafa consumer消费消息时,向broker发出fetch请求去消费特定分区的消息,consumer指定消息在日志中的偏移量(offset),就可以消费从这个位置开始的消息,customer拥有了offset的控制权,可以向后回滚去重新消费之前的消息,这是很有意义的
329 |
330 |
331 |
332 | ### Kafka消息是采用Pull模式,还是Push模式?
333 |
334 | Kafka最初考虑的问题是,customer应该从brokes拉取消息还是brokers将消息推送到consumer,也就是pull还push。在这方面,Kafka遵循了一种大部分消息系统共同的传统的设计:producer将消息推送到broker,consumer从broker拉取消息。
335 |
336 | 一些消息系统比如Scribe和Apache Flume采用了push模式,将消息推送到下游的consumer。这样做有好处也有坏处:由broker决定消息推送的速率,对于不同消费速率的consumer就不太好处理了。消息系统都致力于让consumer以最大的速率最快速的消费消息,但不幸的是,push模式下,当broker推送的速率远大于consumer消费的速率时,consumer恐怕就要崩溃了。最终Kafka还是选取了传统的pull模式。
337 |
338 | Pull模式的另外一个好处是consumer可以自主决定是否批量的从broker拉取数据。Push模式必须在不知道下游consumer消费能力和消费策略的情况下决定是立即推送每条消息还是缓存之后批量推送。如果为了避免consumer崩溃而采用较低的推送速率,将可能导致一次只推送较少的消息而造成浪费。Pull模式下,consumer就可以根据自己的消费能力去决定这些策略。
339 |
340 | Pull有个缺点是,如果broker没有可供消费的消息,将导致consumer不断在循环中轮询,直到新消息到t达。为了避免这点,Kafka有个参数可以让consumer阻塞知道新消息到达(当然也可以阻塞知道消息的数量达到某个特定的量这样就可以批量发
341 |
342 |
343 |
344 | ### Kafka 高效文件存储设计特点
345 |
346 | - Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
347 | - 通过索引信息可以快速定位message和确定response的最大大小。
348 | - 通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。
349 | - 通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小
350 |
351 |
352 |
353 | ### kafka中的broker 是干什么的
354 |
355 | broker 是消息的代理,Producers往Brokers里面的指定Topic中写消息,Consumers从Brokers里面拉取指定Topic的消息,然后进行业务处理,broker在中间起到一个代理保存消息的中转站。
356 |
357 |
358 |
359 | ### Kafka创建Topic时如何将分区放置到不同的Broker中
360 |
361 | - 副本因子不能大于 Broker 的个数;
362 | - 第一个分区(编号为0)的第一个副本放置位置是随机从 brokerList 选择的;
363 | - 其他分区的第一个副本放置位置相对于第0个分区依次往后移。也就是如果我们有5个 Broker,5个分区,假设第一个分区放在第四个 Broker 上,那么第二个分区将会放在第五个 Broker 上;第三个分区将会放在第一个 Broker 上;第四个分区将会放在第二个 Broker 上,依次类推;
364 | - 剩余的副本相对于第一个副本放置位置其实是由 nextReplicaShift 决定的,而这个数也是随机产生的
365 |
366 |
367 |
368 | ### topic的分区数可以增加或减少吗?为什么?
369 |
370 | topic的分区数只能增加不能减少,因为减少掉的分区也就是被删除的分区的数据难以处理。
371 |
372 | 增加topic命令如下:
373 |
374 | ```
375 | bin/kafka-topics.sh --zookeeper localhost:2181/kafka --alter \
376 | --topic topic-config --partitions 3
377 | ```
378 |
379 | 关于topic还有一个面试点要知道:消费者组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据。
380 |
381 |
382 |
383 | ### 你知道kafka是怎么维护offset的吗?
384 |
385 | **1、维护offset的原因**:由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。
386 |
387 | **2、维护offset的方式** :Kafka 0.9版本之前,consumer默认将offset保存在Zookeeper中,从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets。
388 |
389 | **3、需要掌握的关于offset的常识** :消费者提交消费位移时提交的是当前消费到的最新消息的offset+1而不是offset。
390 |
391 |
392 |
393 | ### 你们是怎么对Kafka进行压测的?
394 |
395 | Kafka官方自带了压力测试脚本(kafka-consumer-perf-test.sh、kafka-producer-perf-test.sh), Kafka 压测时,可以查看到哪个地方出现了瓶颈(CPU,内存,网络 IO),一般都是网络 IO 达到瓶颈。
396 |
397 |
398 |
399 | ### 当Kafka消息数据出现了积压,应该怎么处理?
400 |
401 | 数据积压主要可以从两个角度去分析:
402 |
403 | **1、** 如果是 Kafka 消费能力不足,则可以考虑增加 Topic 的分区数,并且同时提升消费 组的消费者数量,消费者数=分区数。(两者缺一不可)
404 |
405 | **2、** 如果是下游的数据处理不及时:提高每批次拉取的数量。如果是因为批次拉取数据过少(拉取 数据/处理时间<生产速度),也会使处理的数据小于生产的数据,造成数据积压。
406 |
407 |
408 |
409 | ### 聊聊Kafka分区分配策略?
410 |
411 | 在 Kafka 内部存在三种默认的分区分配策略:Range , RoundRobin以及0.11.x版本引入的Sticky。Range 是默认策略。Range 是对每个 Topic 而言的(即一个 Topic 一个 Topic 分),首先 对同一个 Topic 里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。然后用 Partitions 分区的个数除以消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。
412 |
413 | 三种分区分配策略详见文章:深入分析Kafka架构(三):消费者消费方式、分区分配策略(Range分配策略、RoundRobin分配策略、Sticky分配策略)、offset维护
414 |
415 | 文中对三种分区分配策略举例并进行了非常详细的对比,值得一看。
416 |
417 |
418 |
419 | ### 谈谈你对Kafka幂等性的理解?
420 |
421 | Producer的幂等性指的是当发送同一条消息时,数据在 Server 端只会被持久化一次,数据不丟不重,但是这里的幂等性是有条件的:
422 |
423 | **1、** 只能保证 Producer 在单个会话内不丟不重,如果 Producer 出现意外挂掉再重启是 无法保证的。**因为幂等性情况下,是无法获取之前的状态信息,因此是无法做到跨会话级别的不丢不重**。
424 |
425 | **2、** 幂等性不能跨多个 Topic-Partition,只能保证单个 Partition 内的幂等性,当涉及多个Topic-Partition 时,这中间的状态并没有同步。
426 |
427 |
428 |
429 | ### 你对Kafka事务了解多少?
430 |
431 | Kafka是在0.11 版本开始引入了事务支持。事务可以保证 Kafka 在 Exactly Once 语义的基 础上,生产和消费可以跨分区和会话,要么全部成功,要么全部失败。
432 |
433 | **1、Producer 事务:**
434 |
435 | 为了实现跨分区跨会话的事务,需要引入一个全局唯一的 Transaction ID,并将 Producer 获得的 PID 和 Transaction ID 绑定。这样当 Producer 重启后就可以通过正在进行的 Transaction ID 获得原来的 PID。
436 |
437 | 为了管理 Transaction,Kafka 引入了一个新的组件 Transaction Coordinator。Producer 就 是通过和 Transaction Coordinator 交互获得 Transaction ID 对应的任务状态。Transaction Coordinator 还负责将事务所有写入 Kafka 的一个内部 Topic,这样即使整个服务重启,由于 事务状态得到保存,进行中的事务状态可以得到恢复,从而继续进行。
438 |
439 | **2、Consumer 事务:**
440 |
441 | 上述事务机制主要是从Producer方面考虑,对于 Consumer 而言,事务的保证就会相对较弱,尤其时无法保证 Commit 的信息被精确消费。这是由于 Consumer 可以通过offset访问任意信息,而且不同的 Segment File生命周期不同,同一事务的消息可能会出现重启后被删除的情况。
442 |
443 |
444 |
445 | ### Kafka怎么实现如此高的读写效率?
446 |
447 | **1、** 首先kafka本身是分布式集群,同时采用了分区技术,具有较高的并发度;
448 |
449 | **2、** 顺序写入磁盘,Kafka 的 producer 生产数据,要写入到 log 文件中,写的过程是一直追加到文件末端,为顺序写。
450 |
451 | 官网有数据表明,同样的磁盘,顺序写能到 600M/s,而随机写只有 100K/s。这 与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
452 |
453 | **3、** 零拷贝技术
454 |
455 |
456 |
457 | ### Kafka新建的分区会在哪个目录下创建
458 |
459 | 在启动 Kafka 集群之前,我们需要配置好 log.dirs 参数,其值是 Kafka 数据的存放目录,这个参数可以配置多个目录,目录之间使用逗号分隔,通常这些目录是分布在不同的磁盘上用于提高读写性能。
460 |
461 | 当然我们也可以配置 log.dir 参数,含义一样。只需要设置其中一个即可。
462 |
463 | 如果 log.dirs 参数只配置了一个目录,那么分配到各个 Broker 上的分区肯定只能在这个目录下创建文件夹用于存放数据。
464 |
465 | 但是如果 log.dirs 参数配置了多个目录,那么 Kafka 会在哪个文件夹中创建分区目录呢?答案是:Kafka 会在含有分区目录最少的文件夹中创建新的分区目录,分区目录名为 Topic名+分区ID。注意,是分区文件夹总数最少的目录,而不是磁盘使用量最少的目录!也就是说,如果你给 log.dirs 参数新增了一个新的磁盘,新的分区目录肯定是先在这个新的磁盘上创建直到这个新的磁盘目录拥有的分区目录不是最少为止。
466 |
467 |
468 |
469 | ### **什么是消费者组?**
470 |
471 | 消费者组是Kafka独有的概念,如果面试官问这个,就说明他对此是有一定了解的。
472 |
473 | **官网上的介绍言简意赅,即消费者组是Kafka提供的可扩展且具有容错性的消费者机制。**
474 |
475 | 但实际上,消费者组(Consumer Group)其实包含两个概念,作为队列,消费者组允许你分割数据处理到一组进程集合上(即一个消费者组中可以包含多个消费者进程,他们共同消费该topic的数据),这有助于你的消费能力的动态调整;作为发布-订阅模型(publish-subscribe),Kafka允许你将同一份消息广播到多个消费者组里,以此来丰富多种数据使用场景。
476 |
477 | 需要注意的是:在消费者组中,多个实例共同订阅若干个主题,实现共同消费。同一个组下的每个实例都配置有相同的组ID,被分配不同的订阅分区。当某个实例挂掉的时候,其他实例会自动地承担起它负责消费的分区。因此,消费者组在一定程度上也保证了消费者程序的高可用性。
478 |
479 |
480 |
481 | 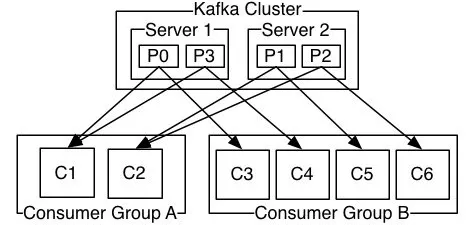
482 |
483 |
484 |
485 | 注意:消费者组的题目,能够帮你在某种程度上掌控下面的面试方向。
486 |
487 | - 如果你擅长位移值原理(Offset),就不妨再提一下消费者组的位移提交机制;
488 | - 如果你擅长Kafka Broker,可以提一下消费者组与Broker之间的交互;
489 | - 如果你擅长与消费者组完全不相关的Producer,那么就可以这么说:“消费者组要消费的数据完全来自于Producer端生产的消息,我对Producer还是比较熟悉的。”
490 |
491 |
492 |
493 | 总之,你总得对consumer group相关的方向有一定理解,然后才能像面试官表名你对某一块很理解。
494 |
495 |
496 |
497 | ### **kafka中的 zookeeper 起到什么作用,可以不用zookeeper么**
498 |
499 | zookeeper 是一个分布式的协调组件,早期版本的kafka用zk做meta信息存储,consumer的消费状态,group的管理以及 offset的值。考虑到zk本身的一些因素以及整个架构较大概率存在单点问题,新版本中逐渐弱化了zookeeper的作用。新的consumer使用了kafka内部的group coordination协议,也减少了对zookeeper的依赖,
500 |
501 | 但是broker依然依赖于ZK,zookeeper 在kafka中还用来选举controller 和 检测broker是否存活等等。
502 |
503 |
504 |
505 |
506 | ### Kafka 为什么那么快
507 |
508 | Cache Filesystem Cache PageCache缓存
509 |
510 | 顺序写 由于现代的操作系统提供了预读和写技术,磁盘的顺序写大多数情况下比随机写内存还要快。
511 |
512 | Zero-copy 零拷技术减少拷贝次数
513 |
514 | Batching of Messages 批量量处理。合并小的请求,然后以流的方式进行交互,直顶网络上限。
515 |
516 | Pull 拉模式 使用拉模式进行消息的获取消费,与消费端处理能力相符。
517 |
518 |
519 |
520 | ### 谈一谈 Kafka 的再均衡
521 |
522 | 在Kafka中,当有新消费者加入或者订阅的topic数发生变化时,会触发Rebalance(再均衡:在同一个消费者组当中,分区的所有权从一个消费者转移到另外一个消费者)机制,Rebalance顾名思义就是重新均衡消费者消费。Rebalance的过程如下:
523 |
524 | **第一步:** 所有成员都向coordinator发送请求,请求入组。一旦所有成员都发送了请求,coordinator会从中选择一个consumer担任leader的角色,并把组成员信息以及订阅信息发给leader。
525 |
526 | **第二步:** leader开始分配消费方案,指明具体哪个consumer负责消费哪些topic的哪些partition。一旦完成分配,leader会将这个方案发给coordinator。coordinator接收到分配方案之后会把方案发给各个consumer,这样组内的所有成员就都知道自己应该消费哪些分区了。
527 |
528 | 所以对于Rebalance来说,Coordinator起着至关重要的作用
529 |
530 |
531 |
532 | ### Kafka 是如何实现高吞吐率的?
533 |
534 | Kafka是分布式消息系统,需要处理海量的消息,Kafka的设计是把所有的消息都写入速度低容量大的硬盘,以此来换取更强的存储能力,但实际上,使用硬盘并没有带来过多的性能损失。kafka主要使用了以下几个方式实现了超高的吞吐率:
535 |
536 | - 顺序读写;
537 | - 零拷贝
538 | - 文件分段
539 | - 批量发送
540 | - 数据压缩。
541 |
542 |
543 |
544 |
545 | ### **如何设置Kafka能接收的最大消息的大小?**
546 |
547 | 对于SRE来讲,该题简直是送分题啊,但是,最大消息的设置通常情况下有生产者端,消费者端,broker端和topic级别的参数,我们需要正确设置,以保证可以正常的生产和消费。
548 |
549 | - Broker端参数:message.max.bytes,max.message.bytes(topic级别),replica.fetch.max.bytes(否则follow会同步失败)
550 | - Consumer端参数:fetch.message.max.bytes
551 |
552 |
553 |
554 | ### **监控Kafka的框架都有哪些?**
555 |
556 | 对于SRE来讲,依然是送分题。但基础的我们要知道,Kafka本身是提供了JMX(Java Management Extensions)的,我们可以通过它来获取到Kafka内部的一些基本数据。
557 |
558 | - **Kafka Manager:**更多是Kafka的管理,对于SRE非常友好,也提供了简单的瞬时指标监控。
559 | - **Kafka Monitor:**LinkedIn开源的免费框架,支持对集群进行系统测试,并实时监控测试结果。
560 | - **CruiseControl:**也是LinkedIn公司开源的监控框架,用于实时监测资源使用率,以及提供常用运维操作等。无UI界面,只提供REST API,可以进行多集群管理。
561 | - **JMX监控:**由于Kafka提供的监控指标都是基于JMX的,因此,市面上任何能够集成JMX的框架都可以使用,比如Zabbix和Prometheus。
562 | - 已有大数据平台自己的监控体系:像Cloudera提供的CDH这类大数据平台,天然就提供Kafka监控方案。
563 | - **JMXTool:**社区提供的命令行工具,能够实时监控JMX指标。可以使用kafka-run-class.sh kafka.tools.JmxTool来查看具体的用法。
564 |
565 |
566 |
567 | ### **如何估算Kafka集群的机器数量?**
568 |
569 | 该题也算是SRE的送分题吧,对于SRE来讲,任何生产的系统第一步需要做的就是容量预估以及集群的架构规划,实际上也就是机器数量和所用资源之间的关联关系,资源通常来讲就是CPU,内存,磁盘容量,带宽。但需要注意的是,Kafka因为独有的设计,对于磁盘的要求并不是特别高,普通机械硬盘足够,而通常的瓶颈会出现在带宽上。
570 |
571 | 在预估磁盘的占用时,你一定不要忘记计算副本同步的开销。如果一条消息占用1KB的磁盘空间,那么,在有3个副本的主题中,你就需要3KB的总空间来保存这条消息。同时,需要考虑到整个业务Topic数据保存的最大时间,以上几个因素,基本可以预估出来磁盘的容量需求。
572 |
573 | 需要注意的是:对于磁盘来讲,一定要提前和业务沟通好场景,而不是等待真正有磁盘容量瓶颈了才去扩容磁盘或者找业务方沟通方案。
574 |
575 | 对于带宽来说,常见的带宽有1Gbps和10Gbps,通常我们需要知道,当带宽占用接近总带宽的90%时,丢包情形就会发生。
576 |
577 |
578 |
579 | ### **Kafka能手动删除消息吗?**
580 |
581 | Kafka不需要用户手动删除消息。它本身提供了留存策略,能够自动删除过期消息。当然,它是支持手动删除消息的。
582 |
583 |
584 |
585 | - 对于设置了Key且参数cleanup.policy=compact的主题而言,我们可以构造一条 的消息发送给Broker,依靠Log Cleaner组件提供的功能删除掉该 Key 的消息。
586 | - 对于普通主题而言,我们可以使用kafka-delete-records命令,或编写程序调用Admin.deleteRecords方法来删除消息。这两种方法殊途同归,底层都是调用Admin的deleteRecords方法,通过将分区Log Start Offset值抬高的方式间接删除消息。
587 |
588 |
589 |
590 | ### **__consumer_offsets是做什么用的?**
591 |
592 | 这是一个内部主题,主要用于存储消费者的偏移量,以及消费者的元数据信息(消费者实例,消费者id等等)
593 |
594 | 需要注意的是:Kafka的GroupCoordinator组件提供对该主题完整的管理功能,包括该主题的创建、写入、读取和Leader维护等。
595 |
596 |
597 |
598 | ### Kafka Stream的一些独特功能是什么?
