├── .vscode
└── settings.json
├── C++.md
├── README.md
├── leetcode刷题.md
├── linux服务器.md
├── 书籍笔记
├── c++语言核心及进阶.md
├── linux高性能服务器.md
├── 操作系统.md
├── 汇编语言.md
└── 设计模式.md
├── 其他技术栈.md
├── 手撕代码.md
├── 操作系统.md
├── 数据库.md
├── 数据结构及算法.md
├── 离谱问题.md
├── 计算机网络.md
└── 设计模式.md
/.vscode/settings.json:
--------------------------------------------------------------------------------
1 | {
2 | "C_Cpp.errorSquiggles": "disabled"
3 | }
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | [](https://pypi.org/project/mmdnn/)
2 | [](LICENSE)
3 | [](https://travis-ci.org/Microsoft/MMdnn)
4 | 
5 |
6 | # 写在前面
7 | 2024.09.09
8 | 工作挺忙,有时候确实没时间没精力维护
9 | 希望发现错误的同学可以帮忙,共同维护
10 | 谢谢!
11 |
12 |
13 | >距离我提交该面试总结已经一年了,当初的想法就是能帮助更多的人去成体系的了解C++,有更多的朋友能够找到其中的错误并且改正。
14 | 虽然当初工作是朝着C++方向找的,但是事与愿违,最后去学了C#这门语言,俗话说的好:“学C++是理想,写C#是生活”,不过我还会抽空修改更正,希望该面试总结能帮助到更多的人!
15 |
16 | 看过市面上很多面经的总结,不论是github上上千star的或者是公众号上的,给我的感觉就是既没有深度也没有广度,仅仅是解释一个概念。如果面试官细问下去,而你仅仅是了解这个概念,很容易就gg了。所以我希望自己总结的这些,当大家看到后都能够发散和思考,找到自己的技术方向和知识框架体系。如有解释不深入的地方,希望每个人都可以自己顺着相关概念查下去,形成自己的一套知识体系。
17 | 时间精力有限有很多知识都没有涉及,希望大家谅解!
18 |
19 | **提示tip:** 所有文章都用的是markdown编写,所以为了方便阅读可以直接下载一个typora(一个简洁的mk阅读和编辑器)。如果直接在网页上阅读的话,可以借助大纲功能来看,这样条理脉络都比较清晰
20 |
21 |
22 |
23 | # :notebook:C++后台开发方向的面经总结:black_nib:
24 | ## [:memo:**C++**](https://github.com/guaguaupup/cpp_interview/blob/main/C%2B%2B.md)
25 | 主要包含三部分内容。第一部分是c++和部分c相关的语言特性,针对这些特性和易错点都做了整理和发散。第二部分是STL知识,一些会被问到的问题的总结,源码的分析等等。第三部分是c++轮子部分,例如线程池、内存池这种写一个工具demo的问题也会被问到。本人2022暑期实习的时候被问到的最多的就是“写一个智能指针类”。
26 |
27 | ## [:memo:**Linux服务器**](https://github.com/guaguaupup/cpp_interview/blob/main/linux%E6%9C%8D%E5%8A%A1%E5%99%A8.md)
28 | 这块会混合这操作系统的一部分内容,因为linux本身就是一种OS,所以范围限制的不是很死。这块很多东西都是服务器开发相关的知识,当然并不全是,还有一些linux系统相关的特性总结。
29 |
30 | ## [:memo:**操作系统**](https://github.com/guaguaupup/cpp_interview/blob/main/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F.md)
31 | 操作系统有关的知识点,进程线程、分页分表、死锁、线程调度机制等等都问的很多
32 |
33 | ## [:memo:**计算机网络**](https://github.com/guaguaupup/cpp_interview/blob/main/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C.md)
34 | TCP/IP协议栈是重点,一般面试官会问的比如:说一下TCP为什么可靠,这个时候需要成体系的说,此外就是应用层的很重要的http协议。协议的细节肯定不好记住,但是多看反复的看就会好很多。
35 |
36 | ## [:memo:**数据库**](https://github.com/guaguaupup/cpp_interview/blob/main/%E6%95%B0%E6%8D%AE%E5%BA%93.md)
37 | 搞c++的基本很少跟数据库打交道,但是美团阿里用java的大厂都很喜欢问数据库,本人曾被问数据库问了一个小时。。。
38 | 该部分包含mysql和redis两大块,日后还需要更新索引优化相关的知识点。
39 |
40 | ## [:memo:**数据结构算法**](https://github.com/guaguaupup/cpp_interview/blob/main/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%8F%8A%E7%AE%97%E6%B3%95.md)
41 | 不多说了,必背必备知识。
42 |
43 | ## [:memo:**手撕代码**](https://github.com/guaguaupup/cpp_interview/blob/main/%E6%89%8B%E6%92%95%E4%BB%A3%E7%A0%81.md)
44 | 抽了一些会被经常问到的知识点的代码,经常会手撕,所以把这部分代码重新集合到一起看一些。我面试前就经常看,效果很好,基本都会问到而且很快都写出来了。
45 |
46 | ## [:memo:**离谱问题**](https://github.com/guaguaupup/cpp_interview/blob/main/%E7%A6%BB%E8%B0%B1%E9%97%AE%E9%A2%98.md)
47 | 离谱问题、逆天问题都可,就是一些很发散的题目,刚开始肯定很没头绪,但是这些题目都是在面经中总结碰到的,看一看没坏处~
48 |
49 | ## [:memo:**设计模式**](https://github.com/guaguaupup/cpp_interview/blob/main/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F.md)
50 | 现在越来越卷,刚找工作的小萌新都需要会设计模式了(话说这不是大牛才需要考虑的东西吗?)
51 |
52 | ## [:memo:**其他技术栈**](https://github.com/guaguaupup/cpp_interview/blob/main/%E5%85%B6%E4%BB%96%E6%8A%80%E6%9C%AF%E6%A0%88.md)
53 | 辅助开发的工具类,云服务、协、嵌入式、python等广泛的技术热点!
54 |
55 |
56 |
57 | # :bookmark_tabs:书籍笔记总结
58 | > 将看过的部分书的重要的知识点做了总结, 定时翻看可以对整本书的体系结构有一个比较清晰的认识。
59 | ## [:memo:**操作系统**](https://github.com/guaguaupup/cpp_interview/blob/main/%E4%B9%A6%E7%B1%8D%E7%AC%94%E8%AE%B0/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F.md)
60 | 总结自电子工业出版社的现代操作系统
61 |
62 | ## [:memo:**c++ primer plus**](https://github.com/guaguaupup/cpp_interview/blob/main/%E4%B9%A6%E7%B1%8D%E7%AC%94%E8%AE%B0/c%2B%2B%E8%AF%AD%E8%A8%80%E6%A0%B8%E5%BF%83%E5%8F%8A%E8%BF%9B%E9%98%B6.md)
63 | 那一本很厚的白色c++书,我都给翻成黑色的了
64 |
65 | ## [:memo:**高性能服务器**](https://github.com/guaguaupup/cpp_interview/blob/main/%E4%B9%A6%E7%B1%8D%E7%AC%94%E8%AE%B0/linux%E9%AB%98%E6%80%A7%E8%83%BD%E6%9C%8D%E5%8A%A1%E5%99%A8.md)
66 | 游双老师的那一本
67 |
68 | ## [:memo:**汇编语言**](https://github.com/guaguaupup/cpp_interview/blob/main/%E4%B9%A6%E7%B1%8D%E7%AC%94%E8%AE%B0/%E6%B1%87%E7%BC%96%E8%AF%AD%E8%A8%80.md)
69 | 一些简单的汇编概念知识
70 |
71 |
72 |
73 | # :bookmark_tabs:刷题
74 | ## [连接在这里](https://github.com/guaguaupup/cpp_interview/blob/main/leetcode%E5%88%B7%E9%A2%98.md)
75 | 包含leetcode各种类型约300道,leetcode热题100, 牛客前100,剑指offer
76 |
--------------------------------------------------------------------------------
/linux服务器.md:
--------------------------------------------------------------------------------
1 | # 什么是gcc
2 |
3 | **gcc的全称是GNU Compiler Collection,它是一个能够编译多种语言的编译器。**
4 |
5 | 最开始gcc是作为C语言的编译器(GNU C Compiler),现在除了c语言,还支持C++、java、Pascal等语言。
6 |
7 |
8 |
9 | # gcc工作流程
10 |
11 | - 预处理(--E)
12 | - 宏替换
13 | - 头文件展开
14 | - 去掉注释
15 | - .c文件变成了.i文件(本质上还是.c文件,只不过#include中的程序给链接进去)
16 | - 编译(--S)
17 | - gcc调用不同语言的编译器
18 | - .i文件编程.s(汇编文件)
19 | - 生成汇编文件
20 |
21 | - 汇编(-c)
22 | - .s文件转化成.o文件
23 | - 翻译成机器语言指令
24 | - 二进制文件
25 | - 链接
26 | - .o文件变成可执行文件,一般不加后缀
27 |
28 | > 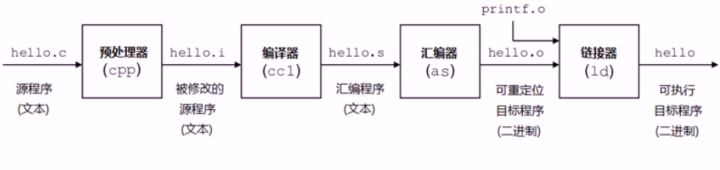
29 | >
30 | > **预处理**实际上是将头文件、宏进行展开。
31 | >
32 | > **编译阶段**gcc调用不同语言的编译器。gcc实际上是个工具链,在编译程序的过程中调用不同的工具。
33 | >
34 | > **汇编阶段**gcc调用汇编器进行汇编。汇编语言是一种低级语言,在不同的设备中对应着不同的机器语言指令,一种汇编语言专用于某种计算机体系结构,可移植性比较差。通过相应的汇编程序可以将汇编语言转换成可执行的机器代码这一过程叫做汇编过程。汇编器生成的是可重定位的目标文件,在源程序中地址是从0开始的,这是一个相对地址,而程序真正在内存中运行时的地址肯定不是从0开始的,而且在编写源代码的时候也不能知道程序的绝对地址,所以**重定位**能够将源代码的代码、变量等定位为内存具体地址。
35 | >
36 | > **链接过程**会将程序所需要的目标文件进行链接成可执行文件。
37 |
38 |
39 |
40 | # gcc常用参数
41 |
42 | - -v/--version:查看gcc的版本
43 | - -I:编译的时候指定头文件路径,不然头文件找不到
44 | - -c:将汇编文件转换成二进制文件,得到.o文件
45 | - -g:gdb调试的时候需要加
46 | - -D:编译的时候指定一个宏(调试代码的时候需要使用例如printf函数,但是这种函数太多了对程序性能有影响,因此如果没有宏,则#ifdefine的内容不起作用)
47 | - -wall:添加警告信息
48 | - -On:-O是优化代码,n是优化级别:1,2,3
49 |
50 |
51 |
52 | # 静态库和动态库
53 |
54 | ![clip_image002[4]](https://images0.cnblogs.com/blog/92071/201310/16201602-9c6047fe25ac46659d0a5ab2945552ce.png)
55 |
56 | 1. 什么是库?
57 |
58 | - 库是写好的现有的,成熟的,可以复用的代码。
59 | - 现实中每个程序都要依赖很多基础的底层库,不可能每个人的代码都从零开始,因此库的存在意义非同寻常。
60 |
61 | - 库是二进制文件,.o文件
62 | - 将源代码变成二进制的源代码
63 | - 主要起到加密的作用,为了防止泄露
64 |
65 | 2. 静态库的制作
66 |
67 | - 原材料:源代码(.c或.cpp文件)
68 |
69 | - 将.c文件生成.o文件(ex:g++ a.c -c)
70 |
71 | - 将.o文件打包
72 | - ar rcs 静态库名称 原材料(ex: ar rcs libtest.a a.0)
73 |
74 | - 态库的使用
75 |
76 |  77 |
78 | 3. 动态库的制作(so代表动态库)
79 | - 命名规则:libxxx.so
80 | - 制作步骤
81 | - 将源文件生产.o文件(gcc a.c -c -fpic)
82 | - 打包(gcc -shared a.o -o libxxx.so)
83 | - 动态库的使用
84 | - 跟静态库一样
85 | - 动态库无法加载的问题
86 | - 使用环境变量(临时设置和全局设置)
87 |
88 |
89 |
90 |
91 | # gdb相关问题
92 |
93 | - gdb 不能显示代码(No symbol table is loaded. Use the "file" command)
94 | - 要是用-g 比如: g++ map_test.cpp -g -o mao
95 |
96 |
97 |
98 | # linux权限相关问题
99 |
100 | 对任意一个文件使用ls -l命令,如下图所示:
101 |
102 |
77 |
78 | 3. 动态库的制作(so代表动态库)
79 | - 命名规则:libxxx.so
80 | - 制作步骤
81 | - 将源文件生产.o文件(gcc a.c -c -fpic)
82 | - 打包(gcc -shared a.o -o libxxx.so)
83 | - 动态库的使用
84 | - 跟静态库一样
85 | - 动态库无法加载的问题
86 | - 使用环境变量(临时设置和全局设置)
87 |
88 |
89 |
90 |
91 | # gdb相关问题
92 |
93 | - gdb 不能显示代码(No symbol table is loaded. Use the "file" command)
94 | - 要是用-g 比如: g++ map_test.cpp -g -o mao
95 |
96 |
97 |
98 | # linux权限相关问题
99 |
100 | 对任意一个文件使用ls -l命令,如下图所示:
101 |
102 |  103 |
104 | **任意取一行,如:drwxr-xr-x 2 root root 4096 2009-01-14 17:34 bin**
105 |
106 | **用序列表示为:0123456789**
107 |
108 | - 第一列
109 |
110 | - d:代表目录
111 | - -:代表文件
112 | - l:代表链接,如同windows的快捷方式
113 |
114 | - 第一到九列
115 |
116 | - r:可读
117 | - w:可写
118 | - x:可执行文件
119 | - 0:代表文件类型
120 | - 123:表示文件所有者的权限
121 | - 456:表示同组用户的权限
122 | - 789:表示其他用户的权限
123 |
124 | - 权限的数字表示
125 |
126 | - 读取的权限等于4,用r表示
127 | - 写入的权限等于2,用w表示
128 | - 执行的权限等于1,用x表示
129 |
130 | - 改变文件权限命令
131 |
132 | > chmod 权限数字(如777) filename
133 |
134 | - 改变目录下所有的文件的权限命令
135 |
136 | > chmod -R 权限数字(如777) 目录(如/home)
137 |
138 |
139 |
140 | # 套接字类型
141 |
142 | 下面是创建套接字所用的socket所用的函数
143 |
144 | ```
145 | #include
146 | int socket(int domain,int type,int protocol);
147 | ```
148 |
149 | - **协议簇(Protocol Family)(int domain)**
150 |
151 | > 套接字有许多不同的通信协议分类,由socket函数第一个参数进行传递。其中最重要的是PF_INET(IPv4互联网协议族)
152 |
153 | - **套接字类型(Type)(int type)**
154 |
155 | > socket函数的第二个参数决定套接字数据传输的方式。
156 | >
157 | > 协议族并不能决定数据传输方式,因为一个协议族也有很多数据传输方式
158 |
159 | - 面向连接的套接字(SOCK_STREAM)
160 |
161 | **面向连接的套接字类似于传送带**
162 |
163 | 
164 |
165 | 有如下特点
166 |
167 | 1. 传输的过程中数据不会丢失
168 | 2. 按需传送数据
169 | 3. 传输数据不存在数据边界问题
170 | 4. 两端套接字必须一一对应
171 |
172 | > 收发的套接字内部有缓冲,就是有字节数组。因此通过套接字传输的数据将保存在数组,因此数据可以填满缓冲一次被读取,也可以分段被读取,不存在数据边界问题。当缓冲区占满后,套接字无法接受数据,停止传输。所以不存在数据丢失问题
173 |
174 | - 面向消息的套接字(SOCK_DGRAM)
175 |
176 | **面向消息的套接字类似于快递**
177 |
178 | 有如下特点
179 |
180 | 1. 强调快速传送而非顺序传送
181 | 2. 传输的数据可能丢失也可能损坏
182 | 3. 传输的数据有边界
183 | 4. 限制每次传输的数据大小
184 |
185 | - **协议信息(int protocol)**
186 |
187 | > 由于socket函数前两个参数的存在,大部分情况可以向第三个参数传递0。但若同一个协议族中存在多个数据传输方式相同的协议,即数据传输方式相同,协议不同,需要第三个参数制定具体协议
188 |
189 | ```c++
190 | //IPv4中面向连接的套接字
191 | int tcp_socket=(PF_INET,SOCK_STREAM,IPPROTO_TCP)
192 | //IPv4中面向消息的套接字
193 | int tcp_socket=(PF_INET,SOCK_STREAM,IPPROTO_UDP)
194 | ```
195 |
196 |
197 |
198 | # 实现基于TCP/IP的客户端服务端
199 |
200 | - **TCP服务端默认函数调用顺序**
201 |
202 | 1. socket() 创建套接字
203 | 2. bind() 分配套接字地址
204 | 3. listen() 等待连接请求状态
205 | 4. accpet() 允许连接
206 | 5. read()/write() 交换数据
207 | 6. close() 断开连接
208 |
209 | - **TCP客户端默认函数调用顺序**
210 |
211 | 1. socket() 创建套接字
212 |
213 | 2. connect() 请求连接
214 |
215 | 3. read()/write() 交换数据
216 |
217 | 4. close() 断开连接
218 |
219 | >实现服务器端重要/必经过程就是给套接字分配IP和端口号(bind),但是客户端实现过程并未出现套接字的分配,而是创建套接字后立即调用了connect函数,为什么?
220 | >
221 | >答:客户端其实是分配了IP和端口号的。在调用connect的时候分配的(何时),在操作系统内核中进行分配(何地),IP用的是主机的IP,端口号随机分配(何种方式)
222 |
223 | - **注意事项**
224 |
225 | - 服务器端创建套接字后连续调用bind、listen函数进入等待状态,客户端通过connect函数发起连接请求
226 | - 客户端只能等到服务端调用listen后才能调用connect函数
227 | - 客户端调用connect函数前,服务器可能率先调用accept函数,然后服务端进入阻塞状态,直到客户端调用connect为止
228 |
229 | - **TCP套接字中的I/O缓冲**
230 |
231 | > write函数调用后并不是立刻传送数据,read函数调用后也不是马上接收数据。而是将这些数据移到输入和输出缓冲中
232 |
233 | 如下图所示:
234 |
235 | 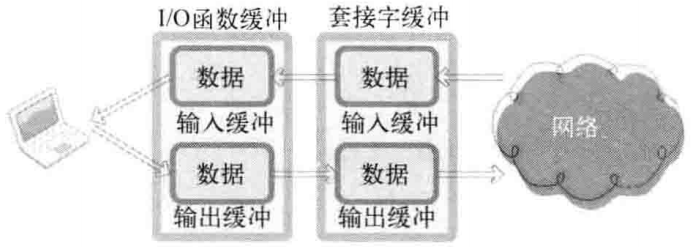
236 |
237 | I/O缓冲有以下特点:
238 |
239 | 1. I/O缓冲在每个TCP套接字中单独存在
240 | 2. I/O缓冲在创建套接字时自动生成
241 | 3. 即使关闭套接字也会继续传递输出缓冲中遗留的数据
242 | 4. 关闭套接字将丢失输入缓冲中的数据
243 |
244 | - **套接字的断开**
245 |
246 | > close()函数表示完全断开套接字链接,并且不能收发任何数据。很显然这样做是不好的,若A主机断开连接后,完全无法调用接收数据和发送数据相关函数,这会导致B向A发送数据,A必须接受的数据也被销毁
247 |
248 | 套接字中会生成两个I/O流,如下图:
249 |
250 | 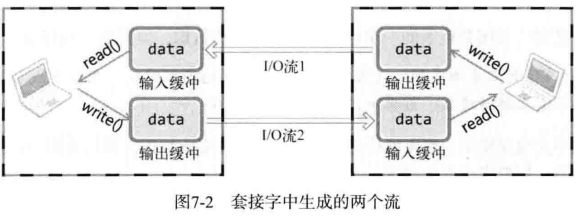
251 |
252 | 一旦两台主机间建立了套接字链接,每个主机就会拥有单独的输入流和输出流
253 |
254 |
255 |
256 | # Linux操作系统中断
257 |
258 | - **中断概念**
259 |
260 | > 中断是指在CPU正常运行期间,由于内外部事件或由程序预先安排的事件引起的CPU暂时停止正在运行的程序,转而为该内部或外部事件或预先安排的事件服务的程序中去,服务完毕后再返回去继续运行被暂时中断的程序。这样的中断机制极大的提高了CPU运行效率。
261 |
262 | 根据CSAPP中所描述,中断是异常的一种类别。(p504)什么是异常?比如说在处理器中,依次执行对应的指令流程,这样的控制转移序列叫做控制流。但是系统会出现一些变化,系统必须对这种变化做出反应,而且这种变化是随机的,也不一定跟执行当前的程序关联,比若说子进程终止时父进程必须得到通知,硬盘定时器定期产生一个信号。这种叫做**控制流发生突变**,这些突变成为**异常控制流**。计算机的各个层次都会发生异常。(p502)
263 |
264 | 异常可以分为:中断、陷阱、故障、终止
265 |
266 | | 类别 | 原因 | 同步/异步 | 返回行为 |
267 | | :--: | :---------------: | :-------: | :------------------: |
268 | | 中断 | 来自I/O设备的信号 | 异步 | 总是返回到下一条指令 |
269 | | 陷阱 | 有意的异常 | 同步 | 总是返回到下一条指令 |
270 | | 故障 | 潜在可恢复的错误 | 同步 | 可能返回到当前指令 |
271 | | 终止 | 不可恢复的错误 | 同步 | 不会返回 |
272 |
273 |
274 |
275 | - **硬中断**
276 |
277 | 硬中断是我们通常所说的中断的概念。硬中断是由硬件产生的,比如,像磁盘,网卡,键盘,时钟等。每个设备或设备集都有它自己的IRQ(中断请求)。内核中维护了一个IDT(中断描述符表),表中是中断处理函数的地址和一些其他的控制位。0-31号中断号位系统为预定义的中断和异常保留的,用户不得使用,所以硬件中断号从32开始分发。每当CPU接收到一个中断或者异常信号,CPU首先要做的决定是否响应这个中断(具体由中断控制器根据中断优先级决定是否给CPU发送中断信号),如果决定响应,就终止当前运行进程的运行,根据IDTR寄存器获取中断描述符表基地址,然后根据中断号定位具体的中断描述符。
278 |
279 | - **软中断**
280 |
281 | 软中断是由当前正在运行的进程所产生的。 软中断并不会直接中断CPU。这种中断是一种需要内核为正在运行的进程去做一些事情(通常为I/O)的请求。
282 |
283 | > 中断在本质上是软件或者硬件发生了某种情形而通知处理器的行为,处理器进而停止正在运行的指令流,去转去执行预定义的中断处理程序。软件中断也就是通知内核的机制的泛化名称,目的是促使系统切换到内核态去执行异常处理程序。这里的异常处理程序其实就是一种系统调用,软件中断可以当做一种异常。总之,软件中断是当前进程切换到系统调用的过程。
284 |
285 |
286 |
287 | # 系统调用知识点
288 |
289 | ## 用户态和内核态
290 |
291 | [l链接](https://blog.csdn.net/u013291303/article/details/63682298)
292 |
293 | ## 系统调用过程
294 |
295 | 用户空间的程序无法直接执行内核代码,它们不能直接调用内核空间中的函数,因为内核驻留在受保护的地址空间上。如果进程可以直接在内核的地址空间上读写的话,系统安全就会失去控制。所以,应用程序应该以某种方式通知系统,告诉内核自己需要执行一个系统调用,希望系统切换到内核态,这样内核就可以代表应用程序来执行该系统调用了。
296 |
297 | 通知内核的机制是靠软件中断实现的。首先,用户程序为系统调用设置参数。其中一个参数是系统调用编号。参数设置完成后,程序执行“系统调用”指令。这个指令会导致一个异常:产生一个事件,这个事件会致使处理器切换到内核态并跳转到一个新的地址,并开始执行那里的异常处理程序。此时的异常处理程序实际上就是系统调用处理程序。它与硬件体系结构紧密相关。
298 |
299 | > **系统调用的过程:**首先将API函数参数压到栈上,然后将函数内调用系统调用的代码放入寄存器,通过陷入中断,进入内核将控制权交给操作系统,操作系统获得控制后,将系统调用代码拿出来,跟操作系统一直维护的一张系统调用表做比较,已找到该系统调用程序体的内存地址,接着访问该地址,执行系统调用。执行完毕后,返回用户程序
300 |
301 | ## 系统调用和函数调用区别
302 |
303 | **库函数调用**
304 |
305 | 函数调用主要通过压栈出栈的操作,面向应用开发。库函数顾名思义是把函数放到库里。是把一些常用到的函数编完放到一个文件里,供别人用。别人用的时候把它所在的文件名用#include<>加到里面就可以了。一般是指编译器提供的可在c源程序中调用的函数。可分为两类,一类是c语言标准规定的库函数,一类是编译器特定的库函数。(由于版权原因,库函数的源代码一般是不可见的,但在头文件中你可以看到它对外的接口)
306 |
307 | **系统调用**
308 |
309 | 系统调用就是用户在程序中调用操作系统所提供的一个子功能,也就是系统API,系统调用可以被看做特殊的公共子程序。通俗的讲是操作系统提供给用户程序调用的一组“特殊”接口。用户程序可以通过这组“特殊”接口来获得操作系统内核提供的服务,比如用户可以通过文件系统相关的调用请求系统打开文件、关闭文件或读写文件,可以通过时钟相关的系统调用获得系统时间或设置定时器等。系统中的各种共享资源都由操作系统统一掌管,因此在用户程序中,凡是与资源有关的操作(如存储分配、进行I/O传输及管理文件等),都必须通过系统调用方式向操作系统提出服务请求,并由操作系统代为完成。
310 |
311 | ------
312 |
313 |
314 |
315 | # 对事件的两种处理方式
316 |
317 | ## reactor
318 |
319 | 如果要让服务器服务多个客户端,那么最直接的方式就是为每一条连接创建线程。其实创建进程也是可以的,原理是一样的,进程和线程的区别在于线程比较轻量级些,线程的创建和线程间切换的成本要小些,为了描述简述,后面都以线程为例。处理完业务逻辑后,随着连接关闭后线程也同样要销毁了,但是这样不停地创建和销毁线程,不仅会带来性能开销,也会造成浪费资源,而且如果要连接几万条连接,创建几万个线程去应对也是不现实的。要这么解决这个问题呢?我们可以使用「资源复用」的方式。也就是不用再为每个连接创建线程,而是创建一个「线程池」,将连接分配给线程,然后一个线程可以处理多个连接的业务。不过,这样又引来一个新的问题,线程怎样才能高效地处理多个连接的业务?
320 |
321 | 当一个连接对应一个线程时,线程一般采用「read -> 业务处理 -> send」的处理流程,如果当前连接没有数据可读,那么线程会阻塞在 `read` 操作上( socket 默认情况是阻塞 I/O),不过这种阻塞方式并不影响其他线程。但是引入了线程池,那么一个线程要处理多个连接的业务,线程在处理某个连接的 `read` 操作时,如果遇到没有数据可读,就会发生阻塞,那么线程就没办法继续处理其他连接的业务。要解决这一个问题,最简单的方式就是将 socket 改成非阻塞,然后线程不断地轮询调用 `read` 操作来判断是否有数据,这种方式虽然该能够解决阻塞的问题,但是解决的方式比较粗暴,因为轮询是要消耗 CPU 的,而且随着一个 线程处理的连接越多,轮询的效率就会越低。
322 |
323 | 有没有办法在只有当连接上有数据的时候,线程才去发起读请求呢?答案是有的,实现这一技术的就是 I/O 多路复用。线程池复用+IO复用就形成了reactor模式。
324 |
325 | **Reactor的定义:**是一种接收多个输入事件的服务器事件驱动处理模式。服务器端通过IO多路复用来处理这些输入事件,并将这些事件同步分派给对应的处理线程。其实reactor模式也叫做Dispatcher 模式,本质上就是将收到的事件进行分发处理。Reactor模式中有两个关键的组成:①主反应堆reactor在一个单独的线程中运行,负责监听和分发事件,将接收到的事件分为监听socket和连接socket,连接socket放入任务队列让线程池线程去抢占式调度。②Handlers或Accepter,处理任务队列中具体的逻辑或者建立连接socket。
326 |
327 | 根据 Reactor 的数量和处理资源池线程的数量不同,有 3 种典型的实现:
328 |
329 | 1. 单 Reactor 单线程;
330 | 2. 单 Reactor 多线程;
331 | 3. 主从 Reactor 多线程。
332 |
333 | 接下来一一介绍:
334 |
335 | - **单 Reactor 单线程**
336 |
337 | 顾名思义,一个主反应堆reactor,一个accepter或者handler来处理接收的事件。
338 |
339 |
103 |
104 | **任意取一行,如:drwxr-xr-x 2 root root 4096 2009-01-14 17:34 bin**
105 |
106 | **用序列表示为:0123456789**
107 |
108 | - 第一列
109 |
110 | - d:代表目录
111 | - -:代表文件
112 | - l:代表链接,如同windows的快捷方式
113 |
114 | - 第一到九列
115 |
116 | - r:可读
117 | - w:可写
118 | - x:可执行文件
119 | - 0:代表文件类型
120 | - 123:表示文件所有者的权限
121 | - 456:表示同组用户的权限
122 | - 789:表示其他用户的权限
123 |
124 | - 权限的数字表示
125 |
126 | - 读取的权限等于4,用r表示
127 | - 写入的权限等于2,用w表示
128 | - 执行的权限等于1,用x表示
129 |
130 | - 改变文件权限命令
131 |
132 | > chmod 权限数字(如777) filename
133 |
134 | - 改变目录下所有的文件的权限命令
135 |
136 | > chmod -R 权限数字(如777) 目录(如/home)
137 |
138 |
139 |
140 | # 套接字类型
141 |
142 | 下面是创建套接字所用的socket所用的函数
143 |
144 | ```
145 | #include
146 | int socket(int domain,int type,int protocol);
147 | ```
148 |
149 | - **协议簇(Protocol Family)(int domain)**
150 |
151 | > 套接字有许多不同的通信协议分类,由socket函数第一个参数进行传递。其中最重要的是PF_INET(IPv4互联网协议族)
152 |
153 | - **套接字类型(Type)(int type)**
154 |
155 | > socket函数的第二个参数决定套接字数据传输的方式。
156 | >
157 | > 协议族并不能决定数据传输方式,因为一个协议族也有很多数据传输方式
158 |
159 | - 面向连接的套接字(SOCK_STREAM)
160 |
161 | **面向连接的套接字类似于传送带**
162 |
163 | 
164 |
165 | 有如下特点
166 |
167 | 1. 传输的过程中数据不会丢失
168 | 2. 按需传送数据
169 | 3. 传输数据不存在数据边界问题
170 | 4. 两端套接字必须一一对应
171 |
172 | > 收发的套接字内部有缓冲,就是有字节数组。因此通过套接字传输的数据将保存在数组,因此数据可以填满缓冲一次被读取,也可以分段被读取,不存在数据边界问题。当缓冲区占满后,套接字无法接受数据,停止传输。所以不存在数据丢失问题
173 |
174 | - 面向消息的套接字(SOCK_DGRAM)
175 |
176 | **面向消息的套接字类似于快递**
177 |
178 | 有如下特点
179 |
180 | 1. 强调快速传送而非顺序传送
181 | 2. 传输的数据可能丢失也可能损坏
182 | 3. 传输的数据有边界
183 | 4. 限制每次传输的数据大小
184 |
185 | - **协议信息(int protocol)**
186 |
187 | > 由于socket函数前两个参数的存在,大部分情况可以向第三个参数传递0。但若同一个协议族中存在多个数据传输方式相同的协议,即数据传输方式相同,协议不同,需要第三个参数制定具体协议
188 |
189 | ```c++
190 | //IPv4中面向连接的套接字
191 | int tcp_socket=(PF_INET,SOCK_STREAM,IPPROTO_TCP)
192 | //IPv4中面向消息的套接字
193 | int tcp_socket=(PF_INET,SOCK_STREAM,IPPROTO_UDP)
194 | ```
195 |
196 |
197 |
198 | # 实现基于TCP/IP的客户端服务端
199 |
200 | - **TCP服务端默认函数调用顺序**
201 |
202 | 1. socket() 创建套接字
203 | 2. bind() 分配套接字地址
204 | 3. listen() 等待连接请求状态
205 | 4. accpet() 允许连接
206 | 5. read()/write() 交换数据
207 | 6. close() 断开连接
208 |
209 | - **TCP客户端默认函数调用顺序**
210 |
211 | 1. socket() 创建套接字
212 |
213 | 2. connect() 请求连接
214 |
215 | 3. read()/write() 交换数据
216 |
217 | 4. close() 断开连接
218 |
219 | >实现服务器端重要/必经过程就是给套接字分配IP和端口号(bind),但是客户端实现过程并未出现套接字的分配,而是创建套接字后立即调用了connect函数,为什么?
220 | >
221 | >答:客户端其实是分配了IP和端口号的。在调用connect的时候分配的(何时),在操作系统内核中进行分配(何地),IP用的是主机的IP,端口号随机分配(何种方式)
222 |
223 | - **注意事项**
224 |
225 | - 服务器端创建套接字后连续调用bind、listen函数进入等待状态,客户端通过connect函数发起连接请求
226 | - 客户端只能等到服务端调用listen后才能调用connect函数
227 | - 客户端调用connect函数前,服务器可能率先调用accept函数,然后服务端进入阻塞状态,直到客户端调用connect为止
228 |
229 | - **TCP套接字中的I/O缓冲**
230 |
231 | > write函数调用后并不是立刻传送数据,read函数调用后也不是马上接收数据。而是将这些数据移到输入和输出缓冲中
232 |
233 | 如下图所示:
234 |
235 | 
236 |
237 | I/O缓冲有以下特点:
238 |
239 | 1. I/O缓冲在每个TCP套接字中单独存在
240 | 2. I/O缓冲在创建套接字时自动生成
241 | 3. 即使关闭套接字也会继续传递输出缓冲中遗留的数据
242 | 4. 关闭套接字将丢失输入缓冲中的数据
243 |
244 | - **套接字的断开**
245 |
246 | > close()函数表示完全断开套接字链接,并且不能收发任何数据。很显然这样做是不好的,若A主机断开连接后,完全无法调用接收数据和发送数据相关函数,这会导致B向A发送数据,A必须接受的数据也被销毁
247 |
248 | 套接字中会生成两个I/O流,如下图:
249 |
250 | 
251 |
252 | 一旦两台主机间建立了套接字链接,每个主机就会拥有单独的输入流和输出流
253 |
254 |
255 |
256 | # Linux操作系统中断
257 |
258 | - **中断概念**
259 |
260 | > 中断是指在CPU正常运行期间,由于内外部事件或由程序预先安排的事件引起的CPU暂时停止正在运行的程序,转而为该内部或外部事件或预先安排的事件服务的程序中去,服务完毕后再返回去继续运行被暂时中断的程序。这样的中断机制极大的提高了CPU运行效率。
261 |
262 | 根据CSAPP中所描述,中断是异常的一种类别。(p504)什么是异常?比如说在处理器中,依次执行对应的指令流程,这样的控制转移序列叫做控制流。但是系统会出现一些变化,系统必须对这种变化做出反应,而且这种变化是随机的,也不一定跟执行当前的程序关联,比若说子进程终止时父进程必须得到通知,硬盘定时器定期产生一个信号。这种叫做**控制流发生突变**,这些突变成为**异常控制流**。计算机的各个层次都会发生异常。(p502)
263 |
264 | 异常可以分为:中断、陷阱、故障、终止
265 |
266 | | 类别 | 原因 | 同步/异步 | 返回行为 |
267 | | :--: | :---------------: | :-------: | :------------------: |
268 | | 中断 | 来自I/O设备的信号 | 异步 | 总是返回到下一条指令 |
269 | | 陷阱 | 有意的异常 | 同步 | 总是返回到下一条指令 |
270 | | 故障 | 潜在可恢复的错误 | 同步 | 可能返回到当前指令 |
271 | | 终止 | 不可恢复的错误 | 同步 | 不会返回 |
272 |
273 |
274 |
275 | - **硬中断**
276 |
277 | 硬中断是我们通常所说的中断的概念。硬中断是由硬件产生的,比如,像磁盘,网卡,键盘,时钟等。每个设备或设备集都有它自己的IRQ(中断请求)。内核中维护了一个IDT(中断描述符表),表中是中断处理函数的地址和一些其他的控制位。0-31号中断号位系统为预定义的中断和异常保留的,用户不得使用,所以硬件中断号从32开始分发。每当CPU接收到一个中断或者异常信号,CPU首先要做的决定是否响应这个中断(具体由中断控制器根据中断优先级决定是否给CPU发送中断信号),如果决定响应,就终止当前运行进程的运行,根据IDTR寄存器获取中断描述符表基地址,然后根据中断号定位具体的中断描述符。
278 |
279 | - **软中断**
280 |
281 | 软中断是由当前正在运行的进程所产生的。 软中断并不会直接中断CPU。这种中断是一种需要内核为正在运行的进程去做一些事情(通常为I/O)的请求。
282 |
283 | > 中断在本质上是软件或者硬件发生了某种情形而通知处理器的行为,处理器进而停止正在运行的指令流,去转去执行预定义的中断处理程序。软件中断也就是通知内核的机制的泛化名称,目的是促使系统切换到内核态去执行异常处理程序。这里的异常处理程序其实就是一种系统调用,软件中断可以当做一种异常。总之,软件中断是当前进程切换到系统调用的过程。
284 |
285 |
286 |
287 | # 系统调用知识点
288 |
289 | ## 用户态和内核态
290 |
291 | [l链接](https://blog.csdn.net/u013291303/article/details/63682298)
292 |
293 | ## 系统调用过程
294 |
295 | 用户空间的程序无法直接执行内核代码,它们不能直接调用内核空间中的函数,因为内核驻留在受保护的地址空间上。如果进程可以直接在内核的地址空间上读写的话,系统安全就会失去控制。所以,应用程序应该以某种方式通知系统,告诉内核自己需要执行一个系统调用,希望系统切换到内核态,这样内核就可以代表应用程序来执行该系统调用了。
296 |
297 | 通知内核的机制是靠软件中断实现的。首先,用户程序为系统调用设置参数。其中一个参数是系统调用编号。参数设置完成后,程序执行“系统调用”指令。这个指令会导致一个异常:产生一个事件,这个事件会致使处理器切换到内核态并跳转到一个新的地址,并开始执行那里的异常处理程序。此时的异常处理程序实际上就是系统调用处理程序。它与硬件体系结构紧密相关。
298 |
299 | > **系统调用的过程:**首先将API函数参数压到栈上,然后将函数内调用系统调用的代码放入寄存器,通过陷入中断,进入内核将控制权交给操作系统,操作系统获得控制后,将系统调用代码拿出来,跟操作系统一直维护的一张系统调用表做比较,已找到该系统调用程序体的内存地址,接着访问该地址,执行系统调用。执行完毕后,返回用户程序
300 |
301 | ## 系统调用和函数调用区别
302 |
303 | **库函数调用**
304 |
305 | 函数调用主要通过压栈出栈的操作,面向应用开发。库函数顾名思义是把函数放到库里。是把一些常用到的函数编完放到一个文件里,供别人用。别人用的时候把它所在的文件名用#include<>加到里面就可以了。一般是指编译器提供的可在c源程序中调用的函数。可分为两类,一类是c语言标准规定的库函数,一类是编译器特定的库函数。(由于版权原因,库函数的源代码一般是不可见的,但在头文件中你可以看到它对外的接口)
306 |
307 | **系统调用**
308 |
309 | 系统调用就是用户在程序中调用操作系统所提供的一个子功能,也就是系统API,系统调用可以被看做特殊的公共子程序。通俗的讲是操作系统提供给用户程序调用的一组“特殊”接口。用户程序可以通过这组“特殊”接口来获得操作系统内核提供的服务,比如用户可以通过文件系统相关的调用请求系统打开文件、关闭文件或读写文件,可以通过时钟相关的系统调用获得系统时间或设置定时器等。系统中的各种共享资源都由操作系统统一掌管,因此在用户程序中,凡是与资源有关的操作(如存储分配、进行I/O传输及管理文件等),都必须通过系统调用方式向操作系统提出服务请求,并由操作系统代为完成。
310 |
311 | ------
312 |
313 |
314 |
315 | # 对事件的两种处理方式
316 |
317 | ## reactor
318 |
319 | 如果要让服务器服务多个客户端,那么最直接的方式就是为每一条连接创建线程。其实创建进程也是可以的,原理是一样的,进程和线程的区别在于线程比较轻量级些,线程的创建和线程间切换的成本要小些,为了描述简述,后面都以线程为例。处理完业务逻辑后,随着连接关闭后线程也同样要销毁了,但是这样不停地创建和销毁线程,不仅会带来性能开销,也会造成浪费资源,而且如果要连接几万条连接,创建几万个线程去应对也是不现实的。要这么解决这个问题呢?我们可以使用「资源复用」的方式。也就是不用再为每个连接创建线程,而是创建一个「线程池」,将连接分配给线程,然后一个线程可以处理多个连接的业务。不过,这样又引来一个新的问题,线程怎样才能高效地处理多个连接的业务?
320 |
321 | 当一个连接对应一个线程时,线程一般采用「read -> 业务处理 -> send」的处理流程,如果当前连接没有数据可读,那么线程会阻塞在 `read` 操作上( socket 默认情况是阻塞 I/O),不过这种阻塞方式并不影响其他线程。但是引入了线程池,那么一个线程要处理多个连接的业务,线程在处理某个连接的 `read` 操作时,如果遇到没有数据可读,就会发生阻塞,那么线程就没办法继续处理其他连接的业务。要解决这一个问题,最简单的方式就是将 socket 改成非阻塞,然后线程不断地轮询调用 `read` 操作来判断是否有数据,这种方式虽然该能够解决阻塞的问题,但是解决的方式比较粗暴,因为轮询是要消耗 CPU 的,而且随着一个 线程处理的连接越多,轮询的效率就会越低。
322 |
323 | 有没有办法在只有当连接上有数据的时候,线程才去发起读请求呢?答案是有的,实现这一技术的就是 I/O 多路复用。线程池复用+IO复用就形成了reactor模式。
324 |
325 | **Reactor的定义:**是一种接收多个输入事件的服务器事件驱动处理模式。服务器端通过IO多路复用来处理这些输入事件,并将这些事件同步分派给对应的处理线程。其实reactor模式也叫做Dispatcher 模式,本质上就是将收到的事件进行分发处理。Reactor模式中有两个关键的组成:①主反应堆reactor在一个单独的线程中运行,负责监听和分发事件,将接收到的事件分为监听socket和连接socket,连接socket放入任务队列让线程池线程去抢占式调度。②Handlers或Accepter,处理任务队列中具体的逻辑或者建立连接socket。
326 |
327 | 根据 Reactor 的数量和处理资源池线程的数量不同,有 3 种典型的实现:
328 |
329 | 1. 单 Reactor 单线程;
330 | 2. 单 Reactor 多线程;
331 | 3. 主从 Reactor 多线程。
332 |
333 | 接下来一一介绍:
334 |
335 | - **单 Reactor 单线程**
336 |
337 | 顾名思义,一个主反应堆reactor,一个accepter或者handler来处理接收的事件。
338 |
339 | 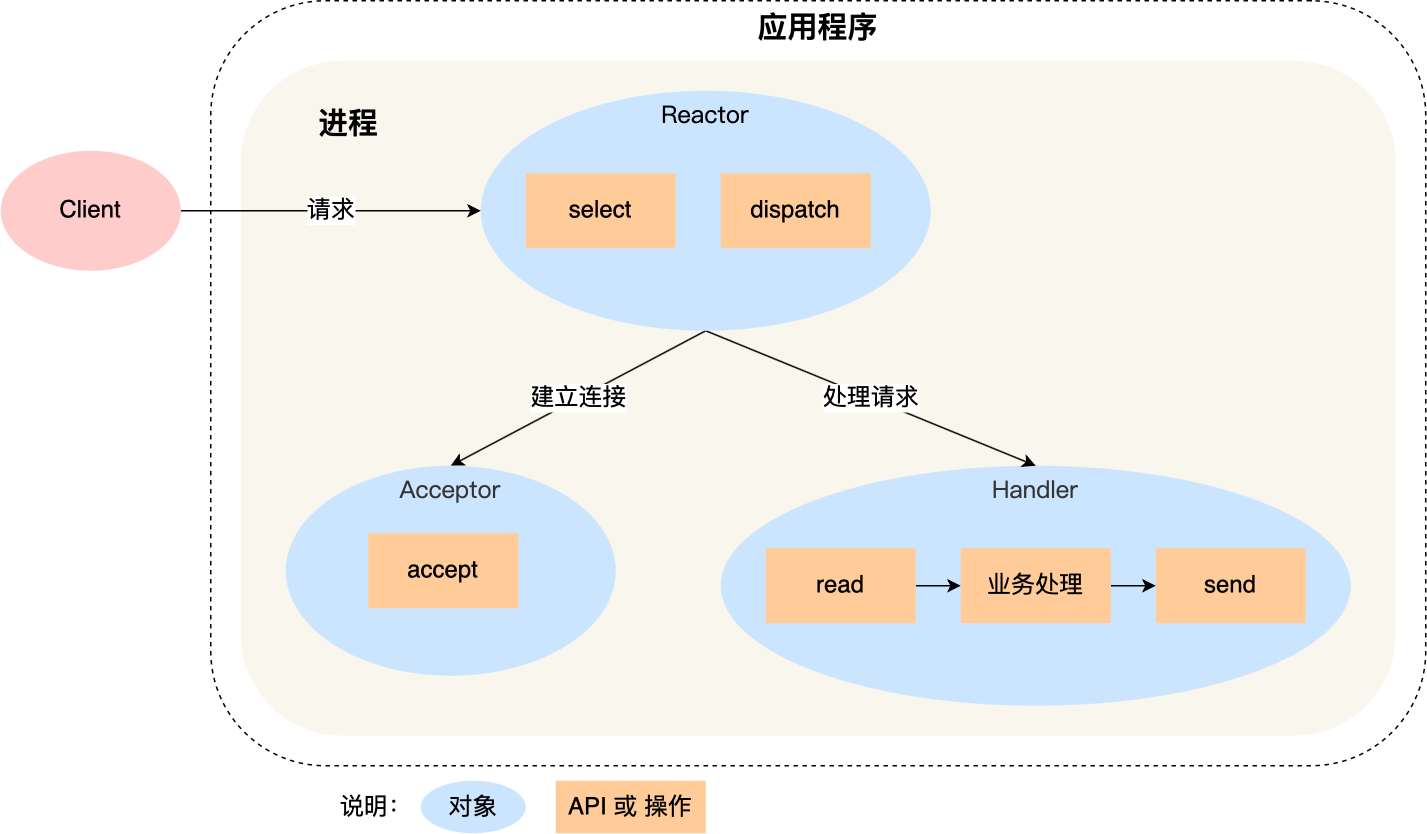 340 |
341 | **优点:**模型简单,没有多线程、进程通信、竞争的问题,全部都在一个线程中完成。
342 |
343 | **缺点:**性能问题,只有一个线程,无法完全发挥多核 CPU 的性能。Handler 在处理某个连接上的业务时,整个进程无法处理其他连接事件,很容易导致性能瓶颈。
344 | 可靠性问题,线程意外跑飞,或者进入死循环,会导致整个系统通信模块不可用,不能接收和处理外部消息,造成节点故障。
345 |
346 | **使用场景:**客户端的数量有限,业务处理非常快速,比如 Redis,业务处理的时间复杂度 O(1),因为 Redis 业务处理主要是在内存中完成,操作的速度是很快的,性能瓶颈不在 CPU 上,所以 Redis 对于命令的处理是单进程的方案。
347 |
348 | - **单 Reactor 多线程**
349 |
350 | 一个主反应堆reactor和一个线程池,线程池用来处理分发的事件
351 |
352 |
340 |
341 | **优点:**模型简单,没有多线程、进程通信、竞争的问题,全部都在一个线程中完成。
342 |
343 | **缺点:**性能问题,只有一个线程,无法完全发挥多核 CPU 的性能。Handler 在处理某个连接上的业务时,整个进程无法处理其他连接事件,很容易导致性能瓶颈。
344 | 可靠性问题,线程意外跑飞,或者进入死循环,会导致整个系统通信模块不可用,不能接收和处理外部消息,造成节点故障。
345 |
346 | **使用场景:**客户端的数量有限,业务处理非常快速,比如 Redis,业务处理的时间复杂度 O(1),因为 Redis 业务处理主要是在内存中完成,操作的速度是很快的,性能瓶颈不在 CPU 上,所以 Redis 对于命令的处理是单进程的方案。
347 |
348 | - **单 Reactor 多线程**
349 |
350 | 一个主反应堆reactor和一个线程池,线程池用来处理分发的事件
351 |
352 | 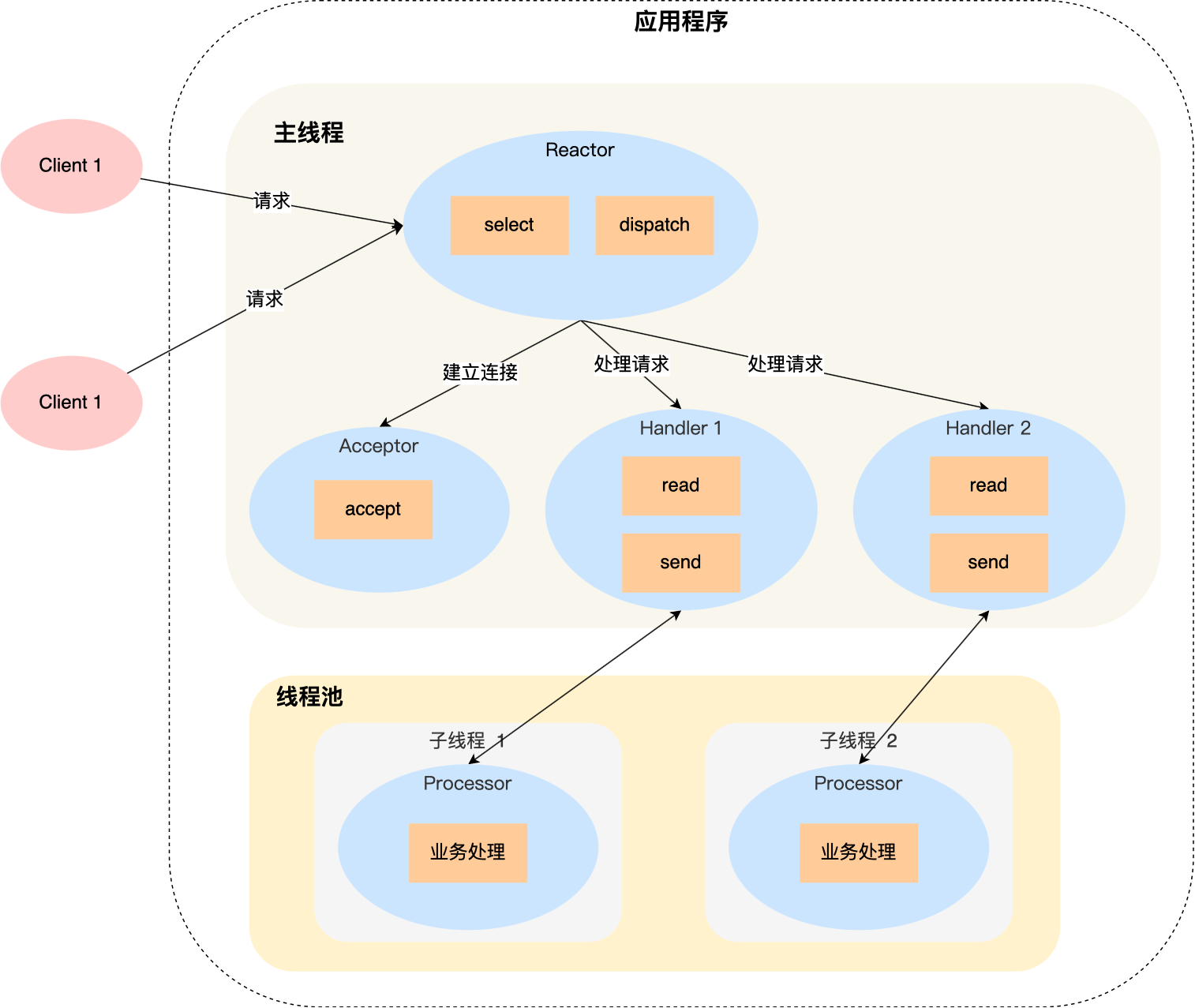 353 |
354 | **优点:**可以充分利用多核 CPU 的处理能力。
355 |
356 | **缺点:**多线程数据共享和访问比较复杂;Reactor 承担所有事件的监听和响应,在单线程中运行,高并发场景下容易成为性能瓶颈。
357 |
358 | - **主从 Reactor 多线程**
359 |
360 | 就是游双书里面的半同步/半反应堆模型,给这个归到了代码逻辑层面。
361 |
362 |
353 |
354 | **优点:**可以充分利用多核 CPU 的处理能力。
355 |
356 | **缺点:**多线程数据共享和访问比较复杂;Reactor 承担所有事件的监听和响应,在单线程中运行,高并发场景下容易成为性能瓶颈。
357 |
358 | - **主从 Reactor 多线程**
359 |
360 | 就是游双书里面的半同步/半反应堆模型,给这个归到了代码逻辑层面。
361 |
362 |  363 |
364 | 主线程和子线程分工明确,主线程只负责接收新连接,子线程负责完成后续的业务处理。
365 |
366 | 主线程和子线程的交互很简单,主线程只需要把新连接传给子线程,子线程无须返回数据,直接就可以在子线程将处理结果发送给客户端。
367 |
368 | **优点:**父线程与子线程的数据交互简单职责明确,父线程只需要接收新连接,子线程完成后续的业务处理。
369 | 父线程与子线程的数据交互简单,Reactor 主线程只需要把新连接传给子线程,子线程无需返回数据。
370 | 这种模型在许多项目中广泛使用,包括 Nginx 主从 Reactor 多进程模型,Memcached 主从多线程,Netty 主从多线程模型的支持。
371 |
372 | ## preactor
373 |
374 | 在 Reactor 模式中,Reactor 等待某个事件或者可应用或者操作的状态发生(比如文件描述符可读写,或者是 Socket 可读写)。
375 | 然后把这个事件传给事先注册的 Handler(事件处理函数或者回调函数),由后者来做实际的读写操作。
376 | 其中的读写操作都需要应用程序同步操作,所以 Reactor 是非阻塞同步网络模型。
377 | 如果把 I/O 操作改为异步,即交给操作系统来完成就能进一步提升性能,这就是异步网络模型 Proactor。
378 |
379 | preactor模型如下图所示:
380 |
381 |
363 |
364 | 主线程和子线程分工明确,主线程只负责接收新连接,子线程负责完成后续的业务处理。
365 |
366 | 主线程和子线程的交互很简单,主线程只需要把新连接传给子线程,子线程无须返回数据,直接就可以在子线程将处理结果发送给客户端。
367 |
368 | **优点:**父线程与子线程的数据交互简单职责明确,父线程只需要接收新连接,子线程完成后续的业务处理。
369 | 父线程与子线程的数据交互简单,Reactor 主线程只需要把新连接传给子线程,子线程无需返回数据。
370 | 这种模型在许多项目中广泛使用,包括 Nginx 主从 Reactor 多进程模型,Memcached 主从多线程,Netty 主从多线程模型的支持。
371 |
372 | ## preactor
373 |
374 | 在 Reactor 模式中,Reactor 等待某个事件或者可应用或者操作的状态发生(比如文件描述符可读写,或者是 Socket 可读写)。
375 | 然后把这个事件传给事先注册的 Handler(事件处理函数或者回调函数),由后者来做实际的读写操作。
376 | 其中的读写操作都需要应用程序同步操作,所以 Reactor 是非阻塞同步网络模型。
377 | 如果把 I/O 操作改为异步,即交给操作系统来完成就能进一步提升性能,这就是异步网络模型 Proactor。
378 |
379 | preactor模型如下图所示:
380 |
381 | 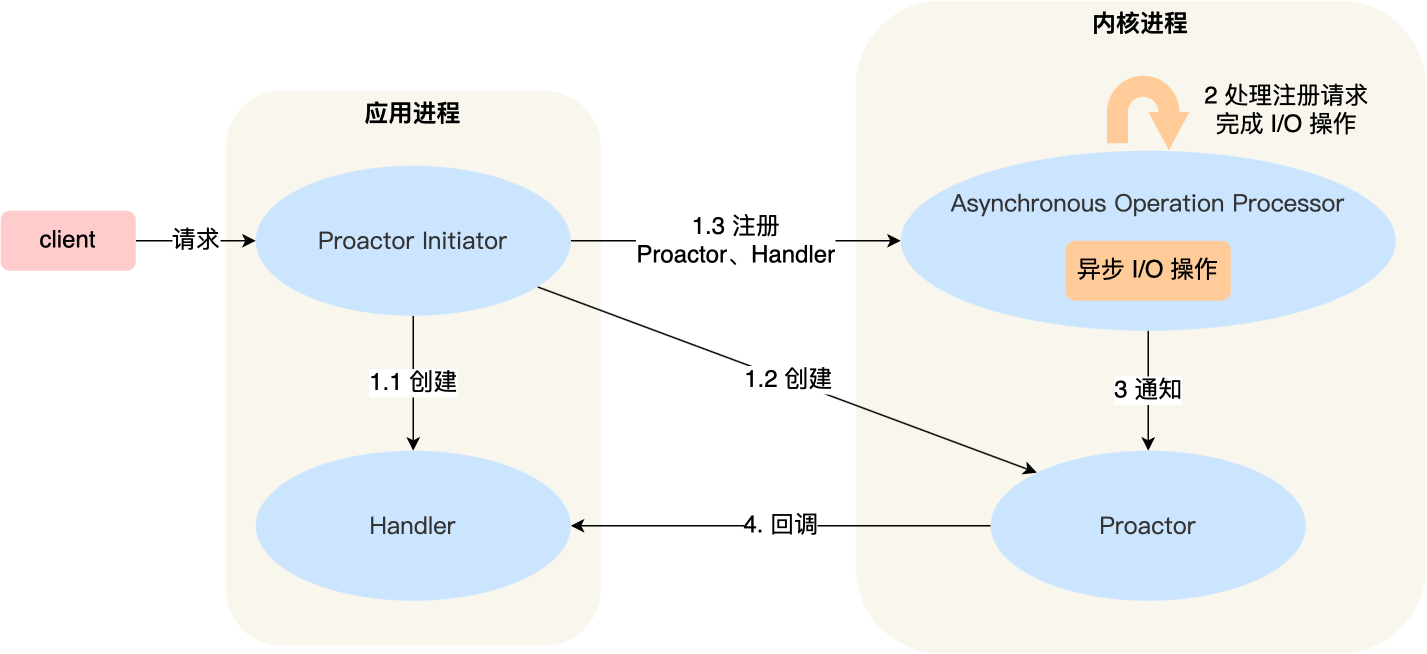 382 |
383 | 工作流程如下:
384 |
385 | 1. Proactor Initiator 负责创建 Proactor 和 Handler 对象,并将 Proactor 和 Handler 都通过
386 | Asynchronous Operation Processor 注册到内核;
387 | 2. Asynchronous Operation Processor 负责处理注册请求,并处理 I/O 操作;
388 | 3. Asynchronous Operation Processor 完成 I/O 操作后通知 Proactor;
389 | 4. Proactor 根据不同的事件类型回调不同的 Handler 进行业务处理;
390 | 5. Handler 完成业务处理;
391 |
392 | 理论上 Proactor 比 Reactor 效率更高,异步 I/O 更加充分发挥 DMA(Direct Memory Access,直接内存存取)的优势。
393 | 但是Proactor有如下缺点:
394 |
395 | 1. 编程复杂性,由于异步操作流程的事件的初始化和事件完成在时间和空间上都是相互分离的,因此开发异步应用程序更加复杂。应用程序还可能因为反向的流控而变得更加难以 Debug;
396 | 2. 内存使用,缓冲区在读或写操作的时间段内必须保持住,可能造成持续的不确定性,并且每个并发操作都要求有独立的缓存,相比 Reactor 模式,在 Socket 已经准备好读或写前,是不要求开辟缓存的;
397 | 3. 操作系统支持,Windows 下通过 IOCP 实现了真正的异步 I/O,而在 Linux 系统下,Linux 2.6 才引入,目前异步 I/O 还不完善。
398 | 4. Reactor处理耗时长的操作会造成事件分发的阻塞,影响到后续事件的处理;
399 |
400 | > 可惜的是,在 Linux 下的异步 I/O 是不完善的,
401 | > `aio` 系列函数是由 POSIX 定义的异步操作接口,不是真正的操作系统级别支持的,而是在用户空间模拟出来的异步,并且仅仅支持基于本地文件的 aio 异步操作,网络编程中的 socket 是不支持的,这也使得基于 Linux 的高性能网络程序都是使用 Reactor 方案。
402 | >
403 | > 而 Windows 里实现了一套完整的支持 socket 的异步编程接口,这套接口就是 `IOCP`,是由操作系统级别实现的异步 I/O,真正意义上异步 I/O,因此在 Windows 里实现高性能网络程序可以使用效率更高的 Proactor 方案。
404 |
405 |
406 |
407 | # 文件(不带缓存的)I/O和标准(带缓存的)I/O
408 |
409 | **首先要明确一个问题:有无缓存是相对于用户层面来说的,而不是系统内核层面。在系统内核层面,一直都存在有“内核高速缓存”**
410 |
411 | - 不带缓存的概念
412 |
413 | > 所谓不带缓存,并不是指内核不提供缓存,而是在用户进程层次没有提供缓存。不带缓存的I/O只存在系统调用(write和read函数),不是函数库的调用。**系统内核对磁盘的读写都会提供一个块缓冲(在有些地方也被称为内核高速缓存)**,当用write函数对其写数据时,直接调用系统调用,将数据写入到块缓存进行排队,当块缓存达到一定的量时,才会把数据写入磁盘。因此所谓的不带缓存的I/O是指用户进程层面不提供缓存功能(但内核还是提供缓冲的)。
414 | >
415 | > 文件I/O以文件标识符(整型)作为文件唯一性的判断依据。这种操作与系统有关,移植有一定的问题。
416 |
417 | - 带缓存的概念
418 |
419 | > 与之相对的就是带缓存I/O。而带缓存的是在不带缓存的基础之上封装了一层,在用户进程层次维护了一个输入输出缓冲区,使之能跨OS,成为ASCI标准,称为标准IO库。其实就是在用户层再建立一个缓存区,这个缓存区的分配和优化长度等细节都是标准IO库代你处理好了,不用去操心。第一次调用带缓存的文件操作函数时标准库会自动分配内存并且读出一段固定大小的内容存储在缓存中。所以以后每次的读写操作并不是针对硬盘上的文件直接进行的,而是针对内存中的缓存的。
420 | >
421 | > 不带缓存的文件操作通常都是系统提供的系统调用, 更加低级,直接从硬盘中读取和写入文件,由于IO瓶颈的原因,速度并不如意,而且原子操作需要程序员自己保证,但使用得当的话效率并不差。另外标准库中的带缓存文件IO 是调用系统提供的不带缓存IO实现的。
422 |
423 | - 因此,标准I/O函数有两个优点:
424 |
425 | 1. 具有良好的移植性
426 |
427 | 2. 利用用户层提供的缓存区(流缓冲)提高性能
428 |
429 | - 标准I/O函数缺点
430 |
431 | 1. 不容易进行双向通信
432 | 2. 有时可能频繁调用fflush函数
433 | 3. 需要以FILE结构体指针的形式返回文件描述符
434 |
435 | - 举例说明
436 |
437 | > **带缓冲的I/O在往磁盘写入相同的数据量时,会比不带缓冲的I/O调用系统调用的次数要少。**比如内核缓冲存储器长度为100字节,在进行写操作时每次写入10个字节,则你需要调用10次write函数才能把内核缓冲区写满。但是要注意此时数据还在缓冲区,不在磁盘中,缓冲区满时才进行实际的I/O操作,把数据写入到磁盘,这样调用了太多次系统调用,显得效率很低。但是若调用标准I/O函数,假设用户层缓冲区为50字节(称为流缓存),则用fwrite将数据写入到流缓存,等到流缓存区存满之后再进入内核缓存区,在调用write函数将数据写入到内核缓冲区中,若内核缓冲区满或执行fflush操作,那么内核缓冲区的数据会写入到磁盘中
438 |
439 | - 无缓存IO操作数据流向路径:**数据——内核缓存区——磁盘**
440 | - 标准IO操作数据流向路径:**数据——流缓存区——内核缓存区——磁盘**
441 |
442 | - apue三种io的总结
443 |
444 | 在apue中有三种io类型,如下:
445 |
446 | 1. 文件I/O(不带缓冲的I/O):open、read、write、lseek、close
447 | 2. 标准I/O(带缓冲的I/O):标准I/O库由ISO C标准说明
448 | 3. 高级I/O:非阻塞I/O、I/O多路转接、异步I/O、readv和writev
449 |
450 |
451 |
452 | # 阻塞非阻塞,同步异步的区别
453 |
454 | [参考](https://blog.51cto.com/yaocoder/1308899)
455 |
456 | [参考2,这个比较符合我的想法](https://blog.csdn.net/historyasamirror/article/details/5778378)
457 |
458 | 进程通讯层面,阻塞就是同步,非阻塞就是异步,一个意思
459 |
460 | IO层面,就不一样。要记住,IO操作只有两个阶段:
461 |
462 | 1. 数据准备阶段
463 | 2. 内核缓冲区(内核空间)复制数据到用户进程缓冲区(用户空间)阶段
464 |
465 | 对于数据准备阶段,是阻塞和非阻塞的层面。对于数据从内核转移到用户空间,就是同步异步阶段。
466 |
467 |
382 |
383 | 工作流程如下:
384 |
385 | 1. Proactor Initiator 负责创建 Proactor 和 Handler 对象,并将 Proactor 和 Handler 都通过
386 | Asynchronous Operation Processor 注册到内核;
387 | 2. Asynchronous Operation Processor 负责处理注册请求,并处理 I/O 操作;
388 | 3. Asynchronous Operation Processor 完成 I/O 操作后通知 Proactor;
389 | 4. Proactor 根据不同的事件类型回调不同的 Handler 进行业务处理;
390 | 5. Handler 完成业务处理;
391 |
392 | 理论上 Proactor 比 Reactor 效率更高,异步 I/O 更加充分发挥 DMA(Direct Memory Access,直接内存存取)的优势。
393 | 但是Proactor有如下缺点:
394 |
395 | 1. 编程复杂性,由于异步操作流程的事件的初始化和事件完成在时间和空间上都是相互分离的,因此开发异步应用程序更加复杂。应用程序还可能因为反向的流控而变得更加难以 Debug;
396 | 2. 内存使用,缓冲区在读或写操作的时间段内必须保持住,可能造成持续的不确定性,并且每个并发操作都要求有独立的缓存,相比 Reactor 模式,在 Socket 已经准备好读或写前,是不要求开辟缓存的;
397 | 3. 操作系统支持,Windows 下通过 IOCP 实现了真正的异步 I/O,而在 Linux 系统下,Linux 2.6 才引入,目前异步 I/O 还不完善。
398 | 4. Reactor处理耗时长的操作会造成事件分发的阻塞,影响到后续事件的处理;
399 |
400 | > 可惜的是,在 Linux 下的异步 I/O 是不完善的,
401 | > `aio` 系列函数是由 POSIX 定义的异步操作接口,不是真正的操作系统级别支持的,而是在用户空间模拟出来的异步,并且仅仅支持基于本地文件的 aio 异步操作,网络编程中的 socket 是不支持的,这也使得基于 Linux 的高性能网络程序都是使用 Reactor 方案。
402 | >
403 | > 而 Windows 里实现了一套完整的支持 socket 的异步编程接口,这套接口就是 `IOCP`,是由操作系统级别实现的异步 I/O,真正意义上异步 I/O,因此在 Windows 里实现高性能网络程序可以使用效率更高的 Proactor 方案。
404 |
405 |
406 |
407 | # 文件(不带缓存的)I/O和标准(带缓存的)I/O
408 |
409 | **首先要明确一个问题:有无缓存是相对于用户层面来说的,而不是系统内核层面。在系统内核层面,一直都存在有“内核高速缓存”**
410 |
411 | - 不带缓存的概念
412 |
413 | > 所谓不带缓存,并不是指内核不提供缓存,而是在用户进程层次没有提供缓存。不带缓存的I/O只存在系统调用(write和read函数),不是函数库的调用。**系统内核对磁盘的读写都会提供一个块缓冲(在有些地方也被称为内核高速缓存)**,当用write函数对其写数据时,直接调用系统调用,将数据写入到块缓存进行排队,当块缓存达到一定的量时,才会把数据写入磁盘。因此所谓的不带缓存的I/O是指用户进程层面不提供缓存功能(但内核还是提供缓冲的)。
414 | >
415 | > 文件I/O以文件标识符(整型)作为文件唯一性的判断依据。这种操作与系统有关,移植有一定的问题。
416 |
417 | - 带缓存的概念
418 |
419 | > 与之相对的就是带缓存I/O。而带缓存的是在不带缓存的基础之上封装了一层,在用户进程层次维护了一个输入输出缓冲区,使之能跨OS,成为ASCI标准,称为标准IO库。其实就是在用户层再建立一个缓存区,这个缓存区的分配和优化长度等细节都是标准IO库代你处理好了,不用去操心。第一次调用带缓存的文件操作函数时标准库会自动分配内存并且读出一段固定大小的内容存储在缓存中。所以以后每次的读写操作并不是针对硬盘上的文件直接进行的,而是针对内存中的缓存的。
420 | >
421 | > 不带缓存的文件操作通常都是系统提供的系统调用, 更加低级,直接从硬盘中读取和写入文件,由于IO瓶颈的原因,速度并不如意,而且原子操作需要程序员自己保证,但使用得当的话效率并不差。另外标准库中的带缓存文件IO 是调用系统提供的不带缓存IO实现的。
422 |
423 | - 因此,标准I/O函数有两个优点:
424 |
425 | 1. 具有良好的移植性
426 |
427 | 2. 利用用户层提供的缓存区(流缓冲)提高性能
428 |
429 | - 标准I/O函数缺点
430 |
431 | 1. 不容易进行双向通信
432 | 2. 有时可能频繁调用fflush函数
433 | 3. 需要以FILE结构体指针的形式返回文件描述符
434 |
435 | - 举例说明
436 |
437 | > **带缓冲的I/O在往磁盘写入相同的数据量时,会比不带缓冲的I/O调用系统调用的次数要少。**比如内核缓冲存储器长度为100字节,在进行写操作时每次写入10个字节,则你需要调用10次write函数才能把内核缓冲区写满。但是要注意此时数据还在缓冲区,不在磁盘中,缓冲区满时才进行实际的I/O操作,把数据写入到磁盘,这样调用了太多次系统调用,显得效率很低。但是若调用标准I/O函数,假设用户层缓冲区为50字节(称为流缓存),则用fwrite将数据写入到流缓存,等到流缓存区存满之后再进入内核缓存区,在调用write函数将数据写入到内核缓冲区中,若内核缓冲区满或执行fflush操作,那么内核缓冲区的数据会写入到磁盘中
438 |
439 | - 无缓存IO操作数据流向路径:**数据——内核缓存区——磁盘**
440 | - 标准IO操作数据流向路径:**数据——流缓存区——内核缓存区——磁盘**
441 |
442 | - apue三种io的总结
443 |
444 | 在apue中有三种io类型,如下:
445 |
446 | 1. 文件I/O(不带缓冲的I/O):open、read、write、lseek、close
447 | 2. 标准I/O(带缓冲的I/O):标准I/O库由ISO C标准说明
448 | 3. 高级I/O:非阻塞I/O、I/O多路转接、异步I/O、readv和writev
449 |
450 |
451 |
452 | # 阻塞非阻塞,同步异步的区别
453 |
454 | [参考](https://blog.51cto.com/yaocoder/1308899)
455 |
456 | [参考2,这个比较符合我的想法](https://blog.csdn.net/historyasamirror/article/details/5778378)
457 |
458 | 进程通讯层面,阻塞就是同步,非阻塞就是异步,一个意思
459 |
460 | IO层面,就不一样。要记住,IO操作只有两个阶段:
461 |
462 | 1. 数据准备阶段
463 | 2. 内核缓冲区(内核空间)复制数据到用户进程缓冲区(用户空间)阶段
464 |
465 | 对于数据准备阶段,是阻塞和非阻塞的层面。对于数据从内核转移到用户空间,就是同步异步阶段。
466 |
467 |  468 |
469 | 阻塞和非阻塞的区别在于内核数据还没准备好时,用户进程在一阶段数据准备时是否会阻塞;
470 |
471 | 同步IO与异步IO的区别在于当数据从内核`copy`到用户空间时,用户进程是否会阻参与第二阶段的数据读写,是由用程序完成还是由内核完成。
472 |
473 |
474 |
475 | # 对于套接字socket的理解
476 |
477 | 这里我类比一下插座和套接字,为什么这样类比呢?因为套接字的中文有插座的含义....
478 |
479 | 电器如何才能供电?电器需要连接上电网。如何连接到电网?需要把电器插销插到插座上,通过插座连接到电网,这样电器就有电可以工作
480 |
481 | 计算机如何收发消息?计算机需要连接上互联网。如何连接互联网?硬件层面我们可以拉一根网线,软件层面需要套接字。通过套接字连接到互联网,进而可以和互利网上的所有主机进行通信。
482 |
483 |
468 |
469 | 阻塞和非阻塞的区别在于内核数据还没准备好时,用户进程在一阶段数据准备时是否会阻塞;
470 |
471 | 同步IO与异步IO的区别在于当数据从内核`copy`到用户空间时,用户进程是否会阻参与第二阶段的数据读写,是由用程序完成还是由内核完成。
472 |
473 |
474 |
475 | # 对于套接字socket的理解
476 |
477 | 这里我类比一下插座和套接字,为什么这样类比呢?因为套接字的中文有插座的含义....
478 |
479 | 电器如何才能供电?电器需要连接上电网。如何连接到电网?需要把电器插销插到插座上,通过插座连接到电网,这样电器就有电可以工作
480 |
481 | 计算机如何收发消息?计算机需要连接上互联网。如何连接互联网?硬件层面我们可以拉一根网线,软件层面需要套接字。通过套接字连接到互联网,进而可以和互利网上的所有主机进行通信。
482 |
483 |  484 |
485 | ***socket* 其实就是操作系统提供给程序员操作「网络协议栈」的接口,说人话就是,你能通过*socket* 的接口,来控制协议找工作,从而实现网络通信**
486 |
487 |
488 |
489 | # C++网络通信中send和receive的为什么会阻塞
490 |
491 |
484 |
485 | ***socket* 其实就是操作系统提供给程序员操作「网络协议栈」的接口,说人话就是,你能通过*socket* 的接口,来控制协议找工作,从而实现网络通信**
486 |
487 |
488 |
489 | # C++网络通信中send和receive的为什么会阻塞
490 |
491 |  492 |
493 | 使用tcp协议进行通讯的双方,都各自有一个发送缓冲区和一个接收缓冲区。而缓冲区是有大小的,因此发生阻塞的本质原因是缓冲区满了,别的字节流消息无法进入缓冲区。
494 |
495 | send函数只是将内存中的数据拷贝到内核中tcp的发送缓冲区或者说写缓冲区,但是什么时候发送数据是send无法控制的。同时tcp是一个可靠传输协议,发送端必须收到确认报文信息后才会清空发送缓冲区中的内容。对于读缓冲区来,收到数据放到自己的读缓冲区,同时要给发送端发送一个确认消息表明自己收到了信息。这个时候如果读缓冲区的数据被填满,由于滑动窗口协议,导致接收端不在读取数据,进而写缓冲区也会阻止发送数据。这个时候write函数就会阻塞。总结:**接收端接收数据的速度小于发送端发送数据的速度,导致接收端的读缓冲区填满,接收端发送报文给发送端告诉他我已经满了,先别发。这样发送端的写缓冲区被占满了,导致阻塞**
496 |
497 | receive阻塞是因为读缓冲区中没数据。
498 |
499 | 记住,send是等到写缓冲区被填满之后才发送,但是write只要发现读缓冲区有数据,就将数据拷贝。
500 |
501 |
502 |
503 | # send和receive在阻塞和非阻塞模式下的表现
504 |
505 | ```c
506 | //第一个参数:指定发送端套接字
507 | //第二个参数:指明需要发送数据的缓冲区
508 | //第三个参数:指明实际发送的数据的字节
509 | //第四个参数:一般不写。可以临时设置为非阻塞
510 | int send( SOCKET s, const char *buf, int len, int flags );
511 |
512 | //第一个参数:指定接收端文件描述符
513 | //第二个参数:指明一个缓冲区,存放接受来的数据
514 | //第三个参数:指明缓冲区的长度
515 | //第四个参数:一般不写。可以临时设置为非阻塞
516 | int recv( SOCKET s, char *buf, int len, int flags);
517 | ```
518 |
519 | - recv和send两种模式设置
520 |
521 | 对于一个socket是阻塞还是非阻塞有两种方式来处理:
522 |
523 | 1. 用fcntl函数
524 |
525 | ```c
526 | flags = fcntl(sockfd, F_GETFL, 0); //获取文件的flags值。
527 | fcntl(sockfd, F_SETFL, flags | O_NONBLOCK); //设置成非阻塞模式;
528 | fcntl(sockfd,F_SETFL,flags&~O_NONBLOCK); //设置成阻塞模式;
529 | ```
530 |
531 | 2. 将recv和send函数的最后一个flag 参数设置成`MSG_DONTWAIT`
532 |
533 | 注意!这种方法是临时的,不管之前是否阻塞
534 |
535 | ```c
536 | recv(sockfd, buff, buff_size,MSG_DONTWAIT); //非阻塞模式的消息发送
537 | send(scokfd, buff, buff_size, MSG_DONTWAIT); //非阻塞模式的消息接受
538 | ```
539 |
540 | - 整体来看
541 |
542 | - 当`socket`处于阻塞模式时,继续调用`send/recv`函数,程序会阻塞在`send/recv`调用处
543 | - 当`socket`处于非阻塞模式时,继续调用`send/recv`函数,会返回错误码
544 |
545 | - 阻塞和非阻塞条件下read/recv的区别
546 |
547 | **阻塞和非阻塞的区别在于没有数据到达的时候是否立刻返回**
548 |
549 | 读或者收的本质是从底层缓冲的数据copy到我们制定的buffer中
550 |
551 | - 阻塞条件下
552 |
553 | 1. 如果读缓冲区中没有数据会一直等待
554 |
555 | 2. 如果读缓冲区有数据,则会把数据读到用户指定的缓冲区。如果读取的数据量比函数参数中指定的长度要小,read会返回读到的数据长度。
556 |
557 | 一般情况下我们都需要采取循环读的方式读取数据
558 |
559 | - 非阻塞条件下
560 |
561 | 1. 如果没有数据直接返回EWOULDBLOCK
562 | 2. 读缓冲区有数据,有多少读多少
563 |
564 | - 阻塞和非阻塞条件下send/write的区别
565 |
566 | 写或者发的本质是把buffer(用户态)中的数据copy到内核态,然后就返回了。发送操作是由系统底层和tcp协议进行。send返回成功,表示数据已经copy到底层缓冲区,而不是表示数据已经发送
567 |
568 | - 阻塞情况下
569 |
570 | 一直等待,直到write将数据发送完(发送过程中可能会中断)。
571 |
572 | 读的时候我们并不知道是否有数据,以及数据是何时结束发送,如果一直等待就会造成死循环
573 |
574 | 对于写由于长度是已知的,所以可以随便写,直到写完。不过写会被打断,造成一次write只能写一部分,可以用循环write。
575 |
576 | - 非阻塞情况下
577 |
578 | 对于本地网络阻塞的情况来说,写缓冲区没有足够的内存来存储buf中的数据,因此会出现写不成功的情况。非阻塞不会等到数据全部发送再返回,而是写多少算多少,
579 |
580 | 返回值是WSAEWOULDDBLOCK
581 |
582 | - [write和read返回值详解](https://blog.csdn.net/songchuwang1868/article/details/90665865?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-3.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-3.no_search_link)
583 |
584 |
585 |
586 | # IO多路复用
587 |
588 | IO多路复用是指内核一旦发现进程指定的一个或者多个IO条件准备读取,它就通知该进程。IO多路复用适用如下场合:
589 |
590 | 1. 当客户处理多个描述字时(一般是交互式输入和网络套接口),必须使用I/O复用。
591 | 2. 如果一个TCP服务器既要处理监听套接口,又要处理已连接套接口,一般也要用到I/O复用。
592 | 3. 如果一个服务器即要处理TCP,又要处理UDP,一般要使用I/O复用。
593 | 4. 如果一个服务器要处理多个服务或多个协议,一般要使用I/O复用。
594 |
595 | 与多进程和多线程技术相比,I/O多路复用技术的最大优势是系统开销小,系统不必创建进程/线程,也不必维护这些进程/线程,从而大大减小了系统的开销。
596 |
597 | ## ☆为什么单线程或者单进程下是用select或者epoll就能实现多个客户端的并发?
598 |
599 | 答: 在套接字中有两种文件描述符,一种是用于监听的文件描述符,一种是用于通信的文件描述符。(对服务器端来说用于监听的文件描述符只有1个,用于通信的文件描述符有n个对应n个连接的客户端)且不论是哪一种文件描述符,都有输入缓冲和输出缓冲。对于用于监听的文件描述符,其读缓冲区会存储来自客户端的链接请求,调用accept函数,如果读缓冲区有数据则解除阻塞,返回对应客户端的文件描述符,用来和响应客户端通信。对于通信的文件描述符,其读缓冲区存储客户端发送来的数据,调用read就能从缓冲区读取,如果没数据就阻塞。写缓冲区同理。从上面来看,accept、read、write函数是互斥的,在单进程中如果有一个陷入了阻塞状态,其余的也没办法工作。因此单线程或者单进程情况下服务器端无法阻止阻塞问题。
600 |
601 | 单进程或单线程下这个问题从使用者或者是用户层面来说无法解决,因此要把这个问题交给内核处理。程序媛不需要维护文件描述符的读缓冲区和写缓冲区,内核可以同时检测多个文 件描述符缓冲区的变化。比如检测读缓冲区,看是否有有数据,写缓冲区是否有剩余空间等等。如果满足,就会形成事件,内核会将满足条件的文件描述符告诉我们。
602 |
603 | 总结一下就是本来程序员来检测IO的使用情况,使用阻塞函数检查,交给了内核做。只有满足事件的文件描述符才调用阻塞函数,因此就不会形成阻塞。
604 |
605 | ## select
606 |
607 | - 原理
608 |
609 | select函数将许多个文件描述符集中到一起进行监视。
610 |
611 | 使用fd_set数组保存被监视的文件描述符的变化,这个数组是以位存储在内核中的。即该数组所在的索引就是对应文件描述符的id。
612 |
613 | 首先创建一个保存监视的数组`fd_set set`,然后将所有文件描述符的状态初始化为0 `FD_ZERO(&set)`,再用`FD_ISSET(i,&set)`查找发生状态的文件描述符,循环查找。
614 |
615 | - 存在额问题
616 |
617 | 1. 单个进程可监视的文件描述符的数量被限制,即监听的端口有限,这个数目的限制和内存有很大关系,32位默认为1024个,对于64位机默认为2048个
618 |
619 | 2. 对这个数组的是线性扫描,时间复杂度为O(n)
620 |
621 | 3. 这个是最主要的开销。**每次调用select函数的时候会向操作系统传递监视对象信息。记住,应用程序向操作系统传递数据会造成很大的开销。**select函数是监视套接字变化的函数,但是套接字是由操作系统来管理的,所以select必须要借助操作系统才能完成功能。所以select函数本身就是一个系统调用。
622 |
623 | (另一种说法:不是拷贝进内核,而是通过mmap系统调用开辟了一坨内核态用户态的共享空间,数据放在了这个共享空间了)
624 |
625 | > 最low的就是在用户代码中自旋实现所有阻塞socket的监听。但是每次判断socket是否产生数据,都涉及到用户态到内核态的切换。
626 | > 于是select改进:将fd_set传入内核态,由内核判断是否有数据返回;
627 | > 然后最low的只能使用自旋来时刻的去判断socket列表中是否有数据达到。
628 | > 于是select改进:使用等待队列,让线程在没有资源时park(阻塞),当有数据到达时唤醒select线程,去处理socket。
629 |
630 |
631 |
632 | ## epoll
633 |
634 | > epoll就是解耦了select的模型:
635 | >
636 | >
492 |
493 | 使用tcp协议进行通讯的双方,都各自有一个发送缓冲区和一个接收缓冲区。而缓冲区是有大小的,因此发生阻塞的本质原因是缓冲区满了,别的字节流消息无法进入缓冲区。
494 |
495 | send函数只是将内存中的数据拷贝到内核中tcp的发送缓冲区或者说写缓冲区,但是什么时候发送数据是send无法控制的。同时tcp是一个可靠传输协议,发送端必须收到确认报文信息后才会清空发送缓冲区中的内容。对于读缓冲区来,收到数据放到自己的读缓冲区,同时要给发送端发送一个确认消息表明自己收到了信息。这个时候如果读缓冲区的数据被填满,由于滑动窗口协议,导致接收端不在读取数据,进而写缓冲区也会阻止发送数据。这个时候write函数就会阻塞。总结:**接收端接收数据的速度小于发送端发送数据的速度,导致接收端的读缓冲区填满,接收端发送报文给发送端告诉他我已经满了,先别发。这样发送端的写缓冲区被占满了,导致阻塞**
496 |
497 | receive阻塞是因为读缓冲区中没数据。
498 |
499 | 记住,send是等到写缓冲区被填满之后才发送,但是write只要发现读缓冲区有数据,就将数据拷贝。
500 |
501 |
502 |
503 | # send和receive在阻塞和非阻塞模式下的表现
504 |
505 | ```c
506 | //第一个参数:指定发送端套接字
507 | //第二个参数:指明需要发送数据的缓冲区
508 | //第三个参数:指明实际发送的数据的字节
509 | //第四个参数:一般不写。可以临时设置为非阻塞
510 | int send( SOCKET s, const char *buf, int len, int flags );
511 |
512 | //第一个参数:指定接收端文件描述符
513 | //第二个参数:指明一个缓冲区,存放接受来的数据
514 | //第三个参数:指明缓冲区的长度
515 | //第四个参数:一般不写。可以临时设置为非阻塞
516 | int recv( SOCKET s, char *buf, int len, int flags);
517 | ```
518 |
519 | - recv和send两种模式设置
520 |
521 | 对于一个socket是阻塞还是非阻塞有两种方式来处理:
522 |
523 | 1. 用fcntl函数
524 |
525 | ```c
526 | flags = fcntl(sockfd, F_GETFL, 0); //获取文件的flags值。
527 | fcntl(sockfd, F_SETFL, flags | O_NONBLOCK); //设置成非阻塞模式;
528 | fcntl(sockfd,F_SETFL,flags&~O_NONBLOCK); //设置成阻塞模式;
529 | ```
530 |
531 | 2. 将recv和send函数的最后一个flag 参数设置成`MSG_DONTWAIT`
532 |
533 | 注意!这种方法是临时的,不管之前是否阻塞
534 |
535 | ```c
536 | recv(sockfd, buff, buff_size,MSG_DONTWAIT); //非阻塞模式的消息发送
537 | send(scokfd, buff, buff_size, MSG_DONTWAIT); //非阻塞模式的消息接受
538 | ```
539 |
540 | - 整体来看
541 |
542 | - 当`socket`处于阻塞模式时,继续调用`send/recv`函数,程序会阻塞在`send/recv`调用处
543 | - 当`socket`处于非阻塞模式时,继续调用`send/recv`函数,会返回错误码
544 |
545 | - 阻塞和非阻塞条件下read/recv的区别
546 |
547 | **阻塞和非阻塞的区别在于没有数据到达的时候是否立刻返回**
548 |
549 | 读或者收的本质是从底层缓冲的数据copy到我们制定的buffer中
550 |
551 | - 阻塞条件下
552 |
553 | 1. 如果读缓冲区中没有数据会一直等待
554 |
555 | 2. 如果读缓冲区有数据,则会把数据读到用户指定的缓冲区。如果读取的数据量比函数参数中指定的长度要小,read会返回读到的数据长度。
556 |
557 | 一般情况下我们都需要采取循环读的方式读取数据
558 |
559 | - 非阻塞条件下
560 |
561 | 1. 如果没有数据直接返回EWOULDBLOCK
562 | 2. 读缓冲区有数据,有多少读多少
563 |
564 | - 阻塞和非阻塞条件下send/write的区别
565 |
566 | 写或者发的本质是把buffer(用户态)中的数据copy到内核态,然后就返回了。发送操作是由系统底层和tcp协议进行。send返回成功,表示数据已经copy到底层缓冲区,而不是表示数据已经发送
567 |
568 | - 阻塞情况下
569 |
570 | 一直等待,直到write将数据发送完(发送过程中可能会中断)。
571 |
572 | 读的时候我们并不知道是否有数据,以及数据是何时结束发送,如果一直等待就会造成死循环
573 |
574 | 对于写由于长度是已知的,所以可以随便写,直到写完。不过写会被打断,造成一次write只能写一部分,可以用循环write。
575 |
576 | - 非阻塞情况下
577 |
578 | 对于本地网络阻塞的情况来说,写缓冲区没有足够的内存来存储buf中的数据,因此会出现写不成功的情况。非阻塞不会等到数据全部发送再返回,而是写多少算多少,
579 |
580 | 返回值是WSAEWOULDDBLOCK
581 |
582 | - [write和read返回值详解](https://blog.csdn.net/songchuwang1868/article/details/90665865?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-3.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-3.no_search_link)
583 |
584 |
585 |
586 | # IO多路复用
587 |
588 | IO多路复用是指内核一旦发现进程指定的一个或者多个IO条件准备读取,它就通知该进程。IO多路复用适用如下场合:
589 |
590 | 1. 当客户处理多个描述字时(一般是交互式输入和网络套接口),必须使用I/O复用。
591 | 2. 如果一个TCP服务器既要处理监听套接口,又要处理已连接套接口,一般也要用到I/O复用。
592 | 3. 如果一个服务器即要处理TCP,又要处理UDP,一般要使用I/O复用。
593 | 4. 如果一个服务器要处理多个服务或多个协议,一般要使用I/O复用。
594 |
595 | 与多进程和多线程技术相比,I/O多路复用技术的最大优势是系统开销小,系统不必创建进程/线程,也不必维护这些进程/线程,从而大大减小了系统的开销。
596 |
597 | ## ☆为什么单线程或者单进程下是用select或者epoll就能实现多个客户端的并发?
598 |
599 | 答: 在套接字中有两种文件描述符,一种是用于监听的文件描述符,一种是用于通信的文件描述符。(对服务器端来说用于监听的文件描述符只有1个,用于通信的文件描述符有n个对应n个连接的客户端)且不论是哪一种文件描述符,都有输入缓冲和输出缓冲。对于用于监听的文件描述符,其读缓冲区会存储来自客户端的链接请求,调用accept函数,如果读缓冲区有数据则解除阻塞,返回对应客户端的文件描述符,用来和响应客户端通信。对于通信的文件描述符,其读缓冲区存储客户端发送来的数据,调用read就能从缓冲区读取,如果没数据就阻塞。写缓冲区同理。从上面来看,accept、read、write函数是互斥的,在单进程中如果有一个陷入了阻塞状态,其余的也没办法工作。因此单线程或者单进程情况下服务器端无法阻止阻塞问题。
600 |
601 | 单进程或单线程下这个问题从使用者或者是用户层面来说无法解决,因此要把这个问题交给内核处理。程序媛不需要维护文件描述符的读缓冲区和写缓冲区,内核可以同时检测多个文 件描述符缓冲区的变化。比如检测读缓冲区,看是否有有数据,写缓冲区是否有剩余空间等等。如果满足,就会形成事件,内核会将满足条件的文件描述符告诉我们。
602 |
603 | 总结一下就是本来程序员来检测IO的使用情况,使用阻塞函数检查,交给了内核做。只有满足事件的文件描述符才调用阻塞函数,因此就不会形成阻塞。
604 |
605 | ## select
606 |
607 | - 原理
608 |
609 | select函数将许多个文件描述符集中到一起进行监视。
610 |
611 | 使用fd_set数组保存被监视的文件描述符的变化,这个数组是以位存储在内核中的。即该数组所在的索引就是对应文件描述符的id。
612 |
613 | 首先创建一个保存监视的数组`fd_set set`,然后将所有文件描述符的状态初始化为0 `FD_ZERO(&set)`,再用`FD_ISSET(i,&set)`查找发生状态的文件描述符,循环查找。
614 |
615 | - 存在额问题
616 |
617 | 1. 单个进程可监视的文件描述符的数量被限制,即监听的端口有限,这个数目的限制和内存有很大关系,32位默认为1024个,对于64位机默认为2048个
618 |
619 | 2. 对这个数组的是线性扫描,时间复杂度为O(n)
620 |
621 | 3. 这个是最主要的开销。**每次调用select函数的时候会向操作系统传递监视对象信息。记住,应用程序向操作系统传递数据会造成很大的开销。**select函数是监视套接字变化的函数,但是套接字是由操作系统来管理的,所以select必须要借助操作系统才能完成功能。所以select函数本身就是一个系统调用。
622 |
623 | (另一种说法:不是拷贝进内核,而是通过mmap系统调用开辟了一坨内核态用户态的共享空间,数据放在了这个共享空间了)
624 |
625 | > 最low的就是在用户代码中自旋实现所有阻塞socket的监听。但是每次判断socket是否产生数据,都涉及到用户态到内核态的切换。
626 | > 于是select改进:将fd_set传入内核态,由内核判断是否有数据返回;
627 | > 然后最low的只能使用自旋来时刻的去判断socket列表中是否有数据达到。
628 | > 于是select改进:使用等待队列,让线程在没有资源时park(阻塞),当有数据到达时唤醒select线程,去处理socket。
629 |
630 |
631 |
632 | ## epoll
633 |
634 | > epoll就是解耦了select的模型:
635 | >
636 | > 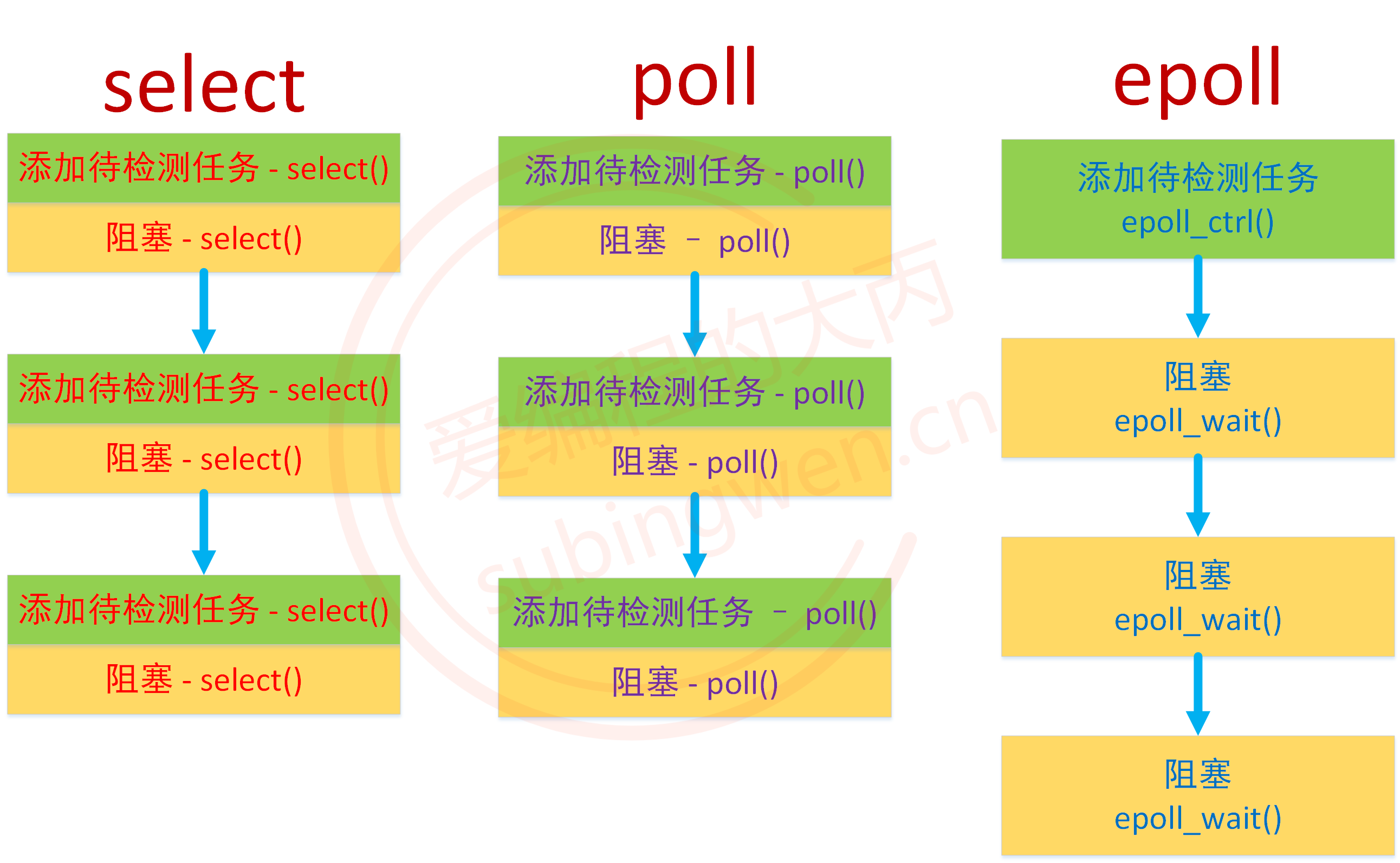 637 |
638 | > 设想一个场景:有100万用户同时与一个进程保持着TCP连接,而每一时刻只有几十个或几百个TCP连接是活跃的(接收TCP包),也就是说在每一时刻进程只需要处理这100万连接中的一小部分连接。那么,如何才能高效的处理这种场景呢?进程是否在每次询问操作系统收集有事件发生的TCP连接时,把这100万个连接告诉操作系统,然后由操作系统找出其中有事件发生的几百个连接呢?实际上,在Linux2.4版本以前,那时的select或者poll事件驱动方式是这样做的.
639 | >
640 | > 这里有个非常明显的问题,即在某一时刻,进程收集有事件的连接时,其实这100万连接中的大部分都是没有事件发生的。因此如果每次收集事件时,都把100万连接的套接字传给操作系统(这首先是用户态内存到内核态内存的大量复制),而由操作系统内核寻找这些连接上有没有未处理的事件,将会是巨大的资源浪费,然后select和poll就是这样做的,因此它们最多只能处理几千个并发连接。而epoll不这样做,它在Linux内核中申请了一个简易的文件系统,把原先的一个select或poll调用分成了3部分:
641 |
642 | 首先介绍一下epoll的函数,主要由三个:
643 |
644 | ```c++
645 | int epoll_create(int size);
646 | int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
647 | int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
648 | ```
649 |
650 | 使用epoll_creat**e向操作系统申请创建文件描述符的空间**(这个文件描述符都是在内核空间中),即建立一个epoll对象。epoll_ctl将刚创立的socket加入到epoll中进行监控,或者将某个正在监控的socket移除,不在监控。epoll_wait即监控socket有状态发生变化时候,就返回用户态的进程
651 |
652 | > 从这三个函数就可以看到epoll函数的优越性。当调用select时需要传递所有监视的socket给系统调用,意味着需要将用户态的fd_set拷贝到内核态,可想而知效率非常低效。但是epoll中内核通过epoll_ctl函数已经拿到监视socket列表。所以,实际上在你调用epoll_create后,内核就已经在内核态开始准备帮你存储要监控的句柄了,每次调用epoll_ctl只是在往内核的数据结构里塞入新的socket句柄。
653 | >
654 | > 1. 调用epoll_create建立一个epoll对象(在epoll文件系统中给这个句柄分配资源);
655 | >
656 | > 2. 调用epoll_ctl向epoll对象中添加这100万个连接的套接字;
657 | >
658 | > 3. 调用epoll_wait收集发生事件的连接。
659 |
660 | epoll会开辟出自己的内核高速cache区,用于安置每一个我们想监控的socket,这些socket会以红黑树的形式保存在内核cache里,以支持快速的查找、插入、删除。同时还会建立一个双向链表,每个节点保存着满足读写条件,返回给用户的事件。
661 |
662 | epoll高效的原因主要是epoll_wait这个函数。由于我们在调用epoll_create时,内核除了帮我们在epoll文件系统里建了个file结点,在内核cache里建了个红黑树用于存储以后epoll_ctl传来的socket外,还会再建立一个list链表,用于存储准备就绪的事件,当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可。有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。所以,epoll_wait非常高效。而且,通常情况下即使我们要监控百万计的句柄,大多一次也只返回很少量的准备就绪句柄而已,所以,epoll_wait仅需要从内核态copy少量的文件描述符到用户态而已,如何能不高效?!
663 |
664 | 那么,这个准备就绪list链表是怎么维护的呢?**当我们执行epoll_ctl时,除了把socket放到epoll文件系统里对应的红黑树上之外,还会给内核中断处理程序注册一个回调函数**,告诉内核,如果这个文件描述符的中断到了,就把它放到准备就绪list链表里。所以,当一个socket上有数据到了,数据copy到内核中后就来把socket插入到准备就绪链表里了。
665 |
666 | **总结: 一颗红黑树,一张准备就绪句柄链表,少量的内核cache,就帮我们解决了大并发下的socket处理问题。**
667 |
668 | [详解epoll](https://mp.weixin.qq.com/s/miOOrLrC4HWXigLy9Ml-jw)
669 |
670 | ## select和epoll效率
671 |
672 | **select原理概述:**
673 |
674 | 1. 从用户空间拷贝fd_set到内核空间;
675 | 2. 遍历所有fd,只要有事件触发,系统调用返回,将fd_set从内核空间拷贝到用户空间,回到用户态,用户就可以对相关的fd作进一步的读或者写操作了。
676 |
677 | **epoll原理概述:**
678 |
679 | 1. 调用epoll_create
680 |
681 | 1. 内核帮我们在epoll文件系统里建了个file结点;
682 | 2. 在内核cache里建了个红黑树用于存储以后epoll_ctl传来的socket;
683 | 3. 建立一个list链表,用于存储准备就绪的事件。
684 |
685 | 2. 调用epoll_ctl
686 |
687 | 1. 把socket放到epoll文件系统里file对象对应的红黑树上;
688 | 2. 给内核中断处理程序注册一个回调函数,告诉内核,如果这个句柄的中断到了,就把它放到准备就绪list链表里。
689 |
690 | 3. 调用epoll_wait
691 |
692 | 观察list链表里有没有数据。有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。而且,通常情况下即使我们要监控百万计的句柄,大多一次也只返回很少量的准备就绪句柄而已,所以,epoll_wait仅需要从内核态copy少量的句柄到用户态而已。
693 |
694 | **select缺点:**
695 |
696 | 1. 最大并发数限制:使用32个整数的32位,即32*32=1024来标识fd,虽然可修改,但是有以下第二点的瓶颈;
697 | 2. 效率低:每次都会线性扫描整个fd_set,集合越大速度越慢;
698 | 3. 内核/用户空间内存拷贝问题。
699 |
700 | **epoll的提升:**
701 |
702 | 1. 本身没有最大并发连接的限制,仅受系统中进程能打开的最大文件数目限制;
703 | 2. 效率提升:只有活跃的socket才会主动的去调用callback函数;
704 | 3. 省去不必要的内存拷贝:epoll通过内核与用户空间mmap同一块内存实现。
705 |
706 | **总结:**需要看所有被观察的事件是否都活跃。
707 |
708 | 假设现在有1024个fd,select 和epoll 都同时维护他,假设这些fd 都是活跃的,这种情况下select一次扫描 可以扫描1024个fd,空闲的fd很少,但是epoll 就有可能不一样了, epoll 是先注册等待回调, 有可能出现1024次回调。所以不好说。
709 |
710 | 如果select 和epoll 同时维护1024个fd ,但是每次只有一个fd有事件,这种情况下 select 每次都会扫描所有的fd, 对比于epoll 每次只有一个fd 回调。 select 做了很多无用功, 此时应该epoll的效率高吧!!
711 |
712 | 或者在短连接多的时候, 一个连接使用epoll 会触发epoll_ctrl_add/del 两次系统调用,但是select 只有一次扫描 ,此时 也许select 效率性能更高。
713 |
714 | ## epoll的水平触发模式(LT)
715 |
716 | 默认模式
717 |
718 | 在LT(水平触发)模式下,只要这个文件描述符还有数据可读,每次 epoll_wait都会返回它的事件,提醒用户程序去操作。
719 |
720 | ## epoll的边缘触发模式(ET)
721 |
722 | ET(边缘触发)模式下,在它检测到有 I/O 事件时,通过 epoll_wait 调用会得到有事件通知的文件描述符,**对于每一个被通知的文件描述符,如可读,则必须将该文件描述符一直读到空**,让 errno 返回 EAGAIN 为止,否则下次的 epoll_wait 不会返回余下的数据,会丢掉事件。如果ET模式不是非阻塞的,那这个一直读或一直写势必会在最后一次阻塞。
723 |
724 | 为什么会有ET模式?
725 |
726 | 答:如果采用EPOLLLT模式的话,系统中一旦有大量你不需要读写的就绪文件描述符,它们每次调用epoll_wait都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率.。而采用EPOLLET这种边缘触发模式的话,当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符。减少epoll_wait的调用次数,系统调用开销是很大的
727 |
728 |
729 |
730 | # tcp 在调用connect失败后要不要重新socket?
731 |
732 | connect(套接字默认阻塞)出错返回的情况:
733 |
734 | 1. 调用connect时内核发送一个SYN分节,若无响应则等待6s后再次发送一个,仍无响应则等待24s再发送一个,若总共等了75s后仍未收到响应则返回ETIMEDOUT错误;
735 |
736 | 2. 若对客户的SYN的响应是RST,则表示该服务器主机在我们指定的端口上面没有进程在等待与之连接,例如服务器进程没运行,客户收到RST就马上返回ECONNREFUSED错误;
737 |
738 | 3. 若客户发出的SYN在中间的某个路由上引发了一个“destination unreachable”(目的不可达)ICMP错误,客户主机内核保存该消息,并按1中所述的时间间隔发送SYN,在某个规定的时间(4.4BSD规定75s)仍未收到响应,则把保存的ICMP错误作为EHOSTUNREACH或ENETUNREACH错误返回给进程。
739 |
740 | 若connect失败则该套接字不再可用,必须关闭,我们不能对这样的套接字再次调用connect函数。在每次connect失败后,都必须close当前套接字描述符并重新调用socket。
741 |
742 |
743 |
744 | # Linux零拷贝技术
745 |
746 | splice( )函数
747 |
748 | tee( )函数
749 |
750 | ## **概述:**
751 |
752 | 零拷贝(Zero-Copy)是一种 `I/O` 操作优化技术,可以快速高效地将数据从文件系统移动到网络接口,而不需要将其从内核空间复制到用户空间。其在 `FTP` 或者 `HTTP` 等协议中可以显著地提升性能。
753 |
754 | ## **由来:**
755 |
756 | 如果服务端要提供文件传输的功能,我们能想到的最简单的方式是:将磁盘上的文件读取出来,然后通过网络协议发送给客户端。传统 I/O 的工作方式是,数据读取和写入是从用户空间到内核空间的复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。其过程如下图所示:
757 |
758 |
637 |
638 | > 设想一个场景:有100万用户同时与一个进程保持着TCP连接,而每一时刻只有几十个或几百个TCP连接是活跃的(接收TCP包),也就是说在每一时刻进程只需要处理这100万连接中的一小部分连接。那么,如何才能高效的处理这种场景呢?进程是否在每次询问操作系统收集有事件发生的TCP连接时,把这100万个连接告诉操作系统,然后由操作系统找出其中有事件发生的几百个连接呢?实际上,在Linux2.4版本以前,那时的select或者poll事件驱动方式是这样做的.
639 | >
640 | > 这里有个非常明显的问题,即在某一时刻,进程收集有事件的连接时,其实这100万连接中的大部分都是没有事件发生的。因此如果每次收集事件时,都把100万连接的套接字传给操作系统(这首先是用户态内存到内核态内存的大量复制),而由操作系统内核寻找这些连接上有没有未处理的事件,将会是巨大的资源浪费,然后select和poll就是这样做的,因此它们最多只能处理几千个并发连接。而epoll不这样做,它在Linux内核中申请了一个简易的文件系统,把原先的一个select或poll调用分成了3部分:
641 |
642 | 首先介绍一下epoll的函数,主要由三个:
643 |
644 | ```c++
645 | int epoll_create(int size);
646 | int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
647 | int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
648 | ```
649 |
650 | 使用epoll_creat**e向操作系统申请创建文件描述符的空间**(这个文件描述符都是在内核空间中),即建立一个epoll对象。epoll_ctl将刚创立的socket加入到epoll中进行监控,或者将某个正在监控的socket移除,不在监控。epoll_wait即监控socket有状态发生变化时候,就返回用户态的进程
651 |
652 | > 从这三个函数就可以看到epoll函数的优越性。当调用select时需要传递所有监视的socket给系统调用,意味着需要将用户态的fd_set拷贝到内核态,可想而知效率非常低效。但是epoll中内核通过epoll_ctl函数已经拿到监视socket列表。所以,实际上在你调用epoll_create后,内核就已经在内核态开始准备帮你存储要监控的句柄了,每次调用epoll_ctl只是在往内核的数据结构里塞入新的socket句柄。
653 | >
654 | > 1. 调用epoll_create建立一个epoll对象(在epoll文件系统中给这个句柄分配资源);
655 | >
656 | > 2. 调用epoll_ctl向epoll对象中添加这100万个连接的套接字;
657 | >
658 | > 3. 调用epoll_wait收集发生事件的连接。
659 |
660 | epoll会开辟出自己的内核高速cache区,用于安置每一个我们想监控的socket,这些socket会以红黑树的形式保存在内核cache里,以支持快速的查找、插入、删除。同时还会建立一个双向链表,每个节点保存着满足读写条件,返回给用户的事件。
661 |
662 | epoll高效的原因主要是epoll_wait这个函数。由于我们在调用epoll_create时,内核除了帮我们在epoll文件系统里建了个file结点,在内核cache里建了个红黑树用于存储以后epoll_ctl传来的socket外,还会再建立一个list链表,用于存储准备就绪的事件,当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可。有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。所以,epoll_wait非常高效。而且,通常情况下即使我们要监控百万计的句柄,大多一次也只返回很少量的准备就绪句柄而已,所以,epoll_wait仅需要从内核态copy少量的文件描述符到用户态而已,如何能不高效?!
