├── docs
├── java
│ ├── 基础面试题
│ │ ├── test.md
│ │ ├── kafka.md
│ │ ├── netty.md
│ │ ├── elasticSearch.md
│ │ ├── spring mvc.md
│ │ ├── tomcat.md
│ │ ├── springboot.md
│ │ ├── rabbitMQ.md
│ │ ├── zookeeper.md
│ │ ├── Nginx.md
│ │ └── springcloud.md
│ ├── Java工程师面试突击
│ │ ├── 第二季笔记.md
│ │ ├── 第三季笔记.md
│ │ └── 第一季笔记.md
│ ├── IO
│ │ └── java IO.md
│ ├── Basis
│ │ └── Java基础知识.md
│ ├── JavaFamily
│ │ └── 面试知识点总结.md
│ ├── Multithread
│ │ └── Java并发.md
│ └── collection
│ │ ├── 集合面试资料汇总.md
│ │ └── Java集合面试题.md
├── dataStructures-algorithms
│ ├── 一文搞定链表基础和链表面试题.md
│ ├── 高频算法题目总结.pdf
│ ├── 程序员代码面试指南-Java实现.md
│ ├── 剑指offer-Java实现版本.md
│ ├── 左神直通 BAT 算法实现.md
│ ├── 算法面试真题汇总.md
│ ├── 递归套路总结.md
│ └── 算法题目难点题目总结.md
├── database
│ └── 数据库优化.md
├── operating-system
│ ├── 后端程序员必备的Linux基础知识.md
│ ├── 操作系统、计算机网络相关知识.md
│ └── linux高频面试题.md
├── microservice
│ └── 微服务相关资料.md
├── project
│ ├── 腾讯项目总结.md
│ └── 秒杀项目总结.md
├── interview
│ ├── 自我介绍和项目介绍.md
│ └── 已投公司情况.md
├── interview-experience
│ └── 各大公司面经.md
└── network
│ ├── http面试问题全解析.md
│ ├── 计算机网络面试-TCP和UDP.md
│ ├── 计算机网络-其他相关面试问题.md
│ └── 计算机网络面试-http.md
├── CNAME
├── _config.yml
├── img.png
├── assets
├── wx.jpg
└── 程序员技术圈子.jpg
├── .gitignore
├── .vscode
└── settings.json
└── README.md
/docs/java/基础面试题/test.md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/CNAME:
--------------------------------------------------------------------------------
1 | github.ouyangsihai.cn
--------------------------------------------------------------------------------
/docs/java/Java工程师面试突击/第二季笔记.md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/_config.yml:
--------------------------------------------------------------------------------
1 | theme: jekyll-theme-cayman
--------------------------------------------------------------------------------
/docs/java/IO/java IO.md:
--------------------------------------------------------------------------------
1 | https://juejin.cn/post/6844904125700784136
--------------------------------------------------------------------------------
/docs/java/基础面试题/kafka.md:
--------------------------------------------------------------------------------
1 | https://juejin.cn/post/6844904025805029383
--------------------------------------------------------------------------------
/docs/java/基础面试题/netty.md:
--------------------------------------------------------------------------------
1 | https://juejin.cn/post/6844904000496599054
--------------------------------------------------------------------------------
/docs/java/Basis/Java基础知识.md:
--------------------------------------------------------------------------------
1 | https://juejin.cn/post/6844904127059738631
--------------------------------------------------------------------------------
/docs/java/JavaFamily/面试知识点总结.md:
--------------------------------------------------------------------------------
1 | https://github.com/AobingJava/JavaFamily
--------------------------------------------------------------------------------
/img.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hello-java-maker/JavaInterview/HEAD/img.png
--------------------------------------------------------------------------------
/docs/java/Java工程师面试突击/第三季笔记.md:
--------------------------------------------------------------------------------
1 | https://blog.csdn.net/u013073869/article/details/105271345
--------------------------------------------------------------------------------
/assets/wx.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hello-java-maker/JavaInterview/HEAD/assets/wx.jpg
--------------------------------------------------------------------------------
/assets/程序员技术圈子.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hello-java-maker/JavaInterview/HEAD/assets/程序员技术圈子.jpg
--------------------------------------------------------------------------------
/docs/dataStructures-algorithms/一文搞定链表基础和链表面试题.md:
--------------------------------------------------------------------------------
1 | ### 链表基础结构
2 |
3 | ### 链表的常见操作
4 |
5 | ### 链表常见面试题
6 |
7 |
--------------------------------------------------------------------------------
/docs/java/Multithread/Java并发.md:
--------------------------------------------------------------------------------
1 | 参考:https://juejin.cn/post/6844904063687983111
2 | 参考:https://www.cmsblogs.com/category/1391296887813967872
--------------------------------------------------------------------------------
/docs/database/数据库优化.md:
--------------------------------------------------------------------------------
1 | ## 数据库优化
2 |
3 | ### 为什么要做优化
4 |
5 |
6 | ### 从哪几个方面考虑优化
7 |
8 |
9 | ### MySQL语句优化
10 |
11 |
12 | ### 其他
--------------------------------------------------------------------------------
/docs/dataStructures-algorithms/高频算法题目总结.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hello-java-maker/JavaInterview/HEAD/docs/dataStructures-algorithms/高频算法题目总结.pdf
--------------------------------------------------------------------------------
/docs/dataStructures-algorithms/程序员代码面试指南-Java实现.md:
--------------------------------------------------------------------------------
1 | https://github.com/LyricYang/Internet-Recruiting-Algorithm-Problems/blob/master/CodeInterviewGuide/README.md
--------------------------------------------------------------------------------
/docs/dataStructures-algorithms/剑指offer-Java实现版本.md:
--------------------------------------------------------------------------------
1 | https://blog.csdn.net/weixin_43774841/article/details/112912070
2 | https://zhuanlan.zhihu.com/p/84481303
3 | https://zhuanlan.zhihu.com/p/84481166
--------------------------------------------------------------------------------
/docs/operating-system/后端程序员必备的Linux基础知识.md:
--------------------------------------------------------------------------------
1 | - [Linux使用大全](https://linuxtools-rst.readthedocs.io/zh_CN/latest/base/index.html)
2 |
3 | - [linux可以看的github](https://github.com/judasn/Linux-Tutorial)
--------------------------------------------------------------------------------
/docs/dataStructures-algorithms/左神直通 BAT 算法实现.md:
--------------------------------------------------------------------------------
1 | https://juejin.cn/post/6844903779289006094
2 | https://juejin.cn/post/6844903779289022478
3 | https://juejin.cn/post/6844903779289006093
4 | https://juejin.cn/post/6844903779289022471
--------------------------------------------------------------------------------
/docs/java/Java工程师面试突击/第一季笔记.md:
--------------------------------------------------------------------------------
1 | https://www.yuque.com/books/share/327d9543-85d2-418f-9315-41c3e19d2768/0dca325c876a0e85f0ba4ea48042e61d
2 | https://github.com/shishan100/Java-Interview-Advanced#%E5%88%86%E5%B8%83%E5%BC%8F%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97
--------------------------------------------------------------------------------
/docs/microservice/微服务相关资料.md:
--------------------------------------------------------------------------------
1 | ### springboot教程
2 |
3 | - [springboot学习教程](http://blog.didispace.com/Spring-Boot%E5%9F%BA%E7%A1%80%E6%95%99%E7%A8%8B/)
4 |
5 | ### springcloud教程
6 |
7 | - [springcloud学习教程](https://blog.csdn.net/hellozpc/article/details/83692496)
--------------------------------------------------------------------------------
/docs/java/collection/集合面试资料汇总.md:
--------------------------------------------------------------------------------
1 | ## Java 集合
2 |
3 | 参考:https://www.cmsblogs.com/article/1391291996752187392
4 | 参考:https://juejin.cn/post/6844904125939843079
5 |
6 | - ArrayList
7 |
8 | - LinkedList
9 |
10 | - HashMap
11 |
12 | - TreeMap
13 |
14 | - TreeSet
15 |
16 | - LinkedHashMap
17 |
18 | - ConcurrentHashMap
19 |
20 | - ArrayBlockingQueue
21 |
22 | - LinkedBlockingQueue
23 |
24 | - PriorityBlockingQueue
25 |
26 |
--------------------------------------------------------------------------------
/docs/operating-system/操作系统、计算机网络相关知识.md:
--------------------------------------------------------------------------------
1 | - https://github.com/CyC2018/CS-Notes
2 |
3 | #### Tip:本来有很多我准备的资料的,但是都是外链,或者不合适的分享方式,所以大家去公众号回复【资料】好了。
4 |
5 | 
6 |
7 | 现在免费送给大家,在我的公众号 **好好学java** 回复 **资料** 即可获取。
8 |
9 | 有收获?希望老铁们来个三连击,给更多的人看到这篇文章
10 |
11 | 1、老铁们,关注我的原创微信公众号「**好好学java**」,专注于Java、数据结构和算法、微服务、中间件等技术分享,保证你看完有所收获。
12 |
13 | 
14 |
15 | 2、给俺一个 **star** 呗,可以让更多的人看到这篇文章,顺便激励下我继续写作,嘻嘻。
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | _config.yml
2 | .gradle
3 | /build/
4 | /**/build/
5 |
6 | ### STS ###
7 | .apt_generated
8 | .classpath
9 | .factorypath
10 | .project
11 | .settings
12 | .springBeans
13 | .sts4-cache
14 | .vscode
15 |
16 | ### IntelliJ IDEA ###
17 | .idea
18 | *.iws
19 | *.iml
20 | *.ipr
21 | /out/
22 | /**/out/
23 | .shelf/
24 | .ideaDataSources/
25 | dataSources/
26 |
27 | ### NetBeans ###
28 | /nbproject/private/
29 | /nbbuild/
30 | /dist/
31 | /nbdist/
32 | /.nb-gradle/
33 | /node_modules/
34 |
35 | ### OS ###
36 | .DS_Store
37 |
--------------------------------------------------------------------------------
/.vscode/settings.json:
--------------------------------------------------------------------------------
1 | {
2 | "qiniu.access_key": "5zQ0AuES-7MGr7y89zIyMIK7JsNUlpTLggi5JtGu",
3 | "qiniu.bucket": "sihai",
4 | "qiniu.domain": "image.ouyangsihai.cn",
5 | "qiniu.enable": true,
6 | "qiniu.secret_key": "Mq3GKXAmESb4QGcv8mY8-lNWt42G0AFHpTKgl5Yh",
7 | "pasteImageToQiniu.access_key": "5zQ0AuES-7MGr7y89zIyMIK7JsNUlpTLggi5JtGu",
8 | "pasteImageToQiniu.bucket": "sihai",
9 | "pasteImageToQiniu.domain": "image.ouyangsihai.cn",
10 | "pasteImageToQiniu.secret_key": "Mq3GKXAmESb4QGcv8mY8-lNWt42G0AFHpTKgl5Yh"
11 | }
--------------------------------------------------------------------------------
/docs/project/腾讯项目总结.md:
--------------------------------------------------------------------------------
1 | # 面试查漏补缺
2 |
3 | - 面试前,查看该公司的面经
4 | - 逻辑表达慢一点,表达清楚
5 | - golang使用不够熟练
6 | - Mysql
7 | - mysql语句实战不够熟练
8 | - redis
9 | - kafka
10 | - kafka 的实现
11 | - 项目(actor-go)
12 | - 项目介绍
13 | - 介绍整个项目的情况
14 | - 介绍个人负责的模块
15 | - actor-sdk-go
16 | - actormodel
17 | - 项目重点、难点
18 | - 设计模式的应用和抽象,提升的架构设计和编码能力
19 | - DDD 的开发模式应用
20 | - 更加深入的理解了 DevOps 开发理念
21 | - DDD
22 | - 消息驱动模型
23 | https://cloud.tencent.com/developer/article/1656611?from=article.detail.1857333
24 | - 设计模式(工厂、模板、单例、回调)
25 | - 分布式项目介绍
26 | https://blog.csdn.net/fanrenxiang/article/details/85083243
27 |
--------------------------------------------------------------------------------
/docs/operating-system/linux高频面试题.md:
--------------------------------------------------------------------------------
1 | linux查找命令
2 |
3 | https://blog.51cto.com/whylinux/2043871
4 | 项目部署常见linux命令
5 |
6 | https://blog.csdn.net/u010938610/article/details/79625988
7 | 进程文件里有哪些信息
8 | sed 和 awk 的区别
9 |
10 | awk用法:https://www.cnblogs.com/isykw/p/6258781.html
11 |
12 | 其实sed和awk都是每次读入一行来处理的,区别是:sed 适合简单的文本替换和搜索;而awk除了自动给你分列之外,里面丰富的函数大大增强了awk的功能。数据统计,正则表达式搜索,逻辑处理,前后置脚本等。因此基本上sed能做的,awk可以全部完成并且做的更好。
13 |
14 | 作者:哩掉掉 链接:https://www.zhihu.com/question/297858714/answer/572046422
15 | linux查看进程并杀死的命令
16 |
17 | https://blog.csdn.net/qingmu0803/article/details/38271077
18 | 有一个文件被锁住,如何查看锁住它的线程?
19 | 如何查看一个文件第100行到150行的内容
20 |
21 | https://blog.csdn.net/zmx19951103/article/details/78575265
22 | 如何查看进程消耗的资源
23 |
24 | https://www.cnblogs.com/freeweb/p/5407105.html
25 | 如何查看每个进程下的线程?
26 |
27 | https://blog.csdn.net/inuyashaw/article/details/55095545
28 | linux 如何查找文件
29 |
30 | linux命令:https://juejin.im/post/5d3857eaf265da1bd04f2437
31 |
32 | select epoll等问题
33 | https://juejin.im/post/5b624f4d518825068302aee9#heading-13
--------------------------------------------------------------------------------
/docs/interview/自我介绍和项目介绍.md:
--------------------------------------------------------------------------------
1 | ### 自我介绍
2 |
3 | 面试官,您好,我叫XXX,我是XXX21届应届毕业生,在校的专业是计算机技术。
4 |
5 | 研究生加入实验室后,在研一这一年中,做了一个####项目,然后在去年的5月份到9月份,去了####实习了几个月,由于那里做的项目不是Java的,所以在简历中没有体现。
6 |
7 | 从大学开始学习计算机专业之后,对技术挺有热情的,喜欢记录自己学过的技术,分享技术,在CSDN博客平台,通过这几年的时间,陆陆续续写了400多篇博客了,同时也获得了CSDN博客专家的称号,博客访问量有150W了。
8 |
9 | 最后,我通过这几年的学习,对于计算机的基础知识掌握的还可以,对于计算机网络,Java相关的技术,数据库等方面有深入学习,我也特别想去贵公司,自己也特别适合这个岗位,谢谢您给我这个机会!
10 |
11 | ### 项目一介绍
12 |
13 | 这个项目项目基于SSM框架开发,采用前后端分离,主要为电厂开发一套人员管理及人事审批的OA系统,实现电厂人员管理、电源审批、栈道审批、工器具审批等功能。
14 |
15 | 在项目中除了用到了ssm技术之外,还有activiti工作流框架,数据库使用的是mysql,缓存框架使用的是redis,权限控制框架使用的是shiro。
16 |
17 | 在这个项目中我担任的角色是项目负责人,负责整个项目的管理工作,同时,我还负责了以下几块工作:
18 | 1、搭建项目环境
19 | 2、实现用户的单点登录系统SSO
20 | 3、项目的权限控制
21 | 4、开发电源管理和栈道管理模块
22 | 5、系统性能调优
23 |
24 |
25 | ### 项目二介绍
26 |
27 | 项目基于SSM框架开发的综合性电商网站,实现会员商城浏览下单、商家入驻商城出售商品、管理员后台管理商品、订单、搜索及会员等功能,同时,系统可以发起抢购活动功能。
28 |
29 | 在项目中用到的技术主要包括ssm框架,数据库用的是mysql,缓存用的是redis,消息队列用的是rocketMQ,微服务分布式项目用到了dubbo框架,对于处理分布式的一些问题,用到了zookeeper框架。
30 |
31 | 在这个项目中我主要责任是
32 | 1、搭建dubbo的分布式的项目(怎么分层)
33 | 2、利用redis提供缓存服务
34 | 3、利用RocketMQ消息队列做消息处理
35 | 4、对数据库性能进行调优
36 | 5、开发抢购活动功能模块(业务需求)
37 |
38 |
39 | 2019年5月–2019年9月,在中国空间技术研究院钱学森空间技术实验室实习,参加了脉冲星导航的项目开发工作。项目的背景是,现在深空探索的研究越来越热,这个项目就是研究及开发脉冲星导航的相关问题,而脉冲星导航的能够解决深空探索航天器的位置问题,这个就是项目的研究目标。
40 | 负责工作:
41 | 1、开发一个脉冲星导航仿真软件
42 | 2、实现相关算法对航天器上的部件精度进行控制
43 | 3、航天器相关的数据进行数据显示
44 | 4、近地卫星轨道5星编队仿真实现
45 | 个人收获:
46 | 通过这个项目的开发,学习到了许多以前没有接触到的航天知识,对于这方面的知识,个人有了很大的提高,同时,由于时间关系,开发的时间非常紧张,对于自己的有了很大的锻炼,不管是从抗压能力还是学习能力,都是得到了一定得锻炼的。
47 |
48 | #### Tip:本来有很多我准备的资料的,但是都是外链,或者不合适的分享方式,所以大家去公众号回复【资料】好了。
49 |
50 | 
51 |
52 | 现在免费送给大家,在我的公众号 **好好学java** 回复 **资料** 即可获取。
53 |
54 | 有收获?希望老铁们来个三连击,给更多的人看到这篇文章
55 |
56 | 1、老铁们,关注我的原创微信公众号「**好好学java**」,专注于Java、数据结构和算法、微服务、中间件等技术分享,保证你看完有所收获。
57 |
58 | 
59 |
60 | 2、给俺一个 **star** 呗,可以让更多的人看到这篇文章,顺便激励下我继续写作,嘻嘻。
61 |
62 |
63 |
--------------------------------------------------------------------------------
/docs/interview/已投公司情况.md:
--------------------------------------------------------------------------------
1 | |公司|官网链接|牛客链接|投递情况|
2 | |-----|-----|-----|-----|
3 | |美团| https://campus.meituan.com/resume-edit | | 二面 |
4 | |快手| https://zhaopin.kuaishou.cn/recruit/e/#/official/my-apply/ | https://www.nowcoder.com/discuss/405019?type=post&order=time&pos=&page=2 | hr面 1113903029@qq.com |
5 | |蘑菇街|http://job.mogujie.com/#/candidate/perfectInfo | | offer |
6 | |虎牙| | | 不匹配 |
7 | |远景|https://campus.envisioncn.com/ | | 笔试 |
8 | |阿里钉钉| https://campus.alibaba.com/myJobApply.htm?saveResume=yes&t=1584782560963 |https://www.nowcoder.com/discuss/368915?type=0&order=0&pos=25&page=3| 二面 |
9 | |阿里新零售| |https://www.nowcoder.com/discuss/374171?type=0&order=0&pos=35&page=1 https://www.nowcoder.com/discuss/372118?type=0&order=0&pos=80&page=2| |
10 | |深信服| |https://www.nowcoder.com/discuss/369399?type=0&order=0&pos=40&page=6| |
11 | |CVTE| |https://www.nowcoder.com/discuss/368463?type=0&order=0&pos=87&page=3| 已投 |
12 | |奇安信| |https://www.nowcoder.com/discuss/365961?type=0&order=0&pos=102&page=6| 已投 |
13 | |携程| http://recruitment.ctrip.com/#/leftIntern | https://www.nowcoder.com/discuss/378021?type=post&order=time&pos=&page=3 | encore2106@163.com |
14 | |小米| https://app.mokahr.com/m/candidate/applications/deliver-query/xiaomi | https://www.nowcoder.com/discuss/375898?type=0&order=0&pos=12&page=5 https://www.nowcoder.com/discuss/377763?type=7| 已投 |
15 | |拼多多| https://pinduoduo.zhiye.com/Portal/Apply/Index | https://www.nowcoder.com/discuss/393350?type=post&order=time&pos=&page=8 | 已投 |
16 | |腾讯| https://join.qq.com/center.php |https://www.nowcoder.com/discuss/377813?type=post&order=time&pos=&page=1| offer |
17 | |猿辅导| https://app.mokahr.com/m/candidate/applications/deliver-query/fenbi |https://www.nowcoder.com/discuss/375610?type=0&order=0&pos=95&page=2| 已投 |
18 | |斗鱼| https://app.mokahr.com/m/candidate/applications/deliver-query/douyu |https://www.nowcoder.com/discuss/375180?type=0&order=0&pos=158&page=1| 一面挂 |
19 | |淘宝技术部| |https://www.nowcoder.com/discuss/374655?type=0&order=0&pos=165&page=6| |
20 | |字节跳动| https://job.bytedance.com/user https://job.bytedance.com/referral/pc/position/application?lightning=1&token=MzsxNTg0MTU2NDIxMDIzOzY2ODgyMjg1NzI1Mjk3MjI4ODM7MA/profile/ |https://www.nowcoder.com/discuss/381888?type=post&order=time&pos=&page=2| 已投 |
21 | |陌陌| | 来自内推军 |已投|
22 | |网易| http://gzgame.campus.163.com/applyPosition.do?&lan=zh |https://www.nowcoder.com/discuss/373132?type=post&order=create&pos=&page=1 一姐| 已投|
23 | |百度| https://talent.baidu.com/external/baidu/index.html#/individualCenter |https://www.nowcoder.com/discuss/376515?type=post&order=time&pos=&page=1| 已投 |
24 | |京东| http://campus.jd.com/web/resume/resume_index?fxType=0 |https://www.nowcoder.com/discuss/372978?type=post&order=time&pos=&page=4| 二面挂 |
25 | |爱奇艺| | | |
26 | |科大讯飞| | | |
27 | |度小满| | https://www.nowcoder.com/discuss/387950?type=post&order=time&pos=&page=13 | 已投 |
--------------------------------------------------------------------------------
/docs/java/collection/Java集合面试题.md:
--------------------------------------------------------------------------------
1 | ### 集合面试题
2 |
3 | > ArrayList、LinkedList和Vector的区别和实现原理
4 |
5 | #### 数据结构实现
6 |
7 | ArrayList和Vector都是基于可改变大小的数据实现的,而LinkedList是基于双链表实现的。
8 |
9 | #### 增删改查效率对比
10 |
11 | ArrayList和Vector都是基于可改变大小的数据实现的,因此,从指定的位置检索对象时,或在集合的末尾插入对象、删除一个对象的时间都是O(1),但是如果在其他位置增加或者删除对象,花费的时间是O(n);
12 |
13 | 而LinkedList是基于双链表实现的,因此,在插入、删除集合中的任何位置上的对象,所花费的时间都是O(1),但基于链表的数据结构在查找元素时的效率是更低的,花费的时间为O(n)。
14 |
15 | 因此,从以上分析我们可以知道,查找特定的对象或者在集合末端增加或者删除对象,ArrayList和Vector的效率是ok的,如果在指定的位置删除或者插入,LinkedList的效率则更高。
16 |
17 | #### 线程安全
18 |
19 | ArrayList、LinkedList不具有线程安全性,在多线程的问题下是不能使用的,如果想要在多线程的环境下使用怎么办呢?我们可以采用Collections的静态方法synchronizedList包装一下,就可以保证线程安全了,但是在实际情况下,并不会使用这种方式,而是会采用更高级的集合进行线程安全的操作。
20 |
21 | Vector是线程安全的,其保证线程安全的机制是采用synchronized关键字,我们都知道,这个关键字的效率是不高的,在后续的很多版本中,线程安全的机制都不会采用这种方式,因此,Vector的效率是比ArrayList、LinkedList更低效的。
22 |
23 | #### 扩容机制
24 |
25 | ArrayList和Vector都是基于数据这种数据结构实现的,因此,在集合的容量满了时,是需要进行扩容操作的。
26 |
27 | 在扩容时,ArrayList扩容后的容量是原先的1.5倍,扩容后,再将原先的数组中的数据拷贝到新建的数组中。
28 |
29 | Vector默认情况下,扩容后的容量是原先的2倍,除此之外,Vector还有一种可以设置**容量增量**的机制,在Vector中有capacityIncrement变量用于控制扩容时的增量,具体的规则是:当capacityIncrement大于0时,扩容时增加的大小就是capacityIncrement的大小,如果capacityIncrement小于等于0时,则将容量增加为之前的2倍。
30 |
31 | > HashMap原理分析
32 |
33 | 在分析HashMap的原理之前,先说明一下,大家应该都知道HashMap在JDK1.7和1.8的实现上是有较大的区别的,而面试官也是非常喜欢考察这一个点,因此,这里也是采用这两个JDK版本对比来进行分析,这样也可以印象更加深刻一些。
34 |
35 | #### 数据结构
36 |
37 | 在数据结构的实现上,大家应该都知道,JDK1.7是数组+单链表的形式,而1.8采用的是数组+单链表+红黑树,具体的表现如下:
38 |
39 | |版本|数据结构|数组+链表的实现形式|红黑树实现形式|
40 | |-|-|-|-|
41 | |JDK1.8|数组+单链表+红黑树|Node|TreeNode|
42 | |JDK1.7|数组+单链表|Entry|-|
43 |
44 | 为了更好的让大家理解后续的讲解,这里先讲解一下HashMap中实现的一些重要参数。
45 |
46 | - 容量(capacity): HashMap中数组的长度
47 | - 容量范围:必须是 2 的幂
48 | - 初始容量 = 哈希表创建时的容量
49 | - 默认容量 = 16 = 1<<4 = 00001中的1向左移4位 = 10000 = 十进制的 2^4 = 16
50 | `static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;`
51 | - 最大容量 = 2的30次方
52 | `static final int MAXIMUM_CAPACITY = 1 << 30;`
53 |
54 | - 加载因子(Load factor):HashMap在其容量自动增加时,会设置加载因子,当达到设置的值时,就会触发自动扩容。
55 | - 加载因子越大、填满的元素越多,也就是说,空间利用率高、但冲突的机会加大、查找效率变低
56 | - 加载因子越小、填满的元素越少,也就是说,空间利用率小、冲突的机会减小、查找效率高
57 | // 实际加载因子
58 | `final float loadFactor;`
59 | // 默认加载因子 = 0.75
60 | `static final float DEFAULT_LOAD_FACTOR = 0.75f;`
61 |
62 | - 扩容阈值(threshold):当哈希表的大小 ≥ 扩容阈值时,就会扩容哈希表(即扩充HashMap的容量)。
63 | - 扩容 = 对哈希表进行resize操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数
64 | - 扩容阈值 = 容量 x 加载因子
65 |
66 | #### 获取数据(get)
67 |
68 | HashMap的获取数据的过程大致如下:
69 |
70 | - 首先,根据key判断是否为空值;
71 | - 如果为空,则到hashmap数组的第1个位置,寻找对应key为null的键;
72 | - 如果不为空,则根据key计算hash值;
73 | - 根据得到的hash值采用`hash & (length - 1)`的计算方式得到key在数组中的位置;
74 | - 结束。
75 |
76 | 以上就是大致的数据获取流程,接下来,我们再对JDK1.7和1.8获取数据的细节做一个对比。
77 |
78 | |版本|hash值的计算方式|
79 | |-|-|
80 | |JDK1.8|1、hash = (key == null) ? 0 : hash(key);
2、扰动处理 = 2次扰动 = 1次位运算+1次异或运算|
81 | |JDK1.7|1、hash = (key == null) ? 0 : hash(key);
2、扰动处理 = 9次扰动 = 4次位运算+5次异或运算|
82 |
83 | #### 保存数据(put)
84 |
85 | HashMap的保存数据的过程大致如下:
86 |
87 | - 判读HashMap是否初始化,如果没有则进行初始化;
88 | - 判断key是否为null,如果为null,则将key-value的数据存储在数组的第1个位置,这里与获取数据时对应的;否则,进行后续操作;
89 | - 根据key计算数据存放的位置;
90 | - 根据位置判断key是否存在,如果存在,则用新值替换旧值;如果不存在,则直接设置;
91 |
92 | 这里也对保存数据的过程进行一个更加细致的对比。
93 |
94 | |版本|hash值的计算方式|存放数据方式|插入数据方式|
95 | |-|-|-|-|
96 | |JDK1.8|1. hash = (key == null) ? 0 : hash(key);
2. 扰动处理 = 2次扰动 = 1次位运算+1次异或运算|数组+单链表+红黑树
- 无冲突,直接保存数据
- 冲突时,当链表长度小于8时,存放到单链表,当长度大于8时,存到到红黑树|尾插法|
97 | |JDK1.7|1、hash = (key == null) ? 0 : hash(key);
2、扰动处理 = 9次扰动 = 4次位运算+5次异或运算|数组+单链表
- 无冲突,直接保存数据
- 冲突时,存放到单链表|头插法|
98 |
99 | #### 扩容机制
100 |
101 | HashMap的扩容的过程大致如下:
102 |
103 | - 当发现容量不足时,开始扩容机制;
104 | - 首先,保存旧数组,再根据旧容量的2倍新建数组;
105 | - 遍历旧数组的每个元素,采用头插法的方式,将每个元素保存到新数组;
106 | - 将新数组引用到hashmap的table属性上;
107 | - 重新设置扩容阀值,完成扩容操作。
108 |
109 | 最后,也对扩容的过程进行一个更加细致的对比。
110 |
111 | |版本|扩容后的位置计算方式|数据转移方式|
112 | |-|-|-|
113 | |JDK1.8|扩容后的位置 = 原位置 or 原位置+旧容量|尾插法|
114 | |JDK1.7|扩容后的位置 = hashCode() -> 扰动处理 -> h & (length - 1)|头插法|
115 |
--------------------------------------------------------------------------------
/docs/dataStructures-algorithms/算法面试真题汇总.md:
--------------------------------------------------------------------------------
1 |
2 | #### 算法题
3 |
4 | 作者:office多多
5 | 链接:[https://www.nowcoder.com/discuss/374134?type=0&order=0&pos=67&page=1](https://www.nowcoder.com/discuss/374134?type=0&order=0&pos=67&page=1)
6 |
7 | 1. 写代码,类似高考成绩,一个表中有很多数据(无序的),给你一个成绩,查出在表中的排名
8 | 2. 找出这两个链表是否有相交的点
9 | 3. 判断链表有没有环,环起点在哪儿。
10 | 4. 手撕topk,时间复杂度是多少。
11 | 5. 写个算法,实现抢红包随机获取金额的过程[参考](https://blog.csdn.net/bjweimengshu/article/details/80045958)
12 | 6. 链表反转
13 | 7. 两数之和(leetcode第一题~、~)
14 | 8. 判断一个字符串是否为另一个字符串子串(暴力写的)
15 | 9. 股票最大利润
16 | 10. 实现单链表前后交叉排序:1,2,3,4,5,6 变成 1,4,2,5,3,6
17 | 11. 因式分解
18 | 12. 有序二叉树,一种遍历方法使之有序,中序遍历。
19 | 13. 非递归实现先序遍历
20 | 14. 找无序数组中第k个数(一开始说用堆实现、后来我又想着用快排的partation实现)
21 | 15. 算法题:从字符串S变到T,插入消耗2、删除消耗2、替换消耗3、求最小消耗
22 | 16. 算法题:两个栈实现一个队列(实现push、pop、count三个函数)(简单)
23 | 17. strcpy的实现
24 | 18. 给出两个链表,找出相同的链接。a->b->c->d->f、b1->a1->c1->d->f
25 | 19. 二叉树的遍历方式,手写先序遍历(参考代码:[https://www.cnblogs.com/anzhengyu/p/11083568.html](https://www.cnblogs.com/anzhengyu/p/11083568.html))
26 | 20. 两个字符串的最长公共子串(参考代码:[https://www.cnblogs.com/anzhengyu/p/11166708.html](https://www.cnblogs.com/anzhengyu/p/11166708.html))
27 | 21. 查找二叉树最大深度
28 | 22. 二叉树遍历
29 | 23. 写代码判断IP地址([https://blog.csdn.net/u014259820/article/details/78833196?utm_source=distribute.pc_relevant.none-task](https://blog.csdn.net/u014259820/article/details/78833196?utm_source=distribute.pc_relevant.none-task))
30 | 24. 在字符串中找出不重复字符的个数
31 | 25. 找出两个只出现一次的数字,其余的数字都出现了两次
32 | 26. 给n元钱,m个人,写个随机分钱的函数
33 | 27. 两个栈实现一个队列
34 | 28. 给个数组求连续子序列最大和
35 | 29. 写一个程序;给一个数组,a【2 -2 3 3 6 -9 7】输出a【2 -2 3 -9 3 6 7】输入正负数都有数组,输出数组正负交替出现,多的那一类都放在后面;
36 | 30. 给定一个数组 输出和为k的两个数的位置 a【2 7 3 5 11】k=9 输出 0 1 [https://leetcode-cn.com/problems/two-sum/solution/liang-shu-zhi-he-by-leetcode-2/](https://leetcode-cn.com/problems/two-sum/solution/liang-shu-zhi-he-by-leetcode-2/)
37 | 31. 算法题:实现两个String字符串寻找最大公共子字符串
38 | 32. 让写一个洗牌的函数,写完问我为啥那样写、再写一个打印牌的函数,问我洗完牌之后345不连在一起的概率 如何模拟一副扑克牌的洗牌过程
39 | 33. 查找字符串中重复的子串,并输出重复的次数 [https://blog.csdn.net/zouheliang/article/details/80649584](https://blog.csdn.net/zouheliang/article/details/80649584)
40 | 34. 判断是否为平衡二叉树
41 | 35. 找出一个字符串的最长不重复子串([https://www.cnblogs.com/linghu-java/p/9037262.html](https://www.cnblogs.com/linghu-java/p/9037262.html))
42 |
43 |
44 | #### 数组
45 |
46 | - 数组求并集(利用set集合的元素唯一性)
47 | - 一个数组中有正数和负数,找出来和最大的子数组
48 | - 16瓶水中有1瓶水有毒,小白鼠喝了有毒的水1个小时后会死,一个小白鼠可以喝多瓶水,一瓶水也可以被多个小白鼠喝,现在给1个小时时间,最少需要几只小白鼠能够判断出来14瓶水是无毒的?
49 | - 小白鼠问题。16瓶正常水,1瓶毒水,小白鼠喝下毒水后一小时死亡,只给一小时时间,最少用多少只小白鼠可以检测出14瓶正常水?
50 |
51 | #### 链表
52 |
53 | #### 二叉树
54 |
55 | #### 动态规划
56 |
57 | - 最长公共子序列
58 |
59 |
60 | dp[i][j]:表示子串A[0...i](数组长度为n)和子串B[0...j](数组长度为m)的最长公共子序列
61 |
62 | 当`A[i] == B[j]`时,`dp[i][j] = dp[i-1][j-1] + 1`;
63 |
64 | 否则,`dp[i][j] = max(dp[i-1][j], dp[i][j-1])`;
65 |
66 | 最优解为dp[n-1][m-1];
67 |
68 | JAVA代码实现:
69 |
70 | ```java
71 | import java.util.Scanner;
72 |
73 | public class Main {
74 | public static void main(String[] args) {
75 | Scanner scanner = new Scanner(System.in);
76 | while (scanner.hasNextLine()) {
77 | String str1 = scanner.nextLine().toLowerCase();
78 | String str2 = scanner.nextLine().toLowerCase();
79 | System.out.println(findLCS(str1, str1.length(), str2, str2.length()));
80 | }
81 | }
82 |
83 | public static int findLCS(String A, int n, String B, int m) {
84 | int[][] dp = new int[n + 1][m + 1];
85 | for (int i = 0; i <= n; i++) {
86 | for (int j = 0; j <= m; j++) {
87 | dp[i][j] = 0;
88 | }
89 | }
90 | for (int i = 1; i <= n; i++) {
91 | for (int j = 1; j <= m; j++) {
92 | if (A.charAt(i - 1) == B.charAt(j - 1)) {
93 | dp[i][j] = dp[i - 1][j - 1] + 1;
94 | } else {
95 | dp[i][j] = dp[i - 1][j] > dp[i][j - 1] ? dp[i - 1][j] : dp[i][j - 1];
96 | }
97 | }
98 | }
99 | return dp[n][m];
100 | }
101 | }
102 | ```
103 |
104 | - 最长回文子串
105 |
106 | https://blog.csdn.net/wolfGuiDao/article/details/104590791
107 |
108 | - 最长上升子序列
109 |
110 | https://blog.csdn.net/zangdaiyang1991/article/details/94555112
111 |
112 | - 最长上升子串
113 |
114 | https://blog.csdn.net/qq_41706331/article/details/90271543
115 |
116 | #### 递归
117 |
118 | - 不用循环找出最大值
119 |
120 |
121 |
122 | #### 数组
123 |
124 | #### 字符串
125 |
126 | #### Tip:本来有很多我准备的资料的,但是都是外链,或者不合适的分享方式,所以大家去公众号回复【资料】好了。
127 |
128 | 
129 |
130 | 现在免费送给大家,在我的公众号 **好好学java** 回复 **资料** 即可获取。
131 |
132 | 有收获?希望老铁们来个三连击,给更多的人看到这篇文章
133 |
134 | 1、老铁们,关注我的原创微信公众号「**好好学java**」,专注于Java、数据结构和算法、微服务、中间件等技术分享,保证你看完有所收获。
135 |
136 | 
137 |
138 | 2、给俺一个 **star** 呗,可以让更多的人看到这篇文章,顺便激励下我继续写作,嘻嘻。
--------------------------------------------------------------------------------
/docs/interview-experience/各大公司面经.md:
--------------------------------------------------------------------------------
1 | # 京东
2 |
3 | ### 京东一面
4 |
5 | 1、Java中的乐观锁悲观锁
6 |
7 | https://segmentfault.com/a/1190000016611415
8 |
9 | 2、单点登录
10 | 3、集合的问题
11 | 4、反转链表
12 | 5、二分查找
13 | 6、堆排序
14 | 7、JUC
15 | 8、Java中如何实现线程安全
16 | 9、ArrayList和linkedList区别
17 | 10、数组和链表区别
18 | 11、volitale
19 |
20 | ### 秋招一面
21 |
22 | 1、数据库死锁及解决方案
23 |
24 | https://blog.csdn.net/cbjcry/article/details/84920174
25 |
26 |
27 | 2、数据库分库分表后的分页查询及相关操作怎么解决
28 |
29 | https://crossoverjie.top/2019/07/24/framework-design/sharding-db-03/
30 | https://juejin.im/entry/6844903478171533320
31 | https://tech.meituan.com/2016/11/18/dianping-order-db-sharding.html
32 |
33 |
34 | ### 秋招二面
35 |
36 | 1、UML
37 | https://www.jianshu.com/p/28200121a33d
38 | 2、超时确认,快速重传原理,快速重传重传几次,3次
39 | https://blog.csdn.net/u010710458/article/details/79968648
40 | https://www.cnblogs.com/postw/p/9678454.html
41 | 3、singleThreadThreadPool相对于ThreadPoolExecutor的优势
42 | 4、可重复读机制
43 | https://www.pianshen.com/article/11361872925/
44 |
45 |
46 |
47 | # 阿里
48 |
49 | - [阿里社招四面(分布式)](https://www.nowcoder.com/discuss/349542)
50 |
51 | ### 笔试两道算法题
52 |
53 | - https://www.nowcoder.com/discuss/389676?type=post&order=time&pos=&page=1
54 | - https://www.nowcoder.com/discuss/394432?type=post&order=time&pos=&page=1
55 |
56 | ### 钉钉一面
57 |
58 | 1、final、finnaly
59 | 2、重写重载
60 | 3、jvm的fullGC排查问题
61 | 4、多线程ArrayBlockingQueue、LinkedBlockingQueue的源码分析,如果用100w数据进行插入,哪个更快(Array)
62 | 5、linux:如果查找一个文件中的一个指定的字符串出现的数量、如何查找被占用的端口、如何查看cpu的load(使用率)
63 | 6、数据库的一个表有name、id、gender、age字段,设置一个联合索引id、name、gender,查询100w的数据用name做where查询,会不会全表查询
64 | 7、git:git如何合并分支、git add、git commit、git push的区别。
65 | 8、maven:如何查找重复的jar包问题
66 | 9、单点登录如何做的,如果保证安全性
67 |
68 | **缺点**:linux实战的不懂
69 |
70 | ### 钉钉二面
71 |
72 | 1、项目有什么难点:应该不管是什么项目都是数据库优化跟JVM问题排查
73 | 2、操作系统内存交换方式
74 | 3、tcp7层模型
75 | 4、平时学习方法
76 | 5、自己博客写的好的进行介绍
77 |
78 | **缺点**:重点不突出、操作系统不清楚。
79 |
80 |
81 | # 腾讯
82 |
83 | ### pcg一面
84 |
85 | 1、接口设计原则
86 | 2、mvc设计原则,如何设计
87 | 3、微服务rpc调用接口如何设计
88 | 4、微服务接口调用出现问题,如何设计接口,使得更好定位bug
89 | 5、springboot、spring、springcloud的区别
90 | 6、数据库如何设计
91 | 7、数据量大的时候,数据库表应该怎么设计,怎么插入、怎么查询,提高效率,单表的数据量能支持多大
92 |
93 | 单表数据量1000W
94 |
95 | 8、**spring AOP**
96 | 9、spring的动态代理,区别,静态代理,动态代理,cglib
97 | 10、dubbo设计架构
98 | 11、**解耦合的设计模式有哪些?应用场景,却别是什么?** 观察者模式等
99 |
100 | - https://blog.csdn.net/liman65727/article/details/79762475
101 |
102 | 12、JVM垃圾回收的过程
103 | 13、多线程如何实现,区别,怎么设计多线程
104 | 14、多线程与多进程的应用场景,多进程的应用场景
105 | 15、list和set的区别,集合其他相关,时间复杂度等等
106 | 16、**tcp如何保证可靠性传输,滑动窗口**
107 |
108 | - https://blog.csdn.net/liuchenxia8/article/details/80428157
109 | - https://juejin.im/post/5c9f1dd651882567b4339bce
110 |
111 | 17、**linux的alias命令**
112 | 18、linux的递归查询文件
113 | 19、回文字符串,最长回文字符串
114 | 20、reverse方法时间复杂度
115 |
116 | ### pcg二面
117 |
118 | 1、tcp可靠性
119 | 2、项目
120 | 3、不包含重复的最长连续子串
121 |
122 | ### pcg三面
123 |
124 | 1、项目
125 | 2、长连接短连接,应用场景
126 | 3、不用循环查找最大值
127 |
128 | # 百度
129 |
130 |
131 |
132 | # 滴滴
133 |
134 |
135 |
136 | # 头条
137 |
138 | ### 一面
139 |
140 | 1、多线程调度原理
141 | https://zhuanlan.zhihu.com/p/58846439
142 | 2、select、poll、epoll
143 | 3、多线程原理与操作系统
144 | https://www.zhihu.com/question/25527028
145 | 4、redis的单线程模型:单核会有多线程切换吗
146 | https://blog.csdn.net/qq_27185561/article/details/82900426
147 | 5、算法、算法、算法、算法。
148 | 6、线程池用到的数据结构
149 | 7、最长上升子序列的个数
150 | 8、为什么myisam快:非聚集索引,B+树,为什么用B+树和B树的区别。为什么B+树IO次数少
151 | 9、MyISAM与InnoDB 的区别
152 | https://www.cnblogs.com/fwqblogs/p/6645274.html
153 | 10、事务隔离级别:可重复读会发生幻读吗?会
154 |
155 | ### 二面
156 |
157 | 1、hashmap解决冲突方法
158 | 2、hashmap扩容机制
159 | 3、jvm的jstack作用
160 | 4、最长不重复子串
161 | 5、https
162 |
163 |
164 |
165 |
166 |
167 |
168 |
169 |
170 | # 拼多多
171 |
172 |
173 |
174 | # 美团
175 |
176 | ### 一面
177 |
178 | 1、多线程相关(如何实现线程、**线程池的相关参数**)
179 | 2、hashmap和hashtable的区别,hashmap的getSize方法需要加锁吗
180 | 3、concurrenthashmap的put的过程
181 | 4、jvm内存模型、垃圾回收器
182 | 5、**哪些可以作为GCRoot**
183 | 6、**new一个对象的过程**
184 |
185 | https://www.cnblogs.com/JackPn/p/9386182.html
186 |
187 | 7、fullGC的原因,如何排查
188 | 8、cpu内存使用过高如何排查
189 | 9、spring的AOP
190 | 10、spring的IOC
191 | 11、redis的删除策略
192 | 12、redis如何实现数据一致性
193 | 13、dubbo的原理
194 | 14、dubbo如何实现远程调用
195 | 15、项目介绍
196 | 16、单点登录
197 | 17、数据库如何调优
198 | 18、联合索引abc,哪些情况会出现索引失效
199 | 19、分布式项目请求操作经历的过程
200 |
201 |
202 | ### 二面
203 |
204 | 1、场景题:4亿用户,访问10个商品,保证等概率,且每个用户每次显示同样的3个商品,不能用数据库,不能用文件保存,不能用redis等框架
205 |
206 | 思路:用concurrentHashMap,分段锁,然后用多台机器,再限流,保证数据一致性
207 |
208 | 2、项目介绍
209 |
210 |
211 | # 小米
212 |
213 |
214 |
215 | # 网易
216 |
217 |
218 |
219 | # 华为
220 |
221 |
222 | # 快手
223 |
224 | 1、项目
225 | 2、两数之和等于target
226 | 3、http介绍
227 | 4、输入网址的过程
228 | 5、dubbo原理
229 | 6、http和dubbo协议的区别
230 |
231 | **缺点**:写算法还不熟练
232 |
233 |
234 | #### Tip:本来有很多我准备的资料的,但是都是外链,或者不合适的分享方式,所以大家去公众号回复【资料】好了。
235 |
236 | 
237 |
238 | 现在免费送给大家,在我的公众号 **好好学java** 回复 **资料** 即可获取。
239 |
240 | 有收获?希望老铁们来个三连击,给更多的人看到这篇文章
241 |
242 | 1、老铁们,关注我的原创微信公众号「**好好学java**」,专注于Java、数据结构和算法、微服务、中间件等技术分享,保证你看完有所收获。
243 |
244 | 
245 |
246 | 2、给俺一个 **star** 呗,可以让更多的人看到这篇文章,顺便激励下我继续写作,嘻嘻。
--------------------------------------------------------------------------------
/docs/network/http面试问题全解析.md:
--------------------------------------------------------------------------------
1 | HTTP协议定义了浏览器怎么向万维网服务器请求万维网文档,以及服务器怎么样把文档传送给浏览器。
2 |
3 | 举个例子来说,**用户单击鼠标后发生的事件**按顺序如下(以访问清华大学为例):
4 |
5 | 1. **浏览器分析链接指向页面的URL。**
6 | 2. **浏览器向DNS请求解析www.tsinghua.edu.c的IP地址。**
7 | 3. **DNS解析出该IP地址。**
8 | 4. **浏览器与该服务器建立TCP链接**(默认port:80)。
9 | 5. **浏览器发出HTTP请求:GET/chn/index.htm**(HTTP请求通过TCP套接字,发送请求报文,该请求报文作为TCP三次握手第三个报文数据发送给服务器)。
10 | 6. **服务器通过HTTP响应把文件index.html发送给服务器。**
11 | 7. **TCP连接释放**(释放连接若connection若为close,服务端主动关闭,客户端被动关闭,若为keepalive,则该连接会保持一段事件,该时间内可以继续接收请求)。
12 | 8. **浏览器将文件进行解析,并将Web页面显示给用户**(先解析状态行,看状态码是否请求成功,然后解析每一个响应头,告知编码规范,对其进行格式化,有脚本还要加载脚本)。
13 |
14 | ### HTTP 状态码含义:
15 |
16 | * **200** OK 服务器已经成功处理了请求并提供了请求的网页。
17 | * **202** Accpted 已经接受请求,但处理尚未完成。
18 | * **204** No Content 没有新文档,浏览器应该继续显示原来的文档。
19 | * **206** Partial Content 客户端进行了范围请求。响应报文中由Content-Range指定实体内容的范围。实现断点续传
20 | * **301** Moved Permanently 永久性重定向。请求的网页已永久移动到新位置。
21 | * **302**(307) Moved Temporatily 临时性重定向。
22 | * **304** Not Moidfied 未修改。自上次请求后,请求的内容未修改过。
23 | * **401** Unauthorized 客户试图未经授权访问受密码保护的页面。该应答中会包含一个WWW-Authenticate头,浏览器由此显示login框,填写合适Authorization头以后再次发出请求。
24 | * **403** Forbidden 服务器拒绝请求。
25 | * **404** Not Found 服务器不存在客户机所请求的资源。
26 | * **500** Intern Server Error 服务器遇到一个错误,使其无法为请求提供服务。
27 |
28 | ### HTTP的请求方法
29 |
30 | * **GET** 向指定的资源发出显示请求,使用GET方法应该只用于在读取数据。
31 | * **HEAD** 与GET方法一样,都是向服务器发出指定资源的请求。只不过HEAD不包含有呈现数据,而仅仅是头部信息(关于该资源的信息)。
32 | * **PUT** 向指定资源位置上传最新位置(与POST相比,PUT指定了存放位置,而PSOT由服务器指定)。
33 | * **DELETE**请求服务器删除某一个资源
34 | * **POST** 向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。
35 | * **TRACE** 请求服务器回送收到的请求信息,主要用于测试和诊断。
36 | * **OPTIONS** 使服务器传回该资源所支持的所有HTTP请求方法。若请求成功,则会在HTTP头中包含一个名为“Allow”的头,值是支持的方法,如“GET,POST”。
37 |
38 | ### GET和POST的区别:
39 |
40 | * **对资源的影响**:GET一般用于获取或者查询资源信息,意味着对同一个URL的多个请求返回的结果一样(幂等),没有修改资源的状态(安全);而POST一般用于更新资源信息,POST既不是安全的也不是幂等的
41 | * **传递的信息量**:采用GET方法时,客户端把发送的数据添加到URL后面(即HTTP协议头中),使用“?”连接,各个变量用“&”连接,但是由于有些浏览器和服务器对URL的长度和字符格式存在限制,所以传递的信息有限;POST则把需要传递的数据放到请求报文的消息体中,HTTP协议对此没有限制,因此可以传递更多信息。
42 | * **安全性**:GET提交的数据,消息以明文出现在URL上,如密码等信息可能被浏览器缓存,从而从历史记录中得到;POST把消息存放在消息体中,安全性高,但是也存在被抓包软件抓取看到内容。
43 |
44 | ### cookie 和 session :
45 |
46 | HTTP协议是无状态:无状态是指协议对于事务处理没有记忆能力,简单来说,即使第一次和服务器连接后并且登陆成功后,第二次请求服务器依然不知道当前请求是哪个用户。为此,cookie和session的使用为此提供了解决方案。
47 |
48 | **cookie:**
49 |
50 | 以文件的形式存在硬盘中的永久性cookie(设置了一定的时限)和停留在浏览器内存中的临时性cookie,当用户访问网站时,浏览器就会在本地寻找相关cookie。如果该cookie存在,浏览器就会将其与页面请求一起通过报头信息发送到站点。
51 |
52 | **session:**
53 |
54 | session与cookie的作用有点类似,不同的时cookie存储在本地,而session存储在服务器。当程序需要为某个客户端的请求创建一个session的时候,服务器首先会检查这个客户端的请求里是否包含了一个session标识session-id,如果已经包含一个session-id则为此客户端创建过session,服务器就按照session-id把这个session检索出来,如果不包含,就创建一个新的键值对,并把session-id返回客户端保存。
55 |
56 | 浏览器提供了三种方式来保存ssesion-id:
57 |
58 | * cookie
59 | * url重写(把session-id附加在url后面,即使用GET)
60 | * 增加隐藏域(使用POST)
61 |
62 | session什么时候被创建?事实上session并不是在有客户端访问的时候被创建,而是知道某sever端程序调用类似function getSession()方法时才会创建。
63 |
64 | ### HTTP请求报文结构和响应报文结构
65 |
66 | **HTTP请求报文结构如下:**
67 |
68 | 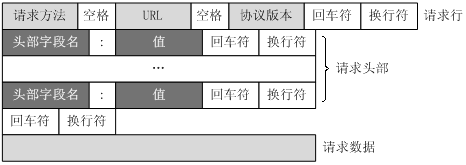
69 |
70 | * 请求行:
71 | * 请求头:为请求报文添加了一些附加信息,如 Host(接受请求的服务器地址 ip;port 或者 域名 等) / User-Agent / Connection(连接属性,如Keep-Alive) / Accept-Charset / Accpet-Encoding / Accept-Language
72 | * 空行:请求头的最后一行会有一个空行,表示请求头部结束,接下俩的请求为正文。
73 | * 请求正文:可选部分,如GET就没有请求正文
74 |
75 | 一个报文实体例子如下:
76 |
77 | ```java
78 | GET /562f25980001b1b106000338.jpg HTTP/1.1
79 | Host img.mukewang.com
80 | User-Agent Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36
81 | Accept image/webp,image/*,*/*;q=0.8
82 | Referer http://www.imooc.com/
83 | Accept-Encoding gzip, deflate, sdch
84 | Accept-Language zh-CN,zh;q=0.8
85 | ```
86 |
87 | HTTP响应报文
88 |
89 | 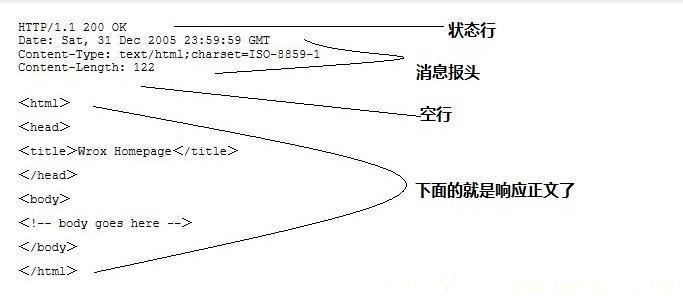
90 |
91 | * 状态行:协议版本,状态码等
92 | * 响应头:与请求头类似,为响应报文添加了一些附加信息。
93 | * 空行
94 | * 响应正文
95 |
96 | 一个报文实体例子如下:
97 |
98 | ```java
99 |
100 | HTTP/1.1 200 OK
101 | Server: nginx
102 | Date: Mon, 20 Feb 2017 09:13:59 GMT
103 | Content-Type: text/plain;charset=UTF-8
104 | Vary: Accept-Encoding
105 | Cache-Control: no-store
106 | Pragrma: no-cache
107 | Expires: Thu, 01 Jan 1970 00:00:00 GMT
108 | Cache-Control: no-cache
109 | Content-Encoding: gzip
110 | Transfer-Encoding: chunked
111 | Proxy-Connection: Keep-alive
112 |
113 | {"code":200,"notice":0,"follow":0,"forward":0,"msg":0,"comment":0,"pushMsg":null,"friend":{"snsCount":0,"count":0,"celebrityCount":0},"lastPrivateMsg":null,"event":0,"newProgramCount":0,"createDJRadioCount":0,"newTheme":true}
114 | ```
115 |
116 | ### 参考文章:
117 |
118 | http详解
119 |
120 | [https://www.cnblogs.com/an-wen/p/11180076.html](https://www.cnblogs.com/an-wen/p/11180076.html)
121 |
122 | cookie和sessions
123 |
124 | [https://www.cnblogs.com/xxtalhr/p/9053906.html](https://www.cnblogs.com/xxtalhr/p/9053906.html)
125 |
126 | 关于HTTP协议
127 |
128 | [https://www.cnblogs.com/ranyonsue/p/5984001.html](https://www.cnblogs.com/ranyonsue/p/5984001.html)
129 |
130 |
131 | #### Tip:本来有很多我准备的资料的,但是都是外链,或者不合适的分享方式,所以大家去公众号回复【资料】好了。
132 |
133 | 
134 |
135 | 现在免费送给大家,在我的公众号 **好好学java** 回复 **资料** 即可获取。
136 |
137 | 有收获?希望老铁们来个三连击,给更多的人看到这篇文章
138 |
139 | 1、老铁们,关注我的原创微信公众号「**好好学java**」,专注于Java、数据结构和算法、微服务、中间件等技术分享,保证你看完有所收获。
140 |
141 | 
142 |
143 | 2、给俺一个 **star** 呗,可以让更多的人看到这篇文章,顺便激励下我继续写作,嘻嘻。
--------------------------------------------------------------------------------
/docs/network/计算机网络面试-TCP和UDP.md:
--------------------------------------------------------------------------------
1 | > OSI与TCP/IP的各层的结构,都有哪些协议呢?
