 530 |
531 | ### 35.Golang Slice的扩容机制,有什么注意点
532 |
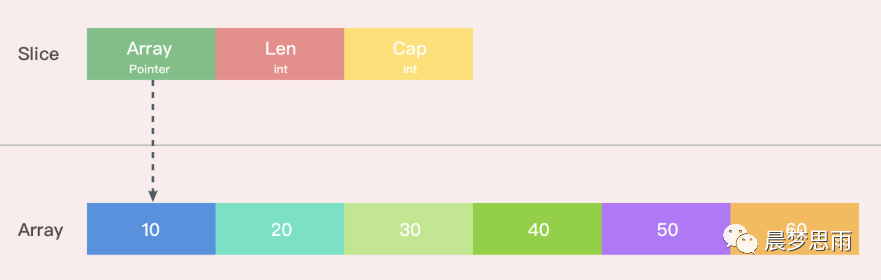
533 | Go 中切片扩容的策略是这样的:
534 |
535 | **首先判断,如果新申请容量大于 2 倍的旧容量,最终容量就是新申请的容量。否则判断,如果旧切片的长度小于 1024,则最终容量就是旧容量的两倍。**
536 |
537 | **否则判断,如果旧切片长度大于等于 1024,则最终容量从旧容量开始循环增加原来的 1/4 , 直到最终容量大于等于新申请的容量。如果最终容量计算值溢出,则最终容量就是新申请容量。**
538 |
539 | 情况一:原数组还有容量可以扩容(实际容量没有填充完),这种情况下,扩容以后的数组还是指向原来的数组,对一个切片的操作可能影响多个指针指向相同地址的Slice。
540 |
541 | 情况二:原来数组的容量已经达到了最大值,再想扩容, Go 默认会先开一片内存区域,把原来的值拷贝过来,然后再执行 append() 操作。这种情况丝毫不影响原数组。
542 |
543 | 要复制一个Slice,最好使用Copy函数。
544 |
545 | ### 36.Golang Map底层实现
546 |
547 | Golang 中 map 的底层实现是一个散列表,因此实现 map 的过程实际上就是实现散表的过程。
548 | 在这个散列表中,主要出现的结构体有两个,**一个叫hmap(a header for a go map),一个叫bmap(a bucket for a Go map,通常叫其bucket)**。
549 |
550 | hmap如下所示:
551 |
552 |
530 |
531 | ### 35.Golang Slice的扩容机制,有什么注意点
532 |
533 | Go 中切片扩容的策略是这样的:
534 |
535 | **首先判断,如果新申请容量大于 2 倍的旧容量,最终容量就是新申请的容量。否则判断,如果旧切片的长度小于 1024,则最终容量就是旧容量的两倍。**
536 |
537 | **否则判断,如果旧切片长度大于等于 1024,则最终容量从旧容量开始循环增加原来的 1/4 , 直到最终容量大于等于新申请的容量。如果最终容量计算值溢出,则最终容量就是新申请容量。**
538 |
539 | 情况一:原数组还有容量可以扩容(实际容量没有填充完),这种情况下,扩容以后的数组还是指向原来的数组,对一个切片的操作可能影响多个指针指向相同地址的Slice。
540 |
541 | 情况二:原来数组的容量已经达到了最大值,再想扩容, Go 默认会先开一片内存区域,把原来的值拷贝过来,然后再执行 append() 操作。这种情况丝毫不影响原数组。
542 |
543 | 要复制一个Slice,最好使用Copy函数。
544 |
545 | ### 36.Golang Map底层实现
546 |
547 | Golang 中 map 的底层实现是一个散列表,因此实现 map 的过程实际上就是实现散表的过程。
548 | 在这个散列表中,主要出现的结构体有两个,**一个叫hmap(a header for a go map),一个叫bmap(a bucket for a Go map,通常叫其bucket)**。
549 |
550 | hmap如下所示:
551 |
552 |  553 |
554 | 图中有很多字段,但是便于理解 map 的架构,你只需要关心的只有一个,就是标红的字段:buckets 数组。Golang 的 map 中用于存储的结构是 bucket数组。而 bucket(即bmap)的结构是怎样的呢?
