├── .gitignore
├── LICENSE
├── README.md
├── dataset
├── __init__.py
├── bl_test_dataset.py
├── davis_test_dataset.py
├── fusion_dataset.py
├── onehot_util.py
├── range_transform.py
├── reseed.py
└── yv_test_dataset.py
├── davis_processor.py
├── docs
├── css
│ ├── materialize.css
│ ├── materialize.min.css
│ └── style.css
├── dataset.html
├── index.html
├── js
│ ├── init.js
│ ├── materialize.js
│ └── materialize.min.js
├── supplementary.pdf
└── video.html
├── download_bl30k.py
├── download_datasets.py
├── download_model.py
├── eval_interactive_davis.py
├── example
└── example.mp4
├── fbrs
├── LICENSE
├── __init__.py
├── controller.py
├── inference
│ ├── __init__.py
│ ├── clicker.py
│ ├── evaluation.py
│ ├── predictors
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── brs.py
│ │ ├── brs_functors.py
│ │ └── brs_losses.py
│ ├── transforms
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── crops.py
│ │ ├── flip.py
│ │ ├── limit_longest_side.py
│ │ └── zoom_in.py
│ └── utils.py
├── model
│ ├── __init__.py
│ ├── initializer.py
│ ├── is_deeplab_model.py
│ ├── is_hrnet_model.py
│ ├── losses.py
│ ├── metrics.py
│ ├── modeling
│ │ ├── __init__.py
│ │ ├── basic_blocks.py
│ │ ├── deeplab_v3.py
│ │ ├── hrnet_ocr.py
│ │ ├── ocr.py
│ │ ├── resnet.py
│ │ └── resnetv1b.py
│ ├── ops.py
│ └── syncbn
│ │ ├── LICENSE
│ │ ├── README.md
│ │ ├── __init__.py
│ │ └── modules
│ │ ├── __init__.py
│ │ ├── functional
│ │ ├── __init__.py
│ │ ├── _csrc.py
│ │ ├── csrc
│ │ │ ├── bn.h
│ │ │ ├── cuda
│ │ │ │ ├── bn_cuda.cu
│ │ │ │ ├── common.h
│ │ │ │ └── ext_lib.h
│ │ │ └── ext_lib.cpp
│ │ └── syncbn.py
│ │ └── nn
│ │ ├── __init__.py
│ │ └── syncbn.py
└── utils
│ ├── __init__.py
│ ├── cython
│ ├── __init__.py
│ ├── _get_dist_maps.pyx
│ ├── _get_dist_maps.pyxbld
│ └── dist_maps.py
│ ├── misc.py
│ └── vis.py
├── generate_fusion.py
├── generation
├── __init__.py
├── blender
│ ├── __init__.py
│ ├── clean_data.py
│ ├── gen_utils.py
│ ├── generate_yaml.py
│ ├── resize_texture.py
│ ├── skybox.json
│ ├── texture.json
│ └── texture_2.json
├── fusion_generator.py
└── test
│ ├── image.png
│ ├── test_spline.py
│ └── test_spline_continuous.py
├── imgs
└── framework.jpg
├── inference_core.py
├── interact
├── __init__.py
├── fbrs_controller.py
├── interaction.py
├── interactive_utils.py
├── s2m_controller.py
└── timer.py
├── interactive_gui.py
├── model
├── __init__.py
├── aggregate.py
├── attn_network.py
├── fusion_model.py
├── fusion_net.py
├── losses.py
├── propagation
│ ├── __init__.py
│ ├── mod_resnet.py
│ ├── modules.py
│ └── prop_net.py
└── s2m
│ ├── __init__.py
│ ├── _deeplab.py
│ ├── s2m_network.py
│ ├── s2m_resnet.py
│ └── utils.py
├── scripts
├── __init__.py
├── resize_length.py
└── resize_youtube.py
├── train.py
└── util
├── __init__.py
├── cv2palette.py
├── davis_subset.txt
├── hyper_para.py
├── image_saver.py
├── load_subset.py
├── log_integrator.py
├── logger.py
├── palette.py
└── tensor_util.py
/.gitignore:
--------------------------------------------------------------------------------
1 | saves/
2 | log/
3 | output/
4 | initmodel/
5 | vis/
6 | run
7 | .vscode/
8 |
9 | # Byte-compiled / optimized / DLL files
10 | __pycache__/
11 | *.py[cod]
12 | *$py.class
13 |
14 | # C extensions
15 | *.so
16 |
17 | # Distribution / packaging
18 | .Python
19 | build/
20 | develop-eggs/
21 | dist/
22 | downloads/
23 | eggs/
24 | .eggs/
25 | lib/
26 | lib64/
27 | parts/
28 | sdist/
29 | var/
30 | wheels/
31 | pip-wheel-metadata/
32 | share/python-wheels/
33 | *.egg-info/
34 | .installed.cfg
35 | *.egg
36 | MANIFEST
37 |
38 | # PyInstaller
39 | # Usually these files are written by a python script from a template
40 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
41 | *.manifest
42 | *.spec
43 |
44 | # Installer logs
45 | pip-log.txt
46 | pip-delete-this-directory.txt
47 |
48 | # Unit test / coverage reports
49 | htmlcov/
50 | .tox/
51 | .nox/
52 | .coverage
53 | .coverage.*
54 | .cache
55 | nosetests.xml
56 | coverage.xml
57 | *.cover
58 | *.py,cover
59 | .hypothesis/
60 | .pytest_cache/
61 |
62 | # Translations
63 | *.mo
64 | *.pot
65 |
66 | # Django stuff:
67 | *.log
68 | local_settings.py
69 | db.sqlite3
70 | db.sqlite3-journal
71 |
72 | # Flask stuff:
73 | instance/
74 | .webassets-cache
75 |
76 | # Scrapy stuff:
77 | .scrapy
78 |
79 | # Sphinx documentation
80 | docs/_build/
81 |
82 | # PyBuilder
83 | target/
84 |
85 | # Jupyter Notebook
86 | .ipynb_checkpoints
87 |
88 | # IPython
89 | profile_default/
90 | ipython_config.py
91 |
92 | # pyenv
93 | .python-version
94 |
95 | # pipenv
96 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
97 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
98 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
99 | # install all needed dependencies.
100 | #Pipfile.lock
101 |
102 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
103 | __pypackages__/
104 |
105 | # Celery stuff
106 | celerybeat-schedule
107 | celerybeat.pid
108 |
109 | # SageMath parsed files
110 | *.sage.py
111 |
112 | # Environments
113 | .env
114 | .venv
115 | env/
116 | venv/
117 | ENV/
118 | env.bak/
119 | venv.bak/
120 |
121 | # Spyder project settings
122 | .spyderproject
123 | .spyproject
124 |
125 | # Rope project settings
126 | .ropeproject
127 |
128 | # mkdocs documentation
129 | /site
130 |
131 | # mypy
132 | .mypy_cache/
133 | .dmypy.json
134 | dmypy.json
135 |
136 | # Pyre type checker
137 | .pyre/
138 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2024 Ho Kei Cheng
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/dataset/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/dataset/__init__.py
--------------------------------------------------------------------------------
/dataset/bl_test_dataset.py:
--------------------------------------------------------------------------------
1 | """
2 | Modified from https://github.com/seoungwugoh/STM/blob/master/dataset.py
3 | """
4 |
5 | import os
6 | from os import path
7 | import numpy as np
8 | from PIL import Image
9 |
10 | import torch
11 | from torchvision import transforms
12 | from torch.utils.data.dataset import Dataset
13 | from dataset.range_transform import im_normalization
14 | from dataset.onehot_util import all_to_onehot
15 |
16 |
17 | class BLTestDataset(Dataset):
18 | def __init__(self, root, subset=None, start=None, end=None):
19 | self.root = root
20 | self.mask_dir = path.join(root, 'Annotations')
21 | self.image_dir = path.join(root, 'JPEGImages')
22 |
23 | self.videos = []
24 | self.num_frames = {}
25 | for _video in os.listdir(self.image_dir):
26 | if subset is not None and _video not in subset:
27 | continue
28 |
29 | self.videos.append(_video)
30 | self.num_frames[_video] = len(os.listdir(path.join(self.image_dir, _video)))
31 |
32 | self.im_transform = transforms.Compose([
33 | transforms.ToTensor(),
34 | im_normalization,
35 | ])
36 |
37 | self.videos = sorted(self.videos)
38 | print('Total amount of videos: ', len(self.videos))
39 | if (start is not None) and (end is not None):
40 | print('Taking crop from %d to %d. ' % (start, end))
41 | self.videos = self.videos[start:end+1]
42 | print('New size: ', len(self.videos))
43 |
44 | def __len__(self):
45 | return len(self.videos)
46 |
47 | def __getitem__(self, index):
48 | video = self.videos[index]
49 | info = {}
50 | info['name'] = video
51 | info['num_frames'] = self.num_frames[video]
52 |
53 | images = []
54 | masks = []
55 | for f in range(self.num_frames[video]):
56 | img_file = path.join(self.image_dir, video, '{:05d}.jpg'.format(f))
57 | images.append(self.im_transform(Image.open(img_file).convert('RGB')))
58 |
59 | mask_file = path.join(self.mask_dir, video, '{:05d}.png'.format(f))
60 | masks.append(np.array(Image.open(mask_file).convert('P'), dtype=np.uint8))
61 |
62 | images = torch.stack(images, 0)
63 | masks = np.stack(masks, 0)
64 |
65 | labels = np.unique(masks)
66 | labels = labels[labels!=0]
67 | masks = torch.from_numpy(all_to_onehot(masks, labels)).float()
68 |
69 | masks = masks.unsqueeze(2)
70 |
71 | info['labels'] = labels
72 |
73 | data = {
74 | 'rgb': images,
75 | 'gt': masks,
76 | 'info': info,
77 | }
78 |
79 | return data
80 |
81 |
--------------------------------------------------------------------------------
/dataset/davis_test_dataset.py:
--------------------------------------------------------------------------------
1 | """
2 | Modified from https://github.com/seoungwugoh/STM/blob/master/dataset.py
3 | """
4 |
5 | import os
6 | from os import path
7 | import numpy as np
8 | from PIL import Image
9 |
10 | import torch
11 | import torch.nn.functional as F
12 | from torchvision import transforms
13 | from torch.utils.data.dataset import Dataset
14 | from dataset.range_transform import im_normalization
15 | from dataset.onehot_util import all_to_onehot
16 |
17 |
18 | class DAVISTestDataset(Dataset):
19 | def __init__(self, root, imset='2017/val.txt', resolution='480p', single_object=False, target_name=None):
20 | self.root = root
21 | self.mask_dir = path.join(root, 'Annotations', resolution)
22 | self.mask480_dir = path.join(root, 'Annotations', '480p')
23 | self.image_dir = path.join(root, 'JPEGImages', resolution)
24 | self.resolution = resolution
25 | _imset_dir = path.join(root, 'ImageSets')
26 | _imset_f = path.join(_imset_dir, imset)
27 |
28 | self.videos = []
29 | self.num_frames = {}
30 | self.num_objects = {}
31 | self.shape = {}
32 | self.size_480p = {}
33 | with open(path.join(_imset_f), "r") as lines:
34 | for line in lines:
35 | _video = line.rstrip('\n')
36 | if target_name is not None and target_name != _video:
37 | continue
38 | self.videos.append(_video)
39 | self.num_frames[_video] = len(os.listdir(path.join(self.image_dir, _video)))
40 | _mask = np.array(Image.open(path.join(self.mask_dir, _video, '00000.png')).convert("P"))
41 | self.num_objects[_video] = np.max(_mask)
42 | self.shape[_video] = np.shape(_mask)
43 | _mask480 = np.array(Image.open(path.join(self.mask480_dir, _video, '00000.png')).convert("P"))
44 | self.size_480p[_video] = np.shape(_mask480)
45 |
46 | self.single_object = single_object
47 |
48 | if resolution == '480p':
49 | self.im_transform = transforms.Compose([
50 | transforms.ToTensor(),
51 | im_normalization,
52 | ])
53 | else:
54 | self.im_transform = transforms.Compose([
55 | transforms.ToTensor(),
56 | im_normalization,
57 | transforms.Resize(600, interpolation=Image.BICUBIC),
58 | ])
59 | self.mask_transform = transforms.Compose([
60 | transforms.Resize(600, interpolation=Image.NEAREST),
61 | ])
62 |
63 | def __len__(self):
64 | return len(self.videos)
65 |
66 | def __getitem__(self, index):
67 | video = self.videos[index]
68 | info = {}
69 | info['name'] = video
70 | info['num_frames'] = self.num_frames[video]
71 | info['size_480p'] = self.size_480p[video]
72 |
73 | images = []
74 | masks = []
75 | for f in range(self.num_frames[video]):
76 | img_file = path.join(self.image_dir, video, '{:05d}.jpg'.format(f))
77 | images.append(self.im_transform(Image.open(img_file).convert('RGB')))
78 |
79 | mask_file = path.join(self.mask_dir, video, '{:05d}.png'.format(f))
80 | if path.exists(mask_file):
81 | masks.append(np.array(Image.open(mask_file).convert('P'), dtype=np.uint8))
82 | else:
83 | # Test-set maybe?
84 | masks.append(np.zeros_like(masks[0]))
85 |
86 | images = torch.stack(images, 0)
87 | masks = np.stack(masks, 0)
88 |
89 | if self.single_object:
90 | labels = [1]
91 | masks = (masks > 0.5).astype(np.uint8)
92 | masks = torch.from_numpy(all_to_onehot(masks, labels)).float()
93 | else:
94 | labels = np.unique(masks[0])
95 | labels = labels[labels!=0]
96 | masks = torch.from_numpy(all_to_onehot(masks, labels)).float()
97 |
98 | if self.resolution != '480p':
99 | masks = self.mask_transform(masks)
100 | masks = masks.unsqueeze(2)
101 |
102 | info['labels'] = labels
103 |
104 | data = {
105 | 'rgb': images,
106 | 'gt': masks,
107 | 'info': info,
108 | }
109 |
110 | return data
111 |
112 |
--------------------------------------------------------------------------------
/dataset/onehot_util.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 |
4 | def all_to_onehot(masks, labels):
5 | Ms = np.zeros((len(labels), masks.shape[0], masks.shape[1], masks.shape[2]), dtype=np.uint8)
6 | for k, l in enumerate(labels):
7 | Ms[k] = (masks == l).astype(np.uint8)
8 | return Ms
9 |
--------------------------------------------------------------------------------
/dataset/range_transform.py:
--------------------------------------------------------------------------------
1 | import torchvision.transforms as transforms
2 |
3 | im_mean = (124, 116, 104)
4 |
5 | im_normalization = transforms.Normalize(
6 | mean=[0.485, 0.456, 0.406],
7 | std=[0.229, 0.224, 0.225]
8 | )
9 |
10 | inv_im_trans = transforms.Normalize(
11 | mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
12 | std=[1/0.229, 1/0.224, 1/0.225])
13 |
--------------------------------------------------------------------------------
/dataset/reseed.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import random
3 |
4 | def reseed(seed):
5 | random.seed(seed)
6 | torch.manual_seed(seed)
--------------------------------------------------------------------------------
/dataset/yv_test_dataset.py:
--------------------------------------------------------------------------------
1 | # Partially taken from STM's dataloader
2 |
3 | import os
4 | from os import path
5 |
6 | import torch
7 | import torch.nn.functional as F
8 | from torch.utils.data.dataset import Dataset
9 | from torchvision import transforms
10 | from PIL import Image
11 | import numpy as np
12 | import random
13 |
14 | from dataset.range_transform import im_normalization
15 |
16 | class YouTubeVOSTestDataset(Dataset):
17 | def __init__(self, data_root, split):
18 | self.image_dir = path.join(data_root, 'vos', 'all_frames', split, 'JPEGImages')
19 | self.mask_dir = path.join(data_root, 'vos', split, 'Annotations')
20 |
21 | self.videos = []
22 | self.shape = {}
23 | self.frames = {}
24 |
25 | vid_list = sorted(os.listdir(self.image_dir))
26 | # Pre-reading
27 | for vid in vid_list:
28 | frames = sorted(os.listdir(os.path.join(self.image_dir, vid)))
29 | self.frames[vid] = frames
30 |
31 | self.videos.append(vid)
32 | first_mask = os.listdir(path.join(self.mask_dir, vid))[0]
33 | _mask = np.array(Image.open(path.join(self.mask_dir, vid, first_mask)).convert("P"))
34 | self.shape[vid] = np.shape(_mask)
35 |
36 | self.im_transform = transforms.Compose([
37 | transforms.ToTensor(),
38 | im_normalization,
39 | ])
40 |
41 | # From STM's code
42 | def To_onehot(self, mask, labels):
43 | M = np.zeros((len(labels), mask.shape[0], mask.shape[1]), dtype=np.uint8)
44 | for k, l in enumerate(labels):
45 | M[k] = (mask == l).astype(np.uint8)
46 | return M
47 |
48 | def All_to_onehot(self, masks, labels):
49 | Ms = np.zeros((len(labels), masks.shape[0], masks.shape[1], masks.shape[2]), dtype=np.uint8)
50 | for n in range(masks.shape[0]):
51 | Ms[:,n] = self.To_onehot(masks[n], labels)
52 | return Ms
53 |
54 | def __getitem__(self, idx):
55 | video = self.videos[idx]
56 | info = {}
57 | info['name'] = video
58 | info['num_objects'] = 0
59 | info['frames'] = self.frames[video]
60 | info['size'] = self.shape[video] # Real sizes
61 | info['gt_obj'] = {} # Frames with labelled objects
62 |
63 | vid_im_path = path.join(self.image_dir, video)
64 | vid_gt_path = path.join(self.mask_dir, video)
65 |
66 | frames = self.frames[video]
67 |
68 | images = []
69 | masks = []
70 | for i, f in enumerate(frames):
71 | img = Image.open(path.join(vid_im_path, f)).convert('RGB')
72 | images.append(self.im_transform(img))
73 |
74 | mask_file = path.join(vid_gt_path, f.replace('.jpg','.png'))
75 | if path.exists(mask_file):
76 | masks.append(np.array(Image.open(mask_file).convert('P'), dtype=np.uint8))
77 | this_labels = np.unique(masks[-1])
78 | this_labels = this_labels[this_labels!=0]
79 | info['gt_obj'][i] = this_labels
80 | else:
81 | # Mask not exists -> nothing in it
82 | masks.append(np.zeros(self.shape[video]))
83 |
84 | images = torch.stack(images, 0)
85 | masks = np.stack(masks, 0)
86 |
87 | # Construct the forward and backward mapping table for labels
88 | labels = np.unique(masks).astype(np.uint8)
89 | labels = labels[labels!=0]
90 | info['label_convert'] = {}
91 | info['label_backward'] = {}
92 | idx = 1
93 | for l in labels:
94 | info['label_convert'][l] = idx
95 | info['label_backward'][idx] = l
96 | idx += 1
97 | masks = torch.from_numpy(self.All_to_onehot(masks, labels)).float()
98 |
99 | # images = images.unsqueeze(0)
100 | masks = masks.unsqueeze(2)
101 |
102 | # Resize to 480p
103 | h, w = masks.shape[-2:]
104 | if h > w:
105 | new_size = (h*480//w, 480)
106 | else:
107 | new_size = (480, w*480//h)
108 | images = F.interpolate(images, size=new_size, mode='bicubic', align_corners=False)
109 | masks = F.interpolate(masks, size=(1, *new_size), mode='nearest')
110 |
111 | info['labels'] = labels
112 |
113 | data = {
114 | 'rgb': images,
115 | 'gt': masks,
116 | 'info': info,
117 | }
118 |
119 | return data
120 |
121 | def __len__(self):
122 | return len(self.videos)
--------------------------------------------------------------------------------
/davis_processor.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | import cv2
4 |
5 | from davisinteractive.utils.scribbles import scribbles2mask
6 | from inference_core import InferenceCore
7 |
8 | from model.s2m.s2m_network import deeplabv3plus_resnet50 as S2M
9 | from util.tensor_util import pad_divide_by, compute_tensor_iou
10 | from model.aggregate import aggregate_sbg, aggregate_wbg
11 |
12 | class DAVISProcessor:
13 | """
14 | Acts as the junction between DAVIS interactive track and our inference_core
15 | """
16 | def __init__(self, prop_net, fuse_net, s2m_net, images, num_objects, device='cuda:0'):
17 | self.s2m_net = s2m_net.to(device, non_blocking=True)
18 |
19 | images, self.pad = pad_divide_by(images, 16, images.shape[-2:])
20 | self.device = device
21 |
22 | # Padded dimensions
23 | nh, nw = images.shape[-2:]
24 | self.nh, self.nw = nh, nw
25 |
26 | # True dimensions
27 | t = images.shape[1]
28 | h, w = images.shape[-2:]
29 |
30 | self.k = num_objects
31 | self.t, self.h, self.w = t, h, w
32 |
33 | self.interacted_count = 0
34 | self.davis_schedule = [2, 5, 7]
35 |
36 | self.processor = InferenceCore(prop_net, fuse_net, images, num_objects, mem_profile=0, device=device)
37 |
38 | def to_mask(self, scribble):
39 | # First we select the only frame with scribble
40 | all_scr = scribble['scribbles']
41 | # all_scr is a list. len(all_scr) == total number of frames
42 | for idx, s in enumerate(all_scr):
43 | # The only non-empty element in all_scr is the frame that has been interacted with
44 | if len(s) != 0:
45 | scribble['scribbles'] = [s]
46 | # since we break here, idx will remain at the interacted frame and can be used below
47 | break
48 |
49 | # Pass to DAVIS to change the path to an array
50 | scr_mask = scribbles2mask(scribble, (self.h, self.w))[0]
51 |
52 | # Run our S2M
53 | kernel = np.ones((3,3), np.uint8)
54 | mask = torch.zeros((self.k, 1, self.nh, self.nw), dtype=torch.float32, device=self.device)
55 | for ki in range(1, self.k+1):
56 | p_srb = (scr_mask==ki).astype(np.uint8)
57 | p_srb = cv2.dilate(p_srb, kernel).astype(np.bool)
58 |
59 | n_srb = ((scr_mask!=ki) * (scr_mask!=-1)).astype(np.uint8)
60 | n_srb = cv2.dilate(n_srb, kernel).astype(np.bool)
61 |
62 | Rs = torch.from_numpy(np.stack([p_srb, n_srb], 0)).unsqueeze(0).float().to(self.device)
63 | Rs, _ = pad_divide_by(Rs, 16, Rs.shape[-2:])
64 |
65 | # Use hard mask because we train S2M with such
66 | inputs = torch.cat([self.processor.get_image_buffered(idx),
67 | (self.processor.masks[idx]==ki).to(self.device).float().unsqueeze(0), Rs], 1)
68 | mask[ki-1] = torch.sigmoid(self.s2m_net(inputs))
69 | mask = aggregate_wbg(mask, keep_bg=True, hard=True)
70 | return mask, idx
71 |
72 | def interact(self, scribble):
73 | mask, idx = self.to_mask(scribble)
74 |
75 | if self.interacted_count == self.davis_schedule[0]:
76 | # Finish the instant interaction loop for this frame
77 | self.davis_schedule = self.davis_schedule[1:]
78 | next_interact = None
79 | out_masks = self.processor.interact(mask, idx)
80 | else:
81 | next_interact = [idx]
82 | out_masks = self.processor.update_mask_only(mask, idx)
83 |
84 | self.interacted_count += 1
85 |
86 | # Trim paddings
87 | if self.pad[2]+self.pad[3] > 0:
88 | out_masks = out_masks[:,self.pad[2]:-self.pad[3],:]
89 | if self.pad[0]+self.pad[1] > 0:
90 | out_masks = out_masks[:,:,self.pad[0]:-self.pad[1]]
91 |
92 | return out_masks, next_interact, idx
93 |
--------------------------------------------------------------------------------
/docs/css/style.css:
--------------------------------------------------------------------------------
1 | /* Custom Stylesheet */
2 | /**
3 | * Use this file to override Materialize files so you can update
4 | * the core Materialize files in the future
5 | *
6 | * Made By MaterializeCSS.com
7 | */
8 |
9 | .icon-block {
10 | padding: 0 15px;
11 | }
12 | .icon-block .material-icons {
13 | font-size: inherit;
14 | }
15 |
16 | .larger-text {
17 | font-size: x-large;
18 | }
--------------------------------------------------------------------------------
/docs/js/init.js:
--------------------------------------------------------------------------------
1 | (function($){
2 | $(function(){
3 |
4 | $('.sidenav').sidenav();
5 |
6 | }); // end of document ready
7 | })(jQuery); // end of jQuery name space
8 |
--------------------------------------------------------------------------------
/docs/supplementary.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/docs/supplementary.pdf
--------------------------------------------------------------------------------
/download_bl30k.py:
--------------------------------------------------------------------------------
1 | # NO LONGER AVAILABLE
2 | # Use https://doi.org/10.13012/B2IDB-1702934_V1
3 |
4 | # import os
5 | # import gdown
6 | # import tarfile
7 |
8 |
9 | # LICENSE = """
10 | # This dataset is a derivative of ShapeNet.
11 | # Please read and respect their licenses and terms before use.
12 | # Textures and skybox image are obtained from Google image search with the "non-commercial reuse" flag.
13 | # Do not use this dataset for commercial purposes.
14 | # You should cite both ShapeNet and our paper if you use this dataset.
15 | # """
16 |
17 | # print(LICENSE)
18 | # print('Datasets will be downloaded and extracted to ../BL30K')
19 | # print('The script will download and extract the segment one by one')
20 | # print('You are going to need ~1TB of free disk space')
21 | # reply = input('[y] to confirm, others to exit: ')
22 | # if reply != 'y':
23 | # exit()
24 |
25 | # links = [
26 | # 'https://drive.google.com/uc?id=1z9V5zxLOJLNt1Uj7RFqaP2FZWKzyXvVc',
27 | # 'https://drive.google.com/uc?id=11-IzgNwEAPxgagb67FSrBdzZR7OKAEdJ',
28 | # 'https://drive.google.com/uc?id=1ZfIv6GTo-OGpXpoKen1fUvDQ0A_WoQ-Q',
29 | # 'https://drive.google.com/uc?id=1G4eXgYS2kL7_Cc0x3N1g1x7Zl8D_aU_-',
30 | # 'https://drive.google.com/uc?id=1Y8q0V_oBwJIY27W_6-8CD1dRqV2gNTdE',
31 | # 'https://drive.google.com/uc?id=1nawBAazf_unMv46qGBHhWcQ4JXZ5883r',
32 | # ]
33 |
34 | # names = [
35 | # 'BL30K_a.tar',
36 | # 'BL30K_b.tar',
37 | # 'BL30K_c.tar',
38 | # 'BL30K_d.tar',
39 | # 'BL30K_e.tar',
40 | # 'BL30K_f.tar',
41 | # ]
42 |
43 | # for i, link in enumerate(links):
44 | # print('Downloading segment %d/%d ...' % (i, len(links)))
45 | # gdown.download(link, output='../%s' % names[i], quiet=False)
46 | # print('Extracting...')
47 | # with tarfile.open('../%s' % names[i], 'r') as tar_file:
48 | # tar_file.extractall('../%s' % names[i])
49 | # print('Cleaning up...')
50 | # os.remove('../%s' % names[i])
51 |
52 |
53 | # print('Done.')
54 |
--------------------------------------------------------------------------------
/download_datasets.py:
--------------------------------------------------------------------------------
1 | import os
2 | import gdown
3 | import zipfile
4 | from scripts import resize_youtube
5 |
6 |
7 | LICENSE = """
8 | These are either re-distribution of the original datasets or derivatives (through simple processing) of the original datasets.
9 | Please read and respect their licenses and terms before use.
10 | You should cite the original papers if you use any of the datasets.
11 |
12 | For BL30K, see download_bl30k.py
13 |
14 | Links:
15 | DUTS: http://saliencydetection.net/duts
16 | HRSOD: https://github.com/yi94code/HRSOD
17 | FSS: https://github.com/HKUSTCV/FSS-1000
18 | ECSSD: https://www.cse.cuhk.edu.hk/leojia/projects/hsaliency/dataset.html
19 | BIG: https://github.com/hkchengrex/CascadePSP
20 |
21 | YouTubeVOS: https://youtube-vos.org
22 | DAVIS: https://davischallenge.org/
23 | BL30K: https://github.com/hkchengrex/MiVOS
24 | """
25 |
26 | print(LICENSE)
27 | print('Datasets will be downloaded and extracted to ../YouTube, ../static, ../DAVIS')
28 | reply = input('[y] to confirm, others to exit: ')
29 | if reply != 'y':
30 | exit()
31 |
32 |
33 | # Static data
34 | os.makedirs('../static', exist_ok=True)
35 | print('Downloading static datasets...')
36 | gdown.download('https://drive.google.com/uc?id=1wUJq3HcLdN-z1t4CsUhjeZ9BVDb9YKLd', output='../static/static_data.zip', quiet=False)
37 | print('Extracting static datasets...')
38 | with zipfile.ZipFile('../static/static_data.zip', 'r') as zip_file:
39 | zip_file.extractall('../static/')
40 | print('Cleaning up static datasets...')
41 | os.remove('../static/static_data.zip')
42 |
43 |
44 | # DAVIS
45 | # Google drive mirror: https://drive.google.com/drive/folders/1hEczGHw7qcMScbCJukZsoOW4Q9byx16A?usp=sharing
46 | os.makedirs('../DAVIS/2017', exist_ok=True)
47 |
48 | print('Downloading DAVIS 2016...')
49 | gdown.download('https://drive.google.com/uc?id=198aRlh5CpAoFz0hfRgYbiNenn_K8DxWD', output='../DAVIS/DAVIS-data.zip', quiet=False)
50 |
51 | print('Downloading DAVIS 2017 trainval...')
52 | gdown.download('https://drive.google.com/uc?id=1kiaxrX_4GuW6NmiVuKGSGVoKGWjOdp6d', output='../DAVIS/2017/DAVIS-2017-trainval-480p.zip', quiet=False)
53 |
54 | print('Downloading DAVIS 2017 testdev...')
55 | gdown.download('https://drive.google.com/uc?id=1fmkxU2v9cQwyb62Tj1xFDdh2p4kDsUzD', output='../DAVIS/2017/DAVIS-2017-test-dev-480p.zip', quiet=False)
56 |
57 | print('Downloading DAVIS 2017 scribbles...')
58 | gdown.download('https://drive.google.com/uc?id=1JzIQSu36h7dVM8q0VoE4oZJwBXvrZlkl', output='../DAVIS/2017/DAVIS-2017-scribbles-trainval.zip', quiet=False)
59 |
60 | print('Extracting DAVIS datasets...')
61 | with zipfile.ZipFile('../DAVIS/DAVIS-data.zip', 'r') as zip_file:
62 | zip_file.extractall('../DAVIS/')
63 | os.rename('../DAVIS/DAVIS', '../DAVIS/2016')
64 |
65 | with zipfile.ZipFile('../DAVIS/2017/DAVIS-2017-trainval-480p.zip', 'r') as zip_file:
66 | zip_file.extractall('../DAVIS/2017/')
67 | with zipfile.ZipFile('../DAVIS/2017/DAVIS-2017-scribbles-trainval.zip', 'r') as zip_file:
68 | zip_file.extractall('../DAVIS/2017/')
69 | os.rename('../DAVIS/2017/DAVIS', '../DAVIS/2017/trainval')
70 |
71 | with zipfile.ZipFile('../DAVIS/2017/DAVIS-2017-test-dev-480p.zip', 'r') as zip_file:
72 | zip_file.extractall('../DAVIS/2017/')
73 | os.rename('../DAVIS/2017/DAVIS', '../DAVIS/2017/test-dev')
74 |
75 | print('Cleaning up DAVIS datasets...')
76 | os.remove('../DAVIS/2017/DAVIS-2017-trainval-480p.zip')
77 | os.remove('../DAVIS/2017/DAVIS-2017-test-dev-480p.zip')
78 | os.remove('../DAVIS/2017/DAVIS-2017-scribbles-trainval.zip')
79 | os.remove('../DAVIS/DAVIS-data.zip')
80 |
81 |
82 | # YouTubeVOS
83 | os.makedirs('../YouTube', exist_ok=True)
84 | os.makedirs('../YouTube/all_frames', exist_ok=True)
85 | print('Downloading YouTubeVOS train...')
86 | gdown.download('https://drive.google.com/uc?id=13Eqw0gVK-AO5B-cqvJ203mZ2vzWck9s4', output='../YouTube/train.zip', quiet=False)
87 | print('Downloading YouTubeVOS val...')
88 | gdown.download('https://drive.google.com/uc?id=1o586Wjya-f2ohxYf9C1RlRH-gkrzGS8t', output='../YouTube/valid.zip', quiet=False)
89 | print('Downloading YouTubeVOS all frames valid...')
90 | gdown.download('https://drive.google.com/uc?id=1rWQzZcMskgpEQOZdJPJ7eTmLCBEIIpEN', output='../YouTube/all_frames/valid.zip', quiet=False)
91 |
92 | print('Extracting YouTube datasets...')
93 | with zipfile.ZipFile('../YouTube/train.zip', 'r') as zip_file:
94 | zip_file.extractall('../YouTube/')
95 | with zipfile.ZipFile('../YouTube/valid.zip', 'r') as zip_file:
96 | zip_file.extractall('../YouTube/')
97 | with zipfile.ZipFile('../YouTube/all_frames/valid.zip', 'r') as zip_file:
98 | zip_file.extractall('../YouTube/all_frames')
99 |
100 | print('Cleaning up YouTubeVOS datasets...')
101 | os.remove('../YouTube/train.zip')
102 | os.remove('../YouTube/valid.zip')
103 | os.remove('../YouTube/all_frames/valid.zip')
104 |
105 | print('Resizing YouTubeVOS to 480p...')
106 | resize_youtube.resize_all('../YouTube/train', '../YouTube/train_480p')
107 |
108 | print('Done.')
--------------------------------------------------------------------------------
/download_model.py:
--------------------------------------------------------------------------------
1 | import os
2 | import gdown
3 | import urllib.request
4 |
5 |
6 | os.makedirs('saves', exist_ok=True)
7 | print('Downloading propagation model...')
8 | gdown.download('https://drive.google.com/uc?id=19dfbVDndFkboGLHESi8DGtuxF1B21Nm8', output='saves/propagation_model.pth', quiet=False)
9 |
10 | print('Downloading fusion model...')
11 | gdown.download('https://drive.google.com/uc?id=1Lc1lI5-ix4WsCRdipACXgvS3G-o0lMoz', output='saves/fusion.pth', quiet=False)
12 |
13 | print('Downloading s2m model...')
14 | gdown.download('https://drive.google.com/uc?id=1HKwklVey3P2jmmdmrACFlkXtcvNxbKMM', output='saves/s2m.pth', quiet=False)
15 |
16 | print('Downloading fbrs model...')
17 | urllib.request.urlretrieve('https://github.com/saic-vul/fbrs_interactive_segmentation/releases/download/v1.0/resnet50_dh128_lvis.pth', 'saves/fbrs.pth')
18 |
19 | print('Done.')
