├── FHENet.pth
├── FHENet.py
├── README.md
├── mobilenetv2.py
├── requirements.txt
└── test_RGBT.py
/FHENet.pth:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hjklearn/Rail-Defect-Detection/2aa8eabf4668cbe737e20ca606b1653d354ac45f/FHENet.pth
--------------------------------------------------------------------------------
/FHENet.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | from .mobilenetv2 import *
4 | import torch.nn.functional as F
5 | # from .van import *
6 |
7 |
8 | class BasicConv2d(nn.Module):
9 | def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1):
10 | super(BasicConv2d, self).__init__()
11 | self.conv = nn.Conv2d(in_planes, out_planes,
12 | kernel_size=kernel_size, stride=stride,
13 | padding=padding, dilation=dilation, bias=False)
14 | self.bn = nn.BatchNorm2d(out_planes)
15 | self.relu = nn.ReLU(inplace=True)
16 |
17 | def forward(self, x):
18 | x = self.conv(x)
19 | x = self.bn(x)
20 | x = self.relu(x)
21 | return x
22 |
23 | class Channel_Att(nn.Module):
24 | def __init__(self, channels, t=16):
25 | super(Channel_Att, self).__init__()
26 | self.channels = channels
27 |
28 | self.bn2 = nn.BatchNorm2d(self.channels, affine=True)
29 |
30 | def forward(self, x):
31 | residual = x
32 |
33 | x = self.bn2(x)
34 | weight_bn = self.bn2.weight.data.abs() / torch.sum(self.bn2.weight.data.abs())
35 | x = x.permute(0, 2, 3, 1).contiguous()
36 | x = torch.mul(weight_bn, x)
37 | x = x.permute(0, 3, 1, 2).contiguous()
38 | # x = torch.sigmoid(x)
39 | x = torch.sigmoid(x) * residual #
40 |
41 | return x
42 |
43 | class DSConv(nn.Module):
44 | def __init__(self, in_channel, out_channel, rate):
45 | super(DSConv, self).__init__()
46 | self.depth = nn.Sequential(nn.Conv2d(in_channel, in_channel, kernel_size=3, padding=rate, stride=1, dilation=rate, groups=in_channel),
47 | nn.BatchNorm2d(in_channel),
48 | nn.PReLU())
49 | self.point = nn.Sequential(nn.Conv2d(in_channel, out_channel, kernel_size=1, padding=0, stride=1),
50 | nn.BatchNorm2d(out_channel),
51 | nn.PReLU())
52 |
53 | def forward(self, x):
54 | x = self.depth(x)
55 | x = self.point(x)
56 |
57 | return x
58 |
59 |
60 |
61 | class Boundry(nn.Module):
62 | def __init__(self, in_channels):
63 | super(Boundry, self).__init__()
64 |
65 | self.conv1x1_1 = nn.Conv2d(in_channels, 2 * in_channels, 1)
66 | self.conv1x1_2 = nn.Conv2d(in_channels, 2 * in_channels, 1)
67 | self.conv1x1_3 = nn.Conv2d(1, in_channels, 1)
68 | self.conv1x1_4 = nn.Conv2d(2 * in_channels, in_channels, 1)
69 |
70 | self.max2 = nn.MaxPool2d(kernel_size=2, stride=2)
71 | self.max4 = nn.MaxPool2d(kernel_size=4, stride=4)
72 | self.max8 = nn.MaxPool2d(kernel_size=8, stride=8)
73 |
74 |
75 | self.conv3_d1 = nn.Sequential(
76 | nn.Conv2d(1, in_channels, kernel_size=(3, 1), padding=(1, 0), stride=1, dilation=(1, 1)
77 | ),
78 | nn.Conv2d(in_channels, in_channels, kernel_size=(1, 3), padding=(0, 1), stride=1, dilation=(1, 1)
79 | ),