2 |
3 | 哦,我好像知道,我说一下我的理解,这个主要有两种参考模型,一种是基于OSI的参考模型,可以分为7层,分别是:物理层、数据链路层、网络层、运输层、会话层、表示层和应用层;另一种是基于TCP、IP的参考模型,可以分为4层,分别是:网络接口层、网络层、运输层和应用层。
4 |
5 | 关于每一层的协议,我知道的还不少呢,我来说说我知道的吧。
6 |
7 | 应用层:RIP、FTP、DNS、Telnet、SMTP、HTTP、WWW
8 |
9 | 我知道的还不少吧,嘚瑟一下,让我一口气说完吧。
10 |
11 | 表示层:JPEG、MPEG、ASCII,MIDI
12 | 会话层:RPC、SQL
13 | 传输层:TCP、UDP、SPX
14 | 网络层:IP、ICMP、ARP、RARP、OSPF、IPX、RIP、IGMP
15 | 数据链路层:PPP、HDLC、VLAN、MAC
16 | 物理层:RJ45、IEEE802.3
17 |
18 | 你能解释一下RJ45吗?
19 |
20 | 嗯嗯嗯,你自己查一下吧。。。
21 |
22 | 
23 |
24 |
25 | > 你能说说三次握手和四次挥手吗?
26 |
27 | 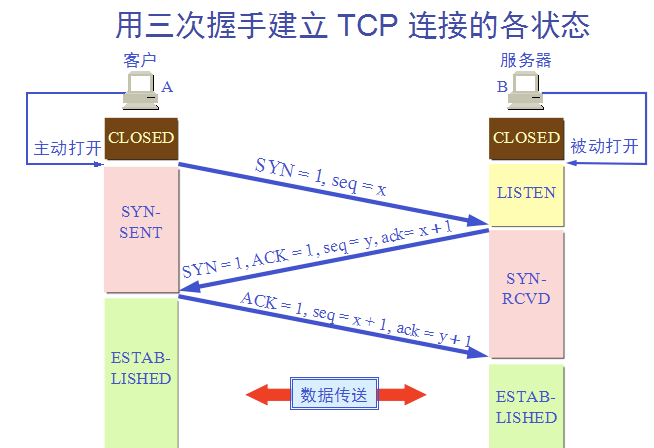
28 |
29 | 三次握手需要经过下面的过程状态:
30 | - LISTEN:表示服务器的某个Socket处于监听状态,可以接受连接了。
31 | - SYN_SENT:当客户端socket执行connet连接时,它首先发送一个SYN报文,紧接着进入SYN_SENT状态,并等待服务端发送三次握手中的第2个报文。
32 | - SYN_RCVD:这个状态表示收到了SYN报文,在正常状态服务端的socket在建立TCP连接时的三次握手会话中的一个中间状态,但是,需要注意的是netstat是很难看到这种状态。当客户端收到服务端的ACK后,服务端就进入到了ESTABLISHED状态了。
33 | - ESTABLISHED:表示已经建立连接了。
34 |
35 | 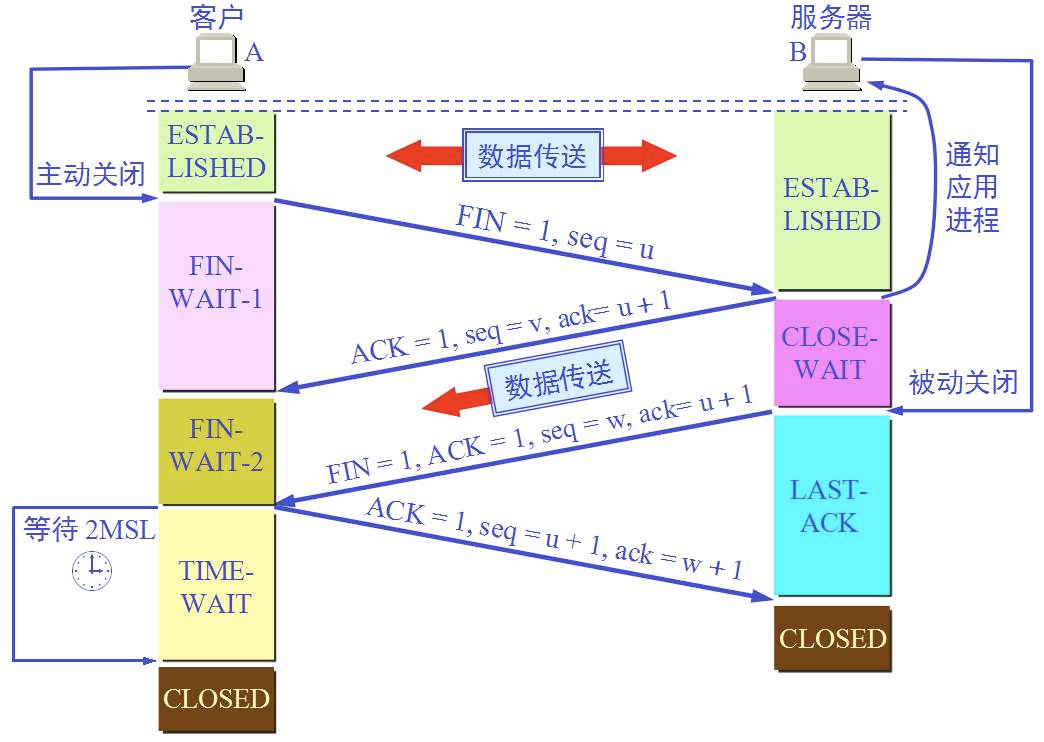
36 |
37 | 四次挥手过程状态:
38 | - FIN_WAIT_1:这个状态其实是在建立连接时,一方想要主动关闭连接,然后向对方发送FIN报文,然后自己进入到此状态;同时,当对方回应ACK后,自己就进入到FIN_WAIT_2状态,FIN_WAIT_1也是比较难以看到的。(主动方状态)
39 | - FIN_WAIT_2:这个状态是当主动要求关闭的一方要求关闭时,但暂时还有数据需要传输,稍后再关闭。(主动方状态)
40 | - TIME_WAIT:表示收到了对方的FIN报文,并发送出了ACK报文,等待2MSL后即可回到CLOSED可用状态了。(主动方状态)
41 | - CLOSE_WAIT:该状态表示在等待关闭,当对方发送FIN报文给自己时,你会发送一个ACK报文给对方,此时就进入到了CLOSE_WAIT状态。接下来,实际上你真正需要考虑的就是你是否还有数据发送给对方,如果此时没有了,那么你就可以close这个SOCKET了,发送FIN报文给对方,关闭连接。(被动方状态)
42 | - LAST_ACK:状态是指被动方发送FIN报文后,最后等待对方的ACK报文,收到后,就可以进入到CLOSED状态。(被动方状态)
43 | - CLOSED:表示连接中断。
44 |
45 | 结合上方的解释和两张图,就可以很好的理解三次握手和四次挥手的整个过程的,这个还是比较重要的,很多面试中都会考察,这也是计算机网络最基础的知识。
46 |
47 | > 在TIME_WAIT状态中,如果TCP客户端的最后一次发送的ACK丢失了,会发生什么?
48 |
49 | 如果丢失了,此时会触发重发机制,因为,在此状态下,等待的时间是依赖于实现方法的,一般可以为30s、1min和2min。等待结束后,就关闭连接了,并且所有的资源都会释放。
50 |
51 | > 为什么收到Server的确认之后,client还需要进行第三次握手?
52 |
53 | 可能由于网络连接延时,已经失效的连接到达服务端,这时服务端以为是客户端的请求,所以发送ack到客户端,�然后等待�客户端的数据传输过来,然而,此时,客户端并没有想要进行连接(因为此时客户端没有发出连接),因此,如果不采用三次握手,进行客户端确认,服务端就会一直等待客户端,导致服务端的资源白白浪费。
54 |
55 | > 为什么要采用四次挥手
56 |
57 | 确保数据能够完全传输。
58 | 挥手的过程是:主机1发送Fin,表示我没有数据要发送了,然后,主机2发送ACK进行确认,但是,这个时候,主机2还是可以发送数据给主机1的,不能就�关闭连接,所以,只有当主机2也发送了Fin之后,才可以进行关闭。
59 |
60 | > time _wait状态产生的原因
61 |
62 | - 可靠的实现tcp全双工连接的终止:考虑网络是不可靠的,当客户端发送ACK服务端一定收到了,如果没有收到,可以重发,如果客户端在time-wait状态等待2MSL时长,还没有收到服务的的FIN,就可以关闭自己的连接了。
63 | - 允许老的重复连接在网络中消逝:网络中可能存在已经失效的连接,time-wait可以使得本连接持续的时间内产生的所有的连接都在网络中消逝,不会出现旧的连接了。
64 |
65 | > time-wait过多的危害
66 |
67 | 本地端口数量有限,如果有大量的time-wait,会发现本地用于新建连接的端口缺乏,本地很难再建立新的对外连接。
68 |
69 | > 如何消除大量TCP短连接引发的time—wait
70 |
71 | - 改为长连接
72 | - 增大可用端口
73 |
74 | > 当关闭连接时,最后一个ACK丢失怎么办
75 |
76 | 如果在time-wait状态下,最后一个ACK丢失,由于有两个MSL时长等待,所有,会有新的FIN从服务端发送过来,这时,客户端会重新发送ACK。
77 | 如果在closed状态下,客户端收不到服务端重传的FIN,客户端也不会重传ACK,那么服务端就永远无法关闭链接。
78 |
79 | > TCP如何保证可靠传输
80 |
81 | - 在传递数据之前,会有**三次握手**来建立连接
82 | - TCP会将数据分割为最合适发送的数据块,也就是分割为合理的长度
83 | - TCP发出一个段后,会启动定时器,等待目的端确认,如果不能收到确认,就会重发,这也就是**超时重发机制**
84 | - 当TCP收到另一端的数据时,会向对方发送一个确认,通常会延迟一点发送,这是因为需要对包的完整性进行验证
85 | - TCP将保持首部和数据的检验和。目的是为了保证数据在传输过程中的任何变化,如果收到的段的检验和由差错,TCP会丢弃这个报文段和不确认收到此报文段
86 | - TCP会对失序的数据进行数据重新排序,然后再交给应用层
87 | - TCP会丢去重复的数据
88 | - TCP会进行**流量控制**。TCP的连接每一方都有一个固定大小的缓冲空间,其只允许接收端只允许另一端发送接收端缓冲区能接纳的数据,这可以防止缓冲区溢出。需要注意的是:TCP使用的流量控制协议是可变大小的滑动窗口协议
89 | - TCP会进行拥塞控制,当网络拥塞时,会适当的减少数据的发送。
90 |
91 | > TCP建立连接之后,怎么保持连接?
92 |
93 | 目前保持连接的方式有两种技术实现,第一,采用TCP协议层实现的Keepalive机制,第二,由应用层实现的HeartBeat心跳包。
94 |
95 | **Keepalive机制**
96 | 该机制的原理是:TCP协议会向对方发一个keepalive探针包,对方收到包之后,正常会回复一个ACK,出现错误会回复一个RST,如果对方没有任何回复,服务器每隔一段时间再发送keepalive探针包,如果连续发送多个包之后都没有回复,则说明连接断开。
97 |
98 | **心跳包机制**
99 | 该机制原理是:客户端或者服务端会发送一个类似心跳一样每隔固定时间发送一次,客户端在一定时间内没有收到服务端的回应,则可认为服务端不可用,同上,如果服务端在一定时间内没有收到客户端发送的心跳包,则认为客户端掉线。
100 |
101 | > TCP三次握手有哪些漏洞?
102 |
103 | 一是,**DDOS攻击(分布式拒绝服务)**:利用攻击软件通过大量的机器同时对服务进行攻击,规模大,危害大。
104 |
105 | 目前有两种主流的DDOS攻击:**SYN Flood攻击**和**TCP全连接攻击**。
106 |
107 | > - SYN Flood攻击:利用tcp协议的缺陷,发送大量伪造的tcp连接请求,导致被攻击方资源耗尽。出现的原因是:在TCP三次握手过程中,假设用户发送了SYN报文后掉线,那么服务器在发出SYN+ACK是无法收到客户端的ACK报文,这时,服务端是会一直不断的重试并等待一段时间后丢弃这个未完成的连接的,如果有大量的伪造的攻击报文,发送到了服务端,服务端将为了维护一个非常大的半连接队列而消耗过多的CPU时间和内存,这就会导致服务器失去响应。
108 | > - TCP全连接攻击:这种攻击是为了绕过防火墙设计的,它能够绕过防火墙,导致服务器有大量的TCP连接,最终导致服务器拒绝服务。
109 |
110 | **解决SYN Flood攻击的方法**
111 |
112 | - 设置SYN timeout时间:SYN timeout时间是指服务端一直不断的重试并等待的这段时间。
113 | - 设置SYN cookie,判断是否连续收到某个ip的重复SYN报文,如果是,以后就丢弃这个ip地址的包
114 | - 设置SYN cache,先不分配系统资源,现用cache保存半开连接,直到收到正确的ACK在分配资源
115 | - 硬件防火墙
116 |
117 | **解决TCP全连接攻击的方法**
118 |
119 | - 限制SYN流量
120 | - 定期扫描缺陷
121 | - 在骨干节点设置防火墙
122 | - 有足够的机器可以承受攻击
123 | - 过滤不必要的服务和端口
124 |
125 | 二是,**Land攻击**,该攻击是利用了TCP三次握手时,通过向一个主机发送一个用于建立连接的TCP SYN报文而实现对目标主机的攻击,这种方式与正常的TCP SYN报文不同的是:Land攻击的报文源ip地址和目标ip地址是一样的,都是目标主机的ip地址。
126 |
127 | 由于目标IP地址和源IP地址是一样的,因此,ACK报文就发给了主机本身,如果大量的SYN报文进行发送,目标计算机也不能正常工作。
128 |
129 | > tcp如何实现流量控制和拥塞控制?
130 |
131 | 流量控制采用**滑动窗口机制**。
132 | 拥塞控制采用**拥塞避免方法**。
133 |
134 | >**滑动窗口原理**
135 | TCP是全双工通信,因此每一方的滑动窗口都包括了接收窗口+发送窗口,接收窗口负责处理自己接收到的数据,发送窗口负责处理自己要发送出去的数据。滑**动窗口的本质其实就是维护几个变量,通过这些变量将TCP处理的数据分为几类,同时在发送出一个报文、接收一个报文对这些变量做一定的处理维护**。
136 | (1)N是发送窗口的起始字节,也就是说:字节序号 < N的字节都已经发送出去且已经收到ack,确认无误了;
137 | (2)nextSeq就是下一次发送报文的首部Seq字段(Seq即b第一个字节的序号,这些这里不讲了),表示字节序号在 [N,nextSeq)区间的都已经使用过,发送出去了,但是还未收到ack确认;
138 | (3) N+size就是窗口的最后一个可用字节序号,size是发送窗口的大小,就是每次接收到的报文中的Win字段的值,Win字段其实就是对方接收窗口的大小。
139 | **如何让维护这几个值呢?**
140 | (1)每接收到一个一个报文要做如下事情:检查接收报文的ack,将N 置为 ack,即往前移到ack这个值;读取报文中的Win字段值,即对方的最新接收窗口大小,从而更新N+size的值。
141 | (2)每发送一个报文,就更改nextSeq的值,发送了多少个字节就把nextSeq往前移多少,但是不要超出N+size。
142 | 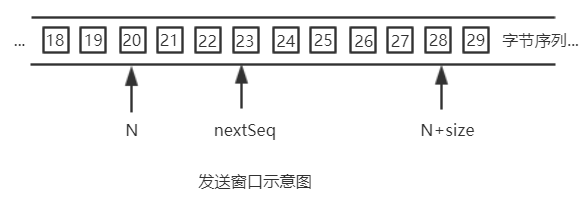
143 |
144 | **拥塞避免方法**
145 | 慢启动、拥塞避免、快重传和快恢复
146 |
147 | 
148 | 
149 |
150 | 以上是两张原理图,根据这两张原理图应该可以比较好理解,如果想要深入理解,可以参考这篇文章:https://www.cnblogs.com/a3192048/p/12241296.html。
151 |
152 | > 经典问题:TCP和UDP的区别?
153 |
154 | - TCP基于连接的协议,UDP是无连接的协议。
155 | - TCP可以保证数据发送的可靠性,UDP不可靠。
156 | - TCP可以重排序,UDP不可以。
157 | - TCP速度慢,UDP较快。
158 | - TCP是重量级协议,UDP是轻量级协议。
159 | - TCP有流量控制和拥塞控制机制,UDP没有。
160 | - TCP面向字节流的协议,UDP面向报文。
161 | - TCP只能单播,不能发送广播和组播,UDP可以。
162 |
163 | **TCP应用场景:** 效率要求不高,但需要数据的准确性,例如,文件传输、邮件传输、远程登录等等。
164 | **UDP应用场景:** 效率要求高,准确性要求不高,例如,微信视频,语音聊天等。
165 |
166 | > 为什么TCP比UDP安全,还有人用UDP、为什么UDP快?
167 |
168 | - UDP不需要建立连接.
169 | - UDP不需要维护连接的状态.
170 | - UDP头部开销小,只需要�8字节.
171 | - UDP没有拥塞控制,不会影响主机的发送频率,所以�速度上比tcp有优势.
172 |
173 |
--------------------------------------------------------------------------------
/docs/network/计算机网络-其他相关面试问题.md:
--------------------------------------------------------------------------------
1 |
2 | > 攻击网站的方法有哪些?
3 |
4 | **一是**,**DDOS攻击(分布式拒绝服务)**:利用攻击软件通过大量的机器同时对服务进行攻击,规模大,危害大。
5 |
6 | 目前有两种主流的DDOS攻击:**SYN Flood攻击**和**TCP全连接攻击**。
7 |
8 | > - SYN Flood攻击:利用tcp协议的缺陷,发送大量伪造的tcp连接请求,导致被攻击方资源耗尽。出现的原因是:在TCP三次握手过程中,假设用户发送了SYN报文后掉线,那么服务器在发出SYN+ACK是无法收到客户端的ACK报文,这时,服务端是会一直不断的重试并等待一段时间后丢弃这个未完成的连接的,如果有大量的伪造的攻击报文,发送到了服务端,服务端将为了维护一个非常大的半连接队列而消耗过多的CPU时间和内存,这就会导致服务器失去响应。
9 | > - TCP全连接攻击:这种攻击是为了绕过防火墙设计的,它能够绕过防火墙,导致服务器有大量的TCP连接,最终导致服务器拒绝服务。
10 |
11 | **解决SYN Flood攻击的方法**
12 |
13 | - 设置SYN timeout时间:SYN timeout时间是指服务端一直不断的重试并等待的这段时间。
14 | - 设置SYN cookie,判断是否连续收到某个ip的重复SYN报文,如果是,以后就丢弃这个ip地址的包
15 | - 设置SYN cache,先不分配系统资源,现用cache保存半开连接,直到收到正确的ACK在分配资源
16 | - 硬件防火墙
17 |
18 | **解决TCP全连接攻击的方法**
19 |
20 | - 限制SYN流量
21 | - 定期扫描缺陷
22 | - 在骨干节点设置防火墙
23 | - 有足够的机器可以承受攻击
24 | - 过滤不必要的服务和端口
25 |
26 | 另外,**Land攻击**,该攻击是利用了TCP三次握手时,通过向一个主机发送一个用于建立连接的TCP SYN报文而实现对目标主机的攻击,这种方式与正常的TCP SYN报文不同的是:Land攻击的报文源ip地址和目标ip地址是一样的,都是目标主机的ip地址。
27 |
28 | 由于目标IP地址和源IP地址是一样的,因此,ACK报文就发给了主机本身,如果大量的SYN报文进行发送,目标计算机也不能正常工作。
29 |
30 | **二是**,**XSS攻击(跨站脚本攻击)**,它是指恶意攻击者在web网页中插入恶意html代码,当用户浏览网页时,嵌入其中的html代码会执行,从而达到恶意攻击的目的。
31 |
32 | **三是**,**CSRF攻击(跨站请求伪造)**,攻击者盗用了你的身份,以你的名义发送恶意请求,一般是在你登录了A网站以后,携带A网站的信息,然后请求危险B网站,从而导致。
33 |
34 | 对于**CSRF攻击(跨站请求伪造)** 可以使用下列方法进行防御:
35 | - 用户关闭页面要及时清理cookie
36 | - 在url后面添加伪随机数
37 | - 图片验证码等
38 |
39 | **四是**,**SQL注入**,SQL注入是一种将SQL代码添加到输入参数中,传递到服务器解析并执行的一种攻击手法。
40 |
41 | **SQL注入攻击**是输入参数未经过滤,然后直接拼接到SQL语句当中解析,执行达到预想之外的一种行为,称之为SQL注入攻击。
42 |
43 | 常见的sql注入,有下列几种:
44 | - 数字注入
45 |
46 | 例如,查询的sql语句为:`SELECT * FROM user WHERE id = 1`,正常是没有问题的,如果我们进行sql注入,写成`SELECT * FROM user WHERE id = 1 or 1=1`,那么,这个语句永远都是成立的,这就有了问题,也就是sql注入。
47 |
48 | - 字符串注入
49 |
50 | 字符串注入是因为注释的原因,导致sql错误的被执行,例如字符`#`、`--`。
51 |
52 | 例如,`SELECT * FROM user WHERE username = 'sihai'#'ADN password = '123456'`,这个sql语句'#'后面都被注释掉了,相当于`SELECT * FROM user WHERE username = 'sihai' `。
53 |
54 | 这种情况我们在mybatis中也是会存在的,所以在服务端写sql时,需要特别注意此类情况。
55 |
56 | 该如何防范此类问题呢?
57 | - 严格检查输入变量的类型和格式,也就是对相关传入的参数进行验证,尽可能降低风险。
58 | - 过滤和转义特殊字符。
59 | - 利用mysql的预编译机制,在Java中mybatis也是有预编译的方法的,所以可以采用这种方式避免。
60 |
61 | > mybatis中的 # 与 $ 区别?
62 |
63 | 这个问题在面试中时常可能被问到,其实,面试官可能一想考考你对mybatis的熟悉程度,二是,想考考你对sql注入的理解。
64 |
65 | 我们都知道,mybatis中的动态sql经常会用到这两个符号。
66 |
67 | 在动态 SQL 解析阶段, #{ } 和 ${ } 会有不同的表现:
68 | - #{ } 解析为一个 JDBC 预编译语句(prepared statement)的参数标记符。
69 | - ${ } 仅仅为一个纯碎的 string 替换,在动态 SQL 解析阶段将会进行变量替换。
70 |
71 | 例如,`select * from user where name = #{name};`会解析为`select * from user where name = ?;`,而`select * from user where name = ${name};`如果我们传递参数"sihai"会解析为`select * from user where name = "sihai"`。
72 |
73 | 因此,**${ } 的变量的替换阶段是在动态 SQL 解析阶段,而 #{ }的变量的替换是在 DBMS 中**。
74 |
75 | 由上也可得,**尽量使用`#{ }`,可以防止sql注入,除非表名作为变量时,才使用`${ }`。**
76 |
77 |
78 | > session的原理
79 |
80 | Session是一种可以存储在内存、文件或者数据库中的键值对。
81 |
82 | 在程序需要为客户端创建一个请求的session时,服务器会先检查客户端的请求里是否包含一个session的标识,这个标识通常称为session id,如果已经存在,说明已经创建了session,就可以直接使用;如果不存在,则需要服务端重新创建一个session。
83 |
84 | 浏览器存储session的方式有三种:
85 | - 使用Cookie存储,这是常见的方式,”记住我“的功能就是这种方式实现的。
86 | - Url重写,这种方式是直接把session id附加在url路径的后面,例如:www.baidu.com?sessionid=xxx。
87 | - 在页面表单中增加隐藏域。
88 |
89 | #### session什么时候创建的呢
90 |
91 | 这个其实很简单,一般都是服务端在需要的时候使用某种方式进行创建,而不同语言的创建方式都是不一样的。
92 |
93 | #### session什么时候删除?
94 |
95 | 删除的时机很难说,但你不需要的时候就可以调用服务端的相关api进行删除,例如,注销登录时,我们就可以对用户session进行删除。
96 |
97 | > Cookie的相关原理
98 |
99 | 在程序中,会话跟踪是很重要的事情。理论上,一个用户的所有请求操作都应该属于同一个会话,而另一个用户的所有请求操作则应该属于另一个会话,二者不能混淆。例如,用户A在超市购买的任何商品都应该放在A的购物车内,不论是用户A什么时间购买的,这都是属于同一个会话的,不能放入用户B或用户C的购物车内,这不属于同一个会话。
100 |
101 | 
102 |
103 | 而Web应用程序是使用HTTP协议传输数据的。HTTP协议是无状态的协议。一旦数据交换完毕,客户端与服务器端的连接就会关闭,再次交换数据需要建立新的连接。这就意味着服务器无法从连接上跟踪会话。即用户A购买了一件商品放入购物车内,当再次购买商品时服务器已经无法判断该购买行为是属于用户A的会话还是用户B的会话了。要跟踪该会话,必须引入一种机制。
104 |
105 | Cookie就是这样的一种机制。它可以弥补HTTP协议无状态的不足。在Session出现之前,基本上所有的网站都采用Cookie来跟踪会话。
106 |
107 | #### Cookie属性项
108 |
109 | |属性名 |描述|
110 | |-----|-----|
111 | |String name|该Cookie的名称。Cookie一旦创建,名称便不可更改
112 | |Object value|该Cookie的值。如果值为Unicode字符,需要为字符编码。如果值为二进制数据,则需要使用BASE64编码
113 | |int maxAge|该Cookie失效的时间,单位秒。如果为正数,则该Cookie在maxAge秒之后失效。如果为负数,该Cookie为临时Cookie,关闭浏览器即失效,浏览器也不会以任何形式保存该Cookie。如果为0,表示删除该Cookie。默认为–1
114 | |boolean secure|该Cookie是否仅被使用安全协议传输。安全协议。安全协议有HTTPS,SSL等,在网络上传输数据之前先将数据加密。默认为false
115 | |String path|该Cookie的使用路径。如果设置为“/sessionWeb/”,则只有contextPath为“/sessionWeb”的程序可以访问该Cookie。如果设置为“/”,则本域名下contextPath都可以访问该Cookie。注意最后一个字符必须为“/”
116 | |String domain|可以访问该Cookie的域名。如果设置为“.google.com”,则所有以“google.com”结尾的域名都可以访问该Cookie。注意第一个字符必须为“.”
117 | |String comment|该Cookie的用处说明。浏览器显示Cookie信息的时候显示该说明
118 | |int version|该Cookie使用的版本号。0表示遵循Netscape的Cookie规范,1表示遵循W3C的RFC 2109规范
119 |
120 | #### Cookie的有效期
121 |
122 | Cookie的maxAge决定着Cookie的有效期,单位为秒(Second)。
123 |
124 | - 如果maxAge属性为正数,则表示该Cookie会在maxAge秒之后自动失效。浏览器会将maxAge为正数的Cookie持久化,即写到对应的Cookie文件中。无论客户关闭了浏览器还是电脑,只要还在maxAge秒之前,登录网站时该Cookie仍然有效。
125 | - 如果maxAge为负数,则表示该Cookie仅在本浏览器窗口以及本窗口打开的子窗口内有效,关闭窗口后该Cookie即失效。maxAge为负数的Cookie,为临时性Cookie,不会被持久化,不会被写到Cookie文件中。Cookie信息保存在浏览器内存中,因此关闭浏览器该Cookie就消失了。Cookie默认的maxAge值为–1。
126 | - 如果maxAge为0,则表示删除该Cookie。Cookie机制没有提供删除Cookie的方法,因此通过设置该Cookie即时失效实现删除Cookie的效果。
127 |
128 | 具体的操作方法每种语言都不一样,可以根据不同语言进行设置。
129 |
130 | #### Cookie的修改和删除
131 |
132 | Cookie不提供修改、删除的方法。如果要修改某个Cookie,只需要新建一个同名的Cookie,添加到response中覆盖原来的Cookie。
133 |
134 | 如果要删除某个Cookie,只需要新建一个同名的Cookie,并将maxAge设置为0。
135 |
136 | #### Cookie跨域问题
137 |
138 | Cookie是不可以跨域名的,隐私安全机制禁止网站非法获取其他网站的Cookie。
139 |
140 | 同一个一级域名下的两个二级域名也不能交互使用Cookie,比如a1.baidu.com和a2.baidu.com,因为二者的域名不完全相同。如果想要baidu.com名下的二级域名都可以使用该Cookie,需要设置Cookie的domain参数为.baidu.com,这样a1.baidu.com和a2.baidu.com就能访问同一个cookie。
141 |
142 | #### Cookie被浏览器禁用怎么办?
143 |
144 | 我们浏览网站的时候,很多网址会让我们选择是否可以使用cookie,如果你选择了禁用是否就没有方法了呢?
145 |
146 | - Url重写,这种方式是直接把session id附加在url路径的后面,例如:www.java1000.com?sessionid=xxx。
147 | - 在页面表单中增加隐藏域。
148 |
149 | > Cookie和Session的区别?
150 |
151 | - 存储位置不同。Cookie存储在客户端,Session一般位于服务器上。
152 | - Session相对更加安全。Cookie是存在于客户端,对客户是可见的;而Session存储在服务端,对客户是透明的,不存在信息安全问题。因此,我们使用Cookie时,是不建议存储敏感信息的。
153 | - Session会消耗服务器资源,会为每个用户分配一个session,所以,当用户量很大时,会消耗大量的服务器内存;而Cookie存在于客户端,不占用服务器资源,如果用户量大,并发高,Cookie是很好的选择。
154 | - Cookie的容量有限制,单个Cookie的容量不能超过4KB,而session没有限制。
155 |
156 | > Session和Cache的区别?
157 |
158 | - Session是单用户的会话状态。当用户访问网站时,就会对其生成一个Seesion,session的sessionid会保存到cookie中,用于后续会话。
159 | - Cache是服务端的缓存,是对项目的所有用户都是共享的,因为采用数据库的方式有些场景的接口响应不够好,所以采用缓存来进行优化,比如使用redis进行优化,提高访问速度。
160 |
161 | > 经典面试题:在浏览器输入url到响应结果的整个过程,会用到哪些协议?
162 |
163 | 整个请求的流程是这样的。
164 | - 输入url,进行域名解析,DNS协议解析域名获得IP
165 | - 依据IP地址浏览器向服务器发送HTTP请求,使用TCP协议与服务器建立连接
166 | - 连接建立时要发送数据,发送数据在网络层使用IP协议
167 | - 期间IP数据包在路由器间路由选择使用OPSF协议
168 | - 路由器与服务器通信,需要将IP转换为MAC地址,使用ARP协议
169 | - 随即服务器处理请求,发回一个HTML响应,浏览器使用HTTP协议显示HTML页面
--------------------------------------------------------------------------------
/docs/dataStructures-algorithms/递归套路总结.md:
--------------------------------------------------------------------------------
1 | ```
2 | 链接:http://39.96.217.32/blog/4#
3 | ```
4 | ## **前言**
5 |
6 | 相信不少同学和我一样,在刚学完数据结构后开始刷算法题时,遇到递归的问题总是很头疼,而一看解答,却发现大佬们几行递归代码就优雅的解决了问题。从我自己的学习经历来看,刚开始理解递归思路都很困难,更别说自己写了。
7 |
8 | 我一直觉得刷算法题和应试一样,既然是应试就一定有套路存在。在刷题中,我总结出了一套解决递归问题的模版思路与解法,用这个思路可以秒解很多递归问题。
9 |
10 | ## **递归解题三部曲**
11 |
12 |
13 | 何为递归?程序反复调用自身即是递归。
14 |
15 | 我自己在刚开始解决递归问题的时候,总是会去纠结这一层函数做了什么,它调用自身后的下一层函数又做了什么…然后就会觉得实现一个递归解法十分复杂,根本就无从下手。
16 |
17 | 相信很多初学者和我一样,这是一个思维误区,一定要走出来。既然递归是一个反复调用自身的过程,这就说明它每一级的功能都是一样的,**因此我们只需要关注一级递归的解决过程即可。**
18 |
19 | > 实在没学过啥绘图的软件,就灵魂手绘了一波,哈哈哈勿喷。
20 |
21 | 
22 |
23 |
24 | 如上图所示,我们需要关心的主要是以下三点:
25 |
26 | 1. 整个递归的终止条件。
27 |
28 | 2. 一级递归需要做什么?
29 |
30 | 3. 应该返回给上一级的返回值是什么?
31 |
32 | **因此,也就有了我们解递归题的三部曲:**
33 |
34 | 1. **找整个递归的终止条件:递归应该在什么时候结束?**
35 |
36 | 2. **找返回值:应该给上一级返回什么信息?**
37 |
38 | 3. **本级递归应该做什么:在这一级递归中,应该完成什么任务?**
39 |
40 | 一定要理解这3步,这就是以后递归秒杀算法题的依据和思路。
41 |
42 | 但这么说好像很空,我们来以题目作为例子,看看怎么套这个模版,相信3道题下来,你就能慢慢理解这个模版。之后再解这种套路递归题都能直接秒了。
43 |
44 | ## **例1:求二叉树的最大深度**
45 |
46 |
47 | 先看一道简单的Leetcode题目: [Leetcode 104\. 二叉树的最大深度](https://leetcode-cn.com/problems/maximum-depth-of-binary-tree/)
48 |
49 | 题目很简单,求二叉树的最大深度,那么直接套递归解题三部曲模版:
50 |
51 | 1. **找终止条件。** 什么情况下递归结束?当然是树为空的时候,此时树的深度为0,递归就结束了。
52 |
53 | 2. **找返回值。** 应该返回什么?题目求的是树的最大深度,我们需要从每一级得到的信息自然是当前这一级对应的树的最大深度,因此我们的返回值应该是当前树的最大深度,这一步可以结合第三步来看。
54 |
55 | 3. **本级递归应该做什么。** 首先,还是强调要走出之前的思维误区,递归后我们眼里的树一定是这个样子的,看下图。此时就三个节点:root、root.left、root.right,其中根据第二步,root.left和root.right分别记录的是root的左右子树的最大深度。那么本级递归应该做什么就很明确了,自然就是在root的左右子树中选择较大的一个,再加上1就是以root为根的子树的最大深度了,然后再返回这个深度即可。
56 |
57 | 
58 |
59 |
60 | 具体Java代码如下:
61 |
62 | ```java
63 | class Solution {
64 | public int maxDepth(TreeNode root) {
65 | //终止条件:当树为空时结束递归,并返回当前深度0
66 | if(root == null){
67 | return 0;
68 | }
69 | //root的左、右子树的最大深度
70 | int leftDepth = maxDepth(root.left);
71 | int rightDepth = maxDepth(root.right);
72 | //返回的是左右子树的最大深度+1
73 | return Math.max(leftDepth, rightDepth) + 1;
74 | }
75 | }
76 | ```
77 |
78 | 当足够熟练后,也可以和Leetcode评论区一样,很骚的几行代码搞定问题,让之后的新手看的一脸懵逼(这道题也是我第一次一行代码搞定一道Leetcode题):
79 |
80 | ```java
81 | class Solution {
82 | public int maxDepth(TreeNode root) {
83 | return root == null ? 0 : Math.max(maxDepth(root.left), maxDepth(root.right)) + 1;
84 | }
85 | }
86 | ```
87 |
88 | ## **例2:两两交换链表中的节点**
89 |
90 |
91 |
92 | 看了一道递归套路解决二叉树的问题后,有点套路搞定递归的感觉了吗?我们再来看一道Leetcode中等难度的链表的问题,掌握套路后这种中等难度的问题真的就是秒:[Leetcode 24\. 两两交换链表中的节点](https://leetcode-cn.com/problems/swap-nodes-in-pairs/)
93 |
94 | 直接上三部曲模版:
95 |
96 | 1. **找终止条件。** 什么情况下递归终止?没得交换的时候,递归就终止了呗。因此当链表只剩一个节点或者没有节点的时候,自然递归就终止了。
97 |
98 | 2. **找返回值。** 我们希望向上一级递归返回什么信息?由于我们的目的是两两交换链表中相邻的节点,因此自然希望交换给上一级递归的是已经完成交换处理,即已经处理好的链表。
99 |
100 | 3. **本级递归应该做什么。** 结合第二步,看下图!由于只考虑本级递归,所以这个链表在我们眼里其实也就三个节点:head、head.next、已处理完的链表部分。而本级递归的任务也就是交换这3个节点中的前两个节点,就很easy了。
101 |
102 | 
103 |
104 |
105 | 附上Java代码:
106 |
107 | ```java
108 | class Solution {
109 | public ListNode swapPairs(ListNode head) {
110 | //终止条件:链表只剩一个节点或者没节点了,没得交换了。返回的是已经处理好的链表
111 | if(head == null || head.next == null){
112 | return head;
113 | }
114 | //一共三个节点:head, next, swapPairs(next.next)
115 | //下面的任务便是交换这3个节点中的前两个节点
116 | ListNode next = head.next;
117 | head.next = swapPairs(next.next);
118 | next.next = head;
119 | //根据第二步:返回给上一级的是当前已经完成交换后,即处理好了的链表部分
120 | return next;
121 | }
122 | }
123 | ```
124 |
125 | ## **例3:平衡二叉树**
126 |
127 |
128 | 相信经过以上2道题,你已经大概理解了这个模版的解题流程了。
129 |
130 | 那么请你先不看以下部分,尝试解决一下这道easy难度的Leetcode题(个人觉得此题比上面的medium难度要难):[Leetcode 110\. 平衡二叉树](https://leetcode-cn.com/problems/balanced-binary-tree/comments/)
131 |
132 | 我觉得这个题真的是集合了模版的精髓所在,下面套三部曲模版:
133 |
134 | 1. **找终止条件。** 什么情况下递归应该终止?自然是子树为空的时候,空树自然是平衡二叉树了。
135 |
136 | 2. **应该返回什么信息:**
137 |
138 | 为什么我说这个题是集合了模版精髓?正是因为此题的返回值。要知道我们搞这么多花里胡哨的,都是为了能写出正确的递归函数,因此在解这个题的时候,我们就需要思考,我们到底希望返回什么值?
139 |
140 | 何为平衡二叉树?平衡二叉树即左右两棵子树高度差不大于1的二叉树。而对于一颗树,它是一个平衡二叉树需要满足三个条件:**它的左子树是平衡二叉树,它的右子树是平衡二叉树,它的左右子树的高度差不大于1**。换句话说:如果它的左子树或右子树不是平衡二叉树,或者它的左右子树高度差大于1,那么它就不是平衡二叉树。
141 |
142 | 而在我们眼里,这颗二叉树就3个节点:root、left、right。那么我们应该返回什么呢?如果返回一个当前树是否是平衡二叉树的boolean类型的值,那么我只知道left和right这两棵树是否是平衡二叉树,无法得出left和right的高度差是否不大于1,自然也就无法得出root这棵树是否是平衡二叉树了。而如果我返回的是一个平衡二叉树的高度的int类型的值,那么我就只知道两棵树的高度,但无法知道这两棵树是不是平衡二叉树,自然也就没法判断root这棵树是不是平衡二叉树了。
143 |
144 | 因此,这里我们返回的信息应该是既包含子树的深度的int类型的值,又包含子树是否是平衡二叉树的boolean类型的值。可以单独定义一个ReturnNode类,如下:
145 |
146 | ```java
147 | class ReturnNode{
148 | boolean isB;
149 | int depth;
150 | //构造方法
151 | public ReturnNode(boolean isB, int depth){
152 | this.isB = isB;
153 | this.depth = depth;
154 | }
155 | }
156 | ```
157 |
158 | 3. **本级递归应该做什么。** 知道了第二步的返回值后,这一步就很简单了。目前树有三个节点:root,left,right。我们首先判断left子树和right子树是否是平衡二叉树,如果不是则直接返回false。再判断两树高度差是否不大于1,如果大于1也直接返回false。否则说明以root为节点的子树是平衡二叉树,那么就返回true和它的高度。
159 |
160 | 具体的Java代码如下:
161 |
162 | ```java
163 | class Solution {
164 | //这个ReturnNode是参考我描述的递归套路的第二步:思考返回值是什么
165 | //一棵树是BST等价于它的左、右俩子树都是BST且俩子树高度差不超过1
166 | //因此我认为返回值应该包含当前树是否是BST和当前树的高度这两个信息
167 | private class ReturnNode{
168 | boolean isB;
169 | int depth;
170 | public ReturnNode(int depth, boolean isB){
171 | this.isB = isB;
172 | this.depth = depth;
173 | }
174 | }
175 | //主函数
176 | public boolean isBalanced(TreeNode root) {
177 | return isBST(root).isB;
178 | }
179 | //参考递归套路的第三部:描述单次执行过程是什么样的
180 | //这里的单次执行过程具体如下:
181 | //是否终止?->没终止的话,判断是否满足不平衡的三个条件->返回值
182 | public ReturnNode isBST(TreeNode root){
183 | if(root == null){
184 | return new ReturnNode(0, true);
185 | }
186 | //不平衡的情况有3种:左树不平衡、右树不平衡、左树和右树差的绝对值大于1
187 | ReturnNode left = isBST(root.left);
188 | ReturnNode right = isBST(root.right);
189 | if(left.isB == false || right.isB == false){
190 | return new ReturnNode(0, false);
191 | }
192 | if(Math.abs(left.depth - right.depth) > 1){
193 | return new ReturnNode(0, false);
194 | }
195 | //不满足上面3种情况,说明平衡了,树的深度为左右俩子树最大深度+1
196 | return new ReturnNode(Math.max(left.depth, right.depth) + 1, true);
197 | }
198 | }
199 | ```
200 |
201 | ## **一些可以用这个套路解决的题**
202 |
203 | * * *
204 |
205 | 暂时就写这么多啦,作为一个高考语文及格分,大学又学了工科的人,表述能力实在差因此啰啰嗦嗦写了一大堆,希望大家能理解这个很好用的套路。
206 |
207 | 下面我再列举几道我在刷题过程中遇到的也是用这个套路秒的题,真的太多了,大部分链表和树的递归题都能这么秒,因为树和链表天生就是适合递归的结构。
208 |
209 | 我会随时补充,正好大家可以看了上面三个题后可以拿这些题来练练手,看看自己是否能独立快速准确的写出递归解法了。
210 |
211 | [Leetcode 101\. 对称二叉树](https://leetcode-cn.com/problems/symmetric-tree/comments/)
212 |
213 | [Leetcode 111\. 二叉树的最小深度](https://leetcode-cn.com/problems/minimum-depth-of-binary-tree/)
214 |
215 | [Leetcode 226\. 翻转二叉树](https://leetcode-cn.com/problems/invert-binary-tree/):这个题的备注是最骚的。Mac OS下载神器homebrew的大佬作者去面试谷歌,没做出来这道算法题,然后被谷歌面试官怼了:”我们90%的工程师使用您编写的软件(Homebrew),但是您却无法在面试时在白板上写出翻转二叉树这道题,这太糟糕了。”
216 |
217 | [Leetcode 617\. 合并二叉树](https://leetcode-cn.com/problems/merge-two-binary-trees/)
218 |
219 | [Leetcode 654\. 最大二叉树](https://leetcode-cn.com/problems/maximum-binary-tree/)
220 |
221 | [Leetcode 83\. 删除排序链表中的重复元素](https://leetcode-cn.com/problems/remove-duplicates-from-sorted-list/)
222 |
223 | [Leetcode 206\. 翻转链表](https://leetcode-cn.com/problems/reverse-linked-list/comments/)
--------------------------------------------------------------------------------
/docs/java/基础面试题/elasticSearch.md:
--------------------------------------------------------------------------------
1 | https://juejin.cn/post/6844904032083902471
2 |
3 | ## 前言
4 |
5 | ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
6 |
7 | 
8 |
9 | ## Elasticsearch 面试题
10 |
11 | 1、elasticsearch 了解多少,说说你们公司 es 的集群架构,索引数据大小,分片有多少,以及一些调优手段 。
12 |
13 | 2、elasticsearch 的倒排索引是什么
14 |
15 | 3、elasticsearch 索引数据多了怎么办,如何调优,部署
16 |
17 | 4、elasticsearch 是如何实现 master 选举的
18 |
19 | 5、详细描述一下 Elasticsearch 索引文档的过程
20 |
21 | 6、详细描述一下 Elasticsearch 搜索的过程?
22 |
23 | 7、Elasticsearch 在部署时,对 Linux 的设置有哪些优化方法
24 |
25 | 8、lucence 内部结构是什么?
26 |
27 | 9、Elasticsearch 是如何实现 Master 选举的?
28 |
29 | 10、Elasticsearch 中的节点(比如共 20 个),其中的 10 个选了一个master,另外 10 个选了另一个 master,怎么办?
30 |
31 | 11、客户端在和集群连接时,如何选择特定的节点执行请求的?
32 |
33 | 12、详细描述一下 Elasticsearch 索引文档的过程。
34 |
35 | 
36 |
37 | ## 1、elasticsearch 了解多少,说说你们公司 es 的集群架构,索引数据大小,分片有多少,以及一些调优手段 。
38 |
39 | 面试官:想了解应聘者之前公司接触的 ES 使用场景、规模,有没有做过比较大规模的索引设计、规划、调优。
40 |
41 | 解答:如实结合自己的实践场景回答即可。
42 |
43 | 比如:ES 集群架构 13 个节点,索引根据通道不同共 20+索引,根据日期,每日递增 20+,索引:10 分片,每日递增 1 亿+数据,每个通道每天索引大小控制:150GB 之内。
44 |
45 | 仅索引层面调优手段:
46 |
47 | ### 1.1、设计阶段调优
48 |
49 | (1)根据业务增量需求,采取基于日期模板创建索引,通过 roll over API 滚动索引;
50 |
51 | (2)使用别名进行索引管理;
52 |
53 | (3)每天凌晨定时对索引做 force_merge 操作,以释放空间;
54 |
55 | (4)采取冷热分离机制,热数据存储到 SSD,提高检索效率;冷数据定期进行 shrink操作,以缩减存储;
56 |
57 | (5)采取 curator 进行索引的生命周期管理;
58 |
59 | (6)仅针对需要分词的字段,合理的设置分词器;
60 |
61 | (7)Mapping 阶段充分结合各个字段的属性,是否需要检索、是否需要存储等。……..