555 | bucket:
556 |
557 |
553 |
554 | 图中有很多字段,但是便于理解 map 的架构,你只需要关心的只有一个,就是标红的字段:buckets 数组。Golang 的 map 中用于存储的结构是 bucket数组。而 bucket(即bmap)的结构是怎样的呢?
555 | bucket:
556 |
557 |  558 |
559 | 相比于 hmap,bucket 的结构显得简单一些,标橙的字段依然是“核心”,我们使用的 map 中的 key 和 value 就存储在这里。
560 |
561 | “高位哈希值”数组记录的是当前 bucket 中 key 相关的”索引”,稍后会详细叙述。还有一个字段是一个指向扩容后的 bucket 的指针,使得 bucket 会形成一个链表结构。
562 | 整体的结构应该是这样的:
563 |
564 |
558 |
559 | 相比于 hmap,bucket 的结构显得简单一些,标橙的字段依然是“核心”,我们使用的 map 中的 key 和 value 就存储在这里。
560 |
561 | “高位哈希值”数组记录的是当前 bucket 中 key 相关的”索引”,稍后会详细叙述。还有一个字段是一个指向扩容后的 bucket 的指针,使得 bucket 会形成一个链表结构。
562 | 整体的结构应该是这样的:
563 |
564 | 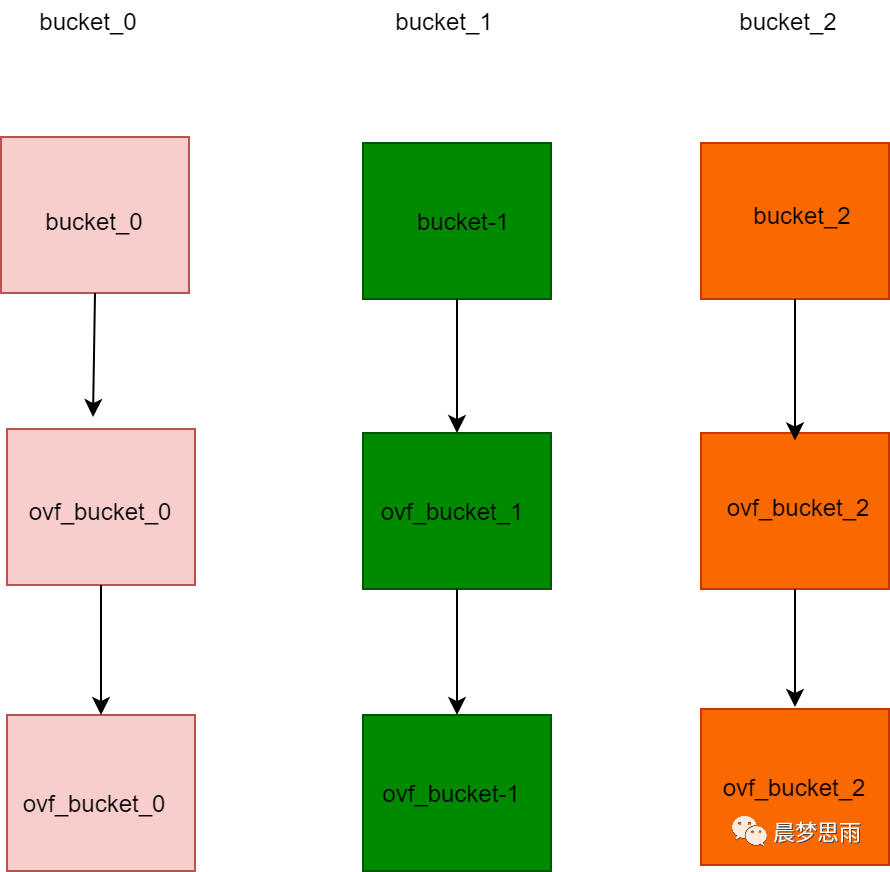 565 |
566 | Golang 把求得的哈希值按照用途一分为二:高位和低位。低位用于寻找当前 key属于 hmap 中的哪个 bucket,而高位用于寻找 bucket 中的哪个 key。
567 | 需要特别指出的一点是:map中的key/value值都是存到同一个数组中的。这样做的好处是:在key和value的长度不同的时候,可以消除padding带来的空间浪费。
568 |
569 | 
570 |
571 | Map 的扩容:当 Go 的 map 长度增长到大于加载因子所需的 map 长度时,Go 语言就会将产生一个新的 bucket 数组,然后把旧的 bucket 数组移到一个属性字段 oldbucket中。
572 |
573 | 注意:并不是立刻把旧的数组中的元素转义到新的 bucket 当中,而是,只有当访问到具体的某个 bucket 的时候,会把 bucket 中的数据转移到新的 bucket 中。
574 |
575 | ### 37.Golang的内存模型,为什么小对象多了会造成gc压力
576 |
577 | 通常**小对象过多会导致 GC 三色法消耗过多的GPU**。优化思路是,减少对象分配。
578 |
579 | ### 38.Data Race问题怎么解决?能不能不加锁解决这个问题
580 |
581 | data race 译作数据竞争,比如不同的goroutine并发读写同一个变量,可能会发生数据竞争。
582 |
583 | **同步访问共享数据**是处理**数据竞争**的一种有效的方法。
584 |
585 | golang在 1.1 之后引入了竞争检测机制,可以使用 go run -race 或者 go build -race来进行静态检测。其在内部的实现是,开启多个协程执行同一个命令, 并且记录下每个变量的状态。
586 |
587 | 竞争检测器基于C/C++的ThreadSanitizer 运行时库,该库在Google内部代码基地和Chromium找到许多错误。这个技术在2012年九月集成到Go中,从那时开始,它已经在标准库中检测到42个竞争条件。现在,它已经是我们持续构建过程的一部分,当竞争条件出现时,它会继续捕捉到这些错误。
588 |
589 | 竞争检测器已经完全集成到Go工具链中,仅仅添加-race标志到命令行就使用了检测器。
590 |
591 | ```
592 | $ go test -race mypkg // 测试包
