├── requirements.txt
├── .ipynb_checkpoints
└── Untitled-checkpoint.ipynb
├── __pycache__
├── BitFlipEnv.cpython-38.pyc
└── DeepQNetwork.cpython-38.pyc
├── results and plots
├── ddpg_with_her_plots
│ ├── actor3
│ ├── critic3
│ ├── target_actor3
│ ├── target_critic3
│ ├── episode_plot.png
│ └── plot_with_avg.png
├── dqn_with_her_plots
│ ├── q_eval_with_her
│ ├── q_next_with_her
│ └── dqn_plot_with_her.png
└── dqn_without_her_plots
│ ├── q_eval_without_her
│ ├── q_next_without_her
│ └── dqn_plot_without_her.png
├── ddpg_with_her
├── __pycache__
│ ├── OUNoise.cpython-38.pyc
│ ├── ActorCritic.cpython-38.pyc
│ ├── DDPGAgent.cpython-38.pyc
│ └── ContinuousEnv.cpython-38.pyc
├── OUNoise.py
├── ContinuousEnv.py
├── ActorCritic.py
├── DDPG_HER_main.py
└── DDPGAgent.py
├── dqn_with_her
├── __pycache__
│ ├── HERMemory.cpython-38.pyc
│ └── DQNAgentWithHER.cpython-38.pyc
├── HERMemory.py
├── HERmain.py
└── DQNAgentWithHER.py
├── .gitignore
├── BitFlipEnv.py
├── DeepQNetwork.py
├── dqn_without_her
├── ExperienceReplayMemory.py
├── main.py
└── DQNAgent.py
└── README.md
/requirements.txt:
--------------------------------------------------------------------------------
1 | numpy==1.18.5
2 | opencv-python==4.4.0.42
3 | matplotlib==3.2.2
4 | gym==0.17.2
5 | torch==1.6.0
6 |
--------------------------------------------------------------------------------
/.ipynb_checkpoints/Untitled-checkpoint.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [],
3 | "metadata": {},
4 | "nbformat": 4,
5 | "nbformat_minor": 4
6 | }
7 |
--------------------------------------------------------------------------------
/__pycache__/BitFlipEnv.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/__pycache__/BitFlipEnv.cpython-38.pyc
--------------------------------------------------------------------------------
/__pycache__/DeepQNetwork.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/__pycache__/DeepQNetwork.cpython-38.pyc
--------------------------------------------------------------------------------
/results and plots/ddpg_with_her_plots/actor3:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/results and plots/ddpg_with_her_plots/actor3
--------------------------------------------------------------------------------
/results and plots/ddpg_with_her_plots/critic3:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/results and plots/ddpg_with_her_plots/critic3
--------------------------------------------------------------------------------
/ddpg_with_her/__pycache__/OUNoise.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/ddpg_with_her/__pycache__/OUNoise.cpython-38.pyc
--------------------------------------------------------------------------------
/dqn_with_her/__pycache__/HERMemory.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/dqn_with_her/__pycache__/HERMemory.cpython-38.pyc
--------------------------------------------------------------------------------
/ddpg_with_her/__pycache__/ActorCritic.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/ddpg_with_her/__pycache__/ActorCritic.cpython-38.pyc
--------------------------------------------------------------------------------
/ddpg_with_her/__pycache__/DDPGAgent.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/ddpg_with_her/__pycache__/DDPGAgent.cpython-38.pyc
--------------------------------------------------------------------------------
/results and plots/ddpg_with_her_plots/target_actor3:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/results and plots/ddpg_with_her_plots/target_actor3
--------------------------------------------------------------------------------
/results and plots/ddpg_with_her_plots/target_critic3:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/results and plots/ddpg_with_her_plots/target_critic3
--------------------------------------------------------------------------------
/results and plots/dqn_with_her_plots/q_eval_with_her:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/results and plots/dqn_with_her_plots/q_eval_with_her
--------------------------------------------------------------------------------
/results and plots/dqn_with_her_plots/q_next_with_her:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/results and plots/dqn_with_her_plots/q_next_with_her
--------------------------------------------------------------------------------
/ddpg_with_her/__pycache__/ContinuousEnv.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/ddpg_with_her/__pycache__/ContinuousEnv.cpython-38.pyc
--------------------------------------------------------------------------------
/results and plots/ddpg_with_her_plots/episode_plot.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/results and plots/ddpg_with_her_plots/episode_plot.png
--------------------------------------------------------------------------------
/dqn_with_her/__pycache__/DQNAgentWithHER.cpython-38.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/dqn_with_her/__pycache__/DQNAgentWithHER.cpython-38.pyc
--------------------------------------------------------------------------------
/results and plots/ddpg_with_her_plots/plot_with_avg.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/results and plots/ddpg_with_her_plots/plot_with_avg.png
--------------------------------------------------------------------------------
/results and plots/dqn_with_her_plots/dqn_plot_with_her.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/results and plots/dqn_with_her_plots/dqn_plot_with_her.png
--------------------------------------------------------------------------------
/results and plots/dqn_without_her_plots/q_eval_without_her:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/results and plots/dqn_without_her_plots/q_eval_without_her
--------------------------------------------------------------------------------
/results and plots/dqn_without_her_plots/q_next_without_her:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/results and plots/dqn_without_her_plots/q_next_without_her
--------------------------------------------------------------------------------
/results and plots/dqn_without_her_plots/dqn_plot_without_her.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hemilpanchiwala/Hindsight-Experience-Replay/HEAD/results and plots/dqn_without_her_plots/dqn_plot_without_her.png
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # IntelliJ
2 | .idea/
3 |
4 | # pyenv
5 | .python-version
6 |
7 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
