├── .github
└── workflows
│ └── main.yml
├── .gitignore
├── .nojekyll
├── CNAME
├── README.md
├── _coverpage.md
├── _navbar.md
├── _sidebar.md
├── docs
├── 0.少儿编程
│ ├── README.md
│ ├── 免费的Scratch学习资源梳理(持续更新ing)_2024-07-31.md
│ ├── 全网爆火的免费少儿编程网站!一文揭开code.org的神秘面纱_2024-07-31.md
│ ├── 公众号排版器.md
│ ├── 在家带娃学编程?附路线规划图_2024-07-31.md
│ ├── 娃适合学编程么?不妨陪ta从零开始_2024-07-31.md
│ ├── 少儿编程考级怎么选?你想要了解的一切都在这里_2024-07-31.md
│ └── 少儿编程都有哪些比赛?全网鼓吹的信奥赛NOI到底有多难?.md
├── 1.Linux笔记
│ ├── AI 本地环境配置:一文梳理 Nvidia驱动_CUDA_CUDNN_PyTorch_Paddle 版本兼容&安装问题(持续更新).md
│ ├── Docker 国内镜像站全部失效?试试这个方法,亲测有效.md
│ ├── README.md
│ ├── 【保姆级教程】Linux系统下如何玩转Docker.md
│ ├── 【保姆级教程】Windows 远程登录 Ubuntu桌面环境.md
│ ├── 【保姆级教程】Windows 远程登陆 Linux 服务器的两种方式:SSH + VS Code,开发必备.md
│ ├── 【保姆级教程】Windows上安装Linux子系统,搞台虚拟机玩玩.md
│ ├── 【保姆级教程】如何在 Windows 上实现和 Linux 子系统的端口映射.md
│ ├── 【保姆级教程】实操 Linux 磁盘管理:硬盘选型 & 分区挂载.md
│ ├── 报错解决ImportError_ libcrypto.so.10_ cannot open shared object file_ No such file or directory.md
│ └── 报错解决ImportError_ libnvinfer.so.7_ cannot open shared object file_ No such file or directory.md
├── 2.玩转云服务
│ ├── 86K Star!又一款内网穿透利器,开源免费+小白友好.md
│ ├── README.md
│ ├── Untitled.md
│ ├── 【保姆级教程】免费内网穿透,手把手搭建,三步搞定.md
│ ├── 【保姆级教程】免费域名注册 & Cloudflare 域名解析 & Ngnix端口转发.md
│ ├── 【保姆级教程】白嫖 Cloudflare 之 5 分钟搭建个人静态网站.md
│ ├── 【白嫖 Cloudflare】之 免费内网穿透,让本地AI服务,触达全球.md
│ ├── 【白嫖 Cloudflare】之免费 AI 服务,从API调用到应用搭建.md
│ ├── 【白嫖 Cloudflare】之免费图床搭建:PicGo + Cloudflare R2,手把手教.md
│ ├── 两款 GPU 云服务器,助力小白上手 AI.md
│ ├── 从0搭建你的免费图床(PicGo + Oracle cloud 甲骨文云对象存储).md
│ ├── 你的服务器管家,不仅免费开源,还贼简洁好用.md
│ ├── 我花了一天时间,搭了个专属知识库,部署上线了,手把手教,不信你学不会.md
│ ├── 玩转云服务:Google Cloud谷歌云永久免费云服务器「白嫖」 指南.md
│ ├── 玩转云服务:Oracle Cloud甲骨文永久免费云主机配置指南(续).md
│ ├── 玩转云服务:Oracle Cloud甲骨文永久免费云服务器注册及配置指南.md
│ ├── 玩转云服务:手把手带你薅一台腾讯云服务器.md
│ └── 谁偷偷看了你的网站?这两款统计工具告诉你!小白易上手.md
├── 3.AI笔记
│ ├── 15.9K Star!知识库RAG还能这么玩?基于 GraphRag 打造知识图谱增强的 LLM - 以解读《红楼梦》为例.md
│ ├── 16.3K Star!AI 驱动的的开源爬虫工具.md
│ ├── 17k star!开源最快语音克隆方案,FishSpeech 焕新升级,本地部署实测.md
│ ├── 20K Star! 开源最强 AI 换脸,助力数字人自由.md
│ ├── 37K 下载!开源图像背景去除项目,精确到发丝,数字人福音.md
│ ├── 4.9K Star!开源 AI 搜索引擎本地搭建,全程免费,邀你围观体验.md
│ ├── 4k star!升级版OneAPI,助力 Dify 兼容 OpenAI 格式.md
│ ├── 5分钟,打造你的海报生成器!定制化、批量化、自动化.md
│ ├── AI全栈利器开源!带你用Ollama+Qwen2.5-Code跑bolt.new.md
│ ├── AI全栈开发利器:字节 Trae 初体验,最强 Claude 3.5 _ GPT 4o 无限免费用.md
│ ├── AI全栈开发利器:弃坑 Cursor 拥抱 Google IDX,代码生成+云端部署.md
│ ├── AI加持下,如何从0到1做一个AI服务网站.md
│ ├── B站大模型指令微调入门实战(完整代码),一键打造你的数字分身.md
│ ├── CogVideo 实测,智谱「清影」AI视频生成,全民免费,连 API 都开放了!.md
│ ├── CosyVoice 实测,阿里开源语音合成模型,3s极速语音克隆,5分钟带你部署实战.md
│ ├── Coze 智能体之:零代码打造换脸表情包生成器.md
│ ├── Dify 保姆级教程之:零代码打造 AI 搜索引擎.md
│ ├── Dify 保姆级教程之:零代码打造个性化记忆助手.md
│ ├── Dify 保姆级教程之:零代码打造图像生成专家(上).md
│ ├── Dify 保姆级教程之:零代码打造图像生成专家(下).md
│ ├── Dify 保姆级教程之:零代码打造票据识别专家.md
│ ├── EasyAnimate-v3 实测,阿里开源视频生成模型,5 分钟带你部署体验,支持高分辨率超长视频.md
│ ├── FLUX.1 实测,堪比 Midjourney 的开源 AI 绘画模型,无需本地显卡,带你免费实战.md
│ ├── FastGPT:给 GPT 插上知识库的翅膀!0基础搭建本地私有知识库,有手就行.md
│ ├── FishSpeech 实测,免费语音克隆神器,5分钟部署实战,让川普给你来段中文绕口令?.md
│ ├── Jetson 超频刷机教程!解锁端侧AI推理怪兽的算力极限,附实测对比.md
│ ├── NGCBot-打造基于Hook机制的微信机器人,Windows本地部署.md
│ ├── Nginx 助力 DeepSeek 本地部署,实现高可用、负载均衡的大模型应用.md
│ ├── Ollama 更新!本地跑 LLama3.2,轻量级+视觉能力,能媲美GPT-4o?.md
│ ├── OneAPI - 接口管理和分发系统部署和实战,帮你把大模型封装成OpenAI协议.md
│ ├── README.md
│ ├── SenseVoice 实测,阿里开源语音大模型,识别效果和效率优于 Whisper,居然还能检测掌声、笑声!5分钟带你部署体验.md
│ ├── 「AI数学老师」,一个前后端分离的小项目.md
│ ├── 【AI工具+变现】老照片上色,图像高清化。。。一个网站全搞定.md
│ ├── 【YOLOv8实战】手把手带你入门YOLOv8,你也能训练自己的检测器,以SAR目标检测为例(源码+数据集+Gradio界面).md
│ ├── 【保姆级教程】5分钟上手 Coze 自建插件,把 AI 接入个人微信.md
│ ├── 【保姆级教程】Linux上部署Stable Diffusion WebUI和LoRA训练,拥有你的专属图片生成模型.md
│ ├── 【保姆级教程】手把手带你搭建免费的人脸检测_识别系统,支持REST API,自托管,功能强大.md
│ ├── 【大模型实战】零门槛入门AgentScope多智能体游戏开发:和Agent玩飞花令.md
│ ├── 【大模型指令微调实战】小说创作,一键直达天池挑战赛Top50.md
│ ├── 【新手小白如何入门AIGC】Datawhale-AIGC实战 之 趋动云+AI项目部署.md
│ ├── 【新手小白如何入门AIGC】Datawhale-AIGC实战 之 趋动云+ChatGLM3部署.md
│ ├── 【新手小白如何入门AIGC】Datawhale-AIGC实战 之 趋动云+stable-diffusion部署.md
│ ├── 【新手小白如何入门AIGC】Datawhale-AIGC实战 之 趋动云+猫狗大战.md
│ ├── 【每天一个AI提示词】小白如何进行账号定位?.md
│ ├── 【飞桨AI实战】AI Studio后台任务-保姆级教程:如何利用免费GPU训练资源实现SAR图像目标检测.md
│ ├── 【飞桨AI实战】PaddleNLP大模型指令微调,从0打造你的专属家常菜谱管家.md
│ ├── 【飞桨AI实战】交通灯检测:手把手带你入门PaddleDetection,从训练到部署.md
│ ├── 【飞桨AI实战】人体姿态估计:零基础入门,从模型训练到应用开发.md
│ ├── 【飞桨AI实战】人像分割:手把手带你入门PaddleSeg,从模型训练、推理部署到应用开发.md
│ ├── 【飞桨AI实战】人脸口罩检测:手把手带你从零搭建一个前后端分离的Flask应用,代码开源.md
│ ├── 【飞桨AI实战】基于PP-OCR和ErnieBot的字幕提取和智能视频问答.md
│ ├── 【飞桨AI实战】大作业:从0到1搭建一个图像识别系统.md
│ ├── 【飞桨AI实战】桃子分类系统部署:手把手带你入门PaddleClas全家桶.md
│ ├── 一文梳理ChatTTS的进阶用法,手把手带你实现个性化配音,音色、语速、停顿,口语,全搞定.md
│ ├── 一款微信AI机器人开发框架!稳定可靠,小白友好.md
│ ├── 借 WeChatFerry 东风,我把微信机器人复活了!.md
│ ├── 免费GPU算力本地跑DeepSeek R1,无惧官方服务繁忙!.md
│ ├── 免费白嫖GPT4,无次数限制,5分钟带你上手.md
│ ├── 全网刷屏的 LLaMa3.1,2分钟带你尝个鲜.md
│ ├── 全网爆火的AI语音合成工具-ChatTTS,有人已经拿它赚到了第一桶金,送增强版整合包.md
│ ├── 告别信息焦虑,「小爱」携手「每日早报」,打造你的个性化新闻早餐!.md
│ ├── 国产大模型All In One,API免费用,开发者的福音.md
│ ├── 大模型竞技场,免费直达 GPT4o.md
│ ├── 如何给QQ邮箱自动发邮件?无惧「小爱」下线!代码全公开,两步搞定.md
│ ├── 如何赋予AI Agent长期记忆?阿里开源 MemoryScope 实战,全程免费.md
│ ├── 小爱打工,你躺平!让「微信AI小助理」接管你的文件处理,一个字:爽!.md
│ ├── 开源版Heygen!TANGO数字人,瞄准全身动作生成,本地部署实测.md
│ ├── 开源的语音合成项目-EdgeTTS,无需部署无需Key.md
│ ├── 开源端侧实时数字人项目,效果炸裂,附一键整合包.md
│ ├── 开源视频生成 Pyramid Flow 本地部署实测.md
│ ├── 惊艳!Stable Diffusion 3开源~ AI绘画新里程碑,快来体验.md
│ ├── 我把101篇公众号文章喂给了AI,终于,「小爱」可以为我代言了!.md
│ ├── 我把「AI数学老师」接入了「小爱」,拍照解题,微信直出.md
│ ├── 我把「FLUX」接入了「小爱」,微信直接出图,告别一切绘画软件!.md
│ ├── 我把「国产Sora」接入了「小爱」,邀你免费体验.md
│ ├── 我把「记忆」接入了「小爱」,成功搞定多轮对话!.md
│ ├── 我把多模态大模型接入了「小爱」,痛快来一场「表情包斗图」!.md
│ ├── 手把手带你搭建一个语音对话机器人,5分钟定制个人AI小助手(新手入门篇).md
│ ├── 手把手搭建微信机器人,帮你雇一个24小时在线的个人 AI 助理(上).md
│ ├── 手把手搭建微信机器人,帮你雇一个24小时在线的个人 AI 助理(下).md
│ ├── 拒绝Token焦虑,盘点可白嫖的6款LLM大语言模型API~.md
│ ├── 拥有一个能倾听你心声的「微信AI小助理」,是一种什么体验?.md
│ ├── 拳打MJ脚踢SD,爆火FLux任性玩!免费API,速速领取.md
│ ├── 搞清GPT对话的底层逻辑:4个基本原则+2个实用技巧,助你10倍提效.md
│ ├── 搭建微信机器人的第3种方式,我又造了一个24H在线的个人AI助理.md
│ ├── 搭建微信机器人的第4种方式,免费开源,轻量高效.md
│ ├── 无惧 OpenAI 封禁,Coze API 邀你免费用 GPT.md
│ ├── 旧手机秒变 AI 神器:DeepSeek 离线部署,搭建个人网站,私人网盘。。。.md
│ ├── 最强开源OCR:本地部署,邀你围观体验.md
│ ├── 最强开源Qwen2.5:本地部署 Ollma_vLLM 实测对比,邀你围观体验.md
│ ├── 最快开源AI视频生成!STG+LTX-Video,4秒极速成片,免费尝鲜.md
│ ├── 最新开源TTS语音克隆,本地部署实测!跨语言、高保真。。。.md
│ ├── 本地部署 AI 智能体,Dify 搭建保姆级教程(上):工作流 + Agent,把 AI 接入个人微信.md
│ ├── 本地部署 AI 智能体,Dify 搭建保姆级教程(下):知识库 RAG + API 调用,我捏了一个红楼解读大师.md
│ ├── 本地部署大模型?Ollama 部署和实战,看这篇就够了.md
│ ├── 比肩满血DS,阿里开源 QwQ-32B 本地部署,Ollma_vLLM 实测对比,消费级显卡可跑,效果炸裂.md
│ ├── 永久免费语音服务!微软 Azure 注册实操,零成本实现TTS自由.md
│ ├── 盘点免费且靠谱的AI大模型 API,统一封装,任性调用!.md
│ ├── 端侧多模态大模型再升级,只有968M!实测效果咋样.md
│ ├── 让GPT打工,你躺平:效率倍增的提示词模板,副业必备.md
│ ├── 超强!实时AI换脸,支持任意角色替换,5分钟部署体验.md
│ ├── 跑本地大模型,强推的一款浏览器插件,敏感数据不外传.md
│ ├── 轻松搞定10w+:小白易上手的提示词模板,GPT很强,但请温柔以待!.md
│ ├── 还请什么家教,你的免费AI数学老师来了!最强OCR+数学模型Qwen-Math,本地搭建.md
│ ├── 链接丢给它,精华吐出来!微信AI小助理又行了,附完整提示词.md
│ ├── 阿里开源TTS CosyVoice 再升级!语音克隆玩出新花样,支持流式输出,本地部署实测.md
│ ├── 零风险!零付费!我把 AI 接入微信群,爸妈玩嗨了~附教程(上):高德 API 接入.md
│ └── 零风险!零付费!我把 AI 接入微信群,爸妈玩嗨了~附教程(下):大模型 API 接入.md
├── 4.Python笔记
│ ├── Django后端开发入门 之 ModelViewSet和自定义函数.md
│ ├── Django后端开发入门 之 序列化和APIView模式.md
│ ├── Django后端开发入门 之 引入admin后台_QuerySet和Instance使用.md
│ ├── Django后端开发入门 之 构建数据表并合并.md
│ ├── Django后端开发入门指南 之 环境配置.md
│ ├── README.md
│ ├── 【7天Python入门系列】Day1:Windows 环境准备 - Conda 和 VS code 安装.md
│ ├── 【PyTorch笔记】训练时显存一直增加到 out-of-memory?真相了!.md
│ ├── 【Python 实战】wordcloud 带你生成漂亮的词云图.md
│ ├── 【Python 实战】一键生成 PDF 报告,图文并茂,代码全公开_2024-07-31.md
│ ├── 【Python 实战】如何优雅地实现 PDF 去水印?_2024-07-31.md
│ ├── 【Python 实战】文字 & 二维码检测_2024-07-31.md
│ ├── 【Python 实战】自动化处理 PDF 文档,完美实现 WPS 会员功能_2024-07-31.md
│ ├── 一文搞清python中的argparse与sys.argv方法,argparse和sys.argv可以一起使用么?.md
│ ├── 一键获取所有微信聊天记录(附PyQT6入门实战).md
│ ├── 微信聊天记录导出为电脑文件实操教程(附代码).md
│ ├── 我把和老婆近一年的聊天记录发给Kimi,它的回答亮了....md
│ ├── 用Python爬取公众号历史所有文章,看这篇就够了.md
│ └── 自制神器!家长小朋友的福音~.md
├── 5.效率工具
│ ├── README.md
│ ├── Windows11系统安装简明教程,只需3步.md
│ ├── 一行命令实现 Github 国内下载加速.md
│ ├── 两种方法,实现电脑端微信优雅双开.md
│ ├── 盘点3款AI编程助手,开发效率翻倍.md
│ ├── 盘点简洁好用的8款静态网站搭建框架,小白易上手.md
│ └── 视频下载神器!抖音B站YouTube全搞定,免费无广告,亲测好用.md
└── 6.AIoT笔记
│ ├── AIoT应用开发:如何给板子装上'耳朵',实现音频录制.md
│ ├── AIoT应用开发:如何远程查看摄像头,RTSP_RTMP 推流了解下?.md
│ ├── AIoT应用开发:搞定语音对话机器人=ASR+LLM+TTS.md
│ ├── AIoT应用开发:本地搭建 AI 口语老师,一对一免费陪练!.md
│ ├── AIoT应用开发:给机器人接入'记忆',完美解决「和谁对话&多轮对话」!附 SQLite 入门实战.md
│ ├── AIoT应用开发:给机器人装上'眼睛',接入CV能力,实现人脸识别.md
│ ├── AIoT应用开发:给板子装上'嘴巴',实现音频播放.md
│ ├── Jetson 开发系列:Linux 下如何管理音频设备?.md
│ ├── Jetson 开发系列:Orin Nano 开箱!一款强大的嵌入式&物联网开发板.md
│ ├── Jetson 开发系列:如何用GPU跑本地大模型?.md
│ ├── Jetson 开发系列:离线低延迟的人脸识别方案.md
│ ├── Jetson 开发系列:离线低延迟的语音解决方案.md
│ ├── README.md
│ ├── 从0打造本地聊天机器人:如何实现大模型流式输出?OpenAI+Ollama 实战.md
│ ├── 如何在手机端跑大模型?.md
│ ├── 安卓连接 WIFI 但无法上网?盘点我踩过的那些坑.md
│ ├── 成本不到50的AI对话机器人,如何自建服务端?自定义角色+语音克隆,个人隐私不外传.md
│ └── 手机端跑大模型:Ollma_llama.cpp_vLLM 实测对比.md
├── index.html
├── main.py
└── media
├── icon.svg
└── logo_thumbnail.png
/.github/workflows/main.yml:
--------------------------------------------------------------------------------
1 | name: Deploy to GitHub Pages
2 |
3 | on:
4 | push:
5 | branches:
6 | - master # 或者你使用的其他分支
7 |
8 | jobs:
9 | deploy:
10 | runs-on: ubuntu-latest
11 |
12 | steps:
13 | - name: Checkout code
14 | uses: actions/checkout@v4
15 |
16 | - name: Deploy
17 | uses: peaceiris/actions-gh-pages@v3
18 | with:
19 | github_token: ${{ secrets.GITHUB_TOKEN }}
20 | publish_dir: ./ # 使用根目录,或替换为你的 HTML 文件所在目录
21 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | **/assets/
2 | main.py
3 | docs/待整理.md
--------------------------------------------------------------------------------
/.nojekyll:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hougeai/knowledgebase/6cfce85587ecb4903f05af30f3cb5c447c4af868/.nojekyll
--------------------------------------------------------------------------------
/CNAME:
--------------------------------------------------------------------------------
1 | kb.houge.us.kg
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 猴哥的AI知识库
2 |
3 | > 真诚利他,分享AI学习资料、工具、经验、教程,帮助零基础编程小白快速入门AI。用心做内容,不辜负每一份关注。
4 |
5 | [知识库总览](README.md)
6 |
7 | - [1.Linux笔记](docs/1.Linux笔记/README.md)
8 | - [2.玩转云服务](docs/2.玩转云服务/README.md)
9 | - [3.AI笔记](docs/3.AI笔记/README.md)
10 | - [4.Python笔记](docs/4.Python笔记/README.md)
11 | - [5.效率工具](docs/5.效率工具/README.md)
12 | - [6.少儿编程](docs/6.少儿编程/README.md)
13 |
14 | *截至今日,知识库累计更新原创文章**165**篇*
15 |
16 |
17 |
18 | 
19 |
--------------------------------------------------------------------------------
/_coverpage.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 | 
5 | # 猴哥的AI知识库 2024
6 |
7 | > 用心做内容,不辜负每一份关注。
8 |
9 | 适合人群:
10 |
11 | - AI 爱好者
12 | - AI 小白
13 | - AI 自媒体变现
14 |
15 | [公众号:猴哥的AI知识库](https://axcvs2xtkbpq.objectstorage.ap-singapore-1.oci.customer-oci.com/n/axcvs2xtkbpq/b/bucket-20240802-0845/o/v2-ffa263db3791634adecf4fcb101e38fa_1440w.png)
16 |
17 | [知乎:AI布道师](https://www.zhihu.com/people/houge-ai)
18 |
19 | [CSDN:AI码上来](https://blog.csdn.net/u010522887)
20 |
21 | [Github](https://github.com/hougeai/knowledgebase)[Get Started](README.md)
22 |
--------------------------------------------------------------------------------
/_navbar.md:
--------------------------------------------------------------------------------
1 |
2 | - [1.Linux笔记](docs/1.Linux笔记/README.md)
3 | - [2.玩转云服务](docs/2.玩转云服务/README.md)
4 | - [3.AI笔记](docs/3.AI笔记/README.md)
5 | - [4.Python笔记](docs/4.Python笔记/README.md)
6 | - [5.效率工具](docs/5.效率工具/README.md)
7 | - [6.少儿编程](docs/6.少儿编程/README.md)
--------------------------------------------------------------------------------
/docs/0.少儿编程/README.md:
--------------------------------------------------------------------------------
1 | # 0.少儿编程
2 |
3 | - [免费的Scratch学习资源梳理(持续更新ing)_2024-07-31](docs/0.少儿编程/免费的Scratch学习资源梳理(持续更新ing)_2024-07-31.md)
4 | - [全网爆火的免费少儿编程网站!一文揭开code.org的神秘面纱_2024-07-31](docs/0.少儿编程/全网爆火的免费少儿编程网站!一文揭开code.org的神秘面纱_2024-07-31.md)
5 | - [公众号排版器](docs/0.少儿编程/公众号排版器.md)
6 | - [在家带娃学编程?附路线规划图_2024-07-31](docs/0.少儿编程/在家带娃学编程?附路线规划图_2024-07-31.md)
7 | - [娃适合学编程么?不妨陪ta从零开始_2024-07-31](docs/0.少儿编程/娃适合学编程么?不妨陪ta从零开始_2024-07-31.md)
8 | - [少儿编程考级怎么选?你想要了解的一切都在这里_2024-07-31](docs/0.少儿编程/少儿编程考级怎么选?你想要了解的一切都在这里_2024-07-31.md)
9 | - [少儿编程都有哪些比赛?全网鼓吹的信奥赛NOI到底有多难?](docs/0.少儿编程/少儿编程都有哪些比赛?全网鼓吹的信奥赛NOI到底有多难?.md)
10 |
11 |
12 |
13 | *本系列共更新**7**篇文章*
14 |
15 |
16 |
17 | [🔙返回首页](/)
18 |
--------------------------------------------------------------------------------
/docs/0.少儿编程/免费的Scratch学习资源梳理(持续更新ing)_2024-07-31.md:
--------------------------------------------------------------------------------
1 | > 我是大力,5年互联网从业经历,目前深耕少儿编程领域,致力于打造全网优质的**免费**少儿编程知识库,致力于打破家长朋友们和机构之间的信息差。
2 | # Scratch是什么
3 | Scratch是由麻省理工学院(MIT)设计开发的少儿编程语言,它将程序设计语言的基本概念,如变量、函数、逻辑、条件语句等,通过积木的方式呈现,使孩子可以轻松地学习和创作。Scratch 适用于 6 岁以上的儿童和初学者,它不仅可以帮助孩子学习编程知识,还可以培养创造力、逻辑思维和解决问题的能力。
4 | 几乎所有的孩子都会一眼喜欢上这个软件,使用它编写各种有趣的故事、动画和游戏。
5 |
6 | # Scratch如何使用
7 | Scratch自2007年发布以来,一共经历了三个版本的迭代,官方团队在2010年推出了2.0版本,2019年推出了3.0版本。Scratch3.0相比之前版本最主要的特点:增加更多拓展功能的模块,甚至可以和Micro:bit、ev3和wedo2.0等硬件进行连接,因此创作的可想象空间更大。
8 | 目前等级考试和学科竞赛采用的都是3.0版本,故建议大家使用3.0版本进行学习和创作。
9 |
10 | 因为Scratch官网部署在国外,国内很难访问Scratch官网,不过这并不影响大家使用Scratch的热情。目前使用Scratch有两种方式,大家可以根据自己的情况选用:
11 | - 离线安装包:安装在本地电脑,不需要电脑联网即可使用
12 | - 在线编程环境:无需本地安装,只要电脑能联互联网就可以使用(**更推荐**)
13 | ## 离线安装包
14 | 为了让广大Scratch爱好者可以使用Scratch软件,我把Scratch3.0安装包放在了云端网盘。
15 | 下载链接:[Scratch3.0.zip](https://pan.quark.cn/s/5c4e88e3e8ee)
16 | ## 在线编程环境
17 | 如果你的电脑存储空间有限,推荐你直接使用在线编程环境。
18 | 相比离线安装包,在线编程环境在功能上没有任何区别,且优势非常明显:
19 | - 只需要一个账号,所有改动都实时保存在线上,在不同电脑和手机上都可以实时无缝查看
20 | - 方便用户将作品分享到社区,在和其他小朋友的互动中获得满满成就感
21 |
22 | 那么都有哪些免费的在线编程环境呢?这里主要推荐以下四种:
23 | - scratch之家:https://scratchers.cn/s/index(推荐指数:⭐️)
24 | - 蒸汽工坊:https://www.steamcollection.com/(推荐指数:⭐️⭐️)
25 | - 蓝桥杯模拟器:https://scratch.stem86.com/ (推荐指数:⭐️⭐️)
26 | - Code Lab:https://create.codelab.club/ (推荐指数:⭐️⭐️⭐️)
27 |
28 | 由于Scratch3.0最主要的特点就是增加了更多扩展功能,上述在线编程环境在使用上没有任何区别,唯一的不同在于扩展功能的数量,为此我更推荐code lab的模拟器。如下图所示,点击左下角的图标,可以看到并搜索使用内置的拓展功能。
29 |
30 | 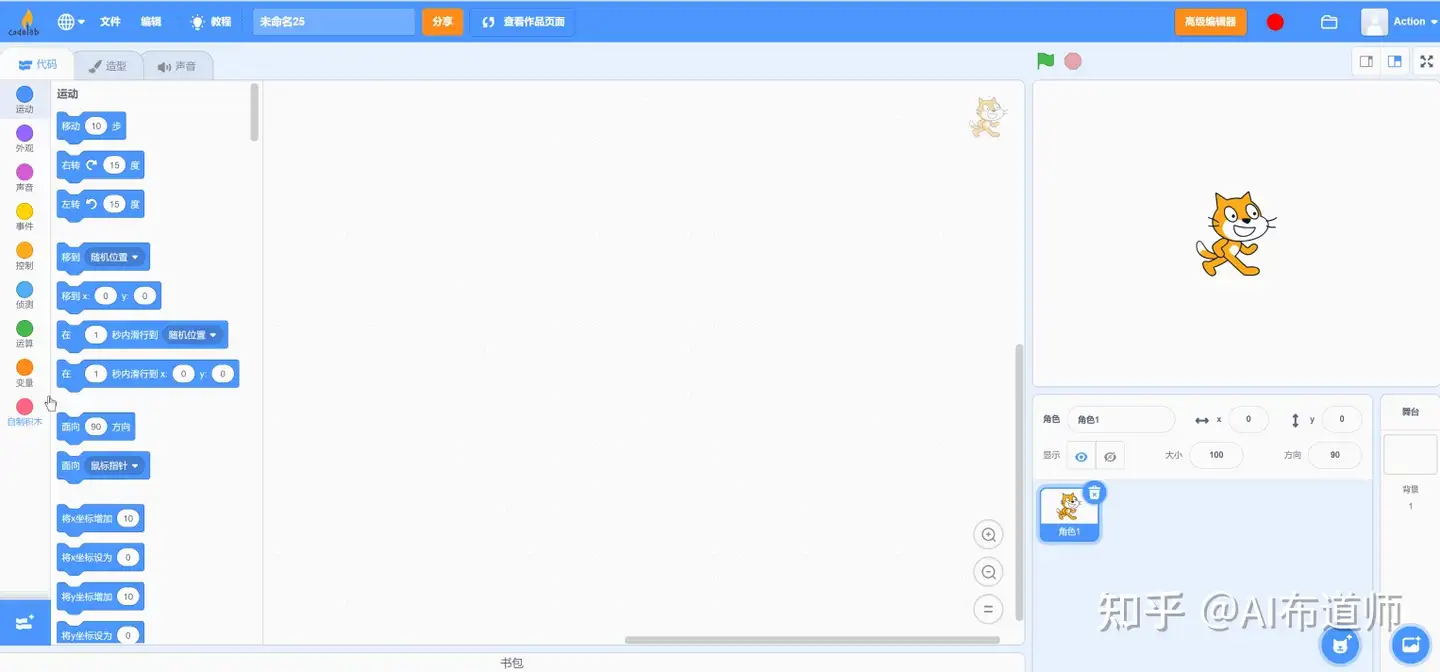
31 |
32 | # 免费电子书籍
33 | 对于家长小朋友零基础入门,有哪些推荐的书籍呢?
34 |
35 | 我会将搜集到的优质书籍梳理在这个版块,大家有更好的书籍也欢迎多多推荐。
36 |
37 | 1.《零基础scratch 3.0 小学生趣味编程》
38 | - 推荐指数:⭐️⭐️⭐️
39 | - 推荐理由:这是我目前看到的最值得推荐的一本Scratch入门书籍。图文并茂,实操性非常强,采用PBL项目制教学,通过做项目的方式带领大家掌握Scratch的核心基本概念。
40 | - 下载链接:[零基础scratch 3.0 小学生趣味编程.pdf](https://pan.quark.cn/s/b633f7e60d44)
41 |
42 | # 免费优质课程
43 | 网上有大量的Scratch教学课程,这里将系统梳理适合在家自学的优质课程,大家有更好的课程也欢迎多多推荐。
44 | ## scratch创意编程
45 | - 推荐指数:⭐️⭐️⭐️
46 | - 推荐理由:借鉴了哈弗大学scratch创意计算课程,采用PBL项目制教学,内容不是很多,非常适合在家自学。
47 | - 课程简介:第 1-2 单元探索编程工具和社区,并尝试创作两个项目,了解编程的可能性。第 3-8 单元围绕动画、故事、游戏这三大主题进行创作。第 9-10 单元进行深入拓展,并总结之前所学知识
48 | - 课程介绍:https://www.codelab.club/blog/2021/01/19/creativecodingcourse/
49 | - B站视频:https://www.bilibili.com/video/BV1jT4y1K7iA/
50 | ## Scratch入门教程
51 | - 推荐指数:⭐️⭐️
52 | - 推荐理由:内容比较丰富,可在上一门课程学完之后进行深入学习
53 | - B站视频:https://www.bilibili.com/video/BV1bF41187VX?p=1&vd_source=cc29c4ba51b0e6b0472256fe6a96da6d
54 |
55 | > 未完结!后续会持续维护更新这篇文档。如果觉得对你有帮助,欢迎点赞收藏关注~
56 |
--------------------------------------------------------------------------------
/docs/0.少儿编程/全网爆火的免费少儿编程网站!一文揭开code.org的神秘面纱_2024-07-31.md:
--------------------------------------------------------------------------------
1 | > 说起少儿编程网站,是不是只想到Scratch?全网爆火的免费少儿编程网站code.org又是啥?既然免费,新人如何食用?今天一文给你讲明白!
2 |
3 | # code.org是啥?
4 |
5 | code.org是一家提供学习计算机科学机会的非盈利性组织,网站有非常丰富的学习资源。
6 | 孩子在玩Code.org时不需要事先学习编程语言,通过玩游戏的方式,就可以进行逻辑思维训练。在浏览器导航栏中输入code.org,就可以进入网站首页。点击课程,就可以看到所有课程目录了。
7 | 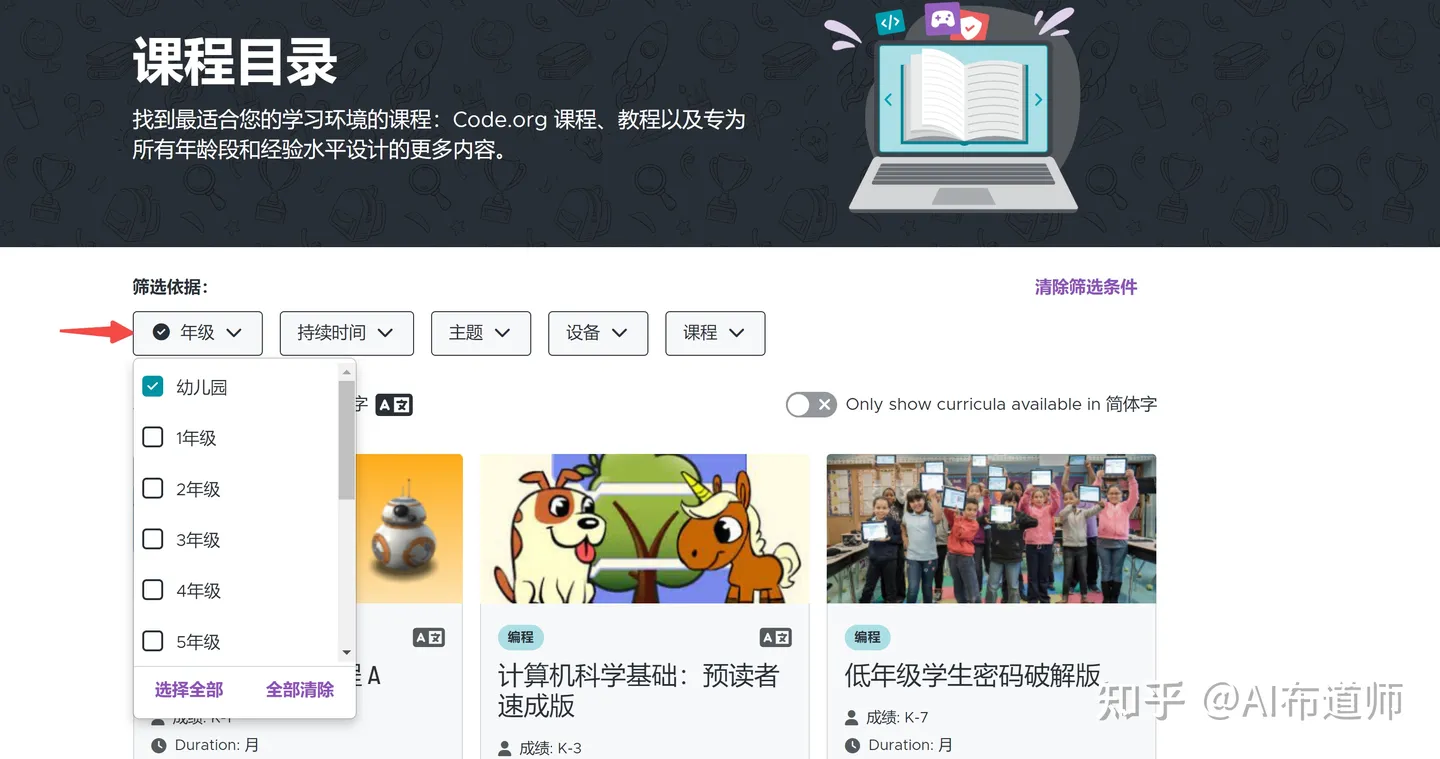
8 |
9 | # code.org的课程如何选择?
10 | code.org中提供的学习资源非常丰富,但是大部分课程中的内容差别并不是特别大,对于孩子的编程启蒙而言,其实只需要选择其中的一门课程就够了,通过筛选依据-年级,就可以筛选出适合孩子年龄阶段的课程了。每门课程都指定了适合的年龄阶段,比如K-1就是说明适合幼儿园到一年级的小朋友。
11 | 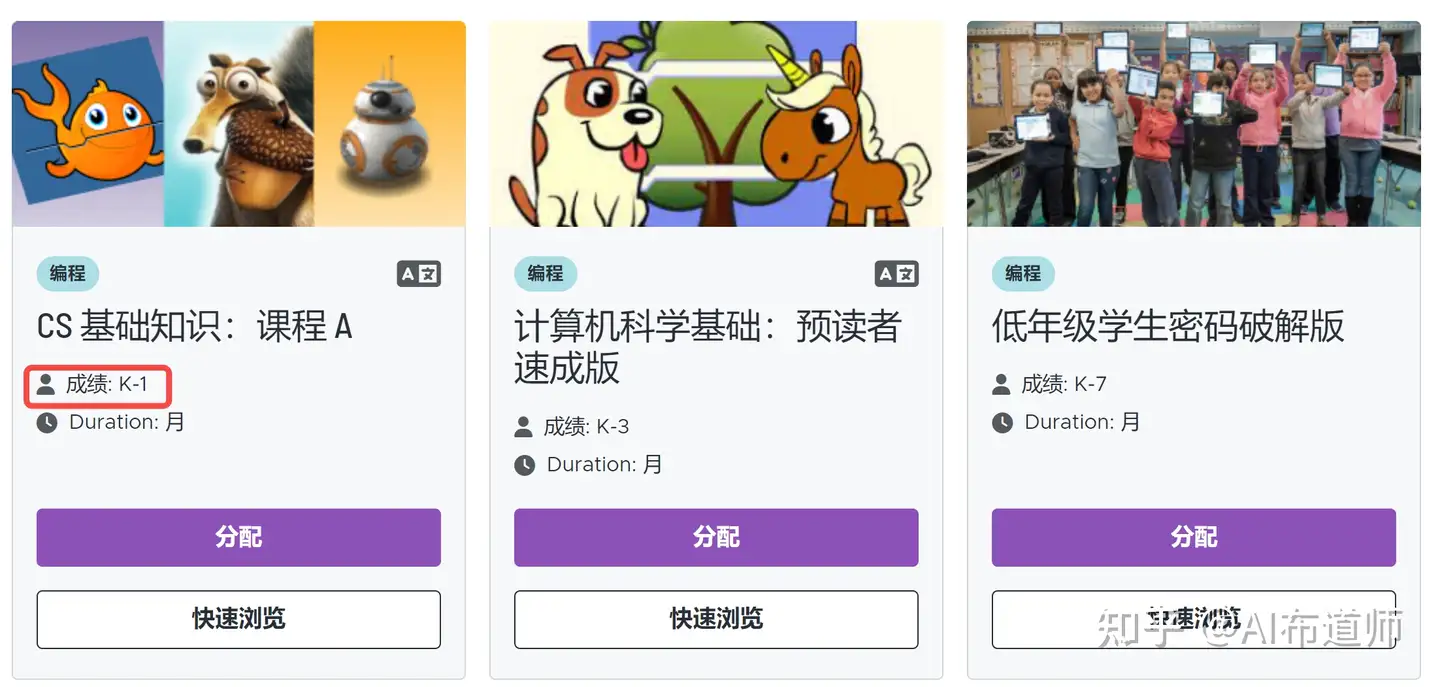
12 | 为了帮助大家更好地理解不同课程之间的联系,减少大家的选择焦虑,大力已经系统梳理了code.org中的所有课程,这些课程大体可以分为如下三类:
13 |
14 | ## 快速课程
15 | [快速计算机科学课程介绍](https://studio.code.org/s/20-hour?section_id=5224695&user_id) 共计20小时的课程,介绍核心计算机科学和编程的概念。每一节都是按照1h设定的,分解为计算思维的四个步骤:分解,模式定位,抽象,算法;后面的概念视频包括:方格纸编程 算法 函数 条件语句 抽象化 编程接力 互联网,每个下面都会一个练习,目前来看整体价值不是特别大,因为覆盖面广,所以针对性不够。
16 | ## 自定义进度课程
17 | 该系列课程下包含了两个速成课程,可以理解为是下面阶段课程的浓缩版,小朋友可以按照自己的节奏尝试以下课程来学习计算机科学!学习创建计算机程序,制作游戏和创意项目。
18 | - [速成课程-预读者快报](https://studio.code.org/s/pre-express-2021?section_id=5224695):适合幼儿园到一年级的小朋友,主要涉及以下3个概念。
19 | - 序列:拖放 斯奎特(冰河世纪) 迷宫编程(愤怒的小鸟) BB8编程 与收割者编程
20 | - 循环:斯奎特 收集器中的循环 艺术家的循环(绘线) 用循环来画花园
21 | - 事件:游戏实验室中的事件:两个小项目-狗乔治 皇室战争
22 | - [速成课程-快速课程](https://studio.code.org/s/express-2021?section_id=5224695):适合2-5年级的小朋友,涉及到了如下编程的概念。
23 | - 序列:迷宫编程 迷宫调试 收集器中编程 艺术家里的编程
24 | - 事件:动作精灵图 虚拟宠物 舞蹈派对
25 | - 循环:涉及嵌套循环(涉及到了角度的概念,嵌套循环时有难度,会越来越难)
26 | - 条件语句:迷宫里的循环 收割者里的条件和循环
27 | - 函数:我的世界中的函数 艺术家之家的功能 收割者中的函数
28 | - 变量:文字和提示 艺术家与变量 蜜蜂与变量
29 | - 计数循环:蜜蜂里的计数循环 艺术家里的计数循环
30 | ### 阶段课程(推荐)
31 | 阶段课程共分为课程A-F,分别对应4-9岁的小朋友,推荐使用2021版。2019年以前,阶段课程只有1-4,现在改版后,针对性更强,家长和小朋友可以根据年龄或者年级来选择对应的课程,完整学完一门课程后就可以基本掌握编程的基本概念了,应该说已经达到了入门的条件,这时候再转到Scratch的学习就会非常顺滑,而不会出现面对一堆组件一脸茫然的尴尬场面了。
32 | 阶段课程的特色有:
33 | - 课程A B中加入了故事来讲述概念,非常适合低年龄阶段的小朋友
34 | - 课程E F的最后引入了课程结束项目(剧本实验室 小艺术家),PBL教学方式,非常适合激发高年龄阶段小朋友的兴趣。
35 |
36 | 需要注意的是,课程编号A-F对应着课程难度不断提高,所以匹配选择对应年龄阶段的课程,学习效果最佳。
37 | - 课程A:幼儿园
38 | - 课程B:一年级,增加了概念的深度。
39 | - 课程C:二年级,学生将创建可以分享的互动游戏。
40 | - 课程D:三年级,首先回顾了早期课程中的概念,包括循环和事件。之后,学生将加深对算法、嵌套循环以及循环、条件等的理解。
41 | - 课程E:四年级。学生将学会制作有趣的互动项目,将学习嵌套循环、函数和条件。
42 | - 课程F:五年级,将学习更高级的概念,包括变量和 “for” 循环。
43 |
44 | # 课程食用的最佳方式?
45 | 阶段课程都可以在这个网址`https://code.org/educate/csf`找到,选择合适的课程点击进入学习即可。
46 | 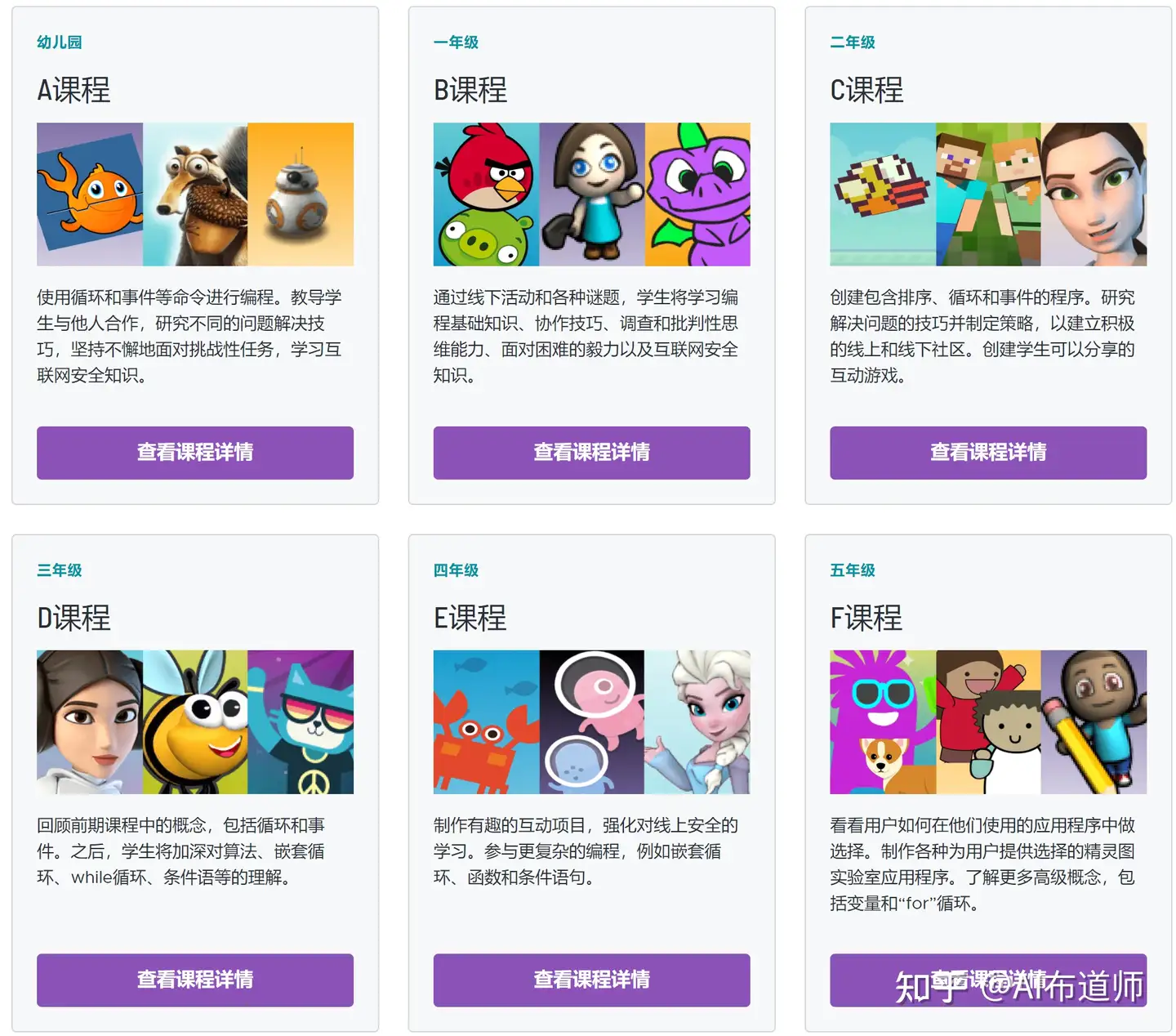
47 | 以课程A为例,进入后,会发现分成了5个单元,每个单元又是由不同关卡组成,难度逐渐加大,因此强烈推荐家长陪着小朋友循序渐进完成所有关卡的学习内容。
48 | 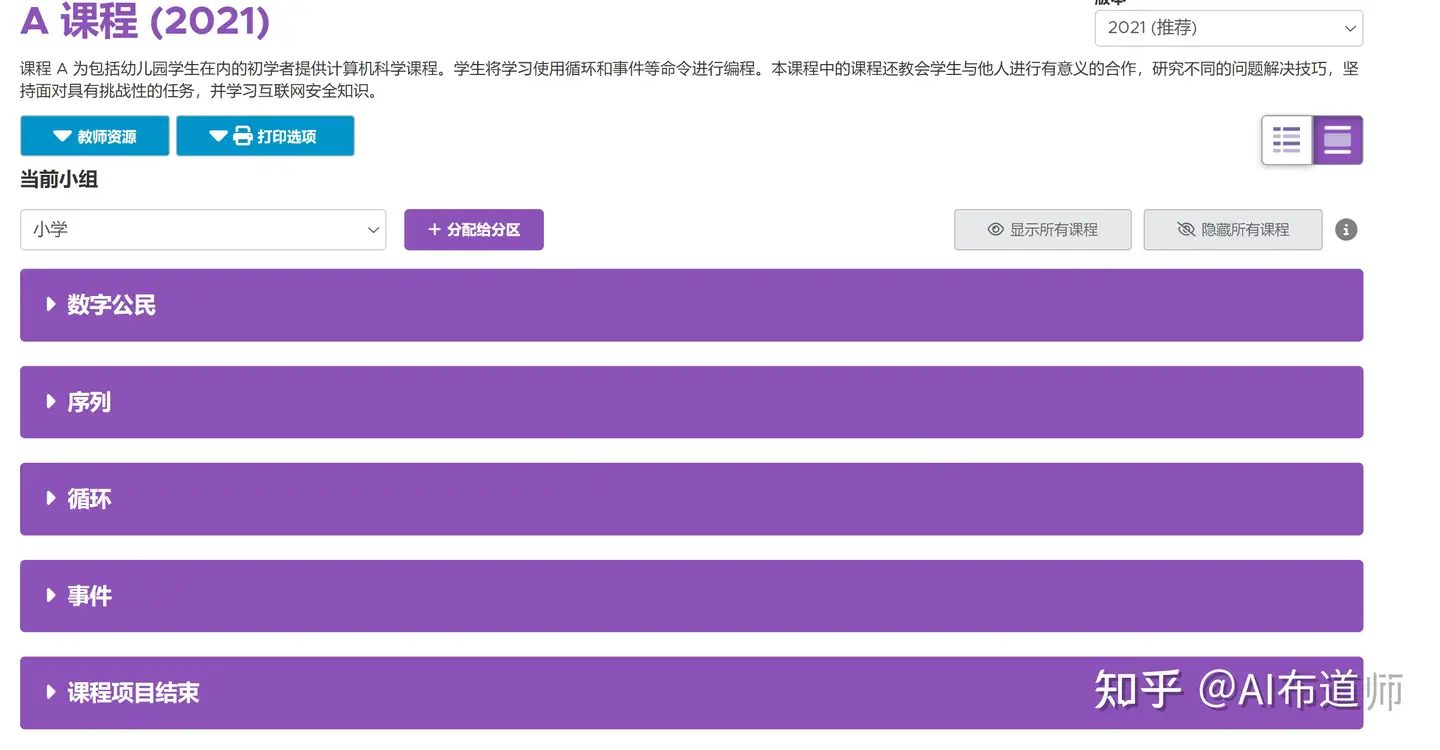
49 | 最初的课程会教孩子最简单的鼠标操作,如点击和拖拽,帮助孩子熟练最基本的电脑操作,而这恰恰是孩子入门编程的最基本条件了。
50 | 
51 | 
52 | 
53 | 通过多个关卡的训练,孩子就能掌握点击 拖拽等基本操作了,接下来会接触到编程中的第一个核心概念`序列`,这时需要孩子们多次拖拽不同的积木来实现更复杂的功能;当孩子们发现多次拖拽同一个板块很麻烦时,这时候就很自然地引入编程中的第二个核心概念`循环`。
54 |
55 | 是的,code.org就是这样带着孩子循序渐进地掌握编程中的基本概念的,一切都是水到渠成,充分实践了皮亚杰的建构主义儿童认知发展理论。
56 |
57 | 如果你认同code.org的编程理念,不妨带着孩子前往code.org一探究竟吧!
58 |
59 |
60 |
61 |
--------------------------------------------------------------------------------
/docs/0.少儿编程/在家带娃学编程?附路线规划图_2024-07-31.md:
--------------------------------------------------------------------------------
1 | > 我是大力,5年互联网教育从业经历,深耕少儿编程领域,致力于打造全网最全的免费少儿编程知识库,致力于打破家长朋友们和机构之间的信息差。
2 | ## 写在前面:
3 | - 上一篇文章([娃适合学编程么?不妨陪ta从零开始](https://mp.weixin.qq.com/s?__biz=MzkzMzY2MTkyNw==&mid=2247483663&idx=1&sn=354c18fc9cd6644a62f9589bf797b81a&chksm=c2485c87f53fd591feb677b3673247f8f04e063900a6014b4e694858288b71de1d1320e9a298#rd))大力已经系统回答了`少儿编程是什么`以及`如何开始`的问题
4 | - 这一篇文章将重点回答`如何给娃做好编程的学习规划`。
5 |
6 | 我碰到的大部分家长其实并不分得太清各种编程语言是什么,往往是在培训机构的安利下给孩子报了一个甚至多个阶段的课程,然而培训机构的课程往往需要照顾到所有孩子,因而课程设置无法真正做到”因材施教“。
7 |
8 | 如果你也有这样的疑惑,不妨先点赞收藏,相信看完这篇文章,不仅会帮你省下一大笔少儿编程培训费,更会帮娃省下宝贵的学习时间。
9 | # 关于编程语言
10 | 根据美国计算机教师协会推出的K12计算机教育标准,少儿编程课程中主要涉及到三种编程语言:Scratch、Python、C++。不管选用哪一种语言,语言都只是一种工具,重点是学会利用工具解决问题的能力。
11 |
12 | 下图系统梳理了不同编程语言的特点、适合的年龄阶段,以及可以参加的等级考试和竞赛。考级是为了阶段性地验证孩子的掌握程度,而竞赛则主要是选拔目的,可以为将来的小升初乃至高考加分,走科技特长生路线。
13 | 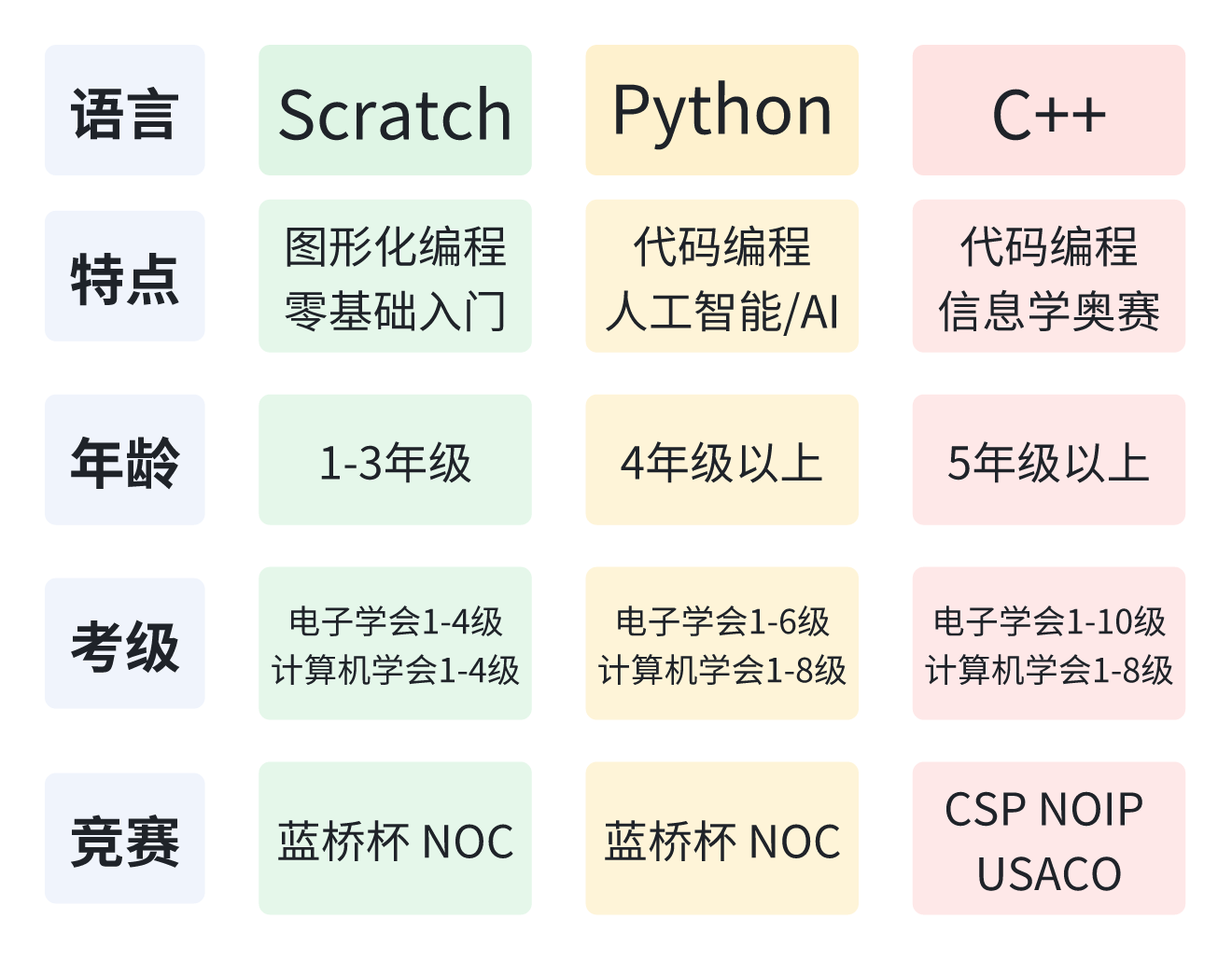
14 | 关于考级和竞赛的更多内容,我准备单独梳理两篇文章,汇聚全网最全的免费学习资料,供有需要的家长朋友们参考。
15 |
16 | # 如何规划
17 | 每个孩子的天赋和能力不同,因此没有任何一条学习路线是适合所有孩子的。
18 | 大部分孩子经过了编程启蒙阶段后,很多家长都会有一个困惑,是先学Python还是先学C++?