663 |
664 | 那么,这个准备就绪list链表是怎么维护的呢?**当我们执行epoll_ctl时,除了把socket放到epoll文件系统里对应的红黑树上之外,还会给内核中断处理程序注册一个回调函数**,告诉内核,如果这个文件描述符的中断到了,就把它放到准备就绪list链表里。所以,当一个socket上有数据到了,数据copy到内核中后就来把socket插入到准备就绪链表里了。
665 |
666 | **总结: 一颗红黑树,一张准备就绪句柄链表,少量的内核cache,就帮我们解决了大并发下的socket处理问题。**
667 |
668 | [详解epoll](https://mp.weixin.qq.com/s/miOOrLrC4HWXigLy9Ml-jw)
669 |
670 | ## select和epoll效率
671 |
672 | **select原理概述:**
673 |
674 | 1. 从用户空间拷贝fd_set到内核空间;
675 | 2. 遍历所有fd,只要有事件触发,系统调用返回,将fd_set从内核空间拷贝到用户空间,回到用户态,用户就可以对相关的fd作进一步的读或者写操作了。
676 |
677 | **epoll原理概述:**
678 |
679 | 1. 调用epoll_create
680 |
681 | 1. 内核帮我们在epoll文件系统里建了个file结点;
682 | 2. 在内核cache里建了个红黑树用于存储以后epoll_ctl传来的socket;
683 | 3. 建立一个list链表,用于存储准备就绪的事件。
684 |
685 | 2. 调用epoll_ctl
686 |
687 | 1. 把socket放到epoll文件系统里file对象对应的红黑树上;
688 | 2. 给内核中断处理程序注册一个回调函数,告诉内核,如果这个句柄的中断到了,就把它放到准备就绪list链表里。
689 |
690 | 3. 调用epoll_wait
691 |
692 | 观察list链表里有没有数据。有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。而且,通常情况下即使我们要监控百万计的句柄,大多一次也只返回很少量的准备就绪句柄而已,所以,epoll_wait仅需要从内核态copy少量的句柄到用户态而已。
693 |
694 | **select缺点:**
695 |
696 | 1. 最大并发数限制:使用32个整数的32位,即32*32=1024来标识fd,虽然可修改,但是有以下第二点的瓶颈;
697 | 2. 效率低:每次都会线性扫描整个fd_set,集合越大速度越慢;
698 | 3. 内核/用户空间内存拷贝问题。
699 |
700 | **epoll的提升:**
701 |
702 | 1. 本身没有最大并发连接的限制,仅受系统中进程能打开的最大文件数目限制;
703 | 2. 效率提升:只有活跃的socket才会主动的去调用callback函数;
704 | 3. 省去不必要的内存拷贝:epoll通过内核与用户空间mmap同一块内存实现。
705 |
706 | **总结:**需要看所有被观察的事件是否都活跃。
707 |
708 | 假设现在有1024个fd,select 和epoll 都同时维护他,假设这些fd 都是活跃的,这种情况下select一次扫描 可以扫描1024个fd,空闲的fd很少,但是epoll 就有可能不一样了, epoll 是先注册等待回调, 有可能出现1024次回调。所以不好说。
709 |
710 | 如果select 和epoll 同时维护1024个fd ,但是每次只有一个fd有事件,这种情况下 select 每次都会扫描所有的fd, 对比于epoll 每次只有一个fd 回调。 select 做了很多无用功, 此时应该epoll的效率高吧!!
711 |
712 | 或者在短连接多的时候, 一个连接使用epoll 会触发epoll_ctrl_add/del 两次系统调用,但是select 只有一次扫描 ,此时 也许select 效率性能更高。
713 |
714 | ## epoll的水平触发模式(LT)
715 |
716 | 默认模式
717 |
718 | 在LT(水平触发)模式下,只要这个文件描述符还有数据可读,每次 epoll_wait都会返回它的事件,提醒用户程序去操作。
719 |
720 | ## epoll的边缘触发模式(ET)
721 |
722 | ET(边缘触发)模式下,在它检测到有 I/O 事件时,通过 epoll_wait 调用会得到有事件通知的文件描述符,**对于每一个被通知的文件描述符,如可读,则必须将该文件描述符一直读到空**,让 errno 返回 EAGAIN 为止,否则下次的 epoll_wait 不会返回余下的数据,会丢掉事件。如果ET模式不是非阻塞的,那这个一直读或一直写势必会在最后一次阻塞。
723 |
724 | 为什么会有ET模式?
725 |
726 | 答:如果采用EPOLLLT模式的话,系统中一旦有大量你不需要读写的就绪文件描述符,它们每次调用epoll_wait都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率.。而采用EPOLLET这种边缘触发模式的话,当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符。减少epoll_wait的调用次数,系统调用开销是很大的
727 |
728 |
729 |
730 | # tcp 在调用connect失败后要不要重新socket?
731 |
732 | connect(套接字默认阻塞)出错返回的情况:
733 |
734 | 1. 调用connect时内核发送一个SYN分节,若无响应则等待6s后再次发送一个,仍无响应则等待24s再发送一个,若总共等了75s后仍未收到响应则返回ETIMEDOUT错误;
735 |
736 | 2. 若对客户的SYN的响应是RST,则表示该服务器主机在我们指定的端口上面没有进程在等待与之连接,例如服务器进程没运行,客户收到RST就马上返回ECONNREFUSED错误;
737 |
738 | 3. 若客户发出的SYN在中间的某个路由上引发了一个“destination unreachable”(目的不可达)ICMP错误,客户主机内核保存该消息,并按1中所述的时间间隔发送SYN,在某个规定的时间(4.4BSD规定75s)仍未收到响应,则把保存的ICMP错误作为EHOSTUNREACH或ENETUNREACH错误返回给进程。
739 |
740 | 若connect失败则该套接字不再可用,必须关闭,我们不能对这样的套接字再次调用connect函数。在每次connect失败后,都必须close当前套接字描述符并重新调用socket。
741 |
742 |
743 |
744 | # Linux零拷贝技术
745 |
746 | splice( )函数
747 |
748 | tee( )函数
749 |
750 | ## **概述:**
751 |
752 | 零拷贝(Zero-Copy)是一种 `I/O` 操作优化技术,可以快速高效地将数据从文件系统移动到网络接口,而不需要将其从内核空间复制到用户空间。其在 `FTP` 或者 `HTTP` 等协议中可以显著地提升性能。
753 |
754 | ## **由来:**
755 |
756 | 如果服务端要提供文件传输的功能,我们能想到的最简单的方式是:将磁盘上的文件读取出来,然后通过网络协议发送给客户端。传统 I/O 的工作方式是,数据读取和写入是从用户空间到内核空间的复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。其过程如下图所示:
757 |
758 | 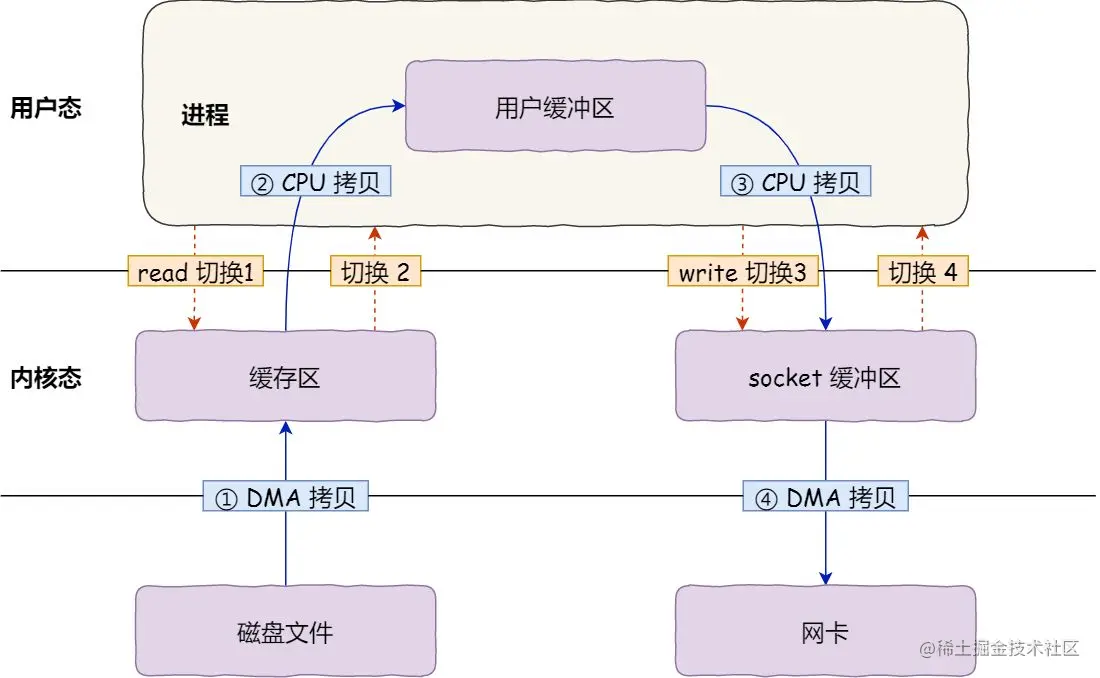 759 |
760 | 可以想想一下这个过程。服务器读从磁盘读取文件的时候,发生一次系统调用,产生用户态到内核态的转换,将磁盘文件拷贝到内核的内存中。然后将位于内核内存中的文件数据拷贝到用户的缓冲区中。用户应用缓冲区需要将这些数据发送到socket缓冲区中,进行一次用户态到内核态的转换,复制这些数据。此时这些数据在内核的socket的缓冲区中,在进行一次拷贝放到网卡上发送出去。
761 |
762 | 所以整个过程一共进行了四次拷贝,四次内核和用户态的切换。这种简单又传统的文件传输方式,存在冗余的上文切换和数据拷贝,在高并发系统里是非常糟糕的,多了很多不必要的开销,会严重影响系统性能。
763 |
764 | ## 零拷贝原理
765 |
766 | 零拷贝主要是用来解决操作系统在处理 I/O 操作时,频繁复制数据的问题。关于零拷贝主要技术有 `mmap+write`、`sendfile`和`splice`等几种方式。
767 |
768 | 看完下图会发现其实零拷贝就是少了CPU拷贝这一步,磁盘拷贝还是要有的
769 |
770 | - mmap/write 方式
771 |
772 |
759 |
760 | 可以想想一下这个过程。服务器读从磁盘读取文件的时候,发生一次系统调用,产生用户态到内核态的转换,将磁盘文件拷贝到内核的内存中。然后将位于内核内存中的文件数据拷贝到用户的缓冲区中。用户应用缓冲区需要将这些数据发送到socket缓冲区中,进行一次用户态到内核态的转换,复制这些数据。此时这些数据在内核的socket的缓冲区中,在进行一次拷贝放到网卡上发送出去。
761 |
762 | 所以整个过程一共进行了四次拷贝,四次内核和用户态的切换。这种简单又传统的文件传输方式,存在冗余的上文切换和数据拷贝,在高并发系统里是非常糟糕的,多了很多不必要的开销,会严重影响系统性能。
763 |
764 | ## 零拷贝原理
765 |
766 | 零拷贝主要是用来解决操作系统在处理 I/O 操作时,频繁复制数据的问题。关于零拷贝主要技术有 `mmap+write`、`sendfile`和`splice`等几种方式。
767 |
768 | 看完下图会发现其实零拷贝就是少了CPU拷贝这一步,磁盘拷贝还是要有的
769 |
770 | - mmap/write 方式
771 |
772 | 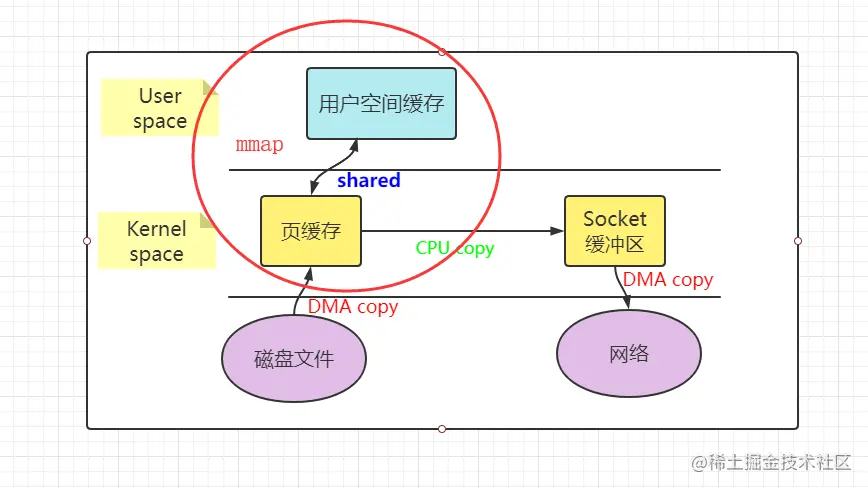 773 |
774 | 把数据读取到内核缓冲区后,应用程序进行写入操作时,直接把内核的`Read Buffer`的数据复制到`Socket Buffer`以便写入,这次内核之间的复制也是需要CPU的参与的。
775 |
776 | - sendfile 方式
777 |
778 |
773 |
774 | 把数据读取到内核缓冲区后,应用程序进行写入操作时,直接把内核的`Read Buffer`的数据复制到`Socket Buffer`以便写入,这次内核之间的复制也是需要CPU的参与的。
775 |
776 | - sendfile 方式
777 |
778 | 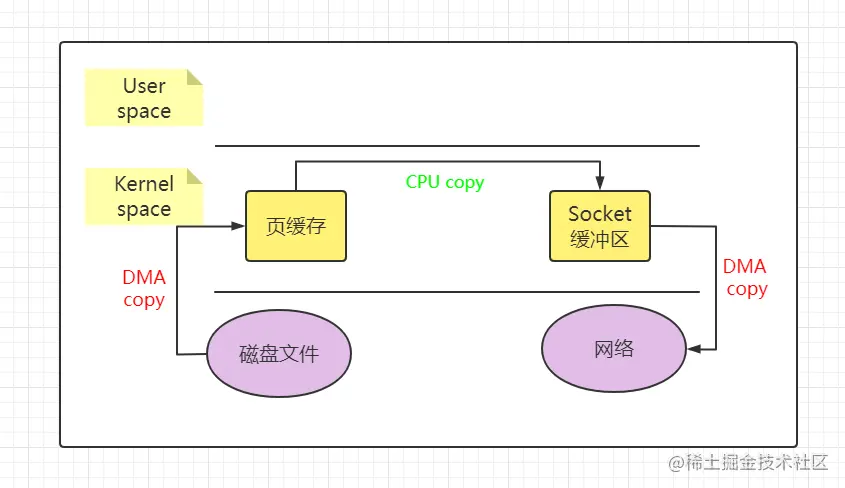 779 |
780 | 可以看到使用sendfile后,没有用户空间的参与,一切操作都在内核中进行。但是还是需要1次拷贝
781 |
782 | - 带有 scatter/gather 的 sendfile方式
783 |
784 | Linux 2.4 内核进行了优化,提供了带有 `scatter/gather` 的 sendfile 操作,这个操作可以把最后一次 `CPU COPY` 去除。其原理就是在内核空间 Read BUffer 和 Socket Buffer 不做数据复制,而是将 Read Buffer 的内存地址、偏移量记录到相应的 Socket Buffer 中,这样就不需要复制。其本质和虚拟内存的解决方法思路一致,就是内存地址的记录。
785 |
786 | **注意: sendfile适用于文件数据到网卡的传输过程,并且用户程序对数据没有修改的场景;**
787 |
788 | - splice 方式
789 |
790 |
779 |
780 | 可以看到使用sendfile后,没有用户空间的参与,一切操作都在内核中进行。但是还是需要1次拷贝
781 |
782 | - 带有 scatter/gather 的 sendfile方式
783 |
784 | Linux 2.4 内核进行了优化,提供了带有 `scatter/gather` 的 sendfile 操作,这个操作可以把最后一次 `CPU COPY` 去除。其原理就是在内核空间 Read BUffer 和 Socket Buffer 不做数据复制,而是将 Read Buffer 的内存地址、偏移量记录到相应的 Socket Buffer 中,这样就不需要复制。其本质和虚拟内存的解决方法思路一致,就是内存地址的记录。
785 |
786 | **注意: sendfile适用于文件数据到网卡的传输过程,并且用户程序对数据没有修改的场景;**
787 |
788 | - splice 方式
789 |
790 | 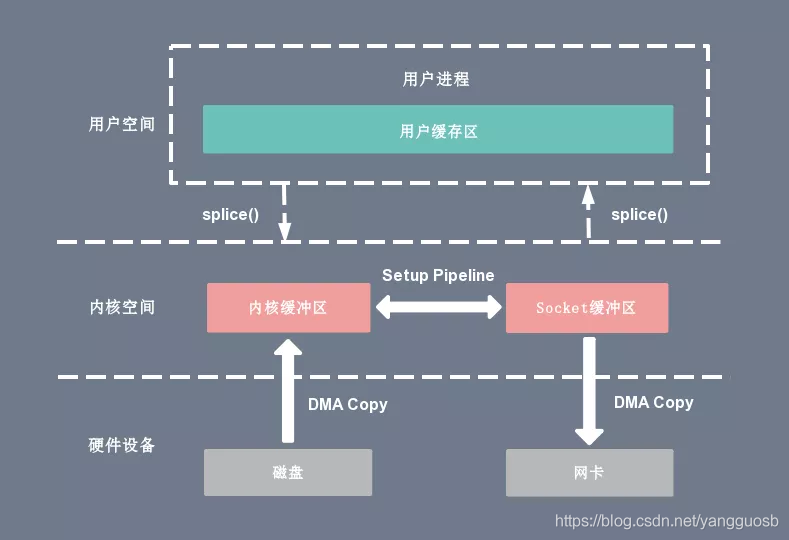 791 |
792 | 其实就是CPU 在内核空间的读缓冲区(read buffer)和网络缓冲区(socket buffer)之间建立管道(pipeline)直接把数据传过去了,不去要CPU复制了
793 |
794 |
795 |
796 |
797 |
798 | # accept()、connect()发生在三次握手的哪一步?
799 |
800 |
791 |
792 | 其实就是CPU 在内核空间的读缓冲区(read buffer)和网络缓冲区(socket buffer)之间建立管道(pipeline)直接把数据传过去了,不去要CPU复制了
793 |
794 |
795 |
796 |
797 |
798 | # accept()、connect()发生在三次握手的哪一步?
799 |
800 |  801 |
802 | 看上图就很明白了,刚准备发SYN同步报文时候,connect函数阻塞,然后服务端收到SYN同步报文的时候,调用accept()阻塞,服务器发送SYN+ACK给客户端,此时connect连接上就返回了,然后等服务器收到ACK报文时,accept也返回。
803 |
804 | 所以只说返回状态的话connect成功返回是在第二步,accept成功返回是在第三步
805 |
806 |
807 |
808 | # accept的队列
809 |
810 | 处于“LISTENING”状态的TCP socket,有两个独立的队列:
811 |
812 | 1. SYN队列(SYN Queue)
813 | 2. Accept队列(Accept Queue)
814 |
815 | **SYN队列**
816 |
817 | SYN队列存储了收到SYN包的连接(对应内核代码的结构体: struct inet_request_sock)。它的职责是回复SYN+ACK包,并且在没有收到ACK包时重传,直到超时。发送完SYN+ACK之后,SYN队列等待从客户端发出的ACK包(也即三次握手的最后一个包)。当收到ACK包时,首先找到对应的SYN队列,再在对应的SYN队列中检查相关的数据看是否匹配,如果匹配,内核将该连接相关的数据从SYN队列中移除
818 |
819 | **accept队列**
820 |
821 | 内核将该连接相关的数据从SYN队列中移除,创建一个完整的连接(对应内核代码的结构体: struct inet_sock ),并将这个连接加入Accept队列。Accept队列中存放的是已建立好的连接,也即等待被上层应用程序取走的连接。当进程调用accept(),这个socket从队列中取出,传递给上层应用程序。一般来说都是select或者epoll上有事件发生时再取走
822 |
823 |
824 |
825 | # 调用close()在哪一步?
826 |
827 |
801 |
802 | 看上图就很明白了,刚准备发SYN同步报文时候,connect函数阻塞,然后服务端收到SYN同步报文的时候,调用accept()阻塞,服务器发送SYN+ACK给客户端,此时connect连接上就返回了,然后等服务器收到ACK报文时,accept也返回。
803 |
804 | 所以只说返回状态的话connect成功返回是在第二步,accept成功返回是在第三步
805 |
806 |
807 |
808 | # accept的队列
809 |
810 | 处于“LISTENING”状态的TCP socket,有两个独立的队列:
811 |
812 | 1. SYN队列(SYN Queue)
813 | 2. Accept队列(Accept Queue)
814 |
815 | **SYN队列**
816 |
817 | SYN队列存储了收到SYN包的连接(对应内核代码的结构体: struct inet_request_sock)。它的职责是回复SYN+ACK包,并且在没有收到ACK包时重传,直到超时。发送完SYN+ACK之后,SYN队列等待从客户端发出的ACK包(也即三次握手的最后一个包)。当收到ACK包时,首先找到对应的SYN队列,再在对应的SYN队列中检查相关的数据看是否匹配,如果匹配,内核将该连接相关的数据从SYN队列中移除
818 |
819 | **accept队列**
820 |
821 | 内核将该连接相关的数据从SYN队列中移除,创建一个完整的连接(对应内核代码的结构体: struct inet_sock ),并将这个连接加入Accept队列。Accept队列中存放的是已建立好的连接,也即等待被上层应用程序取走的连接。当进程调用accept(),这个socket从队列中取出,传递给上层应用程序。一般来说都是select或者epoll上有事件发生时再取走
822 |
823 |
824 |
825 | # 调用close()在哪一步?
826 |
827 |  828 |
829 | 首先注意EOF这个东西。当客户端调用close主动断开时,会在FIN报文后面放入一个文件结束符EOF,会放在服务器端读缓存队列的最后,当接收到EOF时,服务器需要处理这种异常情况,表示以后不会有任何数据到达。因此服务器会返回一个ACK确认报文然后进入closed_wait状态
830 |
831 | 等服务器处理完后,发送FIN报文后也调用close。
832 |
833 |
834 |
835 | # Posix 信号量与System v信号量的区别
836 |
837 | [参考](https://blog.csdn.net/weixin_41413441/article/details/81239859)
838 |
839 | [参考](https://bbs.huaweicloud.com/blogs/detail/232525)
840 |
841 | [参考](https://www.cnblogs.com/sparkdev/p/8692567.html)
842 |
843 | Posix:是“可移植操作系统接口(Portable Operating System Interface )的首字母简写,但它并不是一个单一的标准,而是一个电气与电子工程学会即IEEE开发的一系列标准,它还是由ISO(国际标准化组织)和IEC(国际电工委员会)采纳的国际标准。
844 |
845 | System v是Unix操作系统众多版本的一个分支,它最初是由AT&T在1983年第一次发布,System v一共有四个版本,而最成功的是System V Release 4,或者称为SVR4。这样看来,一个是Unix 的标准之一(另一个标准是Open Group),一个是Unix众多版本的分支之一(其他的分支还有Linux跟BSD),应该来说,Posix标准正变得越来越流行,很多厂家开始采用这一标准。
846 |
847 | 区别如下:
848 |
849 | 1. System v信号量指的是计数信号量集;Posix 信号量指的是单个计数信号量。
850 | 2. Posix信号量是基于内存的,即信号量值是放在共享内存中的,它是由可能与文件系统中的路径名对应的名字来标识的。System v信号量测试基于内核的,它放在内核里面,相同点都是它们都可以用于进程或者线程间的同步。
851 | 3. POSIX信号量常用于线程;system v信号量常用于进程的同步。
852 | 4. POSIX 信号量的头文件是 ,而 System V 信号量的头文件是 。
853 |
854 |
855 |
856 | # 信号通知流程和处理机制
857 |
858 | Linux下的信号采用的异步处理机制,信号处理函数和当前进程是两条不同的执行路线。具体的,当进程收到信号时,操作系统会中断进程当前的正常流程,转而进入信号处理函数执行操作,完成后再返回中断的地方继续执行。为避免信号竞态现象发生,信号处理期间系统不会再次触发它。所以,为确保该信号不被屏蔽太久,信号处理函数需要尽可能快地执行完毕。
859 |
860 | 一般的信号处理函数需要处理该信号对应的逻辑,当该逻辑比较复杂时,信号处理函数执行时间过长,会导致信号屏蔽太久。提供一种解决方案是,信号处理函数仅仅发送信号通知程序主循环,将信号对应的处理逻辑放在程序主循环中,由主循环执行信号对应的逻辑代码。
861 |
862 | > **统一事件源**
863 | >
864 | > 统一事件源,是指将信号事件与其他事件一样被处理。
865 | >
866 | > 具体的,信号处理函数使用管道将信号传递给主循环,信号处理函数往管道的写端写入信号值,主循环则从管道的读端读出信号值,使用I/O复用系统调用来监听管道读端的可读事件,这样信号事件与其他文件描述符都可以通过epoll来监测,从而实现统一处理。
867 |
868 | 信号处理机制如下图:
869 |
870 | 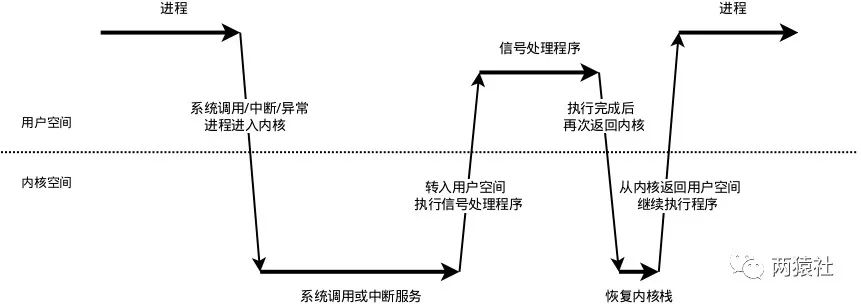
871 |
872 | - 信号的接收
873 |
874 | - 接收信号的任务是由内核代理的,当内核接收到信号后,会将其放到对应进程的信号队列中,同时向进程发送一个中断,使其陷入内核态。注意,此时信号还只是在队列中,对进程来说暂时是不知道有信号到来的。
875 |
876 | - 信号的检测
877 |
878 | - 进程从内核态返回到用户态前进行信号检测
879 |
880 | - 进程在内核态中,从睡眠状态被唤醒的时候进行信号检测
881 | - 进程陷入内核态后,有两种场景会对信号进行检测:
882 | - 当发现有新信号时,便会进入下一步,信号的处理。
883 |
884 | - 信号的处理
885 |
886 | - ( **内核** )信号处理函数是运行在用户态的,调用处理函数前,内核会将当前内核栈的内容备份拷贝到用户栈上,并且修改指令寄存器(eip)将其指向信号处理函数。
887 |
888 | - ( **用户** )接下来进程返回到用户态中,执行相应的信号处理函数。
889 | - ( **内核** )信号处理函数执行完成后,还需要返回内核态,检查是否还有其它信号未处理。
890 | - ( **用户** )如果所有信号都处理完成,就会将内核栈恢复(从用户栈的备份拷贝回来),同时恢复指令寄存器(eip)将其指向中断前的运行位置,最后回到用户态继续执行进程。
891 |
892 | - 至此,一个完整的信号处理流程便结束了,如果同时有多个信号到达,上面的处理流程会在第2步和第3步骤间重复进行。
893 |
894 |
895 |
896 | # 服务器端有100万个TCP长连接,可能会出现的问题
897 |
898 | [参考1](https://www.zhihu.com/question/20831000)
899 |
900 | [参考2](http://www.blogjava.net/yongboy/archive/2013/04/11/397677.html)
901 |
902 |
903 |
904 | # epoll是同步还是异步的?
905 |
906 | 1.
907 | IO层面
908 | 2. 消息处理层面
909 | 3. 从IO层面来看,epoll绝对是同步的;
910 | 4. 从消息处理层面来看,epoll是异步的.
911 |
912 | select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的(可能通过while循环来检测内核将数据准备的怎么样了, 而不是属于内核的一种通知用户态机制),仍然需要read、write去读写数据。
913 |
914 | 用户线程定期轮询epoll文件描述符上的事件,事件发生后,读取事件对应的epoll_data,该结构中包含了文件fd和数据地址,由于采用了mmap,程序可以直接读取数据(epoll_wait函数)。有人把epoll这种方式叫做同步非阻塞(NIO),因为用户线程需要不停地轮询,自己读取数据,看上去好像只有一个线程在做事情。也有人把这种方式叫做异步非阻塞(AIO),因为毕竟是内核线程负责扫描fd列表,并填充事件链表的。个人认为真正理想的异步非阻塞,应该是内核线程填充事件链表后,主动通知用户线程,或者调用应用程序事先注册的回调函数来处理数据,如果还需要用户线程不停的轮询来获取事件信息,就不是太完美了,所以也有不少人认为epoll是伪AIO,还是有道理的。
915 |
916 | # 原子操作的原理
917 |
918 | 原子操作(atomic operation)意为”不可被中断的一个或一系列操作”
919 |
920 |
921 |
922 | # signal机制
923 |
924 |
925 |
926 | # 使用epoll或select时需要将socket设为非阻塞吗?
927 |
928 | **先说结论:**
929 |
930 | 需要的。但是一个 socket 是否设置为阻塞模式,只会影响到 connect/accept/send/recv 等四个 socket API 函数,不会影响到 select/poll/epoll_wait 函数,后三个函数的超时或者阻塞时间是由其函数自身参数控制的。
931 |
932 | **socket 是否被设置成阻塞模式对下列 API 造成的影响:**
933 |
934 | connfd:该端调用 connect 函数主动发起连接;
935 |
936 | listenfd:调用 listen 函数发起侦听的一端(服务端);即监听的socket
937 |
938 | clientfd:调用 accept 函数接受连接,由 accept 函数返回的 socket(服务端)。即连接的socket
939 |
940 | 当connfd 被设置成阻塞模式时(默认行为,无需设置),connect 函数会一直阻塞到连接成功或超时或出错,超时值需要修改内核参数。当 connfd 被设置成非阻塞模式,无论连接是否建立成功,connect 函数都会立刻返回,那如何判断 connect 函数是否连接成功呢?接下来使用 select 和 epoll_wait 函数去判断 socket 是否可写即可,当然,Linux 系统上还需要额外加一步——使用 getsockopt 函数判断此时 socket 是否有错误(因为select中通知有数据达到但是可能数据error checksum或者discard了),这就是所谓的异步 connect 或者叫非阻塞 connect。
941 |
942 | 当 listenfd 设置成阻塞模式(默认行为,无需额外设置)时,如果连接 pending(待办) 队列中有需要处理的连接,accept 函数会立即返回,否则会一直阻塞下去,直到有新的连接到来。当 listenfd 设置成非阻塞模式,无论连接 pending 队列中是否有需要处理的连接,accept 都会立即返回,不会阻塞。如果有连接,则 accept 返回一个大于 0 的值,这个返回值即是我们上文所说的 clientfd;如果没有连接,accept 返回值小于 0,错误码 errno 为 EWOULDBLOCK(或者是 EAGAIN,这两个错误码值相等)。
943 |
944 | 当 connfd 或 clientfd 设置成阻塞模式时:send 函数会尝试发送数据,如果对端因为 TCP 窗口太小导致本端无法将数据发送出去,send 函数会一直阻塞直到对端 TCP 窗口变大足以发数据或者超时;recv 函数则正好相反,如果此时没有数据可收获,recv函数会一直阻塞直到收取到数据或者超时,有的话,取到数据后返回。send 和 recv 函数的超时时间可以分别使用 SO_SNDTIMEO 和 SO_RCVTIMEO 两个 socket 选项来设置。当 connfd 或 clientfd 设置成非阻塞模式时,send 和 recv 函数都会立即返回,send 函数即使因为对端 TCP 窗口太小发不出去也会立即返回,recv 函数如果无数据可收也会立即返回,此时这两个函数的返回值都是 -1,错误码 errno 是 EWOULDBLOCK(或 EAGIN,与上面同)。
945 |
946 | **select/poll/epoll_wait 函数的等待或超时时间**
947 |
948 | select、poll、epoll_wait 函数的超时时间分别由传给各自函数的时间参数决定的,我们来看下这三个函数的签名:
949 |
950 | ```c
951 | int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
952 | int poll(struct pollfd *fds, nfds_t nfds, int timeout);
953 | int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
954 | ```
955 |
956 | 三个函数最后一个参数是 timeout,只不过 select 函数的 timeout 参数的类型是一个结构体指针
957 |
958 | select 函数的 timeout 参数含义有三种:
959 |
960 | 1. timeout 为 NULL 时,select 函数将一直阻塞下去,直到出错或者绑定其上的 socket 有事件;
961 | 2. 当 timeout->tv_sec 和 timeout->tv_usec 同时为 0 时,select 函数会检查一下绑定在其上的 socket 是否有事件,然后立刻返回;
962 | 3. 当 timeout->tv_sec 和 timeout->tv_usec 之和大于 0 时,select 函数检测到绑定其上的 socket 有时间才会返回或者阻塞时长为 timeout->tv_sec + timeout->tv_usec 。
963 |
964 | poll 和 epoll_wait 函数的超时时间为毫秒,设置为 0,和 select 函数一样,检测一下绑定其上的 socket 是否有事件,然后立即返回。
965 |
966 | **为什么使用epoll时候需要将socket设置成阻塞的?**
967 |
968 | 首先epoll 模型通常用于服务端,那讨论的 socket 只有 listenfd 和 clientfd 了。
969 |
970 | 对于listenfd,可以阻塞可以非阻塞。有很多的服务器程序结构确实采用的就是阻塞的 listenfd,为了不让 accept 函数在没有连接时阻塞对程序其他逻辑执行流造成影响,我们通常将 accept 函数放在一个独立的线程中。但是如果不在一个独立线程中获得listenfd的话,如果默认一个监听socket是阻塞的话,有如下场景:客户端通过connect向服务器发起三次握手,三次握手后触发select或者epoll上的事件,但是呢此时客户端发送过来RST报文取消了连接,而此时服务器端调用了accept接收了次连接区去内核队列中取时内核队列中是空的(因为该客户端连接被取消),那么服务器就会阻塞在accept调用,无法响应其他就绪的监听socket,所以我们要吧监听socket即listenfd也设置为阻塞的。
971 |
972 | 对于clientfd,主要涉及到的是读写的问题。当读取的数据很小,比如有个buffer是1024字节,读取的数据小于1024的话,水平边缘触发搭配阻塞和非阻塞其实都一样。那么很多时候我们接受的数据都很大,一个buffer装不下,就需要while循环多次读。那么这种情况水平触发模式显得很鸡肋,阻塞和非阻塞效果都一样。所以我们主要讨论的是边缘触发情况下clientfd的阻塞和非阻塞。首先是ET+阻塞的情况,当最后一个数据读取完后,程序是无法立刻跳出while循环的,因为阻塞IO会在 while(true){ int len=recv(); }这里阻塞住,除非对方关闭连接或者recv出错,这样程序就无法继续往下执行,因为我就绪的文件描述符都在等着处理,这一次的epoll_wait没有办法处理其它的连接,会造成延迟、并发度下降。其次的话select或者epoll返回可读,和recv去读,这是两个独立的系统调用,两个操作之间是有窗口的,也就是说 select 返回可读,紧接着去 read,不能保证一定可读。man select中说了数据到达了但是可能error checksum或者discard了,如果你用阻塞的,就阻塞了进行不下去,这显然不行。如果是ET+非阻塞IO的话,当读取完数据后,recv会立即返回-1,并将errno设置为EAGAIN或EWOULDBLOCK,这就表示数据已经读取完成,已经没有数据了,可以退出循环了。这样就不会像阻塞IO一样卡在那里,这就减少了不必要的等待时间,性能自然更高。
973 |
974 |
975 |
976 |
977 |
978 | # 用过哪些linux命令?
979 |
980 | ## top
981 |
982 | top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
983 |
984 | 常用命令如下:
985 |
986 | 1. P:按%CPU使用率排行
987 | 2. M:按%MEM排行
988 | 3. T: 根据时间/累计时间进行排序。
989 |
990 | ## scp
991 |
992 | 用于不同linux主机之间复制文件的
993 |
994 | ```shell
995 | scp local_file remote_username@remote_ip:remote_file
996 | ```
997 |
998 | ## find
999 |
1000 | 找文件名
1001 |
1002 | ```shell
1003 | find . -name '[A-Z]*.txt' -print
1004 | ```
1005 |
1006 | ## sar
1007 |
1008 | `sar`(System Activity Reporter 系统活动情况报告)是目前 Linux 上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘 I/O、CPU 效率、内存使用状况、进程活动及 IPC 有关的活动等。我们可以使用`sar`命令来获得整个系统性能的报告。这有助于我们定位系统性能的瓶颈,并且有助于我们找出这些烦人的性能问题的解决方法。
1009 |
1010 | [参考](https://shockerli.net/post/linux-tool-sar/)
1011 |
1012 | ## tar
1013 |
1014 | ## df
1015 |
1016 | 用来检查linux服务器的文件系统的磁盘空间占用情况。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
1017 |
1018 | ## free
1019 |
1020 | 显示Linux系统中空闲的、已用的物理内存及swap内存,及被内核使用的buffer。在Linux系统监控的工具中,free命令是最经常使用的命令之一。
1021 |
1022 | total:总计物理内存的大小。
1023 |
1024 | used:已使用多大。
1025 |
1026 | free:可用有多少。
1027 |
1028 | ## netstat
1029 |
1030 | Netstat 命令用于显示各种网络相关信息,如网络连接,路由表,实际的网络连接以及每一个网络接口设备的状态信息。Netstat用于显示与IP、TCP、UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况。
1031 |
1032 | - 直接使用netstat
1033 |
1034 | 输出结果可以分为两个部分:一个是Active Internet connections,称为有源TCP连接,其中"Recv-Q"和"Send-Q"指%0A的是接收队列和发送队列。这些数字一般都应该是0。如果不是则表示软件包正在队列中堆积。这种情况只能在非常少的情况见到。另一个是Active UNIX domain sockets,称为有源Unix域套接口(和网络套接字一样,但是只能用于本机通信,性能可以提高一倍)。
1035 | Proto显示连接使用的协议,RefCnt表示连接到本套接口上的进程号,Types显示套接口的类型,State显示套接口当前的状态,Path表示连接到套接口的其它进程使用的路径名。
1036 |
1037 | - 列出所有端口 #netstat -a
1038 |
1039 | - 列出所有 tcp 端口 #netstat -at
1040 |
1041 | - 列出所有 udp 端口 #netstat -au
1042 |
1043 | ## traceroute
1044 |
1045 | 追踪网络数据包的路由途径,预设数据包大小是40Bytes。
1046 |
1047 | ## route
1048 |
1049 | 跟路由表相关的命令
1050 |
1051 | 可以查看(route),增加(route add -net 224.0.0.0 netmask 240.0.0.0 dev eth0),删除(route del -net 224.0.0.0 netmask 240.0.0.0)
1052 |
1053 | ## ip
1054 |
1055 | linux的ip命令和ifconfig类似,但前者功能更强大,并旨在取代后者。使用ip命令,只需一个命令,你就能很轻松地执行一些网络管理任务。ifconfig是net-tools中已被废弃使用的一个命令,许多年前就已经没有维护了。iproute2套件里提供了许多增强功能的命令,ip命令即是其中之一。
1056 |
1057 |
1058 |
1059 | # Linux惊群效应详解
1060 |
1061 | [参考链接](https://mp.weixin.qq.com/s?__biz=MzU1ODEzNjI2NA==&mid=2247487207&idx=1&sn=08d1a44dcfe978bd97e6735e8e044d06&source=41#wechat_redirect)
1062 |
1063 | **定义:**惊群效应(thundering herd)是指多进程(多线程)在同时阻塞等待同一个事件的时候(休眠状态),如果等待的这个事件发生,那么他就会唤醒等待的所有进程(或者线程),但是最终却只能有一个进程(线程)获得这个时间的“控制权”,对该事件进行处理,而其他进程(线程)获取“控制权”失败,只能重新进入休眠状态,这种现象和性能浪费就叫做惊群效应。
1064 |
1065 | **危害:**
1066 |
1067 | 1. Linux 内核对用户进程(线程)频繁地做无效的调度、上下文切换等使系统性能大打折扣。上下文切换(context switch)过高会导致 cpu 像个搬运工,频繁地在寄存器和运行队列之间奔波,更多的时间花在了进程(线程)切换,而不是在真正工作的进程(线程)上面。直接的消耗包括 cpu 寄存器要保存和加载(例如程序计数器)、系统调度器的代码需要执行。间接的消耗在于多核 cache 之间的共享数据。
1068 | 2. 为了确保只有一个进程(线程)得到资源,需要对资源操作进行加锁保护,加大了系统的开销。目前一些常见的服务器软件有的是通过锁机制解决的,比如 Nginx(它的锁机制是默认开启的,可以关闭);还有些认为惊群对系统性能影响不大,没有去处理,比如 lighttpd
1069 |
1070 | **Linux 解决方案之 Accept**
1071 |
1072 | Linux 2.6 版本之前,监听同一个 socket 的进程会挂在同一个等待队列上,当请求到来时,会唤醒所有等待的进程。Linux 2.6 版本之后,通过引入一个标记位 WQ_FLAG_EXCLUSIVE,解决掉了 Accept 惊群效应。
1073 |
1074 |
1075 |
1076 | # pthread_cond_wait 为什么需要传递 mutex 参数?
1077 |
1078 | 本质上这个问题想问这个锁是用来保护什么的?其实这个互斥锁不是用来保护条件变量的内部状态的,而是用来保护外部条件的,就是那个while()循环中的判断。
1079 |
1080 | 游双书里面说"pthread_cond_wait函数用于等待目标条件变量,mutex是保护条件变量的互斥锁,以确保pthread_cond_wait的原子性。"在看完这个回答你就该知道,**pthread_cond_wait的原子性指的是while条件判断成立和这个线程调用wait函数进入唤醒队列的原子性。**
1081 |
1082 | - 错误写法
1083 |
1084 | ```c
1085 | //threadA
1086 | pthread_mutex_lock(&mutex);
1087 | while (false == ready) {
1088 | pthread_cond_wait(&cond, &mutex);
1089 | }
1090 | pthread_mutex_unlock(&mutex);
1091 |
1092 | //threadB
1093 | ready = true;
1094 | pthread_cond_signal(&cond);
1095 | ```
1096 |
1097 | 这个写法为什么有错误?如图:
1098 |
1099 |
828 |
829 | 首先注意EOF这个东西。当客户端调用close主动断开时,会在FIN报文后面放入一个文件结束符EOF,会放在服务器端读缓存队列的最后,当接收到EOF时,服务器需要处理这种异常情况,表示以后不会有任何数据到达。因此服务器会返回一个ACK确认报文然后进入closed_wait状态
830 |
831 | 等服务器处理完后,发送FIN报文后也调用close。
832 |
833 |
834 |
835 | # Posix 信号量与System v信号量的区别
836 |
837 | [参考](https://blog.csdn.net/weixin_41413441/article/details/81239859)
838 |
839 | [参考](https://bbs.huaweicloud.com/blogs/detail/232525)
840 |
841 | [参考](https://www.cnblogs.com/sparkdev/p/8692567.html)
842 |
843 | Posix:是“可移植操作系统接口(Portable Operating System Interface )的首字母简写,但它并不是一个单一的标准,而是一个电气与电子工程学会即IEEE开发的一系列标准,它还是由ISO(国际标准化组织)和IEC(国际电工委员会)采纳的国际标准。
844 |
845 | System v是Unix操作系统众多版本的一个分支,它最初是由AT&T在1983年第一次发布,System v一共有四个版本,而最成功的是System V Release 4,或者称为SVR4。这样看来,一个是Unix 的标准之一(另一个标准是Open Group),一个是Unix众多版本的分支之一(其他的分支还有Linux跟BSD),应该来说,Posix标准正变得越来越流行,很多厂家开始采用这一标准。
846 |
847 | 区别如下:
848 |
849 | 1. System v信号量指的是计数信号量集;Posix 信号量指的是单个计数信号量。
850 | 2. Posix信号量是基于内存的,即信号量值是放在共享内存中的,它是由可能与文件系统中的路径名对应的名字来标识的。System v信号量测试基于内核的,它放在内核里面,相同点都是它们都可以用于进程或者线程间的同步。
851 | 3. POSIX信号量常用于线程;system v信号量常用于进程的同步。
852 | 4. POSIX 信号量的头文件是 ,而 System V 信号量的头文件是 。
853 |
854 |
855 |
856 | # 信号通知流程和处理机制
857 |
858 | Linux下的信号采用的异步处理机制,信号处理函数和当前进程是两条不同的执行路线。具体的,当进程收到信号时,操作系统会中断进程当前的正常流程,转而进入信号处理函数执行操作,完成后再返回中断的地方继续执行。为避免信号竞态现象发生,信号处理期间系统不会再次触发它。所以,为确保该信号不被屏蔽太久,信号处理函数需要尽可能快地执行完毕。
859 |
860 | 一般的信号处理函数需要处理该信号对应的逻辑,当该逻辑比较复杂时,信号处理函数执行时间过长,会导致信号屏蔽太久。提供一种解决方案是,信号处理函数仅仅发送信号通知程序主循环,将信号对应的处理逻辑放在程序主循环中,由主循环执行信号对应的逻辑代码。
861 |
862 | > **统一事件源**
863 | >
864 | > 统一事件源,是指将信号事件与其他事件一样被处理。
865 | >
866 | > 具体的,信号处理函数使用管道将信号传递给主循环,信号处理函数往管道的写端写入信号值,主循环则从管道的读端读出信号值,使用I/O复用系统调用来监听管道读端的可读事件,这样信号事件与其他文件描述符都可以通过epoll来监测,从而实现统一处理。
867 |
868 | 信号处理机制如下图:
869 |
870 | 
871 |
872 | - 信号的接收
873 |
874 | - 接收信号的任务是由内核代理的,当内核接收到信号后,会将其放到对应进程的信号队列中,同时向进程发送一个中断,使其陷入内核态。注意,此时信号还只是在队列中,对进程来说暂时是不知道有信号到来的。
875 |
876 | - 信号的检测
877 |
878 | - 进程从内核态返回到用户态前进行信号检测
879 |
880 | - 进程在内核态中,从睡眠状态被唤醒的时候进行信号检测
881 | - 进程陷入内核态后,有两种场景会对信号进行检测:
882 | - 当发现有新信号时,便会进入下一步,信号的处理。
883 |
884 | - 信号的处理
885 |
886 | - ( **内核** )信号处理函数是运行在用户态的,调用处理函数前,内核会将当前内核栈的内容备份拷贝到用户栈上,并且修改指令寄存器(eip)将其指向信号处理函数。
887 |
888 | - ( **用户** )接下来进程返回到用户态中,执行相应的信号处理函数。
889 | - ( **内核** )信号处理函数执行完成后,还需要返回内核态,检查是否还有其它信号未处理。
890 | - ( **用户** )如果所有信号都处理完成,就会将内核栈恢复(从用户栈的备份拷贝回来),同时恢复指令寄存器(eip)将其指向中断前的运行位置,最后回到用户态继续执行进程。
891 |
892 | - 至此,一个完整的信号处理流程便结束了,如果同时有多个信号到达,上面的处理流程会在第2步和第3步骤间重复进行。
893 |
894 |
895 |
896 | # 服务器端有100万个TCP长连接,可能会出现的问题
897 |
898 | [参考1](https://www.zhihu.com/question/20831000)
899 |
900 | [参考2](http://www.blogjava.net/yongboy/archive/2013/04/11/397677.html)
901 |
902 |
903 |
904 | # epoll是同步还是异步的?
905 |
906 | 1.
907 | IO层面
908 | 2. 消息处理层面
909 | 3. 从IO层面来看,epoll绝对是同步的;
910 | 4. 从消息处理层面来看,epoll是异步的.
911 |
912 | select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的(可能通过while循环来检测内核将数据准备的怎么样了, 而不是属于内核的一种通知用户态机制),仍然需要read、write去读写数据。
913 |
914 | 用户线程定期轮询epoll文件描述符上的事件,事件发生后,读取事件对应的epoll_data,该结构中包含了文件fd和数据地址,由于采用了mmap,程序可以直接读取数据(epoll_wait函数)。有人把epoll这种方式叫做同步非阻塞(NIO),因为用户线程需要不停地轮询,自己读取数据,看上去好像只有一个线程在做事情。也有人把这种方式叫做异步非阻塞(AIO),因为毕竟是内核线程负责扫描fd列表,并填充事件链表的。个人认为真正理想的异步非阻塞,应该是内核线程填充事件链表后,主动通知用户线程,或者调用应用程序事先注册的回调函数来处理数据,如果还需要用户线程不停的轮询来获取事件信息,就不是太完美了,所以也有不少人认为epoll是伪AIO,还是有道理的。
915 |
916 | # 原子操作的原理
917 |
918 | 原子操作(atomic operation)意为”不可被中断的一个或一系列操作”
919 |
920 |
921 |
922 | # signal机制
923 |
924 |
925 |
926 | # 使用epoll或select时需要将socket设为非阻塞吗?
927 |
928 | **先说结论:**
929 |
930 | 需要的。但是一个 socket 是否设置为阻塞模式,只会影响到 connect/accept/send/recv 等四个 socket API 函数,不会影响到 select/poll/epoll_wait 函数,后三个函数的超时或者阻塞时间是由其函数自身参数控制的。
931 |
932 | **socket 是否被设置成阻塞模式对下列 API 造成的影响:**
933 |
934 | connfd:该端调用 connect 函数主动发起连接;
935 |
936 | listenfd:调用 listen 函数发起侦听的一端(服务端);即监听的socket
937 |
938 | clientfd:调用 accept 函数接受连接,由 accept 函数返回的 socket(服务端)。即连接的socket
939 |
940 | 当connfd 被设置成阻塞模式时(默认行为,无需设置),connect 函数会一直阻塞到连接成功或超时或出错,超时值需要修改内核参数。当 connfd 被设置成非阻塞模式,无论连接是否建立成功,connect 函数都会立刻返回,那如何判断 connect 函数是否连接成功呢?接下来使用 select 和 epoll_wait 函数去判断 socket 是否可写即可,当然,Linux 系统上还需要额外加一步——使用 getsockopt 函数判断此时 socket 是否有错误(因为select中通知有数据达到但是可能数据error checksum或者discard了),这就是所谓的异步 connect 或者叫非阻塞 connect。
941 |
942 | 当 listenfd 设置成阻塞模式(默认行为,无需额外设置)时,如果连接 pending(待办) 队列中有需要处理的连接,accept 函数会立即返回,否则会一直阻塞下去,直到有新的连接到来。当 listenfd 设置成非阻塞模式,无论连接 pending 队列中是否有需要处理的连接,accept 都会立即返回,不会阻塞。如果有连接,则 accept 返回一个大于 0 的值,这个返回值即是我们上文所说的 clientfd;如果没有连接,accept 返回值小于 0,错误码 errno 为 EWOULDBLOCK(或者是 EAGAIN,这两个错误码值相等)。
943 |
944 | 当 connfd 或 clientfd 设置成阻塞模式时:send 函数会尝试发送数据,如果对端因为 TCP 窗口太小导致本端无法将数据发送出去,send 函数会一直阻塞直到对端 TCP 窗口变大足以发数据或者超时;recv 函数则正好相反,如果此时没有数据可收获,recv函数会一直阻塞直到收取到数据或者超时,有的话,取到数据后返回。send 和 recv 函数的超时时间可以分别使用 SO_SNDTIMEO 和 SO_RCVTIMEO 两个 socket 选项来设置。当 connfd 或 clientfd 设置成非阻塞模式时,send 和 recv 函数都会立即返回,send 函数即使因为对端 TCP 窗口太小发不出去也会立即返回,recv 函数如果无数据可收也会立即返回,此时这两个函数的返回值都是 -1,错误码 errno 是 EWOULDBLOCK(或 EAGIN,与上面同)。
945 |
946 | **select/poll/epoll_wait 函数的等待或超时时间**
947 |
948 | select、poll、epoll_wait 函数的超时时间分别由传给各自函数的时间参数决定的,我们来看下这三个函数的签名:
949 |
950 | ```c
951 | int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
952 | int poll(struct pollfd *fds, nfds_t nfds, int timeout);
953 | int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
954 | ```
955 |
956 | 三个函数最后一个参数是 timeout,只不过 select 函数的 timeout 参数的类型是一个结构体指针
957 |
958 | select 函数的 timeout 参数含义有三种:
959 |
960 | 1. timeout 为 NULL 时,select 函数将一直阻塞下去,直到出错或者绑定其上的 socket 有事件;
961 | 2. 当 timeout->tv_sec 和 timeout->tv_usec 同时为 0 时,select 函数会检查一下绑定在其上的 socket 是否有事件,然后立刻返回;
962 | 3. 当 timeout->tv_sec 和 timeout->tv_usec 之和大于 0 时,select 函数检测到绑定其上的 socket 有时间才会返回或者阻塞时长为 timeout->tv_sec + timeout->tv_usec 。
963 |
964 | poll 和 epoll_wait 函数的超时时间为毫秒,设置为 0,和 select 函数一样,检测一下绑定其上的 socket 是否有事件,然后立即返回。
965 |
966 | **为什么使用epoll时候需要将socket设置成阻塞的?**
967 |
968 | 首先epoll 模型通常用于服务端,那讨论的 socket 只有 listenfd 和 clientfd 了。
969 |
970 | 对于listenfd,可以阻塞可以非阻塞。有很多的服务器程序结构确实采用的就是阻塞的 listenfd,为了不让 accept 函数在没有连接时阻塞对程序其他逻辑执行流造成影响,我们通常将 accept 函数放在一个独立的线程中。但是如果不在一个独立线程中获得listenfd的话,如果默认一个监听socket是阻塞的话,有如下场景:客户端通过connect向服务器发起三次握手,三次握手后触发select或者epoll上的事件,但是呢此时客户端发送过来RST报文取消了连接,而此时服务器端调用了accept接收了次连接区去内核队列中取时内核队列中是空的(因为该客户端连接被取消),那么服务器就会阻塞在accept调用,无法响应其他就绪的监听socket,所以我们要吧监听socket即listenfd也设置为阻塞的。
971 |
972 | 对于clientfd,主要涉及到的是读写的问题。当读取的数据很小,比如有个buffer是1024字节,读取的数据小于1024的话,水平边缘触发搭配阻塞和非阻塞其实都一样。那么很多时候我们接受的数据都很大,一个buffer装不下,就需要while循环多次读。那么这种情况水平触发模式显得很鸡肋,阻塞和非阻塞效果都一样。所以我们主要讨论的是边缘触发情况下clientfd的阻塞和非阻塞。首先是ET+阻塞的情况,当最后一个数据读取完后,程序是无法立刻跳出while循环的,因为阻塞IO会在 while(true){ int len=recv(); }这里阻塞住,除非对方关闭连接或者recv出错,这样程序就无法继续往下执行,因为我就绪的文件描述符都在等着处理,这一次的epoll_wait没有办法处理其它的连接,会造成延迟、并发度下降。其次的话select或者epoll返回可读,和recv去读,这是两个独立的系统调用,两个操作之间是有窗口的,也就是说 select 返回可读,紧接着去 read,不能保证一定可读。man select中说了数据到达了但是可能error checksum或者discard了,如果你用阻塞的,就阻塞了进行不下去,这显然不行。如果是ET+非阻塞IO的话,当读取完数据后,recv会立即返回-1,并将errno设置为EAGAIN或EWOULDBLOCK,这就表示数据已经读取完成,已经没有数据了,可以退出循环了。这样就不会像阻塞IO一样卡在那里,这就减少了不必要的等待时间,性能自然更高。
973 |
974 |
975 |
976 |
977 |
978 | # 用过哪些linux命令?
979 |
980 | ## top
981 |
982 | top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
983 |
984 | 常用命令如下:
985 |
986 | 1. P:按%CPU使用率排行
987 | 2. M:按%MEM排行
988 | 3. T: 根据时间/累计时间进行排序。
989 |
990 | ## scp
991 |
992 | 用于不同linux主机之间复制文件的
993 |
994 | ```shell
995 | scp local_file remote_username@remote_ip:remote_file
996 | ```
997 |
998 | ## find
999 |
1000 | 找文件名
1001 |
1002 | ```shell
1003 | find . -name '[A-Z]*.txt' -print
1004 | ```
1005 |
1006 | ## sar
1007 |
1008 | `sar`(System Activity Reporter 系统活动情况报告)是目前 Linux 上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘 I/O、CPU 效率、内存使用状况、进程活动及 IPC 有关的活动等。我们可以使用`sar`命令来获得整个系统性能的报告。这有助于我们定位系统性能的瓶颈,并且有助于我们找出这些烦人的性能问题的解决方法。
1009 |
1010 | [参考](https://shockerli.net/post/linux-tool-sar/)
1011 |
1012 | ## tar
1013 |
1014 | ## df
1015 |
1016 | 用来检查linux服务器的文件系统的磁盘空间占用情况。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
1017 |
1018 | ## free
1019 |
1020 | 显示Linux系统中空闲的、已用的物理内存及swap内存,及被内核使用的buffer。在Linux系统监控的工具中,free命令是最经常使用的命令之一。
1021 |
1022 | total:总计物理内存的大小。
1023 |
1024 | used:已使用多大。
1025 |
1026 | free:可用有多少。
1027 |
1028 | ## netstat
1029 |
1030 | Netstat 命令用于显示各种网络相关信息,如网络连接,路由表,实际的网络连接以及每一个网络接口设备的状态信息。Netstat用于显示与IP、TCP、UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况。
1031 |
1032 | - 直接使用netstat
1033 |
1034 | 输出结果可以分为两个部分:一个是Active Internet connections,称为有源TCP连接,其中"Recv-Q"和"Send-Q"指%0A的是接收队列和发送队列。这些数字一般都应该是0。如果不是则表示软件包正在队列中堆积。这种情况只能在非常少的情况见到。另一个是Active UNIX domain sockets,称为有源Unix域套接口(和网络套接字一样,但是只能用于本机通信,性能可以提高一倍)。
1035 | Proto显示连接使用的协议,RefCnt表示连接到本套接口上的进程号,Types显示套接口的类型,State显示套接口当前的状态,Path表示连接到套接口的其它进程使用的路径名。
1036 |
1037 | - 列出所有端口 #netstat -a
1038 |
1039 | - 列出所有 tcp 端口 #netstat -at
1040 |
1041 | - 列出所有 udp 端口 #netstat -au
1042 |
1043 | ## traceroute
1044 |
1045 | 追踪网络数据包的路由途径,预设数据包大小是40Bytes。
1046 |
1047 | ## route
1048 |
1049 | 跟路由表相关的命令
1050 |
1051 | 可以查看(route),增加(route add -net 224.0.0.0 netmask 240.0.0.0 dev eth0),删除(route del -net 224.0.0.0 netmask 240.0.0.0)
1052 |
1053 | ## ip
1054 |
1055 | linux的ip命令和ifconfig类似,但前者功能更强大,并旨在取代后者。使用ip命令,只需一个命令,你就能很轻松地执行一些网络管理任务。ifconfig是net-tools中已被废弃使用的一个命令,许多年前就已经没有维护了。iproute2套件里提供了许多增强功能的命令,ip命令即是其中之一。
1056 |
1057 |
1058 |
1059 | # Linux惊群效应详解
1060 |
1061 | [参考链接](https://mp.weixin.qq.com/s?__biz=MzU1ODEzNjI2NA==&mid=2247487207&idx=1&sn=08d1a44dcfe978bd97e6735e8e044d06&source=41#wechat_redirect)
1062 |
1063 | **定义:**惊群效应(thundering herd)是指多进程(多线程)在同时阻塞等待同一个事件的时候(休眠状态),如果等待的这个事件发生,那么他就会唤醒等待的所有进程(或者线程),但是最终却只能有一个进程(线程)获得这个时间的“控制权”,对该事件进行处理,而其他进程(线程)获取“控制权”失败,只能重新进入休眠状态,这种现象和性能浪费就叫做惊群效应。
1064 |
1065 | **危害:**
1066 |
1067 | 1. Linux 内核对用户进程(线程)频繁地做无效的调度、上下文切换等使系统性能大打折扣。上下文切换(context switch)过高会导致 cpu 像个搬运工,频繁地在寄存器和运行队列之间奔波,更多的时间花在了进程(线程)切换,而不是在真正工作的进程(线程)上面。直接的消耗包括 cpu 寄存器要保存和加载(例如程序计数器)、系统调度器的代码需要执行。间接的消耗在于多核 cache 之间的共享数据。
1068 | 2. 为了确保只有一个进程(线程)得到资源,需要对资源操作进行加锁保护,加大了系统的开销。目前一些常见的服务器软件有的是通过锁机制解决的,比如 Nginx(它的锁机制是默认开启的,可以关闭);还有些认为惊群对系统性能影响不大,没有去处理,比如 lighttpd
1069 |
1070 | **Linux 解决方案之 Accept**
1071 |
1072 | Linux 2.6 版本之前,监听同一个 socket 的进程会挂在同一个等待队列上,当请求到来时,会唤醒所有等待的进程。Linux 2.6 版本之后,通过引入一个标记位 WQ_FLAG_EXCLUSIVE,解决掉了 Accept 惊群效应。
1073 |
1074 |
1075 |
1076 | # pthread_cond_wait 为什么需要传递 mutex 参数?
1077 |
1078 | 本质上这个问题想问这个锁是用来保护什么的?其实这个互斥锁不是用来保护条件变量的内部状态的,而是用来保护外部条件的,就是那个while()循环中的判断。
1079 |
1080 | 游双书里面说"pthread_cond_wait函数用于等待目标条件变量,mutex是保护条件变量的互斥锁,以确保pthread_cond_wait的原子性。"在看完这个回答你就该知道,**pthread_cond_wait的原子性指的是while条件判断成立和这个线程调用wait函数进入唤醒队列的原子性。**
1081 |
1082 | - 错误写法
1083 |
1084 | ```c
1085 | //threadA
1086 | pthread_mutex_lock(&mutex);
1087 | while (false == ready) {
1088 | pthread_cond_wait(&cond, &mutex);
1089 | }
1090 | pthread_mutex_unlock(&mutex);
1091 |
1092 | //threadB
1093 | ready = true;
1094 | pthread_cond_signal(&cond);
1095 | ```
1096 |
1097 | 这个写法为什么有错误?如图:
1098 |
1099 |  1100 |
1101 | ThreadA进入while循环后,准备进入唤醒队列,此时ThreadB进来横插一脚,把`ready`改成`true`然后提前唤醒,这个时候线程A还没有进入唤醒队列,因此A会丢失唤醒条件进而永久wait
1102 |
1103 | - 正确写法
1104 |
1105 | ```c
1106 | //Thread A
1107 | pthread_mutex_lock(&mutex);
1108 | while (false == ready) {
1109 | pthread_cond_wait(&cond, &mutex);
1110 | }
1111 | pthread_mutex_unlock(&mutex);
1112 |
1113 | //Thread B
1114 | pthread_mutex_lock(&mutex);
1115 | ready = true;
1116 | pthread_mutex_unlock(&mutex);
1117 | pthread_cond_signal(&cond);
1118 | ```
1119 |
1120 |
1121 | [参考链接](https://zhuanlan.zhihu.com/p/55123862)
1122 |
1123 |
1124 |
1125 | # 什么是虚假唤醒?
1126 |
1127 | 一般来说我们要在等待wait的时候用while循环。因为会产生虚假唤醒。
1128 |
1129 | pthread 的条件变量等待 `pthread_cond_wait` 是使用阻塞的系统调用实现的(比如 Linux 上的 `futex`),这些阻塞的系统调用在进程被信号中断后,通常会中止阻塞、直接返回 EINTR 错误。同样是阻塞系统调用,你从 `read` 拿到 EINTR 错误后可以直接决定重试,因为这通常不影响它本身的语义。而条件变量等待则不能,因为本线程拿到 EINTR 错误和重新调用 `futex` 等待之间,可能别的线程已经通过 `pthread_cond_signal` 或者 `pthread_cond_broadcast`发过通知了。所以,虚假唤醒的一个可能性是条件变量的等待被信号中断。
1130 |
1131 | 在多核处理器下,pthread_cond_signal可能会激活多于一个线程(阻塞在条件变量上的线程)。结果是,当一个线程调用pthread_cond_signal()后,因为多个线程都被唤醒了,很可能其中一个唤醒的线程,先一步改变的condition. 此时另一个线程的condition已经不满足,因此需要加Where再次判断。这种效应成为”**虚假唤醒**”(spurious wakeup)。所以我们把判断条件从if改成while,pthread_cond_wait中的while()不仅仅在等待条件变量**前**检查条件变量,实际上在等待条件变量**后**也检查条件变量。
1132 |
1133 |
1134 |
1135 | # 套接字文件描述符和端口号的关系
1136 |
1137 | 个socket句柄代表两个地址对 “本地ip:port”--“远程ip:port”
1138 |
1139 | 在windows下叫句柄,在linux下叫文件描述符
1140 |
1141 | socket为内核对象,由操作系统内核来维护其缓冲区,引用计数,并且可以在多个进程中使用。
1142 |
1143 |
1144 |
1145 | # 进程线程协程
1146 |
1147 | [参考链接](https://www.cnblogs.com/Survivalist/p/11527949.html#%E5%8D%8F%E7%A8%8B)
1148 |
1149 |
1150 |
1151 | # linux栈大小
1152 |
1153 | 用命令ulimit -s查看
1154 |
1155 | 8M左右
1156 |
1157 |
1158 |
1159 | # 服务器集群
1160 |
1161 |
1162 |
1163 |
1164 |
1165 | # Linux进程、进程组、会话、僵尸
1166 |
1167 | > 研究 Linux 之前,首先要对进程、进程组、会话,线程有个整体的了解:一个会话包含多个进程组,一个进程组包含多个进程,一个进程包含多个线程。
1168 |
1169 | **进程:**
1170 |
1171 | 进程是 Linux 操作系统环境的基础,它控制着系统上几乎所有的活动。每个进程都有自己唯一的标识:进程 ID,也有自己的生命周期。进程都有父进程,父进程也有父进程,从而形成了一个以 init 进程 (PID = 1)为根的家族树。除此以外,进程还有其他层次关系:进程组和会话。
1172 |
1173 | 有几种比较特殊的进程:
1174 |
1175 | 1. 孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被 init 进程(进程号为1)所收养,并由 init 进程对它们完成状态收集工作。
1176 | 2. 僵尸进程:一个进程使用 fork 创建子进程,如果子进程先退出,而父进程并没有调用 wait 或 waitpid 获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。
1177 | 3. 守护进程:(英语:daemon)是一种在后台执行的程序。此类程序会被以**进程**的形式初始化。**守护进程**程序的名称通常以字母“d”结尾:例如,syslogd 就是指管理系统日志的守护进程。
1178 |
1179 | **进程ID:**
1180 |
1181 | Linux每个进程都会有一个非负整数表示的唯一进程 ID,简称 pid。Linux 提供了getpid 函数来获取进程的 pid,同时还提供了 getppid 函数来获取父进程的 pid。
1182 |
1183 | **进程组:**
1184 |
1185 | 进程组的概念并不难理解,可以将人与人之间的关系做类比。一起工作的同事,自然比毫不相干的路人更加亲近。shell 中协同工作的进程属于同一个进程组,就如同协同工作的人属于同一个部门一样。引入了进程组的概念,可以更方便地管理这一组进程了。比如这项工作放弃了,不必向每个进程一一发送信号,可以直接将信号发送给进程组,进程组内的所有进程都会收到该信号。
1186 |
1187 | **会话(session):**
1188 |
1189 | 一般是指 shell session。Shell session 是终端中当前的状态,在终端中只能有一个 session。当我们打开一个新的终端时,总会创建一个新的 shell session。
1190 |
1191 | 就进程间的关系来说,session 由一个或多个进程组组成。我们可以通过下图来理解进程、进程组和 session 之间的关系:
1192 |
1193 |
1100 |
1101 | ThreadA进入while循环后,准备进入唤醒队列,此时ThreadB进来横插一脚,把`ready`改成`true`然后提前唤醒,这个时候线程A还没有进入唤醒队列,因此A会丢失唤醒条件进而永久wait
1102 |
1103 | - 正确写法
1104 |
1105 | ```c
1106 | //Thread A
1107 | pthread_mutex_lock(&mutex);
1108 | while (false == ready) {
1109 | pthread_cond_wait(&cond, &mutex);
1110 | }
1111 | pthread_mutex_unlock(&mutex);
1112 |
1113 | //Thread B
1114 | pthread_mutex_lock(&mutex);
1115 | ready = true;
1116 | pthread_mutex_unlock(&mutex);
1117 | pthread_cond_signal(&cond);
1118 | ```
1119 |
1120 |
1121 | [参考链接](https://zhuanlan.zhihu.com/p/55123862)
1122 |
1123 |
1124 |
1125 | # 什么是虚假唤醒?
1126 |
1127 | 一般来说我们要在等待wait的时候用while循环。因为会产生虚假唤醒。
1128 |
1129 | pthread 的条件变量等待 `pthread_cond_wait` 是使用阻塞的系统调用实现的(比如 Linux 上的 `futex`),这些阻塞的系统调用在进程被信号中断后,通常会中止阻塞、直接返回 EINTR 错误。同样是阻塞系统调用,你从 `read` 拿到 EINTR 错误后可以直接决定重试,因为这通常不影响它本身的语义。而条件变量等待则不能,因为本线程拿到 EINTR 错误和重新调用 `futex` 等待之间,可能别的线程已经通过 `pthread_cond_signal` 或者 `pthread_cond_broadcast`发过通知了。所以,虚假唤醒的一个可能性是条件变量的等待被信号中断。
1130 |
1131 | 在多核处理器下,pthread_cond_signal可能会激活多于一个线程(阻塞在条件变量上的线程)。结果是,当一个线程调用pthread_cond_signal()后,因为多个线程都被唤醒了,很可能其中一个唤醒的线程,先一步改变的condition. 此时另一个线程的condition已经不满足,因此需要加Where再次判断。这种效应成为”**虚假唤醒**”(spurious wakeup)。所以我们把判断条件从if改成while,pthread_cond_wait中的while()不仅仅在等待条件变量**前**检查条件变量,实际上在等待条件变量**后**也检查条件变量。
1132 |
1133 |
1134 |
1135 | # 套接字文件描述符和端口号的关系
1136 |
1137 | 个socket句柄代表两个地址对 “本地ip:port”--“远程ip:port”
1138 |
1139 | 在windows下叫句柄,在linux下叫文件描述符
1140 |
1141 | socket为内核对象,由操作系统内核来维护其缓冲区,引用计数,并且可以在多个进程中使用。
1142 |
1143 |
1144 |
1145 | # 进程线程协程
1146 |
1147 | [参考链接](https://www.cnblogs.com/Survivalist/p/11527949.html#%E5%8D%8F%E7%A8%8B)
1148 |
1149 |
1150 |
1151 | # linux栈大小
1152 |
1153 | 用命令ulimit -s查看
1154 |
1155 | 8M左右
1156 |
1157 |
1158 |
1159 | # 服务器集群
1160 |
1161 |
1162 |
1163 |
1164 |
1165 | # Linux进程、进程组、会话、僵尸
1166 |
1167 | > 研究 Linux 之前,首先要对进程、进程组、会话,线程有个整体的了解:一个会话包含多个进程组,一个进程组包含多个进程,一个进程包含多个线程。
1168 |
1169 | **进程:**
1170 |
1171 | 进程是 Linux 操作系统环境的基础,它控制着系统上几乎所有的活动。每个进程都有自己唯一的标识:进程 ID,也有自己的生命周期。进程都有父进程,父进程也有父进程,从而形成了一个以 init 进程 (PID = 1)为根的家族树。除此以外,进程还有其他层次关系:进程组和会话。
1172 |
1173 | 有几种比较特殊的进程:
1174 |
1175 | 1. 孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被 init 进程(进程号为1)所收养,并由 init 进程对它们完成状态收集工作。
1176 | 2. 僵尸进程:一个进程使用 fork 创建子进程,如果子进程先退出,而父进程并没有调用 wait 或 waitpid 获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。
1177 | 3. 守护进程:(英语:daemon)是一种在后台执行的程序。此类程序会被以**进程**的形式初始化。**守护进程**程序的名称通常以字母“d”结尾:例如,syslogd 就是指管理系统日志的守护进程。
1178 |
1179 | **进程ID:**
1180 |
1181 | Linux每个进程都会有一个非负整数表示的唯一进程 ID,简称 pid。Linux 提供了getpid 函数来获取进程的 pid,同时还提供了 getppid 函数来获取父进程的 pid。
1182 |
1183 | **进程组:**
1184 |
1185 | 进程组的概念并不难理解,可以将人与人之间的关系做类比。一起工作的同事,自然比毫不相干的路人更加亲近。shell 中协同工作的进程属于同一个进程组,就如同协同工作的人属于同一个部门一样。引入了进程组的概念,可以更方便地管理这一组进程了。比如这项工作放弃了,不必向每个进程一一发送信号,可以直接将信号发送给进程组,进程组内的所有进程都会收到该信号。
1186 |
1187 | **会话(session):**
1188 |
1189 | 一般是指 shell session。Shell session 是终端中当前的状态,在终端中只能有一个 session。当我们打开一个新的终端时,总会创建一个新的 shell session。
1190 |
1191 | 就进程间的关系来说,session 由一个或多个进程组组成。我们可以通过下图来理解进程、进程组和 session 之间的关系:
1192 |
1193 |  1194 |
1195 |
1196 |
1197 |
1198 |
1199 | # 守护进程
1200 |
1201 | **概念:**
1202 |
1203 | 守护进程(Daemon)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。守护进程是一种很有用的进程。 Linux的大多数服务器就是用守护进程实现的。比如,Internet服务器inetd,Web服务器httpd等。同时,守护进程完成许多系统任务。 比如,作业规划进程crond,打印进程lpd等。守护进程的编程本身并不复杂,复杂的是各种版本的Unix的实现机制不尽相同,造成不同 Unix环境下守护进程的编程规则并不一致。
1204 |
1205 | 当我们在命令行提示符后输入类似./helloworld程序时,在程序运行时终端被占用,此时无法执行其它操作。即使使用./helloworld &方式后台运行,当连接终端的网络出现问题,那么也会导致运行程序中断。这些因素对于长期运行的服务来说很不友好,而「守护进程」可以很好的解决这个问题。
1206 |
1207 | **特性:**
1208 |
1209 | 守护进程最重要的特性是后台运行。其次,守护进程必须与其运行前的环境隔离开来。这些环境包括未关闭的文件描述符,控制终端,会话和进程组,工作目录以及文件创建掩模等。这些环境通常是守护进程从执行它的父进程(特别是shell)中继承下来的。最后,守护进程的启动方式有其特殊之处。它可以在Linux系统启动时从启动脚本/etc/rc.d中启动,可以由作业规划进程crond启动,还可以由用户终端(通常是 shell)执行。总之,除开这些特殊性以外,守护进程与普通进程基本上没有什么区别。因此,编写守护进程实际上是把一个普通进程按照上述的守护进程的特性改造成为守护进程。如果对进程有比较深入的认识就更容易理解和编程了。
1210 |
1211 | **编程:**
1212 |
1213 | setsid()函数主要是重新创建一个session,子进程从父进程继承了SessionID、进程组ID和打开的终端,子进程如果要脱离父进程,不受父进程控制,我们可以用这个setsid命令。想脱离父进程,自己自由自在的活着,就要用这个命令执行后面的操作,简单粗暴。
1214 |
1215 | 编写守护进程过程如下:
1216 |
1217 | 1. 创建子进程,父进程退出
1218 |
1219 | 进程 fork 后,父进程退出。这么做的原因有 2 点:
1220 |
1221 | - 如果守护进程是通过 Shell 启动,父进程退出,Shell 就会认为任务执行完毕,这时子进程由 init 收养
1222 | - 子进程继承父进程的进程组 ID,保证了子进程不是进程组组长,因为后边调用setsid()要求必须不是进程组长
1223 | 2. 子进程创建新会话
1224 |
1225 | 调用setsid()创建一个新的会话,并成为新会话组长。这个步骤主要是要与继承父进程的会话、进程组、终端脱离关系。fork()的目的是想成功调用setsid()来建 立新会话,子进程有单独的sid,并且成为新进程组的组长,不关联任何终端。
1226 |
1227 | 3. 禁止子进程重新打开终端
1228 |
1229 | 此刻子进程是会话组长,为了防止子进程重新打开终端,再次 fork 后退出父进程,也就是此子进程。这时子进程 2 不再是会话组长,无法再打开终端。其实这一步骤不是必须的,不过加上这一步骤会显得更加严谨。
1230 |
1231 | 4. 设置当前目录为根目录
1232 |
1233 | 如果守护进程的当前工作目录是/usr/home目录,那么管理员在卸载/usr分区时会报错的。为了避免这个问题,可以调用chdir()函数将工作目录设置为根目录/。
1234 |
1235 | 5. 设置文件权限掩码
1236 |
1237 | 文件权限掩码是指屏蔽掉文件权限中的对应位。由于使用 fork()函数新建的子进程继承了父进程的文件权限掩码,这就给该子进程使用文件带来了诸多的麻烦。因此,把文件权限掩码设置为 0,可以大大增强该守护进程的灵活性。通常使用方法是umask(0)。
1238 |
1239 | 6. 关闭文件描述符
1240 |
1241 | 子进程会继承已经打开的文件,它们占用系统资源,且可能导致所在文件系统无法卸载。此时守护进程与终端脱离,常说的输入、输出、错误描述符也应该关闭。
1242 |
1243 |
1244 | ```c++
1245 | pid_t pid, sid;
1246 | int i;
1247 | pid = fork(); // 第1步
1248 | if (pid < 0)
1249 | exit(-1);
1250 | else if (pid > 0)
1251 | exit(0); // 父进程第一次退出
1252 |
1253 | if ((sid = setsid()) < 0) // 第2步
1254 | {
1255 | syslog(LOG_ERR, "%s\n", "setsid");
1256 | exit(-1);
1257 | }
1258 |
1259 | // 第3步 第二次父进程退出
1260 | if ((pid = fork()) > 0)
1261 | exit(0);
1262 | if ((sid = chdir("/")) < 0) // 第4步
1263 | {
1264 | syslog(LOG_ERR, "%s\n", "chdir");
1265 | exit(-1);
1266 | }
1267 |
1268 | umask(0); // 第5步
1269 |
1270 | // 第6步:关闭继承的文件描述符
1271 | for(i = 0; i < getdtablesize(); i++)
1272 | {
1273 | close(i);
1274 | }
1275 | while(1)
1276 | {
1277 | do_something();
1278 | }
1279 | closelog();
1280 | exit(0);
1281 | ```
1282 |
1283 |
1284 |
1285 | # 系统调用的详细过程
1286 |
1287 | **系统调用:**系统调用是操作系统为用户提供的一系列API;系统调用将用户的请求发给内核,内核执行完以后,将结果返回给用户;
1288 |
1289 | [参考](https://blog.csdn.net/Agoni_xiao/article/details/79034290)
1290 |
--------------------------------------------------------------------------------
/书籍笔记/c++语言核心及进阶.md:
--------------------------------------------------------------------------------
1 | # 核心编程
2 |
3 | ## 内存分区模型
4 |
5 | 根据c++执行将内存划分为5个区域:
6 |
7 | 1. 代码区,存放函数体的二进制,即CPU执行的机器指令,并且是只读的;
8 | 1. 常量区,存放常量,即程序运行期间不能被改变的量。
9 | 2. 全局区(静态区),存放全局变量和静态变量。
10 | 3. 栈区,由编译器自动分配释放,存放函数形参,局部变量,返回值等。
11 | 4. 堆区,由程序员分配和释放,若程序员不释放,程序结束时由操作系统CPU释放
12 |
13 |
1194 |
1195 |
1196 |
1197 |
1198 |
1199 | # 守护进程
1200 |
1201 | **概念:**
1202 |
1203 | 守护进程(Daemon)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。守护进程是一种很有用的进程。 Linux的大多数服务器就是用守护进程实现的。比如,Internet服务器inetd,Web服务器httpd等。同时,守护进程完成许多系统任务。 比如,作业规划进程crond,打印进程lpd等。守护进程的编程本身并不复杂,复杂的是各种版本的Unix的实现机制不尽相同,造成不同 Unix环境下守护进程的编程规则并不一致。
1204 |
1205 | 当我们在命令行提示符后输入类似./helloworld程序时,在程序运行时终端被占用,此时无法执行其它操作。即使使用./helloworld &方式后台运行,当连接终端的网络出现问题,那么也会导致运行程序中断。这些因素对于长期运行的服务来说很不友好,而「守护进程」可以很好的解决这个问题。
1206 |
1207 | **特性:**
1208 |
1209 | 守护进程最重要的特性是后台运行。其次,守护进程必须与其运行前的环境隔离开来。这些环境包括未关闭的文件描述符,控制终端,会话和进程组,工作目录以及文件创建掩模等。这些环境通常是守护进程从执行它的父进程(特别是shell)中继承下来的。最后,守护进程的启动方式有其特殊之处。它可以在Linux系统启动时从启动脚本/etc/rc.d中启动,可以由作业规划进程crond启动,还可以由用户终端(通常是 shell)执行。总之,除开这些特殊性以外,守护进程与普通进程基本上没有什么区别。因此,编写守护进程实际上是把一个普通进程按照上述的守护进程的特性改造成为守护进程。如果对进程有比较深入的认识就更容易理解和编程了。
1210 |
1211 | **编程:**
1212 |
1213 | setsid()函数主要是重新创建一个session,子进程从父进程继承了SessionID、进程组ID和打开的终端,子进程如果要脱离父进程,不受父进程控制,我们可以用这个setsid命令。想脱离父进程,自己自由自在的活着,就要用这个命令执行后面的操作,简单粗暴。
1214 |
1215 | 编写守护进程过程如下:
1216 |
1217 | 1. 创建子进程,父进程退出
1218 |
1219 | 进程 fork 后,父进程退出。这么做的原因有 2 点:
1220 |
1221 | - 如果守护进程是通过 Shell 启动,父进程退出,Shell 就会认为任务执行完毕,这时子进程由 init 收养
1222 | - 子进程继承父进程的进程组 ID,保证了子进程不是进程组组长,因为后边调用setsid()要求必须不是进程组长
1223 | 2. 子进程创建新会话
1224 |
1225 | 调用setsid()创建一个新的会话,并成为新会话组长。这个步骤主要是要与继承父进程的会话、进程组、终端脱离关系。fork()的目的是想成功调用setsid()来建 立新会话,子进程有单独的sid,并且成为新进程组的组长,不关联任何终端。
1226 |
1227 | 3. 禁止子进程重新打开终端
1228 |
1229 | 此刻子进程是会话组长,为了防止子进程重新打开终端,再次 fork 后退出父进程,也就是此子进程。这时子进程 2 不再是会话组长,无法再打开终端。其实这一步骤不是必须的,不过加上这一步骤会显得更加严谨。
1230 |
1231 | 4. 设置当前目录为根目录
1232 |
1233 | 如果守护进程的当前工作目录是/usr/home目录,那么管理员在卸载/usr分区时会报错的。为了避免这个问题,可以调用chdir()函数将工作目录设置为根目录/。
1234 |
1235 | 5. 设置文件权限掩码
1236 |
1237 | 文件权限掩码是指屏蔽掉文件权限中的对应位。由于使用 fork()函数新建的子进程继承了父进程的文件权限掩码,这就给该子进程使用文件带来了诸多的麻烦。因此,把文件权限掩码设置为 0,可以大大增强该守护进程的灵活性。通常使用方法是umask(0)。
1238 |
1239 | 6. 关闭文件描述符
1240 |
1241 | 子进程会继承已经打开的文件,它们占用系统资源,且可能导致所在文件系统无法卸载。此时守护进程与终端脱离,常说的输入、输出、错误描述符也应该关闭。
1242 |
1243 |
1244 | ```c++
1245 | pid_t pid, sid;
1246 | int i;
1247 | pid = fork(); // 第1步
1248 | if (pid < 0)
1249 | exit(-1);
1250 | else if (pid > 0)
1251 | exit(0); // 父进程第一次退出
1252 |
1253 | if ((sid = setsid()) < 0) // 第2步
1254 | {
1255 | syslog(LOG_ERR, "%s\n", "setsid");
1256 | exit(-1);
1257 | }
1258 |
1259 | // 第3步 第二次父进程退出
1260 | if ((pid = fork()) > 0)
1261 | exit(0);
1262 | if ((sid = chdir("/")) < 0) // 第4步
1263 | {
1264 | syslog(LOG_ERR, "%s\n", "chdir");
1265 | exit(-1);
1266 | }
1267 |
1268 | umask(0); // 第5步
1269 |
1270 | // 第6步:关闭继承的文件描述符
1271 | for(i = 0; i < getdtablesize(); i++)
1272 | {
1273 | close(i);
1274 | }
1275 | while(1)
1276 | {
1277 | do_something();
1278 | }
1279 | closelog();
1280 | exit(0);
1281 | ```
1282 |
1283 |
1284 |
1285 | # 系统调用的详细过程
1286 |
1287 | **系统调用:**系统调用是操作系统为用户提供的一系列API;系统调用将用户的请求发给内核,内核执行完以后,将结果返回给用户;
1288 |
1289 | [参考](https://blog.csdn.net/Agoni_xiao/article/details/79034290)
1290 |
--------------------------------------------------------------------------------
/书籍笔记/c++语言核心及进阶.md:
--------------------------------------------------------------------------------
1 | # 核心编程
2 |
3 | ## 内存分区模型
4 |
5 | 根据c++执行将内存划分为5个区域:
6 |
7 | 1. 代码区,存放函数体的二进制,即CPU执行的机器指令,并且是只读的;
8 | 1. 常量区,存放常量,即程序运行期间不能被改变的量。
9 | 2. 全局区(静态区),存放全局变量和静态变量。
10 | 3. 栈区,由编译器自动分配释放,存放函数形参,局部变量,返回值等。
11 | 4. 堆区,由程序员分配和释放,若程序员不释放,程序结束时由操作系统CPU释放
12 |
13 |  14 |
15 | > 代码区中存放的其实就是CPU执行的机器指令,代码区是共享和只读的,共享是指对于频繁被执行的程序,只需要在内存中有一份代码就行。而只读则表示防止程序意外修改指令。
16 | >
17 | > 全局区是全局变量、静态变量和常量区、字符串常量和const修饰的常量存放在这里。
18 | >
19 | > **代码区和常量区、全局区在代码编译后就存在了**
20 | >
21 | > 栈区和堆区是程序运行后才有。
22 | >
23 | > 不要返回局部变量的地址,栈区的数据由编译器开辟和释放。形参数据也是放在栈区的。
24 | >
25 | > 堆区由程序员开辟,若程序员不释放,则由操作系统回收
26 |
27 | ## 引用
28 |
29 | ### 引用的本质是什么?
30 |
31 | 其实这就是说道引用到底是什么的问题了。
32 |
33 | 其实到现在这个阶段,不能说引用就是起别名这么低俗的说法。
34 |
35 | 下面看一段代码:
36 |
37 | ```
38 | //引用
39 | int i=5;
40 | int &ri=i;
41 | ri=8;
42 |
43 | //引用汇编
44 | int i=5;
45 | 00A013DE mov dword ptr [i],5 //将文字常量5送入变量i
46 | int &ri=i;
47 | 00A013E5 lea eax,[i] //将变量i的地址送入寄存器eax
48 | 00A013E8 mov dword ptr [ri],eax //将寄存器的内容(也就是变量i的地址)送入变量ri
49 | ri=8;
50 | 00A013EB mov eax,dword ptr [ri] //将变量ri的值送入寄存器eax
51 | 00A013EE mov dword ptr [eax],8 //将数值8送入以eax的内容为地址的单元中
52 | return 0;
53 | 00A013F4 xor eax,eax
54 |
55 |
56 | //常量指针
57 | int i=5;
58 | int* const pi=&i;
59 | *pi=8;
60 |
61 | //常量指针汇编
62 | int i=5;
63 | 011F13DE mov dword ptr [i],5
64 | int * const pi=&i;
65 | 011F13E5 lea eax,[i]
66 | 011F13E8 mov dword ptr [pi],eax
67 | *pi=8;
68 | 011F13EB mov eax,dword ptr [pi]
69 | 011F13EE mov dword ptr [eax],8
70 |
71 | ```
72 |
73 | - 引用是一个变量,有地址,数据类型为dword,也就是说,ri要在内存中占据4个字节的位置。
74 | - 看一下引用的汇编和常量指针的汇编可以发现是相同的,ri对应pi,因此可以说在底层汇编实现上引用是按照指针常量的方式实现的
75 |
76 | 在高级语言层面,有一点注意就是数组元素允许是常量指针的,但不允许是引用。主要是为了避免二义性,假如定义一个“引用的数组”,那么array[0]=8;这条语句该如何理解?是将数组元素array[0]本身的值变成8呢,还是将array[0]所引用的对象的值变成8呢?对于程序员来说,这种解释上的二义性对正确编程是一种严重的威胁,毕竟程序员在编写程序的时候,不可能每次使用数组时都要回过头去检查数组的原始定义。
77 |
78 | ```
79 | //可以
80 | int i=5, j=6;
81 | int* const array[]={&i,&j};
82 |
83 | //不行
84 | int i=5, j=6;
85 | int& array[]={i,j};
86 |
87 | ```
88 |
89 | ### 引用注意事项
90 |
91 | - 引用必须初始化
92 | - 引用初始化以后就不能更改了
93 | - 具体见面试总结里面有说
94 |
95 | ### 引用做函数参数
96 |
97 | 引用作为函数参数传递可以简化指针操作,直接修改实参
98 |
99 | 值传递,形参不会修饰实参
100 |
101 | 地址传递和引用传递,形参会修饰实参
102 |
103 | ### 引用作为函数的返回值
104 |
105 | - 不要返回局部变量的引用
106 | - 函数返回值如果是引用,则可以作为左值使用
107 |
108 | ### 常量引用
109 |
110 | 用来修饰形参,防止误操作
111 |
112 | ```c++
113 | int & ref = 10 //不行
114 | const int& ref = 10 //可以
115 | ```
116 |
117 | ## 函数其他性质
118 |
119 | ### 函数默认参数
120 |
121 | ```c++
122 | int func(int a, int b = 20, int c = 30){
123 | return a + b + c;
124 | }
125 | int main(){
126 | func(10);
127 | return 0;
128 | }
129 | ```
130 |
131 | 即函数有默认参数的话,在调用该函数的时候就不用再传入参数了,因为有默认的
132 |
133 | 注意:
134 |
135 | 1. 如果函数的某个参数已经有了默认值,那么从该位置往后从左到右都必须有默认值
136 |
137 | 2. 如果函数声明有默认参数,那么实现就不能有默认参数。如下,会报错
138 |
139 | ```c++
140 | //声明
141 | int func(int a=10, int b = 20);
142 | //实现
143 | int func(int a, int b = 20){ //会出现二义性
144 | return a + b;
145 | }
146 | ```
147 |
148 |
149 | ### 函数重载
150 |
151 | > 函数名称相同,参数不同(或者个数,或者顺序),提高复用性
152 |
153 | - 注意事项
154 |
155 | 1. 引用作为重载的时候
156 |
157 | 引用的时候加入const是可以作为重载条件的,有两个重载函数如下:
158 |
159 | ```c+
160 | void func(int& a);
161 | void func(const int& a);
162 |
163 | //void func(int& a)版本
164 | int a = 10;
165 | func(a);
166 |
167 | //void func(const int& a)版本
168 | func(10)
169 | ```
170 |
171 | 为什么会这样,原因是`a=10`是一个变量,但是直接传入10是临时空间,只能用`const int& a`去接收这块临时的空间
172 |
173 | 2. 重载碰到默认参数
174 |
175 | 由于c++避免二义性,因此带默认参数的函数会出现二义性,所以要避免这类型情况。
176 |
177 | - 本质(底层逻辑)
178 |
179 | - 如果没有函数重载,那么会产生命名空间污染问题,导致为了实现同一个功能起了很多不同的名字
180 |
181 | - 编译器在编译`.c`文件的时候会给函数进行简单的重命名,就是在原函数名称前面加上“_”,比如原函数名叫做`add`,编译后就叫做`_add`,如下图所示:
182 |
183 |
14 |
15 | > 代码区中存放的其实就是CPU执行的机器指令,代码区是共享和只读的,共享是指对于频繁被执行的程序,只需要在内存中有一份代码就行。而只读则表示防止程序意外修改指令。
16 | >
17 | > 全局区是全局变量、静态变量和常量区、字符串常量和const修饰的常量存放在这里。
18 | >
19 | > **代码区和常量区、全局区在代码编译后就存在了**
20 | >
21 | > 栈区和堆区是程序运行后才有。
22 | >
23 | > 不要返回局部变量的地址,栈区的数据由编译器开辟和释放。形参数据也是放在栈区的。
24 | >
25 | > 堆区由程序员开辟,若程序员不释放,则由操作系统回收
26 |
27 | ## 引用
28 |
29 | ### 引用的本质是什么?
30 |
31 | 其实这就是说道引用到底是什么的问题了。
32 |
33 | 其实到现在这个阶段,不能说引用就是起别名这么低俗的说法。
34 |
35 | 下面看一段代码:
36 |
37 | ```
38 | //引用
39 | int i=5;
40 | int &ri=i;
41 | ri=8;
42 |
43 | //引用汇编
44 | int i=5;
45 | 00A013DE mov dword ptr [i],5 //将文字常量5送入变量i
46 | int &ri=i;
47 | 00A013E5 lea eax,[i] //将变量i的地址送入寄存器eax
48 | 00A013E8 mov dword ptr [ri],eax //将寄存器的内容(也就是变量i的地址)送入变量ri
49 | ri=8;
50 | 00A013EB mov eax,dword ptr [ri] //将变量ri的值送入寄存器eax
51 | 00A013EE mov dword ptr [eax],8 //将数值8送入以eax的内容为地址的单元中
52 | return 0;
53 | 00A013F4 xor eax,eax
54 |
55 |
56 | //常量指针
57 | int i=5;
58 | int* const pi=&i;
59 | *pi=8;
60 |
61 | //常量指针汇编
62 | int i=5;
63 | 011F13DE mov dword ptr [i],5
64 | int * const pi=&i;
65 | 011F13E5 lea eax,[i]
66 | 011F13E8 mov dword ptr [pi],eax
67 | *pi=8;
68 | 011F13EB mov eax,dword ptr [pi]
69 | 011F13EE mov dword ptr [eax],8
70 |
71 | ```
72 |
73 | - 引用是一个变量,有地址,数据类型为dword,也就是说,ri要在内存中占据4个字节的位置。
74 | - 看一下引用的汇编和常量指针的汇编可以发现是相同的,ri对应pi,因此可以说在底层汇编实现上引用是按照指针常量的方式实现的
75 |
76 | 在高级语言层面,有一点注意就是数组元素允许是常量指针的,但不允许是引用。主要是为了避免二义性,假如定义一个“引用的数组”,那么array[0]=8;这条语句该如何理解?是将数组元素array[0]本身的值变成8呢,还是将array[0]所引用的对象的值变成8呢?对于程序员来说,这种解释上的二义性对正确编程是一种严重的威胁,毕竟程序员在编写程序的时候,不可能每次使用数组时都要回过头去检查数组的原始定义。
77 |
78 | ```
79 | //可以
80 | int i=5, j=6;
81 | int* const array[]={&i,&j};
82 |
83 | //不行
84 | int i=5, j=6;
85 | int& array[]={i,j};
86 |
87 | ```
88 |
89 | ### 引用注意事项
90 |
91 | - 引用必须初始化
92 | - 引用初始化以后就不能更改了
93 | - 具体见面试总结里面有说
94 |
95 | ### 引用做函数参数
96 |
97 | 引用作为函数参数传递可以简化指针操作,直接修改实参
98 |
99 | 值传递,形参不会修饰实参
100 |
101 | 地址传递和引用传递,形参会修饰实参
102 |
103 | ### 引用作为函数的返回值
104 |
105 | - 不要返回局部变量的引用
106 | - 函数返回值如果是引用,则可以作为左值使用
107 |
108 | ### 常量引用
109 |
110 | 用来修饰形参,防止误操作
111 |
112 | ```c++
113 | int & ref = 10 //不行
114 | const int& ref = 10 //可以
115 | ```
116 |
117 | ## 函数其他性质
118 |
119 | ### 函数默认参数
120 |
121 | ```c++
122 | int func(int a, int b = 20, int c = 30){
123 | return a + b + c;
124 | }
125 | int main(){
126 | func(10);
127 | return 0;
128 | }
129 | ```
130 |
131 | 即函数有默认参数的话,在调用该函数的时候就不用再传入参数了,因为有默认的
132 |
133 | 注意:
134 |
135 | 1. 如果函数的某个参数已经有了默认值,那么从该位置往后从左到右都必须有默认值
136 |
137 | 2. 如果函数声明有默认参数,那么实现就不能有默认参数。如下,会报错
138 |
139 | ```c++
140 | //声明
141 | int func(int a=10, int b = 20);
142 | //实现
143 | int func(int a, int b = 20){ //会出现二义性
144 | return a + b;
145 | }
146 | ```
147 |
148 |
149 | ### 函数重载
150 |
151 | > 函数名称相同,参数不同(或者个数,或者顺序),提高复用性
152 |
153 | - 注意事项
154 |
155 | 1. 引用作为重载的时候
156 |
157 | 引用的时候加入const是可以作为重载条件的,有两个重载函数如下:
158 |
159 | ```c+
160 | void func(int& a);
161 | void func(const int& a);
162 |
163 | //void func(int& a)版本
164 | int a = 10;
165 | func(a);
166 |
167 | //void func(const int& a)版本
168 | func(10)
169 | ```
170 |
171 | 为什么会这样,原因是`a=10`是一个变量,但是直接传入10是临时空间,只能用`const int& a`去接收这块临时的空间
172 |
173 | 2. 重载碰到默认参数
174 |
175 | 由于c++避免二义性,因此带默认参数的函数会出现二义性,所以要避免这类型情况。
176 |
177 | - 本质(底层逻辑)
178 |
179 | - 如果没有函数重载,那么会产生命名空间污染问题,导致为了实现同一个功能起了很多不同的名字
180 |
181 | - 编译器在编译`.c`文件的时候会给函数进行简单的重命名,就是在原函数名称前面加上“_”,比如原函数名叫做`add`,编译后就叫做`_add`,如下图所示:
182 |
183 |  184 |
185 | - c++在底层编译`.cpp`文件的时候,虽然函数名称一样,但是在后面添加了一些其他东西导致名称是不一样的,如图:
186 |
187 |
184 |
185 | - c++在底层编译`.cpp`文件的时候,虽然函数名称一样,但是在后面添加了一些其他东西导致名称是不一样的,如图:
186 |
187 | 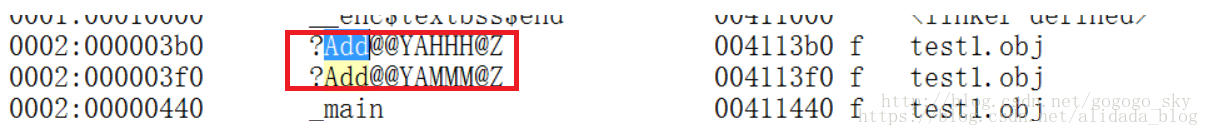 188 |
189 | 其中“?”表示开始,“@@YA”表示参数的开始,后面三个字符“HHH”和“MMM”分别表示函数返回值类型,两个参数类型,“@Z”表示函数名称结束,所以由于函数生成的符号表中的名称不一样,因此可以编译通过。
190 |
191 | ------
192 |
193 |
194 |
195 | ## 类和对象
196 |
197 | 三大特性:封装、继承、多态
198 |
199 | ```
200 | Class test{
201 | //成员变量
202 | //成员函数
203 | };
204 | ```
205 |
206 | - 封装
207 |
208 | - 三种访问权限
209 |
210 | 1. public。对成员来说,可以在类内被访问,类外也可以访问
211 | 2. protected。对成员来说,可以在类内被访问,类外不可以访问,主要用在继承,子类可以访问父类的一些保护权限的内容。
212 | 3. private。对成员来说,可以在类内被访问,类外不可以访问。子类不能访问父类的私有内容。
213 |
214 | 一般将成员变量属性设置为私有,可以自己控制读写权限,成员函数为共有。
215 |
216 | 类对象的默认访问控制是private的,但是结构的默认访问类型是public,结构没有成员函数只能纯粹的表示数据对象
217 |
218 | - 成员函数
219 |
220 | 成员函数必须使用作用域解析符来指出函数所属的类,代码如下:
221 |
222 | ```c++
223 | void Stock::update(double price);
224 | ```
225 |
226 | 位于类声明中的函数都将自动成为内联函数,但是内联函数也可以在类外定义,如下:
227 |
228 | ```c++
229 | inline void Stock::update(double price);
230 | ```
231 |
232 | 由于内联函数的规则要求每个使用该函数的文件中都要对其进行定义,因此将内联函数放在头文件中是最好的。
233 |
234 | ------
235 |
236 | - 类对象
237 |
238 | 每个新对象都有自己的存储空间,用于存储其内部变量和类成员。但是同一个类的所有对象共享类的方法,即类的函数。所有类对象都会执行同一个代码块,只是入栈的数据不同而已。
239 |
240 | ------
241 |
242 |
243 |
244 | ### 类的构造函数
245 |
246 | 由于类设计的初衷是隐藏数据成员,因此类的初始化不能像结构那样,必须通过成员函数来访问成员数据。
247 |
248 | 因此c++提供了一个类构造函数,在创造对象时自动对它进行初始化。
249 |
250 | > 注意事项:不能将类成员用作构造函数的参数名
251 | >
252 | > 因为构造函数的作用是初始化成员变量的值,因此构造函数的参数肯定是传入的值,不可能是类成员变量的值!因此为了避免这种混乱,需要在类成员函数的名称前加一个前缀,比如“m_”这样的。
253 |
254 | - **使用构造函数**
255 |
256 | c++使用了两种用构造函数来初始化对象的方式:
257 |
258 | ```c++
259 | //显示的调用构造函数
260 | Stock food = Stock("World Cabbage", 250, 1.25);
261 | //隐式的调用构造函数
262 | Stock garment("Furry Mason", 50, 2.5);
263 | //动态分配new
264 | Stock *pstock = new Stock("Furry Mason", 50, 2.5);
265 | /*动态的创建一个Stock对象,并将对象的地址赋给pstock指针,用指针管理该对象*/
266 | ```
267 |
268 | 切记,无法使用对象来调用构造函数,因为在构造函数构造出对象之前,对象是不存在的!因此构造函数是用来创建对象的,不能通过对象调用
269 |
270 | - **默认构造函数**
271 |
272 | 默认构造函数是指在没有显示的赋值时,用来创建对象的构造函数。如下:
273 |
274 | ```c++
275 | Stock fluffyp;
276 | ```
277 |
278 | 上面这行代码之所以可以使用是因为对于类没有构造函数的话,c++编译器将自动提供一个默认构造函数,用来创建对象但不初始化值,一般默认构造函数的形式如`Stokc::Stock(){}`
279 |
280 | **如果类没有定义任何构造函数的时候,编译器才会提供默认构造函数。但是如果类定义了构造函数,就必须要写一个默认构造函数!**
281 |
282 | 因此在以后设计类的时候,通常应提供所有成员隐式初始化的默认构造函数
283 |
284 | - **赋值(构造函数作用2)**
285 |
286 | 与结构赋值一样,在默认情况下给类对象赋值时,把一个对象的成员复制给另一个。这样一来,构造函数不仅仅可用于初始化新对象,还可以执行赋值操作
287 |
288 | ```c++
289 | stock1 = Stock("wuhu", 10, 50.0);
290 | ```
291 |
292 | 上述代码右边指的是构造函数产生了一个新的临时的对象,然后将该临时对象的内容赋值给了stock1
293 |
294 | 我们将上述代码放在一起比较:
295 |
296 | ```c++
297 | //显示的调用构造函数
298 | Stock food = Stock("World Cabbage", 250, 1.25);
299 | stock1 = Stock("wuhu", 10, 50.0);
300 | ```
301 |
302 | 第一条语句有可能会创建临时变量也可能不会,创建临时变量的话就变成第二条语句这样的赋值了,因此如果可以初始化尽量不要赋值,提高效率。因此我们就有c++11的列表初始化。
303 |
304 | ------
305 |
306 |
307 |
308 | ### 类的析构函数
309 |
310 | 当构造函数创建对象后,程序负责跟踪该对象,知道过期为止。对象过期时程序将自动调用一个特殊的成员函数 —析构函数,由析构函数完成清理工作。如果构造函数使用new分配内存,那么析构函数就要使用delete释放。如果构造函数不适用new,则析构函数什么都不用做。
311 |
312 | ------
313 |
314 |
315 |
316 | ### this指针
317 |
318 | 下面给一段代码进行解释:
319 |
320 | ```c++
321 | const Stock& topval(const Stock& s);
322 | top = stock1.topval(stock2);
323 | top = stock2.topval(stock1);
324 | ```
325 |
326 | 这段代码比较两个对象的股票价格最高的,返回其中过一个,传入参数只有一个显示的引用。
327 |
328 | c++使用this这种特殊的指针,指向用来调用成员函数的对象(谁调用该成员函数,this对象就是谁)。其实每个成员方法都有一个隐藏的形参this指针上述代码中stock1调用了topval函数,因此this指针就是stock1.
329 |
330 | 所有的类方法都将this指针设置为调用它的对象的地址
331 |
332 | 每个成员函数(包括构造函数和析构函数)都有`this`指针。`this`指针指向调用的对象,是对象的地址,因此`*this`才是这个对象,`this`只是个地址,`*this`作为对象的别名。
333 |
334 | ------
335 |
336 |
337 |
338 | ### 对象数组
339 |
340 | 如果要创建类的多个对象,可以使用数组的方式,声明对象数组的方法与声明标准类型数组相同:
341 |
342 | ```c++
343 | Stock mystuff[4];
344 | ```
345 |
346 | ------
347 |
348 | ### 类作用域
349 |
350 | 在类中定义的作用域为整个类,名称在类内是已知的,在类外不是。因此可以在不同类使用相同的成员名称而不引起冲突,必须通过对象来访问类的成员或方法。
351 |
352 | - **在类中声明常量**
353 |
354 | 要注意,在类中类只是描述一个结构的形式,在没有创建对象之前,类是没有用于存储的空间的,因此不能如下直接在类中生命一个变量值:
355 |
356 | ```c++
357 | class temp{
358 | private:
359 | const int Months = 12;//这样是不行的
360 | };
361 | ```
362 |
363 | 如果我们要声明一个变量,要在前面加上`static`关键字,表明该常量是与其他静态变量存储在一起的,而不是存储在对象中的。因此month可以被所有的对象共享。
364 |
365 | - **作用域内枚举(枚举类)(c++11)**
366 |
367 | ```c++
368 | enum egg{small, medium, large}
369 | enum t_shirt{small, medium, large}
370 | ```
371 |
372 | 上述代码是常规的枚举类型,可以看到存在问题,即两个枚举定义的枚举量可能发生冲突,因为egg small和t_shirt small在一个作用域内。因此c++11提供了一种新的枚举类型,枚举作用域为类,叫做枚举类。
373 |
374 | ```c++
375 | enum class egg{small, medium, large}
376 | enum class t_shirt{small, medium, large}
377 |
378 | egg choice = egg::small;
379 | tshirt choic = t_shirt::small;
380 | ```
381 |
382 | 不同枚举定义的枚举量就不会发生冲突了
383 |
384 | ------
385 |
386 | 同时枚举类还提高了作用域内枚举的类型安全。在有些情况下,常规枚举将自动转化为整型,比如赋值给int类型或者用于比较表达式时候,但是枚举类不能隐式的转换成整型。有必要的时候只能进行显示的转换`int(枚举)`
387 |
388 | 默认情况下c++11作用域内枚举的底层类型为int,但可以显示的更改底层类型,比如:
389 |
390 | ```c++
391 | enum class : short pizza{small, medium,large}
392 | ```
393 |
394 | 如上述代码底层就变成了short类型。
395 |
396 | ------
397 |
398 |
399 |
400 | ### 运算符重载
401 |
402 | c++多态有函数重载和运算符重载
403 |
404 | 运算符重载的格式如下:
405 |
406 | `(返回类型) operator OP (argument-list)`,例如`operator +()`重载+运算符,`operator *()`重载*运算符。但要切记,OP这个运算符一定是有效的,不能虚构一个运算符,比如`@#`等,因为这些符号在实际中本来就不是运算符。
407 |
408 | > 举个例子:
409 | >
410 | > A,B,C都是一个类的对象
411 | >
412 | > ```c++
413 | > //想求对象相加
414 | > A = B + C;
415 | > //编译器角度
416 | > A = B.operator+(C)
417 | > ```
418 | >
419 | > 该函数隐式的使用A(调用了operator方法),显式的调用C(因为被当做参数传递了)
420 |
421 | **在重载运算符中,运算符左侧的对象是调用对象,而运算符右侧的对象是作为参数传递的**
422 |
423 | > 看一段代码:
424 | >
425 | > ```c++
426 | > class Time{
427 | > private:
428 | > int hours;
429 | > int minutes;
430 | > public:
431 | > Time();
432 | > Time operator +(const Time& t) const;
433 | > };
434 | >
435 | > Time::Time operator+(const Time& t) const{
436 | > Time sum;
437 | > sum.minutes = minutes + t.minutes;
438 | > sum.hours = hours + t.houts + sum.minutes/60;
439 | > return sum
440 | > }
441 | >
442 | > //使用重载运算符
443 | > time1 = time2 + time3;
444 | > ```
445 | >
446 | > 在这里面有两点需要注意:
447 | >
448 | > 1. 要主要operator的返回值,到底返回什么。
449 | >
450 | > 上面代码中我们是要用time1来接收operator的返回,由于time1的类型是Time类,因此上面代码中operator的返回值也是Time。
451 | >
452 | > 2. 注意返回值不能是引用。因为sum是局部变量,在函数结束时会被删除,因此引用将指向一个不存在的对象(vs编译器中会保存一次该引用,但是只能调用一次)。但是上述代码返回的是sum,是一个局部变量,在函数结束删除sum时候会构造一个sum的拷贝放到临时变量中。
453 |
454 | ------
455 |
456 | **重载有以下两个限制:**
457 |
458 | 1. 重载后的运算符必须至少有一个操作数是用户自定义的类型,不能两个操作数都是系统原有的类型。这样是防止用户对标准类型重载运算符,比如不能将+重载后作用于两个int类型的变量上
459 | 2. 重载后的运算符不能违背原来的规则,比如不能将运算符变成一个变量类型
460 | 3. 不能创建新的运算符,比如说创建一个**去求幂。
461 | 4. 有以下几个运算符不能重载:`sizeof`、`.` 、`::` 、`?: ` 、`.*`、`const_cast`、`dynamic_cast`、 `static_cast`等
462 | 5. 下面四个运算符必须通过**成员函数**去重载:`=`、`()`、`[]`、`->`。
463 |
464 | ------
465 |
466 | ### 友元
467 |
468 | c++对私有部分成员的访问非常严格,在没有友元之前只能通过公有方法去访问。但是提供了对私有成员的另一种访问:友元,有3种:
469 |
470 | 1. 友元函数
471 | 2. 友元类
472 | 3. 友元成员函数
473 |
474 | ------
475 |
476 | #### 友元函数
477 |
478 | 在为类重载二元运算符(带两个参数的运算符)常常需要友元,因为问题描述如下:
479 |
480 | > 对于重载的乘法运算符来说,比如代码如下:
481 | >
482 | > ```c++
483 | > Time operator*(const double num);
484 | > ```
485 | >
486 | > 比如上述代码可以满足:A = B * 2.75
487 | >
488 | > 但是我要写成A = 2.75 * B呢?由于重载运算符左边是double类型,而代码中左边是调用operator的对象,是Time类,所以就有问题。由于左侧的操作对象应该是Time类对象,而不应该是doule变量,所以编译器不能使用成员函数来调用该表达式。
489 |
490 | 上述问题的解决办法就是采用非成员函数,非成员函数不是对象调用的,它所使用的值都是显式的参数,比如下面的代码:
491 |
492 | ```c++
493 | Time operator* (double m, const Time& t);
494 | ```
495 |
496 | 上述代码解决了`A = 2.75 * B`这个问题,但又有一个新的问题即非成员函数不能访问私有成员,所以就需要友元函数。
497 |
498 | +++
499 |
500 | 创建友元函数:
501 |
502 | ```c++
503 | friend Time operator*(double m, const Time& t);
504 | ```
505 |
506 | 加了friend前缀后,该函数就和成员函数有着一样的访问权限。
507 |
508 | 可能刚开始学的时候认为友元这个性质违背了OOP数据隐藏的概念,因为友元机制允许非成员函数访问私有数据。这个有些片面,应该将友元函数看作类的扩展接口的组成部分。类方法和友元只是表达类接口的两种不同机制而已。
509 |
510 | +++
511 |
512 | **重载<<运算符**
513 |
514 | 最初<<运算符是C和C++的位运算符,表示左移。ostream类对该运算符进行了重载,变成了一个输出工具。cout是一个ostream对象,能够识别所有的c++**基本类型**,原因是对于每种类型,ostream类声明都包含了相应的重载。
515 |
516 | 但要注意一点,重载<<符号的时候,函数的返回值一定要写成ostream&,如下代码:
517 |
518 | ```c++
519 | ostream & operator<<(ostream& os, const Time& t);
520 | ```
521 |
522 | 因为`cout<<`不是调用一次,而是很多次,比如`cout<<"hello"< 友元类举例:
533 | >
534 | > 一个电视机类TV和一个遥控器Remote类,这两个不是包含也不是继承关系,但是遥控器可以控制电视机,也就意味着遥控器这个类可以访问电视机类中的成员,因此用友元类比较好。
535 | >
536 | > ```c++
537 | > class TV{
538 | > public:
539 | > friend class Remote;
540 | > bool volup();
541 | > bool voldown();
542 | > void chanup();
543 | > void chandown();
544 | > private:
545 | > int state;
546 | > int volume;
547 | > int maxchannel;
548 | > int channel;
549 | > };
550 | >
551 | > class Remote{
552 | > private:
553 | > int mode;
554 | > public:
555 | > bool volup(Tv& t){
556 | > return t.volup();
557 | > }
558 | > bool voldown(Tv& t){
559 | > return t.voldown();
560 | > }
561 | > void chanup(Tv& t){
562 | > return t.chanup();
563 | > }
564 | > void chandown(Tv& t){
565 | > return t.chandown();
566 | > }
567 | > void set_chan(Tv& t, int c){
568 | > t.channel = c;
569 | > }
570 | > };
571 | > ```
572 |
573 | #### 友元成员函数
574 |
575 | 在上面两个类中的代码,大部分Remote类中的方法都是用Tv类的共有接口实现的,意味着这些方法不是真正需要用作友元。但是有一个Remote类中的函数直接访问了TV类中的私有成员,就是set_chan函数,因此这个方法才是唯一需要作为友元的方法。
576 |
577 | 可以选择**让特定的类成员成为另一个类的友元**,而不用让整个类成为友元,修改一下上述代码如下:
578 |
579 | ```c++
580 | class Tv{
581 | public:
582 | friend void Remote::set_chan(Tv& t, int c);
583 | ...