--------------------------------------------------------------------------------
/eval_interactive_davis.py:
--------------------------------------------------------------------------------
1 | import os
2 | from os import path
3 | from argparse import ArgumentParser
4 |
5 | import torch
6 | from torch.utils.data import Dataset, DataLoader
7 | import numpy as np
8 | from PIL import Image
9 | import cv2
10 |
11 | from model.propagation.prop_net import PropagationNetwork
12 | from model.fusion_net import FusionNet
13 | from model.s2m.s2m_network import deeplabv3plus_resnet50 as S2M
14 | from dataset.davis_test_dataset import DAVISTestDataset
15 | from davis_processor import DAVISProcessor
16 |
17 | from davisinteractive.session.session import DavisInteractiveSession
18 |
19 | """
20 | Arguments loading
21 | """
22 | parser = ArgumentParser()
23 | parser.add_argument('--prop_model', default='saves/propagation_model.pth')
24 | parser.add_argument('--fusion_model', default='saves/fusion.pth')
25 | parser.add_argument('--s2m_model', default='saves/s2m.pth')
26 | parser.add_argument('--davis', default='../DAVIS/2017')
27 | parser.add_argument('--output')
28 | parser.add_argument('--save_mask', action='store_true')
29 |
30 | args = parser.parse_args()
31 |
32 | davis_path = args.davis
33 | out_path = args.output
34 | save_mask = args.save_mask
35 |
36 | # Simple setup
37 | os.makedirs(out_path, exist_ok=True)
38 | palette = Image.open(path.expanduser(davis_path + '/trainval/Annotations/480p/blackswan/00000.png')).getpalette()
39 |
40 | torch.autograd.set_grad_enabled(False)
41 |
42 | # Setup Dataset
43 | test_dataset = DAVISTestDataset(davis_path+'/trainval', imset='2017/val.txt')
44 | test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False, num_workers=2)
45 |
46 | images = {}
47 | num_objects = {}
48 | # Loads all the images
49 | for data in test_loader:
50 | rgb = data['rgb']
51 | k = len(data['info']['labels'][0])
52 | name = data['info']['name'][0]
53 | images[name] = rgb
54 | num_objects[name] = k
55 | print('Finished loading %d sequences.' % len(images))
56 |
57 | # Load our checkpoint
58 | prop_saved = torch.load(args.prop_model)
59 | prop_model = PropagationNetwork().cuda().eval()
60 | prop_model.load_state_dict(prop_saved)
61 |
62 | fusion_saved = torch.load(args.fusion_model)
63 | fusion_model = FusionNet().cuda().eval()
64 | fusion_model.load_state_dict(fusion_saved)
65 |
66 | s2m_saved = torch.load(args.s2m_model)
67 | s2m_model = S2M().cuda().eval()
68 | s2m_model.load_state_dict(s2m_saved)
69 |
70 | total_iter = 0
71 | user_iter = 0
72 | last_seq = None
73 | pred_masks = None
74 | with DavisInteractiveSession(davis_root=davis_path+'/trainval', report_save_dir='../output', max_nb_interactions=8, max_time=8*30) as sess:
75 | while sess.next():
76 | sequence, scribbles, new_seq = sess.get_scribbles(only_last=True)
77 |
78 | if new_seq:
79 | if 'processor' in locals():
80 | # Note that ALL pre-computed features are flushed in this step
81 | # We are not using pre-computed features for the same sequence with different user-id
82 | del processor # Should release some juicy mem
83 | processor = DAVISProcessor(prop_model, fusion_model, s2m_model, images[sequence], num_objects[sequence])
84 | print(sequence)
85 |
86 | # Save last time
87 | if save_mask:
88 | if pred_masks is not None:
89 | seq_path = path.join(out_path, str(user_iter), last_seq)
90 | os.makedirs(seq_path, exist_ok=True)
91 | for i in range(len(pred_masks)):
92 | img_E = Image.fromarray(pred_masks[i])
93 | img_E.putpalette(palette)
94 | img_E.save(os.path.join(seq_path, '{:05d}.png'.format(i)))
95 |
96 | if (last_seq is None) or (sequence != last_seq):
97 | last_seq = sequence
98 | user_iter = 0
99 | else:
100 | user_iter += 1
101 |
102 | pred_masks, next_masks, this_idx = processor.interact(scribbles)
103 | sess.submit_masks(pred_masks, next_masks)
104 |
105 | total_iter += 1
106 |
107 | report = sess.get_report()
108 | summary = sess.get_global_summary(save_file=path.join(out_path, 'summary.json'))
109 |
--------------------------------------------------------------------------------
/example/example.mp4:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/example/example.mp4
--------------------------------------------------------------------------------
/fbrs/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/fbrs/__init__.py
--------------------------------------------------------------------------------
/fbrs/controller.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | from torchvision import transforms
4 |
5 | from fbrs.inference import clicker
6 | from fbrs.inference.predictors import get_predictor
7 | from fbrs.utils.vis import draw_with_blend_and_clicks
8 |
9 |
10 | class InteractiveController:
11 | def __init__(self, net, device, predictor_params, prob_thresh=0.5):
12 | self.net = net.to(device)
13 | self.prob_thresh = prob_thresh
14 | self.clicker = clicker.Clicker()
15 | self.states = []
16 | self.probs_history = []
17 | self.object_count = 0
18 | self._result_mask = None
19 |
20 | self.image = None
21 | self.predictor = None
22 | self.device = device
23 | self.predictor_params = predictor_params
24 | self.reset_predictor()
25 |
26 | def set_image(self, image):
27 | self.image = image
28 | self._result_mask = torch.zeros(image.shape[-2:], dtype=torch.uint8)
29 | self.object_count = 0
30 | self.reset_last_object()
31 |
32 | def add_click(self, x, y, is_positive):
33 | self.states.append({
34 | 'clicker': self.clicker.get_state(),
35 | 'predictor': self.predictor.get_states()
36 | })
37 |
38 | click = clicker.Click(is_positive=is_positive, coords=(y, x))
39 | self.clicker.add_click(click)
40 | pred = self.predictor.get_prediction(self.clicker)
41 | torch.cuda.empty_cache()
42 |
43 | if self.probs_history:
44 | self.probs_history.append((self.probs_history[-1][0], pred))
45 | else:
46 | self.probs_history.append((torch.zeros_like(pred), pred))
47 |
48 | def undo_click(self):
49 | if not self.states:
50 | return
51 |
52 | prev_state = self.states.pop()
53 | self.clicker.set_state(prev_state['clicker'])
54 | self.predictor.set_states(prev_state['predictor'])
55 | self.probs_history.pop()
56 |
57 | def partially_finish_object(self):
58 | object_prob = self.current_object_prob
59 | if object_prob is None:
60 | return
61 |
62 | self.probs_history.append((object_prob, torch.zeros_like(object_prob)))
63 | self.states.append(self.states[-1])
64 |
65 | self.clicker.reset_clicks()
66 | self.reset_predictor()
67 |
68 | def finish_object(self):
69 | object_prob = self.current_object_prob
70 | if object_prob is None:
71 | return
72 |
73 | self.object_count += 1
74 | object_mask = object_prob > self.prob_thresh
75 | self._result_mask[object_mask] = self.object_count
76 | self.reset_last_object()
77 |
78 | def reset_last_object(self):
79 | self.states = []
80 | self.probs_history = []
81 | self.clicker.reset_clicks()
82 | self.reset_predictor()
83 |
84 | def reset_predictor(self, predictor_params=None):
85 | if predictor_params is not None:
86 | self.predictor_params = predictor_params
87 | self.predictor = get_predictor(self.net, device=self.device,
88 | **self.predictor_params)
89 | if self.image is not None:
90 | self.predictor.set_input_image(self.image)
91 |
92 | @property
93 | def current_object_prob(self):
94 | if self.probs_history:
95 | current_prob_total, current_prob_additive = self.probs_history[-1]
96 | return torch.maximum(current_prob_total, current_prob_additive)
97 | else:
98 | return None
99 |
100 | @property
101 | def is_incomplete_mask(self):
102 | return len(self.probs_history) > 0
103 |
104 | @property
105 | def result_mask(self):
106 | return self._result_mask.clone()
107 |
--------------------------------------------------------------------------------
/fbrs/inference/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/fbrs/inference/__init__.py
--------------------------------------------------------------------------------
/fbrs/inference/clicker.py:
--------------------------------------------------------------------------------
1 | from collections import namedtuple
2 |
3 | import numpy as np
4 | from copy import deepcopy
5 | from scipy.ndimage import distance_transform_edt
6 |
7 | Click = namedtuple('Click', ['is_positive', 'coords'])
8 |
9 |
10 | class Clicker(object):
11 | def __init__(self, gt_mask=None, init_clicks=None, ignore_label=-1):
12 | if gt_mask is not None:
13 | self.gt_mask = gt_mask == 1
14 | self.not_ignore_mask = gt_mask != ignore_label
15 | else:
16 | self.gt_mask = None
17 |
18 | self.reset_clicks()
19 |
20 | if init_clicks is not None:
21 | for click in init_clicks:
22 | self.add_click(click)
23 |
24 | def make_next_click(self, pred_mask):
25 | assert self.gt_mask is not None
26 | click = self._get_click(pred_mask)
27 | self.add_click(click)
28 |
29 | def get_clicks(self, clicks_limit=None):
30 | return self.clicks_list[:clicks_limit]
31 |
32 | def _get_click(self, pred_mask, padding=True):
33 | fn_mask = np.logical_and(np.logical_and(self.gt_mask, np.logical_not(pred_mask)), self.not_ignore_mask)
34 | fp_mask = np.logical_and(np.logical_and(np.logical_not(self.gt_mask), pred_mask), self.not_ignore_mask)
35 |
36 | if padding:
37 | fn_mask = np.pad(fn_mask, ((1, 1), (1, 1)), 'constant')
38 | fp_mask = np.pad(fp_mask, ((1, 1), (1, 1)), 'constant')
39 |
40 | fn_mask_dt = distance_transform_edt(fn_mask)
41 | fp_mask_dt = distance_transform_edt(fp_mask)
42 |
43 | if padding:
44 | fn_mask_dt = fn_mask_dt[1:-1, 1:-1]
45 | fp_mask_dt = fp_mask_dt[1:-1, 1:-1]
46 |
47 | fn_mask_dt = fn_mask_dt * self.not_clicked_map
48 | fp_mask_dt = fp_mask_dt * self.not_clicked_map
49 |
50 | fn_max_dist = np.max(fn_mask_dt)
51 | fp_max_dist = np.max(fp_mask_dt)
52 |
53 | is_positive = fn_max_dist > fp_max_dist
54 | if is_positive:
55 | coords_y, coords_x = np.where(fn_mask_dt == fn_max_dist) # coords is [y, x]
56 | else:
57 | coords_y, coords_x = np.where(fp_mask_dt == fp_max_dist) # coords is [y, x]
58 |
59 | return Click(is_positive=is_positive, coords=(coords_y[0], coords_x[0]))
60 |
61 | def add_click(self, click):
62 | coords = click.coords
63 |
64 | if click.is_positive:
65 | self.num_pos_clicks += 1
66 | else:
67 | self.num_neg_clicks += 1
68 |
69 | self.clicks_list.append(click)
70 | if self.gt_mask is not None:
71 | self.not_clicked_map[coords[0], coords[1]] = False
72 |
73 | def _remove_last_click(self):
74 | click = self.clicks_list.pop()
75 | coords = click.coords
76 |
77 | if click.is_positive:
78 | self.num_pos_clicks -= 1
79 | else:
80 | self.num_neg_clicks -= 1
81 |
82 | if self.gt_mask is not None:
83 | self.not_clicked_map[coords[0], coords[1]] = True
84 |
85 | def reset_clicks(self):
86 | if self.gt_mask is not None:
87 | self.not_clicked_map = np.ones_like(self.gt_mask, dtype=np.bool)
88 |
89 | self.num_pos_clicks = 0
90 | self.num_neg_clicks = 0
91 |
92 | self.clicks_list = []
93 |
94 | def get_state(self):
95 | return deepcopy(self.clicks_list)
96 |
97 | def set_state(self, state):
98 | self.reset_clicks()
99 | for click in state:
100 | self.add_click(click)
101 |
102 | def __len__(self):
103 | return len(self.clicks_list)
104 |
--------------------------------------------------------------------------------
/fbrs/inference/evaluation.py:
--------------------------------------------------------------------------------
1 | from time import time
2 |
3 | import numpy as np
4 | import torch
5 |
6 | from fbrs.inference import utils
7 | from fbrs.inference.clicker import Clicker
8 |
9 | try:
10 | get_ipython()
11 | from tqdm import tqdm_notebook as tqdm
12 | except NameError:
13 | from tqdm import tqdm
14 |
15 |
16 | def evaluate_dataset(dataset, predictor, oracle_eval=False, **kwargs):
17 | all_ious = []
18 |
19 | start_time = time()
20 | for index in tqdm(range(len(dataset)), leave=False):
21 | sample = dataset.get_sample(index)
22 | item = dataset[index]
23 |
24 | if oracle_eval:
25 | gt_mask = torch.tensor(sample['instances_mask'], dtype=torch.float32)
26 | gt_mask = gt_mask.unsqueeze(0).unsqueeze(0)
27 | predictor.opt_functor.mask_loss.set_gt_mask(gt_mask)
28 | _, sample_ious, _ = evaluate_sample(item['images'], sample['instances_mask'], predictor, **kwargs)
29 | all_ious.append(sample_ious)
30 | end_time = time()
31 | elapsed_time = end_time - start_time
32 |
33 | return all_ious, elapsed_time
34 |
35 |
36 | def evaluate_sample(image_nd, instances_mask, predictor, max_iou_thr,
37 | pred_thr=0.49, max_clicks=20):
38 | clicker = Clicker(gt_mask=instances_mask)
39 | pred_mask = np.zeros_like(instances_mask)
40 | ious_list = []
41 |
42 | with torch.no_grad():
43 | predictor.set_input_image(image_nd)
44 |
45 | for click_number in range(max_clicks):
46 | clicker.make_next_click(pred_mask)
47 | pred_probs = predictor.get_prediction(clicker)
48 | pred_mask = pred_probs > pred_thr
49 |
50 | iou = utils.get_iou(instances_mask, pred_mask)
51 | ious_list.append(iou)
52 |
53 | if iou >= max_iou_thr:
54 | break
55 |
56 | return clicker.clicks_list, np.array(ious_list, dtype=np.float32), pred_probs
57 |
--------------------------------------------------------------------------------
/fbrs/inference/predictors/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import BasePredictor
2 | from .brs import InputBRSPredictor, FeatureBRSPredictor, HRNetFeatureBRSPredictor
3 | from .brs_functors import InputOptimizer, ScaleBiasOptimizer
4 | from fbrs.inference.transforms import ZoomIn
5 | from fbrs.model.is_hrnet_model import DistMapsHRNetModel
6 |
7 |
8 | def get_predictor(net, brs_mode, device,
9 | prob_thresh=0.49,
10 | with_flip=True,
11 | zoom_in_params=dict(),
12 | predictor_params=None,
13 | brs_opt_func_params=None,
14 | lbfgs_params=None):
15 | lbfgs_params_ = {
16 | 'm': 20,
17 | 'factr': 0,
18 | 'pgtol': 1e-8,
19 | 'maxfun': 20,
20 | }
21 |
22 | predictor_params_ = {
23 | 'optimize_after_n_clicks': 1
24 | }
25 |
26 | if zoom_in_params is not None:
27 | zoom_in = ZoomIn(**zoom_in_params)
28 | else:
29 | zoom_in = None
30 |
31 | if lbfgs_params is not None:
32 | lbfgs_params_.update(lbfgs_params)
33 | lbfgs_params_['maxiter'] = 2 * lbfgs_params_['maxfun']
34 |
35 | if brs_opt_func_params is None:
36 | brs_opt_func_params = dict()
37 |
38 | if brs_mode == 'NoBRS':
39 | if predictor_params is not None:
40 | predictor_params_.update(predictor_params)
41 | predictor = BasePredictor(net, device, zoom_in=zoom_in, with_flip=with_flip, **predictor_params_)
42 | elif brs_mode.startswith('f-BRS'):
43 | predictor_params_.update({
44 | 'net_clicks_limit': 8,
45 | })
46 | if predictor_params is not None:
47 | predictor_params_.update(predictor_params)
48 |
49 | insertion_mode = {
50 | 'f-BRS-A': 'after_c4',
51 | 'f-BRS-B': 'after_aspp',
52 | 'f-BRS-C': 'after_deeplab'
53 | }[brs_mode]
54 |
55 | opt_functor = ScaleBiasOptimizer(prob_thresh=prob_thresh,
56 | with_flip=with_flip,
57 | optimizer_params=lbfgs_params_,
58 | **brs_opt_func_params)
59 |
60 | if isinstance(net, DistMapsHRNetModel):
61 | FeaturePredictor = HRNetFeatureBRSPredictor
62 | insertion_mode = {'after_c4': 'A', 'after_aspp': 'A', 'after_deeplab': 'C'}[insertion_mode]
63 | else:
64 | FeaturePredictor = FeatureBRSPredictor
65 |
66 | predictor = FeaturePredictor(net, device,
67 | opt_functor=opt_functor,
68 | with_flip=with_flip,
69 | insertion_mode=insertion_mode,
70 | zoom_in=zoom_in,
71 | **predictor_params_)
72 | elif brs_mode == 'RGB-BRS' or brs_mode == 'DistMap-BRS':
73 | use_dmaps = brs_mode == 'DistMap-BRS'
74 |
75 | predictor_params_.update({
76 | 'net_clicks_limit': 5,
77 | })
78 | if predictor_params is not None:
79 | predictor_params_.update(predictor_params)
80 |
81 | opt_functor = InputOptimizer(prob_thresh=prob_thresh,
82 | with_flip=with_flip,
83 | optimizer_params=lbfgs_params_,
84 | **brs_opt_func_params)
85 |
86 | predictor = InputBRSPredictor(net, device,
87 | optimize_target='dmaps' if use_dmaps else 'rgb',
88 | opt_functor=opt_functor,
89 | with_flip=with_flip,
90 | zoom_in=zoom_in,
91 | **predictor_params_)
92 | else:
93 | raise NotImplementedError
94 |
95 | return predictor
96 |
--------------------------------------------------------------------------------
/fbrs/inference/predictors/base.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 |
4 | from fbrs.inference.transforms import AddHorizontalFlip, SigmoidForPred, LimitLongestSide
5 |
6 |
7 | class BasePredictor(object):
8 | def __init__(self, net, device,
9 | net_clicks_limit=None,
10 | with_flip=False,
11 | zoom_in=None,
12 | max_size=None,
13 | **kwargs):
14 | self.net = net
15 | self.with_flip = with_flip
16 | self.net_clicks_limit = net_clicks_limit
17 | self.original_image = None
18 | self.device = device
19 | self.zoom_in = zoom_in
20 |
21 | self.transforms = [zoom_in] if zoom_in is not None else []
22 | if max_size is not None:
23 | self.transforms.append(LimitLongestSide(max_size=max_size))
24 | self.transforms.append(SigmoidForPred())
25 | if with_flip:
26 | self.transforms.append(AddHorizontalFlip())
27 |
28 | def set_input_image(self, image_nd):
29 | for transform in self.transforms:
30 | transform.reset()
31 | self.original_image = image_nd.to(self.device)
32 | if len(self.original_image.shape) == 3:
33 | self.original_image = self.original_image.unsqueeze(0)
34 |
35 | def get_prediction(self, clicker):
36 | clicks_list = clicker.get_clicks()
37 |
38 | image_nd, clicks_lists, is_image_changed = self.apply_transforms(
39 | self.original_image, [clicks_list]
40 | )
41 |
42 | pred_logits = self._get_prediction(image_nd, clicks_lists, is_image_changed)
43 | prediction = F.interpolate(pred_logits, mode='bilinear', align_corners=True,
44 | size=image_nd.size()[2:])
45 |
46 | for t in reversed(self.transforms):
47 | prediction = t.inv_transform(prediction)
48 |
49 | if self.zoom_in is not None and self.zoom_in.check_possible_recalculation():
50 | print('zooming')
51 | return self.get_prediction(clicker)
52 |
53 | # return prediction.cpu().numpy()[0, 0]
54 | return prediction
55 |
56 | def _get_prediction(self, image_nd, clicks_lists, is_image_changed):
57 | points_nd = self.get_points_nd(clicks_lists)
58 | return self.net(image_nd, points_nd)['instances']
59 |
60 | def _get_transform_states(self):
61 | return [x.get_state() for x in self.transforms]
62 |
63 | def _set_transform_states(self, states):
64 | assert len(states) == len(self.transforms)
65 | for state, transform in zip(states, self.transforms):
66 | transform.set_state(state)
67 |
68 | def apply_transforms(self, image_nd, clicks_lists):
69 | is_image_changed = False
70 | for t in self.transforms:
71 | image_nd, clicks_lists = t.transform(image_nd, clicks_lists)
72 | is_image_changed |= t.image_changed
73 |
74 | return image_nd, clicks_lists, is_image_changed
75 |
76 | def get_points_nd(self, clicks_lists):
77 | total_clicks = []
78 | num_pos_clicks = [sum(x.is_positive for x in clicks_list) for clicks_list in clicks_lists]
79 | num_neg_clicks = [len(clicks_list) - num_pos for clicks_list, num_pos in zip(clicks_lists, num_pos_clicks)]
80 | num_max_points = max(num_pos_clicks + num_neg_clicks)
81 | if self.net_clicks_limit is not None:
82 | num_max_points = min(self.net_clicks_limit, num_max_points)
83 | num_max_points = max(1, num_max_points)
84 |
85 | for clicks_list in clicks_lists:
86 | clicks_list = clicks_list[:self.net_clicks_limit]
87 | pos_clicks = [click.coords for click in clicks_list if click.is_positive]
88 | pos_clicks = pos_clicks + (num_max_points - len(pos_clicks)) * [(-1, -1)]
89 |
90 | neg_clicks = [click.coords for click in clicks_list if not click.is_positive]
91 | neg_clicks = neg_clicks + (num_max_points - len(neg_clicks)) * [(-1, -1)]
92 | total_clicks.append(pos_clicks + neg_clicks)
93 |
94 | return torch.tensor(total_clicks, device=self.device)
95 |
96 | def get_states(self):
97 | return {'transform_states': self._get_transform_states()}
98 |
99 | def set_states(self, states):
100 | self._set_transform_states(states['transform_states'])
101 |
--------------------------------------------------------------------------------
/fbrs/inference/predictors/brs_functors.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 |
4 | from fbrs.model.metrics import _compute_iou
5 | from .brs_losses import BRSMaskLoss
6 |
7 |
8 | class BaseOptimizer:
9 | def __init__(self, optimizer_params,
10 | prob_thresh=0.49,
11 | reg_weight=1e-3,
12 | min_iou_diff=0.01,
13 | brs_loss=BRSMaskLoss(),
14 | with_flip=False,
15 | flip_average=False,
16 | **kwargs):
17 | self.brs_loss = brs_loss
18 | self.optimizer_params = optimizer_params
19 | self.prob_thresh = prob_thresh
20 | self.reg_weight = reg_weight
21 | self.min_iou_diff = min_iou_diff
22 | self.with_flip = with_flip
23 | self.flip_average = flip_average
24 |
25 | self.best_prediction = None
26 | self._get_prediction_logits = None
27 | self._opt_shape = None
28 | self._best_loss = None
29 | self._click_masks = None
30 | self._last_mask = None
31 | self.device = None
32 |
33 | def init_click(self, get_prediction_logits, pos_mask, neg_mask, device, shape=None):
34 | self.best_prediction = None
35 | self._get_prediction_logits = get_prediction_logits
36 | self._click_masks = (pos_mask, neg_mask)
37 | self._opt_shape = shape
38 | self._last_mask = None
39 | self.device = device
40 |
41 | def __call__(self, x):
42 | opt_params = torch.from_numpy(x).float().to(self.device)
43 | opt_params.requires_grad_(True)
44 |
45 | with torch.enable_grad():
46 | opt_vars, reg_loss = self.unpack_opt_params(opt_params)
47 | result_before_sigmoid = self._get_prediction_logits(*opt_vars)
48 | result = torch.sigmoid(result_before_sigmoid)
49 |
50 | pos_mask, neg_mask = self._click_masks
51 | if self.with_flip and self.flip_average:
52 | result, result_flipped = torch.chunk(result, 2, dim=0)
53 | result = 0.5 * (result + torch.flip(result_flipped, dims=[3]))
54 | pos_mask, neg_mask = pos_mask[:result.shape[0]], neg_mask[:result.shape[0]]
55 |
56 | loss, f_max_pos, f_max_neg = self.brs_loss(result, pos_mask, neg_mask)
57 | loss = loss + reg_loss
58 |
59 | f_val = loss.detach().cpu().numpy()
60 | if self.best_prediction is None or f_val < self._best_loss:
61 | self.best_prediction = result_before_sigmoid.detach()
62 | self._best_loss = f_val
63 |
64 | if f_max_pos < (1 - self.prob_thresh) and f_max_neg < self.prob_thresh:
65 | return [f_val, np.zeros_like(x)]
66 |
67 | current_mask = result > self.prob_thresh
68 | if self._last_mask is not None and self.min_iou_diff > 0:
69 | diff_iou = _compute_iou(current_mask, self._last_mask)
70 | if len(diff_iou) > 0 and diff_iou.mean() > 1 - self.min_iou_diff:
71 | return [f_val, np.zeros_like(x)]
72 | self._last_mask = current_mask
73 |
74 | loss.backward()
75 | f_grad = opt_params.grad.cpu().numpy().ravel().astype(np.float)
76 |
77 | return [f_val, f_grad]
78 |
79 | def unpack_opt_params(self, opt_params):
80 | raise NotImplementedError
81 |
82 |
83 | class InputOptimizer(BaseOptimizer):
84 | def unpack_opt_params(self, opt_params):
85 | opt_params = opt_params.view(self._opt_shape)
86 | if self.with_flip:
87 | opt_params_flipped = torch.flip(opt_params, dims=[3])
88 | opt_params = torch.cat([opt_params, opt_params_flipped], dim=0)
89 | reg_loss = self.reg_weight * torch.sum(opt_params**2)
90 |
91 | return (opt_params,), reg_loss
92 |
93 |
94 | class ScaleBiasOptimizer(BaseOptimizer):
95 | def __init__(self, *args, scale_act=None, reg_bias_weight=10.0, **kwargs):
96 | super().__init__(*args, **kwargs)
97 | self.scale_act = scale_act
98 | self.reg_bias_weight = reg_bias_weight
99 |
100 | def unpack_opt_params(self, opt_params):
101 | scale, bias = torch.chunk(opt_params, 2, dim=0)
102 | reg_loss = self.reg_weight * (torch.sum(scale**2) + self.reg_bias_weight * torch.sum(bias**2))
103 |
104 | if self.scale_act == 'tanh':
105 | scale = torch.tanh(scale)
106 | elif self.scale_act == 'sin':
107 | scale = torch.sin(scale)
108 |
109 | return (1 + scale, bias), reg_loss
110 |
--------------------------------------------------------------------------------
/fbrs/inference/predictors/brs_losses.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | from fbrs.model.losses import SigmoidBinaryCrossEntropyLoss
4 |
5 |
6 | class BRSMaskLoss(torch.nn.Module):
7 | def __init__(self, eps=1e-5):
8 | super().__init__()
9 | self._eps = eps
10 |
11 | def forward(self, result, pos_mask, neg_mask):
12 | pos_diff = (1 - result) * pos_mask
13 | pos_target = torch.sum(pos_diff ** 2)
14 | pos_target = pos_target / (torch.sum(pos_mask) + self._eps)
15 |
16 | neg_diff = result * neg_mask
17 | neg_target = torch.sum(neg_diff ** 2)
18 | neg_target = neg_target / (torch.sum(neg_mask) + self._eps)
19 |
20 | loss = pos_target + neg_target
21 |
22 | with torch.no_grad():
23 | f_max_pos = torch.max(torch.abs(pos_diff)).item()
24 | f_max_neg = torch.max(torch.abs(neg_diff)).item()
25 |
26 | return loss, f_max_pos, f_max_neg
27 |
28 |
29 | class OracleMaskLoss(torch.nn.Module):
30 | def __init__(self):
31 | super().__init__()
32 | self.gt_mask = None
33 | self.loss = SigmoidBinaryCrossEntropyLoss(from_sigmoid=True)
34 | self.predictor = None
35 | self.history = []
36 |
37 | def set_gt_mask(self, gt_mask):
38 | self.gt_mask = gt_mask
39 | self.history = []
40 |
41 | def forward(self, result, pos_mask, neg_mask):
42 | gt_mask = self.gt_mask.to(result.device)
43 | if self.predictor.object_roi is not None:
44 | r1, r2, c1, c2 = self.predictor.object_roi[:4]
45 | gt_mask = gt_mask[:, :, r1:r2 + 1, c1:c2 + 1]
46 | gt_mask = torch.nn.functional.interpolate(gt_mask, result.size()[2:], mode='bilinear', align_corners=True)
47 |
48 | if result.shape[0] == 2:
49 | gt_mask_flipped = torch.flip(gt_mask, dims=[3])
50 | gt_mask = torch.cat([gt_mask, gt_mask_flipped], dim=0)
51 |
52 | loss = self.loss(result, gt_mask)
53 | self.history.append(loss.detach().cpu().numpy()[0])
54 |
55 | if len(self.history) > 5 and abs(self.history[-5] - self.history[-1]) < 1e-5:
56 | return 0, 0, 0
57 |
58 | return loss, 1.0, 1.0
59 |
--------------------------------------------------------------------------------
/fbrs/inference/transforms/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import SigmoidForPred
2 | from .flip import AddHorizontalFlip
3 | from .zoom_in import ZoomIn
4 | from .limit_longest_side import LimitLongestSide
5 | from .crops import Crops
6 |
--------------------------------------------------------------------------------
/fbrs/inference/transforms/base.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 |
4 | class BaseTransform(object):
5 | def __init__(self):
6 | self.image_changed = False
7 |
8 | def transform(self, image_nd, clicks_lists):
9 | raise NotImplementedError
10 |
11 | def inv_transform(self, prob_map):
12 | raise NotImplementedError
13 |
14 | def reset(self):
15 | raise NotImplementedError
16 |
17 | def get_state(self):
18 | raise NotImplementedError
19 |
20 | def set_state(self, state):
21 | raise NotImplementedError
22 |
23 |
24 | class SigmoidForPred(BaseTransform):
25 | def transform(self, image_nd, clicks_lists):
26 | return image_nd, clicks_lists
27 |
28 | def inv_transform(self, prob_map):
29 | return torch.sigmoid(prob_map)
30 |
31 | def reset(self):
32 | pass
33 |
34 | def get_state(self):
35 | return None
36 |
37 | def set_state(self, state):
38 | pass
39 |
--------------------------------------------------------------------------------
/fbrs/inference/transforms/crops.py:
--------------------------------------------------------------------------------
1 | import math
2 |
3 | import torch
4 | import numpy as np
5 |
6 | from fbrs.inference.clicker import Click
7 | from .base import BaseTransform
8 |
9 |
10 | class Crops(BaseTransform):
11 | def __init__(self, crop_size=(320, 480), min_overlap=0.2):
12 | super().__init__()
13 | self.crop_height, self.crop_width = crop_size
14 | self.min_overlap = min_overlap
15 |
16 | self.x_offsets = None
17 | self.y_offsets = None
18 | self._counts = None
19 |
20 | def transform(self, image_nd, clicks_lists):
21 | assert image_nd.shape[0] == 1 and len(clicks_lists) == 1
22 | image_height, image_width = image_nd.shape[2:4]
23 | self._counts = None
24 |
25 | if image_height < self.crop_height or image_width < self.crop_width:
26 | return image_nd, clicks_lists
27 |
28 | self.x_offsets = get_offsets(image_width, self.crop_width, self.min_overlap)
29 | self.y_offsets = get_offsets(image_height, self.crop_height, self.min_overlap)
30 | self._counts = np.zeros((image_height, image_width))
31 |
32 | image_crops = []
33 | for dy in self.y_offsets:
34 | for dx in self.x_offsets:
35 | self._counts[dy:dy + self.crop_height, dx:dx + self.crop_width] += 1
36 | image_crop = image_nd[:, :, dy:dy + self.crop_height, dx:dx + self.crop_width]
37 | image_crops.append(image_crop)
38 | image_crops = torch.cat(image_crops, dim=0)
39 | self._counts = torch.tensor(self._counts, device=image_nd.device, dtype=torch.float32)
40 |
41 | clicks_list = clicks_lists[0]
42 | clicks_lists = []
43 | for dy in self.y_offsets:
44 | for dx in self.x_offsets:
45 | crop_clicks = [Click(is_positive=x.is_positive, coords=(x.coords[0] - dy, x.coords[1] - dx))
46 | for x in clicks_list]
47 | clicks_lists.append(crop_clicks)
48 |
49 | return image_crops, clicks_lists
50 |
51 | def inv_transform(self, prob_map):
52 | if self._counts is None:
53 | return prob_map
54 |
55 | new_prob_map = torch.zeros((1, 1, *self._counts.shape),
56 | dtype=prob_map.dtype, device=prob_map.device)
57 |
58 | crop_indx = 0
59 | for dy in self.y_offsets:
60 | for dx in self.x_offsets:
61 | new_prob_map[0, 0, dy:dy + self.crop_height, dx:dx + self.crop_width] += prob_map[crop_indx, 0]
62 | crop_indx += 1
63 | new_prob_map = torch.div(new_prob_map, self._counts)
64 |
65 | return new_prob_map
66 |
67 | def get_state(self):
68 | return self.x_offsets, self.y_offsets, self._counts
69 |
70 | def set_state(self, state):
71 | self.x_offsets, self.y_offsets, self._counts = state
72 |
73 | def reset(self):
74 | self.x_offsets = None
75 | self.y_offsets = None
76 | self._counts = None
77 |
78 |
79 | def get_offsets(length, crop_size, min_overlap_ratio=0.2):
80 | if length == crop_size:
81 | return [0]
82 |
83 | N = (length / crop_size - min_overlap_ratio) / (1 - min_overlap_ratio)
84 | N = math.ceil(N)
85 |
86 | overlap_ratio = (N - length / crop_size) / (N - 1)
87 | overlap_width = int(crop_size * overlap_ratio)
88 |
89 | offsets = [0]
90 | for i in range(1, N):
91 | new_offset = offsets[-1] + crop_size - overlap_width
92 | if new_offset + crop_size > length:
93 | new_offset = length - crop_size
94 |
95 | offsets.append(new_offset)
96 |
97 | return offsets
98 |
--------------------------------------------------------------------------------
/fbrs/inference/transforms/flip.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | from fbrs.inference.clicker import Click
4 | from .base import BaseTransform
5 |
6 |
7 | class AddHorizontalFlip(BaseTransform):
8 | def transform(self, image_nd, clicks_lists):
9 | assert len(image_nd.shape) == 4
10 | image_nd = torch.cat([image_nd, torch.flip(image_nd, dims=[3])], dim=0)
11 |
12 | image_width = image_nd.shape[3]
13 | clicks_lists_flipped = []
14 | for clicks_list in clicks_lists:
15 | clicks_list_flipped = [Click(is_positive=click.is_positive,
16 | coords=(click.coords[0], image_width - click.coords[1] - 1))
17 | for click in clicks_list]
18 | clicks_lists_flipped.append(clicks_list_flipped)
19 | clicks_lists = clicks_lists + clicks_lists_flipped
20 |
21 | return image_nd, clicks_lists
22 |
23 | def inv_transform(self, prob_map):
24 | assert len(prob_map.shape) == 4 and prob_map.shape[0] % 2 == 0
25 | num_maps = prob_map.shape[0] // 2
26 | prob_map, prob_map_flipped = prob_map[:num_maps], prob_map[num_maps:]
27 |
28 | return 0.5 * (prob_map + torch.flip(prob_map_flipped, dims=[3]))
29 |
30 | def get_state(self):
31 | return None
32 |
33 | def set_state(self, state):
34 | pass
35 |
36 | def reset(self):
37 | pass
38 |
--------------------------------------------------------------------------------
/fbrs/inference/transforms/limit_longest_side.py:
--------------------------------------------------------------------------------
1 | from .zoom_in import ZoomIn, get_roi_image_nd
2 |
3 |
4 | class LimitLongestSide(ZoomIn):
5 | def __init__(self, max_size=800):
6 | super().__init__(target_size=max_size, skip_clicks=0)
7 |
8 | def transform(self, image_nd, clicks_lists):
9 | assert image_nd.shape[0] == 1 and len(clicks_lists) == 1
10 | image_max_size = max(image_nd.shape[2:4])
11 | self.image_changed = False
12 |
13 | if image_max_size <= self.target_size:
14 | return image_nd, clicks_lists
15 | self._input_image = image_nd
16 |
17 | self._object_roi = (0, image_nd.shape[2] - 1, 0, image_nd.shape[3] - 1)
18 | self._roi_image = get_roi_image_nd(image_nd, self._object_roi, self.target_size)
19 | self.image_changed = True
20 |
21 | tclicks_lists = [self._transform_clicks(clicks_lists[0])]
22 | return self._roi_image, tclicks_lists
23 |
--------------------------------------------------------------------------------
/fbrs/model/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/fbrs/model/__init__.py
--------------------------------------------------------------------------------
/fbrs/model/initializer.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import numpy as np
4 |
5 |
6 | class Initializer(object):
7 | def __init__(self, local_init=True, gamma=None):
8 | self.local_init = local_init
9 | self.gamma = gamma
10 |
11 | def __call__(self, m):
12 | if getattr(m, '__initialized', False):
13 | return
14 |
15 | if isinstance(m, (nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d,
16 | nn.InstanceNorm1d, nn.InstanceNorm2d, nn.InstanceNorm3d,
17 | nn.GroupNorm, nn.SyncBatchNorm)) or 'BatchNorm' in m.__class__.__name__:
18 | if m.weight is not None:
19 | self._init_gamma(m.weight.data)
20 | if m.bias is not None:
21 | self._init_beta(m.bias.data)
22 | else:
23 | if getattr(m, 'weight', None) is not None:
24 | self._init_weight(m.weight.data)
25 | if getattr(m, 'bias', None) is not None:
26 | self._init_bias(m.bias.data)
27 |
28 | if self.local_init:
29 | object.__setattr__(m, '__initialized', True)
30 |
31 | def _init_weight(self, data):
32 | nn.init.uniform_(data, -0.07, 0.07)
33 |
34 | def _init_bias(self, data):
35 | nn.init.constant_(data, 0)
36 |
37 | def _init_gamma(self, data):
38 | if self.gamma is None:
39 | nn.init.constant_(data, 1.0)
40 | else:
41 | nn.init.normal_(data, 1.0, self.gamma)
42 |
43 | def _init_beta(self, data):
44 | nn.init.constant_(data, 0)
45 |
46 |
47 | class Bilinear(Initializer):
48 | def __init__(self, scale, groups, in_channels, **kwargs):
49 | super().__init__(**kwargs)
50 | self.scale = scale
51 | self.groups = groups
52 | self.in_channels = in_channels
53 |
54 | def _init_weight(self, data):
55 | """Reset the weight and bias."""
56 | bilinear_kernel = self.get_bilinear_kernel(self.scale)
57 | weight = torch.zeros_like(data)
58 | for i in range(self.in_channels):
59 | if self.groups == 1:
60 | j = i
61 | else:
62 | j = 0
63 | weight[i, j] = bilinear_kernel
64 | data[:] = weight
65 |
66 | @staticmethod
67 | def get_bilinear_kernel(scale):
68 | """Generate a bilinear upsampling kernel."""
69 | kernel_size = 2 * scale - scale % 2
70 | scale = (kernel_size + 1) // 2
71 | center = scale - 0.5 * (1 + kernel_size % 2)
72 |
73 | og = np.ogrid[:kernel_size, :kernel_size]
74 | kernel = (1 - np.abs(og[0] - center) / scale) * (1 - np.abs(og[1] - center) / scale)
75 |
76 | return torch.tensor(kernel, dtype=torch.float32)
77 |
78 |
79 | class XavierGluon(Initializer):
80 | def __init__(self, rnd_type='uniform', factor_type='avg', magnitude=3, **kwargs):
81 | super().__init__(**kwargs)
82 |
83 | self.rnd_type = rnd_type
84 | self.factor_type = factor_type
85 | self.magnitude = float(magnitude)
86 |
87 | def _init_weight(self, arr):
88 | fan_in, fan_out = nn.init._calculate_fan_in_and_fan_out(arr)
89 |
90 | if self.factor_type == 'avg':
91 | factor = (fan_in + fan_out) / 2.0
92 | elif self.factor_type == 'in':
93 | factor = fan_in
94 | elif self.factor_type == 'out':
95 | factor = fan_out
96 | else:
97 | raise ValueError('Incorrect factor type')
98 | scale = np.sqrt(self.magnitude / factor)
99 |
100 | if self.rnd_type == 'uniform':
101 | nn.init.uniform_(arr, -scale, scale)
102 | elif self.rnd_type == 'gaussian':
103 | nn.init.normal_(arr, 0, scale)
104 | else:
105 | raise ValueError('Unknown random type')
106 |
--------------------------------------------------------------------------------
/fbrs/model/is_deeplab_model.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 |
4 | from fbrs.model.ops import DistMaps
5 | from .modeling.deeplab_v3 import DeepLabV3Plus
6 | from .modeling.basic_blocks import SepConvHead
7 |
8 |
9 | def get_deeplab_model(backbone='resnet50', deeplab_ch=256, aspp_dropout=0.5,
10 | norm_layer=nn.BatchNorm2d, backbone_norm_layer=None,
11 | use_rgb_conv=True, cpu_dist_maps=False,
12 | norm_radius=260):
13 | model = DistMapsModel(
14 | feature_extractor=DeepLabV3Plus(backbone=backbone,
15 | ch=deeplab_ch,
16 | project_dropout=aspp_dropout,
17 | norm_layer=norm_layer,
18 | backbone_norm_layer=backbone_norm_layer),
19 | head=SepConvHead(1, in_channels=deeplab_ch, mid_channels=deeplab_ch // 2,
20 | num_layers=2, norm_layer=norm_layer),
21 | use_rgb_conv=use_rgb_conv,
22 | norm_layer=norm_layer,
23 | norm_radius=norm_radius,
24 | cpu_dist_maps=cpu_dist_maps
25 | )
26 |
27 | return model
28 |
29 |
30 | class DistMapsModel(nn.Module):
31 | def __init__(self, feature_extractor, head, norm_layer=nn.BatchNorm2d, use_rgb_conv=True,
32 | cpu_dist_maps=False, norm_radius=260):
33 | super(DistMapsModel, self).__init__()
34 |
35 | if use_rgb_conv:
36 | self.rgb_conv = nn.Sequential(
37 | nn.Conv2d(in_channels=5, out_channels=8, kernel_size=1),
38 | nn.LeakyReLU(negative_slope=0.2),
39 | norm_layer(8),
40 | nn.Conv2d(in_channels=8, out_channels=3, kernel_size=1),
41 | )
42 | else:
43 | self.rgb_conv = None
44 |
45 | self.dist_maps = DistMaps(norm_radius=norm_radius, spatial_scale=1.0,
46 | cpu_mode=cpu_dist_maps)
47 | self.feature_extractor = feature_extractor
48 | self.head = head
49 |
50 | def forward(self, image, points):
51 | coord_features = self.dist_maps(image, points)
52 |
53 | if self.rgb_conv is not None:
54 | x = self.rgb_conv(torch.cat((image, coord_features), dim=1))
55 | else:
56 | c1, c2 = torch.chunk(coord_features, 2, dim=1)
57 | c3 = torch.ones_like(c1)
58 | coord_features = torch.cat((c1, c2, c3), dim=1)
59 | x = 0.8 * image * coord_features + 0.2 * image
60 |
61 | backbone_features = self.feature_extractor(x)
62 | instance_out = self.head(backbone_features[0])
63 | instance_out = nn.functional.interpolate(instance_out, size=image.size()[2:],
64 | mode='bilinear', align_corners=True)
65 |
66 | return {'instances': instance_out}
67 |
68 | def load_weights(self, path_to_weights):
69 | current_state_dict = self.state_dict()
70 | new_state_dict = torch.load(path_to_weights, map_location='cpu')
71 | current_state_dict.update(new_state_dict)
72 | self.load_state_dict(current_state_dict)
73 |
74 | def get_trainable_params(self):
75 | backbone_params = nn.ParameterList()
76 | other_params = nn.ParameterList()
77 |
78 | for name, param in self.named_parameters():
79 | if param.requires_grad:
80 | if 'backbone' in name:
81 | backbone_params.append(param)
82 | else:
83 | other_params.append(param)
84 | return backbone_params, other_params
85 |
86 |
87 |
--------------------------------------------------------------------------------
/fbrs/model/is_hrnet_model.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 |
4 | from fbrs.model.ops import DistMaps
5 | from .modeling.hrnet_ocr import HighResolutionNet
6 |
7 |
8 | def get_hrnet_model(width=48, ocr_width=256, small=False, norm_radius=260,
9 | use_rgb_conv=True, with_aux_output=False, cpu_dist_maps=False,
10 | norm_layer=nn.BatchNorm2d):
11 | model = DistMapsHRNetModel(
12 | feature_extractor=HighResolutionNet(width=width, ocr_width=ocr_width, small=small,
13 | num_classes=1, norm_layer=norm_layer),
14 | use_rgb_conv=use_rgb_conv,
15 | with_aux_output=with_aux_output,
16 | norm_layer=norm_layer,
17 | norm_radius=norm_radius,
18 | cpu_dist_maps=cpu_dist_maps
19 | )
20 |
21 | return model
22 |
23 |
24 | class DistMapsHRNetModel(nn.Module):
25 | def __init__(self, feature_extractor, use_rgb_conv=True, with_aux_output=False,
26 | norm_layer=nn.BatchNorm2d, norm_radius=260, cpu_dist_maps=False):
27 | super(DistMapsHRNetModel, self).__init__()
28 | self.with_aux_output = with_aux_output
29 |
30 | if use_rgb_conv:
31 | self.rgb_conv = nn.Sequential(
32 | nn.Conv2d(in_channels=5, out_channels=8, kernel_size=1),
33 | nn.LeakyReLU(negative_slope=0.2),
34 | norm_layer(8),
35 | nn.Conv2d(in_channels=8, out_channels=3, kernel_size=1),
36 | )
37 | else:
38 | self.rgb_conv = None
39 |
40 | self.dist_maps = DistMaps(norm_radius=norm_radius, spatial_scale=1.0, cpu_mode=cpu_dist_maps)
41 | self.feature_extractor = feature_extractor
42 |
43 | def forward(self, image, points):
44 | coord_features = self.dist_maps(image, points)
45 |
46 | if self.rgb_conv is not None:
47 | x = self.rgb_conv(torch.cat((image, coord_features), dim=1))
48 | else:
49 | c1, c2 = torch.chunk(coord_features, 2, dim=1)
50 | c3 = torch.ones_like(c1)
51 | coord_features = torch.cat((c1, c2, c3), dim=1)
52 | x = 0.8 * image * coord_features + 0.2 * image
53 |
54 | feature_extractor_out = self.feature_extractor(x)
55 | instance_out = feature_extractor_out[0]
56 | instance_out = nn.functional.interpolate(instance_out, size=image.size()[2:],
57 | mode='bilinear', align_corners=True)
58 | outputs = {'instances': instance_out}
59 | if self.with_aux_output:
60 | instance_aux_out = feature_extractor_out[1]
61 | instance_aux_out = nn.functional.interpolate(instance_aux_out, size=image.size()[2:],
62 | mode='bilinear', align_corners=True)
63 | outputs['instances_aux'] = instance_aux_out
64 |
65 | return outputs
66 |
67 | def load_weights(self, path_to_weights):
68 | current_state_dict = self.state_dict()
69 | new_state_dict = torch.load(path_to_weights)
70 | current_state_dict.update(new_state_dict)
71 | self.load_state_dict(current_state_dict)
72 |
73 | def get_trainable_params(self):
74 | backbone_params = nn.ParameterList()
75 | other_params = nn.ParameterList()
76 | other_params_keys = []
77 | nonbackbone_keywords = ['rgb_conv', 'aux_head', 'cls_head', 'conv3x3_ocr', 'ocr_distri_head']
78 |
79 | for name, param in self.named_parameters():
80 | if param.requires_grad:
81 | if any(x in name for x in nonbackbone_keywords):
82 | other_params.append(param)
83 | other_params_keys.append(name)
84 | else:
85 | backbone_params.append(param)
86 | print('Nonbackbone params:', sorted(other_params_keys))
87 | return backbone_params, other_params
88 |
--------------------------------------------------------------------------------
/fbrs/model/losses.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 |
6 | from fbrs.utils import misc
7 |
8 |
9 | class NormalizedFocalLossSigmoid(nn.Module):
10 | def __init__(self, axis=-1, alpha=0.25, gamma=2,
11 | from_logits=False, batch_axis=0,
12 | weight=None, size_average=True, detach_delimeter=True,
13 | eps=1e-12, scale=1.0,
14 | ignore_label=-1):
15 | super(NormalizedFocalLossSigmoid, self).__init__()
16 | self._axis = axis
17 | self._alpha = alpha
18 | self._gamma = gamma
19 | self._ignore_label = ignore_label
20 | self._weight = weight if weight is not None else 1.0
21 | self._batch_axis = batch_axis
22 |
23 | self._scale = scale
24 | self._from_logits = from_logits
25 | self._eps = eps
26 | self._size_average = size_average
27 | self._detach_delimeter = detach_delimeter
28 | self._k_sum = 0
29 |
30 | def forward(self, pred, label, sample_weight=None):
31 | one_hot = label > 0
32 | sample_weight = label != self._ignore_label
33 |
34 | if not self._from_logits:
35 | pred = torch.sigmoid(pred)
36 |
37 | alpha = torch.where(one_hot, self._alpha * sample_weight, (1 - self._alpha) * sample_weight)
38 | pt = torch.where(one_hot, pred, 1 - pred)
39 | pt = torch.where(sample_weight, pt, torch.ones_like(pt))
40 |
41 | beta = (1 - pt) ** self._gamma
42 |
43 | sw_sum = torch.sum(sample_weight, dim=(-2, -1), keepdim=True)
44 | beta_sum = torch.sum(beta, dim=(-2, -1), keepdim=True)
45 | mult = sw_sum / (beta_sum + self._eps)
46 | if self._detach_delimeter:
47 | mult = mult.detach()
48 | beta = beta * mult
49 |
50 | ignore_area = torch.sum(label == self._ignore_label, dim=tuple(range(1, label.dim()))).cpu().numpy()
51 | sample_mult = torch.mean(mult, dim=tuple(range(1, mult.dim()))).cpu().numpy()
52 | if np.any(ignore_area == 0):
53 | self._k_sum = 0.9 * self._k_sum + 0.1 * sample_mult[ignore_area == 0].mean()
54 |
55 | loss = -alpha * beta * torch.log(torch.min(pt + self._eps, torch.ones(1, dtype=torch.float).to(pt.device)))
56 | loss = self._weight * (loss * sample_weight)
57 |
58 | if self._size_average:
59 | bsum = torch.sum(sample_weight, dim=misc.get_dims_with_exclusion(sample_weight.dim(), self._batch_axis))
60 | loss = torch.sum(loss, dim=misc.get_dims_with_exclusion(loss.dim(), self._batch_axis)) / (bsum + self._eps)
61 | else:
62 | loss = torch.sum(loss, dim=misc.get_dims_with_exclusion(loss.dim(), self._batch_axis))
63 |
64 | return self._scale * loss
65 |
66 | def log_states(self, sw, name, global_step):
67 | sw.add_scalar(tag=name + '_k', value=self._k_sum, global_step=global_step)
68 |
69 |
70 | class FocalLoss(nn.Module):
71 | def __init__(self, axis=-1, alpha=0.25, gamma=2,
72 | from_logits=False, batch_axis=0,
73 | weight=None, num_class=None,
74 | eps=1e-9, size_average=True, scale=1.0):
75 | super(FocalLoss, self).__init__()
76 | self._axis = axis
77 | self._alpha = alpha
78 | self._gamma = gamma
79 | self._weight = weight if weight is not None else 1.0
80 | self._batch_axis = batch_axis
81 |
82 | self._scale = scale
83 | self._num_class = num_class
84 | self._from_logits = from_logits
85 | self._eps = eps
86 | self._size_average = size_average
87 |
88 | def forward(self, pred, label, sample_weight=None):
89 | if not self._from_logits:
90 | pred = F.sigmoid(pred)
91 |
92 | one_hot = label > 0
93 | pt = torch.where(one_hot, pred, 1 - pred)
94 |
95 | t = label != -1
96 | alpha = torch.where(one_hot, self._alpha * t, (1 - self._alpha) * t)
97 | beta = (1 - pt) ** self._gamma
98 |
99 | loss = -alpha * beta * torch.log(torch.min(pt + self._eps, torch.ones(1, dtype=torch.float).to(pt.device)))
100 | sample_weight = label != -1
101 |
102 | loss = self._weight * (loss * sample_weight)
103 |
104 | if self._size_average:
105 | tsum = torch.sum(label == 1, dim=misc.get_dims_with_exclusion(label.dim(), self._batch_axis))
106 | loss = torch.sum(loss, dim=misc.get_dims_with_exclusion(loss.dim(), self._batch_axis)) / (tsum + self._eps)
107 | else:
108 | loss = torch.sum(loss, dim=misc.get_dims_with_exclusion(loss.dim(), self._batch_axis))
109 |
110 | return self._scale * loss
111 |
112 |
113 | class SigmoidBinaryCrossEntropyLoss(nn.Module):
114 | def __init__(self, from_sigmoid=False, weight=None, batch_axis=0, ignore_label=-1):
115 | super(SigmoidBinaryCrossEntropyLoss, self).__init__()
116 | self._from_sigmoid = from_sigmoid
117 | self._ignore_label = ignore_label
118 | self._weight = weight if weight is not None else 1.0
119 | self._batch_axis = batch_axis
120 |
121 | def forward(self, pred, label):
122 | label = label.view(pred.size())
123 | sample_weight = label != self._ignore_label
124 | label = torch.where(sample_weight, label, torch.zeros_like(label))
125 |
126 | if not self._from_sigmoid:
127 | loss = torch.relu(pred) - pred * label + F.softplus(-torch.abs(pred))
128 | else:
129 | eps = 1e-12
130 | loss = -(torch.log(pred + eps) * label
131 | + torch.log(1. - pred + eps) * (1. - label))
132 |
133 | loss = self._weight * (loss * sample_weight)
134 | return torch.mean(loss, dim=misc.get_dims_with_exclusion(loss.dim(), self._batch_axis))
135 |
--------------------------------------------------------------------------------
/fbrs/model/metrics.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 |
4 | from fbrs.utils import misc
5 |
6 |
7 | class TrainMetric(object):
8 | def __init__(self, pred_outputs, gt_outputs):
9 | self.pred_outputs = pred_outputs
10 | self.gt_outputs = gt_outputs
11 |
12 | def update(self, *args, **kwargs):
13 | raise NotImplementedError
14 |
15 | def get_epoch_value(self):
16 | raise NotImplementedError
17 |
18 | def reset_epoch_stats(self):
19 | raise NotImplementedError
20 |
21 | def log_states(self, sw, tag_prefix, global_step):
22 | pass
23 |
24 | @property
25 | def name(self):
26 | return type(self).__name__
27 |
28 |
29 | class AdaptiveIoU(TrainMetric):
30 | def __init__(self, init_thresh=0.4, thresh_step=0.025, thresh_beta=0.99, iou_beta=0.9,
31 | ignore_label=-1, from_logits=True,
32 | pred_output='instances', gt_output='instances'):
33 | super().__init__(pred_outputs=(pred_output,), gt_outputs=(gt_output,))
34 | self._ignore_label = ignore_label
35 | self._from_logits = from_logits
36 | self._iou_thresh = init_thresh
37 | self._thresh_step = thresh_step
38 | self._thresh_beta = thresh_beta
39 | self._iou_beta = iou_beta
40 | self._ema_iou = 0.0
41 | self._epoch_iou_sum = 0.0
42 | self._epoch_batch_count = 0
43 |
44 | def update(self, pred, gt):
45 | gt_mask = gt > 0
46 | if self._from_logits:
47 | pred = torch.sigmoid(pred)
48 |
49 | gt_mask_area = torch.sum(gt_mask, dim=(1, 2)).detach().cpu().numpy()
50 | if np.all(gt_mask_area == 0):
51 | return
52 |
53 | ignore_mask = gt == self._ignore_label
54 | max_iou = _compute_iou(pred > self._iou_thresh, gt_mask, ignore_mask).mean()
55 | best_thresh = self._iou_thresh
56 | for t in [best_thresh - self._thresh_step, best_thresh + self._thresh_step]:
57 | temp_iou = _compute_iou(pred > t, gt_mask, ignore_mask).mean()
58 | if temp_iou > max_iou:
59 | max_iou = temp_iou
60 | best_thresh = t
61 |
62 | self._iou_thresh = self._thresh_beta * self._iou_thresh + (1 - self._thresh_beta) * best_thresh
63 | self._ema_iou = self._iou_beta * self._ema_iou + (1 - self._iou_beta) * max_iou
64 | self._epoch_iou_sum += max_iou
65 | self._epoch_batch_count += 1
66 |
67 | def get_epoch_value(self):
68 | if self._epoch_batch_count > 0:
69 | return self._epoch_iou_sum / self._epoch_batch_count
70 | else:
71 | return 0.0
72 |
73 | def reset_epoch_stats(self):
74 | self._epoch_iou_sum = 0.0
75 | self._epoch_batch_count = 0
76 |
77 | def log_states(self, sw, tag_prefix, global_step):
78 | sw.add_scalar(tag=tag_prefix + '_ema_iou', value=self._ema_iou, global_step=global_step)
79 | sw.add_scalar(tag=tag_prefix + '_iou_thresh', value=self._iou_thresh, global_step=global_step)
80 |
81 | @property
82 | def iou_thresh(self):
83 | return self._iou_thresh
84 |
85 |
86 | def _compute_iou(pred_mask, gt_mask, ignore_mask=None, keep_ignore=False):
87 | if ignore_mask is not None:
88 | pred_mask = torch.where(ignore_mask, torch.zeros_like(pred_mask), pred_mask)
89 |
90 | reduction_dims = misc.get_dims_with_exclusion(gt_mask.dim(), 0)
91 | union = torch.mean((pred_mask | gt_mask).float(), dim=reduction_dims).detach().cpu().numpy()
92 | intersection = torch.mean((pred_mask & gt_mask).float(), dim=reduction_dims).detach().cpu().numpy()
93 | nonzero = union > 0
94 |
95 | iou = intersection[nonzero] / union[nonzero]
96 | if not keep_ignore:
97 | return iou
98 | else:
99 | result = np.full_like(intersection, -1)
100 | result[nonzero] = iou
101 | return result
102 |
--------------------------------------------------------------------------------
/fbrs/model/modeling/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/fbrs/model/modeling/__init__.py
--------------------------------------------------------------------------------
/fbrs/model/modeling/basic_blocks.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 |
3 | from fbrs.model import ops
4 |
5 |
6 | class ConvHead(nn.Module):
7 | def __init__(self, out_channels, in_channels=32, num_layers=1,
8 | kernel_size=3, padding=1,
9 | norm_layer=nn.BatchNorm2d):
10 | super(ConvHead, self).__init__()
11 | convhead = []
12 |
13 | for i in range(num_layers):
14 | convhead.extend([
15 | nn.Conv2d(in_channels, in_channels, kernel_size, padding=padding),
16 | nn.ReLU(),
17 | norm_layer(in_channels) if norm_layer is not None else nn.Identity()
18 | ])
19 | convhead.append(nn.Conv2d(in_channels, out_channels, 1, padding=0))
20 |
21 | self.convhead = nn.Sequential(*convhead)
22 |
23 | def forward(self, *inputs):
24 | return self.convhead(inputs[0])
25 |
26 |
27 | class SepConvHead(nn.Module):
28 | def __init__(self, num_outputs, in_channels, mid_channels, num_layers=1,
29 | kernel_size=3, padding=1, dropout_ratio=0.0, dropout_indx=0,
30 | norm_layer=nn.BatchNorm2d):
31 | super(SepConvHead, self).__init__()
32 |
33 | sepconvhead = []
34 |
35 | for i in range(num_layers):
36 | sepconvhead.append(
37 | SeparableConv2d(in_channels=in_channels if i == 0 else mid_channels,
38 | out_channels=mid_channels,
39 | dw_kernel=kernel_size, dw_padding=padding,
40 | norm_layer=norm_layer, activation='relu')
41 | )
42 | if dropout_ratio > 0 and dropout_indx == i:
43 | sepconvhead.append(nn.Dropout(dropout_ratio))
44 |
45 | sepconvhead.append(
46 | nn.Conv2d(in_channels=mid_channels, out_channels=num_outputs, kernel_size=1, padding=0)
47 | )
48 |
49 | self.layers = nn.Sequential(*sepconvhead)
50 |
51 | def forward(self, *inputs):
52 | x = inputs[0]
53 |
54 | return self.layers(x)
55 |
56 |
57 | class SeparableConv2d(nn.Module):
58 | def __init__(self, in_channels, out_channels, dw_kernel, dw_padding, dw_stride=1,
59 | activation=None, use_bias=False, norm_layer=None):
60 | super(SeparableConv2d, self).__init__()
61 | _activation = ops.select_activation_function(activation)
62 | self.body = nn.Sequential(
63 | nn.Conv2d(in_channels, in_channels, kernel_size=dw_kernel, stride=dw_stride,
64 | padding=dw_padding, bias=use_bias, groups=in_channels),
65 | nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, bias=use_bias),
66 | norm_layer(out_channels) if norm_layer is not None else nn.Identity(),
67 | _activation()
68 | )
69 |
70 | def forward(self, x):
71 | return self.body(x)
72 |
--------------------------------------------------------------------------------
/fbrs/model/modeling/resnet.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from .resnetv1b import resnet34_v1b, resnet50_v1s, resnet101_v1s, resnet152_v1s
3 |
4 |
5 | class ResNetBackbone(torch.nn.Module):
6 | def __init__(self, backbone='resnet50', pretrained_base=True, dilated=True, **kwargs):
7 | super(ResNetBackbone, self).__init__()
8 |
9 | if backbone == 'resnet34':
10 | pretrained = resnet34_v1b(pretrained=pretrained_base, dilated=dilated, **kwargs)
11 | elif backbone == 'resnet50':
12 | pretrained = resnet50_v1s(pretrained=pretrained_base, dilated=dilated, **kwargs)
13 | elif backbone == 'resnet101':
14 | pretrained = resnet101_v1s(pretrained=pretrained_base, dilated=dilated, **kwargs)
15 | elif backbone == 'resnet152':
16 | pretrained = resnet152_v1s(pretrained=pretrained_base, dilated=dilated, **kwargs)
17 | else:
18 | raise RuntimeError(f'unknown backbone: {backbone}')
19 |
20 | self.conv1 = pretrained.conv1
21 | self.bn1 = pretrained.bn1
22 | self.relu = pretrained.relu
23 | self.maxpool = pretrained.maxpool
24 | self.layer1 = pretrained.layer1
25 | self.layer2 = pretrained.layer2
26 | self.layer3 = pretrained.layer3
27 | self.layer4 = pretrained.layer4
28 |
29 | def forward(self, x):
30 | x = self.conv1(x)
31 | x = self.bn1(x)
32 | x = self.relu(x)
33 | x = self.maxpool(x)
34 | c1 = self.layer1(x)
35 | c2 = self.layer2(c1)
36 | c3 = self.layer3(c2)
37 | c4 = self.layer4(c3)
38 |
39 | return c1, c2, c3, c4
40 |
--------------------------------------------------------------------------------
/fbrs/model/ops.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import nn as nn
3 | import numpy as np
4 |
5 | import fbrs.model.initializer as initializer
6 | from fbrs.utils.cython import get_dist_maps
7 |
8 |
9 | def select_activation_function(activation):
10 | if isinstance(activation, str):
11 | if activation.lower() == 'relu':
12 | return nn.ReLU
13 | elif activation.lower() == 'softplus':
14 | return nn.Softplus
15 | else:
16 | raise ValueError(f"Unknown activation type {activation}")
17 | elif isinstance(activation, nn.Module):
18 | return activation
19 | else:
20 | raise ValueError(f"Unknown activation type {activation}")
21 |
22 |
23 | class BilinearConvTranspose2d(nn.ConvTranspose2d):
24 | def __init__(self, in_channels, out_channels, scale, groups=1):
25 | kernel_size = 2 * scale - scale % 2
26 | self.scale = scale
27 |
28 | super().__init__(
29 | in_channels, out_channels,
30 | kernel_size=kernel_size,
31 | stride=scale,
32 | padding=1,
33 | groups=groups,
34 | bias=False)
35 |
36 | self.apply(initializer.Bilinear(scale=scale, in_channels=in_channels, groups=groups))
37 |
38 |
39 | class DistMaps(nn.Module):
40 | def __init__(self, norm_radius, spatial_scale=1.0, cpu_mode=False):
41 | super(DistMaps, self).__init__()
42 | self.spatial_scale = spatial_scale
43 | self.norm_radius = norm_radius
44 | self.cpu_mode = cpu_mode
45 |
46 | def get_coord_features(self, points, batchsize, rows, cols):
47 | if self.cpu_mode:
48 | coords = []
49 | for i in range(batchsize):
50 | norm_delimeter = self.spatial_scale * self.norm_radius
51 | coords.append(get_dist_maps(points[i].cpu().float().numpy(), rows, cols,
52 | norm_delimeter))
53 | coords = torch.from_numpy(np.stack(coords, axis=0)).to(points.device).float()
54 | else:
55 | num_points = points.shape[1] // 2
56 | points = points.view(-1, 2)
57 | invalid_points = torch.max(points, dim=1, keepdim=False)[0] < 0
58 | row_array = torch.arange(start=0, end=rows, step=1, dtype=torch.float32, device=points.device)
59 | col_array = torch.arange(start=0, end=cols, step=1, dtype=torch.float32, device=points.device)
60 |
61 | coord_rows, coord_cols = torch.meshgrid(row_array, col_array)
62 | coords = torch.stack((coord_rows, coord_cols), dim=0).unsqueeze(0).repeat(points.size(0), 1, 1, 1)
63 |
64 | add_xy = (points * self.spatial_scale).view(points.size(0), points.size(1), 1, 1)
65 | coords.add_(-add_xy)
66 | coords.div_(self.norm_radius * self.spatial_scale)
67 | coords.mul_(coords)
68 |
69 | coords[:, 0] += coords[:, 1]
70 | coords = coords[:, :1]
71 |
72 | coords[invalid_points, :, :, :] = 1e6
73 |
74 | coords = coords.view(-1, num_points, 1, rows, cols)
75 | coords = coords.min(dim=1)[0] # -> (bs * num_masks * 2) x 1 x h x w
76 | coords = coords.view(-1, 2, rows, cols)
77 |
78 | coords.sqrt_().mul_(2).tanh_()
79 |
80 | return coords
81 |
82 | def forward(self, x, coords):
83 | return self.get_coord_features(coords, x.shape[0], x.shape[2], x.shape[3])
84 |
--------------------------------------------------------------------------------
/fbrs/model/syncbn/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2018 Tamaki Kojima
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/fbrs/model/syncbn/README.md:
--------------------------------------------------------------------------------
1 | # pytorch-syncbn
2 |
3 | Tamaki Kojima(tamakoji@gmail.com)
4 |
5 | ## Announcement
6 |
7 | **Pytorch 1.0 support**
8 |
9 | ## Overview
10 | This is alternative implementation of "Synchronized Multi-GPU Batch Normalization" which computes global stats across gpus instead of locally computed. SyncBN are getting important for those input image is large, and must use multi-gpu to increase the minibatch-size for the training.