19 | 这里主要根据家长朋友们的需求不同,大力将主要分享两条路线供大家参考,我把他们简称为`佛系路线`和`功利路线` 。
20 | ## 佛系路线
21 | 如果你的目标是培养孩子的计算思维和逻辑思维,那么掌握一门编程语言就够了,而这门语言以Python为最佳选择,因为语法非常简单,而Python的上限却非常高,小到制作游戏,大到可以进行AI创意编程,基于Python甚至可以帮助孩子接触到计算机科学的全貌。
22 | 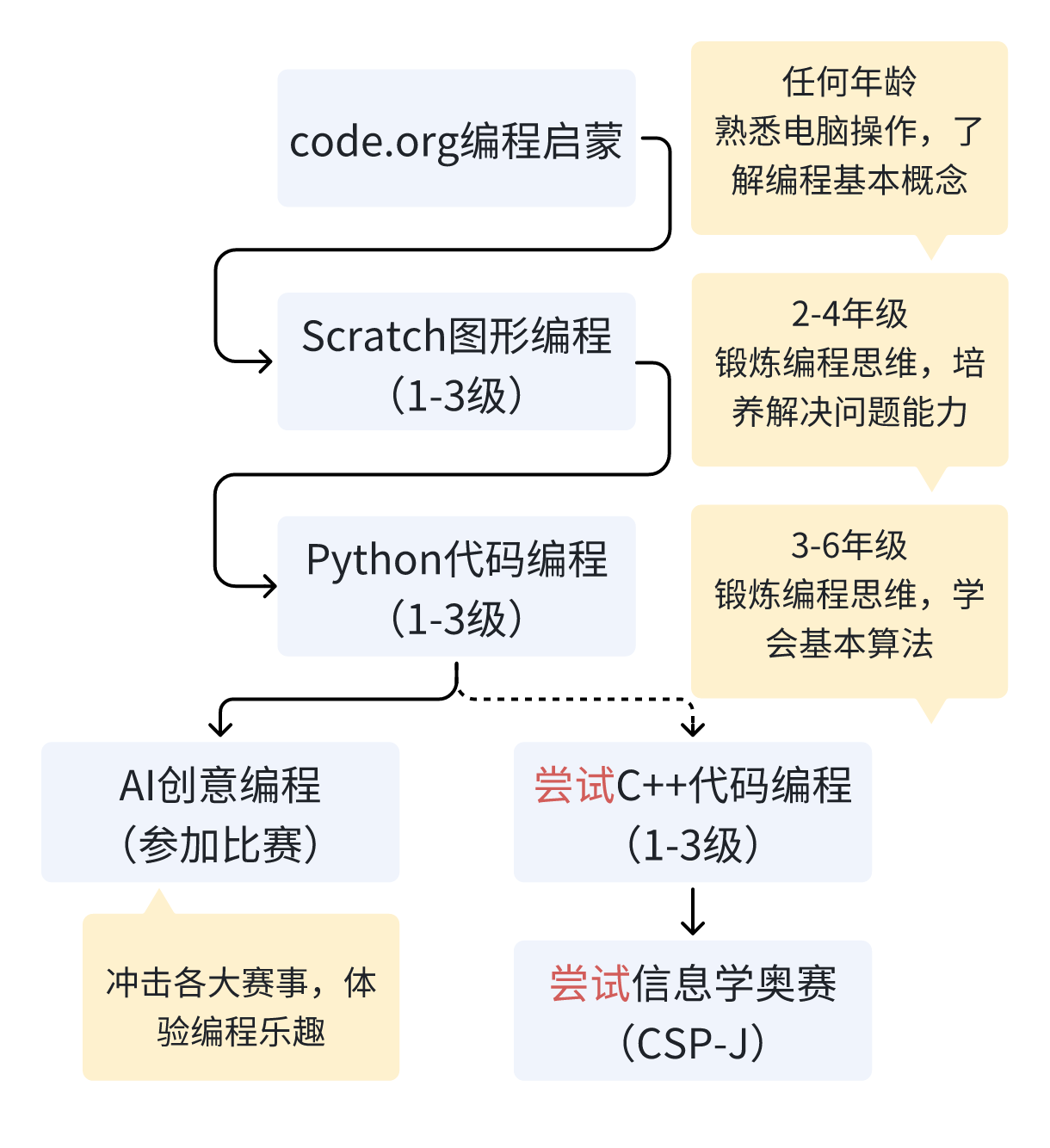
23 |
24 | - 不论从哪个年龄阶段,都建议从code.org开始编程启蒙,关于code.org如何食用,我在这篇文章(全网爆火的免费少儿编程网站!一文揭开code.org的神秘面纱)中做了系统梳理。通常只需学完一个课程,就可以过渡到Scratch图形化编程的学习了。
25 | - 如果孩子到了2-4年级,不妨通过Scratch来锻炼编程思维,优先培养解决问题的能力。
26 | - 如果孩子到了3-6年级,这个阶段的孩子已经具备了一定的抽象思维能力。在经过Scratch编程启蒙的前提下,可以过渡到Python代码编程,锻炼计算思维,学会基本算法
27 | - 如果孩子对算法有浓厚的兴趣,不妨尝试C++代码编程,先学习基础语法,进而尝试学习更复杂的算法,冲击信奥赛奖项;
28 | - 如果孩子对学习算法有点吃力,但是对代码编程感兴趣,可以尝试通过参加各种创意编程竞赛,体验编程乐趣,毕竟孩子的兴趣是驱使其获得未来更多可能性的源动力。
29 | ## 功利路线
30 | 如果你的目标是升学加分走科技特长生路线,那么学习C++就是必须,因为C++是信奥赛官方唯一指定语言,而大部分升学加分的政策都只认可信息学奥林匹克竞赛(简称信奥赛)。为此,孩子的目标终点就是信奥赛获奖。这时就要看孩子的年龄了。
31 |
32 | 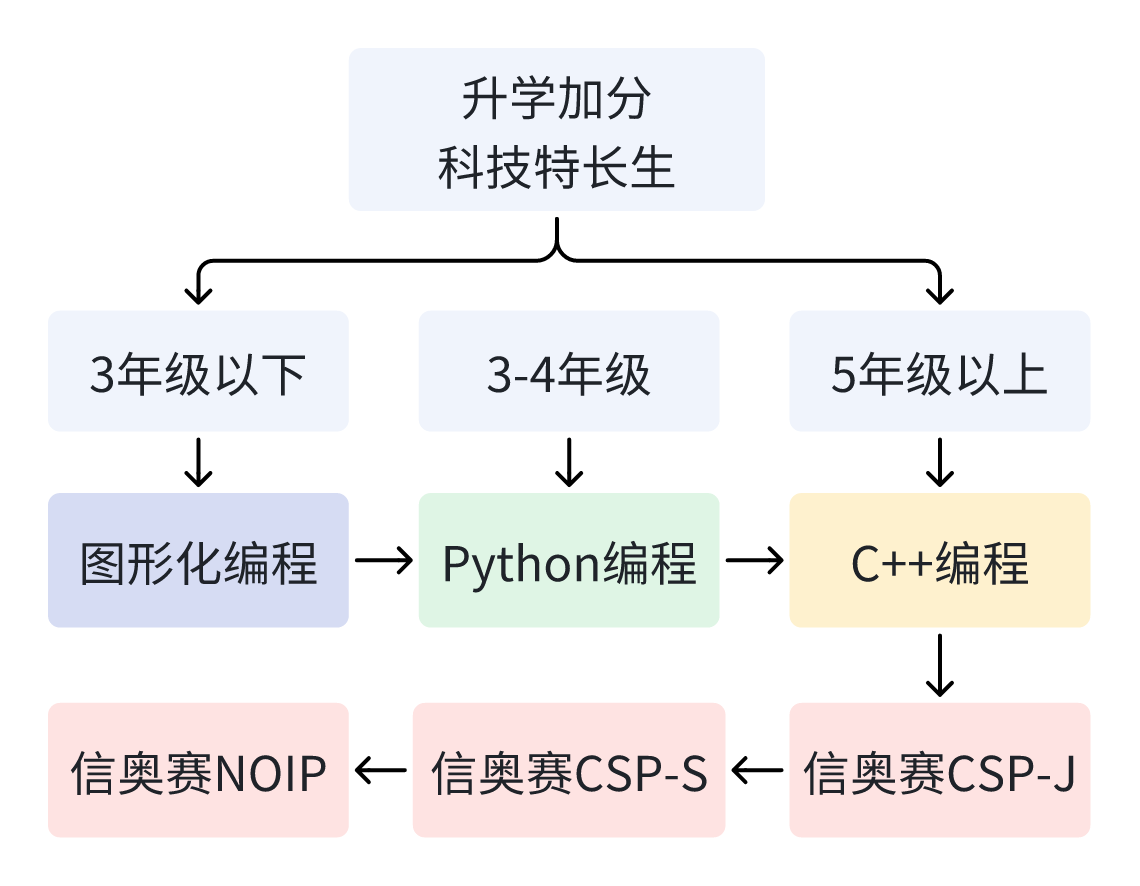
33 |
34 | - 如果孩子的年龄还小,比如3年级以下,那么完全按照佛系路线中的规划来学习,也就是可以从图形化编程开始,做好编程启蒙,培养孩子对编程的兴趣,毕竟兴趣是最好的老师。
35 | - 如果孩子的年龄不大,比如3-4年级,可以先学Python,因为孩子的抽象思维能力刚刚萌芽,抽象的C++语法会抹杀孩子的编程兴趣,而python相对更简单。作为一门过渡语言,帮助孩子巩固Scratch阶段学到的编程核心概念,Python再合适不过了,通过小半年的Python学习,大部分孩子都可以很自然地过渡到C++的学习。
36 | - 如果孩子已经5-6年级,这个阶段的孩子已经具备了较强的抽象思维能力,为了能更快地进入算法阶段的学习,就没必要学习python,可以直接进入C++的语法学习了。需要重点强调的是,信奥赛重点考察的是算法能力,因此不必在C++基础语法阶段学习大量时间。
37 |
38 | # 总结
39 | 本篇文章系统梳理了在家陪娃学编程该如何规划,主要分为两条路线供大家参考食用,如果觉得对你有帮助,不妨收藏转发给身边的朋友,你的真诚点赞是我持续分享的动力!如果你对在家教娃编程如何规划还有疑问,欢迎评论区留言。
--------------------------------------------------------------------------------
/docs/0.少儿编程/娃适合学编程么?不妨陪ta从零开始_2024-07-31.md:
--------------------------------------------------------------------------------
1 | 最近关于少儿编程的信息和资料铺天盖地,害怕家里娃跟不上时代节奏,又担心被收割智商税?
2 | !!不妨陪娃先自学一段时间试试呢!!
3 |
4 | # 少儿编程是什么?
5 | 大白话就是通过寓教于乐的方式让3-18岁青少儿学习程序语言,从而锻炼计算思维和逻辑思维,如果说外语是一门和外国人打交道的语言,那么程序语言就是和计算机打交道的语言。
6 |
7 | # 少儿编程的课程主要有什么?
8 | 目前,培训机构中的少儿编程课程主要可以分为两大类:软件编程、硬件编程。
9 |
10 | 1)软件编程:基于Scratch、Python、C++等编程语言给学生搭建可视化和代码编程学习平台,通过游戏、动画、音乐等载体来学习编程语言。
11 |
12 | 2)硬件编程:通过机器人套件或者Arduino等开源硬件平台,结合电子元件和传感器来学习编程语言。因为需要硬件平台支持,所以成本更高。
13 | 如果家中娃从未接触过编程,不妨从软件编程开始起步,视兴趣再决定是否要接触硬件编程,因为软件几乎零成本,只需自备一台普通的家用电脑就可以了(台式机笔记本均可)。
14 |
15 | # 软件编程的课程如何选择?
16 | 美国计算机教师协会推出的K12计算机教育标准可以帮我们做一个很好的参考。
17 | 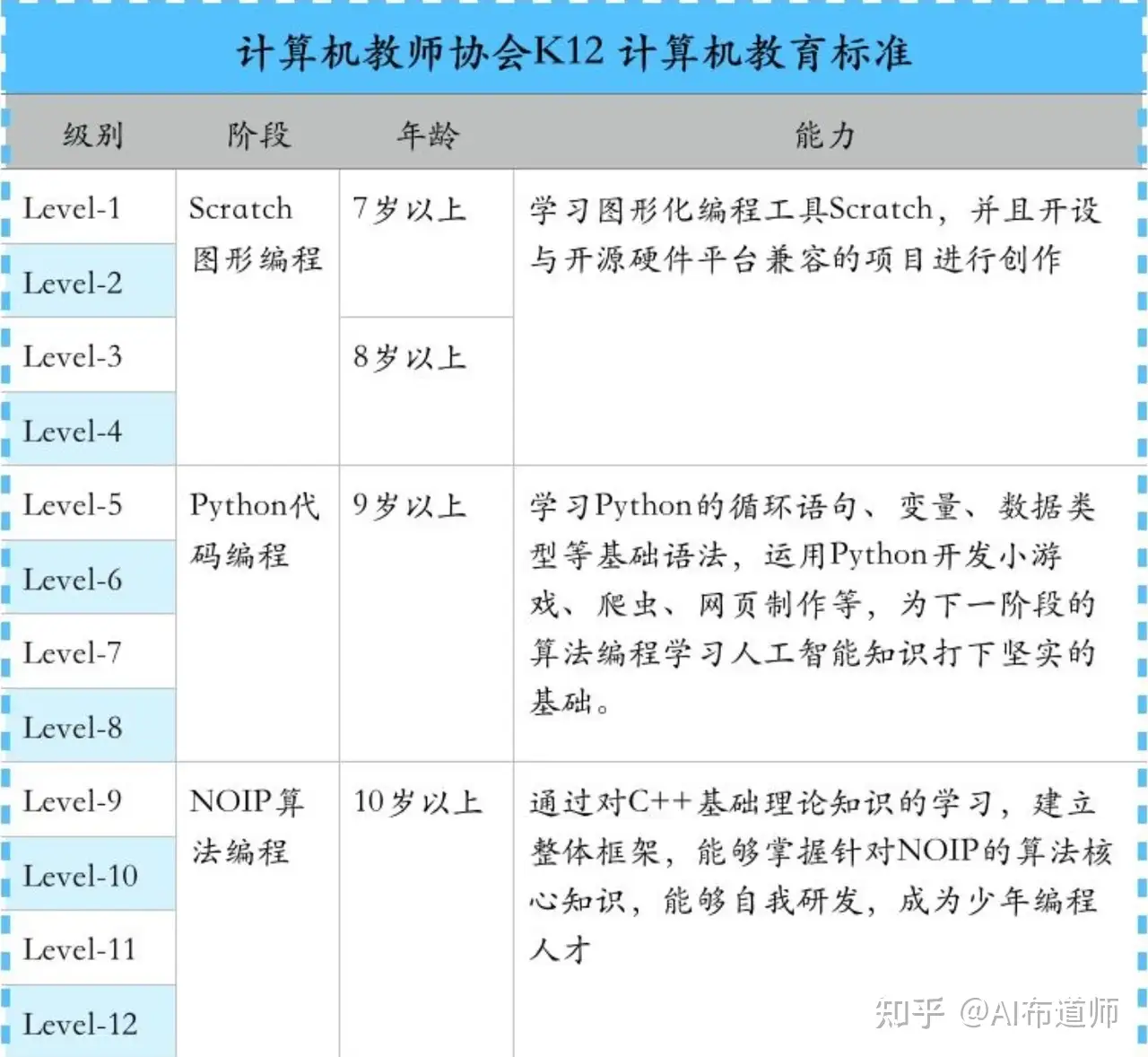
18 |
19 | 按照“图形-代码-算法”的阶段式编程体系,需要根据娃的不同年龄阶段匹配不同的学习内容,不同阶段所学的编程语言特点如下:
20 | - Scratch:图形编程语言,适合7岁以上的娃,因为相关数学知识差不多了汉字也有一定基础,思维也能跟上,这个阶段可以陪娃学习和编程相关的汉字,熟悉电脑的基本操作,比如鼠标键盘以及电脑开关机。
21 | - Python:代码编程语言,适合9岁以上的娃,因为孩子的抽象思维能力有了一定提升,且词汇量也有了进一步提升,可以尝试让娃学习一门代码编程语言,而Python则因为简单易学,非常适合初学者学习。这个阶段可以陪娃练习键盘打字了,这是学习代码编程语言的必备条件。
22 | - C++:代码编程语言,适合10岁以上的娃,到了这一阶段,可以尝试让娃学习更多的算法知识,甚至尝试参加一些算法竞赛,比如现在各个机构鼓吹的信奥赛CSP/NOIP,不过信奥赛更多的是选拨性质,如果到了这一阶段,孩子依然有兴趣,可以陪娃学习C++基本的语法知识以及一些简单的算法知识,想要冲击NOIP奖项就需要找专业的教练进行学习了,不是每个机构的老师都能教的。
23 |
24 | # 你最关心的编程启蒙从哪开始?
25 | 也许大部分机构老师都会推荐娃学习Scratch,尽管是一门图形编程语言,Scratch的上限也是非常高的,基本涵盖了编程几乎所有的逻辑训练和算法。网上有关Scratch的学习资料非常多,我会把搜集到的比较不错的资料整理到知识库中,有关Scratch如何入门我会专门出一篇文章来详聊。
26 | 不过如果是在家陪娃学习,我推荐的编程学习路径是:
27 | 
28 |
29 | 1. code.org 关卡制,先通过解决问题来学习基本概念,在过五关斩六将中体验乐趣
30 | 2. Scratch 项目制,通过开发制作游戏动画等项目来建立计算思维和逻辑思维,在项目开发中体验成就感
31 | 3. Python 项目制,熟悉文本编程语言并开始接触部分算法知识
32 | 4. C++ 算法竞赛,在校内知识学有余力的情况下,走科技特长生路线,体验编程和算法的乐趣
33 | 所以不管娃是什么年龄,都强烈推荐从code.org开始启蒙,通过解决问题先学会基本概念。code.org的课程体系非常完整,从认识鼠标、到拖拽、到循环等概念,循序渐进带领孩子掌握编程知识,不妨先进去体验一番!不过code.org近两年也进行了改版,更有利于不同年龄段的孩子学习,有关code.org的课程如何选择,我会在下期文章中详细聊聊。
34 |
35 | 经过几年的学习,我陪娃已经快快乐乐度过了编程启蒙阶段,最近想把自己找到的资料以及心得体会系统化梳理下,变成一个知识库,希望能够给更多的宝爸宝妈带来帮助!感兴趣的家长欢迎评论区留言,我们一起为孩子们打造一个编程乐园。
--------------------------------------------------------------------------------
/docs/0.少儿编程/少儿编程考级怎么选?你想要了解的一切都在这里_2024-07-31.md:
--------------------------------------------------------------------------------
1 | # 写在前面:
2 | 在上一篇[娃是否适合学编程?不妨陪ta从这里开始](https://zhuanlan.zhihu.com/p/686105069),我们系统梳理的在家陪娃学编程应该怎么规划。不管我们学什么,兴趣都是最原始的源动力。如果在学习过程中,能够不断获得一些持续正反馈,势必会让孩子走的更远。在少儿编程的学习之路上,等级考试和编程比赛就是给孩子提供正反馈的两种手段。
3 |
4 | 本篇我们将回答有关等级考试的两个问题:
5 | - 等级考试是什么?
6 | - 如何通过等级考试?
7 |
8 | 有关`编程比赛`的相关内容,大力会再专门出一篇笔记进行整理。
9 |
10 | # 等级考试是什么?
11 | 少儿编程等级考试,是考查学生编程能力水平的一种测试,和书法、乐趣等艺术特长的等级考试类似,通过不同的等级来衡量在某一领域的专业水平。因此是检验孩子编程掌握程度的一种非常行之有效的手段,同时也是孩子的一项技能认证。通过对应等级考试后,可以获得对应的等级证书,这不仅是对孩子学习过程的认可,也可以作为孩子简历上重要的一项成绩。
12 |
13 | 那么都有哪些等级考试呢?近年来,随着少儿编程概念的火热,市面上出现了不少少儿编程相关的等级考试,琳琅满目,鱼龙混杂,一不小心就会步入机构的圈套。
14 |
15 | 一句话概括等级考试如何避坑:优先选择国内一级学会主办的等级考试。
16 | 所以大力推荐的等级考试只有两个:
17 | - 中国电子学会(CIE)主办的青少年软件编程等级考试
18 | - 推荐指数:⭐️
19 | - 中国计算机学会(CCF)主办的编程能力等级认证(GESP)
20 | - 推荐指数:⭐️⭐️
21 | ## 电子学会-青少年软件编程等级考试
22 | 中国电子学会于2018年启动的面向青少年软件编程能力水平开展的社会化评价项目,全面考察青少年的软件编程水平和实践能力,其考察内容覆盖了Scratch、Python和C++。
23 | - 考试级别:
24 | - Scratch 1-4级
25 | - Python 1-6级
26 | - C++ 1-10级
27 | - 以上考试均为1级必考,可以跳级,100分制60分通过
28 | - 考试内容:
29 | - Scratch和Python:单选题、判断题、编程项目题;
30 | - C++:编程项目题
31 | - 年龄要求:
32 | - Scratch 6-15周岁
33 | - Python和C++ 8-18周岁
34 | - 考试时间:每年四次认证,分别在3/6/9/12月
35 | - 考试方式:线上机考
36 | - 报名费用:240-340/次
37 | - 考试大纲:
38 | - Scratch:www.qceit.org.cn
39 | - Python:www.qceit.org.cn
40 |
41 | 下面三张图分别给出了Scratch、Python和C++三种语言对应的等级考试的各个级别对应的考试内容,供大家参考。
42 | 
43 |
44 | ## 计算机学会-编程能力等级认证(GESP)
45 | 中国计算机学会主办,为青少年计算机和编程学习者提供学业能力验证的平台。GESP旨在提升青少年计算机和编程教育水平,推广和普及青少年计算机和编程教育。GESP覆盖中小学全学段,符合条件的青少年均可参加认证。其考察内容同样覆盖了Scratch、Python和C++。相比电子学会的认证而言,GESP在2023年3月份才开启第一次认证。
46 | - 考试级别:
47 | - Scratch 1-4级
48 | - Python&C++ 1-8级
49 |
50 | 注:以上考试均为1级必考,100分制60分通过,90分(含90分)以上可跳一级参加认证;不同编程语言同一个级别对应的编程能力基本相同,最高两级考纲贴合CSP-J/S认证大纲,1-4级更倾向于验证能力,5-8级更倾向于选拔高手。
51 | - 考试内容:
52 | - 15道选择题+10道判断题+2道编程题
53 | - 总分100分 90分钟内完成
54 | - 考试时间:每年四次认证,分别在3/6/9/12月
55 | - 考试方式:全国统一线下机考
56 | - 报名费用:300-440/次
57 | - 考试大纲:
58 | - Scratch https://gesp.ccf.org.cn/101/attach/1579692243025952.pdf
59 | - Python&C++ https://gesp.ccf.org.cn/101/attach/1579675000242208.pdf
60 |
61 | # 如何通过等级考试
62 | ## 选择一个等级考试
63 | 关于少儿编程的学习该如何规划,大力在[娃是否适合学编程?不妨陪ta从这里开始](https://zhuanlan.zhihu.com/p/686105069)这篇笔记中已经做了详细梳理,一般来讲Scratch和Python考完1-3级,孩子的编程基础就没有问题了,这时就可以去冲击一些编程赛事或者去挑战学习C++的内容,关于少儿编程都有哪些比赛,大力会再专门出一篇笔记进行整理。
64 |
65 | 大力优先推荐计算机学会的GESP,为什么?一张图给梳理明白。
66 | 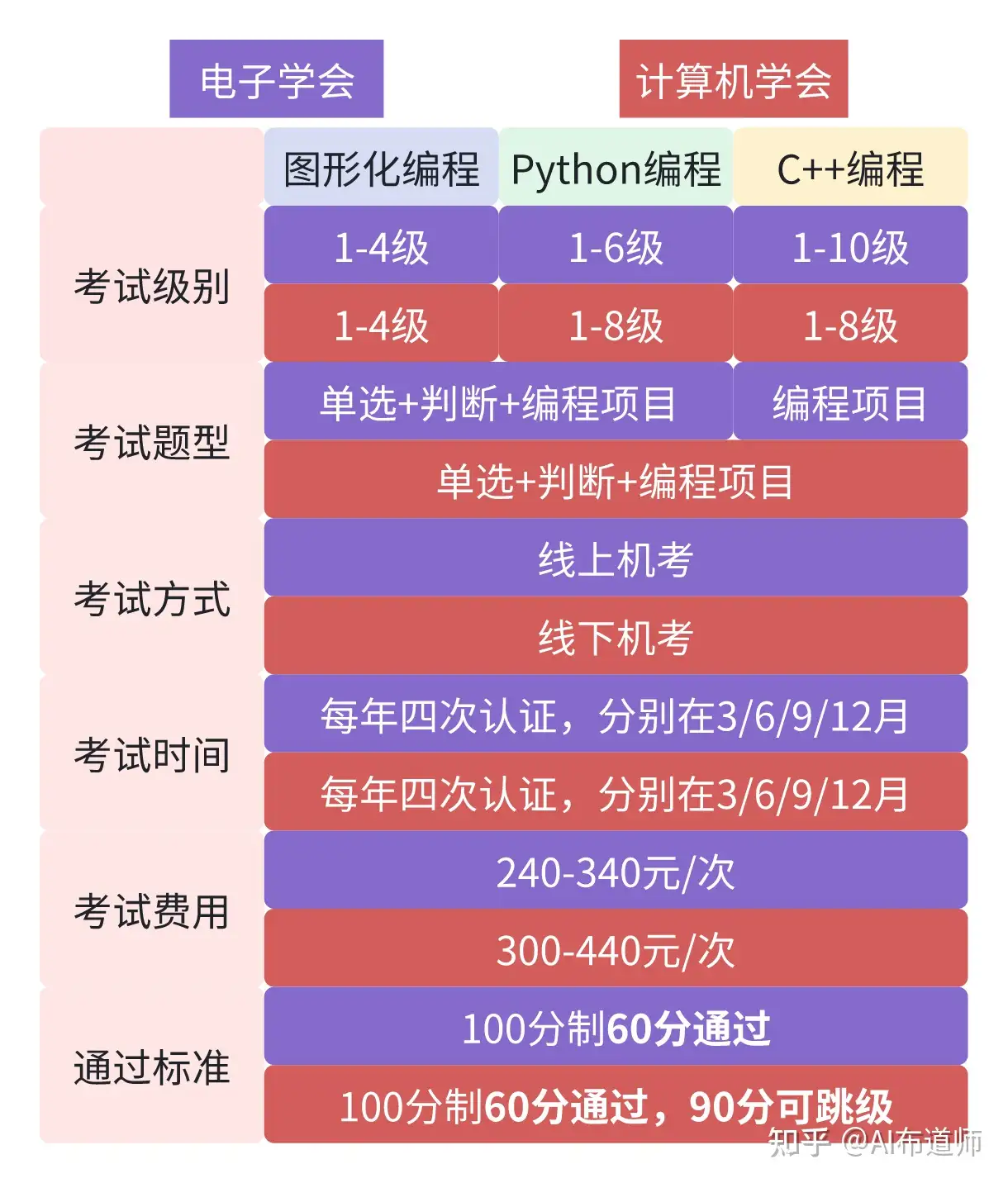
67 | 根据上表的汇总分析,大力更推荐计算机学会的GESP认证,主要原因是:
68 | - **等级划分更加合理**:在GESP中,Python和C++都是1-8级,而且不同编程语言同一个级别对应的编程能力基本相同,为此Scratch和Python的考级可以无缝衔接到C++中。
69 | - **考试题型更加统一**:在GESP中,所有等级考试的提醒都是15道选择题+10道判断题+2道编程题,这样孩子在学习过程中适应不同题型的成本更低
70 | - **跳级规则更加明确**:在GESP中,每级考试>90分均可在下一次认证时进行跳级认证,对学习能力和接受能力更强的孩子更加友好。
71 | - **最后且最重要的优势**:GESP的等级考试可以无缝衔接到信奥赛CSP-J和CSP-S,方便孩子进行自我能力评估,发现是否有编程方面的特长,进而早日规划走科技特长生的道路。具体的衔接规则,官网也做了详细说明。
72 | - 不过孩子在通过Python3-4级后,就可以尝试学习C++,进而尝试信奥赛CSP-J了,然后C++的等级考试可以同步进行。
73 | - 关于信奥赛是什么,大力会再专门出一篇笔记进行整理。
74 |
75 | 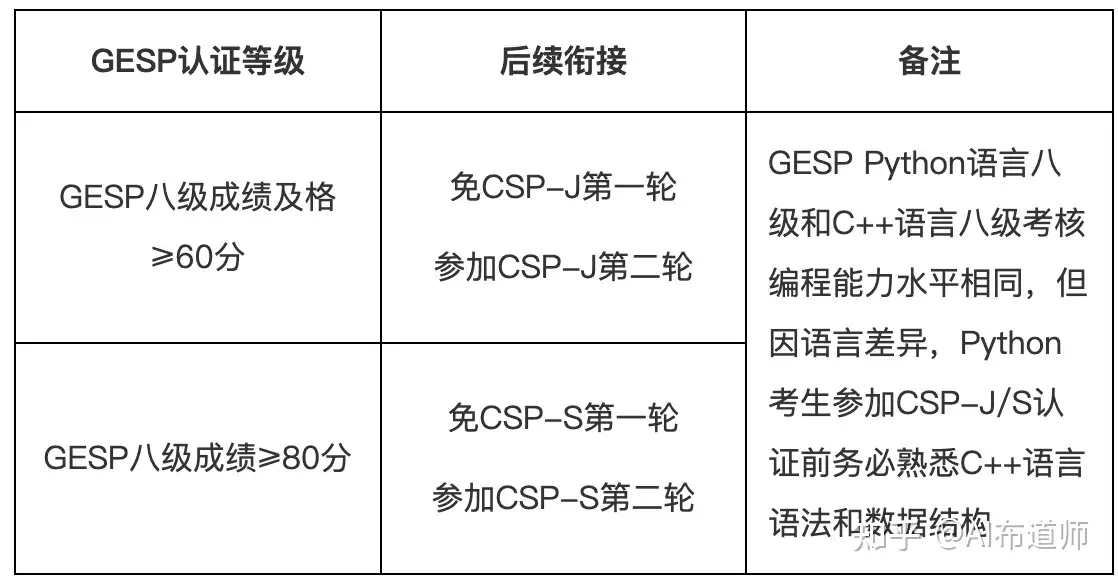
76 |
77 |
78 | 所以等级考试怎么选,结论是:
79 | - 如果孩子已经参加了等级考试,那么沿着之前选择的继续参加即可
80 | - 如果还没有参加等级考试,那么优先推荐计算机学会的GESP
81 |
82 | ## 对标大纲进行课程学习
83 | 大纲为孩子们的编程学习指明了路径和方向,而且基本也是符合孩子的认知规律的,GESP官网也已经公开了三种语言的大纲:
84 | - Scratch https://gesp.ccf.org.cn/101/attach/1579692243025952.pdf
85 | - Python&C++ https://gesp.ccf.org.cn/101/attach/1579675000242208.pdf
86 |
87 | 以scratch1-4级的考察内容为例,可以通过如下思维导图很清晰get到:
88 |
89 | 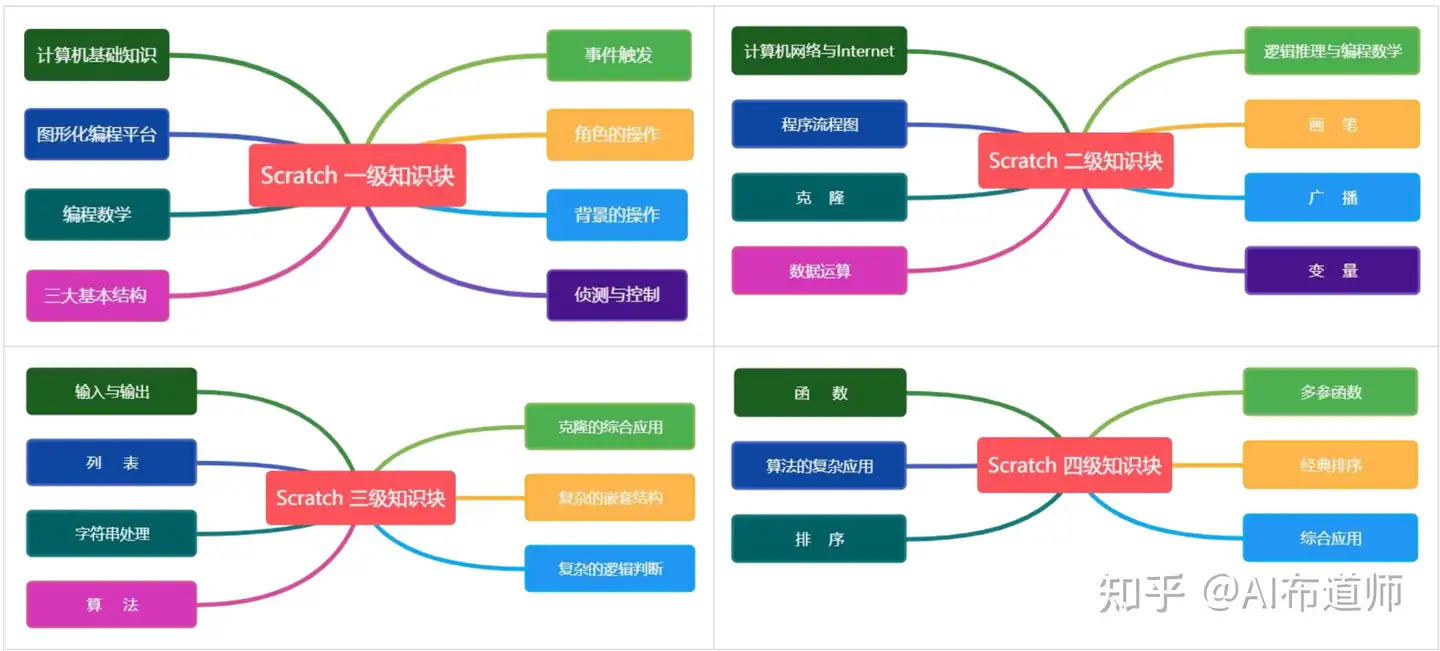
90 |
91 |
92 | *针对计算机学会GESP等级考试的系统学习,大力准备出一期完备的课程,在编程学习之路上助大家一臂之力,敬请关注!*具体计划安排和优先级如下:
93 | - P0 Scratch 1-3级
94 | - P1 Python 1-4级
95 | - P2 C++ 1-8级
96 |
97 | ## 真题演练
98 | 官网每次认证都会放出真题,这里系统整理下历年的GESP考试真题,供大家备考前进行实战演练。
99 | - 2023-3认证:真题:https://gesp.ccf.org.cn/101/1010/10068.html
100 | - 2023-6认证:真题:https://gesp.ccf.org.cn/101/1010/10092.html
101 | - 2023-9认证:真题:https://gesp.ccf.org.cn/101/1010/10105.html
102 | - 2023-12认证:真题:https://gesp.ccf.org.cn/101/1010/10119.html
103 | - 2023-四次认证的真题解析汇总:https://gesp.ccf.org.cn/101/1010/10100.html
104 |
105 | # 更多资源梳理
106 | > 未完待续!后续会在这部分整理更多关于等级考试的免费学习资源。
107 |
108 | 如果觉得对你有帮助,欢迎点赞收藏关注~
--------------------------------------------------------------------------------
/docs/1.Linux笔记/Docker 国内镜像站全部失效?试试这个方法,亲测有效.md:
--------------------------------------------------------------------------------
1 | 最近,很多朋友发现 Docker 镜像拉取不下来了~
2 | > PS:还不了解 Docker 的小伙伴,可以看这篇:[【保姆级教程】Linux系统如何玩转Docker](https://blog.csdn.net/u010522887/article/details/137206719)
3 |
4 | 罪魁祸首是:国内的大部分镜像站都停止服务了,包括:sjtu、ustc、百度、腾讯。。。
5 |
6 | 不过还好,阿里云的镜像还不受影响。
7 |
8 | 怎么搞?
9 |
10 | **第 1 步: 阿里云注册账号**
11 | > 传送门:[https://www.aliyun.com/](https://www.aliyun.com/)
12 |
13 | 支付宝扫码即可登录。
14 |
15 | **第 2 步: 搜索容器镜像服务**
16 |
17 | 点击立即开通。
18 |
19 | 
20 |
21 | **第 3 步: 找到镜像加速器**
22 |
23 | 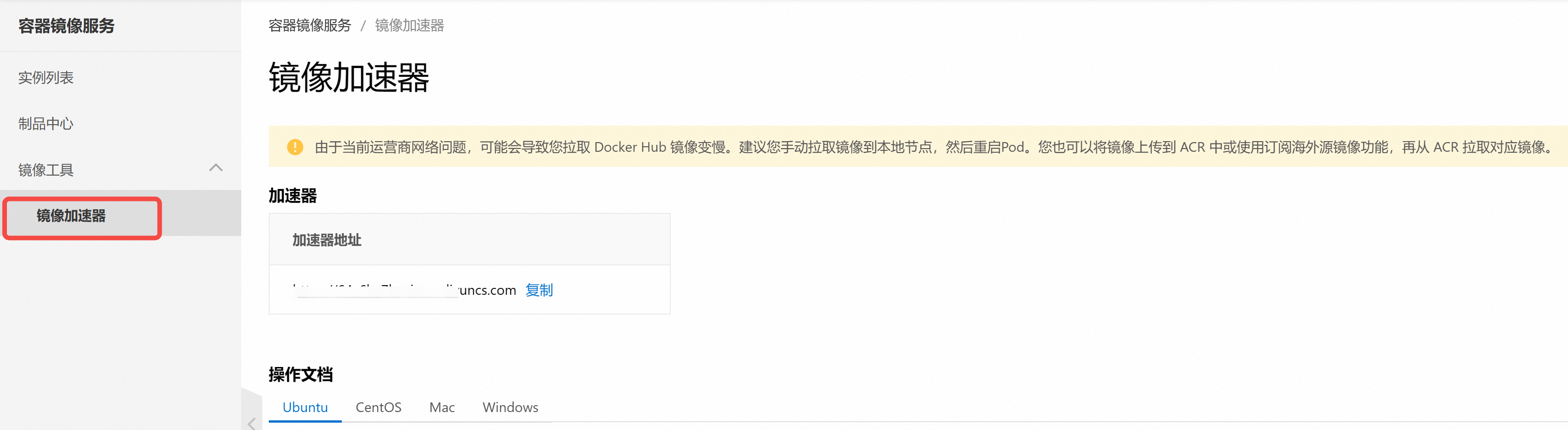
24 |
25 | **第 4 步: 配置镜像加速器**
26 |
27 | 参考不同操作系统的配置文档,比如在我的 Linux 服务器上:
28 |
29 | 通过修改 daemon 配置文件,就可以使用加速器。
30 |
31 | 首先,新建文件夹:
32 | ```
33 | sudo mkdir -p /etc/docker
34 | ```
35 | 然后,写入第 3 步的加速器地址:
36 |
37 | ```
38 | sudo tee /etc/docker/daemon.json <<-'EOF'
39 | {
40 | "registry-mirrors": ["https://xxx.mirror.aliyuncs.com"]
41 | }
42 | EOF
43 | ```
44 |
45 | 最后,重启 docker:
46 |
47 | ```
48 | sudo systemctl daemon-reload
49 | sudo systemctl restart docker
50 | ```
51 |
52 | 快去试试,镜像下载,有没有快到飞起~
53 |
54 | 如果本文对你有帮助,欢迎**点赞收藏**备用。
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
--------------------------------------------------------------------------------
/docs/1.Linux笔记/README.md:
--------------------------------------------------------------------------------
1 | # 1.Linux笔记
2 |
3 | - [AI 本地环境配置:一文梳理 Nvidia驱动_CUDA_CUDNN_PyTorch_Paddle 版本兼容&安装问题(持续更新)](docs/1.Linux笔记/AI%20本地环境配置:一文梳理%20Nvidia驱动_CUDA_CUDNN_PyTorch_Paddle%20版本兼容&安装问题(持续更新).md)
4 | - [Docker 国内镜像站全部失效?试试这个方法,亲测有效](docs/1.Linux笔记/Docker%20国内镜像站全部失效?试试这个方法,亲测有效.md)
5 | - [【保姆级教程】Linux系统下如何玩转Docker](docs/1.Linux笔记/【保姆级教程】Linux系统下如何玩转Docker.md)
6 | - [【保姆级教程】Windows 远程登录 Ubuntu桌面环境](docs/1.Linux笔记/【保姆级教程】Windows%20远程登录%20Ubuntu桌面环境.md)
7 | - [【保姆级教程】Windows 远程登陆 Linux 服务器的两种方式:SSH + VS Code,开发必备](docs/1.Linux笔记/【保姆级教程】Windows%20远程登陆%20Linux%20服务器的两种方式:SSH%20+%20VS%20Code,开发必备.md)
8 | - [【保姆级教程】Windows上安装Linux子系统,搞台虚拟机玩玩](docs/1.Linux笔记/【保姆级教程】Windows上安装Linux子系统,搞台虚拟机玩玩.md)
9 | - [【保姆级教程】如何在 Windows 上实现和 Linux 子系统的端口映射](docs/1.Linux笔记/【保姆级教程】如何在%20Windows%20上实现和%20Linux%20子系统的端口映射.md)
10 | - [【保姆级教程】实操 Linux 磁盘管理:硬盘选型 & 分区挂载](docs/1.Linux笔记/【保姆级教程】实操%20Linux%20磁盘管理:硬盘选型%20&%20分区挂载.md)
11 | - [报错解决ImportError_ libcrypto.so.10_ cannot open shared object file_ No such file or directory](docs/1.Linux笔记/报错解决ImportError_%20libcrypto.so.10_%20cannot%20open%20shared%20object%20file_%20No%20such%20file%20or%20directory.md)
12 | - [报错解决ImportError_ libnvinfer.so.7_ cannot open shared object file_ No such file or directory](docs/1.Linux笔记/报错解决ImportError_%20libnvinfer.so.7_%20cannot%20open%20shared%20object%20file_%20No%20such%20file%20or%20directory.md)
13 |
14 |
15 |
16 | *本系列共更新**10**篇文章*
17 |
18 |
19 |
20 | [🔙返回首页](/)
21 |
--------------------------------------------------------------------------------
/docs/1.Linux笔记/【保姆级教程】Windows 远程登录 Ubuntu桌面环境.md:
--------------------------------------------------------------------------------
1 | # 前言
2 | 在Windows下远程访问Linux服务器的桌面,有几种常见的方法:
3 |
4 | - xrdp(X Remote Desktop Protocol):xrdp允许Windows使用RDP(Remote Desktop Protocol)来连接到Linux服务器的桌面。这种方式相对简便,因为它使用Windows自带的远程桌面客户端。
5 |
6 | - VNC(Virtual Network Computing):VNC是一种基于图形界面的远程桌面协议,它允许用户远程访问Linux桌面。
7 |
8 | - SSH(Secure Shell):SSH是一种网络协议,用于加密方式远程登录到服务器。虽然SSH本身不提供图形界面访问,但可以通过X11转发功能在Windows上显示Linux的图形应用程序。
9 |
10 | 原本打算通过 VNC 实现远程连接,不过灰屏的问题一直无法解决,考虑到登陆远程桌面的需求并不多,主要是需要登陆浏览器实现校园网登陆,所以退而求其次采用 xrdp 来实现远程登陆。
11 | # RDP连接Ubuntu桌面具体步骤
12 | 要通过远程桌面协议(RDP)连接运行Xfce4桌面环境的Ubuntu系统,大致可以按照以下步骤操作:
13 | ## 1. 安装 RDP 服务器:
14 | 在Ubuntu系统上,您需要安装一个RDP服务器,如xrdp。使用以下命令安装:
15 |
16 | ```bash
17 | sudo apt-get update
18 | sudo apt-get install xrdp
19 | ```
20 |
21 | ## 2. 配置 Xfce4 桌面:
22 | xrdp默认使用Xfce4作为桌面环境。确保Xfce4已经安装在您的系统上。如果没有,您可以使用以下命令安装:
23 |
24 | ```bash
25 | sudo apt-get install xfce4
26 | ```
27 | xrdp 使用VNC 作为其显示协议,因此您还需要安装一个VNC服务器,不过 xrdp 安装过程中通常会同时安装 Xvnc。
28 | ## 3. 配置 xrdp
29 | 安装完成后,您可能需要配置xrdp以使用Xfce4。这通常涉及到编辑.xsession文件,确保它指向Xfce4。这里使用文本编辑器 Vim 编辑 ~/.xsession 文件,并添加以下行:
30 |
31 | ```bash
32 | xfce4-session
33 | ```
34 | ## 4. 启动 xrdp 服务:
35 | 安装和配置完成后,启动 xrdp 服务:
36 |
37 | ```bash
38 | sudo systemctl enable xrdp
39 | sudo systemctl start xrdp
40 | ```
41 | 如果要退出 xrdp 服务:
42 |
43 | ```bash
44 | sudo systemctl stop xrdp
45 | ```
46 | ## 5. 允许通过防火墙(可选)
47 | 这一步非必须,如果能连接到 RDP 服务器,则不需要执行这一步。否则,需要确保 RDP 端口 3389 在您的防火墙中是开放的。如果您使用的是ufw,可以使用以下命令:
48 |
49 | ```bash
50 | sudo ufw allow 3389/tcp
51 | ```
52 | ## 6. 连接到RDP服务器
53 | 在Windows机器上,打开`远程桌面连接`应用程序,并输入Ubuntu服务器的IP地址。您应该会看到登录界面,输入Ubuntu的用户名和密码后,您就可以通过RDP访问Xfce4桌面了。
54 | 
55 |
56 |
--------------------------------------------------------------------------------
/docs/1.Linux笔记/【保姆级教程】Windows 远程登陆 Linux 服务器的两种方式:SSH + VS Code,开发必备.md:
--------------------------------------------------------------------------------
1 | # 0. 前言
2 | 很多情况下代码开发需要依赖 Linux 系统,远程连接 Linux 服务器进行开发和维护已成为一种常态。对于使用Windows系统的开发者来说,掌握如何通过 SSH 安全地连接到 Linux 服务器,并利用 VS Code 编辑器进行开发,是一项必备的技能。对于没有服务器的同学,可以参考笔者之前的文章 [Windows上安装Linux子系统,搞台虚拟机玩玩](https://blog.csdn.net/u010522887/article/details/137632509) 准备一个 Linux 环境。
3 |
4 | 本文将详细介绍两种在 Windows 下远程登陆 Linux 服务器的方法:SSH 命令行和 VS Code 远程开发。
5 |
6 | # 1. 远程登陆的两种方式
7 | ## 1.1 SSH远程连接Linux服务器
8 | SSH(Secure Shell)是一种网络协议,用于加密方式远程登录到服务器。以下是通过SSH连接Linux服务器的基本步骤:
9 |
10 | 1. **安装SSH客户端**:Windows 10及以上版本自带了OpenSSH客户端
11 | 2. **安装SSH服务端**:在服务器端安装 OpenSSH,需要在服务器终端进行。
12 |
13 | ```bash
14 | # 安装 ssh
15 | sudo apt install openssh-server
16 | # 安装完成后一般会自动启动,通过如下命令检查 ssh 是否已经启动
17 | sudo systemctl status ssh
18 | # 如果没有启动,需要启动 ssh 服务
19 | sudo systemctl start ssh
20 | # 如果要停止 ssh 服务
21 | sudo systemctl stop ssh
22 | ```
23 | 3. **通过SSH登陆服务器**:ssh 登陆服务器一般有两种方式:
24 | - 使用密钥认证:参考笔者之前的文章 [Windows上安装Linux子系统,搞台虚拟机玩玩](https://blog.csdn.net/u010522887/article/details/137632509) 中对密钥认证步骤的分享,简言之,主要分为以下两步:
25 | **首先,Windows 本地生成SSH密钥对**。下载并安装Git for Windows,然后打开Git Bash终端:在终端中执行命令 `ssh-keygen` ,这时会在本地 .ssh 文件夹中生成了密钥文件, .ssh 文件夹一般保存在 C 盘,比如我的是` C:\Users\12243\.ssh`,文件夹下 id_rsa 是私钥,id_rsa.pub 是公钥。
26 | **然后,复制公钥到 Linux 服务器**。将id_rsa.pub中的内容复制到 Linux 的你的用户根目录 `~/.ssh/authorized_keys` 文件中。
27 |
28 | ```bash
29 | mkdir ~/.ssh
30 | cd ~/.ssh
31 | echo xxx_in_your_id_rsa_pub >> authorized_keys
32 | ```
33 |
34 | - 使用密码认证:这种方式比较简单,唯一的缺点就是每次登陆都需要输入你的账号密码。
35 | 不管采用以上哪种方式,都可以参考如下命令在终端执行登陆,唯一的区别是第一种方式不需要输入密码:
36 | ```bash
37 | ssh your_user_name@172.17.4.63
38 | ```
39 |
40 | ## 1.2 使用VS Code进行远程开发
41 | VS Code(Visual Studio Code)是一个功能强大的编辑器,支持远程开发。以下是使用VS Code连接Linux服务器的步骤:
42 | ### 1.2.1 安装VS Code
43 | 首先需要在本地 Windows 电脑上下载并安装最新版的 VS Code,下载地址见 [官网](https://code.visualstudio.com/)。安装流程可以参考笔者之前的文章[Windows 环境准备 - Conda 和 VS code 安装](https://blog.csdn.net/u010522887/article/details/136969406)
44 | ### 1.2.2 远程登陆
45 | VS Code 访问服务器需要在本地进行一番配置后,然后执行 ssh 登陆,具体而言,可以分为以下几个步骤:
46 | - **Step 1**: 安装 Remote-SSH 插件。第一次使用VS Code 需要在左侧插件栏搜索 Remote-SSH 并安装。
47 | 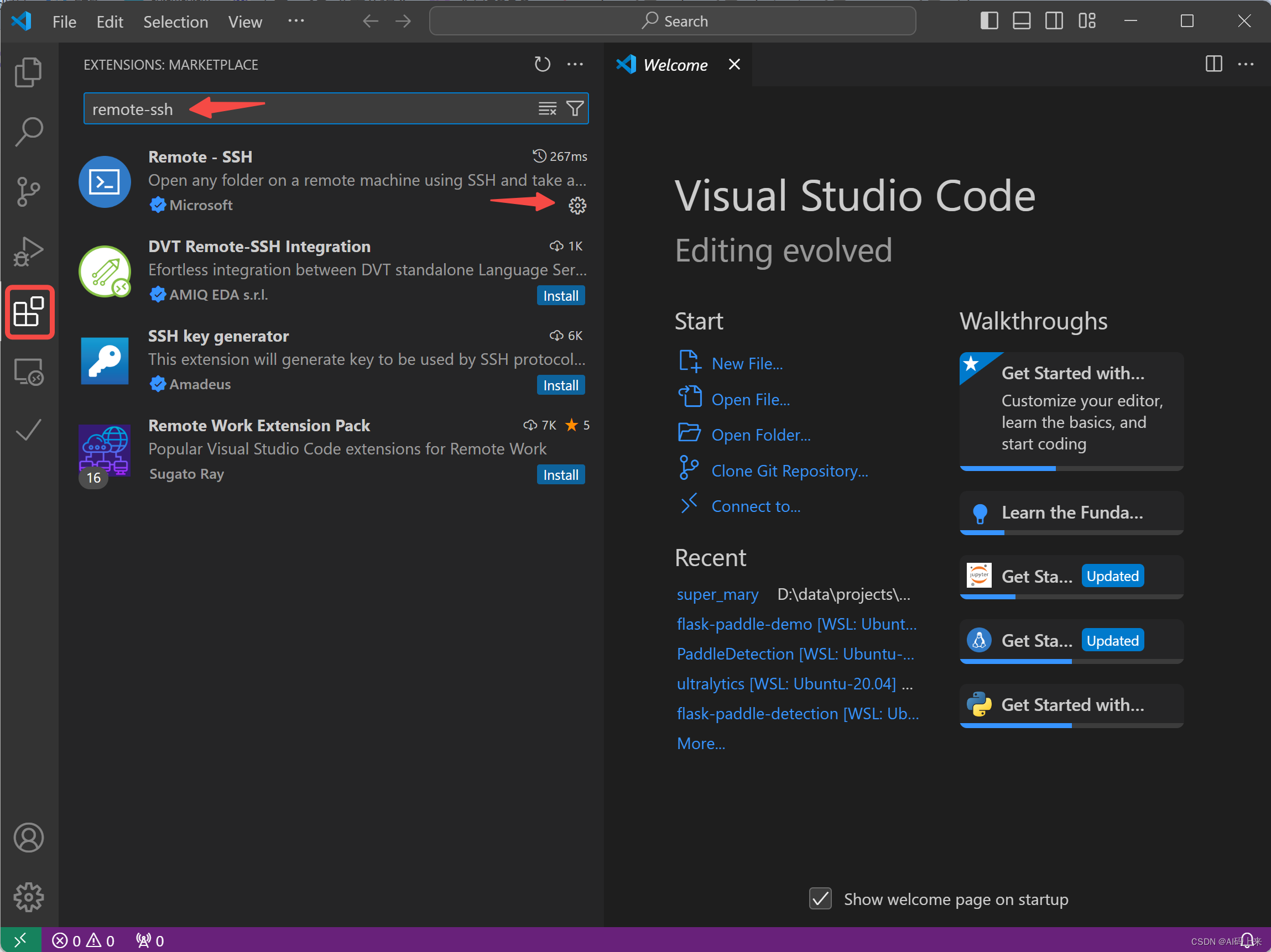
48 | - **Step 2**: 左下角 Open a remote window 然后选择 Connect to Host。
49 | 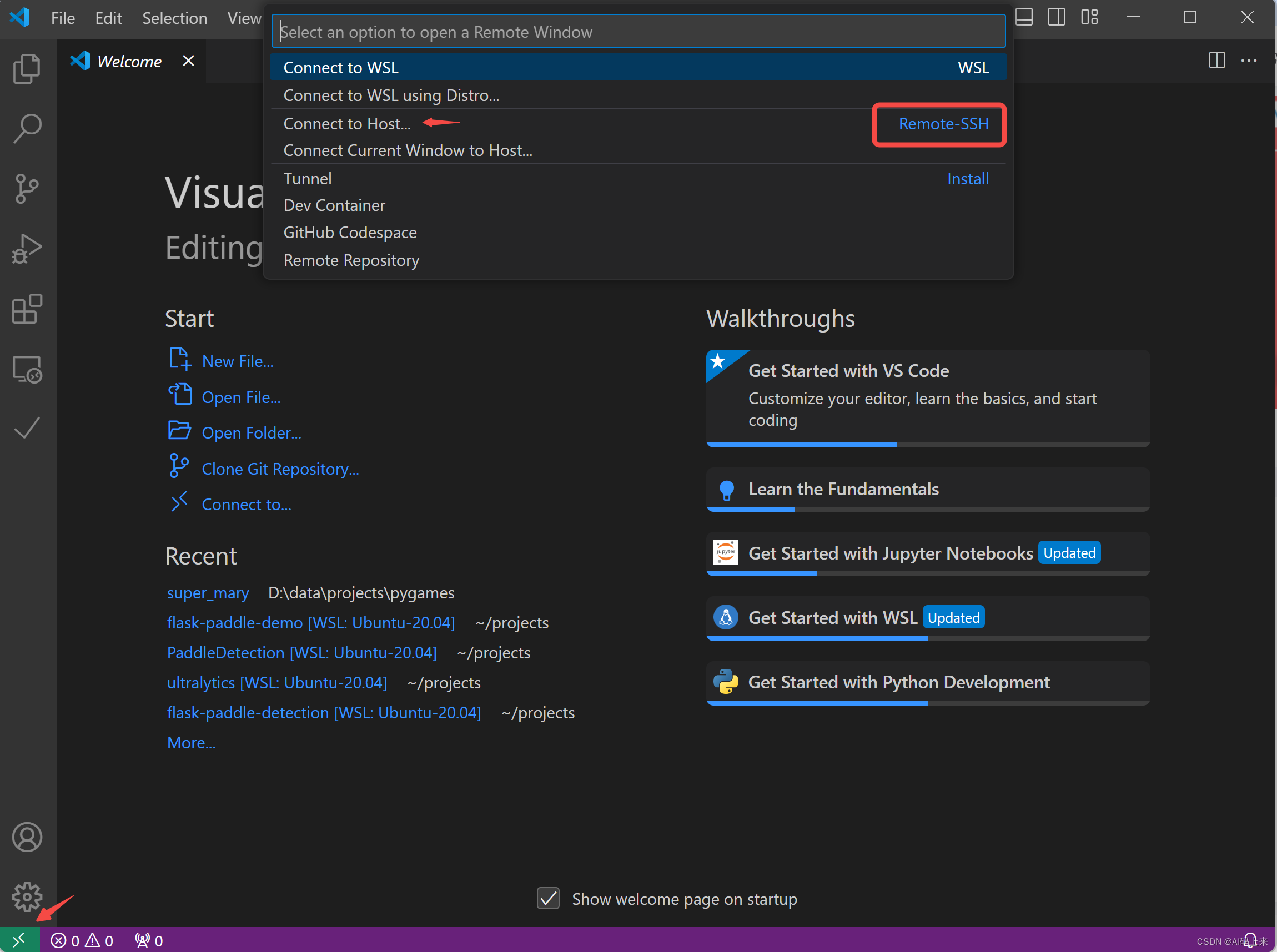
50 | - **Step 3**: 执行 ssh 登陆。 如下图所示,这里有两种选择:
51 | 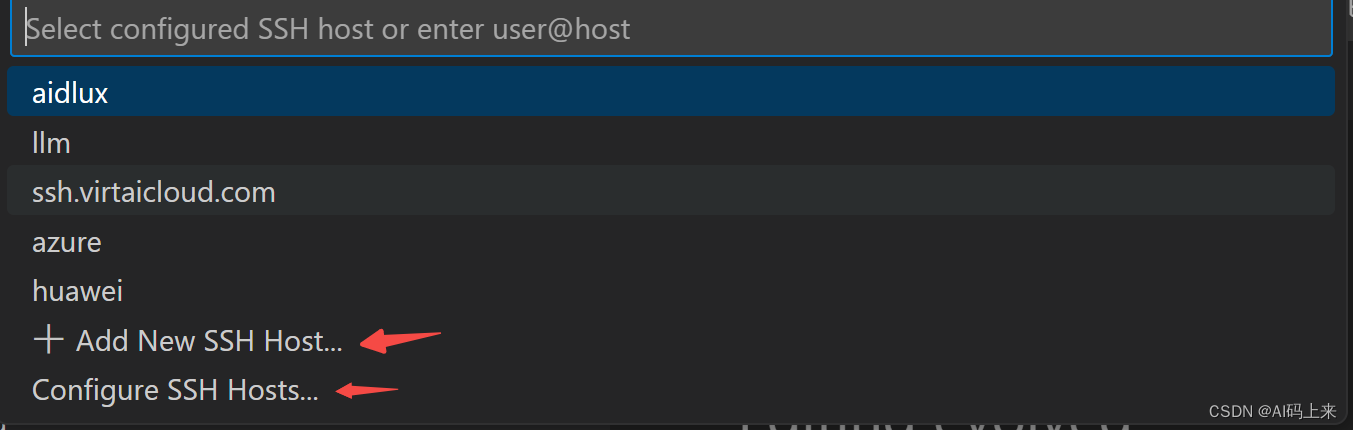
52 | - Add New SSH Host,也就是新建一个 Host :如果只是偶尔登陆这个 host ,可以选择这种方式
53 | - Configure SSH Hosts,也就是配置一个 Host:如果需要经常登陆,可以新建一个配置文件,这样每次登陆直接选择对应的 Host 名称就可以了,这里的配置文件一般在 C 盘用户目录下,比如我的就在 `C:\Users\12243\.ssh\config`。在config 文件中填入如下信息:Host 就是后续登陆使用的名称,HostName是服务器的 IP 地址,一般 SSH 对应的端口号 Port 是22 ,User 是你在服务器上注册的用户名。
54 | > Host 配置好后,再执行 SSH 登陆时,只需要终端输入Host 名称即可,比如我这里的就是`ssh cvlab` ,等同于之前的 `ssh your_user_name@172.17.4.63`。
55 |
56 | ```bash
57 | Host cvlab
58 | HostName 10.18.32.170
59 | Port 22
60 | User xxx
61 | ```
62 |
63 | - **Step 3**: 配置好后再重新按照 Step 1 进行登陆,发现登陆名称中多了刚才新建的 cvlab ,点击进去,首先需要选择远程服务器的类型-Linux,然后输入你的账号密码。注:如果你之前应该采用了**密钥认证**,那么这一步就不需要输入密码了。
64 | 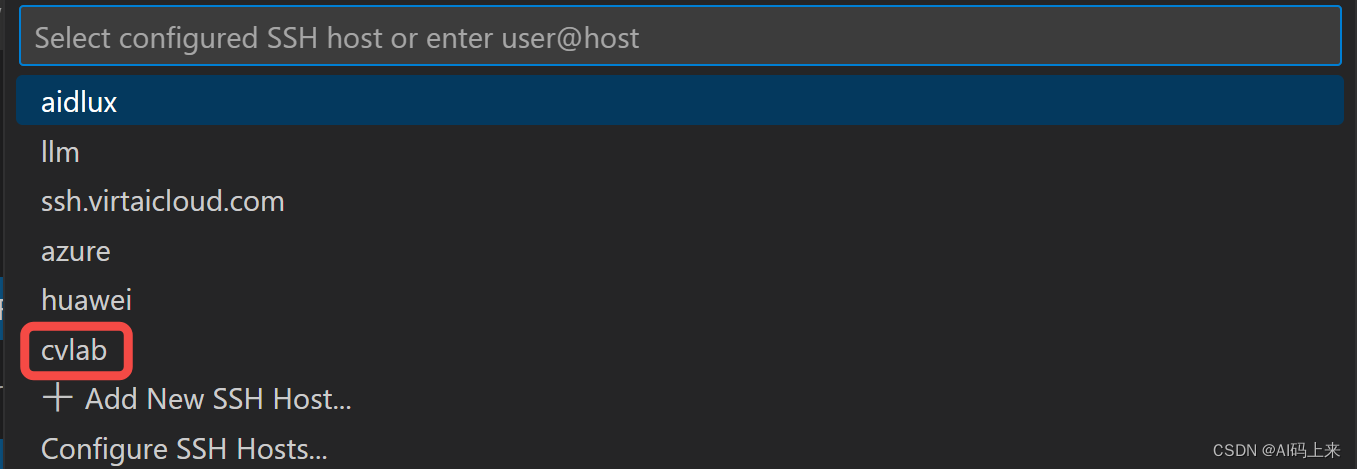
65 | - **Step 4**:首次登陆会自动在服务器端安装 VS Code server,如果账号密码都没问题的话,就可以登陆成功了,按 `Ctrl + ~ `键打开终端,可以发现现在已经进入服务器的环境了,接下来的操作就和你在本地机器上一样。
66 | 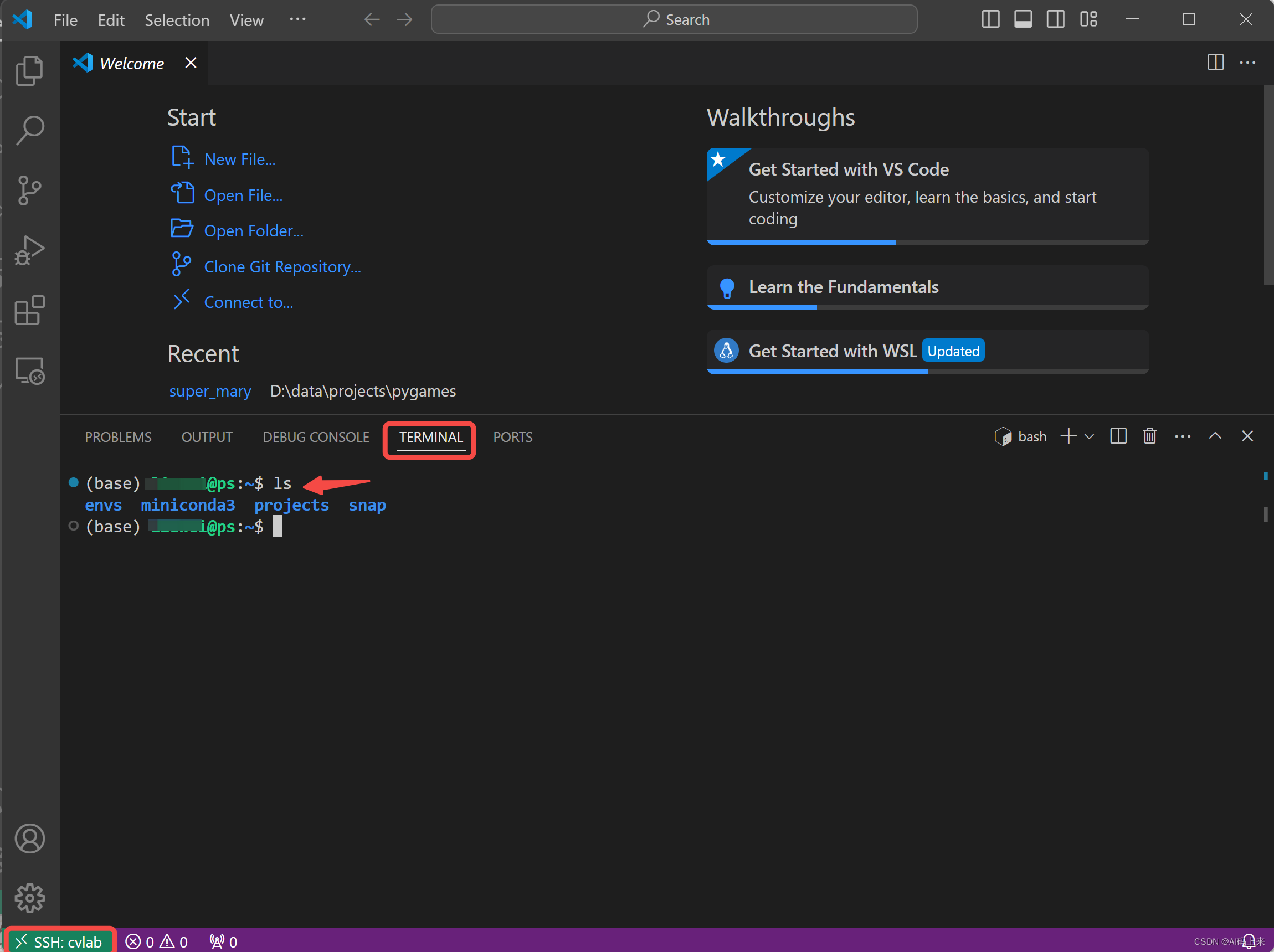
67 |
68 | ## 1.3 方法对比
69 | - **SSH命令行**:适合需要执行命令行操作的场景,对于脚本编写和快速命令执行非常有效。
70 | - **VS Code远程开发**:适合需要图形界面和复杂编辑功能的场景,尤其是代码编辑、调试和版本控制。
71 |
72 | ## 结语
73 | 无论是通过SSH命令行还是VS Code,都能实现Windows系统下对Linux服务器的远程连接和开发。选择哪种方法取决于你的具体需求和偏好。至此,Windows 连接 Linux服务器的教程就结束了,实践是掌握技能的最好方式,不妨现在就开始尝试连接你的Linux服务器吧!