8 | __pypackages__/
9 |
10 | # Environments
11 | .env
12 | .venv
13 | env/
14 | venv/
15 | ENV/
16 |
--------------------------------------------------------------------------------
/ddpg_with_her/OUNoise.py:
--------------------------------------------------------------------------------
1 | # This implementation is taken from https://github.com/openai/baselines/blob/master/baselines/ddpg/noise.py
2 | import numpy as np
3 |
4 |
5 | class OrnsteinUhlenbeckActionNoise:
6 | def __init__(self, mu, sigma=0.2, theta=.15, dt=1e-2, x0=None):
7 | self.theta = theta
8 | self.mu = mu
9 | self.sigma = sigma
10 | self.dt = dt
11 | self.x0 = x0
12 | self.reset()
13 |
14 | def __call__(self):
15 | x = self.x_prev + self.theta * (self.mu - self.x_prev) * self.dt + self.sigma * np.sqrt(
16 | self.dt) * np.random.normal(size=self.mu.shape)
17 | self.x_prev = x
18 | return x
19 |
20 | def reset(self):
21 | self.x_prev = self.x0 if self.x0 is not None else np.zeros_like(self.mu)
22 |
23 | def __repr__(self):
24 | return 'OrnsteinUhlenbeckActionNoise(mu={}, sigma={})'.format(self.mu, self.sigma)
25 |
--------------------------------------------------------------------------------
/BitFlipEnv.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 |
4 | class BitFlipEnv:
5 | """
6 | A simple bit flip environment
7 | Bit of the current state flips as an action
8 | Reward of -1 for each step
9 | """
10 | def __init__(self, n_bits):
11 | self.n_bits = n_bits
12 | self.state = np.random.randint(2, size=self.n_bits)
13 | self.goal = np.random.randint(2, size=self.n_bits)
14 |
15 | def reset_env(self):
16 | """
17 | Resets the environment with new state and goal
18 | """
19 | self.state = np.random.randint(2, size=self.n_bits)
20 | self.goal = np.random.randint(2, size=self.n_bits)
21 |
22 | def take_step(self, action):
23 | """
24 | Returns updated_state, reward, and done for the step taken
25 | """
26 | self.state[action] = self.state[action] ^ 1
27 | done = False
28 | if np.array_equal(self.state, self.goal):
29 | done = True
30 | reward = 0
31 | else:
32 | reward = -1
33 | return np.copy(self.state), reward, done
34 |
35 | def print_state(self):
36 | """
37 | Prints the current state
38 | """
39 | print('Current State:', self.state)
40 |
--------------------------------------------------------------------------------
/ddpg_with_her/ContinuousEnv.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 |
4 | class ContinuousEnv:
5 | """
6 | A continuous environment
7 | A state is defined as a numpy array of size 2 with random values
8 | """
9 | def __init__(self, size):
10 | self.size = size
11 | self.state = size * (2 * np.random.random(2) - 1)
12 | self.goal = size * (2 * np.random.random(2) - 1)
13 | self.threshold = 0.5
14 |
15 | def reset_env(self):
16 | """
17 | Resets the environment with new state and goal
18 | """
19 | self.state = self.size * (2 * np.random.random(2) - 1)
20 | self.goal = self.size * (2 * np.random.random(2) - 1)
21 |
22 | def take_step(self, action):
23 | """
24 | Returns updated_state, reward, and done for the step taken
25 | """
26 | self.state += (action / 4)
27 | good_done = np.linalg.norm(self.goal) <= self.threshold
28 | bad_done = np.max(np.abs(self.state)) > self.size
29 | if good_done:
30 | reward = 0
31 | else:
32 | reward = -1
33 | return np.copy(self.state / self.size), reward, good_done or bad_done
34 |
35 | def print_state(self):
36 | """
37 | Prints the current state
38 | """
39 | print('Current State:', self.state)
40 |
--------------------------------------------------------------------------------
/DeepQNetwork.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import torch
4 | import torch.nn as nn
5 | import torch.nn.functional as F
6 | import torch.optim as optim
7 |
8 |
9 | class DeepQNetwork(nn.Module):
10 | """
11 | Defines a deep Q network with a single hidden layer
12 | """
13 | def __init__(self, learning_rate, n_actions, input_dims, checkpoint_dir, name):
14 | super(DeepQNetwork, self).__init__()
15 |
16 | self.fc1 = nn.Linear(input_dims, 512)
17 | self.fc2 = nn.Linear(512, 256)
18 | self.fc3 = nn.Linear(256, n_actions)
19 |
20 | self.optimizer = optim.RMSprop(self.parameters(), lr=learning_rate)
21 | self.loss = nn.MSELoss()
22 |
23 | self.device_type = 'cuda:0' if torch.cuda.is_available() else 'cpu'
24 | self.device = torch.device(self.device_type)
25 | self.to(self.device)
26 |
27 | self.checkpoint_dir = checkpoint_dir
28 | self.checkpoint_name = os.path.join(checkpoint_dir, name)
29 |
30 | def forward(self, data):
31 | fc_layer1 = F.relu(self.fc1(data))
32 | fc_layer2 = F.relu(self.fc2(fc_layer1))
33 | actions = self.fc3(fc_layer2)
34 |
35 | return actions
36 |
37 | def save_checkpoint(self):
38 | print('Saving checkpoint ...')
39 | torch.save(self.state_dict(), self.checkpoint_name)
40 |
41 | def load_checkpoint(self):
42 | print('Loading checkpoint ...')
43 | self.load_state_dict(torch.load(self.checkpoint_name))
44 |
45 |
46 |
--------------------------------------------------------------------------------
/dqn_without_her/ExperienceReplayMemory.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 |
4 | class ExperienceReplayMemory(object):
5 | def __init__(self, memory_size, input_dims):
6 | super(ExperienceReplayMemory, self).__init__()
7 | self.max_mem_size = memory_size
8 | self.counter = 0
9 |
10 | # initializes the state, next_state, action, reward, and terminal experience memory
11 | print(type(input_dims))
12 | self.state_memory = np.zeros((memory_size, input_dims), dtype=np.float32)
13 | self.next_state_memory = np.zeros((memory_size, input_dims), dtype=np.float32)
14 | self.reward_memory = np.zeros(memory_size, dtype=np.float32)
15 | self.action_memory = np.zeros(memory_size, dtype=np.int64)
16 | self.terminal_memory = np.zeros(memory_size, dtype=bool)
17 |
18 | def add_experience(self, state, action, reward, next_state, done):
19 | """
20 | Adds new experience to the memory.
21 | """
22 | curr_index = self.counter % self.max_mem_size
23 |
24 | self.state_memory[curr_index] = state
25 | self.action_memory[curr_index] = action
26 | self.reward_memory[curr_index] = reward
27 | self.next_state_memory[curr_index] = next_state
28 | self.terminal_memory[curr_index] = done
29 |
30 | self.counter += 1
31 |
32 | def get_random_experience(self, batch_size):
33 | """
34 | Returns any random memory from the experience replay memory.