11 |
12 | The code was inspired by [Pytorch-Encoding](https://github.com/zhanghang1989/PyTorch-Encoding) and [Inplace-ABN](https://github.com/mapillary/inplace_abn)
13 |
14 | ## Remarks
15 | - Unlike [Pytorch-Encoding](https://github.com/zhanghang1989/PyTorch-Encoding), you don't need custom `nn.DataParallel`
16 | - Unlike [Inplace-ABN](https://github.com/mapillary/inplace_abn), you can just replace your `nn.BatchNorm2d` to this module implementation, since it will not mark for inplace operation
17 | - You can plug into arbitrary module written in PyTorch to enable Synchronized BatchNorm
18 | - Backward computation is rewritten and tested against behavior of `nn.BatchNorm2d`
19 |
20 | ## Requirements
21 | For PyTorch, please refer to https://pytorch.org/
22 |
23 | NOTE : The code is tested only with PyTorch v1.0.0, CUDA10/CuDNN7.4.2 on ubuntu18.04
24 |
25 | It utilize Pytorch JIT mechanism to compile seamlessly, using ninja. Please install ninja-build before use.
26 |
27 | ```
28 | sudo apt-get install ninja-build
29 | ```
30 |
31 | Also install all dependencies for python. For pip, run:
32 |
33 |
34 | ```
35 | pip install -U -r requirements.txt
36 | ```
37 |
38 | ## Build
39 |
40 | There is no need to build. just run and JIT will take care.
41 | JIT and cpp extensions are supported after PyTorch0.4, however it is highly recommended to use PyTorch > 1.0 due to huge design changes.
42 |
43 | ## Usage
44 |
45 | Please refer to [`test.py`](./test.py) for testing the difference between `nn.BatchNorm2d` and `modules.nn.BatchNorm2d`
46 |
47 | ```
48 | import torch
49 | from modules import nn as NN
50 | num_gpu = torch.cuda.device_count()
51 | model = nn.Sequential(
52 | nn.Conv2d(3, 3, 1, 1, bias=False),
53 | NN.BatchNorm2d(3),
54 | nn.ReLU(inplace=True),
55 | nn.Conv2d(3, 3, 1, 1, bias=False),
56 | NN.BatchNorm2d(3),
57 | ).cuda()
58 | model = nn.DataParallel(model, device_ids=range(num_gpu))
59 | x = torch.rand(num_gpu, 3, 2, 2).cuda()
60 | z = model(x)
61 | ```
62 |
63 | ## Math
64 |
65 | ### Forward
66 | 1. compute 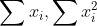 in each gpu
67 | 2. gather all from workers to master and compute
in each gpu
67 | 2. gather all from workers to master and compute 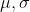 where
68 |
69 |
where
68 |
69 | 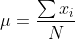 70 |
71 | and
72 |
73 |
70 |
71 | and
72 |
73 | 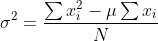 74 |
75 | and then above global stats to be shared to all gpus, update running_mean and running_var by moving average using global stats.
76 |
77 | 3. forward batchnorm using global stats by
78 |
79 |
74 |
75 | and then above global stats to be shared to all gpus, update running_mean and running_var by moving average using global stats.
76 |
77 | 3. forward batchnorm using global stats by
78 |
79 | 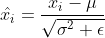 80 |
81 | and then
82 |
83 |
80 |
81 | and then
82 |
83 | 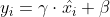 84 |
85 | where
84 |
85 | where 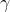 is weight parameter and
is weight parameter and 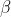 is bias parameter.
86 |
87 | 4. save
is bias parameter.
86 |
87 | 4. save 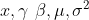 for backward
88 |
89 | ### Backward
90 |
91 | 1. Restore saved
92 |
93 | 2. Compute below sums on each gpu
94 |
95 |
for backward
88 |
89 | ### Backward
90 |
91 | 1. Restore saved
92 |
93 | 2. Compute below sums on each gpu
94 |
95 | ) 96 |
97 | and
98 |
99 |
96 |
97 | and
98 |
99 | ) 100 |
101 | where
100 |
101 | where 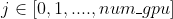 102 |
103 | then gather them at master node to sum up global, and normalize with N where N is total number of elements for each channels. Global sums are then shared among all gpus.
104 |
105 | 3. compute gradients using global stats
106 |
107 |
102 |
103 | then gather them at master node to sum up global, and normalize with N where N is total number of elements for each channels. Global sums are then shared among all gpus.
104 |
105 | 3. compute gradients using global stats
106 |
107 | 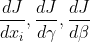 108 |
109 | where
110 |
111 |
108 |
109 | where
110 |
111 | ) 112 |
113 | and
114 |
115 |
112 |
113 | and
114 |
115 | ) 116 |
117 | and finally,
118 |
119 |
116 |
117 | and finally,
118 |
119 | 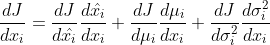 120 |
121 |
120 |
121 | }}(N\frac{dJ}{d\hat{x_i}}-\sum_{j=1}^{N}(\frac{dJ}{d\hat{x_j}})-\hat{x_i}\sum_{j=1}^{N}(\frac{dJ}{d\hat{x_j}}\hat{x_j}))) 122 |
123 |
122 |
123 | }}(N\frac{dJ}{dy_i}-\sum_{j=1}^{N}(\frac{dJ}{dy_j})-\hat{x_i}\sum_{j=1}^{N}(\frac{dJ}{dy_j}\hat{x_j}))) 124 |
125 | Note that in the implementation, normalization with N is performed at step (2) and above equation and implementation is not exactly the same, but mathematically is same.
126 |
127 | You can go deeper on above explanation at [Kevin Zakka's Blog](https://kevinzakka.github.io/2016/09/14/batch_normalization/)
--------------------------------------------------------------------------------
/fbrs/model/syncbn/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/fbrs/model/syncbn/__init__.py
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/fbrs/model/syncbn/modules/__init__.py
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/functional/__init__.py:
--------------------------------------------------------------------------------
1 | from .syncbn import batchnorm2d_sync
2 |
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/functional/_csrc.py:
--------------------------------------------------------------------------------
1 | """
2 | /*****************************************************************************/
3 |
4 | Extension module loader
5 |
6 | code referenced from : https://github.com/facebookresearch/maskrcnn-benchmark
7 |
8 | /*****************************************************************************/
9 | """
10 | from __future__ import absolute_import
11 | from __future__ import division
12 | from __future__ import print_function
13 |
14 | import glob
15 | import os.path
16 |
17 | import torch
18 |
19 | try:
20 | from torch.utils.cpp_extension import load
21 | from torch.utils.cpp_extension import CUDA_HOME
22 | except ImportError:
23 | raise ImportError(
24 | "The cpp layer extensions requires PyTorch 0.4 or higher")
25 |
26 |
27 | def _load_C_extensions():
28 | this_dir = os.path.dirname(os.path.abspath(__file__))
29 | this_dir = os.path.join(this_dir, "csrc")
30 |
31 | main_file = glob.glob(os.path.join(this_dir, "*.cpp"))
32 | sources_cpu = glob.glob(os.path.join(this_dir, "cpu", "*.cpp"))
33 | sources_cuda = glob.glob(os.path.join(this_dir, "cuda", "*.cu"))
34 |
35 | sources = main_file + sources_cpu
36 |
37 | extra_cflags = []
38 | extra_cuda_cflags = []
39 | if torch.cuda.is_available() and CUDA_HOME is not None:
40 | sources.extend(sources_cuda)
41 | extra_cflags = ["-O3", "-DWITH_CUDA"]
42 | extra_cuda_cflags = ["--expt-extended-lambda"]
43 | sources = [os.path.join(this_dir, s) for s in sources]
44 | extra_include_paths = [this_dir]
45 | return load(
46 | name="ext_lib",
47 | sources=sources,
48 | extra_cflags=extra_cflags,
49 | extra_include_paths=extra_include_paths,
50 | extra_cuda_cflags=extra_cuda_cflags,
51 | )
52 |
53 |
54 | _backend = _load_C_extensions()
55 |
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/functional/csrc/bn.h:
--------------------------------------------------------------------------------
1 | /*****************************************************************************
2 |
3 | SyncBN
4 |
5 | *****************************************************************************/
6 | #pragma once
7 |
8 | #ifdef WITH_CUDA
9 | #include "cuda/ext_lib.h"
10 | #endif
11 |
12 | /// SyncBN
13 |
14 | std::vector syncbn_sum_sqsum(const at::Tensor& x) {
15 | if (x.is_cuda()) {
16 | #ifdef WITH_CUDA
17 | return syncbn_sum_sqsum_cuda(x);
18 | #else
19 | AT_ERROR("Not compiled with GPU support");
20 | #endif
21 | } else {
22 | AT_ERROR("CPU implementation not supported");
23 | }
24 | }
25 |
26 | at::Tensor syncbn_forward(const at::Tensor& x, const at::Tensor& weight,
27 | const at::Tensor& bias, const at::Tensor& mean,
28 | const at::Tensor& var, bool affine, float eps) {
29 | if (x.is_cuda()) {
30 | #ifdef WITH_CUDA
31 | return syncbn_forward_cuda(x, weight, bias, mean, var, affine, eps);
32 | #else
33 | AT_ERROR("Not compiled with GPU support");
34 | #endif
35 | } else {
36 | AT_ERROR("CPU implementation not supported");
37 | }
38 | }
39 |
40 | std::vector syncbn_backward_xhat(const at::Tensor& dz,
41 | const at::Tensor& x,
42 | const at::Tensor& mean,
43 | const at::Tensor& var, float eps) {
44 | if (dz.is_cuda()) {
45 | #ifdef WITH_CUDA
46 | return syncbn_backward_xhat_cuda(dz, x, mean, var, eps);
47 | #else
48 | AT_ERROR("Not compiled with GPU support");
49 | #endif
50 | } else {
51 | AT_ERROR("CPU implementation not supported");
52 | }
53 | }
54 |
55 | std::vector syncbn_backward(
56 | const at::Tensor& dz, const at::Tensor& x, const at::Tensor& weight,
57 | const at::Tensor& bias, const at::Tensor& mean, const at::Tensor& var,
58 | const at::Tensor& sum_dz, const at::Tensor& sum_dz_xhat, bool affine,
59 | float eps) {
60 | if (dz.is_cuda()) {
61 | #ifdef WITH_CUDA
62 | return syncbn_backward_cuda(dz, x, weight, bias, mean, var, sum_dz,
63 | sum_dz_xhat, affine, eps);
64 | #else
65 | AT_ERROR("Not compiled with GPU support");
66 | #endif
67 | } else {
68 | AT_ERROR("CPU implementation not supported");
69 | }
70 | }
71 |
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/functional/csrc/cuda/common.h:
--------------------------------------------------------------------------------
1 | /*****************************************************************************
2 |
3 | CUDA utility funcs
4 |
5 | code referenced from : https://github.com/mapillary/inplace_abn
6 |
7 | *****************************************************************************/
8 | #pragma once
9 |
10 | #include
11 |
12 | // Checks
13 | #ifndef AT_CHECK
14 | #define AT_CHECK AT_ASSERT
15 | #endif
16 | #define CHECK_CUDA(x) AT_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
17 | #define CHECK_CONTIGUOUS(x) AT_CHECK(x.is_contiguous(), #x " must be contiguous")
18 | #define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
19 |
20 | /*
21 | * General settings
22 | */
23 | const int WARP_SIZE = 32;
24 | const int MAX_BLOCK_SIZE = 512;
25 |
26 | template
27 | struct Pair {
28 | T v1, v2;
29 | __device__ Pair() {}
30 | __device__ Pair(T _v1, T _v2) : v1(_v1), v2(_v2) {}
31 | __device__ Pair(T v) : v1(v), v2(v) {}
32 | __device__ Pair(int v) : v1(v), v2(v) {}
33 | __device__ Pair &operator+=(const Pair &a) {
34 | v1 += a.v1;
35 | v2 += a.v2;
36 | return *this;
37 | }
38 | };
39 |
40 | /*
41 | * Utility functions
42 | */
43 | template
44 | __device__ __forceinline__ T WARP_SHFL_XOR(T value, int laneMask,
45 | int width = warpSize,
46 | unsigned int mask = 0xffffffff) {
47 | #if CUDART_VERSION >= 9000
48 | return __shfl_xor_sync(mask, value, laneMask, width);
49 | #else
50 | return __shfl_xor(value, laneMask, width);
51 | #endif
52 | }
53 |
54 | __device__ __forceinline__ int getMSB(int val) { return 31 - __clz(val); }
55 |
56 | static int getNumThreads(int nElem) {
57 | int threadSizes[5] = {32, 64, 128, 256, MAX_BLOCK_SIZE};
58 | for (int i = 0; i != 5; ++i) {
59 | if (nElem <= threadSizes[i]) {
60 | return threadSizes[i];
61 | }
62 | }
63 | return MAX_BLOCK_SIZE;
64 | }
65 |
66 | template
67 | static __device__ __forceinline__ T warpSum(T val) {
68 | #if __CUDA_ARCH__ >= 300
69 | for (int i = 0; i < getMSB(WARP_SIZE); ++i) {
70 | val += WARP_SHFL_XOR(val, 1 << i, WARP_SIZE);
71 | }
72 | #else
73 | __shared__ T values[MAX_BLOCK_SIZE];
74 | values[threadIdx.x] = val;
75 | __threadfence_block();
76 | const int base = (threadIdx.x / WARP_SIZE) * WARP_SIZE;
77 | for (int i = 1; i < WARP_SIZE; i++) {
78 | val += values[base + ((i + threadIdx.x) % WARP_SIZE)];
79 | }
80 | #endif
81 | return val;
82 | }
83 |
84 | template
85 | static __device__ __forceinline__ Pair warpSum(Pair value) {
86 | value.v1 = warpSum(value.v1);
87 | value.v2 = warpSum(value.v2);
88 | return value;
89 | }
90 |
91 | template
92 | __device__ T reduce(Op op, int plane, int N, int C, int S) {
93 | T sum = (T)0;
94 | for (int batch = 0; batch < N; ++batch) {
95 | for (int x = threadIdx.x; x < S; x += blockDim.x) {
96 | sum += op(batch, plane, x);
97 | }
98 | }
99 |
100 | // sum over NumThreads within a warp
101 | sum = warpSum(sum);
102 |
103 | // 'transpose', and reduce within warp again
104 | __shared__ T shared[32];
105 | __syncthreads();
106 | if (threadIdx.x % WARP_SIZE == 0) {
107 | shared[threadIdx.x / WARP_SIZE] = sum;
108 | }
109 | if (threadIdx.x >= blockDim.x / WARP_SIZE && threadIdx.x < WARP_SIZE) {
110 | // zero out the other entries in shared
111 | shared[threadIdx.x] = (T)0;
112 | }
113 | __syncthreads();
114 | if (threadIdx.x / WARP_SIZE == 0) {
115 | sum = warpSum(shared[threadIdx.x]);
116 | if (threadIdx.x == 0) {
117 | shared[0] = sum;
118 | }
119 | }
120 | __syncthreads();
121 |
122 | // Everyone picks it up, should be broadcast into the whole gradInput
123 | return shared[0];
124 | }
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/functional/csrc/cuda/ext_lib.h:
--------------------------------------------------------------------------------
1 | /*****************************************************************************
2 |
3 | CUDA SyncBN code
4 |
5 | *****************************************************************************/
6 | #pragma once
7 | #include
8 | #include
9 |
10 | /// Sync-BN
11 | std::vector syncbn_sum_sqsum_cuda(const at::Tensor& x);
12 | at::Tensor syncbn_forward_cuda(const at::Tensor& x, const at::Tensor& weight,
13 | const at::Tensor& bias, const at::Tensor& mean,
14 | const at::Tensor& var, bool affine, float eps);
15 | std::vector syncbn_backward_xhat_cuda(const at::Tensor& dz,
16 | const at::Tensor& x,
17 | const at::Tensor& mean,
18 | const at::Tensor& var,
19 | float eps);
20 | std::vector syncbn_backward_cuda(
21 | const at::Tensor& dz, const at::Tensor& x, const at::Tensor& weight,
22 | const at::Tensor& bias, const at::Tensor& mean, const at::Tensor& var,
23 | const at::Tensor& sum_dz, const at::Tensor& sum_dz_xhat, bool affine,
24 | float eps);
25 |
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/functional/csrc/ext_lib.cpp:
--------------------------------------------------------------------------------
1 | #include "bn.h"
2 |
3 | PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
4 | m.def("syncbn_sum_sqsum", &syncbn_sum_sqsum, "Sum and Sum^2 computation");
5 | m.def("syncbn_forward", &syncbn_forward, "SyncBN forward computation");
6 | m.def("syncbn_backward_xhat", &syncbn_backward_xhat,
7 | "First part of SyncBN backward computation");
8 | m.def("syncbn_backward", &syncbn_backward,
9 | "Second part of SyncBN backward computation");
10 | }
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/functional/syncbn.py:
--------------------------------------------------------------------------------
1 | """
2 | /*****************************************************************************/
3 |
4 | BatchNorm2dSync with multi-gpu
5 |
6 | code referenced from : https://github.com/mapillary/inplace_abn
7 |
8 | /*****************************************************************************/
9 | """
10 | from __future__ import absolute_import
11 | from __future__ import division
12 | from __future__ import print_function
13 |
14 | import torch.cuda.comm as comm
15 | from torch.autograd import Function
16 | from torch.autograd.function import once_differentiable
17 | from ._csrc import _backend
18 |
19 |
20 | def _count_samples(x):
21 | count = 1
22 | for i, s in enumerate(x.size()):
23 | if i != 1:
24 | count *= s
25 | return count
26 |
27 |
28 | class BatchNorm2dSyncFunc(Function):
29 |
30 | @staticmethod
31 | def forward(ctx, x, weight, bias, running_mean, running_var,
32 | extra, compute_stats=True, momentum=0.1, eps=1e-05):
33 | def _parse_extra(ctx, extra):
34 | ctx.is_master = extra["is_master"]
35 | if ctx.is_master:
36 | ctx.master_queue = extra["master_queue"]
37 | ctx.worker_queues = extra["worker_queues"]
38 | ctx.worker_ids = extra["worker_ids"]
39 | else:
40 | ctx.master_queue = extra["master_queue"]
41 | ctx.worker_queue = extra["worker_queue"]
42 | # Save context
43 | if extra is not None:
44 | _parse_extra(ctx, extra)
45 | ctx.compute_stats = compute_stats
46 | ctx.momentum = momentum
47 | ctx.eps = eps
48 | ctx.affine = weight is not None and bias is not None
49 | if ctx.compute_stats:
50 | N = _count_samples(x) * (ctx.master_queue.maxsize + 1)
51 | assert N > 1
52 | # 1. compute sum(x) and sum(x^2)
53 | xsum, xsqsum = _backend.syncbn_sum_sqsum(x.detach())
54 | if ctx.is_master:
55 | xsums, xsqsums = [xsum], [xsqsum]
56 | # master : gatther all sum(x) and sum(x^2) from slaves
57 | for _ in range(ctx.master_queue.maxsize):
58 | xsum_w, xsqsum_w = ctx.master_queue.get()
59 | ctx.master_queue.task_done()
60 | xsums.append(xsum_w)
61 | xsqsums.append(xsqsum_w)
62 | xsum = comm.reduce_add(xsums)
63 | xsqsum = comm.reduce_add(xsqsums)
64 | mean = xsum / N
65 | sumvar = xsqsum - xsum * mean
66 | var = sumvar / N
67 | uvar = sumvar / (N - 1)
68 | # master : broadcast global mean, variance to all slaves
69 | tensors = comm.broadcast_coalesced(
70 | (mean, uvar, var), [mean.get_device()] + ctx.worker_ids)
71 | for ts, queue in zip(tensors[1:], ctx.worker_queues):
72 | queue.put(ts)
73 | else:
74 | # slave : send sum(x) and sum(x^2) to master
75 | ctx.master_queue.put((xsum, xsqsum))
76 | # slave : get global mean and variance
77 | mean, uvar, var = ctx.worker_queue.get()
78 | ctx.worker_queue.task_done()
79 |
80 | # Update running stats
81 | running_mean.mul_((1 - ctx.momentum)).add_(ctx.momentum * mean)
82 | running_var.mul_((1 - ctx.momentum)).add_(ctx.momentum * uvar)
83 | ctx.N = N
84 | ctx.save_for_backward(x, weight, bias, mean, var)
85 | else:
86 | mean, var = running_mean, running_var
87 |
88 | # do batch norm forward
89 | z = _backend.syncbn_forward(x, weight, bias, mean, var,
90 | ctx.affine, ctx.eps)
91 | return z
92 |
93 | @staticmethod
94 | @once_differentiable
95 | def backward(ctx, dz):
96 | x, weight, bias, mean, var = ctx.saved_tensors
97 | dz = dz.contiguous()
98 |
99 | # 1. compute \sum(\frac{dJ}{dy_i}) and \sum(\frac{dJ}{dy_i}*\hat{x_i})
100 | sum_dz, sum_dz_xhat = _backend.syncbn_backward_xhat(
101 | dz, x, mean, var, ctx.eps)
102 | if ctx.is_master:
103 | sum_dzs, sum_dz_xhats = [sum_dz], [sum_dz_xhat]
104 | # master : gatther from slaves
105 | for _ in range(ctx.master_queue.maxsize):
106 | sum_dz_w, sum_dz_xhat_w = ctx.master_queue.get()
107 | ctx.master_queue.task_done()
108 | sum_dzs.append(sum_dz_w)
109 | sum_dz_xhats.append(sum_dz_xhat_w)
110 | # master : compute global stats
111 | sum_dz = comm.reduce_add(sum_dzs)
112 | sum_dz_xhat = comm.reduce_add(sum_dz_xhats)
113 | sum_dz /= ctx.N
114 | sum_dz_xhat /= ctx.N
115 | # master : broadcast global stats
116 | tensors = comm.broadcast_coalesced(
117 | (sum_dz, sum_dz_xhat), [mean.get_device()] + ctx.worker_ids)
118 | for ts, queue in zip(tensors[1:], ctx.worker_queues):
119 | queue.put(ts)
120 | else:
121 | # slave : send to master
122 | ctx.master_queue.put((sum_dz, sum_dz_xhat))
123 | # slave : get global stats
124 | sum_dz, sum_dz_xhat = ctx.worker_queue.get()
125 | ctx.worker_queue.task_done()
126 |
127 | # do batch norm backward
128 | dx, dweight, dbias = _backend.syncbn_backward(
129 | dz, x, weight, bias, mean, var, sum_dz, sum_dz_xhat,
130 | ctx.affine, ctx.eps)
131 |
132 | return dx, dweight, dbias, \
133 | None, None, None, None, None, None
134 |
135 | batchnorm2d_sync = BatchNorm2dSyncFunc.apply
136 |
137 | __all__ = ["batchnorm2d_sync"]
138 |
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/nn/__init__.py:
--------------------------------------------------------------------------------
1 | from .syncbn import *
2 |
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/nn/syncbn.py:
--------------------------------------------------------------------------------
1 | """
2 | /*****************************************************************************/
3 |
4 | BatchNorm2dSync with multi-gpu
5 |
6 | /*****************************************************************************/
7 | """
8 | from __future__ import absolute_import
9 | from __future__ import division
10 | from __future__ import print_function
11 |
12 | try:
13 | # python 3
14 | from queue import Queue
15 | except ImportError:
16 | # python 2
17 | from Queue import Queue
18 |
19 | import torch
20 | import torch.nn as nn
21 | from torch.nn import functional as F
22 | from torch.nn.parameter import Parameter
23 | from isegm.model.syncbn.modules.functional import batchnorm2d_sync
24 |
25 |
26 | class _BatchNorm(nn.Module):
27 | """
28 | Customized BatchNorm from nn.BatchNorm
29 | >> added freeze attribute to enable bn freeze.
30 | """
31 |
32 | def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,
33 | track_running_stats=True):
34 | super(_BatchNorm, self).__init__()
35 | self.num_features = num_features
36 | self.eps = eps
37 | self.momentum = momentum
38 | self.affine = affine
39 | self.track_running_stats = track_running_stats
40 | self.freezed = False
41 | if self.affine:
42 | self.weight = Parameter(torch.Tensor(num_features))
43 | self.bias = Parameter(torch.Tensor(num_features))
44 | else:
45 | self.register_parameter('weight', None)
46 | self.register_parameter('bias', None)
47 | if self.track_running_stats:
48 | self.register_buffer('running_mean', torch.zeros(num_features))
49 | self.register_buffer('running_var', torch.ones(num_features))
50 | else:
51 | self.register_parameter('running_mean', None)
52 | self.register_parameter('running_var', None)
53 | self.reset_parameters()
54 |
55 | def reset_parameters(self):
56 | if self.track_running_stats:
57 | self.running_mean.zero_()
58 | self.running_var.fill_(1)
59 | if self.affine:
60 | self.weight.data.uniform_()
61 | self.bias.data.zero_()
62 |
63 | def _check_input_dim(self, input):
64 | return NotImplemented
65 |
66 | def forward(self, input):
67 | self._check_input_dim(input)
68 |
69 | compute_stats = not self.freezed and \
70 | self.training and self.track_running_stats
71 |
72 | ret = F.batch_norm(input, self.running_mean, self.running_var,
73 | self.weight, self.bias, compute_stats,
74 | self.momentum, self.eps)
75 | return ret
76 |
77 | def extra_repr(self):
78 | return '{num_features}, eps={eps}, momentum={momentum}, '\
79 | 'affine={affine}, ' \
80 | 'track_running_stats={track_running_stats}'.format(
81 | **self.__dict__)
82 |
83 |
84 | class BatchNorm2dNoSync(_BatchNorm):
85 | """
86 | Equivalent to nn.BatchNorm2d
87 | """
88 |
89 | def _check_input_dim(self, input):
90 | if input.dim() != 4:
91 | raise ValueError('expected 4D input (got {}D input)'
92 | .format(input.dim()))
93 |
94 |
95 | class BatchNorm2dSync(BatchNorm2dNoSync):
96 | """
97 | BatchNorm2d with automatic multi-GPU Sync
98 | """
99 |
100 | def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,
101 | track_running_stats=True):
102 | super(BatchNorm2dSync, self).__init__(
103 | num_features, eps=eps, momentum=momentum, affine=affine,
104 | track_running_stats=track_running_stats)
105 | self.sync_enabled = True
106 | self.devices = list(range(torch.cuda.device_count()))
107 | if len(self.devices) > 1:
108 | # Initialize queues
109 | self.worker_ids = self.devices[1:]
110 | self.master_queue = Queue(len(self.worker_ids))
111 | self.worker_queues = [Queue(1) for _ in self.worker_ids]
112 |
113 | def forward(self, x):
114 | compute_stats = not self.freezed and \
115 | self.training and self.track_running_stats
116 | if self.sync_enabled and compute_stats and len(self.devices) > 1:
117 | if x.get_device() == self.devices[0]:
118 | # Master mode
119 | extra = {
120 | "is_master": True,
121 | "master_queue": self.master_queue,
122 | "worker_queues": self.worker_queues,
123 | "worker_ids": self.worker_ids
124 | }
125 | else:
126 | # Worker mode
127 | extra = {
128 | "is_master": False,
129 | "master_queue": self.master_queue,
130 | "worker_queue": self.worker_queues[
131 | self.worker_ids.index(x.get_device())]
132 | }
133 | return batchnorm2d_sync(x, self.weight, self.bias,
134 | self.running_mean, self.running_var,
135 | extra, compute_stats, self.momentum,
136 | self.eps)
137 | return super(BatchNorm2dSync, self).forward(x)
138 |
139 | def __repr__(self):
140 | """repr"""
141 | rep = '{name}({num_features}, eps={eps}, momentum={momentum},' \
142 | 'affine={affine}, ' \
143 | 'track_running_stats={track_running_stats},' \
144 | 'devices={devices})'
145 | return rep.format(name=self.__class__.__name__, **self.__dict__)
146 |
147 | #BatchNorm2d = BatchNorm2dNoSync
148 | BatchNorm2d = BatchNorm2dSync
149 |
--------------------------------------------------------------------------------
/fbrs/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/fbrs/utils/__init__.py
--------------------------------------------------------------------------------
/fbrs/utils/cython/__init__.py:
--------------------------------------------------------------------------------
1 | # noinspection PyUnresolvedReferences
2 | from .dist_maps import get_dist_maps
--------------------------------------------------------------------------------
/fbrs/utils/cython/_get_dist_maps.pyx:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | cimport cython
3 | cimport numpy as np
4 | from libc.stdlib cimport malloc, free
5 |
6 | ctypedef struct qnode:
7 | int row
8 | int col
9 | int layer
10 | int orig_row
11 | int orig_col
12 |
13 | @cython.infer_types(True)
14 | @cython.boundscheck(False)
15 | @cython.wraparound(False)
16 | @cython.nonecheck(False)
17 | def get_dist_maps(np.ndarray[np.float32_t, ndim=2, mode="c"] points,
18 | int height, int width, float norm_delimeter):
19 | cdef np.ndarray[np.float32_t, ndim=3, mode="c"] dist_maps = \
20 | np.full((2, height, width), 1e6, dtype=np.float32, order="C")
21 |
22 | cdef int *dxy = [-1, 0, 0, -1, 0, 1, 1, 0]
23 | cdef int i, j, x, y, dx, dy
24 | cdef qnode v
25 | cdef qnode *q = malloc((4 * height * width + 1) * sizeof(qnode))
26 | cdef int qhead = 0, qtail = -1
27 | cdef float ndist
28 |
29 | for i in range(points.shape[0]):
30 | x, y = round(points[i, 0]), round(points[i, 1])
31 | if x >= 0:
32 | qtail += 1
33 | q[qtail].row = x
34 | q[qtail].col = y
35 | q[qtail].orig_row = x
36 | q[qtail].orig_col = y
37 | if i >= points.shape[0] / 2:
38 | q[qtail].layer = 1
39 | else:
40 | q[qtail].layer = 0
41 | dist_maps[q[qtail].layer, x, y] = 0
42 |
43 | while qtail - qhead + 1 > 0:
44 | v = q[qhead]
45 | qhead += 1
46 |
47 | for k in range(4):
48 | x = v.row + dxy[2 * k]
49 | y = v.col + dxy[2 * k + 1]
50 |
51 | ndist = ((x - v.orig_row)/norm_delimeter) ** 2 + ((y - v.orig_col)/norm_delimeter) ** 2
52 | if (x >= 0 and y >= 0 and x < height and y < width and
53 | dist_maps[v.layer, x, y] > ndist):
54 | qtail += 1
55 | q[qtail].orig_col = v.orig_col
56 | q[qtail].orig_row = v.orig_row
57 | q[qtail].layer = v.layer
58 | q[qtail].row = x
59 | q[qtail].col = y
60 | dist_maps[v.layer, x, y] = ndist
61 |
62 | free(q)
63 | return dist_maps
64 |
--------------------------------------------------------------------------------
/fbrs/utils/cython/_get_dist_maps.pyxbld:
--------------------------------------------------------------------------------
1 | import numpy
2 |
3 | def make_ext(modname, pyxfilename):
4 | from distutils.extension import Extension
5 | return Extension(modname, [pyxfilename],
6 | include_dirs=[numpy.get_include()],
7 | extra_compile_args=['-O3'], language='c++')
8 |
--------------------------------------------------------------------------------
/fbrs/utils/cython/dist_maps.py:
--------------------------------------------------------------------------------
1 | import pyximport; pyximport.install(pyximport=True, language_level=3)
2 | # noinspection PyUnresolvedReferences
3 | from ._get_dist_maps import get_dist_maps
--------------------------------------------------------------------------------
/fbrs/utils/misc.py:
--------------------------------------------------------------------------------
1 | from functools import partial
2 |
3 | import torch
4 | import numpy as np
5 |
6 |
7 | def get_dims_with_exclusion(dim, exclude=None):
8 | dims = list(range(dim))
9 | if exclude is not None:
10 | dims.remove(exclude)
11 |
12 | return dims
13 |
14 |
15 | def get_unique_labels(mask):
16 | return np.nonzero(np.bincount(mask.flatten() + 1))[0] - 1
17 |
18 |
19 | def get_bbox_from_mask(mask):
20 | rows = np.any(mask, axis=1)
21 | cols = np.any(mask, axis=0)
22 | rmin, rmax = np.where(rows)[0][[0, -1]]
23 | cmin, cmax = np.where(cols)[0][[0, -1]]
24 |
25 | return rmin, rmax, cmin, cmax
26 |
27 |
28 | def expand_bbox(bbox, expand_ratio, min_crop_size=None):
29 | rmin, rmax, cmin, cmax = bbox
30 | rcenter = 0.5 * (rmin + rmax)
31 | ccenter = 0.5 * (cmin + cmax)
32 | height = expand_ratio * (rmax - rmin + 1)
33 | width = expand_ratio * (cmax - cmin + 1)
34 | if min_crop_size is not None:
35 | height = max(height, min_crop_size)
36 | width = max(width, min_crop_size)
37 |
38 | rmin = int(round(rcenter - 0.5 * height))
39 | rmax = int(round(rcenter + 0.5 * height))
40 | cmin = int(round(ccenter - 0.5 * width))
41 | cmax = int(round(ccenter + 0.5 * width))
42 |
43 | return rmin, rmax, cmin, cmax
44 |
45 |
46 | def clamp_bbox(bbox, rmin, rmax, cmin, cmax):
47 | return (max(rmin, bbox[0]), min(rmax, bbox[1]),
48 | max(cmin, bbox[2]), min(cmax, bbox[3]))
49 |
50 |
51 | def get_bbox_iou(b1, b2):
52 | h_iou = get_segments_iou(b1[:2], b2[:2])
53 | w_iou = get_segments_iou(b1[2:4], b2[2:4])
54 | return h_iou * w_iou
55 |
56 |
57 | def get_segments_iou(s1, s2):
58 | a, b = s1
59 | c, d = s2
60 | intersection = max(0, min(b, d) - max(a, c) + 1)
61 | union = max(1e-6, max(b, d) - min(a, c) + 1)
62 | return intersection / union
63 |
--------------------------------------------------------------------------------
/fbrs/utils/vis.py:
--------------------------------------------------------------------------------
1 | from functools import lru_cache
2 |
3 | import cv2
4 | import numpy as np
5 |
6 |
7 | def visualize_instances(imask, bg_color=255,
8 | boundaries_color=None, boundaries_width=1, boundaries_alpha=0.8):
9 | num_objects = imask.max() + 1
10 | palette = get_palette(num_objects)
11 | if bg_color is not None:
12 | palette[0] = bg_color
13 |
14 | result = palette[imask].astype(np.uint8)
15 | if boundaries_color is not None:
16 | boundaries_mask = get_boundaries(imask, boundaries_width=boundaries_width)
17 | tresult = result.astype(np.float32)
18 | tresult[boundaries_mask] = boundaries_color
19 | tresult = tresult * boundaries_alpha + (1 - boundaries_alpha) * result
20 | result = tresult.astype(np.uint8)
21 |
22 | return result
23 |
24 |
25 | @lru_cache(maxsize=16)
26 | def get_palette(num_cls):
27 | palette = np.zeros(3 * num_cls, dtype=np.int32)
28 |
29 | for j in range(0, num_cls):
30 | lab = j
31 | i = 0
32 |
33 | while lab > 0:
34 | palette[j*3 + 0] |= (((lab >> 0) & 1) << (7-i))
35 | palette[j*3 + 1] |= (((lab >> 1) & 1) << (7-i))
36 | palette[j*3 + 2] |= (((lab >> 2) & 1) << (7-i))
37 | i = i + 1
38 | lab >>= 3
39 |
40 | return palette.reshape((-1, 3))
41 |
42 |
43 | def visualize_mask(mask, num_cls):
44 | palette = get_palette(num_cls)
45 | mask[mask == -1] = 0
46 |
47 | return palette[mask].astype(np.uint8)
48 |
49 |
50 | def visualize_proposals(proposals_info, point_color=(255, 0, 0), point_radius=1):
51 | proposal_map, colors, candidates = proposals_info
52 |
53 | proposal_map = draw_probmap(proposal_map)
54 | for x, y in candidates:
55 | proposal_map = cv2.circle(proposal_map, (y, x), point_radius, point_color, -1)
56 |
57 | return proposal_map
58 |
59 |
60 | def draw_probmap(x):
61 | return cv2.applyColorMap((x * 255).astype(np.uint8), cv2.COLORMAP_HOT)
62 |
63 |
64 | def draw_points(image, points, color, radius=3):
65 | image = image.copy()
66 | for p in points:
67 | image = cv2.circle(image, (int(p[1]), int(p[0])), radius, color, -1)
68 |
69 | return image
70 |
71 |
72 | def draw_instance_map(x, palette=None):
73 | num_colors = x.max() + 1
74 | if palette is None:
75 | palette = get_palette(num_colors)
76 |
77 | return palette[x].astype(np.uint8)
78 |
79 |
80 | def blend_mask(image, mask, alpha=0.6):
81 | if mask.min() == -1:
82 | mask = mask.copy() + 1
83 |
84 | imap = draw_instance_map(mask)
85 | result = (image * (1 - alpha) + alpha * imap).astype(np.uint8)
86 | return result
87 |
88 |
89 | def get_boundaries(instances_masks, boundaries_width=1):
90 | boundaries = np.zeros((instances_masks.shape[0], instances_masks.shape[1]), dtype=np.bool)
91 |
92 | for obj_id in np.unique(instances_masks.flatten()):
93 | if obj_id == 0:
94 | continue
95 |
96 | obj_mask = instances_masks == obj_id
97 | kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
98 | inner_mask = cv2.erode(obj_mask.astype(np.uint8), kernel, iterations=boundaries_width).astype(np.bool)
99 |
100 | obj_boundary = np.logical_xor(obj_mask, np.logical_and(inner_mask, obj_mask))
101 | boundaries = np.logical_or(boundaries, obj_boundary)
102 | return boundaries
103 |
104 |
105 | def draw_with_blend_and_clicks(img, mask=None, alpha=0.6, clicks_list=None, pos_color=(0, 255, 0),
106 | neg_color=(255, 0, 0), radius=4):
107 | result = img.copy()
108 |
109 | if mask is not None:
110 | palette = get_palette(np.max(mask) + 1)
111 | rgb_mask = palette[mask.astype(np.uint8)]
112 |
113 | mask_region = (mask > 0).astype(np.uint8)
114 | result = result * (1 - mask_region[:, :, np.newaxis]) + \
115 | (1 - alpha) * mask_region[:, :, np.newaxis] * result + \
116 | alpha * rgb_mask
117 | result = result.astype(np.uint8)
118 |
119 | # result = (result * (1 - alpha) + alpha * rgb_mask).astype(np.uint8)
120 |
121 | if clicks_list is not None and len(clicks_list) > 0:
122 | pos_points = [click.coords for click in clicks_list if click.is_positive]
123 | neg_points = [click.coords for click in clicks_list if not click.is_positive]
124 |
125 | result = draw_points(result, pos_points, pos_color, radius=radius)
126 | result = draw_points(result, neg_points, neg_color, radius=radius)
127 |
128 | return result
129 |
130 |
--------------------------------------------------------------------------------
/generate_fusion.py:
--------------------------------------------------------------------------------
1 | """
2 | Generate fusion data for the DAVIS dataset.
