├── .gitignore
├── .github
└── images
│ └── screenshot.png
├── requirements.txt
├── static
├── index.html
├── index.css
└── index.js
├── README.md
├── main.py
├── prompt.txt
└── model.py
/.gitignore:
--------------------------------------------------------------------------------
1 | vmvenv
2 | venv
3 | .venv
4 | .vim
5 | .mypy_cache
6 | .vscode
7 | __pycache__
8 | *.pth
--------------------------------------------------------------------------------
/.github/images/screenshot.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hizkifw/WebChatRWKVstic/HEAD/.github/images/screenshot.png
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | rwkvstic==0.1.9
2 | inquirer==3.1.2
3 | tqdm==4.64.1
4 | transformers==4.26.1
5 | scipy==1.10.0
6 | tensorflow
7 | torch==1.13.1
8 | fastapi[all]
9 | websockets==10.4
10 | psutil==5.9.4
11 | requests==2.28.2
12 | requests-oauthlib==1.3.1
13 |
--------------------------------------------------------------------------------
/static/index.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 | ChatRWKV
5 |
6 |
7 |
8 |
9 |
10 |
11 |
22 |
23 |
27 |
28 |
29 |
30 |
31 |
--------------------------------------------------------------------------------
/static/index.css:
--------------------------------------------------------------------------------
1 | html,
2 | body {
3 | margin: 0;
4 | background-color: #222;
5 | color: #fff;
6 | height: 100%;
7 | font-family: sans-serif;
8 | }
9 |
10 | .container {
11 | max-width: 640px;
12 | margin: 0 auto;
13 | display: flex;
14 | flex-direction: column;
15 | height: 100%;
16 | padding: 1em;
17 | box-sizing: border-box;
18 | }
19 |
20 | .messagecontent > p {
21 | white-space: pre-line;
22 | }
23 |
24 | .history {
25 | flex: 1;
26 | overflow-y: scroll;
27 | padding-bottom: 5rem;
28 | }
29 |
30 | .history::-webkit-scrollbar {
31 | width: 5px;
32 | background-color: #333;
33 | }
34 |
35 | .history::-webkit-scrollbar-thumb {
36 | background: #555;
37 | }
38 |
39 | .history h4 {
40 | margin-bottom: 0;
41 | }
42 | .history p {
43 | margin-top: 0;
44 | word-wrap: break-word;
45 | }
46 | .history a:link,
47 | .history a:visited {
48 | color: #91bbfd;
49 | }
50 | .history li::marker {
51 | color: #aaa;
52 | }
53 |
54 | .chatbar {
55 | width: 100%;
56 | display: flex;
57 | }
58 |
59 | #chatbox {
60 | flex: 1;
61 | background-color: #333;
62 | border: 0;
63 | font-size: 1rem;
64 | padding: 0.8em;
65 | color: #fff;
66 | outline: none;
67 | font-family: sans-serif;
68 | resize: none;
69 | }
70 |
71 | .btn {
72 | background-color: #333;
73 | color: #fff;
74 | border: 0;
75 | cursor: pointer;
76 | outline: none;
77 | padding: 0 1em;
78 | }
79 | .btn:hover,
80 | .btn:focus {
81 | background-color: #444;
82 | }
83 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # ! NO LONGER MAINTAINED !
2 |
3 | > **Warning**
4 | > This repository is no longer maintained. Please see other forks,
5 | > such as [wfox4/WebChatRWKVv2](https://github.com/wfox4/WebChatRWKVv2). For
6 | > more info on the RWKV language model, check the
7 | > [BlinkDL/ChatRWKV](https://github.com/BlinkDL/ChatRWKV) repository.
