4 | ![]() 5 |
5 |
8 |  9 |
9 |  10 |
10 |  11 |
11 |
12 |
13 |
19 | Generate a report with charts and statistics about cracked passwords in XLSX format 20 |
21 |
22 | Introduction
23 | •
24 | Authors
25 | •
26 | Features
27 | •
28 | Usage
29 |
30 |
33 | For more information check out this article 34 |
35 | 57 | - Stefano Alberto, Security Analyst at HN Security
57 | - Stefano Alberto, Security Analyst at HN Security  58 |
59 |
60 | ## Features
61 |
62 | Kraken performs different types of analytics to visualize the results from different points of view, trying to identify patterns in the provided data. We will now take a brief look at the charts automatically generated by Kraken.
63 |
58 |
59 |
60 | ## Features
61 |
62 | Kraken performs different types of analytics to visualize the results from different points of view, trying to identify patterns in the provided data. We will now take a brief look at the charts automatically generated by Kraken.
63 |
69 | 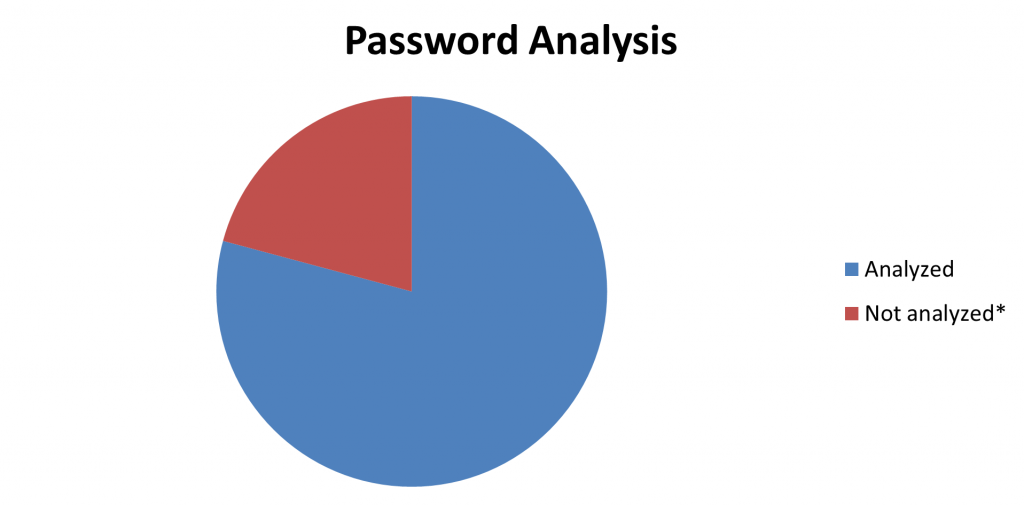 70 |
70 |
show-not-cracked option.
75 |
76 |
80 | 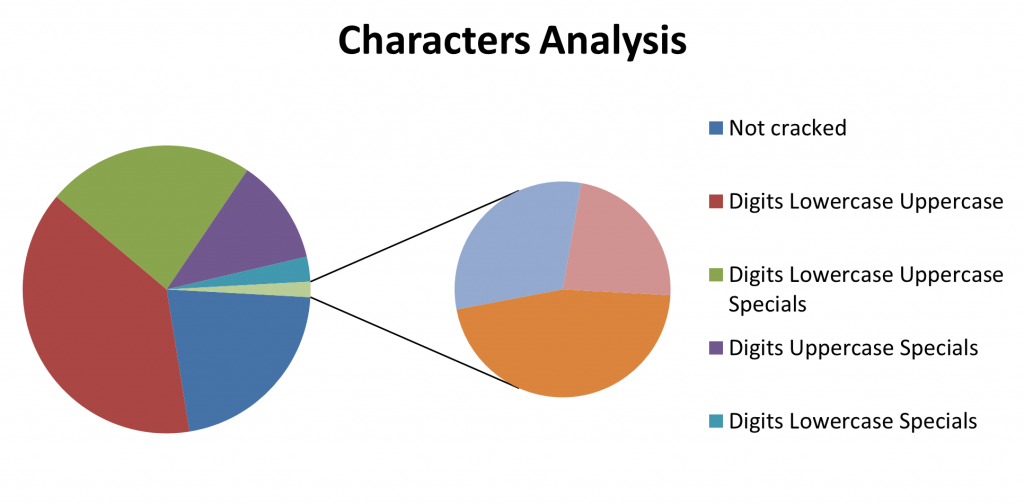 81 |
81 |
show-not-cracked option can be used.
86 |
87 |
91 | 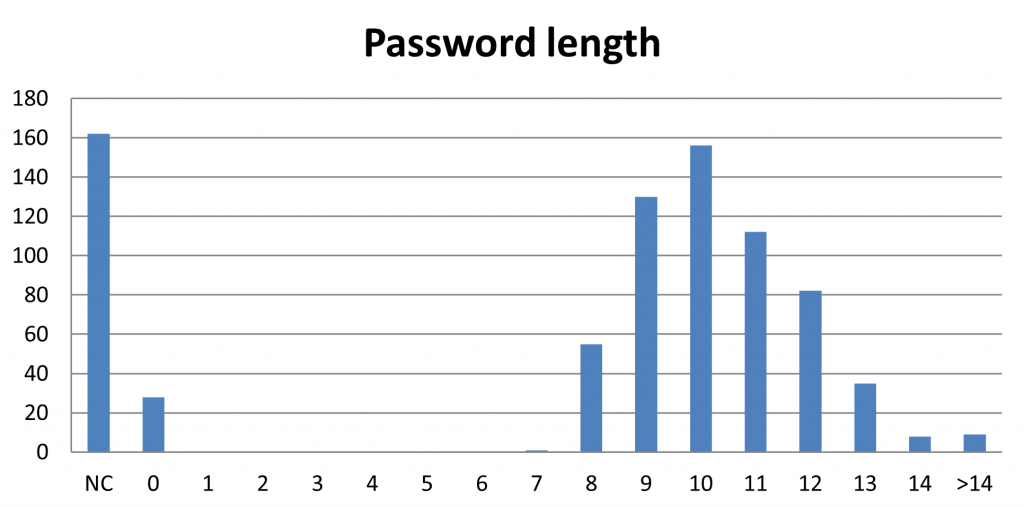 92 |
92 |
dictionary and the regex options.
96 |
97 |
102 | 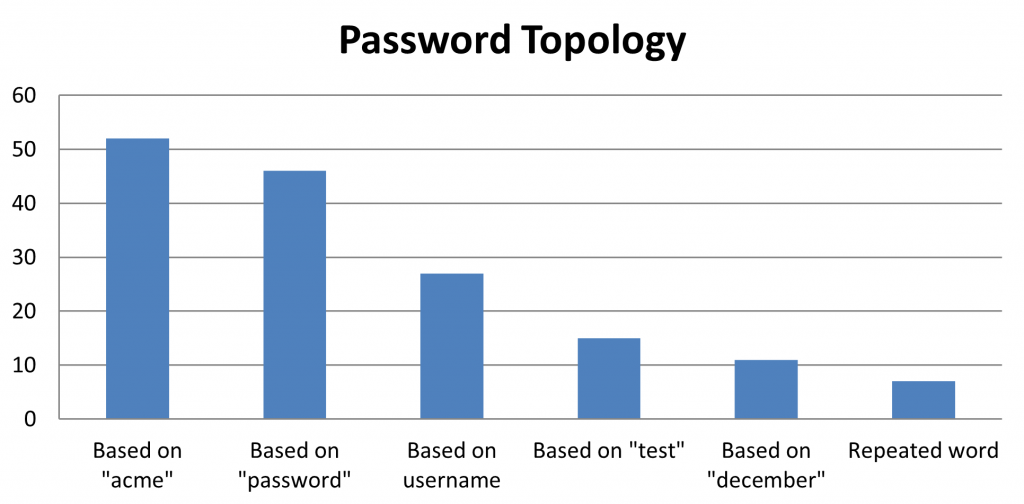 103 |
103 |
refresh_token file. If this file is found, the tool will check for the validity of the token, reusing it when possible.