80 | nn.BatchNorm2d(in_channels),
81 | nn.ReLU())
82 | self.conv3_d2 = nn.Sequential(
83 | nn.Conv2d(6 * in_channels, in_channels, kernel_size=(3, 1), padding=(1, 0), stride=1, dilation=(1, 1)
84 | ),
85 | nn.Conv2d(in_channels, in_channels, kernel_size=(1, 3), padding=(0, 1), stride=1, dilation=(1, 1)
86 | ),
87 | nn.BatchNorm2d(in_channels),
88 | nn.ReLU())
89 |
90 |
91 | def forward(self, rgb, d):
92 | rgb_c = self.conv1x1_1(rgb)
93 | d_c = self.conv1x1_2(d)
94 | mul1 = rgb_c.mul(d_c)
95 | # add = torch.cat([mul1, rgb_c, d_c], dim=1)
96 | # add = self.conv3_d1(add)
97 | add = mul1 + rgb_c + d_c
98 | add_c = self.conv1x1_4(add)
99 |
100 | avgmax1 = self.max2(add)
101 | avgmax3 = self.max4(add)
102 | avgmax5 = self.max8(add)
103 | max1, _ = torch.max(add, dim=1, keepdim=True)
104 | max1 = self.conv1x1_3(max1)
105 |
106 | avgmax1_up = F.interpolate(input=avgmax1, size=(add.size()[2], add.size()[3]))
107 | avgmax3_up = F.interpolate(input=avgmax3, size=(add.size()[2], add.size()[3]))
108 | avgmax5_up = F.interpolate(input=avgmax5, size=(add.size()[2], add.size()[3]))
109 |
110 | cat = torch.cat([avgmax1_up, avgmax3_up, avgmax5_up], dim=1)
111 | cat_conv = self.conv3_d2(cat)
112 | out = cat_conv + max1 + add_c
113 |
114 |
115 | return out
116 |
117 |
118 |
119 | class fusion(nn.Module):
120 | def __init__(self, in_channels):
121 | super(fusion, self).__init__()
122 | self.sigmoid = nn.Sigmoid()
123 | self.conv3_d = nn.Sequential(
124 | nn.Conv2d(2 * in_channels, in_channels, kernel_size=(3, 1), padding=(1, 0), stride=1, dilation=(1, 1)
125 | ),
126 | nn.Conv2d(in_channels, in_channels, kernel_size=(1, 3), padding=(0, 1), stride=1, dilation=(1, 1)
127 | ),
128 | nn.BatchNorm2d(in_channels),
129 | nn.ReLU())
130 |
131 | def forward(self, rgb, t):
132 | mul_rt = rgb.mul(t)
133 |
134 | rgb_sig = self.sigmoid(rgb)
135 | t_sig = self.sigmoid(t)
136 |
137 | mul_r = rgb_sig.mul(t)
138 | add_r = mul_r + rgb
139 | mul_t = t_sig.mul(rgb)
140 | add_t = mul_t + t
141 |
142 | r_mul = add_r.mul(mul_rt)
143 | t_mul = add_t.mul(mul_rt)
144 |
145 | cat_all = torch.cat((r_mul, t_mul), dim=1)
146 | out = self.conv3_d(cat_all)
147 |
148 |
149 | return out
150 |
151 |
152 |
153 | class MFI(nn.Module):
154 | def __init__(self, in_channels):
155 | super(MFI, self).__init__()
156 |
157 | self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size=1)
158 | self.conv2 = nn.Conv2d(in_channels, in_channels, kernel_size=1)
159 | self.avgmax = nn.AdaptiveMaxPool2d(1)
160 | self.sig = nn.Sigmoid()
161 | self.conv3_d1 = nn.Sequential(
162 | nn.Conv2d(2 * in_channels, in_channels, kernel_size=(3, 1), padding=(1, 0), stride=1, dilation=(1, 1)
163 | ),
164 | nn.Conv2d(in_channels, in_channels, kernel_size=(1, 3), padding=(0, 1), stride=1, dilation=(1, 1)
165 | ),
166 | nn.BatchNorm2d(in_channels),
167 | nn.ReLU())
168 |
169 | def forward(self, rgb, depth, edge):
170 |
171 | jian_r = rgb - edge
172 | jian_d = depth - edge