8 |
9 | ---
10 |
11 | # WebChatRWKVstic
12 |
13 | 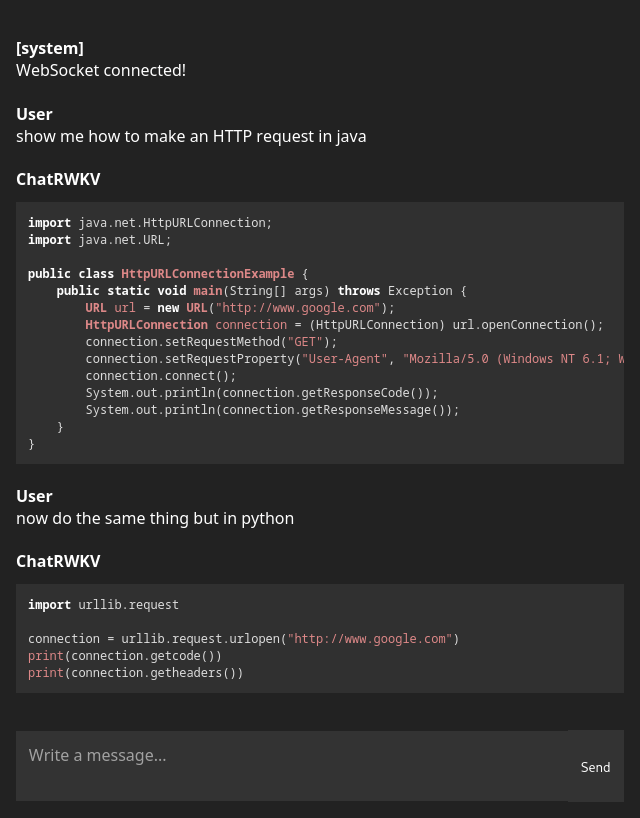
14 |
15 | [RWKV-V4](https://github.com/BlinkDL/RWKV-LM) inference via
16 | [rwkvstic](https://github.com/harrisonvanderbyl/rwkvstic), with a ChatGPT-like
17 | web UI, including real-time response streaming.
18 |
19 | ## How to use
20 |
21 | ```sh
22 | # Clone this repository
23 | git clone https://github.com/hizkifw/WebChatRWKVstic.git
24 | cd WebChatRWKVstic
25 |
26 | # Recommended: set up a virtual environment
27 | python -m venv venv
28 | source ./venv/bin/activate
29 |
30 | # Install requirements
31 | pip install -r requirements.txt
32 |
33 | # Run the webserver
34 | python main.py
35 | ```
36 |
37 | The script will automatically download a suitable RWKV model into the `models`
38 | folder. If you already have a model, you can create the `models` directory and
39 | place your `.pth` file there.
40 |
41 | ## Currently state
42 |
43 | - Mobile-friendly web UI with autoscroll, response streaming, markdown
44 | formatting, and syntax highlighting
45 | - Input is formatted into a question/answer format for the model, and earlier
46 | chat messages are included in the context
47 |
48 | ## TODO
49 |
50 | - Tune the model to better match ChatGPT
51 | - Clean up the code
52 | - Create a Docker image
53 |
--------------------------------------------------------------------------------
/main.py:
--------------------------------------------------------------------------------
1 | print(
2 | r"""
3 | __ __ _ _____ _ _
4 | \ \ / / | | / ____| | | |
5 | \ \ /\ / /__| |__ | | | |__ __ _| |_
6 | \ \/ \/ / _ \ '_ \| | | '_ \ / _` | __|
7 | \ /\ / __/ |_) | |____| | | | (_| | |_
8 | ___\/__\/ \___|_.__/ \_____|_| |_|\__,_|\__|
9 | | __ \ \ / / |/ /\ \ / / | | (_)
10 | | |__) \ \ /\ / /| ' / \ \ / /__| |_ _ ___
11 | | _ / \ \/ \/ / | < \ \/ / __| __| |/ __|
12 | | | \ \ \ /\ / | . \ \ /\__ \ |_| | (__
13 | |_| \_\ \/ \/ |_|\_\ \/ |___/\__|_|\___|
14 |
15 | """
16 | )
17 |
18 | print("Importing modules...")
19 |
20 | import asyncio
21 |
22 | from fastapi import FastAPI, WebSocket
23 | from fastapi.staticfiles import StaticFiles
24 |
25 | import model
26 |
27 | app = FastAPI()
28 |
29 |
30 | @app.websocket("/ws")
31 | async def websocket(ws: WebSocket):
32 | loop = asyncio.get_running_loop()
33 | await ws.accept()
34 |
35 | session = {"state": None}
36 |
37 | async def reply(id, *, result=None, error=None):
38 | either = (result is None) is not (error is None)
39 | assert either, "Either result or error must be set!"