120 |
121 |
125 |  126 |
126 |
138 |  139 |
139 |
145 | 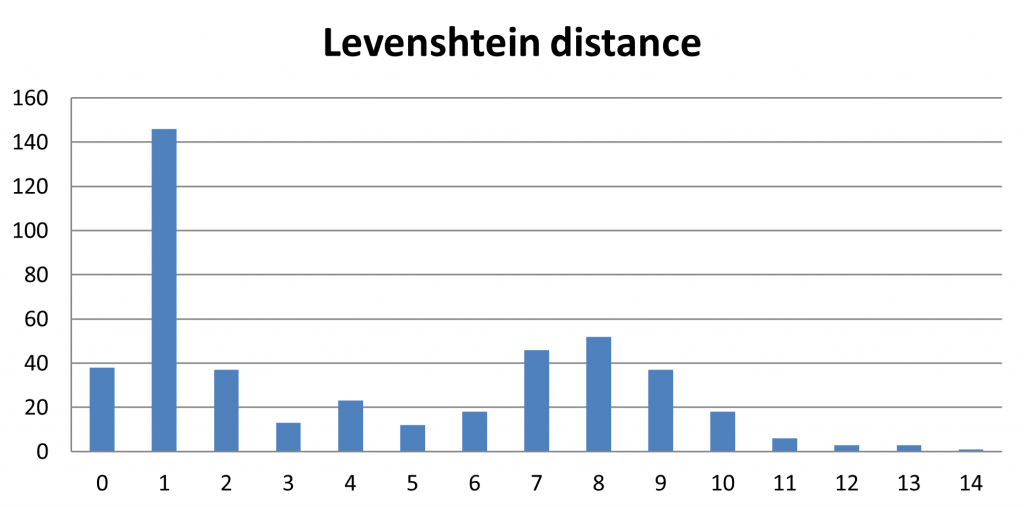 146 |
146 |
154 | 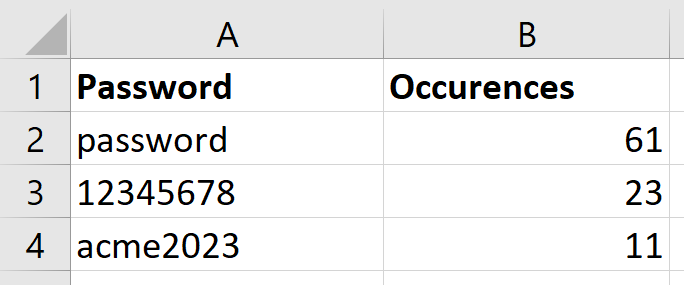 155 |
155 |
162 | 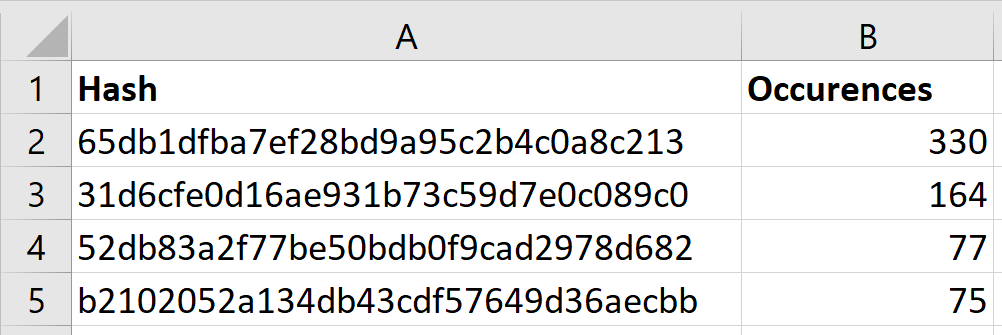 163 |
163 |
python kraken.py --pwd passwords.txt --out report.xlsx174 |
username:password 177 | user2:p4ssw0rd 178 | anotheruser:$HEX[706124243a776f726421]179 | Note that the tool also supports the process of historical password data. Previous passwords are identified by appending to the username the suffix
_history and an incremental number. For example, this file contains the password history for the user username.
180 | username:currentpassword 182 | username_history0:previouspassword 183 | username_history1:oldpassword184 |
--group user_file.txt where each line of the user file is a username that we want to consider in the analysis, as in the following example:
197 |
198 | user 201 | user1 202 | user2203 |
--show-not-cracked option to the command.
208 | --dictionary dictionary_file. Each line of the dictionary file contains a word that we want to use to categorize passwords, as in the following example:
218 | acme 220 | 2023 221 | password222 |
.*\d{8}.*. This regex would match all of the following passwords:
228 |
229 | 02121999 232 | test06072022 233 | tt00000000!234 |
--regex regex_file.txt. Each line of the regex file contains a python regex that will be used to match the cracked passwords, as in the following example:
238 | p(a|4)s.+rd
240 | .*\d{6}.*
241 | pwdump hash_dump_file.txt. The file format expected by Kraken is the output format of secretsdump.py. An example of this file format is the following:
246 | octagon.local\Administrator:500:aad3b435b51404eeaad3b435b51404ee:c8ca0f8d1f3ca975464bee8843bceda3::: 248 | Guest:501:aad3b435b51404eeaad3b435b51404ee:31d6cfe0d16ae931b73c59d7e0c089c0::: 249 | krbtgt:502:aad3b435b51404eeaad3b435b51404ee:52db83a2f77be50bdb0f9cad2978d682::: 250 | octagon.local\REVA_JOYCE:1103:aad3b435b51404eeaad3b435b51404ee:b2102052a134db43cdf57649d36aecbb::: 251 | octagon.local\MARYANN_HANSON:1104:aad3b435b51404eeaad3b435b51404ee:57cbd01ad63e05402db21fb22cdedda2::: 252 | octagon.local\MICHELLE_WOLF:1105:aad3b435b51404eeaad3b435b51404ee:65db1dfba7ef28bd9a95c2b4c0a8c213:::253 |
--check-leaked in the command.
258 |
259 | If you also what to enable the API used by Google password manager you can add the --check-leaked-google flag too.