62 |
63 | ### 1.2、写入调优
64 |
65 | (1)写入前副本数设置为 0;
66 |
67 | (2)写入前关闭 refresh_interval 设置为-1,禁用刷新机制;
68 |
69 | (3)写入过程中:采取 bulk 批量写入;
70 |
71 | (4)写入后恢复副本数和刷新间隔;
72 |
73 | (5)尽量使用自动生成的 id。
74 |
75 | ### 1.3、查询调优
76 |
77 | (1)禁用 wildcard;
78 |
79 | (2)禁用批量 terms(成百上千的场景);
80 |
81 | (3)充分利用倒排索引机制,能 keyword 类型尽量 keyword;
82 |
83 | (4)数据量大时候,可以先基于时间敲定索引再检索;
84 |
85 | (5)设置合理的路由机制。
86 |
87 | ### 1.4、其他调优
88 |
89 | 部署调优,业务调优等。
90 |
91 | 上面的提及一部分,面试者就基本对你之前的实践或者运维经验有所评估了。
92 |
93 | ## 2、elasticsearch 的倒排索引是什么
94 |
95 | 面试官:想了解你对基础概念的认知。
96 |
97 | 解答:通俗解释一下就可以。
98 |
99 | 传统的我们的检索是通过文章,逐个遍历找到对应关键词的位置。
100 |
101 | 而倒排索引,是通过分词策略,形成了词和文章的映射关系表,这种词典+映射表即为倒排索引。有了倒排索引,就能实现 o(1)时间复杂度的效率检索文章了,极大的提高了检索效率。
102 |
103 | 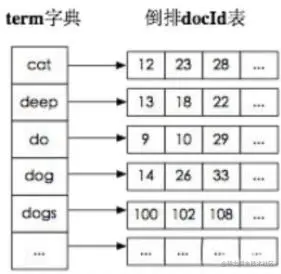
104 |
105 | 学术的解答方式:
106 |
107 | 倒排索引,相反于一篇文章包含了哪些词,它从词出发,记载了这个词在哪些文档中出现过,由两部分组成——词典和倒排表。
108 |
109 | 加分项:倒排索引的底层实现是基于:FST(Finite State Transducer)数据结构。
110 |
111 | lucene 从 4+版本后开始大量使用的数据结构是 FST。FST 有两个优点:
112 |
113 | (1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
114 |
115 | (2)查询速度快。O(len(str))的查询时间复杂度。
116 |
117 | ## 3、elasticsearch 索引数据多了怎么办,如何调优,部署
118 |
119 | 面试官:想了解大数据量的运维能力。
120 |
121 | 解答:索引数据的规划,应在前期做好规划,正所谓“设计先行,编码在后”,这样才能有效的避免突如其来的数据激增导致集群处理能力不足引发的线上客户检索或者其他业务受到影响。
122 |
123 | 如何调优,正如问题 1 所说,这里细化一下:
124 |
125 | ### 3.1 动态索引层面
126 |
127 | 基于模板+时间+rollover api 滚动创建索引,举例:设计阶段定义:blog 索引的模板格式为:blog_index_时间戳的形式,每天递增数据。这样做的好处:不至于数据量激增导致单个索引数据量非常大,接近于上线 2 的32 次幂-1,索引存储达到了 TB+甚至更大。
128 |
129 | 一旦单个索引很大,存储等各种风险也随之而来,所以要提前考虑+及早避免。
130 |
131 | ### 3.2 存储层面
132 |
133 | 冷热数据分离存储,热数据(比如最近 3 天或者一周的数据),其余为冷数据。
134 |
135 | 对于冷数据不会再写入新数据,可以考虑定期 force_merge 加 shrink 压缩操作,节省存储空间和检索效率。
136 |
137 | ### 3.3 部署层面
138 |
139 | 一旦之前没有规划,这里就属于应急策略。
140 |
141 | 结合 ES 自身的支持动态扩展的特点,动态新增机器的方式可以缓解集群压力,注意:如果之前主节点等规划合理,不需要重启集群也能完成动态新增的。
142 |
143 | ## 4、elasticsearch 是如何实现 master 选举的
144 |
145 | 面试官:想了解 ES 集群的底层原理,不再只关注业务层面了。
146 |
147 | 解答:
148 |
149 | 前置前提:
150 |
151 | (1)只有候选主节点(master:true)的节点才能成为主节点。
152 |
153 | (2)最小主节点数(min_master_nodes)的目的是防止脑裂。
154 |
155 | 核对了一下代码,核心入口为 findMaster,选择主节点成功返回对应 Master,否则返回 null。选举流程大致描述如下:
156 |
157 | 第一步:确认候选主节点数达标,elasticsearch.yml 设置的值
158 |
159 | discovery.zen.minimum_master_nodes;
160 |
161 | 第二步:比较:先判定是否具备 master 资格,具备候选主节点资格的优先返回;
162 |
163 | 若两节点都为候选主节点,则 id 小的值会主节点。注意这里的 id 为 string 类型。
164 |
165 | 题外话:获取节点 id 的方法。
166 |
167 | 1GET /_cat/nodes?v&h=ip,port,heapPercent,heapMax,id,name
168 |
169 | 2ip port heapPercent heapMax id name复制代码
170 | ## 5、详细描述一下 Elasticsearch 索引文档的过程
171 |
172 | 面试官:想了解 ES 的底层原理,不再只关注业务层面了。
173 |
174 | 解答:
175 |
176 | 这里的索引文档应该理解为文档写入 ES,创建索引的过程。
177 |
178 | 文档写入包含:单文档写入和批量 bulk 写入,这里只解释一下:单文档写入流程。
179 |
180 | 记住官方文档中的这个图。
181 |
182 | 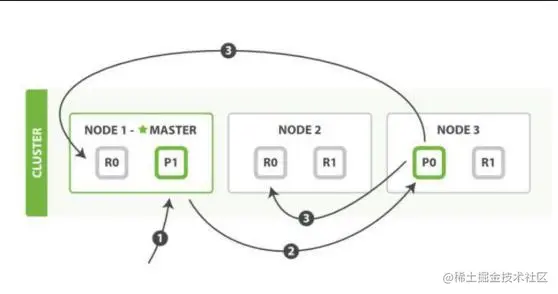
183 |
184 | 第一步:客户写集群某节点写入数据,发送请求。(如果没有指定路由/协调节点,请求的节点扮演路由节点的角色。)
185 |
186 | 第二步:节点 1 接受到请求后,使用文档_id 来确定文档属于分片 0。请求会被转到另外的节点,假定节点 3。因此分片 0 的主分片分配到节点 3 上。
187 |
188 | 第三步:节点 3 在主分片上执行写操作,如果成功,则将请求并行转发到节点 1和节点 2 的副本分片上,等待结果返回。所有的副本分片都报告成功,节点 3 将向协调节点(节点 1)报告成功,节点 1 向请求客户端报告写入成功。
189 |
190 | 如果面试官再问:第二步中的文档获取分片的过程?
191 |
192 | 回答:借助路由算法获取,路由算法就是根据路由和文档 id 计算目标的分片 id 的过程。
193 |
194 | 1shard = hash(_routing) % (num_of_primary_shards)复制代码
195 | ## 6、详细描述一下 Elasticsearch 搜索的过程?
196 |
197 | 面试官:想了解 ES 搜索的底层原理,不再只关注业务层面了。
198 |
199 | 解答:
200 |
201 | 搜索拆解为“query then fetch” 两个阶段。
202 |
203 | query 阶段的目的:定位到位置,但不取。
204 |
205 | 步骤拆解如下:
206 |
207 | (1)假设一个索引数据有 5 主+1 副本 共 10 分片,一次请求会命中(主或者副本分片中)的一个。
208 |
209 | (2)每个分片在本地进行查询,结果返回到本地有序的优先队列中。
210 |
211 | (3)第 2)步骤的结果发送到协调节点,协调节点产生一个全局的排序列表。
212 |
213 | fetch 阶段的目的:取数据。
214 |
215 | 路由节点获取所有文档,返回给客户端。
216 |
217 | 
218 |
219 | ## 7、Elasticsearch 在部署时,对 Linux 的设置有哪些优化方法
220 |
221 | 面试官:想了解对 ES 集群的运维能力。
222 |
223 | 解答:
224 |
225 | (1)关闭缓存 swap;
226 |
227 | (2)堆内存设置为:Min(节点内存/2, 32GB);
228 |
229 | (3)设置最大文件句柄数;
230 |
231 | (4)线程池+队列大小根据业务需要做调整;
232 |
233 | (5)磁盘存储 raid 方式——存储有条件使用 RAID10,增加单节点性能以及避免单节点存储故障。
234 |
235 | ## 8、lucence 内部结构是什么?
236 |
237 | 面试官:想了解你的知识面的广度和深度。
238 |
239 | 解答:
240 |
241 | 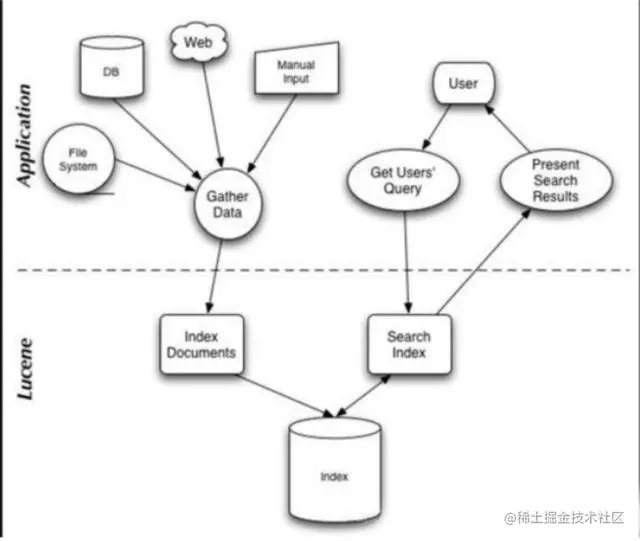
242 |
243 | Lucene 是有索引和搜索的两个过程,包含索引创建,索引,搜索三个要点。可以基于这个脉络展开一些。
244 |
245 | ## 9、Elasticsearch 是如何实现 Master 选举的?
246 |
247 | (1)Elasticsearch 的选主是 ZenDiscovery 模块负责的,主要包含 Ping(节点之间通过这个 RPC 来发现彼此)和 Unicast(单播模块包含一个主机列表以控制哪些节点需要 ping 通)这两部分;
248 |
249 | (2)对所有可以成为 master 的节点(node.master: true)根据 nodeId 字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第 0 位)节点,暂且认为它是 master 节点。
250 |
251 | (3)如果对某个节点的投票数达到一定的值(可以成为 master 节点数 n/2+1)并且该节点自己也选举自己,那这个节点就是 master。否则重新选举一直到满足上述条件。
252 |
253 | (4)补充:master 节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data 节点可以关闭 http 功能*。
254 |
255 | ## 10、Elasticsearch 中的节点(比如共 20 个),其中的 10 个
256 |
257 | 选了一个 master,另外 10 个选了另一个 master,怎么办?
258 |
259 | (1)当集群 master 候选数量不小于 3 个时,可以通过设置最少投票通过数量(discovery.zen.minimum_master_nodes)超过所有候选节点一半以上来解决脑裂问题;
260 |
261 | (3)当候选数量为两个时,只能修改为唯一的一个 master 候选,其他作为 data节点,避免脑裂问题。
262 |
263 | ## 11、客户端在和集群连接时,如何选择特定的节点执行请求的?
264 |
265 | TransportClient 利用 transport 模块远程连接一个 elasticsearch 集群。它并不加入到集群中,只是简单的获得一个或者多个初始化的 transport 地址,并以 轮询 的方式与这些地址进行通信。
266 |
267 | ## 12、详细描述一下 Elasticsearch 索引文档的过程。
268 |
269 | 协调节点默认使用文档 ID 参与计算(也支持通过 routing),以便为路由提供合适的分片。
270 |
271 | shard = hash(document_id) % (num_of_primary_shards)复制代码
272 |
273 | (1)当分片所在的节点接收到来自协调节点的请求后,会将请求写入到 MemoryBuffer,然后定时(默认是每隔 1 秒)写入到 Filesystem Cache,这个从 MomeryBuffer 到 Filesystem Cache 的过程就叫做 refresh;
274 |
275 | (2)当然在某些情况下,存在 Momery Buffer 和 Filesystem Cache 的数据可能会丢失,ES 是通过 translog 的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到 translog 中 ,当 Filesystem cache 中的数据写入到磁盘中时,才会清除掉,这个过程叫做 flush;
276 |
277 | (3)在 flush 过程中,内存中的缓冲将被清除,内容被写入一个新段,段的 fsync将创建一个新的提交点,并将内容刷新到磁盘,旧的 translog 将被删除并开始一个新的 translog。
278 |
279 | (4)flush 触发的时机是定时触发(默认 30 分钟)或者 translog 变得太大(默认为 512M)时;
280 |
281 | 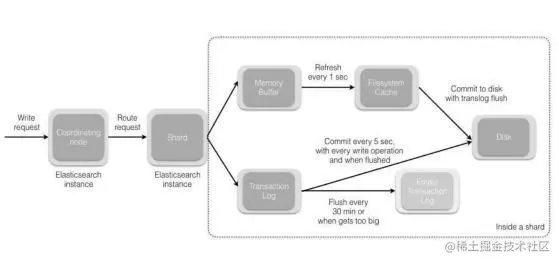
282 |
283 | 补充:关于 Lucene 的 Segement:
284 |
285 | (1)Lucene 索引是由多个段组成,段本身是一个功能齐全的倒排索引。
286 |
287 | (2)段是不可变的,允许 Lucene 将新的文档增量地添加到索引中,而不用从头重建索引。
288 |
289 | (3)对于每一个搜索请求而言,索引中的所有段都会被搜索,并且每个段会消耗CPU 的时钟周、文件句柄和内存。这意味着段的数量越多,搜索性能会越低。
290 |
291 | (4)为了解决这个问题,Elasticsearch 会合并小段到一个较大的段,提交新的合并段到磁盘,并删除那些旧的小段。
292 |
293 | 作者:程序员追风
294 | 链接:https://juejin.cn/post/6844904031555420167
295 | 来源:稀土掘金
296 | 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
--------------------------------------------------------------------------------
/docs/java/基础面试题/spring mvc.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ## 概述
4 |
5 | ### 什么是Spring MVC?简单介绍下你对Spring MVC的理解?
6 |
7 | * Spring MVC是一个基于Java的实现了MVC设计模式的请求驱动类型的轻量级Web框架,通过把模型-视图-控制器分离,将web层进行职责解耦,把复杂的web应用分成逻辑清晰的几部分,简化开发,减少出错,方便组内开发人员之间的配合。
8 |
9 | ### Spring MVC的优点
10 |
11 | * (1)可以支持各种视图技术,而不仅仅局限于JSP;
12 |
13 | * (2)与Spring框架集成(如IoC容器、AOP等);
14 |
15 | * (3)清晰的角色分配:前端控制器(dispatcherServlet) , 请求到处理器映射(handlerMapping), 处理器适配器(HandlerAdapter), 视图解析器(ViewResolver)。
16 |
17 | * (4) 支持各种请求资源的映射策略。
18 |
19 | ## 核心组件
20 |
21 | ### Spring MVC的主要组件?
22 |
23 | * (1)前端控制器 DispatcherServlet(不需要程序员开发)
24 |
25 | * 作用:接收请求、响应结果,相当于转发器,有了DispatcherServlet 就减少了其它组件之间的耦合度。
26 | * (2)处理器映射器HandlerMapping(不需要程序员开发)
27 |
28 | * 作用:根据请求的URL来查找Handler
29 | * (3)处理器适配器HandlerAdapter
30 |
31 | * 注意:在编写Handler的时候要按照HandlerAdapter要求的规则去编写,这样适配器HandlerAdapter才可以正确的去执行Handler。
32 | * (4)处理器Handler(需要程序员开发)
33 |
34 | * (5)视图解析器 ViewResolver(不需要程序员开发)
35 |
36 | * 作用:进行视图的解析,根据视图逻辑名解析成真正的视图(view)
37 | * (6)视图View(需要程序员开发jsp)
38 |
39 | * View是一个接口, 它的实现类支持不同的视图类型(jsp,freemarker,pdf等等)
40 |
41 | ### 什么是DispatcherServlet
42 |
43 | * Spring的MVC框架是围绕DispatcherServlet来设计的,它用来处理所有的HTTP请求和响应。
44 |
45 | ### 什么是Spring MVC框架的控制器?
46 |
47 | * 控制器提供一个访问应用程序的行为,此行为通常通过服务接口实现。控制器解析用户输入并将其转换为一个由视图呈现给用户的模型。Spring用一个非常抽象的方式实现了一个控制层,允许用户创建多种用途的控制器。
48 |
49 | ### Spring MVC的控制器是不是单例模式,如果是,有什么问题,怎么解决?
50 |
51 | * 答:是单例模式,所以在多线程访问的时候有线程安全问题,不要用同步,会影响性能的,解决方案是在控制器里面不能写字段。
52 |
53 | ## 工作原理
54 |
55 | ### 请描述Spring MVC的工作流程?描述一下 DispatcherServlet 的工作流程?
56 |
57 | 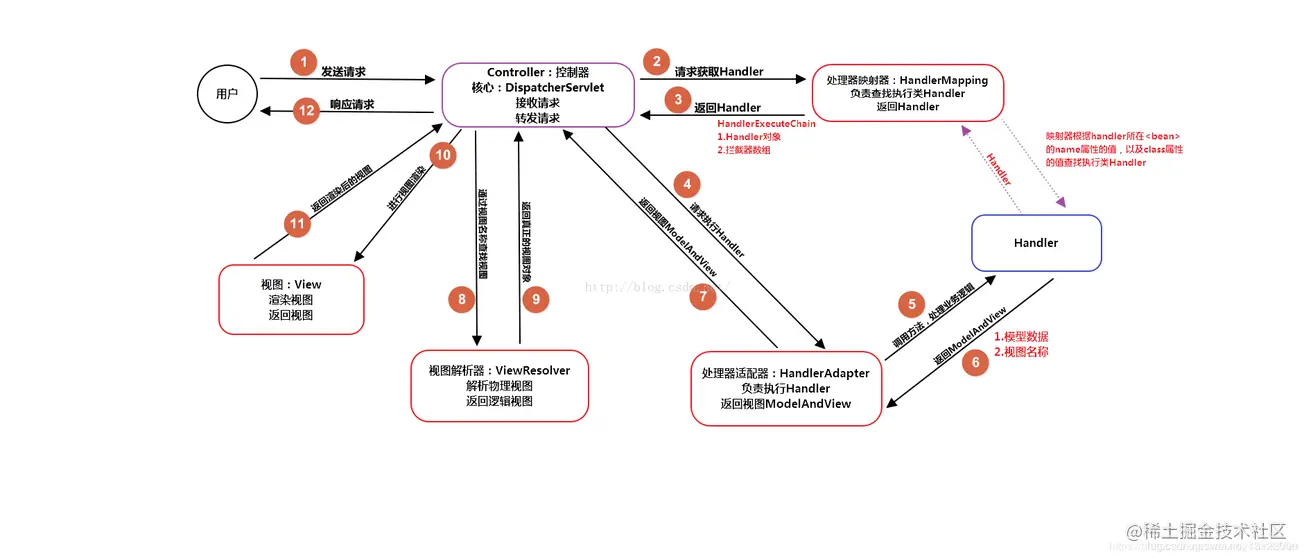
58 |
59 | * (1)用户发送请求至前端控制器DispatcherServlet;
60 | * (2) DispatcherServlet收到请求后,调用HandlerMapping处理器映射器,请求获取Handle;
61 | * (3)处理器映射器根据请求url找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet;
62 | * (4)DispatcherServlet 调用 HandlerAdapter处理器适配器;
63 | * (5)HandlerAdapter 经过适配调用 具体处理器(Handler,也叫后端控制器);
64 | * (6)Handler执行完成返回ModelAndView;
65 | * (7)HandlerAdapter将Handler执行结果ModelAndView返回给DispatcherServlet;
66 | * (8)DispatcherServlet将ModelAndView传给ViewResolver视图解析器进行解析;
67 | * (9)ViewResolver解析后返回具体View;
68 | * (10)DispatcherServlet对View进行渲染视图(即将模型数据填充至视图中)
69 | * (11)DispatcherServlet响应用户。
70 |
71 | ## MVC框架
72 |
73 | ### MVC是什么?MVC设计模式的好处有哪些
74 |
75 | * mvc是一种设计模式(设计模式就是日常开发中编写代码的一种好的方法和经验的总结)。模型(model)-视图(view)-控制器(controller),三层架构的设计模式。用于实现前端页面的展现与后端业务数据处理的分离。
76 |
77 | * mvc设计模式的好处
78 |
79 | 1. 分层设计,实现了业务系统各个组件之间的解耦,有利于业务系统的可扩展性,可维护性。
80 | 2. 有利于系统的并行开发,提升开发效率。
81 |
82 | ## 常用注解
83 |
84 | ### 注解原理是什么
85 |
86 | * 注解本质是一个继承了Annotation的特殊接口,其具体实现类是Java运行时生成的动态代理类。我们通过反射获取注解时,返回的是Java运行时生成的动态代理对象。通过代理对象调用自定义注解的方法,会最终调用AnnotationInvocationHandler的invoke方法。该方法会从memberValues这个Map中索引出对应的值。而memberValues的来源是Java常量池。
87 |
88 | ### Spring MVC常用的注解有哪些?
89 |
90 | * @RequestMapping:用于处理请求 url 映射的注解,可用于类或方法上。用于类上,则表示类中的所有响应请求的方法都是以该地址作为父路径。
91 |
92 | * @RequestBody:注解实现接收http请求的json数据,将json转换为java对象。
93 |
94 | * @ResponseBody:注解实现将conreoller方法返回对象转化为json对象响应给客户。
95 |
96 | * @Conntroller:控制器的注解,表示是表现层,不能用用别的注解代替
97 |
98 | ### SpingMvc中的控制器的注解一般用哪个,有没有别的注解可以替代?
99 |
100 | * 答:一般用@Controller注解,也可以使用@RestController,@RestController注解相当于@ResponseBody + @Controller,表示是表现层,除此之外,一般不用别的注解代替。
101 |
102 | ### @Controller注解的作用
103 |
104 | * 在Spring MVC 中,控制器Controller 负责处理由DispatcherServlet 分发的请求,它把用户请求的数据经过业务处理层处理之后封装成一个Model ,然后再把该Model 返回给对应的View 进行展示。在Spring MVC 中提供了一个非常简便的定义Controller 的方法,你无需继承特定的类或实现特定的接口,只需使用@Controller 标记一个类是Controller ,然后使用@RequestMapping 和@RequestParam 等一些注解用以定义URL 请求和Controller 方法之间的映射,这样的Controller 就能被外界访问到。此外Controller 不会直接依赖于HttpServletRequest 和HttpServletResponse 等HttpServlet 对象,它们可以通过Controller 的方法参数灵活的获取到。
105 |
106 | * @Controller 用于标记在一个类上,使用它标记的类就是一个Spring MVC Controller 对象。分发处理器将会扫描使用了该注解的类的方法,并检测该方法是否使用了@RequestMapping 注解。@Controller 只是定义了一个控制器类,而使用@RequestMapping 注解的方法才是真正处理请求的处理器。单单使用@Controller 标记在一个类上还不能真正意义上的说它就是Spring MVC 的一个控制器类,因为这个时候Spring 还不认识它。那么要如何做Spring 才能认识它呢?这个时候就需要我们把这个控制器类交给Spring 来管理。有两种方式:
107 |
108 | * 在Spring MVC 的配置文件中定义MyController 的bean 对象。
109 | * 在Spring MVC 的配置文件中告诉Spring 该到哪里去找标记为@Controller 的Controller 控制器。
110 |
111 | ### @RequestMapping注解的作用
112 |
113 | * RequestMapping是一个用来处理请求地址映射的注解,可用于类或方法上。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。
114 |
115 | * RequestMapping注解有六个属性,下面我们把她分成三类进行说明(下面有相应示例)。
116 |
117 | * **value, method**
118 |
119 | * value: 指定请求的实际地址,指定的地址可以是URI Template 模式(后面将会说明);
120 |
121 | * method: 指定请求的method类型, GET、POST、PUT、DELETE等;
122 |
123 | * **consumes,produces**
124 |
125 | * consumes: 指定处理请求的提交内容类型(Content-Type),例如application/json, text/html;
126 |
127 | * produces: 指定返回的内容类型,仅当request请求头中的(Accept)类型中包含该指定类型才返回;
128 |
129 | * **params,headers**
130 |
131 | * params: 指定request中必须包含某些参数值是,才让该方法处理。
132 |
133 | * headers: 指定request中必须包含某些指定的header值,才能让该方法处理请求。
134 |
135 | ### @ResponseBody注解的作用
136 |
137 | * 作用: 该注解用于将Controller的方法返回的对象,通过适当的HttpMessageConverter转换为指定格式后,写入到Response对象的body数据区。
138 |
139 | * 使用时机:返回的数据不是html标签的页面,而是其他某种格式的数据时(如json、xml等)使用;
140 |
141 | ### @PathVariable和@RequestParam的区别
142 |
143 | * 请求路径上有个id的变量值,可以通过@PathVariable来获取 @RequestMapping(value = “/page/{id}”, method = RequestMethod.GET)
144 |
145 | * @RequestParam用来获得静态的URL请求入参 spring注解时action里用到。
146 |
147 | ## 其他
148 |
149 | ### Spring MVC与Struts2区别
150 |
151 | * 相同点
152 |
153 | * 都是基于mvc的表现层框架,都用于web项目的开发。
154 | * 不同点
155 |
156 | 1. 前端控制器不一样。Spring MVC的前端控制器是servlet:DispatcherServlet。struts2的前端控制器是filter:StrutsPreparedAndExcutorFilter。
157 |
158 | 2. 请求参数的接收方式不一样。Spring MVC是使用方法的形参接收请求的参数,基于方法的开发,线程安全,可以设计为单例或者多例的开发,推荐使用单例模式的开发(执行效率更高),默认就是单例开发模式。struts2是通过类的成员变量接收请求的参数,是基于类的开发,线程不安全,只能设计为多例的开发。
159 |
160 | 3. Struts采用值栈存储请求和响应的数据,通过OGNL存取数据,Spring MVC通过参数解析器是将request请求内容解析,并给方法形参赋值,将数据和视图封装成ModelAndView对象,最后又将ModelAndView中的模型数据通过reques域传输到页面。Jsp视图解析器默认使用jstl。
161 |
162 | 4. 与spring整合不一样。Spring MVC是spring框架的一部分,不需要整合。在企业项目中,Spring MVC使用更多一些。
163 |
164 | ### Spring MVC怎么样设定重定向和转发的?
165 |
166 | * (1)转发:在返回值前面加"forward:",譬如"forward:user.do?name=method4"
167 |
168 | * (2)重定向:在返回值前面加"redirect:",譬如"redirect:[www.baidu.com](https://link.juejin.cn?target=http%3A%2F%2Fwww.baidu.com "http://www.baidu.com")"
169 |
170 | ### Spring MVC怎么和AJAX相互调用的?
171 |
172 | * 通过Jackson框架就可以把Java里面的对象直接转化成Js可以识别的Json对象。具体步骤如下 :
173 |
174 | * (1)加入Jackson.jar
175 |
176 | * (2)在配置文件中配置json的映射
177 |
178 | * (3)在接受Ajax方法里面可以直接返回Object,List等,但方法前面要加上@ResponseBody注解。
179 |
180 | ### 如何解决POST请求中文乱码问题,GET的又如何处理呢?
181 |
182 | * (1)解决post请求乱码问题:
183 |
184 | * 在web.xml中配置一个CharacterEncodingFilter过滤器,设置成utf-8;
185 |
186 |
187 | CharacterEncodingFilter
188 | org.springframework.web.filter.CharacterEncodingFilter
189 |
190 | encoding
191 | utf-8
192 |
193 |
194 |
195 |
196 | CharacterEncodingFilter
197 | /*
198 |
199 | 复制代码
200 | * (2)get请求中文参数出现乱码解决方法有两个:
201 |
202 | * 1、修改tomcat配置文件添加编码与工程编码一致,如下:
203 |
204 |
205 | 复制代码
206 | * 2、另外一种方法对参数进行重新编码:
207 |
208 | String userName = new String(request.getParamter(“userName”).getBytes(“ISO8859-1”),“utf-8”)
209 |
210 | ISO8859-1是tomcat默认编码,需要将tomcat编码后的内容按utf-8编码。
211 |
212 | ### Spring MVC的异常处理?
213 |
214 | * 答:可以将异常抛给Spring框架,由Spring框架来处理;我们只需要配置简单的异常处理器,在异常处理器中添视图页面即可。
215 |
216 | ### 如果在拦截请求中,我想拦截get方式提交的方法,怎么配置
217 |
218 | * 答:可以在@RequestMapping注解里面加上method=RequestMethod.GET。
219 |
220 | ### 怎样在方法里面得到Request,或者Session?
221 |
222 | * 答:直接在方法的形参中声明request,Spring MVC就自动把request对象传入。
223 |
224 | ### 如果想在拦截的方法里面得到从前台传入的参数,怎么得到?
225 |
226 | * 答:直接在形参里面声明这个参数就可以,但必须名字和传过来的参数一样。
227 |
228 | ### 如果前台有很多个参数传入,并且这些参数都是一个对象的,那么怎么样快速得到这个对象?
229 |
230 | * 答:直接在方法中声明这个对象,Spring MVC就自动会把属性赋值到这个对象里面。
231 |
232 | ### Spring MVC中函数的返回值是什么?
233 |
234 | * 答:返回值可以有很多类型,有String, ModelAndView。ModelAndView类把视图和数据都合并的一起的,但一般用String比较好。
235 |
236 | ### Spring MVC用什么对象从后台向前台传递数据的?
237 |
238 | * 答:通过ModelMap对象,可以在这个对象里面调用put方法,把对象加到里面,前台就可以通过el表达式拿到。
239 |
240 | ### 怎么样把ModelMap里面的数据放入Session里面?
241 |
242 | * 答:可以在类上面加上@SessionAttributes注解,里面包含的字符串就是要放入session里面的key。
243 |
244 | ### Spring MVC里面拦截器是怎么写的
245 |
246 | * 有两种写法,一种是实现HandlerInterceptor接口,另外一种是继承适配器类,接着在接口方法当中,实现处理逻辑;然后在Spring MVC的配置文件中配置拦截器即可:
247 |
248 |
249 |
250 |
251 |
252 |
253 |
254 |
255 |
256 |
257 |
258 | 复制代码
259 |
260 | ### 介绍一下 WebApplicationContext
261 |
262 | * WebApplicationContext 继承了ApplicationContext 并增加了一些WEB应用必备的特有功能,它不同于一般的ApplicationContext ,因为它能处理主题,并找到被关联的servlet。
263 |
264 | 作者:小杰要吃蛋
265 | 链接:https://juejin.cn/post/6844904127059722253
266 | 来源:稀土掘金
267 | 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
--------------------------------------------------------------------------------
/docs/network/计算机网络面试-http.md:
--------------------------------------------------------------------------------
1 | > Http的请求报文结构和响应报文结构
2 |
3 | Http的请求报文主要由`请求行、请求头、空行、请求正文`。
4 |
5 | **请求行**由请求方法、URL以及协议版本组成。
6 | 请求方法:GET、HEAD、PUT、POST、TRACE、OPTIONS、DELETE以及扩展方法
7 | 协议版本:常用的有HTTP/1.0和HTTP/1.1
8 |
9 | **HTTP请求头**
10 | | Header | 解释 | 示例 |
11 | | --- | --- | --- |
12 | | Accept | 指定客户端能够接收的内容类型 | Accept: text/plain, text/html |
13 | | Accept-Charset | 浏览器可以接受的字符编码集。 | Accept-Charset: iso-8859-5 |
14 | | Accept-Encoding | 指定浏览器可以支持的web服务器返回内容压缩编码类型。 | Accept-Encoding: compress, gzip |
15 | | Accept-Language | 浏览器可接受的语言 | Accept-Language: en,zh |
16 | | Accept-Ranges | 可以请求网页实体的一个或者多个子范围字段 | Accept-Ranges: bytes |
17 | | Authorization | HTTP授权的授权证书 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
18 | | Cache-Control | 指定请求和响应遵循的缓存机制 | Cache-Control: no-cache |
19 | | Connection | 表示是否需要持久连接。(HTTP 1.1默认进行持久连接) | Connection: close |
20 | | Cookie | HTTP请求发送时,会把保存在该请求域名下的所有cookie值一起发送给web服务器。 | Cookie: $Version=1; Skin=new; |
21 | | Content-Length | 请求的内容长度 | Content-Length: 348 |
22 | | Content-Type | 请求的与实体对应的MIME信息 | Content-Type: application/x-www-form-urlencoded |
23 | | Date | 请求发送的日期和时间 | Date: Tue, 15 Nov 2010 08:12:31 GMT |
24 | | Expect | 请求的特定的服务器行为 | Expect: 100-continue |
25 | | From | 发出请求的用户的Email | From: user@email.com |
26 | | Host | 指定请求的服务器的域名和端口号 | Host: www.zcmhi.com |
27 | | If-Match | 只有请求内容与实体相匹配才有效 | If-Match: “737060cd8c284d8af7ad3082f209582d” |
28 | | If-Modified-Since | 如果请求的部分在指定时间之后被修改则请求成功,未被修改则返回304代码 | If-Modified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
29 | | If-None-Match | 如果内容未改变返回304代码,参数为服务器先前发送的Etag,与服务器回应的Etag比较判断是否改变 | If-None-Match: “737060cd8c284d8af7ad3082f209582d” |
30 | | If-Range | 如果实体未改变,服务器发送客户端丢失的部分,否则发送整个实体。参数也为Etag | If-Range: “737060cd8c284d8af7ad3082f209582d” |
31 | | If-Unmodified-Since | 只在实体在指定时间之后未被修改才请求成功 | If-Unmodified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
32 | | Max-Forwards | 限制信息通过代理和网关传送的时间 | Max-Forwards: 10 |
33 | | Pragma | 用来包含实现特定的指令 | Pragma: no-cache |
34 | | Proxy-Authorization | 连接到代理的授权证书 | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
35 | | Range | 只请求实体的一部分,指定范围 | Range: bytes=500-999 |
36 | | Referer | 先前网页的地址,当前请求网页紧随其后,即来路 | Referer: http://www.zcmhi.com/archives/71.html |
37 | | TE | 客户端愿意接受的传输编码,并通知服务器接受接受尾加头信息 | TE: trailers,deflate;q=0.5 |
38 | | Upgrade | 向服务器指定某种传输协议以便服务器进行转换(如果支持) | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
39 | | User-Agent | User-Agent的内容包含发出请求的用户信息 | User-Agent: Mozilla/5.0 (Linux; X11) |
40 | | Via | 通知中间网关或代理服务器地址,通信协议 | Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
41 | | Warning | 关于消息实体的警告信息 | Warn: 199 Miscellaneous warning |
42 |
43 | **请求正文**
44 |
45 | 请求正文不一定都有的,比如,get请求方法就没有请求正文部分。
46 |
47 | 
48 |
49 | 例如,上图就是一个请求的实例,分别有:**请求行、请求头**,由于是一个Get请求,所以是没有请求体的,当然,比如post、put等请求,就会有请求体。
50 |
51 | 那么,http的响应报文结构,也是类似的。
52 |
53 | 主要由**状态行、响应头、空行、响应正文**组成。
54 |
55 | 
56 |
57 | 常见的响应头有:
58 |
59 |
60 |
61 | 响应头 | 说明 |
62 | ---------|----------|
63 | Server | 服务器应用程序软件的名称和版本 |
64 | Content-Type | 响应正文的类型(是图片或者二进制字符串等) |
65 | Content-Length | 响应正文长度 |
66 | Content-Charset | 响应正文使用的编码 |
67 | Content-Encoding | 文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。利用gzip压缩文档能够显著地减少HTML文档的下载时间。Java的GZIPOutputStream可以很方便地进行gzip压缩,但只有Unix上的Netscape和Windows上的IE 4、IE 5才支持它。因此,Servlet应该通过查看Accept-Encoding头(即request.getHeader("Accept-Encoding"))检查浏览器是否支持gzip,为支持gzip的浏览器返回经gzip压缩的HTML页面,为其他浏览器返回普通页面。 |
68 | Content-Language | 响应正文使用的语言 |
69 | Expires |应该在什么时候认为文档已经过期,从而不再缓存它?
70 | Last-Modified | 文档的最后改动时间。客户可以通过If-Modified-Since请求头提供一个日期,该请求将被视为一个条件GET,只有改动时间迟于指定时间的文档才会返回,否则返回一个304(Not Modified)状态。Last-Modified也可用setDateHeader方法来设置。
71 |
72 | > http状态码
73 |
74 | **HTTP状态码分类**
75 | HTTP状态码共分为5种类型:
76 | | 分类 | 分类描述 |
77 | |-----|-----|
78 | | 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
79 | | 2** | 成功,操作被成功接收并处理 |
80 | | 3** | 重定向,需要进一步的操作以完成请求 |
81 | | 4** | 客户端错误,请求包含语法错误或无法完成请求 |
82 | | 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
83 |
84 | HTTP的状态码列表:
85 |
86 | | 状态码 | 状态码英文名称 | 中文描述 |
87 | |-----|-----|-----|
88 | | 100 | Continue | 继续。客户端应继续其请求 |
89 | | 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
90 | | |
91 | | 200 | OK | 请求成功。一般用于GET与POST请求 |
92 | | 201 | Created | 已创建。成功请求并创建了新的资源 |
93 | | 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
94 | | 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
95 | | 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
96 | | 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
97 | | 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
98 | | |
99 | | 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
100 | | 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
101 | | 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
102 | | 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
103 | | 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
104 | | 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
105 | | 306 | Unused | 已经被废弃的HTTP状态码 |
106 | | 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
107 | | |
108 | | 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
109 | | 401 | Unauthorized | 请求要求用户的身份认证 |
110 | | 402 | Payment Required | 保留,将来使用 |
111 | | 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
112 | | 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
113 | | 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
114 | | 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
115 | | 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
116 | | 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
117 | | 409 | Conflict | 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突 |
118 | | 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
119 | | 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
120 | | 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
121 | | 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
122 | | 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
123 | | 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
124 | | 416 | Requested range not satisfiable | 客户端请求的范围无效 |
125 | | 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
126 | | |
127 | | 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
128 | | 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
129 | | 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
130 | | 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
131 | | 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
132 | | 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
133 |
134 | > http的缓存机制了解吗?有关缓存的首部字段有哪些呢?
135 |
136 | **Last-Modified和If-Modifed-since**
137 |
138 | Last-Modified:是由服务器发往客户端的最后的时间
139 | If-Modified-since:是由客户端发往服务器的最后时间
140 |
141 | 用于记录页面最后修改的时间的Http头信息:服务器将请求的Last-Modified发往客户端,客户端如果没有缓存,则缓存在浏览器,然后,客户端每次将If-Modified-Since发往服务端,每次如果服务端发现服务端资源没有发生改变,则自动返回304,内容为空,这样节省了传输的数据量,如果服务端发现有新的资源,则返回200,并且返回新的资源,然后浏览器丢弃旧的资源,缓存新的资源。
142 |
143 | **ETag和if-None-Match**
144 |
145 | ETag是服务器会为每个资源分配对应的ETag值,当资源内容发生改变时,其值也会发生改变。
146 |
147 | ETag和if-None-Match的工作原理是在Http的Response中添加ETags,当客户端再次请求该资源时,将在Http的Request中加入if-None-Match信息(ETag值)。如果服务器资源验证的ETags没有改变,将返回一个304状态;否则,服务器返回一个200状态,并返回该资源和新的ETags。
148 |
149 | **Expires/Cache-Control(优先使用)**
150 |
151 | Expires用于控制缓存的失效时间,但是有一个缺点就是失效时间是服务器返回的时间,跟客户端会存在延时,所以,在http1.1中,加入了Cache-Control,这声明是一种相对秒级,可以避免服务端和客户端时间不一致的问题。
152 |
153 | Expires的格式:`expires=Fri, 17 Jul 2020 21:15:42 GMT`。
154 |
155 | Cache-Control的格式:`'Cache-Control': 'max-age=2000000, no-store'`
156 |
157 |
158 | > Last-Modified和Etag 如何帮助提高性能?
159 |
160 | 一起使用,利用客户端缓存,服务端判断页面是否被修改。
161 |
162 | > 有了Last-Modified为什么还要用ETag字段呢?
163 |
164 | - 文件修改非常频繁时,If-Modifed-since能检查到的粒度是秒级的,这种修改无法使用If-Modifed-since。
165 | - 某些文件周期性的修改,但是内容没有改变,这种无法体现,导致重新get。
166 | - 某些服务器不能精准的得到文件的最后修改时间,利用ETag提供了更加严格的验证。
167 |
168 |
169 | > http1.1和http1.0的区别?
170 |
171 | - 长连接与短连接的区别:http1.1使用长连接,在请求消息中会包含Connection:Keep-Alive的头域。
172 | - 分块传输:
173 | 在http1.0中,用于指定实体长度的唯一机制是通过content-length,静态资源没有问题,但对于动态资源,为了获取长度,只有等他完全生成以后才能获取content-length的值,这要求缓存整个响应,延长了响应用户的时间。
174 | 在http1.1中,引入了分块的传输方法,该方法使得发送方可以将消息实体分割为任意大小的组块,在每个组块的前面都加上长度,最后的一块为空块,标识完成传输,这样避免了服务器端大量的占用缓存。
175 | - http状态码100 Continue:
176 | 当客户端发送的post请求的数据大于1024字节是,客户端并不是直接发起POST请求,而是分为两步,1)发送一个请求,包含Expect:100-continue,询问服务端是否接受数据;2)接受到服务端返回的100 continue后,才将数据发送给服务端。
177 | 这是为了避免发送一个冗长的请求,占用服务端的资源。
178 | - Host域:
179 | http1.1中,随着虚拟主机技术的发展,物理服务器上可以存在多个虚拟主机,所以,在1.1中可以在host中存在多个ip地址。
180 |
181 | > http常用方法有哪些?
182 |
183 | |方法 | 说明 | 支持的HTTP协议版本|
184 | |-----|------|------|
185 | |GET | 获取资源| 1.0、1.1|
186 | |POST | 传输实体主体 | 1.0、1.1|
187 | |PUT | 传输文件 | 1.0、1.1|
188 | |HEAD | 获得报文首部 | 1.0、1.1|
189 | |DELETE | 删除文件 | 1.0、1.1|
190 | |OPTIONS | 询问支持的方法 | 1.1|
191 | |TRACE | 追踪路径 | 1.1|
192 | |CONNECT | 要求用隧道协议连接代理 | 1.1|
193 |
194 | > http哪些是幂等的呢?
195 |
196 | 幂等性是指一次或者多次操作所产生的副作用是一样的。
197 |
198 | GET、Put、Delete是幂等的,Post不是幂等的。
199 |
200 | > http的请求方法get和post的区别?
201 |
202 | - 从幂等性和安全性来说:Get是指查询或者获取资源,它是幂等的,同时也是安全的,而post一般是更新资源,既不是幂等的也不是安全的。
203 | - 从传输方式和传输数量大小限制方面:get请求放在请求行后面,有传输大小限制;post请求放在消息体中,没有传输大小限制。
204 | - 从是否缓存的角度:get请求的数据会被浏览器缓存起来,post则不会。
205 |
206 | > 为什么http是无状态的,如何保持状态?
207 |
208 | 无状态性是指:对事务处理没有记忆的能力,每一次的请求信息返回之后,就会丢弃,服务器无法知道与上次请求的联系,
209 | 好处:不用分配内存记录大量状态,节省服务端资源;
210 | 缺点:每次需要重新传输大量的数据。
211 |
212 | 保持状态采用的是会话跟踪技术(解决无状态性),主要的方法有:Cookie、Url重写、session和利用html嵌入表单域。
213 |
214 | > http短连接和长连接原理
215 |
216 | http1.0默认使用短连接,http1.1默认使用长连接,长连接是request中添加Connection:keep-alive,这样就是长连接。
217 |
218 | 另外,http的短连接和长连接,实质上就是TCP协议的长连接和短连接。
219 |
220 | http长连接的优点:
221 | - 通过开启或者关闭更少的连接,节约cpu时间和内存
222 | - 通过减少TCP开启和关闭引起的包的数量,降低网络阻塞
223 |
224 | http长连接的缺点:服务器维护一个长连接会增加开销,消耗服务器资源。
225 |
226 | > 说说http的特点
227 |
228 | - 支持客户端、服务端通信模式
229 | - 简单方便快捷:发送请求,只需要简单的输入请求路径和请求方法即可,然后通过浏览器发送就可以了。
230 | - 灵活:http协议允许客户端和服务端传输任意类型任意合适的数据对象,这些不同类型由Content-Type标记。
231 | - 无连接:每次客户端发送请求到服务端,服务端响应之后,就会断开连接。
232 | - 无状态:http是无状态的协议,请求的处理没有记忆能力。
233 |
234 | > http存在哪些安全性问题?怎么解决
235 |
236 | - 通过使用明文不加密,内容可能被窃听
237 | - 不验证通信方的身份,可能遭到伪装
238 | - 无法验证报文的完整性,可能被篡改
239 |
240 | 可以采用https进行解决。
241 |
242 | > https的作用,https中的安全性技术有哪些
243 |
244 | https可以对内容进行加密,进行身份验证,同时可以检验数据完整性。
245 |
246 | https的安全性技术:
247 | - 对称性加密算法:用于真正传输的数据进行加密。
248 | - 非对称性加密算法:用于在握手过程中加密生成的密码,非对称性加密算法会生成公钥和私钥。
249 | - 散列算法:用于验证数据的完整性。
250 | - 数字证书:使用数字证书进行证明自己的身份。
251 |
252 | > https和http的区别?
253 |
254 | - https更加安全:https可以通过加密、数据完整性验证和身份验证的方法保证数据的安全。
255 | - https需要申请证书,在CA申请证书。
256 | - 端口不同:http采用80,https采用443。
257 | - http协议运行在tcp之上,https运行在ssl、TLS之上的http协议,ssl、TLS运行在TCP之上。
258 |
259 | > http和socket的区别?
260 |
261 | - http只能走tcp协议,socket可以走tcp和udp协议。
262 | - http基于请求响应模式,只有客户端发送给了服务端,服务端才可以响应,socket则可以通过服务端推送给客户端。
263 | - socket效率高,因为不需要解析报文头部字段等。
264 |
265 |
--------------------------------------------------------------------------------
/docs/java/基础面试题/tomcat.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ## Tomcat是什么?
4 |
5 | * Tomcat 服务器Apache软件基金会项目中的一个核心项目,是一个免费的开放源代码的Web 应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP 程序的首选。
6 |
7 | ## Tomcat的缺省端口是多少,怎么修改
8 |
9 | * 默认8080
10 |
11 | * 修改端口号方式
12 |
13 | 1. 找到Tomcat目录下的conf文件夹
14 |
15 | 2. 进入conf文件夹里面找到server.xml文件
16 |
17 | 3. 打开server.xml文件
18 |
19 | 4. 在server.xml文件里面找到下列信息
20 |
21 | 5. 把Connector标签的8080端口改成你想要的端口
22 |
23 | ## 怎么在Linux上安装Tomcat
24 |
25 | 1. 先去下载Tomcat的安装包,gz结尾的(代表Linux上的Tomcat)
26 | 2. 上传到Linux上,解压
27 | 3. 修改端口号,也可以不修改把。如果要修改在server.xml内改
28 | 4. 修改好了之后,你就进入你这个tomcat下的bin目录,输入:./startup.sh 这样就启动成功了。
29 |
30 | ## 怎么在Linux部署项目
31 |
32 | * 先使用eclipse或IDEA把项目打成.war包,然后上传到Linux服务器,然后把项目放在Tomcat的bin目录下的webapps,在重启Tomcat就行了。
33 |
34 | ## Tomcat的目录结构
35 |
36 | * /bin:存放用于启动和暂停Tomcat的脚本
37 | * /conf:存放Tomcat的配置文件
38 | * /lib:存放Tomcat服务器需要的各种jar包
39 | * /logs:存放Tomcat的日志文件
40 | * /temp:Tomcat运行时用于存放临时文件
41 | * /webapps:web应用的发布目录
42 | * /work:Tomcat把有jsp生成Servlet防御此目录下
43 |
44 | ## 类似Tomcat,发布jsp运行的web服务器还有那些:
45 |
46 | * 1、Resin Resin提供了最快的jsp/servlets运行平台。在java和javascript的支持下,Resin可以为任务灵活选用合适的开发语言。Resin的一种先进的语言XSL(XML stylesheet language)可以使得形式和内容相分离。
47 |
48 | * 2、Jetty Jetty是一个开源的servlet容器,它为基于Java的web内容,例如JSP和servlet提供运行环境。Jetty是使用Java语言编写的,它的API以一组JAR包的形式发布。开发人员可以将Jetty容器实例化成一个对象,可以迅速为一些独立运行(stand-alone)的Java应用提供网络和web连接。
49 |
50 | * 3、WebLogic BEA WebLogic是用于开发、集成、部署和管理大型分布式Web应用、网络应用和数据库应用的Java应用服务器。将Java的动态功能和Java Enterprise标准的安全性引入大型网络应用的开发、集成、部署和管理之中。
51 |
52 | * 4、jboss Jboss是一个基于J2EE的开放源代码的应用服务器。 JBoss代码遵循LGPL许可,可以在任何商业应用中免费使用,而不用支付费用。JBoss是一个管理EJB的容器和服务器,支持EJB 1.1、EJB 2.0和EJB3的规范。但JBoss核心服务不包括支持servlet/JSP的WEB容器,一般与Tomcat或Jetty绑定使用。
53 |
54 | ## tomcat 如何优化?
55 |
56 | 1. 改Tomcat最大线程连接数 需要修改conf/server.xml文件,修改里面的配置文件: maxThreads=”150”//Tomcat使用线程来处理接收的每个请求。这个值表示Tomcat可 创建的最大的线程数。默认值200。可以根据机器的时期性能和内存大小调整,一般 可以在400-500。最大可以在800左右。
57 |
58 | 2. Tomcat内存优化,启动时告诉JVM我要多大内存 调优方式的话,修改: Windows 下的catalina.bat Linux 下的catalina.sh 修改方式如: JAVA_OPTS=’-Xms256m -Xmx512m’-Xms JVM初始化堆的大小-Xmx JVM堆的最大值 实际参数大
59 |
60 | ## tomcat 有哪几种Connector 运行模式(优化)?
61 |
62 | **下面,我们先大致了解Tomcat Connector的三种运行模式。**
63 |
64 | 1. **BIO:同步并阻塞** 一个线程处理一个请求。缺点:并发量高时,线程数较多,浪费资源。Tomcat7或以下,在Linux系统中默认使用这种方式。 **配制项**:protocol=”HTTP/1.1”
65 |
66 | 2. **NIO:同步非阻塞IO** 利用Java的异步IO处理,可以通过少量的线程处理大量的请求,可以复用同一个线程处理多个connection(多路复用)。
67 |
68 | Tomcat8在Linux系统中默认使用这种方式。 Tomcat7必须修改Connector配置来启动。 **配制项**:protocol=”org.apache.coyote.http11.Http11NioProtocol” **备注**:我们常用的Jetty,Mina,ZooKeeper等都是基于java nio实现.
