├── aae
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
└── aae.py
├── gan
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
└── gan.py
├── acgan
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
└── acgan.py
├── bgan
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
└── bgan.py
├── bigan
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
└── bigan.py
├── ccgan
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
└── ccgan.py
├── cgan
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
└── cgan.py
├── cogan
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
└── cogan.py
├── cyclegan
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
├── download_dataset.sh
├── data_loader.py
└── cyclegan.py
├── dcgan
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
└── dcgan.py
├── discogan
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
├── download_dataset.sh
├── data_loader.py
└── discogan.py
├── dualgan
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
└── dualgan.py
├── infogan
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
└── infogan.py
├── lsgan
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
└── lsgan.py
├── pix2pix
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
├── download_dataset.sh
├── data_loader.py
└── pix2pix.py
├── pixelda
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
├── test.py
├── data_loader.py
└── pixelda.py
├── sgan
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
└── sgan.py
├── srgan
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
├── data_loader.py
└── srgan.py
├── wgan
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
└── wgan.py
├── wgan_gp
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
└── wgan_gp.py
├── context_encoder
├── images
│ └── .gitignore
├── saved_model
│ └── .gitignore
└── context_encoder.py
├── assets
└── keras_gan.png
├── .gitignore
├── requirements.txt
├── LICENSE
└── README.md
/aae/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/gan/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/aae/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/acgan/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/bgan/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/bigan/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/ccgan/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/cgan/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/cogan/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/cyclegan/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/dcgan/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/discogan/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/dualgan/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/gan/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/infogan/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/lsgan/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/pix2pix/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/pixelda/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/sgan/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/srgan/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/wgan/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/wgan_gp/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/acgan/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/bgan/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/bigan/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/ccgan/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/cgan/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/cogan/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/cyclegan/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/dcgan/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/discogan/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/dualgan/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/infogan/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/lsgan/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/pix2pix/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/pixelda/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/sgan/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/srgan/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/wgan/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/wgan_gp/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/context_encoder/images/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/context_encoder/saved_model/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/assets/keras_gan.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/horoscopes/Keras-GAN/master/assets/keras_gan.png
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | */images/*.png
2 | */images/*.jpg
3 | */*.jpg
4 | */*.png
5 | *.json
6 | *.h5
7 | *.hdf5
8 | .DS_Store
9 | */datasets
10 |
11 | __pycache__
12 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | keras
2 | git+https://www.github.com/keras-team/keras-contrib.git
3 | matplotlib
4 | numpy
5 | scipy
6 | pillow
7 | #urllib
8 | #skimage
9 | scikit-image
10 | #gzip
11 | #pickle
12 |
--------------------------------------------------------------------------------
/discogan/download_dataset.sh:
--------------------------------------------------------------------------------
1 | mkdir datasets
2 | FILE=$1
3 | URL=https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets/$FILE.tar.gz
4 | TAR_FILE=./datasets/$FILE.tar.gz
5 | TARGET_DIR=./datasets/$FILE/
6 | wget -N $URL -O $TAR_FILE
7 | mkdir $TARGET_DIR
8 | tar -zxvf $TAR_FILE -C ./datasets/
9 | rm $TAR_FILE
10 |
--------------------------------------------------------------------------------
/pix2pix/download_dataset.sh:
--------------------------------------------------------------------------------
1 | mkdir datasets
2 | FILE=$1
3 | URL=https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets/$FILE.tar.gz
4 | TAR_FILE=./datasets/$FILE.tar.gz
5 | TARGET_DIR=./datasets/$FILE/
6 | wget -N $URL -O $TAR_FILE
7 | mkdir $TARGET_DIR
8 | tar -zxvf $TAR_FILE -C ./datasets/
9 | rm $TAR_FILE
10 |
--------------------------------------------------------------------------------
/cyclegan/download_dataset.sh:
--------------------------------------------------------------------------------
1 | mkdir datasets
2 | FILE=$1
3 |
4 | if [[ $FILE != "ae_photos" && $FILE != "apple2orange" && $FILE != "summer2winter_yosemite" && $FILE != "horse2zebra" && $FILE != "monet2photo" && $FILE != "cezanne2photo" && $FILE != "ukiyoe2photo" && $FILE != "vangogh2photo" && $FILE != "maps" && $FILE != "cityscapes" && $FILE != "facades" && $FILE != "iphone2dslr_flower" && $FILE != "ae_photos" ]]; then
5 | echo "Available datasets are: apple2orange, summer2winter_yosemite, horse2zebra, monet2photo, cezanne2photo, ukiyoe2photo, vangogh2photo, maps, cityscapes, facades, iphone2dslr_flower, ae_photos"
6 | exit 1
7 | fi
8 |
9 | URL=https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/$FILE.zip
10 | ZIP_FILE=./datasets/$FILE.zip
11 | TARGET_DIR=./datasets/$FILE/
12 | wget -N $URL -O $ZIP_FILE
13 | mkdir $TARGET_DIR
14 | unzip $ZIP_FILE -d ./datasets/
15 | rm $ZIP_FILE
16 |
--------------------------------------------------------------------------------
/pixelda/test.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 | import scipy
3 |
4 | import datetime
5 | import matplotlib.pyplot as plt
6 | import sys
7 | from data_loader import DataLoader
8 | import numpy as np
9 | import os
10 |
11 |
12 | # Configure MNIST and MNIST-M data loader
13 | data_loader = DataLoader(img_res=(32, 32))
14 |
15 | mnist, _ = data_loader.load_data(domain="A", batch_size=25)
16 | mnistm, _ = data_loader.load_data(domain="B", batch_size=25)
17 |
18 | r, c = 5, 5
19 |
20 | for img_i, imgs in enumerate([mnist, mnistm]):
21 |
22 | #titles = ['Original', 'Translated']
23 | fig, axs = plt.subplots(r, c)
24 | cnt = 0
25 | for i in range(r):
26 | for j in range(c):
27 | axs[i,j].imshow(imgs[cnt])
28 | #axs[i, j].set_title(titles[i])
29 | axs[i,j].axis('off')
30 | cnt += 1
31 | fig.savefig("%d.png" % (img_i))
32 | plt.close()
33 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2017 Erik Linder-Norén
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/srgan/data_loader.py:
--------------------------------------------------------------------------------
1 | import scipy
2 | from glob import glob
3 | import numpy as np
4 | import matplotlib.pyplot as plt
5 |
6 | class DataLoader():
7 | def __init__(self, dataset_name, img_res=(128, 128)):
8 | self.dataset_name = dataset_name
9 | self.img_res = img_res
10 |
11 | def load_data(self, batch_size=1, is_testing=False):
12 | data_type = "train" if not is_testing else "test"
13 |
14 | path = glob('./datasets/%s/*' % (self.dataset_name))
15 |
16 | batch_images = np.random.choice(path, size=batch_size)
17 |
18 | imgs_hr = []
19 | imgs_lr = []
20 | for img_path in batch_images:
21 | img = self.imread(img_path)
22 |
23 | h, w = self.img_res
24 | low_h, low_w = int(h / 4), int(w / 4)
25 |
26 | img_hr = scipy.misc.imresize(img, self.img_res)
27 | img_lr = scipy.misc.imresize(img, (low_h, low_w))
28 |
29 | # If training => do random flip
30 | if not is_testing and np.random.random() < 0.5:
31 | img_hr = np.fliplr(img_hr)
32 | img_lr = np.fliplr(img_lr)
33 |
34 | imgs_hr.append(img_hr)
35 | imgs_lr.append(img_lr)
36 |
37 | imgs_hr = np.array(imgs_hr) / 127.5 - 1.
38 | imgs_lr = np.array(imgs_lr) / 127.5 - 1.
39 |
40 | return imgs_hr, imgs_lr
41 |
42 |
43 | def imread(self, path):
44 | return scipy.misc.imread(path, mode='RGB').astype(np.float)
45 |
--------------------------------------------------------------------------------
/pix2pix/data_loader.py:
--------------------------------------------------------------------------------
1 | import scipy
2 | from glob import glob
3 | import numpy as np
4 | import matplotlib.pyplot as plt
5 |
6 | class DataLoader():
7 | def __init__(self, dataset_name, img_res=(128, 128)):
8 | self.dataset_name = dataset_name
9 | self.img_res = img_res
10 |
11 | def load_data(self, batch_size=1, is_testing=False):
12 | data_type = "train" if not is_testing else "test"
13 | path = glob('./datasets/%s/%s/*' % (self.dataset_name, data_type))
14 |
15 | batch_images = np.random.choice(path, size=batch_size)
16 |
17 | imgs_A = []
18 | imgs_B = []
19 | for img_path in batch_images:
20 | img = self.imread(img_path)
21 |
22 | h, w, _ = img.shape
23 | _w = int(w/2)
24 | img_A, img_B = img[:, :_w, :], img[:, _w:, :]
25 |
26 | img_A = scipy.misc.imresize(img_A, self.img_res)
27 | img_B = scipy.misc.imresize(img_B, self.img_res)
28 |
29 | # If training => do random flip
30 | if not is_testing and np.random.random() < 0.5:
31 | img_A = np.fliplr(img_A)
32 | img_B = np.fliplr(img_B)
33 |
34 | imgs_A.append(img_A)
35 | imgs_B.append(img_B)
36 |
37 | imgs_A = np.array(imgs_A)/127.5 - 1.
38 | imgs_B = np.array(imgs_B)/127.5 - 1.
39 |
40 | return imgs_A, imgs_B
41 |
42 | def load_batch(self, batch_size=1, is_testing=False):
43 | data_type = "train" if not is_testing else "val"
44 | path = glob('./datasets/%s/%s/*' % (self.dataset_name, data_type))
45 |
46 | self.n_batches = int(len(path) / batch_size)
47 |
48 | for i in range(self.n_batches-1):
49 | batch = path[i*batch_size:(i+1)*batch_size]
50 | imgs_A, imgs_B = [], []
51 | for img in batch:
52 | img = self.imread(img)
53 | h, w, _ = img.shape
54 | half_w = int(w/2)
55 | img_A = img[:, :half_w, :]
56 | img_B = img[:, half_w:, :]
57 |
58 | img_A = scipy.misc.imresize(img_A, self.img_res)
59 | img_B = scipy.misc.imresize(img_B, self.img_res)
60 |
61 | if not is_testing and np.random.random() > 0.5:
62 | img_A = np.fliplr(img_A)
63 | img_B = np.fliplr(img_B)
64 |
65 | imgs_A.append(img_A)
66 | imgs_B.append(img_B)
67 |
68 | imgs_A = np.array(imgs_A)/127.5 - 1.
69 | imgs_B = np.array(imgs_B)/127.5 - 1.
70 |
71 | yield imgs_A, imgs_B
72 |
73 |
74 | def imread(self, path):
75 | return scipy.misc.imread(path, mode='RGB').astype(np.float)
76 |
--------------------------------------------------------------------------------
/discogan/data_loader.py:
--------------------------------------------------------------------------------
1 | import scipy
2 | from glob import glob
3 | import numpy as np
4 |
5 | class DataLoader():
6 | def __init__(self, dataset_name, img_res=(128, 128)):
7 | self.dataset_name = dataset_name
8 | self.img_res = img_res
9 |
10 | def load_data(self, batch_size=1, is_testing=False):
11 | data_type = "train" if not is_testing else "val"
12 | path = glob('./datasets/%s/%s/*' % (self.dataset_name, data_type))
13 |
14 | batch = np.random.choice(path, size=batch_size)
15 |
16 | imgs_A, imgs_B = [], []
17 | for img in batch:
18 | img = self.imread(img)
19 | h, w, _ = img.shape
20 | half_w = int(w/2)
21 | img_A = img[:, :half_w, :]
22 | img_B = img[:, half_w:, :]
23 |
24 | img_A = scipy.misc.imresize(img_A, self.img_res)
25 | img_B = scipy.misc.imresize(img_B, self.img_res)
26 |
27 | if not is_testing and np.random.random() > 0.5:
28 | img_A = np.fliplr(img_A)
29 | img_B = np.fliplr(img_B)
30 |
31 | imgs_A.append(img_A)
32 | imgs_B.append(img_B)
33 |
34 | imgs_A = np.array(imgs_A)/127.5 - 1.
35 | imgs_B = np.array(imgs_B)/127.5 - 1.
36 |
37 | return imgs_A, imgs_B
38 |
39 | def load_batch(self, batch_size=1, is_testing=False):
40 | data_type = "train" if not is_testing else "val"
41 | path = glob('./datasets/%s/%s/*' % (self.dataset_name, data_type))
42 |
43 | self.n_batches = int(len(path) / batch_size)
44 |
45 | for i in range(self.n_batches-1):
46 | batch = path[i*batch_size:(i+1)*batch_size]
47 | imgs_A, imgs_B = [], []
48 | for img in batch:
49 | img = self.imread(img)
50 | h, w, _ = img.shape
51 | half_w = int(w/2)
52 | img_A = img[:, :half_w, :]
53 | img_B = img[:, half_w:, :]
54 |
55 | img_A = scipy.misc.imresize(img_A, self.img_res)
56 | img_B = scipy.misc.imresize(img_B, self.img_res)
57 |
58 | if not is_testing and np.random.random() > 0.5:
59 | img_A = np.fliplr(img_A)
60 | img_B = np.fliplr(img_B)
61 |
62 | imgs_A.append(img_A)
63 | imgs_B.append(img_B)
64 |
65 | imgs_A = np.array(imgs_A)/127.5 - 1.
66 | imgs_B = np.array(imgs_B)/127.5 - 1.
67 |
68 | yield imgs_A, imgs_B
69 |
70 | def load_img(self, path):
71 | img = self.imread(path)
72 | img = scipy.misc.imresize(img, self.img_res)
73 | img = img/127.5 - 1.
74 | return img[np.newaxis, :, :, :]
75 |
76 | def imread(self, path):
77 | return scipy.misc.imread(path, mode='RGB').astype(np.float)
78 |
--------------------------------------------------------------------------------
/cyclegan/data_loader.py:
--------------------------------------------------------------------------------
1 | import scipy
2 | from glob import glob
3 | import numpy as np
4 |
5 | class DataLoader():
6 | def __init__(self, dataset_name, img_res=(128, 128)):
7 | self.dataset_name = dataset_name
8 | self.img_res = img_res
9 |
10 | def load_data(self, domain, batch_size=1, is_testing=False):
11 | data_type = "train%s" % domain if not is_testing else "test%s" % domain
12 | path = glob('./datasets/%s/%s/*' % (self.dataset_name, data_type))
13 |
14 | batch_images = np.random.choice(path, size=batch_size)
15 |
16 | imgs = []
17 | for img_path in batch_images:
18 | img = self.imread(img_path)
19 | if not is_testing:
20 | img = scipy.misc.imresize(img, self.img_res)
21 |
22 | if np.random.random() > 0.5:
23 | img = np.fliplr(img)
24 | else:
25 | img = scipy.misc.imresize(img, self.img_res)
26 | imgs.append(img)
27 |
28 | imgs = np.array(imgs)/127.5 - 1.
29 |
30 | return imgs
31 |
32 | def load_batch(self, batch_size=1, is_testing=False):
33 | data_type = "train" if not is_testing else "val"
34 | path_A = glob('./datasets/%s/%sA/*' % (self.dataset_name, data_type))
35 | path_B = glob('./datasets/%s/%sB/*' % (self.dataset_name, data_type))
36 |
37 | self.n_batches = int(min(len(path_A), len(path_B)) / batch_size)
38 | total_samples = self.n_batches * batch_size
39 |
40 | # Sample n_batches * batch_size from each path list so that model sees all
41 | # samples from both domains
42 | path_A = np.random.choice(path_A, total_samples, replace=False)
43 | path_B = np.random.choice(path_B, total_samples, replace=False)
44 |
45 | for i in range(self.n_batches-1):
46 | batch_A = path_A[i*batch_size:(i+1)*batch_size]
47 | batch_B = path_B[i*batch_size:(i+1)*batch_size]
48 | imgs_A, imgs_B = [], []
49 | for img_A, img_B in zip(batch_A, batch_B):
50 | img_A = self.imread(img_A)
51 | img_B = self.imread(img_B)
52 |
53 | img_A = scipy.misc.imresize(img_A, self.img_res)
54 | img_B = scipy.misc.imresize(img_B, self.img_res)
55 |
56 | if not is_testing and np.random.random() > 0.5:
57 | img_A = np.fliplr(img_A)
58 | img_B = np.fliplr(img_B)
59 |
60 | imgs_A.append(img_A)
61 | imgs_B.append(img_B)
62 |
63 | imgs_A = np.array(imgs_A)/127.5 - 1.
64 | imgs_B = np.array(imgs_B)/127.5 - 1.
65 |
66 | yield imgs_A, imgs_B
67 |
68 | def load_img(self, path):
69 | img = self.imread(path)
70 | img = scipy.misc.imresize(img, self.img_res)
71 | img = img/127.5 - 1.
72 | return img[np.newaxis, :, :, :]
73 |
74 | def imread(self, path):
75 | return scipy.misc.imread(path, mode='RGB').astype(np.float)
76 |
--------------------------------------------------------------------------------
/pixelda/data_loader.py:
--------------------------------------------------------------------------------
1 | import scipy
2 | from glob import glob
3 | import numpy as np
4 | from keras.datasets import mnist
5 | from skimage.transform import resize as imresize
6 | import pickle
7 | import os
8 | import urllib
9 | import gzip
10 |
11 | class DataLoader():
12 | """Loads images from MNIST (domain A) and MNIST-M (domain B)"""
13 | def __init__(self, img_res=(128, 128)):
14 | self.img_res = img_res
15 |
16 | self.mnistm_url = 'https://github.com/VanushVaswani/keras_mnistm/releases/download/1.0/keras_mnistm.pkl.gz'
17 |
18 | self.setup_mnist(img_res)
19 | self.setup_mnistm(img_res)
20 |
21 | def normalize(self, images):
22 | return images.astype(np.float32) / 127.5 - 1.
23 |
24 | def setup_mnist(self, img_res):
25 |
26 | print ("Setting up MNIST...")
27 |
28 | if not os.path.exists('datasets/mnist_x.npy'):
29 | # Load the dataset
30 | (mnist_X, mnist_y), (_, _) = mnist.load_data()
31 |
32 | # Normalize and rescale images
33 | mnist_X = self.normalize(mnist_X)
34 | mnist_X = np.array([imresize(x, img_res) for x in mnist_X])
35 | mnist_X = np.expand_dims(mnist_X, axis=-1)
36 | mnist_X = np.repeat(mnist_X, 3, axis=-1)
37 |
38 | self.mnist_X, self.mnist_y = mnist_X, mnist_y
39 |
40 | # Save formatted images
41 | np.save('datasets/mnist_x.npy', self.mnist_X)
42 | np.save('datasets/mnist_y.npy', self.mnist_y)
43 | else:
44 | self.mnist_X = np.load('datasets/mnist_x.npy')
45 | self.mnist_y = np.load('datasets/mnist_y.npy')
46 |
47 | print ("+ Done.")
48 |
49 | def setup_mnistm(self, img_res):
50 |
51 | print ("Setting up MNIST-M...")
52 |
53 | if not os.path.exists('datasets/mnistm_x.npy'):
54 |
55 | # Download the MNIST-M pkl file
56 | filepath = 'datasets/keras_mnistm.pkl.gz'
57 | if not os.path.exists(filepath.replace('.gz', '')):
58 | print('+ Downloading ' + self.mnistm_url)
59 | data = urllib.request.urlopen(self.mnistm_url)
60 | with open(filepath, 'wb') as f:
61 | f.write(data.read())
62 | with open(filepath.replace('.gz', ''), 'wb') as out_f, \
63 | gzip.GzipFile(filepath) as zip_f:
64 | out_f.write(zip_f.read())
65 | os.unlink(filepath)
66 |
67 | # load MNIST-M images from pkl file
68 | with open('datasets/keras_mnistm.pkl', "rb") as f:
69 | data = pickle.load(f, encoding='bytes')
70 |
71 | # Normalize and rescale images
72 | mnistm_X = np.array(data[b'train'])
73 | mnistm_X = self.normalize(mnistm_X)
74 | mnistm_X = np.array([imresize(x, img_res) for x in mnistm_X])
75 |
76 | self.mnistm_X, self.mnistm_y = mnistm_X, self.mnist_y.copy()
77 |
78 | # Save formatted images
79 | np.save('datasets/mnistm_x.npy', self.mnistm_X)
80 | np.save('datasets/mnistm_y.npy', self.mnistm_y)
81 | else:
82 | self.mnistm_X = np.load('datasets/mnistm_x.npy')
83 | self.mnistm_y = np.load('datasets/mnistm_y.npy')
84 |
85 | print ("+ Done.")
86 |
87 |
88 | def load_data(self, domain, batch_size=1):
89 |
90 | X = self.mnist_X if domain == 'A' else self.mnistm_X
91 | y = self.mnist_y if domain == 'A' else self.mnistm_y
92 |
93 | idx = np.random.choice(list(range(len(X))), size=batch_size)
94 |
95 | return X[idx], y[idx]
96 |
--------------------------------------------------------------------------------
/lsgan/lsgan.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 |
3 | from keras.datasets import mnist
4 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout
5 | from keras.layers import BatchNormalization, Activation, ZeroPadding2D
6 | from keras.layers.advanced_activations import LeakyReLU
7 | from keras.layers.convolutional import UpSampling2D, Conv2D
8 | from keras.models import Sequential, Model
9 | from keras.optimizers import Adam
10 |
11 | import matplotlib.pyplot as plt
12 |
13 | import sys
14 |
15 | import numpy as np
16 |
17 | class LSGAN():
18 | def __init__(self):
19 | self.img_rows = 28
20 | self.img_cols = 28
21 | self.channels = 1
22 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
23 | self.latent_dim = 100
24 |
25 | optimizer = Adam(0.0002, 0.5)
26 |
27 | # Build and compile the discriminator
28 | self.discriminator = self.build_discriminator()
29 | self.discriminator.compile(loss='mse',
30 | optimizer=optimizer,
31 | metrics=['accuracy'])
32 |
33 | # Build the generator
34 | self.generator = self.build_generator()
35 |
36 | # The generator takes noise as input and generated imgs
37 | z = Input(shape=(self.latent_dim,))
38 | img = self.generator(z)
39 |
40 | # For the combined model we will only train the generator
41 | self.discriminator.trainable = False
42 |
43 | # The valid takes generated images as input and determines validity
44 | valid = self.discriminator(img)
45 |
46 | # The combined model (stacked generator and discriminator)
47 | # Trains generator to fool discriminator
48 | self.combined = Model(z, valid)
49 | # (!!!) Optimize w.r.t. MSE loss instead of crossentropy
50 | self.combined.compile(loss='mse', optimizer=optimizer)
51 |
52 | def build_generator(self):
53 |
54 | model = Sequential()
55 |
56 | model.add(Dense(256, input_dim=self.latent_dim))
57 | model.add(LeakyReLU(alpha=0.2))
58 | model.add(BatchNormalization(momentum=0.8))
59 | model.add(Dense(512))
60 | model.add(LeakyReLU(alpha=0.2))
61 | model.add(BatchNormalization(momentum=0.8))
62 | model.add(Dense(1024))
63 | model.add(LeakyReLU(alpha=0.2))
64 | model.add(BatchNormalization(momentum=0.8))
65 | model.add(Dense(np.prod(self.img_shape), activation='tanh'))
66 | model.add(Reshape(self.img_shape))
67 |
68 | model.summary()
69 |
70 | noise = Input(shape=(self.latent_dim,))
71 | img = model(noise)
72 |
73 | return Model(noise, img)
74 |
75 | def build_discriminator(self):
76 |
77 | model = Sequential()
78 |
79 | model.add(Flatten(input_shape=self.img_shape))
80 | model.add(Dense(512))
81 | model.add(LeakyReLU(alpha=0.2))
82 | model.add(Dense(256))
83 | model.add(LeakyReLU(alpha=0.2))
84 | # (!!!) No softmax
85 | model.add(Dense(1))
86 | model.summary()
87 |
88 | img = Input(shape=self.img_shape)
89 | validity = model(img)
90 |
91 | return Model(img, validity)
92 |
93 | def train(self, epochs, batch_size=128, sample_interval=50):
94 |
95 | # Load the dataset
96 | (X_train, _), (_, _) = mnist.load_data()
97 |
98 | # Rescale -1 to 1
99 | X_train = (X_train.astype(np.float32) - 127.5) / 127.5
100 | X_train = np.expand_dims(X_train, axis=3)
101 |
102 | # Adversarial ground truths
103 | valid = np.ones((batch_size, 1))
104 | fake = np.zeros((batch_size, 1))
105 |
106 | for epoch in range(epochs):
107 |
108 | # ---------------------
109 | # Train Discriminator
110 | # ---------------------
111 |
112 | # Select a random batch of images
113 | idx = np.random.randint(0, X_train.shape[0], batch_size)
114 | imgs = X_train[idx]
115 |
116 | # Sample noise as generator input
117 | noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
118 |
119 | # Generate a batch of new images
120 | gen_imgs = self.generator.predict(noise)
121 |
122 | # Train the discriminator
123 | d_loss_real = self.discriminator.train_on_batch(imgs, valid)
124 | d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
125 | d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
126 |
127 |
128 | # ---------------------
129 | # Train Generator
130 | # ---------------------
131 |
132 | g_loss = self.combined.train_on_batch(noise, valid)
133 |
134 | # Plot the progress
135 | print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
136 |
137 | # If at save interval => save generated image samples
138 | if epoch % sample_interval == 0:
139 | self.sample_images(epoch)
140 |
141 | def sample_images(self, epoch):
142 | r, c = 5, 5
143 | noise = np.random.normal(0, 1, (r * c, self.latent_dim))
144 | gen_imgs = self.generator.predict(noise)
145 |
146 | # Rescale images 0 - 1
147 | gen_imgs = 0.5 * gen_imgs + 0.5
148 |
149 | fig, axs = plt.subplots(r, c)
150 | cnt = 0
151 | for i in range(r):
152 | for j in range(c):
153 | axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
154 | axs[i,j].axis('off')
155 | cnt += 1
156 | fig.savefig("images/mnist_%d.png" % epoch)
157 | plt.close()
158 |
159 |
160 | if __name__ == '__main__':
161 | gan = LSGAN()
162 | gan.train(epochs=30000, batch_size=32, sample_interval=200)
163 |
--------------------------------------------------------------------------------
/gan/gan.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 |
3 | from keras.datasets import mnist
4 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout
5 | from keras.layers import BatchNormalization, Activation, ZeroPadding2D
6 | from keras.layers.advanced_activations import LeakyReLU
7 | from keras.layers.convolutional import UpSampling2D, Conv2D
8 | from keras.models import Sequential, Model
9 | from keras.optimizers import Adam
10 |
11 | import matplotlib.pyplot as plt
12 |
13 | import sys
14 |
15 | import numpy as np
16 |
17 | class GAN():
18 | def __init__(self):
19 | self.img_rows = 28
20 | self.img_cols = 28
21 | self.channels = 1
22 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
23 | self.latent_dim = 100
24 |
25 | optimizer = Adam(0.0002, 0.5)
26 |
27 | # Build and compile the discriminator
28 | self.discriminator = self.build_discriminator()
29 | self.discriminator.compile(loss='binary_crossentropy',
30 | optimizer=optimizer,
31 | metrics=['accuracy'])
32 |
33 | # Build the generator
34 | self.generator = self.build_generator()
35 |
36 | # The generator takes noise as input and generates imgs
37 | z = Input(shape=(self.latent_dim,))
38 | img = self.generator(z)
39 |
40 | # For the combined model we will only train the generator
41 | self.discriminator.trainable = False
42 |
43 | # The discriminator takes generated images as input and determines validity
44 | validity = self.discriminator(img)
45 |
46 | # The combined model (stacked generator and discriminator)
47 | # Trains the generator to fool the discriminator
48 | self.combined = Model(z, validity)
49 | self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
50 |
51 |
52 | def build_generator(self):
53 |
54 | model = Sequential()
55 |
56 | model.add(Dense(256, input_dim=self.latent_dim))
57 | model.add(LeakyReLU(alpha=0.2))
58 | model.add(BatchNormalization(momentum=0.8))
59 | model.add(Dense(512))
60 | model.add(LeakyReLU(alpha=0.2))
61 | model.add(BatchNormalization(momentum=0.8))
62 | model.add(Dense(1024))
63 | model.add(LeakyReLU(alpha=0.2))
64 | model.add(BatchNormalization(momentum=0.8))
65 | model.add(Dense(np.prod(self.img_shape), activation='tanh'))
66 | model.add(Reshape(self.img_shape))
67 |
68 | model.summary()
69 |
70 | noise = Input(shape=(self.latent_dim,))
71 | img = model(noise)
72 |
73 | return Model(noise, img)
74 |
75 | def build_discriminator(self):
76 |
77 | model = Sequential()
78 |
79 | model.add(Flatten(input_shape=self.img_shape))
80 | model.add(Dense(512))
81 | model.add(LeakyReLU(alpha=0.2))
82 | model.add(Dense(256))
83 | model.add(LeakyReLU(alpha=0.2))
84 | model.add(Dense(1, activation='sigmoid'))
85 | model.summary()
86 |
87 | img = Input(shape=self.img_shape)
88 | validity = model(img)
89 |
90 | return Model(img, validity)
91 |
92 | def train(self, epochs, batch_size=128, sample_interval=50):
93 |
94 | # Load the dataset
95 | (X_train, _), (_, _) = mnist.load_data()
96 |
97 | # Rescale -1 to 1
98 | X_train = X_train / 127.5 - 1.