599 |
600 | Kafka Stream是理想的实时数据流工具。以下是确立Kafka Stream受欢迎程度的独特功能。
601 |
602 | - 高可扩展性和容错能力。
603 | - 轻松部署到云,容器,裸机或虚拟机。
604 | - 通过与Kafka安全性的集成。
605 | - 编写标准Java应用程序的工具。
606 | - 一次性处理语义。
607 | - 适用于小型,中型和大型用例。
608 | - 无需单独的处理集群。
609 |
610 |
611 |
612 | ### 为什么说Kafka是分布式流媒体平台?
613 |
614 | 首先,它可以帮助轻松地推动记录。此外,Apache Kafka还可以帮助你存储大量记录而不会遇到存储问题。最重要的是,Kafka能够处理到达的记录。这些功能显然将Kafka确立为可靠的分布式流媒体平台。
--------------------------------------------------------------------------------
/interviewDoc/Java/middleware/RabbitMQ.md:
--------------------------------------------------------------------------------
1 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
2 |
3 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
4 |
5 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
6 |
7 |
8 |
9 |
10 | - [RabbitMQ是什么?](#rabbitmq是什么)
11 | - [为什么要用RocketMq?](#为什么要用rocketmq)
12 | - [RocketMQ的消息堆积如何处理?](#rocketmq的消息堆积如何处理)
13 | - [使用 MQ 的缺陷有哪些?](#使用-mq-的缺陷有哪些)
14 | - [你了解哪些常用的 MQ?](#你了解哪些常用的-mq)
15 | - [MQ 有哪些使用场景?](#mq-有哪些使用场景)
16 | - [使用RabbitMQ有什么好处?](#使用rabbitmq有什么好处)
17 | - [RabbitMQ特点?](#rabbitmq特点)
18 | - [AMQP是什么?](#amqp是什么)
19 | - [AMQP协议3层?](#amqp协议3层)
20 | - [rocketmq的工作流程是怎样的?](#rocketmq的工作流程是怎样的)
21 | - [rocketmq如何保证高可用性?](#rocketmq如何保证高可用性)
22 | - [RocketMq如何负载均衡?](#rocketmq如何负载均衡)
23 | - [RocketMq的存储机制了解吗?](#rocketmq的存储机制了解吗)
24 | - [RocketMq的存储结构是怎样的?](#rocketmq的存储结构是怎样的)
25 | - [RocketMq性能比较高的原因?](#rocketmq性能比较高的原因)
26 | - [AMQP模型的几大组件?](#amqp模型的几大组件)
27 | - [生产者Producer?](#生产者producer)
28 | - [消费者Consumer?](#消费者consumer)
29 | - [Broker服务节点?](#broker服务节点)
30 | - [Queue队列?](#queue队列)
31 | - [Exchange交换器?](#exchange交换器)
32 | - [RoutingKey路由键?](#routingkey路由键)
33 | - [Binding绑定?](#binding绑定)
34 | - [交换器4种类型?](#交换器4种类型)
35 | - [如何保证消息不被重复消费?](#如何保证消息不被重复消费)
36 | - [消息重复消费如何解决?](#消息重复消费如何解决)
37 | - [如何让 RocketMQ 保证消息的顺序消费?](#如何让-rocketmq-保证消息的顺序消费)
38 | - [怎么保证消息发到同一个queue?](#怎么保证消息发到同一个queue)
39 | - [如何保证消息不丢失?](#如何保证消息不丢失)
40 | - [如何保证消息的顺序性?](#如何保证消息的顺序性)
41 | - [消息大量积压怎么解决?](#消息大量积压怎么解决)
42 | - [如何保证MQ的高可用?](#如何保证mq的高可用)
43 | - [RocketMQ Broker中的消息被消费后会立即删除吗?](#rocketmq-broker中的消息被消费后会立即删除吗)
44 | - [RocketMQ消费模式有几种?](#rocketmq消费模式有几种)
45 | - [生产者消息运转?](#生产者消息运转)
46 | - [RocketMQ消息是push还是pull?](#rocketmq消息是push还是pull)
47 | - [当消费负载均衡consumer和queue不对等的时候会发生什么?](#当消费负载均衡consumer和queue不对等的时候会发生什么)
48 | - [为什么要主动拉取消息而不使用事件监听方式?](#为什么要主动拉取消息而不使用事件监听方式)
49 | - [消费者接收消息过程?](#消费者接收消息过程)
50 | - [Broker如何处理拉取请求的?](#broker如何处理拉取请求的)
51 | - [交换器无法根据自身类型和路由键找到符合条件队列时,有哪些处理?](#交换器无法根据自身类型和路由键找到符合条件队列时有哪些处理)
52 | - [死信队列?](#死信队列)
53 | - [导致的死信的几种原因?](#导致的死信的几种原因)
54 | - [延迟队列?](#延迟队列)
55 | - [优先级队列?](#优先级队列)
56 | - [事务机制?](#事务机制)
57 | - [发送确认机制?](#发送确认机制)
58 | - [消费者获取消息的方式?](#消费者获取消息的方式)
59 | - [消费者某些原因无法处理当前接受的消息如何来拒绝?](#消费者某些原因无法处理当前接受的消息如何来拒绝)
60 | - [消息传输保证层级?](#消息传输保证层级)
61 | - [vhost?](#vhost)
62 | - [集群中的节点类型?](#集群中的节点类型)
63 | - [队列结构?](#队列结构)
64 | - [RabbitMQ中消息可能有的几种状态?](#rabbitmq中消息可能有的几种状态)
65 | - [它有哪几种部署类型?分别有什么特点?](#它有哪几种部署类型分别有什么特点)
66 |
67 |
68 |
69 | ### RabbitMQ是什么?
70 |
71 | MQ(Message Queue)消息队列,是 "先进先出" 的一种数据结构。
72 |
73 | MQ 一般用来解决应用解耦,异步处理,流量削峰等问题,实现高性能,高可用,可伸缩和最终一致性架构。
74 |
75 | **应用解耦**:当 A 系统生产关键数据,发送数据给多个其他系统消费,此时 A 系统和其他系统产生了严重的耦合,如果将 A 系统产生的数据放到 MQ 当中,其他系统去 MQ 获取消费数据,此时各系统独立运行只与 MQ 交互,添加新系统消费 A 系统的数据也不需要去修改 A 系统的代码,达到了解耦的效果。
76 |
77 | **异步处理**:互联网类企业对用户的直接操作,一般要求每个请求在 200ms 以内完成。对于一个系统调用多个系统,不使用 MQ 的情况下,它执行完返回的耗时是调用完所有系统所需时间的总和;使用 MQ 进行优化后,执行的耗时则是执行主系统的耗时加上发送数据到消息队列的耗时,大幅度提升系统性能和用户体验。
78 |
79 | **流量削峰**:MySQL 每秒最高并发请求在 2000 左右,用户访问量高峰期的时候涌入的大量请求,会将 MySQL 打死,然后系统就挂掉,但过了高峰期,请求量可能远低于 2000,这种情况去增加服务器就不值得,如果使用 MQ 的情况,将用户的请求全部放到 MQ 中,让系统去消费用户的请求,不要超过系统所能承受的最大请求数量,保证系统不会再高峰期挂掉,高峰期过后系统还是按照最大请求数量处理完请求。
80 |
81 |
82 |
83 | ### 为什么要用RocketMq?
84 |
85 | 总得来说,RocketMq具有以下几个优势:
86 |
87 | - 吞吐量高:单机吞吐量可达十万级
88 |
89 | - 可用性高:分布式架构
90 |
91 | - 消息可靠性高:经过参数优化配置,消息可以做到0丢失
92 |
93 | - 功能支持完善:MQ功能较为完善,还是分布式的,扩展性好
94 |
95 | - 支持10亿级别的消息堆积:不会因为堆积导致性能下降
96 |
97 | - 源码是java:方便我们查看源码了解它的每个环节的实现逻辑,并针对不同的业务场景进行扩展
98 |
99 | - 可靠性高:天生为金融互联网领域而生,对于要求很高的场景,尤其是电商里面的订单扣款,以及业务削峰,在大量交易涌入时,后端可能无法及时处理的情况
100 |
101 | - 稳定性高:RoketMQ在上可能更值得信赖,这些业务场景在阿里双11已经经历了多次考验
102 |
103 |
104 |
105 |
106 | ### RocketMQ的消息堆积如何处理?
107 |
108 | 首先要找到是什么原因导致的消息堆积,是 Producer 太多了,Consumer 太少了导致的还是说其他情况,总之先定位问题。
109 |
110 | 然后看下消息消费速度是否正常,正常的话,可以通过上线更多 Consumer 临时解决消息堆积问题
111 |
112 |
113 |
114 | ### 使用 MQ 的缺陷有哪些?
115 |
116 | **系统可用性降低**:以前只要担心系统的问题,现在还要考虑 MQ 挂掉的问题,MQ 挂掉,所关联的系统都会无法提供服务。
117 |
118 | **系统复杂性变高**:要考虑消息丢失、消息重复消费等问题。
119 |
120 | **一致性问题**:多个 MQ 消费系统,部分成功,部分失败,要考虑事务问题。
121 |
122 |
123 |
124 | ### 你了解哪些常用的 MQ?
125 |
126 | **ActiveMQ**:支持万级的吞吐量,较成熟完善;官方更新迭代较少,社区的活跃度不是很高,有消息丢失的情况。
127 |
128 | **RabbitMQ**:延时低,微妙级延时,社区活跃度高,bug 修复及时,而且提供了很友善的后台界面;用 Erlang 语言开发,只熟悉 Java 的无法阅读源码和自行修复 bug。
129 |
130 | **RocketMQ**:阿里维护的消息中间件,可以达到十万级的吞吐量,支持分布式事务。
131 |
132 | **Kafka**:分布式的中间件,最大优点是其吞吐量高,一般运用于大数据系统的实时运算和日志采集的场景,功能简单,可靠性高,扩展性高;缺点是可能导致重复消费。
133 |
134 |
135 |
136 | ### MQ 有哪些使用场景?
137 |
138 | **异步处理**:用户注册后,发送注册邮件和注册短信。用户注册完成后,提交任务到 MQ,发送模块并行获取 MQ 中的任务。
139 |
140 | **系统解耦**:比如用注册完成,再加一个发送微信通知。只需要新增发送微信消息模块,从 MQ 中读取任务,发送消息即可。无需改动注册模块的代码,这样注册模块与发送模块通过 MQ 解耦。
141 |
142 | **流量削峰**:秒杀和抢购等场景经常使用 MQ 进行流量削峰。活动开始时流量暴增,用户的请求写入 MQ,超过 MQ 最大长度丢弃请求,业务系统接收 MQ 中的消息进行处理,达到流量削峰、保证系统可用性的目的。
143 |
144 | **日志处理**:日志采集方收集日志写入 kafka 的消息队列中,处理方订阅并消费 kafka 队列中的日志数据。
145 |
146 | **消息通讯**:点对点或者订阅发布模式,通过消息进行通讯。如微信的消息发送与接收、聊天室等。
147 |
148 |
149 |
150 | ### 使用RabbitMQ有什么好处?
151 |
152 | **解耦**,系统A在代码中直接调用系统B和系统C的代码,如果将来D系统接入,系统A还需要修改代码,过于麻烦!
153 |
154 | **异步**,将消息写入消息队列,非必要的业务逻辑以异步的方式运行,加快响应速度
155 |
156 | **削峰**,并发量大的时候,所有的请求直接怼到数据库,造成数据库连接异常
157 |
158 |
159 |
160 | ### RabbitMQ特点?
161 |
162 | **1、可靠性:** RabbitMQ使用一些机制来保证可靠性, 如持久化、传输确认及发布确认等。
163 |
164 | **2、灵活的路由 :** 在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能, RabbitMQ 己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个 交换器绑定在一起, 也可以通过插件机制来实现自己的交换器。
165 |
166 | **3、扩展性:** 多个RabbitMQ节点可以组成一个集群,也可以根据实际业务情况动态地扩展 集群中节点。
167 |
168 | **4、高可用性 :** 队列可以在集群中的机器上设置镜像,使得在部分节点出现问题的情况下队 列仍然可用。
169 |
170 | **5、多种协议:** RabbitMQ除了原生支持AMQP协议,还支持STOMP, MQTT等多种消息 中间件协议。
171 |
172 | **6、多语言客户端 :**RabbitMQ 几乎支持所有常用语言,比如 Java、 Python、 Ruby、 PHP、 C#、 JavaScript 等。
173 |
174 | **7、管理界面 :** RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息、集 群中的节点等。
175 |
176 | **8、令插件机制:** RabbitMQ 提供了许多插件 , 以实现从多方面进行扩展,当然也可以编写自 己的插件。
177 |
178 |
179 |
180 | ### AMQP是什么?
181 |
182 | RabbitMQ就是 AMQP 协议的 Erlang 的实现(当然 RabbitMQ 还支持 STOMP2、 MQTT3 等协议 ) AMQP 的模型架构 和 RabbitMQ 的模型架构是一样的,生产者将消息发送给交换器,交换器和队列绑定 。
183 |
184 | RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都是遵循的 AMQP 协议中相 应的概念。目前 RabbitMQ 最新版本默认支持的是 AMQP 0-9-1。
185 |
186 |
187 |
188 | ### AMQP协议3层?
189 |
190 | **1、Module Layer:** 协议最高层,主要定义了一些客户端调用的命令,客户端可以用这些命令实现自己的业务逻辑。
191 |
192 | **2、Session Layer:** 中间层,主要负责客户端命令发送给服务器,再将服务端应答返回客户端,提供可靠性同步机制和错误处理。
193 |
194 | **3、TransportLayer:** 最底层,主要传输二进制数据流,提供帧的处理、信道服用、错误检测和数据表示等。
195 |
196 |
197 |
198 | ### rocketmq的工作流程是怎样的?
199 |
200 | RocketMq的工作流程如下:
201 |
202 | **1、首先启动NameServer**。NameServer启动后监听端口,等待Broker、Producer以及Consumer连上来
203 |
204 | **2、启动Broker**。启动之后,会跟所有的NameServer建立并保持一个长连接,定时发送心跳包。心跳包中包含当前Broker信息(ip、port等)、Topic信息以及Borker与Topic的映射关系
205 |
206 | **3、创建Topic**。创建时需要指定该Topic要存储在哪些Broker上,也可以在发送消息时自动创建Topic
207 |
208 | **4、Producer发送消息**。启动时先跟NameServer集群中的其中一台建立长连接,并从NameServer中获取当前发送的Topic所在的Broker;然后从队列列表中轮询选择一个队列,与队列所在的Broker建立长连接,进行消息的发送
209 |
210 | **5、Consumer消费消息**。跟其中一台NameServer建立长连接,获取当前订阅Topic存在哪些Broker上,然后直接跟Broker建立连接通道,进行消息的消费
211 |
212 |
213 |
214 | ### rocketmq如何保证高可用性?
215 |
216 | 1、集群化部署NameServer。Broker集群会将所有的broker基本信息、topic信息以及两者之间的映射关系,轮询存储在每个NameServer中(也就是说每个NameServer存储的信息完全一样)。因此,NameServer集群化,不会因为其中的一两台服务器挂掉,而影响整个架构的消息发送与接收;
217 |
218 |
219 |
220 | 2、集群化部署多broker。producer发送消息到broker的master,若当前的master挂掉,则会自动切换到其他的master
221 |
222 | cosumer默认会访问broker的master节点获取消息,那么master节点挂了之后,该怎么办呢?它就会自动切换到同一个broker组的slave节点进行消费
223 |
224 | 那么你肯定会想到会有这样一个问题:consumer要是直接消费slave节点,那master在宕机前没有来得及把消息同步到slave节点,那这个时候,不就会出现消费者不就取不到消息的情况了?
225 |
226 | 这样,就引出了下一个措施,来保证消息的高可用性
227 |
228 |
229 |
230 | 3、设置同步复制
231 |
232 | 前面已经提到,消息发送到broker的master节点上,master需要将消息复制到slave节点上,rocketmq提供两种复制方式:同步复制和异步复制
233 |
234 | 异步复制,就是消息发送到master节点,只要master写成功,就直接向客户端返回成功,后续再异步写入slave节点
235 |
236 | 同步复制,就是等master和slave都成功写入内存之后,才会向客户端返回成功
237 |
238 | 那么,要保证高可用性,就需要将复制方式配置成同步复制,这样即使master节点挂了,slave上也有当前master的所有备份数据,那么不仅保证消费者消费到的消息是完整的,并且当master节点恢复之后,也容易恢复消息数据
239 |
240 | 在master的配置文件中直接配置brokerRole:SYNC_MASTER即可
241 |
242 |
243 |
244 | ### RocketMq如何负载均衡?