3 | """
4 |
5 | import os
6 | from os import path
7 | from argparse import ArgumentParser
8 |
9 | import torch
10 | from torch.utils.data import Dataset, DataLoader
11 | import numpy as np
12 | from PIL import Image
13 | import cv2
14 |
15 | from model.propagation.prop_net import PropagationNetwork
16 | from dataset.davis_test_dataset import DAVISTestDataset
17 | from dataset.bl_test_dataset import BLTestDataset
18 | from generation.fusion_generator import FusionGenerator
19 |
20 | from progressbar import progressbar
21 |
22 |
23 | """
24 | Arguments loading
25 | """
26 | parser = ArgumentParser()
27 | parser.add_argument('--model', default='saves/propagation_model.pth')
28 | parser.add_argument('--davis_root', default='../DAVIS/2017')
29 | parser.add_argument('--bl_root', default='../BL30K')
30 | parser.add_argument('--dataset', help='DAVIS/BL')
31 | parser.add_argument('--output')
32 | parser.add_argument('--separation', default=None, type=int)
33 | parser.add_argument('--range', default=None, type=int)
34 | parser.add_argument('--mem_freq', default=None, type=int)
35 | parser.add_argument('--start', default=None, type=int)
36 | parser.add_argument('--end', default=None, type=int)
37 | args = parser.parse_args()
38 |
39 | davis_path = args.davis_root
40 | bl_path = args.bl_root
41 | out_path = args.output
42 | dataset_option = args.dataset
43 |
44 | # Simple setup
45 | os.makedirs(out_path, exist_ok=True)
46 | palette = Image.open(path.expanduser(davis_path+'/trainval/Annotations/480p/blackswan/00000.png')).getpalette()
47 |
48 | torch.autograd.set_grad_enabled(False)
49 |
50 | # Setup Dataset
51 | if dataset_option == 'DAVIS':
52 | test_dataset = DAVISTestDataset(davis_path+'/trainval', imset='2017/train.txt')
53 | elif dataset_option == 'BL':
54 | test_dataset = BLTestDataset(bl_path, start=args.start, end=args.end)
55 | else:
56 | print('Use --dataset DAVIS or --dataset BL')
57 | raise NotImplementedError
58 |
59 | # test_dataset = BLTestDataset(args.bl, start=args.start, end=args.end, subset=load_sub_bl())
60 | test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False, num_workers=1, pin_memory=False)
61 |
62 | # Load our checkpoint
63 | prop_saved = torch.load(args.model)
64 | prop_model = PropagationNetwork().cuda().eval()
65 | prop_model.load_state_dict(prop_saved)
66 |
67 | # Start evaluation
68 | for data in progressbar(test_loader, max_value=len(test_loader), redirect_stdout=True):
69 |
70 | rgb = data['rgb'].cuda()
71 | msk = data['gt'][0].cuda()
72 | info = data['info']
73 |
74 | total_t = rgb.shape[1]
75 | processor = FusionGenerator(prop_model, rgb, args.mem_freq)
76 |
77 | for frame in range(0, total_t, args.separation):
78 |
79 | usable_keys = []
80 | for k in range(msk.shape[0]):
81 | if (msk[k,frame] > 0.5).sum() > 10*10:
82 | usable_keys.append(k)
83 | if len(usable_keys) == 0:
84 | continue
85 | if len(usable_keys) > 5:
86 | # Memory limit
87 | usable_keys = usable_keys[:5]
88 |
89 | k = len(usable_keys)
90 | processor.reset(k)
91 | this_msk = msk[usable_keys]
92 |
93 | # Make this directory
94 | this_out_path = path.join(out_path, info['name'][0], '%05d'%frame)
95 | os.makedirs(this_out_path, exist_ok=True)
96 |
97 | # Propagate
98 | if dataset_option == 'DAVIS':
99 | left_limit = 0
100 | right_limit = total_t-1
101 | else:
102 | left_limit = max(0, frame-args.range)
103 | right_limit = min(total_t-1, frame+args.range)
104 |
105 | pred_range = range(left_limit, right_limit+1)
106 | out_probs = processor.interact_mask(this_msk[:,frame], frame, left_limit, right_limit)
107 |
108 | for kidx, obj_id in enumerate(usable_keys):
109 | obj_out_path = path.join(this_out_path, '%05d'%(obj_id+1))
110 | os.makedirs(obj_out_path, exist_ok=True)
111 | prob_Es = (out_probs[kidx+1]*255).cpu().numpy().astype(np.uint8)
112 |
113 | for f in pred_range:
114 | img_E = Image.fromarray(prob_Es[f])
115 | img_E.save(os.path.join(obj_out_path, '{:05d}.png'.format(f)))
116 |
117 | del out_probs
118 |
119 | print(info['name'][0])
120 | torch.cuda.empty_cache()
--------------------------------------------------------------------------------
/generation/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/generation/__init__.py
--------------------------------------------------------------------------------
/generation/blender/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/generation/blender/__init__.py
--------------------------------------------------------------------------------
/generation/blender/clean_data.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 | from os import path
4 | import shutil
5 |
6 | """
7 | Look at a "rendered" folder, move the rendered to the output path
8 | Keep the empty folders in place (don't delete since it might still be rendered right)
9 | Also copy the corresponding yaml in there
10 | """
11 |
12 | input_path = sys.argv[1]
13 | output_path = sys.argv[2]
14 | yaml_path = sys.argv[3]
15 |
16 | # This overrides the softlink
17 | # os.makedirs(output_path, exist_ok=True)
18 |
19 | renders = os.listdir(input_path)
20 | is_rendered = [len(os.listdir(path.join(input_path, r, 'segmentation')))==160 for r in renders]
21 |
22 | updated = 0
23 | for i, r in enumerate(renders):
24 | if is_rendered[i]:
25 | if not path.exists(path.join(output_path, r)):
26 | shutil.move(path.join(input_path, r), output_path)
27 | prefix = r[:3]
28 |
29 | shutil.copy2(path.join(yaml_path, 'yaml_%s'%prefix, '%s.yaml'%r), path.join(output_path, r))
30 | updated += 1
31 | else:
32 | print('path exist')
33 | else:
34 | # Nothing for now. Can do something later
35 | pass
36 |
37 | print('Number of completed renders: ', len(os.listdir(output_path)))
38 | print('Number of updated renders: ', updated)
--------------------------------------------------------------------------------
/generation/blender/gen_utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import numpy.polynomial.polynomial as poly
3 | from scipy import optimize
4 |
5 |
6 | class Sampler:
7 | def __init__(self, data_list):
8 | self.data_list = data_list
9 | self.idx = 0
10 | self.permute()
11 |
12 | def permute(self):
13 | self.data_list = np.random.permutation(self.data_list)
14 |
15 | def next(self):
16 | if self.idx == len(self.data_list):
17 | self.permute()
18 | self.idx = 0
19 | data = self.data_list[self.idx]
20 | self.idx += 1
21 | return data
22 |
23 | def step_back(self):
24 | self.idx -= 1
25 | if self.idx == -1:
26 | self.idx = len(self.data_list) - 1
27 |
28 | def test_path(prev_paths, path, tol=0.75):
29 | min_dist = float('inf')
30 | path = np.array(path)
31 | for p in prev_paths:
32 | p = np.array(p)
33 | # Find min distance as a constrained optimization problem
34 | poly_vals = p - path
35 | f = lambda x: np.linalg.norm(poly.polyval(x, poly_vals))
36 | optim_x = optimize.minimize_scalar(f, bounds=(0, 1), method='bounded')
37 | if optim_x.fun < tol:
38 | # print('Fail')
39 | return False
40 | # print('Success')
41 | return True
42 |
43 | def pick_rand(min_v, max_v, shape=None):
44 | if shape is not None:
45 | return np.random.rand(shape)*(max_v-min_v) + min_v
46 | else:
47 | return np.random.rand()*(max_v-min_v) + min_v
48 |
49 | def pick_normal_rand(mean, std, shape=None):
50 | return np.random.normal(mean, std, shape)
51 |
52 | def pick_randint(min_v, max_v):
53 | return np.random.randint(min_v, max_v+1)
54 |
55 | def normalize(a):
56 | return a / np.linalg.norm(a)
57 |
58 | def get_2side_rand(max_delta, shape=1):
59 | return np.random.rand(shape)*2*max_delta-max_delta
60 |
61 | def get_vector_in_frustum(min_base, max_base, min_into, max_into, cam_min_into):
62 | y = pick_rand(min_into, max_into)
63 |
64 | f_min_base = min_base * ((y - cam_min_into) / (min_into - cam_min_into))
65 | f_max_base = max_base * ((y - cam_min_into) / (min_into - cam_min_into))
66 |
67 | x = pick_rand(f_min_base, f_max_base)
68 | z = pick_rand(f_min_base, f_max_base)
69 | return np.array((x, y, z))
70 |
71 | def get_vector_in_block(min_base, max_base, min_into, max_into):
72 | x = pick_rand(min_base, max_base)
73 | y = pick_rand(min_into, max_into)
74 | z = pick_rand(min_base, max_base)
75 | return np.array((x, y, z))
76 |
77 | def get_vector_on_sphere(radius):
78 | x1 = np.random.normal(0, 1)
79 | x2 = np.random.normal(0, 1)
80 | x3 = np.random.normal(0, 1)
81 | norm = (x1*x1 + x2*x2 + x3*x3)**(1/2)
82 | pt = radius*np.array((x1,x2,x3))/norm
83 | return pt
84 |
85 | def get_next_vector_in_block(curr_vec, max_delta, min_base, max_base, min_into, max_into):
86 | new_point = get_vector_in_block(min_base, max_base, min_into, max_into)
87 |
88 | max_delta = np.abs(max_delta)
89 | dist_vec = (new_point - curr_vec)
90 | for i in range(3):
91 | if dist_vec[i] > max_delta[i]:
92 | dist_vec[i] = np.sign(dist_vec[i]) * max_delta[i]
93 |
94 | new_point = curr_vec + dist_vec
95 | return new_point
96 |
97 | def get_next_vector_in_frustum(curr_vec, max_delta, min_base, max_base, min_into, max_into, cam_min_into):
98 | new_point = get_vector_in_frustum(min_base, max_base, min_into, max_into, cam_min_into)
99 |
100 | max_delta = np.abs(max_delta)
101 | dist_vec = (new_point - curr_vec)
102 | for i in range(3):
103 | if dist_vec[i] > max_delta[i]:
104 | dist_vec[i] = np.sign(dist_vec[i]) * max_delta[i]
105 |
106 | new_point = curr_vec + dist_vec
107 | return new_point
--------------------------------------------------------------------------------
/generation/blender/resize_texture.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 | import cv2
4 |
5 | from multiprocessing import Pool
6 | from progressbar import progressbar
7 |
8 | input_dir = sys.argv[1]
9 | output_dir = sys.argv[2]
10 |
11 | min_size = 512
12 |
13 | def process_fun(sub_dir):
14 | this_in_dir = os.path.join(input_dir, sub_dir)
15 | this_out_dir = os.path.join(output_dir, sub_dir)
16 | os.makedirs(this_out_dir, exist_ok=True)
17 |
18 | for f in os.listdir(this_in_dir):
19 | img = cv2.imread(os.path.join(this_in_dir, f))
20 | if img is None:
21 | continue
22 | h, w, _ = img.shape
23 |
24 | scale = min(h, w) / min_size
25 |
26 | img = cv2.resize(img, (int(w/scale), int(h/scale)), interpolation=cv2.INTER_AREA)
27 | if len(img.shape) == 3:
28 | img = img[0:min_size, 0:min_size, :]
29 | else:
30 | img = img[0:min_size, 0:min_size]
31 | cv2.imwrite(os.path.join(this_out_dir, os.path.basename(f)), img)
32 |
33 | if __name__ == '__main__':
34 | pool = Pool()
35 | chunksize = 1
36 |
37 | os.makedirs(output_dir, exist_ok=True)
38 | for _ in progressbar(pool.map(process_fun, os.listdir(input_dir)), chunksize):
39 | pass
40 |
41 | print('All done.')
--------------------------------------------------------------------------------
/generation/blender/texture.json:
--------------------------------------------------------------------------------
1 | {
2 | "Records": [
3 | {
4 | "keywords": "wood texture",
5 | "limit": 300,
6 | "usage_rights": "labeled-for-nocommercial-reuse",
7 | "print_urls": true,
8 | "output_directory": "texture"
9 | },
10 | {
11 | "keywords": "metal texture",
12 | "limit": 300,
13 | "usage_rights": "labeled-for-nocommercial-reuse",
14 | "print_urls": true,
15 | "output_directory": "texture"
16 | },
17 | {
18 | "keywords": "tree texture",
19 | "limit": 300,
20 | "usage_rights": "labeled-for-nocommercial-reuse",
21 | "print_urls": true,
22 | "output_directory": "texture"
23 | },
24 | {
25 | "keywords": "glass texture",
26 | "limit": 300,
27 | "usage_rights": "labeled-for-nocommercial-reuse",
28 | "print_urls": true,
29 | "output_directory": "texture"
30 | },
31 | {
32 | "keywords": "plastic texture",
33 | "limit": 300,
34 | "usage_rights": "labeled-for-nocommercial-reuse",
35 | "print_urls": true,
36 | "output_directory": "texture"
37 | },
38 | {
39 | "keywords": "brick texture",
40 | "limit": 300,
41 | "usage_rights": "labeled-for-nocommercial-reuse",
42 | "print_urls": true,
43 | "output_directory": "texture"
44 | },
45 | {
46 | "keywords": "wall texture",
47 | "limit": 300,
48 | "usage_rights": "labeled-for-nocommercial-reuse",
49 | "print_urls": true,
50 | "output_directory": "texture"
51 | },
52 | {
53 | "keywords": "concrete texture",
54 | "limit": 300,
55 | "usage_rights": "labeled-for-nocommercial-reuse",
56 | "print_urls": true,
57 | "output_directory": "texture"
58 | },
59 | {
60 | "keywords": "dirt texture",
61 | "limit": 300,
62 | "usage_rights": "labeled-for-nocommercial-reuse",
63 | "print_urls": true,
64 | "output_directory": "texture"
65 | },
66 | {
67 | "keywords": "paper texture",
68 | "limit": 300,
69 | "usage_rights": "labeled-for-nocommercial-reuse",
70 | "print_urls": true,
71 | "output_directory": "texture"
72 | },
73 | {
74 | "keywords": "skin texture",
75 | "limit": 300,
76 | "usage_rights": "labeled-for-nocommercial-reuse",
77 | "print_urls": true,
78 | "output_directory": "texture"
79 | },
80 | {
81 | "keywords": "meat texture",
82 | "limit": 300,
83 | "usage_rights": "labeled-for-nocommercial-reuse",
84 | "print_urls": true,
85 | "output_directory": "texture"
86 | },
87 | {
88 | "keywords": "hair texture",
89 | "limit": 300,
90 | "usage_rights": "labeled-for-nocommercial-reuse",
91 | "print_urls": true,
92 | "output_directory": "texture"
93 | },
94 | {
95 | "keywords": "electronics texture",
96 | "limit": 300,
97 | "usage_rights": "labeled-for-nocommercial-reuse",
98 | "print_urls": true,
99 | "output_directory": "texture"
100 | },
101 | {
102 | "keywords": "fur texture",
103 | "limit": 300,
104 | "usage_rights": "labeled-for-nocommercial-reuse",
105 | "print_urls": true,
106 | "output_directory": "texture"
107 | }
108 | ]
109 | }
--------------------------------------------------------------------------------
/generation/blender/texture_2.json:
--------------------------------------------------------------------------------
1 | {
2 | "Records": [
3 | {
4 | "keywords": "stone texture",
5 | "limit": 300,
6 | "usage_rights": "labeled-for-nocommercial-reuse",
7 | "print_urls": true,
8 | "output_directory": "texture"
9 | },
10 | {
11 | "keywords": "fabric texture",
12 | "limit": 300,
13 | "usage_rights": "labeled-for-nocommercial-reuse",
14 | "print_urls": true,
15 | "output_directory": "texture"
16 | },
17 | {
18 | "keywords": "pebble texture",
19 | "limit": 300,
20 | "usage_rights": "labeled-for-nocommercial-reuse",
21 | "print_urls": true,
22 | "output_directory": "texture"
23 | },
24 | {
25 | "keywords": "sand texture",
26 | "limit": 300,
27 | "usage_rights": "labeled-for-nocommercial-reuse",
28 | "print_urls": true,
29 | "output_directory": "texture"
30 | },
31 | {
32 | "keywords": "beach texture",
33 | "limit": 300,
34 | "usage_rights": "labeled-for-nocommercial-reuse",
35 | "print_urls": true,
36 | "output_directory": "texture"
37 | }
38 | ]
39 | }
--------------------------------------------------------------------------------
/generation/fusion_generator.py:
--------------------------------------------------------------------------------
1 | """
2 | A helper class for generating data used to train the fusion module.
3 | This part is rather crude as it is used only once/twice.
4 | """
5 | import torch
6 | import numpy as np
7 |
8 | from model.propagation.prop_net import PropagationNetwork
9 | from model.aggregate import aggregate_sbg, aggregate_wbg
10 |
11 | from util.tensor_util import pad_divide_by
12 |
13 | class FusionGenerator:
14 | def __init__(self, prop_net:PropagationNetwork, images, mem_freq):
15 | self.prop_net = prop_net
16 | self.mem_freq = mem_freq
17 |
18 | # True dimensions
19 | t = images.shape[1]
20 | h, w = images.shape[-2:]
21 |
22 | # Pad each side to multiple of 16
23 | images, self.pad = pad_divide_by(images, 16, images.shape[-2:])
24 | # Padded dimensions
25 | nh, nw = images.shape[-2:]
26 |
27 | self.images = images
28 | self.device = self.images.device
29 |
30 | self.t, self.h, self.w = t, h, w
31 | self.nh, self.nw = nh, nw
32 |
33 | def reset(self, k):
34 | self.k = k
35 | self.prob = torch.zeros((self.k+1, self.t, 1, self.nh, self.nw), dtype=torch.float32, device=self.device)
36 |
37 | def get_im(self, idx):
38 | return self.images[:,idx]
39 |
40 | def get_query_buf(self, idx):
41 | query = self.prop_net.get_query_values(self.get_im(idx))
42 | return query
43 |
44 | def do_pass(self, key_k, key_v, idx, left_limit, right_limit, forward=True):
45 | keys = key_k
46 | values = key_v
47 | prev_k = prev_v = None
48 | last_ti = idx
49 |
50 | Es = self.prob
51 |
52 | if forward:
53 | this_range = range(idx+1, right_limit+1)
54 | step = +1
55 | end = right_limit
56 | else:
57 | this_range = range(idx-1, left_limit-1, -1)
58 | step = -1
59 | end = left_limit
60 |
61 | for ti in this_range:
62 | if prev_k is not None:
63 | this_k = torch.cat([keys, prev_k], 2)
64 | this_v = torch.cat([values, prev_v], 2)
65 | else:
66 | this_k = keys
67 | this_v = values
68 | query = self.get_query_buf(ti)
69 | out_mask = self.prop_net.segment_with_query(this_k, this_v, *query)
70 | out_mask = aggregate_wbg(out_mask, keep_bg=True)
71 |
72 | Es[:,ti] = out_mask
73 |
74 | if ti != end:
75 | prev_k, prev_v = self.prop_net.memorize(self.get_im(ti), out_mask[1:])
76 | if abs(ti-last_ti) >= self.mem_freq:
77 | last_ti = ti
78 | keys = torch.cat([keys, prev_k], 2)
79 | values = torch.cat([values, prev_v], 2)
80 | prev_k = prev_v = None
81 |
82 | def interact_mask(self, mask, idx, left_limit, right_limit):
83 |
84 | mask, _ = pad_divide_by(mask, 16, mask.shape[-2:])
85 | mask = aggregate_wbg(mask, keep_bg=True)
86 |
87 | self.prob[:, idx] = mask
88 | key_k, key_v = self.prop_net.memorize(self.get_im(idx), mask[1:])
89 |
90 | self.do_pass(key_k, key_v, idx, left_limit, right_limit, True)
91 | self.do_pass(key_k, key_v, idx, left_limit, right_limit, False)
92 |
93 | # Prepare output
94 | out_prob = self.prob[:,:,0,:,:]
95 |
96 | if self.pad[2]+self.pad[3] > 0:
97 | out_prob = out_prob[:,:,self.pad[2]:-self.pad[3],:]
98 | if self.pad[0]+self.pad[1] > 0:
99 | out_prob = out_prob[:,:,:,self.pad[0]:-self.pad[1]]
100 |
101 | return out_prob
102 |
--------------------------------------------------------------------------------
/generation/test/image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/generation/test/image.png
--------------------------------------------------------------------------------
/generation/test/test_spline.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 |
4 | import numpy as np
5 | import matplotlib.pyplot as plt
6 | from PIL import Image
7 | import cv2
8 | import thinplate as tps
9 |
10 |
11 | def show_warped(img, warped):
12 | fig, axs = plt.subplots(1, 2, figsize=(16,8))
13 | axs[0].axis('off')
14 | axs[1].axis('off')
15 | axs[0].imshow(img[...,::-1], origin='upper')
16 | axs[0].scatter(c_src[:, 0]*img.shape[1], c_src[:, 1]*img.shape[0], marker='+', color='black')
17 | axs[1].imshow(warped[...,::-1], origin='upper')
18 | axs[1].scatter(c_dst[:, 0]*warped.shape[1], c_dst[:, 1]*warped.shape[0], marker='+', color='black')
19 | plt.show()
20 |
21 | def warp_image_cv(img, c_src, c_dst, dshape=None):
22 | dshape = dshape or img.shape
23 | theta = tps.tps_theta_from_points(c_src, c_dst, reduced=True)
24 | grid = tps.tps_grid(theta, c_dst, dshape)
25 | mapx, mapy = tps.tps_grid_to_remap(grid, img.shape)
26 | return cv2.remap(img, mapx, mapy, cv2.INTER_CUBIC)
27 |
28 | img = cv2.imread('image.png')
29 |
30 | c_src = np.array([
31 | [0.0, 0.0],
32 | [1., 0],
33 | [1, 1],
34 | [0, 1],
35 | [0.3, 0.3],
36 | [0.7, 0.7],
37 | ])
38 |
39 | c_dst = np.array([
40 | [-0.2, -0.2],
41 | [1., 0],
42 | [1, 1],
43 | [0, 1],
44 | [0.4, 0.4],
45 | [0.6, 0.6],
46 | ])
47 |
48 | warped = warp_image_cv(img, c_src, c_dst)
49 | print(warped.shape)
50 | show_warped(img, warped)
--------------------------------------------------------------------------------
/generation/test/test_spline_continuous.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 |
4 | import numpy as np
5 | import matplotlib.pyplot as plt
6 | from PIL import Image
7 | import cv2
8 | import thinplate as tps
9 |
10 |
11 | def warp_image_cv(img, c_src, c_dst, dshape=None):
12 | dshape = dshape or img.shape
13 | theta = tps.tps_theta_from_points(c_src, c_dst, reduced=True)
14 | grid = tps.tps_grid(theta, c_dst, dshape)
15 | mapx, mapy = tps.tps_grid_to_remap(grid, img.shape)
16 | return cv2.remap(img, mapx, mapy, cv2.INTER_CUBIC)
17 |
18 | img = cv2.imread('image.png')
19 |
20 | c_src = np.array([
21 | [0.0, 0.0],
22 | [1., 0],
23 | [1, 1],
24 | [0, 1],
25 | [0.3, 0.3],
26 | [0.7, 0.7],
27 | ])
28 |
29 | c_dst = np.array([
30 | [-0.2, -0.2],
31 | [1., 0],
32 | [1, 1],
33 | [0, 1],
34 | [0.4, 0.4],
35 | [0.6, 0.6],
36 | ])
37 |
38 | for i in range(5):
39 | c_this_dst = c_src*(5-i)/5 + c_dst*i/5
40 | warped = warp_image_cv(img, c_src, c_this_dst)
41 | cv2.imwrite('%d.png'%i, warped)
--------------------------------------------------------------------------------
/imgs/framework.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/imgs/framework.jpg
--------------------------------------------------------------------------------
/interact/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/interact/__init__.py
--------------------------------------------------------------------------------
/interact/fbrs_controller.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from fbrs.controller import InteractiveController
3 | from fbrs.inference import utils
4 |
5 |
6 | class FBRSController:
7 | def __init__(self, checkpoint_path, device='cuda:0', max_size=800):
8 | model = utils.load_is_model(checkpoint_path, device, cpu_dist_maps=True, norm_radius=260)
9 |
10 | # Predictor params
11 | zoomin_params = {
12 | 'skip_clicks': 1,
13 | 'target_size': 480,
14 | 'expansion_ratio': 1.4,
15 | }
16 |
17 | predictor_params = {
18 | 'brs_mode': 'f-BRS-B',
19 | 'prob_thresh': 0.5,
20 | 'zoom_in_params': zoomin_params,
21 | 'predictor_params': {
22 | 'net_clicks_limit': 8,
23 | 'max_size': 800,
24 | },
25 | 'brs_opt_func_params': {'min_iou_diff': 1e-3},
26 | 'lbfgs_params': {'maxfun': 20}
27 | }
28 |
29 | self.controller = InteractiveController(model, device, predictor_params)
30 | self.anchored = False
31 | self.device = device
32 |
33 | def unanchor(self):
34 | self.anchored = False
35 |
36 | def interact(self, image, x, y, is_positive):
37 | image = image.to(self.device, non_blocking=True)
38 | if not self.anchored:
39 | self.controller.set_image(image)
40 | self.controller.reset_predictor()
41 | self.anchored = True
42 |
43 | self.controller.add_click(x, y, is_positive)
44 | # return self.controller.result_mask
45 | # return self.controller.probs_history[-1][1]
46 | return (self.controller.probs_history[-1][1]>0.5).float()
47 |
48 | def undo(self):
49 | self.controller.undo_click()
50 | if len(self.controller.probs_history) == 0:
51 | return None
52 | else:
53 | return (self.controller.probs_history[-1][1]>0.5).float()
--------------------------------------------------------------------------------
/interact/interactive_utils.py:
--------------------------------------------------------------------------------
1 | # Modifed from https://github.com/seoungwugoh/ivs-demo
2 |
3 | import numpy as np
4 | import os
5 | import copy
6 | import cv2
7 | import glob
8 |
9 | import matplotlib.pyplot as plt
10 | from scipy.ndimage.morphology import binary_erosion, binary_dilation
11 | from PIL import Image, ImageDraw, ImageFont
12 |
13 | import torch
14 | from torchvision import models
15 | from dataset.range_transform import im_normalization
16 |
17 |
18 | def images_to_torch(frames, device):
19 | frames = torch.from_numpy(frames.transpose(0, 3, 1, 2)).float().unsqueeze(0)/255
20 | b, t, c, h, w = frames.shape
21 | for ti in range(t):
22 | frames[0, ti] = im_normalization(frames[0, ti])
23 | return frames.to(device)
24 |
25 | def load_images(path, min_side=None):
26 | fnames = sorted(glob.glob(os.path.join(path, '*.jpg')))
27 | if len(fnames) == 0:
28 | fnames = sorted(glob.glob(os.path.join(path, '*.png')))
29 | frame_list = []
30 | for i, fname in enumerate(fnames):
31 | if min_side:
32 | image = Image.open(fname).convert('RGB')
33 | w, h = image.size
34 | new_w = (w*min_side//min(w, h))
35 | new_h = (h*min_side//min(w, h))
36 | frame_list.append(np.array(image.resize((new_w, new_h), Image.BICUBIC), dtype=np.uint8))
37 | else:
38 | frame_list.append(np.array(Image.open(fname).convert('RGB'), dtype=np.uint8))
39 | frames = np.stack(frame_list, axis=0)
40 | return frames
41 |
42 | def load_masks(path, min_side=None):
43 | fnames = sorted(glob.glob(os.path.join(path, '*.png')))
44 | frame_list = []
45 |
46 | first_frame = np.array(Image.open(fnames[0]))
47 | binary_mask = (first_frame.max() == 255)
48 |
49 | for i, fname in enumerate(fnames):
50 | if min_side:
51 | image = Image.open(fname)
52 | w, h = image.size
53 | new_w = (w*min_side//min(w, h))
54 | new_h = (h*min_side//min(w, h))
55 | frame_list.append(np.array(image.resize((new_w, new_h), Image.NEAREST), dtype=np.uint8))
56 | else:
57 | frame_list.append(np.array(Image.open(fname), dtype=np.uint8))
58 |
59 | frames = np.stack(frame_list, axis=0)
60 | if binary_mask:
61 | frames = (frames > 128).astype(np.uint8)
62 | return frames
63 |
64 | def load_video(path, min_side=None):
65 | frame_list = []
66 | cap = cv2.VideoCapture(path)
67 | while(cap.isOpened()):
68 | _, frame = cap.read()
69 | if frame is None:
70 | break
71 | frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
72 | if min_side:
73 | h, w = frame.shape[:2]
74 | new_w = (w*min_side//min(w, h))
75 | new_h = (h*min_side//min(w, h))
76 | frame = cv2.resize(frame, (new_w, new_h), interpolation=cv2.INTER_CUBIC)
77 | frame_list.append(frame)
78 | frames = np.stack(frame_list, axis=0)
79 | return frames
80 |
81 | def _pascal_color_map(N=256, normalized=False):
82 | """
83 | Python implementation of the color map function for the PASCAL VOC data set.