173 | jian_r = torch.abs(jian_r)
174 | jian_d = torch.abs(jian_d)
175 |
176 | mul_r_d = jian_r.mul(jian_d)
177 | add_r_d = jian_r + jian_d
178 |
179 | cat = torch.cat((mul_r_d, add_r_d), dim=1)
180 | cat_conv = self.conv3_d1(cat)
181 |
182 | out = cat_conv + edge
183 |
184 | return out
185 |
186 |
187 | class Mirror_model(nn.Module):
188 | def __init__(self):
189 | super(Mirror_model, self).__init__()
190 | self.layer1_rgb = mobilenet_v2().features[0:2]
191 | self.layer2_rgb = mobilenet_v2().features[2:4]
192 | self.layer3_rgb = mobilenet_v2().features[4:7]
193 | self.layer4_rgb = mobilenet_v2().features[7:17]
194 | self.layer5_rgb = mobilenet_v2().features[17:18]
195 |
196 | self.layer1_t = mobilenet_v2().features[0:2]
197 | self.layer2_t = mobilenet_v2().features[2:4]
198 | self.layer3_t = mobilenet_v2().features[4:7]
199 | self.layer4_t = mobilenet_v2().features[7:17]
200 | self.layer5_t = mobilenet_v2().features[17:18]
201 |
202 | self.boundary = Boundry(16)
203 |
204 |
205 |
206 | self.fusion1 = fusion(24)
207 | self.fusion2 = fusion(32)
208 | self.fusion3 = fusion(160)
209 | self.fusion4 = fusion(320)
210 |
211 | self.MFI1 = MFI(160)
212 | self.MFI2 = MFI(16)
213 | self.MFI3 = MFI(16)
214 |
215 |
216 | self.conv16_1_1 = nn.Sequential(nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
217 | nn.Conv2d(16, 1, 1))
218 | self.conv16_1_2 = nn.Sequential(nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
219 | nn.Conv2d(16, 1, 1))
220 | self.conv16_1_3 = nn.Sequential(nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
221 | nn.Conv2d(16, 1, 1))
222 | self.conv16_1_4 = nn.Sequential(nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
223 | nn.Conv2d(16, 1, 1))
224 | self.conv16_1_5 = nn.Sequential(nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
225 | nn.Conv2d(16, 1, 1))
226 |
227 | self.conv16_160 = nn.Sequential(nn.Conv2d(16, 160, 1),
228 | nn.Upsample(scale_factor=0.125, mode='bilinear', align_corners=True))
229 | self.conv16_32 = nn.Conv2d(16, 32, 1)
230 | self.conv16_24 = nn.Conv2d(16, 24, 1)
231 |
232 |
233 | self.conv32_16 = nn.Sequential(nn.Upsample(scale_factor=4, mode='bilinear', align_corners=True),
234 | nn.Conv2d(32, 16, 1)
235 | )
236 | self.conv24_16 = nn.Sequential(nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
237 | nn.Conv2d(24, 16, 1)
238 | )
239 |
240 |
241 | self.conv160_16 = nn.Sequential(nn.Upsample(scale_factor=8, mode='bilinear', align_corners=True),
242 | nn.Conv2d(160, 16, 1),
243 | )
244 | self.conv32_16 = nn.Sequential(nn.Upsample(scale_factor=4, mode='bilinear', align_corners=True),
245 | nn.Conv2d(32, 16, 1)
246 | )
247 | self.conv24_16 = nn.Sequential(nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
248 | nn.Conv2d(24, 16, 1)
249 | )
250 |
251 |
252 |
253 | self.conv_480_160 = nn.Sequential(nn.Conv2d(480, 160, 1),
254 | nn.BatchNorm2d(160),
255 | nn.ReLU(inplace=True))