584 | };
585 | ```
586 |
587 | +++
588 |
589 | ### 类的自动转换和强制类型转换
590 |
591 | **c++处理内置类型转换:**
592 |
593 | 在两种类型兼容的情况下,将一种标准类型变量的值赋给另一种标准类型变量的值时,c++将自动转换,代码如下:
594 |
595 | ```c++
596 | long count = 8;
597 | int side = 3.33
598 | ```
599 |
600 | c++内部将各种数值类型都看作是同样的东西—数字。但是c++不自动转换不兼容的类型,比如下面的语句是非法的,左边是指针,右边是整形数字
601 |
602 | ```c++
603 | //不支持
604 | int* p = 10;
605 | //强转成int指针类型,指针值为10
606 | int* p = (int*)10
607 | ```
608 |
609 | +++
610 |
611 | 下面说一说类相关的转换
612 |
613 | **有参的构造函数为类的转换提供了蓝图,或者说提供了原动力**
614 |
615 | ```c++
616 | //一个类的构造函数
617 | Stonewt(double lbs);
618 | //隐式转换
619 | Stonewt myCat;
620 | myCat = 16.9;
621 | ```
622 |
623 | 对于上面代码,使用构造函数`Stonewt(double)`来创建一个临时的Stonewt对象,并将19.6作为double参数传入,随后采用成员赋值的方式将该临时对象的值复制到myCat中,成为隐式转换,是自动进行的,不需要显式强制类型转换。
624 |
625 | 但有一个问题,即因为只有一个19.6类型的double变量,因此只支持一个参数的构造函数。
626 |
627 | 将构造函数用作类型转换函数仔细一看其实很棒,不用我们自己操作。但是有个问题,我们并不是总是需要,可能会导致意外的类型转换。因此c++新增了一个`explicit`关键字,用于关闭这种自动转换的特性。可以如下声明构造函数:
628 |
629 | ```c++
630 | explicit Stonewt(double lbs);
631 | //无法隐式转换
632 | Stonewt myCat;
633 | myCat = 16.9;
634 | //必须显式转换
635 | myCat = (Stonewt)16.9;
636 | ```
637 |
638 | 一旦加入了explicit,则不能隐式转换,必须显示转换
639 |
640 | +++
641 |
642 | 我们可以将数字转换为类对象,那么可以反过来,将类对象转换为数字吗?如下所示:
643 |
644 | ```c++
645 | Stonewt wolfe(285.7);
646 | double host = wolfe;
647 | ```
648 |
649 | 其实是可以这样做的,但是不能使用构造函数了,因为**构造函数只能用于从某种类型到类类型的转换**
650 |
651 | 要进行类类型到某种类型的转换,使用特殊的c++运算符函数——转换函数。转换函数是用户自定义的强制类型转换,可以像使用强制类型转换那样使用它们。
652 |
653 | 原型 `operator typename()`
654 |
655 | 转换函数有几个注意事项:
656 |
657 | 1. 转换函数必须是类方法
658 | 2. 转换函数不能指定返回类型
659 | 3. 转换函数不能有参数
660 |
661 | 比如上面我要将类类型转换成double类型,则要在类中添加转换函数:
662 |
663 | ```c++
664 | class Stonewt{
665 | private:
666 | ...
667 | int pounds;
668 | public:
669 | ...
670 | //这里面我以内联函数的形式写
671 | operator int() const{
672 | return pounds;
673 | }
674 | operator double() const{
675 | return double(pounds);
676 | }
677 | };
678 |
679 | //调用如下,之间调用即可,因为我们在类中定义了转换函数
680 | Stonewt temp;
681 | doule d = temp;
682 | ```
683 |
684 | +++
685 |
686 |
687 |
688 | # 进阶编程
689 |
690 | ## 类和动态内存分配
691 |
692 | 我们最好在程序的运行阶段,而不是编译阶段确定问题,这样动态的比较方便
693 |
694 | 因此一些问题也是因为动态分配内存导致的
695 |
696 | ### 类中动态内存相关问题
697 |
698 | **静态成员变量**
699 |
700 | 对于静态成员来说,无论创建了多少个对象,程序都只创建一个静态类变量的副本。
701 |
702 | 不能在类声明中初始化静态成员变量,因为类声明只是描述了**如何分配内存,但是不实际分配内存**。必须在类声明之外使用单独的语句来初始化,这是因为静态类成员是单独存储的,而不是对象的组成部分。所以一般静态数据成员在类声明中声明,在包含类方法的文件中初始化,初始化时使用作用域运算符来指出静态成员所属的类。但是如果静态成员是const或者枚举类型,则可以在类声明中初始化。
703 |
704 | +++
705 |
706 | 问:为什么要有析构函数?
707 |
708 | 答:当删除类对象的时候可以释放掉对象本身所占用的内存,但是并不能自动释放属于对象成员指针所指向的内存。因此必须使用析构函数,在析构函数中使用delete来保证当对象过期时,可以释放掉由new所分配的内存。
709 |
710 | 在构造函数中使用new来分配内存时,必须在相应的析构函数中使用delete释放内存,如果使用new[]来分配内存,则应该使用delete[]来释放内存。
711 |
712 | +++
713 |
714 | **类创建中一些特殊的成员函数**
715 |
716 | 很多类中产生的问题都是由于特殊成员函数引起的,C++自动提供了下面这些成员函数:
717 |
718 | 1. 默认构造函数,如果没有定义构造函数
719 | 2. 默认析构函数,如果没有定义
720 | 3. 拷贝构造函数,如果没有定义
721 | 4. 赋值运算符,如果没有定义
722 | 5. 地址运算符,如果没有定义
723 |
724 | 比如说我们自己设计一个string类,那么这几个函数都要着重考虑一下了。
725 |
726 | - 默认构造函数
727 |
728 | 如果没有提供任何构造函数,c++将创建默认构造函数。因为创建对象时总会调用到构造函数。
729 |
730 | 但是类智能有一个构造函数,因为如果有多个构造函数就会产生二义性,如下:
731 |
732 | ```c++
733 | class_temp A;
734 | ```
735 |
736 | 对象A对于编译器来说不知道去调用哪一个构造函数
737 |
738 | - 拷贝构造函数
739 |
740 | 拷贝构造函数用于将一个对象复制到新创建的对象中,用于初始化过程中,而不是常规的赋值过程。赋值过程有赋值运算符,要重载赋值运算符。
741 |
742 | 拷贝构造函数原型如下:
743 |
744 | ```c++
745 | Class_name(const Class_name &);
746 | //example
747 | String(const String& s);
748 | ```
749 |
750 | 当新建一个对象并且将其初始化为现有对象时,会调用拷贝构造函数,有如下例子:
751 |
752 | ```c++
753 | StringBad ditto(motto);
754 | StringBad ditto = motto;
755 | StringBad ditto = StringBad(motto);
756 | StringBad * p = new StringBad(motto);
757 | ```
758 |
759 | 上面有四种使用拷贝构造的情况,第一种是最直接的拷贝构造使用方式,第二种和第三种可能使用拷贝构造函数直接创建ditto对象,也可能使用拷贝构造函数创建一个临时对象,然后将临时对象的值通过赋值运算符(没有自定义重载“=”就是编译器默认的赋值运算符)将内容赋值给ditto,这取决于具体实现。最后一个是生成一个匿名对象,并将匿名对象的地址赋给p指针。
760 |
761 | 当函数按值传递或者函数返回对象时都将使用拷贝构造函数。由于按值传递对象将调用拷贝构造函数,因此应该尽量按照引用传递对象,可以节省调用构造函数消耗的时间以及数据复制的空间。
762 |
763 | +++
764 |
765 | 但是默认拷贝构造函数也是有问题的。
766 |
767 | 默认的拷贝构造函数将逐个复制非静态成员的值,因为是值复制,所以也叫做浅拷贝。默认拷贝构造函数即浅拷贝会有如下两个问题:
768 |
769 | 1. 如果没有显式的定义拷贝构造函数,那么析构函数的调用次数肯定比构造函数的调用次数多的,因为默认拷贝构造函数也会调用析构函数,而我们没有显式的定义拷贝构造函数,因此调用次数上不平均。这意味着程序无法准确地记录创建对象的个数,因此只能显式的创建拷贝构造函数来统计。
770 |
771 | 2. 最重要的一个问题,如果类中有用new创建的动态变量,则默认拷贝构造函数能整出点问题。
772 |
773 | 由于隐式的拷贝构造函数是按照值进行复制的,如下:
774 |
775 | ```c++
776 | //A和B是对象
777 | //str是new char创建的
778 | A.str = B.str;
779 | ```
780 |
781 | 上述代码复制的并不是字符串本身,而是指向字符串的指针!!!即上述代码得到的不是两个字符串,而是两个指向同一个字符串的指针!!真相大白了家人们!之前我们说过默认拷贝构造函数也是要调用析构函数的,而我们的析构函数是自定义的delete,这就导致我们释放掉了指针指向的那个空间,那个空间已经没有字符串了,因此我们要访问字符串就会出现乱码,比如打印`A.str`就可能会出错,但是有的编译器像vs会保留一次空间的值。更恐怖的是当B对象使用结束后也会调用析构函数释放掉str那片空间,但是str之前在调用默认拷贝构造函数的时候就已经没了,所以后果不可预测。**(本质上)**就是指针悬挂的问题
782 |
783 | +++
784 |
785 | **唯一解决办法就是定义一个显式构造函数**,代码如下:
786 |
787 | ```c++
788 | StringTemp::StringTemp(const StringTemp& st){
789 | //引用计数
790 | num_count++;
791 | len = st.size();
792 | str = new char[len + 1];
793 | //把st对象的str赋给本对象定义的str
794 | std:strcpy(str, st.str);
795 | }
796 | ```
797 |
798 | **可以看到必须定义显式拷贝构造函数的原因在于有一些类成员使用的是new初始化,指向数据的指针而不是数据本身。**
799 |
800 | - 赋值运算符
801 |
802 | c++允许类对象赋值,并且自动为类重载赋值运算符,原型如下:
803 |
804 | `Class_name & Class_name::operator=(const Class_name&);`接收并返回一个类对象的引用。
805 |
806 | +++
807 |
808 | 当将已经有的对象赋给另外一个对象的时候必调用这个,比如
809 |
810 | ```c++
811 | StringTemp A;
812 | StringTemp B;
813 | ...
814 | //调用赋值运算符
815 | A = B;
816 | ```
817 |
818 | **一定要分清楚初始化与已有的对象给另一个对象赋值的区别**
819 |
820 | ```c++
821 | StringBad ditto = motto;
822 | StringBad ditto = StringBad(motto);
823 | ```
824 |
825 | 上面这两个代码就是初始化,但是有可能会调用赋值运算符,这个取决于编译器
826 |
827 | +++
828 |
829 | **赋值运算符也会出现相同的问题:数据受损。**和隐式拷贝构造函数一样的问题,解决办法就是提供深度赋值,但是要注意,赋值语算符重载的返回值是对象。
830 |
831 | 比如举个例子:
832 |
833 | ```c++
834 | StringTemp& StringTemp::operator=(const StringTemp& st){
835 | if(this == &st){
836 | return *this;
837 | }
838 | delete [] str;
839 | len = st.size();
840 | str = new char[len + 1];
841 | std:strcpy(str, st.str);
842 | return *this;
843 | }
844 | ```
845 |
846 | 1. 代码首先检查自我复制,如果是自己赋值自己,则返回*this,因为this是指针
847 | 2. 如果地址不同,先释放掉str指向的内存。因为每个对象都有个str,但是我们要接收来自另一个对象的str,这样的话必须把自己对象的str所占用的内存给释放掉,这样不会浪费内存
848 | 3. 接下来操作和显式拷贝构造一样。
849 |
850 | +++
851 |
852 | **静态类成员函数**
853 |
854 | 可以将成员函数声明为静态的,当类中函数成为静态的以后,有两个后果:
855 |
856 | 1. 不能通过对象调用静态成员函数,此外静态成员函数都不能用this指针。
857 |
858 | 如果静态成员函数是在共有部分声明的,则可以使用类名+作用域解析符来调用,如下
859 |
860 | ```c++
861 | //类中共有部分的static函数
862 | static int HowMany(){
863 | return num_strings;
864 | }
865 | //调用形式
866 | int count = String::HowMany();
867 | ```
868 |
869 | 2. 由于静态成员函数不与特定对象关联,因此只能使用静态数据成员。如上面代码,静态类成员函数可以访问静态类成员,但不能访问len,str这些变量。
870 |
871 | ### 在构造函数中使用new应该注意的事项
872 |
873 | 当在类中使用new时,应该注意一下几点:
874 |
875 | 1. 如果在构造函数中用new初始化指针成员,那么在析构函数中应该使用delete
876 | 2. new和delete必须成对出现
877 | 3. 应该定义一个复制构造函数,通过深拷贝将一个对象初始化为另一个对象
878 | 4. 重载一个赋值运算符,通过深拷贝将一个对象复制给另一个对象。
879 |
880 | ### 有关返回对象的说明
881 |
882 | 当成员函数或者普通函数返回对象时,有几种返回方式可以选择:
883 |
884 | 1. 返回指向对象的引用
885 | 2. 指向对象的const引用
886 | 3. const对象
887 |
888 | - 返回指向const对象的引用
889 |
890 | 使用const引用的常见原因是提高效率。代码如下:
891 |
892 | ```c++
893 | //version1
894 | Vector Max(const Vector& v1, const Vector& v2){
895 | if(...){
896 | return v1;
897 | }else{
898 | return v2;
899 | }
900 | }
901 | //version2
902 | const Vector& Max(const Vector& v1, const Vector& v2){
903 | if(...){
904 | return v1;
905 | }else{
906 | return v2;
907 | }
908 | }
909 | ```
910 |
911 |
912 |
913 | 1. 返回对象的话会调用拷贝构造函数,而返回引用则不会。
914 | 2. 引用指向的对象应该在调用函数执行时候存在
915 | 3. 参数被声明为const对象,因此返回类型也得为const
916 |
917 | +++
918 |
919 | - 返回指向非const对象的引用
920 |
921 | 一般两种情况会这样,即不加const的引用:
922 |
923 | 1. 重载赋值运算符,为了提高效率
924 |
925 | ```c++
926 | String s1("hello");
927 | String s2,s3;
928 | s3 = s2 = s1;
929 | ```
930 |
931 | `s2.operator=()`的返回值被赋值给s3,因此返回String对象或者引用都可以,通过使用引用可以避免String的拷贝构造函数创建出来的新的临时的对象,提高效率。不加const是因为指向s2的引用可以对其进行修改而不是不变的。
932 |
933 | 2. 重载`<<`运算符
934 |
935 | ```c++
936 | String s1("hello");
937 | cout< 总之,如果函数要返回局部对象,则千万不要返回引用,而应该返回对象即可。
949 |
950 | +++
951 |
952 | ### 再谈new和delete
953 |
954 | 先放一段代码:
955 |
956 | ```c++
957 | class Act{...};
958 | Act nice; //静态变量(外部变量)
959 | int main(){
960 | Act *pt = new Act; //动态变量
961 | delete pt;
962 |
963 | {
964 | Act up; //动态变量
965 | }
966 | ....
967 |
968 | }
969 | ```
970 |
971 | 分析上述代码析构函数被调用情况
972 |
973 | 1. 如果对象是静态变量(外部、静态或来自命名空间),则在程序结束时候才会调用对象的析构函数。
974 | 2. 如果对象是动态变量,当执行完该对象的程序块时就调用析构函数
975 | 3. 如果对象是用new创建的,则当显式调用delete时才会调用析构函数。
976 |
977 | ### 成员列表初始化
978 |
979 | c++程序执行构造函数的顺序如下:
980 |
981 | 1. 调用构造函数
982 | 2. 创建对象(对象在构造函数代码执行前被创建)
983 | 3. 给类成员分配内存
984 | 4. 执行构造函数内部代码,将值存储在内存中。
985 |
986 | > 思考一个问题,一个类中有const成员变量,那如果用构造函数赋值会出现问题吗??
987 | >
988 | > 答案是会的,因为const数据成员必须在创建对象时就初始化,而不能在内部初始化。
989 |
990 | 所以c++提供了一类特殊的语法,成员列表初始化,形式如下:
991 |
992 | ```c++
993 | Classy::Classy(int n, int m)::mem1(n), mem2(m),mem3(n*m){
994 | ...
995 | }
996 | ```
997 |
998 | **只有构造函数可以使用这种语法!!!**
999 |
1000 | **对于const成员和引用的类成员,也必须这样使用**
1001 |
1002 | +++
1003 |
1004 | 初始化工作是在对象创建时候完成的,还未执行括号中的任何代码,要注意一下几点:
1005 |
1006 | 1. 这种语法只能用于构造函数
1007 | 2. 必须用这种语法初始化非静态const成员
1008 | 3. 必须用这种语法初始化引用数据成员
1009 |
1010 | +++
1011 |
1012 | C++11允许更直观的方式初始化,类内初始化:
1013 |
1014 | ```c++
1015 | class Classy{
1016 | int mem1 = 10;
1017 | const int mem2 = 20;
1018 | }
1019 | ```
1020 |
1021 | 上面代码与在构造函数中等价
1022 |
1023 | +++
1024 |
1025 | ## 类继承
1026 |
1027 | ### 基类与派生类特性
1028 |
1029 | 从一个类派生出另外一个类时,原始类成为基类,继承类成为派生类。也叫做父类和子类。
1030 |
1031 | 使用公有派生,基类的公有成员将成为派生类的公有成员;基类的私有部分也成为了派生类的一部分,但只能通过基类的公有和保护方法去访问。但是需要在派生类中添加自己的构造函数和自己所需的额外的数据成员和成员函数。
1032 |
1033 | +++
1034 |
1035 | 由于派生类不能直接访问基类的私有成员,必须通过基类方法进行访问。那么就是说派生类构造函数不能直接设置哪些继承过来的数据,而必须使用基类的公有方法来访问私有的基类成员,具体说就是派生类构造函数必须是有基类构造函数。
1036 |
1037 | 创建派生类对象时,程序首先创建基类对象,也就是说**基类对象应当在程序进入派生类构造函数之前被创建**。c++使用成员初始化列表来完成,如下:
1038 |
1039 | ```c++
1040 | //RatedPlayer构造函数
1041 | RatedPlayer::RatedPlayer(unsigned int r, const string& fn, const string& ln, bool ht):TableTennisPlayer(fn, ln, ht){
1042 | rating = r;
1043 | }
1044 | RatedPlayer player1(1140, "mary", "duck", true);
1045 | ```
1046 |
1047 | RatedPlayer构造函数把实参`"mary", "duck", true`赋给形参`fn, ln, ht`通过成员初始化列表,然后将这些实参传递给TableTennisPlayer构造函数中,TableTennisPlayer将创建一个对象,并将实参存储在对象中。然后程序进入RatedPlayer构造函数,完成RatedPlayer对象的创建,然后执行构造函数中的代码,将r赋值给rating。
1048 |
1049 | 但是如果没有成员列表初始化,程序还是要创建基类对象,就会使用默认的的基类构造函数。否则就显式的调用构造函数。
1050 |
1051 | > 总结一下有关派生类构造函数的要点:
1052 | >
1053 | > 1. 创建派生类对象前先创建基类对象
1054 | > 2. 派生类构造函数应该通过成员初始化列表将基类信息传递给基类构造函数
1055 | > 3. **派生类构造函数应该初始化新增的数据成员**
1056 | >
1057 | > 释放对象的顺序与创建对象的顺序相反,即首先执行派生类的析构函数,然后执行基类的析构函数
1058 | >
1059 | > 基类构造函数主要负责初始化那些继承的数据成员,派生类构造函数主要用于初始化新增的数据成员。派生类构造函数总是调用一个基类的构造函数,可以使用成员列表初始化指明要使用的基类构造函数,否则使用默认的基类构造函数
1060 |
1061 | +++
1062 |
1063 | 派生类与基类之间有一些特殊的关系:
1064 |
1065 | 1. 派生类对象可以使用基类的方法,条件是该方法不是私有的
1066 |
1067 | 2. 基类指针可以在不进行显式类型转换的情况下指向派生类对象
1068 |
1069 | 3. 基类引用可以在不进行显式类型转换的情况下引用派生类对象
1070 |
1071 | ```c++
1072 | RatedPlayer player1(1140, "mary", "duck", true);
1073 | TableTennisPlayer& rt = player1;
1074 | TableTennisPlayer* pt = &player1;
1075 | ```
1076 |
1077 | > **注意事项:**基类指针或者引用只能用于调用基类方法,不能使用rt或者pt来调用派生类方法。对于c++来说引用和指针类型要与赋给的类型匹配才行,但是对于继承来说是例外的。但是这种例外是单向的,即只能将基类的引用或指针赋给派生类对象,而不能将派生类对象的引用或指针赋给基类对象
1078 |
1079 | ### 继承关系汇总
1080 |
1081 | c++有3中继承方式:公有继承,保护继承和私有继承。
1082 |
1083 | 公有继承是最常用的方式,他建立的是一种is-a的关系,即派生类对象也是一个基类对象。进而可以对基类对象执行的操作对派生类对象也可以。
1084 |
1085 | > 举个例子,香蕉是一种水果,进而香蕉就是派生类,水果就是基类。香蕉可以继承水果类的重量和热量成员
1086 |
1087 | 公有继承不建立has-a的关系。比如午餐可能包含水果,但是午餐并不是水果。我们只能说午餐李有水果,但是午餐并不能从水果哪里继承,就只能has-a,将水果对象作为午餐类的数据成员。
1088 |
1089 | 公有继承不建立is-like-a的关系。比如人们说律师就像鲨鱼,但是律师并不是鲨鱼。
1090 |
1091 | 公有继承不建立is-implemented-as-a关系(作为……来实现)。例如可以用数组来实现栈,但从数组类派生出栈类是不合适的,因为栈并不是数组。
1092 |
1093 | 公有继承不建立uses-a关系。比如计算机可以使激光打印机,但是从计算机类派生出打印机类是没有意义的,当然了,可以使用友元函数或类来处理双方通信。
1094 |
1095 | 综上,c++中最多的还是is-a的关系!!
1096 |
1097 | ### 多态公有继承
1098 |
1099 | 在使用继承的时候,最简单的就是对派生类对象使用基类的方法,不作任何修改。但很多时候我们都希望同一个方法在派生类和基类中表现得不同,即方法的行为应该取决于调用方法的对象。这种复杂的行为成为多态——方法随着上下文而异。多态公有继承有两种实现方式:
1100 |
1101 | 1. 在派生类中重新定义基类的方法(重载)
1102 | 2. 使用虚方法
1103 |
1104 | +++
1105 |
1106 | ```c++
1107 | //1. viewcount不是virtual的
1108 | void viewcount() const;
1109 | //2.viewcount是virtual的
1110 | virtual void viewcount() const;
1111 |
1112 | //1情况下
1113 | Brass dom(arg1, arg2);
1114 | BrassPlus dot(arg1,arg2);
1115 | Brass& b1_ref = dom;
1116 | Brass& b2_ref = dot;
1117 | b1_ref.viewcount(); //使用Brass::viewcount()
1118 | b2_ref.viewcount(); //使用Brass::viewcount()
1119 |
1120 | //2情况下
1121 | Brass dom(arg1, arg2);
1122 | BrassPlus dot(arg1,arg2);
1123 | Brass& b1_ref = dom;
1124 | Brass& b2_ref = dot;
1125 | b1_ref.viewcount(); //使用Brass::viewcount()
1126 | b2_ref.viewcount(); //使用BrassPlus::viewcount()
1127 | ```
1128 |
1129 | 首先方法前面加上关键字`virtual`时,这些方法被称为**虚方法**。
1130 |
1131 | > 如果类方法没有使用virtual关键字,程序将根据引用或指针本身的类型来选择调用基类的方法还是派生类的方法。
1132 | >
1133 | > 如果类使用了virtual,程序将根据引用或者指针指向的对象的类型来选择方法。
1134 |
1135 | 经常在基类中将派生类会重新定义的方法称为虚方法,方法在基类中被声明为虚的以后,在派生类中将自动称为虚方法。但是,在派生类中将某些方法用virtual标注也是可以的。如果想在派生类中重新定义基类的方法,通常将基类的方法定义为虚的,因为这样程序会根据对象类型来选择调用的方法。
1136 |
1137 | +++
1138 |
1139 | **虚析构函数**
1140 |
1141 | 如果没有虚析构函数,那么程序结束时候,就只会调用对应于指针类型的析构函数,对于上述代码来说只会调用Brass类的析构函数。
1142 |
1143 | 如果析构函数是虚的,将会调用对象类型的析构函数,比如上面代码第二种情况,指针指向的是BrassPlus对象,调用BrassPlus的析构函数,然后自动调用基类的析构函数(基类和继承类那里有说)
1144 |
1145 | 因此必须要有虚析构函数,不然只能调用对应指针类型的那个类的析构函数,而不能调用对象对应类的析构函数。
1146 |
1147 | +++
1148 |
1149 | ### 静态连联编和动态联编
1150 |
1151 | 将源代码中的函数调用解释为执行特定的函数代码块成为**函数名联编**。在c语言中很简单,因为每个函数名对应一个不同的函数,没有重载。但是c++有重载了,编译器必须查看函数参数以及函数名称才能确定使用哪一个函数。
1152 |
1153 | 在编译过程中进行联编称为静态联编。编译器生成能够在程序运行时选择正确的虚方法的代码,成为动态联编。(dynamic binding)
1154 |
1155 | +++
1156 |
1157 | 在c++中,动态联编通过指针和引用调用方法相关,由继承控制的。通常c++不允许将一种类型的地址赋给另外一种类型的指针,也不允许一种类型的引用指向另一种类型。但是指向基类的指针或者引用可以转换成派生类对象,而不必进行显示类型转换。
1158 |
1159 | 将派生类引用或指针转换为基类引用或指针成为**向上强制转换**,改规则是is-a关系的一部分,比如之前的BrassPlus 对象都是Brass对象,因为继承。反过来,将基类指针或引用转换为派生类指针或引用成为**向下强制转换**。如果不使用显式转换类型,向下强制转换是不允许的,因为is-a关系式不可逆的,派生类可以新增数据成员,但这些新增的数据成员不能应用与基类。
1160 |
1161 | +++
1162 |
1163 | **问:为什么有两种联编同时默认是静态联编?**
1164 |
1165 | 答:效率和概念模型。首先是效率,为了使得程序能够早运行阶段做策略,必须用一些方法来跟踪基类指针或引用指向的类型,会增加额外的处理开销。大多数情况下都不太会对基类方法重定义或重载,使用静态联编更合理。其次是概念模型,指的是有一些派生类中的成员函数不应该重新定义,就应该继承基类的定义。总之就是,如果要在派生类中重新定义基类的方法,就设置为虚方法,否则别设置虚方法。
1166 |
1167 | ### 虚函数的工作原理和注意事项
1168 |
1169 | > 虚函数表(vtbl),虚函数表指针(vptr)
1170 |
1171 | 首先要知道每一个派生类对象实际上是由两个部分组成的:
1172 |
1173 | 1. 父类部分,包括成员变量,成员函数,vptr等这些都是共享给子类的,当然要加上权限限制
1174 | 2. 子类部分,子类自己定义的成员变量成员函数。
1175 |
1176 | 可以看到子类其实就是一个特殊的父类,享有父类的所有属性,是is-a的关系,因此子类可以强制转换成父类,通常是用`dynamic_cast`将子类指针转为父类指针。当转换成父类指针的时候,父类指针的访问域就变成了下图内存模型中的上半部分,下半部分属于子类的域是没有办法访问的。
1177 |
1178 |
188 |
189 | 其中“?”表示开始,“@@YA”表示参数的开始,后面三个字符“HHH”和“MMM”分别表示函数返回值类型,两个参数类型,“@Z”表示函数名称结束,所以由于函数生成的符号表中的名称不一样,因此可以编译通过。
190 |
191 | ------
192 |
193 |
194 |
195 | ## 类和对象
196 |
197 | 三大特性:封装、继承、多态
198 |
199 | ```
200 | Class test{
201 | //成员变量
202 | //成员函数
203 | };
204 | ```
205 |
206 | - 封装
207 |
208 | - 三种访问权限
209 |
210 | 1. public。对成员来说,可以在类内被访问,类外也可以访问
211 | 2. protected。对成员来说,可以在类内被访问,类外不可以访问,主要用在继承,子类可以访问父类的一些保护权限的内容。
212 | 3. private。对成员来说,可以在类内被访问,类外不可以访问。子类不能访问父类的私有内容。
213 |
214 | 一般将成员变量属性设置为私有,可以自己控制读写权限,成员函数为共有。
215 |
216 | 类对象的默认访问控制是private的,但是结构的默认访问类型是public,结构没有成员函数只能纯粹的表示数据对象
217 |
218 | - 成员函数
219 |
220 | 成员函数必须使用作用域解析符来指出函数所属的类,代码如下:
221 |
222 | ```c++
223 | void Stock::update(double price);
224 | ```
225 |
226 | 位于类声明中的函数都将自动成为内联函数,但是内联函数也可以在类外定义,如下:
227 |
228 | ```c++
229 | inline void Stock::update(double price);
230 | ```
231 |
232 | 由于内联函数的规则要求每个使用该函数的文件中都要对其进行定义,因此将内联函数放在头文件中是最好的。
233 |
234 | ------
235 |
236 | - 类对象
237 |
238 | 每个新对象都有自己的存储空间,用于存储其内部变量和类成员。但是同一个类的所有对象共享类的方法,即类的函数。所有类对象都会执行同一个代码块,只是入栈的数据不同而已。
239 |
240 | ------
241 |
242 |
243 |
244 | ### 类的构造函数
245 |
246 | 由于类设计的初衷是隐藏数据成员,因此类的初始化不能像结构那样,必须通过成员函数来访问成员数据。
247 |
248 | 因此c++提供了一个类构造函数,在创造对象时自动对它进行初始化。
249 |
250 | > 注意事项:不能将类成员用作构造函数的参数名
251 | >
252 | > 因为构造函数的作用是初始化成员变量的值,因此构造函数的参数肯定是传入的值,不可能是类成员变量的值!因此为了避免这种混乱,需要在类成员函数的名称前加一个前缀,比如“m_”这样的。
253 |
254 | - **使用构造函数**
255 |
256 | c++使用了两种用构造函数来初始化对象的方式:
257 |
258 | ```c++
259 | //显示的调用构造函数
260 | Stock food = Stock("World Cabbage", 250, 1.25);
261 | //隐式的调用构造函数
262 | Stock garment("Furry Mason", 50, 2.5);
263 | //动态分配new
264 | Stock *pstock = new Stock("Furry Mason", 50, 2.5);
265 | /*动态的创建一个Stock对象,并将对象的地址赋给pstock指针,用指针管理该对象*/
266 | ```
267 |
268 | 切记,无法使用对象来调用构造函数,因为在构造函数构造出对象之前,对象是不存在的!因此构造函数是用来创建对象的,不能通过对象调用
269 |
270 | - **默认构造函数**
271 |
272 | 默认构造函数是指在没有显示的赋值时,用来创建对象的构造函数。如下:
273 |
274 | ```c++
275 | Stock fluffyp;
276 | ```
277 |
278 | 上面这行代码之所以可以使用是因为对于类没有构造函数的话,c++编译器将自动提供一个默认构造函数,用来创建对象但不初始化值,一般默认构造函数的形式如`Stokc::Stock(){}`
279 |
280 | **如果类没有定义任何构造函数的时候,编译器才会提供默认构造函数。但是如果类定义了构造函数,就必须要写一个默认构造函数!**
281 |
282 | 因此在以后设计类的时候,通常应提供所有成员隐式初始化的默认构造函数
283 |
284 | - **赋值(构造函数作用2)**
285 |
286 | 与结构赋值一样,在默认情况下给类对象赋值时,把一个对象的成员复制给另一个。这样一来,构造函数不仅仅可用于初始化新对象,还可以执行赋值操作
287 |
288 | ```c++
289 | stock1 = Stock("wuhu", 10, 50.0);
290 | ```
291 |
292 | 上述代码右边指的是构造函数产生了一个新的临时的对象,然后将该临时对象的内容赋值给了stock1
293 |
294 | 我们将上述代码放在一起比较:
295 |
296 | ```c++
297 | //显示的调用构造函数
298 | Stock food = Stock("World Cabbage", 250, 1.25);
299 | stock1 = Stock("wuhu", 10, 50.0);
300 | ```
301 |
302 | 第一条语句有可能会创建临时变量也可能不会,创建临时变量的话就变成第二条语句这样的赋值了,因此如果可以初始化尽量不要赋值,提高效率。因此我们就有c++11的列表初始化。
303 |
304 | ------
305 |
306 |
307 |
308 | ### 类的析构函数
309 |
310 | 当构造函数创建对象后,程序负责跟踪该对象,知道过期为止。对象过期时程序将自动调用一个特殊的成员函数 —析构函数,由析构函数完成清理工作。如果构造函数使用new分配内存,那么析构函数就要使用delete释放。如果构造函数不适用new,则析构函数什么都不用做。
311 |
312 | ------
313 |
314 |
315 |
316 | ### this指针
317 |
318 | 下面给一段代码进行解释:
319 |
320 | ```c++
321 | const Stock& topval(const Stock& s);
322 | top = stock1.topval(stock2);
323 | top = stock2.topval(stock1);
324 | ```
325 |
326 | 这段代码比较两个对象的股票价格最高的,返回其中过一个,传入参数只有一个显示的引用。
327 |
328 | c++使用this这种特殊的指针,指向用来调用成员函数的对象(谁调用该成员函数,this对象就是谁)。其实每个成员方法都有一个隐藏的形参this指针上述代码中stock1调用了topval函数,因此this指针就是stock1.
329 |
330 | 所有的类方法都将this指针设置为调用它的对象的地址
331 |
332 | 每个成员函数(包括构造函数和析构函数)都有`this`指针。`this`指针指向调用的对象,是对象的地址,因此`*this`才是这个对象,`this`只是个地址,`*this`作为对象的别名。
333 |
334 | ------
335 |
336 |
337 |
338 | ### 对象数组
339 |
340 | 如果要创建类的多个对象,可以使用数组的方式,声明对象数组的方法与声明标准类型数组相同:
341 |
342 | ```c++
343 | Stock mystuff[4];
344 | ```
345 |
346 | ------
347 |
348 | ### 类作用域
349 |
350 | 在类中定义的作用域为整个类,名称在类内是已知的,在类外不是。因此可以在不同类使用相同的成员名称而不引起冲突,必须通过对象来访问类的成员或方法。
351 |
352 | - **在类中声明常量**
353 |
354 | 要注意,在类中类只是描述一个结构的形式,在没有创建对象之前,类是没有用于存储的空间的,因此不能如下直接在类中生命一个变量值:
355 |
356 | ```c++
357 | class temp{
358 | private:
359 | const int Months = 12;//这样是不行的
360 | };
361 | ```
362 |
363 | 如果我们要声明一个变量,要在前面加上`static`关键字,表明该常量是与其他静态变量存储在一起的,而不是存储在对象中的。因此month可以被所有的对象共享。
364 |
365 | - **作用域内枚举(枚举类)(c++11)**
366 |
367 | ```c++
368 | enum egg{small, medium, large}
369 | enum t_shirt{small, medium, large}
370 | ```
371 |
372 | 上述代码是常规的枚举类型,可以看到存在问题,即两个枚举定义的枚举量可能发生冲突,因为egg small和t_shirt small在一个作用域内。因此c++11提供了一种新的枚举类型,枚举作用域为类,叫做枚举类。
373 |
374 | ```c++
375 | enum class egg{small, medium, large}
376 | enum class t_shirt{small, medium, large}
377 |
378 | egg choice = egg::small;
379 | tshirt choic = t_shirt::small;
380 | ```
381 |
382 | 不同枚举定义的枚举量就不会发生冲突了
383 |
384 | ------
385 |
386 | 同时枚举类还提高了作用域内枚举的类型安全。在有些情况下,常规枚举将自动转化为整型,比如赋值给int类型或者用于比较表达式时候,但是枚举类不能隐式的转换成整型。有必要的时候只能进行显示的转换`int(枚举)`
387 |
388 | 默认情况下c++11作用域内枚举的底层类型为int,但可以显示的更改底层类型,比如:
389 |
390 | ```c++
391 | enum class : short pizza{small, medium,large}
392 | ```
393 |
394 | 如上述代码底层就变成了short类型。
395 |
396 | ------
397 |
398 |
399 |
400 | ### 运算符重载
401 |
402 | c++多态有函数重载和运算符重载
403 |
404 | 运算符重载的格式如下:
405 |
406 | `(返回类型) operator OP (argument-list)`,例如`operator +()`重载+运算符,`operator *()`重载*运算符。但要切记,OP这个运算符一定是有效的,不能虚构一个运算符,比如`@#`等,因为这些符号在实际中本来就不是运算符。
407 |
408 | > 举个例子:
409 | >
410 | > A,B,C都是一个类的对象
411 | >
412 | > ```c++
413 | > //想求对象相加
414 | > A = B + C;
415 | > //编译器角度
416 | > A = B.operator+(C)
417 | > ```
418 | >
419 | > 该函数隐式的使用A(调用了operator方法),显式的调用C(因为被当做参数传递了)
420 |
421 | **在重载运算符中,运算符左侧的对象是调用对象,而运算符右侧的对象是作为参数传递的**
422 |
423 | > 看一段代码:
424 | >
425 | > ```c++
426 | > class Time{
427 | > private:
428 | > int hours;
429 | > int minutes;
430 | > public:
431 | > Time();
432 | > Time operator +(const Time& t) const;
433 | > };
434 | >
435 | > Time::Time operator+(const Time& t) const{
436 | > Time sum;
437 | > sum.minutes = minutes + t.minutes;
438 | > sum.hours = hours + t.houts + sum.minutes/60;
439 | > return sum
440 | > }
441 | >
442 | > //使用重载运算符
443 | > time1 = time2 + time3;
444 | > ```
445 | >
446 | > 在这里面有两点需要注意:
447 | >
448 | > 1. 要主要operator的返回值,到底返回什么。
449 | >
450 | > 上面代码中我们是要用time1来接收operator的返回,由于time1的类型是Time类,因此上面代码中operator的返回值也是Time。
451 | >
452 | > 2. 注意返回值不能是引用。因为sum是局部变量,在函数结束时会被删除,因此引用将指向一个不存在的对象(vs编译器中会保存一次该引用,但是只能调用一次)。但是上述代码返回的是sum,是一个局部变量,在函数结束删除sum时候会构造一个sum的拷贝放到临时变量中。
453 |
454 | ------
455 |
456 | **重载有以下两个限制:**
457 |
458 | 1. 重载后的运算符必须至少有一个操作数是用户自定义的类型,不能两个操作数都是系统原有的类型。这样是防止用户对标准类型重载运算符,比如不能将+重载后作用于两个int类型的变量上
459 | 2. 重载后的运算符不能违背原来的规则,比如不能将运算符变成一个变量类型
460 | 3. 不能创建新的运算符,比如说创建一个**去求幂。
461 | 4. 有以下几个运算符不能重载:`sizeof`、`.` 、`::` 、`?: ` 、`.*`、`const_cast`、`dynamic_cast`、 `static_cast`等
462 | 5. 下面四个运算符必须通过**成员函数**去重载:`=`、`()`、`[]`、`->`。
463 |
464 | ------
465 |
466 | ### 友元
467 |
468 | c++对私有部分成员的访问非常严格,在没有友元之前只能通过公有方法去访问。但是提供了对私有成员的另一种访问:友元,有3种:
469 |
470 | 1. 友元函数
471 | 2. 友元类
472 | 3. 友元成员函数
473 |
474 | ------
475 |
476 | #### 友元函数
477 |
478 | 在为类重载二元运算符(带两个参数的运算符)常常需要友元,因为问题描述如下:
479 |
480 | > 对于重载的乘法运算符来说,比如代码如下:
481 | >
482 | > ```c++
483 | > Time operator*(const double num);
484 | > ```
485 | >
486 | > 比如上述代码可以满足:A = B * 2.75
487 | >
488 | > 但是我要写成A = 2.75 * B呢?由于重载运算符左边是double类型,而代码中左边是调用operator的对象,是Time类,所以就有问题。由于左侧的操作对象应该是Time类对象,而不应该是doule变量,所以编译器不能使用成员函数来调用该表达式。
489 |
490 | 上述问题的解决办法就是采用非成员函数,非成员函数不是对象调用的,它所使用的值都是显式的参数,比如下面的代码:
491 |
492 | ```c++
493 | Time operator* (double m, const Time& t);
494 | ```
495 |
496 | 上述代码解决了`A = 2.75 * B`这个问题,但又有一个新的问题即非成员函数不能访问私有成员,所以就需要友元函数。
497 |
498 | +++
499 |
500 | 创建友元函数:
501 |
502 | ```c++
503 | friend Time operator*(double m, const Time& t);
504 | ```
505 |
506 | 加了friend前缀后,该函数就和成员函数有着一样的访问权限。
507 |
508 | 可能刚开始学的时候认为友元这个性质违背了OOP数据隐藏的概念,因为友元机制允许非成员函数访问私有数据。这个有些片面,应该将友元函数看作类的扩展接口的组成部分。类方法和友元只是表达类接口的两种不同机制而已。
509 |
510 | +++
511 |
512 | **重载<<运算符**
513 |
514 | 最初<<运算符是C和C++的位运算符,表示左移。ostream类对该运算符进行了重载,变成了一个输出工具。cout是一个ostream对象,能够识别所有的c++**基本类型**,原因是对于每种类型,ostream类声明都包含了相应的重载。
515 |
516 | 但要注意一点,重载<<符号的时候,函数的返回值一定要写成ostream&,如下代码:
517 |
518 | ```c++
519 | ostream & operator<<(ostream& os, const Time& t);
520 | ```
521 |
522 | 因为`cout<<`不是调用一次,而是很多次,比如`cout<<"hello"< 友元类举例:
533 | >
534 | > 一个电视机类TV和一个遥控器Remote类,这两个不是包含也不是继承关系,但是遥控器可以控制电视机,也就意味着遥控器这个类可以访问电视机类中的成员,因此用友元类比较好。
535 | >
536 | > ```c++
537 | > class TV{
538 | > public:
539 | > friend class Remote;
540 | > bool volup();
541 | > bool voldown();
542 | > void chanup();
543 | > void chandown();
544 | > private:
545 | > int state;
546 | > int volume;
547 | > int maxchannel;
548 | > int channel;
549 | > };
550 | >
551 | > class Remote{
552 | > private:
553 | > int mode;
554 | > public:
555 | > bool volup(Tv& t){
556 | > return t.volup();
557 | > }
558 | > bool voldown(Tv& t){
559 | > return t.voldown();
560 | > }
561 | > void chanup(Tv& t){
562 | > return t.chanup();
563 | > }
564 | > void chandown(Tv& t){
565 | > return t.chandown();
566 | > }
567 | > void set_chan(Tv& t, int c){
568 | > t.channel = c;
569 | > }
570 | > };
571 | > ```
572 |
573 | #### 友元成员函数
574 |
575 | 在上面两个类中的代码,大部分Remote类中的方法都是用Tv类的共有接口实现的,意味着这些方法不是真正需要用作友元。但是有一个Remote类中的函数直接访问了TV类中的私有成员,就是set_chan函数,因此这个方法才是唯一需要作为友元的方法。
576 |
577 | 可以选择**让特定的类成员成为另一个类的友元**,而不用让整个类成为友元,修改一下上述代码如下:
578 |
579 | ```c++
580 | class Tv{
581 | public:
582 | friend void Remote::set_chan(Tv& t, int c);
583 | ...
584 | };
585 | ```
586 |
587 | +++
588 |
589 | ### 类的自动转换和强制类型转换
590 |
591 | **c++处理内置类型转换:**
592 |
593 | 在两种类型兼容的情况下,将一种标准类型变量的值赋给另一种标准类型变量的值时,c++将自动转换,代码如下:
594 |
595 | ```c++
596 | long count = 8;
597 | int side = 3.33
598 | ```
599 |
600 | c++内部将各种数值类型都看作是同样的东西—数字。但是c++不自动转换不兼容的类型,比如下面的语句是非法的,左边是指针,右边是整形数字
601 |
602 | ```c++
603 | //不支持
604 | int* p = 10;
605 | //强转成int指针类型,指针值为10
606 | int* p = (int*)10
607 | ```
608 |
609 | +++
610 |
611 | 下面说一说类相关的转换
612 |
613 | **有参的构造函数为类的转换提供了蓝图,或者说提供了原动力**
614 |
615 | ```c++
616 | //一个类的构造函数
617 | Stonewt(double lbs);
618 | //隐式转换
619 | Stonewt myCat;
620 | myCat = 16.9;
621 | ```
622 |
623 | 对于上面代码,使用构造函数`Stonewt(double)`来创建一个临时的Stonewt对象,并将19.6作为double参数传入,随后采用成员赋值的方式将该临时对象的值复制到myCat中,成为隐式转换,是自动进行的,不需要显式强制类型转换。
624 |
625 | 但有一个问题,即因为只有一个19.6类型的double变量,因此只支持一个参数的构造函数。
626 |
627 | 将构造函数用作类型转换函数仔细一看其实很棒,不用我们自己操作。但是有个问题,我们并不是总是需要,可能会导致意外的类型转换。因此c++新增了一个`explicit`关键字,用于关闭这种自动转换的特性。可以如下声明构造函数:
628 |
629 | ```c++
630 | explicit Stonewt(double lbs);
631 | //无法隐式转换
632 | Stonewt myCat;
633 | myCat = 16.9;
634 | //必须显式转换
635 | myCat = (Stonewt)16.9;
636 | ```
637 |
638 | 一旦加入了explicit,则不能隐式转换,必须显示转换
639 |
640 | +++
641 |
642 | 我们可以将数字转换为类对象,那么可以反过来,将类对象转换为数字吗?如下所示:
643 |
644 | ```c++
645 | Stonewt wolfe(285.7);
646 | double host = wolfe;
647 | ```
648 |
649 | 其实是可以这样做的,但是不能使用构造函数了,因为**构造函数只能用于从某种类型到类类型的转换**
650 |
651 | 要进行类类型到某种类型的转换,使用特殊的c++运算符函数——转换函数。转换函数是用户自定义的强制类型转换,可以像使用强制类型转换那样使用它们。
652 |
653 | 原型 `operator typename()`
654 |
655 | 转换函数有几个注意事项:
656 |
657 | 1. 转换函数必须是类方法
658 | 2. 转换函数不能指定返回类型
659 | 3. 转换函数不能有参数
660 |
661 | 比如上面我要将类类型转换成double类型,则要在类中添加转换函数:
662 |
663 | ```c++
664 | class Stonewt{
665 | private:
666 | ...
667 | int pounds;
668 | public:
669 | ...
670 | //这里面我以内联函数的形式写
671 | operator int() const{
672 | return pounds;
673 | }
674 | operator double() const{
675 | return double(pounds);
676 | }
677 | };
678 |
679 | //调用如下,之间调用即可,因为我们在类中定义了转换函数
680 | Stonewt temp;
681 | doule d = temp;
682 | ```
683 |
684 | +++
685 |
686 |
687 |
688 | # 进阶编程
689 |
690 | ## 类和动态内存分配
691 |
692 | 我们最好在程序的运行阶段,而不是编译阶段确定问题,这样动态的比较方便
693 |
694 | 因此一些问题也是因为动态分配内存导致的
695 |
696 | ### 类中动态内存相关问题
697 |
698 | **静态成员变量**
699 |
700 | 对于静态成员来说,无论创建了多少个对象,程序都只创建一个静态类变量的副本。
701 |
702 | 不能在类声明中初始化静态成员变量,因为类声明只是描述了**如何分配内存,但是不实际分配内存**。必须在类声明之外使用单独的语句来初始化,这是因为静态类成员是单独存储的,而不是对象的组成部分。所以一般静态数据成员在类声明中声明,在包含类方法的文件中初始化,初始化时使用作用域运算符来指出静态成员所属的类。但是如果静态成员是const或者枚举类型,则可以在类声明中初始化。
703 |
704 | +++
705 |
706 | 问:为什么要有析构函数?
707 |
708 | 答:当删除类对象的时候可以释放掉对象本身所占用的内存,但是并不能自动释放属于对象成员指针所指向的内存。因此必须使用析构函数,在析构函数中使用delete来保证当对象过期时,可以释放掉由new所分配的内存。
709 |
710 | 在构造函数中使用new来分配内存时,必须在相应的析构函数中使用delete释放内存,如果使用new[]来分配内存,则应该使用delete[]来释放内存。
711 |
712 | +++
713 |
714 | **类创建中一些特殊的成员函数**
715 |
716 | 很多类中产生的问题都是由于特殊成员函数引起的,C++自动提供了下面这些成员函数:
717 |
718 | 1. 默认构造函数,如果没有定义构造函数
719 | 2. 默认析构函数,如果没有定义
720 | 3. 拷贝构造函数,如果没有定义
721 | 4. 赋值运算符,如果没有定义
722 | 5. 地址运算符,如果没有定义
723 |
724 | 比如说我们自己设计一个string类,那么这几个函数都要着重考虑一下了。
725 |
726 | - 默认构造函数
727 |
728 | 如果没有提供任何构造函数,c++将创建默认构造函数。因为创建对象时总会调用到构造函数。
729 |
730 | 但是类智能有一个构造函数,因为如果有多个构造函数就会产生二义性,如下:
731 |
732 | ```c++
733 | class_temp A;
734 | ```
735 |
736 | 对象A对于编译器来说不知道去调用哪一个构造函数
737 |
738 | - 拷贝构造函数
739 |
740 | 拷贝构造函数用于将一个对象复制到新创建的对象中,用于初始化过程中,而不是常规的赋值过程。赋值过程有赋值运算符,要重载赋值运算符。
741 |
742 | 拷贝构造函数原型如下:
743 |
744 | ```c++
745 | Class_name(const Class_name &);
746 | //example
747 | String(const String& s);
748 | ```
749 |
750 | 当新建一个对象并且将其初始化为现有对象时,会调用拷贝构造函数,有如下例子:
751 |
752 | ```c++
753 | StringBad ditto(motto);
754 | StringBad ditto = motto;
755 | StringBad ditto = StringBad(motto);
756 | StringBad * p = new StringBad(motto);
757 | ```
758 |
759 | 上面有四种使用拷贝构造的情况,第一种是最直接的拷贝构造使用方式,第二种和第三种可能使用拷贝构造函数直接创建ditto对象,也可能使用拷贝构造函数创建一个临时对象,然后将临时对象的值通过赋值运算符(没有自定义重载“=”就是编译器默认的赋值运算符)将内容赋值给ditto,这取决于具体实现。最后一个是生成一个匿名对象,并将匿名对象的地址赋给p指针。
760 |
761 | 当函数按值传递或者函数返回对象时都将使用拷贝构造函数。由于按值传递对象将调用拷贝构造函数,因此应该尽量按照引用传递对象,可以节省调用构造函数消耗的时间以及数据复制的空间。
762 |
763 | +++
764 |
765 | 但是默认拷贝构造函数也是有问题的。
766 |
767 | 默认的拷贝构造函数将逐个复制非静态成员的值,因为是值复制,所以也叫做浅拷贝。默认拷贝构造函数即浅拷贝会有如下两个问题:
768 |
769 | 1. 如果没有显式的定义拷贝构造函数,那么析构函数的调用次数肯定比构造函数的调用次数多的,因为默认拷贝构造函数也会调用析构函数,而我们没有显式的定义拷贝构造函数,因此调用次数上不平均。这意味着程序无法准确地记录创建对象的个数,因此只能显式的创建拷贝构造函数来统计。
770 |
771 | 2. 最重要的一个问题,如果类中有用new创建的动态变量,则默认拷贝构造函数能整出点问题。
772 |
773 | 由于隐式的拷贝构造函数是按照值进行复制的,如下:
774 |
775 | ```c++
776 | //A和B是对象
777 | //str是new char创建的
778 | A.str = B.str;
779 | ```
780 |
781 | 上述代码复制的并不是字符串本身,而是指向字符串的指针!!!即上述代码得到的不是两个字符串,而是两个指向同一个字符串的指针!!真相大白了家人们!之前我们说过默认拷贝构造函数也是要调用析构函数的,而我们的析构函数是自定义的delete,这就导致我们释放掉了指针指向的那个空间,那个空间已经没有字符串了,因此我们要访问字符串就会出现乱码,比如打印`A.str`就可能会出错,但是有的编译器像vs会保留一次空间的值。更恐怖的是当B对象使用结束后也会调用析构函数释放掉str那片空间,但是str之前在调用默认拷贝构造函数的时候就已经没了,所以后果不可预测。**(本质上)**就是指针悬挂的问题
782 |
783 | +++
784 |
785 | **唯一解决办法就是定义一个显式构造函数**,代码如下:
786 |
787 | ```c++
788 | StringTemp::StringTemp(const StringTemp& st){
789 | //引用计数
790 | num_count++;
791 | len = st.size();
792 | str = new char[len + 1];
793 | //把st对象的str赋给本对象定义的str
794 | std:strcpy(str, st.str);
795 | }
796 | ```
797 |
798 | **可以看到必须定义显式拷贝构造函数的原因在于有一些类成员使用的是new初始化,指向数据的指针而不是数据本身。**
799 |
800 | - 赋值运算符
801 |
802 | c++允许类对象赋值,并且自动为类重载赋值运算符,原型如下:
803 |
804 | `Class_name & Class_name::operator=(const Class_name&);`接收并返回一个类对象的引用。
805 |
806 | +++
807 |
808 | 当将已经有的对象赋给另外一个对象的时候必调用这个,比如
809 |
810 | ```c++
811 | StringTemp A;
812 | StringTemp B;
813 | ...
814 | //调用赋值运算符
815 | A = B;
816 | ```
817 |
818 | **一定要分清楚初始化与已有的对象给另一个对象赋值的区别**
819 |
820 | ```c++
821 | StringBad ditto = motto;
822 | StringBad ditto = StringBad(motto);
823 | ```
824 |
825 | 上面这两个代码就是初始化,但是有可能会调用赋值运算符,这个取决于编译器
826 |
827 | +++
828 |
829 | **赋值运算符也会出现相同的问题:数据受损。**和隐式拷贝构造函数一样的问题,解决办法就是提供深度赋值,但是要注意,赋值语算符重载的返回值是对象。
830 |
831 | 比如举个例子:
832 |
833 | ```c++
834 | StringTemp& StringTemp::operator=(const StringTemp& st){
835 | if(this == &st){
836 | return *this;
837 | }
838 | delete [] str;
839 | len = st.size();
840 | str = new char[len + 1];
841 | std:strcpy(str, st.str);
842 | return *this;
843 | }
844 | ```
845 |
846 | 1. 代码首先检查自我复制,如果是自己赋值自己,则返回*this,因为this是指针
847 | 2. 如果地址不同,先释放掉str指向的内存。因为每个对象都有个str,但是我们要接收来自另一个对象的str,这样的话必须把自己对象的str所占用的内存给释放掉,这样不会浪费内存
848 | 3. 接下来操作和显式拷贝构造一样。
849 |
850 | +++
851 |
852 | **静态类成员函数**
853 |
854 | 可以将成员函数声明为静态的,当类中函数成为静态的以后,有两个后果:
855 |
856 | 1. 不能通过对象调用静态成员函数,此外静态成员函数都不能用this指针。
857 |
858 | 如果静态成员函数是在共有部分声明的,则可以使用类名+作用域解析符来调用,如下
859 |
860 | ```c++
861 | //类中共有部分的static函数
862 | static int HowMany(){
863 | return num_strings;
864 | }
865 | //调用形式
866 | int count = String::HowMany();
867 | ```
868 |
869 | 2. 由于静态成员函数不与特定对象关联,因此只能使用静态数据成员。如上面代码,静态类成员函数可以访问静态类成员,但不能访问len,str这些变量。
870 |
871 | ### 在构造函数中使用new应该注意的事项
872 |
873 | 当在类中使用new时,应该注意一下几点:
874 |
875 | 1. 如果在构造函数中用new初始化指针成员,那么在析构函数中应该使用delete
876 | 2. new和delete必须成对出现
877 | 3. 应该定义一个复制构造函数,通过深拷贝将一个对象初始化为另一个对象
878 | 4. 重载一个赋值运算符,通过深拷贝将一个对象复制给另一个对象。
879 |
880 | ### 有关返回对象的说明
881 |
882 | 当成员函数或者普通函数返回对象时,有几种返回方式可以选择:
883 |
884 | 1. 返回指向对象的引用
885 | 2. 指向对象的const引用
886 | 3. const对象
887 |
888 | - 返回指向const对象的引用
889 |
890 | 使用const引用的常见原因是提高效率。代码如下:
891 |
892 | ```c++
893 | //version1
894 | Vector Max(const Vector& v1, const Vector& v2){
895 | if(...){
896 | return v1;
897 | }else{
898 | return v2;
899 | }
900 | }
901 | //version2
902 | const Vector& Max(const Vector& v1, const Vector& v2){
903 | if(...){
904 | return v1;
905 | }else{
906 | return v2;
907 | }
908 | }
909 | ```
910 |
911 |
912 |
913 | 1. 返回对象的话会调用拷贝构造函数,而返回引用则不会。
914 | 2. 引用指向的对象应该在调用函数执行时候存在
915 | 3. 参数被声明为const对象,因此返回类型也得为const
916 |
917 | +++
918 |
919 | - 返回指向非const对象的引用
920 |
921 | 一般两种情况会这样,即不加const的引用:
922 |
923 | 1. 重载赋值运算符,为了提高效率
924 |
925 | ```c++
926 | String s1("hello");
927 | String s2,s3;
928 | s3 = s2 = s1;
929 | ```
930 |
931 | `s2.operator=()`的返回值被赋值给s3,因此返回String对象或者引用都可以,通过使用引用可以避免String的拷贝构造函数创建出来的新的临时的对象,提高效率。不加const是因为指向s2的引用可以对其进行修改而不是不变的。
932 |
933 | 2. 重载`<<`运算符
934 |
935 | ```c++
936 | String s1("hello");
937 | cout< 总之,如果函数要返回局部对象,则千万不要返回引用,而应该返回对象即可。
949 |
950 | +++
951 |
952 | ### 再谈new和delete
953 |
954 | 先放一段代码:
955 |
956 | ```c++
957 | class Act{...};
958 | Act nice; //静态变量(外部变量)
959 | int main(){
960 | Act *pt = new Act; //动态变量
961 | delete pt;
962 |
963 | {
964 | Act up; //动态变量
965 | }
966 | ....
967 |
968 | }
969 | ```
970 |
971 | 分析上述代码析构函数被调用情况
972 |
973 | 1. 如果对象是静态变量(外部、静态或来自命名空间),则在程序结束时候才会调用对象的析构函数。
974 | 2. 如果对象是动态变量,当执行完该对象的程序块时就调用析构函数
975 | 3. 如果对象是用new创建的,则当显式调用delete时才会调用析构函数。
976 |
977 | ### 成员列表初始化
978 |
979 | c++程序执行构造函数的顺序如下:
980 |
981 | 1. 调用构造函数
982 | 2. 创建对象(对象在构造函数代码执行前被创建)
983 | 3. 给类成员分配内存
984 | 4. 执行构造函数内部代码,将值存储在内存中。
985 |
986 | > 思考一个问题,一个类中有const成员变量,那如果用构造函数赋值会出现问题吗??
987 | >
988 | > 答案是会的,因为const数据成员必须在创建对象时就初始化,而不能在内部初始化。
989 |
990 | 所以c++提供了一类特殊的语法,成员列表初始化,形式如下:
991 |
992 | ```c++
993 | Classy::Classy(int n, int m)::mem1(n), mem2(m),mem3(n*m){
994 | ...
995 | }
996 | ```
997 |
998 | **只有构造函数可以使用这种语法!!!**
999 |
1000 | **对于const成员和引用的类成员,也必须这样使用**
1001 |
1002 | +++
1003 |
1004 | 初始化工作是在对象创建时候完成的,还未执行括号中的任何代码,要注意一下几点:
1005 |
1006 | 1. 这种语法只能用于构造函数
1007 | 2. 必须用这种语法初始化非静态const成员
1008 | 3. 必须用这种语法初始化引用数据成员
1009 |
1010 | +++
1011 |
1012 | C++11允许更直观的方式初始化,类内初始化:
1013 |
1014 | ```c++
1015 | class Classy{
1016 | int mem1 = 10;
1017 | const int mem2 = 20;
1018 | }
1019 | ```
1020 |
1021 | 上面代码与在构造函数中等价
1022 |
1023 | +++
1024 |
1025 | ## 类继承
1026 |
1027 | ### 基类与派生类特性
1028 |
1029 | 从一个类派生出另外一个类时,原始类成为基类,继承类成为派生类。也叫做父类和子类。
1030 |
1031 | 使用公有派生,基类的公有成员将成为派生类的公有成员;基类的私有部分也成为了派生类的一部分,但只能通过基类的公有和保护方法去访问。但是需要在派生类中添加自己的构造函数和自己所需的额外的数据成员和成员函数。
1032 |
1033 | +++
1034 |
1035 | 由于派生类不能直接访问基类的私有成员,必须通过基类方法进行访问。那么就是说派生类构造函数不能直接设置哪些继承过来的数据,而必须使用基类的公有方法来访问私有的基类成员,具体说就是派生类构造函数必须是有基类构造函数。
1036 |
1037 | 创建派生类对象时,程序首先创建基类对象,也就是说**基类对象应当在程序进入派生类构造函数之前被创建**。c++使用成员初始化列表来完成,如下:
1038 |
1039 | ```c++
1040 | //RatedPlayer构造函数
1041 | RatedPlayer::RatedPlayer(unsigned int r, const string& fn, const string& ln, bool ht):TableTennisPlayer(fn, ln, ht){
1042 | rating = r;
1043 | }
1044 | RatedPlayer player1(1140, "mary", "duck", true);
1045 | ```
1046 |
1047 | RatedPlayer构造函数把实参`"mary", "duck", true`赋给形参`fn, ln, ht`通过成员初始化列表,然后将这些实参传递给TableTennisPlayer构造函数中,TableTennisPlayer将创建一个对象,并将实参存储在对象中。然后程序进入RatedPlayer构造函数,完成RatedPlayer对象的创建,然后执行构造函数中的代码,将r赋值给rating。
1048 |
1049 | 但是如果没有成员列表初始化,程序还是要创建基类对象,就会使用默认的的基类构造函数。否则就显式的调用构造函数。
1050 |
1051 | > 总结一下有关派生类构造函数的要点:
1052 | >
1053 | > 1. 创建派生类对象前先创建基类对象
1054 | > 2. 派生类构造函数应该通过成员初始化列表将基类信息传递给基类构造函数
1055 | > 3. **派生类构造函数应该初始化新增的数据成员**
1056 | >
1057 | > 释放对象的顺序与创建对象的顺序相反,即首先执行派生类的析构函数,然后执行基类的析构函数
1058 | >
1059 | > 基类构造函数主要负责初始化那些继承的数据成员,派生类构造函数主要用于初始化新增的数据成员。派生类构造函数总是调用一个基类的构造函数,可以使用成员列表初始化指明要使用的基类构造函数,否则使用默认的基类构造函数
1060 |
1061 | +++
1062 |
1063 | 派生类与基类之间有一些特殊的关系:
1064 |
1065 | 1. 派生类对象可以使用基类的方法,条件是该方法不是私有的
1066 |
1067 | 2. 基类指针可以在不进行显式类型转换的情况下指向派生类对象
1068 |
1069 | 3. 基类引用可以在不进行显式类型转换的情况下引用派生类对象
1070 |
1071 | ```c++
1072 | RatedPlayer player1(1140, "mary", "duck", true);
1073 | TableTennisPlayer& rt = player1;
1074 | TableTennisPlayer* pt = &player1;
1075 | ```
1076 |
1077 | > **注意事项:**基类指针或者引用只能用于调用基类方法,不能使用rt或者pt来调用派生类方法。对于c++来说引用和指针类型要与赋给的类型匹配才行,但是对于继承来说是例外的。但是这种例外是单向的,即只能将基类的引用或指针赋给派生类对象,而不能将派生类对象的引用或指针赋给基类对象
1078 |
1079 | ### 继承关系汇总
1080 |
1081 | c++有3中继承方式:公有继承,保护继承和私有继承。
1082 |
1083 | 公有继承是最常用的方式,他建立的是一种is-a的关系,即派生类对象也是一个基类对象。进而可以对基类对象执行的操作对派生类对象也可以。
1084 |
1085 | > 举个例子,香蕉是一种水果,进而香蕉就是派生类,水果就是基类。香蕉可以继承水果类的重量和热量成员
1086 |
1087 | 公有继承不建立has-a的关系。比如午餐可能包含水果,但是午餐并不是水果。我们只能说午餐李有水果,但是午餐并不能从水果哪里继承,就只能has-a,将水果对象作为午餐类的数据成员。
1088 |
1089 | 公有继承不建立is-like-a的关系。比如人们说律师就像鲨鱼,但是律师并不是鲨鱼。
1090 |
1091 | 公有继承不建立is-implemented-as-a关系(作为……来实现)。例如可以用数组来实现栈,但从数组类派生出栈类是不合适的,因为栈并不是数组。
1092 |
1093 | 公有继承不建立uses-a关系。比如计算机可以使激光打印机,但是从计算机类派生出打印机类是没有意义的,当然了,可以使用友元函数或类来处理双方通信。
1094 |
1095 | 综上,c++中最多的还是is-a的关系!!
1096 |
1097 | ### 多态公有继承
1098 |
1099 | 在使用继承的时候,最简单的就是对派生类对象使用基类的方法,不作任何修改。但很多时候我们都希望同一个方法在派生类和基类中表现得不同,即方法的行为应该取决于调用方法的对象。这种复杂的行为成为多态——方法随着上下文而异。多态公有继承有两种实现方式:
1100 |
1101 | 1. 在派生类中重新定义基类的方法(重载)
1102 | 2. 使用虚方法
1103 |
1104 | +++
1105 |
1106 | ```c++
1107 | //1. viewcount不是virtual的
1108 | void viewcount() const;
1109 | //2.viewcount是virtual的
1110 | virtual void viewcount() const;
1111 |
1112 | //1情况下
1113 | Brass dom(arg1, arg2);
1114 | BrassPlus dot(arg1,arg2);
1115 | Brass& b1_ref = dom;
1116 | Brass& b2_ref = dot;
1117 | b1_ref.viewcount(); //使用Brass::viewcount()
1118 | b2_ref.viewcount(); //使用Brass::viewcount()
1119 |
1120 | //2情况下
1121 | Brass dom(arg1, arg2);
1122 | BrassPlus dot(arg1,arg2);
1123 | Brass& b1_ref = dom;
1124 | Brass& b2_ref = dot;
1125 | b1_ref.viewcount(); //使用Brass::viewcount()
1126 | b2_ref.viewcount(); //使用BrassPlus::viewcount()
1127 | ```
1128 |
1129 | 首先方法前面加上关键字`virtual`时,这些方法被称为**虚方法**。
1130 |
1131 | > 如果类方法没有使用virtual关键字,程序将根据引用或指针本身的类型来选择调用基类的方法还是派生类的方法。
1132 | >
1133 | > 如果类使用了virtual,程序将根据引用或者指针指向的对象的类型来选择方法。
1134 |
1135 | 经常在基类中将派生类会重新定义的方法称为虚方法,方法在基类中被声明为虚的以后,在派生类中将自动称为虚方法。但是,在派生类中将某些方法用virtual标注也是可以的。如果想在派生类中重新定义基类的方法,通常将基类的方法定义为虚的,因为这样程序会根据对象类型来选择调用的方法。
1136 |
1137 | +++
1138 |
1139 | **虚析构函数**
1140 |
1141 | 如果没有虚析构函数,那么程序结束时候,就只会调用对应于指针类型的析构函数,对于上述代码来说只会调用Brass类的析构函数。
1142 |
1143 | 如果析构函数是虚的,将会调用对象类型的析构函数,比如上面代码第二种情况,指针指向的是BrassPlus对象,调用BrassPlus的析构函数,然后自动调用基类的析构函数(基类和继承类那里有说)
1144 |
1145 | 因此必须要有虚析构函数,不然只能调用对应指针类型的那个类的析构函数,而不能调用对象对应类的析构函数。
1146 |
1147 | +++
1148 |
1149 | ### 静态连联编和动态联编
1150 |
1151 | 将源代码中的函数调用解释为执行特定的函数代码块成为**函数名联编**。在c语言中很简单,因为每个函数名对应一个不同的函数,没有重载。但是c++有重载了,编译器必须查看函数参数以及函数名称才能确定使用哪一个函数。
1152 |
1153 | 在编译过程中进行联编称为静态联编。编译器生成能够在程序运行时选择正确的虚方法的代码,成为动态联编。(dynamic binding)
1154 |
1155 | +++
1156 |
1157 | 在c++中,动态联编通过指针和引用调用方法相关,由继承控制的。通常c++不允许将一种类型的地址赋给另外一种类型的指针,也不允许一种类型的引用指向另一种类型。但是指向基类的指针或者引用可以转换成派生类对象,而不必进行显示类型转换。
1158 |
1159 | 将派生类引用或指针转换为基类引用或指针成为**向上强制转换**,改规则是is-a关系的一部分,比如之前的BrassPlus 对象都是Brass对象,因为继承。反过来,将基类指针或引用转换为派生类指针或引用成为**向下强制转换**。如果不使用显式转换类型,向下强制转换是不允许的,因为is-a关系式不可逆的,派生类可以新增数据成员,但这些新增的数据成员不能应用与基类。
1160 |
1161 | +++
1162 |
1163 | **问:为什么有两种联编同时默认是静态联编?**
1164 |
1165 | 答:效率和概念模型。首先是效率,为了使得程序能够早运行阶段做策略,必须用一些方法来跟踪基类指针或引用指向的类型,会增加额外的处理开销。大多数情况下都不太会对基类方法重定义或重载,使用静态联编更合理。其次是概念模型,指的是有一些派生类中的成员函数不应该重新定义,就应该继承基类的定义。总之就是,如果要在派生类中重新定义基类的方法,就设置为虚方法,否则别设置虚方法。
1166 |
1167 | ### 虚函数的工作原理和注意事项
1168 |
1169 | > 虚函数表(vtbl),虚函数表指针(vptr)
1170 |
1171 | 首先要知道每一个派生类对象实际上是由两个部分组成的:
1172 |
1173 | 1. 父类部分,包括成员变量,成员函数,vptr等这些都是共享给子类的,当然要加上权限限制
1174 | 2. 子类部分,子类自己定义的成员变量成员函数。
1175 |
1176 | 可以看到子类其实就是一个特殊的父类,享有父类的所有属性,是is-a的关系,因此子类可以强制转换成父类,通常是用`dynamic_cast`将子类指针转为父类指针。当转换成父类指针的时候,父类指针的访问域就变成了下图内存模型中的上半部分,下半部分属于子类的域是没有办法访问的。
1177 |
1178 | 
 1179 |
1180 | 通常函数的地址都在编译的时候确定好了,但虚函数的地址需要等到运行的时候才能确定,因为你无法确定一个基类的指针或引用指向的是基类对象还是派生类对象。综上,**虚函数表指针是在对象执行构造函数的时候确定的**,对于基类来说执行基类构造函数时直接把虚函数表填充为基类的虚函数地址,基类对象的vptr指向vtbl。对于派生类,创建对象时先执行基类构造函数,因此派生类对象的vptr指向的虚函数表vtbl里的内容首先是基类中的所有虚函数的地址,然后接着执行派生类构造函数,修改派生类对象vptr指向的虚函数表中的内容,将派生类的虚函数地址填进去。
1181 |
1182 | +++
1183 |
1184 | **虚函数的内存分布**
1185 |
1186 | 根据下面代码会给出一个该类的内存分布图:
1187 |
1188 | ```c++
1189 | class A {
1190 | public:
1191 | virtual void v_a(){}
1192 | virtual ~A(){}
1193 | int64_t _m_a;
1194 | };
1195 |
1196 | int main(){
1197 | A* a = new A();
1198 | return 0;
1199 | }
1200 | ```
1201 |
1202 | 内存分布图如下:
1203 |
1204 | 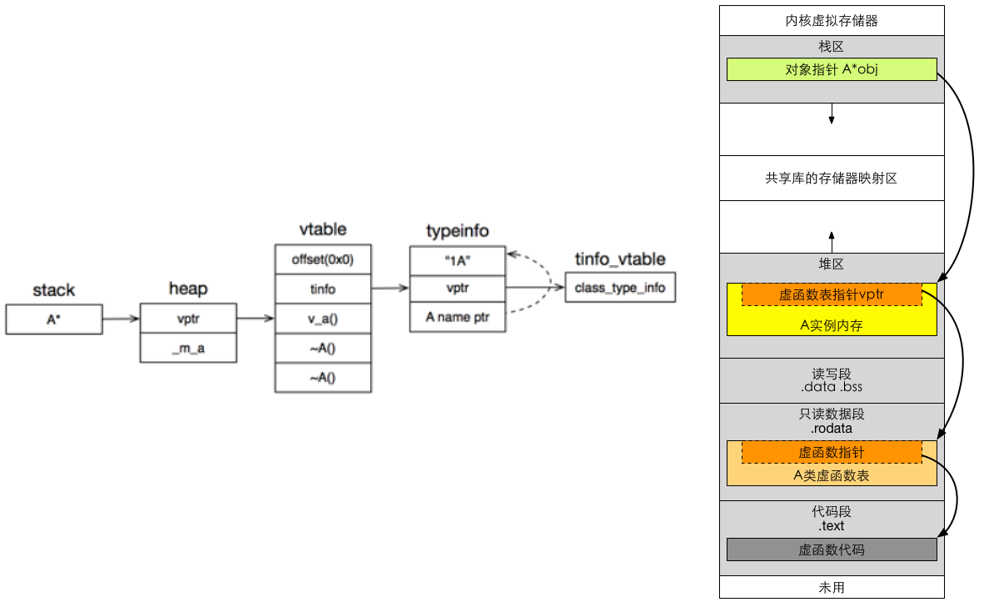
1205 |
1206 | > 1. main函数内部使用new创建的对象,因此主函数main的栈帧上有一个A类类型的指针指向堆里面分配好的A对象的实例(stack→heap)
1207 | > 2. 在堆中,对象a的实例由上到下是一个vptr和声明的成员变量
1208 | > 3. vptr指向虚函数表中的第一个虚函数起始地址
1209 | > 4. 虚函数表中还有一个tinfo的指针指向typeinfo表,存储着A类的基础信息,包括父类名称、类名称
1210 |
1211 | +++
1212 |
1213 | **虚函数执行过程**
1214 |
1215 | 当调用一个虚函数时,首先通过对象内存中的vptr找到虚函数表vtbl,接着通过vtbl找到对应虚函数的实现区域并进行调用。 当一个类声明了虚函数或者继承了虚函数,这个类就会有自己的vtbl。vtbl核心就是一个函数指针数组,有的编译器用的是链表,不过方法都是差不多。vtbl数组中的每一个元素对应一个函数指针指向该类的一个虚函数,同时该类的每一个对象都会包含一个vptr,vptr指向该vtbl的地址。 在有继承关系时(子类相对于其直接父类)
1216 |
1217 | 1. 一般继承时,子类的虚函数表中先将父类虚函数放在前,再放自己的虚函数指针。
1218 | 2. 如果子类覆盖了父类的虚函数,将被放到了虚表中**原来父类虚函数**的位置。
1219 | 3. 在多继承的情况下,**每个父类都有自己的虚表,子类的成员函数被放到了第一个父类的表中。**也就是说当类在多重继承中时,其实例对象的内存结构并不只记录一个虚函数表指针。基类中有几个存在虚函数,则子类就会保存几个虚函数表指针
1220 |
1221 | 下图是c++ primer plus中虚函数实现机制的示意图:
1222 |
1223 | 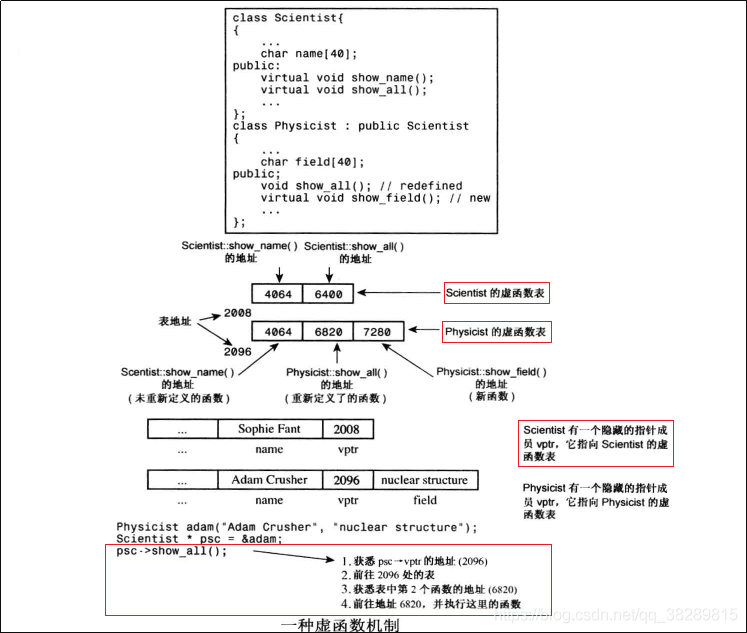
1224 |
1225 | > 先看最下面,首先根据`Scientist* psc = &adam`这局代码找到adam对象中的vptr为2096,然后找到vptr指向的2096地址的虚函数表,在上图中间位置,虚函数表示数组指针形式的。然后前往地址6820,并执行这里的函数。
1226 |
1227 | 总结一下调用过程:
1228 |
1229 | 1. 首先获取对象内存中的vptr指针指向的虚函数表vtbl
1230 | 2. 进入vtbl,一般是数组指针形式的,找到对应虚函数的地址并调用
1231 |
1232 | +++
1233 |
1234 | **性能分析**
1235 |
1236 | 第一步是通过对象的vptr找到该类的vtbl,因为虚函数表指针是编译器加上去的,通过vptr找到vtbl就是指针的寻址而已。
1237 |
1238 | 第二部就是找到对应vtbl中虚函数的指针,因为vtbl大部分是指针数组的形式实现的
1239 |
1240 | 在单继承的情况下调用虚函数所需的代价基本上和非虚函数效率一样,在大多数计算机上它多执行了很少的一些指令
1241 |
1242 | 在多继承的情况由于会根据多个父类生成多个vptr,在对象里为寻找 vptr 而进行的偏移量计算会变得复杂一些
1243 |
1244 | 空间层面为了实现运行时多态机制,编译器会给每一个包含虚函数或继承了虚函数的类自动建立一个虚函数表,所以虚函数的一个代价就是会增加类的体积。在虚函数接口较少的类中这个代价并不明显,虚函数表vtbl的体积相当于几个函数指针的体积,如果你有大量的类或者在每个类中有大量的虚函数,你会发现 vtbl 会占用大量的地址空间。但这并不是最主要的代价,主要的代价是发生在类的继承过程中,在上面的分析中,可以看到,当子类继承父类的虚函数时,子类会有自己的vtbl,如果子类只覆盖父类的一两个虚函数接口,子类vtbl的其余部分内容会与父类重复。**如果存在大量的子类继承,且重写父类的虚函数接口只占总数的一小部分的情况下,会造成大量地址空间浪费**。同时由于虚函数指针vptr的存在,虚函数也会增加该类的每个对象的体积。在单继承或没有继承的情况下,类的每个对象只会多一个vptr指针的体积,也就是4个字节;在多继承的情况下,类的每个对象会多N个(N=包含虚函数的父类个数)vptr的体积,也就是4N个字节。当一个类的对象体积较大时,这个代价不是很明显,但当一个类的对象很轻量的时候,如成员变量只有4个字节,那么再加上4(或4N)个字节的vptr,对象的体积相当于翻了1(或N)倍,这个代价是非常大的。
1245 |
1246 | +++
1247 |
1248 | **虚函数注意事项**
1249 |
1250 | - 构造函数
1251 |
1252 | 首先要知道构造函数不能是虚函数。
1253 |
1254 | 原因:如果构造函数时虚的,也要从虚函数表中找,但是创建对象要用到构造函数,如果构造函数是虚的话,vptr指针就没有了,因为你找不到构造函数,构造不出对象,构造不出对象你就没有vptr。而且在构造函数中调用虚函数实际执行的肯定是父类的函数,因为你派生类的都没构造好,调个锤子。
1255 |
1256 | - 析构函数
1257 |
1258 | 析构函数当然是虚的,除非类不做基类。**并且通常要给基类一个虚析构函数,即使他并不需要**
1259 |
1260 | 原因:**(主要针对基类指针来销毁派生类对象这个行为)如果析构函数不是虚的,派生类析构的时候调用的是基类的析构函数,而基类的构造函数只是对基类部分做了析构,从而导致派生类部分出现内存泄露。如果加了virtual,则先回调用派生类对象的析构函数,然后再调用基类的析构函数**
1261 |
1262 | - 友元
1263 |
1264 | 友元不能是虚函数,因为友元又不是类成员,而只有类成员才能使虚函数。
1265 |
1266 | 但是友元函数可以是虚成员函数
1267 |
1268 | - 内联函数
1269 |
1270 | 虚函数在c++中叫做dynamic binding。内联函数为了提高效率,通常是在编译期间对调用内联函数的地方做代码替换而已,所以内联函数对于程序中频繁调用的小函数非常有用。同时要知道,再类中定义的函数,会被默认的当成内联函数。
1271 |
1272 | 所以,**当使用基类指针或引用来调用虚函数的时候,不能使用内联函数**。
1273 |
1274 | 但是**使用对象(并不时指针或者引用)来调用时,可以当做内联函数**,**因为编译器是默认静态联编的**。
1275 |
1276 | - 静态成员函数
1277 |
1278 | static成员不属于任何类对象或类实例,所以即使给此函数加上virutal也是没有任何意义的。
1279 |
1280 | 此外静态与非静态成员函数之间有一个主要的区别,那就是**静态成员函数没有this指针**,从而导致两者调用方式不同。
1281 |
1282 | 虚函数依靠vptr和vtable来处理。vptr是一个指针,在类的构造函数中创建生成,并且只能用this指针来访问它,因为它是类的一个成员,并且vptr指向保存虚函数地址的vtable,因此虚函数的执行顺序是:**虚函数的调用关系:this -> vptr -> vtable ->virtual function**
1283 |
1284 | 对于静态成员函数,它没有this指针,所以无法访问vptr. 这就是为何**static函数不能为virtual**。
1285 |
1286 | - 纯虚函数
1287 |
1288 | 析构函数可以是纯虚的,但**纯虚析构函数必须有定义体**,因为析构函数的调用是在子类中隐含的。
1289 |
1290 | +++
1291 |
1292 | ### Protected权限
1293 |
1294 | 关键字protected与private相似,再类外只能通过共有方法来访问protected成员
1295 |
1296 | private和protected的区别主要在继承里面。派生类的成员可以直接访问基类的保护成员,但不能访问基类的私有成员。
1297 |
1298 | **对于外部世界来说,保护成员的行为和私有成员一致;对派生类来说,保护成员的行为和公有成员一致**
1299 |
1300 | ### 纯虚函数
1301 |
1302 | 在很多情况下,基类本身生成对象是不合情理的。例如,动物作为一个基类可以派生出老虎、孔雀等子类,但动物本身生成对象明显不合常理。而针对每种动物的方法又有所不同,此时需要使用多态特性,也就需要在基类中定义虚函数。
1303 |
1304 | 纯虚函数是在基类中声明的虚函数,它要求任何派生类都要定义自己的实现方法,以实现多态性。实现了纯虚函数的子类,该纯虚函数在子类中就变成了虚函数。
1305 |
1306 | 定义纯虚函数是为了实现一个接口,用来规范派生类的行为,也即规范继承这个类的程序员必须实现这个函数。派生类仅仅只是继承函数的接口。纯虚函数的意义在于,让所有的类对象(主要是派生类对象)都可以执行纯虚函数的动作,但基类无法为纯虚函数提供一个合理的缺省实现。所以类纯虚函数的声明就是在告诉子类的设计者,“你必须提供一个纯虚函数的实现,但我不知道你会怎样实现它”。
1307 |
1308 | 含有纯虚函数的类称之为抽象类,它不能生成对象(创建实例),只能创建它的派生类的实例。抽象类是一种特殊的类,它是为了抽象和设计的目的为建立的,它处于继承层次结构的较上层。抽象类的主要作用是将有关的操作作为结果接口组织在一个继承层次结构中,由它来为派生类提供一个公共的根,派生类将具体实现在其基类中作为接口的操作。抽象类只能作为基类来使用,其纯虚函数的实现由派生类给出。如果派生类中没有重新定义纯虚函数,而只是继承基类的纯虚函数,则这个派生类仍然还是一个抽象类。如果派生类中给出了基类纯虚函数的实现,则该派生类就不再是抽象类了,它是一个可以建立对象的具体的类。
1309 |
1310 | ### 继承和动态内存分配
1311 |
1312 | 代码如下:
1313 |
1314 | ```c++
1315 | //baseDMA.h
1316 | #ifndef BASEDMA_H_
1317 | #define BASEDMA_H_
1318 |
1319 | #include
1320 | class baseDMA{
1321 | private:
1322 | char * label;
1323 | int rating;
1324 | public:
1325 | baseDMA(const char * s = "null", int r = 0); //构造函数
1326 | baseDMA(const baseDMA & bd); //复制构造函数
1327 | baseDMA & operator=(const baseDMA & bd); //赋值运算符函数
1328 | virtual ~baseDMA();
1329 | friend std::ostream & operator<<(std::ostream & os, const baseDMA & bd); //输出运算符,友元函数
1330 | };
1331 |
1332 |
1333 |
1334 | //不用动态内存分配的派生类
1335 | class lacksDMA : public baseDMA
1336 | {
1337 | private:
1338 | enum {LEN = 40};
1339 | char color[LEN];
1340 | public:
1341 | lacksDMA(const char * s = "null", int r = 0, const char * c = "none");
1342 | lacksDMA(const baseDMA & bd, const char * c = "none");
1343 | //友元函数并不属于类,所以不能被继承,必须自己写哦
1344 | friend std::ostream & operator<<(std::ostream & os, const lacksDMA & ld);
1345 | };
1346 |
1347 | //用动态内存分配的派生类
1348 | class hasDMA : public baseDMA
1349 | {
1350 | private:
1351 | char *style;
1352 | public:
1353 | hasDMA(const char * s = "null", int r = 0, const char * sty = "none");
1354 | hasDMA(const baseDMA & bd, const char * sty = "none");
1355 | ~hasDMA();//析构函数
1356 | hasDMA(const hasDMA & hd);//复制构造函数
1357 | hasDMA & operator=(const hasDMA & hd);//赋值运算符函数
1358 | //友元函数并不属于类,所以不能被继承,必须自己写哦
1359 | friend std::ostream & operator<<(std::ostream & os, const hasDMA & ld);
1360 | };
1361 | #endif // BASEDMA_H_
1362 | ```
1363 |
1364 | - 第一种情况,基类使用new,派生类不使用new
1365 |
1366 | 对应上述代码中不用动态内存分配的派生类。不需要为lackDMA类定义显式析构函数、拷贝构造函数、赋值运算符。
1367 |
1368 | 不需要析构函数。如果派生类为定义析构函数则编译器将定义一个不执行任何操作的默认构造函数。但派生类的默认构造函数需要执行完自身代码后调用基类构造函数。由于派生类lackDMA成员没有动态分配内存,所以不用做什么操作。
1369 |
1370 | 不需要拷贝构造函数。首先之前说过默认拷贝构造函数对有动态内存分配的成员是不合适的,但是对于没有动态内存分配的成员是合适的。但是派生类是从baseDMA类继承而来的,也是不需要的,原因如下。派生类的默认拷贝构造函数会使用显式的baseDMA拷贝构造函数来复制lackDMA对象的baseDMA部分。因此如果派生类没有动态内存分配的话,用默认拷贝构造函数是可以的。
1371 |
1372 | 不需要赋值运算符重载。跟上面一样,派生类的默认赋值运算符将会使用基类的赋值运算符对基类组件进行赋值
1373 |
1374 | - 第二种情况,基类使用new,派生类使用new
1375 |
1376 | 上述代码中hasDMA就是使用了动态内存分配。在这种情况下必须为派生类定义显式的析构函数、拷贝构造函数和赋值运算符
1377 |
1378 | +++
1379 |
1380 | ### 继承方式
1381 |
1382 | 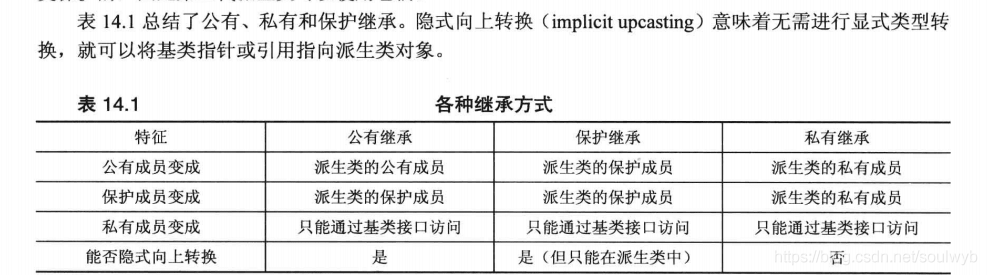
1383 |
1384 | ### 多重继承
1385 |
1386 | 在现实生活中,一些新事物往往会拥有两个或者两个以上事物的属性,为了解决这个问题,C++引入了多重继承的概念,C++允许为一个派生类指定多个基类,这样的继承结构被称做多重继承。(派生类有两个或两个以上的直接基类)
1387 | 当一个派生类要使用多重继承的时候,必须在派生类名和冒号之后列出所有基类的类名,并用逗好分隔。如下:
1388 |
1389 | ```c++
1390 | class Derived : public Base1, public Base2, … {};
1391 | ```
1392 |
1393 | 多继承会出现问题:在派生类中对基类成员的访问应该是唯一的。但是,在多继承情况下,可能造成对基类中某个成员的访问出现了不一致的情况,这时就称对基类成员的访问产生了二义性。
1394 |
1395 | - 问题1:派生类在访问基类成员函数时,由于基类存在同名的成员函数,导致无法确定访问的是哪个基类的成员函数,因此出现了二义性错误。
1396 |
1397 | 代码如下:
1398 |
1399 | ```c++
1400 | class Base1
1401 | {
1402 | public:
1403 | void fun(){cout<<"base1 "<
1460 |
1461 | 解决方法也是两个:
1462 |
1463 | 1. 还是使用作用域运算符,指明访问哪一个基类的数据
1464 |
1465 | ```c++
1466 | d.BC1::x = 2; // from BC1
1467 | d.BC2::x = 3; // from BC2
1468 | d.K = 4; // error C2385: 对"K"的访问不明确(编译错误)
1469 | d.BC1::K = 5; // from BC1
1470 | d.BC2::K = 6;
1471 | ```
1472 |
1473 | 2. 使用虚基类。产生二义性的最主要的原因就是BC0在派生类DC中产生了2个对象,从而导致了对基类BC0的成员k访问的不一致性。要解决这个问题,只需使这个公共基类Base在派生类中只产生一个子对象即可。
1474 |
1475 | ```c++
1476 | class BC0
1477 | {
1478 | public:
1479 | int K;
1480 | };
1481 | class BC1 : virtual public BC0
1482 | {
1483 | public:
1484 | int x;
1485 | };
1486 | class BC2 : virtual public BC0
1487 | {
1488 | public:
1489 | int x;
1490 | };
1491 | class DC : public BC1, public BC2
1492 | {
1493 | };
1494 | void main( )
1495 | {
1496 | DC d; //虚继承使得BC0仅被DC间接继承一份
1497 | d.K = 13; // OK
1498 | }
1499 | ```
1500 |
1501 |
1502 |
1503 | +++
1504 |
1505 |
1506 |
1507 | ## 类设计总结
1508 |
1509 |
1510 |
1511 | - 默认构造函数
1512 |
1513 | 默认构造函数要么没有参数,要么所有参数都有默认值才行。如果类为定义任何构造函数,编译器将自动定义一个默认构造函数用来创建对象。
1514 |
1515 | 如果派生类构造函数的成员初始化列表没有显式的调用基类构造函数,则编译器将使用基类的默认构造函数来构造派生类对象的基类部分。
1516 |
1517 | - 拷贝构造函数
1518 |
1519 | 拷贝构造函数接受其所属类的对象作为参数,在下面几种情况下将使用拷贝构造函数:
1520 |
1521 | 1. 将新对象初始化为一个已存在的对象
1522 | 2. 按值将对象作为参数传递给函数
1523 | 3. 函数按值类型返回对象
1524 | 4. 编译器临城临时对象
1525 |
1526 | 编译器会默认提供拷贝构造函数,但不提供具体定义。当类中有动态内存分配的情况时需要自定义拷贝构造函数
1527 |
1528 | - 赋值运算符
1529 |
1530 | 默认的赋值运算符用于处理同类对象之间的赋值。
1531 |
1532 | **切记,不要讲赋值和初始化搞混了!!!如果语句创建新的对象则使用初始化,如果不是新鲜创建的对象则是赋值**
1533 |
1534 | - 构造函数
1535 |
1536 | 构造函数不同于其他类方法,因为他创建新对象,而其他类方法仅仅是被现有对象调用,这是构造函数不被继承的原因。
1537 |
1538 | 如果构造函数能被继承,表示派生类对象可以使用基类对象的方法,但是构造函数在执行的时候,对象并不存在。
1539 |
1540 | - 转换
1541 |
1542 | 默认是隐式的转换,从参数类型到类类型的转换
1543 |
1544 | 在构造函数中使用关键字`explicit`将禁止进行隐式转换,代码如下:
1545 |
1546 | ```c++
1547 | class Star{
1548 | public:
1549 | explicit Star(const char*);
1550 | ...
1551 | };
1552 |
1553 | int main(){
1554 | Star north;
1555 | north = "polaris"; //不允许
1556 | north = Star("polaris"); //可以转换
1557 | }
1558 | ```
1559 |
1560 | 要将类对象转换成其他类型需要定义相应的转换函数,前面说过了。转换函数可以使没有参数的类成员函数,也可以是返回类型是目标类型的函数
1561 |
1562 | ``` c++
1563 | Star::Star double(){...} //将star类转换成double
1564 | Star::Star const char*(){...} //将star类转换成const char
1565 | ```
1566 |
1567 | - 按值传递与传递引用
1568 |
1569 | 在编写参数类型是类对象的函数时,应该按照引用而不是值来传递对象。这样做是为了提高效率。因为按值传递对象将会涉及到临时拷贝,调用拷贝构造函数,然后调用析构函数,调用这些函数需要花费时间,当对象非常大的时候就会显得很耗时。
1570 |
1571 | 另外如果不修改对象就传const。
1572 |
1573 | 按引用传递对象的另一个原因就是在继承使用虚函数的时候,被定义为接受基类引用参数的函数可以接受派生类
1574 |
1575 | - 返回对象和返回引用
1576 |
1577 | 应该返回引用而不是类对象的原因在于返回对象涉及生成对象的临时副本,因此调用对象的时间成本包括调用拷贝构造函数来生成副本所需要的时间和调用析构函数删除副本所需要的时间。返回引用可以节省时间和内存。
1578 |
1579 | 其实直接返回对象与函数参数按值传递类似
1580 |
1581 | 但有时候必须返回对象,而不涉及返回引用。函数不能返回在函数中创建的临时对象的引用,因为当函数结束时,临时对象将会消失,引用是非法的。在这种情况下应该返回对象,以生成一个程序可以使用的副本。
1582 |
1583 | +++
1584 |
1585 | ## 泛型编程——模板
1586 |
1587 | c++提供了两种模板机制:函数模板和类模板
1588 |
1589 | ### 函数模板
1590 |
1591 | > 含义:建立一个通用的函数,其函数返回值类型和形参类型可以不具体指定,用一个虚拟类型代表
1592 |
1593 | **语法如下:**
1594 |
1595 | ```c++
1596 | template
1597 | 函数声明定义
1598 | ```
1599 |
1600 | **解释:**
1601 |
1602 | 1. template——声明创建一个模板
1603 | 2. typename——表明后面符号的一个数据类型,也可以用class代替
1604 | 3. T就是数据类型,抽象出来
1605 |
1606 | **调用方式(重要):**
1607 |
1608 | 1. 自动类型推导
1609 |
1610 | `mySwap(a, b)`
1611 |
1612 | 2. 显式指定类型
1613 |
1614 | `mySwap(a, b)`
1615 |
1616 | **意义**:
1617 |
1618 | 模板将数据类型参数化,还是为了编程方便
1619 |
1620 | +++
1621 |
1622 | **模板注意事项:**
1623 |
1624 | 1. 自动类型推导,必须推导出一致的数据类型T才可以使用。也就是说参数类型和你模板定义的得一致才行。
1625 | 2. 模板必须要确定出T的类型
1626 |
1627 | **普通函数与模板函数的区别:**
1628 |
1629 | 1. 普通函数调用时可以发生自动类型转换(隐式类型转换)
1630 | 2. 如果使用函数模板,自动类型推导的话,则不会发生隐式转换
1631 | 3. 如果使用函数模板,显式指定类型,则可以发生隐式转换
1632 |
1633 | **普通函数与函数模板的调用规则:**
1634 |
1635 | 1. 优先调用普通函数
1636 |
1637 | 2. 可以使用空模板参数来强制调用模板函数
1638 |
1639 | `myPrint<>(arg1, arg2,...)`
1640 |
1641 | 3. 函数模板也可以重载
1642 |
1643 | 4. 如果函数模板可以产生更好的匹配,优先调用函数模板
1644 |
1645 | +++
1646 |
1647 |
1648 |
1649 | ### 类模板
1650 |
1651 | > 定义:建立一个通用类,类中的成员的数据类型可以不具体制定,和函数模板差不多
1652 |
1653 | **类模板和函数模板的区别:**
1654 |
1655 | 1. 类模板没有自动类型推导的使用方式,只有显式指定参数类型
1656 |
1657 | ```c++
1658 | template
1659 | class Person{.....};
1660 |
1661 | Person p1; //error!!
1662 | Person p2; //correct!!
1663 | ```
1664 |
1665 | 2. 类模板在模板参数列表中可以有默认参数
1666 |
1667 | ```c++
1668 | template
1669 | class Person{.....};
1670 |
1671 | Person p2; //正确!!
1672 | ```
1673 |
1674 |
1675 |
1676 | **类模板中成员函数创建时间:**
1677 |
1678 | 1. 普通类中的成员函数在编译的时候就创建
1679 |
1680 | 2. 类模板中的成员函数在调用的时候才会创建
1681 |
1682 | ```c++
1683 | class MyClass1{
1684 | void show1(){cout<<"show1";}
1685 | };
1686 | class MyClass2{
1687 | void show2(){cout<<"show2";}
1688 | };
1689 |
1690 | template
1691 | class Myclass_template{
1692 | T obj;
1693 | void showClass1(){
1694 | obj.show1();
1695 | }
1696 | void showClass2(){
1697 | obj.show2();
1698 | }
1699 | };
1700 | int main(){
1701 | Myclass_template m1;
1702 | m1.showClass1(); //编译不报错,运行不报错
1703 | m1.showClass2(); //编译不报错,运行时候报错
1704 | }
1705 | ```
1706 |
1707 |
1708 |
1709 | **类模板对象做函数参数:**
1710 |
1711 | 就是类模板实例化出的对象,作为参数的形式传入函数
1712 |
1713 | 1. 指定传入的类型 —— 直接显示对象的数据类型
1714 |
1715 | ```c++
1716 | void print(Person&p);
1717 | ```
1718 |
1719 | 2. 参数模板化 —— 将对象中的参数变为模板进行传递
1720 |
1721 | ```c++
1722 | template
1723 | void print(Person& p);
1724 | ```
1725 |
1726 | 3. 整个类模板化 —— 将整个对象类型模板化进行传递
1727 |
1728 | ```c++
1729 | template
1730 | void print(T& p);
1731 | ```
1732 |
1733 |
1734 |
1735 | **类模板与继承:**
1736 |
1737 | 1. 当派生类继承基类的一个类模板时,子类在声明时,要指定出分类中的T类型
1738 |
1739 | ```c++
1740 | template
1741 | class Father{
1742 | T m;
1743 | };
1744 |
1745 | //报错
1746 | class Son: public Father{
1747 |
1748 | };
1749 |
1750 | //正确
1751 | class Son: public Father{
1752 |
1753 | };
1754 | ```
1755 |
1756 | > 因为子类要继承父类中的成员变量,但是模板没有指定内存大小,所以是不确定的,而不确定性是c++所嗤之以鼻的。因此继承的时候得指定要继承模板的数据类型才行。
1757 | >
1758 | > 但是这样不灵活,父类中的类型就被定死了,有违背c++灵活编程,所以这种方法不太实用
1759 |
1760 | 2. 如果不指定,编译器无法给子类非配内存
1761 |
1762 | 3. 如果要灵活的话,子类也需变为类模板
1763 |
1764 | ```c++
1765 | template
1766 | class Son: public Father{
1767 | T1 obj;
1768 | };
1769 | ```
1770 |
1771 |
1772 |
1773 | **类模板成员函数的类外实现**
1774 |
1775 | ```c++
1776 | //构造函数类外实现
1777 | template
1778 | Person::Person(T1 name, T2 age){}
1779 |
1780 | //成员函数类外实现
1781 | template
1782 | void Person::show(){}
1783 | ```
1784 |
1785 |
1786 |
1787 | **类模板分文件编写**
1788 |
1789 | 出现问题:类模板中成员函数创建时机是在调用阶段,导致分文件编写是链接不到。
1790 |
1791 | 解决方案:
1792 |
1793 | 1. 直接包含.cpp源文件
1794 |
1795 | 2. 将声明和实现写到同一个文件中,并更改后缀名成.hpp(主流实现)
1796 |
1797 | ```c++
1798 | #pragma once //防止头文件重复包含
1799 | #include
1800 | using namespace std;
1801 | //类模板与继承
1802 | template
1803 | class Baba
1804 | {
1805 | public:
1806 | void fun();
1807 | };
1808 | //成员函数类外实现
1809 | //第二种写法
1810 | template
1811 | void Baba::fun()
1812 | {
1813 | cout << "成员函数类外实现" << endl;
1814 | }
1815 | ```
1816 |
1817 | 上述文件要改成.hpp后缀
1818 |
1819 |
1820 |
1821 |
1822 |
1823 |
1824 |
1825 |
1826 |
1827 |
1828 |
1829 |
1830 |
1831 |
1832 |
1833 |
1834 |
1835 |
1836 |
1837 |
1838 |
1839 |
1840 |
1841 |
1842 |
1843 |
1844 |
1845 |
1846 |
1847 |
1848 |
1849 |
1850 |
1851 |
1852 |
1853 |
1854 |
1855 |
1856 |
1857 |
--------------------------------------------------------------------------------
/书籍笔记/操作系统.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # 基础知识—引论
4 |
5 | ## 实模式和保护模式
6 |
7 | - **实模式**
8 |
9 | 将实模式主要先了解内存寻址
10 |
11 | 我们的代码分为代码段、数据段等,所有的内存寻址都是根据 **段基址:段内偏移** 来访问的,这样的地址形式称为**逻辑地址**,为什么搞这么复杂呢?因为早期的8086处理器寄存器宽度只有16位,16位的寄存器只能进行 64 KB 的寻址,而 8086 有 20 根地址线,按照地址线来计算可以进行 1 MB 的寻址,所以16 位宽度的寄存器是显然不能满足需求的,为了解决这个问题,聪明的程序员想出了用 **段基址:段内偏移** 的方式来扩展寻址空间。
12 |
13 | 实际物理地址 = 段基址 << 4(左移四位) + 段内偏移。这样两个 16 位的寄存器合在一起,宽度便成了 20 位。
14 |
15 | 在实模式下,段寄存器直接存放的就是段基址,比如 CPU 中用来存放当前指令地址的 CS:IP 寄存器,CS 中存放的便是代码段的基址。这样就会出现一个问题,超级不安全,程序可以随意访问任何物理地址,就像逛菜市场一样,无拘无束。为了不让某些非法分子到处瞎转悠,保护模式孕育而生!