593 | $ go run -race mysrc.go // 编译和运行程序 $ go build -race mycmd
594 | // 构建程序 $ go install -race mypkg // 安装程序
595 | ```
596 |
597 | 要想解决数据竞争的问题**可以使用互斥锁sync.Mutex,解决数据竞争(Data race)**,也**可以使用管道解决,使用管道的效率要比互斥锁高**。
598 |
599 | ### 39.在 range 迭代 slice 时,你怎么修改值的
600 |
601 | 在 range 迭代中,得到的值其实是元素的一份值拷贝,更新拷贝并不会更改原来的元素,即是拷贝的地址并不是原有元素的地址。
602 |
603 | ```go
604 | func main() {
605 | data := []int{1, 2, 3}
606 | for _, v := range data {
607 | v *= 10 // data 中原有元素是不会被修改的
608 | }
609 | fmt.Println("data: ", data) // data: [1 2 3]
610 | }
611 | ```
612 |
613 | **如果要修改原有元素的值,应该**使用索引直接访问。
614 |
615 | ```go
616 | func main() {
617 | data := []int{1, 2, 3}
618 | for i, v := range data {
619 | data[i] = v * 10
620 | }
621 | fmt.Println("data: ", data) // data: [10 20 30]
622 | }
623 | ```
624 |
625 | **如果你的集合保存的是指向值的指针,需稍作修改。依旧需要使用索引访问元素,不过可以使用 range 出来的元素直接更新原有值。**
626 |
627 | ```go
628 | func main() {
629 | data := []*struct{ num int }{{1}, {2}, {3},}
630 | for _, v := range data {
631 | v.num *= 10 // 直接使用指针更新
632 | }
633 | fmt.Println(data[0], data[1], data[2]) // &{10} &{20} &{30}
634 | }
635 | ```
636 |
637 | ### 40.nil 和 nil interface 的区别
638 |
639 | 虽然 interface 看起来像指针类型,但它不是。interface 类型的变量只有在类型和值均为 nil 时才为 nil.如果你的 interface 变量的值是跟随其他变量变化的,与 nil 比较相等时小心。如果你的函数返回值类型是 interface,更要小心这个坑:
640 |
641 | ```go
642 | func main() {
643 | var data *byte
644 | var in interface{}
645 |
646 | fmt.Println(data, data == nil) //
565 |
566 | Golang 把求得的哈希值按照用途一分为二:高位和低位。低位用于寻找当前 key属于 hmap 中的哪个 bucket,而高位用于寻找 bucket 中的哪个 key。
567 | 需要特别指出的一点是:map中的key/value值都是存到同一个数组中的。这样做的好处是:在key和value的长度不同的时候,可以消除padding带来的空间浪费。
568 |
569 | 
570 |
571 | Map 的扩容:当 Go 的 map 长度增长到大于加载因子所需的 map 长度时,Go 语言就会将产生一个新的 bucket 数组,然后把旧的 bucket 数组移到一个属性字段 oldbucket中。
