31 |
--------------------------------------------------------------------------------
/_posts/2015-11-28-elasticsearch-ve-gelistirme-araclari-part-1.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Elasticsearch ve Geliştirme Araçları - Part 1
4 | categories:
5 | - blog
6 | summary: Elasticsearch nedir? Nasıl hızlıca nasıl giriş yapabilirsiniz? Plugin nedir? Başlangıç için hangi plugin'leri kullanabilirsiniz? Geliştirme ortamı için neler gerekli?
7 | ---
8 |
9 | Elasticsearch'e yeni başlayanlar için hızlı ve rahat bir başlangıç yapmalarını
10 | sağlayacak araçlardan biraz bahsetmek istiyorum ve bu arada da kısaca
11 | Elasticsearch (ES kısaltması ile devam edeceğim) hakkında bilgi vermeye
12 | çalışacağım.
13 |
14 | [Elasticsearch](https://en.wikipedia.org/wiki/Elasticsearch) wikipedia'da
15 | bahsedildiği üzere [Lucene](https://lucene.apache.org/core/) tabanlı bir arama
16 | sunucusudur. Genel bilinmesi gerekenler:
17 |
18 | - Full-text arama yapabilmenizi sağlar
19 | - Java ile geliştirilmiştir.
20 | - Apache Lisansı ile yayınlanmıştır.
21 | - Apache Solr'dan sonra gelen ikinci en populer arama motorudur.
22 | [1](http://db-engines.com/en/ranking/search+engine)
23 |
24 | Elasticsearch kurulumu ve çalıştırılması hakkında
25 | [buradan](https://www.elastic.co/downloads/elasticsearch) bilgi alabilirsiniz.
26 | Ben genel olarak kurulumdan bahsetmeyeceğim. Elimden geldiğince ES'i daha
27 | hızlı nasıl öğrenirsiniz ve çalışma ortamınızı nasıl hızlıca kurabilirsiniz
28 | bundan bahsedeceğim.
29 |
30 | Elasticsearch'de verilerin tutulduğu [index](https://www.elastic.co/blog/what-is-an-elasticsearch-index)'ler
31 | vardır. Bunları ilişkili bir veritabanındaki `database`ler gibi düşünebilirsiniz.
32 | Indexler içerisinde farklı tipteki verileri tutabilmeniz için `type` kavramı
33 | vardır bunu da tablolar gibi düşünebilirsiniz. Aralarındaki ilişkiyi daha rahat
34 | anlamak için aşağıdaki açıklamaya bakabilirsiniz.
35 |
36 | ```
37 | MySQL => Databases => Tables => Columns/Rows
38 | Elasticsearch => Indices => Types => Documents with Properties
39 | ```
40 |
41 | Şimdi ES'i [şu](https://www.elastic.co/downloads/elasticsearch) adresteki
42 | açıklamalar ışığında kuralım ve çalıştıralım. Burada ES'in default ayarlarını
43 | kullanabilirsiniz. Normalde production sunucusuna kurulum yapmıyorsanız default
44 | ayarlarda kullanmanız bir sakınca yaratmaz. İlerleyen yazılarımızda ES'i daha verimli
45 | nasıl kullanırsınız ve yüksek erişilebilir hale nasıl getirirsiniz ya da ileri seviye
46 | ayarlamaları konfigürasyonları nelerdir bunlardan bahsedeceğiz. Şimdi, ilk olarak
47 | çalışma ortamını ayarlamak için bir iki eklenti ve bir de Chrome Plugin'i
48 | kuracağız.
49 |
50 | Eklentilerden başlayacak olursak, [head](https://github.com/mobz/elasticsearch-head)
51 | eklentisi Elasticsearch'ün API arayüzüne rahatça kullanabilmenizi sağlar. Bu
52 | eklenti ile index'leri type'ları rahatça görebilirsiniz. MySQL'in PhpMyAdmin'i
53 | ile aynı görevi görüyor diyebiliriz. Bu eklenti ile index'lerinizi rahatça
54 | yönetebilirsiniz.
55 |
56 | İkinci eklentimiz olan [inquisitor](https://github.com/polyfractal/elasticsearch-inquisitor)
57 | eklentisi ile sorgularınızı debug edebilir ve anlamaya çalışabilirsiniz. Bu
58 | eklenti ile oluşturmuş olduğunuz analyzer'larınızı kolayca debug edebilirsiniz
59 | ve nasıl çalıştığını görebilirsiniz. Burada doğal olarak analyzer ne sorusu
60 | geliyordur aklınıza. [Analyzer](https://www.elastic.co/guide/en/elasticsearch/reference/1.4/analysis-analyzers.html)'lar
61 | [Tokenizer](https://www.elastic.co/guide/en/elasticsearch/reference/1.4/analysis-tokenizers.html)
62 | ve [TokenFilter](https://www.elastic.co/guide/en/elasticsearch/reference/1.4/analysis-tokenfilters.html)'lardan
63 | oluşurlar. Tokenizer kavramını kısaca anlatacak olursak, verilen bir string'i daha
64 | küçük parçalara ayırma işlemini yaparlar. TokenFilter'lar ise bu parçaları bir
65 | filtreden geçirirler. Böylelikle Analyzer'lar ile ES'de tuttuğunuz verileriniz
66 | bir takım işlemlerden geçirerek arama yapılabilir bir halde hazırda bekletiyor
67 | olacaksınız. Bu konuya daha ilerde ayrı bir yazıda bahsetmeyi düşünüyorum. Şimdilik
68 | böyle bir şeyin olduğunu ve ileride kullanacağınızı bilmeniz yeterli.
69 |
70 | Bunlar dışında bir çok eklenti mevcut. Hepsinden bahsedemeyeceğim ama zamanı
71 | geldikçe eklentiler hakkında kısaca bilgi vermeye çalışacağım.
72 |
73 | Şimdi development ortamımızı şenlendirecek Chrome Eklentimize.
74 | [Sense](https://www.elastic.co/blog/found-sense-a-cool-json-aware-interface-to-elasticsearch)
75 | eklentisi ile ES sorgularını hızlı ve rahat bir şekilde çalıştırabilirsiniz.
76 | Aşağıda bir dizi komut yazacağım ve Sense eklentisi ile hızlıca deneyebileceksiniz.
77 | Sense ile sorgu çalıştırmak için aşağıdaki formatta bir sorgu yapmamız gerekiyor.
78 |
79 | ```json
80 | METHOD /es/paths
81 | {
82 | "JSON" : "DATA"
83 | }
84 | ```
85 |
86 | Bu sorgu formatında METHOD isteğin metodunu belirlemektedir. GET, POST, DELETE, ...
87 | gibi methodlar ile ES'e sorgu atabileceğiz. `/es/paths` kısmı ise ES'de sorgu
88 | yapacağınız index, type'ı belirlemek için kullanılan bir URL. Geri kalan kısmı ise
89 | veri kısmı. Bundan sonraki yazılarımızda sorguları bu formatta yazacağımız için
90 | çabuk ısınacağınıza inanıyorum.
91 |
92 | Aşağıda Sense ile çalıştırabileceğiniz bir kaç komut dizisi oluşturdum. Bunlar
93 | üzerinden giderek kısaca başlangıç yapabilirsiniz.
94 |
95 | Yeni bir index oluşturmak.
96 |
97 | ```
98 | POST /test-index
99 | ```
100 |
101 | Yeni bir döküman oluşturmak.
102 |
103 | ```json
104 | POST /test-index/test/1
105 | {
106 | "id": 1,
107 | "name": "haydar külekci"
108 | }
109 | ```
110 |
111 | Yeni bir döküman oluşturmak
112 |
113 | ```json
114 | POST /test-index/test/2
115 | {
116 | "id": 1,
117 | "name": "Test Name"
118 | }
119 | ```
120 |
121 | Type Mapping Bilgilerini Getirmek
122 |
123 | ```
124 | GET /test-index/test/_mapping
125 | ```
126 |
127 | Oluşturulmuş bir dökümanı getirmek
128 |
129 | ```
130 | GET /test-index/test/1
131 | ```
132 |
133 | Arama yapmak:
134 |
135 | ```json
136 | GET /test-index/test/_search
137 | {
138 | "query": {
139 | "match_all": {}
140 | }
141 | }
142 | ```
143 |
144 |
145 |
146 | Bağlantılar
147 |
148 | - [https://www.elastic.co/blog/what-is-an-elasticsearch-index](https://www.elastic.co/blog/what-is-an-elasticsearch-index)
149 | - [https://lucene.apache.org/core/](https://lucene.apache.org/core/)
150 | - [https://en.wikipedia.org/wiki/Elasticsearch](https://en.wikipedia.org/wiki/Elasticsearch)
151 |
152 | Diğer Bazı Eklentiler
153 |
154 | - [ICU Analysis plugin for Elasticsearch](https://github.com/elastic/elasticsearch-analysis-icu)
155 | - [ElasticSearch analysis plugin providing Turkish stemming functionality](https://github.com/skroutz/elasticsearch-analysis-turkishstemmer/)
156 | - [Web admin interface for elasticsearch](https://github.com/lmenezes/elasticsearch-kopf)
157 |
--------------------------------------------------------------------------------
/_posts/2015-11-29-elasticsearch-index-olusturmak.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Elasticsearch Index Oluşturmak
4 | categories:
5 | - blog
6 | summary: Elasticsearch'de index nedir ve nasıl oluşturulur? Index `settings` nedir ve nasıl kullanılır? `Analyzer` nedir, nasıl oluşturulur.
7 | ---
8 |
9 | Elasticsearch arama motoru hakkında bir önceki yazımda kullanabileceğiniz
10 | araçlar, eklentiler ve kullanımları hakkında kısa bir önbilgi vermiştim. Bu
11 | yazımda ise nasıl index oluşturacağız, mapping nedir ve nasıl oluşturabiliriz,
12 | bir index'in ne gibi özellikleri vardır, gibi sorulara cevap vermeye çalışacağım.
13 |
14 | Index daha önceki yazımda da bahsettiğim gibi verilerin tutulduğu
15 | veritabanlarıdır. Index'leri iki şekilde oluşturabilirsiniz. Birincisi otomatik
16 | oluşturma yöntemi diğeri ise manuel index oluşturma yöntemidir. Bu
17 | yöntemleri sırayla örneklemeye çalışayım.
18 |
19 | Elasticsearch API arayüzünde `create` işlemleri için `POST` metodu kullanılır.
20 | Bir index oluşturmak için de `POST` metodunu kullanıyoruz. Aşağıdaki gibi
21 | bir komut ile Sense arayüzünden `users` adında test bir index oluşturalım.
22 |
23 | ```
24 | POST /users
25 | ```
26 |
27 | Bu yöntem 1. yöntem olsun. Index oluşturmak için çeşitli yollar vardır.
28 | Örneğin siz veri oluşturmak için aşağıdaki sorguyu çalıştırdığınızda da bir
29 | `users` index'i oluşacaktır.
30 |
31 | ```json
32 | POST /users/user/1
33 | {
34 | "name":"Haydar"
35 | }
36 | ```
37 |
38 | Bu yönteme de 2. yöntem diyelim. Bu yöntem ile index oluşturulduğunda
39 | aynı zamanda bir kullanıcı da oluşacaktır ve sonuç olarak aşağıdaki gibi bir
40 | cevap dönecektir.
41 |
42 | ```json
43 | {
44 | "_index": "users",
45 | "_type": "user",
46 | "_id": "1",
47 | "_version": 1,
48 | "created": true
49 | }
50 | ```
51 | Burada iki yöntemde de index oluşacaktır. Ancak ikinci yöntem diğerine göre
52 | biraz daha sakıncalı bir yöntemdir. Bunun sakıncalarına daha ilerde
53 | değineceğiz. Şimdi oluşturduğumuz index'e bir göz atalım.
54 |
55 | ```
56 | GET /users
57 | ```
58 |
59 | Bu komutu Sense arayüzünden çalıştırdığımda eğer index'i birinci yöntem ile
60 | oluşturursam `mappings` alanı boş gelecektir. Ancak eğer ikinci yöntem ile
61 | kullanılmış olsaydı aşağıdaki gibi olacaktı. Burada ikinci yöntemde aslında biz
62 | bir veri oluşturmaya çalışıyoruz. Eğer index yok ise ES o index'i otomatik
63 | oluşturuyor. Bu sırada veri oluşturma işinide yaptığımız için index'in ve
64 | mapping'i (yani veriyi tutma şeklinide) otomatik oluşturmuş oluyoruz. Mapping
65 | mapping verinin yapısını belirler. Eğer biz bunu kendimiz belirlemez ise ES
66 | otomatik yapacaktır.
67 |
68 | ```json
69 | {
70 | "index-name": {
71 | "aliases": {},
72 | "mappings": {
73 | "user": {
74 | "properties": {
75 | "name": {
76 | "type": "string"
77 | }
78 | }
79 | }
80 | },
81 | "settings": {
82 | "index": {
83 | "creation_date": "1447004861339",
84 | "uuid": "KzZW7zJyTPavy4n1TTeNkg",
85 | "number_of_replicas": "1",
86 | "number_of_shards": "5",
87 | "version": {
88 | "created": "1070399"
89 | }
90 | }
91 | },
92 | "warmers": {}
93 | }
94 | }
95 | ```
96 |
97 | Bu yanıttan anlaşılacağı üzere index'leri oluşturan şeyler `mappings`,
98 | `settings`, `warmers` ve `aliases`lardan oluşur. Bunların hepsinden bu yazımda
99 | tabiki bahsedemeyeceğim. Ancak sadece kısaca ne işe yaradıklarından
100 | bahsedeceğim.
101 |
102 | `aliases` kısmında index'inize verdiğiniz takma isimler listelenmektedir. Bu
103 | isimlendirme yöntemi sizi uygulama katmanındaki index'e erişiminiz çok
104 | kolaylaştıracak bir özelliktir. Bu konu hakkında ayrı bir yazıda özellikle
105 | değineceğim. Uygulamanın kesinti yaşamadan index değiştirebilmesi için
106 | çok güzel bir özelliktir.
107 |
108 | `mappings` kısmında ise index'in içerisinde saklanacak verinin yapısı
109 | tutulmaktadır. Ben bunu tabloların yapılarına benzetiyorum. Tabiki aklınızdan
110 | NoSQL veritabanında yapıya ne gerek var. Zaten JSON tutulmuyor mu diye
111 | düşünebilirsiniz. Ancak performans açısından bazı verilerin belirli bir yapıda
112 | kaydedilmesi daha hızlı sonuç dönebilmenize olanak sağlamaktadır. Özellikle
113 | üzerinde arama yapacağınız alanların ell belirlenmesi çok daha iyi sonuçlar
114 | doğuracaktır. Arama yapmayacağınız alanları ise arama yapmayacağım diye
115 | belirtmeniz aramalarınız hızlandıracaktır.
116 |
117 | `settings` kısmında ise index ile ilgili olarak ayarlamalar tutulmaktadır. Örneğin
118 | bu index kaç shard olacaktır ve replica sayısı ne olacaktır. Bunlar dışında
119 | `analyzer` bilgileri de index'lerin `settings`leri içerisinde tutulmaktadır.
120 |
121 | Genel olarak index'lerin yapısını inceledik. Şimdi farklı şekillerde index'ler
122 | oluşturarak daha iyi pekiştirmeye çalışalım. Örneğin aşağıda 2 shard ve
123 | 2 replica ile bir index oluşturalım.
124 |
125 | ```json
126 | POST /index-name
127 | {
128 | "settings": {
129 | "index": {
130 | "number_of_replicas": "2",
131 | "number_of_shards": "2"
132 | }
133 | }
134 | }
135 | ```
136 |
137 | Yukarıdaki sorguyu Sense ile çalıştırdığınızda index oluşacaktır ve bu index'deki
138 | veriler 2 shard ile bölünecektir. Aynı zamanda 2 makinede replica'ları oluşacaktır.
139 | Burada tabiki iki makineniz var ise. Eğer bu ayarları vermez iseniz Elasticsearch
140 | varsayılan ayarları kullanacaktır ve 5 shard 1 replica ile bir index oluşturacaktır.
141 |
142 | Varsayılan ayarlarınızı elasticsearch'ün config klasöründeki `yaml` dosyalarından
143 | değiştirebilirsiniz. Elasticsearch dizininde `config` klasörü altında `elasticsearch.yml`
144 | ve `logging.yml` dosyaları bulunmaktadır. Adlarından da anlaşılacağı gibi
145 | loglama ayarları için `logging.yml` dosyasını Elasticsearch'in genel ayarları için
146 | `elasticsearch.yml` dosyasını kullanabilirsiniz. Ayarlar klasörü için yine ayrı bir
147 | yazımda değineceğim. Ayarların tümüne zaten bir yazıda değinmek çok yetersiz
148 | olur. Buradaki ayarlamalar ile çok daha performanslı bir yapı kurabilirsiniz ya da
149 | yanlış kullanım nedeniyle performansınızı tamamen kaybedebilirsiniz.
150 |
151 | Sağlıcakla.
152 |
--------------------------------------------------------------------------------
/_posts/2015-12-04-elasticsearch-type-and-mapping.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Elasticsearch Type ve Mapping
4 | categories:
5 | - blog
6 | summary: Elasticsearch'de `type`ın ne olduğunu ve nasıl oluşturabilsiniz? `Type`ı ne için kullanabilirsiniz? `Type Mapping` nedir ve ne için kullanılır?
7 | ---
8 |
9 | Elasticsearch'te `type` benzer dökümanlar sınıfıdır. Örneğin `users` adında bir index'iniz
10 | var. Bu index içerisinde `user` diye bir `type` oluşturabilirsiniz. Ya da kullanıcı role'lerine
11 | göre `type`'lar oluşturabilirsiniz. `admin`, `user`, `staff` gibi.
12 |
13 | Elasticsearch `mapping` kavramı daha önceden de belirttiğim üzere verinin yapısıdır.
14 | Veritabanı şeması gibi düşünün. Verilerinizin hangi alanlardan oluştuğunu ve bu
15 | alanların tiplerinin ve özelliklerinin neler olduğunu belirtirler. Hangi alanların `index`e
16 | alınacağı ya da hangi alanların Lucene'de tutulacağını belirler.
17 |
18 | Elasticsearch daha önceden belirttiğimiz üzere Lucene tabanlıdır. Peki Lucene
19 | Elasticsearch üzerinden gönderdiğimiz dökümanları nasıl görür ve nasıl saklar.
20 |
21 | Lucene'de bir döküman basit `field-value` (`alan-değer`) çiftlerini içerir. Bir alanın en az
22 | bir değeri ya da birden fazla değeri olmalıdır. Bazen, tek bir `string` değer analiz
23 | işlemleri sonunda birden fazla değere dönüşebilir. Bazen de uzun bir `string` değeri
24 | analizler sonucunda kısa bir string değerine dönüşebilir. Bunu örneklemek gerekirse
25 |
26 | ```json
27 | {
28 | "title": "Örnek bir başlık"
29 | }
30 | ```
31 |
32 | değeri bazı analizler sonunda aşağıdak gibi
33 |
34 | ```json
35 | {
36 | "title": {
37 | "original": "Örnek bir başlık",
38 | "filtered": "Ornek bir baslik"
39 | }
40 | }
41 | ```
42 |
43 | bir hal almış olabilir. Lucene değerin `string` ya da sayı ya da tarih formatında olmasını
44 | önemsemez. Tüm değerler `opaque bytes` olarak kabul edilir.
45 |
46 | Lucene'de biz bir dökümanı `index`lediğimizde her bir alan (field) için değerler (values) ilgili
47 | alan için `inverted index`e eklenir. İsteğe bağlı olarak, orjinal değerler sonradan ulaşılabilir
48 | olması için değişmeden de saklanabilir.
49 |
50 | Lucene'de şimdiye kadar her seferinde `field-value` tutulur diye konuştuk ve `type`dan hiç
51 | bahsetmedik. Peki, `Lucene`de bütün veriler `field-value` tutulurken Elasticsearch'deki
52 | `type` kavramı nasıl uygulanır? `Type`ların Lucene tarafında direk olarak bir karşılığı
53 | yoktur. Elasticsearch tarafında ise bir `index`te birden fazla `type` ve bunların her birinin
54 | kendi yapıları (mapping) vardır. Lucene tarafında bu veriler her bir dokümanın
55 | `meta data`sında `_type` diye bir alanında tutulur. Biz özel bir type'a göre bir arama
56 | yaptığımızda Lucene tarafında `_type` alanında bir filtreleme yapar.
57 |
58 | Lucene'de aynı zamanda `mapping` diye bir kavramda yoktur. `Mapping`ler Elasticsearch'ün
59 | karışık JSON dökümanlarını Lucene'in beklediği bir yapıya sokmak için kullandığı bir ara
60 | katmandır.
61 |
62 | Burada dikkat edilmesi gereken konu şudur. Biz Elasticsearch'de verileri `type`lara ayırdık
63 | gibi düşünsekte temelde o veriler Lucene'de aynı yerde tutulmaktadır. Bu da aynı index
64 | içerisinde aynı alan (field) adı ile farklı türde ya da farklı analiz edilmiş veriler tutmak
65 | ileride başımızı ağrıtabilir.
66 |
67 | Burana çıkacak sorunları [azaltmak](https://www.elastic.co/guide/en/elasticsearch/guide/current/mapping.html#_avoiding_type_gotchas)
68 | için bu tür verileri farklı alan isimleri ile ya da farklı indexlerde tanımlayarak sorunları
69 | çözebilirsiniz.
70 |
71 | Örneğin, kullanıcı ve şirket bilgileri tuttuğunuz bir Elasticsearch node'unuz olsun. Burada
72 | bilgileri bir index altında `type`lar ile tutabilirsiniz.
73 |
74 | ```json
75 | POST /core/user/_mapping
76 | {
77 | "properties": {
78 | "id": {
79 | "type": "integer"
80 | },
81 | "name": {
82 | "type": "string"
83 | }
84 | }
85 | }
86 |
87 | POST /core/company/_mapping
88 | {
89 | "properties": {
90 | "id": {
91 | "type": "integer"
92 | },
93 | "name": {
94 | "type": "string"
95 | },
96 | "description": {
97 | "type": "string"
98 | }
99 | }
100 | }
101 | ```
102 |
103 | Gördüğünüz gibi `name` ve `id` alanları aynı. Eğer index'imiz bu şekilde olacaksa bir sorun ile
104 | karşılaşmayabilirsiniz. Ancak ileride şirket isimleri için bir analiz işlemi uygulayarak aramalarda
105 | data doğru sonuç vermesini isteyebilirsiniz. Bu durumda bir `type`da bir analiz işlemi çalışırken
106 | diğerinde başka bir analiz işlemi çalışacaktır. Aramalarda bir karmaşa oluşacaktır. Bu iki `type`ı
107 | ayrı index'ler olarak ayırmak daha mantıklı olacaktır. Ya da name alanlarını `user_name` ve
108 | `company_name` olarak değiştirmekte bir çözüm olacaktır. Böylelikle filtreleme yaparken
109 | bu alanlarda karışıklık olmayacaktır.
110 |
111 | #### Kaynakça
112 |
113 | - [Elasticsearch - Mapping](https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping.html)
114 | - [Elasticsearch - Mapping Intro](https://www.elastic.co/guide/en/elasticsearch/guide/current/mapping-intro.html)
115 | - [Types and Mappings](https://www.elastic.co/guide/en/elasticsearch/guide/current/mapping.html)
116 |
--------------------------------------------------------------------------------
/_posts/2015-12-06-mapping-nedir.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Mapping Nedir?
4 | categories:
5 | - blog
6 | summary: Mapping nedir? Nasıl oluşturulur? Nasıl değiştirilir? Nasıl çalışır?
7 | ---
8 |
9 | Bir önceki yazımda daha çok `Type` kavramından bahsetmiştim. `Mapping` hakkında da
10 | kısa bir kaç cümle söylemiştim. Elasticsearch'de `mapping` verilerin index'lerde nasıl
11 | tutulacağını belirleyen yapılarıdır. Normalde Lucene'de `mapping` yapısı yoktur. Lucene'de
12 | veriler `field-value` olarak tutulur ve değerlerin sayı, `string` ya da tarih mi olduğunu
13 | önemsemez. Tüm değerler `opaque byte`lar halinde tutulur.
14 |
15 | Elasticsearch'ün en güzel özelliklerinden birisi hızlıca verilerini oluşturabilrmenizi ve
16 | erişebilmenizi sağlar. Bir dökümanı index'lemek için bir index oluşturmanıza ya da bir
17 | `mapping type` belirlemenize, alanlarınızı tanımlamanıza gerek yoktur.
18 |
19 | ```json
20 | PUT core_index/user/1
21 | {
22 | "name": "Haydar KULEKCI",
23 | "age" : 1
24 | }
25 | ```
26 |
27 | ES otomatik olarak anlayacaktır ve bir index bir `type` ve alanlarınız otomatik olarak
28 | tiplerinize göre oluşturacaktır. Yukarıdaki sorguyu çalıştırdığınızda aşağıdaki gibi bir
29 | mapping otomatik olarak oluşacaktır.