16 |
17 | - **保护模式**
18 |
19 | 在保护模式下,很重要的一点就是**段寄存器不是直接存放段基址了,而是存放着段选择子**(选择子也可以叫做selector,索引描述符)。从这里可以看到,我们访问段寄存器就不是放的地址,其实访问的是一张表叫做GDT(全局描述符表)
20 |
21 | 保护模式下的寻址方式如下:
22 |
23 | 1. 段寄存器存放段选择子;
24 |
25 | 2. CPU 根据段选择子从GDT中找到对应段描述符;
26 |
27 | 3. 从段描述符中取出段基址。
28 |
29 | 4. 根据之前的公式,结合段基址和段内偏移,计算出物理地址。
30 |
31 | 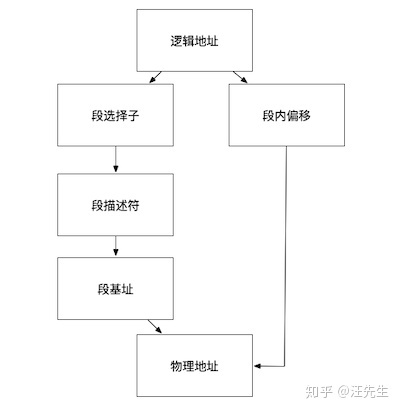
32 |
33 | 保护模式的开关主要存在在CR0控制寄存器中的相关标志位中。
34 |
35 | --------------------------------------------------------------------------------------------------------------------
36 |
37 | 除了寻址方式不同外,保护模式还增加了一个特权级的特性。特权级共四层,0为最高特权级,为内核代码所运行级别,3为最低特权级,为用户程序所运行级别。段描述符中会记录访问当前段所需特权级,程序在访问一个段时需要先构建段选择子,段选择子中中有两位专门负责表示当前程序请求访问目标段的时的特权级,即为RPL。一般来说,RPL = CPL,CPL即为当前程序所在代码段的特权级,存在CS寄存器中的后两位(因为CS 寄存器存放的就是当前代码段的段选择子)。目标段的特权级被称为DPL,当程序访问目标段的时候,如果 DPL 特权比 CPL 和 RPL 中任何一个高,那么就会拒绝访问,从而起到了保护作用
38 |
39 | ## x86PC机开机过程
40 |
41 | - 总体描述
42 |
43 | 当 PC 的电源打开后, 80x86 结构的CPU将自动进入实模式,并从地址0xFFFF0开始自动执行程序代码,这个地址通常是ROM BIOS 中的地址。 PC 机的BIOS将执行系统的某些硬件检测和诊断功能 ,并在物理地址0处开始设置和初始化中断向量。此后,它将可启动设备的第一个扇区(磁盘引导扇区, 512 字节)读入内存绝对地址 0x7C00 处,
44 | 并跳转到这个地方开始引导启动机器运行了。 启动设备通常是软驱或是硬盘。
45 |
46 |
1179 |
1180 | 通常函数的地址都在编译的时候确定好了,但虚函数的地址需要等到运行的时候才能确定,因为你无法确定一个基类的指针或引用指向的是基类对象还是派生类对象。综上,**虚函数表指针是在对象执行构造函数的时候确定的**,对于基类来说执行基类构造函数时直接把虚函数表填充为基类的虚函数地址,基类对象的vptr指向vtbl。对于派生类,创建对象时先执行基类构造函数,因此派生类对象的vptr指向的虚函数表vtbl里的内容首先是基类中的所有虚函数的地址,然后接着执行派生类构造函数,修改派生类对象vptr指向的虚函数表中的内容,将派生类的虚函数地址填进去。
1181 |
1182 | +++
1183 |
1184 | **虚函数的内存分布**
1185 |
1186 | 根据下面代码会给出一个该类的内存分布图:
1187 |
1188 | ```c++
1189 | class A {
1190 | public:
1191 | virtual void v_a(){}
1192 | virtual ~A(){}
1193 | int64_t _m_a;
1194 | };
1195 |
1196 | int main(){
1197 | A* a = new A();
1198 | return 0;
1199 | }
1200 | ```
1201 |
1202 | 内存分布图如下:
1203 |
1204 | 
1205 |
1206 | > 1. main函数内部使用new创建的对象,因此主函数main的栈帧上有一个A类类型的指针指向堆里面分配好的A对象的实例(stack→heap)
1207 | > 2. 在堆中,对象a的实例由上到下是一个vptr和声明的成员变量
1208 | > 3. vptr指向虚函数表中的第一个虚函数起始地址
1209 | > 4. 虚函数表中还有一个tinfo的指针指向typeinfo表,存储着A类的基础信息,包括父类名称、类名称
1210 |
1211 | +++
1212 |
1213 | **虚函数执行过程**
1214 |
1215 | 当调用一个虚函数时,首先通过对象内存中的vptr找到虚函数表vtbl,接着通过vtbl找到对应虚函数的实现区域并进行调用。 当一个类声明了虚函数或者继承了虚函数,这个类就会有自己的vtbl。vtbl核心就是一个函数指针数组,有的编译器用的是链表,不过方法都是差不多。vtbl数组中的每一个元素对应一个函数指针指向该类的一个虚函数,同时该类的每一个对象都会包含一个vptr,vptr指向该vtbl的地址。 在有继承关系时(子类相对于其直接父类)
1216 |
1217 | 1. 一般继承时,子类的虚函数表中先将父类虚函数放在前,再放自己的虚函数指针。
1218 | 2. 如果子类覆盖了父类的虚函数,将被放到了虚表中**原来父类虚函数**的位置。
1219 | 3. 在多继承的情况下,**每个父类都有自己的虚表,子类的成员函数被放到了第一个父类的表中。**也就是说当类在多重继承中时,其实例对象的内存结构并不只记录一个虚函数表指针。基类中有几个存在虚函数,则子类就会保存几个虚函数表指针
1220 |
1221 | 下图是c++ primer plus中虚函数实现机制的示意图:
1222 |
1223 | 
1224 |
1225 | > 先看最下面,首先根据`Scientist* psc = &adam`这局代码找到adam对象中的vptr为2096,然后找到vptr指向的2096地址的虚函数表,在上图中间位置,虚函数表示数组指针形式的。然后前往地址6820,并执行这里的函数。
1226 |
1227 | 总结一下调用过程:
1228 |
1229 | 1. 首先获取对象内存中的vptr指针指向的虚函数表vtbl
1230 | 2. 进入vtbl,一般是数组指针形式的,找到对应虚函数的地址并调用
1231 |
1232 | +++
1233 |
1234 | **性能分析**
1235 |
1236 | 第一步是通过对象的vptr找到该类的vtbl,因为虚函数表指针是编译器加上去的,通过vptr找到vtbl就是指针的寻址而已。
1237 |
1238 | 第二部就是找到对应vtbl中虚函数的指针,因为vtbl大部分是指针数组的形式实现的
1239 |
1240 | 在单继承的情况下调用虚函数所需的代价基本上和非虚函数效率一样,在大多数计算机上它多执行了很少的一些指令
1241 |
1242 | 在多继承的情况由于会根据多个父类生成多个vptr,在对象里为寻找 vptr 而进行的偏移量计算会变得复杂一些
1243 |
1244 | 空间层面为了实现运行时多态机制,编译器会给每一个包含虚函数或继承了虚函数的类自动建立一个虚函数表,所以虚函数的一个代价就是会增加类的体积。在虚函数接口较少的类中这个代价并不明显,虚函数表vtbl的体积相当于几个函数指针的体积,如果你有大量的类或者在每个类中有大量的虚函数,你会发现 vtbl 会占用大量的地址空间。但这并不是最主要的代价,主要的代价是发生在类的继承过程中,在上面的分析中,可以看到,当子类继承父类的虚函数时,子类会有自己的vtbl,如果子类只覆盖父类的一两个虚函数接口,子类vtbl的其余部分内容会与父类重复。**如果存在大量的子类继承,且重写父类的虚函数接口只占总数的一小部分的情况下,会造成大量地址空间浪费**。同时由于虚函数指针vptr的存在,虚函数也会增加该类的每个对象的体积。在单继承或没有继承的情况下,类的每个对象只会多一个vptr指针的体积,也就是4个字节;在多继承的情况下,类的每个对象会多N个(N=包含虚函数的父类个数)vptr的体积,也就是4N个字节。当一个类的对象体积较大时,这个代价不是很明显,但当一个类的对象很轻量的时候,如成员变量只有4个字节,那么再加上4(或4N)个字节的vptr,对象的体积相当于翻了1(或N)倍,这个代价是非常大的。
1245 |
1246 | +++
1247 |
1248 | **虚函数注意事项**
1249 |
1250 | - 构造函数
1251 |
1252 | 首先要知道构造函数不能是虚函数。
1253 |
1254 | 原因:如果构造函数时虚的,也要从虚函数表中找,但是创建对象要用到构造函数,如果构造函数是虚的话,vptr指针就没有了,因为你找不到构造函数,构造不出对象,构造不出对象你就没有vptr。而且在构造函数中调用虚函数实际执行的肯定是父类的函数,因为你派生类的都没构造好,调个锤子。
1255 |
1256 | - 析构函数
1257 |
1258 | 析构函数当然是虚的,除非类不做基类。**并且通常要给基类一个虚析构函数,即使他并不需要**
1259 |
1260 | 原因:**(主要针对基类指针来销毁派生类对象这个行为)如果析构函数不是虚的,派生类析构的时候调用的是基类的析构函数,而基类的构造函数只是对基类部分做了析构,从而导致派生类部分出现内存泄露。如果加了virtual,则先回调用派生类对象的析构函数,然后再调用基类的析构函数**
1261 |
1262 | - 友元
1263 |
1264 | 友元不能是虚函数,因为友元又不是类成员,而只有类成员才能使虚函数。
1265 |
1266 | 但是友元函数可以是虚成员函数
1267 |
1268 | - 内联函数
1269 |
1270 | 虚函数在c++中叫做dynamic binding。内联函数为了提高效率,通常是在编译期间对调用内联函数的地方做代码替换而已,所以内联函数对于程序中频繁调用的小函数非常有用。同时要知道,再类中定义的函数,会被默认的当成内联函数。
1271 |
1272 | 所以,**当使用基类指针或引用来调用虚函数的时候,不能使用内联函数**。
1273 |
1274 | 但是**使用对象(并不时指针或者引用)来调用时,可以当做内联函数**,**因为编译器是默认静态联编的**。
1275 |
1276 | - 静态成员函数
1277 |
1278 | static成员不属于任何类对象或类实例,所以即使给此函数加上virutal也是没有任何意义的。
1279 |
1280 | 此外静态与非静态成员函数之间有一个主要的区别,那就是**静态成员函数没有this指针**,从而导致两者调用方式不同。
1281 |
1282 | 虚函数依靠vptr和vtable来处理。vptr是一个指针,在类的构造函数中创建生成,并且只能用this指针来访问它,因为它是类的一个成员,并且vptr指向保存虚函数地址的vtable,因此虚函数的执行顺序是:**虚函数的调用关系:this -> vptr -> vtable ->virtual function**
1283 |
1284 | 对于静态成员函数,它没有this指针,所以无法访问vptr. 这就是为何**static函数不能为virtual**。
1285 |
1286 | - 纯虚函数
1287 |
1288 | 析构函数可以是纯虚的,但**纯虚析构函数必须有定义体**,因为析构函数的调用是在子类中隐含的。
1289 |
1290 | +++
1291 |
1292 | ### Protected权限
1293 |
1294 | 关键字protected与private相似,再类外只能通过共有方法来访问protected成员
1295 |
1296 | private和protected的区别主要在继承里面。派生类的成员可以直接访问基类的保护成员,但不能访问基类的私有成员。
1297 |
1298 | **对于外部世界来说,保护成员的行为和私有成员一致;对派生类来说,保护成员的行为和公有成员一致**
1299 |
1300 | ### 纯虚函数
1301 |
1302 | 在很多情况下,基类本身生成对象是不合情理的。例如,动物作为一个基类可以派生出老虎、孔雀等子类,但动物本身生成对象明显不合常理。而针对每种动物的方法又有所不同,此时需要使用多态特性,也就需要在基类中定义虚函数。
1303 |
1304 | 纯虚函数是在基类中声明的虚函数,它要求任何派生类都要定义自己的实现方法,以实现多态性。实现了纯虚函数的子类,该纯虚函数在子类中就变成了虚函数。
1305 |
1306 | 定义纯虚函数是为了实现一个接口,用来规范派生类的行为,也即规范继承这个类的程序员必须实现这个函数。派生类仅仅只是继承函数的接口。纯虚函数的意义在于,让所有的类对象(主要是派生类对象)都可以执行纯虚函数的动作,但基类无法为纯虚函数提供一个合理的缺省实现。所以类纯虚函数的声明就是在告诉子类的设计者,“你必须提供一个纯虚函数的实现,但我不知道你会怎样实现它”。
1307 |
1308 | 含有纯虚函数的类称之为抽象类,它不能生成对象(创建实例),只能创建它的派生类的实例。抽象类是一种特殊的类,它是为了抽象和设计的目的为建立的,它处于继承层次结构的较上层。抽象类的主要作用是将有关的操作作为结果接口组织在一个继承层次结构中,由它来为派生类提供一个公共的根,派生类将具体实现在其基类中作为接口的操作。抽象类只能作为基类来使用,其纯虚函数的实现由派生类给出。如果派生类中没有重新定义纯虚函数,而只是继承基类的纯虚函数,则这个派生类仍然还是一个抽象类。如果派生类中给出了基类纯虚函数的实现,则该派生类就不再是抽象类了,它是一个可以建立对象的具体的类。
1309 |
1310 | ### 继承和动态内存分配
1311 |
1312 | 代码如下:
1313 |
1314 | ```c++
1315 | //baseDMA.h
1316 | #ifndef BASEDMA_H_
1317 | #define BASEDMA_H_
1318 |
1319 | #include
1320 | class baseDMA{
1321 | private:
1322 | char * label;
1323 | int rating;
1324 | public:
1325 | baseDMA(const char * s = "null", int r = 0); //构造函数
1326 | baseDMA(const baseDMA & bd); //复制构造函数
1327 | baseDMA & operator=(const baseDMA & bd); //赋值运算符函数
1328 | virtual ~baseDMA();
1329 | friend std::ostream & operator<<(std::ostream & os, const baseDMA & bd); //输出运算符,友元函数
1330 | };
1331 |
1332 |
1333 |
1334 | //不用动态内存分配的派生类
1335 | class lacksDMA : public baseDMA
1336 | {
1337 | private:
1338 | enum {LEN = 40};
1339 | char color[LEN];
1340 | public:
1341 | lacksDMA(const char * s = "null", int r = 0, const char * c = "none");
1342 | lacksDMA(const baseDMA & bd, const char * c = "none");
1343 | //友元函数并不属于类,所以不能被继承,必须自己写哦
1344 | friend std::ostream & operator<<(std::ostream & os, const lacksDMA & ld);
1345 | };
1346 |
1347 | //用动态内存分配的派生类
1348 | class hasDMA : public baseDMA
1349 | {
1350 | private:
1351 | char *style;
1352 | public:
1353 | hasDMA(const char * s = "null", int r = 0, const char * sty = "none");
1354 | hasDMA(const baseDMA & bd, const char * sty = "none");
1355 | ~hasDMA();//析构函数
1356 | hasDMA(const hasDMA & hd);//复制构造函数
1357 | hasDMA & operator=(const hasDMA & hd);//赋值运算符函数
1358 | //友元函数并不属于类,所以不能被继承,必须自己写哦
1359 | friend std::ostream & operator<<(std::ostream & os, const hasDMA & ld);
1360 | };
1361 | #endif // BASEDMA_H_
1362 | ```
1363 |
1364 | - 第一种情况,基类使用new,派生类不使用new
1365 |
1366 | 对应上述代码中不用动态内存分配的派生类。不需要为lackDMA类定义显式析构函数、拷贝构造函数、赋值运算符。
1367 |
1368 | 不需要析构函数。如果派生类为定义析构函数则编译器将定义一个不执行任何操作的默认构造函数。但派生类的默认构造函数需要执行完自身代码后调用基类构造函数。由于派生类lackDMA成员没有动态分配内存,所以不用做什么操作。
1369 |
1370 | 不需要拷贝构造函数。首先之前说过默认拷贝构造函数对有动态内存分配的成员是不合适的,但是对于没有动态内存分配的成员是合适的。但是派生类是从baseDMA类继承而来的,也是不需要的,原因如下。派生类的默认拷贝构造函数会使用显式的baseDMA拷贝构造函数来复制lackDMA对象的baseDMA部分。因此如果派生类没有动态内存分配的话,用默认拷贝构造函数是可以的。
1371 |
1372 | 不需要赋值运算符重载。跟上面一样,派生类的默认赋值运算符将会使用基类的赋值运算符对基类组件进行赋值
1373 |
1374 | - 第二种情况,基类使用new,派生类使用new
1375 |
1376 | 上述代码中hasDMA就是使用了动态内存分配。在这种情况下必须为派生类定义显式的析构函数、拷贝构造函数和赋值运算符
1377 |
1378 | +++
1379 |
1380 | ### 继承方式
1381 |
1382 | 
1383 |
1384 | ### 多重继承
1385 |
1386 | 在现实生活中,一些新事物往往会拥有两个或者两个以上事物的属性,为了解决这个问题,C++引入了多重继承的概念,C++允许为一个派生类指定多个基类,这样的继承结构被称做多重继承。(派生类有两个或两个以上的直接基类)
1387 | 当一个派生类要使用多重继承的时候,必须在派生类名和冒号之后列出所有基类的类名,并用逗好分隔。如下:
1388 |
1389 | ```c++
1390 | class Derived : public Base1, public Base2, … {};
1391 | ```
1392 |
1393 | 多继承会出现问题:在派生类中对基类成员的访问应该是唯一的。但是,在多继承情况下,可能造成对基类中某个成员的访问出现了不一致的情况,这时就称对基类成员的访问产生了二义性。
1394 |
1395 | - 问题1:派生类在访问基类成员函数时,由于基类存在同名的成员函数,导致无法确定访问的是哪个基类的成员函数,因此出现了二义性错误。
1396 |
1397 | 代码如下:
1398 |
1399 | ```c++
1400 | class Base1
1401 | {
1402 | public:
1403 | void fun(){cout<<"base1 "<
1460 |
1461 | 解决方法也是两个:
1462 |
1463 | 1. 还是使用作用域运算符,指明访问哪一个基类的数据
1464 |
1465 | ```c++
1466 | d.BC1::x = 2; // from BC1
1467 | d.BC2::x = 3; // from BC2
1468 | d.K = 4; // error C2385: 对"K"的访问不明确(编译错误)
1469 | d.BC1::K = 5; // from BC1
1470 | d.BC2::K = 6;
1471 | ```
1472 |
1473 | 2. 使用虚基类。产生二义性的最主要的原因就是BC0在派生类DC中产生了2个对象,从而导致了对基类BC0的成员k访问的不一致性。要解决这个问题,只需使这个公共基类Base在派生类中只产生一个子对象即可。
1474 |
1475 | ```c++
1476 | class BC0
1477 | {
1478 | public:
1479 | int K;
1480 | };
1481 | class BC1 : virtual public BC0
1482 | {
1483 | public:
1484 | int x;
1485 | };
1486 | class BC2 : virtual public BC0
1487 | {
1488 | public:
1489 | int x;
1490 | };
1491 | class DC : public BC1, public BC2
1492 | {
1493 | };
1494 | void main( )
1495 | {
1496 | DC d; //虚继承使得BC0仅被DC间接继承一份
1497 | d.K = 13; // OK
1498 | }
1499 | ```
1500 |
1501 |
1502 |
1503 | +++
1504 |
1505 |
1506 |
1507 | ## 类设计总结
1508 |
1509 |
1510 |
1511 | - 默认构造函数
1512 |
1513 | 默认构造函数要么没有参数,要么所有参数都有默认值才行。如果类为定义任何构造函数,编译器将自动定义一个默认构造函数用来创建对象。
1514 |
1515 | 如果派生类构造函数的成员初始化列表没有显式的调用基类构造函数,则编译器将使用基类的默认构造函数来构造派生类对象的基类部分。
1516 |
1517 | - 拷贝构造函数
1518 |
1519 | 拷贝构造函数接受其所属类的对象作为参数,在下面几种情况下将使用拷贝构造函数:
1520 |
1521 | 1. 将新对象初始化为一个已存在的对象
1522 | 2. 按值将对象作为参数传递给函数
1523 | 3. 函数按值类型返回对象
1524 | 4. 编译器临城临时对象
1525 |
1526 | 编译器会默认提供拷贝构造函数,但不提供具体定义。当类中有动态内存分配的情况时需要自定义拷贝构造函数
1527 |
1528 | - 赋值运算符
1529 |
1530 | 默认的赋值运算符用于处理同类对象之间的赋值。
1531 |
1532 | **切记,不要讲赋值和初始化搞混了!!!如果语句创建新的对象则使用初始化,如果不是新鲜创建的对象则是赋值**
1533 |
1534 | - 构造函数
1535 |
1536 | 构造函数不同于其他类方法,因为他创建新对象,而其他类方法仅仅是被现有对象调用,这是构造函数不被继承的原因。
1537 |
1538 | 如果构造函数能被继承,表示派生类对象可以使用基类对象的方法,但是构造函数在执行的时候,对象并不存在。
1539 |
1540 | - 转换
1541 |
1542 | 默认是隐式的转换,从参数类型到类类型的转换
1543 |
1544 | 在构造函数中使用关键字`explicit`将禁止进行隐式转换,代码如下:
1545 |
1546 | ```c++
1547 | class Star{
1548 | public:
1549 | explicit Star(const char*);
1550 | ...
1551 | };
1552 |
1553 | int main(){
1554 | Star north;
1555 | north = "polaris"; //不允许
1556 | north = Star("polaris"); //可以转换
1557 | }
1558 | ```
1559 |
1560 | 要将类对象转换成其他类型需要定义相应的转换函数,前面说过了。转换函数可以使没有参数的类成员函数,也可以是返回类型是目标类型的函数
1561 |
1562 | ``` c++
1563 | Star::Star double(){...} //将star类转换成double
1564 | Star::Star const char*(){...} //将star类转换成const char
1565 | ```
1566 |
1567 | - 按值传递与传递引用
1568 |
1569 | 在编写参数类型是类对象的函数时,应该按照引用而不是值来传递对象。这样做是为了提高效率。因为按值传递对象将会涉及到临时拷贝,调用拷贝构造函数,然后调用析构函数,调用这些函数需要花费时间,当对象非常大的时候就会显得很耗时。
1570 |
1571 | 另外如果不修改对象就传const。
1572 |
1573 | 按引用传递对象的另一个原因就是在继承使用虚函数的时候,被定义为接受基类引用参数的函数可以接受派生类
1574 |
1575 | - 返回对象和返回引用
1576 |
1577 | 应该返回引用而不是类对象的原因在于返回对象涉及生成对象的临时副本,因此调用对象的时间成本包括调用拷贝构造函数来生成副本所需要的时间和调用析构函数删除副本所需要的时间。返回引用可以节省时间和内存。
1578 |
1579 | 其实直接返回对象与函数参数按值传递类似
1580 |
1581 | 但有时候必须返回对象,而不涉及返回引用。函数不能返回在函数中创建的临时对象的引用,因为当函数结束时,临时对象将会消失,引用是非法的。在这种情况下应该返回对象,以生成一个程序可以使用的副本。
1582 |
1583 | +++
1584 |
1585 | ## 泛型编程——模板
1586 |
1587 | c++提供了两种模板机制:函数模板和类模板
1588 |
1589 | ### 函数模板
1590 |
1591 | > 含义:建立一个通用的函数,其函数返回值类型和形参类型可以不具体指定,用一个虚拟类型代表
1592 |
1593 | **语法如下:**
1594 |
1595 | ```c++
1596 | template
1597 | 函数声明定义
1598 | ```
1599 |
1600 | **解释:**
1601 |
1602 | 1. template——声明创建一个模板
1603 | 2. typename——表明后面符号的一个数据类型,也可以用class代替
1604 | 3. T就是数据类型,抽象出来
1605 |
1606 | **调用方式(重要):**
1607 |
1608 | 1. 自动类型推导
1609 |
1610 | `mySwap(a, b)`
1611 |
1612 | 2. 显式指定类型
1613 |
1614 | `mySwap(a, b)`
1615 |
1616 | **意义**:
1617 |
1618 | 模板将数据类型参数化,还是为了编程方便
1619 |
1620 | +++
1621 |
1622 | **模板注意事项:**
1623 |
1624 | 1. 自动类型推导,必须推导出一致的数据类型T才可以使用。也就是说参数类型和你模板定义的得一致才行。
1625 | 2. 模板必须要确定出T的类型
1626 |
1627 | **普通函数与模板函数的区别:**
1628 |
1629 | 1. 普通函数调用时可以发生自动类型转换(隐式类型转换)
1630 | 2. 如果使用函数模板,自动类型推导的话,则不会发生隐式转换
1631 | 3. 如果使用函数模板,显式指定类型,则可以发生隐式转换
1632 |
1633 | **普通函数与函数模板的调用规则:**
1634 |
1635 | 1. 优先调用普通函数
1636 |
1637 | 2. 可以使用空模板参数来强制调用模板函数
1638 |
1639 | `myPrint<>(arg1, arg2,...)`
1640 |
1641 | 3. 函数模板也可以重载
1642 |
1643 | 4. 如果函数模板可以产生更好的匹配,优先调用函数模板
1644 |
1645 | +++
1646 |
1647 |
1648 |
1649 | ### 类模板
1650 |
1651 | > 定义:建立一个通用类,类中的成员的数据类型可以不具体制定,和函数模板差不多
1652 |
1653 | **类模板和函数模板的区别:**
1654 |
1655 | 1. 类模板没有自动类型推导的使用方式,只有显式指定参数类型
1656 |
1657 | ```c++
1658 | template
1659 | class Person{.....};
1660 |
1661 | Person p1; //error!!
1662 | Person p2; //correct!!
1663 | ```
1664 |
1665 | 2. 类模板在模板参数列表中可以有默认参数
1666 |
1667 | ```c++
1668 | template
1669 | class Person{.....};
1670 |
1671 | Person p2; //正确!!
1672 | ```
1673 |
1674 |
1675 |
1676 | **类模板中成员函数创建时间:**
1677 |
1678 | 1. 普通类中的成员函数在编译的时候就创建
1679 |
1680 | 2. 类模板中的成员函数在调用的时候才会创建
1681 |
1682 | ```c++
1683 | class MyClass1{
1684 | void show1(){cout<<"show1";}
1685 | };
1686 | class MyClass2{
1687 | void show2(){cout<<"show2";}
1688 | };
1689 |
1690 | template
1691 | class Myclass_template{
1692 | T obj;
1693 | void showClass1(){
1694 | obj.show1();
1695 | }
1696 | void showClass2(){
1697 | obj.show2();
1698 | }
1699 | };
1700 | int main(){
1701 | Myclass_template m1;
1702 | m1.showClass1(); //编译不报错,运行不报错
1703 | m1.showClass2(); //编译不报错,运行时候报错
1704 | }
1705 | ```
1706 |
1707 |
1708 |
1709 | **类模板对象做函数参数:**
1710 |
1711 | 就是类模板实例化出的对象,作为参数的形式传入函数
1712 |
1713 | 1. 指定传入的类型 —— 直接显示对象的数据类型
1714 |
1715 | ```c++
1716 | void print(Person&p);
1717 | ```
1718 |
1719 | 2. 参数模板化 —— 将对象中的参数变为模板进行传递
1720 |
1721 | ```c++
1722 | template
1723 | void print(Person& p);
1724 | ```
1725 |
1726 | 3. 整个类模板化 —— 将整个对象类型模板化进行传递
1727 |
1728 | ```c++
1729 | template
1730 | void print(T& p);
1731 | ```
1732 |
1733 |
1734 |
1735 | **类模板与继承:**
1736 |
1737 | 1. 当派生类继承基类的一个类模板时,子类在声明时,要指定出分类中的T类型
1738 |
1739 | ```c++
1740 | template
1741 | class Father{
1742 | T m;
1743 | };
1744 |
1745 | //报错
1746 | class Son: public Father{
1747 |
1748 | };
1749 |
1750 | //正确
1751 | class Son: public Father{
1752 |
1753 | };
1754 | ```
1755 |
1756 | > 因为子类要继承父类中的成员变量,但是模板没有指定内存大小,所以是不确定的,而不确定性是c++所嗤之以鼻的。因此继承的时候得指定要继承模板的数据类型才行。
1757 | >
1758 | > 但是这样不灵活,父类中的类型就被定死了,有违背c++灵活编程,所以这种方法不太实用
1759 |
1760 | 2. 如果不指定,编译器无法给子类非配内存
1761 |
1762 | 3. 如果要灵活的话,子类也需变为类模板
1763 |
1764 | ```c++
1765 | template
1766 | class Son: public Father{
1767 | T1 obj;
1768 | };
1769 | ```
1770 |
1771 |
1772 |
1773 | **类模板成员函数的类外实现**
1774 |
1775 | ```c++
1776 | //构造函数类外实现
1777 | template
1778 | Person::Person(T1 name, T2 age){}
1779 |
1780 | //成员函数类外实现
1781 | template
1782 | void Person::show(){}
1783 | ```
1784 |
1785 |
1786 |
1787 | **类模板分文件编写**
1788 |
1789 | 出现问题:类模板中成员函数创建时机是在调用阶段,导致分文件编写是链接不到。
1790 |
1791 | 解决方案:
1792 |
1793 | 1. 直接包含.cpp源文件
1794 |
1795 | 2. 将声明和实现写到同一个文件中,并更改后缀名成.hpp(主流实现)
1796 |
1797 | ```c++
1798 | #pragma once //防止头文件重复包含
1799 | #include
1800 | using namespace std;
1801 | //类模板与继承
1802 | template
1803 | class Baba
1804 | {
1805 | public:
1806 | void fun();
1807 | };
1808 | //成员函数类外实现
1809 | //第二种写法
1810 | template
1811 | void Baba::fun()
1812 | {
1813 | cout << "成员函数类外实现" << endl;
1814 | }
1815 | ```
1816 |
1817 | 上述文件要改成.hpp后缀
1818 |
1819 |
1820 |
1821 |
1822 |
1823 |
1824 |
1825 |
1826 |
1827 |
1828 |
1829 |
1830 |
1831 |
1832 |
1833 |
1834 |
1835 |
1836 |
1837 |
1838 |
1839 |
1840 |
1841 |
1842 |
1843 |
1844 |
1845 |
1846 |
1847 |
1848 |
1849 |
1850 |
1851 |
1852 |
1853 |
1854 |
1855 |
1856 |
1857 |
--------------------------------------------------------------------------------
/书籍笔记/操作系统.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # 基础知识—引论
4 |
5 | ## 实模式和保护模式
6 |
7 | - **实模式**
8 |
9 | 将实模式主要先了解内存寻址
10 |
11 | 我们的代码分为代码段、数据段等,所有的内存寻址都是根据 **段基址:段内偏移** 来访问的,这样的地址形式称为**逻辑地址**,为什么搞这么复杂呢?因为早期的8086处理器寄存器宽度只有16位,16位的寄存器只能进行 64 KB 的寻址,而 8086 有 20 根地址线,按照地址线来计算可以进行 1 MB 的寻址,所以16 位宽度的寄存器是显然不能满足需求的,为了解决这个问题,聪明的程序员想出了用 **段基址:段内偏移** 的方式来扩展寻址空间。
12 |
13 | 实际物理地址 = 段基址 << 4(左移四位) + 段内偏移。这样两个 16 位的寄存器合在一起,宽度便成了 20 位。
14 |
15 | 在实模式下,段寄存器直接存放的就是段基址,比如 CPU 中用来存放当前指令地址的 CS:IP 寄存器,CS 中存放的便是代码段的基址。这样就会出现一个问题,超级不安全,程序可以随意访问任何物理地址,就像逛菜市场一样,无拘无束。为了不让某些非法分子到处瞎转悠,保护模式孕育而生!
16 |
17 | - **保护模式**
18 |
19 | 在保护模式下,很重要的一点就是**段寄存器不是直接存放段基址了,而是存放着段选择子**(选择子也可以叫做selector,索引描述符)。从这里可以看到,我们访问段寄存器就不是放的地址,其实访问的是一张表叫做GDT(全局描述符表)
20 |
21 | 保护模式下的寻址方式如下:
22 |
23 | 1. 段寄存器存放段选择子;
24 |
25 | 2. CPU 根据段选择子从GDT中找到对应段描述符;
26 |
27 | 3. 从段描述符中取出段基址。
28 |
29 | 4. 根据之前的公式,结合段基址和段内偏移,计算出物理地址。
30 |
31 | 
32 |
33 | 保护模式的开关主要存在在CR0控制寄存器中的相关标志位中。
34 |
35 | --------------------------------------------------------------------------------------------------------------------
36 |
37 | 除了寻址方式不同外,保护模式还增加了一个特权级的特性。特权级共四层,0为最高特权级,为内核代码所运行级别,3为最低特权级,为用户程序所运行级别。段描述符中会记录访问当前段所需特权级,程序在访问一个段时需要先构建段选择子,段选择子中中有两位专门负责表示当前程序请求访问目标段的时的特权级,即为RPL。一般来说,RPL = CPL,CPL即为当前程序所在代码段的特权级,存在CS寄存器中的后两位(因为CS 寄存器存放的就是当前代码段的段选择子)。目标段的特权级被称为DPL,当程序访问目标段的时候,如果 DPL 特权比 CPL 和 RPL 中任何一个高,那么就会拒绝访问,从而起到了保护作用
38 |
39 | ## x86PC机开机过程
40 |
41 | - 总体描述
42 |
43 | 当 PC 的电源打开后, 80x86 结构的CPU将自动进入实模式,并从地址0xFFFF0开始自动执行程序代码,这个地址通常是ROM BIOS 中的地址。 PC 机的BIOS将执行系统的某些硬件检测和诊断功能 ,并在物理地址0处开始设置和初始化中断向量。此后,它将可启动设备的第一个扇区(磁盘引导扇区, 512 字节)读入内存绝对地址 0x7C00 处,
44 | 并跳转到这个地方开始引导启动机器运行了。 启动设备通常是软驱或是硬盘。
45 |
46 |  47 |
48 | 上图表示从系统加电开始执行程序的顺序
49 |
50 | - 具体描述
51 |
52 | - 总结:x86 PC刚开机时固化在ROM中的BIOS程序开始运行,当完成加电自检等操作后,会从磁盘中寻找boot引导程序加载。CPU处于实模式(实模式的寻址CS:IP,CS左移4位)
53 |
54 | - 开机时,CS=0xFFFF;IP=0x0000,寻址0xFFFF0(ROM BIOS的地址)
55 |
56 | - 检查RAM,键盘,显示器,软硬磁盘(加电自检)
57 |
58 | - 将磁盘0磁头0磁道第1扇区(引导扇区)读入0x7c00处
59 |
60 | - 引导扇区就是启动设备的第一个扇区
61 |
62 | - 启动设备信息被设置在CMOS(用来存储时钟和硬件配置信息)中
63 |
64 | - 因此,磁盘的第一个扇区上存放着开机后第一段我们可以控制的程序
65 |
66 | - 设置cs=0x7c00, ip=0x0000
67 |
68 | ## 16位和32位下CPU寻址方式的不同
69 |
70 | 在实模式下:cs左移4位+ip
71 |
72 | 保护模式下:cs查表+ip(GDT表 )
73 |
74 |
75 |
76 | # 进程与线程
77 |
78 | ## 进程
79 |
80 | ### 进程模型
81 |
82 | 首先进程是对一个正在运行程序的抽象,这样我们才好去定义,利用它。
83 |
84 | 一个进程就是一个程序执行的实例,该程序得到CPU,有程序计数器,寄存器和当前变量值等 。
85 |
86 | > 有一个比喻来说明程序和进程之间的关系:程序就是做蛋糕的食谱,这个食谱是存储到书上的。当我们(CPU)想做蛋糕的时候就把食谱调出来,而做蛋糕的各种材料就是输入数据。那么进程就是我们阅读食谱,把材料混合操作等这一系列操作的总和。
87 | >
88 | > **因此可以说进程是某种活动,他得到CPU,有输入,输出和状态。**
89 |
90 | ### 进程的创建
91 |
92 | 一下几种事件的发生会创建进程
93 |
94 | 1. 系统初始化
95 | 2. 一个正在运行的程序执行了创建进程的系统调用,以便协助其工作
96 | 3. 用户请求创建新进程,比如用户打开多个窗口
97 | 4. 一个批处理作业的初始化。不常见,仅在大型机的批处理系统中有应用。
98 |
99 | > 在unix系统中,只有一个系统调用能用来创建新进程:**fork命令**。这个系统调用函数会创建一个和父进程相同的副本,两个进程拥有相同的内存映像
100 | >
101 | > 但是父进程和子进程各自拥有不同的地址空间。
102 | >
103 | > 注意的是不可写的内存区是共享的,有些可以使得程序在父进程和子进程间共享是因为这个程序不能被修改。
104 | >
105 | > 或者子进程可以通过**写时复制**共享父进程的内存,即读的时候可以共享,写的时候即要修改一部分内存的时候必须先将内存复制,然后在自己的私有内存上进行修改才行。
106 |
107 | ### 进程的终止
108 |
109 | 有以下几种情况会引起进程终止
110 |
111 | 1. 进程正常退出。即进程完成了自己的工作,编译器通过一个系统调用告诉操作系统该进程已经结束工作可以收回,在unix中时exit函数。
112 | 2. 进程执行的时候发现错误退出,自愿的行为。比如要编译一个不存在的文件。
113 | 3. 由进程引起的错误而退出,非自愿的。通常这类情况是由程序中的错误造成的,比如除零,执行非法指令,引用一块不存在的内存。
114 | 4. 被其他进程杀死,非自愿。有一个进程执行了系统调用通知操作系统杀死某个进程。
115 |
116 | ### 进程的状态
117 |
118 | >
47 |
48 | 上图表示从系统加电开始执行程序的顺序
49 |
50 | - 具体描述
51 |
52 | - 总结:x86 PC刚开机时固化在ROM中的BIOS程序开始运行,当完成加电自检等操作后,会从磁盘中寻找boot引导程序加载。CPU处于实模式(实模式的寻址CS:IP,CS左移4位)
53 |
54 | - 开机时,CS=0xFFFF;IP=0x0000,寻址0xFFFF0(ROM BIOS的地址)
55 |
56 | - 检查RAM,键盘,显示器,软硬磁盘(加电自检)
57 |
58 | - 将磁盘0磁头0磁道第1扇区(引导扇区)读入0x7c00处
59 |
60 | - 引导扇区就是启动设备的第一个扇区
61 |
62 | - 启动设备信息被设置在CMOS(用来存储时钟和硬件配置信息)中
63 |
64 | - 因此,磁盘的第一个扇区上存放着开机后第一段我们可以控制的程序
65 |
66 | - 设置cs=0x7c00, ip=0x0000
67 |
68 | ## 16位和32位下CPU寻址方式的不同
69 |
70 | 在实模式下:cs左移4位+ip
71 |
72 | 保护模式下:cs查表+ip(GDT表 )
73 |
74 |
75 |
76 | # 进程与线程
77 |
78 | ## 进程
79 |
80 | ### 进程模型
81 |
82 | 首先进程是对一个正在运行程序的抽象,这样我们才好去定义,利用它。
83 |
84 | 一个进程就是一个程序执行的实例,该程序得到CPU,有程序计数器,寄存器和当前变量值等 。
85 |
86 | > 有一个比喻来说明程序和进程之间的关系:程序就是做蛋糕的食谱,这个食谱是存储到书上的。当我们(CPU)想做蛋糕的时候就把食谱调出来,而做蛋糕的各种材料就是输入数据。那么进程就是我们阅读食谱,把材料混合操作等这一系列操作的总和。
87 | >
88 | > **因此可以说进程是某种活动,他得到CPU,有输入,输出和状态。**
89 |
90 | ### 进程的创建
91 |
92 | 一下几种事件的发生会创建进程
93 |
94 | 1. 系统初始化
95 | 2. 一个正在运行的程序执行了创建进程的系统调用,以便协助其工作
96 | 3. 用户请求创建新进程,比如用户打开多个窗口
97 | 4. 一个批处理作业的初始化。不常见,仅在大型机的批处理系统中有应用。
98 |
99 | > 在unix系统中,只有一个系统调用能用来创建新进程:**fork命令**。这个系统调用函数会创建一个和父进程相同的副本,两个进程拥有相同的内存映像
100 | >
101 | > 但是父进程和子进程各自拥有不同的地址空间。
102 | >
103 | > 注意的是不可写的内存区是共享的,有些可以使得程序在父进程和子进程间共享是因为这个程序不能被修改。
104 | >
105 | > 或者子进程可以通过**写时复制**共享父进程的内存,即读的时候可以共享,写的时候即要修改一部分内存的时候必须先将内存复制,然后在自己的私有内存上进行修改才行。
106 |
107 | ### 进程的终止
108 |
109 | 有以下几种情况会引起进程终止
110 |
111 | 1. 进程正常退出。即进程完成了自己的工作,编译器通过一个系统调用告诉操作系统该进程已经结束工作可以收回,在unix中时exit函数。
112 | 2. 进程执行的时候发现错误退出,自愿的行为。比如要编译一个不存在的文件。
113 | 3. 由进程引起的错误而退出,非自愿的。通常这类情况是由程序中的错误造成的,比如除零,执行非法指令,引用一块不存在的内存。
114 | 4. 被其他进程杀死,非自愿。有一个进程执行了系统调用通知操作系统杀死某个进程。
115 |
116 | ### 进程的状态
117 |
118 | >  >
119 | >
120 | > 1. 就绪态。可以运行,但因为其他进程正在运行而暂停
121 | > 2. 阻塞态。除非某种外部事件发生,否则就会被一直挂起
122 | > 3. 运行态。实际上正在占用CPU的进程。
123 |
124 | 一个进程刚被创建的时候是就绪状态。当一个进程在概念上不能运行的时候就会被阻塞,有两种情况。第一种是等待后续的输入,因此进程挂起是程序自身的原因,比如用户键入命令之前无法执行。第二种是一个概念上可以运行的进程被迫停止,因为操作系统调度了另一个进程占用了CPU,由系统造成的。
125 |
126 | 就绪态和执行态之间的转换是进程调度程序控制的,进程调度程序是操作系统的一部分。系统认为一个进程占用处理器时间已经很长,决定让其他进程使用就会发生执行到就绪的转变。当有外部事件发生时,某进程就可以由阻塞态变成就绪状态,进入调度程序的调度。
127 |
128 | ### 进程的实现
129 |
130 | 为了实现进程,操作系统中维护了一张表,叫做进程表。进程表是由进程表项(进程控制块)所组成的,一个进程的全部信息就保存在进程控制块中。
131 |
132 | > 每当创建一个进程的时候,linux系统就会为该进程在内存中创建一个task_struct结构体。**这个task_struct结构体就是进程表。**这个结构体或者说进程表存放的是进程在运行过程中与该进程有关的所有信息,其中比如文件描述符就包括在其中。里面的信息如下图所示:
133 | >
134 | >
>
119 | >
120 | > 1. 就绪态。可以运行,但因为其他进程正在运行而暂停
121 | > 2. 阻塞态。除非某种外部事件发生,否则就会被一直挂起
122 | > 3. 运行态。实际上正在占用CPU的进程。
123 |
124 | 一个进程刚被创建的时候是就绪状态。当一个进程在概念上不能运行的时候就会被阻塞,有两种情况。第一种是等待后续的输入,因此进程挂起是程序自身的原因,比如用户键入命令之前无法执行。第二种是一个概念上可以运行的进程被迫停止,因为操作系统调度了另一个进程占用了CPU,由系统造成的。
125 |
126 | 就绪态和执行态之间的转换是进程调度程序控制的,进程调度程序是操作系统的一部分。系统认为一个进程占用处理器时间已经很长,决定让其他进程使用就会发生执行到就绪的转变。当有外部事件发生时,某进程就可以由阻塞态变成就绪状态,进入调度程序的调度。
127 |
128 | ### 进程的实现
129 |
130 | 为了实现进程,操作系统中维护了一张表,叫做进程表。进程表是由进程表项(进程控制块)所组成的,一个进程的全部信息就保存在进程控制块中。
131 |
132 | > 每当创建一个进程的时候,linux系统就会为该进程在内存中创建一个task_struct结构体。**这个task_struct结构体就是进程表。**这个结构体或者说进程表存放的是进程在运行过程中与该进程有关的所有信息,其中比如文件描述符就包括在其中。里面的信息如下图所示:
133 | >
134 | > 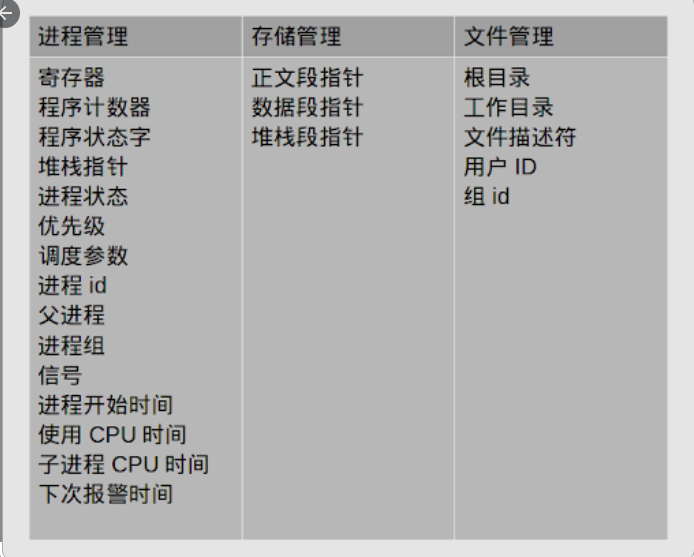 135 |
136 | 在计算机内存底部的固定区域有一个位置叫做**中断向量**(可能叫中断指针数组好理解)的地方,这些中断指针数组指向中断程序的入口地址。加入当磁盘中断发生时候,进程A正在运行,那么中断硬件就会将A进程的进程控制块中的寄存器,程序计数器,程序状态字等压入堆栈,随后计算机就跳入到中断指针所指的位置,然后中断服务程序就开始接管工作。
137 |
138 | 中断发生后系统底层的工作步骤:
139 |
140 | 1. 由计算机硬件将进程管理相关的信息压入堆栈
141 | 2. 计算机跳转到中断指针所指向的程序入口,装入新的程序计数器
142 | 3. 汇编语言来保存寄存器的值
143 | 4. 汇编语言来设置新的堆栈
144 | 5. 运行由C语言写的中断服务程序
145 | 6. 调度程序决定下一个运行的进程(哪个进程获得CPU)
146 | 7. 将控制转给一段汇编代码,为当前的进程装入寄存器的值、内存映射并启动该进程
147 |
148 | > **对于中断的理解:**
149 | >
150 | > 中断就是干扰别人做事。从计算机方面来说就是干扰CPU做事。而CPU是干啥的?cpu是执行指令的!
151 | >
152 | > 所以cpu在执行指令的时候能感受到干扰信号,即中断信号。CPU的工作粒度是机器指令级别的,在每条机器指令执行结束后就会检查一下是否有中断信号产生。就比如你在玩游戏,别人喊你,你不用去轮询有没有人喊你,直接就能听到有没有人喊你。
153 | >
154 | > 所以CPU的硬件特性决定中断处理机制也及其高效。
155 |
156 | ## 线程
157 |
158 | ### 线程概述
159 |
160 | > 有了进程,还需要多线程的理由:
161 | >
162 | > 1. 在一个应用程序中同时发生着多种活动(可以想象一下word应用,打字、显示、磁盘备份等工作。当磁盘备份的时候按理来说鼠标键盘不能用,因为CPU不在这些控制上。)其中某些活动会随着时间的推移被阻塞,如果我们将这些应用分解成可以准并行运行的多个顺序线程,设计模型会比较简单。如果不这样设计,你得考虑单线程下的两种情况吧。第一种是顺序进行,但是阻塞,就得等阻塞的应用得到相应的输出你才能继续进行下面的活动,在阻塞的时候CPU是没有被利用的。第二种就是有限状态机,回调函数这种的。这种非阻塞调用,当没有资源的时候返回一个值,然后等资源来了,就中断然后去处理这个资源,这在编程上会比较复杂。
163 | >
164 | > **从上面的理由可以看出,有了进程后我们就不用考虑中断,定时器和上下文切换这种繁琐的概念。同时线程之间共享同一个地址空间和所用可用数据的能力。**
165 | >
166 | > 2. 线程比进程更加的轻量级,所以比进程更容易创建和撤销。在许多系统中,创建一个线程比进程快10-100倍。
167 | >
168 | > 3. 从性能方面来讲,如果存在着大量计算和I/O处理,多线程允许这些操作彼此并行进行,会加快程序的执行速度。
169 |
170 | > 举个多线程的例子,字处理软件比如word这些。第一个线程和用户交互,捕捉用户的操作。第二个线程在得到输入通知的时候在后台自动进行格式处理。第三个线程周期性的将文档中的内容写到磁盘上。如果用到三个进程的话是做不到的,因为这是同一份文件,而进程之前说了,可以一起读,但是是写时复制,必须是不同的内存空间上进行。
171 | >
172 | > 另一个例子就是web服务器。
173 |
174 | 其实介绍了线程我们可以感受到线程和进程的区别,不要在乎细微的区别。从大方向我们可以看到,线程是相同程序之间的协作关系,线程的出现为的是让程序更好的高效工作。而进程更多的是不同程序之间的关系,有一种互相竞争的属性在里面。
175 |
176 | ### 线程模型
177 |
178 | 进程模型其实就是**资源分组处理和执行**。那么对于不同资源分组处理很好理解,这也是进程的意义所在,可以想象一下,同一资源是否还需要分组呢?当然需要,我上面已经说了。举了打字程序和web服务器的例子就能很好的说明。
179 |
180 | > 题外话,说一说程序计数器,寄存器,堆栈是干嘛的,为啥需要。
181 | >
182 | > - 程序计数器。主要用来记录接下来该执行哪一条指令
183 | > - 寄存器。用来保存当前进程\线程的工作变量
184 | > - 堆栈。用来记录程序执行历史,每一个栈帧保存了一个已经调用但是还没有返回的过程。在该栈帧中存放了相应过程的局部变量以及过程调用完成之后返回的地址。因为每个线程或进程会有自己的任务,有不同的调用过程,这就是为什么每个线程也需要有自己的栈帧的原因。
185 | >
186 | > 以上这三个是每一个线程都独有的东西,而不是公共的。
187 |
188 | > 下图表示各个线程共有和独有的:
189 | >
190 | >
135 |
136 | 在计算机内存底部的固定区域有一个位置叫做**中断向量**(可能叫中断指针数组好理解)的地方,这些中断指针数组指向中断程序的入口地址。加入当磁盘中断发生时候,进程A正在运行,那么中断硬件就会将A进程的进程控制块中的寄存器,程序计数器,程序状态字等压入堆栈,随后计算机就跳入到中断指针所指的位置,然后中断服务程序就开始接管工作。
137 |
138 | 中断发生后系统底层的工作步骤:
139 |
140 | 1. 由计算机硬件将进程管理相关的信息压入堆栈
141 | 2. 计算机跳转到中断指针所指向的程序入口,装入新的程序计数器
142 | 3. 汇编语言来保存寄存器的值
143 | 4. 汇编语言来设置新的堆栈
144 | 5. 运行由C语言写的中断服务程序
145 | 6. 调度程序决定下一个运行的进程(哪个进程获得CPU)
146 | 7. 将控制转给一段汇编代码,为当前的进程装入寄存器的值、内存映射并启动该进程
147 |
148 | > **对于中断的理解:**
149 | >
150 | > 中断就是干扰别人做事。从计算机方面来说就是干扰CPU做事。而CPU是干啥的?cpu是执行指令的!
151 | >
152 | > 所以cpu在执行指令的时候能感受到干扰信号,即中断信号。CPU的工作粒度是机器指令级别的,在每条机器指令执行结束后就会检查一下是否有中断信号产生。就比如你在玩游戏,别人喊你,你不用去轮询有没有人喊你,直接就能听到有没有人喊你。
153 | >
154 | > 所以CPU的硬件特性决定中断处理机制也及其高效。
155 |
156 | ## 线程
157 |
158 | ### 线程概述
159 |
160 | > 有了进程,还需要多线程的理由:
161 | >
162 | > 1. 在一个应用程序中同时发生着多种活动(可以想象一下word应用,打字、显示、磁盘备份等工作。当磁盘备份的时候按理来说鼠标键盘不能用,因为CPU不在这些控制上。)其中某些活动会随着时间的推移被阻塞,如果我们将这些应用分解成可以准并行运行的多个顺序线程,设计模型会比较简单。如果不这样设计,你得考虑单线程下的两种情况吧。第一种是顺序进行,但是阻塞,就得等阻塞的应用得到相应的输出你才能继续进行下面的活动,在阻塞的时候CPU是没有被利用的。第二种就是有限状态机,回调函数这种的。这种非阻塞调用,当没有资源的时候返回一个值,然后等资源来了,就中断然后去处理这个资源,这在编程上会比较复杂。
163 | >
164 | > **从上面的理由可以看出,有了进程后我们就不用考虑中断,定时器和上下文切换这种繁琐的概念。同时线程之间共享同一个地址空间和所用可用数据的能力。**
165 | >
166 | > 2. 线程比进程更加的轻量级,所以比进程更容易创建和撤销。在许多系统中,创建一个线程比进程快10-100倍。
167 | >
168 | > 3. 从性能方面来讲,如果存在着大量计算和I/O处理,多线程允许这些操作彼此并行进行,会加快程序的执行速度。
169 |
170 | > 举个多线程的例子,字处理软件比如word这些。第一个线程和用户交互,捕捉用户的操作。第二个线程在得到输入通知的时候在后台自动进行格式处理。第三个线程周期性的将文档中的内容写到磁盘上。如果用到三个进程的话是做不到的,因为这是同一份文件,而进程之前说了,可以一起读,但是是写时复制,必须是不同的内存空间上进行。
171 | >
172 | > 另一个例子就是web服务器。
173 |
174 | 其实介绍了线程我们可以感受到线程和进程的区别,不要在乎细微的区别。从大方向我们可以看到,线程是相同程序之间的协作关系,线程的出现为的是让程序更好的高效工作。而进程更多的是不同程序之间的关系,有一种互相竞争的属性在里面。
175 |
176 | ### 线程模型
177 |
178 | 进程模型其实就是**资源分组处理和执行**。那么对于不同资源分组处理很好理解,这也是进程的意义所在,可以想象一下,同一资源是否还需要分组呢?当然需要,我上面已经说了。举了打字程序和web服务器的例子就能很好的说明。
179 |
180 | > 题外话,说一说程序计数器,寄存器,堆栈是干嘛的,为啥需要。
181 | >
182 | > - 程序计数器。主要用来记录接下来该执行哪一条指令
183 | > - 寄存器。用来保存当前进程\线程的工作变量
184 | > - 堆栈。用来记录程序执行历史,每一个栈帧保存了一个已经调用但是还没有返回的过程。在该栈帧中存放了相应过程的局部变量以及过程调用完成之后返回的地址。因为每个线程或进程会有自己的任务,有不同的调用过程,这就是为什么每个线程也需要有自己的栈帧的原因。
185 | >
186 | > 以上这三个是每一个线程都独有的东西,而不是公共的。
187 |
188 | > 下图表示各个线程共有和独有的:
189 | >
190 | >  191 | >
192 | > 因为所有线程都有完全一样的地址空间,因此所以共享全局变量。
193 | >
194 | > 又因为每一个线程都可以访问公共空间的内存,因此一个线程可以读、写、清除另一个线程的堆栈。
195 | >
196 | > 不同的进程来自不同的应用程序,他们彼此之间可能有敌意,因为一个进程总是由某一个应用程序所有,但是应用创建线程是为了让他们之间相互合作而不是竞争。
197 |
198 |
199 |
200 | ### 线程的实现
201 |
202 | #### 用户空间实现线程
203 |
204 | 放在用户空间的线程对内核空间来说就是按照单进程管理,这样有的操作系统不支持线程但也可以运行。
205 |
206 | 在用户空间中实现的线程,每个进程都有一个专属的线程表,记录了线程的属性比如线程的程序计数器、堆栈、寄存器和状态等。
207 |
208 | - 优点
209 | 1. 当一个线程运行完成的时候,可以调用线程调度程序来选择另一个要运行的线程。保存线程状态的过程和调度程序都只是本地过程,所以启动他们比内核调用效率高,同时不需要陷入内核,不需要进行上下文切换,不需要对内存高速缓存刷新,快
210 | 2. 用户级线程允许每个进程都有一套定制的调度算法。、
211 | 3. 比较好的扩展性,因为在内核空间中的内核线程需要一定固定的表格空间和堆栈空间,如果内核线程的数量很大的话,会非常消耗内存。
212 | - 缺点
213 | 1. 如何实现阻塞?假如有一个线程读取键盘,但是没有任何敲击键盘的行为,如果让该线程进行系统调用,由于内核感知不到线程的存在会阻塞该进程,导致进程中的所有线程都会停止。因此我们用户实现线程是能够实现阻塞但是不能影响其他线程。第一种方式是非阻塞,比如没有输入就返回0字节,但是这需要修改操作系统,如果改变read的一些东西会修改许多用户程序这显然不现实。第二种是如果某个调用阻塞,会提前通知。
214 | 2. 如果一个用户控件实现的线程开始运行,其他线程就不能运行除非让该线程放弃CPU。但是一个单独的线程内部没有时钟信号(中断)的,所以不可能采用轮转的方式实现线程调度。如果让线程也有时钟,一是会增大开销二是会和系统使用的时钟发生冲突。
215 |
216 | #### 内核中实现线程
217 |
218 | 在内核中有用来记录系统中所有线程的线程表。当某个线程希望创建一个新线程或者撤销一个已有的线程时,会进行系统调用,通过对内存表的更新完成创建和撤销工作。内核的线程表保存了每个线程的寄存器,栈帧、程序计数器等。
219 |
220 | 所有能够阻塞线程的调用都是以系统调用的形式实现。当一个线程阻塞时,内核根据其选择会运行同一个进程中处于就绪状态的线程或者另一个进程中的线程。而在用户级线程中只能运行自己进程中的线程,直到被CPU剥夺使用权。
221 |
222 | 提高内核线程创建和撤销的开销方法是当撤销某个线程时不直接删除其线程表中的表项和数据结构,而是把它标志为不可运行的,其内核数据结构没有收到影响。当创建某个新线程时就重启那些被标志位不可运行的线程,这样节省开销。
223 |
224 | #### 混合实现
225 |
226 |
191 | >
192 | > 因为所有线程都有完全一样的地址空间,因此所以共享全局变量。
193 | >
194 | > 又因为每一个线程都可以访问公共空间的内存,因此一个线程可以读、写、清除另一个线程的堆栈。
195 | >
196 | > 不同的进程来自不同的应用程序,他们彼此之间可能有敌意,因为一个进程总是由某一个应用程序所有,但是应用创建线程是为了让他们之间相互合作而不是竞争。
197 |
198 |
199 |
200 | ### 线程的实现
201 |
202 | #### 用户空间实现线程
203 |
204 | 放在用户空间的线程对内核空间来说就是按照单进程管理,这样有的操作系统不支持线程但也可以运行。
205 |
206 | 在用户空间中实现的线程,每个进程都有一个专属的线程表,记录了线程的属性比如线程的程序计数器、堆栈、寄存器和状态等。
207 |
208 | - 优点
209 | 1. 当一个线程运行完成的时候,可以调用线程调度程序来选择另一个要运行的线程。保存线程状态的过程和调度程序都只是本地过程,所以启动他们比内核调用效率高,同时不需要陷入内核,不需要进行上下文切换,不需要对内存高速缓存刷新,快
210 | 2. 用户级线程允许每个进程都有一套定制的调度算法。、
211 | 3. 比较好的扩展性,因为在内核空间中的内核线程需要一定固定的表格空间和堆栈空间,如果内核线程的数量很大的话,会非常消耗内存。
212 | - 缺点
213 | 1. 如何实现阻塞?假如有一个线程读取键盘,但是没有任何敲击键盘的行为,如果让该线程进行系统调用,由于内核感知不到线程的存在会阻塞该进程,导致进程中的所有线程都会停止。因此我们用户实现线程是能够实现阻塞但是不能影响其他线程。第一种方式是非阻塞,比如没有输入就返回0字节,但是这需要修改操作系统,如果改变read的一些东西会修改许多用户程序这显然不现实。第二种是如果某个调用阻塞,会提前通知。
214 | 2. 如果一个用户控件实现的线程开始运行,其他线程就不能运行除非让该线程放弃CPU。但是一个单独的线程内部没有时钟信号(中断)的,所以不可能采用轮转的方式实现线程调度。如果让线程也有时钟,一是会增大开销二是会和系统使用的时钟发生冲突。
215 |
216 | #### 内核中实现线程
217 |
218 | 在内核中有用来记录系统中所有线程的线程表。当某个线程希望创建一个新线程或者撤销一个已有的线程时,会进行系统调用,通过对内存表的更新完成创建和撤销工作。内核的线程表保存了每个线程的寄存器,栈帧、程序计数器等。
219 |
220 | 所有能够阻塞线程的调用都是以系统调用的形式实现。当一个线程阻塞时,内核根据其选择会运行同一个进程中处于就绪状态的线程或者另一个进程中的线程。而在用户级线程中只能运行自己进程中的线程,直到被CPU剥夺使用权。
221 |
222 | 提高内核线程创建和撤销的开销方法是当撤销某个线程时不直接删除其线程表中的表项和数据结构,而是把它标志为不可运行的,其内核数据结构没有收到影响。当创建某个新线程时就重启那些被标志位不可运行的线程,这样节省开销。
223 |
224 | #### 混合实现
225 |
226 |  227 |
228 | 使用内核级线程,然后将内核级线程和用户级线程多路复用起来。内核只识别内核级线程调度,其中一些内核级线程会被多个用户级线程复用。在这种模型中,每个内核线程有一个可以轮流使用的用户级线程集合。
229 |
230 |
231 |
232 | ## 进程间通信
233 |
234 | > 进程间通信不仅仅考虑通信的问题,主要解决一下三个问题:
235 | >
236 | > 1. 一个进程如何把信息传递给另外一个(传递)
237 | > 2. 确保两个进程或者更多进程之间不会出现冲突。比如两个进程抢一个火车座位(互斥)
238 | > 3. 进程执行的正确顺序。比如进程A产生数据进程B打印,那么进程B就必须等待有数据了才能打印(同步)
239 | >
240 | > 进程的互斥和同步都放在一起说,但是要注意其区别。
241 | >
242 | > 要注意线程也有后面两个问题,但是线程没有第一个问题。但是不同地址空间需要通信的线程数据其实是不同进程之间的通信。
243 |
244 | - 竞态条件
245 |
246 | 即两个或者多个进程读写某些共享数据,会产生争用的情况,两个或多个线程竞相访问数据,而最后的结果取决于进程运行的精确时序。
247 |
248 | 比如当A进程检查到内存中某个值,标记完成后在准备修改时,检测到时钟中断,然后CPU切换到进程B。此时进程B把相同内存中的某个值给改了,然后时钟中断切回到进程A,由于A标记了值,不知道进程B修改了,就会把这个值修改一遍。
249 |
250 | - 临界区
251 |
252 | 出现竞争条件的原因是多个进程同时读取了公共内存或者公共文件造成的。
253 |
254 | 我们把对公共内存进行访问的一段程序称为临界区。
255 |
256 | ### 进程间信息的传递
257 |
258 | 这个在c++面试资料里面的操作系统那部分也有说到,在这里就不在赘述
259 |
260 | ### 进程间互斥同步方案
261 |
262 | > 下图是抽象的角度看待进程间互斥的:
263 | >
264 | >
227 |
228 | 使用内核级线程,然后将内核级线程和用户级线程多路复用起来。内核只识别内核级线程调度,其中一些内核级线程会被多个用户级线程复用。在这种模型中,每个内核线程有一个可以轮流使用的用户级线程集合。
229 |
230 |
231 |
232 | ## 进程间通信
233 |
234 | > 进程间通信不仅仅考虑通信的问题,主要解决一下三个问题:
235 | >
236 | > 1. 一个进程如何把信息传递给另外一个(传递)
237 | > 2. 确保两个进程或者更多进程之间不会出现冲突。比如两个进程抢一个火车座位(互斥)
238 | > 3. 进程执行的正确顺序。比如进程A产生数据进程B打印,那么进程B就必须等待有数据了才能打印(同步)
239 | >
240 | > 进程的互斥和同步都放在一起说,但是要注意其区别。
241 | >
242 | > 要注意线程也有后面两个问题,但是线程没有第一个问题。但是不同地址空间需要通信的线程数据其实是不同进程之间的通信。
243 |
244 | - 竞态条件
245 |
246 | 即两个或者多个进程读写某些共享数据,会产生争用的情况,两个或多个线程竞相访问数据,而最后的结果取决于进程运行的精确时序。
247 |
248 | 比如当A进程检查到内存中某个值,标记完成后在准备修改时,检测到时钟中断,然后CPU切换到进程B。此时进程B把相同内存中的某个值给改了,然后时钟中断切回到进程A,由于A标记了值,不知道进程B修改了,就会把这个值修改一遍。
249 |
250 | - 临界区
251 |
252 | 出现竞争条件的原因是多个进程同时读取了公共内存或者公共文件造成的。
253 |
254 | 我们把对公共内存进行访问的一段程序称为临界区。
255 |
256 | ### 进程间信息的传递
257 |
258 | 这个在c++面试资料里面的操作系统那部分也有说到,在这里就不在赘述
259 |
260 | ### 进程间互斥同步方案
261 |
262 | > 下图是抽象的角度看待进程间互斥的:
263 | >
264 | > 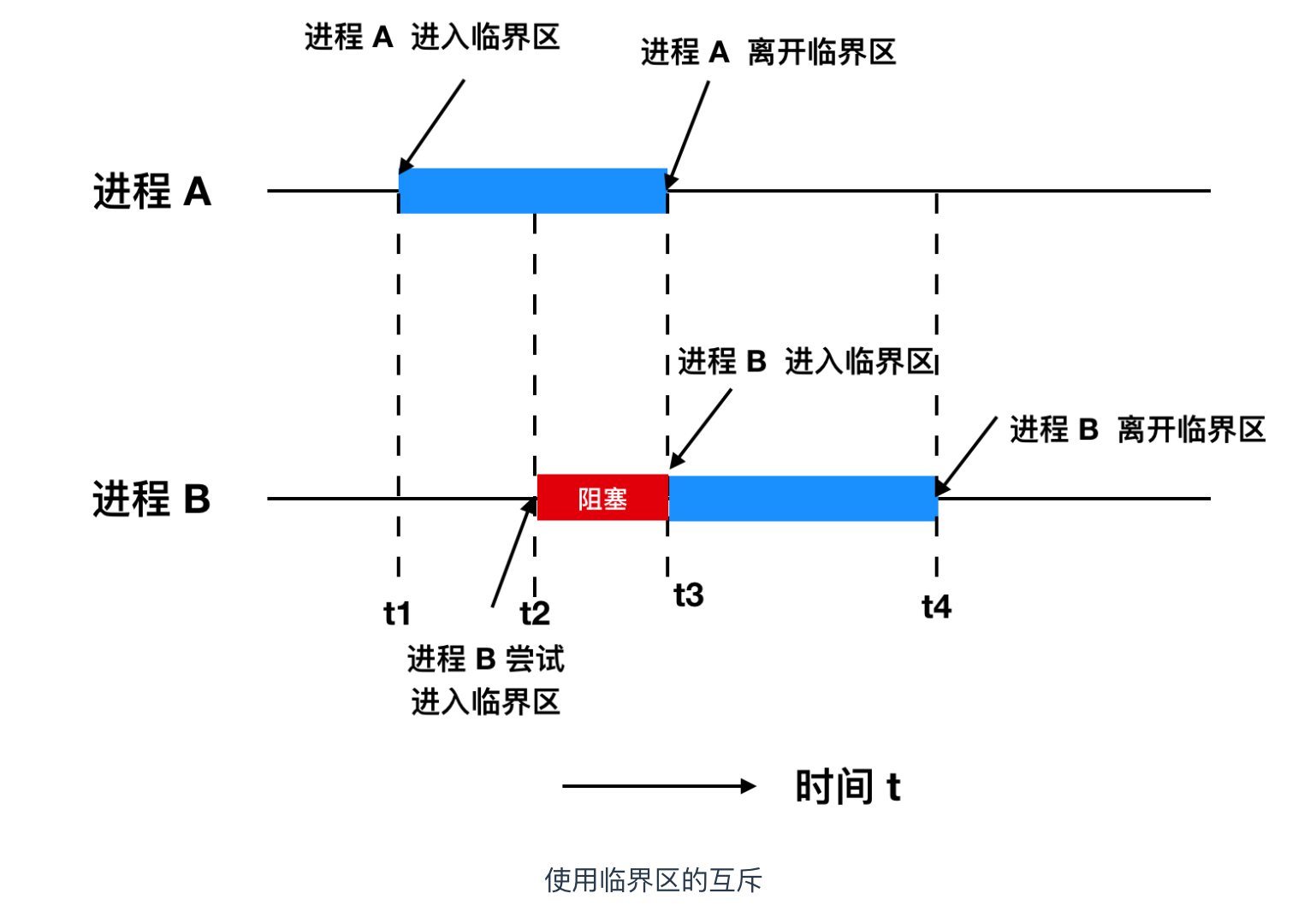 265 | >
266 | >
267 |
268 | - 屏蔽中断
269 |
270 | 最暴力的方案就是在进程进入临界区后立即屏蔽中断,并且在完成任务之后再打开中断。
271 |
272 | 对于单处理器来说,由于CPU只有发生中断才进行切换,这样就不用担心切换到其他进程了。但是把中断的权利交给进程是不明智的,因为如果一个进程屏蔽中断后不再打开,整个系统可能会因此而停止。
273 |
274 | 如果说是多处理器,屏蔽中断指令仅针对一个CPU处理器有效,而其他处理器操作的进程照样还是能够进入公共内存区进行读写。所以主要是多核处理器时代来说屏蔽中断没啥吊用。
275 |
276 | - 锁变量
277 |
278 | 这个也有问题,主要是锁变量这个东西也是公共的,谁都能加锁,那不和操作公共内存区没啥区别吗。
279 |
280 | 当进程A检查锁是0的时候恰巧进程B也检查到锁是0,所以俩进程又进去同时修改内存了
281 |
282 | - 轮换法
283 |
284 |
265 | >
266 | >
267 |
268 | - 屏蔽中断
269 |
270 | 最暴力的方案就是在进程进入临界区后立即屏蔽中断,并且在完成任务之后再打开中断。
271 |
272 | 对于单处理器来说,由于CPU只有发生中断才进行切换,这样就不用担心切换到其他进程了。但是把中断的权利交给进程是不明智的,因为如果一个进程屏蔽中断后不再打开,整个系统可能会因此而停止。
273 |
274 | 如果说是多处理器,屏蔽中断指令仅针对一个CPU处理器有效,而其他处理器操作的进程照样还是能够进入公共内存区进行读写。所以主要是多核处理器时代来说屏蔽中断没啥吊用。
275 |
276 | - 锁变量
277 |
278 | 这个也有问题,主要是锁变量这个东西也是公共的,谁都能加锁,那不和操作公共内存区没啥区别吗。
279 |
280 | 当进程A检查锁是0的时候恰巧进程B也检查到锁是0,所以俩进程又进去同时修改内存了
281 |
282 | - 轮换法
283 |
284 | 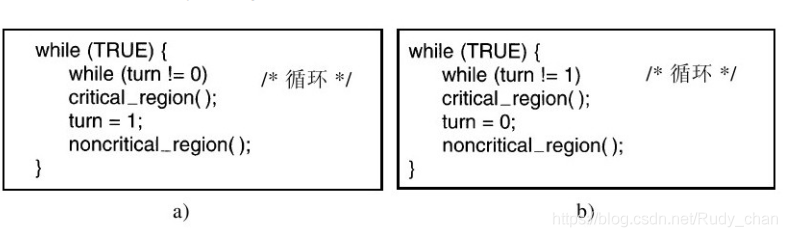 285 |
286 | 如图所示,这是两个进程之间轮换的,分别是进程0和进程1
287 |
288 | 对于进程0来说检查turn=0进入内存区域操作,结束后出来把turn=1。然后进程1发现turn=1就可以进内存区操作。
289 |
290 | 问题:当进程0结束完成后将turn=1。如果此时进程0还想再进去就会被阻塞,只能等待进程1进去吧turn值修改才能使用公共内存,这样显然不合理,进程0被一个其他进程阻塞,这是不允许的。
291 |
292 | - 几个经典的进程间通信的问题
293 |
294 | 生产者消费者问题,银行家就餐,读和写问题
295 |
296 | 放在c++面试操作系统里面了
297 |
298 | - 信号量
299 |
300 | 其实信号量这个概念就是从生产者消费者问题里面来的。
301 |
302 | 具体操作谷歌吧
303 |
304 | 要切记检查变量,修改变量以及可能发生的阻塞操作作为一个原子操作进行的。
305 |
306 | 信号量的用途就是实现同步的。
307 |
308 | - 互斥量
309 |
310 | ## 进程/线程调度
311 |
312 | 当多个处于就绪状态的进程/线程竞争CPU的时候就会出现调度问题。
313 |
314 | ### 调度的一些概念
315 |
316 | - 分类
317 |
318 | 几乎所有进程的I/O请求和计算都是交替发生的。CPU计算一段时间后发出一个系统调用以便读取文件,在完成系统调用之后CPU又开始处理文件。
319 |
320 |
285 |
286 | 如图所示,这是两个进程之间轮换的,分别是进程0和进程1
287 |
288 | 对于进程0来说检查turn=0进入内存区域操作,结束后出来把turn=1。然后进程1发现turn=1就可以进内存区操作。
289 |
290 | 问题:当进程0结束完成后将turn=1。如果此时进程0还想再进去就会被阻塞,只能等待进程1进去吧turn值修改才能使用公共内存,这样显然不合理,进程0被一个其他进程阻塞,这是不允许的。
291 |
292 | - 几个经典的进程间通信的问题
293 |
294 | 生产者消费者问题,银行家就餐,读和写问题
295 |
296 | 放在c++面试操作系统里面了
297 |
298 | - 信号量
299 |
300 | 其实信号量这个概念就是从生产者消费者问题里面来的。
301 |
302 | 具体操作谷歌吧
303 |
304 | 要切记检查变量,修改变量以及可能发生的阻塞操作作为一个原子操作进行的。
305 |
306 | 信号量的用途就是实现同步的。
307 |
308 | - 互斥量
309 |
310 | ## 进程/线程调度
311 |
312 | 当多个处于就绪状态的进程/线程竞争CPU的时候就会出现调度问题。
313 |
314 | ### 调度的一些概念
315 |
316 | - 分类
317 |
318 | 几乎所有进程的I/O请求和计算都是交替发生的。CPU计算一段时间后发出一个系统调用以便读取文件,在完成系统调用之后CPU又开始处理文件。
319 |
320 | 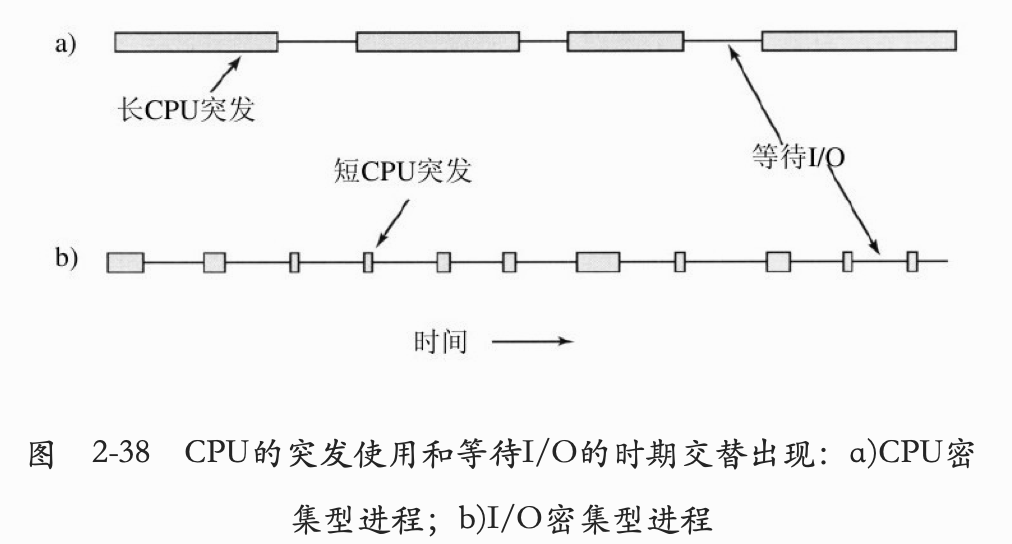 321 |
322 | 计算密集型进程:CPU绝大多数时间花在计算上。
323 |
324 | I/O密集型进程:CPU绝大时间花费在等待I/O上。
325 |
326 | 随着CPU速度越来越快,更多倾向于I/O密集型,因为CPU的改进比磁盘改进快的多,都花费时间在I/O上了。
327 |
328 | - 何时调度
329 | - 父进程创建子进程后,这两个进程都处于就绪状态,可以任意决定。
330 | - 在一个进程退出时必须进行调度决策,从就绪队列中选择一个。如果没有就绪的进程,调度程序会让操作系统提供一个空闲的进程。
331 | - 当进程阻塞时,必须选择运行另外一个进程。
332 | - 当发生I/O中断时必须做出调度决策
333 | - 调度系统分类
334 | - 批处理系统
335 | - 交互式
336 | - 实时系统
337 |
338 | ### 交互式系统的一些调度方式
339 |
340 | - 轮转调度
341 |
342 | 最古老、最简单、最公平的调度方式。每个进程被分配一个时间段叫做时间片,即允许该进程在该时间段中运行。如果时间片结束后该进程的CPU就会被剥夺分配给另一个进程。如果该进程在时间片内阻塞,则会立刻切换CPU。
343 |
344 | 时间片设置的时间太短会造成过多的CPU切换,降低CPU的效率。设置时间太长可能对短的交互时间边长。所以一般设置成20-50ms。
345 |
346 | - 优先级调度
347 |
348 | 轮转调度做了一个假设即所有进程优先级相同。但事实上很多进程的优先级是不同的。每个进程被赋予一个优先级,高的先得到CPU。一般结合时间片来用,即时间片结束后次优先级的进程就得到了机会运行。
349 |
350 | - 多级队列
351 |
352 | 对于进程设立优先级类。属于最高优先级类的进程运行一个时间片,属于次高优先级进程分配两个时间片,以此类推。当一个进程用完分配的时间片后被移到下一类。
353 |
354 | - 最短进程优先
355 |
356 | - 保证调度
357 |
358 | - 彩票调度
359 |
360 | ### 进程中的线程调度
361 |
362 | 由于多线程并不能感知时钟的存在,因此这个线程可以按照意愿任意运行多长时间。如果该线程用完了进程的全部时间片,内核就会选择另一个内核运行。
363 |
364 | 用户级线程:内核选进程,然后运行时系统选择线程
365 |
366 | 内核级线程:内核直接选择哪一个线程。
367 |
368 | 用户级线程的线程切换需要少量的机器指令,而内核级线程需要完整的上下文切换,修改内存映像,使高速缓存失效,这样会导致若干数量及的延迟。另一方面,使用内核线程时一旦线程阻塞在I/O上就不需要像在用户级线程中那样将整个进程挂起。
369 |
370 | 用户级线程可以为应用程序定值专门的线程调度程序。而在内核线程中内核从来不了解每个线程的作用。
371 |
372 | ------
373 |
374 |
375 |
376 | # 内存管理
377 |
378 | > 目前在使用的电脑都是分层存储器体系,即MB的高速缓存cache,GB的内存和TB的磁盘存储。
379 |
380 | ## 内存技术发展历程
381 |
382 | - 1、无存储器抽象
383 |
384 | 早期计算机没有存储器抽象,每一个程序都是直接访问物理内存。这种情况下在内存中同时运行两个程序是不可能的,因为如果第一个程序比如在内存2000的位置写入一个新的值,那么第二个程序运行的时候就会擦掉第一个程序的值。
385 |
386 | 但是即使没有抽象概念,运行两个程序也是可能的。。。
387 |
388 | 操作系统把当前内存中的内容保存在磁盘文件中,然后把下一个程序读入到内存中再运行就行,即某个时间内内存只有一个程序在运行就不会发生冲突。(最早期的交换的概念)
389 |
390 | 还有就是借助硬件来实现并发运行多个程序,比如IBM360中内存被划分为2KB的块,每个块有一个4位的保护键,保护键存储在CPU的特殊寄存器中。一个运行中的程序如果访问的保护键与操作系统中保存的不相符,则硬件会捕获到该异常,由于只有操作系统可以修改保护键,因此这样就可以防止用户进程之间、用户进程和操作系统间的干扰。
391 |
392 | - 2、地址空间(存储抽象)
393 |
394 | > 把物理地址暴露给进程会带来几个问题:
395 | >
396 | > 1. 如果用户进程可以寻址内存中的每一个字节,就可以很容易的破坏操作系统,从而时电脑出故障。
397 | > 2. 想要同时运行多个程序比较困难
398 |
399 | 在之前所说的解决多个程序在内存中互不影响的办法主要有两个:保护和重定位,也就是说并不是所有内存你都能访问,因此出现了地址空间的概念。
400 |
401 | **地址空间**是一个进程可用于寻址内存的一套地址的集合。每个进程都有自己的地址空间,并且这个地址空间独立于其他进程的地址空间
402 |
403 | 最开始的地址空间的解决办法是动态重定位,就是简单地把每个进程的地址空间映射到物理内存的不同部分。但是也有问题,即每个进程都有内存,如果同时运行多个进程,那所需要的内存是很庞大的,这个ram数远远超过存储器支持的。比如在Linux和Windows中,计算机完成引导后会启动50-100个进程,那你需要的空间可大了去了。
404 |
405 | 处理上述内存超载问题有两个办法,就是交换技术和虚拟内存。
406 |
407 | 交换技术就是把一个进程完整的调入内存,使得该进程完整运行一段时间后在调入磁盘。但是这样的话,你把一个完整的进程调入进去,可能很大程度只会使用一部分内存,这样是不划算的。
408 |
409 | 所以有了虚拟内存,每个进程的一部分调入内存。
410 |
411 | - 3、虚拟内存
412 |
413 | 这个要重点说
414 |
415 | ## 虚拟内存
416 |
417 | 根据上面所说,虚拟内存就是来解决“**程序大于内存的问题**”,即如何不把程序内存全部装进去。
418 |
419 | > **虚拟内存的基本思想是每个程序都拥有自己的地址空间,这些空间被分割成多个块儿。每一块儿被称作一页或者页面。每一个页面有连续的地址范围。这些页面被映射到物理内存,但是并不是所有的页面都必须在内存中才能运行**。当程序引用到一部分在物理内存中的地址空间时,由硬件立刻执行映射。当程序引用到一部分不在物理内存中的地址空间时,由操作系统负责将缺失部分装入物理内存并重新执行指令。
420 | >
421 | > **虚拟内存** 使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。与没有使用虚拟内存技术的系统相比,使用这种技术的系统使得大型程序的编写变得更容易,对真正的物理内存(例如RAM)的使用也更有效率。
422 |
423 | ### 分页
424 |
425 | 在没有虚拟内存的计算机上,系统直接将虚拟地址送到内存总线上,读写操作使用具有同样地址的物理内存字。在使用虚拟内存的情况下,虚拟地址不是直接被送到内存总线上的,而是被送往内存管理单元MMU,然后MMU把虚拟地址映射为物理内存地址
426 |
427 | >
321 |
322 | 计算密集型进程:CPU绝大多数时间花在计算上。
323 |
324 | I/O密集型进程:CPU绝大时间花费在等待I/O上。
325 |
326 | 随着CPU速度越来越快,更多倾向于I/O密集型,因为CPU的改进比磁盘改进快的多,都花费时间在I/O上了。
327 |
328 | - 何时调度
329 | - 父进程创建子进程后,这两个进程都处于就绪状态,可以任意决定。
330 | - 在一个进程退出时必须进行调度决策,从就绪队列中选择一个。如果没有就绪的进程,调度程序会让操作系统提供一个空闲的进程。
331 | - 当进程阻塞时,必须选择运行另外一个进程。
332 | - 当发生I/O中断时必须做出调度决策
333 | - 调度系统分类
334 | - 批处理系统
335 | - 交互式
336 | - 实时系统
337 |
338 | ### 交互式系统的一些调度方式
339 |
340 | - 轮转调度
341 |
342 | 最古老、最简单、最公平的调度方式。每个进程被分配一个时间段叫做时间片,即允许该进程在该时间段中运行。如果时间片结束后该进程的CPU就会被剥夺分配给另一个进程。如果该进程在时间片内阻塞,则会立刻切换CPU。
343 |
344 | 时间片设置的时间太短会造成过多的CPU切换,降低CPU的效率。设置时间太长可能对短的交互时间边长。所以一般设置成20-50ms。
345 |
346 | - 优先级调度
347 |
348 | 轮转调度做了一个假设即所有进程优先级相同。但事实上很多进程的优先级是不同的。每个进程被赋予一个优先级,高的先得到CPU。一般结合时间片来用,即时间片结束后次优先级的进程就得到了机会运行。
349 |
350 | - 多级队列
351 |
352 | 对于进程设立优先级类。属于最高优先级类的进程运行一个时间片,属于次高优先级进程分配两个时间片,以此类推。当一个进程用完分配的时间片后被移到下一类。
353 |
354 | - 最短进程优先
355 |
356 | - 保证调度
357 |
358 | - 彩票调度
359 |
360 | ### 进程中的线程调度
361 |
362 | 由于多线程并不能感知时钟的存在,因此这个线程可以按照意愿任意运行多长时间。如果该线程用完了进程的全部时间片,内核就会选择另一个内核运行。
363 |
364 | 用户级线程:内核选进程,然后运行时系统选择线程
365 |
366 | 内核级线程:内核直接选择哪一个线程。
367 |
368 | 用户级线程的线程切换需要少量的机器指令,而内核级线程需要完整的上下文切换,修改内存映像,使高速缓存失效,这样会导致若干数量及的延迟。另一方面,使用内核线程时一旦线程阻塞在I/O上就不需要像在用户级线程中那样将整个进程挂起。
369 |
370 | 用户级线程可以为应用程序定值专门的线程调度程序。而在内核线程中内核从来不了解每个线程的作用。
371 |
372 | ------
373 |
374 |
375 |
376 | # 内存管理
377 |
378 | > 目前在使用的电脑都是分层存储器体系,即MB的高速缓存cache,GB的内存和TB的磁盘存储。
379 |
380 | ## 内存技术发展历程
381 |
382 | - 1、无存储器抽象
383 |
384 | 早期计算机没有存储器抽象,每一个程序都是直接访问物理内存。这种情况下在内存中同时运行两个程序是不可能的,因为如果第一个程序比如在内存2000的位置写入一个新的值,那么第二个程序运行的时候就会擦掉第一个程序的值。
385 |
386 | 但是即使没有抽象概念,运行两个程序也是可能的。。。
387 |
388 | 操作系统把当前内存中的内容保存在磁盘文件中,然后把下一个程序读入到内存中再运行就行,即某个时间内内存只有一个程序在运行就不会发生冲突。(最早期的交换的概念)
389 |
390 | 还有就是借助硬件来实现并发运行多个程序,比如IBM360中内存被划分为2KB的块,每个块有一个4位的保护键,保护键存储在CPU的特殊寄存器中。一个运行中的程序如果访问的保护键与操作系统中保存的不相符,则硬件会捕获到该异常,由于只有操作系统可以修改保护键,因此这样就可以防止用户进程之间、用户进程和操作系统间的干扰。
391 |
392 | - 2、地址空间(存储抽象)
393 |
394 | > 把物理地址暴露给进程会带来几个问题:
395 | >
396 | > 1. 如果用户进程可以寻址内存中的每一个字节,就可以很容易的破坏操作系统,从而时电脑出故障。
397 | > 2. 想要同时运行多个程序比较困难
398 |
399 | 在之前所说的解决多个程序在内存中互不影响的办法主要有两个:保护和重定位,也就是说并不是所有内存你都能访问,因此出现了地址空间的概念。
400 |
401 | **地址空间**是一个进程可用于寻址内存的一套地址的集合。每个进程都有自己的地址空间,并且这个地址空间独立于其他进程的地址空间
402 |
403 | 最开始的地址空间的解决办法是动态重定位,就是简单地把每个进程的地址空间映射到物理内存的不同部分。但是也有问题,即每个进程都有内存,如果同时运行多个进程,那所需要的内存是很庞大的,这个ram数远远超过存储器支持的。比如在Linux和Windows中,计算机完成引导后会启动50-100个进程,那你需要的空间可大了去了。
404 |
405 | 处理上述内存超载问题有两个办法,就是交换技术和虚拟内存。
406 |
407 | 交换技术就是把一个进程完整的调入内存,使得该进程完整运行一段时间后在调入磁盘。但是这样的话,你把一个完整的进程调入进去,可能很大程度只会使用一部分内存,这样是不划算的。
408 |
409 | 所以有了虚拟内存,每个进程的一部分调入内存。
410 |
411 | - 3、虚拟内存
412 |
413 | 这个要重点说
414 |
415 | ## 虚拟内存
416 |
417 | 根据上面所说,虚拟内存就是来解决“**程序大于内存的问题**”,即如何不把程序内存全部装进去。
418 |
419 | > **虚拟内存的基本思想是每个程序都拥有自己的地址空间,这些空间被分割成多个块儿。每一块儿被称作一页或者页面。每一个页面有连续的地址范围。这些页面被映射到物理内存,但是并不是所有的页面都必须在内存中才能运行**。当程序引用到一部分在物理内存中的地址空间时,由硬件立刻执行映射。当程序引用到一部分不在物理内存中的地址空间时,由操作系统负责将缺失部分装入物理内存并重新执行指令。
420 | >
421 | > **虚拟内存** 使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。与没有使用虚拟内存技术的系统相比,使用这种技术的系统使得大型程序的编写变得更容易,对真正的物理内存(例如RAM)的使用也更有效率。
422 |
423 | ### 分页
424 |
425 | 在没有虚拟内存的计算机上,系统直接将虚拟地址送到内存总线上,读写操作使用具有同样地址的物理内存字。在使用虚拟内存的情况下,虚拟地址不是直接被送到内存总线上的,而是被送往内存管理单元MMU,然后MMU把虚拟地址映射为物理内存地址
426 |
427 | > 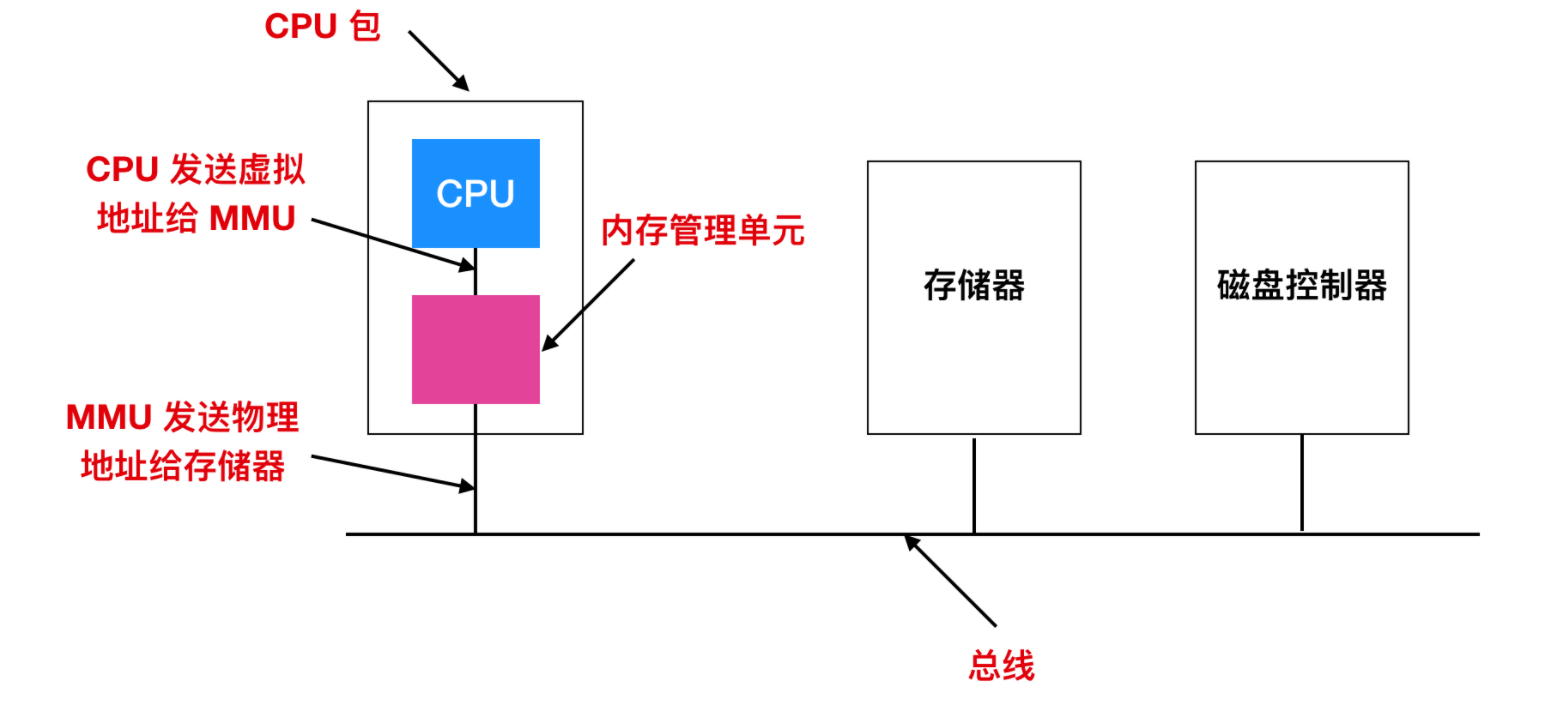 428 | >
429 | > 在这里MMU是作为CPU芯片的一部分,通常就是这样的。
430 |
431 | **具体页表中虚拟地址与物理内存地址之间的映射关系如下:**
432 |
433 | >
428 | >
429 | > 在这里MMU是作为CPU芯片的一部分,通常就是这样的。
430 |
431 | **具体页表中虚拟地址与物理内存地址之间的映射关系如下:**
432 |
433 | > 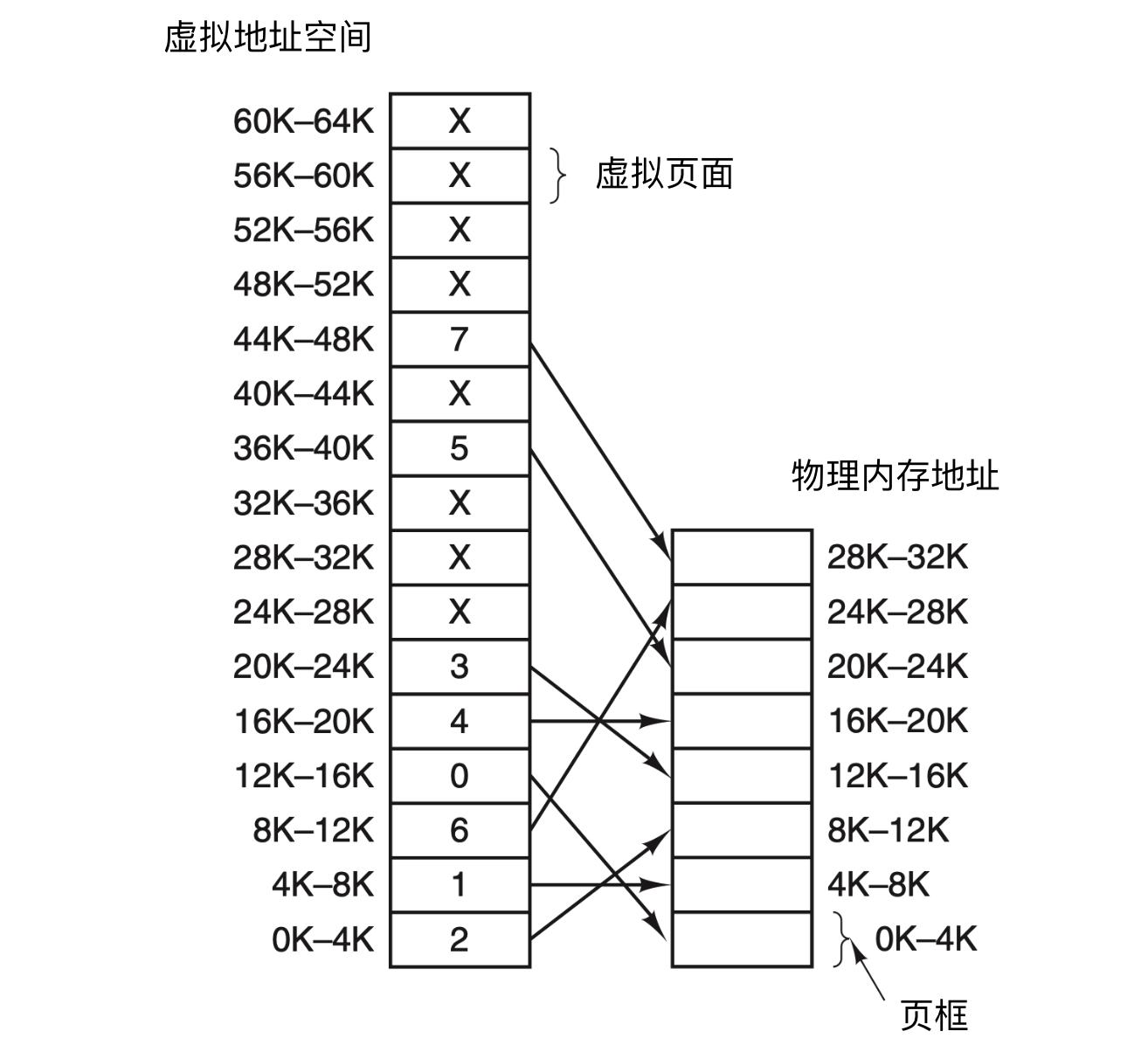 434 | >
435 | > 上图可以看到虚拟地址被划分成多个页面组成的单位,而物理内存地址中对应的是页框的概念。页面和页框的大小通常是一样的,在这里是4KB作为例子,实际系统中可能是512KB-1GB。上图虚拟地址空间有64KB,物理内存有32KB,因此由16个虚拟页面和8个页框。请记住,ram和也磁盘之间的交换总是以整个页面为单位进行的。
436 | >
437 | > 比如当程序访问地址0的时候,其实是访问虚拟地址,然后将虚拟地址0送到MMU,MMU根据映射关系发现虚拟地址0在页面0-4095这个页面上,然后根据映射找到实际物理内存地址是第二个页框,即8192,然后把地址8192送到总线上。内存对MMU是一无所知的,他只看到了一个读写8192的请求并执行。
438 | >
439 | > 当程序访问了一个未被映射的页面,即虚拟地址没有对应的页框索引。此时MMU注意到该页面没有映射,使CPU陷入到操作系统,即缺页中断或者缺页错误(page fault)。随后操作系统找到了一个很少使用的页框并把该页框内容写入磁盘,然后把需要访问的页面读到刚才被回收的那个页框上,修改映射关系,重新启动引起中断的指令就好。
440 | >
441 | > 例如如果操作系统放弃页框1,即重新映射页框1,那么重新改变映射关系,将页面8装入物理地址4096(页框1),并且对MMU映射做两处修改:①由于页框1之前被页面1映射,因此要将页面1标记为未映射,使得以后对页面1的访问都将导致缺页中断。②把虚拟页面8的叉号改为1,表明虚拟页面8映射到页框1上去,当指令重新启动时候就会产生新的映射。
442 |
443 | **MMU的内部操作:**
444 |
445 | >
434 | >
435 | > 上图可以看到虚拟地址被划分成多个页面组成的单位,而物理内存地址中对应的是页框的概念。页面和页框的大小通常是一样的,在这里是4KB作为例子,实际系统中可能是512KB-1GB。上图虚拟地址空间有64KB,物理内存有32KB,因此由16个虚拟页面和8个页框。请记住,ram和也磁盘之间的交换总是以整个页面为单位进行的。
436 | >
437 | > 比如当程序访问地址0的时候,其实是访问虚拟地址,然后将虚拟地址0送到MMU,MMU根据映射关系发现虚拟地址0在页面0-4095这个页面上,然后根据映射找到实际物理内存地址是第二个页框,即8192,然后把地址8192送到总线上。内存对MMU是一无所知的,他只看到了一个读写8192的请求并执行。
438 | >
439 | > 当程序访问了一个未被映射的页面,即虚拟地址没有对应的页框索引。此时MMU注意到该页面没有映射,使CPU陷入到操作系统,即缺页中断或者缺页错误(page fault)。随后操作系统找到了一个很少使用的页框并把该页框内容写入磁盘,然后把需要访问的页面读到刚才被回收的那个页框上,修改映射关系,重新启动引起中断的指令就好。
440 | >
441 | > 例如如果操作系统放弃页框1,即重新映射页框1,那么重新改变映射关系,将页面8装入物理地址4096(页框1),并且对MMU映射做两处修改:①由于页框1之前被页面1映射,因此要将页面1标记为未映射,使得以后对页面1的访问都将导致缺页中断。②把虚拟页面8的叉号改为1,表明虚拟页面8映射到页框1上去,当指令重新启动时候就会产生新的映射。
442 |
443 | **MMU的内部操作:**
444 |
445 | > 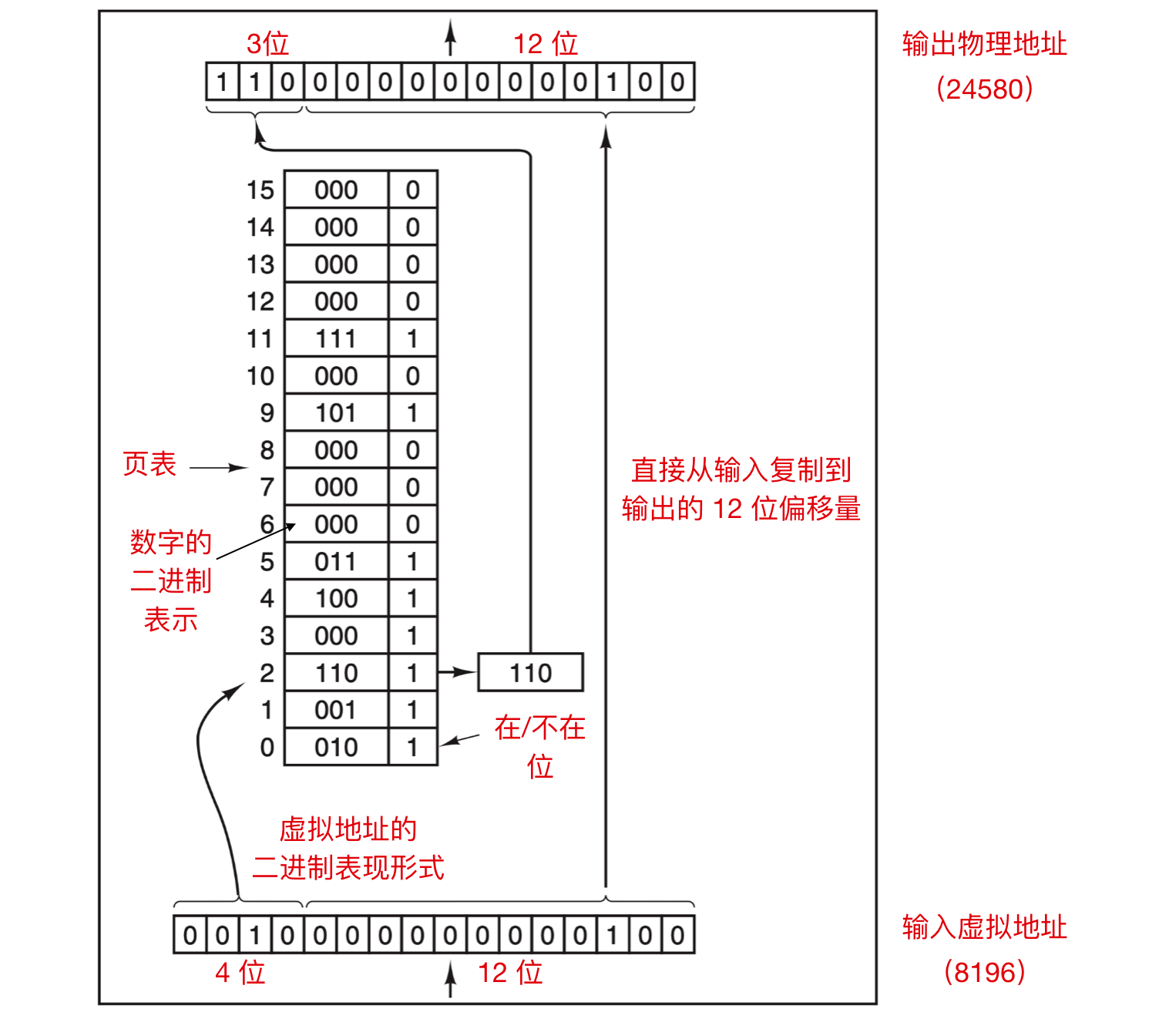 446 | >
447 | > 输入虚拟地址8196的二进制在最底下即0010000000000100,用MMU映射机进行映射,这16位虚拟地址被分解成4位的页号+12位的偏移量。4位页号表示16个页面,是页面的索引,12位的位偏移可以为一页内的全部4096个字节编址。
448 |
449 | ### 页表
450 |
451 | 虚拟地址到物理地址的映射可以概括如下:虚拟地址被分成虚拟页号+偏移量。虚拟页号是一个页表的索引,可以有该索引即页面号找到对应的页框号,然后将该页框号放到16位地址的前4位,替换掉虚拟页号,就形成了送往内存的地址。可以参考上面那个图中,两个二进制字符串的替换形式。如下图:
452 |
453 |
446 | >
447 | > 输入虚拟地址8196的二进制在最底下即0010000000000100,用MMU映射机进行映射,这16位虚拟地址被分解成4位的页号+12位的偏移量。4位页号表示16个页面,是页面的索引,12位的位偏移可以为一页内的全部4096个字节编址。
448 |
449 | ### 页表
450 |
451 | 虚拟地址到物理地址的映射可以概括如下:虚拟地址被分成虚拟页号+偏移量。虚拟页号是一个页表的索引,可以有该索引即页面号找到对应的页框号,然后将该页框号放到16位地址的前4位,替换掉虚拟页号,就形成了送往内存的地址。可以参考上面那个图中,两个二进制字符串的替换形式。如下图:
452 |
453 | 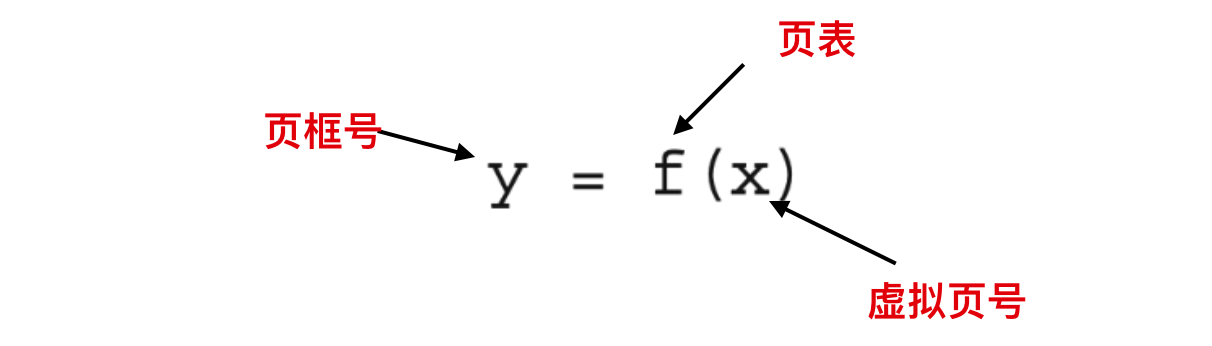 454 |
455 | 页表的目的是将虚拟页面映射为页框,从数学角度说页表是一个函数,输入参数是虚拟页号,输出结果是物理页框号。
456 |
457 | 页表的结构如下:
458 |
459 |
454 |
455 | 页表的目的是将虚拟页面映射为页框,从数学角度说页表是一个函数,输入参数是虚拟页号,输出结果是物理页框号。
456 |
457 | 页表的结构如下:
458 |
459 | 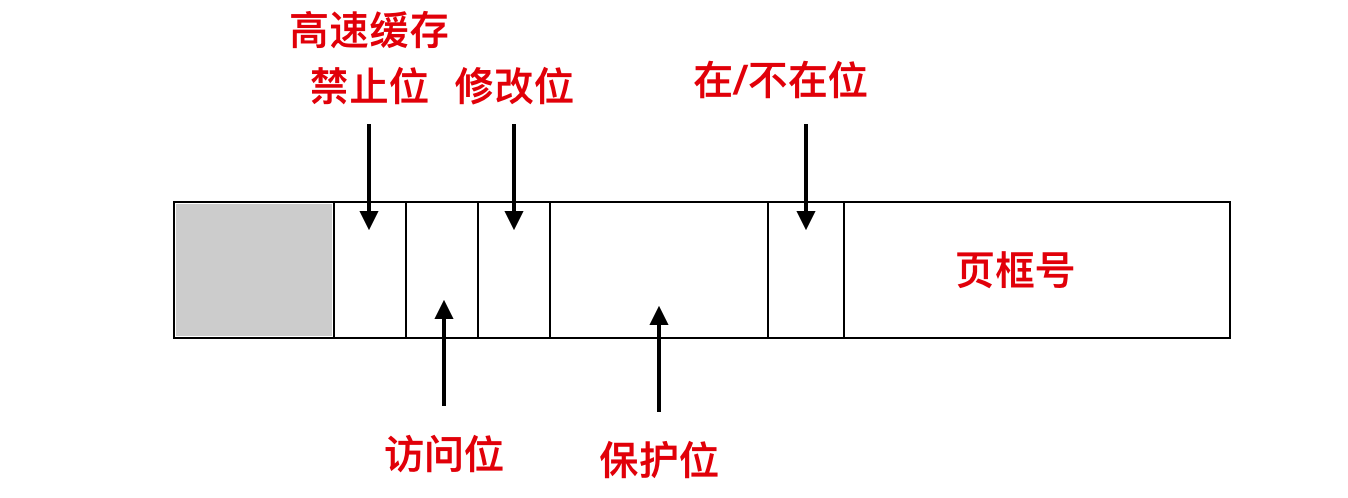 460 |
461 | 页表项中最重要的字段就是`页框号(Page frame number)`。毕竟,页表到页框最重要的一步操作就是要把此值映射过去。下一个比较重要的就是`在/不在`位,如果此位上的值是 1,那么页表项是有效的并且能够被`使用`。如果此值是 0 的话,则表示该页表项对应的虚拟页面`不在`内存中,访问该页面会引起一个`缺页异常(page fault)`。`保护位(Protection)` 告诉我们哪一种访问是允许的,啥意思呢?最简单的表示形式是这个域只有一位,**0 表示可读可写,1 表示的是只读**。`修改位(Modified)` 和 `访问位(Referenced)` 会跟踪页面的使用情况。当一个页面被写入时,硬件会自动的设置修改位。修改位在页面重新分配页框时很有用。如果一个页面已经被修改过(即它是 `脏` 的),则必须把它写回磁盘。如果一个页面没有被修改过(即它是 `干净`的),那么重新分配时这个页框会被直接丢弃,因为磁盘上的副本仍然是有效的。这个位有时也叫做 `脏位(dirty bit)`,因为它反映了页面的状态。`访问位(Referenced)` 在页面被访问时被设置,不管是读还是写。这个值能够帮助操作系统在发生缺页中断时选择要淘汰的页。不再使用的页要比正在使用的页更适合被淘汰。这个位在后面要讨论的`页面置换`算法中作用很大。最后一位用于禁止该页面被高速缓存,这个功能对于映射到设备寄存器还是内存中起到了关键作用。通过这一位可以禁用高速缓存。具有独立的 I/O 空间而不是用内存映射 I/O 的机器来说,并不需要这一位。
462 |
463 | ### 分页带来的问题
464 |
465 | 分页系统中要考虑两个问题:
466 |
467 | 1. 虚拟地址到物理地址的映射必须非常快
468 |
469 | 由于每次访问内存都需要进行虚拟地址到物理地址的映射,所有的指令最终都必须来自内存,并且很多指令也会访问内存中的操作数。因此每条指令进行多次页表访问是必要的。如果执行一条指令需要1ns,则页表查询必须在0.2ns之内完成,以避免映射成为主要的瓶颈。
470 |
471 | 2. 如果虚拟地址空间很大,页表也会很大
472 |
473 | 现代计算机使用的虚拟地址至少为32位,而且越来越多的64位。假设一个页面大小为4KB,则32位的地址空间将有100万页,那么64位地址空间更多了。一个页表有100万条表项,你个存储开销就很大。而且每个进程都有自己的页表还
474 |
475 | 所以我们接下来主要解决的就是这两个问题。
476 |
477 | ### 加速分页过程(优化)
478 |
479 | 大多数优化技术都是从内存中的页表开始的,因为这里面会存在这有巨大影响的问题。比如一条1字节指令要把一个寄存器中的数据复制到另一个寄存器,在不分页的情况下这条指令只访问一次内存。有了分页机制之后,会因为要访问页表而引起多次的内存访问。同时,CPU的执行速度会被内存中取指令执行和取数据的速度拉低,所以会使性能下降。解决方案如下:
480 |
481 | 由于大多数程序总是对少量页面进行多次访问,因此只有很少的页表项会被反复读取,而其他页表项很少会被访问。针对这个问题,为计算机设置一个小型的硬件设备,将虚拟地址直接映射到物理地址,而不必再去访问页表通过MMU得到物理地址,这个设备叫做**转换检测缓冲区**又叫做**快表(TLB)**。通常在MMU中,包含少量的表项,实际中应该有256个,每一个表项都记录了一个页面相关信息,即虚拟页号、修改为、保护码、对应的物理页框号,如下表所示:
482 |
483 | | 有效位 | 虚拟页面号 | 修改位 | 保护位 | 页框号 |
484 | | :----: | :--------: | :----: | :----: | :----: |
485 | | 1 | 140 | 1 | RW | 31 |
486 | | 1 | 20 | 0 | R X | 38 |
487 | | 1 | 130 | 1 | RW | 29 |
488 | | 1 | 129 | 1 | RW | 62 |
489 | | 1 | 19 | 0 | R X | 50 |
490 | | 1 | 21 | 0 | R X | 45 |
491 | | 1 | 860 | 1 | RW | 14 |
492 | | 1 | 861 | 1 | RW | 75 |
493 |
494 | TLB 其实就是一种内存缓存,用于减少访问内存所需要的时间,它就是 MMU 的一部分,TLB 会将虚拟地址到物理地址的转换存储起来,通常可以称为`地址翻译缓存(address-translation cache)`。TLB 通常位于 CPU 和 CPU 缓存之间,它与 CPU 缓存是不同的缓存级别。下面我们来看一下 TLB 是如何工作的。
495 |
496 | 当一个 MMU 中的虚拟地址需要进行转换时,硬件首先检查虚拟页号与 TLB 中所有表项进行并行匹配,判断虚拟页是否在 TLB 中。如果找到了有效匹配项,并且要进行的访问操作没有违反保护位的话,则将页框号直接从 TLB 中取出而不用再直接访问页表。如果虚拟页在 TLB 中但是违反了保护位的权限的话(比如只允许读但是是一个写指令),则会生成一个`保护错误(protection fault)` 返回。上面探讨的是虚拟地址在 TLB 中的情况,那么如果虚拟地址不再 TLB 中该怎么办?如果 MMU 检测到没有有效的匹配项,就会进行正常的页表查找,然后从 TLB 中逐出一个表项然后把从页表中找到的项放在 TLB 中。当一个表项被从 TLB 中清除出,将修改位复制到内存中页表项,除了访问位之外,其他位保持不变。当页表项从页表装入 TLB 中时,所有的值都来自于内存。
497 |
498 | 下面给出流程图:
499 |
500 |
460 |
461 | 页表项中最重要的字段就是`页框号(Page frame number)`。毕竟,页表到页框最重要的一步操作就是要把此值映射过去。下一个比较重要的就是`在/不在`位,如果此位上的值是 1,那么页表项是有效的并且能够被`使用`。如果此值是 0 的话,则表示该页表项对应的虚拟页面`不在`内存中,访问该页面会引起一个`缺页异常(page fault)`。`保护位(Protection)` 告诉我们哪一种访问是允许的,啥意思呢?最简单的表示形式是这个域只有一位,**0 表示可读可写,1 表示的是只读**。`修改位(Modified)` 和 `访问位(Referenced)` 会跟踪页面的使用情况。当一个页面被写入时,硬件会自动的设置修改位。修改位在页面重新分配页框时很有用。如果一个页面已经被修改过(即它是 `脏` 的),则必须把它写回磁盘。如果一个页面没有被修改过(即它是 `干净`的),那么重新分配时这个页框会被直接丢弃,因为磁盘上的副本仍然是有效的。这个位有时也叫做 `脏位(dirty bit)`,因为它反映了页面的状态。`访问位(Referenced)` 在页面被访问时被设置,不管是读还是写。这个值能够帮助操作系统在发生缺页中断时选择要淘汰的页。不再使用的页要比正在使用的页更适合被淘汰。这个位在后面要讨论的`页面置换`算法中作用很大。最后一位用于禁止该页面被高速缓存,这个功能对于映射到设备寄存器还是内存中起到了关键作用。通过这一位可以禁用高速缓存。具有独立的 I/O 空间而不是用内存映射 I/O 的机器来说,并不需要这一位。
462 |
463 | ### 分页带来的问题
464 |
465 | 分页系统中要考虑两个问题:
466 |
467 | 1. 虚拟地址到物理地址的映射必须非常快
468 |
469 | 由于每次访问内存都需要进行虚拟地址到物理地址的映射,所有的指令最终都必须来自内存,并且很多指令也会访问内存中的操作数。因此每条指令进行多次页表访问是必要的。如果执行一条指令需要1ns,则页表查询必须在0.2ns之内完成,以避免映射成为主要的瓶颈。
470 |
471 | 2. 如果虚拟地址空间很大,页表也会很大
472 |
473 | 现代计算机使用的虚拟地址至少为32位,而且越来越多的64位。假设一个页面大小为4KB,则32位的地址空间将有100万页,那么64位地址空间更多了。一个页表有100万条表项,你个存储开销就很大。而且每个进程都有自己的页表还
474 |
475 | 所以我们接下来主要解决的就是这两个问题。
476 |
477 | ### 加速分页过程(优化)
478 |
479 | 大多数优化技术都是从内存中的页表开始的,因为这里面会存在这有巨大影响的问题。比如一条1字节指令要把一个寄存器中的数据复制到另一个寄存器,在不分页的情况下这条指令只访问一次内存。有了分页机制之后,会因为要访问页表而引起多次的内存访问。同时,CPU的执行速度会被内存中取指令执行和取数据的速度拉低,所以会使性能下降。解决方案如下:
480 |
481 | 由于大多数程序总是对少量页面进行多次访问,因此只有很少的页表项会被反复读取,而其他页表项很少会被访问。针对这个问题,为计算机设置一个小型的硬件设备,将虚拟地址直接映射到物理地址,而不必再去访问页表通过MMU得到物理地址,这个设备叫做**转换检测缓冲区**又叫做**快表(TLB)**。通常在MMU中,包含少量的表项,实际中应该有256个,每一个表项都记录了一个页面相关信息,即虚拟页号、修改为、保护码、对应的物理页框号,如下表所示:
482 |
483 | | 有效位 | 虚拟页面号 | 修改位 | 保护位 | 页框号 |
484 | | :----: | :--------: | :----: | :----: | :----: |
485 | | 1 | 140 | 1 | RW | 31 |
486 | | 1 | 20 | 0 | R X | 38 |
487 | | 1 | 130 | 1 | RW | 29 |
488 | | 1 | 129 | 1 | RW | 62 |
489 | | 1 | 19 | 0 | R X | 50 |
490 | | 1 | 21 | 0 | R X | 45 |
491 | | 1 | 860 | 1 | RW | 14 |
492 | | 1 | 861 | 1 | RW | 75 |
493 |
494 | TLB 其实就是一种内存缓存,用于减少访问内存所需要的时间,它就是 MMU 的一部分,TLB 会将虚拟地址到物理地址的转换存储起来,通常可以称为`地址翻译缓存(address-translation cache)`。TLB 通常位于 CPU 和 CPU 缓存之间,它与 CPU 缓存是不同的缓存级别。下面我们来看一下 TLB 是如何工作的。
495 |
496 | 当一个 MMU 中的虚拟地址需要进行转换时,硬件首先检查虚拟页号与 TLB 中所有表项进行并行匹配,判断虚拟页是否在 TLB 中。如果找到了有效匹配项,并且要进行的访问操作没有违反保护位的话,则将页框号直接从 TLB 中取出而不用再直接访问页表。如果虚拟页在 TLB 中但是违反了保护位的权限的话(比如只允许读但是是一个写指令),则会生成一个`保护错误(protection fault)` 返回。上面探讨的是虚拟地址在 TLB 中的情况,那么如果虚拟地址不再 TLB 中该怎么办?如果 MMU 检测到没有有效的匹配项,就会进行正常的页表查找,然后从 TLB 中逐出一个表项然后把从页表中找到的项放在 TLB 中。当一个表项被从 TLB 中清除出,将修改位复制到内存中页表项,除了访问位之外,其他位保持不变。当页表项从页表装入 TLB 中时,所有的值都来自于内存。
497 |
498 | 下面给出流程图:
499 |
500 | 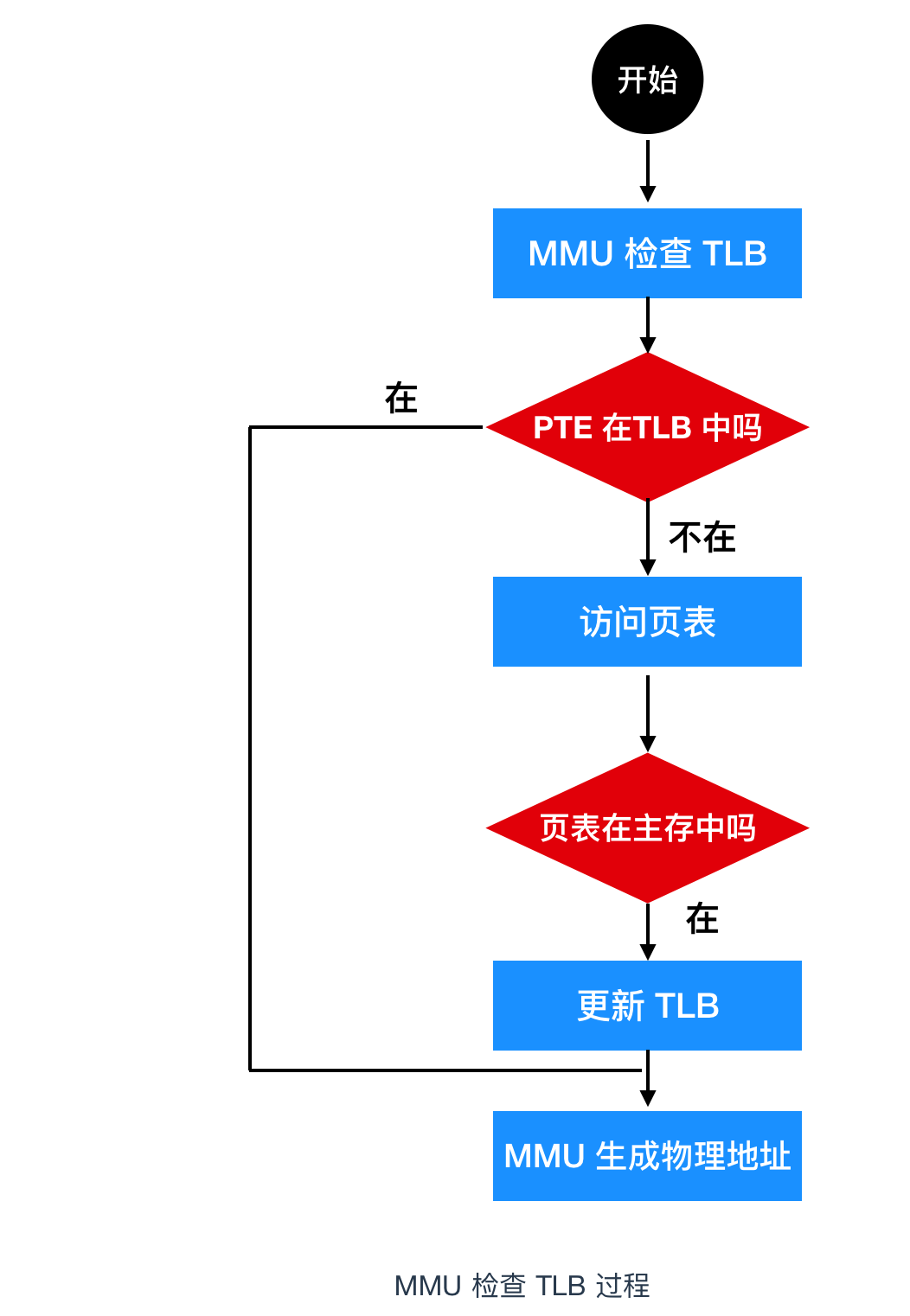 501 |
502 | **软件 TLB 管理**
503 |
504 | 直到现在,我们假设每台电脑都有可以被硬件识别的页表,外加一个 TLB。在这个设计中,TLB 管理和处理 TLB 错误完全由硬件来完成。仅仅当页面不在内存中时,才会发生操作系统的`陷入(trap)`。
505 |
506 | 但是有些机器几乎所有的页面管理都是在软件中完成的。
507 |
508 | 在这些计算机上,TLB 条目由操作系统显示加载。当发生 TLB 访问丢失时,**不再是由 MMU 到页表中查找并取出需要的页表项,而是生成一个 TLB 失效并将问题交给操作系统解决**。操作系统必须找到该页,把它从 TLB 中移除(移除页表中的一项),然后把新找到的页放在 TLB 中,最后再执行先前出错的指令。然而,所有这些操作都必须通过少量指令完成,因为 TLB 丢失的发生率要比出错率高很多。
509 |
510 | 无论是用硬件还是用软件来处理 TLB 失效,常见的方式都是找到页表并执行索引操作以定位到将要访问的页面,在软件中进行搜索的问题是保存页表的页可能不在 TLB 中,这将在处理过程中导致其他 TLB 错误。改善方法是可以在内存中的固定位置维护一个大的 TLB 表项的高速缓存来减少 TLB 失效。通过首先检查软件的高速缓存,`操作系统` 能够有效的减少 TLB 失效问题。
511 |
512 | TLB 软件管理会有两种 TLB 失效问题,当一个页访问在内存中而不在 TLB 中时,将产生 `软失效(soft miss)`,那么此时要做的就是把页表更新到 TLB 中(我们上面探讨的过程),而不会产生磁盘 I/O,处理仅仅需要一些机器指令在几纳秒的时间内完成。然而,当页本身不在内存中时,将会产生`硬失效(hard miss)`,那么此时就需要从磁盘中进行页表提取,硬失效的处理时间通常是软失效的百万倍。在页表结构中查找映射的过程称为 `页表遍历(page table walk)`。如图:
513 |
514 |
501 |
502 | **软件 TLB 管理**
503 |
504 | 直到现在,我们假设每台电脑都有可以被硬件识别的页表,外加一个 TLB。在这个设计中,TLB 管理和处理 TLB 错误完全由硬件来完成。仅仅当页面不在内存中时,才会发生操作系统的`陷入(trap)`。
505 |
506 | 但是有些机器几乎所有的页面管理都是在软件中完成的。
507 |
508 | 在这些计算机上,TLB 条目由操作系统显示加载。当发生 TLB 访问丢失时,**不再是由 MMU 到页表中查找并取出需要的页表项,而是生成一个 TLB 失效并将问题交给操作系统解决**。操作系统必须找到该页,把它从 TLB 中移除(移除页表中的一项),然后把新找到的页放在 TLB 中,最后再执行先前出错的指令。然而,所有这些操作都必须通过少量指令完成,因为 TLB 丢失的发生率要比出错率高很多。
509 |
510 | 无论是用硬件还是用软件来处理 TLB 失效,常见的方式都是找到页表并执行索引操作以定位到将要访问的页面,在软件中进行搜索的问题是保存页表的页可能不在 TLB 中,这将在处理过程中导致其他 TLB 错误。改善方法是可以在内存中的固定位置维护一个大的 TLB 表项的高速缓存来减少 TLB 失效。通过首先检查软件的高速缓存,`操作系统` 能够有效的减少 TLB 失效问题。
511 |
512 | TLB 软件管理会有两种 TLB 失效问题,当一个页访问在内存中而不在 TLB 中时,将产生 `软失效(soft miss)`,那么此时要做的就是把页表更新到 TLB 中(我们上面探讨的过程),而不会产生磁盘 I/O,处理仅仅需要一些机器指令在几纳秒的时间内完成。然而,当页本身不在内存中时,将会产生`硬失效(hard miss)`,那么此时就需要从磁盘中进行页表提取,硬失效的处理时间通常是软失效的百万倍。在页表结构中查找映射的过程称为 `页表遍历(page table walk)`。如图:
513 |
514 | 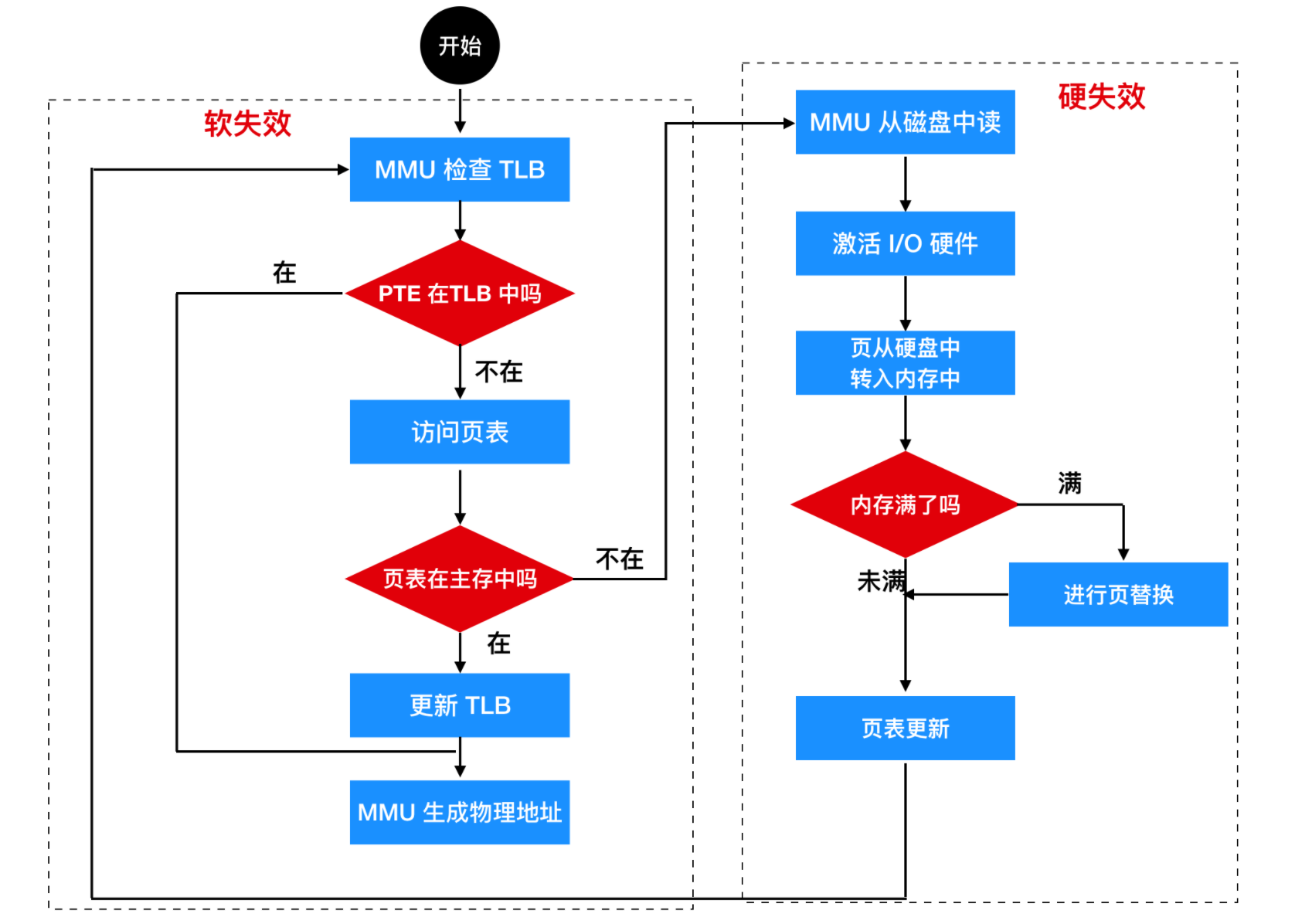 515 |
516 | 上面的这两种情况都是理想情况下出现的现象,但是在实际应用过程中情况会更加复杂,未命中的情况可能既不是硬失效又不是软失效。一些未命中可能更`软`或更`硬`。比如,如果页表遍历的过程中没有找到所需要的页,那么此时会出现三种情况:
517 |
518 | 1. 所需的页面就在内存中,但是却没有记录在进程的页表中,这种情况可能是由其他进程从磁盘掉入内存,这种情况只需要把页正确映射就可以了,而不需要在从硬盘调入,这是一种软失效,称为 `次要缺页错误(minor page fault)`。
519 | 2. 基于上述情况,如果需要从硬盘直接调入页面,这就是`严重缺页错误(major page falut)`。
520 | 3. 还有一种情况是,程序可能访问了一个非法地址,根本无需向 TLB 中增加映射。此时,操作系统会报告一个 `段错误(segmentation fault)` 来终止程序。只有第三种缺页属于程序错误,其他缺页情况都会被硬件或操作系统以降低程序性能为代价来修复
521 |
522 | ### 针对大内存的页表
523 |
524 | 上面引入TLB加快虚拟地址到物理地址的转换,另一个要解决的问题就是处理巨大的虚拟空间,有两种解决方法:多级页表和倒排页表。
525 |
526 | #### 多级页表
527 |
528 | > 从整体来过一遍虚拟地址的概念,虚拟存储器的基本思想是:程序、数据和堆栈的总大小可能超过可用的物理内存的大小。由操作系统把程序当前使用的那些部分保留在主存中,而把其他部分保存在磁盘上。例如,对于一个16MB的程序,通过仔细地选择在每个时刻将哪4MB内容保留在内存中,并在需要时在内存和磁盘间交换程序的片段,这样这个程序就可以在一个4MB的机器上运行。
529 | >
530 | > 由程序产生的地址被称为虚拟地址,它们构成了一个虚拟地址空间。在使用虚拟存储器的情况下,虚拟地址不是被直接送到内存总线上,而且是被送到内存管理单元(Memory Management Unt,MMU),MMU把虚拟地址映射为物理内存地址。
531 | >
532 | > 虚拟地址空间以页面为单位划分。在物理内存中对应的单位称为页帧。页面和页帧的大小总是一样的。
533 |
534 | - 页表在哪儿
535 |
536 | 任何进程的切换都会更换活动页表集,Linux中为每一个进程维护了一个tast_struct结构体(进程描述符PCB),其中tast_struct->mm_struct结构体成员用来保存该进程页表。在进程切换的过程中,内核把新的页表的地址写入CR3控制寄存器。CR3中含有页目录表的物理内存基地址,如下图:
537 |
538 | 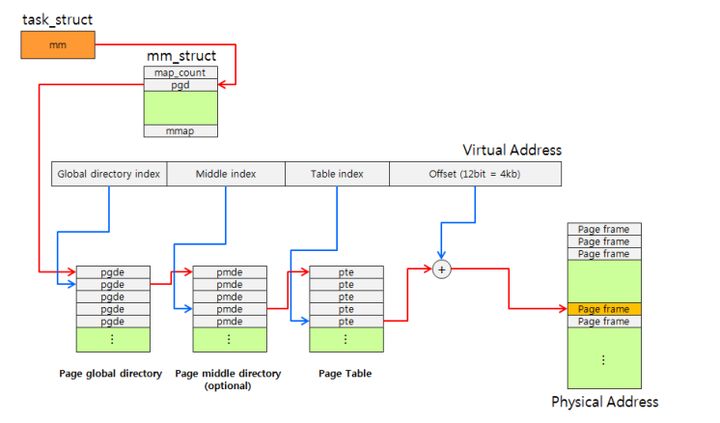
539 |
540 | - 为什么省空间?