260 |
--------------------------------------------------------------------------------
/google_api/ECCommutativeCipher.py:
--------------------------------------------------------------------------------
1 |
2 | from ecpy.curves import Curve, Point
3 | from math import ceil
4 | from hashlib import sha256
5 | from Crypto.Util.number import inverse
6 | from libnum import sqrtmod_prime_power
7 | import random
8 |
9 |
10 | class ECCommutativeCipher:
11 |
12 | cv = Curve.get_curve("NIST-P256")
13 |
14 | p = 0xffffffff00000001000000000000000000000000ffffffffffffffffffffffff
15 | a = 0xffffffff00000001000000000000000000000000fffffffffffffffffffffffc
16 | b = 0x5ac635d8aa3a93e7b3ebbd55769886bc651d06b0cc53b0f63bce3c3e27d2604b
17 | order = 0xffffffff00000000ffffffffffffffffbce6faada7179e84f3b9cac2fc632551
18 |
19 | def __init__(self, private_key=None):
20 | if (private_key is None):
21 | self.key = random.randint(1, self.order)
22 | else:
23 | self.key = int.from_bytes(private_key, 'big')
24 |
25 | def random_oracle(self, x, max_value):
26 |
27 | hash_output_length = 256
28 | output_bit_length = max_value.bit_length() + hash_output_length
29 | iter_count = ceil(output_bit_length / hash_output_length)
30 | assert (iter_count * hash_output_length < 130048)
31 | excess_bit_count = (
32 | iter_count * hash_output_length) - output_bit_length
33 | hash_output = 0
34 |
35 | for i in range(1, iter_count+1):
36 | hash_output = hash_output << hash_output_length
37 | bignum_bytes = i.to_bytes(ceil(i.bit_length()/8), 'big')
38 | bignum_bytes += x
39 | # print(' bytes: ', bignum_bytes.hex())
40 | hashed_string = sha256(bignum_bytes).digest()
41 | hash_output = hash_output + int.from_bytes(hashed_string, 'big')
42 | #print(' ', hash_output)
43 | return (hash_output >> excess_bit_count) % max_value
44 |
45 | def hashToTheCurve(self, m):
46 | m = m.split(b'\x00')[0]
47 | x = self.random_oracle(m, self.p)
48 | while True:
49 | # print('x: ', x)
50 | mod_x = x % self.p
51 | y2 = (mod_x**3 + self.a*mod_x + self.b) % self.p
52 | try:
53 | sqrt = list(sqrtmod_prime_power(y2, self.p, 1))[0]
54 | if (sqrt & 1 == 1):
55 | return Point(mod_x, (-sqrt) % self.p, self.cv)
56 | return Point(mod_x, sqrt, self.cv)
57 | except:
58 | pass
59 | x = self.random_oracle(x.to_bytes(
60 | ceil(x.bit_length()/8), 'big'), self.p)
61 |
62 | def encrypt(self, plaintext):
63 | point = self.hashToTheCurve(plaintext)
64 | ep = self.key*point
65 |
66 | ser_x = ep.x.to_bytes(32, 'big')
67 | ser_y = ep.y.to_bytes(32, 'big')
68 | return bytes([2 + (ser_y[-1] & 1)]) + ser_x
69 |
70 | def decrypt(self, ciphertext):
71 | assert (ciphertext[0] == 2 or ciphertext[0] == 3)
72 |
73 | x = int.from_bytes(ciphertext[1:], 'big')
74 | y = self.cv.y_recover(x)
75 |
76 | point = Point(x, y, self.cv)
77 |
78 | dp = inverse(self.key, self.order) * point
79 |
80 | ser_x = dp.x.to_bytes(32, 'big')
81 | ser_y = dp.y.to_bytes(32, 'big')
82 |
83 | return bytes([2 + (ser_y[-1] & 1)]) + ser_x
84 |
85 |
86 | if (__name__ == '__main__'):
87 |
88 | x = b'\x39\x4f\xf8\x31\x41\xc4\xaf\x41\xbd\x3b\x5e\xf9\x1d\xeb\x72\x9d\xab\x98\x9e\x72\x31\xfe\xd8\x20\xd2\x22\xb3\xbc\xec\x89\x14\x8e'
89 |
90 | cipher = ECCommutativeCipher()
91 |
92 | c = cipher.encrypt(x)
93 |
94 | print(c.hex())
95 |
96 | with open('reencrypted_lookup_hash', 'rb') as f:
97 | reencrypted_lookup_hash = f.read()
98 |
99 | d = cipher.decrypt(reencrypted_lookup_hash)
100 |
101 | print(d.hex())
102 |
--------------------------------------------------------------------------------
/google_api/__init__.py:
--------------------------------------------------------------------------------
1 | import requests
2 | from hashlib import sha256, scrypt
3 | import google_api.leak_detection_api_pb2 as LookupSingleLeakRequest
4 | from google_api.get_token import get_token
5 | from google_api.ECCommutativeCipher import ECCommutativeCipher
6 |
7 |
8 | def username_hash_prefix(username):
9 | username_salt = b'\xC4\x94\xA3\x95\xF8\xC0\xE2\x3E\xA9\x23\x04\x78\x70\x2C\x72\x18\x56\x54\x99\xB3\xE9\x21\x18\x6C\x21\x1A\x01\x22\x3C\x45\x4A\xFA'
10 | hash = sha256(username.encode()+username_salt).hexdigest()[:8]
11 | x = bytes.fromhex(hash)
12 | x = x[:3] + bytes([x[3] & 0b11000000])
13 | return x
14 |
15 |
16 | def scrypt_hash_username_and_password(username, password):
17 | password_salt = b'\x30\x76\x2A\xD2\x3F\x7B\xA1\x9B\xF8\xE3\x42\xFC\xA1\xA7\x8D\x06\xE6\x6B\xE4\xDB\xB8\x4F\x81\x53\xC5\x03\xC8\xDB\xBd\xDE\xA5\x20'
18 | username_password = username.encode() + password.encode()
19 | salt = username.encode() + password_salt
20 | hash = scrypt(username_password, salt=salt, n=4096, r=8, p=1)[:32]
21 | return hash
22 |
23 |
24 | class GoogleApi():
25 |
26 | def __init__(self):
27 | self.access_token = get_token()
28 | self.cipher = ECCommutativeCipher()
29 |
30 | def lookup_request(self, username, password):
31 | lookup_hash = scrypt_hash_username_and_password(username, password)
32 |
33 | req = LookupSingleLeakRequest.LookupSingleLeakRequest()
34 |
35 | req.username_hash_prefix = username_hash_prefix(username)
36 | req.username_hash_prefix_length = 26
37 | req.encrypted_lookup_hash = self.cipher.encrypt(lookup_hash)
38 |
39 | serialized = req.SerializeToString()
40 |
41 | r = requests.post(
42 | 'https://passwordsleakcheck-pa.googleapis.com/v1/leaks:lookupSingle',
43 | headers={'authorization': 'Bearer ' + self.access_token, 'content-type': 'application/x-protobuf', 'sec-fetch-site': 'none', 'sec-fetch-mode': 'no-cors', 'sec-fetch-dest': 'empty',
44 | 'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'},
45 | data=serialized)
46 |
47 | if (r.status_code != 200):
48 | print(r)
49 | print(r.text)
50 | raise "Request failed"
51 |
52 | res = LookupSingleLeakRequest.LookupSingleLeakResponse()
53 | res.ParseFromString(r.content)
54 |
55 | return res
56 |
57 | def is_leaked(self, username, password):
58 | res = self.lookup_request(username, password)
59 |
60 | dec = self.cipher.decrypt(res.reencrypted_lookup_hash)
61 |
62 | hash1 = sha256(b'\x02' + dec[1:]).digest()
63 | hash2 = sha256(b'\x03' + dec[1:]).digest()
64 |
65 | for x in res.encrypted_leak_match_prefix:
66 | if (hash1.startswith(x) or hash2.startswith(x)):
67 | return True
68 |
69 | return False
70 |
--------------------------------------------------------------------------------
/google_api/get_token.py:
--------------------------------------------------------------------------------
1 | import requests
2 | import subprocess
3 | from google_api.proxy import getTokenFromChrome
4 |
5 |
6 | def refresh_token(old_token):
7 | r = requests.post('https://www.googleapis.com/oauth2/v4/token', headers={'sec-fetch-site': 'none', 'sec-fetch-mode': 'no-cors', 'sec-fetch-dest': 'empty',
8 | 'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'},
9 | data={"scope": "https://www.googleapis.com/auth/identity.passwords.leak.check",
10 | "grant_type": "refresh_token",
11 | "refresh_token": old_token,
12 | "client_id": "77185425430.apps.googleusercontent.com",
13 | "client_secret": "OTJgUOQcT7lO7GsGZq2G4IlT"})
14 |
15 | return r.json()['access_token']
16 |
17 |
18 | def get_token():
19 | try:
20 | with open('refresh_token', 'r') as f:
21 | rt = f.read()
22 | return refresh_token(rt)
23 | except:
24 | rt = getTokenFromChrome()
25 |
26 | with open('refresh_token', 'w') as f:
27 | f.write(rt)
28 |
29 | return refresh_token(rt)
30 |
--------------------------------------------------------------------------------
/google_api/leak_detection_api_pb2.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # Generated by the protocol buffer compiler. DO NOT EDIT!