35 | """
36 | rand_index = np.random.choice(min(self.counter, self.max_mem_size), batch_size)
37 |
38 | rand_state = self.state_memory[rand_index]
39 | rand_action = self.action_memory[rand_index]
40 | rand_reward = self.reward_memory[rand_index]
41 | rand_next_state = self.next_state_memory[rand_index]
42 | rand_done = self.terminal_memory[rand_index]
43 |
44 | return rand_state, rand_action, rand_reward, rand_next_state, rand_done
45 |
--------------------------------------------------------------------------------
/dqn_with_her/HERMemory.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 |
4 | class HindsightExperienceReplayMemory(object):
5 | """
6 | Hindsight Experience replay - Takes size, input dimensions and number of actions as parameters
7 | """
8 | def __init__(self, memory_size, input_dims, n_actions):
9 | super(HindsightExperienceReplayMemory, self).__init__()
10 | self.max_mem_size = memory_size
11 | self.counter = 0
12 |
13 | # initializes the state, next_state, action, reward, and terminal experience memory
14 | self.state_memory = np.zeros((memory_size, input_dims), dtype=np.float32)
15 | self.next_state_memory = np.zeros((memory_size, input_dims), dtype=np.float32)
16 | self.reward_memory = np.zeros(memory_size, dtype=np.float32)
17 | self.action_memory = np.zeros(memory_size, dtype=np.int64)
18 | self.terminal_memory = np.zeros(memory_size, dtype=bool)
19 | self.goal_memory = np.zeros((memory_size, input_dims), dtype=np.float32)
20 |
21 | def add_experience(self, state, action, reward, next_state, done, goal):
22 | """
23 | Adds new experience to the memory
24 | """
25 | curr_index = self.counter % self.max_mem_size
26 |
27 | self.state_memory[curr_index] = state
28 | self.action_memory[curr_index] = action
29 | self.reward_memory[curr_index] = reward
30 | self.next_state_memory[curr_index] = next_state
31 | self.terminal_memory[curr_index] = done
32 | self.goal_memory[curr_index] = goal
33 |
34 | self.counter += 1
35 |
36 | def get_random_experience(self, batch_size):
37 | """
38 | Returns any random memory from the experience replay memory
39 | """
40 | rand_index = np.random.choice(min(self.counter, self.max_mem_size), batch_size, replace=False)
41 |
42 | rand_state = self.state_memory[rand_index]
43 | rand_action = self.action_memory[rand_index]
44 | rand_reward = self.reward_memory[rand_index]
45 | rand_next_state = self.next_state_memory[rand_index]
46 | rand_done = self.terminal_memory[rand_index]
47 | rand_goal = self.goal_memory[rand_index]
48 |
49 | return rand_state, rand_action, rand_reward, rand_next_state, rand_done, rand_goal
50 |
--------------------------------------------------------------------------------
/dqn_without_her/main.py:
--------------------------------------------------------------------------------
1 | import os
2 | import matplotlib.pyplot as plt
3 |
4 | import BitFlipEnv as bflip
5 | from dqn_without_her import DQNAgent as dqn
6 |
7 | if __name__ == '__main__':
8 |
9 | n_bits = 8
10 | env = bflip.BitFlipEnv(n_bits)
11 |
12 | n_episodes = 30000
13 | epsilon_history = []
14 | episodes = []
15 | win_percent = []
16 | success = 0
17 |
18 | load_checkpoint = False
19 |
20 | checkpoint_dir = os.path.join(os.getcwd(), '/checkpoint/')
21 |
22 | # Initializes the DQN agent with simple experience replay
23 | agent = dqn.DQNAgent(learning_rate=0.0001, n_actions=n_bits,
24 | input_dims=n_bits, gamma=0.99,
25 | epsilon=0.9, batch_size=64, memory_size=10000,
26 | replace_network_count=50,
27 | checkpoint_dir=checkpoint_dir)
28 |
29 | if load_checkpoint:
30 | agent.load_model()
31 |
32 | # Iterate through the episodes
33 | for episode in range(n_episodes):
34 | env.reset_env()
35 | state = env.state
36 | goal = env.goal
37 | done = False
38 |
39 | for p in range(n_bits):
40 | if not done:
41 | action = agent.choose_action(state)
42 | next_state, reward, done = env.take_step(action)
43 | if not load_checkpoint:
44 | agent.store_experience(state, action, reward, next_state, done)
45 | agent.learn()
46 | state = next_state
47 |
48 | if done:
49 | success += 1
50 |
51 | # Average over last 500 episodes to avoid spikes
52 | if episode % 500 == 0:
53 | print('success rate for last 500 episodes after', episode, ':', success/5)
54 | if len(win_percent) > 0 and (success / 500) > win_percent[len(win_percent) - 1]:
55 | agent.save_model()
56 | epsilon_history.append(agent.epsilon)
57 | episodes.append(episode)
58 | win_percent.append(success/500.0)
59 | success = 0
60 |
61 | print('Epsilon History:', epsilon_history)
62 | print('Episodes:', episodes)
63 | print('Win percentage:', win_percent)
64 |
65 | figure = plt.figure()
66 | plt.plot(episodes, win_percent)
67 |
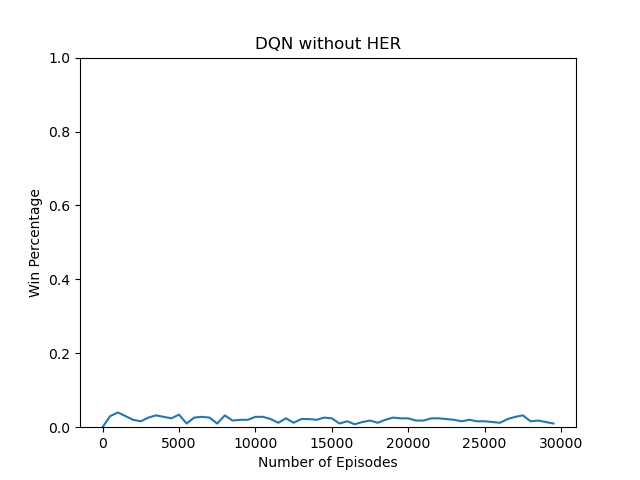
68 | plt.title('DQN without HER')
69 | plt.ylabel('Win Percentage')
70 | plt.xlabel('Number of Episodes')
71 | plt.ylim([0, 1])
72 |
73 | plt.savefig(plt.savefig(os.path.join(os.getcwd(), '/plots/')))
74 |
--------------------------------------------------------------------------------
/ddpg_with_her/ActorCritic.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import torch
4 | import torch.nn as nn
5 | import torch.nn.functional as F
6 | import torch.optim as optim
7 |
8 |
9 | class Actor(nn.Module):
10 | """
11 | Defines a neural network for the actor (that derives the actions)
12 | """
13 | def __init__(self, input_dims, n_actions, learning_rate, checkpoint_dir, name):
14 | super(Actor, self).__init__()
15 |
16 | self.input = input_dims
17 | self.fc1 = nn.Linear(2*input_dims, 512)
18 | self.fc2 = nn.Linear(512, 256)
19 | self.fc3 = nn.Linear(256, n_actions)
20 |
21 | self.optimizer = optim.RMSprop(self.parameters(), lr=learning_rate)
22 | self.loss = nn.MSELoss()
23 |
24 | self.device_type = 'cuda:0' if torch.cuda.is_available() else 'cpu'
25 | self.device = torch.device(self.device_type)
26 | self.to(self.device)
27 |
28 | self.checkpoint_dir = checkpoint_dir
29 | self.checkpoint_name = os.path.join(checkpoint_dir, name)
30 |
31 | def forward(self, data):
32 | fc_layer1 = F.relu(self.fc1(data))
33 | fc_layer2 = F.relu(self.fc2(fc_layer1))
34 | actions = self.fc3(fc_layer2)
35 |
36 | return actions
37 |
38 | def save_checkpoint(self):
39 | print('Saving checkpoint ...')