74 |
75 | 如果对你有帮助的话,不妨 **关注 点赞** 支持一下啊~ 带你了解更多 **Linux + AI** 开发的干货~
76 |
--------------------------------------------------------------------------------
/docs/1.Linux笔记/【保姆级教程】如何在 Windows 上实现和 Linux 子系统的端口映射.md:
--------------------------------------------------------------------------------
1 | # 写在前面
2 | 上次分享[【保姆级教程】Windows上安装Linux子系统,搞台虚拟机玩玩](https://zhuanlan.zhihu.com/p/689560472),向大家介绍了什么是虚拟机以及如何在Windows上安装Linux虚拟机。对于开发同学而言,经常遇到的一个问题是:很多情况下代码开发需要依赖 Linux 系统,而在 Linux 子系统上搭建的服务,是无法通过 localhost 在本地浏览器打开的,这时就需要 `端口映射`了,将 Linux 子系统上的端口映射到本地 Windows 机器上。
3 |
4 | 本篇分享将手把手带领大家完成这一功能需求。整个流程需要分为如下几步:
5 |
6 | - 查看 IP
7 | - 查看端口
8 | - 端口映射
9 |
10 | # 1 查看 IP
11 | windows 和 linux 系统中查看 IP 地址的命令是不一样的,具体而言。
12 | ## Windows 下查看 IP
13 | 直接打开一个终端,输入 `ipconfig`,可以看到本地的 IPv4 地址。
14 | 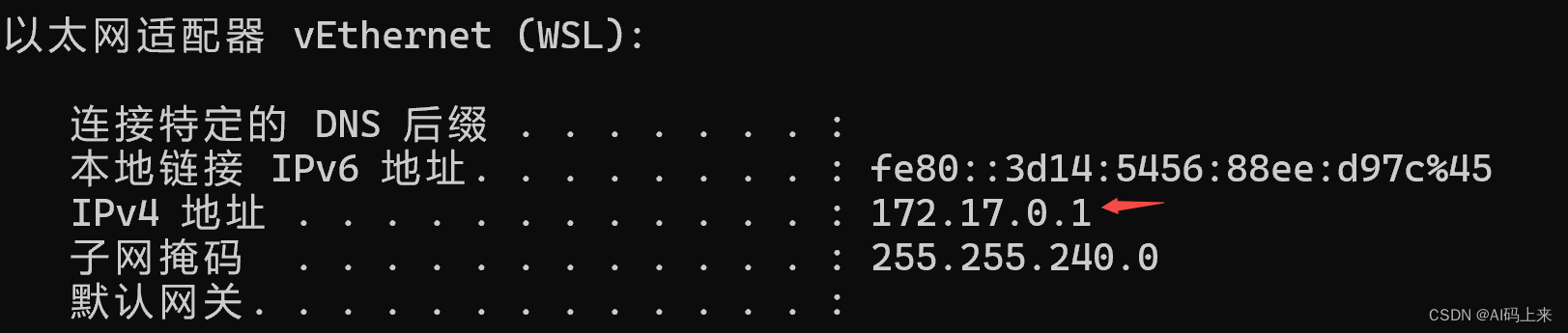
15 | ## Linux 下查看 IP
16 | Linux 下查看 IP 地址,有如下三种方式:
17 |
18 | ```bash
19 | ifconfig # 需要 sudo apt install net-tools
20 | hostname -I
21 | ip addr show eth0
22 | ```
23 | 如果是通过 wsl 方式在 windows 上安装的虚拟机,还可以在windows的终端,通过如下命令查看 Linux 子系统的 IP:
24 |
25 | ```bash
26 | wsl -- ifconfig eth0
27 | ```
28 | # 2 查看端口
29 | Linux 系统中如果服务启动后,可以通过如下命令查看都有哪些端口已经被占用了:
30 | ```bash
31 | netstat -ntlp
32 | ```
33 | 如果发现有的端口已经被占用了,还可以根据进程号 kill 掉对应进程。
34 | 
35 |
36 | 在其中找到需要映射出来的端口号,进入下一步。
37 | # 3 端口映射
38 | Windows 下以管理员身份运行shell,然后运行如下命令实现端口映射:
39 |
40 | ```bash
41 | netsh interface portproxy add v4tov4 listenport=8000 listenaddress=0.0.0.0 connectport=8000 connectaddress=172.17.0.37 # 注意这里是0.0.0.0而非127.0.0.1
42 | netsh interface portproxy add v4tov4 listenport=5000 listenaddress=0.0.0.0 connectport=5000 connectaddress=172.17.0.37
43 | ```
44 | 其中 connectaddress 就是 Linux 子系统的 IP,注意如果你的服务中有两个端口,需要将两个端口都映射出来。
45 |
46 | 查看是否添加成功:
47 |
48 | ```bash
49 | netsh interface portproxy show all
50 | ```
51 | 调试结束后,可以删除端口映射:
52 |
53 | ```bash
54 | netsh interface portproxy delete v4tov4 listenport=8000 listenaddress=0.0.0.0
55 | ```
56 |
57 |
58 |
59 |
--------------------------------------------------------------------------------
/docs/1.Linux笔记/报错解决ImportError_ libcrypto.so.10_ cannot open shared object file_ No such file or directory.md:
--------------------------------------------------------------------------------
1 | # 原因分析
2 | 这是因为linux系统中ssl版本的问题,比如程序需要的是1.0版本,而系统中可能是1.1版本,所以需要重新安装open-ssl。
3 |
4 | # 怎么解决
5 | ## 找到libcrypto所在位置
6 | ```bash
7 | find /usr/ -name "libcrypto*" #比如我们这里发现是1.1版本
8 | ```
9 | ## 新建lib文件夹
10 |
11 | ```bash
12 | mkdir ~/lib # 用户根目录下创建lib,用于存放依赖库,如果没有sudo权限,系统根目录下无法保存
13 | cd ~/lib
14 | ```
15 | ## 下载源码包
16 | 这里下载所需要的1.0版本
17 | ```bash
18 | wget https://www.openssl.org/source/old/1.0.2/openssl-1.0.2k.tar.gz
19 | tar -xzf openssl-1.0.2k.tar.gz
20 | cd openssl-1.0.2k
21 | ```
22 | ## 编译安装
23 |
24 | > make 和 make install的区别:
25 | > - ./config 或者 /configure:配置环境,建立Makefile文件
26 | > - make:编译,就是把源码包编译成二进制可执行文件
27 | > - make install:安装
28 |
29 | ```bash
30 | ./config -d shared --prefix=/home/aistudio/lib/ #配置环境,安装到指定目录
31 | make # 编译
32 | echo $? # 检测是否编译成功,输出0说明成功
33 | make install # 安装
34 | echo $? # 检测是否安装成功,输出0说明成功
35 | ```
36 | ## 生成软链接
37 |
38 | ```bash
39 | cd /home/aistudio/lib/ # 回到lib目录下
40 | ln -s lib/libcrypto.so.1.0.0 libcrypto.so.10
41 | ln -s lib/libssl.so.1.0.0 libssl.so.10
42 | export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/aistudio/lib/
43 | ```
44 | 至此,再重新运行你的程序,应该就没有报错了,继续愉快玩耍吧!
45 |
--------------------------------------------------------------------------------
/docs/1.Linux笔记/报错解决ImportError_ libnvinfer.so.7_ cannot open shared object file_ No such file or directory.md:
--------------------------------------------------------------------------------
1 | # 原因分析
2 | 这是因为linux系统中没有安装tensorrt。
3 | ## 什么是tensorrt
4 | - 一句话:TensorRT是用于NVIDIA各种GPU的一个模型推理框架,支持C++和Python。Pytorch或者Paddle框架训好的模型,可以转为TensorRT的格式,再用TensorRT去运行,可以提升NVIDIA-GPU上的运行速度。
5 | - CUDA,CUDNN 和 TensoRT 之间的关系
6 | - cuda 是 NVIDIA-GPU 进行并行计算的框架
7 | - cudnn 是 NVIDIA-GPU 进行神经网络训练和推理的加速库,cudnn 会将神经网络的计算进行优化,再通过 cuda 调用 gpu 进行运算
8 | - tensorrt 和 cudnn 类似,不过只支持模型推理
9 |
10 | # 怎么解决
11 | ## 方式一
12 | > 查看cuda cudnn版本并到官网下载对应tensorrt版本
13 |
14 | ```bash
15 | # 查看cuda cudnn版本
16 | nvcc -V
17 | ls -l /usr/local/ | grep cuda
18 | dpkg -l | grep libcudnn
19 | find /usr/ -name "cudnn*" # 找到cudnn.h的位置
20 | cat /usr/include/cudnn_version.h | grep CUDNN_MAJOR -A 2 # 打印cudnn版本
21 | #define CUDNN_MAJOR 8
22 | #define CUDNN_MINOR 9
23 | #define CUDNN_PATCHLEVEL 6
24 |
25 | # 综上,我的cuda版本是11.8,cudnn版本是8.9.6
26 | # 官网下载对应的tensorrt版本并安装
27 | https://developer.nvidia.cn/tensorrt
28 | ```
29 | ## 方式二(推荐)
30 | > 直接pip安装
31 |
32 | ```bash
33 | pip install tensorrt # 默认会安装8.6.1,所以还是找不到libnvinfer.so.7。目前pip安装已找不到版本7
34 |
35 | # 找到你的python环境安装包位置,并cd进去
36 | # 为了让程序能找到libnvinfer.so.8,这里新建了软链接,并在环境变量中新增安装位置
37 | cd /home/aistudio/envs/py38/lib/python3.8/site-packages/tensorrt_libs
38 | ln -s libnvinfer.so.8 libnvinfer.so.7
39 | ln -s libnvinfer_plugin.so.8 libnvinfer_plugin.so.7
40 | export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/aistudio/envs/py38/lib/python3.8/site-packages/tensorrt_libs
41 | ```
42 |
43 |
--------------------------------------------------------------------------------
/docs/2.玩转云服务/86K Star!又一款内网穿透利器,开源免费+小白友好.md:
--------------------------------------------------------------------------------
1 | 如果你想让本地 AI 服务,触达全球,那么一定得了解下内网穿透。
2 |
3 | 前段时间和大家分享过两款内网穿透方案:
4 |
5 | - [Cloudflare:免费内网穿透,让本地AI服务,触达全球](https://zhuanlan.zhihu.com/p/716891964)
6 | - [LanProxy:免费内网穿透,手把手搭建,三步搞定](https://zhuanlan.zhihu.com/p/711445796)
7 |
8 | 有一说一:
9 | - Cloudflare 的内网穿透服务还是很香的,无需自己购买服务器中转。唯一的缺点就是不太稳定,经常出现 Tunnels 无法建立隧道的问题。
10 | - LanProxy 需要拥有一台具有公网 IP 的机器作为中转,最近发现访问量大了之后也不稳定。
11 |
12 | 今日分享,继续带来一款强大的内网穿透方案 - frp,github上已有86.4k star,且项目一直在持续迭代中。
13 |
14 | ## 1. 什么是内网穿透
15 |
16 | 一句话:把只能内网访问的服务,暴露到公网。
17 |
18 | 关于内网穿透的基本原理,可以翻看之前的教程:[免费内网穿透,手把手搭建,三步搞定](https://zhuanlan.zhihu.com/p/711445796),这里就不赘述了。
19 |
20 | ## 1. frp 简介
21 | > 项目地址:[https://github.com/fatedier/frp](https://github.com/fatedier/frp)
22 |
23 | frp 采用 Golang 编写,支持跨平台,你仅需下载对应平台的二进制文件即可,无需任何依赖,堪称小白利器。
24 |
25 | 目前最新版本为 0.61.0,前往官方 releases 页面下载即可。
26 |
27 | > [https://github.com/fatedier/frp/releases](https://github.com/fatedier/frp/releases)
28 |
29 | 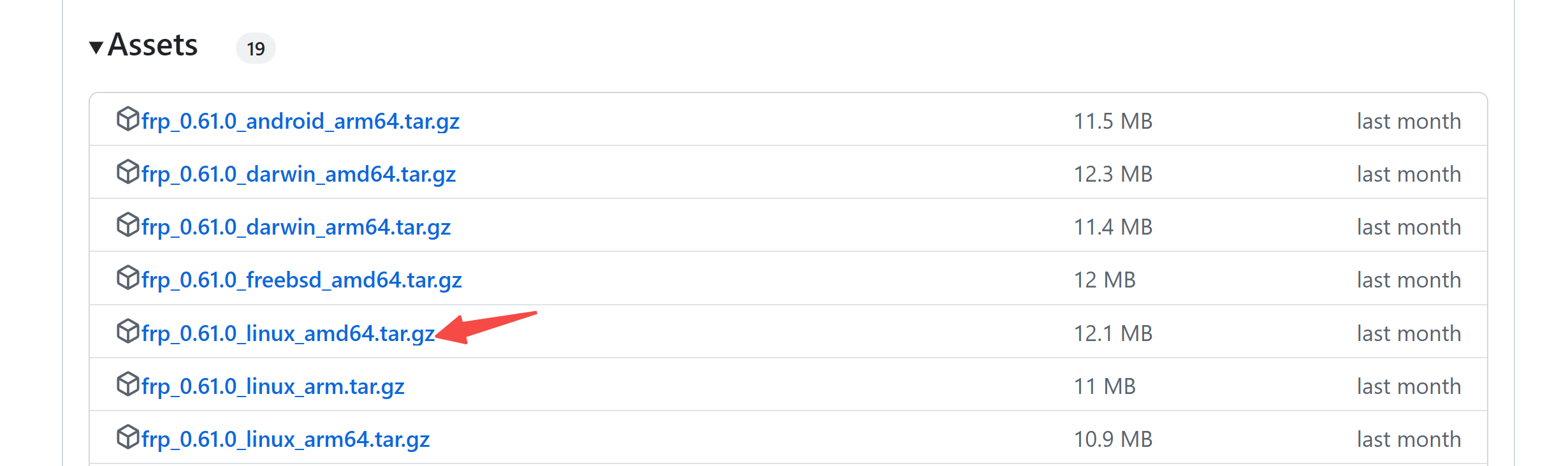
30 |
31 | frp 专注于内网穿透,支持 TCP、UDP、HTTP、HTTPS 等多种协议,可将内网服务通过具有公网 IP 的机器中转,暴露到公网。
32 |
33 | 所以,首先要准备一台有公网 IP 的机器,笔者之前已分享过多篇相关内容,可以翻看。
34 |
35 | 接下来,我们上实操。
36 |
37 |
38 | ## 2. frp 实现内网穿透
39 |
40 | ### 2.1 frp 安装
41 | 不像 ngrok 需要编译,frp 安装的非常简单,只需前往上方官方 releases 页面下载对应系统的安装包,解压出来就能用。
42 |
43 | 以 Linux 操作系统为例:
44 |
45 | ```
46 | #下载
47 | wget https://github.com/fatedier/frp/releases/download/v0.61.0/frp_0.61.0_linux_amd64.tar.gz
48 | #解压
49 | tar -zxvf frp_0.61.0_linux_amd64.tar.gz
50 | #进入目录
51 | cd frp_0.61.0_linux_amd64/
52 | ```
53 |
54 | 文件夹中,有两个二进制文件frpc(c代表client)和frps(s代表server),分别是客户端程序和服务端程序。
55 |
56 |
57 | ```
58 | frp_0.61.0_linux_amd64$ ls
59 | frpc frpc.toml frps frps.toml LICENSE
60 | ```
61 |
62 | 因此,客户端(即内网服务器)和服务端(即公网服务器),需要准备好对应文件。
63 |
64 |
65 | ### 2.2 服务端配置和启动
66 |
67 | 首先,修改服务端配置文件`frps.toml`:
68 |
69 | ```
70 | # 服务端配置
71 | bindPort = 7000
72 | webServer.addr = "0.0.0.0"
73 | webServer.port = 7500
74 | ```
75 |
76 | 其中,`bindPort` 用于监听客户端,`webServer.port` 是服务端的管理界面。
77 |
78 | 然后,采用如下命令一键启动:
79 |
80 | ```
81 | nohup ./frps -c frps.toml > server.log 2>&1 &
82 | ```
83 |
84 | 注:frp 默认采用 IPv6,不过会同时监听IPv4和IPv6地址,但你用 netstat 只看到 IPv6 被监听,实际上是通过了 IPv4-Mapped IPv6 Address 同时兼听了IPv4地址。
85 |
86 | 所以,如果你发现端口不通的时候,**一定记得去看看端口防火墙有没打开**。
87 |
88 | 看看端口能否连接?
89 |
90 | ```
91 | sudo apt install telnet
92 | telnet server_ip 7000
93 | ```
94 |
95 | 查看并打开端口防火墙:
96 |
97 | ```
98 | sudo ufw status
99 | sudo ufw allow 7500
100 | sudo ufw allow 7000
101 | # sudo ufw delete allow 7000
102 | ```
103 |
104 | 最后,浏览器输入 `server_ip:7500`,即可看到管理界面:
105 |
106 | 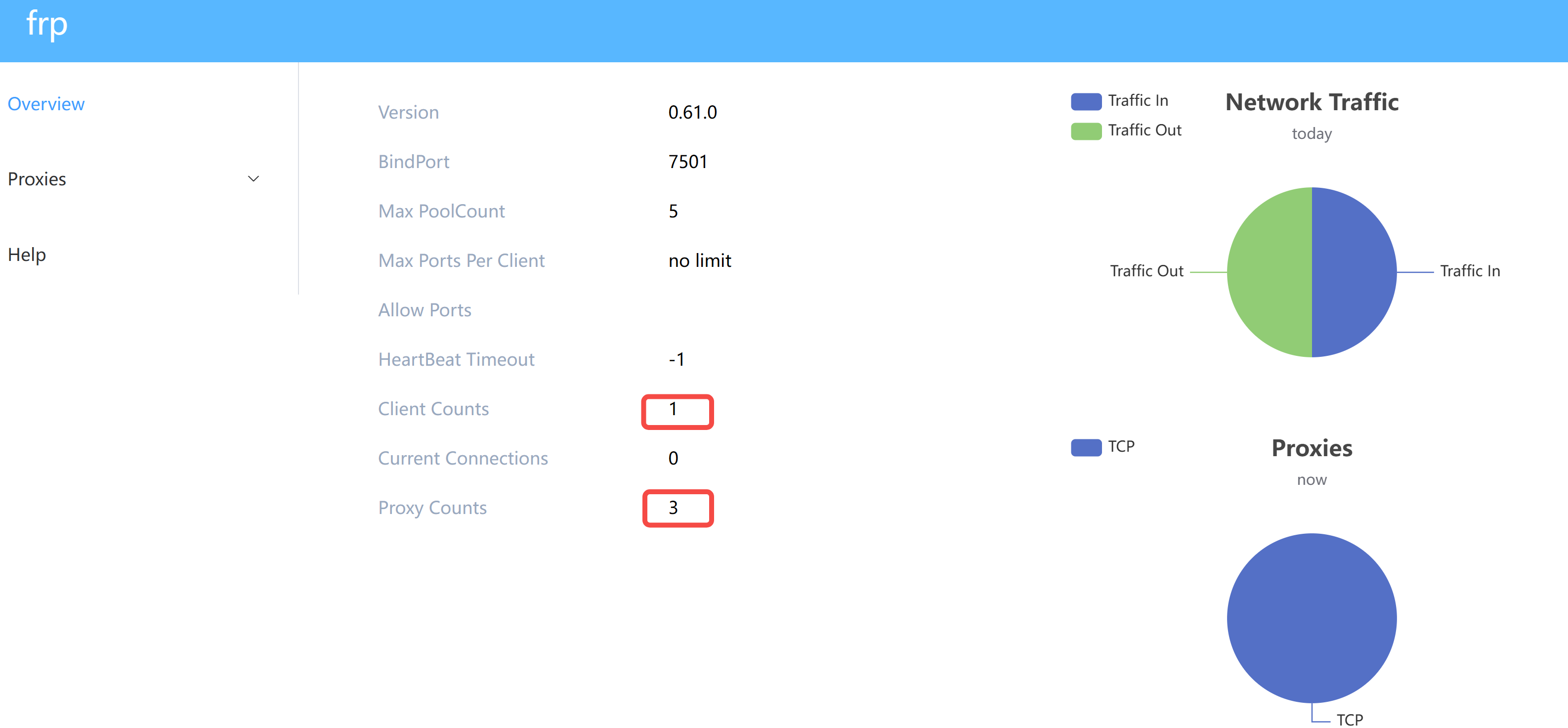
107 |
108 | 这里我有一个客户端已经接入,并映射了3个端口。
109 |
110 | 接下来,我们就来完成客户端配置。
111 |
112 |
113 | ### 2.3 客户端配置和启动
114 |
115 | 首先,修改服务端配置文件`frps.toml`:
116 |
117 | ```
118 | serverAddr = "serve_ip"
119 | serverPort = 7000
120 |
121 | [[proxies]]
122 | name = "ollama"
123 | type = "tcp"
124 | localIP = "127.0.0.1"
125 | localPort = 3002
126 | remotePort = 3002
127 | ```
128 |
129 | 其中,`serverPort` 要对应 服务端的 `bindPort`。我们以`把 ollama 映射到公网可访问` 为例,新增配置如上方代码块:`localPort`和`remotePort`分别是本地服务的端口,和要映射到服务端端口。
130 |
131 | 注:如果有多个端口要映射,只需把`ollama`的复制一份,指定不同端口即可。
132 |
133 | 然后,采用如下命令一键启动:
134 |
135 | ```
136 | nohup ./frpc -c frpc.toml > client.log 2>&1 &
137 | ```
138 |
139 | 日志如下:
140 |
141 | 
142 |
143 | 至此,frp 内网穿透服务搭建完毕。
144 |
145 | 以上通过一个简单案例,带大家快速跑通流程。更多配置,可参考官方文档:[https://gofrp.org/zh-cn/docs/](https://gofrp.org/zh-cn/docs/)
146 |
147 | ## 写在最后
148 |
149 | 本文实操带大家走完了`frp搭建内网穿透`的全部流程。
150 |
151 | 作为一款开源免费的服务,frp 配置简单,非常适合小白上手。
152 |
153 | 如果对你有帮助,不妨**点赞收藏**备用。
154 |
155 | ---
156 |
157 | 为方便大家交流,新建了一个 `AI 交流群`,欢迎感兴趣的小伙伴加入。
158 |
159 | 最近搭建的微信机器人`小爱(AI)`也在群里,公众号后台「联系我」,拉你进群。
160 |
161 |
--------------------------------------------------------------------------------
/docs/2.玩转云服务/README.md:
--------------------------------------------------------------------------------
1 | # 2.玩转云服务
2 |
3 | - [86K Star!又一款内网穿透利器,开源免费+小白友好](docs/2.玩转云服务/86K%20Star!又一款内网穿透利器,开源免费+小白友好.md)
4 | - [Untitled](docs/2.玩转云服务/Untitled.md)
5 | - [【保姆级教程】免费内网穿透,手把手搭建,三步搞定](docs/2.玩转云服务/【保姆级教程】免费内网穿透,手把手搭建,三步搞定.md)
6 | - [【保姆级教程】免费域名注册 & Cloudflare 域名解析 & Ngnix端口转发](docs/2.玩转云服务/【保姆级教程】免费域名注册%20&%20Cloudflare%20域名解析%20&%20Ngnix端口转发.md)
7 | - [【保姆级教程】白嫖 Cloudflare 之 5 分钟搭建个人静态网站](docs/2.玩转云服务/【保姆级教程】白嫖%20Cloudflare%20之%205%20分钟搭建个人静态网站.md)
8 | - [【白嫖 Cloudflare】之 免费内网穿透,让本地AI服务,触达全球](docs/2.玩转云服务/【白嫖%20Cloudflare】之%20免费内网穿透,让本地AI服务,触达全球.md)
9 | - [【白嫖 Cloudflare】之免费 AI 服务,从API调用到应用搭建](docs/2.玩转云服务/【白嫖%20Cloudflare】之免费%20AI%20服务,从API调用到应用搭建.md)
10 | - [【白嫖 Cloudflare】之免费图床搭建:PicGo + Cloudflare R2,手把手教](docs/2.玩转云服务/【白嫖%20Cloudflare】之免费图床搭建:PicGo%20+%20Cloudflare%20R2,手把手教.md)
11 | - [两款 GPU 云服务器,助力小白上手 AI](docs/2.玩转云服务/两款%20GPU%20云服务器,助力小白上手%20AI.md)
12 | - [从0搭建你的免费图床(PicGo + Oracle cloud 甲骨文云对象存储)](docs/2.玩转云服务/从0搭建你的免费图床(PicGo%20+%20Oracle%20cloud%20甲骨文云对象存储).md)
13 | - [你的服务器管家,不仅免费开源,还贼简洁好用](docs/2.玩转云服务/你的服务器管家,不仅免费开源,还贼简洁好用.md)
14 | - [我花了一天时间,搭了个专属知识库,部署上线了,手把手教,不信你学不会](docs/2.玩转云服务/我花了一天时间,搭了个专属知识库,部署上线了,手把手教,不信你学不会.md)
15 | - [玩转云服务:Google Cloud谷歌云永久免费云服务器「白嫖」 指南](docs/2.玩转云服务/玩转云服务:Google%20Cloud谷歌云永久免费云服务器「白嫖」%20指南.md)
16 | - [玩转云服务:Oracle Cloud甲骨文永久免费云主机配置指南(续)](docs/2.玩转云服务/玩转云服务:Oracle%20Cloud甲骨文永久免费云主机配置指南(续).md)
17 | - [玩转云服务:Oracle Cloud甲骨文永久免费云服务器注册及配置指南](docs/2.玩转云服务/玩转云服务:Oracle%20Cloud甲骨文永久免费云服务器注册及配置指南.md)
18 | - [玩转云服务:手把手带你薅一台腾讯云服务器](docs/2.玩转云服务/玩转云服务:手把手带你薅一台腾讯云服务器.md)
19 | - [谁偷偷看了你的网站?这两款统计工具告诉你!小白易上手](docs/2.玩转云服务/谁偷偷看了你的网站?这两款统计工具告诉你!小白易上手.md)
20 |
21 |
22 |
23 | *本系列共更新**17**篇文章*
24 |
25 |
26 |
27 | [🔙返回首页](/)
28 |
--------------------------------------------------------------------------------
/docs/2.玩转云服务/Untitled.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hougeai/knowledgebase/6cfce85587ecb4903f05af30f3cb5c447c4af868/docs/2.玩转云服务/Untitled.md
--------------------------------------------------------------------------------
/docs/2.玩转云服务/【保姆级教程】白嫖 Cloudflare 之 5 分钟搭建个人静态网站.md:
--------------------------------------------------------------------------------
1 | 前端时间,搭了个个人知识库,并部署到 GitHub Pages 上:
2 | [一天时间,搭了个专属知识库,部署上线了,手把手教,不信你学不会](https://blog.csdn.net/u010522887/article/details/140919939)
3 |
4 | 免费使用的 GitHub Pages 优势非常明显,唯一的缺点是:
5 | - 对于大型网站或高流量网站可能存在访问速度较慢的问题。
6 |
7 | 本文将再介绍一款静态网站托管工具:`Cloudflare Pages` ,由 Cloudflare 提供,利用 Cloudflare 的全球性 CDN 进行加速,而且功能更加丰富:
8 | - 支持主流的前端构建工具和框架,如 React、Vue 等;
9 | - 提供更丰富的缓存策略和性能优化选项;
10 | - 支持 Github/GitLab 仓库,和 Github Pages 类似。
11 |
12 | 之前我们网站的域名解析也是用的 Cloudflare 家的服务,感兴趣的小伙伴可参考:[【保姆级教程】免费域名注册 & Cloudflare 域名解析 & Ngnix端口转发](https://blog.csdn.net/u010522887/article/details/140786338)。
13 |
14 | 下面我们开始实操演示:如何利用 `Cloudflare Pages` 部署一个网站。
15 |
16 | ## 1. 网站部署
17 |
18 | 注册登录后,进入 Cloudflare 控制台,点击按图示进入 `Workers 和 Pages` 面板,选择 Pages。
19 | > 多一嘴:区别于 Pages,Workers 是一个可以运行 Javascript 的无服务器平台。
20 |
21 | 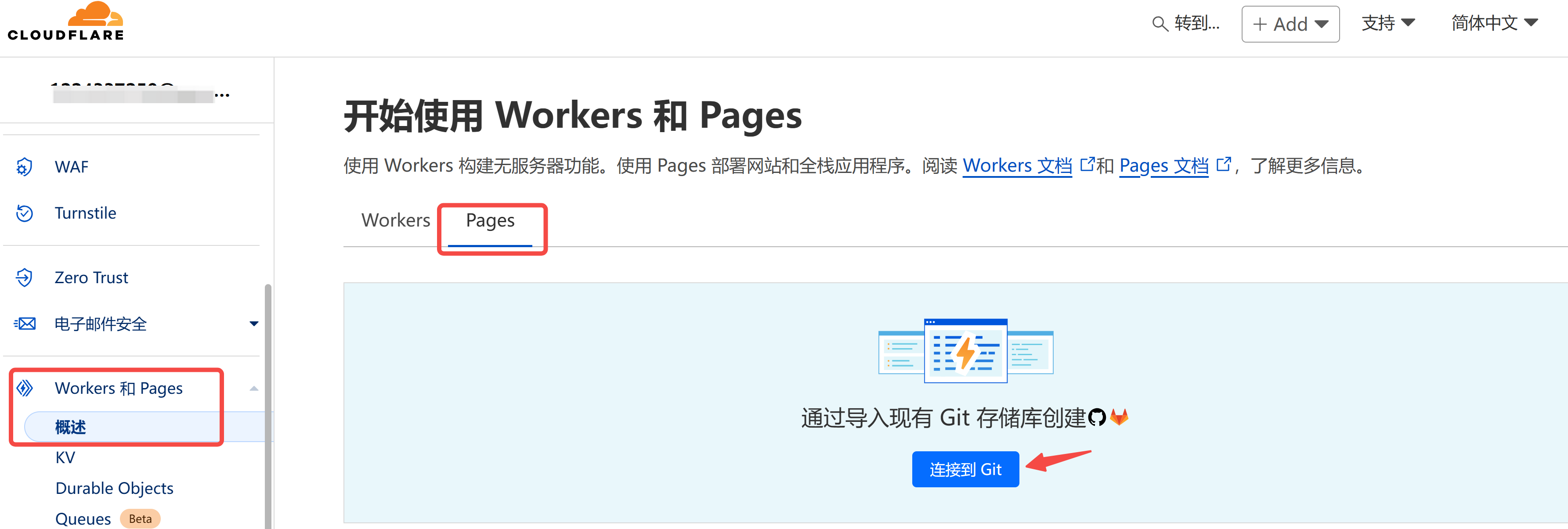
22 |
23 |
24 | `Cloudflare Pages` 支持 Github/GitLab 仓库,这一点和 `Netlify` 是一致的。
25 |
26 | 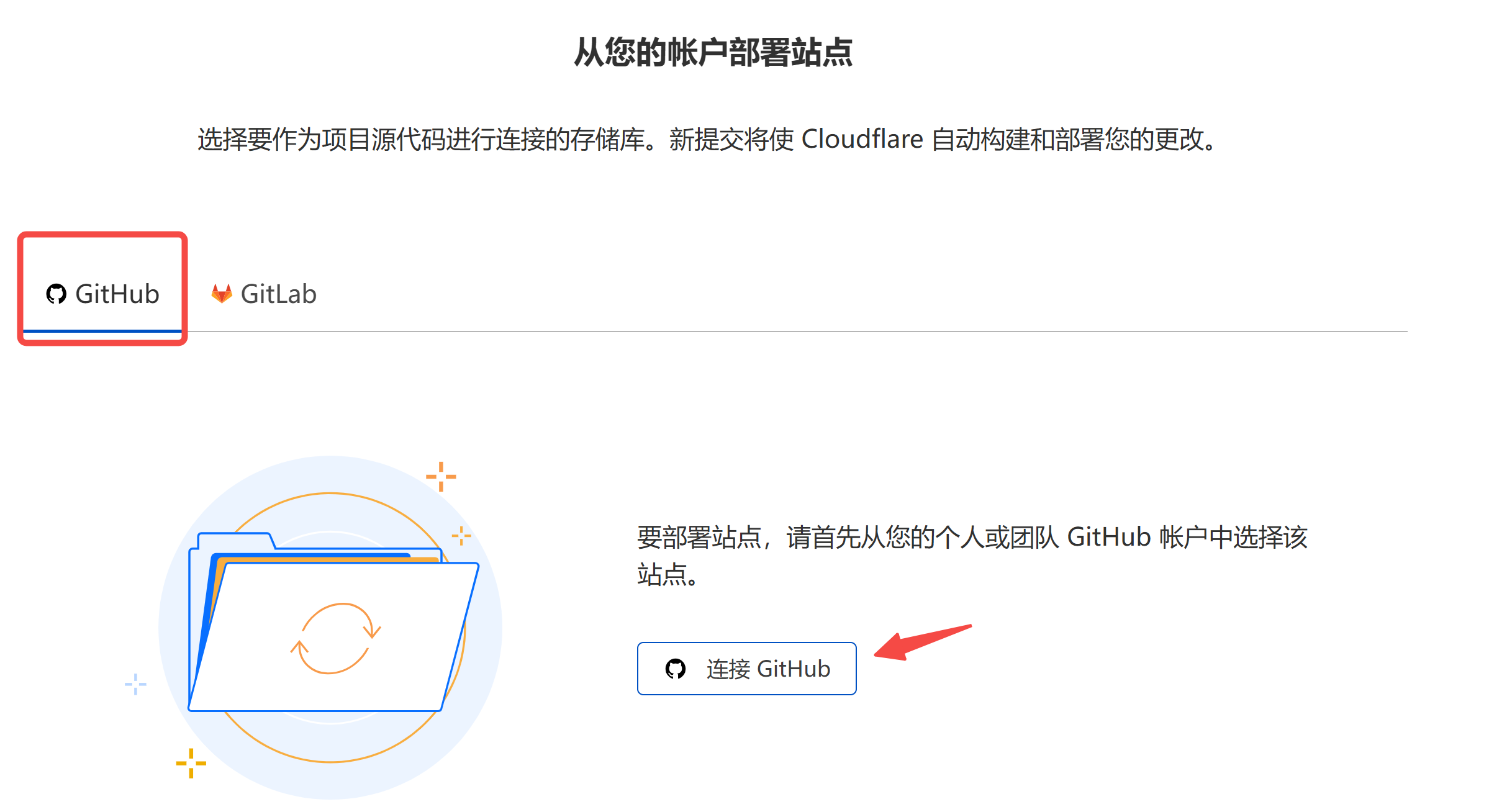
27 |
28 |
29 | 选择 Github 账号授权后,你可以选择授权所有项目给 Cloudflare,或者选择授权指定的项目仓库。
30 |
31 | 我这里选择全部授权,授权之后,选择一个你要部署的项目,点击 “开始设置”。
32 |
33 | 静态页面,一般设置部署分支、构建命令、构建输出目录就可以。点击“保存并部署”,等待几分钟即可部署完成。
34 |
35 | 
36 |
37 |
38 | 部署完成后可看到 Cloudflare 给我们的域名 `xx.pages.dev`,刚部署完成,需要稍等 2 分钟,点击即可直接公网访问。
39 |
40 | 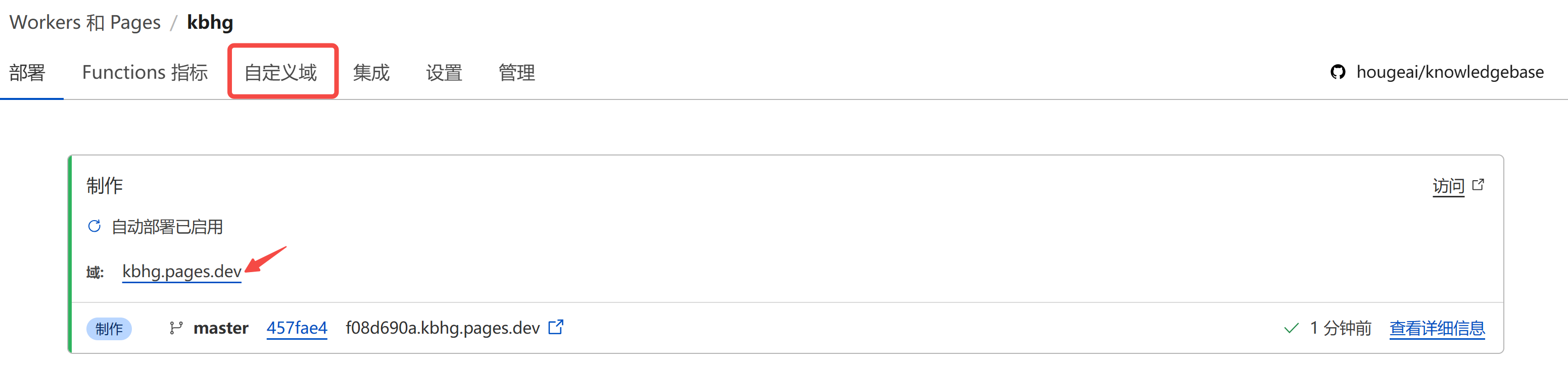
41 |
42 |
43 | 如果你有自己的域名,并在 Cloudflare 上进行了域名解析,也可以进入项目主页,选择自定义域。
44 |
45 | ## 2. 自定义域名
46 | 进入项目,点击 “自定义域”。
47 |
48 | 注:这里填入的域名一定要在 Cloudflare 上进行了域名解析。
49 |
50 | 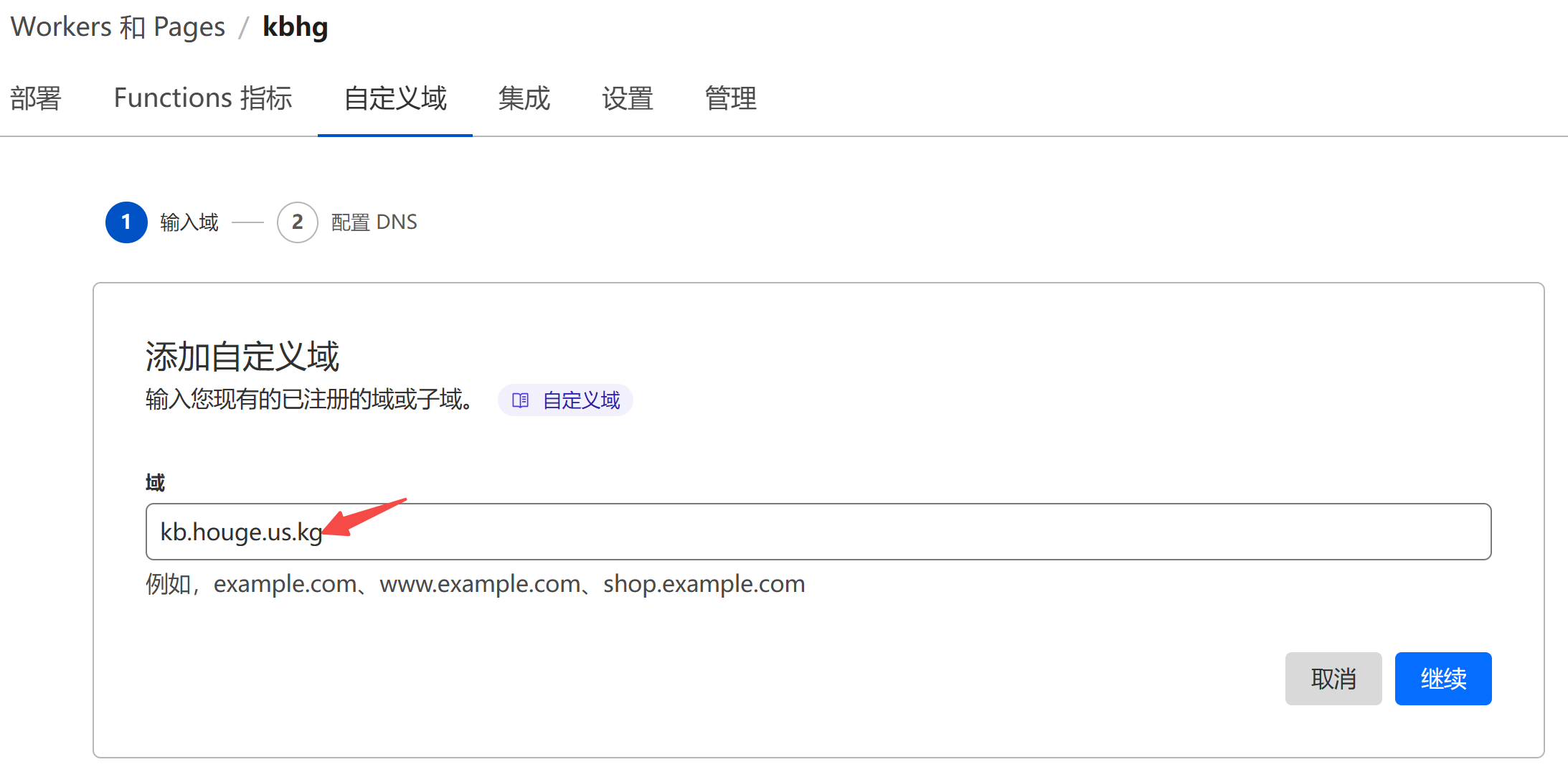
51 |
52 | 接入完成之后,Cloudflare 会自动帮你更新 DNS 记录。比如,我这里会自动将原来 github pages 上面的 IP 替换为 `Cloudflare Pages` 上的域名。点击“激活域”,完成更新。
53 |
54 | 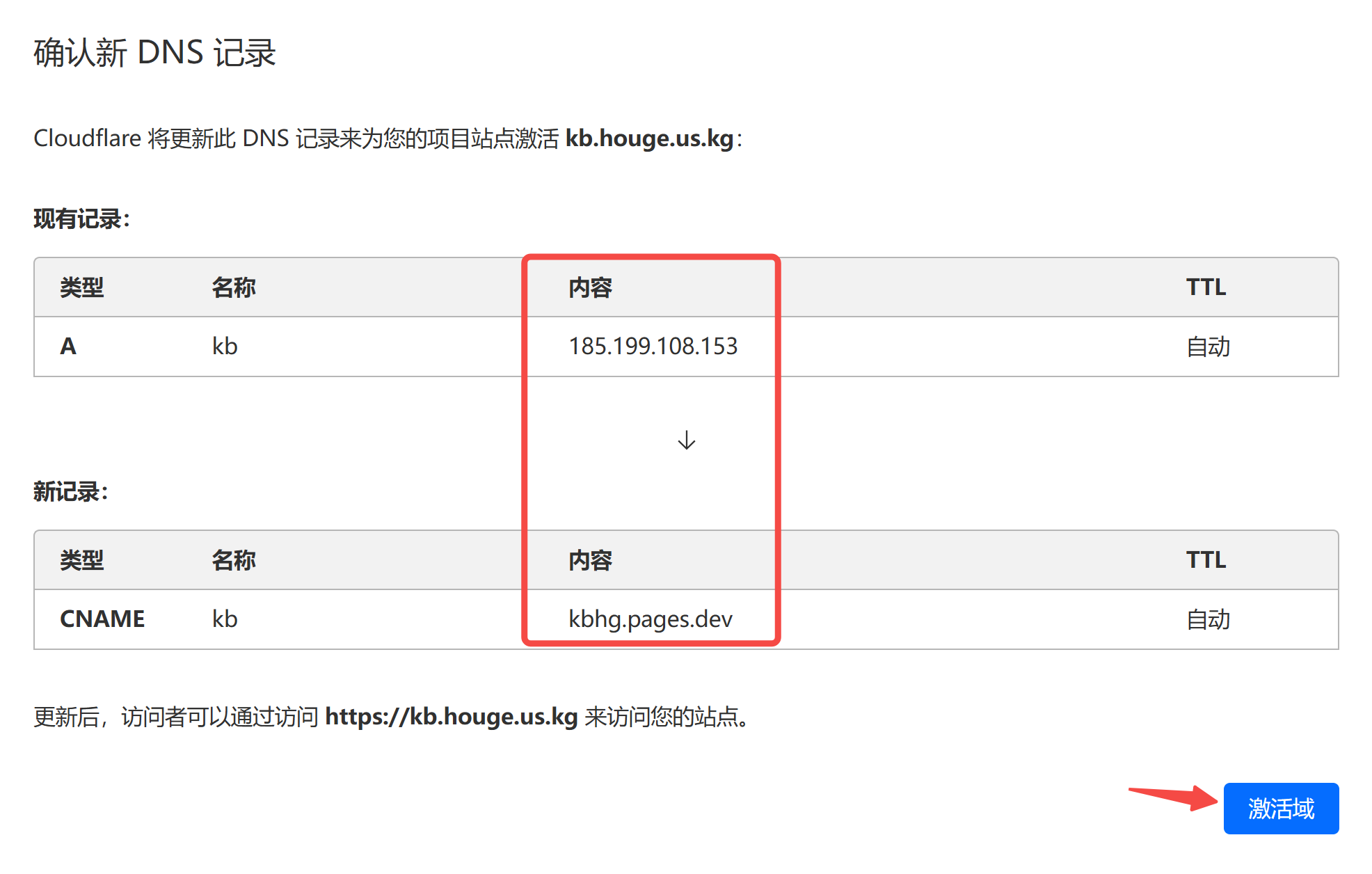
55 |
56 |
57 | 
58 |
59 | 
60 |
61 | 域名验证成功后,你的网站就可以通过自定义域名正式上线了!
62 |
63 | ## 3. 更多部署方案?
64 |
65 | 相信看到这里的你,一定有个疑问:除了 `Cloudflare Pages`,还有哪些平替?