541 |
542 | 假如每个进程都有4GB的虚拟地址空间,而显然对于大多数程序来说,其使用到的空间远未达到4GB,何必去映射不可能用到的空间呢?一级页表覆盖了整个4GB虚拟地址空间,但如果某个一级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表。
543 |
544 | 如果每个页表项都存在对应的映射地址那也就算了,但是,绝大部分程序仅仅使用了几个页,也就是说,只需要几个页的映射就可以了,如下图(左),进程1的页表,只用到了0,1,1024三个页,剩下的1048573页表项是空的,这就造成了巨大的浪费,为了避免内存浪费,计算机系统开发人员想出了一个方案,多级页表。
545 |
546 |
515 |
516 | 上面的这两种情况都是理想情况下出现的现象,但是在实际应用过程中情况会更加复杂,未命中的情况可能既不是硬失效又不是软失效。一些未命中可能更`软`或更`硬`。比如,如果页表遍历的过程中没有找到所需要的页,那么此时会出现三种情况:
517 |
518 | 1. 所需的页面就在内存中,但是却没有记录在进程的页表中,这种情况可能是由其他进程从磁盘掉入内存,这种情况只需要把页正确映射就可以了,而不需要在从硬盘调入,这是一种软失效,称为 `次要缺页错误(minor page fault)`。
519 | 2. 基于上述情况,如果需要从硬盘直接调入页面,这就是`严重缺页错误(major page falut)`。
520 | 3. 还有一种情况是,程序可能访问了一个非法地址,根本无需向 TLB 中增加映射。此时,操作系统会报告一个 `段错误(segmentation fault)` 来终止程序。只有第三种缺页属于程序错误,其他缺页情况都会被硬件或操作系统以降低程序性能为代价来修复
521 |
522 | ### 针对大内存的页表
523 |
524 | 上面引入TLB加快虚拟地址到物理地址的转换,另一个要解决的问题就是处理巨大的虚拟空间,有两种解决方法:多级页表和倒排页表。
525 |
526 | #### 多级页表
527 |
528 | > 从整体来过一遍虚拟地址的概念,虚拟存储器的基本思想是:程序、数据和堆栈的总大小可能超过可用的物理内存的大小。由操作系统把程序当前使用的那些部分保留在主存中,而把其他部分保存在磁盘上。例如,对于一个16MB的程序,通过仔细地选择在每个时刻将哪4MB内容保留在内存中,并在需要时在内存和磁盘间交换程序的片段,这样这个程序就可以在一个4MB的机器上运行。
529 | >
530 | > 由程序产生的地址被称为虚拟地址,它们构成了一个虚拟地址空间。在使用虚拟存储器的情况下,虚拟地址不是被直接送到内存总线上,而且是被送到内存管理单元(Memory Management Unt,MMU),MMU把虚拟地址映射为物理内存地址。
531 | >
532 | > 虚拟地址空间以页面为单位划分。在物理内存中对应的单位称为页帧。页面和页帧的大小总是一样的。
533 |
534 | - 页表在哪儿
535 |
536 | 任何进程的切换都会更换活动页表集,Linux中为每一个进程维护了一个tast_struct结构体(进程描述符PCB),其中tast_struct->mm_struct结构体成员用来保存该进程页表。在进程切换的过程中,内核把新的页表的地址写入CR3控制寄存器。CR3中含有页目录表的物理内存基地址,如下图:
537 |
538 | 
539 |
540 | - 为什么省空间?
541 |
542 | 假如每个进程都有4GB的虚拟地址空间,而显然对于大多数程序来说,其使用到的空间远未达到4GB,何必去映射不可能用到的空间呢?一级页表覆盖了整个4GB虚拟地址空间,但如果某个一级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表。
543 |
544 | 如果每个页表项都存在对应的映射地址那也就算了,但是,绝大部分程序仅仅使用了几个页,也就是说,只需要几个页的映射就可以了,如下图(左),进程1的页表,只用到了0,1,1024三个页,剩下的1048573页表项是空的,这就造成了巨大的浪费,为了避免内存浪费,计算机系统开发人员想出了一个方案,多级页表。
545 |
546 | 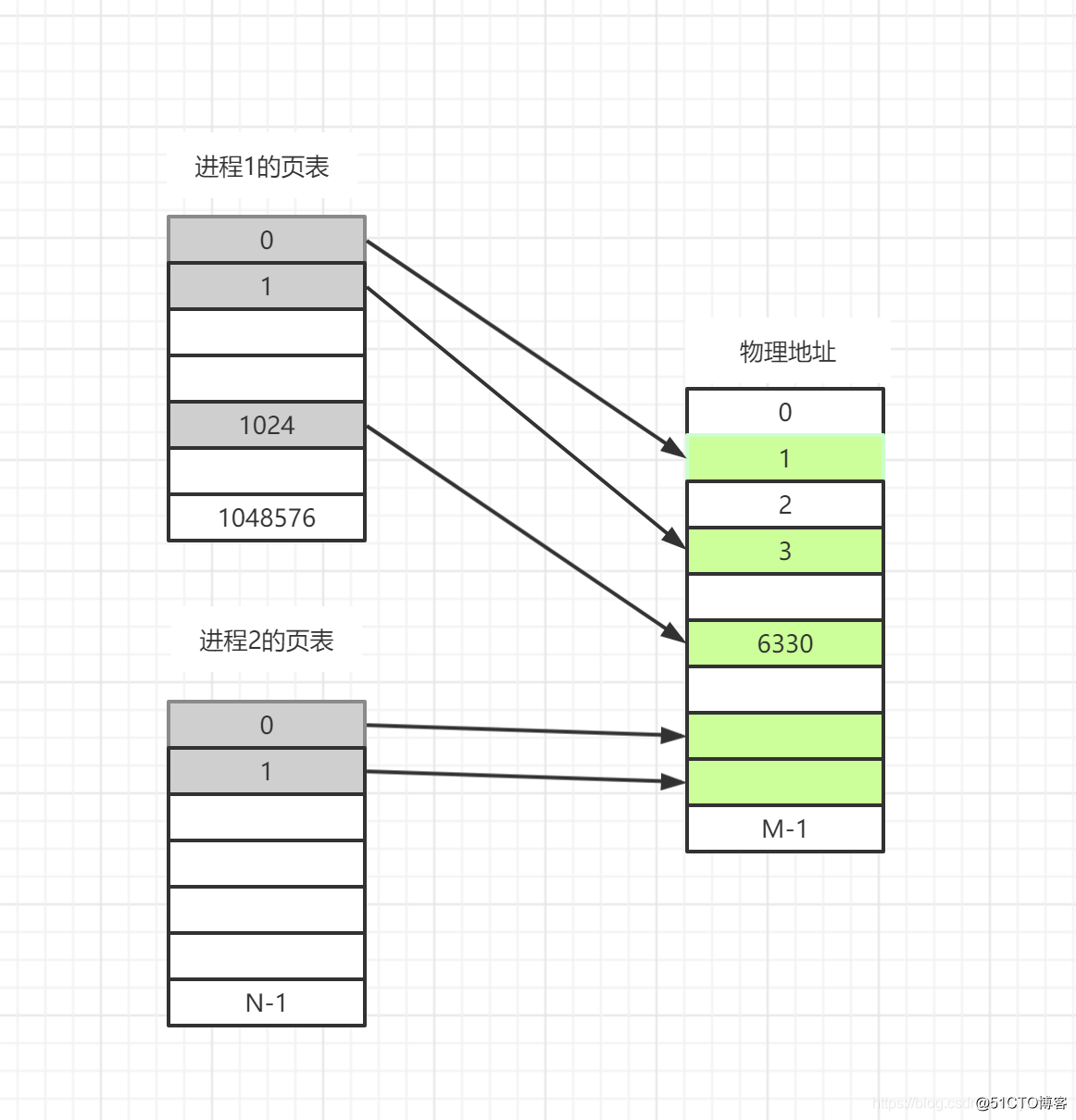
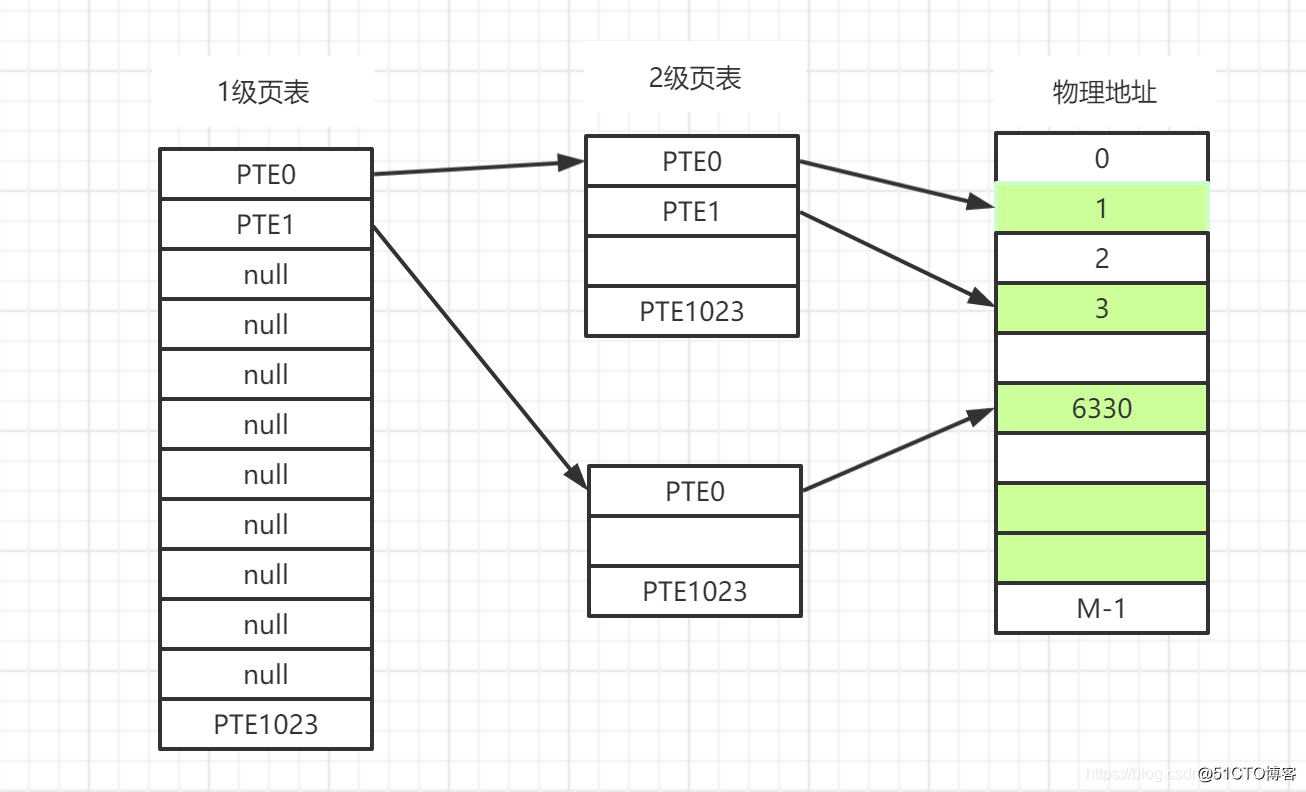 547 |
548 | 下面计算一下上图(右)的内存占用情况,对于一级页表来说,假设一个表项是4B,则
549 |
550 | 一级页表占用:1024 * 4 B= 4K
551 |
552 | 2级页表占用 = (1024 * 4 B) * 2 = 8K。
553 |
554 | 总共的占用情况是 12K,相比只有一个页表 4M,节省了99.7%的内存占用。
555 |
556 | **因此引入多级页表的原因就是避免把全部页表一直保存在内存中。**
557 |
558 | - 《深入理解计算机操作系统》 中的解释
559 |
560 |
547 |
548 | 下面计算一下上图(右)的内存占用情况,对于一级页表来说,假设一个表项是4B,则
549 |
550 | 一级页表占用:1024 * 4 B= 4K
551 |
552 | 2级页表占用 = (1024 * 4 B) * 2 = 8K。
553 |
554 | 总共的占用情况是 12K,相比只有一个页表 4M,节省了99.7%的内存占用。
555 |
556 | **因此引入多级页表的原因就是避免把全部页表一直保存在内存中。**
557 |
558 | - 《深入理解计算机操作系统》 中的解释
559 |
560 | 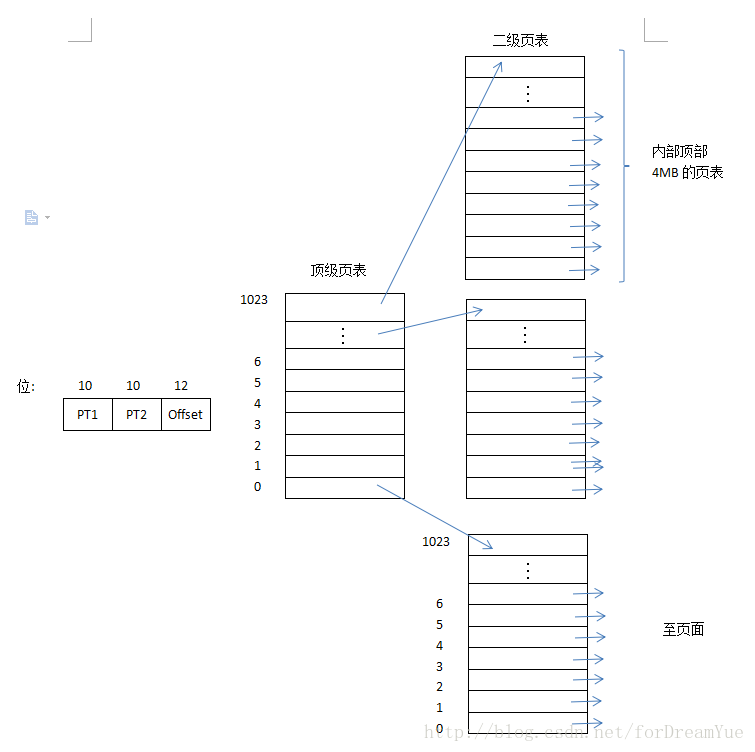 561 |
562 | 假设32位的虚拟地址被划分为10位的PT1域、10位的PT2域和12位的偏移量域,工作过程如下:当一个虚拟地址被送到MMU时,MMU首先提取PT1域并把该值作为访问顶级页表的索引。由于虚拟空间为32G,顶级页表有2^10(PT1)^=1024个表项,则二级页表有2^10(PT2)^=1024个表项,每一个二级页表都含有虚拟地址对应物理地址的页框号,该页框号与偏移量结合便形成物理地址,放到地址总线送入内存中。
563 |
564 | 如果没有多级页表,则32位虚拟内存应该有100万个页面,这个存储开销是很大的,而有了多级页表,则实际只需要4个页表,顶级页表、0、1、1024这四个,顶级页表中的其他表项的“在/不在”为被设置为0,访问他们是强制产生一个缺页中断。
565 |
566 | #### 倒排页表
567 |
568 | 针对不断分级的页表的替代方案是**倒排页表**,实际内存中的每个页框对应一个表项,而不是每个虚拟页面对应一个表项。
569 |
570 | 对于64位虚拟地址,4KB的页,4GB的RAM,一个倒排页表仅需要1048576个表项。
571 |
572 | 由于4KB的页面,因此需要2^64^/2^12^=2^52^个页面,但是1GB物理内存只能有2^18^个4KB页框
573 |
574 | > 虽然倒排页表节省了大量的空间,但是它也有自己的缺陷:那就是从虚拟地址到物理地址的转换会变得很困难。当进程 n 访问虚拟页面 p 时,硬件不能再通过把 p 当作指向页表的一个索引来查找物理页。而是必须搜索整个倒排表来查找某个表项。另外,搜索必须对每一个内存访问操作都执行一次,而不是在发生缺页中断时执行。解决这一问题的方式时使用 TLB。当发生 TLB 失效时,需要用软件搜索整个倒排页表。一个可行的方式是建立一个散列表,用虚拟地址来散列。当前所有内存中的具有相同散列值的虚拟页面被链接在一起。如下图所示
575 | >
576 | > 如果散列表中的槽数与机器中物理页面数一样多,那么散列表的冲突链的长度将会是 1 个表项的长度,这将会大大提高映射速度。一旦页框被找到,新的(虚拟页号,物理页框号)就会被装在到 TLB 中。
577 | >
578 | >
561 |
562 | 假设32位的虚拟地址被划分为10位的PT1域、10位的PT2域和12位的偏移量域,工作过程如下:当一个虚拟地址被送到MMU时,MMU首先提取PT1域并把该值作为访问顶级页表的索引。由于虚拟空间为32G,顶级页表有2^10(PT1)^=1024个表项,则二级页表有2^10(PT2)^=1024个表项,每一个二级页表都含有虚拟地址对应物理地址的页框号,该页框号与偏移量结合便形成物理地址,放到地址总线送入内存中。
563 |
564 | 如果没有多级页表,则32位虚拟内存应该有100万个页面,这个存储开销是很大的,而有了多级页表,则实际只需要4个页表,顶级页表、0、1、1024这四个,顶级页表中的其他表项的“在/不在”为被设置为0,访问他们是强制产生一个缺页中断。
565 |
566 | #### 倒排页表
567 |
568 | 针对不断分级的页表的替代方案是**倒排页表**,实际内存中的每个页框对应一个表项,而不是每个虚拟页面对应一个表项。
569 |
570 | 对于64位虚拟地址,4KB的页,4GB的RAM,一个倒排页表仅需要1048576个表项。
571 |
572 | 由于4KB的页面,因此需要2^64^/2^12^=2^52^个页面,但是1GB物理内存只能有2^18^个4KB页框
573 |
574 | > 虽然倒排页表节省了大量的空间,但是它也有自己的缺陷:那就是从虚拟地址到物理地址的转换会变得很困难。当进程 n 访问虚拟页面 p 时,硬件不能再通过把 p 当作指向页表的一个索引来查找物理页。而是必须搜索整个倒排表来查找某个表项。另外,搜索必须对每一个内存访问操作都执行一次,而不是在发生缺页中断时执行。解决这一问题的方式时使用 TLB。当发生 TLB 失效时,需要用软件搜索整个倒排页表。一个可行的方式是建立一个散列表,用虚拟地址来散列。当前所有内存中的具有相同散列值的虚拟页面被链接在一起。如下图所示
575 | >
576 | > 如果散列表中的槽数与机器中物理页面数一样多,那么散列表的冲突链的长度将会是 1 个表项的长度,这将会大大提高映射速度。一旦页框被找到,新的(虚拟页号,物理页框号)就会被装在到 TLB 中。
577 | >
578 | > 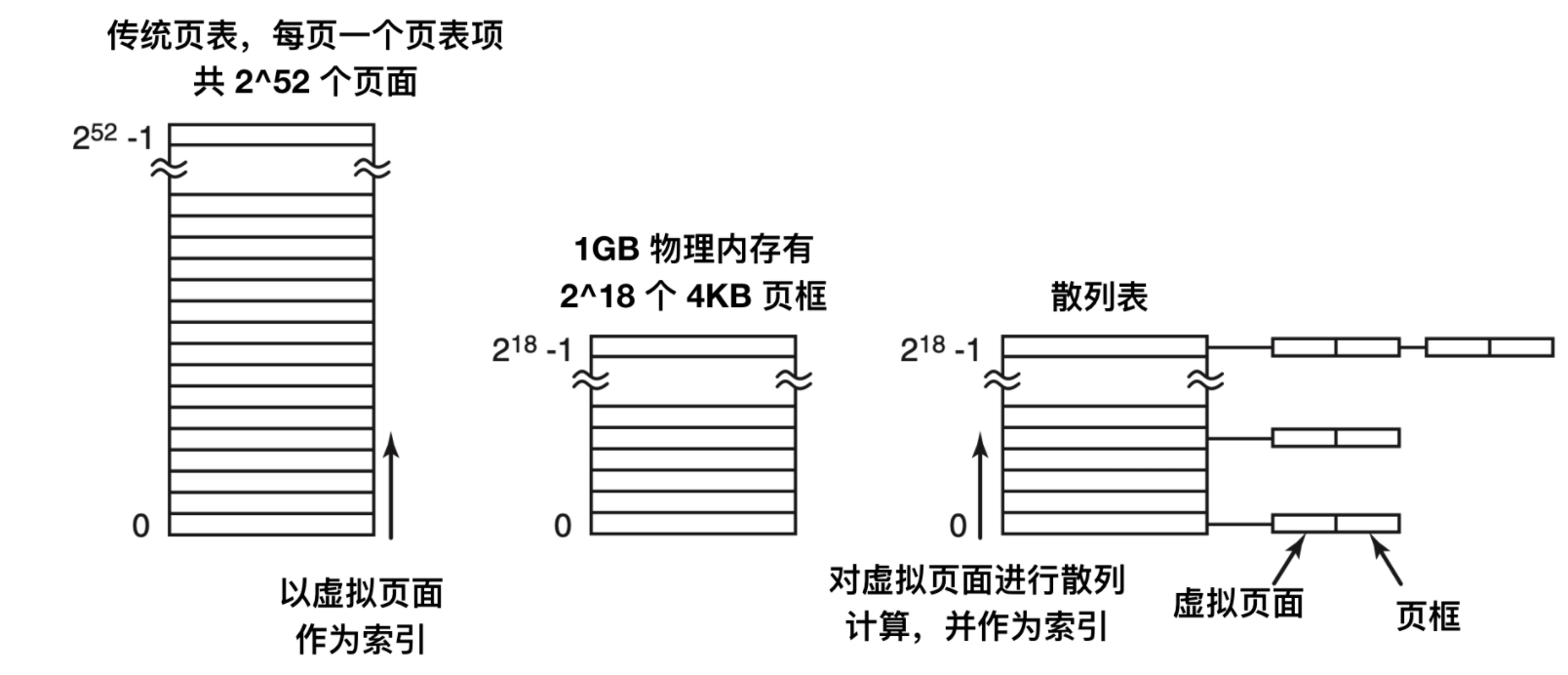 579 | >
580 | >
581 | >
582 | >
583 |
584 |
585 |
586 | ## 页面置换算法
587 |
588 | 当发生缺页中断时,操作系统必须在内存中选择一个页面将其换出,以便为调入的页面腾出空间。如果被换出的页面在内存驻留期间被修改过,则必须写回磁盘更新,如果没有被修改过,不需要写回磁盘。
589 |
590 | 当发生缺页中断时候,可以随机的选择一个页面置换,但如果每次都选择不常使用的页面会提高性能。因为被频繁使用的页面在正常认知中都不可能要被换出,这会带来没必要的开销问题。
591 |
592 | 多说一句,页面置换思想在别的问题上也存在用武之地:
593 |
594 | 1. 计算机的高速缓存cache。高速缓存满了之后就必须要丢掉,但是相比页面置换花费时间短,因为都是在内存中操作和获得,而内存没有寻道时间也没有旋转延迟。
595 | 2. Web服务器。服务器把经常访问的页面放入存储器的高速缓存中,但当高速缓存已经满同时要访问一个不在高速缓存中的页面时候,就必须置换高速缓存中的某些web页面。不一样的地方在于高速缓存中的web页面不会被修改,虚拟内存中的页面有可能被修改过。
596 |
597 | > 页面置换中的相关计算问题
598 | >
599 | > 缺页率:缺页次数/总次数
600 | >
601 | > 命中次数:总次数-缺页次数
602 |
603 | 接下来说一下具体的页面置换算法
604 |
605 | ### 最优页面置换算法(OPT)
606 |
607 | 该算法是一个理想算法,具体实现如下:
608 |
609 | 每个页面都有一个标记,记录了访问该页面要到多少条指令才能访问到。很显然,我们应该替换掉指令数最大的那个页面,比如页面A的指令数为2(两条指令后),页面B的指令数为1000(1000条指令后访问),这样我们就可以轻易淘汰页面B。
610 |
611 | ------
612 |
613 | **但是这个算法的问题是无法实现,因为在缺页中断时操作系统无法预知每个页面将在什么时候被访问到**
614 |
615 | ------
616 |
617 | 可用作其他算法的性能评价的依据(在一个模拟器上运行某个程序,并记录每一次的页面访问情况,这样会得到访问序列,根据这个序列来预知未来,在第二遍运行时即可使用最优算法),看一个实例:
618 |
619 | > 
620 | >
621 | > 如图,在0时刻时,内存中已经有了访问序列(a,b,c,d),页帧表中可以看出给程序分配了4个物理页框,但是整个程序需要访问5个页面(abcde),物理页框不够,会产生页替换。随着时间的运行,在1-4 时间段内,都不会产生缺页中断,直到t=5 ,需要访问e,但是e的虚拟页不在内存中,需要选一个页替换出去。基于最优置换算法,选取离下一次访问时间最长的那个页是要被选择替换出去的,计算得出d访问时间距离为10,值最大,将d替换出去,把d留出的物理页空间给e。
622 | >
623 | > **结论**:直到 t=10时,最优页面置换算法一共产生2次中断。
624 |
625 | ### 最近未使用页面置换(NRU)
626 |
627 | 为了能够使得操作系统收集有用的统计信息,在大部分具有虚拟内存的计算机上,系统为每一个页面设置了**两个状态位**。当页面被访问时(读或者写)设置**R**位,当页面被修改时设置**M**位(这两个位都用01表示)。这些位包含在每一个页表项中,每次访问内存中时候会更新这些位。一旦某些位被设置为1,就保持1直到操作系统将他复位。
628 |
629 | 可以有R和M构造一个简单的页面置换算法,当启动一个进程时候,两个状态位由操作系统设置为0,R在每次时钟中断后就被清零,以区别最近没有被访问的页面和访问的页面。当发生缺页中断时,操作系统检查RM值,分为以下4类:
630 |
631 | 1. 没有被访问没有被修改
632 | 2. 没有被访问但被修改(这种情况一般由第四类过来,R位被时钟中断清零)
633 | 3. 已被访问但没有修改
634 | 4. 已被访问已被修改
635 |
636 | 该算法需要淘汰一个没有被访问但已修改页面,因为被频繁使用的的干净的页面总归要占据主要位置的。
637 |
638 | ### 先进先出页面置换(FIFO)
639 |
640 | **基本思路**:选择在内存中驻留时间最长的页面并将它淘汰。
641 | 具体来说,系统中维护着一个链表,记录了所有位于内存当中的逻辑页面。从链表的排列顺序来看,链首页面的驻留时间最长,链尾页面的驻留时间最短。
642 | 当发生一个缺页中断时,把链首位置的页面淘汰出局,并把新的页面添加到链表的末尾。
643 |
644 | **缺点:**性能较差,调出的页面有可能是经常要访问的页面,并且有Belady现象 (给的物理页越多,缺页就越多)。
645 |
646 | ------
647 |
648 | > 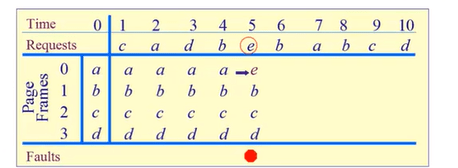
649 | >
650 | > 在0时刻时,内存中已经有了访问序列(a,b,c,d),页帧表中可以看出给跑的程序分配了4个物理页帧,但是整个程序需要访问5个页,物理页 不够,会产生页替换。随着时间的运行,在1-4 时间段内,都不会产生缺页中断,直到t=5 ,需要访问e,但是e的虚拟页不在内存中,需要选一个页替换出去。基于FIFO换算法,链表顺序为 a - b -c -d ,计算当前内存中驻留时间最久的页即a,将a替换出去,把a留出的物理页空间给e。接下来,当t=7时,访问a,a已经在t=5 时被替换出去了,产生一次中断,基于FIFO,将b换成a。
651 | >
652 | > 
653 | >
654 | > 。。。。
655 | >
656 | > **结论**:FIFO算法一共产生了5次中断,多于最优页面置换算法。
657 |
658 | ### 第二次机会页面置换算法
659 |
660 | 先进先出页面置换算法有一个缺点就是是按照时间来排序的,那如果最先进去的在链表首位的是经常要用的页面,把这个页面换出去是非常耗费效率的事情,因此该算法就是在先进先出算法上做一个简单的修改。
661 |
662 | **含义:**检查最老页面(位于链首的页面)的R位。如果R位是0表明这个页面又老有没有被使用过,就直接换出该页面。如果R为1,则将R置为0.然后将该页面放到链尾处,这个时候这个页面相当于一个新的页面。非常的简单易懂。
663 |
664 | ### 时钟页面置换算法
665 |
666 | 在链表中移动页面降低效率又没有必要,因此更好的办法就是把所有页面保存在环形链表中,用指针指向最老的页面。如果发生缺页中断,算法首先检查指针指向的页面,如果R位是0就淘汰出局,并把新的页面插入该位置,然后指针下一移位。如果R是1就把指针下移,该工作模式更像是一个时钟,因此叫做时钟置换。
667 |
668 |
579 | >
580 | >
581 | >
582 | >
583 |
584 |
585 |
586 | ## 页面置换算法
587 |
588 | 当发生缺页中断时,操作系统必须在内存中选择一个页面将其换出,以便为调入的页面腾出空间。如果被换出的页面在内存驻留期间被修改过,则必须写回磁盘更新,如果没有被修改过,不需要写回磁盘。
589 |
590 | 当发生缺页中断时候,可以随机的选择一个页面置换,但如果每次都选择不常使用的页面会提高性能。因为被频繁使用的页面在正常认知中都不可能要被换出,这会带来没必要的开销问题。
591 |
592 | 多说一句,页面置换思想在别的问题上也存在用武之地:
593 |
594 | 1. 计算机的高速缓存cache。高速缓存满了之后就必须要丢掉,但是相比页面置换花费时间短,因为都是在内存中操作和获得,而内存没有寻道时间也没有旋转延迟。
595 | 2. Web服务器。服务器把经常访问的页面放入存储器的高速缓存中,但当高速缓存已经满同时要访问一个不在高速缓存中的页面时候,就必须置换高速缓存中的某些web页面。不一样的地方在于高速缓存中的web页面不会被修改,虚拟内存中的页面有可能被修改过。
596 |
597 | > 页面置换中的相关计算问题
598 | >
599 | > 缺页率:缺页次数/总次数
600 | >
601 | > 命中次数:总次数-缺页次数
602 |
603 | 接下来说一下具体的页面置换算法
604 |
605 | ### 最优页面置换算法(OPT)
606 |
607 | 该算法是一个理想算法,具体实现如下:
608 |
609 | 每个页面都有一个标记,记录了访问该页面要到多少条指令才能访问到。很显然,我们应该替换掉指令数最大的那个页面,比如页面A的指令数为2(两条指令后),页面B的指令数为1000(1000条指令后访问),这样我们就可以轻易淘汰页面B。
610 |
611 | ------
612 |
613 | **但是这个算法的问题是无法实现,因为在缺页中断时操作系统无法预知每个页面将在什么时候被访问到**
614 |
615 | ------
616 |
617 | 可用作其他算法的性能评价的依据(在一个模拟器上运行某个程序,并记录每一次的页面访问情况,这样会得到访问序列,根据这个序列来预知未来,在第二遍运行时即可使用最优算法),看一个实例:
618 |
619 | > 
620 | >
621 | > 如图,在0时刻时,内存中已经有了访问序列(a,b,c,d),页帧表中可以看出给程序分配了4个物理页框,但是整个程序需要访问5个页面(abcde),物理页框不够,会产生页替换。随着时间的运行,在1-4 时间段内,都不会产生缺页中断,直到t=5 ,需要访问e,但是e的虚拟页不在内存中,需要选一个页替换出去。基于最优置换算法,选取离下一次访问时间最长的那个页是要被选择替换出去的,计算得出d访问时间距离为10,值最大,将d替换出去,把d留出的物理页空间给e。
622 | >
623 | > **结论**:直到 t=10时,最优页面置换算法一共产生2次中断。
624 |
625 | ### 最近未使用页面置换(NRU)
626 |
627 | 为了能够使得操作系统收集有用的统计信息,在大部分具有虚拟内存的计算机上,系统为每一个页面设置了**两个状态位**。当页面被访问时(读或者写)设置**R**位,当页面被修改时设置**M**位(这两个位都用01表示)。这些位包含在每一个页表项中,每次访问内存中时候会更新这些位。一旦某些位被设置为1,就保持1直到操作系统将他复位。
628 |
629 | 可以有R和M构造一个简单的页面置换算法,当启动一个进程时候,两个状态位由操作系统设置为0,R在每次时钟中断后就被清零,以区别最近没有被访问的页面和访问的页面。当发生缺页中断时,操作系统检查RM值,分为以下4类:
630 |
631 | 1. 没有被访问没有被修改
632 | 2. 没有被访问但被修改(这种情况一般由第四类过来,R位被时钟中断清零)
633 | 3. 已被访问但没有修改
634 | 4. 已被访问已被修改
635 |
636 | 该算法需要淘汰一个没有被访问但已修改页面,因为被频繁使用的的干净的页面总归要占据主要位置的。
637 |
638 | ### 先进先出页面置换(FIFO)
639 |
640 | **基本思路**:选择在内存中驻留时间最长的页面并将它淘汰。
641 | 具体来说,系统中维护着一个链表,记录了所有位于内存当中的逻辑页面。从链表的排列顺序来看,链首页面的驻留时间最长,链尾页面的驻留时间最短。
642 | 当发生一个缺页中断时,把链首位置的页面淘汰出局,并把新的页面添加到链表的末尾。
643 |
644 | **缺点:**性能较差,调出的页面有可能是经常要访问的页面,并且有Belady现象 (给的物理页越多,缺页就越多)。
645 |
646 | ------
647 |
648 | > 
649 | >
650 | > 在0时刻时,内存中已经有了访问序列(a,b,c,d),页帧表中可以看出给跑的程序分配了4个物理页帧,但是整个程序需要访问5个页,物理页 不够,会产生页替换。随着时间的运行,在1-4 时间段内,都不会产生缺页中断,直到t=5 ,需要访问e,但是e的虚拟页不在内存中,需要选一个页替换出去。基于FIFO换算法,链表顺序为 a - b -c -d ,计算当前内存中驻留时间最久的页即a,将a替换出去,把a留出的物理页空间给e。接下来,当t=7时,访问a,a已经在t=5 时被替换出去了,产生一次中断,基于FIFO,将b换成a。
651 | >
652 | > 
653 | >
654 | > 。。。。
655 | >
656 | > **结论**:FIFO算法一共产生了5次中断,多于最优页面置换算法。
657 |
658 | ### 第二次机会页面置换算法
659 |
660 | 先进先出页面置换算法有一个缺点就是是按照时间来排序的,那如果最先进去的在链表首位的是经常要用的页面,把这个页面换出去是非常耗费效率的事情,因此该算法就是在先进先出算法上做一个简单的修改。
661 |
662 | **含义:**检查最老页面(位于链首的页面)的R位。如果R位是0表明这个页面又老有没有被使用过,就直接换出该页面。如果R为1,则将R置为0.然后将该页面放到链尾处,这个时候这个页面相当于一个新的页面。非常的简单易懂。
663 |
664 | ### 时钟页面置换算法
665 |
666 | 在链表中移动页面降低效率又没有必要,因此更好的办法就是把所有页面保存在环形链表中,用指针指向最老的页面。如果发生缺页中断,算法首先检查指针指向的页面,如果R位是0就淘汰出局,并把新的页面插入该位置,然后指针下一移位。如果R是1就把指针下移,该工作模式更像是一个时钟,因此叫做时钟置换。
667 |
668 | 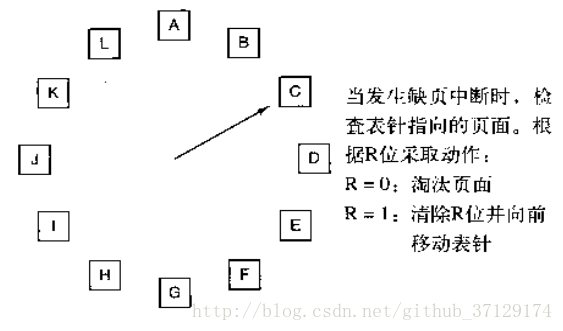 669 |
670 | ### 最近最少使用页面置换算法(LRU)
671 |
672 | 由于很久未被使用的页面在未来一段时间内仍然不会被使用(程序局部性原理),根据该思想就实现一个算法:在缺页中断发生时,置换未使用时间最长的页面,叫做LRU。
673 |
674 | **实现:**在内存中维护一个所有页面的链表,最近最多使用的在表头,最近最少使用的在表尾。主要难点在于每次访问内存时候都必须更新整个链表(每一次访问内存时,找到相应的页面,把它从链表中摘下来,再移动到链表之首)。在链表中找到一个页面,删除他,然后把它移动到表头是一个非常费时的操作,即使用硬件实现也是一样的。
675 |
676 | ### LRU改进(LRU→NFU→老化算法)
677 |
678 | 用软件实现LRU的解决方案如下:
679 |
680 | 首先是NFU方案,该算法将没一个页面与一个软件技术器关联,计数器的初始值为0,每次缺页中断就由操作系统扫描内存中的所有页面,将所有页面的R位的值(0或1)加到计数器上,这个计数器大体上各个页面被访问的频繁程度,发生缺页中断时候置换计数器上值最小的页面。但是这个方案有个缺点就是计数器的值不会归零,导致会出现问题,即置换那些有用的页面而不是不再使用的页面,因此又出现了下面的改进算法。
681 |
682 | ------
683 |
684 | 老化算法,只是对NFU方案进行了小小的修改,用来模拟LRU。首先在R位被加到计数器上时将计数器右移一位,然后将R的值加到计数器的最左端。计数器用二进制表示哈。工作图如下:
685 |
686 |
669 |
670 | ### 最近最少使用页面置换算法(LRU)
671 |
672 | 由于很久未被使用的页面在未来一段时间内仍然不会被使用(程序局部性原理),根据该思想就实现一个算法:在缺页中断发生时,置换未使用时间最长的页面,叫做LRU。
673 |
674 | **实现:**在内存中维护一个所有页面的链表,最近最多使用的在表头,最近最少使用的在表尾。主要难点在于每次访问内存时候都必须更新整个链表(每一次访问内存时,找到相应的页面,把它从链表中摘下来,再移动到链表之首)。在链表中找到一个页面,删除他,然后把它移动到表头是一个非常费时的操作,即使用硬件实现也是一样的。
675 |
676 | ### LRU改进(LRU→NFU→老化算法)
677 |
678 | 用软件实现LRU的解决方案如下:
679 |
680 | 首先是NFU方案,该算法将没一个页面与一个软件技术器关联,计数器的初始值为0,每次缺页中断就由操作系统扫描内存中的所有页面,将所有页面的R位的值(0或1)加到计数器上,这个计数器大体上各个页面被访问的频繁程度,发生缺页中断时候置换计数器上值最小的页面。但是这个方案有个缺点就是计数器的值不会归零,导致会出现问题,即置换那些有用的页面而不是不再使用的页面,因此又出现了下面的改进算法。
681 |
682 | ------
683 |
684 | 老化算法,只是对NFU方案进行了小小的修改,用来模拟LRU。首先在R位被加到计数器上时将计数器右移一位,然后将R的值加到计数器的最左端。计数器用二进制表示哈。工作图如下:
685 |
686 | 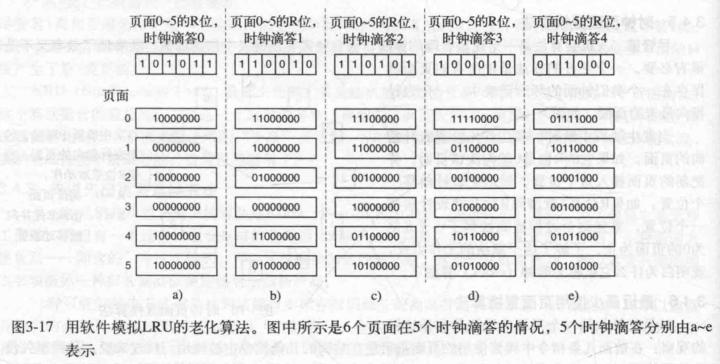 687 |
688 | 上图a表示在时钟滴答0的时候访问了页面0245,因此最左边的值为1,对应上面五个页面的R位,就是这样看。
689 |
690 | 发生缺页中断的时候操作系统会比较六个计数器中的值然后置换最小的那个,这样就不会误伤。
691 |
692 | 在实践中,如果时钟滴答是20ms,则8位一般够用。
693 |
694 | ### 工作集页面置换算法
695 |
696 | > 前提知识
697 | >
698 | > 在分页系统中刚启动进程时候,内存中是没有页面的,因此CPU试图取第一条指令时就会产生一次缺页中断,使操作系统装入含有第一条指令的页面。其他因为访问全局数据和堆栈引起的缺页中断也会紧接着发生。**因此,页面是在需要的时候才会被装入,而不是预先装入。**
699 | >
700 | > 一个进程当前正在使用的页面的集合称为工作集。如果一个工作集被装入到内存,那么进程在运行到下一运行阶段之前,不会产生很多缺页中断。如果内存比较小装不下一个工作集,就会产生大量缺页中断导致运行速度变得缓慢,因为几个纳秒就可以执行完一条指令,而需要几十毫秒才能从磁盘上读取一个页面。如果每执行几条指令就引发一次缺页中断,那么称该程序发生了**颠簸**
701 | >
702 | > 在多道程序设计系统中,经常把进程转移到磁盘上(移走全部页面),但是再转换回来就很容易发生缺页中断,遂引入**工作集模型**,确保进程在运行前,它的工作集就已经在内存中了.在程序运行前预先装入其工作集页面也称为**预先调页**.
703 |
704 |
705 |
706 | ### 工作集时钟页面置换算法
707 |
708 | ### 总结
709 |
710 | 最好的算法是老化算法和工作集时钟算法,他们分别基于LRU和工作集,都具有良好的页面调度性能,可以有效地实现。
711 |
712 | ------
713 |
714 |
715 |
716 | ## 分页系统的一些细节
717 |
718 | ### 局部分配策略和全局分配策略
719 |
720 | 我们说缺页中断发生时候会选择一个被页面来置换,但有一个主要问题就是怎样在相互竞争的可运行进程之间分配内存?因此有两种选择
721 |
722 | **局部页面置换算法:**局部页面置换指的是只在本进程相关的页面中找一个进行置换。
723 |
724 | **全局页面置换算法:**在所有的进程中找到一个合适的页面进行置换,这个页面可能是属于其他进程的。
725 |
726 | 全局算法在通常情况下工作的要比局部算法好,特别是当工作集大小随着进程运行时间而发生变化的情况下更明显。如果使用局部算法,即便有大量的空闲页框存在,工作集的增长也会导致颠簸。如果工作集缩小了,局部算法又会浪费内存。
727 |
728 | ### 页面大小
729 |
730 | 要确定最佳页面大小需要在几个因素之间进行权衡,不存在全局最优。
731 |
732 | 文章更倾向于选择小页面,有几个理由:
733 |
734 | 1. 随便选择一个正文段、数据段或堆栈段很可能不会恰好装满整个页面,平均情况下最后一个页面中有一半会是空的,而另一半空间就会被浪费掉了,这属于内部碎片。根据这方面考虑,还是小页面更好一点
735 | 2. 如果一个程序每个阶段需要4KB内存,但是页面大小为32KB,就会浪费掉这些内存,但是页面大小如果是4KB就不会产生浪费。
736 |
737 | 小页面又有一些不足之处:
738 |
739 | 1. 页面小意味着程序需要更多的页面,因此页表也就会变得更大。**由于内存与磁盘之间的传输一般是一次一页,传输中的大部分时间都花在寻道和旋转延迟上,所以传输一个小页面所用的时间和传输一个大页面基本是相同的。**因此装入64个512字节的页面需要64×10ms,但是装入4个8KB的页面只需要4×12ms
740 | 2. 每次CPU从一个进程切换到另一个进程时都必须把新进程的页表装入硬件寄存器中。页面越小,页表越多意味着装入寄存器花费的时间就会越长,而且页表占用的空间也会随着页面减小而增大。
741 |
742 | ------
743 |
744 | 小页面能够更充分的利用TLB空间。假设程序使用的内存为1MB,工作单元为64KB。若使用4KB的页面,则程序将至少占用TLB中的16个表项。使用2MB的页面时,1TLB表就够了。由于TLB表相对比较稀缺,条件允许的情况下使用大页面是值得的。为了进行必要的平衡,操作系统有时会为系统中的不同部分使用不同的页面大小。比如内核使用大页面,用户进程使用小页面。
745 |
746 | ### 内存映射文件
747 |
748 | 思想:进程可以通过发起一个系统调用将一个文件映射到其虚拟地址空间的一部分。在多数实现中,在映射共享的页面时候不会实际读入页面的内容,而是在访问页面时才会被每次一页的读入,磁盘文件则被当做后备存储。
749 |
750 | 如果两个或以上的进程同时映射了同一个文件,他们就可以通过共享内存来通信。 一个进程在共享内存上完成了写操作,此刻当另一个进程在映射到这个文件的虚拟地址空间上执行读操作时候,可以看到上面有一个进程写操作的结果。
751 |
752 | ### 分页守护进程
753 |
754 | 如果发生缺页中断时系统中有大量的空闲页框,此时分页系统工作在最佳状态。
755 |
756 | 如果每个页框都被占用,而且被修改过得话,当换入一个新页面时,旧页面应该首先被写回磁盘。
757 |
758 | 为保证有足够的空间页框,很多分页系统有一个称为分页守护进程的后台进程,它在大多数时候是睡眠的,但定期被唤醒已检查内存状态。如果空闲页框过少,分页守护进程通过预定的页面置换算法选择页面换出内存,如果这些页面被修改过,则写回磁盘。
759 |
760 | ### 与分页有关的工作
761 |
762 | 与分页有关的工作主要有四段:进程创建时,进程执行时,缺页中断时,进程终止时。
763 |
764 | - **进程创建时**
765 |
766 | 创建一个新进程的时候,操作系统要确定程序和数据在初始化时有多大,并为他们创建一个页表。然后OS还要在内存中为页表分配空间并对其初始化。
767 |
768 | 当进程被换出时,页表就不需要驻留在内存中了,但是运行的时候必须在内存中。
769 |
770 | OS在磁盘交换区中分配内存,以便在一个进程换出时在磁盘上有放置次进程的空间。OS还要用程序正文和数据对交换区初始化,这样当新进程发生缺页中断时候,可以调入需要的页面。
771 |
772 | 最后,OS必须把有关页表和磁盘交换区的信息存储在进程表中。
773 |
774 | - **进程执行时**
775 |
776 | 当调度一个新进程时候,必须重置MMU,刷新TLB,以清除以前的进程遗留的痕迹。新进程的页表必须成为当前页表,通常是复制该页表或者把指向该页表的指针放入某个硬件寄存器来实现的
777 |
778 | 在进程初始化时可以把该进程的部分或者全部页面装入内存以防止缺页中断
779 |
780 | - **缺页中断时**
781 |
782 | 当发生缺页中断时,OS通过读取硬件寄存器来确定是哪个虚拟地址造成了缺页中断,并在磁盘上对该页面进行定位。
783 |
784 | 然后找到合适的页框来存放新页面,必要时还要置换老的页面,然后把所需的页面读入页框。
785 |
786 | 然后回退程序计数器,使得程序计数器指向引起缺页中断的指令,并重新执行该指令。
787 |
788 | - **进程终止时**
789 |
790 | 进程退出的时候OS释放进程的页表,页面和页面在磁盘上所占用的空间。如果某些页面与其他进程共享,则当最后使用他的进程终止时才释放内存和磁盘。
791 |
792 | ### 对缺页中断的处理
793 |
794 | 1. 硬件陷入内核,在堆栈中保存程序计数器。大多数机器将当前的指令,各种状态信息保存在特殊的CPU寄存器中。
795 |
796 | 2. 启动一个汇编代码保存通用寄存器和其他易失信息,防止被操作系统破坏
797 |
798 | 3. 当操作系统收到缺页中断信号后,定位到需要的虚拟页面。
799 |
800 | 4. 找到发生缺页中断的虚拟地址,操作系统检查这个地址是否有效,并检查存取与保护是否一致。
801 |
802 | 如果不一致则杀掉该进程
803 |
804 | 如果地址有效且没有保护错误发生,系统会检查是否有空闲页框。如果没有空闲页框就执行页面置换算法淘汰一个页面。
805 |
806 | 5. 如果选择的页框对应的页面发生了修改,即为“脏页面”,需要写回磁盘,并发生一次上下文切换,挂起产生缺页中断的进程,让其他进程运行直至全部把内容写到磁盘。
807 |
808 | 6. 一旦页框是干净的,则OS会查找要发生置换的页面对应磁盘上的地址,通过磁盘操作将其装入。在装入该页面的时候,产生缺页中断的进程仍然被挂起,运行其他可运行的进程
809 |
810 | 7. 当发生磁盘中断时表明该页面已经被装入,页表已经更新可以反映其位置,页框也被标记为正常状态。
811 |
812 | 8. 恢复发生缺页中断指令以前的状态,程序计数器重新指向引起缺页中断的指令
813 |
814 | 9. 调度引发缺页中断的进程
815 |
816 | 10. 该进程恢复寄存器和其他状态信息,返回用户空间继续执行。
817 |
818 | ## 分段
819 |
820 | ### 概述
821 |
822 | 在没有分段之前我们讨论的都是一维的虚拟内存,如下图所示:
823 |
824 |
687 |
688 | 上图a表示在时钟滴答0的时候访问了页面0245,因此最左边的值为1,对应上面五个页面的R位,就是这样看。
689 |
690 | 发生缺页中断的时候操作系统会比较六个计数器中的值然后置换最小的那个,这样就不会误伤。
691 |
692 | 在实践中,如果时钟滴答是20ms,则8位一般够用。
693 |
694 | ### 工作集页面置换算法
695 |
696 | > 前提知识
697 | >
698 | > 在分页系统中刚启动进程时候,内存中是没有页面的,因此CPU试图取第一条指令时就会产生一次缺页中断,使操作系统装入含有第一条指令的页面。其他因为访问全局数据和堆栈引起的缺页中断也会紧接着发生。**因此,页面是在需要的时候才会被装入,而不是预先装入。**
699 | >
700 | > 一个进程当前正在使用的页面的集合称为工作集。如果一个工作集被装入到内存,那么进程在运行到下一运行阶段之前,不会产生很多缺页中断。如果内存比较小装不下一个工作集,就会产生大量缺页中断导致运行速度变得缓慢,因为几个纳秒就可以执行完一条指令,而需要几十毫秒才能从磁盘上读取一个页面。如果每执行几条指令就引发一次缺页中断,那么称该程序发生了**颠簸**
701 | >
702 | > 在多道程序设计系统中,经常把进程转移到磁盘上(移走全部页面),但是再转换回来就很容易发生缺页中断,遂引入**工作集模型**,确保进程在运行前,它的工作集就已经在内存中了.在程序运行前预先装入其工作集页面也称为**预先调页**.
703 |
704 |
705 |
706 | ### 工作集时钟页面置换算法
707 |
708 | ### 总结
709 |
710 | 最好的算法是老化算法和工作集时钟算法,他们分别基于LRU和工作集,都具有良好的页面调度性能,可以有效地实现。
711 |
712 | ------
713 |
714 |
715 |
716 | ## 分页系统的一些细节
717 |
718 | ### 局部分配策略和全局分配策略
719 |
720 | 我们说缺页中断发生时候会选择一个被页面来置换,但有一个主要问题就是怎样在相互竞争的可运行进程之间分配内存?因此有两种选择
721 |
722 | **局部页面置换算法:**局部页面置换指的是只在本进程相关的页面中找一个进行置换。
723 |
724 | **全局页面置换算法:**在所有的进程中找到一个合适的页面进行置换,这个页面可能是属于其他进程的。
725 |
726 | 全局算法在通常情况下工作的要比局部算法好,特别是当工作集大小随着进程运行时间而发生变化的情况下更明显。如果使用局部算法,即便有大量的空闲页框存在,工作集的增长也会导致颠簸。如果工作集缩小了,局部算法又会浪费内存。
727 |
728 | ### 页面大小
729 |
730 | 要确定最佳页面大小需要在几个因素之间进行权衡,不存在全局最优。
731 |
732 | 文章更倾向于选择小页面,有几个理由:
733 |
734 | 1. 随便选择一个正文段、数据段或堆栈段很可能不会恰好装满整个页面,平均情况下最后一个页面中有一半会是空的,而另一半空间就会被浪费掉了,这属于内部碎片。根据这方面考虑,还是小页面更好一点
735 | 2. 如果一个程序每个阶段需要4KB内存,但是页面大小为32KB,就会浪费掉这些内存,但是页面大小如果是4KB就不会产生浪费。
736 |
737 | 小页面又有一些不足之处:
738 |
739 | 1. 页面小意味着程序需要更多的页面,因此页表也就会变得更大。**由于内存与磁盘之间的传输一般是一次一页,传输中的大部分时间都花在寻道和旋转延迟上,所以传输一个小页面所用的时间和传输一个大页面基本是相同的。**因此装入64个512字节的页面需要64×10ms,但是装入4个8KB的页面只需要4×12ms
740 | 2. 每次CPU从一个进程切换到另一个进程时都必须把新进程的页表装入硬件寄存器中。页面越小,页表越多意味着装入寄存器花费的时间就会越长,而且页表占用的空间也会随着页面减小而增大。
741 |
742 | ------
743 |
744 | 小页面能够更充分的利用TLB空间。假设程序使用的内存为1MB,工作单元为64KB。若使用4KB的页面,则程序将至少占用TLB中的16个表项。使用2MB的页面时,1TLB表就够了。由于TLB表相对比较稀缺,条件允许的情况下使用大页面是值得的。为了进行必要的平衡,操作系统有时会为系统中的不同部分使用不同的页面大小。比如内核使用大页面,用户进程使用小页面。
745 |
746 | ### 内存映射文件
747 |
748 | 思想:进程可以通过发起一个系统调用将一个文件映射到其虚拟地址空间的一部分。在多数实现中,在映射共享的页面时候不会实际读入页面的内容,而是在访问页面时才会被每次一页的读入,磁盘文件则被当做后备存储。
749 |
750 | 如果两个或以上的进程同时映射了同一个文件,他们就可以通过共享内存来通信。 一个进程在共享内存上完成了写操作,此刻当另一个进程在映射到这个文件的虚拟地址空间上执行读操作时候,可以看到上面有一个进程写操作的结果。
751 |
752 | ### 分页守护进程
753 |
754 | 如果发生缺页中断时系统中有大量的空闲页框,此时分页系统工作在最佳状态。
755 |
756 | 如果每个页框都被占用,而且被修改过得话,当换入一个新页面时,旧页面应该首先被写回磁盘。
757 |
758 | 为保证有足够的空间页框,很多分页系统有一个称为分页守护进程的后台进程,它在大多数时候是睡眠的,但定期被唤醒已检查内存状态。如果空闲页框过少,分页守护进程通过预定的页面置换算法选择页面换出内存,如果这些页面被修改过,则写回磁盘。
759 |
760 | ### 与分页有关的工作
761 |
762 | 与分页有关的工作主要有四段:进程创建时,进程执行时,缺页中断时,进程终止时。
763 |
764 | - **进程创建时**
765 |
766 | 创建一个新进程的时候,操作系统要确定程序和数据在初始化时有多大,并为他们创建一个页表。然后OS还要在内存中为页表分配空间并对其初始化。
767 |
768 | 当进程被换出时,页表就不需要驻留在内存中了,但是运行的时候必须在内存中。
769 |
770 | OS在磁盘交换区中分配内存,以便在一个进程换出时在磁盘上有放置次进程的空间。OS还要用程序正文和数据对交换区初始化,这样当新进程发生缺页中断时候,可以调入需要的页面。
771 |
772 | 最后,OS必须把有关页表和磁盘交换区的信息存储在进程表中。
773 |
774 | - **进程执行时**
775 |
776 | 当调度一个新进程时候,必须重置MMU,刷新TLB,以清除以前的进程遗留的痕迹。新进程的页表必须成为当前页表,通常是复制该页表或者把指向该页表的指针放入某个硬件寄存器来实现的
777 |
778 | 在进程初始化时可以把该进程的部分或者全部页面装入内存以防止缺页中断
779 |
780 | - **缺页中断时**
781 |
782 | 当发生缺页中断时,OS通过读取硬件寄存器来确定是哪个虚拟地址造成了缺页中断,并在磁盘上对该页面进行定位。
783 |
784 | 然后找到合适的页框来存放新页面,必要时还要置换老的页面,然后把所需的页面读入页框。
785 |
786 | 然后回退程序计数器,使得程序计数器指向引起缺页中断的指令,并重新执行该指令。
787 |
788 | - **进程终止时**
789 |
790 | 进程退出的时候OS释放进程的页表,页面和页面在磁盘上所占用的空间。如果某些页面与其他进程共享,则当最后使用他的进程终止时才释放内存和磁盘。
791 |
792 | ### 对缺页中断的处理
793 |
794 | 1. 硬件陷入内核,在堆栈中保存程序计数器。大多数机器将当前的指令,各种状态信息保存在特殊的CPU寄存器中。
795 |
796 | 2. 启动一个汇编代码保存通用寄存器和其他易失信息,防止被操作系统破坏
797 |
798 | 3. 当操作系统收到缺页中断信号后,定位到需要的虚拟页面。
799 |
800 | 4. 找到发生缺页中断的虚拟地址,操作系统检查这个地址是否有效,并检查存取与保护是否一致。
801 |
802 | 如果不一致则杀掉该进程
803 |
804 | 如果地址有效且没有保护错误发生,系统会检查是否有空闲页框。如果没有空闲页框就执行页面置换算法淘汰一个页面。
805 |
806 | 5. 如果选择的页框对应的页面发生了修改,即为“脏页面”,需要写回磁盘,并发生一次上下文切换,挂起产生缺页中断的进程,让其他进程运行直至全部把内容写到磁盘。
807 |
808 | 6. 一旦页框是干净的,则OS会查找要发生置换的页面对应磁盘上的地址,通过磁盘操作将其装入。在装入该页面的时候,产生缺页中断的进程仍然被挂起,运行其他可运行的进程
809 |
810 | 7. 当发生磁盘中断时表明该页面已经被装入,页表已经更新可以反映其位置,页框也被标记为正常状态。
811 |
812 | 8. 恢复发生缺页中断指令以前的状态,程序计数器重新指向引起缺页中断的指令
813 |
814 | 9. 调度引发缺页中断的进程
815 |
816 | 10. 该进程恢复寄存器和其他状态信息,返回用户空间继续执行。
817 |
818 | ## 分段
819 |
820 | ### 概述
821 |
822 | 在没有分段之前我们讨论的都是一维的虚拟内存,如下图所示:
823 |
824 | 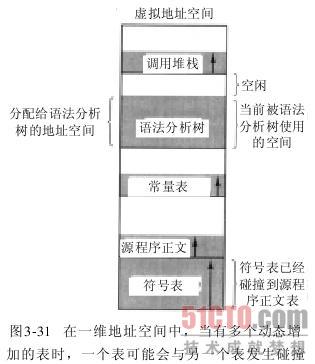 825 |
826 | 可以看到有调用堆栈、语法分析树、常量表、源程序正文、符号表这五部分。
827 |
828 | 堆栈的增长或者缩小是不可预估的,但是其他四个部分都是随着程序的运行而不断增长的。那么这个时候分配就是个问题了,这几个部分应该怎么分配才会在之间不会出现冲突呢?我们需要一个不需要程序员管理表扩展和收缩的方法。
829 |
830 | 因此一个直观并且通用的方法是在机器上提供多个互相独立的称为段的地址空间。每个段由一个从0到最大的线性地址序列构成。不同段的长度可以不同,段的长度在运行期间可以动态的改变。
831 |
832 | 每个段都构成了一个独立的地址空间,所以可以独立的增长或者减小而不影响到其他的段。如果一个在某个段中的堆栈需要更多的空间,就可以立刻得到需要的空间,因为其地址空间中没有其他的东西阻止其增长。段都很大,被装满的可能性很小。
833 |
834 | 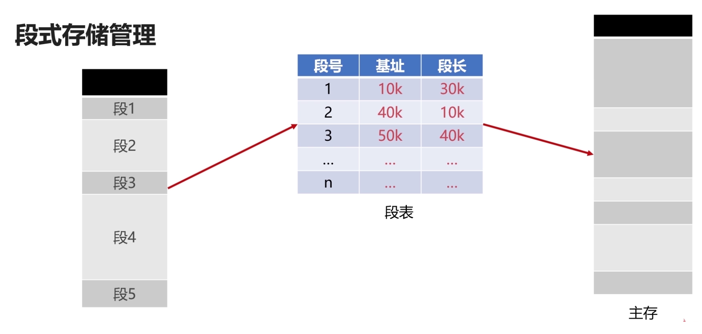
835 |
836 | **对比两种存储管理的方法:**
837 |
838 | **共同点:**
839 |
840 | 段式存储和页式存储都离散地管理了进程的逻辑空间
841 |
842 | **不同点:**
843 |
844 | 1. 页是物理单位,段是逻辑单位
845 | 2. 分页是为了合理利用空间,分段是为了满足用户要求
846 | 3. 页的大小由硬件固定,段的长度可以动态的变化
847 | 4. 页表信息是一维的,段表信息是二维的
848 |
849 | ### 段页式存储管理系统(Intel x86)
850 |
851 | 集分页和分段有点于一体的一种存储管理方法
852 |
853 | 1. 分页可以有效提高内存利用率
854 | 2. 分段可以更好满足用户需求
855 |
856 | > 段页式存储管理先将逻辑空间按段氏管理分成若干段再把段内空间按页式管理分成若干页,如下图:
857 | >
858 | > 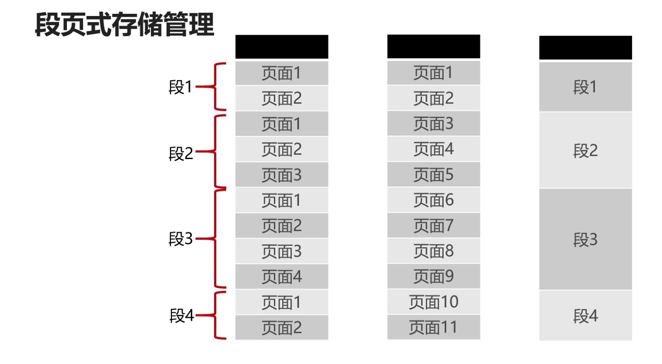
859 |
860 |
861 |
862 | # 死锁
863 |
864 | 考察几类死锁
865 |
866 | 了解如何出现,如何避免
867 |
868 | ## 资源
869 |
870 | 大部分死锁都可资源有关。
871 |
872 | **资源的定义:**在进程对设备,文件取得排他性访问时,有可能出现死锁。这类需要排他性使用的对象叫做死锁,资源可以使硬件设备或者一组信息。分为两类,可抢占资源和不可抢占资源。
873 |
874 | - 可抢占资源
875 |
876 | 定义:可以从拥有他的进程中抢占而不会产生任何副作用,存储器就是一类可抢占资源。
877 |
878 | 比如现在A进程拥有了打印机,但是内存被B进程所占用,因此会产生死锁的风险。但是我们可以将B进程换出内存,把A进程换入内存就可以实现抢占进程B的内存,这样的内存资源就是可抢占的。
879 |
880 | - 不可抢占资源
881 |
882 | 定义:在不引起相关的计算失败的情况下,无法把相关资源从占有他的进程处抢占过来。(反过来说就是如果这些资源被抢占了, 那么会引起相关操作失败)。比如磁盘光刻机,如果一个进程A开始刻录磁盘,但是突然刻录机被进程B占用了,那么这次磁盘刻录将失败,磁盘会被划坏。
883 |
884 | +++
885 |
886 | 因此某个资源是否可以抢占主要取决于上下文环境。
887 |
888 | 总体来说死锁与不可抢占资源有关,有关抢占资源而引发的潜在死锁可以通过进程之间重新分配资源而化解,因此我们这里只关注不可抢占资源引起的死锁。
889 |
890 | 使用一个资源的过程可以概括为如下的三部分:
891 |
892 | 1. 请求资源
893 | 2. 使用资源
894 | 3. 释放资源
895 |
896 | 当一个进程请求资源失败时,通常会处于请求资源、休眠、再请求这个循环中。这个进程虽然没有阻塞,但是确实没有做有价值的工作,实际和阻塞是一样的。
897 |
898 | +++
899 |
900 | 死锁简介
901 |
902 | > 死锁定义:如果一个进程集合中的每一个进程都在等待其他进程才能引发的事件,那么该进程就是死锁的。
903 | >
904 | > 由于所有进程都在等待,所以没有一个进程能够唤醒该进程集合中的其他进程的事件,因此所有的进程都只好无限等待下去
905 |
906 | 在大多数情况下每个进程所等待的是其他进程所释放的资源。换句话说就是产生死锁的进程集合中的每一个进程都在等待另一个死锁进程已经占有的资源,但是由于所有进程都不允许,任何一个都无法释放资源。这叫做资源死锁,是最常见的类型。
907 |
908 | +++
909 |
910 | 发生资源死锁的四个必要条件:
911 |
912 | 1. 互斥条件。每个资源要么分配给了一个进程,要么就是可用的。
913 | 2. 占有和等待条件。已经得到某个资源的进程可以请求新的资源
914 | 3. 不可抢占条件。已经分配给一个进程的资源不能强制性的被抢占,只能由占有它的进程释放掉
915 | 4. 环路等待条件。死锁发生时,系统中一定有两个或两个以上的进程组成环路,该环路中的每个进程都等待着下一个进程所占用的资源。
916 |
917 | 死锁发生时,这四个条件一定是同时满足的,如果其中任意一条不成立就不会发生死锁!
918 |
919 | +++
920 |
921 | ## 处理死锁
922 |
923 | 有四种处理死锁的策略:
924 |
925 | 1. 忽略该问题
926 | 2. 检测死锁并回复
927 | 3. 仔细对资源进行分配
928 | 4. 通过破坏引起死锁的必要条件之一
929 |
930 | ### 忽略该问题—鸵鸟算法
931 |
932 | 鸵鸟算法:把头埋在沙子里,当做无事发生。
933 |
934 | 有些人认为不论多大代价都要避免死锁,有的人认为假如死锁没五年发生一次,而每个月系统都因为硬件故障,编译错误而崩溃,那么大多数人肯定不会以性能损失和可用性为代价防止死锁
935 |
936 | +++
937 |
938 | ### 死锁检测和恢复
939 |
940 | 这种技术指的是系统并不阻止死锁的产生,而是允许死锁发生,当检测到发生死锁后采取相应措施恢复
941 |
942 | #### 检测
943 |
944 | - 每种类型一个资源的死锁检测
945 |
946 | 每种资源类型只有一个资源,比如扫描仪、刻录机、磁带机等,但是每个设备只有一台,不能有多台。
947 |
948 | > 我们可以为一个系统构造一个资源分配图,如下:
949 | >
950 | > 
951 | >
952 | > 上图为资源分配图,其中方框表示资源,圆圈表示进程。资源指向进程表示该资源已经分配给该进程,进程指向资源表示进程请求获取该资源。
953 | >
954 | > 图 a 可以抽取出环,如图 b,它满足了环路等待条件,因此会发生死锁。
955 | >
956 | > 每种类型一个资源的死锁检测算法是通过检测有向图是否存在环来实现,从一个节点出发进行深度优先搜索,对访问过的节点进行标记,如果访问了已经标记的节点,就表示有向图存在环,也就是检测到死锁的发生。
957 |
958 | +++
959 |
960 | - 每种类型多个资源的死锁检测
961 |
962 | 如果有多种相同资源的存在就需要用另一种办法检测死锁。
963 |
964 | > 
965 | >
966 | > 上图中,有三个进程四个资源,每个数据代表的含义如下:
967 | >
968 | > 1. E 向量:资源总量
969 | > 2. A 向量:资源剩余量
970 | > 3. C 矩阵:每个进程所拥有的资源数量,每一行都代表一个进程拥有资源的数量
971 | > 4. R 矩阵:每个进程请求的资源数量
972 | >
973 | > 进程 P1 和 P2 所请求的资源都得不到满足,只有进程 P3 可以,让 P3 执行,之后释放 P3 拥有的资源,此时 A = (2 2 2 0)。P2 可以执行,执行后释放 P2 拥有的资源,A = (4 2 2 1) 。P1 也可以执行。所有进程都可以顺利执行,没有死锁。
974 |
975 | 算法总结如下:
976 |
977 | 每个进程最开始时都不被标记,执行过程有可能被标记。当算法结束时,任何没有被标记的进程都是死锁进程。
978 |
979 | 1. 寻找一个没有标记的进程 Pi,它所请求的资源小于等于 A。
980 | 2. 如果找到了这样一个进程,那么将 C 矩阵的第 i 行向量加到 A 中,标记该进程,并转回 1。
981 | 3. 如果没有这样一个进程,算法终止。
982 |
983 | +++
984 |
985 | 现在我们知道了如何检测死锁,但是另一个问题是何时去检测他们。
986 |
987 | 1. 每当有资源请求时去检测,越早发现越好,但是这样会占用昂贵的CPU时间
988 | 2. 每个k分钟检测一次,或当CPU的使用频率降到某一阈值的时候去
989 |
990 | 考虑到CPU使用效率的原因,如果死锁进程数达到了一定数量,就没有多少进程可以运行了,所以CPU会经常性空闲。
991 |
992 | #### 恢复
993 |
994 | - 利用抢占恢复
995 |
996 | 在不通知原进程的情况下,将某一资源从一个进程强行取走给另外一个进程使用,接着又送回,这种做法是否可行取决于该资源本身的特性。用这种方法恢复通常来说比较困难或者不太可能。若选择挂起某个进程,则取决于那一个进程比较容易回收资源
997 |
998 | - 利用回滚恢复
999 |
1000 | 周期性的对进程进行备份,就是将进程的状态写入一个文件以备以后重启。这个行为叫做检查点检查,检查点中不仅包括存储映像,还有状态资源。同时新的检查点不应该覆盖原有的文件,而应该写到新文件中去。
1001 |
1002 | 有死锁发生就回滚到某一个时间点,该时间点后的所有工作全部丢失
1003 |
1004 | - 通过杀死进程恢复
1005 |
1006 | 最直接最野蛮,就是打破环中的进行,或者原则环外的一个进程牺牲掉。
1007 |
1008 | ### 死锁避免(P255)
1009 |
1010 | 大多数系统中,一次只能请求一个资源。系统必须能够判断分配资源是否安全,并且只能在保证安全的条件下分配资源、因此是否存在一种算法总能正确作出选择从而避免死锁?答案是肯定的,但条件是必须事先获得一些信息。
1011 |
1012 | #### 安全状态
1013 |
1014 | 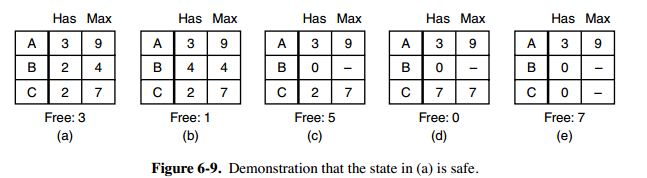
1015 |
1016 | 图 a 的第二列 Has 表示已拥有的资源数,第三列 Max 表示总共需要的资源数,Free 表示还有可以使用的资源数。从图 a 开始出发,先让 B 拥有所需的所有资源(图 b),运行结束后释放 B,此时 Free 变为 5(图 c);接着以同样的方式运行 C 和 A,使得所有进程都能成功运行,因此可以称图 a 所示的状态时安全的。
1017 |
1018 | 定义:如果没有死锁发生,并且即使所有进程突然请求对资源的最大需求,也仍然存在某种调度次序能够使得每一个进程运行完毕,则称该状态是安全的。
1019 |
1020 | 安全状态的检测与死锁的检测类似,因为安全状态必须要求不能发生死锁。下面的银行家算法与死锁检测算法非常类似,可以结合着做参考对比。
1021 |
1022 | #### 单个资源的银行家算法
1023 |
1024 | 一个小城镇的银行家,他向一群客户分别承诺了一定的贷款额度,算法要做的是判断对请求的满足是否会进入不安全状态,如果是,就拒绝请求;否则予以分配。
1025 |
1026 | 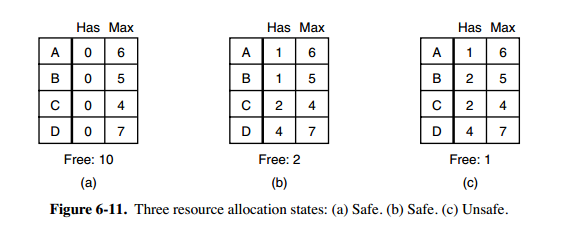
1027 |
1028 | 上图 c 为不安全状态,因此算法会拒绝之前的请求,从而避免进入图 c 中的状态
1029 |
1030 | #### 多个资源的银行家算法
1031 |
1032 | 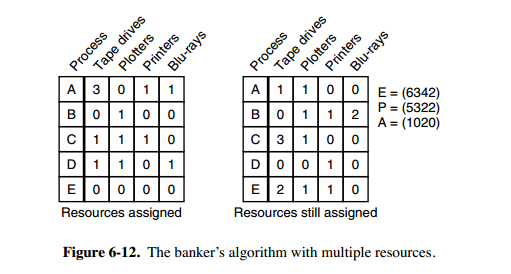
1033 |
1034 | 上图中有五个进程,四个资源。左边的图表示已经分配的资源,右边的图表示还需要分配的资源。最右边的 E、P 以及 A 分别表示:总资源、已分配资源以及可用资源,注意这三个为向量,而不是具体数值,例如 A=(1020),表示 4 个资源分别还剩下 1/0/2/0。
1035 |
1036 | 检查一个状态是否安全的算法如下:
1037 |
1038 | - 查找右边的矩阵是否存在一行小于等于向量 A。如果不存在这样的行,那么系统将会发生死锁,状态是不安全的。
1039 | - 假若找到这样一行,将该进程标记为终止,并将其已分配资源加到 A 中。
1040 | - 重复以上两步,直到所有进程都标记为终止,则状态时安全的。
1041 |
1042 | 如果一个状态不是安全的,需要拒绝进入这个状态。
1043 |
1044 | ### 死锁预防
1045 |
1046 | - 破坏互斥条件
1047 |
1048 | - 破坏占有并等待条件
1049 |
1050 | - 破坏不可抢占条件
1051 |
1052 | - 破坏环路等待条件
1053 |
1054 | 在面试那一篇文章中都有写。
1055 |
--------------------------------------------------------------------------------
/书籍笔记/汇编语言.md:
--------------------------------------------------------------------------------
1 | ## 汇编语言的不同种类
2 |
3 | - as86汇编:能产生16位代码的Intel 8086汇编
4 |
5 | ```
6 | mov ax, cs //cs→ax,目标操作数在前
7 | ```
8 |
9 | - GNU as汇编:产生32位代码,使用AT&T系统V语法
10 |
11 | ```
12 | movl var, %eax // var→%eax,目标操作数在后
13 | ```
14 |
15 | - 内嵌汇编,gcc编译x.c文件会产生中间结果汇编文件
16 |
17 | ## 汇编语言的组成
18 |
19 | 汇编语言由三部分组成:
20 |
21 | 1. 汇编指令。通过编译器把指令翻译成机器指令,也就是机器码
22 | 2. 伪指令。告诉编译器如何翻译
23 | 3. 符号体系。`+-*/`
24 |
25 | ## RAM和ROM
26 |
27 | 内存最小单元:**字节**
28 |
29 | RAM(Random Access Memory)(随机存取存储器):允许读和写,断电后指令和数据就丢失了,直接与cpu交换数据
30 |
31 | ROM(Read-Only Memory(只读存储器):只允许读,断电后指令和数据都存在
32 |
33 | ## CPU中的三条总线
34 |
35 | CPU通过地址总线,数据总线和控制总线实现对外部元器件的控制,三种总线的宽度标志了CPU不同方面的性能:
36 |
37 | 1. 地址总线的宽度决定了CPU的寻址能力
38 | 2. 数据总线的宽度决定了CPU与其他器件进行数据传输的能力(一次传输的数据量)
39 | 3. 控制总线的宽度决定了CPU对系统中其他器件的控制能力
40 |
41 |
42 |
43 | ## 8086CPU给出读取物理地址的方法
44 |
45 |
825 |
826 | 可以看到有调用堆栈、语法分析树、常量表、源程序正文、符号表这五部分。
827 |
828 | 堆栈的增长或者缩小是不可预估的,但是其他四个部分都是随着程序的运行而不断增长的。那么这个时候分配就是个问题了,这几个部分应该怎么分配才会在之间不会出现冲突呢?我们需要一个不需要程序员管理表扩展和收缩的方法。
829 |
830 | 因此一个直观并且通用的方法是在机器上提供多个互相独立的称为段的地址空间。每个段由一个从0到最大的线性地址序列构成。不同段的长度可以不同,段的长度在运行期间可以动态的改变。
831 |
832 | 每个段都构成了一个独立的地址空间,所以可以独立的增长或者减小而不影响到其他的段。如果一个在某个段中的堆栈需要更多的空间,就可以立刻得到需要的空间,因为其地址空间中没有其他的东西阻止其增长。段都很大,被装满的可能性很小。
833 |
834 | 
835 |
836 | **对比两种存储管理的方法:**
837 |
838 | **共同点:**
839 |
840 | 段式存储和页式存储都离散地管理了进程的逻辑空间
841 |
842 | **不同点:**
843 |
844 | 1. 页是物理单位,段是逻辑单位
845 | 2. 分页是为了合理利用空间,分段是为了满足用户要求
846 | 3. 页的大小由硬件固定,段的长度可以动态的变化
847 | 4. 页表信息是一维的,段表信息是二维的
848 |
849 | ### 段页式存储管理系统(Intel x86)
850 |
851 | 集分页和分段有点于一体的一种存储管理方法
852 |
853 | 1. 分页可以有效提高内存利用率
854 | 2. 分段可以更好满足用户需求
855 |
856 | > 段页式存储管理先将逻辑空间按段氏管理分成若干段再把段内空间按页式管理分成若干页,如下图:
857 | >
858 | > 
859 |
860 |
861 |
862 | # 死锁
863 |
864 | 考察几类死锁
865 |
866 | 了解如何出现,如何避免
867 |
868 | ## 资源
869 |
870 | 大部分死锁都可资源有关。
871 |
872 | **资源的定义:**在进程对设备,文件取得排他性访问时,有可能出现死锁。这类需要排他性使用的对象叫做死锁,资源可以使硬件设备或者一组信息。分为两类,可抢占资源和不可抢占资源。
873 |
874 | - 可抢占资源
875 |
876 | 定义:可以从拥有他的进程中抢占而不会产生任何副作用,存储器就是一类可抢占资源。
877 |
878 | 比如现在A进程拥有了打印机,但是内存被B进程所占用,因此会产生死锁的风险。但是我们可以将B进程换出内存,把A进程换入内存就可以实现抢占进程B的内存,这样的内存资源就是可抢占的。
879 |
880 | - 不可抢占资源
881 |
882 | 定义:在不引起相关的计算失败的情况下,无法把相关资源从占有他的进程处抢占过来。(反过来说就是如果这些资源被抢占了, 那么会引起相关操作失败)。比如磁盘光刻机,如果一个进程A开始刻录磁盘,但是突然刻录机被进程B占用了,那么这次磁盘刻录将失败,磁盘会被划坏。
883 |
884 | +++
885 |
886 | 因此某个资源是否可以抢占主要取决于上下文环境。
887 |
888 | 总体来说死锁与不可抢占资源有关,有关抢占资源而引发的潜在死锁可以通过进程之间重新分配资源而化解,因此我们这里只关注不可抢占资源引起的死锁。
889 |
890 | 使用一个资源的过程可以概括为如下的三部分:
891 |
892 | 1. 请求资源
893 | 2. 使用资源
894 | 3. 释放资源
895 |
896 | 当一个进程请求资源失败时,通常会处于请求资源、休眠、再请求这个循环中。这个进程虽然没有阻塞,但是确实没有做有价值的工作,实际和阻塞是一样的。
897 |
898 | +++
899 |
900 | 死锁简介
901 |
902 | > 死锁定义:如果一个进程集合中的每一个进程都在等待其他进程才能引发的事件,那么该进程就是死锁的。
903 | >
904 | > 由于所有进程都在等待,所以没有一个进程能够唤醒该进程集合中的其他进程的事件,因此所有的进程都只好无限等待下去
905 |
906 | 在大多数情况下每个进程所等待的是其他进程所释放的资源。换句话说就是产生死锁的进程集合中的每一个进程都在等待另一个死锁进程已经占有的资源,但是由于所有进程都不允许,任何一个都无法释放资源。这叫做资源死锁,是最常见的类型。
907 |
908 | +++
909 |
910 | 发生资源死锁的四个必要条件:
911 |
912 | 1. 互斥条件。每个资源要么分配给了一个进程,要么就是可用的。
913 | 2. 占有和等待条件。已经得到某个资源的进程可以请求新的资源
914 | 3. 不可抢占条件。已经分配给一个进程的资源不能强制性的被抢占,只能由占有它的进程释放掉
915 | 4. 环路等待条件。死锁发生时,系统中一定有两个或两个以上的进程组成环路,该环路中的每个进程都等待着下一个进程所占用的资源。
916 |
917 | 死锁发生时,这四个条件一定是同时满足的,如果其中任意一条不成立就不会发生死锁!