99 | X_train = np.expand_dims(X_train, axis=3)
100 |
101 | # Adversarial ground truths
102 | valid = np.ones((batch_size, 1))
103 | fake = np.zeros((batch_size, 1))
104 |
105 | for epoch in range(epochs):
106 |
107 | # ---------------------
108 | # Train Discriminator
109 | # ---------------------
110 |
111 | # Select a random batch of images
112 | idx = np.random.randint(0, X_train.shape[0], batch_size)
113 | imgs = X_train[idx]
114 |
115 | noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
116 |
117 | # Generate a batch of new images
118 | gen_imgs = self.generator.predict(noise)
119 |
120 | # Train the discriminator
121 | d_loss_real = self.discriminator.train_on_batch(imgs, valid)
122 | d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
123 | d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
124 |
125 | # ---------------------
126 | # Train Generator
127 | # ---------------------
128 |
129 | noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
130 |
131 | # Train the generator (to have the discriminator label samples as valid)
132 | g_loss = self.combined.train_on_batch(noise, valid)
133 |
134 | # Plot the progress
135 | print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
136 |
137 | # If at save interval => save generated image samples
138 | if epoch % sample_interval == 0:
139 | self.sample_images(epoch)
140 |
141 | def sample_images(self, epoch):
142 | r, c = 5, 5
143 | noise = np.random.normal(0, 1, (r * c, self.latent_dim))
144 | gen_imgs = self.generator.predict(noise)
145 |
146 | # Rescale images 0 - 1
147 | gen_imgs = 0.5 * gen_imgs + 0.5
148 |
149 | fig, axs = plt.subplots(r, c)
150 | cnt = 0
151 | for i in range(r):
152 | for j in range(c):
153 | axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
154 | axs[i,j].axis('off')
155 | cnt += 1
156 | fig.savefig("images/%d.png" % epoch)
157 | plt.close()
158 |
159 |
160 | if __name__ == '__main__':
161 | gan = GAN()
162 | gan.train(epochs=30000, batch_size=32, sample_interval=200)
163 |
--------------------------------------------------------------------------------
/bgan/bgan.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 |
3 | from keras.datasets import mnist
4 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout
5 | from keras.layers import BatchNormalization, Activation, ZeroPadding2D
6 | from keras.layers.advanced_activations import LeakyReLU
7 | from keras.layers.convolutional import UpSampling2D, Conv2D
8 | from keras.models import Sequential, Model
9 | from keras.optimizers import Adam
10 | import keras.backend as K
11 |
12 | import matplotlib.pyplot as plt
13 |
14 | import sys
15 |
16 | import numpy as np
17 |
18 | class BGAN():
19 | """Reference: https://wiseodd.github.io/techblog/2017/03/07/boundary-seeking-gan/"""
20 | def __init__(self):
21 | self.img_rows = 28
22 | self.img_cols = 28
23 | self.channels = 1
24 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
25 | self.latent_dim = 100
26 |
27 | optimizer = Adam(0.0002, 0.5)
28 |
29 | # Build and compile the discriminator
30 | self.discriminator = self.build_discriminator()
31 | self.discriminator.compile(loss='binary_crossentropy',
32 | optimizer=optimizer,
33 | metrics=['accuracy'])
34 |
35 | # Build the generator
36 | self.generator = self.build_generator()
37 |
38 | # The generator takes noise as input and generated imgs
39 | z = Input(shape=(self.latent_dim,))
40 | img = self.generator(z)
41 |
42 | # For the combined model we will only train the generator
43 | self.discriminator.trainable = False
44 |
45 | # The valid takes generated images as input and determines validity
46 | valid = self.discriminator(img)
47 |
48 | # The combined model (stacked generator and discriminator)
49 | # Trains the generator to fool the discriminator
50 | self.combined = Model(z, valid)
51 | self.combined.compile(loss=self.boundary_loss, optimizer=optimizer)
52 |
53 | def build_generator(self):
54 |
55 | model = Sequential()
56 |
57 | model.add(Dense(256, input_dim=self.latent_dim))
58 | model.add(LeakyReLU(alpha=0.2))
59 | model.add(BatchNormalization(momentum=0.8))
60 | model.add(Dense(512))
61 | model.add(LeakyReLU(alpha=0.2))
62 | model.add(BatchNormalization(momentum=0.8))
63 | model.add(Dense(1024))
64 | model.add(LeakyReLU(alpha=0.2))
65 | model.add(BatchNormalization(momentum=0.8))
66 | model.add(Dense(np.prod(self.img_shape), activation='tanh'))
67 | model.add(Reshape(self.img_shape))
68 |
69 | model.summary()
70 |
71 | noise = Input(shape=(self.latent_dim,))
72 | img = model(noise)
73 |
74 | return Model(noise, img)
75 |
76 | def build_discriminator(self):
77 |
78 | model = Sequential()
79 |
80 | model.add(Flatten(input_shape=self.img_shape))
81 | model.add(Dense(512))
82 | model.add(LeakyReLU(alpha=0.2))
83 | model.add(Dense(256))
84 | model.add(LeakyReLU(alpha=0.2))
85 | model.add(Dense(1, activation='sigmoid'))
86 | model.summary()
87 |
88 | img = Input(shape=self.img_shape)
89 | validity = model(img)
90 |
91 | return Model(img, validity)
92 |
93 | def boundary_loss(self, y_true, y_pred):
94 | """
95 | Boundary seeking loss.
96 | Reference: https://wiseodd.github.io/techblog/2017/03/07/boundary-seeking-gan/
97 | """
98 | return 0.5 * K.mean((K.log(y_pred) - K.log(1 - y_pred))**2)
99 |
100 | def train(self, epochs, batch_size=128, sample_interval=50):
101 |
102 | # Load the dataset
103 | (X_train, _), (_, _) = mnist.load_data()
104 |
105 | # Rescale -1 to 1
106 | X_train = X_train / 127.5 - 1.
107 | X_train = np.expand_dims(X_train, axis=3)
108 |
109 | # Adversarial ground truths
110 | valid = np.ones((batch_size, 1))
111 | fake = np.zeros((batch_size, 1))
112 |
113 | for epoch in range(epochs):
114 |
115 | # ---------------------
116 | # Train Discriminator
117 | # ---------------------
118 |
119 | # Select a random batch of images
120 | idx = np.random.randint(0, X_train.shape[0], batch_size)
121 | imgs = X_train[idx]
122 |
123 | noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
124 |
125 | # Generate a batch of new images
126 | gen_imgs = self.generator.predict(noise)
127 |
128 | # Train the discriminator
129 | d_loss_real = self.discriminator.train_on_batch(imgs, valid)
130 | d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
131 | d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
132 |
133 |
134 | # ---------------------
135 | # Train Generator
136 | # ---------------------
137 |
138 | g_loss = self.combined.train_on_batch(noise, valid)
139 |
140 | # Plot the progress
141 | print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
142 |
143 | # If at save interval => save generated image samples
144 | if epoch % sample_interval == 0:
145 | self.sample_images(epoch)
146 |
147 | def sample_images(self, epoch):
148 | r, c = 5, 5
149 | noise = np.random.normal(0, 1, (r * c, self.latent_dim))
150 | gen_imgs = self.generator.predict(noise)
151 | # Rescale images 0 - 1
152 | gen_imgs = 0.5 * gen_imgs + 0.5
153 |
154 | fig, axs = plt.subplots(r, c)
155 | cnt = 0
156 | for i in range(r):
157 | for j in range(c):
158 | axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
159 | axs[i,j].axis('off')
160 | cnt += 1
161 | fig.savefig("images/mnist_%d.png" % epoch)
162 | plt.close()
163 |
164 |
165 | if __name__ == '__main__':
166 | bgan = BGAN()
167 | bgan.train(epochs=30000, batch_size=32, sample_interval=200)
168 |
--------------------------------------------------------------------------------
/dcgan/dcgan.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 |
3 | from keras.datasets import mnist
4 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout
5 | from keras.layers import BatchNormalization, Activation, ZeroPadding2D
6 | from keras.layers.advanced_activations import LeakyReLU
7 | from keras.layers.convolutional import UpSampling2D, Conv2D
8 | from keras.models import Sequential, Model
9 | from keras.optimizers import Adam
10 |
11 | import matplotlib.pyplot as plt
12 |
13 | import sys
14 |
15 | import numpy as np
16 |
17 | class DCGAN():
18 | def __init__(self):
19 | # Input shape
20 | self.img_rows = 28
21 | self.img_cols = 28
22 | self.channels = 1
23 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
24 | self.latent_dim = 100
25 |
26 | optimizer = Adam(0.0002, 0.5)
27 |
28 | # Build and compile the discriminator
29 | self.discriminator = self.build_discriminator()
30 | self.discriminator.compile(loss='binary_crossentropy',
31 | optimizer=optimizer,
32 | metrics=['accuracy'])
33 |
34 | # Build the generator
35 | self.generator = self.build_generator()
36 |
37 | # The generator takes noise as input and generates imgs
38 | z = Input(shape=(self.latent_dim,))
39 | img = self.generator(z)
40 |
41 | # For the combined model we will only train the generator
42 | self.discriminator.trainable = False
43 |
44 | # The discriminator takes generated images as input and determines validity
45 | valid = self.discriminator(img)
46 |
47 | # The combined model (stacked generator and discriminator)
48 | # Trains the generator to fool the discriminator
49 | self.combined = Model(z, valid)
50 | self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
51 |
52 | def build_generator(self):
53 |
54 | model = Sequential()
55 |
56 | model.add(Dense(128 * 7 * 7, activation="relu", input_dim=self.latent_dim))
57 | model.add(Reshape((7, 7, 128)))
58 | model.add(UpSampling2D())
59 | model.add(Conv2D(128, kernel_size=3, padding="same"))
60 | model.add(BatchNormalization(momentum=0.8))
61 | model.add(Activation("relu"))
62 | model.add(UpSampling2D())
63 | model.add(Conv2D(64, kernel_size=3, padding="same"))
64 | model.add(BatchNormalization(momentum=0.8))
65 | model.add(Activation("relu"))
66 | model.add(Conv2D(self.channels, kernel_size=3, padding="same"))
67 | model.add(Activation("tanh"))
68 |
69 | model.summary()
70 |
71 | noise = Input(shape=(self.latent_dim,))
72 | img = model(noise)
73 |
74 | return Model(noise, img)
75 |
76 | def build_discriminator(self):
77 |
78 | model = Sequential()
79 |
80 | model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
81 | model.add(LeakyReLU(alpha=0.2))
82 | model.add(Dropout(0.25))
83 | model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
84 | model.add(ZeroPadding2D(padding=((0,1),(0,1))))
85 | model.add(BatchNormalization(momentum=0.8))
86 | model.add(LeakyReLU(alpha=0.2))
87 | model.add(Dropout(0.25))
88 | model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
89 | model.add(BatchNormalization(momentum=0.8))
90 | model.add(LeakyReLU(alpha=0.2))
91 | model.add(Dropout(0.25))
92 | model.add(Conv2D(256, kernel_size=3, strides=1, padding="same"))
93 | model.add(BatchNormalization(momentum=0.8))
94 | model.add(LeakyReLU(alpha=0.2))
95 | model.add(Dropout(0.25))
96 | model.add(Flatten())
97 | model.add(Dense(1, activation='sigmoid'))
98 |
99 | model.summary()
100 |
101 | img = Input(shape=self.img_shape)
102 | validity = model(img)
103 |
104 | return Model(img, validity)
105 |
106 | def train(self, epochs, batch_size=128, save_interval=50):
107 |
108 | # Load the dataset
109 | (X_train, _), (_, _) = mnist.load_data()
110 |
111 | # Rescale -1 to 1
112 | X_train = X_train / 127.5 - 1.
113 | X_train = np.expand_dims(X_train, axis=3)
114 |
115 | # Adversarial ground truths
116 | valid = np.ones((batch_size, 1))
117 | fake = np.zeros((batch_size, 1))
118 |
119 | for epoch in range(epochs):
120 |
121 | # ---------------------
122 | # Train Discriminator
123 | # ---------------------
124 |
125 | # Select a random half of images
126 | idx = np.random.randint(0, X_train.shape[0], batch_size)
127 | imgs = X_train[idx]
128 |
129 | # Sample noise and generate a batch of new images
130 | noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
131 | gen_imgs = self.generator.predict(noise)
132 |
133 | # Train the discriminator (real classified as ones and generated as zeros)
134 | d_loss_real = self.discriminator.train_on_batch(imgs, valid)
135 | d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
136 | d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
137 |
138 | # ---------------------
139 | # Train Generator
140 | # ---------------------
141 |
142 | # Train the generator (wants discriminator to mistake images as real)
143 | g_loss = self.combined.train_on_batch(noise, valid)
144 |
145 | # Plot the progress
146 | print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
147 |
148 | # If at save interval => save generated image samples
149 | if epoch % save_interval == 0:
150 | self.save_imgs(epoch)
151 |
152 | def save_imgs(self, epoch):
153 | r, c = 5, 5
154 | noise = np.random.normal(0, 1, (r * c, self.latent_dim))
155 | gen_imgs = self.generator.predict(noise)
156 |
157 | # Rescale images 0 - 1
158 | gen_imgs = 0.5 * gen_imgs + 0.5
159 |
160 | fig, axs = plt.subplots(r, c)
161 | cnt = 0
162 | for i in range(r):
163 | for j in range(c):
164 | axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
165 | axs[i,j].axis('off')
166 | cnt += 1
167 | fig.savefig("images/mnist_%d.png" % epoch)
168 | plt.close()
169 |
170 |
171 | if __name__ == '__main__':
172 | dcgan = DCGAN()
173 | dcgan.train(epochs=4000, batch_size=32, save_interval=50)
174 |
--------------------------------------------------------------------------------
/bigan/bigan.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 |
3 | from keras.datasets import mnist
4 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout, multiply, GaussianNoise
5 | from keras.layers import BatchNormalization, Activation, Embedding, ZeroPadding2D
6 | from keras.layers import MaxPooling2D, concatenate
7 | from keras.layers.advanced_activations import LeakyReLU
8 | from keras.layers.convolutional import UpSampling2D, Conv2D
9 | from keras.models import Sequential, Model
10 | from keras.optimizers import Adam
11 | from keras import losses
12 | from keras.utils import to_categorical
13 | import keras.backend as K
14 |
15 | import matplotlib.pyplot as plt
16 |
17 | import numpy as np
18 |
19 | class BIGAN():
20 | def __init__(self):
21 | self.img_rows = 28
22 | self.img_cols = 28
23 | self.channels = 1
24 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
25 | self.latent_dim = 100
26 |
27 | optimizer = Adam(0.0002, 0.5)
28 |
29 | # Build and compile the discriminator
30 | self.discriminator = self.build_discriminator()
31 | self.discriminator.compile(loss=['binary_crossentropy'],
32 | optimizer=optimizer,
33 | metrics=['accuracy'])
34 |
35 | # Build the generator
36 | self.generator = self.build_generator()
37 |
38 | # Build the encoder
39 | self.encoder = self.build_encoder()
40 |
41 | # The part of the bigan that trains the discriminator and encoder
42 | self.discriminator.trainable = False
43 |
44 | # Generate image from sampled noise
45 | z = Input(shape=(self.latent_dim, ))
46 | img_ = self.generator(z)
47 |
48 | # Encode image
49 | img = Input(shape=self.img_shape)
50 | z_ = self.encoder(img)
51 |
52 | # Latent -> img is fake, and img -> latent is valid
53 | fake = self.discriminator([z, img_])
54 | valid = self.discriminator([z_, img])
55 |
56 | # Set up and compile the combined model
57 | # Trains generator to fool the discriminator
58 | self.bigan_generator = Model([z, img], [fake, valid])
59 | self.bigan_generator.compile(loss=['binary_crossentropy', 'binary_crossentropy'],
60 | optimizer=optimizer)
61 |
62 |
63 | def build_encoder(self):
64 | model = Sequential()
65 |
66 | model.add(Flatten(input_shape=self.img_shape))
67 | model.add(Dense(512))
68 | model.add(LeakyReLU(alpha=0.2))
69 | model.add(BatchNormalization(momentum=0.8))
70 | model.add(Dense(512))
71 | model.add(LeakyReLU(alpha=0.2))
72 | model.add(BatchNormalization(momentum=0.8))
73 | model.add(Dense(self.latent_dim))
74 |
75 | model.summary()
76 |
77 | img = Input(shape=self.img_shape)
78 | z = model(img)
79 |
80 | return Model(img, z)
81 |
82 | def build_generator(self):
83 | model = Sequential()
84 |
85 | model.add(Dense(512, input_dim=self.latent_dim))
86 | model.add(LeakyReLU(alpha=0.2))
87 | model.add(BatchNormalization(momentum=0.8))
88 | model.add(Dense(512))
89 | model.add(LeakyReLU(alpha=0.2))
90 | model.add(BatchNormalization(momentum=0.8))
91 | model.add(Dense(np.prod(self.img_shape), activation='tanh'))
92 | model.add(Reshape(self.img_shape))
93 |
94 | model.summary()
95 |
96 | z = Input(shape=(self.latent_dim,))
97 | gen_img = model(z)
98 |
99 | return Model(z, gen_img)
100 |
101 | def build_discriminator(self):
102 |
103 | z = Input(shape=(self.latent_dim, ))
104 | img = Input(shape=self.img_shape)
105 | d_in = concatenate([z, Flatten()(img)])
106 |
107 | model = Dense(1024)(d_in)
108 | model = LeakyReLU(alpha=0.2)(model)
109 | model = Dropout(0.5)(model)
110 | model = Dense(1024)(model)
111 | model = LeakyReLU(alpha=0.2)(model)
112 | model = Dropout(0.5)(model)
113 | model = Dense(1024)(model)
114 | model = LeakyReLU(alpha=0.2)(model)
115 | model = Dropout(0.5)(model)
116 | validity = Dense(1, activation="sigmoid")(model)
117 |
118 | return Model([z, img], validity)
119 |
120 | def train(self, epochs, batch_size=128, sample_interval=50):
121 |
122 | # Load the dataset
123 | (X_train, _), (_, _) = mnist.load_data()
124 |
125 | # Rescale -1 to 1
126 | X_train = (X_train.astype(np.float32) - 127.5) / 127.5
127 | X_train = np.expand_dims(X_train, axis=3)
128 |
129 | # Adversarial ground truths
130 | valid = np.ones((batch_size, 1))
131 | fake = np.zeros((batch_size, 1))
132 |
133 | for epoch in range(epochs):
134 |
135 |
136 | # ---------------------
137 | # Train Discriminator
138 | # ---------------------
139 |
140 | # Sample noise and generate img
141 | z = np.random.normal(size=(batch_size, self.latent_dim))
142 | imgs_ = self.generator.predict(z)
143 |
144 | # Select a random batch of images and encode
145 | idx = np.random.randint(0, X_train.shape[0], batch_size)
146 | imgs = X_train[idx]
147 | z_ = self.encoder.predict(imgs)
148 |
149 | # Train the discriminator (img -> z is valid, z -> img is fake)
150 | d_loss_real = self.discriminator.train_on_batch([z_, imgs], valid)
151 | d_loss_fake = self.discriminator.train_on_batch([z, imgs_], fake)
152 | d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
153 |
154 | # ---------------------
155 | # Train Generator
156 | # ---------------------
157 |
158 | # Train the generator (z -> img is valid and img -> z is is invalid)
159 | g_loss = self.bigan_generator.train_on_batch([z, imgs], [valid, fake])
160 |
161 | # Plot the progress
162 | print ("%d [D loss: %f, acc: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss[0]))
163 |
164 | # If at save interval => save generated image samples
165 | if epoch % sample_interval == 0:
166 | self.sample_interval(epoch)
167 |
168 | def sample_interval(self, epoch):
169 | r, c = 5, 5
170 | z = np.random.normal(size=(25, self.latent_dim))
171 | gen_imgs = self.generator.predict(z)
172 |
173 | gen_imgs = 0.5 * gen_imgs + 0.5
174 |
175 | fig, axs = plt.subplots(r, c)
176 | cnt = 0
177 | for i in range(r):
178 | for j in range(c):
179 | axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
180 | axs[i,j].axis('off')
181 | cnt += 1
182 | fig.savefig("images/mnist_%d.png" % epoch)
183 | plt.close()
184 |
185 |
186 | if __name__ == '__main__':
187 | bigan = BIGAN()
188 | bigan.train(epochs=40000, batch_size=32, sample_interval=400)
189 |
--------------------------------------------------------------------------------
/wgan/wgan.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 |
3 | from keras.datasets import mnist
4 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout
5 | from keras.layers import BatchNormalization, Activation, ZeroPadding2D
6 | from keras.layers.advanced_activations import LeakyReLU
7 | from keras.layers.convolutional import UpSampling2D, Conv2D
8 | from keras.models import Sequential, Model
9 | from keras.optimizers import RMSprop
10 |
11 | import keras.backend as K
12 |
13 | import matplotlib.pyplot as plt
14 |
15 | import sys
16 |
17 | import numpy as np
18 |
19 | class WGAN():
20 | def __init__(self):
21 | self.img_rows = 28
22 | self.img_cols = 28
23 | self.channels = 1
24 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
25 | self.latent_dim = 100
26 |
27 | # Following parameter and optimizer set as recommended in paper
28 | self.n_critic = 5
29 | self.clip_value = 0.01
30 | optimizer = RMSprop(lr=0.00005)
31 |
32 | # Build and compile the critic
33 | self.critic = self.build_critic()
34 | self.critic.compile(loss=self.wasserstein_loss,
35 | optimizer=optimizer,
36 | metrics=['accuracy'])
37 |
38 | # Build the generator
39 | self.generator = self.build_generator()
40 |
41 | # The generator takes noise as input and generated imgs
42 | z = Input(shape=(self.latent_dim,))
43 | img = self.generator(z)
44 |
45 | # For the combined model we will only train the generator
46 | self.critic.trainable = False
47 |
48 | # The critic takes generated images as input and determines validity
49 | valid = self.critic(img)
50 |
51 | # The combined model (stacked generator and critic)
52 | self.combined = Model(z, valid)
53 | self.combined.compile(loss=self.wasserstein_loss,
54 | optimizer=optimizer,
55 | metrics=['accuracy'])
56 |
57 | def wasserstein_loss(self, y_true, y_pred):
58 | return K.mean(y_true * y_pred)
59 |
60 | def build_generator(self):
61 |
62 | model = Sequential()
63 |
64 | model.add(Dense(128 * 7 * 7, activation="relu", input_dim=self.latent_dim))
65 | model.add(Reshape((7, 7, 128)))
66 | model.add(UpSampling2D())
67 | model.add(Conv2D(128, kernel_size=4, padding="same"))
68 | model.add(BatchNormalization(momentum=0.8))
69 | model.add(Activation("relu"))
70 | model.add(UpSampling2D())
71 | model.add(Conv2D(64, kernel_size=4, padding="same"))
72 | model.add(BatchNormalization(momentum=0.8))
73 | model.add(Activation("relu"))
74 | model.add(Conv2D(self.channels, kernel_size=4, padding="same"))
75 | model.add(Activation("tanh"))
76 |
77 | model.summary()
78 |
79 | noise = Input(shape=(self.latent_dim,))
80 | img = model(noise)
81 |
82 | return Model(noise, img)
83 |
84 | def build_critic(self):
85 |
86 | model = Sequential()
87 |
88 | model.add(Conv2D(16, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
89 | model.add(LeakyReLU(alpha=0.2))
90 | model.add(Dropout(0.25))
91 | model.add(Conv2D(32, kernel_size=3, strides=2, padding="same"))
92 | model.add(ZeroPadding2D(padding=((0,1),(0,1))))
93 | model.add(BatchNormalization(momentum=0.8))
94 | model.add(LeakyReLU(alpha=0.2))
95 | model.add(Dropout(0.25))
96 | model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
97 | model.add(BatchNormalization(momentum=0.8))
98 | model.add(LeakyReLU(alpha=0.2))
99 | model.add(Dropout(0.25))
100 | model.add(Conv2D(128, kernel_size=3, strides=1, padding="same"))
101 | model.add(BatchNormalization(momentum=0.8))
102 | model.add(LeakyReLU(alpha=0.2))
103 | model.add(Dropout(0.25))
104 | model.add(Flatten())
105 | model.add(Dense(1))
106 |
107 | model.summary()
108 |
109 | img = Input(shape=self.img_shape)
110 | validity = model(img)
111 |
112 | return Model(img, validity)
113 |
114 | def train(self, epochs, batch_size=128, sample_interval=50):
115 |
116 | # Load the dataset
117 | (X_train, _), (_, _) = mnist.load_data()
118 |
119 | # Rescale -1 to 1
120 | X_train = (X_train.astype(np.float32) - 127.5) / 127.5
121 | X_train = np.expand_dims(X_train, axis=3)
122 |
123 | # Adversarial ground truths
124 | valid = -np.ones((batch_size, 1))
125 | fake = np.ones((batch_size, 1))
126 |
127 | for epoch in range(epochs):
128 |
129 | for _ in range(self.n_critic):
130 |
131 | # ---------------------
132 | # Train Discriminator
133 | # ---------------------
134 |
135 | # Select a random batch of images
136 | idx = np.random.randint(0, X_train.shape[0], batch_size)
137 | imgs = X_train[idx]
138 |
139 | # Sample noise as generator input
140 | noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
141 |
142 | # Generate a batch of new images
143 | gen_imgs = self.generator.predict(noise)
144 |
145 | # Train the critic
146 | d_loss_real = self.critic.train_on_batch(imgs, valid)
147 | d_loss_fake = self.critic.train_on_batch(gen_imgs, fake)
148 | d_loss = 0.5 * np.add(d_loss_fake, d_loss_real)
149 |
150 | # Clip critic weights
151 | for l in self.critic.layers:
152 | weights = l.get_weights()
153 | weights = [np.clip(w, -self.clip_value, self.clip_value) for w in weights]
154 | l.set_weights(weights)
155 |
156 |
157 | # ---------------------