3 | # source: leak_detection_api.proto
4 | """Generated protocol buffer code."""
5 | from google.protobuf.internal import builder as _builder
6 | from google.protobuf import descriptor as _descriptor
7 | from google.protobuf import descriptor_pool as _descriptor_pool
8 | from google.protobuf import symbol_database as _symbol_database
9 | # @@protoc_insertion_point(imports)
10 |
11 | _sym_db = _symbol_database.Default()
12 |
13 |
14 | DESCRIPTOR = _descriptor_pool.Default().AddSerializedFile(
15 | b'\n\x18leak_detection_api.proto\x12\x30google.internal.identity.passwords.leak.check.v1\"{\n\x17LookupSingleLeakRequest\x12\x1c\n\x14username_hash_prefix\x18\x01 \x01(\x0c\x12#\n\x1busername_hash_prefix_length\x18\x02 \x01(\r\x12\x1d\n\x15\x65ncrypted_lookup_hash\x18\x03 \x01(\x0c\"`\n\x18LookupSingleLeakResponse\x12#\n\x1b\x65ncrypted_leak_match_prefix\x18\x01 \x03(\x0c\x12\x1f\n\x17reencrypted_lookup_hash\x18\x02 \x01(\x0c\x42\x02H\x03\x62\x06proto3')
16 |
17 | _builder.BuildMessageAndEnumDescriptors(DESCRIPTOR, globals())
18 | _builder.BuildTopDescriptorsAndMessages(
19 | DESCRIPTOR, 'leak_detection_api_pb2', globals())
20 | if _descriptor._USE_C_DESCRIPTORS == False:
21 |
22 | DESCRIPTOR._options = None
23 | DESCRIPTOR._serialized_options = b'H\003'
24 | _LOOKUPSINGLELEAKREQUEST._serialized_start = 78
25 | _LOOKUPSINGLELEAKREQUEST._serialized_end = 201
26 | _LOOKUPSINGLELEAKRESPONSE._serialized_start = 203
27 | _LOOKUPSINGLELEAKRESPONSE._serialized_end = 299
28 | # @@protoc_insertion_point(module_scope)
29 |
--------------------------------------------------------------------------------
/google_api/proxy.py:
--------------------------------------------------------------------------------
1 | from mitm import MITM, protocol, crypto, middleware
2 | from base64 import b64encode
3 | import subprocess
4 | from hashlib import sha256
5 | import OpenSSL
6 | from mitm.core import Connection, Middleware
7 | import re
8 |
9 |
10 | def getTokenFromChrome():
11 |
12 | while True:
13 | ans = input('''Using the reverse engineered Google api requires a valid token.
14 | We need to launch Google Chrome to extract a token from your browser, the browser will be closed as soon as we get the token.
15 | Type Y to continue or N to exit: ''')
16 | if ans.lower() == 'y':
17 | break
18 | if ans.lower() == 'n':
19 | exit(1)
20 |
21 | ca = crypto.CertificateAuthority()
22 |
23 | # pk = ca.cert.get_pubkey()
24 | # der = OpenSSL.crypto.dump_publickey(OpenSSL.crypto.FILETYPE_ASN1, pk)
25 | # fingerprint = b64encode(sha256(der).digest()).decode()
26 |
27 | mitm_server = None
28 |
29 | class GetRefreshToken(Middleware):
30 | def __init__(self):
31 | self.connection: Connection = None
32 |
33 | async def mitm_started(self, host: str, port: int):
34 | # print(f"MITM server started on {host}:{port}.")
35 | pass
36 |
37 | async def client_connected(self, connection: Connection):
38 | pass
39 |
40 | async def server_connected(self, connection: Connection):
41 | pass
42 |
43 | async def client_data(self, connection: Connection, data: bytes) -> bytes:
44 | m = re.search(b'refresh_token=([^&]+)&', data)
45 | if m:
46 | global refresh_token
47 | refresh_token = m[1].decode()
48 | mitm_server.stop()
49 |
50 | return data
51 |
52 | async def server_data(self, connection: Connection, data: bytes) -> bytes:
53 | return data
54 |
55 | async def client_disconnected(self, connection: Connection):
56 | pass
57 |
58 | async def server_disconnected(self, connection: Connection):
59 | pass
60 |
61 | mitm = MITM(
62 | host="127.0.0.1",
63 | port=8899,
64 | protocols=[protocol.HTTP],
65 | middlewares=[GetRefreshToken],
66 | certificate_authority=ca
67 | )
68 |
69 | p = subprocess.Popen(
70 | ['google-chrome', '--proxy-server=localhost:8899', '--ignore-certificate-errors', 'https://account.google.com'], stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
71 |
72 | mitm_server = mitm
73 |
74 | try:
75 | mitm.run()
76 | except:
77 | pass
78 |
79 | p.kill()
80 | return refresh_token
81 |
82 |
83 | if __name__ == '__main__':
84 | print(getTokenFromChrome())
85 |
--------------------------------------------------------------------------------
/img/logo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hnsecurity/kraken/6cc4f460e7b4da99b133744bc795bb75fce2df6d/img/logo.png
--------------------------------------------------------------------------------
/kraken.py:
--------------------------------------------------------------------------------
1 | from stats import levenshtein_distance_stats
2 | from openpyxl.styles import Font
3 | import re
4 | import collections
5 | import openpyxl
6 | import argparse
7 | from stats import *
8 | import logging
9 | import traceback
10 |
11 | parser = argparse.ArgumentParser(description='Password stats generator')
12 |
13 | parser.add_argument('--pwd', dest='filename_password',
14 | help='pasword file', required=True)
15 | parser.add_argument('--out', dest='out_file',
16 | help='output file', required=True)
17 | parser.add_argument('--group', dest='filename_users',
18 | help='group file', required=False)
19 | parser.add_argument('--regex', dest='regex_file',
20 | help='regex file', required=False)
21 | parser.add_argument('--dictionary', dest='dictionary_file',
22 | help='dictionary file', required=False)
23 |
24 | parser.add_argument('--debug', dest='debug',
25 | help='enable debug logs', action='store_true')
26 | parser.add_argument('--show-not-cracked', dest='show_not_cracked',
27 | help='enable not cracked password into the XLSX', action='store_true', required=False)
28 | parser.add_argument('--ignore-case', dest='ignore_case',
29 | help='ignore case change in Levenshtein distance', action='store_true', required=False)
30 | parser.add_argument('--pwdump', dest='pwdump_file',
31 | help='enable hash count', required=False)
32 |
33 | parser.add_argument('--check-leaked', dest='check_leaked',
34 | help='check if leaked', action='store_true')
35 | parser.add_argument('--check-leaked-google', dest='check_leaked_google',
36 | help='check leaked username,password pair in google database', action='store_true')
37 |
38 | args = parser.parse_args()
39 |
40 | dictionary_list = []
41 | list_user_password = {}
42 | list_user_password_with_history = {}
43 | list_users = None
44 | list_regex = []
45 | list_user_hash = {}
46 |
47 |
48 | logger = logging.getLogger('logger')
49 |
50 | if args.debug:
51 | logger.setLevel(logging.DEBUG)
52 | logger.info('Debug logs enabled')
53 |
54 | # load user list
55 | try:
56 | if args.filename_users:
57 | with open(args.filename_users) as f:
58 | list_users = f.read().splitlines()
59 | logger.info(f'Loaded {len(list_users)} users')
60 | logger.debug('Loaded users: ' + str(list_users))
61 | except:
62 | logger.warning(
63 | 'Error while reading users file, skipping...')