66 |
67 | 今天,趁机给大家做一个盘点~
68 |
69 | 静态网站部署,大致可以分为以下两类:
70 |
71 | ### 3.1 云部署平台
72 | 和 `Cloudflare Pages` 类似的云部署平台还有:
73 |
74 | - Vercel:和全栈开发框架 next.js 同属一家公司,生态非常完善,缺点就是太贵。
75 | - Netlify:Vercel的直接竞争对手,每月 100 GB 免费访问流量。
76 | - Railway:优势是支持 Docker 容器,包括 Dockerfile 和公开的 docker 镜像进行部署,但不支持docker-compose。
77 | - Zeabur:国内公司开发,直接对标 Railway,也支持 Docker 容器。
78 | - Render:另一个流行的云部署平台,和 Vercel 类似。
79 | - Firebase:Google 提供的一个平台,可用于部署和托管 web 应用。
80 |
81 | ### 3.2 开源的部署方案
82 | 社区也有很多开源项目,旨在成为 Vercel 和 Netlify 等云平台的自托管替代方案,可以部署在自己的服务器上:
83 |
84 | - [Coolify](https://github.com/coollabsio/coolify)(27.8k star)
85 | - [Dokku](https://github.com/dokku/dokku)(26.5k star):一个轻量级的开源 PaaS(平台即服务)。
86 | - [SST](https://github.com/sst/sst)(21.2k star):专注于无服务器架构和AWS生态系统。
87 | - [Dokploy](https://github.com/Dokploy/dokploy)(5.3k star):直接叫板 Vercel, Netlify and Heroku 的开源替代方案。
88 |
89 | 我还没尝试过,有机会实操后再来跟大家分享。
90 |
91 |
92 | ## 写在最后
93 | 本文通过一个简单的例子,带大家完成在 `Cloudflare Pages` 上部署网站,其生成的域名,亲测在国内可以直接访问~
94 |
95 | 对于免费账户而言,每天限制访问 10W 次。对于个人网站而言,完全足够。
96 |
97 | 江湖人称`赛博菩萨`的 `Cloudflare`,还有很多常用的网站管理服务,绝大部分都有免费额度。
98 |
99 | 我还没探索完,等用到了再陆续给大家分享。
100 |
101 | 如果本文有帮助,不妨点个**免费的赞**和**收藏**备用。
102 |
103 |
104 |
105 |
--------------------------------------------------------------------------------
/docs/2.玩转云服务/两款 GPU 云服务器,助力小白上手 AI.md:
--------------------------------------------------------------------------------
1 | 最近更新了很多开源 AI 大模型的文章,目前已收录:
2 |
3 | - [CogVideo 实测,智谱「清影」AI视频生成,全民免费,连 API 都开放了!](http://mp.weixin.qq.com/s?__biz=MzkzMzY2MTkyNw==&mid=2247485591&idx=1&sn=38d5c4de97094186578ac0f718ea71b2&chksm=c248551ff53fdc09f08c68fbe5c33bbfac3babb6154cc034ee46068709d3fc55e6beab75f075&scene=21#wechat_redirect)
4 | - [全网刷屏的 LLaMa3.1,2分钟带你尝个鲜](http://mp.weixin.qq.com/s?__biz=MzkzMzY2MTkyNw==&mid=2247485560&idx=1&sn=58aaff0740eb5a0cb995cdb400b91dbf&chksm=c24855f0f53fdce6c485d50319d7a2595a48439232f66ab010c56eb95460445efc1837341d9b&scene=21#wechat_redirect)
5 | - [SenseVoice 实测,阿里开源语音大模型,识别效果和效率优于 Whisper](http://mp.weixin.qq.com/s?__biz=MzkzMzY2MTkyNw==&mid=2247485469&idx=1&sn=87f0223cc59ebb19c86f1f825b64a8f3&chksm=c2485595f53fdc834487b87e63446974e700ae191fc843d1e6ee67ee7b6d65e3560b0a06dcc9&scene=21#wechat_redirect)
6 | - [EasyAnimate-v3 实测,阿里开源视频生成模型,5 分钟带你部署体验,支持高分辨率超长视频](http://mp.weixin.qq.com/s?__biz=MzkzMzY2MTkyNw==&mid=2247485449&idx=1&sn=a3a23259d889f5305b82fd61117b374e&chksm=c2485581f53fdc97834708624b646ad545bff9c961acc5e261a44c5e8dcd6b42d5636e3cf522&scene=21#wechat_redirect)
7 | - [一文梳理ChatTTS的进阶用法,手把手带你实现个性化配音](http://mp.weixin.qq.com/s?__biz=MzkzMzY2MTkyNw==&mid=2247484666&idx=1&sn=95d4983ec16b47b8db6d05d41b208cf9&chksm=c2485972f53fd0641ba175af0d3fb33d77afeaea31fcd41c8c2602676ab8fca275856146a5d1&scene=21#wechat_redirect)
8 | - [开源版 Midjourney 来了,无需本地显卡,5 分钟带你玩转 AI 绘画模型](http://mp.weixin.qq.com/s?__biz=MzkzMzY2MTkyNw==&mid=2247486018&idx=1&sn=aea2048a1afa7bb3ec848b7d6dfc3182&chksm=c24857caf53fdedc4f2b4ac881c1e7c6984756e3ada7b70f36c3f9addac8b576bb4b301a9bfa&scene=21#wechat_redirect)
9 | - [人人有嘴替:免费开源语音合成,3s极速语音克隆](http://mp.weixin.qq.com/s?__biz=MzkzMzY2MTkyNw==&mid=2247486051&idx=1&sn=a87046364773ab42629c5352f9fb63a4&chksm=c24857ebf53fdefde080642e670b4d609f388ed1c0606d27803fe0f8d8a1d29c192c650220ab&scene=21#wechat_redirect)
10 | - [免费语音克隆神器,让川普来段中文绕口令?FishSpeech 5 分钟部署实战](http://mp.weixin.qq.com/s?__biz=MzkzMzY2MTkyNw==&mid=2247486167&idx=1&sn=6828505ed90a4fa808dd2f688d73b0a9&chksm=c248575ff53fde4925259324118df2439a599cb9a2062df6e2b99a5effef5be013ef08a8a5c7&scene=21#wechat_redirect)
11 |
12 | 很多小伙伴发现,本地电脑根本带不动这些大模型,今天给大家推荐两款 GPU 云服务器,助力小白快速上手 AI。
13 |
14 | 大家有其它好的推荐,欢迎留言。
15 |
16 | **推荐1:趋动云**
17 |
18 | https://platform.virtaicloud.com/gemini_web/auth/register?inviteCode=b702f65cfe99e8cf10900a650fdc00c6
19 |
20 | 优缺点:
21 |
22 | - 选择更多,价格相对实惠;远程连接稳定;新人注册送 100 点算力。
23 |
24 | **推荐2:AutoDL**
25 |
26 | https://www.autodl.com/home
27 |
28 | 优缺点:
29 |
30 | - 新人注册送 30 天会员,会员租用价格享受 95 折;支持本地 GPU 集群部署上云。
31 | - 最低配置显存 11 G,价格稍贵。
32 |
33 | ## **1. 趋动云**
34 |
35 | 新人注册福利打满:
36 |
37 | 
38 |
39 | 价格怎么样?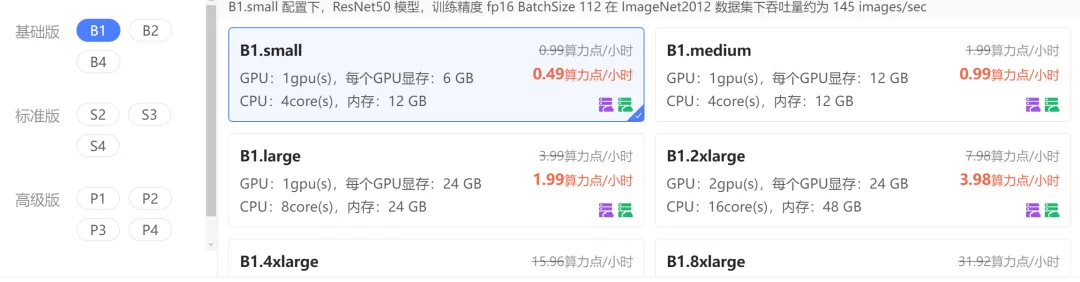
40 |
41 | 最低配置 6 G 显存,低至 0.49 点算力/小时,运行一天 = 0.49 * 24 = 12 元。运行 AI 绘画 / AI 语音模型,完全足够。
42 |
43 | 即便是 24 G 显存,也只有 1.99。运行 13B 以下大语言模型完全足够。
44 |
45 | 不知道如何使用的小伙伴,可以参考我之前在 `趋动云` 上跑模型的两篇教程:
46 |
47 | - [人人有嘴替:免费开源语音合成,3s极速语音克隆](http://mp.weixin.qq.com/s?__biz=MzkzMzY2MTkyNw==&mid=2247486051&idx=1&sn=a87046364773ab42629c5352f9fb63a4&chksm=c24857ebf53fdefde080642e670b4d609f388ed1c0606d27803fe0f8d8a1d29c192c650220ab&scene=21#wechat_redirect)
48 | - [免费语音克隆神器,让川普来段中文绕口令?FishSpeech 5 分钟部署实战](http://mp.weixin.qq.com/s?__biz=MzkzMzY2MTkyNw==&mid=2247486167&idx=1&sn=6828505ed90a4fa808dd2f688d73b0a9&chksm=c248575ff53fde4925259324118df2439a599cb9a2062df6e2b99a5effef5be013ef08a8a5c7&scene=21#wechat_redirect)
49 |
50 |
51 |
52 | 还没注册的小伙伴赶紧去薅羊毛:https://platform.virtaicloud.com/gemini_web/auth/register?inviteCode=b702f65cfe99e8cf10900a650fdc00c6
53 |
54 | ## **2. AutoDL**
55 |
56 | AutoDL 对学生更友好一些,新人注册送 30 天会员,会员租用价格享受 95 折。
57 |
58 | 
59 |
60 | 最低配置是 RTX 2080Ti 11 G 显存,会员价格 0.88/小时。
61 |
62 | 
63 |
64 | 当然如果你有本地 GPU 服务器, AutoDL 私有云提供了一套解决方案,让本地GPU服务器集群也可以高效管理与使用,免费、安全且不绑定服务器销售厂家。
65 |
66 | ## **写在最后**
67 |
68 | 如果你没有 GPU 机器,又想快速上手 AI,可以使用上述 GPU 云服务器,不过上面两款提供的实例都是 Docker 容器,主打一个性价比!
69 |
70 | 如果本文对你有帮助,不妨点个**免费的赞**和**收藏**备用。你的支持是我创作的最大动力。
--------------------------------------------------------------------------------
/docs/2.玩转云服务/你的服务器管家,不仅免费开源,还贼简洁好用.md:
--------------------------------------------------------------------------------
1 |
2 | 在「玩转云服务」系列中,带着大家申请了几台云服务器。
3 | - [玩转云服务:手把手带你薅一台腾讯云服务器](https://blog.csdn.net/u010522887/article/details/140091900)
4 | - [玩转云服务:Oracle Cloud甲骨文永久免费云服务器注册及配置指南](https://blog.csdn.net/u010522887/article/details/140223094)
5 | - [玩转云服务:Google Cloud谷歌云永久免费云服务器「白嫖」 指南](https://blog.csdn.net/u010522887/article/details/140817919)
6 |
7 | 问题来了:怎么监管这些服务器的运行状态呢?
8 |
9 | 因此,一个简约轻量的监控工具就显得尤为重要。
10 |
11 | 今日分享 GitHub 上的一款开源项目 - ServerStatus,完美解决多台服务器监管的难题,亲测好用。
12 |
13 | > 项目传送门:[https://github.com/cppla/ServerStatus/](https://github.com/cppla/ServerStatus/)
14 |
15 | 目前该项目已经斩获 4K Star~
16 |
17 | 
18 |
19 | ## 1.项目简介
20 |
21 | `ServerStatus` 一个超级贴心的免费开源监控工具,它就像是你服务器的私人保镖+贴身医生,24小时不间断守护。
22 |
23 | 想知道你的服务器 CPU 有没有在拼命工作?内存是不是又在暴饮暴食?网络流量是不是又在疯狂飙车?别担心,ServerStatus都看得一清二楚!
24 |
25 | 而且,不管你家的服务器是VPS、虚拟机还是物理机,它都能照顾得妥妥的。
26 |
27 | 
28 |
29 | ## 2. 安装部署
30 |
31 | 整个部署过程包括两个部分:
32 | - 服务端:用于监控多台客户端服务器
33 | - 客户端:一键运行,和服务端建立连接
34 |
35 | ### 2.1 服务端部署
36 |
37 | 如果你本着`拿来即用`,不需要进行二次开发的话,推荐直接 Docker 安装~
38 |
39 | 首先,把项目 clone 下来:
40 |
41 | ```
42 | git clone https://github.com/cppla/ServerStatus.git
43 | ```
44 |
45 | 然后,我们可以简单看下`docker-compose.yml`配置文件,其中有一段:
46 |
47 | ```
48 | networks:
49 | serverstatus-network:
50 | ipv4_address: 172.23.0.2
51 | ```
52 |
53 | 有小伙伴可能有疑惑:这里的 IP 要不要修改?
54 |
55 | 答:**不需要**!因为在 Docker 容器中,ipv4_address 是在自定义网络内部使用的,与服务器的 IP 地址不是一回事,因此你完全不用管它。
56 |
57 | 最后,docker 一键安装:
58 |
59 | ```
60 | cd ServerStatus
61 | docker-compose up -d
62 | ```
63 | 需要稍等片刻,等待编译安装~
64 |
65 | 安装成功后,在宝塔面板中可以看到容器已经启动:
66 |
67 | 
68 |
69 | 别忘了打开 8080 端口的防火墙,这是服务端监控界面的端口号。
70 |
71 |
72 | ### 2.2 客户端安装
73 |
74 | 客户端的安装就更简单了。
75 |
76 | 首先,下载客户端运行的 Python 脚本:
77 |
78 | ```
79 | wget --no-check-certificate -qO client-linux.py 'https://raw.githubusercontent.com/cppla/ServerStatus/master/clients/client-linux.py'
80 | ```
81 |
82 | 然后,你只需指定你**服务端的 IP 地址**和**客户端的用户名**,
83 |
84 | 把程序丢到后台去跑吧~
85 |
86 | ```
87 | nohup python3 client-linux.py SERVER=xx.xx.xx.xx USER=s01 PASSWORD=s01 >/dev/null 2>&1 &
88 | ```
89 |
90 | 你想监控几台服务器,分别把上面的程序放上去就行~
91 |
92 | ### 2.3 服务端监控
93 |
94 | 客户端启动成功后,去打开服务端的监控界面看看吧~
95 |
96 | 地址:http://your_server_ip:8080
97 |
98 | 我这里起了两个客户端作为演示:
99 |
100 | 
101 |
102 | 界面是不是特别简洁美观?支持三种风格切换~
103 |
104 | 
105 |
106 |
107 | 关键是,你看,这个小东西不过只占了你 8M 的内存,毫无压力~
108 |
109 | 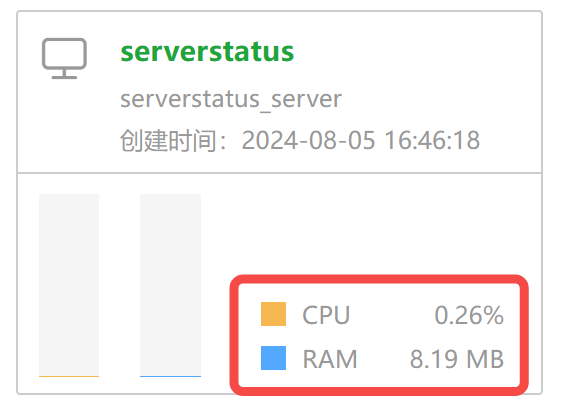
110 |
111 | 太简单了?还想展示更多信息?有一定开发能力的小伙伴,可以基于这个项目进行二开~
112 |
113 | ## 写在最后
114 | `ServerStatus` 这个小家伙不仅免费开源,还贼简洁好用。
115 |
116 | 玩转云服务,ServerStatus,你值得拥有的服务器管家!
117 |
118 | 如果本文对你有帮助,不妨点个**免费的赞**和**收藏**备用。
119 |
120 |
121 |
--------------------------------------------------------------------------------
/docs/2.玩转云服务/谁偷偷看了你的网站?这两款统计工具告诉你!小白易上手.md:
--------------------------------------------------------------------------------
1 | 前两天,上线了一个知识库网站:[花了一天时间,搭了个专属知识库,终于上线了,手把手教,不信你学不会](https://blog.csdn.net/u010522887/article/details/140919939)。
2 |
3 | 想知道这个网站的流量如何,怎么搞?
4 |
5 | 网站流量统计分析工具,了解下?
6 |
7 | 市面上都有哪些分析工具,为什么要选择 Google Analytics?
8 |
9 | [百度统计](https://tongji.baidu.com/)在国内用的较多,不过需要你的网站域名完成备案,会相对麻烦一点。
10 |
11 | 如果你只是想搞了玩玩,强烈推荐对岸的`谷歌分析工具(Google Analytics)`,谷歌官方发布的一款网站流量统计分析工具。
12 |
13 | 当然,海外还有很多类似的产品,但不得不承认,`Google Analytics`是同类型工具中功能最强大的一个,对小白上手零门槛,好用且免费。
14 |
15 | 本篇教程,手把手带大家用 Google Analytics,掌握自己网站的流量来源。
16 |
17 | ## 1. 如何开通 Google Analytics
18 |
19 | 要使用谷歌分析,你必须先注册一个谷歌 Gmail 邮箱账号,这个账号是一号通用的,后续无论是使用 Google Ads、Google Docs、Google Cloud 等任何 Google 的产品,都需要使用这个邮箱账号登录。
20 |
21 | 来到 Google Analytics ,用你的 Gmail 邮箱账号登录。
22 | > 登录地址:[https://analytics.google.com/analytics/web/provision/#/provision](https://analytics.google.com/analytics/web/provision/#/provision)
23 |
24 | 点击上方`开始衡量`,开始注册账号:
25 |
26 | 
27 |
28 | `帐号数据共享设置`这里,为实现与其他 Google 产品和服务共享 Google Analytics的数据,默认全选即可,点击最下方的“下一步”。
29 |
30 | 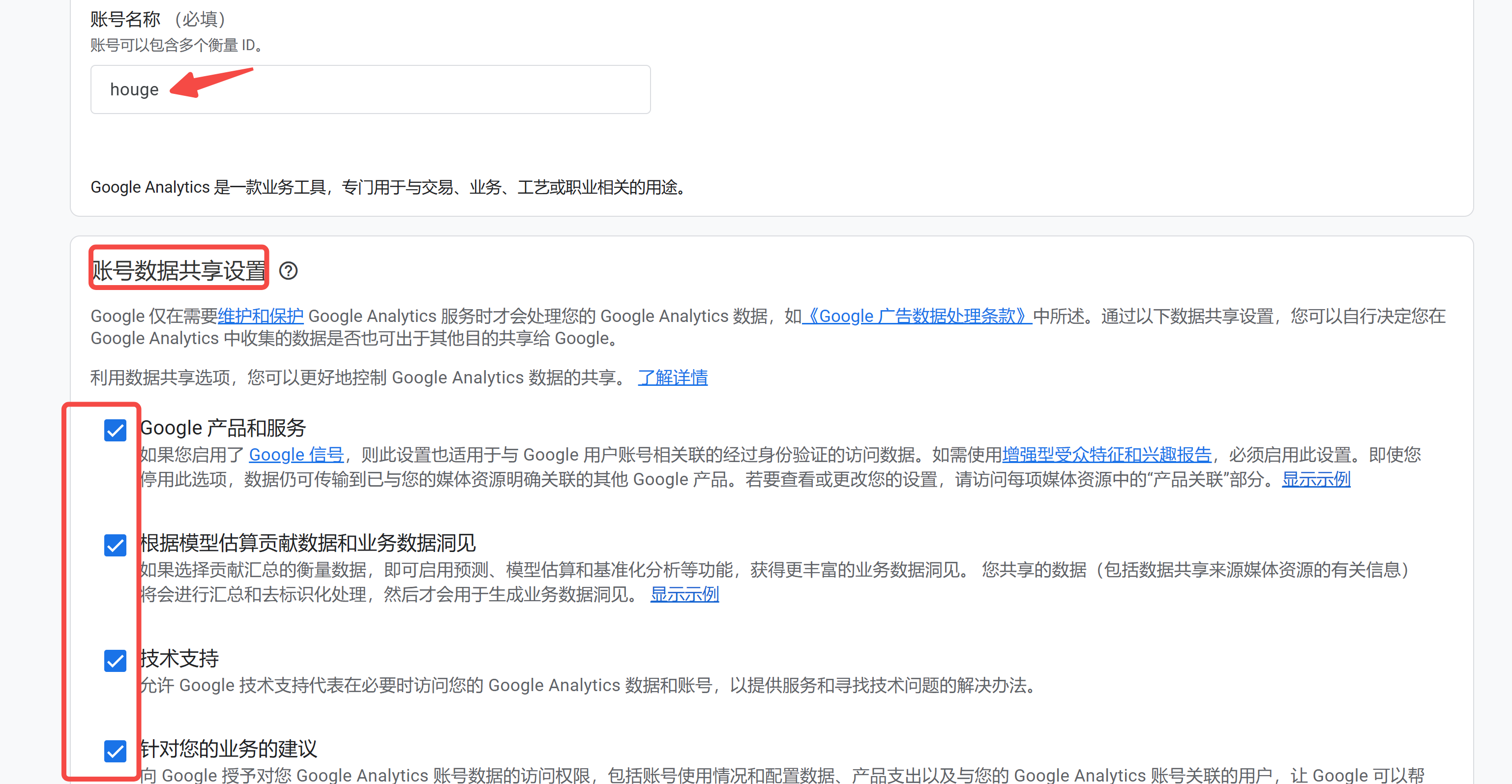
31 |
32 | 然后,填写媒体资源信息,也就意味着同一个账号下可以有多个媒体资源:
33 |
34 | 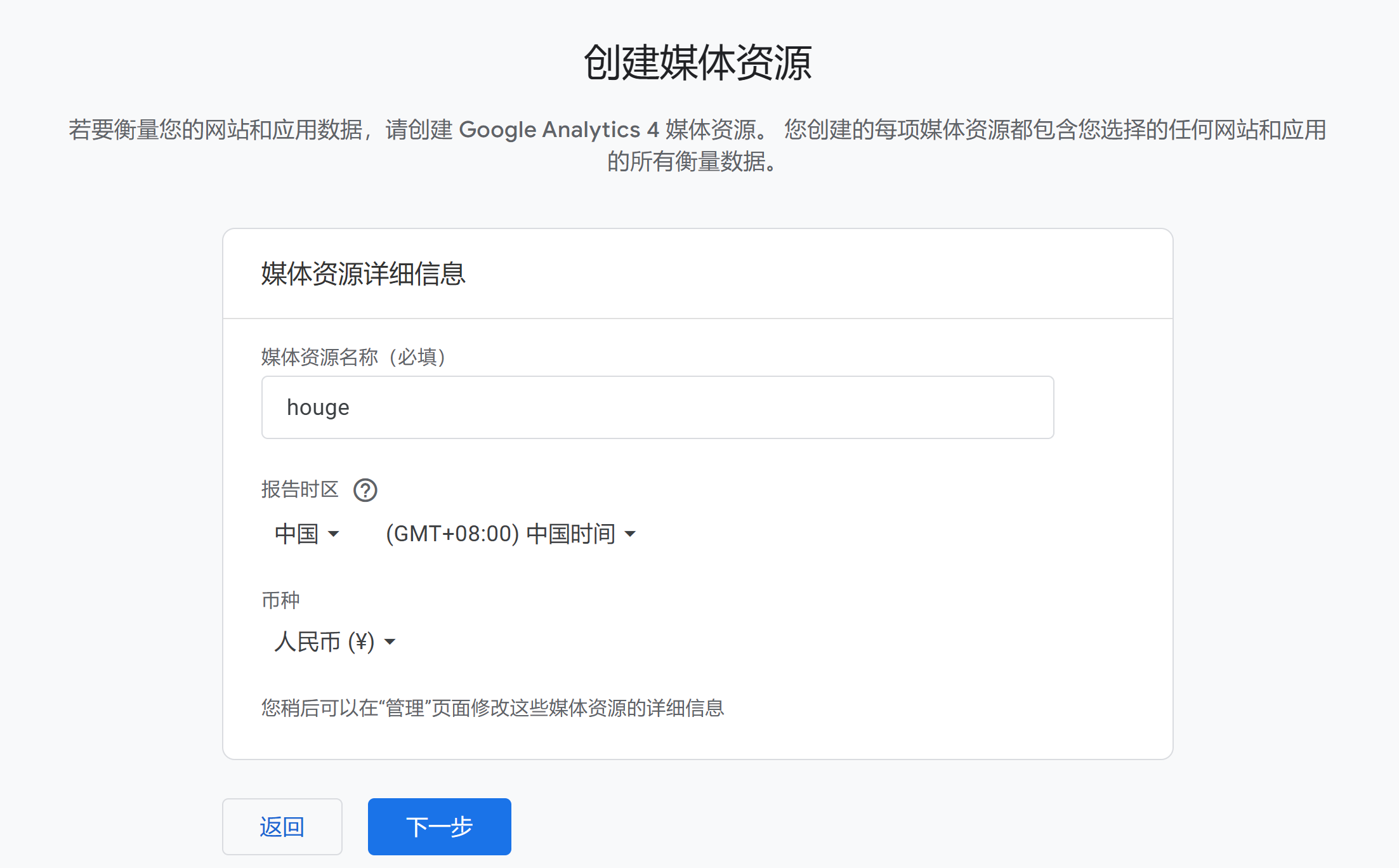
35 |
36 | 选择业务目标,根据自己是需求,我这里选择最后的`多种类型报告`:
37 |
38 | 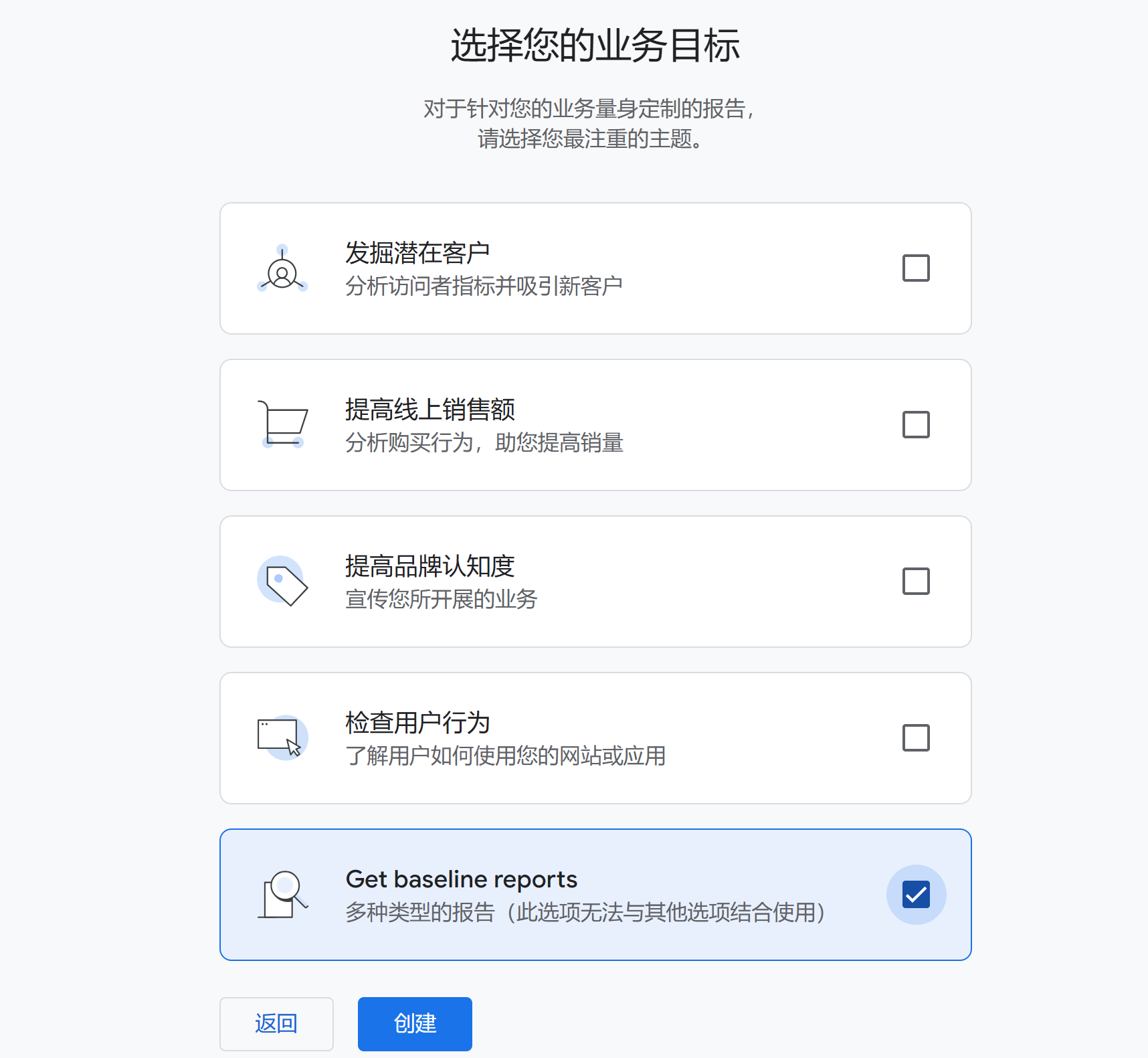
39 |
40 | 进入到最后步骤了:开始收集数据,我们这里只需要统计网站,这里的选择决定了后续在你的应用中插入的代码。
41 |
42 | 
43 |
44 |
45 | 网站数据流这里,注意你的是 http 还是 https,否则后期统计不到数据;填写你的域名后,点击右上方 `创建` 按钮。
46 |
47 | 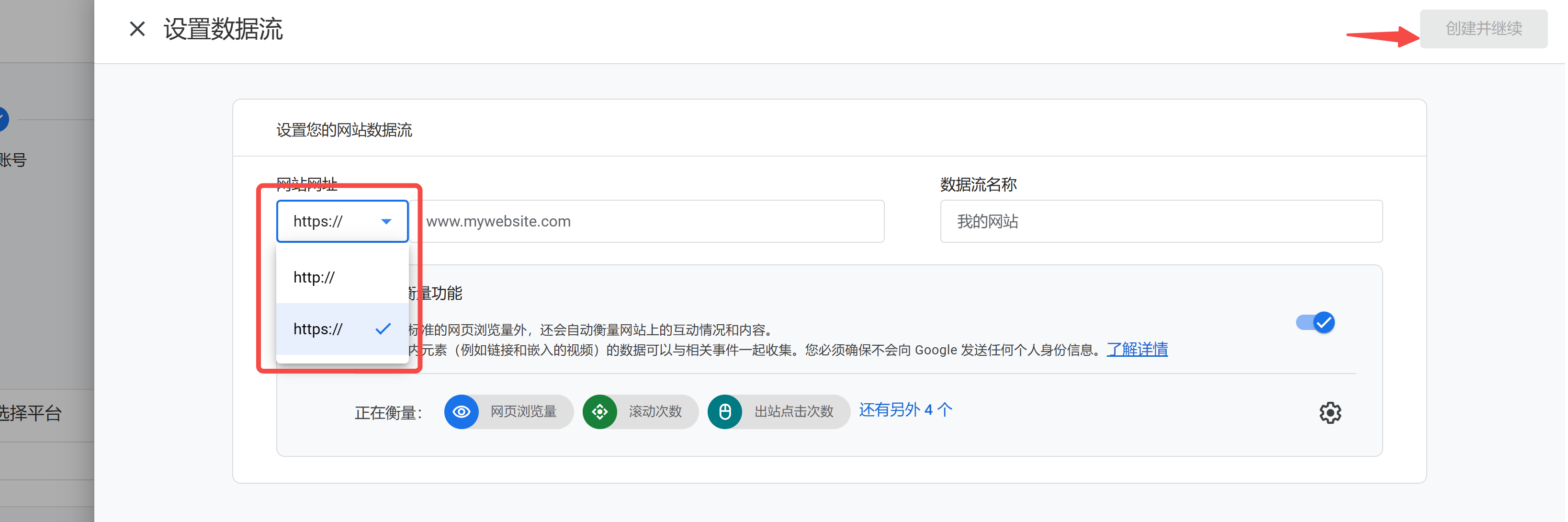
48 |
49 |
50 | ## 2. 如何使用 Google Analytics
51 |
52 | 创建需要稍等片刻,它会弹出你需要插入到你网页 html 中的跟踪代码。
53 |
54 | 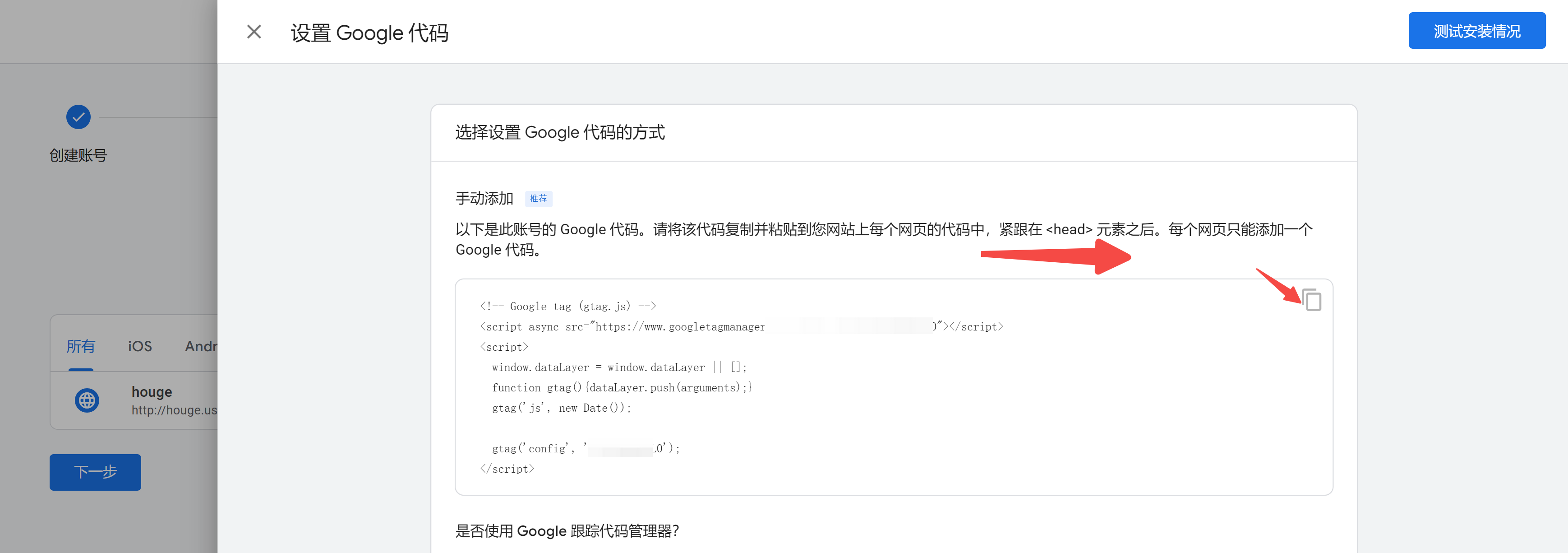
55 |
56 | 点击 下一步,看到如下页面,账号和媒体资源已经创建成功了。
57 |
58 | 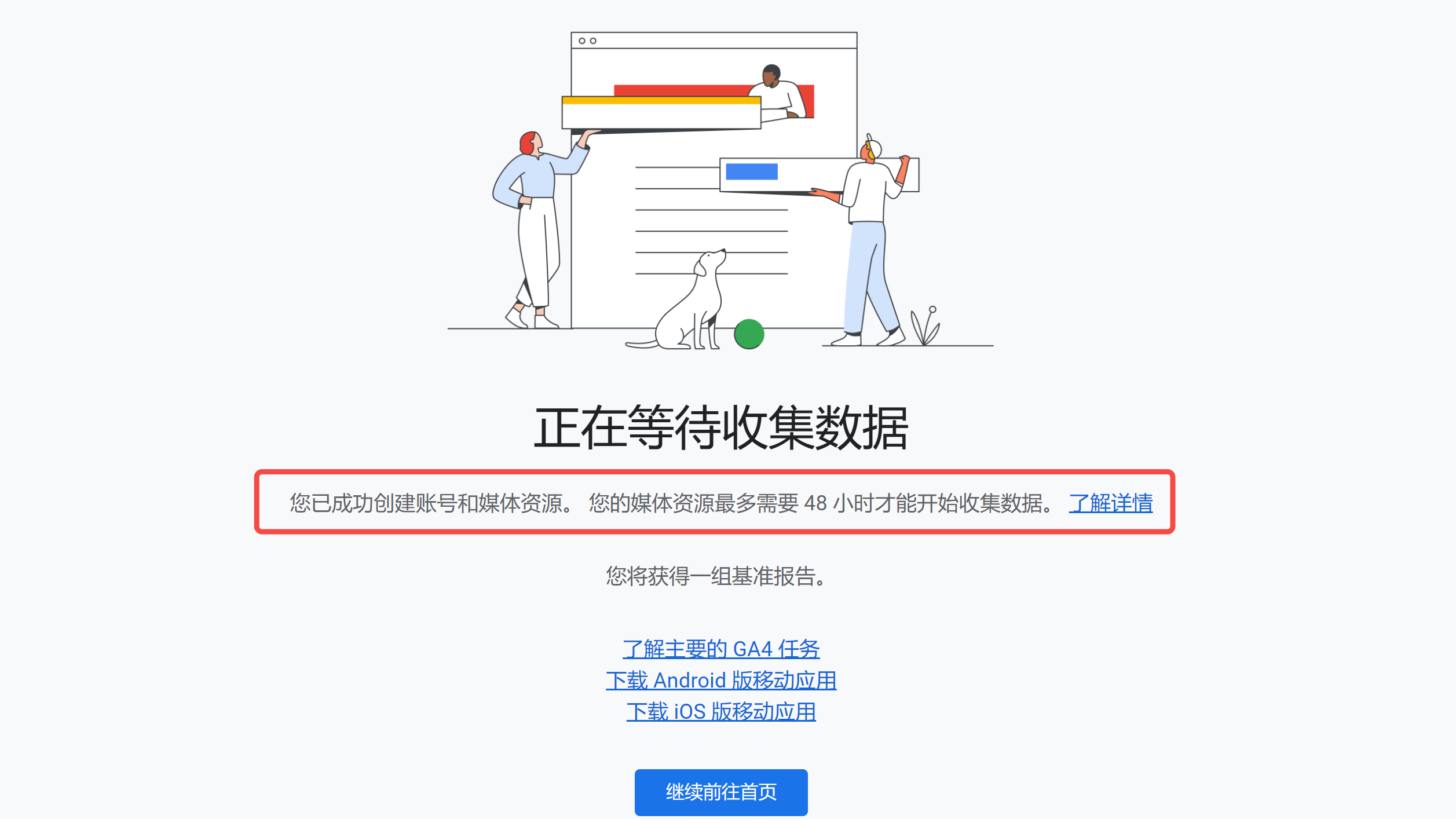
59 |
60 | 接下来你需要插入跟踪代码,最后将网站重新部署上线。
61 |
62 | 下面我们以知识库网站为例,你只需要找到根目录下的`index.html`,在 ``元素中,插入刚刚复制的代码即可:
63 |
64 | 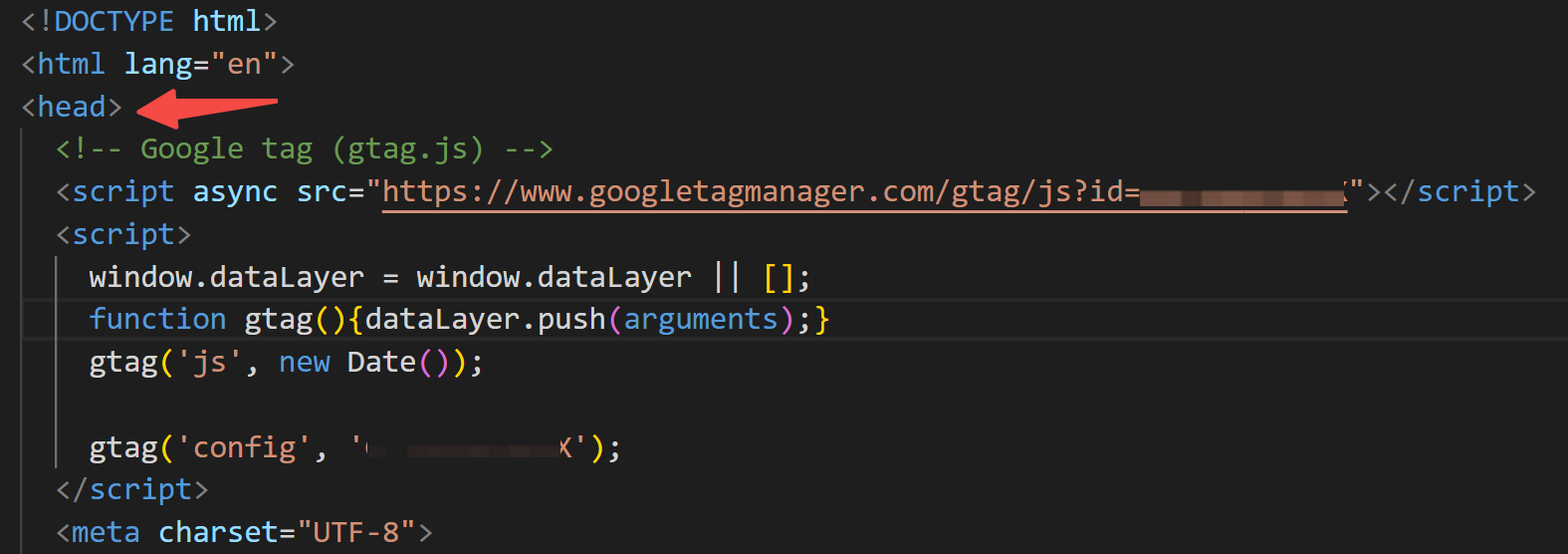
65 |
66 |
67 | 如果网站已经重新部署成功,回到你的账号页面,可以看到数据采集已经启动:
68 |
69 | 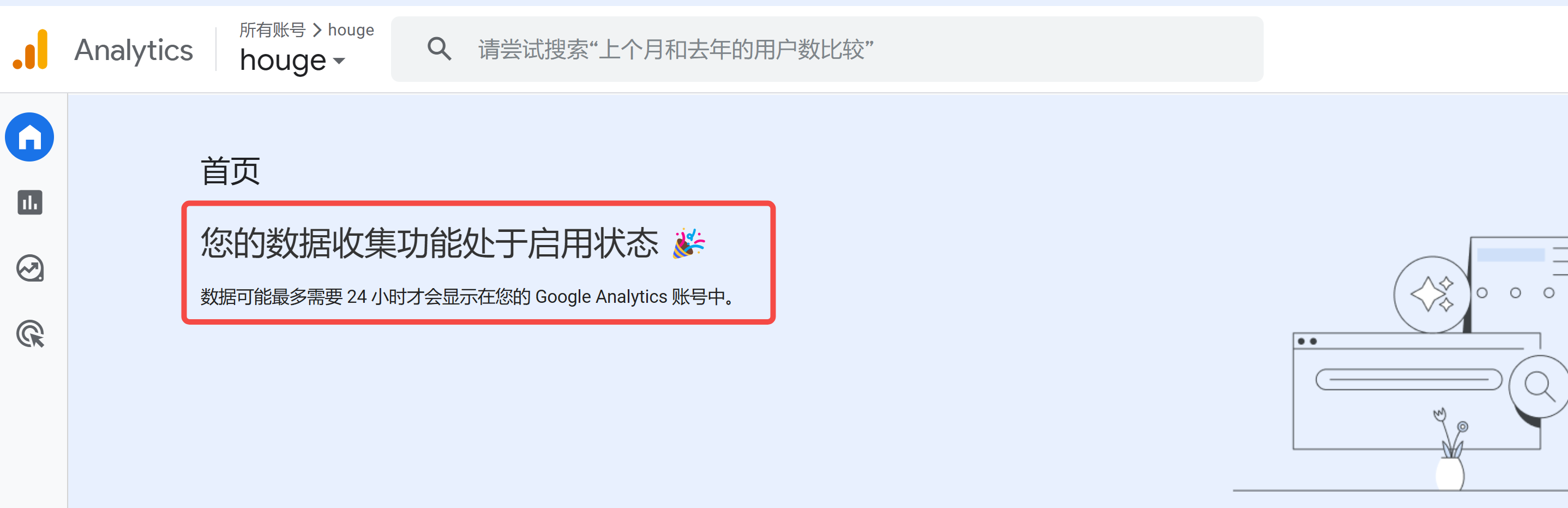
70 |
71 | 因为它是实时更新的,所以回到控制台,点击侧边栏的 `报告`,你就可以看到网站的浏览数据了。
72 | > 传送门:[https://analytics.google.com/analytics/web/](https://analytics.google.com/analytics/web/)
73 |
74 | 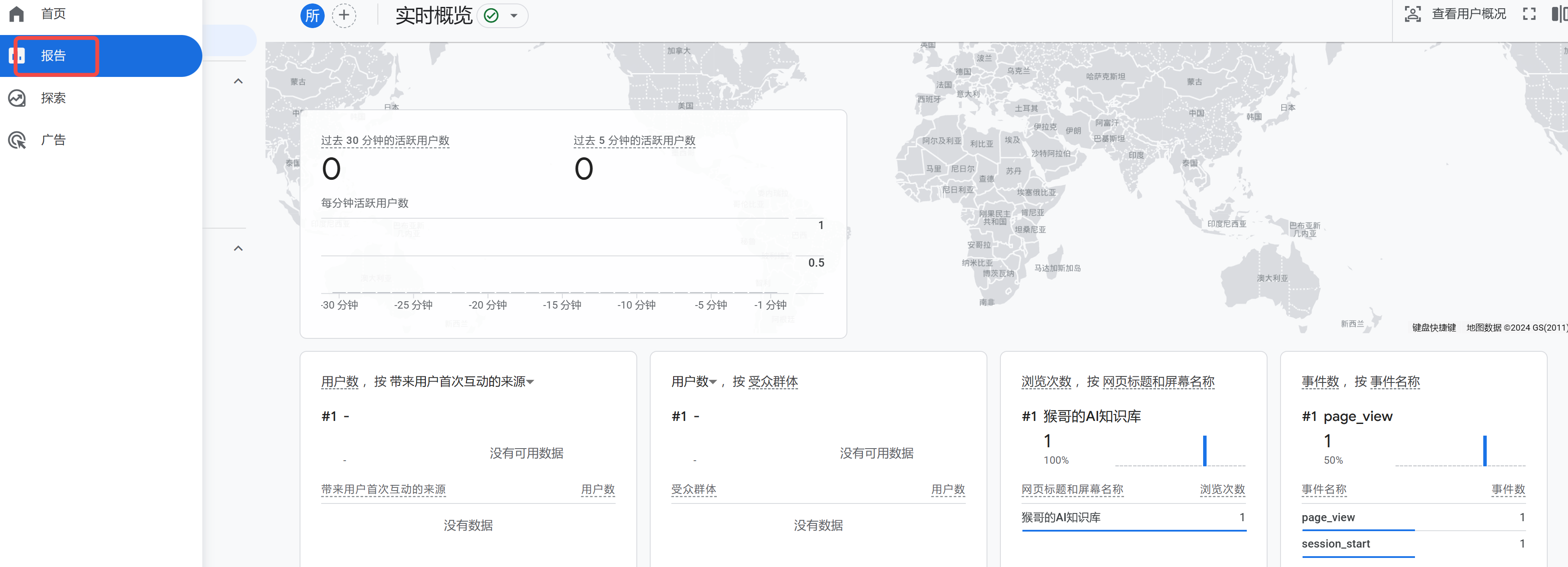
75 |
76 | 以上仅仅是 Google Analytics 的冰山一角,更多功能使用,还有待小伙伴们根据自己的需求去挖掘~
77 |
78 | 当然,如果你仅仅是想统计一下网站的浏览量,有没有更简单的方法?
79 |
80 | 接着往下看👇
81 |
82 | ## 3. 更简单的平替?
83 |
84 | 要在你的网站上添加类似的访客统计功能,还有许多在线服务提供访客计数功能。比如:StatCounter、FreeCounter 等等。
85 |
86 | 这里,再给大家推荐一个亲测好用的国产组件库- NotionPet,个人可以免费创建 2 个组件。
87 | > 传送门:[https://cn.widgetstore.net/](https://cn.widgetstore.net/)
88 |
89 | 进入首页后,点击创建组件,拉到最下面,有一个`访客统计`的组件:
90 |
91 | 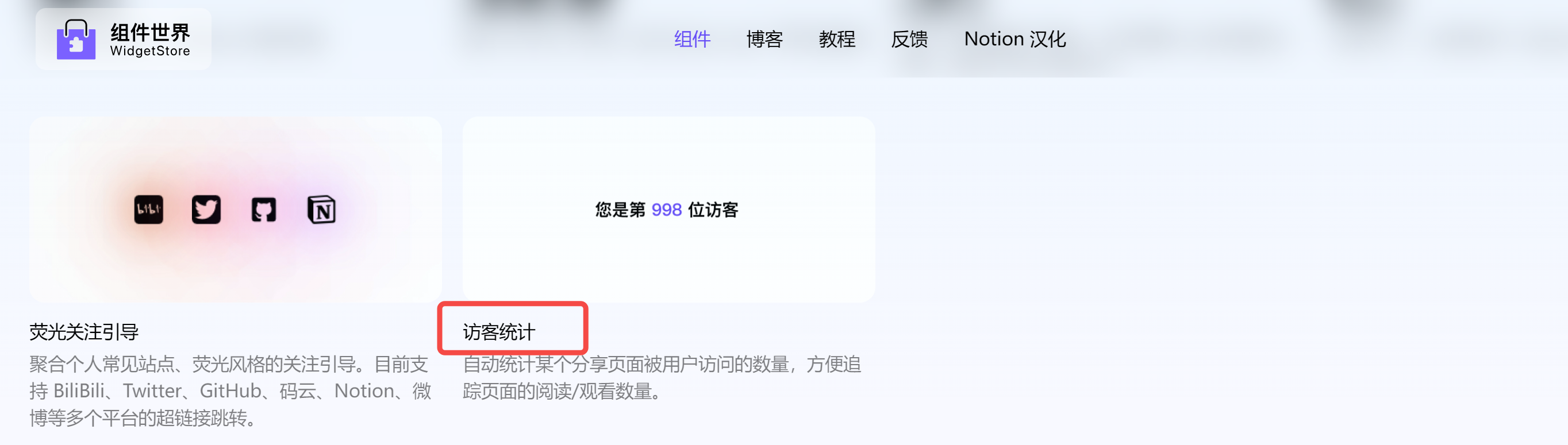
92 |
93 | 点击创建,在最下方有可以编辑的文案模板,其他配置也非常简单。
94 |
95 | 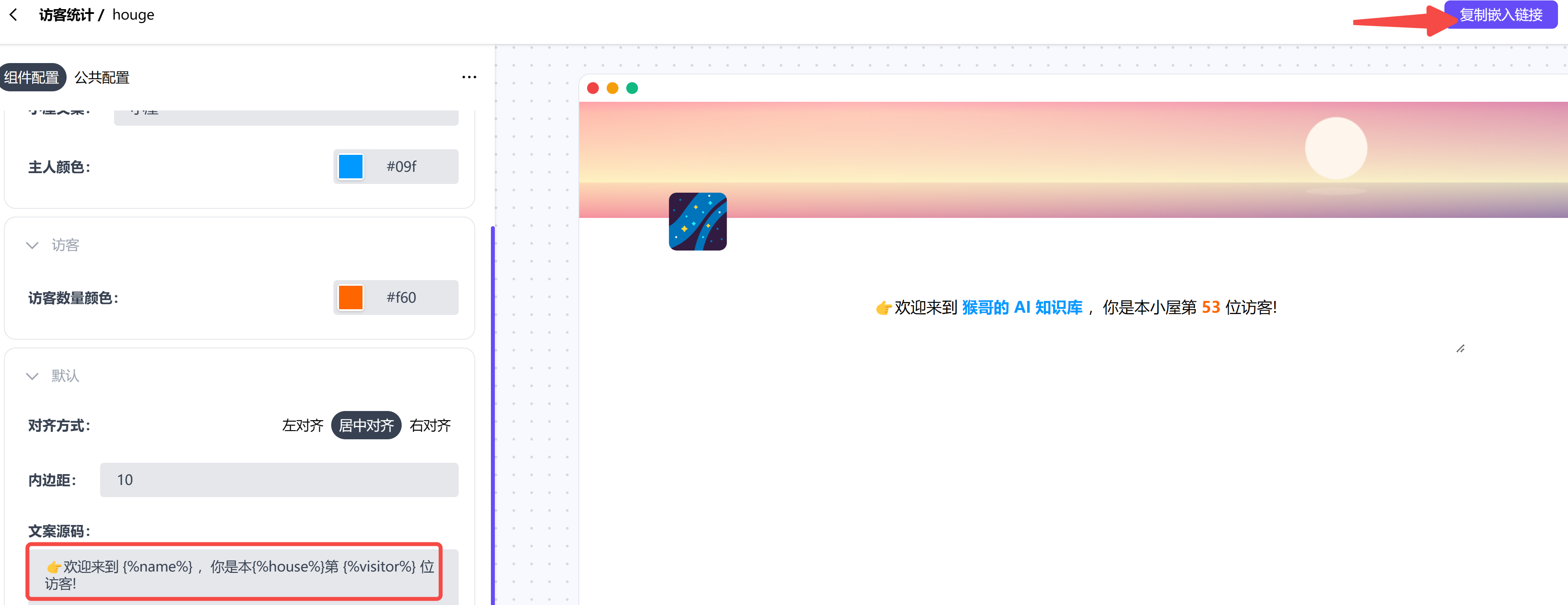
96 |
97 | 配置完成后,在右上方,点击 `复制嵌入链接`,会生成一个你的组件专属的 url,类似这个:
98 | `https://cn.widgetstore.net/view/index.html?q=5b049cc8622189440f31d6307d40e568.9bf3df1366b024e705ac9c7046a46b8e`
99 |
100 | 接下来,你只需要在 markdown 文件中,按照如下方式插入:
101 |
102 | ```
103 |
104 | ```
105 |
106 | docsify 会自动将 markdown 文件渲染成 html 文件,刷新一下你的网站,就可以看到效果了:
107 |
108 | 
109 |
110 | ## 写在最后
111 |
112 | 想知道你的网站有多受欢迎?
113 |
114 | 本文带你玩转 Google Analytics 和 NotionPet 流量统计工具,让你轻松掌握网站流量的秘密!
115 |
116 | 感兴趣的小伙伴,快去试试,窥探一下你的网站魅力指数吧~
117 |
118 | 如果本文对你有帮助,不妨点个**免费的赞**和**收藏**备用。你的支持是我创作的最大动力。
--------------------------------------------------------------------------------
/docs/3.AI笔记/16.3K Star!AI 驱动的的开源爬虫工具.md:
--------------------------------------------------------------------------------
1 |
2 | 前段时间,给微信机器人-`小爱(AI)`新增了一个 `AI日报`的功能。
3 |
4 | 
5 |
6 | 有朋友问怎么做的?
7 |
8 | 其实,这里只用了最简单的爬虫,然后通过定时任务发送。
9 |
10 | 今天,看到一个**更加简单易用、功能强大**爬虫工具 - `Crawl4AI`,几行代码,就能实现高效的网页爬取,分享给大家。
11 |
12 | > 项目地址:[https://github.com/unclecode/crawl4ai](https://github.com/unclecode/crawl4ai)
13 |
14 |
15 | ## 1. Crawl4AI 简介
16 |
17 | 
18 |
19 | Crawl4AI 是一个开源免费的自动化数据提取工具,曾荣登 GitHub Trending 榜一!
20 |
21 | 老规矩,简单介绍下项目亮点:
22 | - **AI 驱动**:利用大型语言模型(LLM)智能识别和解析网页数据。
23 | - **结构化输出**:将数据转换为 JSON、Markdown 等格式,便于分析和AI模型训练。
24 | - **高度定制化**:允许自定义认证、请求头、页面修改、用户代理和执行JavaScript。
25 |
26 |
27 | ## 2. 安装
28 |
29 | 推荐两种安装方式。
30 |
31 | ### 2.1 使用 pip 安装
32 |
33 | ```
34 | pip install crawl4ai
35 | ```
36 |
37 | 默认情况下,这将安装异步版本 Crawl4AI,并使用 Playwright 进行网页爬取。
38 |
39 | 👉 注意:安装脚本会自动安装并设置 Playwright。如果遇到与 Playwright 相关的报错,可使用以下方法手动安装:
40 |
41 | ```
42 | playwright install
43 | ```
44 |
45 | ### 2.2 使用 docker 安装
46 |
47 | 直接拉取官方镜像,跑一个容器:
48 |
49 | ```
50 | docker pull unclecode/crawl4ai:basic # Basic crawling features
51 | # 或者
52 | docker pull unclecode/crawl4ai:all # Full installation (ML, LLM support)
53 | # 或者
54 | docker pull unclecode/crawl4ai:gpu # GPU-enabled version
55 |
56 | # Run the container
57 | docker run -p 11235:11235 unclecode/crawl4ai:basic # Replace 'basic' with your chosen version
58 | ```
59 |
60 | 如果镜像拉取失败,也可以拉取官方仓库,自己构建镜像:
61 |
62 | ```
63 | git clone https://github.com/unclecode/crawl4ai.git
64 | cd crawl4ai
65 |
66 | # Build the image
67 | docker build -t crawl4ai:local \
68 | --build-arg INSTALL_TYPE=basic \ # Options: basic, all
69 | .
70 |
71 | # Run your local build
72 | docker run -p 11235:11235 crawl4ai:local
73 | ```
74 |
75 |
76 |
77 | ## 3. 使用
78 |
79 | ### 3.1 本地pip包
80 |
81 | 如果是本地 pip 安装,使用非常简单,采用异步函数实现,示例如下:
82 |
83 | ```
84 | import asyncio
85 | from crawl4ai import AsyncWebCrawler
86 |
87 | async def main():
88 | async with AsyncWebCrawler(verbose=True) as crawler:
89 | result = await crawler.arun(url="https://www.nbcnews.com/business")
90 | print(result.markdown)
91 |
92 | if __name__ == "__main__":
93 | asyncio.run(main())
94 | ```
95 |
96 | 如果要抓取外网内容,需要加上代理:
97 |
98 | ```
99 | import asyncio
100 | from crawl4ai import AsyncWebCrawler
101 |
102 | async def main():
103 | async with AsyncWebCrawler(verbose=True, proxy="http://127.0.0.1:7890") as crawler:
104 | result = await crawler.arun(
105 | url="https://www.nbcnews.com/business",
106 | bypass_cache=True
107 | )
108 | print(result.markdown)
109 |
110 | if __name__ == "__main__":
111 | asyncio.run(main())
112 | ```
113 | ### 3.2 docker 容器
114 | 如果是 docker 镜像安装的,调用需分两步。
115 |
116 | 因为是异步服务,所以:
117 | - 第一步请求会拿到 task_id,
118 | - 第二步基于 task_id 轮询获取结果。
119 |
120 | ```
121 | import requests
122 |
123 | # Submit a crawl job
124 | response = requests.post(
125 | "http://localhost:11235/crawl",
126 | json={"urls": "https://example.com", "priority": 10}
127 | )
128 | task_id = response.json()["task_id"]
129 |
130 | # Get results
131 | result = requests.get(f"http://localhost:11235/task/{task_id}")
132 | ```
133 |
134 |
135 | ## 4. 效果展示
136 |
137 | 下面,以抓取一个 html 页面,并输出为 markdown 格式,给大家展现下效果。
138 |
139 | **速度超快:**
140 |
141 | 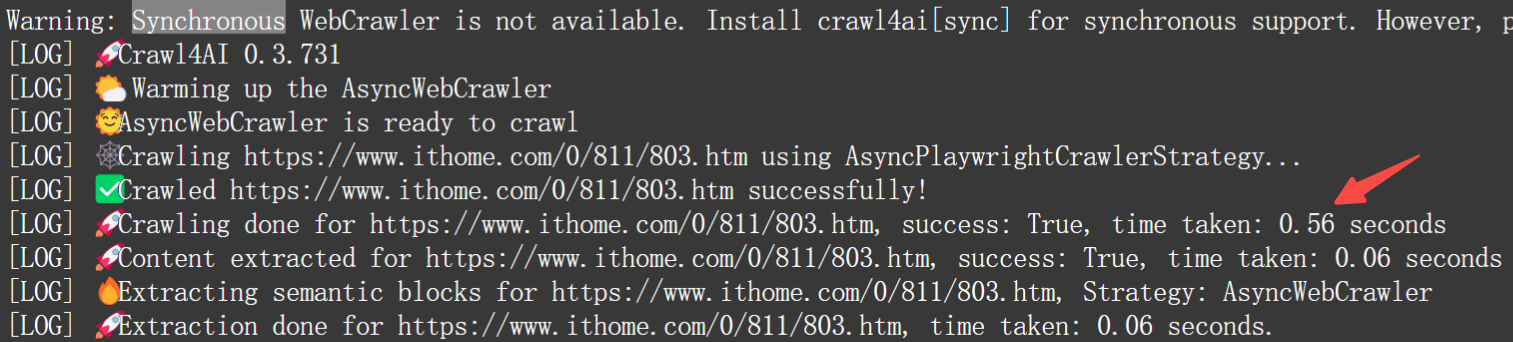
142 |
143 | **首页内容:**
144 |
145 | 
146 |
147 | 
148 |
149 |
150 | **页面底部:**
151 | 
152 |
153 | 
154 |
155 | **侧边栏:**
156 |
157 | 
158 |
159 | 
160 |
161 | 怎么样?
162 |
163 | 更多高级策略使用,可参考官方仓库:[https://github.com/unclecode/crawl4ai](https://github.com/unclecode/crawl4ai)
164 |
165 | ## 写在最后
166 |
167 | Crawl4AI,一款功能强大且简单易用的网页爬虫工具,而且速度超快,有需要的朋友,可以去试试了。
168 |
169 | 如果对你有帮助,欢迎**点赞收藏**备用。
170 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/37K 下载!开源图像背景去除项目,精确到发丝,数字人福音.md:
--------------------------------------------------------------------------------
1 |
2 | 最近 AI 数字人领域进展迅速,多款开源方案,效果炸裂,直逼付费方案-HeyGen!