158 | # Train Generator
159 | # ---------------------
160 |
161 | g_loss = self.combined.train_on_batch(noise, valid)
162 |
163 | # Plot the progress
164 | print ("%d [D loss: %f] [G loss: %f]" % (epoch, 1 - d_loss[0], 1 - g_loss[0]))
165 |
166 | # If at save interval => save generated image samples
167 | if epoch % sample_interval == 0:
168 | self.sample_images(epoch)
169 |
170 | def sample_images(self, epoch):
171 | r, c = 5, 5
172 | noise = np.random.normal(0, 1, (r * c, self.latent_dim))
173 | gen_imgs = self.generator.predict(noise)
174 |
175 | # Rescale images 0 - 1
176 | gen_imgs = 0.5 * gen_imgs + 0.5
177 |
178 | fig, axs = plt.subplots(r, c)
179 | cnt = 0
180 | for i in range(r):
181 | for j in range(c):
182 | axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
183 | axs[i,j].axis('off')
184 | cnt += 1
185 | fig.savefig("images/mnist_%d.png" % epoch)
186 | plt.close()
187 |
188 |
189 | if __name__ == '__main__':
190 | wgan = WGAN()
191 | wgan.train(epochs=4000, batch_size=32, sample_interval=50)
192 |
--------------------------------------------------------------------------------
/cgan/cgan.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 |
3 | from keras.datasets import mnist
4 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout, multiply
5 | from keras.layers import BatchNormalization, Activation, Embedding, ZeroPadding2D
6 | from keras.layers.advanced_activations import LeakyReLU
7 | from keras.layers.convolutional import UpSampling2D, Conv2D
8 | from keras.models import Sequential, Model
9 | from keras.optimizers import Adam
10 |
11 | import matplotlib.pyplot as plt
12 |
13 | import numpy as np
14 |
15 | class CGAN():
16 | def __init__(self):
17 | # Input shape
18 | self.img_rows = 28
19 | self.img_cols = 28
20 | self.channels = 1
21 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
22 | self.num_classes = 10
23 | self.latent_dim = 100
24 |
25 | optimizer = Adam(0.0002, 0.5)
26 |
27 | # Build and compile the discriminator
28 | self.discriminator = self.build_discriminator()
29 | self.discriminator.compile(loss=['binary_crossentropy'],
30 | optimizer=optimizer,
31 | metrics=['accuracy'])
32 |
33 | # Build the generator
34 | self.generator = self.build_generator()
35 |
36 | # The generator takes noise and the target label as input
37 | # and generates the corresponding digit of that label
38 | noise = Input(shape=(self.latent_dim,))
39 | label = Input(shape=(1,))
40 | img = self.generator([noise, label])
41 |
42 | # For the combined model we will only train the generator
43 | self.discriminator.trainable = False
44 |
45 | # The discriminator takes generated image as input and determines validity
46 | # and the label of that image
47 | valid = self.discriminator([img, label])
48 |
49 | # The combined model (stacked generator and discriminator)
50 | # Trains generator to fool discriminator
51 | self.combined = Model([noise, label], valid)
52 | self.combined.compile(loss=['binary_crossentropy'],
53 | optimizer=optimizer)
54 |
55 | def build_generator(self):
56 |
57 | model = Sequential()
58 |
59 | model.add(Dense(256, input_dim=self.latent_dim))
60 | model.add(LeakyReLU(alpha=0.2))
61 | model.add(BatchNormalization(momentum=0.8))
62 | model.add(Dense(512))
63 | model.add(LeakyReLU(alpha=0.2))
64 | model.add(BatchNormalization(momentum=0.8))
65 | model.add(Dense(1024))
66 | model.add(LeakyReLU(alpha=0.2))
67 | model.add(BatchNormalization(momentum=0.8))
68 | model.add(Dense(np.prod(self.img_shape), activation='tanh'))
69 | model.add(Reshape(self.img_shape))
70 |
71 | model.summary()
72 |
73 | noise = Input(shape=(self.latent_dim,))
74 | label = Input(shape=(1,), dtype='int32')
75 | label_embedding = Flatten()(Embedding(self.num_classes, self.latent_dim)(label))
76 |
77 | model_input = multiply([noise, label_embedding])
78 | img = model(model_input)
79 |
80 | return Model([noise, label], img)
81 |
82 | def build_discriminator(self):
83 |
84 | model = Sequential()
85 |
86 | model.add(Dense(512, input_dim=np.prod(self.img_shape)))
87 | model.add(LeakyReLU(alpha=0.2))
88 | model.add(Dense(512))
89 | model.add(LeakyReLU(alpha=0.2))
90 | model.add(Dropout(0.4))
91 | model.add(Dense(512))
92 | model.add(LeakyReLU(alpha=0.2))
93 | model.add(Dropout(0.4))
94 | model.add(Dense(1, activation='sigmoid'))
95 | model.summary()
96 |
97 | img = Input(shape=self.img_shape)
98 | label = Input(shape=(1,), dtype='int32')
99 |
100 | label_embedding = Flatten()(Embedding(self.num_classes, np.prod(self.img_shape))(label))
101 | flat_img = Flatten()(img)
102 |
103 | model_input = multiply([flat_img, label_embedding])
104 |
105 | validity = model(model_input)
106 |
107 | return Model([img, label], validity)
108 |
109 | def train(self, epochs, batch_size=128, sample_interval=50):
110 |
111 | # Load the dataset
112 | (X_train, y_train), (_, _) = mnist.load_data()
113 |
114 | # Configure input
115 | X_train = (X_train.astype(np.float32) - 127.5) / 127.5
116 | X_train = np.expand_dims(X_train, axis=3)
117 | y_train = y_train.reshape(-1, 1)
118 |
119 | # Adversarial ground truths
120 | valid = np.ones((batch_size, 1))
121 | fake = np.zeros((batch_size, 1))
122 |
123 | for epoch in range(epochs):
124 |
125 | # ---------------------
126 | # Train Discriminator
127 | # ---------------------
128 |
129 | # Select a random half batch of images
130 | idx = np.random.randint(0, X_train.shape[0], batch_size)
131 | imgs, labels = X_train[idx], y_train[idx]
132 |
133 | # Sample noise as generator input
134 | noise = np.random.normal(0, 1, (batch_size, 100))
135 |
136 | # Generate a half batch of new images
137 | gen_imgs = self.generator.predict([noise, labels])
138 |
139 | # Train the discriminator
140 | d_loss_real = self.discriminator.train_on_batch([imgs, labels], valid)
141 | d_loss_fake = self.discriminator.train_on_batch([gen_imgs, labels], fake)
142 | d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
143 |
144 | # ---------------------
145 | # Train Generator
146 | # ---------------------
147 |
148 | # Condition on labels
149 | sampled_labels = np.random.randint(0, 10, batch_size).reshape(-1, 1)
150 |
151 | # Train the generator
152 | g_loss = self.combined.train_on_batch([noise, sampled_labels], valid)
153 |
154 | # Plot the progress
155 | print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
156 |
157 | # If at save interval => save generated image samples
158 | if epoch % sample_interval == 0:
159 | self.sample_images(epoch)
160 |
161 | def sample_images(self, epoch):
162 | r, c = 2, 5
163 | noise = np.random.normal(0, 1, (r * c, 100))
164 | sampled_labels = np.arange(0, 10).reshape(-1, 1)
165 |
166 | gen_imgs = self.generator.predict([noise, sampled_labels])
167 |
168 | # Rescale images 0 - 1
169 | gen_imgs = 0.5 * gen_imgs + 0.5
170 |
171 | fig, axs = plt.subplots(r, c)
172 | cnt = 0
173 | for i in range(r):
174 | for j in range(c):
175 | axs[i,j].imshow(gen_imgs[cnt,:,:,0], cmap='gray')
176 | axs[i,j].set_title("Digit: %d" % sampled_labels[cnt])
177 | axs[i,j].axis('off')
178 | cnt += 1
179 | fig.savefig("images/%d.png" % epoch)
180 | plt.close()
181 |
182 |
183 | if __name__ == '__main__':
184 | cgan = CGAN()
185 | cgan.train(epochs=20000, batch_size=32, sample_interval=200)
186 |
--------------------------------------------------------------------------------
/aae/aae.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 |
3 | from keras.datasets import mnist
4 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout, multiply, GaussianNoise
5 | from keras.layers import BatchNormalization, Activation, Embedding, ZeroPadding2D
6 | from keras.layers import MaxPooling2D, merge
7 | from keras.layers.advanced_activations import LeakyReLU
8 | from keras.layers.convolutional import UpSampling2D, Conv2D
9 | from keras.models import Sequential, Model
10 | from keras.optimizers import Adam
11 | from keras import losses
12 | from keras.utils import to_categorical
13 | import keras.backend as K
14 |
15 | import matplotlib.pyplot as plt
16 |
17 | import numpy as np
18 |
19 | class AdversarialAutoencoder():
20 | def __init__(self):
21 | self.img_rows = 28
22 | self.img_cols = 28
23 | self.channels = 1
24 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
25 | self.latent_dim = 10
26 |
27 | optimizer = Adam(0.0002, 0.5)
28 |
29 | # Build and compile the discriminator
30 | self.discriminator = self.build_discriminator()
31 | self.discriminator.compile(loss='binary_crossentropy',
32 | optimizer=optimizer,
33 | metrics=['accuracy'])
34 |
35 | # Build the encoder / decoder
36 | self.encoder = self.build_encoder()
37 | self.decoder = self.build_decoder()
38 |
39 | img = Input(shape=self.img_shape)
40 | # The generator takes the image, encodes it and reconstructs it
41 | # from the encoding
42 | encoded_repr = self.encoder(img)
43 | reconstructed_img = self.decoder(encoded_repr)
44 |
45 | # For the adversarial_autoencoder model we will only train the generator
46 | self.discriminator.trainable = False
47 |
48 | # The discriminator determines validity of the encoding
49 | validity = self.discriminator(encoded_repr)
50 |
51 | # The adversarial_autoencoder model (stacked generator and discriminator)
52 | self.adversarial_autoencoder = Model(img, [reconstructed_img, validity])
53 | self.adversarial_autoencoder.compile(loss=['mse', 'binary_crossentropy'],
54 | loss_weights=[0.999, 0.001],
55 | optimizer=optimizer)
56 |
57 |
58 | def build_encoder(self):
59 | # Encoder
60 |
61 | img = Input(shape=self.img_shape)
62 |
63 | h = Flatten()(img)
64 | h = Dense(512)(h)
65 | h = LeakyReLU(alpha=0.2)(h)
66 | h = Dense(512)(h)
67 | h = LeakyReLU(alpha=0.2)(h)
68 | mu = Dense(self.latent_dim)(h)
69 | log_var = Dense(self.latent_dim)(h)
70 | latent_repr = merge([mu, log_var],
71 | mode=lambda p: p[0] + K.random_normal(K.shape(p[0])) * K.exp(p[1] / 2),
72 | output_shape=lambda p: p[0])
73 |
74 | return Model(img, latent_repr)
75 |
76 | def build_decoder(self):
77 |
78 | model = Sequential()
79 |
80 | model.add(Dense(512, input_dim=self.latent_dim))
81 | model.add(LeakyReLU(alpha=0.2))
82 | model.add(Dense(512))
83 | model.add(LeakyReLU(alpha=0.2))
84 | model.add(Dense(np.prod(self.img_shape), activation='tanh'))
85 | model.add(Reshape(self.img_shape))
86 |
87 | model.summary()
88 |
89 | z = Input(shape=(self.latent_dim,))
90 | img = model(z)
91 |
92 | return Model(z, img)
93 |
94 | def build_discriminator(self):
95 |
96 | model = Sequential()
97 |
98 | model.add(Dense(512, input_dim=self.latent_dim))
99 | model.add(LeakyReLU(alpha=0.2))
100 | model.add(Dense(256))
101 | model.add(LeakyReLU(alpha=0.2))
102 | model.add(Dense(1, activation="sigmoid"))
103 | model.summary()
104 |
105 | encoded_repr = Input(shape=(self.latent_dim, ))
106 | validity = model(encoded_repr)
107 |
108 | return Model(encoded_repr, validity)
109 |
110 | def train(self, epochs, batch_size=128, sample_interval=50):
111 |
112 | # Load the dataset
113 | (X_train, _), (_, _) = mnist.load_data()
114 |
115 | # Rescale -1 to 1
116 | X_train = (X_train.astype(np.float32) - 127.5) / 127.5
117 | X_train = np.expand_dims(X_train, axis=3)
118 |
119 | # Adversarial ground truths
120 | valid = np.ones((batch_size, 1))
121 | fake = np.zeros((batch_size, 1))
122 |
123 | for epoch in range(epochs):
124 |
125 | # ---------------------
126 | # Train Discriminator
127 | # ---------------------
128 |
129 | # Select a random batch of images
130 | idx = np.random.randint(0, X_train.shape[0], batch_size)
131 | imgs = X_train[idx]
132 |
133 | latent_fake = self.encoder.predict(imgs)
134 | latent_real = np.random.normal(size=(batch_size, self.latent_dim))
135 |
136 | # Train the discriminator
137 | d_loss_real = self.discriminator.train_on_batch(latent_real, valid)
138 | d_loss_fake = self.discriminator.train_on_batch(latent_fake, fake)
139 | d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
140 |
141 | # ---------------------
142 | # Train Generator
143 | # ---------------------
144 |
145 | # Train the generator
146 | g_loss = self.adversarial_autoencoder.train_on_batch(imgs, [imgs, valid])
147 |
148 | # Plot the progress
149 | print ("%d [D loss: %f, acc: %.2f%%] [G loss: %f, mse: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss[0], g_loss[1]))
150 |
151 | # If at save interval => save generated image samples
152 | if epoch % sample_interval == 0:
153 | self.sample_images(epoch)
154 |
155 | def sample_images(self, epoch):
156 | r, c = 5, 5
157 |
158 | z = np.random.normal(size=(r*c, self.latent_dim))
159 | gen_imgs = self.decoder.predict(z)
160 |
161 | gen_imgs = 0.5 * gen_imgs + 0.5
162 |
163 | fig, axs = plt.subplots(r, c)
164 | cnt = 0
165 | for i in range(r):
166 | for j in range(c):
167 | axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
168 | axs[i,j].axis('off')
169 | cnt += 1
170 | fig.savefig("images/mnist_%d.png" % epoch)
171 | plt.close()
172 |
173 | def save_model(self):
174 |
175 | def save(model, model_name):
176 | model_path = "saved_model/%s.json" % model_name
177 | weights_path = "saved_model/%s_weights.hdf5" % model_name
178 | options = {"file_arch": model_path,
179 | "file_weight": weights_path}
180 | json_string = model.to_json()
181 | open(options['file_arch'], 'w').write(json_string)
182 | model.save_weights(options['file_weight'])
183 |
184 | save(self.generator, "aae_generator")
185 | save(self.discriminator, "aae_discriminator")
186 |
187 |
188 | if __name__ == '__main__':
189 | aae = AdversarialAutoencoder()
190 | aae.train(epochs=20000, batch_size=32, sample_interval=200)
191 |
--------------------------------------------------------------------------------
/cogan/cogan.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 | import scipy
3 |
4 | from keras.datasets import mnist
5 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout
6 | from keras.layers import BatchNormalization, Activation, ZeroPadding2D
7 | from keras.layers.advanced_activations import LeakyReLU
8 | from keras.layers.convolutional import UpSampling2D, Conv2D
9 | from keras.models import Sequential, Model
10 | from keras.optimizers import Adam
11 |
12 | import matplotlib.pyplot as plt
13 |
14 | import sys
15 |
16 | import numpy as np
17 |
18 | class COGAN():
19 | """Reference: https://wiseodd.github.io/techblog/2017/02/18/coupled_gan/"""
20 | def __init__(self):
21 | self.img_rows = 28
22 | self.img_cols = 28
23 | self.channels = 1
24 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
25 | self.latent_dim = 100
26 |
27 | optimizer = Adam(0.0002, 0.5)
28 |
29 | # Build and compile the discriminator
30 | self.d1, self.d2 = self.build_discriminators()
31 | self.d1.compile(loss='binary_crossentropy',
32 | optimizer=optimizer,
33 | metrics=['accuracy'])
34 | self.d2.compile(loss='binary_crossentropy',
35 | optimizer=optimizer,
36 | metrics=['accuracy'])
37 |
38 | # Build the generator
39 | self.g1, self.g2 = self.build_generators()
40 |
41 | # The generator takes noise as input and generated imgs
42 | z = Input(shape=(self.latent_dim,))
43 | img1 = self.g1(z)
44 | img2 = self.g2(z)
45 |
46 | # For the combined model we will only train the generators
47 | self.d1.trainable = False
48 | self.d2.trainable = False
49 |
50 | # The valid takes generated images as input and determines validity
51 | valid1 = self.d1(img1)
52 | valid2 = self.d2(img2)
53 |
54 | # The combined model (stacked generators and discriminators)
55 | # Trains generators to fool discriminators
56 | self.combined = Model(z, [valid1, valid2])
57 | self.combined.compile(loss=['binary_crossentropy', 'binary_crossentropy'],
58 | optimizer=optimizer)
59 |
60 | def build_generators(self):
61 |
62 | # Shared weights between generators
63 | model = Sequential()
64 | model.add(Dense(256, input_dim=self.latent_dim))
65 | model.add(LeakyReLU(alpha=0.2))
66 | model.add(BatchNormalization(momentum=0.8))
67 | model.add(Dense(512))
68 | model.add(LeakyReLU(alpha=0.2))
69 | model.add(BatchNormalization(momentum=0.8))
70 |
71 | noise = Input(shape=(self.latent_dim,))
72 | feature_repr = model(noise)
73 |
74 | # Generator 1
75 | g1 = Dense(1024)(feature_repr)
76 | g1 = LeakyReLU(alpha=0.2)(g1)
77 | g1 = BatchNormalization(momentum=0.8)(g1)
78 | g1 = Dense(np.prod(self.img_shape), activation='tanh')(g1)
79 | img1 = Reshape(self.img_shape)(g1)
80 |
81 | # Generator 2
82 | g2 = Dense(1024)(feature_repr)
83 | g2 = LeakyReLU(alpha=0.2)(g2)
84 | g2 = BatchNormalization(momentum=0.8)(g2)
85 | g2 = Dense(np.prod(self.img_shape), activation='tanh')(g2)
86 | img2 = Reshape(self.img_shape)(g2)
87 |
88 | model.summary()
89 |
90 | return Model(noise, img1), Model(noise, img2)
91 |
92 | def build_discriminators(self):
93 |
94 | img1 = Input(shape=self.img_shape)
95 | img2 = Input(shape=self.img_shape)
96 |
97 | # Shared discriminator layers
98 | model = Sequential()
99 | model.add(Flatten(input_shape=self.img_shape))
100 | model.add(Dense(512))
101 | model.add(LeakyReLU(alpha=0.2))
102 | model.add(Dense(256))
103 | model.add(LeakyReLU(alpha=0.2))
104 |
105 | img1_embedding = model(img1)
106 | img2_embedding = model(img2)
107 |
108 | # Discriminator 1
109 | validity1 = Dense(1, activation='sigmoid')(img1_embedding)
110 | # Discriminator 2
111 | validity2 = Dense(1, activation='sigmoid')(img2_embedding)
112 |
113 | return Model(img1, validity1), Model(img2, validity2)
114 |
115 | def train(self, epochs, batch_size=128, sample_interval=50):
116 |
117 | # Load the dataset
118 | (X_train, _), (_, _) = mnist.load_data()
119 |
120 | # Rescale -1 to 1
121 | X_train = (X_train.astype(np.float32) - 127.5) / 127.5
122 | X_train = np.expand_dims(X_train, axis=3)
123 |
124 | # Images in domain A and B (rotated)
125 | X1 = X_train[:int(X_train.shape[0]/2)]
126 | X2 = X_train[int(X_train.shape[0]/2):]
127 | X2 = scipy.ndimage.interpolation.rotate(X2, 90, axes=(1, 2))
128 |
129 | # Adversarial ground truths
130 | valid = np.ones((batch_size, 1))
131 | fake = np.zeros((batch_size, 1))
132 |
133 | for epoch in range(epochs):
134 |
135 | # ----------------------
136 | # Train Discriminators
137 | # ----------------------
138 |
139 | # Select a random batch of images
140 | idx = np.random.randint(0, X1.shape[0], batch_size)
141 | imgs1 = X1[idx]
142 | imgs2 = X2[idx]
143 |
144 | # Sample noise as generator input
145 | noise = np.random.normal(0, 1, (batch_size, 100))
146 |
147 | # Generate a batch of new images
148 | gen_imgs1 = self.g1.predict(noise)
149 | gen_imgs2 = self.g2.predict(noise)
150 |
151 | # Train the discriminators
152 | d1_loss_real = self.d1.train_on_batch(imgs1, valid)
153 | d2_loss_real = self.d2.train_on_batch(imgs2, valid)
154 | d1_loss_fake = self.d1.train_on_batch(gen_imgs1, fake)
155 | d2_loss_fake = self.d2.train_on_batch(gen_imgs2, fake)
156 | d1_loss = 0.5 * np.add(d1_loss_real, d1_loss_fake)
157 | d2_loss = 0.5 * np.add(d2_loss_real, d2_loss_fake)
158 |
159 |
160 | # ------------------
161 | # Train Generators
162 | # ------------------
163 |
164 | g_loss = self.combined.train_on_batch(noise, [valid, valid])
165 |
166 | # Plot the progress
167 | print ("%d [D1 loss: %f, acc.: %.2f%%] [D2 loss: %f, acc.: %.2f%%] [G loss: %f]" \
168 | % (epoch, d1_loss[0], 100*d1_loss[1], d2_loss[0], 100*d2_loss[1], g_loss[0]))
169 |
170 | # If at save interval => save generated image samples
171 | if epoch % sample_interval == 0:
172 | self.sample_images(epoch)
173 |
174 | def sample_images(self, epoch):
175 | r, c = 4, 4
176 | noise = np.random.normal(0, 1, (r * int(c/2), 100))
177 | gen_imgs1 = self.g1.predict(noise)
178 | gen_imgs2 = self.g2.predict(noise)
179 |
180 | gen_imgs = np.concatenate([gen_imgs1, gen_imgs2])
181 |
182 | # Rescale images 0 - 1
183 | gen_imgs = 0.5 * gen_imgs + 0.5
184 |
185 | fig, axs = plt.subplots(r, c)
186 | cnt = 0
187 | for i in range(r):
188 | for j in range(c):
189 | axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
190 | axs[i,j].axis('off')
191 | cnt += 1
192 | fig.savefig("images/mnist_%d.png" % epoch)
193 | plt.close()
194 |
195 |
196 | if __name__ == '__main__':
197 | gan = COGAN()
198 | gan.train(epochs=30000, batch_size=32, sample_interval=200)
199 |
--------------------------------------------------------------------------------
/sgan/sgan.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 |
3 | from keras.datasets import mnist
4 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout, multiply, GaussianNoise
5 | from keras.layers import BatchNormalization, Activation, Embedding, ZeroPadding2D
6 | from keras.layers.advanced_activations import LeakyReLU
7 | from keras.layers.convolutional import UpSampling2D, Conv2D
8 | from keras.models import Sequential, Model
9 | from keras.optimizers import Adam
10 | from keras import losses
11 | from keras.utils import to_categorical
12 | import keras.backend as K
13 |
14 | import matplotlib.pyplot as plt
15 |
16 | import numpy as np
17 |
18 | class SGAN:
19 | def __init__(self):
20 | self.img_rows = 28
21 | self.img_cols = 28
22 | self.channels = 1
23 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
24 | self.num_classes = 10
25 | self.latent_dim = 100
26 |
27 | optimizer = Adam(0.0002, 0.5)
28 |
29 | # Build and compile the discriminator
30 | self.discriminator = self.build_discriminator()
31 | self.discriminator.compile(
32 | loss=['binary_crossentropy', 'categorical_crossentropy'],
33 | loss_weights=[0.5, 0.5],
34 | optimizer=optimizer,
35 | metrics=['accuracy']
36 | )
37 |
38 | # Build the generator
39 | self.generator = self.build_generator()
40 |
41 | # The generator takes noise as input and generates imgs
42 | noise = Input(shape=(100,))
43 | img = self.generator(noise)
44 |
45 | # For the combined model we will only train the generator
46 | self.discriminator.trainable = False
47 |
48 | # The valid takes generated images as input and determines validity
49 | valid, _ = self.discriminator(img)
50 |
51 | # The combined model (stacked generator and discriminator)
52 | # Trains generator to fool discriminator
53 | self.combined = Model(noise, valid)
54 | self.combined.compile(loss=['binary_crossentropy'], optimizer=optimizer)
55 |
56 | def build_generator(self):
57 |
58 | model = Sequential()
59 |
60 | model.add(Dense(128 * 7 * 7, activation="relu", input_dim=self.latent_dim))
61 | model.add(Reshape((7, 7, 128)))
62 | model.add(BatchNormalization(momentum=0.8))
63 | model.add(UpSampling2D())
64 | model.add(Conv2D(128, kernel_size=3, padding="same"))
65 | model.add(Activation("relu"))
66 | model.add(BatchNormalization(momentum=0.8))
67 | model.add(UpSampling2D())
68 | model.add(Conv2D(64, kernel_size=3, padding="same"))
69 | model.add(Activation("relu"))
70 | model.add(BatchNormalization(momentum=0.8))
71 | model.add(Conv2D(1, kernel_size=3, padding="same"))
72 | model.add(Activation("tanh"))
73 |
74 | model.summary()
75 |
76 | noise = Input(shape=(self.latent_dim,))
77 | img = model(noise)
78 |
79 | return Model(noise, img)
80 |
81 | def build_discriminator(self):
82 |
83 | model = Sequential()
84 |
85 | model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
86 | model.add(LeakyReLU(alpha=0.2))
87 | model.add(Dropout(0.25))
88 | model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
89 | model.add(ZeroPadding2D(padding=((0,1),(0,1))))
90 | model.add(LeakyReLU(alpha=0.2))
91 | model.add(Dropout(0.25))
92 | model.add(BatchNormalization(momentum=0.8))
93 | model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
94 | model.add(LeakyReLU(alpha=0.2))
95 | model.add(Dropout(0.25))
96 | model.add(BatchNormalization(momentum=0.8))
97 | model.add(Conv2D(256, kernel_size=3, strides=1, padding="same"))
98 | model.add(LeakyReLU(alpha=0.2))
99 | model.add(Dropout(0.25))
100 | model.add(Flatten())
101 |
102 | model.summary()
103 |
104 | img = Input(shape=self.img_shape)
105 |
106 | features = model(img)
107 | valid = Dense(1, activation="sigmoid")(features)
108 | label = Dense(self.num_classes+1, activation="softmax")(features)
109 |
110 | return Model(img, [valid, label])
111 |
112 | def train(self, epochs, batch_size=128, sample_interval=50):
113 |
114 | # Load the dataset
115 | (X_train, y_train), (_, _) = mnist.load_data()
116 |
117 | # Rescale -1 to 1
118 | X_train = (X_train.astype(np.float32) - 127.5) / 127.5
119 | X_train = np.expand_dims(X_train, axis=3)
120 | y_train = y_train.reshape(-1, 1)
121 |
122 | # Class weights:
123 | # To balance the difference in occurences of digit class labels.