64 | list_users = None
65 |
66 | # load regex
67 | try:
68 | if args.regex_file:
69 | with open(args.regex_file) as f:
70 | list_regex = f.read().splitlines()
71 | logger.info(f'Loaded {len(list_regex)} regexs')
72 | logger.debug('Loaded regexs: ' + str(list_regex))
73 | except:
74 | logger.warning('Error while reading regex file, skipping...')
75 | list_regex = []
76 |
77 | # load dictionary
78 | try:
79 | if args.dictionary_file:
80 | with open(args.dictionary_file) as f:
81 | for cur_line in f.readlines():
82 | cur_line = cur_line.rstrip()
83 | dictionary_list.append(cur_line)
84 | logger.info(f'Loaded {len(dictionary_list)} words from dictionary')
85 | logger.debug('Loaded words: ' + str(dictionary_list))
86 | except:
87 | logger.warning('Error while reading dictionary file, skipping...')
88 | dictionary_list = []
89 |
90 | # load only password in user list
91 | n_passwords = 0
92 |
93 | try:
94 | with open(args.filename_password) as f:
95 | for cur_line in f:
96 |
97 | try:
98 | cur_user, cur_password = cur_line.split(':', 1)
99 |
100 | # decode the $HEX[] hashcat format
101 | m = re.search(r'^\$HEX\[([0-9a-f]+)\]$',cur_password)
102 | if m:
103 | cur_password = bytes.fromhex(m[1]).decode()
104 | except:
105 | continue
106 |
107 | # clean user from history
108 | cur_user_clean = re.sub("_history[0-9]*$", "", cur_user)
109 |
110 | # insert in list only present users
111 | if not list_users or cur_user_clean in list_users:
112 | n_passwords += 1
113 | if "_history" in cur_user:
114 | list_user_password_with_history[cur_user] = cur_password.rstrip(
115 | '\r\n')
116 | else:
117 | list_user_password[cur_user] = cur_password.rstrip('\r\n')
118 | except:
119 | logger.critical('Error while reading password file, exiting...')
120 | logger.debug(traceback.format_exc())
121 | exit(1)
122 |
123 | logger.info(f'Loaded {n_passwords} passwords')
124 |
125 | # load only NTHASH in user list
126 | if args.pwdump_file:
127 | try:
128 | n_hashes = 0
129 | with open(args.pwdump_file) as f:
130 | for cur_line in f:
131 |
132 | try:
133 | cur_user, a, b, cur_password, c = cur_line.split(':', 4)
134 | except:
135 | continue
136 |
137 | # clean user from history
138 | cur_user_clean = re.sub("_history[0-9]*$", "", cur_user)
139 |
140 | # insert in list only present users
141 | if not list_users or cur_user_clean in list_users:
142 |
143 | list_user_hash[cur_user] = cur_password.rstrip('\r\n')
144 | n_hashes += 1
145 |
146 | logger.info(f'Loaded {n_hashes} hashes')
147 | except:
148 | logger.warning('Error while reading pwdump file, skipping...')
149 |
150 |
151 | # create the excel workbook
152 | wb = openpyxl.Workbook()
153 |
154 | ws_stats = wb.create_sheet('Stats')
155 | ws_hash = wb.create_sheet('Hash')
156 | ws_pwd = wb.create_sheet('Most used')
157 |
158 | # remove the default sheet
159 | wb.remove(wb['Sheet'])
160 |
161 | ws_stats.column_dimensions['B'].width = 20
162 |
163 |
164 | # statistics
165 | cur_line = 2
166 |
167 | if not list_users is None:
168 | logger.debug('Starting password analysis...')
169 | cur_line = password_analysis_stats(ws_stats, cur_line, args, list_users,
170 | list_user_password)
171 | cur_line += 5
172 |
173 | logger.debug('Starting characters analysis...')
174 | cur_line = characters_analysis_stats(ws_stats, cur_line, args, list_users,
175 | list_user_password)
176 |
177 | logger.debug('Starting password length analysis...')
178 | cur_line = password_length_stats(ws_stats, cur_line + 5, args, list_users,
179 | list_user_password)
180 |
181 | logger.debug('Starting password topology analysis...')
182 | cur_line = password_topology_stats(
183 | ws_stats, cur_line + 5, args, list_users, list_user_password, list_regex, dictionary_list)
184 |
185 | if args.check_leaked:
186 | logger.info('Starting leaked password analysis, this could take some time...')
187 | cur_line = password_leaked_stats(
188 | ws_stats, cur_line + 5, args, list_users, list_user_password, list_regex, dictionary_list)
189 | else:
190 | logger.debug('Skipping leaked password analysis...')
191 |
192 | if len(list_user_password_with_history) != 0:
193 | logger.debug('Starting levenshtein distance analysis...')
194 | cur_line = levenshtein_distance_stats(ws_stats, cur_line + 5, args, list_users,
195 | list_user_password, list_user_password_with_history)
196 | else:
197 | logger.debug('Skipping levenshtein distance analysis...')