256 | self.conv_192_16 = nn.Sequential(nn.Conv2d(192, 16, 1),
257 | nn.BatchNorm2d(16),
258 | nn.ReLU(inplace=True))
259 | self.conv_40_16 = nn.Sequential(nn.Conv2d(40, 16, 1),
260 | nn.BatchNorm2d(16),
261 | nn.ReLU(inplace=True))
262 |
263 | self.conv_480_160_1 = nn.Sequential(nn.Conv2d(480, 160, 1),
264 | nn.BatchNorm2d(160),
265 | nn.ReLU(inplace=True))
266 | self.conv_192_16_1 = nn.Sequential(nn.Conv2d(192, 16, 1),
267 | nn.BatchNorm2d(16),
268 | nn.ReLU(inplace=True))
269 | self.conv_40_16_1 = nn.Sequential(nn.Conv2d(40, 16, 1),
270 | nn.BatchNorm2d(16),
271 | nn.ReLU(inplace=True))
272 |
273 | self.up2 = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
274 | self.up4 = nn.Upsample(scale_factor=4, mode='bilinear', align_corners=True)
275 | self.up8 = nn.Upsample(scale_factor=8, mode='bilinear', align_corners=True)
276 |
277 |
278 |
279 |
280 |
281 | def forward(self, rgb, depth):
282 | x1_rgb = self.layer1_rgb(rgb)
283 | x2_rgb = self.layer2_rgb(x1_rgb)
284 | x3_rgb = self.layer3_rgb(x2_rgb)
285 | x4_rgb = self.layer4_rgb(x3_rgb)
286 | x5_rgb = self.layer5_rgb(x4_rgb)
287 |
288 | depth = torch.cat([depth, depth, depth], dim=1)
289 | x1_depth = self.layer1_t(depth)
290 | x2_depth = self.layer2_t(x1_depth)
291 | x3_depth = self.layer3_t(x2_depth)
292 | x4_depth = self.layer4_t(x3_depth)
293 | x5_depth = self.layer5_t(x4_depth)
294 |
295 |
296 | edge = self.boundary(x1_rgb, x1_depth)
297 | edge_conv = self.conv16_1_4(edge)
298 | edge_160 = self.conv16_160(edge)
299 |
300 | x2_r_t = self.fusion1(x2_rgb, x2_depth)
301 | x2_rgb_en = x2_rgb + x2_r_t
302 | x2_depth_en = x2_depth + x2_r_t
303 |
304 | x3_r_t = self.fusion2(x3_rgb, x3_depth)
305 | x3_rgb_en = x3_rgb + x3_r_t
306 | x3_depth_en = x3_depth + x3_r_t
307 |
308 | x4_r_t = self.fusion3(x4_rgb, x4_depth)
309 | x4_rgb_en = x4_rgb + x4_r_t
310 | x4_depth_en = x4_depth + x4_r_t
311 |
312 | x5_r_t = self.fusion4(x5_rgb, x5_depth)
313 | x5_rgb_en = x5_rgb + x5_r_t
314 | x5_depth_en = x5_depth + x5_r_t
315 |
316 | x5_rgb_en_up2 = self.up2(x5_rgb_en)
317 | x5_depth_en_up2 = self.up2(x5_depth_en)
318 | cat_5_4_r = torch.cat((x5_rgb_en_up2, x4_rgb_en), dim=1)
319 | cat_5_4_r_480_160 = self.conv_480_160(cat_5_4_r)
320 | cat_5_4_t = torch.cat((x5_depth_en_up2, x4_depth_en), dim=1)
321 | cat_5_4_t_480_160 = self.conv_480_160_1(cat_5_4_t)
322 | add_5_4 = self.MFI1(cat_5_4_r_480_160, cat_5_4_t_480_160, edge_160)
323 | add_5_4_conv = self.conv160_16(add_5_4)
324 | f3 = add_5_4_conv.mul(edge) + edge
325 |
326 |
327 | cat_5_4_r_480_160_up2 = self.up2(cat_5_4_r_480_160)
328 | cat_5_4_3_r = torch.cat((cat_5_4_r_480_160_up2, x3_rgb_en), dim=1)
329 | cat_5_4_3_r_192_16 = self.conv_192_16(cat_5_4_3_r)
330 | cat_5_4_3_r_192_16_up4 = self.up4(cat_5_4_3_r_192_16)
331 | cat_5_4_t_480_160_up2 = self.up2(cat_5_4_t_480_160)
332 | cat_5_4_3_t = torch.cat((cat_5_4_t_480_160_up2, x3_depth_en), dim=1)
333 | cat_5_4_3_t_196_16 = self.conv_192_16_1(cat_5_4_3_t)