124 | # 50% of labels that the discriminator trains on are 'fake'.
125 | # Weight = 1 / frequency
126 | half_batch = batch_size // 2
127 | cw1 = {0: 1, 1: 1}
128 | cw2 = {i: self.num_classes / half_batch for i in range(self.num_classes)}
129 | cw2[self.num_classes] = 1 / half_batch
130 |
131 | # Adversarial ground truths
132 | valid = np.ones((batch_size, 1))
133 | fake = np.zeros((batch_size, 1))
134 |
135 | for epoch in range(epochs):
136 |
137 | # ---------------------
138 | # Train Discriminator
139 | # ---------------------
140 |
141 | # Select a random batch of images
142 | idx = np.random.randint(0, X_train.shape[0], batch_size)
143 | imgs = X_train[idx]
144 |
145 | # Sample noise and generate a batch of new images
146 | noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
147 | gen_imgs = self.generator.predict(noise)
148 |
149 | # One-hot encoding of labels
150 | labels = to_categorical(y_train[idx], num_classes=self.num_classes+1)
151 | fake_labels = to_categorical(np.full((batch_size, 1), self.num_classes), num_classes=self.num_classes+1)
152 |
153 | # Train the discriminator
154 | d_loss_real = self.discriminator.train_on_batch(imgs, [valid, labels], class_weight=[cw1, cw2])
155 | d_loss_fake = self.discriminator.train_on_batch(gen_imgs, [fake, fake_labels], class_weight=[cw1, cw2])
156 | d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
157 |
158 |
159 | # ---------------------
160 | # Train Generator
161 | # ---------------------
162 |
163 | g_loss = self.combined.train_on_batch(noise, valid, class_weight=[cw1, cw2])
164 |
165 | # Plot the progress
166 | print ("%d [D loss: %f, acc: %.2f%%, op_acc: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[3], 100*d_loss[4], g_loss))
167 |
168 | # If at save interval => save generated image samples
169 | if epoch % sample_interval == 0:
170 | self.sample_images(epoch)
171 |
172 | def sample_images(self, epoch):
173 | r, c = 5, 5
174 | noise = np.random.normal(0, 1, (r * c, self.latent_dim))
175 | gen_imgs = self.generator.predict(noise)
176 |
177 | # Rescale images 0 - 1
178 | gen_imgs = 0.5 * gen_imgs + 0.5
179 |
180 | fig, axs = plt.subplots(r, c)
181 | cnt = 0
182 | for i in range(r):
183 | for j in range(c):
184 | axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
185 | axs[i,j].axis('off')
186 | cnt += 1
187 | fig.savefig("images/mnist_%d.png" % epoch)
188 | plt.close()
189 |
190 | def save_model(self):
191 |
192 | def save(model, model_name):
193 | model_path = "saved_model/%s.json" % model_name
194 | weights_path = "saved_model/%s_weights.hdf5" % model_name
195 | options = {"file_arch": model_path,
196 | "file_weight": weights_path}
197 | json_string = model.to_json()
198 | open(options['file_arch'], 'w').write(json_string)
199 | model.save_weights(options['file_weight'])
200 |
201 | save(self.generator, "mnist_sgan_generator")
202 | save(self.discriminator, "mnist_sgan_discriminator")
203 | save(self.combined, "mnist_sgan_adversarial")
204 |
205 |
206 | if __name__ == '__main__':
207 | sgan = SGAN()
208 | sgan.train(epochs=20000, batch_size=32, sample_interval=50)
209 |
210 |
--------------------------------------------------------------------------------
/dualgan/dualgan.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 | import scipy
3 |
4 | from keras.datasets import mnist
5 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout, Concatenate
6 | from keras.layers import BatchNormalization, Activation, ZeroPadding2D
7 | from keras.layers.advanced_activations import LeakyReLU
8 | from keras.layers.convolutional import UpSampling2D, Conv2D
9 | from keras.models import Sequential, Model
10 | from keras.optimizers import RMSprop, Adam
11 | from keras.utils import to_categorical
12 | import keras.backend as K
13 |
14 | import matplotlib.pyplot as plt
15 |
16 | import sys
17 |
18 | import numpy as np
19 |
20 | class DUALGAN():
21 | def __init__(self):
22 | self.img_rows = 28
23 | self.img_cols = 28
24 | self.channels = 1
25 | self.img_dim = self.img_rows*self.img_cols
26 |
27 | optimizer = Adam(0.0002, 0.5)
28 |
29 | # Build and compile the discriminators
30 | self.D_A = self.build_discriminator()
31 | self.D_A.compile(loss=self.wasserstein_loss,
32 | optimizer=optimizer,
33 | metrics=['accuracy'])
34 | self.D_B = self.build_discriminator()
35 | self.D_B.compile(loss=self.wasserstein_loss,
36 | optimizer=optimizer,
37 | metrics=['accuracy'])
38 |
39 | #-------------------------
40 | # Construct Computational
41 | # Graph of Generators
42 | #-------------------------
43 |
44 | # Build the generators
45 | self.G_AB = self.build_generator()
46 | self.G_BA = self.build_generator()
47 |
48 | # For the combined model we will only train the generators
49 | self.D_A.trainable = False
50 | self.D_B.trainable = False
51 |
52 | # The generator takes images from their respective domains as inputs
53 | imgs_A = Input(shape=(self.img_dim,))
54 | imgs_B = Input(shape=(self.img_dim,))
55 |
56 | # Generators translates the images to the opposite domain
57 | fake_B = self.G_AB(imgs_A)
58 | fake_A = self.G_BA(imgs_B)
59 |
60 | # The discriminators determines validity of translated images
61 | valid_A = self.D_A(fake_A)
62 | valid_B = self.D_B(fake_B)
63 |
64 | # Generators translate the images back to their original domain
65 | recov_A = self.G_BA(fake_B)
66 | recov_B = self.G_AB(fake_A)
67 |
68 | # The combined model (stacked generators and discriminators)
69 | self.combined = Model(inputs=[imgs_A, imgs_B], outputs=[valid_A, valid_B, recov_A, recov_B])
70 | self.combined.compile(loss=[self.wasserstein_loss, self.wasserstein_loss, 'mae', 'mae'],
71 | optimizer=optimizer,
72 | loss_weights=[1, 1, 100, 100])
73 |
74 | def build_generator(self):
75 |
76 | X = Input(shape=(self.img_dim,))
77 |
78 | model = Sequential()
79 | model.add(Dense(256, input_dim=self.img_dim))
80 | model.add(LeakyReLU(alpha=0.2))
81 | model.add(BatchNormalization(momentum=0.8))
82 | model.add(Dropout(0.4))
83 | model.add(Dense(512))
84 | model.add(LeakyReLU(alpha=0.2))
85 | model.add(BatchNormalization(momentum=0.8))
86 | model.add(Dropout(0.4))
87 | model.add(Dense(1024))
88 | model.add(LeakyReLU(alpha=0.2))
89 | model.add(BatchNormalization(momentum=0.8))
90 | model.add(Dropout(0.4))
91 | model.add(Dense(self.img_dim, activation='tanh'))
92 |
93 | X_translated = model(X)
94 |
95 | return Model(X, X_translated)
96 |
97 | def build_discriminator(self):
98 |
99 | img = Input(shape=(self.img_dim,))
100 |
101 | model = Sequential()
102 | model.add(Dense(512, input_dim=self.img_dim))
103 | model.add(LeakyReLU(alpha=0.2))
104 | model.add(Dense(256))
105 | model.add(LeakyReLU(alpha=0.2))
106 | model.add(BatchNormalization(momentum=0.8))
107 | model.add(Dense(1))
108 |
109 | validity = model(img)
110 |
111 | return Model(img, validity)
112 |
113 | def sample_generator_input(self, X, batch_size):
114 | # Sample random batch of images from X
115 | idx = np.random.randint(0, X.shape[0], batch_size)
116 | return X[idx]
117 |
118 | def wasserstein_loss(self, y_true, y_pred):
119 | return K.mean(y_true * y_pred)
120 |
121 | def train(self, epochs, batch_size=128, sample_interval=50):
122 |
123 | # Load the dataset
124 | (X_train, _), (_, _) = mnist.load_data()
125 |
126 | # Rescale -1 to 1
127 | X_train = (X_train.astype(np.float32) - 127.5) / 127.5
128 |
129 | # Domain A and B (rotated)
130 | X_A = X_train[:int(X_train.shape[0]/2)]
131 | X_B = scipy.ndimage.interpolation.rotate(X_train[int(X_train.shape[0]/2):], 90, axes=(1, 2))
132 |
133 | X_A = X_A.reshape(X_A.shape[0], self.img_dim)
134 | X_B = X_B.reshape(X_B.shape[0], self.img_dim)
135 |
136 | clip_value = 0.01
137 | n_critic = 4
138 |
139 | # Adversarial ground truths
140 | valid = -np.ones((batch_size, 1))
141 | fake = np.ones((batch_size, 1))
142 |
143 | for epoch in range(epochs):
144 |
145 | # Train the discriminator for n_critic iterations
146 | for _ in range(n_critic):
147 |
148 | # ----------------------
149 | # Train Discriminators
150 | # ----------------------
151 |
152 | # Sample generator inputs
153 | imgs_A = self.sample_generator_input(X_A, batch_size)
154 | imgs_B = self.sample_generator_input(X_B, batch_size)
155 |
156 | # Translate images to their opposite domain
157 | fake_B = self.G_AB.predict(imgs_A)
158 | fake_A = self.G_BA.predict(imgs_B)
159 |
160 | # Train the discriminators
161 | D_A_loss_real = self.D_A.train_on_batch(imgs_A, valid)
162 | D_A_loss_fake = self.D_A.train_on_batch(fake_A, fake)
163 |
164 | D_B_loss_real = self.D_B.train_on_batch(imgs_B, valid)
165 | D_B_loss_fake = self.D_B.train_on_batch(fake_B, fake)
166 |
167 | D_A_loss = 0.5 * np.add(D_A_loss_real, D_A_loss_fake)
168 | D_B_loss = 0.5 * np.add(D_B_loss_real, D_B_loss_fake)
169 |
170 | # Clip discriminator weights
171 | for d in [self.D_A, self.D_B]:
172 | for l in d.layers:
173 | weights = l.get_weights()
174 | weights = [np.clip(w, -clip_value, clip_value) for w in weights]
175 | l.set_weights(weights)
176 |
177 | # ------------------
178 | # Train Generators
179 | # ------------------
180 |
181 | # Train the generators
182 | g_loss = self.combined.train_on_batch([imgs_A, imgs_B], [valid, valid, imgs_A, imgs_B])
183 |
184 | # Plot the progress
185 | print ("%d [D1 loss: %f] [D2 loss: %f] [G loss: %f]" \
186 | % (epoch, D_A_loss[0], D_B_loss[0], g_loss[0]))
187 |
188 | # If at save interval => save generated image samples
189 | if epoch % sample_interval == 0:
190 | self.save_imgs(epoch, X_A, X_B)
191 |
192 | def save_imgs(self, epoch, X_A, X_B):
193 | r, c = 4, 4
194 |
195 | # Sample generator inputs
196 | imgs_A = self.sample_generator_input(X_A, c)
197 | imgs_B = self.sample_generator_input(X_B, c)
198 |
199 | # Images translated to their opposite domain
200 | fake_B = self.G_AB.predict(imgs_A)
201 | fake_A = self.G_BA.predict(imgs_B)
202 |
203 | gen_imgs = np.concatenate([imgs_A, fake_B, imgs_B, fake_A])
204 | gen_imgs = gen_imgs.reshape((r, c, self.img_rows, self.img_cols, 1))
205 |
206 | # Rescale images 0 - 1
207 | gen_imgs = 0.5 * gen_imgs + 0.5
208 |
209 | fig, axs = plt.subplots(r, c)
210 | cnt = 0
211 | for i in range(r):
212 | for j in range(c):
213 | axs[i,j].imshow(gen_imgs[i, j, :,:,0], cmap='gray')
214 | axs[i,j].axis('off')
215 | cnt += 1
216 | fig.savefig("images/mnist_%d.png" % epoch)
217 | plt.close()
218 |
219 |
220 | if __name__ == '__main__':
221 | gan = DUALGAN()
222 | gan.train(epochs=30000, batch_size=32, sample_interval=200)
223 |
--------------------------------------------------------------------------------
/acgan/acgan.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 |
3 | from keras.datasets import mnist
4 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout, multiply
5 | from keras.layers import BatchNormalization, Activation, Embedding, ZeroPadding2D
6 | from keras.layers.advanced_activations import LeakyReLU
7 | from keras.layers.convolutional import UpSampling2D, Conv2D
8 | from keras.models import Sequential, Model
9 | from keras.optimizers import Adam
10 |
11 | import matplotlib.pyplot as plt
12 |
13 | import numpy as np
14 |
15 | class ACGAN():
16 | def __init__(self):
17 | # Input shape
18 | self.img_rows = 28
19 | self.img_cols = 28
20 | self.channels = 1
21 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
22 | self.num_classes = 10
23 | self.latent_dim = 100
24 |
25 | optimizer = Adam(0.0002, 0.5)
26 | losses = ['binary_crossentropy', 'sparse_categorical_crossentropy']
27 |
28 | # Build and compile the discriminator
29 | self.discriminator = self.build_discriminator()
30 | self.discriminator.compile(loss=losses,
31 | optimizer=optimizer,
32 | metrics=['accuracy'])
33 |
34 | # Build the generator
35 | self.generator = self.build_generator()
36 |
37 | # The generator takes noise and the target label as input
38 | # and generates the corresponding digit of that label
39 | noise = Input(shape=(self.latent_dim,))
40 | label = Input(shape=(1,))
41 | img = self.generator([noise, label])
42 |
43 | # For the combined model we will only train the generator
44 | self.discriminator.trainable = False
45 |
46 | # The discriminator takes generated image as input and determines validity
47 | # and the label of that image
48 | valid, target_label = self.discriminator(img)
49 |
50 | # The combined model (stacked generator and discriminator)
51 | # Trains the generator to fool the discriminator
52 | self.combined = Model([noise, label], [valid, target_label])
53 | self.combined.compile(loss=losses,
54 | optimizer=optimizer)
55 |
56 | def build_generator(self):
57 |
58 | model = Sequential()
59 |
60 | model.add(Dense(128 * 7 * 7, activation="relu", input_dim=self.latent_dim))
61 | model.add(Reshape((7, 7, 128)))
62 | model.add(BatchNormalization(momentum=0.8))
63 | model.add(UpSampling2D())
64 | model.add(Conv2D(128, kernel_size=3, padding="same"))
65 | model.add(Activation("relu"))
66 | model.add(BatchNormalization(momentum=0.8))
67 | model.add(UpSampling2D())
68 | model.add(Conv2D(64, kernel_size=3, padding="same"))
69 | model.add(Activation("relu"))
70 | model.add(BatchNormalization(momentum=0.8))
71 | model.add(Conv2D(self.channels, kernel_size=3, padding='same'))
72 | model.add(Activation("tanh"))
73 |
74 | model.summary()
75 |
76 | noise = Input(shape=(self.latent_dim,))
77 | label = Input(shape=(1,), dtype='int32')
78 | label_embedding = Flatten()(Embedding(self.num_classes, self.latent_dim)(label))
79 |
80 | model_input = multiply([noise, label_embedding])
81 | img = model(model_input)
82 |
83 | return Model([noise, label], img)
84 |
85 | def build_discriminator(self):
86 |
87 | model = Sequential()
88 |
89 | model.add(Conv2D(16, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
90 | model.add(LeakyReLU(alpha=0.2))
91 | model.add(Dropout(0.25))
92 | model.add(Conv2D(32, kernel_size=3, strides=2, padding="same"))
93 | model.add(ZeroPadding2D(padding=((0,1),(0,1))))
94 | model.add(LeakyReLU(alpha=0.2))
95 | model.add(Dropout(0.25))
96 | model.add(BatchNormalization(momentum=0.8))
97 | model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
98 | model.add(LeakyReLU(alpha=0.2))
99 | model.add(Dropout(0.25))
100 | model.add(BatchNormalization(momentum=0.8))
101 | model.add(Conv2D(128, kernel_size=3, strides=1, padding="same"))
102 | model.add(LeakyReLU(alpha=0.2))
103 | model.add(Dropout(0.25))
104 |
105 | model.add(Flatten())
106 | model.summary()
107 |
108 | img = Input(shape=self.img_shape)
109 |
110 | # Extract feature representation
111 | features = model(img)
112 |
113 | # Determine validity and label of the image
114 | validity = Dense(1, activation="sigmoid")(features)
115 | label = Dense(self.num_classes, activation="softmax")(features)
116 |
117 | return Model(img, [validity, label])
118 |
119 | def train(self, epochs, batch_size=128, sample_interval=50):
120 |
121 | # Load the dataset
122 | (X_train, y_train), (_, _) = mnist.load_data()
123 |
124 | # Configure inputs
125 | X_train = (X_train.astype(np.float32) - 127.5) / 127.5
126 | X_train = np.expand_dims(X_train, axis=3)
127 | y_train = y_train.reshape(-1, 1)
128 |
129 | # Adversarial ground truths
130 | valid = np.ones((batch_size, 1))
131 | fake = np.zeros((batch_size, 1))
132 |
133 | for epoch in range(epochs):
134 |
135 | # ---------------------
136 | # Train Discriminator
137 | # ---------------------
138 |
139 | # Select a random batch of images
140 | idx = np.random.randint(0, X_train.shape[0], batch_size)
141 | imgs = X_train[idx]
142 |
143 | # Sample noise as generator input
144 | noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
145 |
146 | # The labels of the digits that the generator tries to create an
147 | # image representation of
148 | sampled_labels = np.random.randint(0, 10, (batch_size, 1))
149 |
150 | # Generate a half batch of new images
151 | gen_imgs = self.generator.predict([noise, sampled_labels])
152 |
153 | # Image labels. 0-9
154 | img_labels = y_train[idx]
155 |
156 | # Train the discriminator
157 | d_loss_real = self.discriminator.train_on_batch(imgs, [valid, img_labels])
158 | d_loss_fake = self.discriminator.train_on_batch(gen_imgs, [fake, sampled_labels])
159 | d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
160 |
161 | # ---------------------
162 | # Train Generator
163 | # ---------------------
164 |
165 | # Train the generator
166 | g_loss = self.combined.train_on_batch([noise, sampled_labels], [valid, sampled_labels])
167 |
168 | # Plot the progress
169 | print ("%d [D loss: %f, acc.: %.2f%%, op_acc: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[3], 100*d_loss[4], g_loss[0]))
170 |
171 | # If at save interval => save generated image samples
172 | if epoch % sample_interval == 0:
173 | self.save_model()
174 | self.sample_images(epoch)
175 |
176 | def sample_images(self, epoch):
177 | r, c = 10, 10
178 | noise = np.random.normal(0, 1, (r * c, self.latent_dim))
179 | sampled_labels = np.array([num for _ in range(r) for num in range(c)])
180 | gen_imgs = self.generator.predict([noise, sampled_labels])
181 | # Rescale images 0 - 1
182 | gen_imgs = 0.5 * gen_imgs + 0.5
183 |
184 | fig, axs = plt.subplots(r, c)
185 | cnt = 0
186 | for i in range(r):
187 | for j in range(c):
188 | axs[i,j].imshow(gen_imgs[cnt,:,:,0], cmap='gray')
189 | axs[i,j].axis('off')
190 | cnt += 1
191 | fig.savefig("images/%d.png" % epoch)
192 | plt.close()
193 |
194 | def save_model(self):
195 |
196 | def save(model, model_name):
197 | model_path = "saved_model/%s.json" % model_name
198 | weights_path = "saved_model/%s_weights.hdf5" % model_name
199 | options = {"file_arch": model_path,
200 | "file_weight": weights_path}
201 | json_string = model.to_json()
202 | open(options['file_arch'], 'w').write(json_string)
203 | model.save_weights(options['file_weight'])
204 |
205 | save(self.generator, "generator")
206 | save(self.discriminator, "discriminator")
207 |
208 |
209 | if __name__ == '__main__':
210 | acgan = ACGAN()
211 | acgan.train(epochs=14000, batch_size=32, sample_interval=200)
212 |
--------------------------------------------------------------------------------
/pix2pix/pix2pix.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 | import scipy
3 |
4 | from keras.datasets import mnist
5 | from keras_contrib.layers.normalization.instancenormalization import InstanceNormalization
6 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout, Concatenate
7 | from keras.layers import BatchNormalization, Activation, ZeroPadding2D
8 | from keras.layers.advanced_activations import LeakyReLU
9 | from keras.layers.convolutional import UpSampling2D, Conv2D
10 | from keras.models import Sequential, Model
11 | from keras.optimizers import Adam
12 | import datetime
13 | import matplotlib.pyplot as plt
14 | import sys
15 | from data_loader import DataLoader
16 | import numpy as np
17 | import os
18 |
19 | class Pix2Pix():
20 | def __init__(self):
21 | # Input shape
22 | self.img_rows = 256
23 | self.img_cols = 256
24 | self.channels = 3
25 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
26 |
27 | # Configure data loader
28 | self.dataset_name = 'facades'
29 | self.data_loader = DataLoader(dataset_name=self.dataset_name,
30 | img_res=(self.img_rows, self.img_cols))
31 |
32 |
33 | # Calculate output shape of D (PatchGAN)
34 | patch = int(self.img_rows / 2**4)
35 | self.disc_patch = (patch, patch, 1)
36 |
37 | # Number of filters in the first layer of G and D
38 | self.gf = 64
39 | self.df = 64
40 |
41 | optimizer = Adam(0.0002, 0.5)
42 |
43 | # Build and compile the discriminator
44 | self.discriminator = self.build_discriminator()
45 | self.discriminator.compile(loss='mse',
46 | optimizer=optimizer,
47 | metrics=['accuracy'])
48 |
49 | #-------------------------
50 | # Construct Computational
51 | # Graph of Generator
52 | #-------------------------
53 |
54 | # Build the generator
55 | self.generator = self.build_generator()
56 |
57 | # Input images and their conditioning images
58 | img_A = Input(shape=self.img_shape)
59 | img_B = Input(shape=self.img_shape)
60 |
61 | # By conditioning on B generate a fake version of A
62 | fake_A = self.generator(img_B)
63 |
64 | # For the combined model we will only train the generator
65 | self.discriminator.trainable = False
66 |
67 | # Discriminators determines validity of translated images / condition pairs
68 | valid = self.discriminator([fake_A, img_B])
69 |
70 | self.combined = Model(inputs=[img_A, img_B], outputs=[valid, fake_A])
71 | self.combined.compile(loss=['mse', 'mae'],
72 | loss_weights=[1, 100],
73 | optimizer=optimizer)
74 |
75 | def build_generator(self):
76 | """U-Net Generator"""
77 |
78 | def conv2d(layer_input, filters, f_size=4, bn=True):
79 | """Layers used during downsampling"""
80 | d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
81 | d = LeakyReLU(alpha=0.2)(d)
82 | if bn:
83 | d = BatchNormalization(momentum=0.8)(d)
84 | return d
85 |
86 | def deconv2d(layer_input, skip_input, filters, f_size=4, dropout_rate=0):
87 | """Layers used during upsampling"""
88 | u = UpSampling2D(size=2)(layer_input)
89 | u = Conv2D(filters, kernel_size=f_size, strides=1, padding='same', activation='relu')(u)
90 | if dropout_rate:
91 | u = Dropout(dropout_rate)(u)
92 | u = BatchNormalization(momentum=0.8)(u)
93 | u = Concatenate()([u, skip_input])
94 | return u
95 |
96 | # Image input
97 | d0 = Input(shape=self.img_shape)
98 |
99 | # Downsampling
100 | d1 = conv2d(d0, self.gf, bn=False)
101 | d2 = conv2d(d1, self.gf*2)
102 | d3 = conv2d(d2, self.gf*4)
103 | d4 = conv2d(d3, self.gf*8)
104 | d5 = conv2d(d4, self.gf*8)
105 | d6 = conv2d(d5, self.gf*8)
106 | d7 = conv2d(d6, self.gf*8)
107 |
108 | # Upsampling
109 | u1 = deconv2d(d7, d6, self.gf*8)
110 | u2 = deconv2d(u1, d5, self.gf*8)
111 | u3 = deconv2d(u2, d4, self.gf*8)
112 | u4 = deconv2d(u3, d3, self.gf*4)
113 | u5 = deconv2d(u4, d2, self.gf*2)
114 | u6 = deconv2d(u5, d1, self.gf)
115 |
116 | u7 = UpSampling2D(size=2)(u6)
117 | output_img = Conv2D(self.channels, kernel_size=4, strides=1, padding='same', activation='tanh')(u7)
118 |
119 | return Model(d0, output_img)
120 |
121 | def build_discriminator(self):
122 |
123 | def d_layer(layer_input, filters, f_size=4, bn=True):
124 | """Discriminator layer"""
125 | d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
126 | d = LeakyReLU(alpha=0.2)(d)
127 | if bn:
128 | d = BatchNormalization(momentum=0.8)(d)
129 | return d
130 |
131 | img_A = Input(shape=self.img_shape)
132 | img_B = Input(shape=self.img_shape)
133 |
134 | # Concatenate image and conditioning image by channels to produce input
135 | combined_imgs = Concatenate(axis=-1)([img_A, img_B])
136 |
137 | d1 = d_layer(combined_imgs, self.df, bn=False)
138 | d2 = d_layer(d1, self.df*2)
139 | d3 = d_layer(d2, self.df*4)
140 | d4 = d_layer(d3, self.df*8)
141 |
142 | validity = Conv2D(1, kernel_size=4, strides=1, padding='same')(d4)
143 |
144 | return Model([img_A, img_B], validity)
145 |
146 | def train(self, epochs, batch_size=1, sample_interval=50):
147 |
148 | start_time = datetime.datetime.now()
149 |
150 | # Adversarial loss ground truths
151 | valid = np.ones((batch_size,) + self.disc_patch)
152 | fake = np.zeros((batch_size,) + self.disc_patch)
153 |
154 | for epoch in range(epochs):
155 | for batch_i, (imgs_A, imgs_B) in enumerate(self.data_loader.load_batch(batch_size)):
156 |
157 | # ---------------------
158 | # Train Discriminator
159 | # ---------------------
160 |
161 | # Condition on B and generate a translated version
162 | fake_A = self.generator.predict(imgs_B)
163 |
164 | # Train the discriminators (original images = real / generated = Fake)
165 | d_loss_real = self.discriminator.train_on_batch([imgs_A, imgs_B], valid)