198 |
199 | # Password occurences
200 | ws_pwd["A1"] = "Password"
201 | ws_pwd["B1"] = "Occurences"
202 |
203 | cur_line = 2
204 |
205 | c = collections.Counter(list_user_password[elem]
206 | for elem in list_user_password)
207 |
208 | for i in c.most_common():
209 | if i[1] > 3:
210 | ws_pwd["A" + str(cur_line)] = i[0]
211 | ws_pwd["B" + str(cur_line)] = i[1]
212 | cur_line += 1
213 |
214 | # Hash occurences
215 | ws_hash["A1"] = "Hash"
216 | ws_hash["B1"] = "Occurences"
217 |
218 | cur_line = 2
219 |
220 | c = collections.Counter(list_user_hash[elem] for elem in list_user_hash)
221 |
222 | for i in c.most_common():
223 | if i[1] > 3:
224 | ws_hash["A" + str(cur_line)] = i[0]
225 | ws_hash["B" + str(cur_line)] = i[1]
226 | cur_line += 1
227 |
228 |
229 | logger.info('Saving output file')
230 | wb.save(args.out_file)
231 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | appdirs
2 | certifi
3 | cffi
4 | charset-normalizer
5 | cryptography
6 | ECPy
7 | et-xmlfile
8 | future
9 | httpq
10 | idna
11 | Levenshtein
12 | libnum
13 | mitm
14 | openpyxl
15 | pbr
16 | protobuf
17 | pwnedpasswords
18 | pycparser
19 | pycryptodome
20 | pyOpenSSL
21 | rapidfuzz
22 | requests
23 | toolbox
24 | tqdm
25 | urllib3
26 |
--------------------------------------------------------------------------------
/stats.py:
--------------------------------------------------------------------------------
1 | from tqdm import tqdm
2 | import re
3 | from openpyxl.chart import PieChart3D, PieChart, ProjectedPieChart, BarChart, Reference, Series
4 | from openpyxl.styles import Font
5 | import operator
6 | from Levenshtein import distance
7 | import logging
8 |
9 | from google_api import GoogleApi
10 | import pwnedpasswords
11 |
12 | logger = logging.getLogger('logger')
13 |
14 |
15 | def password_analysis_stats(ws_stats, start_line, args, list_users, list_user_password):
16 | ws_stats[f"B{start_line}"] = "Passwords Analysis"
17 | ws_stats[f"B{start_line}"].font = Font(bold=True)
18 |
19 | ws_stats[f"B{start_line+1}"] = "Analyzed"
20 | ws_stats[f"C{start_line+1}"] = len(list_user_password)
21 |
22 | ws_stats[f"B{start_line+2}"] = "Not analyzed*"
23 |
24 | if list_users:
25 | ws_stats[f"C{start_line+2}"] = len(list_users) - \
26 | len(list_user_password)
27 | else:
28 | ws_stats[f"C{start_line+2}"] = 0
29 |
30 | chart = PieChart3D()
31 | chart.add_data(
32 | Reference(ws_stats, range_string=f'Stats!C{start_line+1}:C{start_line+2}'))
33 | chart.set_categories(
34 | Reference(ws_stats, range_string=f'Stats!B{start_line+1}:B{start_line+2}'))
35 | chart.title = "Password Analysis"
36 | ws_stats.add_chart(chart, f'E{start_line}')
37 |
38 | return start_line + 15
39 |
40 |
41 | def characters_analysis_stats(ws_stats, start_line, args, list_users, list_user_password):
42 | password_chars = {}
43 | password_chars["Uppercase"] = 0
44 | password_chars["Lowercase"] = 0
45 | password_chars["Digits"] = 0
46 | password_chars["Specials"] = 0
47 | password_chars["Digits Lowercase"] = 0
48 | password_chars["Digits Uppercase"] = 0
49 | password_chars["Digits Specials"] = 0
50 | password_chars["Lowercase Uppercase"] = 0
51 | password_chars["Lowercase Specials"] = 0
52 | password_chars["Uppercase Specials"] = 0
53 | password_chars["Digits Lowercase Uppercase"] = 0
54 | password_chars["Digits Lowercase Specials"] = 0
55 | password_chars["Digits Uppercase Specials"] = 0
56 | password_chars["Lowercase Uppercase Specials"] = 0
57 | password_chars["Digits Lowercase Uppercase Specials"] = 0
58 |
59 | for cur_user in list_user_password:
60 |
61 | # don't count on password history
62 | if re.search(r"_history[0-9]*$", cur_user):
63 | continue
64 |
65 | # check password chars
66 | if re.search(r"(?=^[^\x0d\x0a]*$)(?!.*\d)(?=.*[A-Z])(?!.*[a-z])(?!.*[\W])", list_user_password[cur_user]):
67 | password_chars["Uppercase"] += 1
68 | continue
69 | if re.search(r"(?=^[^\x0d\x0a]*$)(?!.*\d)(?!.*[A-Z])(?=.*[a-z])(?!.*[\W])", list_user_password[cur_user]):
70 | password_chars["Lowercase"] += 1
71 | continue
72 | if re.search(r"(?=^[^\x0d\x0a]*$)(?=.*\d)(?!.*[A-Z])(?!.*[a-z])(?!.*[\W])", list_user_password[cur_user]):
73 | password_chars["Digits"] += 1
74 | continue
75 | if re.search(r"(?=^[^\x0d\x0a]*$)(?!.*\d)(?!.*[A-Z])(?!.*[a-z])(?=.*[\W])", list_user_password[cur_user]):
76 | password_chars["Specials"] += 1
77 | continue
78 | if re.search(r"(?=^[^\x0d\x0a]*$)(?=.*\d)(?!.*[A-Z])(?=.*[a-z])(?!.*[\W])", list_user_password[cur_user]):
79 | password_chars["Digits Lowercase"] += 1
80 | continue
81 | if re.search(r"(?=^[^\x0d\x0a]*$)(?=.*\d)(?=.*[A-Z])(?!.*[a-z])(?!.*[\W])", list_user_password[cur_user]):
82 | password_chars["Digits Uppercase"] += 1
83 | continue
84 | if re.search(r"(?=^[^\x0d\x0a]*$)(?=.*\d)(?!.*[A-Z])(?!.*[a-z])(?=.*[\W])", list_user_password[cur_user]):
85 | password_chars["Digits Specials"] += 1
86 | continue
87 | if re.search(r"(?=^[^\x0d\x0a]*$)(?!.*\d)(?=.*[A-Z])(?=.*[a-z])(?!.*[\W])", list_user_password[cur_user]):
88 | password_chars["Lowercase Uppercase"] += 1
89 | continue
90 | if re.search(r"(?=^[^\x0d\x0a]*$)(?!.*\d)(?!.*[A-Z])(?=.*[a-z])((?=.*[\W])|(?=.*[\s]))", list_user_password[cur_user]):
91 | password_chars["Lowercase Specials"] += 1
92 | continue
93 | if re.search(r"(?=^[^\x0d\x0a]*$)(?!.*\d)(?=.*[A-Z])(?!.*[a-z])(?=.*[\W])", list_user_password[cur_user]):
94 | password_chars["Uppercase Specials"] += 1
95 | continue
96 | if re.search(r"(?=^[^\x0d\x0a]*$)(?=.*\d)(?=.*[A-Z])(?=.*[a-z])(?!.*[\W])", list_user_password[cur_user]):
97 | password_chars["Digits Lowercase Uppercase"] += 1
98 | continue
99 | if re.search(r"(?=^[^\x0d\x0a]*$)(?=.*\d)(?!.*[A-Z])(?=.*[a-z])(?=.*[\W])", list_user_password[cur_user]):
100 | password_chars["Digits Lowercase Specials"] += 1
101 | continue
102 | if re.search(r"(?=^[^\x0d\x0a]*$)(?=.*\d)(?=.*[A-Z])(?!.*[a-z])(?=.*[\W])", list_user_password[cur_user]):
103 | password_chars["Digits Uppercase Specials"] += 1
104 | continue
105 | if re.search(r"(?=^[^\x0d\x0a]*$)(?!.*\d)(?=.*[A-Z])(?=.*[a-z])(?=.*[\W])", list_user_password[cur_user]):
106 | password_chars["Lowercase Uppercase Specials"] += 1
107 | continue
108 | if re.search(r"(?=^[^\x0d\x0a]*$)(?=.*\d)(?=.*[A-Z])(?=.*[a-z])(?=.*[\W])", list_user_password[cur_user]):
109 | password_chars["Digits Lowercase Uppercase Specials"] += 1
110 | continue
111 |
112 | ws_stats[f"B{start_line}"] = "Characters Analysis"
113 | ws_stats[f"B{start_line}"].font = Font(bold=True)
114 |
115 | cur_line = start_line + 1
116 |