918 |
919 | +++
920 |
921 | ## 处理死锁
922 |
923 | 有四种处理死锁的策略:
924 |
925 | 1. 忽略该问题
926 | 2. 检测死锁并回复
927 | 3. 仔细对资源进行分配
928 | 4. 通过破坏引起死锁的必要条件之一
929 |
930 | ### 忽略该问题—鸵鸟算法
931 |
932 | 鸵鸟算法:把头埋在沙子里,当做无事发生。
933 |
934 | 有些人认为不论多大代价都要避免死锁,有的人认为假如死锁没五年发生一次,而每个月系统都因为硬件故障,编译错误而崩溃,那么大多数人肯定不会以性能损失和可用性为代价防止死锁
935 |
936 | +++
937 |
938 | ### 死锁检测和恢复
939 |
940 | 这种技术指的是系统并不阻止死锁的产生,而是允许死锁发生,当检测到发生死锁后采取相应措施恢复
941 |
942 | #### 检测
943 |
944 | - 每种类型一个资源的死锁检测
945 |
946 | 每种资源类型只有一个资源,比如扫描仪、刻录机、磁带机等,但是每个设备只有一台,不能有多台。
947 |
948 | > 我们可以为一个系统构造一个资源分配图,如下:
949 | >
950 | > 
951 | >
952 | > 上图为资源分配图,其中方框表示资源,圆圈表示进程。资源指向进程表示该资源已经分配给该进程,进程指向资源表示进程请求获取该资源。
953 | >
954 | > 图 a 可以抽取出环,如图 b,它满足了环路等待条件,因此会发生死锁。
955 | >
956 | > 每种类型一个资源的死锁检测算法是通过检测有向图是否存在环来实现,从一个节点出发进行深度优先搜索,对访问过的节点进行标记,如果访问了已经标记的节点,就表示有向图存在环,也就是检测到死锁的发生。
957 |
958 | +++
959 |
960 | - 每种类型多个资源的死锁检测
961 |
962 | 如果有多种相同资源的存在就需要用另一种办法检测死锁。
963 |
964 | > 
965 | >
966 | > 上图中,有三个进程四个资源,每个数据代表的含义如下:
967 | >
968 | > 1. E 向量:资源总量
969 | > 2. A 向量:资源剩余量
970 | > 3. C 矩阵:每个进程所拥有的资源数量,每一行都代表一个进程拥有资源的数量
971 | > 4. R 矩阵:每个进程请求的资源数量
972 | >
973 | > 进程 P1 和 P2 所请求的资源都得不到满足,只有进程 P3 可以,让 P3 执行,之后释放 P3 拥有的资源,此时 A = (2 2 2 0)。P2 可以执行,执行后释放 P2 拥有的资源,A = (4 2 2 1) 。P1 也可以执行。所有进程都可以顺利执行,没有死锁。
974 |
975 | 算法总结如下:
976 |
977 | 每个进程最开始时都不被标记,执行过程有可能被标记。当算法结束时,任何没有被标记的进程都是死锁进程。
978 |
979 | 1. 寻找一个没有标记的进程 Pi,它所请求的资源小于等于 A。
980 | 2. 如果找到了这样一个进程,那么将 C 矩阵的第 i 行向量加到 A 中,标记该进程,并转回 1。
981 | 3. 如果没有这样一个进程,算法终止。
982 |
983 | +++
984 |
985 | 现在我们知道了如何检测死锁,但是另一个问题是何时去检测他们。
986 |
987 | 1. 每当有资源请求时去检测,越早发现越好,但是这样会占用昂贵的CPU时间
988 | 2. 每个k分钟检测一次,或当CPU的使用频率降到某一阈值的时候去
989 |
990 | 考虑到CPU使用效率的原因,如果死锁进程数达到了一定数量,就没有多少进程可以运行了,所以CPU会经常性空闲。
991 |
992 | #### 恢复
993 |
994 | - 利用抢占恢复
995 |
996 | 在不通知原进程的情况下,将某一资源从一个进程强行取走给另外一个进程使用,接着又送回,这种做法是否可行取决于该资源本身的特性。用这种方法恢复通常来说比较困难或者不太可能。若选择挂起某个进程,则取决于那一个进程比较容易回收资源
997 |
998 | - 利用回滚恢复
999 |
1000 | 周期性的对进程进行备份,就是将进程的状态写入一个文件以备以后重启。这个行为叫做检查点检查,检查点中不仅包括存储映像,还有状态资源。同时新的检查点不应该覆盖原有的文件,而应该写到新文件中去。
1001 |
1002 | 有死锁发生就回滚到某一个时间点,该时间点后的所有工作全部丢失
1003 |
1004 | - 通过杀死进程恢复
1005 |
1006 | 最直接最野蛮,就是打破环中的进行,或者原则环外的一个进程牺牲掉。
1007 |
1008 | ### 死锁避免(P255)
1009 |
1010 | 大多数系统中,一次只能请求一个资源。系统必须能够判断分配资源是否安全,并且只能在保证安全的条件下分配资源、因此是否存在一种算法总能正确作出选择从而避免死锁?答案是肯定的,但条件是必须事先获得一些信息。
1011 |
1012 | #### 安全状态
1013 |
1014 | 
1015 |
1016 | 图 a 的第二列 Has 表示已拥有的资源数,第三列 Max 表示总共需要的资源数,Free 表示还有可以使用的资源数。从图 a 开始出发,先让 B 拥有所需的所有资源(图 b),运行结束后释放 B,此时 Free 变为 5(图 c);接着以同样的方式运行 C 和 A,使得所有进程都能成功运行,因此可以称图 a 所示的状态时安全的。
1017 |
1018 | 定义:如果没有死锁发生,并且即使所有进程突然请求对资源的最大需求,也仍然存在某种调度次序能够使得每一个进程运行完毕,则称该状态是安全的。
1019 |
1020 | 安全状态的检测与死锁的检测类似,因为安全状态必须要求不能发生死锁。下面的银行家算法与死锁检测算法非常类似,可以结合着做参考对比。
1021 |
1022 | #### 单个资源的银行家算法
1023 |
1024 | 一个小城镇的银行家,他向一群客户分别承诺了一定的贷款额度,算法要做的是判断对请求的满足是否会进入不安全状态,如果是,就拒绝请求;否则予以分配。
1025 |
1026 | 
1027 |
1028 | 上图 c 为不安全状态,因此算法会拒绝之前的请求,从而避免进入图 c 中的状态
1029 |
1030 | #### 多个资源的银行家算法
1031 |
1032 | 
1033 |
1034 | 上图中有五个进程,四个资源。左边的图表示已经分配的资源,右边的图表示还需要分配的资源。最右边的 E、P 以及 A 分别表示:总资源、已分配资源以及可用资源,注意这三个为向量,而不是具体数值,例如 A=(1020),表示 4 个资源分别还剩下 1/0/2/0。
1035 |
1036 | 检查一个状态是否安全的算法如下:
1037 |
1038 | - 查找右边的矩阵是否存在一行小于等于向量 A。如果不存在这样的行,那么系统将会发生死锁,状态是不安全的。
1039 | - 假若找到这样一行,将该进程标记为终止,并将其已分配资源加到 A 中。
1040 | - 重复以上两步,直到所有进程都标记为终止,则状态时安全的。
1041 |
1042 | 如果一个状态不是安全的,需要拒绝进入这个状态。
1043 |
1044 | ### 死锁预防
1045 |
1046 | - 破坏互斥条件
1047 |
1048 | - 破坏占有并等待条件
1049 |
1050 | - 破坏不可抢占条件
1051 |
1052 | - 破坏环路等待条件
1053 |
1054 | 在面试那一篇文章中都有写。
1055 |
--------------------------------------------------------------------------------
/书籍笔记/汇编语言.md:
--------------------------------------------------------------------------------
1 | ## 汇编语言的不同种类
2 |
3 | - as86汇编:能产生16位代码的Intel 8086汇编
4 |
5 | ```
6 | mov ax, cs //cs→ax,目标操作数在前
7 | ```
8 |
9 | - GNU as汇编:产生32位代码,使用AT&T系统V语法
10 |
11 | ```
12 | movl var, %eax // var→%eax,目标操作数在后
13 | ```
14 |
15 | - 内嵌汇编,gcc编译x.c文件会产生中间结果汇编文件
16 |
17 | ## 汇编语言的组成
18 |
19 | 汇编语言由三部分组成:
20 |
21 | 1. 汇编指令。通过编译器把指令翻译成机器指令,也就是机器码
22 | 2. 伪指令。告诉编译器如何翻译
23 | 3. 符号体系。`+-*/`
24 |
25 | ## RAM和ROM
26 |
27 | 内存最小单元:**字节**
28 |
29 | RAM(Random Access Memory)(随机存取存储器):允许读和写,断电后指令和数据就丢失了,直接与cpu交换数据
30 |
31 | ROM(Read-Only Memory(只读存储器):只允许读,断电后指令和数据都存在
32 |
33 | ## CPU中的三条总线
34 |
35 | CPU通过地址总线,数据总线和控制总线实现对外部元器件的控制,三种总线的宽度标志了CPU不同方面的性能:
36 |
37 | 1. 地址总线的宽度决定了CPU的寻址能力
38 | 2. 数据总线的宽度决定了CPU与其他器件进行数据传输的能力(一次传输的数据量)
39 | 3. 控制总线的宽度决定了CPU对系统中其他器件的控制能力
40 |
41 |
42 |
43 | ## 8086CPU给出读取物理地址的方法
44 |
45 |  46 |
47 | 1. CPU中的相关部件提供两个16位的地址,一个是段地址,一个是偏移地址
48 | 2. 段地址和偏移地址通过内部总线送入一个成为地址加法器的部件
49 | 3. 地址加法器将两个16位的地址合成为一个20位的物理地址
50 | 4. 地址加法器通过内部总线将20位物理地址送入输入输出控制电路
51 | 5. 20位物理地址被地址总线传送到存储器
52 |
53 | **物理地址 = 段地址 * 16 + 偏移地址(段地址*16就相当于左移4位)**
54 |
55 | 上述的本质含义是:CPU在访问内存时,用一个基础地址和一个相对于基础地址的偏移地址相加,给出内存单元的物理地址。
56 |
57 |
46 |
47 | 1. CPU中的相关部件提供两个16位的地址,一个是段地址,一个是偏移地址
48 | 2. 段地址和偏移地址通过内部总线送入一个成为地址加法器的部件
49 | 3. 地址加法器将两个16位的地址合成为一个20位的物理地址
50 | 4. 地址加法器通过内部总线将20位物理地址送入输入输出控制电路
51 | 5. 20位物理地址被地址总线传送到存储器
52 |
53 | **物理地址 = 段地址 * 16 + 偏移地址(段地址*16就相当于左移4位)**
54 |
55 | 上述的本质含义是:CPU在访问内存时,用一个基础地址和一个相对于基础地址的偏移地址相加,给出内存单元的物理地址。
56 |
57 |  58 |
59 | 为什么非得是基础地址+偏移地址的思想如上图所示
60 |
61 |
62 |
63 | ## 段寄存器
64 |
65 | 由于CPU访问内存时候需要相关部件提供内存单元的段地址和偏移地址,以便送入地址加法器合成物理地址,因此段寄存器主要提供段地址,8086CPU有4个段寄存器:**CS **
66 |
67 | ** 、DS、SS、ES**
68 |
69 | CS:代码段寄存器
70 |
71 | IP:指令指针寄存器
72 |
73 | 加入CS中的内容为M,IP中的内容为N,则从内存M*16+N单元开始读取一条指令并执行。**即将CS:IP寄存器指向的内存单元当做指令,CS当做指令的段地址,IP当做偏移地址**
74 |
75 | > 总结一下寄存器和段寄存器的种类
76 | >
77 | > 寄存器:ax、bx、cx、dx、ah、al、bh、bl、ch、cl、dh、dl、sp、bp、si、di
78 | >
79 | > 段寄存器:ds、ss、cs、es
80 |
81 | ## CPU中的栈
82 |
83 | 段寄存器SS和寄存器SP表示了栈顶的位置,栈顶的段地址存放在SS中,偏移地址存放在SP中。**即SS:SP指向栈顶元素**
84 |
85 | push和pop指令执行时,CPU从SS和SP中得到栈顶的地址。
86 |
87 | 入栈的时候,栈顶从高地址向低地址方向增长。
88 |
89 | 8086处理器不会去管理栈顶超界的问题,需要我们自己小心是否会有越界行为。
90 |
91 | 总结:
92 |
93 | 
94 |
95 | 
96 |
97 |
98 |
99 | ## 源程序和程序
100 |
101 | 一段源程序包含汇编指令和伪指令,汇编指令是由计算机执行、处理的指令或者数据,一般叫做程序
102 |
103 | 伪指令就是不由计算机执行,而是编译器执行的代码
104 |
105 | 源程序就是程序+伪指令
106 |
107 |
58 |
59 | 为什么非得是基础地址+偏移地址的思想如上图所示
60 |
61 |
62 |
63 | ## 段寄存器
64 |
65 | 由于CPU访问内存时候需要相关部件提供内存单元的段地址和偏移地址,以便送入地址加法器合成物理地址,因此段寄存器主要提供段地址,8086CPU有4个段寄存器:**CS **
66 |
67 | ** 、DS、SS、ES**
68 |
69 | CS:代码段寄存器
70 |
71 | IP:指令指针寄存器
72 |
73 | 加入CS中的内容为M,IP中的内容为N,则从内存M*16+N单元开始读取一条指令并执行。**即将CS:IP寄存器指向的内存单元当做指令,CS当做指令的段地址,IP当做偏移地址**
74 |
75 | > 总结一下寄存器和段寄存器的种类
76 | >
77 | > 寄存器:ax、bx、cx、dx、ah、al、bh、bl、ch、cl、dh、dl、sp、bp、si、di
78 | >
79 | > 段寄存器:ds、ss、cs、es
80 |
81 | ## CPU中的栈
82 |
83 | 段寄存器SS和寄存器SP表示了栈顶的位置,栈顶的段地址存放在SS中,偏移地址存放在SP中。**即SS:SP指向栈顶元素**
84 |
85 | push和pop指令执行时,CPU从SS和SP中得到栈顶的地址。
86 |
87 | 入栈的时候,栈顶从高地址向低地址方向增长。
88 |
89 | 8086处理器不会去管理栈顶超界的问题,需要我们自己小心是否会有越界行为。
90 |
91 | 总结:
92 |
93 | 
94 |
95 | 
96 |
97 |
98 |
99 | ## 源程序和程序
100 |
101 | 一段源程序包含汇编指令和伪指令,汇编指令是由计算机执行、处理的指令或者数据,一般叫做程序
102 |
103 | 伪指令就是不由计算机执行,而是编译器执行的代码
104 |
105 | 源程序就是程序+伪指令
106 |
107 |  108 |
109 | ## 程序执行过程的跟踪
110 |
111 | 
112 |
113 | 1.obj是目标文件
114 |
115 | 目标文件要连接外界需要的库形成可执行文件
116 |
117 | 可执行文件被操作系统提供的shell程序加载进入内存,然后获得cpu执行
118 |
119 | 可执行文件中程序执行完毕后,cpu返还给shell0
120 |
121 | ## [BX]和loop指令
122 |
123 | [bx]和[0]有些类似,[0]表示内存单元,其偏移量是0,例如:
124 |
125 | 1. mov ax, [0]
126 |
127 | 表示将一个内存单元的内容送入ax中,这个内存单元的长度为2字节,存1个字,偏移地址为0,段地址在ds中
128 |
129 | 2. mov al, [0]
130 |
131 | 将一个内存单元的内容送入al中,这个内存单元的长度为1字节,存1个字节,偏移地址为0,段地址在ds中
132 |
133 | 3. mov ax, [bx]
134 |
135 | 将一个内存单元的内容送入ax中,这个内存单元的长度为2字节,存1个字,偏移地址在bx中,段地址在ds中
136 |
137 | 也可以**段前缀**来表示:
138 |
139 | 1. mov ax,ds:[bx]
140 |
141 | 表示将一个内存单元的内容送入ax,这个内存单元2个字节,存放1个字,偏移地址在bx中,段地址在ds中
142 |
143 | ## 可执行文件的组成
144 |
145 | 可执行文件由**描述信息**和**程序**组成,程序来自于源程序中的汇编指令和定义的数据。描述信息则主要是编译,连接程序对源程序中相关伪指令进行处理所得到的信息。
146 |
147 | ## 数据、指令、栈放入不同的栈
148 |
149 | CPU到底如何处理我们定义的段中的内容,是当做指令执行,当做数据访问还是当做栈空间,完全是靠程序中具体的汇编指令,即:
150 |
151 | 1. CS:IP -----指令
152 | 2. SS:SP----- 栈
153 | 3. DS-----数据
154 |
155 | ## 与运算和或运算
156 |
157 | - 与(and)
158 |
159 | 这个操作可以将操作对象的相应位置设为0,因为全1才为1。
160 |
161 | - 或(or)
162 |
163 | 该操作可以将操作对象的相应位设为1,因为有1就为1。
164 |
165 | ## [bx+idata]:一种更灵活的指明内存的方式
166 |
167 | 之前前面说到过用[bx]来指明一个内存单元,我们还可以用一种更为灵活的方式指明内存单元。
168 |
169 | [bx+idata]表明一个内存单元,它的偏移地址为bx+idata(bx中的数值加上idata)
170 |
171 | 比如mov ax, [bx + 200]指的是将一个内存单元的内容送入ax,这个内存单元长2字节,存放1个字,偏移地址为bx中的数值加上200,段地址在ds中
172 |
173 | ## 几种不同的寻址方式
174 |
175 | 1. **[idata]**用一个常量表示地址,可用于直接定位一个内存单元
176 | 2. **[bx]**用一个变量来表示内存地址,可用于简介定位一个内存单元
177 | 3. **[bx+idata]**用一个变量和常量来表示地址,可在一个起始地址的基础上用变量简介定位一个内存单元
178 | 4. **[bx+si]**用两个变量表示地址
179 | 5. **[bx+si+idata]**用两个变量和一个常量表示地址
180 |
181 | ## 汇编语言中数据位置的表达
182 |
183 | 1. 立即数(idata)
184 |
185 | 直接包含在机器指令中的数据(执行前在CPU的指令缓冲器中)
186 |
187 | 2. 寄存器
188 |
189 | 指令要处理的数据在寄存器中,给出相应寄存器的名就行
190 |
191 | 3. 段地址(SA)和偏移地址(EA)
192 |
193 | 如果指令要处理的数据在内存中,在汇编指令中用[X]的格式给出SA、EA在某个段寄存器中
194 |
195 | ## 转移指令的原理
196 |
197 | > 可以修改IP或同时修改CS和IP的指令统称为转移指令。转移指令就是可以控制CPU执行内存中某处代码的指令。
198 |
199 | 8086CPU的转移指令分为以下几类:
200 |
201 | - 无条件转移指令
202 |
203 | 主要有jmp指令,可以同时修改CS和IP。主要给出两种信息:
204 |
205 | 1. 转移的目的地址
206 |
207 | 2. 转移的距离(段间转移、段内转移、段内近转移)
208 |
209 | - 条件转移指令
210 |
211 | jcxz指令,所有的有条件转移指令都是短转移,对IP的修改范围是:-128~127
212 |
213 | - 循环指令
214 |
215 | loop指令,短转移,对IP的修改范围是:-128~127循环指令
216 |
217 | - 过程
218 |
219 | - 中断
220 |
221 | ## CALL和RET指令
222 |
223 | call和ret指令都是转移指令,他们都修改IP,或同时修改CS和IP。
224 |
225 | - ret和retf
226 |
227 | ret指令用栈中的数据修改IP的内容,从而实现近转移
228 |
229 | retf指令用栈中的数据修改CS和IP的内容,从而实现远转移
230 |
231 | - call
232 |
233 | CPU执行call指令时,有两步操作:
234 |
235 | 1. 将当前的IP或CS和IP压入栈中
236 | 2. 转移
237 |
238 | call指令不能实现短转移
239 |
240 | ## flag寄存器
241 |
242 |
108 |
109 | ## 程序执行过程的跟踪
110 |
111 | 
112 |
113 | 1.obj是目标文件
114 |
115 | 目标文件要连接外界需要的库形成可执行文件
116 |
117 | 可执行文件被操作系统提供的shell程序加载进入内存,然后获得cpu执行
118 |
119 | 可执行文件中程序执行完毕后,cpu返还给shell0
120 |
121 | ## [BX]和loop指令
122 |
123 | [bx]和[0]有些类似,[0]表示内存单元,其偏移量是0,例如:
124 |
125 | 1. mov ax, [0]
126 |
127 | 表示将一个内存单元的内容送入ax中,这个内存单元的长度为2字节,存1个字,偏移地址为0,段地址在ds中
128 |
129 | 2. mov al, [0]
130 |
131 | 将一个内存单元的内容送入al中,这个内存单元的长度为1字节,存1个字节,偏移地址为0,段地址在ds中
132 |
133 | 3. mov ax, [bx]
134 |
135 | 将一个内存单元的内容送入ax中,这个内存单元的长度为2字节,存1个字,偏移地址在bx中,段地址在ds中
136 |
137 | 也可以**段前缀**来表示:
138 |
139 | 1. mov ax,ds:[bx]
140 |
141 | 表示将一个内存单元的内容送入ax,这个内存单元2个字节,存放1个字,偏移地址在bx中,段地址在ds中
142 |
143 | ## 可执行文件的组成
144 |
145 | 可执行文件由**描述信息**和**程序**组成,程序来自于源程序中的汇编指令和定义的数据。描述信息则主要是编译,连接程序对源程序中相关伪指令进行处理所得到的信息。
146 |
147 | ## 数据、指令、栈放入不同的栈
148 |
149 | CPU到底如何处理我们定义的段中的内容,是当做指令执行,当做数据访问还是当做栈空间,完全是靠程序中具体的汇编指令,即:
150 |
151 | 1. CS:IP -----指令
152 | 2. SS:SP----- 栈
153 | 3. DS-----数据
154 |
155 | ## 与运算和或运算
156 |
157 | - 与(and)
158 |
159 | 这个操作可以将操作对象的相应位置设为0,因为全1才为1。
160 |
161 | - 或(or)
162 |
163 | 该操作可以将操作对象的相应位设为1,因为有1就为1。
164 |
165 | ## [bx+idata]:一种更灵活的指明内存的方式
166 |
167 | 之前前面说到过用[bx]来指明一个内存单元,我们还可以用一种更为灵活的方式指明内存单元。
168 |
169 | [bx+idata]表明一个内存单元,它的偏移地址为bx+idata(bx中的数值加上idata)
170 |
171 | 比如mov ax, [bx + 200]指的是将一个内存单元的内容送入ax,这个内存单元长2字节,存放1个字,偏移地址为bx中的数值加上200,段地址在ds中
172 |
173 | ## 几种不同的寻址方式
174 |
175 | 1. **[idata]**用一个常量表示地址,可用于直接定位一个内存单元
176 | 2. **[bx]**用一个变量来表示内存地址,可用于简介定位一个内存单元
177 | 3. **[bx+idata]**用一个变量和常量来表示地址,可在一个起始地址的基础上用变量简介定位一个内存单元
178 | 4. **[bx+si]**用两个变量表示地址
179 | 5. **[bx+si+idata]**用两个变量和一个常量表示地址
180 |
181 | ## 汇编语言中数据位置的表达
182 |
183 | 1. 立即数(idata)
184 |
185 | 直接包含在机器指令中的数据(执行前在CPU的指令缓冲器中)
186 |
187 | 2. 寄存器
188 |
189 | 指令要处理的数据在寄存器中,给出相应寄存器的名就行
190 |
191 | 3. 段地址(SA)和偏移地址(EA)
192 |
193 | 如果指令要处理的数据在内存中,在汇编指令中用[X]的格式给出SA、EA在某个段寄存器中
194 |
195 | ## 转移指令的原理
196 |
197 | > 可以修改IP或同时修改CS和IP的指令统称为转移指令。转移指令就是可以控制CPU执行内存中某处代码的指令。
198 |
199 | 8086CPU的转移指令分为以下几类:
200 |
201 | - 无条件转移指令
202 |
203 | 主要有jmp指令,可以同时修改CS和IP。主要给出两种信息:
204 |
205 | 1. 转移的目的地址
206 |
207 | 2. 转移的距离(段间转移、段内转移、段内近转移)
208 |
209 | - 条件转移指令
210 |
211 | jcxz指令,所有的有条件转移指令都是短转移,对IP的修改范围是:-128~127
212 |
213 | - 循环指令
214 |
215 | loop指令,短转移,对IP的修改范围是:-128~127循环指令
216 |
217 | - 过程
218 |
219 | - 中断
220 |
221 | ## CALL和RET指令
222 |
223 | call和ret指令都是转移指令,他们都修改IP,或同时修改CS和IP。
224 |
225 | - ret和retf
226 |
227 | ret指令用栈中的数据修改IP的内容,从而实现近转移
228 |
229 | retf指令用栈中的数据修改CS和IP的内容,从而实现远转移
230 |
231 | - call
232 |
233 | CPU执行call指令时,有两步操作:
234 |
235 | 1. 将当前的IP或CS和IP压入栈中
236 | 2. 转移
237 |
238 | call指令不能实现短转移
239 |
240 | ## flag寄存器
241 |
242 |  243 |
244 | - ZF标志
245 |
246 | 零标志位,如果执行相关指令后结果为0,zf=1,若不为0,zf=0
247 |
248 | 对于运算指令如add、sub、mul、div等会影响标志寄存器
249 |
250 | 对于传送指令mov、push、pop等不会对寄存器有什么影响
251 |
252 | - PF标志
253 |
254 | 奇偶标志位。如果执行指令后结果所有bit位中1的个数是偶数,pf=1,为奇数,pf=0
255 |
256 | - SF标志
257 |
258 | 符号标志位。执行指令后结果如果为负数,sf=1,如果非负数,sf=0。
259 |
260 | SF标志就是CPU对有符号数运算的一种记录,记录数据的正负。
261 |
262 | - CF标志
263 |
264 | 进位标志位。在进行无符号数运算的时候,它记录了运算结果的最高有效位向更高位的进位值,或从更高位的借位值。
265 |
266 | 当出现进位的时候,会将最高位保存起来,记录在CF位中
267 |
268 | - OF标志
269 |
270 | 溢出:在进行有符号数运算时,如果超过了机器所能表示的范围成为溢出。
271 |
272 | 溢出标志位。记录有符号数运算的结果是否发生了溢出,如果溢出of=1,否则of=0
273 |
274 | > cf和of的区别:cf是对无符号数运算有意义的标志位,of是对有符号数运算有意义的标志位
275 |
276 | ## CPU的内中断
277 |
278 | 任何一个通用的CPU都具备一种能力,可以在执行完当前正在执行的指令后,检测到从CPU外部发送过来的或内部产生的一种特殊信息,并且可以立即对所接收到的信息进行处理。这种特殊的信息,称为:中断信息。
279 |
280 | 中断表明CPU不再接着向下执行,而是转去处理这个特殊的信息。
281 |
282 | 中断可以来自内部和外部,本书主要讨论内中断
283 |
284 | > 内中断有以下几种情况产生:
285 | >
286 | > 1. 除法错误
287 | > 2. 单步执行
288 | > 3. 执行into指令
289 | > 4. 执行int指令
290 | >
291 | > 中断是不同的信息,因此必须先识别不同信息来源。所以中断信息中必须包含识别来源的编码,叫做中断类型码。这个中断类型码是一个字节型数据,可以表示256种中断信息的来源。
292 |
293 | - 中断过程
294 | 1. 从中断信息中获取中断类型码
295 | 2. 标志寄存器的值入栈(因为在中断过程中要改变标志寄存器的值,因此先将其保存在栈中)
296 | 3. 设置标志寄存器的第8位TF和第9位IF的值为0
297 | 4. CS的内容入栈
298 | 5. IP的内容入栈
299 | 6. 从内存地址为中断类型码*4和中断类型码 *4+2的两个字单元中读取中断处理程序的入口地址设置IP和CS
300 |
301 | ## 端口的读写
302 |
303 | CPU可以直接读写一下3个地方的数据:
304 |
305 | 1. CPU内部的寄存器
306 | 2. 内存单元
307 | 3. 端口
308 |
309 | 端口所在的芯片和CPU通过总线相连,所以端口地址和内存地址一样,通过地址总线来传送。CPU总共可以定位64KB个不同的端口,因此端口的范围是0~65535
310 |
311 | 端口的读写指令只有两条:in和out
312 |
313 | ## 外中断
314 |
315 | CPU除了能够执行指令进行运算以外,还应该能够对外部设备进行控制,接收它们的输入,向它们进行输出。要及时处理外设的输入,要解决一下两个问题:
316 |
317 | 1. 外设的输入随时可能发生,CPU如何得知
318 | 2. CPU从何处得到外设的输入?
319 |
320 | 答:外设接口芯片中有若干寄存器,CPU将这些寄存器当做端口来访问。外设的输入不直接送入内存和CPU中,而是送入相关的接口芯片的端口中;同理,CPU向外设的输出也不是直接送入外设,而是先送入端口,再由相关芯片送到外设。因此,**CPU通过端口和外部设备进行联系。**由于外设的输入随时可能到达,因此CPU提供中断机制来满足这种要求。这种中断信息来自CPU外部,相关芯片向CPU发出相应的中断信息,CPU执行完当前的指令后,可以检测到发送过来的中断信息,引发中断过程进而处理外设输入。
321 |
322 | 外中断一共有两类:
323 |
324 | 1. 可屏蔽中断。该中断CPU可以不响应。是否响应要看标志寄存器中IF位的设置,当CPU检测到可屏蔽中断信息时,IF=1,则CPU在执行完当前指令后响应中断,如果IF=0,则不响应可屏蔽中断。(键盘输入就属于可屏蔽中断)
325 | 2. 不可屏蔽中断。指CPU必须响应的外中断,CPU执行完当前指令后,立即响应引发中断过程。
326 |
--------------------------------------------------------------------------------
/书籍笔记/设计模式.md:
--------------------------------------------------------------------------------
1 | # 设计模式
--------------------------------------------------------------------------------
/数据库.md:
--------------------------------------------------------------------------------
1 | # MySQL
2 |
3 | ## 什么是数据库?
4 |
5 | 首先数据库不仅仅是一堆数据的集合,实际上比这个复杂的多。
6 |
7 | 有两个重要组成部分:数据库和实例。
8 |
9 | 1. 数据库:物理操作文件系统或者其他文件形式的集合
10 | 2. 实例:后台进程和共享内存区组成的运行态
11 |
12 | 在 MySQL 中,实例和数据库往往都是一一对应的,而我们也无法直接操作数据库,而是要通过数据库实例来操作数据库文件,可以理解为数据库实例是数据库为上层提供的一个专门用于操作的接口。在 Unix 上,启动一个 MySQL 实例往往会产生两个进程,`mysqld` 就是真正的数据库服务守护进程,而 `mysqld_safe` 是一个用于检查和设置 `mysqld` 启动的控制程序,它负责监控 MySQL 进程的执行,当 `mysqld` 发生错误时,`mysqld_safe` 会对其状态进行检查并在合适的条件下重启。
13 |
14 |
15 |
16 | ## 什么是SQL?什么是MySQL?
17 |
18 | sql是一种结构化查询语言,用于在数据库中存储,查询和删除数据用的。
19 |
20 | mysql是一个数据库管理系统,开源免费。
21 |
22 | [参考链接](https://draveness.me/mysql-innodb/)
23 |
24 |
25 |
26 | ## MySQL都有哪些存储引擎?说一说InnoDB
27 |
28 |
29 |
30 |
243 |
244 | - ZF标志
245 |
246 | 零标志位,如果执行相关指令后结果为0,zf=1,若不为0,zf=0
247 |
248 | 对于运算指令如add、sub、mul、div等会影响标志寄存器
249 |
250 | 对于传送指令mov、push、pop等不会对寄存器有什么影响
251 |
252 | - PF标志
253 |
254 | 奇偶标志位。如果执行指令后结果所有bit位中1的个数是偶数,pf=1,为奇数,pf=0
255 |
256 | - SF标志
257 |
258 | 符号标志位。执行指令后结果如果为负数,sf=1,如果非负数,sf=0。
259 |
260 | SF标志就是CPU对有符号数运算的一种记录,记录数据的正负。
261 |
262 | - CF标志
263 |
264 | 进位标志位。在进行无符号数运算的时候,它记录了运算结果的最高有效位向更高位的进位值,或从更高位的借位值。
265 |
266 | 当出现进位的时候,会将最高位保存起来,记录在CF位中
267 |
268 | - OF标志
269 |
270 | 溢出:在进行有符号数运算时,如果超过了机器所能表示的范围成为溢出。
271 |
272 | 溢出标志位。记录有符号数运算的结果是否发生了溢出,如果溢出of=1,否则of=0
273 |
274 | > cf和of的区别:cf是对无符号数运算有意义的标志位,of是对有符号数运算有意义的标志位
275 |
276 | ## CPU的内中断
277 |
278 | 任何一个通用的CPU都具备一种能力,可以在执行完当前正在执行的指令后,检测到从CPU外部发送过来的或内部产生的一种特殊信息,并且可以立即对所接收到的信息进行处理。这种特殊的信息,称为:中断信息。
279 |
280 | 中断表明CPU不再接着向下执行,而是转去处理这个特殊的信息。
281 |
282 | 中断可以来自内部和外部,本书主要讨论内中断
283 |
284 | > 内中断有以下几种情况产生:
285 | >
286 | > 1. 除法错误
287 | > 2. 单步执行
288 | > 3. 执行into指令
289 | > 4. 执行int指令
290 | >
291 | > 中断是不同的信息,因此必须先识别不同信息来源。所以中断信息中必须包含识别来源的编码,叫做中断类型码。这个中断类型码是一个字节型数据,可以表示256种中断信息的来源。
292 |
293 | - 中断过程
294 | 1. 从中断信息中获取中断类型码
295 | 2. 标志寄存器的值入栈(因为在中断过程中要改变标志寄存器的值,因此先将其保存在栈中)
296 | 3. 设置标志寄存器的第8位TF和第9位IF的值为0
297 | 4. CS的内容入栈
298 | 5. IP的内容入栈
299 | 6. 从内存地址为中断类型码*4和中断类型码 *4+2的两个字单元中读取中断处理程序的入口地址设置IP和CS
300 |
301 | ## 端口的读写
302 |
303 | CPU可以直接读写一下3个地方的数据:
304 |
305 | 1. CPU内部的寄存器
306 | 2. 内存单元
307 | 3. 端口
308 |
309 | 端口所在的芯片和CPU通过总线相连,所以端口地址和内存地址一样,通过地址总线来传送。CPU总共可以定位64KB个不同的端口,因此端口的范围是0~65535
310 |
311 | 端口的读写指令只有两条:in和out
312 |
313 | ## 外中断
314 |
315 | CPU除了能够执行指令进行运算以外,还应该能够对外部设备进行控制,接收它们的输入,向它们进行输出。要及时处理外设的输入,要解决一下两个问题:
316 |
317 | 1. 外设的输入随时可能发生,CPU如何得知
318 | 2. CPU从何处得到外设的输入?
319 |
320 | 答:外设接口芯片中有若干寄存器,CPU将这些寄存器当做端口来访问。外设的输入不直接送入内存和CPU中,而是送入相关的接口芯片的端口中;同理,CPU向外设的输出也不是直接送入外设,而是先送入端口,再由相关芯片送到外设。因此,**CPU通过端口和外部设备进行联系。**由于外设的输入随时可能到达,因此CPU提供中断机制来满足这种要求。这种中断信息来自CPU外部,相关芯片向CPU发出相应的中断信息,CPU执行完当前的指令后,可以检测到发送过来的中断信息,引发中断过程进而处理外设输入。
321 |
322 | 外中断一共有两类:
323 |
324 | 1. 可屏蔽中断。该中断CPU可以不响应。是否响应要看标志寄存器中IF位的设置,当CPU检测到可屏蔽中断信息时,IF=1,则CPU在执行完当前指令后响应中断,如果IF=0,则不响应可屏蔽中断。(键盘输入就属于可屏蔽中断)
325 | 2. 不可屏蔽中断。指CPU必须响应的外中断,CPU执行完当前指令后,立即响应引发中断过程。
326 |
--------------------------------------------------------------------------------
/书籍笔记/设计模式.md:
--------------------------------------------------------------------------------
1 | # 设计模式
--------------------------------------------------------------------------------
/数据库.md:
--------------------------------------------------------------------------------
1 | # MySQL
2 |
3 | ## 什么是数据库?
4 |
5 | 首先数据库不仅仅是一堆数据的集合,实际上比这个复杂的多。
6 |
7 | 有两个重要组成部分:数据库和实例。
8 |
9 | 1. 数据库:物理操作文件系统或者其他文件形式的集合
10 | 2. 实例:后台进程和共享内存区组成的运行态
11 |
12 | 在 MySQL 中,实例和数据库往往都是一一对应的,而我们也无法直接操作数据库,而是要通过数据库实例来操作数据库文件,可以理解为数据库实例是数据库为上层提供的一个专门用于操作的接口。在 Unix 上,启动一个 MySQL 实例往往会产生两个进程,`mysqld` 就是真正的数据库服务守护进程,而 `mysqld_safe` 是一个用于检查和设置 `mysqld` 启动的控制程序,它负责监控 MySQL 进程的执行,当 `mysqld` 发生错误时,`mysqld_safe` 会对其状态进行检查并在合适的条件下重启。
13 |
14 |
15 |
16 | ## 什么是SQL?什么是MySQL?
17 |
18 | sql是一种结构化查询语言,用于在数据库中存储,查询和删除数据用的。
19 |
20 | mysql是一个数据库管理系统,开源免费。
21 |
22 | [参考链接](https://draveness.me/mysql-innodb/)
23 |
24 |
25 |
26 | ## MySQL都有哪些存储引擎?说一说InnoDB
27 |
28 |
29 |
30 |  31 |
32 |
33 |
34 | ### MySQL存储架构
35 |
36 |
31 |
32 |
33 |
34 | ### MySQL存储架构
35 |
36 |  37 |
38 | 第一层用于连接、线程处理的部分并不是 MySQL 『发明』的,很多服务都有类似的组成部分;
39 |
40 | 第二层中包含了大多数 MySQL 的核心服务,包括了对 SQL 的解析、分析、优化和缓存等功能,存储过程、触发器和视图都是在这里实现的;
41 |
42 | 第三层就是 MySQL 中真正负责数据的存储和提取的存储引擎,例如:[InnoDB](https://en.wikipedia.org/wiki/InnoDB)、[MyISAM](https://en.wikipedia.org/wiki/MyISAM) 等,文中对存储引擎的介绍都是对 InnoDB 实现的分析。
43 |
44 |
45 |
46 | ### innoDB引擎存储结构
47 |
48 | 在 InnoDB 存储引擎中,所有的数据都被**逻辑地**存放在表空间中,表空间(tablespace)是存储引擎中最高的存储逻辑单位,在表空间的下面又包括段(segment)、区(extent)、页(page):
49 |
50 |
37 |
38 | 第一层用于连接、线程处理的部分并不是 MySQL 『发明』的,很多服务都有类似的组成部分;
39 |
40 | 第二层中包含了大多数 MySQL 的核心服务,包括了对 SQL 的解析、分析、优化和缓存等功能,存储过程、触发器和视图都是在这里实现的;
41 |
42 | 第三层就是 MySQL 中真正负责数据的存储和提取的存储引擎,例如:[InnoDB](https://en.wikipedia.org/wiki/InnoDB)、[MyISAM](https://en.wikipedia.org/wiki/MyISAM) 等,文中对存储引擎的介绍都是对 InnoDB 实现的分析。
43 |
44 |
45 |
46 | ### innoDB引擎存储结构
47 |
48 | 在 InnoDB 存储引擎中,所有的数据都被**逻辑地**存放在表空间中,表空间(tablespace)是存储引擎中最高的存储逻辑单位,在表空间的下面又包括段(segment)、区(extent)、页(page):
49 |
50 |  51 |
52 | 同一个数据库实例的所有表空间都有相同的页大小;默认情况下,表空间中的页大小都为 16KB,当然也可以通过改变 `innodb_page_size` 选项对默认大小进行修改,需要注意的是不同的页大小最终也会导致区大小的不同:
53 |
54 |
51 |
52 | 同一个数据库实例的所有表空间都有相同的页大小;默认情况下,表空间中的页大小都为 16KB,当然也可以通过改变 `innodb_page_size` 选项对默认大小进行修改,需要注意的是不同的页大小最终也会导致区大小的不同:
53 |
54 | 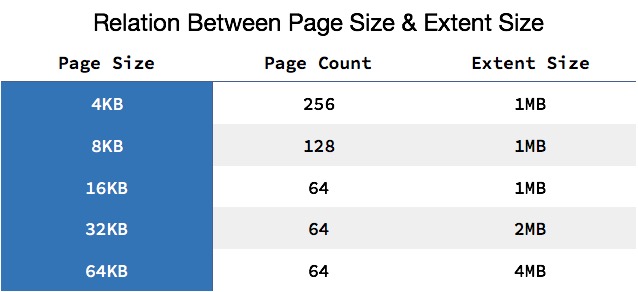 55 |
56 | 从图中可以看出,在 InnoDB 存储引擎中,一个区的大小最小为 1MB,页的数量最少为 64 个。
57 |
58 | ### 如何存储?
59 |
60 | MySQL 使用 InnoDB 存储表时,会将**表的定义**和**数据,索引**等信息分开存储,其中前者存储在 `.frm` 文件中,后者存储在 `.ibd` 文件中,这一节就会对这两种不同的文件分别进行介绍。
61 |
62 | **.frm 文件**
63 |
64 | 无论在 MySQL 中选择了哪个存储引擎,所有的 MySQL 表都会在硬盘上创建一个 `.frm` 文件用来描述表的格式或者说定义;`.frm` 文件的格式在不同的平台上都是相同的。
65 |
66 | **.ibd 文件**
67 |
68 | 储了当前表的数据和相关的索引数据。
69 |
70 | **如何存储?**
71 |
72 | 与现有的大多数存储引擎一样,InnoDB 使用页作为磁盘管理的最小单位;数据在 InnoDB 存储引擎中都是按行存储的,每个 16KB 大小的页中可以存放 2-200 行的记录。
73 |
74 |
75 |
76 | ## 数据库的三大范式?
77 |
78 | 一范式就是属性不可分割。第一范式是关系型数据库的基本要求,表示每一列都是不可分割的基本数据项。比如数据库中的“地址”属性,如果要经常访问地址中的"所在城市",就要把“地址”属性分割成“省份”、“城市”、“街道”等基本项
79 |
80 | 二范式就是要有主键,其他字段都依赖于主键。就是说一张表的每一列都和主键相关,而不能只与主键的某一部分相关,不能把多种数据保存到同一张表中。
81 |
82 | 三范式就是要消除传递依赖,消除冗余,就是各种信息只在一个地方存储,不出现在多张表中(很多时候会牺牲第三范式)。比如下图这样:
83 |
84 |
55 |
56 | 从图中可以看出,在 InnoDB 存储引擎中,一个区的大小最小为 1MB,页的数量最少为 64 个。
57 |
58 | ### 如何存储?
59 |
60 | MySQL 使用 InnoDB 存储表时,会将**表的定义**和**数据,索引**等信息分开存储,其中前者存储在 `.frm` 文件中,后者存储在 `.ibd` 文件中,这一节就会对这两种不同的文件分别进行介绍。
61 |
62 | **.frm 文件**
63 |
64 | 无论在 MySQL 中选择了哪个存储引擎,所有的 MySQL 表都会在硬盘上创建一个 `.frm` 文件用来描述表的格式或者说定义;`.frm` 文件的格式在不同的平台上都是相同的。
65 |
66 | **.ibd 文件**
67 |
68 | 储了当前表的数据和相关的索引数据。
69 |
70 | **如何存储?**
71 |
72 | 与现有的大多数存储引擎一样,InnoDB 使用页作为磁盘管理的最小单位;数据在 InnoDB 存储引擎中都是按行存储的,每个 16KB 大小的页中可以存放 2-200 行的记录。
73 |
74 |
75 |
76 | ## 数据库的三大范式?
77 |
78 | 一范式就是属性不可分割。第一范式是关系型数据库的基本要求,表示每一列都是不可分割的基本数据项。比如数据库中的“地址”属性,如果要经常访问地址中的"所在城市",就要把“地址”属性分割成“省份”、“城市”、“街道”等基本项
79 |
80 | 二范式就是要有主键,其他字段都依赖于主键。就是说一张表的每一列都和主键相关,而不能只与主键的某一部分相关,不能把多种数据保存到同一张表中。
81 |
82 | 三范式就是要消除传递依赖,消除冗余,就是各种信息只在一个地方存储,不出现在多张表中(很多时候会牺牲第三范式)。比如下图这样:
83 |
84 |  85 |
86 | 第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。
87 |
88 |
89 |
90 | ## 什么是存储过程?有哪些优缺点?
91 |
92 | **定义:** 就是数据库 SQL 语言层面的代码封装与重用。存储过程是数据库系统中为了完成特定功能的SQL语句集合,经编译后保存在数据库中。普通的SQL语句我们都是保存到其他地方,每次需要编译后才能执行,效率比较的低。而有了存储过程后,第一次编译后再次调用不需要再次编译,用户通过存储过程的名字来调用。
93 |
94 | - 优点
95 | 1. 效率高。编译一次后,就会存到数据库,每次调用时都直接执行。而普通的sql语句我们要保存到其他地方(记事本 ),都要先分析编译才会执行。
96 | 2. 维护方便。当发生改动时候,修改之前的存储过程比较容易
97 | 3. 复用性高。存储过程往往针对特定功能编写的,因此可以重复调用
98 | 4. 安全性高。使用的时候有身份限制,只能特定用户使用
99 | 4. 降低网络流量。存储过程编译好会放在数据库,我们在远程调用时,不会传输大量的字符串类型的sql语句。
100 | - 缺点
101 | 1. 不同厂商数据库系统之间不兼容。
102 |
103 |
104 |
105 | ## mysql索引是什么?有哪几种类型?优缺点?
106 |
107 | ### 索引的定义
108 |
109 | **MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。**是加快检索表中数据的方法。对于一张表来说,如果不加索引的话就要从表的第一行开始查找,如果一个表有百万行的话效率会非常低。如果有了索引,利用数据结构就可以快速查找。
110 |
111 | ### 优缺点
112 |
113 | - 索引的优点
114 | 1. 加快数据的检索速度
115 | - 索引的缺点
116 | 1. 创建和维护高效的索引表比较麻烦
117 | 2. 占用物理空间
118 |
119 | ### 索引的类型
120 |
121 | - 索引的类型
122 |
123 | - 字段类型分类:
124 | 1. 普通索引。没有任何约束,**允许空值和重复值,纯粹为了提高查询效率而存在**。
125 | 2. 唯一索引。在普通索引上加上数据不允许重复,允许为null
126 | 3. 主键索引。在唯一索引上加上不允许为null,一个表只能有一个主键
127 | 4. 全文索引。没见过。
128 | - 按数据结构分类可分为:
129 | 1. **B+tree索引**
130 | 2. **Hash索引**
131 | 3. **Full-text索引**
132 | - 其他
133 | 1. 聚簇索引
134 | 2. 非聚簇索引
135 |
136 |
137 | ### 算法原理
138 |
139 |
140 |
141 | ## 数据库事务
142 |
143 | > 事务是并发控制的基本单位。事务他是一个操作序列,这些操作要么都执行,要么都不执行,是一个不可分割的单位。最简单的例子就是银行转账了,从一个账户汇钱到另一个账户,两个操作要么都执行要么都不执行。
144 |
145 | - 数据库中的事务有以下四个特征:
146 |
147 | 1. 原子性。事务中的操作被看成一个逻辑单元,这个逻辑单元的操作要么全做,要么全部做。
148 | 2. 一致性。当对数据进行更改后,如果回滚会回到最初状态。
149 |
150 | 3. 隔离性。允许多个用户对同一个数据进行并发访问同时不破坏数据的完整性和正确性。同时并行事务的修改必须和其他并行事务独立。
151 | 4. 持久性。事务结束后,结果必须能持久保存。
152 | - 事务的语句
153 | 1. 开始事务。`BEGIN TRANSACTION`
154 | 2. 提交事务。`COMMIT TRANSACTION`
155 | 3. 回滚事务。`ROLLBACK TRANSACTION`
156 |
157 |
158 |
159 | ## 数据库锁机制
160 |
161 | ### 并发控制机制
162 |
163 | 并发控制的任务就是保证多个事务存取数据统一数据时候不破坏事务的隔离性和统一性。乐观锁和悲观锁其实都是并发控制的机制,同时它们在原理上就有着本质的差别:
164 |
165 | - 悲观锁
166 |
167 | 定义:悲观锁顾名思义,认为当前操作的数据会被外界其他事务所修改,因此在整个数据处理过程中,将数据锁定,屏蔽一切可能违反事务性质的操作。因此每次获取数据的时候都会进行加锁操作,防止外界修改。由于该数据加锁,因此对改数据进行读写操作的其他进程会进入等待状态。**悲观锁的实现需要数据库的锁机制来完成**,只有数据库系统的锁机制才能保证访问的排他性。
168 |
169 | 评价:效率上,加锁会让数据库产生额外的开销,同时还有增加死锁的机会。另外,如果是只读型事务的话,加锁是没必要的,因此频繁写入的业务可能需要。而且一旦某数据被加锁了,其它数据必须等待才行。
170 |
171 | - 乐观锁
172 |
173 | 定义:乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。
174 |
175 | 实现方式:**使用版本号实现乐观锁**,**版本号的实现方式有两种,一个是数据版本机制,一个是时间戳机制。具体如下。**
176 |
177 | 1. 为数据增加一个版本标识,一般是通过为数据库表增加一个数字类型的 “version” 字段来实现。当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据。
178 | 2. 时间戳机制,同样是在需要乐观锁控制的table中增加一个字段,名称无所谓,字段类型使用时间戳(timestamp), 和上面的version类似,也是在更新提交的时候检查当前数据库中数据的时间戳和自己更新前取到的时间戳进行对比,如果一致则OK,否则就是版本冲突。
179 |
180 | **乐观锁和悲观锁在本质上并不是同一种东西,一个是一种思想,另一个是一种真正的锁,但是它们都是一种并发控制机制。**
181 |
182 | 乐观锁不会存在死锁的问题,但是由于更新后验证,所以当**冲突频率**和**重试成本**较高时更推荐使用悲观锁,而需要非常高的**响应速度**并且**并发量**非常大的时候使用乐观锁就能较好的解决问题,在这时使用悲观锁就可能出现严重的性能问题;在选择并发控制机制时,需要综合考虑上面的四个方面(冲突频率、重试成本、响应速度和并发量)进行选择。
183 |
184 | ### 锁的种类
185 |
186 | 对数据的操作其实只有两种,也就是读和写,而数据库在实现锁时,也会对这两种操作使用不同的锁;InnoDB 实现了标准的行级锁,也就是共享锁(Shared Lock)和互斥锁(Exclusive Lock)
187 |
188 | - **共享锁(读锁)**:允许事务对一条行数据进行读取;
189 | - **互斥锁(写锁)**:允许事务对一条行数据进行删除或更新;
190 |
191 | 而它们的名字也暗示着各自的另外一个特性,共享锁之间是兼容的,而互斥锁与其他任意锁都不兼容:稍微对它们的使用进行思考就能想明白它们为什么要这么设计,因为共享锁代表了读操作、互斥锁代表了写操作,所以我们可以在数据库中**并行读**,但是只能**串行写**,只有这样才能保证不会发生线程竞争,实现线程安全。
192 |
193 | ### 锁的粒度
194 |
195 | 无论是共享锁还是互斥锁其实都只是对某一个数据行进行加锁
196 |
197 | InnoDB 支持多种粒度的锁,也就是**行锁**和**表锁**;为了支持多粒度锁定,InnoDB 存储引擎引入了意向锁(Intention Lock),意向锁就是一种表级锁。
198 |
199 | - 行锁
200 |
201 | 行级锁是Mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突,提高并发度。其加锁粒度最小,但加锁的开销也最大,还会出现死锁。行级锁分为共享锁和排他锁。
202 |
203 | - 表锁
204 |
205 | 级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分MySQL引擎支持。表级锁分为共享锁和排他锁。开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。
206 |
207 | - 意向锁
208 |
209 | 为了支持多粒度锁定,InnoDB 存储引擎引入了意向锁(Intention Lock)
210 |
211 | 1. **意向共享锁**:事务想要在获得表中某些记录的共享锁,需要在表上先加意向共享锁;
212 | 2. **意向互斥锁**:事务想要在获得表中某些记录的互斥锁,需要在表上先加意向互斥锁;
213 |
214 | 意向锁其实不会阻塞全表扫描之外的任何请求,它们的主要目的是为了表示**是否有人请求锁定表中的某一行数据**。
215 |
216 | > 有的人可能会对意向锁的目的并不是完全的理解,我们在这里可以举一个例子:如果没有意向锁,当已经有人使用行锁对表中的某一行进行修改时,如果另外一个请求要对全表进行修改,那么就需要对所有的行是否被锁定进行扫描,在这种情况下,效率是非常低的;不过,在引入意向锁之后,当有人使用行锁对表中的某一行进行修改之前,会先为表添加意向互斥锁(IX),再为行记录添加互斥锁(X),在这时如果有人尝试对全表进行修改就不需要判断表中的每一行数据是否被加锁了,只需要通过等待意向互斥锁被释放就可以了。
217 |
218 | ### 锁的算法
219 |
220 | 介绍三种锁的算法:Record Lock、Gap Lock 和 Next-Key Lock。
221 |
222 | - Record Lock记录锁
223 |
224 | 通过索引建立的 B+ 树找到行记录并添加锁。但是如果InnoDB 不知道待修改的记录具体存放的位置,也无法对将要修改哪条记录提前做出判断就会锁定整个表。
225 |
226 | - Gap Lock间隙锁
227 |
228 | 记录锁是在存储引擎中最为常见的锁,除了记录锁之外,InnoDB 中还存在间隙锁(Gap Lock),间隙锁是对索引记录中的一段连续区域的锁;
229 |
230 | 当使用类似 `SELECT * FROM users WHERE id BETWEEN 10 AND 20 FOR UPDATE;` 的 SQL 语句时,就会阻止其他事务向表中插入 `id = 15` 的记录,因为整个范围都被间隙锁锁定了。
231 |
232 | - Next-Key Lock
233 |
234 | Gap Lock+Record Lock,锁定一个范围,并且锁定记录本身
235 |
236 | 当我们更新一条记录,比如 `SELECT * FROM users WHERE age = 30 FOR UPDATE;`,InnoDB 不仅会在范围 `(21, 30]` 上加 Next-Key 锁,还会在这条记录后面的范围 `(30, 40]` 加间隙锁,所以插入 `(21, 40]` 范围内的记录都会被锁定。
237 |
238 | ### 死锁的产生
239 |
240 | 既然 InnoDB 中实现的锁是悲观的,那么不同事务之间就可能会互相等待对方释放锁造成死锁,最终导致事务发生错误;想要在 MySQL 中制造死锁的问题其实非常容易:两个会话都持有一个锁,并且尝试获取对方的锁时就会发生死锁,不过 MySQL 也能在发生死锁时及时发现问题,并保证其中的一个事务能够正常工作,这对我们来说也是一个好消息。
241 |
242 |
243 |
244 | ## drop、truncate和delete的区别
245 |
246 | - delete删除的过程是每次从表中删除一行,并且将该操作记录到日志中,可以回滚。
247 | - truncate指一次性从表中删除所有的数据,不保存在日志中因此是不可恢复的。
248 | - drop将表占用的空间删除掉
249 |
250 |
251 |
252 | ## SQL的组成主要有四部分
253 |
254 | - 数据定义。
255 |
256 | **DDL(Data Definition Language)数据库定义语言。**
257 |
258 | 用于定义数据库的三级结构,包括外模式、概念模式、内模式及其相互之间的映像,定义数据的完整性、安全控制等约束。
259 |
260 | DDL不需要commit。
261 |
262 | `CREATE
263 | ALTER
264 | DROP
265 | TRUNCATE
266 | COMMENT
267 | RENAME`
268 |
269 | - 数据操纵。
270 |
271 | **DML**(**Data Manipulation Language**)**数据操纵语言**
272 |
273 | 用于让用户或程序员使用,实现对数据库中数据的操作。
274 |
275 | 需要commit.。
276 |
277 | `SELECT
278 | INSERT
279 | UPDATE
280 | DELETE
281 | MERGE
282 | CALL
283 | EXPLAIN PLAN
284 | LOCK TABLE`
285 |
286 | - 数据控制
287 |
288 | **DCL**(**Data Control Language**)**数据库控制语言**
289 |
290 | **TCL**(**Transaction Control Language**)**事务控制语言**
291 |
292 | GRANT 授权
293 | REVOKE 取消授权
294 |
295 | SAVEPOINT 设置保存点
296 | ROLLBACK 回滚
297 | SET TRANSACTION
298 |
299 | - 嵌入式中的SQL
300 |
301 |
302 |
303 | ## 什么是视图?视图的使用场景有哪些?
304 |
305 | 定义:视图是一种虚拟的表,其内容由查询语句定义。同真实的表一样,视图包含一系列带有名称的列和行数据。可以对视图进行增,改,查,操作,视图通常是有一个表或者多个表的行或列的子集。视图本身并不包含任何数据,不在数据库中以存储的数据值集形式存在,它只包含映射到基表的一个查询语句,当基表数据发生变化,视图数据也随之变化。一种抽象的概念如下:
306 |
307 |
85 |
86 | 第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。
87 |
88 |
89 |
90 | ## 什么是存储过程?有哪些优缺点?
91 |
92 | **定义:** 就是数据库 SQL 语言层面的代码封装与重用。存储过程是数据库系统中为了完成特定功能的SQL语句集合,经编译后保存在数据库中。普通的SQL语句我们都是保存到其他地方,每次需要编译后才能执行,效率比较的低。而有了存储过程后,第一次编译后再次调用不需要再次编译,用户通过存储过程的名字来调用。
93 |
94 | - 优点
95 | 1. 效率高。编译一次后,就会存到数据库,每次调用时都直接执行。而普通的sql语句我们要保存到其他地方(记事本 ),都要先分析编译才会执行。
96 | 2. 维护方便。当发生改动时候,修改之前的存储过程比较容易
97 | 3. 复用性高。存储过程往往针对特定功能编写的,因此可以重复调用
98 | 4. 安全性高。使用的时候有身份限制,只能特定用户使用
99 | 4. 降低网络流量。存储过程编译好会放在数据库,我们在远程调用时,不会传输大量的字符串类型的sql语句。
100 | - 缺点
101 | 1. 不同厂商数据库系统之间不兼容。
102 |
103 |
104 |
105 | ## mysql索引是什么?有哪几种类型?优缺点?
106 |
107 | ### 索引的定义
108 |
109 | **MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。**是加快检索表中数据的方法。对于一张表来说,如果不加索引的话就要从表的第一行开始查找,如果一个表有百万行的话效率会非常低。如果有了索引,利用数据结构就可以快速查找。
110 |
111 | ### 优缺点
112 |
113 | - 索引的优点
114 | 1. 加快数据的检索速度
115 | - 索引的缺点
116 | 1. 创建和维护高效的索引表比较麻烦
117 | 2. 占用物理空间
118 |
119 | ### 索引的类型
120 |
121 | - 索引的类型
122 |
123 | - 字段类型分类:
124 | 1. 普通索引。没有任何约束,**允许空值和重复值,纯粹为了提高查询效率而存在**。
125 | 2. 唯一索引。在普通索引上加上数据不允许重复,允许为null
126 | 3. 主键索引。在唯一索引上加上不允许为null,一个表只能有一个主键
127 | 4. 全文索引。没见过。
128 | - 按数据结构分类可分为:
129 | 1. **B+tree索引**
130 | 2. **Hash索引**
131 | 3. **Full-text索引**
132 | - 其他
133 | 1. 聚簇索引
134 | 2. 非聚簇索引
135 |
136 |
137 | ### 算法原理
138 |
139 |
140 |
141 | ## 数据库事务
142 |
143 | > 事务是并发控制的基本单位。事务他是一个操作序列,这些操作要么都执行,要么都不执行,是一个不可分割的单位。最简单的例子就是银行转账了,从一个账户汇钱到另一个账户,两个操作要么都执行要么都不执行。
144 |
145 | - 数据库中的事务有以下四个特征:
146 |
147 | 1. 原子性。事务中的操作被看成一个逻辑单元,这个逻辑单元的操作要么全做,要么全部做。
148 | 2. 一致性。当对数据进行更改后,如果回滚会回到最初状态。
149 |
150 | 3. 隔离性。允许多个用户对同一个数据进行并发访问同时不破坏数据的完整性和正确性。同时并行事务的修改必须和其他并行事务独立。
151 | 4. 持久性。事务结束后,结果必须能持久保存。
152 | - 事务的语句
153 | 1. 开始事务。`BEGIN TRANSACTION`
154 | 2. 提交事务。`COMMIT TRANSACTION`
155 | 3. 回滚事务。`ROLLBACK TRANSACTION`
156 |
157 |
158 |
159 | ## 数据库锁机制
160 |
161 | ### 并发控制机制
162 |
163 | 并发控制的任务就是保证多个事务存取数据统一数据时候不破坏事务的隔离性和统一性。乐观锁和悲观锁其实都是并发控制的机制,同时它们在原理上就有着本质的差别:
164 |
165 | - 悲观锁
166 |
167 | 定义:悲观锁顾名思义,认为当前操作的数据会被外界其他事务所修改,因此在整个数据处理过程中,将数据锁定,屏蔽一切可能违反事务性质的操作。因此每次获取数据的时候都会进行加锁操作,防止外界修改。由于该数据加锁,因此对改数据进行读写操作的其他进程会进入等待状态。**悲观锁的实现需要数据库的锁机制来完成**,只有数据库系统的锁机制才能保证访问的排他性。
168 |
169 | 评价:效率上,加锁会让数据库产生额外的开销,同时还有增加死锁的机会。另外,如果是只读型事务的话,加锁是没必要的,因此频繁写入的业务可能需要。而且一旦某数据被加锁了,其它数据必须等待才行。
170 |
171 | - 乐观锁
172 |
173 | 定义:乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。
174 |
175 | 实现方式:**使用版本号实现乐观锁**,**版本号的实现方式有两种,一个是数据版本机制,一个是时间戳机制。具体如下。**
176 |
177 | 1. 为数据增加一个版本标识,一般是通过为数据库表增加一个数字类型的 “version” 字段来实现。当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据。
178 | 2. 时间戳机制,同样是在需要乐观锁控制的table中增加一个字段,名称无所谓,字段类型使用时间戳(timestamp), 和上面的version类似,也是在更新提交的时候检查当前数据库中数据的时间戳和自己更新前取到的时间戳进行对比,如果一致则OK,否则就是版本冲突。
179 |
180 | **乐观锁和悲观锁在本质上并不是同一种东西,一个是一种思想,另一个是一种真正的锁,但是它们都是一种并发控制机制。**
181 |
182 | 乐观锁不会存在死锁的问题,但是由于更新后验证,所以当**冲突频率**和**重试成本**较高时更推荐使用悲观锁,而需要非常高的**响应速度**并且**并发量**非常大的时候使用乐观锁就能较好的解决问题,在这时使用悲观锁就可能出现严重的性能问题;在选择并发控制机制时,需要综合考虑上面的四个方面(冲突频率、重试成本、响应速度和并发量)进行选择。
183 |
184 | ### 锁的种类
185 |
186 | 对数据的操作其实只有两种,也就是读和写,而数据库在实现锁时,也会对这两种操作使用不同的锁;InnoDB 实现了标准的行级锁,也就是共享锁(Shared Lock)和互斥锁(Exclusive Lock)
187 |
188 | - **共享锁(读锁)**:允许事务对一条行数据进行读取;
189 | - **互斥锁(写锁)**:允许事务对一条行数据进行删除或更新;
190 |
191 | 而它们的名字也暗示着各自的另外一个特性,共享锁之间是兼容的,而互斥锁与其他任意锁都不兼容:稍微对它们的使用进行思考就能想明白它们为什么要这么设计,因为共享锁代表了读操作、互斥锁代表了写操作,所以我们可以在数据库中**并行读**,但是只能**串行写**,只有这样才能保证不会发生线程竞争,实现线程安全。
192 |
193 | ### 锁的粒度
194 |
195 | 无论是共享锁还是互斥锁其实都只是对某一个数据行进行加锁
196 |
197 | InnoDB 支持多种粒度的锁,也就是**行锁**和**表锁**;为了支持多粒度锁定,InnoDB 存储引擎引入了意向锁(Intention Lock),意向锁就是一种表级锁。
198 |
199 | - 行锁
200 |
201 | 行级锁是Mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突,提高并发度。其加锁粒度最小,但加锁的开销也最大,还会出现死锁。行级锁分为共享锁和排他锁。
202 |
203 | - 表锁
204 |
205 | 级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分MySQL引擎支持。表级锁分为共享锁和排他锁。开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。
206 |
207 | - 意向锁
208 |
209 | 为了支持多粒度锁定,InnoDB 存储引擎引入了意向锁(Intention Lock)
210 |
211 | 1. **意向共享锁**:事务想要在获得表中某些记录的共享锁,需要在表上先加意向共享锁;
212 | 2. **意向互斥锁**:事务想要在获得表中某些记录的互斥锁,需要在表上先加意向互斥锁;
213 |
214 | 意向锁其实不会阻塞全表扫描之外的任何请求,它们的主要目的是为了表示**是否有人请求锁定表中的某一行数据**。
215 |
216 | > 有的人可能会对意向锁的目的并不是完全的理解,我们在这里可以举一个例子:如果没有意向锁,当已经有人使用行锁对表中的某一行进行修改时,如果另外一个请求要对全表进行修改,那么就需要对所有的行是否被锁定进行扫描,在这种情况下,效率是非常低的;不过,在引入意向锁之后,当有人使用行锁对表中的某一行进行修改之前,会先为表添加意向互斥锁(IX),再为行记录添加互斥锁(X),在这时如果有人尝试对全表进行修改就不需要判断表中的每一行数据是否被加锁了,只需要通过等待意向互斥锁被释放就可以了。
217 |
218 | ### 锁的算法
219 |
220 | 介绍三种锁的算法:Record Lock、Gap Lock 和 Next-Key Lock。
221 |
222 | - Record Lock记录锁
223 |
224 | 通过索引建立的 B+ 树找到行记录并添加锁。但是如果InnoDB 不知道待修改的记录具体存放的位置,也无法对将要修改哪条记录提前做出判断就会锁定整个表。
225 |
226 | - Gap Lock间隙锁
227 |
228 | 记录锁是在存储引擎中最为常见的锁,除了记录锁之外,InnoDB 中还存在间隙锁(Gap Lock),间隙锁是对索引记录中的一段连续区域的锁;
229 |
230 | 当使用类似 `SELECT * FROM users WHERE id BETWEEN 10 AND 20 FOR UPDATE;` 的 SQL 语句时,就会阻止其他事务向表中插入 `id = 15` 的记录,因为整个范围都被间隙锁锁定了。
231 |
232 | - Next-Key Lock
233 |
234 | Gap Lock+Record Lock,锁定一个范围,并且锁定记录本身
235 |
236 | 当我们更新一条记录,比如 `SELECT * FROM users WHERE age = 30 FOR UPDATE;`,InnoDB 不仅会在范围 `(21, 30]` 上加 Next-Key 锁,还会在这条记录后面的范围 `(30, 40]` 加间隙锁,所以插入 `(21, 40]` 范围内的记录都会被锁定。
237 |
238 | ### 死锁的产生
239 |
240 | 既然 InnoDB 中实现的锁是悲观的,那么不同事务之间就可能会互相等待对方释放锁造成死锁,最终导致事务发生错误;想要在 MySQL 中制造死锁的问题其实非常容易:两个会话都持有一个锁,并且尝试获取对方的锁时就会发生死锁,不过 MySQL 也能在发生死锁时及时发现问题,并保证其中的一个事务能够正常工作,这对我们来说也是一个好消息。
241 |
242 |
243 |
244 | ## drop、truncate和delete的区别
245 |
246 | - delete删除的过程是每次从表中删除一行,并且将该操作记录到日志中,可以回滚。
247 | - truncate指一次性从表中删除所有的数据,不保存在日志中因此是不可恢复的。
248 | - drop将表占用的空间删除掉
249 |
250 |
251 |
252 | ## SQL的组成主要有四部分
253 |
254 | - 数据定义。
255 |
256 | **DDL(Data Definition Language)数据库定义语言。**
257 |
258 | 用于定义数据库的三级结构,包括外模式、概念模式、内模式及其相互之间的映像,定义数据的完整性、安全控制等约束。
259 |
260 | DDL不需要commit。
261 |
262 | `CREATE
263 | ALTER
264 | DROP
265 | TRUNCATE
266 | COMMENT
267 | RENAME`
268 |
269 | - 数据操纵。
270 |
271 | **DML**(**Data Manipulation Language**)**数据操纵语言**
272 |
273 | 用于让用户或程序员使用,实现对数据库中数据的操作。
274 |
275 | 需要commit.。
276 |
277 | `SELECT
278 | INSERT
279 | UPDATE
280 | DELETE
281 | MERGE
282 | CALL
283 | EXPLAIN PLAN
284 | LOCK TABLE`
285 |
286 | - 数据控制
287 |
288 | **DCL**(**Data Control Language**)**数据库控制语言**
289 |
290 | **TCL**(**Transaction Control Language**)**事务控制语言**
291 |
292 | GRANT 授权
293 | REVOKE 取消授权
294 |
295 | SAVEPOINT 设置保存点
296 | ROLLBACK 回滚
297 | SET TRANSACTION
298 |
299 | - 嵌入式中的SQL
300 |
301 |
302 |
303 | ## 什么是视图?视图的使用场景有哪些?
304 |
305 | 定义:视图是一种虚拟的表,其内容由查询语句定义。同真实的表一样,视图包含一系列带有名称的列和行数据。可以对视图进行增,改,查,操作,视图通常是有一个表或者多个表的行或列的子集。视图本身并不包含任何数据,不在数据库中以存储的数据值集形式存在,它只包含映射到基表的一个查询语句,当基表数据发生变化,视图数据也随之变化。一种抽象的概念如下:
306 |
307 |  308 |
309 | **为什么用视图?**关系型数据库中的数据是由一张一张的二维关系表所组成,简单的单表查询只需要遍历一个表,而复杂的多表查询需要将多个表连接起来进行查询任务。对于复杂的查询事件,每次查询都需要编写MySQL代码效率低下。为了解决这个问题,数据库提供了视图(view)功能。
310 |
311 | 查询的数据来源于不同的表,而查询者希望以统一的方式查询,这样也可以建立一个视图,把多个表查询结果联合起来,查询者只需要直接从视图中获取数据,不必考虑数据来源于不同表所带来的差异
312 |
313 | **常用场景:**视图适合于多表连接浏览时使用。不适合增、删、改。
314 |
315 |
316 |
317 | ## MYSQL索引和算法原理
318 |
319 | [MySQL索引背后的数据结构及算法原理](http://blog.codinglabs.org/articles/theory-of-mysql-index.html)
320 |
321 | MySQL数据库支持多种索引类型,如BTree索引,哈希索引,全文索引等等。主要说一说Btree索引
322 |
323 | **对于索引的定义:**数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linear search),这种复杂度为O(n)的算法在数据量很大时显然是糟糕的,好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binary search)、二叉树查找(binary tree search)等。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
324 |
325 | 目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构
326 |
327 | ### Btree索引
328 |
329 | 关于BTree和B+Tree的介绍再数据结构篇中,可以先去看一下,弄清楚B树和B+树的区别。
330 |
331 | 一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级(内存是纳秒,磁盘是毫秒),所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。下面先介绍内存和磁盘存取原理,然后再结合这些原理分析B-/+Tree作为索引的效率。
332 |
333 | **主存存取**
334 |
335 | 目前计算机使用的主存基本都是随机读写存储器(RAM),现代RAM的结构和存取原理比较复杂,所以这里就抽象出一个十分简单的存取模型来说明RAM的工作原理。
336 |
337 | 
338 |
339 | 从抽象角度看,主存是一系列的存储单元组成的矩阵,每个存储单元存储固定大小的数据。每个存储单元有唯一的地址,现代主存的编址规则比较复杂,这里将其简化成一个二维地址:通过一个行地址和一个列地址可以唯一定位到一个存储单元。上
340 |
341 | 主存的存取过程如下:
342 |
343 | 1. 当系统需要读取主存时,则将地址信号放到地址总线上传给主存,主存读到地址信号后,解析信号并定位到指定存储单元,然后将此存储单元数据放到数据总线上,供其它部件读取。
344 | 2. 写主存的过程类似,系统将要写入单元地址和数据分别放在地址总线和数据总线上,主存读取两个总线的内容,做相应的写操作。
345 |
346 | 所以可以得出结论:这里可以看出,主存存取的时间仅与存取次数呈线性关系,因为不存在机械操作,两次存取的数据的“距离”不会对时间有任何影响,例如,先取A0再取A1和先取A0再取D3的时间消耗是一样的。
347 |
348 | **磁盘存取原理**
349 |
350 | 索引一般以文件形式存储在磁盘上,索引检索需要磁盘I/O操作。与主存不同,磁盘I/O存在机械运动耗费,因此磁盘I/O的时间消耗是巨大的。
351 |
352 |
308 |
309 | **为什么用视图?**关系型数据库中的数据是由一张一张的二维关系表所组成,简单的单表查询只需要遍历一个表,而复杂的多表查询需要将多个表连接起来进行查询任务。对于复杂的查询事件,每次查询都需要编写MySQL代码效率低下。为了解决这个问题,数据库提供了视图(view)功能。
310 |
311 | 查询的数据来源于不同的表,而查询者希望以统一的方式查询,这样也可以建立一个视图,把多个表查询结果联合起来,查询者只需要直接从视图中获取数据,不必考虑数据来源于不同表所带来的差异
312 |
313 | **常用场景:**视图适合于多表连接浏览时使用。不适合增、删、改。
314 |
315 |
316 |
317 | ## MYSQL索引和算法原理
318 |
319 | [MySQL索引背后的数据结构及算法原理](http://blog.codinglabs.org/articles/theory-of-mysql-index.html)
320 |
321 | MySQL数据库支持多种索引类型,如BTree索引,哈希索引,全文索引等等。主要说一说Btree索引
322 |
323 | **对于索引的定义:**数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linear search),这种复杂度为O(n)的算法在数据量很大时显然是糟糕的,好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binary search)、二叉树查找(binary tree search)等。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
324 |
325 | 目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构
326 |
327 | ### Btree索引
328 |
329 | 关于BTree和B+Tree的介绍再数据结构篇中,可以先去看一下,弄清楚B树和B+树的区别。
330 |
331 | 一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级(内存是纳秒,磁盘是毫秒),所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。下面先介绍内存和磁盘存取原理,然后再结合这些原理分析B-/+Tree作为索引的效率。
332 |
333 | **主存存取**
334 |
335 | 目前计算机使用的主存基本都是随机读写存储器(RAM),现代RAM的结构和存取原理比较复杂,所以这里就抽象出一个十分简单的存取模型来说明RAM的工作原理。
336 |
337 | 
338 |
339 | 从抽象角度看,主存是一系列的存储单元组成的矩阵,每个存储单元存储固定大小的数据。每个存储单元有唯一的地址,现代主存的编址规则比较复杂,这里将其简化成一个二维地址:通过一个行地址和一个列地址可以唯一定位到一个存储单元。上
340 |
341 | 主存的存取过程如下:
342 |
343 | 1. 当系统需要读取主存时,则将地址信号放到地址总线上传给主存,主存读到地址信号后,解析信号并定位到指定存储单元,然后将此存储单元数据放到数据总线上,供其它部件读取。
344 | 2. 写主存的过程类似,系统将要写入单元地址和数据分别放在地址总线和数据总线上,主存读取两个总线的内容,做相应的写操作。
345 |
346 | 所以可以得出结论:这里可以看出,主存存取的时间仅与存取次数呈线性关系,因为不存在机械操作,两次存取的数据的“距离”不会对时间有任何影响,例如,先取A0再取A1和先取A0再取D3的时间消耗是一样的。
347 |
348 | **磁盘存取原理**
349 |
350 | 索引一般以文件形式存储在磁盘上,索引检索需要磁盘I/O操作。与主存不同,磁盘I/O存在机械运动耗费,因此磁盘I/O的时间消耗是巨大的。
351 |
352 | 
 353 |
354 | 一个个磁盘,磁盘由磁道和扇区组成
355 |
356 | 当需要从磁盘读取数据时,系统会将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。为了读取这个扇区的数据,需要将磁头放到这个扇区上方,为了实现这一点,磁头需要移动对准相应磁道,这个过程叫做寻道,所耗费时间叫做寻道时间,然后磁盘旋转将目标扇区旋转到磁头下,这个过程耗费的时间叫做旋转时间。所以机械时间加上存储介质的特性,磁盘IO肯定很慢。
357 |
358 | 解决办法:根据计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。
359 |
360 | 由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。**预读的长度一般为页(page)的整倍数**。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
361 |
362 | **性能分析**
363 |
364 | > 数据存储最小单元
365 | >
366 | > 在计算机中磁盘存储数据最小单元是扇区,一个扇区的大小是512字节
367 | >
368 | > 虚拟内存中小单元是页,一个页的大小是4k
369 | >
370 | > InnoDB存储引擎也有自己的最小储存单元——页(Page),一个页的大小是默认16K。
371 | >
372 | > 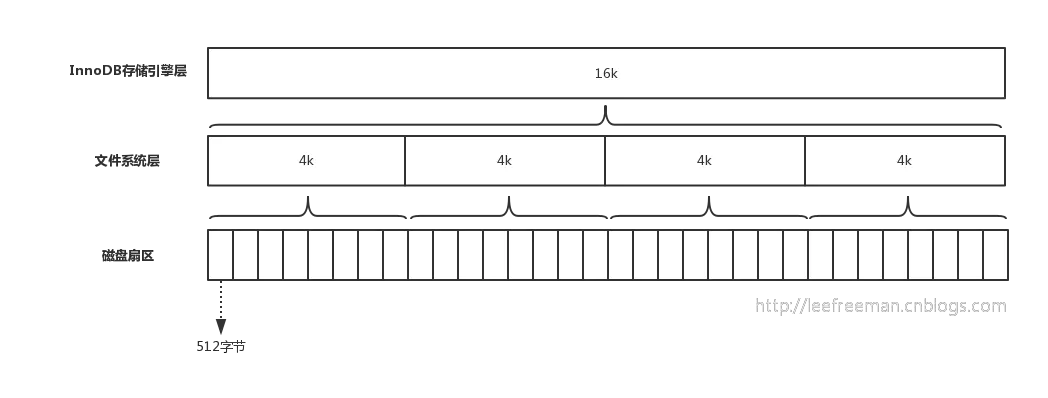
373 |
374 | - 首先说Btree
375 |
376 | 假设Btree一次检索要访问n个节点,数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
377 |
378 | B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为$O(h)=O(log_dN)$。一般实际应用中,阶d是非常大的数字,通常超过100,因此h非常小(通常不超过3)。综上所述,用B-Tree作为索引结构效率是非常高的。
379 |
380 | - 再说B+tree
381 |
382 | 为什么B+tree比Btree更适合索引呢?因为d越大索引的性能越好,而阶的上限取决于节点内key和data的大小。因为一页大小有限,又存数据又存索引,导致阶会变小。所以B+数就是想方设法将数据去掉,使得节点里面全是索引(key)就行,因此d越大,$O(log_dN)$就会越小。
383 |
384 | - 为什么红黑树不行?
385 |
386 | 红黑树本质上是一种自平衡的二叉查找树,数据量大的话树的高度太高了。同时由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
387 |
388 | - 一个B+索引树可以存多少行数据?
389 |
390 | 答:首先看是几层树。对于 B+树而言,树的高度一般不超过 4 层。
391 |
392 | 对于 MySQL 的 InnoDB 存储引擎而言,一个结点默认的存储空间为 16Kb。MySQL 的 InnoDB 存储引擎的索引一般用 bigint 存储,占用 8 个 byte,一个索引又会关联一个指向孩子结点的指针,这个指针占用 6 个 byte,也就是说结点中的一个关键字大概要用 14 byte 的空间,而一个结点的默认大小为 16kb ,那么一个结点可以存储关键的个数最多为$16kb / 14byte = 1170$,即一个节点可以存储1170个指针,所以阶m=1170。
393 |
394 | 一行数据是大小是1k,一个页的大小是16k,因此一页可以放16条数据。一个指针指向一个存放记录的页,一个页可以存放16条数据。这样我们根据高度就可以大致算出一颗B+树能存放多少数据了。**B+树索引本身并不能直接找到具体的一条记录,只能知道该记录在哪个页上,数据库会把页载入到内存,再通过二分查找定位到具体的记录。**
395 |
396 | 所以一颗高度为2的B+树可以存放的数据是:`1170*16=18720`条数据。一颗高度为3的B+树可以存放的数据是:`1170*1170*16=21902400`条记录(两千万条)
397 |
398 | 理论上就是这样,在InnoDB存储引擎中,B+树的高度一般为2-4层,就可以满足千万级数据的存储。查找数据的时候,一次页的查找代表一次IO,那我们通过主键索引查询的时候,其实最多只需要2-4次IO就可以了。
399 |
400 |
401 |
402 | ### 哈希索引
403 |
404 | 哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
405 |
406 | 哈希缺点:
407 |
408 | 1. Hash 索引仅仅能满足等值查询,不能使用范围查询。
409 | 2. Hash 索引无法被用来避免数据的排序操作,由于 Hash 索引中存放的是经过 Hash 计算之后的 Hash 值,而且Hash值的大小关系并不一定和 Hash 运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
410 | 3. 当碰撞太高的话,性能不一定很好,比如拉链法,后面跟了一长串。
411 |
412 | ### 聚簇索引和非聚簇索引
413 |
414 | **通俗解释:**
415 |
416 | 聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
417 |
418 | 非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因
419 |
420 | **聚簇索引:**聚簇索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的就是整张表的行记录数据,也将聚集索引的叶子节点称为数据页。这个特性决定了索引组织表中数据也是索引的一部分,每张表只能拥有一个聚簇索引。
421 |
422 | 优点:
423 |
424 | 1. 数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快
425 | 2. 聚簇索引对于主键的排序查找和范围查找速度非常快
426 |
427 | 缺点:
428 |
429 | 1. 更新主键的代价很高,维护索引很昂贵,因为将会导致被更新的行移动,导致数据被分到不同的页上。因此,对于InnoDB表,我们一般定义主键为不可更新。
430 |
431 | 使用聚簇索引的场景:
432 |
433 | 1. 适合用在排序的场合
434 | 2. 取出一定范围数据的时候
435 |
436 | **非聚簇索引:**辅助索引叶子节点存储的不再是行的物理位置,而是主键值。通过辅助索引首先找到的是主键值,再通过主键值找到数据行的数据页,再通过数据页中的Page Directory找到数据行。
437 |
438 | > 辅助索引使用主键作为"指针"而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"。也就是说行的位置(实现中通过16K的Page来定位)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响。
439 |
440 | 二级索引需要两次索引查找,而不是一次才能取到数据,因为存储引擎第一次需要通过二级索引找到索引的叶子节点,从而找到数据的主键,然后在聚簇索引中用主键再次查找索引,再找到数据
441 |
442 |
443 |
444 | ## mysql隔离级别
445 |
446 | [参考链接](https://zhuanlan.zhihu.com/p/117476959)
447 |
448 | 本文所说的 MySQL 事务都是指在 InnoDB 引擎下
449 |
450 | 数据库事务指的是一组数据操作,事务内的操作要么就是全部成功,要么就是全部失败,什么都不做,其实不是没做,是可能做了一部分但是只要有一步失败,就要回滚所有操作,有点一不做二不休的意思。
451 |
452 | 事务具有原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)四个特性,简称 ACID,缺一不可。今天要说的就是**隔离性**。
453 |
454 | - 概念说明,先搞清都是什么意思
455 |
456 | - 脏读:指的是读到了其他事务未提交的数据,未提交意味着这些数据可能会回滚,也就是可能最终不会存到数据库中,也就是不存在的数据。
457 | - 可重复读:事务A在读到一条数据之后,此时事务B对该数据进行了修改并提交,那么事务A再读该数据,读到的还是原来的内容。
458 | - 不可重复读:对比可重复读,不可重复读指的是在同一事务内,不同的时刻读到的同一批数据可能是不一样的,可能会受到其他事务的影响。
459 | - 幻读:针对数据插入操作来说的。假设事务A对某些行的内容作了更改,但是还未提交,此时事务B插入了与事务A更改前的记录相同的记录行,并且在事务A提交之前先提交了,而这时,在事务A中查询,会发现好像刚刚的更改对于某些数据未起作用,但其实是事务B刚插入进来的,让用户感觉很魔幻,感觉出现了幻觉
460 |
461 | - 事务的隔离级别
462 |
463 | > MySQL的事务隔离级别一共有四个,分别是读未提交、读已提交、可重复读以及可串行化。MySQL的隔离级别的作用就是让事务之间互相隔离,互不影响,这样可以保证事务的一致性。在Oracle,SqlServer中都是选择读已提交(Read Commited)作为默认的隔离级别,为什么Mysql不选择读已提交(Read Commited)作为默认隔离级别,而选择可重复读(Repeatable Read)作为默认的隔离级别
464 | >
465 | > 隔离级别比较:可串行化>可重复读>读已提交>读未提交
466 | >
467 | > 隔离级别对性能的影响比较:可串行化>可重复读>读已提交>读未提交
468 | >
469 | > 由此看出,隔离级别越高,所需要消耗的MySQL性能越大(如事务并发严重性),为了平衡二者,一般建议设置的隔离级别为可重复读,MySQL默认的隔离级别也是可重复读。
470 |
471 |
353 |
354 | 一个个磁盘,磁盘由磁道和扇区组成
355 |
356 | 当需要从磁盘读取数据时,系统会将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。为了读取这个扇区的数据,需要将磁头放到这个扇区上方,为了实现这一点,磁头需要移动对准相应磁道,这个过程叫做寻道,所耗费时间叫做寻道时间,然后磁盘旋转将目标扇区旋转到磁头下,这个过程耗费的时间叫做旋转时间。所以机械时间加上存储介质的特性,磁盘IO肯定很慢。
357 |
358 | 解决办法:根据计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。
359 |
360 | 由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。**预读的长度一般为页(page)的整倍数**。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
361 |
362 | **性能分析**
363 |
364 | > 数据存储最小单元
365 | >
366 | > 在计算机中磁盘存储数据最小单元是扇区,一个扇区的大小是512字节
367 | >
368 | > 虚拟内存中小单元是页,一个页的大小是4k
369 | >
370 | > InnoDB存储引擎也有自己的最小储存单元——页(Page),一个页的大小是默认16K。
371 | >
372 | > 
373 |
374 | - 首先说Btree
375 |
376 | 假设Btree一次检索要访问n个节点,数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
377 |
378 | B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为$O(h)=O(log_dN)$。一般实际应用中,阶d是非常大的数字,通常超过100,因此h非常小(通常不超过3)。综上所述,用B-Tree作为索引结构效率是非常高的。
379 |
380 | - 再说B+tree
381 |
382 | 为什么B+tree比Btree更适合索引呢?因为d越大索引的性能越好,而阶的上限取决于节点内key和data的大小。因为一页大小有限,又存数据又存索引,导致阶会变小。所以B+数就是想方设法将数据去掉,使得节点里面全是索引(key)就行,因此d越大,$O(log_dN)$就会越小。
383 |
384 | - 为什么红黑树不行?
385 |
386 | 红黑树本质上是一种自平衡的二叉查找树,数据量大的话树的高度太高了。同时由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
387 |
388 | - 一个B+索引树可以存多少行数据?
389 |
390 | 答:首先看是几层树。对于 B+树而言,树的高度一般不超过 4 层。
391 |
392 | 对于 MySQL 的 InnoDB 存储引擎而言,一个结点默认的存储空间为 16Kb。MySQL 的 InnoDB 存储引擎的索引一般用 bigint 存储,占用 8 个 byte,一个索引又会关联一个指向孩子结点的指针,这个指针占用 6 个 byte,也就是说结点中的一个关键字大概要用 14 byte 的空间,而一个结点的默认大小为 16kb ,那么一个结点可以存储关键的个数最多为$16kb / 14byte = 1170$,即一个节点可以存储1170个指针,所以阶m=1170。
393 |
394 | 一行数据是大小是1k,一个页的大小是16k,因此一页可以放16条数据。一个指针指向一个存放记录的页,一个页可以存放16条数据。这样我们根据高度就可以大致算出一颗B+树能存放多少数据了。**B+树索引本身并不能直接找到具体的一条记录,只能知道该记录在哪个页上,数据库会把页载入到内存,再通过二分查找定位到具体的记录。**
395 |
396 | 所以一颗高度为2的B+树可以存放的数据是:`1170*16=18720`条数据。一颗高度为3的B+树可以存放的数据是:`1170*1170*16=21902400`条记录(两千万条)
397 |
398 | 理论上就是这样,在InnoDB存储引擎中,B+树的高度一般为2-4层,就可以满足千万级数据的存储。查找数据的时候,一次页的查找代表一次IO,那我们通过主键索引查询的时候,其实最多只需要2-4次IO就可以了。
399 |
400 |
401 |
402 | ### 哈希索引
403 |
404 | 哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
405 |
406 | 哈希缺点:
407 |
408 | 1. Hash 索引仅仅能满足等值查询,不能使用范围查询。
409 | 2. Hash 索引无法被用来避免数据的排序操作,由于 Hash 索引中存放的是经过 Hash 计算之后的 Hash 值,而且Hash值的大小关系并不一定和 Hash 运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
410 | 3. 当碰撞太高的话,性能不一定很好,比如拉链法,后面跟了一长串。
411 |
412 | ### 聚簇索引和非聚簇索引
413 |
414 | **通俗解释:**
415 |
416 | 聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
417 |
418 | 非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因
419 |
420 | **聚簇索引:**聚簇索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的就是整张表的行记录数据,也将聚集索引的叶子节点称为数据页。这个特性决定了索引组织表中数据也是索引的一部分,每张表只能拥有一个聚簇索引。
421 |
422 | 优点:
423 |
424 | 1. 数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快
425 | 2. 聚簇索引对于主键的排序查找和范围查找速度非常快
426 |
427 | 缺点:
428 |
429 | 1. 更新主键的代价很高,维护索引很昂贵,因为将会导致被更新的行移动,导致数据被分到不同的页上。因此,对于InnoDB表,我们一般定义主键为不可更新。
430 |
431 | 使用聚簇索引的场景:
432 |
433 | 1. 适合用在排序的场合
434 | 2. 取出一定范围数据的时候
435 |
436 | **非聚簇索引:**辅助索引叶子节点存储的不再是行的物理位置,而是主键值。通过辅助索引首先找到的是主键值,再通过主键值找到数据行的数据页,再通过数据页中的Page Directory找到数据行。
437 |
438 | > 辅助索引使用主键作为"指针"而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"。也就是说行的位置(实现中通过16K的Page来定位)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响。
439 |
440 | 二级索引需要两次索引查找,而不是一次才能取到数据,因为存储引擎第一次需要通过二级索引找到索引的叶子节点,从而找到数据的主键,然后在聚簇索引中用主键再次查找索引,再找到数据
441 |
442 |
443 |
444 | ## mysql隔离级别
445 |
446 | [参考链接](https://zhuanlan.zhihu.com/p/117476959)
447 |
448 | 本文所说的 MySQL 事务都是指在 InnoDB 引擎下
449 |
450 | 数据库事务指的是一组数据操作,事务内的操作要么就是全部成功,要么就是全部失败,什么都不做,其实不是没做,是可能做了一部分但是只要有一步失败,就要回滚所有操作,有点一不做二不休的意思。
451 |
452 | 事务具有原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)四个特性,简称 ACID,缺一不可。今天要说的就是**隔离性**。
453 |
454 | - 概念说明,先搞清都是什么意思
455 |
456 | - 脏读:指的是读到了其他事务未提交的数据,未提交意味着这些数据可能会回滚,也就是可能最终不会存到数据库中,也就是不存在的数据。
457 | - 可重复读:事务A在读到一条数据之后,此时事务B对该数据进行了修改并提交,那么事务A再读该数据,读到的还是原来的内容。
458 | - 不可重复读:对比可重复读,不可重复读指的是在同一事务内,不同的时刻读到的同一批数据可能是不一样的,可能会受到其他事务的影响。
459 | - 幻读:针对数据插入操作来说的。假设事务A对某些行的内容作了更改,但是还未提交,此时事务B插入了与事务A更改前的记录相同的记录行,并且在事务A提交之前先提交了,而这时,在事务A中查询,会发现好像刚刚的更改对于某些数据未起作用,但其实是事务B刚插入进来的,让用户感觉很魔幻,感觉出现了幻觉
460 |
461 | - 事务的隔离级别
462 |
463 | > MySQL的事务隔离级别一共有四个,分别是读未提交、读已提交、可重复读以及可串行化。MySQL的隔离级别的作用就是让事务之间互相隔离,互不影响,这样可以保证事务的一致性。在Oracle,SqlServer中都是选择读已提交(Read Commited)作为默认的隔离级别,为什么Mysql不选择读已提交(Read Commited)作为默认隔离级别,而选择可重复读(Repeatable Read)作为默认的隔离级别
464 | >
465 | > 隔离级别比较:可串行化>可重复读>读已提交>读未提交
466 | >
467 | > 隔离级别对性能的影响比较:可串行化>可重复读>读已提交>读未提交
468 | >
469 | > 由此看出,隔离级别越高,所需要消耗的MySQL性能越大(如事务并发严重性),为了平衡二者,一般建议设置的隔离级别为可重复读,MySQL默认的隔离级别也是可重复读。
470 |
471 | 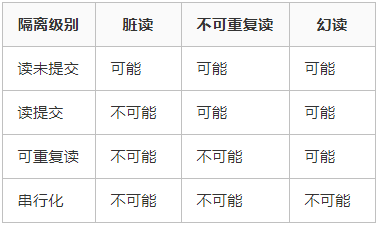 472 |
473 | - 读未提交
474 |
475 | 读未提交,其实就是可以读到其他事务未提交的数据,但没有办法保证你读到的数据最终一定是提交后的数据,如果中间发生回滚,那就会出现脏数据问题,读未提交没办法解决脏数据问题。更别提可重复读和幻读了,想都不要想。
476 |
477 | 例子:启动两个事务,分别为事务A和事务B,在事务A中使用 update 语句,修改 age 的值为10,初始是1 ,在执行完 update 语句之后,在事务B中查询 user 表,会看到 age 的值已经是 10 了,这时候事务A还没有提交,而此时事务B有可能拿着已经修改过的 age=10 去进行其他操作了。在事务B进行操作的过程中,很有可能事务A由于某些原因,进行了事务回滚操作,那其实事务B得到的就是脏数据了,拿着脏数据去进行其他的计算,那结果肯定也是有问题的。
478 |
479 | - 读提交
480 |
481 | 读提交就是一个事务只能读到其他事务已经提交过的数据,也就是其他事务调用 commit 命令之后的数据。
482 |
483 | 读提交事务隔离级别是大多数流行数据库的默认事务隔离界别,比如 Oracle
484 |
485 | 例子:同样开启事务A和事务B两个事务,在事务A中使用 update 语句将 id=1 的记录行 age 字段改为 10。此时,在事务B中使用 select 语句进行查询,我们发现在事务A提交之前,事务B中查询到的记录 age 一直是1,直到事务A提交,此时在事务B中 select 查询,发现 age 的值已经是 10 了。这就出现了一个问题,在同一事务中(本例中的事务B),事务的不同时刻同样的查询条件,查询出来的记录内容是不一样的,事务A的提交影响了事务B的查询结果,这就是不可重复读,也就是读提交隔离级别。
486 |
487 | - 可重复读
488 |
489 | 上面说不可重复读是指同一事物不同时刻读到的数据值可能不一致。而可重复读是指,事务不会读到其他事务对已有数据的修改,即使其他事务已提交。也就是说,事务开始时读到的已有数据是什么,在事务提交前的任意时刻,这些数据的值都是一样的。但是,对于其他事务新插入的数据是可以读到的,这也就引发了幻读问题。
490 |
491 | 例子:事务A开始后,执行 update 操作,将 age = 1 的记录的 name 改为“风筝2号”;事务B开始后,在事务执行完 update 后,执行 insert 操作,插入记录 age =1,name = 古时的风筝,这和事务A修改的那条记录值相同,然后提交。事务B提交后,事务A中执行 select,查询 age=1 的数据,这时,会发现多了一行,并且发现还有一条 name = 古时的风筝,age = 1 的记录,这其实就是事务B刚刚插入的,这就是幻读。
492 |
493 | - 串行化
494 |
495 | 串行化是4种事务隔离级别中隔离效果最好的,解决了脏读、可重复读、幻读的问题,但是效果最差,它将事务的执行变为顺序执行,与其他三个隔离级别相比,它就相当于单线程,后一个事务的执行必须等待前一个事务结束。
496 |
497 | - 应用场景
498 |
499 | 项目中是不用读未提交(Read UnCommitted)和串行化(Serializable)两个隔离级别,原因有二:
500 |
501 | 1. 采用读未提交(Read UnCommitted),一个事务读到另一个事务未提交读数据,这个不用多说吧,从逻辑上都说不过去!
502 | 2. 采用串行化(Serializable),每个次读操作都会加锁,快照读失效,一般是使用mysql自带分布式事务功能时才使用该隔离级别!(笔者从未用过mysql自带的这个功能,因为这是XA事务,是强一致性事务,性能不佳!互联网的分布式方案,多采用最终一致性的事务解决方案!)
503 |
504 | 所以我们只用考虑read committed或者read repeatable。一般互联网项目都用读已提交这个。
505 |
506 | [参考](https://blog.csdn.net/qq_26024869/article/details/107034616?spm=1001.2101.3001.6650.5&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-5.pc_relevant_aa&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-5.pc_relevant_aa&utm_relevant_index=10)
507 |
508 |
509 |
510 | ## **Mysql里面为什么用B+树?**
511 |
512 | [上面有写](#MYSQL索引和算法原理)
513 |
514 |
515 |
516 | ## 一条MySQL语句执行过程
517 |
518 | 首先了解一下mysql的架构
519 |
520 | 首先大方向上要分为两层,server层和存储引擎层。
521 |
522 | - server层
523 |
524 | Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
525 |
526 | - 存储引擎层
527 |
528 | 存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎,现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
529 |
530 | **下面来说一下过程:**
531 |
532 | **①第一步连接器**
533 |
534 | 连接到mysql服务器会首先碰到连接器,连接器负责跟客户端建立连接、获取权限、维持和管理连接。完成经典的 TCP 握手后,连接器就要开始认证你的身份,这个时候用的就是你输入的用户名和密码。
535 |
536 | **②查询缓存**
537 |
538 | MySQL 拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中。key 是查询的语句,value 是查询的结果。如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。
539 |
540 | 如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。
541 |
542 | 查询缓存也有不好的地方。查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非你的业务就是有一张静态表,很长时间才会更新一次。比如,一个系统配置表,那这张表上的查询才适合使用查询缓存。
543 |
544 | **③分析器**
545 |
546 | 分析器先会做“词法分析”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么。做完了这些识别以后,就要做“语法分析”。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法规则,只有遵循它的规则,才能获取到在它规则管理内的数据
547 |
548 | **④优化器**
549 |
550 | 优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一个方案。
551 |
552 | **⑤执行器**
553 |
554 | 开始执行语句。开始执行的时候,要先判断一下你对这个表 有没有执行对应操作的权限,如果没有,就会返回没有权限的错误;如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
555 |
556 | 如果表没有索引,会从第一行一行一行地读取,根据where后面的条件是否满足,如果有索引则会根据索引的规则去寻找,然后执行生成结果集。
557 |
558 |
559 |
560 | ## 分库分表有哪些方案?有什么区别?
561 |
562 | ## mysql调优
563 |
564 | ### 简单的优化方式
565 |
566 | **MySQL 分析表**
567 |
568 | 分析表用于分析和存储表的关键字分布,分析的结果可以使得系统得到准确的统计信息,使得 SQL 生成正确的执行计划。如果用于感觉实际执行计划与预期不符,可以执行分析表来解决问题,分析表语法如下:
569 |
570 | ```
571 | analyze table cxuan005;
572 | ```
573 |
574 | 分析结果涉及到的字段属性如下
575 |
576 | Table:表示表的名称;
577 |
578 | Op:表示执行的操作,analyze 表示进行分析操作,check 表示进行检查查找,optimize 表示进行优化操作;
579 |
580 | Msg_type:表示信息类型,其显示的值通常是状态、警告、错误和信息这四者之一;
581 |
582 | Msg_text:显示信息。
583 |
584 | 对表的定期分析可以改善性能,应该成为日常工作的一部分。因为通过更新表的索引信息对表进行分析,可改善数据库性能。
585 |
586 | **MySQL 检查表**
587 |
588 | 数据库经常可能遇到错误,比如数据写入磁盘时发生错误,或是索引没有同步更新,或是数据库未关闭 MySQL 就停止了。遇到这些情况,数据就可能发生错误: **Incorrect key file for table: ' '. Try to repair it**. 此时,我们可以使用 Check Table 语句来检查表及其对应的索引。
589 |
590 | ```
591 | check table cxuan005;
592 | ```
593 |
594 | 检查表的主要目的就是检查一个或者多个表是否有错误。Check Table 对 MyISAM 和 InnoDB 表有作用。Check Table 也可以检查视图的错误。
595 |
596 | **MySQL 优化表**
597 |
598 | MySQL 优化表适用于删除了大量的表数据,或者对包含 VARCHAR、BLOB 或则 TEXT 命令进行大量修改的情况。MySQL 优化表可以将大量的空间碎片进行合并,消除由于删除或者更新造成的空间浪费情况。它的命令如下
599 |
600 | ```
601 | optimize table cxuan005;
602 | ```
603 |
604 | ### 查询时的优化
605 |
606 | **小表驱动大表**
607 |
608 | 
609 |
610 | **避免全表扫描**
611 |
612 | mysql在使用不等于(!=或者<>)的时候无法使用导致全表扫描。在查询的时候,如果对索引使用不等于的操作将会导致索引失效,进行全表扫描
613 |
614 | **避免mysql放弃索引查询**
615 |
616 | 如果mysql估计使用全表扫描要比使用索引快,则不使用索引。(最典型的场景就是数据量少的时候)
617 |
618 | **使用覆盖索引,少使用select***
619 |
620 | 需要用到什么数据就查询什么数据,这样可以减少网络的传输和mysql的全表扫描。
621 |
622 | 尽量使用覆盖索引,比如索引为name,age,address的组合索引,那么尽量覆盖这三个字段之中的值,mysql将会直接在索引上取值(using index),并且返回值不包含不是索引的字段。
623 |
624 | ## MySQL 对于千万级的大表要怎么优化?
625 |
626 | https://www.zhihu.com/question/19719997
627 |
628 |
629 |
630 | +++
631 |
632 |
633 |
634 | # Redis
635 |
636 | ## 关系型数据库和非关系型数据库
637 |
638 | ### **关系型数据库**
639 |
640 | **含义:**采用关系模型来组织数据的数据库。简单说关系模型就是二维表格模型,而关系型数据库就是由二维表及其之间的联系组成的数据结构
641 |
642 | **优点:**
643 |
644 | 1. 容易理解:二维表结构是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型来说更容易理解
645 | 2. 使用方便:通用的SQL语言使得操作关系型数据库非常方便
646 | 3. 易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率
647 |
648 | **缺点:**
649 |
650 | 1. 高并发读写需求。 网站的用户并发性非常高,往往达到每秒上万次读写请求,对于传统关系型数据库来说,硬盘I/O是一个很大的瓶颈
651 | 2. 海量数据的高效率读写。 网站每天产生的数据量是巨大的,对于关系型数据库来说,在一张包含海量数据的表中查询和修改,效率是非常低的
652 | 3. 高扩展性和可用性。在基于web的结构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移。
653 |
654 | **一些不需要关系型数据库的情况:**
655 |
656 | 1. 关系型数据库在对事物一致性的维护中有很大的开销,而现在很多web2.0系统对事物的读写一致性都不高
657 |
658 | 2. 对关系数据库来说,插入一条数据之后立刻查询,是肯定可以读出这条数据的,但是对于很多web应用来说,并不要求这么高的实时性,比如发一条消息之后,过几秒乃至十几秒之后才看到这条动态是完全可以接受的
659 |
660 | 3. 任何大数据量的web系统,都非常忌讳多个大表的关联查询,以及复杂的数据分析类型的复杂SQL报表查询,特别是SNS类型的网站**(SNS,专指社交网络服务,包括了社交软件和社交网站。)**
661 |
662 |
663 |
664 | ### **非关系型数据库**
665 |
666 | **含义:**NoSQL一词首先是Carlo Strozzi在1998年提出来的,指的是他开发的一个没有SQL功能,轻量级的,开源的关系型数据库。但是NoSQL的发展慢慢偏离了初衷,我们要的不是“no sql”,而是“no relational(not noly)”,也就是我们现在常说的非关系型数据库了。
667 |
668 | **优点:**
669 |
670 | 1. 格式灵活:存储数据的格式可以是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
671 | 2. 速度快:nosql可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘;
672 | 3. 高扩展性。
673 | 4. 成本低:nosql数据库部署简单,基本都是开源软件。
674 |
675 | **缺点:**
676 |
677 | 1. 不提供sql支持,学习和使用成本较高;
678 | 2. 无事务处理;
679 | 3. 数据结构相对复杂,复杂查询方面稍欠。
680 |
681 | ### 总结
682 |
683 | 关系型数据库的最大特点就是事务的一致性:传统的关系型数据库读写操作都是事务的,具有ACID的特点,这个特性使得关系型数据库可以用于几乎所有对一致性有要求的系统中,如典型的银行系统。
684 |
685 |
686 | 但是,在网页应用中,尤其是SNS应用中,一致性却不是显得那么重要,用户A看到的内容和用户B看到同一用户C内容更新不一致是可以容忍的,或者说,两个人看到同一好友的数据更新的时间差那么几秒是可以容忍的,因此,关系型数据库的最大特点在这里已经无用武之地,起码不是那么重要了。
687 |
688 | 相反地,关系型数据库为了维护一致性所付出的巨大代价就是其读写性能比较差,而像微博、facebook这类SNS的应用,对并发读写能力要求极高,关系型数据库已经无法应付因此,必须用新的一种数据结构存储来代替关系数据库。
689 |
690 |
691 | 关系数据库的另一个特点就是其具有固定的表结构,因此,其扩展性极差,而在SNS中,系统的升级,功能的增加,往往意味着数据结构巨大变动,这一点关系型数据库也难以应付,需要新的结构化数据存储。
692 |
693 |
694 | 于是,非关系型数据库应运而生,由于不可能用一种数据结构化存储应付所有的新的需求,因此,非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。
695 |
696 |
697 | 必须强调的是,数据的持久存储,尤其是海量数据的持久存储,还是需要一种关系数据库这员老将。
698 |
699 |
700 |
701 | ## 什么时候用redis什么时候用mysql?
702 |
703 | Redis和MySQL不是相互替代的关系,而是相辅相成的,越来越多的项目组已经采用了redis+MySQL的架构来开发平台工具。
704 |
705 | 首先mysql是持久化数据库,是关系型数据库,是直接保存在硬盘上的。redis是非关系型数据库,是内存运行的数据存储获取工具。
706 |
707 | 但是数据量多少并不是redis和mysql选择的标准,因为都可以集群括展。
708 |
709 | 他们的使用场景是不同的:
710 |
711 | 1. 关系型数据库最重要的有两个点,第一是持久化存储的功能,即数据都存储在硬盘中。第二就是关系型数据库可以提供复杂的查询和统计功能。
712 | 2. 关系型数据库偏向于快速存取数据,用于实时响应要求高的场景,响应时间在毫秒级,通常作为热点数据的缓存使用。
713 |
714 | 数据多而且调用频繁的话,用mysql存储的话数据库连接被一直占用,其它的数据请求就进来了,导致连接超时,数据量大的话,数据库直接死机了。只能重启才能解决问题。这个时候如果把数据请求量大的数据放在redis中的话就可以分担一下mysql的压力,从而提高系统的性能,解决请求并发问题。
715 |
716 |
717 |
718 | ## Redis持久化
719 |
720 | RDB模式和AOF模式
721 |
722 | 在默认情况下,Redis将数据库快照保存在名为dump.rdb的二进制文件中
723 |
724 | 两个模式的选择:
725 |
726 | 1. **如果主要充当缓存功能,或者可以承受数分钟数据的丢失, 通常生产环境一般只需启用RDB可,此也是默认值**
727 |
728 | 2. **如果数据需要持久保存,一点不能丢失,可以选择同时开启RDB和AOF,一般不建议只开启AOF**
729 |
730 | ### RDB模式
731 |
732 | 具体原理有两种SAVE,BGSAVE
733 |
734 | **SAVE**
735 |
736 | SAVE是阻塞服务,在创建新文件dump.rdb替代旧文件时候无法响应客户端请求,生产环境中很少这样,一般都是停机维护时候才考虑
737 |
738 |
472 |
473 | - 读未提交
474 |
475 | 读未提交,其实就是可以读到其他事务未提交的数据,但没有办法保证你读到的数据最终一定是提交后的数据,如果中间发生回滚,那就会出现脏数据问题,读未提交没办法解决脏数据问题。更别提可重复读和幻读了,想都不要想。
476 |
477 | 例子:启动两个事务,分别为事务A和事务B,在事务A中使用 update 语句,修改 age 的值为10,初始是1 ,在执行完 update 语句之后,在事务B中查询 user 表,会看到 age 的值已经是 10 了,这时候事务A还没有提交,而此时事务B有可能拿着已经修改过的 age=10 去进行其他操作了。在事务B进行操作的过程中,很有可能事务A由于某些原因,进行了事务回滚操作,那其实事务B得到的就是脏数据了,拿着脏数据去进行其他的计算,那结果肯定也是有问题的。
478 |
479 | - 读提交
480 |
481 | 读提交就是一个事务只能读到其他事务已经提交过的数据,也就是其他事务调用 commit 命令之后的数据。
482 |
483 | 读提交事务隔离级别是大多数流行数据库的默认事务隔离界别,比如 Oracle
484 |
485 | 例子:同样开启事务A和事务B两个事务,在事务A中使用 update 语句将 id=1 的记录行 age 字段改为 10。此时,在事务B中使用 select 语句进行查询,我们发现在事务A提交之前,事务B中查询到的记录 age 一直是1,直到事务A提交,此时在事务B中 select 查询,发现 age 的值已经是 10 了。这就出现了一个问题,在同一事务中(本例中的事务B),事务的不同时刻同样的查询条件,查询出来的记录内容是不一样的,事务A的提交影响了事务B的查询结果,这就是不可重复读,也就是读提交隔离级别。
486 |
487 | - 可重复读
488 |
489 | 上面说不可重复读是指同一事物不同时刻读到的数据值可能不一致。而可重复读是指,事务不会读到其他事务对已有数据的修改,即使其他事务已提交。也就是说,事务开始时读到的已有数据是什么,在事务提交前的任意时刻,这些数据的值都是一样的。但是,对于其他事务新插入的数据是可以读到的,这也就引发了幻读问题。
490 |
491 | 例子:事务A开始后,执行 update 操作,将 age = 1 的记录的 name 改为“风筝2号”;事务B开始后,在事务执行完 update 后,执行 insert 操作,插入记录 age =1,name = 古时的风筝,这和事务A修改的那条记录值相同,然后提交。事务B提交后,事务A中执行 select,查询 age=1 的数据,这时,会发现多了一行,并且发现还有一条 name = 古时的风筝,age = 1 的记录,这其实就是事务B刚刚插入的,这就是幻读。
492 |
493 | - 串行化
494 |
495 | 串行化是4种事务隔离级别中隔离效果最好的,解决了脏读、可重复读、幻读的问题,但是效果最差,它将事务的执行变为顺序执行,与其他三个隔离级别相比,它就相当于单线程,后一个事务的执行必须等待前一个事务结束。
496 |
497 | - 应用场景
498 |
499 | 项目中是不用读未提交(Read UnCommitted)和串行化(Serializable)两个隔离级别,原因有二:
500 |
501 | 1. 采用读未提交(Read UnCommitted),一个事务读到另一个事务未提交读数据,这个不用多说吧,从逻辑上都说不过去!
502 | 2. 采用串行化(Serializable),每个次读操作都会加锁,快照读失效,一般是使用mysql自带分布式事务功能时才使用该隔离级别!(笔者从未用过mysql自带的这个功能,因为这是XA事务,是强一致性事务,性能不佳!互联网的分布式方案,多采用最终一致性的事务解决方案!)
503 |
504 | 所以我们只用考虑read committed或者read repeatable。一般互联网项目都用读已提交这个。
505 |
506 | [参考](https://blog.csdn.net/qq_26024869/article/details/107034616?spm=1001.2101.3001.6650.5&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-5.pc_relevant_aa&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-5.pc_relevant_aa&utm_relevant_index=10)
507 |
508 |
509 |
510 | ## **Mysql里面为什么用B+树?**
511 |
512 | [上面有写](#MYSQL索引和算法原理)
513 |
514 |
515 |
516 | ## 一条MySQL语句执行过程
517 |
518 | 首先了解一下mysql的架构
519 |
520 | 首先大方向上要分为两层,server层和存储引擎层。
521 |
522 | - server层
523 |
524 | Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
525 |
526 | - 存储引擎层
527 |
528 | 存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎,现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
529 |
530 | **下面来说一下过程:**
531 |
532 | **①第一步连接器**
533 |
534 | 连接到mysql服务器会首先碰到连接器,连接器负责跟客户端建立连接、获取权限、维持和管理连接。完成经典的 TCP 握手后,连接器就要开始认证你的身份,这个时候用的就是你输入的用户名和密码。
535 |
536 | **②查询缓存**
537 |
538 | MySQL 拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中。key 是查询的语句,value 是查询的结果。如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。
539 |
540 | 如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。
541 |
542 | 查询缓存也有不好的地方。查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非你的业务就是有一张静态表,很长时间才会更新一次。比如,一个系统配置表,那这张表上的查询才适合使用查询缓存。
543 |
544 | **③分析器**
545 |
546 | 分析器先会做“词法分析”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么。做完了这些识别以后,就要做“语法分析”。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法规则,只有遵循它的规则,才能获取到在它规则管理内的数据
547 |
548 | **④优化器**
549 |
550 | 优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一个方案。
551 |
552 | **⑤执行器**
553 |
554 | 开始执行语句。开始执行的时候,要先判断一下你对这个表 有没有执行对应操作的权限,如果没有,就会返回没有权限的错误;如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
555 |
556 | 如果表没有索引,会从第一行一行一行地读取,根据where后面的条件是否满足,如果有索引则会根据索引的规则去寻找,然后执行生成结果集。
557 |
558 |
559 |
560 | ## 分库分表有哪些方案?有什么区别?
561 |
562 | ## mysql调优
563 |
564 | ### 简单的优化方式
565 |
566 | **MySQL 分析表**
567 |
568 | 分析表用于分析和存储表的关键字分布,分析的结果可以使得系统得到准确的统计信息,使得 SQL 生成正确的执行计划。如果用于感觉实际执行计划与预期不符,可以执行分析表来解决问题,分析表语法如下:
569 |
570 | ```
571 | analyze table cxuan005;
572 | ```
573 |
574 | 分析结果涉及到的字段属性如下
575 |
576 | Table:表示表的名称;
577 |
578 | Op:表示执行的操作,analyze 表示进行分析操作,check 表示进行检查查找,optimize 表示进行优化操作;
579 |
580 | Msg_type:表示信息类型,其显示的值通常是状态、警告、错误和信息这四者之一;
581 |
582 | Msg_text:显示信息。
583 |
584 | 对表的定期分析可以改善性能,应该成为日常工作的一部分。因为通过更新表的索引信息对表进行分析,可改善数据库性能。
585 |
586 | **MySQL 检查表**
587 |
588 | 数据库经常可能遇到错误,比如数据写入磁盘时发生错误,或是索引没有同步更新,或是数据库未关闭 MySQL 就停止了。遇到这些情况,数据就可能发生错误: **Incorrect key file for table: ' '. Try to repair it**. 此时,我们可以使用 Check Table 语句来检查表及其对应的索引。
589 |
590 | ```
591 | check table cxuan005;
592 | ```
593 |
594 | 检查表的主要目的就是检查一个或者多个表是否有错误。Check Table 对 MyISAM 和 InnoDB 表有作用。Check Table 也可以检查视图的错误。
595 |
596 | **MySQL 优化表**
597 |
598 | MySQL 优化表适用于删除了大量的表数据,或者对包含 VARCHAR、BLOB 或则 TEXT 命令进行大量修改的情况。MySQL 优化表可以将大量的空间碎片进行合并,消除由于删除或者更新造成的空间浪费情况。它的命令如下
599 |
600 | ```
601 | optimize table cxuan005;
602 | ```
603 |
604 | ### 查询时的优化
605 |
606 | **小表驱动大表**
607 |
608 | 
609 |
610 | **避免全表扫描**
611 |
612 | mysql在使用不等于(!=或者<>)的时候无法使用导致全表扫描。在查询的时候,如果对索引使用不等于的操作将会导致索引失效,进行全表扫描
613 |
614 | **避免mysql放弃索引查询**
615 |
616 | 如果mysql估计使用全表扫描要比使用索引快,则不使用索引。(最典型的场景就是数据量少的时候)
617 |
618 | **使用覆盖索引,少使用select***
619 |
620 | 需要用到什么数据就查询什么数据,这样可以减少网络的传输和mysql的全表扫描。
621 |
622 | 尽量使用覆盖索引,比如索引为name,age,address的组合索引,那么尽量覆盖这三个字段之中的值,mysql将会直接在索引上取值(using index),并且返回值不包含不是索引的字段。
623 |
624 | ## MySQL 对于千万级的大表要怎么优化?
625 |
626 | https://www.zhihu.com/question/19719997
627 |
628 |
629 |
630 | +++
631 |
632 |
633 |
634 | # Redis
635 |
636 | ## 关系型数据库和非关系型数据库
637 |
638 | ### **关系型数据库**
639 |
640 | **含义:**采用关系模型来组织数据的数据库。简单说关系模型就是二维表格模型,而关系型数据库就是由二维表及其之间的联系组成的数据结构
641 |
642 | **优点:**
643 |
644 | 1. 容易理解:二维表结构是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型来说更容易理解
645 | 2. 使用方便:通用的SQL语言使得操作关系型数据库非常方便
646 | 3. 易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率
647 |
648 | **缺点:**
649 |
650 | 1. 高并发读写需求。 网站的用户并发性非常高,往往达到每秒上万次读写请求,对于传统关系型数据库来说,硬盘I/O是一个很大的瓶颈
651 | 2. 海量数据的高效率读写。 网站每天产生的数据量是巨大的,对于关系型数据库来说,在一张包含海量数据的表中查询和修改,效率是非常低的
652 | 3. 高扩展性和可用性。在基于web的结构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移。
653 |
654 | **一些不需要关系型数据库的情况:**
655 |
656 | 1. 关系型数据库在对事物一致性的维护中有很大的开销,而现在很多web2.0系统对事物的读写一致性都不高
657 |
658 | 2. 对关系数据库来说,插入一条数据之后立刻查询,是肯定可以读出这条数据的,但是对于很多web应用来说,并不要求这么高的实时性,比如发一条消息之后,过几秒乃至十几秒之后才看到这条动态是完全可以接受的
659 |
660 | 3. 任何大数据量的web系统,都非常忌讳多个大表的关联查询,以及复杂的数据分析类型的复杂SQL报表查询,特别是SNS类型的网站**(SNS,专指社交网络服务,包括了社交软件和社交网站。)**
661 |
662 |
663 |
664 | ### **非关系型数据库**
665 |
666 | **含义:**NoSQL一词首先是Carlo Strozzi在1998年提出来的,指的是他开发的一个没有SQL功能,轻量级的,开源的关系型数据库。但是NoSQL的发展慢慢偏离了初衷,我们要的不是“no sql”,而是“no relational(not noly)”,也就是我们现在常说的非关系型数据库了。
667 |
668 | **优点:**
669 |
670 | 1. 格式灵活:存储数据的格式可以是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
671 | 2. 速度快:nosql可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘;
672 | 3. 高扩展性。
673 | 4. 成本低:nosql数据库部署简单,基本都是开源软件。
674 |
675 | **缺点:**
676 |
677 | 1. 不提供sql支持,学习和使用成本较高;
678 | 2. 无事务处理;
679 | 3. 数据结构相对复杂,复杂查询方面稍欠。
680 |
681 | ### 总结
682 |
683 | 关系型数据库的最大特点就是事务的一致性:传统的关系型数据库读写操作都是事务的,具有ACID的特点,这个特性使得关系型数据库可以用于几乎所有对一致性有要求的系统中,如典型的银行系统。
684 |
685 |
686 | 但是,在网页应用中,尤其是SNS应用中,一致性却不是显得那么重要,用户A看到的内容和用户B看到同一用户C内容更新不一致是可以容忍的,或者说,两个人看到同一好友的数据更新的时间差那么几秒是可以容忍的,因此,关系型数据库的最大特点在这里已经无用武之地,起码不是那么重要了。
687 |
688 | 相反地,关系型数据库为了维护一致性所付出的巨大代价就是其读写性能比较差,而像微博、facebook这类SNS的应用,对并发读写能力要求极高,关系型数据库已经无法应付因此,必须用新的一种数据结构存储来代替关系数据库。
689 |
690 |
691 | 关系数据库的另一个特点就是其具有固定的表结构,因此,其扩展性极差,而在SNS中,系统的升级,功能的增加,往往意味着数据结构巨大变动,这一点关系型数据库也难以应付,需要新的结构化数据存储。
692 |
693 |
694 | 于是,非关系型数据库应运而生,由于不可能用一种数据结构化存储应付所有的新的需求,因此,非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。
695 |
696 |
697 | 必须强调的是,数据的持久存储,尤其是海量数据的持久存储,还是需要一种关系数据库这员老将。
698 |
699 |
700 |
701 | ## 什么时候用redis什么时候用mysql?