40 |
41 | if result is not None:
42 | await ws.send_json({"jsonrpc": "2.0", "result": result, "id": id})
43 | elif error is not None:
44 | await ws.send_json({"jsonrpc": "2.0", "error": error, "id": id})
45 |
46 | def on_progress(id):
47 | def callback(res):
48 | asyncio.run_coroutine_threadsafe(reply(id, result={"token": res}), loop)
49 |
50 | return callback
51 |
52 | def on_done(input):
53 | def callback(result):
54 | print("--- input ---")
55 | print(input)
56 | print("--- output ---")
57 | print(result["output"])
58 | print("---")
59 |
60 | session["state"] = result["state"]
61 |
62 | return callback
63 |
64 | while True:
65 | data = await ws.receive_json()
66 | if "jsonrpc" not in data or data["jsonrpc"] != "2.0":
67 | await reply(
68 | data.get("id", None) if type(data) == dict else None,
69 | error="invalid message",
70 | )
71 |
72 | method, params, id = (
73 | data.get("method", None),
74 | data.get("params", None),
75 | data.get("id", None),
76 | )
77 |
78 | if method == "chat":
79 | text = params.get("text", None)
80 | if text is None:
81 | await reply(id, error="text is required")
82 |
83 | await loop.run_in_executor(
84 | None,
85 | model.chat,
86 | session["state"],
87 | text,
88 | on_progress(id),
89 | on_done(text),
90 | )
91 | else:
92 | await reply(id, error=f"invalid method '{method}'")
93 |
94 |
95 | app.mount("/", StaticFiles(directory="static", html=True), name="static")
96 |
97 | if __name__ == "__main__":
98 | import uvicorn
99 |
100 | uvicorn.run(app)
101 |
--------------------------------------------------------------------------------
/static/index.js:
--------------------------------------------------------------------------------
1 | (() => {
2 | const messages = {};
3 | let isReady = false;
4 |
5 | // Wait until the whole page has loaded
6 | window.addEventListener("load", () => {
7 | const chatbox = document.querySelector("#chatbox");
8 | const chatform = document.querySelector("#chatform");
9 | const historybox = document.querySelector("#history");
10 |
11 | marked.setOptions({
12 | highlight: function (code, lang) {
13 | const language = hljs.getLanguage(lang) ? lang : "plaintext";
14 | return hljs.highlight(code, { language }).value;
15 | },
16 | langPrefix: "hljs language-",
17 | });
18 |
19 | const renderMessage = (id, from, message) => {
20 | messages[id] = message;
21 |
22 | const div = document.createElement("div");
23 | div.id = id;
24 | div.className = "message";
25 |
26 | const tname = document.createElement("h4");
27 | tname.innerText = from;
28 | div.appendChild(tname);
29 |
30 | const txt = document.createElement("div");
31 | txt.innerHTML = marked.parse(message);
32 | txt.className = "messagecontent";
33 | div.appendChild(txt);
34 |
35 | historybox.appendChild(div);
36 | };
37 |
38 | const appendMessage = (id, message) => {
39 | messages[id] += message;
40 |
41 | let markdown = messages[id];
42 | // Check for open code blocks and close them
43 | if ((markdown.match(/```/g) || []).length % 2 !== 0) markdown += "\n```";
44 |
45 | // Append to the p
46 | const p = document.querySelector("#" + id + " > .messagecontent");
47 | p.innerHTML = marked.parse(markdown);
48 |
49 | // Scroll the history box
50 | historybox.scrollTo({
51 | behavior: "smooth",
52 | top: historybox.scrollHeight,
53 | left: 0,
54 | });
55 | };
56 |
57 | const makeId = () =>
58 | (Date.now().toString(36) + Math.random().toString(36)).replace(".", "");
59 |
60 | // Connect to websocket
61 | const ws = new WebSocket(
62 | location.protocol.replace("http", "ws") + "//" + location.host + "/ws"
63 | );
64 |
65 | // Attach event listener
66 | ws.addEventListener("message", (ev) => {
67 | data = JSON.parse(ev.data);
68 | if ("result" in data && "token" in data["result"]) {
69 | if (data.result.token === null) isReady = true;
70 | else appendMessage(data.id, data.result.token.replace("<", "<"));
71 | }
72 | });
73 | ws.addEventListener("open", () => {
74 | isReady = true;
75 | renderMessage(makeId(), "[system]", "WebSocket connected!");
76 | });
77 | ws.addEventListener("close", () => {
78 | isReady = false;
79 | renderMessage(makeId(), "[system]", "WebSocket disconnected!");
80 | });
81 |
82 | const sendMessage = async (message) => {
83 | isReady = false;
84 |
85 | // Generate an ID for the response
86 | respid = makeId();
87 |
88 | // Add message to the page
89 | renderMessage(makeId(), "User", message);
90 | renderMessage(respid, "ChatRWKV", "");
91 |