40 | torch.save(self.state_dict(), self.checkpoint_name)
41 |
42 | def load_checkpoint(self):
43 | print('Loading checkpoint ...')
44 | self.load_state_dict(torch.load(self.checkpoint_name))
45 |
46 |
47 | class Critic(nn.Module):
48 | """
49 | Defines a neural network for the critic (that derives the value)
50 | """
51 | def __init__(self, input_dims, n_actions, learning_rate, checkpoint_dir, name):
52 | super(Critic, self).__init__()
53 |
54 | self.fc1 = nn.Linear(2*input_dims + n_actions, 512)
55 | self.fc2 = nn.Linear(512, 256)
56 | self.fc3 = nn.Linear(256, 1)
57 |
58 | self.optimizer = optim.RMSprop(self.parameters(), lr=learning_rate)
59 | self.loss = nn.MSELoss()
60 |
61 | self.device_type = 'cuda:0' if torch.cuda.is_available() else 'cpu'
62 | self.device = torch.device(self.device_type)
63 | self.to(self.device)
64 |
65 | self.checkpoint_dir = checkpoint_dir
66 | self.checkpoint_name = os.path.join(checkpoint_dir, name)
67 |
68 | def forward(self, data1, data2):
69 | fc_layer1 = F.relu(self.fc1(torch.cat((data1, data2), 1)))
70 | fc_layer2 = F.relu(self.fc2(fc_layer1))
71 | value = self.fc3(fc_layer2)
72 |
73 | return value
74 |
75 | def save_checkpoint(self):
76 | print('Saving checkpoint ...')
77 | torch.save(self.state_dict(), self.checkpoint_name)
78 |
79 | def load_checkpoint(self):
80 | print('Loading checkpoint ...')
81 | self.load_state_dict(torch.load(self.checkpoint_name))
82 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Hindsight-Experience-Replay
2 |
3 | This repository provides the Pytorch implementation of Hindsight Experience Replay on Deep Q Network and Deep Deterministic Policy Gradient algorithms.
4 |
5 | Link to the paper: https://arxiv.org/pdf/1707.01495.pdf
6 |
7 | Authors: Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, Pieter Abbeel, Wojciech Zaremba
8 |
9 | ## Training
10 |
11 | - You can train the model simply by running the main.py files.
12 | DQN With HER -> HERmain.py
13 | DDPG With HER -> DDPG_HER_main.py
14 | DQN Without HER -> main.py
15 |
16 | - You can set the hyper-parameters such as learning_rate, discount factor (gamma), epsilon, and others while initializing the agent variable in the above-mentioned files
17 |
18 | ## Running the pre-trained model
19 |
20 |
21 | - Just run the files mentioned in the Training section with making the load_checkpoint variable to True which will load the saved parameters of the model and output the results. Just update the paths as per the saved results path.
22 |
23 | ## Results
24 |
25 |
47 |
48 | ## References
49 | - [Continuous Control With Deep Reinforcement Learning paper](https://arxiv.org/pdf/1509.02971.pdf)
50 | - [Reinforcement Learning with Hindsight Experience Replay blog](https://towardsdatascience.com/reinforcement-learning-with-hindsight-experience-replay-1fee5704f2f8)
51 | - [OpenAI Spinning Up](https://spinningup.openai.com/en/latest/index.html)
52 | - [HER implementation in tensorflow](https://github.com/kwea123/hindsight_experience_replay)
53 | - [OpenAI baselines](https://github.com/openai/baselines/tree/master/baselines/ddpg)
54 |
--------------------------------------------------------------------------------
/ddpg_with_her/DDPG_HER_main.py:
--------------------------------------------------------------------------------
1 | import os
2 | import matplotlib.pyplot as plt
3 | import numpy as np
4 |
5 | from ddpg_with_her import DDPGAgent, ContinuousEnv as cenv
6 |
7 | if __name__ == '__main__':
8 | size = 5
9 | env = cenv.ContinuousEnv(size=size)
10 |
11 | n_episodes = 10000
12 | print(n_episodes)
13 | episodes = []
14 | win_percent = []
15 | success = 0
16 |
17 | load_checkpoint = False
18 |
19 | checkpoint_dir = os.path.join(os.getcwd(), '/checkpoint/')
20 |
21 | # Initializes the DDPG agent
22 | agent = DDPGAgent.DDPGAgent(actor_learning_rate=0.0001, critic_learning_rate=0.001, n_actions=2,
23 | input_dims=2, gamma=0.99,
24 | memory_size=10000, batch_size=64,
25 | checkpoint_dir=checkpoint_dir)
26 |
27 | if load_checkpoint:
28 | agent.load_model()
29 |
30 | # Iterate through the episodes
31 | for episode in range(n_episodes):
32 | env.reset_env()
33 | state = env.state
34 | goal = env.goal
35 | done = False
36 | transitions = []
37 |
38 | for p in range(10):
39 | if not done:
40 | action = agent.choose_action(state, goal)
41 | next_state, reward, done = env.take_step(action)
42 | if not load_checkpoint:
43 | agent.store_experience(state, action, reward, next_state, done, goal)
44 | transitions.append((state, action, reward, next_state))
45 | agent.learn()
46 | state = next_state
47 |
48 | if done:
49 | success += 1
50 |
51 | if not done:
52 | new_goal = np.copy(state)
53 | if not np.array_equal(new_goal, goal):
54 | for q in range(4):
55 | transition = transitions[q]
56 | good_done = np.linalg.norm(new_goal) <= 0.5