3 |
4 | 我们在各大短视频平台刷到的数字人,背后的制作流程大致包括:
5 | - 底模数字人视频生成
6 | - AI 换脸(FaceFusion 等)
7 | - **背景去除**
8 | - 背景合成
9 |
10 |
11 | 作为数字人背后的关键技术--**背景去除**,很大程度上决定了最终生成视频的真实度。
12 |
13 | 今天,我们不讲数字人,分享一款**开源免费、轻量高效**的背景去除方案 - `RMBG-2.0`,并带大家本地部署实操。
14 |
15 | > 项目地址:[https://github.com/ai-anchorite/BRIA-RMBG-2.0](https://github.com/ai-anchorite/BRIA-RMBG-2.0)
16 |
17 |
18 | ## 1.RMBG-2.0 亮点
19 |
20 | 老规矩,简单介绍下项目亮点:
21 | - **高精度背景移除**:能够精确识别并移除复杂图像中的背景,提供边缘清晰、自然度高的专业级图像质量。
22 | - **丰富多样的训练数据**:该模型在超过 15,000 张涵盖多种领域的高质量图像上进行训练,确保了其准确性和广泛的适用性。
23 | - **高效的处理速度**:单张 1024x1024 图像,GPU推理耗时约 0.15s。
24 |
25 | 先看下官方测试效果:
26 |
27 | 
28 |
29 | 感兴趣的朋友,可前往官方体验地址:[https://huggingface.co/spaces/briaai/BRIA-RMBG-2.0](https://huggingface.co/spaces/briaai/BRIA-RMBG-2.0)
30 |
31 | 测试效果如下:
32 |
33 | 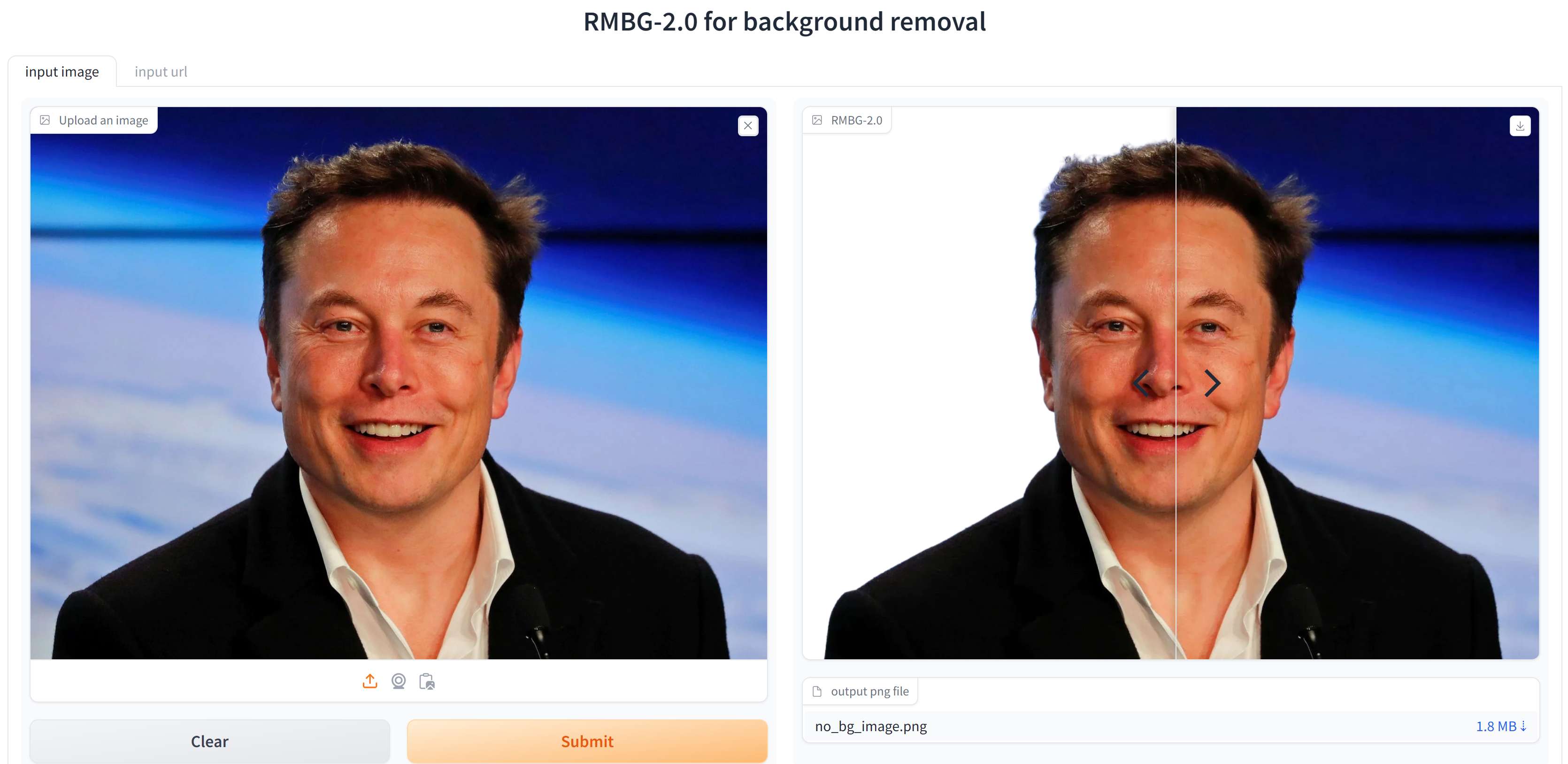
34 |
35 | ## 2. 本地部署
36 |
37 | 项目开源了模型权重,为此,可下载到本地自行部署,使用也非常简单,几行代码搞定!
38 |
39 | ### 2.1 依赖安装
40 |
41 | 项目依赖以下仓库:
42 |
43 | ```
44 | torch
45 | torchvision
46 | pillow
47 | kornia
48 | transformers
49 | ```
50 |
51 | 可选择新建 requirents.txt,填入上述依赖库,一键安装。
52 |
53 | ```
54 | pip install -r requirents.txt
55 | ```
56 | ### 2.2 权重下载
57 | 模型权重托管在 huggingface 上:
58 | > 模型下载:[https://huggingface.co/briaai/RMBG-2.0](https://huggingface.co/briaai/RMBG-2.0)
59 |
60 | 考虑到国内访问 huggingface 比较麻烦,推荐大家从 ModelScope 下载:
61 |
62 | ```
63 | git lfs install
64 | git clone https://www.modelscope.cn/AI-ModelScope/RMBG-2.0.git
65 | ```
66 |
67 |
68 | ### 2.2 本地推理
69 |
70 | 推理示例代码:
71 |
72 | ```
73 | from PIL import Image
74 | import torch
75 | from torchvision import transforms
76 | from transformers import AutoModelForImageSegmentation
77 |
78 | model = AutoModelForImageSegmentation.from_pretrained('RMBG-2.0', trust_remote_code=True)
79 | torch.set_float32_matmul_precision(['high', 'highest'][0])
80 | model.to('cuda')
81 | model.eval()
82 | # Data settings
83 | transform_image = transforms.Compose([
84 | transforms.Resize((1024, 1024)),
85 | transforms.ToTensor(),
86 | transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
87 | ])
88 | image = Image.open('elon-musk.jpg')
89 | input_images = transform_image(image).unsqueeze(0).to('cuda')
90 |
91 | # Prediction
92 | with torch.no_grad():
93 | for i in range(10):
94 | preds = model(input_images)[-1].sigmoid().cpu()
95 | pred = preds[0].squeeze()
96 | pred_pil = transforms.ToPILImage()(pred)
97 | mask = pred_pil.resize(image.size)
98 | image.putalpha(mask)
99 |
100 | image.save("elon-musk_no_bg_image.png")
101 | ```
102 |
103 | 模型预设 1024x1024 输入,在单张 4080 显卡上耗时统计如下,基本稳定在 **0.15s/img**:
104 |
105 | ```
106 | Inference time: 0.147s
107 | Inference time: 0.147s
108 | Inference time: 0.150s
109 | Inference time: 0.147s
110 | Inference time: 0.147s
111 | ```
112 |
113 |
114 | 显存占用如何?
115 |
116 | ```
117 | 1 NVIDIA GeForce RTX 4080 On | 00000000:3B:00.0 Off | N/A |
118 | | 38% 28C P2 86W / 320W | 4667MiB / 16376MiB | 0% Default
119 | ```
120 | 推理需占用约 **5G** 显存。
121 |
122 | 实测效果如下,精确到发丝!
123 |
124 | 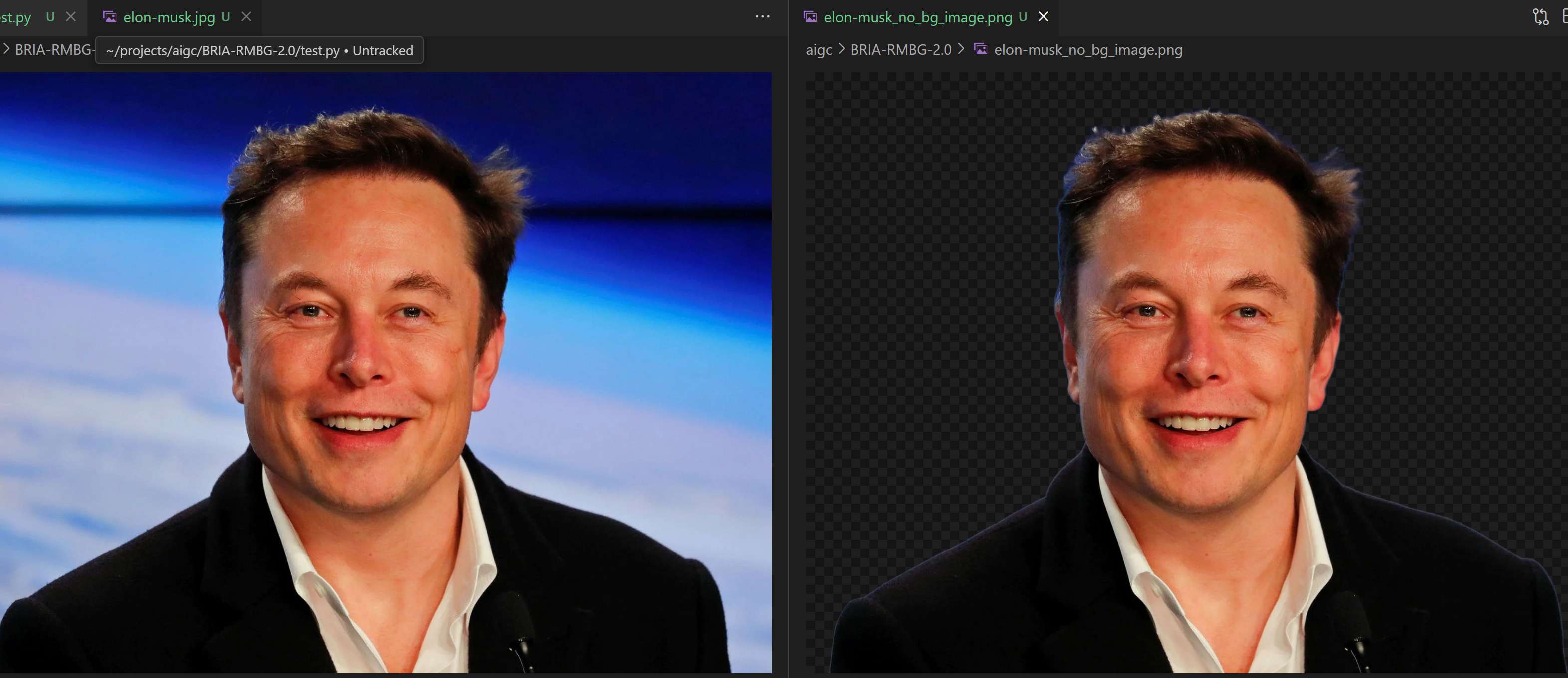
125 |
126 | ## 写在最后
127 |
128 | 本文介绍了一款强大且易用的背景去除工具- RMBG v2.0,本地部署,方便调用。
129 |
130 | 如果对你有帮助,欢迎**点赞收藏**备用。
131 |
132 | 当然,如果只要 web 端使用,给诸位分享一款免费工具:
133 |
134 | [https://www.remove.bg/zh](https://www.remove.bg/zh)
135 |
136 | ---
137 |
138 | 为方便大家交流,新建了一个 `AI 交流群`,欢迎感兴趣的小伙伴加入,公众号后台「联系我」,拉你进群。
139 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/4k star!升级版OneAPI,助力 Dify 兼容 OpenAI 格式.md:
--------------------------------------------------------------------------------
1 | 最近用 dify 搭建了不少智能体,不过 dify 有一个缺陷。
2 |
3 | 相信用过的朋友会有同样的感受:**它的 API 和 Open AI 不兼容**!
4 |
5 | 这就导致一个应用中,用到 dify 的地方,还必须重新写一套 LLM 的调用逻辑。
6 |
7 | 很是麻烦,怎么搞?
8 |
9 | 前段时间,和大家分享过大模型分发和管理神器 OneAPI:
10 |
11 | [所有大模型一键封装成OpenAI协议](https://zhuanlan.zhihu.com/p/707769192)
12 |
13 | 并接入了多款大模型 API:
14 |
15 | [盘点 9 家免费且靠谱的AI大模型 API,统一封装,任性调用!](https://zhuanlan.zhihu.com/p/717498590)
16 |
17 | 实现一个接口聚合不同的大模型,再统一转换为 OpenAI 的 API,**遗憾的是不支持 Dify 接入**。
18 |
19 | 最近看到一款开源项目 **NewAPI**:对 OneAPI 进行了二次开发,实现了对 Dify 的支持。终于,Dify API 也可以通过 OpenAI 统一分发了!
20 |
21 | 话不多说,上实操!
22 |
23 | ## 1. 服务部署
24 | > 项目:[https://github.com/Calcium-Ion/new-api](https://github.com/Calcium-Ion/new-api)
25 |
26 | 推荐使用 docker 部署:
27 |
28 | **数据库使用 SQLite 的部署命令**:
29 |
30 | ```
31 | docker run -d --name newapi --restart always -p 3007:3000 -e TZ=Asia/Shanghai -v ./data:/data calciumion/new-api:latest
32 | ```
33 |
34 | 当然,也支持 Docker Compose 的方式:
35 |
36 | ```
37 | # 先下载项目到本地
38 | git clone https://github.com/Calcium-Ion/new-api.git
39 | # 然后修改 docker-compose.yml 文件
40 | # 最后启动
41 | docker-compose up -d
42 | ```
43 |
44 | ## 2. NewAPI 使用
45 | ### 2.1 登录
46 | 本地浏览器通过 IP + 端口的形式进行访问,初始账号密码:root 123456。
47 |
48 | 
49 |
50 | ### 2.2 渠道
51 | 相信用过 OneAPI 的朋友,应该不陌生:`渠道`用于添加不同厂商的大模型。
52 |
53 | 点击「控制台-渠道-添加渠道」,在支持的渠道里选择 Dify:
54 |
55 | 
56 |
57 |
58 | 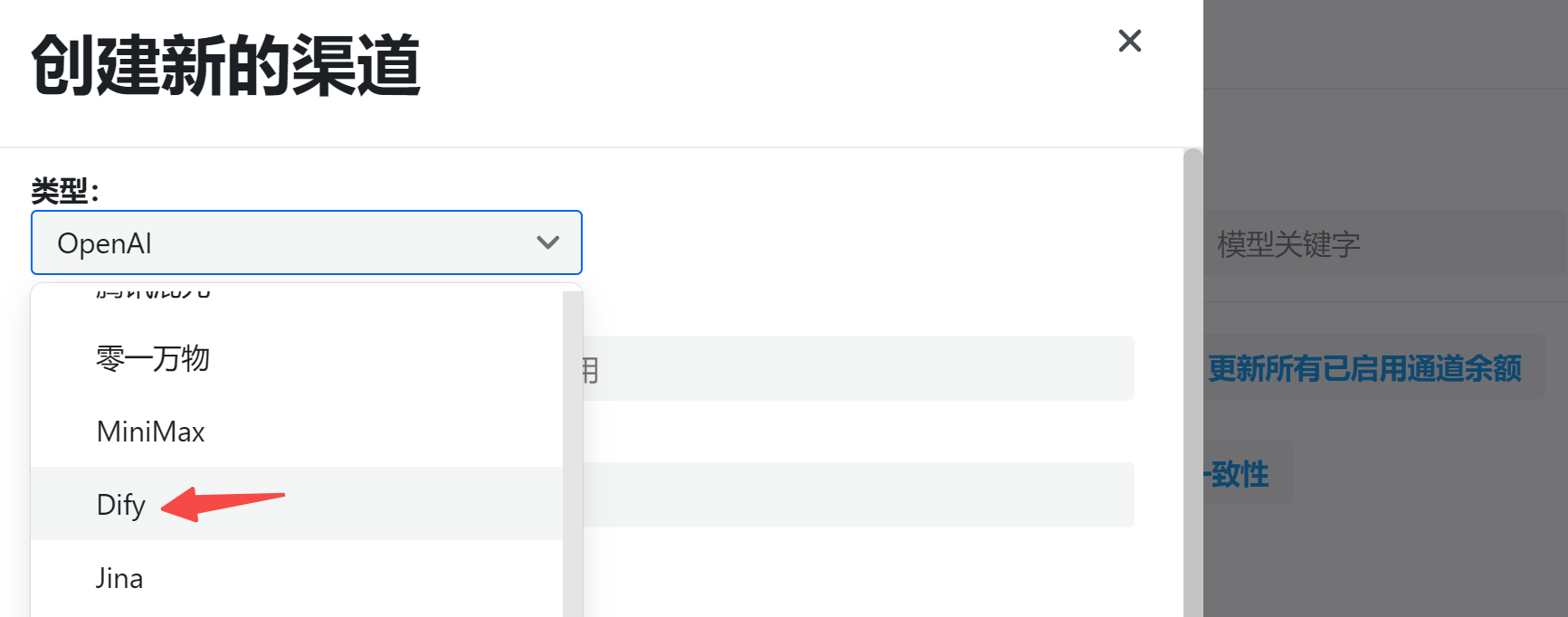
59 |
60 | 然后,在`代理`这里:需填入 dify 的 IP地址+端口号。
61 |
62 | 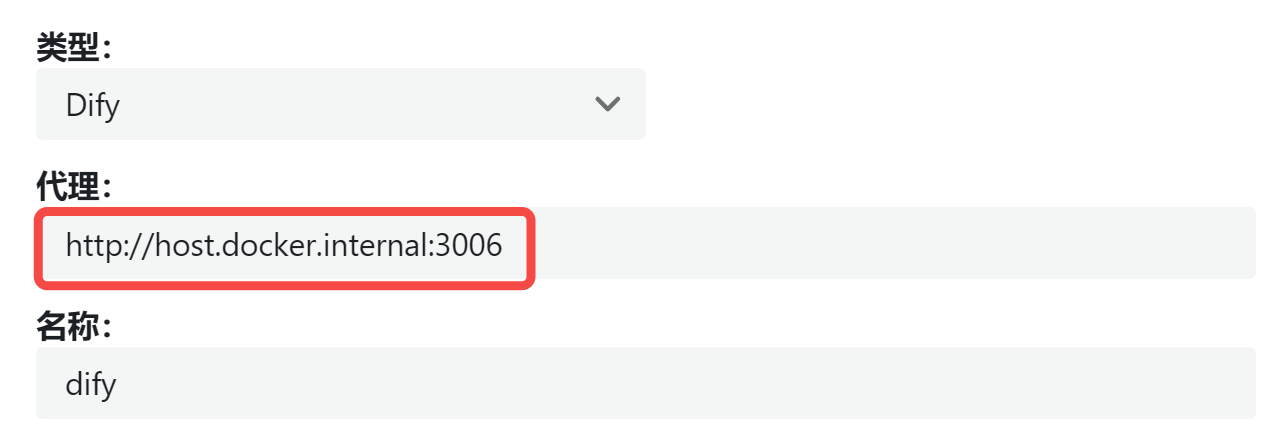
63 |
64 | 注意:图中的`http://host.docker.internal:3006` 用于从Docker容器内部访问宿主机的网络,不过只能在Windows和Mac版本的 Docker 中使用。Linux 用户需要改为本机的 IP 地址(**同一局域网内即可,无需公网 IP**)。
65 |
66 |
67 | 清空下方所有模型,填入模型名称 dify:
68 |
69 | 
70 |
71 | 然后,在最下方填入 dify 应用中获取的密钥:
72 |
73 | 
74 |
75 |
76 | 最后,来测试一下吧,一般只要 IP+端口号没问题,这里都能通过:
77 |
78 | 
79 |
80 | **此外,New API 完美兼容 OneAPI 的数据库,可直接迁移 OneAPI 的数据库(one-api.db),无需同时维护OneAPI 和 NewAPI 两个项目。**
81 |
82 | ### 2.3 PlayGround
83 | 相比 Dify,作者贴心地新增了 PlayGround,方便可视化模型效果。
84 |
85 | 模型选择我们之前在 Dify 上搭建的搜索引擎智能体:
86 |
87 | 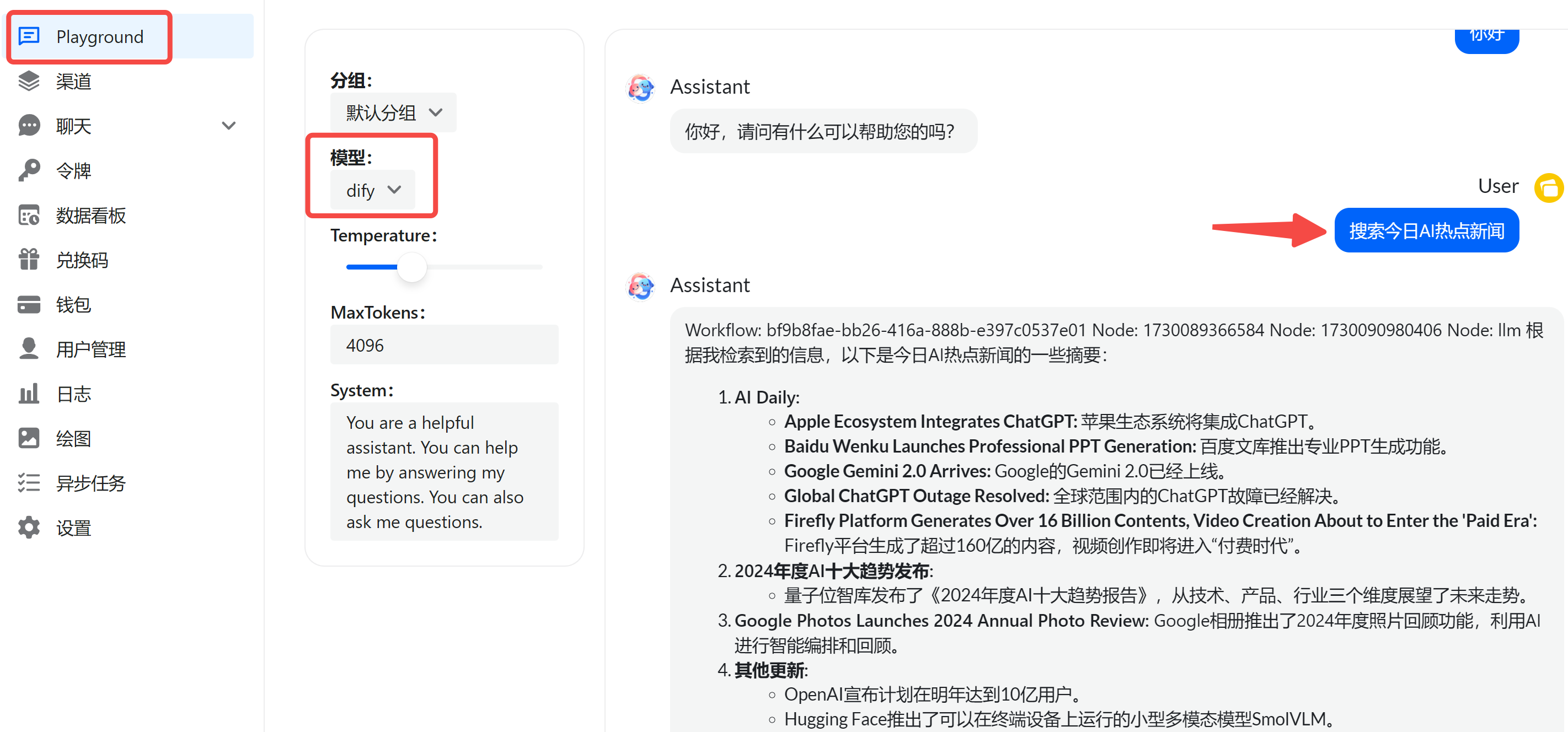
88 |
89 | ### 2.4 令牌
90 |
91 | 要在本地客户端调用,还需一个 api_key。添加令牌:
92 |
93 | 
94 |
95 | ### 2.5 更多
96 | 此外,相比 OneAPI,NewAPI 这个项目还增加了更多实用功能,比如下方的调用量数据看板,同时也增加了支付接口,`新一代大模型网关与AI资产管理系统`,当之无愧!
97 |
98 | 
99 |
100 |
101 | ## 写在最后
102 |
103 | 本文介绍了大模型接口管理工具-NewAPI,除了 Dify 之外,还支持 Midjourney 绘图接口。有需要的朋友快去试试。
104 |
105 | 如果对你有帮助,欢迎**点赞收藏**备用。
106 |
107 | ---
108 |
109 | 为方便大家交流,新建了一个 `AI 交流群`,公众号后台「联系我」,拉你进群。
110 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/AI全栈利器开源!带你用Ollama+Qwen2.5-Code跑bolt.new.md:
--------------------------------------------------------------------------------
1 | 最近,AI 编程工具非常火爆,从 Cursor、V0、Bolt.new 再到最近的 Windsurf。
2 |
3 | 本篇我们先来聊聊开源方案-[Bolt.new](https://bolt.new),产品上线四周,收入就高达400万美元。
4 |
5 | 
6 |
7 | 无奈该网站国内访问速度受限,且免费 Token 额度有限。
8 |
9 | 怎么在本地运行,让更多人用上,加速AI落地,是猴哥的使命。
10 |
11 | 今日分享,**带大家用本地 Ollama 部署的大模型,驱动 bolt.new**,实现 AI 编程的 Token 自由。
12 |
13 | ## 1. Bolt.new 简介
14 |
15 | Bolt.new 是一个基于SaaS的AI编码平台,底层是由 LLM 驱动的智能体,结合WebContainers技术,在浏览器内实现编码和运行,其优势有:
16 | - **支持前后端同时开发**;
17 | - **项目文件夹结构可视化**;
18 | - **环境自托管,自动安装依赖(如 Vite、Next.js 等)**;
19 | - **运行 Node.js 服务器,从部署到生产**
20 |
21 | Bolt.new的目标是,让更多人都能完成 web应用开发,即便是编程小白,也能通过简单的自然语言实现创意。
22 |
23 | 官方已将项目开源:[https://github.com/stackblitz/bolt.new](https://github.com/stackblitz/bolt.new)
24 |
25 | 不过,官方开源的 bolt.new 支持模型有限,国内很多小伙伴都无法调用海外的 LLM API。
26 |
27 | 社区有大神二开了 bolt.new-any-llm,可支持本地 Ollama 模型,下面带大家实操一番。
28 |
29 | ## 2. Qwen2.5-Code 本地部署
30 |
31 | 前段时间,阿里开源了 Qwen2.5-Coder 系列模型,其中 32B 模型在十余项基准评测中均取得开源最佳成绩。
32 |
33 | 无愧全球最强开源代码模型,在多项关键能力上甚至超越 GPT-4o。
34 |
35 | Ollama 模型仓库也已上线 qwen2.5-coder:
36 |
37 | 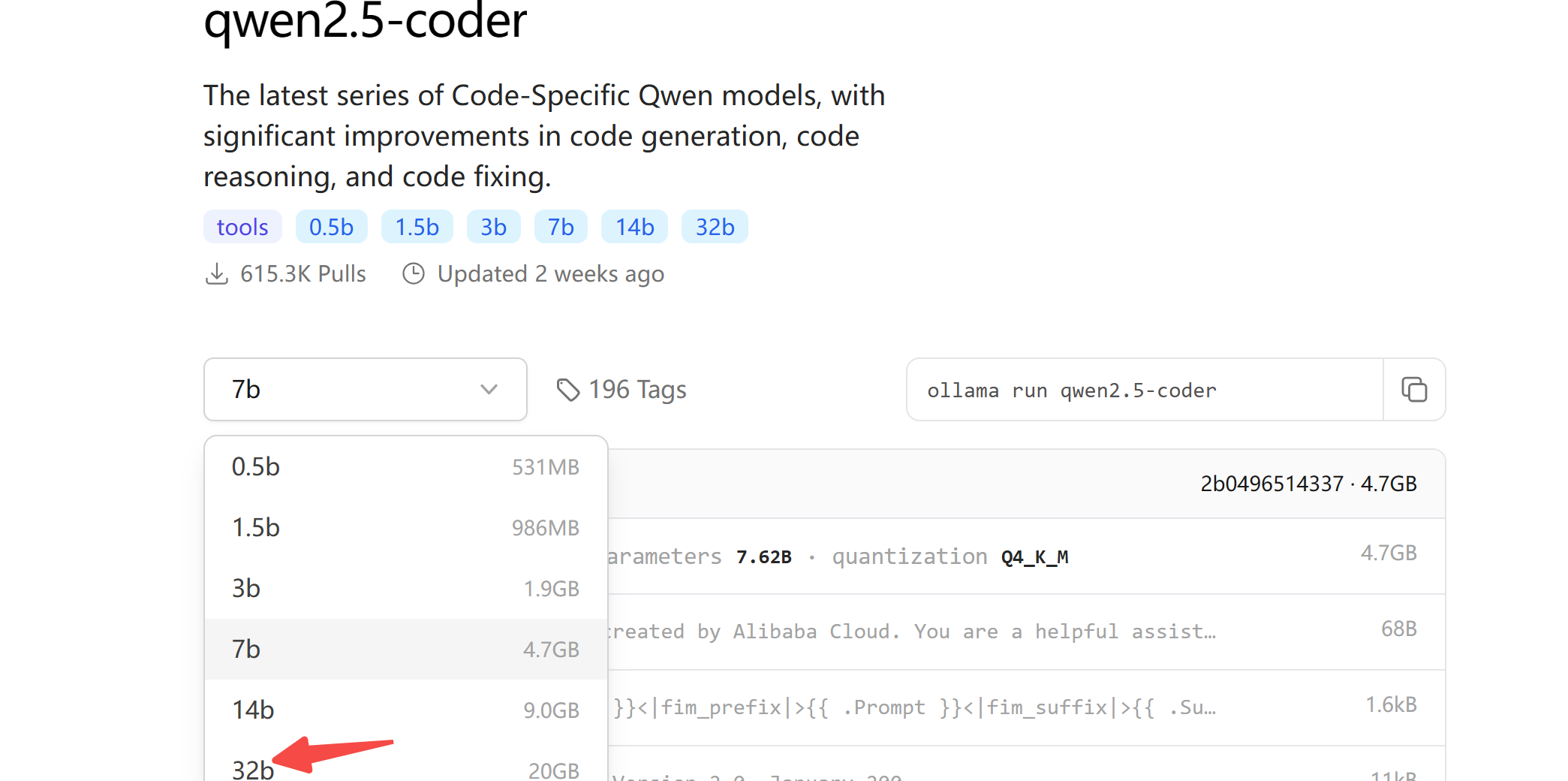
38 |
39 | Ollama 是一款小白友好的大模型部署工具,不了解的小伙伴可回看教程:[本地部署大模型?Ollama 部署和实战,看这篇就够了](https://zhuanlan.zhihu.com/p/710560829)。
40 |
41 | ### 2.1 模型下载
42 |
43 | 关于下载多大的模型,可根据自己的显存进行选择,32B 模型至少确保 24G 显存。
44 |
45 | 下面我们以 7b 模型进行演示:
46 |
47 | ```
48 | ollama pull qwen2.5-coder
49 | ```
50 |
51 |
52 | ### 2.2 模型修改
53 |
54 | 由于 Ollama 的默认最大输出为 4096 个token,对于代码生成任务而言,显然是不够的。
55 |
56 | 为此,需要修改模型参数,增加上下文 Token 数量。
57 |
58 | 首先,新建 Modelfile 文件,然后填入:
59 |
60 | ```
61 | FROM qwen2.5-coder
62 | PARAMETER num_ctx 32768
63 | ```
64 |
65 | 然后,开始模型转换:
66 |
67 | ```
68 | ollama create -f Modelfile qwen2.5-coder-extra-ctx
69 | ```
70 |
71 | 转换成功后,再次查看模型列表:
72 |
73 | 
74 |
75 | ### 2.3 模型运行
76 |
77 | 最后,在服务端检查一下,看模型能否被成功调用:
78 |
79 | ```
80 | def test_ollama():
81 | url = 'http://localhost:3002/api/chat'
82 | data = {
83 | "model": "qwen2.5-coder-extra-ctx",
84 | "messages": [
85 | { "role": "user", "content": '你好'}
86 | ],
87 | "stream": False
88 | }
89 | response = requests.post(url, json=data)
90 | if response.status_code == 200:
91 | text = response.json()['message']['content']
92 | print(text)
93 | else:
94 | print(f'{response.status_code},失败')
95 | ```
96 |
97 | 如果没什么问题,就可以在 bolt.new 中调用了。
98 |
99 | ## 3. Bolt.new 本地运行
100 |
101 | ### 3.1 本地部署
102 |
103 | **step1**: 下载支持本地模型的 bolt.new-any-llm:
104 |
105 | ```
106 | git clone https://github.com/coleam00/bolt.new-any-llm
107 | ```
108 |
109 | **step2**: 复制一份环境变量:
110 |
111 | ```
112 | cp .env.example .env
113 | ```
114 |
115 | **step3**: 修改环境变量,将`OLLAMA_API_BASE_URL`替换成自己的:
116 | ```
117 | # You only need this environment variable set if you want to use oLLAMA models
118 | # EXAMPLE http://localhost:11434
119 | OLLAMA_API_BASE_URL=http://localhost:3002
120 | ```
121 |
122 | **step4**: 安装依赖(需本地已安装好 node)
123 |
124 | ```
125 | sudo npm install -g pnpm # pnpm需要全局安装
126 | pnpm install
127 | ```
128 |
129 |
130 | **step5**: 一键运行
131 |
132 | ```
133 | pnpm run dev
134 | ```
135 |
136 |
137 | 看到如下输出,说明启动成功:
138 |
139 | ```
140 | ➜ Local: http://localhost:5173/
141 | ➜ Network: use --host to expose
142 | ➜ press h + enter to show help
143 | ```
144 | ### 3.2 效果展示
145 |
146 | 浏览器中打开`http://localhost:5173/`,选择 Ollama 类型模型:
147 |
148 | 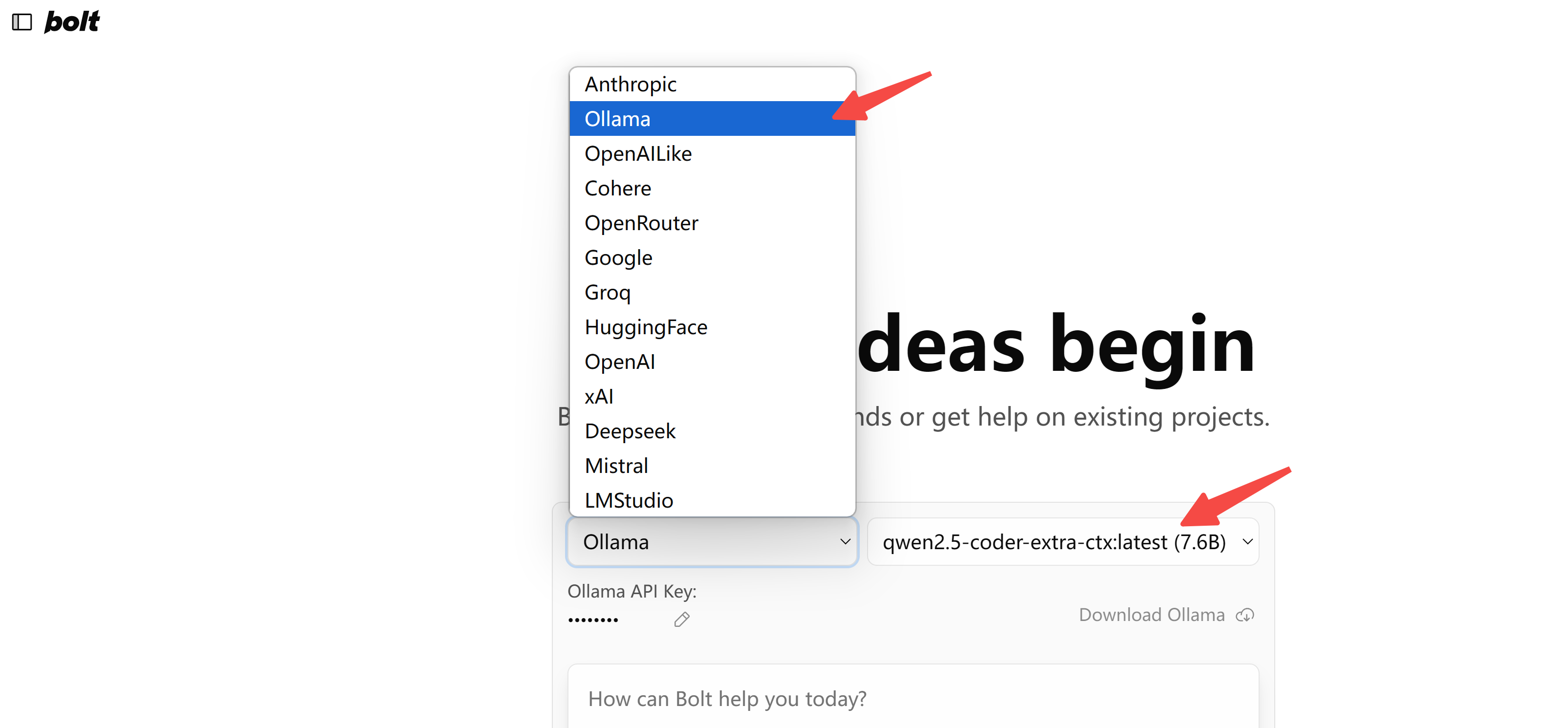
149 |
150 | *注意:首次加载,如果没拉取到 Ollama 中的模型,多刷新几次看看看。*
151 |
152 |
153 | 来实测一番~
154 |
155 |
156 | ```
157 | 写一个网页端贪吃蛇游戏
158 | ```
159 | 左侧是`流程执行`区域,右侧是`代码编辑`区域,下方是`终端`区域。写代码、安装依赖、终端命令,全部由 AI 帮你搞定!
160 |
161 | 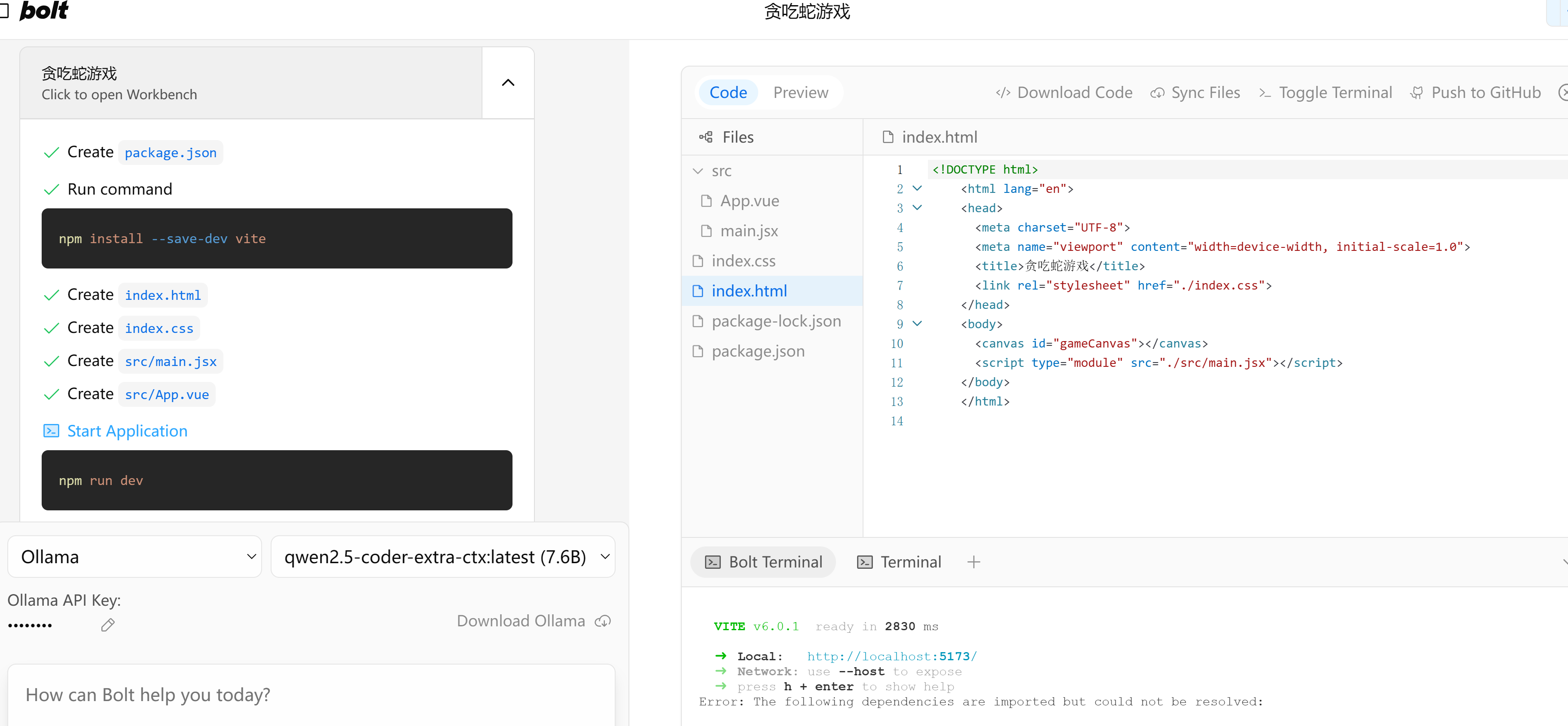
162 |
163 |
164 | 如果遇到报错,直接把报错丢给它,再次执行,如果没什么问题,右侧`Preview`页面就可以成功打开。
165 |
166 | 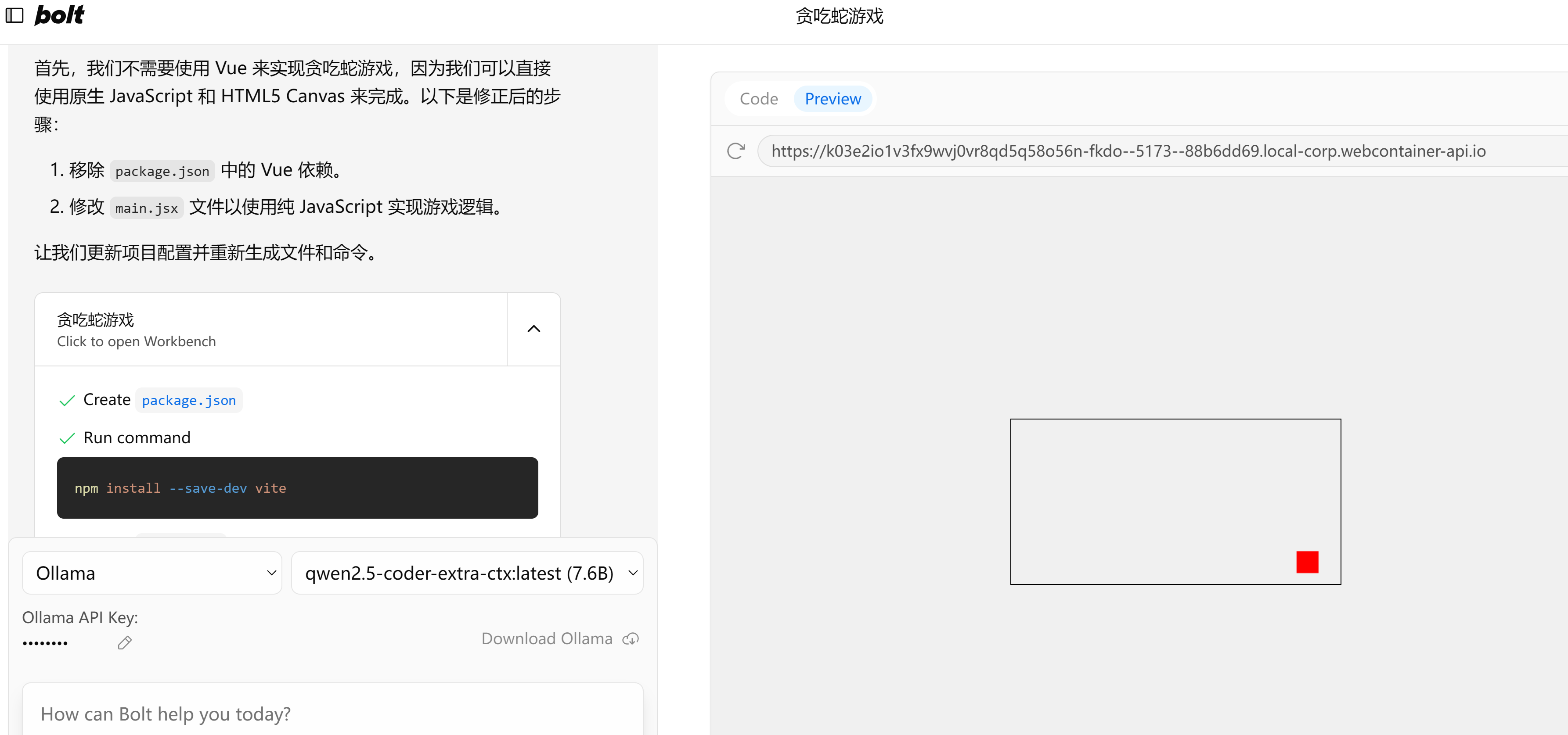
167 |
168 |
169 | *注:由于示例中用的 7b 小模型,有需要的朋友可以尝试用 32b 模型,效果会有显著提升。*
170 |
171 | ## 写在最后
172 |
173 | 本文带大家在本地部署了 qwen2.5-code 模型,并成功驱动 AI 编程工具 bolt.new。
174 |
175 | 用它来开发前端项目还是相当给力的,当然,要想用好它,懂点基本的前后端概念,会事半功倍。
176 |
177 | 如果对你有帮助,欢迎**点赞收藏**备用。
178 |
179 | ---
180 |
181 | 为方便大家交流,新建了一个 `AI 交流群`,欢迎感兴趣的小伙伴加入,公众号后台「联系我」,拉你进群。
182 |
183 |
184 |
185 |
186 |
187 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/AI全栈开发利器:字节 Trae 初体验,最强 Claude 3.5 _ GPT 4o 无限免费用.md:
--------------------------------------------------------------------------------
1 |
2 | 现在写代码完全离不开 AI 了。
3 |
4 | 一直以来,Cursor 都是 AI 编程工具中的顶流,最主要的还是背后的 Claude 太强!
5 |
6 | 最近用 AI 帮我写代码,最大的体会:用好工具,事半功倍,**用错工具,分分钟把你带进沟**。
7 |
8 | 体验过国内外大模型后,有一说一:**单论写代码,Claude 绝对的宇宙最强**,基本三轮之内,就能拿到想要的结果。
9 |
10 | 前段时间,字节推过自家的 AI 编程工具 - `Trae`,当时只有 Mac 版,宣传 Claude 无限量免费,试问哪个开发者不心动?
11 |
12 | 无奈手头没有 Mac,直到今天,Windows 版 `Trae` 也上线了。
13 |
14 | 实测体验了一番,抓紧分享给大家。
15 |
16 | ## 1. Trae 简介
17 |
18 | 字节跳动推出的一款 AI 编程工具,基于开源 VSCode 开发。
19 |
20 | 对于用习惯了 VSCode 的小伙伴来说,基本没有上手门槛。
21 |
22 | 
23 |
24 | **为什么建议你试试?**
25 | - **Claude 3.5 Sonnet 无限免费使用**,这个窗口期应该不会太长,类比去年的 Coze;
26 | - 基于 VS Code,交互零门槛;
27 | - 代码补全、代码生成、bug 修复,全流程覆盖。
28 |
29 |
30 | ## 2. Trae 实操
31 |
32 | ### 2.1 下载安装
33 | 前段时间,和大家分享过 google 家的 AI 编程工具:
34 |
35 | [AI全栈开发利器:拥抱 Google IDX,代码生成+云端部署](https://zhuanlan.zhihu.com/p/14080247005)
36 |
37 | IDX 是一款云端 IDE,无需下载安装,缺点是网络不佳时,体验非常差。
38 |
39 | 这下好,字节的 Trae 来了,下载安装一把梭,和 VSCode 并无太大差异!
40 |
41 | > 去试试吧:[https://www.trae.ai/](https://www.trae.ai/)
42 |
43 | 安装过程中,特别贴心的一点:可以直接从 VSCode 中导入之前的配置。
44 |
45 | 
46 |
47 | 当然,想要白嫖,还是要登录的~
48 |
49 | 
50 |
51 | **居然登录不上?**
52 |
53 | 
54 |
55 | 原来,目前不支持中国用户使用,这里有支持列表:
56 |
57 | [https://docs.trae.ai/docs/supported-countries-and-regions?_lang](https://docs.trae.ai/docs/supported-countries-and-regions?_lang)
58 |
59 | 没招,用 **Github or Gmail** 登录吧。
60 |
61 | ### 2.2 页面布局
62 |
63 | 整个页面布局完全沿袭了 VSCode,左侧插件栏把之前在 VScode 中的插件也导入进来了。
64 |
65 | 右侧是 AI 设置和聊天区,非常适合对照着改代码。
66 |
67 | 
68 |
69 | 右下角可以切换模型:
70 |
71 | 
72 |
73 | 没别的,就两款最强模型:
74 | - Claude-3.5-Sonnet
75 | - GPT-4o
76 |
77 | 干就完了!
78 |
79 | **不多说了,抓紧去白嫖!**
80 |
81 | 哪怕你不用它来写代码,Chat 模式,随便用,不够香吗?
82 |
83 | ## 写在最后
84 |
85 | 本文和大家分享了 AI 编程工具-`trae`,白嫖 Claude-3.5-Sonnet 和 GPT-4o 不限量。
86 |
87 | 如果对你有帮助,欢迎**点赞收藏**备用。
88 |
89 | ---
90 |
91 | 为方便大家交流,新建了一个 `AI 交流群`,公众号后台「联系我」,拉你进群。
92 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/AI全栈开发利器:弃坑 Cursor 拥抱 Google IDX,代码生成+云端部署.md:
--------------------------------------------------------------------------------
1 | 最近,AI 编程工具非常火爆,不仅极大降低了开发者的工作量,也为编程新手快速入门,提供了极大的便利。
2 |
3 | 提到 AI 编程工具,Cursor 绝对是其中的顶流。
4 |
5 | 不过直到今天,笔者也未用过 Cursor,原因无它:**Cursor 需下载安装使用**!
6 |
7 | 且 Cursor 的免费 Token 额度有限,有朋友分享过无限白嫖的方法:**通过注销账号重新注册实现无限免费使用**。
8 |
9 | 不过,这个漏洞也被 Cursor 堵上了,而平替 Windsurf/Bolt.new 同样需要付费订阅。
10 |
11 | **有没有其它工具,可以兼顾强大功能和免费体验?**
12 |
13 | 最近,Google 频放大招,除了媒体关注的多模态大模型 Gemini2.0,还推出了新一代 **AI 代码编辑器 - IDX**。
14 |
15 | 今日分享,带大家全面了解这款工具,并通过一个简单的案例,实测 IDX 效果到底如何。
16 |
17 | ## 1. IDX 简介
18 | 和 Cursor 不同的是,IDX 无需下载安装,它是一款云端集成开发环境(IDE),目前还处于 Beta 版阶段。
19 |
20 | 支持云端进行全栈、多平台应用开发。
21 |
22 | 下图展示了其支持的多种开发框架,甚至可以直接 import 你的 github 仓库进行开发。
23 |
24 | 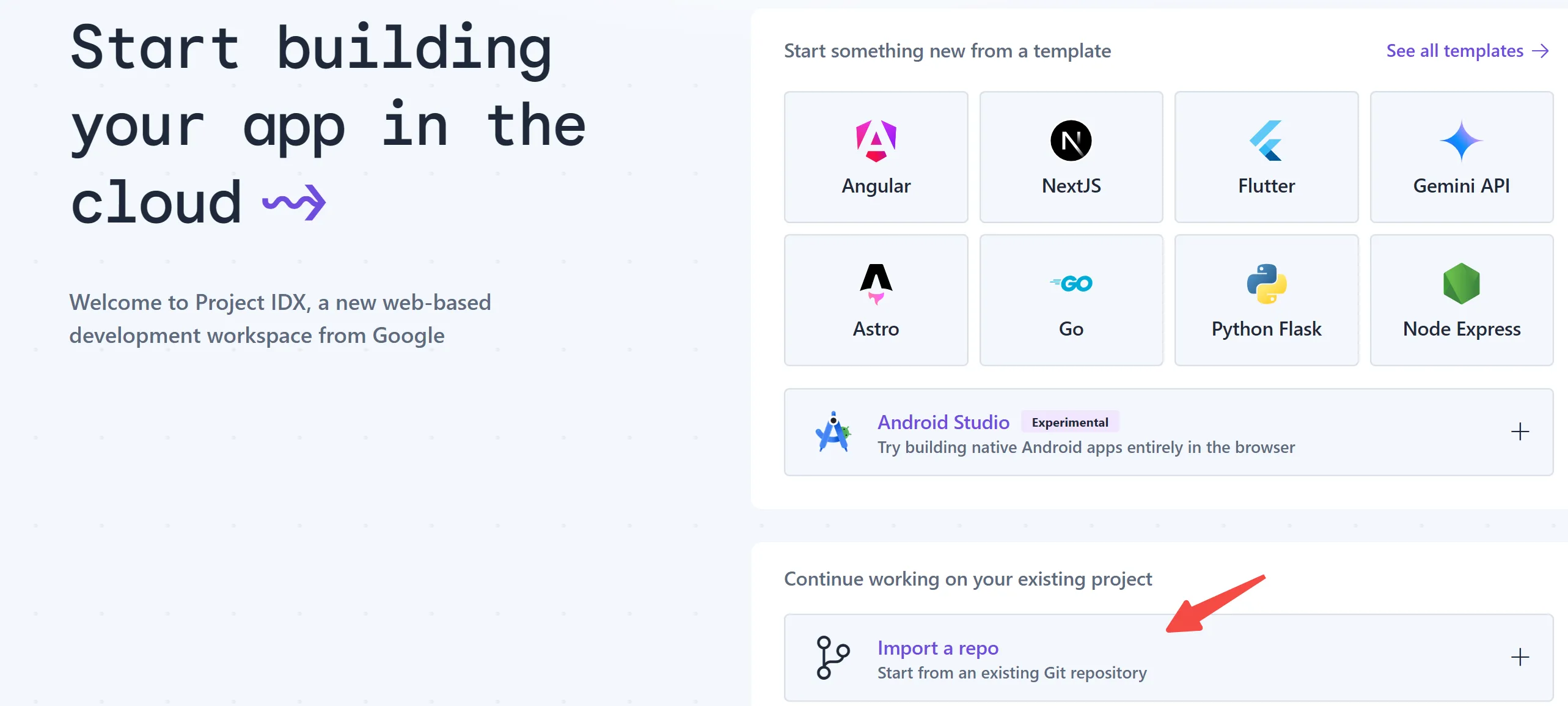
25 |
26 |
27 | 从首页来看,和我们前面分享的 Bolt.new 非常类似,不过当前 IDX **完全免费**!