92 | // Send message to server
93 | ws.send(
94 | JSON.stringify({
95 | jsonrpc: "2.0",
96 | method: "chat",
97 | params: {
98 | text: message,
99 | },
100 | id: respid,
101 | })
102 | );
103 | };
104 |
105 | const onSubmit = () => {
106 | if (!isReady) return;
107 | sendMessage(chatbox.value.trim());
108 | chatbox.value = "";
109 | };
110 |
111 | chatform.addEventListener("submit", (e) => {
112 | e.preventDefault();
113 | onSubmit();
114 | });
115 | chatbox.addEventListener("keydown", (e) => {
116 | if (e.key == "Enter" && !e.shiftKey) onSubmit();
117 | });
118 | });
119 | })();
120 |
--------------------------------------------------------------------------------
/prompt.txt:
--------------------------------------------------------------------------------
1 | Question:
2 | tell me the meta tag to set the viewport for mobile
3 |
4 | Full Answer in Markdown:
5 | The meta tag to set the viewport for mobile is:
6 |
7 | ```html
8 |
9 | ```
10 |
11 | This meta tag tells the browser to set the width of the viewport to the width of the device and to set the initial zoom level to 1.0, which means that the content will be displayed at the actual size and won't be scaled up or down. This is important for creating a responsive design that looks good on different screen sizes and devices.
12 |
13 | Question:
14 | can you show an example on how it's used?
15 |
16 | Full Answer in Markdown:
17 | Sure! Here's an example of how to use the viewport meta tag in an HTML document:
18 |
19 | ```html
20 |
21 |
22 |
23 |
24 | My Website
25 |
26 |
27 |
28 |
29 |
30 |
31 | ```
32 |
33 | In this example, the viewport meta tag is included in the head section of the HTML document. The `content` attribute of the meta tag specifies the properties of the viewport, which are:
34 |
35 | - `width=device-width`: sets the width of the viewport to the width of the device screen.
36 | - `initial-scale=1.0`: sets the initial zoom level to 1.0, which means that the content will be displayed at the actual size.
37 |
38 | By setting the viewport to the width of the device screen, the content will adjust to fit the screen size of the device, making it more readable and user-friendly on mobile devices.
39 |
40 | ---
41 |
42 | Question:
43 | What is the meaning of life?
44 |
45 | Full Answer in Markdown:
46 | The meaning of life is a complex and subjective question that has puzzled philosophers, theologians, scientists, and individuals throughout history. There is no one definitive answer to this question, as the meaning of life can vary depending on a person's cultural, religious, philosophical, and personal beliefs.
47 |
48 | Some people believe that the meaning of life is to seek happiness, love, and fulfillment. Others may argue that the purpose of life is to find meaning through personal growth, learning, and exploration. Some may believe that the meaning of life is to fulfill a certain destiny or purpose, while others may believe that life is ultimately meaningless.
49 |
50 | Ultimately, the meaning of life is a deeply personal and subjective question that each individual must answer for themselves based on their own experiences, beliefs, and values.
51 |
52 | ---
53 |
54 | Question:
55 | help me pick an open source license for my project
56 |
57 | Full Answer in Markdown:
58 | Choosing an open source license for your project is an important decision that can affect how others use and contribute to your code. Here are a few popular open source licenses to consider:
59 |
60 | 1. MIT License: This is a permissive license that allows others to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of your code. This license is popular among open source projects because it is very permissive and has very few restrictions.
61 | 2. Apache License 2.0: This is another permissive license that allows others to use, modify, distribute, and sublicense your code, but also includes patent protection. The Apache License 2.0 requires that any modified code include a notice of the changes made.
62 | 3. GNU General Public License (GPL): This is a copyleft license that requires any derivative works to be distributed under the same license. The GPL is often used for software that is intended to be shared and modified by a community of users.
63 | 4. Creative Commons Licenses: These licenses are often used for non-software projects, such as documentation, music, and art. They provide a way to share creative works while retaining some rights.