245 |
246 | **1、**producer发送消息的负载均衡:默认会**轮询**向Topic的所有queue发送消息,以达到消息平均落到不同的queue上;而由于queue可以落在不同的broker上,就可以发到不同broker上(当然也可以指定发送到某个特定的queue上)
247 |
248 |
249 |
250 | **2、**consumer订阅消息的负载均衡:假设有5个队列,两个消费者,则第一个消费者消费3个队列,第二个则消费2个队列,以达到平均消费的效果。而需要注意的是,当consumer的数量大于队列的数量的话,根据rocketMq的机制,多出来的队列不会去消费数据,因此建议consumer的数量小于或者等于queue的数量,避免不必要的浪费
251 |
252 |
253 |
254 | ### RocketMq的存储机制了解吗?
255 |
256 | RocketMq采用文件系统进行消息的存储,相对于ActiveMq采用关系型数据库进行存储的方式就更直接,性能更高了
257 |
258 | **RocketMq与Kafka在写消息与发送消息上,继续沿用了Kafka的这两个方面:顺序写和零拷贝**
259 |
260 | **1、顺序写**
261 |
262 | 我们知道,操作系统每次从磁盘读写数据的时候,都需要找到数据在磁盘上的地址,再进行读写。而如果是机械硬盘,寻址需要的时间往往会比较长
263 |
264 | 而一般来说,如果把数据存储在内存上面,少了寻址的过程,性能会好很多;但Kafka 的数据存储在磁盘上面,依然性能很好,这是为什么呢?
265 |
266 | 这是因为,Kafka采用的是顺序写,直接追加数据到末尾。实际上,磁盘顺序写的性能极高,在磁盘个数一定,转数一定的情况下,基本和内存速度一致
267 |
268 | 因此,磁盘的顺序写这一机制,极大地保证了Kafka本身的性能
269 |
270 |
271 |
272 | **2、零拷贝**
273 |
274 | 比如:读取文件,再用socket发送出去这一过程
275 |
276 | ```
277 | buffer = File.read
278 | Socket.send(buffer)
279 | ```
280 |
281 | 传统方式实现:
282 | 先读取、再发送,实际会经过以下四次复制
283 |
284 | 1、将磁盘文件,读取到操作系统内核缓冲区**Read Buffer**
285 | 2、将内核缓冲区的数据,复制到应用程序缓冲区**Application Buffer**
286 | 3、将应用程序缓冲区**Application Buffer**中的数据,复制到socket网络发送缓冲区
287 | 4、将**Socket buffer**的数据,复制到**网卡**,由网卡进行网络传输
288 |
289 | 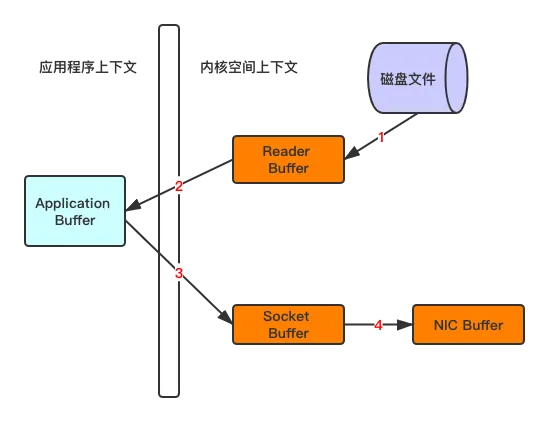
290 |
291 | 传统方式,读取磁盘文件并进行网络发送,经过的四次数据copy是非常繁琐的
292 |
293 | 重新思考传统IO方式,会注意到**在读取磁盘文件后,不需要做其他处理,直接用网络发送出去的这种场景下**,第二次和第三次数据的复制过程,不仅没有任何帮助,反而带来了巨大的开销。那么这里使用了**零拷贝**,也就是说,直接由内核缓冲区**Read Buffer**将数据复制到**网卡**,省去第二步和第三步的复制。
294 |
295 | 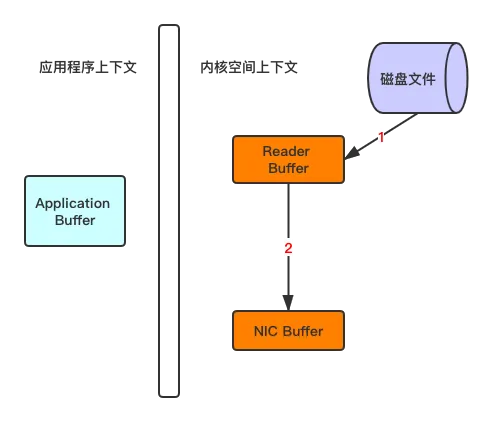
296 |
297 | 那么采用零拷贝的方式发送消息,必定会大大减少读取的开销,使得RocketMq读取消息的性能有一个质的提升
298 | 此外,还需要再提一点,零拷贝技术采用了MappedByteBuffer内存映射技术,采用这种技术有一些限制,其中有一条就是传输的文件不能超过2G,这也就是为什么RocketMq的存储消息的文件CommitLog的大小规定为1G的原因
299 |
300 |
301 |
302 | **小结:**RocketMq采用文件系统存储消息,并采用顺序写写入消息,使用零拷贝发送消息,极大得保证了RocketMq的性能
303 |
304 |
305 |
306 | ### RocketMq的存储结构是怎样的?
307 |
308 | 如图所示,消息生产者发送消息到broker,都是会按照顺序存储在CommitLog文件中,每个commitLog文件的大小为1G
309 |
310 |
311 |
312 | 
313 |
314 | CommitLog-存储所有的消息元数据,包括Topic、QueueId以及message
315 |
316 | CosumerQueue-消费逻辑队列:存储消息在CommitLog的offset
317 |
318 | IndexFile-索引文件:存储消息的key和时间戳等信息,使得RocketMq可以采用key和时间区间来查询消息
319 |
320 |
321 |
322 | 也就是说,rocketMq将消息均存储在CommitLog中,并分别提供了CosumerQueue和IndexFile两个索引,来快速检索消息
323 |
324 |
325 |
326 | ### RocketMq性能比较高的原因?
327 |
328 | RocketMq采用文件系统存储消息,采用顺序写的方式写入消息,使用零拷贝发送消息,这三者的结合极大地保证了RocketMq的性能
329 |
330 |
331 |
332 | ### AMQP模型的几大组件?
333 |
334 | - 交换器 (Exchange):消息代理服务器中用于把消息路由到队列的组件。
335 | - 队列 (Queue):用来存储消息的数据结构,位于硬盘或内存中。
336 | - 绑定 (Binding):一套规则,告知交换器消息应该将消息投递给哪个队列。
337 |
338 |
339 |
340 | ### 生产者Producer?
341 |
342 | 消息生产者,就是投递消息的一方。
343 |
344 | 消息一般包含两个部分:消息体(payload)和标签(Label)。
345 |
346 |
347 |
348 | ### 消费者Consumer?
349 |
350 | 消费消息,也就是接收消息的一方。
351 |
352 | 消费者连接到RabbitMQ服务器,并订阅到队列上。消费消息时只消费消息体,丢弃标签。
353 |
354 |
355 |
356 | ### Broker服务节点?
357 |
358 | Broker可以看做RabbitMQ的服务节点。一般请下一个Broker可以看做一个RabbitMQ服务器。
359 |
360 |
361 |
362 | ### Queue队列?
363 |
364 | Queue:RabbitMQ的内部对象,用于存储消息。多个消费者可以订阅同一队列,这时队列中的消息会被平摊(轮询)给多个消费者进行处理。
365 |
366 |
367 |
368 | ### Exchange交换器?
369 |
370 | Exchange:生产者将消息发送到交换器,有交换器将消息路由到一个或者多个队列中。当路由不到时,或返回给生产者或直接丢弃。
371 |
372 |
373 |
374 | ### RoutingKey路由键?
375 |
376 | 生产者将消息发送给交换器的时候,会指定一个RoutingKey,用来指定这个消息的路由规则,这个RoutingKey需要与交换器类型和绑定键(BindingKey)联合使用才能最终生效。
377 |
378 |
379 |
380 | ### Binding绑定?
381 |
382 | 通过绑定将交换器和队列关联起来,一般会指定一个BindingKey,这样RabbitMq就知道如何正确路由消息到队列了。
383 |
384 |
385 |
386 | ### 交换器4种类型?
387 |
388 | 主要有以下4种。
389 |
390 | **fanout:** 把所有发送到该交换器的消息路由到所有与该交换器绑定的队列中。
391 |
392 | **direct:**把消息路由到BindingKey和RoutingKey完全匹配的队列中。
393 |
394 | **topic:** 匹配规则:
395 |
396 | RoutingKey 为一个 点号'.': 分隔的字符串。比如: java.xiaoka.show
397 |
398 | BindingKey和RoutingKey一样也是点号“.“分隔的字符串。
399 |
400 | BindingKey可使用 * 和 # 用于做模糊匹配,*匹配一个单词,#匹配多个或者0个
401 |
402 | **headers:**不依赖路由键匹配规则路由消息。是根据发送消息内容中的headers属性进行匹配。性能差,基本用不到。
403 |
404 |
405 |
406 | ### 如何保证消息不被重复消费?
407 |
408 | 消息被重复消费,就是消费方多次接受到了同一条消息。根本原因就是,第一次消费完之后,消费方给 MQ 确认已消费的反馈,MQ 没有成功接受。比如网络原因、MQ 重启等。
409 |
410 | 所以 MQ 是无法保证消息不被重复消费的,只能业务系统层面考虑。
411 |
412 | 不被重复消费的问题,就被转化为消息消费的幂等性的问题。幂等性就是指一次和多次请求的结果一致,多次请求不会产生副作用。
413 |
414 | 保证消息消费的幂等性可以考虑下面的方式:
415 |
416 | - 给消息生成全局 id,消费成功过的消息可以直接丢弃
417 | - 消息中保存业务数据的主键字段,结合业务系统需求场景进行处理,避免多次插入、是否可以根据主键多次更新而并不影响结果等
418 |
419 |
420 |
421 | ### 消息重复消费如何解决?
422 |
423 | 影响消息正常发送和消费的**「重要原因是网络的不确定性。」**
424 |
425 | - **「引起重复消费的原因」**
426 |
427 | - - **「ACK」** 正常情况下在consumer真正消费完消息后应该发送ack,通知broker该消息已正常消费,从queue中剔除
428 |
429 | 当ack因为网络原因无法发送到broker,broker会认为词条消息没有被消费,此后会开启消息重投机制把消息再次投递到consumer
430 |
431 | - **「消费模式」** 在CLUSTERING模式下,消息在broker中会保证相同group的consumer消费一次,但是针对不同group的consumer会推送多次
432 |
433 | - **「解决方案」**
434 |
435 | - - **「数据库表」**
436 |
437 | 处理消息前,使用消息主键在表中带有约束的字段中insert
438 |
439 | - **「Map」**
440 |
441 | 单机时可以使用map ConcurrentHashMap -> putIfAbsent guava cache
442 |
443 | - **「Redis」**
444 |
445 | 分布式锁搞起来。
446 |
447 |
448 |
449 | ### 如何让 RocketMQ 保证消息的顺序消费?
450 |
451 | 首先多个 queue 只能保证单个 queue 里的顺序,queue 是典型的 FIFO,天然顺序。多个 queue 同时消费是无法绝对保证消息的有序性的。所以总结如下:
452 |
453 | 同一 topic,同一个 QUEUE,发消息的时候一个线程去发送消息,消费的时候 一个线程去消费一个 queue 里的消息。
454 |
455 |
456 |
457 | ### 怎么保证消息发到同一个queue?
458 |
459 | Rocket MQ给我们提供了MessageQueueSelector接口,可以自己重写里面的接口,实现自己的算法,举个最简单的例子:判断`i % 2 == 0`,那就都放到queue1里,否则放到queue2里。
460 |
461 | ```java
462 | for (int i = 0; i < 5; i++) {
463 | Message message = new Message("orderTopic", ("hello!" + i).getBytes());
464 | producer.send(
465 | // 要发的那条消息
466 | message,
467 | // queue 选择器 ,向 topic中的哪个queue去写消息
468 | new MessageQueueSelector() {
469 | // 手动 选择一个queue
470 | @Override
471 | public MessageQueue select(
472 | // 当前topic 里面包含的所有queue
473 | List mqs,
474 | // 具体要发的那条消息
475 | Message msg,
476 | // 对应到 send() 里的 args,也就是2000前面的那个0
477 | Object arg) {
478 | // 向固定的一个queue里写消息,比如这里就是向第一个queue里写消息
479 | if (Integer.parseInt(arg.toString()) % 2 == 0) {
480 | return mqs.get(0);
481 | } else {
482 | return mqs.get(1);
483 | }
484 | }
485 | },
486 | // 自定义参数:0
487 | // 2000代表2000毫秒超时时间
488 | i, 2000);
489 | }
490 | ```
491 |
492 |
493 |
494 |
495 |
496 | ### 如何保证消息不丢失?
497 |
498 | **生产者丢失消息**:如网络传输中丢失消息、MQ 发生异常未成功接收消息等情况。**解决办法**:主流的 MQ 都有确认或事务机制,可以保证生产者将消息送达到 MQ。如 RabbitMQ 就有事务模式和 confirm 模式。
499 |
500 |
501 |
502 | **MQ 丢失消息**:MQ 成功接收消息内部处理出错、宕机等情况。**解决办法**:开启 MQ 的持久化配置。
503 |
504 |
505 |
506 | **消费者丢失消息**:采用消息自动确认模式,消费者取到消息未处理挂掉了。**解决办法**:改为手动确认模式,消费者成功消费消息再确认。
507 |
508 |
509 |
510 | ### 如何保证消息的顺序性?
511 |
512 | 生产者保证消息入队的顺序。
513 |
514 | MQ 本身是一种先进先出的数据接口,将同一类消息,发到同一个 queue 中,保证出队是有序的。
515 |
516 | 避免多消费者并发消费同一个 queue 中的消息。
517 |
518 |
519 |
520 | ### 消息大量积压怎么解决?
521 |
522 | 消息的积压来自于两方面:要么发送快了,要么消费变慢了。
523 |
524 | 单位时间发送的消息增多,比如赶上大促或者抢购,短时间内不太可能优化消费端的代码来提升消费性能,唯一的办法是通过扩容消费端的实例数来提升总体的消费能力。严重影响 QM 甚至整个系统时,可以考虑临时启用多个消费者,并发接受消息,持久化之后再单独处理,或者直接丢弃消息,回头让生产者重新生产。
525 |
526 | 如果短时间内没有服务器资源扩容,没办法的办法是将系统降级,通过关闭某些不重要的业务,减少发送的数据量,最低限度让系统还能正常运转,服务重要业务。
527 |
528 | 监控发现,产生和消费消息的速度没什么变化,出现消息积压的情况,检查是有消费失败反复消费的情况。
529 |
530 | 监控发现,消费消息的速度变慢,检查消费实例,日志中是否有大量消费错误、消费线程是否死锁、是否卡在某些资源上。
531 |
532 |
533 | ### 如何保证MQ的高可用?
534 |
535 | **ActiveMQ:**
536 |
537 | Master-Slave 部署方式主从热备,方式包括通过共享存储目录来实现(shared filesystem Master-Slave)、通过共享数据库来实现(shared database Master-Slave)、5.9版本后新特性使用 ZooKeeper 协调选择 master(Replicated LevelDB Store)。
538 |
539 | Broker-Cluster 部署方式进行负载均衡。
540 |
541 |
542 |
543 | **RabbitMQ:**
544 |
545 | 单机模式与普通集群模式无法满足高可用,镜像集群模式指定多个节点复制 queue 中的消息做到高可用,但消息之间的同步网络性能开销较大。
546 |
547 |
548 |
549 | **RocketMQ:**
550 |
551 | 有多 master 多 slave 异步复制模式和多 master 多 slave 同步双写模式支持集群部署模式。
552 |
553 | Producer 随机选择 NameServer 集群中的其中一个节点建立长连接,定期从 NameServer 获取 Topic 路由信息,并向提供 Topic 服务的 Broker Master 建立长连接,且定时向 Master 发送心跳,只能将消息发送到 Broker master。
554 |
555 | Consumer 同时与提供 Topic 服务的 Master、Slave 建立长连接,从 Master、Slave 订阅消息都可以,订阅规则由 Broker 配置决定。
556 |
557 |
558 |
559 | **Kafka:**
560 |
561 | 由多个 broker 组成,每个 broker 是一个节点;topic 可以划分为多个 partition,每个 partition 可以存在于不同的 broker 上,每个 partition 存放一部分数据,这样每个 topic 的数据就分散存放在多个机器上的。
562 |
563 | replica 副本机制保证每个 partition 的数据同步到其他节点,形成多 replica 副本;所有 replica 副本会选举一个 leader 与 Producer、Consumer 交互,其他 replica 就是 follower;写入消息 leader 会把数据同步到所有 follower,从 leader 读取消息。
564 |
565 | 每个 partition 的所有 replica 分布在不同的机器上。某个 broker 宕机,它上面的 partition 在其他节点有副本,如果有 partition 的 leader,会进行重新选举 leader。
566 |
567 |
568 |
569 | ### RocketMQ Broker中的消息被消费后会立即删除吗?