572 |
573 | 注意:并不是立刻把旧的数组中的元素转义到新的 bucket 当中,而是,只有当访问到具体的某个 bucket 的时候,会把 bucket 中的数据转移到新的 bucket 中。
574 |
575 | ### 37.Golang的内存模型,为什么小对象多了会造成gc压力
576 |
577 | 通常**小对象过多会导致 GC 三色法消耗过多的GPU**。优化思路是,减少对象分配。
578 |
579 | ### 38.Data Race问题怎么解决?能不能不加锁解决这个问题
580 |
581 | data race 译作数据竞争,比如不同的goroutine并发读写同一个变量,可能会发生数据竞争。
582 |
583 | **同步访问共享数据**是处理**数据竞争**的一种有效的方法。
584 |
585 | golang在 1.1 之后引入了竞争检测机制,可以使用 go run -race 或者 go build -race来进行静态检测。其在内部的实现是,开启多个协程执行同一个命令, 并且记录下每个变量的状态。
586 |
587 | 竞争检测器基于C/C++的ThreadSanitizer 运行时库,该库在Google内部代码基地和Chromium找到许多错误。这个技术在2012年九月集成到Go中,从那时开始,它已经在标准库中检测到42个竞争条件。现在,它已经是我们持续构建过程的一部分,当竞争条件出现时,它会继续捕捉到这些错误。
588 |
589 | 竞争检测器已经完全集成到Go工具链中,仅仅添加-race标志到命令行就使用了检测器。
590 |
591 | ```
592 | $ go test -race mypkg // 测试包
593 | $ go run -race mysrc.go // 编译和运行程序 $ go build -race mycmd
594 | // 构建程序 $ go install -race mypkg // 安装程序
595 | ```
596 |
597 | 要想解决数据竞争的问题**可以使用互斥锁sync.Mutex,解决数据竞争(Data race)**,也**可以使用管道解决,使用管道的效率要比互斥锁高**。
598 |
599 | ### 39.在 range 迭代 slice 时,你怎么修改值的
600 |
601 | 在 range 迭代中,得到的值其实是元素的一份值拷贝,更新拷贝并不会更改原来的元素,即是拷贝的地址并不是原有元素的地址。
602 |
603 | ```go
604 | func main() {
605 | data := []int{1, 2, 3}
606 | for _, v := range data {
607 | v *= 10 // data 中原有元素是不会被修改的
608 | }
609 | fmt.Println("data: ", data) // data: [1 2 3]
610 | }
611 | ```
612 |
613 | **如果要修改原有元素的值,应该**使用索引直接访问。
614 |
615 | ```go
616 | func main() {
617 | data := []int{1, 2, 3}
618 | for i, v := range data {
619 | data[i] = v * 10
620 | }
621 | fmt.Println("data: ", data) // data: [10 20 30]
622 | }
623 | ```
624 |
625 | **如果你的集合保存的是指向值的指针,需稍作修改。依旧需要使用索引访问元素,不过可以使用 range 出来的元素直接更新原有值。**
626 |
627 | ```go
628 | func main() {
629 | data := []*struct{ num int }{{1}, {2}, {3},}