166 | d_loss_fake = self.discriminator.train_on_batch([fake_A, imgs_B], fake)
167 | d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
168 |
169 | # -----------------
170 | # Train Generator
171 | # -----------------
172 |
173 | # Train the generators
174 | g_loss = self.combined.train_on_batch([imgs_A, imgs_B], [valid, imgs_A])
175 |
176 | elapsed_time = datetime.datetime.now() - start_time
177 | # Plot the progress
178 | print ("[Epoch %d/%d] [Batch %d/%d] [D loss: %f, acc: %3d%%] [G loss: %f] time: %s" % (epoch, epochs,
179 | batch_i, self.data_loader.n_batches,
180 | d_loss[0], 100*d_loss[1],
181 | g_loss[0],
182 | elapsed_time))
183 |
184 | # If at save interval => save generated image samples
185 | if batch_i % sample_interval == 0:
186 | self.sample_images(epoch, batch_i)
187 |
188 | def sample_images(self, epoch, batch_i):
189 | os.makedirs('images/%s' % self.dataset_name, exist_ok=True)
190 | r, c = 3, 3
191 |
192 | imgs_A, imgs_B = self.data_loader.load_data(batch_size=3, is_testing=True)
193 | fake_A = self.generator.predict(imgs_B)
194 |
195 | gen_imgs = np.concatenate([imgs_B, fake_A, imgs_A])
196 |
197 | # Rescale images 0 - 1
198 | gen_imgs = 0.5 * gen_imgs + 0.5
199 |
200 | titles = ['Condition', 'Generated', 'Original']
201 | fig, axs = plt.subplots(r, c)
202 | cnt = 0
203 | for i in range(r):
204 | for j in range(c):
205 | axs[i,j].imshow(gen_imgs[cnt])
206 | axs[i, j].set_title(titles[i])
207 | axs[i,j].axis('off')
208 | cnt += 1
209 | fig.savefig("images/%s/%d_%d.png" % (self.dataset_name, epoch, batch_i))
210 | plt.close()
211 |
212 |
213 | if __name__ == '__main__':
214 | gan = Pix2Pix()
215 | gan.train(epochs=200, batch_size=1, sample_interval=200)
216 |
--------------------------------------------------------------------------------
/pixelda/pixelda.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 | import scipy
3 |
4 | from keras.datasets import mnist
5 | from keras_contrib.layers.normalization.instancenormalization import InstanceNormalization
6 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout, Concatenate
7 | from keras.layers import BatchNormalization, Activation, ZeroPadding2D, Add
8 | from keras.layers.advanced_activations import LeakyReLU
9 | from keras.layers.convolutional import UpSampling2D, Conv2D
10 | from keras.models import Sequential, Model
11 | from keras.optimizers import Adam
12 | from keras.utils import to_categorical
13 | import datetime
14 | import matplotlib.pyplot as plt
15 | import sys
16 | from data_loader import DataLoader
17 | import numpy as np
18 | import os
19 |
20 | class PixelDA():
21 | def __init__(self):
22 | # Input shape
23 | self.img_rows = 32
24 | self.img_cols = 32
25 | self.channels = 3
26 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
27 | self.num_classes = 10
28 |
29 | # Configure MNIST and MNIST-M data loader
30 | self.data_loader = DataLoader(img_res=(self.img_rows, self.img_cols))
31 |
32 | # Loss weights
33 | lambda_adv = 10
34 | lambda_clf = 1
35 |
36 | # Calculate output shape of D (PatchGAN)
37 | patch = int(self.img_rows / 2**4)
38 | self.disc_patch = (patch, patch, 1)
39 |
40 | # Number of residual blocks in the generator
41 | self.residual_blocks = 6
42 |
43 | optimizer = Adam(0.0002, 0.5)
44 |
45 | # Number of filters in first layer of discriminator and classifier
46 | self.df = 64
47 | self.cf = 64
48 |
49 | # Build and compile the discriminators
50 | self.discriminator = self.build_discriminator()
51 | self.discriminator.compile(loss='mse',
52 | optimizer=optimizer,
53 | metrics=['accuracy'])
54 |
55 | # Build the generator
56 | self.generator = self.build_generator()
57 |
58 | # Build the task (classification) network
59 | self.clf = self.build_classifier()
60 |
61 | # Input images from both domains
62 | img_A = Input(shape=self.img_shape)
63 | img_B = Input(shape=self.img_shape)
64 |
65 | # Translate images from domain A to domain B
66 | fake_B = self.generator(img_A)
67 |
68 | # Classify the translated image
69 | class_pred = self.clf(fake_B)
70 |
71 | # For the combined model we will only train the generator and classifier
72 | self.discriminator.trainable = False
73 |
74 | # Discriminator determines validity of translated images
75 | valid = self.discriminator(fake_B)
76 |
77 | self.combined = Model(img_A, [valid, class_pred])
78 | self.combined.compile(loss=['mse', 'categorical_crossentropy'],
79 | loss_weights=[lambda_adv, lambda_clf],
80 | optimizer=optimizer,
81 | metrics=['accuracy'])
82 |
83 | def build_generator(self):
84 | """Resnet Generator"""
85 |
86 | def residual_block(layer_input):
87 | """Residual block described in paper"""
88 | d = Conv2D(64, kernel_size=3, strides=1, padding='same')(layer_input)
89 | d = BatchNormalization(momentum=0.8)(d)
90 | d = Activation('relu')(d)
91 | d = Conv2D(64, kernel_size=3, strides=1, padding='same')(d)
92 | d = BatchNormalization(momentum=0.8)(d)
93 | d = Add()([d, layer_input])
94 | return d
95 |
96 | # Image input
97 | img = Input(shape=self.img_shape)
98 |
99 | l1 = Conv2D(64, kernel_size=3, padding='same', activation='relu')(img)
100 |
101 | # Propogate signal through residual blocks
102 | r = residual_block(l1)
103 | for _ in range(self.residual_blocks - 1):
104 | r = residual_block(r)
105 |
106 | output_img = Conv2D(self.channels, kernel_size=3, padding='same', activation='tanh')(r)
107 |
108 | return Model(img, output_img)
109 |
110 |
111 | def build_discriminator(self):
112 |
113 | def d_layer(layer_input, filters, f_size=4, normalization=True):
114 | """Discriminator layer"""
115 | d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
116 | d = LeakyReLU(alpha=0.2)(d)
117 | if normalization:
118 | d = InstanceNormalization()(d)
119 | return d
120 |
121 | img = Input(shape=self.img_shape)
122 |
123 | d1 = d_layer(img, self.df, normalization=False)
124 | d2 = d_layer(d1, self.df*2)
125 | d3 = d_layer(d2, self.df*4)
126 | d4 = d_layer(d3, self.df*8)
127 |
128 | validity = Conv2D(1, kernel_size=4, strides=1, padding='same')(d4)
129 |
130 | return Model(img, validity)
131 |
132 | def build_classifier(self):
133 |
134 | def clf_layer(layer_input, filters, f_size=4, normalization=True):
135 | """Classifier layer"""
136 | d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
137 | d = LeakyReLU(alpha=0.2)(d)
138 | if normalization:
139 | d = InstanceNormalization()(d)
140 | return d
141 |
142 | img = Input(shape=self.img_shape)
143 |
144 | c1 = clf_layer(img, self.cf, normalization=False)
145 | c2 = clf_layer(c1, self.cf*2)
146 | c3 = clf_layer(c2, self.cf*4)
147 | c4 = clf_layer(c3, self.cf*8)
148 | c5 = clf_layer(c4, self.cf*8)
149 |
150 | class_pred = Dense(self.num_classes, activation='softmax')(Flatten()(c5))
151 |
152 | return Model(img, class_pred)
153 |
154 | def train(self, epochs, batch_size=128, sample_interval=50):
155 |
156 | half_batch = int(batch_size / 2)
157 |
158 | # Classification accuracy on 100 last batches of domain B
159 | test_accs = []
160 |
161 | # Adversarial ground truths
162 | valid = np.ones((batch_size, *self.disc_patch))
163 | fake = np.zeros((batch_size, *self.disc_patch))
164 |
165 | for epoch in range(epochs):
166 |
167 | # ---------------------
168 | # Train Discriminator
169 | # ---------------------
170 |
171 | imgs_A, labels_A = self.data_loader.load_data(domain="A", batch_size=batch_size)
172 | imgs_B, labels_B = self.data_loader.load_data(domain="B", batch_size=batch_size)
173 |
174 | # Translate images from domain A to domain B
175 | fake_B = self.generator.predict(imgs_A)
176 |
177 | # Train the discriminators (original images = real / translated = Fake)
178 | d_loss_real = self.discriminator.train_on_batch(imgs_B, valid)
179 | d_loss_fake = self.discriminator.train_on_batch(fake_B, fake)
180 | d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
181 |
182 |
183 | # --------------------------------
184 | # Train Generator and Classifier
185 | # --------------------------------
186 |
187 | # One-hot encoding of labels
188 | labels_A = to_categorical(labels_A, num_classes=self.num_classes)
189 |
190 | # Train the generator and classifier
191 | g_loss = self.combined.train_on_batch(imgs_A, [valid, labels_A])
192 |
193 | #-----------------------
194 | # Evaluation (domain B)
195 | #-----------------------
196 |
197 | pred_B = self.clf.predict(imgs_B)
198 | test_acc = np.mean(np.argmax(pred_B, axis=1) == labels_B)
199 |
200 | # Add accuracy to list of last 100 accuracy measurements
201 | test_accs.append(test_acc)
202 | if len(test_accs) > 100:
203 | test_accs.pop(0)
204 |
205 |
206 | # Plot the progress
207 | print ( "%d : [D - loss: %.5f, acc: %3d%%], [G - loss: %.5f], [clf - loss: %.5f, acc: %3d%%, test_acc: %3d%% (%3d%%)]" % \
208 | (epoch, d_loss[0], 100*float(d_loss[1]),
209 | g_loss[1], g_loss[2], 100*float(g_loss[-1]),
210 | 100*float(test_acc), 100*float(np.mean(test_accs))))
211 |
212 |
213 | # If at save interval => save generated image samples
214 | if epoch % sample_interval == 0:
215 | self.sample_images(epoch)
216 |
217 | def sample_images(self, epoch):
218 | r, c = 2, 5
219 |
220 | imgs_A, _ = self.data_loader.load_data(domain="A", batch_size=5)
221 |
222 | # Translate images to the other domain
223 | fake_B = self.generator.predict(imgs_A)
224 |
225 | gen_imgs = np.concatenate([imgs_A, fake_B])
226 |
227 | # Rescale images 0 - 1
228 | gen_imgs = 0.5 * gen_imgs + 0.5
229 |
230 | #titles = ['Original', 'Translated']
231 | fig, axs = plt.subplots(r, c)
232 | cnt = 0
233 | for i in range(r):
234 | for j in range(c):
235 | axs[i,j].imshow(gen_imgs[cnt])
236 | #axs[i, j].set_title(titles[i])
237 | axs[i,j].axis('off')
238 | cnt += 1
239 | fig.savefig("images/%d.png" % (epoch))
240 | plt.close()
241 |
242 |
243 | if __name__ == '__main__':
244 | gan = PixelDA()
245 | gan.train(epochs=30000, batch_size=32, sample_interval=500)
246 |
--------------------------------------------------------------------------------
/infogan/infogan.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 |
3 | from keras.datasets import mnist
4 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout, multiply, concatenate
5 | from keras.layers import BatchNormalization, Activation, Embedding, ZeroPadding2D, Lambda
6 | from keras.layers.advanced_activations import LeakyReLU
7 | from keras.layers.convolutional import UpSampling2D, Conv2D
8 | from keras.models import Sequential, Model
9 | from keras.optimizers import Adam
10 | from keras.utils import to_categorical
11 | import keras.backend as K
12 |
13 | import matplotlib.pyplot as plt
14 |
15 | import numpy as np
16 |
17 | class INFOGAN():
18 | def __init__(self):
19 | self.img_rows = 28
20 | self.img_cols = 28
21 | self.channels = 1
22 | self.num_classes = 10
23 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
24 | self.latent_dim = 72
25 |
26 |
27 | optimizer = Adam(0.0002, 0.5)
28 | losses = ['binary_crossentropy', self.mutual_info_loss]
29 |
30 | # Build and the discriminator and recognition network
31 | self.discriminator, self.auxilliary = self.build_disk_and_q_net()
32 |
33 | self.discriminator.compile(loss=['binary_crossentropy'],
34 | optimizer=optimizer,
35 | metrics=['accuracy'])
36 |
37 | # Build and compile the recognition network Q
38 | self.auxilliary.compile(loss=[self.mutual_info_loss],
39 | optimizer=optimizer,
40 | metrics=['accuracy'])
41 |
42 | # Build the generator
43 | self.generator = self.build_generator()
44 |
45 | # The generator takes noise and the target label as input
46 | # and generates the corresponding digit of that label
47 | gen_input = Input(shape=(self.latent_dim,))
48 | img = self.generator(gen_input)
49 |
50 | # For the combined model we will only train the generator
51 | self.discriminator.trainable = False
52 |
53 | # The discriminator takes generated image as input and determines validity
54 | valid = self.discriminator(img)
55 | # The recognition network produces the label
56 | target_label = self.auxilliary(img)
57 |
58 | # The combined model (stacked generator and discriminator)
59 | self.combined = Model(gen_input, [valid, target_label])
60 | self.combined.compile(loss=losses,
61 | optimizer=optimizer)
62 |
63 |
64 | def build_generator(self):
65 |
66 | model = Sequential()
67 |
68 | model.add(Dense(128 * 7 * 7, activation="relu", input_dim=self.latent_dim))
69 | model.add(Reshape((7, 7, 128)))
70 | model.add(BatchNormalization(momentum=0.8))
71 | model.add(UpSampling2D())
72 | model.add(Conv2D(128, kernel_size=3, padding="same"))
73 | model.add(Activation("relu"))
74 | model.add(BatchNormalization(momentum=0.8))
75 | model.add(UpSampling2D())
76 | model.add(Conv2D(64, kernel_size=3, padding="same"))
77 | model.add(Activation("relu"))
78 | model.add(BatchNormalization(momentum=0.8))
79 | model.add(Conv2D(self.channels, kernel_size=3, padding='same'))
80 | model.add(Activation("tanh"))
81 |
82 | gen_input = Input(shape=(self.latent_dim,))
83 | img = model(gen_input)
84 |
85 | model.summary()
86 |
87 | return Model(gen_input, img)
88 |
89 |
90 | def build_disk_and_q_net(self):
91 |
92 | img = Input(shape=self.img_shape)
93 |
94 | # Shared layers between discriminator and recognition network
95 | model = Sequential()
96 | model.add(Conv2D(64, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
97 | model.add(LeakyReLU(alpha=0.2))
98 | model.add(Dropout(0.25))
99 | model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
100 | model.add(ZeroPadding2D(padding=((0,1),(0,1))))
101 | model.add(LeakyReLU(alpha=0.2))
102 | model.add(Dropout(0.25))
103 | model.add(BatchNormalization(momentum=0.8))
104 | model.add(Conv2D(256, kernel_size=3, strides=2, padding="same"))
105 | model.add(LeakyReLU(alpha=0.2))
106 | model.add(Dropout(0.25))
107 | model.add(BatchNormalization(momentum=0.8))
108 | model.add(Conv2D(512, kernel_size=3, strides=2, padding="same"))
109 | model.add(LeakyReLU(alpha=0.2))
110 | model.add(Dropout(0.25))
111 | model.add(BatchNormalization(momentum=0.8))
112 | model.add(Flatten())
113 |
114 | img_embedding = model(img)
115 |
116 | # Discriminator
117 | validity = Dense(1, activation='sigmoid')(img_embedding)
118 |
119 | # Recognition
120 | q_net = Dense(128, activation='relu')(img_embedding)
121 | label = Dense(self.num_classes, activation='softmax')(q_net)
122 |
123 | # Return discriminator and recognition network
124 | return Model(img, validity), Model(img, label)
125 |
126 |
127 | def mutual_info_loss(self, c, c_given_x):
128 | """The mutual information metric we aim to minimize"""
129 | eps = 1e-8
130 | conditional_entropy = K.mean(- K.sum(K.log(c_given_x + eps) * c, axis=1))
131 | entropy = K.mean(- K.sum(K.log(c + eps) * c, axis=1))
132 |
133 | return conditional_entropy + entropy
134 |
135 | def sample_generator_input(self, batch_size):
136 | # Generator inputs
137 | sampled_noise = np.random.normal(0, 1, (batch_size, 62))
138 | sampled_labels = np.random.randint(0, self.num_classes, batch_size).reshape(-1, 1)
139 | sampled_labels = to_categorical(sampled_labels, num_classes=self.num_classes)
140 |
141 | return sampled_noise, sampled_labels
142 |
143 | def train(self, epochs, batch_size=128, sample_interval=50):
144 |
145 | # Load the dataset
146 | (X_train, y_train), (_, _) = mnist.load_data()
147 |
148 | # Rescale -1 to 1
149 | X_train = (X_train.astype(np.float32) - 127.5) / 127.5
150 | X_train = np.expand_dims(X_train, axis=3)
151 | y_train = y_train.reshape(-1, 1)
152 |
153 | # Adversarial ground truths
154 | valid = np.ones((batch_size, 1))
155 | fake = np.zeros((batch_size, 1))
156 |
157 | for epoch in range(epochs):
158 |
159 | # ---------------------
160 | # Train Discriminator
161 | # ---------------------
162 |
163 | # Select a random half batch of images
164 | idx = np.random.randint(0, X_train.shape[0], batch_size)
165 | imgs = X_train[idx]
166 |
167 | # Sample noise and categorical labels
168 | sampled_noise, sampled_labels = self.sample_generator_input(batch_size)
169 | gen_input = np.concatenate((sampled_noise, sampled_labels), axis=1)
170 |
171 | # Generate a half batch of new images
172 | gen_imgs = self.generator.predict(gen_input)
173 |
174 | # Train on real and generated data
175 | d_loss_real = self.discriminator.train_on_batch(imgs, valid)
176 | d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
177 |
178 | # Avg. loss
179 | d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
180 |
181 | # ---------------------
182 | # Train Generator and Q-network
183 | # ---------------------
184 |
185 | g_loss = self.combined.train_on_batch(gen_input, [valid, sampled_labels])
186 |
187 | # Plot the progress
188 | print ("%d [D loss: %.2f, acc.: %.2f%%] [Q loss: %.2f] [G loss: %.2f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss[1], g_loss[2]))
189 |
190 | # If at save interval => save generated image samples
191 | if epoch % sample_interval == 0:
192 | self.sample_images(epoch)
193 |
194 | def sample_images(self, epoch):
195 | r, c = 10, 10
196 |
197 | fig, axs = plt.subplots(r, c)
198 | for i in range(c):
199 | sampled_noise, _ = self.sample_generator_input(c)
200 | label = to_categorical(np.full(fill_value=i, shape=(r,1)), num_classes=self.num_classes)
201 | gen_input = np.concatenate((sampled_noise, label), axis=1)
202 | gen_imgs = self.generator.predict(gen_input)
203 | gen_imgs = 0.5 * gen_imgs + 0.5
204 | for j in range(r):
205 | axs[j,i].imshow(gen_imgs[j,:,:,0], cmap='gray')
206 | axs[j,i].axis('off')
207 | fig.savefig("images/%d.png" % epoch)
208 | plt.close()
209 |
210 | def save_model(self):
211 |
212 | def save(model, model_name):
213 | model_path = "saved_model/%s.json" % model_name
214 | weights_path = "saved_model/%s_weights.hdf5" % model_name
215 | options = {"file_arch": model_path,
216 | "file_weight": weights_path}
217 | json_string = model.to_json()
218 | open(options['file_arch'], 'w').write(json_string)
219 | model.save_weights(options['file_weight'])
220 |
221 | save(self.generator, "generator")
222 | save(self.discriminator, "discriminator")
223 |
224 |
225 | if __name__ == '__main__':
226 | infogan = INFOGAN()
227 | infogan.train(epochs=50000, batch_size=128, sample_interval=50)
228 |
--------------------------------------------------------------------------------
/context_encoder/context_encoder.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 |
3 | from keras.datasets import cifar10
4 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout, multiply, GaussianNoise
5 | from keras.layers import BatchNormalization, Activation, Embedding, ZeroPadding2D
6 | from keras.layers import MaxPooling2D
7 | from keras.layers.advanced_activations import LeakyReLU
8 | from keras.layers.convolutional import UpSampling2D, Conv2D
9 | from keras.models import Sequential, Model
10 | from keras.optimizers import Adam
11 | from keras import losses
12 | from keras.utils import to_categorical
13 | import keras.backend as K
14 |
15 | import matplotlib.pyplot as plt
16 |
17 | import numpy as np
18 |
19 | class ContextEncoder():
20 | def __init__(self):
21 | self.img_rows = 32
22 | self.img_cols = 32
23 | self.mask_height = 8
24 | self.mask_width = 8
25 | self.channels = 3
26 | self.num_classes = 2
27 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
28 | self.missing_shape = (self.mask_height, self.mask_width, self.channels)
29 |
30 | optimizer = Adam(0.0002, 0.5)
31 |
32 | # Build and compile the discriminator
33 | self.discriminator = self.build_discriminator()
34 | self.discriminator.compile(loss='binary_crossentropy',
35 | optimizer=optimizer,
36 | metrics=['accuracy'])
37 |
38 | # Build the generator
39 | self.generator = self.build_generator()
40 |
41 | # The generator takes noise as input and generates the missing
42 | # part of the image
43 | masked_img = Input(shape=self.img_shape)
44 | gen_missing = self.generator(masked_img)
45 |
46 | # For the combined model we will only train the generator
47 | self.discriminator.trainable = False
48 |
49 | # The discriminator takes generated images as input and determines
50 | # if it is generated or if it is a real image
51 | valid = self.discriminator(gen_missing)
52 |
53 | # The combined model (stacked generator and discriminator)
54 | # Trains generator to fool discriminator
55 | self.combined = Model(masked_img , [gen_missing, valid])
56 | self.combined.compile(loss=['mse', 'binary_crossentropy'],
57 | loss_weights=[0.999, 0.001],
58 | optimizer=optimizer)
59 |
60 | def build_generator(self):
61 |
62 |
63 | model = Sequential()
64 |
65 | # Encoder
66 | model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
67 | model.add(LeakyReLU(alpha=0.2))
68 | model.add(BatchNormalization(momentum=0.8))
69 | model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
70 | model.add(LeakyReLU(alpha=0.2))
71 | model.add(BatchNormalization(momentum=0.8))
72 | model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
73 | model.add(LeakyReLU(alpha=0.2))
74 | model.add(BatchNormalization(momentum=0.8))
75 |
76 | model.add(Conv2D(512, kernel_size=1, strides=2, padding="same"))
77 | model.add(LeakyReLU(alpha=0.2))
78 | model.add(Dropout(0.5))
79 |
80 | # Decoder
81 | model.add(UpSampling2D())
82 | model.add(Conv2D(128, kernel_size=3, padding="same"))
83 | model.add(Activation('relu'))
84 | model.add(BatchNormalization(momentum=0.8))
85 | model.add(UpSampling2D())
86 | model.add(Conv2D(64, kernel_size=3, padding="same"))
87 | model.add(Activation('relu'))
88 | model.add(BatchNormalization(momentum=0.8))
89 | model.add(Conv2D(self.channels, kernel_size=3, padding="same"))
90 | model.add(Activation('tanh'))
91 |
92 | model.summary()
93 |
94 | masked_img = Input(shape=self.img_shape)
95 | gen_missing = model(masked_img)
96 |
97 | return Model(masked_img, gen_missing)
98 |
99 | def build_discriminator(self):
100 |
101 | model = Sequential()
102 |
103 | model.add(Conv2D(64, kernel_size=3, strides=2, input_shape=self.missing_shape, padding="same"))
104 | model.add(LeakyReLU(alpha=0.2))
105 | model.add(BatchNormalization(momentum=0.8))
106 | model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
107 | model.add(LeakyReLU(alpha=0.2))
108 | model.add(BatchNormalization(momentum=0.8))
109 | model.add(Conv2D(256, kernel_size=3, padding="same"))
110 | model.add(LeakyReLU(alpha=0.2))
111 | model.add(BatchNormalization(momentum=0.8))
112 | model.add(Flatten())
113 | model.add(Dense(1, activation='sigmoid'))
114 | model.summary()
115 |
116 | img = Input(shape=self.missing_shape)
117 | validity = model(img)
118 |
119 | return Model(img, validity)
120 |
121 | def mask_randomly(self, imgs):
122 | y1 = np.random.randint(0, self.img_rows - self.mask_height, imgs.shape[0])
123 | y2 = y1 + self.mask_height
124 | x1 = np.random.randint(0, self.img_rows - self.mask_width, imgs.shape[0])
125 | x2 = x1 + self.mask_width
126 |
127 | masked_imgs = np.empty_like(imgs)
128 | missing_parts = np.empty((imgs.shape[0], self.mask_height, self.mask_width, self.channels))
129 | for i, img in enumerate(imgs):
130 | masked_img = img.copy()
131 | _y1, _y2, _x1, _x2 = y1[i], y2[i], x1[i], x2[i]
132 | missing_parts[i] = masked_img[_y1:_y2, _x1:_x2, :].copy()
133 | masked_img[_y1:_y2, _x1:_x2, :] = 0
134 | masked_imgs[i] = masked_img
135 |
136 | return masked_imgs, missing_parts, (y1, y2, x1, x2)
137 |
138 |
139 |
140 | def train(self, epochs, batch_size=128, sample_interval=50):
141 |
142 | # Load the dataset
143 | (X_train, y_train), (_, _) = cifar10.load_data()
144 |
145 | # Extract dogs and cats
146 | X_cats = X_train[(y_train == 3).flatten()]
147 | X_dogs = X_train[(y_train == 5).flatten()]
148 | X_train = np.vstack((X_cats, X_dogs))
149 |
150 | # Rescale -1 to 1
151 | X_train = X_train / 127.5 - 1.