69 |
70 | 3. APR:即Apache Portable Runtime,从操作系统层面解决io阻塞问题。 **AIO方式**,**异步非阻塞IO**(Java NIO2又叫AIO) 主要与NIO的区别主要是操作系统的底层区别.可以做个比喻:比作快递,NIO就是网购后要自己到官网查下快递是否已经到了(可能是多次),然后自己去取快递;AIO就是快递员送货上门了(不用关注快递进度)。
71 |
72 | **配制项**:protocol=”org.apache.coyote.http11.Http11AprProtocol” **备注**:需在本地服务器安装APR库。Tomcat7或Tomcat8在Win7或以上的系统中启动默认使用这种方式。Linux如果安装了apr和native,Tomcat直接启动就支持apr。
73 |
74 | ## Tomcat有几种部署方式?
75 |
76 | **在Tomcat中部署Web应用的方式主要有如下几种:**
77 |
78 | 1. 利用Tomcat的自动部署。
79 |
80 | 把web应用拷贝到webapps目录。Tomcat在启动时会加载目录下的应用,并将编译后的结果放入work目录下。
81 |
82 | 2. 使用Manager App控制台部署。
83 |
84 | 在tomcat主页点击“Manager App” 进入应用管理控制台,可以指定一个web应用的路径或war文件。
85 |
86 | 3. 修改conf/server.xml文件部署。
87 |
88 | 修改conf/server.xml文件,增加Context节点可以部署应用。
89 |
90 | 4. 增加自定义的Web部署文件。
91 |
92 | 在conf/Catalina/localhost/ 路径下增加 xyz.xml文件,内容是Context节点,可以部署应用。
93 |
94 | ## tomcat容器是如何创建servlet类实例?用到了什么原理?
95 |
96 | 1. 当容器启动时,会读取在webapps目录下所有的web应用中的web.xml文件,然后对 **xml文件进行解析,并读取servlet注册信息**。然后,将每个应用中注册的servlet类都进行加载,并通过 **反射的方式实例化**。(有时候也是在第一次请求时实例化)
97 | 2. 在servlet注册时加上1如果为正数,则在一开始就实例化,如果不写或为负数,则第一次请求实例化。
98 |
99 | ## Tomcat工作模式
100 |
101 | * Tomcat作为servlet容器,有三种工作模式:
102 |
103 | * 1、独立的servlet容器,servlet容器是web服务器的一部分;
104 | * 2、进程内的servlet容器,servlet容器是作为web服务器的插件和java容器的实现,web服务器插件在内部地址空间打开一个jvm使得java容器在内部得以运行。反应速度快但伸缩性不足;
105 | * 3、进程外的servlet容器,servlet容器运行于web服务器之外的地址空间,并作为web服务器的插件和java容器实现的结合。反应时间不如进程内但伸缩性和稳定性比进程内优;
106 | * 进入Tomcat的请求可以根据Tomcat的工作模式分为如下两类:
107 |
108 | * Tomcat作为应用程序服务器:请求来自于前端的web服务器,这可能是Apache, IIS, Nginx等;
109 | * Tomcat作为独立服务器:请求来自于web浏览器;
110 | * 面试时问到Tomcat相关问题的几率并不高,正式因为如此,很多人忽略了对Tomcat相关技能的掌握,下面这一篇文章整理了Tomcat相关的系统架构,介绍了Server、Service、Connector、Container之间的关系,各个模块的功能,可以说把这几个掌握住了,Tomcat相关的面试题你就不会有任何问题了!另外,在面试的时候你还要有意识无意识的往Tomcat这个地方引,就比如说常见的Spring MVC的执行流程,一个URL的完整调用链路,这些相关的题目你是可以往Tomcat处理请求的这个过程去说的!掌握了Tomcat这些技能,面试官一定会佩服你的!
111 |
112 | * 学了本章之后你应该明白的是:
113 |
114 | * Server、Service、Connector、Container四大组件之间的关系和联系,以及他们的主要功能点;
115 | * Tomcat执行的整体架构,请求是如何被一步步处理的;
116 | * Engine、Host、Context、Wrapper相关的概念关系;
117 | * Container是如何处理请求的;
118 | * Tomcat用到的相关设计模式;
119 |
120 | ## Tomcat顶层架构
121 |
122 | * 俗话说,站在巨人的肩膀上看世界,一般学习的时候也是先总览一下整体,然后逐个部分个个击破,最后形成思路,了解具体细节,Tomcat的结构很复杂,但是 Tomcat 非常的模块化,找到了 Tomcat 最核心的模块,问题才可以游刃而解,了解了 Tomcat 的整体架构对以后深入了解 Tomcat 来说至关重要!
123 |
124 | * 先上一张Tomcat的顶层结构图(图A),如下:
125 |
126 | 
127 |
128 | * Tomcat中最顶层的容器是Server,代表着整个服务器,从上图中可以看出,一个Server可以包含至少一个Service,即可以包含多个Service,用于具体提供服务。
129 |
130 | * Service主要包含两个部分:Connector和Container。从上图中可以看出 Tomcat 的心脏就是这两个组件,他们的作用如下:
131 |
132 | * Connector用于处理连接相关的事情,并提供Socket与Request请求和Response响应相关的转化;
133 | * Container用于封装和管理Servlet,以及具体处理Request请求;
134 | * 一个Tomcat中只有一个Server,一个Server可以包含多个Service,一个Service只有一个Container,但是可以有多个Connectors,这是因为一个服务可以有多个连接,如同时提供Http和Https链接,也可以提供向相同协议不同端口的连接,示意图如下(Engine、Host、Context下面会说到):
135 |
136 | 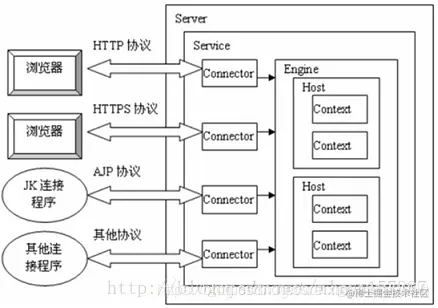
137 |
138 | * 多个 Connector 和一个 Container 就形成了一个 Service,有了 Service 就可以对外提供服务了,但是 Service 还要一个生存的环境,必须要有人能够给她生命、掌握其生死大权,那就非 Server 莫属了!所以整个 Tomcat 的生命周期由 Server 控制。
139 |
140 | * 另外,上述的包含关系或者说是父子关系,都可以在tomcat的conf目录下的server.xml配置文件中看出,下图是删除了注释内容之后的一个完整的server.xml配置文件(Tomcat版本为8.0)
141 |
142 | 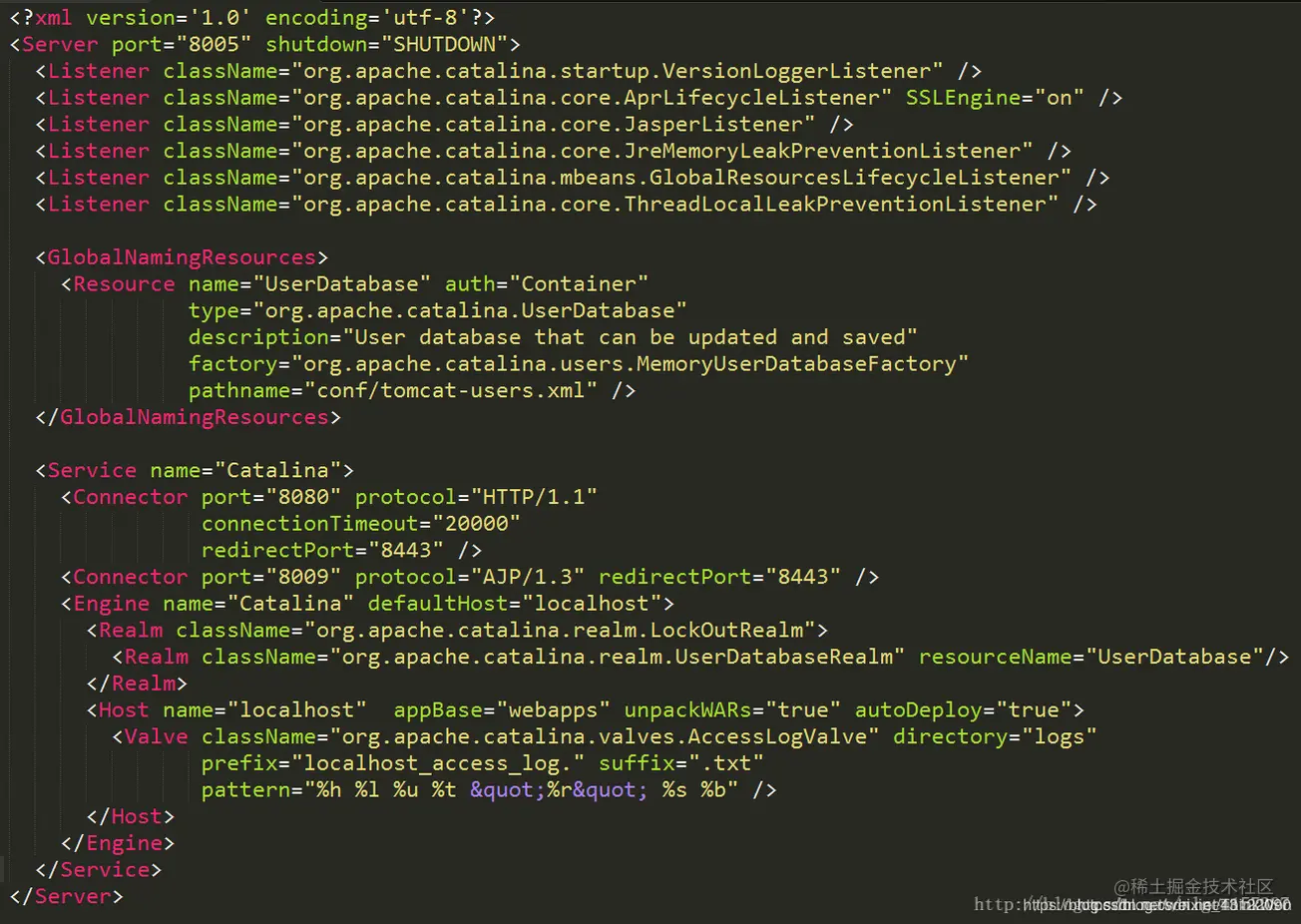
143 |
144 | * 详细的配置文件内容可以到Tomcat官网查看:[Tomcat配置文件](https://link.juejin.cn?target=http%3A%2F%2Ftomcat.apache.org%2Ftomcat-8.0-doc%2Findex.html "http://tomcat.apache.org/tomcat-8.0-doc/index.html")
145 |
146 | * 上边的配置文件,还可以通过下边的一张结构图更清楚的理解:
147 |
148 | 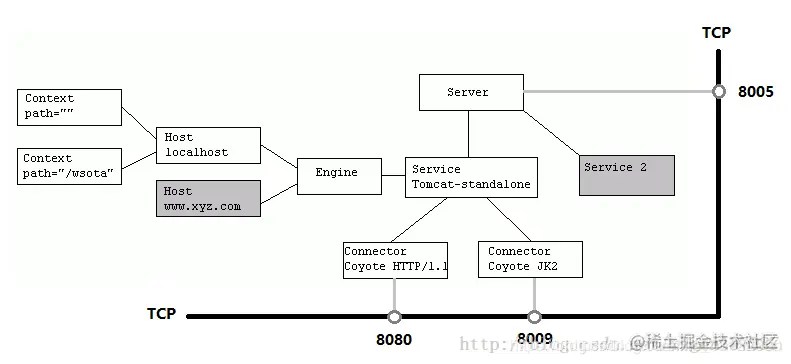
149 |
150 | * Server标签设置的端口号为8005,shutdown=”SHUTDOWN” ,表示在8005端口监听“SHUTDOWN”命令,如果接收到了就会关闭Tomcat。一个Server有一个Service,当然还可以进行配置,一个Service有多个Connector,Service左边的内容都属于Container的,Service下边是Connector。
151 |
152 | ### Tomcat顶层架构小结
153 |
154 | 1. Tomcat中只有一个Server,一个Server可以有多个Service,一个Service可以有多个Connector和一个Container;
155 |
156 | 2. Server掌管着整个Tomcat的生死大权;
157 |
158 | 3. Service 是对外提供服务的;
159 |
160 | 4. Connector用于接受请求并将请求封装成Request和Response来具体处理;
161 |
162 | 5. Container用于封装和管理Servlet,以及具体处理request请求;
163 |
164 | * 知道了整个Tomcat顶层的分层架构和各个组件之间的关系以及作用,对于绝大多数的开发人员来说Server和Service对我们来说确实很远,而我们开发中绝大部分进行配置的内容是属于Connector和Container的,所以接下来介绍一下Connector和Container。
165 |
166 | ## Connector和Container的微妙关系
167 |
168 | * 由上述内容我们大致可以知道一个请求发送到Tomcat之后,首先经过Service然后会交给我们的Connector,Connector用于接收请求并将接收的请求封装为Request和Response来具体处理,Request和Response封装完之后再交由Container进行处理,Container处理完请求之后再返回给Connector,最后在由Connector通过Socket将处理的结果返回给客户端,这样整个请求的就处理完了!
169 |
170 | * Connector最底层使用的是Socket来进行连接的,Request和Response是按照HTTP协议来封装的,所以Connector同时需要实现TCP/IP协议和HTTP协议!
171 |
172 | * Tomcat既然需要处理请求,那么肯定需要先接收到这个请求,接收请求这个东西我们首先就需要看一下Connector!
173 |
174 | * Connector架构分析
175 |
176 | * Connector用于接受请求并将请求封装成Request和Response,然后交给Container进行处理,Container处理完之后在交给Connector返回给客户端。
177 |
178 | * 因此,我们可以把Connector分为四个方面进行理解:
179 |
180 | * Connector如何接受请求的?
181 | * 如何将请求封装成Request和Response的?
182 | * 封装完之后的Request和Response如何交给Container进行处理的?
183 | * Container处理完之后如何交给Connector并返回给客户端的?
184 | * 首先看一下Connector的结构图(图B),如下所示:
185 |
186 | 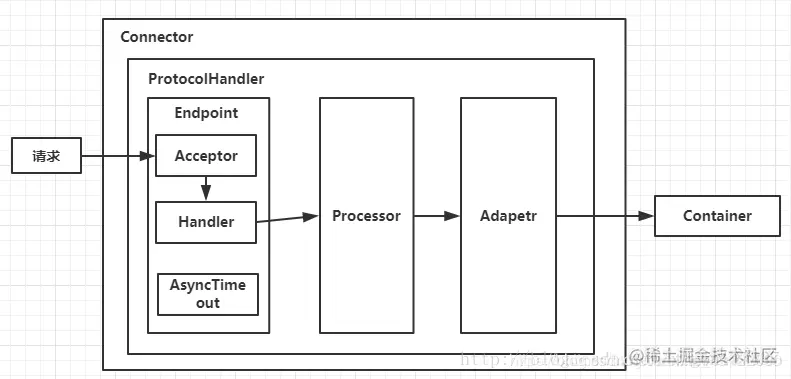
187 | * Connector就是使用ProtocolHandler来处理请求的,不同的ProtocolHandler代表不同的连接类型,比如:Http11Protocol使用的是普通Socket来连接的,Http11NioProtocol使用的是NioSocket来连接的。
188 |
189 | * 其中ProtocolHandler由包含了三个部件:Endpoint、Processor、Adapter。
190 |
191 | 1. Endpoint用来处理底层Socket的网络连接,Processor用于将Endpoint接收到的Socket封装成Request,Adapter用于将Request交给Container进行具体的处理。
192 | 2. Endpoint由于是处理底层的Socket网络连接,因此Endpoint是用来实现TCP/IP协议的,而Processor用来实现HTTP协议的,Adapter将请求适配到Servlet容器进行具体的处理。
193 | 3. Endpoint的抽象实现AbstractEndpoint里面定义的Acceptor和AsyncTimeout两个内部类和一个Handler接口。Acceptor用于监听请求,AsyncTimeout用于检查异步Request的超时,Handler用于处理接收到的Socket,在内部调用Processor进行处理。
194 | * 至此,我们应该很轻松的回答1,2,3的问题了,但是4还是不知道,那么我们就来看一下Container是如何进行处理的以及处理完之后是如何将处理完的结果返回给Connector的?
195 |
196 | ## Container架构分析
197 |
198 | * Container用于封装和管理Servlet,以及具体处理Request请求,在Container内部包含了4个子容器,结构图如下(图C):
199 |
200 | 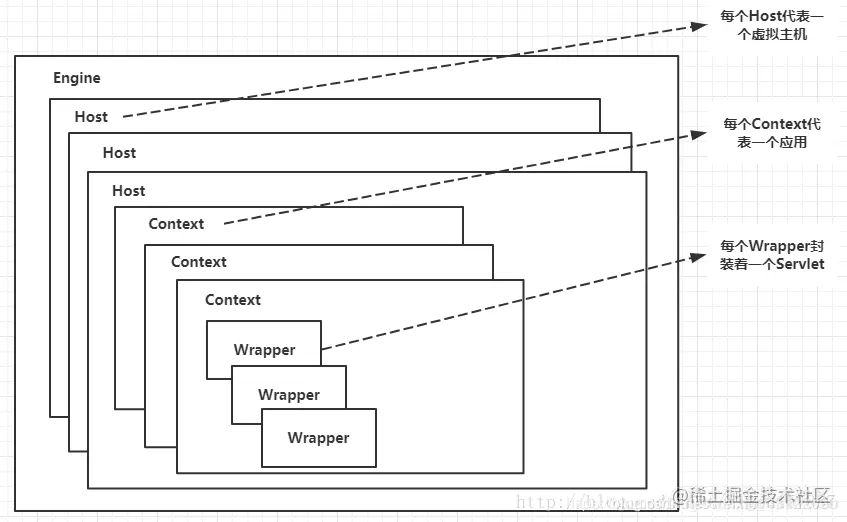
201 |
202 | * 4个子容器的作用分别是:
203 |
204 | 1. Engine:引擎,用来管理多个站点,一个Service最多只能有一个Engine;
205 | 2. Host:代表一个站点,也可以叫虚拟主机,通过配置Host就可以添加站点;
206 | 3. Context:代表一个应用程序,对应着平时开发的一套程序,或者一个WEB-INF目录以及下面的web.xml文件;
207 | 4. Wrapper:每一Wrapper封装着一个Servlet;
208 | * 下面找一个Tomcat的文件目录对照一下,如下图所示:
209 |
210 | 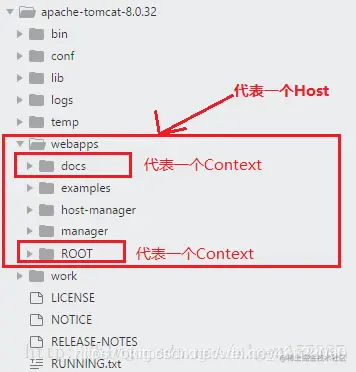
211 |
212 | * Context和Host的区别是Context表示一个应用,我们的Tomcat中默认的配置下webapps下的每一个文件夹目录都是一个Context,其中ROOT目录中存放着主应用,其他目录存放着子应用,而整个webapps就是一个Host站点。
213 |
214 | * 我们访问应用Context的时候,如果是ROOT下的则直接使用域名就可以访问,例如:www.baidu.com,如果是Host(webapps)下的其他应用,则可以使用www.baidu.com/docs进行访问,当然默认指定的根应用(ROOT)是可以进行设定的,只不过Host站点下默认的主应用是ROOT目录下的。
215 |
216 | * 看到这里我们知道Container是什么,但是还是不知道Container是如何进行请求处理的以及处理完之后是如何将处理完的结果返回给Connector的?别急!下边就开始探讨一下Container是如何进行处理的!
217 |
218 | ### Container如何处理请求的
219 |
220 | * Container处理请求是使用Pipeline-Valve管道来处理的!(Valve是阀门之意)
221 |
222 | * Pipeline-Valve是**责任链模式**,责任链模式是指在一个请求处理的过程中有很多处理者依次对请求进行处理,每个处理者负责做自己相应的处理,处理完之后将处理后的结果返回,再让下一个处理者继续处理。
223 |
224 | 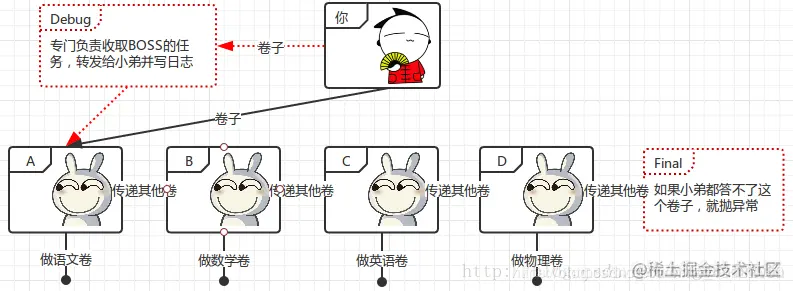
225 |
226 | * 但是!Pipeline-Valve使用的责任链模式和普通的责任链模式有些不同!区别主要有以下两点:
227 |
228 | * 每个Pipeline都有特定的Valve,而且是在管道的最后一个执行,这个Valve叫做BaseValve,BaseValve是不可删除的;
229 |
230 | * 在上层容器的管道的BaseValve中会调用下层容器的管道。
231 |
232 | * 我们知道Container包含四个子容器,而这四个子容器对应的BaseValve分别在:StandardEngineValve、StandardHostValve、StandardContextValve、StandardWrapperValve。
233 |
234 | * Pipeline的处理流程图如下(图D):
235 |
236 | 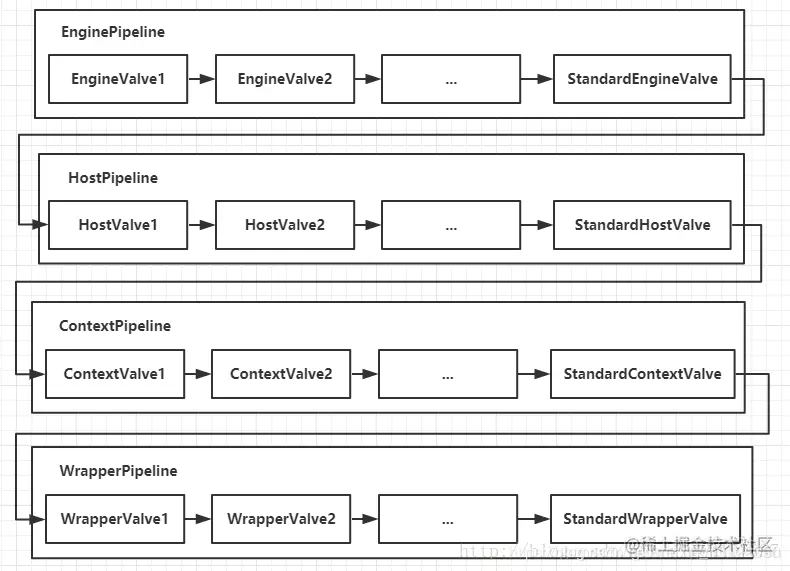
237 |
238 | * Connector在接收到请求后会首先调用最顶层容器的Pipeline来处理,这里的最顶层容器的Pipeline就是EnginePipeline(Engine的管道);
239 |
240 | * 在Engine的管道中依次会执行EngineValve1、EngineValve2等等,最后会执行StandardEngineValve,在StandardEngineValve中会调用Host管道,然后再依次执行Host的HostValve1、HostValve2等,最后在执行StandardHostValve,然后再依次调用Context的管道和Wrapper的管道,最后执行到StandardWrapperValve。
241 |
242 | * 当执行到StandardWrapperValve的时候,会在StandardWrapperValve中创建FilterChain,并调用其doFilter方法来处理请求,这个FilterChain包含着我们配置的与请求相匹配的Filter和Servlet,其doFilter方法会依次调用所有的Filter的doFilter方法和Servlet的service方法,这样请求就得到了处理!
243 |
244 | * 当所有的Pipeline-Valve都执行完之后,并且处理完了具体的请求,这个时候就可以将返回的结果交给Connector了,Connector在通过Socket的方式将结果返回给客户端。
245 |
246 | ## 总结
247 |
248 | * 至此,我们已经对Tomcat的整体架构有了大致的了解,从图A、B、C、D可以看出来每一个组件的基本要素和作用。我们在脑海里应该有一个大概的轮廓了!如果你面试的时候,让你简单的聊一下Tomcat,上面的内容你能脱口而出吗?当你能够脱口而出的时候,面试官一定会对你刮目相看的!
249 |
250 | 作者:小杰要吃蛋
251 | 链接:https://juejin.cn/post/6844904127059722247
252 | 来源:稀土掘金
253 | 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
--------------------------------------------------------------------------------
/docs/project/秒杀项目总结.md:
--------------------------------------------------------------------------------
1 | 1 介绍项目
2 |
3 | 1)项目整体设计的感受(可以画架构图)
4 | 2)你负责了什么,承担了什么角色,做了什么
5 | 3)项目描述,最好体现自己的综合素质:如何协调开发,遇到问题如何解决,用什么技术实现了什么功能
6 |
7 | 2 缓存雪崩
8 |
9 | 3 问题:秒杀地址不应该爆漏给用户
10 |
11 | 写脚本,LRU缓存控制请求数量
12 |
13 | 4 不同数据库的数据读写
14 |
15 | 分布式锁,消息队列(提高性能,降低耦合度,流量削峰)
16 |
17 | 5 分布式事物解决方案
18 |
19 | 6 数据库与redis缓存如何保持一致性
20 |
21 | 7 秒杀多个步骤如何保证线程安全性
22 |
23 | 客观锁,悲观锁
24 |
25 | 8 用的什么测试工具
26 |
27 | Redis缓存服务
28 |
29 | 缓存商品和商品详情信息,如果不存在,则从数据库查询,并且加入到redis缓存,如果存在,直接返回。
30 |
31 |
32 |
33 | ##### RabbitMQ
34 |
35 | 1)异步订单
36 | 2)异步支付
37 | 3)订单超时处理(quartz)
38 |
39 | #### 缓存的信息:商品信息,商品详情信息,订单信息
40 |
41 | #### 查询订单优化
42 |
43 |
44 | 面杀系统架构设计思路
45 |
46 |
47 |
48 | ### 面试经验相关
49 |
50 | - https://github.com/AobingJava/JavaFamily
51 | - [互联网公司的面试官是如何360°无死角考察候选人的?(上篇)](https://mp.weixin.qq.com/s/vhP-2Jrd0Ow2wOqImavrIQ)
52 | - [互联网公司面试官是如何360°无死角考察候选人的?(下篇)](https://mp.weixin.qq.com/s/_NLRJeM1o_QxtsOxmeSTNA)
53 | - [记一位朋友斩获BAT技术专家Offer的面试经历](https://mp.weixin.qq.com/s/AENPcDuVdMAUDtlGM-X8zQ)
54 |
55 | ### 秒杀系统相关
56 |
57 | - [分布式架构图](https://juejin.im/post/5a9ced09518825555f0c72c7)
58 |
59 | #### 秒杀架构设计
60 |
61 | - [秒杀架构设计思路详解](https://blog.csdn.net/qq_35190492/article/details/103105780)
62 |
63 | - **[秒杀关键细节设计](https://blog.csdn.net/fanrenxiang/article/details/85083243)**
64 |
65 | ### 项目技术点
66 |
67 | #### ssm
68 |
69 | #### activiti
70 |
71 | #### lombok、日志log4j
72 |
73 |
74 | ### 分布式相关
75 |
76 | - [分布式相关面试题](https://juejin.im/post/5e9591dee51d4546cf7785ca?utm_source=gold_browser_extension)
77 |
78 | - [扎心!线上服务宕机时,如何保证数据100%不丢失?](https://mp.weixin.qq.com/s/HwAc6o8jdIHQTnE3ghXhIA)
79 |
80 | #### ehcache
81 |
82 | - [EhCache在项目中的使用](https://blog.csdn.net/feng_an_qi/article/details/41819865)
83 |
84 | #### Redis
85 |
86 | - [redis和数据库一致性](https://blog.csdn.net/gly1256288307/article/details/88739612)
87 | - [Redis设计与实现总结文章](https://blog.csdn.net/qq_41594698/category_9067680.html)
88 | - [Redis面试题必备:基础,面试题](https://mp.weixin.qq.com/s/3Fmv7h5p2QDtLxc9n1dp5A)
89 | - [Redis面试相关:其中包含redis知识](https://blog.csdn.net/qq_35190492/article/details/103105780)
90 | - [Redis源码分析](http://cmsblogs.com/?p=4570)
91 | - [redis其他数据结构](https://blog.csdn.net/c_royi/article/details/82011208)
92 | - [redis面试题](https://github.com/AobingJava/JavaFamily/tree/master/docs/redis)
93 |
94 | 其他
95 |
96 | - [gossip协议](https://www.jianshu.com/p/8279d6fd65bb)
97 | - [Raft协议](https://www.jianshu.com/p/aa77c8f4cb5c)
98 |
99 | #### dubbo
100 |
101 | - [dubbo教程](https://blog.ouyangsihai.cn/dubbo-yi-pian-wen-zhang-jiu-gou-liao-dubbo-yu-dao-chu-lian.html)
102 | - [dubbo源码分析](http://cmsblogs.com/?p=5324)
103 | - [dubbo面试题](https://mp.weixin.qq.com/s/PdWRHgm83XwPYP08KnkIsw)
104 | - [dubbo面试题2](https://mp.weixin.qq.com/s/Kz0s9K3J9Lpvh37oP_CtCA)
105 |
106 | #### zookeeper
107 |
108 | - [什么是zookeeper?](https://mp.weixin.qq.com/s/i2_c4A0146B7Ev8QnofbfQ)
109 |
110 | - [Zookeeper教程](http://cmsblogs.com/?p=4139)
111 |
112 | - [zookeeper源码分析](http://cmsblogs.com/?p=4190)
113 |
114 | - [zookeeeper面试题](https://segmentfault.com/a/1190000014479433)
115 |
116 | - [zookeeper面试题2](https://juejin.im/post/5dbac7a0f265da4d2c5e9b3b)
117 |
118 | ### 消息队列
119 |
120 | - [为什么要用消息队列?](https://mp.weixin.qq.com/s/fJwhfqWy0cxH74qs_YBiIg)
121 | - [* 你们的系统架构中为什么要引入消息中间件?](http://mp.weixin.qq.com/s?__biz=MzU0OTk3ODQ3Ng==&mid=2247484149&idx=1&sn=98186297335e13ec7222b3fd43cfae5a&chksm=fba6eaf6ccd163e0c2c3086daa725de224a97814d31e7b3f62dd3ec763b4abbb0689cc7565b0&scene=21#wechat_redirect)
122 | - [哥们,那你说说系统架构引入消息中间件有什么缺点?](https://mp.weixin.qq.com/s/DsowfyzYXcD-OyiL1JOFZw)
123 | - [哥们,消息中间件在你们项目里是如何落地的?](https://mp.weixin.qq.com/s/ZAWPRToPQFcwzHBf47jZ-A)
124 | - [消息中间件集群崩溃,如何保证百万生产数据不丢失?](https://mp.weixin.qq.com/s/AEn3j2lVJOHZx9yegwTsvw)
125 |
126 |
127 | #### RocketMQ
128 |
129 | - [RocketMQ简单教程](https://juejin.im/post/5af02571f265da0b9e64fcfd)
130 | - [RocketMQ教程](https://mp.weixin.qq.com/s/VAZaU1DuKbpnaALjp_-9Qw)
131 | - [RocketMQ源码分析](http://cmsblogs.com/?p=3236)
132 | - [RocketMQ面试题](https://blog.csdn.net/dingshuo168/article/details/102970988)
133 |
134 | #### RabbitMQ
135 |
136 | - [RabbitMQ教程](https://blog.csdn.net/hellozpc/article/details/81436980)
137 | - [RabbitMQ面试题](https://blog.csdn.net/qq_42629110/article/details/84965084)
138 | - [RabbitMQ面试题2](https://my.oschina.net/u/4162503/blog/3073693)
139 | - [RabbitMQ面试题3](https://blog.csdn.net/jerryDzan/article/details/89183625)
140 |
141 | #### kafka
142 |
143 | - [全网最通俗易懂的Kafka入门](https://mp.weixin.qq.com/s/FlSsrzu1FwjBjmlNy5QyOg)
144 | - [全网最通俗易懂的Kafka入门2](https://mp.weixin.qq.com/s/opAYVXIJoy4tCWaPcX5u6g)
145 | - [kafka入门教程](https://www.orchome.com/kafka/index)
146 | - [kafka面试题](https://blog.csdn.net/qq_28900249/article/details/90346599)
147 | - [kafka面试题2](http://trumandu.github.io/2019/04/13/Kafka%E9%9D%A2%E8%AF%95%E9%A2%98%E4%B8%8E%E7%AD%94%E6%A1%88%E5%85%A8%E5%A5%97%E6%95%B4%E7%90%86/)
148 |
149 | ### 分布式解决方案
150 |
151 | - [如果20万用户同时访问一个热点缓存,如何优化你的缓存架构?](https://mp.weixin.qq.com/s/RqBla4rg8ut3zEBKhyBo1w)
152 | - [高并发场景下,如何保证生产者投递到消息中间件的消息不丢失?](https://mp.weixin.qq.com/s/r2_o5wa6Gn94NY4ViRnjpA)
153 | - [从团队自研的百万并发中间件系统的内核设计看Java并发性能优化](https://mp.weixin.qq.com/s/d4qfu2MxESc1YJV4Ud5mnA)
154 | - [支撑日活百万用户的高并发系统,应该如何设计其数据库架构?](https://mp.weixin.qq.com/s/lAB4C1sTpZ9mPEdGp-A7Cg)
155 | - [支撑百万连接的系统应该如何设计其高并发架构?](https://mp.weixin.qq.com/s/12MVd1i-ZRyohI4rh9P4uw)
156 | - [如何保证消息中间件全链路数据100%不丢失(1)](https://mp.weixin.qq.com/s/uqWIf0MAet_StszuOrZCwQ)
157 | - [如何保证消息中间件全链路数据100%不丢失(2)](https://mp.weixin.qq.com/s/9SFrwaCCLnNyuCqP_KQ0zw)
158 | - [消息中间件如何实现消费吞吐量的百倍优化?](https://mp.weixin.qq.com/s/vZ4KVC2eGmssnQUyIKgzfw)
159 | - [优雅的告诉面试官消息中间件该如何实现高可用架构?](https://mp.weixin.qq.com/s/CSLMgoOr8S3Z5DSk86UZ0g)
160 | - [消息中间件如何实现每秒几十万的高并发写入?](https://mp.weixin.qq.com/s/sCRC5h0uw2DWD2MixI6pZw)
161 | - [请谈谈写入消息中间件的数据,如何保证不丢失?](https://mp.weixin.qq.com/s/wbqA9vZOCQ0M_N9Q0NXWVg)
162 | - [如果让你设计一个消息中间件,如何将其网络通信性能优化10倍以上?](https://mp.weixin.qq.com/s/AzNfb7b6MmNUdGcsrwj9Iw)
163 |
164 |
165 | ##### 分布式锁
166 |
167 | - [拜托,面试请不要再问我Redis分布式锁的实现原理](https://mp.weixin.qq.com/s/y_Uw3P2Ll7wvk_j5Fdlusw)
168 | - [每秒上千订单场景下的分布式锁高并发优化实践!](https://mp.weixin.qq.com/s/RLeujAj5rwZGNYMD0uLbrg)
169 | - [彻底讲清楚ZooKeeper分布式锁的实现原理](https://mp.weixin.qq.com/s/jn4LkPKlWJhfUwIKkp3KpQ)
170 |
171 |
172 | ##### 分布式事务
173 |
174 | - [拜托,面试请不要再问我TCC分布式事务的实现原理!](https://mp.weixin.qq.com/s/mIW1_K5fAoa2OlSLdXSHpQ)
175 |
176 | - [分布式事务如何保障实际生产中99.99%高可用?](https://mp.weixin.qq.com/s/yRDUQtVPz5eqCx961xL6nw)
177 |
178 | - [TCC-Transaction实战](https://blog.csdn.net/qq_43253123/article/details/83277580)
179 |
180 | #### 微服务
181 |
182 | - [拜托!面试请不要再问我Spring Cloud底层原理](https://mp.weixin.qq.com/s/mOk0KuEWQUiugyRA3-FXwg)
183 | - [微服务注册中心如何承载大型系统的千万级访问?](https://mp.weixin.qq.com/s/qjMphuPiihBmU2QtFMIfzw)
184 | - [每秒上万并发下的Spring Cloud参数优化实战](https://mp.weixin.qq.com/s/aH0LHgfhxpvp1IY-XbEMWA)
185 | - [微服务架构如何保障双11狂欢下的99.99%高可用](https://mp.weixin.qq.com/s/lBeQSSPX7OeWO6SmWYf1Mg)
186 |
187 | ##### 分布式session
188 |
189 | https://blog.csdn.net/qq_35620501/article/details/95047642
190 |
191 | ##### 分库分表
192 | ##### 读写分离
193 |
194 | ### 亿级流量架构设计方案
195 |
196 | - [分布式主键算法](https://juejin.im/post/6844904065747402759)
197 | - [分布式系统的唯一id生成算法你了解吗?](https://mp.weixin.qq.com/s/dhQ8BCPKfQqMMm9QxpFwow)
198 | - [用大白话给你讲小白都能看懂的分布式系统容错架构](https://mp.weixin.qq.com/s/DKf63ZDJQKoEiOmGqn3NxQ)
199 | - [亿级流量系统架构之如何支撑百亿级数据的存储与计算](https://mp.weixin.qq.com/s/eqtR9QAMIm3F4QnGut1vrA)
200 | - [亿级流量系统架构之如何设计高容错分布式计算系统](https://mp.weixin.qq.com/s/Omzkr-9BoL3GjyiWn9Nhdg)
201 | - [亿级流量系统架构之如何设计承载百亿流量的高性能架构](https://mp.weixin.qq.com/s/o8rZwDGkJwPxHsPpBcQh9w)
202 | - [亿级流量系统架构之如何设计每秒十万查询的高并发架构](https://mp.weixin.qq.com/s/Fw7WL8BiBrQ9osqqWSwqEw)
203 | - [亿级流量系统架构之如何设计全链路99.99%高可用架构](https://mp.weixin.qq.com/s/3-eWMVje_PWnwGmsZZBJog)
204 | - [亿级流量系统架构之如何在上万并发场景下设计可扩展架构(上)?](https://mp.weixin.qq.com/s/8zHlTwTQkl3LNS5beOf5AA)
205 | - [亿级流量系统架构之如何在上万并发场景下设计可扩展架构(中)?](https://mp.weixin.qq.com/s/ThoeXs-Dz7xbs-Nl7Mbfag)
206 | - [亿级流量系统架构之如何在上万并发场景下设计可扩展架构(下)?](https://mp.weixin.qq.com/s/f4We1V8EAIyM8wpvwAHmwQ)
207 | - [亿级流量系统架构之如何保证百亿流量下的数据一致性(上)](https://mp.weixin.qq.com/s/hh-kpRLwKRLLK8fG-5jzTQ)
208 | - [亿级流量系统架构之如何保证百亿流量下的数据一致性(中)?](https://mp.weixin.qq.com/s/suPMfwaXc4ze_csS2WfzHA)
209 | - [亿级流量系统架构之如何保证百亿流量下的数据一致性(下)?](https://mp.weixin.qq.com/s/TdGiiBzaOTo1TeY40NpSTw)
210 |
211 |
212 |
213 | ### 项目工具
214 |
215 | #### git
216 |
217 | - [实际开发中的git命令大全](https://www.jianshu.com/p/53a00fafbe99)
218 |
219 | #### maven
220 |
221 | ### 项目功能点
222 |
223 | #### 单点登录
224 |
225 | - [什么是单点登录](https://mp.weixin.qq.com/s/J6YJls05t2C4OGOqHVijhw)
226 | - [单点登录机制原理](https://mp.weixin.qq.com/s/LGnUueNC-EuoxiF-8b-TeQ)
227 |
228 | #### 前后端分离
229 |
230 | - [前后端分离概述](https://blog.csdn.net/fuzhongmin05/article/details/81591072)
231 | - [前后端分离之JWT用户认证](https://www.jianshu.com/p/180a870a308a)
232 |
233 | #### mysql(优化)
234 |
235 | - [MySQL高频面试题](https://mp.weixin.qq.com/s/KFCkvfF84l6Eu43CH_TmXA)
236 | - [MySQL查询优化过程](https://mp.weixin.qq.com/s/jtuLb8uAIHJNvNpwcIZfpA)
237 |
238 | >生成数据工具:mockaroo
239 |
240 | 1、如果有子查询,改为连接语句
241 | 2、在where条件建立索引:user的id
242 | 3、如果有连接关键词,也建立索引:user的id
243 | 4、如果有分组或者排序,建立索引:order by time
244 | 5、同时也可以建立联合索引
245 |
246 | **需求1**
247 | 某个部门查看审核人员的所有审批信息:先查询某个部门所有的审核人员,根据审批建议、审批时间及审批人查询审批信息(审批数据70w)
248 | ```
249 | select u.* , c.* from user u inner join checklog c
250 | on c.uid == u.id
251 | where u.deptmentId = 1
252 | and time > {1} and time < {2}
253 | and desc like ' %'
254 | ```
255 |
256 | ①子查询:先查询部门的用户id然后再查询相关的审批信息
257 | ②没有加索引:70w数据查询用了3w s。
258 | ③给user的id建立索引,时间减少到了1.003s
259 | ④然后考虑到子查询,所以,改成连接操作,时间变为0.057s
260 | ⑤再给连接字段建立索引,时间变为0.001s
261 | ⑥模拟数据增加到300w时间增加到了0.016s,在部门id和用户id建立联合索引,时间降到了0.005s。
262 | ⑦用时间进行排序,建立时间索引。
263 |
264 | - [MVCC原理](https://liuzhengyang.github.io/2017/04/18/innodb-mvcc/)
265 | - [MySQL锁](https://blog.ouyangsihai.cn/mysql-de-you-yi-shen-qi-suo.html)
266 |
267 | #### 权限控制(设计、shiro)
268 |
269 | - [权限控制设计](https://mp.weixin.qq.com/s/WTgz07xDIf9FbAfCDyTheQ)
270 | - [shiro相关教程](https://blog.csdn.net/sihai12345/category_9268544.html)
271 | - [springboot+vue+shiro前后端分离实战项目](https://blog.csdn.net/neuf_soleil/category_9287210.html)
272 | - [shiro挺好的教程](https://how2j.cn/k/shiro/shiro-springboot/1728.html)
273 |
274 | #### 线上问题调优(虚拟机,tomcat)
275 | - [垃圾收集器ZGC](https://juejin.im/post/5dc361d3f265da4d1f51c670)
276 | - [jvm系列文章](https://crowhawk.github.io/tags/#JVM)
277 | - [* 一次JVM FullGC的背后,竟隐藏着惊心动魄的线上生产事故!](https://mp.weixin.qq.com/s/5SeGxKtwp6KZhUKn8jXi6A)
278 | - [Java虚拟机调优文章](https://blog.ouyangsihai.cn/categories/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3Java%E8%99%9A%E6%8B%9F%E6%9C%BA/)
279 | - [利用VisualVM对高并发项目进行性能分析](https://blog.ouyangsihai.cn/shen-ru-li-jie-java-xu-ni-ji-ru-he-li-yong-visualvm-dui-gao-bing-fa-xiang-mu-jin-xing-xing-neng-fen-xi.html#toc-heading-8)
280 | - [JVM性能调优](https://www.iteye.com/blog/uule-2114697)
281 | - [百亿吞吐量服务的JVM性能调优实战](https://mp.weixin.qq.com/s?__biz=MzIwMzY1OTU1NQ==&mid=2247484236&idx=1&sn=b9743b2d7436f84e4617ff34e07abdd8&chksm=96cd4300a1baca1635a137294bc93c518c033ce01f843c9e012a1454b9f3ea3158fa1412e9da&scene=27&ascene=0&devicetype=android-24&version=26060638&nettype=WIFI&abtest_cookie=BAABAAoACwASABMABAAjlx4AUJkeAFmZHgBomR4AAAA%3D&lang=zh_CN&pass_ticket=%2F%2BLqr9N2EZtrEGLFo9vLA6Eqs89DSJ2CBKoAJFZ%2BBngphEP28dwmMQeSZcUB77qZ&wx_header=1)
282 | - [一次线上JVM调优实践,FullGC40次/天到10天一次的优化过程](https://blog.csdn.net/cml_blog/article/details/81057966)
283 | - [JVM调优工具](https://www.jianshu.com/p/e36fac926539)
284 |
285 | #### 性能优化
286 |
287 | - [记一次接口压力测试与性能调优](https://zhuanlan.zhihu.com/p/45067134)
288 | - [下单接口调优实战,性能提高10倍](https://blog.csdn.net/linsongbin1/article/details/82656887)
289 | - [接口性能优化怎么做?](https://blog.csdn.net/justnow_/article/details/105905560)
290 | - [记一次接口性能优化实践总结:优化接口性能的八个建议](https://www.cnblogs.com/jay-huaxiao/p/12995510.html)
291 |
292 | #### 架构设计
293 |
294 | - [架构演变](https://segmentfault.com/a/1190000018626163)
295 |
296 | #### 并发问题
297 |
298 | #### Tip:本来有很多我准备的资料的,但是都是外链,或者不合适的分享方式,所以大家去公众号回复【资料】好了。
299 |
300 | 
301 |
302 | 现在免费送给大家,在我的公众号 **好好学java** 回复 **资料** 即可获取。
303 |
304 | 有收获?希望老铁们来个三连击,给更多的人看到这篇文章
305 |
306 | 1、老铁们,关注我的原创微信公众号「**好好学java**」,专注于Java、数据结构和算法、微服务、中间件等技术分享,保证你看完有所收获。
307 |
308 | 
309 |
310 | 2、给俺一个 **star** 呗,可以让更多的人看到这篇文章,顺便激励下我继续写作,嘻嘻。
--------------------------------------------------------------------------------
/docs/java/基础面试题/springboot.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ### 什么是 Spring Boot?
4 |
5 | * Spring Boot 是 Spring 开源组织下的子项目,是 Spring 组件一站式解决方案,主要是简化了使用 Spring 的难度,简省了繁重的配置,提供了各种启动器,使开发者能快速上手。
6 |
7 | ### 为什么要用SpringBoot
8 |
9 | * 快速开发,快速整合,配置简化、内嵌服务容器
10 |
11 | ### SpringBoot与SpringCloud 区别
12 |
13 | * SpringBoot是快速开发的Spring框架,SpringCloud是完整的微服务框架,SpringCloud依赖于SpringBoot。
14 |
15 | ### Spring Boot 有哪些优点?
16 |
17 | * Spring Boot 主要有如下优点:
18 | 1. 容易上手,提升开发效率,为 Spring 开发提供一个更快、更简单的开发框架。
19 | 2. 开箱即用,远离繁琐的配置。
20 | 3. 提供了一系列大型项目通用的非业务性功能,例如:内嵌服务器、安全管理、运行数据监控、运行状况检查和外部化配置等。
21 | 4. SpringBoot总结就是使编码变简单、配置变简单、部署变简单、监控变简单等等
22 |
23 | ### Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
24 |
25 | * 启动类上面的注解是@SpringBootApplication,它也是 Spring Boot 的核心注解,主要组合包含了以下 3 个注解:
26 |
27 | * @SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
28 |
29 | * @EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项, 例如:`java 如关闭数据源自动配置功能: @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。`
30 |
31 | * @ComponentScan:Spring组件扫描。
32 |
33 | ### Spring Boot 支持哪些日志框架?推荐和默认的日志框架是哪个?
34 |
35 | * Spring Boot 支持 Java Util Logging, Log4j2, Lockback 作为日志框架,如果你使用 Starters 启动器,Spring Boot 将使用 Logback 作为默认日志框架,但是不管是那种日志框架他都支持将配置文件输出到控制台或者文件中。
36 |
37 | ### SpringBoot Starter的工作原理
38 |
39 | * `我个人理解SpringBoot就是由各种Starter组合起来的,我们自己也可以开发Starter`
40 |
41 | * 在sprinBoot启动时由@SpringBootApplication注解会自动去maven中读取每个starter中的spring.factories文件,该文件里配置了所有需要被创建spring容器中的bean,并且进行自动配置把bean注入SpringContext中 //(SpringContext是Spring的配置文件)
42 |
43 | ### Spring Boot 2.X 有什么新特性?与 1.X 有什么区别?
44 |
45 | * 配置变更
46 | * JDK 版本升级
47 | * 第三方类库升级
48 | * 响应式 Spring 编程支持
49 | * HTTP/2 支持
50 | * 配置属性绑定
51 | * 更多改进与加强
52 |
53 | ### SpringBoot支持什么前端模板,
54 |
55 | * thymeleaf,freemarker,jsp,官方不推荐JSP会有限制
56 |
57 | ### SpringBoot的缺点
58 |
59 | * 我觉得是为难人,SpringBoot在目前我觉得没有什么缺点,非要找一个出来我觉得就是
60 | * 由于不用自己做的配置,报错时很难定位。
61 |
62 | ### 运行 Spring Boot 有哪几种方式?
63 |
64 | 1. 打包用命令或者放到容器中运行
65 |
66 | 2. 用 Maven/ Gradle 插件运行
67 |
68 | 3. 直接执行 main 方法运行
69 |
70 | ### Spring Boot 需要独立的容器运行吗?
71 |
72 | * 可以不需要,内置了 Tomcat/ Jetty 等容器。
73 |
74 | ### 开启 Spring Boot 特性有哪几种方式?
75 |
76 | 1. 继承spring-boot-starter-parent项目
77 |
78 | 2. 导入spring-boot-dependencies项目依赖
79 |
80 | ### SpringBoot 实现热部署有哪几种方式?
81 |
82 | * 热部署就是可以不用重新运行SpringBoot项目可以实现操作后台代码自动更新到以运行的项目中
83 | * 主要有两种方式:
84 | * Spring Loaded
85 | * Spring-boot-devtools
86 |
87 | ### SpringBoot事物的使用
88 |
89 | * SpringBoot的事物很简单,首先使用注解EnableTransactionManagement开启事物之后,然后在Service方法上添加注解Transactional便可。
90 |
91 | ### Async异步调用方法
92 |
93 | * 在SpringBoot中使用异步调用是很简单的,只需要在方法上使用@Async注解即可实现方法的异步调用。 注意:需要在启动类加入@EnableAsync使异步调用@Async注解生效。
94 |
95 | ### 如何在 Spring Boot 启动的时候运行一些特定的代码?
96 |
97 | * 可以实现接口 ApplicationRunner 或者 CommandLineRunner,这两个接口实现方式一样,它们都只提供了一个 run 方法
98 |
99 | ### Spring Boot 有哪几种读取配置的方式?
100 |
101 | * Spring Boot 可以通过 @PropertySource,@Value,@Environment, @ConfigurationPropertie注解来绑定变量
102 |
103 | ### 什么是 JavaConfig?