570 |
571 | **「不会」**,每条消息都会持久化到CommitLog中,每个Consumer连接到Broker后会维持消费进度信息,当有消息消费后只是当前Consumer的消费进度(CommitLog的offset)更新了。
572 |
573 | 4.6版本默认48小时后会删除不再使用的CommitLog文件
574 |
575 | - 检查这个文件最后访问时间
576 | - 判断是否大于过期时间
577 | - 指定时间删除,默认凌晨4点
578 |
579 | 源码如下:
580 |
581 | ```java
582 | /**
583 | * {@link org.apache.rocketmq.store.DefaultMessageStore.CleanCommitLogService#isTimeToDelete()}
584 | */
585 | private boolean isTimeToDelete() {
586 | // when = "04";
587 | String when = DefaultMessageStore.this.getMessageStoreConfig().getDeleteWhen();
588 | // 是04点,就返回true
589 | if (UtilAll.isItTimeToDo(when)) {
590 | return true;
591 | }
592 | // 不是04点,返回false
593 | return false;
594 | }
595 | /**
596 | * {@link org.apache.rocketmq.store.DefaultMessageStore.CleanCommitLogService#deleteExpiredFiles()}
597 | */
598 | private void deleteExpiredFiles() {
599 | // isTimeToDelete()这个方法是判断是不是凌晨四点,是的话就执行删除逻辑。
600 | if (isTimeToDelete()) {
601 | // 默认是72,但是broker配置文件默认改成了48,所以新版本都是48。
602 | long fileReservedTime = 48 * 60 * 60 * 1000;
603 | deleteCount = DefaultMessageStore.this.commitLog.deleteExpiredFile(72 * 60 * 60 * 1000, xx, xx, xx);
604 | }
605 | }
606 | /**
607 | * {@link org.apache.rocketmq.store.CommitLog#deleteExpiredFile()}
608 | */
609 | public int deleteExpiredFile(xxx) {
610 | // 这个方法的主逻辑就是遍历查找最后更改时间+过期时间,小于当前系统时间的话就删了(也就是小于48小时)。
611 | return this.mappedFileQueue.deleteExpiredFileByTime(72 * 60 * 60 * 1000, xx, xx, xx);
612 | }
613 | ```
614 |
615 |
616 |
617 | ### RocketMQ消费模式有几种?
618 |
619 | 消费模型由 Consumer 决定,消费维度为 Topic。
620 |
621 | - 集群消费
622 |
623 | - - 一条消息只会被同Group中的一个Consumer消费
624 | - 多个Group同时消费一个Topic时,每个Group都会有一个Consumer消费到数据
625 |
626 | - 广播消费 消息将对一 个 Consumer Group 下的各个 Consumer 实例都消费一遍。即即使这些 Consumer 属于同一个 Consumer Group ,消息也会被 Consumer Group 中的每个 Consumer 都消费一次。
627 |
628 |
629 |
630 | ### 生产者消息运转?
631 |
632 | **1、**Producer先连接到Broker,建立连接Connection,开启一个信道(Channel)。
633 |
634 | **2、**Producer声明一个交换器并设置好相关属性。
635 |
636 | **3、**Producer声明一个队列并设置好相关属性。
637 |
638 | **4、**Producer通过路由键将交换器和队列绑定起来。
639 |
640 | **5、**Producer发送消息到Broker,其中包含路由键、交换器等信息。
641 |
642 | **6、**相应的交换器根据接收到的路由键查找匹配的队列。
643 |
644 | **7、**如果找到,将消息存入对应的队列,如果没有找到,会根据生产者的配置丢弃或者退回给生产者。
645 |
646 | **8、**关闭信道。
647 |
648 | **9、**管理连接。
649 |
650 |
651 |
652 | ### RocketMQ消息是push还是pull?
653 |
654 | RocketMQ没有真正意义的push,都是pull,虽然有push类,但实际底层实现采用的是**「长轮询机制」**,即拉取方式
655 |
656 | > broker端属性 longPollingEnable 标记是否开启长轮询。默认开启
657 |
658 | 源码如下:
659 |
660 | ```java
661 | // {@link org.apache.rocketmq.client.impl.consumer.DefaultMQPushConsumerImpl#pullMessage()}
662 | // 看到没,这是一只披着羊皮的狼,名字叫PushConsumerImpl,实际干的确是pull的活。
663 | // 拉取消息,结果放到pullCallback里
664 | this.pullAPIWrapper.pullKernelImpl(pullCallback);
665 | ```
666 |
667 |
668 |
669 | ### 当消费负载均衡consumer和queue不对等的时候会发生什么?
670 |
671 | Consumer 和 queue 会优先平均分配,如果 Consumer 少于 queue 的个数,则会存在部分 Consumer 消费多个 queue 的情况,如果 Consumer 等于 queue 的个数,那就是一个 Consumer 消费一个 queue,如果 Consumer 个数大于 queue 的个数,那么会有部分 Consumer 空余出来,白白的浪费了。
672 |
673 |
674 |
675 | ### 为什么要主动拉取消息而不使用事件监听方式?
676 |
677 | 事件驱动方式是建立好长连接,由事件(发送数据)的方式来实时推送。
678 |
679 | 如果broker主动推送消息的话有可能push速度快,消费速度慢的情况,那么就会造成消息在 Consumer 端堆积过多,同时又不能被其他 Consumer 消费的情况。而 pull 的方式可以根据当前自身情况来 pull,不会造成过多的压力而造成瓶颈。所以采取了 pull 的方式。
680 |
681 |
682 |
683 | ### 消费者接收消息过程?
684 |
685 | **1、**Producer先连接到Broker,建立连接Connection,开启一个信道(Channel)。
686 |
687 | **2、**向Broker请求消费响应的队列中消息,可能会设置响应的回调函数。
688 |
689 | **3、**等待Broker回应并投递相应队列中的消息,接收消息。
690 |
691 | **4、**消费者确认收到的消息,ack。
692 |
693 | **5、**RabbitMq从队列中删除已经确定的消息。
694 |
695 | **6、**关闭信道。
696 |
697 | **7、**关闭连接。
698 |
699 |
700 |
701 | ### Broker如何处理拉取请求的?
702 |
703 | Consumer首次请求Broker Broker中是否有符合条件的消息
704 |
705 | - 有
706 |
707 | - - 响应 Consumer
708 | - 等待下次 Consumer 的请求
709 |
710 | - 没有
711 |
712 | - - DefaultMessageStore#ReputMessageService#run方法
713 | - PullRequestHoldService 来 Hold 连接,每个 5s 执行一次检查 pullRequestTable 有没有消息,有的话立即推送
714 | - 每隔 1ms 检查 commitLog 中是否有新消息,有的话写入到 pullRequestTable
715 | - 当有新消息的时候返回请求
716 | - 挂起 consumer 的请求,即不断开连接,也不返回数据
717 | - 使用 consumer 的 offset,
718 |
719 |
720 |
721 | ### 交换器无法根据自身类型和路由键找到符合条件队列时,有哪些处理?
722 |
723 | **mandatory :**true 返回消息给生产者。
724 |
725 | **mandatory:** false 直接丢弃。
726 |
727 |
728 |
729 | ### 死信队列?
730 |
731 | DLX,全称为 Dead-Letter-Exchange,死信交换器,死信邮箱。当消息在一个队列中变成死信 (dead message) 之后,它能被重新被发送到另一个交换器中,这个交换器就是 DLX,绑定 DLX 的队列就称之为死信队列。
732 |
733 |
734 |
735 | ### 导致的死信的几种原因?
736 |
737 | - 消息被拒(Basic.Reject /Basic.Nack) 且 requeue = false。
738 | - 消息TTL过期。
739 | - 队列满了,无法再添加。
740 |
741 |
742 |
743 | ### 延迟队列?
744 |
745 | 存储对应的延迟消息,指当消息被发送以后,并不想让消费者立刻拿到消息,而是等待特定时间后,消费者才能拿到这个消息进行消费。
746 |
747 |
748 |
749 | ### 优先级队列?
750 |
751 | 优先级高的队列会先被消费。
752 |
753 | 可以通过x-max-priority参数来实现。
754 |
755 | 当消费速度大于生产速度且Broker没有堆积的情况下,优先级显得没有意义。
756 |
757 |
758 |
759 | ### 事务机制?
760 |
761 | RabbitMQ 客户端中与事务机制相关的方法有三个:
762 |
763 | **1、**channel.txSelect 用于将当前的信道设置成事务模式。
764 |
765 | **2、**channel . txCommit 用于提交事务 。
766 |
767 | **3、**channel . txRollback 用于事务回滚,如果在事务提交执行之前由于 RabbitMQ 异常崩溃或者其他原因抛出异常,通过txRollback来回滚。
768 |
769 |
770 |
771 | ### 发送确认机制?
772 |
773 | 生产者把信道设置为confirm确认模式,设置后,所有再改信道发布的消息都会被指定一个唯一的ID,一旦消息被投递到所有匹配的队列之后,RabbitMQ就会发送一个确认(Basic.Ack)给生产者(包含消息的唯一ID),这样生产者就知道消息到达对应的目的地了。
774 |
775 |
776 |
777 | ### 消费者获取消息的方式?
778 |
779 | - 推
780 | - 拉
781 |
782 |
783 |
784 | ### 消费者某些原因无法处理当前接受的消息如何来拒绝?
785 |
786 | - channel .basicNack
787 | - channel .basicReject
788 |
789 |
790 |
791 | ### 消息传输保证层级?
792 |
793 | **At most once:**最多一次。消息可能会丢失,单不会重复传输。
794 |
795 | **At least once:**最少一次。消息觉不会丢失,但可能会重复传输。
796 |
797 | **Exactly once:** 恰好一次,每条消息肯定仅传输一次。
798 |
799 |
800 |
801 | ### vhost?
802 |
803 | 每一个RabbitMQ服务器都能创建虚拟的消息服务器,也叫虚拟主机(virtual host),简称vhost。
804 |
805 | 默认为“/”。
806 |
807 |
808 |
809 | ### 集群中的节点类型?
810 |
811 | **内存节点:**ram,将变更写入内存。
812 |
813 | **磁盘节点:**disc,磁盘写入操作。
814 |
815 | RabbitMQ要求最少有一个磁盘节点。
816 |
817 |
818 |
819 | ### 队列结构?
820 |
821 | 通常由以下两部分组成?
822 |
823 | - rabbit_amqqueue_process :负责协议相关的消息处理,即接收生产者发布的消息、向消费者交付消息、处理消息的确认(包括生产端的 confirm 和消费端的 ack) 等。
824 | - backing_queue:是消息存储的具体形式和引擎,并向 rabbit amqqueue process 提供相关的接口以供调用。
825 |
826 |
827 |
828 | ### RabbitMQ中消息可能有的几种状态?
829 |
830 | **alpha:** 消息内容(包括消息体、属性和 headers) 和消息索引都存储在内存中 。
831 |
832 | **beta:** 消息内容保存在磁盘中,消息索引保存在内存中。
833 |
834 | **gamma:** 消息内容保存在磁盘中,消息索引在磁盘和内存中都有 。
835 |
836 | **delta:** 消息内容和索引都在磁盘中 。
837 |
838 |
839 |
840 | ### **它有哪几种部署类型?分别有什么特点?**
841 |
842 | RocketMQ有4种部署类型
843 |
844 |
845 |
846 | **1、单Master**
847 |
848 | 单机模式, 即只有一个Broker, 如果Broker宕机了, 会导致RocketMQ服务不可用, 不推荐使用
849 |
850 |
851 |
852 | **2、多Master模式**
853 |
854 | 组成一个集群, 集群每个节点都是Master节点, 配置简单, 性能也是最高, 某节点宕机重启不会影响RocketMQ服务
855 |
856 | 缺点:如果某个节点宕机了, 会导致该节点存在未被消费的消息在节点恢复之前不能被消费
857 |
858 |
859 |
860 | **3、多Master多Slave模式,异步复制**
861 |
862 | 每个Master配置一个Slave, 多对Master-Slave, Master与Slave消息采用异步复制方式, 主从消息一致只会有毫秒级的延迟
863 |
864 | 优点是弥补了多Master模式(无slave)下节点宕机后在恢复前不可订阅的问题。在Master宕机后, 消费者还可以从Slave节点进行消费。采用异步模式复制,提升了一定的吞吐量。总结一句就是,采用
865 |
866 | 多Master多Slave模式,异步复制模式进行部署,系统将会有较低的延迟和较高的吞吐量
867 |
868 | 缺点就是如果Master宕机, 磁盘损坏的情况下, 如果没有及时将消息复制到Slave, 会导致有少量消息丢失
869 |
870 |
871 |
872 | **4、多Master多Slave模式,同步双写**
873 |
874 | 与多Master多Slave模式,异步复制方式基本一致,唯一不同的是消息复制采用同步方式,只有master和slave都写成功以后,才会向客户端返回成功
875 |
876 | 优点:数据与服务都无单点,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高
877 |
878 | 缺点就是会降低消息写入的效率,并影响系统的吞吐量
879 |
880 | 实际部署中,一般会根据业务场景的所需要的性能和消息可靠性等方面来选择后两种
--------------------------------------------------------------------------------
/interviewDoc/Java/middleware/zookeeper.md:
--------------------------------------------------------------------------------
1 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
2 |
3 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
4 |
5 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
6 |
7 |
8 |
9 |
10 | - [ZooKeeper 是什么?](#zookeeper-是什么)
11 | - [ZooKeeper 提供了什么?](#zookeeper-提供了什么)
12 | - [Zookeeper 都有哪些功能?](#zookeeper-都有哪些功能)
13 | - [Zookeeper 文件系统](#zookeeper-文件系统)
14 | - [有哪些著名的开源项目用到了 ZooKeeper?](#有哪些著名的开源项目用到了-zookeeper)
15 | - [说一下 Zookeeper 的通知机制?](#说一下-zookeeper-的通知机制)
16 | - [Zookeeper 机制的特点](#zookeeper-机制的特点)
17 | - [Zookeeper 和 Dubbo 的关系?](#zookeeper-和-dubbo-的关系)
18 | - [Zookeeper的java客户端都有哪些?](#zookeeper的java客户端都有哪些)
19 | - [四种类型的数据节点 Znode](#四种类型的数据节点-znode)
20 | - [Zookeeper 的典型应用场景](#zookeeper-的典型应用场景)
21 | - [Zookeeper 怎么保证主从节点的状态同步?](#zookeeper-怎么保证主从节点的状态同步)
22 | - [集群中有 3 台服务器,其中一个节点宕机,这个时候 Zookeeper 还可以使用吗?](#集群中有-3-台服务器其中一个节点宕机这个时候-zookeeper-还可以使用吗)
23 | - [ZAB 协议](#zab-协议)
24 | - [四种类型的数据节点 Znode](#四种类型的数据节点-znode)
25 | - [说几个 zookeeper 常用的命令](#说几个-zookeeper-常用的命令)
26 | - [Zookeeper Watcher 机制 -- 数据变更通知](#zookeeper-watcher-机制----数据变更通知)
27 | - [zookeeper 是如何保证事务的顺序一致性的?](#zookeeper-是如何保证事务的顺序一致性的)
28 | - [分布式集群中为什么会有 Master?](#分布式集群中为什么会有-master)
29 | - [集群支持动态添加机器吗?](#集群支持动态添加机器吗)
30 | - [zk 节点宕机如何处理?](#zk-节点宕机如何处理)
31 | - [zookeeper 负载均衡和 nginx 负载均衡区别](#zookeeper-负载均衡和-nginx-负载均衡区别)
32 | - [Zookeeper 有哪几种几种部署模式?](#zookeeper-有哪几种几种部署模式)
33 | - [集群最少要几台机器,集群规则是怎样的?](#集群最少要几台机器集群规则是怎样的)
34 | - [集群支持动态添加机器吗?](#集群支持动态添加机器吗)
35 | - [客户端注册 Watcher 实现](#客户端注册-watcher-实现)
36 | - [服务端处理 Watcher 实现](#服务端处理-watcher-实现)
37 | - [客户端回调 Watcher](#客户端回调-watcher)
38 | - [ACL 权限控制机制](#acl-权限控制机制)
39 | - [Chroot 特性](#chroot-特性)
40 | - [zk 节点宕机如何处理?](#zk-节点宕机如何处理)
41 | - [Zookeeper 对节点的 watch 监听通知是永久的吗?为什么不是永久的?](#zookeeper-对节点的-watch-监听通知是永久的吗为什么不是永久的)
42 | - [服务器角色](#服务器角色)
43 | - [Zookeeper 下 Server 工作状态](#zookeeper-下-server-工作状态)
44 | - [数据同步](#数据同步)
45 | - [zookeeper是如何保证事务的顺序一致性的?](#zookeeper是如何保证事务的顺序一致性的)
46 | - [ZAB 和 Paxos 算法的联系与区别?](#zab-和-paxos-算法的联系与区别)
47 |
48 |
49 |
50 | ### ZooKeeper 是什么?
51 |
52 | ZooKeeper是一个开放源码的分布式协调服务,它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
53 |
54 | 分布式应用程序可以基于Zookeeper实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
55 |
56 | Zookeeper 保证了如下分布式一致性特性:
57 |
58 | **1、**顺序一致性
59 |
60 | **2、**原子性
61 |
62 | **3、**单一视图
63 |
64 | **4、**可靠性
65 |
66 | **5、**实时性(最终一致性)
67 |
68 | 客户端的读请求可以被集群中的任意一台机器处理,如果读请求在节点上注册了监听器,这个监听器也是由所连接的 zookeeper 机器来处理。对于写请求,这些请求会同时发给其他 zookeeper 机器并且达成一致后,请求才会返回成功。因此,随着 zookeeper 的集群机器增多,读请求的吞吐会提高但是写请求的吞吐会下降。
69 |
70 | 有序性是 zookeeper 中非常重要的一个特性,所有的更新都是全局有序的,每个更新都有一个唯一的时间戳,这个时间戳称为 zxid(Zookeeper Transaction Id)。而读请求只会相对于更新有序,也就是读请求的返回结果中会带有这个zookeeper 最新的 zxid。
71 |
72 |
73 |
74 | ### ZooKeeper 提供了什么?