64 |
65 | It's important to consider your goals for your project and how you want others to be able to use and contribute to your code when choosing a license.
66 |
67 | ---
--------------------------------------------------------------------------------
/model.py:
--------------------------------------------------------------------------------
1 | import queue
2 | import threading
3 | import traceback
4 | from dataclasses import dataclass, field
5 | from typing import Any, Callable
6 |
7 | import torch
8 | from rwkvstic.agnostic.backends import TORCH
9 | from rwkvstic.load import RWKV
10 |
11 |
12 | def no_tqdm():
13 | from functools import partialmethod
14 |
15 | from tqdm import tqdm
16 |
17 | tqdm.__init__ = partialmethod(tqdm.__init__, disable=True)
18 |
19 |
20 | @dataclass
21 | class OnlineModel:
22 | name: str
23 | url: str
24 | sha256: str
25 | vram_gb: int
26 |
27 |
28 | online_models = [
29 | # TODO: add more models here
30 | OnlineModel(
31 | name="RWKV-4-Pile-7B-ctx4096",
32 | url="https://huggingface.co/BlinkDL/rwkv-4-pile-7b/resolve/main/RWKV-4-Pile-7B-20230109-ctx4096.pth",
33 | sha256="9ea1271b25deb6c72bd29f629147d5013cc7d7c69f9715192f6b6b92fca08f64",
34 | vram_gb=14,
35 | ),
36 | OnlineModel(
37 | name="RWKV-4-Pile-3B-ctx4096",
38 | url="https://huggingface.co/BlinkDL/rwkv-4-pile-3b/resolve/main/RWKV-4-Pile-3B-20221110-ctx4096.pth",
39 | sha256="9500633f23d86fbae3cb3cbe7908b97b971e9561edf583c2c5c60b10b02bcc27",
40 | vram_gb=6,
41 | ),
42 | OnlineModel(
43 | name="RWKV-4-Pile-1B5-ctx4096",
44 | url="https://huggingface.co/BlinkDL/rwkv-4-pile-1b5/resolve/main/RWKV-4-Pile-1B5-20220929-ctx4096.pth",
45 | sha256="6c97043e1bb0867368249290c97a2fe8ffc5ec12ceb1b5251f4ee911f9982c23",
46 | vram_gb=3.7,
47 | ),
48 | OnlineModel(
49 | name="RWKV-4-Pile-1B5-Instruct-test2",
50 | url="https://huggingface.co/BlinkDL/rwkv-4-pile-1b5/resolve/main/RWKV-4-Pile-1B5-Instruct-test2-20230209.pth",
51 | sha256="19aafd001257702bd66c81e5e05dcbc088341e825cc41b4feaeb35aa1b55624c",
52 | vram_gb=3.7,
53 | ),
54 | OnlineModel(
55 | name="RWKV-4-Pile-169M",
56 | url="https://huggingface.co/BlinkDL/rwkv-4-pile-169m/resolve/main/RWKV-4-Pile-169M-20220807-8023.pth",
57 | sha256="713c6f6137a08d3a86ab57df4f09ea03563329beb3bbabc23509d6c57aa0f9e2",
58 | vram_gb=1.3,
59 | ),
60 | ]
61 |
62 |
63 | def hash_file(filename):
64 | import hashlib
65 |
66 | file_hash = hashlib.sha256()
67 | with open(filename, "rb") as f:
68 | while True:
69 | data = f.read(4 * 1024)
70 | if not data:
71 | break
72 | file_hash.update(data)
73 | return file_hash.hexdigest()
74 |
75 |
76 | # https://stackoverflow.com/a/63831344
77 | def download(url, filename, sha256=None):
78 | import functools
79 | import pathlib
80 | import shutil
81 | import requests
82 | from tqdm.auto import tqdm
83 |
84 | r = requests.get(url, stream=True, allow_redirects=True)
85 | if r.status_code != 200:
86 | r.raise_for_status() # Will only raise for 4xx codes, so...
87 | raise RuntimeError(f"Request to {url} returned status code {r.status_code}")
88 | file_size = int(r.headers.get("Content-Length", 0))
89 |
90 | path = pathlib.Path(filename).expanduser().resolve()
91 | path.parent.mkdir(parents=True, exist_ok=True)
92 |
93 | desc = "(Unknown total file size)" if file_size == 0 else ""
94 | r.raw.read = functools.partial(
95 | r.raw.read, decode_content=True
96 | ) # Decompress if needed
97 | with tqdm.wrapattr(r.raw, "read", total=file_size, desc=desc) as r_raw:
98 | with path.open("wb") as f:
99 | shutil.copyfileobj(r_raw, f)
100 |
101 | if sha256 is not None:
102 | print("Verifying file integrity...")