30 |
31 | ```json
32 | {
33 | "core_index": {
34 | "mappings": {
35 | "user": {
36 | "properties": {
37 | "age": {
38 | "type": "long"
39 | },
40 | "name": {
41 | "type": "string"
42 | }
43 | }
44 | }
45 | }
46 | }
47 | }
48 | ```
49 |
50 | Gördüğünüz gbi `name` alanı `string` olarak `age` alanı da `long` olarak tanımlandı.
51 | ES'de yeni bir veriyi içeri almak aslında bu kadar kolay. İşler her zaman ub kadar da
52 | kolay olmayabiliyor. Bazı veriler sayı gelse dahi string olarak tutmamız gerekebilir.
53 | Ya da ilk değer sayı denk gelen bir index oluşturmuş olabiliriz. Ilk olarak `long` olarak
54 | otomatik oluşturulmuş alana daha sonrasında `string` geldiğinde sıkıntı yaşayabiliriz.
55 |
56 | Her bir index'te bir veya daha fazla `type` vardır. Bu `type`lar index'leri belirli gruplara
57 | böler. Her bir `type`'daki dökümanlarda dökümanı ilişkilendirmek için kullanılan
58 | `_index`, `_type`, `_id` ve `_source` gibi `meta` alanlar(field) vardır. Bunlar dışında
59 | kendi belirleyeceğiniz alanlarınız yani `properties`ler vardır.
60 |
61 | Daha iyi anlamak için bir örnek belirleyelim ve bunun üzerinden devam edelim. Aşağıda
62 | aynı index içerisinde iki `type` tanımlayalım ve bunların `mapping` bilgilerini yani index'te
63 | verilerin nasıl tutulacağını biz belirleyelim.
64 |
65 | ```json
66 | POST core_index
67 | {
68 | "index": {
69 | "number_of_replicas": "1",
70 | "number_of_shards": "2"
71 | },
72 | "mappings": {
73 | "user": {
74 | "_all": {
75 | "enabled": false
76 | },
77 | "properties": {
78 | "title": {
79 | "type": "string"
80 | },
81 | "name": {
82 | "type": "string"
83 | },
84 | "age": {
85 | "type": "integer"
86 | }
87 | }
88 | },
89 | "post": {
90 | "properties": {
91 | "title": {
92 | "type": "string"
93 | },
94 | "body": {
95 | "type": "string"
96 | },
97 | "user_id": {
98 | "type": "string",
99 | "index": "not_analyzed"
100 | },
101 | "created": {
102 | "type": "date"
103 | }
104 | }
105 | }
106 | }
107 | }
108 | ```
109 |
110 | Yukarıdaki index'i oluştururken görüldüğü üzere `user` ve `post` adında iki tane `type`
111 | oluşturuyoruz ve `mapping` bilgilerini yazıyoruz. `Type`larda alanları `properties` alanı
112 | altında belirtiyoruz. `Properties` altındaki yapı aşağıdaki gibidir:
113 |
114 | ```
115 | "field-name": {
116 | "type": "type-name",
117 | "other-attribute-name": "value"
118 | },
119 | ```
120 |
121 | `field-name` kısmını siz alana vereceğiniz ismi yazıyorsunuz ve `type-name` kısmına da o
122 | alanın tipini yazıyorsunuz. Yukarıda göreceğiniz gibi `user` `type`'ı için `title`, `name`, `age`
123 | alanları var ve sırasıyla `string`, `string` ve `integer` tipinde. Aynı index'teki `post` `type`ınde
124 | ise `title`, `body`, `user_id` ve `created` alanları bulunuyor ve bu alanlar sırasıyla `string`,
125 | `string`, `string` ve `date` tipindedir.
126 |
127 | Elasticsearch'te `string`, `date`, `long`, `double`, `boolean` ve `ip` basit tipleri mevcuttur.
128 | Bunlar dışında `object` ve `nested` tipleri bulunmaktadır. Daha özelleşmiş olan `geo_point`,
129 | `geo_shape`, ve `completion` tipleri de bulunmaktadır. Tİpleri ilerleyen zamanlarda
130 | kullandıkça açıklayacağız. Yine de erkenden bilgi sahibi olmak isterseniz
131 | [buradan](https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html)
132 | bilgi alabilirsiniz.
133 |
134 | Yukarıdaki örnekte göreceğiniz `post` type'ındaki `user_id` alanında `index` diye ayrı bir
135 | özellikte mevcut. Bu özellik alandaki değerin nasıl index'e alınacağını belirler. Eğer bu alan
136 | hiç yazılmaz ise `standart analyzer` ile analiz edilerek index'e alınır. Buraya kendi
137 | oluşturduğunuz `analyzer`ları ya da varsayılanları kullanabilirsiniz.
138 |
139 | #### Kaynakça
140 |
141 | - [Elasticsearch - Mapping](https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping.html)
142 | - [Elasticsearch - Mapping Intro](https://www.elastic.co/guide/en/elasticsearch/guide/current/mapping-intro.html)
143 | - [Types and Mappings](https://www.elastic.co/guide/en/elasticsearch/guide/current/mapping.html)
144 |
--------------------------------------------------------------------------------
/_posts/2016-01-10-elasticsearch-references-2-x-ye-gecmeden-bir-goz-atin.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Elasticsearch References 2.x'ye Geçmeden Bir Göz Atın
4 | categories:
5 | - blog
6 | summary: Elasticsearch 2.x ile birlikte neler gidiyor, neler değişiyor. 2.x sürümüne taşınmadan önce hızlıca göz atabileceğiniz bir döküman.
7 | ---
8 |
9 | Elasticsearch 2.0 ile birlikte silinen ya da ismi değişen özellikleri bir
10 | dökümanda toplayayım dedim baya uzun bir liste çıktı. Genel bilgi olması
11 | açısından sırasıyla başlıklar ve kısa açıklamaları aşağıdaki gibi.
12 |
13 | ### Nodes shutdown
14 | `_shutdown` API silindi. Bunun yerine Elasticsearch'ü işletim sisteminizde
15 | `service` olarak çalıştırabilirsiniz ya da `-p` komut satırı özelliğini
16 | kullanarak PID'i bir dosyaya yazdırabilirsiniz.
17 |
18 | ### Bulk UDP API
19 | Bulk UDP servisi silindi. Bunun yerine [`Bulk API`](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/docs-bulk.html)'ı
20 | kullanabilirsiniz.
21 |
22 | ### Mapping Silmek
23 | Bir `type` için mapping'i silme özelliği artık olmayacak. Bunun yerine index'i
24 | silip yeni bir mapping ile oluşturabilirsiniz. Burada bir index'de zor durumda
25 | kalmadıkça birden fazla type barındırmamak gerekiyor gibi.
26 |
27 | ### Index Status
28 | `_status` API [Indices Stats](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/indices-stats.html)
29 | ve [Indices Recovery API](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/indices-recovery.html)
30 | ile değiştirildi.
31 |
32 | ### `_analyzer`
33 | Type Mapping'deki `_analyzer` alanı artık desteklenmeyecek ve 2.x ile birlikte
34 | mapping'den otomatik olarak silinecek.
35 |
36 | ### `_boost`
37 | Type Mapping'deki `_boost` alanı artık desteklenmeyecek ve 2.x ile birlikte
38 | mapping'den otomatik olarak silinecek.
39 |
40 | ### Config mappings
41 | `config` klasöründe özel mapping'ler artık kullanılmayacak. Mapping oluşturma
42 | artık aşağıdaki API arayüzleri ile olabilecek:
43 |
44 | - [Create Index](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/indices-create-index.html)
45 | - [Put Mapping](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/indices-put-mapping.html)
46 | - [Index Templates](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/indices-templates.html)
47 |
48 | ### memcached
49 | `memcached` transport artık desteklenmeyecek. Bunun yerine HTTP veya Java API
50 | üzerinden REST arayüzünü kullanın.
51 |
52 | ### Thrift
53 | `thrift` transport artık desteklenmeyecek. Bunun yerine HTTP veya Java API
54 | üzerinden REST arayüzünü kullanın.
55 |
56 | ### Queries, Filters
57 | Query'ler ve Filter'lar birleştirildi. Herhangi bir `query` deyimi artık
58 | `query context` içerisinde `query` olarak, `filter context` içeriside `filter`
59 | olarak kullanılabilecek. (Daha fazla bilgi için [`Query DSL`](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl.html))
60 |
61 |
62 | | Silinen Filter'lar | Kullanılabilecek Query Hali |
63 | | ------------------------- | --------------------------- |
64 | | And | [And Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-and-query.html) |
65 | | Or | [Or Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-or-query.html) |
66 | | Not | [Not Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-not-query.html) |
67 | | Bool | [Bool Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-bool-query.html) |
68 | | Exists | [Exists Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-exists-query.html) |
69 | | Missing | [Missing Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-missing-query.html) |
70 | | geo_bounding_box | [Geo Bounding Box Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-geo-bounding-box-query.html) |
71 | | geo_distance | [Geo Distance Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-geo-distance-query.html) |
72 | | geo_distance_range | [Geo Distance Range Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-geo-distance-range-query.html) |
73 | | geo_polygon | [Geo Polygon Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-geo-polygon-query.html) |
74 | | geo_shape | [GeoShape Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-geo-shape-query.html) |
75 | | geohash_cell | [Geohash Cell Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-geohash-cell-query.html) |
76 | | has_child | [Has Child Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-has-child-query.html) |
77 | | has_parent | [Has Parent Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-has-parent-query.html) |
78 | | ids | [Ids Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-ids-query.html) |
79 | | indices | [Indices Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-indices-query.html) |
80 | | limit | [Limit Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-limit-query.html) |
81 | | match_all | [Match All Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-match-all-query.html) |
82 | | nested | [Nested Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-nested-query.html) |
83 | | prefix | [Prefix Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-prefix-query.html) |
84 | | query | - |
85 | | range | [Range Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-range-query.html) |
86 | | regexp | [Regexp Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-regexp-query.html) |
87 | | script | [Script Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-script-query.html) |
88 | | term | [Term Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-term-query.html) |
89 | | terms | [Terms Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-terms-query.html) |
90 | | type | [Type Query](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-type-query.html) |
91 | | fuzzy_like_this veya flt | [fuzziness](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-match-query.html#query-dsl-match-query-fuzziness) parametresini `match` query ile kullanın veya [`More Like This Query`](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-mlt-query.html) kullanın. |
92 | | fuzzy_like_this_field veya flt_field | [fuzziness](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-match-query.html#query-dsl-match-query-fuzziness) parametresini `match` query ile kullanın veya [`More Like This Query`](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-mlt-query.html) kullanın. |
93 |
94 | Bakınız: [Query DSL](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl.html)
95 |
96 | ### Top Children Query
97 | `top_children` query silindi. Bunun yerine [`Has Child Query`](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-has-child-query.html) kullanın.
98 |
99 | ### More Like This API
100 | `More Like This API` silindi. Bunun yerine [`More Like This Query`](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/query-dsl-mlt-query.html) kullanın.
101 |
102 | ### Facet'ler siliniyor `Aggregation`lar geliyor
103 | `Facet`ler büyük veri kümelerinde özel bilgiler çıkarmak için çok güzel bir
104 | araçtır. Elasticsearch 1.0 ile birlikte `facet`lar `aggregation` olarak
105 | değişmiştir. `Aggregation`lar `facet`ların üst kümesidir.
106 |
107 | Aşağıda genel bir liste oluşturmaya çalıştım:
108 |
109 | | Silinen `Facet`lar | `Aggregation`lar |
110 | | ------------------------- | ------------------------- |
111 | | Filter veya Query Facet | [filter aggregation](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/search-aggregations-bucket-filter-aggregation.html) [filters aggregation](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/search-aggregations-bucket-filters-aggregation.html) |
112 | | Geo Distance Facet | [geo_distance aggregation](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/search-aggregations-bucket-geodistance-aggregation.html) |
113 | | Histogram Facet | [histogram aggregation](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/search-aggregations-bucket-histogram-aggregation.html) |
114 | | Date Histogram Facet | [date_histogram aggregation](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/search-aggregations-bucket-datehistogram-aggregation.html) |
115 | | Range Facet | [range aggregation](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/search-aggregations-bucket-range-aggregation.html) |
116 | | Terms Facet | [terms aggregation](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/search-aggregations-bucket-terms-aggregation.html) |
117 | | Terms Stats Facet | [terms aggregation](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/search-aggregations-bucket-terms-aggregation.html) [stats aggregation](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/search-aggregations-metrics-stats-aggregation.html) [extended_stats aggregation](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/search-aggregations-metrics-extendedstats-aggregation.html) |
118 | | Statistical Facet | [stats aggregation](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/search-aggregations-metrics-stats-aggregation.html) [extended_stats aggregation](https://www.elastic.co/guide/en/elasticsearch/reference/2.x/search-aggregations-metrics-extendedstats-aggregation.html) |
119 |
120 |
121 | ### Shard request cache
122 | `shard query cache`in ismi `Shard request cache` olarak değişti.
123 |
124 | ### Query cache
125 | `filter cache`, `Node Query Cache` olarak değişti.
126 |
127 | ### `Nested tipi
128 | The docs for the nested field datatype have moved to Nested datatype.
129 |
130 |
131 | #### Kaynakça
132 |
133 | - [Breaking changes in 2.0](https://www.elastic.co/guide/en/elasticsearch/reference/current/breaking-changes-2.0.html)
134 | - [WHAT'S NEW IN ELASTICSEARCH 2.0](http://david.pilato.fr/presentations/what-s-new-in-elasticsearch-20.html)
135 |
--------------------------------------------------------------------------------
/_posts/2016-02-09-bazi-kavramlar--index-inverted-index-shard-segment.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Bazı Kavramlar (index, inverted index, shard, segment)
4 | categories:
5 | - blog
6 | summary: Elasticsearch'de bazı kavramlar anlaması zor olabiliyor. `index` tam olarak ne demek, `inverted index` nedir? `shard`, `segment` nedir? gibi soruları kısaca açıklamalarını bulabileceğiniz bir döküman.
7 | ---
8 |
9 | "index" kelimesi Elasticsearch'de biraz istismar edilmiş. Anlamak için kısaca bakalım:
10 |
11 | #### index
12 |
13 | Elasticsearch'de bir `index` ilişkili bir veritabanındaki veritabanları gibidir.
14 | Verileri sakladığınız yerlerdir. Ama gerçekte, bu sadece senin uygulamanın gördüğüdür.
15 | Temelde, bir `index` bir veya daha fazla `shard`ı temsil eden mantıksal bir alan adıdır.
16 |
17 | Ayrıca, "to index" (index'lemek) kavramıda veriyi Elasticsearch'e koymak/yüklemek
18 | anlamına gelmektedir. Verinizin geri istenebilecek şekilde saklandığını ve arama
19 | yapılabileceğini ifade eder.
20 |
21 |
22 | #### inverted index
23 |
24 | `inverted index` Lucene'in verileri aranabilir yapmak için kullandığı bir veri yapısıdır.
25 | Bu işlemde dökümanın içerdiği verilerden `token`lar ve tekil terimler ortaya çıkarılır.
26 | Bu konu hakkında daha fazla bilgi almak için [buraya](https://en.wikipedia.org/wiki/Inverted_index)
27 | bakabilirsiniz.
28 |
29 | #### shard
30 |
31 | `shard` bir Lucene instance'ıdır. Kendi başına tamamen işlevsel bir arama motorudur. Bir
32 | `index` tek başına bir `shard`dan oluşabilir, ama genellikle `index` in büyüyebilmesi
33 | ve bir kaç `node` üzerinde dağıtılabilmesi için bir kaç `shard`dan oluşmaktadır.
34 |
35 | `primary shard` bir döküman için ev sahipliği yapmaktadır. Bir `replica shard` ise
36 | `primary shard` bir kopyasıdır ve (1) `primary` bir şekilde hata verdiğinde ya da
37 | düştüğünde, (2) okuma çok arttığında, kullanılmaktadır.
38 |
39 |
40 | #### segment
41 |
42 | Her `shard` birden fazla `segment` içermektedir ve bu `segment`ler bir `inverted index`tir.
43 | Bir `shard` üzerindeki bir arama sırayla her bir `segment`'de aranacaktır ve sonra
44 | sonuçlar bu `shard` için son bir sonuçlar kümesinde toplanacaktır.
45 |
46 | Siz bir dökümanı `index`lerken(indexing), Elasticsearch onları bellekte(memory)
47 | toplayacaktır (ve güvenlik için `transaction log`'da), sonra her saniye veya daha fazla
48 | zamanda bir bunu yapar, disk'e yeni bir `segment` oluşturur, ve aramaları `refresh` eder.
49 |
50 | Bu veriyi yeni bir `segment` içerisinde aranabilir yapar, ama bu `segment` diske
51 | `fsync` edilmemiş haldedir. (Bende aynı soruyu kendime sordum. `fsync` nedir?) Veri halen
52 | kaybolma riskine sahiptir.
53 |
54 | Elasticsearch, sık sık `fsync` anlamına gelen `flush` işlemini yapar, (şimdi veri
55 | işlenmiştir.) ve artık gereksiz hale gelen `transaction log`u temizler. Çünkü biz artık
56 | biliyoruz ki veri diske yazılmıştır.
57 |
58 | Ne kadar çok `segment` varsa aramalar o kadar uzun sürer. Yani Elasticsearch arkaplanda
59 | çalışan birleştirici işlemler (merge process) ile benzer büyüklükteki bir kaç `segment`i
60 | daha büyük bir `segment`e birleştirecektir. Yeni oluşan daha büyük `segment` diske
61 | yazıldıktan sonra eskileri silinecektir. Bu işlem bir çok aynı büyüklükte `segment`
62 | olduğu sürece tekrar eder.
63 |
64 | `Segment`ler değişmezdir. Bir döküman update edildiğinde, eski döküman silindi olarak
65 | işaretlenir, ve yeni bir döküman eklenir. Birleştirme işlemleri aynı zamanda silinen
66 | dökümanlarıda çıkarır.
67 |
68 | #### Kaynakça
69 |
70 | - [Basics about segments in elasticsearch](http://stackoverflow.com/a/15429578/721600)
71 | - [Basic Concepts](https://www.elastic.co/guide/en/elasticsearch/reference/current/_basic_concepts.html)
72 |
--------------------------------------------------------------------------------
/_posts/2016-03-26-inverted-index-nedir.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Inverted Index Nedir?
4 | categories:
5 | - blog
6 | summary: Inverted Index ne demektir ve terim bazlı aramalarınızın nasıl çalıştığını ve nasıl daha hızlı çalıştığına bir gözün atın.
7 | ---
8 |
9 | Text tabanlı bir döküman kümeniz olduğunu düşünün. Bu dökümanlar içerisindeki terimlerinizi
10 | bu terimlerin hangi dökümanlar ile ilişkili olduğunu dökümanın bilgisini bir yerde
11 | tuttuğunuzu düşünün. Bu terimler içerisinde bir arama yaptığınızda terimlere karşılık
12 | gelen dökümanları hızlıca bulabileceksiniz. Yani siz dökümanlarınıza terimler üzerinden
13 | ulaşıyor olacaksınız. İşte buna inverted(ters) index denir.
14 |
15 | Aşağıdaki örnekte inverted index kavramını görsel olarak daha iyi anlayabilirsiniz.
16 | Burada dikkat edilmesi gereken bir diğer önemli kısımda `analyzers` kısmıdır. Burada
17 | bizim metnimizi bir takım `tokenizer` ve `filter`lardan geçirerek inverted index olarak
18 | kaydediyoruz. Aşağıdaki örnekte veriler sırasıyla `Standart Tokenizer`, `Lowercase Filter`
19 | ve `Stopwords Filter`'dan geçirilmektedir. Daha sonrada inverted index olarak
20 | kaydedilmektedir.
21 |
22 | 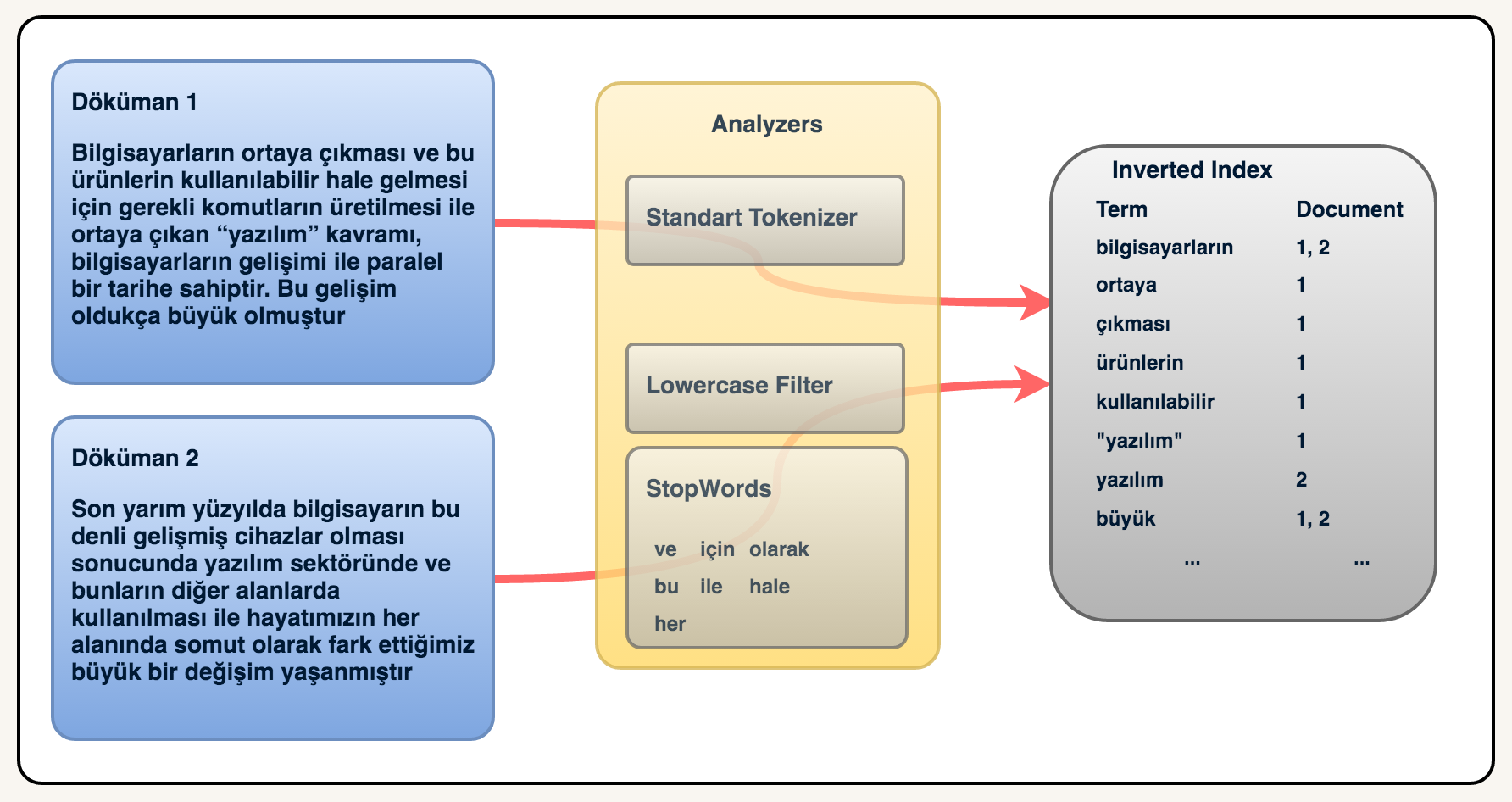
23 |
24 | Burada ekstra olarak bir terimin döküman içerisindeki pozisyonunu da kaydettiğinizi
25 | düşünürsek kolayca terim için her döküman karşılık bir puan da çıkarabilirsiniz ve
26 | aramalarda bunu sonuçları sıralamak için kullanabilirsiniz.
27 |
28 | Aşağıdaki örnekte ise aynı dökümanı inverted index'e kaydederken dökümandaki terimlerin
29 | döküman içerisindeki pozisyonları ile birlikte kaydettik. Mesela "bilgisayarın" terimi
30 | 1. döküman içerisinde 2 yerde geçmektedir ve sırasıyla 1. ve 14. sıradadırlar.