117 | if args.show_not_cracked and list_users:
118 | ws_stats["B" + str(cur_line)] = "Not cracked"
119 | ws_stats["C" + str(cur_line)] = len(list_users) - \
120 | len(list_user_password)
121 | cur_line += 1
122 |
123 | for i in sorted(password_chars.items(), key=operator.itemgetter(1), reverse=True):
124 | if i[1] > 0:
125 | ws_stats["B" + str(cur_line)] = i[0]
126 | ws_stats["C" + str(cur_line)] = i[1]
127 | cur_line += 1
128 |
129 | chart = ProjectedPieChart()
130 | chart.add_data(
131 | Reference(ws_stats, range_string=f'Stats!C{start_line+1}:C{cur_line-1}'))
132 | chart.set_categories(
133 | Reference(ws_stats, range_string=f'Stats!B{start_line+1}:B{cur_line-1}'))
134 | chart.title = "Characters Analysis"
135 | ws_stats.add_chart(chart, f'E{start_line}')
136 |
137 | return max(cur_line, start_line+15)
138 |
139 |
140 | def password_length_stats(ws_stats, start_line, args, list_users, list_user_password):
141 | cut_length = 14
142 |
143 | password_len = {}
144 | for i in range(0, cut_length+2):
145 | password_len[i] = 0
146 |
147 | for cur_user in list_user_password:
148 | # compute len of password
149 | if len(list_user_password[cur_user]) > cut_length:
150 | password_len[cut_length+1] += 1
151 | else:
152 | password_len[len(list_user_password[cur_user])] += 1
153 |
154 | ws_stats[f"B{start_line}"] = "Password Length"
155 | ws_stats[f"B{start_line}"].font = Font(bold=True)
156 |
157 | cur_line = start_line + 1
158 |
159 | if args.show_not_cracked and list_users:
160 | ws_stats["B" + str(cur_line)] = "NC"
161 | ws_stats["C" + str(cur_line)] = len(list_users) - \
162 | len(list_user_password)
163 | cur_line += 1
164 |
165 | max_length = max([i for i in range(cut_length+1) if password_len[i] != 0]+[0])
166 | if password_len[cut_length+1] != 0:
167 | max_length = cut_length
168 |
169 | for i in range(0, max_length+1):
170 | ws_stats["B" + str(cur_line)] = i
171 | ws_stats["C" + str(cur_line)] = password_len[i]
172 | cur_line += 1
173 |
174 | if password_len[cut_length+1] != 0:
175 | ws_stats["B" + str(cur_line)] = f">{cut_length}"
176 | ws_stats["C" + str(cur_line)] = password_len[cut_length+1]
177 | cur_line += 1
178 |
179 | chart = BarChart()
180 | chart.add_data(
181 | Reference(ws_stats, range_string=f'Stats!C{start_line+1}:C{cur_line-1}'))
182 | chart.set_categories(
183 | Reference(ws_stats, range_string=f'Stats!B{start_line+1}:B{cur_line-1}'))
184 | chart.title = "Password length"
185 | chart.legend = None
186 | ws_stats.add_chart(chart, f'E{start_line}')
187 |
188 | return max(cur_line, start_line+15)
189 |
190 |
191 | def convert_into_l33t_regex(s):
192 | n = ""
193 |
194 | for c in s:
195 | n = n + '[' + str(c) + c.swapcase()
196 |
197 | if c == 'a':
198 | n = n + '4'
199 | elif c == 'e':
200 | n = n + '3'
201 | elif c == 'i':
202 | n = n + '1'
203 | elif c == 'o':
204 | n = n + '0'
205 |
206 | n = n + ']+'
207 |
208 | return n
209 |
210 | def password_leaked_stats(ws_stats, start_line, args, list_users, list_user_password, list_regex, dictionary_list):
211 | leaked_passwords_google = 0
212 | leaked_passwords_HIBP = 0
213 | count_leaked = 0
214 | count_not_leaked = 0
215 |
216 | if args.check_leaked_google:
217 | logger.debug('Getting token to use the google api (leaked passwords)')
218 | google_leak_api = GoogleApi()
219 | logger.debug('Google token found')
220 |
221 | leaked_set_HIBP = set()
222 | leaked_set_google = set()
223 |
224 | for cur_user in tqdm(list_user_password):
225 | # don't count on password history
226 | if re.search(r"_history[0-9]*$", cur_user):
227 | continue
228 |
229 | leaked = False
230 | # check if password was leaked
231 |
232 | if args.check_leaked_google:
233 | # clean the username
234 | cleaned_username = cur_user.split('\\')[-1]
235 | if google_leak_api.is_leaked(cleaned_username, list_user_password[cur_user]):
236 | leaked_passwords_google += 1
237 | leaked_set_google.add((cleaned_username,list_user_password[cur_user]))
238 | leaked = True
239 |
240 | if pwnedpasswords.check(list_user_password[cur_user]):
241 | leaked_passwords_HIBP += 1
242 | leaked_set_HIBP.add(list_user_password[cur_user])
243 | leaked = True
244 |
245 | if not leaked:
246 | count_not_leaked += 1
247 | else:
248 | count_leaked += 1
249 |
250 | logger.debug('Leaked passwords HIBP: ' + str(leaked_set_HIBP))
251 | logger.debug('Leaked passwords Google: ' + str(leaked_set_google))
252 |
253 | ws_stats[f"B{start_line}"] = "Leaked Password"
254 | ws_stats[f"B{start_line}"].font = Font(bold=True)
255 |
256 | cur_line = start_line+1
257 |
258 | ws_stats["B" + str(cur_line)] = 'Leaked'
259 | ws_stats["C" + str(cur_line)] = count_leaked
260 | cur_line += 1
261 |
262 | ws_stats["B" + str(cur_line)] = 'Not leaked'
263 | ws_stats["C" + str(cur_line)] = count_not_leaked
264 | cur_line += 1
265 |
266 | if args.check_leaked_google:
267 | ws_stats["B" + str(cur_line)] = 'Leaked HIBP'
268 | ws_stats["C" + str(cur_line)] = leaked_passwords_HIBP
269 | cur_line += 1
270 |
271 | ws_stats["B" + str(cur_line)] = 'Leaked Google'
272 | ws_stats["C" + str(cur_line)] = leaked_passwords_google
273 | cur_line += 1
274 |
275 | chart = BarChart()
276 | chart.add_data(
277 | Reference(ws_stats, range_string=f'Stats!C{start_line+1}:C{cur_line-1}'))
278 | chart.set_categories(
279 | Reference(ws_stats, range_string=f'Stats!B{start_line+1}:B{cur_line-1}'))
280 | chart.title = "Leaked Password"
281 | chart.legend = None
282 | ws_stats.add_chart(chart, f'E{start_line}')
283 |
284 | return max(cur_line, start_line+15)
285 |
286 | def password_topology_stats(ws_stats, start_line, args, list_users, list_user_password, list_regex, dictionary_list):
287 | username_based = 0
288 | username_same = 0
289 | repeated_word = 0
290 |
291 | regex_results = {}
292 | dictionary_results = {}
293 |
294 | for cur_user in list_user_password:
295 |
296 | # don't count on password history
297 | if re.search(r"_history[0-9]*$", cur_user):
298 | continue
299 |
300 | # check if password is the username
301 | if cur_user.upper() == list_user_password[cur_user].upper():
302 | username_same += 1
303 | else:
304 | # check if password is derived from username
305 | r = convert_into_l33t_regex(cur_user)
306 | r_i = convert_into_l33t_regex(cur_user[::-1])
307 |
308 | if re.search(r, list_user_password[cur_user]) or re.search(r_i, list_user_password[cur_user]):
309 | username_based += 1
310 |
311 | # check is in the password there is repeated words
312 | for i in range(0, len(list_user_password[cur_user]) - 2):