103 | file_hash = hash_file(path)
104 | if file_hash != sha256:
105 | print("Error downloading file: checksums do not match")
106 | print("Expected", sha256)
107 | print("But got ", file_hash)
108 | raise Exception("Checksums do not match!")
109 |
110 | return path
111 |
112 |
113 | def get_checkpoint():
114 | import psutil
115 | import os
116 | from glob import glob
117 | from os import path
118 |
119 | has_cuda = torch.cuda.is_available()
120 | ram_total = psutil.virtual_memory().total
121 | vram_total = 0
122 |
123 | # Check if CUDA is available
124 | if has_cuda:
125 | print("CUDA available")
126 | vram_total = torch.cuda.mem_get_info()[1]
127 | else:
128 | print(
129 | """
130 | **************************************
131 | WARN: CUDA not available, will use CPU
132 | If you want to use CUDA, try running this command:
133 |
134 | pip install torch --extra-index-url https://download.pytorch.org/whl/cu117 --upgrade
135 |
136 | For more information, see: https://pytorch.org/get-started/locally/
137 | *************************************
138 | """
139 | )
140 |
141 | models_dir = "models"
142 | if not path.exists(models_dir):
143 | os.makedirs(models_dir)
144 |
145 | # Check if there are any models in the models/ folder
146 | models = glob(path.join(models_dir, "*.pth"))
147 |
148 | if len(models) == 0:
149 | print("No *.pth models found in the `models` folder, downloading...")
150 | print(" -> RAM:", ram_total)
151 | print(" -> VRAM:", vram_total)
152 | memtarget = vram_total if has_cuda else ram_total
153 | for m in online_models:
154 | if m.vram_gb * 1024 * 1024 * 1024 <= memtarget:
155 | print("Downloading model", m.name)
156 | download(
157 | m.url,
158 | path.join(models_dir, m.name + ".pth"),
159 | sha256=m.sha256,
160 | )
161 | break
162 |
163 | models = glob(path.join(models_dir, "*.pth"))
164 | if len(models) == 0:
165 | raise Exception("Could not find a suitable model to download.")
166 |
167 | # TODO: get model name from command line args / config file
168 | print("-> Using model", models[0])
169 | return models[0]
170 |
171 |
172 | # Load the model (supports full path, relative path, and remote paths)
173 | model = RWKV(
174 | get_checkpoint(),
175 | mode=TORCH,
176 | useGPU=torch.cuda.is_available(),
177 | runtimedtype=torch.float32,
178 | dtype=torch.bfloat16 if torch.cuda.is_available() else torch.float32,
179 | )
180 |
181 | # Disable tqdm
182 | no_tqdm()
183 |
184 |
185 | @dataclass
186 | class Task:
187 | state: Any = model.emptyState
188 | context: str = ""
189 | progress_callback: Callable[[str], None] = lambda x: None
190 | done_callback: Callable[[dict[str, Any]], None] = lambda x: None
191 | forward_kwargs: dict = field(default_factory=dict)
192 |
193 |
194 | inferqueue: queue.Queue[Task] = queue.Queue()
195 |
196 |
197 | def inferthread():
198 | while True:
199 | try:
200 | # Get task
201 | task = inferqueue.get()
202 |
203 | # Perform inference
204 | model.setState(task.state)
205 | model.loadContext(newctx=task.context)
206 | res = model.forward(
207 | number=512,
208 | temp=1,
209 | top_p_usual=0.7,
210 | end_adj=-2,
211 | progressLambda=task.progress_callback,
212 | **task.forward_kwargs,
213 | )
214 |
215 | task.done_callback(res)
216 | except Exception:
217 | traceback.print_exc()
218 | finally:
219 | task.progress_callback(None)
220 |
221 |
222 | def infer(
223 | *,
224 | context: str,
225 | state=None,
226 | on_progress=None,
227 | on_done=None,
228 | forward_kwargs={},
229 | ):
230 | ev = threading.Event()
231 |
232 | # args['logits', 'state', 'output', 'progress', 'tokens', 'total', 'current']
233 | def _progress_callback(args):
234 | if on_progress is None:
235 | return
236 |
237 | if args is None:
238 | on_progress(None, None)