630 | for _, v := range data {
631 | v.num *= 10 // 直接使用指针更新
632 | }
633 | fmt.Println(data[0], data[1], data[2]) // &{10} &{20} &{30}
634 | }
635 | ```
636 |
637 | ### 40.nil 和 nil interface 的区别
638 |
639 | 虽然 interface 看起来像指针类型,但它不是。interface 类型的变量只有在类型和值均为 nil 时才为 nil.如果你的 interface 变量的值是跟随其他变量变化的,与 nil 比较相等时小心。如果你的函数返回值类型是 interface,更要小心这个坑:
640 |
641 | ```go
642 | func main() {
643 | var data *byte
644 | var in interface{}
645 |
646 | fmt.Println(data, data == nil) // 答案
init() 函数是 Go 程序初始化的一部分。Go 程序初始化先于 main 函数,由 runtime 初始化每个导入的包,初始化顺序不是按照从上到下的导入顺序,而是按照解析的依赖关系,没有依赖的包最先初始化。
每个包首先初始化包作用域的常量和变量(常量优先于变量),然后执行包的 init() 函数。同一个包,甚至是同一个源文件可以有多个 init() 函数。init() 函数没有入参和返回值,不能被其他函数调用,同一个包内多个 init() 函数的执行顺序不作保证。
一句话总结: import –> const –> var –> init() –> main()
示例:
package main |
答案
由编译器决定。Go 语言编译器会自动决定把一个变量放在栈还是放在堆,编译器会做逃逸分析(escape analysis),当发现变量的作用域没有超出函数范围,就可以在栈上,反之则必须分配在堆上。
func foo() *int { |
foo() 函数中,如果 v 分配在栈上,foo 函数返回时,&v 就不存在了,但是这段函数是能够正常运行的。Go 编译器发现 v 的引用脱离了 foo 的作用域,会将其分配在堆上。因此,main 函数中仍能够正常访问该值。
答案
Go 语言中,interface 的内部实现包含了 2 个字段,类型 T 和 值 V,interface 可以使用 == 或 != 比较。2 个 interface 相等有以下 2 种情况
- 两个 interface 均等于 nil(此时 V 和 T 都处于 unset 状态)
- 类型 T 相同,且对应的值 V 相等。
看下面的例子:
type Stu struct { |
stu1 和 stu2 对应的类型是 *Stu,值是 Stu 结构体的地址,两个地址不同,因此结果为 false。stu3 和 stu4 对应的类型是 Stu,值是 Stu 结构体,且各字段相等,因此结果为 true。
答案
可能。
接口(interface) 是对非接口值(例如指针,struct等)的封装,内部实现包含 2 个字段,类型 T 和 值 V。一个接口等于 nil,当且仅当 T 和 V 处于 unset 状态(T=nil,V is unset)。
- 两个接口值比较时,会先比较 T,再比较 V。
- 接口值与非接口值比较时,会先将非接口值尝试转换为接口值,再比较。
func main() { |
上面这个例子中,将一个 nil 非接口值 p 赋值给接口 i,此时,i 的内部字段为(T=*int, V=nil),i 与 p 作比较时,将 p 转换为接口后再比较,因此 i == p,p 与 nil 比较,直接比较值,所以 p == nil。
但是当 i 与 nil 比较时,会将 nil 转换为接口 (T=nil, V=nil),与i (T=*int, V=nil) 不相等,因此 i != nil。因此 V 为 nil ,但 T 不为 nil 的接口不等于 nil。