334 | cat_5_4_3_t_196_16_up4 = self.up4(cat_5_4_3_t_196_16)
335 | add_5_4_3 = self.MFI2(cat_5_4_3_r_192_16_up4, cat_5_4_3_t_196_16_up4, f3)
336 | f2 = add_5_4_3.mul(edge) + edge
337 |
338 |
339 | cat_5_4_3_r_192_16_up2 = self.up2(cat_5_4_3_r_192_16)
340 | cat_5_4_3_t_196_16_up2 = self.up2(cat_5_4_3_t_196_16)
341 | cat_5_4_3_2_r = torch.cat((cat_5_4_3_r_192_16_up2, x2_rgb_en), dim=1)
342 | cat_5_4_3_2_r_40_16 = self.conv_40_16(cat_5_4_3_2_r)
343 | cat_5_4_3_2_r_40_16_up2 = self.up2(cat_5_4_3_2_r_40_16)
344 | cat_5_4_3_2_t = torch.cat((cat_5_4_3_t_196_16_up2, x2_depth_en), dim=1)
345 | cat_5_4_3_2_t_40_16 = self.conv_40_16_1(cat_5_4_3_2_t)
346 | cat_5_4_3_2_t_40_16_up2 = self.up2(cat_5_4_3_2_t_40_16)
347 | add_5_4_3_2 = self.MFI3(cat_5_4_3_2_r_40_16_up2, cat_5_4_3_2_t_40_16_up2, f2)
348 | f1 = add_5_4_3_2
349 |
350 |
351 | out3 = self.conv16_1_1(add_5_4_conv)
352 | out2 = self.conv16_1_2(add_5_4_3)
353 | out1 = self.conv16_1_3(f1)
354 | edge1 = self.conv16_1_4(f2)
355 | edge2 = self.conv16_1_5(f3)
356 |
357 | return out1, out2, out3, edge_conv, edge1, edge2
358 |
359 |
360 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # FHENet-PyTorch
2 |
3 | The official pytorch implementation of FHENet:**Lightweight Feature Hierarchical Exploration Network for Real-Time Rail SurfaceDefect Inspection in RGB-D Images**.[[PDF](https://ieeexplore.ieee.org/document/10019291)].The model structure is as follows:
4 |
5 | 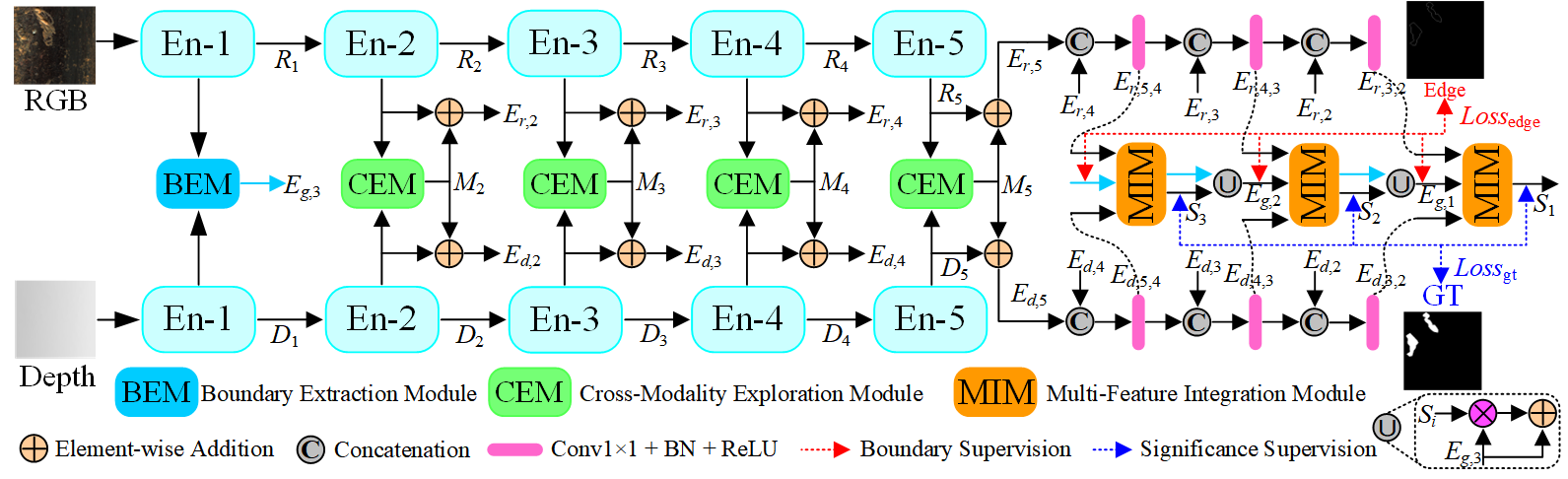 6 |
7 | # Requirements
8 | Python 3.6, Pytorch 1.7.1, Cuda 10.2, TensorboardX 2.1, opencv-python.
6 |
7 | # Requirements
8 | Python 3.6, Pytorch 1.7.1, Cuda 10.2, TensorboardX 2.1, opencv-python.
9 | If anthying goes wrong with environment, please check requirements.txt for details.
10 |
11 | # Feature Maps
12 | Baidu [RGB-D](https://pan.baidu.com/s/1xcK303N9WScaOHdVFqsHIg?pwd=na4e) 提取码: na4e
13 |
14 | # Comparison of results table
15 | Table I Evaluation metrics obtained from compared methods. The best results are shown in bold.
16 |
17 | | Models | Sm↑ | maxEm↑ | maxFm↑ | MAE↓ |
18 | | :----: | :-------: | :-------: | :-------: | :-------: |
19 | | DCMC | 0.484 | 0.595 | 0.498 | 0.287 |
20 | | ACSD | 0.556 | 0.670 | 0.575 | 0.360 |
21 | | DF | 0.564 | 0.713 | 0.636 | 0.241 |
22 | | CDCP | 0.574 | 0.694 | 0.591 | 0.236 |
23 | | DMRA | 0.736 | 0.834 | 0.783 | 0.141 |
24 | | HAI | 0.718 | 0.829 | 0.803 | 0.171 |
25 | | S2MA | 0.775 | 0.864 | 0.817 | 0.141 |
26 | | CONET | 0.786 | 0.878 | 0.834 | 0.101 |
27 | | EMI | 0.800 | 0.876 | 0.850 | 0.104 |
28 | | CSEP | 0.814 | 0.899 | 0.866 | 0.085 |
29 | | EDR | 0.811 | 0.893 | 0.850 | 0.082 |
30 | | BBS | 0.828 | 0.909 | 0.867 | 0.074 |
31 | | DAC | 0.824 | 0.911 | 0.875 | 0.071 |
32 | | CLA | 0.835 | 0.920 | 0.878 | 0.069 |
33 | | Ours | **0.836** | **0.926** | **0.881** | **0.064** |
34 |
35 | Table II Test results of the performance of the relevant methods. The best results are shown in bold.