84 | Official Matlab version can be found in the PASCAL VOC devkit
85 | http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html#devkit
86 | """
87 |
88 | def bitget(byteval, idx):
89 | return (byteval & (1 << idx)) != 0
90 |
91 | dtype = 'float32' if normalized else 'uint8'
92 | cmap = np.zeros((N, 3), dtype=dtype)
93 | for i in range(N):
94 | r = g = b = 0
95 | c = i
96 | for j in range(8):
97 | r = r | (bitget(c, 0) << 7 - j)
98 | g = g | (bitget(c, 1) << 7 - j)
99 | b = b | (bitget(c, 2) << 7 - j)
100 | c = c >> 3
101 |
102 | cmap[i] = np.array([r, g, b])
103 |
104 | cmap = cmap / 255 if normalized else cmap
105 | return cmap
106 |
107 | color_map = [
108 | [0, 0, 0],
109 | [255, 50, 50],
110 | [50, 255, 50],
111 | [50, 50, 255],
112 | [255, 50, 255],
113 | [50, 255, 255],
114 | [255, 255, 50],
115 | ]
116 |
117 | color_map_np = np.array(color_map)
118 |
119 | def overlay_davis(image, mask, alpha=0.5):
120 | """ Overlay segmentation on top of RGB image. from davis official"""
121 | im_overlay = image.copy()
122 |
123 | colored_mask = color_map_np[mask]
124 | foreground = image*alpha + (1-alpha)*colored_mask
125 | binary_mask = (mask > 0)
126 | # Compose image
127 | im_overlay[binary_mask] = foreground[binary_mask]
128 | countours = binary_dilation(binary_mask) ^ binary_mask
129 | im_overlay[countours,:] = 0
130 | return im_overlay.astype(image.dtype)
131 |
132 | def overlay_davis_fade(image, mask, alpha=0.5):
133 | im_overlay = image.copy()
134 |
135 | colored_mask = color_map_np[mask]
136 | foreground = image*alpha + (1-alpha)*colored_mask
137 | binary_mask = (mask > 0)
138 | # Compose image
139 | im_overlay[binary_mask] = foreground[binary_mask]
140 | countours = binary_dilation(binary_mask) ^ binary_mask
141 | im_overlay[countours,:] = 0
142 | im_overlay[~binary_mask] = im_overlay[~binary_mask] * 0.6
143 | return im_overlay.astype(image.dtype)
--------------------------------------------------------------------------------
/interact/s2m_controller.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | from model.s2m.s2m_network import deeplabv3plus_resnet50 as S2M
4 |
5 | from util.tensor_util import pad_divide_by
6 |
7 |
8 | class S2MController:
9 | """
10 | A controller for Scribble-to-Mask (for user interaction, not for DAVIS)
11 | Takes the image, previous mask, and scribbles to produce a new mask
12 | ignore_class is usually 255
13 | 0 is NOT the ignore class -- it is the label for the background
14 | """
15 | def __init__(self, s2m_net:S2M, num_objects, ignore_class, device='cuda:0'):
16 | self.s2m_net = s2m_net
17 | self.num_objects = num_objects
18 | self.ignore_class = ignore_class
19 | self.device = device
20 |
21 | def interact(self, image, prev_mask, scr_mask):
22 | image = image.to(self.device, non_blocking=True)
23 | prev_mask = prev_mask.to(self.device, non_blocking=True)
24 |
25 | h, w = image.shape[-2:]
26 | unaggre_mask = torch.zeros((self.num_objects, 1, h, w), dtype=torch.float32, device=image.device)
27 |
28 | for ki in range(1, self.num_objects+1):
29 | p_srb = (scr_mask==ki).astype(np.uint8)
30 | n_srb = ((scr_mask!=ki) * (scr_mask!=self.ignore_class)).astype(np.uint8)
31 |
32 | Rs = torch.from_numpy(np.stack([p_srb, n_srb], 0)).unsqueeze(0).float().to(image.device)
33 | Rs, _ = pad_divide_by(Rs, 16, Rs.shape[-2:])
34 |
35 | inputs = torch.cat([image, (prev_mask==ki).float().unsqueeze(0), Rs], 1)
36 | unaggre_mask[ki-1] = torch.sigmoid(self.s2m_net(inputs))
37 |
38 | return unaggre_mask
--------------------------------------------------------------------------------
/interact/timer.py:
--------------------------------------------------------------------------------
1 | import time
2 |
3 | class Timer:
4 | def __init__(self):
5 | self._acc_time = 0
6 | self._paused = True
7 |
8 | def start(self):
9 | if self._paused:
10 | self.last_time = time.time()
11 | self._paused = False
12 | return self
13 |
14 | def pause(self):
15 | self.count()
16 | self._paused = True
17 | return self
18 |
19 | def count(self):
20 | if self._paused:
21 | return self._acc_time
22 | t = time.time()
23 | self._acc_time += t - self.last_time
24 | self.last_time = t
25 | return self._acc_time
26 |
27 | def format(self):
28 | # count = int(self.count()*100)
29 | # return '%02d:%02d:%02d' % (count//6000, (count//100)%60, count%100)
30 | return '%03.2f' % self.count()
31 |
32 | def __str__(self):
33 | return self.format()
--------------------------------------------------------------------------------
/model/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/model/__init__.py
--------------------------------------------------------------------------------
/model/aggregate.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 |
4 | def aggregate_sbg(prob, keep_bg=False, hard=False):
5 | device = prob.device
6 | k, _, h, w = prob.shape
7 | ex_prob = torch.zeros((k+1, 1, h, w), device=device)
8 | ex_prob[0] = 0.5
9 | ex_prob[1:] = prob
10 | ex_prob = torch.clamp(ex_prob, 1e-7, 1-1e-7)
11 | logits = torch.log((ex_prob /(1-ex_prob)))
12 |
13 | if hard:
14 | # Very low temperature o((⊙﹏⊙))o 🥶
15 | logits *= 1000
16 |
17 | if keep_bg:
18 | return F.softmax(logits, dim=0)
19 | else:
20 | return F.softmax(logits, dim=0)[1:]
21 |
22 | def aggregate_wbg(prob, keep_bg=False, hard=False):
23 | k, _, h, w = prob.shape
24 | new_prob = torch.cat([
25 | torch.prod(1-prob, dim=0, keepdim=True),
26 | prob
27 | ], 0).clamp(1e-7, 1-1e-7)
28 | logits = torch.log((new_prob /(1-new_prob)))
29 |
30 | if hard:
31 | # Very low temperature o((⊙﹏⊙))o 🥶
32 | logits *= 1000
33 |
34 | if keep_bg:
35 | return F.softmax(logits, dim=0)
36 | else:
37 | return F.softmax(logits, dim=0)[1:]
38 |
39 | def aggregate_wbg_channel(prob, keep_bg=False, hard=False):
40 | new_prob = torch.cat([
41 | torch.prod(1-prob, dim=1, keepdim=True),
42 | prob
43 | ], 1).clamp(1e-7, 1-1e-7)
44 | logits = torch.log((new_prob /(1-new_prob)))
45 |
46 | if hard:
47 | # Very low temperature o((⊙﹏⊙))o 🥶
48 | logits *= 1000
49 |
50 | if keep_bg:
51 | return logits, F.softmax(logits, dim=1)
52 | else:
53 | return logits, F.softmax(logits, dim=1)[:, 1:]
--------------------------------------------------------------------------------
/model/attn_network.py:
--------------------------------------------------------------------------------
1 | """
2 | Modifed from the original STM code https://github.com/seoungwugoh/STM
3 | """
4 | import math
5 |
6 | import torch
7 | import torch.nn as nn
8 | import torch.nn.functional as F
9 |
10 | from model.propagation.modules import MaskRGBEncoder, RGBEncoder, KeyValue
11 |
12 | class AttentionMemory(nn.Module):
13 | def __init__(self, k=50):
14 | super().__init__()
15 | self.k = k
16 |
17 | def forward(self, mk, qk):
18 | B, CK, H, W = mk.shape
19 |
20 | mk = mk.view(B, CK, H*W)
21 | mk = torch.transpose(mk, 1, 2) # B * HW * CK
22 |
23 | qk = qk.view(B, CK, H*W).expand(B, -1, -1) / math.sqrt(CK) # B * CK * HW
24 |
25 | affinity = torch.bmm(mk, qk) # B * HW * HW
26 | affinity = F.softmax(affinity, dim=1)
27 |
28 | return affinity
29 |
30 | class AttentionReadNetwork(nn.Module):
31 | def __init__(self):
32 | super().__init__()
33 | self.mask_rgb_encoder = MaskRGBEncoder()
34 | self.rgb_encoder = RGBEncoder()
35 |
36 | self.kv_m_f16 = KeyValue(1024, keydim=128, valdim=512)
37 | self.kv_q_f16 = KeyValue(1024, keydim=128, valdim=512)
38 | self.memory = AttentionMemory()
39 |
40 | for p in self.parameters():
41 | p.requires_grad = False
42 |
43 | def get_segment(self, f16, qk):
44 | k16, _ = self.kv_m_f16(f16)
45 | p = self.memory(k16, qk)
46 | return p
47 |
48 | def forward(self, image, mask11, mask21, mask12, mask22, query_image):
49 | b, _, h, w = mask11.shape
50 | nh = h//16
51 | nw = w//16
52 |
53 | with torch.no_grad():
54 | pos_mask1 = (mask21-mask11).clamp(0, 1)
55 | neg_mask1 = (mask11-mask21).clamp(0, 1)
56 | pos_mask2 = (mask22-mask12).clamp(0, 1)
57 | neg_mask2 = (mask12-mask22).clamp(0, 1)
58 |
59 | f16_1 = self.mask_rgb_encoder(image, mask21, mask22)
60 | f16_2 = self.mask_rgb_encoder(image, mask22, mask21)
61 |
62 | qf16, _, _ = self.rgb_encoder(query_image)
63 | qk16, _ = self.kv_q_f16(qf16)
64 |
65 | W1 = self.get_segment(f16_1, qk16)
66 | W2 = self.get_segment(f16_2, qk16)
67 |
68 | pos_map1 = (F.interpolate(pos_mask1, size=(nh,nw), mode='area').view(b, 1, nh*nw) @ W1)
69 | neg_map1 = (F.interpolate(neg_mask1, size=(nh,nw), mode='area').view(b, 1, nh*nw) @ W1)
70 | attn_map1 = torch.cat([pos_map1, neg_map1], 1)
71 | attn_map1 = attn_map1.reshape(b, 2, nh, nw)
72 | attn_map1 = F.interpolate(attn_map1, mode='bilinear', size=(h,w), align_corners=False)
73 |
74 | pos_map2 = (F.interpolate(pos_mask2, size=(nh,nw), mode='area').view(b, 1, nh*nw) @ W2)
75 | neg_map2 = (F.interpolate(neg_mask2, size=(nh,nw), mode='area').view(b, 1, nh*nw) @ W2)
76 | attn_map2 = torch.cat([pos_map2, neg_map2], 1)
77 | attn_map2 = attn_map2.reshape(b, 2, nh, nw)
78 | attn_map2 = F.interpolate(attn_map2, mode='bilinear', size=(h,w), align_corners=False)
79 |
80 | return attn_map1, attn_map2
81 |
--------------------------------------------------------------------------------
/model/fusion_net.py:
--------------------------------------------------------------------------------
1 | import math
2 |
3 | import torch
4 | import torch.nn as nn
5 | import torch.nn.functional as F
6 |
7 |
8 | class FusionNet(nn.Module):
9 | def __init__(self):
10 | super().__init__()
11 |
12 | self.conv1 = nn.Sequential(
13 | nn.Conv2d(9, 32, kernel_size=3, padding=1, stride=1),
14 | nn.ReLU(),
15 | )
16 |
17 | self.conv2 = nn.Sequential(
18 | nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1),
19 | nn.ReLU(),
20 | nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1),
21 | )
22 |
23 | self.conv3 = nn.Sequential(
24 | nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1),
25 | nn.ReLU(),
26 | nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1),
27 | )
28 |
29 | self.relu = nn.ReLU()
30 | self.final_conv = nn.Conv2d(32, 1, kernel_size=3, padding=1, stride=1)
31 |
32 | def forward(self, im, seg1, seg2, attn, time):
33 | h, w = im.shape[-2:]
34 |
35 | time = time.unsqueeze(2).unsqueeze(2)
36 | time = time.expand(-1, -1, h, w)
37 |
38 | x = torch.cat([im, seg1, seg2, attn, time], 1)
39 |
40 | x = self.conv1(x)
41 |
42 | r = self.conv2(x)
43 | x = self.relu(x + r)
44 |
45 | r = self.conv3(x)
46 | x = self.relu(x + r)
47 |
48 | x = self.final_conv(x)
49 |
50 | return x
51 |
--------------------------------------------------------------------------------
/model/losses.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 | from util.tensor_util import compute_tensor_iu
5 | from collections import defaultdict
6 |
7 |
8 | def get_iou_hook(values):
9 | return 'iou/iou', (values['hide_iou/i']+1)/(values['hide_iou/u']+1)
10 |
11 | def get_sec_iou_hook(values):
12 | return 'iou/sec_iou', (values['hide_iou/sec_i']+1)/(values['hide_iou/sec_u']+1)
13 |
14 | iou_hooks = [
15 | get_iou_hook,
16 | get_sec_iou_hook,
17 | ]
18 |
19 |
20 | # https://stackoverflow.com/questions/63735255/how-do-i-compute-bootstrapped-cross-entropy-loss-in-pytorch
21 | class BootstrappedCE(nn.Module):
22 | def __init__(self, start_warm, end_warm, top_p=0.15):
23 | super().__init__()
24 |
25 | self.start_warm = start_warm
26 | self.end_warm = end_warm
27 | self.top_p = top_p
28 |
29 | def forward(self, input, target, it):
30 | if it < self.start_warm:
31 | return F.cross_entropy(input, target), 1.0
32 |
33 | raw_loss = F.cross_entropy(input, target, reduction='none').view(-1)
34 | num_pixels = raw_loss.numel()
35 |
36 | if it > self.end_warm:
37 | this_p = self.top_p
38 | else:
39 | this_p = self.top_p + (1-self.top_p)*((self.end_warm-it)/(self.end_warm-self.start_warm))
40 | loss, _ = torch.topk(raw_loss, int(num_pixels * this_p), sorted=False)
41 | return loss.mean(), this_p
42 |
43 |
44 | class LossComputer:
45 | def __init__(self, para):
46 | super().__init__()
47 | self.para = para
48 | self.bce = BootstrappedCE(start_warm=int(para['iterations']*0.2), end_warm=int(para['iterations']*0.5))
49 |
50 | def compute(self, data, it):
51 | losses = defaultdict(int)
52 |
53 | b = data['gt'].shape[0]
54 | selector = data.get('selector', None)
55 | selector = data['selector']
56 |
57 | for j in range(b):
58 | if selector[j][1] > 0.5:
59 | loss, p = self.bce(data['logits'][j:j+1], data['cls_gt'][j:j+1], it)
60 | else:
61 | loss, p = self.bce(data['logits'][j:j+1,:2], data['cls_gt'][j:j+1], it)
62 |
63 | losses['total_loss'] += loss / b
64 | losses['p'] += p / b
65 |
66 | new_total_i, new_total_u = compute_tensor_iu(data['mask'][:,1:2]>0.5, data['gt']>0.5)
67 | losses['hide_iou/i'] += new_total_i
68 | losses['hide_iou/u'] += new_total_u
69 |
70 | if selector is not None:
71 | new_total_i, new_total_u = compute_tensor_iu(data['mask'][:,2:3]>0.5, data['gt2']>0.5)
72 | losses['hide_iou/sec_i'] += new_total_i
73 | losses['hide_iou/sec_u'] += new_total_u
74 |
75 | return losses
--------------------------------------------------------------------------------
/model/propagation/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/model/propagation/__init__.py
--------------------------------------------------------------------------------
/model/propagation/mod_resnet.py:
--------------------------------------------------------------------------------
1 | from collections import OrderedDict
2 | import math
3 |
4 | import torch
5 | import torch.nn as nn
6 | import torch.nn.functional as F
7 | from torch.utils import model_zoo
8 |
9 | def load_weights_sequential(target, source_state, extra_chan=1):
10 |
11 | new_dict = OrderedDict()
12 |
13 | for k1, v1 in target.state_dict().items():
14 | if not 'num_batches_tracked' in k1:
15 | if k1 in source_state:
16 | tar_v = source_state[k1]
17 |
18 | if v1.shape != tar_v.shape:
19 | # Init the new segmentation channel with zeros
20 | # print(v1.shape, tar_v.shape)
21 | c, _, w, h = v1.shape
22 | tar_v = torch.cat([
23 | tar_v,
24 | torch.zeros((c,extra_chan,w,h)),
25 | ], 1)
26 |
27 | new_dict[k1] = tar_v
28 | elif 'bias' not in k1:
29 | print('Not OK', k1)
30 |
31 | target.load_state_dict(new_dict, strict=False)
32 |
33 |
34 | model_urls = {
35 | 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
36 | }
37 |
38 |
39 | def conv3x3(in_planes, out_planes, stride=1, dilation=1):
40 | return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
41 | padding=dilation, dilation=dilation)
42 |
43 |
44 | class BasicBlock(nn.Module):
45 | expansion = 1
46 |
47 | def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1):
48 | super(BasicBlock, self).__init__()
49 | self.conv1 = conv3x3(inplanes, planes, stride=stride, dilation=dilation)
50 | self.bn1 = nn.BatchNorm2d(planes)
51 | self.relu = nn.ReLU(inplace=True)
52 | self.conv2 = conv3x3(planes, planes, stride=1, dilation=dilation)
53 | self.bn2 = nn.BatchNorm2d(planes)
54 | self.downsample = downsample
55 | self.stride = stride
56 |
57 | def forward(self, x):
58 | residual = x
59 |
60 | out = self.conv1(x)
61 | out = self.bn1(out)
62 | out = self.relu(out)
63 |
64 | out = self.conv2(out)
65 | out = self.bn2(out)
66 |
67 | if self.downsample is not None:
68 | residual = self.downsample(x)
69 |
70 | out += residual
71 | out = self.relu(out)
72 |
73 | return out
74 |
75 |
76 | class Bottleneck(nn.Module):
77 | expansion = 4
78 |
79 | def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1):
80 | super(Bottleneck, self).__init__()
81 | self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1)
82 | self.bn1 = nn.BatchNorm2d(planes)
83 | self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, dilation=dilation,
84 | padding=dilation)
85 | self.bn2 = nn.BatchNorm2d(planes)
86 | self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1)
87 | self.bn3 = nn.BatchNorm2d(planes * 4)
88 | self.relu = nn.ReLU(inplace=True)
89 | self.downsample = downsample
90 | self.stride = stride
91 |
92 | def forward(self, x):
93 | residual = x
94 |
95 | out = self.conv1(x)
96 | out = self.bn1(out)
97 | out = self.relu(out)
98 |
99 | out = self.conv2(out)
100 | out = self.bn2(out)
101 | out = self.relu(out)
102 |
103 | out = self.conv3(out)
104 | out = self.bn3(out)
105 |
106 | if self.downsample is not None:
107 | residual = self.downsample(x)
108 |
109 | out += residual
110 | out = self.relu(out)
111 |
112 | return out
113 |
114 |
115 | class ResNet(nn.Module):
116 | def __init__(self, block, layers=(3, 4, 23, 3), extra_chan=1):
117 | self.inplanes = 64
118 | super(ResNet, self).__init__()
119 | self.conv1 = nn.Conv2d(3+extra_chan, 64, kernel_size=7, stride=2, padding=3)
120 | self.bn1 = nn.BatchNorm2d(64)
121 | self.relu = nn.ReLU(inplace=True)
122 | self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
123 | self.layer1 = self._make_layer(block, 64, layers[0])
124 | self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
125 | self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
126 | self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
127 |
128 | for m in self.modules():
129 | if isinstance(m, nn.Conv2d):
130 | n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
131 | m.weight.data.normal_(0, math.sqrt(2. / n))
132 | m.bias.data.zero_()
133 | elif isinstance(m, nn.BatchNorm2d):
134 | m.weight.data.fill_(1)
135 | m.bias.data.zero_()
136 |
137 | def _make_layer(self, block, planes, blocks, stride=1, dilation=1):
138 | downsample = None
139 | if stride != 1 or self.inplanes != planes * block.expansion:
140 | downsample = nn.Sequential(
141 | nn.Conv2d(self.inplanes, planes * block.expansion,
142 | kernel_size=1, stride=stride),
143 | nn.BatchNorm2d(planes * block.expansion),
144 | )
145 |
146 | layers = [block(self.inplanes, planes, stride, downsample)]
147 | self.inplanes = planes * block.expansion
148 | for i in range(1, blocks):
149 | layers.append(block(self.inplanes, planes, dilation=dilation))
150 |
151 | return nn.Sequential(*layers)
152 |
153 | def resnet50(pretrained=True, extra_chan=0):
154 | model = ResNet(Bottleneck, [3, 4, 6, 3], extra_chan)
155 | if pretrained:
156 | load_weights_sequential(model, model_zoo.load_url(model_urls['resnet50']), extra_chan)
157 | return model
158 |
159 |
--------------------------------------------------------------------------------
/model/propagation/modules.py:
--------------------------------------------------------------------------------
1 | """
2 | Modifed from the original STM code https://github.com/seoungwugoh/STM
3 | """
4 | import math
5 |
6 | import torch
7 | import torch.nn as nn
8 | import torch.nn.functional as F
9 | import torch.utils.model_zoo as model_zoo
10 | from torchvision import models
11 |
12 | from model.propagation import mod_resnet
13 |
14 |
15 | class ResBlock(nn.Module):
16 | def __init__(self, indim, outdim=None):
17 | super(ResBlock, self).__init__()
18 | if outdim == None:
19 | outdim = indim
20 | if indim == outdim:
21 | self.downsample = None
22 | else:
23 | self.downsample = nn.Conv2d(indim, outdim, kernel_size=3, padding=1)
24 |
25 | self.conv1 = nn.Conv2d(indim, outdim, kernel_size=3, padding=1)
26 | self.conv2 = nn.Conv2d(outdim, outdim, kernel_size=3, padding=1)
27 |
28 | def forward(self, x):
29 | r = self.conv1(F.relu(x))
30 | r = self.conv2(F.relu(r))
31 |
32 | if self.downsample is not None:
33 | x = self.downsample(x)
34 |
35 | return x + r
36 |
37 |
38 | class MaskRGBEncoder(nn.Module):
39 | def __init__(self):
40 | super().__init__()
41 |
42 | resnet = mod_resnet.resnet50(pretrained=True, extra_chan=2)
43 | self.conv1 = resnet.conv1
44 | self.bn1 = resnet.bn1
45 | self.relu = resnet.relu # 1/2, 64
46 | self.maxpool = resnet.maxpool
47 |
48 | self.layer1 = resnet.layer1 # 1/4, 256
49 | self.layer2 = resnet.layer2 # 1/8, 512
50 | self.layer3 = resnet.layer3 # 1/16, 1024
51 |
52 | def forward(self, f, m, o):
53 |
54 | f = torch.cat([f, m, o], 1)
55 |
56 | x = self.conv1(f)
57 | x = self.bn1(x)
58 | x = self.relu(x) # 1/2, 64
59 | x = self.maxpool(x) # 1/4, 64
60 | x = self.layer1(x) # 1/4, 256
61 | x = self.layer2(x) # 1/8, 512
62 | x = self.layer3(x) # 1/16, 1024
63 |
64 | return x
65 |
66 |
67 | class RGBEncoder(nn.Module):
68 | def __init__(self):
69 | super().__init__()
70 | resnet = models.resnet50(pretrained=True)
71 | self.conv1 = resnet.conv1
72 | self.bn1 = resnet.bn1
73 | self.relu = resnet.relu # 1/2, 64
74 | self.maxpool = resnet.maxpool
75 |
76 | self.res2 = resnet.layer1 # 1/4, 256
77 | self.layer2 = resnet.layer2 # 1/8, 512
78 | self.layer3 = resnet.layer3 # 1/16, 1024
79 |
80 | def forward(self, f):
81 | x = self.conv1(f)
82 | x = self.bn1(x)
83 | x = self.relu(x) # 1/2, 64
84 | x = self.maxpool(x) # 1/4, 64
85 | f4 = self.res2(x) # 1/4, 256
86 | f8 = self.layer2(f4) # 1/8, 512
87 | f16 = self.layer3(f8) # 1/16, 1024
88 |
89 | return f16, f8, f4
90 |
91 |
92 | class UpsampleBlock(nn.Module):
93 | def __init__(self, skip_c, up_c, out_c, scale_factor=2):
94 | super().__init__()
95 | self.skip_conv1 = nn.Conv2d(skip_c, up_c, kernel_size=3, padding=1)
96 | self.skip_conv2 = ResBlock(up_c, up_c)
97 | self.out_conv = ResBlock(up_c, out_c)
98 | self.scale_factor = scale_factor
99 |
100 | def forward(self, skip_f, up_f):
101 | x = self.skip_conv2(self.skip_conv1(skip_f))
102 | x = x + F.interpolate(up_f, scale_factor=self.scale_factor, mode='bilinear', align_corners=False)
103 | x = self.out_conv(x)
104 | return x
105 |
106 |
107 | class KeyValue(nn.Module):
108 | def __init__(self, indim, keydim, valdim):
109 | super().__init__()
110 | self.key_proj = nn.Conv2d(indim, keydim, kernel_size=3, padding=1)
111 | self.val_proj = nn.Conv2d(indim, valdim, kernel_size=3, padding=1)
112 |
113 | def forward(self, x):
114 | return self.key_proj(x), self.val_proj(x)
115 |
--------------------------------------------------------------------------------
/model/s2m/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/model/s2m/__init__.py
--------------------------------------------------------------------------------
/model/s2m/s2m_network.py:
--------------------------------------------------------------------------------
1 | # Credit: https://github.com/VainF/DeepLabV3Plus-Pytorch
2 |
3 | from model.s2m.utils import IntermediateLayerGetter
4 | from model.s2m._deeplab import DeepLabHead, DeepLabHeadV3Plus, DeepLabV3
5 | from model.s2m import s2m_resnet
6 |
7 | def _segm_resnet(name, backbone_name, num_classes, output_stride, pretrained_backbone):
8 |
9 | if output_stride==8:
10 | replace_stride_with_dilation=[False, True, True]
11 | aspp_dilate = [12, 24, 36]
12 | else:
13 | replace_stride_with_dilation=[False, False, True]
14 | aspp_dilate = [6, 12, 18]
15 |
16 | backbone = s2m_resnet.__dict__[backbone_name](
17 | pretrained=pretrained_backbone,
18 | replace_stride_with_dilation=replace_stride_with_dilation)
19 |
20 | inplanes = 2048
21 | low_level_planes = 256
22 |
23 | if name=='deeplabv3plus':
24 | return_layers = {'layer4': 'out', 'layer1': 'low_level'}
25 | classifier = DeepLabHeadV3Plus(inplanes, low_level_planes, num_classes, aspp_dilate)
26 | elif name=='deeplabv3':
27 | return_layers = {'layer4': 'out'}
28 | classifier = DeepLabHead(inplanes , num_classes, aspp_dilate)
29 | backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
30 |
31 | model = DeepLabV3(backbone, classifier)
32 | return model
33 |
34 | def _load_model(arch_type, backbone, num_classes, output_stride, pretrained_backbone):
35 |
36 | if backbone.startswith('resnet'):
37 | model = _segm_resnet(arch_type, backbone, num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
38 | else:
39 | raise NotImplementedError
40 | return model
41 |
42 |
43 | # Deeplab v3
44 | def deeplabv3_resnet50(num_classes=1, output_stride=16, pretrained_backbone=False):
45 | """Constructs a DeepLabV3 model with a ResNet-50 backbone.
46 |
47 | Args:
48 | num_classes (int): number of classes.
49 | output_stride (int): output stride for deeplab.
50 | pretrained_backbone (bool): If True, use the pretrained backbone.
51 | """
52 | return _load_model('deeplabv3', 'resnet50', num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
53 |
54 |
55 | # Deeplab v3+
56 | def deeplabv3plus_resnet50(num_classes=1, output_stride=16, pretrained_backbone=False):
57 | """Constructs a DeepLabV3 model with a ResNet-50 backbone.
58 |
59 | Args:
60 | num_classes (int): number of classes.
61 | output_stride (int): output stride for deeplab.
62 | pretrained_backbone (bool): If True, use the pretrained backbone.
63 | """
64 | return _load_model('deeplabv3plus', 'resnet50', num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
65 |
66 |
--------------------------------------------------------------------------------
/model/s2m/utils.py:
--------------------------------------------------------------------------------
1 | # Credit: https://github.com/VainF/DeepLabV3Plus-Pytorch
2 |
3 | import torch
4 | import torch.nn as nn
5 | import numpy as np
6 | import torch.nn.functional as F
7 | from collections import OrderedDict
8 |
9 | class _SimpleSegmentationModel(nn.Module):
10 | def __init__(self, backbone, classifier):
11 | super(_SimpleSegmentationModel, self).__init__()
12 | self.backbone = backbone
13 | self.classifier = classifier
14 |
15 | def forward(self, x):
16 | input_shape = x.shape[-2:]
17 | features = self.backbone(x)
18 | x = self.classifier(features)
19 | x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)
20 | return x
21 |
22 |
23 | class IntermediateLayerGetter(nn.ModuleDict):
24 | """
25 | Module wrapper that returns intermediate layers from a model
26 |
27 | It has a strong assumption that the modules have been registered
28 | into the model in the same order as they are used.
29 | This means that one should **not** reuse the same nn.Module
30 | twice in the forward if you want this to work.
31 |
32 | Additionally, it is only able to query submodules that are directly
33 | assigned to the model. So if `model` is passed, `model.feature1` can
34 | be returned, but not `model.feature1.layer2`.
35 |
36 | Arguments:
37 | model (nn.Module): model on which we will extract the features
38 | return_layers (Dict[name, new_name]): a dict containing the names
39 | of the modules for which the activations will be returned as
40 | the key of the dict, and the value of the dict is the name
41 | of the returned activation (which the user can specify).
42 |
43 | Examples::
44 |
45 | >>> m = torchvision.models.resnet18(pretrained=True)
46 | >>> # extract layer1 and layer3, giving as names `feat1` and feat2`
47 | >>> new_m = torchvision.models._utils.IntermediateLayerGetter(m,
48 | >>> {'layer1': 'feat1', 'layer3': 'feat2'})
49 | >>> out = new_m(torch.rand(1, 3, 224, 224))
50 | >>> print([(k, v.shape) for k, v in out.items()])
51 | >>> [('feat1', torch.Size([1, 64, 56, 56])),
52 | >>> ('feat2', torch.Size([1, 256, 14, 14]))]
53 | """
54 | def __init__(self, model, return_layers):
55 | if not set(return_layers).issubset([name for name, _ in model.named_children()]):
56 | raise ValueError("return_layers are not present in model")
57 |
58 | orig_return_layers = return_layers
59 | return_layers = {k: v for k, v in return_layers.items()}
60 | layers = OrderedDict()
61 | for name, module in model.named_children():
62 | layers[name] = module
63 | if name in return_layers:
64 | del return_layers[name]
65 | if not return_layers:
66 | break
67 |
68 | super(IntermediateLayerGetter, self).__init__(layers)
69 | self.return_layers = orig_return_layers
70 |
71 | def forward(self, x):
72 | out = OrderedDict()
73 | for name, module in self.named_children():
74 | x = module(x)
75 | if name in self.return_layers:
76 | out_name = self.return_layers[name]
77 | out[out_name] = x
78 | return out
79 |
--------------------------------------------------------------------------------
/scripts/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/scripts/__init__.py
--------------------------------------------------------------------------------
/scripts/resize_length.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 | import cv2
4 |
5 | from progressbar import progressbar
6 |
7 | input_dir = sys.argv[1]
8 | output_dir = sys.argv[2]
9 |
10 | # max_length = 500
11 | min_length = 384
12 |
13 | def process_fun():
14 |
15 | for f in progressbar(os.listdir(input_dir)):
16 | img = cv2.imread(os.path.join(input_dir, f))
17 | h, w, _ = img.shape
18 |
19 | # scale = max(h, w) / max_length
20 | scale = min(h, w) / min_length
21 |
22 | img = cv2.resize(img, (int(w/scale), int(h/scale)), interpolation=cv2.INTER_AREA)
23 | cv2.imwrite(os.path.join(output_dir, os.path.basename(f)), img)
24 |
25 | if __name__ == '__main__':
26 |
27 | os.makedirs(output_dir, exist_ok=True)
28 | process_fun()
29 |
30 | print('All done.')
--------------------------------------------------------------------------------
/scripts/resize_youtube.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 | from os import path
4 |
5 | from PIL import Image
6 | import numpy as np
7 | from progressbar import progressbar
8 | from multiprocessing import Pool
9 |
10 | new_min_size = 480
11 |
12 | def resize_vid_jpeg(inputs):
13 | vid_name, folder_path, out_path = inputs
14 |
15 | vid_path = path.join(folder_path, vid_name)
16 | vid_out_path = path.join(out_path, 'JPEGImages', vid_name)
17 | os.makedirs(vid_out_path, exist_ok=True)
18 |
19 | for im_name in os.listdir(vid_path):
20 | hr_im = Image.open(path.join(vid_path, im_name))
21 | w, h = hr_im.size
22 |
23 | ratio = new_min_size / min(w, h)
24 |
25 | lr_im = hr_im.resize((int(w*ratio), int(h*ratio)), Image.BICUBIC)
26 | lr_im.save(path.join(vid_out_path, im_name))
27 |
28 | def resize_vid_anno(inputs):
29 | vid_name, folder_path, out_path = inputs
30 |
31 | vid_path = path.join(folder_path, vid_name)
32 | vid_out_path = path.join(out_path, 'Annotations', vid_name)
33 | os.makedirs(vid_out_path, exist_ok=True)
34 |
35 | for im_name in os.listdir(vid_path):
36 | hr_im = Image.open(path.join(vid_path, im_name)).convert('P')
37 | w, h = hr_im.size
38 |
39 | ratio = new_min_size / min(w, h)
40 |
41 | lr_im = hr_im.resize((int(w*ratio), int(h*ratio)), Image.NEAREST)
42 | lr_im.save(path.join(vid_out_path, im_name))
43 |
44 |
45 | def resize_all(in_path, out_path):
46 | for folder in os.listdir(in_path):
47 |
48 | if folder not in ['JPEGImages', 'Annotations']:
49 | continue
50 | folder_path = path.join(in_path, folder)
51 | videos = os.listdir(folder_path)
52 |
53 | videos = [(v, folder_path, out_path) for v in videos]
54 |
55 | if folder == 'JPEGImages':
56 | print('Processing images')
57 | os.makedirs(path.join(out_path, 'JPEGImages'), exist_ok=True)
58 |
59 | pool = Pool(processes=8)
60 | for _ in progressbar(pool.imap_unordered(resize_vid_jpeg, videos), max_value=len(videos)):
61 | pass
62 | else:
63 | print('Processing annotations')
64 | os.makedirs(path.join(out_path, 'Annotations'), exist_ok=True)
65 |
66 | pool = Pool(processes=8)
67 | for _ in progressbar(pool.imap_unordered(resize_vid_anno, videos), max_value=len(videos)):
68 | pass
69 |
70 |
71 | if __name__ == '__main__':
72 | in_path = sys.argv[1]
73 | out_path = sys.argv[2]
74 |
75 | resize_all(in_path, out_path)
76 |
77 | print('Done.')
--------------------------------------------------------------------------------
/train.py:
--------------------------------------------------------------------------------
1 | import time
2 | from os import path
3 | import datetime
4 | import math
5 |
6 | import random
7 | import numpy as np
8 | import torch
9 | from torch.utils.data import Dataset, DataLoader, ConcatDataset
10 | import torch.multiprocessing as mp
11 | import torch.distributed as distributed
12 |
13 | from model.fusion_model import FusionModel
14 | from dataset.fusion_dataset import FusionDataset
15 |
16 | from util.logger import TensorboardLogger
17 | from util.hyper_para import HyperParameters
18 | from util.load_subset import *
19 |
20 |
21 | """
22 | Initial setup
23 | """
24 | torch.backends.cudnn.benchmark = True
25 |
26 | # Init distributed environment
27 | distributed.init_process_group(backend="nccl")
28 | # Set seed to ensure the same initialization
29 | torch.manual_seed(14159265)
30 | np.random.seed(14159265)
31 | random.seed(14159265)
32 |
33 | print('CUDA Device count: ', torch.cuda.device_count())
34 |
35 | # Parse command line arguments
36 | para = HyperParameters()
37 | para.parse()
38 |
39 | local_rank = torch.distributed.get_rank()
40 | world_size = torch.distributed.get_world_size()
41 | torch.cuda.set_device(local_rank)
42 |
43 | print('I am rank %d in the world of %d!' % (local_rank, world_size))
44 |
45 | """
46 | Model related
47 | """
48 | if local_rank == 0:
49 | # Logging
50 | if para['id'].lower() != 'null':
51 | long_id = '%s_%s' % (datetime.datetime.now().strftime('%b%d_%H.%M.%S'), para['id'])
52 | else:
53 | long_id = None
54 | logger = TensorboardLogger(para['id'], long_id)
55 | logger.log_string('hyperpara', str(para))
56 |
57 | # Construct rank 0 model
58 | model = FusionModel(para, logger=logger,
59 | save_path=path.join('saves', long_id, long_id) if long_id is not None else None,
60 | local_rank=local_rank, world_size=world_size).train()
61 | else:
62 | # Construct models of other ranks
63 | model = FusionModel(para, local_rank=local_rank, world_size=world_size).train()
64 |
65 | # Load pertrained model if needed
66 | if para['load_model'] is not None:
67 | total_iter = model.load_model(para['load_model'])
68 | else:
69 | total_iter = 0
70 |
71 | if para['load_network'] is not None:
72 | model.load_network(para['load_network'])
73 |
74 | """
75 | Dataloader related
76 | """
77 | if para['load_prop'] is None:
78 | print('Fusion module can only be trained with a pre-trained propagation module!')
79 | print('Use --load_prop [model_path]')
80 | raise NotImplementedError
81 | model.load_prop(para['load_prop'])
82 | torch.cuda.empty_cache()
83 |
84 | if para['stage'] == 0:
85 | data_root = path.join(path.expanduser(para['bl_root']))
86 | train_dataset = FusionDataset(path.join(data_root, 'JPEGImages'),
87 | path.join(data_root, 'Annotations'), para['fusion_bl_root'])
88 | elif para['stage'] == 1:
89 | data_root = path.join(path.expanduser(para['davis_root']), '2017', 'trainval')
90 | train_dataset = FusionDataset(path.join(data_root, 'JPEGImages', '480p'),
91 | path.join(data_root, 'Annotations', '480p'), para['fusion_root'])
92 |
93 |
94 | def worker_init_fn(worker_id):
95 | return np.random.seed((torch.initial_seed()%2**31) + worker_id + local_rank*100)
96 | train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset, rank=local_rank, shuffle=True)
97 | train_loader = DataLoader(train_dataset, para['batch_size'], sampler=train_sampler, num_workers=8,
98 | worker_init_fn=worker_init_fn, drop_last=True, pin_memory=True)
99 |
100 | """
101 | Determine current/max epoch
102 | """
103 | start_epoch = total_iter//len(train_loader)
104 | total_epoch = math.ceil(para['iterations']/len(train_loader))
105 | print('Actual training epoch: ', total_epoch)
106 |
107 | """
108 | Starts training
109 | """
110 | # Need this to select random bases in different workers
111 | np.random.seed(np.random.randint(2**30-1) + local_rank*100)
112 | try:
113 | for e in range(start_epoch, total_epoch):
114 | # Crucial for randomness!
115 | train_sampler.set_epoch(e)
116 |
117 | # Train loop
118 | model.train()
119 | for data in train_loader:
120 | model.do_pass(data, total_iter)
121 | total_iter += 1
122 |
123 | if total_iter >= para['iterations']:
124 | break
125 | finally:
126 | if not para['debug'] and model.logger is not None and total_iter > 5000:
127 | model.save(total_iter)
128 | # Clean up
129 | distributed.destroy_process_group()
130 |
131 |
--------------------------------------------------------------------------------
/util/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/util/__init__.py
--------------------------------------------------------------------------------
/util/cv2palette.py:
--------------------------------------------------------------------------------
1 | import tempfile
2 | from PIL import Image
3 | import cv2
4 | import os
5 |
6 |
7 | # A stupid trick to force palette into cv2
8 | def cv2palette(image, palette):
9 | img_E = Image.fromarray(image)
10 | img_E.putpalette(palette)
11 | with tempfile.TemporaryDirectory() as tmppath:
12 | full_path = os.path.join(tmppath, 'temp.png')
13 | img_E.save(full_path)
14 | image = cv2.imread(full_path)
15 | return image
--------------------------------------------------------------------------------
/util/davis_subset.txt:
--------------------------------------------------------------------------------
1 | bear
2 | bmx-bumps
3 | boat
4 | boxing-fisheye
5 | breakdance-flare
6 | bus
7 | car-turn
8 | cat-girl
9 | classic-car
10 | color-run
11 | crossing
12 | dance-jump
13 | dancing
14 | disc-jockey
15 | dog-agility
16 | dog-gooses
17 | dogs-scale
18 | drift-turn
19 | drone
20 | elephant
21 | flamingo
22 | hike
23 | hockey
24 | horsejump-low
25 | kid-football
26 | kite-walk
27 | koala
28 | lady-running
29 | lindy-hop
30 | longboard
31 | lucia
32 | mallard-fly
33 | mallard-water
34 | miami-surf
35 | motocross-bumps
36 | motorbike
37 | night-race
38 | paragliding
39 | planes-water
40 | rallye
41 | rhino
42 | rollerblade
43 | schoolgirls
44 | scooter-board
45 | scooter-gray
46 | sheep
47 | skate-park
48 | snowboard
49 | soccerball
50 | stroller
51 | stunt
52 | surf
53 | swing
54 | tennis
55 | tractor-sand
56 | train
57 | tuk-tuk
58 | upside-down
59 | varanus-cage
60 | walking
--------------------------------------------------------------------------------
/util/hyper_para.py:
--------------------------------------------------------------------------------
1 | from argparse import ArgumentParser
2 |
3 |
4 | def none_or_default(x, default):
5 | return x if x is not None else default
6 |
7 | class HyperParameters():
8 | def parse(self, unknown_arg_ok=False):
9 | parser = ArgumentParser()
10 |
11 | # Data parameters
12 | parser.add_argument('--yv_root', help='YouTubeVOS data root', default='../YouTube')
13 | parser.add_argument('--davis_root', help='DAVIS data root', default='../DAVIS')
14 | parser.add_argument('--bl_root', default='../BL30K')
15 |
16 | parser.add_argument('--fusion_root', default='../fusion_data/davis')
17 | parser.add_argument('--fusion_bl_root', default='../fusion_data/bl')
18 |
19 | parser.add_argument('--stage', type=int, default=0)
20 |
21 | # Generic learning parameters
22 | parser.add_argument('-i', '--iterations', help='Number of training iterations', default=None, type=int)
23 | parser.add_argument('-b', '--batch_size', help='Batch size', default=12, type=int)
24 | parser.add_argument('--lr', help='Initial learning rate', default=1e-4, type=float)
25 | parser.add_argument('--steps', help='Iteration at which learning rate is decayed by gamma', default=None, type=int, nargs='*')
26 | parser.add_argument('--gamma', help='Gamma used in learning rate decay', default=0.1, type=float)
27 |
28 | # Loading
29 | parser.add_argument('--load_network', help='Path to pretrained network weight only')
30 | parser.add_argument('--load_prop', default='saves/propagation_model.pth')
31 | parser.add_argument('--load_model', help='Path to the model file, including network, optimizer and such')
32 |
33 | # Logging information
34 | parser.add_argument('--id', help='Experiment UNIQUE id, use NULL to disable logging to tensorboard', default='NULL')
35 | parser.add_argument('--debug', help='Debug mode which logs information more often', action='store_true')
36 |
37 | # Multiprocessing parameters
38 | parser.add_argument('--local_rank', default=0, type=int, help='Local rank of this process')
39 |
40 | if unknown_arg_ok:
41 | args, _ = parser.parse_known_args()
42 | self.args = vars(args)
43 | else:
44 | self.args = vars(parser.parse_args())
45 |
46 | # Stage-dependent hyperparameters
47 | # Assign default if not given
48 | if self.args['stage'] == 0:
49 | self.args['iterations'] = none_or_default(self.args['iterations'], 30000)
50 | self.args['steps'] = none_or_default(self.args['steps'], [20000])
51 | elif self.args['stage'] == 1:
52 | self.args['iterations'] = none_or_default(self.args['iterations'], 10000)
53 | self.args['steps'] = none_or_default(self.args['steps'], [7500])
54 |
55 | def __getitem__(self, key):
56 | return self.args[key]
57 |
58 | def __str__(self):
59 | return str(self.args)
60 |
--------------------------------------------------------------------------------
/util/image_saver.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import numpy as np
3 |
4 | import torch
5 | import torchvision.transforms as transforms
6 | from dataset.range_transform import inv_im_trans
7 | from collections import defaultdict
8 |
9 | def tensor_to_numpy(image):
10 | image_np = (image.numpy() * 255).astype('uint8')
11 | return image_np
12 |
13 | def tensor_to_np_float(image):
14 | image_np = image.numpy().astype('float32')
15 | return image_np
16 |
17 | def detach_to_cpu(x):
18 | return x.detach().cpu()
19 |
20 | def transpose_np(x):
21 | return np.transpose(x, [1,2,0])
22 |
23 | def tensor_to_gray_im(x):
24 | x = detach_to_cpu(x)
25 | x = tensor_to_numpy(x)
26 | x = transpose_np(x)
27 | return x
28 |
29 | def tensor_to_im(x):
30 | x = detach_to_cpu(x)
31 | x = inv_im_trans(x).clamp(0, 1)
32 | x = tensor_to_numpy(x)
33 | x = transpose_np(x)
34 | return x
35 |
36 | # Predefined key <-> caption dict
37 | key_captions = {
38 | 'im': 'Image',
39 | 'gt': 'GT',
40 | }
41 |
42 | """
43 | Return an image array with captions
44 | keys in dictionary will be used as caption if not provided
45 | values should contain lists of cv2 images
46 | """
47 | def get_image_array(images, grid_shape, captions={}):
48 | h, w = grid_shape
49 | cate_counts = len(images)
50 | rows_counts = len(next(iter(images.values())))
51 |
52 | font = cv2.FONT_HERSHEY_SIMPLEX
53 |
54 | output_image = np.zeros([w*cate_counts, h*(rows_counts+1), 3], dtype=np.uint8)
55 | col_cnt = 0
56 | for k, v in images.items():
57 |
58 | # Default as key value itself
59 | caption = captions.get(k, k)
60 |
61 | # Handles new line character
62 | dy = 40
63 | for i, line in enumerate(caption.split('\n')):
64 | if h > 200:
65 | cv2.putText(output_image, line, (10, col_cnt*w+100+i*dy),
66 | font, 0.8, (255,255,255), 2, cv2.LINE_AA)
67 | else:
68 | cv2.putText(output_image, line, (10, col_cnt*w+10+i*dy),
69 | font, 0.4, (255,255,255), 1, cv2.LINE_AA)
70 |
71 | # Put images
72 | for row_cnt, img in enumerate(v):
73 | im_shape = img.shape
74 | if len(im_shape) == 2:
75 | img = img[..., np.newaxis]
76 |
77 | img = (img * 255).astype('uint8')
78 |
79 | output_image[(col_cnt+0)*w:(col_cnt+1)*w,
80 | (row_cnt+1)*h:(row_cnt+2)*h, :] = img
81 |
82 | col_cnt += 1
83 |
84 | return output_image
85 |
86 | def base_transform(im, size):
87 | im = tensor_to_np_float(im)
88 | if len(im.shape) == 3:
89 | im = im.transpose((1, 2, 0))
90 | else:
91 | im = im[:, :, None]
92 |
93 | # Resize
94 | if size is not None and im.shape[1] != size:
95 | im = cv2.resize(im, size, interpolation=cv2.INTER_NEAREST)
96 |
97 | return im.clip(0, 1)
98 |
99 | def im_transform(im, size):
100 | return base_transform(inv_im_trans(detach_to_cpu(im)), size=size)
101 |
102 | def mask_transform(mask, size):
103 | return base_transform(detach_to_cpu(mask), size=size)
104 |
105 | def out_transform(mask, size):
106 | return base_transform(detach_to_cpu(torch.sigmoid(mask)), size=size)
107 |
108 | def get_click_points(image, pos_map, neg_map):
109 | image[pos_map<0.02, :] = [0, 1, 0]
110 | image[neg_map<0.02, :] = [1, 0, 0]
111 |
112 | return image
113 |
114 | def get_clicked_torch(image, pos_map, neg_map):
115 | rgb = im_transform(image, None)
116 | pos_map = mask_transform(pos_map, None)[:, :, 0]
117 | neg_map = mask_transform(neg_map, None)[:, :, 0]
118 |
119 | rgb[pos_map<0.02, :] = [0, 1, 0]
120 | rgb[neg_map<0.02, :] = [1, 0, 0]
121 |
122 | return (rgb*255).astype(np.uint8)
123 |
124 | def pool_fusion(images, size):
125 | req_images = defaultdict(list)
126 |
127 | b = images['gt'].shape[0]
128 |
129 | # Save storage
130 | b = max(4, b)
131 |
132 | GT_name = 'GT'
133 |
134 | for b_idx in range(b):
135 | req_images['RGB'].append(im_transform(images['rgb'][b_idx], size))
136 | req_images['S11'].append(mask_transform(images['seg1'][b_idx], size))
137 | req_images['S21'].append(mask_transform(images['seg2'][b_idx], size))
138 | req_images['S12'].append(mask_transform(images['seg12'][b_idx], size))
139 | req_images['S22'].append(mask_transform(images['seg22'][b_idx], size))
140 | req_images['Pos Attn1'].append(mask_transform(images['attn1'][b_idx,0:1], size))
141 | req_images['Neg Attn1'].append(mask_transform(images['attn1'][b_idx,1:2], size))
142 | req_images['Pos Attn2'].append(mask_transform(images['attn2'][b_idx,0:1], size))
143 | req_images['Neg Attn2'].append(mask_transform(images['attn2'][b_idx,1:2], size))
144 |
145 | req_images['MSK1'].append(mask_transform(images['mask'][b_idx,1:2], size))
146 | req_images['MSK2'].append(mask_transform(images['mask'][b_idx,2:3], size))
147 |
148 | req_images[GT_name+'1'].append(mask_transform(images['gt'][b_idx], size))
149 | req_images[GT_name+'2'].append(mask_transform(images['gt2'][b_idx], size))
150 |
151 | return get_image_array(req_images, size, key_captions)
--------------------------------------------------------------------------------
/util/load_subset.py:
--------------------------------------------------------------------------------
1 | def load_sub_davis(path='util/davis_subset.txt'):
2 | with open(path, mode='r') as f:
3 | subset = set(f.read().splitlines())
4 | return subset
5 |
6 | def load_sub_yv(path='util/yv_subset.txt'):
7 | with open(path, mode='r') as f:
8 | subset = set(f.read().splitlines())
9 | return subset
10 |
--------------------------------------------------------------------------------
/util/log_integrator.py:
--------------------------------------------------------------------------------
1 | """
2 | Integrate numerical values for some iterations
3 | Typically used for loss computation / logging to tensorboard
4 | Call finalize and create a new Integrator when you want to display/log
5 | """
6 |
7 | import torch
8 |
9 |
10 | class Integrator:
11 | def __init__(self, logger, distributed=True, local_rank=0, world_size=1):
12 | self.values = {}
13 | self.counts = {}
14 | self.hooks = [] # List is used here to maintain insertion order
15 |
16 | self.logger = logger
17 |
18 | self.distributed = distributed
19 | self.local_rank = local_rank
20 | self.world_size = world_size
21 |
22 | def add_tensor(self, key, tensor):
23 | if key not in self.values:
24 | self.counts[key] = 1
25 | if type(tensor) == float or type(tensor) == int:
26 | self.values[key] = tensor
27 | else:
28 | self.values[key] = tensor.mean().item()
29 | else:
30 | self.counts[key] += 1
31 | if type(tensor) == float or type(tensor) == int:
32 | self.values[key] += tensor
33 | else:
34 | self.values[key] += tensor.mean().item()
35 |
36 | def add_dict(self, tensor_dict):
37 | for k, v in tensor_dict.items():
38 | self.add_tensor(k, v)
39 |
40 | def add_hook(self, hook):
41 | """
42 | Adds a custom hook, i.e. compute new metrics using values in the dict
43 | The hook takes the dict as argument, and returns a (k, v) tuple
44 | e.g. for computing IoU
45 | """
46 | if type(hook) == list:
47 | self.hooks.extend(hook)
48 | else:
49 | self.hooks.append(hook)
50 |
51 | def reset_except_hooks(self):
52 | self.values = {}
53 | self.counts = {}
54 |
55 | # Average and output the metrics
56 | def finalize(self, prefix, it, f=None):
57 |
58 | for hook in self.hooks:
59 | k, v = hook(self.values)
60 | self.add_tensor(k, v)
61 |
62 | for k, v in self.values.items():
63 |
64 | if k[:4] == 'hide':
65 | continue
66 |
67 | avg = v / self.counts[k]
68 |
69 | if self.distributed:
70 | # Inplace operation
71 | avg = torch.tensor(avg).cuda()
72 | torch.distributed.reduce(avg, dst=0)
73 |
74 | if self.local_rank == 0:
75 | avg = (avg/self.world_size).cpu().item()
76 | self.logger.log_metrics(prefix, k, avg, it, f)
77 | else:
78 | # Simple does it
79 | self.logger.log_metrics(prefix, k, avg, it, f)
80 |
81 |
--------------------------------------------------------------------------------
/util/logger.py:
--------------------------------------------------------------------------------
1 | """
2 | Dumps things to tensorboard and console
3 | """
4 |
5 | import os
6 | import warnings
7 | import git
8 |
9 | import torchvision.transforms as transforms
10 | from torch.utils.tensorboard import SummaryWriter
11 |
12 |
13 | def tensor_to_numpy(image):
14 | image_np = (image.numpy() * 255).astype('uint8')
15 | return image_np
16 |
17 | def detach_to_cpu(x):
18 | return x.detach().cpu()
19 |
20 | def fix_width_trunc(x):
21 | return ('{:.9s}'.format('{:0.9f}'.format(x)))
22 |
23 | class TensorboardLogger:
24 | def __init__(self, short_id, id):
25 | self.short_id = short_id
26 | if self.short_id == 'NULL':
27 | self.short_id = 'DEBUG'
28 |
29 | if id is None:
30 | self.no_log = True
31 | warnings.warn('Logging has been disbaled.')