313 | sub = re.escape(list_user_password[cur_user][i:i+3])
314 |
315 | if len(re.findall(sub, list_user_password[cur_user])) > 1:
316 |
317 | repeated_word += 1
318 | break
319 |
320 | # check password on regex
321 | try:
322 | for reg in list_regex:
323 | if re.search(reg, list_user_password[cur_user]):
324 | try:
325 | regex_results[reg] += 1
326 | except:
327 | regex_results[reg] = 1
328 | except:
329 | pass
330 |
331 | # check password on dictionary
332 | try:
333 | for w in dictionary_list:
334 | r = convert_into_l33t_regex(w)
335 | if re.search(r, list_user_password[cur_user]):
336 | if w in dictionary_results:
337 | dictionary_results[w] += 1
338 | else:
339 | dictionary_results[w] = 1
340 | except:
341 | pass
342 | # create password type stats
343 | password_type = {}
344 |
345 | password_type["Same as username"] = username_same
346 | password_type["Based on username"] = username_based
347 | password_type["Repeated word"] = repeated_word
348 | password_type["Others"] = len(list_user_password) - username_same - username_based - repeated_word
349 |
350 |
351 | try:
352 | for i in list_regex:
353 | try:
354 | password_type["Based on \"" + str(i) + "\""] = regex_results[i]
355 | except:
356 | pass
357 | except:
358 | pass
359 |
360 | try:
361 | for i in dictionary_results:
362 | try:
363 | password_type["Based on \"" +
364 | str(i) + "\""] = dictionary_results[i]
365 | except:
366 | pass
367 | except:
368 | pass
369 |
370 | ws_stats[f"B{start_line}"] = "Password Topology"
371 | ws_stats[f"B{start_line}"].font = Font(bold=True)
372 |
373 | cur_line = start_line+1
374 |
375 | for i in sorted(password_type.items(), key=operator.itemgetter(1), reverse=True):
376 | if i[1] > 0:
377 | ws_stats["B" + str(cur_line)] = i[0]
378 | ws_stats["C" + str(cur_line)] = i[1]
379 | cur_line += 1
380 |
381 | chart = BarChart()
382 | chart.add_data(
383 | Reference(ws_stats, range_string=f'Stats!C{start_line+1}:C{cur_line-1}'))
384 | chart.set_categories(
385 | Reference(ws_stats, range_string=f'Stats!B{start_line+1}:B{cur_line-1}'))
386 | chart.title = "Password Topology"
387 | chart.legend = None
388 | ws_stats.add_chart(chart, f'E{start_line}')
389 |
390 | return max(cur_line, start_line+15)
391 |
392 |
393 | def levenshtein_distance_stats(ws_stats, start_line, args, list_users, list_user_password, list_user_password_with_history):
394 |
395 | cut_distance = 14
396 |
397 | levenshtein_distance = {}
398 | for i in range(0, cut_distance+2):
399 | levenshtein_distance[i] = 0
400 |
401 | for cur_user in list_user_password:
402 |
403 | # don't count on password history
404 | if re.search(r"_history[0-9]*$", cur_user):
405 | continue
406 |
407 | # check Levenshtein distance if history0 exist
408 | try:
409 |
410 | if list_user_password_with_history[cur_user + "_history0"]:
411 |
412 | if args.ignore_case:
413 | dis = distance(list_user_password[cur_user].upper(), list_user_password_with_history[cur_user + "_history0"].upper())
414 | else:
415 | dis = distance(list_user_password[cur_user], list_user_password_with_history[cur_user + "_history0"])
416 |
417 | if dis > cut_distance:
418 | levenshtein_distance[cut_distance+1] += 1
419 | else:
420 | levenshtein_distance[dis] += 1
421 |
422 | except:
423 | pass
424 |
425 |
426 |
427 |
428 | ws_stats[f"B{start_line}"] = "Levenshtein distance"
429 | ws_stats[f"B{start_line}"].font = Font(bold=True)
430 |
431 | cur_line = start_line + 1
432 |
433 | if args.show_not_cracked and list_users:
434 | ws_stats["B" + str(cur_line)] = "NC"
435 | ws_stats["C" + str(cur_line)] = len(list_users) - \
436 | len(list_user_password)
437 | cur_line += 1
438 |
439 | ws_stats["B" + str(cur_line)] = "Unk"
440 | ws_stats["C" + str(cur_line)] = len(list_user_password) - \
441 | sum(levenshtein_distance.values())
442 | cur_line += 1
443 |
444 | max_dist = max([i for i in range(cut_distance+1) if levenshtein_distance[i] != 0]+[0])
445 |
446 | if levenshtein_distance[cut_distance+1] != 0:
447 | max_dist = cut_distance
448 |
449 | for i in range(max_dist+1):
450 | ws_stats["B" + str(cur_line)] = i
451 | ws_stats["C" + str(cur_line)] = levenshtein_distance[i]
452 | cur_line += 1
453 |
454 | if levenshtein_distance[cut_distance+1] != 0:
455 | ws_stats["B" + str(cur_line)] = f">{cut_distance}"
456 | ws_stats["C" + str(cur_line)] = levenshtein_distance[cut_distance+1]
457 | cur_line += 1
458 |
459 | chart = BarChart()
460 | chart.add_data(
461 | Reference(ws_stats, range_string=f'Stats!C{start_line+1}:C{cur_line-1}'))
462 | chart.set_categories(
463 | Reference(ws_stats, range_string=f'Stats!B{start_line+1}:B{cur_line-1}'))
464 | chart.title = "Levenshtein distance"
465 | chart.legend = None
466 | ws_stats.add_chart(chart, f'E{start_line}')
467 |
468 | return max(cur_line, start_line+15)
469 |
--------------------------------------------------------------------------------
/test_files/dictionary.txt:
--------------------------------------------------------------------------------
1 | password
2 | test
--------------------------------------------------------------------------------
/test_files/password.txt:
--------------------------------------------------------------------------------
1 | user:password
2 | user2:password
3 | user3:password
4 | user3_history0:123488726
5 | user4:abababab
6 | user5:qwerty
7 | user6:qwerty
8 | user7:test
9 | user7_history0:asdasd
10 | user8:password
11 | user8_history0:PaSSworD
12 | user8_history1:PASSWORD
13 | user8_history2:12345567
14 | user9:$HEX[706124243a776f726421]
15 | testuser:t3s7us3r
16 | qwerty:qwerty
17 | aaaa:abcabcabc
18 | bbbb:p4ssword
19 | cccc:testing123
20 | dddd:t3stttt
21 | eeee:zxzxzxzxz
22 | ffff:passzssword12
23 | gggg:hhhhhhh
24 | hhhh:qwqwqwqw
25 | iiii:IiIihhhh
--------------------------------------------------------------------------------
/test_files/regexs.txt:
--------------------------------------------------------------------------------
1 | pa.+wor.+
2 | te.+ing.+
--------------------------------------------------------------------------------
/test_files/users.txt:
--------------------------------------------------------------------------------
1 | aaaa
2 | bbbb
3 | cccc
4 | dddd
5 | eeee
6 | ffff
7 | gggg
8 | hhhh
9 | iiii
10 | qwerty
11 | testuser
12 | user
13 | user2
14 | user3
15 | user4
16 | user5
17 | user6
18 | user7
19 | user8
20 | user9
21 | notcrackeduser
22 | otheruser
23 | notcrackeduser2
24 | notcrackeduser23
--------------------------------------------------------------------------------