702 |
703 | Redis和MySQL不是相互替代的关系,而是相辅相成的,越来越多的项目组已经采用了redis+MySQL的架构来开发平台工具。
704 |
705 | 首先mysql是持久化数据库,是关系型数据库,是直接保存在硬盘上的。redis是非关系型数据库,是内存运行的数据存储获取工具。
706 |
707 | 但是数据量多少并不是redis和mysql选择的标准,因为都可以集群括展。
708 |
709 | 他们的使用场景是不同的:
710 |
711 | 1. 关系型数据库最重要的有两个点,第一是持久化存储的功能,即数据都存储在硬盘中。第二就是关系型数据库可以提供复杂的查询和统计功能。
712 | 2. 关系型数据库偏向于快速存取数据,用于实时响应要求高的场景,响应时间在毫秒级,通常作为热点数据的缓存使用。
713 |
714 | 数据多而且调用频繁的话,用mysql存储的话数据库连接被一直占用,其它的数据请求就进来了,导致连接超时,数据量大的话,数据库直接死机了。只能重启才能解决问题。这个时候如果把数据请求量大的数据放在redis中的话就可以分担一下mysql的压力,从而提高系统的性能,解决请求并发问题。
715 |
716 |
717 |
718 | ## Redis持久化
719 |
720 | RDB模式和AOF模式
721 |
722 | 在默认情况下,Redis将数据库快照保存在名为dump.rdb的二进制文件中
723 |
724 | 两个模式的选择:
725 |
726 | 1. **如果主要充当缓存功能,或者可以承受数分钟数据的丢失, 通常生产环境一般只需启用RDB可,此也是默认值**
727 |
728 | 2. **如果数据需要持久保存,一点不能丢失,可以选择同时开启RDB和AOF,一般不建议只开启AOF**
729 |
730 | ### RDB模式
731 |
732 | 具体原理有两种SAVE,BGSAVE
733 |
734 | **SAVE**
735 |
736 | SAVE是阻塞服务,在创建新文件dump.rdb替代旧文件时候无法响应客户端请求,生产环境中很少这样,一般都是停机维护时候才考虑
737 |
738 |  739 |
740 | **BGSAVE**
741 |
742 | 与之对应的,BGSAVE就是非阻塞的。当创建RDB文件时候,会fork一个子进程来做这件事,同时父进程会正常接收处理来自客户端的请求。子进程执行RDB操作,处理完后会向父进程发送一个信号,通知父进程处理完毕,父进程用新的dump.rdb文件替代旧文件。可以说BGSAVE是一个异步命令。fork是指redis通过创建子进程来进行RDB操作,cow指的是**copy on write**,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
743 |
744 | **RDB优点:**
745 |
746 | 1. RDB保存了某个时间点的数据,可以保留多个备份。当出现问题的时候方便恢复到不同时间节点(多版本恢复),同事文件格式支持不少第三方工具分析
747 | 2. RDB可以最大化Redis性能,父进程在保存RDB文件时候,唯一要做的就是fork一个子进程,接着子进程会接替保存工作,父进程无需执行任何磁盘io操作
748 | 3. RDB在大量数据的时候,恢复比AOF快
749 | 4. 文件单一紧凑,方便网络传输,适合灾难恢复
750 |
751 | **RDB缺点:**
752 |
753 | 1. RDB不能实时保存数据,即这次保存数据和上次保存数据之间这段时间如果有新数据,可能会丢失这部分新数据。虽然Redis允许设置不同的保存点来控制保存RDB文件的频率,但是由于数据集的属性,这不是一个轻松地操作,因此会丢失好几分钟内的数据
754 | 2. 当数据量非常大的时候,从父进程fork子进程来保存RDB文件时候需要一点时间。当数据集很庞大的时候,fork会非常耗时,造成服务器在一定时间内停止处理客户端,会有毫秒或秒级响应。
755 |
756 | ### AOF模式
757 |
758 | AOF即Append Only File,需要手动开启,采用追加的方式保存,默认文件是appendonly.aof,记录所有写的命令。
759 |
760 | AOF 方式不能保证绝对不丢失数据,目前常见的操作系统中,执行系统调用 write 函数,将一些内容写入到某个文件里面时,为了提高效率,系统通常不会直接将内容写入硬盘里 面,而是先将内容放入一个内存缓冲区(buffer)里面,等到缓冲区被填满,或者用户执行 fsync 调用和 fdatasync 调用时才将储存在缓冲区里的内容真正的写入到硬盘里,未写入磁盘之前,数据可能会丢失 。过程:
761 |
762 | 1. 命令追加:写到aof_buf中;
763 | 2. 写入文件:执行write操作;
764 | 3. 同步文件:同步到磁盘中。
765 |
766 | **优点:**
767 |
768 | 1. 数据安全性相对较高,根据所使用的fsync策略(fsync是同步内存中redis所有已经修改的文件到存储设备),默认是appendfsync everysec,即每秒执行一次 fsync,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync会在后台线程执行,所以主线程可以继续努力地处理命令请求)
769 | 2. 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中不需要seek, 即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,可以通过 redis-check-aof 工具来解决数据一致性的问题
770 | 3. Redis可以在 AOF文件体积变得过大时,自动地在后台对AOF进行重写,重写后的新AOF文件包含了恢复当前数据集所需的最小命令集合。整个重写操作是绝对安全的,因为Redis在创建新 AOF文件的过程中,append模式不断的将修改数据追加到现有的 AOF文件里面,即使重写过程中发停机,现有的 AOF文件也不会丢失。而一旦新AOF文件创建完毕,Redis就会从旧AOF文件切换到新AOF文件,并开始对新AOF文件进行追加操作。
771 | 4. AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,也可以通过该文件完成数据的重建AOF文件有序地保存了对数据库执行的所有写入操作,这些写入操作以Redis协议的格式保存,因此 AOF文件的内容非常容易被人读懂,对文件进行分析(parse)也很轻松。导出(export)AOF文件也非常简单:
772 | 5. 举个例子,如果你不小心执行了FLUSHALL.命令,但只要AOF文件未被重写,那么只要停止服务器,移除 AOF文件末尾的FLUSHAL命令,并重启Redis ,就可以将数据集恢复到
773 | FLUSHALL执行之前的状态。
774 |
775 | **缺点:**
776 |
777 | 1. 即使有些操作是重复的也会全部记录,AOF 的文件大小要大于 RDB 格式的文件
778 |
779 | 2. AOF 在恢复大数据集时的速度比 RDB 的恢复速度要慢
780 |
781 | 3. 根据fsync策略不同,AOF速度可能会慢于RDB
782 |
783 | 4. bug 出现的可能性更多
784 |
785 |
786 |
787 | ## Redis的数据结构讲一讲 + 使用场景
788 |
789 | [详细参考链接](https://www.cnblogs.com/xiaolincoding/p/15628854.html)
790 |
791 | 五种基本的数据类型:**String**、**Hash**、**List**、**Set**、**SortedSet**
792 |
793 | 更高级的有:**HyperLogLog、Geo、BloomFilter**
794 |
795 | ### 键值对数据库是怎么实现的?
796 |
797 | > Redis 的键值对中的 key 就是字符串对象,而 **value 可以是字符串对象,也可以是集合数据类型的对象**,比如 List 对象、Hash 对象、Set 对象和 Zset 对象。
798 |
799 | Redis 是使用了一个「哈希表」保存所有键值对,哈希表的最大好处就是让我们可以用 O(1) 的时间复杂度来快速查找到键值对。哈希表其实就是一个数组,数组中的元素叫做哈希桶。哈希桶存放的是指向键值对数据的指针,这样通过指针就能找到键值对数据,然后因为键值对的值可以保存字符串对象和集合数据类型的对象,所以键值对的数据结构中并不是直接保存值本身,而是保存了 void * key 和 void * value 指针,分别指向了实际的键对象和值对象,这样一来,即使值是集合数据,也可以通过 void * value 指针找到。如图:
800 |
801 |
739 |
740 | **BGSAVE**
741 |
742 | 与之对应的,BGSAVE就是非阻塞的。当创建RDB文件时候,会fork一个子进程来做这件事,同时父进程会正常接收处理来自客户端的请求。子进程执行RDB操作,处理完后会向父进程发送一个信号,通知父进程处理完毕,父进程用新的dump.rdb文件替代旧文件。可以说BGSAVE是一个异步命令。fork是指redis通过创建子进程来进行RDB操作,cow指的是**copy on write**,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
743 |
744 | **RDB优点:**
745 |
746 | 1. RDB保存了某个时间点的数据,可以保留多个备份。当出现问题的时候方便恢复到不同时间节点(多版本恢复),同事文件格式支持不少第三方工具分析
747 | 2. RDB可以最大化Redis性能,父进程在保存RDB文件时候,唯一要做的就是fork一个子进程,接着子进程会接替保存工作,父进程无需执行任何磁盘io操作
748 | 3. RDB在大量数据的时候,恢复比AOF快
749 | 4. 文件单一紧凑,方便网络传输,适合灾难恢复
750 |
751 | **RDB缺点:**
752 |
753 | 1. RDB不能实时保存数据,即这次保存数据和上次保存数据之间这段时间如果有新数据,可能会丢失这部分新数据。虽然Redis允许设置不同的保存点来控制保存RDB文件的频率,但是由于数据集的属性,这不是一个轻松地操作,因此会丢失好几分钟内的数据
754 | 2. 当数据量非常大的时候,从父进程fork子进程来保存RDB文件时候需要一点时间。当数据集很庞大的时候,fork会非常耗时,造成服务器在一定时间内停止处理客户端,会有毫秒或秒级响应。
755 |
756 | ### AOF模式
757 |
758 | AOF即Append Only File,需要手动开启,采用追加的方式保存,默认文件是appendonly.aof,记录所有写的命令。
759 |
760 | AOF 方式不能保证绝对不丢失数据,目前常见的操作系统中,执行系统调用 write 函数,将一些内容写入到某个文件里面时,为了提高效率,系统通常不会直接将内容写入硬盘里 面,而是先将内容放入一个内存缓冲区(buffer)里面,等到缓冲区被填满,或者用户执行 fsync 调用和 fdatasync 调用时才将储存在缓冲区里的内容真正的写入到硬盘里,未写入磁盘之前,数据可能会丢失 。过程:
761 |
762 | 1. 命令追加:写到aof_buf中;
763 | 2. 写入文件:执行write操作;
764 | 3. 同步文件:同步到磁盘中。
765 |
766 | **优点:**
767 |
768 | 1. 数据安全性相对较高,根据所使用的fsync策略(fsync是同步内存中redis所有已经修改的文件到存储设备),默认是appendfsync everysec,即每秒执行一次 fsync,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync会在后台线程执行,所以主线程可以继续努力地处理命令请求)
769 | 2. 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中不需要seek, 即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,可以通过 redis-check-aof 工具来解决数据一致性的问题
770 | 3. Redis可以在 AOF文件体积变得过大时,自动地在后台对AOF进行重写,重写后的新AOF文件包含了恢复当前数据集所需的最小命令集合。整个重写操作是绝对安全的,因为Redis在创建新 AOF文件的过程中,append模式不断的将修改数据追加到现有的 AOF文件里面,即使重写过程中发停机,现有的 AOF文件也不会丢失。而一旦新AOF文件创建完毕,Redis就会从旧AOF文件切换到新AOF文件,并开始对新AOF文件进行追加操作。
771 | 4. AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,也可以通过该文件完成数据的重建AOF文件有序地保存了对数据库执行的所有写入操作,这些写入操作以Redis协议的格式保存,因此 AOF文件的内容非常容易被人读懂,对文件进行分析(parse)也很轻松。导出(export)AOF文件也非常简单:
772 | 5. 举个例子,如果你不小心执行了FLUSHALL.命令,但只要AOF文件未被重写,那么只要停止服务器,移除 AOF文件末尾的FLUSHAL命令,并重启Redis ,就可以将数据集恢复到
773 | FLUSHALL执行之前的状态。
774 |
775 | **缺点:**
776 |
777 | 1. 即使有些操作是重复的也会全部记录,AOF 的文件大小要大于 RDB 格式的文件
778 |
779 | 2. AOF 在恢复大数据集时的速度比 RDB 的恢复速度要慢
780 |
781 | 3. 根据fsync策略不同,AOF速度可能会慢于RDB
782 |
783 | 4. bug 出现的可能性更多
784 |
785 |
786 |
787 | ## Redis的数据结构讲一讲 + 使用场景
788 |
789 | [详细参考链接](https://www.cnblogs.com/xiaolincoding/p/15628854.html)
790 |
791 | 五种基本的数据类型:**String**、**Hash**、**List**、**Set**、**SortedSet**
792 |
793 | 更高级的有:**HyperLogLog、Geo、BloomFilter**
794 |
795 | ### 键值对数据库是怎么实现的?
796 |
797 | > Redis 的键值对中的 key 就是字符串对象,而 **value 可以是字符串对象,也可以是集合数据类型的对象**,比如 List 对象、Hash 对象、Set 对象和 Zset 对象。
798 |
799 | Redis 是使用了一个「哈希表」保存所有键值对,哈希表的最大好处就是让我们可以用 O(1) 的时间复杂度来快速查找到键值对。哈希表其实就是一个数组,数组中的元素叫做哈希桶。哈希桶存放的是指向键值对数据的指针,这样通过指针就能找到键值对数据,然后因为键值对的值可以保存字符串对象和集合数据类型的对象,所以键值对的数据结构中并不是直接保存值本身,而是保存了 void * key 和 void * value 指针,分别指向了实际的键对象和值对象,这样一来,即使值是集合数据,也可以通过 void * value 指针找到。如图:
800 |
801 | 
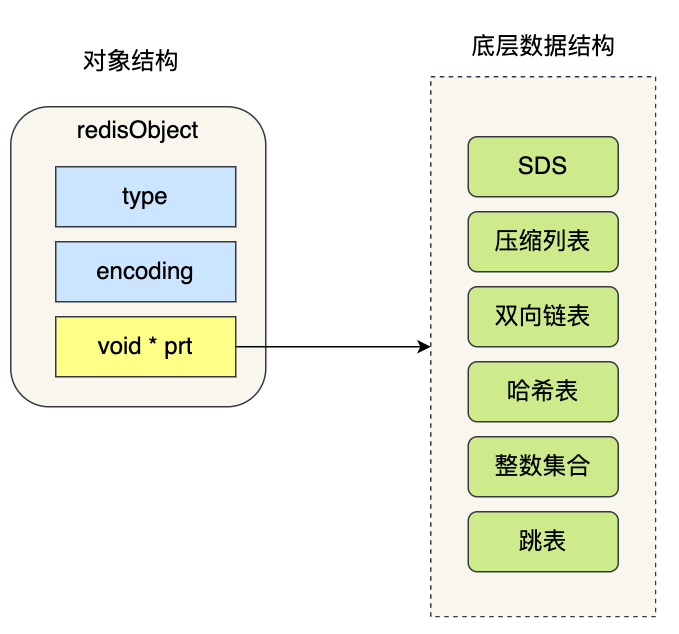 802 |
803 | 特别说明:void * key 和 void * value 指针指向的是 **Redis 对象**,Redis 中的每个对象都由 redisObject 结构表示
804 |
805 | ### string
806 |
807 | **String** 是 Redis 最简单最常用的数据结构
808 |
809 | Redis中的字符串,不是 C 语言中的字符串(即以空字符’\0’结尾的字符数组),是自己构建了一种名为 **简单动态字符串(simple dynamic string,SDS**)的抽象类型,并将 SDS 作为 Redis的默认字符串表示。其数据结构如下所示:
810 |
811 |
802 |
803 | 特别说明:void * key 和 void * value 指针指向的是 **Redis 对象**,Redis 中的每个对象都由 redisObject 结构表示
804 |
805 | ### string
806 |
807 | **String** 是 Redis 最简单最常用的数据结构
808 |
809 | Redis中的字符串,不是 C 语言中的字符串(即以空字符’\0’结尾的字符数组),是自己构建了一种名为 **简单动态字符串(simple dynamic string,SDS**)的抽象类型,并将 SDS 作为 Redis的默认字符串表示。其数据结构如下所示:
810 |
811 |  812 |
813 | > 上图中,uint8_t表示8位无符号整数
814 |
815 | **为什么使用SDS?**
816 |
817 | 1. 由于 len 属性的存在,我们获取 SDS 字符串的长度只需要读取 len 属性,时间复杂度为 O(1)。而对于 C 语言,获取字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。
818 | 2. C 语言中使用 `strcat` 函数来进行两个字符串的拼接,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。而对于 SDS 数据类型,在进行字符修改的时候,会首先根据记录的 len 属性检查内存空间是否满足需求,如果不满足,会进行相应的空间扩展,然后在进行修改操作,所以不会出现缓冲区溢出。
819 | 3. C语言由于不记录字符串的长度,所以如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。而对于SDS,由于`len`属性和`alloc`属性的存在,对于修改字符串SDS实现了**空间预分配**和**惰性空间释放**两种策略
820 | 4. 因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而所有 SDS 的API 都是以处理二进制的方式来处理 `buf` 里面的元素,并且 SDS 不是以空字符串来判断是否结束,而是以 len 属性表示的长度来判断字符串是否结束。
821 |
822 | ### ZipList(压缩列表)
823 |
824 | 压缩列表的最大特点,就是它被设计成一种内存紧凑型的数据结构,占用一块连续的内存空间,不仅可以利用 CPU 缓存,而且会针对不同长度的数据,进行相应编码,这种方法可以有效地节省内存开销。
825 |
826 | 压缩列表的构成如下:
827 |
828 |
812 |
813 | > 上图中,uint8_t表示8位无符号整数
814 |
815 | **为什么使用SDS?**
816 |
817 | 1. 由于 len 属性的存在,我们获取 SDS 字符串的长度只需要读取 len 属性,时间复杂度为 O(1)。而对于 C 语言,获取字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。
818 | 2. C 语言中使用 `strcat` 函数来进行两个字符串的拼接,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。而对于 SDS 数据类型,在进行字符修改的时候,会首先根据记录的 len 属性检查内存空间是否满足需求,如果不满足,会进行相应的空间扩展,然后在进行修改操作,所以不会出现缓冲区溢出。
819 | 3. C语言由于不记录字符串的长度,所以如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。而对于SDS,由于`len`属性和`alloc`属性的存在,对于修改字符串SDS实现了**空间预分配**和**惰性空间释放**两种策略
820 | 4. 因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而所有 SDS 的API 都是以处理二进制的方式来处理 `buf` 里面的元素,并且 SDS 不是以空字符串来判断是否结束,而是以 len 属性表示的长度来判断字符串是否结束。
821 |
822 | ### ZipList(压缩列表)
823 |
824 | 压缩列表的最大特点,就是它被设计成一种内存紧凑型的数据结构,占用一块连续的内存空间,不仅可以利用 CPU 缓存,而且会针对不同长度的数据,进行相应编码,这种方法可以有效地节省内存开销。
825 |
826 | 压缩列表的构成如下:
827 |
828 | 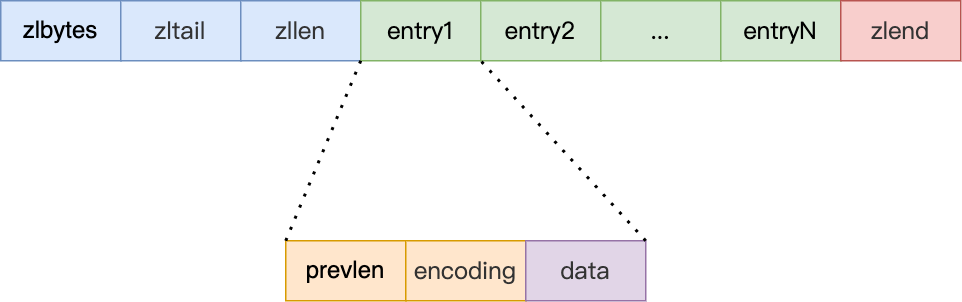 829 |
830 | 1. zlbytes,记录整个压缩列表占用对内存字节数;
831 | 2. zltail,记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量;
832 | 3. zllen,记录压缩列表包含的节点数量;
833 | 4. zlend,标记压缩列表的结束点,固定值 0xFF(十进制255)。
834 | 5. prevlen,记录了「前一个节点」的长度;
835 | 6. encoding,记录了当前节点实际数据的类型以及长度;
836 | 7. data,记录了当前节点的实际数据;
837 |
838 | 当往压缩列表中插入数据时,压缩列表就会根据数据是字符串还是整数,以及数据的大小,会使用不同空间大小的 prevlen 和 encoding 这两个元素里保存的信息,这种根据数据大小和类型进行不同的空间大小分配的设计思想,正是 Redis 为了节省内存而采用的。
839 |
840 | **缺点:**空间扩展操作也就是重新分配内存,因此连锁更新一旦发生,就会导致压缩列表占用的内存空间要多次重新分配,这就会直接影响到压缩列表的访问性能。所以说,虽然压缩列表紧凑型的内存布局能节省内存开销,但是如果保存的元素数量增加了,或是元素变大了,会导致内存重新分配,最糟糕的是会有「连锁更新」的问题。
841 |
842 | ### hash表
843 |
844 | Redis 散列可以存储多个键值对之间的映射。和字符串一样,散列存储的值既可以是字符串又可以是数值,并且用户同样可以对散列存储的数字值执行自增或自减操作。
845 |
846 | ### 整数集合
847 |
848 | 整数集合是 Set 对象的底层实现之一。当一个 Set 对象只包含整数值元素,并且元素数量不时,就会使用整数集这个数据结构作为底层实现。整数集合本质上是一块连续内存空间,它的结构定义如下:
849 |
850 | ```c
851 | typedef struct intset {
852 | //编码方式
853 | uint32_t encoding;
854 | //集合包含的元素数量
855 | uint32_t length;
856 | //保存元素的数组
857 | int8_t contents[];
858 | } intset;
859 | ```
860 |
861 | 保存元素的容器是一个 contents 数组,虽然 contents 被声明为 int8_t 类型的数组,但是实际上 contents 数组并不保存任何 int8_t 类型的元素,contents 数组的真正类型取决于 intset 结构体里的 encoding 属性的值。
862 |
863 | **整数集合的升级操作**
864 |
865 | 整数集合会有一个升级规则,就是当我们将一个新元素加入到整数集合里面,如果新元素的类型(int32_t)比整数集合现有所有元素的类型(int16_t)都要长时,整数集合需要先进行升级,也就是按新元素的类型(int32_t)扩展 contents 数组的空间大小,然后才能将新元素加入到整数集合里,当然升级的过程中,也要维持整数集合的有序性。
866 |
867 | 整数集合升级的过程不会重新分配一个新类型的数组,而是在原本的数组上扩展空间,然后在将每个元素按间隔类型大小分割。整数集合升级的好处是**节省内存资源**。
868 |
869 | ### 跳表
870 |
871 | Redis 只有在 Zset 对象的底层实现用到了跳表,跳表的优势是能支持平均 O(logN) 复杂度的节点查找。Zset 对象是唯一一个同时使用了两个数据结构来实现的 Redis 对象,这两个数据结构一个是跳表,一个是哈希表。这样的好处是既能进行高效的范围查询,也能进行高效单点查询。
872 |
873 | 链表在查找元素的时候,因为需要逐一查找,所以查询效率非常低,时间复杂度是O(N),于是就出现了跳表。**跳表是在链表基础上改进过来的,实现了一种「多层」的有序链表**,这样的好处是能快读定位数据。如图:
874 |
875 |
829 |
830 | 1. zlbytes,记录整个压缩列表占用对内存字节数;
831 | 2. zltail,记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量;
832 | 3. zllen,记录压缩列表包含的节点数量;
833 | 4. zlend,标记压缩列表的结束点,固定值 0xFF(十进制255)。
834 | 5. prevlen,记录了「前一个节点」的长度;
835 | 6. encoding,记录了当前节点实际数据的类型以及长度;
836 | 7. data,记录了当前节点的实际数据;
837 |
838 | 当往压缩列表中插入数据时,压缩列表就会根据数据是字符串还是整数,以及数据的大小,会使用不同空间大小的 prevlen 和 encoding 这两个元素里保存的信息,这种根据数据大小和类型进行不同的空间大小分配的设计思想,正是 Redis 为了节省内存而采用的。
839 |
840 | **缺点:**空间扩展操作也就是重新分配内存,因此连锁更新一旦发生,就会导致压缩列表占用的内存空间要多次重新分配,这就会直接影响到压缩列表的访问性能。所以说,虽然压缩列表紧凑型的内存布局能节省内存开销,但是如果保存的元素数量增加了,或是元素变大了,会导致内存重新分配,最糟糕的是会有「连锁更新」的问题。
841 |
842 | ### hash表
843 |
844 | Redis 散列可以存储多个键值对之间的映射。和字符串一样,散列存储的值既可以是字符串又可以是数值,并且用户同样可以对散列存储的数字值执行自增或自减操作。
845 |
846 | ### 整数集合
847 |
848 | 整数集合是 Set 对象的底层实现之一。当一个 Set 对象只包含整数值元素,并且元素数量不时,就会使用整数集这个数据结构作为底层实现。整数集合本质上是一块连续内存空间,它的结构定义如下:
849 |
850 | ```c
851 | typedef struct intset {
852 | //编码方式
853 | uint32_t encoding;
854 | //集合包含的元素数量
855 | uint32_t length;
856 | //保存元素的数组
857 | int8_t contents[];
858 | } intset;
859 | ```
860 |
861 | 保存元素的容器是一个 contents 数组,虽然 contents 被声明为 int8_t 类型的数组,但是实际上 contents 数组并不保存任何 int8_t 类型的元素,contents 数组的真正类型取决于 intset 结构体里的 encoding 属性的值。
862 |
863 | **整数集合的升级操作**
864 |
865 | 整数集合会有一个升级规则,就是当我们将一个新元素加入到整数集合里面,如果新元素的类型(int32_t)比整数集合现有所有元素的类型(int16_t)都要长时,整数集合需要先进行升级,也就是按新元素的类型(int32_t)扩展 contents 数组的空间大小,然后才能将新元素加入到整数集合里,当然升级的过程中,也要维持整数集合的有序性。
866 |
867 | 整数集合升级的过程不会重新分配一个新类型的数组,而是在原本的数组上扩展空间,然后在将每个元素按间隔类型大小分割。整数集合升级的好处是**节省内存资源**。
868 |
869 | ### 跳表
870 |
871 | Redis 只有在 Zset 对象的底层实现用到了跳表,跳表的优势是能支持平均 O(logN) 复杂度的节点查找。Zset 对象是唯一一个同时使用了两个数据结构来实现的 Redis 对象,这两个数据结构一个是跳表,一个是哈希表。这样的好处是既能进行高效的范围查询,也能进行高效单点查询。
872 |
873 | 链表在查找元素的时候,因为需要逐一查找,所以查询效率非常低,时间复杂度是O(N),于是就出现了跳表。**跳表是在链表基础上改进过来的,实现了一种「多层」的有序链表**,这样的好处是能快读定位数据。如图:
874 |
875 | 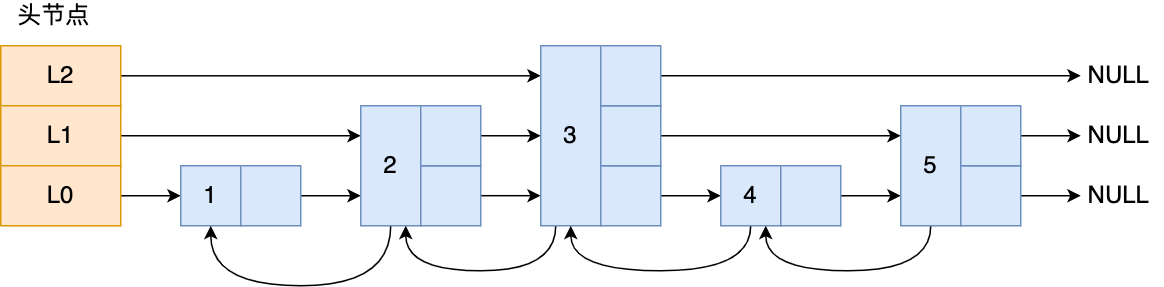 876 |
877 | 如果我们要在链表中查找节点 4 这个元素,只能从头开始遍历链表,需要查找 4 次,而使用了跳表后,只需要查找 2 次就能定位到节点 4,因为可以在头节点直接从 L2 层级跳到节点 3,然后再往前遍历找到节点 4。
878 |
879 | ### quicklist(快表)
880 |
881 | 在 Redis 3.0 之前,List 对象的底层数据结构是双向链表或者压缩列表。然后在 Redis 3.2 的时候,List 对象的底层改由 quicklist 数据结构实现。
882 |
883 | 其实 quicklist 就是「双向链表 + 压缩列表」组合,因为一个 quicklist 就是一个链表,而链表中的每个元素又是一个压缩列表。
884 |
885 | 在前面讲压缩列表的时候,我也提到了压缩列表的不足,虽然压缩列表是通过紧凑型的内存布局节省了内存开销,但是因为它的结构设计,如果保存的元素数量增加,或者元素变大了,压缩列表会有「连锁更新」的风险,一旦发生,会造成性能下降。
886 |
887 | quicklist 解决办法,**通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越小,连锁更新带来的影响就越小,从而提供了更好的访问性能。**
888 |
889 |
876 |
877 | 如果我们要在链表中查找节点 4 这个元素,只能从头开始遍历链表,需要查找 4 次,而使用了跳表后,只需要查找 2 次就能定位到节点 4,因为可以在头节点直接从 L2 层级跳到节点 3,然后再往前遍历找到节点 4。
878 |
879 | ### quicklist(快表)
880 |
881 | 在 Redis 3.0 之前,List 对象的底层数据结构是双向链表或者压缩列表。然后在 Redis 3.2 的时候,List 对象的底层改由 quicklist 数据结构实现。
882 |
883 | 其实 quicklist 就是「双向链表 + 压缩列表」组合,因为一个 quicklist 就是一个链表,而链表中的每个元素又是一个压缩列表。
884 |
885 | 在前面讲压缩列表的时候,我也提到了压缩列表的不足,虽然压缩列表是通过紧凑型的内存布局节省了内存开销,但是因为它的结构设计,如果保存的元素数量增加,或者元素变大了,压缩列表会有「连锁更新」的风险,一旦发生,会造成性能下降。
886 |
887 | quicklist 解决办法,**通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越小,连锁更新带来的影响就越小,从而提供了更好的访问性能。**
888 |
889 | 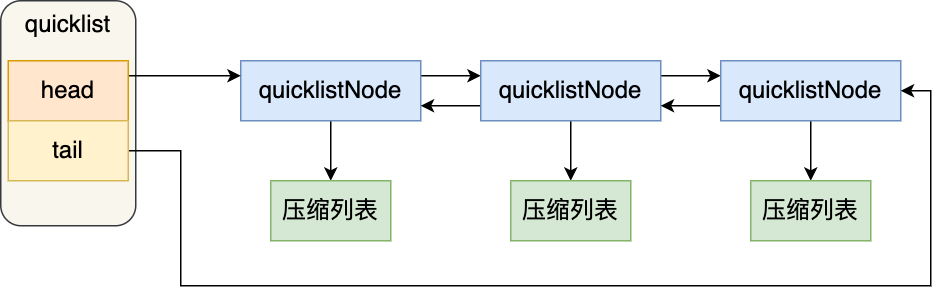 890 |
891 | ### 使用场景
892 |
893 |
890 |
891 | ### 使用场景
892 |
893 |  894 |
895 |
896 |
897 | ## 避免缓存穿透的利器之BloomFilter
898 |
899 | 本质就是用单向散列函数把数据映射到二进制向量中
900 |
901 | 布隆过滤器优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。即假阳性,就是说如果每一位为0表示一定没有,为1表示可能会出现没有的情况。
902 |
903 | Bloom Filter跟单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。
904 |
905 | 因为布隆过滤器可以明确知道某个查询数据库不存在,所以可以过滤掉无效的查询到数据库,减少数据库的压力。
906 |
907 |
908 |
909 | ## 如果有大量的key需要设置同一时间过期,一般需要注意什么?
910 |
911 | 如果大量的key过期时间设置的过于集中,到过期的那个时间点,**Redis**可能会出现短暂的卡顿现象。严重的话会出现缓存雪崩,我们一般需要在时间上加一个随机值,使得过期时间分散一些。
912 |
913 |
914 |
915 | ## 缓存穿透,缓存击穿,缓存血崩
916 |
917 | [参考](https://segmentfault.com/a/1190000039688578)
918 |
919 | - **缓存穿透**
920 |
921 | 定义:缓存穿透是指缓存和数据库都没有的数据,被大量请求,比如订单号不可能为`-1`,但是用户请求了大量订单号为`-1`的数据,由于数据不存在,缓存就也不会存在该数据,所有的请求都会直接穿透到数据库。
922 | 如果被恶意用户利用,疯狂请求不存在的数据,就会导致数据库压力过大,甚至垮掉。
923 |
924 | 解决:
925 |
926 | - **缓存击穿**
927 |
928 | 定义:缓存击穿是指数据库原本有得数据,但是缓存中没有,一般是缓存突然失效了,这时候如果有大量用户请求该数据,缓存没有则会去数据库请求,会引发数据库压力增大,可能会瞬间打垮。
929 |
930 | 解决:
931 |
932 | - **缓存血崩**
933 |
934 | 定义:缓存雪崩是指缓存中有大量的数据,在同一个时间点,或者较短的时间段内,全部过期了,这个时候请求过来,缓存没有数据,都会请求数据库,则数据库的压力就会突增,扛不住就会宕机。
935 |
936 | 解决:
937 |
938 |
939 |
940 | ## redis高并发和快的原因
941 |
942 | 1. redis是基于内存的,内存的读写速度非常快;没有磁盘IO的开销
943 |
944 | 2. redis是单线程的,省去了很多上下文切换线程的时间;
945 |
946 | 3. redis使用多路复用技术,可以处理并发的连接。非阻塞IO 内部实现采用epoll,采用了epoll+自己实现的简单的事件框架。
947 |
948 |
949 |
950 | ## Redis的单线程
951 |
952 | Redis由很多个模块组成,如网络请求模块、索引模块、存储模块、高可用集群支撑模块、数据操作模块等。
953 |
954 | 很多人说Redis是单线程的,就认为Redis中所有模块的操作都是单线程的,其实这是不对的。我们所说的Redis单线程,指的是"其网络IO和键值对读写是由一个线程完成的",也就是说,**Redis中只有网络请求模块和数据操作模块是单线程的。而其他的如持久化存储模块、集群支撑模块等是多线程的。**
955 |
956 | **原因:**
957 |
958 | 1. 锁带来的性能消耗。多线程可能会产生竞态条件,如果要对数据进行细粒度操作需要加锁,会加大开销增大延时。
959 | 2. CPU上下文切换带来的性能消耗。在多核CPU架构下,Redis如果在不同的核上运行,就需要频繁地进行上下文切换,这个过程会增加Redis的执行时间,客户端也会观察到较高的尾延迟了
960 | 3. redis是IO密集型程序,对于CPU是利用率没那么高,CPU并不是性能瓶颈
961 | 4. 在单线程中使用多路复用 I/O技术也能提升Redis的I/O利用率
962 |
963 | **总结:**上面的原因说的也是多线程实现redis的劣势。我们可以从整体来看,一个计算机程序在执行的过程中,主要需要进行两种操作分别是读写操作和计算操作。其中读写操作主要是涉及到的就是I/O操作,其中包括网络I/O和磁盘I/O,计算操作主要涉及到CPU。**而多线程的目的,就是通过并发的方式来提升I/O的利用率和CPU的利用率。**那么,Redis需不需要通过多线程的方式来提升提升I/O的利用率和CPU的利用率呢?首先redis数据的存取对CPU的要求很小,所以说CPU不是redis性能的瓶颈。那么再看IO,提高IO效率多线程是一种方案,但不是唯一的一种,还有IO多路复用这个技术。所以在redis采用的是IO复用的技术来提高IO并发。
964 |
965 |
966 |
967 | ## Redis的IO多路复用
968 |
969 | redis是非阻塞IO+IO多路复用的技术来实现的
970 |
971 | Linux的IO多路复用机制是指一个线程处理多个IO流,也就是select/epoll机制。
972 |
973 |
894 |
895 |
896 |
897 | ## 避免缓存穿透的利器之BloomFilter
898 |
899 | 本质就是用单向散列函数把数据映射到二进制向量中
900 |
901 | 布隆过滤器优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。即假阳性,就是说如果每一位为0表示一定没有,为1表示可能会出现没有的情况。
902 |
903 | Bloom Filter跟单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。
904 |
905 | 因为布隆过滤器可以明确知道某个查询数据库不存在,所以可以过滤掉无效的查询到数据库,减少数据库的压力。
906 |
907 |
908 |
909 | ## 如果有大量的key需要设置同一时间过期,一般需要注意什么?
910 |
911 | 如果大量的key过期时间设置的过于集中,到过期的那个时间点,**Redis**可能会出现短暂的卡顿现象。严重的话会出现缓存雪崩,我们一般需要在时间上加一个随机值,使得过期时间分散一些。
912 |
913 |
914 |
915 | ## 缓存穿透,缓存击穿,缓存血崩
916 |
917 | [参考](https://segmentfault.com/a/1190000039688578)
918 |
919 | - **缓存穿透**
920 |
921 | 定义:缓存穿透是指缓存和数据库都没有的数据,被大量请求,比如订单号不可能为`-1`,但是用户请求了大量订单号为`-1`的数据,由于数据不存在,缓存就也不会存在该数据,所有的请求都会直接穿透到数据库。
922 | 如果被恶意用户利用,疯狂请求不存在的数据,就会导致数据库压力过大,甚至垮掉。
923 |
924 | 解决:
925 |
926 | - **缓存击穿**
927 |
928 | 定义:缓存击穿是指数据库原本有得数据,但是缓存中没有,一般是缓存突然失效了,这时候如果有大量用户请求该数据,缓存没有则会去数据库请求,会引发数据库压力增大,可能会瞬间打垮。
929 |
930 | 解决:
931 |
932 | - **缓存血崩**
933 |
934 | 定义:缓存雪崩是指缓存中有大量的数据,在同一个时间点,或者较短的时间段内,全部过期了,这个时候请求过来,缓存没有数据,都会请求数据库,则数据库的压力就会突增,扛不住就会宕机。
935 |
936 | 解决:
937 |
938 |
939 |
940 | ## redis高并发和快的原因
941 |
942 | 1. redis是基于内存的,内存的读写速度非常快;没有磁盘IO的开销
943 |
944 | 2. redis是单线程的,省去了很多上下文切换线程的时间;
945 |
946 | 3. redis使用多路复用技术,可以处理并发的连接。非阻塞IO 内部实现采用epoll,采用了epoll+自己实现的简单的事件框架。
947 |
948 |
949 |
950 | ## Redis的单线程
951 |
952 | Redis由很多个模块组成,如网络请求模块、索引模块、存储模块、高可用集群支撑模块、数据操作模块等。
953 |
954 | 很多人说Redis是单线程的,就认为Redis中所有模块的操作都是单线程的,其实这是不对的。我们所说的Redis单线程,指的是"其网络IO和键值对读写是由一个线程完成的",也就是说,**Redis中只有网络请求模块和数据操作模块是单线程的。而其他的如持久化存储模块、集群支撑模块等是多线程的。**
955 |
956 | **原因:**
957 |
958 | 1. 锁带来的性能消耗。多线程可能会产生竞态条件,如果要对数据进行细粒度操作需要加锁,会加大开销增大延时。
959 | 2. CPU上下文切换带来的性能消耗。在多核CPU架构下,Redis如果在不同的核上运行,就需要频繁地进行上下文切换,这个过程会增加Redis的执行时间,客户端也会观察到较高的尾延迟了
960 | 3. redis是IO密集型程序,对于CPU是利用率没那么高,CPU并不是性能瓶颈
961 | 4. 在单线程中使用多路复用 I/O技术也能提升Redis的I/O利用率
962 |
963 | **总结:**上面的原因说的也是多线程实现redis的劣势。我们可以从整体来看,一个计算机程序在执行的过程中,主要需要进行两种操作分别是读写操作和计算操作。其中读写操作主要是涉及到的就是I/O操作,其中包括网络I/O和磁盘I/O,计算操作主要涉及到CPU。**而多线程的目的,就是通过并发的方式来提升I/O的利用率和CPU的利用率。**那么,Redis需不需要通过多线程的方式来提升提升I/O的利用率和CPU的利用率呢?首先redis数据的存取对CPU的要求很小,所以说CPU不是redis性能的瓶颈。那么再看IO,提高IO效率多线程是一种方案,但不是唯一的一种,还有IO多路复用这个技术。所以在redis采用的是IO复用的技术来提高IO并发。
964 |
965 |
966 |
967 | ## Redis的IO多路复用
968 |
969 | redis是非阻塞IO+IO多路复用的技术来实现的
970 |
971 | Linux的IO多路复用机制是指一个线程处理多个IO流,也就是select/epoll机制。
972 |
973 |  974 |
975 |
976 |
977 | ## Redis怎么统计在线用户
978 |
979 | [参考链接](https://blog.huangz.me/diary/2016/redis-count-online-users.html#)
980 |
981 | | 方案 | 特点 |
982 | | :---------- | :----------------------------------------------------------- |
983 | | 有序集合 | 能够同时储存在线用户的名单以及用户的上线时间,能够执行非常多的聚合计算操作,但是耗费的内存也非常多。 |
984 | | 集合 | 能够储存在线用户的名单,也能够执行聚合计算,消耗的内存比有序集合少,但是跟有序集合一样,这个方案消耗的内存也会随着用户数量的增多而增多。 |
985 | | HyperLogLog | 无论需要统计的用户有多少,只需要耗费 12 KB 内存,但由于概率算法的特性,只能给出在线人数的估算值,并且也无法获取准确的在线用户名单。 |
986 | | 位图 | 在尽可能节约内存的情况下,记录在线用户的名单,并且能够对这些名单执行聚合操作。 |
987 |
988 |
989 |
990 | ## redis,讲讲缓存一致性问题
991 |
992 |
974 |
975 |
976 |
977 | ## Redis怎么统计在线用户
978 |
979 | [参考链接](https://blog.huangz.me/diary/2016/redis-count-online-users.html#)
980 |
981 | | 方案 | 特点 |
982 | | :---------- | :----------------------------------------------------------- |
983 | | 有序集合 | 能够同时储存在线用户的名单以及用户的上线时间,能够执行非常多的聚合计算操作,但是耗费的内存也非常多。 |
984 | | 集合 | 能够储存在线用户的名单,也能够执行聚合计算,消耗的内存比有序集合少,但是跟有序集合一样,这个方案消耗的内存也会随着用户数量的增多而增多。 |
985 | | HyperLogLog | 无论需要统计的用户有多少,只需要耗费 12 KB 内存,但由于概率算法的特性,只能给出在线人数的估算值,并且也无法获取准确的在线用户名单。 |
986 | | 位图 | 在尽可能节约内存的情况下,记录在线用户的名单,并且能够对这些名单执行聚合操作。 |
987 |
988 |
989 |
990 | ## redis,讲讲缓存一致性问题
991 |
992 | 
 993 |
994 | 果你的业务处于起步阶段,流量非常小,那无论是读请求还是写请求,直接操作数据库即可。但随着业务量的增长,你的项目请求量越来越大,这时如果每次都从数据库中读数据,那肯定会有性能问题。这个阶段通常的做法是,引入「缓存」来提高读性能,架构模型如上图。当下优秀的缓存中间件,当属 Redis 莫属,它不仅性能非常高,还提供了很多友好的数据类型,可以很好地满足我们的业务需求。但引入缓存之后,你就会面临一个问题:之前数据只存在数据库中,现在要放到缓存中读取,具体要怎么存呢?
995 |
996 | **最简单的方案:**
997 |
998 | 1. 数据库的数据,全量刷入缓存(不设置失效时间)
999 | 2. 写请求只更新数据库,不更新缓存
1000 | 3. 启动一个定时任务,定时把数据库的数据,更新到缓存中
1001 |
1002 | **缺点:**
1003 |
1004 | 1. 缓存利用率低:不经常访问的数据,还一直留在缓存中
1005 | 2. 数据不一致:因为是「定时」刷新缓存,缓存和数据库存在不一致(取决于定时任务的执行频率)
1006 |
1007 | 所以,这种方案一般更适合业务「体量小」,且对数据一致性要求不高的业务场景。
1008 |
1009 | 那么现在就有两个问题,缓存利用率和一致性问题
1010 |
1011 | **缓存利用率**
1012 |
1013 | 想要缓存利用率「最大化」,只需要缓存中只保留最近访问的「热数据,可以这样做:
1014 |
1015 | 1. 写请求依旧只写数据库
1016 | 2. 读请求先读缓存,如果缓存不存在,则从数据库读取,并重建缓存
1017 | 3. 同时,写入缓存中的数据,都设置失效时间
1018 |
1019 | 这样一来,缓存中不经常访问的数据,随着时间的推移,都会逐渐「过期」淘汰掉,最终缓存中保留的,都是经常被访问的「热数据」,缓存利用率得以最大化。
1020 |
1021 | **一致性问题**
1022 |
1023 | 大部分观点认为,做缓存不应该是去更新缓存,而是应该删除缓存,然后由下个请求去去缓存,发现不存在后再读取数据库,写入缓存。原因有如下两个:
1024 |
1025 | 1. 线程安全问题。有请求A和请求B进行更新操作,假如有以下情况:(1)线程A更新了数据库(2)线程B更新了数据库(3)线程B更新了缓存(4)线程A更新了缓存,于是这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。这就导致了脏数据
1026 | 2. 业务场景角度。如果你是一个写数据库场景比较多,而读数据场景比较少的业务需求,采用更新操作而不是删除,就会导致数据压根还没读到,缓存就被频繁的更新,浪费性能。其次,如果你写入数据库的值,并不是直接写入缓存的,而是要经过一系列复杂的计算再写入缓存。那么,每次写入数据库后,都再次计算写入缓存的值,无疑是浪费性能的。显然,删除缓存更为适合。
1027 |
1028 | 当数据发生更新时,我们不仅要操作数据库,还要一并操作缓存。具体操作就是,修改一条数据时,不仅要更新数据库,也要连带缓存一起更新。但数据库和缓存都更新,又存在先后问题,那对应的方案就有 2 个:
1029 |
1030 | - 先更新缓存,后更新数据库
1031 |
1032 | 如果缓存更新成功了,但数据库更新失败,那么此时缓存中是最新值,但数据库中是「旧值」。虽然此时读请求可以命中缓存,拿到正确的值,但是,一旦缓存「失效」,就会从数据库中读取到「旧值」,重建缓存也是这个旧值。这时用户会发现自己之前修改的数据又「变回去」了,对业务造成影响。
1033 |
1034 | - 先更新数据库,后更新缓存
1035 |
1036 | 如果数据库更新成功了,但缓存更新失败,那么此时数据库中是最新值,缓存中是「旧值」。之后的读请求读到的都是旧数据,只有当缓存「失效」后,才能从数据库中得到正确的值。这时用户会发现,自己刚刚修改了数据,但却看不到变更,一段时间过后,数据才变更过来,对业务也会有影响。
1037 |
1038 | 上述这两个方案都不行,以下给出解决方案:
1039 |
1040 | - 如果先更新缓存,后更新数据库的话,使用延时双删策略
1041 |
1042 | 延时双删的方案的思路是,为了避免更新数据库的时候,其他线程从缓存中读取不到数据,就在更新完数据库之后,再sleep一段时间,然后再次删除缓存。sleep的时间要对业务读写缓存的时间做出评估,sleep时间大于读写缓存的时间即可。
1043 |
1044 | - 如果先更新数据库,后更新缓存的话,设置缓存过期时间,消息队列
1045 |
1046 | 设置过期时间:每次放入缓存的时候,设置一个过期时间,比如5分钟,以后的操作只修改数据库,不操作缓存,等待缓存超时后从数据库重新读取。如果对于一致性要求不是很高的情况,可以采用这种方案。
1047 |
1048 | 消息队列:先更新数据库,成功后往消息队列发消息,消费到消息后再删除缓存,借助消息队列的重试机制来实现,达到最终一致性的效果。
1049 |
1050 | 基于以上原因,redis官方选择了更简单、更快的方法,不支持错误回滚。这样的话,如果在我们的业务场景中需要保证原子性,那么就要求了开发者通过其他手段保证命令全部执行成功或失败,例如在执行命令前进行参数类型的校验,或在事务执行出现错误时及时做事务补偿。
1051 |
1052 |
1053 |
1054 | ## Redis的事务满足原子性吗?
1055 |
1056 | redis中的事务是不满足原子性的,在运行错误的情况下,并没有提供类似数据库中的回滚功能。那么为什么redis不支持回滚呢,官方文档给出了说明,大意如下:
1057 |
1058 | 1. redis命令失败只会发生在语法错误或数据类型错误的情况,这一结果都是由编程过程中的错误导致,这种情况应该在开发环境中检测出来,而不是生产环境
1059 | 2. 不使用回滚,能使redis内部设计更简单,速度更快
1060 | 3. 回滚不能避免编程逻辑中的错误,如果想要将一个键的值增加2却只增加了1,这种情况即使提供回滚也无法提供帮助
1061 |
1062 |
1063 |
1064 | ## redis有那些命令是原子指令
1065 |
1066 |
1067 |
1068 |
1069 |
1070 | ## 为何Redis使用跳表而非红黑树实现SortedSet?
1071 |
1072 | [参考链接](https://juejin.cn/post/6844903446475177998)
1073 |
1074 | 首先要知道红黑树和跳表的插入删除,删除,查找时间复杂度是一样的。
1075 |
1076 | redis作者说了三个原因:
1077 |
1078 | 1. 范围查找。跳表在区间查询的时候效率是高于红黑树的,跳表进行查找O(logn)的时间复杂度定位到区间的起点,然后在原始链表往后遍历就可以了 ,其他插入和单个条件查询,更新两者的复杂度都是相同的O(logn)。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。
1079 | 2. 易于实现
1080 | 3. 从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
1081 |
1082 | ## redis如何实现消息队列
1083 |
1084 | 消息队列是指利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。
1085 |
1086 | 回顾下我们使用的消息队列有如下特点:
1087 |
1088 | 1. 三个角色:生产者、消费者、消息处理中心
1089 | 2. 异步处理模式:生产者将消息发送到一条虚拟的通道(消息队列)上,而无须等待响应。消费者则订阅或是监听该通道,取出消息。两者互不干扰,甚至都不需要同时在线,也就是我们说的松耦合
1090 | 3. 可靠性:消息要可以保证不丢失、不重复消费、有时可能还需要顺序性的保证
1091 |
1092 |
1093 |
1094 | ## 大key如何处理
1095 |
--------------------------------------------------------------------------------
/离谱问题.md:
--------------------------------------------------------------------------------
1 | # **电脑开机的时候系统做了什么?**
2 |
3 | 1)加载BIOS
4 |
5 | 因为ROM的发明,开机程序会被刷入ROM中。当计算机通电的时候,首先读取ROM。
6 |
7 | ROM里面的程序叫做**基本输入输出系统(Basic Input Output System BIOS)**
8 |
9 | BIOS首先“硬件自检”,查看硬件是否能够工作。完成后BIOS把权限交给启动程序,用来对启动设备进行排序,依次启动。基本就是对主板上的键盘、鼠标、外部接口、频率、电源、磁盘驱动器等方面进行
10 |
11 | 2)读取MBR
12 |
13 | BIOS首先把控制权交给存储设备。系统会读取该设备的最前面512字节,如果最后两个字节分别是0x55和0xAA则表示可以启动,然后把控制权交给下一个设备
14 |
15 | 存储设备最前面的512个叫做**主引导记录(MBR)**,由三部分组成:
16 |
17 | ①1-446字节,调用操作系统的机器码
18 |
19 | ②447-510字节,分区表(选择在那个分区启动,以前是把不同操作系统放在两个硬盘)
20 |
21 | ③511-512字节,主引导记录签名(0x55和0xAA)
22 |
23 | 3)Bootloader
24 |
25 | Boot Loader 就是在操作系统内核运行之前运行的一段小程序。通过这段小程序,我们可以初始化硬件设备、建立内存空间的映射图,从而将系统的软硬件环境带到一个合适的状态,以便为最终调用操作系统内核做好一切准备。Boot Loader有若干种,其中Grub、Lilo和spfdisk是常见的Loader。Linux环境中,目前最流行的启动管理器是 Grub。
26 |
27 | 4)加载内核
28 |
29 | 内核加载后,接开始操作系统初始化,根据进程的优先级启动进程,这时候linux操作系统已经可以运行了
30 |
31 | 5)Loading Kernel image 和 initial RAM disk
32 |
33 | 6)用户层init依据inittab文件来设定运行等级
34 |
35 |
993 |
994 | 果你的业务处于起步阶段,流量非常小,那无论是读请求还是写请求,直接操作数据库即可。但随着业务量的增长,你的项目请求量越来越大,这时如果每次都从数据库中读数据,那肯定会有性能问题。这个阶段通常的做法是,引入「缓存」来提高读性能,架构模型如上图。当下优秀的缓存中间件,当属 Redis 莫属,它不仅性能非常高,还提供了很多友好的数据类型,可以很好地满足我们的业务需求。但引入缓存之后,你就会面临一个问题:之前数据只存在数据库中,现在要放到缓存中读取,具体要怎么存呢?
995 |
996 | **最简单的方案:**
997 |
998 | 1. 数据库的数据,全量刷入缓存(不设置失效时间)
999 | 2. 写请求只更新数据库,不更新缓存
1000 | 3. 启动一个定时任务,定时把数据库的数据,更新到缓存中
1001 |
1002 | **缺点:**
1003 |
1004 | 1. 缓存利用率低:不经常访问的数据,还一直留在缓存中
1005 | 2. 数据不一致:因为是「定时」刷新缓存,缓存和数据库存在不一致(取决于定时任务的执行频率)
1006 |
1007 | 所以,这种方案一般更适合业务「体量小」,且对数据一致性要求不高的业务场景。
1008 |
1009 | 那么现在就有两个问题,缓存利用率和一致性问题
1010 |
1011 | **缓存利用率**
1012 |
1013 | 想要缓存利用率「最大化」,只需要缓存中只保留最近访问的「热数据,可以这样做:
1014 |
1015 | 1. 写请求依旧只写数据库
1016 | 2. 读请求先读缓存,如果缓存不存在,则从数据库读取,并重建缓存
1017 | 3. 同时,写入缓存中的数据,都设置失效时间
1018 |
1019 | 这样一来,缓存中不经常访问的数据,随着时间的推移,都会逐渐「过期」淘汰掉,最终缓存中保留的,都是经常被访问的「热数据」,缓存利用率得以最大化。
1020 |
1021 | **一致性问题**
1022 |
1023 | 大部分观点认为,做缓存不应该是去更新缓存,而是应该删除缓存,然后由下个请求去去缓存,发现不存在后再读取数据库,写入缓存。原因有如下两个:
1024 |
1025 | 1. 线程安全问题。有请求A和请求B进行更新操作,假如有以下情况:(1)线程A更新了数据库(2)线程B更新了数据库(3)线程B更新了缓存(4)线程A更新了缓存,于是这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。这就导致了脏数据
1026 | 2. 业务场景角度。如果你是一个写数据库场景比较多,而读数据场景比较少的业务需求,采用更新操作而不是删除,就会导致数据压根还没读到,缓存就被频繁的更新,浪费性能。其次,如果你写入数据库的值,并不是直接写入缓存的,而是要经过一系列复杂的计算再写入缓存。那么,每次写入数据库后,都再次计算写入缓存的值,无疑是浪费性能的。显然,删除缓存更为适合。
1027 |
1028 | 当数据发生更新时,我们不仅要操作数据库,还要一并操作缓存。具体操作就是,修改一条数据时,不仅要更新数据库,也要连带缓存一起更新。但数据库和缓存都更新,又存在先后问题,那对应的方案就有 2 个:
1029 |
1030 | - 先更新缓存,后更新数据库
1031 |
1032 | 如果缓存更新成功了,但数据库更新失败,那么此时缓存中是最新值,但数据库中是「旧值」。虽然此时读请求可以命中缓存,拿到正确的值,但是,一旦缓存「失效」,就会从数据库中读取到「旧值」,重建缓存也是这个旧值。这时用户会发现自己之前修改的数据又「变回去」了,对业务造成影响。
1033 |
1034 | - 先更新数据库,后更新缓存
1035 |
1036 | 如果数据库更新成功了,但缓存更新失败,那么此时数据库中是最新值,缓存中是「旧值」。之后的读请求读到的都是旧数据,只有当缓存「失效」后,才能从数据库中得到正确的值。这时用户会发现,自己刚刚修改了数据,但却看不到变更,一段时间过后,数据才变更过来,对业务也会有影响。
1037 |
1038 | 上述这两个方案都不行,以下给出解决方案:
1039 |
1040 | - 如果先更新缓存,后更新数据库的话,使用延时双删策略
1041 |
1042 | 延时双删的方案的思路是,为了避免更新数据库的时候,其他线程从缓存中读取不到数据,就在更新完数据库之后,再sleep一段时间,然后再次删除缓存。sleep的时间要对业务读写缓存的时间做出评估,sleep时间大于读写缓存的时间即可。
1043 |
1044 | - 如果先更新数据库,后更新缓存的话,设置缓存过期时间,消息队列
1045 |
1046 | 设置过期时间:每次放入缓存的时候,设置一个过期时间,比如5分钟,以后的操作只修改数据库,不操作缓存,等待缓存超时后从数据库重新读取。如果对于一致性要求不是很高的情况,可以采用这种方案。
1047 |
1048 | 消息队列:先更新数据库,成功后往消息队列发消息,消费到消息后再删除缓存,借助消息队列的重试机制来实现,达到最终一致性的效果。
1049 |
1050 | 基于以上原因,redis官方选择了更简单、更快的方法,不支持错误回滚。这样的话,如果在我们的业务场景中需要保证原子性,那么就要求了开发者通过其他手段保证命令全部执行成功或失败,例如在执行命令前进行参数类型的校验,或在事务执行出现错误时及时做事务补偿。
1051 |
1052 |
1053 |
1054 | ## Redis的事务满足原子性吗?
1055 |
1056 | redis中的事务是不满足原子性的,在运行错误的情况下,并没有提供类似数据库中的回滚功能。那么为什么redis不支持回滚呢,官方文档给出了说明,大意如下:
1057 |
1058 | 1. redis命令失败只会发生在语法错误或数据类型错误的情况,这一结果都是由编程过程中的错误导致,这种情况应该在开发环境中检测出来,而不是生产环境
1059 | 2. 不使用回滚,能使redis内部设计更简单,速度更快
1060 | 3. 回滚不能避免编程逻辑中的错误,如果想要将一个键的值增加2却只增加了1,这种情况即使提供回滚也无法提供帮助
1061 |
1062 |
1063 |
1064 | ## redis有那些命令是原子指令
1065 |
1066 |
1067 |
1068 |
1069 |
1070 | ## 为何Redis使用跳表而非红黑树实现SortedSet?
1071 |
1072 | [参考链接](https://juejin.cn/post/6844903446475177998)
1073 |
1074 | 首先要知道红黑树和跳表的插入删除,删除,查找时间复杂度是一样的。
1075 |
1076 | redis作者说了三个原因:
1077 |
1078 | 1. 范围查找。跳表在区间查询的时候效率是高于红黑树的,跳表进行查找O(logn)的时间复杂度定位到区间的起点,然后在原始链表往后遍历就可以了 ,其他插入和单个条件查询,更新两者的复杂度都是相同的O(logn)。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。
1079 | 2. 易于实现
1080 | 3. 从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
1081 |
1082 | ## redis如何实现消息队列
1083 |
1084 | 消息队列是指利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。
1085 |
1086 | 回顾下我们使用的消息队列有如下特点:
1087 |
1088 | 1. 三个角色:生产者、消费者、消息处理中心
1089 | 2. 异步处理模式:生产者将消息发送到一条虚拟的通道(消息队列)上,而无须等待响应。消费者则订阅或是监听该通道,取出消息。两者互不干扰,甚至都不需要同时在线,也就是我们说的松耦合
1090 | 3. 可靠性:消息要可以保证不丢失、不重复消费、有时可能还需要顺序性的保证
1091 |
1092 |
1093 |
1094 | ## 大key如何处理
1095 |
--------------------------------------------------------------------------------
/离谱问题.md:
--------------------------------------------------------------------------------
1 | # **电脑开机的时候系统做了什么?**
2 |
3 | 1)加载BIOS
4 |
5 | 因为ROM的发明,开机程序会被刷入ROM中。当计算机通电的时候,首先读取ROM。
6 |
7 | ROM里面的程序叫做**基本输入输出系统(Basic Input Output System BIOS)**
8 |
9 | BIOS首先“硬件自检”,查看硬件是否能够工作。完成后BIOS把权限交给启动程序,用来对启动设备进行排序,依次启动。基本就是对主板上的键盘、鼠标、外部接口、频率、电源、磁盘驱动器等方面进行
10 |
11 | 2)读取MBR
12 |
13 | BIOS首先把控制权交给存储设备。系统会读取该设备的最前面512字节,如果最后两个字节分别是0x55和0xAA则表示可以启动,然后把控制权交给下一个设备
14 |
15 | 存储设备最前面的512个叫做**主引导记录(MBR)**,由三部分组成:
16 |
17 | ①1-446字节,调用操作系统的机器码
18 |
19 | ②447-510字节,分区表(选择在那个分区启动,以前是把不同操作系统放在两个硬盘)
20 |
21 | ③511-512字节,主引导记录签名(0x55和0xAA)
22 |
23 | 3)Bootloader
24 |
25 | Boot Loader 就是在操作系统内核运行之前运行的一段小程序。通过这段小程序,我们可以初始化硬件设备、建立内存空间的映射图,从而将系统的软硬件环境带到一个合适的状态,以便为最终调用操作系统内核做好一切准备。Boot Loader有若干种,其中Grub、Lilo和spfdisk是常见的Loader。Linux环境中,目前最流行的启动管理器是 Grub。
26 |
27 | 4)加载内核
28 |
29 | 内核加载后,接开始操作系统初始化,根据进程的优先级启动进程,这时候linux操作系统已经可以运行了
30 |
31 | 5)Loading Kernel image 和 initial RAM disk
32 |
33 | 6)用户层init依据inittab文件来设定运行等级
34 |
35 |  36 |
37 | > - BIOS和UEFI(Unified Extensible Firmware Interface)则是取代传统BIOS的,相比传统BIOS来说,它更易实现,容错和纠错特性也更强。
38 | > - **MBR与GPT:**MBR是传统的分区表类型,当一台电脑启动时,它会先启动主板上的BIOS系统,BIOS再从硬盘上读取MBR主引导记录,硬盘上的MBR运行后,就会启动操作系统,但最大的缺点则是不支持容量大于2T的硬盘。而GPT是另一种更先进的磁盘系统分区方式,它的出现弥补了MBR这个缺点,最大支持`18EB`的硬盘,是基于`UEFI`使用的磁盘分区架构。
39 | >
40 | >
41 |
42 |
43 |
44 | # 都有那些编程范式?
45 |
46 | - 面向过程(Process Oriented Programming,POP)
47 |
48 | 最原始,也是我们最熟悉的一种编程语言。他的编程思维源自于计算机指令的顺序排列。
49 |
50 | 步骤:首先将待解决的问题抽象为一系列概念化的步骤。然后一步一步的按照顺序实现所有步骤。
51 |
52 | 优点:流程化使得编程任务明确,在开发之前基本考虑了实现方式和最终结果,具体步骤清楚,便于节点分析。效率高,面向过程强调代码的短小精悍,善于结合数据结构来开发高效率的程序。
53 |
54 | 缺点:需要深入的思考,耗费精力,代码重用性低,扩展能力差,后期维护难度比较大。
55 |
56 | - 面向对象(Object Oriented Pr
57 |
58 | - ogramming,OOP)
59 |
60 | 所有事物都是对象。易于维护,扩展和复用
61 |
62 | 优点:结构清晰,程序是模块化和结构化,更加符合人类的思维方式;易扩展,代码重用率高,可继承,可覆盖,可以设计出低耦合的系统;易维护,系统低耦合的特点有利于减少程序的后期维护工作量。
63 |
64 | 缺点:开销大,当要修改对象内部时,对象的属性不允许外部直接存取,所以要增加许多没有其他意义、只负责读或写的行为。这会为编程工作增加负担,增加运行开销,并且使程序显得臃肿。
65 |
66 | 性能低,由于面向更高的逻辑抽象层,使得面向对象在实现的时候,不得不做出性能上面的牺牲,计算时间和空间存储大小都开销很大。
67 |
68 | > 举个例子:下五子棋
69 | >
70 | > 面向过程:开始游戏();
71 | > 黑子先走();
72 | > 绘制画面();
73 | > 判断输赢();
74 | > 轮到白子();
75 | > 绘制画面();
76 | > 判断输赢();
77 | > 返回到 黑子先走();
78 | > 输出最后结果;
79 | >
80 | > 面向对象:黑白双方,这两方的行为是一样的。棋盘系统,负责绘制画面。规则系统,负责判定犯规、输赢等。
81 |
82 | - 事件驱动编程
83 |
84 | 主要是用在图形用户界面,比如C#这种
85 |
86 | 功能都是提前写好的,就等着触发
87 |
88 | - 面向接口(Interface Oriented Programming, IOP)
89 |
90 | - 面向切面(Aspect Oriented Programming,AOP)
91 |
92 | - 函数式(Funtional Programming,FP)
93 |
94 | - 响应式(Reactive Programming,RP)
95 |
96 | - 数响应式(Functional Reactive Programming,FRP)
97 |
98 |
99 |
100 |
101 |
102 | # 软件开发模型
103 |
104 | ## 瀑布模型
105 |
106 | 瀑布模型(Waterfall Model) 是一个软件生命周期模型,开发过程是通过设计一系列阶段顺序展开的,从系统需求分析开始直到产品发布和维护,项目开发进程从一个阶段“流动”到下一个阶段,这也是瀑布模型名称的由来。
107 |
108 | 瀑布模型核心思想是按工序将问题化简,将功能的实现与设计分开,便于分工协作,即采用结构化的分析与设计方法将逻辑实现与物理实现分开。将软件生命周期划分为制定计划、需求分析、软件设计、程序编写、软件测试和运行维护等六个基本活动,并且规定了它们自上而下、相互衔接的固定次序,如同瀑布流水,逐级下落。
109 |
110 | 现在的互联网项目已经不再像传统的瀑布模型的项目,有明确的需求。现在项目迭代的速度和需求的变更都非常的迅速。在软件开发的编码之前我们不可能事先了解所有的需求,软件设计肯定会有考虑不周到不全面的地方;而且随着项目需求的不断变更,很有可能原来的代码设计结构已经不能满足当前的需求。
111 |
112 | **优点:**
113 |
114 | 每个阶段交出的所有产品都必须经过质量保证小组的仔细验证。
115 |
116 | **缺点:**
117 |
118 | 瀑布模型是由文档驱动,在可运行的软件产品交付给用户之前,用户只能通过文档来了解产品是什么样的。瀑布模型几乎完全依赖于书面的规格说明,很可能导致最终开发出的软件产品不能真正满足用户的需要。也不适合需求模糊的系统。
119 |
120 |
121 |
122 | ## **迭代开发**
123 |
124 | 迭代增量式开发,也越来越接近现代的开发流程。
125 |
126 | 在迭代式开发中,整个开发工作被组织 为一系列短小的、固定长度的小项目,每次选代都包括需求分析、设计、实现与测试。采用迭代式开发时, 工作可以在需求被完整地确定之前启动, 并在一次选代中完成系统的一部分功能 或业务,再通过客户的反馈来细化需求,并开始新一轮的迭代。
127 |
128 | ## 敏捷开发模型
129 |
130 | 敏捷开发(Agile)是一种以人为核心、迭代、循序渐进的开发方法。在敏捷开发中,软件项目的构建被切分成多个子项目,各个子项目的成果都经过测试,具备集成和可运行的特征。简单地来说,敏捷开发并不追求前期完美的设计、完美编码,而是力求在很短的周期内开发出产品的核心功能,尽早发布出可用的版本。然后在后续的生产周期内,按照新需求不断迭代升级,完善产品。
131 |
132 | 首要任务是尽早地、持续地交付可评价的软件,以使客户满意。
133 |
134 | 频繁交付可使用的软件,交付的间隔越短越好,可以从几个月缩减到几个星期。
135 |
136 | 在整个项目开发期间,业务人员和开发人员必须朝夕工作在一起。
137 |
138 | 围绕那些有推动力的人们来构建项目,给予他们所需的环境和支持,并且相信他们能够把工作做好。
139 |
140 | ## scrum开发模型
141 |
142 | scrum的团队不需要那么大,十几个人即可。
143 |
144 | > **下面先给出scrum的模型:**
145 | >
146 | >
36 |
37 | > - BIOS和UEFI(Unified Extensible Firmware Interface)则是取代传统BIOS的,相比传统BIOS来说,它更易实现,容错和纠错特性也更强。
38 | > - **MBR与GPT:**MBR是传统的分区表类型,当一台电脑启动时,它会先启动主板上的BIOS系统,BIOS再从硬盘上读取MBR主引导记录,硬盘上的MBR运行后,就会启动操作系统,但最大的缺点则是不支持容量大于2T的硬盘。而GPT是另一种更先进的磁盘系统分区方式,它的出现弥补了MBR这个缺点,最大支持`18EB`的硬盘,是基于`UEFI`使用的磁盘分区架构。
39 | >
40 | >
41 |
42 |
43 |
44 | # 都有那些编程范式?
45 |
46 | - 面向过程(Process Oriented Programming,POP)
47 |
48 | 最原始,也是我们最熟悉的一种编程语言。他的编程思维源自于计算机指令的顺序排列。
49 |
50 | 步骤:首先将待解决的问题抽象为一系列概念化的步骤。然后一步一步的按照顺序实现所有步骤。
51 |
52 | 优点:流程化使得编程任务明确,在开发之前基本考虑了实现方式和最终结果,具体步骤清楚,便于节点分析。效率高,面向过程强调代码的短小精悍,善于结合数据结构来开发高效率的程序。
53 |
54 | 缺点:需要深入的思考,耗费精力,代码重用性低,扩展能力差,后期维护难度比较大。
55 |
56 | - 面向对象(Object Oriented Pr
57 |
58 | - ogramming,OOP)
59 |
60 | 所有事物都是对象。易于维护,扩展和复用
61 |
62 | 优点:结构清晰,程序是模块化和结构化,更加符合人类的思维方式;易扩展,代码重用率高,可继承,可覆盖,可以设计出低耦合的系统;易维护,系统低耦合的特点有利于减少程序的后期维护工作量。
63 |
64 | 缺点:开销大,当要修改对象内部时,对象的属性不允许外部直接存取,所以要增加许多没有其他意义、只负责读或写的行为。这会为编程工作增加负担,增加运行开销,并且使程序显得臃肿。
65 |
66 | 性能低,由于面向更高的逻辑抽象层,使得面向对象在实现的时候,不得不做出性能上面的牺牲,计算时间和空间存储大小都开销很大。
67 |
68 | > 举个例子:下五子棋
69 | >
70 | > 面向过程:开始游戏();
71 | > 黑子先走();
72 | > 绘制画面();
73 | > 判断输赢();
74 | > 轮到白子();
75 | > 绘制画面();
76 | > 判断输赢();
77 | > 返回到 黑子先走();
78 | > 输出最后结果;
79 | >
80 | > 面向对象:黑白双方,这两方的行为是一样的。棋盘系统,负责绘制画面。规则系统,负责判定犯规、输赢等。
81 |
82 | - 事件驱动编程
83 |
84 | 主要是用在图形用户界面,比如C#这种
85 |
86 | 功能都是提前写好的,就等着触发
87 |
88 | - 面向接口(Interface Oriented Programming, IOP)
89 |
90 | - 面向切面(Aspect Oriented Programming,AOP)
91 |
92 | - 函数式(Funtional Programming,FP)
93 |
94 | - 响应式(Reactive Programming,RP)
95 |
96 | - 数响应式(Functional Reactive Programming,FRP)
97 |
98 |
99 |
100 |
101 |
102 | # 软件开发模型
103 |
104 | ## 瀑布模型
105 |
106 | 瀑布模型(Waterfall Model) 是一个软件生命周期模型,开发过程是通过设计一系列阶段顺序展开的,从系统需求分析开始直到产品发布和维护,项目开发进程从一个阶段“流动”到下一个阶段,这也是瀑布模型名称的由来。
107 |
108 | 瀑布模型核心思想是按工序将问题化简,将功能的实现与设计分开,便于分工协作,即采用结构化的分析与设计方法将逻辑实现与物理实现分开。将软件生命周期划分为制定计划、需求分析、软件设计、程序编写、软件测试和运行维护等六个基本活动,并且规定了它们自上而下、相互衔接的固定次序,如同瀑布流水,逐级下落。
109 |
110 | 现在的互联网项目已经不再像传统的瀑布模型的项目,有明确的需求。现在项目迭代的速度和需求的变更都非常的迅速。在软件开发的编码之前我们不可能事先了解所有的需求,软件设计肯定会有考虑不周到不全面的地方;而且随着项目需求的不断变更,很有可能原来的代码设计结构已经不能满足当前的需求。
111 |
112 | **优点:**
113 |
114 | 每个阶段交出的所有产品都必须经过质量保证小组的仔细验证。
115 |
116 | **缺点:**
117 |
118 | 瀑布模型是由文档驱动,在可运行的软件产品交付给用户之前,用户只能通过文档来了解产品是什么样的。瀑布模型几乎完全依赖于书面的规格说明,很可能导致最终开发出的软件产品不能真正满足用户的需要。也不适合需求模糊的系统。
119 |
120 |
121 |
122 | ## **迭代开发**
123 |
124 | 迭代增量式开发,也越来越接近现代的开发流程。
125 |
126 | 在迭代式开发中,整个开发工作被组织 为一系列短小的、固定长度的小项目,每次选代都包括需求分析、设计、实现与测试。采用迭代式开发时, 工作可以在需求被完整地确定之前启动, 并在一次选代中完成系统的一部分功能 或业务,再通过客户的反馈来细化需求,并开始新一轮的迭代。
127 |
128 | ## 敏捷开发模型
129 |
130 | 敏捷开发(Agile)是一种以人为核心、迭代、循序渐进的开发方法。在敏捷开发中,软件项目的构建被切分成多个子项目,各个子项目的成果都经过测试,具备集成和可运行的特征。简单地来说,敏捷开发并不追求前期完美的设计、完美编码,而是力求在很短的周期内开发出产品的核心功能,尽早发布出可用的版本。然后在后续的生产周期内,按照新需求不断迭代升级,完善产品。
131 |
132 | 首要任务是尽早地、持续地交付可评价的软件,以使客户满意。
133 |
134 | 频繁交付可使用的软件,交付的间隔越短越好,可以从几个月缩减到几个星期。
135 |
136 | 在整个项目开发期间,业务人员和开发人员必须朝夕工作在一起。
137 |
138 | 围绕那些有推动力的人们来构建项目,给予他们所需的环境和支持,并且相信他们能够把工作做好。
139 |
140 | ## scrum开发模型
141 |
142 | scrum的团队不需要那么大,十几个人即可。
143 |
144 | > **下面先给出scrum的模型:**
145 | >
146 | >  147 |
148 |
149 |
150 | **scrum所包含的角色**
151 |
152 | 1. PO:Product Owner,产品负责人,确定「大家要做什么」。互联网公司的 PO 一般由相关的产品经理担任;如果是为客户做项目,PO 就是客户负责人。
153 | 2. Scrum Master:Scrum的推动者,掌控大节奏的人。
154 | 3. Scrum Team :Developer,开发的主力。
155 |
156 | 三种角色有各自的责任,但三者间并没有上司和下属的关系。这正是 Scrum 区别于传统开发流程的精华:
157 |
158 | - 传统的开发流程,是由领导拍板的中央集权制;
159 | - Scurm 是人人平等的民主制,每个人的能力都被信任,更加自主,能发挥出更高的效率。
160 |
161 |
162 |
163 | **scrum的一些名词**
164 |
165 | 1. Sprint:周期指的是一次迭代,而一次迭代的周期一般是2-4周,也就是我们要把一次迭代的开发内容以最快的速度完成它,这个过程我们称它为Sprint。
166 | 2. Backlog :待办工作事项的集合。
167 | 3. Product Backlog :PO将产品待办事项列表放入,是量化的用户需求,条目化地表达实际需要开发的需求。一般来说这个是以sprint来计算
168 | 4. Sprint Backlog:任务列表。是一次迭代中需要完成的任务,也是开发过程用得最多的Backlog,非常细化。一般来说以天来计算。
169 |
170 |
171 |
172 | **如何进行Scrum开发?**
173 |
174 | 1. 我们首先需要确定一个Product Backlog(按优先顺序排列的一个产品需求列表),这个是由Product Owner 负责的;
175 | 2. Scrum Team根据Product Backlog列表,做工作量的预估和安排;
176 | 3. 有了Product Backlog列表,我们需要通过 Sprint Planning Meeting(Sprint计划会议) 来从中挑选出一个Story作为本次迭代完成的目标,这个目标的时间周期是1~4个星期(intel我们组是2周),然后把这个Story进行细化,形成一个Sprint Backlog;
177 | 4. Sprint Backlog是由Scrum Team去完成的,每个成员根据Sprint Backlog再细化成更小的任务(细到每个任务的工作量在2天内能完成);
178 | 5. 在Scrum Team完成计划会议上选出的Sprint Backlog过程中,需要进行 Daily Scrum Meeting(每日站立会议),每次会议控制在15分钟左右,每个人都必须发言,并且要向所有成员当面汇报你昨天完成了什么,并且向所有成员承诺你今天要完成什么,同时遇到不能解决的问题也可以提出,每个人回答完成后,要走到黑板前更新自己的 Sprint burn down(Sprint燃尽图);
179 | 6. 做到每日集成,也就是每天都要有一个可以成功编译、并且可以演示的版本;很多人可能还没有用过自动化的每日集成,其实TFS就有这个功能,它可以支持每次有成员进行签入操作的时候,在服务器上自动获取最新版本,然后在服务器中编译,如果通过则马上再执行单元测试代码,如果也全部通过,则将该版本发布,这时一次正式的签入操作才保存到TFS中,中间有任何失败,都会用邮件通知项目管理人员;
180 | 7. 当一个Story完成,也就是Sprint Backlog被完成,也就表示一次Sprint完成,这时,我们要进行 Srpint Review Meeting(演示会议),也称为评审会议,产品负责人和客户都要参加(最好本公司老板也参加),每一个Scrum Team的成员都要向他们演示自己完成的软件产品(这个会议非常重要,一定不能取消);
181 | 8. 最后就是 Sprint Retrospective Meeting(回顾会议),也称为总结会议,以轮流发言方式进行,每个人都要发言,总结并讨论改进的地方,放入下一轮Sprint的产品需求中;
182 |
183 | # C++和C的区别
184 |
185 | **面向对象和面向过程语言的区别**
186 |
187 | 首要要知道这两个都是一种编程思想
188 |
189 | **面向过程**就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了。
190 |
191 | **面向对象**是把构成问题事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个事物在整个解决问题的步骤中的行为。
192 |
193 | **举一个例子:**
194 |
195 | 例如五子棋,面向过程的设计思路就是首先分析问题的步骤:1、开始游戏,2、黑子先走,3、绘制画面,4、判断输赢,5、轮到白子,6、绘制画面,7、判断输赢,8、返回步骤2,9、输出最后结果。把上面每个步骤用分别的函数来实现,问题就解决了。
196 |
197 | 而面向对象的设计则是从另外的思路来解决问题。整个五子棋可以分为 1、黑白双方,这两方的行为是一模一样的,2、棋盘系统,负责绘制画面,3、规则系统,负责判定诸如犯规、输赢等。第一类对象(玩家对象)负责接受用户输入,并告知第二类对象(棋盘对象)棋子布局的变化,棋盘对象接收到了棋子的i变化就要负责在屏幕上面显示出这种变化,同时利用第三类对象(规则系统)来对棋局进行判定。
198 |
199 | 可以明显地看出,面向对象是以功能来划分问题,而不是步骤。同样是绘制棋局,这样的行为在面向过程的设计中分散在了总多步骤中,很可能出现不同的绘制版本,因为通常设计人员会考虑到实际情况进行各种各样的简化。而面向对象的设计中,绘图只可能在棋盘对象中出现,从而保证了绘图的统一。功能上的统一保证了面向对象设计的可扩展性。
200 |
201 | **面向过程**
202 |
203 | 优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源;比如单片机、嵌入式开发、 Linux/Unix等一般采用面向过程开发,性能是最重要的因素。
204 |
205 | 缺点:没有面向对象易维护、易复用、易扩展
206 |
207 | **面向对象**
208 |
209 | 优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统 更加灵活、更加易于维护
210 |
211 | 缺点:性能比面向过程低
212 |
213 | # C++和java的区别
214 |
215 | **指针:**java语言在程序员层面屏蔽了指针,让程序员没办法根据指针找到内存,所以没有指针这一概念。但是java有内存的自动管理功能,从而能够避免c++那种内存泄露的事务。
216 |
217 | **多重继承:**c++支持多重继承,但是java好像不支持,但是java有接口(抽象类,是一系列方法的声明,是一些方法特征的集合,一个接口只有方法的特征没有方法的实现),一个类可以继承多个接口。c++多重继承的问题。c++多重继承有虚继承来解决问题。
218 |
219 | **数据类型和类:**java是一门完全面向对象的语言,因此所有的函数和变量必须是类的一部分,除了基本数据类型之外,其余都是作为类对象而存在的,对象将数据和方法结合起来把其封装在类中。
220 |
221 | **struct和union:**java取消了struct和union,我的理解是struct本来就是类的始祖,用起来不方便,而且java一切皆对象,没必要使用struct。
222 |
223 | **操作符重载:**java不支持操作符重载,这是c++突出特性之一。
224 |
225 | **预处理机制:**c/c++都在编译前有一个预处理阶段,该阶段主要有源文件替换,宏替换,去掉注释等功能。java没有,但是提供了import(*import* 关键字. 为了能够使用某一个包的成员,我们需要在*Java* 程序中明确导入该包。)。
226 |
227 | **自动内存管理:**java在堆上建立内存无需手动释放,java无用内存回收是用现成的方式在后台运行,利用空闲时间删除。
228 |
229 |
230 |
231 |
232 |
233 | # c++为什么不加入垃圾回收机制
234 |
235 | [参考链接](https://mp.weixin.qq.com/s/Tyhq8mr3-6g1mDwnKQF4mw)
236 |
237 | 作为支持指针的编程语言,C++将动态管理存储器资源的便利性交给了程序员。在使用指针形式的对象时(请注意,由于引用在初始化后不能更改引用目标的语言机制的限制,多态性应用大多数情况下依赖于指针进行),程序员必须自己完成存储器的分配、使用和释放,语言本身在此过程中不能提供任何帮助,也许除了按照你的要求正确的和操作系统亲密合作,完成实际的存储器管理。
238 |
239 | C++的设计者Bjarne Stroustrup关于问题给了一段说法:我很害怕那种严重的空间和时间开销,也害怕由于实现和移植垃圾回收系统而带来的复杂性。还有,垃圾回收将使C++不适合做许多底层的工作,而这却正是它的一个设计目标。但我喜欢垃圾回收的思想,它是一种机制,能够简化设计、排除掉许多产生错误的根源。
240 |
241 | 需要垃圾回收的基本理由是很容易理解的:用户的使用方便以及比用户提供的存储管理模式更可靠。而反对垃圾回收的理由也有很多,但都不是最根本的,而是关于实现和效率方面的。
242 |
243 | 我的结论是,从原则上和可行性上说,垃圾回收都是需要的。但是对今天的用户以及普遍的使用和硬件而言,我们还无法承受将C++的语义和它的基本库定义在垃圾回收系统之上的负担。”
244 |
245 |
246 |
247 | # 原码反码和补码
248 |
249 | ## 机器数和真值
250 |
251 | 在学习原码, 反码和补码之前, 需要先了解机器数和真值的概念.
252 |
253 | **机器数**
254 |
255 | 一个数在计算机中的二进制表示形式, 叫做这个数的机器数。机器数是带符号的,在计算机用一个数的最高位存放符号, 正数为0, 负数为1.
256 |
257 | 比如,十进制中的数 +3 ,计算机字长为8位,转换成二进制就是00000011。如果是 -3 ,就是 10000011 。
258 |
259 | 那么,这里的 00000011 和 10000011 就是机器数。
260 |
261 | **真值**
262 |
263 | 因为第一位是符号位,所以机器数的值就不等于真正的数值。例如上面的有符号数 10000011,其最高位1代表负,其真正数值是 -3 而不是形式值131(10000011转换成十进制等于131)。所以,为区别起见,将带符号位的机器数对应的真正数值称为机器数的真值。
264 |
265 | 对于一个数, 计算机要使用一定的编码方式进行存储. 原码, 反码, 补码是机器存储一个具体数字的编码方式.
266 |
267 | ## 原码
268 |
269 | 原码是人脑最容易理解和计算的表示方式.
270 |
271 | 原码就是符号位加上真值的绝对值, 即用第一位表示符号, 其余位表示值. 比如如果是8位二进制:
272 |
273 | [+1]原 = 0000 0001
274 |
275 | [-1]原 = 1000 0001
276 |
277 | ## 反码
278 |
279 | 正数的反码是其本身
280 |
281 | 负数的反码是在其原码的基础上, 符号位不变,其余各个位取反.
282 |
283 | [+1] = [00000001]原 = [00000001]反
284 |
285 | [-1] = [10000001]原 = [11111110]反
286 |
287 | 可见如果一个反码表示的是负数, 人脑无法直观的看出来它的数值. 通常要将其转换成原码再计算.
288 |
289 | ## 补码
290 |
291 | 正数的补码就是其本身
292 |
293 | 负数的补码是在其原码的基础上, 符号位不变, 其余各位取反, 最后+1. (即在反码的基础上+1)
294 |
295 | [+1] = [00000001]原 = [00000001]反 = [00000001]补
296 |
297 | [-1] = [10000001]原 = [11111110]反 = [11111111]补
298 |
299 | 负数, 补码表示方式也是人脑无法直观看出其数值的. 通常也需要转换成原码在计算其数值.
300 |
301 | ## 有了原码为什么还要有补码?
302 |
303 | 现在我们知道了计算机可以有三种编码方式表示一个数. 对于正数因为三种编码方式的结果都相同:
304 |
305 | > [+1] = [00000001]原 = [00000001]反 = [00000001]补
306 |
307 | 所以不需要过多解释. 但是对于负数:
308 |
309 | > [-1] = [10000001]原 = [11111110]反 = [11111111]补
310 |
311 | 可见原码, 反码和补码是完全不同的. 既然原码才是被人脑直接识别并用于计算表示方式, 为何还会有反码和补码呢?
312 |
313 | 首先, 因为人脑可以知道第一位是符号位, 在计算的时候我们会根据符号位, 选择对真值区域的加减. (真值的概念在本文最开头). 但是对于计算机, 加减乘数已经是最基础的运算, 要设计的尽量简单. 计算机辨别"符号位"显然会让计算机的基础电路设计变得十分复杂! 于是人们想出了将符号位也参与运算的方法. 我们知道, 根据运算法则减去一个正数等于加上一个负数, 即: 1-1 = 1 + (-1) = 0 , 所以机器可以只有加法而没有减法, 这样计算机运算的设计就更简单了。于是人们开始探索 **将符号位参与运算, 并且只保留加法的方法**. 首先来看原码:
314 |
315 | 计算十进制的表达式: 1-1=0
316 |
317 | > 1 - 1 = 1 + (-1) = [00000001]原 + [10000001]原 = [10000010]原 = -2
318 |
319 | 如果用原码表示, 让符号位也参与计算, 显然对于减法来说, 结果是不正确的.这也就是为何计算机内部不使用原码表示一个数.
320 |
321 | 为了解决原码做减法的问题, 出现了反码:
322 |
323 | 计算十进制的表达式: 1-1=0
324 |
325 | > 1 - 1 = 1 + (-1) = [0000 0001]原 + [1000 0001]原= [0000 0001]反 + [1111 1110]反 = [1111 1111]反 = [1000 0000]原 = -0
326 |
327 | 发现用反码计算减法, 结果的真值部分是正确的. 而唯一的问题其实就出现在"0"这个特殊的数值上. 虽然人们理解上+0和-0是一样的, 但是0带符号是没有任何意义的. 而且会有[0000 0000]原和[1000 0000]原两个编码表示0.
328 |
329 | 于是补码的出现, 解决了0的符号以及两个编码的问题:
330 |
331 | > 1-1 = 1 + (-1) = [0000 0001]原 + [1000 0001]原 = [0000 0001]补 + [1111 1111]补 = [0000 0000]补=[0000 0000]原
332 |
333 | 使用补码, 不仅仅修复了0的符号以及存在两个编码的问题, 而且还能够多表示一个最低数. 这就是为什么8位二进制, 使用原码或反码表示的范围为[-127, +127], 而使用补码表示的范围为[-128, 127].
334 |
335 | 因为机器使用补码, 所以对于编程中常用到的32位int类型, 可以表示范围是: [-231, 231-1] 因为第一位表示的是符号位.而使用补码表示时又可以多保存一个最小值.
336 |
337 | # Linux系统各个目录的一般作用
338 |
339 |
147 |
148 |
149 |
150 | **scrum所包含的角色**
151 |
152 | 1. PO:Product Owner,产品负责人,确定「大家要做什么」。互联网公司的 PO 一般由相关的产品经理担任;如果是为客户做项目,PO 就是客户负责人。
153 | 2. Scrum Master:Scrum的推动者,掌控大节奏的人。
154 | 3. Scrum Team :Developer,开发的主力。
155 |
156 | 三种角色有各自的责任,但三者间并没有上司和下属的关系。这正是 Scrum 区别于传统开发流程的精华:
157 |
158 | - 传统的开发流程,是由领导拍板的中央集权制;
159 | - Scurm 是人人平等的民主制,每个人的能力都被信任,更加自主,能发挥出更高的效率。
160 |
161 |
162 |
163 | **scrum的一些名词**
164 |
165 | 1. Sprint:周期指的是一次迭代,而一次迭代的周期一般是2-4周,也就是我们要把一次迭代的开发内容以最快的速度完成它,这个过程我们称它为Sprint。
166 | 2. Backlog :待办工作事项的集合。
167 | 3. Product Backlog :PO将产品待办事项列表放入,是量化的用户需求,条目化地表达实际需要开发的需求。一般来说这个是以sprint来计算
168 | 4. Sprint Backlog:任务列表。是一次迭代中需要完成的任务,也是开发过程用得最多的Backlog,非常细化。一般来说以天来计算。
169 |
170 |
171 |
172 | **如何进行Scrum开发?**
173 |
174 | 1. 我们首先需要确定一个Product Backlog(按优先顺序排列的一个产品需求列表),这个是由Product Owner 负责的;
175 | 2. Scrum Team根据Product Backlog列表,做工作量的预估和安排;
176 | 3. 有了Product Backlog列表,我们需要通过 Sprint Planning Meeting(Sprint计划会议) 来从中挑选出一个Story作为本次迭代完成的目标,这个目标的时间周期是1~4个星期(intel我们组是2周),然后把这个Story进行细化,形成一个Sprint Backlog;
177 | 4. Sprint Backlog是由Scrum Team去完成的,每个成员根据Sprint Backlog再细化成更小的任务(细到每个任务的工作量在2天内能完成);
178 | 5. 在Scrum Team完成计划会议上选出的Sprint Backlog过程中,需要进行 Daily Scrum Meeting(每日站立会议),每次会议控制在15分钟左右,每个人都必须发言,并且要向所有成员当面汇报你昨天完成了什么,并且向所有成员承诺你今天要完成什么,同时遇到不能解决的问题也可以提出,每个人回答完成后,要走到黑板前更新自己的 Sprint burn down(Sprint燃尽图);
179 | 6. 做到每日集成,也就是每天都要有一个可以成功编译、并且可以演示的版本;很多人可能还没有用过自动化的每日集成,其实TFS就有这个功能,它可以支持每次有成员进行签入操作的时候,在服务器上自动获取最新版本,然后在服务器中编译,如果通过则马上再执行单元测试代码,如果也全部通过,则将该版本发布,这时一次正式的签入操作才保存到TFS中,中间有任何失败,都会用邮件通知项目管理人员;
180 | 7. 当一个Story完成,也就是Sprint Backlog被完成,也就表示一次Sprint完成,这时,我们要进行 Srpint Review Meeting(演示会议),也称为评审会议,产品负责人和客户都要参加(最好本公司老板也参加),每一个Scrum Team的成员都要向他们演示自己完成的软件产品(这个会议非常重要,一定不能取消);
181 | 8. 最后就是 Sprint Retrospective Meeting(回顾会议),也称为总结会议,以轮流发言方式进行,每个人都要发言,总结并讨论改进的地方,放入下一轮Sprint的产品需求中;
182 |
183 | # C++和C的区别
184 |
185 | **面向对象和面向过程语言的区别**
186 |
187 | 首要要知道这两个都是一种编程思想
188 |
189 | **面向过程**就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了。
190 |
191 | **面向对象**是把构成问题事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个事物在整个解决问题的步骤中的行为。
192 |
193 | **举一个例子:**
194 |
195 | 例如五子棋,面向过程的设计思路就是首先分析问题的步骤:1、开始游戏,2、黑子先走,3、绘制画面,4、判断输赢,5、轮到白子,6、绘制画面,7、判断输赢,8、返回步骤2,9、输出最后结果。把上面每个步骤用分别的函数来实现,问题就解决了。
196 |
197 | 而面向对象的设计则是从另外的思路来解决问题。整个五子棋可以分为 1、黑白双方,这两方的行为是一模一样的,2、棋盘系统,负责绘制画面,3、规则系统,负责判定诸如犯规、输赢等。第一类对象(玩家对象)负责接受用户输入,并告知第二类对象(棋盘对象)棋子布局的变化,棋盘对象接收到了棋子的i变化就要负责在屏幕上面显示出这种变化,同时利用第三类对象(规则系统)来对棋局进行判定。
198 |
199 | 可以明显地看出,面向对象是以功能来划分问题,而不是步骤。同样是绘制棋局,这样的行为在面向过程的设计中分散在了总多步骤中,很可能出现不同的绘制版本,因为通常设计人员会考虑到实际情况进行各种各样的简化。而面向对象的设计中,绘图只可能在棋盘对象中出现,从而保证了绘图的统一。功能上的统一保证了面向对象设计的可扩展性。
200 |
201 | **面向过程**
202 |
203 | 优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源;比如单片机、嵌入式开发、 Linux/Unix等一般采用面向过程开发,性能是最重要的因素。
204 |
205 | 缺点:没有面向对象易维护、易复用、易扩展
206 |
207 | **面向对象**
208 |
209 | 优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统 更加灵活、更加易于维护
210 |
211 | 缺点:性能比面向过程低
212 |
213 | # C++和java的区别
214 |
215 | **指针:**java语言在程序员层面屏蔽了指针,让程序员没办法根据指针找到内存,所以没有指针这一概念。但是java有内存的自动管理功能,从而能够避免c++那种内存泄露的事务。
216 |
217 | **多重继承:**c++支持多重继承,但是java好像不支持,但是java有接口(抽象类,是一系列方法的声明,是一些方法特征的集合,一个接口只有方法的特征没有方法的实现),一个类可以继承多个接口。c++多重继承的问题。c++多重继承有虚继承来解决问题。
218 |
219 | **数据类型和类:**java是一门完全面向对象的语言,因此所有的函数和变量必须是类的一部分,除了基本数据类型之外,其余都是作为类对象而存在的,对象将数据和方法结合起来把其封装在类中。
220 |
221 | **struct和union:**java取消了struct和union,我的理解是struct本来就是类的始祖,用起来不方便,而且java一切皆对象,没必要使用struct。
222 |
223 | **操作符重载:**java不支持操作符重载,这是c++突出特性之一。
224 |
225 | **预处理机制:**c/c++都在编译前有一个预处理阶段,该阶段主要有源文件替换,宏替换,去掉注释等功能。java没有,但是提供了import(*import* 关键字. 为了能够使用某一个包的成员,我们需要在*Java* 程序中明确导入该包。)。
226 |
227 | **自动内存管理:**java在堆上建立内存无需手动释放,java无用内存回收是用现成的方式在后台运行,利用空闲时间删除。
228 |
229 |
230 |
231 |
232 |
233 | # c++为什么不加入垃圾回收机制
234 |
235 | [参考链接](https://mp.weixin.qq.com/s/Tyhq8mr3-6g1mDwnKQF4mw)
236 |
237 | 作为支持指针的编程语言,C++将动态管理存储器资源的便利性交给了程序员。在使用指针形式的对象时(请注意,由于引用在初始化后不能更改引用目标的语言机制的限制,多态性应用大多数情况下依赖于指针进行),程序员必须自己完成存储器的分配、使用和释放,语言本身在此过程中不能提供任何帮助,也许除了按照你的要求正确的和操作系统亲密合作,完成实际的存储器管理。
238 |
239 | C++的设计者Bjarne Stroustrup关于问题给了一段说法:我很害怕那种严重的空间和时间开销,也害怕由于实现和移植垃圾回收系统而带来的复杂性。还有,垃圾回收将使C++不适合做许多底层的工作,而这却正是它的一个设计目标。但我喜欢垃圾回收的思想,它是一种机制,能够简化设计、排除掉许多产生错误的根源。
240 |
241 | 需要垃圾回收的基本理由是很容易理解的:用户的使用方便以及比用户提供的存储管理模式更可靠。而反对垃圾回收的理由也有很多,但都不是最根本的,而是关于实现和效率方面的。
242 |
243 | 我的结论是,从原则上和可行性上说,垃圾回收都是需要的。但是对今天的用户以及普遍的使用和硬件而言,我们还无法承受将C++的语义和它的基本库定义在垃圾回收系统之上的负担。”
244 |
245 |
246 |
247 | # 原码反码和补码
248 |
249 | ## 机器数和真值
250 |
251 | 在学习原码, 反码和补码之前, 需要先了解机器数和真值的概念.
252 |
253 | **机器数**
254 |
255 | 一个数在计算机中的二进制表示形式, 叫做这个数的机器数。机器数是带符号的,在计算机用一个数的最高位存放符号, 正数为0, 负数为1.
256 |
257 | 比如,十进制中的数 +3 ,计算机字长为8位,转换成二进制就是00000011。如果是 -3 ,就是 10000011 。
258 |
259 | 那么,这里的 00000011 和 10000011 就是机器数。
260 |
261 | **真值**
262 |
263 | 因为第一位是符号位,所以机器数的值就不等于真正的数值。例如上面的有符号数 10000011,其最高位1代表负,其真正数值是 -3 而不是形式值131(10000011转换成十进制等于131)。所以,为区别起见,将带符号位的机器数对应的真正数值称为机器数的真值。
264 |
265 | 对于一个数, 计算机要使用一定的编码方式进行存储. 原码, 反码, 补码是机器存储一个具体数字的编码方式.
266 |
267 | ## 原码
268 |
269 | 原码是人脑最容易理解和计算的表示方式.
270 |
271 | 原码就是符号位加上真值的绝对值, 即用第一位表示符号, 其余位表示值. 比如如果是8位二进制:
272 |
273 | [+1]原 = 0000 0001
274 |
275 | [-1]原 = 1000 0001
276 |
277 | ## 反码
278 |
279 | 正数的反码是其本身
280 |
281 | 负数的反码是在其原码的基础上, 符号位不变,其余各个位取反.
282 |
283 | [+1] = [00000001]原 = [00000001]反
284 |
285 | [-1] = [10000001]原 = [11111110]反
286 |
287 | 可见如果一个反码表示的是负数, 人脑无法直观的看出来它的数值. 通常要将其转换成原码再计算.
288 |
289 | ## 补码
290 |
291 | 正数的补码就是其本身
292 |
293 | 负数的补码是在其原码的基础上, 符号位不变, 其余各位取反, 最后+1. (即在反码的基础上+1)
294 |
295 | [+1] = [00000001]原 = [00000001]反 = [00000001]补
296 |
297 | [-1] = [10000001]原 = [11111110]反 = [11111111]补
298 |
299 | 负数, 补码表示方式也是人脑无法直观看出其数值的. 通常也需要转换成原码在计算其数值.
300 |
301 | ## 有了原码为什么还要有补码?
302 |
303 | 现在我们知道了计算机可以有三种编码方式表示一个数. 对于正数因为三种编码方式的结果都相同:
304 |
305 | > [+1] = [00000001]原 = [00000001]反 = [00000001]补
306 |
307 | 所以不需要过多解释. 但是对于负数:
308 |
309 | > [-1] = [10000001]原 = [11111110]反 = [11111111]补
310 |
311 | 可见原码, 反码和补码是完全不同的. 既然原码才是被人脑直接识别并用于计算表示方式, 为何还会有反码和补码呢?
312 |
313 | 首先, 因为人脑可以知道第一位是符号位, 在计算的时候我们会根据符号位, 选择对真值区域的加减. (真值的概念在本文最开头). 但是对于计算机, 加减乘数已经是最基础的运算, 要设计的尽量简单. 计算机辨别"符号位"显然会让计算机的基础电路设计变得十分复杂! 于是人们想出了将符号位也参与运算的方法. 我们知道, 根据运算法则减去一个正数等于加上一个负数, 即: 1-1 = 1 + (-1) = 0 , 所以机器可以只有加法而没有减法, 这样计算机运算的设计就更简单了。于是人们开始探索 **将符号位参与运算, 并且只保留加法的方法**. 首先来看原码:
314 |
315 | 计算十进制的表达式: 1-1=0
316 |
317 | > 1 - 1 = 1 + (-1) = [00000001]原 + [10000001]原 = [10000010]原 = -2
318 |
319 | 如果用原码表示, 让符号位也参与计算, 显然对于减法来说, 结果是不正确的.这也就是为何计算机内部不使用原码表示一个数.
320 |
321 | 为了解决原码做减法的问题, 出现了反码:
322 |
323 | 计算十进制的表达式: 1-1=0
324 |
325 | > 1 - 1 = 1 + (-1) = [0000 0001]原 + [1000 0001]原= [0000 0001]反 + [1111 1110]反 = [1111 1111]反 = [1000 0000]原 = -0
326 |
327 | 发现用反码计算减法, 结果的真值部分是正确的. 而唯一的问题其实就出现在"0"这个特殊的数值上. 虽然人们理解上+0和-0是一样的, 但是0带符号是没有任何意义的. 而且会有[0000 0000]原和[1000 0000]原两个编码表示0.
328 |
329 | 于是补码的出现, 解决了0的符号以及两个编码的问题:
330 |
331 | > 1-1 = 1 + (-1) = [0000 0001]原 + [1000 0001]原 = [0000 0001]补 + [1111 1111]补 = [0000 0000]补=[0000 0000]原
332 |
333 | 使用补码, 不仅仅修复了0的符号以及存在两个编码的问题, 而且还能够多表示一个最低数. 这就是为什么8位二进制, 使用原码或反码表示的范围为[-127, +127], 而使用补码表示的范围为[-128, 127].
334 |
335 | 因为机器使用补码, 所以对于编程中常用到的32位int类型, 可以表示范围是: [-231, 231-1] 因为第一位表示的是符号位.而使用补码表示时又可以多保存一个最小值.
336 |
337 | # Linux系统各个目录的一般作用
338 |
339 |  340 |
341 | | 目录 | 说明 |
342 | | ----------- | ------------------------------------------------------------ |
343 | | /bin | 存放二进制可执行文件(ls,cat,mkdir等),常用命令一般都在这里。 |
344 | | /home | 存放所有用户文件的根目录,是用户主目录的基点,比如用户user的主目录就是/home/user,可以用~user表示 |
345 | | /usr | 用于存放系统应用程序,比较重要的目录 /usr/local 本地系统管理员软件安装目录(安装系统级的应用)。这是最庞大的目录,要用到的应用程序和文件几乎都在这个目录。 /usr/x11r6 存放x window的目录 /usr/bin 众多的应用程序 /usr/sbin 超级用户的一些管理程序 /usr/doc linux文档 /usr/include linux下开发和编译应用程序所需要的头文件 /usr/lib 常用的动态链接库和软件包的配置文件 /usr/man 帮助文档 /usr/src 源代码,linux内核的源代码就放在/usr/src/linux里 /usr/local/bin 本地增加的命令 /usr/local/lib 本地增加的库 |
346 | | /opt | 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把tomcat等都安装到这里。 |
347 | | /proc | 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息。 |
348 | | /root | 超级用户(系统管理员)的主目录(特权阶级^o^) |
349 | | /sbin | 存放二进制可执行文件,只有root才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如ifconfig等。 |
350 | | /dev | 用于存放设备文件。 |
351 | | /mnt | 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统。 |
352 | | /boot | 存放用于系统引导时使用的各种文件 |
353 | | /lib | 存放跟文件系统中的程序运行所需要的共享库及内核模块。共享库又叫动态链接共享库,作用类似windows里的.dll文件,存放了根文件系统程序运行所需的共享文件。 |
354 | | /tmp | 用于存放各种临时文件,是公用的临时文件存储点。 |
355 | | /var | 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等。 |
356 | | /lost+found | 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows下叫什么.chk)就在这里 |
357 |
358 |
359 |
360 |
361 |
362 | # 谷歌C++编程规范
363 |
364 | ## 命名约定
365 |
366 | **通用规则**
367 |
368 | 函数命名,变量命名、文件命名要有描述性,少用缩写
369 |
370 | **文件命名**
371 |
372 | 文件名要全部小写,用下划线(_)连起来,c++文件要以.cc结尾,头文件以.h结尾,专门插入文本的文件以.inc结尾
373 |
374 | **类命名**
375 |
376 | 类的每个单词首字母均大写,不包含下划线,比如:MyExcitingClass
377 |
378 | **变量命名**
379 |
380 | 变量名一律小写,单词之间用下划线连接
381 |
382 | 类的成员变量以下划线结尾
383 |
384 | 结构体成员变量和类一样
385 |
386 | **常量命名**
387 |
388 | 在全局或类里的常量名称前加 k: `kDaysInAWeek`. 且除去开头的 k 之外每个单词开头字母均大写。
389 |
390 | 所有编译时常量, 无论是局部的, 全局的还是类中的, 和其他变量稍微区别一下. k 后接大写字母开头的单词:
391 |
392 | ```c++
393 | const int kDaysInAWeek = 7;
394 | ```
395 |
396 | **函数命名**
397 |
398 | 常规函数使用大小写混合,如MyExcitingFunction()
399 |
400 | 如果您的某函数出错时就要直接 crash, 那么就在函数名加上 OrDie.
401 |
402 | 取值(Accessors)和设值(Mutators)函数要与存取的变量名匹配,用小写:int num_entries() const { return num_entries_; }
403 |
404 | **函数参数**
405 |
406 | 跟变量命名一样
407 |
408 | **宏命名**
409 |
410 | 全部大写,像这样命名: MY_MACRO_THAT_SCARES_SMALL_CHILDREN
411 |
412 | **总结**
413 |
414 | Google 的命名约定很高明,比如写了简单的类QueryResult, 接着又可以直接定义一个变量query_result, 区分度很好;再次,类内变量以下划线结尾,那么就可以直接传入同名的形参,比如 TextQuery::TextQuery(std::string word) : word_(word) {} , 其中 word_ 自然是类内私有成员。
415 |
416 |
417 |
418 |
419 |
420 | # 海量数据处理题问题
421 |
422 | **第一题**
423 |
424 | 问题:海量日志数据,提取出某日访问百度次数最多的IP。
425 |
426 | 答案:假设内存无穷大,我们可以用常规的HashMap(ip,value)来统计ip出现的频率,统计完后利用排序算法得到次数最多的IP,这里的排序算法一般是堆排序或快速排序。但考虑实际情况,我们的内存是有限的,所以无法将海量日志数据一次性塞进内存里,那应该如何处理呢?很简单,分而治之!即将这些IP数据通过Hash映射算法划分为多个小文件,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文件中出现频率最大的IP,最后在这1000个最大的IP中,找出那个频率最大的IP,即为所求(是不是很像Map Reduce的思想?)。
427 |
428 | 这里再多说一句:Hash取模是一种等价映射算法,不会存在同一个元素分散到不同小文件中的情况,这保证了我们分别在小文件统计IP出现频率的正确性。我们对IP进行模1000的时候,相同的IP在Hash取模后,只可能落在同一个小文件中,不可能被分散的。因为如果两个IP相等,那么经过Hash(IP)之后的哈希值是相同的,将此哈希值取模(如模1000),必定仍然相等。
429 |
430 | 总结一下,该类题型的解决方法分三步走:
431 |
432 | 1. 分而治之、hash映射;
433 | 2. HashMap(或前缀树)统计频率;
434 | 3. 应用排序算法(堆排序或快速排序)。
435 |
436 | **第二题**
437 |
438 | 问:搜索引擎会通过日志文件把用户每次检索使用的所有查询串都记录下来,每个查询长度不超过 255 字节。假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
439 |
440 | 答:我们首先分析题意:一千万个记录,除去重复后,实际上只有300万个不同的记录,每个记录假定为最大长度255Byte,则最多占用内存为:3M*1K/4=0.75G<1G,完全可以将所以查询记录存放在内存中进行处理。相较于第一道题目,这题还更简单了,直接HashMap(或前缀树)+堆排序即可。
441 |
442 | 具体做法如下:
443 |
444 | 1. 遍历一遍左右的Query串,利用HashMap(或前缀树)统计频率,时间复杂度为O(N),N=1000万;
445 | 2. 建立并维护一个大小为10的最小堆,然后遍历300万Query的频率,分别和根元素(最小值)进行对比,最后找到Top K,时间复杂度为N‘logK,N‘=300万,K=10。
446 |
447 | **第三题**
448 |
449 | 问:有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
450 |
451 | 答:经过前两道题的训练,第三道题相信大家已经游刃有余了,这类题型都有相同的特点:文件size很大,内存有限,解决方法还是经典三步走:分而治之 + hash统计 + 堆/快速排序。
452 |
453 | 具体做法如下:
454 |
455 | 1. 分而治之、hash映射:遍历一遍文件,对于每个词x,取hash(x)并模5000,这样可以将文件里的所有词分别存到5000个小文件中,如果哈希函数设计得合理的话,每个文件大概是200k左右。就算其中有些文件超过了1M大小,还可以按照同样的方法继续往下分,直到分解得到的小文件的大小都不超过1M;
456 | 2. HashMap(或前缀树)统计频率:对于每个小文件,利用HashMap(或前缀树)统计词频;
457 | 3. 堆排序:构建最小堆,堆的大小为100,找到频率最高的100个词。
458 |
459 | **第四题**
460 |
461 | 问:给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
462 |
463 | 答:每个url是64字节,50亿*64=5G×64=320G,内存限制为4G,所以不能直接放入内存中。怎么办?分而治之!