31 |
32 | 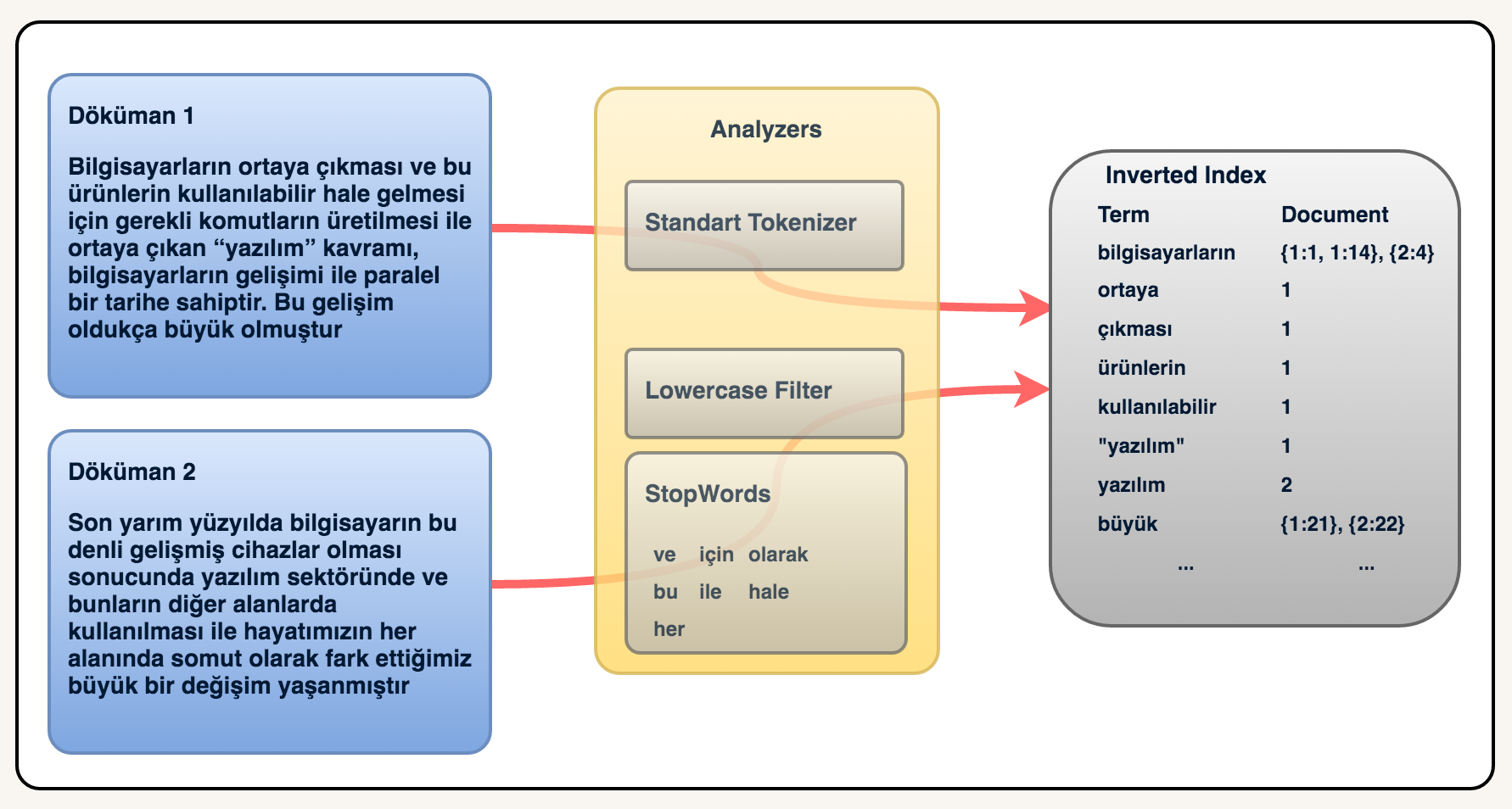
33 |
34 | Bir arama yaparken ise inverted index'ler üzerinde hızlıca dökümanlara ulaşabiliriz.
35 | Örneğin, `bilgisayarın` kelimesi ile bir arama yaptığımızda hem birinci döküman hem de
36 | ikinci döküman gelecektir. Eğer bir score mekanizmamız olsaydı birinci döküman daha önce gelecektir. Çünkü birinci dökümanda aynı terim 2 kez geçmektedir.
37 |
38 | Bir diğer terim olan `yazılım` teriminde arama yapsaydık sadece 2. döküman gelecekti.
39 | Belki aklınıza 1. döküman neden gelmedi sorusu gelebilir. Burada dikkat etmeniz gereken inverted index'e nasıl kaydedildiği olmalıdır. `"yazılım"` terimi ile `yazılım` terimi
40 | aynı değildir. Bu yüzden biz `yazılım` diye arattığımızda `"yazılım"` terimi geçen
41 | dökümanlar gelmeyecektir.
42 |
43 | #### Kaynakça:
44 |
45 | - [Inverted Index](https://www.elastic.co/guide/en/elasticsearch/guide/current/inverted-index.html)
46 | - [Elasticsearch from the Bottom Up, Part 1](https://www.elastic.co/blog/found-elasticsearch-from-the-bottom-up)
47 | - [What Is Relevance?](https://www.elastic.co/guide/en/elasticsearch/guide/current/relevance-intro.html)
48 |
--------------------------------------------------------------------------------
/_posts/2016-04-22-nginx-ile-elasticsearch-icin-koruma-olusturun.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Nginx ile Elasticsearch için Koruma Oluşturun
4 | categories:
5 | - blog
6 | summary: Nginx ile elasticsearch sorgularını şifre koruması altında yapabilirsiniz ve nginx logları ile elasticsearch sunucularınıza gelen yükü görebilir ve hatalarınızı ayıklayabilirsiniz.
7 | ---
8 |
9 | Elasticsearch HTTP API arayüzü üzerinden çalıştığı için bir sunucu üzerinde çalıştırdığınızda
10 | dış dünya tarafından ulaşılabilir halde çalışıyor olacaktır. Burada Elasticsearch erişimini dış
11 | dünyaya yani sizin uygulamanız dışındaki kişilere erişimini kapatmak için bir kaç yol
12 | bulunmakta. Bunlardan birisi de "Basic Authentication". Yani bir kullanıcı adı şifre ile
13 | koruma yöntemi. Bu yöntem sizin sunucularınızı tabiki tamamen koruyamayabilir. Önerim
14 | firewall seviyesinde ya da network seviyesinde erişimin kısıtlanmasıdır. Ancak bu kısıtlama
15 | iç ağdan birilerinin de elasticsearch içerisinde rahatça işlem yapmalarını engelleyemez.
16 | Bunun için kullanıcı adı ve şifre ile koruyarak buradaki erişimi iç ağ üzerinde de kısıtlamaya
17 | çalışacağız.
18 |
19 | Bunu nasıl yapacağız şimdi kısaca buna değinelim. Gerekli araç ve gereçler :
20 |
21 | - Nginx
22 | - Elasticsearch
23 |
24 | Hepsi bu kadar. Ben şimdilik Elasticsearch'ün varsayılan port'u üzerinden örnekleyeceğim.
25 | İlk olarak bir Elasticsearch makinesini çalıştırıyoruz ve [http://127.0.0.1:9200/](http://127.0.0.1:9200/)
26 | adresinden çalıştığını görüyoruz.
27 |
28 | Daha sonra Nginx üzerinden aşağıdaki gibi bir server oluşturuyoruz.
29 |
30 | ```
31 | server {
32 | listen 80;
33 | server_name elastic.local;
34 |
35 | location / {
36 | proxy_pass http://127.0.0.1:9200;
37 | proxy_set_header Host $host;
38 | proxy_set_header X-Real-IP $remote_addr;
39 |
40 | auth_basic "Restricted Content";
41 | auth_basic_user_file /usr/local/etc/nginx/.htpasswd;
42 | }
43 | }
44 | ```
45 |
46 | Burada dikkat ettiyseniz `127.0.0.1:9200` adresi üzerinden çalışan Elasticsearch için
47 | `elastic.local` domain'inde ve 80. porttan çalışacak şekilde bir server oluşturduk. Daha sonra
48 | bu adrese gelecek bütün istekleri `proxy_pass http://127.0.0.1:9200;` ile Elasticsearch
49 | adresimize yönlendirdik. Böylelikle uygulamamız içerisinden Elasticsearch'e erişmek için
50 | `elastic.local` yazmamız yeterli olacaktır. Bunun yanında firewall üzerinden 9200 portuna
51 | ulaşımı engelliyoruz ki 9200 portu üzerinden API arayüzü kullanılmaya devam etmesin
52 | sadece nginx'in olduğu sunucu üzerinden erişilebilir olsun. Bu örnekte ben kendi
53 | bilgisayarımda bu işlemi yaptığım için 9200 portu üzerinden erişim konusunu gözardı ettim.
54 | Domain yönlendirmesi için bilgisayarımdaki `/etc/hosts` dosyasına aşağıdaki gibi bir
55 | tanımlama yaptım. Eğer siz bunu sunucu düzeyinde yapmak istiyorsanız DNS tanımlamalarınızı
56 | yapmanız gerekmektedir. Ya da burada server_name olarak bir IP adresi kullanabilirsiniz.
57 |
58 | ```
59 | # Host Dosyası tanımlaması
60 | 127.0.0.1 elastic.local
61 | ```
62 |
63 | Şimdi bunları yaptık ancak koruma nerede. Koruma kısmıda yukarıdaki script'in devamında.
64 |
65 | ```
66 | auth_basic "Restricted Content";
67 | auth_basic_user_file /usr/local/etc/nginx/.htpasswd;
68 | ```
69 |
70 | Bu kısımda da sayfamıza bir koruma ekledik ve Nginx'e `/usr/local/etc/nginx/.htpasswd` bu
71 | dosyada yazan bilgilere göre bu alana gelen istekleri koru dedik. Bu dosyada da aşağıdaki
72 | gibi Nginx'in anlayacağı dilde şifremizi oluşturduk. Kaynaklar arasında benim online da test
73 | için kullandığım bir şifre oluşturma sitesi vardı. Ancak tabiki dışarıdaki bir aracı şifre oluşturmak
74 | için önermiyorum. Ben bu örnekte de şifrem olan `123456` için bu siteden kodu oluşturdum.
75 | Dosyanın içeriğide aşağıdaki gibi :
76 |
77 | ```
78 | hkulekci:$apr1$0DffSiqd$IX9t3AE92RfD.zZc0E97t/
79 | ```
80 |
81 | Şimdi son olarak Nginx'i yeniden başlatalım.
82 |
83 | ```
84 | sudo nginx -s reload
85 | ```
86 |
87 | Artık Elasticsearch'e `elastic.local` adresi üzerinden erişebileceksiniz. İlk denememizi yapalım.
88 |
89 | ```
90 | ➜ ~ curl -XGET "http://elastic.local"
91 |
92 | 401 Authorization Required
93 |
94 |
401 Authorization Required
95 |
nginx/1.8.0
96 |
97 |
98 | ```
99 |
100 | Gördüğünüz gibi elasticsearch erişimini kısıtladık, ve erişmeye çalıştığımızda bize kullanıcı adı ve
101 | şifre soruyor. Şimdi elasticsearch için oluşturduğumuz şifre ile erişmeye çalışalım.
102 |
103 | ```json
104 | ➜ ~ curl --user hkulekci:123456 -XGET "http://elastic.local"
105 | {
106 | "name" : "Black Jack Tarr",
107 | "cluster_name" : "elasticsearch",
108 | "version" : {
109 | "number" : "2.3.1",
110 | "build_hash" : "bd980929010aef404e7cb0843e61d0665269fc39",
111 | "build_timestamp" : "2016-04-04T12:25:05Z",
112 | "build_snapshot" : false,
113 | "lucene_version" : "5.5.0"
114 | },
115 | "tagline" : "You Know, for Search"
116 | }
117 | ```
118 |
119 | Bu işlem sonrasında elasticsearh'ü nginx arkasına aldık ve kullanıcı adı ve şifre ile koruduk. Bu
120 | korumanın yanı sıra nginx `access.log` ve `error.log` ile elasticsearch sorgularınız hakkında
121 | analizler de yapabileceksiniz. Benim örnek loglarım aşağıdaki gibi :
122 |
123 | ```
124 | 127.0.0.1 - hkulekci [23/Apr/2016:07:14:59 +0300] "GET / HTTP/1.1" 200 340 "http://elastic.local/_plugin/head/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.110 Safari/537.36"
125 | 127.0.0.1 - hkulekci [23/Apr/2016:07:15:00 +0300] "GET /_cluster/state HTTP/1.1" 200 97713 "http://elastic.local/_plugin/head/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.110 Safari/537.36"
126 | 127.0.0.1 - hkulekci [23/Apr/2016:07:15:00 +0300] "GET /_status HTTP/1.1" 200 12427 "http://elastic.local/_plugin/head/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.110 Safari/537.36"
127 | 127.0.0.1 - hkulekci [23/Apr/2016:07:15:00 +0300] "GET /_nodes HTTP/1.1" 200 3650 "http://elastic.local/_plugin/head/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.110 Safari/537.36"
128 | ```
129 |
130 | Teşekkürler.
131 |
132 |
133 | ### Kaynaklar :
134 | - https://www.digitalocean.com/community/tutorials/understanding-nginx-http-proxying-load-balancing-buffering-and-caching
135 | - https://www.nginx.com/resources/admin-guide/reverse-proxy/
136 | - https://gist.github.com/soheilhy/8b94347ff8336d971ad0
137 | - http://www.htaccesstools.com/htpasswd-generator/
--------------------------------------------------------------------------------
/_posts/2016-05-06-index-adi-olarak-alias-kullanmak-ve-reindex-api.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Index adı olarak `Alias` Kullanmak ve Reindex API
4 | categories:
5 | - blog
6 | summary: Index isimleri olarak alias kullanarak index değişikliklerinde veya verileri taşımak zorunda kaldığınızda uygulama katmanınızı değiştirmeden verileriniz taşıyın.
7 | ---
8 |
9 | Elasticsearch API arayüzü `index` isimleri üzerinden çalışmaktadır ve bir cluster içerisinde
10 | çoğu zaman bir çok `index`iniz bulunmaktadır. Index Alias API arayüzü ile `index` isimlerinize
11 | takma isimler verebilirsiniz. Bunun önemini bir örnek üzerinden açıklamaya çalışayım.
12 |
13 | Bir kullanıcıların verilerini tuttuğunuz `index`iniz var ve yapısı aşağıdaki gibi:
14 |
15 | ```json
16 | GET users/user/_mapping
17 | {
18 | "users": {
19 | "mappings": {
20 | "user": {
21 | "properties": {
22 | "id": {
23 | "type": "string"
24 | },
25 | "name": {
26 | "type": "string"
27 | },
28 | "tags": {
29 | "type": "string",
30 | "index": "not_analyzed"
31 | }
32 | }
33 | }
34 | }
35 | }
36 | }
37 | ```
38 |
39 | Bir takım verileriniz birikti ve sonradan farkettiniz ki `id` alanını integer yerine string olarak
40 | kaydetmişsiniz. Hemen değiştirmek için bir mapping update sorgusu hazırladınız:
41 |
42 | ```json
43 | PUT users/user/_mapping
44 | {
45 | "properties": {
46 | "id": {
47 | "type": "integer"
48 | }
49 | }
50 | }
51 | ```
52 |
53 | Ancak hali hazırda olan bir alanın veri tipini değiştirmeye çalıştığınızda Elasticsearch
54 | bundan pek hoşlanmayacaktır ve aşağıdaki gibi bir hata verecektir:
55 |
56 | ```json
57 | {
58 | "error": {
59 | "root_cause": [
60 | {
61 | "type": "illegal_argument_exception",
62 | "reason": "mapper [id] of different type, current_type [string], merged_type [integer]"
63 | }
64 | ],
65 | "type": "illegal_argument_exception",
66 | "reason": "mapper [id] of different type, current_type [string], merged_type [integer]"
67 | },
68 | "status": 400
69 | }
70 | ```
71 |
72 | Uygulamanız hali hazırda kullanılıyor olduğu için index'i silip tekrar oluşturamazsınız. Uygulama
73 | içerisinde de bir çok yerde index ismini kullandığınız için farklı bir isimle index oluşturmanız
74 | da sizin için zor olacak. Bu durumlarda `alias`lar hayat kurtarıcı olabiliyor. Hemen kısaca
75 | açıklayalım.
76 |
77 | İlk olarak yeni bir index oluşturup yeni yapımız ile `type`ı oluşturuyoruz.
78 |
79 | ```json
80 | POST users_20160506
81 |
82 | POST users_20160506/user/_mapping
83 | {
84 | "properties": {
85 | "id": {
86 | "type": "integer"
87 | },
88 | "name": {
89 | "type": "string"
90 | },
91 | "tags": {
92 | "type": "string",
93 | "index": "not_analyzed"
94 | }
95 | }
96 | }
97 | ```
98 |
99 | Daha sonrasında verilerimizi yeni index'imize taşıyoruz. Bunun için Elasticsearch 2.3.1 ile gelen
100 | yeni özelliği `_reindex` API arayüzü kullanabilirsiniz.
101 |
102 | ```json
103 | POST /_reindex
104 | {
105 | "source": {
106 | "index": "users"
107 | },
108 | "dest": {
109 | "index": "users_20160506"
110 | }
111 | }
112 | ```
113 | Buradaki örneğimizde tabiki `id` alanımız integer tipine rahatça çevrilebilecek bir alan olduğu
114 | için rahatça bunu yapabildik. Burada eğer bir alan üzerinde ekstra işlem yaparak taşımak isteseydik
115 | nasıl olacaktı. Bunun için de script kullanabilirsiniz:
116 |
117 | ```json
118 | POST /_reindex
119 | {
120 | "source": {
121 | "index": "users"
122 | },
123 | "dest": {
124 | "index": "users_20160506"
125 | },
126 | "script":{
127 | "inline": "if (ctx._source.foo == 'bar') { ctx._source.id = parseInt(ctx._source.id) }"
128 | }
129 | }
130 | ```
131 | Şimdi verimizi taşıdık. Şimdi sıra geldi takma isim kısmına. Şimdi yeni verdiğimiz index için bir
132 | takma isim vereceğiz ve eski index'imizi sileceğiz ya da takma ismini kaldıracağız. Bizim
133 | senaryomuzda `users` adında bir index'imiz vardı ve biz bu index'deki verileri yeni bir index'e
134 | taşıdık. Bu durumda eski index'imizi kaldırmamız ya da silmemiz gerekmekte. Eğer alias olarak
135 | eski index'imizin adını vereceksek ve index'imizi silmeden bu işlemi yapmaya çalışırsak
136 | Elasticsearch alias oluşturma sırasında bize hata verecektir. Bu ismi kullanan bir `index` var
137 | diyecektir. Şimdi bizim adımlarımızı şöyle yapalım. Verilerimizi yeni index'imize taşıdığımıza
138 | göre eski index'imize ihtiyaç kalmadı. Bunun için o index'i silelim ve yeni oluşturduğumuz
139 | index'e `users` takma adını verelim.
140 |
141 | ```json
142 | DELETE users
143 |
144 | POST _aliases
145 | {
146 | "actions" : [
147 | { "add" : { "index" : "users_20160506", "alias" : "users" } }
148 | ]
149 | }
150 | ```
151 |
152 | Bu işlemleri tamamladıktan sonra halen `/users/user/_search` sorgusu yaptığınızda verilerinizi
153 | görebilirsiniz.
154 |
155 | ```json
156 | {
157 | "took": 9,
158 | "timed_out": false,
159 | "_shards": {
160 | "total": 5,
161 | "successful": 5,
162 | "failed": 0
163 | },
164 | "hits": {
165 | "total": 4,
166 | "max_score": 1,
167 | "hits": [
168 | {
169 | "_index": "users_20160506",
170 | "_type": "user",
171 | "_id": "AVSB74LRHQRC9fPqMzsA",
172 | "_score": 1,
173 | "_source": {
174 | "tags": [
175 | "php",
176 | "python",
177 | "html"
178 | ],
179 | "name": "Haydar"
180 | }
181 | },
182 | ...
183 | ]
184 | }
185 | }
186 | ```
187 |
188 | Peki olan bir takma ismi bir index'den diğerine taşımak için ne yapmalısını.z Bunun için
189 | tek bir komut çalıştırmanız yeterli. İki komut birden çalıştırmanız gerekmez. Bir örnek ile
190 | anlatmaya çalışayım. Gün geldi bu yazımızda oluşturduğumuz `users_20160506` index'ini
191 | yine değiştirmeniz ve taşımanız gerekti. Verileriniz `users_20160720` index'ine taşıdınız ve
192 | şimdi `users` takma adınızı taşımak istiyorsunuz. İşiniz gayet basit:
193 |
194 | ```json
195 | POST /_aliases
196 | {
197 | "actions" : [
198 | { "remove" : { "index" : "users_20160506", "alias" : "users" } },
199 | { "add" : { "index" : "users_20160720", "alias" : "users" } }
200 | ]
201 | }
202 | ```
203 |
204 | Sonuç olarak takma isimler (`_aliases`) ve 2.3.1 versiyonu ile gelen `_reindex` API arayüzü
205 | işlerinizi ve hayatınızı baya kolaylaştırabilir. Bu API arayüzlerini kullanarak verinizi uygulama
206 | katmanından ayırarak kolay yönetebilir ve rahatlıkla taşıyabilirsiniz.
--------------------------------------------------------------------------------
/_posts/2016-06-20-takma-isim-alias-kullanarak-verileri-filtrelemek.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Takma isim (Alias) kullanarak verileri filtrelemek
4 | categories:
5 | - blog
6 | summary: Takma isimler kullanarak verilerinizi kolayca filtrelenmiş halleriyle sorgulayabilirsiniz.
7 | ---
8 |
9 | Bir önceki yazımda `index` için takma isim oluşturmayı ve bu takma ismi kullanmayı
10 | görmüştük. Elasticsearch'ün yeni sürümü (2.x) ile birlikte takma isimler ile birlikte
11 | index üzerinde filtreleme de yapabiliyorsunuz. Bir örnek ile açıklamaya çalışalım.
12 |
13 | `id`, `type`, `keywords` alanlarından oluşan bir index ve tipimiz var. Aşağıdakine
14 | benzer verilerin olduğunu düşünün.
15 |
16 | ```
17 | {
18 | "id": 1,
19 | "type": "search",
20 | "keywords": ["elasticsearch", "elastic", "framework"]
21 | },
22 | {
23 | "id": 4,
24 | "type": "client",
25 | "keywords": ["golang", "elasticsearch"]
26 | }
27 | ```
28 |
29 | Örnek veri için bir gist hazırladım.
30 | Göz atabilirsiniz: [https://gist.github.com/hkulekci/2146c1da124e42cd02ed3c4635934f62](https://gist.github.com/hkulekci/2146c1da124e42cd02ed3c4635934f62)
31 |
32 | Bu verilerimiz bir için bir takma isim oluşturacağız ve ayrıca bu takma isim
33 | üzerinden yaptığımız bütün aramalarıda `type` alanı `client` olanları filtrelemesini
34 | isteyeceğiz. Böylelikle bu alias aslında `index`imizin sadece bazı kısımlarını
35 | temsil etmiş olacak.
36 |
37 | Peki bunu nasıl yapacağız. Bunun için önceki yazımızda gördüğünüz takma isim
38 | oluşturma yönteminde olduğu gibi `_aliases` arayüzünü kullanacağız ancak bu arayüze
39 | verimizi gönderirken ekstra olarak `filter` diye bir parametre daha göndereceğiz.
40 |
41 | Hemen bir örnek yapalım:
42 |
43 | ```
44 | POST /_aliases
45 | {
46 | "actions": [
47 | {
48 | "add": {
49 | "index": "test",
50 | "alias": "test_client",
51 | "filter": {
52 | "term": {
53 | "type": "search"
54 | }
55 | }
56 | }
57 | }
58 | ]
59 | }
60 | ```
61 |
62 | Yukarıdaki örnekte `test` index'i için bir filtreleme oluşturdum ve bu takma ismi
63 | kullandığım zaman sadece `type` alanı `search` olan verileri kullanmak istediğimi
64 | belirtmiş oldum.
65 |
66 | Şimdi gidip `/test_client/_search` aramasını yaptığımda bana sadece `type` alanı
67 | `search` değerinde olan verileri geri döndürecektir. Diğer veriler sanki bu
68 | index'te yok gibi davranacaktır.
69 |
70 | Bu özelliği bir çok şey için rahatça kullanabiliriz. Örneğin kendimize büyük
71 | filtrelemeler sonucu hazırladığımız sorgularımızı bir alias olarak tanımlayarak
72 | sanki SQL'deki view'lar gibi ya da `procedure`ler gibi kullanabiliriz.
73 |
--------------------------------------------------------------------------------
/_posts/2016-07-13-panama_belgelerini_analiz_etmek_için_elastic_graph_ve_kibana_kullanmak_ceviri.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Panama Belgelerini Analiz Etmek için Elastic Graph ve Kibana Kullanmak (Çeviri)
4 | categories:
5 | - blog
6 | summary: Elasticsearch'ün eklentisi Graph ile Panama Belgelerini inceleyeceğiz ve Graph Kibana eklentisi ile de bu verileri görselleştireceğiz.