152 | y_train = y_train.reshape(-1, 1)
153 |
154 | # Adversarial ground truths
155 | valid = np.ones((batch_size, 1))
156 | fake = np.zeros((batch_size, 1))
157 |
158 | for epoch in range(epochs):
159 |
160 | # ---------------------
161 | # Train Discriminator
162 | # ---------------------
163 |
164 | # Select a random batch of images
165 | idx = np.random.randint(0, X_train.shape[0], batch_size)
166 | imgs = X_train[idx]
167 |
168 | masked_imgs, missing_parts, _ = self.mask_randomly(imgs)
169 |
170 | # Generate a batch of new images
171 | gen_missing = self.generator.predict(masked_imgs)
172 |
173 | # Train the discriminator
174 | d_loss_real = self.discriminator.train_on_batch(missing_parts, valid)
175 | d_loss_fake = self.discriminator.train_on_batch(gen_missing, fake)
176 | d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
177 |
178 | # ---------------------
179 | # Train Generator
180 | # ---------------------
181 |
182 | g_loss = self.combined.train_on_batch(masked_imgs, [missing_parts, valid])
183 |
184 | # Plot the progress
185 | print ("%d [D loss: %f, acc: %.2f%%] [G loss: %f, mse: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss[0], g_loss[1]))
186 |
187 | # If at save interval => save generated image samples
188 | if epoch % sample_interval == 0:
189 | idx = np.random.randint(0, X_train.shape[0], 6)
190 | imgs = X_train[idx]
191 | self.sample_images(epoch, imgs)
192 |
193 | def sample_images(self, epoch, imgs):
194 | r, c = 3, 6
195 |
196 | masked_imgs, missing_parts, (y1, y2, x1, x2) = self.mask_randomly(imgs)
197 | gen_missing = self.generator.predict(masked_imgs)
198 |
199 | imgs = 0.5 * imgs + 0.5
200 | masked_imgs = 0.5 * masked_imgs + 0.5
201 | gen_missing = 0.5 * gen_missing + 0.5
202 |
203 | fig, axs = plt.subplots(r, c)
204 | for i in range(c):
205 | axs[0,i].imshow(imgs[i, :,:])
206 | axs[0,i].axis('off')
207 | axs[1,i].imshow(masked_imgs[i, :,:])
208 | axs[1,i].axis('off')
209 | filled_in = imgs[i].copy()
210 | filled_in[y1[i]:y2[i], x1[i]:x2[i], :] = gen_missing[i]
211 | axs[2,i].imshow(filled_in)
212 | axs[2,i].axis('off')
213 | fig.savefig("images/%d.png" % epoch)
214 | plt.close()
215 |
216 | def save_model(self):
217 |
218 | def save(model, model_name):
219 | model_path = "saved_model/%s.json" % model_name
220 | weights_path = "saved_model/%s_weights.hdf5" % model_name
221 | options = {"file_arch": model_path,
222 | "file_weight": weights_path}
223 | json_string = model.to_json()
224 | open(options['file_arch'], 'w').write(json_string)
225 | model.save_weights(options['file_weight'])
226 |
227 | save(self.generator, "generator")
228 | save(self.discriminator, "discriminator")
229 |
230 |
231 | if __name__ == '__main__':
232 | context_encoder = ContextEncoder()
233 | context_encoder.train(epochs=30000, batch_size=64, sample_interval=50)
234 |
--------------------------------------------------------------------------------
/wgan_gp/wgan_gp.py:
--------------------------------------------------------------------------------
1 |
2 | # Large amount of credit goes to:
3 | # https://github.com/keras-team/keras-contrib/blob/master/examples/improved_wgan.py
4 | # which I've used as a reference for this implementation
5 |
6 | from __future__ import print_function, division
7 |
8 | from keras.datasets import mnist
9 | from keras.layers.merge import _Merge
10 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout
11 | from keras.layers import BatchNormalization, Activation, ZeroPadding2D
12 | from keras.layers.advanced_activations import LeakyReLU
13 | from keras.layers.convolutional import UpSampling2D, Conv2D
14 | from keras.models import Sequential, Model
15 | from keras.optimizers import RMSprop
16 | from functools import partial
17 |
18 | import keras.backend as K
19 |
20 | import matplotlib.pyplot as plt
21 |
22 | import sys
23 |
24 | import numpy as np
25 |
26 | class RandomWeightedAverage(_Merge):
27 | """Provides a (random) weighted average between real and generated image samples"""
28 | def _merge_function(self, inputs):
29 | alpha = K.random_uniform((32, 1, 1, 1))
30 | return (alpha * inputs[0]) + ((1 - alpha) * inputs[1])
31 |
32 | class WGANGP():
33 | def __init__(self):
34 | self.img_rows = 28
35 | self.img_cols = 28
36 | self.channels = 1
37 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
38 | self.latent_dim = 100
39 |
40 | # Following parameter and optimizer set as recommended in paper
41 | self.n_critic = 5
42 | optimizer = RMSprop(lr=0.00005)
43 |
44 | # Build the generator and critic
45 | self.generator = self.build_generator()
46 | self.critic = self.build_critic()
47 |
48 | #-------------------------------
49 | # Construct Computational Graph
50 | # for the Critic
51 | #-------------------------------
52 |
53 | # Freeze generator's layers while training critic
54 | self.generator.trainable = False
55 |
56 | # Image input (real sample)
57 | real_img = Input(shape=self.img_shape)
58 |
59 | # Noise input
60 | z_disc = Input(shape=(self.latent_dim,))
61 | # Generate image based of noise (fake sample)
62 | fake_img = self.generator(z_disc)
63 |
64 | # Discriminator determines validity of the real and fake images
65 | fake = self.critic(fake_img)
66 | valid = self.critic(real_img)
67 |
68 | # Construct weighted average between real and fake images
69 | interpolated_img = RandomWeightedAverage()([real_img, fake_img])
70 | # Determine validity of weighted sample
71 | validity_interpolated = self.critic(interpolated_img)
72 |
73 | # Use Python partial to provide loss function with additional
74 | # 'averaged_samples' argument
75 | partial_gp_loss = partial(self.gradient_penalty_loss,
76 | averaged_samples=interpolated_img)
77 | partial_gp_loss.__name__ = 'gradient_penalty' # Keras requires function names
78 |
79 | self.critic_model = Model(inputs=[real_img, z_disc],
80 | outputs=[valid, fake, validity_interpolated])
81 | self.critic_model.compile(loss=[self.wasserstein_loss,
82 | self.wasserstein_loss,
83 | partial_gp_loss],
84 | optimizer=optimizer,
85 | loss_weights=[1, 1, 10])
86 | #-------------------------------
87 | # Construct Computational Graph
88 | # for Generator
89 | #-------------------------------
90 |
91 | # For the generator we freeze the critic's layers
92 | self.critic.trainable = False
93 | self.generator.trainable = True
94 |
95 | # Sampled noise for input to generator
96 | z_gen = Input(shape=(self.latent_dim,))
97 | # Generate images based of noise
98 | img = self.generator(z_gen)
99 | # Discriminator determines validity
100 | valid = self.critic(img)
101 | # Defines generator model
102 | self.generator_model = Model(z_gen, valid)
103 | self.generator_model.compile(loss=self.wasserstein_loss, optimizer=optimizer)
104 |
105 |
106 | def gradient_penalty_loss(self, y_true, y_pred, averaged_samples):
107 | """
108 | Computes gradient penalty based on prediction and weighted real / fake samples
109 | """
110 | gradients = K.gradients(y_pred, averaged_samples)[0]
111 | # compute the euclidean norm by squaring ...
112 | gradients_sqr = K.square(gradients)
113 | # ... summing over the rows ...
114 | gradients_sqr_sum = K.sum(gradients_sqr,
115 | axis=np.arange(1, len(gradients_sqr.shape)))
116 | # ... and sqrt
117 | gradient_l2_norm = K.sqrt(gradients_sqr_sum)
118 | # compute lambda * (1 - ||grad||)^2 still for each single sample
119 | gradient_penalty = K.square(1 - gradient_l2_norm)
120 | # return the mean as loss over all the batch samples
121 | return K.mean(gradient_penalty)
122 |
123 |
124 | def wasserstein_loss(self, y_true, y_pred):
125 | return K.mean(y_true * y_pred)
126 |
127 | def build_generator(self):
128 |
129 | model = Sequential()
130 |
131 | model.add(Dense(128 * 7 * 7, activation="relu", input_dim=self.latent_dim))
132 | model.add(Reshape((7, 7, 128)))
133 | model.add(UpSampling2D())
134 | model.add(Conv2D(128, kernel_size=4, padding="same"))
135 | model.add(BatchNormalization(momentum=0.8))
136 | model.add(Activation("relu"))
137 | model.add(UpSampling2D())
138 | model.add(Conv2D(64, kernel_size=4, padding="same"))
139 | model.add(BatchNormalization(momentum=0.8))
140 | model.add(Activation("relu"))
141 | model.add(Conv2D(self.channels, kernel_size=4, padding="same"))
142 | model.add(Activation("tanh"))
143 |
144 | model.summary()
145 |
146 | noise = Input(shape=(self.latent_dim,))
147 | img = model(noise)
148 |
149 | return Model(noise, img)
150 |
151 | def build_critic(self):
152 |
153 | model = Sequential()
154 |
155 | model.add(Conv2D(16, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
156 | model.add(LeakyReLU(alpha=0.2))
157 | model.add(Dropout(0.25))
158 | model.add(Conv2D(32, kernel_size=3, strides=2, padding="same"))
159 | model.add(ZeroPadding2D(padding=((0,1),(0,1))))
160 | model.add(BatchNormalization(momentum=0.8))
161 | model.add(LeakyReLU(alpha=0.2))
162 | model.add(Dropout(0.25))
163 | model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
164 | model.add(BatchNormalization(momentum=0.8))
165 | model.add(LeakyReLU(alpha=0.2))
166 | model.add(Dropout(0.25))
167 | model.add(Conv2D(128, kernel_size=3, strides=1, padding="same"))
168 | model.add(BatchNormalization(momentum=0.8))
169 | model.add(LeakyReLU(alpha=0.2))
170 | model.add(Dropout(0.25))
171 | model.add(Flatten())
172 | model.add(Dense(1))
173 |
174 | model.summary()
175 |
176 | img = Input(shape=self.img_shape)
177 | validity = model(img)
178 |
179 | return Model(img, validity)
180 |
181 | def train(self, epochs, batch_size, sample_interval=50):
182 |
183 | # Load the dataset
184 | (X_train, _), (_, _) = mnist.load_data()
185 |
186 | # Rescale -1 to 1
187 | X_train = (X_train.astype(np.float32) - 127.5) / 127.5
188 | X_train = np.expand_dims(X_train, axis=3)
189 |
190 | # Adversarial ground truths
191 | valid = -np.ones((batch_size, 1))
192 | fake = np.ones((batch_size, 1))
193 | dummy = np.zeros((batch_size, 1)) # Dummy gt for gradient penalty
194 | for epoch in range(epochs):
195 |
196 | for _ in range(self.n_critic):
197 |
198 | # ---------------------
199 | # Train Discriminator
200 | # ---------------------
201 |
202 | # Select a random batch of images
203 | idx = np.random.randint(0, X_train.shape[0], batch_size)
204 | imgs = X_train[idx]
205 | # Sample generator input
206 | noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
207 | # Train the critic
208 | d_loss = self.critic_model.train_on_batch([imgs, noise],
209 | [valid, fake, dummy])
210 |
211 | # ---------------------
212 | # Train Generator
213 | # ---------------------
214 |
215 | g_loss = self.generator_model.train_on_batch(noise, valid)
216 |
217 | # Plot the progress
218 | print ("%d [D loss: %f] [G loss: %f]" % (epoch, d_loss[0], g_loss))
219 |
220 | # If at save interval => save generated image samples
221 | if epoch % sample_interval == 0:
222 | self.sample_images(epoch)
223 |
224 | def sample_images(self, epoch):
225 | r, c = 5, 5
226 | noise = np.random.normal(0, 1, (r * c, self.latent_dim))
227 | gen_imgs = self.generator.predict(noise)
228 |
229 | # Rescale images 0 - 1
230 | gen_imgs = 0.5 * gen_imgs + 0.5
231 |
232 | fig, axs = plt.subplots(r, c)
233 | cnt = 0
234 | for i in range(r):
235 | for j in range(c):
236 | axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
237 | axs[i,j].axis('off')
238 | cnt += 1
239 | fig.savefig("images/mnist_%d.png" % epoch)
240 | plt.close()
241 |
242 |
243 | if __name__ == '__main__':
244 | wgan = WGANGP()
245 | wgan.train(epochs=30000, batch_size=32, sample_interval=100)
246 |
--------------------------------------------------------------------------------
/ccgan/ccgan.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 |
3 | from keras.datasets import mnist
4 | from keras_contrib.layers.normalization.instancenormalization import InstanceNormalization
5 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout, multiply, GaussianNoise
6 | from keras.layers import BatchNormalization, Activation, Embedding, ZeroPadding2D
7 | from keras.layers import Concatenate
8 | from keras.layers.advanced_activations import LeakyReLU
9 | from keras.layers.convolutional import UpSampling2D, Conv2D
10 | from keras.models import Sequential, Model
11 | from keras.optimizers import Adam
12 | from keras import losses
13 | from keras.utils import to_categorical
14 | import keras.backend as K
15 | import scipy
16 |
17 | import matplotlib.pyplot as plt
18 |
19 | import numpy as np
20 |
21 | class CCGAN():
22 | def __init__(self):
23 | self.img_rows = 32
24 | self.img_cols = 32
25 | self.channels = 1
26 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
27 | self.mask_height = 10
28 | self.mask_width = 10
29 | self.num_classes = 10
30 |
31 | # Number of filters in first layer of generator and discriminator
32 | self.gf = 32
33 | self.df = 32
34 |
35 | optimizer = Adam(0.0002, 0.5)
36 |
37 | # Build and compile the discriminator
38 | self.discriminator = self.build_discriminator()
39 | self.discriminator.compile(loss=['mse', 'categorical_crossentropy'],
40 | loss_weights=[0.5, 0.5],
41 | optimizer=optimizer,
42 | metrics=['accuracy'])
43 |
44 | # Build the generator
45 | self.generator = self.build_generator()
46 |
47 | # The generator takes noise as input and generates imgs
48 | masked_img = Input(shape=self.img_shape)
49 | gen_img = self.generator(masked_img)
50 |
51 | # For the combined model we will only train the generator
52 | self.discriminator.trainable = False
53 |
54 | # The valid takes generated images as input and determines validity
55 | valid, _ = self.discriminator(gen_img)
56 |
57 | # The combined model (stacked generator and discriminator)
58 | # Trains the generator to fool the discriminator
59 | self.combined = Model(masked_img , valid)
60 | self.combined.compile(loss=['mse'],
61 | optimizer=optimizer)
62 |
63 |
64 | def build_generator(self):
65 | """U-Net Generator"""
66 |
67 | def conv2d(layer_input, filters, f_size=4, bn=True):
68 | """Layers used during downsampling"""
69 | d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
70 | d = LeakyReLU(alpha=0.2)(d)
71 | if bn:
72 | d = BatchNormalization(momentum=0.8)(d)
73 | return d
74 |
75 | def deconv2d(layer_input, skip_input, filters, f_size=4, dropout_rate=0):
76 | """Layers used during upsampling"""
77 | u = UpSampling2D(size=2)(layer_input)
78 | u = Conv2D(filters, kernel_size=f_size, strides=1, padding='same', activation='relu')(u)
79 | if dropout_rate:
80 | u = Dropout(dropout_rate)(u)
81 | u = BatchNormalization(momentum=0.8)(u)
82 | u = Concatenate()([u, skip_input])
83 | return u
84 |
85 | img = Input(shape=self.img_shape)
86 |
87 | # Downsampling
88 | d1 = conv2d(img, self.gf, bn=False)
89 | d2 = conv2d(d1, self.gf*2)
90 | d3 = conv2d(d2, self.gf*4)
91 | d4 = conv2d(d3, self.gf*8)
92 |
93 | # Upsampling
94 | u1 = deconv2d(d4, d3, self.gf*4)
95 | u2 = deconv2d(u1, d2, self.gf*2)
96 | u3 = deconv2d(u2, d1, self.gf)
97 |
98 | u4 = UpSampling2D(size=2)(u3)
99 | output_img = Conv2D(self.channels, kernel_size=4, strides=1, padding='same', activation='tanh')(u4)
100 |
101 | return Model(img, output_img)
102 |
103 | def build_discriminator(self):
104 |
105 | img = Input(shape=self.img_shape)
106 |
107 | model = Sequential()
108 | model.add(Conv2D(64, kernel_size=4, strides=2, padding='same', input_shape=self.img_shape))
109 | model.add(LeakyReLU(alpha=0.8))
110 | model.add(Conv2D(128, kernel_size=4, strides=2, padding='same'))
111 | model.add(LeakyReLU(alpha=0.2))
112 | model.add(InstanceNormalization())
113 | model.add(Conv2D(256, kernel_size=4, strides=2, padding='same'))
114 | model.add(LeakyReLU(alpha=0.2))
115 | model.add(InstanceNormalization())
116 |
117 | model.summary()
118 |
119 | img = Input(shape=self.img_shape)
120 | features = model(img)
121 |
122 | validity = Conv2D(1, kernel_size=4, strides=1, padding='same')(features)
123 |
124 | label = Flatten()(features)
125 | label = Dense(self.num_classes+1, activation="softmax")(label)
126 |
127 | return Model(img, [validity, label])
128 |
129 | def mask_randomly(self, imgs):
130 | y1 = np.random.randint(0, self.img_rows - self.mask_height, imgs.shape[0])
131 | y2 = y1 + self.mask_height
132 | x1 = np.random.randint(0, self.img_rows - self.mask_width, imgs.shape[0])
133 | x2 = x1 + self.mask_width
134 |
135 | masked_imgs = np.empty_like(imgs)
136 | for i, img in enumerate(imgs):
137 | masked_img = img.copy()
138 | _y1, _y2, _x1, _x2 = y1[i], y2[i], x1[i], x2[i],
139 | masked_img[_y1:_y2, _x1:_x2, :] = 0
140 | masked_imgs[i] = masked_img
141 |
142 | return masked_imgs
143 |
144 |
145 | def train(self, epochs, batch_size=128, sample_interval=50):
146 |
147 | # Load the dataset
148 | (X_train, y_train), (_, _) = mnist.load_data()
149 |
150 | # Rescale MNIST to 32x32
151 | X_train = np.array([scipy.misc.imresize(x, [self.img_rows, self.img_cols]) for x in X_train])
152 |
153 | # Rescale -1 to 1
154 | X_train = (X_train.astype(np.float32) - 127.5) / 127.5
155 | X_train = np.expand_dims(X_train, axis=3)
156 | y_train = y_train.reshape(-1, 1)
157 |
158 | # Adversarial ground truths
159 | valid = np.ones((batch_size, 4, 4, 1))
160 | fake = np.zeros((batch_size, 4, 4, 1))
161 |
162 | for epoch in range(epochs):
163 |
164 | # ---------------------
165 | # Train Discriminator
166 | # ---------------------
167 |
168 | # Sample half batch of images
169 | idx = np.random.randint(0, X_train.shape[0], batch_size)
170 | imgs = X_train[idx]
171 | labels = y_train[idx]
172 |
173 | masked_imgs = self.mask_randomly(imgs)
174 |
175 | # Generate a half batch of new images
176 | gen_imgs = self.generator.predict(masked_imgs)
177 |
178 | # One-hot encoding of labels
179 | labels = to_categorical(labels, num_classes=self.num_classes+1)