75 |
76 | **1、 **文件系统
77 |
78 | **2、** 通知机制
79 |
80 |
81 |
82 | ### Zookeeper 都有哪些功能?
83 |
84 | **1、** 集群管理:监控节点存活状态、运行请求等;
85 |
86 | **2、** 主节点选举:主节点挂掉了之后可以从备用的节点开始新一轮选主,主节点选举说的就是这个选举的过程,使用 Zookeeper 可以协助完成这个过程;
87 |
88 | **3、** 分布式锁:Zookeeper 提供两种锁:独占锁、共享锁。独占锁即一次只能有一个线程使用资源,共享锁是读锁共享,读写互斥,即可以有多线线程同时读同一个资源,如果要使用写锁也只能有一个线程使用。Zookeeper 可以对分布式锁进行控制。
89 |
90 | **4、** 命名服务:在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。
91 |
92 |
93 |
94 |
95 |
96 |
97 | ### Zookeeper 文件系统
98 |
99 | Zookeeper 提供一个多层级的节点命名空间(节点称为 znode)。与文件系统不同的是,这些节点都可以设置关联的数据,而文件系统中只有文件节点可以存放数据而目录节点不行。
100 |
101 | Zookeeper 为了保证高吞吐和低延迟,在内存中维护了这个树状的目录结构,这种特性使得 Zookeeper 不能用于存放大量的数据,每个节点的存放数据上限为1M。
102 |
103 |
104 | ### 有哪些著名的开源项目用到了 ZooKeeper?
105 |
106 | **1、Kafka** : ZooKeeper 主要为 Kafka 提供 Broker 和 Topic 的注册以及多个 Partition 的负载均衡等功能。
107 |
108 | **2、Hbase** : ZooKeeper 为 Hbase 提供确保整个集群只有一个 Master 以及保存和提供 regionserver 状态信息(是否在线)等功能。
109 |
110 | **3、Hadoop** : ZooKeeper 为 Namenode 提供高可用支持。
111 |
112 |
113 |
114 | ### 说一下 Zookeeper 的通知机制?
115 |
116 | client 端会对某个 znode 建立一个 watcher 事件,当该 znode 发生变化时,这些 client 会收到 zk 的通知,然后 client 可以根据 znode 变化来做出业务上的改变等。
117 |
118 |
119 |
120 | ### Zookeeper 机制的特点
121 |
122 | **1、** 一次性触发数据发生改变时,一个 watcher event 会被发送到 client,但 是 client 只会收到一次这样的信息。
123 |
124 | **2、** watcher event 异步发送 watcher 的通知事件从 server 发送到 client是异步的,这就存在一个问题,不同的客户端和服务器之间通过 socket 进行通信, 由于网络延迟或其他因素导致客户端在不通的时刻监听到事件,由于 Zookeeper 本身提供了 ordering guarantee,即客户端监听事件后,才会感知它所监视 znode 发生了变化。所以我们使用 Zookeeper 不能期望能够监控到节点每次的变化。**Zookeeper 只能保证最终的一致性,而无法保证强一致性**。
125 |
126 | **3、** 数据监视 Zookeeper 有数据监视和子数据监视 getdata() and exists()设置 数据监视,getchildren()设置了子节点监视。
127 |
128 | **4、** 注册 watcher getData、exists、getChildren
129 |
130 | **5、** 触发 watcher create、delete、setData
131 |
132 | **6、 **setData()会触发 znode 上设置的 data watch(如果 set 成功的话)。一个 成功的 create() 操作会触发被创建的 znode 上的数据 watch,以及其父节点上 的 child watch。而一个成功的 delete()操作将会同时触发一个 znode 的 data watch 和 child watch(因为这样就没有子节点了),同时也会触发其父节点的 childwatch。
133 |
134 | **7、** 当一个客户端连接到一个新的服务器上时,watch 将会被以任意会话事件触发。当与一个服务器失去连接的时候,是无法接收到 watch 的。而当client 重新连接时,如果需要的话,所有先前注册过的 watch,都会被重新注册。通常这是完全透明的。
135 |
136 | 只有在一个特殊情况下,watch 可能会丢失:对于一个未创建 的 znode 的 exist watch,如果在客户端断开连接期间被创建了,并且随后在客户端连接上之前又删除了,这种情况下,这个 watch 事件可能会被丢失。
137 |
138 | **8、** Watch是轻量级的,其实就是本地 JVM 的 Callback,服务器端只是存了是否有设置了 Watcher 的布尔类型。
139 |
140 |
141 |
142 | ### Zookeeper 和 Dubbo 的关系?
143 |
144 | Dubbo 的将注册中心进行抽象,是得它可以外接不同的存储媒介给注册中心提供服务,有 ZooKeeper,Memcached,Redis 等。
145 |
146 | 引入了 ZooKeeper 作为存储媒介,也就把 ZooKeeper 的特性引进来。首先是负载均衡,单注册中心的承载能力是有限的,在流量达到一定程度的时 候就需要分流,负载均衡就是为了分流而存在的,一个 ZooKeeper 群配合相应的 Web 应用就可以很容易达到负载均衡;资源同步,单单有负载均衡还不 够,节点之间的数据和资源需要同步,ZooKeeper 集群就天然具备有这样的功能;命名服务,将树状结构用于维护全局的服务地址列表,服务提供者在启动 的时候,向 ZooKeeper 上的指定节点 /dubbo/${serviceName}/providers 目录下写入自己的 URL 地址,这个操作就完成了服务的发布。 其他特性还有 Mast 选举,分布式锁等。
147 |
148 |
149 | 
150 |
151 |
152 |
153 | ### Zookeeper的java客户端都有哪些?
154 |
155 | java客户端:zk自带的zkclient及Apache开源的Curator。
156 |
157 |
158 |
159 | ### 四种类型的数据节点 Znode
160 |
161 | **1、PERSISTENT-持久节点**
162 |
163 | 除非手动删除,否则节点一直存在于 Zookeeper 上
164 |
165 | **2、EPHEMERAL-临时节点**
166 |
167 | 临时节点的生命周期与客户端会话绑定,一旦客户端会话失效(客户端与zookeeper 连接断开不一定会话失效),那么这个客户端创建的所有临时节点都会被移除。
168 |
169 | 3、PERSISTENT_SEQUENTIAL-持久顺序节点
170 |
171 | 基本特性同持久节点,只是增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字。
172 |
173 | 4、EPHEMERAL_SEQUENTIAL-临时顺序节点
174 |
175 | 基本特性同临时节点,增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字。
176 |
177 |
178 |
179 |
180 |
181 | ### Zookeeper 的典型应用场景
182 |
183 | Zookeeper 是一个典型的发布/订阅模式的分布式数据管理与协调框架,开发人员可以使用它来进行分布式数据的发布和订阅。
184 |
185 | 通过对 Zookeeper 中丰富的数据节点进行交叉使用,配合 Watcher 事件通知机制,可以非常方便的构建一系列分布式应用中年都会涉及的核心功能,如:
186 |
187 | **1、** 数据发布/订阅
188 |
189 | **2、** 负载均衡
190 |
191 | **3、** 命名服务
192 |
193 | **4、** 分布式协调/通知
194 |
195 | **5、** 集群管理
196 |
197 | **6、** Master 选举
198 |
199 | **7、** 分布式锁
200 |
201 | **8、** 分布式队列
202 |
203 |
204 |
205 | **数据发布/订阅**
206 |
207 | 介绍
208 |
209 | 数据发布/订阅系统,即所谓的配置中心,顾名思义就是发布者发布数据供订阅者进行数据订阅。
210 |
211 | 目的
212 |
213 | 动态获取数据(配置信息)
214 |
215 | 实现数据(配置信息)的集中式管理和数据的动态更新
216 |
217 | 设计模式
218 |
219 | Push 模式
220 |
221 | Pull 模式
222 |
223 | 数据(配置信息)特性
224 |
225 | (1)数据量通常比较小
226 |
227 | (2)数据内容在运行时会发生动态更新
228 |
229 | (3)集群中各机器共享,配置一致
230 |
231 | 如:机器列表信息、运行时开关配置、数据库配置信息等
232 |
233 | 基于 Zookeeper 的实现方式
234 |
235 | · 数据存储:将数据(配置信息)存储到 Zookeeper 上的一个数据节点
236 |
237 | · 数据获取:应用在启动初始化节点从 Zookeeper 数据节点读取数据,并在该节点上注册一个数据变更 Watcher
238 |
239 | · 数据变更:当变更数据时,更新 Zookeeper 对应节点数据,Zookeeper会将数据变更通知发到各客户端,客户端接到通知后重新读取变更后的数据即可。
240 |
241 |
242 |
243 | **负载均衡**
244 |
245 | zk 的命名服务
246 |
247 | 命名服务是指通过指定的名字来获取资源或者服务的地址,利用 zk 创建一个全局的路径,这个路径就可以作为一个名字,指向集群中的集群,提供的服务的地址,或者一个远程的对象等等。
248 |
249 |
250 |
251 | **分布式通知和协调**
252 |
253 | 对于系统调度来说:操作人员发送通知实际是通过控制台改变某个节点的状态,然后 zk 将这些变化发送给注册了这个节点的 watcher 的所有客户端。
254 |
255 | 对于执行情况汇报:每个工作进程都在某个目录下创建一个临时节点。并携带工作的进度数据,这样汇总的进程可以监控目录子节点的变化获得工作进度的实时的全局情况。
256 |
257 |
258 |
259 | **zk 的命名服务(文件系统)**
260 |
261 | 命名服务是指通过指定的名字来获取资源或者服务的地址,利用 zk 创建一个全局的路径,即是唯一的路径,这个路径就可以作为一个名字,指向集群中的集群,提供的服务的地址,或者一个远程的对象等等。
262 |
263 |
264 |
265 | **zk 的配置管理(文件系统、通知机制)**
266 |
267 | 程序分布式的部署在不同的机器上,将程序的配置信息放在 zk 的 znode 下,当有配置发生改变时,也就是 znode 发生变化时,可以通过改变 zk 中某个目录节点的内容,利用 watcher 通知给各个客户端,从而更改配置。
268 |
269 |
270 |
271 | **Zookeeper 集群管理(文件系统、通知机制)**
272 |
273 | 所谓集群管理无在乎两点:是否有机器退出和加入、选举 master。
274 |
275 | 对于第一点,所有机器约定在父目录下创建临时目录节点,然后监听父目录节点
276 |
277 | 的子节点变化消息。一旦有机器挂掉,该机器与 zookeeper 的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知:某个兄弟目录被删除,于是,所有人都知道:它上船了。
278 |
279 | 新机器加入也是类似,所有机器收到通知:新兄弟目录加入,highcount 又有了,对于第二点,我们稍微改变一下,所有机器创建临时顺序编号目录节点,每次选取编号最小的机器作为 master 就好。
280 |
281 |
282 |
283 | **Zookeeper 分布式锁(文件系统、通知机制)**
284 |
285 | 有了 zookeeper 的一致性文件系统,锁的问题变得容易。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
286 |
287 | 对于第一类,我们将 zookeeper 上的一个 znode 看作是一把锁,通过 createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。用完删除掉自己创建的 distribute_lock 节点就释放出锁。
288 |
289 | 对于第二类, /distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选 master 一样,编号最小的获得锁,用完删除,依次方便。
290 |
291 | Zookeeper 队列管理(文件系统、通知机制)
292 |
293 | 两种类型的队列:
294 |
295 | (1)同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
296 |
297 | (2)队列按照 FIFO 方式进行入队和出队操作。
298 |
299 | 第一类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
300 |
301 | 第二类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号。在特定的目录下创建 PERSISTENT_SEQUENTIAL 节点,创建成功时Watcher 通知等待的队列,队列删除序列号最小的节点用以消费。此场景下Zookeeper 的 znode 用于消息存储,znode 存储的数据就是消息队列中的消息内容,SEQUENTIAL 序列号就是消息的编号,按序取出即可。由于创建的节点是持久化的,所以不必担心队列消息的丢失问题。
302 |
303 |
304 |
305 | ### Zookeeper 怎么保证主从节点的状态同步?
306 |
307 | Zookeeper 的核心是原子广播机制,这个机制保证了各个 server 之间的同步。实现这个机制的协议叫做 Zab 协议。Zab 协议有两种模式,它们分别是恢复模式和广播模式。
308 |
309 | **1、恢复模式**
310 |
311 | 当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数 server 完成了和 leader 的状态同步以后,恢复模式就结束了。状态同步保证了 leader 和 server 具有相同的系统状态。
312 |
313 | **2、广播模式**
314 |
315 | 一旦 leader 已经和多数的 follower 进行了状态同步后,它就可以开始广播消息了,即进入广播状态。这时候当一个 server 加入 ZooKeeper 服务中,它会在恢复模式下启动,发现 leader,并和 leader 进行状态同步。待到同步结束,它也参与消息广播。ZooKeeper 服务一直维持在 Broadcast 状态,直到 leader 崩溃了或者 leader 失去了大部分的 followers 支持。
316 |
317 |
318 |
319 | ### 集群中有 3 台服务器,其中一个节点宕机,这个时候 Zookeeper 还可以使用吗?
320 |
321 | 可以继续使用,单数服务器只要没超过一半的服务器宕机就可以继续使用。
322 |
323 | 集群规则为 2N+1 台,N >0,即最少需要 3 台。
324 |
325 |
326 |
327 | ### ZAB 协议
328 |
329 | ZAB 协议是为分布式协调服务 Zookeeper 专门设计的一种支持崩溃恢复的原子广播协议。
330 |
331 | ZAB 协议包括两种基本的模式:崩溃恢复和消息广播。
332 |
333 | 当整个 zookeeper 集群刚刚启动或者 Leader 服务器宕机、重启或者网络故障导致不存在过半的服务器与 Leader 服务器保持正常通信时,所有进程(服务器)进入崩溃恢复模式,首先选举产生新的 Leader 服务器,然后集群中 Follower 服务器开始与新的 Leader 服务器进行数据同步,当集群中超过半数机器与该 Leader服务器完成数据同步之后,退出恢复模式进入消息广播模式,Leader 服务器开始接收客户端的事务请求生成事物提案来进行事务请求处理。
334 |
335 |
336 |
337 | ### 四种类型的数据节点 Znode
338 |
339 | **1、PERSISTENT-持久节点**
340 |
341 | 除非手动删除,否则节点一直存在于 Zookeeper 上
342 |
343 | **2、EPHEMERAL-临时节点**
344 |
345 | 临时节点的生命周期与客户端会话绑定,一旦客户端会话失效(客户端与zookeeper 连接断开不一定会话失效),那么这个客户端创建的所有临时节点都会被移除。
346 |
347 | **3、PERSISTENT_SEQUENTIAL-持久顺序节点**
348 |
349 | 基本特性同持久节点,只是增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字。
350 |
351 | **4、EPHEMERAL_SEQUENTIAL-临时顺序节点**
352 |
353 | 基本特性同临时节点,增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字。
354 |
355 |
356 |
357 | ### 说几个 zookeeper 常用的命令
358 |
359 | 常用命令:ls get set create delete 等。
360 |
361 |
362 |
363 | ### Zookeeper Watcher 机制 -- 数据变更通知
364 |
365 | Zookeeper 允许客户端向服务端的某个 Znode 注册一个 Watcher 监听,当服务端的一些指定事件触发了这个 Watcher,服务端会向指定客户端发送一个事件通知来实现分布式的通知功能,然后客户端根据 Watcher 通知状态和事件类型做出业务上的改变。
366 |
367 | 工作机制:
368 |
369 | **1、** 客户端注册 watcher
370 |
371 | **2、** 服务端处理 watcher
372 |
373 | **3、** 客户端回调 watcher
374 |
375 | > Watcher 特性总结:
376 | >
377 | > (1)一次性
378 | >
379 | > 无论是服务端还是客户端,一旦一个 Watcher 被 触 发 ,Zookeeper 都会将其从相应的存储中移除。这样的设计有效的减轻了服务端的压力,不然对于更新非常频繁的节点,服务端会不断的向客户端发送事件通知,无论对于网络还是服务端的压力都非常大。
380 | >
381 | > (2)客户端串行执行
382 | >
383 | > 客户端 Watcher 回调的过程是一个串行同步的过程。
384 | >
385 | > (3)轻量
386 | >
387 | > - Watcher 通知非常简单,只会告诉客户端发生了事件,而不会说明事件的具体内容。
388 | >
389 | > - 客户端向服务端注册 Watcher 的时候,并不会把客户端真实的 Watcher 对象实体传递到服务端,仅仅是在客户端请求中使用 boolean 类型属性进行了标记。
390 |
391 |
392 |
393 | **4、** watcher event 异步发送 watcher 的通知事件从 server 发送到 client 是异步的,这就存在一个问题,不同的客户端和服务器之间通过 socket 进行通信,由于网络延迟或其他因素导致客户端在不通的时刻监听到事件,由于 Zookeeper 本身提供了 ordering guarantee,即客户端监听事件后,才会感知它所监视 znode发生了变化。所以我们使用 Zookeeper 不能期望能够监控到节点每次的变化。Zookeeper 只能保证最终的一致性,而无法保证强一致性。
394 |
395 | **5、** 注册 watcher getData、exists、getChildren
396 |
397 | **6、** 触发 watcher create、delete、setData
398 |
399 | **7、** 当一个客户端连接到一个新的服务器上时,watch 将会被以任意会话事件触发。当与一个服务器失去连接的时候,是无法接收到 watch 的。而当 client 重新连接时,如果需要的话,所有先前注册过的 watch,都会被重新注册。通常这是完全透明的。只有在一个特殊情况下,watch 可能会丢失:对于一个未创建的 znode的 exist watch,如果在客户端断开连接期间被创建了,并且随后在客户端连接上之前又删除了,这种情况下,这个 watch 事件可能会被丢失。
400 |
401 |
402 |
403 | ### zookeeper 是如何保证事务的顺序一致性的?