7 | ---
8 |
9 | Yeni Elastic Graph'ın yetenekleri veri içerisindeki bağlantıları daha kolay
10 | analiz etmemizi sağlar. Eğer işiniz Panama Belgelerindeki yabancı ülkelerin
11 | içinden çıkılmayacak finansal düzenlemelerini veya revaçtaki bir e-ticaret
12 | sitesinin yüksek seviye tıklama davranışlarını takip etmek ise, Graph
13 | teknolojisi bu ilişkileri size sağlamakta yardımcı olabilir.
14 |
15 | Graph'ın yetenekleri Elastic Stack için ticari X-Pack eklentisinin bir parçası
16 | olarak gelmektedir. Paket bir Kibana uygulaması ve yeni bir Elasticsearch API
17 | uçnoktası içermektedir. Bu ilk Graph yazımızca biz API'ın ve Kibana arayüzünün
18 | bize ne sundukları ile ilgili kısa bir göz atacağız.
19 |
20 | ### Forensic Analiz: Panama Papers
21 |
22 | Panama Belgeleri, Off-shore hukuk firması Mossack Fonseca tarafından
23 | [Mali ve Yasal kayıtların yayınlanması](https://panamapapers.icij.org/) 2016'nın
24 | en çok tepki toplayan haberlerinden birisidir. Kayıtlar bir çok politikacı,
25 | kraliyet üyesi, zengin ve onların ailelerinin deniz aşırı vergi rejimlerini
26 | kullanmak için kurulan petrol şirketlerini açığa çıkardı. Gazeteciler ve finans
27 | kuruluşları dikkatli bir şekilde bu veriler üzerinde odaklandılar(çalıştılar)
28 | ama bağlantıları ortaya çıkarmak gerçekten çok zor oldu ve de zaman aldı ama
29 | Kibana Graph uygulaması bunu herkes için kolay hale getirdi:
30 |
31 | 
32 |
33 | Yukarıda Viladimir Putin'in yakın arkadaşı
34 | [Sergei Roldugin](http://www.theguardian.com/news/2016/apr/03/panama-papers-money-hidden-offshore)'in,
35 | şirketler ve bireysel kişiler ile ilişkilerini görüyorsunuz. Bu resim Graph ile
36 | bir kaç basit adım ile oluşturulabilir:
37 |
38 | ### Veri kaynağını seçmek
39 |
40 | Başlangıçta indis listemizden "panama"yı seçiyoruz ve sonra içerisinde diagramda
41 | göstermek istediğimiz veriler bulunan bir kaç alan(field) seçiyoruz (Varsayılan
42 | olarak tek bir alan(field) seçimine izin veriliyor ancak sağ üssteki tuşlarda
43 | "Advanced Mode"a tıkladığınızda daha fazla alan seçebiliyor olacaksınız).
44 | Diagramda görünen "düğüm"ler için her bir alanı temsil eden bir ikon ve renk
45 | verilir.
46 |
47 | 
48 |
49 | ### Arama Yapmak
50 |
51 | Şimdi Putin'in arkadaşının adını "Roldugin" içeren dökümanlara ulaşmak için bir
52 | normal bir metin araması çalıştıralım.
53 |
54 | 
55 |
56 | Döküman içerisinde eşleşen terimler bir ağ olarak gösterildi - her bir çizgi
57 | terimler ile eşleşen bir veya daha fazla dökümanı göstermektedir.
58 |
59 | ICIJ'deki veriyi çıkaran gazeteciler belgelere eklenmiş her bir dökümanın
60 | referans verdiği gerçek hayattaki her bir birim/varlık için (person/company/
61 | address) tekil bir ID vermeyi denediler. Ne yazık ki, insan isimleri ve adresler
62 | eşleşmeler için uygun olmayabilir - gazeteciler 3 dökümanda ilişkili halde
63 | bulunan 12180773 kimlik numaralı Person varlığı belirlediler ama bu kişi ile
64 | benzer isimde iki kişi daha olduğunu rahatça görebiliriz ve bu kişiler farklı
65 | bir kimliğe sahipler. Gelecekteki bir yazımızda da, otomatik varlık çözümleme
66 | (Automated Entity Resolution) için Graph API'ın kullanımı hakkında konuşacağız.
67 | Şimdilik bunu elle (gruplama aracı ile) düzenleyelim.
68 |
69 |
70 | ### Düğümleri Gruplama
71 |
72 | Gelişmiş mod aracını kullanarak seçebiliriz(Sağdaki "Selections" kutusunu),
73 | sonra düğümleri birleştirmek için `group` düğmesine basın. Bu bize daha temiz
74 | bir resim verecektir. (Bir düğüme tıklayın ve daha sonra "linked" tuşuna
75 | tıklayarak bağlantılı diğer düğümleri seçin. Sonrasında bazılarının seçimini
76 | kaldırmak istiyorsanız listelenen düğümlerin ikonlarına tıklayarak
77 | kaldırabilirsiniz.)
78 |
79 | 
80 |
81 | Eğer istiyorsak, gruplanmışları da ayrıca gruplayabiliriz. Örn, farklı
82 | kimliklere sahip kişilerin bir düğümde toplanması ve sonra bunları şirket
83 | düğümünde birleştirme.
84 |
85 | ### "Spidering out"
86 |
87 | Graph en ilişkili bağlantıları gösterecektir. Ancak siz farzedelim varlıklarla
88 | bağlantılı diğer varlıklarıda (entities) görmek istiyoruz? Araç çubuğundaki "+"
89 | düğmesini kullanarak varlıklar ile ilişkili diğer bağlantıları keşfetmeye devam
90 | edebiliriz.
91 |
92 | 
93 |
94 | "+" tuşuna tekrar tekrar basarak resmi genişletebiliriz ve grafiğin belirli bir
95 | alanına odaklananabiliriz. "undo" ve "redo" tuşları ilgisiz sonuçlardan geri
96 | dönmek için önemli tuşlardır. Ek olarak, "delete" ve "blacklist" tuşları ile
97 | düğümlerin tamamen sonuçlardan çıkarılmasını ya da sadece karalisteye alınmasını
98 | sağlayabilirsiniz. Seçilen düğümlerin örnek dökümanlarıda "Show example docs"
99 | tuşu ile ayrıca görüntüleyebilirsiniz.
100 |
101 | Eğer Panama Belgelerini kendiniz görüntülemek istiyorsanız.
102 | [Elasticsearch](https://www.elastic.co/downloads/elasticsearch),
103 | [Kibana](https://www.elastic.co/downloads/kibana),
104 | ve [Graph plugin](https://www.elastic.co/downloads/graph) eklentisinin birer
105 | kopyasını edinin ve [bit.ly/espanama](bit.ly/espanama) şuradaki kurulum
106 | adımlarını izleyin.
107 |
108 | ### Wisdom of crowds
109 |
110 | Panama Belgeleri her tekil dökümanın önemli bağlantılarının olduğu "forensic" tipinde
111 | bir soruşturma örneğidir.
112 |
113 | Ama, Elastic Graph kullanıcı tıklama günlüklerinin bulunduğu verilerin
114 | davranışlarının özetlenmesi için de rahatça kullanılabilir. Analizin bu formunu
115 | tanımlamak için kullanılan genel ifadeler "collective intellegence" veya "wisdom
116 | of crowds"dur. Bu senaryoda, her bir dökümanın kendisi ilgili değildir ama bir
117 | çok kullanıcının davranışları bir desen oluşturabilir ve onlar öneri sisteminde
118 | kullanılabilir. Örn; "X ürününü satın alan kullanıcılar Y ürününü almak
119 | isteyebilir.". Bu senaryoda bizim sahte bağlantılar oluşturan tek seferlik
120 | dökümanların bağlantılarını ve zaten bilinen bağlantıları önlememiz gerekir
121 | (Örneğin X ürünü alan insanlar zaten süt almak zorunda ise). Bu düşüncede
122 | varsayılan ayarlar sadece en önemli bağlantıları tanımlamak için ayarlanmıştır.
123 |
124 | Öneri kullanımı için [LastFM dataset](http://mtg.upf.edu/node/1671) veri setine
125 | bir bakalım. Eğer, her bir dökümanında her bir dinleyici için sevdiği
126 | şarkıcıları bir dizi içerisinde tutan kullanıcı merkezli bir index oluşturursak,
127 | bu index içerisinde insanların "Chopin"i aradığımızda bu şarkıcıyı sevenlerin
128 | başka kimleri sevdiğine ulaşabiliriz.
129 |
130 | 
131 |
132 | Birbiri ile ilişkili klasik müzik sanatçıları dönecektir. Bu sanatçılar
133 | arasıdaki çizgilere tıkladığımızda ne kadar dinleyicinin ilgili olduğunu
134 | görebilirsiniz. Neredeyse tüm Mendelssohn dinleyicilerinin yarısı ayrıca Chopin
135 | dinlemektedirler.
136 |
137 | Graph API sadece _önemli ilişkileri_ tanımladı. Bu diğer Graph arama
138 | teknolojilerinden önemli bir ayrımdır.
139 |
140 | ### Popüler != Önemli
141 |
142 | Ayalar sekmesine geçip "sadece önemli bağlantılar" özelliğini kasten kapatıp
143 | neler olduğunu bir görelim.
144 |
145 | 
146 |
147 | "significant links" kutusu seçili değilken Chopin dinleyenler aramasını tekrar
148 | çalıştıralım ve farkı görelim.
149 |
150 | 
151 |
152 | Radiohead ve Coldplay gibi (dünyada) popüler sanatçılar şimdi sonuçlara
153 | sızmıştır kesin. 5,721 Cohip severin 1,843 tanesi Beatles'da sevmektedir. Biz
154 | bunu süt satın alan kişiler gibi
155 | ["commonly common"](http://www.infoq.com/presentations/elasticsearch-revealing-uncommonly-common)
156 | olarak tanımlıyoruz. "Significant links" düğmesini açtığımızda "uncommonly
157 | common" olarak cağırdığımız gürültülere dikkat etmeden direk konumuza
158 | odaklanıyor olacağız. Aslında yıllardır arama motorlarına güç veren TF-IDF
159 | algoritması da aynı ilkelere dayanmaktadır.
160 |
161 | _By reusing these relevance ranking techniques we can stay "on topic" when exploring connections in data. This is an important distinction from graph databases which have no concept of relevance ranking and are typically forced to employ a strategy of just deleting popular items (see the problem of "supernodes")._
162 |
163 | _Note: When performing detailed forensic work such as exploring the Panama Papers, it can help to keep "significant links" turned on to try avoid the super-popular companies but the "certainty" setting should be lowered from its default value of three to one. For wisdom-of-crowds type scenarios we want at least three documents to assert a link before we trust it whereas in forensics every document is potentially interesting._
164 |
165 | ### Özet
166 |
167 | Umarız bu yazı Graph'ın iki ana modun kullanımı için hızlı bir girişi olmuştur:
168 |
169 | - Forensics: Her döküman potansiyel olarak ilgi çekicidir. Arama bireysel
170 | kayıt ve aktörlere odaklanır.
171 | - Wisdom of crowds: Büyük ölçekli davranışların "büyük resmine" odaklanır.
172 | Bir çok gürültü yaratacak bağlantı mevcuttur ancak verideki sadece gerçekten
173 | önemli olan bağlantılara odaklanır.
174 |
175 | Gelecekteki yazılarımızda diğer özel kullanım alanlarına ve Kibana
176 | uygulamasının arka planda kullandığı Elasticsearch API'ını nasıl kullandığına
177 | daha derin bakıyor olacağız.
178 |
179 | Bizi takip edin...
180 |
181 |
182 | Kaynak : [https://www.elastic.co/blog/using-elastic-graph-and-kibana-to-analyze-panama-papers](https://www.elastic.co/blog/using-elastic-graph-and-kibana-to-analyze-panama-papers)
--------------------------------------------------------------------------------
/_posts/2016-07-17-eszamanlilik-kontrolu.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Eşzamanlılık Kontrolü
4 | categories:
5 | - blog
6 | summary: Elasticsearch dağıtık bir yapıya sahiptir ve bu dağıtık yapıda eşzamanlı işlemlerimizde verilerimizi kaybetmeden nasıl sürümleriz ve sürümleri yönetiriz.
7 | ---
8 |
9 | Eğer Dağıtık çalışan bir uygulamanız varsa ve uygulamanızda dökümanları
10 | güncelleyen silen ya da oluşturan bir mekanizmanızda varsa ki vardır; Genellikle
11 | dökümanlar üzerindeki işlemlerde çakışmalar olur ve bu çakışmalar yüzünden veri
12 | kayıpları meydana gelir. Örnek olarak aşağıdaki grafige bir göz atabilirsiniz.
13 |
14 | 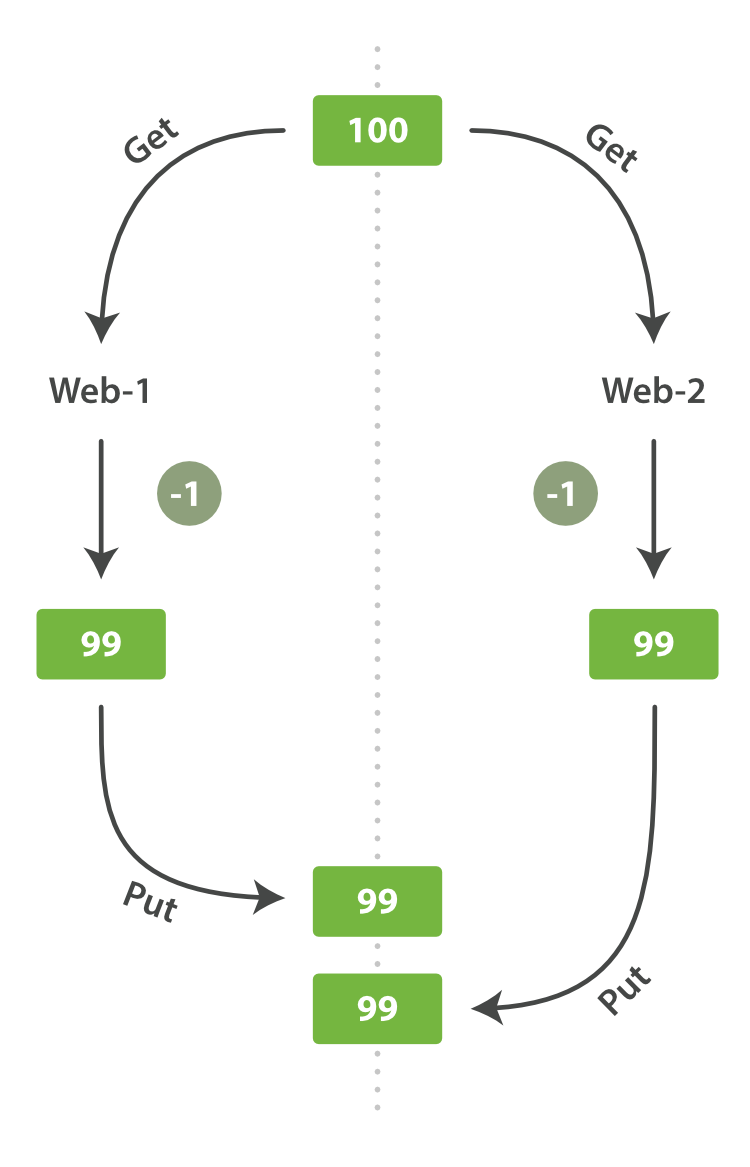
15 |
16 | Örnekte görüldüğü üzere `web-1` ve `web-2` paralel işleyen iki web sunucusu
17 | ve aynı döküman üzerinden işlem yapıyorlar ve bu dökümandaki `stock_count`
18 | alanının ilk değeri 100 iken ikiside aynı anda dökümanı çekiyor ve sonra
19 | dökümanın değerini güncelleyip tekrar yazıyorlar. Sonuç itibariyle
20 | dökümanın son değeri 98 olması gerekirken 99 olarak kalıyor. Veritabanı
21 | dünyasında buna sıklıkla rastlanır ve 2 genel yaklaşım vardır.
22 |
23 | - Pessimistic concurrency control (Kötümser eşzamanlılık kontrolü)
24 | İlişkili veritabanı sistemlerinde kullanılan satır ya da tablo bazında
25 | erişimi engelleyerek veri kaybını önleme yönetmidir.
26 | - Optimistic concurrency control (İyimser eşzamanlılık kontrolü)
27 | Elasticsearch tarafından kullanılan yöntemdir ve işlemi engellemez ancak
28 | güncelleme sırasında hata fırlatır ve çakışmayı çözme kararını uygulama
29 | bırakır.
30 |
31 | Elasticsearch dağıtıktır. Döküman oluşturulduğunda, güncellendiğinde ya da
32 | silindiğinde dökümanın yeni sürümü diğer `node`lara ya da yansılar ile
33 | paylaşılır. Elasticsearch aynı zamanda asenkron ve eşzamanlı çalışır,
34 | bunun anlamı replikasyon işlemi isteklerini paralelde göndermesidir.
35 | Elasticsearch eski sürüm bir dökümanın yeni sürüm bir döküman üzerine
36 | yazılmaması için bir yola ihtiyaç duyarmaktadır.
37 |
38 | Daha öncede bahsettiğimiz üzere döküman için çekildiğinde ya da silindiğinde
39 | her bir dökümana ait bir `_version` alanında bir numarası bulunmaktadır. Bu
40 | numara döküman her değiştiğinde artmaktadır. Elasticsearch bu numarayı
41 | değişiklikleri düzgün sırayla onaylamak için kullanmaktadır. Eğer eski
42 | sürüm yeni bir sürümden sonra ulaşırsa sessizce göz ardı eder.
43 |
44 | Biz `_version` numarasını kullanarak veri kaybı yaşamadan değişiklikleri
45 | uygulama içerisinde uygulayabiliriz. Değiştirmeyi düşündüğümüz döküman için
46 | özel bir sürüm numarası vererek bunu yapabiliriz. Eğer bu sürüm şimdi sürüm
47 | değil ise isteğimiz hata alır.
48 |
49 | Şimdi bir blog yazısı oluşturalım:
50 |
51 | ```
52 | PUT /website/blog/1/_create
53 | {
54 | "title": "My first blog entry",
55 | "text": "Just trying this out..."
56 | }
57 | ```
58 |
59 | Cevap gövdesi bize yeni oluşturulan döküman için bir sürüm dönecektir. Şimdi
60 | bu dökümanı düzenleyeceğimizi hayal edin: Bu veriyi bir form arayüzüne yükledik
61 | ve değişikliklerimizi yaptık ve yeni bir sürüm kaydettik.
62 |
63 | Öncelikle dökümanı çekelim.
64 |
65 | ```
66 | GET /website/blog/1
67 | ```
68 | Cevap gözdesi aynı sürüm numarasına sahip 1:
69 |
70 | ```
71 | {
72 | "_index" : "website",
73 | "_type" : "blog",
74 | "_id" : "1",
75 | "_version" : 1,
76 | "found" : true,
77 | "_source" : {
78 | "title": "My first blog entry",
79 | "text": "Just trying this out..."
80 | }
81 | }
82 | ```
83 |
84 | Şimdi dökümanın değişikliklerini kaydetmeyi denerken özel bir sürüm numarası
85 | gönderirsek:
86 |
87 | ```
88 | PUT /website/blog/1?version=1
89 | {
90 | "title": "My first blog entry",
91 | "text": "Starting to get the hang of this..."
92 | }
93 | ```
94 |
95 | Şu durumda biz sadece bizim `_version` numaramız 1 olduğu durumda güncellemenin
96 | doğru bir şekilde sonuçlanması gerektiğini belirtmiş oluruz. Bu istek başarıya
97 | ulaşacaktır ve cevap gövdesi bize yeni bir sürüm numarası olarak 2 dönecektir:
98 |
99 | ````
100 | {
101 | "_index": "website",
102 | "_type": "blog",
103 | "_id": "1",
104 | "_version": 2
105 | "created": false
106 | }
107 | ```
108 |
109 | Ancak, biz aynı isteği tekrar gönderecek olursak bu (yani sürüm numarası 1
110 | olarak) Elasticsearch bize "409 Conflict" başlıklı cevap ile aşağıdaki gibi bir
111 | cevap dönecektir:
112 |
113 | ```
114 | {
115 | "error": {
116 | "root_cause": [
117 | {
118 | "type": "version_conflict_engine_exception",
119 | "reason": "[blog][1]: version conflict, current [2], provided [1]",
120 | "index": "website",
121 | "shard": "3"
122 | }
123 | ],
124 | "type": "version_conflict_engine_exception",
125 | "reason": "[blog][1]: version conflict, current [2], provided [1]",
126 | "index": "website",
127 | "shard": "3"
128 | },
129 | "status": 409
130 | }
131 | ```
132 |
133 | Bu bize `_version` numarasının 2 olduğunu gösterir ve bizim 1. sürümü
134 | değiştirmeye çalıştığımızı gösterir.
135 |
136 | Şimdi uygulamamızın gerekliliklerine göre, kullanıcılarımıza bu dökümanı
137 | başkalarının zaten değiştirdiğini söyleyebiliriz, kaydetmeye çalıştığı dökümanı
138 | gösterebiliriz. Alternatif olarak, biz en son dökümanı tekrar çekip değişikliği
139 | tekrar kaydetmeyi deneyebilirsiniz.
140 |
141 | Dökümanı güncelleyen ya da silen her API uygulamanızın eşzamanlılık kontrolü
142 | yapabilmesine izin vermek için `version` parametresi alır.
143 |
144 | ### Dışardan (Kendimiz) Sürüm Kullanmak
145 |
146 | Ana veritabanı olarak Elasticsearch dışında bir veritabanı sistemi kullanmak
147 | genel bir yöntemdir ve Elasticsearch veriyi aranabilir kılar. Bunun anlamı
148 | bütün verinizin bir yansısı ana veritabanından bulunmasıdır ve Elasticsearch'e
149 | ayrı bir işlemler ile taşınır. Eğer birden fazla uygulama ya da işlemci bu
150 | eşzamanlamadan sorumlu ise daha önce de bahsettiğimiz eşzamanlılık sorunları
151 | ile karşılaşabilirsiniz.
152 |
153 | Eğer sizin ana olarak kullandığınız veritabanı sisteminizin bir sürüm numarası
154 | veya değeri varsa bu numara Elasticsearch arayüzünde de sürüm numaralandırması
155 | için kullanılabilir. Bunun için ekstra olarak `version_type=external`
156 | parametresini ve sürüm numarasını göndermeniz yeterlidir. Sürüm numarası
157 | `integer` değerinde olması ve sıfırdan büyük olmadıdır. Ekstra olarak
158 | `9.2e+18--a` pozitif sayısından küçük olmalıdır.
159 |
160 | Dış sürüm numarası içeride kullanılan sürümlemeye göre biraz farklı çalışır.
161 | Elasticsearch şu anki sürüm numarasının gönderilen ile aynı mı değil mi
162 | olduğunu kontrol etmek yerine, şu anki sürüm gönderilenden daha küçük mü
163 | diye kontrol eder. Eğer küçük ise yeni gönderilen sürüm numarası dökümanın
164 | yeni sürüm numarası olarak kaydedilir.
165 |
166 | Dış sürüm numaraları sadece güncelleme ve silme sırasında değil ayrıca yeni
167 | döküman oluşturulurken de gönderilebilir.
168 |
169 | Örneğin, yeni bir blog yazısı oluşturuken dışardan bir sürüm numarası olarak
170 | 5 değerini göndermek için aşağıdaki gibi bir istekte bulunuruz:
171 |
172 | ```
173 | PUT /website/blog/2?version=5&version_type=external
174 | {
175 | "title": "My first external blog entry",
176 | "text": "Starting to get the hang of this..."
177 | }
178 | ```
179 | Cevapta yeni sürüm numarasını 5 olarak görebilirsiniz:
180 |
181 | ```
182 | {
183 | "_index": "website",
184 | "_type": "blog",
185 | "_id": "2",
186 | "_version": 5,
187 | "created": true
188 | }
189 | ```
190 |
191 | Şimdi dökümanı tekrar güncelleyip yeni sürüm numarasını 10 olarak gönderelim:
192 |
193 | ```
194 | PUT /website/blog/2?version=10&version_type=external
195 | {
196 | "title": "My first external blog entry",
197 | "text": "This is a piece of cake..."
198 | }
199 | ```
200 |
201 | Sonuç başarılı ve yeni sürüm numarası 10:
202 |
203 | ```
204 | {
205 | "_index": "website",
206 | "_type": "blog",
207 | "_id": "2",
208 | "_version": 10,
209 | "created": false
210 | }
211 | ```
212 |
213 | Eğer bu sorguyu tekrar çalıştırırsanız çakışma hatası ile karşılaşacaksınız
214 | çünkü yeni göndereceğiniz sürüm numarası eskisinden daha büyük olmalı.
