46 |
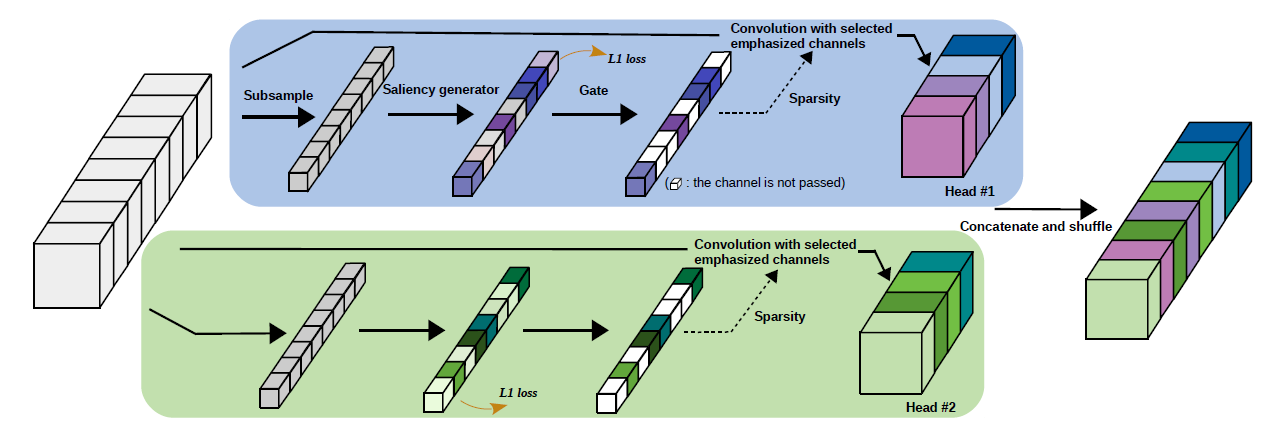
47 | Figure 1: Overview of a DGC layer.
48 |