104 |
105 | * Spring JavaConfig 是 Spring 社区的产品,Spring 3.0引入了他,它提供了配置 Spring IOC 容器的纯Java 方法。因此它有助于避免使用 XML 配置。使用 JavaConfig 的优点在于:
106 |
107 | * 面向对象的配置。由于配置被定义为 JavaConfig 中的类,因此用户可以充分利用 Java 中的面向对象功能。一个配置类可以继承另一个,重写它的@Bean 方法等。
108 |
109 | * 减少或消除 XML 配置。基于依赖注入原则的外化配置的好处已被证明。但是,许多开发人员不希望在 XML 和 Java 之间来回切换。JavaConfig 为开发人员提供了一种纯 Java 方法来配置与 XML 配置概念相似的 Spring 容器。从技术角度来讲,只使用 JavaConfig 配置类来配置容器是可行的,但实际上很多人认为将JavaConfig 与 XML 混合匹配是理想的。
110 |
111 | * 类型安全和重构友好。JavaConfig 提供了一种类型安全的方法来配置 Spring容器。由于 Java 5.0 对泛型的支持,现在可以按类型而不是按名称检索 bean,不需要任何强制转换或基于字符串的查找。
112 |
113 | * 常用的Java config:
114 |
115 | * @Configuration:在类上打上写下此注解,表示这个类是配置类
116 | * @ComponentScan:在配置类上添加 @ComponentScan 注解。该注解默认会扫描该类所在的包下所有的配置类,相当于之前的 。
117 | * @Bean:bean的注入:相当于以前的< bean id="objectMapper" class="org.codehaus.jackson.map.ObjectMapper" />
118 | * @EnableWebMvc:相当于xml的
119 | * @ImportResource: 相当于xml的 < import resource="applicationContext-cache.xml">
120 |
121 | ### SpringBoot的自动配置原理是什么
122 |
123 | * 主要是Spring Boot的启动类上的核心注解SpringBootApplication注解主配置类,有了这个主配置类启动时就会为SpringBoot开启一个@EnableAutoConfiguration注解自动配置功能。
124 |
125 | * 有了这个EnableAutoConfiguration的话就会:
126 |
127 | 1. 从配置文件META_INF/Spring.factories加载可能用到的自动配置类
128 | 2. 去重,并将exclude和excludeName属性携带的类排除
129 | 3. 过滤,将满足条件(@Conditional)的自动配置类返回
130 |
131 | ### 你如何理解 Spring Boot 配置加载顺序?
132 |
133 | * 在 Spring Boot 里面,可以使用以下几种方式来加载配置。
134 |
135 | * 1.properties文件;
136 |
137 | * 2.YAML文件;
138 |
139 | * 3.系统环境变量;
140 |
141 | * 4.命令行参数;
142 |
143 | * 等等……
144 |
145 | ### 什么是 YAML?
146 |
147 | * YAML 是一种人类可读的数据序列化语言。它通常用于配置文件。与属性文件相比,如果我们想要在配置文件中添加复杂的属性,YAML 文件就更加结构化,而且更少混淆。可以看出 YAML 具有分层配置数据。
148 |
149 | ### YAML 配置的优势在哪里 ?
150 |
151 | * YAML 现在可以算是非常流行的一种配置文件格式了,无论是前端还是后端,都可以见到 YAML 配置。那么 YAML 配置和传统的 properties 配置相比到底有哪些优势呢?
152 |
153 | * 配置有序,在一些特殊的场景下,配置有序很关键
154 |
155 | * 简洁明了,他还支持数组,数组中的元素可以是基本数据类型也可以是对象
156 |
157 | * 相比 properties 配置文件,YAML 还有一个缺点,就是不支持 @PropertySource 注解导入自定义的 YAML 配置。
158 |
159 | ### Spring Boot 是否可以使用 XML 配置 ?
160 |
161 | * Spring Boot 推荐使用 Java 配置而非 XML 配置,但是 Spring Boot 中也可以使用 XML 配置,通过 @ImportResource 注解可以引入一个 XML 配置。
162 |
163 | ### spring boot 核心配置文件是什么?bootstrap.properties 和 application.properties 有何区别 ?
164 |
165 | * 单纯做 Spring Boot 开发,可能不太容易遇到 bootstrap.properties 配置文件,但是在结合 Spring Cloud 时,这个配置就会经常遇到了,特别是在需要加载一些远程配置文件的时侯。
166 |
167 | * spring boot 核心的两个配置文件:
168 |
169 | * bootstrap (. yml 或者 . properties):boostrap 由父 ApplicationContext 加载的,比 applicaton 优先加载,配置在应用程序上下文的引导阶段生效。一般来说我们在 Spring Cloud 配置就会使用这个文件。且 boostrap 里面的属性不能被覆盖;
170 | * application (. yml 或者 . properties): 由ApplicatonContext 加载,用于 spring boot 项目的自动化配置。
171 |
172 | ### 什么是 Spring Profiles?
173 |
174 | * 在项目的开发中,有些配置文件在开发、测试或者生产等不同环境中可能是不同的,例如数据库连接、redis的配置等等。那我们如何在不同环境中自动实现配置的切换呢?Spring给我们提供了profiles机制给我们提供的就是来回切换配置文件的功能
175 | * Spring Profiles 允许用户根据配置文件(dev,test,prod 等)来注册 bean。因此,当应用程序在开发中运行时,只有某些 bean 可以加载,而在 PRODUCTION中,某些其他 bean 可以加载。假设我们的要求是 Swagger 文档仅适用于 QA 环境,并且禁用所有其他文档。这可以使用配置文件来完成。Spring Boot 使得使用配置文件非常简单。
176 |
177 | ### SpringBoot多数据源拆分的思路
178 |
179 | * 先在properties配置文件中配置两个数据源,创建分包mapper,使用@ConfigurationProperties读取properties中的配置,使用@MapperScan注册到对应的mapper包中
180 |
181 | ### SpringBoot多数据源事务如何管理
182 |
183 | * 第一种方式是在service层的@TransactionManager中使用transactionManager指定DataSourceConfig中配置的事务
184 |
185 | * 第二种是使用jta-atomikos实现分布式事务管理
186 |
187 | ### 保护 Spring Boot 应用有哪些方法?
188 |
189 | * 在生产中使用HTTPS
190 | * 使用Snyk检查你的依赖关系
191 | * 升级到最新版本
192 | * 启用CSRF保护
193 | * 使用内容安全策略防止XSS攻击
194 |
195 | ### 如何实现 Spring Boot 应用程序的安全性?
196 |
197 | * 为了实现 Spring Boot 的安全性,我们使用 spring-boot-starter-security 依赖项,并且必须添加安全配置。它只需要很少的代码。配置类将必须扩展WebSecurityConfigurerAdapter 并覆盖其方法。
198 |
199 | ### 比较一下 Spring Security 和 Shiro 各自的优缺点 ?
200 |
201 | * 由于 Spring Boot 官方提供了大量的非常方便的开箱即用的 Starter ,包括 Spring Security 的 Starter ,使得在 Spring Boot 中使用 Spring Security 变得更加容易,甚至只需要添加一个依赖就可以保护所有的接口,所以,如果是 Spring Boot 项目,一般选择 Spring Security 。当然这只是一个建议的组合,单纯从技术上来说,无论怎么组合,都是没有问题的。Shiro 和 Spring Security 相比,主要有如下一些特点:
202 |
203 | * Spring Security 是一个重量级的安全管理框架;Shiro 则是一个轻量级的安全管理框架
204 |
205 | * Spring Security 概念复杂,配置繁琐;Shiro 概念简单、配置简单
206 |
207 | * Spring Security 功能强大;Shiro 功能简单
208 |
209 | ### Spring Boot 中如何解决跨域问题 ?
210 |
211 | * 跨域可以在前端通过 JSONP 来解决,但是 JSONP 只可以发送 GET 请求,无法发送其他类型的请求,在 RESTful 风格的应用中,就显得非常鸡肋,因此我们推荐在后端通过 (CORS,Cross-origin resource sharing) 来解决跨域问题。这种解决方案并非 Spring Boot 特有的,在传统的 SSM 框架中,就可以通过 CORS 来解决跨域问题,只不过之前我们是在 XML 文件中配置 CORS ,现在可以通过实现WebMvcConfigurer接口然后重写addCorsMappings方法解决跨域问题。
212 |
213 | @Configuration
214 | public class CorsConfig implements WebMvcConfigurer {
215 |
216 | @Override
217 | public void addCorsMappings(CorsRegistry registry) {
218 | registry.addMapping("/**")
219 | .allowedOrigins("*")
220 | .allowCredentials(true)
221 | .allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS")
222 | .maxAge(3600);
223 | }
224 |
225 | }
226 | 复制代码
227 | ### Spring Boot 中的监视器是什么?
228 |
229 | * Spring boot actuator 是 spring 启动框架中的重要功能之一。Spring boot 监视器可帮助您访问生产环境中正在运行的应用程序的当前状态。有几个指标必须在生产环境中进行检查和监控。即使一些外部应用程序可能正在使用这些服务来向相关人员触发警报消息。监视器模块公开了一组可直接作为 HTTP URL 访问的REST 端点来检查状态。
230 |
231 | ### 如何使用 Spring Boot 实现全局异常处理?
232 |
233 | * Spring 提供了一种使用 ControllerAdvice 处理异常的非常有用的方法。 我们通过实现一个 ControlerAdvice 类,来处理控制器类抛出的所有异常。
234 |
235 | ### 我们如何监视所有 Spring Boot 微服务?
236 |
237 | * Spring Boot 提供监视器端点以监控各个微服务的度量。这些端点对于获取有关应用程序的信息(如它们是否已启动)以及它们的组件(如数据库等)是否正常运行很有帮助。但是,使用监视器的一个主要缺点或困难是,我们必须单独打开应用程序的知识点以了解其状态或健康状况。想象一下涉及 50 个应用程序的微服务,管理员将不得不击中所有 50 个应用程序的执行终端。为了帮助我们处理这种情况,我们将使用位于的开源项目。 它建立在 Spring Boot Actuator 之上,它提供了一个 Web UI,使我们能够可视化多个应用程序的度量。
238 |
239 | ### SpringBoot性能如何优化
240 |
241 | * 如果项目比较大,类比较多,不使用@SpringBootApplication,采用@Compoment指定扫包范围
242 |
243 | * 在项目启动时设置JVM初始内存和最大内存相同
244 |
245 | * 将springboot内置服务器由tomcat设置为undertow
246 |
247 | ### 如何重新加载 Spring Boot 上的更改,而无需重新启动服务器?Spring Boot项目如何热部署?
248 |
249 | * 这可以使用 DEV 工具来实现。通过这种依赖关系,您可以节省任何更改,嵌入式tomcat 将重新启动。Spring Boot 有一个开发工具(DevTools)模块,它有助于提高开发人员的生产力。Java 开发人员面临的一个主要挑战是将文件更改自动部署到服务器并自动重启服务器。开发人员可以重新加载 Spring Boot 上的更改,而无需重新启动服务器。这将消除每次手动部署更改的需要。Spring Boot 在发布它的第一个版本时没有这个功能。这是开发人员最需要的功能。DevTools 模块完全满足开发人员的需求。该模块将在生产环境中被禁用。它还提供 H2 数据库控制台以更好地测试应用程序。
250 |
251 |
252 | org.springframework.boot
253 | spring-boot-devtools
254 |
255 | 复制代码
256 | ### SpringBoot微服务中如何实现 session 共享 ?
257 |
258 | * 在微服务中,一个完整的项目被拆分成多个不相同的独立的服务,各个服务独立部署在不同的服务器上,各自的 session 被从物理空间上隔离开了,但是经常,我们需要在不同微服务之间共享 session ,常见的方案就是 Spring Session + Redis 来实现 session 共享。将所有微服务的 session 统一保存在 Redis 上,当各个微服务对 session 有相关的读写操作时,都去操作 Redis 上的 session 。这样就实现了 session 共享,Spring Session 基于 Spring 中的代理过滤器实现,使得 session 的同步操作对开发人员而言是透明的,非常简便。
259 |
260 | ### 您使用了哪些 starter maven 依赖项?
261 |
262 | * 使用了下面的一些依赖项
263 | * spring-boot-starter-web 嵌入tomcat和web开发需要servlet与jsp支持
264 | * spring-boot-starter-data-jpa 数据库支持
265 | * spring-boot-starter-data-redis redis数据库支持
266 | * spring-boot-starter-data-solr solr支持
267 | * mybatis-spring-boot-starter 第三方的mybatis集成starter
268 | * 自定义的starter(如果自己开发过就可以说出来)
269 |
270 | ### Spring Boot 中的 starter 到底是什么 ?
271 |
272 | * 首先,这个 Starter 并非什么新的技术点,基本上还是基于 Spring 已有功能来实现的。首先它提供了一个自动化配置类,一般命名为 `XXXAutoConfiguration` ,在这个配置类中通过条件注解来决定一个配置是否生效(条件注解就是 Spring 中原本就有的),然后它还会提供一系列的默认配置,也允许开发者根据实际情况自定义相关配置,然后通过类型安全的属性(spring.factories)注入将这些配置属性注入进来,新注入的属性会代替掉默认属性。正因为如此,很多第三方框架,我们只需要引入依赖就可以直接使用了。当然,开发者也可以自定义 Starter
273 |
274 | ### Spring Boot 中如何实现定时任务 ?
275 |
276 | * 在 Spring Boot 中使用定时任务主要有两种不同的方式,一个就是使用 Spring 中的 @Scheduled 注解,另一-个则是使用第三方框架 Quartz。
277 |
278 | * 使用 Spring 中的 @Scheduled 的方式主要通过 @Scheduled 注解来实现。
279 |
280 | ### spring-boot-starter-parent 有什么用 ?
281 |
282 | * 我们都知道,新创建一个 Spring Boot 项目,默认都是有 parent 的,这个 parent 就是 spring-boot-starter-parent ,spring-boot-starter-parent 主要有如下作用:
283 |
284 | 1. 定义了 Java 编译版本为 1.8 。
285 | 2. 使用 UTF-8 格式编码。
286 | 3. 继承自 spring-boot-dependencies,这个里边定义了依赖的版本,也正是因为继承了这个依赖,所以我们在写依赖时才不需要写版本号。
287 | 4. 执行打包操作的配置。
288 | 5. 自动化的资源过滤。
289 | 6. 自动化的插件配置。
290 | 7. 针对 application.properties 和 application.yml 的资源过滤,包括通过 profile 定义的不同环境的配置文件,例如 application-dev.properties 和 application-dev.yml。
291 | * 总结就是打包用的
292 |
293 | ### SpringBoot如何实现打包
294 |
295 | * 进入项目目录在控制台输入mvn clean package,clean是清空已存在的项目包,package进行打包
296 | * 或者点击左边选项栏中的Mavne,先点击clean在点击package
297 |
298 | ### Spring Boot 打成的 jar 和普通的 jar 有什么区别 ?
299 |
300 | * Spring Boot 项目最终打包成的 jar 是可执行 jar ,这种 jar 可以直接通过 `java -jar xxx.jar` 命令来运行,这种 jar 不可以作为普通的 jar 被其他项目依赖,即使依赖了也无法使用其中的类。
301 |
302 | * Spring Boot 的 jar 无法被其他项目依赖,主要还是他和普通 jar 的结构不同。普通的 jar 包,解压后直接就是包名,包里就是我们的代码,而 Spring Boot 打包成的可执行 jar 解压后,在 `\BOOT-INF\classes` 目录下才是我们的代码,因此无法被直接引用。如果非要引用,可以在 pom.xml 文件中增加配置,将 Spring Boot 项目打包成两个 jar ,一个可执行,一个可引用。
303 |
304 | 作者:小杰要吃蛋
305 | 链接:https://juejin.cn/post/6844904125709156359
306 | 来源:稀土掘金
307 | 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
--------------------------------------------------------------------------------
/docs/java/基础面试题/rabbitMQ.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ## 什么是MQ
4 |
5 | * MQ就是消息队列。是软件和软件进行通信的中间件产品
6 |
7 | ## MQ的优点
8 |
9 | * 简答
10 |
11 | * 异步处理 - 相比于传统的串行、并行方式,提高了系统吞吐量。
12 | * 应用解耦 - 系统间通过消息通信,不用关心其他系统的处理。
13 | * 流量削锋 - 可以通过消息队列长度控制请求量;可以缓解短时间内的高并发请求。
14 | * 日志处理 - 解决大量日志传输。
15 | * 消息通讯 - 消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。
16 | * 详答
17 |
18 | ## 解耦、异步、削峰是什么?。
19 |
20 | * **解耦**:A 系统发送数据到 BCD 三个系统,通过接口调用发送。如果 E 系统也要这个数据呢?那如果 C 系统现在不需要了呢?A 系统负责人几乎崩溃…A 系统跟其它各种乱七八糟的系统严重耦合,A 系统产生一条比较关键的数据,很多系统都需要 A 系统将这个数据发送过来。如果使用 MQ,A 系统产生一条数据,发送到 MQ 里面去,哪个系统需要数据自己去 MQ 里面消费。如果新系统需要数据,直接从 MQ 里消费即可;如果某个系统不需要这条数据了,就取消对 MQ 消息的消费即可。这样下来,A 系统压根儿不需要去考虑要给谁发送数据,不需要维护这个代码,也不需要考虑人家是否调用成功、失败超时等情况。
21 |
22 | `就是一个系统或者一个模块,调用了多个系统或者模块,互相之间的调用很复杂,维护起来很麻烦。但是其实这个调用是不需要直接同步调用接口的,如果用 MQ 给它异步化解耦。`
23 |
24 | * **异步**:A 系统接收一个请求,需要在自己本地写库,还需要在 BCD 三个系统写库,自己本地写库要 3ms,BCD 三个系统分别写库要 300ms、450ms、200ms。最终请求总延时是 3 + 300 + 450 + 200 = 953ms,接近 1s,用户感觉搞个什么东西,慢死了慢死了。用户通过浏览器发起请求。如果使用 MQ,那么 A 系统连续发送 3 条消息到 MQ 队列中,假如耗时 5ms,A 系统从接受一个请求到返回响应给用户,总时长是 3 + 5 = 8ms。
25 |
26 | * **削峰**:减少高峰时期对服务器压力。
27 |
28 | ## 消息队列有什么缺点
29 |
30 | * 缺点有以下几个:
31 |
32 | 1. **系统可用性降低**
33 |
34 | 本来系统运行好好的,现在你非要加入个消息队列进去,那消息队列挂了,你的系统不是呵呵了。因此,系统可用性会降低;
35 |
36 | 2. **系统复杂度提高**
37 |
38 | 加入了消息队列,要多考虑很多方面的问题,比如:一致性问题、如何保证消息不被重复消费、如何保证消息可靠性传输等。因此,需要考虑的东西更多,复杂性增大。
39 |
40 | 3. **一致性问题**
41 |
42 | A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。
43 |
44 | `所以消息队列实际是一种非常复杂的架构,你引入它有很多好处,但是也得针对它带来的坏处做各种额外的技术方案和架构来规避掉,做好之后,你会发现,妈呀,系统复杂度提升了一个数量级,也许是复杂了 10 倍。但是关键时刻,用,还是得用的。`
45 |
46 | ## 你们公司生产环境用的是什么消息中间件?
47 |
48 | * 这个首先你可以说下你们公司选用的是什么消息中间件,比如用的是RabbitMQ,然后可以初步给一些你对不同MQ中间件技术的选型分析。
49 |
50 | * 举个例子:比如说ActiveMQ是老牌的消息中间件,国内很多公司过去运用的还是非常广泛的,功能很强大。
51 |
52 | * 但是问题在于没法确认ActiveMQ可以支撑互联网公司的高并发、高负载以及高吞吐的复杂场景,在国内互联网公司落地较少。而且使用较多的是一些传统企业,用ActiveMQ做异步调用和系统解耦。
53 |
54 | * 然后你可以说说RabbitMQ,他的好处在于可以支撑高并发、高吞吐、性能很高,同时有非常完善便捷的后台管理界面可以使用。
55 |
56 | * 另外,他还支持集群化、高可用部署架构、消息高可靠支持,功能较为完善。
57 |
58 | * 而且经过调研,国内各大互联网公司落地大规模RabbitMQ集群支撑自身业务的case较多,国内各种中小型互联网公司使用RabbitMQ的实践也比较多。
59 |
60 | * 除此之外,RabbitMQ的开源社区很活跃,较高频率的迭代版本,来修复发现的bug以及进行各种优化,因此综合考虑过后,公司采取了RabbitMQ。
61 |
62 | * 但是RabbitMQ也有一点缺陷,就是他自身是基于erlang语言开发的,所以导致较为难以分析里面的源码,也较难进行深层次的源码定制和改造,毕竟需要较为扎实的erlang语言功底才可以。
63 |
64 | * 然后可以聊聊RocketMQ,是阿里开源的,经过阿里的生产环境的超高并发、高吞吐的考验,性能卓越,同时还支持分布式事务等特殊场景。
65 |
66 | * 而且RocketMQ是基于Java语言开发的,适合深入阅读源码,有需要可以站在源码层面解决线上生产问题,包括源码的二次开发和改造。
67 |
68 | * 另外就是Kafka。Kafka提供的消息中间件的功能明显较少一些,相对上述几款MQ中间件要少很多。
69 |
70 | * 但是Kafka的优势在于专为超高吞吐量的实时日志采集、实时数据同步、实时数据计算等场景来设计。
71 |
72 | * 因此Kafka在大数据领域中配合实时计算技术(比如Spark Streaming、Storm、Flink)使用的较多。但是在传统的MQ中间件使用场景中较少采用。
73 |
74 | ## Kafka、ActiveMQ、RabbitMQ、RocketMQ 有什么优缺点?
75 |
76 | 
77 |
78 | * 综上,各种对比之后,有如下建议:
79 |
80 | * 一般的业务系统要引入 MQ,最早大家都用 ActiveMQ,但是现在确实大家用的不多了,没经过大规模吞吐量场景的验证,社区也不是很活跃,所以大家还是算了吧,我个人不推荐用这个了;
81 |
82 | * 后来大家开始用 RabbitMQ,但是确实 erlang 语言阻止了大量的 Java 工程师去深入研究和掌控它,对公司而言,几乎处于不可控的状态,但是确实人家是开源的,比较稳定的支持,活跃度也高;
83 |
84 | * 不过现在确实越来越多的公司会去用 RocketMQ,确实很不错,毕竟是阿里出品,但社区可能有突然黄掉的风险(目前 RocketMQ 已捐给 [Apache](https://link.juejin.cn?target=https%3A%2F%2Fgithub.com%2Fapache%2Frocketmq "https://github.com/apache/rocketmq"),但 GitHub 上的活跃度其实不算高)对自己公司技术实力有绝对自信的,推荐用 RocketMQ,否则回去老老实实用 RabbitMQ 吧,人家有活跃的开源社区,绝对不会黄。
85 |
86 | * 所以**中小型公司**,技术实力较为一般,技术挑战不是特别高,用 RabbitMQ 是不错的选择;**大型公司**,基础架构研发实力较强,用 RocketMQ 是很好的选择。
87 |
88 | * 如果是**大数据领域**的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范。
89 |
90 | ## MQ 有哪些常见问题?如何解决这些问题?
91 |
92 | * MQ 的常见问题有:
93 | * 消息的顺序问题
94 | * 消息的重复问题
95 |
96 | **消息的顺序问题**
97 |
98 | * 消息有序指的是可以按照消息的发送顺序来消费。
99 |
100 | * 假如生产者产生了 2 条消息:M1、M2,假定 M1 发送到 S1,M2 发送到 S2,如果要保证 M1 先于 M2 被消费,怎么做?
101 |
102 | 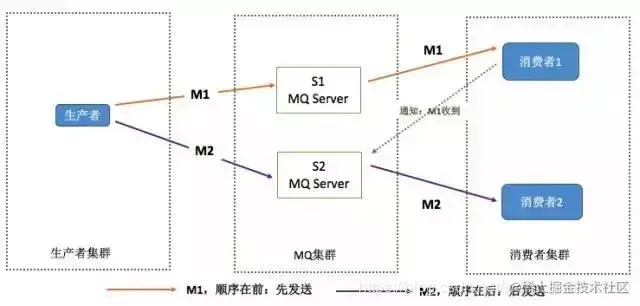
103 |
104 | * 解决方案:
105 | 1. 保证生产者 - MQServer - 消费者是一对一对一的关系
106 |
107 | 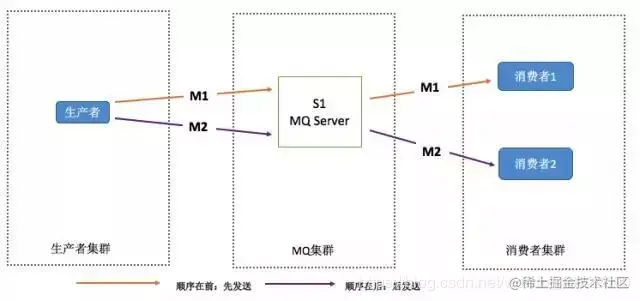
108 |
109 | * 缺陷:
110 | * 并行度就会成为消息系统的瓶颈(吞吐量不够)
111 | * 更多的异常处理,比如:只要消费端出现问题,就会导致整个处理流程阻塞,我们不得不花费更多的精力来解决阻塞的问题。 (2)通过合理的设计或者将问题分解来规避。
112 | * 不关注乱序的应用实际大量存在
113 | * 队列无序并不意味着消息无序 所以从业务层面来保证消息的顺序而不仅仅是依赖于消息系统,是一种更合理的方式。
114 |
115 | **消息的重复问题**
116 |
117 | * 造成消息重复的根本原因是:网络不可达。
118 |
119 | * 所以解决这个问题的办法就是绕过这个问题。那么问题就变成了:如果消费端收到两条一样的消息,应该怎样处理?
120 |
121 | * 消费端处理消息的业务逻辑保持幂等性。只要保持幂等性,不管来多少条重复消息,最后处理的结果都一样。保证每条消息都有唯一编号且保证消息处理成功与去重表的日志同时出现。利用一张日志表来记录已经处理成功的消息的 ID,如果新到的消息 ID 已经在日志表中,那么就不再处理这条消息。
122 |
123 | ## 什么是RabbitMQ?
124 |
125 | * RabbitMQ是一款开源的,Erlang编写的,消息中间件; 最大的特点就是消费并不需要确保提供方存在,实现了服务之间的高度解耦 可以用它来:解耦、异步、削峰。
126 |
127 | ## rabbitmq 的使用场景
128 |
129 | (1)服务间异步通信
130 |
131 | (2)顺序消费
132 |
133 | (3)定时任务
134 |
135 | (4)请求削峰
136 |
137 | ## RabbitMQ基本概念
138 |
139 | * Broker: 简单来说就是消息队列服务器实体
140 | * Exchange: 消息交换机,它指定消息按什么规则,路由到哪个队列
141 | * Queue: 消息队列载体,每个消息都会被投入到一个或多个队列
142 | * Binding: 绑定,它的作用就是把exchange和queue按照路由规则绑定起来
143 | * Routing Key: 路由关键字,exchange根据这个关键字进行消息投递
144 | * VHost: vhost 可以理解为虚拟 broker ,即 mini-RabbitMQ server。其内部均含有独立的 queue、exchange 和 binding 等,但最最重要的是,其拥有独立的权限系统,可以做到 vhost 范围的用户控制。当然,从 RabbitMQ 的全局角度,vhost 可以作为不同权限隔离的手段(一个典型的例子就是不同的应用可以跑在不同的 vhost 中)。
145 | * Producer: 消息生产者,就是投递消息的程序
146 | * Consumer: 消息消费者,就是接受消息的程序
147 | * Channel: 消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务
148 |
149 | `由Exchange、Queue、RoutingKey三个才能决定一个从Exchange到Queue的唯一的线路。`
150 |
151 | ## RabbitMQ的工作模式
152 |
153 | **一.simple模式(即最简单的收发模式)**
154 |
155 | 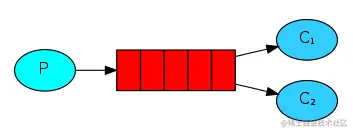
156 |
157 | 1. 消息产生消息,将消息放入队列
158 |
159 | 2. 消息的消费者(consumer) 监听 消息队列,如果队列中有消息,就消费掉,消息被拿走后,自动从队列中删除(隐患 消息可能没有被消费者正确处理,已经从队列中消失了,造成消息的丢失,这里可以设置成手动的ack,但如果设置成手动ack,处理完后要及时发送ack消息给队列,否则会造成内存溢出)。
160 |
161 | **二.work工作模式(资源的竞争)**
162 |
163 | 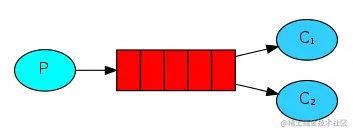
164 |
165 | 1. 消息产生者将消息放入队列消费者可以有多个,消费者1,消费者2同时监听同一个队列,消息被消费。C1 C2共同争抢当前的消息队列内容,谁先拿到谁负责消费消息(隐患:高并发情况下,默认会产生某一个消息被多个消费者共同使用,可以设置一个开关(syncronize) 保证一条消息只能被一个消费者使用)。
166 |
167 | **三.publish/subscribe发布订阅(共享资源)**
168 |
169 | 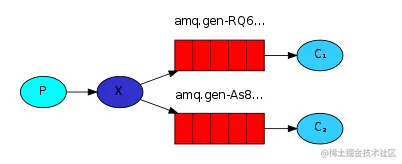
170 |
171 | 1. 每个消费者监听自己的队列;
172 |
173 | 2. 生产者将消息发给broker,由交换机将消息转发到绑定此交换机的每个队列,每个绑定交换机的队列都将接收到消息。
174 |
175 | **四.routing路由模式**
176 |
177 | 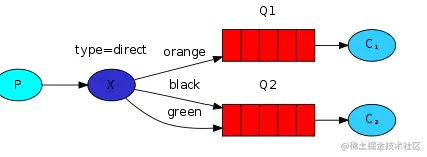
178 |
179 | 1. 消息生产者将消息发送给交换机按照路由判断,路由是字符串(info) 当前产生的消息携带路由字符(对象的方法),交换机根据路由的key,只能匹配上路由key对应的消息队列,对应的消费者才能消费消息;
180 |
181 | 2. 根据业务功能定义路由字符串
182 |
183 | 3. 从系统的代码逻辑中获取对应的功能字符串,将消息任务扔到对应的队列中。
184 |
185 | 4. 业务场景:error 通知;EXCEPTION;错误通知的功能;传统意义的错误通知;客户通知;利用key路由,可以将程序中的错误封装成消息传入到消息队列中,开发者可以自定义消费者,实时接收错误;
186 |
187 | **五.topic 主题模式(路由模式的一种)**
188 |
189 | 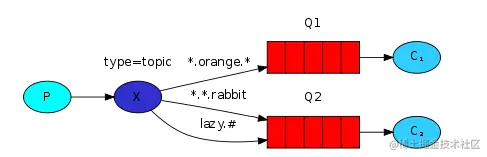
190 |
191 | 1. 星号井号代表通配符
192 |
193 | 2. 星号代表多个单词,井号代表一个单词
194 |
195 | 3. 路由功能添加模糊匹配
196 |
197 | 4. 消息产生者产生消息,把消息交给交换机
198 |
199 | 5. 交换机根据key的规则模糊匹配到对应的队列,由队列的监听消费者接收消息消费
200 |
201 | `(在我的理解看来就是routing查询的一种模糊匹配,就类似sql的模糊查询方式)`
202 |
203 | ## 如何保证RabbitMQ消息的顺序性?
204 |
205 | * 拆分多个 queue(消息队列),每个 queue(消息队列) 一个 consumer(消费者),就是多一些 queue (消息队列)而已,确实是麻烦点;
206 |
207 | * 或者就一个 queue (消息队列)但是对应一个 consumer(消费者),然后这个 consumer(消费者)内部用内存队列做排队,然后分发给底层不同的 worker 来处理。
208 |
209 | ## 消息如何分发?
210 |
211 | * 若该队列至少有一个消费者订阅,消息将以循环(round-robin)的方式发送给消费者。每条消息只会分发给一个订阅的消费者(前提是消费者能够正常处理消息并进行确认)。通过路由可实现多消费的功能
212 |
213 | ## 消息怎么路由?
214 |
215 | * 消息提供方->路由->一至多个队列消息发布到交换器时,消息将拥有一个路由键(routing key),在消息创建时设定。通过队列路由键,可以把队列绑定到交换器上。消息到达交换器后,RabbitMQ 会将消息的路由键与队列的路由键进行匹配(针对不同的交换器有不同的路由规则);
216 |
217 | * 常用的交换器主要分为一下三种:
218 |
219 | 1. fanout:如果交换器收到消息,将会广播到所有绑定的队列上
220 |
221 | 2. direct:如果路由键完全匹配,消息就被投递到相应的队列
222 |
223 | 3. topic:可以使来自不同源头的消息能够到达同一个队列。 使用 topic 交换器时,可以使用通配符
224 |
225 | ## 消息基于什么传输?
226 |
227 | * 由于 TCP 连接的创建和销毁开销较大,且并发数受系统资源限制,会造成性能瓶颈。RabbitMQ 使用信道的方式来传输数据。信道是建立在真实的 TCP 连接内的虚拟连接,且每条 TCP 连接上的信道数量没有限制。
228 |
229 | ## 如何保证消息不被重复消费?或者说,如何保证消息消费时的幂等性?
230 |
231 | * 先说为什么会重复消费:正常情况下,消费者在消费消息的时候,消费完毕后,会发送一个确认消息给消息队列,消息队列就知道该消息被消费了,就会将该消息从消息队列中删除;
232 |
233 | * 但是因为网络传输等等故障,确认信息没有传送到消息队列,导致消息队列不知道自己已经消费过该消息了,再次将消息分发给其他的消费者。
234 |
235 | * 针对以上问题,一个解决思路是:保证消息的唯一性,就算是多次传输,不要让消息的多次消费带来影响;保证消息等幂性;
236 |
237 | * 比如:在写入消息队列的数据做唯一标示,消费消息时,根据唯一标识判断是否消费过;
238 |
239 | * 假设你有个系统,消费一条消息就往数据库里插入一条数据,要是你一个消息重复两次,你不就插入了两条,这数据不就错了?但是你要是消费到第二次的时候,自己判断一下是否已经消费过了,若是就直接扔了,这样不就保留了一条数据,从而保证了数据的正确性。
240 |
241 | ## 如何确保消息正确地发送至 RabbitMQ? 如何确保消息接收方消费了消息?
242 |
243 | **发送方确认模式**
244 |
245 | * 将信道设置成 confirm 模式(发送方确认模式),则所有在信道上发布的消息都会被指派一个唯一的 ID。
246 |
247 | * 一旦消息被投递到目的队列后,或者消息被写入磁盘后(可持久化的消息),信道会发送一个确认给生产者(包含消息唯一 ID)。
248 |
249 | * 如果 RabbitMQ 发生内部错误从而导致消息丢失,会发送一条 nack(notacknowledged,未确认)消息。
250 |
251 | * 发送方确认模式是异步的,生产者应用程序在等待确认的同时,可以继续发送消息。当确认消息到达生产者应用程序,生产者应用程序的回调方法就会被触发来处理确认消息。
252 |
253 | **接收方确认机制**
254 |
255 | * 消费者接收每一条消息后都必须进行确认(消息接收和消息确认是两个不同操作)。只有消费者确认了消息,RabbitMQ 才能安全地把消息从队列中删除。
256 |
257 | * 这里并没有用到超时机制,RabbitMQ 仅通过 Consumer 的连接中断来确认是否需要重新发送消息。也就是说,只要连接不中断,RabbitMQ 给了 Consumer 足够长的时间来处理消息。保证数据的最终一致性;
258 |
259 | **下面罗列几种特殊情况**
260 |
261 | * 如果消费者接收到消息,在确认之前断开了连接或取消订阅,RabbitMQ 会认为消息没有被分发,然后重新分发给下一个订阅的消费者。(可能存在消息重复消费的隐患,需要去重)
262 | * 如果消费者接收到消息却没有确认消息,连接也未断开,则 RabbitMQ 认为该消费者繁忙,将不会给该消费者分发更多的消息。
263 |
264 | ## 如何保证RabbitMQ消息的可靠传输?
265 |
266 | * 消息不可靠的情况可能是消息丢失,劫持等原因;
267 |
268 | * 丢失又分为:生产者丢失消息、消息列表丢失消息、消费者丢失消息;
269 |
270 | 1. **生产者丢失消息**:从生产者弄丢数据这个角度来看,RabbitMQ提供transaction和confirm模式来确保生产者不丢消息;
271 |
272 | transaction机制就是说:发送消息前,开启事务(channel.txSelect()),然后发送消息,如果发送过程中出现什么异常,事务就会回滚(channel.txRollback()),如果发送成功则提交事务(channel.txCommit())。然而,这种方式有个缺点:吞吐量下降;
273 |
274 | confirm模式用的居多:一旦channel进入confirm模式,所有在该信道上发布的消息都将会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列之后;
275 |
276 | rabbitMQ就会发送一个ACK给生产者(包含消息的唯一ID),这就使得生产者知道消息已经正确到达目的队列了;
277 |
278 | 如果rabbitMQ没能处理该消息,则会发送一个Nack消息给你,你可以进行重试操作。
279 |
280 | 2. **消息队列丢数据**:消息持久化。
281 |
282 | 处理消息队列丢数据的情况,一般是开启持久化磁盘的配置。
283 |
284 | 这个持久化配置可以和confirm机制配合使用,你可以在消息持久化磁盘后,再给生产者发送一个Ack信号。
285 |
286 | 这样,如果消息持久化磁盘之前,rabbitMQ阵亡了,那么生产者收不到Ack信号,生产者会自动重发。
287 |
288 | 那么如何持久化呢?
289 |
290 | 这里顺便说一下吧,其实也很容易,就下面两步
291 |
292 | 1\. 将queue的持久化标识durable设置为true,则代表是一个持久的队列
293 |
294 | 2\. 发送消息的时候将deliveryMode=2
295 |
296 | 这样设置以后,即使rabbitMQ挂了,重启后也能恢复数据
297 |
298 | 3. **消费者丢失消息**:消费者丢数据一般是因为采用了自动确认消息模式,改为手动确认消息即可!
299 |
300 | 消费者在收到消息之后,处理消息之前,会自动回复RabbitMQ已收到消息;
301 |
302 | 如果这时处理消息失败,就会丢失该消息;
303 |
304 | 解决方案:处理消息成功后,手动回复确认消息。
305 |
306 | ## 为什么不应该对所有的 message 都使用持久化机制?
307 |
308 | * 首先,必然导致性能的下降,因为写磁盘比写 RAM 慢的多,message 的吞吐量可能有 10 倍的差距。
309 |
310 | * 其次,message 的持久化机制用在 RabbitMQ 的内置 cluster 方案时会出现“坑爹”问题。矛盾点在于,若 message 设置了 persistent 属性,但 queue 未设置 durable 属性,那么当该 queue 的 owner node 出现异常后,在未重建该 queue 前,发往该 queue 的 message 将被 blackholed ;若 message 设置了 persistent 属性,同时 queue 也设置了 durable 属性,那么当 queue 的 owner node 异常且无法重启的情况下,则该 queue 无法在其他 node 上重建,只能等待其 owner node 重启后,才能恢复该 queue 的使用,而在这段时间内发送给该 queue 的 message 将被 blackholed 。
311 |
312 | * 所以,是否要对 message 进行持久化,需要综合考虑性能需要,以及可能遇到的问题。若想达到 100,000 条/秒以上的消息吞吐量(单 RabbitMQ 服务器),则要么使用其他的方式来确保 message 的可靠 delivery ,要么使用非常快速的存储系统以支持全持久化(例如使用 SSD)。另外一种处理原则是:仅对关键消息作持久化处理(根据业务重要程度),且应该保证关键消息的量不会导致性能瓶颈。
313 |
314 | ## 如何保证高可用的?RabbitMQ 的集群
315 |
316 | * RabbitMQ 是比较有代表性的,因为是基于主从(非分布式)做高可用性的,我们就以 RabbitMQ 为例子讲解第一种 MQ 的高可用性怎么实现。RabbitMQ 有三种模式:单机模式、普通集群模式、镜像集群模式。
317 |
318 | 1. **单机模式**,就是 Demo 级别的,一般就是你本地启动了玩玩儿的?,没人生产用单机模式
319 |
320 | 2. **普通集群模式**:
321 |
322 | * 意思就是在多台机器上启动多个 RabbitMQ 实例,每个机器启动一个。
323 | * 你创建的 queue,只会放在一个 RabbitMQ 实例上,但是每个实例都同步 queue 的元数据(元数据可以认为是 queue 的一些配置信息,通过元数据,可以找到 queue 所在实例)。你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从 queue 所在实例上拉取数据过来。这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个 queue 的读写操作。
324 | 3. **镜像集群模式**:
325 |
326 | * 这种模式,才是所谓的 RabbitMQ 的高可用模式。跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。RabbitMQ 有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
327 |
328 | * 这样的好处在于,你任何一个机器宕机了,没事儿,其它机器(节点)还包含了这个 queue 的完整数据,别的 consumer 都可以到其它节点上去消费数据。坏处在于,第一,这个性能开销也太大了吧,消息需要同步到所有机器上,导致网络带宽压力和消耗很重!RabbitMQ 一个 queue 的数据都是放在一个节点里的,镜像集群下,也是每个节点都放这个 queue 的完整数据。
329 |
330 | ## 如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,怎么办?
331 |
332 | * 消息积压处理办法:临时紧急扩容:
333 |
334 | * 先修复 consumer 的问题,确保其恢复消费速度,然后将现有 cnosumer 都停掉。
335 | 新建一个 topic,partition 是原来的 10 倍,临时建立好原先 10 倍的 queue 数量。
336 | 然后写一个临时的分发数据的 consumer 程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的 10 倍数量的 queue。
337 | 接着临时征用 10 倍的机器来部署 consumer,每一批 consumer 消费一个临时 queue 的数据。这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据。
338 | 等快速消费完积压数据之后,得恢复原先部署的架构,重新用原先的 consumer 机器来消费消息。
339 | MQ中消息失效:假设你用的是 RabbitMQ,RabbtiMQ 是可以设置过期时间的,也就是 TTL。如果消息在 queue 中积压超过一定的时间就会被 RabbitMQ 给清理掉,这个数据就没了。那这就是第二个坑了。这就不是说数据会大量积压在 mq 里,而是大量的数据会直接搞丢。我们可以采取一个方案,就是批量重导,这个我们之前线上也有类似的场景干过。就是大量积压的时候,我们当时就直接丢弃数据了,然后等过了高峰期以后,比如大家一起喝咖啡熬夜到晚上12点以后,用户都睡觉了。这个时候我们就开始写程序,将丢失的那批数据,写个临时程序,一点一点的查出来,然后重新灌入 mq 里面去,把白天丢的数据给他补回来。也只能是这样了。假设 1 万个订单积压在 mq 里面,没有处理,其中 1000 个订单都丢了,你只能手动写程序把那 1000 个订单给查出来,手动发到 mq 里去再补一次。
340 |
341 | * mq消息队列块满了:如果消息积压在 mq 里,你很长时间都没有处理掉,此时导致 mq 都快写满了,咋办?这个还有别的办法吗?没有,谁让你第一个方案执行的太慢了,你临时写程序,接入数据来消费,消费一个丢弃一个,都不要了,快速消费掉所有的消息。然后走第二个方案,到了晚上再补数据吧。
342 |
343 | ## 设计MQ思路
344 |
345 | * 比如说这个消息队列系统,我们从以下几个角度来考虑一下:
346 |
347 | * 首先这个 mq 得支持可伸缩性吧,就是需要的时候快速扩容,就可以增加吞吐量和容量,那怎么搞?设计个分布式的系统呗,参照一下 kafka 的设计理念,broker -> topic -> partition,每个 partition 放一个机器,就存一部分数据。如果现在资源不够了,简单啊,给 topic 增加 partition,然后做数据迁移,增加机器,不就可以存放更多数据,提供更高的吞吐量了?
348 |
349 | * 其次你得考虑一下这个 mq 的数据要不要落地磁盘吧?那肯定要了,落磁盘才能保证别进程挂了数据就丢了。那落磁盘的时候怎么落啊?顺序写,这样就没有磁盘随机读写的寻址开销,磁盘顺序读写的性能是很高的,这就是 kafka 的思路。
350 |
351 | * 其次你考虑一下你的 mq 的可用性啊?这个事儿,具体参考之前可用性那个环节讲解的 kafka 的高可用保障机制。多副本 -> leader & follower -> broker 挂了重新选举 leader 即可对外服务。
352 |
353 | * 能不能支持数据 0 丢失啊?可以呀,有点复杂的。
354 |
355 | 作者:小杰要吃蛋
356 | 链接:https://juejin.cn/post/6844904125935665160
357 | 来源:稀土掘金
358 | 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
--------------------------------------------------------------------------------
/docs/java/基础面试题/zookeeper.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ## ZooKeeper 是什么?
4 |
5 | * ZooKeeper 是一个开源的分布式协调服务。它是一个为分布式应用提供一致性服务的软件,分布式应用程序可以基于 Zookeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
6 |
7 | * ZooKeeper 的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
8 |
9 | * Zookeeper 保证了如下分布式一致性特性:
10 |
11 | (1)顺序一致性
12 |
13 | (2)原子性
14 |
15 | (3)单一视图
16 |
17 | (4)可靠性
18 |
19 | (5)实时性(最终一致性)
20 |
21 | * 客户端的读请求可以被集群中的任意一台机器处理,如果读请求在节点上注册了监听器,这个监听器也是由所连接的 zookeeper 机器来处理。对于写请求,这些请求会同时发给其他 zookeeper 机器并且达成一致后,请求才会返回成功。因此,随着 zookeeper 的集群机器增多,读请求的吞吐会提高但是写请求的吞吐会下降。
22 |
23 | * 有序性是 zookeeper 中非常重要的一个特性,所有的更新都是全局有序的,每个更新都有一个唯一的时间戳,这个时间戳称为 zxid(Zookeeper Transaction Id)。而读请求只会相对于更新有序,也就是读请求的返回结果中会带有这个zookeeper 最新的 zxid。
24 |
25 | ## ZooKeeper 提供了什么?
26 |
27 | * 文件系统
28 |
29 | * 通知机制
30 |
31 | ## Zookeeper 文件系统
32 |
33 | * Zookeeper 提供一个多层级的节点命名空间(节点称为 znode)。与文件系统不同的是,这些节点都可以设置关联的数据,而文件系统中只有文件节点可以存放数据而目录节点不行。
34 |
35 | * Zookeeper 为了保证高吞吐和低延迟,在内存中维护了这个树状的目录结构,这种特性使得 Zookeeper 不能用于存放大量的数据,每个节点的存放数据上限为1M。
36 |
37 | ## Zookeeper 怎么保证主从节点的状态同步?