180 | fake_labels = to_categorical(np.full((batch_size, 1), self.num_classes), num_classes=self.num_classes+1)
181 |
182 | # Train the discriminator
183 | d_loss_real = self.discriminator.train_on_batch(imgs, [valid, labels])
184 | d_loss_fake = self.discriminator.train_on_batch(gen_imgs, [fake, fake_labels])
185 | d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
186 |
187 | # ---------------------
188 | # Train Generator
189 | # ---------------------
190 |
191 | # Train the generator
192 | g_loss = self.combined.train_on_batch(masked_imgs, valid)
193 |
194 | # Plot the progress
195 | print ("%d [D loss: %f, op_acc: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[4], g_loss))
196 |
197 | # If at save interval => save generated image samples
198 | if epoch % sample_interval == 0:
199 | # Select a random half batch of images
200 | idx = np.random.randint(0, X_train.shape[0], 6)
201 | imgs = X_train[idx]
202 | self.sample_images(epoch, imgs)
203 | self.save_model()
204 |
205 | def sample_images(self, epoch, imgs):
206 | r, c = 3, 6
207 |
208 | masked_imgs = self.mask_randomly(imgs)
209 | gen_imgs = self.generator.predict(masked_imgs)
210 |
211 | imgs = (imgs + 1.0) * 0.5
212 | masked_imgs = (masked_imgs + 1.0) * 0.5
213 | gen_imgs = (gen_imgs + 1.0) * 0.5
214 |
215 | gen_imgs = np.where(gen_imgs < 0, 0, gen_imgs)
216 |
217 | fig, axs = plt.subplots(r, c)
218 | for i in range(c):
219 | axs[0,i].imshow(imgs[i, :, :, 0], cmap='gray')
220 | axs[0,i].axis('off')
221 | axs[1,i].imshow(masked_imgs[i, :, :, 0], cmap='gray')
222 | axs[1,i].axis('off')
223 | axs[2,i].imshow(gen_imgs[i, :, :, 0], cmap='gray')
224 | axs[2,i].axis('off')
225 | fig.savefig("images/%d.png" % epoch)
226 | plt.close()
227 |
228 | def save_model(self):
229 |
230 | def save(model, model_name):
231 | model_path = "saved_model/%s.json" % model_name
232 | weights_path = "saved_model/%s_weights.hdf5" % model_name
233 | options = {"file_arch": model_path,
234 | "file_weight": weights_path}
235 | json_string = model.to_json()
236 | open(options['file_arch'], 'w').write(json_string)
237 | model.save_weights(options['file_weight'])
238 |
239 | save(self.generator, "ccgan_generator")
240 | save(self.discriminator, "ccgan_discriminator")
241 |
242 |
243 | if __name__ == '__main__':
244 | ccgan = CCGAN()
245 | ccgan.train(epochs=20000, batch_size=32, sample_interval=200)
246 |
--------------------------------------------------------------------------------
/discogan/discogan.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 | import scipy
3 |
4 | from keras.datasets import mnist
5 | from keras_contrib.layers.normalization.instancenormalization import InstanceNormalization
6 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout, Concatenate
7 | from keras.layers import BatchNormalization, Activation, ZeroPadding2D
8 | from keras.layers.advanced_activations import LeakyReLU
9 | from keras.layers.convolutional import UpSampling2D, Conv2D
10 | from keras.models import Sequential, Model
11 | from keras.optimizers import Adam
12 | import datetime
13 | import matplotlib.pyplot as plt
14 | import sys
15 | from data_loader import DataLoader
16 | import numpy as np
17 | import os
18 |
19 | class DiscoGAN():
20 | def __init__(self):
21 | # Input shape
22 | self.img_rows = 128
23 | self.img_cols = 128
24 | self.channels = 3
25 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
26 |
27 | # Configure data loader
28 | self.dataset_name = 'edges2shoes'
29 | self.data_loader = DataLoader(dataset_name=self.dataset_name,
30 | img_res=(self.img_rows, self.img_cols))
31 |
32 |
33 | # Calculate output shape of D (PatchGAN)
34 | patch = int(self.img_rows / 2**4)
35 | self.disc_patch = (patch, patch, 1)
36 |
37 | # Number of filters in the first layer of G and D
38 | self.gf = 64
39 | self.df = 64
40 |
41 | optimizer = Adam(0.0002, 0.5)
42 |
43 | # Build and compile the discriminators
44 | self.d_A = self.build_discriminator()
45 | self.d_B = self.build_discriminator()
46 | self.d_A.compile(loss='mse',
47 | optimizer=optimizer,
48 | metrics=['accuracy'])
49 | self.d_B.compile(loss='mse',
50 | optimizer=optimizer,
51 | metrics=['accuracy'])
52 |
53 | #-------------------------
54 | # Construct Computational
55 | # Graph of Generators
56 | #-------------------------
57 |
58 | # Build the generators
59 | self.g_AB = self.build_generator()
60 | self.g_BA = self.build_generator()
61 |
62 | # Input images from both domains
63 | img_A = Input(shape=self.img_shape)
64 | img_B = Input(shape=self.img_shape)
65 |
66 | # Translate images to the other domain
67 | fake_B = self.g_AB(img_A)
68 | fake_A = self.g_BA(img_B)
69 | # Translate images back to original domain
70 | reconstr_A = self.g_BA(fake_B)
71 | reconstr_B = self.g_AB(fake_A)
72 |
73 | # For the combined model we will only train the generators
74 | self.d_A.trainable = False
75 | self.d_B.trainable = False
76 |
77 | # Discriminators determines validity of translated images
78 | valid_A = self.d_A(fake_A)
79 | valid_B = self.d_B(fake_B)
80 |
81 | # Objectives
82 | # + Adversarial: Fool domain discriminators
83 | # + Translation: Minimize MAE between e.g. fake B and true B
84 | # + Cycle-consistency: Minimize MAE between reconstructed images and original
85 | self.combined = Model(inputs=[img_A, img_B],
86 | outputs=[ valid_A, valid_B,
87 | fake_B, fake_A,
88 | reconstr_A, reconstr_B ])
89 | self.combined.compile(loss=['mse', 'mse',
90 | 'mae', 'mae',
91 | 'mae', 'mae'],
92 | optimizer=optimizer)
93 |
94 | def build_generator(self):
95 | """U-Net Generator"""
96 |
97 | def conv2d(layer_input, filters, f_size=4, normalize=True):
98 | """Layers used during downsampling"""
99 | d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
100 | d = LeakyReLU(alpha=0.2)(d)
101 | if normalize:
102 | d = InstanceNormalization()(d)
103 | return d
104 |
105 | def deconv2d(layer_input, skip_input, filters, f_size=4, dropout_rate=0):
106 | """Layers used during upsampling"""
107 | u = UpSampling2D(size=2)(layer_input)
108 | u = Conv2D(filters, kernel_size=f_size, strides=1, padding='same', activation='relu')(u)
109 | if dropout_rate:
110 | u = Dropout(dropout_rate)(u)
111 | u = InstanceNormalization()(u)
112 | u = Concatenate()([u, skip_input])
113 | return u
114 |
115 | # Image input
116 | d0 = Input(shape=self.img_shape)
117 |
118 | # Downsampling
119 | d1 = conv2d(d0, self.gf, normalize=False)
120 | d2 = conv2d(d1, self.gf*2)
121 | d3 = conv2d(d2, self.gf*4)
122 | d4 = conv2d(d3, self.gf*8)
123 | d5 = conv2d(d4, self.gf*8)
124 | d6 = conv2d(d5, self.gf*8)
125 | d7 = conv2d(d6, self.gf*8)
126 |
127 | # Upsampling
128 | u1 = deconv2d(d7, d6, self.gf*8)
129 | u2 = deconv2d(u1, d5, self.gf*8)
130 | u3 = deconv2d(u2, d4, self.gf*8)
131 | u4 = deconv2d(u3, d3, self.gf*4)
132 | u5 = deconv2d(u4, d2, self.gf*2)
133 | u6 = deconv2d(u5, d1, self.gf)
134 |
135 | u7 = UpSampling2D(size=2)(u6)
136 | output_img = Conv2D(self.channels, kernel_size=4, strides=1,
137 | padding='same', activation='tanh')(u7)
138 |
139 | return Model(d0, output_img)
140 |
141 | def build_discriminator(self):
142 |
143 | def d_layer(layer_input, filters, f_size=4, normalization=True):
144 | """Discriminator layer"""
145 | d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
146 | d = LeakyReLU(alpha=0.2)(d)
147 | if normalization:
148 | d = InstanceNormalization()(d)
149 | return d
150 |
151 | img = Input(shape=self.img_shape)
152 |
153 | d1 = d_layer(img, self.df, normalization=False)
154 | d2 = d_layer(d1, self.df*2)
155 | d3 = d_layer(d2, self.df*4)
156 | d4 = d_layer(d3, self.df*8)
157 |
158 | validity = Conv2D(1, kernel_size=4, strides=1, padding='same')(d4)
159 |
160 | return Model(img, validity)
161 |
162 | def train(self, epochs, batch_size=128, sample_interval=50):
163 |
164 | start_time = datetime.datetime.now()
165 |
166 | # Adversarial loss ground truths
167 | valid = np.ones((batch_size,) + self.disc_patch)
168 | fake = np.zeros((batch_size,) + self.disc_patch)
169 |
170 | for epoch in range(epochs):
171 |
172 | for batch_i, (imgs_A, imgs_B) in enumerate(self.data_loader.load_batch(batch_size)):
173 |
174 | # ----------------------
175 | # Train Discriminators
176 | # ----------------------
177 |
178 | # Translate images to opposite domain
179 | fake_B = self.g_AB.predict(imgs_A)
180 | fake_A = self.g_BA.predict(imgs_B)
181 |
182 | # Train the discriminators (original images = real / translated = Fake)
183 | dA_loss_real = self.d_A.train_on_batch(imgs_A, valid)
184 | dA_loss_fake = self.d_A.train_on_batch(fake_A, fake)
185 | dA_loss = 0.5 * np.add(dA_loss_real, dA_loss_fake)
186 |
187 | dB_loss_real = self.d_B.train_on_batch(imgs_B, valid)
188 | dB_loss_fake = self.d_B.train_on_batch(fake_B, fake)
189 | dB_loss = 0.5 * np.add(dB_loss_real, dB_loss_fake)
190 |
191 | # Total disciminator loss
192 | d_loss = 0.5 * np.add(dA_loss, dB_loss)
193 |
194 | # ------------------
195 | # Train Generators
196 | # ------------------
197 |
198 | # Train the generators
199 | g_loss = self.combined.train_on_batch([imgs_A, imgs_B], [valid, valid, \
200 | imgs_B, imgs_A, \
201 | imgs_A, imgs_B])
202 |
203 | elapsed_time = datetime.datetime.now() - start_time
204 | # Plot the progress
205 | print ("[%d] [%d/%d] time: %s, [d_loss: %f, g_loss: %f]" % (epoch, batch_i,
206 | self.data_loader.n_batches,
207 | elapsed_time,
208 | d_loss[0], g_loss[0]))
209 |
210 | # If at save interval => save generated image samples
211 | if batch_i % sample_interval == 0:
212 | self.sample_images(epoch, batch_i)
213 |
214 | def sample_images(self, epoch, batch_i):
215 | os.makedirs('images/%s' % self.dataset_name, exist_ok=True)
216 | r, c = 2, 3
217 |
218 | imgs_A, imgs_B = self.data_loader.load_data(batch_size=1, is_testing=True)
219 |
220 | # Translate images to the other domain
221 | fake_B = self.g_AB.predict(imgs_A)
222 | fake_A = self.g_BA.predict(imgs_B)
223 | # Translate back to original domain
224 | reconstr_A = self.g_BA.predict(fake_B)
225 | reconstr_B = self.g_AB.predict(fake_A)
226 |
227 | gen_imgs = np.concatenate([imgs_A, fake_B, reconstr_A, imgs_B, fake_A, reconstr_B])
228 |
229 | # Rescale images 0 - 1
230 | gen_imgs = 0.5 * gen_imgs + 0.5
231 |
232 | titles = ['Original', 'Translated', 'Reconstructed']
233 | fig, axs = plt.subplots(r, c)
234 | cnt = 0
235 | for i in range(r):
236 | for j in range(c):
237 | axs[i,j].imshow(gen_imgs[cnt])
238 | axs[i, j].set_title(titles[j])
239 | axs[i,j].axis('off')
240 | cnt += 1
241 | fig.savefig("images/%s/%d_%d.png" % (self.dataset_name, epoch, batch_i))
242 | plt.close()
243 |
244 |
245 | if __name__ == '__main__':
246 | gan = DiscoGAN()
247 | gan.train(epochs=20, batch_size=1, sample_interval=200)
248 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |  3 |
3 |
4 |
5 | **This repository has gone stale as I unfortunately do not have the time to maintain it anymore. If you would like to continue the development of it as a collaborator send me an email at eriklindernoren@gmail.com.**
6 |
7 | ## Keras-GAN
8 | Collection of Keras implementations of Generative Adversarial Networks (GANs) suggested in research papers. These models are in some cases simplified versions of the ones ultimately described in the papers, but I have chosen to focus on getting the core ideas covered instead of getting every layer configuration right. Contributions and suggestions of GAN varieties to implement are very welcomed.
9 |
10 | See also: [PyTorch-GAN](https://github.com/eriklindernoren/PyTorch-GAN)
11 |
12 | ## Table of Contents
13 | * [Installation](#installation)
14 | * [Implementations](#implementations)
15 | + [Auxiliary Classifier GAN](#ac-gan)
16 | + [Adversarial Autoencoder](#adversarial-autoencoder)
17 | + [Bidirectional GAN](#bigan)
18 | + [Boundary-Seeking GAN](#bgan)
19 | + [Conditional GAN](#cgan)
20 | + [Context-Conditional GAN](#cc-gan)
21 | + [Context Encoder](#context-encoder)
22 | + [Coupled GANs](#cogan)
23 | + [CycleGAN](#cyclegan)
24 | + [Deep Convolutional GAN](#dcgan)
25 | + [DiscoGAN](#discogan)
26 | + [DualGAN](#dualgan)
27 | + [Generative Adversarial Network](#gan)
28 | + [InfoGAN](#infogan)
29 | + [LSGAN](#lsgan)
30 | + [Pix2Pix](#pix2pix)
31 | + [PixelDA](#pixelda)
32 | + [Semi-Supervised GAN](#sgan)
33 | + [Super-Resolution GAN](#srgan)
34 | + [Wasserstein GAN](#wgan)
35 | + [Wasserstein GAN GP](#wgan-gp)
36 |
37 | ## Installation
38 | $ git clone https://github.com/eriklindernoren/Keras-GAN
39 | $ cd Keras-GAN/
40 | $ sudo pip3 install -r requirements.txt
41 |
42 | ## Implementations
43 | ### AC-GAN
44 | Implementation of _Auxiliary Classifier Generative Adversarial Network_.
45 |
46 | [Code](acgan/acgan.py)
47 |
48 | Paper: https://arxiv.org/abs/1610.09585
49 |
50 | #### Example
51 | ```
52 | $ cd acgan/
53 | $ python3 acgan.py
54 | ```
55 |
56 |
57 |  58 |
58 |
59 |
60 | ### Adversarial Autoencoder
61 | Implementation of _Adversarial Autoencoder_.
62 |
63 | [Code](aae/aae.py)
64 |
65 | Paper: https://arxiv.org/abs/1511.05644
66 |
67 | #### Example
68 | ```
69 | $ cd aae/
70 | $ python3 aae.py
71 | ```
72 |
73 |
74 |  75 |
75 |
76 |
77 | ### BiGAN
78 | Implementation of _Bidirectional Generative Adversarial Network_.
79 |
80 | [Code](bigan/bigan.py)
81 |
82 | Paper: https://arxiv.org/abs/1605.09782
83 |
84 | #### Example
85 | ```
86 | $ cd bigan/
87 | $ python3 bigan.py
88 | ```
89 |
90 | ### BGAN
91 | Implementation of _Boundary-Seeking Generative Adversarial Networks_.
92 |
93 | [Code](bgan/bgan.py)
94 |
95 | Paper: https://arxiv.org/abs/1702.08431
96 |
97 | #### Example
98 | ```
99 | $ cd bgan/
100 | $ python3 bgan.py
101 | ```
102 |
103 | ### CC-GAN
104 | Implementation of _Semi-Supervised Learning with Context-Conditional Generative Adversarial Networks_.
105 |
106 | [Code](ccgan/ccgan.py)
107 |
108 | Paper: https://arxiv.org/abs/1611.06430
109 |
110 | #### Example
111 | ```
112 | $ cd ccgan/
113 | $ python3 ccgan.py
114 | ```
115 |
116 |
117 |  118 |
118 |
119 |
120 | ### CGAN
121 | Implementation of _Conditional Generative Adversarial Nets_.
122 |
123 | [Code](cgan/cgan.py)
124 |
125 | Paper:https://arxiv.org/abs/1411.1784
126 |
127 | #### Example
128 | ```
129 | $ cd cgan/
130 | $ python3 cgan.py
131 | ```
132 |
133 |
134 |  135 |
135 |
136 |
137 | ### Context Encoder
138 | Implementation of _Context Encoders: Feature Learning by Inpainting_.
139 |
140 | [Code](context_encoder/context_encoder.py)
141 |
142 | Paper: https://arxiv.org/abs/1604.07379
143 |
144 | #### Example
145 | ```
146 | $ cd context_encoder/
147 | $ python3 context_encoder.py
148 | ```
149 |
150 |
151 |  152 |
152 |
153 |
154 | ### CoGAN
155 | Implementation of _Coupled generative adversarial networks_.
156 |
157 | [Code](cogan/cogan.py)
158 |
159 | Paper: https://arxiv.org/abs/1606.07536
160 |
161 | #### Example
162 | ```
163 | $ cd cogan/
164 | $ python3 cogan.py
165 | ```
166 |
167 | ### CycleGAN
168 | Implementation of _Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks_.
169 |
170 | [Code](cyclegan/cyclegan.py)
171 |
172 | Paper: https://arxiv.org/abs/1703.10593
173 |
174 |
175 | 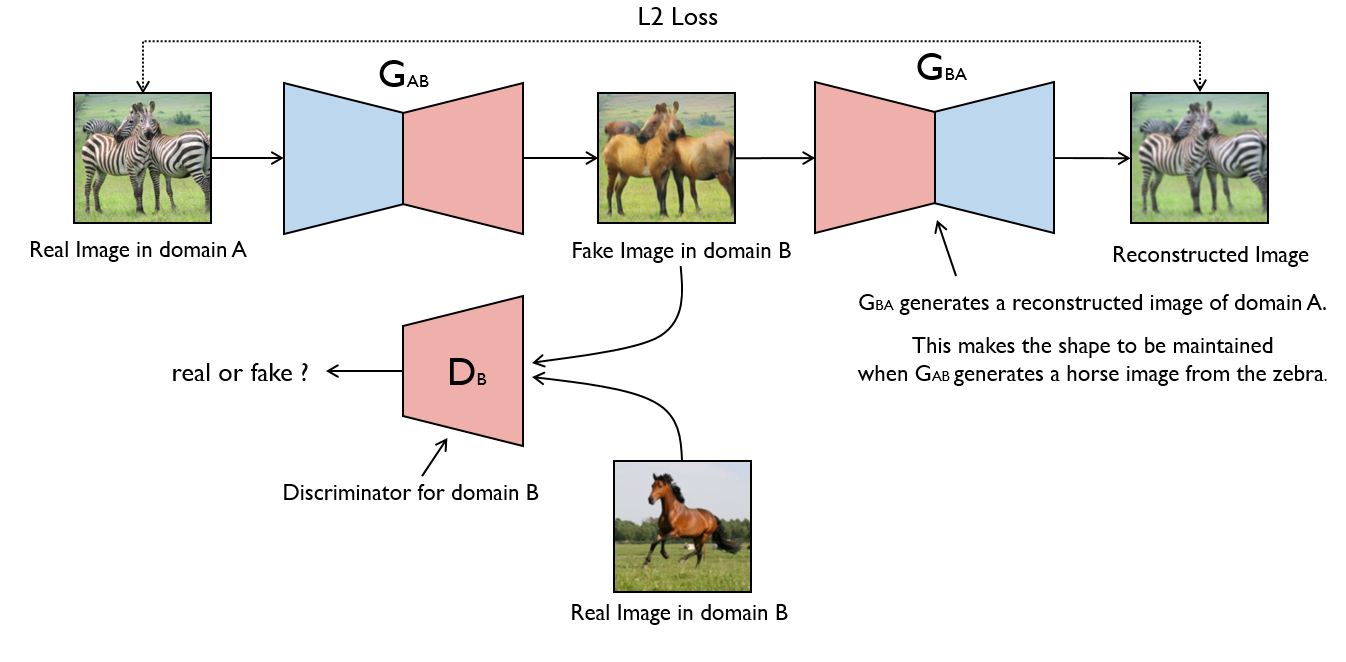 176 |
176 |
177 |
178 | #### Example
179 | ```
180 | $ cd cyclegan/
181 | $ bash download_dataset.sh apple2orange
182 | $ python3 cyclegan.py
183 | ```
184 |
185 |
186 |  187 |
187 |
188 |
189 |
190 | ### DCGAN
191 | Implementation of _Deep Convolutional Generative Adversarial Network_.
192 |
193 | [Code](dcgan/dcgan.py)
194 |
195 | Paper: https://arxiv.org/abs/1511.06434
196 |
197 | #### Example
198 | ```
199 | $ cd dcgan/
200 | $ python3 dcgan.py
201 | ```
202 |
203 |
204 |  205 |
205 |
206 |
207 | ### DiscoGAN
208 | Implementation of _Learning to Discover Cross-Domain Relations with Generative Adversarial Networks_.
209 |
210 | [Code](discogan/discogan.py)
211 |
212 | Paper: https://arxiv.org/abs/1703.05192
213 |
214 |
215 |  216 |
216 |
217 |
218 | #### Example
219 | ```
220 | $ cd discogan/
221 | $ bash download_dataset.sh edges2shoes
222 | $ python3 discogan.py
223 | ```
224 |
225 |
226 |  227 |
227 |
228 |
229 | ### DualGAN
230 | Implementation of _DualGAN: Unsupervised Dual Learning for Image-to-Image Translation_.
231 |
232 | [Code](dualgan/dualgan.py)
233 |
234 | Paper: https://arxiv.org/abs/1704.02510
235 |
236 | #### Example
237 | ```
238 | $ cd dualgan/
239 | $ python3 dualgan.py
240 | ```
241 |
242 | ### GAN
243 | Implementation of _Generative Adversarial Network_ with a MLP generator and discriminator.
244 |
245 | [Code](gan/gan.py)
246 |
247 | Paper: https://arxiv.org/abs/1406.2661
248 |
249 | #### Example
250 | ```
251 | $ cd gan/
252 | $ python3 gan.py
253 | ```
254 |
255 |
256 |  257 |
257 |
258 |
259 | ### InfoGAN
260 | Implementation of _InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets_.
261 |
262 | [Code](infogan/infogan.py)
263 |
264 | Paper: https://arxiv.org/abs/1606.03657
265 |
266 | #### Example
267 | ```
268 | $ cd infogan/
269 | $ python3 infogan.py
270 | ```
271 |
272 |
273 |  274 |
274 |
275 |
276 | ### LSGAN
277 | Implementation of _Least Squares Generative Adversarial Networks_.
278 |
279 | [Code](lsgan/lsgan.py)
280 |
281 | Paper: https://arxiv.org/abs/1611.04076
282 |
283 | #### Example
284 | ```
285 | $ cd lsgan/
286 | $ python3 lsgan.py
287 | ```
288 |
289 | ### Pix2Pix
290 | Implementation of _Image-to-Image Translation with Conditional Adversarial Networks_.
291 |
292 | [Code](pix2pix/pix2pix.py)
293 |
294 | Paper: https://arxiv.org/abs/1611.07004
295 |
296 |
297 |  298 |
298 |
299 |
300 | #### Example
301 | ```
302 | $ cd pix2pix/
303 | $ bash download_dataset.sh facades
304 | $ python3 pix2pix.py
305 | ```
306 |
307 |
308 |  309 |
309 |
310 |
311 | ### PixelDA
312 | Implementation of _Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial Networks_.