57 | bad_done = np.max(np.abs(transition[3])) > size
58 | if good_done or bad_done:
59 | agent.store_experience(transition[0], transition[1], transition[2],
60 | transition[3], True, new_goal)
61 | agent.learn()
62 | break
63 |
64 | agent.store_experience(transition[0], transition[1], transition[2],
65 | transition[3], False, new_goal)
66 | agent.learn()
67 |
68 | # Average over last 100 episodes to avoid spikes
69 | if episode > 0 and episode % 100 == 0:
70 | print('success rate for last 100 episodes after', episode, ':', success)
71 | if len(win_percent) > 0 and (success / 100) > win_percent[len(win_percent) - 1]:
72 | agent.save_model()
73 | episodes.append(episode)
74 | win_percent.append(success / 100)
75 | success = 0
76 |
77 | print('Episodes:', episodes)
78 | print('Win percentage:', win_percent)
79 |
80 | figure = plt.figure()
81 | plt.plot(episodes, win_percent)
82 |
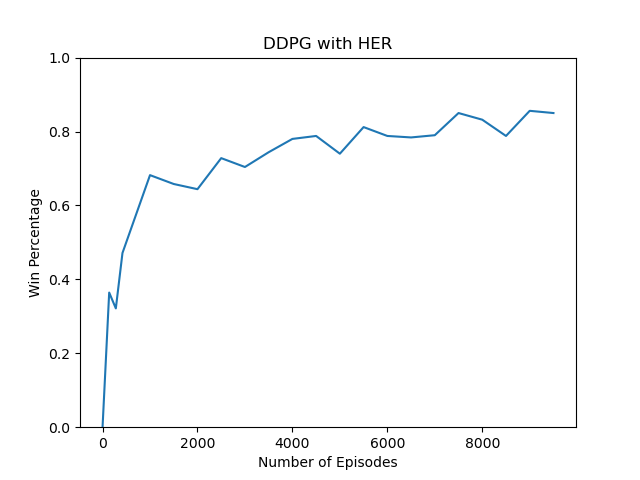
83 | plt.title('DDPG with HER')
84 | plt.ylabel('Win Percentage')
85 | plt.xlabel('Number of Episodes')
86 | plt.ylim([0, 1])
87 |
88 | plt.savefig(os.path.join(os.getcwd(), '/plots/'))
89 |
--------------------------------------------------------------------------------
/dqn_with_her/HERmain.py:
--------------------------------------------------------------------------------
1 | import os
2 | import matplotlib.pyplot as plt
3 | import numpy as np
4 |
5 | import BitFlipEnv as bflip
6 | from dqn_with_her import DQNAgentWithHER as dqnHER
7 |
8 | if __name__ == '__main__':
9 |
10 | n_bits = 8
11 | env = bflip.BitFlipEnv(n_bits)
12 |
13 | n_episodes = 30000
14 | epsilon_history = []
15 | episodes = []
16 | win_percent = []
17 | success = 0
18 |
19 | load_checkpoint = False
20 |
21 | checkpoint_dir = os.path.join(os.getcwd(), '/checkpoint/')
22 |
23 | # Initializes the DQN agent with Hindsight Experience Replay
24 | agent = dqnHER.DQNAgentWithHER(learning_rate=0.0001, n_actions=n_bits,
25 | input_dims=n_bits, gamma=0.99,
26 | epsilon=0.9, batch_size=64, memory_size=10000,
27 | replace_network_count=50,
28 | checkpoint_dir=checkpoint_dir)
29 |
30 | if load_checkpoint:
31 | agent.load_model()
32 |
33 | # Iterate through the episodes
34 | for episode in range(n_episodes):
35 | env.reset_env()
36 | state = env.state
37 | goal = env.goal
38 | done = False
39 | transitions = []
40 |
41 | for p in range(n_bits):
42 | if not done:
43 | action = agent.choose_action(state, goal)
44 | next_state, reward, done = env.take_step(action)
45 | if not load_checkpoint:
46 | agent.store_experience(state, action, reward, next_state, done, goal)
47 | transitions.append((state, action, reward, next_state))
48 | agent.learn()
49 | state = next_state
50 |
51 | if done:
52 | success += 1
53 |
54 | if not done:
55 | new_goal = np.copy(state)
56 | if not np.array_equal(new_goal, goal):
57 | for p in range(n_bits):
58 | transition = transitions[p]
59 | if np.array_equal(transition[3], new_goal):
60 | agent.store_experience(transition[0], transition[1], 0.0,
61 | transition[3], True, new_goal)
62 | agent.learn()
63 | break
64 |
65 | agent.store_experience(transition[0], transition[1], transition[2],
66 | transition[3], False, new_goal)
67 | agent.learn()
68 |
69 | # Average over last 500 episodes to avoid spikes
70 | if episode % 500 == 0:
71 | print('success rate for last 500 episodes after', episode, ':', success / 5)
72 | if len(win_percent) > 0 and (success / 500) > win_percent[len(win_percent) - 1]:
73 | agent.save_model()
74 | epsilon_history.append(agent.epsilon)
75 | episodes.append(episode)
76 | win_percent.append(success / 500.0)
77 | success = 0
78 |
79 | print('Epsilon History:', epsilon_history)
80 | print('Episodes:', episodes)
81 | print('Win percentage:', win_percent)
82 |
83 | figure = plt.figure()
84 | plt.plot(episodes, win_percent)
85 |
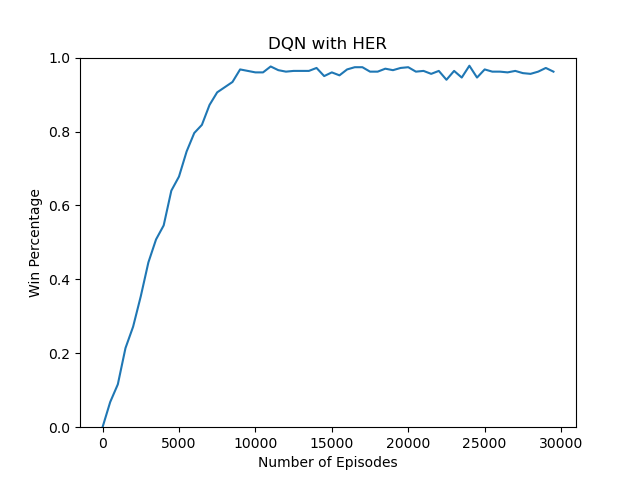
86 | plt.title('DQN with HER')
87 | plt.ylabel('Win Percentage')
88 | plt.xlabel('Number of Episodes')
89 | plt.ylim([0, 1])
90 |
91 | plt.savefig(os.path.join(os.getcwd(), '/plots/'))
92 |
--------------------------------------------------------------------------------
/dqn_without_her/DQNAgent.py:
--------------------------------------------------------------------------------
1 | import DeepQNetwork as dqn
2 | from dqn_without_her import ExperienceReplayMemory as erm
3 |
4 | import numpy as np
5 | import torch
6 |
7 |
8 | class DQNAgent(object):
9 | def __init__(self, learning_rate, n_actions, input_dims, gamma,
10 | epsilon, batch_size, memory_size, replace_network_count,
11 | dec_epsilon=1e-5, min_epsilon=0.1, checkpoint_dir='/tmp/ddqn/'):
12 | self.learning_rate = learning_rate
13 | self.n_actions = n_actions
14 | self.input_dims = input_dims
15 | self.gamma = gamma
16 | self.epsilon = epsilon
17 | self.batch_size = batch_size
18 | self.memory_size = memory_size
19 | self.replace_network_count = replace_network_count