38 |
39 | * Zookeeper 的核心是原子广播机制,这个机制保证了各个 server 之间的同步。实现这个机制的协议叫做 Zab 协议。Zab 协议有两种模式,它们分别是恢复模式和广播模式。
40 |
41 | ### 恢复模式
42 |
43 | * 当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数 server 完成了和 leader 的状态同步以后,恢复模式就结束了。状态同步保证了 leader 和 server 具有相同的系统状态。
44 |
45 | ### 广播模式
46 |
47 | * 一旦 leader 已经和多数的 follower 进行了状态同步后,它就可以开始广播消息了,即进入广播状态。这时候当一个 server 加入 ZooKeeper 服务中,它会在恢复模式下启动,发现 leader,并和 leader 进行状态同步。待到同步结束,它也参与消息广播。ZooKeeper 服务一直维持在 Broadcast 状态,直到 leader 崩溃了或者 leader 失去了大部分的 followers 支持。
48 |
49 | ## 四种类型的数据节点 Znode
50 |
51 | * (1)PERSISTENT-持久节点 除非手动删除,否则节点一直存在于 Zookeeper 上
52 |
53 | * (2)EPHEMERAL-临时节点 临时节点的生命周期与客户端会话绑定,一旦客户端会话失效(客户端与zookeeper 连接断开不一定会话失效),那么这个客户端创建的所有临时节点都会被移除。
54 |
55 | * (3)PERSISTENT_SEQUENTIAL-持久顺序节点 基本特性同持久节点,只是增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字。
56 |
57 | * (4)EPHEMERAL_SEQUENTIAL-临时顺序节点 基本特性同临时节点,增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字。
58 |
59 | ## Zookeeper Watcher 机制 – 数据变更通知
60 |
61 | * Zookeeper 允许客户端向服务端的某个 Znode 注册一个 Watcher 监听,当服务端的一些指定事件触发了这个 Watcher,服务端会向指定客户端发送一个事件通知来实现分布式的通知功能,然后客户端根据 Watcher 通知状态和事件类型做出业务上的改变。
62 |
63 | * 工作机制:
64 |
65 | (1)客户端注册 watcher
66 |
67 | (2)服务端处理 watcher
68 |
69 | (3)客户端回调 watcher
70 |
71 | #### Watcher 特性总结
72 |
73 | 1. 一次性 无论是服务端还是客户端,一旦一个 Watcher 被 触 发 ,Zookeeper 都会将其从相应的存储中移除。这样的设计有效的减轻了服务端的压力,不然对于更新非常频繁的节点,服务端会不断的向客户端发送事件通知,无论对于网络还是服务端的压力都非常大。
74 |
75 | 2. 客户端串行执行 客户端 Watcher 回调的过程是一个串行同步的过程。
76 |
77 | 3. 轻量 3.1、Watcher 通知非常简单,只会告诉客户端发生了事件,而不会说明事件的具体内容。 3.2、客户端向服务端注册 Watcher 的时候,并不会把客户端真实的 Watcher 对象实体传递到服务端,仅仅是在客户端请求中使用 boolean 类型属性进行了标记。
78 |
79 | 4. watcher event 异步发送 watcher 的通知事件从 server 发送到 client 是异步的,这就存在一个问题,不同的客户端和服务器之间通过 socket 进行通信,由于网络延迟或其他因素导致客户端在不通的时刻监听到事件,由于 Zookeeper 本身提供了 ordering guarantee,即客户端监听事件后,才会感知它所监视 znode发生了变化。所以我们使用 Zookeeper 不能期望能够监控到节点每次的变化。Zookeeper 只能保证最终的一致性,而无法保证强一致性。
80 |
81 | 5. 注册 watcher getData、exists、getChildren
82 |
83 | 6. 触发 watcher create、delete、setData
84 |
85 | 7. 当一个客户端连接到一个新的服务器上时,watch 将会被以任意会话事件触发。当与一个服务器失去连接的时候,是无法接收到 watch 的。而当 client 重新连接时,如果需要的话,所有先前注册过的 watch,都会被重新注册。通常这是完全透明的。只有在一个特殊情况下,watch 可能会丢失:对于一个未创建的 znode的 exist watch,如果在客户端断开连接期间被创建了,并且随后在客户端连接上之前又删除了,这种情况下,这个 watch 事件可能会被丢失。
86 |
87 | ## 客户端注册 Watcher 实现
88 |
89 | * (1)调用 getData()/getChildren()/exist()三个 API,传入 Watcher 对象
90 |
91 | * (2)标记请求 request,封装 Watcher 到 WatchRegistration
92 |
93 | * (3)封装成 Packet 对象,发服务端发送 request
94 |
95 | * (4)收到服务端响应后,将 Watcher 注册到 ZKWatcherManager 中进行管理
96 |
97 | * (5)请求返回,完成注册。
98 |
99 | ## 服务端处理 Watcher 实现
100 |
101 | 1. 服务端接收 Watcher 并存储 接收到客户端请求,处理请求判断是否需要注册 Watcher,需要的话将数据节点的节点路径和 ServerCnxn(ServerCnxn 代表一个客户端和服务端的连接,实现了 Watcher 的 process 接口,此时可以看成一个 Watcher 对象)存储在WatcherManager 的 WatchTable 和 watch2Paths 中去。
102 |
103 | 2. Watcher 触发 以服务端接收到 setData() 事务请求触发 NodeDataChanged 事件为例:
104 |
105 | 2.1 封装 WatchedEvent 将通知状态(SyncConnected)、事件类型(NodeDataChanged)以及节点路径封装成一个 WatchedEvent 对象
106 |
107 | 2.2 查询 Watcher 从 WatchTable 中根据节点路径查找 Watcher
108 |
109 | 2.3 没找到;说明没有客户端在该数据节点上注册过 Watcher
110 |
111 | 2.4 找到;提取并从 WatchTable 和 Watch2Paths 中删除对应 Watcher(从这里可以看出 Watcher 在服务端是一次性的,触发一次就失效了)
112 |
113 | 3. 调用 process 方法来触发 Watcher 这里 process 主要就是通过 ServerCnxn 对应的 TCP 连接发送 Watcher 事件通知。
114 |
115 | ## 客户端回调 Watcher
116 |
117 | * 客户端 SendThread 线程接收事件通知,交由 EventThread 线程回调 Watcher。
118 |
119 | * 客户端的 Watcher 机制同样是一次性的,一旦被触发后,该 Watcher 就失效了。
120 |
121 | ## ACL 权限控制机制
122 |
123 | * UGO(User/Group/Others)
124 |
125 | * 目前在 Linux/Unix 文件系统中使用,也是使用最广泛的权限控制方式。是一种粗粒度的文件系统权限控制模式。
126 |
127 | * ACL(Access Control List)访问控制列表
128 |
129 | * **包括三个方面:**
130 |
131 | * 权限模式(Scheme) (1)IP:从 IP 地址粒度进行权限控制 (2)Digest:最常用,用类似于 username:password 的权限标识来进行权限配置,便于区分不同应用来进行权限控制 (3)World:最开放的权限控制方式,是一种特殊的 digest 模式,只有一个权限标识“world:anyone” (4)Super:超级用户
132 |
133 | * **授权对象** 授权对象指的是权限赋予的用户或一个指定实体,例如 IP 地址或是机器灯。
134 |
135 | * **权限 Permission** (1)CREATE:数据节点创建权限,允许授权对象在该 Znode 下创建子节点 (2)DELETE:子节点删除权限,允许授权对象删除该数据节点的子节点 (3)READ:数据节点的读取权限,允许授权对象访问该数据节点并读取其数据内容或子节点列表等 (4)WRITE:数据节点更新权限,允许授权对象对该数据节点进行更新操作 (5)ADMIN:数据节点管理权限,允许授权对象对该数据节点进行 ACL 相关设置操作
136 |
137 | ## Chroot 特性
138 |
139 | * 3.2.0 版本后,添加了 Chroot 特性,该特性允许每个客户端为自己设置一个命名空间。如果一个客户端设置了 Chroot,那么该客户端对服务器的任何操作,都将会被限制在其自己的命名空间下。
140 |
141 | * 通过设置 Chroot,能够将一个客户端应用于 Zookeeper 服务端的一颗子树相对应,在那些多个应用公用一个 Zookeeper 进群的场景下,对实现不同应用间的相互隔离非常有帮助。
142 |
143 | ## 会话管理
144 |
145 | * 分桶策略:将类似的会话放在同一区块中进行管理,以便于 Zookeeper 对会话进行不同区块的隔离处理以及同一区块的统一处理。
146 |
147 | * 分配原则:每个会话的“下次超时时间点”(ExpirationTime)
148 |
149 | * 计算公式:
150 |
151 | ExpirationTime_ = currentTime + sessionTimeout
152 |
153 | ExpirationTime = (ExpirationTime_ / ExpirationInrerval + 1) *
154 |
155 | ExpirationInterval , ExpirationInterval 是指 Zookeeper 会话超时检查时间间隔,默认 tickTime
156 |
157 | ## 服务器角色
158 |
159 | * Leader
160 |
161 | (1)事务请求的唯一调度和处理者,保证集群事务处理的顺序性
162 |
163 | (2)集群内部各服务的调度者
164 |
165 | * Follower
166 |
167 | (1)处理客户端的非事务请求,转发事务请求给 Leader 服务器
168 |
169 | (2)参与事务请求 Proposal 的投票
170 |
171 | (3)参与 Leader 选举投票
172 |
173 | * Observer
174 |
175 | (1)3.0 版本以后引入的一个服务器角色,在不影响集群事务处理能力的基础上提升集群的非事务处理能力
176 |
177 | (2)处理客户端的非事务请求,转发事务请求给 Leader 服务器
178 |
179 | (3)不参与任何形式的投票
180 |
181 | ## Zookeeper 下 Server 工作状态
182 |
183 | * 服务器具有四种状态,分别是 LOOKING、FOLLOWING、LEADING、OBSERVING。
184 |
185 | (1)LOOKING:寻 找 Leader 状态。当服务器处于该状态时,它会认为当前集群中没有 Leader,因此需要进入 Leader 选举状态。
186 |
187 | (2)FOLLOWING:跟随者状态。表明当前服务器角色是 Follower。
188 |
189 | (3)LEADING:领导者状态。表明当前服务器角色是 Leader。
190 |
191 | (4)OBSERVING:观察者状态。表明当前服务器角色是 Observer。
192 |
193 | ## 数据同步
194 |
195 | * 整个集群完成 Leader 选举之后,Learner(Follower 和 Observer 的统称)回向Leader 服务器进行注册。当 Learner 服务器想 Leader 服务器完成注册后,进入数据同步环节。
196 |
197 | * 数据同步流程:(均以消息传递的方式进行)
198 |
199 | * Learner 向 Learder 注册
200 | * 数据同步
201 | * 同步确认
202 | * Zookeeper 的数据同步通常分为四类:
203 |
204 | (1)直接差异化同步(DIFF 同步)
205 |
206 | (2)先回滚再差异化同步(TRUNC+DIFF 同步)
207 |
208 | (3)仅回滚同步(TRUNC 同步)
209 |
210 | (4)全量同步(SNAP 同步)
211 |
212 | * 在进行数据同步前,Leader服务器会完成数据同步初始化:
213 |
214 | * peerLastZxid:从learner服务器注册时发送的ACKEPOCH消息中提取lastZxid(该Learner服务器最后处理的ZXID)
215 | * minCommittedLog:Leader服务器Proposal缓存队列committedLog中最小ZXID
216 | * maxCommittedLog:Leader服务器Proposal缓存队列committedLog中最大ZXID
217 | * 直接差异化同步(DIFF同步) 场景:peerLastZxid介于minCommittedLog和maxCommittedLog之间
218 |
219 | 
220 |
221 | * 先回滚再差异化同步(TRUNC+DIFF同步) 场景:当新的Leader服务器发现某个Learner服务器包含了一条自己没有的事务记录,那么就需要让该Learner服务器进行事务回滚--回滚到Leader服务器上存在的,同时也是最接近于peerLastZxid的ZXID
222 |
223 | * 仅回滚同步(TRUNC同步) 场景:peerLastZxid 大于 maxCommittedLog
224 |
225 | * 全量同步(SNAP同步) 场景一:peerLastZxid 小于 minCommittedLog 场景二:Leader服务器上没有Proposal缓存队列且peerLastZxid不等于lastProcessZxid
226 |
227 | ## zookeeper 是如何保证事务的顺序一致性的?
228 |
229 | * zookeeper 采用了全局递增的事务 Id 来标识,所有的 proposal(提议)都在被提出的时候加上了 zxid,zxid 实际上是一个 64 位的数字,高 32 位是 epoch( 时期; 纪元; 世; 新时代)用来标识 leader 周期,如果有新的 leader 产生出来,epoch会自增,低 32 位用来递增计数。当新产生 proposal 的时候,会依据数据库的两阶段过程,首先会向其他的 server 发出事务执行请求,如果超过半数的机器都能执行并且能够成功,那么就会开始执行。
230 |
231 | ## 分布式集群中为什么会有 Master主节点?
232 |
233 | * 在分布式环境中,有些业务逻辑只需要集群中的某一台机器进行执行,其他的机器可以共享这个结果,这样可以大大减少重复计算,提高性能,于是就需要进行 leader 选举。
234 |
235 | ## zk 节点宕机如何处理?
236 |
237 | * Zookeeper 本身也是集群,推荐配置不少于 3 个服务器。Zookeeper 自身也要保证当一个节点宕机时,其他节点会继续提供服务。
238 |
239 | * 如果是一个 Follower 宕机,还有 2 台服务器提供访问,因为 Zookeeper 上的数据是有多个副本的,数据并不会丢失;
240 |
241 | * 如果是一个 Leader 宕机,Zookeeper 会选举出新的 Leader。
242 |
243 | * ZK 集群的机制是只要超过半数的节点正常,集群就能正常提供服务。只有在 ZK节点挂得太多,只剩一半或不到一半节点能工作,集群才失效。
244 |
245 | **所以**
246 |
247 | * 3 个节点的 cluster 可以挂掉 1 个节点(leader 可以得到 2 票>1.5)
248 | * 2 个节点的 cluster 就不能挂掉任何 1 个节点了(leader 可以得到 1 票<=1)
249 |
250 | ## zookeeper 负载均衡和 nginx 负载均衡区别
251 |
252 | * zk 的负载均衡是可以调控,nginx 只是能调权重,其他需要可控的都需要自己写插件;但是 nginx 的吞吐量比 zk 大很多,应该说按业务选择用哪种方式。
253 |
254 | ## Zookeeper 有哪几种几种部署模式?
255 |
256 | * Zookeeper 有三种部署模式:
257 | 1. 单机部署:一台集群上运行;
258 | 2. 集群部署:多台集群运行;
259 | 3. 伪集群部署:一台集群启动多个 Zookeeper 实例运行。
260 |
261 | ## 集群最少要几台机器,集群规则是怎样的?集群中有 3 台服务器,其中一个节点宕机,这个时候 Zookeeper 还可以使用吗?
262 |
263 | * 集群规则为 2N+1 台,N>0,即 3 台。可以继续使用,单数服务器只要没超过一半的服务器宕机就可以继续使用。
264 |
265 | ## 集群支持动态添加机器吗?
266 |
267 | * 其实就是水平扩容了,Zookeeper 在这方面不太好。两种方式:
268 |
269 | * 全部重启:关闭所有 Zookeeper 服务,修改配置之后启动。不影响之前客户端的会话。
270 |
271 | * 逐个重启:在过半存活即可用的原则下,一台机器重启不影响整个集群对外提供服务。这是比较常用的方式。
272 |
273 | * 3.5 版本开始支持动态扩容。
274 |
275 | ## Zookeeper 对节点的 watch 监听通知是永久的吗?为什么不是永久的?
276 |
277 | * 不是。官方声明:一个 Watch 事件是一个一次性的触发器,当被设置了 Watch的数据发生了改变的时候,则服务器将这个改变发送给设置了 Watch 的客户端,以便通知它们。
278 |
279 | * 为什么不是永久的,举个例子,如果服务端变动频繁,而监听的客户端很多情况下,每次变动都要通知到所有的客户端,给网络和服务器造成很大压力。
280 |
281 | * 一般是客户端执行 getData(“/节点 A”,true),如果节点 A 发生了变更或删除,客户端会得到它的 watch 事件,但是在之后节点 A 又发生了变更,而客户端又没有设置 watch 事件,就不再给客户端发送。
282 |
283 | * 在实际应用中,很多情况下,我们的客户端不需要知道服务端的每一次变动,我只要最新的数据即可。
284 |
285 | ## Zookeeper 的 java 客户端都有哪些?
286 |
287 | * java 客户端:zk 自带的 zkclient 及 Apache 开源的 Curator。
288 |
289 | ## chubby 是什么,和 zookeeper 比你怎么看?
290 |
291 | * chubby 是 google 的,完全实现 paxos 算法,不开源。zookeeper 是 chubby的开源实现,使用 zab 协议,paxos 算法的变种。
292 |
293 | ## 说几个 zookeeper 常用的命令。
294 |
295 | * 常用命令:ls get set create delete 等。
296 |
297 | ## ZAB 和 Paxos 算法的联系与区别?
298 |
299 | * 相同点:
300 |
301 | (1)两者都存在一个类似于 Leader 进程的角色,由其负责协调多个 Follower 进程的运行
302 |
303 | (2)Leader 进程都会等待超过半数的 Follower 做出正确的反馈后,才会将一个提案进行提交
304 |
305 | (3)ZAB 协议中,每个 Proposal 中都包含一个 epoch 值来代表当前的 Leader周期,Paxos 中名字为 Ballot
306 |
307 | * 不同点:
308 |
309 | ZAB 用来构建高可用的分布式数据主备系统(Zookeeper),Paxos 是用来构建分布式一致性状态机系统。
310 |
311 | ## Zookeeper 的典型应用场景
312 |
313 | * Zookeeper 是一个典型的发布/订阅模式的分布式数据管理与协调框架,开发人员可以使用它来进行分布式数据的发布和订阅。
314 |
315 | * 通过对 Zookeeper 中丰富的数据节点进行交叉使用,配合 Watcher 事件通知机制,可以非常方便的构建一系列分布式应用中年都会涉及的核心功能,如:
316 |
317 | (1)数据发布/订阅
318 |
319 | (2)负载均衡
320 |
321 | (3)命名服务
322 |
323 | (4)分布式协调/通知
324 |
325 | (5)集群管理
326 |
327 | (6)Master 选举
328 |
329 | (7)分布式锁
330 |
331 | (8)分布式队列
332 |
333 | #### 1 数据发布/订阅
334 |
335 | **介绍**
336 |
337 | * 数据发布/订阅系统,即所谓的配置中心,顾名思义就是发布者发布数据供订阅者进行数据订阅。
338 |
339 | **目的**
340 |
341 | * 动态获取数据(配置信息)
342 | * 实现数据(配置信息)的集中式管理和数据的动态更新
343 |
344 | **设计模式**
345 |
346 | * Push 模式
347 | * Pull 模式
348 |
349 | **数据(配置信息)特性**
350 |
351 | (1)数据量通常比较小 (2)数据内容在运行时会发生动态更新 (3)集群中各机器共享,配置一致
352 |
353 | * 如:机器列表信息、运行时开关配置、数据库配置信息等
354 |
355 | **基于 Zookeeper 的实现方式**
356 |
357 | * · 数据存储:将数据(配置信息)存储到 Zookeeper 上的一个数据节点
358 | * · 数据获取:应用在启动初始化节点从 Zookeeper 数据节点读取数据,并在该节点上注册一个数据变更 Watcher
359 | * · 数据变更:当变更数据时,更新 Zookeeper 对应节点数据,Zookeeper会将数据变更通知发到各客户端,客户端接到通知后重新读取变更后的数据即可。
360 |
361 | #### 2 负载均衡
362 |
363 | * zk 的命名服务
364 | * 命名服务是指通过指定的名字来获取资源或者服务的地址,利用 zk 创建一个全局的路径,这个路径就可以作为一个名字,指向集群中的集群,提供的服务的地址,或者一个远程的对象等等。
365 |
366 | **分布式通知和协调**
367 |
368 | * 对于系统调度来说:操作人员发送通知实际是通过控制台改变某个节点的状态,然后 zk 将这些变化发送给注册了这个节点的 watcher 的所有客户端。
369 |
370 | * 对于执行情况汇报:每个工作进程都在某个目录下创建一个临时节点。并携带工作的进度数据,这样汇总的进程可以监控目录子节点的变化获得工作进度的实时的全局情况。
371 |
372 | **zk 的命名服务(文件系统)**
373 |
374 | * 命名服务是指通过指定的名字来获取资源或者服务的地址,利用 zk 创建一个全局的路径,即是唯一的路径,这个路径就可以作为一个名字,指向集群中的集群,提供的服务的地址,或者一个远程的对象等等。
375 |
376 | **zk 的配置管理(文件系统、通知机制)**
377 |
378 | * 程序分布式的部署在不同的机器上,将程序的配置信息放在 zk 的 znode 下,当有配置发生改变时,也就是 znode 发生变化时,可以通过改变 zk 中某个目录节点的内容,利用 watcher 通知给各个客户端,从而更改配置。
379 |
380 | **Zookeeper 集群管理(文件系统、通知机制)**
381 |
382 | * 所谓集群管理无在乎两点:是否有机器退出和加入、选举 master。
383 |
384 | * 对于第一点,所有机器约定在父目录下创建临时目录节点,然后监听父目录节点
385 |
386 | * 的子节点变化消息。一旦有机器挂掉,该机器与 zookeeper 的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知:某个兄弟目录被删除,于是,所有人都知道:它上船了。
387 |
388 | * 新机器加入也是类似,所有机器收到通知:新兄弟目录加入,highcount 又有了,对于第二点,我们稍微改变一下,所有机器创建临时顺序编号目录节点,每次选取编号最小的机器作为 master 就好。
389 |
390 | **Zookeeper 分布式锁(文件系统、通知机制)**
391 |
392 | * 有了 zookeeper 的一致性文件系统,锁的问题变得容易。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
393 |
394 | * 对于第一类,我们将 zookeeper 上的一个 znode 看作是一把锁,通过 createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。用完删除掉自己创建的 distribute_lock 节点就释放出锁。
395 |
396 | * 对于第二类, /distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选 master 一样,编号最小的获得锁,用完删除,依次方便。
397 |
398 | **Zookeeper 队列管理(文件系统、通知机制)**
399 |
400 | * 两种类型的队列:
401 |
402 | (1)同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。 (2)队列按照 FIFO 方式进行入队和出队操作。
403 |
404 | * 第一类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
405 |
406 | * 第二类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号。在特定的目录下创建 PERSISTENT_SEQUENTIAL 节点,创建成功时Watcher 通知等待的队列,队列删除序列号最小的节点用以消费。此场景下Zookeeper 的 znode 用于消息存储,znode 存储的数据就是消息队列中的消息内容,SEQUENTIAL 序列号就是消息的编号,按序取出即可。由于创建的节点是持久化的,所以不必担心队列消息的丢失问题。
407 |
408 | ## Zookeeper 都有哪些功能?
409 |
410 | 1. 集群管理:监控节点存活状态、运行请求等;
411 |
412 | 2. 主节点选举:主节点挂掉了之后可以从备用的节点开始新一轮选主,主节点选举说的就是这个选举的过程,使用 Zookeeper 可以协助完成这个过程;
413 |
414 | 3. 分布式锁:Zookeeper 提供两种锁:独占锁、共享锁。独占锁即一次只能有一个线程使用资源,共享锁是读锁共享,读写互斥,即可以有多线线程同时读同一个资源,如果要使用写锁也只能有一个线程使用。Zookeeper 可以对分布式锁进行控制。
415 |
416 | 4. 命名服务:在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。
417 |
418 | ## 说一下 Zookeeper 的通知机制?
419 |
420 | * client 端会对某个 znode 建立一个 watcher 事件,当该 znode 发生变化时,这些 client 会收到 zk 的通知,然后 client 可以根据 znode 变化来做出业务上的改变等。
421 |
422 | ## Zookeeper 和 Dubbo 的关系?
423 |
424 | * Zookeeper的作用: zookeeper用来注册服务和进行负载均衡,哪一个服务由哪一个机器来提供必需让调用者知道,简单来说就是ip地址和服务名称的对应关系。当然也可以通过硬编码的方式把这种对应关系在调用方业务代码中实现,但是如果提供服务的机器挂掉调用者无法知晓,如果不更改代码会继续请求挂掉的机器提供服务。zookeeper通过心跳机制可以检测挂掉的机器并将挂掉机器的ip和服务对应关系从列表中删除。至于支持高并发,简单来说就是横向扩展,在不更改代码的情况通过添加机器来提高运算能力。通过添加新的机器向zookeeper注册服务,服务的提供者多了能服务的客户就多了。
425 |
426 | * dubbo: 是管理中间层的工具,在业务层到数据仓库间有非常多服务的接入和服务提供者需要调度,dubbo提供一个框架解决这个问题。
427 | 注意这里的dubbo只是一个框架,至于你架子上放什么是完全取决于你的,就像一个汽车骨架,你需要配你的轮子引擎。这个框架中要完成调度必须要有一个分布式的注册中心,储存所有服务的元数据,你可以用zk,也可以用别的,只是大家都用zk。
428 |
429 | * zookeeper和dubbo的关系: Dubbo 的将注册中心进行抽象,它可以外接不同的存储媒介给注册中心提供服务,有 ZooKeeper,Memcached,Redis 等。
430 |
431 | 引入了 ZooKeeper 作为存储媒介,也就把 ZooKeeper 的特性引进来。首先是负载均衡,单注册中心的承载能力是有限的,在流量达到一定程度的时 候就需要分流,负载均衡就是为了分流而存在的,一个 ZooKeeper 群配合相应的 Web 应用就可以很容易达到负载均衡;资源同步,单单有负载均衡还不 够,节点之间的数据和资源需要同步,ZooKeeper 集群就天然具备有这样的功能;命名服务,将树状结构用于维护全局的服务地址列表,服务提供者在启动 的时候,向 ZooKeeper 上的指定节点 /dubbo/${serviceName}/providers 目录下写入自己的 URL 地址,这个操作就完成了服务的发布。 其他特性还有 Mast 选举,分布式锁等。
432 |
433 | 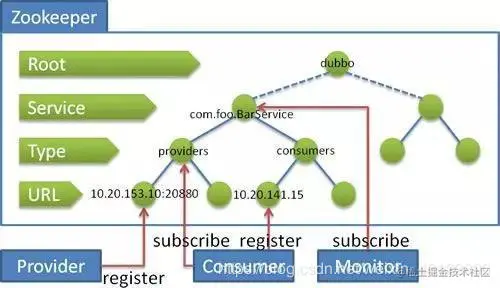
434 |
435 | 作者:小杰要吃蛋
436 | 链接:https://juejin.cn/post/6844904127076499464
437 | 来源:稀土掘金
438 | 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
--------------------------------------------------------------------------------
/docs/java/基础面试题/Nginx.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ### 什么是Nginx?
4 |
5 | * Nginx是一个 轻量级/高性能的反向代理Web服务器,他实现非常高效的反向代理、负载平衡,他可以处理2-3万并发连接数,官方监测能支持5万并发,现在中国使用nginx网站用户有很多,例如:新浪、网易、 腾讯等。
6 |
7 | ### 为什么要用Nginx?
8 |
9 | * 跨平台、配置简单、方向代理、高并发连接:处理2-3万并发连接数,官方监测能支持5万并发,内存消耗小:开启10个nginx才占150M内存 ,nginx处理静态文件好,耗费内存少,
10 |
11 | * 而且Nginx内置的健康检查功能:如果有一个服务器宕机,会做一个健康检查,再发送的请求就不会发送到宕机的服务器了。重新将请求提交到其他的节点上。
12 |
13 | * 使用Nginx的话还能:
14 |
15 | 1. 节省宽带:支持GZIP压缩,可以添加浏览器本地缓存
16 | 2. 稳定性高:宕机的概率非常小
17 | 3. 接收用户请求是异步的
18 |
19 | ### 为什么Nginx性能这么高?
20 |
21 | * 因为他的事件处理机制:异步非阻塞事件处理机制:运用了epoll模型,提供了一个队列,排队解决
22 |
23 | ### Nginx怎么处理请求的?
24 |
25 | * nginx接收一个请求后,首先由listen和server_name指令匹配server模块,再匹配server模块里的location,location就是实际地址
26 |
27 | ```java
28 | server { # 第一个Server区块开始,表示一个独立的虚拟主机站点
29 | listen 80; # 提供服务的端口,默认80
30 | server_name localhost; # 提供服务的域名主机名
31 | location / { # 第一个location区块开始
32 | root html; # 站点的根目录,相当于Nginx的安装目录
33 | index index.html index.htm; # 默认的首页文件,多个用空格分开
34 | } # 第一个location区块结果
35 | }
36 | ```
37 | ### 什么是正向代理和反向代理?
38 |
39 | 1. 正向代理就是一个人发送一个请求直接就到达了目标的服务器
40 | 2. 反方代理就是请求统一被Nginx接收,nginx反向代理服务器接收到之后,按照一定的规 则分发给了后端的业务处理服务器进行处理了
41 |
42 | ### 使用“反向代理服务器的优点是什么?
43 |
44 | * 反向代理服务器可以隐藏源服务器的存在和特征。它充当互联网云和web服务器之间的中间层。这对于安全方面来说是很好的,特别是当您使用web托管服务时。
45 |
46 | ### Nginx的优缺点?
47 |
48 | * 优点:
49 |
50 | 1. 占内存小,可实现高并发连接,处理响应快
51 | 2. 可实现http服务器、虚拟主机、方向代理、负载均衡
52 | 3. Nginx配置简单
53 | 4. 可以不暴露正式的服务器IP地址
54 | * 缺点: 动态处理差:nginx处理静态文件好,耗费内存少,但是处理动态页面则很鸡肋,现在一般前端用nginx作为反向代理抗住压力,
55 |
56 | ### Nginx应用场景?
57 |
58 | 1. http服务器。Nginx是一个http服务可以独立提供http服务。可以做网页静态服务器。
59 | 2. 虚拟主机。可以实现在一台服务器虚拟出多个网站,例如个人网站使用的虚拟机。
60 | 3. 反向代理,负载均衡。当网站的访问量达到一定程度后,单台服务器不能满足用户的请求时,需要用多台服务器集群可以使用nginx做反向代理。并且多台服务器可以平均分担负载,不会应为某台服务器负载高宕机而某台服务器闲置的情况。
61 | 4. nginz 中也可以配置安全管理、比如可以使用Nginx搭建API接口网关,对每个接口服务进行拦截。
62 |
63 | ### Nginx目录结构有哪些?
64 |
65 | ```java
66 | [root@localhost ~]# tree /usr/local/nginx
67 | /usr/local/nginx
68 | ├── client_body_temp
69 | ├── conf # Nginx所有配置文件的目录
70 | │ ├── fastcgi.conf # fastcgi相关参数的配置文件
71 | │ ├── fastcgi.conf.default # fastcgi.conf的原始备份文件
72 | │ ├── fastcgi_params # fastcgi的参数文件
73 | │ ├── fastcgi_params.default
74 | │ ├── koi-utf
75 | │ ├── koi-win
76 | │ ├── mime.types # 媒体类型
77 | │ ├── mime.types.default
78 | │ ├── nginx.conf # Nginx主配置文件
79 | │ ├── nginx.conf.default
80 | │ ├── scgi_params # scgi相关参数文件
81 | │ ├── scgi_params.default
82 | │ ├── uwsgi_params # uwsgi相关参数文件
83 | │ ├── uwsgi_params.default
84 | │ └── win-utf
85 | ├── fastcgi_temp # fastcgi临时数据目录
86 | ├── html # Nginx默认站点目录
87 | │ ├── 50x.html # 错误页面优雅替代显示文件,例如当出现502错误时会调用此页面
88 | │ └── index.html # 默认的首页文件
89 | ├── logs # Nginx日志目录
90 | │ ├── access.log # 访问日志文件
91 | │ ├── error.log # 错误日志文件
92 | │ └── nginx.pid # pid文件,Nginx进程启动后,会把所有进程的ID号写到此文件
93 | ├── proxy_temp # 临时目录
94 | ├── sbin # Nginx命令目录
95 | │ └── nginx # Nginx的启动命令
96 | ├── scgi_temp # 临时目录
97 | └── uwsgi_temp # 临时目录
98 | ```
99 | ### Nginx配置文件nginx.conf有哪些属性模块?
100 |
101 | ```java
102 | worker_processes 1; # worker进程的数量
103 | events { # 事件区块开始
104 | worker_connections 1024; # 每个worker进程支持的最大连接数
105 | } # 事件区块结束
106 | http { # HTTP区块开始
107 | include mime.types; # Nginx支持的媒体类型库文件
108 | default_type application/octet-stream; # 默认的媒体类型
109 | sendfile on; # 开启高效传输模式
110 | keepalive_timeout 65; # 连接超时
111 | server { # 第一个Server区块开始,表示一个独立的虚拟主机站点
112 | listen 80; # 提供服务的端口,默认80
113 | server_name localhost; # 提供服务的域名主机名
114 | location / { # 第一个location区块开始
115 | root html; # 站点的根目录,相当于Nginx的安装目录
116 | index index.html index.htm; # 默认的首页文件,多个用空格分开
117 | } # 第一个location区块结果
118 | error_page 500502503504 /50x.html; # 出现对应的http状态码时,使用50x.html回应客户
119 | location = /50x.html { # location区块开始,访问50x.html
120 | root html; # 指定对应的站点目录为html
121 | }
122 | }
123 | ......
124 | ```
125 | ### Nginx静态资源?
126 |
127 | * 静态资源访问,就是存放在nginx的html页面,我们可以自己编写
128 |
129 | ### 如何用Nginx解决前端跨域问题?
130 |
131 | * 使用Nginx转发请求。把跨域的接口写成调本域的接口,然后将这些接口转发到真正的请求地址。
132 |
133 | ### Nginx虚拟主机怎么配置?
134 |
135 | * 1、基于域名的虚拟主机,通过域名来区分虚拟主机——应用:外部网站
136 |
137 | * 2、基于端口的虚拟主机,通过端口来区分虚拟主机——应用:公司内部网站,外部网站的管理后台
138 |
139 | * 3、基于ip的虚拟主机。
140 |
141 | #### 基于虚拟主机配置域名
142 |
143 | * 需要建立/data/www /data/bbs目录,windows本地hosts添加虚拟机ip地址对应的域名解析;对应域名网站目录下新增index.html文件;
144 |
145 | ```java
146 | #当客户端访问www.lijie.com,监听端口号为80,直接跳转到data/www目录下文件
147 | server {
148 | listen 80;
149 | server_name www.lijie.com;
150 | location / {
151 | root data/www;
152 | index index.html index.htm;
153 | }
154 | }
155 |
156 | #当客户端访问www.lijie.com,监听端口号为80,直接跳转到data/bbs目录下文件
157 | server {
158 | listen 80;
159 | server_name bbs.lijie.com;
160 | location / {
161 | root data/bbs;
162 | index index.html index.htm;
163 | }
164 | }
165 | ```
166 | #### 基于端口的虚拟主机
167 |
168 | * 使用端口来区分,浏览器使用域名或ip地址:端口号 访问
169 |
170 | ```java
171 | #当客户端访问www.lijie.com,监听端口号为8080,直接跳转到data/www目录下文件
172 | server {
173 | listen 8080;
174 | server_name 8080.lijie.com;
175 | location / {
176 | root data/www;
177 | index index.html index.htm;
178 | }
179 | }
180 |
181 | #当客户端访问www.lijie.com,监听端口号为80直接跳转到真实ip服务器地址 127.0.0.1:8080
182 | server {
183 | listen 80;
184 | server_name www.lijie.com;
185 | location / {
186 | proxy_pass http://127.0.0.1:8080;
187 | index index.html index.htm;
188 | }
189 | }
190 | ```
191 | ### location的作用是什么?
192 |
193 | * location指令的作用是根据用户请求的URI来执行不同的应用,也就是根据用户请求的网站URL进行匹配,匹配成功即进行相关的操作。
194 |
195 | #### location的语法能说出来吗?
196 |
197 | > 注意:~ 代表自己输入的英文字母
198 | >
199 | > | 匹配符 | 匹配规则 | 优先级 |
200 | > | --- | --- | --- |
201 | > | = | 精确匹配 | 1 |
202 | > | ^~ | 以某个字符串开头 | 2 |
203 | > | ~ | 区分大小写的正则匹配 | 3 |
204 | > | ~* | 不区分大小写的正则匹配 | 4 |
205 | > | !~ | 区分大小写不匹配的正则 | 5 |
206 | > | !~* | 不区分大小写不匹配的正则 | 6 |
207 | > | / | 通用匹配,任何请求都会匹配到 | 7 |
208 |
209 | #### Location正则案例
210 |
211 | * 示例:
212 |
213 | ```java
214 | #优先级1,精确匹配,根路径
215 | location =/ {
216 | return 400;
217 | }
218 |
219 | #优先级2,以某个字符串开头,以av开头的,优先匹配这里,区分大小写
220 | location ^~ /av {
221 | root /data/av/;
222 | }
223 |
224 | #优先级3,区分大小写的正则匹配,匹配/media*****路径
225 | location ~ /media {
226 | alias /data/static/;
227 | }
228 |
229 | #优先级4 ,不区分大小写的正则匹配,所有的****.jpg|gif|png 都走这里
230 | location ~* .*\.(jpg|gif|png|js|css)$ {
231 | root /data/av/;
232 | }
233 |
234 | #优先7,通用匹配
235 | location / {
236 | return 403;
237 | }
238 | ```
239 | ### 限流怎么做的?
240 |
241 | * Nginx限流就是限制用户请求速度,防止服务器受不了
242 |
243 | * 限流有3种
244 |
245 | 1. 正常限制访问频率(正常流量)
246 | 2. 突发限制访问频率(突发流量)
247 | 3. 限制并发连接数
248 | * Nginx的限流都是基于漏桶流算法,底下会说道什么是桶铜流
249 |
250 | **实现三种限流算法**
251 |
252 | ##### 1、正常限制访问频率(正常流量):
253 |
254 | * 限制一个用户发送的请求,我Nginx多久接收一个请求。
255 |
256 | * Nginx中使用ngx_http_limit_req_module模块来限制的访问频率,限制的原理实质是基于漏桶算法原理来实现的。在nginx.conf配置文件中可以使用limit_req_zone命令及limit_req命令限制单个IP的请求处理频率。
257 |
258 | ```java
259 | #定义限流维度,一个用户一分钟一个请求进来,多余的全部漏掉
260 | limit_req_zone $binary_remote_addr zone=one:10m rate=1r/m;
261 |
262 | #绑定限流维度
263 | server{
264 |
265 | location/seckill.html{
266 | limit_req zone=zone;
267 | proxy_pass http://lj_seckill;
268 | }
269 |
270 | }
271 | ```
272 |
273 | * 1r/s代表1秒一个请求,1r/m一分钟接收一个请求, 如果Nginx这时还有别人的请求没有处理完,Nginx就会拒绝处理该用户请求。
274 |
275 | ##### 2、突发限制访问频率(突发流量):
276 |
277 | * 限制一个用户发送的请求,我Nginx多久接收一个。
278 |
279 | * 上面的配置一定程度可以限制访问频率,但是也存在着一个问题:如果突发流量超出请求被拒绝处理,无法处理活动时候的突发流量,这时候应该如何进一步处理呢?Nginx提供burst参数结合nodelay参数可以解决流量突发的问题,可以设置能处理的超过设置的请求数外能额外处理的请求数。我们可以将之前的例子添加burst参数以及nodelay参数:
280 |
281 | ```java
282 | #定义限流维度,一个用户一分钟一个请求进来,多余的全部漏掉
283 | limit_req_zone $binary_remote_addr zone=one:10m rate=1r/m;
284 |
285 | #绑定限流维度
286 | server{
287 |
288 | location/seckill.html{
289 | limit_req zone=zone burst=5 nodelay;
290 | proxy_pass http://lj_seckill;
291 | }
292 |
293 | }
294 | ```
295 |
296 | * 为什么就多了一个 burst=5 nodelay; 呢,多了这个可以代表Nginx对于一个用户的请求会立即处理前五个,多余的就慢慢来落,没有其他用户的请求我就处理你的,有其他的请求的话我Nginx就漏掉不接受你的请求
297 |
298 | ##### 3、 限制并发连接数
299 |
300 | * Nginx中的ngx_http_limit_conn_module模块提供了限制并发连接数的功能,可以使用limit_conn_zone指令以及limit_conn执行进行配置。接下来我们可以通过一个简单的例子来看下:
301 |
302 | ```java
303 | http {
304 | limit_conn_zone $binary_remote_addr zone=myip:10m;
305 | limit_conn_zone $server_name zone=myServerName:10m;
306 | }
307 |
308 | server {
309 | location / {
310 | limit_conn myip 10;
311 | limit_conn myServerName 100;
312 | rewrite / http://www.lijie.net permanent;
313 | }
314 | }
315 | ```
316 |
317 | * 上面配置了单个IP同时并发连接数最多只能10个连接,并且设置了整个虚拟服务器同时最大并发数最多只能100个链接。当然,只有当请求的header被服务器处理后,虚拟服务器的连接数才会计数。刚才有提到过Nginx是基于漏桶算法原理实现的,实际上限流一般都是基于漏桶算法和令牌桶算法实现的。接下来我们来看看两个算法的介绍:
318 |
319 | ### 漏桶流算法和令牌桶算法知道?
320 |
321 | #### 漏桶算法
322 |
323 | * 漏桶算法是网络世界中流量整形或速率限制时经常使用的一种算法,它的主要目的是控制数据注入到网络的速率,平滑网络上的突发流量。漏桶算法提供了一种机制,通过它,突发流量可以被整形以便为网络提供一个稳定的流量。也就是我们刚才所讲的情况。漏桶算法提供的机制实际上就是刚才的案例:**突发流量会进入到一个漏桶,漏桶会按照我们定义的速率依次处理请求,如果水流过大也就是突发流量过大就会直接溢出,则多余的请求会被拒绝。所以漏桶算法能控制数据的传输速率。**
324 |
325 | #### 令牌桶算法
326 |
327 | * 令牌桶算法是网络流量整形和速率限制中最常使用的一种算法。典型情况下,令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送。Google开源项目Guava中的RateLimiter使用的就是令牌桶控制算法。**令牌桶算法的机制如下:存在一个大小固定的令牌桶,会以恒定的速率源源不断产生令牌。如果令牌消耗速率小于生产令牌的速度,令牌就会一直产生直至装满整个令牌桶。**
328 |
329 | 
330 | ### 为什么要做动静分离?
331 |
332 | * Nginx是当下最热的Web容器,网站优化的重要点在于静态化网站,网站静态化的关键点则是是动静分离,动静分离是让动态网站里的动态网页根据一定规则把不变的资源和经常变的资源区分开来,动静资源做好了拆分以后,我们则根据静态资源的特点将其做缓存操作。
333 |
334 | * 让静态的资源只走静态资源服务器,动态的走动态的服务器
335 |
336 | * Nginx的静态处理能力很强,但是动态处理能力不足,因此,在企业中常用动静分离技术。
337 |
338 | * 对于静态资源比如图片,js,css等文件,我们则在反向代理服务器nginx中进行缓存。这样浏览器在请求一个静态资源时,代理服务器nginx就可以直接处理,无需将请求转发给后端服务器tomcat。 若用户请求的动态文件,比如servlet,jsp则转发给Tomcat服务器处理,从而实现动静分离。这也是反向代理服务器的一个重要的作用。
339 |
340 | ### Nginx怎么做的动静分离?
341 |
342 | * 只需要指定路径对应的目录。location/可以使用正则表达式匹配。并指定对应的硬盘中的目录。如下:(操作都是在Linux上)
343 |
344 | ```java
345 | location /image/ {
346 | root /usr/local/static/;
347 | autoindex on;
348 | }
349 | ```
350 |
351 | 1. 创建目录
352 |
353 | ```java
354 | mkdir /usr/local/static/image
355 | ```
356 | 1. 进入目录
357 |
358 | ```java
359 | cd /usr/local/static/image
360 | ```
361 | 1. 放一张照片上去#
362 |
363 | ```java
364 | 1.jpg
365 | ```
366 | 1. 重启 nginx
367 |
368 | ```java
369 | sudo nginx -s reload
370 | ```
371 | 1. 打开浏览器 输入 server_name/image/1.jpg 就可以访问该静态图片了
372 |
373 | ### Nginx负载均衡的算法怎么实现的?策略有哪些?
374 |
375 | * 为了避免服务器崩溃,大家会通过负载均衡的方式来分担服务器压力。将对台服务器组成一个集群,当用户访问时,先访问到一个转发服务器,再由转发服务器将访问分发到压力更小的服务器。
376 |
377 | * Nginx负载均衡实现的策略有以下五种:
378 |
379 | #### 1 轮询(默认)
380 |
381 | * 每个请求按时间顺序逐一分配到不同的后端服务器,如果后端某个服务器宕机,能自动剔除故障系统。
382 |
383 | ```java
384 | upstream backserver {
385 | server 192.168.0.12;
386 | server 192.168.0.13;
387 | }
388 | ```
389 | #### 2 权重 weight
390 |
391 | * weight的值越大分配
392 |
393 | * 到的访问概率越高,主要用于后端每台服务器性能不均衡的情况下。其次是为在主从的情况下设置不同的权值,达到合理有效的地利用主机资源。
394 |
395 | ```java
396 | upstream backserver {
397 | server 192.168.0.12 weight=2;
398 | server 192.168.0.13 weight=8;
399 | }
400 | ```
401 |
402 | * 权重越高,在被访问的概率越大,如上例,分别是20%,80%。
403 |
404 | #### 3 ip_hash( IP绑定)
405 |
406 | * 每个请求按访问IP的哈希结果分配,使来自同一个IP的访客固定访问一台后端服务器,`并且可以有效解决动态网页存在的session共享问题`
407 |
408 | ```java
409 | upstream backserver {
410 | ip_hash;
411 | server 192.168.0.12:88;
412 | server 192.168.0.13:80;
413 | }
414 | ```
415 | #### 4 fair(第三方插件)
416 |
417 | * 必须安装upstream_fair模块。
418 |
419 | * 对比 weight、ip_hash更加智能的负载均衡算法,fair算法可以根据页面大小和加载时间长短智能地进行负载均衡,响应时间短的优先分配。
420 |
421 | ```java
422 | upstream backserver {
423 | server server1;
424 | server server2;
425 | fair;
426 | }
427 |
428 | ```
429 |
430 | * 哪个服务器的响应速度快,就将请求分配到那个服务器上。
431 |
432 | #### 5、url_hash(第三方插件)
433 |
434 | * 必须安装Nginx的hash软件包
435 |
436 | * 按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,可以进一步提高后端缓存服务器的效率。
437 |
438 | ```java
439 | upstream backserver {
440 | server squid1:3128;
441 | server squid2:3128;
442 | hash $request_uri;
443 | hash_method crc32;
444 | }
445 |
446 | ```
447 | ### Nginx配置高可用性怎么配置?
448 |
449 | * 当上游服务器(真实访问服务器),一旦出现故障或者是没有及时相应的话,应该直接轮训到下一台服务器,保证服务器的高可用
450 |
451 | * Nginx配置代码:
452 |
453 | ```java
454 | server {
455 | listen 80;
456 | server_name www.lijie.com;
457 | location / {
458 | ### 指定上游服务器负载均衡服务器
459 | proxy_pass http://backServer;
460 | ###nginx与上游服务器(真实访问的服务器)超时时间 后端服务器连接的超时时间_发起握手等候响应超时时间
461 | proxy_connect_timeout 1s;
462 | ###nginx发送给上游服务器(真实访问的服务器)超时时间
463 | proxy_send_timeout 1s;
464 | ### nginx接受上游服务器(真实访问的服务器)超时时间
465 | proxy_read_timeout 1s;
466 | index index.html index.htm;
467 | }
468 | }
469 |
470 | ```
471 | ### Nginx怎么判断别IP不可访问?
472 |
473 | ```java
474 | # 如果访问的ip地址为192.168.9.115,则返回403
475 | if ($remote_addr = 192.168.9.115) {
476 | return 403;
477 | }
478 | ```
479 | ### 怎么限制浏览器访问?
480 |
481 | ```java
482 | ## 不允许谷歌浏览器访问 如果是谷歌浏览器返回500
483 | if ($http_user_agent ~ Chrome) {
484 | return 500;
485 | }
486 | ```
487 | ### Rewrite全局变量是什么?
488 |
489 | > | 变量 | 含义 |
490 | > | --- | --- |
491 | > | $args | 这个变量等于请求行中的参数,同$query_string |
492 | > | $content length | 请求头中的Content-length字段。 |
493 | > | $content_type | 请求头中的Content-Type字段。 |
494 | > | $document_root | 当前请求在root指令中指定的值。 |
495 | > | $host | 请求主机头字段,否则为服务器名称。 |
496 | > | $http_user_agent | 客户端agent信息 |
497 | > | $http_cookie | 客户端cookie信息 |
498 | > | $limit_rate | 这个变量可以限制连接速率。 |
499 | > | $request_method | 客户端请求的动作,通常为GET或POST。 |
500 | > | $remote_addr | 客户端的IP地址。 |
501 | > | $remote_port | 客户端的端口。 |
502 | > | $remote_user | 已经经过Auth Basic Module验证的用户名。 |
503 | > | $request_filename | 当前请求的文件路径,由root或alias指令与URI请求生成。 |
504 | > | $scheme | HTTP方法(如http,https)。 |
505 | > | $server_protocol | 请求使用的协议,通常是HTTP/1.0或HTTP/1.1。 |
506 | > | $server_addr | 服务器地址,在完成一次系统调用后可以确定这个值。 |
507 | > | $server_name | 服务器名称。 |
508 | > | $server_port | 请求到达服务器的端口号。 |
509 | > | $request_uri | 包含请求参数的原始URI,不包含主机名,如”/foo/bar.php?arg=baz”。 |
510 | > | $uri | 不带请求参数的当前URI,$uri不包含主机名,如”/foo/bar.html”。 |
511 | > | $document_uri | 与$uri相同。 |
512 |
513 | 作者:小杰要吃蛋
514 | 链接:https://juejin.cn/post/6844904125784653837
515 | 来源:稀土掘金
516 | 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
--------------------------------------------------------------------------------
/docs/java/基础面试题/springcloud.md:
--------------------------------------------------------------------------------
1 | 可参考:
2 | https://juejin.cn/post/6885611453651681293
3 | https://juejin.cn/post/6844904153643221005
4 |
5 | # 什么是微服务架构
6 |
7 | * 微服务架构就是将单体的应用程序分成多个应用程序,这多个应用程序就成为微服务,每个微服务运行在自己的进程中,并使用轻量级的机制通信。这些服务围绕业务能力来划分,并通过自动化部署机制来独立部署。这些服务可以使用不同的编程语言,不同数据库,以保证最低限度的集中式管理。
8 |
9 | ## 为什么需要学习Spring Cloud
10 |
11 | * 首先springcloud基于spingboot的优雅简洁,可还记得我们被无数xml支配的恐惧?可还记得springmvc,mybatis错综复杂的配置,有了spingboot,这些东西都不需要了,spingboot好处不再赘诉,springcloud就基于SpringBoot把市场上优秀的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理
12 |
13 | * 什么叫做开箱即用?即使是当年的黄金搭档dubbo+zookeeper下载配置起来也是颇费心神的!而springcloud完成这些只需要一个jar的依赖就可以了!
14 |
15 | * springcloud大多数子模块都是直击痛点,像zuul解决的跨域,fegin解决的负载均衡,hystrix的熔断机制等等等等
16 |
17 | ## Spring Cloud 是什么
18 |
19 | * Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、智能路由、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。
20 | * Spring Cloud并没有重复制造轮子,它只是将各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
21 |
22 | ## SpringCloud的优缺点
23 |
24 | 优点:
25 |
26 | 1.耦合度比较低。不会影响其他模块的开发。
27 |
28 | 2.减轻团队的成本,可以并行开发,不用关注其他人怎么开发,先关注自己的开发。
29 |
30 | 3.配置比较简单,基本用注解就能实现,不用使用过多的配置文件。
31 |
32 | 4.微服务跨平台的,可以用任何一种语言开发。
33 |
34 | 5.每个微服务可以有自己的独立的数据库也有用公共的数据库。
35 |
36 | 6.直接写后端的代码,不用关注前端怎么开发,直接写自己的后端代码即可,然后暴露接口,通过组件进行服务通信。
37 | 复制代码
38 |
39 | 缺点:
40 |
41 | 1.部署比较麻烦,给运维工程师带来一定的麻烦。
42 |
43 | 2.针对数据的管理比麻烦,因为微服务可以每个微服务使用一个数据库。
44 |
45 | 3.系统集成测试比较麻烦
46 |
47 | 4.性能的监控比较麻烦。【最好开发一个大屏监控系统】
48 | 复制代码
49 |
50 | * 总的来说优点大过于缺点,目前看来Spring Cloud是一套非常完善的分布式框架,目前很多企业开始用微服务、Spring Cloud的优势是显而易见的。因此对于想研究微服务架构的同学来说,学习Spring Cloud是一个不错的选择。
51 |
52 | ## SpringBoot和SpringCloud的区别?
53 |
54 | * SpringBoot专注于快速方便的开发单个个体微服务。
55 |
56 | * SpringCloud是关注全局的微服务协调整理治理框架,它将SpringBoot开发的一个个单体微服务整合并管理起来,
57 |
58 | * 为各个微服务之间提供,配置管理、服务发现、断路器、路由、微代理、事件总线、全局锁、决策竞选、分布式会话等等集成服务
59 |
60 | * SpringBoot可以离开SpringCloud独立使用开发项目, 但是SpringCloud离不开SpringBoot ,属于依赖的关系
61 |
62 | * SpringBoot专注于快速、方便的开发单个微服务个体,SpringCloud关注全局的服务治理框架。
63 |
64 | ## Spring Cloud和SpringBoot版本对应关系
65 |
66 | > | Spring Cloud Version | SpringBoot Version |
67 | > | --- | --- |
68 | > | Hoxton | 2.2.x |
69 | > | Greenwich | 2.1.x |
70 | > | Finchley | 2.0.x |
71 | > | Edgware | 1.5.x |
72 | > | Dalston | 1.5.x |
73 |
74 | ## SpringCloud由什么组成
75 |
76 | * 这就有很多了,我讲几个开发中最重要的
77 | * Spring Cloud Eureka:服务注册与发现
78 | * Spring Cloud Zuul:服务网关
79 | * Spring Cloud Ribbon:客户端负载均衡
80 | * Spring Cloud Feign:声明性的Web服务客户端
81 | * Spring Cloud Hystrix:断路器
82 | * Spring Cloud Config:分布式统一配置管理
83 | * 等20几个框架,开源一直在更新
84 |
85 | ## 使用 Spring Boot 开发分布式微服务时,我们面临什么问题
86 |
87 | * (1)与分布式系统相关的复杂性-这种开销包括网络问题,延迟开销,带宽问题,安全问题。
88 |
89 | * (2)服务发现-服务发现工具管理群集中的流程和服务如何查找和互相交谈。它涉及一个服务目录,在该目录中注册服务,然后能够查找并连接到该目录中的服务。
90 |
91 | * (3)冗余-分布式系统中的冗余问题。
92 |
93 | * (4)负载平衡 --负载平衡改善跨多个计算资源的工作负荷,诸如计算机,计算机集群,网络链路,中央处理单元,或磁盘驱动器的分布。
94 |
95 | * (5)性能-问题 由于各种运营开销导致的性能问题。
96 |
97 | ## Spring Cloud 和dubbo区别?
98 |
99 | * (1)服务调用方式:dubbo是RPC springcloud Rest Api
100 |
101 | * (2)注册中心:dubbo 是zookeeper springcloud是eureka,也可以是zookeeper
102 |
103 | * (3)服务网关,dubbo本身没有实现,只能通过其他第三方技术整合,springcloud有Zuul路由网关,作为路由服务器,进行消费者的请求分发,springcloud支持断路器,与git完美集成配置文件支持版本控制,事物总线实现配置文件的更新与服务自动装配等等一系列的微服务架构要素。
104 |
105 | # Eureka
106 |
107 | ## 服务注册和发现是什么意思?Spring Cloud 如何实现?