313 |
314 | [Code](pixelda/pixelda.py)
315 |
316 | Paper: https://arxiv.org/abs/1612.05424
317 |
318 | #### MNIST to MNIST-M Classification
319 | Trains a classifier on MNIST images that are translated to resemble MNIST-M (by performing unsupervised image-to-image domain adaptation). This model is compared to the naive solution of training a classifier on MNIST and evaluating it on MNIST-M. The naive model manages a 55% classification accuracy on MNIST-M while the one trained during domain adaptation gets a 95% classification accuracy.
320 |
321 | ```
322 | $ cd pixelda/
323 | $ python3 pixelda.py
324 | ```
325 |
326 | | Method | Accuracy |
327 | | ------------ |:---------:|
328 | | Naive | 55% |
329 | | PixelDA | 95% |
330 |
331 | ### SGAN
332 | Implementation of _Semi-Supervised Generative Adversarial Network_.
333 |
334 | [Code](sgan/sgan.py)
335 |
336 | Paper: https://arxiv.org/abs/1606.01583
337 |
338 | #### Example
339 | ```
340 | $ cd sgan/
341 | $ python3 sgan.py
342 | ```
343 |
344 |
345 |  346 |
346 |
347 |
348 | ### SRGAN
349 | Implementation of _Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network_.
350 |
351 | [Code](srgan/srgan.py)
352 |
353 | Paper: https://arxiv.org/abs/1609.04802
354 |
355 |
356 | 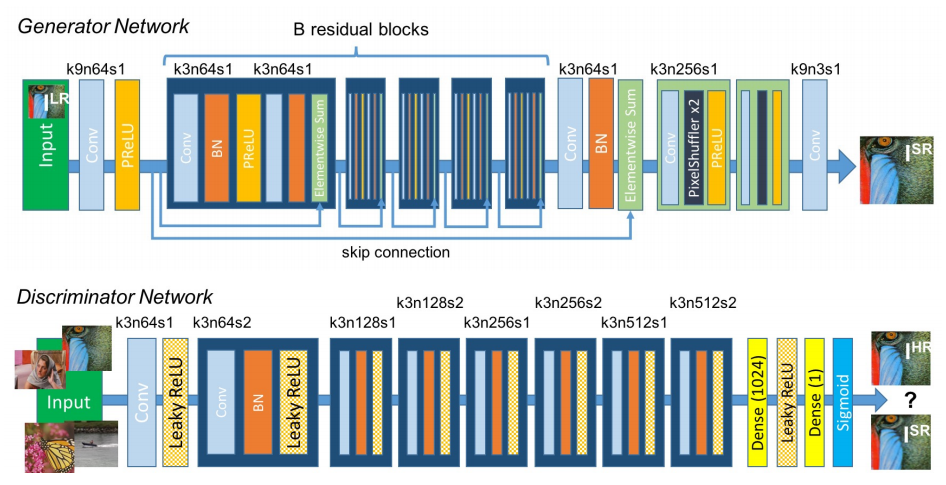 357 |
357 |
358 |
359 |
360 | #### Example
361 | ```
362 | $ cd srgan/
363 |
364 | $ python3 srgan.py
365 | ```
366 |
367 |
368 |  369 |
369 |
370 |
371 | ### WGAN
372 | Implementation of _Wasserstein GAN_ (with DCGAN generator and discriminator).
373 |
374 | [Code](wgan/wgan.py)
375 |
376 | Paper: https://arxiv.org/abs/1701.07875
377 |
378 | #### Example
379 | ```
380 | $ cd wgan/
381 | $ python3 wgan.py
382 | ```
383 |
384 |
385 |  386 |
386 |
387 |
388 | ### WGAN GP
389 | Implementation of _Improved Training of Wasserstein GANs_.
390 |
391 | [Code](wgan_gp/wgan_gp.py)
392 |
393 | Paper: https://arxiv.org/abs/1704.00028
394 |
395 | #### Example
396 | ```
397 | $ cd wgan_gp/
398 | $ python3 wgan_gp.py
399 | ```
400 |
401 |
402 |  403 |
403 |
404 |
--------------------------------------------------------------------------------
/srgan/srgan.py:
--------------------------------------------------------------------------------
1 | """
2 | Super-resolution of CelebA using Generative Adversarial Networks.
3 |
4 | The dataset can be downloaded from: https://www.dropbox.com/sh/8oqt9vytwxb3s4r/AADIKlz8PR9zr6Y20qbkunrba/Img/img_align_celeba.zip?dl=0
5 |
6 | Instrustion on running the script:
7 | 1. Download the dataset from the provided link
8 | 2. Save the folder 'img_align_celeba' to 'datasets/'
9 | 4. Run the sript using command 'python srgan.py'
10 | """
11 |
12 | from __future__ import print_function, division
13 | import scipy
14 |
15 | from keras.datasets import mnist
16 | from keras_contrib.layers.normalization.instancenormalization import InstanceNormalization
17 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout, Concatenate
18 | from keras.layers import BatchNormalization, Activation, ZeroPadding2D, Add
19 | from keras.layers.advanced_activations import PReLU, LeakyReLU
20 | from keras.layers.convolutional import UpSampling2D, Conv2D
21 | from keras.applications import VGG19
22 | from keras.models import Sequential, Model
23 | from keras.optimizers import Adam
24 | import datetime
25 | import matplotlib.pyplot as plt
26 | import sys
27 | from data_loader import DataLoader
28 | import numpy as np
29 | import os
30 |
31 | import keras.backend as K
32 |
33 | class SRGAN():
34 | def __init__(self):
35 | # Input shape
36 | self.channels = 3
37 | self.lr_height = 64 # Low resolution height
38 | self.lr_width = 64 # Low resolution width
39 | self.lr_shape = (self.lr_height, self.lr_width, self.channels)
40 | self.hr_height = self.lr_height*4 # High resolution height
41 | self.hr_width = self.lr_width*4 # High resolution width
42 | self.hr_shape = (self.hr_height, self.hr_width, self.channels)
43 |
44 | # Number of residual blocks in the generator
45 | self.n_residual_blocks = 16
46 |
47 | optimizer = Adam(0.0002, 0.5)
48 |
49 | # We use a pre-trained VGG19 model to extract image features from the high resolution
50 | # and the generated high resolution images and minimize the mse between them
51 | self.vgg = self.build_vgg()
52 | self.vgg.trainable = False
53 | self.vgg.compile(loss='mse',
54 | optimizer=optimizer,
55 | metrics=['accuracy'])
56 |
57 | # Configure data loader
58 | self.dataset_name = 'img_align_celeba'
59 | self.data_loader = DataLoader(dataset_name=self.dataset_name,
60 | img_res=(self.hr_height, self.hr_width))
61 |
62 | # Calculate output shape of D (PatchGAN)
63 | patch = int(self.hr_height / 2**4)
64 | self.disc_patch = (patch, patch, 1)
65 |
66 | # Number of filters in the first layer of G and D
67 | self.gf = 64
68 | self.df = 64
69 |
70 | # Build and compile the discriminator
71 | self.discriminator = self.build_discriminator()
72 | self.discriminator.compile(loss='mse',
73 | optimizer=optimizer,
74 | metrics=['accuracy'])
75 |
76 | # Build the generator
77 | self.generator = self.build_generator()
78 |
79 | # High res. and low res. images
80 | img_hr = Input(shape=self.hr_shape)
81 | img_lr = Input(shape=self.lr_shape)
82 |
83 | # Generate high res. version from low res.
84 | fake_hr = self.generator(img_lr)
85 |
86 | # Extract image features of the generated img
87 | fake_features = self.vgg(fake_hr)
88 |
89 | # For the combined model we will only train the generator
90 | self.discriminator.trainable = False
91 |
92 | # Discriminator determines validity of generated high res. images
93 | validity = self.discriminator(fake_hr)
94 |
95 | self.combined = Model([img_lr, img_hr], [validity, fake_features])
96 | self.combined.compile(loss=['binary_crossentropy', 'mse'],
97 | loss_weights=[1e-3, 1],
98 | optimizer=optimizer)
99 |
100 |
101 | def build_vgg(self):
102 | """
103 | Builds a pre-trained VGG19 model that outputs image features extracted at the
104 | third block of the model
105 | """
106 | vgg = VGG19(weights="imagenet")
107 | # Set outputs to outputs of last conv. layer in block 3
108 | # See architecture at: https://github.com/keras-team/keras/blob/master/keras/applications/vgg19.py
109 | vgg.outputs = [vgg.layers[9].output]
110 |
111 | img = Input(shape=self.hr_shape)
112 |
113 | # Extract image features
114 | img_features = vgg(img)
115 |
116 | return Model(img, img_features)
117 |
118 | def build_generator(self):
119 |
120 | def residual_block(layer_input, filters):
121 | """Residual block described in paper"""
122 | d = Conv2D(filters, kernel_size=3, strides=1, padding='same')(layer_input)
123 | d = Activation('relu')(d)
124 | d = BatchNormalization(momentum=0.8)(d)
125 | d = Conv2D(filters, kernel_size=3, strides=1, padding='same')(d)
126 | d = BatchNormalization(momentum=0.8)(d)
127 | d = Add()([d, layer_input])
128 | return d
129 |
130 | def deconv2d(layer_input):
131 | """Layers used during upsampling"""
132 | u = UpSampling2D(size=2)(layer_input)
133 | u = Conv2D(256, kernel_size=3, strides=1, padding='same')(u)
134 | u = Activation('relu')(u)
135 | return u
136 |
137 | # Low resolution image input
138 | img_lr = Input(shape=self.lr_shape)
139 |
140 | # Pre-residual block
141 | c1 = Conv2D(64, kernel_size=9, strides=1, padding='same')(img_lr)
142 | c1 = Activation('relu')(c1)
143 |
144 | # Propogate through residual blocks
145 | r = residual_block(c1, self.gf)
146 | for _ in range(self.n_residual_blocks - 1):
147 | r = residual_block(r, self.gf)
148 |
149 | # Post-residual block
150 | c2 = Conv2D(64, kernel_size=3, strides=1, padding='same')(r)
151 | c2 = BatchNormalization(momentum=0.8)(c2)
152 | c2 = Add()([c2, c1])
153 |
154 | # Upsampling
155 | u1 = deconv2d(c2)
156 | u2 = deconv2d(u1)
157 |
158 | # Generate high resolution output
159 | gen_hr = Conv2D(self.channels, kernel_size=9, strides=1, padding='same', activation='tanh')(u2)
160 |
161 | return Model(img_lr, gen_hr)
162 |
163 | def build_discriminator(self):
164 |
165 | def d_block(layer_input, filters, strides=1, bn=True):
166 | """Discriminator layer"""
167 | d = Conv2D(filters, kernel_size=3, strides=strides, padding='same')(layer_input)
168 | d = LeakyReLU(alpha=0.2)(d)
169 | if bn:
170 | d = BatchNormalization(momentum=0.8)(d)
171 | return d
172 |
173 | # Input img
174 | d0 = Input(shape=self.hr_shape)
175 |
176 | d1 = d_block(d0, self.df, bn=False)
177 | d2 = d_block(d1, self.df, strides=2)
178 | d3 = d_block(d2, self.df*2)
179 | d4 = d_block(d3, self.df*2, strides=2)
180 | d5 = d_block(d4, self.df*4)
181 | d6 = d_block(d5, self.df*4, strides=2)
182 | d7 = d_block(d6, self.df*8)
183 | d8 = d_block(d7, self.df*8, strides=2)
184 |
185 | d9 = Dense(self.df*16)(d8)
186 | d10 = LeakyReLU(alpha=0.2)(d9)
187 | validity = Dense(1, activation='sigmoid')(d10)
188 |
189 | return Model(d0, validity)
190 |
191 | def train(self, epochs, batch_size=1, sample_interval=50):
192 |
193 | start_time = datetime.datetime.now()
194 |
195 | for epoch in range(epochs):
196 |
197 | # ----------------------
198 | # Train Discriminator
199 | # ----------------------
200 |
201 | # Sample images and their conditioning counterparts
202 | imgs_hr, imgs_lr = self.data_loader.load_data(batch_size)
203 |
204 | # From low res. image generate high res. version
205 | fake_hr = self.generator.predict(imgs_lr)
206 |
207 | valid = np.ones((batch_size,) + self.disc_patch)
208 | fake = np.zeros((batch_size,) + self.disc_patch)
209 |
210 | # Train the discriminators (original images = real / generated = Fake)
211 | d_loss_real = self.discriminator.train_on_batch(imgs_hr, valid)
212 | d_loss_fake = self.discriminator.train_on_batch(fake_hr, fake)
213 | d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
214 |
215 | # ------------------
216 | # Train Generator
217 | # ------------------
218 |
219 | # Sample images and their conditioning counterparts
220 | imgs_hr, imgs_lr = self.data_loader.load_data(batch_size)
221 |
222 | # The generators want the discriminators to label the generated images as real
223 | valid = np.ones((batch_size,) + self.disc_patch)
224 |
225 | # Extract ground truth image features using pre-trained VGG19 model
226 | image_features = self.vgg.predict(imgs_hr)
227 |
228 | # Train the generators
229 | g_loss = self.combined.train_on_batch([imgs_lr, imgs_hr], [valid, image_features])
230 |
231 | elapsed_time = datetime.datetime.now() - start_time
232 | # Plot the progress
233 | print ("%d time: %s" % (epoch, elapsed_time))
234 |
235 | # If at save interval => save generated image samples
236 | if epoch % sample_interval == 0:
237 | self.sample_images(epoch)
238 |
239 | def sample_images(self, epoch):
240 | os.makedirs('images/%s' % self.dataset_name, exist_ok=True)
241 | r, c = 2, 2
242 |
243 | imgs_hr, imgs_lr = self.data_loader.load_data(batch_size=2, is_testing=True)
244 | fake_hr = self.generator.predict(imgs_lr)
245 |
246 | # Rescale images 0 - 1
247 | imgs_lr = 0.5 * imgs_lr + 0.5
248 | fake_hr = 0.5 * fake_hr + 0.5
249 | imgs_hr = 0.5 * imgs_hr + 0.5
250 |
251 | # Save generated images and the high resolution originals
252 | titles = ['Generated', 'Original']
253 | fig, axs = plt.subplots(r, c)
254 | cnt = 0
255 | for row in range(r):
256 | for col, image in enumerate([fake_hr, imgs_hr]):
257 | axs[row, col].imshow(image[row])
258 | axs[row, col].set_title(titles[col])
259 | axs[row, col].axis('off')
260 | cnt += 1
261 | fig.savefig("images/%s/%d.png" % (self.dataset_name, epoch))
262 | plt.close()
263 |
264 | # Save low resolution images for comparison
265 | for i in range(r):
266 | fig = plt.figure()
267 | plt.imshow(imgs_lr[i])
268 | fig.savefig('images/%s/%d_lowres%d.png' % (self.dataset_name, epoch, i))
269 | plt.close()
270 |
271 | if __name__ == '__main__':
272 | gan = SRGAN()
273 | gan.train(epochs=30000, batch_size=1, sample_interval=50)
274 |
--------------------------------------------------------------------------------
/cyclegan/cyclegan.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, division
2 | import scipy
3 |
4 | from keras.datasets import mnist
5 | from keras_contrib.layers.normalization.instancenormalization import InstanceNormalization
6 | from keras.layers import Input, Dense, Reshape, Flatten, Dropout, Concatenate
7 | from keras.layers import BatchNormalization, Activation, ZeroPadding2D
8 | from keras.layers.advanced_activations import LeakyReLU
9 | from keras.layers.convolutional import UpSampling2D, Conv2D
10 | from keras.models import Sequential, Model
11 | from keras.optimizers import Adam
12 | import datetime
13 | import matplotlib.pyplot as plt
14 | import sys
15 | from data_loader import DataLoader
16 | import numpy as np
17 | import os
18 |
19 | class CycleGAN():
20 | def __init__(self):
21 | # Input shape
22 | self.img_rows = 128
23 | self.img_cols = 128
24 | self.channels = 3
25 | self.img_shape = (self.img_rows, self.img_cols, self.channels)
26 |
27 | # Configure data loader
28 | self.dataset_name = 'apple2orange'
29 | self.data_loader = DataLoader(dataset_name=self.dataset_name,
30 | img_res=(self.img_rows, self.img_cols))
31 |
32 |
33 | # Calculate output shape of D (PatchGAN)
34 | patch = int(self.img_rows / 2**4)
35 | self.disc_patch = (patch, patch, 1)
36 |
37 | # Number of filters in the first layer of G and D
38 | self.gf = 32
39 | self.df = 64
40 |
41 | # Loss weights
42 | self.lambda_cycle = 10.0 # Cycle-consistency loss
43 | self.lambda_id = 0.1 * self.lambda_cycle # Identity loss
44 |
45 | optimizer = Adam(0.0002, 0.5)
46 |
47 | # Build and compile the discriminators
48 | self.d_A = self.build_discriminator()
49 | self.d_B = self.build_discriminator()
50 | self.d_A.compile(loss='mse',
51 | optimizer=optimizer,
52 | metrics=['accuracy'])
53 | self.d_B.compile(loss='mse',
54 | optimizer=optimizer,
55 | metrics=['accuracy'])
56 |
57 | #-------------------------
58 | # Construct Computational
59 | # Graph of Generators
60 | #-------------------------
61 |
62 | # Build the generators
63 | self.g_AB = self.build_generator()
64 | self.g_BA = self.build_generator()
65 |
66 | # Input images from both domains
67 | img_A = Input(shape=self.img_shape)
68 | img_B = Input(shape=self.img_shape)
69 |
70 | # Translate images to the other domain
71 | fake_B = self.g_AB(img_A)
72 | fake_A = self.g_BA(img_B)
73 | # Translate images back to original domain
74 | reconstr_A = self.g_BA(fake_B)
75 | reconstr_B = self.g_AB(fake_A)
76 | # Identity mapping of images
77 | img_A_id = self.g_BA(img_A)
78 | img_B_id = self.g_AB(img_B)
79 |
80 | # For the combined model we will only train the generators
81 | self.d_A.trainable = False
82 | self.d_B.trainable = False
83 |
84 | # Discriminators determines validity of translated images
85 | valid_A = self.d_A(fake_A)
86 | valid_B = self.d_B(fake_B)
87 |
88 | # Combined model trains generators to fool discriminators
89 | self.combined = Model(inputs=[img_A, img_B],
90 | outputs=[ valid_A, valid_B,
91 | reconstr_A, reconstr_B,
92 | img_A_id, img_B_id ])
93 | self.combined.compile(loss=['mse', 'mse',
94 | 'mae', 'mae',
95 | 'mae', 'mae'],
96 | loss_weights=[ 1, 1,
97 | self.lambda_cycle, self.lambda_cycle,
98 | self.lambda_id, self.lambda_id ],
99 | optimizer=optimizer)
100 |
101 | def build_generator(self):
102 | """U-Net Generator"""
103 |
104 | def conv2d(layer_input, filters, f_size=4):
105 | """Layers used during downsampling"""
106 | d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
107 | d = LeakyReLU(alpha=0.2)(d)
108 | d = InstanceNormalization()(d)
109 | return d
110 |
111 | def deconv2d(layer_input, skip_input, filters, f_size=4, dropout_rate=0):
112 | """Layers used during upsampling"""
113 | u = UpSampling2D(size=2)(layer_input)
114 | u = Conv2D(filters, kernel_size=f_size, strides=1, padding='same', activation='relu')(u)
115 | if dropout_rate:
116 | u = Dropout(dropout_rate)(u)
117 | u = InstanceNormalization()(u)
118 | u = Concatenate()([u, skip_input])
119 | return u
120 |
121 | # Image input
122 | d0 = Input(shape=self.img_shape)
123 |
124 | # Downsampling
125 | d1 = conv2d(d0, self.gf)
126 | d2 = conv2d(d1, self.gf*2)
127 | d3 = conv2d(d2, self.gf*4)
128 | d4 = conv2d(d3, self.gf*8)
129 |
130 | # Upsampling
131 | u1 = deconv2d(d4, d3, self.gf*4)
132 | u2 = deconv2d(u1, d2, self.gf*2)
133 | u3 = deconv2d(u2, d1, self.gf)
134 |
135 | u4 = UpSampling2D(size=2)(u3)
136 | output_img = Conv2D(self.channels, kernel_size=4, strides=1, padding='same', activation='tanh')(u4)
137 |
138 | return Model(d0, output_img)
139 |
140 | def build_discriminator(self):
141 |
142 | def d_layer(layer_input, filters, f_size=4, normalization=True):
143 | """Discriminator layer"""
144 | d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
145 | d = LeakyReLU(alpha=0.2)(d)
146 | if normalization:
147 | d = InstanceNormalization()(d)
148 | return d
149 |
150 | img = Input(shape=self.img_shape)
151 |
152 | d1 = d_layer(img, self.df, normalization=False)
153 | d2 = d_layer(d1, self.df*2)
154 | d3 = d_layer(d2, self.df*4)
155 | d4 = d_layer(d3, self.df*8)
156 |
157 | validity = Conv2D(1, kernel_size=4, strides=1, padding='same')(d4)
158 |
159 | return Model(img, validity)
160 |
161 | def train(self, epochs, batch_size=1, sample_interval=50):
162 |
163 | start_time = datetime.datetime.now()
164 |
165 | # Adversarial loss ground truths
166 | valid = np.ones((batch_size,) + self.disc_patch)
167 | fake = np.zeros((batch_size,) + self.disc_patch)
168 |
169 | for epoch in range(epochs):
170 | for batch_i, (imgs_A, imgs_B) in enumerate(self.data_loader.load_batch(batch_size)):
171 |
172 | # ----------------------
173 | # Train Discriminators
174 | # ----------------------
175 |
176 | # Translate images to opposite domain
177 | fake_B = self.g_AB.predict(imgs_A)
178 | fake_A = self.g_BA.predict(imgs_B)
179 |
180 | # Train the discriminators (original images = real / translated = Fake)
181 | dA_loss_real = self.d_A.train_on_batch(imgs_A, valid)
182 | dA_loss_fake = self.d_A.train_on_batch(fake_A, fake)
183 | dA_loss = 0.5 * np.add(dA_loss_real, dA_loss_fake)
184 |
185 | dB_loss_real = self.d_B.train_on_batch(imgs_B, valid)
186 | dB_loss_fake = self.d_B.train_on_batch(fake_B, fake)
187 | dB_loss = 0.5 * np.add(dB_loss_real, dB_loss_fake)
188 |
189 | # Total disciminator loss
190 | d_loss = 0.5 * np.add(dA_loss, dB_loss)
191 |
192 |
193 | # ------------------
194 | # Train Generators
195 | # ------------------
196 |
197 | # Train the generators
198 | g_loss = self.combined.train_on_batch([imgs_A, imgs_B],
199 | [valid, valid,
200 | imgs_A, imgs_B,
201 | imgs_A, imgs_B])
202 |
203 | elapsed_time = datetime.datetime.now() - start_time
204 |
205 | # Plot the progress
206 | print ("[Epoch %d/%d] [Batch %d/%d] [D loss: %f, acc: %3d%%] [G loss: %05f, adv: %05f, recon: %05f, id: %05f] time: %s " \
207 | % ( epoch, epochs,
208 | batch_i, self.data_loader.n_batches,
209 | d_loss[0], 100*d_loss[1],
210 | g_loss[0],
211 | np.mean(g_loss[1:3]),
212 | np.mean(g_loss[3:5]),
213 | np.mean(g_loss[5:6]),
214 | elapsed_time))
215 |
216 | # If at save interval => save generated image samples
217 | if batch_i % sample_interval == 0:
218 | self.sample_images(epoch, batch_i)
219 |
220 | def sample_images(self, epoch, batch_i):
221 | os.makedirs('images/%s' % self.dataset_name, exist_ok=True)
222 | r, c = 2, 3
223 |
224 | imgs_A = self.data_loader.load_data(domain="A", batch_size=1, is_testing=True)
225 | imgs_B = self.data_loader.load_data(domain="B", batch_size=1, is_testing=True)
226 |
227 | # Demo (for GIF)
228 | #imgs_A = self.data_loader.load_img('datasets/apple2orange/testA/n07740461_1541.jpg')
229 | #imgs_B = self.data_loader.load_img('datasets/apple2orange/testB/n07749192_4241.jpg')
230 |
231 | # Translate images to the other domain
232 | fake_B = self.g_AB.predict(imgs_A)
233 | fake_A = self.g_BA.predict(imgs_B)
234 | # Translate back to original domain
235 | reconstr_A = self.g_BA.predict(fake_B)
236 | reconstr_B = self.g_AB.predict(fake_A)
237 |
238 | gen_imgs = np.concatenate([imgs_A, fake_B, reconstr_A, imgs_B, fake_A, reconstr_B])
239 |
240 | # Rescale images 0 - 1
241 | gen_imgs = 0.5 * gen_imgs + 0.5
242 |
243 | titles = ['Original', 'Translated', 'Reconstructed']
244 | fig, axs = plt.subplots(r, c)
245 | cnt = 0
246 | for i in range(r):
247 | for j in range(c):
248 | axs[i,j].imshow(gen_imgs[cnt])
249 | axs[i, j].set_title(titles[j])
250 | axs[i,j].axis('off')
251 | cnt += 1
252 | fig.savefig("images/%s/%d_%d.png" % (self.dataset_name, epoch, batch_i))
253 | plt.close()
254 |
255 |
256 | if __name__ == '__main__':
257 | gan = CycleGAN()
258 | gan.train(epochs=200, batch_size=1, sample_interval=200)
259 |
--------------------------------------------------------------------------------