32 | else:
33 | self.no_log = False
34 |
35 | self.inv_im_trans = transforms.Normalize(
36 | mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
37 | std=[1/0.229, 1/0.224, 1/0.225])
38 |
39 | self.inv_seg_trans = transforms.Normalize(
40 | mean=[-0.5/0.5],
41 | std=[1/0.5])
42 |
43 | log_path = os.path.join('.', 'log', '%s' % id)
44 | self.logger = SummaryWriter(log_path)
45 |
46 | repo = git.Repo(".")
47 | self.log_string('git', str(repo.active_branch) + ' ' + str(repo.head.commit.hexsha))
48 |
49 | def log_scalar(self, tag, x, step):
50 | if self.no_log:
51 | warnings.warn('Logging has been disabled.')
52 | return
53 | self.logger.add_scalar(tag, x, step)
54 |
55 | def log_metrics(self, l1_tag, l2_tag, val, step, f=None):
56 | tag = l1_tag + '/' + l2_tag
57 | text = '{:s} - It {:6d} [{:5s}] [{:13}]: {:s}'.format(self.short_id, step, l1_tag.upper(), l2_tag, fix_width_trunc(val))
58 | print(text)
59 | if f is not None:
60 | f.write(text + '\n')
61 | f.flush()
62 | self.log_scalar(tag, val, step)
63 |
64 | def log_im(self, tag, x, step):
65 | if self.no_log:
66 | warnings.warn('Logging has been disabled.')
67 | return
68 | x = detach_to_cpu(x)
69 | x = self.inv_im_trans(x)
70 | x = tensor_to_numpy(x)
71 | self.logger.add_image(tag, x, step)
72 |
73 | def log_cv2(self, tag, x, step):
74 | if self.no_log:
75 | warnings.warn('Logging has been disabled.')
76 | return
77 | x = x.transpose((2, 0, 1))
78 | self.logger.add_image(tag, x, step)
79 |
80 | def log_seg(self, tag, x, step):
81 | if self.no_log:
82 | warnings.warn('Logging has been disabled.')
83 | return
84 | x = detach_to_cpu(x)
85 | x = self.inv_seg_trans(x)
86 | x = tensor_to_numpy(x)
87 | self.logger.add_image(tag, x, step)
88 |
89 | def log_gray(self, tag, x, step):
90 | if self.no_log:
91 | warnings.warn('Logging has been disabled.')
92 | return
93 | x = detach_to_cpu(x)
94 | x = tensor_to_numpy(x)
95 | self.logger.add_image(tag, x, step)
96 |
97 | def log_string(self, tag, x):
98 | print(tag, x)
99 | if self.no_log:
100 | warnings.warn('Logging has been disabled.')
101 | return
102 | self.logger.add_text(tag, x)
103 |
--------------------------------------------------------------------------------
/util/palette.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | def get_color_map(N=256):
4 | def bitget(byteval, idx):
5 | return ((byteval & (1 << idx)) != 0)
6 |
7 | cmap = np.zeros((N, 3), dtype=np.uint8)
8 | for i in range(N):
9 | r = g = b = 0
10 | c = i
11 | for j in range(8):
12 | r = r | (bitget(c, 0) << 7-j)
13 | g = g | (bitget(c, 1) << 7-j)
14 | b = b | (bitget(c, 2) << 7-j)
15 | c = c >> 3
16 |
17 | cmap[i] = np.array([r, g, b])
18 |
19 | return cmap
20 |
21 | color_map = get_color_map()
22 | def pal_color_map():
23 | return color_map
--------------------------------------------------------------------------------
/util/tensor_util.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 | import numpy as np
4 |
5 | def compute_tensor_iu(seg, gt):
6 | intersection = (seg & gt).float().sum()
7 | union = (seg | gt).float().sum()
8 |
9 | return intersection, union
10 |
11 | def compute_np_iu(seg, gt):
12 | intersection = (seg & gt).astype(np.float32).sum()
13 | union = (seg | gt).astype(np.float32).sum()
14 |
15 | return intersection, union
16 |
17 | def compute_tensor_iou(seg, gt):
18 | intersection, union = compute_tensor_iu(seg, gt)
19 | iou = (intersection + 1e-6) / (union + 1e-6)
20 |
21 | return iou
22 |
23 | def compute_np_iou(seg, gt):
24 | intersection, union = compute_np_iu(seg, gt)
25 | iou = (intersection + 1e-6) / (union + 1e-6)
26 |
27 | return iou
28 |
29 | def compute_multi_class_iou(seg, gt):
30 | # seg -> k*h*w
31 | # gt -> k*1*h*w
32 | num_classes = gt.shape[0]
33 | pred_idx = torch.argmax(seg, dim=0)
34 | iou_sum = 0
35 | for ki in range(num_classes):
36 | # seg includes BG class
37 | iou_sum += compute_tensor_iou(pred_idx==(ki+1), gt[ki,0]>0.5)
38 |
39 | return (iou_sum+1e-6)/(num_classes+1e-6)
40 |
41 | def compute_multi_class_iou_idx(seg, gt):
42 | # seg -> h*w
43 | # gt -> k*h*w
44 | num_classes = gt.shape[0]
45 | iou_sum = 0
46 | for ki in range(num_classes):
47 | # seg includes BG class
48 | iou_sum += compute_np_iou(seg==(ki+1), gt[ki]>0.5)
49 |
50 | return (iou_sum+1e-6)/(num_classes+1e-6)
51 |
52 | def compute_multi_class_iou_both_idx(seg, gt):
53 | # seg -> h*w
54 | # gt -> h*w
55 | num_classes = gt.max()
56 | iou_sum = 0
57 | for ki in range(1, num_classes+1):
58 | iou_sum += compute_np_iou(seg==ki, gt==ki)
59 | return (iou_sum+1e-6)/(num_classes+1e-6)
60 |
61 | # STM
62 | def pad_divide_by(in_img, d, in_size=None):
63 | if in_size is None:
64 | h, w = in_img.shape[-2:]
65 | else:
66 | h, w = in_size
67 |
68 | if h % d > 0:
69 | new_h = h + d - h % d
70 | else:
71 | new_h = h
72 | if w % d > 0:
73 | new_w = w + d - w % d
74 | else:
75 | new_w = w
76 | lh, uh = int((new_h-h) / 2), int(new_h-h) - int((new_h-h) / 2)
77 | lw, uw = int((new_w-w) / 2), int(new_w-w) - int((new_w-w) / 2)
78 | pad_array = (int(lw), int(uw), int(lh), int(uh))
79 | out = F.pad(in_img, pad_array)
80 | return out, pad_array
81 |
82 | def unpad(img, pad):
83 | if pad[2]+pad[3] > 0:
84 | img = img[:,:,pad[2]:-pad[3],:]
85 | if pad[0]+pad[1] > 0:
86 | img = img[:,:,:,pad[0]:-pad[1]]
87 | return img
88 |
89 | def unpad_3dim(img, pad):
90 | if pad[2]+pad[3] > 0:
91 | img = img[:,pad[2]:-pad[3],:]
92 | if pad[0]+pad[1] > 0:
93 | img = img[:,:,pad[0]:-pad[1]]
94 | return img
--------------------------------------------------------------------------------
124 |
125 | Note that in the implementation, normalization with N is performed at step (2) and above equation and implementation is not exactly the same, but mathematically is same.
126 |
127 | You can go deeper on above explanation at [Kevin Zakka's Blog](https://kevinzakka.github.io/2016/09/14/batch_normalization/)
--------------------------------------------------------------------------------
/fbrs/model/syncbn/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/fbrs/model/syncbn/__init__.py
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/fbrs/model/syncbn/modules/__init__.py
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/functional/__init__.py:
--------------------------------------------------------------------------------
1 | from .syncbn import batchnorm2d_sync
2 |
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/functional/_csrc.py:
--------------------------------------------------------------------------------
1 | """
2 | /*****************************************************************************/
3 |
4 | Extension module loader
5 |
6 | code referenced from : https://github.com/facebookresearch/maskrcnn-benchmark
7 |
8 | /*****************************************************************************/
9 | """
10 | from __future__ import absolute_import
11 | from __future__ import division
12 | from __future__ import print_function
13 |
14 | import glob
15 | import os.path
16 |
17 | import torch
18 |
19 | try:
20 | from torch.utils.cpp_extension import load
21 | from torch.utils.cpp_extension import CUDA_HOME
22 | except ImportError:
23 | raise ImportError(
24 | "The cpp layer extensions requires PyTorch 0.4 or higher")
25 |
26 |
27 | def _load_C_extensions():
28 | this_dir = os.path.dirname(os.path.abspath(__file__))
29 | this_dir = os.path.join(this_dir, "csrc")
30 |
31 | main_file = glob.glob(os.path.join(this_dir, "*.cpp"))
32 | sources_cpu = glob.glob(os.path.join(this_dir, "cpu", "*.cpp"))
33 | sources_cuda = glob.glob(os.path.join(this_dir, "cuda", "*.cu"))
34 |
35 | sources = main_file + sources_cpu
36 |
37 | extra_cflags = []
38 | extra_cuda_cflags = []
39 | if torch.cuda.is_available() and CUDA_HOME is not None:
40 | sources.extend(sources_cuda)
41 | extra_cflags = ["-O3", "-DWITH_CUDA"]
42 | extra_cuda_cflags = ["--expt-extended-lambda"]
43 | sources = [os.path.join(this_dir, s) for s in sources]
44 | extra_include_paths = [this_dir]
45 | return load(
46 | name="ext_lib",
47 | sources=sources,
48 | extra_cflags=extra_cflags,
49 | extra_include_paths=extra_include_paths,
50 | extra_cuda_cflags=extra_cuda_cflags,
51 | )
52 |
53 |
54 | _backend = _load_C_extensions()
55 |
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/functional/csrc/bn.h:
--------------------------------------------------------------------------------
1 | /*****************************************************************************
2 |
3 | SyncBN
4 |
5 | *****************************************************************************/
6 | #pragma once
7 |
8 | #ifdef WITH_CUDA
9 | #include "cuda/ext_lib.h"
10 | #endif
11 |
12 | /// SyncBN
13 |
14 | std::vector syncbn_sum_sqsum(const at::Tensor& x) {
15 | if (x.is_cuda()) {
16 | #ifdef WITH_CUDA
17 | return syncbn_sum_sqsum_cuda(x);
18 | #else
19 | AT_ERROR("Not compiled with GPU support");
20 | #endif
21 | } else {
22 | AT_ERROR("CPU implementation not supported");
23 | }
24 | }
25 |
26 | at::Tensor syncbn_forward(const at::Tensor& x, const at::Tensor& weight,
27 | const at::Tensor& bias, const at::Tensor& mean,
28 | const at::Tensor& var, bool affine, float eps) {
29 | if (x.is_cuda()) {
30 | #ifdef WITH_CUDA
31 | return syncbn_forward_cuda(x, weight, bias, mean, var, affine, eps);
32 | #else
33 | AT_ERROR("Not compiled with GPU support");
34 | #endif
35 | } else {
36 | AT_ERROR("CPU implementation not supported");
37 | }
38 | }
39 |
40 | std::vector syncbn_backward_xhat(const at::Tensor& dz,
41 | const at::Tensor& x,
42 | const at::Tensor& mean,
43 | const at::Tensor& var, float eps) {
44 | if (dz.is_cuda()) {
45 | #ifdef WITH_CUDA
46 | return syncbn_backward_xhat_cuda(dz, x, mean, var, eps);
47 | #else
48 | AT_ERROR("Not compiled with GPU support");
49 | #endif
50 | } else {
51 | AT_ERROR("CPU implementation not supported");
52 | }
53 | }
54 |
55 | std::vector syncbn_backward(
56 | const at::Tensor& dz, const at::Tensor& x, const at::Tensor& weight,
57 | const at::Tensor& bias, const at::Tensor& mean, const at::Tensor& var,
58 | const at::Tensor& sum_dz, const at::Tensor& sum_dz_xhat, bool affine,
59 | float eps) {
60 | if (dz.is_cuda()) {
61 | #ifdef WITH_CUDA
62 | return syncbn_backward_cuda(dz, x, weight, bias, mean, var, sum_dz,
63 | sum_dz_xhat, affine, eps);
64 | #else
65 | AT_ERROR("Not compiled with GPU support");
66 | #endif
67 | } else {
68 | AT_ERROR("CPU implementation not supported");
69 | }
70 | }
71 |
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/functional/csrc/cuda/common.h:
--------------------------------------------------------------------------------
1 | /*****************************************************************************
2 |
3 | CUDA utility funcs
4 |
5 | code referenced from : https://github.com/mapillary/inplace_abn
6 |
7 | *****************************************************************************/
8 | #pragma once
9 |
10 | #include
11 |
12 | // Checks
13 | #ifndef AT_CHECK
14 | #define AT_CHECK AT_ASSERT
15 | #endif
16 | #define CHECK_CUDA(x) AT_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
17 | #define CHECK_CONTIGUOUS(x) AT_CHECK(x.is_contiguous(), #x " must be contiguous")
18 | #define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
19 |
20 | /*
21 | * General settings
22 | */
23 | const int WARP_SIZE = 32;
24 | const int MAX_BLOCK_SIZE = 512;
25 |
26 | template
27 | struct Pair {
28 | T v1, v2;
29 | __device__ Pair() {}
30 | __device__ Pair(T _v1, T _v2) : v1(_v1), v2(_v2) {}
31 | __device__ Pair(T v) : v1(v), v2(v) {}
32 | __device__ Pair(int v) : v1(v), v2(v) {}
33 | __device__ Pair &operator+=(const Pair &a) {
34 | v1 += a.v1;
35 | v2 += a.v2;
36 | return *this;
37 | }
38 | };
39 |
40 | /*
41 | * Utility functions
42 | */
43 | template
44 | __device__ __forceinline__ T WARP_SHFL_XOR(T value, int laneMask,
45 | int width = warpSize,
46 | unsigned int mask = 0xffffffff) {
47 | #if CUDART_VERSION >= 9000
48 | return __shfl_xor_sync(mask, value, laneMask, width);
49 | #else
50 | return __shfl_xor(value, laneMask, width);
51 | #endif
52 | }
53 |
54 | __device__ __forceinline__ int getMSB(int val) { return 31 - __clz(val); }
55 |
56 | static int getNumThreads(int nElem) {
57 | int threadSizes[5] = {32, 64, 128, 256, MAX_BLOCK_SIZE};
58 | for (int i = 0; i != 5; ++i) {
59 | if (nElem <= threadSizes[i]) {
60 | return threadSizes[i];
61 | }
62 | }
63 | return MAX_BLOCK_SIZE;
64 | }
65 |
66 | template
67 | static __device__ __forceinline__ T warpSum(T val) {
68 | #if __CUDA_ARCH__ >= 300
69 | for (int i = 0; i < getMSB(WARP_SIZE); ++i) {
70 | val += WARP_SHFL_XOR(val, 1 << i, WARP_SIZE);
71 | }
72 | #else
73 | __shared__ T values[MAX_BLOCK_SIZE];
74 | values[threadIdx.x] = val;
75 | __threadfence_block();
76 | const int base = (threadIdx.x / WARP_SIZE) * WARP_SIZE;
77 | for (int i = 1; i < WARP_SIZE; i++) {
78 | val += values[base + ((i + threadIdx.x) % WARP_SIZE)];
79 | }
80 | #endif
81 | return val;
82 | }
83 |
84 | template
85 | static __device__ __forceinline__ Pair warpSum(Pair value) {
86 | value.v1 = warpSum(value.v1);
87 | value.v2 = warpSum(value.v2);
88 | return value;
89 | }
90 |
91 | template
92 | __device__ T reduce(Op op, int plane, int N, int C, int S) {
93 | T sum = (T)0;
94 | for (int batch = 0; batch < N; ++batch) {
95 | for (int x = threadIdx.x; x < S; x += blockDim.x) {
96 | sum += op(batch, plane, x);
97 | }
98 | }
99 |
100 | // sum over NumThreads within a warp
101 | sum = warpSum(sum);
102 |
103 | // 'transpose', and reduce within warp again
104 | __shared__ T shared[32];
105 | __syncthreads();
106 | if (threadIdx.x % WARP_SIZE == 0) {
107 | shared[threadIdx.x / WARP_SIZE] = sum;
108 | }
109 | if (threadIdx.x >= blockDim.x / WARP_SIZE && threadIdx.x < WARP_SIZE) {
110 | // zero out the other entries in shared
111 | shared[threadIdx.x] = (T)0;
112 | }
113 | __syncthreads();
114 | if (threadIdx.x / WARP_SIZE == 0) {
115 | sum = warpSum(shared[threadIdx.x]);
116 | if (threadIdx.x == 0) {
117 | shared[0] = sum;
118 | }
119 | }
120 | __syncthreads();
121 |
122 | // Everyone picks it up, should be broadcast into the whole gradInput
123 | return shared[0];
124 | }
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/functional/csrc/cuda/ext_lib.h:
--------------------------------------------------------------------------------
1 | /*****************************************************************************
2 |
3 | CUDA SyncBN code
4 |
5 | *****************************************************************************/
6 | #pragma once
7 | #include
8 | #include
9 |
10 | /// Sync-BN
11 | std::vector syncbn_sum_sqsum_cuda(const at::Tensor& x);
12 | at::Tensor syncbn_forward_cuda(const at::Tensor& x, const at::Tensor& weight,
13 | const at::Tensor& bias, const at::Tensor& mean,
14 | const at::Tensor& var, bool affine, float eps);
15 | std::vector syncbn_backward_xhat_cuda(const at::Tensor& dz,
16 | const at::Tensor& x,
17 | const at::Tensor& mean,
18 | const at::Tensor& var,
19 | float eps);
20 | std::vector syncbn_backward_cuda(
21 | const at::Tensor& dz, const at::Tensor& x, const at::Tensor& weight,
22 | const at::Tensor& bias, const at::Tensor& mean, const at::Tensor& var,
23 | const at::Tensor& sum_dz, const at::Tensor& sum_dz_xhat, bool affine,
24 | float eps);
25 |
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/functional/csrc/ext_lib.cpp:
--------------------------------------------------------------------------------
1 | #include "bn.h"
2 |
3 | PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
4 | m.def("syncbn_sum_sqsum", &syncbn_sum_sqsum, "Sum and Sum^2 computation");
5 | m.def("syncbn_forward", &syncbn_forward, "SyncBN forward computation");
6 | m.def("syncbn_backward_xhat", &syncbn_backward_xhat,
7 | "First part of SyncBN backward computation");
8 | m.def("syncbn_backward", &syncbn_backward,
9 | "Second part of SyncBN backward computation");
10 | }
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/functional/syncbn.py:
--------------------------------------------------------------------------------
1 | """
2 | /*****************************************************************************/
3 |
4 | BatchNorm2dSync with multi-gpu
5 |
6 | code referenced from : https://github.com/mapillary/inplace_abn
7 |
8 | /*****************************************************************************/
9 | """
10 | from __future__ import absolute_import
11 | from __future__ import division
12 | from __future__ import print_function
13 |
14 | import torch.cuda.comm as comm
15 | from torch.autograd import Function
16 | from torch.autograd.function import once_differentiable
17 | from ._csrc import _backend
18 |
19 |
20 | def _count_samples(x):
21 | count = 1
22 | for i, s in enumerate(x.size()):
23 | if i != 1:
24 | count *= s
25 | return count
26 |
27 |
28 | class BatchNorm2dSyncFunc(Function):
29 |
30 | @staticmethod
31 | def forward(ctx, x, weight, bias, running_mean, running_var,
32 | extra, compute_stats=True, momentum=0.1, eps=1e-05):
33 | def _parse_extra(ctx, extra):
34 | ctx.is_master = extra["is_master"]
35 | if ctx.is_master:
36 | ctx.master_queue = extra["master_queue"]
37 | ctx.worker_queues = extra["worker_queues"]
38 | ctx.worker_ids = extra["worker_ids"]
39 | else:
40 | ctx.master_queue = extra["master_queue"]
41 | ctx.worker_queue = extra["worker_queue"]
42 | # Save context
43 | if extra is not None:
44 | _parse_extra(ctx, extra)
45 | ctx.compute_stats = compute_stats
46 | ctx.momentum = momentum
47 | ctx.eps = eps
48 | ctx.affine = weight is not None and bias is not None
49 | if ctx.compute_stats:
50 | N = _count_samples(x) * (ctx.master_queue.maxsize + 1)
51 | assert N > 1
52 | # 1. compute sum(x) and sum(x^2)
53 | xsum, xsqsum = _backend.syncbn_sum_sqsum(x.detach())
54 | if ctx.is_master:
55 | xsums, xsqsums = [xsum], [xsqsum]
56 | # master : gatther all sum(x) and sum(x^2) from slaves
57 | for _ in range(ctx.master_queue.maxsize):
58 | xsum_w, xsqsum_w = ctx.master_queue.get()
59 | ctx.master_queue.task_done()
60 | xsums.append(xsum_w)
61 | xsqsums.append(xsqsum_w)
62 | xsum = comm.reduce_add(xsums)
63 | xsqsum = comm.reduce_add(xsqsums)
64 | mean = xsum / N
65 | sumvar = xsqsum - xsum * mean
66 | var = sumvar / N
67 | uvar = sumvar / (N - 1)
68 | # master : broadcast global mean, variance to all slaves
69 | tensors = comm.broadcast_coalesced(
70 | (mean, uvar, var), [mean.get_device()] + ctx.worker_ids)
71 | for ts, queue in zip(tensors[1:], ctx.worker_queues):
72 | queue.put(ts)
73 | else:
74 | # slave : send sum(x) and sum(x^2) to master
75 | ctx.master_queue.put((xsum, xsqsum))
76 | # slave : get global mean and variance
77 | mean, uvar, var = ctx.worker_queue.get()
78 | ctx.worker_queue.task_done()
79 |
80 | # Update running stats
81 | running_mean.mul_((1 - ctx.momentum)).add_(ctx.momentum * mean)
82 | running_var.mul_((1 - ctx.momentum)).add_(ctx.momentum * uvar)
83 | ctx.N = N
84 | ctx.save_for_backward(x, weight, bias, mean, var)
85 | else:
86 | mean, var = running_mean, running_var
87 |
88 | # do batch norm forward
89 | z = _backend.syncbn_forward(x, weight, bias, mean, var,
90 | ctx.affine, ctx.eps)
91 | return z
92 |
93 | @staticmethod
94 | @once_differentiable
95 | def backward(ctx, dz):
96 | x, weight, bias, mean, var = ctx.saved_tensors
97 | dz = dz.contiguous()
98 |
99 | # 1. compute \sum(\frac{dJ}{dy_i}) and \sum(\frac{dJ}{dy_i}*\hat{x_i})
100 | sum_dz, sum_dz_xhat = _backend.syncbn_backward_xhat(
101 | dz, x, mean, var, ctx.eps)
102 | if ctx.is_master:
103 | sum_dzs, sum_dz_xhats = [sum_dz], [sum_dz_xhat]
104 | # master : gatther from slaves
105 | for _ in range(ctx.master_queue.maxsize):
106 | sum_dz_w, sum_dz_xhat_w = ctx.master_queue.get()
107 | ctx.master_queue.task_done()
108 | sum_dzs.append(sum_dz_w)
109 | sum_dz_xhats.append(sum_dz_xhat_w)
110 | # master : compute global stats
111 | sum_dz = comm.reduce_add(sum_dzs)
112 | sum_dz_xhat = comm.reduce_add(sum_dz_xhats)
113 | sum_dz /= ctx.N
114 | sum_dz_xhat /= ctx.N
115 | # master : broadcast global stats
116 | tensors = comm.broadcast_coalesced(
117 | (sum_dz, sum_dz_xhat), [mean.get_device()] + ctx.worker_ids)
118 | for ts, queue in zip(tensors[1:], ctx.worker_queues):
119 | queue.put(ts)
120 | else:
121 | # slave : send to master
122 | ctx.master_queue.put((sum_dz, sum_dz_xhat))
123 | # slave : get global stats
124 | sum_dz, sum_dz_xhat = ctx.worker_queue.get()
125 | ctx.worker_queue.task_done()
126 |
127 | # do batch norm backward
128 | dx, dweight, dbias = _backend.syncbn_backward(
129 | dz, x, weight, bias, mean, var, sum_dz, sum_dz_xhat,
130 | ctx.affine, ctx.eps)
131 |
132 | return dx, dweight, dbias, \
133 | None, None, None, None, None, None
134 |
135 | batchnorm2d_sync = BatchNorm2dSyncFunc.apply
136 |
137 | __all__ = ["batchnorm2d_sync"]
138 |
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/nn/__init__.py:
--------------------------------------------------------------------------------
1 | from .syncbn import *
2 |
--------------------------------------------------------------------------------
/fbrs/model/syncbn/modules/nn/syncbn.py:
--------------------------------------------------------------------------------
1 | """
2 | /*****************************************************************************/
3 |
4 | BatchNorm2dSync with multi-gpu
5 |
6 | /*****************************************************************************/
7 | """
8 | from __future__ import absolute_import
9 | from __future__ import division
10 | from __future__ import print_function
11 |
12 | try:
13 | # python 3
14 | from queue import Queue
15 | except ImportError:
16 | # python 2
17 | from Queue import Queue
18 |
19 | import torch
20 | import torch.nn as nn
21 | from torch.nn import functional as F
22 | from torch.nn.parameter import Parameter
23 | from isegm.model.syncbn.modules.functional import batchnorm2d_sync
24 |
25 |
26 | class _BatchNorm(nn.Module):
27 | """
28 | Customized BatchNorm from nn.BatchNorm
29 | >> added freeze attribute to enable bn freeze.
30 | """
31 |
32 | def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,
33 | track_running_stats=True):
34 | super(_BatchNorm, self).__init__()
35 | self.num_features = num_features
36 | self.eps = eps
37 | self.momentum = momentum
38 | self.affine = affine
39 | self.track_running_stats = track_running_stats
40 | self.freezed = False
41 | if self.affine:
42 | self.weight = Parameter(torch.Tensor(num_features))
43 | self.bias = Parameter(torch.Tensor(num_features))
44 | else:
45 | self.register_parameter('weight', None)
46 | self.register_parameter('bias', None)
47 | if self.track_running_stats:
48 | self.register_buffer('running_mean', torch.zeros(num_features))
49 | self.register_buffer('running_var', torch.ones(num_features))
50 | else:
51 | self.register_parameter('running_mean', None)
52 | self.register_parameter('running_var', None)
53 | self.reset_parameters()
54 |
55 | def reset_parameters(self):
56 | if self.track_running_stats:
57 | self.running_mean.zero_()
58 | self.running_var.fill_(1)
59 | if self.affine:
60 | self.weight.data.uniform_()
61 | self.bias.data.zero_()
62 |
63 | def _check_input_dim(self, input):
64 | return NotImplemented
65 |
66 | def forward(self, input):
67 | self._check_input_dim(input)
68 |
69 | compute_stats = not self.freezed and \
70 | self.training and self.track_running_stats
71 |
72 | ret = F.batch_norm(input, self.running_mean, self.running_var,
73 | self.weight, self.bias, compute_stats,
74 | self.momentum, self.eps)
75 | return ret
76 |
77 | def extra_repr(self):
78 | return '{num_features}, eps={eps}, momentum={momentum}, '\
79 | 'affine={affine}, ' \
80 | 'track_running_stats={track_running_stats}'.format(
81 | **self.__dict__)
82 |
83 |
84 | class BatchNorm2dNoSync(_BatchNorm):
85 | """
86 | Equivalent to nn.BatchNorm2d
87 | """
88 |
89 | def _check_input_dim(self, input):
90 | if input.dim() != 4:
91 | raise ValueError('expected 4D input (got {}D input)'
92 | .format(input.dim()))
93 |
94 |
95 | class BatchNorm2dSync(BatchNorm2dNoSync):
96 | """
97 | BatchNorm2d with automatic multi-GPU Sync
98 | """
99 |
100 | def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,
101 | track_running_stats=True):
102 | super(BatchNorm2dSync, self).__init__(
103 | num_features, eps=eps, momentum=momentum, affine=affine,
104 | track_running_stats=track_running_stats)
105 | self.sync_enabled = True
106 | self.devices = list(range(torch.cuda.device_count()))
107 | if len(self.devices) > 1:
108 | # Initialize queues
109 | self.worker_ids = self.devices[1:]
110 | self.master_queue = Queue(len(self.worker_ids))
111 | self.worker_queues = [Queue(1) for _ in self.worker_ids]
112 |
113 | def forward(self, x):
114 | compute_stats = not self.freezed and \
115 | self.training and self.track_running_stats
116 | if self.sync_enabled and compute_stats and len(self.devices) > 1:
117 | if x.get_device() == self.devices[0]:
118 | # Master mode
119 | extra = {
120 | "is_master": True,
121 | "master_queue": self.master_queue,
122 | "worker_queues": self.worker_queues,
123 | "worker_ids": self.worker_ids
124 | }
125 | else:
126 | # Worker mode
127 | extra = {
128 | "is_master": False,
129 | "master_queue": self.master_queue,
130 | "worker_queue": self.worker_queues[
131 | self.worker_ids.index(x.get_device())]
132 | }
133 | return batchnorm2d_sync(x, self.weight, self.bias,
134 | self.running_mean, self.running_var,
135 | extra, compute_stats, self.momentum,
136 | self.eps)
137 | return super(BatchNorm2dSync, self).forward(x)
138 |
139 | def __repr__(self):
140 | """repr"""
141 | rep = '{name}({num_features}, eps={eps}, momentum={momentum},' \
142 | 'affine={affine}, ' \
143 | 'track_running_stats={track_running_stats},' \
144 | 'devices={devices})'
145 | return rep.format(name=self.__class__.__name__, **self.__dict__)
146 |
147 | #BatchNorm2d = BatchNorm2dNoSync
148 | BatchNorm2d = BatchNorm2dSync
149 |
--------------------------------------------------------------------------------
/fbrs/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/fbrs/utils/__init__.py
--------------------------------------------------------------------------------
/fbrs/utils/cython/__init__.py:
--------------------------------------------------------------------------------
1 | # noinspection PyUnresolvedReferences
2 | from .dist_maps import get_dist_maps
--------------------------------------------------------------------------------
/fbrs/utils/cython/_get_dist_maps.pyx:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | cimport cython
3 | cimport numpy as np
4 | from libc.stdlib cimport malloc, free
5 |
6 | ctypedef struct qnode:
7 | int row
8 | int col
9 | int layer
10 | int orig_row
11 | int orig_col
12 |
13 | @cython.infer_types(True)
14 | @cython.boundscheck(False)
15 | @cython.wraparound(False)
16 | @cython.nonecheck(False)
17 | def get_dist_maps(np.ndarray[np.float32_t, ndim=2, mode="c"] points,
18 | int height, int width, float norm_delimeter):
19 | cdef np.ndarray[np.float32_t, ndim=3, mode="c"] dist_maps = \
20 | np.full((2, height, width), 1e6, dtype=np.float32, order="C")
21 |
22 | cdef int *dxy = [-1, 0, 0, -1, 0, 1, 1, 0]
23 | cdef int i, j, x, y, dx, dy
24 | cdef qnode v
25 | cdef qnode *q = malloc((4 * height * width + 1) * sizeof(qnode))
26 | cdef int qhead = 0, qtail = -1
27 | cdef float ndist
28 |
29 | for i in range(points.shape[0]):
30 | x, y = round(points[i, 0]), round(points[i, 1])
31 | if x >= 0:
32 | qtail += 1
33 | q[qtail].row = x
34 | q[qtail].col = y
35 | q[qtail].orig_row = x
36 | q[qtail].orig_col = y
37 | if i >= points.shape[0] / 2:
38 | q[qtail].layer = 1
39 | else:
40 | q[qtail].layer = 0
41 | dist_maps[q[qtail].layer, x, y] = 0
42 |
43 | while qtail - qhead + 1 > 0:
44 | v = q[qhead]
45 | qhead += 1
46 |
47 | for k in range(4):
48 | x = v.row + dxy[2 * k]
49 | y = v.col + dxy[2 * k + 1]
50 |
51 | ndist = ((x - v.orig_row)/norm_delimeter) ** 2 + ((y - v.orig_col)/norm_delimeter) ** 2
52 | if (x >= 0 and y >= 0 and x < height and y < width and
53 | dist_maps[v.layer, x, y] > ndist):
54 | qtail += 1
55 | q[qtail].orig_col = v.orig_col
56 | q[qtail].orig_row = v.orig_row
57 | q[qtail].layer = v.layer
58 | q[qtail].row = x
59 | q[qtail].col = y
60 | dist_maps[v.layer, x, y] = ndist
61 |
62 | free(q)
63 | return dist_maps
64 |
--------------------------------------------------------------------------------
/fbrs/utils/cython/_get_dist_maps.pyxbld:
--------------------------------------------------------------------------------
1 | import numpy
2 |
3 | def make_ext(modname, pyxfilename):
4 | from distutils.extension import Extension
5 | return Extension(modname, [pyxfilename],
6 | include_dirs=[numpy.get_include()],
7 | extra_compile_args=['-O3'], language='c++')
8 |
--------------------------------------------------------------------------------
/fbrs/utils/cython/dist_maps.py:
--------------------------------------------------------------------------------
1 | import pyximport; pyximport.install(pyximport=True, language_level=3)
2 | # noinspection PyUnresolvedReferences
3 | from ._get_dist_maps import get_dist_maps
--------------------------------------------------------------------------------
/fbrs/utils/misc.py:
--------------------------------------------------------------------------------
1 | from functools import partial
2 |
3 | import torch
4 | import numpy as np
5 |
6 |
7 | def get_dims_with_exclusion(dim, exclude=None):
8 | dims = list(range(dim))
9 | if exclude is not None:
10 | dims.remove(exclude)
11 |
12 | return dims
13 |
14 |
15 | def get_unique_labels(mask):
16 | return np.nonzero(np.bincount(mask.flatten() + 1))[0] - 1
17 |
18 |
19 | def get_bbox_from_mask(mask):
20 | rows = np.any(mask, axis=1)
21 | cols = np.any(mask, axis=0)
22 | rmin, rmax = np.where(rows)[0][[0, -1]]
23 | cmin, cmax = np.where(cols)[0][[0, -1]]
24 |
25 | return rmin, rmax, cmin, cmax
26 |
27 |
28 | def expand_bbox(bbox, expand_ratio, min_crop_size=None):
29 | rmin, rmax, cmin, cmax = bbox
30 | rcenter = 0.5 * (rmin + rmax)
31 | ccenter = 0.5 * (cmin + cmax)
32 | height = expand_ratio * (rmax - rmin + 1)
33 | width = expand_ratio * (cmax - cmin + 1)
34 | if min_crop_size is not None:
35 | height = max(height, min_crop_size)
36 | width = max(width, min_crop_size)
37 |
38 | rmin = int(round(rcenter - 0.5 * height))
39 | rmax = int(round(rcenter + 0.5 * height))
40 | cmin = int(round(ccenter - 0.5 * width))
41 | cmax = int(round(ccenter + 0.5 * width))
42 |
43 | return rmin, rmax, cmin, cmax
44 |
45 |
46 | def clamp_bbox(bbox, rmin, rmax, cmin, cmax):
47 | return (max(rmin, bbox[0]), min(rmax, bbox[1]),
48 | max(cmin, bbox[2]), min(cmax, bbox[3]))
49 |
50 |
51 | def get_bbox_iou(b1, b2):
52 | h_iou = get_segments_iou(b1[:2], b2[:2])
53 | w_iou = get_segments_iou(b1[2:4], b2[2:4])
54 | return h_iou * w_iou
55 |
56 |
57 | def get_segments_iou(s1, s2):
58 | a, b = s1
59 | c, d = s2
60 | intersection = max(0, min(b, d) - max(a, c) + 1)
61 | union = max(1e-6, max(b, d) - min(a, c) + 1)
62 | return intersection / union
63 |
--------------------------------------------------------------------------------
/fbrs/utils/vis.py:
--------------------------------------------------------------------------------
1 | from functools import lru_cache
2 |
3 | import cv2
4 | import numpy as np
5 |
6 |
7 | def visualize_instances(imask, bg_color=255,
8 | boundaries_color=None, boundaries_width=1, boundaries_alpha=0.8):
9 | num_objects = imask.max() + 1
10 | palette = get_palette(num_objects)
11 | if bg_color is not None:
12 | palette[0] = bg_color
13 |
14 | result = palette[imask].astype(np.uint8)
15 | if boundaries_color is not None:
16 | boundaries_mask = get_boundaries(imask, boundaries_width=boundaries_width)
17 | tresult = result.astype(np.float32)
18 | tresult[boundaries_mask] = boundaries_color
19 | tresult = tresult * boundaries_alpha + (1 - boundaries_alpha) * result
20 | result = tresult.astype(np.uint8)
21 |
22 | return result
23 |
24 |
25 | @lru_cache(maxsize=16)
26 | def get_palette(num_cls):
27 | palette = np.zeros(3 * num_cls, dtype=np.int32)
28 |
29 | for j in range(0, num_cls):
30 | lab = j
31 | i = 0
32 |
33 | while lab > 0:
34 | palette[j*3 + 0] |= (((lab >> 0) & 1) << (7-i))
35 | palette[j*3 + 1] |= (((lab >> 1) & 1) << (7-i))
36 | palette[j*3 + 2] |= (((lab >> 2) & 1) << (7-i))
37 | i = i + 1
38 | lab >>= 3
39 |
40 | return palette.reshape((-1, 3))
41 |
42 |
43 | def visualize_mask(mask, num_cls):
44 | palette = get_palette(num_cls)
45 | mask[mask == -1] = 0
46 |
47 | return palette[mask].astype(np.uint8)
48 |
49 |
50 | def visualize_proposals(proposals_info, point_color=(255, 0, 0), point_radius=1):
51 | proposal_map, colors, candidates = proposals_info
52 |
53 | proposal_map = draw_probmap(proposal_map)
54 | for x, y in candidates:
55 | proposal_map = cv2.circle(proposal_map, (y, x), point_radius, point_color, -1)
56 |
57 | return proposal_map
58 |
59 |
60 | def draw_probmap(x):
61 | return cv2.applyColorMap((x * 255).astype(np.uint8), cv2.COLORMAP_HOT)
62 |
63 |
64 | def draw_points(image, points, color, radius=3):
65 | image = image.copy()
66 | for p in points:
67 | image = cv2.circle(image, (int(p[1]), int(p[0])), radius, color, -1)
68 |
69 | return image
70 |
71 |
72 | def draw_instance_map(x, palette=None):
73 | num_colors = x.max() + 1
74 | if palette is None:
75 | palette = get_palette(num_colors)
76 |
77 | return palette[x].astype(np.uint8)
78 |
79 |
80 | def blend_mask(image, mask, alpha=0.6):
81 | if mask.min() == -1:
82 | mask = mask.copy() + 1
83 |
84 | imap = draw_instance_map(mask)
85 | result = (image * (1 - alpha) + alpha * imap).astype(np.uint8)
86 | return result
87 |
88 |
89 | def get_boundaries(instances_masks, boundaries_width=1):
90 | boundaries = np.zeros((instances_masks.shape[0], instances_masks.shape[1]), dtype=np.bool)
91 |
92 | for obj_id in np.unique(instances_masks.flatten()):
93 | if obj_id == 0:
94 | continue
95 |
96 | obj_mask = instances_masks == obj_id
97 | kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
98 | inner_mask = cv2.erode(obj_mask.astype(np.uint8), kernel, iterations=boundaries_width).astype(np.bool)
99 |
100 | obj_boundary = np.logical_xor(obj_mask, np.logical_and(inner_mask, obj_mask))
101 | boundaries = np.logical_or(boundaries, obj_boundary)
102 | return boundaries
103 |
104 |
105 | def draw_with_blend_and_clicks(img, mask=None, alpha=0.6, clicks_list=None, pos_color=(0, 255, 0),
106 | neg_color=(255, 0, 0), radius=4):
107 | result = img.copy()
108 |
109 | if mask is not None:
110 | palette = get_palette(np.max(mask) + 1)
111 | rgb_mask = palette[mask.astype(np.uint8)]
112 |
113 | mask_region = (mask > 0).astype(np.uint8)
114 | result = result * (1 - mask_region[:, :, np.newaxis]) + \
115 | (1 - alpha) * mask_region[:, :, np.newaxis] * result + \
116 | alpha * rgb_mask
117 | result = result.astype(np.uint8)
118 |
119 | # result = (result * (1 - alpha) + alpha * rgb_mask).astype(np.uint8)
120 |
121 | if clicks_list is not None and len(clicks_list) > 0:
122 | pos_points = [click.coords for click in clicks_list if click.is_positive]
123 | neg_points = [click.coords for click in clicks_list if not click.is_positive]
124 |
125 | result = draw_points(result, pos_points, pos_color, radius=radius)
126 | result = draw_points(result, neg_points, neg_color, radius=radius)
127 |
128 | return result
129 |
130 |
--------------------------------------------------------------------------------
/generate_fusion.py:
--------------------------------------------------------------------------------
1 | """
2 | Generate fusion data for the DAVIS dataset.