215 |
216 | Kaynaklar :
217 | - [https://www.elastic.co/guide/en/elasticsearch/guide/current/optimistic-concurrency-control.html](https://www.elastic.co/guide/en/elasticsearch/guide/current/optimistic-concurrency-control.html)
218 | - [https://www.elastic.co/guide/en/elasticsearch/guide/current/version-control.html](https://www.elastic.co/guide/en/elasticsearch/guide/current/version-control.html)
--------------------------------------------------------------------------------
/_posts/2016-09-28-ingest-node-nedir-ceviri.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Ingest Node Nedir (Çeviri)
4 | categories:
5 | - blog
6 | summary: Elasticsearch 5.0 sürümü ile birlikte yeni gelen yeni bir özelliği nasıl kullanacağımıza kısaca bir göz atalım. "Ingest Node".
7 | ---
8 |
9 | > Elasticsearch 5.0 sürümü ile birlikte yeni gelen yeni bir özelliği nasıl
10 | kullanacağımıza kısaca bir göz atalım. "Ingest Node".
11 |
12 | ## "Ingest Node" Nedir?
13 |
14 | "Ingest Node" genel veri dönüştürmeleri ve zenginleştirmeleri için kullanabileceğiniz
15 | yeni bir Elasticsearch node türüdür.
16 |
17 | Her bir görev bir `processor` olarak temsil edilir. Her bir `processor` bir `pipeline`lar
18 | dizisinden ile oluşur. (Buradaki terimlerin çevirilerini yapmadım ancak `processor`'ü
19 | veri işleyen bir yapı, `pipeline`'ı ise veri işleme hattı olarak düşünebilirsiniz.)
20 |
21 | Şu anda hali hazırda Elasticsearch içerisinde 20 tane `processor` bulunmaktadır.
22 | Örneğin: grok, date, gsub, lowercase/uppercase, remove ve rename. Tam listeye
23 | [şu adresten](https://www.elastic.co/guide/en/elasticsearch/reference/master/ingest-processors.html)(adres içeriği ingilizcedir) ulaşabilirsiniz.
24 |
25 | Bunun yanında `ingest` özelliği için ayrıca 3 tane eklenti daha bulunmaktadır:
26 |
27 | - [Ingest Attachment](https://www.elastic.co/guide/en/elasticsearch/plugins/master/ingest-attachment.html) : Powerpoint, Excel Spreadsheets, ve PDF gibi ikili
28 | kodlanmış dökümanları metin ve üstveri(metadata) haline getirir.
29 | - [Ingest Geoip](https://www.elastic.co/guide/en/elasticsearch/plugins/master/ingest-geoip.html) : IP adreslerin coğrafi yerine göre metinsel hale dönüştürür.
30 | - [Ingest User Agent](https://www.elastic.co/guide/en/elasticsearch/plugins/master/ingest-user-agent.html) : Tarayıcıların ve diğer uygulamaların HTTP'yi kullanırken
31 | kullandıkları kullanıcı aracısı(user agent) verisini işler ve bilgilerini yapısal bir hale
32 | getirir.
33 |
34 | ### Ingest Pipeline Oluşturma ve Kullanma
35 |
36 | `_ingest` arayüzü ile kolayca yeni bir "ingest pipeline" oluşturabilirsiniz.
37 |
38 | ```
39 | PUT _ingest/pipeline/rename_hostname
40 | {
41 | "processors": [
42 | {
43 | "rename": {
44 | "field": "hostname",
45 | "target_field": "host",
46 | "ignore_missing": true
47 | }
48 | }
49 | ]
50 | }
51 | ```
52 |
53 | Bu örnekte `rename_hostname` adında bir "pipeline" oluşturduk ve bu sadece
54 | `hostname` alanını alıp adını değiştirip `host` olarak geri yazıyor. Eğer `hostname`
55 | yok ise `processor` işlemine hata vermeden devam ediyor.
56 |
57 | "Pipeline"ı kullanmak için çeşitli yollar mevcut.
58 |
59 | Direk Elasticsearch API üzeriden kullanırken, `pipeline` parametresini url parametresi
60 | olarak göndermeniz yeterlidir. Örneğin :
61 |
62 | ```
63 | POST server/values/?pipeline=rename_hostname
64 | {
65 | "hostname": "myserver"
66 | }
67 | ```
68 |
69 | Logstash ile kullanırken çıktı ayarlamaları arasına `pipeline` parametresini eklemelisiniz:
70 |
71 | ```
72 | output {
73 | elasticsearch {
74 | hosts => "192.168.100.39"
75 | index => "server"
76 | pipeline => "rename_hostname"
77 | }
78 | }
79 | ```
80 |
81 | Benzer şekilde Beat uygulamasını kullanırken yine çıktı ayarları arasına `pipeline`
82 | parametresini eklemeniz gerekir:
83 |
84 | ```
85 | output.elasticsearch:
86 | hosts: ["192.168.100.39:9200"]
87 | index: "server"
88 | pipeline: "convert_value"
89 | ```
90 |
91 | > Note: Alpha 5.0 sürümünde, Beat ayarlarında `parameters.pipeline` şeklinde
92 | > kullanmalısınız
93 |
94 | ### Simulasyon
95 |
96 | Yeni bir pipeline oluşturduğunuzda, gerçek veri üzerinde kullanmadan önce test
97 | edebilmek ve bir hata fırlatıp fırlatmayacağını araştırmak gerçekten çok önemlidir.
98 |
99 | Bunun için bir [Simulate API](https://www.elastic.co/guide/en/elasticsearch/reference/master/simulate-pipeline-api.html) mevcuttur:
100 |
101 | ```
102 | POST _ingest/pipeline/rename_hostname/_simulate
103 | {
104 | "docs": [
105 | {
106 | "_source": {
107 | "hostname": "myserver"
108 | }
109 | }
110 | ]
111 | }
112 | ```
113 |
114 | Sonuçlar bize alanın başarılı bir şekilde değiştiğini gösterecektir:
115 |
116 | ```
117 | [...]
118 | "_source": {
119 | "host": "myserver"
120 | },
121 | [...]
122 | ```
123 |
124 | ### Gerçek bir örnek : Web Günlükleri
125 |
126 | Gerçek dünyadan bir örnek ile devam edelim: Web Günlükleri.
127 |
128 | Bu "[Combined Log Format](http://httpd.apache.org/docs/current/mod/mod_log_config.html)" içerisinde Apache httpd ve nginx tarafından desteklenen girdi günlüğünün bir örneği:
129 |
130 | ```
131 | 212.87.37.154 - - [12/Sep/2016:16:21:15 +0000] "GET /favicon.ico HTTP/1.1" 200 3638 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"
132 | ```
133 |
134 | Gördüğünüz gibi birkaç parça bilgiden oluşan bir metin: IP adres, zaman damgası,
135 | kullanıcı aracısı(user agent) ve daha fazlası. Hızlı bir arama ve görselleştirme sunmak
136 | için verimizi parçalara ayırıp Elasticsearch'de kendi alanları içerisine koyacağız. İsteğin
137 | nereden geldiğini bilmemiz de gerçekten çok yararlı olurdu. Bunları hepsini
138 | aşağıdaki pipeline ile yapabiliriz.
139 |
140 | ```
141 | PUT _ingest/pipeline/access_log
142 | {
143 | "description" : "Ingest pipeline for Combined Log Format",
144 | "processors" : [
145 | {
146 | "grok": {
147 | "field": "message",
148 | "patterns": ["%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \\[%{HTTPDATE:timestamp}\\] \"%{WORD:verb} %{DATA:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response:int} (?:-|%{NUMBER:bytes:int}) %{QS:referrer} %{QS:agent}"]
149 | }
150 | },
151 | {
152 | "date": {
153 | "field": "timestamp",
154 | "formats": [ "dd/MMM/YYYY:HH:mm:ss Z" ]
155 | }
156 | },
157 | {
158 | "geoip": {
159 | "field": "clientip"
160 | }
161 | },
162 | {
163 | "user_agent": {
164 | "field": "agent"
165 | }
166 | }
167 | ]
168 | }
169 | ```
170 | Bu örnek 4 `processor` içermektedir:
171 |
172 | - `grok` regular expression ile metin halindeki günlük verisini işleyip kendi alanları olan yapısal bir hale getirmektedir.
173 | - `date` dökümanın zaman dangası bilgisini tanımlamaktadır.
174 | - `geoip` istekte bulunanın IP adresini alıp iç bir veritabanına sorarak coğrafi konumunu belirlemektedir.
175 | - `user-agent` kullanıcı aracı bilgisini metin olarak alıp yapısal bir hale getirmektedir.
176 |
177 | Son iki `processor` Elasticsearch'e eklenti olarak gelmektedir. Bu yüzden onları
178 | öncelikli olarak kurmalıyız:
179 |
180 | ```
181 | bin/elasticsearch-plugin install ingest-geoip
182 | bin/elasticsearch-plugin install ingest-user-agent
183 | ```
184 |
185 | Pipeline'ı test etmek için Simutale API'ı kullanabiliriz :
186 |
187 | ```
188 | POST _ingest/pipeline/httpd_weblogs/_simulate
189 | {
190 | "docs": [
191 | {
192 | "_source": {
193 | "message": "212.87.37.154 - - [12/Sep/2016:16:21:15 +0000] \"GET /favicon.ico HTTP/1.1\" 200 3638 \"-\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36\""
194 | }
195 | }
196 | ]
197 | }
198 | ```
199 |
200 | Sonuç bize çalıştığını göstercektir:
201 |
202 | ```
203 | {
204 | "docs": [
205 | {
206 | "doc": {
207 | "_index": "_index",
208 | "_type": "_type",
209 | "_id": "_id",
210 | "_source": {
211 | "request": "/favicon.ico",
212 | "agent": "\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36\"",
213 | "geoip": {
214 | "continent_name": "Europe",
215 | "city_name": null,
216 | "country_iso_code": "DE",
217 | "region_name": null,
218 | "location": {
219 | "lon": 9,
220 | "lat": 51
221 | }
222 | },
223 | "auth": "-",
224 | "ident": "-",
225 | "verb": "GET",
226 | "message": "212.87.37.154 - - [12/Sep/2016:16:21:15 +0000] \"GET /favicon.ico HTTP/1.1\" 200 3638 \"-\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36\"",
227 | "referrer": "\"-\"",
228 | "@timestamp": "2016-09-12T16:21:15.000Z",
229 | "response": 200,
230 | "bytes": 3638,
231 | "clientip": "212.87.37.154",
232 | "httpversion": "1.1",
233 | "user_agent": {
234 | "patch": "2743",
235 | "major": "52",
236 | "minor": "0",
237 | "os": "Mac OS X 10.11.6",
238 | "os_minor": "11",
239 | "os_major": "10",
240 | "name": "Chrome",
241 | "os_name": "Mac OS X",
242 | "device": "Other"
243 | },
244 | "timestamp": "12/Sep/2016:16:21:15 +0000"
245 | },
246 | "_ingest": {
247 | "timestamp": "2016-09-13T14:35:58.746+0000"
248 | }
249 | }
250 | }
251 | ]
252 | }
253 | ```
254 |
255 | ### Sonraki
256 |
257 | İkinici kısımda Filebeat kullanarak ingest pipeline nasıl oluşturulur göstereceğiz ve
258 | Elasticsearch ve Kibana ile günlükleri görselleştireceğiz.
259 |
260 | > Note : Bazı terimlerin çevirisinde anlama sıkıntısı ortaya çıkaracağı için çevirisini
261 | yapmadım.
262 |
263 | Kaynak : [https://www.elastic.co/blog/new-way-to-ingest-part-1](https://www.elastic.co/blog/new-way-to-ingest-part-1)
--------------------------------------------------------------------------------
/_posts/2016-09-29-elasticsearch-ve-kibana-nin-beta-surumleri-icin-docker-imajlarina-giris.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Elasticsearch ve Kibana'nın Beta Sürümleri için Docker İmajlarına Giriş (Çeviri)
4 | categories:
5 | - blog
6 | summary: Elasticsearch ve Kibana 5.0 sürümünü docker üzerinden nasıl çalıştırırız ve hızlı bir geliştirme ortamını nasıl kurarız.
7 | ---
8 |
9 | Elasticsearch ve Kibana için beta sürümleri için docker imajları burada! 5.0 sürümlerinin son sürümleri ve
10 | ayrıca [x-pack eklentisinin](https://www.elastic.co/downloads/x-pack) de içinde gelecektir. İmajlar
11 | Elastic'in kendi docker servisinde tutulmaktadır.
12 |
13 | Talimatlar [elasticsearch-docker](https://github.com/elastic/elasticsearch-docker) ve
14 | [kibana-docker](https://github.com/elastic/kibana-docker) github sayfalarında da bulunabilir, ama şimdi
15 | Elasticsearch + Kibana ikilisinini bunlar ile ne kadar kolay olduğunu görelim.
16 |
17 | Öncelikle şunlardan emin olalım:
18 |
19 | - [Docker Engine](https://docs.docker.com/engine/installation/) kurulu olmalı
20 | - [Ön hazırlıklar](https://github.com/elastic/elasticsearch-docker#host-prerequisites) yapılmış olmalı
21 | - Eğer Linux kullanıyorsanız [docker-compose](https://github.com/docker/compose/releases/latest) kurulu olmalı
22 |
23 | Elasticsearch ve Kibana kurulumunda yardımcı olarak örnek [docker-compose.yml]() dosyanızı indir:
24 |
25 | ```
26 | ---
27 | version: '2'
28 | services:
29 | kibana:
30 | image: docker.elastic.co/kibana/kibana
31 | links:
32 | - elasticsearch
33 | ports:
34 | - 5601:5601
35 |
36 | elasticsearch:
37 | image: docker.elastic.co/elasticsearch/elasticsearch
38 | cap_add:
39 | - IPC_LOCK
40 | volumes:
41 | - esdata1:/usr/share/elasticsearch/data
42 | ports:
43 | - 9200:9200
44 |
45 | volumes:
46 | esdata1:
47 | driver: local
48 | ```
49 |
50 | Daha sonra aşağıdaki komutları çalıştıralım:
51 |
52 | ```
53 | $ docker-compose up
54 | ```
55 |
56 | > Note: Yukarıdaki kurulum sizin hali hazırda Elasticsearch ve Kibana için
57 | > [varsayılan portları](https://gist.github.com/dliappis/52de1f4bb10fd23f5b91ea5fcb5d2560#file-docker-compose-yml-L9-L18)
58 | > kullanmadığınızı varsayar. Kendiniz bu portları docker-compose.yml dosyasından ayarlayabilirsiniz.
59 |
60 | Ekranda Elasticsearch ve Kibana'dan bazı günlükleri oluştuğunu göreceksiniz. Kibana arayüzüne girmek için
61 | [http://localhost:5601](http://localhost:5601) adresini kullanın ve sizi bir Kibana 5.0 giriş sayfası
62 | karşılayacaktır.
63 |
64 | 
65 |
66 | [X-Pack](https://www.elastic.co/downloads/x-pack) önceden yüklenmiş olduğundan giriş yapmak için
67 | varsayılan bilgileri kullanabilirsiniz.(Kullanıcı adı: `elastic`, şifre: `changeme`) Bu bilgileri Kibana'da bulunan
68 | yönetim aracını kullanarak kesinlikle değiştirmelisiniz.
69 |
70 | Şimdi biraz veri ekleyelim. Bunun için curl kullanarak `users` index'ine iki tane kullanıcı ekleyeceğiz:
71 |
72 | ```
73 | curl -u elastic -XPOST 'localhost:9200/users/1' -d '{"first_name": "John","last_name": "Doe","email_address": "user@example.com"}'
74 | curl -u elastic -XPOST 'localhost:9200/users/2' -d '{"first_name":"James","last_name":"Kirk","email_address":"jkirk@unknowngalaxy.com"}'
75 | ```
76 |
77 | Kibana arayüzüne dönelim, ve veriler için hangi index'i kullanacağımızı ayarlayalım. Bu alana index adı
78 | olarak `users` girelim ve `Index contains time-based events` kutusunu işaretlemeyelim. (Çünkü şu anda
79 | zaman damgası olan bir verimiz yok. Eğer zaman damgası olan bir verimiz olursa, günlükler gibi, o zaman bu alanı işaretlemeniz iyi olur.). Ekranımız aşağıdaki gibi olacaktır:
80 |
81 | 
82 |
83 | `Create` düğmesine tıklayalım ve eklemiş olduğumuz verileri Kibana arayüzünde artık görebiliriz.
84 |
85 | 
86 |
87 | Konteynerlarınızı `docker-compose down` komutu ile kapatabilirsiniz; bu komut oluşturduğunuz
88 | Elasticsearch veri klasörleri dahil konteynerleri tamamen silmeyecektir. `docker-compose up`u tekrar
89 | çalıştırdığınızda verilerinize tekrar ulaşabilirsiniz. `docker-compose down -v` ile hem verilerini hem de
90 | konteyneri kaldırabilirsiniz.
91 |
92 | İmajlar beta sürümüdür ve production ortamında kullanmanızı önermiyoruz. Ama Github sayfamızda bir kaç
93 | öneri bulunmaktadır, [kontrol edebilirsiniz](https://github.com/elastic/elasticsearch-docker#notes-for-production-use-and-defaults).
94 |
95 | Kaynak : [https://www.elastic.co/blog/releasing-beta-version-of-elastic-docker-images](https://www.elastic.co/blog/releasing-beta-version-of-elastic-docker-images)
--------------------------------------------------------------------------------
/_posts/2016-10-26-node-nedir.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Node Nedir?
4 | categories:
5 | - blog
6 | summary: Elasticsearch Node Nedir? Çeşitleri nelerdir?
7 | ---
8 |
9 | Bir Elasticsearch programı çalıştırdığınızda her zaman bir `node` ile başlarsınız. Birbiri ile bağlantılı `node`ların oluşturduğu yapıya da `cluster` denir. Sadece bir `node` ile çalıştırırsanız, bir `node`dan oluşan bir `cluster` oluşur. Şöyle düşünün; bir sunucuda ya da bilgisayarda Elasticsearch uygulamasını ayağa kaldırdığınızda bir node'unuz olur. Aynı makinede ikinci bir Elasticsearch uygulaması ayağa kaldırdığınızda ikinci bir node'unuz olur. İki makine eğer aynı cluster ismine sahip ise birbirlerini görürler/tanırlar ve bir cluster oluştururlar. Burada ben her bir Elasticsearch node'u için düğüm kavramını kullanacağım. ()Aslında bu kelime beni çeviri konusuda tatmin etmedi ancak daha iyisinide bulamadım.) Yani bu örnek ile birlikte bir sunucuda 2 düğüm ile bir cluster(küme) oluşturmuş olduk. Bazı terimleri çeviri yapmadan direk ingilizce isimleri ile kullanacağım ki çok fazla kafa karışıklığı da olmasın.
10 |
11 | Bir `cluster` içerisindeki her `node`(düğüm) HTTP ve Transport trafiğini varsayılan olarak işleyebilmektedir. Transport katmanı düğümler arasındaki ve Java TransportClient arayüzü ile iletişimde kullanılmaktadır. HTTP katmanı ise sadece REST arayüzü için kullanılmaktadır.
12 |
13 | Bir küme(cluster) içerisindeki her düğüm(node) diğer düğümlerden haberdardır ve gelen istekleri uygun diğer düğümlere yönlendirmektedir. Bunun yanı sıra, her bir düğüm(node) bir ya da bir kaç tür amaca hizmet eder:
14 |
15 | - **Master-eligible node (Master olmak için uygun node)** : Konfigürasyonununda `node.master` kısmı `true` olarak işaretlenmiş (varsayılanda böyledir) düğümlerdir. Bu düğümler aslında kümeyi kontrol eden düğümlerdir. Birden fazla ana düğüm işaretlenmiş düğümünüz olabilir. Burada Elasticsearch `Zen Discovery` özelliği ile bir tanesini ana düğüm olarak seçecektir.
16 | - **Data Node** : Konfigürasyonunda `node.data` kısmı `true` olarak işaretlenmiş düğümlerdir. Data node (veri düğümü) veriyi tutar ve veriyle ilgili CRUD, arama ve aggregation gibi işlemleri yürütür.
17 | - **Client Node** : Bir Client Node hem `node.master` hem de `node.data` kısımları `false` olarak işaretlenmiş düğümlerdir. Bunlar "smart router" (akıllı yönlendirici) olarak davranır ve kümeye(cluster) gelen istekleri uygun ana düğümlere(master node) ve veri ile ilgili istekleri uygun veri düğümlerine(data node) yönlendirir.
18 |
19 | Varsayılan olarak bir düğüm hem veri düğümü(data node) hem de ana düğümdür(master-eligible node). Küçük kümeler için bu gerçekten iyi olabilir ancak kümeler büyüdükçe bu koordinasyonu ele almak ve sabit veri düğümleri ve ana düğümleri belirlemek daha iyi olabilir.
20 |
21 | Kaynak : [https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html]()
--------------------------------------------------------------------------------
/_posts/2016-11-03-arama-sonucunda-metni-vurgulamak.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Arama Sonucunda Metni Vurgulamak
4 | categories:
5 | - blog
6 | summary: Arama sonuçlarınızda aramalarda eşleşen sonuçları vurgulamak için Elasticsearch hali hazırda bir özellik sunmaktadır. Bu yazıda bu özelliğin nasıl çalıştığını ve en efektif yöntem nedir öğreneceğiz.
7 | ---
8 |
9 | Bir ya da birden fazla alanda arama sonuçlardaki metinleri vurgulamak için kullanılan özelliktir. Bunun için Elasticsearch arka planda Lucene `highlighter`, `fast-vector-highlighter` veya `postings-highlighter` kullanmaktadır. Daha iyi anlamanız için örneğin google.com üzeride bir arama yaptığınızda eşleşen kelimelerin arama sonuçlarında koyu renkli geldiğini görebilirsiniz. Elasticsearch Highlight özelliği bunu yapabilmenizi sağlamaktadır. Bu özellik ile ilgili bir arama örneği oluşturalım:
10 |
11 | ```
12 | {
13 | "query" : {...},
14 | "highlight" : {
15 | "fields" : {
16 | "content" : {}
17 | }
18 | }
19 | }
20 | ```
21 |
22 | Yukarıdaki örnekte, `content` alanı her bir arama için vurgulama yapılacak alandır. `highlight` parametresi içerisinde belirttiğiniz taktirde bu herhangi başka bir alan da olabilir. Alan isimleri joker semboller ile de belirtilebilir. Örneğin `comment_*` ile `comment_` ile başlayan alanlar seçilmiş olacaktır. İstediğini kadar alanda vurgulama işlemi yapabilirsiniz. Ancak dikkat etmeniz gereken şey vurgulama yapma türünüze göre seçtiğiniz alanlarda doğru şekilde vurgulama yapabilirsiniz.
23 |
24 | ### Plain Highlighter
25 |
26 | Varsayılan seçenek olarak `plain` vurgulama türü kullanılmaktadır ve bu tür vurgulama tabanda Lucene Highlighter kullanılır. Diğer tür vurgulama algoritmalarına göre daha yavaş çalışır. Ekstra hiçbir konfigürasyon yapmazsanız bu tür vurgulama kullanılacaktır.
27 |
28 | ### Posting Highlighter
29 |
30 | Eğer mapping oluşturulurken arama yapmak istediğiniz alanların `index_options` parametresine `offsets` değerini verirseniz varsayılanın yerine `Posting` tipi vurgulama yöntemi kullanılacaktır. `Plain` olana göre daha hızlıdır. Çünkü metni vurgulama işlemi sırasında tekrar analiz etmeniz gerekmez ve büyük dökümanlar için daha performanslıdır. Bir sonraki vurgulama tipi olan `term_vector`'a göre daha az alan(disk alanı) harcar. Doğal dillerde gerçekten iyidir ancak html içeren metinlerde o kadar da iyi değildir.
31 |
32 | Mapping ayarlarını yaparken aşağıdaki gibi bir konfigürasyon yapabilirsiniz:
33 |
34 | ```
35 | {
36 | "type_name" : {
37 | "content" : {"index_options" : "offsets"}
38 | }
39 | }
40 | ```
41 |
42 | ### Fast Vector Highlighter
43 |
44 | Eğer mapping oluşturulurken arama yapmak istediğiniz alanların `term_vector` parametresine `with_positions_offsets` verirseniz varsayılanın yerine `Fast Vector` vurgulama yöntemi kullanılmaktadır. Özellikle büyük (> 1MB) alanlar için daha hızlıdır. Index boyutunu diğerlerine göre daha fazla büyütecektir. `matched_fields` özelliği ile birden fazla alandaki eşleşen sonuçları birleştirebilmektedir. Aşağıda bir `content` alanı için `Fast Vector` vurgulama yöntemini uygulayalım:
45 |
46 | ```
47 | {
48 | "type_name" : {
49 | "content" : {"term_vector" : "with_positions_offsets"}
50 | }
51 | }
52 | ```
53 |
54 | ### Vurgulama Tipini Seçmek
55 |
56 | Sorgulama yaparken vurgulama yapmak istediğiniz alan için vurgu türünü seçebilirsiniz. Örneğin:
57 |
58 | ```
59 | {
60 | "query" : {...},
61 | "highlight" : {
62 | "fields" : {
63 | "content" : {"type" : "plain"}
64 | }
65 | }
66 | }
67 | ```
68 |
69 | ### Vurgulama için Etiket Seçimi
70 |
71 | Vurgulamak istediğiniz sonuçları belli bir html etiketleri arasında göstermek istiyorsak bunun için `pre_tags` and `post_tags` parametrelerini kullanabiliriz. Bunlar için varsayılan değerler `` ve ``dir. Farklı bir etiket vermenin örneği aşağıdaki gibidir:
72 |
73 | ```
74 | {
75 | "query" : {...},
76 | "highlight" : {
77 | "pre_tags" : [""],
78 | "post_tags" : [""],
79 | "fields" : {
80 | "_all" : {}
81 | }
82 | }
83 | }
84 | ```
85 |
86 | ### Örnek Sorgu ve Sonuç
87 |
88 | Örnek Sorgu aşağıdaki gibidir ve vurgulama türü olarak `fvh` kullanılmıştır.