464 |
465 | 具体做法如下:
466 |
467 | 1. 遍历文件a中的url,对url进行hash(url)%1000,将50亿的url分到1000个文件中存储(a0,a1,a2.......),每个文件大约300多M,对文件b进行同样的操作,因为hash函数相同,所以相同的url必然会落到对应的文件中,比如文件a中的url1与文件b中的url2相同,那么它们经过hash(url)%1000也是相同的。即url1落入第n个文件中,url2也会落入到第n个文件中。
468 | 2. 遍历a0中的url,存入HashSet中,同时遍历b0中的url,查看是否在HashSet中存在,如果存在则保存到单独的文件中。然后以此遍历剩余的小文件即可。
469 |
470 | **总结**
471 |
472 | 这几道题都有一个共性, **那就是要求在海量数据中找出重复次数最多的一个/前N个数据**,我们的解决方法也很朴实: 分而治之/Hash映射 + HashMap/前缀树统计频率 + 堆/快速/归并排序,具体来说就是先做hash,然后求模映射为小文件,求出每个小文件中重复次数最多的一个,并记录重复次数,最后利用堆这个数据结构高效地取出前N个出现次数最多的数据。
473 |
474 |
475 |
476 | # HelloWorld程序开始到打印到屏幕上的全过程
477 |
478 | 1. 用户告诉操作系统执行 HelloWorld 程序(通过键盘输⼊等);
479 |
480 | 2. 操作系统找到 HelloWorld 程序,检查其类型是否是可执⾏⽂件;并通过程序首部信息,确定代码和数据在可执行文件中的位置并计算出对应的磁盘块地址;
481 | 3. 操作系统创建⼀个新进程,将 HelloWorld 可执行⽂件映射到该进程结构,表示由该进程执行HelloWorld 程序;
482 | 4. 操作系统为 HelloWorld 程序设置 cpu 上下文环境,并跳到程序开始处;
483 | 5. 执行 HelloWorld 程序的第⼀条指令,发生缺页异常;然后分配⼀页物理内存,并将代码从磁盘读入内存,然后继续执行 HelloWorld 程序;
484 | 6. HelloWorld 程序执行 puts 函数(系统调用),在显示器上写⼀字符串;
485 | 7. 操作系统找到要将字符串送往的显示设备,通常设备是由⼀个进程控制的,所以操作系统将要写的字符串 送给该进程;
486 | 8. 操作系统控制设备的进程告诉设备的窗口系统,它要显示该字符串,窗⼝系统确定这是⼀个合法的操作,然后将字符串转换成像素,将像素写⼊设备的存储映像区;
487 | 9. 视频硬件将像素转换成显示器可接收和⼀组控制数据信号;
488 | 10. 显示器解释信号,激发液晶屏; OK,我们在屏幕上看到了 HelloWorld;
489 |
490 |
491 |
492 |
493 |
494 | # 大整数运算和构造
495 |
496 | [参考连接](https://frostime.github.io/2019/07/23/%E5%A4%A7%E6%95%B4%E6%95%B0%E8%BF%90%E7%AE%97/)
497 |
498 | **构造**
499 |
500 | 可以用一个数组来存储数字的每一位来表示一个大整数。
501 |
502 | 使用一个类来包装,大整数类中有保存数据的数组,数位长度
503 |
504 | **表示**
505 |
506 | 在构造一个大整数的时候,我们应该有两个步骤。
507 |
508 | 1. 把整个数组填充为 0
509 | 2. 大部分情况下我们需要构造的整数的各个数位逆序填入数组中
510 |
511 | 第 1 点比较好理解,因为我们要做加减乘除的时候,肯定需要进位借位,这时候把暂时没有用到的位数设置为 0 是非常合理的。
512 |
513 | > 我们所做的大部分运算都是从低位往高位进行的,而且往往会涉及到进位。这时采用逆序保存的方法就会很方便进位操作,反之如果我们按照原始顺序进行保存,想要进位的话,还需要把整个数组往后移动。当然并不是说,任何情况下都需要用这种顺序来保存。但是在做题的时候,往往只会涉及到加法和乘法,偶尔还有减法,几乎不会涉及到除法。这种情况下采用逆序保存就很合适了。
514 |
515 |
516 |
517 | # 字符编码笔记:ASCII,Unicode 和 UTF-8
518 |
519 | ## **ASCII 码**
520 |
521 | 计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有`0`和`1`两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态。60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。ASCII 码一共规定了128个字符的编码
522 |
523 | 英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。
524 |
525 | ## **Unicode**
526 |
527 | 是否有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode,就像它的名字都表示的,这是一种所有符号的编码。Unicode 当然是一个很大的集合,现在的规模可以容纳100多万个符号。
528 |
529 | 但是Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
530 |
531 | ## **UTF-8**
532 |
533 | 互联网的普及,强烈要求出现一种统一的编码方式。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。
534 |
535 | UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
536 |
537 | # 编译器优化
538 |
539 | **O0:**编译器默认就是O0,该选项下不会开启优化,方便开发者调试。
540 |
541 | **O1:**致力于在不需要过多的编译时间情况下,尽量减少代码大小和尽量提高程序运行速度,它开启了下面的优化标志:
542 |
543 | ```
544 | -fauto-inc-dec
545 | -fbranch-count-reg
546 | -fcombine-stack-adjustments
547 | -fcompare-elim
548 | -fcprop-registers
549 | -fdce
550 | -fdefer-pop
551 | -fdelayed-branch
552 | -fdse
553 | -fforward-propagate
554 | -fguess-branch-probability
555 | -fif-conversion
556 | -fif-conversion2
557 | -finline-functions-called-once
558 | -fipa-modref
559 | -fipa-profile
560 | -fipa-pure-const
561 | -fipa-reference
562 | -fipa-reference-addressable
563 | -fmerge-constants
564 | -fmove-loop-invariants
565 | -fomit-frame-pointer
566 | -freorder-blocks
567 | -fshrink-wrap
568 | -fshrink-wrap-separate
569 | -fsplit-wide-types
570 | -fssa-backprop
571 | -fssa-phiopt
572 | -ftree-bit-ccp
573 | -ftree-ccp
574 | -ftree-ch
575 | -ftree-coalesce-vars
576 | -ftree-copy-prop
577 | -ftree-dce
578 | -ftree-dominator-opts
579 | -ftree-dse
580 | -ftree-forwprop
581 | -ftree-fre
582 | -ftree-phiprop
583 | -ftree-pta
584 | -ftree-scev-cprop
585 | -ftree-sink
586 | -ftree-slsr
587 | -ftree-sra
588 | -ftree-ter
589 | -funit-at-a-time
590 | ```
591 |
592 |
593 |
594 | **O2:**常见的Release级别,该选项下几乎执行了所有支持的优化选项,它增加了编译时间,提高了程序的运行速度,又额外打开了以下优化标志:
595 |
596 | ```text
597 | -falign-functions -falign-jumps
598 | -falign-labels -falign-loops
599 | -fcaller-saves
600 | -fcode-hoisting
601 | -fcrossjumping
602 | -fcse-follow-jumps -fcse-skip-blocks
603 | -fdelete-null-pointer-checks
604 | -fdevirtualize -fdevirtualize-speculatively
605 | -fexpensive-optimizations
606 | -ffinite-loops
607 | -fgcse -fgcse-lm
608 | -fhoist-adjacent-loads
609 | -finline-functions
610 | -finline-small-functions
611 | -findirect-inlining
612 | -fipa-bit-cp -fipa-cp -fipa-icf
613 | -fipa-ra -fipa-sra -fipa-vrp
614 | -fisolate-erroneous-paths-dereference
615 | -flra-remat
616 | -foptimize-sibling-calls
617 | -foptimize-strlen
618 | -fpartial-inlining
619 | -fpeephole2
620 | -freorder-blocks-algorithm=stc
621 | -freorder-blocks-and-partition -freorder-functions
622 | -frerun-cse-after-loop
623 | -fschedule-insns -fschedule-insns2
624 | -fsched-interblock -fsched-spec
625 | -fstore-merging
626 | -fstrict-aliasing
627 | -fthread-jumps
628 | -ftree-builtin-call-dce
629 | -ftree-pre
630 | -ftree-switch-conversion -ftree-tail-merge
631 | -ftree-vrp
632 | ```
633 |
634 | **Os:**打开了几乎所有的O2优化标志,除了那些经常会增加代码大小的优化标志:使编译器根据代码大小而不是程序运行速度进行优化,为了减少代码大小。
635 |
636 | **O3:**较为激进的优化选项(对错误编码容忍度最低),在O2的基础上额外打开了十多个优化选项,在O2的基础上又打开了以下优化标志:
637 |
638 | ```
639 | fgcse-after-reload
640 | -fipa-cp-clone
641 | -floop-interchange
642 | -floop-unroll-and-jam
643 | -fpeel-loops
644 | -fpredictive-commoning
645 | -fsplit-loops
646 | -fsplit-paths
647 | -ftree-loop-distribution
648 | -ftree-loop-vectorize
649 | -ftree-partial-pre
650 | -ftree-slp-vectorize
651 | -funswitch-loops
652 | -fvect-cost-model
653 | -fvect-cost-model=dynamic
654 | -fversion-loops-for-strides
655 | ```
656 |
657 |
658 |
659 | # Debug和Release版本的区别
660 |
661 | Debug通常称为调试版本,通过一系列编译选项的配合,编译的结果通常包含调试信息,而且不做任何优化,以为开发 人员提供强大的应用程序调试能力。
662 |
663 | Release通常称为发布版本,是为用户使用的,一般客户不允许在发布版本上进行调试。所以不保存调试信 息,同时,它往往进行了各种优化,以期达到代码最小和速度最优。为用户的使用提供便利。
664 |
665 | 有以下几个不同:
666 |
667 | 1. Debug模式下在内存分配上有所区别,在我们申请内存时,Debug模式会多申请一部分空间,分布在内存块的前后,用于存放调试信息。
668 | 2. 对于未初始化的变量,Debug模式下会默认对其进行初始化,而Release模式则不会,所以就有个常见的问题,局部变量未初始化时,Debug模式下可能运行正常,但Release模式下可能会返回错误结果
669 | 3. Debug模式下可以使用assert,运行过程中有异常现象会及时crash,Release模式下模式下不会编译assert,遇到不期望的情况不会及时crash,稀里糊涂继续运行,到后期可能会产生奇奇怪怪的错误,不易调试,殊不知其实在很早之前就出现了问题。编译器在Debug模式下定义_DEBUG宏,Release模式下定义NDEBUG宏,预处理器就是根据对应宏来判断是否开启assert的。
670 | 4. 数据溢出问题,在一个函数中,存在某些从未被使用的变量,且函数内存在数据溢出问题,在Debug模式下可能不会产生问题,因为不会对该变量进行优化,它在栈空间中还是占有几个字节,但是Release模式下可能会出问题,Release模式下可能会优化掉此变量,栈空间相应变小,数据溢出就会导致栈内存损坏,有可能会产生奇奇怪怪的错误。
671 |
672 | > **问:有时候程序在Debug模式下运行的好好的,Release模式下就crash了,怎么办?**
673 | >
674 | > 答:看一下代码中是否有未初始化的变量,是否有数组越界问题,从这个思路入手。
675 | >
676 | > **问:有些时候程序在Debug模式下会崩溃,Release模式下却正常运行,怎么办?**
677 | >
678 | > 答:可以尝试着找一找代码中的assert,看一下是否是assert导致的两种模式下的差异,从这个思路入手。
679 |
680 |
681 |
682 | # Intel CPU型号解读
683 |
684 | Intel生产的CPU分为高中低端,最低端的G系列,然后是低端i3系列,中端i5系列,高端i7系列和至尊i9系列。
685 |
686 | U:代表超低电压以15W和28为主
687 |
688 | M:代表标准电压cpu
689 |
690 | U:代表低电压节能的
691 |
692 | H:是高电压的
693 |
694 | X:代表高性能
695 |
696 | Q:代表至高性能级别
697 |
698 | Y:代表超低电压的
699 |
700 | K:代表不锁倍频的处理器
701 |
702 | “MX”:代表旗舰级,
703 |
704 | “HQ”:封装方式FCBGA1364,并且部分支持Trusted Execution Technology和博锐技术,
705 |
706 | “MQ”:版本封装方式FCBGA946。
707 |
708 | # 在 4GB 物理内存的机器上,申请 8G 内存会怎么样?
709 |
710 | 这个问题要考虑三个前置条件:
711 |
712 | - 操作系统是 32 位的,还是 64 位的?
713 | - 申请完 8G 内存后会不会被使用?
714 | - 操作系统有没有使用 Swap 机制?
715 |
716 | 首先,应用程序通过 malloc 函数申请内存的时候,实际上申请的是虚拟内存,此时并不会分配物理内存。当应用程序读写了这块虚拟内存,CPU 就会去访问这个虚拟内存, 这时会发现这个虚拟内存没有映射到物理内存, CPU 就会产生缺页中断,进程会从用户态切换到内核态,并将缺页中断交给内核的 Page Fault Handler (缺页中断函数)处理。缺页中断处理函数会看是否有空闲的物理内存:
717 |
718 | 1. 如果有,就直接分配物理内存,并建立虚拟内存与物理内存之间的映射关系。
719 | 2. 如果没有空闲的物理内存,那么内核就会开始进行回收内存 (opens new window)的工作,如果回收内存工作结束后,空闲的物理内存仍然无法满足此次物理内存的申请,那么内核就会放最后的大招了触发 OOM (Out of Memory)机制。
720 |
721 | ## 32还是64
722 |
723 | 另外,32 位操作系统和 64 位操作系统的虚拟地址空间大小是不同的,在 Linux 操作系统中,虚拟地址空间的内部又被分为内核空间和用户空间两部分:
724 |
725 | 1. `32` 位系统的内核空间占用 `1G`,位于最高处,剩下的 `3G` 是用户空间;
726 | 2. `64` 位系统的内核空间和用户空间都是 `128T`,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
727 |
728 | **32 位操作系统**
729 |
730 | 因为 32 位操作系统,进程最多只能申请 3 GB 大小的虚拟内存空间,所以进程申请 8GB 内存的话,在申请虚拟内存阶段就会失败
731 |
732 | **64位操作系统**
733 |
734 | 64 位操作系统,进程可以使用 128 TB 大小的虚拟内存空间,所以进程申请 8GB 内存是没问题的,因为进程申请内存是申请虚拟内存,只要不读写这个虚拟内存,操作系统就不会分配物理内存。
735 |
736 | ## 有没有swap
737 |
738 | > **什么是 Swap 机制?**
739 | >
740 | > 当系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间会被临时保存到磁盘,等到那些程序要运行时,再从磁盘中恢复保存的数据到内存中。另外,当内存使用存在压力的时候,会开始触发内存回收行为,会把这些不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
741 | >
742 | > 将内存数据换出磁盘,又从磁盘中恢复数据到内存的过程,就是 Swap 机制负责的。
743 | >
744 | > Swap 就是把一块磁盘空间或者本地文件,当成内存来使用,它包含换出和换入两个过程:
745 | >
746 | > 1. 换出(Swap Out) ,是把进程暂时不用的内存数据存储到磁盘中,并释放这些数据占用的内存;
747 | > 2. 换入(Swap In),是在进程再次访问这些内存的时候,把它们从磁盘读到内存中来;
748 | >
749 | > **Linux 中的 Swap 机制会在内存不足和内存闲置的场景下触发:**
750 | >
751 | > 1. 内存不足:当系统需要的内存超过了可用的物理内存时,内核会将内存中不常使用的内存页交换到磁盘上为当前进程让出内存,保证正在执行的进程的可用性,这个内存回收的过程是强制的直接内存回收(Direct Page Reclaim)。直接内存回收是同步的过程,会阻塞当前申请内存的进程。
752 | > 2. 内存闲置:应用程序在启动阶段使用的大量内存在启动后往往都不会使用,通过后台运行的守护进程(kSwapd),我们可以将这部分只使用一次的内存交换到磁盘上为其他内存的申请预留空间。kSwapd 是 Linux 负责页面置换(Page replacement)的守护进程,它也是负责交换闲置内存的主要进程,它会在[空闲内存低于一定水位 (opens new window)](https://xiaolincoding.com/os/3_memory/mem_reclaim.html#尽早触发-kSwapd-内核线程异步回收内存)时,回收内存页中的空闲内存保证系统中的其他进程可以尽快获得申请的内存。kSwapd 是后台进程,所以回收内存的过程是异步的,不会阻塞当前申请内存的进程。
753 | >
754 | > **Swap 换入换出的是什么类型的内存?**
755 | >
756 | > 内核缓存的文件数据,因为都有对应的磁盘文件,所以在回收文件数据的时候, 直接写回到对应的文件就可以了。但是像进程的堆、栈数据等,它们是没有实际载体,这部分内存被称为匿名页。而且这部分内存很可能还要再次被访问,所以不能直接释放内存,于是就需要有一个能保存匿名页的磁盘载体,这个载体就是 Swap 分区。
757 | >
758 | > **swap的优缺点**
759 | >
760 | > 使用 Swap 机制优点是,应用程序实际可以使用的内存空间将远远超过系统的物理内存。由于硬盘空间的价格远比内存要低,因此这种方式无疑是经济实惠的。当然,频繁地读写硬盘,会显著降低操作系统的运行速率,这也是 Swap 的弊端。
761 |
762 | 使用`free -m`命令查看有没有swap分区
763 |
764 | **没有开启 Swap 机制**
765 |
766 | 当申请完,使用们memset函数访问的时候,超过了机器的物理内存(2GB),进程(test)被操作系统杀掉了。
767 |
768 | 通过`var/log/message`可以看到报错了 Out of memory,也就是发生 OOM(内存溢出错误)。
769 |
770 | > 什么是 OOM?
771 | >
772 | > 内存溢出(Out Of Memory,简称OOM)是指应用系统中存在无法回收的内存或使用的内存过多,最终使得程序运行要用到的内存大于能提供的最大内存。此时程序就运行不了,系统会提示内存溢出。
773 |
774 | **开启 Swap 机制**
775 |
776 | 在有 Swap 分区的情况下,即使笔记本物理内存是 8 GB,申请并使用 32 GB 内存是没问题,程序正常运行了,并没有发生 OOM。
777 |
778 | 但是磁盘 I/O 达到了一个峰值,非常高
779 |
780 | > 有了 Swap 分区,是不是意味着进程可以使用的内存是无上限的?
781 | >
782 | > 当然不是,我把上面的代码改成了申请 64GB 内存后,当进程申请完 64GB 虚拟内存后,使用到 56 GB (这个不要理解为占用的物理内存,理解为已被访问的虚拟内存大小,也就是在物理内存呆过的内存大小)的时候,进程就被系统 kill 掉了,当系统多次尝试回收内存,还是无法满足所需使用的内存大小,进程就会被系统 kill 掉了,意味着发生了 OOM
783 |
784 |
785 |
786 | # CPU和GPU的区别
787 |
788 | https://mp.weixin.qq.com/s/jPh5o5LXDWi7WogyN6AHvQ
789 |
790 |
791 |
792 | # C++性能调优
793 |
794 | https://www.cnblogs.com/wujianlundao/archive/2012/11/18/2776372.html
795 |
796 | ## **冗余的变量拷贝**
797 |
798 | **参数**
799 |
800 | 相对C而言,写C++代码经常一不小心就会引入一些临时变量,比如函数实参、函数返回值。在临时变量之外,也会有其他一些情况会带来一些冗余的变量拷贝。
801 |
802 | 这个要看要不要修改参数,可能会修改,则需要用值传递无可避免
803 |
804 | 如果参数不会被函数给修改,那么引用传递可以
805 |
806 | **返回值**
807 |
808 | RVO(return value optimization),这时候只能在函数返回一个未命名变量的时候进行优化。
809 |
810 | ## **字符数组的初始化**
811 |
812 | 写代码时,很多人为了省事或者说安全起见,每次申请一段内存之后都先全部初始化为0。
813 |
814 | 用了一些API,不了解底层实现,把申请的内存全部初始化为0了,比如char buf[1024]=""的方式,
815 |
816 | 上面提到两种内存初始化为0的情况,其实有些时候并不是必须的。比如把char型数组作为string使用的时候只需要初始化第一个元素为0即可,或者把char型数组作为一个buffer使用的大部分时候根本不需要初始化。
817 |
818 | ## **频繁的内存申请、释放操作**
819 |
820 | https://bbs.csdn.net/topics/330179712
821 |
822 | ## **提前计算**
823 |
824 | 这里需要提到的有两类问题:
825 |
826 | 1. 局部的冗余计算:循环体内的计算提到循环体之前
827 |
828 | 2. 全局的冗余计算
829 |
830 | 问题1很简单,大部分人应该都接触到过。有人会问编译器不是对此有对应的优化措施么?对,公共子表达式优化是可以解决一些这个问题。不过实测发现**如果循环体内是调用的某个函数**,即使这个函数是没有side effect的,编译器也无法针对这种情况进行优化。(我是用gcc 3.4.5测试的,不排除更高版本的gcc或者其他编译器可以针对这种情况进行优化)
831 |
832 | 对于问题2,我遇到的情况是:服务代码中定义了一个const变量,假设叫做MAX_X,处理请求是,会计算一个pow(MAX_X)用作判断(y的x次方),而性能分析发现,这个pow操作占了整体系统CPU占用的10%左右。对于这个问题,我的优化方式很简单,直接计算定义一个MAX_X_POW变量用作过滤即可。代码修改2行,性能提升10%。
833 |
834 | ## **空间换时间**
835 |
836 | 哈希表的思想
837 |
838 | ## **内联频繁调用的短小函数**
839 |
840 | 小函数尽量内联,频繁调用会提高效率
841 |
842 | ## **位运算代替乘除法**
843 |
844 | %2的次方可以用位运算代替,a%8=a&7(两倍多效率提升)
845 |
846 | /2的次方可以用移位运算代替,a/8=a>>3(两倍多效率提升)
847 |
848 | `*2`的次方可以用移位运算代替,a*8=a<<3(小数值测试效率不明显,大数值1.5倍效率)
849 |
850 | 整数次方不要用pow,`i*i`比pow(i,2)快8倍,`i*i*i`比pow快40倍
851 |
852 | ## C++为什么提供move函数?
853 |
854 | 我想说一下一个我的个人经历
855 |
856 | 有一段代码,作用是把数据库表保存到XML文件。这个转换的过程,有个中间容器,大概是这样:
857 |
858 | ```c++
859 | std::map> mapTable;
860 | ```
861 |
862 | 可以理解为map的key是数据表的列名,std::vector是那列数据(一行一行的)。
863 |
864 | 我之前是这么填充的:
865 |
866 | ```c++
867 | std::vector vecRow;
868 | for(){
869 | vecRow.push_back(...);
870 | }
871 | mapTable["列名1"] = vecRow;
872 | ```
873 |
874 | codereview的时候我的mentor就和我讲了这个事情,本质上上述代码,把vecRow中的所有元素都复制了以便然后放到mapTable中,白白的重新创建了一遍所有行数据,又把不再需要的vecRow释放掉了。这样就很蠢。
875 |
876 | 改进:当我们知道vecRow生命(作用域后),我们可以利用这个vecRow,在std::move之前,还是有办法的,创建vecRow 的时候就让它是mapTable里某列的引用,如下:
877 |
878 | ```c++
879 | std::vector &vecRow = mapTable["列名1"];
880 | for(){
881 | vecRow.push_back(...);
882 | }
883 | ```
884 |
885 | 但是考虑到这样的话会改动别的代码,所哟用谁提的std::move是最好的
886 |
887 | `mapTable["列名1"]= std::move(vecRow);`
888 |
889 | 就这么一点点改动,就能让vecRow里的东西放进mapTable里,又没避免大规模创建、析构对象。执行完上面的函数,应该会发现vecRow空了。
890 |
891 | **总结**
892 |
893 | 其实编译器已经在力所能及的优化他能够优化的东西了,但是编译器的优化不是万能的。有时候某个变量的生命周期编译器不可预见,但是我们自己是可以知道的,因此对于这些生命周期很短的变量我们为了节省效率就可以使用move函数。举个例子:比如黄金交易,张三买了李四的黄金,就应该把黄金从李四家移动到张三家里。但如果黄金量很大,移动的成本就会非常高。另一种方式就是大家的黄金都存在银行里,张三买李四的黄金,无非就是账户里的黄金数发生个变化,实体黄金不移动,这样效率就高很多。至于"为什么管理机构(编译器)不优化全世界的黄金交易为纸上黄金交易?",**那是因为真的有人需要搬黄金回家用啊**
894 |
--------------------------------------------------------------------------------
/设计模式.md:
--------------------------------------------------------------------------------
1 | # c++单例模式
2 |
3 | > 定义:单例模式是创建型设计模式,指的是在系统的生命周期中只能产生一个实例(对象),确保该类的唯一性。
4 | >
5 | > 一般遇到的写进程池类、日志类、内存池(用来缓存数据的结构,在一处写多出读或者多处写多处读)的话都会用到单例模式
6 |
7 | **实现方法:**全局只有一个实例也就意味着不能用new调用构造函数来创建对象,因此构造函数必须是虚有的。但是由于不能new出对象,所以类的内部必须提供一个函数来获取对象,而且由于不能外部构造对象,因此这个函数不能是通过对象调出来,换句话说这个函数应该是属于对象的,很自然我们就想到了用static。由于静态成员函数属于整个类,在类实例化对象之前就已经分配了空间,而类的非静态成员函数必须在类实例化后才能有内存空间。
8 |
9 | 单例模式的要点总结:
10 |
11 | 1. 全局只有一个实例,用static特性实现,构造函数设为私有
12 | 2. 通过公有接口获得实例
13 | 3. 线程安全
14 | 4. 禁止拷贝和赋值
15 |
16 | 单例模式可以**分为懒汉式和饿汉式**,两者之间的区别在于创建实例的时间不同:懒汉式指系统运行中,实例并不存在,只有当需要使用该实例时,才会去创建并使用实例(这种方式要考虑线程安全)。饿汉式指系统一运行,就初始化创建实例,当需要时,直接调用即可。(本身就线程安全,没有多线程的问题)
17 |
18 | ## 懒汉式
19 |
20 | - 普通懒汉式会让线程不安全
21 |
22 | 因为不加锁的话当线程并发时会产生多个实例,导致线程不安全
23 |
24 | ```c++
25 | /// 普通懒汉式实现 -- 线程不安全 //
26 | #include // std::cout
27 | #include // std::mutex
28 | #include // pthread_create
29 |
30 | class SingleInstance
31 | {
32 | public:
33 | // 获取单例对象
34 | static SingleInstance *GetInstance();
35 | // 释放单例,进程退出时调用
36 | static void deleteInstance();
37 | // 打印单例地址
38 | void Print();
39 | private:
40 | // 将其构造和析构成为私有的, 禁止外部构造和析构
41 | SingleInstance();
42 | ~SingleInstance();
43 | // 将其拷贝构造和赋值构造成为私有函数, 禁止外部拷贝和赋值
44 | SingleInstance(const SingleInstance &signal);
45 | const SingleInstance &operator=(const SingleInstance &signal);
46 | private:
47 | // 唯一单例对象指针
48 | static SingleInstance *m_SingleInstance;
49 | };
50 |
51 | //初始化静态成员变量
52 | SingleInstance *SingleInstance::m_SingleInstance = NULL;
53 |
54 | SingleInstance* SingleInstance::GetInstance()
55 | {
56 | if (m_SingleInstance == NULL)
57 | {
58 | m_SingleInstance = new (std::nothrow) SingleInstance; // 没有加锁是线程不安全的,当线程并发时会创建多个实例
59 | }
60 | return m_SingleInstance;
61 | }
62 |
63 | void SingleInstance::deleteInstance()
64 | {
65 | if (m_SingleInstance)
66 | {
67 | delete m_SingleInstance;
68 | m_SingleInstance = NULL;
69 | }
70 | }
71 |
72 | void SingleInstance::Print()
73 | {
74 | std::cout << "我的实例内存地址是:" << this << std::endl;
75 | }
76 |
77 | SingleInstance::SingleInstance()
78 | {
79 | std::cout << "构造函数" << std::endl;
80 | }
81 |
82 | SingleInstance::~SingleInstance()
83 | {
84 | std::cout << "析构函数" << std::endl;
85 | }
86 | /// 普通懒汉式实现 -- 线程不安全 //
87 | ```
88 |
89 | - 线程安全、内存安全的懒汉式
90 |
91 | 上述代码出现的问题:
92 |
93 | 1. GetInstance()可能会引发竞态条件,第一个线程在if中判断 `m_instance_ptr`是空的,于是开始实例化单例;同时第2个线程也尝试获取单例,这个时候判断`m_instance_ptr`还是空的,于是也开始实例化单例;这样就会实例化出两个对象,这就是线程安全问题的由来
94 |
95 | 解决办法:①加锁。②局部变量实例
96 |
97 | 2. 类中只负责new出对象,却没有负责delete对象,因此只有构造函数被调用,析构函数却没有被调用;因此会导致内存泄漏。
98 |
99 | 解决办法:使用共享指针
100 |
101 | > c++11标准中有一个特性:如果当变量在初始化的时候,并发同时进入声明语句,并发线程将会阻塞等待初始化结束。这样保证了并发线程在获取静态局部变量的时候一定是初始化过的,所以具有线程安全性。因此这种懒汉式是最推荐的,因为:
102 | >
103 | > 1. 通过局部静态变量的特性保证了线程安全 (C++11, GCC > 4.3, VS2015支持该特性);
104 | > 2. 不需要使用共享指针和锁
105 | > 3. get_instance()函数要返回引用而尽量不要返回指针,
106 |
107 | ```c++
108 | /// 内部静态变量的懒汉实现 //
109 | class Singleton
110 | {
111 | public:
112 | ~Singleton(){
113 | std::cout<<"destructor called!"< 使用锁、共享指针实现的懒汉式单例模式
137 | >
138 | > - 基于 shared_ptr, 用了C++比较倡导的 RAII思想,用对象管理资源,当 shared_ptr 析构的时候,new 出来的对象也会被 delete掉。以此避免内存泄漏。
139 | > - 加了锁,使用互斥量来达到线程安全。这里使用了两个 if判断语句的技术称为**双检锁**;好处是,只有判断指针为空的时候才加锁,避免每次调用 get_instance的方法都加锁,锁的开销毕竟还是有点大的。
140 | >
141 | > 不足之处在于: 使用智能指针会要求用户也得使用智能指针,非必要不应该提出这种约束; 使用锁也有开销; 同时代码量也增多了,实现上我们希望越简单越好。
142 |
143 | ```c++
144 | #include
145 | #include // shared_ptr
146 | #include // mutex
147 |
148 | // version 2:
149 | // with problems below fixed:
150 | // 1. thread is safe now
151 | // 2. memory doesn't leak
152 |
153 | class Singleton {
154 | public:
155 | typedef std::shared_ptr Ptr;
156 | ~Singleton() {
157 | std::cout << "destructor called!" << std::endl;
158 | }
159 | Singleton(Singleton&) = delete;
160 | Singleton& operator=(const Singleton&) = delete;
161 | static Ptr get_instance() {
162 |
163 | // "double checked lock"
164 | if (m_instance_ptr == nullptr) {
165 | std::lock_guard lk(m_mutex);
166 | if (m_instance_ptr == nullptr) {
167 | m_instance_ptr = std::shared_ptr(new Singleton);
168 | }
169 | }
170 | return m_instance_ptr;
171 | }
172 |
173 |
174 | private:
175 | Singleton() {
176 | std::cout << "constructor called!" << std::endl;
177 | }
178 | static Ptr m_instance_ptr;
179 | static std::mutex m_mutex;
180 | };
181 |
182 | // initialization static variables out of class
183 | Singleton::Ptr Singleton::m_instance_ptr = nullptr;
184 | std::mutex Singleton::m_mutex;
185 | ```
186 |
187 |
188 |
189 | ## 饿汉式
190 |
191 | ```c++
192 |
193 | // 饿汉实现 /
194 | class Singleton
195 | {
196 |
197 | public:
198 | // 获取单实例
199 | static Singleton* GetInstance();
200 | // 释放单实例,进程退出时调用
201 | static void deleteInstance();
202 | // 打印实例地址
203 | void Print();
204 |
205 | private:
206 | // 将其构造和析构成为私有的, 禁止外部构造和析构
207 | Singleton();
208 | ~Singleton();
209 |
210 | // 将其拷贝构造和赋值构造成为私有函数, 禁止外部拷贝和赋值
211 | Singleton(const Singleton &signal);
212 | const Singleton &operator=(const Singleton &signal);
213 |
214 | private:
215 | // 唯一单实例对象指针
216 | static Singleton *g_pSingleton;
217 | };
218 |
219 | // 代码一运行就初始化创建实例 ,本身就线程安全
220 | Singleton* Singleton::g_pSingleton = new (std::nothrow) Singleton;
221 |
222 | Singleton* Singleton::GetInstance()
223 | {
224 | return g_pSingleton;
225 | }
226 |
227 | void Singleton::deleteInstance()
228 | {
229 | if (g_pSingleton)
230 | {
231 |
232 | delete g_pSingleton;
233 | g_pSingleton = NULL;
234 | }
235 | }
236 |
237 | void Singleton::Print()
238 | {
239 | std::cout << "我的实例内存地址是:" << this << std::endl;
240 | }
241 |
242 | Singleton::Singleton()
243 | {
244 | std::cout << "构造函数" << std::endl;
245 | }
246 |
247 | Singleton::~Singleton()
248 | {
249 | std::cout << "析构函数" << std::endl;
250 | }
251 | // 饿汉实现 /
252 | ```
253 |
254 | ## 面试题
255 |
256 | - 懒汉模式和恶汉模式的实现(判空!!!加锁!!!),并且要能说明原因(为什么判空两次?)
257 | - 构造函数的设计(为什么私有?除了私有还可以怎么实现(进阶)?)
258 | - 对外接口的设计(为什么这么设计?)
259 | - 单例对象的设计(为什么是static?如何初始化?如何销毁?(进阶))
260 | - 对于C++编码者,需尤其注意C++11以后的单例模式的实现(为什么这么简化?怎么保证的(进阶))
261 |
262 |
263 |
264 | # Observe模式
265 |
266 | ## 定义
267 |
268 | 又叫做观察者模式,被观察者叫做subjec,观察者叫做observer
269 |
270 | **观察者模式(Observer Pattern)**: 定义对象间一种一对多的依赖关系,使得当每一个对象改变状态,则所有依赖于它的对象都会得到通知并自动更新。
271 |
272 | 观察者模式所做的工作其实就是在解耦,让耦合的双方都依赖于抽象而不是具体,从而使得各自的变化都不会影响另一边的变化。当一个对象的改变需要改变其他对象的时候,而且它不知道具体有多少对象有待改变的时候,应该考虑使用观察者模式。一旦观察目标的状态发生改变,所有的观察者都将得到通知。具体来说就是被观察者需要用一个容器比如vector存放所有观察者对象,以便状态发生变化时给观察着发通知。观察者内部需要实例化被观察者对象的实例(需要前向声明)
273 |
274 |
340 |
341 | | 目录 | 说明 |
342 | | ----------- | ------------------------------------------------------------ |
343 | | /bin | 存放二进制可执行文件(ls,cat,mkdir等),常用命令一般都在这里。 |
344 | | /home | 存放所有用户文件的根目录,是用户主目录的基点,比如用户user的主目录就是/home/user,可以用~user表示 |
345 | | /usr | 用于存放系统应用程序,比较重要的目录 /usr/local 本地系统管理员软件安装目录(安装系统级的应用)。这是最庞大的目录,要用到的应用程序和文件几乎都在这个目录。 /usr/x11r6 存放x window的目录 /usr/bin 众多的应用程序 /usr/sbin 超级用户的一些管理程序 /usr/doc linux文档 /usr/include linux下开发和编译应用程序所需要的头文件 /usr/lib 常用的动态链接库和软件包的配置文件 /usr/man 帮助文档 /usr/src 源代码,linux内核的源代码就放在/usr/src/linux里 /usr/local/bin 本地增加的命令 /usr/local/lib 本地增加的库 |
346 | | /opt | 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把tomcat等都安装到这里。 |
347 | | /proc | 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息。 |
348 | | /root | 超级用户(系统管理员)的主目录(特权阶级^o^) |
349 | | /sbin | 存放二进制可执行文件,只有root才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如ifconfig等。 |
350 | | /dev | 用于存放设备文件。 |
351 | | /mnt | 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统。 |
352 | | /boot | 存放用于系统引导时使用的各种文件 |
353 | | /lib | 存放跟文件系统中的程序运行所需要的共享库及内核模块。共享库又叫动态链接共享库,作用类似windows里的.dll文件,存放了根文件系统程序运行所需的共享文件。 |
354 | | /tmp | 用于存放各种临时文件,是公用的临时文件存储点。 |
355 | | /var | 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等。 |
356 | | /lost+found | 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows下叫什么.chk)就在这里 |
357 |
358 |
359 |
360 |
361 |
362 | # 谷歌C++编程规范
363 |
364 | ## 命名约定
365 |
366 | **通用规则**
367 |
368 | 函数命名,变量命名、文件命名要有描述性,少用缩写
369 |
370 | **文件命名**
371 |
372 | 文件名要全部小写,用下划线(_)连起来,c++文件要以.cc结尾,头文件以.h结尾,专门插入文本的文件以.inc结尾
373 |
374 | **类命名**
375 |
376 | 类的每个单词首字母均大写,不包含下划线,比如:MyExcitingClass
377 |
378 | **变量命名**
379 |
380 | 变量名一律小写,单词之间用下划线连接
381 |
382 | 类的成员变量以下划线结尾
383 |
384 | 结构体成员变量和类一样
385 |
386 | **常量命名**
387 |
388 | 在全局或类里的常量名称前加 k: `kDaysInAWeek`. 且除去开头的 k 之外每个单词开头字母均大写。
389 |
390 | 所有编译时常量, 无论是局部的, 全局的还是类中的, 和其他变量稍微区别一下. k 后接大写字母开头的单词:
391 |
392 | ```c++
393 | const int kDaysInAWeek = 7;
394 | ```
395 |
396 | **函数命名**
397 |
398 | 常规函数使用大小写混合,如MyExcitingFunction()
399 |
400 | 如果您的某函数出错时就要直接 crash, 那么就在函数名加上 OrDie.
401 |
402 | 取值(Accessors)和设值(Mutators)函数要与存取的变量名匹配,用小写:int num_entries() const { return num_entries_; }
403 |
404 | **函数参数**
405 |
406 | 跟变量命名一样
407 |
408 | **宏命名**
409 |
410 | 全部大写,像这样命名: MY_MACRO_THAT_SCARES_SMALL_CHILDREN
411 |
412 | **总结**
413 |
414 | Google 的命名约定很高明,比如写了简单的类QueryResult, 接着又可以直接定义一个变量query_result, 区分度很好;再次,类内变量以下划线结尾,那么就可以直接传入同名的形参,比如 TextQuery::TextQuery(std::string word) : word_(word) {} , 其中 word_ 自然是类内私有成员。
415 |
416 |
417 |
418 |
419 |
420 | # 海量数据处理题问题
421 |
422 | **第一题**
423 |
424 | 问题:海量日志数据,提取出某日访问百度次数最多的IP。
425 |
426 | 答案:假设内存无穷大,我们可以用常规的HashMap(ip,value)来统计ip出现的频率,统计完后利用排序算法得到次数最多的IP,这里的排序算法一般是堆排序或快速排序。但考虑实际情况,我们的内存是有限的,所以无法将海量日志数据一次性塞进内存里,那应该如何处理呢?很简单,分而治之!即将这些IP数据通过Hash映射算法划分为多个小文件,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文件中出现频率最大的IP,最后在这1000个最大的IP中,找出那个频率最大的IP,即为所求(是不是很像Map Reduce的思想?)。
427 |
428 | 这里再多说一句:Hash取模是一种等价映射算法,不会存在同一个元素分散到不同小文件中的情况,这保证了我们分别在小文件统计IP出现频率的正确性。我们对IP进行模1000的时候,相同的IP在Hash取模后,只可能落在同一个小文件中,不可能被分散的。因为如果两个IP相等,那么经过Hash(IP)之后的哈希值是相同的,将此哈希值取模(如模1000),必定仍然相等。
429 |
430 | 总结一下,该类题型的解决方法分三步走:
431 |
432 | 1. 分而治之、hash映射;
433 | 2. HashMap(或前缀树)统计频率;
434 | 3. 应用排序算法(堆排序或快速排序)。
435 |
436 | **第二题**
437 |
438 | 问:搜索引擎会通过日志文件把用户每次检索使用的所有查询串都记录下来,每个查询长度不超过 255 字节。假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
439 |
440 | 答:我们首先分析题意:一千万个记录,除去重复后,实际上只有300万个不同的记录,每个记录假定为最大长度255Byte,则最多占用内存为:3M*1K/4=0.75G<1G,完全可以将所以查询记录存放在内存中进行处理。相较于第一道题目,这题还更简单了,直接HashMap(或前缀树)+堆排序即可。
441 |
442 | 具体做法如下:
443 |
444 | 1. 遍历一遍左右的Query串,利用HashMap(或前缀树)统计频率,时间复杂度为O(N),N=1000万;
445 | 2. 建立并维护一个大小为10的最小堆,然后遍历300万Query的频率,分别和根元素(最小值)进行对比,最后找到Top K,时间复杂度为N‘logK,N‘=300万,K=10。
446 |
447 | **第三题**
448 |
449 | 问:有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
450 |
451 | 答:经过前两道题的训练,第三道题相信大家已经游刃有余了,这类题型都有相同的特点:文件size很大,内存有限,解决方法还是经典三步走:分而治之 + hash统计 + 堆/快速排序。
452 |
453 | 具体做法如下:
454 |
455 | 1. 分而治之、hash映射:遍历一遍文件,对于每个词x,取hash(x)并模5000,这样可以将文件里的所有词分别存到5000个小文件中,如果哈希函数设计得合理的话,每个文件大概是200k左右。就算其中有些文件超过了1M大小,还可以按照同样的方法继续往下分,直到分解得到的小文件的大小都不超过1M;
456 | 2. HashMap(或前缀树)统计频率:对于每个小文件,利用HashMap(或前缀树)统计词频;
457 | 3. 堆排序:构建最小堆,堆的大小为100,找到频率最高的100个词。
458 |
459 | **第四题**
460 |
461 | 问:给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
462 |
463 | 答:每个url是64字节,50亿*64=5G×64=320G,内存限制为4G,所以不能直接放入内存中。怎么办?分而治之!
464 |
465 | 具体做法如下:
466 |
467 | 1. 遍历文件a中的url,对url进行hash(url)%1000,将50亿的url分到1000个文件中存储(a0,a1,a2.......),每个文件大约300多M,对文件b进行同样的操作,因为hash函数相同,所以相同的url必然会落到对应的文件中,比如文件a中的url1与文件b中的url2相同,那么它们经过hash(url)%1000也是相同的。即url1落入第n个文件中,url2也会落入到第n个文件中。
468 | 2. 遍历a0中的url,存入HashSet中,同时遍历b0中的url,查看是否在HashSet中存在,如果存在则保存到单独的文件中。然后以此遍历剩余的小文件即可。
469 |
470 | **总结**
471 |
472 | 这几道题都有一个共性, **那就是要求在海量数据中找出重复次数最多的一个/前N个数据**,我们的解决方法也很朴实: 分而治之/Hash映射 + HashMap/前缀树统计频率 + 堆/快速/归并排序,具体来说就是先做hash,然后求模映射为小文件,求出每个小文件中重复次数最多的一个,并记录重复次数,最后利用堆这个数据结构高效地取出前N个出现次数最多的数据。
473 |
474 |
475 |
476 | # HelloWorld程序开始到打印到屏幕上的全过程
477 |
478 | 1. 用户告诉操作系统执行 HelloWorld 程序(通过键盘输⼊等);
479 |
480 | 2. 操作系统找到 HelloWorld 程序,检查其类型是否是可执⾏⽂件;并通过程序首部信息,确定代码和数据在可执行文件中的位置并计算出对应的磁盘块地址;
481 | 3. 操作系统创建⼀个新进程,将 HelloWorld 可执行⽂件映射到该进程结构,表示由该进程执行HelloWorld 程序;
482 | 4. 操作系统为 HelloWorld 程序设置 cpu 上下文环境,并跳到程序开始处;
483 | 5. 执行 HelloWorld 程序的第⼀条指令,发生缺页异常;然后分配⼀页物理内存,并将代码从磁盘读入内存,然后继续执行 HelloWorld 程序;
484 | 6. HelloWorld 程序执行 puts 函数(系统调用),在显示器上写⼀字符串;
485 | 7. 操作系统找到要将字符串送往的显示设备,通常设备是由⼀个进程控制的,所以操作系统将要写的字符串 送给该进程;
486 | 8. 操作系统控制设备的进程告诉设备的窗口系统,它要显示该字符串,窗⼝系统确定这是⼀个合法的操作,然后将字符串转换成像素,将像素写⼊设备的存储映像区;
487 | 9. 视频硬件将像素转换成显示器可接收和⼀组控制数据信号;
488 | 10. 显示器解释信号,激发液晶屏; OK,我们在屏幕上看到了 HelloWorld;
489 |
490 |
491 |
492 |
493 |
494 | # 大整数运算和构造
495 |
496 | [参考连接](https://frostime.github.io/2019/07/23/%E5%A4%A7%E6%95%B4%E6%95%B0%E8%BF%90%E7%AE%97/)
497 |
498 | **构造**
499 |
500 | 可以用一个数组来存储数字的每一位来表示一个大整数。
501 |
502 | 使用一个类来包装,大整数类中有保存数据的数组,数位长度
503 |
504 | **表示**
505 |
506 | 在构造一个大整数的时候,我们应该有两个步骤。
507 |
508 | 1. 把整个数组填充为 0
509 | 2. 大部分情况下我们需要构造的整数的各个数位逆序填入数组中
510 |
511 | 第 1 点比较好理解,因为我们要做加减乘除的时候,肯定需要进位借位,这时候把暂时没有用到的位数设置为 0 是非常合理的。
512 |
513 | > 我们所做的大部分运算都是从低位往高位进行的,而且往往会涉及到进位。这时采用逆序保存的方法就会很方便进位操作,反之如果我们按照原始顺序进行保存,想要进位的话,还需要把整个数组往后移动。当然并不是说,任何情况下都需要用这种顺序来保存。但是在做题的时候,往往只会涉及到加法和乘法,偶尔还有减法,几乎不会涉及到除法。这种情况下采用逆序保存就很合适了。
514 |
515 |
516 |
517 | # 字符编码笔记:ASCII,Unicode 和 UTF-8
518 |
519 | ## **ASCII 码**
520 |
521 | 计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有`0`和`1`两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态。60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。ASCII 码一共规定了128个字符的编码
522 |
523 | 英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。
524 |
525 | ## **Unicode**
526 |
527 | 是否有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode,就像它的名字都表示的,这是一种所有符号的编码。Unicode 当然是一个很大的集合,现在的规模可以容纳100多万个符号。
528 |
529 | 但是Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
530 |
531 | ## **UTF-8**
532 |
533 | 互联网的普及,强烈要求出现一种统一的编码方式。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。
534 |
535 | UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
536 |
537 | # 编译器优化
538 |
539 | **O0:**编译器默认就是O0,该选项下不会开启优化,方便开发者调试。
540 |
541 | **O1:**致力于在不需要过多的编译时间情况下,尽量减少代码大小和尽量提高程序运行速度,它开启了下面的优化标志:
542 |
543 | ```
544 | -fauto-inc-dec
545 | -fbranch-count-reg
546 | -fcombine-stack-adjustments
547 | -fcompare-elim
548 | -fcprop-registers
549 | -fdce
550 | -fdefer-pop
551 | -fdelayed-branch
552 | -fdse
553 | -fforward-propagate
554 | -fguess-branch-probability
555 | -fif-conversion
556 | -fif-conversion2
557 | -finline-functions-called-once
558 | -fipa-modref
559 | -fipa-profile
560 | -fipa-pure-const
561 | -fipa-reference
562 | -fipa-reference-addressable
563 | -fmerge-constants
564 | -fmove-loop-invariants
565 | -fomit-frame-pointer
566 | -freorder-blocks
567 | -fshrink-wrap
568 | -fshrink-wrap-separate
569 | -fsplit-wide-types
570 | -fssa-backprop
571 | -fssa-phiopt
572 | -ftree-bit-ccp
573 | -ftree-ccp
574 | -ftree-ch
575 | -ftree-coalesce-vars
576 | -ftree-copy-prop
577 | -ftree-dce
578 | -ftree-dominator-opts
579 | -ftree-dse
580 | -ftree-forwprop
581 | -ftree-fre
582 | -ftree-phiprop
583 | -ftree-pta
584 | -ftree-scev-cprop
585 | -ftree-sink
586 | -ftree-slsr
587 | -ftree-sra
588 | -ftree-ter
589 | -funit-at-a-time
590 | ```
591 |
592 |
593 |
594 | **O2:**常见的Release级别,该选项下几乎执行了所有支持的优化选项,它增加了编译时间,提高了程序的运行速度,又额外打开了以下优化标志:
595 |
596 | ```text
597 | -falign-functions -falign-jumps
598 | -falign-labels -falign-loops
599 | -fcaller-saves
600 | -fcode-hoisting
601 | -fcrossjumping
602 | -fcse-follow-jumps -fcse-skip-blocks
603 | -fdelete-null-pointer-checks
604 | -fdevirtualize -fdevirtualize-speculatively
605 | -fexpensive-optimizations
606 | -ffinite-loops
607 | -fgcse -fgcse-lm
608 | -fhoist-adjacent-loads
609 | -finline-functions
610 | -finline-small-functions
611 | -findirect-inlining
612 | -fipa-bit-cp -fipa-cp -fipa-icf
613 | -fipa-ra -fipa-sra -fipa-vrp
614 | -fisolate-erroneous-paths-dereference
615 | -flra-remat
616 | -foptimize-sibling-calls
617 | -foptimize-strlen
618 | -fpartial-inlining
619 | -fpeephole2
620 | -freorder-blocks-algorithm=stc
621 | -freorder-blocks-and-partition -freorder-functions
622 | -frerun-cse-after-loop
623 | -fschedule-insns -fschedule-insns2
624 | -fsched-interblock -fsched-spec
625 | -fstore-merging
626 | -fstrict-aliasing
627 | -fthread-jumps
628 | -ftree-builtin-call-dce
629 | -ftree-pre
630 | -ftree-switch-conversion -ftree-tail-merge
631 | -ftree-vrp
632 | ```
633 |
634 | **Os:**打开了几乎所有的O2优化标志,除了那些经常会增加代码大小的优化标志:使编译器根据代码大小而不是程序运行速度进行优化,为了减少代码大小。
635 |
636 | **O3:**较为激进的优化选项(对错误编码容忍度最低),在O2的基础上额外打开了十多个优化选项,在O2的基础上又打开了以下优化标志:
637 |
638 | ```
639 | fgcse-after-reload
640 | -fipa-cp-clone
641 | -floop-interchange
642 | -floop-unroll-and-jam
643 | -fpeel-loops
644 | -fpredictive-commoning
645 | -fsplit-loops
646 | -fsplit-paths
647 | -ftree-loop-distribution
648 | -ftree-loop-vectorize
649 | -ftree-partial-pre
650 | -ftree-slp-vectorize
651 | -funswitch-loops
652 | -fvect-cost-model
653 | -fvect-cost-model=dynamic
654 | -fversion-loops-for-strides
655 | ```
656 |
657 |
658 |
659 | # Debug和Release版本的区别
660 |
661 | Debug通常称为调试版本,通过一系列编译选项的配合,编译的结果通常包含调试信息,而且不做任何优化,以为开发 人员提供强大的应用程序调试能力。
662 |
663 | Release通常称为发布版本,是为用户使用的,一般客户不允许在发布版本上进行调试。所以不保存调试信 息,同时,它往往进行了各种优化,以期达到代码最小和速度最优。为用户的使用提供便利。
664 |
665 | 有以下几个不同:
666 |
667 | 1. Debug模式下在内存分配上有所区别,在我们申请内存时,Debug模式会多申请一部分空间,分布在内存块的前后,用于存放调试信息。
668 | 2. 对于未初始化的变量,Debug模式下会默认对其进行初始化,而Release模式则不会,所以就有个常见的问题,局部变量未初始化时,Debug模式下可能运行正常,但Release模式下可能会返回错误结果
669 | 3. Debug模式下可以使用assert,运行过程中有异常现象会及时crash,Release模式下模式下不会编译assert,遇到不期望的情况不会及时crash,稀里糊涂继续运行,到后期可能会产生奇奇怪怪的错误,不易调试,殊不知其实在很早之前就出现了问题。编译器在Debug模式下定义_DEBUG宏,Release模式下定义NDEBUG宏,预处理器就是根据对应宏来判断是否开启assert的。
670 | 4. 数据溢出问题,在一个函数中,存在某些从未被使用的变量,且函数内存在数据溢出问题,在Debug模式下可能不会产生问题,因为不会对该变量进行优化,它在栈空间中还是占有几个字节,但是Release模式下可能会出问题,Release模式下可能会优化掉此变量,栈空间相应变小,数据溢出就会导致栈内存损坏,有可能会产生奇奇怪怪的错误。
671 |
672 | > **问:有时候程序在Debug模式下运行的好好的,Release模式下就crash了,怎么办?**
673 | >
674 | > 答:看一下代码中是否有未初始化的变量,是否有数组越界问题,从这个思路入手。
675 | >
676 | > **问:有些时候程序在Debug模式下会崩溃,Release模式下却正常运行,怎么办?**
677 | >
678 | > 答:可以尝试着找一找代码中的assert,看一下是否是assert导致的两种模式下的差异,从这个思路入手。
679 |
680 |
681 |
682 | # Intel CPU型号解读
683 |
684 | Intel生产的CPU分为高中低端,最低端的G系列,然后是低端i3系列,中端i5系列,高端i7系列和至尊i9系列。
685 |
686 | U:代表超低电压以15W和28为主
687 |
688 | M:代表标准电压cpu
689 |
690 | U:代表低电压节能的
691 |
692 | H:是高电压的
693 |
694 | X:代表高性能
695 |
696 | Q:代表至高性能级别
697 |
698 | Y:代表超低电压的
699 |
700 | K:代表不锁倍频的处理器
701 |
702 | “MX”:代表旗舰级,
703 |
704 | “HQ”:封装方式FCBGA1364,并且部分支持Trusted Execution Technology和博锐技术,
705 |
706 | “MQ”:版本封装方式FCBGA946。
707 |
708 | # 在 4GB 物理内存的机器上,申请 8G 内存会怎么样?
709 |
710 | 这个问题要考虑三个前置条件:
711 |
712 | - 操作系统是 32 位的,还是 64 位的?
713 | - 申请完 8G 内存后会不会被使用?
714 | - 操作系统有没有使用 Swap 机制?
715 |
716 | 首先,应用程序通过 malloc 函数申请内存的时候,实际上申请的是虚拟内存,此时并不会分配物理内存。当应用程序读写了这块虚拟内存,CPU 就会去访问这个虚拟内存, 这时会发现这个虚拟内存没有映射到物理内存, CPU 就会产生缺页中断,进程会从用户态切换到内核态,并将缺页中断交给内核的 Page Fault Handler (缺页中断函数)处理。缺页中断处理函数会看是否有空闲的物理内存:
717 |
718 | 1. 如果有,就直接分配物理内存,并建立虚拟内存与物理内存之间的映射关系。
719 | 2. 如果没有空闲的物理内存,那么内核就会开始进行回收内存 (opens new window)的工作,如果回收内存工作结束后,空闲的物理内存仍然无法满足此次物理内存的申请,那么内核就会放最后的大招了触发 OOM (Out of Memory)机制。
720 |
721 | ## 32还是64
722 |
723 | 另外,32 位操作系统和 64 位操作系统的虚拟地址空间大小是不同的,在 Linux 操作系统中,虚拟地址空间的内部又被分为内核空间和用户空间两部分:
724 |
725 | 1. `32` 位系统的内核空间占用 `1G`,位于最高处,剩下的 `3G` 是用户空间;
726 | 2. `64` 位系统的内核空间和用户空间都是 `128T`,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
727 |
728 | **32 位操作系统**
729 |
730 | 因为 32 位操作系统,进程最多只能申请 3 GB 大小的虚拟内存空间,所以进程申请 8GB 内存的话,在申请虚拟内存阶段就会失败
731 |
732 | **64位操作系统**
733 |
734 | 64 位操作系统,进程可以使用 128 TB 大小的虚拟内存空间,所以进程申请 8GB 内存是没问题的,因为进程申请内存是申请虚拟内存,只要不读写这个虚拟内存,操作系统就不会分配物理内存。
735 |
736 | ## 有没有swap
737 |
738 | > **什么是 Swap 机制?**
739 | >
740 | > 当系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间会被临时保存到磁盘,等到那些程序要运行时,再从磁盘中恢复保存的数据到内存中。另外,当内存使用存在压力的时候,会开始触发内存回收行为,会把这些不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
741 | >
742 | > 将内存数据换出磁盘,又从磁盘中恢复数据到内存的过程,就是 Swap 机制负责的。
743 | >
744 | > Swap 就是把一块磁盘空间或者本地文件,当成内存来使用,它包含换出和换入两个过程:
745 | >
746 | > 1. 换出(Swap Out) ,是把进程暂时不用的内存数据存储到磁盘中,并释放这些数据占用的内存;
747 | > 2. 换入(Swap In),是在进程再次访问这些内存的时候,把它们从磁盘读到内存中来;
748 | >
749 | > **Linux 中的 Swap 机制会在内存不足和内存闲置的场景下触发:**
750 | >
751 | > 1. 内存不足:当系统需要的内存超过了可用的物理内存时,内核会将内存中不常使用的内存页交换到磁盘上为当前进程让出内存,保证正在执行的进程的可用性,这个内存回收的过程是强制的直接内存回收(Direct Page Reclaim)。直接内存回收是同步的过程,会阻塞当前申请内存的进程。
752 | > 2. 内存闲置:应用程序在启动阶段使用的大量内存在启动后往往都不会使用,通过后台运行的守护进程(kSwapd),我们可以将这部分只使用一次的内存交换到磁盘上为其他内存的申请预留空间。kSwapd 是 Linux 负责页面置换(Page replacement)的守护进程,它也是负责交换闲置内存的主要进程,它会在[空闲内存低于一定水位 (opens new window)](https://xiaolincoding.com/os/3_memory/mem_reclaim.html#尽早触发-kSwapd-内核线程异步回收内存)时,回收内存页中的空闲内存保证系统中的其他进程可以尽快获得申请的内存。kSwapd 是后台进程,所以回收内存的过程是异步的,不会阻塞当前申请内存的进程。
753 | >
754 | > **Swap 换入换出的是什么类型的内存?**
755 | >
756 | > 内核缓存的文件数据,因为都有对应的磁盘文件,所以在回收文件数据的时候, 直接写回到对应的文件就可以了。但是像进程的堆、栈数据等,它们是没有实际载体,这部分内存被称为匿名页。而且这部分内存很可能还要再次被访问,所以不能直接释放内存,于是就需要有一个能保存匿名页的磁盘载体,这个载体就是 Swap 分区。
757 | >
758 | > **swap的优缺点**
759 | >
760 | > 使用 Swap 机制优点是,应用程序实际可以使用的内存空间将远远超过系统的物理内存。由于硬盘空间的价格远比内存要低,因此这种方式无疑是经济实惠的。当然,频繁地读写硬盘,会显著降低操作系统的运行速率,这也是 Swap 的弊端。
761 |
762 | 使用`free -m`命令查看有没有swap分区
763 |
764 | **没有开启 Swap 机制**
765 |
766 | 当申请完,使用们memset函数访问的时候,超过了机器的物理内存(2GB),进程(test)被操作系统杀掉了。
767 |
768 | 通过`var/log/message`可以看到报错了 Out of memory,也就是发生 OOM(内存溢出错误)。
769 |
770 | > 什么是 OOM?
771 | >
772 | > 内存溢出(Out Of Memory,简称OOM)是指应用系统中存在无法回收的内存或使用的内存过多,最终使得程序运行要用到的内存大于能提供的最大内存。此时程序就运行不了,系统会提示内存溢出。
773 |
774 | **开启 Swap 机制**
775 |
776 | 在有 Swap 分区的情况下,即使笔记本物理内存是 8 GB,申请并使用 32 GB 内存是没问题,程序正常运行了,并没有发生 OOM。
777 |
778 | 但是磁盘 I/O 达到了一个峰值,非常高
779 |
780 | > 有了 Swap 分区,是不是意味着进程可以使用的内存是无上限的?
781 | >
782 | > 当然不是,我把上面的代码改成了申请 64GB 内存后,当进程申请完 64GB 虚拟内存后,使用到 56 GB (这个不要理解为占用的物理内存,理解为已被访问的虚拟内存大小,也就是在物理内存呆过的内存大小)的时候,进程就被系统 kill 掉了,当系统多次尝试回收内存,还是无法满足所需使用的内存大小,进程就会被系统 kill 掉了,意味着发生了 OOM
783 |
784 |
785 |
786 | # CPU和GPU的区别
787 |
788 | https://mp.weixin.qq.com/s/jPh5o5LXDWi7WogyN6AHvQ
789 |
790 |
791 |
792 | # C++性能调优
793 |
794 | https://www.cnblogs.com/wujianlundao/archive/2012/11/18/2776372.html
795 |
796 | ## **冗余的变量拷贝**
797 |
798 | **参数**
799 |
800 | 相对C而言,写C++代码经常一不小心就会引入一些临时变量,比如函数实参、函数返回值。在临时变量之外,也会有其他一些情况会带来一些冗余的变量拷贝。
801 |
802 | 这个要看要不要修改参数,可能会修改,则需要用值传递无可避免
803 |
804 | 如果参数不会被函数给修改,那么引用传递可以
805 |
806 | **返回值**
807 |
808 | RVO(return value optimization),这时候只能在函数返回一个未命名变量的时候进行优化。
809 |
810 | ## **字符数组的初始化**
811 |
812 | 写代码时,很多人为了省事或者说安全起见,每次申请一段内存之后都先全部初始化为0。
813 |
814 | 用了一些API,不了解底层实现,把申请的内存全部初始化为0了,比如char buf[1024]=""的方式,
815 |
816 | 上面提到两种内存初始化为0的情况,其实有些时候并不是必须的。比如把char型数组作为string使用的时候只需要初始化第一个元素为0即可,或者把char型数组作为一个buffer使用的大部分时候根本不需要初始化。
817 |
818 | ## **频繁的内存申请、释放操作**
819 |
820 | https://bbs.csdn.net/topics/330179712
821 |
822 | ## **提前计算**
823 |
824 | 这里需要提到的有两类问题:
825 |
826 | 1. 局部的冗余计算:循环体内的计算提到循环体之前
827 |
828 | 2. 全局的冗余计算
829 |
830 | 问题1很简单,大部分人应该都接触到过。有人会问编译器不是对此有对应的优化措施么?对,公共子表达式优化是可以解决一些这个问题。不过实测发现**如果循环体内是调用的某个函数**,即使这个函数是没有side effect的,编译器也无法针对这种情况进行优化。(我是用gcc 3.4.5测试的,不排除更高版本的gcc或者其他编译器可以针对这种情况进行优化)
831 |
832 | 对于问题2,我遇到的情况是:服务代码中定义了一个const变量,假设叫做MAX_X,处理请求是,会计算一个pow(MAX_X)用作判断(y的x次方),而性能分析发现,这个pow操作占了整体系统CPU占用的10%左右。对于这个问题,我的优化方式很简单,直接计算定义一个MAX_X_POW变量用作过滤即可。代码修改2行,性能提升10%。
833 |
834 | ## **空间换时间**
835 |
836 | 哈希表的思想
837 |
838 | ## **内联频繁调用的短小函数**
839 |
840 | 小函数尽量内联,频繁调用会提高效率
841 |
842 | ## **位运算代替乘除法**
843 |
844 | %2的次方可以用位运算代替,a%8=a&7(两倍多效率提升)
845 |
846 | /2的次方可以用移位运算代替,a/8=a>>3(两倍多效率提升)
847 |
848 | `*2`的次方可以用移位运算代替,a*8=a<<3(小数值测试效率不明显,大数值1.5倍效率)
849 |
850 | 整数次方不要用pow,`i*i`比pow(i,2)快8倍,`i*i*i`比pow快40倍
851 |
852 | ## C++为什么提供move函数?
853 |
854 | 我想说一下一个我的个人经历
855 |
856 | 有一段代码,作用是把数据库表保存到XML文件。这个转换的过程,有个中间容器,大概是这样:
857 |
858 | ```c++
859 | std::map> mapTable;
860 | ```
861 |
862 | 可以理解为map的key是数据表的列名,std::vector是那列数据(一行一行的)。
863 |
864 | 我之前是这么填充的:
865 |
866 | ```c++
867 | std::vector vecRow;
868 | for(){
869 | vecRow.push_back(...);
870 | }
871 | mapTable["列名1"] = vecRow;
872 | ```
873 |
874 | codereview的时候我的mentor就和我讲了这个事情,本质上上述代码,把vecRow中的所有元素都复制了以便然后放到mapTable中,白白的重新创建了一遍所有行数据,又把不再需要的vecRow释放掉了。这样就很蠢。
875 |
876 | 改进:当我们知道vecRow生命(作用域后),我们可以利用这个vecRow,在std::move之前,还是有办法的,创建vecRow 的时候就让它是mapTable里某列的引用,如下:
877 |
878 | ```c++
879 | std::vector &vecRow = mapTable["列名1"];
880 | for(){
881 | vecRow.push_back(...);
882 | }
883 | ```
884 |
885 | 但是考虑到这样的话会改动别的代码,所哟用谁提的std::move是最好的
886 |
887 | `mapTable["列名1"]= std::move(vecRow);`
888 |
889 | 就这么一点点改动,就能让vecRow里的东西放进mapTable里,又没避免大规模创建、析构对象。执行完上面的函数,应该会发现vecRow空了。
890 |
891 | **总结**
892 |
893 | 其实编译器已经在力所能及的优化他能够优化的东西了,但是编译器的优化不是万能的。有时候某个变量的生命周期编译器不可预见,但是我们自己是可以知道的,因此对于这些生命周期很短的变量我们为了节省效率就可以使用move函数。举个例子:比如黄金交易,张三买了李四的黄金,就应该把黄金从李四家移动到张三家里。但如果黄金量很大,移动的成本就会非常高。另一种方式就是大家的黄金都存在银行里,张三买李四的黄金,无非就是账户里的黄金数发生个变化,实体黄金不移动,这样效率就高很多。至于"为什么管理机构(编译器)不优化全世界的黄金交易为纸上黄金交易?",**那是因为真的有人需要搬黄金回家用啊**
894 |
--------------------------------------------------------------------------------
/设计模式.md:
--------------------------------------------------------------------------------
1 | # c++单例模式
2 |
3 | > 定义:单例模式是创建型设计模式,指的是在系统的生命周期中只能产生一个实例(对象),确保该类的唯一性。
4 | >
5 | > 一般遇到的写进程池类、日志类、内存池(用来缓存数据的结构,在一处写多出读或者多处写多处读)的话都会用到单例模式
6 |
7 | **实现方法:**全局只有一个实例也就意味着不能用new调用构造函数来创建对象,因此构造函数必须是虚有的。但是由于不能new出对象,所以类的内部必须提供一个函数来获取对象,而且由于不能外部构造对象,因此这个函数不能是通过对象调出来,换句话说这个函数应该是属于对象的,很自然我们就想到了用static。由于静态成员函数属于整个类,在类实例化对象之前就已经分配了空间,而类的非静态成员函数必须在类实例化后才能有内存空间。
8 |
9 | 单例模式的要点总结:
10 |
11 | 1. 全局只有一个实例,用static特性实现,构造函数设为私有
12 | 2. 通过公有接口获得实例
13 | 3. 线程安全
14 | 4. 禁止拷贝和赋值
15 |
16 | 单例模式可以**分为懒汉式和饿汉式**,两者之间的区别在于创建实例的时间不同:懒汉式指系统运行中,实例并不存在,只有当需要使用该实例时,才会去创建并使用实例(这种方式要考虑线程安全)。饿汉式指系统一运行,就初始化创建实例,当需要时,直接调用即可。(本身就线程安全,没有多线程的问题)
17 |
18 | ## 懒汉式
19 |
20 | - 普通懒汉式会让线程不安全
21 |
22 | 因为不加锁的话当线程并发时会产生多个实例,导致线程不安全
23 |
24 | ```c++
25 | /// 普通懒汉式实现 -- 线程不安全 //
26 | #include // std::cout
27 | #include // std::mutex
28 | #include // pthread_create
29 |
30 | class SingleInstance
31 | {
32 | public:
33 | // 获取单例对象
34 | static SingleInstance *GetInstance();
35 | // 释放单例,进程退出时调用
36 | static void deleteInstance();
37 | // 打印单例地址
38 | void Print();
39 | private:
40 | // 将其构造和析构成为私有的, 禁止外部构造和析构
41 | SingleInstance();
42 | ~SingleInstance();
43 | // 将其拷贝构造和赋值构造成为私有函数, 禁止外部拷贝和赋值
44 | SingleInstance(const SingleInstance &signal);
45 | const SingleInstance &operator=(const SingleInstance &signal);
46 | private:
47 | // 唯一单例对象指针
48 | static SingleInstance *m_SingleInstance;
49 | };
50 |
51 | //初始化静态成员变量
52 | SingleInstance *SingleInstance::m_SingleInstance = NULL;
53 |
54 | SingleInstance* SingleInstance::GetInstance()
55 | {
56 | if (m_SingleInstance == NULL)
57 | {
58 | m_SingleInstance = new (std::nothrow) SingleInstance; // 没有加锁是线程不安全的,当线程并发时会创建多个实例
59 | }
60 | return m_SingleInstance;
61 | }
62 |
63 | void SingleInstance::deleteInstance()
64 | {
65 | if (m_SingleInstance)
66 | {
67 | delete m_SingleInstance;
68 | m_SingleInstance = NULL;
69 | }
70 | }
71 |
72 | void SingleInstance::Print()
73 | {
74 | std::cout << "我的实例内存地址是:" << this << std::endl;
75 | }
76 |
77 | SingleInstance::SingleInstance()
78 | {
79 | std::cout << "构造函数" << std::endl;
80 | }
81 |
82 | SingleInstance::~SingleInstance()
83 | {
84 | std::cout << "析构函数" << std::endl;
85 | }
86 | /// 普通懒汉式实现 -- 线程不安全 //
87 | ```
88 |
89 | - 线程安全、内存安全的懒汉式
90 |
91 | 上述代码出现的问题:
92 |
93 | 1. GetInstance()可能会引发竞态条件,第一个线程在if中判断 `m_instance_ptr`是空的,于是开始实例化单例;同时第2个线程也尝试获取单例,这个时候判断`m_instance_ptr`还是空的,于是也开始实例化单例;这样就会实例化出两个对象,这就是线程安全问题的由来
94 |
95 | 解决办法:①加锁。②局部变量实例
96 |
97 | 2. 类中只负责new出对象,却没有负责delete对象,因此只有构造函数被调用,析构函数却没有被调用;因此会导致内存泄漏。
98 |
99 | 解决办法:使用共享指针
100 |
101 | > c++11标准中有一个特性:如果当变量在初始化的时候,并发同时进入声明语句,并发线程将会阻塞等待初始化结束。这样保证了并发线程在获取静态局部变量的时候一定是初始化过的,所以具有线程安全性。因此这种懒汉式是最推荐的,因为:
102 | >
103 | > 1. 通过局部静态变量的特性保证了线程安全 (C++11, GCC > 4.3, VS2015支持该特性);
104 | > 2. 不需要使用共享指针和锁
105 | > 3. get_instance()函数要返回引用而尽量不要返回指针,
106 |
107 | ```c++
108 | /// 内部静态变量的懒汉实现 //
109 | class Singleton
110 | {
111 | public:
112 | ~Singleton(){
113 | std::cout<<"destructor called!"< 使用锁、共享指针实现的懒汉式单例模式
137 | >
138 | > - 基于 shared_ptr, 用了C++比较倡导的 RAII思想,用对象管理资源,当 shared_ptr 析构的时候,new 出来的对象也会被 delete掉。以此避免内存泄漏。
139 | > - 加了锁,使用互斥量来达到线程安全。这里使用了两个 if判断语句的技术称为**双检锁**;好处是,只有判断指针为空的时候才加锁,避免每次调用 get_instance的方法都加锁,锁的开销毕竟还是有点大的。
140 | >
141 | > 不足之处在于: 使用智能指针会要求用户也得使用智能指针,非必要不应该提出这种约束; 使用锁也有开销; 同时代码量也增多了,实现上我们希望越简单越好。
142 |
143 | ```c++
144 | #include
145 | #include // shared_ptr
146 | #include // mutex
147 |
148 | // version 2:
149 | // with problems below fixed:
150 | // 1. thread is safe now
151 | // 2. memory doesn't leak
152 |
153 | class Singleton {
154 | public:
155 | typedef std::shared_ptr Ptr;
156 | ~Singleton() {
157 | std::cout << "destructor called!" << std::endl;
158 | }
159 | Singleton(Singleton&) = delete;
160 | Singleton& operator=(const Singleton&) = delete;
161 | static Ptr get_instance() {
162 |
163 | // "double checked lock"
164 | if (m_instance_ptr == nullptr) {
165 | std::lock_guard lk(m_mutex);
166 | if (m_instance_ptr == nullptr) {
167 | m_instance_ptr = std::shared_ptr(new Singleton);
168 | }
169 | }
170 | return m_instance_ptr;
171 | }
172 |
173 |
174 | private:
175 | Singleton() {
176 | std::cout << "constructor called!" << std::endl;
177 | }
178 | static Ptr m_instance_ptr;
179 | static std::mutex m_mutex;
180 | };
181 |
182 | // initialization static variables out of class
183 | Singleton::Ptr Singleton::m_instance_ptr = nullptr;
184 | std::mutex Singleton::m_mutex;
185 | ```
186 |
187 |
188 |
189 | ## 饿汉式
190 |
191 | ```c++
192 |
193 | // 饿汉实现 /
194 | class Singleton
195 | {
196 |
197 | public:
198 | // 获取单实例
199 | static Singleton* GetInstance();
200 | // 释放单实例,进程退出时调用
201 | static void deleteInstance();
202 | // 打印实例地址
203 | void Print();
204 |
205 | private:
206 | // 将其构造和析构成为私有的, 禁止外部构造和析构
207 | Singleton();
208 | ~Singleton();
209 |
210 | // 将其拷贝构造和赋值构造成为私有函数, 禁止外部拷贝和赋值
211 | Singleton(const Singleton &signal);
212 | const Singleton &operator=(const Singleton &signal);
213 |
214 | private:
215 | // 唯一单实例对象指针
216 | static Singleton *g_pSingleton;
217 | };
218 |
219 | // 代码一运行就初始化创建实例 ,本身就线程安全
220 | Singleton* Singleton::g_pSingleton = new (std::nothrow) Singleton;
221 |
222 | Singleton* Singleton::GetInstance()
223 | {
224 | return g_pSingleton;
225 | }
226 |
227 | void Singleton::deleteInstance()
228 | {
229 | if (g_pSingleton)
230 | {
231 |
232 | delete g_pSingleton;
233 | g_pSingleton = NULL;
234 | }
235 | }
236 |
237 | void Singleton::Print()
238 | {
239 | std::cout << "我的实例内存地址是:" << this << std::endl;
240 | }
241 |
242 | Singleton::Singleton()
243 | {
244 | std::cout << "构造函数" << std::endl;
245 | }
246 |
247 | Singleton::~Singleton()
248 | {
249 | std::cout << "析构函数" << std::endl;
250 | }
251 | // 饿汉实现 /
252 | ```
253 |
254 | ## 面试题
255 |
256 | - 懒汉模式和恶汉模式的实现(判空!!!加锁!!!),并且要能说明原因(为什么判空两次?)
257 | - 构造函数的设计(为什么私有?除了私有还可以怎么实现(进阶)?)
258 | - 对外接口的设计(为什么这么设计?)
259 | - 单例对象的设计(为什么是static?如何初始化?如何销毁?(进阶))
260 | - 对于C++编码者,需尤其注意C++11以后的单例模式的实现(为什么这么简化?怎么保证的(进阶))
261 |
262 |
263 |
264 | # Observe模式
265 |
266 | ## 定义
267 |
268 | 又叫做观察者模式,被观察者叫做subjec,观察者叫做observer
269 |
270 | **观察者模式(Observer Pattern)**: 定义对象间一种一对多的依赖关系,使得当每一个对象改变状态,则所有依赖于它的对象都会得到通知并自动更新。
271 |
272 | 观察者模式所做的工作其实就是在解耦,让耦合的双方都依赖于抽象而不是具体,从而使得各自的变化都不会影响另一边的变化。当一个对象的改变需要改变其他对象的时候,而且它不知道具体有多少对象有待改变的时候,应该考虑使用观察者模式。一旦观察目标的状态发生改变,所有的观察者都将得到通知。具体来说就是被观察者需要用一个容器比如vector存放所有观察者对象,以便状态发生变化时给观察着发通知。观察者内部需要实例化被观察者对象的实例(需要前向声明)
273 |
274 | 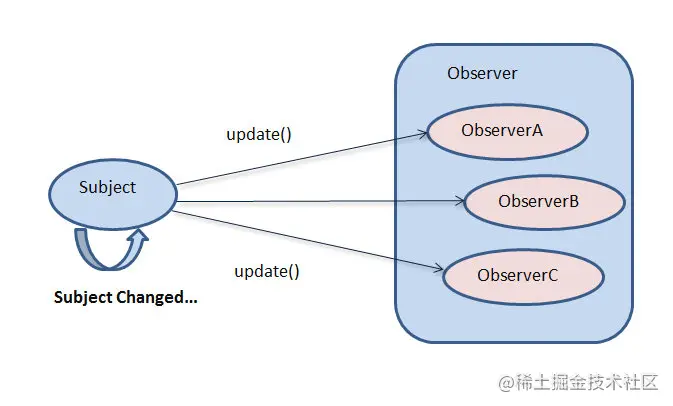 275 |
276 | **观察者模式中主要角色--2个接口,2个类**
277 |
278 | 1. 抽象主题(Subject)角色(接口):主题角色将所有对观察者对象的引用保存在一个集合中,每个主题可以有任意多个观察者。 抽象主题提供了增加和删除观察者对象的接口。
279 | 2. 抽象观察者(Observer)角色(接口):为所有的具体观察者定义一个接口,在观察的主题发生改变时更新自己。
280 | 3. 具体主题(ConcreteSubject)角色(1个):存储相关状态到具体观察者对象,当具体主题的内部状态改变时,给所有登记过的观察者发出通知。具体主题角色通常用一个具体子类实现。
281 | 4. 具体观察者(ConcretedObserver)角色(多个):存储一个具体主题对象,存储相关状态,实现抽象观察者角色所要求的更新接口,以使得其自身状态和主题的状态保持一致。
282 |
283 | ```java
284 | //观察者
285 | interface Observer {
286 | public void update();
287 | }
288 | //被观察者
289 | abstract class Subject {
290 | private Vector obs = new Vector();
291 |
292 | public void addObserver(Observer obs){
293 | this.obs.add(obs);
294 | }
295 | public void delObserver(Observer obs){
296 | this.obs.remove(obs);
297 | }
298 | protected void notifyObserver(){
299 | for(Observer o: obs){
300 | o.update();
301 | }
302 | }
303 | public abstract void doSomething();
304 | }
305 | //具体被观察者
306 | class ConcreteObserver1 implements Observer {
307 | public void update() {
308 | System.out.println("观察者1收到信息,并进行处理");
309 | }
310 | }
311 | class ConcreteObserver2 implements Observer {
312 | public void update() {
313 | System.out.println("观察者2收到信息,并进行处理");
314 | }
315 | }
316 | //客户端
317 | public class Client {
318 | public static void main(String[] args){
319 | Subject sub = new ConcreteSubject();
320 | sub.addObserver(new ConcreteObserver1()); //添加观察者1
321 | sub.addObserver(new ConcreteObserver2()); //添加观察者2
322 | sub.doSomething();
323 | }
324 | }
325 | //输出
326 | 被观察者事件发生改变
327 | 观察者1收到信息,并进行处理
328 | 观察者2收到信息,并进行处理
329 | 可以看到当被观察者发生改变过后,观察者都收到了通知
330 | ```
331 |
332 | ## 优点
333 |
334 | - 观察者模式在被观察者和观察者之间建立一个抽象的耦合。被观察者角色所知道的只是一个具体观察者列表,每一个具体观察者都符合一个抽象观察者的接口。被观察者并不认识任何一个具体观察者,它只知道它们都有一个共同的接口。
335 | - 观察者模式支持广播通讯。被观察者会向所有的登记过的观察者发出通知
336 |
337 | ## 缺点
338 |
339 | - 当观察者对象很多的时候,通知的发布会产生很多时间,影响程序的效率。一个被观察者,多个观察者时,开发代码和调试会比较复杂,java中消息的通知是默认顺序执行的,若其中一个观察者卡壳,会影响到此观察者后面的观察者执行,影响整体的执行, 多级触发时的效率更让人担忧。
340 | - 虽然观察者模式可以随时使观察者知道所观察的对象发生了变化,但是观察者模式没有相应的机制使观察者知道所观察的对象是怎么发生变化的。
341 | - 如果在被观察者之间有循环依赖的话,被观察者会触发它们之间进行循环调用,导致系统崩溃。在使用观察者模式是要特别注意这一点。
342 |
343 | # 工厂模式
344 | https://blog.csdn.net/qq_55882840/article/details/139043332
345 |
346 | ## 1.工厂模式简介
347 | 工厂模式的三种类型:
348 | - 简单工厂模式
349 | - 工厂方法模式
350 | - 抽象工厂模式
351 | 工厂模式的作用是生产对象,可以简化代码、提高可维护性,并旦可以通过工厂类生产多种对象。简单工厂模式适用于创建简单的对象,工厂模式适用于创建复杂的对象,而抽象工厂模式适用于创建更复杂的对象。
352 |
353 | ## 2. 简单工厂模式
354 | 简单工厂模式是一种创建型设计模式,旨在通过一个工厂方法来创建对象,而无需直接暴露对象的实例化逻辑。简单工厂模式通常包括一个工厂类和多个产品类。工厂类负责根据客户端的请求,返回对应的产品类实例。就是用户申请一个产品,由工厂负责创建对象。而不是用户自己创建对象。在简单工厂模式中,客户端只需要通过调用工厂类的方法,并传入相应的参数,而无需直接实例化产品类。工厂类根据客户端传入的参数决定创建哪个产品类的实例,并将实例返回给客户端。
355 |
356 | ### 优点:
357 | 封装了实例化的细节,使得客户端与具体产品类解耦,增强了灵活性和可维护性。客户端只需要知道需要什么类型的产品,而无需关心具体的实现细节。同时,如果需要新增产品类时,只需修改工厂类即可,不需要修改客户端代码。
358 | ### 缺点:
359 | 简单工厂模式也有一些限制。例如,当需要创建多种类型的产品实例时,工厂类的代码可能会变得复杂,并且随着产品类型的增加,工厂类的责任也会越来越大。因此,在一些复杂的场景下,可能需要使用其他更灵活的创建型设计模式,如工厂方法模式或抽象工厂模式。总的来说,简单工厂模式提供了一种简单而灵活的方式来创建对象,对于一些简单的对象创建场景是很有用的。
360 |
361 | 简单工厂模式
362 | ```c++
363 | class Product {
364 | public:
365 | virtual void operation() = 0;
366 | };
367 | class ConcreteProductA : public Product {
368 | public:
369 | void operation() override {
370 | // 具体产品A的操作实现
371 | }
372 | };
373 | class ConcreteProductB : public Product {
374 | public:
375 | void operation() override {
376 | // 具体产品B的操作实现
377 | }
378 | };
379 | ```
380 | 简单工厂类
381 | ```c++
382 | class SimpleFactory {
383 | public:
384 | static Product* createProduct(const std::string& type) {
385 | if (type == "A") {
386 | return new ConcreteProductA();
387 | } else if (type == "B") {
388 | return new ConcreteProductB();
389 | } else {
390 | return nullptr; // 可以添加默认处理逻辑或抛出异常
391 | }
392 | }
393 | };
394 | ```
395 | 客户端调用方式
396 | ```c++
397 | int main() {
398 | Product* productA = SimpleFactory::createProduct("A");
399 | productA->operation(); // 调用具体产品A的操作
400 | Product* productB = SimpleFactory::createProduct("B");
401 | productB->operation(); // 调用具体产品B的操作
402 | delete productA;
403 | delete productB;
404 | return 0;
405 | }
406 | ```
407 |
408 | ## 3. 工厂方法模式
409 | 工厂方法模式(Factory Method Pattern)是一种创建型设计模式,它定义了一个用于创建对象的接口,但将具体的对象创建过程交给子类来实现。工厂方法模式通过让子类决定实例化哪个具体类来实现对象的创建,从而实现了将对象的创建和使用解耦的目的。
410 | 工厂方法模式一般包括以下角色:
411 | 抽象产品(Product):定义了产品的共同接口,具体的产品类必须实现这个接口。
412 | 具体产品(ConcreteProduct):实现了抽象产品接口,是工厂方法模式中具体创建的对象。
413 | 抽象工厂(Factory):定义了一个工厂的接口,包含一个创建产品的抽象方法,具体的工厂类必须实现这个接口。
414 | 具体工厂(ConcreteFactory):实现了抽象工厂接口,负责实例化具体的产品对象。
415 | 工厂方法模式的关键在于通过抽象工厂和具体工厂的组合,将对象的创建过程推迟到子类中实现。客户端通过使用抽象工厂来创建产品对象,而无需关心具体的产品类和实例化细节。
416 | ```c++
417 | // 抽象产品
418 | class Product {
419 | public:
420 | virtual void operation() = 0;
421 | };
422 | // 具体产品 A
423 | class ConcreteProductA : public Product {
424 | public:
425 | void operation() override {
426 | // 具体产品 A 的操作实现
427 | }
428 | };
429 | // 具体产品 B
430 | class ConcreteProductB : public Product {
431 | public:
432 | void operation() override {
433 | // 具体产品 B 的操作实现
434 | }
435 | };
436 | // 抽象工厂
437 | class Factory {
438 | public:
439 | virtual Product* createProduct() = 0;
440 | };
441 | // 具体工厂 A
442 | class ConcreteFactoryA : public Factory {
443 | public:
444 | Product* createProduct() override {
445 | return new ConcreteProductA();
446 | }
447 | };
448 | // 具体工厂 B
449 | class ConcreteFactoryB : public Factory {
450 | public:
451 | Product* createProduct() override {
452 | return new ConcreteProductB();
453 | }
454 | };
455 | ```
456 | ```c++
457 | int main() {
458 | Factory* factoryA = new ConcreteFactoryA();
459 | Product* productA = factoryA->createProduct();
460 | productA->operation(); // 调用具体产品 A 的操作
461 | Factory* factoryB = new ConcreteFactoryB();
462 | Product* productB = factoryB->createProduct();
463 | productB->operation(); // 调用具体产品 B 的操作
464 | delete factoryA;
465 | delete productA;
466 | delete factoryB;
467 | delete productB;
468 | return 0;
469 | }
470 | ```
471 | ### 4. 抽象工厂模式
472 | 抽象工厂模式(Abstract Factory Pattern)是一种创建型设计模式,它提供了一个接口,用于创建一系列相关或相互依赖的对象,而无需指定具体的类。抽象工厂模式通过将对象的创建和使用解耦,使得客户端代码与具体类的实现分离,从而实现了对象的变化和替换的灵活性。抽象工厂模式一般包括以下角色:
473 |
474 | 抽象工厂(Abstract Factory):定义了创建一系列产品对象的接口,通常包含多个创建产品的抽象方法。
475 | 具体工厂(Concrete Factory):实现了抽象工厂接口,负责创建具体的产品对象。
476 | 抽象产品(Abstract Product):定义了产品的共同接口,具体的产品类必须实现这个接口。
477 | 具体产品(Concrete Product):实现了抽象产品接口,是抽象工厂模式中具体创建的对象。
478 | ```c++
479 | // 抽象产品 A
480 | class AbstractProductA {
481 | public:
482 | virtual void operationA() = 0;
483 | };
484 | // 具体产品 A1
485 | class ConcreteProductA1 : public AbstractProductA {
486 | public:
487 | void operationA() override {
488 | // 具体产品 A1 的操作实现
489 | }
490 | };
491 | // 具体产品 A2
492 | class ConcreteProductA2 : public AbstractProductA {
493 | public:
494 | void operationA() override {
495 | // 具体产品 A2 的操作实现
496 | }
497 | };
498 | // 抽象产品 B
499 | class AbstractProductB {
500 | public:
501 | virtual void operationB() = 0;
502 | };
503 | // 具体产品 B1
504 | class ConcreteProductB1 : public AbstractProductB {
505 | public:
506 | void operationB() override {
507 | // 具体产品 B1 的操作实现
508 | }
509 | };
510 | // 具体产品 B2
511 | class ConcreteProductB2 : public AbstractProductB {
512 | public:
513 | void operationB() override {
514 | // 具体产品 B2 的操作实现
515 | }
516 | };
517 | // 抽象工厂
518 | class AbstractFactory {
519 | public:
520 | virtual AbstractProductA* createProductA() = 0;
521 | virtual AbstractProductB* createProductB() = 0;
522 | };
523 | // 具体工厂 1
524 | class ConcreteFactory1 : public AbstractFactory {
525 | public:
526 | AbstractProductA* createProductA() override {
527 | return new ConcreteProductA1();
528 | }
529 | AbstractProductB* createProductB() override {
530 | return new ConcreteProductB1();
531 | }
532 | };
533 | // 具体工厂 2
534 | class ConcreteFactory2 : public AbstractFactory {
535 | public:
536 | AbstractProductA* createProductA() override {
537 | return new ConcreteProductA2();
538 | }
539 | AbstractProductB* createProductB() override {
540 | return new ConcreteProductB2();
541 | }
542 | };
543 | ```
544 | 客户端
545 | ```c++
546 | int main() {
547 | AbstractFactory* factory1 = new ConcreteFactory1();
548 | AbstractProductA* productA1 = factory1->createProductA();
549 | AbstractProductB* productB1 = factory1->createProductB();
550 | productA1->operationA(); // 调用具体产品 A1 的操作
551 | productB1->operationB(); // 调用具体产品 B1 的操作
552 | delete factory1;
553 | delete productA1;
554 | delete productB1;
555 | AbstractFactory* factory2 = new ConcreteFactory2();
556 | AbstractProductA* productA2 = factory2->createProductA();
557 | AbstractProductB* productB2 = factory2->createProductB();
558 | productA2->operationA(); // 调用具体产品 A2 的操作
559 | productB2->operationB(); // 调用具体产品 B2 的操作
560 | delete factory2;
561 | delete productA2;
562 | delete productB2;
563 | return 0;
564 | }
565 | ```
566 |
567 |
568 | # MVC模式
569 |
570 | MVC 模式的目的是实现一种动态的程序设计,简化后续对程序的修改和扩展,并且使程序某一部分的重复利用成为可能。除此之外,MVC 模式通过对复杂度的简化,使程序的结构更加直观。软件系统在分离了自身的基本部分的同时,也赋予了各个基本部分应有的功能。专业人员可以通过自身的专长进行相关的分组:
571 |
572 | 软件系统分为三个基本部分:模型(Model)、视图(View)和控制器(Controller)。
573 |
574 | - 模型(Model):程序员编写程序应有的功能(实现算法等)、数据库专家进行数据管理和数据库设计(可以实现具体的功能);
575 | - 控制器(Controller):负责转发请求,对请求进行处理;
576 | - 视图(View):界面设计人员进行图形界面设计。
577 |
578 | ## MVC模式的优点
579 |
580 | **低耦合**
581 |
582 | 通过将视图层和业务层分离,允许更改视图层代码而不必重新编译模型和控制器代码,同样,一个应用的业务流程或者业务规则的改变,只需要改动 MVC 的模型层(及控制器)即可。因为模型与控制器和视图相分离,所以很容易改变应用程序的数据层和业务规则。
583 |
584 | 模型层是自包含的,并且与控制器和视图层相分离,所以很容易改变应用程序的数据层和业务规则。如果想把数据库从 MySQL 移植到 Oracle,或者改变基于 RDBMS 的数据源到 LDAP,只需改变模型层即可。一旦正确的实现了模型层,不管数据来自数据库或是 LDAP 服务器,视图层都将会正确的显示它们。由于运用 MVC 的应用程序的三个部件是相互独立,改变其中一个部件并不会影响其它两个,所以依据这种设计思想能构造出良好的松耦合的构件。
585 |
586 | **重用性高**
587 |
588 | 随着技术的不断进步,当前需要使用越来越多的方式来访问应用程序了。MVC 模式允许使用各种不同样式的视图来访问同一个服务端的代码,这得益于多个视图(如 WEB(HTTP)浏览器或者无线浏览器(WAP))能共享一个模型。
589 |
590 | 比如,用户可以通过电脑或通过手机来订购某样产品,虽然订购的方式不一样,但处理订购产品的方式(流程)是一样的。由于模型返回的数据没有进行格式化,所以同样的构件能被不同的界面(视图)使用。例如,很多数据可能用 HTML 来表示,但是也有可能用 WAP 来表示,而这些表示的变化所需要的是仅仅是改变视图层的实现方式,而控制层和模型层无需做任何改变。
591 |
592 | 由于已经将数据和业务规则从表示层分开,所以可以最大化的进行代码重用了。另外,模型层也有状态管理和数据持久性处理的功能,所以,基于会话的购物车和电子商务过程,也能被 Flash 网站或者无线联网的应用程序所重用。
593 |
594 | **生命周期成本低**
595 |
596 | MVC 模式使开发和维护用户接口的技术含量降低。
597 |
598 | **部署快**
599 |
600 | 使用 MVC 模式进行软件开发,使得软件开发时间得到相当大的缩减,它使后台程序员集中精力于业务逻辑,界面(前端)程序员集中精力于表现形式上。
601 |
602 | **可维护性高**
603 |
604 | 分离视图层和业务逻辑层使得 WEB 应用更易于维护和修改。
605 |
606 | **有利软件工程化管理**
607 |
608 | 由于不同的组件(层)各司其职,每一层不同的应用会具有某些相同的特征,这样就有利于通过工程化、工具化的方式管理程序代码。控制器同时还提供了一个好处,就是可以使用控制器来联接不同的模型和视图,来实现用户的需求,这样控制器可以为构造应用程序提供强有力的手段。给定一些**可重用的**模型和视图,控制器可以根据用户的需求选择模型进行处理,然后选择视图将处理结果显示给用户。
609 |
--------------------------------------------------------------------------------
275 |
276 | **观察者模式中主要角色--2个接口,2个类**
277 |
278 | 1. 抽象主题(Subject)角色(接口):主题角色将所有对观察者对象的引用保存在一个集合中,每个主题可以有任意多个观察者。 抽象主题提供了增加和删除观察者对象的接口。
279 | 2. 抽象观察者(Observer)角色(接口):为所有的具体观察者定义一个接口,在观察的主题发生改变时更新自己。
280 | 3. 具体主题(ConcreteSubject)角色(1个):存储相关状态到具体观察者对象,当具体主题的内部状态改变时,给所有登记过的观察者发出通知。具体主题角色通常用一个具体子类实现。
281 | 4. 具体观察者(ConcretedObserver)角色(多个):存储一个具体主题对象,存储相关状态,实现抽象观察者角色所要求的更新接口,以使得其自身状态和主题的状态保持一致。
282 |
283 | ```java
284 | //观察者
285 | interface Observer {
286 | public void update();
287 | }
288 | //被观察者
289 | abstract class Subject {
290 | private Vector obs = new Vector();
291 |
292 | public void addObserver(Observer obs){
293 | this.obs.add(obs);
294 | }
295 | public void delObserver(Observer obs){
296 | this.obs.remove(obs);
297 | }
298 | protected void notifyObserver(){
299 | for(Observer o: obs){
300 | o.update();
301 | }
302 | }
303 | public abstract void doSomething();
304 | }
305 | //具体被观察者
306 | class ConcreteObserver1 implements Observer {
307 | public void update() {
308 | System.out.println("观察者1收到信息,并进行处理");
309 | }
310 | }
311 | class ConcreteObserver2 implements Observer {
312 | public void update() {
313 | System.out.println("观察者2收到信息,并进行处理");
314 | }
315 | }
316 | //客户端
317 | public class Client {
318 | public static void main(String[] args){
319 | Subject sub = new ConcreteSubject();
320 | sub.addObserver(new ConcreteObserver1()); //添加观察者1
321 | sub.addObserver(new ConcreteObserver2()); //添加观察者2
322 | sub.doSomething();
323 | }
324 | }
325 | //输出
326 | 被观察者事件发生改变
327 | 观察者1收到信息,并进行处理
328 | 观察者2收到信息,并进行处理
329 | 可以看到当被观察者发生改变过后,观察者都收到了通知
330 | ```
331 |
332 | ## 优点
333 |
334 | - 观察者模式在被观察者和观察者之间建立一个抽象的耦合。被观察者角色所知道的只是一个具体观察者列表,每一个具体观察者都符合一个抽象观察者的接口。被观察者并不认识任何一个具体观察者,它只知道它们都有一个共同的接口。
335 | - 观察者模式支持广播通讯。被观察者会向所有的登记过的观察者发出通知
336 |
337 | ## 缺点
338 |
339 | - 当观察者对象很多的时候,通知的发布会产生很多时间,影响程序的效率。一个被观察者,多个观察者时,开发代码和调试会比较复杂,java中消息的通知是默认顺序执行的,若其中一个观察者卡壳,会影响到此观察者后面的观察者执行,影响整体的执行, 多级触发时的效率更让人担忧。
340 | - 虽然观察者模式可以随时使观察者知道所观察的对象发生了变化,但是观察者模式没有相应的机制使观察者知道所观察的对象是怎么发生变化的。
341 | - 如果在被观察者之间有循环依赖的话,被观察者会触发它们之间进行循环调用,导致系统崩溃。在使用观察者模式是要特别注意这一点。
342 |
343 | # 工厂模式
344 | https://blog.csdn.net/qq_55882840/article/details/139043332
345 |
346 | ## 1.工厂模式简介
347 | 工厂模式的三种类型:
348 | - 简单工厂模式
349 | - 工厂方法模式
350 | - 抽象工厂模式
351 | 工厂模式的作用是生产对象,可以简化代码、提高可维护性,并旦可以通过工厂类生产多种对象。简单工厂模式适用于创建简单的对象,工厂模式适用于创建复杂的对象,而抽象工厂模式适用于创建更复杂的对象。
352 |
353 | ## 2. 简单工厂模式
354 | 简单工厂模式是一种创建型设计模式,旨在通过一个工厂方法来创建对象,而无需直接暴露对象的实例化逻辑。简单工厂模式通常包括一个工厂类和多个产品类。工厂类负责根据客户端的请求,返回对应的产品类实例。就是用户申请一个产品,由工厂负责创建对象。而不是用户自己创建对象。在简单工厂模式中,客户端只需要通过调用工厂类的方法,并传入相应的参数,而无需直接实例化产品类。工厂类根据客户端传入的参数决定创建哪个产品类的实例,并将实例返回给客户端。
355 |
356 | ### 优点:
357 | 封装了实例化的细节,使得客户端与具体产品类解耦,增强了灵活性和可维护性。客户端只需要知道需要什么类型的产品,而无需关心具体的实现细节。同时,如果需要新增产品类时,只需修改工厂类即可,不需要修改客户端代码。
358 | ### 缺点:
359 | 简单工厂模式也有一些限制。例如,当需要创建多种类型的产品实例时,工厂类的代码可能会变得复杂,并且随着产品类型的增加,工厂类的责任也会越来越大。因此,在一些复杂的场景下,可能需要使用其他更灵活的创建型设计模式,如工厂方法模式或抽象工厂模式。总的来说,简单工厂模式提供了一种简单而灵活的方式来创建对象,对于一些简单的对象创建场景是很有用的。
360 |
361 | 简单工厂模式
362 | ```c++
363 | class Product {
364 | public:
365 | virtual void operation() = 0;
366 | };
367 | class ConcreteProductA : public Product {
368 | public:
369 | void operation() override {
370 | // 具体产品A的操作实现
371 | }
372 | };
373 | class ConcreteProductB : public Product {
374 | public:
375 | void operation() override {
376 | // 具体产品B的操作实现
377 | }
378 | };
379 | ```
380 | 简单工厂类
381 | ```c++
382 | class SimpleFactory {
383 | public:
384 | static Product* createProduct(const std::string& type) {
385 | if (type == "A") {
386 | return new ConcreteProductA();
387 | } else if (type == "B") {
388 | return new ConcreteProductB();
389 | } else {
390 | return nullptr; // 可以添加默认处理逻辑或抛出异常
391 | }
392 | }
393 | };
394 | ```
395 | 客户端调用方式
396 | ```c++
397 | int main() {
398 | Product* productA = SimpleFactory::createProduct("A");
399 | productA->operation(); // 调用具体产品A的操作
400 | Product* productB = SimpleFactory::createProduct("B");
401 | productB->operation(); // 调用具体产品B的操作
402 | delete productA;
403 | delete productB;
404 | return 0;
405 | }
406 | ```
407 |
408 | ## 3. 工厂方法模式
409 | 工厂方法模式(Factory Method Pattern)是一种创建型设计模式,它定义了一个用于创建对象的接口,但将具体的对象创建过程交给子类来实现。工厂方法模式通过让子类决定实例化哪个具体类来实现对象的创建,从而实现了将对象的创建和使用解耦的目的。
410 | 工厂方法模式一般包括以下角色:
411 | 抽象产品(Product):定义了产品的共同接口,具体的产品类必须实现这个接口。
412 | 具体产品(ConcreteProduct):实现了抽象产品接口,是工厂方法模式中具体创建的对象。
413 | 抽象工厂(Factory):定义了一个工厂的接口,包含一个创建产品的抽象方法,具体的工厂类必须实现这个接口。
414 | 具体工厂(ConcreteFactory):实现了抽象工厂接口,负责实例化具体的产品对象。
415 | 工厂方法模式的关键在于通过抽象工厂和具体工厂的组合,将对象的创建过程推迟到子类中实现。客户端通过使用抽象工厂来创建产品对象,而无需关心具体的产品类和实例化细节。
416 | ```c++
417 | // 抽象产品
418 | class Product {
419 | public:
420 | virtual void operation() = 0;
421 | };
422 | // 具体产品 A
423 | class ConcreteProductA : public Product {
424 | public:
425 | void operation() override {
426 | // 具体产品 A 的操作实现
427 | }
428 | };
429 | // 具体产品 B
430 | class ConcreteProductB : public Product {
431 | public:
432 | void operation() override {
433 | // 具体产品 B 的操作实现
434 | }
435 | };
436 | // 抽象工厂
437 | class Factory {
438 | public:
439 | virtual Product* createProduct() = 0;
440 | };
441 | // 具体工厂 A
442 | class ConcreteFactoryA : public Factory {
443 | public:
444 | Product* createProduct() override {
445 | return new ConcreteProductA();
446 | }
447 | };
448 | // 具体工厂 B
449 | class ConcreteFactoryB : public Factory {
450 | public:
451 | Product* createProduct() override {
452 | return new ConcreteProductB();
453 | }
454 | };
455 | ```
456 | ```c++
457 | int main() {
458 | Factory* factoryA = new ConcreteFactoryA();
459 | Product* productA = factoryA->createProduct();
460 | productA->operation(); // 调用具体产品 A 的操作
461 | Factory* factoryB = new ConcreteFactoryB();
462 | Product* productB = factoryB->createProduct();
463 | productB->operation(); // 调用具体产品 B 的操作
464 | delete factoryA;
465 | delete productA;
466 | delete factoryB;
467 | delete productB;
468 | return 0;
469 | }
470 | ```
471 | ### 4. 抽象工厂模式
472 | 抽象工厂模式(Abstract Factory Pattern)是一种创建型设计模式,它提供了一个接口,用于创建一系列相关或相互依赖的对象,而无需指定具体的类。抽象工厂模式通过将对象的创建和使用解耦,使得客户端代码与具体类的实现分离,从而实现了对象的变化和替换的灵活性。抽象工厂模式一般包括以下角色:
473 |
474 | 抽象工厂(Abstract Factory):定义了创建一系列产品对象的接口,通常包含多个创建产品的抽象方法。
475 | 具体工厂(Concrete Factory):实现了抽象工厂接口,负责创建具体的产品对象。
476 | 抽象产品(Abstract Product):定义了产品的共同接口,具体的产品类必须实现这个接口。
477 | 具体产品(Concrete Product):实现了抽象产品接口,是抽象工厂模式中具体创建的对象。
478 | ```c++
479 | // 抽象产品 A
480 | class AbstractProductA {
481 | public:
482 | virtual void operationA() = 0;
483 | };
484 | // 具体产品 A1
485 | class ConcreteProductA1 : public AbstractProductA {
486 | public:
487 | void operationA() override {
488 | // 具体产品 A1 的操作实现
489 | }
490 | };
491 | // 具体产品 A2
492 | class ConcreteProductA2 : public AbstractProductA {
493 | public:
494 | void operationA() override {
495 | // 具体产品 A2 的操作实现
496 | }
497 | };
498 | // 抽象产品 B
499 | class AbstractProductB {
500 | public:
501 | virtual void operationB() = 0;
502 | };
503 | // 具体产品 B1
504 | class ConcreteProductB1 : public AbstractProductB {
505 | public:
506 | void operationB() override {
507 | // 具体产品 B1 的操作实现
508 | }
509 | };
510 | // 具体产品 B2
511 | class ConcreteProductB2 : public AbstractProductB {
512 | public:
513 | void operationB() override {
514 | // 具体产品 B2 的操作实现
515 | }
516 | };
517 | // 抽象工厂
518 | class AbstractFactory {
519 | public:
520 | virtual AbstractProductA* createProductA() = 0;
521 | virtual AbstractProductB* createProductB() = 0;
522 | };
523 | // 具体工厂 1
524 | class ConcreteFactory1 : public AbstractFactory {
525 | public:
526 | AbstractProductA* createProductA() override {
527 | return new ConcreteProductA1();
528 | }
529 | AbstractProductB* createProductB() override {
530 | return new ConcreteProductB1();
531 | }
532 | };
533 | // 具体工厂 2
534 | class ConcreteFactory2 : public AbstractFactory {
535 | public:
536 | AbstractProductA* createProductA() override {
537 | return new ConcreteProductA2();
538 | }
539 | AbstractProductB* createProductB() override {
540 | return new ConcreteProductB2();
541 | }
542 | };
543 | ```
544 | 客户端
545 | ```c++
546 | int main() {
547 | AbstractFactory* factory1 = new ConcreteFactory1();
548 | AbstractProductA* productA1 = factory1->createProductA();
549 | AbstractProductB* productB1 = factory1->createProductB();
550 | productA1->operationA(); // 调用具体产品 A1 的操作
551 | productB1->operationB(); // 调用具体产品 B1 的操作
552 | delete factory1;
553 | delete productA1;
554 | delete productB1;
555 | AbstractFactory* factory2 = new ConcreteFactory2();
556 | AbstractProductA* productA2 = factory2->createProductA();
557 | AbstractProductB* productB2 = factory2->createProductB();
558 | productA2->operationA(); // 调用具体产品 A2 的操作
559 | productB2->operationB(); // 调用具体产品 B2 的操作
560 | delete factory2;
561 | delete productA2;
562 | delete productB2;
563 | return 0;
564 | }
565 | ```
566 |
567 |
568 | # MVC模式
569 |
570 | MVC 模式的目的是实现一种动态的程序设计,简化后续对程序的修改和扩展,并且使程序某一部分的重复利用成为可能。除此之外,MVC 模式通过对复杂度的简化,使程序的结构更加直观。软件系统在分离了自身的基本部分的同时,也赋予了各个基本部分应有的功能。专业人员可以通过自身的专长进行相关的分组:
571 |
572 | 软件系统分为三个基本部分:模型(Model)、视图(View)和控制器(Controller)。
573 |
574 | - 模型(Model):程序员编写程序应有的功能(实现算法等)、数据库专家进行数据管理和数据库设计(可以实现具体的功能);
575 | - 控制器(Controller):负责转发请求,对请求进行处理;
576 | - 视图(View):界面设计人员进行图形界面设计。
577 |
578 | ## MVC模式的优点
579 |
580 | **低耦合**
581 |
582 | 通过将视图层和业务层分离,允许更改视图层代码而不必重新编译模型和控制器代码,同样,一个应用的业务流程或者业务规则的改变,只需要改动 MVC 的模型层(及控制器)即可。因为模型与控制器和视图相分离,所以很容易改变应用程序的数据层和业务规则。
583 |
584 | 模型层是自包含的,并且与控制器和视图层相分离,所以很容易改变应用程序的数据层和业务规则。如果想把数据库从 MySQL 移植到 Oracle,或者改变基于 RDBMS 的数据源到 LDAP,只需改变模型层即可。一旦正确的实现了模型层,不管数据来自数据库或是 LDAP 服务器,视图层都将会正确的显示它们。由于运用 MVC 的应用程序的三个部件是相互独立,改变其中一个部件并不会影响其它两个,所以依据这种设计思想能构造出良好的松耦合的构件。
585 |
586 | **重用性高**
587 |
588 | 随着技术的不断进步,当前需要使用越来越多的方式来访问应用程序了。MVC 模式允许使用各种不同样式的视图来访问同一个服务端的代码,这得益于多个视图(如 WEB(HTTP)浏览器或者无线浏览器(WAP))能共享一个模型。
589 |
590 | 比如,用户可以通过电脑或通过手机来订购某样产品,虽然订购的方式不一样,但处理订购产品的方式(流程)是一样的。由于模型返回的数据没有进行格式化,所以同样的构件能被不同的界面(视图)使用。例如,很多数据可能用 HTML 来表示,但是也有可能用 WAP 来表示,而这些表示的变化所需要的是仅仅是改变视图层的实现方式,而控制层和模型层无需做任何改变。
591 |
592 | 由于已经将数据和业务规则从表示层分开,所以可以最大化的进行代码重用了。另外,模型层也有状态管理和数据持久性处理的功能,所以,基于会话的购物车和电子商务过程,也能被 Flash 网站或者无线联网的应用程序所重用。
593 |
594 | **生命周期成本低**
595 |
596 | MVC 模式使开发和维护用户接口的技术含量降低。
597 |
598 | **部署快**
599 |
600 | 使用 MVC 模式进行软件开发,使得软件开发时间得到相当大的缩减,它使后台程序员集中精力于业务逻辑,界面(前端)程序员集中精力于表现形式上。
601 |
602 | **可维护性高**
603 |
604 | 分离视图层和业务逻辑层使得 WEB 应用更易于维护和修改。
605 |
606 | **有利软件工程化管理**
607 |
608 | 由于不同的组件(层)各司其职,每一层不同的应用会具有某些相同的特征,这样就有利于通过工程化、工具化的方式管理程序代码。控制器同时还提供了一个好处,就是可以使用控制器来联接不同的模型和视图,来实现用户的需求,这样控制器可以为构造应用程序提供强有力的手段。给定一些**可重用的**模型和视图,控制器可以根据用户的需求选择模型进行处理,然后选择视图将处理结果显示给用户。
609 |
--------------------------------------------------------------------------------