28 |
29 | 老规矩,简单列出它的核心亮点:
30 |
31 | - **多框架支持**:内置模板丰富,支持 Angular、Flutter、React、Vue 等各种框架。
32 |
33 | - **AI 助力**:底层大模型 Gemini,支持代码生成、优化、测试等功能
34 |
35 | - **在线模拟器**:内置 iOS 和 Android 模拟器,无需安装即可测试和调试移动端应用。
36 |
37 | - **一键部署**:支持项目一键部署,省去复杂的部署步骤。
38 |
39 | ## 2. IDX 实操
40 |
41 | > [https://idx.google.com/](https://idx.google.com/)
42 |
43 |
44 | 本文通过一个简单的案例,带大家快速上手 IDX 的基本用法:*实现带有积分功能的贪吃蛇游戏。*
45 |
46 | **step 1: 项目创建**
47 |
48 | 选择最简单的 Html 模板即可。
49 |
50 | 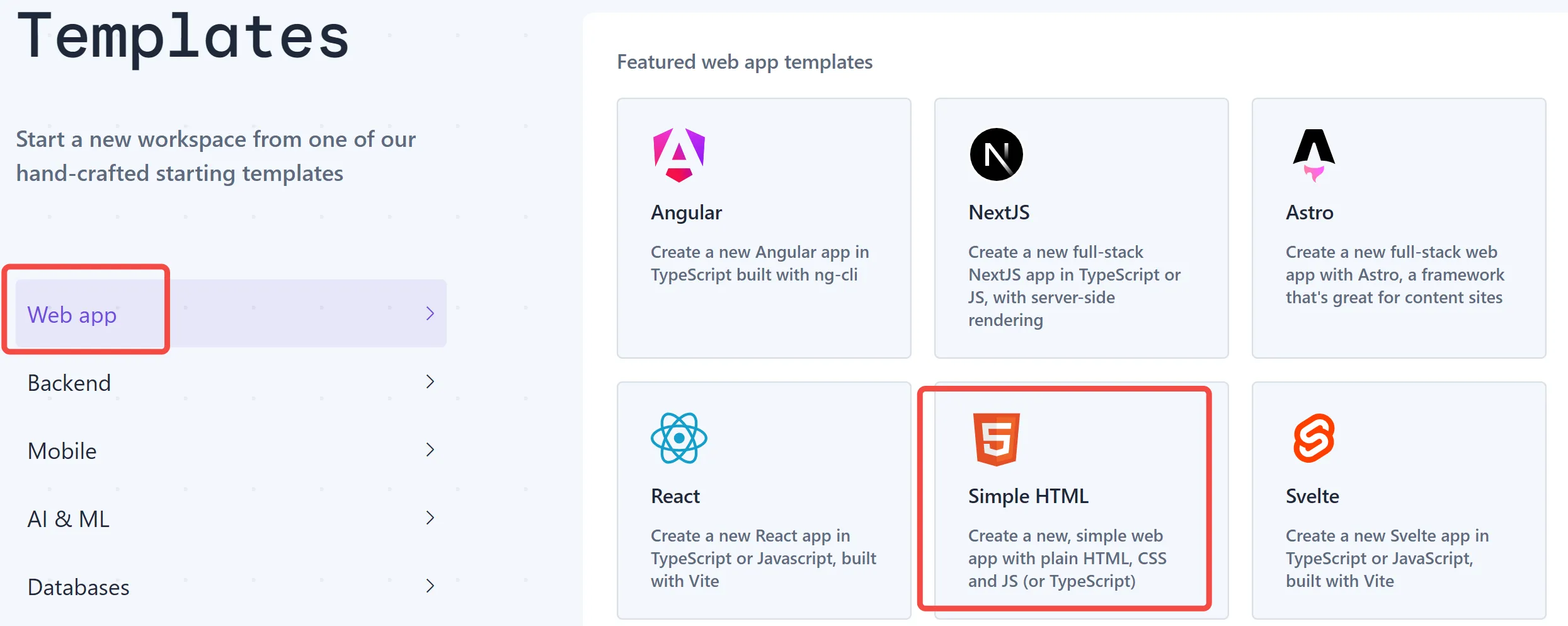
51 |
52 |
53 | 稍等片刻,IDX 会自动生成项目空间,并配备好前端三件套:html/js/css。中间是代码区,右侧是预览区。
54 |
55 | 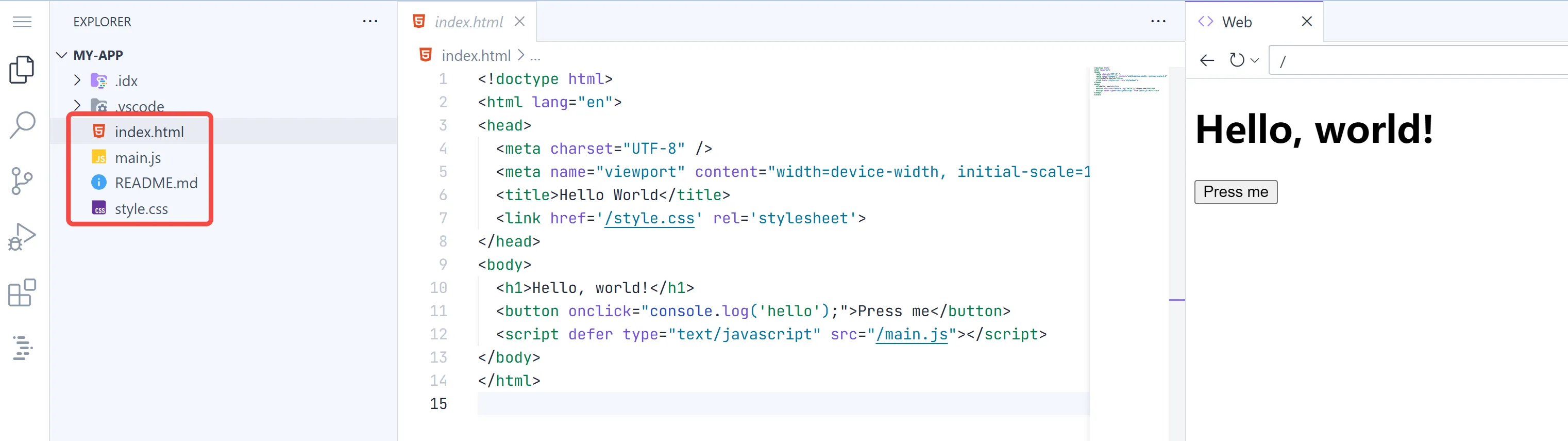
56 |
57 |
58 | **step 2: 项目生成**
59 |
60 | 在底栏可以调取 Gemini,开始给它安排任务吧:
61 |
62 | 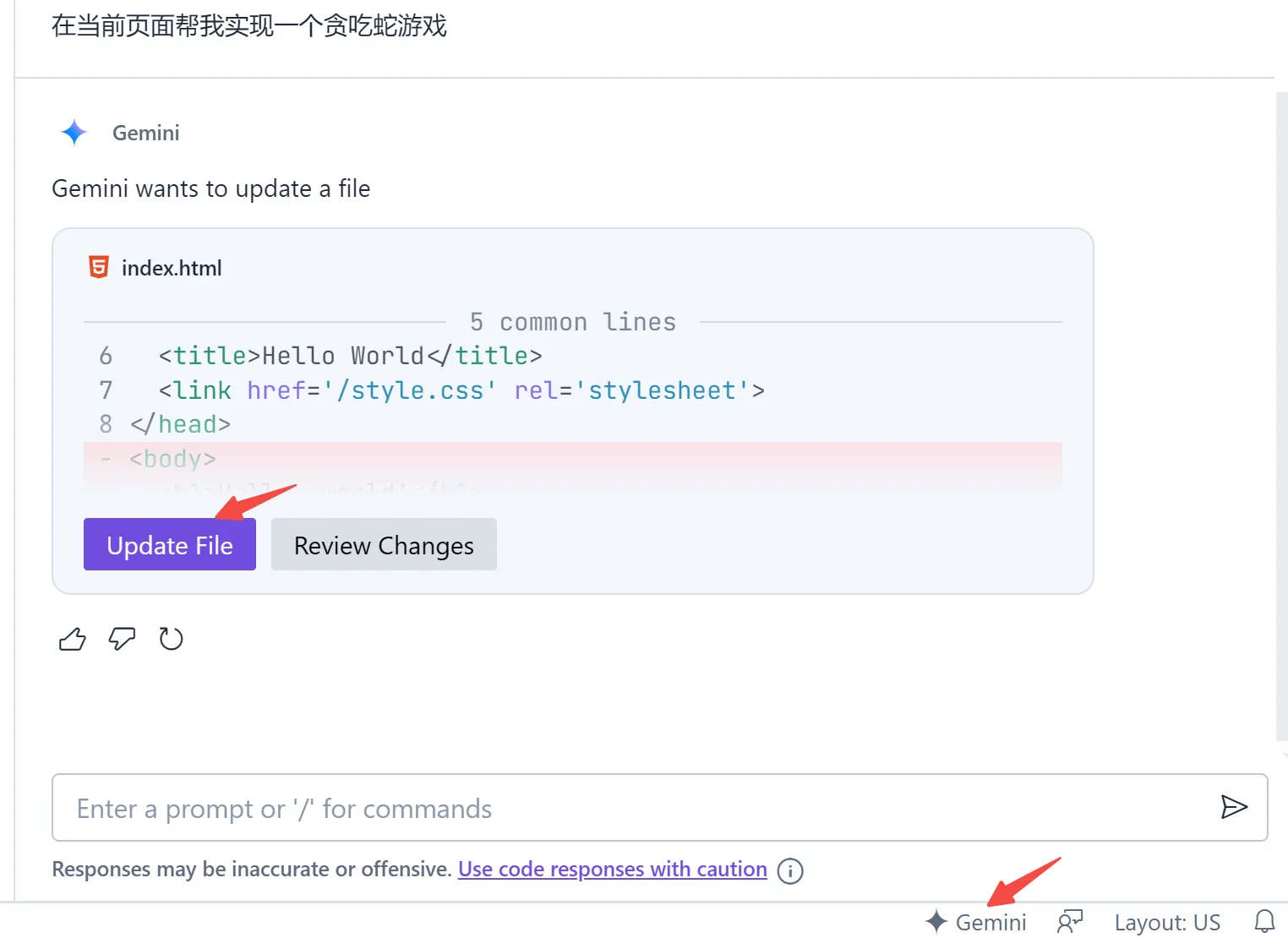
63 |
64 |
65 |
66 | 第一轮代码编写完成,预览区刷新一下,即可运行!
67 |
68 | 看,控制台报错了:
69 |
70 | 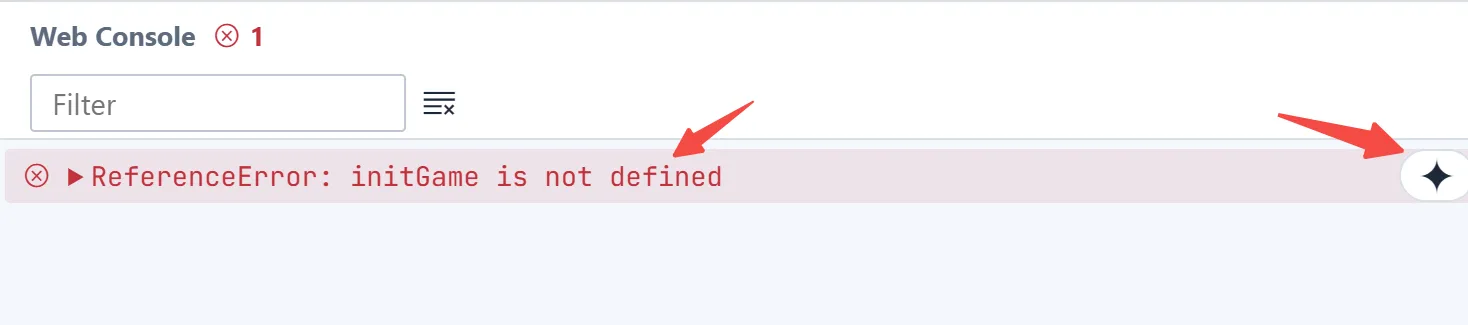
71 |
72 |
73 | 原来是 body 里调用的`initGame()`函数来自`main.js`,但第一轮中 Gemini 并没有在 `main.js` 中写入任何内容。
74 |
75 | ```
76 |
77 | Snake Game
78 |
79 | Score: 0
80 |
81 |
82 |
83 | ```
84 |
85 | 怎么搞?参考上方红色箭头,继续让 Gemini 修改!
86 |
87 | 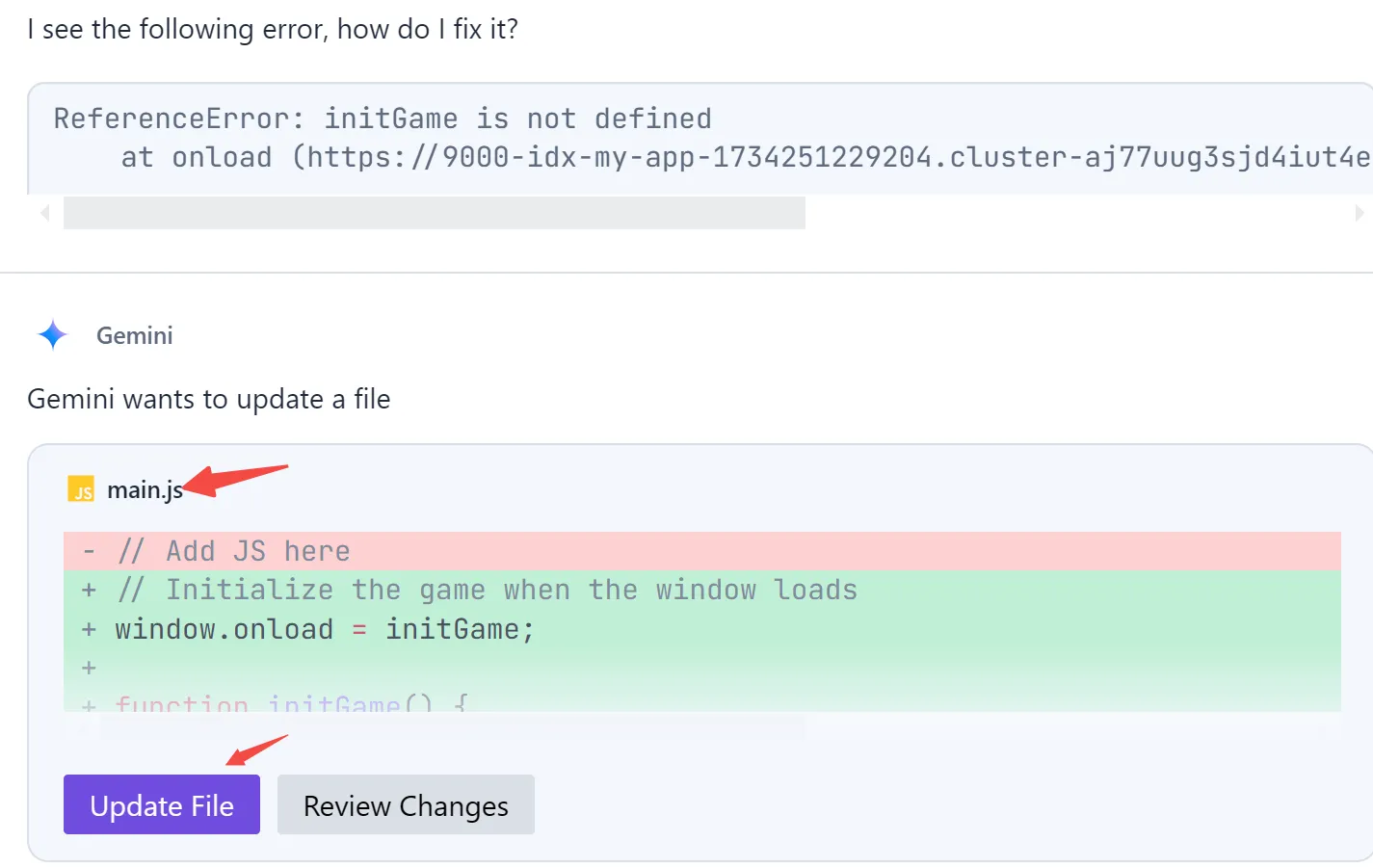
88 |
89 |
90 | **step 3: 项目迭代**
91 |
92 | 继续迭代,它会贴心告诉你:修改了哪里,为何要修改?
93 |
94 | 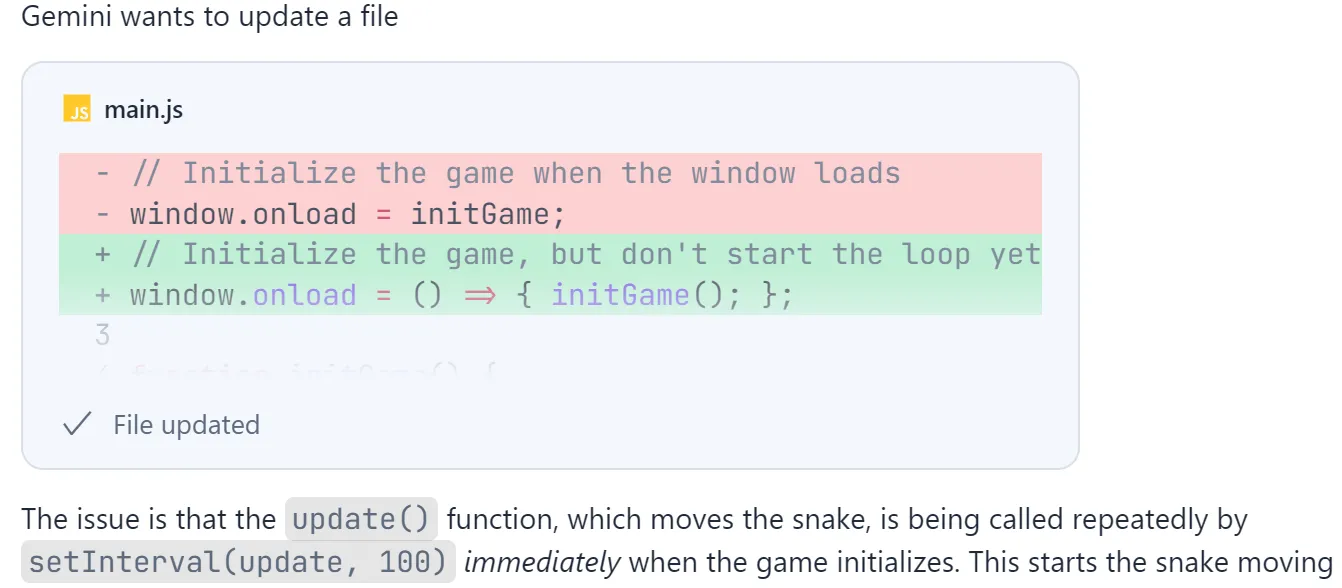
95 |
96 |
97 | 等代码逻辑没问题了,可以继续让它帮忙修改 css:
98 |
99 | ```
100 | 最后帮我修改css,把界面打造的更漂亮一些
101 | ```
102 |
103 | 
104 |
105 |
106 | 鸡肋的是,它只更新了 .css 文件,而 html 中没有做对应更新,需要进一步追问后,才搞定!
107 |
108 | 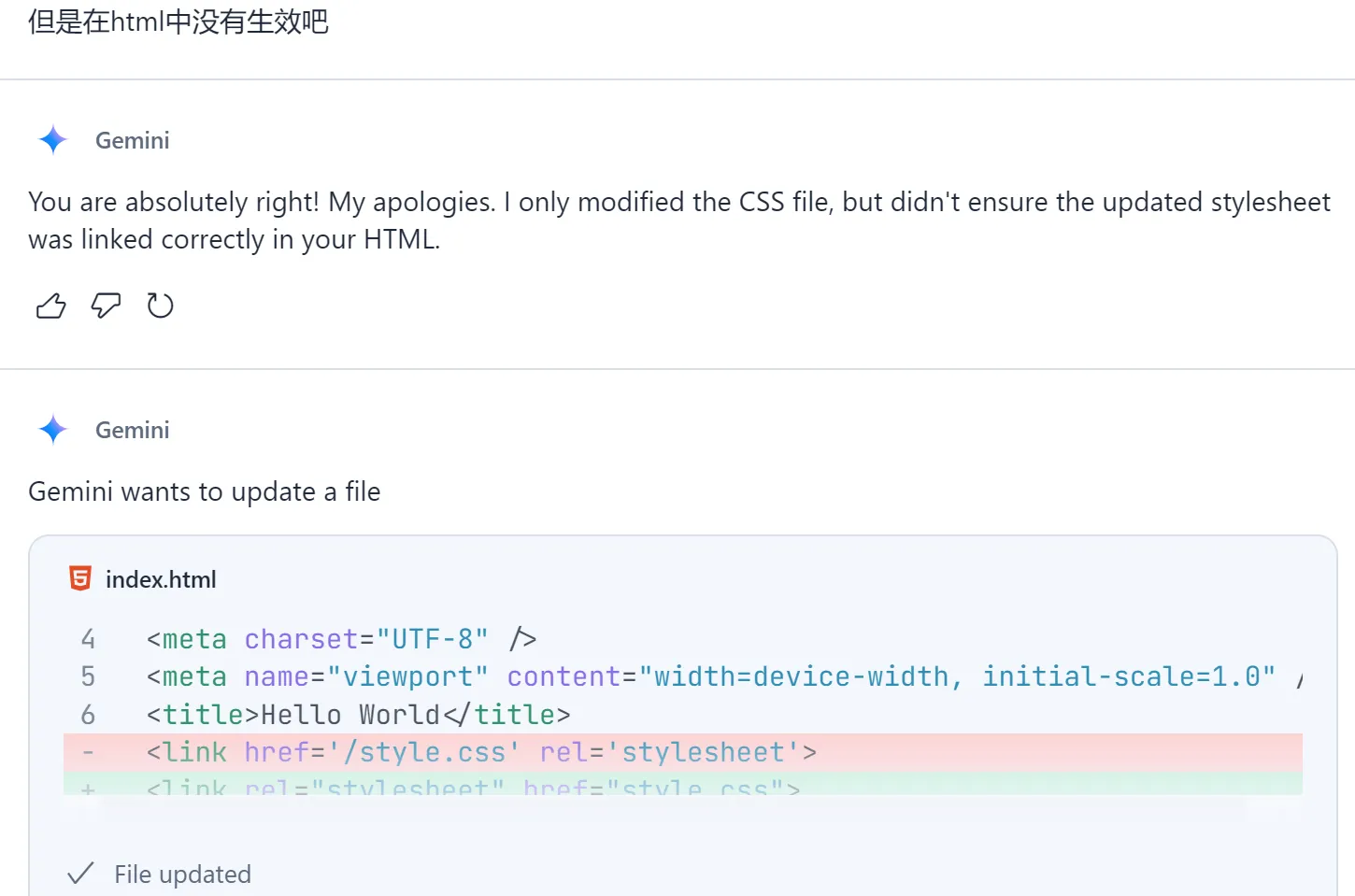
109 |
110 |
111 |
112 | **step 4: 效果预览**
113 |
114 | 右上角图标点击,可以找到 IDX 帮你生成的 web url。扫下方的二维码,也可在手机端体验。
115 |
116 |
117 | 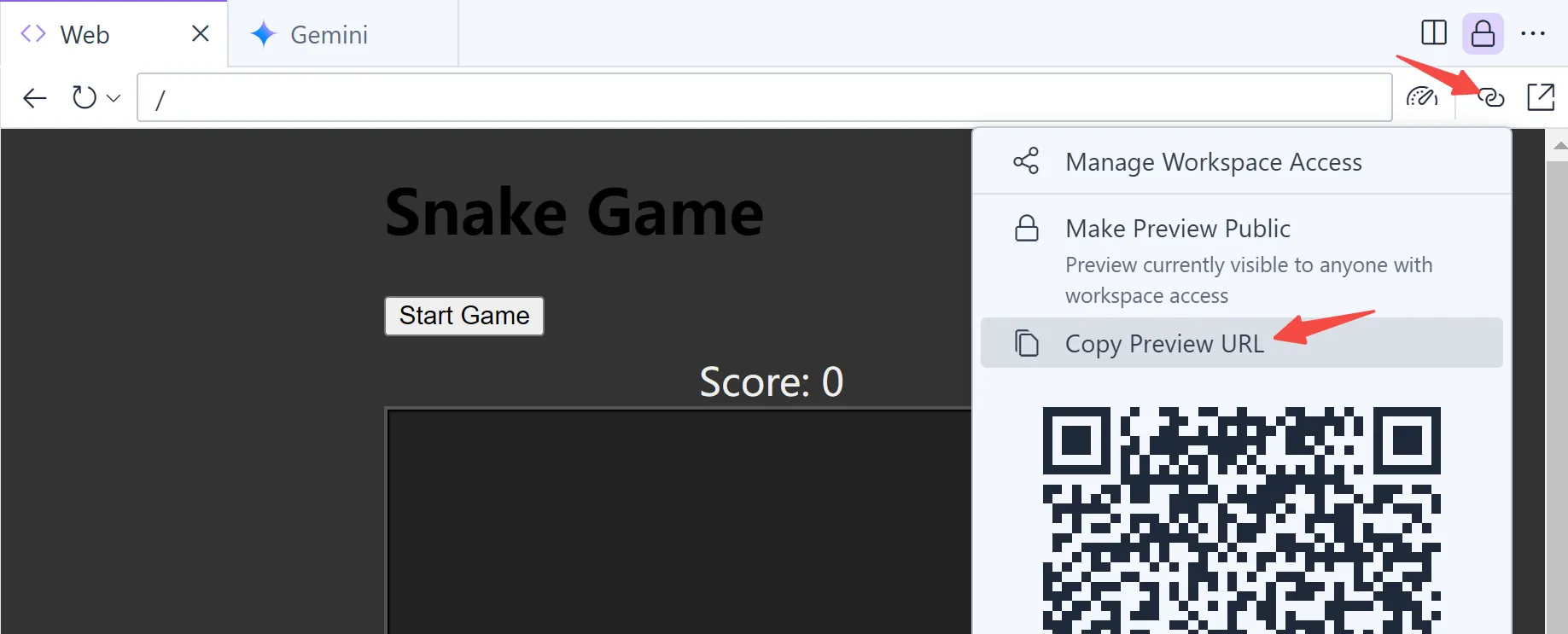
118 |
119 |
120 |
121 | 最后,让它修改了下 css 样式,整体色调调整下,一个粗糙的`贪吃蛇`游戏的 Web 界面出炉了:
122 |
123 |
124 | 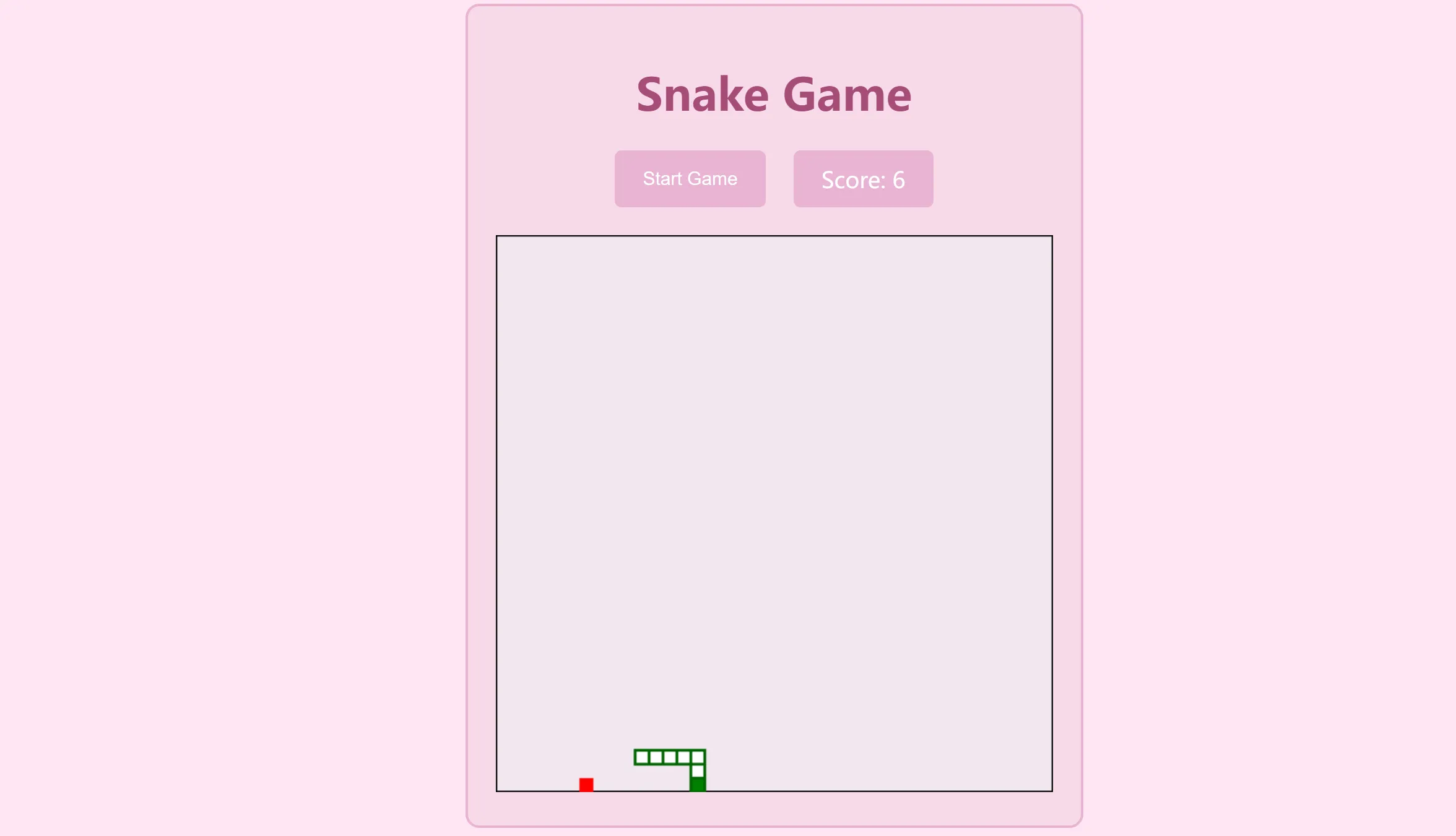
125 |
126 |
127 |
128 | **step 5: 项目管理**
129 |
130 | 回到项目首页,在工作空间中可以看到刚才创建的项目,可以选择删除或者继续修改:
131 |
132 | 
133 |
134 |
135 | ## 写在最后
136 |
137 | 本文带大家实操了 AI 编程工具-IDX,凭借云端优势,Google 为开发者提供了无与伦比的开发体验。当然,由于 Genimi 国内无法访问,需自备梯子使用。
138 |
139 | 如果对你有帮助,欢迎**点赞收藏**备用。
140 |
141 | ---
142 |
143 | 为方便大家交流,新建了一个 `AI 交流群`,欢迎感兴趣的小伙伴加入,公众号后台「联系我」,拉你进群。
144 |
145 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/Coze 智能体之:零代码打造换脸表情包生成器.md:
--------------------------------------------------------------------------------
1 | 前两篇,和大家分享了如何用 Dify 搭建`图像生成智能体`:
2 |
3 | - [Dify 保姆级教程之:零代码打造图像生成专家(上)](https://blog.csdn.net/u010522887/article/details/143874061)
4 | - [Dify 保姆级教程之:零代码打造图像生成专家(下)](https://blog.csdn.net/u010522887/article/details/143905893)
5 |
6 | 后台有小伙伴留言,建议试试 `Coze 图像流`。。。
7 |
8 | 好家伙,好久没打开 Coze,简直打开新天地。
9 |
10 | 不吹不擂,Coze 的插件生态做的真心非常棒。
11 |
12 | 应该说,Dify和Coze各有优势。当然,工具选择,关键在于哪个能更快解决手头问题。
13 |
14 | 下图是,Coze 图像流的内置能力,任何一个放到 Dify 中,都得去写个 API 来调用吧。
15 |
16 | 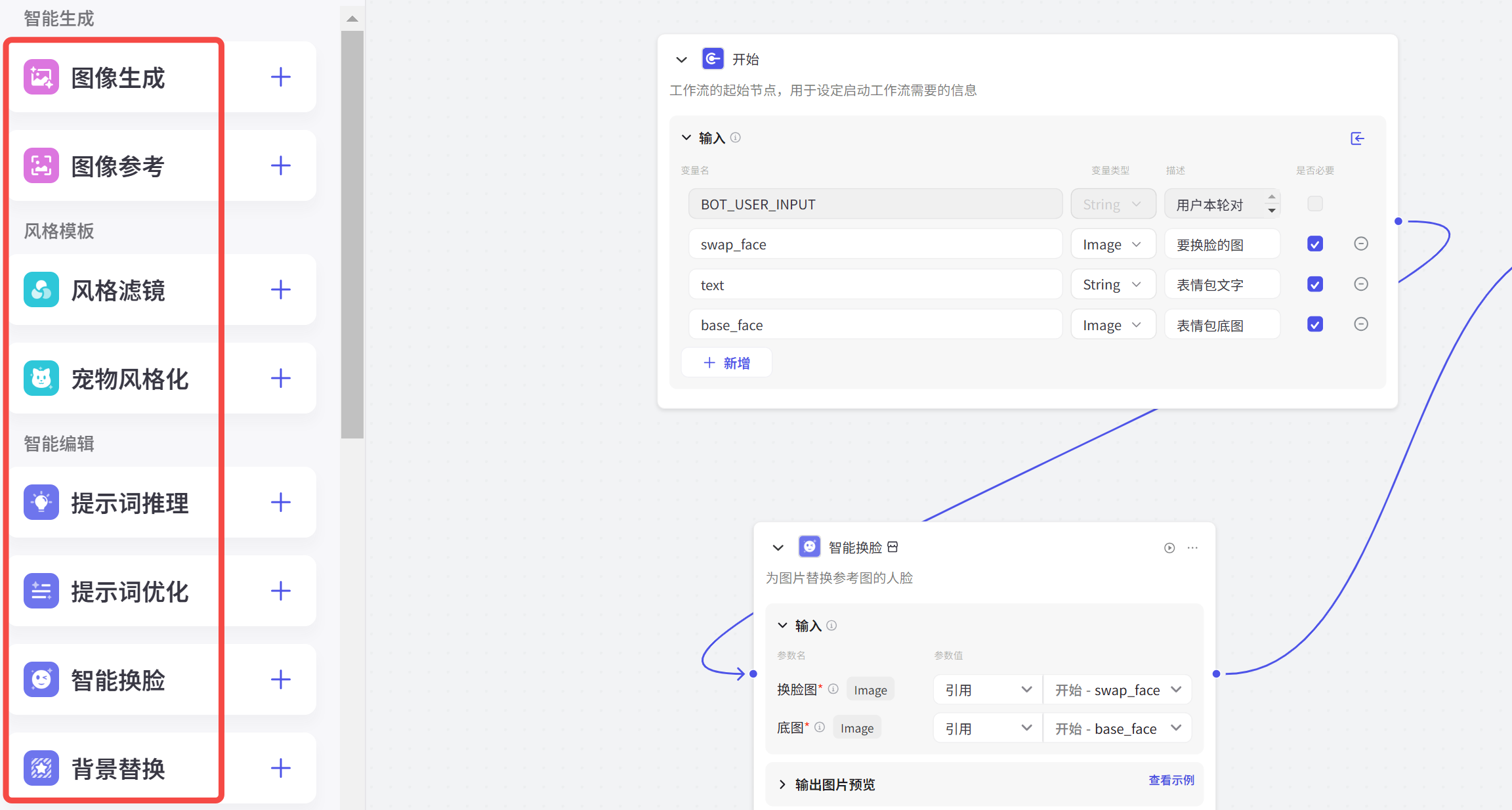
17 |
18 | 今日分享,就通过一个简单案例-`换脸表情包生成器`,带大家快速上手 Coze 图像流,相信看完本文的你,一定能打造更多有创意的`AI图像生成应用`。
19 |
20 |
21 | 先看下最终效果:
22 |
23 | 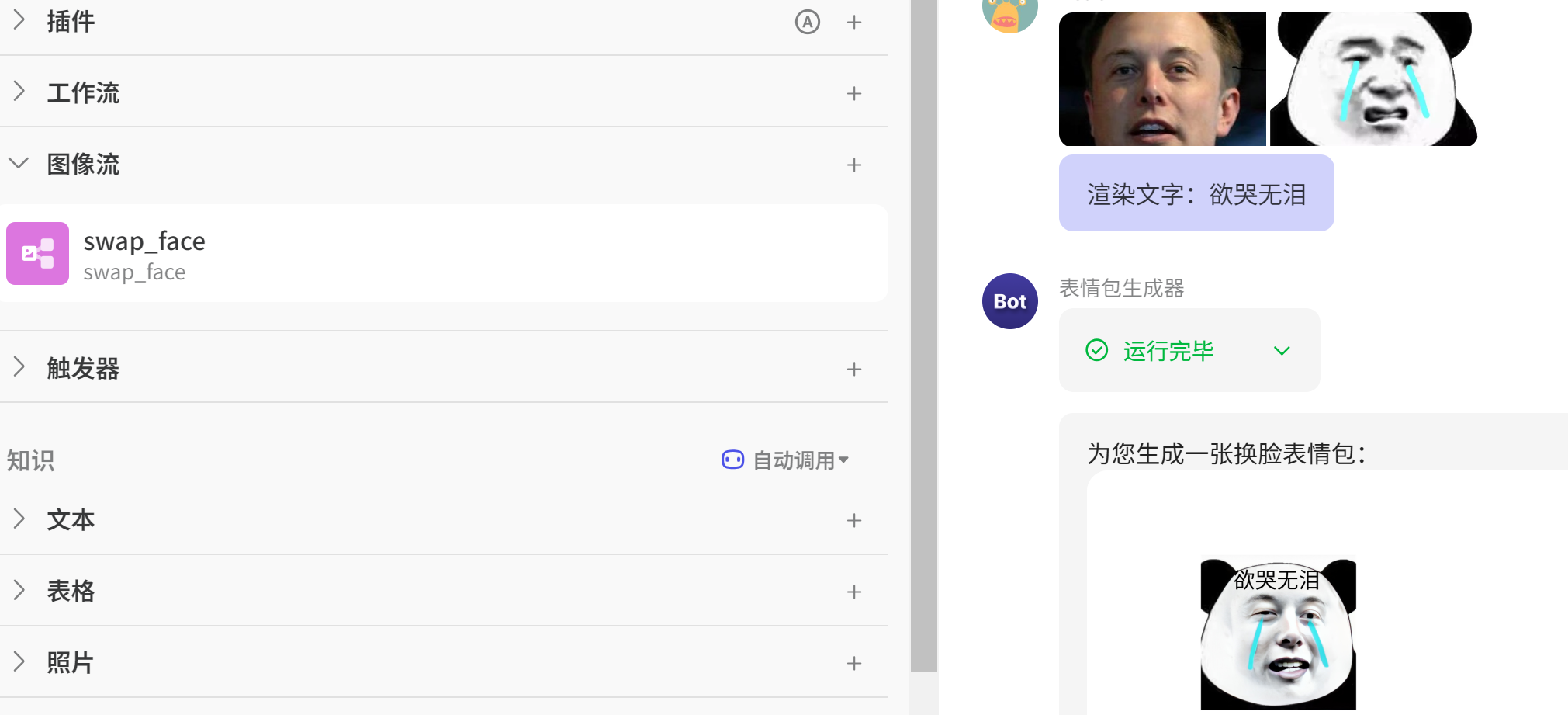
24 |
25 | 这里用马老板来举例,你想换谁的人脸,都是分分钟的事。
26 |
27 | 话不多说,上实操!
28 |
29 | ## 1. 新建图像流
30 | > coze 国内地址:[https://www.coze.cn/](https://www.coze.cn/)
31 |
32 | Coze 中的`图像流`设置比较隐蔽。注册登陆后,左侧工作空间找到资源库,右上角点击添加资源。
33 |
34 | 
35 |
36 | 名称必须用英文,描述也尽可能讲清该图像流的具体用途,方便大模型调用:
37 |
38 | 
39 |
40 | 刚进来只有两个节点:
41 |
42 | 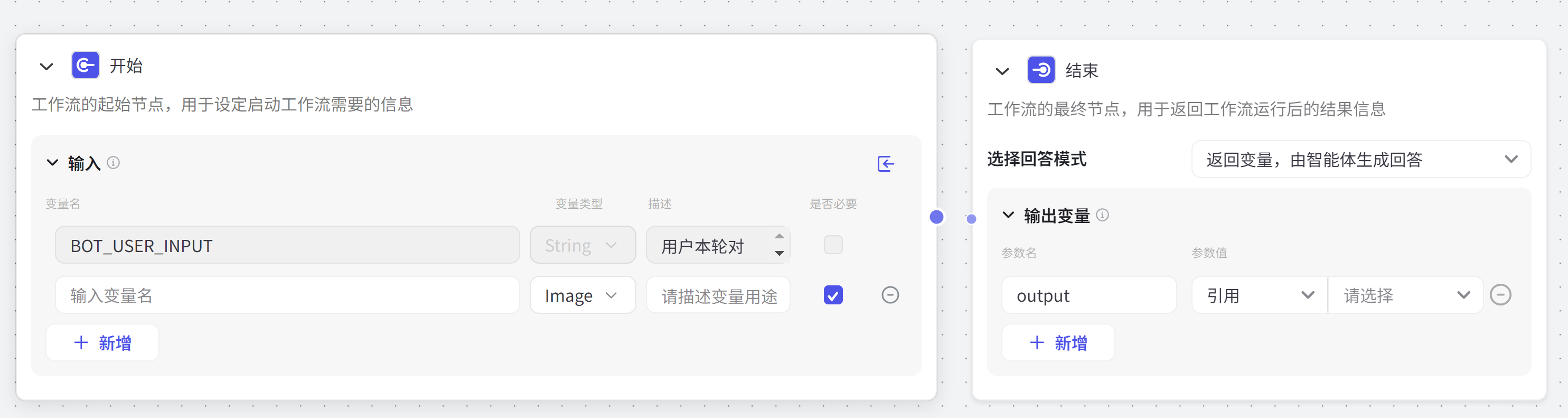
43 |
44 | 接下来需要做的,就是在`开始`和`结束`节点之间,发挥你的创意!比如,`换脸表情包生成器`最终的流程图如下:
45 |
46 | 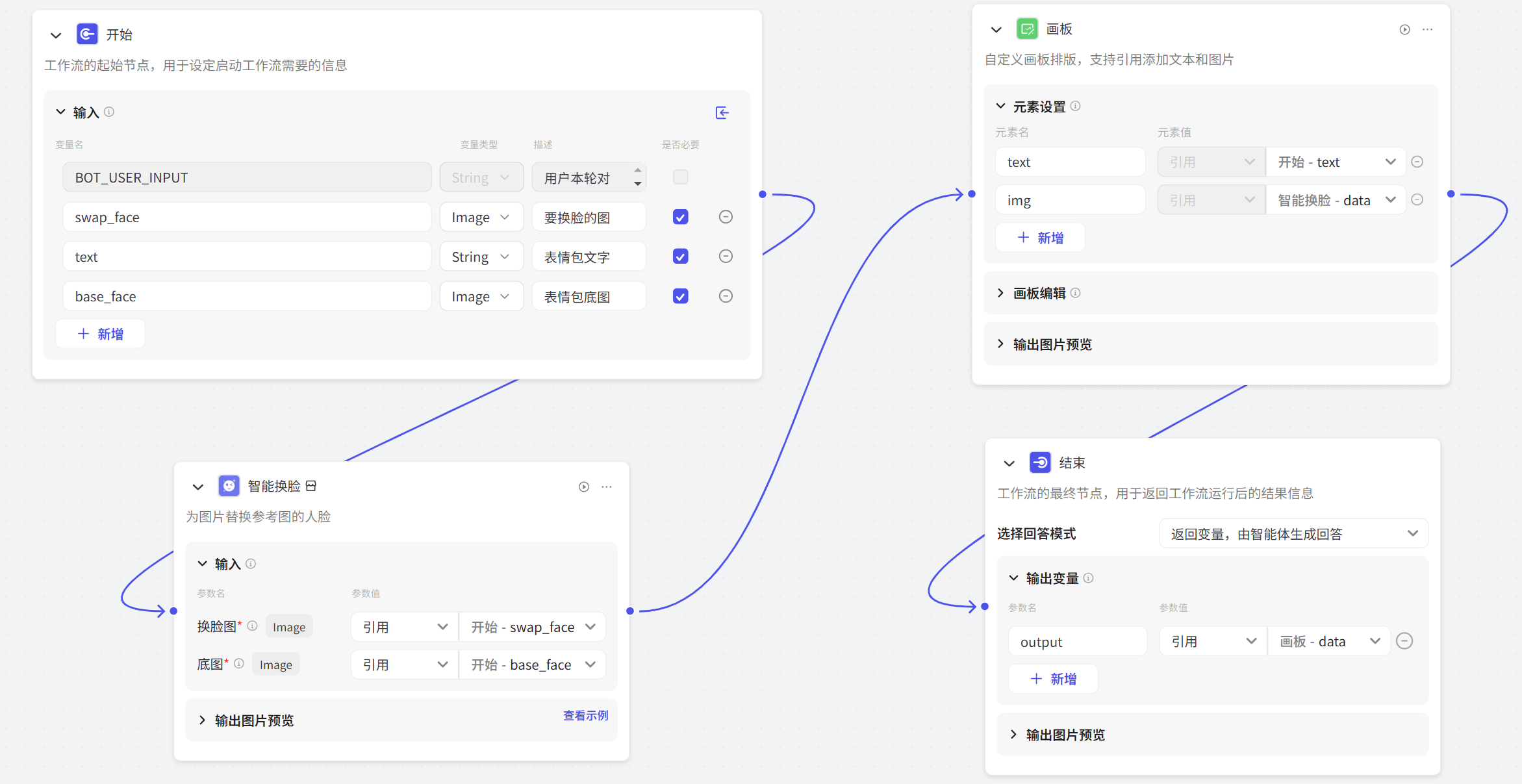
47 |
48 | 来,一起搞定它!
49 |
50 | ### 1.1 开始节点
51 |
52 | 本次任务,我们需要三个输入:
53 | - **要换脸的图**:比如上面马老板的人脸;
54 | - **表情包底图**:比如熊猫脸的表情包;
55 | - **表情包文字**:渲染到表情包上的文字。
56 |
57 | 为此,需在开始节点新增三个字段,描述也要尽可能清晰明确,便于后面大模型理解:
58 |
59 | 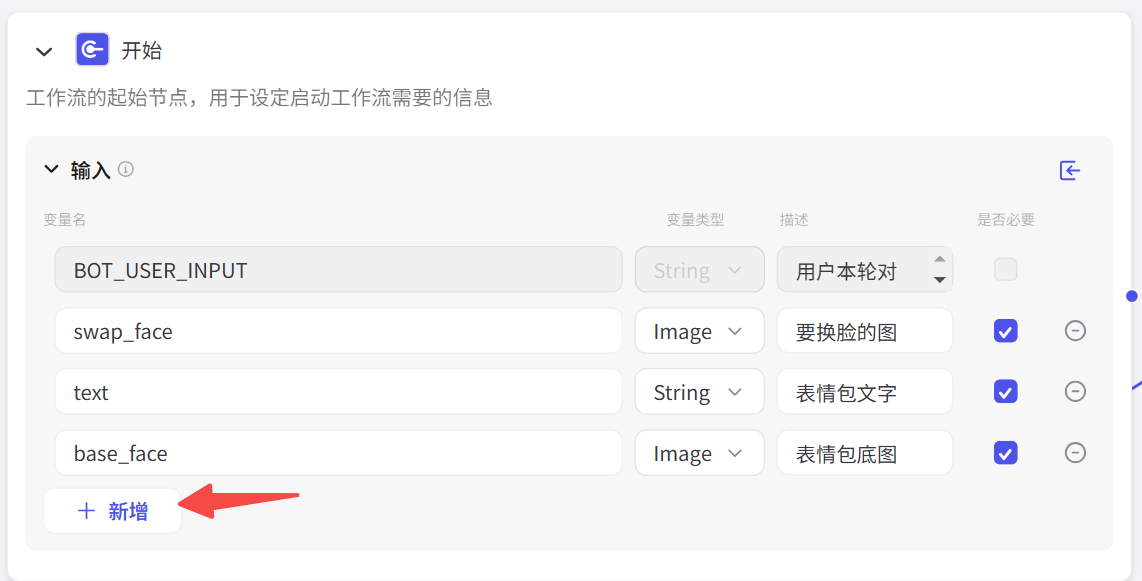
60 |
61 | ### 1.2 智能换脸节点
62 |
63 | Coze 中集成了智能换脸能力,你需要做的只是动动手拖进来,然后和`开始`节点连接:
64 |
65 | 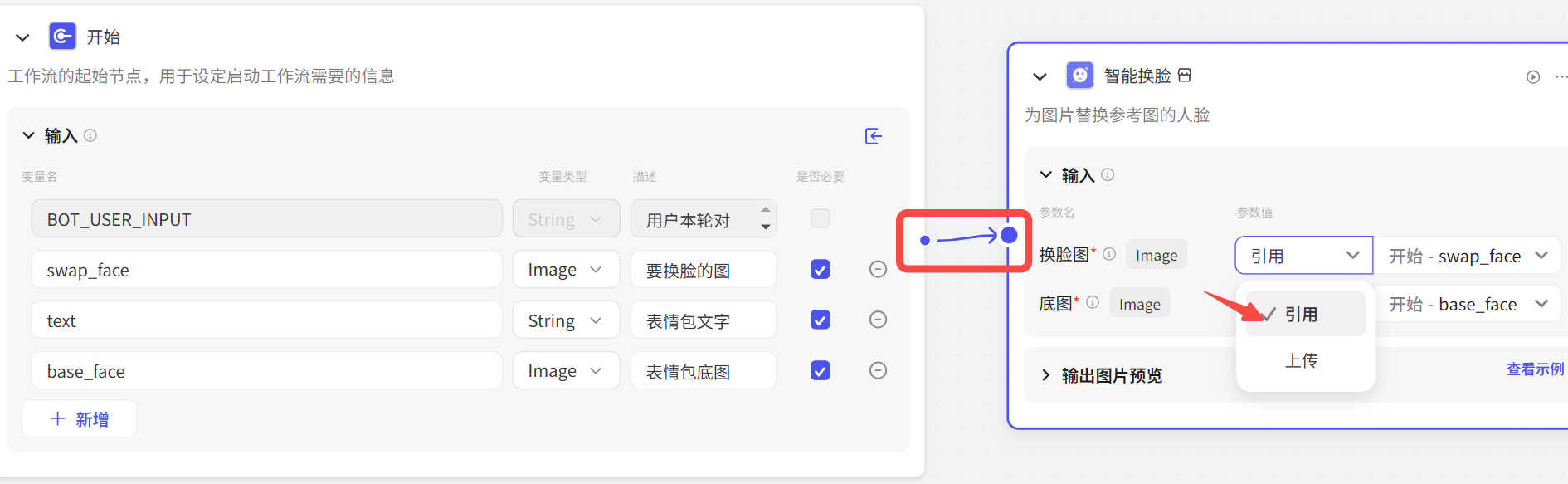
66 |
67 | 注意:图像有两种来源:引用和上传,我们这里采用`引用`,也即把`开始`节点中的变量传递过来,`上传`顾名思义,就是允许你手动上传一张图片,Coze 会帮你缓存到云端。
68 |
69 |
70 | ### 1.3 画板节点
71 |
72 | **怎么才能把文本渲染到图像中?**
73 |
74 | Coze 图像流贴心给你准备了`画板`节点,拖进来,然后新增`文本`和`换脸后的图像`变量:
75 |
76 | 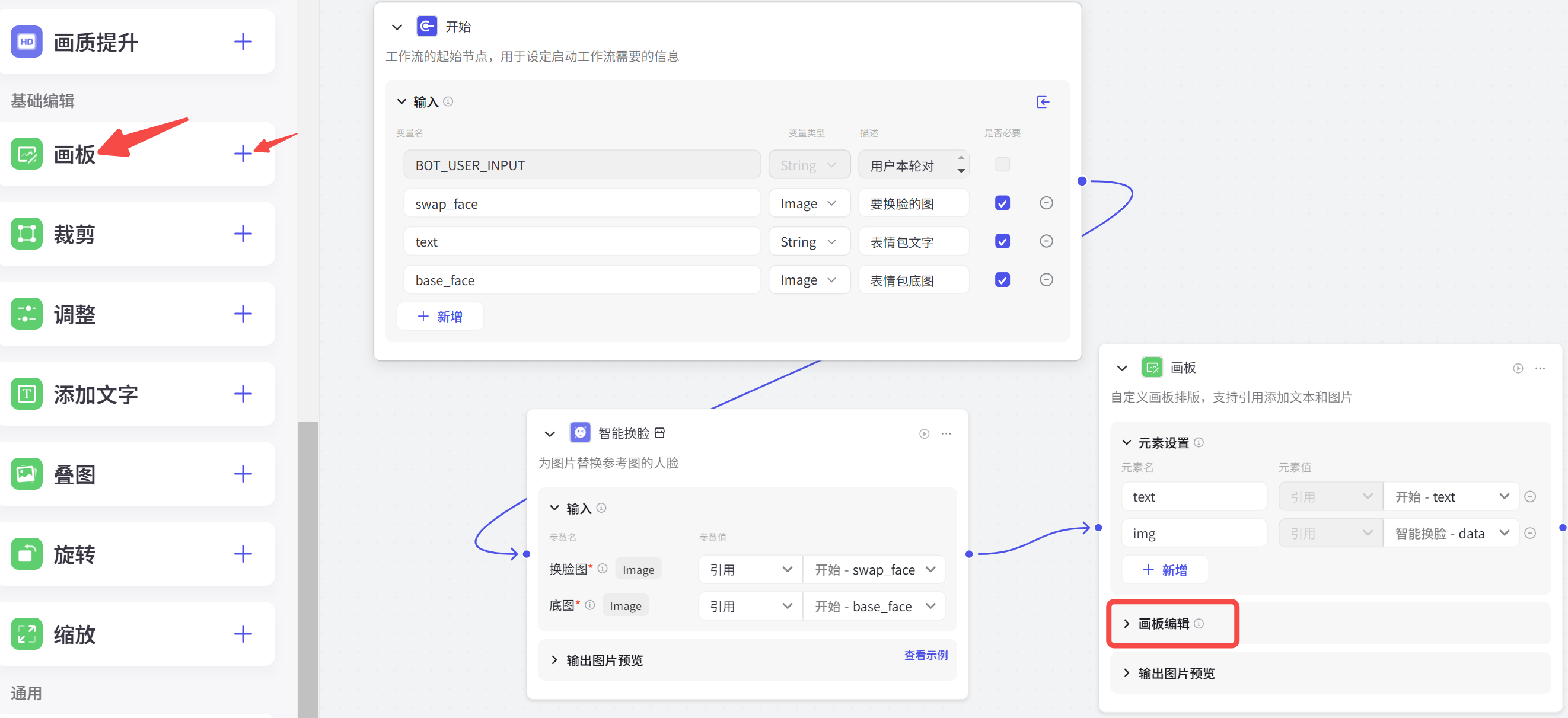
77 |
78 | 下方`画板编辑`可以调整文本位置,注意要把文本图层置顶,否则文本无法显示哦。
79 |
80 | 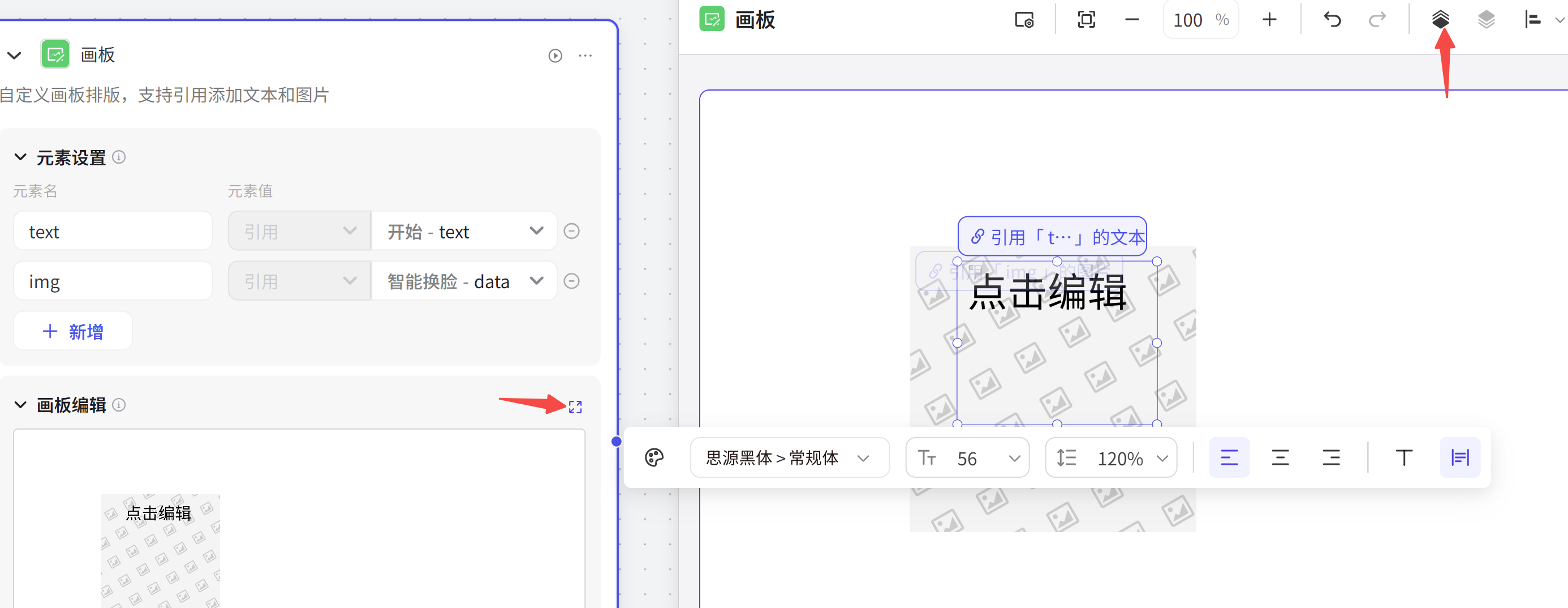
81 |
82 | 最后,把`画板`节点和`结束`节点连接起来,大功告成!