89 |
90 | ```
91 | GET test/type/_search
92 | {
93 | "query": {
94 | "match": {
95 | "text": "şarkı"
96 | }
97 | },
98 | "highlight": {
99 | "fields" : {
100 | "pre_tags":[""],
101 | "post_tags":["<\/em>"],
102 | "text" : {}
103 | }
104 | }
105 | }
106 | ```
107 |
108 | Sorgu sonucu olarak aşağıdaki gibi bir cevap alınacaktır:
109 |
110 | ```
111 | {
112 | "took": 47,
113 | "timed_out": false,
114 | "_shards": {
115 | "total": 5,
116 | "successful": 5,
117 | "failed": 0
118 | },
119 | "hits": {
120 | "total": 1,
121 | "max_score": 0.11506981,
122 | "hits": [
123 | {
124 | "_index": "test",
125 | "_type": "type",
126 | "_id": "2",
127 | "_score": 0.11506981,
128 | "_source": {
129 | "id": 2,
130 | "text": "Güzel söyleri olan şarkılar gerçektende beni derinden etkiler"
131 | },
132 | "highlight": {
133 | "text": [
134 | "Güzel söyleri olan şarkılar gerçektende beni derinden etkiler"
135 | ]
136 | }
137 | }
138 | ]
139 | }
140 | }
141 | ```
--------------------------------------------------------------------------------
/_posts/2016-12-21-Elasticsearch-5-0-ile-gelen-degisiklikler-eklentiler.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Elasticsearch 5.0 ile gelen Değişiklikler - Eklentiler
4 | categories:
5 | - blog
6 | summary: Elastic 5.0 ile birlikte birçok değişikliğe gitti. Örneğin özellikle daha önceden önerdiğim Head ve Kopf eklentilerinin 5.x sürümlerinde eklenti olarak yüklenemiyor. Bu yazıda bu gibi eklentiler üzerinde ne gibi değişiklikler yaşandı bahsetmeye çalışacağım.
7 | ---
8 |
9 |
10 | Elastic 5 sürümü ile birlikte bazı servislerini farklı ürünler olarak elasticsearch
11 | bünyesinden çıkardı. Bununla birlikte eklentilerde de biraz değişiklikler oldu. Bu
12 | yazımda buna biraz değineceğim.
13 |
14 | İlk olarak bir eklenti yüklerken ya da silerken kullandığımız `bin/plugin` komutu
15 | isim değiştirdi. yeni ismi şu şekilde `bin/elasticsearch-plugin`. `analysis-icu`
16 | eklentisini kurarken aşağıdaki gibi bir komut çalıştırmamız gerekiyor.
17 |
18 | ```
19 | bin/elasticsearch-plugin install analysis-icu
20 | ```
21 |
22 | Site arayüzü olan eklentiler elasticsearch eklentisi olamayacaklar artık. Bu da
23 | belkide en çok kullandığımız [Head](https://github.com/mobz/elasticsearch-head)
24 | ve [Kopf](https://github.com/lmenezes/elasticsearch-kopf) eklentilerinin olmayacağı
25 | anlamına geliyor. Tabiki de tamamen hayatımızdan silinmiyorlar. Bunları kullanabileceğiniz
26 | çeşitli yöntemler mevcut. Head eklentisi kendi başına bir
27 | [node server](https://github.com/mobz/elasticsearch-head#running-as-a-plugin-of-elasticsearch)
28 | üzerinde çalışabiliyor mesela.
29 |
30 | Bunlar genel yapı ile ilgili iken bazı eklentiler direk Elasticsearch içerisine
31 | alındı. Örneğin `Delete-By-Query` eklentisi [Delete By Query API](https://www.elastic.co/guide/en/elasticsearch/reference/5.1/docs-delete-by-query.html) olarak içeri alındı. Bunun dışında Mapper Attachements
32 | eklentisi [`ingest-attachment`](https://www.elastic.co/guide/en/elasticsearch/plugins/5.1/ingest-attachment.html)
33 | olarak değişti. Tabi buradan şunuda anlamamız gerekiyor. Daha öncede bahsetmiştik
34 | IngestNode diye de bir kavram oluştu. Bu kavram ile birlikte ES, dışardan gelen verileri
35 | bir süzgeçten geçirmemize de olanak sağlıyor. Bunu ben Logstash'in input bacağındaki
36 | filtrelere benzetiyorum.
37 |
38 | Eklentiler dışında bir çok konuda değişikler mevcut. Hatta bu değişikleri daha
39 | kolay üstesinden gelmek için ES ekibi
40 | [elasticsearch-migration eklentisi](https://github.com/elastic/elasticsearch-migration/blob/2.x/README.asciidoc)
41 | çıkardılar. Bu eklenti, 5.x sürümlerine geçiş için neleri değiştirmeniz gerektiğiyle
42 | ilgili bir liste sunuyor.
43 |
--------------------------------------------------------------------------------
/_posts/2017-01-10-nested-veri-tipi.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Nested Veri Tipi
4 | categories:
5 | - blog
6 | summary: Nested veri tipine kısaca bir göz atacağız ve Elasticsearch bu veriyi nasıl tutuyor onu inceleyeceğiz. İçerisinde nested veriler bulunan bir index üzerinde aramalar yapıp aslında belkide bilmeden yanlış aramalar yaptığımız bir index'i düzelteceğiz.
7 | ---
8 |
9 | Aslında `nested` veri tipi `object` veri tipinin biraz daha özelleştirilmiş halidir. Bu özellik alt nesne olarak eklediğimiz verilerimizi bağımsız olarak indexleme imkanı ve her birini bağımsız olarak arama imkanı sağlar. Bunu nasıl sağlamaktadır kısaca bir göz atalım.
10 |
11 | Lucene'de nested objeler için bir yapı bulunmamaktadır. Örneğin siz aşağıdaki gibi nested bir yapıda olan JSON objesini Lucene'de store etmek isterseniz:
12 |
13 | ```
14 | {
15 | "id": 1,
16 | "type": {
17 | "id": 1,
18 | "name": "Dram"
},
19 | "name": "Schindler's List"
}
20 | ```
21 |
22 | Lucene'de bu şöyle bir yapıda olacaktır:
23 |
24 | ```
25 | {
26 | "id": 1,
27 | "type.id": 1,
28 | "type.name": "Dram",
29 | "name": "Schindler's List"
}
30 | ```
31 |
32 | Aslında Elasticsearch'de Lucene üzerine kurulduğu için bu gibi durumlarda aramaya Lucene gibi yaklaşmaktadır. Bu verdiğimiz küçük örnekte arama tarafında aslında bir sıkıntı çıkmamaktadır. Siz "Dram" diye arama yaptığınızda `type.name` alanında kelimeyi arayacaktır. Şimdi biraz daha karmaşık bir JSON objesi yazalım:
33 |
34 | ```
35 | {
36 | "id": 1,
37 | "producers": [
38 | {
39 | "firstname": "Steven",
40 | "lastname": "Spielberg"
41 | },
42 | {
43 | "firstname": "Gerald",
44 | "lastname": "R. Molen"
45 | },
46 | {
47 | "firstname": "Branko",
48 | "lastname": "Lustig"
49 | }
50 | ],
51 | "name": "Schindler's List"
52 | }
53 | ```
54 |
55 | Şimdi bu karmaşık verinin Lucene'de nasıl olduğuna bir göz atalım:
56 |
57 | ```
58 | {
59 | "id": 1,
60 | "producers.firstname": [ "Steven", "Gerald", "Branko" ],
61 | "producers.lastname": [ "Spielberg", "R. Molen", "Lustig" ],
62 | "name": "Schindler's List"
63 | }
64 | ```
65 |
66 | Görsel olarak verimiz biraz küçüldü ve başka bir farklılık göremiyoruz gibi ancak şöyle bir durum oluştu. Nested olarak tuttuğumuz JSON objesinde `Steven Spielberg` için bir bağ vardı ve bu bir `producer`ı niteliyordu, isim ve soyisim olarak. Ancak ikinci objede bu bağı kurmak pek mümkün görünmüyor. Yani bu bağ kayboldu. Burada adı yine `Steven` olup soy ismi `Lustig` olan bir şahsı aradığımızda yukarıdaki döküman eşleşecektir. Ancak bu eşleşme doğru değildir. Aslında bizim verimizde `Steven Lustig` diye birisi yoktur. `Steven Spielberg` vardır.
67 |
68 | ```
69 | GET movies/_search
70 | {
71 | "query": {
72 | "bool": {
73 | "must": [
74 | { "match": { "producers.firstname": "Steven" }},
75 | { "match": { "producers.lastname": "Lustig" }}
76 | ]
77 | }
78 | }
79 | }
80 | ```
81 |
82 | Bu durumda dizi olan alt objeleri bağımsız olarak indexlemek ve bunu yönetmeniz gerekmektedir. Bunun için iki yol var. Ya kendiniz ayrıca bir index açıp içerisine bu verileri ayrıca index'leyebilirsiniz ya da `nested` objeler kullanabilirsiniz. `nested` tipini kullanırsanız bu alt objeleri Elasticsearch zaten bağımsız olarak index'leyecektir. Bunun anlamıda her bir obje diğerlerinden bağımsız olarak aranabilecektir. Bunu bir görelim.
83 |
84 | ```
85 | PUT movies
86 |
87 | PUT movies/movie/_mapping
88 | {
89 | "properties": {
90 | "producers": {
91 | "type": "nested"
92 | }
93 | }
94 | }
95 | ```
96 |
97 | Bu mapping ile birlikte normal obje yapısından farklı olarak `producers` alanı için tip olarak `nested` tipini kullandık. Veriyi kaydetme yönteminde herhangi bir değişikliğimiz oluşmadı. Buradaki değişikliği Elasticsearch hallediyor. Ancak arama yöntemi olarak eskisi gibi düz bir `match` arama sorgusu gönderemeyeceğiz. Arama sorgumuzu da `nested` olarak değiştirmemiz gerekmektedir. Aşağıdaki örnek sorguya bir göz atalım:
98 |
99 | ```
100 | GET movies/_search
101 | {
102 | "query": {
103 | "nested": {
104 | "path": "producers",
105 | "query": {
106 | "bool": {
107 | "must": [
108 | { "match": { "producers.firstname": "Steven" }},
109 | { "match": { "producers.lastname": "Lustig" }} 
110 | ]
111 | }
112 | }
113 | }
114 | }
115 | }
116 | ```
117 |
118 | Gördüğünüz üzre bu sorguda `Steven Lustig` diye arama yaptığımızda sonuç vermezken `Steven Spielberg` diye arama yaptığımızda sonuç verecektir.
119 |
120 |
121 |
122 |
123 |
124 |
--------------------------------------------------------------------------------
/_posts/2017-03-19-Shard-ve-Replica.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Shard ve Replica
4 | categories:
5 | - blog
6 | summary: Elasticsearch'ün temel konularından olan Shard ve Replica nedir, neden önemlidir ve hayatımıza ne katmaktadır kısa bir göz atacağız.
7 | ---
8 |
9 |
10 | > Bazı kavramları bilerek ve isteyerek Türkçe'ye çevirmedim. Çünkü araştırma yaparken ingilizcesi üzerinden araştırma yapmak daha çok sonuç getirecektir ve bilgiye daha rahat ulaşılacaktır.
11 |
12 | Bir "index", bir "node"a sığmayacak kadar büyük veri setini içerebilir. Örneğin bir "index" içerisinde milyarlarca döküman olabilir ve bunların büyüklükleri 1TB'a ulaşabilir ve bir "node" üzerindeki disklerinizin büyüklüğü bu kadar olmayabilir. Diğer taraftan sadece bir node üzerinden bu büyük veriyi sunmanız aramalarınızı yavaşlatabilir.
13 |
14 | Bu problemi çözmek için, Elasticsearch "shard" adı verilen, index'inizi alt parçalara bölen, bir yapı sunmaktadır. Elasticsearch sayesinde bir "index" oluşturueken rahatça kaç "shard" olması gerektiğini belirtebilirsiniz. Her bir "shard" aslında kendi başına tam donanımlı birer "index"dir.
15 |
16 | "Sharding" 2 sebeple önemlidir:
17 |
18 | - Yatayda ölçeklendirme imkanı sunar
19 | - Arama Performansınızı/İşlem hacminizi artırmak için işlemlerinizi birden fazla "shard"a(ya da "node"a) dağıtır ve paralel bir şekilde çalışmasını sağlar.
20 |
21 | "Shard"ların nasıl dağıtık olduğunu ve "shard"lara ayrılmış dökümanların arama sırasında nasıl geri birleştirildiği tamamen Elasticsearch tarafından yönetilmektedir ve kullanıcı olarak ekstra bir çaba harcamanız gerekmez.
22 |
23 | Ağ ve bulut mimarilerinde herhangi bir zamanda hatalar olabilmektedir. Bir "node" ya da "shard" herhangi bir sebeple ulaşılamaz olduğunda ya da bozulduğunda, bu hata durumunu düzeltecek bir sistemin olması gerçekten çok yararlıdır ve aynı zamanda tavsiye edilmektedir. Bu amaçla, Elasticsearch "index shard"larının bir veya daha fazla kopyalarını oluşturmaktadır ve bunlara "replica shard" denilmektedir. İngilizce olarak kısaca "replicas" denilmektedir.
24 |
25 | "Replication" 2 sebeple çok önemlidir:
26 |
27 | - Shard veya node hata verdiğinde yüksek erişilebilirlik imkanı sunar. Bu sebeple, bir replica shard'ın, kendini kopyaladığı ana shard ile aynı node içerisinde olmamaması gerekmektedir.
28 | - Aramalarınız paralel olarak tüm replica'larda çalıştığı için arama hazminizi veya işlem hacminizi ölçeklendirmenize olanak sağlar.
29 |
30 | Özetlemek gerekirse, her bir "index" bir veya daha fazla "shard"a ayrılır. Bir "index"te hiç "replica" olmayabilir veya birden fazla da olabilir. Bir kez "replica" edilirse her bir "index"in bir "primary shard"ları ve aynı zamanda "primary shard"ların kopyaları olan "replica shard"ları olacaktır. "Shard" sayıları ve "replica" sayıları "index" oluşturulurken her bir "index" için ayrı ayrı verilebilir. "index" oluşturulduktan sonra "replica shard" sayısı dinamik olarak değişitirilebilirken, "shard" sayısı değişitirilemez.
31 |
32 | Varsayılan olarak, Elasticsearch'de her bir "index" 5 "primary shard" 1 "replica" ile oluşturulur. Bunun anlamı, eğer "cluster" içerisinde 2 "node" var ise 5 "primary shard" ve 5 "replica shard" ile birlikte toplamda her bir "index"iniz için 10 "shard" olacaktır.
33 |
34 | > **Note:**
35 | > Her Elascticsearch shard'ı bir **Lucene Index**'dir. Bu "index" için bir maximum döküman sayısı mevcuttur. [LUCENE-5843](https://issues.apache.org/jira/browse/LUCENE-5843)'e göre limit 2,147,483,519 (= Integer.MAX_VALUE - 128) dökümandır. Shard boyutunuzu `_cat/shards` isteğinde bulunarak görebilirsiniz.
--------------------------------------------------------------------------------
/_posts/2017-04-03-kapasite-planlama.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Kapasite Planlaması
4 | categories:
5 | - blog
6 | summary: Elasticsearch ile uğraşan herkesin sorduğu bir soru olan "Bu veri için kaç Shard'lık bir Index oluşturmam lazım?" sorusuna yanıt bulmaya çalışacağız.
7 | ---
8 |
9 | Çoğu zaman kullanıcılar kaç shard kullanmalıyım. En doğru yaklaşım nedir diye düşünmketedirler. 1 shard çok az ya da 1000 shard çok fazla ise kaç shard kullanmam gerektiğini nerden bileceğim. Bu soru genellikle cevaplanması en imkansız sorulardan birisidir. Çünkü genellikle kişilerin ya da sistemlerin kendine has sorunları ve baş etmesi gereken kısımları olmaktadır. İşte bu yüzden bu sorunun cevabını etkileyecek çok fazla değişken mevcuttur: kullanıdığınız sunucu ya da donanım, dökümanınızın büyüklüğü ve karmaşıklığı, dökümanlarınızı nasıl analiz ettiğiniz ve index'e gönderme yönteminiz, çalıştırdığınız sorguların tipleri, yaptığınız `aggregation` çeşitliliğiniz, veriyi nasıl modellediğiniz, ve böyle bir çok konu vardır.
10 |
11 | Neyseki, bunun için bir yöntem geliştirebiliriz:
12 |
13 | - Production'da kullanılacağınız konfigürasyona çok yakın olacak donanıma sahip bir tek sunucudan oluşan bir cluster(küme) oluşturalım.
14 | - Yine production'da kullanacağınızı düşündüğünüz index ile aynı `settings` ve `analyzers`a sahip bir index oluşturalım, ama sadece 1 primary shard'dan oluşsun ve hiç yansısı olmasın.
15 | - Bu index'i gerçek ya da gerçeğe çok yakın olabilecek dökümanlar ile dolduralım.
16 | - Bu idnex üzerinde gerçek sorgular ve gerçek `aggregations` sorgularını çalıştıralım.
17 |
18 | Aslında, gerçek dünyadaki kullanımı neredeyse aynısını yapmak istemekteyiz ancak bu her zaman mümkün olmayabilir. Ancak bu örnek ile birlikte bu bir shard'lık index'imizi biraz zorlayalım (bol bol sorgular ve veriler göndererek). Hatta kırılma noktası da size bağlı: kimi kullanıcılar her bir cevap 50ms'den az olması lazım diyebilir; diğerleri 5s benim için uygundur diyebilir. Burada kırılma noktalarını da kendimiz belirleyip kendi sistemimize saldıralım. Burada aldığımı sonuçlardan sonra tekil bir shard için bir kapasite belirlemiş olduk.
19 |
20 | Bir tekil shard için kapasiteyi belirledikten sonra, artık tüm index'iniz için bilinmeyenlere ulaşmak daha kolay olacaktır. Index'inizde bulunan toplam verinizin boyutunu alın, veya yakın gelecekteki büyümeyi de hesaplayıp , ve bir shard için kapasitenize bölün. Sonuç, neredeyse sizin primary shard olarak ihtiyacınızı verecektir. Buradaki sonuçlar kesinlik ifade etmez. 1 shard için denediğinizde ağ gecikmeleri vs olmayacaktır. Ancak sorgularınızda birden fazla shard'da sonuç dönerken farklo sunuculardaki verilerinizde ağ gecikmeleri yaşanabilir.
21 |
22 | > **Uyarılar**
23 | >
24 | > Kapasite planlama sizin birinci adımınız olmaması gerekir.
25 | >
26 | > Ilk olarak bakmanız gereken başka yerler vardır. Mesela, efektif çalışmayan sorgularınız olabilir mi?, RAM yetersiz olabilir mi?, Swap belleğe düştünüz mü?, ağdan dolayı bir gecikme yaşıyor olabilir misiniz? ...
27 | >
28 | > Bir çok kullanıcı, basit bir wildcard sorgusunu silmek yerine garbage collector'u nasıl daha hızlandırırım veya thread sayılarını nasıl daha efektif ayarlarım diye uğraşmaktadır.
--------------------------------------------------------------------------------
/_posts/2017-04-06-elasticsearch-te-sayfalama-yapma-1.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Elasticsearch'te Sayfalama Yapma (From ve Size) - 1
4 | categories:
5 | - blog
6 | summary: Elasticsearch üzerindeki verimiz ile sayfalama nasıl yaparız ne gibi sorunlar bizi bekliyor bir göz atacağız. Örnekler ile bu konuyu açıklamaya çalışacağız.
7 | ---
8 |
9 | Elasticsearch üzerinde hızlıca arama yapabileceğimizden, veri yapılarından, veri türlerinden, index düzenleme ve takma isimlerinden bolca bahsettik. Bu yazıda çektiğimiz verileri kullanıcıya sayfa sayfa kullanıcıya nasıl ulaştırırız, bunun için nasıl yöntemler var, ondan bahsetmeye çalışacağım. Konu biraz uzun olduğu için 3 kısımdan oluşan bir seri halinde yayınlayacağım.
10 |
11 | ### `from` ve `size`
12 |
13 | İlk olarak en basit yöntem olan ve SQL'de de kullandığımız `from`, `size` yöntemi ile başlayalım. Elasticsearch bize verilerimiz üzerinde dolaşabilmek adına `_search` API üzerinde `from` ve `size` alanlarını sunuyor. Bu alanlarla birlikte bir ofset bir de boyut belirterek sayfalama işlemini kolayca yapabiliyoruz. Aşağıdaki iki sorgudan birincisinde 1. sayfadaki verilerimizi alırken
14 | ikincisinde ise 2. sayfadaki verileri aldık.
15 |
16 | ```
17 | GET myindex/_search
18 | {
19 | "from": 0,
20 | "size": 10
21 | }
22 |
23 | GET myindex/_search
24 | {
25 | "from": 10,
26 | "size": 10
27 | }
28 | ```
29 |
30 | Aslında bu açıdan baktığımızda gayet kolay gibi. Ancak veriniz eğer gerçekten de büyük ise karşınıza çıkacak bir Elasticsearch'te de bazı sınırlar mevcut. Bu sınırlamayı en kısa şöyle ifade edebiliriz => `from + size <= index.max_result_window`. Örnek bir sorgu yapalım. Diyelim ki içerisinde 1M kayıt olan bir index'iniz mevcut. Aşağıdaki gibi bir sorgu rahatça karşılaşabileceğiniz bir sorgu:
31 |
32 | ```
33 | GET myindex/_search
34 | {
35 | "from": 20000,
36 | "size": 20,
37 | "_source": ["ID", "offset"]
38 | }
39 | ```
40 |
41 | Ancak alacağınız cevap sizi çok üzecektir.
42 |
43 | ```
44 | {
45 | "error": {
46 | "root_cause": [
47 | {
48 | "type": "query_phase_execution_exception",
49 | "reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [20020]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
50 | }
51 | ],
52 | "type": "search_phase_execution_exception",
53 | "reason": "all shards failed",
54 | "phase": "query",
55 | "grouped": true,
56 | "failed_shards": [
57 | {
58 | "shard": 0,
59 | "index": "myindex",
60 | "node": "B1Csa5g8T0uprYLCqPy3kw",
61 | "reason": {
62 | "type": "query_phase_execution_exception",
63 | "reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [20020]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
64 | }
65 | }
66 | ],
67 | "caused_by": {
68 | "type": "query_phase_execution_exception",
69 | "reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [20020]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
70 | }
71 | },
72 | "status": 500
73 | }
74 | ```
75 |
76 | Yani size `index.max_result_window` değerinden daha büyük sıradaki değerlere hiç ulaşamayacaksınız. `index.max_result_window` özelliği dinamik index ayarı olarak geçmektedir. Bu özelliği aşağıdaki gibi bir istek ile değiştirebilirsiniz.
77 |
78 | ```
79 | PUT myindex/_settings
80 | {
81 | "index": {
82 | "max_result_window": 10000
83 | }
84 | }
85 | ```
86 |
87 | Ancak, şunuda düşünmeliyiz. Bu değişikliğiniz size `from + size` değeriyle orantılı, bellek kullanımı olarak dönecektir. Burada karar verirken dikkat etmek gerekmektedir.
88 |
89 | > [`index.max_result_window`](https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules.html#dynamic-index-settings) özelliği varsayılan olarak 10000'dir.
90 |
91 | Bir sonraki yazımda bu konuya bir çözüm olarak Elasticsearch'ün sunduğu diğer bir özellik olan "Scroll" özelliğinden bahsedeceğim.