404 |
405 | zookeeper 采用了全局递增的事务 Id 来标识,所有的 proposal(提议)都在被提出的时候加上了 zxid,zxid 实际上是一个 64 位的数字,高 32 位是 epoch( 时期; 纪元; 世; 新时代)用来标识 leader 周期,如果有新的 leader 产生出来,epoch会自增,低 32 位用来递增计数。当新产生 proposal 的时候,会依据数据库的两阶段过程,首先会向其他的 server 发出事务执行请求,如果超过半数的机器都能执行并且能够成功,那么就会开始执行。
406 |
407 |
408 |
409 | ### 分布式集群中为什么会有 Master?
410 |
411 | 在分布式环境中,有些业务逻辑只需要集群中的某一台机器进行执行,其他的机器可以共享这个结果,这样可以大大减少重复计算,提高性能,于是就需要进行leader 选举。
412 |
413 |
414 |
415 | ### 集群支持动态添加机器吗?
416 |
417 | 其实就是水平扩容了,Zookeeper在这方面不太好。两种方式:
418 |
419 | 全部重启:关闭所有Zookeeper服务,修改配置之后启动。不影响之前客户端的会话。
420 | 逐个重启:在过半存活即可用的原则下,一台机器重启不影响整个集群对外提供服务。这是比较常用的方式。
421 | 3.5版本开始支持动态扩容。
422 |
423 |
424 |
425 | ### zk 节点宕机如何处理?
426 |
427 | Zookeeper 本身也是集群,推荐配置不少于 3 个服务器。Zookeeper 自身也要保证当一个节点宕机时,其他节点会继续提供服务。
428 |
429 | 如果是一个 Follower 宕机,还有 2 台服务器提供访问,因为 Zookeeper 上的数据是有多个副本的,数据并不会丢失;
430 |
431 | 如果是一个 Leader 宕机,Zookeeper 会选举出新的 Leader。
432 |
433 | ZK 集群的机制是只要超过半数的节点正常,集群就能正常提供服务。只有在 ZK节点挂得太多,只剩一半或不到一半节点能工作,集群才失效。
434 |
435 | 所以
436 |
437 | 3 个节点的 cluster 可以挂掉 1 个节点(leader 可以得到 2 票>1.5)
438 |
439 | 2 个节点的 cluster 就不能挂掉任何 1 个节点了(leader 可以得到 1 票<=1)
440 |
441 |
442 |
443 | ### zookeeper 负载均衡和 nginx 负载均衡区别
444 |
445 | zk 的负载均衡是可以调控,nginx 只是能调权重,其他需要可控的都需要自己写插件;但是 nginx 的吞吐量比 zk 大很多,应该说按业务选择用哪种方式。
446 |
447 |
448 |
449 | ### Zookeeper 有哪几种几种部署模式?
450 |
451 | 部署模式:单机模式、伪集群模式、集群模式。
452 |
453 |
454 |
455 | ### 集群最少要几台机器,集群规则是怎样的?
456 |
457 | 集群规则为 2N+1 台,N>0。
458 |
459 |
460 |
461 | ### 集群支持动态添加机器吗?
462 |
463 | 其实就是水平扩容了,Zookeeper 在这方面不太好。两种方式:
464 |
465 | 全部重启:关闭所有 Zookeeper 服务,修改配置之后启动。不影响之前客户端的会话。
466 |
467 | 逐个重启:在过半存活即可用的原则下,一台机器重启不影响整个集群对外提供服务。这是比较常用的方式。
468 |
469 | 3.5 版本开始支持动态扩容。
470 |
471 |
472 |
473 | ### 客户端注册 Watcher 实现
474 |
475 | **1、** 调用 getData()/getChildren()/exist()三个 API,传入 Watcher 对象
476 |
477 | **2、** 标记请求 request,封装 Watcher 到 WatchRegistration
478 |
479 | **3、** 封装成 Packet 对象,发服务端发送 request
480 |
481 | **4、** 收到服务端响应后,将 Watcher 注册到 ZKWatcherManager 中进行管理
482 |
483 | **5、** 请求返回,完成注册。
484 |
485 |
486 |
487 | ### 服务端处理 Watcher 实现
488 |
489 | **1、服务端接收 Watcher 并存储**
490 |
491 | 接收到客户端请求,处理请求判断是否需要注册 Watcher,需要的话将数据节点的节点路径和 ServerCnxn(ServerCnxn 代表一个客户端和服务端的连接,实现了 Watcher 的 process 接口,此时可以看成一个 Watcher 对象)存储在WatcherManager 的 WatchTable 和 watch2Paths 中去。
492 |
493 | **2、Watcher 触发**
494 |
495 | 以服务端接收到 setData() 事务请求触发 NodeDataChanged 事件为例:
496 |
497 | - 封装 WatchedEvent
498 |
499 | 将通知状态(SyncConnected)、事件类型(NodeDataChanged)以及节点路径封装成一个 WatchedEvent 对象
500 |
501 | - 查询 Watcher
502 |
503 | 从 WatchTable 中根据节点路径查找 Watcher
504 |
505 | - 没找到;说明没有客户端在该数据节点上注册过 Watcher
506 |
507 | - 找到;提取并从 WatchTable 和 Watch2Paths 中删除对应 Watcher(从这里可以看出 Watcher 在服务端是一次性的,触发一次就失效了)
508 |
509 | **3、调用 process 方法来触发 Watcher**
510 |
511 | 这里 process 主要就是通过 ServerCnxn 对应的 TCP 连接发送 Watcher 事件通知。
512 |
513 |
514 |
515 | ### 客户端回调 Watcher
516 |
517 | 客户端 SendThread 线程接收事件通知,交由 EventThread 线程回调 Watcher。
518 |
519 | 客户端的 Watcher 机制同样是一次性的,一旦被触发后,该 Watcher 就失效了。
520 |
521 |
522 |
523 | ### ACL 权限控制机制
524 |
525 | **UGO(User/Group/Others)**
526 |
527 | 目前在 Linux/Unix 文件系统中使用,也是使用最广泛的权限控制方式。是一种粗粒度的文件系统权限控制模式。
528 |
529 | ACL(Access Control List)访问控制列表
530 |
531 | 包括三个方面:
532 |
533 | **权限模式(Scheme)**
534 |
535 | (1)IP:从 IP 地址粒度进行权限控制
536 |
537 | (2)Digest:最常用,用类似于 username:password 的权限标识来进行权限配置,便于区分不同应用来进行权限控制
538 |
539 | (3)World:最开放的权限控制方式,是一种特殊的 digest 模式,只有一个权限标识“world:anyone”
540 |
541 | (4)Super:超级用户
542 |
543 | **授权对象**
544 |
545 | 授权对象指的是权限赋予的用户或一个指定实体,例如 IP 地址或是机器灯。
546 |
547 | **权限 Permission**
548 |
549 | (1)CREATE:数据节点创建权限,允许授权对象在该 Znode 下创建子节点
550 |
551 | (2)DELETE:子节点删除权限,允许授权对象删除该数据节点的子节点
552 |
553 | (3)READ:数据节点的读取权限,允许授权对象访问该数据节点并读取其数据内容或子节点列表等
554 |
555 | (4)WRITE:数据节点更新权限,允许授权对象对该数据节点进行更新操作
556 |
557 | (5)ADMIN:数据节点管理权限,允许授权对象对该数据节点进行 ACL 相关设置操作
558 |
559 |
560 |
561 |
562 |
563 | ### Chroot 特性
564 |
565 | 3.2.0 版本后,添加了 Chroot 特性,该特性允许每个客户端为自己设置一个命名空间。如果一个客户端设置了 Chroot,那么该客户端对服务器的任何操作,都将会被限制在其自己的命名空间下。
566 |
567 | 通过设置 Chroot,能够将一个客户端应用于 Zookeeper 服务端的一颗子树相对应,在那些多个应用公用一个 Zookeeper 进群的场景下,对实现不同应用间的相互隔离非常有帮助。
568 |
569 |
570 |
571 | ### zk 节点宕机如何处理?
572 |
573 | Zookeeper 本身也是集群,推荐配置不少于 3 个服务器。Zookeeper 自身也要保证当一个节点宕机时,其他节点会继续提供服务。
574 |
575 | 如果是一个 Follower 宕机,还有 2 台服务器提供访问,因为 Zookeeper 上的数据是有多个副本的,数据并不会丢失;
576 |
577 | 如果是一个 Leader 宕机,Zookeeper 会选举出新的 Leader。
578 |
579 | ZK 集群的机制是只要超过半数的节点正常,集群就能正常提供服务。只有在 ZK节点挂得太多,只剩一半或不到一半节点能工作,集群才失效。
580 |
581 | 所以
582 |
583 | 3 个节点的 cluster 可以挂掉 1 个节点(leader 可以得到 2 票>1.5)
584 |
585 | 2 个节点的 cluster 就不能挂掉任何 1 个节点了(leader 可以得到 1 票<=1)
586 |
587 |
588 |
589 | ### Zookeeper 对节点的 watch 监听通知是永久的吗?为什么不是永久的?
590 |
591 | 不是。官方声明:一个 Watch 事件是一个一次性的触发器,当被设置了 Watch的数据发生了改变的时候,则服务器将这个改变发送给设置了 Watch 的客户端,以便通知它们。
592 |
593 | 为什么不是永久的,举个例子,如果服务端变动频繁,而监听的客户端很多情况下,每次变动都要通知到所有的客户端,给网络和服务器造成很大压力。
594 |
595 | 一般是客户端执行 getData(“/节点 A”,true),如果节点 A 发生了变更或删除,客户端会得到它的 watch 事件,但是在之后节点 A 又发生了变更,而客户端又没有设置 watch 事件,就不再给客户端发送。
596 |
597 | 在实际应用中,很多情况下,我们的客户端不需要知道服务端的每一次变动,我只要最新的数据即可。
598 |
599 |
600 |
601 | ### 服务器角色
602 |
603 | **Leader**
604 |
605 | (1)事务请求的唯一调度和处理者,保证集群事务处理的顺序性
606 |
607 | (2)集群内部各服务的调度者
608 |
609 | **Follower**
610 |
611 | (1)处理客户端的非事务请求,转发事务请求给 Leader 服务器
612 |
613 | (2)参与事务请求 Proposal 的投票
614 |
615 | (3)参与 Leader 选举投票
616 |
617 | **Observer**
618 |
619 | (1)3.0 版本以后引入的一个服务器角色,在不影响集群事务处理能力的基础上提升集群的非事务处理能力
620 |
621 | (2)处理客户端的非事务请求,转发事务请求给 Leader 服务器
622 |
623 | (3)不参与任何形式的投票
624 |
625 |
626 |
627 | ### Zookeeper 下 Server 工作状态
628 |
629 | 服务器具有四种状态,分别是 LOOKING、FOLLOWING、LEADING、OBSERVING。
630 |
631 | **1、**LOOKING:寻 找 Leader 状态。当服务器处于该状态时,它会认为当前集群中没有 Leader,因此需要进入 Leader 选举状态。
632 |
633 | **2、**FOLLOWING:跟随者状态。表明当前服务器角色是 Follower。
634 |
635 | **3、**LEADING:领导者状态。表明当前服务器角色是 Leader。
636 |
637 | **4、**OBSERVING:观察者状态。表明当前服务器角色是 Observer。
638 |
639 |
640 |
641 | ### 数据同步
642 |
643 | 整个集群完成 Leader 选举之后,Learner(Follower 和 Observer 的统称)回向Leader 服务器进行注册。当 Learner 服务器想 Leader 服务器完成注册后,进入数据同步环节。
644 |
645 | 数据同步流程:(均以消息传递的方式进行)
646 |
647 | Learner 向 Learder 注册
648 |
649 | 数据同步
650 |
651 | 同步确认
652 |
653 | Zookeeper 的数据同步通常分为四类:
654 |
655 | **1、**直接差异化同步(DIFF 同步)
656 |
657 | **2、**先回滚再差异化同步(TRUNC+DIFF 同步)
658 |
659 | **3、**仅回滚同步(TRUNC 同步)
660 |
661 | **4、**全量同步(SNAP 同步)
662 |
663 | 在进行数据同步前,Leader 服务器会完成数据同步初始化:
664 |
665 | **peerLastZxid:**
666 |
667 | · 从 learner 服务器注册时发送的 ACKEPOCH 消息中提取 lastZxid(该Learner 服务器最后处理的 ZXID)
668 |
669 | **minCommittedLog:**
670 |
671 | · Leader 服务器 Proposal 缓存队列 committedLog 中最小 ZXIDmaxCommittedLog:
672 |
673 | · Leader 服务器 Proposal 缓存队列 committedLog 中最大 ZXID直接差异化同步(DIFF 同步)
674 |
675 | · 场景:peerLastZxid 介于 minCommittedLog 和 maxCommittedLog之间先回滚再差异化同步(TRUNC+DIFF 同步)
676 |
677 | · 场景:当新的 Leader 服务器发现某个 Learner 服务器包含了一条自己没有的事务记录,那么就需要让该 Learner 服务器进行事务回滚--回滚到 Leader服务器上存在的,同时也是最接近于 peerLastZxid 的 ZXID仅回滚同步(TRUNC 同步)
678 |
679 | · 场景:peerLastZxid 大于 maxCommittedLog
680 |
681 | 全量同步(SNAP 同步)
682 |
683 | · 场景一:peerLastZxid 小于 minCommittedLog
684 |
685 | · 场景二:Leader 服务器上没有 Proposal 缓存队列且 peerLastZxid 不等于 lastProcessZxid
686 |
687 |
688 |
689 | ### zookeeper是如何保证事务的顺序一致性的?
690 |
691 | zookeeper采用了全局递增的事务Id来标识,所有的proposal(提议)都在被提出的时候加上了zxid,zxid实际上是一个64位的数字,高32位是epoch(时期; 纪元; 世; 新时代)用来标识leader周期,如果有新的leader产生出来,epoch会自增,低32位用来递增计数。当新产生proposal的时候,会依据数据库的两阶段过程,首先会向其他的server发出事务执行请求,如果超过半数的机器都能执行并且能够成功,那么就会开始执行。
692 |
693 |
694 |
695 | ### ZAB 和 Paxos 算法的联系与区别?