36 |
37 | | Models | DCMC | ACSD | DF | CDCP | DMRA | HAI | S2MA | CONET | EMI | CSEP | EDR | BBS | DAC | CLA | Ours |
38 | | :------: | :----: | :----: | :----: | :----: | :----: | :--------: | :----: | ------ | :----: | :----: | :----: | :----: | :----: | ---------- | :--------: |
39 | | **Pre↑** | 66.16% | 55.93% | 78.88% | 73.07% | 80.36% | 73.90% | 76.91% | 86.85% | 82.65% | 85.29% | 85.32% | 86.27% | 86.71% | **87.27%** | 87.22% |
40 | | **Rec↑** | 25.46% | 63.88% | 31.02% | 36.14% | 74.18% | **91.67%** | 82.83% | 78.61% | 87.76% | 87.61% | 86.60% | 87.31% | 88.09% | 86.59% | 88.34% |
41 | | **F1↑** | 33.36% | 55.65% | 42.12% | 44.98% | 74.84% | 78.98% | 78.20% | 80.55% | 83.31% | 85.14% | 84.12% | 85.63% | 86.23% | 86.07% | **87.01%** |
42 | | **IOU↑** | 19.23% | 40.63% | 22.41% | 27.86% | 62.96% | 68.91% | 70.39% | 70.57% | 74.82% | 76.65% | 75.39% | 77.27% | 77.77% | 77.87% | **78.93%** |
43 |
44 | # Citation
45 |
46 | If you use FHENet in your academic work, please cite:
47 |
48 | @article{zhou2023fhenet,
49 | title={FHENet: Lightweight Feature Hierarchical Exploration Network for Real-Time Rail Surface Defect Inspection in RGB-D Images},
50 | author={Zhou, Wujie and Hong, Jiankang},
51 | journal={IEEE Transactions on Instrumentation and Measurement},
52 | year={2023},
53 | publisher={IEEE}
54 | }
55 |
56 | # Pretaining Model
57 |
58 | Model weights loading: [Baidu](https://pan.baidu.com/s/1X3iEf7yK65yraI4NYSWMTQ) 提取码:01xe
59 |
--------------------------------------------------------------------------------
/mobilenetv2.py:
--------------------------------------------------------------------------------
1 | from torch import nn
2 | from torchvision.models.utils import load_state_dict_from_url
3 |
4 |
5 | __all__ = ['MobileNetV2', 'mobilenet_v2']
6 |
7 |
8 | model_urls = {
9 | 'mobilenet_v2': 'https://download.pytorch.org/models/mobilenet_v2-b0353104.pth',
10 | }
11 |
12 |
13 | def _make_divisible(v, divisor, min_value=None):
14 | """
15 | This function is taken from the original tf repo.
16 | It ensures that all layers have a channel number that is divisible by 8
17 | It can be seen here:
18 | https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
19 | :param v:
20 | :param divisor:
21 | :param min_value:
22 | :return:
23 | """
24 | if min_value is None:
25 | min_value = divisor
26 | new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
27 | # Make sure that round down does not go down by more than 10%.
28 | if new_v < 0.9 * v:
29 | new_v += divisor
30 | return new_v
31 |
32 |
33 | class ConvBNReLU(nn.Sequential):
34 | def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, dilation=1, groups=1):
35 | padding = ((kernel_size - 1) * dilation + 1) // 2
36 | # padding = (kernel_size - 1) // 2
37 | super(ConvBNReLU, self).__init__(
38 | nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, dilation=dilation, groups=groups, bias=False),
39 | nn.BatchNorm2d(out_planes),
40 | nn.ReLU6(inplace=True)
41 | )
42 |
43 |
44 | class InvertedResidual(nn.Module):
45 | def __init__(self, inp, oup, stride, expand_ratio, dilation):
46 | super(InvertedResidual, self).__init__()
47 | self.stride = stride
48 | assert stride in [1, 2]
49 |
50 | hidden_dim = int(round(inp * expand_ratio))
51 | self.use_res_connect = self.stride == 1 and inp == oup
52 |
53 | layers = []
54 | if expand_ratio != 1:
55 | # pw
56 | layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1))
57 | layers.extend([
58 | # dw
59 | ConvBNReLU(hidden_dim, hidden_dim, stride=stride, dilation=dilation, groups=hidden_dim),
60 | # pw-linear
61 | nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
62 | nn.BatchNorm2d(oup),
63 | ])
64 | self.conv = nn.Sequential(*layers)
65 |
66 | def forward(self, x):
67 | if self.use_res_connect:
68 | return x + self.conv(x)
69 | else:
70 | return self.conv(x)
71 |
72 |
73 | class MobileNetV2(nn.Module):
74 | def __init__(self, num_classes=1000, width_mult=1.0, inverted_residual_setting=None, round_nearest=8):
75 | """
76 | MobileNet V2 main class
77 |
78 | Args:
79 | num_classes (int): Number of classes
80 | width_mult (float): Width multiplier - adjusts number of channels in each layer by this amount
81 | inverted_residual_setting: Network structure