92 |
93 | ### Kaynaklar
94 |
95 | - [https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-from-size.html](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-from-size.html)
96 | - [https://www.elastic.co/guide/en/elasticsearch/guide/master/pagination.html](https://www.elastic.co/guide/en/elasticsearch/guide/master/pagination.html)
--------------------------------------------------------------------------------
/_posts/2017-04-08-elasticsearch-te-sayfalama-yapma-2.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Elasticsearch'te Sayfalama Yapma (Scroll) - 2
4 | categories:
5 | - blog
6 | summary: Bir önceki yazımda `from` ve `size` özelliğinden bahsetmiştim. Bu yazımda daha farklı bir sayfalama yöntemi olan Scroll özelliğinden bahsedeceğim.
7 | ---
8 |
9 | Bir önceki yazımda `from` ve `size` özelliğinden bahsetmiştim. Bu yazımda daha farklı bir sayfalama yöntemi olan Scroll özelliğinden bahsedeceğim. Scroll özelliği ise bize daha farklı bir sunuş imkanı sağlıyor. Ben Scroll özelliğini Twitter'ın arayüzleri olarak düşünüyorum. Herkes biliyordur, aşağı doğru kaydırdıkça kaldığımız yerden veriler gelmektedir.
10 |
11 | Örnek bir sorgu ile konuyu biraz inceleyelim. İlk olarak scroll kullanmak istediğimizi ve ne kadar süre bu sorguyu aklında tutması gerektiğini `?scroll=1m` sorgu parametresi ile gönderiyoruz.
12 |
13 | ```
14 | POST /myindex/_search?scroll=1m
15 | {
16 | "size": 100
17 | }
18 | ```
19 |
20 | Bu sorguyu çalıştırdığınızda Elasticsearch size yanıt içerisinde bir `scroll_id` değeri ve sonuçları dönecektir.
21 |
22 | ```
23 | {
24 | "_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAAcrFkIxQ3NhNWc4VDB1cHJZTENxUHkza3cAAAAAAAAHKBZCMUNzYTVnOFQwdXByWUxDcVB5M2t3AAAAAAAABywWQjFDc2E1ZzhUMHVwcllMQ3FQeTNrdwAAAAAAAAcqFkIxQ3NhNWc4VDB1cHJZTENxUHkza3cAAAAAAAAHKRZCMUNzYTVnOFQwdXByWUxDcVB5M2t3",
25 | "took": 7,
26 | "timed_out": false,
27 | "_shards": {
28 | "total": 5,
29 | "successful": 5,
30 | "failed": 0
31 | },
32 | "hits": {
33 | "total": 1029761,
34 | "max_score": 1,
35 | "hits": [...]
36 | }
37 | }
38 | ```
39 |
40 | Bu değer ile birlikte sorgunuzuda aklında tutmaya başlayacaktır. Siz `scroll_id` ile her istekte bulunduğunuzda aklındaki `offset` bilgisine göre size sorgunuza uyan sonraki kayıtları dönecektir. `scroll_id` ile sorgulama ise aşağıdaki şekildedir:
41 |
42 | ```
43 | POST /_search/scroll
44 | {
45 | "scroll" : "1m",
46 | "scroll_id" : "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAAcrFkIxQ3NhNWc4VDB1cHJZTENxUHkza3cAAAAAAAAHKBZCMUNzYTVnOFQwdXByWUxDcVB5M2t3AAAAAAAABywWQjFDc2E1ZzhUMHVwcllMQ3FQeTNrdwAAAAAAAAcqFkIxQ3NhNWc4VDB1cHJZTENxUHkza3cAAAAAAAAHKRZCMUNzYTVnOFQwdXByWUxDcVB5M2t3"
47 | }
48 | ```
49 |
50 | > Sorgu `index` ya da `type` adı içermez. Zaten kalında tuttuğu sorguda mevcuttur.
51 |
52 | Bu sorgu sonucu olarak yine aynı `scroll_id` bize geri dönecektir. Siz her sorgu gönderdiğinizde `1m`lik süre sıfırlanacaktır ve tekrar başlayacaktır. Burada süre `1m`lik süre boyunca hiç gelmediğinizde ve bu `id` ile süreniz bittikten sonradan geldiğinizde Elasticsearch aşağıdaki gibi bir yanıt verecektir.
53 |
54 | ```
55 | {
56 | "error": {
57 | "root_cause": [
58 | {
59 | "type": "search_context_missing_exception",
60 | "reason": "No search context found for id [1893]"
61 | },
62 | ....
63 | ],
64 | "type": "search_phase_execution_exception",
65 | "reason": "all shards failed",
66 | "phase": "query",
67 | "grouped": true,
68 | "failed_shards": [
69 | {
70 | "shard": -1,
71 | "index": null,
72 | "reason": {
73 | "type": "search_context_missing_exception",
74 | "reason": "No search context found for id [1893]"
75 | }
76 | },
77 | ...
78 | ],
79 | "caused_by": {
80 | "type": "search_context_missing_exception",
81 | "reason": "No search context found for id [1895]"
82 | }
83 | },
84 | "status": 404
85 | }
86 | ```
87 |
88 | Scroll özelliğinde dikkat ettiysek istediğimiz sayfaya bir anda atlayıp gidemiyoruz. Bu özelliğin olmaması kaynak kullanımı açısından bize kazanç sağlamaktadır. Burada hep aklıma şu söz gelir: "her seçim bir kaybediştir". Hız yönünden kazanırken ya da daha fazla veriye erişim imkanı kazanırken deneyim olarak daha farklı bir deneyimle karşı karşıya kalabiliyoruz.
89 |
90 | Bir sonraki yazımda Scroll ile benzer bir yapıda ancak `stateless` bir yapısı olan `search_after` özelliğinden bahsedeceğim.
91 |
92 | ### Kaynaklar
93 |
94 | - [https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-scroll.html]()
95 | - [https://www.elastic.co/guide/en/elasticsearch/guide/master/pagination.html]()
--------------------------------------------------------------------------------
/_posts/2017-04-10-elasticsearch-te-sayfalama-yapma-3.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Elasticsearch'te Sayfalama Yapma (`start_after`) - 3
4 | categories:
5 | - blog
6 | summary: Bir önceki yazımda `from`,`size` ve Scroll özelliklerinden bahsetmiştim. Bu yazımda Scroll özelliği ile benzer ancak bir durum bilgisi barındırmayan daha farklı bir sayfalama yöntemi olan `start_after` özelliğinden bahsedeceğim.
7 | ---
8 |
9 | Scroll özelliği ile sorgularımızın sonuçlarını rahat bir şekilde sayfalama yapabiliyoruz. Ancak scroll özelliğinde sorgumuz `context` içerisinde tutulduğu için sayfalama sırasında sorgumuzu değiştiremiyoruz. Bu durum bizi gerçek zamanlı uygulamalarda sıkıntılı durumlara sokacaktır. Her seferinde sorgularınızı tekrar tekrar bir `context`e eklemeniz gerekecektir.
10 |
11 | "Search After" özelliği ile bu soruna da bir nebze çözüm bulabiliriz. Bu özellik ile canlı bir işaretçi oluşturabiliriz. İlk olarak örnek verimizdeki değerlere hızlıca bir bakalım:
12 |
13 | ```
14 | Offset | ID
15 | 262444821 | 10093220
16 | 262444572 | 10093219
17 | 262444331 | 10093218
18 | 262444090 | 10093216
19 | ```
20 |
21 | Şimdi bu veriseti üzerinde bir sorgu ile sayfalama için nasıl bir yol izleyeceğimize bir göz atalım.
22 |
23 | ```
24 | GET myindex/_search
25 | {
26 | "from": 0,
27 | "size": 2,
28 | "sort": [
29 | {
30 | "offset": {
31 | "order": "desc"
32 | }
33 | }
34 | ],
35 | "_source": ["ID", "offset"]
36 | }
37 | ```
38 |
39 | Yukarıdaki bizim için ilk sorgumuz. 0'dan başlayıp 2 tane veri çekiyoruz. Şimdi bu örneğimizde tabiki basit gideceğiz. İlerleyen aşamada daha büyük sayılar ile tekrar örneklendirebiliriz. Farkettiysek sorgumuzda sıralama mevcut. Diğer örneklerde bir sıralama yoktu. "Search After" özelliği için bir sıralama yapmamız **zorunludur**. Çünkü sıralama yaptığımız alana göre bir sonraki sayfada çekeceğimiz veriyi seçeceğiz. Burada bize dönen veriye hızlıca bir göz atalım.
40 |
41 | ```
42 | {
43 | "took": 26,
44 | "timed_out": false,
45 | "_shards": {
46 | "total": 5,
47 | "successful": 5,
48 | "failed": 0
49 | },
50 | "hits": {
51 | "total": 1029761,
52 | "max_score": null,
53 | "hits": [
54 | {
55 | "_index": "myindex",
56 | "_type": "mytype",
57 | "_id": "AVreenrAIMPgDpuvzEzN",
58 | "_score": null,
59 | "_source": {
60 | "offset": 262444821,
61 | "ID": "10093220"
62 | },
63 | "sort": [
64 | 262444821
65 | ]
66 | },
67 | {
68 | "_index": "myindex",
69 | "_type": "mytype",
70 | "_id": "AVreenrAIMPgDpuvzEzM",
71 | "_score": null,
72 | "_source": {
73 | "offset": 262444572,
74 | "ID": "10093219"
75 | },
76 | "sort": [
77 | 262444572
78 | ]
79 | }
80 | ]
81 | }
82 | }
83 | ```
84 |
85 | Şimdi Bir sonraki sayfayı çekelim:
86 |
87 | ```
88 | GET myindex/_search
89 | {
90 | "size": 2,
91 | "search_after": [262444572],
92 | "sort": [
93 | {
94 | "offset": {
95 | "order": "desc"
96 | }
97 | }
98 | ],
99 | "_source": ["ID", "offset"]
100 | }
101 | ```
102 |
103 | Bu sorgu sonucunda dönen ID değerlerinin `10093218` ve `10093216` olduğunu görebilirsiniz. Yukarıdaki tablomuzda da zaten sırasıyla bunların gelmesi gerektiğini biliyorduk. Dikkat ettiysek ikinci sorgumuzda `"search_after": [262444572]` parametresini kullanarak aslında sayfalamayı yapmış olduk.
104 |
105 | ```
106 | {
107 | "took": 18,
108 | "timed_out": false,
109 | "_shards": {
110 | "total": 5,
111 | "successful": 5,
112 | "failed": 0
113 | },
114 | "hits": {
115 | "total": 1029761,
116 | "max_score": null,
117 | "hits": [
118 | {
119 | "_index": "myindex",
120 | "_type": "mytype",
121 | "_id": "AVreenrAIMPgDpuvzEzL",
122 | "_score": null,
123 | "_source": {
124 | "offset": 262444331,
125 | "ID": "10093218"
126 | },
127 | "sort": [
128 | 262444331
129 | ]
130 | },
131 | {
132 | "_index": "myindex",
133 | "_type": "mytype",
134 | "_id": "AVreenrAIMPgDpuvzEzK",
135 | "_score": null,
136 | "_source": {
137 | "offset": 262444090,
138 | "ID": "10093216"
139 | },
140 | "sort": [
141 | 262444090
142 | ]
143 | }
144 | ]
145 | }
146 | }
147 | ```
148 |
149 | Scroll özelliğinden farklı olarak `search_after` değerini sorgumuzu değiştirerek ilerletebiliyor olmamızdır. Scroll özelliğinde ise sorguyu bir kez gönderdikten sonra `scroll_id` ile ilerleyebiliyorduk. Buradaki sorgudan da göreceğimiz üzere rasgele erişimler için bu seçenekte çözüm değil. Ancak `from & size` özelliğini kullanarak erişemediğimiz verilerimize bu özellik sayesinde erişebileceğiz.
150 |
151 | ### Kaynaklar
152 |
153 | - [https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-search-after.html]()
154 | - [https://www.elastic.co/guide/en/elasticsearch/guide/master/pagination.html]()
--------------------------------------------------------------------------------
/_posts/2017-06-02-elasticsearch-ile-pdf-metin-veya-word-dosyalari-uzerinde-arama.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Elasticsearch ile PDF, Metin veya Word Dosyaları Üzerinde Arama
4 | categories:
5 | - blog
6 | summary: Bir proje kapsamında üerinde uğraştığımız PDF, Word ya da diğer metin türündeki dosyaları Elasticsearch üzerinde nasıl aranabilir hale getirdik nelerle karşılaştık kısaca bahsettim. Adım adım projeyi nasıl gerçek hayata getirdik düşündüklerim nelerdi onlara değindim.
7 | ---
8 |
9 | ##
10 |
11 | Bir süre önce bir proje bünyesinde PDF, Metin veya Word dökümanları arama yapma ihtiyacı doğdu. Bu ihtiyaç üzerine bende konu hakkında biraz araştırmalar yaptım ve buradan da süreç içerisinde yaşadıklarımı adım adım paylaşmak istedim.
12 |
13 | Proje sahibi ile ihtiyaçları ve neler yapılacağı hakkında biraz konuştuk ve ihtiyacı şu şekilde tanımladık.
14 |
15 | > Bir kütüphanede farklı firmalara ait bir takım dökümanlar var ve bu dökümanlar PDF, metin veya word döküman formatında. Kullanıcılarımız bir arama kutusu üzerinden arama yaparak bu dökümanlar içerisinde aramalar yapıp dökümana ulaşmak istiyorlar. Başlangıç olarak döküman içerisindeki yerini önemsemeden, arama sayfasında arama içerisinde eşleşen bölümün bir kısmını da göstermek istiyorlar. (*)
16 |
17 | İhtiyacı tam olarak anladıktan sonra çözüm için nasıl bir yol izleyebiliriz diye düşündüm ve konuyu araştırmaya başladım. Biraz araştırmanın ardından Apache Tika’ya ulaştım. Aramayı Elasticsearch üzerinde yapacaktım ve aklıma gelen ilk şey şu oldu. Apache Tika’yı kullanan bir API arayüzü hazırlarım dosyaları bana bu API üzerinden gönderirler, API dosyaların metin çıktılarını Elasticsearch’e kayıt eder ve sonuçta aramak için hazır hale gelir. Daha önce kullanmamıştım ve bu geliştirme hızı açısından benim için sıkıntılı olacaktı. Araştırmaya devam ettim.
18 |
19 | Daha sonrasında bunu Elasticsearch eklentisi olarak yazan biri var mı diye bakıyordum ki zaten Elasticsearch içerisinde bu zaten var olduğunu gördüm.(**)
20 |
21 | > [Ingest Attachment Processor Plugin](https://www.elastic.co/guide/en/elasticsearch/plugins/5.4/ingest-attachment.html)
22 |
23 | Eklentiyi hemen kurdum:
24 |
25 | ```
26 | bin/elasticsearch-plugin install ingest-attachment
27 | ```
28 |
29 | Ve hızlıca denemeye başladım. İlk olarak aramanın yapılacağı dökümanı ve aklımdan geçen veriyi görsel hale getirmek için kendime örnek bir veri kümesi oluşturdum. (***)
30 |
31 | ```
32 | {
33 | "filename": "sample.txt",
34 | "companyId": 1,
35 | "type": "txt",
36 | "content": "dosya-içeriği"
37 | }
38 | ```
39 |
40 | Bu veri örneğinde aramalarımı yaparken şöyle bir arama yapmak istiyorum. İlk olarak şirkete göre ve dosya tipine göre filtreleme yapmak istiyorum. Daha sonrasında bunlarla birlikte içerik ve dosya adına göre hem otomatik tamamlamalı ve hem de terim araması yapmak istiyorum. (!) Burası arama kısmındaki ihtiyaçları halleder nitelikte. Ancak veriyi kaydereken bir sıkıntı dikkat etmem gereken bir durum var. Elasticsearch JSON ile çalışıyor ve benim ikili formattaki olan dosyalarımı oraya atmak için bir yol bulmam lazım. Hemen yine dökümantasyona koştum. “Ingest attachment” eklentisinin kullanımına baktığımda dosya alanını Base64 ile şifreleyip gönderildiğini gördüm. Bu bana“content” olarak açtığım alana gelecek veriler için özel bir çalışma yapmam ve dosyayı o şekilde kaydetmem gerektiğini gösterdi dökümana göre ilerleyip bunun için aşağıdaki gibi bir “ingest pipeline” oluşturdum.
41 |
42 | ```
43 | PUT _ingest/pipeline/attachment
44 | {
45 | "description" : "Extract attachment information",
46 | "processors" : [
47 | {
48 | "attachment" : {
49 | "field" : "content"
50 | }
51 | }
52 | ]
53 | }
54 | ```
55 | Artık “content” alanı için gönderdiğimiz verilerimizi “attachment pipeline” üzerinden gönderirsek Base64 ile gönderdiğimiz dosyaların içeriklerini Elasticsearch eklentisi bizim için okunur bir metin formatına getirecek. Şimdi bunu deneyelim ve görelim:
56 |
57 | ```
58 | # Index Oluşturdum
59 | PUT files
60 | # Ilk Verimi Kaydettim
61 | PUT files/file/1?pipeline=attachment
62 | {
63 | "filename": "sample.txt",
64 | "companyId": 1,
65 | "type": "txt",
66 | "content": "RWxhc3RpY3NlYXJjaCBoYWtrxLFuZGEgdMO8cmvDp2Ugw6dldmlyaWxlciB2ZSBhw6fEsWtsYW1hbMSxIGFubGF0xLFtbGFyCkdlbGnFn21lbGVyZGVuIGhhYmVyZGFyIG9sbWFrIGnDp2luIGJlbmkgdmUgcmVwbyd5dSB0YWtpcCBlZGluLg=="
67 | }
68 | ```
69 |
70 | Veriyi geri çektiğimde aşağıdaki gibi bir sonuç aldım.
71 |
72 | ```
73 | # Istek
74 | GET files/file/1
75 | # Cevap
76 | {
77 | "_index": "files",
78 | "_type": "file",
79 | "_id": "1",
80 | "_version": 1,
81 | "found": true,
82 | "_source": {
83 | "companyId": 1,
84 | "filename": "sample.txt",
85 | "attachment": {
86 | "content_type": "text/plain; charset=UTF-8",
87 | "language": "lt",
88 | "content": "Elasticsearch hakkında türkçe çeviriler ve açıklamalı anlatımlar\nGelişmelerden haberdar olmak için beni ve repo'yu takip edin.",
89 | "content_length": 127
90 | },
91 | "type": "txt",
92 | "content": "RWxhc3RpY3NlYXJjaCBoYWtrxLFuZGEgdMO8cmvDp2Ugw6dldmlyaWxlciB2ZSBhw6fEsWtsYW1hbMSxIGFubGF0xLFtbGFyCkdlbGnFn21lbGVyZGVuIGhhYmVyZGFyIG9sbWFrIGnDp2luIGJlbmkgdmUgcmVwbyd5dSB0YWtpcCBlZGluLg=="
93 | }
94 | }
95 | ```
96 |
97 | Artık veriyi kaydetmiştim. Biraz yol kat ettim ancak daha sona ulaşamadım. Veri kayıt işlemini bitirdikten sonra şimdi sıra arama kısmına gelmişti. Bunun için yukarıda belirtmiştim nasıl bir arama için çalışma yapacağımı. Otomatik tamamlamalı ve terim aramaları yapacaktım. Ayrıca sonuç kümesinde eşleşen kelimeleri ön plana çıkaracaktım. İlk olarak verileri kaydettiğimde tüm veriler standard bir analyzer sürecinden geçti. Ancak bu analyzer benim istediğim sonuçları vermedi haliyle. Benim aramalarımı karşılayacak şekilde index için aşağıdaki gibi bir ayar oluşturdum.
98 |
99 | ```
100 | PUT files
101 | {
102 | "analysis": {
103 | "analyzer": {
104 | "keywordSearchAnalyzer": {
105 | "tokenizer": "whitespace",
106 | "filter": [
107 | "apostrophe",
108 | "turkishLowercaseFilter",
109 | "turkishStopwordsFilter",
110 | "asciiFilter"
111 | ]
112 | },
113 | "keywordSearchInputAnalyzer": {
114 | "tokenizer": "whitespace",
115 | "filter": [
116 | "apostrophe",
117 | "turkishLowercaseFilter",
118 | "turkishStopwordsFilter",
119 | "asciiFilter"
120 | ]
121 | },
122 | "autocompleteSearchInputAnalyzer": {
123 | "type": "custom",
124 | "tokenizer": "whitespace",
125 | "filter": [
126 | "apostrophe",
127 | "turkishLowercaseFilter",
128 | "asciiFilter"
129 | ]
130 | },
131 | "autocompleteSearchAnalyzer": {
132 | "type": "custom",
133 | "tokenizer": "whitespace",
134 | "filter": [
135 | "apostrophe",
136 | "turkishLowercaseFilter",
137 | "turkishStopwordsFilter",
138 | "asciiFilter",
139 | "autocompleteFilter",
140 | "unique"
141 | ]
142 | }
143 | },
144 | "filter": {
145 | "autocompleteFilter": {
146 | "type": "edge_ngram",
147 | "min_gram": 3,
148 | "max_gram": 20
149 | },
150 | "turkishStopwordsFilter": {
151 | "type": "stop",
152 | "stopwords": "_turkish_"
153 | },
154 | "turkishLowercaseFilter": {
155 | "type": "lowercase",
156 | "language": "turkish"
157 | },
158 | "asciiFilter": {
159 | "type": "asciifolding",
160 | "preserve_original": true
161 | }
162 | }
163 | }
164 | }
165 | ```
166 |
167 | Daha sonra bu bir “file” tipi için aşağıdaki gibi bir “mapping” ile verimin yapısını oluşturmuş oldum:
168 |
169 | ```
170 | PUT files/file/_mapping
171 | {
172 | "properties": {
173 | "filename": {
174 | "type": "text",
175 | "fields": {
176 | "autocomplete": {
177 | "type": "text",
178 | "analyzer": "autocompleteSearchAnalyzer",
179 | "search_analyzer": "autocompleteSearchInputAnalyzer"
180 | },
181 | "keyword": {
182 | "type": "text",
183 | "analyzer": "keywordSearchAnalyzer",
184 | "search_analyzer": "keywordSearchInputAnalyzer"
185 | }
186 | }
187 | },
188 | "companyId": {
189 | "type": "integer"
190 | },
191 | "fileType": {
192 | "type": "keyword"
193 | },
194 | "content": {
195 | "type": "text"
196 | },
197 | "attachment": {
198 | "properties": {
199 | "content": {
200 | "type": "text",
201 | "fields": {
202 | "autocomplete": {
203 | "type": "text",
204 | "term_vector": "with_positions_offsets",
205 | "store": true,
206 | "analyzer": "autocompleteSearchAnalyzer",
207 | "search_analyzer": "autocompleteSearchInputAnalyzer"
208 | },
209 | "keyword": {
210 | "type": "text",
211 | "term_vector": "with_positions_offsets",
212 | "store": true,
213 | "analyzer": "keywordSearchAnalyzer",
214 | "search_analyzer": "keywordSearchInputAnalyzer"
215 | }
216 | }
217 | }
218 | }
219 | }
220 | }
221 | }
222 | ```
223 |
224 | Şimdi bir arama yaparken eğer otomatik tamamlama yapmak istiyorsam “attachment.content.autocomplete” alanında eğer terim araması yapacaksam “attachment.content.keyword” alanında arama yapabilirim. Örnek bir arama çalıştıralım:
225 |
226 | ```
227 | GET files/_search
228 | {
229 | "query": {
230 | "match": {
231 | "attachment.content.keyword": "hakkinda"
232 | }
233 | }
234 | }
235 | ```
236 |
237 | Kaydetmiş olduğum veride “hakkında” kelimesi geçtiği için sonuç olarak bana döndü. Ancak bu aramada “hakkin” terimini arayınca sonuç vermedi. Otomatik tamamlama için bu aramayı da aşağıdaki gibi değiştirdim:
238 |
239 | ```
240 | GET files/_search
241 | {
242 | "query": {
243 | "match": {
244 | "attachment.content.autocomplete": "hak"
245 | }
246 | }
247 | }
248 | ```
249 |
250 | Bu değişiklik sonunda “hak” diye aradığımda “hak” ile terimleri içeren tüm dökümanlar dönmüş oldu. Artık arama işleminide tamamladım. Son olarak döküman içerisinde nerede geçtiğini gösterecektik. Yani metni vurgulama işlemi yapacaktık. Onunu için zaten mapping tarafında bir hazırlık yapmıştık.