答案
最常见的垃圾回收算法有标记清除(Mark-Sweep) 和引用计数(Reference Count),Go 语言采用的是标记清除算法。并在此基础上使用了三色标记法和写屏障技术,提高了效率。
标记清除收集器是跟踪式垃圾收集器,其执行过程可以分成标记(Mark)和清除(Sweep)两个阶段:
- 标记阶段 — 从根对象出发查找并标记堆中所有存活的对象;
- 清除阶段 — 遍历堆中的全部对象,回收未被标记的垃圾对象并将回收的内存加入空闲链表。
标记清除算法的一大问题是在标记期间,需要暂停程序(Stop the world,STW),标记结束之后,用户程序才可以继续执行。为了能够异步执行,减少 STW 的时间,Go 语言采用了三色标记法。
三色标记算法将程序中的对象分成白色、黑色和灰色三类。
- 白色:不确定对象。
- 灰色:存活对象,子对象待处理。
- 黑色:存活对象。
标记开始时,所有对象加入白色集合(这一步需 STW )。首先将根对象标记为灰色,加入灰色集合,垃圾搜集器取出一个灰色对象,将其标记为黑色,并将其指向的对象标记为灰色,加入灰色集合。重复这个过程,直到灰色集合为空为止,标记阶段结束。那么白色对象即可需要清理的对象,而黑色对象均为根可达的对象,不能被清理。
三色标记法因为多了一个白色的状态来存放不确定对象,所以后续的标记阶段可以并发地执行。当然并发执行的代价是可能会造成一些遗漏,因为那些早先被标记为黑色的对象可能目前已经是不可达的了。所以三色标记法是一个 false negative(假阴性)的算法。
三色标记法并发执行仍存在一个问题,即在 GC 过程中,对象指针发生了改变。比如下面的例子:
A (黑) -> B (灰) -> C (白) -> D (白) |
正常情况下,D 对象最终会被标记为黑色,不应被回收。但在标记和用户程序并发执行过程中,用户程序删除了 C 对 D 的引用,而 A 获得了 D 的引用。标记继续进行,D 就没有机会被标记为黑色了(A 已经处理过,这一轮不会再被处理)。
A (黑) -> B (灰) -> C (白) |
为了解决这个问题,Go 使用了内存屏障技术,它是在用户程序读取对象、创建新对象以及更新对象指针时执行的一段代码,类似于一个钩子。垃圾收集器使用了写屏障(Write Barrier)技术,当对象新增或更新时,会将其着色为灰色。这样即使与用户程序并发执行,对象的引用发生改变时,垃圾收集器也能正确处理了。
一次完整的 GC 分为四个阶段:
- 1)标记准备(Mark Setup,需 STW),打开写屏障(Write Barrier)
- 2)使用三色标记法标记(Marking, 并发)
- 3)标记结束(Mark Termination,需 STW),关闭写屏障。
- 4)清理(Sweeping, 并发)
- 参考 fullstack
答案
这在 Go 中是安全的,Go 编译器将会对每个局部变量进行逃逸分析。如果发现局部变量的作用域超出该函数,则不会将内存分配在栈上,而是分配在堆上。
答案
- 一个T类型的值可以调用为
*T类型声明的方法,但是仅当此T的值是可寻址(addressable) 的情况下。编译器在调用指针属主方法前,会自动取此T值的地址。因为不是任何T值都是可寻址的,所以并非任何T值都能够调用为类型*T声明的方法。 - 反过来,一个
*T类型的值可以调用为类型T声明的方法,这是因为解引用指针总是合法的。事实上,你可以认为对于每一个为类型 T 声明的方法,编译器都会为类型*T自动隐式声明一个同名和同签名的方法。
哪些值是不可寻址的呢?
- 字符串中的字节;
- map 对象中的元素(slice 对象中的元素是可寻址的,slice的底层是数组);
- 常量;
- 包级别的函数等。
举一个例子,定义类型 T,并为类型 *T 声明一个方法 hello(),变量 t1 可以调用该方法,但是常量 t2 调用该方法时,会产生编译错误。
type T string |