239 | return
240 |
241 | last_token = args["tokens"][-1]
242 | token_str = model.tokenizer.decode(last_token)
243 |
244 | on_progress(token_str, args["state"])
245 |
246 | def _done_callback(result):
247 | ev.set()
248 | if on_done is None:
249 | return
250 | on_done(result)
251 |
252 | task = Task(
253 | state=state if state is not None else model.emptyState,
254 | context=context,
255 | progress_callback=_progress_callback,
256 | done_callback=_done_callback,
257 | forward_kwargs=forward_kwargs,
258 | )
259 | inferqueue.put(task)
260 | ev.wait()
261 |
262 |
263 | print("Loading context")
264 | chat_initial_context = open("prompt.txt").read().strip()
265 | model.loadContext(
266 | newctx=chat_initial_context,
267 | progressCallBack=lambda p: print(model.tokenizer.decode(p[-1]), end=""),
268 | )
269 | chat_initial_state = model.getState()
270 | model.resetState()
271 | print("Chat context loaded")
272 |
273 | t = threading.Thread(target=inferthread, daemon=True)
274 | t.start()
275 |
276 |
277 | def chat(state, input: str, on_progress, on_done):
278 | # Format the input to be a Q & A
279 | input = f"""
280 | Question:
281 | {input}
282 |
283 | Full Answer in Markdown:
284 | """
285 |
286 | # Set empty state if not provided
287 | if state is None:
288 | state = chat_initial_state
289 |
290 | ctx = {"buf": "", "buf_state": None}
291 | stop_sequences = ["\nQuestion:", "\n---"]
292 |
293 | def _on_progress(token: str, state=None):
294 | print("token", repr(token))
295 | if token is None:
296 | on_progress(None)
297 | return
298 |
299 | # This chunk of code will look for stop sequences. If found, all text
300 | # will be stored in the `buf` until either the whole stop sequence is
301 | # matched, in which case all subsequent progress is dropped, or the
302 | # sequence doesn't match fully, in which case the buffer will be flushed
303 | # to the callback.
304 | #
305 | # The model state is also stored in the `buf_state`, only when the stop
306 | # sequences do not match. This allows us to restore the model to right
307 | # before the stop sequence was produced.
308 | for ss in stop_sequences:
309 | if ss == ctx["buf"]:
310 | return
311 |
312 | if ss.startswith(ctx["buf"] + token):
313 | ctx["buf"] += token
314 | if ss == ctx["buf"]:
315 | on_progress(None)
316 | return
317 |
318 | for ss in stop_sequences:
319 | if ss.startswith(token):
320 | if len(ctx["buf"]) > 0:
321 | on_progress(ctx["buf"])
322 | ctx["buf"] = token
323 | if ss == ctx["buf"]:
324 | on_progress(None)
325 | return
326 |
327 | if len(ctx["buf"]) > 0:
328 | on_progress(ctx["buf"])
329 | ctx["buf"] = ""
330 |
331 | ctx["buf_state"] = state
332 | on_progress(token)
333 |
334 | def _on_done(result):
335 | result["state"] = ctx["buf_state"]
336 | on_done(result)
337 |
338 | infer(
339 | context=input,
340 | state=state,
341 | on_progress=_on_progress,
342 | on_done=_on_done,
343 | forward_kwargs={
344 | "stopStrings": [
345 | "<|endoftext|>",
346 | "---",
347 | "Question:",
348 | "Full Answer in Markdown:",
349 | ]
350 | },
351 | )
352 |
353 |
354 | if __name__ == "__main__":
355 | session = {"state": None}
356 |
357 | while True:
358 | print("")
359 | line_in = input("You> ").replace("\\n", "\n").strip()
360 | if line_in == "/reset":
361 | session["state"] = None
362 | print("State has been reset.")
363 | continue
364 |
365 | def on_progress(result):
366 | if result is None:
367 | print("")
368 | return
369 | print(result, end="")
370 |
371 | def on_done(result):
372 | session["state"] = result["state"]
373 |
374 | print("Bot> ", end="")
375 | chat(session["state"], line_in, on_progress, on_done)
376 |
--------------------------------------------------------------------------------