696 |
697 | **相同点:**
698 |
699 | **1、**两者都存在一个类似于 Leader 进程的角色,由其负责协调多个 Follower 进程的运行
700 |
701 | **2、**Leader 进程都会等待超过半数的 Follower 做出正确的反馈后,才会将一个提案进行提交
702 |
703 | **3、**ZAB 协议中,每个 Proposal 中都包含一个 epoch 值来代表当前的 Leader周期,Paxos 中名字为 Ballot
704 |
705 | **不同点:**
706 |
707 | ZAB 用来构建高可用的分布式数据主备系统(Zookeeper),Paxos 是用来构建分布式一致性状态机系统。
708 |
709 |
--------------------------------------------------------------------------------
/interviewDoc/Java/other/Git常用命令.md:
--------------------------------------------------------------------------------
1 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
2 |
3 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
4 |
5 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
6 |
7 |
8 |
9 |
10 | - [配置操作](#配置操作)
11 | - [全局配置](#全局配置)
12 | - [当前仓库配置](#当前仓库配置)
13 | - [查看 global 配置](#查看-global-配置)
14 | - [查看当前仓库配置](#查看当前仓库配置)
15 | - [删除 global 配置](#删除-global-配置)
16 | - [删除当前仓库配置](#删除当前仓库配置)
17 | - [本地操作](#本地操作)
18 | - [查看变更情况](#查看变更情况)
19 | - [将当前目录及其子目录下所有变更都加入到暂存区](#将当前目录及其子目录下所有变更都加入到暂存区)
20 | - [将仓库内所有变更都加入到暂存区](#将仓库内所有变更都加入到暂存区)
21 | - [将指定文件添加到暂存区](#将指定文件添加到暂存区)
22 | - [比较工作区和暂存区的所有差异](#比较工作区和暂存区的所有差异)
23 | - [比较某文件工作区和暂存区的差异](#比较某文件工作区和暂存区的差异)
24 | - [比较暂存区和 HEAD 的所有差异](#比较暂存区和-head-的所有差异)
25 | - [比较某文件暂存区和 HEAD 的差异](#比较某文件暂存区和-head-的差异)
26 | - [比较某文件工作区和 HEAD 的差异](#比较某文件工作区和-head-的差异)
27 | - [创建 commit](#创建-commit)
28 | - [将工作区指定文件恢复成和暂存区一致](#将工作区指定文件恢复成和暂存区一致)
29 | - [将暂存区指定文件恢复成和 HEAD 一致](#将暂存区指定文件恢复成和-head-一致)
30 | - [将暂存区和工作区所有文件恢复成和 HEAD 一样](#将暂存区和工作区所有文件恢复成和-head-一样)
31 | - [用 difftool 比较任意两个 commit 的差异](#用-difftool-比较任意两个-commit-的差异)
32 | - [查看哪些文件没被 Git 管控](#查看哪些文件没被-git-管控)
33 | - [将未处理完的变更先保存到 stash 中](#将未处理完的变更先保存到-stash-中)
34 | - [临时任务处理完后继续之前的工作](#临时任务处理完后继续之前的工作)
35 | - [查看所有 stash](#查看所有-stash)
36 | - [取回某次 stash 的变更](#取回某次-stash-的变更)
37 | - [优雅修改最后一次 commit](#优雅修改最后一次-commit)
38 | - [分支操作](#分支操作)
39 | - [查看当前工作分支及本地分支](#查看当前工作分支及本地分支)
40 | - [查看本地和远端分支](#查看本地和远端分支)
41 | - [查看远端分支](#查看远端分支)
42 | - [切换到指定分支](#切换到指定分支)
43 | - [基于当前分支创建新分支](#基于当前分支创建新分支)
44 | - [基于指定分支创建新分支](#基于指定分支创建新分支)
45 | - [基于某个 commit 创建分支](#基于某个-commit-创建分支)
46 | - [创建并切换到该分支](#创建并切换到该分支)
47 | - [安全删除本地某分支](#安全删除本地某分支)
48 | - [强行删除本地某分支](#强行删除本地某分支)
49 | - [删除已合并到 master 分支的所有本地分支](#删除已合并到-master-分支的所有本地分支)
50 | - [删除远端 origin 已不存在的所有本地分支](#删除远端-origin-已不存在的所有本地分支)
51 | - [将 A 分支合入到当前分支中且为 merge 创建 commit](#将-a-分支合入到当前分支中且为-merge-创建-commit)
52 | - [将 A 分支合入到 B 分支中且为 merge 创建 commit](#将-a-分支合入到-b-分支中且为-merge-创建-commit)
53 | - [将当前分支基于 B 分支做 rebase,以便将B分支合入到当前分支](#将当前分支基于-b-分支做-rebase以便将b分支合入到当前分支)
54 | - [将 A 分支基于 B 分支做 rebase,以便将 B 分支合入到 A 分支](#将-a-分支基于-b-分支做-rebase以便将-b-分支合入到-a-分支)
55 | - [变更历史](#变更历史)
56 | - [当前分支各个 commit 用一行显示](#当前分支各个-commit-用一行显示)
57 | - [显示就近的 n 个 commit](#显示就近的-n-个-commit)
58 | - [用图示显示所有分支的历史](#用图示显示所有分支的历史)
59 | - [查看涉及到某文件变更的所有 commit](#查看涉及到某文件变更的所有-commit)
60 | - [某文件各行最后修改对应的 commit 以及作者](#某文件各行最后修改对应的-commit-以及作者)
61 | - [标签操作](#标签操作)
62 | - [查看已有标签](#查看已有标签)
63 | - [新建标签](#新建标签)
64 | - [新建带备注标签](#新建带备注标签)
65 | - [给指定的 commit 打标签](#给指定的-commit-打标签)
66 | - [推送一个本地标签](#推送一个本地标签)
67 | - [推送全部未推送过的本地标签](#推送全部未推送过的本地标签)
68 | - [删除一个本地标签](#删除一个本地标签)
69 | - [删除一个远端标签](#删除一个远端标签)
70 | - [远端交互](#远端交互)
71 | - [查看所有远端仓库](#查看所有远端仓库)
72 | - [添加远端仓库](#添加远端仓库)
73 | - [删除远端仓库](#删除远端仓库)
74 | - [重命名远端仓库](#重命名远端仓库)
75 | - [将远端所有分支和标签的变更都拉到本地](#将远端所有分支和标签的变更都拉到本地)
76 | - [把远端分支的变更拉到本地,且 merge 到本地分支](#把远端分支的变更拉到本地且-merge-到本地分支)
77 | - [将本地分支 push 到远端](#将本地分支-push-到远端)
78 | - [删除远端分支](#删除远端分支)
79 |
80 |
81 |
82 | 本文整理了一些常用的 Git 操作,老司机可以温故知新,新手可以点赞收藏。文末提供了入门教程及学习资源,请自行下滑~
83 |
84 | ## 配置操作
85 |
86 | ### 全局配置
87 |
88 | `git config --global user.name '你的名字'
89 | git config --global user.email '你的邮箱'
90 | `
91 |
92 | ### 当前仓库配置
93 |
94 | `git config --local user.name '你的名字'
95 | git config --local user.email '你的邮箱'
96 | `
97 |
98 | ### 查看 global 配置
99 |
100 | `git config --global --list
101 | `
102 |
103 | ### 查看当前仓库配置
104 |
105 | `git config --local --list
106 | `
107 |
108 | ### 删除 global 配置
109 |
110 | `git config --unset --global 要删除的配置项
111 | `
112 |
113 | ### 删除当前仓库配置
114 |
115 | `git config --unset --local 要删除的配置项
116 | `
117 |
118 | ## 本地操作
119 |
120 | ### 查看变更情况
121 |
122 | `git status
123 | `
124 |
125 | ### 将当前目录及其子目录下所有变更都加入到暂存区
126 |
127 | `git add .
128 | `
129 |
130 | ### 将仓库内所有变更都加入到暂存区
131 |
132 | `git add -A
133 | `
134 |
135 | ### 将指定文件添加到暂存区
136 |
137 | `git add 文件1 文件2 文件3
138 | `
139 |
140 | ### 比较工作区和暂存区的所有差异
141 |
142 | `git diff
143 | `
144 |
145 | ### 比较某文件工作区和暂存区的差异
146 |
147 | `git diff 文件
148 | `
149 |
150 | ### 比较暂存区和 HEAD 的所有差异
151 |
152 | `git diff --cached
153 | `
154 |
155 | ### 比较某文件暂存区和 HEAD 的差异
156 |
157 | `git diff --cached 文件
158 | `
159 |
160 | ### 比较某文件工作区和 HEAD 的差异
161 |
162 | `git diff HEAD 文件
163 | `
164 |
165 | ### 创建 commit
166 |
167 | `git commit
168 | `
169 |
170 | ### 将工作区指定文件恢复成和暂存区一致
171 |
172 | `git checkout 文件1 文件2 文件3
173 | `
174 |
175 | ### 将暂存区指定文件恢复成和 HEAD 一致
176 |
177 | `git reset 文件1 文件2 文件3
178 | `
179 |
180 | ### 将暂存区和工作区所有文件恢复成和 HEAD 一样
181 |
182 | `git reset --hard
183 | `
184 |
185 | ### 用 difftool 比较任意两个 commit 的差异
186 |
187 | `git difftool 提交1 提交2
188 | `
189 |
190 | ### 查看哪些文件没被 Git 管控
191 |
192 | `git ls-files --others
193 | `
194 |
195 | ### 将未处理完的变更先保存到 stash 中
196 |
197 | `git stash
198 | `
199 |
200 | ### 临时任务处理完后继续之前的工作
201 |
202 | *
203 |
204 | *
205 |
206 | `git stash pop
207 | `
208 |
209 | `git stash apply
210 | `
211 |
212 | ### 查看所有 stash
213 |
214 | `git stash list
215 | `
216 |
217 | ### 取回某次 stash 的变更
218 |
219 | `git stash pop stash@{数字n}
220 | `
221 |
222 | ### 优雅修改最后一次 commit
223 |
224 | `git add.
225 | git commit --amend
226 | `
227 |
228 | ## 分支操作
229 |
230 | ### 查看当前工作分支及本地分支
231 |
232 | `git branch -v
233 | `
234 |
235 | ### 查看本地和远端分支
236 |
237 | `git branch -av
238 | `
239 |
240 | ### 查看远端分支
241 |
242 | `git branch -rv
243 | `
244 |
245 | ### 切换到指定分支
246 |
247 | `git checkout 指定分支
248 | `
249 |
250 | ### 基于当前分支创建新分支
251 |
252 | `git branch 新分支
253 | `
254 |
255 | ### 基于指定分支创建新分支
256 |
257 | `git branch 新分支 指定分支
258 | `
259 |
260 | ### 基于某个 commit 创建分支
261 |
262 | `git branch 新分支 某个 commit 的 id
263 | `
264 |
265 | ### 创建并切换到该分支
266 |
267 | `git checkout -b 新分支
268 | `
269 |
270 | ### 安全删除本地某分支
271 |
272 | `git branch -d 要删除的分支
273 | `
274 |
275 | ### 强行删除本地某分支
276 |
277 | `git branch -D 要删除的分支
278 | `
279 |
280 | ### 删除已合并到 master 分支的所有本地分支
281 |
282 | `git branch --merged master | grep -v '^\*\| master' | xargs -n 1 git branch -d
283 | `
284 |
285 | ### 删除远端 origin 已不存在的所有本地分支
286 |
287 | `git remote prune orign
288 | `
289 |
290 | ### 将 A 分支合入到当前分支中且为 merge 创建 commit
291 |
292 | `git merge A分支
293 | `
294 |
295 | ### 将 A 分支合入到 B 分支中且为 merge 创建 commit
296 |
297 | `git merge A分支 B分支
298 | `
299 |
300 | ### 将当前分支基于 B 分支做 rebase,以便将B分支合入到当前分支
301 |
302 | `git rebase B分支
303 | `
304 |
305 | ### 将 A 分支基于 B 分支做 rebase,以便将 B 分支合入到 A 分支
306 |
307 | `git rebase B分支 A分支
308 | `
309 |
310 | ## 变更历史
311 |
312 | ### 当前分支各个 commit 用一行显示
313 |
314 | `git log --oneline
315 | `
316 |
317 | ### 显示就近的 n 个 commit
318 |
319 | `git log -n
320 | `
321 |
322 | ### 用图示显示所有分支的历史
323 |
324 | `git log --oneline --graph --all
325 | `
326 |
327 | ### 查看涉及到某文件变更的所有 commit
328 |
329 | `git log 文件
330 | `
331 |
332 | ### 某文件各行最后修改对应的 commit 以及作者
333 |
334 | `git blame 文件
335 | `
336 |
337 | ## 标签操作
338 |
339 | ### 查看已有标签
340 |
341 | `git tag
342 | `
343 |
344 | ### 新建标签
345 |
346 | `git tag v1.0
347 | `
348 |
349 | ### 新建带备注标签
350 |
351 | `git tag -a v1.0 -m '前端食堂'
352 | `
353 |
354 | ### 给指定的 commit 打标签
355 |
356 | `git tag v1.0 commitid
357 | `
358 |
359 | ### 推送一个本地标签
360 |
361 | `git push origin v1.0
362 | `
363 |
364 | ### 推送全部未推送过的本地标签
365 |
366 | `git push origin --tags
367 | `
368 |
369 | ### 删除一个本地标签
370 |
371 | `git tag -d v1.0
372 | `
373 |
374 | ### 删除一个远端标签
375 |
376 | `git push origin :refs/tags/v1.0
377 | `
378 |
379 | ## 远端交互
380 |
381 | ### 查看所有远端仓库
382 |
383 | `git remote -v
384 | `
385 |
386 | ### 添加远端仓库
387 |
388 | `git remote add url
389 | `
390 |
391 | ### 删除远端仓库
392 |
393 | `git remote remove remote的名称
394 | `
395 |
396 | ### 重命名远端仓库
397 |
398 | `git remote rename 旧名称 新名称
399 | `
400 |
401 | ### 将远端所有分支和标签的变更都拉到本地
402 |
403 | `git fetch remote
404 | `
405 |
406 | ### 把远端分支的变更拉到本地,且 merge 到本地分支
407 |
408 | `git pull origin 分支名`
409 |
410 | ### 将本地分支 push 到远端
411 |
412 | `git push origin 分支名
413 | `
414 |
415 | ### 删除远端分支
416 |
417 | `git push remote --delete 远端分支名
418 | `
419 |
420 | `git push remote :远端分支名`
421 |
422 |
--------------------------------------------------------------------------------
/interviewDoc/Java/qr.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 |
4 | ### 下载链接:[高清完整版 Java 面试 合集 PDF 下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)
5 |
6 | ### 下载链接:[高清完整版 Java 面试 合集 PDF 下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)
7 |
8 | ### 下载链接:[高清完整版 Java 面试 合集 PDF 下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)
--------------------------------------------------------------------------------
/interviewDoc/Java/框架/MyBatis.md:
--------------------------------------------------------------------------------
1 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
2 |
3 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
4 |
5 | **所有问题以及答案,我都整理成了高清PDF,并且带目录:[Java面试整理高清PDF下载](https://gitee.com/tiger-a/java-interview/blob/master/interviewDoc/Java/index.md)**
6 |
7 |
8 |
9 |
10 | - [什么是Mybatis?](#什么是mybatis)
11 | - [Mybaits的优点:](#mybaits的优点)
12 | - [MyBatis框架的缺点:](#mybatis框架的缺点)
13 | - [MyBatis框架适用场合:](#mybatis框架适用场合)
14 | - [MyBatis与Hibernate有哪些不同?](#mybatis与hibernate有哪些不同)
15 | - [Mybatis 比 IBatis 比较大的几个改进是什么?](#mybatis-比-ibatis-比较大的几个改进是什么)
16 | - [ORM是什么](#orm是什么)
17 | - [传统JDBC开发存在的问题](#传统jdbc开发存在的问题)
18 | - [为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?](#为什么说mybatis是半自动orm映射工具它与全自动的区别在哪里)
19 | - [传统JDBC开发存在什么问题?](#传统jdbc开发存在什么问题)
20 | - [JDBC编程有哪些不足之处,MyBatis是如何解决的?](#jdbc编程有哪些不足之处mybatis是如何解决的)
21 | - [JDBC编程有哪些不足之处,MyBatis 是如何解决这些问题的?](#jdbc编程有哪些不足之处mybatis-是如何解决这些问题的)
22 | - [MyBatis编程步骤是什么样的?](#mybatis编程步骤是什么样的)
23 | - [请说说MyBatis的工作原理](#请说说mybatis的工作原理)
24 | - [MyBatis的功能架构是怎样的](#mybatis的功能架构是怎样的)
25 | - [MyBatis的框架架构设计是怎么样的](#mybatis的框架架构设计是怎么样的)
26 | - [什么是DBMS](#什么是dbms)
27 | - [为什么需要预编译](#为什么需要预编译)
28 | - [#{}和${}的区别是什么?](#和的区别是什么)
29 | - [当实体类中的属性名和表中的字段名不一样 ,怎么办 ?](#当实体类中的属性名和表中的字段名不一样-怎么办-)
30 | - [模糊查询like语句该怎么写?](#模糊查询like语句该怎么写)
31 | - [Mybatis都有哪些Executor执行器?它们之间的区别是什么?](#mybatis都有哪些executor执行器它们之间的区别是什么)
32 | - [Mybatis中如何指定使用哪一种Executor执行器?](#mybatis中如何指定使用哪一种executor执行器)
33 | - [通常一个Xml映射文件,都会写一个Dao接口与之对应,请问,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗?](#通常一个xml映射文件都会写一个dao接口与之对应请问这个dao接口的工作原理是什么dao接口里的方法参数不同时方法能重载吗)
34 | - [Mybatis是如何进行分页的?分页插件的原理是什么?](#mybatis是如何进行分页的分页插件的原理是什么)
35 | - [Mybatis是如何将sql执行结果封装为目标对象并返回的?都有哪些映射形式?](#mybatis是如何将sql执行结果封装为目标对象并返回的都有哪些映射形式)
36 | - [如何获取自动生成的(主)键值?](#如何获取自动生成的主键值)
37 | - [在mapper中如何传递多个参数?](#在mapper中如何传递多个参数)
38 | - [Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?](#mybatis是否支持延迟加载如果支持它的实现原理是什么)
39 | - [Mybatis动态sql有什么用?执行原理?有哪些动态sql?](#mybatis动态sql有什么用执行原理有哪些动态sql)
40 | - [Xml映射文件中,除了常见的select|insert|updae|delete标签之外,还有哪些标签?](#xml映射文件中除了常见的selectinsertupdaedelete标签之外还有哪些标签)
41 | - [Mybatis的Xml映射文件中,不同的Xml映射文件,id是否可以重复?](#mybatis的xml映射文件中不同的xml映射文件id是否可以重复)
42 | - [为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?](#为什么说mybatis是半自动orm映射工具它与全自动的区别在哪里)
43 | - [一对一、一对多的关联查询 ?](#一对一一对多的关联查询-)
44 | - [MyBatis 里面的动态 Sql 是怎么设定的?用什么语法?](#mybatis-里面的动态-sql-是怎么设定的用什么语法)
45 | - [Mybatis 能执行一对一、一对多的关联查询吗?都有哪些实现方式,以及它们之间的区别?](#mybatis-能执行一对一一对多的关联查询吗都有哪些实现方式以及它们之间的区别)
46 | - [MyBatis实现一对一有几种方式?具体怎么操作的?](#mybatis实现一对一有几种方式具体怎么操作的)
47 | - [MyBatis实现一对多有几种方式,怎么操作的?](#mybatis实现一对多有几种方式怎么操作的)
48 | - [Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?](#mybatis是否支持延迟加载如果支持它的实现原理是什么)
49 | - [Mybatis的一级、二级缓存:](#mybatis的一级二级缓存)
50 | - [什么是MyBatis的接口绑定?有哪些实现方式?](#什么是mybatis的接口绑定有哪些实现方式)
51 | - [接口绑定有几种实现方式,分别是怎么实现的?](#接口绑定有几种实现方式分别是怎么实现的)
52 | - [什么情况下用注解绑定,什么情况下用 xml 绑定?](#什么情况下用注解绑定什么情况下用-xml-绑定)
53 | - [使用MyBatis的mapper接口调用时有哪些要求?](#使用mybatis的mapper接口调用时有哪些要求)
54 | - [Mybais 常用注解 ?](#mybais-常用注解-)
55 | - [Mapper编写有哪几种方式?](#mapper编写有哪几种方式)
56 | - [Mybatis 映射文件中,如果 A 标签通过 include 引用了 B 标签的内容,请问,B 标签能****否定义在 A 标签的后面,还是说必须定义在 A 标签的前面?](#mybatis-映射文件中如果-a-标签通过-include-引用了-b-标签的内容请问b-标签能否定义在-a-标签的后面还是说必须定义在-a-标签的前面)
57 | - [简述Mybatis的插件运行原理,以及如何编写一个插件。](#简述mybatis的插件运行原理以及如何编写一个插件)
58 | - [Mybatis 动态 sql 是做什么的?都有哪些动态 sql?能简述一下动态 sql 的执行原理不?](#mybatis-动态-sql-是做什么的都有哪些动态-sql能简述一下动态-sql-的执行原理不)
59 | - [简述 Mybatis 的 Xml 映射文件和 Mybatis 内部数据结构之间的映射关系?](#简述-mybatis-的-xml-映射文件和-mybatis-内部数据结构之间的映射关系)
60 |
61 |
62 |
63 |
64 | ### 什么是Mybatis?