3 | """
4 |
5 | import os
6 | from os import path
7 | from argparse import ArgumentParser
8 |
9 | import torch
10 | from torch.utils.data import Dataset, DataLoader
11 | import numpy as np
12 | from PIL import Image
13 | import cv2
14 |
15 | from model.propagation.prop_net import PropagationNetwork
16 | from dataset.davis_test_dataset import DAVISTestDataset
17 | from dataset.bl_test_dataset import BLTestDataset
18 | from generation.fusion_generator import FusionGenerator
19 |
20 | from progressbar import progressbar
21 |
22 |
23 | """
24 | Arguments loading
25 | """
26 | parser = ArgumentParser()
27 | parser.add_argument('--model', default='saves/propagation_model.pth')
28 | parser.add_argument('--davis_root', default='../DAVIS/2017')
29 | parser.add_argument('--bl_root', default='../BL30K')
30 | parser.add_argument('--dataset', help='DAVIS/BL')
31 | parser.add_argument('--output')
32 | parser.add_argument('--separation', default=None, type=int)
33 | parser.add_argument('--range', default=None, type=int)
34 | parser.add_argument('--mem_freq', default=None, type=int)
35 | parser.add_argument('--start', default=None, type=int)
36 | parser.add_argument('--end', default=None, type=int)
37 | args = parser.parse_args()
38 |
39 | davis_path = args.davis_root
40 | bl_path = args.bl_root
41 | out_path = args.output
42 | dataset_option = args.dataset
43 |
44 | # Simple setup
45 | os.makedirs(out_path, exist_ok=True)
46 | palette = Image.open(path.expanduser(davis_path+'/trainval/Annotations/480p/blackswan/00000.png')).getpalette()
47 |
48 | torch.autograd.set_grad_enabled(False)
49 |
50 | # Setup Dataset
51 | if dataset_option == 'DAVIS':
52 | test_dataset = DAVISTestDataset(davis_path+'/trainval', imset='2017/train.txt')
53 | elif dataset_option == 'BL':
54 | test_dataset = BLTestDataset(bl_path, start=args.start, end=args.end)
55 | else:
56 | print('Use --dataset DAVIS or --dataset BL')
57 | raise NotImplementedError
58 |
59 | # test_dataset = BLTestDataset(args.bl, start=args.start, end=args.end, subset=load_sub_bl())
60 | test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False, num_workers=1, pin_memory=False)
61 |
62 | # Load our checkpoint
63 | prop_saved = torch.load(args.model)
64 | prop_model = PropagationNetwork().cuda().eval()
65 | prop_model.load_state_dict(prop_saved)
66 |
67 | # Start evaluation
68 | for data in progressbar(test_loader, max_value=len(test_loader), redirect_stdout=True):
69 |
70 | rgb = data['rgb'].cuda()
71 | msk = data['gt'][0].cuda()
72 | info = data['info']
73 |
74 | total_t = rgb.shape[1]
75 | processor = FusionGenerator(prop_model, rgb, args.mem_freq)
76 |
77 | for frame in range(0, total_t, args.separation):
78 |
79 | usable_keys = []
80 | for k in range(msk.shape[0]):
81 | if (msk[k,frame] > 0.5).sum() > 10*10:
82 | usable_keys.append(k)
83 | if len(usable_keys) == 0:
84 | continue
85 | if len(usable_keys) > 5:
86 | # Memory limit
87 | usable_keys = usable_keys[:5]
88 |
89 | k = len(usable_keys)
90 | processor.reset(k)
91 | this_msk = msk[usable_keys]
92 |
93 | # Make this directory
94 | this_out_path = path.join(out_path, info['name'][0], '%05d'%frame)
95 | os.makedirs(this_out_path, exist_ok=True)
96 |
97 | # Propagate
98 | if dataset_option == 'DAVIS':
99 | left_limit = 0
100 | right_limit = total_t-1
101 | else:
102 | left_limit = max(0, frame-args.range)
103 | right_limit = min(total_t-1, frame+args.range)
104 |
105 | pred_range = range(left_limit, right_limit+1)
106 | out_probs = processor.interact_mask(this_msk[:,frame], frame, left_limit, right_limit)
107 |
108 | for kidx, obj_id in enumerate(usable_keys):
109 | obj_out_path = path.join(this_out_path, '%05d'%(obj_id+1))
110 | os.makedirs(obj_out_path, exist_ok=True)
111 | prob_Es = (out_probs[kidx+1]*255).cpu().numpy().astype(np.uint8)
112 |
113 | for f in pred_range:
114 | img_E = Image.fromarray(prob_Es[f])
115 | img_E.save(os.path.join(obj_out_path, '{:05d}.png'.format(f)))
116 |
117 | del out_probs
118 |
119 | print(info['name'][0])
120 | torch.cuda.empty_cache()
--------------------------------------------------------------------------------
/generation/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/generation/__init__.py
--------------------------------------------------------------------------------
/generation/blender/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/generation/blender/__init__.py
--------------------------------------------------------------------------------
/generation/blender/clean_data.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 | from os import path
4 | import shutil
5 |
6 | """
7 | Look at a "rendered" folder, move the rendered to the output path
8 | Keep the empty folders in place (don't delete since it might still be rendered right)
9 | Also copy the corresponding yaml in there
10 | """
11 |
12 | input_path = sys.argv[1]
13 | output_path = sys.argv[2]
14 | yaml_path = sys.argv[3]
15 |
16 | # This overrides the softlink
17 | # os.makedirs(output_path, exist_ok=True)
18 |
19 | renders = os.listdir(input_path)
20 | is_rendered = [len(os.listdir(path.join(input_path, r, 'segmentation')))==160 for r in renders]
21 |
22 | updated = 0
23 | for i, r in enumerate(renders):
24 | if is_rendered[i]:
25 | if not path.exists(path.join(output_path, r)):
26 | shutil.move(path.join(input_path, r), output_path)
27 | prefix = r[:3]
28 |
29 | shutil.copy2(path.join(yaml_path, 'yaml_%s'%prefix, '%s.yaml'%r), path.join(output_path, r))
30 | updated += 1
31 | else:
32 | print('path exist')
33 | else:
34 | # Nothing for now. Can do something later
35 | pass
36 |
37 | print('Number of completed renders: ', len(os.listdir(output_path)))
38 | print('Number of updated renders: ', updated)
--------------------------------------------------------------------------------
/generation/blender/gen_utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import numpy.polynomial.polynomial as poly
3 | from scipy import optimize
4 |
5 |
6 | class Sampler:
7 | def __init__(self, data_list):
8 | self.data_list = data_list
9 | self.idx = 0
10 | self.permute()
11 |
12 | def permute(self):
13 | self.data_list = np.random.permutation(self.data_list)
14 |
15 | def next(self):
16 | if self.idx == len(self.data_list):
17 | self.permute()
18 | self.idx = 0
19 | data = self.data_list[self.idx]
20 | self.idx += 1
21 | return data
22 |
23 | def step_back(self):
24 | self.idx -= 1
25 | if self.idx == -1:
26 | self.idx = len(self.data_list) - 1
27 |
28 | def test_path(prev_paths, path, tol=0.75):
29 | min_dist = float('inf')
30 | path = np.array(path)
31 | for p in prev_paths:
32 | p = np.array(p)
33 | # Find min distance as a constrained optimization problem
34 | poly_vals = p - path
35 | f = lambda x: np.linalg.norm(poly.polyval(x, poly_vals))
36 | optim_x = optimize.minimize_scalar(f, bounds=(0, 1), method='bounded')
37 | if optim_x.fun < tol:
38 | # print('Fail')
39 | return False
40 | # print('Success')
41 | return True
42 |
43 | def pick_rand(min_v, max_v, shape=None):
44 | if shape is not None:
45 | return np.random.rand(shape)*(max_v-min_v) + min_v
46 | else:
47 | return np.random.rand()*(max_v-min_v) + min_v
48 |
49 | def pick_normal_rand(mean, std, shape=None):
50 | return np.random.normal(mean, std, shape)
51 |
52 | def pick_randint(min_v, max_v):
53 | return np.random.randint(min_v, max_v+1)
54 |
55 | def normalize(a):
56 | return a / np.linalg.norm(a)
57 |
58 | def get_2side_rand(max_delta, shape=1):
59 | return np.random.rand(shape)*2*max_delta-max_delta
60 |
61 | def get_vector_in_frustum(min_base, max_base, min_into, max_into, cam_min_into):
62 | y = pick_rand(min_into, max_into)
63 |
64 | f_min_base = min_base * ((y - cam_min_into) / (min_into - cam_min_into))
65 | f_max_base = max_base * ((y - cam_min_into) / (min_into - cam_min_into))
66 |
67 | x = pick_rand(f_min_base, f_max_base)
68 | z = pick_rand(f_min_base, f_max_base)
69 | return np.array((x, y, z))
70 |
71 | def get_vector_in_block(min_base, max_base, min_into, max_into):
72 | x = pick_rand(min_base, max_base)
73 | y = pick_rand(min_into, max_into)
74 | z = pick_rand(min_base, max_base)
75 | return np.array((x, y, z))
76 |
77 | def get_vector_on_sphere(radius):
78 | x1 = np.random.normal(0, 1)
79 | x2 = np.random.normal(0, 1)
80 | x3 = np.random.normal(0, 1)
81 | norm = (x1*x1 + x2*x2 + x3*x3)**(1/2)
82 | pt = radius*np.array((x1,x2,x3))/norm
83 | return pt
84 |
85 | def get_next_vector_in_block(curr_vec, max_delta, min_base, max_base, min_into, max_into):
86 | new_point = get_vector_in_block(min_base, max_base, min_into, max_into)
87 |
88 | max_delta = np.abs(max_delta)
89 | dist_vec = (new_point - curr_vec)
90 | for i in range(3):
91 | if dist_vec[i] > max_delta[i]:
92 | dist_vec[i] = np.sign(dist_vec[i]) * max_delta[i]
93 |
94 | new_point = curr_vec + dist_vec
95 | return new_point
96 |
97 | def get_next_vector_in_frustum(curr_vec, max_delta, min_base, max_base, min_into, max_into, cam_min_into):
98 | new_point = get_vector_in_frustum(min_base, max_base, min_into, max_into, cam_min_into)
99 |
100 | max_delta = np.abs(max_delta)
101 | dist_vec = (new_point - curr_vec)
102 | for i in range(3):
103 | if dist_vec[i] > max_delta[i]:
104 | dist_vec[i] = np.sign(dist_vec[i]) * max_delta[i]
105 |
106 | new_point = curr_vec + dist_vec
107 | return new_point
--------------------------------------------------------------------------------
/generation/blender/resize_texture.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 | import cv2
4 |
5 | from multiprocessing import Pool
6 | from progressbar import progressbar
7 |
8 | input_dir = sys.argv[1]
9 | output_dir = sys.argv[2]
10 |
11 | min_size = 512
12 |
13 | def process_fun(sub_dir):
14 | this_in_dir = os.path.join(input_dir, sub_dir)
15 | this_out_dir = os.path.join(output_dir, sub_dir)
16 | os.makedirs(this_out_dir, exist_ok=True)
17 |
18 | for f in os.listdir(this_in_dir):
19 | img = cv2.imread(os.path.join(this_in_dir, f))
20 | if img is None:
21 | continue
22 | h, w, _ = img.shape
23 |
24 | scale = min(h, w) / min_size
25 |
26 | img = cv2.resize(img, (int(w/scale), int(h/scale)), interpolation=cv2.INTER_AREA)
27 | if len(img.shape) == 3:
28 | img = img[0:min_size, 0:min_size, :]
29 | else:
30 | img = img[0:min_size, 0:min_size]
31 | cv2.imwrite(os.path.join(this_out_dir, os.path.basename(f)), img)
32 |
33 | if __name__ == '__main__':
34 | pool = Pool()
35 | chunksize = 1
36 |
37 | os.makedirs(output_dir, exist_ok=True)
38 | for _ in progressbar(pool.map(process_fun, os.listdir(input_dir)), chunksize):
39 | pass
40 |
41 | print('All done.')
--------------------------------------------------------------------------------
/generation/blender/texture.json:
--------------------------------------------------------------------------------
1 | {
2 | "Records": [
3 | {
4 | "keywords": "wood texture",
5 | "limit": 300,
6 | "usage_rights": "labeled-for-nocommercial-reuse",
7 | "print_urls": true,
8 | "output_directory": "texture"
9 | },
10 | {
11 | "keywords": "metal texture",
12 | "limit": 300,
13 | "usage_rights": "labeled-for-nocommercial-reuse",
14 | "print_urls": true,
15 | "output_directory": "texture"
16 | },
17 | {
18 | "keywords": "tree texture",
19 | "limit": 300,
20 | "usage_rights": "labeled-for-nocommercial-reuse",
21 | "print_urls": true,
22 | "output_directory": "texture"
23 | },
24 | {
25 | "keywords": "glass texture",
26 | "limit": 300,
27 | "usage_rights": "labeled-for-nocommercial-reuse",
28 | "print_urls": true,
29 | "output_directory": "texture"
30 | },
31 | {
32 | "keywords": "plastic texture",
33 | "limit": 300,
34 | "usage_rights": "labeled-for-nocommercial-reuse",
35 | "print_urls": true,
36 | "output_directory": "texture"
37 | },
38 | {
39 | "keywords": "brick texture",
40 | "limit": 300,
41 | "usage_rights": "labeled-for-nocommercial-reuse",
42 | "print_urls": true,
43 | "output_directory": "texture"
44 | },
45 | {
46 | "keywords": "wall texture",
47 | "limit": 300,
48 | "usage_rights": "labeled-for-nocommercial-reuse",
49 | "print_urls": true,
50 | "output_directory": "texture"
51 | },
52 | {
53 | "keywords": "concrete texture",
54 | "limit": 300,
55 | "usage_rights": "labeled-for-nocommercial-reuse",
56 | "print_urls": true,
57 | "output_directory": "texture"
58 | },
59 | {
60 | "keywords": "dirt texture",
61 | "limit": 300,
62 | "usage_rights": "labeled-for-nocommercial-reuse",
63 | "print_urls": true,
64 | "output_directory": "texture"
65 | },
66 | {
67 | "keywords": "paper texture",
68 | "limit": 300,
69 | "usage_rights": "labeled-for-nocommercial-reuse",
70 | "print_urls": true,
71 | "output_directory": "texture"
72 | },
73 | {
74 | "keywords": "skin texture",
75 | "limit": 300,
76 | "usage_rights": "labeled-for-nocommercial-reuse",
77 | "print_urls": true,
78 | "output_directory": "texture"
79 | },
80 | {
81 | "keywords": "meat texture",
82 | "limit": 300,
83 | "usage_rights": "labeled-for-nocommercial-reuse",
84 | "print_urls": true,
85 | "output_directory": "texture"
86 | },
87 | {
88 | "keywords": "hair texture",
89 | "limit": 300,
90 | "usage_rights": "labeled-for-nocommercial-reuse",
91 | "print_urls": true,
92 | "output_directory": "texture"
93 | },
94 | {
95 | "keywords": "electronics texture",
96 | "limit": 300,
97 | "usage_rights": "labeled-for-nocommercial-reuse",
98 | "print_urls": true,
99 | "output_directory": "texture"
100 | },
101 | {
102 | "keywords": "fur texture",
103 | "limit": 300,
104 | "usage_rights": "labeled-for-nocommercial-reuse",
105 | "print_urls": true,
106 | "output_directory": "texture"
107 | }
108 | ]
109 | }
--------------------------------------------------------------------------------
/generation/blender/texture_2.json:
--------------------------------------------------------------------------------
1 | {
2 | "Records": [
3 | {
4 | "keywords": "stone texture",
5 | "limit": 300,
6 | "usage_rights": "labeled-for-nocommercial-reuse",
7 | "print_urls": true,
8 | "output_directory": "texture"
9 | },
10 | {
11 | "keywords": "fabric texture",
12 | "limit": 300,
13 | "usage_rights": "labeled-for-nocommercial-reuse",
14 | "print_urls": true,
15 | "output_directory": "texture"
16 | },
17 | {
18 | "keywords": "pebble texture",
19 | "limit": 300,
20 | "usage_rights": "labeled-for-nocommercial-reuse",
21 | "print_urls": true,
22 | "output_directory": "texture"
23 | },
24 | {
25 | "keywords": "sand texture",
26 | "limit": 300,
27 | "usage_rights": "labeled-for-nocommercial-reuse",
28 | "print_urls": true,
29 | "output_directory": "texture"
30 | },
31 | {
32 | "keywords": "beach texture",
33 | "limit": 300,
34 | "usage_rights": "labeled-for-nocommercial-reuse",
35 | "print_urls": true,
36 | "output_directory": "texture"
37 | }
38 | ]
39 | }
--------------------------------------------------------------------------------
/generation/fusion_generator.py:
--------------------------------------------------------------------------------
1 | """
2 | A helper class for generating data used to train the fusion module.
3 | This part is rather crude as it is used only once/twice.
4 | """
5 | import torch
6 | import numpy as np
7 |
8 | from model.propagation.prop_net import PropagationNetwork
9 | from model.aggregate import aggregate_sbg, aggregate_wbg
10 |
11 | from util.tensor_util import pad_divide_by
12 |
13 | class FusionGenerator:
14 | def __init__(self, prop_net:PropagationNetwork, images, mem_freq):
15 | self.prop_net = prop_net
16 | self.mem_freq = mem_freq
17 |
18 | # True dimensions
19 | t = images.shape[1]
20 | h, w = images.shape[-2:]
21 |
22 | # Pad each side to multiple of 16
23 | images, self.pad = pad_divide_by(images, 16, images.shape[-2:])
24 | # Padded dimensions
25 | nh, nw = images.shape[-2:]
26 |
27 | self.images = images
28 | self.device = self.images.device
29 |
30 | self.t, self.h, self.w = t, h, w
31 | self.nh, self.nw = nh, nw
32 |
33 | def reset(self, k):
34 | self.k = k
35 | self.prob = torch.zeros((self.k+1, self.t, 1, self.nh, self.nw), dtype=torch.float32, device=self.device)
36 |
37 | def get_im(self, idx):
38 | return self.images[:,idx]
39 |
40 | def get_query_buf(self, idx):
41 | query = self.prop_net.get_query_values(self.get_im(idx))
42 | return query
43 |
44 | def do_pass(self, key_k, key_v, idx, left_limit, right_limit, forward=True):
45 | keys = key_k
46 | values = key_v
47 | prev_k = prev_v = None
48 | last_ti = idx
49 |
50 | Es = self.prob
51 |
52 | if forward:
53 | this_range = range(idx+1, right_limit+1)
54 | step = +1
55 | end = right_limit
56 | else:
57 | this_range = range(idx-1, left_limit-1, -1)
58 | step = -1
59 | end = left_limit
60 |
61 | for ti in this_range:
62 | if prev_k is not None:
63 | this_k = torch.cat([keys, prev_k], 2)
64 | this_v = torch.cat([values, prev_v], 2)
65 | else:
66 | this_k = keys
67 | this_v = values
68 | query = self.get_query_buf(ti)
69 | out_mask = self.prop_net.segment_with_query(this_k, this_v, *query)
70 | out_mask = aggregate_wbg(out_mask, keep_bg=True)
71 |
72 | Es[:,ti] = out_mask
73 |
74 | if ti != end:
75 | prev_k, prev_v = self.prop_net.memorize(self.get_im(ti), out_mask[1:])
76 | if abs(ti-last_ti) >= self.mem_freq:
77 | last_ti = ti
78 | keys = torch.cat([keys, prev_k], 2)
79 | values = torch.cat([values, prev_v], 2)
80 | prev_k = prev_v = None
81 |
82 | def interact_mask(self, mask, idx, left_limit, right_limit):
83 |
84 | mask, _ = pad_divide_by(mask, 16, mask.shape[-2:])
85 | mask = aggregate_wbg(mask, keep_bg=True)
86 |
87 | self.prob[:, idx] = mask
88 | key_k, key_v = self.prop_net.memorize(self.get_im(idx), mask[1:])
89 |
90 | self.do_pass(key_k, key_v, idx, left_limit, right_limit, True)
91 | self.do_pass(key_k, key_v, idx, left_limit, right_limit, False)
92 |
93 | # Prepare output
94 | out_prob = self.prob[:,:,0,:,:]
95 |
96 | if self.pad[2]+self.pad[3] > 0:
97 | out_prob = out_prob[:,:,self.pad[2]:-self.pad[3],:]
98 | if self.pad[0]+self.pad[1] > 0:
99 | out_prob = out_prob[:,:,:,self.pad[0]:-self.pad[1]]
100 |
101 | return out_prob
102 |
--------------------------------------------------------------------------------
/generation/test/image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/generation/test/image.png
--------------------------------------------------------------------------------
/generation/test/test_spline.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 |
4 | import numpy as np
5 | import matplotlib.pyplot as plt
6 | from PIL import Image
7 | import cv2
8 | import thinplate as tps
9 |
10 |
11 | def show_warped(img, warped):
12 | fig, axs = plt.subplots(1, 2, figsize=(16,8))
13 | axs[0].axis('off')
14 | axs[1].axis('off')
15 | axs[0].imshow(img[...,::-1], origin='upper')
16 | axs[0].scatter(c_src[:, 0]*img.shape[1], c_src[:, 1]*img.shape[0], marker='+', color='black')
17 | axs[1].imshow(warped[...,::-1], origin='upper')
18 | axs[1].scatter(c_dst[:, 0]*warped.shape[1], c_dst[:, 1]*warped.shape[0], marker='+', color='black')
19 | plt.show()
20 |
21 | def warp_image_cv(img, c_src, c_dst, dshape=None):
22 | dshape = dshape or img.shape
23 | theta = tps.tps_theta_from_points(c_src, c_dst, reduced=True)
24 | grid = tps.tps_grid(theta, c_dst, dshape)
25 | mapx, mapy = tps.tps_grid_to_remap(grid, img.shape)
26 | return cv2.remap(img, mapx, mapy, cv2.INTER_CUBIC)
27 |
28 | img = cv2.imread('image.png')
29 |
30 | c_src = np.array([
31 | [0.0, 0.0],
32 | [1., 0],
33 | [1, 1],
34 | [0, 1],
35 | [0.3, 0.3],
36 | [0.7, 0.7],
37 | ])
38 |
39 | c_dst = np.array([
40 | [-0.2, -0.2],
41 | [1., 0],
42 | [1, 1],
43 | [0, 1],
44 | [0.4, 0.4],
45 | [0.6, 0.6],
46 | ])
47 |
48 | warped = warp_image_cv(img, c_src, c_dst)
49 | print(warped.shape)
50 | show_warped(img, warped)
--------------------------------------------------------------------------------
/generation/test/test_spline_continuous.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 |
4 | import numpy as np
5 | import matplotlib.pyplot as plt
6 | from PIL import Image
7 | import cv2
8 | import thinplate as tps
9 |
10 |
11 | def warp_image_cv(img, c_src, c_dst, dshape=None):
12 | dshape = dshape or img.shape
13 | theta = tps.tps_theta_from_points(c_src, c_dst, reduced=True)
14 | grid = tps.tps_grid(theta, c_dst, dshape)
15 | mapx, mapy = tps.tps_grid_to_remap(grid, img.shape)
16 | return cv2.remap(img, mapx, mapy, cv2.INTER_CUBIC)
17 |
18 | img = cv2.imread('image.png')
19 |
20 | c_src = np.array([
21 | [0.0, 0.0],
22 | [1., 0],
23 | [1, 1],
24 | [0, 1],
25 | [0.3, 0.3],
26 | [0.7, 0.7],
27 | ])
28 |
29 | c_dst = np.array([
30 | [-0.2, -0.2],
31 | [1., 0],
32 | [1, 1],
33 | [0, 1],
34 | [0.4, 0.4],
35 | [0.6, 0.6],
36 | ])
37 |
38 | for i in range(5):
39 | c_this_dst = c_src*(5-i)/5 + c_dst*i/5
40 | warped = warp_image_cv(img, c_src, c_this_dst)
41 | cv2.imwrite('%d.png'%i, warped)
--------------------------------------------------------------------------------
/imgs/framework.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/imgs/framework.jpg
--------------------------------------------------------------------------------
/interact/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/interact/__init__.py
--------------------------------------------------------------------------------
/interact/fbrs_controller.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from fbrs.controller import InteractiveController
3 | from fbrs.inference import utils
4 |
5 |
6 | class FBRSController:
7 | def __init__(self, checkpoint_path, device='cuda:0', max_size=800):
8 | model = utils.load_is_model(checkpoint_path, device, cpu_dist_maps=True, norm_radius=260)
9 |
10 | # Predictor params
11 | zoomin_params = {
12 | 'skip_clicks': 1,
13 | 'target_size': 480,
14 | 'expansion_ratio': 1.4,
15 | }
16 |
17 | predictor_params = {
18 | 'brs_mode': 'f-BRS-B',
19 | 'prob_thresh': 0.5,
20 | 'zoom_in_params': zoomin_params,
21 | 'predictor_params': {
22 | 'net_clicks_limit': 8,
23 | 'max_size': 800,
24 | },
25 | 'brs_opt_func_params': {'min_iou_diff': 1e-3},
26 | 'lbfgs_params': {'maxfun': 20}
27 | }
28 |
29 | self.controller = InteractiveController(model, device, predictor_params)
30 | self.anchored = False
31 | self.device = device
32 |
33 | def unanchor(self):
34 | self.anchored = False
35 |
36 | def interact(self, image, x, y, is_positive):
37 | image = image.to(self.device, non_blocking=True)
38 | if not self.anchored:
39 | self.controller.set_image(image)
40 | self.controller.reset_predictor()
41 | self.anchored = True
42 |
43 | self.controller.add_click(x, y, is_positive)
44 | # return self.controller.result_mask
45 | # return self.controller.probs_history[-1][1]
46 | return (self.controller.probs_history[-1][1]>0.5).float()
47 |
48 | def undo(self):
49 | self.controller.undo_click()
50 | if len(self.controller.probs_history) == 0:
51 | return None
52 | else:
53 | return (self.controller.probs_history[-1][1]>0.5).float()
--------------------------------------------------------------------------------
/interact/interactive_utils.py:
--------------------------------------------------------------------------------
1 | # Modifed from https://github.com/seoungwugoh/ivs-demo
2 |
3 | import numpy as np
4 | import os
5 | import copy
6 | import cv2
7 | import glob
8 |
9 | import matplotlib.pyplot as plt
10 | from scipy.ndimage.morphology import binary_erosion, binary_dilation
11 | from PIL import Image, ImageDraw, ImageFont
12 |
13 | import torch
14 | from torchvision import models
15 | from dataset.range_transform import im_normalization
16 |
17 |
18 | def images_to_torch(frames, device):
19 | frames = torch.from_numpy(frames.transpose(0, 3, 1, 2)).float().unsqueeze(0)/255
20 | b, t, c, h, w = frames.shape
21 | for ti in range(t):
22 | frames[0, ti] = im_normalization(frames[0, ti])
23 | return frames.to(device)
24 |
25 | def load_images(path, min_side=None):
26 | fnames = sorted(glob.glob(os.path.join(path, '*.jpg')))
27 | if len(fnames) == 0:
28 | fnames = sorted(glob.glob(os.path.join(path, '*.png')))
29 | frame_list = []
30 | for i, fname in enumerate(fnames):
31 | if min_side:
32 | image = Image.open(fname).convert('RGB')
33 | w, h = image.size
34 | new_w = (w*min_side//min(w, h))
35 | new_h = (h*min_side//min(w, h))
36 | frame_list.append(np.array(image.resize((new_w, new_h), Image.BICUBIC), dtype=np.uint8))
37 | else:
38 | frame_list.append(np.array(Image.open(fname).convert('RGB'), dtype=np.uint8))
39 | frames = np.stack(frame_list, axis=0)
40 | return frames
41 |
42 | def load_masks(path, min_side=None):
43 | fnames = sorted(glob.glob(os.path.join(path, '*.png')))
44 | frame_list = []
45 |
46 | first_frame = np.array(Image.open(fnames[0]))
47 | binary_mask = (first_frame.max() == 255)
48 |
49 | for i, fname in enumerate(fnames):
50 | if min_side:
51 | image = Image.open(fname)
52 | w, h = image.size
53 | new_w = (w*min_side//min(w, h))
54 | new_h = (h*min_side//min(w, h))
55 | frame_list.append(np.array(image.resize((new_w, new_h), Image.NEAREST), dtype=np.uint8))
56 | else:
57 | frame_list.append(np.array(Image.open(fname), dtype=np.uint8))
58 |
59 | frames = np.stack(frame_list, axis=0)
60 | if binary_mask:
61 | frames = (frames > 128).astype(np.uint8)
62 | return frames
63 |
64 | def load_video(path, min_side=None):
65 | frame_list = []
66 | cap = cv2.VideoCapture(path)
67 | while(cap.isOpened()):
68 | _, frame = cap.read()
69 | if frame is None:
70 | break
71 | frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
72 | if min_side:
73 | h, w = frame.shape[:2]
74 | new_w = (w*min_side//min(w, h))
75 | new_h = (h*min_side//min(w, h))
76 | frame = cv2.resize(frame, (new_w, new_h), interpolation=cv2.INTER_CUBIC)
77 | frame_list.append(frame)
78 | frames = np.stack(frame_list, axis=0)
79 | return frames
80 |
81 | def _pascal_color_map(N=256, normalized=False):
82 | """
83 | Python implementation of the color map function for the PASCAL VOC data set.
84 | Official Matlab version can be found in the PASCAL VOC devkit
85 | http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html#devkit
86 | """
87 |
88 | def bitget(byteval, idx):
89 | return (byteval & (1 << idx)) != 0
90 |
91 | dtype = 'float32' if normalized else 'uint8'
92 | cmap = np.zeros((N, 3), dtype=dtype)
93 | for i in range(N):
94 | r = g = b = 0
95 | c = i
96 | for j in range(8):
97 | r = r | (bitget(c, 0) << 7 - j)
98 | g = g | (bitget(c, 1) << 7 - j)
99 | b = b | (bitget(c, 2) << 7 - j)
100 | c = c >> 3
101 |
102 | cmap[i] = np.array([r, g, b])
103 |
104 | cmap = cmap / 255 if normalized else cmap
105 | return cmap
106 |
107 | color_map = [
108 | [0, 0, 0],
109 | [255, 50, 50],
110 | [50, 255, 50],
111 | [50, 50, 255],
112 | [255, 50, 255],
113 | [50, 255, 255],
114 | [255, 255, 50],
115 | ]
116 |
117 | color_map_np = np.array(color_map)
118 |
119 | def overlay_davis(image, mask, alpha=0.5):
120 | """ Overlay segmentation on top of RGB image. from davis official"""
121 | im_overlay = image.copy()
122 |
123 | colored_mask = color_map_np[mask]
124 | foreground = image*alpha + (1-alpha)*colored_mask
125 | binary_mask = (mask > 0)
126 | # Compose image
127 | im_overlay[binary_mask] = foreground[binary_mask]
128 | countours = binary_dilation(binary_mask) ^ binary_mask
129 | im_overlay[countours,:] = 0
130 | return im_overlay.astype(image.dtype)
131 |
132 | def overlay_davis_fade(image, mask, alpha=0.5):
133 | im_overlay = image.copy()
134 |
135 | colored_mask = color_map_np[mask]
136 | foreground = image*alpha + (1-alpha)*colored_mask
137 | binary_mask = (mask > 0)
138 | # Compose image
139 | im_overlay[binary_mask] = foreground[binary_mask]
140 | countours = binary_dilation(binary_mask) ^ binary_mask
141 | im_overlay[countours,:] = 0
142 | im_overlay[~binary_mask] = im_overlay[~binary_mask] * 0.6
143 | return im_overlay.astype(image.dtype)
--------------------------------------------------------------------------------
/interact/s2m_controller.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | from model.s2m.s2m_network import deeplabv3plus_resnet50 as S2M
4 |
5 | from util.tensor_util import pad_divide_by
6 |
7 |
8 | class S2MController:
9 | """
10 | A controller for Scribble-to-Mask (for user interaction, not for DAVIS)
11 | Takes the image, previous mask, and scribbles to produce a new mask
12 | ignore_class is usually 255
13 | 0 is NOT the ignore class -- it is the label for the background
14 | """
15 | def __init__(self, s2m_net:S2M, num_objects, ignore_class, device='cuda:0'):
16 | self.s2m_net = s2m_net
17 | self.num_objects = num_objects
18 | self.ignore_class = ignore_class
19 | self.device = device
20 |
21 | def interact(self, image, prev_mask, scr_mask):
22 | image = image.to(self.device, non_blocking=True)
23 | prev_mask = prev_mask.to(self.device, non_blocking=True)
24 |
25 | h, w = image.shape[-2:]
26 | unaggre_mask = torch.zeros((self.num_objects, 1, h, w), dtype=torch.float32, device=image.device)
27 |
28 | for ki in range(1, self.num_objects+1):
29 | p_srb = (scr_mask==ki).astype(np.uint8)
30 | n_srb = ((scr_mask!=ki) * (scr_mask!=self.ignore_class)).astype(np.uint8)
31 |
32 | Rs = torch.from_numpy(np.stack([p_srb, n_srb], 0)).unsqueeze(0).float().to(image.device)
33 | Rs, _ = pad_divide_by(Rs, 16, Rs.shape[-2:])
34 |
35 | inputs = torch.cat([image, (prev_mask==ki).float().unsqueeze(0), Rs], 1)
36 | unaggre_mask[ki-1] = torch.sigmoid(self.s2m_net(inputs))
37 |
38 | return unaggre_mask
--------------------------------------------------------------------------------
/interact/timer.py:
--------------------------------------------------------------------------------
1 | import time
2 |
3 | class Timer:
4 | def __init__(self):
5 | self._acc_time = 0
6 | self._paused = True
7 |
8 | def start(self):
9 | if self._paused:
10 | self.last_time = time.time()
11 | self._paused = False
12 | return self
13 |
14 | def pause(self):
15 | self.count()
16 | self._paused = True
17 | return self
18 |
19 | def count(self):
20 | if self._paused:
21 | return self._acc_time
22 | t = time.time()
23 | self._acc_time += t - self.last_time
24 | self.last_time = t
25 | return self._acc_time
26 |
27 | def format(self):
28 | # count = int(self.count()*100)
29 | # return '%02d:%02d:%02d' % (count//6000, (count//100)%60, count%100)
30 | return '%03.2f' % self.count()
31 |
32 | def __str__(self):
33 | return self.format()
--------------------------------------------------------------------------------
/model/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/model/__init__.py
--------------------------------------------------------------------------------
/model/aggregate.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 |
4 | def aggregate_sbg(prob, keep_bg=False, hard=False):
5 | device = prob.device
6 | k, _, h, w = prob.shape
7 | ex_prob = torch.zeros((k+1, 1, h, w), device=device)
8 | ex_prob[0] = 0.5
9 | ex_prob[1:] = prob
10 | ex_prob = torch.clamp(ex_prob, 1e-7, 1-1e-7)
11 | logits = torch.log((ex_prob /(1-ex_prob)))
12 |
13 | if hard:
14 | # Very low temperature o((⊙﹏⊙))o 🥶
15 | logits *= 1000
16 |
17 | if keep_bg:
18 | return F.softmax(logits, dim=0)
19 | else:
20 | return F.softmax(logits, dim=0)[1:]
21 |
22 | def aggregate_wbg(prob, keep_bg=False, hard=False):
23 | k, _, h, w = prob.shape
24 | new_prob = torch.cat([
25 | torch.prod(1-prob, dim=0, keepdim=True),
26 | prob
27 | ], 0).clamp(1e-7, 1-1e-7)
28 | logits = torch.log((new_prob /(1-new_prob)))
29 |
30 | if hard:
31 | # Very low temperature o((⊙﹏⊙))o 🥶
32 | logits *= 1000
33 |
34 | if keep_bg:
35 | return F.softmax(logits, dim=0)
36 | else:
37 | return F.softmax(logits, dim=0)[1:]
38 |
39 | def aggregate_wbg_channel(prob, keep_bg=False, hard=False):
40 | new_prob = torch.cat([
41 | torch.prod(1-prob, dim=1, keepdim=True),
42 | prob
43 | ], 1).clamp(1e-7, 1-1e-7)
44 | logits = torch.log((new_prob /(1-new_prob)))
45 |
46 | if hard:
47 | # Very low temperature o((⊙﹏⊙))o 🥶
48 | logits *= 1000
49 |
50 | if keep_bg:
51 | return logits, F.softmax(logits, dim=1)
52 | else:
53 | return logits, F.softmax(logits, dim=1)[:, 1:]
--------------------------------------------------------------------------------
/model/attn_network.py:
--------------------------------------------------------------------------------
1 | """
2 | Modifed from the original STM code https://github.com/seoungwugoh/STM
3 | """
4 | import math
5 |
6 | import torch
7 | import torch.nn as nn
8 | import torch.nn.functional as F
9 |
10 | from model.propagation.modules import MaskRGBEncoder, RGBEncoder, KeyValue
11 |
12 | class AttentionMemory(nn.Module):
13 | def __init__(self, k=50):
14 | super().__init__()
15 | self.k = k
16 |
17 | def forward(self, mk, qk):
18 | B, CK, H, W = mk.shape
19 |
20 | mk = mk.view(B, CK, H*W)
21 | mk = torch.transpose(mk, 1, 2) # B * HW * CK
22 |
23 | qk = qk.view(B, CK, H*W).expand(B, -1, -1) / math.sqrt(CK) # B * CK * HW
24 |
25 | affinity = torch.bmm(mk, qk) # B * HW * HW
26 | affinity = F.softmax(affinity, dim=1)
27 |
28 | return affinity
29 |
30 | class AttentionReadNetwork(nn.Module):
31 | def __init__(self):
32 | super().__init__()
33 | self.mask_rgb_encoder = MaskRGBEncoder()
34 | self.rgb_encoder = RGBEncoder()
35 |
36 | self.kv_m_f16 = KeyValue(1024, keydim=128, valdim=512)
37 | self.kv_q_f16 = KeyValue(1024, keydim=128, valdim=512)
38 | self.memory = AttentionMemory()
39 |
40 | for p in self.parameters():
41 | p.requires_grad = False
42 |
43 | def get_segment(self, f16, qk):
44 | k16, _ = self.kv_m_f16(f16)
45 | p = self.memory(k16, qk)
46 | return p
47 |
48 | def forward(self, image, mask11, mask21, mask12, mask22, query_image):
49 | b, _, h, w = mask11.shape
50 | nh = h//16
51 | nw = w//16
52 |
53 | with torch.no_grad():
54 | pos_mask1 = (mask21-mask11).clamp(0, 1)
55 | neg_mask1 = (mask11-mask21).clamp(0, 1)
56 | pos_mask2 = (mask22-mask12).clamp(0, 1)
57 | neg_mask2 = (mask12-mask22).clamp(0, 1)
58 |
59 | f16_1 = self.mask_rgb_encoder(image, mask21, mask22)
60 | f16_2 = self.mask_rgb_encoder(image, mask22, mask21)
61 |
62 | qf16, _, _ = self.rgb_encoder(query_image)
63 | qk16, _ = self.kv_q_f16(qf16)
64 |
65 | W1 = self.get_segment(f16_1, qk16)
66 | W2 = self.get_segment(f16_2, qk16)
67 |
68 | pos_map1 = (F.interpolate(pos_mask1, size=(nh,nw), mode='area').view(b, 1, nh*nw) @ W1)
69 | neg_map1 = (F.interpolate(neg_mask1, size=(nh,nw), mode='area').view(b, 1, nh*nw) @ W1)
70 | attn_map1 = torch.cat([pos_map1, neg_map1], 1)
71 | attn_map1 = attn_map1.reshape(b, 2, nh, nw)
72 | attn_map1 = F.interpolate(attn_map1, mode='bilinear', size=(h,w), align_corners=False)
73 |
74 | pos_map2 = (F.interpolate(pos_mask2, size=(nh,nw), mode='area').view(b, 1, nh*nw) @ W2)
75 | neg_map2 = (F.interpolate(neg_mask2, size=(nh,nw), mode='area').view(b, 1, nh*nw) @ W2)
76 | attn_map2 = torch.cat([pos_map2, neg_map2], 1)
77 | attn_map2 = attn_map2.reshape(b, 2, nh, nw)
78 | attn_map2 = F.interpolate(attn_map2, mode='bilinear', size=(h,w), align_corners=False)
79 |
80 | return attn_map1, attn_map2
81 |
--------------------------------------------------------------------------------
/model/fusion_net.py:
--------------------------------------------------------------------------------
1 | import math
2 |
3 | import torch
4 | import torch.nn as nn
5 | import torch.nn.functional as F
6 |
7 |
8 | class FusionNet(nn.Module):
9 | def __init__(self):
10 | super().__init__()
11 |
12 | self.conv1 = nn.Sequential(
13 | nn.Conv2d(9, 32, kernel_size=3, padding=1, stride=1),
14 | nn.ReLU(),
15 | )
16 |
17 | self.conv2 = nn.Sequential(
18 | nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1),
19 | nn.ReLU(),
20 | nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1),
21 | )
22 |
23 | self.conv3 = nn.Sequential(
24 | nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1),
25 | nn.ReLU(),
26 | nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1),
27 | )
28 |
29 | self.relu = nn.ReLU()
30 | self.final_conv = nn.Conv2d(32, 1, kernel_size=3, padding=1, stride=1)
31 |
32 | def forward(self, im, seg1, seg2, attn, time):
33 | h, w = im.shape[-2:]
34 |
35 | time = time.unsqueeze(2).unsqueeze(2)
36 | time = time.expand(-1, -1, h, w)
37 |
38 | x = torch.cat([im, seg1, seg2, attn, time], 1)
39 |
40 | x = self.conv1(x)
41 |
42 | r = self.conv2(x)
43 | x = self.relu(x + r)
44 |
45 | r = self.conv3(x)
46 | x = self.relu(x + r)
47 |
48 | x = self.final_conv(x)
49 |
50 | return x
51 |
--------------------------------------------------------------------------------
/model/losses.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 | from util.tensor_util import compute_tensor_iu
5 | from collections import defaultdict
6 |
7 |
8 | def get_iou_hook(values):
9 | return 'iou/iou', (values['hide_iou/i']+1)/(values['hide_iou/u']+1)
10 |
11 | def get_sec_iou_hook(values):
12 | return 'iou/sec_iou', (values['hide_iou/sec_i']+1)/(values['hide_iou/sec_u']+1)
13 |
14 | iou_hooks = [
15 | get_iou_hook,
16 | get_sec_iou_hook,
17 | ]
18 |
19 |
20 | # https://stackoverflow.com/questions/63735255/how-do-i-compute-bootstrapped-cross-entropy-loss-in-pytorch
21 | class BootstrappedCE(nn.Module):
22 | def __init__(self, start_warm, end_warm, top_p=0.15):
23 | super().__init__()
24 |
25 | self.start_warm = start_warm
26 | self.end_warm = end_warm
27 | self.top_p = top_p
28 |
29 | def forward(self, input, target, it):
30 | if it < self.start_warm:
31 | return F.cross_entropy(input, target), 1.0
32 |
33 | raw_loss = F.cross_entropy(input, target, reduction='none').view(-1)
34 | num_pixels = raw_loss.numel()
35 |
36 | if it > self.end_warm:
37 | this_p = self.top_p
38 | else:
39 | this_p = self.top_p + (1-self.top_p)*((self.end_warm-it)/(self.end_warm-self.start_warm))
40 | loss, _ = torch.topk(raw_loss, int(num_pixels * this_p), sorted=False)
41 | return loss.mean(), this_p
42 |
43 |
44 | class LossComputer:
45 | def __init__(self, para):
46 | super().__init__()
47 | self.para = para
48 | self.bce = BootstrappedCE(start_warm=int(para['iterations']*0.2), end_warm=int(para['iterations']*0.5))
49 |
50 | def compute(self, data, it):
51 | losses = defaultdict(int)
52 |
53 | b = data['gt'].shape[0]
54 | selector = data.get('selector', None)
55 | selector = data['selector']
56 |
57 | for j in range(b):
58 | if selector[j][1] > 0.5:
59 | loss, p = self.bce(data['logits'][j:j+1], data['cls_gt'][j:j+1], it)
60 | else:
61 | loss, p = self.bce(data['logits'][j:j+1,:2], data['cls_gt'][j:j+1], it)
62 |
63 | losses['total_loss'] += loss / b
64 | losses['p'] += p / b
65 |
66 | new_total_i, new_total_u = compute_tensor_iu(data['mask'][:,1:2]>0.5, data['gt']>0.5)
67 | losses['hide_iou/i'] += new_total_i
68 | losses['hide_iou/u'] += new_total_u
69 |
70 | if selector is not None:
71 | new_total_i, new_total_u = compute_tensor_iu(data['mask'][:,2:3]>0.5, data['gt2']>0.5)
72 | losses['hide_iou/sec_i'] += new_total_i
73 | losses['hide_iou/sec_u'] += new_total_u
74 |
75 | return losses
--------------------------------------------------------------------------------
/model/propagation/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/model/propagation/__init__.py
--------------------------------------------------------------------------------
/model/propagation/mod_resnet.py:
--------------------------------------------------------------------------------
1 | from collections import OrderedDict
2 | import math
3 |
4 | import torch
5 | import torch.nn as nn
6 | import torch.nn.functional as F
7 | from torch.utils import model_zoo
8 |
9 | def load_weights_sequential(target, source_state, extra_chan=1):
10 |
11 | new_dict = OrderedDict()
12 |
13 | for k1, v1 in target.state_dict().items():
14 | if not 'num_batches_tracked' in k1:
15 | if k1 in source_state:
16 | tar_v = source_state[k1]
17 |
18 | if v1.shape != tar_v.shape:
19 | # Init the new segmentation channel with zeros
20 | # print(v1.shape, tar_v.shape)
21 | c, _, w, h = v1.shape
22 | tar_v = torch.cat([
23 | tar_v,
24 | torch.zeros((c,extra_chan,w,h)),
25 | ], 1)
26 |
27 | new_dict[k1] = tar_v
28 | elif 'bias' not in k1:
29 | print('Not OK', k1)
30 |
31 | target.load_state_dict(new_dict, strict=False)
32 |
33 |
34 | model_urls = {
35 | 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
36 | }
37 |
38 |
39 | def conv3x3(in_planes, out_planes, stride=1, dilation=1):
40 | return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
41 | padding=dilation, dilation=dilation)
42 |
43 |
44 | class BasicBlock(nn.Module):
45 | expansion = 1
46 |
47 | def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1):
48 | super(BasicBlock, self).__init__()
49 | self.conv1 = conv3x3(inplanes, planes, stride=stride, dilation=dilation)
50 | self.bn1 = nn.BatchNorm2d(planes)
51 | self.relu = nn.ReLU(inplace=True)
52 | self.conv2 = conv3x3(planes, planes, stride=1, dilation=dilation)
53 | self.bn2 = nn.BatchNorm2d(planes)
54 | self.downsample = downsample
55 | self.stride = stride
56 |
57 | def forward(self, x):
58 | residual = x
59 |
60 | out = self.conv1(x)
61 | out = self.bn1(out)
62 | out = self.relu(out)
63 |
64 | out = self.conv2(out)
65 | out = self.bn2(out)
66 |
67 | if self.downsample is not None:
68 | residual = self.downsample(x)
69 |
70 | out += residual
71 | out = self.relu(out)
72 |
73 | return out
74 |
75 |
76 | class Bottleneck(nn.Module):
77 | expansion = 4
78 |
79 | def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1):
80 | super(Bottleneck, self).__init__()
81 | self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1)
82 | self.bn1 = nn.BatchNorm2d(planes)
83 | self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, dilation=dilation,
84 | padding=dilation)
85 | self.bn2 = nn.BatchNorm2d(planes)
86 | self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1)
87 | self.bn3 = nn.BatchNorm2d(planes * 4)
88 | self.relu = nn.ReLU(inplace=True)
89 | self.downsample = downsample
90 | self.stride = stride
91 |
92 | def forward(self, x):
93 | residual = x
94 |
95 | out = self.conv1(x)
96 | out = self.bn1(out)
97 | out = self.relu(out)
98 |
99 | out = self.conv2(out)
100 | out = self.bn2(out)
101 | out = self.relu(out)
102 |
103 | out = self.conv3(out)
104 | out = self.bn3(out)
105 |
106 | if self.downsample is not None:
107 | residual = self.downsample(x)
108 |
109 | out += residual
110 | out = self.relu(out)
111 |
112 | return out
113 |
114 |
115 | class ResNet(nn.Module):
116 | def __init__(self, block, layers=(3, 4, 23, 3), extra_chan=1):
117 | self.inplanes = 64
118 | super(ResNet, self).__init__()
119 | self.conv1 = nn.Conv2d(3+extra_chan, 64, kernel_size=7, stride=2, padding=3)
120 | self.bn1 = nn.BatchNorm2d(64)
121 | self.relu = nn.ReLU(inplace=True)
122 | self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
123 | self.layer1 = self._make_layer(block, 64, layers[0])
124 | self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
125 | self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
126 | self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
127 |
128 | for m in self.modules():
129 | if isinstance(m, nn.Conv2d):
130 | n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
131 | m.weight.data.normal_(0, math.sqrt(2. / n))
132 | m.bias.data.zero_()
133 | elif isinstance(m, nn.BatchNorm2d):
134 | m.weight.data.fill_(1)
135 | m.bias.data.zero_()
136 |
137 | def _make_layer(self, block, planes, blocks, stride=1, dilation=1):
138 | downsample = None
139 | if stride != 1 or self.inplanes != planes * block.expansion:
140 | downsample = nn.Sequential(
141 | nn.Conv2d(self.inplanes, planes * block.expansion,
142 | kernel_size=1, stride=stride),
143 | nn.BatchNorm2d(planes * block.expansion),
144 | )
145 |
146 | layers = [block(self.inplanes, planes, stride, downsample)]
147 | self.inplanes = planes * block.expansion
148 | for i in range(1, blocks):
149 | layers.append(block(self.inplanes, planes, dilation=dilation))
150 |
151 | return nn.Sequential(*layers)
152 |
153 | def resnet50(pretrained=True, extra_chan=0):
154 | model = ResNet(Bottleneck, [3, 4, 6, 3], extra_chan)
155 | if pretrained:
156 | load_weights_sequential(model, model_zoo.load_url(model_urls['resnet50']), extra_chan)
157 | return model
158 |
159 |
--------------------------------------------------------------------------------
/model/propagation/modules.py:
--------------------------------------------------------------------------------
1 | """
2 | Modifed from the original STM code https://github.com/seoungwugoh/STM
3 | """
4 | import math
5 |
6 | import torch
7 | import torch.nn as nn
8 | import torch.nn.functional as F
9 | import torch.utils.model_zoo as model_zoo
10 | from torchvision import models
11 |
12 | from model.propagation import mod_resnet
13 |
14 |
15 | class ResBlock(nn.Module):
16 | def __init__(self, indim, outdim=None):
17 | super(ResBlock, self).__init__()
18 | if outdim == None:
19 | outdim = indim
20 | if indim == outdim:
21 | self.downsample = None
22 | else:
23 | self.downsample = nn.Conv2d(indim, outdim, kernel_size=3, padding=1)
24 |
25 | self.conv1 = nn.Conv2d(indim, outdim, kernel_size=3, padding=1)
26 | self.conv2 = nn.Conv2d(outdim, outdim, kernel_size=3, padding=1)
27 |
28 | def forward(self, x):
29 | r = self.conv1(F.relu(x))
30 | r = self.conv2(F.relu(r))
31 |
32 | if self.downsample is not None:
33 | x = self.downsample(x)
34 |
35 | return x + r
36 |
37 |
38 | class MaskRGBEncoder(nn.Module):
39 | def __init__(self):
40 | super().__init__()
41 |
42 | resnet = mod_resnet.resnet50(pretrained=True, extra_chan=2)
43 | self.conv1 = resnet.conv1
44 | self.bn1 = resnet.bn1
45 | self.relu = resnet.relu # 1/2, 64
46 | self.maxpool = resnet.maxpool
47 |
48 | self.layer1 = resnet.layer1 # 1/4, 256
49 | self.layer2 = resnet.layer2 # 1/8, 512
50 | self.layer3 = resnet.layer3 # 1/16, 1024
51 |
52 | def forward(self, f, m, o):
53 |
54 | f = torch.cat([f, m, o], 1)
55 |
56 | x = self.conv1(f)
57 | x = self.bn1(x)
58 | x = self.relu(x) # 1/2, 64
59 | x = self.maxpool(x) # 1/4, 64
60 | x = self.layer1(x) # 1/4, 256
61 | x = self.layer2(x) # 1/8, 512
62 | x = self.layer3(x) # 1/16, 1024
63 |
64 | return x
65 |
66 |
67 | class RGBEncoder(nn.Module):
68 | def __init__(self):
69 | super().__init__()
70 | resnet = models.resnet50(pretrained=True)
71 | self.conv1 = resnet.conv1
72 | self.bn1 = resnet.bn1
73 | self.relu = resnet.relu # 1/2, 64
74 | self.maxpool = resnet.maxpool
75 |
76 | self.res2 = resnet.layer1 # 1/4, 256
77 | self.layer2 = resnet.layer2 # 1/8, 512
78 | self.layer3 = resnet.layer3 # 1/16, 1024
79 |
80 | def forward(self, f):
81 | x = self.conv1(f)
82 | x = self.bn1(x)
83 | x = self.relu(x) # 1/2, 64
84 | x = self.maxpool(x) # 1/4, 64
85 | f4 = self.res2(x) # 1/4, 256
86 | f8 = self.layer2(f4) # 1/8, 512
87 | f16 = self.layer3(f8) # 1/16, 1024
88 |
89 | return f16, f8, f4
90 |
91 |
92 | class UpsampleBlock(nn.Module):
93 | def __init__(self, skip_c, up_c, out_c, scale_factor=2):
94 | super().__init__()
95 | self.skip_conv1 = nn.Conv2d(skip_c, up_c, kernel_size=3, padding=1)
96 | self.skip_conv2 = ResBlock(up_c, up_c)
97 | self.out_conv = ResBlock(up_c, out_c)
98 | self.scale_factor = scale_factor
99 |
100 | def forward(self, skip_f, up_f):
101 | x = self.skip_conv2(self.skip_conv1(skip_f))
102 | x = x + F.interpolate(up_f, scale_factor=self.scale_factor, mode='bilinear', align_corners=False)
103 | x = self.out_conv(x)
104 | return x
105 |
106 |
107 | class KeyValue(nn.Module):
108 | def __init__(self, indim, keydim, valdim):
109 | super().__init__()
110 | self.key_proj = nn.Conv2d(indim, keydim, kernel_size=3, padding=1)
111 | self.val_proj = nn.Conv2d(indim, valdim, kernel_size=3, padding=1)
112 |
113 | def forward(self, x):
114 | return self.key_proj(x), self.val_proj(x)
115 |
--------------------------------------------------------------------------------
/model/s2m/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/model/s2m/__init__.py
--------------------------------------------------------------------------------
/model/s2m/s2m_network.py:
--------------------------------------------------------------------------------
1 | # Credit: https://github.com/VainF/DeepLabV3Plus-Pytorch
2 |
3 | from model.s2m.utils import IntermediateLayerGetter
4 | from model.s2m._deeplab import DeepLabHead, DeepLabHeadV3Plus, DeepLabV3
5 | from model.s2m import s2m_resnet
6 |
7 | def _segm_resnet(name, backbone_name, num_classes, output_stride, pretrained_backbone):
8 |
9 | if output_stride==8:
10 | replace_stride_with_dilation=[False, True, True]
11 | aspp_dilate = [12, 24, 36]
12 | else:
13 | replace_stride_with_dilation=[False, False, True]
14 | aspp_dilate = [6, 12, 18]
15 |
16 | backbone = s2m_resnet.__dict__[backbone_name](
17 | pretrained=pretrained_backbone,
18 | replace_stride_with_dilation=replace_stride_with_dilation)
19 |
20 | inplanes = 2048
21 | low_level_planes = 256
22 |
23 | if name=='deeplabv3plus':
24 | return_layers = {'layer4': 'out', 'layer1': 'low_level'}
25 | classifier = DeepLabHeadV3Plus(inplanes, low_level_planes, num_classes, aspp_dilate)
26 | elif name=='deeplabv3':
27 | return_layers = {'layer4': 'out'}
28 | classifier = DeepLabHead(inplanes , num_classes, aspp_dilate)
29 | backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
30 |
31 | model = DeepLabV3(backbone, classifier)
32 | return model
33 |
34 | def _load_model(arch_type, backbone, num_classes, output_stride, pretrained_backbone):
35 |
36 | if backbone.startswith('resnet'):
37 | model = _segm_resnet(arch_type, backbone, num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
38 | else:
39 | raise NotImplementedError
40 | return model
41 |
42 |
43 | # Deeplab v3
44 | def deeplabv3_resnet50(num_classes=1, output_stride=16, pretrained_backbone=False):
45 | """Constructs a DeepLabV3 model with a ResNet-50 backbone.