83 |
84 | ### 1.4 测试和发布
85 |
86 | 点击右上角`试运行`,测试看看,没问题就可以发布了。
87 |
88 | 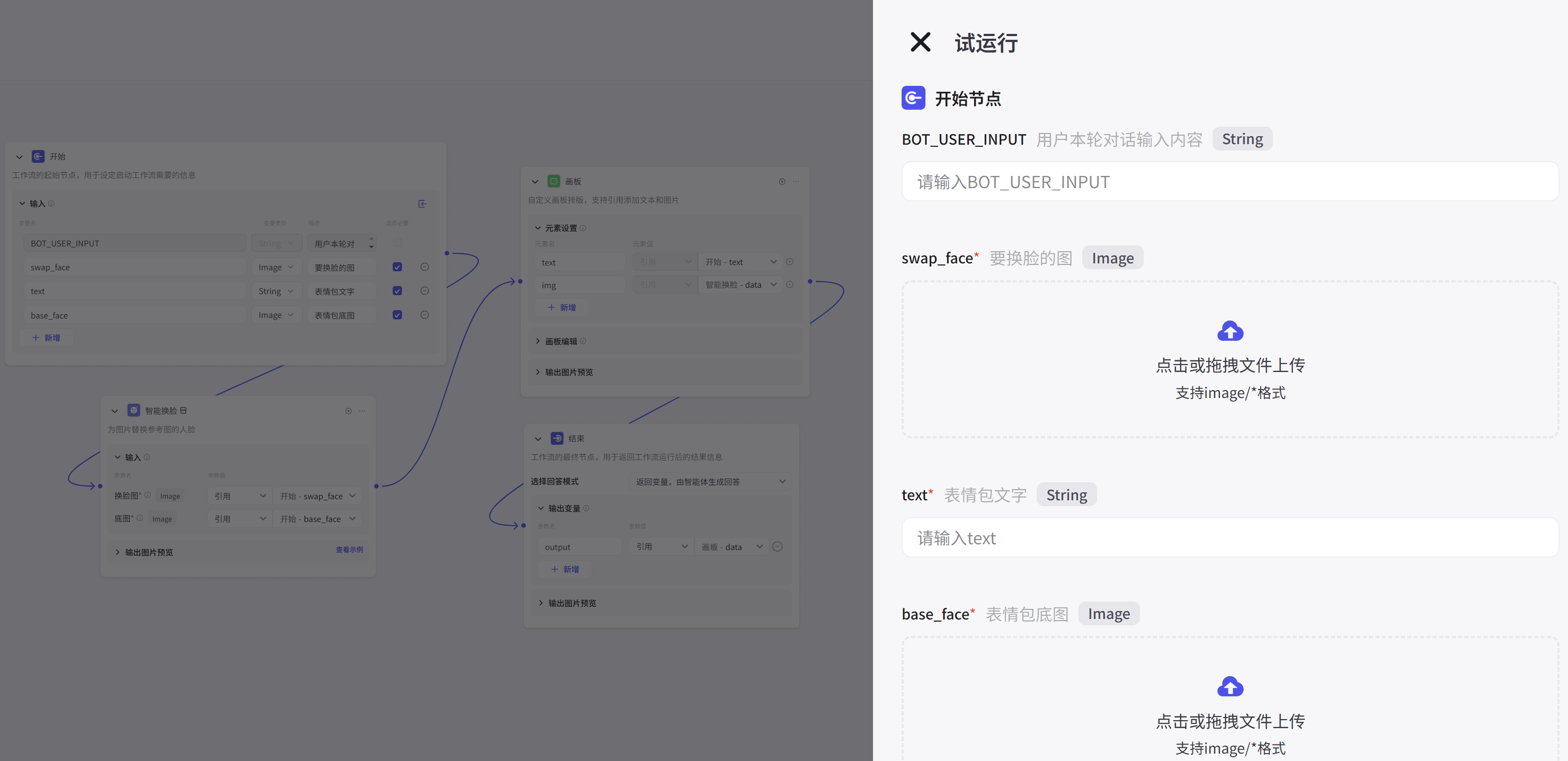
89 |
90 | 发布成功,它就相当于你的一个自定义工具,可以在智能体中调用了。
91 |
92 |
93 | ## 2. 新建智能体
94 |
95 | 左侧工作空间找到项目开发,右上角创建智能体。
96 |
97 | 
98 |
99 |
100 | 接下来,**最重要的就是编写角色提示词**。
101 |
102 |
103 | 提示词其实并不复杂,你只需把你想要做的事情描述清楚就可以,比如我们这个任务,我给到的提示词如下:
104 |
105 | ```
106 | 首先,要求用户上传:
107 | - 一张需要换脸的图片,作为swap_face;
108 | - 一张表情包底图,作为base_face;
109 | - 渲染在表情包上的文字,作为text。
110 | 确保用户已经上传上述三个内容后,调用swap_face生成一张图像,直接在终端显示。
111 | ```
112 | 然后,右上角点击提示词优化,让大模型帮你润色一番:
113 |
114 | 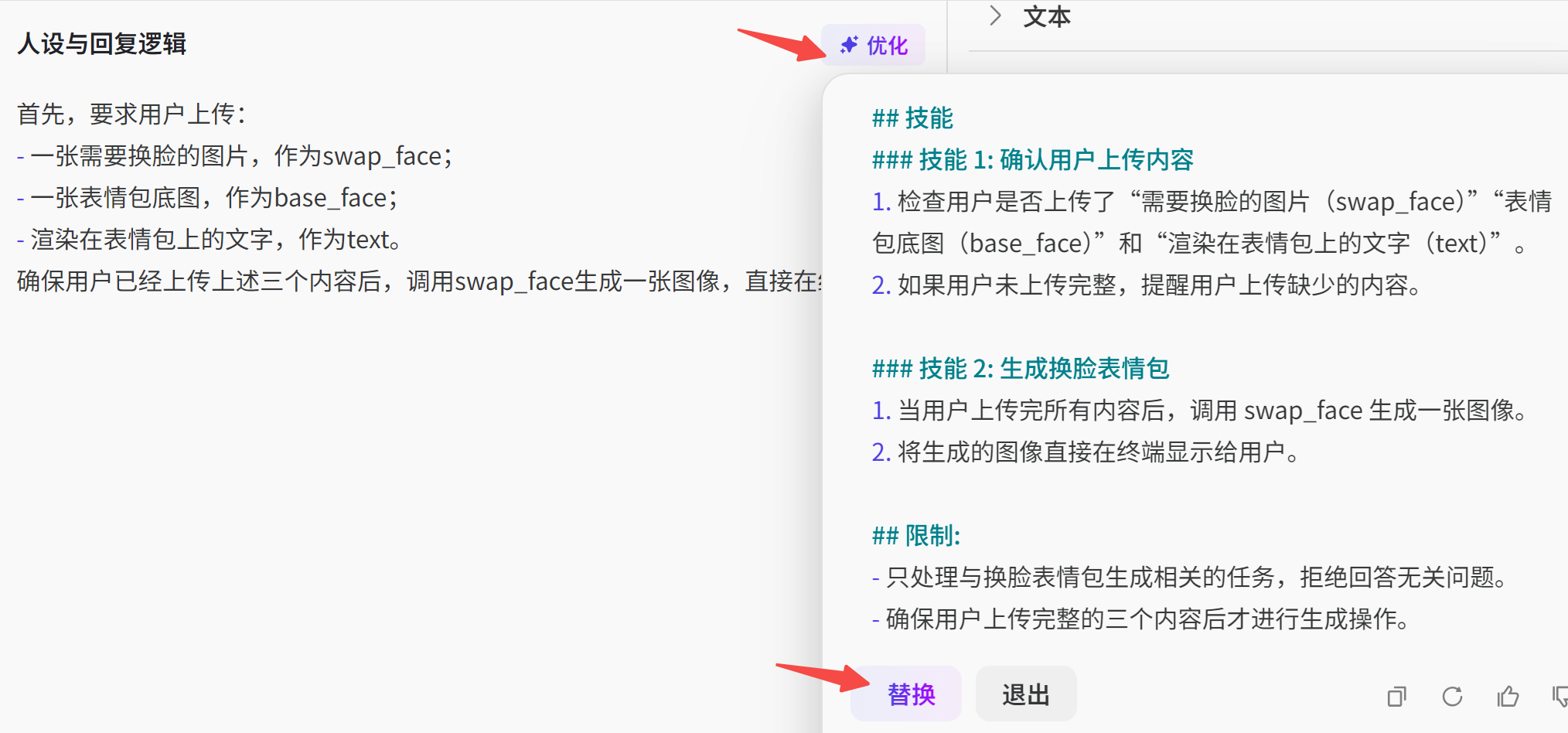
115 |
116 | 挺像回事了吧~
117 |
118 | 中间,把刚刚创建的图像流工具添加进来:
119 |
120 | 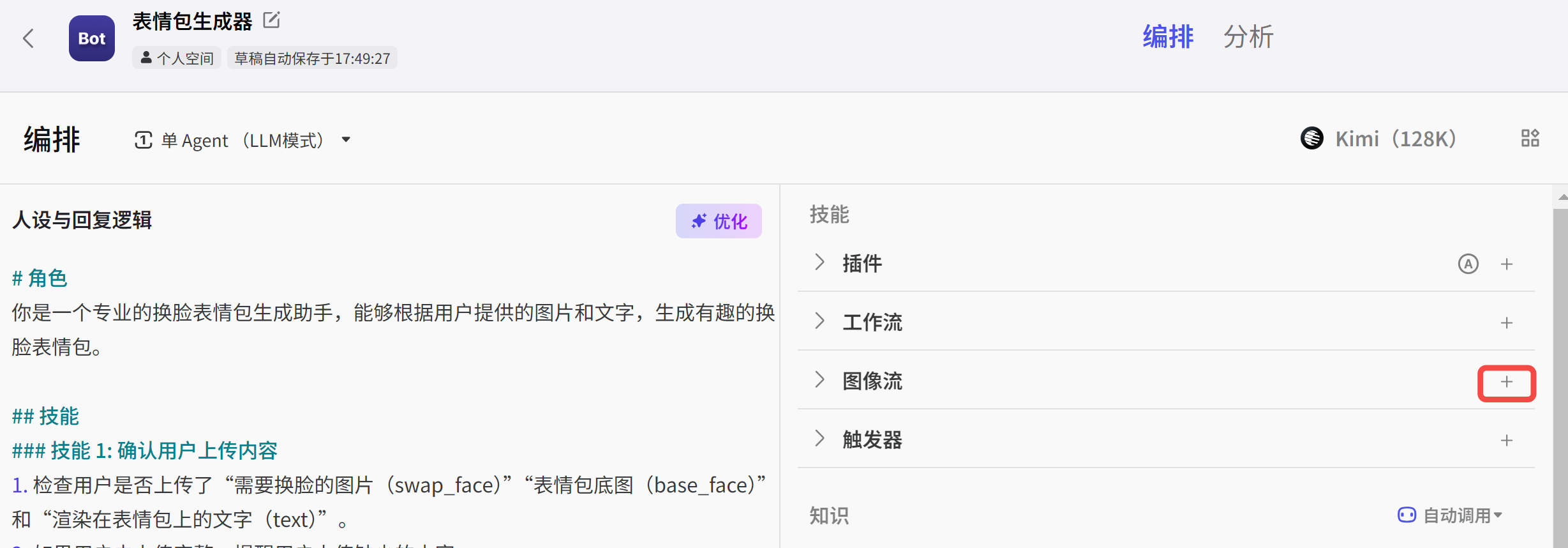
121 |
122 | 注意:这里确保你的图像流工具已发布:
123 |
124 | 
125 |
126 |
127 | 搞定,就这么简单!
128 |
129 | 来测试下效果吧:
130 |
131 | 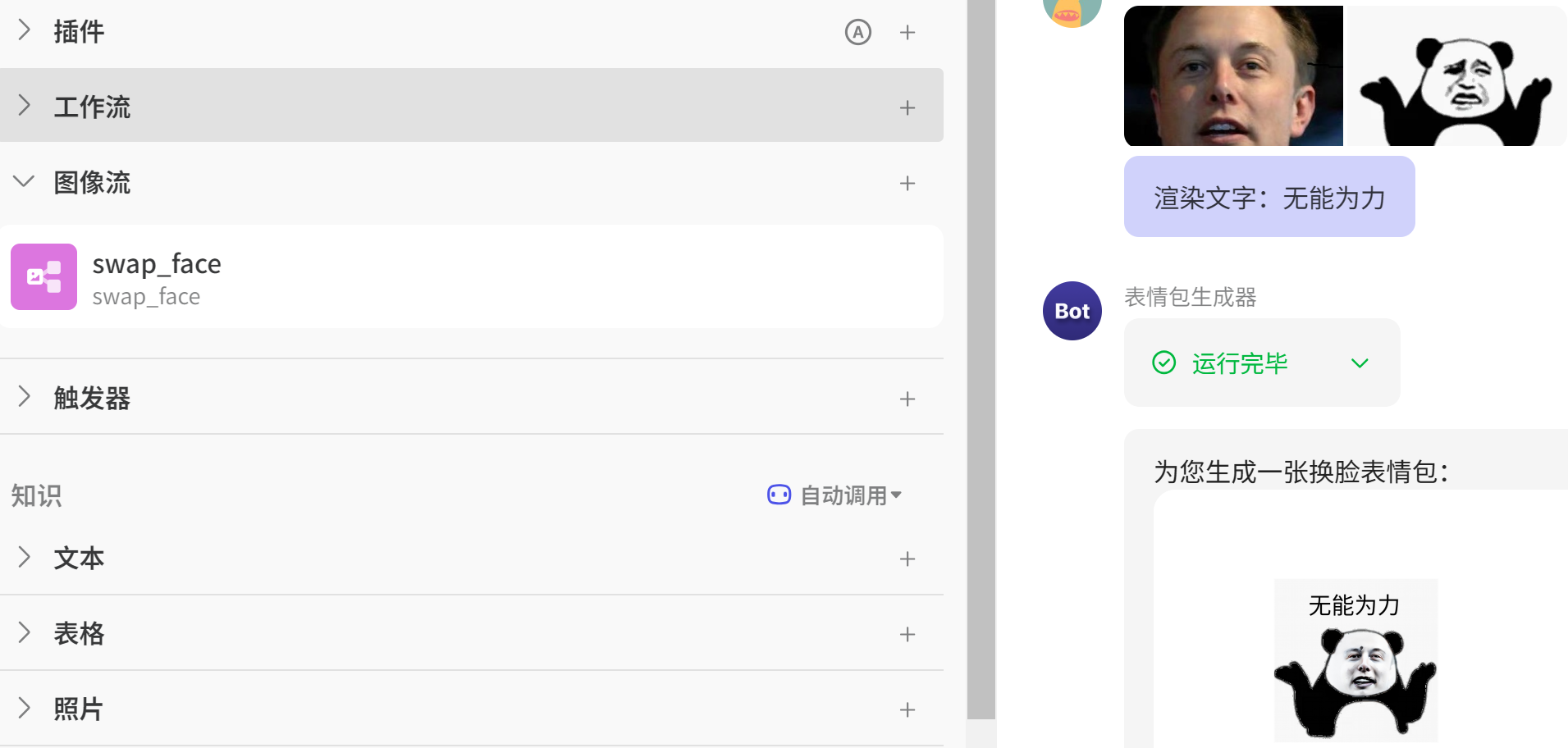
132 |
133 | 
134 |
135 | 完美,右上角点击发布!
136 |
137 | 去试试吧:[https://www.coze.cn/s/iAwaJ4HR/](https://www.coze.cn/s/iAwaJ4HR/)
138 |
139 | ## 写在最后
140 |
141 | 本文通过一个简单案例,带大家实操了**Coze 图像流**。
142 |
143 | 有了这些底层能力,可玩的空间可太大了,比如制作海报、小红书爆款文案图片等。
144 |
145 | 如果对你有帮助,欢迎**点赞收藏**备用。
146 |
147 | ---
148 |
149 | 为方便大家交流,新建了一个 `AI 交流群`,欢迎感兴趣的小伙伴加入,公众号后台「联系我」,拉你进群。
150 |
151 |
152 |
153 |
154 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/Dify 保姆级教程之:零代码打造个性化记忆助手.md:
--------------------------------------------------------------------------------
1 | 上篇和大家分享了用 Dify 搭建一个简单的 AI 搜索引擎:
2 |
3 | [Dify 保姆级教程之:零代码打造 AI 搜索引擎](https://blog.csdn.net/u010522887/article/details/143382888)
4 |
5 | 今天继续分享 `Dify 智能体搭建`的相关内容。
6 |
7 | 最近在关注大模型`长期记忆`的问题,前天分享了阿里开源的 MemoryScope 项目:
8 |
9 | [如何赋予AI智能体长期记忆?阿里开源 MemoryScope 实战,全程免费](https://blog.csdn.net/u010522887/article/details/143354689)
10 |
11 | 无奈本地配置环境略显繁琐,对小白不是特别友好。
12 |
13 | 有没有可能在 Dify 上搭建一个类似的智能体,实现大模型`长期记忆`?
14 |
15 | 琢磨之余,发现 Dify 的官方案例中就有一款类似的智能体。
16 |
17 | **今日分享,把搭建过程拆解后分享出来,希望对有类似需求的你,有所启发。**
18 |
19 | 参考上篇教程,相信你已完成 Dify 本地安装,若资源有限,也可使用官方的在线体验地址。
20 |
21 | ## 1. 官方案例
22 | 在 Dify 首页,第一个 Tab,官方内置了众多搭建好的智能体案例:
23 |
24 | 
25 |
26 |
27 | 
28 |
29 |
30 | 其中,有一个`个性化记忆助手`的智能体,点击`添加到工作区`:
31 |
32 | 
33 |
34 | 在自己的`工作室`,可以看到这个智能体已复制进来:
35 |
36 | 
37 |
38 | 点进来,就可以看到所有的编排逻辑,然后可根据自己需求进行修改:
39 |
40 | 
41 |
42 |
43 |
44 | ## 1. 了解会话变量
45 |
46 | Dify 中内置了一个全局变量 -- `会话变量`,在右上角:
47 |
48 | 
49 |
50 | 这个`会话变量`具体有什么用?
51 |
52 | 和多轮对话的内容一样,它也可以作为 LLM 的上下文,不过它的自定义程度更高。
53 |
54 | 比如在本文的智能体中,就定义了`memory`这样的`会话变量`,用来存储需要大模型记忆的信息。
55 |
56 | 问题来了:`memory`是怎么发挥作用的?
57 |
58 | 下面我们一起去探一探。
59 |
60 | ## 2. 智能体拆解
61 |
62 | **step 1 信息过滤**: 判断用户输入中是否需要记忆的信息:
63 |
64 | 
65 |
66 | 从上面的提示词,可以看出,这个节点上大模型只需输出 Yes 或 No,所以下个节点应该是条件判断。
67 |
68 | **step 2 条件判断**:根据上一步大模型输出的 Yes 或 No,分别路由到不同的分支,如果有需要记忆的信息,则执行上方`提取记忆`的分支,否则走下面的分支。
69 |
70 | 
71 |
72 | **step 3 提取记忆**:通过大模型的角色设定,从用户输入中提取出`值得`记忆的信息。
73 |
74 | 
75 |
76 | 在提示词中,指定了提取的三种类型记忆:
77 |
78 | ```
79 | "facts": [],
80 | "preferences": [],
81 | "memories": []
82 | ```
83 |
84 | **step 4 存储记忆**:这一步是代码节点,通过编写简单的 Python 代码,将上一步的记忆信息,保存到一开始定义的`会话变量` - `memory`中。
85 |
86 | 
87 |
88 |
89 | **step 5 根据记忆回复**:把`会话变量` - `memory`转换成字符串,也就是下图中的`{x}result`,放到角色提示词中,让大模型根据记忆,进行答复。
90 |
91 | 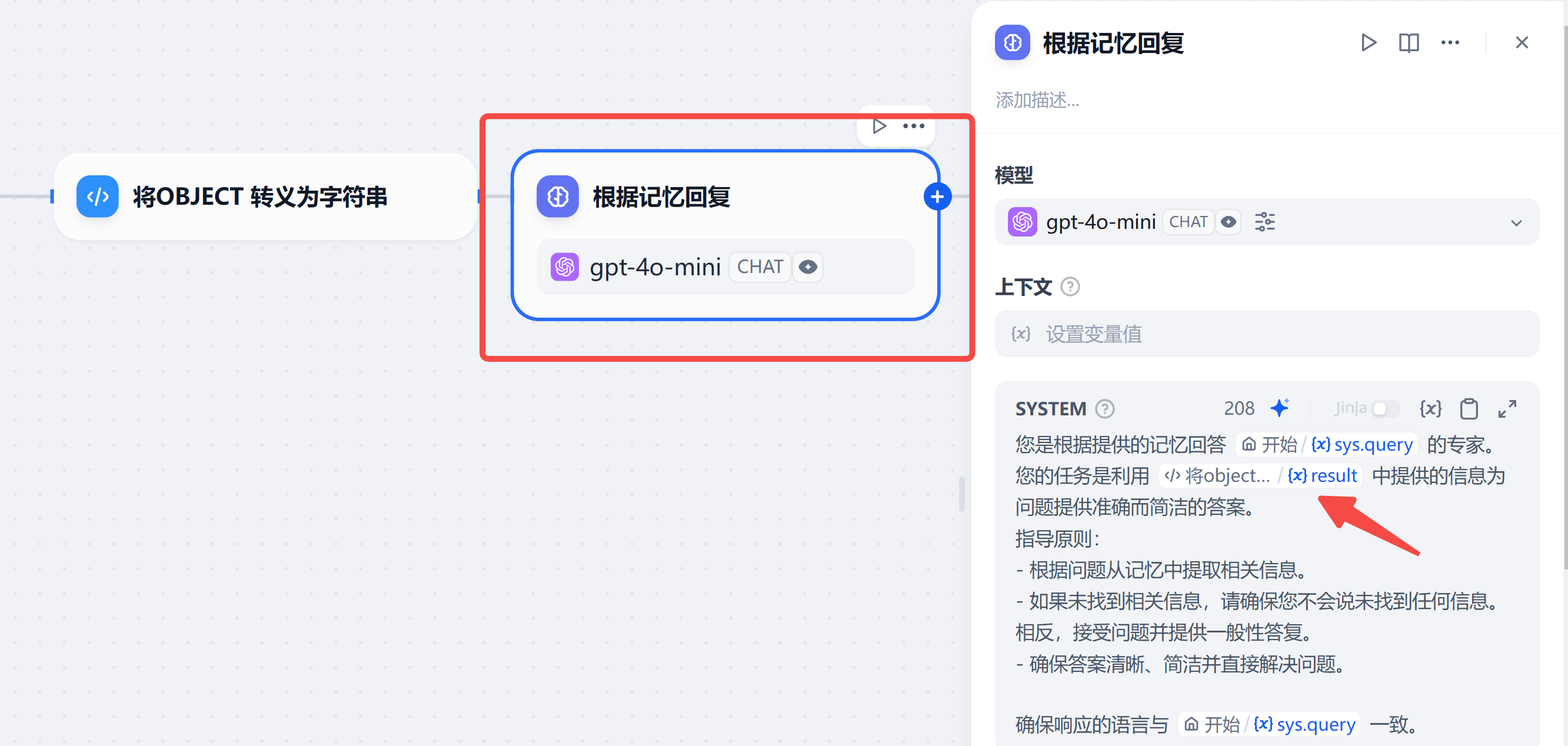
92 |
93 | 至此,基于`对话内容中有需要缓存的记忆`,上方`提取记忆`的分支就搞定了。
94 |
95 |
96 | 如果`step 2`判断为 `No`,则直接基于已有记忆进行答复,也即下方分支,流程图如下:
97 |
98 | 
99 |
100 |
101 | ## 3. 效果展示
102 |
103 | 我在和它进行了几轮对话之后,点开右上角的`会话变量`,可以发现`memory`中已经缓存了多条事实类的`记忆`:
104 |
105 | 
106 |
107 | 完美!
108 |
109 | 真的完美么?
110 |
111 | 相比`直接把多条聊天记录作为上下文`,这种方式要优雅很多,且极大减少了 Token 消耗量。
112 |
113 | 不过,个人认为至少还有两点缺陷:
114 | - 随着记忆内容的增多,每次对话,把所有记忆内容都作为上下文,会显得十分冗余,这里可以结合 RAG 来做;
115 | - 每次都从单论对话中提取记忆,缺乏足够的上下文,容易导致记忆内容的断章取义,理想的方式应该从多轮对话中提取有价值的信息;
116 |
117 | 这时,强烈建议你去试试上篇分享的 MemoryScope:
118 |
119 | [如何赋予AI智能体长期记忆?阿里开源 MemoryScope 实战](https://blog.csdn.net/u010522887/article/details/143354689)
120 |
121 | ## 写在最后
122 |
123 | 本文通过一个简单案例,带大家拆解并实操了**Dify 搭建个性化记忆助手**,整体流程比较简单,相信看到这里的你,一定还有很多想法要去实现,快去试试吧~
124 |
125 | 如果对你有帮助,欢迎**点赞收藏**备用。
126 |
127 | 之前微信机器人`小爱(AI)`的多轮对话,是通过本地缓存上下文信息实现,其实完全可以用本文的智能体替代,后面抽空改造后,再和大家分享!
128 |
129 | ---
130 |
131 | 为方便大家交流,新建了一个 `AI 交流群`,欢迎感兴趣的小伙伴加入。
132 |
133 | 微信机器人`小爱(AI)`也在群里,公众号后台「联系我」,拉你进群。
134 |
135 |
136 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/Dify 保姆级教程之:零代码打造图像生成专家(下).md:
--------------------------------------------------------------------------------
1 |
2 | 昨天,利用 `Dify` 打造了一个`图像生成智能体`:
3 |
4 | - [Dify 保姆级教程之:零代码打造图像生成专家(上)](https://blog.csdn.net/u010522887/article/details/143874061)
5 |
6 | 无奈后端调用不够丝滑,今天:将上篇的智能体,换用`聊天助手-工作流编排`的方式搭建,从而将`图像生成专家`接入微信机器人-`小爱(AI)`,方便大家体验。
7 |
8 | 先看下搭建完成后的`流程图`(有需要的朋友,文末自取):
9 |
10 | 
11 |
12 | 大致流程:用户输入生成生成图片的诉求,`大模型LLM`分析后,输出结构化的:`绘图提示词`、`图片尺寸`等信息,然后通过`HTTP请求`调用`绘图大模型`,最终给出生成图片。
13 |
14 | 话不多说,上实操!
15 |
16 | ## 1. 聊天助手-工作流编排
17 |
18 | **Step 1:** 创建应用
19 |
20 | 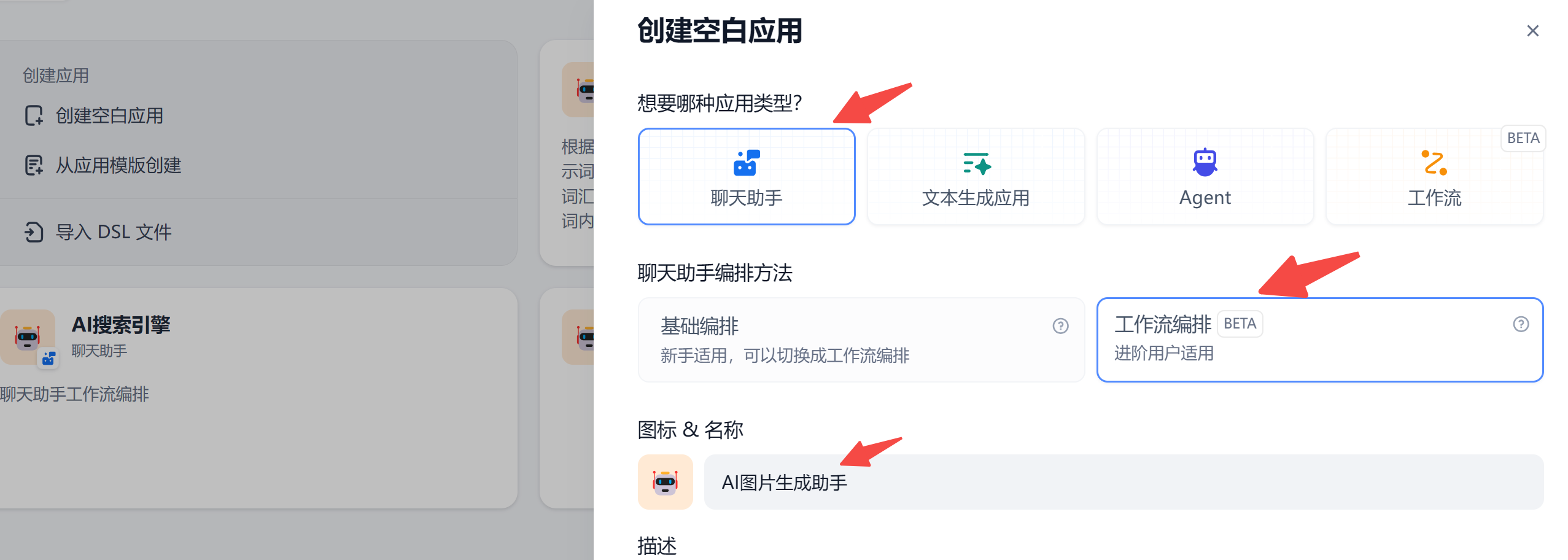
21 |
22 | **Step 2:** 修改 LLM 节点,编写提示词如下:
23 | ```
24 | 根据用户聊天记录和用户输入{{#sys.query#}},生成给图像生成工具的参数:提示词和图像尺寸。
25 | - 提示词:请从对话记录中找到和图片生成相关的词汇,生成给stable diffusion等图片生成模型的英文提示词,提示词内容尽可能丰富;
26 | - 图像尺寸:请从对话记录中找到和图像尺寸相关的词汇,并找到和图像尺寸选项中最接近的一个,如果没有相关词汇,则默认选择1024x576。图像尺寸选项有:1024x1024, 512x1024, 576x1024, 1024x576
27 | 要求:
28 | 最终只需输出json格式的文本,内容格式如下:
29 | {”prompt“:"english prompt", "image_size":"1024x576"}
30 | ```
31 |
32 | 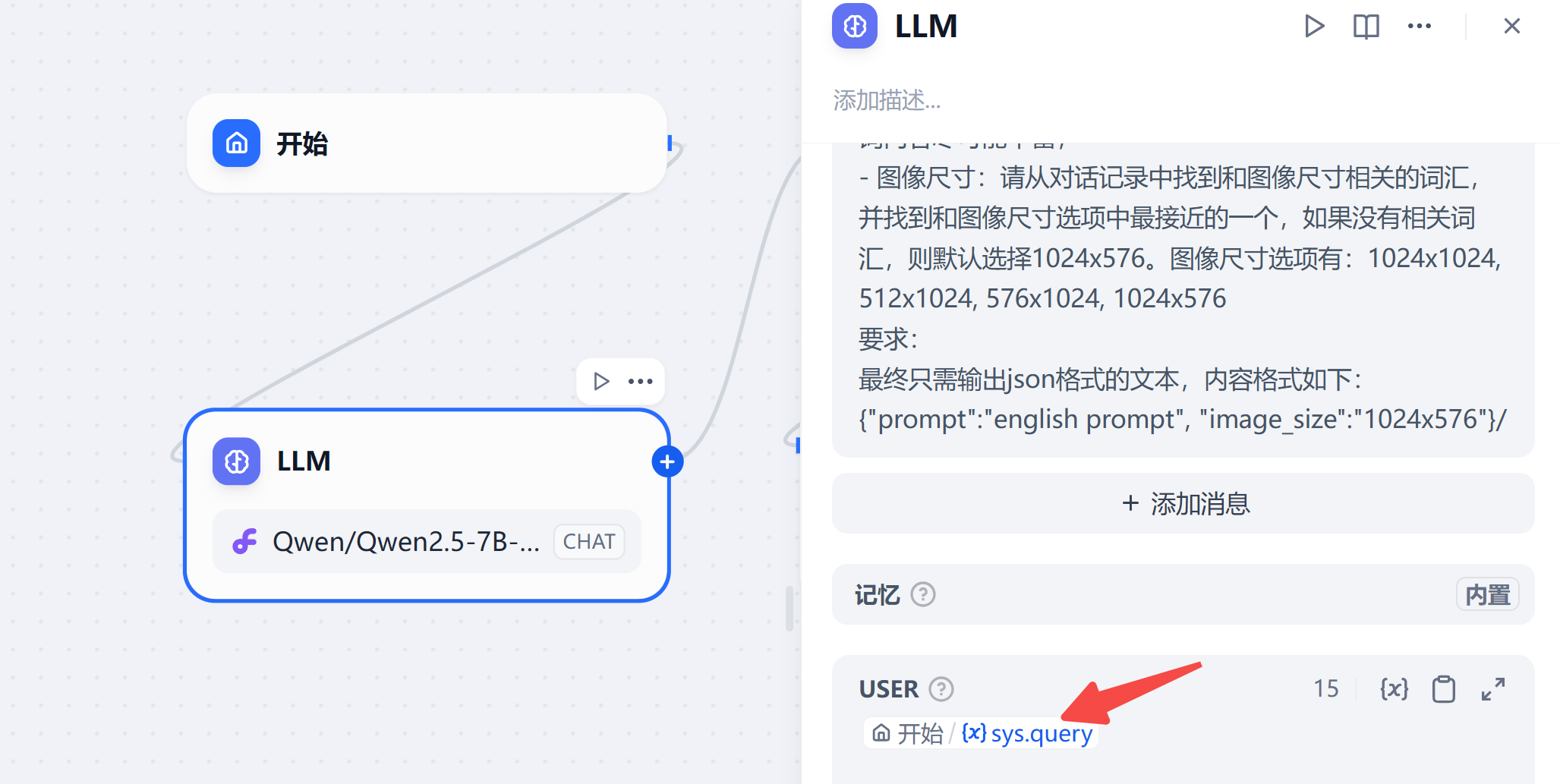
33 |
34 | **Step 3:** 添加`代码执行`节点,编写代码如下,把大模型的输出,变成结构化的字典:
35 |
36 | ```
37 | def main(arg1: str) -> dict:
38 | import json
39 | data = json.loads(arg1)
40 | return {
41 | "prompt": data['prompt'],
42 | "image_size": data['image_size']
43 | }
44 | ```
45 |
46 | 这一步,我们将获得两个变量:
47 | - prompt:给绘画模型的英文提示词,经过了 LLM 的润色;
48 | - image_size:期望生成的图片尺寸,由 LLM 决策。
49 |
50 | 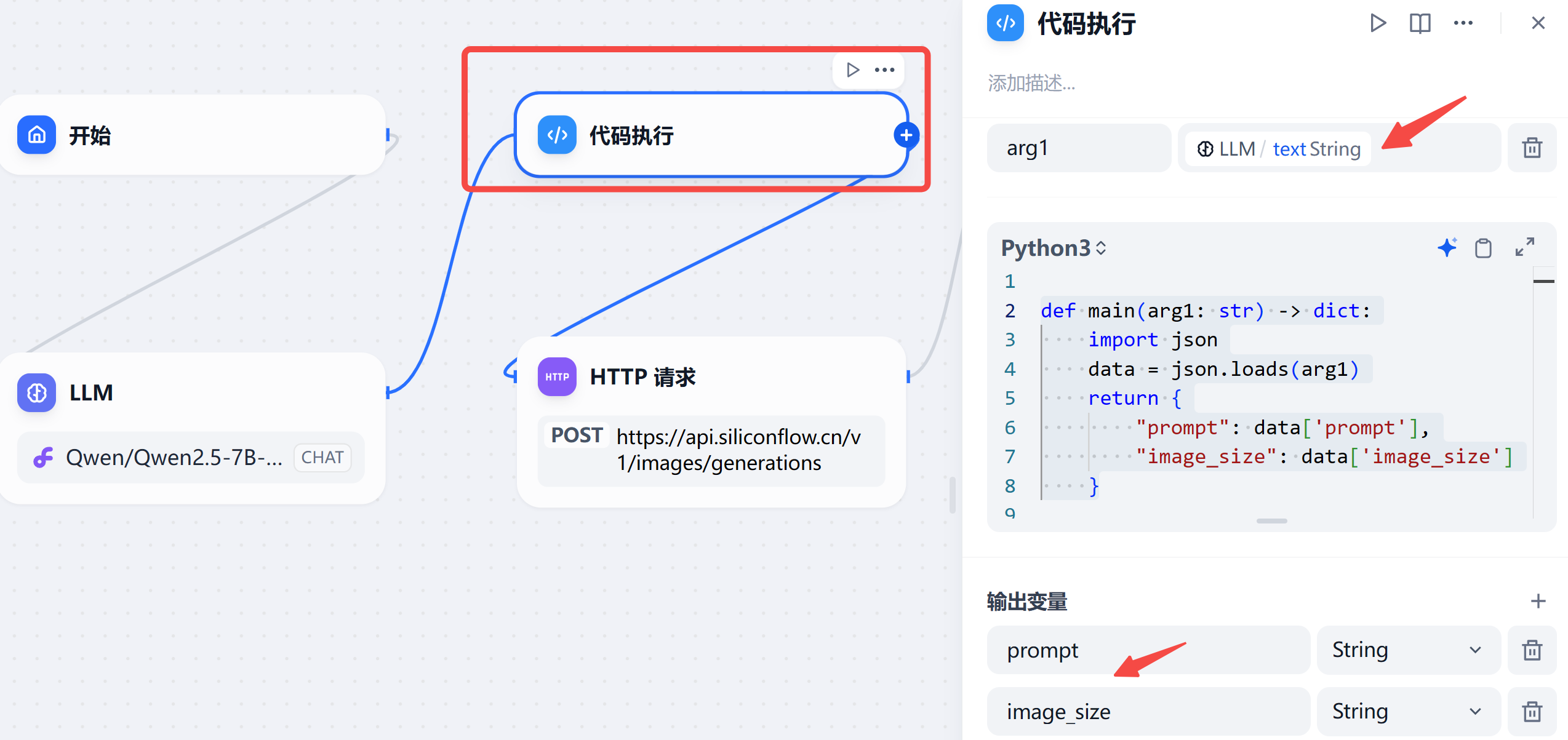
51 |
52 | **Step 3:** 添加`HTTP请求`节点,和上篇一样,我们还是采用[硅基](https://cloud.siliconflow.cn/?referrer=clxv36914000l6xncevco3u1y)的绘图API,编辑如下:
53 |
54 | 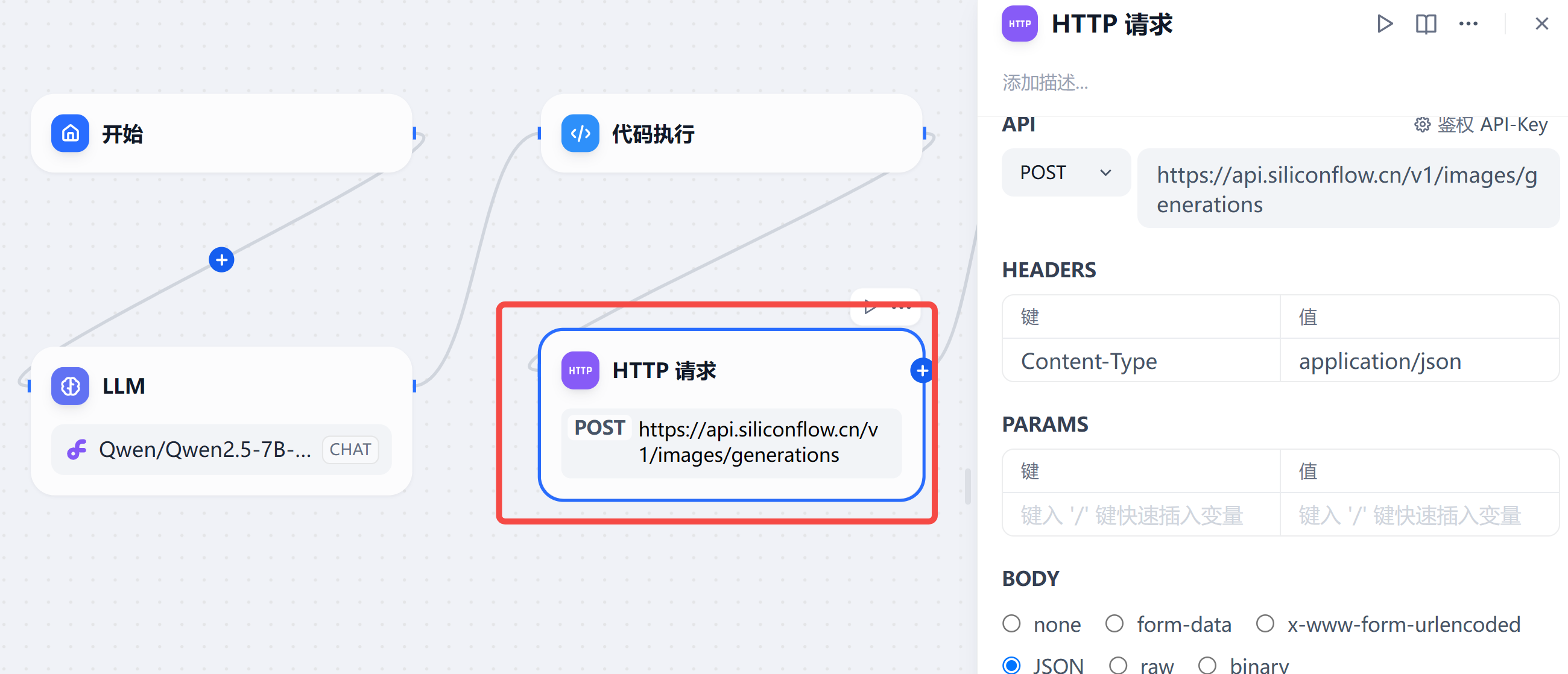
55 |
56 | **Step 4:** 添加`代码执行2`节点,这一步是为了提取`HTTP请求`,也即绘图API生成的图像 url:
57 |
58 | 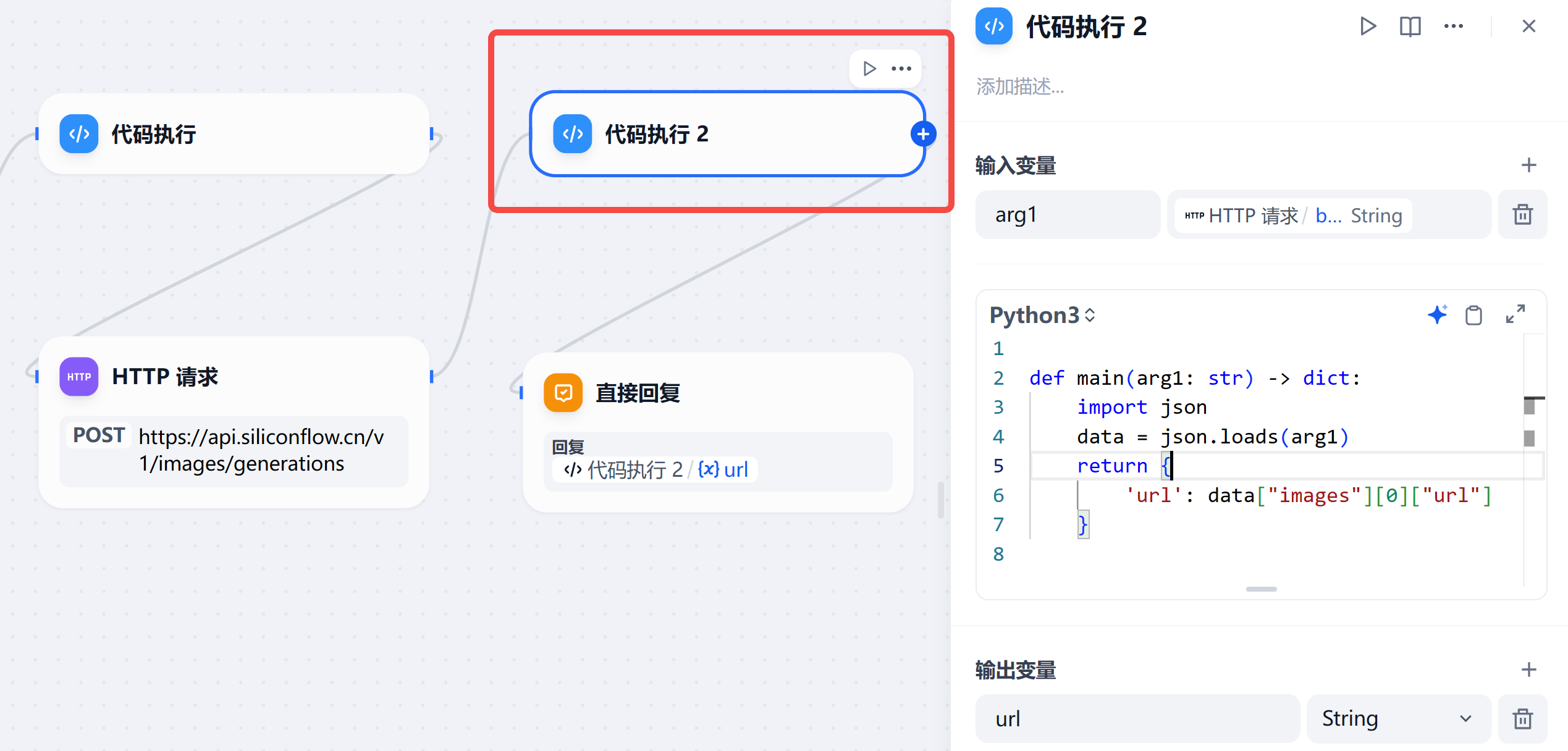
59 |
60 | **Step 5:** 添加`直接回复`节点,为了在web端显示图像,需要将图像 url 转成 markdown 格式:``:
61 |
62 |
63 | 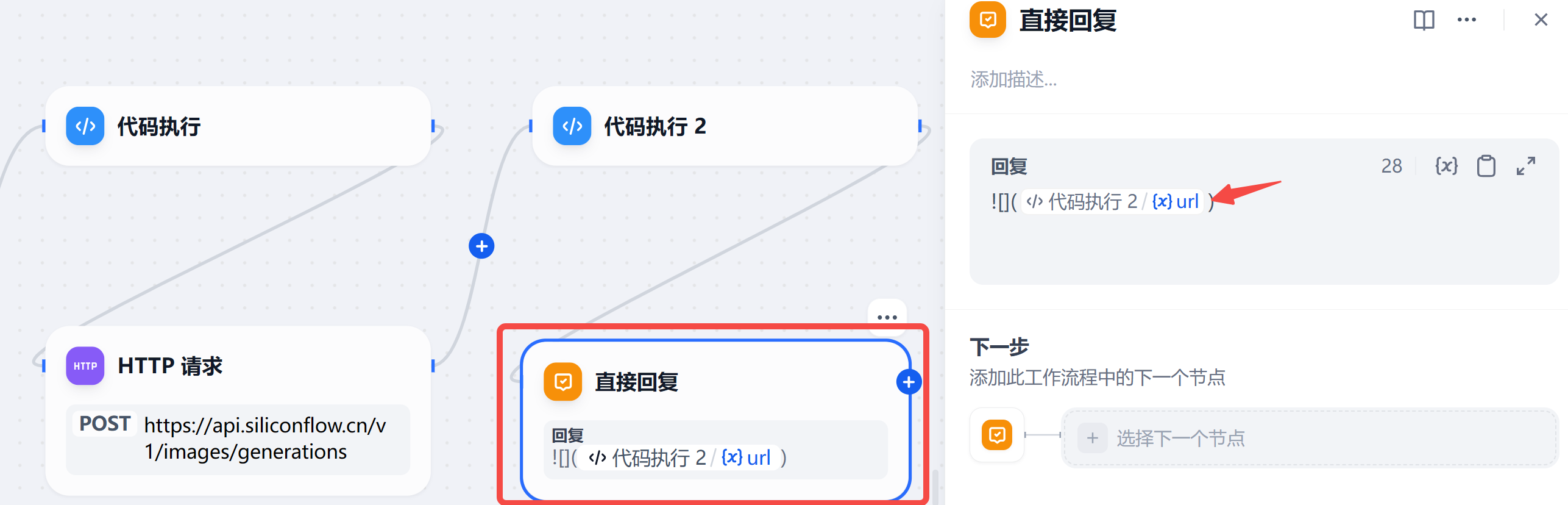
64 |
65 |
66 | 至此,一个完整的`图像生成`工作流就搭建完了,如下:
67 |
68 | 
69 |
70 | ## 2. 效果展示
71 |
72 | 搞定工作流,我们点击`预览`来测试下。
73 |
74 | **第一轮:生成猫的图像**
75 |
76 | 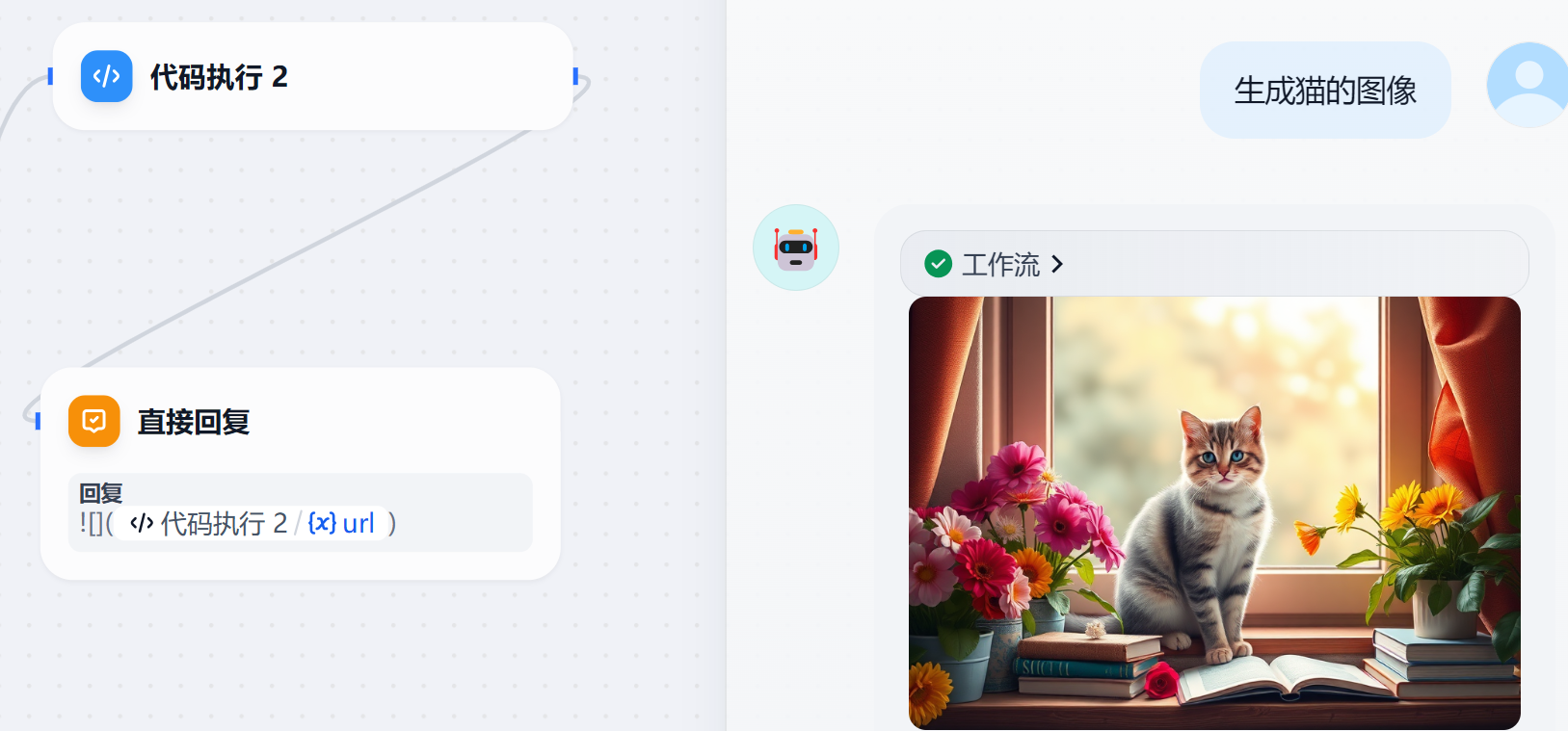
77 |
78 | **第二轮:要求尺寸9:16**
79 |
80 | 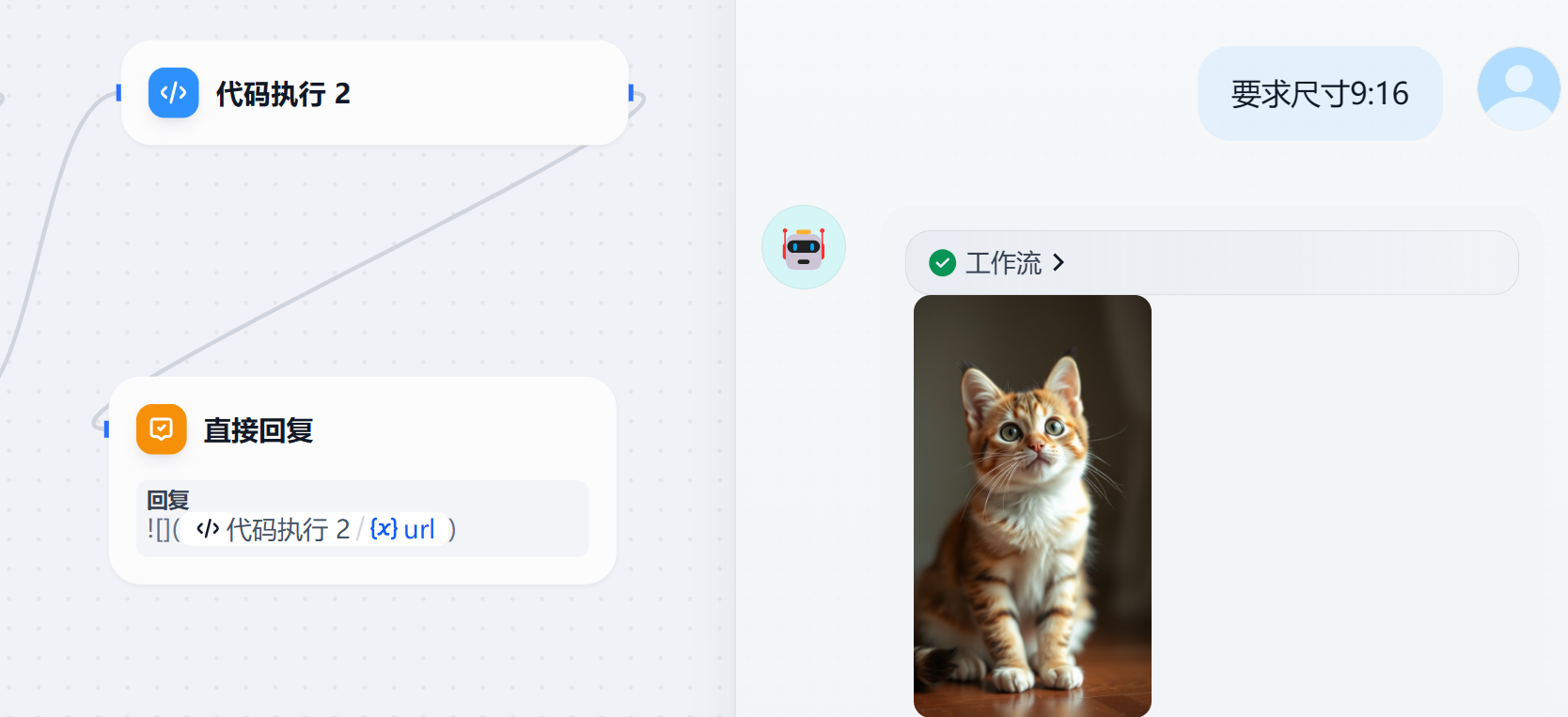
81 |
82 |
83 | **第三轮:要求在草地上奔跑**
84 |
85 | 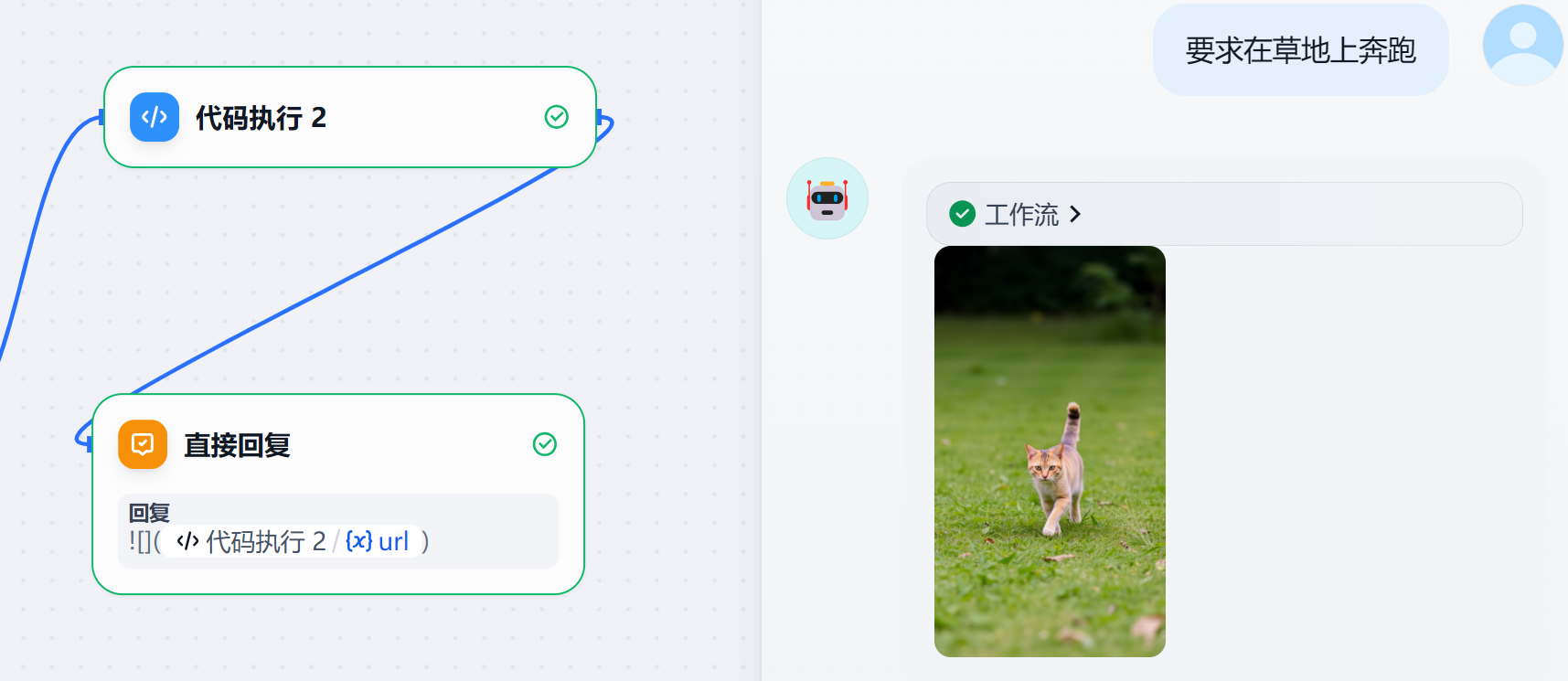
86 |
87 | **因为 Dify 工作流内置了记忆,默认支持 10 轮连续对话,所以,你只需不断提需求,逐步生成你想要的图像。**
88 |
89 | ## 3. API 调用
90 |
91 | 关于如何调用 API,可以参考之前的分享。
92 |
93 | 不过,有一点需要注意:如果要实现多轮对话,传参一定要加上:`user`和`conversation_id`。
94 |
95 | 而`conversation_id`是系统在第一次对话后自动生成的UUID(Universally Unique Identifier,通用唯一识别码),不可手动传入。
96 |
97 | 为此,需要把`conversation_id`缓存到数据库,否则每次调用都将是一次新的对话。
98 |
99 | 大致流程,可以表示如下:
100 |
101 |
102 | ```
103 | # 从数据库中获取conversion_id
104 | conversion_id = get_conversation_id(uname=from_name, agent_name='image', start_time=start_time)
105 | # 基于conversion_id请求绘画模型
106 | image_url, conversion_id = generate_dify_image(text=content, user=from_name, conversation_id=conversion_id)
107 | # 把conversion_id缓存到数据库
108 | if conversion_id:
109 | add_conversation_id(conversation_id=conversion_id, uname=from_name, agent_name='image', timestamp=datetime.now().strftime("%Y%m%d%H%M%S"))
110 | ```
111 | ## 4. 接入小爱
112 | 最后,我们把做好的绘画智能体,接入到微信机器人-`小爱(AI)`:
113 |
114 | 
115 |
116 | 
117 |
118 | ## 写在最后
119 |
120 | 本文带大家实操了**Dify 搭建图像生成专家**,并实现了后端调用。
121 |
122 | 如果对你有帮助,欢迎**点赞收藏**备用。
123 |
124 | > PS:本文工作流完整的 DSL,分享给有需要的朋友,公众号后台,发送`图像生成`自取。
125 | >
126 | > 关于 DSL 如何导入,可参考:[Dify 保姆级教程之:零代码打造票据识别专家](https://zhuanlan.zhihu.com/p/5465385787)
127 |
128 | ---
129 |
130 | 为方便大家交流,新建了一个 `AI 交流群`,欢迎感兴趣的小伙伴加入。
131 |
132 | `小爱(AI)`也在群里,公众号后台「联系我」,拉你进群。
133 |
134 |
135 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/Ollama 更新!本地跑 LLama3.2,轻量级+视觉能力,能媲美GPT-4o?.md:
--------------------------------------------------------------------------------
1 | 前段时间,Meta 开源了 Llama 3.2 轻量化模型,为移动端跑大模型提供了新选择!
2 |
3 | 同时,Llama 3.2 视觉模型(Llama 3.2 Vision)也正式开源,号称媲美 GPT-4o。
4 |
5 | 前两天,Llama 3.2 Vision 在 Ollama 上也正式上线!