65 |
66 | **1、** Mybatis是一个半ORM(对象关系映射)框架,它内部封装了JDBC,开发时只需要关注SQL语句本身,不需要花费精力去处理加载驱动、创建连接、创建statement等繁杂的过程。程序员直接编写原生态sql,可以严格控制sql执行性能,灵活度高。
67 |
68 | **2、** MyBatis 可以使用 XML 或注解来配置和映射原生信息,将 POJO映射成数据库中的记录,避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。
69 |
70 | **3、** 通过xml 文件或注解的方式将要执行的各种 statement 配置起来,并通过java对象和 statement中sql的动态参数进行映射生成最终执行的sql语句,最后由mybatis框架执行sql并将结果映射为java对象并返回。(从执行sql到返回result的过程)。
71 |
72 |
73 |
74 | ### Mybaits的优点:
75 |
76 | **1、** 基于SQL语句编程,相当灵活,不会对应用程序或者数据库的现有设计造成任何影响,SQL写在XML里,解除sql与程序代码的耦合,便于统一管理;提供XML标签,支持编写动态SQL语句,并可重用。
77 |
78 | **2、 **与JDBC相比,减少了50%以上的代码量,消除了JDBC大量冗余的代码,不需要手动开关连接;
79 |
80 | **3、 **很好的与各种数据库兼容(因为MyBatis使用JDBC来连接数据库,所以只要JDBC支持的数据库MyBatis都支持)。
81 |
82 | **4、** 能够与Spring很好的集成;
83 |
84 | **5、 ** 提供映射标签,支持对象与数据库的ORM字段关系映射;提供对象关系映射标签,支持对象关系组件维护。
85 |
86 |
87 |
88 | ### MyBatis框架的缺点:
89 |
90 | **1、 ** SQL语句的编写工作量较大,尤其当字段多、关联表多时,对开发人员编写SQL语句的功底有一定要求。
91 |
92 | **2、 ** SQL语句依赖于数据库,导致数据库移植性差,不能随意更换数据库。
93 |
94 |
95 |
96 | ### MyBatis框架适用场合:
97 |
98 | **1、** MyBatis专注于SQL本身,是一个足够灵活的DAO层解决方案。
99 |
100 | **2、** 对性能的要求很高,或者需求变化较多的项目,如互联网项目,MyBatis将是不错的选择。
101 |
102 |
103 |
104 | ### MyBatis与Hibernate有哪些不同?
105 |
106 | **相同点**
107 |
108 | - 都是对jdbc的封装,都是持久层的框架,都用于dao层的开发。
109 |
110 | **不同点**
111 |
112 | - 映射关系
113 | - MyBatis 是一个半自动映射的框架,配置Java对象与sql语句执行结果的对应关系,多表关联关系配置简单
114 | - Hibernate 是一个全表映射的框架,配置Java对象与数据库表的对应关系,多表关联关系配置复杂
115 |
116 | **SQL优化和移植性**
117 |
118 | - Hibernate 对SQL语句封装,提供了日志、缓存、级联(级联比 MyBatis 强大)等特性,此外还提供 HQL(Hibernate Query Language)操作数据库,数据库无关性支持好,但会多消耗性能。如果项目需要支持多种数据库,代码开发量少,但SQL语句优化困难。
119 | - MyBatis 需要手动编写 SQL,支持动态 SQL、处理列表、动态生成表名、支持存储过程。开发工作量相对大些。直接使用SQL语句操作数据库,不支持数据库无关性,但sql语句优化容易。
120 |
121 |
122 |
123 | ### Mybatis 比 IBatis 比较大的几个改进是什么?
124 |
125 | **1、** 有接口绑定,包括注解绑定 sql 和 xml 绑定 Sql
126 |
127 | **2、** 动态 sql 由原来的节点配置变成 OGNL 表达式 3) 在一对一,一对多的时候引进了association,在一对多的时候引入了 collection 节点,不过都是在 resultMap 里面配置
128 |
129 |
130 |
131 | ### ORM是什么
132 |
133 | ORM(Object Relational Mapping),对象关系映射,是一种为了解决关系型数据库数据与简单Java对象(POJO)的映射关系的技术。简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系型数据库中。
134 |
135 |
136 |
137 | ### 传统JDBC开发存在的问题
138 |
139 | **1、** 频繁创建数据库连接对象,释放造成系统浪费,影响性能. 使用连接池解决这问题但是需要自己实现连接池
140 |
141 | **2、 **sql语句,参数设置,结果集处理存在硬编码,代码不易维护,sql变动需要修改java代码
142 |
143 | **3、** 使用perparedStatement 向占有位符号传参存在硬编码,
144 |
145 | **4、** 结果集处理存在重复代码,处理麻烦
146 |
147 |
148 |
149 | ### 为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?
150 |
151 | - Hibernate属于全自动ORM映射工具,使用Hibernate查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。
152 | - 而Mybatis在查询关联对象或关联集合对象时,需要手动编写sql来完成,所以,称之为半自动ORM映射工具。
153 |
154 |
155 |
156 | ### 传统JDBC开发存在什么问题?
157 |
158 | - 频繁创建数据库连接对象、释放,容易造成系统资源浪费,影响系统性能。可以使用连接池解决这个问题。但是使用jdbc需要自己实现连接池。
159 | - sql语句定义、参数设置、结果集处理存在硬编码。实际项目中sql语句变化的可能性较大,一旦发生变化,需要修改java代码,系统需要重新编译,重新发布。不好维护。
160 | - 使用preparedStatement向占有位符号传参数存在硬编码,因为sql语句的where条件不一定,可能多也可能少,修改sql还要修改代码,系统不易维护。
161 | - 结果集处理存在重复代码,处理麻烦。如果可以映射成Java对象会比较方便。
162 |
163 |
164 |
165 | ### JDBC编程有哪些不足之处,MyBatis是如何解决的?
166 |
167 | **1、**数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库连接池可解决此问题。
168 |
169 | - 解决:在mybatis-config.xml中配置数据链接池,使用连接池管理数据库连接。
170 |
171 | **2、**Sql语句写在代码中造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变java代码。-
172 |
173 | - 解决:将Sql语句配置在XXXXmapper.xml文件中与java代码分离。
174 |
175 | **3、**向sql语句传参数麻烦,因为sql语句的where条件不一定,可能多也可能少,占位符需要和参数一一对应。
176 |
177 | - 解决: Mybatis自动将java对象映射至sql语句。
178 |
179 | **4、**对结果集解析麻烦,sql变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成pojo对象解析比较方便。
180 |
181 | - 解决:Mybatis自动将sql执行结果映射至java对象。
182 |
183 |
184 |
185 | ### JDBC编程有哪些不足之处,MyBatis 是如何解决这些问题的?
186 |
187 | mybatis-config.xml中配置数据库连接池,使用连接池管理数据可连接,解决频繁创建数据库连接对象
188 |
189 | mapper.xml中编写sql语句与java代码分离
190 |
191 | mybatis自动将java对象映射到sql语句
192 |
193 | mybatis自动将结果集映射大java对象
194 |
195 |
196 |
197 | ### MyBatis编程步骤是什么样的?
198 |
199 | **1、** 创建SqlSessionFactory
200 |
201 | **2、** 通过SqlSessionFactory创建SqlSession
202 |
203 | **3、** 通过sqlsession执行数据库操作
204 |
205 | **4、** 调用session.commit()提交事务
206 |
207 | **5、** 调用session.close()关闭会话
208 |
209 |
210 |
211 | ### 请说说MyBatis的工作原理
212 |
213 | 
214 |
215 | **1、** 读取 MyBatis 配置文件:mybatis-config.xml 为 MyBatis 的全局配置文件,配置了 MyBatis 的运行环境等信息,例如数据库连接信息。
216 |
217 | **2、** 加载映射文件。映射文件即 SQL 映射文件,该文件中配置了操作数据库的 SQL 语句,需要在 MyBatis 配置文件 mybatis-config.xml 中加载。mybatis-config.xml 文件可以加载多个映射文件,每个文件对应数据库中的一张表。
218 |
219 | **3、** 构造会话工厂:通过 MyBatis 的环境等配置信息构建会话工厂 SqlSessionFactory。
220 |
221 | **4、** 创建会话对象:由会话工厂创建 SqlSession 对象,该对象中包含了执行 SQL 语句的所有方法。
222 |
223 | **5、** Executor 执行器:MyBatis 底层定义了一个 Executor 接口来操作数据库,它将根据 SqlSession 传递的参数动态地生成需要执行的 SQL 语句,同时负责查询缓存的维护。
224 |
225 | **6、** MappedStatement 对象:在 Executor 接口的执行方法中有一个 MappedStatement 类型的参数,该参数是对映射信息的封装,用于存储要映射的 SQL 语句的 id、参数等信息。
226 |
227 | **7、** 输入参数映射:输入参数类型可以是 Map、List 等集合类型,也可以是基本数据类型和 POJO 类型。输入参数映射过程类似于 JDBC 对 preparedStatement 对象设置参数的过程。
228 |
229 | **8、** 输出结果映射:输出结果类型可以是 Map、 List 等集合类型,也可以是基本数据类型和 POJO 类型。输出结果映射过程类似于 JDBC 对结果集的解析过程。
230 |
231 |
232 |
233 | ### MyBatis的功能架构是怎样的
234 |
235 | 
236 |
237 | 我们把Mybatis的功能架构分为三层:
238 |
239 | - API接口层:提供给外部使用的接口API,开发人员通过这些本地API来操纵数据库。接口层一接收到调用请求就会调用数据处理层来完成具体的数据处理。
240 | - 数据处理层:负责具体的SQL查找、SQL解析、SQL执行和执行结果映射处理等。它主要的目的是根据调用的请求完成一次数据库操作。
241 | - 基础支撑层:负责最基础的功能支撑,包括连接管理、事务管理、配置加载和缓存处理,这些都是共用的东西,将他们抽取出来作为最基础的组件。为上层的数据处理层提供最基础的支撑。
242 |
243 |
244 |
245 | ### MyBatis的框架架构设计是怎么样的
246 |
247 | 
248 |
249 | 这张图从上往下看。MyBatis的初始化,会从mybatis-config.xml配置文件,解析构造成Configuration这个类,就是图中的红框。
250 |
251 | **1、加载配置:**配置来源于两个地方,一处是配置文件,一处是Java代码的注解,将SQL的配置信息加载成为一个个MappedStatement对象(包括了传入参数映射配置、执行的SQL语句、结果映射配置),存储在内存中。
252 |
253 | **2、SQL解析:**当API接口层接收到调用请求时,会接收到传入SQL的ID和传入对象(可以是Map、JavaBean或者基本数据类型),Mybatis会根据SQL的ID找到对应的MappedStatement,然后根据传入参数对象对MappedStatement进行解析,解析后可以得到最终要执行的SQL语句和参数。
254 |
255 | **3、SQL执行:**将最终得到的SQL和参数拿到数据库进行执行,得到操作数据库的结果。
256 |
257 | **4、结果映射:**将操作数据库的结果按照映射的配置进行转换,可以转换成HashMap、JavaBean或者基本数据类型,并将最终结果返回。
258 |
259 |
260 |
261 | ### 什么是DBMS
262 |
263 | 数据库管理系统(database management system)是一种操纵和管理数据库的大型软件,用于建立、使用和维护数zd据库,简称dbms。它对数据库进行统一的管理和控制,以保证数据库的安全性和完整性。用户通过dbms访问数据库中的数据,数据库管理员也通过dbms进行数据库的维护工作。它可使多个应用程序和用户用不同的方法在同时版或不同时刻去建立,修改和询问数据库。DBMS提供数据定义语言DDL(Data Definition Language)与数据操作语言DML(Data Manipulation Language),供用户定义数据库的模式结构与权限约束,实现对数据的追加权、删除等操作。
264 |
265 |
266 |
267 | ### 为什么需要预编译
268 |
269 | **定义:**
270 |
271 | - SQL 预编译指的是数据库驱动在发送 SQL 语句和参数给 DBMS 之前对 SQL 语句进行编译,这样 DBMS 执行 SQL 时,就不需要重新编译。
272 |
273 | **为什么需要预编译**
274 |
275 | - JDBC 中使用对象 PreparedStatement 来抽象预编译语句,使用预编译。预编译阶段可以优化 SQL 的执行。预编译之后的 SQL 多数情况下可以直接执行,DBMS 不需要再次编译,越复杂的SQL,编译的复杂度将越大,预编译阶段可以合并多次操作为一个操作。同时预编译语句对象可以重复利用。把一个 SQL 预编译后产生的 PreparedStatement 对象缓存下来,下次对于同一个SQL,可以直接使用这个缓存的 PreparedState 对象。Mybatis默认情况下,将对所有的 SQL 进行预编译。
276 | - 还有一个重要的原因,复制SQL注入
277 |
278 |
279 |
280 | ### #{}和${}的区别是什么?
281 |
282 | - `#{}`是预编译处理
283 |
284 | - `${}`是字符串替换。
285 |
286 | Mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值;
287 |
288 | Mybatis在处理${}时,就是把${}替换成变量的值。
289 |
290 | 使用#{}可以有效的防止SQL注入,提高系统安全性。
291 |
292 |
293 |
294 | ### 当实体类中的属性名和表中的字段名不一样 ,怎么办 ?
295 |
296 | **第1种:** 通过在查询的sql语句中定义字段名的别名,让字段名的别名和实体类的属性名一致。
297 |
298 | ```
299 |
302 | ```
303 |
304 |
305 |
306 | **第2种:** 通过 ``来映射字段名和实体类属性名的一一对应的关系。
307 |
308 | ```
309 |
310 |
311 |
312 | ```
313 |
314 |
315 |
316 | ### 模糊查询like语句该怎么写?
317 |
318 | **第1种:** 在Java代码中添加sql通配符。
319 |
320 | ```xml
321 | string wildcardname = “%smi%”;
322 | list names = mapper.selectlike(wildcardname);
323 |
324 |
327 | ```
328 |
329 |
330 |
331 | **第2种:** 在sql语句中拼接通配符,会引起sql注入
332 |
333 | ```xml
334 | string wildcardname = “smi”;
335 | list names = mapper.selectlike(wildcardname);
336 |
337 |
340 | ```
341 |
342 |
343 |
344 | ### Mybatis都有哪些Executor执行器?它们之间的区别是什么?
345 |
346 | - Mybatis有三种基本的Executor执行器,SimpleExecutor、ReuseExecutor、BatchExecutor。
347 | - **SimpleExecutor** :每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。
348 | - **ReuseExecutor** :执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map内,供下一次使用。简言之,就是重复使用Statement对象。
349 | - **BatchExecutor** :执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理。与JDBC批处理相同。
350 |
351 | ```
352 | 作用范围:Executor的这些特点,都严格限制在SqlSession生命周期范围内。
353 | ```
354 |
355 |
356 |
357 | ### Mybatis中如何指定使用哪一种Executor执行器?
358 |
359 | - 在Mybatis配置文件中,在设置(settings)可以指定默认的ExecutorType执行器类型,也可以手动给DefaultSqlSessionFactory的创建SqlSession的方法传递ExecutorType类型参数,如SqlSession openSession(ExecutorType execType)。
360 | - 配置默认的执行器。SIMPLE 就是普通的执行器;REUSE 执行器会重用预处理语句(prepared statements); BATCH 执行器将重用语句并执行批量更新。
361 |
362 |
363 |
364 |
365 |
366 |
367 |
368 | ### 通常一个Xml映射文件,都会写一个Dao接口与之对应,请问,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗?
369 |
370 | Dao 接口,就是人们常说的 `Mapper`接口,接口的全限名,就是映射文件中的 namespace 的值,接口的方法名,就是映射文件中`MappedStatement`的 id 值,接口方法内的参数,就是传递给 sql 的参数。`Mapper`接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为 key 值,可唯一定位一个`MappedStatement`,举例:`com.mybatis3.mappers.StudentDao.findStudentById`,可以唯一找到 namespace 为`com.mybatis3.mappers.StudentDao`下面`id = findStudentById`的`MappedStatement`。在 MyBatis 中,每一个`