20 | self.dec_epsilon = dec_epsilon
21 | self.min_epsilon = min_epsilon
22 | self.checkpoint_dir = checkpoint_dir
23 | self.action_indices = [i for i in range(n_actions)]
24 | self.learn_steps_count = 0
25 |
26 | self.q_eval = dqn.DeepQNetwork(learning_rate=learning_rate, n_actions=n_actions,
27 | input_dims=input_dims, name='q_eval',
28 | checkpoint_dir=checkpoint_dir)
29 |
30 | self.q_next = dqn.DeepQNetwork(learning_rate=learning_rate, n_actions=n_actions,
31 | input_dims=input_dims, name='q_next',
32 | checkpoint_dir=checkpoint_dir)
33 |
34 | self.experience_replay_memory = erm.ExperienceReplayMemory(memory_size=memory_size,
35 | input_dims=input_dims)
36 |
37 | def decrement_epsilon(self):
38 | """
39 | Decrements the epsilon after each step till it reaches minimum epsilon (0.1)
40 | epsilon = epsilon - decrement (default is 1e-5)
41 | """
42 | self.epsilon = self.epsilon - self.dec_epsilon if self.epsilon > self.min_epsilon \
43 | else self.min_epsilon
44 |
45 | def store_experience(self, state, action, reward, next_state, done):
46 | """
47 | Saves the experience to the replay memory
48 | """
49 | self.experience_replay_memory.add_experience(state=state, action=action,
50 | reward=reward, next_state=next_state,
51 | done=done)
52 |
53 | def get_sample_experience(self):
54 | """
55 | Gives a sample experience from the experience replay memory
56 | """
57 | state, action, reward, next_state, done = self.experience_replay_memory.get_random_experience(
58 | self.batch_size)
59 |
60 | t_state = torch.tensor(state).to(self.q_eval.device)
61 | t_action = torch.tensor(action).to(self.q_eval.device)
62 | t_reward = torch.tensor(reward).to(self.q_eval.device)
63 | t_next_state = torch.tensor(next_state).to(self.q_eval.device)
64 | t_done = torch.tensor(done).to(self.q_eval.device)
65 |
66 | return t_state, t_action, t_reward, t_next_state, t_done
67 |
68 | def replace_target_network(self):
69 | """
70 | Updates the parameters after replace_network_count steps
71 | """
72 | if self.learn_steps_count % self.replace_network_count == 0:
73 | self.q_next.load_state_dict(self.q_eval.state_dict())
74 |
75 | def choose_action(self, observation):
76 | """
77 | Chooses an action with epsilon-greedy method
78 | """
79 | if np.random.random() > self.epsilon:
80 | state = torch.tensor([observation], dtype=torch.float).to(self.q_eval.device)
81 | actions = self.q_eval.forward(state)
82 |
83 | action = torch.argmax(actions).item()
84 | else:
85 | action = np.random.choice(self.n_actions)
86 |
87 | return action
88 |
89 | def learn(self):
90 | if self.experience_replay_memory.counter < self.batch_size:
91 | return
92 |
93 | self.q_eval.optimizer.zero_grad()
94 | self.replace_target_network()
95 |
96 | state, action, reward, next_state, done = self.get_sample_experience()
97 | # Gets the evenly spaced batches
98 | batches = np.arange(self.batch_size)
99 |
100 | q_pred = self.q_eval.forward(state)[batches, action]
101 | q_next = self.q_next.forward(next_state).max(dim=1)[0]
102 |
103 | q_next[done] = 0.0
104 | q_target = reward + self.gamma * q_next
105 |
106 | # Computes loss and performs backpropagation
107 | loss = self.q_eval.loss(q_target, q_pred).to(self.q_eval.device)
108 | loss.backward()
109 |
110 | self.q_eval.optimizer.step()
111 | self.decrement_epsilon()
112 | self.learn_steps_count += 1
113 |
114 | def save_model(self):
115 | """
116 | Saves the values of q_eval and q_next at the checkpoint
117 | """
118 | self.q_eval.save_checkpoint()
119 | self.q_next.save_checkpoint()
120 |
121 | def load_model(self):
122 | """
123 | Loads the values of q_eval and q_next at the checkpoint
124 | """
125 | self.q_eval.load_checkpoint()
126 | self.q_next.load_checkpoint()
127 |
--------------------------------------------------------------------------------
/dqn_with_her/DQNAgentWithHER.py:
--------------------------------------------------------------------------------
1 | import DeepQNetwork as dqn
2 | from dqn_with_her import HERMemory as her
3 |
4 | import numpy as np
5 | import torch
6 |
7 |
8 | class DQNAgentWithHER(object):
9 | def __init__(self, learning_rate, n_actions, input_dims, gamma,
10 | epsilon, batch_size, memory_size, replace_network_count,
11 | dec_epsilon=1e-5, min_epsilon=0.1, checkpoint_dir='/tmp/ddqn/'):
12 | self.learning_rate = learning_rate
13 | self.n_actions = n_actions
14 | self.input_dims = input_dims
15 | self.gamma = gamma
16 | self.epsilon = epsilon
17 | self.batch_size = batch_size
18 | self.memory_size = memory_size
19 | self.replace_network_count = replace_network_count
20 | self.dec_epsilon = dec_epsilon
21 | self.min_epsilon = min_epsilon
22 | self.checkpoint_dir = checkpoint_dir
23 | self.action_indices = [i for i in range(n_actions)]
24 | self.learn_steps_count = 0
25 |