82 | round_nearest (int): Round the number of channels in each layer to be a multiple of this number
83 | Set to 1 to turn off rounding
84 | """
85 | super(MobileNetV2, self).__init__()
86 | block = InvertedResidual
87 | input_channel = 32
88 | last_channel = 1280
89 |
90 | if inverted_residual_setting is None:
91 | inverted_residual_setting = [
92 | # t, c, n, s, d
93 | [1, 16, 1, 1, 1],
94 | [6, 24, 2, 2, 1],
95 | [6, 32, 3, 2, 1],
96 | [6, 64, 4, 2, 1],
97 | [6, 96, 3, 1, 2],
98 | [6, 160, 3, 1, 4],
99 | [6, 320, 1, 2, 1],
100 | ]
101 |
102 | # only check the first element, assuming user knows t,c,n,s are required
103 | # if len(inverted_residual_setting) == 0 or len(inverted_residual_setting[0]) != 4:
104 | # raise ValueError("inverted_residual_setting should be non-empty "
105 | # "or a 4-element list, got {}".format(inverted_residual_setting))
106 |
107 | # building first layer
108 | input_channel = _make_divisible(input_channel * width_mult, round_nearest)
109 | self.last_channel = _make_divisible(last_channel * max(1.0, width_mult), round_nearest)
110 | features = [ConvBNReLU(3, input_channel, stride=2)]
111 | # building inverted residual blocks
112 | for t, c, n, s, d in inverted_residual_setting:
113 | output_channel = _make_divisible(c * width_mult, round_nearest)
114 | for i in range(n):
115 | stride = s if i == 0 else 1
116 | features.append(block(input_channel, output_channel, stride, expand_ratio=t, dilation=d))
117 | input_channel = output_channel
118 | # building last several layers
119 | features.append(ConvBNReLU(input_channel, self.last_channel, kernel_size=1))
120 | # make it nn.Sequential
121 | self.features = nn.Sequential(*features)
122 |
123 | # building classifier
124 | self.classifier = nn.Sequential(
125 | nn.Dropout(0.2),
126 | nn.Linear(self.last_channel, num_classes),
127 | )
128 |
129 | # weight initialization
130 | for m in self.modules():
131 | if isinstance(m, nn.Conv2d):
132 | nn.init.kaiming_normal_(m.weight, mode='fan_out')
133 | if m.bias is not None:
134 | nn.init.zeros_(m.bias)
135 | elif isinstance(m, nn.BatchNorm2d):
136 | nn.init.ones_(m.weight)
137 | nn.init.zeros_(m.bias)
138 | elif isinstance(m, nn.Linear):
139 | nn.init.normal_(m.weight, 0, 0.01)
140 | nn.init.zeros_(m.bias)
141 |
142 | def forward(self, x):
143 | x = self.features(x)
144 | x = x.mean([2, 3])
145 | x = self.classifier(x)
146 | return x
147 |
148 |
149 | def mobilenet_v2(pretrained=True, progress=True, **kwargs):
150 | """
151 | Constructs a MobileNetV2 architecture from
152 | `"MobileNetV2: Inverted Residuals and Linear Bottlenecks" `_.
153 |
154 | Args:
155 | pretrained (bool): If True, returns a model pre-trained on ImageNet
156 | progress (bool): If True, displays a progress bar of the download to stderr
157 | """
158 | model = MobileNetV2(**kwargs)
159 | if pretrained:
160 | state_dict = load_state_dict_from_url(model_urls['mobilenet_v2'],
161 | progress=progress)
162 | model.load_state_dict(state_dict)
163 | print('loading>>>>>>>>>>')
164 | return model
165 |
166 |
167 |
168 | if __name__ == '__main__':
169 | import torch
170 | model = mobilenet_v2(pretrained=True)
171 | print(model)
172 | # model = mobilenet_v2_shallow()
173 |
174 | x = torch.randn((2, 3, 224, 224))
175 | x = model.features[0:2](x)
176 | out1 = model.features[2:4](x)
177 | out2 = model.features[4:7](out1)
178 | out3 = model.features[7:17](out2)
179 | out4 = model.features[17:18](out3)
180 | # out5 = model.features[14:17](out4)
181 | # out6 = model.features[17:18](out5)
182 | #
183 | print(x.shape)
184 | print(out1.shape)
185 | print(out2.shape)
186 | print(out3.shape)
187 | print(out4.shape)
188 | # print(out5.shape)
189 | # print(out6.shape)
190 |
191 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | absl-py==1.0.0
2 | addict==2.4.0
3 | apex==0.1
4 | astor==0.8.1
5 | astunparse==1.6.3
6 | attr==0.3.2
7 | backcall==0.2.0
8 | cached-property==1.5.2
9 | cachetools==4.2.4
10 | certifi==2022.9.24
11 | charset-normalizer==2.0.12
12 | clang==5.0
13 | colorama @ file:///tmp/build/80754af9/colorama_1607707115595/work
14 | cycler==0.11.0
15 | dataclasses @ file:///tmp/build/80754af9/dataclasses_1614363715916/work
16 | decorator==5.1.1
17 | einops==0.4.1
18 | flatbuffers==1.12
19 | gast==0.4.0
20 | google-auth==2.6.5