251 |
252 | >"term_vector": "with_positions_offsets",
253 |
254 | Bu özellik ile birlikte artık her döküman içerisinden türetilen metinlerin her bir terimi için pozisyon bilgiside bir kenarda tutuluyor olacak. Arama sonucunda eşleşen terim `` etiketleri arasında gelecek. Bu konuda daha fazla bilgi için şu blog yazısına bir göz atabilirsiniz. Sorguma bazı eklemeler yaparak sonuçlar içerisinde vurgulamayı da yaptım:
255 |
256 | ```
257 | # Istek
258 | GET files/_search
259 | {
260 | "query": {
261 | "match": {
262 | "attachment.content.keyword": "hakkinda"
263 | }
264 | },
265 | "highlight" : {
266 | "fields" : {
267 | "attachment.content.keyword" : {}
268 | }
269 | }
270 | }
271 | # Cevap
272 | {
273 | "took": 13,
274 | "timed_out": false,
275 | "_shards": {
276 | "total": 5,
277 | "successful": 5,
278 | "failed": 0
279 | },
280 | "hits": {
281 | "total": 1,
282 | "max_score": 0.2947756,
283 | "hits": [
284 | {
285 | "_index": "files",
286 | "_type": "file",
287 | "_id": "2",
288 | "_score": 0.2947756,
289 | "_source": {
290 | "companyId": 1,
291 | "filename": "sample.txt",
292 | "attachment": {
293 | "content_type": "text/plain; charset=UTF-8",
294 | "language": "lt",
295 | "content": "Elasticsearch hakkında türkçe çeviriler ve açıklamalı anlatımlar\nGelişmelerden haberdar olmak için beni ve repo'yu takip edin.",
296 | "content_length": 127
297 | },
298 | "type": "txt",
299 | "content": "RWxhc3RpY3NlYXJjaCBoYWtrxLFuZGEgdMO8cmvDp2Ugw6dldmlyaWxlciB2ZSBhw6fEsWtsYW1hbMSxIGFubGF0xLFtbGFyCkdlbGnFn21lbGVyZGVuIGhhYmVyZGFyIG9sbWFrIGnDp2luIGJlbmkgdmUgcmVwbyd5dSB0YWtpcCBlZGluLg=="
300 | },
301 | "highlight": {
302 | "attachment.content.keyword": [
303 | "Elasticsearch hakkında türkçe çeviriler ve açıklamalı anlatımlar\nGelişmelerden haberdar olmak için beni"
304 | ]
305 | }
306 | }
307 | ]
308 | }
309 | }
310 | ```
311 |
312 | Gördüğünüz gibi “highlight” alanı altında eşleşen kelime `` etiketleri arasında geldi. Burada küçük bir CSS eklemesi ile eşleşen kelimeyi vurgulayabilirsiniz ve aşağıdakine benzer bir görüntü elde edebilirsiniz.
313 |
314 |
315 |
316 | ### Son Söz
317 |
318 | Bu yazıda PDF, metin ya da word dosyalarını nasıl Elasticsearch ile aranabilir hale getireceğimizi bir problemi çözerken gördük. Bu çözüm yöntemlerinden birisiydi. Bu yöntemin bazı artıları ve bazı da eksileri tabiki var. Hiç ekstra bir API ya da uygulamaya ihtiyaç duymadan bu işlemi yapabilmek bize artı sağlarken, veriniz içerisindeki metin alanlarının çok büyük olması performans açısından bazı sıkıntılar çıkaracak ve bunları çözmeniz gerekecek. Onun dışında Base64'e çevirdiğimiz dosyalarımız boştan yere %30–40 gibi bir oranlarda yer kaplayacak. Bunları ile ilgili nelere yapabiliriz nasıl çözüm üretebiliriz ilerleyen zamanlarda bir yazı ile anlatmaya çalışacağım.
319 |
320 | ### Duyuru
321 |
322 | Elasticsearch ile ilgili kullanımı, veri yapısının oluşturulması ve verilerin aranması konuları hakkında daha detaylı bahsedeceğimiz bir eğitimim var. Katılmak isteyenler [http://datademi.com/index.php/tr/elastic-online-egitim/](http://datademi.com/index.php/tr/elastic-online-egitim/) şu adresten iletişime geçebilirler.
323 |
324 | ---
325 |
326 | Yazı ilk olarak [şu adreste](https://medium.com/@kulekci/elasticsearch-ile-pdf-metin-veya-word-dosyaları-üzerinde-arama-a37f66435bf6) yayınlanmıştır.
--------------------------------------------------------------------------------
/_posts/2017-09-30-kibana-yi-zaman-damgasiz-kayitlar-ile-kullanma.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Kibana'yı Zaman Damgası (Timestamp) Olmayan Kayıtlar İle Kullanma
4 | categories:
5 | - blog
6 | summary: Kibana arayüzü genellikle zaman damgası olan log kayıtları üzeribde grafikler oluşturarak kullanılır. Bu sadece bununla sınırlı değildir. Index'i tanımlarken zaman damgasını göz ardı ederek verilerinizi görselleştirebilirsiniz.
7 | ---
8 |
9 | Daha önceden sunumlarımda ve sohbetlerde bir çok kez şunu söylemiştim. Kibana
10 | arayüzünde zaman damgası olan kayıtlar üzerinde görselleştirme yapıyoruz. Bu
11 | konuda öncelikle beni dinleyenlerden özür dileyerek bu yazıma başlamak istiyorum.
12 | Bir arkadaşım ile kibana arayüzü hakkında sohbet ederken farkettik ki
13 | olabiliyormuş. Kendisine de bu konuda beni bilgilendirdiği için çok teşekkür
14 | ederim.
15 |
16 | Zaman damgası olmayan kayıtları da rahatlıkla bu arayüzden görselleştirebilirsiniz.
17 | Nasıl mı? Çok basit. Kibana arayüzünde index'inizi tanımlarken bir işaret
18 | kutusundaki işareti kaldırarak.
19 |
20 | 
21 |
22 | Arayüzde bir kaç farklılık dışında diğer herşey aynı şekilde ilerleyecektir.
23 | Ancak bu durumda şuna dikkat etmeniz gerekir. Verileriniz artık tarihe göre
24 | sıralanmıyor. Kayıtlarınızı sıralaması zaman bazlı olmadığından en son gelen
25 | kayıt en üst sırada olmayacaktır. Ayrıca üst başlık satırındaki zamana göre
26 | verilerinizi kısıtlama ekranı da gelmeyecektir. Burada tarih alanınız varsa bu
27 | kısıtlamayı kendiniz arama çubuğundan yapmalısınız.
28 |
29 | 
30 |
31 | Eğer tarih bazlı olmayan şekilde index'i eklerseniz varsayılan sıralamanız
32 | `_score`'a göre eğer tarih bazlı eklerseniz bu durumda seçtiğiniz tarih
33 | alanına göre azalan olarak gelecektir.
34 |
35 | Tarih bazlı kullanımlarda `Discover` ekranında varsayılan olarak tarih alanı
36 | gelirken, tarih bazlı kullanmazsanız gelmeyecektir. Bunlar dışında gördüğüm
37 | kadarıyla çok fazla da farklılık yok. Aramalar ve grafikler iki yöntem için de
38 | geçerli ve çalışıyor.
--------------------------------------------------------------------------------
/_posts/2018-05-25-elasticsearch-de-turkce-karakterli-siralama.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: Elasticsearch'de Türkçe Karaterli Sıralama
4 | categories:
5 | - blog
6 | summary: Elasticsearch'de Türkçe karakter içeren verilerde sıralama nasıl yaparız ve neden böyle bir yöntem kullandık açıklamaya çalıştık.
7 | ---
8 |
9 | Uzun zamandır yazamadığım Elasticsearch yazılarına tekrar sık aralıklarıla devam edebilmek ümidiyle bir yazı daha yazayım dedim. Herkesin projelerinde çoğunlukla kullanacağı bir özelliği ES'de nasıl yaparız bir iredeleyelim. Örnek için ES 6.2.4 sürümünü kullandım. Daha öndeki sürümlerde çalışmayabilir. İlk olarak Türkçe sıralama için neden bir ekstra uğraşa ihtiyaç duyduğumuzu anlayalım.
10 |
11 | İlk olarak örnek için bir index ve type oluşturalım.
12 |
13 | ```
14 | PUT users
15 | {
16 | "settings": {
17 | "number_of_shards": 1
18 | }
19 | }
20 | POST users/user/_mapping
21 | {
22 | "properties": {
23 | "name": {
24 | "type": "keyword"
25 | }
26 | }
27 | }
28 | ```
29 |
30 | Şimdi index'e biraz veri ekleyelim.
31 |
32 | ```
33 | POST users/user/1
34 | {
35 | "name": "Haydar"
36 | }
37 | POST users/user/2
38 | {
39 | "name": "Ümit"
40 | }
41 | POST users/user/3
42 | {
43 | "name": "Rasim"
44 | }
45 | POST users/user/4
46 | {
47 | "name": "zeynep"
48 | }
49 | POST users/user/5
50 | {
51 | "name": "İsmail"
52 | }
53 | ```
54 |
55 | Verileri ekledikten sonra artık bir arama yapıp varsayılan değerler ile bir sıralama yaptığımızda nasıl bir sonuç verecek görelim.
56 |
57 | ```
58 | GET users/user/_search
59 | {
60 | "query": {
61 | "match_all": {}
62 | },
63 | "sort": [
64 | {
65 | "name": {
66 | "order": "asc"
67 | }
68 | }
69 | ]
70 | }
71 | ```
72 |
73 | Sıralama sonucu dönene değerler şu şekilde olacaktır:
74 |
75 | ```
76 | Haydar
77 | Rasim
78 | zeynep
79 | Ümit
80 | İsmail
81 | ```
82 |
83 | şeklinde olacaktır. Peki bunun sebebi ne? Bunun için biraz kodları eşeleyelim. İlk olarak sorgumuzun nerelere gittiğini inceleyelim. ES'e gönderdiğimiz sorgu aşağıdaki kod kısımlarından geçiyor. Bu sırasıyla ya da arada başka katmanlar olmadan geçiyor demek değil. Bunlara uğruyor diyelim.
84 |
85 | - `org.apache.lucene.search.IndexSearcher:searchAfter(....)`
86 | - `org.apache.lucene.search.TopDocs:merge(....)`
87 | - `org.apache.lucene.search.TopDocs:mergeAux(....)`
88 | - `org.apache.lucene.search.MergeSortQueue/ScoreMergeSortQueue` (Biz `field sort` yaptığımız için `MergeSortQueue`ye yöneldik. Sort gelirse Score'a göre sıralama yapılıyor.)
89 | - `org.apache.lucene.search.FieldComparator`
90 | - `org.apache.lucene.search.TermValComparator:compareValues(T first, T second)` bu sınıfta FieldComparator'u kapsıyor. Bu sınıf değerleri byte array olarak karşılaştırıyor.
91 | - `java.lang.Comparable` interface'i uygulayan `java.lang.String:compareTo(...)` veya `java.lang.Byte:compateTo(...)` metodları kullanılıyor.
92 |
93 | Burada anlatmak istediğim sıralama için Java'nın temel metodları kullanıyor. Şimdi türkçe karakterli bir compate yapacağımız küçük bir Java konsol uygulaması yazalım ve sonuçları görelim:
94 |
95 | ```
96 | public class Main {
97 |
98 | public static int compareValues(String first, String second) {
99 | if (first == null) {
100 | if (second == null) {
101 | return 0;
102 | } else {
103 | return -1;
104 | }
105 | } else if (second == null) {
106 | return 1;
107 | } else {
108 | return first.compareTo(second);
109 | }
110 | }
111 |
112 | public static void main(String[] args) {
113 | System.out.println(compareValues("İsmail", "Zeynep"));
114 | System.out.println(compareValues("Haydar", "Zeynep"));
115 | }
116 | }
117 |
118 | // Result:
119 | // 214
120 | // -18
121 | ```
122 |
123 | Gördüğünüz gibi iki sonuçta aslında `-` eksi çıkması gerekirken `İ` sanki `Z`den sonra geliyormuş gibi oldu. Bu da bize neden sıralamanın bizim için hatalı çıktığını açıklıyor. Şimdi sorunu anladık. Gelelim çözüme.
124 |
125 | Burada bizim ilk olarak sıralamaya gönderdiğimiz verilerde Türkçe karakter varsa onları bir süzgeçten geçirmemiz gerekecek. İlk olarak bizim [ICU* Analysis Plugin](https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-icu.html) eklentisini yükleyelim.
126 |
127 | ```
128 | sudo bin/elasticsearch-plugin install analysis-icu
129 | ```
130 |
131 | Daha sonra verilerimizi barındıracağımız `type` için mapping'i biraz değiştirelim.
132 |
133 | ```
134 | PUT users/user/_mapping
135 | {
136 | "properties": {
137 | "name": {
138 | "type": "keyword",
139 | "fields": {
140 | "sort": {
141 | "type": "icu_collation_keyword",
142 | "index": false,
143 | "language": "tr",
144 | "country": "TR"
145 | }
146 | }
147 | }
148 | }
149 | }
150 | ```
151 |
152 | Son olarak verilerimizi tekrar index'leyip sorgumuzuda yeni veri yapımıza uygun hale getirdikten sonra :
153 |
154 | ```
155 | GET users/user/_search
156 | {
157 | "query": {
158 | "match_all": {}
159 | },
160 | "sort": [
161 | {
162 | "name.sort": {
163 | "order": "asc"
164 | }
165 | }
166 | ]
167 | }
168 | ```
169 |
170 | Sonuç seti artık aşağıdaki gibi olacaktır.
171 |
172 | ```
173 | Haydar
174 | İsmail
175 | Rasim
176 | Ümit
177 | zeynep
178 | ```
179 |
180 |
181 | - * ICU => [International Components for Unicode](http://site.icu-project.org/)
--------------------------------------------------------------------------------
/_posts/2018-06-04-jvm-ayarlari--es-6-2-x.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: JVM Ayarları (ES 6.2.x)
4 | categories:
5 | - blog
6 | summary: JVM ayarları için ne yapmak gerekir ve nasıl değiştirilir değinmeye çalıştık ve bu ayarlardan bazılarını daha detaylıca açıklamaya çalıştık.
7 | ---
8 |
9 | JVM ayarları sıklıkla değiştirilmese de geliştirme ortamından canlı ortama geçiş sırasında daha performanslı bir cluster için bazı değişiklikler yapılması gerekir. ES'in eski sürümlerinde bu ayarları verirken ES'i çalıştırma komutuna parametre olarak veriyorduk:
10 |
11 | ```
12 | bin/elasticsearch -Xms1g -Xmx1g
13 | ```
14 |
15 | 5.x ve Daha sonraki sürümlerde JVM ayarları için `jvm.options` dosyası ve `ES_JAVA_OPTS` çevresel değişkeni üzerinden yapabiliyor olduk. Bu yazıda ben kısaca `jvm.options` dosyasından bahsedeceğim.
16 |
17 | `jvm.options` dosyasını elasticsearch kurulumunun yapıldığı dizindeki `config` klasörü altında ya da Debian ya da RPM üzerinden kurulumlarda `/etc/elasticsearch` klasörü altında bulabilirsiniz. Bu dosya içerisinde bazı satırlar `#` karakteri ile başlar bir çok dilde de olduğu gibi bu satırlar yorum satırıdır.
18 |
19 | Bu dosya üzerinden JVM ayarlamaları yaparken Java'nın farklı sürümleri için farklı ayarlamalar yapabilirsiniz. Örneğin tüm java sürümleri için bir ayarlama yapmak istiyorsanız satırı `-` ile başlatmanız yeterliyken sadece JDK 8 sürümü için bir ayarlama yapmak istiyorsanız `8:` başlatmanız gerekir. Örneğin 9+ JDK sürümleri için bir ayarlama yapmak isterseniz bu durumda da satır başınız `9-:` ile başlamalıdır. Bunlar için örnekler vermek gerekirse, ES'in varsayılan `jvm.options` dosyasına kısa bir göz atmak yeterli olacaktır.
20 |
21 | ```
22 | ....
23 | # log4j 2
24 | -Dlog4j.shutdownHookEnabled=false
25 | -Dlog4j2.disable.jmx=true
26 |
27 | ....
28 | ## JDK 8 GC logging
29 |
30 | 8:-XX:+PrintGCDetails
31 | 8:-XX:+PrintGCDateStamps
32 | ....
33 |
34 | # JDK 9+ GC logging
35 | 9-:-Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m
36 | ....
37 | ```
38 |
39 | Tabiki varsayılan dosya bu kadar ayarlama içermiyor ben sadece kısa kesitler halinde örnekleri buraya ekledim. Daha detaylı bakmak için şu adresi kullanabilirsiniz.
40 |
41 | [https://github.com/hkulekci/elastic-docker/blob/6.2.4/.docker/elasticsearch/config/jvm.options]()
42 |
43 | #### JVM Heap Size
44 |
45 | Java uygulamasının (ES'in) başlangıçta ayıracağı ve maksimum kullanabileceği bellek miktarını belirler. Bunun için aşağıdaki parametreleri `jvm.options` dosyasına yazabiliriz ya da var ise değiştirebiliriz.
46 |
47 | ```
48 | # Xms represents the initial size of total heap space
49 | # Xmx represents the maximum size of total heap space
50 |
51 | -Xms1g
52 | -Xmx1g
53 | ```
54 |
55 | Buradaki parametrelerin ne olduğunu daha iyi anlamak için Heap Bellek (heap memory) ne demek onu anlamak gerekir. Java uygulamalar bir takım verileri belleğe kaydetmek için iki tür yöntem kullanır. Birisi `stack` diğeri ise `heap`dir. `stack` türünde verilerin bellekte tutulup silinmesini uygulamanın kendisi değil işletim sistemi/alt katmanlar yönetir. `heap` türünde ise bellek kullanımını ve temizlenmesini uygulama yönetir. Java'da objeler `heap` bellekte tutulur ve `Garbage Collector` denen yapılar sayesinde `heap` bellek yönetimi sağlanır.
56 |
57 | Burada sorulacak soru aslında çok fazla. Java'da farklı türlerde Garbage Collector'lar mevcut. Bunların seçimleri bazı durumlarda performans artışı sağlarken bazı durumlarda sağlamayabiliyor. Ya da GC nasıl çalışıyor? gibi gibi. Bu soruları cevaplarken yazının asıl amacından sapacağımız için şimdilik bu onuyu kaynaklar bölümündeki linkler ile devam ettirmeyi öneriyorum. Daha fazla güzel kaynak için yorumlardan bana yazabilirsiniz.
58 |
59 | #### Garbage Collector Ayarlamaları
60 |
61 | Yukarıda da bahsettiğimiz gibi `heap` bellek alanının dolduğunda ya da belirli aralıklarla temizlenmesi için gerekli bir araç olan Garbage Collector için ayarlamalar yapabiliriz. Örneğin, bazı kaynaklarda çok önerilmese de, `+UseG1GC` ile GC türünüzü daha yeni bir GC olan G1GC ile değiştirebilirsiniz. Ancak ES bazı hatalardan dolayı daha G1GC'i desteklemiyor. [?](https://docs.datastax.com/en/cassandra/3.0/cassandra/operations/opsTuneJVM.html#opsTuneJVM__choose-gc) [?](https://discuss.elastic.co/t/g1gc-in-production-with-regard-to-consistency/47561/3) [*](https://discuss.elastic.co/t/elasticsearch-appears-to-ignore-xx-useg1gc-in-jvm-options/96862)
62 |
63 | Diğer `CMSInitiatingOccupancyFraction` ayarı ile `heap` bellek doluluk oranına göre GC'nin çalışmasını sağlayan bir oran belirleyebilirsiniz. Java dünyasında ortalama %70-75 civarları ideal görülüyor. ES için varsayılan değer %75.
64 |
65 | GC için varsayılan değerler aşağıdaki gibi:
66 |
67 | ```
68 | ## GC configuration
69 | -XX:+UseConcMarkSweepGC
70 | -XX:CMSInitiatingOccupancyFraction=75
71 | -XX:+UseCMSInitiatingOccupancyOnly
72 | ```
73 |
74 | #### Heap Bellek Hata Ayarları
75 |
76 | Heap bellek yönetimi sırasında bazı hatalar oluşabilir. Bu hataları yakalamak ve bir yerlere kaydetmen için aşağıdaki jvm ayarlarını kullanabilirsiniz. `HeapDumpPath` ile bir klasör belirleyerek hataları bu klasör içerisine yazdırabilirsiniz.
77 |
78 | ```
79 | # generate a heap dump when an allocation from the Java heap fails
80 | # heap dumps are created in the working directory of the JVM
81 | -XX:+HeapDumpOnOutOfMemoryError
82 |
83 | # specify an alternative path for heap dumps
84 | # ensure the directory exists and has sufficient space
85 | #-XX:HeapDumpPath=/heap/dump/path
86 | ```
87 |
88 | Bunlar dışında daha bir sürü ayarlamalar mevcut. Yazının başında da paylaştığım linkten bu ayarlara ulaşabilirsiniz. Yazıyı hazırlarken okuduğum yazıları kaynaklar olarak paylaşıyorum. Umarım yararlı olur.
89 |
90 |
91 | **Genel Kaynaklar :**
92 |
93 | - https://www.elastic.co/guide/en/elasticsearch/reference/current/jvm-options.html
94 | - https://docs.oracle.com/cd/E22289_01/html/821-1274/configuring-the-default-jvm-and-java-arguments.html
95 | - https://www.gribblelab.org/CBootCamp/7_Memory_Stack_vs_Heap.html
96 | - https://www.elastic.co/blog/a-heap-of-trouble
97 | - http://blog.sokolenko.me/2014/11/javavm-options-production.html
98 |
99 | **Garbage Collector Kaynakları :**
100 |
101 | - https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/cms.html
102 | - https://blog.takipi.com/garbage-collectors-serial-vs-parallel-vs-cms-vs-the-g1-and-whats-new-in-java-8/
103 | - https://www.cakesolutions.net/teamblogs/low-pause-gc-on-the-jvm
104 | - https://dzone.com/articles/java-garbage-collectors-when-will-g1gc-force-cms-out
105 | - https://dzone.com/articles/garbage-collectors-serial-vs-0
106 | - https://blog.novatec-gmbh.de/g1-action-better-cms/
107 | - https://stackoverflow.com/questions/16695874/why-does-the-jvm-full-gc-need-to-stop-the-world
108 | - https://www.journaldev.com/4098/java-heap-space-vs-stack-memory
109 | - http://blog.ragozin.info/2011/12/garbage-collection-in-hotspot-jvm.html
110 | - http://www.javainuse.com/java/permgen
111 | - http://blog.sokolenko.me/2014/11/javavm-options-production.html
--------------------------------------------------------------------------------
/assets/css/all.css:
--------------------------------------------------------------------------------
1 | ---
2 | ---
3 | {% include css/base.css %}
4 | {% include css/skeleton.css %}
5 | {% include css/screen.css %}
6 | {% include css/layout.css %}
7 | {% include css/syntax.css %}
8 | {% include css/custom.css %}
9 |
--------------------------------------------------------------------------------
/assets/img/inverted-index-with-score.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkulekci/elasticsearch/f2d0d6ee8e202f2366d10e5e95c10e5b69bb60d7/assets/img/inverted-index-with-score.png
--------------------------------------------------------------------------------
/assets/img/inverted-index.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkulekci/elasticsearch/f2d0d6ee8e202f2366d10e5e95c10e5b69bb60d7/assets/img/inverted-index.png
--------------------------------------------------------------------------------
/assets/img/kibana-index-contains-time-based-events-checkbox.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkulekci/elasticsearch/f2d0d6ee8e202f2366d10e5e95c10e5b69bb60d7/assets/img/kibana-index-contains-time-based-events-checkbox.png
--------------------------------------------------------------------------------
/assets/img/kibana-time-range.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hkulekci/elasticsearch/f2d0d6ee8e202f2366d10e5e95c10e5b69bb60d7/assets/img/kibana-time-range.png
--------------------------------------------------------------------------------
/atom.xml:
--------------------------------------------------------------------------------
1 | ---
2 | ---
3 |
4 |
5 |
6 | The blog of {{ site.data.theme.name }}
7 |
8 |
9 | {{ site.time | date_to_xmlschema }}
10 | {{ site.url }}
11 |
12 | {{ site.data.theme.name }}
13 | {{ site.data.theme.email }}
14 |
15 |
16 | {% for post in site.posts %}
17 |
18 | {{ post.title }}
19 |
20 | {{ post.date | date_to_xmlschema }}
21 | {{ site.url }}{{ post.id }}
22 | {{ post.content | xml_escape }}
23 |
24 | {% endfor %}
25 |
26 |
27 |
--------------------------------------------------------------------------------
/contact.html:
--------------------------------------------------------------------------------
1 | ---
2 | layout: default
3 | title: Elasticsearch Türkçe Blog - Videolar
4 | ---
5 |
6 |
7 | Motivolog Yazılım Biliş. Teknol. Medik. San. ve Tic. Ltd. Şti. şirketinde
8 | yazılımcı ve aynı zamanda şirket ortağıyım. Uzun zamandır Elasticsearch konusunda çeşitli çalışmalar yapmaktayım.
9 | Elasticsearch ve çevresindeki uygulamalar hakkında bir çok sunum ve eğitim verdim.
10 | Elasticsaerch, Kibana, Logstash, Beat(Filebeat, Metricbeat, ...) hakkındaki sorularınız için aşağıdaki e-posta
11 | adresinden rahatlıkla bana ulaşabilirsiniz.