26 | self.q_eval = dqn.DeepQNetwork(learning_rate=learning_rate, n_actions=n_actions,
27 | input_dims=2*input_dims, name='q_eval',
28 | checkpoint_dir=checkpoint_dir)
29 |
30 | self.q_next = dqn.DeepQNetwork(learning_rate=learning_rate, n_actions=n_actions,
31 | input_dims=2*input_dims, name='q_next',
32 | checkpoint_dir=checkpoint_dir)
33 |
34 | self.experience_replay_memory = her.HindsightExperienceReplayMemory(memory_size=memory_size,
35 | input_dims=input_dims,
36 | n_actions=n_actions)
37 |
38 | def decrement_epsilon(self):
39 | """
40 | Decrements the epsilon after each step till it reaches minimum epsilon (0.1)
41 | epsilon = epsilon - decrement (default is 1e-5)
42 | """
43 | self.epsilon = self.epsilon - self.dec_epsilon if self.epsilon > self.min_epsilon \
44 | else self.min_epsilon
45 |
46 | def store_experience(self, state, action, reward, next_state, done, goal):
47 | """
48 | Saves the experience to the hindsight experience replay memory
49 | """
50 | self.experience_replay_memory.add_experience(state=state, action=action,
51 | reward=reward, next_state=next_state,
52 | done=done, goal=goal)
53 |
54 | def get_sample_experience(self):
55 | """
56 | Gives a sample experience from the hindsight experience replay memory
57 | """
58 | state, action, reward, next_state, done, goal = self.experience_replay_memory.get_random_experience(
59 | self.batch_size)
60 |
61 | t_state = torch.tensor(state).to(self.q_eval.device)
62 | t_action = torch.tensor(action).to(self.q_eval.device)
63 | t_reward = torch.tensor(reward).to(self.q_eval.device)
64 | t_next_state = torch.tensor(next_state).to(self.q_eval.device)
65 | t_done = torch.tensor(done).to(self.q_eval.device)
66 | t_goal = torch.tensor(goal).to(self.q_eval.device)
67 |
68 | return t_state, t_action, t_reward, t_next_state, t_done, t_goal
69 |
70 | def replace_target_network(self):
71 | """
72 | Updates the parameters after replace_network_count steps
73 | """
74 | if self.learn_steps_count % self.replace_network_count == 0:
75 | self.q_next.load_state_dict(self.q_eval.state_dict())
76 |
77 | def choose_action(self, observation, goal):
78 | """
79 | Chooses an action with epsilon-greedy method
80 | """
81 | if np.random.random() > self.epsilon:
82 | concat_state_goal = np.concatenate([observation, goal])
83 | state = torch.tensor([concat_state_goal], dtype=torch.float).to(self.q_eval.device)
84 | actions = self.q_eval.forward(state)
85 |
86 | action = torch.argmax(actions).item()
87 | else:
88 | action = np.random.choice(self.n_actions)
89 |
90 | return action
91 |
92 | def learn(self):
93 | if self.experience_replay_memory.counter < self.batch_size:
94 | return
95 |
96 | self.q_eval.optimizer.zero_grad()
97 | self.replace_target_network()
98 |
99 | state, action, reward, next_state, done, goal = self.get_sample_experience()
100 | # Gets the evenly spaced batches
101 | batches = np.arange(self.batch_size)
102 |
103 | concat_state_goal = torch.cat((state, goal), 1)
104 | concat_next_state_goal = torch.cat((next_state, goal), 1)
105 |
106 | q_pred = self.q_eval.forward(concat_state_goal)[batches, action]
107 | q_next = self.q_next.forward(concat_next_state_goal).max(dim=1)[0]
108 |
109 | q_next[done] = 0.0
110 | q_target = reward + self.gamma * q_next
111 |
112 | # Computes loss and performs backpropagation
113 | loss = self.q_eval.loss(q_target, q_pred).to(self.q_eval.device)
114 | loss.backward()
115 |
116 | self.q_eval.optimizer.step()
117 | self.decrement_epsilon()
118 | self.learn_steps_count += 1
119 |
120 | def save_model(self):
121 | """
122 | Saves the values of q_eval and q_next at the checkpoint
123 | """
124 | self.q_eval.save_checkpoint()
125 | self.q_next.save_checkpoint()
126 |
127 | def load_model(self):
128 | """
129 | Loads the values of q_eval and q_next at the checkpoint
130 | """
131 | self.q_eval.load_checkpoint()
132 | self.q_next.load_checkpoint()
133 |
--------------------------------------------------------------------------------
/ddpg_with_her/DDPGAgent.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | import torch
4 |
5 | from ddpg_with_her.ActorCritic import Actor, Critic
6 | from dqn_with_her import HERMemory as her
7 | from ddpg_with_her import OUNoise as noise
8 |
9 |
10 | class DDPGAgent:
11 | def __init__(self, actor_learning_rate, critic_learning_rate, n_actions,
12 | input_dims, gamma, memory_size, batch_size, tau=0.001,
13 | checkpoint_dir='/tmp/ddqn/'):
14 | self.actor_learning_rate = actor_learning_rate
15 | self.critic_learning_rate = critic_learning_rate
16 | self.n_actions = n_actions
17 | self.input_dims = input_dims
18 | self.gamma = gamma
19 | self.memory_size = memory_size
20 | self.batch_size = batch_size
21 | self.tau = tau
22 |
23 | self.actor = Actor(input_dims=input_dims, n_actions=n_actions,
24 | learning_rate=actor_learning_rate, checkpoint_dir=checkpoint_dir,
25 | name='actor3')