21 | google-auth-oauthlib==0.4.6
22 | google-pasta==0.2.0
23 | grpcio==1.48.2
24 | h5py==3.1.0
25 | idna==3.4
26 | imageio @ file:///tmp/build/80754af9/imageio_1617700267927/work
27 | importlib-metadata==4.8.3
28 | ipython==7.16.3
29 | ipython-genutils==0.2.0
30 | jedi==0.17.2
31 | joblib @ file:///tmp/build/80754af9/joblib_1613502643832/work
32 | keras==2.6.0
33 | Keras-Preprocessing==1.1.2
34 | kiwisolver==1.3.1
35 | Markdown==3.3.7
36 | matplotlib==3.3.4
37 | mkl-fft==1.3.0
38 | mkl-random==1.1.1
39 | mkl-service==2.3.0
40 | mmcv-full==1.2.6
41 | ninja==1.11.1
42 | nose @ file:///opt/conda/conda-bld/nose_1642704612149/work
43 | numpy==1.19.5
44 | oauthlib==3.2.1
45 | olefile==0.46
46 | opencv-python==4.5.5.62
47 | opt-einsum==3.3.0
48 | packaging==21.3
49 | paddle-bfloat==0.1.7
50 | paddlepaddle==2.4.0
51 | pandas==1.1.5
52 | parso==0.7.1
53 | pexpect==4.8.0
54 | pickleshare==0.7.5
55 | Pillow @ file:///tmp/build/80754af9/pillow_1625649052827/work
56 | portalocker @ file:///tmp/build/80754af9/portalocker_1617135543485/work
57 | progress @ file:///tmp/build/80754af9/progress_1614269494850/work
58 | prompt-toolkit==3.0.30
59 | protobuf==3.19.6
60 | ptflops==0.6.7
61 | ptyprocess==0.7.0
62 | pyasn1==0.4.8
63 | pyasn1-modules==0.2.8
64 | pydensecrf==1.0rc3
65 | Pygments==2.12.0
66 | pyparsing==3.0.6
67 | python-dateutil==2.8.2
68 | pytorch-ssim==0.1
69 | pytz==2022.1
70 | PyYAML==6.0
71 | requests==2.27.1
72 | requests-oauthlib==1.3.1
73 | rsa==4.9
74 | scikit-learn @ file:///tmp/build/80754af9/scikit-learn_1621365798935/work
75 | scipy @ file:///tmp/build/80754af9/scipy_1597686625380/work
76 | six @ file:///tmp/build/80754af9/six_1623709665295/work
77 | tb-nightly==2.9.0a20220420
78 | tensorboard==2.6.0
79 | tensorboard-data-server==0.6.1
80 | tensorboard-plugin-wit==1.8.1
81 | tensorboardX==2.4.1
82 | tensorflow==2.6.2
83 | tensorflow-estimator==2.6.0
84 | termcolor==1.1.0
85 | tf-slim==1.1.0
86 | thop==0.0.31.post2005241907
87 | threadpoolctl @ file:///Users/ktietz/demo/mc3/conda-bld/threadpoolctl_1629802263681/work
88 | timm==0.5.4
89 | torch==1.7.1
90 | torchaudio==0.7.0a0+a853dff
91 | torchvision==0.8.2
92 | tqdm @ file:///opt/conda/conda-bld/tqdm_1647339053476/work
93 | traitlets==4.3.3
94 | typing-extensions @ file:///tmp/build/80754af9/typing_extensions_1631814937681/work
95 | urllib3==1.26.12
96 | wcwidth==0.2.5
97 | Werkzeug==2.0.3
98 | wrapt==1.12.1
99 | yapf==0.32.0
100 | zipp==3.6.0
101 |
--------------------------------------------------------------------------------
/test_RGBT.py:
--------------------------------------------------------------------------------
1 | import torch as t
2 | from torch import nn
3 | # from RGBT_dataprocessing_CNet import testData1,testData2,testData3
4 | from train_test1.RGBT_dataprocessing_CNet import testData1
5 | from torch.utils.data import DataLoader
6 | import os
7 | from torch.autograd import Variable
8 | import matplotlib.pyplot as plt
9 | import torch
10 | from FHENet import Mirror_model
11 | import numpy as np
12 | from datetime import datetime
13 |
14 | test_dataloader1 = DataLoader(testData1, batch_size=1, shuffle=False, num_workers=4)
15 | net = Mirror_model()
16 |
17 | net.load_state_dict(t.load('../Pth/FHENet_RGB_D_SOD_rail.pth'))
18 |
19 | a = '../Documents/RGBT-EvaluationTools/SalMap/'
20 | b = 'Net_SOD_rail'
21 | c = ''
22 | path = a + b + c
23 |
24 | path1 = path
25 | isExist = os.path.exists(path1)
26 | if not isExist:
27 | os.makedirs(path1)
28 | else:
29 | print('path1 exist')
30 |
31 | with torch.no_grad():
32 | net.eval()
33 | net.cuda()
34 | test_mae = 0
35 |
36 | for i, sample in enumerate(test_dataloader1):
37 | image = sample['RGB']
38 | depth = sample['depth']
39 | label = sample['label']
40 | name = sample['name']
41 | name = "".join(name)
42 |
43 | image = Variable(image).cuda()
44 | depth = Variable(depth).cuda()
45 | label = Variable(label).cuda()
46 |
47 |
48 | out1 = net(image, depth)
49 | out = torch.sigmoid(out1[0])
50 |
51 | out_img = out.cpu().detach().numpy()
52 | out_img = out_img.squeeze()
53 |
54 | plt.imsave(path1 + name + '.png', arr=out_img, cmap='gray')
55 | print(path1 + name + '.png')
56 |
57 |
58 |
59 |
60 |
61 |
--------------------------------------------------------------------------------