108 |
109 | * 当我们开始一个项目时,我们通常在属性文件中进行所有的配置。随着越来越多的服务开发和部署,添加和修改这些属性变得更加复杂。有些服务可能会下降,而某些位置可能会发生变化。手动更改属性可能会产生问题。 Eureka 服务注册和发现可以在这种情况下提供帮助。由于所有服务都在 Eureka 服务器上注册并通过调用 Eureka 服务器完成查找,因此无需处理服务地点的任何更改和处理。
110 |
111 | ## 什么是Eureka
112 |
113 | * Eureka作为SpringCloud的服务注册功能服务器,他是服务注册中心,系统中的其他服务使用Eureka的客户端将其连接到Eureka Service中,并且保持心跳,这样工作人员可以通过Eureka Service来监控各个微服务是否运行正常。
114 |
115 | ## Eureka怎么实现高可用
116 |
117 | * 集群吧,注册多台Eureka,然后把SpringCloud服务互相注册,客户端从Eureka获取信息时,按照Eureka的顺序来访问。
118 |
119 | ## 什么是Eureka的自我保护模式,
120 |
121 | * 默认情况下,如果Eureka Service在一定时间内没有接收到某个微服务的心跳,Eureka Service会进入自我保护模式,在该模式下Eureka Service会保护服务注册表中的信息,不在删除注册表中的数据,当网络故障恢复后,Eureka Servic 节点会自动退出自我保护模式
122 |
123 | ## DiscoveryClient的作用
124 |
125 | * 可以从注册中心中根据服务别名获取注册的服务器信息。
126 |
127 | ## Eureka和ZooKeeper都可以提供服务注册与发现的功能,请说说两个的区别
128 |
129 | 1. ZooKeeper中的节点服务挂了就要选举 在选举期间注册服务瘫痪,虽然服务最终会恢复,但是选举期间不可用的, 选举就是改微服务做了集群,必须有一台主其他的都是从
130 |
131 | 2. Eureka各个节点是平等关系,服务器挂了没关系,只要有一台Eureka就可以保证服务可用,数据都是最新的。 如果查询到的数据并不是最新的,就是因为Eureka的自我保护模式导致的
132 |
133 | 3. Eureka本质上是一个工程,而ZooKeeper只是一个进程
134 |
135 | 4. Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像ZooKeeper 一样使得整个注册系统瘫痪
136 |
137 | 5. ZooKeeper保证的是CP,Eureka保证的是AP
138 |
139 | CAP: C:一致性>Consistency; 取舍:(强一致性、单调一致性、会话一致性、最终一致性、弱一致性) A:可用性>Availability; P:分区容错性>Partition tolerance;
140 |
141 | # Zuul
142 |
143 | ## 什么是网关?
144 |
145 | * 网关相当于一个网络服务架构的入口,所有网络请求必须通过网关转发到具体的服务。
146 |
147 | ## 网关的作用是什么
148 |
149 | * 统一管理微服务请求,权限控制、负载均衡、路由转发、监控、安全控制黑名单和白名单等
150 |
151 | ## 什么是Spring Cloud Zuul(服务网关)
152 |
153 | * Zuul是对SpringCloud提供的成熟对的路由方案,他会根据请求的路径不同,网关会定位到指定的微服务,并代理请求到不同的微服务接口,他对外隐蔽了微服务的真正接口地址。 三个重要概念:动态路由表,路由定位,反向代理:
154 |
155 | * 动态路由表:Zuul支持Eureka路由,手动配置路由,这俩种都支持自动更新
156 | * 路由定位:根据请求路径,Zuul有自己的一套定位服务规则以及路由表达式匹配
157 | * 反向代理:客户端请求到路由网关,网关受理之后,在对目标发送请求,拿到响应之后在 给客户端
158 | * 它可以和Eureka,Ribbon,Hystrix等组件配合使用,
159 |
160 | * Zuul的应用场景:
161 |
162 | * 对外暴露,权限校验,服务聚合,日志审计等
163 |
164 | ## 网关与过滤器有什么区别
165 |
166 | * 网关是对所有服务的请求进行分析过滤,过滤器是对单个服务而言。
167 |
168 | ## 常用网关框架有那些?
169 |
170 | * Nginx、Zuul、Gateway
171 |
172 | ## Zuul与Nginx有什么区别?
173 |
174 | * Zuul是java语言实现的,主要为java服务提供网关服务,尤其在微服务架构中可以更加灵活的对网关进行操作。Nginx是使用C语言实现,性能高于Zuul,但是实现自定义操作需要熟悉lua语言,对程序员要求较高,可以使用Nginx做Zuul集群。
175 |
176 | ## 既然Nginx可以实现网关?为什么还需要使用Zuul框架
177 |
178 | * Zuul是SpringCloud集成的网关,使用Java语言编写,可以对SpringCloud架构提供更灵活的服务。
179 |
180 | ## 如何设计一套API接口
181 |
182 | * 考虑到API接口的分类可以将API接口分为开发API接口和内网API接口,内网API接口用于局域网,为内部服务器提供服务。开放API接口用于对外部合作单位提供接口调用,需要遵循Oauth2.0权限认证协议。同时还需要考虑安全性、幂等性等问题。
183 |
184 | ## ZuulFilter常用有那些方法
185 |
186 | * Run():过滤器的具体业务逻辑
187 |
188 | * shouldFilter():判断过滤器是否有效
189 |
190 | * filterOrder():过滤器执行顺序
191 |
192 | * filterType():过滤器拦截位置
193 |
194 | ## 如何实现动态Zuul网关路由转发
195 |
196 | * 通过path配置拦截请求,通过ServiceId到配置中心获取转发的服务列表,Zuul内部使用Ribbon实现本地负载均衡和转发。
197 |
198 | ## Zuul网关如何搭建集群
199 |
200 | * 使用Nginx的upstream设置Zuul服务集群,通过location拦截请求并转发到upstream,默认使用轮询机制对Zuul集群发送请求。
201 |
202 | # Ribbon
203 |
204 | ## 负载平衡的意义什么?
205 |
206 | * 简单来说: 先将集群,集群就是把一个的事情交给多个人去做,假如要做1000个产品给一个人做要10天,我叫10个人做就是一天,这就是集群,负载均衡的话就是用来控制集群,他把做的最多的人让他慢慢做休息会,把做的最少的人让他加量让他做多点。
207 |
208 | * 在计算中,负载平衡可以改善跨计算机,计算机集群,网络链接,中央处理单元或磁盘驱动器等多种计算资源的工作负载分布。负载平衡旨在优化资源使用,最大化吞吐量,最小化响应时间并避免任何单一资源的过载。使用多个组件进行负载平衡而不是单个组件可能会通过冗余来提高可靠性和可用性。负载平衡通常涉及专用软件或硬件,例如多层交换机或域名系统服务器进程。
209 |
210 | ## Ribbon是什么?
211 |
212 | * Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法
213 |
214 | * Ribbon客户端组件提供一系列完善的配置项,如连接超时,重试等。简单的说,就是在配置文件中列出后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随即连接等)去连接这些机器。我们也很容易使用Ribbon实现自定义的负载均衡算法。(有点类似Nginx)
215 |
216 | ## Nginx与Ribbon的区别
217 |
218 | * Nginx是反向代理同时可以实现负载均衡,nginx拦截客户端请求采用负载均衡策略根据upstream配置进行转发,相当于请求通过nginx服务器进行转发。Ribbon是客户端负载均衡,从注册中心读取目标服务器信息,然后客户端采用轮询策略对服务直接访问,全程在客户端操作。
219 |
220 | ## Ribbon底层实现原理
221 |
222 | * Ribbon使用discoveryClient从注册中心读取目标服务信息,对同一接口请求进行计数,使用%取余算法获取目标服务集群索引,返回获取到的目标服务信息。
223 |
224 | ## @LoadBalanced注解的作用
225 |
226 | 开启客户端负载均衡。
227 |
228 | # Hystrix
229 |
230 | ## 什么是断路器
231 |
232 | * 当一个服务调用另一个服务由于网络原因或自身原因出现问题,调用者就会等待被调用者的响应 当更多的服务请求到这些资源导致更多的请求等待,发生连锁效应(雪崩效应)
233 |
234 | * 断路器有三种状态
235 |
236 | * 打开状态:一段时间内 达到一定的次数无法调用 并且多次监测没有恢复的迹象 断路器完全打开 那么下次请求就不会请求到该服务
237 | * 半开状态:短时间内 有恢复迹象 断路器会将部分请求发给该服务,正常调用时 断路器关闭
238 | * 关闭状态:当服务一直处于正常状态 能正常调用
239 |
240 | ## 什么是 Hystrix?
241 |
242 | * 在分布式系统,我们一定会依赖各种服务,那么这些个服务一定会出现失败的情况,就会导致雪崩,Hystrix就是这样的一个工具,防雪崩利器,它具有服务降级,服务熔断,服务隔离,监控等一些防止雪崩的技术。
243 |
244 | * Hystrix有四种防雪崩方式:
245 |
246 | * 服务降级:接口调用失败就调用本地的方法返回一个空
247 | * 服务熔断:接口调用失败就会进入调用接口提前定义好的一个熔断的方法,返回错误信息
248 | * 服务隔离:隔离服务之间相互影响
249 | * 服务监控:在服务发生调用时,会将每秒请求数、成功请求数等运行指标记录下来。
250 |
251 | ## 谈谈服务雪崩效应
252 |
253 | * 雪崩效应是在大型互联网项目中,当某个服务发生宕机时,调用这个服务的其他服务也会发生宕机,大型项目的微服务之间的调用是互通的,这样就会将服务的不可用逐步扩大到各个其他服务中,从而使整个项目的服务宕机崩溃.发生雪崩效应的原因有以下几点
254 |
255 | * 单个服务的代码存在bug. 2请求访问量激增导致服务发生崩溃(如大型商城的枪红包,秒杀功能). 3.服务器的硬件故障也会导致部分服务不可用.
256 |
257 | ## 在微服务中,如何保护服务?
258 |
259 | * 一般使用使用Hystrix框架,实现服务隔离来避免出现服务的雪崩效应,从而达到保护服务的效果。当微服务中,高并发的数据库访问量导致服务线程阻塞,使单个服务宕机,服务的不可用会蔓延到其他服务,引起整体服务灾难性后果,使用服务降级能有效为不同的服务分配资源,一旦服务不可用则返回友好提示,不占用其他服务资源,从而避免单个服务崩溃引发整体服务的不可用.
260 |
261 | ## 服务雪崩效应产生的原因
262 |
263 | * 因为Tomcat默认情况下只有一个线程池来维护客户端发送的所有的请求,这时候某一接口在某一时刻被大量访问就会占据tomcat线程池中的所有线程,其他请求处于等待状态,无法连接到服务接口。
264 |
265 | ## 谈谈服务降级、熔断、服务隔离
266 |
267 | * 服务降级:当客户端请求服务器端的时候,防止客户端一直等待,不会处理业务逻辑代码,直接返回一个友好的提示给客户端。
268 |
269 | * 服务熔断是在服务降级的基础上更直接的一种保护方式,当在一个统计时间范围内的请求失败数量达到设定值(requestVolumeThreshold)或当前的请求错误率达到设定的错误率阈值(errorThresholdPercentage)时开启断路,之后的请求直接走fallback方法,在设定时间(sleepWindowInMilliseconds)后尝试恢复。
270 |
271 | * 服务隔离就是Hystrix为隔离的服务开启一个独立的线程池,这样在高并发的情况下不会影响其他服务。服务隔离有线程池和信号量两种实现方式,一般使用线程池方式。
272 |
273 | ## 服务降级底层是如何实现的?
274 |
275 | * Hystrix实现服务降级的功能是通过重写HystrixCommand中的getFallback()方法,当Hystrix的run方法或construct执行发生错误时转而执行getFallback()方法。
276 |
277 | # Feign
278 |
279 | ## 什么是Feign?
280 |
281 | * Feign 是一个声明web服务客户端,这使得编写web服务客户端更容易
282 |
283 | * 他将我们需要调用的服务方法定义成抽象方法保存在本地就可以了,不需要自己构建Http请求了,直接调用接口就行了,不过要注意,调用方法要和本地抽象方法的签名完全一致。
284 |
285 | ## SpringCloud有几种调用接口方式
286 |
287 | * Feign
288 |
289 | * RestTemplate
290 |
291 | ## Ribbon和Feign调用服务的区别
292 |
293 | * 调用方式同:Ribbon需要我们自己构建Http请求,模拟Http请求然后通过RestTemplate发给其他服务,步骤相当繁琐
294 |
295 | * 而Feign则是在Ribbon的基础上进行了一次改进,采用接口的形式,将我们需要调用的服务方法定义成抽象方法保存在本地就可以了,不需要自己构建Http请求了,直接调用接口就行了,不过要注意,调用方法要和本地抽象方法的签名完全一致。
296 |
297 | # Bus
298 |
299 | ## 什么是 Spring Cloud Bus?
300 |
301 | * Spring Cloud Bus就像一个分布式执行器,用于扩展的Spring Boot应用程序的配置文件,但也可以用作应用程序之间的通信通道。
302 | * Spring Cloud Bus 不能单独完成通信,需要配合MQ支持
303 | * Spring Cloud Bus一般是配合Spring Cloud Config做配置中心的
304 | * Springcloud config实时刷新也必须采用SpringCloud Bus消息总线
305 |
306 | # Config
307 |
308 | ## 什么是Spring Cloud Config?
309 |
310 | * Spring Cloud Config为分布式系统中的外部配置提供服务器和客户端支持,可以方便的对微服务各个环境下的配置进行集中式管理。Spring Cloud Config分为Config Server和Config Client两部分。Config Server负责读取配置文件,并且暴露Http API接口,Config Client通过调用Config Server的接口来读取配置文件。
311 |
312 | ## 分布式配置中心有那些框架?
313 |
314 | * Apollo、zookeeper、springcloud config。
315 |
316 | ## 分布式配置中心的作用?
317 |
318 | * 动态变更项目配置信息而不必重新部署项目。
319 |
320 | ## SpringCloud Config 可以实现实时刷新吗?
321 |
322 | * springcloud config实时刷新采用SpringCloud Bus消息总线。
323 |
324 | # Gateway
325 |
326 | ## 什么是Spring Cloud Gateway?
327 |
328 | * Spring Cloud Gateway是Spring Cloud官方推出的第二代网关框架,取代Zuul网关。网关作为流量的,在微服务系统中有着非常作用,网关常见的功能有路由转发、权限校验、限流控制等作用。
329 |
330 | * 使用了一个RouteLocatorBuilder的bean去创建路由,除了创建路由RouteLocatorBuilder可以让你添加各种predicates和filters,predicates断言的意思,顾名思义就是根据具体的请求的规则,由具体的route去处理,filters是各种过滤器,用来对请求做各种判断和修改。
331 |
332 | # SpringCloud主要项目
333 |
334 | * Spring Cloud的子项目,大致可分成两类,一类是对现有成熟框架"Spring Boot化"的封装和抽象,也是数量最多的项目;第二类是开发了一部分分布式系统的基础设施的实现,如Spring Cloud Stream扮演的就是kafka, ActiveMQ这样的角色。
335 |
336 | ### Spring Cloud Config
337 |
338 | * Config能够管理所有微服务的配置文件
339 |
340 | * 集中配置管理工具,分布式系统中统一的外部配置管理,默认使用Git来存储配置,可以支持客户端配置的刷新及加密、解密操作。
341 |
342 | ### Spring Cloud Netflix(重点,这些组件用的最多)
343 |
344 | * Netflix OSS 开源组件集成,包括Eureka、Hystrix、Ribbon、Feign、Zuul等核心组件。
345 | * Eureka:服务治理组件,包括服务端的注册中心和客户端的服务发现机制;
346 | * Ribbon:负载均衡的服务调用组件,具有多种负载均衡调用策略;
347 | * Hystrix:服务容错组件,实现了断路器模式,为依赖服务的出错和延迟提供了容错能力;
348 | * Feign:基于Ribbon和Hystrix的声明式服务调用组件;
349 | * Zuul:API网关组件,对请求提供路由及过滤功能。
350 |
351 | `我觉得SpringCloud的福音是Netflix,他把人家的组件都搬来进行封装了,使开发者能快速简单安全的使用`
352 |
353 | ### Spring Cloud Bus
354 |
355 | * 用于传播集群状态变化的消息总线,使用轻量级消息代理链接分布式系统中的节点,可以用来动态刷新集群中的服务配置信息。
356 | * 简单来说就是修改了配置文件,发送一次请求,所有客户端便会重新读取配置文件。
357 | * 需要利用中间插件MQ
358 |
359 | ### Spring Cloud Consul
360 |
361 | * Consul 是 HashiCorp 公司推出的开源工具,用于实现分布式系统的服务发现与配置。与其它分布式服务注册与发现的方案,Consul 的方案更“一站式”,内置了服务注册与发现框架、分布一致性协议实现、健康检查、Key/Value 存储、多数据中心方案,不再需要依赖其它工具(比如 ZooKeeper 等)。使用起来也较为简单。Consul 使用 Go 语言编写,因此具有天然可移植性(支持Linux、windows和Mac OS X);安装包仅包含一个可执行文件,方便部署,与 Docker 等轻量级容器可无缝配合。
362 |
363 | ### Spring Cloud Security
364 |
365 | * 安全工具包,他可以对
366 |
367 | * 对Zuul代理中的负载均衡从前端到后端服务中获取SSO令牌
368 | * 资源服务器之间的中继令牌
369 | * 使Feign客户端表现得像`OAuth2RestTemplate`(获取令牌等)的拦截器
370 | * 在Zuul代理中配置下游身份验证
371 | * Spring Cloud Security提供了一组原语,用于构建安全的应用程序和服务,而且操作简便。可以在外部(或集中)进行大量配置的声明性模型有助于实现大型协作的远程组件系统,通常具有中央身份管理服务。它也非常易于在Cloud Foundry等服务平台中使用。在Spring Boot和Spring Security OAuth2的基础上,可以快速创建实现常见模式的系统,如单点登录,令牌中继和令牌交换。
372 |
373 | ### Spring Cloud Sleuth
374 |
375 | * 在微服务中,通常根据业务模块分服务,项目中前端发起一个请求,后端可能跨几个服务调用才能完成这个请求(如下图)。如果系统越来越庞大,服务之间的调用与被调用关系就会变得很复杂,假如一个请求中需要跨几个服务调用,其中一个服务由于网络延迟等原因挂掉了,那么这时候我们需要分析具体哪一个服务出问题了就会显得很困难。Spring Cloud Sleuth服务链路跟踪功能就可以帮助我们快速的发现错误根源以及监控分析每条请求链路上的性能等等。 
376 |
377 | ### Spring Cloud Stream
378 |
379 | * 轻量级事件驱动微服务框架,可以使用简单的声明式模型来发送及接收消息,主要实现为Apache Kafka及RabbitMQ。
380 |
381 | ### Spring Cloud Task
382 |
383 | * Spring Cloud Task的目标是为Spring Boot应用程序提供创建短运行期微服务的功能。在Spring Cloud Task中,我们可以灵活地动态运行任何任务,按需分配资源并在任务完成后检索结果。Tasks是Spring Cloud Data Flow中的一个基础项目,允许用户将几乎任何Spring Boot应用程序作为一个短期任务执行。
384 |
385 | ### Spring Cloud Zookeeper
386 |
387 | * SpringCloud支持三种注册方式Eureka, Consul(go语言编写),zookeeper
388 |
389 | * Spring Cloud Zookeeper是基于Apache Zookeeper的服务治理组件。
390 |
391 | ### Spring Cloud Gateway
392 |
393 | * Spring cloud gateway是spring官方基于Spring 5.0、Spring Boot2.0和Project Reactor等技术开发的网关,Spring Cloud Gateway旨在为微服务架构提供简单、有效和统一的API路由管理方式,Spring Cloud Gateway作为Spring Cloud生态系统中的网关,目标是替代Netflix Zuul,其不仅提供统一的路由方式,并且还基于Filer链的方式提供了网关基本的功能,例如:安全、监控/埋点、限流等。
394 |
395 | ### Spring Cloud OpenFeign
396 |
397 | * Feign是一个声明性的Web服务客户端。它使编写Web服务客户端变得更容易。要使用Feign,我们可以将调用的服务方法定义成抽象方法保存在本地添加一点点注解就可以了,不需要自己构建Http请求了,直接调用接口就行了,不过要注意,调用方法要和本地抽象方法的签名完全一致。
398 |
399 | ## Spring Cloud的版本关系
400 |
401 | * Spring Cloud是一个由许多子项目组成的综合项目,各子项目有不同的发布节奏。 为了管理Spring Cloud与各子项目的版本依赖关系,发布了一个清单,其中包括了某个Spring Cloud版本对应的子项目版本。 为了避免Spring Cloud版本号与子项目版本号混淆,Spring Cloud版本采用了名称而非版本号的命名,这些版本的名字采用了伦敦地铁站的名字,根据字母表的顺序来对应版本时间顺序,例如Angel是第一个版本,Brixton是第二个版本。 当Spring Cloud的发布内容积累到临界点或者一个重大BUG被解决后,会发布一个"service releases"版本,简称SRX版本,比如Greenwich.SR2就是Spring Cloud发布的Greenwich版本的第2个SRX版本。目前Spring Cloud的最新版本是Hoxton。
402 |
403 | ### Spring Cloud和SpringBoot版本对应关系
404 |
405 | > | Spring Cloud Version | SpringBoot Version |
406 | > | --- | --- |
407 | > | Hoxton | 2.2.x |
408 | > | Greenwich | 2.1.x |
409 | > | Finchley | 2.0.x |
410 | > | Edgware | 1.5.x |
411 | > | Dalston | 1.5.x |
412 |
413 | ### Spring Cloud和各子项目版本对应关系
414 |
415 | * Edgware.SR6:我理解为最低版本号
416 |
417 | * Greenwich.SR2 :我理解为最高版本号
418 |
419 | * Greenwich.BUILD-SNAPSHOT(快照):是一种特殊的版本,指定了某个当前的开发进度的副本。不同于常规的版本,几乎每天都要提交更新的版本,如果每次提交都申明一个版本号那不是版本号都不够用?
420 |
421 | > | Component | Edgware.SR6 | Greenwich.SR2 | Greenwich.BUILD-SNAPSHOT |
422 | > | --- | --- | --- | --- |
423 | > | spring-cloud-aws | 1.2.4.RELEASE | 2.1.2.RELEASE | 2.1.3.BUILD-SNAPSHOT |
424 | > | spring-cloud-bus | 1.3.4.RELEASE | 2.1.2.RELEASE | 2.1.3.BUILD-SNAPSHOT |
425 | > | spring-cloud-cli | 1.4.1.RELEASE | 2.0.0.RELEASE | 2.0.1.BUILD-SNAPSHOT |
426 | > | spring-cloud-commons | 1.3.6.RELEASE | 2.1.2.RELEASE | 2.1.3.BUILD-SNAPSHOT |
427 | > | spring-cloud-contract | 1.2.7.RELEASE | 2.1.2.RELEASE | 2.1.3.BUILD-SNAPSHOT |
428 | > | spring-cloud-config | 1.4.7.RELEASE | 2.1.3.RELEASE | 2.1.4.BUILD-SNAPSHOT |
429 | > | spring-cloud-netflix | 1.4.7.RELEASE | 2.1.2.RELEASE | 2.1.3.BUILD-SNAPSHOT |
430 | > | spring-cloud-security | 1.2.4.RELEASE | 2.1.3.RELEASE | 2.1.4.BUILD-SNAPSHOT |
431 | > | spring-cloud-cloudfoundry | 1.1.3.RELEASE | 2.1.2.RELEASE | 2.1.3.BUILD-SNAPSHOT |
432 | > | spring-cloud-consul | 1.3.6.RELEASE | 2.1.2.RELEASE | 2.1.3.BUILD-SNAPSHOT |
433 | > | spring-cloud-sleuth | 1.3.6.RELEASE | 2.1.1.RELEASE | 2.1.2.BUILD-SNAPSHOT |
434 | > | spring-cloud-stream | Ditmars.SR5 | Fishtown.SR3 | Fishtown.BUILD-SNAPSHOT |
435 | > | spring-cloud-zookeeper | 1.2.3.RELEASE | 2.1.2.RELEASE | 2.1.3.BUILD-SNAPSHOT |
436 | > | spring-boot | 1.5.21.RELEASE | 2.1.5.RELEASE | 2.1.8.BUILD-SNAPSHOT |
437 | > | spring-cloud-task | 1.2.4.RELEASE | 2.1.2.RELEASE | 2.1.3.BUILD-SNAPSHOT |
438 | > | spring-cloud-vault | 1.1.3.RELEASE | 2.1.2.RELEASE | 2.1.3.BUILD-SNAPSHOT |
439 | > | spring-cloud-gateway | 1.0.3.RELEASE | 2.1.2.RELEASE | 2.1.3.BUILD-SNAPSHOT |
440 | > | spring-cloud-openfeign | | 2.1.2.RELEASE | 2.1.3.BUILD-SNAPSHOT |
441 | > | spring-cloud-function | 1.0.2.RELEASE | 2.0.2.RELEASE | 2.0.3.BUILD-SNAPSHOT |
442 |
443 | 作者:小杰要吃蛋
444 | 链接:https://juejin.cn/post/6844904125717544973
445 | 来源:稀土掘金
446 | 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
--------------------------------------------------------------------------------
/docs/dataStructures-algorithms/算法题目难点题目总结.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 | #### 智力题
5 |
6 | 作者:office多多
7 | 链接:[https://www.nowcoder.com/discuss/374134?type=0&order=0&pos=67&page=1](https://www.nowcoder.com/discuss/374134?type=0&order=0&pos=67&page=1)
8 |
9 | 1. 10个堆,每堆10个苹果,其中9个堆里苹果是50g/个,一个堆里苹果是40g/个,有一杆秤只能称一次,所称重量为x,求40g苹果所在堆。
10 |
11 | * 将堆编码为1-10;然后每堆拿出k个,最后少了k*10克,则知道是第几堆的苹果。
12 | 2. 5L和6L水桶,得到三升水。
13 |
14 | * 1、6L的水桶装满水,倒满5L的桶。 2、将5L桶里的水倒了,将6L桶里剩余的1L放入5L桶。 3、6L的桶装满水,倒满5L桶里,6L桶里还剩2L(6-4)水。 4、 将5L桶里的水倒了,将6L桶里剩余的2L水放入5L桶里。 5、将6L桶装满水,倒满5L的桶,这时6L的桶里还剩3L水。
15 | 3. 两个一小时蚊香怎么得到15分钟的记时
16 |
17 | * 同时点燃AB两只蚊香,其中A蚊香点燃两头,等A蚊香烧完后(30分钟),点燃B蚊香的另一头。
18 | 4. 4分钟沙漏和7分钟沙漏怎么漏出9分钟
19 |
20 | * 4分钟的和7分钟的同时开始,4分钟的完后又倒过来开始。7分钟的沙漏完后立马倒过来,(4分钟的沙漏还剩1分钟)。等4分钟的沙漏完后,将7分钟的又立马倒过来,等漏完就是9分钟。
21 | 5. 八个球,其中有一个是其余球重量的1.5倍,有什么方案找出来
22 |
23 | * 3次。 AB两边,一边放4个,如果A重,则把B端的去了,A端的4个分成AB端一边两个。在把轻的那端去了,重的那端的2个分成一边一个,重的那个球就找出来了。
24 | 6. 桌上100个球,每次可以拿一到五个, 现在我们两个人依次拿球,你先拿,使用怎样的拿球策略,可以使你最终能拿到最后一个球?
25 |
26 | * 第一次拿四个,后来每个你拿球的时候只要保证剩下的球是6的倍数就行了如果他拿n个球 ,你就拿6-n个球。
27 | 7. 有10个石头,每人每次可以拿1-2个,轮流拿,最后一个拿的人算输,有什么必赢的方案。
28 |
29 | * 对方先拿、保证两个人每一轮回拿满3个(对方拿一个,我拿两个、对方拿两个,我拿一个)。
30 | 8. 一亿数据获取前1000个最大值 [https://zhuanlan.zhihu.com/p/73233544](https://zhuanlan.zhihu.com/p/73233544)
31 |
32 | * 把一亿个数字的前100个 首先放入数组。 然后把最小值放在ary[0]。然后再循环100到一亿之间的。 每次循环判断当前数字是否大于ary[0]当大于时,当前数字放入ary[0] 并再次重构数组最小值进入ary[0]以此类推 。当循环完这一亿个数字后。 最大的前100个数字就出来了。
33 | 9. [经典智力题:飞机加油问题](https://blog.csdn.net/qins_superlover/article/details/21158269)
34 |
35 |
36 | ### 左神总结
37 |
38 | - [左神直通BAT算法笔记(基础篇)-上](https://juejin.im/post/5c6b9c696fb9a049ed316ef9)
39 | - [左神直通BAT算法笔记(基础篇)-下](https://juejin.im/post/5c6b9d0a6fb9a04a05403cbc)
40 | - [左神直通BAT算法(进阶篇)-上](https://juejin.im/post/5c6b9d4c6fb9a04a05403cbe)
41 | - [左神直通BAT算法(进阶篇)-下](https://juejin.im/post/5c6b9ea76fb9a04a05403cc1)
42 | - [剑指offer解析-上(Java实现)](https://juejin.im/post/5c6b9a976fb9a049d2369f2f)
43 | - [剑指offer解析-下(Java实现)](https://juejin.im/post/5c6b9bad518825266c3f064f)
44 |
45 | ### leetcode经典题目
46 |
47 | - https://blog.csdn.net/zangdaiyang1991/article/details/89338652
48 |
49 | ### 红黑树
50 |
51 | - [原来手写红黑树可以这么简单](https://juejin.im/post/5de72ae66fb9a016214cae91)
52 |
53 | ### 链表
54 |
55 | #### 链表思路总结
56 |
57 | - https://www.jianshu.com/p/91acadc982ff
58 |
59 | #### 1 将单向链表按某值划分成左边小、中间相等、右边大的形式(p59)
60 |
61 | 如果要求**不按照**原来的顺序排列
62 |
63 | 1、荷兰国旗问题解决。
64 |
65 | 如果要求**按照**原来的顺序排列
66 |
67 | 2、将原链表划分为三个链表,然后再连接起来。
68 |
69 | #### 2 复制含有随机指针节点的链表(p64)
70 |
71 | 1、 `用hash表`,但是空间复杂度为n。
72 |
73 | ```java
74 | map.put(cur,new Node(cur.value));
75 | ```
76 |
77 | 2、不用hash表,空间复杂度为1.
78 |
79 | 将链表复制为:1->1'->2->2'->3->3'->null
80 | 1)可以设置每一个节点的复制节点
81 | 2)设置rand节点:例如,1的rand节点为3,1的复制节点为1',那么1'应该指向3',如何找到3'呢?令1'.next=3.next。
82 | 3)将节点和复制节点拆分。
83 |
84 | #### 3 两个单链表生成相加链表(p66)
85 |
86 | 将两个链表代表的整数相加之后的数,再成为一个新的链表。
87 |
88 | 1、使用`栈结构`,空间复杂度为n
89 |
90 | 用两个栈保存两个链表的值,然后弹出相加,如果有进位,用ca记录,最后成为一个链表。
91 |
92 | ```java
93 | Node node = null;
94 | whlie(!s1.isEmpty() || !s2.isEmpty()){
95 | n1 = s1.isEmpty() ? 0 : s1.pop();
96 | n2 = s2.isEmpty() ? 0 : s2.pop();
97 | n = n1+n2;
98 | //*******头插法:倒着连接链表**********
99 | pre = node
100 | node = new Node(n%10);
101 | node.next = pre;
102 | ca = n/10;
103 |
104 | }
105 |
106 | if(ca == 1){
107 | pre = node;
108 | node = new Node(1);
109 | node.next = pre;
110 | }
111 | return node;
112 | ```
113 |
114 | 2、将两个`链表逆序`,然后相加即可。
115 |
116 | ```java
117 | public Node reverseList(Node head){
118 | Node pre = null;
119 | Node next = null;
120 | while(head != null){
121 | next = head.next;
122 | head.next = pre;
123 | pre = head;
124 | head = next;
125 | }
126 | return pre;
127 | }
128 | ```
129 |
130 | ### 4 将单链表的每k个节点之间逆序
131 |
132 | 1、使用`栈结构`,每个k个节点入栈,然后将这个k个节点连接,注意节点之间的连接与头节点的设置。
133 |
134 | - 每k个节点之间的栈连接
135 | 
136 |
137 | ```java
138 | public Node resign(Stack stack,Node left,Node right){
139 | Node cur = stack.pop();
140 | if(left != null){
141 | left.next = cur;
142 | }
143 | Node next = null;
144 | while(!stack.isEmpty()){
145 | next = stack.pop();
146 | cur.next = next;
147 | cur = next;
148 | }
149 | cur.next = right;
150 | return cur;
151 | }
152 | ```
153 |
154 | 2、使用`单链表逆序`
155 |
156 | ```java
157 | public void resign(Node left,Node start,Node end,Node right){
158 | Node pre = start;
159 | Node cur = start.next;
160 | Node next = null;
161 | while(cur != null){
162 | next = cur.next;
163 | cur.next = pre;
164 | pre = cur;
165 | cur = next;
166 | }
167 | if(left != null){
168 | left.next = end;
169 | }
170 | start.next = right;
171 | }
172 | ```
173 |
174 | #### 5 将搜索二叉树转换为双向链表
175 |
176 | #### 一般链表的题目都可以使用`容器(栈、队列)`来辅助完成。同时,一般需要`cur、pre`节点辅助连接。
177 |
178 | 1、使用队列收集遍历到的节点,然后再连接为双向链表。
179 |
180 | - 双向链表连接
181 | ```java
182 | Node pre = head;
183 | pre.left = null;
184 | Node cur = null;
185 | while(!queue.isEmpty()){
186 | cur = queue.poll();
187 | pre.right = cur;
188 | cur.left = pre;
189 | pre = cur;
190 | }
191 | pre.right = null;
192 | return head;
193 | ```
194 |
195 | ### 二叉树
196 |
197 | - [二叉树递归调用题解](https://www.jianshu.com/p/2db48864c314)
198 |
199 | #### 1 二叉树遍历问题(P94)
200 |
201 | - 递归遍历模板
202 |
203 | ```java
204 | public void pre�(Node head){
205 | if(head == null){
206 | return;
207 | }
208 | System.out.println(head.value + " ");
209 | pre(head.left);
210 | pre(head.right);
211 | }
212 | ```
213 |
214 | - 非递归遍历
215 |
216 | - 前序遍历
217 |
218 | 用栈来保存信息,但是遍历的时候,是:**先输出根节点信息,然后压入右节点信息,然后再压入左节点信息。**
219 |
220 | ```java
221 | public void pre�(Node head){
222 | if(head == null){
223 | return;
224 | }
225 | Stack stack = new Stack<>();
226 | stack.push(head);
227 | while(!stack.isEmpty()){
228 | head = stack.poll();
229 | System.out.println(head.value + " ");
230 | if(head.right != null){
231 | stack.push(head.right);
232 | }
233 | if(head.left != null){
234 | stack.push(head.left);
235 | }
236 | }
237 | System.out.println();
238 | }
239 | ```
240 |
241 | - 中序遍历
242 |
243 | 中序遍历的顺序是**左中右**,先一直左节点遍历,并压入栈中,当做节点为空时,输出当前节点,往右节点遍历。
244 |
245 | ```java
246 | public void inorder(Node head){
247 | if(head == null){
248 | return;
249 | }
250 | Stack stack = new Stack<>();
251 | stack.push(head);
252 | while(!stack.isEmpty() || head != null){
253 | if(head != null){
254 | stack.push(head);
255 | head = head.left
256 | } else {
257 | head = stack.poll();
258 | System.out.println(head.value + " ");
259 | head = head.right;
260 | }
261 | }
262 | System.out.println();
263 | }
264 | ```
265 |
266 | - 后序遍历
267 |
268 | 用两个栈来实现,压入栈1的时候为**先左后右**,栈1弹出来就是**中右左**,栈2收集起来就是**左右中**。
269 |
270 | ##### 遍历变形题:根据后续数组重建搜索二叉树(P148)
271 |
272 | 根据搜索二叉树性质,最后一个元素是头节点,比后序数组最后一个元素小的数组会在数组左边,比数组最后一个元素值大的数组在数组的右边。所以,我们需要找到后续数组中,小的数组的中的最后一个元素和大的数组中的第一个元素。
273 |
274 | ##### 遍历变形题:判断一颗二叉树是否为搜索二叉树和完全二叉树(P150)
275 |
276 | 搜索二叉树:中序遍历,递增。
277 | 完全二叉树:层次遍历二叉树,有右孩子没有左孩子,为false,如果当前节点并不是左右孩子都有,那么后面的节点都必须是叶子节点。
278 |
279 | #### 2 打印二叉树的边界节点(P100)
280 |
281 | ##### 经验:二叉树的大多数问题都是用递归来解决的,所以,碰到二叉树的问题,一定得想递归版本!
282 |
283 | - 递归的收集左右边界信息
284 | ```java
285 | public void setMap(Node head,int level,int[][] map){
286 | if(head == null){
287 | return;
288 | }
289 | map[l][0] = map[l][0] == null ? h : map[l][0];
290 | map[l][1] = h;
291 | setMap(head.left,level+1,map);
292 | setMap(head.right,level+1,map);
293 | }
294 | ```
295 |
296 | - 递归获取树的高度
297 |
298 | ```java
299 | public int getHeight(Node head,int level){
300 | if(head == null){
301 | return level;
302 | }
303 | return Math.max(getHeight(head.left,level+1),getHeight(head.right,level+1));
304 | }
305 | ```
306 |
307 | - 递归打印叶子节点(非左右边界节点)
308 |
309 | ```java
310 | public int printLeafNotInMap(Node head,int level,int[][] map){
311 | if(head == null){
312 | return;
313 | }
314 | if(head.left == null && head.right == null && head != map[level][0] && head != map[level][1]){
315 | System.out.println(head.value + " ");
316 | }
317 | printLeafNotInMap(head.left,level+1,map);
318 | printLeafNotInMap(head.right,level+1,map);
319 | }
320 | ```
321 |
322 | #### 3 在二叉树中找到累加和为指定值的最长路径长度(P119)
323 |
324 | **思路:** 用一个 hashmap (key是累加和sum,value是当前层level) 保存每一步的累加和sum,例如,当到第三层的第一个节点的时候,当前的累加和sum的值,如果sum在hashmap中不存在,保存到hashmap中。然后递归的遍历求每个sum,同时,求最长路径长度`Math.max(level-map.get(sum-k),max)`。
325 |
326 | 这个思路也可以用到数组中的累加和问题。
327 |
328 | #### 4 找到二叉树中的最大搜索二叉子树(P121)
329 |
330 | ##### 思路
331 | 这个题目是二叉树中很多题目中的套路:**树形dp**。
332 |
333 | ##### 解题步骤
334 |
335 | 1、**列出所有可能性**,比如,这个题目的可能性有:左子树上的可能性、右子树的可能性、左右子树整体的可能性。
336 | 2、根据第一步的可能性,**确定需要的信息**,比如,这个题目,我们需要左子树的满足的最大搜索树头结点leftMaxBSTHead,左子树的最大搜索树的大小leftBSTSize,左子树的最大值max。
337 | 3、合并第二步的信息,写出信息结构。
338 |
339 | ```java
340 | public class ReturnType{
341 | public Node maxBSTHead;
342 | public int maxBSTSize;
343 | public int min;
344 | public int max;
345 |
346 | public ReturnType(Ndoe maxBSTHead,int maxBSTSize,int min,int max){
347 | this.maxBSTHead = maxBSTHead;
348 | this.maxBSTSize - maxBSTSize;
349 | this.min = min;
350 | this.max = max;
351 | }
352 | }
353 | ```
354 | 4、设计递归函数,以及设计base case。
355 |
356 | ##### 树形dp题目:判断二叉树是否是平衡二叉树(P146)
357 |
358 | 平衡二叉树的左右子树高度相差不能超过1,所以,我们需要的信息有`height、isBST`(是否是平衡二叉树)
359 |
360 | ##### 树形dp题目:二叉树节点的最大距离问题(P168)
361 |
362 | ##### 树形dp题目:排队的最大快乐值(P169)
363 |
364 | 保存yes_X_max:X来的情况。
365 | 保存no_X_max:X不来的情况。
366 |
367 | - 返回结构
368 | ```java
369 | public class ReturnType{
370 | public int yesHeadMax;
371 | public int noHeadMax;
372 | }
373 | ```
374 |
375 | #### 5 二叉树的按层打印与ZigZag打印(P132)
376 |
377 | 本来按层打印只需要利用**queue宽度遍历**即可,但是,因为这里需要**换行**,所以,需要添加额外的辅助变量来换行的操作。
378 |
379 | **换行需要的变量**:last表示正在打印的当前行的最右节点,nlast表示下一行的最右节点。
380 |
381 | ZigZag打印:需要用到LinkedList双端队列。
382 |
383 | 原则1:从左往右打印,头部弹出元素打印,如果有孩子,孩子尾部加入队列。
384 |
385 | 原则2:从右往左打印,尾部弹出元素打印,如果有孩子,孩子头部加入队列。
386 |
387 | #### 6 调整搜索二叉树中两个错误的节点(P137)
388 |
389 | 搜索二叉树的中序遍历应该为递增的,找到两个节点,过程为:第一个错误节点为第一次降序时较大的节点,第二个错误的节点是最后一次降序时较小的节点。
390 |
391 | #### 7 判断t1树中是否有与t2树拓扑结构完全相同的子树(P144)
392 |
393 | 序列化二叉树,然后判断子串即可。
394 |
395 | #### 8 在二叉树中找到一个节点的后继节点(P153)
396 |
397 | #### 最简单方法
398 |
399 | 利用node的parent节点找到头结点,然后中序遍历,当前节点的后一个节点就是。
400 |
401 | #### 思路
402 | 这种题目都是有一个parent节点指向父节点的,一般会有最优解,减少时间复杂度。
403 |
404 | 情况1:如果node有右子树,那么后继节点就是右子树上最左边的节点。
405 | 情况2:如果没有右子树。
406 | 1)如果是当前节点的父节点的左孩子,则当前节点就是后继节点。
407 | 2)如果是当前节点的额父节点的右孩子,则向上寻找,假设向上寻找移动到的节点为s,s的父节点为p,如果发现s是p的左孩子,那么p就是后继节点。
408 |
409 | ```java
410 | public Node getNextNode(Node node){
411 | if(node == null){
412 | return node ;
413 | }
414 | if(node.right != null){
415 | //寻找右节点的最左节点
416 | return getLeftMost(node.right);
417 | } else {
418 | Node parent = node.parent;
419 | while(parent != null && parent.left != node){
420 | node = parent;
421 | parent = node.parent;
422 | }
423 | return parent;
424 | }
425 | }
426 | ```
427 |
428 | #### 变形题:在二叉树中找到两个节点的最近公共祖先(P155)
429 |
430 | ##### 方法1:利用后序遍历,递归方法。
431 | 1)如果cur等于null,或者等于o1或者o2,那么返回cur。
432 | 2)如果cur的left和right都为空,那么返回null,说明没有。
433 | 3)如果cur的left和right都不为空,那么cur就是。
434 | 4)如果cur的left和right一个为空,一个不为空,返回不是空的节点即可。
435 |
436 | #### 方法2:用hashmap给每个节点设置父节点。
437 |
438 | 利用hashmap,然后将o1节点往上遍历到节点,并把每个节点放入集合A中,然后o2往上遍历到头节点,只要遍历的节点发现在集合A中,那么这个节点就是公共祖先节点。
439 |
440 | #### 9 统计完全二叉树的节点数(P176)
441 |
442 | 1)找到右子树的最左节点,如果到达最后一层,说明左子树为满二叉树,节点数为:2^(h-1),递归右子树bs(node.right,level+1,h),所以为:2^(h-1)+bs(node.right,level+1,h)。
443 | 2)找到右子树的最左节点,如果没有到达最后一层,说明右子树为满二叉树,所以为:2^(h-level-1)+bs(node.left,level+1,h)。
444 |
445 | #### 未解决问题
446 |
447 | P173、P172、神级遍历方法
448 |
449 | ### 动态规划
450 |
451 | #### 背包九讲
452 |
453 | - https://www.cnblogs.com/jbelial/articles/2116074.html
454 | - https://www.bilibili.com/video/av33930433/
455 |
456 | #### 动态规划思路总结
457 |
458 | - https://www.jianshu.com/p/d0950aa36b43
459 |
460 | #### ACM动态规划总结
461 |
462 | - https://blog.csdn.net/cc_again/article/details/25866971
463 |
464 | #### leetcode动态规划总结(不错)
465 |
466 | - https://www.cnblogs.com/JasonBUPT/p/11868558.html
467 |
468 | #### 1 动态规划空间压缩解题思路(P232、P188)
469 |
470 | ##### 思路
471 |
472 | 1、用一维数组代替二维数组,降低空间复杂度
473 | 2、需要记录的值:
474 | 必须值:一维数组的第一个值(累加值)
475 | 可能值:一维数组的上一行的前一个值(i-1)、一维数组的上一行的当前值(i)
476 | 3、初始化第一行的数据
477 | 4、有了相关值之后,从左到右,从上到下遍历。
478 |
479 | ##### tips(P185、P198、P203、P232、P235)
480 |
481 | 1、一般一位变量是:更新的维度(更短的维度),同时,需要求出哪个是长字符串、短字符串
482 | 2、字符串的题目循环时:1-n
483 | 3、如果是3个方向a[i-1][j-1]、a[i-1][j]、a[i][j-1]来更新值,那么循环时,需要一个变量pre记录左上角a[i-1][j-1]的值,并且循环时,需要记录初始值`(P198)`
484 | 4、一般题目根据循环i、j直接将二维根据变量替换成一维的即可
485 | 5、如果需要比较当前dp[i][j]的值的大小,则需要用temp变量记录dp[i][j]的值,并且将当前值替换成temp`(P232)`
486 |
487 | #### 2 动态规划解题思路
488 |
489 | ##### 1)找到base case
490 |
491 | ##### 2)找到依赖的位置有哪些
492 |
493 | - **通常依赖的位置**
494 | ```java
495 | dp[i][j]、dp[i-1][j]、dp[i][j-1]、dp[i-1][j-1]。
496 | ```
497 | 累加:依赖某一行、某一列、行和列
498 |
499 | - **方法**
500 |
501 | 方法1:如果题目简单,通过题目直接找出依赖。
502 | 方法2:如果题目复杂,写出递归版本,然后,根据递归版本,用普通的值代入,找出依赖哪些值。
503 |
504 |
505 | #### 3 递归方法解题思路(P204、P238、P240、P245、P249)
506 |
507 | 1、确定递归函数变量有哪些?