26 |
27 | self.critic = Critic(input_dims=input_dims, n_actions=n_actions,
28 | learning_rate=critic_learning_rate, checkpoint_dir=checkpoint_dir,
29 | name='critic3')
30 |
31 | self.target_actor = Actor(input_dims=input_dims, n_actions=n_actions,
32 | learning_rate=actor_learning_rate, checkpoint_dir=checkpoint_dir,
33 | name='target_actor3')
34 |
35 | self.target_critic = Critic(input_dims=input_dims, n_actions=n_actions,
36 | learning_rate=critic_learning_rate, checkpoint_dir=checkpoint_dir,
37 | name='target_critic3')
38 |
39 | self.memory = her.HindsightExperienceReplayMemory(memory_size=memory_size,
40 | input_dims=input_dims, n_actions=n_actions)
41 |
42 | self.ou_noise = noise.OrnsteinUhlenbeckActionNoise(mu=np.zeros(n_actions))
43 |
44 | def store_experience(self, state, action, reward, next_state, done, goal):
45 | """
46 | Saves the experience to the hindsight replay memory
47 | """
48 | self.memory.add_experience(state=state, action=action,
49 | reward=reward, next_state=next_state,
50 | done=done, goal=goal)
51 |
52 | def get_sample_experience(self):
53 | """
54 | Gives a sample experience from the hindsight replay memory
55 | """
56 | state, action, reward, next_state, done, goal = self.memory.get_random_experience(
57 | self.batch_size)
58 |
59 | t_state = torch.tensor(state).to(self.actor.device)
60 | t_action = torch.tensor(action).to(self.actor.device)
61 | t_reward = torch.tensor(reward).to(self.actor.device)
62 | t_next_state = torch.tensor(next_state).to(self.actor.device)
63 | t_done = torch.tensor(done).to(self.actor.device)
64 | t_goal = torch.tensor(goal).to(self.actor.device)
65 |
66 | return t_state, t_action, t_reward, t_next_state, t_done, t_goal
67 |
68 | def choose_action(self, observation, goal):
69 | """
70 | Selects actions using epsilon-greedy approach with OU-noise added to the greedy actions
71 | """
72 | if np.random.random() > 0.1:
73 | state = torch.tensor([np.concatenate([observation, goal])], dtype=torch.float).to(self.actor.device)
74 | mu = self.actor.forward(state).to(self.actor.device)
75 | action = mu + torch.tensor(self.ou_noise(), dtype=torch.float).to(self.actor.device)
76 |
77 | self.actor.train()
78 | selected_action = action.cpu().detach().numpy()[0]
79 | else:
80 | selected_action = np.random.rand(2)
81 |
82 | return selected_action
83 |
84 | def learn(self):
85 | """
86 | Learns the y function
87 | """
88 | if self.memory.counter < self.batch_size:
89 | return
90 |
91 | self.actor.optimizer.zero_grad()
92 | self.critic.optimizer.zero_grad()
93 |
94 | state, action, reward, next_state, done, goal = self.get_sample_experience()
95 | concat_state_goal = torch.cat((state, goal), 1)
96 | concat_next_state_goal = torch.cat((next_state, goal), 1)
97 |
98 | target_actions = self.target_actor.forward(concat_state_goal)
99 | critic_next_value = self.target_critic.forward(concat_next_state_goal, target_actions).view(-1)
100 |
101 | actor_value = self.actor.forward(concat_state_goal)
102 | critic_value = self.critic.forward(concat_state_goal, action)
103 |
104 | critic_value[done] = 0.0
105 |
106 | target = (reward + self.gamma * critic_next_value).view(self.batch_size, -1)
107 |
108 | loss_critic = self.critic.loss(target, critic_value)
109 | loss_critic.backward()
110 | self.critic.optimizer.step()
111 |
112 | loss_actor = -torch.mean(self.critic.forward(concat_state_goal, actor_value))
113 | loss_actor.backward()
114 | self.actor.optimizer.step()
115 |
116 | actor_parameters = dict(self.actor.named_parameters())
117 | critic_parameters = dict(self.critic.named_parameters())
118 | target_actor_parameters = dict(self.target_actor.named_parameters())
119 | target_critic_parameters = dict(self.target_critic.named_parameters())
120 |
121 | for i in actor_parameters:
122 | actor_parameters[i] = self.tau * actor_parameters[i].clone() + (1 - self.tau) * target_actor_parameters[i].clone()
123 |
124 | for i in critic_parameters:
125 | critic_parameters[i] = self.tau * critic_parameters[i].clone() + (1 - self.tau) * target_critic_parameters[i].clone()
126 |
127 | self.target_actor.load_state_dict(actor_parameters)
128 | self.target_critic.load_state_dict(critic_parameters)
129 |
130 | def save_model(self):
131 | """
132 | Saves the values at the checkpoint
133 | """
134 | self.actor.save_checkpoint()
135 | self.critic.save_checkpoint()
136 | self.target_actor.save_checkpoint()
137 | self.target_critic.save_checkpoint()
138 |
139 | def load_model(self):
140 | """
141 | Loads the values at the checkpoint
142 | """
143 | self.actor.load_checkpoint()
144 | self.critic.load_checkpoint()
145 | self.target_actor.load_checkpoint()
146 | self.target_critic.load_checkpoint()
147 |
--------------------------------------------------------------------------------
 37 |
37 | 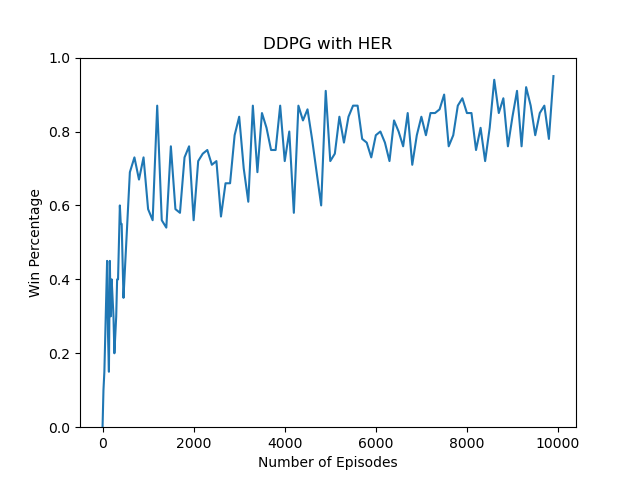 42 |
42 |