46 |
47 | Args:
48 | num_classes (int): number of classes.
49 | output_stride (int): output stride for deeplab.
50 | pretrained_backbone (bool): If True, use the pretrained backbone.
51 | """
52 | return _load_model('deeplabv3', 'resnet50', num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
53 |
54 |
55 | # Deeplab v3+
56 | def deeplabv3plus_resnet50(num_classes=1, output_stride=16, pretrained_backbone=False):
57 | """Constructs a DeepLabV3 model with a ResNet-50 backbone.
58 |
59 | Args:
60 | num_classes (int): number of classes.
61 | output_stride (int): output stride for deeplab.
62 | pretrained_backbone (bool): If True, use the pretrained backbone.
63 | """
64 | return _load_model('deeplabv3plus', 'resnet50', num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
65 |
66 |
--------------------------------------------------------------------------------
/model/s2m/utils.py:
--------------------------------------------------------------------------------
1 | # Credit: https://github.com/VainF/DeepLabV3Plus-Pytorch
2 |
3 | import torch
4 | import torch.nn as nn
5 | import numpy as np
6 | import torch.nn.functional as F
7 | from collections import OrderedDict
8 |
9 | class _SimpleSegmentationModel(nn.Module):
10 | def __init__(self, backbone, classifier):
11 | super(_SimpleSegmentationModel, self).__init__()
12 | self.backbone = backbone
13 | self.classifier = classifier
14 |
15 | def forward(self, x):
16 | input_shape = x.shape[-2:]
17 | features = self.backbone(x)
18 | x = self.classifier(features)
19 | x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)
20 | return x
21 |
22 |
23 | class IntermediateLayerGetter(nn.ModuleDict):
24 | """
25 | Module wrapper that returns intermediate layers from a model
26 |
27 | It has a strong assumption that the modules have been registered
28 | into the model in the same order as they are used.
29 | This means that one should **not** reuse the same nn.Module
30 | twice in the forward if you want this to work.
31 |
32 | Additionally, it is only able to query submodules that are directly
33 | assigned to the model. So if `model` is passed, `model.feature1` can
34 | be returned, but not `model.feature1.layer2`.
35 |
36 | Arguments:
37 | model (nn.Module): model on which we will extract the features
38 | return_layers (Dict[name, new_name]): a dict containing the names
39 | of the modules for which the activations will be returned as
40 | the key of the dict, and the value of the dict is the name
41 | of the returned activation (which the user can specify).
42 |
43 | Examples::
44 |
45 | >>> m = torchvision.models.resnet18(pretrained=True)
46 | >>> # extract layer1 and layer3, giving as names `feat1` and feat2`
47 | >>> new_m = torchvision.models._utils.IntermediateLayerGetter(m,
48 | >>> {'layer1': 'feat1', 'layer3': 'feat2'})
49 | >>> out = new_m(torch.rand(1, 3, 224, 224))
50 | >>> print([(k, v.shape) for k, v in out.items()])
51 | >>> [('feat1', torch.Size([1, 64, 56, 56])),
52 | >>> ('feat2', torch.Size([1, 256, 14, 14]))]
53 | """
54 | def __init__(self, model, return_layers):
55 | if not set(return_layers).issubset([name for name, _ in model.named_children()]):
56 | raise ValueError("return_layers are not present in model")
57 |
58 | orig_return_layers = return_layers
59 | return_layers = {k: v for k, v in return_layers.items()}
60 | layers = OrderedDict()
61 | for name, module in model.named_children():
62 | layers[name] = module
63 | if name in return_layers:
64 | del return_layers[name]
65 | if not return_layers:
66 | break
67 |
68 | super(IntermediateLayerGetter, self).__init__(layers)
69 | self.return_layers = orig_return_layers
70 |
71 | def forward(self, x):
72 | out = OrderedDict()
73 | for name, module in self.named_children():
74 | x = module(x)
75 | if name in self.return_layers:
76 | out_name = self.return_layers[name]
77 | out[out_name] = x
78 | return out
79 |
--------------------------------------------------------------------------------
/scripts/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/scripts/__init__.py
--------------------------------------------------------------------------------
/scripts/resize_length.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 | import cv2
4 |
5 | from progressbar import progressbar
6 |
7 | input_dir = sys.argv[1]
8 | output_dir = sys.argv[2]
9 |
10 | # max_length = 500
11 | min_length = 384
12 |
13 | def process_fun():
14 |
15 | for f in progressbar(os.listdir(input_dir)):
16 | img = cv2.imread(os.path.join(input_dir, f))
17 | h, w, _ = img.shape
18 |
19 | # scale = max(h, w) / max_length
20 | scale = min(h, w) / min_length
21 |
22 | img = cv2.resize(img, (int(w/scale), int(h/scale)), interpolation=cv2.INTER_AREA)
23 | cv2.imwrite(os.path.join(output_dir, os.path.basename(f)), img)
24 |
25 | if __name__ == '__main__':
26 |
27 | os.makedirs(output_dir, exist_ok=True)
28 | process_fun()
29 |
30 | print('All done.')
--------------------------------------------------------------------------------
/scripts/resize_youtube.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 | from os import path
4 |
5 | from PIL import Image
6 | import numpy as np
7 | from progressbar import progressbar
8 | from multiprocessing import Pool
9 |
10 | new_min_size = 480
11 |
12 | def resize_vid_jpeg(inputs):
13 | vid_name, folder_path, out_path = inputs
14 |
15 | vid_path = path.join(folder_path, vid_name)
16 | vid_out_path = path.join(out_path, 'JPEGImages', vid_name)
17 | os.makedirs(vid_out_path, exist_ok=True)
18 |
19 | for im_name in os.listdir(vid_path):
20 | hr_im = Image.open(path.join(vid_path, im_name))
21 | w, h = hr_im.size
22 |
23 | ratio = new_min_size / min(w, h)
24 |
25 | lr_im = hr_im.resize((int(w*ratio), int(h*ratio)), Image.BICUBIC)
26 | lr_im.save(path.join(vid_out_path, im_name))
27 |
28 | def resize_vid_anno(inputs):
29 | vid_name, folder_path, out_path = inputs
30 |
31 | vid_path = path.join(folder_path, vid_name)
32 | vid_out_path = path.join(out_path, 'Annotations', vid_name)
33 | os.makedirs(vid_out_path, exist_ok=True)
34 |
35 | for im_name in os.listdir(vid_path):
36 | hr_im = Image.open(path.join(vid_path, im_name)).convert('P')
37 | w, h = hr_im.size
38 |
39 | ratio = new_min_size / min(w, h)
40 |
41 | lr_im = hr_im.resize((int(w*ratio), int(h*ratio)), Image.NEAREST)
42 | lr_im.save(path.join(vid_out_path, im_name))
43 |
44 |
45 | def resize_all(in_path, out_path):
46 | for folder in os.listdir(in_path):
47 |
48 | if folder not in ['JPEGImages', 'Annotations']:
49 | continue
50 | folder_path = path.join(in_path, folder)
51 | videos = os.listdir(folder_path)
52 |
53 | videos = [(v, folder_path, out_path) for v in videos]
54 |
55 | if folder == 'JPEGImages':
56 | print('Processing images')
57 | os.makedirs(path.join(out_path, 'JPEGImages'), exist_ok=True)
58 |
59 | pool = Pool(processes=8)
60 | for _ in progressbar(pool.imap_unordered(resize_vid_jpeg, videos), max_value=len(videos)):
61 | pass
62 | else:
63 | print('Processing annotations')
64 | os.makedirs(path.join(out_path, 'Annotations'), exist_ok=True)
65 |
66 | pool = Pool(processes=8)
67 | for _ in progressbar(pool.imap_unordered(resize_vid_anno, videos), max_value=len(videos)):
68 | pass
69 |
70 |
71 | if __name__ == '__main__':
72 | in_path = sys.argv[1]
73 | out_path = sys.argv[2]
74 |
75 | resize_all(in_path, out_path)
76 |
77 | print('Done.')
--------------------------------------------------------------------------------
/train.py:
--------------------------------------------------------------------------------
1 | import time
2 | from os import path
3 | import datetime
4 | import math
5 |
6 | import random
7 | import numpy as np
8 | import torch
9 | from torch.utils.data import Dataset, DataLoader, ConcatDataset
10 | import torch.multiprocessing as mp
11 | import torch.distributed as distributed
12 |
13 | from model.fusion_model import FusionModel
14 | from dataset.fusion_dataset import FusionDataset
15 |
16 | from util.logger import TensorboardLogger
17 | from util.hyper_para import HyperParameters
18 | from util.load_subset import *
19 |
20 |
21 | """
22 | Initial setup
23 | """
24 | torch.backends.cudnn.benchmark = True
25 |
26 | # Init distributed environment
27 | distributed.init_process_group(backend="nccl")
28 | # Set seed to ensure the same initialization
29 | torch.manual_seed(14159265)
30 | np.random.seed(14159265)
31 | random.seed(14159265)
32 |
33 | print('CUDA Device count: ', torch.cuda.device_count())
34 |
35 | # Parse command line arguments
36 | para = HyperParameters()
37 | para.parse()
38 |
39 | local_rank = torch.distributed.get_rank()
40 | world_size = torch.distributed.get_world_size()
41 | torch.cuda.set_device(local_rank)
42 |
43 | print('I am rank %d in the world of %d!' % (local_rank, world_size))
44 |
45 | """
46 | Model related
47 | """
48 | if local_rank == 0:
49 | # Logging
50 | if para['id'].lower() != 'null':
51 | long_id = '%s_%s' % (datetime.datetime.now().strftime('%b%d_%H.%M.%S'), para['id'])
52 | else:
53 | long_id = None
54 | logger = TensorboardLogger(para['id'], long_id)
55 | logger.log_string('hyperpara', str(para))
56 |
57 | # Construct rank 0 model
58 | model = FusionModel(para, logger=logger,
59 | save_path=path.join('saves', long_id, long_id) if long_id is not None else None,
60 | local_rank=local_rank, world_size=world_size).train()
61 | else:
62 | # Construct models of other ranks
63 | model = FusionModel(para, local_rank=local_rank, world_size=world_size).train()
64 |
65 | # Load pertrained model if needed
66 | if para['load_model'] is not None:
67 | total_iter = model.load_model(para['load_model'])
68 | else:
69 | total_iter = 0
70 |
71 | if para['load_network'] is not None:
72 | model.load_network(para['load_network'])
73 |
74 | """
75 | Dataloader related
76 | """
77 | if para['load_prop'] is None:
78 | print('Fusion module can only be trained with a pre-trained propagation module!')
79 | print('Use --load_prop [model_path]')
80 | raise NotImplementedError
81 | model.load_prop(para['load_prop'])
82 | torch.cuda.empty_cache()
83 |
84 | if para['stage'] == 0:
85 | data_root = path.join(path.expanduser(para['bl_root']))
86 | train_dataset = FusionDataset(path.join(data_root, 'JPEGImages'),
87 | path.join(data_root, 'Annotations'), para['fusion_bl_root'])
88 | elif para['stage'] == 1:
89 | data_root = path.join(path.expanduser(para['davis_root']), '2017', 'trainval')
90 | train_dataset = FusionDataset(path.join(data_root, 'JPEGImages', '480p'),
91 | path.join(data_root, 'Annotations', '480p'), para['fusion_root'])
92 |
93 |
94 | def worker_init_fn(worker_id):
95 | return np.random.seed((torch.initial_seed()%2**31) + worker_id + local_rank*100)
96 | train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset, rank=local_rank, shuffle=True)
97 | train_loader = DataLoader(train_dataset, para['batch_size'], sampler=train_sampler, num_workers=8,
98 | worker_init_fn=worker_init_fn, drop_last=True, pin_memory=True)
99 |
100 | """
101 | Determine current/max epoch
102 | """
103 | start_epoch = total_iter//len(train_loader)
104 | total_epoch = math.ceil(para['iterations']/len(train_loader))
105 | print('Actual training epoch: ', total_epoch)
106 |
107 | """
108 | Starts training
109 | """
110 | # Need this to select random bases in different workers
111 | np.random.seed(np.random.randint(2**30-1) + local_rank*100)
112 | try:
113 | for e in range(start_epoch, total_epoch):
114 | # Crucial for randomness!
115 | train_sampler.set_epoch(e)
116 |
117 | # Train loop
118 | model.train()
119 | for data in train_loader:
120 | model.do_pass(data, total_iter)
121 | total_iter += 1
122 |
123 | if total_iter >= para['iterations']:
124 | break
125 | finally:
126 | if not para['debug'] and model.logger is not None and total_iter > 5000:
127 | model.save(total_iter)
128 | # Clean up
129 | distributed.destroy_process_group()
130 |
131 |
--------------------------------------------------------------------------------
/util/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkchengrex/MiVOS/f2600a6eea8709c7b9f1a7575adc725def680b81/util/__init__.py
--------------------------------------------------------------------------------
/util/cv2palette.py:
--------------------------------------------------------------------------------
1 | import tempfile
2 | from PIL import Image
3 | import cv2
4 | import os
5 |
6 |
7 | # A stupid trick to force palette into cv2
8 | def cv2palette(image, palette):
9 | img_E = Image.fromarray(image)
10 | img_E.putpalette(palette)
11 | with tempfile.TemporaryDirectory() as tmppath:
12 | full_path = os.path.join(tmppath, 'temp.png')
13 | img_E.save(full_path)
14 | image = cv2.imread(full_path)
15 | return image
--------------------------------------------------------------------------------
/util/davis_subset.txt:
--------------------------------------------------------------------------------
1 | bear
2 | bmx-bumps
3 | boat
4 | boxing-fisheye
5 | breakdance-flare
6 | bus
7 | car-turn
8 | cat-girl
9 | classic-car
10 | color-run
11 | crossing
12 | dance-jump
13 | dancing
14 | disc-jockey
15 | dog-agility
16 | dog-gooses
17 | dogs-scale
18 | drift-turn
19 | drone
20 | elephant
21 | flamingo
22 | hike
23 | hockey
24 | horsejump-low
25 | kid-football
26 | kite-walk
27 | koala
28 | lady-running
29 | lindy-hop
30 | longboard
31 | lucia
32 | mallard-fly
33 | mallard-water
34 | miami-surf
35 | motocross-bumps
36 | motorbike
37 | night-race
38 | paragliding
39 | planes-water
40 | rallye
41 | rhino
42 | rollerblade
43 | schoolgirls
44 | scooter-board
45 | scooter-gray
46 | sheep
47 | skate-park
48 | snowboard
49 | soccerball
50 | stroller
51 | stunt
52 | surf
53 | swing
54 | tennis
55 | tractor-sand
56 | train
57 | tuk-tuk
58 | upside-down
59 | varanus-cage
60 | walking
--------------------------------------------------------------------------------
/util/hyper_para.py:
--------------------------------------------------------------------------------
1 | from argparse import ArgumentParser
2 |
3 |
4 | def none_or_default(x, default):
5 | return x if x is not None else default
6 |
7 | class HyperParameters():
8 | def parse(self, unknown_arg_ok=False):
9 | parser = ArgumentParser()
10 |
11 | # Data parameters
12 | parser.add_argument('--yv_root', help='YouTubeVOS data root', default='../YouTube')
13 | parser.add_argument('--davis_root', help='DAVIS data root', default='../DAVIS')
14 | parser.add_argument('--bl_root', default='../BL30K')
15 |
16 | parser.add_argument('--fusion_root', default='../fusion_data/davis')
17 | parser.add_argument('--fusion_bl_root', default='../fusion_data/bl')
18 |
19 | parser.add_argument('--stage', type=int, default=0)
20 |
21 | # Generic learning parameters
22 | parser.add_argument('-i', '--iterations', help='Number of training iterations', default=None, type=int)
23 | parser.add_argument('-b', '--batch_size', help='Batch size', default=12, type=int)
24 | parser.add_argument('--lr', help='Initial learning rate', default=1e-4, type=float)
25 | parser.add_argument('--steps', help='Iteration at which learning rate is decayed by gamma', default=None, type=int, nargs='*')
26 | parser.add_argument('--gamma', help='Gamma used in learning rate decay', default=0.1, type=float)
27 |
28 | # Loading
29 | parser.add_argument('--load_network', help='Path to pretrained network weight only')
30 | parser.add_argument('--load_prop', default='saves/propagation_model.pth')
31 | parser.add_argument('--load_model', help='Path to the model file, including network, optimizer and such')
32 |
33 | # Logging information
34 | parser.add_argument('--id', help='Experiment UNIQUE id, use NULL to disable logging to tensorboard', default='NULL')
35 | parser.add_argument('--debug', help='Debug mode which logs information more often', action='store_true')
36 |
37 | # Multiprocessing parameters
38 | parser.add_argument('--local_rank', default=0, type=int, help='Local rank of this process')
39 |
40 | if unknown_arg_ok:
41 | args, _ = parser.parse_known_args()
42 | self.args = vars(args)
43 | else:
44 | self.args = vars(parser.parse_args())
45 |
46 | # Stage-dependent hyperparameters
47 | # Assign default if not given
48 | if self.args['stage'] == 0:
49 | self.args['iterations'] = none_or_default(self.args['iterations'], 30000)
50 | self.args['steps'] = none_or_default(self.args['steps'], [20000])
51 | elif self.args['stage'] == 1:
52 | self.args['iterations'] = none_or_default(self.args['iterations'], 10000)
53 | self.args['steps'] = none_or_default(self.args['steps'], [7500])
54 |
55 | def __getitem__(self, key):
56 | return self.args[key]
57 |
58 | def __str__(self):
59 | return str(self.args)
60 |
--------------------------------------------------------------------------------
/util/image_saver.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import numpy as np
3 |
4 | import torch
5 | import torchvision.transforms as transforms
6 | from dataset.range_transform import inv_im_trans
7 | from collections import defaultdict
8 |
9 | def tensor_to_numpy(image):
10 | image_np = (image.numpy() * 255).astype('uint8')
11 | return image_np
12 |
13 | def tensor_to_np_float(image):
14 | image_np = image.numpy().astype('float32')
15 | return image_np
16 |
17 | def detach_to_cpu(x):
18 | return x.detach().cpu()
19 |
20 | def transpose_np(x):
21 | return np.transpose(x, [1,2,0])
22 |
23 | def tensor_to_gray_im(x):
24 | x = detach_to_cpu(x)
25 | x = tensor_to_numpy(x)
26 | x = transpose_np(x)
27 | return x
28 |
29 | def tensor_to_im(x):
30 | x = detach_to_cpu(x)
31 | x = inv_im_trans(x).clamp(0, 1)
32 | x = tensor_to_numpy(x)
33 | x = transpose_np(x)
34 | return x
35 |
36 | # Predefined key <-> caption dict
37 | key_captions = {
38 | 'im': 'Image',
39 | 'gt': 'GT',
40 | }
41 |
42 | """
43 | Return an image array with captions
44 | keys in dictionary will be used as caption if not provided
45 | values should contain lists of cv2 images
46 | """
47 | def get_image_array(images, grid_shape, captions={}):
48 | h, w = grid_shape
49 | cate_counts = len(images)
50 | rows_counts = len(next(iter(images.values())))
51 |
52 | font = cv2.FONT_HERSHEY_SIMPLEX
53 |
54 | output_image = np.zeros([w*cate_counts, h*(rows_counts+1), 3], dtype=np.uint8)
55 | col_cnt = 0
56 | for k, v in images.items():
57 |
58 | # Default as key value itself
59 | caption = captions.get(k, k)
60 |
61 | # Handles new line character
62 | dy = 40
63 | for i, line in enumerate(caption.split('\n')):
64 | if h > 200:
65 | cv2.putText(output_image, line, (10, col_cnt*w+100+i*dy),
66 | font, 0.8, (255,255,255), 2, cv2.LINE_AA)
67 | else:
68 | cv2.putText(output_image, line, (10, col_cnt*w+10+i*dy),
69 | font, 0.4, (255,255,255), 1, cv2.LINE_AA)
70 |
71 | # Put images
72 | for row_cnt, img in enumerate(v):
73 | im_shape = img.shape
74 | if len(im_shape) == 2:
75 | img = img[..., np.newaxis]
76 |
77 | img = (img * 255).astype('uint8')
78 |
79 | output_image[(col_cnt+0)*w:(col_cnt+1)*w,
80 | (row_cnt+1)*h:(row_cnt+2)*h, :] = img
81 |
82 | col_cnt += 1
83 |
84 | return output_image
85 |
86 | def base_transform(im, size):
87 | im = tensor_to_np_float(im)
88 | if len(im.shape) == 3:
89 | im = im.transpose((1, 2, 0))
90 | else:
91 | im = im[:, :, None]
92 |
93 | # Resize
94 | if size is not None and im.shape[1] != size:
95 | im = cv2.resize(im, size, interpolation=cv2.INTER_NEAREST)
96 |
97 | return im.clip(0, 1)
98 |
99 | def im_transform(im, size):
100 | return base_transform(inv_im_trans(detach_to_cpu(im)), size=size)
101 |
102 | def mask_transform(mask, size):
103 | return base_transform(detach_to_cpu(mask), size=size)
104 |
105 | def out_transform(mask, size):
106 | return base_transform(detach_to_cpu(torch.sigmoid(mask)), size=size)
107 |
108 | def get_click_points(image, pos_map, neg_map):
109 | image[pos_map<0.02, :] = [0, 1, 0]
110 | image[neg_map<0.02, :] = [1, 0, 0]
111 |
112 | return image
113 |
114 | def get_clicked_torch(image, pos_map, neg_map):
115 | rgb = im_transform(image, None)
116 | pos_map = mask_transform(pos_map, None)[:, :, 0]
117 | neg_map = mask_transform(neg_map, None)[:, :, 0]
118 |
119 | rgb[pos_map<0.02, :] = [0, 1, 0]
120 | rgb[neg_map<0.02, :] = [1, 0, 0]
121 |
122 | return (rgb*255).astype(np.uint8)
123 |
124 | def pool_fusion(images, size):
125 | req_images = defaultdict(list)
126 |
127 | b = images['gt'].shape[0]
128 |
129 | # Save storage
130 | b = max(4, b)
131 |
132 | GT_name = 'GT'
133 |
134 | for b_idx in range(b):
135 | req_images['RGB'].append(im_transform(images['rgb'][b_idx], size))
136 | req_images['S11'].append(mask_transform(images['seg1'][b_idx], size))
137 | req_images['S21'].append(mask_transform(images['seg2'][b_idx], size))
138 | req_images['S12'].append(mask_transform(images['seg12'][b_idx], size))
139 | req_images['S22'].append(mask_transform(images['seg22'][b_idx], size))
140 | req_images['Pos Attn1'].append(mask_transform(images['attn1'][b_idx,0:1], size))
141 | req_images['Neg Attn1'].append(mask_transform(images['attn1'][b_idx,1:2], size))
142 | req_images['Pos Attn2'].append(mask_transform(images['attn2'][b_idx,0:1], size))
143 | req_images['Neg Attn2'].append(mask_transform(images['attn2'][b_idx,1:2], size))
144 |
145 | req_images['MSK1'].append(mask_transform(images['mask'][b_idx,1:2], size))
146 | req_images['MSK2'].append(mask_transform(images['mask'][b_idx,2:3], size))
147 |
148 | req_images[GT_name+'1'].append(mask_transform(images['gt'][b_idx], size))
149 | req_images[GT_name+'2'].append(mask_transform(images['gt2'][b_idx], size))
150 |
151 | return get_image_array(req_images, size, key_captions)
--------------------------------------------------------------------------------
/util/load_subset.py:
--------------------------------------------------------------------------------
1 | def load_sub_davis(path='util/davis_subset.txt'):
2 | with open(path, mode='r') as f:
3 | subset = set(f.read().splitlines())
4 | return subset
5 |
6 | def load_sub_yv(path='util/yv_subset.txt'):
7 | with open(path, mode='r') as f:
8 | subset = set(f.read().splitlines())
9 | return subset
10 |
--------------------------------------------------------------------------------
/util/log_integrator.py:
--------------------------------------------------------------------------------
1 | """
2 | Integrate numerical values for some iterations
3 | Typically used for loss computation / logging to tensorboard
4 | Call finalize and create a new Integrator when you want to display/log
5 | """
6 |
7 | import torch
8 |
9 |
10 | class Integrator:
11 | def __init__(self, logger, distributed=True, local_rank=0, world_size=1):
12 | self.values = {}
13 | self.counts = {}
14 | self.hooks = [] # List is used here to maintain insertion order
15 |
16 | self.logger = logger
17 |
18 | self.distributed = distributed
19 | self.local_rank = local_rank
20 | self.world_size = world_size
21 |
22 | def add_tensor(self, key, tensor):
23 | if key not in self.values:
24 | self.counts[key] = 1
25 | if type(tensor) == float or type(tensor) == int:
26 | self.values[key] = tensor
27 | else:
28 | self.values[key] = tensor.mean().item()
29 | else:
30 | self.counts[key] += 1
31 | if type(tensor) == float or type(tensor) == int:
32 | self.values[key] += tensor
33 | else:
34 | self.values[key] += tensor.mean().item()
35 |
36 | def add_dict(self, tensor_dict):
37 | for k, v in tensor_dict.items():
38 | self.add_tensor(k, v)
39 |
40 | def add_hook(self, hook):
41 | """
42 | Adds a custom hook, i.e. compute new metrics using values in the dict
43 | The hook takes the dict as argument, and returns a (k, v) tuple
44 | e.g. for computing IoU
45 | """
46 | if type(hook) == list:
47 | self.hooks.extend(hook)
48 | else:
49 | self.hooks.append(hook)
50 |
51 | def reset_except_hooks(self):
52 | self.values = {}
53 | self.counts = {}
54 |
55 | # Average and output the metrics
56 | def finalize(self, prefix, it, f=None):
57 |
58 | for hook in self.hooks:
59 | k, v = hook(self.values)
60 | self.add_tensor(k, v)
61 |
62 | for k, v in self.values.items():
63 |
64 | if k[:4] == 'hide':
65 | continue
66 |
67 | avg = v / self.counts[k]
68 |
69 | if self.distributed:
70 | # Inplace operation
71 | avg = torch.tensor(avg).cuda()
72 | torch.distributed.reduce(avg, dst=0)
73 |
74 | if self.local_rank == 0:
75 | avg = (avg/self.world_size).cpu().item()
76 | self.logger.log_metrics(prefix, k, avg, it, f)
77 | else:
78 | # Simple does it
79 | self.logger.log_metrics(prefix, k, avg, it, f)
80 |
81 |
--------------------------------------------------------------------------------
/util/logger.py:
--------------------------------------------------------------------------------
1 | """
2 | Dumps things to tensorboard and console
3 | """
4 |
5 | import os
6 | import warnings
7 | import git
8 |
9 | import torchvision.transforms as transforms
10 | from torch.utils.tensorboard import SummaryWriter
11 |
12 |
13 | def tensor_to_numpy(image):
14 | image_np = (image.numpy() * 255).astype('uint8')
15 | return image_np
16 |
17 | def detach_to_cpu(x):
18 | return x.detach().cpu()
19 |
20 | def fix_width_trunc(x):
21 | return ('{:.9s}'.format('{:0.9f}'.format(x)))
22 |
23 | class TensorboardLogger:
24 | def __init__(self, short_id, id):
25 | self.short_id = short_id
26 | if self.short_id == 'NULL':
27 | self.short_id = 'DEBUG'
28 |
29 | if id is None:
30 | self.no_log = True
31 | warnings.warn('Logging has been disbaled.')
32 | else:
33 | self.no_log = False
34 |
35 | self.inv_im_trans = transforms.Normalize(
36 | mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
37 | std=[1/0.229, 1/0.224, 1/0.225])
38 |
39 | self.inv_seg_trans = transforms.Normalize(
40 | mean=[-0.5/0.5],
41 | std=[1/0.5])
42 |
43 | log_path = os.path.join('.', 'log', '%s' % id)
44 | self.logger = SummaryWriter(log_path)
45 |
46 | repo = git.Repo(".")
47 | self.log_string('git', str(repo.active_branch) + ' ' + str(repo.head.commit.hexsha))
48 |
49 | def log_scalar(self, tag, x, step):
50 | if self.no_log:
51 | warnings.warn('Logging has been disabled.')
52 | return
53 | self.logger.add_scalar(tag, x, step)
54 |
55 | def log_metrics(self, l1_tag, l2_tag, val, step, f=None):
56 | tag = l1_tag + '/' + l2_tag
57 | text = '{:s} - It {:6d} [{:5s}] [{:13}]: {:s}'.format(self.short_id, step, l1_tag.upper(), l2_tag, fix_width_trunc(val))
58 | print(text)
59 | if f is not None:
60 | f.write(text + '\n')
61 | f.flush()
62 | self.log_scalar(tag, val, step)
63 |
64 | def log_im(self, tag, x, step):
65 | if self.no_log:
66 | warnings.warn('Logging has been disabled.')
67 | return
68 | x = detach_to_cpu(x)
69 | x = self.inv_im_trans(x)
70 | x = tensor_to_numpy(x)
71 | self.logger.add_image(tag, x, step)
72 |
73 | def log_cv2(self, tag, x, step):
74 | if self.no_log:
75 | warnings.warn('Logging has been disabled.')
76 | return
77 | x = x.transpose((2, 0, 1))
78 | self.logger.add_image(tag, x, step)
79 |
80 | def log_seg(self, tag, x, step):
81 | if self.no_log:
82 | warnings.warn('Logging has been disabled.')
83 | return
84 | x = detach_to_cpu(x)
85 | x = self.inv_seg_trans(x)
86 | x = tensor_to_numpy(x)
87 | self.logger.add_image(tag, x, step)
88 |
89 | def log_gray(self, tag, x, step):
90 | if self.no_log:
91 | warnings.warn('Logging has been disabled.')
92 | return
93 | x = detach_to_cpu(x)
94 | x = tensor_to_numpy(x)
95 | self.logger.add_image(tag, x, step)
96 |
97 | def log_string(self, tag, x):
98 | print(tag, x)
99 | if self.no_log:
100 | warnings.warn('Logging has been disabled.')
101 | return
102 | self.logger.add_text(tag, x)
103 |
--------------------------------------------------------------------------------
/util/palette.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | def get_color_map(N=256):
4 | def bitget(byteval, idx):
5 | return ((byteval & (1 << idx)) != 0)
6 |
7 | cmap = np.zeros((N, 3), dtype=np.uint8)
8 | for i in range(N):
9 | r = g = b = 0
10 | c = i
11 | for j in range(8):
12 | r = r | (bitget(c, 0) << 7-j)
13 | g = g | (bitget(c, 1) << 7-j)
14 | b = b | (bitget(c, 2) << 7-j)
15 | c = c >> 3
16 |
17 | cmap[i] = np.array([r, g, b])
18 |
19 | return cmap
20 |
21 | color_map = get_color_map()
22 | def pal_color_map():
23 | return color_map
--------------------------------------------------------------------------------
/util/tensor_util.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 | import numpy as np
4 |
5 | def compute_tensor_iu(seg, gt):
6 | intersection = (seg & gt).float().sum()
7 | union = (seg | gt).float().sum()
8 |
9 | return intersection, union
10 |
11 | def compute_np_iu(seg, gt):
12 | intersection = (seg & gt).astype(np.float32).sum()
13 | union = (seg | gt).astype(np.float32).sum()
14 |
15 | return intersection, union
16 |
17 | def compute_tensor_iou(seg, gt):
18 | intersection, union = compute_tensor_iu(seg, gt)
19 | iou = (intersection + 1e-6) / (union + 1e-6)
20 |
21 | return iou
22 |
23 | def compute_np_iou(seg, gt):
24 | intersection, union = compute_np_iu(seg, gt)
25 | iou = (intersection + 1e-6) / (union + 1e-6)
26 |
27 | return iou
28 |
29 | def compute_multi_class_iou(seg, gt):
30 | # seg -> k*h*w
31 | # gt -> k*1*h*w
32 | num_classes = gt.shape[0]
33 | pred_idx = torch.argmax(seg, dim=0)
34 | iou_sum = 0
35 | for ki in range(num_classes):
36 | # seg includes BG class
37 | iou_sum += compute_tensor_iou(pred_idx==(ki+1), gt[ki,0]>0.5)
38 |
39 | return (iou_sum+1e-6)/(num_classes+1e-6)
40 |
41 | def compute_multi_class_iou_idx(seg, gt):
42 | # seg -> h*w
43 | # gt -> k*h*w
44 | num_classes = gt.shape[0]
45 | iou_sum = 0
46 | for ki in range(num_classes):
47 | # seg includes BG class
48 | iou_sum += compute_np_iou(seg==(ki+1), gt[ki]>0.5)
49 |
50 | return (iou_sum+1e-6)/(num_classes+1e-6)
51 |
52 | def compute_multi_class_iou_both_idx(seg, gt):
53 | # seg -> h*w
54 | # gt -> h*w
55 | num_classes = gt.max()
56 | iou_sum = 0
57 | for ki in range(1, num_classes+1):
58 | iou_sum += compute_np_iou(seg==ki, gt==ki)
59 | return (iou_sum+1e-6)/(num_classes+1e-6)
60 |
61 | # STM
62 | def pad_divide_by(in_img, d, in_size=None):
63 | if in_size is None:
64 | h, w = in_img.shape[-2:]
65 | else:
66 | h, w = in_size
67 |
68 | if h % d > 0:
69 | new_h = h + d - h % d
70 | else:
71 | new_h = h
72 | if w % d > 0:
73 | new_w = w + d - w % d
74 | else:
75 | new_w = w
76 | lh, uh = int((new_h-h) / 2), int(new_h-h) - int((new_h-h) / 2)
77 | lw, uw = int((new_w-w) / 2), int(new_w-w) - int((new_w-w) / 2)
78 | pad_array = (int(lw), int(uw), int(lh), int(uh))
79 | out = F.pad(in_img, pad_array)
80 | return out, pad_array
81 |
82 | def unpad(img, pad):
83 | if pad[2]+pad[3] > 0:
84 | img = img[:,:,pad[2]:-pad[3],:]
85 | if pad[0]+pad[1] > 0:
86 | img = img[:,:,:,pad[0]:-pad[1]]
87 | return img
88 |
89 | def unpad_3dim(img, pad):
90 | if pad[2]+pad[3] > 0:
91 | img = img[:,pad[2]:-pad[3],:]
92 | if pad[0]+pad[1] > 0:
93 | img = img[:,:,pad[0]:-pad[1]]
94 | return img
--------------------------------------------------------------------------------