508 | 2、解决局部问题,剩下的问题递归解决,写出递归模板。
509 | 3、写出base case。
510 |
511 | - **换钱的最少货币数**(P189)
512 | 1、`process(arr,int i,int aim)`
513 | 2、`process(arr,i+1,aim-k*arr[i])`
514 |
515 | - **机器人到达指定位置的方法数**(P192、P199)
516 | 1、`process(int N,int cur,int rest,int P)`
517 | 2
518 | 2.1)当前位置在1时
519 | `process(N,2,rest-1,P)`
520 | 2.2)当前位置在N时
521 | `process(N,N-1,rest-1,P)`
522 | 2.3)当前位置在i时
523 | `process(N,cur-1,rest-1,P)+process(N,cur+1,rest-1,P)`
524 |
525 | #### 4 字符串动态规划总结
526 |
527 | ##### 最长递增子序列(P210)
528 |
529 | - 求出dp数组
530 | ```java
531 | dp[i] = {dp[j]+1(0<=j  29 |
30 |
31 |
32 | ### 目录(ctrl + f 查找更香:不能点击的,还在写)
33 |
34 | - [个人经验](#个人经验)
35 | - [项目准备](#项目准备)
36 | - [面试知识点](#面试知识点)
37 | - [公司面经](#公司面经)
38 | - [Java](#java)
39 | - [基础](#基础)
40 | - [容器(包括juc)](#容器包括juc)
41 | - [基础容器](#基础容器)
42 | - [阻塞容器](#阻塞容器)
43 | - [并发](#并发)
44 | - [JVM](#jvm)
45 | - [Java8](#java8)
46 | - [计算机网络](#计算机网络)
47 | - [计算机操作系统](#计算机操作系统)
48 | - [Linux](#linux)
49 | - [数据结构与算法](#数据结构与算法)
50 | - [数据结构](#数据结构)
51 | - [算法](#算法)
52 | - [数据库](#数据库)
53 | - [MySQL](#mysql)
54 | - [MySQL(优化思路)](#mysql优化思路)
55 | - [系统设计](#系统设计)
56 | - [秒杀系统相关](#秒杀系统相关)
57 | - [前后端分离](#前后端分离)
58 | - [单点登录](#单点登录)
59 | - [常用框架](#常用框架)
60 | - [Spring](#spring)
61 | - [SpringBoot](#springboot)
62 | - [分布式](#分布式)
63 | - [dubbo](#dubbo)
64 | - [zookeeper](#zookeeper)
65 | - [RocketMQ](#rocketmq)
66 | - [RabbitMQ](#rabbitmq)
67 | - [kafka](#kafka)
68 | - [消息中间件](#消息中间件)
69 | - [redis](#redis)
70 | - [分布式系统](#分布式系统)
71 | - [线上问题调优(虚拟机,tomcat)](#线上问题调优虚拟机tomcat)
72 | - [面试指南](#面试指南)
73 | - [工具](#工具)
74 | - [Git](#git)
75 | - [Docker](#docker)
76 | - [其他](#其他)
77 | - [权限控制(设计、shiro)](#权限控制设计shiro)
78 | - [Java学习资源](#java学习资源)
79 | - [Java书籍推荐](#java书籍推荐)
80 | - [实战项目推荐](#实战项目推荐)
81 | - [程序人生](#程序人生)
82 | - [说明](#说明)
83 | - [JavaInterview介绍](#javainterview介绍)
84 | - [关于转载](#关于转载)
85 | - [如何对该开源文档进行贡献](#如何对该开源文档进行贡献)
86 | - [为什么要做这个开源文档?](#为什么要做这个开源文档)
87 | - [投稿](#投稿)
88 | - [联系我](#联系我)
89 | - [公众号](#公众号)
90 |
91 | ## 个人经验
92 |
93 | - [应届生如何准备校招,用我这一年的校招经历告诉你](https://sihai.blog.csdn.net/article/details/114258312?spm=1001.2014.3001.5502)
94 | - [【大学到研究生自学Java的学习路线】这是一份最适合普通大众、非科班的路线,帮你快速找到一份满意的工作](https://sihai.blog.csdn.net/article/details/105964718?spm=1001.2014.3001.5502)
95 | - [两个月的面试真实经历,告诉大家如何能够进入大厂工作?](https://sihai.blog.csdn.net/article/details/105807642)
96 |
97 | ## 项目准备
98 |
99 | - [我的个人项目介绍模板](docs/interview/自我介绍和项目介绍.md)
100 | - [本人面试两个月真实经历:面试了20家大厂之后,发现这样介绍项目经验,显得项目很牛逼!](https://sihai.blog.csdn.net/article/details/105854760)
101 | - [项目必备知识及解决方案](docs/project/秒杀项目总结.md)
102 |
103 | ## 面试知识点
104 |
105 | - [各大公司面试知识点汇总](docs/interview-experience/各大公司面经.md)
106 | - [Java后端面试常见问题分类汇总(高频考点)](docs/interview-experience/面试常见问题分类汇总.md)
107 |
108 |
109 | ## 公司面经
110 |
111 | - [2020年各公司面试经验汇总](docs/interview-experience/各大公司面经.md)
112 | - [最新!!招银网络科技Java面经,整理附答案](https://mp.weixin.qq.com/s/HAUOH-EYS_3Ho2XxYkTGXA)
113 | - [拿了 30K 的 offer!](https://mp.weixin.qq.com/s/R4gZ8IuskxgxA1SZwfCOoA)
114 | - [重磅面经!!四面美团最终拿到了 offer](https://mp.weixin.qq.com/s/P1mDcH5hEXqNp2Jpz5Qjmg)
115 | - [十面阿里,七面头条](https://mp.weixin.qq.com/s/FErQnLvYnuZxiaDkYWPO5A)
116 |
117 | ## Java
118 |
119 | ### 基础
120 |
121 | 这几篇文章虽然是基础,但是确实深入理解基础,如果你能很好的理解这些基础,那么对于Java基础面试题也是没有什么问题的,背面试题不如理解原理,很重要。
122 |
123 | - [Java基础思维导图](http://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247483823&idx=1&sn=4588a874055e8ca54f2bbe1ede12cff4&scene=19#wechat_redirect)
124 | - [Java基础(一) 深入解析基本类型](http://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247483948&idx=1&sn=cb0ae3d82a1629e3a0538b6f31e2473b&scene=19#wechat_redirect)
125 | - [Java基础(二) 自增自减与贪心规则](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247483951&idx=1&sn=af5b54ed2e26d975f96643d9dfd66fab&scene=19#wechat_redirect)
126 | - [Java基础(三) 加强型for循环与Iterator](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247483952&idx=1&sn=43130fdf815970e0e12347d057c6b24f&scene=19#wechat_redirect)
127 | - [Java基础(四) java运算顺序的深入解析](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247483955&idx=1&sn=abfb3e8ac31cb84bb78216d9c953abc0&scene=19#wechat_redirect)
128 | - [Java基础(五) String性质深入解析](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247483956&idx=1&sn=1c19164967621fa5449a7830d006c8f9&scene=19#wechat_redirect)
129 | - [Java基础(六) switch语句的深入解析](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247483999&idx=1&sn=092ad983f87798360ef33b1485f3201b&scene=19#wechat_redirect)
130 | - [Java基础(七) 深入解析java四种访问权限](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484000&idx=1&sn=0b188c70ac54c65a0419ab0d5da14af4&scene=19#wechat_redirect)
131 | - [Java基础(八) 深入解析常量池与装拆箱机制](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484002&idx=1&sn=a1d9ec01c91537aca444408c989f5a50&scene=19#wechat_redirect)
132 | - [Java基础(九) 可变参数列表介绍](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484003&idx=1&sn=84366ed430c332d4b8e2b2d6b54280f4&scene=19#wechat_redirect)
133 | - [Java基础(十) 深入理解数组类型](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484004&idx=1&sn=9c58b6948f05bbeffea3552fec9ee9a6&scene=19#wechat_redirect)
134 | - [Java基础(十一) 枚举类型](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484005&idx=1&sn=5aaec133dca189fcabc86defcd54c5b8&scene=19#wechat_redirect)
135 | - [类与接口(二)java的四种内部类详解](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484075&idx=1&sn=e0fd37cc5c1eb5fb359ed3dc9c15af66&scene=19#wechat_redirect)
136 | - [类与接口(三)java中的接口与嵌套接口](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484076&idx=1&sn=1903edbc469b2660e51e1154a8b63a27&scene=19#wechat_redirect)
137 | - [类与接口(四)方法重载解析](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484078&idx=1&sn=db5f231dc64974057d4ee29af1649e8b&scene=19#wechat_redirect)
138 | - [类与接口(五)java多态、方法重写、隐藏](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484083&idx=1&sn=d5b3d1daca2eb4e8d9583d75e6f6ad6c&scene=19#wechat_redirect)
139 |
140 |
141 | ### 容器(包括juc)
142 |
143 | #### 基础容器
144 |
145 | - [ArrayList源码分析及真实大厂面试题精讲](https://blog.csdn.net/sihai12345/article/details/138413307?spm=1001.2014.3001.5501)
146 | - [LinkedList源码分析及真实大厂面试题精讲](https://blog.csdn.net/sihai12345/article/details/138413722?spm=1001.2014.3001.5501)
147 | - [HashMap源码分析及真实大厂面试题精讲](https://blog.csdn.net/sihai12345/article/details/138416578?spm=1001.2014.3001.5501)
148 | - TreeMap源码分析及真实大厂面试题精讲
149 | - TreeSet源码分析及真实大厂面试题精讲
150 | - LinkedHashMap源码分析及真实大厂面试题精讲
151 |
152 | #### 阻塞容器
153 |
154 | - [ConcurrentHashMap源码分析及真实大厂面试题精讲](https://blog.csdn.net/sihai12345/article/details/138420403)
155 | - ArrayBlockingQueue源码分析及真实大厂面试题精讲
156 | - LinkedBlockingQueue源码分析及真实大厂面试题精讲
157 | - PriorityBlockingQueue源码分析及真实大厂面试题精讲
158 |
159 | ### 并发
160 |
161 | - [Synchronized关键字精讲及真实大厂面试题解析](https://blog.csdn.net/sihai12345/article/details/138420474)
162 | - [Volitale关键字精讲及真实大厂面试题解析](https://blog.csdn.net/sihai12345/article/details/138420521)
163 | - 关于LRU的实现
164 | - [ThreadLocal面试中会怎么提问呢?](https://blog.csdn.net/sihai12345/article/details/138420558)
165 | - [线程池的面试题,这篇文章帮你搞定它!](https://blog.csdn.net/sihai12345/article/details/138420591)
166 |
167 |
168 | ### JVM
169 |
170 | - [深入理解Java虚拟机系列](https://mp.weixin.qq.com/s/SZ87s3fmKL3Kc_tAMcOFQw)
171 | - [深入理解Java虚拟机系列--完全解决面试问题](https://blog.ouyangsihai.cn/shen-ru-li-jie-java-xu-ni-ji-xi-lie-jiao-cheng.html)
172 | - [深入理解Java虚拟机-Java内存区域透彻分析](https://mp.weixin.qq.com/s/WuyxyelaXbU-lg-HVZ95TA)
173 | - [深入理解Java虚拟机-JVM内存分配与回收策略原理,从此告别JVM内存分配文盲](https://mp.weixin.qq.com/s/IG_zU5xa7y4BB6PVP0Fmow)
174 | - [深入理解Java虚拟机-常用vm参数分析](https://mp.weixin.qq.com/s/l8fsq07jI0svqBdBGxuOzA)
175 | - [深入理解Java虚拟机-如何利用JDK自带的命令行工具监控上百万的高并发的虚拟机性能](https://mp.weixin.qq.com/s/wPgA5SDURCAqPsWkZGGX0g)
176 | - [深入理解Java虚拟机-如何利用VisualVM对高并发项目进行性能分析](https://mp.weixin.qq.com/s/hhA9tI_rYNkJVbF-R45hbA)
177 | - [深入理解Java虚拟机-你了解GC算法原理吗](https://mp.weixin.qq.com/s/SZ87s3fmKL3Kc_tAMcOFQw)
178 | - [几个面试官常问的垃圾回收器,下次面试就拿这篇文章怼回去!](https://sihai.blog.csdn.net/article/details/105700527)
179 | - [面试官100%会严刑拷打的 CMS 垃圾回收器,下次面试就拿这篇文章怼回去!](https://sihai.blog.csdn.net/article/details/105808878)
180 | - [JVM 面试题 87 题详解](https://sihai.blog.csdn.net/article/details/118737581)
181 |
182 |
183 | ### Java8
184 |
185 | - [Java8 Stream:2万字20个实例,玩转集合的筛选、归约、分组、聚合](https://mp.weixin.qq.com/s/u042M2Sw2glBlevIDVoSXg)
186 | - [利用Java8新特征,重构传统设计模式,你学会了吗?](https://mp.weixin.qq.com/s/zZ6rWz_t_snYNiNyOtaGiQ)
187 | - [Java8 之 lambda 表达式、方法引用、函数式接口、默认方式、静态方法](https://mp.weixin.qq.com/s/FdzNWIsEmHVe9Nehxvfa3w)
188 | - [Java8之Consumer、Supplier、Predicate和Function攻略](https://sihai.blog.csdn.net/article/details/98193777)
189 | - [Java8 的 Stream 流式操作之王者归来](https://sihai.blog.csdn.net/article/details/100434684)
190 | - [Java11-17的最新特性](https://mp.weixin.qq.com/s/QPGdNn56mCCDIUS047_1cQ)
191 |
192 | ## 计算机网络
193 |
194 | - [http面试问题全解析](docs/network/http面试问题全解析.md)
195 | - [计算机网络常见面试题](https://sihai.blog.csdn.net/article/details/118737663)
196 | - 关于tcp、udp网络模型的问题,这篇文章告诉你
197 | - http、https还不了解,别慌!
198 | - 面试官问我计算机网络的问题,我一个问题给他讲半个小时
199 |
200 | ## 计算机操作系统
201 |
202 | - [操作系统、计算机网络相关知识](docs/operating-system/操作系统、计算机网络相关知识.md)
203 |
204 | ## Linux
205 |
206 | - [java工程师linux命令,这篇文章就够了](https://mp.weixin.qq.com/s/bj28tvF9TwgwrH65OPjXZg)
207 | - [linux常见面试题(基础版)](https://sihai.blog.csdn.net/article/details/118737736)
208 | - [linux高频面试题](docs/operating-system/linux高频面试题.md)
209 | - 常问的几个Linux面试题,通通解决它
210 |
211 | ## 数据结构与算法
212 |
213 | ### 数据结构
214 |
215 | - [跳表这种数据结构,你真的清楚吗,面试官可能会问这些问题!](https://blog.csdn.net/sihai12345/article/details/138419109)
216 | - 红黑树你了解多少,不会肯定会被面试官怼坏
217 | - [B树,B+树,你了解多少,面试官问那些问题?](https://segmentfault.com/a/1190000020416577)
218 | - [这篇文章带你彻底理解红黑树](https://sihai.blog.csdn.net/article/details/118738496)
219 | - 二叉树、二叉搜索树、二叉平衡树、红黑树、B树、B+树
220 |
221 | ### 算法
222 |
223 | - [从大学入门到研究生拿大厂offer,必须看的数据结构与算法书籍推荐,不好不推荐!](https://sihai.blog.csdn.net/article/details/106011624?spm=1001.2014.3001.5502)
224 | - [2021年面试高频算法题题解](docs/dataStructures-algorithms/高频算法题目总结.md)
225 | - [2021年最新剑指offer难题解析](docs/dataStructures-algorithms/剑指offer难点总结.md)
226 | - [关于贪心算法的leetcode题目,这篇文章可以帮你解决80%](https://blog.ouyangsihai.cn/jie-shao-yi-xia-guan-yu-leetcode-de-tan-xin-suan-fa-de-jie-ti-fang-fa.html)
227 | - [dfs题目这样去接题,秒杀leetcode题目](https://sihai.blog.csdn.net/article/details/106895319)
228 | - [回溯算法不会,这篇文章一定得看](https://sihai.blog.csdn.net/article/details/106993339)
229 | - 动态规划你了解多少,我来帮你入个们
230 | - 链表的题目真的不难,看了这篇文章你就知道有多简单了
231 | - 还在怕二叉树的题目吗?
232 | = 栈和队列的题目可以这样出题型,你掌握了吗
233 | - 数组中常用的几种leetcode解题技巧!
234 |
235 | ## 数据库
236 |
237 | ### MySQL
238 |
239 | - [InnoDB与MyISAM等存储引擎对比](https://sihai.blog.csdn.net/article/details/100832158)
240 | - [MySQL:从B树到B+树到索引再到存储引擎](https://mp.weixin.qq.com/s/QmG1FyWPp23klTVkTJvcUQ)
241 | - [MySQL全文索引最强教程](https://blog.ouyangsihai.cn/mysql-quan-wen-suo-yin.html)
242 | - [MySQL的又一神器-锁,MySQL面试必备](https://sihai.blog.csdn.net/article/details/102680104)
243 | - [MySQL事务,这篇文章就够了](https://sihai.blog.csdn.net/article/details/102815801)
244 | - [mysqldump工具命令参数大全](https://blog.ouyangsihai.cn/mysqldump-gong-ju-ming-ling-can-shu-da-quan.html)
245 | - [看完这篇MySQL备份的文章,再也不用担心删库跑路了](https://blog.ouyangsihai.cn/kan-wan-zhe-pian-mysql-bei-fen-de-wen-zhang-zai-ye-bu-yong-dan-xin-shan-ku-pao-lu-liao.html)
246 | - 关于MySQL索引,面试中面试官会怎么为难你,一定得注意
247 | - MySQL中的乐观锁、悲观锁,JDK中的乐观锁、悲观锁?
248 |
249 | #### MySQL(优化思路)
250 |
251 | - [MySQL高频面试题](https://mp.weixin.qq.com/s/KFCkvfF84l6Eu43CH_TmXA)
252 | - [MySQL查询优化过程](https://mp.weixin.qq.com/s/jtuLb8uAIHJNvNpwcIZfpA)
253 | - [面试官:MySQL 上亿大表,如何深度优化?](https://mp.weixin.qq.com/s/g-_Oz9CLJfBn_asJrzn6Yg)
254 | - [老司机总结的12条 SQL 优化方案(非常实用)](https://mp.weixin.qq.com/s/7QuASKTpXOm54CgLiHqEJg)
255 |
256 |
257 | ## 系统设计
258 |
259 | ### 秒杀系统相关
260 |
261 | - [分布式架构图](https://juejin.im/post/5a9ced09518825555f0c72c7)
262 |
263 | - [秒杀架构设计思路详解](https://blog.csdn.net/qq_35190492/article/details/103105780)
264 |
265 | - **[秒杀关键细节设计](https://blog.csdn.net/fanrenxiang/article/details/85083243)**
266 |
267 | ### 前后端分离
268 |
269 | - [前后端分离概述](https://blog.csdn.net/fuzhongmin05/article/details/81591072)
270 | - [前后端分离之JWT用户认证](https://www.jianshu.com/p/180a870a308a)
271 |
272 | ### 单点登录
273 |
274 | - [什么是单点登录](https://mp.weixin.qq.com/s/J6YJls05t2C4OGOqHVijhw)
275 | - [单点登录机制原理](https://mp.weixin.qq.com/s/LGnUueNC-EuoxiF-8b-TeQ)
276 |
277 | ### 常用框架
278 |
279 | #### Spring
280 |
281 | - [微信支付和支付宝支付到springmvc+spring+mybatis环境全过程(支付宝和微信支付)](https://mp.weixin.qq.com/s/c1GMlpRZNcZdsTUNuG8WUw)
282 |
283 | #### SpringBoot
284 |
285 | - [springboot史上最全教程,11篇文章全解析](https://blog.csdn.net/sihai12345/category_7779682.html)
286 | - [微服务面试相关资料](docs/microservice/微服务相关资料.md)
287 |
288 | ## 分布式
289 |
290 | ### dubbo
291 |
292 | - [dubbo入门实战教程,这篇文章真的再好不过了](https://segmentfault.com/a/1190000019896723)
293 | - [dubbo源码分析](http://cmsblogs.com/?p=5324)
294 | - [dubbo面试题](https://mp.weixin.qq.com/s/PdWRHgm83XwPYP08KnkIsw)
295 | - [dubbo面试题2](https://mp.weixin.qq.com/s/Kz0s9K3J9Lpvh37oP_CtCA)
296 |
297 | ### zookeeper
298 |
299 | - [什么是zookeeper?](https://mp.weixin.qq.com/s/i2_c4A0146B7Ev8QnofbfQ)
300 | - [zookeeeper面试题](https://segmentfault.com/a/1190000014479433)
301 | - [zookeeper面试题2](https://juejin.im/post/5dbac7a0f265da4d2c5e9b3b)
302 |
303 |
304 | ### RocketMQ
305 |
306 | - [RocketMQ简单教程](https://juejin.im/post/5af02571f265da0b9e64fcfd)
307 | - [RocketMQ教程](https://mp.weixin.qq.com/s/VAZaU1DuKbpnaALjp_-9Qw)
308 | - [RocketMQ面试题](https://blog.csdn.net/dingshuo168/article/details/102970988)
309 |
310 | ### RabbitMQ
311 |
312 | - [RabbitMQ教程](https://blog.csdn.net/hellozpc/article/details/81436980)
313 | - [RabbitMQ面试题](https://blog.csdn.net/qq_42629110/article/details/84965084)
314 | - [RabbitMQ面试题2](https://my.oschina.net/u/4162503/blog/3073693)
315 | - [RabbitMQ面试题3](https://blog.csdn.net/jerryDzan/article/details/89183625)
316 |
317 | ### kafka
318 |
319 | - [全网最通俗易懂的Kafka入门](https://mp.weixin.qq.com/s/FlSsrzu1FwjBjmlNy5QyOg)
320 | - [全网最通俗易懂的Kafka入门2](https://mp.weixin.qq.com/s/opAYVXIJoy4tCWaPcX5u6g)
321 | - [kafka入门教程](https://www.orchome.com/kafka/index)
322 | - [kafka面试题](https://blog.csdn.net/qq_28900249/article/details/90346599)
323 | - [kafka面试题2](http://trumandu.github.io/2019/04/13/Kafka%E9%9D%A2%E8%AF%95%E9%A2%98%E4%B8%8E%E7%AD%94%E6%A1%88%E5%85%A8%E5%A5%97%E6%95%B4%E7%90%86/)
324 |
325 | ### 消息中间件
326 |
327 | - [消息中间件面试题总结](docs/project/消息中间件面试题.md)
328 |
329 | ### redis
330 |
331 | - [Redis设计与实现总结文章](https://blog.csdn.net/qq_41594698/category_9067680.html)
332 | - [Redis面试题必备:基础,面试题](https://mp.weixin.qq.com/s/3Fmv7h5p2QDtLxc9n1dp5A)
333 | - [Redis面试相关:其中包含redis知识](https://blog.csdn.net/qq_35190492/article/details/103105780)
334 | - [redis其他数据结构](https://blog.csdn.net/c_royi/article/details/82011208)
335 |
336 | ### 分布式系统
337 |
338 | ## 线上问题调优(虚拟机,tomcat)
339 | - [垃圾收集器ZGC](https://juejin.im/post/5dc361d3f265da4d1f51c670)
340 | - [jvm系列文章](https://crowhawk.github.io/tags/#JVM)
341 | - [一次JVM FullGC的背后,竟隐藏着惊心动魄的线上生产事故!](https://mp.weixin.qq.com/s/5SeGxKtwp6KZhUKn8jXi6A)
342 | - [深入理解Java虚拟机-如何利用JDK自带的命令行工具监控上百万的高并发的虚拟机性能](https://mp.weixin.qq.com/s/wPgA5SDURCAqPsWkZGGX0g)
343 | - [深入理解Java虚拟机-如何利用VisualVM对高并发项目进行性能分析](https://mp.weixin.qq.com/s/hhA9tI_rYNkJVbF-R45hbA)
344 | - [JVM性能调优](https://www.iteye.com/blog/uule-2114697)
345 | - [百亿吞吐量服务的JVM性能调优实战](https://mp.weixin.qq.com/s?__biz=MzIwMzY1OTU1NQ==&mid=2247484236&idx=1&sn=b9743b2d7436f84e4617ff34e07abdd8&chksm=96cd4300a1baca1635a137294bc93c518c033ce01f843c9e012a1454b9f3ea3158fa1412e9da&scene=27&ascene=0&devicetype=android-24&version=26060638&nettype=WIFI&abtest_cookie=BAABAAoACwASABMABAAjlx4AUJkeAFmZHgBomR4AAAA%3D&lang=zh_CN&pass_ticket=%2F%2BLqr9N2EZtrEGLFo9vLA6Eqs89DSJ2CBKoAJFZ%2BBngphEP28dwmMQeSZcUB77qZ&wx_header=1)
346 | - [一次线上JVM调优实践,FullGC40次/天到10天一次的优化过程](https://blog.csdn.net/cml_blog/article/details/81057966)
347 | - [JVM调优工具](https://www.jianshu.com/p/e36fac926539)
348 |
349 |
350 | ## 面试指南
351 |
352 |
353 | ## 工具
354 |
355 | ### Git
356 |
357 | - [实际开发中的git命令大全](https://sihai.blog.csdn.net/article/details/106418135)
358 |
359 | ### Docker
360 |
361 | ## 其他
362 |
363 | ### 权限控制(设计、shiro)
364 |
365 | - [权限控制设计](https://mp.weixin.qq.com/s/WTgz07xDIf9FbAfCDyTheQ)
366 | - [shiro相关教程](https://blog.csdn.net/sihai12345/category_9268544.html)
367 | - [springboot+vue+shiro前后端分离实战项目](https://blog.csdn.net/neuf_soleil/category_9287210.html)
368 | - [shiro挺好的教程](https://how2j.cn/k/shiro/shiro-springboot/1728.html)
369 |
370 | ## Java学习资源
371 |
372 | - [2021年Java视频学习教程+项目实战](https://github.com/hello-go-maker/cs-learn-source)
373 | - [2021 Java 1000G 最新学习资源大汇总](https://mp.weixin.qq.com/s/I0jimqziHqRNaIy0kXRCnw)
374 |
375 |
376 | ## Java书籍推荐
377 |
378 | - [从入门到拿大厂offer,必须看的数据结构与算法书籍推荐](https://blog.csdn.net/sihai12345/article/details/106011624)
379 | - [全网最全电子书下载](https://github.com/hello-go-maker/cs-books)
380 |
381 | ## 实战项目推荐
382 |
383 | >小心翼翼的告诉你,上面的资源当中就有很多**企业级项目**,没有项目一点不用怕,因为你看到了这个。
384 |
385 | - [找工作,没有上的了台面的项目怎么办?](https://mp.weixin.qq.com/s/0oK43_z99pVY9dYVXyIeiw)
386 | - [Java 实战项目推荐](https://github.com/hello-go-maker/cs-learn-source)
387 |
388 | ## 程序人生
389 |
390 | - [我想是时候跟大学告别了](https://blog.csdn.net/sihai12345/article/details/86934341)
391 | - [坚持,这两个字非常重要!](https://blog.csdn.net/sihai12345/article/details/89507366)
392 | - [关于考研,这是我给大家的经验](https://blog.csdn.net/sihai12345/article/details/88548630)
393 | - [从普通二本到研究生再到自媒体的年轻人,这是我的故事](https://segmentfault.com/a/1190000020317748)
394 |
395 | ## 说明
396 |
397 | ### JavaInterview介绍
398 |
399 | 目的很简单,写这些文章,以及整个github的资料,都是为了面试而准备的,只希望能够给面试提供一些帮助,都能够进大厂最好了。
400 |
401 | ### 关于转载
402 |
403 | 如果你需要转载本仓库的一些文章到自己的博客的话,记得注明原文地址就可以了。
404 |
405 | ### 如何对该开源文档进行贡献
406 |
407 | 1. 里面很多都是我的原创,能力有限,欢迎指正。
408 | 2. 很多知识点我可能没有涉及到,所以你可以对其他知识点进行补充。
409 | 3. 现有的知识点难免存在不完善或者错误,所以你可以对已有知识点进行修改/补充。
410 |
411 | ### 为什么要做这个开源文档?
412 |
413 | 初始想法源于自己的个人那一段比较迷茫的学习经历。主要目的是为了通过这个开源平台来帮助一些在学习 Java 或者面试过程中遇到问题的小伙伴。
414 |
415 | ### 投稿
416 |
417 | 由于我个人能力有限,很多知识点我可能没有涉及到,所以你可以对其他知识点进行补充。
418 |
419 | ### 联系我
420 |
421 | 添加我的微信备注 **github**, 即可入群。
422 |
423 |
29 |
30 |
31 |
32 | ### 目录(ctrl + f 查找更香:不能点击的,还在写)
33 |
34 | - [个人经验](#个人经验)
35 | - [项目准备](#项目准备)
36 | - [面试知识点](#面试知识点)
37 | - [公司面经](#公司面经)
38 | - [Java](#java)
39 | - [基础](#基础)
40 | - [容器(包括juc)](#容器包括juc)
41 | - [基础容器](#基础容器)
42 | - [阻塞容器](#阻塞容器)
43 | - [并发](#并发)
44 | - [JVM](#jvm)
45 | - [Java8](#java8)
46 | - [计算机网络](#计算机网络)
47 | - [计算机操作系统](#计算机操作系统)
48 | - [Linux](#linux)
49 | - [数据结构与算法](#数据结构与算法)
50 | - [数据结构](#数据结构)
51 | - [算法](#算法)
52 | - [数据库](#数据库)
53 | - [MySQL](#mysql)
54 | - [MySQL(优化思路)](#mysql优化思路)
55 | - [系统设计](#系统设计)
56 | - [秒杀系统相关](#秒杀系统相关)
57 | - [前后端分离](#前后端分离)
58 | - [单点登录](#单点登录)
59 | - [常用框架](#常用框架)
60 | - [Spring](#spring)
61 | - [SpringBoot](#springboot)
62 | - [分布式](#分布式)
63 | - [dubbo](#dubbo)
64 | - [zookeeper](#zookeeper)
65 | - [RocketMQ](#rocketmq)
66 | - [RabbitMQ](#rabbitmq)
67 | - [kafka](#kafka)
68 | - [消息中间件](#消息中间件)
69 | - [redis](#redis)
70 | - [分布式系统](#分布式系统)
71 | - [线上问题调优(虚拟机,tomcat)](#线上问题调优虚拟机tomcat)
72 | - [面试指南](#面试指南)
73 | - [工具](#工具)
74 | - [Git](#git)
75 | - [Docker](#docker)
76 | - [其他](#其他)
77 | - [权限控制(设计、shiro)](#权限控制设计shiro)
78 | - [Java学习资源](#java学习资源)
79 | - [Java书籍推荐](#java书籍推荐)
80 | - [实战项目推荐](#实战项目推荐)
81 | - [程序人生](#程序人生)
82 | - [说明](#说明)
83 | - [JavaInterview介绍](#javainterview介绍)
84 | - [关于转载](#关于转载)
85 | - [如何对该开源文档进行贡献](#如何对该开源文档进行贡献)
86 | - [为什么要做这个开源文档?](#为什么要做这个开源文档)
87 | - [投稿](#投稿)
88 | - [联系我](#联系我)
89 | - [公众号](#公众号)
90 |
91 | ## 个人经验
92 |
93 | - [应届生如何准备校招,用我这一年的校招经历告诉你](https://sihai.blog.csdn.net/article/details/114258312?spm=1001.2014.3001.5502)
94 | - [【大学到研究生自学Java的学习路线】这是一份最适合普通大众、非科班的路线,帮你快速找到一份满意的工作](https://sihai.blog.csdn.net/article/details/105964718?spm=1001.2014.3001.5502)
95 | - [两个月的面试真实经历,告诉大家如何能够进入大厂工作?](https://sihai.blog.csdn.net/article/details/105807642)
96 |
97 | ## 项目准备
98 |
99 | - [我的个人项目介绍模板](docs/interview/自我介绍和项目介绍.md)
100 | - [本人面试两个月真实经历:面试了20家大厂之后,发现这样介绍项目经验,显得项目很牛逼!](https://sihai.blog.csdn.net/article/details/105854760)
101 | - [项目必备知识及解决方案](docs/project/秒杀项目总结.md)
102 |
103 | ## 面试知识点
104 |
105 | - [各大公司面试知识点汇总](docs/interview-experience/各大公司面经.md)
106 | - [Java后端面试常见问题分类汇总(高频考点)](docs/interview-experience/面试常见问题分类汇总.md)
107 |
108 |
109 | ## 公司面经
110 |
111 | - [2020年各公司面试经验汇总](docs/interview-experience/各大公司面经.md)
112 | - [最新!!招银网络科技Java面经,整理附答案](https://mp.weixin.qq.com/s/HAUOH-EYS_3Ho2XxYkTGXA)
113 | - [拿了 30K 的 offer!](https://mp.weixin.qq.com/s/R4gZ8IuskxgxA1SZwfCOoA)
114 | - [重磅面经!!四面美团最终拿到了 offer](https://mp.weixin.qq.com/s/P1mDcH5hEXqNp2Jpz5Qjmg)
115 | - [十面阿里,七面头条](https://mp.weixin.qq.com/s/FErQnLvYnuZxiaDkYWPO5A)
116 |
117 | ## Java
118 |
119 | ### 基础
120 |
121 | 这几篇文章虽然是基础,但是确实深入理解基础,如果你能很好的理解这些基础,那么对于Java基础面试题也是没有什么问题的,背面试题不如理解原理,很重要。
122 |
123 | - [Java基础思维导图](http://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247483823&idx=1&sn=4588a874055e8ca54f2bbe1ede12cff4&scene=19#wechat_redirect)
124 | - [Java基础(一) 深入解析基本类型](http://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247483948&idx=1&sn=cb0ae3d82a1629e3a0538b6f31e2473b&scene=19#wechat_redirect)
125 | - [Java基础(二) 自增自减与贪心规则](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247483951&idx=1&sn=af5b54ed2e26d975f96643d9dfd66fab&scene=19#wechat_redirect)
126 | - [Java基础(三) 加强型for循环与Iterator](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247483952&idx=1&sn=43130fdf815970e0e12347d057c6b24f&scene=19#wechat_redirect)
127 | - [Java基础(四) java运算顺序的深入解析](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247483955&idx=1&sn=abfb3e8ac31cb84bb78216d9c953abc0&scene=19#wechat_redirect)
128 | - [Java基础(五) String性质深入解析](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247483956&idx=1&sn=1c19164967621fa5449a7830d006c8f9&scene=19#wechat_redirect)
129 | - [Java基础(六) switch语句的深入解析](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247483999&idx=1&sn=092ad983f87798360ef33b1485f3201b&scene=19#wechat_redirect)
130 | - [Java基础(七) 深入解析java四种访问权限](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484000&idx=1&sn=0b188c70ac54c65a0419ab0d5da14af4&scene=19#wechat_redirect)
131 | - [Java基础(八) 深入解析常量池与装拆箱机制](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484002&idx=1&sn=a1d9ec01c91537aca444408c989f5a50&scene=19#wechat_redirect)
132 | - [Java基础(九) 可变参数列表介绍](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484003&idx=1&sn=84366ed430c332d4b8e2b2d6b54280f4&scene=19#wechat_redirect)
133 | - [Java基础(十) 深入理解数组类型](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484004&idx=1&sn=9c58b6948f05bbeffea3552fec9ee9a6&scene=19#wechat_redirect)
134 | - [Java基础(十一) 枚举类型](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484005&idx=1&sn=5aaec133dca189fcabc86defcd54c5b8&scene=19#wechat_redirect)
135 | - [类与接口(二)java的四种内部类详解](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484075&idx=1&sn=e0fd37cc5c1eb5fb359ed3dc9c15af66&scene=19#wechat_redirect)
136 | - [类与接口(三)java中的接口与嵌套接口](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484076&idx=1&sn=1903edbc469b2660e51e1154a8b63a27&scene=19#wechat_redirect)
137 | - [类与接口(四)方法重载解析](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484078&idx=1&sn=db5f231dc64974057d4ee29af1649e8b&scene=19#wechat_redirect)
138 | - [类与接口(五)java多态、方法重写、隐藏](https://mp.weixin.qq.com/s?__biz=MzI2OTQ4OTQ1NQ==&mid=2247484083&idx=1&sn=d5b3d1daca2eb4e8d9583d75e6f6ad6c&scene=19#wechat_redirect)
139 |
140 |
141 | ### 容器(包括juc)
142 |
143 | #### 基础容器
144 |
145 | - [ArrayList源码分析及真实大厂面试题精讲](https://blog.csdn.net/sihai12345/article/details/138413307?spm=1001.2014.3001.5501)
146 | - [LinkedList源码分析及真实大厂面试题精讲](https://blog.csdn.net/sihai12345/article/details/138413722?spm=1001.2014.3001.5501)
147 | - [HashMap源码分析及真实大厂面试题精讲](https://blog.csdn.net/sihai12345/article/details/138416578?spm=1001.2014.3001.5501)
148 | - TreeMap源码分析及真实大厂面试题精讲
149 | - TreeSet源码分析及真实大厂面试题精讲
150 | - LinkedHashMap源码分析及真实大厂面试题精讲
151 |
152 | #### 阻塞容器
153 |
154 | - [ConcurrentHashMap源码分析及真实大厂面试题精讲](https://blog.csdn.net/sihai12345/article/details/138420403)
155 | - ArrayBlockingQueue源码分析及真实大厂面试题精讲
156 | - LinkedBlockingQueue源码分析及真实大厂面试题精讲
157 | - PriorityBlockingQueue源码分析及真实大厂面试题精讲
158 |
159 | ### 并发
160 |
161 | - [Synchronized关键字精讲及真实大厂面试题解析](https://blog.csdn.net/sihai12345/article/details/138420474)
162 | - [Volitale关键字精讲及真实大厂面试题解析](https://blog.csdn.net/sihai12345/article/details/138420521)
163 | - 关于LRU的实现
164 | - [ThreadLocal面试中会怎么提问呢?](https://blog.csdn.net/sihai12345/article/details/138420558)
165 | - [线程池的面试题,这篇文章帮你搞定它!](https://blog.csdn.net/sihai12345/article/details/138420591)
166 |
167 |
168 | ### JVM
169 |
170 | - [深入理解Java虚拟机系列](https://mp.weixin.qq.com/s/SZ87s3fmKL3Kc_tAMcOFQw)
171 | - [深入理解Java虚拟机系列--完全解决面试问题](https://blog.ouyangsihai.cn/shen-ru-li-jie-java-xu-ni-ji-xi-lie-jiao-cheng.html)
172 | - [深入理解Java虚拟机-Java内存区域透彻分析](https://mp.weixin.qq.com/s/WuyxyelaXbU-lg-HVZ95TA)
173 | - [深入理解Java虚拟机-JVM内存分配与回收策略原理,从此告别JVM内存分配文盲](https://mp.weixin.qq.com/s/IG_zU5xa7y4BB6PVP0Fmow)
174 | - [深入理解Java虚拟机-常用vm参数分析](https://mp.weixin.qq.com/s/l8fsq07jI0svqBdBGxuOzA)
175 | - [深入理解Java虚拟机-如何利用JDK自带的命令行工具监控上百万的高并发的虚拟机性能](https://mp.weixin.qq.com/s/wPgA5SDURCAqPsWkZGGX0g)
176 | - [深入理解Java虚拟机-如何利用VisualVM对高并发项目进行性能分析](https://mp.weixin.qq.com/s/hhA9tI_rYNkJVbF-R45hbA)
177 | - [深入理解Java虚拟机-你了解GC算法原理吗](https://mp.weixin.qq.com/s/SZ87s3fmKL3Kc_tAMcOFQw)
178 | - [几个面试官常问的垃圾回收器,下次面试就拿这篇文章怼回去!](https://sihai.blog.csdn.net/article/details/105700527)
179 | - [面试官100%会严刑拷打的 CMS 垃圾回收器,下次面试就拿这篇文章怼回去!](https://sihai.blog.csdn.net/article/details/105808878)
180 | - [JVM 面试题 87 题详解](https://sihai.blog.csdn.net/article/details/118737581)
181 |
182 |
183 | ### Java8
184 |
185 | - [Java8 Stream:2万字20个实例,玩转集合的筛选、归约、分组、聚合](https://mp.weixin.qq.com/s/u042M2Sw2glBlevIDVoSXg)
186 | - [利用Java8新特征,重构传统设计模式,你学会了吗?](https://mp.weixin.qq.com/s/zZ6rWz_t_snYNiNyOtaGiQ)
187 | - [Java8 之 lambda 表达式、方法引用、函数式接口、默认方式、静态方法](https://mp.weixin.qq.com/s/FdzNWIsEmHVe9Nehxvfa3w)
188 | - [Java8之Consumer、Supplier、Predicate和Function攻略](https://sihai.blog.csdn.net/article/details/98193777)
189 | - [Java8 的 Stream 流式操作之王者归来](https://sihai.blog.csdn.net/article/details/100434684)
190 | - [Java11-17的最新特性](https://mp.weixin.qq.com/s/QPGdNn56mCCDIUS047_1cQ)
191 |
192 | ## 计算机网络
193 |
194 | - [http面试问题全解析](docs/network/http面试问题全解析.md)
195 | - [计算机网络常见面试题](https://sihai.blog.csdn.net/article/details/118737663)
196 | - 关于tcp、udp网络模型的问题,这篇文章告诉你
197 | - http、https还不了解,别慌!
198 | - 面试官问我计算机网络的问题,我一个问题给他讲半个小时
199 |
200 | ## 计算机操作系统
201 |
202 | - [操作系统、计算机网络相关知识](docs/operating-system/操作系统、计算机网络相关知识.md)
203 |
204 | ## Linux
205 |
206 | - [java工程师linux命令,这篇文章就够了](https://mp.weixin.qq.com/s/bj28tvF9TwgwrH65OPjXZg)
207 | - [linux常见面试题(基础版)](https://sihai.blog.csdn.net/article/details/118737736)
208 | - [linux高频面试题](docs/operating-system/linux高频面试题.md)
209 | - 常问的几个Linux面试题,通通解决它
210 |
211 | ## 数据结构与算法
212 |
213 | ### 数据结构
214 |
215 | - [跳表这种数据结构,你真的清楚吗,面试官可能会问这些问题!](https://blog.csdn.net/sihai12345/article/details/138419109)
216 | - 红黑树你了解多少,不会肯定会被面试官怼坏
217 | - [B树,B+树,你了解多少,面试官问那些问题?](https://segmentfault.com/a/1190000020416577)
218 | - [这篇文章带你彻底理解红黑树](https://sihai.blog.csdn.net/article/details/118738496)
219 | - 二叉树、二叉搜索树、二叉平衡树、红黑树、B树、B+树
220 |
221 | ### 算法
222 |
223 | - [从大学入门到研究生拿大厂offer,必须看的数据结构与算法书籍推荐,不好不推荐!](https://sihai.blog.csdn.net/article/details/106011624?spm=1001.2014.3001.5502)
224 | - [2021年面试高频算法题题解](docs/dataStructures-algorithms/高频算法题目总结.md)
225 | - [2021年最新剑指offer难题解析](docs/dataStructures-algorithms/剑指offer难点总结.md)
226 | - [关于贪心算法的leetcode题目,这篇文章可以帮你解决80%](https://blog.ouyangsihai.cn/jie-shao-yi-xia-guan-yu-leetcode-de-tan-xin-suan-fa-de-jie-ti-fang-fa.html)
227 | - [dfs题目这样去接题,秒杀leetcode题目](https://sihai.blog.csdn.net/article/details/106895319)
228 | - [回溯算法不会,这篇文章一定得看](https://sihai.blog.csdn.net/article/details/106993339)
229 | - 动态规划你了解多少,我来帮你入个们
230 | - 链表的题目真的不难,看了这篇文章你就知道有多简单了
231 | - 还在怕二叉树的题目吗?
232 | = 栈和队列的题目可以这样出题型,你掌握了吗
233 | - 数组中常用的几种leetcode解题技巧!
234 |
235 | ## 数据库
236 |
237 | ### MySQL
238 |
239 | - [InnoDB与MyISAM等存储引擎对比](https://sihai.blog.csdn.net/article/details/100832158)
240 | - [MySQL:从B树到B+树到索引再到存储引擎](https://mp.weixin.qq.com/s/QmG1FyWPp23klTVkTJvcUQ)
241 | - [MySQL全文索引最强教程](https://blog.ouyangsihai.cn/mysql-quan-wen-suo-yin.html)
242 | - [MySQL的又一神器-锁,MySQL面试必备](https://sihai.blog.csdn.net/article/details/102680104)
243 | - [MySQL事务,这篇文章就够了](https://sihai.blog.csdn.net/article/details/102815801)
244 | - [mysqldump工具命令参数大全](https://blog.ouyangsihai.cn/mysqldump-gong-ju-ming-ling-can-shu-da-quan.html)
245 | - [看完这篇MySQL备份的文章,再也不用担心删库跑路了](https://blog.ouyangsihai.cn/kan-wan-zhe-pian-mysql-bei-fen-de-wen-zhang-zai-ye-bu-yong-dan-xin-shan-ku-pao-lu-liao.html)
246 | - 关于MySQL索引,面试中面试官会怎么为难你,一定得注意
247 | - MySQL中的乐观锁、悲观锁,JDK中的乐观锁、悲观锁?
248 |
249 | #### MySQL(优化思路)
250 |
251 | - [MySQL高频面试题](https://mp.weixin.qq.com/s/KFCkvfF84l6Eu43CH_TmXA)
252 | - [MySQL查询优化过程](https://mp.weixin.qq.com/s/jtuLb8uAIHJNvNpwcIZfpA)
253 | - [面试官:MySQL 上亿大表,如何深度优化?](https://mp.weixin.qq.com/s/g-_Oz9CLJfBn_asJrzn6Yg)
254 | - [老司机总结的12条 SQL 优化方案(非常实用)](https://mp.weixin.qq.com/s/7QuASKTpXOm54CgLiHqEJg)
255 |
256 |
257 | ## 系统设计
258 |
259 | ### 秒杀系统相关
260 |
261 | - [分布式架构图](https://juejin.im/post/5a9ced09518825555f0c72c7)
262 |
263 | - [秒杀架构设计思路详解](https://blog.csdn.net/qq_35190492/article/details/103105780)
264 |
265 | - **[秒杀关键细节设计](https://blog.csdn.net/fanrenxiang/article/details/85083243)**
266 |
267 | ### 前后端分离
268 |
269 | - [前后端分离概述](https://blog.csdn.net/fuzhongmin05/article/details/81591072)
270 | - [前后端分离之JWT用户认证](https://www.jianshu.com/p/180a870a308a)
271 |
272 | ### 单点登录
273 |
274 | - [什么是单点登录](https://mp.weixin.qq.com/s/J6YJls05t2C4OGOqHVijhw)
275 | - [单点登录机制原理](https://mp.weixin.qq.com/s/LGnUueNC-EuoxiF-8b-TeQ)
276 |
277 | ### 常用框架
278 |
279 | #### Spring
280 |
281 | - [微信支付和支付宝支付到springmvc+spring+mybatis环境全过程(支付宝和微信支付)](https://mp.weixin.qq.com/s/c1GMlpRZNcZdsTUNuG8WUw)
282 |
283 | #### SpringBoot
284 |
285 | - [springboot史上最全教程,11篇文章全解析](https://blog.csdn.net/sihai12345/category_7779682.html)
286 | - [微服务面试相关资料](docs/microservice/微服务相关资料.md)
287 |
288 | ## 分布式
289 |
290 | ### dubbo
291 |
292 | - [dubbo入门实战教程,这篇文章真的再好不过了](https://segmentfault.com/a/1190000019896723)
293 | - [dubbo源码分析](http://cmsblogs.com/?p=5324)
294 | - [dubbo面试题](https://mp.weixin.qq.com/s/PdWRHgm83XwPYP08KnkIsw)
295 | - [dubbo面试题2](https://mp.weixin.qq.com/s/Kz0s9K3J9Lpvh37oP_CtCA)
296 |
297 | ### zookeeper
298 |
299 | - [什么是zookeeper?](https://mp.weixin.qq.com/s/i2_c4A0146B7Ev8QnofbfQ)
300 | - [zookeeeper面试题](https://segmentfault.com/a/1190000014479433)
301 | - [zookeeper面试题2](https://juejin.im/post/5dbac7a0f265da4d2c5e9b3b)
302 |
303 |
304 | ### RocketMQ
305 |
306 | - [RocketMQ简单教程](https://juejin.im/post/5af02571f265da0b9e64fcfd)
307 | - [RocketMQ教程](https://mp.weixin.qq.com/s/VAZaU1DuKbpnaALjp_-9Qw)
308 | - [RocketMQ面试题](https://blog.csdn.net/dingshuo168/article/details/102970988)
309 |
310 | ### RabbitMQ
311 |
312 | - [RabbitMQ教程](https://blog.csdn.net/hellozpc/article/details/81436980)
313 | - [RabbitMQ面试题](https://blog.csdn.net/qq_42629110/article/details/84965084)
314 | - [RabbitMQ面试题2](https://my.oschina.net/u/4162503/blog/3073693)
315 | - [RabbitMQ面试题3](https://blog.csdn.net/jerryDzan/article/details/89183625)
316 |
317 | ### kafka
318 |
319 | - [全网最通俗易懂的Kafka入门](https://mp.weixin.qq.com/s/FlSsrzu1FwjBjmlNy5QyOg)
320 | - [全网最通俗易懂的Kafka入门2](https://mp.weixin.qq.com/s/opAYVXIJoy4tCWaPcX5u6g)
321 | - [kafka入门教程](https://www.orchome.com/kafka/index)
322 | - [kafka面试题](https://blog.csdn.net/qq_28900249/article/details/90346599)
323 | - [kafka面试题2](http://trumandu.github.io/2019/04/13/Kafka%E9%9D%A2%E8%AF%95%E9%A2%98%E4%B8%8E%E7%AD%94%E6%A1%88%E5%85%A8%E5%A5%97%E6%95%B4%E7%90%86/)
324 |
325 | ### 消息中间件
326 |
327 | - [消息中间件面试题总结](docs/project/消息中间件面试题.md)
328 |
329 | ### redis
330 |
331 | - [Redis设计与实现总结文章](https://blog.csdn.net/qq_41594698/category_9067680.html)
332 | - [Redis面试题必备:基础,面试题](https://mp.weixin.qq.com/s/3Fmv7h5p2QDtLxc9n1dp5A)
333 | - [Redis面试相关:其中包含redis知识](https://blog.csdn.net/qq_35190492/article/details/103105780)
334 | - [redis其他数据结构](https://blog.csdn.net/c_royi/article/details/82011208)
335 |
336 | ### 分布式系统
337 |
338 | ## 线上问题调优(虚拟机,tomcat)
339 | - [垃圾收集器ZGC](https://juejin.im/post/5dc361d3f265da4d1f51c670)
340 | - [jvm系列文章](https://crowhawk.github.io/tags/#JVM)
341 | - [一次JVM FullGC的背后,竟隐藏着惊心动魄的线上生产事故!](https://mp.weixin.qq.com/s/5SeGxKtwp6KZhUKn8jXi6A)
342 | - [深入理解Java虚拟机-如何利用JDK自带的命令行工具监控上百万的高并发的虚拟机性能](https://mp.weixin.qq.com/s/wPgA5SDURCAqPsWkZGGX0g)
343 | - [深入理解Java虚拟机-如何利用VisualVM对高并发项目进行性能分析](https://mp.weixin.qq.com/s/hhA9tI_rYNkJVbF-R45hbA)
344 | - [JVM性能调优](https://www.iteye.com/blog/uule-2114697)
345 | - [百亿吞吐量服务的JVM性能调优实战](https://mp.weixin.qq.com/s?__biz=MzIwMzY1OTU1NQ==&mid=2247484236&idx=1&sn=b9743b2d7436f84e4617ff34e07abdd8&chksm=96cd4300a1baca1635a137294bc93c518c033ce01f843c9e012a1454b9f3ea3158fa1412e9da&scene=27&ascene=0&devicetype=android-24&version=26060638&nettype=WIFI&abtest_cookie=BAABAAoACwASABMABAAjlx4AUJkeAFmZHgBomR4AAAA%3D&lang=zh_CN&pass_ticket=%2F%2BLqr9N2EZtrEGLFo9vLA6Eqs89DSJ2CBKoAJFZ%2BBngphEP28dwmMQeSZcUB77qZ&wx_header=1)
346 | - [一次线上JVM调优实践,FullGC40次/天到10天一次的优化过程](https://blog.csdn.net/cml_blog/article/details/81057966)
347 | - [JVM调优工具](https://www.jianshu.com/p/e36fac926539)
348 |
349 |
350 | ## 面试指南
351 |
352 |
353 | ## 工具
354 |
355 | ### Git
356 |
357 | - [实际开发中的git命令大全](https://sihai.blog.csdn.net/article/details/106418135)
358 |
359 | ### Docker
360 |
361 | ## 其他
362 |
363 | ### 权限控制(设计、shiro)
364 |
365 | - [权限控制设计](https://mp.weixin.qq.com/s/WTgz07xDIf9FbAfCDyTheQ)
366 | - [shiro相关教程](https://blog.csdn.net/sihai12345/category_9268544.html)
367 | - [springboot+vue+shiro前后端分离实战项目](https://blog.csdn.net/neuf_soleil/category_9287210.html)
368 | - [shiro挺好的教程](https://how2j.cn/k/shiro/shiro-springboot/1728.html)
369 |
370 | ## Java学习资源
371 |
372 | - [2021年Java视频学习教程+项目实战](https://github.com/hello-go-maker/cs-learn-source)
373 | - [2021 Java 1000G 最新学习资源大汇总](https://mp.weixin.qq.com/s/I0jimqziHqRNaIy0kXRCnw)
374 |
375 |
376 | ## Java书籍推荐
377 |
378 | - [从入门到拿大厂offer,必须看的数据结构与算法书籍推荐](https://blog.csdn.net/sihai12345/article/details/106011624)
379 | - [全网最全电子书下载](https://github.com/hello-go-maker/cs-books)
380 |
381 | ## 实战项目推荐
382 |
383 | >小心翼翼的告诉你,上面的资源当中就有很多**企业级项目**,没有项目一点不用怕,因为你看到了这个。
384 |
385 | - [找工作,没有上的了台面的项目怎么办?](https://mp.weixin.qq.com/s/0oK43_z99pVY9dYVXyIeiw)
386 | - [Java 实战项目推荐](https://github.com/hello-go-maker/cs-learn-source)
387 |
388 | ## 程序人生
389 |
390 | - [我想是时候跟大学告别了](https://blog.csdn.net/sihai12345/article/details/86934341)
391 | - [坚持,这两个字非常重要!](https://blog.csdn.net/sihai12345/article/details/89507366)
392 | - [关于考研,这是我给大家的经验](https://blog.csdn.net/sihai12345/article/details/88548630)
393 | - [从普通二本到研究生再到自媒体的年轻人,这是我的故事](https://segmentfault.com/a/1190000020317748)
394 |
395 | ## 说明
396 |
397 | ### JavaInterview介绍
398 |
399 | 目的很简单,写这些文章,以及整个github的资料,都是为了面试而准备的,只希望能够给面试提供一些帮助,都能够进大厂最好了。
400 |
401 | ### 关于转载
402 |
403 | 如果你需要转载本仓库的一些文章到自己的博客的话,记得注明原文地址就可以了。
404 |
405 | ### 如何对该开源文档进行贡献
406 |
407 | 1. 里面很多都是我的原创,能力有限,欢迎指正。
408 | 2. 很多知识点我可能没有涉及到,所以你可以对其他知识点进行补充。
409 | 3. 现有的知识点难免存在不完善或者错误,所以你可以对已有知识点进行修改/补充。
410 |
411 | ### 为什么要做这个开源文档?
412 |
413 | 初始想法源于自己的个人那一段比较迷茫的学习经历。主要目的是为了通过这个开源平台来帮助一些在学习 Java 或者面试过程中遇到问题的小伙伴。
414 |
415 | ### 投稿
416 |
417 | 由于我个人能力有限,很多知识点我可能没有涉及到,所以你可以对其他知识点进行补充。
418 |
419 | ### 联系我
420 |
421 | 添加我的微信备注 **github**, 即可入群。
422 |
423 |  424 |
425 | ### 公众号
426 |
427 | 如果大家想要实时关注我更新的文章以及分享的干货的话,关注我的公众号 **程序员的技术圈子**。
428 |
429 |
430 |
431 |
432 |
--------------------------------------------------------------------------------
424 |
425 | ### 公众号
426 |
427 | 如果大家想要实时关注我更新的文章以及分享的干货的话,关注我的公众号 **程序员的技术圈子**。
428 |
429 |
430 |
431 |
432 |
--------------------------------------------------------------------------------