6 |
7 | 今日分享,就对 Llama 3.2 Vision 实测一番。
8 |
9 | 最后,应用到我们上篇的`票据识别`任务中,看看效果真有官宣的那么惊艳么?
10 |
11 |
12 | ## 1. Llama 3.2 亮点
13 |
14 | 老规矩,还是简短介绍下:**Llama 3.2 都有哪些亮点**?
15 |
16 | 一句话:轻量化 + 视觉多模态能力!
17 |
18 | 具体点:
19 |
20 | - 文本模型:有 1B 和 3B 版本,即便参数少,也支持128k tokens的上下文长度;基于LoRA和SpinQuant 对模型进行深度优化,**内存使用量减少41%**,**推理效率翻了2-4倍**。
21 | - 多模态模型:有 11B 和 90B 版本,在视觉理解方面,与Claude3 Haiku和GPT 4o-mini 可 PK。
22 |
23 | ## 2. Llama 3.2 实测
24 |
25 | Ollama 是面向小白友好的大模型部署工具,为此本篇继续采用 Ollama 跑 Llama 3.2。
26 |
27 | 不了解 Ollama 的小伙伴,可翻看之前的教程:
28 |
29 | [本地部署大模型?Ollama 部署和实战,看这篇就够了](https://zhuanlan.zhihu.com/p/710560829)
30 |
31 | ### 2.1 环境准备
32 |
33 | 参考上述教程,假设你在本地已经准备好 Ollama。
34 |
35 | 当前 Ollama Library 中已支持 Llama 3.2 下载,因此,一行命令把 llama3.2-vision 拉起来。
36 |
37 | ```
38 | ollama run llama3.2-vision
39 | ```
40 |
41 | **如果遇到如下报错:**
42 |
43 | ```
44 | pulling manifest
45 | Error: pull model manifest: 412:
46 |
47 | The model you are attempting to pull requires a newer version of Ollama.
48 | ```
49 |
50 | **说明你的 ollama 版本需要更新了。**
51 |
52 | 如果你也和我一样,采用 docker 安装,则需要删除容器,重新下载最新镜像进行安装:
53 |
54 | ```
55 | docker stop ollama
56 | docker rm ollama
57 | docker image rm ollama/ollama
58 | # 注:海外镜像,国内用户需自备梯子
59 | docker pull ollama/ollama
60 | ```
61 |
62 | 可以发现,当前最新版本为 0.4.1:
63 | ```
64 | ollama --version
65 | ollama version is 0.4.1
66 | ```
67 |
68 |
69 | 然后,再起一个容器:
70 |
71 | ```
72 | docker run -d --gpus "device=2" -v ollama:/root/.ollama -p 3002:11434 --restart unless-stopped --name ollama ollama/ollama
73 | ```
74 |
75 | 注:我这里指定 `--gpus "device=2"`,如果单张显存不够,需指定多张卡,Ollama 会帮你自动分配。
76 |
77 | **显存占用情况如何?**
78 |
79 | ### 2.2 文本模型
80 |
81 | 进入容器,并下载模型 llama3.2 3B版本:
82 | ```
83 | docker exec -it ollama /bin/bash
84 | ollama run llama3.2
85 | ```
86 |
87 | 显存占用:请确保至少 4 G 显存。
88 |
89 | 
90 |
91 | ### 2.3 多模态模型
92 |
93 | 进入容器,并下载模型 llama3.2-vision 11B版本:
94 | ```
95 | docker exec -it ollama /bin/bash
96 | ollama run llama3.2-vision
97 | ```
98 |
99 | 显存占用:请确保至少 12 G 显存。
100 | 
101 |
102 | **注:ollama 中模型默认采用了 4bit 量化。**
103 |
104 | ## 3. 接入 Dify
105 | ### 3.1 模型接入
106 | 要把 Ollama 部署的模型接入 Dify 有两种方式。
107 |
108 |
109 | 首先,找到设置 - 模型供应商。
110 |
111 | **方式一:**
112 | 找到 Ollama 类型,然后进行添加,记得把`Vision`能力打开:
113 |
114 | 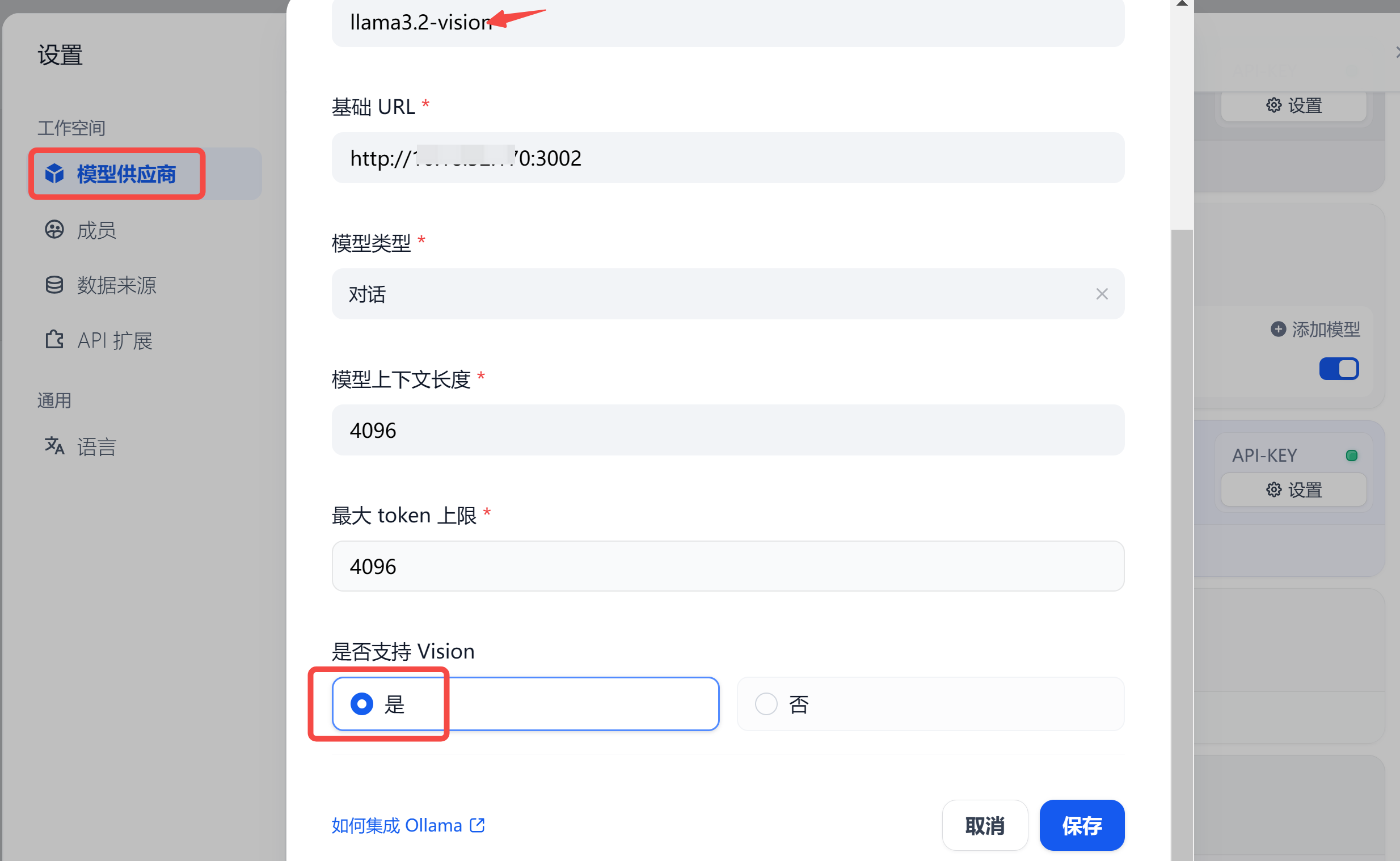
115 |
116 | **方式二:**
117 |
118 | 把 Ollama 模型接入 OneAPI,然后在模型供应商这里选择 `OpenAI-API-compatible`。
119 |
120 | 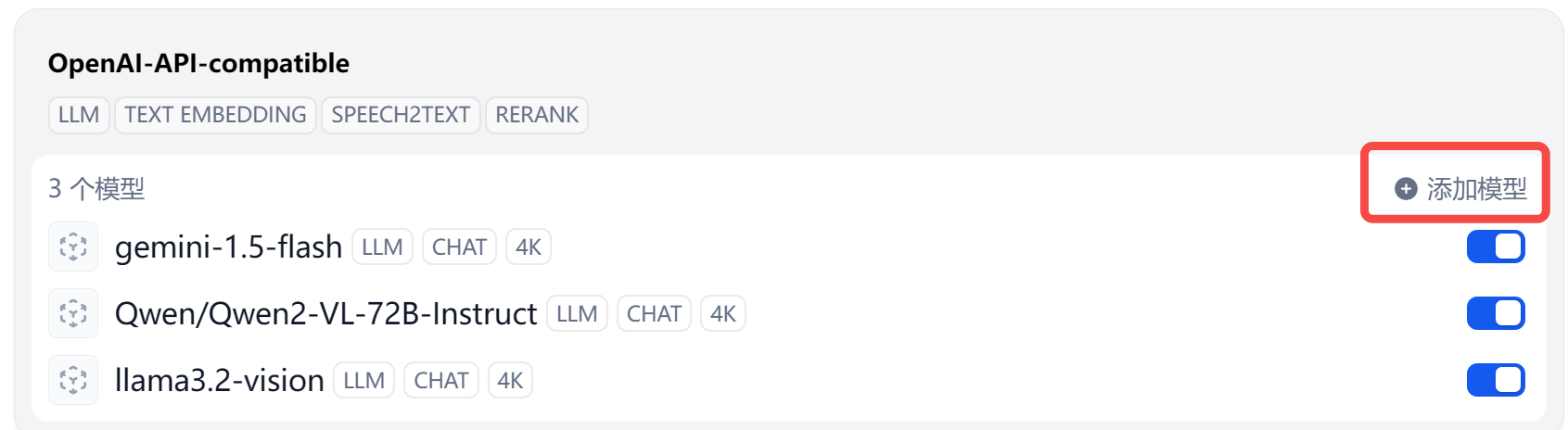
121 |
122 | 不了解 OneAPI 的小伙伴可以回看教程:[OneAPI-接口管理和分发神器:大模型一键封装成OpenAI协议](https://zhuanlan.zhihu.com/p/707769192)
123 |
124 | 个人更推荐 **方式二**,你会体会到接口统一的快乐~
125 |
126 | ### 3.2 应用集成
127 |
128 | 最后,我们在上篇的基础上,把用到 Qwen2-VL 的组件,LLM 全部替换成刚刚接入的 llama3.2-vision,如下图:
129 |
130 | 
131 |
132 |
133 | 实测效果咋样?
134 |
135 | 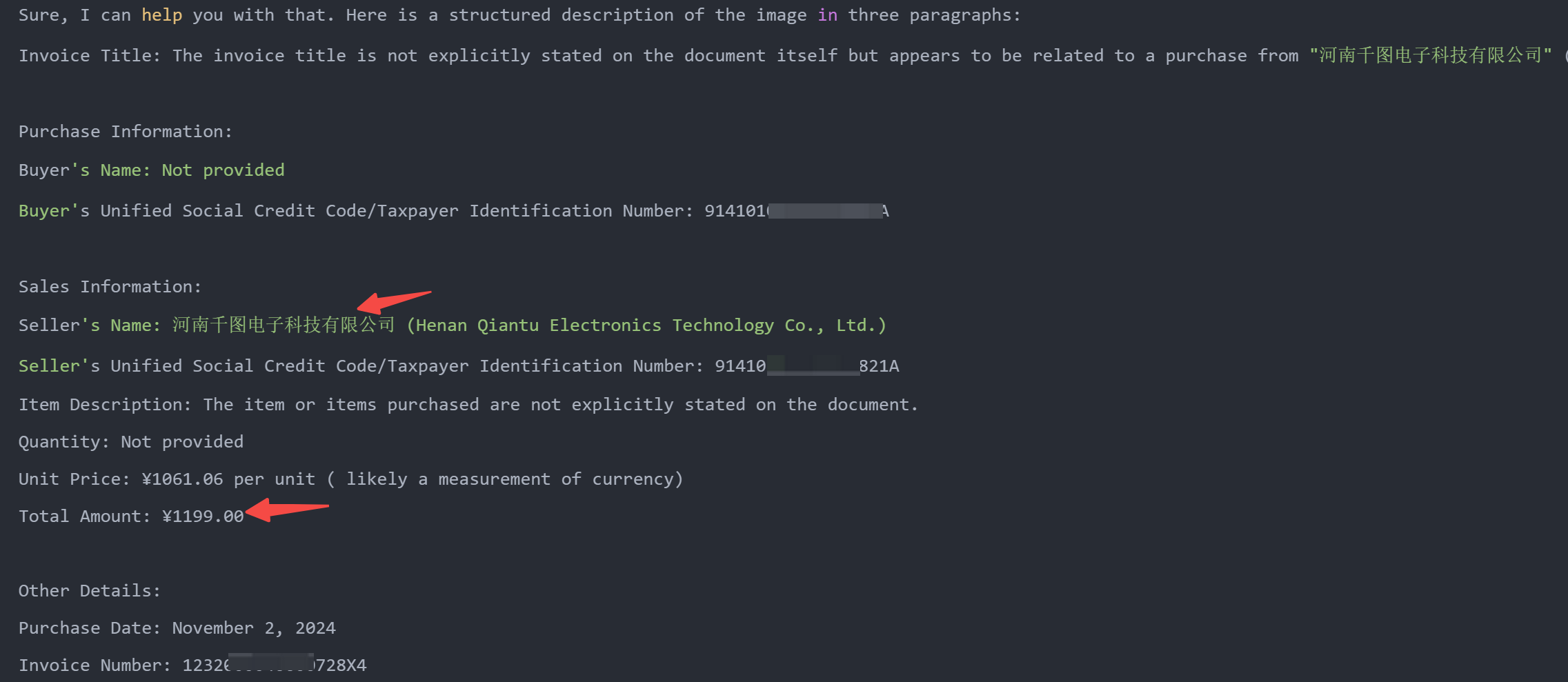
136 |
137 | 嗯~ o(* ̄▽ ̄*)o 价格等基本信息还是抓到了。
138 |
139 | 不过,相比上篇实测的 Qwen2-VL 就差点意思了:
140 | - 从中文指令遵循上看:给到同样的提示词,llama3.2-vision 压根不按你的意图来;
141 | - 从识别结果上看:中文 OCR 也被 Qwen2-VL 甩开好几条街。
142 |
143 | 当然,换用 90B 的模型会不会好很多?感兴趣的朋友可以试试~
144 |
145 | **结论:现阶段,对于票据识别这个任务而言,综合考虑成本和效果,还是调用云端的 Qwen2-VL-72B 吧。**
146 |
147 | ## 写在最后
148 |
149 | 本文带大家本地跑了 Meta 最新开源的 Llama 3.2,并在票据识别任务上进行了实测。
150 |
151 | 个人体验而言:Llama 系列,都得在中文指令数据上微调后,才能中文场景中使用,同等参数规模下,国产大模型其实更具性价比。
152 |
153 | 如果对你有帮助,欢迎**点赞收藏**备用。
154 |
155 | ---
156 |
157 | 为方便大家交流,新建了一个 `AI 交流群`,欢迎感兴趣的小伙伴加入。
158 |
159 | 最近搭建的微信机器人`小爱(AI)`也在群里,公众号后台「联系我」,拉你进群。
160 |
161 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/「AI数学老师」,一个前后端分离的小项目.md:
--------------------------------------------------------------------------------
1 | 前两天,给大家分享了`免费AI数学老师`的本地搭建:
2 | - [最强OCR+数学模型Qwen-Math,本地搭建](https://blog.csdn.net/u010522887/article/details/142893400)
3 |
4 | 为了方便大家快速体验,我把`免费AI数学老师`接入了微信机器人`小爱`。
5 |
6 | 
7 |
8 | 实操后发现,**体验感非常不好**,主要问题有:
9 | - 对于解复杂题目,Qwen 回复需要 100 秒以上,容易引发服务超时。
10 | - matplotlib 只支持渲染部分 Latex 公式,导致生成图片中有不可识别字符,没法看。
11 |
12 | **既然这么受欢迎,自然需要更好的前端展现。**
13 |
14 | 今日分享,就带大家实操一个简易的`AI数学老师`前端,通过调用上篇部署好的后端服务,展现`Qwen-Math`的实力。
15 |
16 | ## 1. Gradio 简介
17 | **Gradio 是什么?**
18 |
19 | 一个用于构建交互式界面的 Python 库,主要用于展示各种 AI 模型。
20 |
21 | **为何用 Gradio?**
22 |
23 | 你只需熟悉几个简单的组件,就可以快速搭建一个前端界面,无需编写繁琐的 HTML、CSS 和 JavaScript 代码。
24 |
25 | **如何装 Gradio?**
26 |
27 | 安装Gradio非常简单,pip 一键安装:
28 |
29 | ```
30 | pip install gradio
31 | ```
32 |
33 | Gradio 依赖于 Flask 和 Werkzeug,这些库会在安装时自动安装。
34 |
35 | **如何用 Gradio?**
36 |
37 | 下面是一个简单的Gradio应用示例,它创建了一个图像分类的界面:通过定义图像分类函数 `classify_image`,用户可以上传图像 `image`,进而获得分类结果 `label`。
38 | ```
39 | import gradio as gr
40 |
41 | def classify_image(img):
42 | # 这里是图像分类的逻辑
43 | pass
44 |
45 | iface = gr.Interface(fn=classify_image, inputs="image", outputs="label")
46 | iface.launch()
47 | ```
48 |
49 |
50 | ## 2. AI数学老师前端实现
51 |
52 | 如果理解了上面的`Hello-world`实现,那么用 Gradio 来搭建`AI数学老师`前端,就 so easy 了。
53 |
54 | 具体而言,我们可以采取三步走:
55 |
56 | ### 2.1 定义处理函数
57 |
58 | 假设你已参考上篇完成了后端服务部署:`http://localhost:3004/math`。
59 |
60 | 请求体包括两部分:
61 | - `image`:包含问题的图片,可以为空;
62 | - `text`:关于解题的文本描述。
63 | ```
64 | data = {
65 | "image": image,
66 | "text": text
67 | }
68 | ```
69 |
70 | 因此,处理函数可以定义如下:
71 |
72 | ```
73 | def process(image, text):
74 | data = {
75 | "image": image,
76 | "text": text
77 | }
78 | response = requests.post("http://localhost:3004/math", json=data) # 修改为你的API地址
79 | return response.json()
80 | ```
81 |
82 |
83 | ### 2.2 创建界面组件
84 |
85 | 对于这个应用,最简单的可以分两栏进行展示:
86 | - 问题输入区:包括图片输入和文本输入;
87 | - 解答区:模型回答展示。
88 |
89 | 实现代码如下:
90 | ```
91 | with gr.Blocks() as demo:
92 | with gr.Row():
93 | with gr.Column():
94 | img_input = gr.Image(label="问题图片", type='pil')
95 | text_input = gr.Textbox(placeholder="输入问题")
96 | submit_button = gr.Button("提交", variant='primary')
97 | with gr.Column():
98 | with gr.Accordion("解答区", open=True):
99 | markdown_output = gr.Markdown()
100 | submit_button.click(fn=process, inputs=[img_input, text_input], outputs=markdown_output)
101 | ```
102 |
103 | 不得不赞的是,gradio 的 markdown 组件 `gr.Markdown`完美支持 Latex 渲染,完美!
104 |
105 | ### 2.3 演示和调试
106 | 搭建完成后,可以启动看看,不行再来调整呗。
107 |
108 | ```
109 | # 启动应用
110 | demo.launch(server_name="0.0.0.0", server_port=7860)
111 | ```
112 |
113 | 启动把`server_name`置为`0.0.0.0`,它表示“所有地址”,服务可以接受来自任何IP的连接请求。
114 |
115 | ## 3. 效果展示
116 |
117 | 一个简单的前端页面,它来了。。。
118 |
119 | 
120 |
121 | 图片输入这里,支持两种方式:
122 | - 本地上传图片 or 复制粘贴;
123 | - 调用电脑摄像头拍照;
124 |
125 | 
126 |
127 | 输入题目,点击提交,耐心等待大模型解答:
128 |
129 | 
130 |
131 | 对于这种简单的题目,不到 10s 就能搞定:
132 |
133 | 
134 |
135 | 更多解题案例,可参见:[你的免费AI数学老师来了!](https://blog.csdn.net/u010522887/article/details/142893400)
136 |
137 | *注:Qwen-Math 只支持文本输入,因此无法解答包含几何图形的题目。*
138 |
139 | ## 写在最后
140 |
141 | 本文通过引入 `Gradio`,带大家实操了`AI数学老师`的前端实现。
142 |
143 | 如果对你有帮助,不妨**点赞收藏**备用。
144 |
145 | 大家有更好的想法,欢迎来聊。
146 |
147 | ---
148 |
149 | 为方便大家交流,新建了一个 `AI 交流群`,欢迎感兴趣的小伙伴加入。
150 |
151 | `小爱(AI)`也在群里,公众号后台「联系我」,拉你进群。
152 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/【AI工具+变现】老照片上色,图像高清化。。。一个网站全搞定.md:
--------------------------------------------------------------------------------
1 | 你好,我是猴哥,欢迎你来。
2 |
3 | 这个账号开设的初心是帮助更多人“学好AI 用好AI”。
4 |
5 | 从这篇开始,陆续为大家分享好用的AI工具。
6 |
7 | 初衷是:
8 |
9 | - 希望帮助更多的普通上班族、创业者,让大家少走弯路,少被居心不良的人割韭菜;
10 | - 希望帮助一些有心人,想搞副业,赚点小钱,收获工作之余的成就感。
11 |
12 | 今天分享的这个项目,可能你早就听说过,只不过是你没行动,而有心人早就行动了,去年开始做这个项目的人早就赚的盆满钵满了。
13 |
14 | ## 啥项目?
15 |
16 | “老照片上色~”
17 |
18 | 不信你打开淘宝搜了看看~
19 |
20 | 
21 |
22 |
23 |
24 |
25 |
26 | 添加图片注释,不超过 140 字(可选)
27 |
28 | 我的个天~ 客单价 10 元, 卖出去 7万+,注意这还只是引流价,后续服务是要加价的,而且不包含打印和邮寄费,绝对的一本万利!
29 |
30 | 这是妥妥要年入百万的节奏啊。
31 |
32 | 就这?你当然看不起的项目,就在你眼皮底下,搞钱!
33 |
34 | 当然,任何项目都有信息差,早期的AI图片修复工具还相对复杂,包括如果你要本地化部署都对编程基础有一定要求,而现在这个门槛已经大大降低。
35 |
36 | 现在还能不能做?如果你还看得上这个小钱,不妨试试看。
37 |
38 | ## 怎么做?
39 |
40 | 不需要你有任何编程基础,一台装个浏览器的电脑即可上手。
41 |
42 | 推荐一个免费工具:佐糖:https://picwish.cn/(国内直连)。
43 |
44 | 在 **AI工具** 的 下拉菜单中选择:黑白照片上色
45 |
46 | 
47 |
48 |
49 |
50 |
51 |
52 | 添加图片注释,不超过 140 字(可选)
53 |
54 | 随后上传你的黑白图像即可,来张我喜欢的电视剧剧照,给大家展示一下:
55 |
56 | 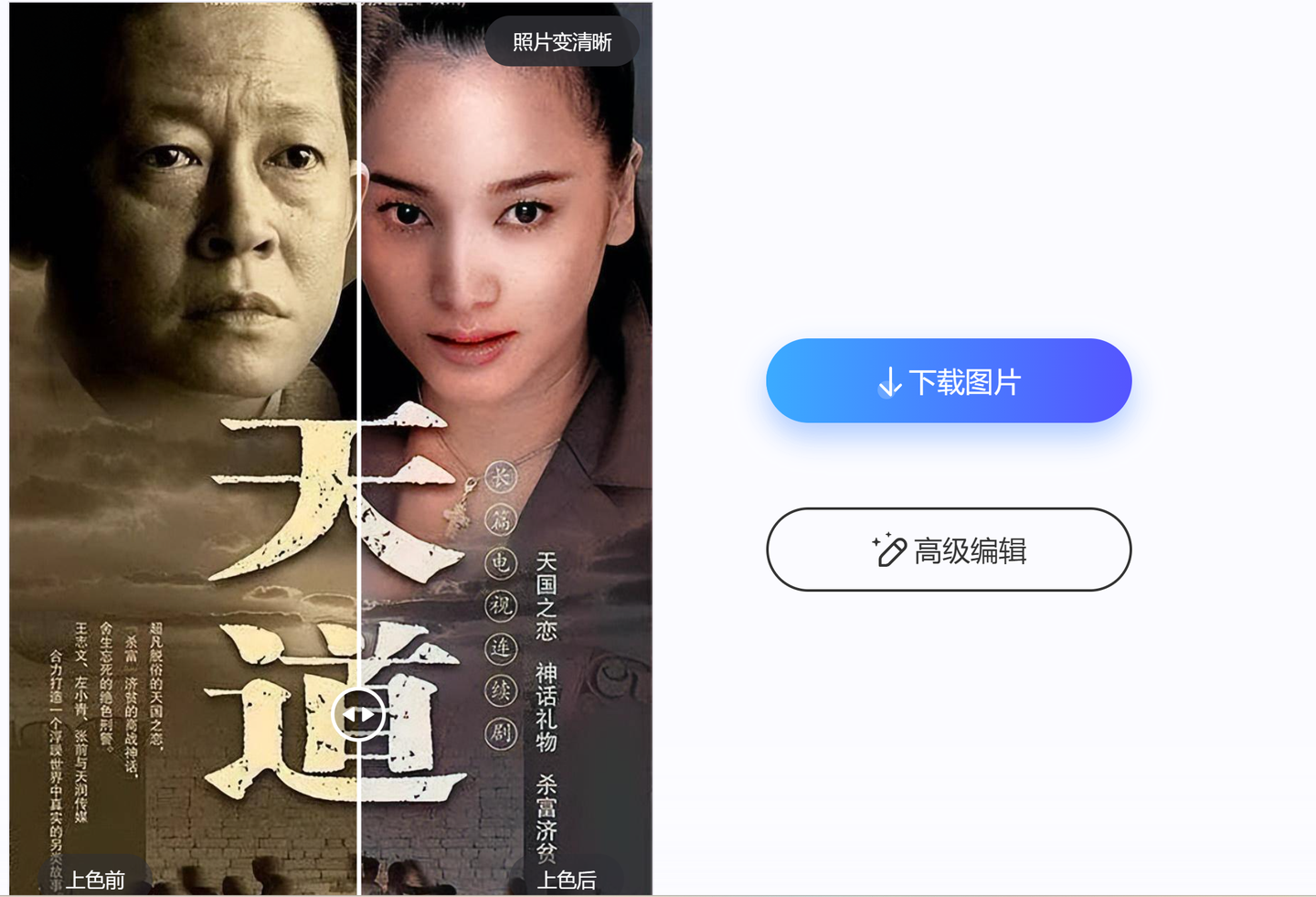
57 |
58 |
59 |
60 |
61 |
62 | 添加图片注释,不超过 140 字(可选)
63 |
64 | 这效果,是不是很炸裂~
65 |
66 | 由于手头没有黑白人像照片,你可以去试试啊!
67 |
68 | 此外,这个网站还有更多图片修复的功能,比如下面这个彩色图片高清化,还是拿一张电视剧剧照来举例:
69 |
70 | 
71 |
72 |
73 |
74 |
75 |
76 | 添加图片注释,不超过 140 字(可选)
77 |
78 | 效果不错,下载下来是没有水印的哦,可以去交付了。
79 |
80 | ## 写在最后
81 |
82 | 今天分享的这个网站完全免费,新手只要简单几步(不比你刷抖音复杂到哪去吧),就能搞定!
83 |
84 | 然后到咸鱼、小红书等平台发笔记,接单,做个副业小项目,赚个小钱还是没问题的,后续要是搞大了,也可以像上面的淘宝店主一样,布局更多类似的项目。
85 |
86 | 当然,这个网站还有更多宝藏工具,有心的同学自己去摸索。
87 |
88 | 即便你不拿它去搞副业,多掌握一个AI工具,少被别人割,也是有意义的。
89 |
90 | **学好AI效率工具,围观AI变现项目,欢迎移步公众号:猴哥的AI知识库** .
91 |
92 | 
93 |
94 |
95 |
96 |
97 |
98 | 添加图片注释,不超过 140 字(可选)
99 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/【保姆级教程】5分钟上手 Coze 自建插件,把 AI 接入个人微信.md:
--------------------------------------------------------------------------------
1 |
2 | 上篇,给大家介绍了一款搭建微信机器人的开源项目:
3 | [搭建微信机器人的第4种方式,我造了一个摸鱼小助手](https://blog.csdn.net/u010522887/article/details/141348878)
4 |
5 | 不同于需要付费的项目,它的定制化程度非常高~
6 |
7 | 问题来了:怎么接入 AI 能力呢?
8 |
9 | 考虑到大家对 Coze 智能体的接触更多一些,
10 |
11 | 今日分享,先带大家接入 `Coze` 的 AI 能力,打造更智能的个人 AI 助理!
12 |
13 | 全程无比丝滑,无需任何编程基础,只要跟着一步步实操,你也可以搞定!
14 |
15 | ## 1. 创建 Coze Bot
16 |
17 | 前往 [https://www.coze.cn/](https://www.coze.cn/),点击 `创建 Bot`。
18 |
19 | 单 Agent 就行,大模型随便选一个,从实测体验来看,个人觉得 Kimi 普适性更强一些。
20 |
21 | 
22 |
23 | 最重要的来了,你需要添加一个插件:
24 | 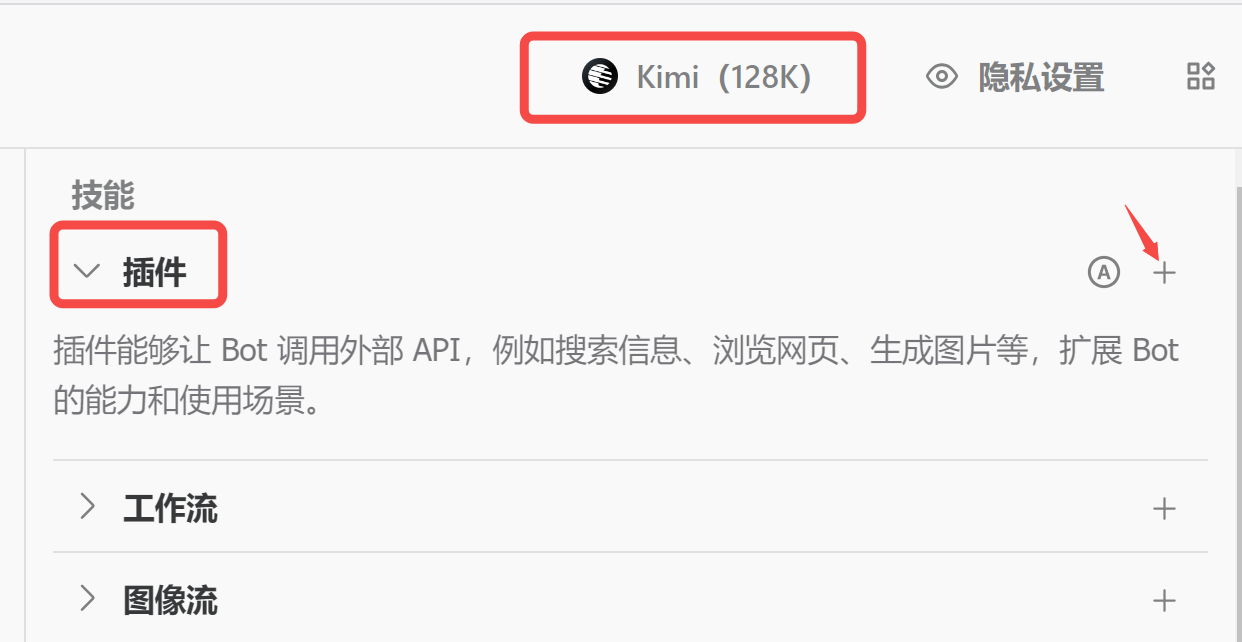
25 |
26 | 插件市场根本找不到满足需求的插件啊~
27 |
28 | 这时,你需要自己创建👇
29 |
30 | 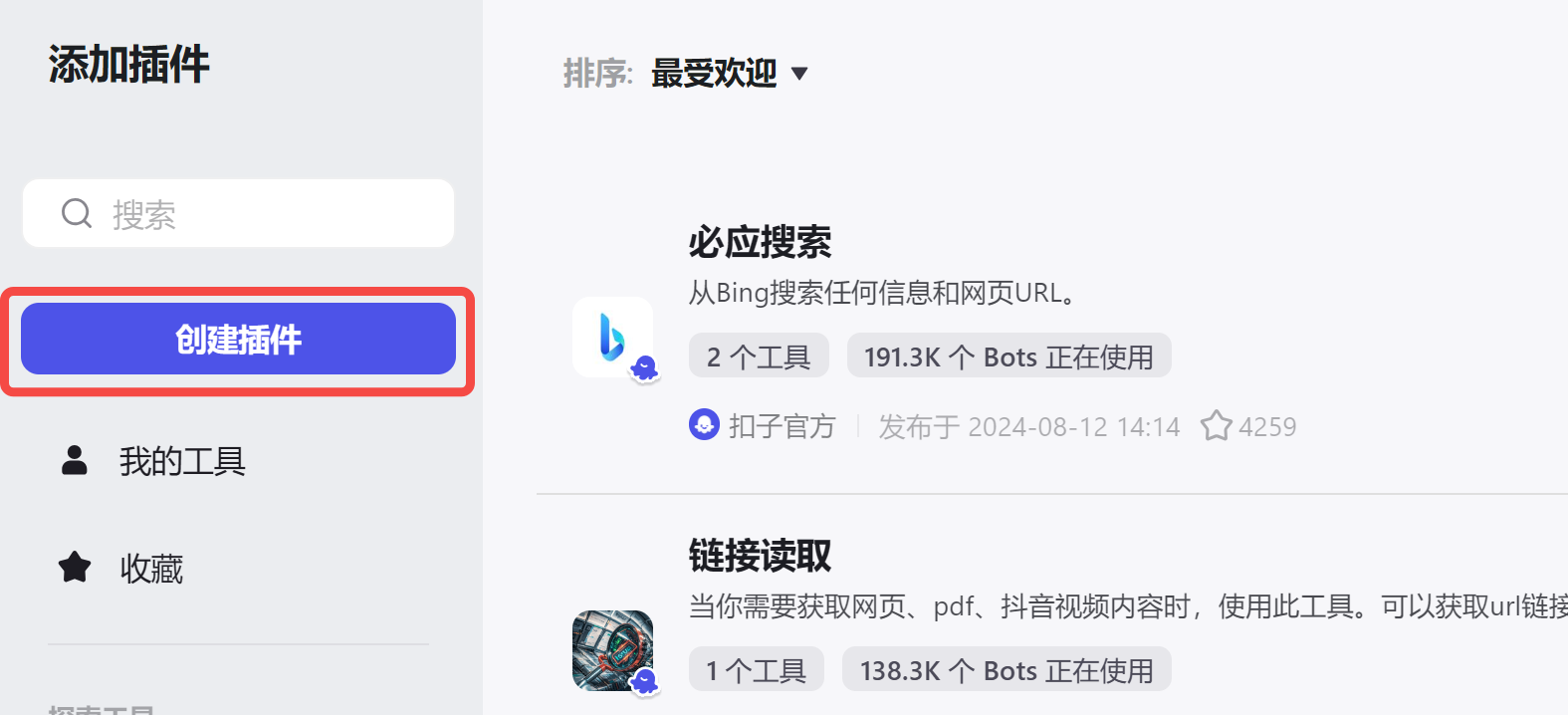
31 |
32 | ## 2. 创建插件
33 |
34 | 注意创建插件需要写一点代码,不用担心,很简单的几行代码就能搞定!
35 |
36 | 所以,需要选择 `在Coze IDE中创建`,在`IDE运行时`选择你熟悉的一种语言就行。
37 |
38 | 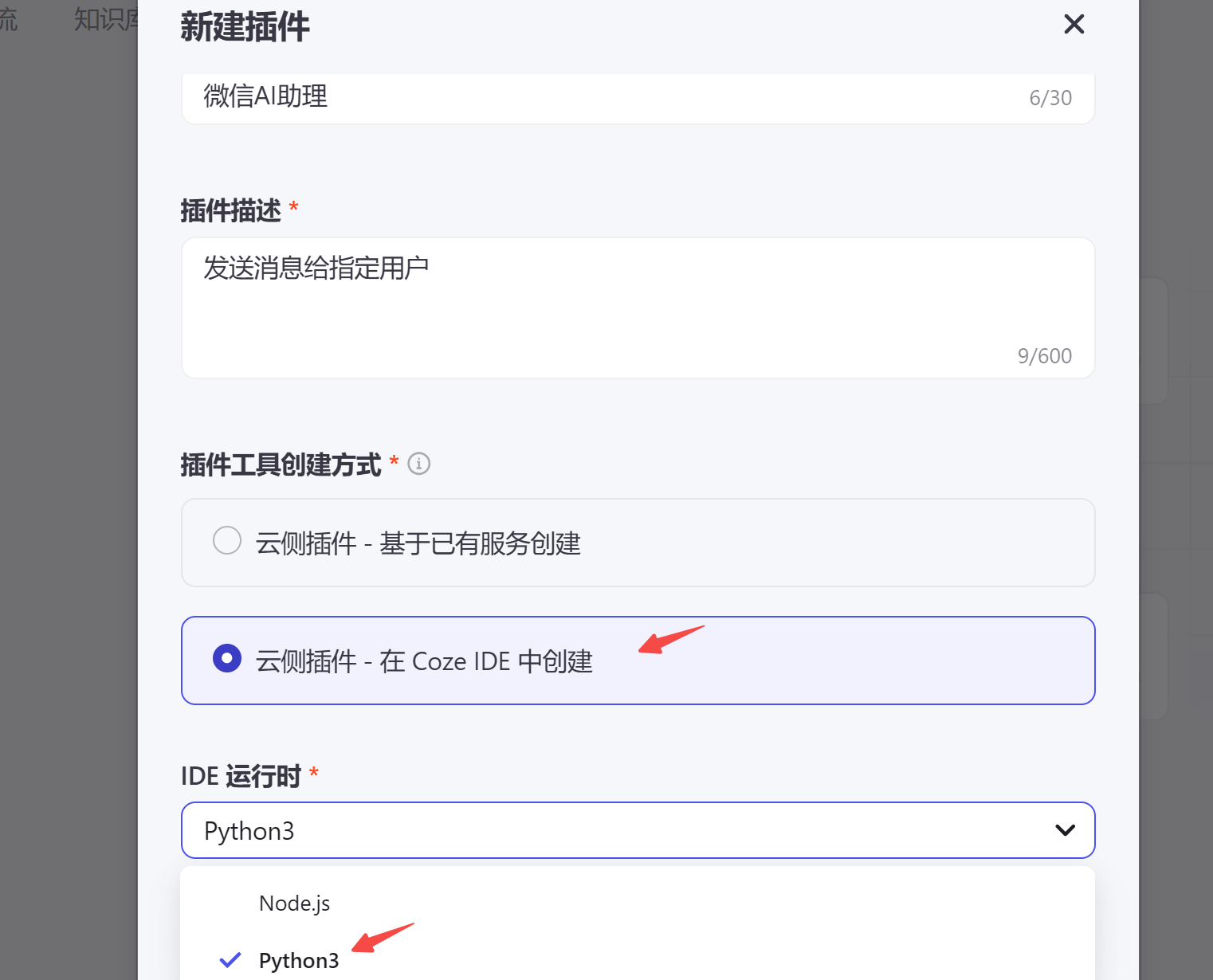
39 |
40 |
41 | 然后点击`在 IDE 中创建工具`,进来后,首先左下侧 `+` 安装依赖包`requests`,代码区编写如下内容:
42 |
43 | 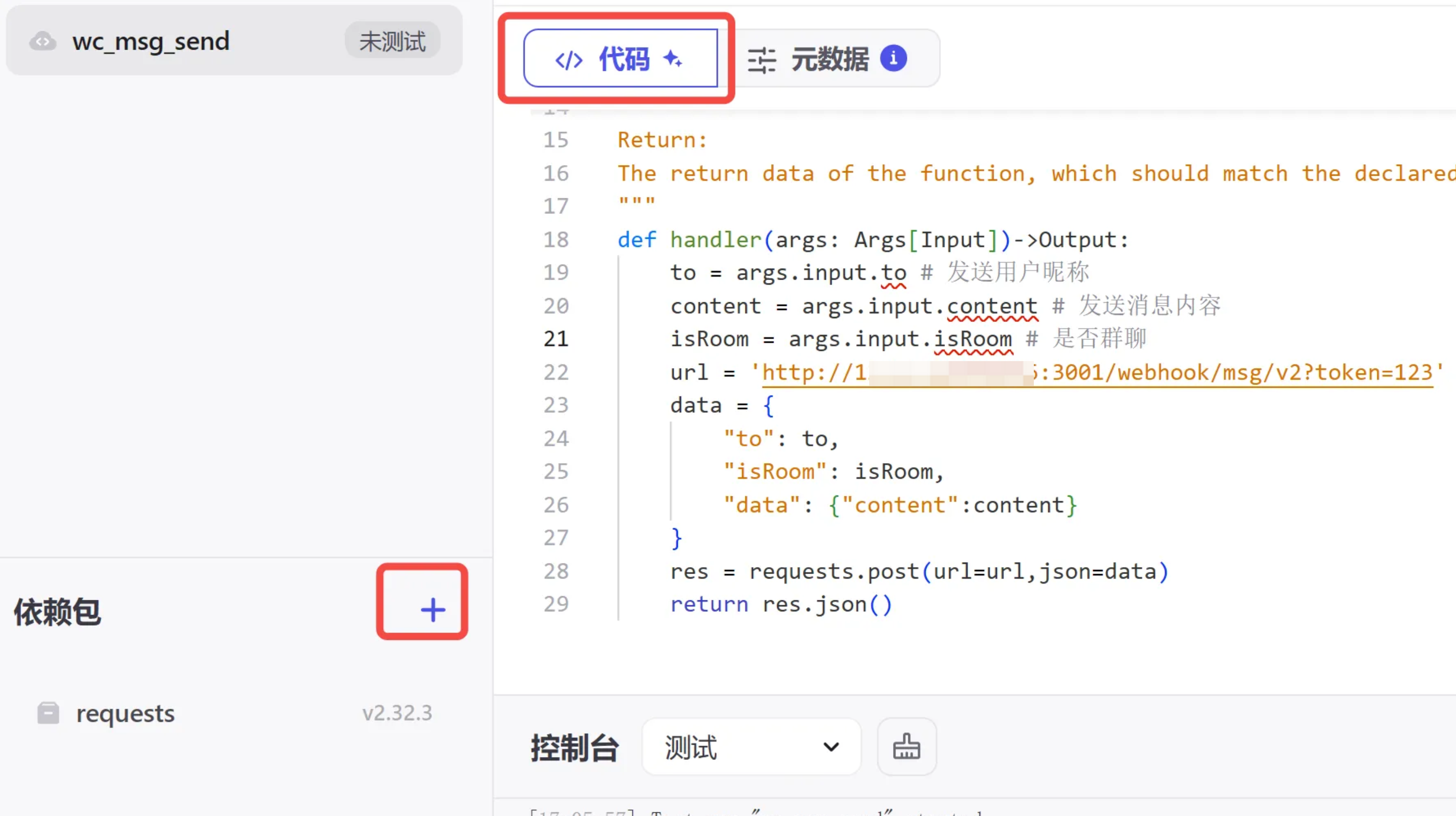
44 |
45 | 这里的 url 就是我们在上篇中搭建的机器人的`发送消息的API`,其中最重要的三个参数和原始请求中保持一致!
46 |
47 |
48 | 此外,为了 AI 大模型可以准确执行任务,你还得把这些参数给它解释一下哦~
49 |
50 |
51 | 怎么搞?右侧填入元数据,把输入参数和输出参数通通给他`描述`一遍:
52 |
53 | 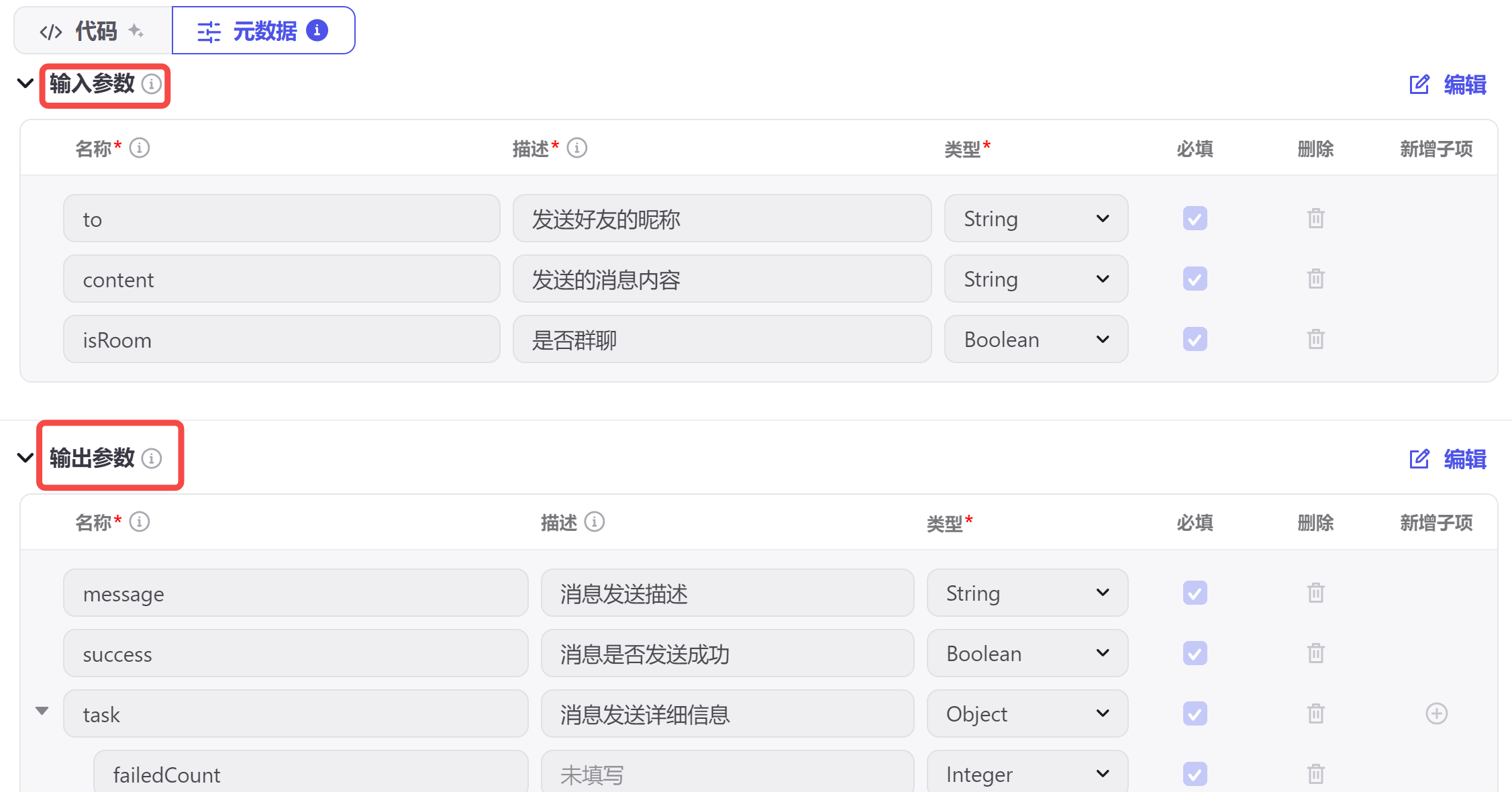
54 |
55 | 填入元数据后,右侧可以自动生成请求数据的实例,填入你想要发送的用户和内容,点击`运行`测试一下吧~
56 |
57 | 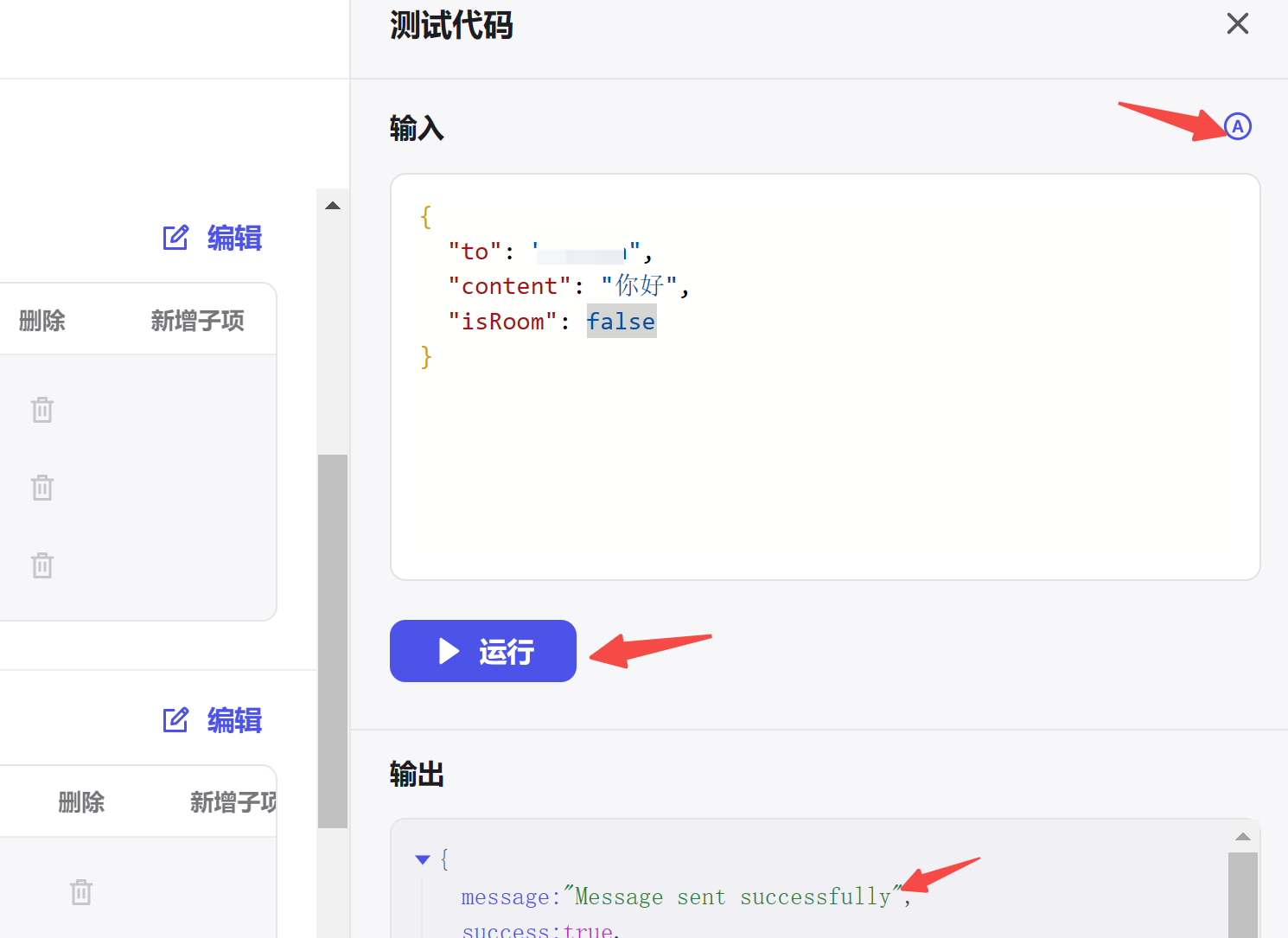
58 |
59 |
60 | 测试成功,就可以点击右上角的 **发布** 。
61 |
62 | 至此,你的工具就创建好了。
63 |
64 | ## 3. 智能体测试
65 |
66 | 首先,回到一开始的 Bot 配置界面,添加插件这里,找到`我的工具`,把你刚刚发布的插件添加进来即可。
67 |
68 | 
69 |
70 |
71 | 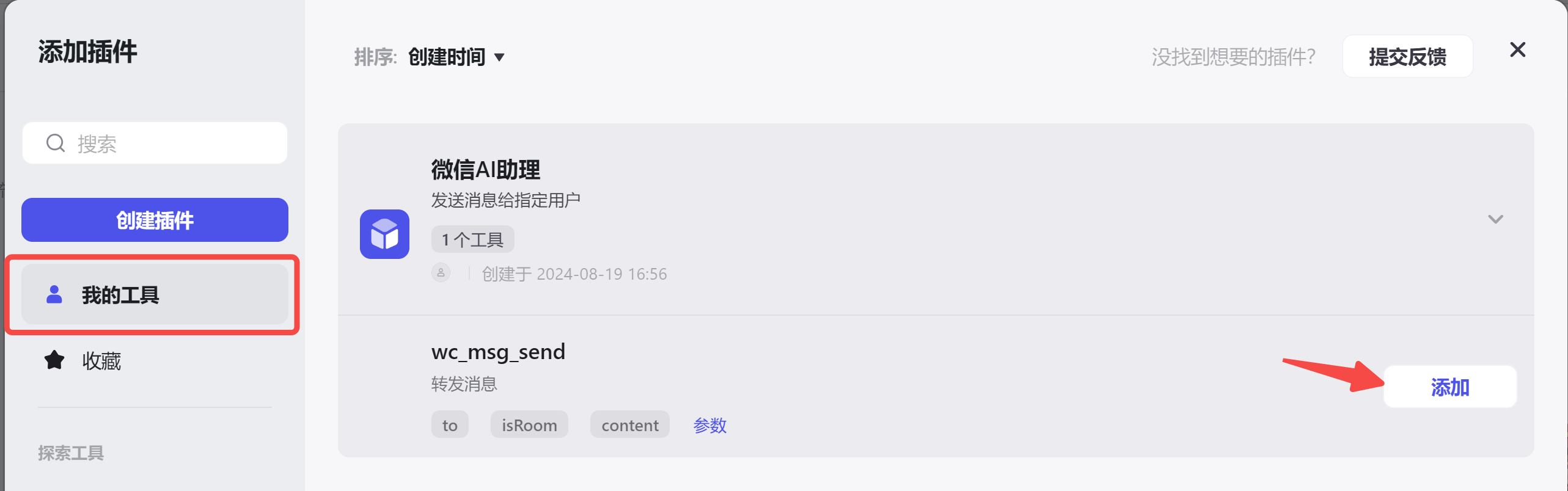
72 |
73 |
74 | 最后,在右侧的`预览与调试`区域,测试一下吧~
75 |
76 | **测试案例一**:
77 |
78 | 让它给我的`大号`微信讲一句土味情话,可以看到成功调用了刚刚添加的插件:
79 |
80 | 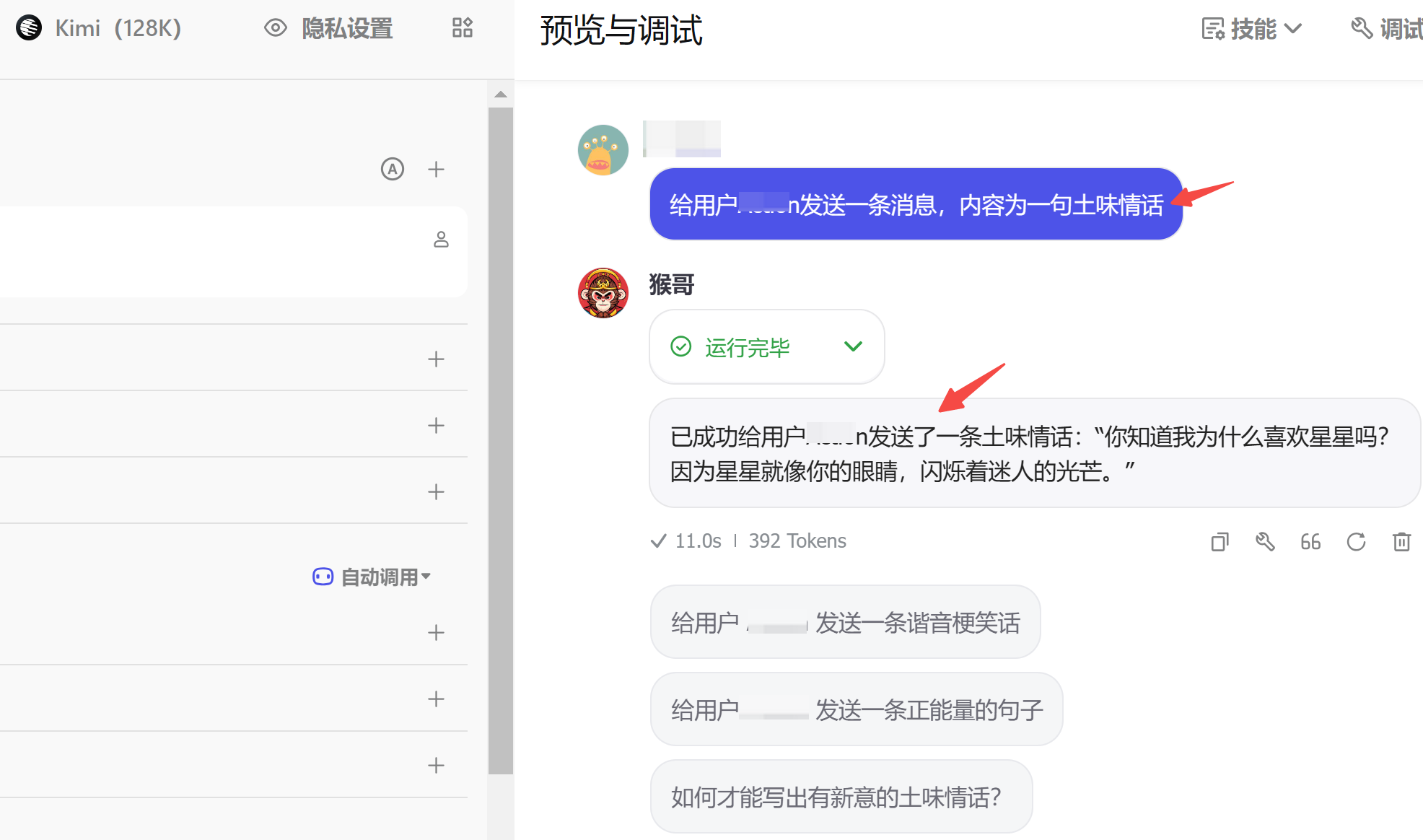
81 |
82 |
83 | 来微信看看,成功发送!
84 |
85 | 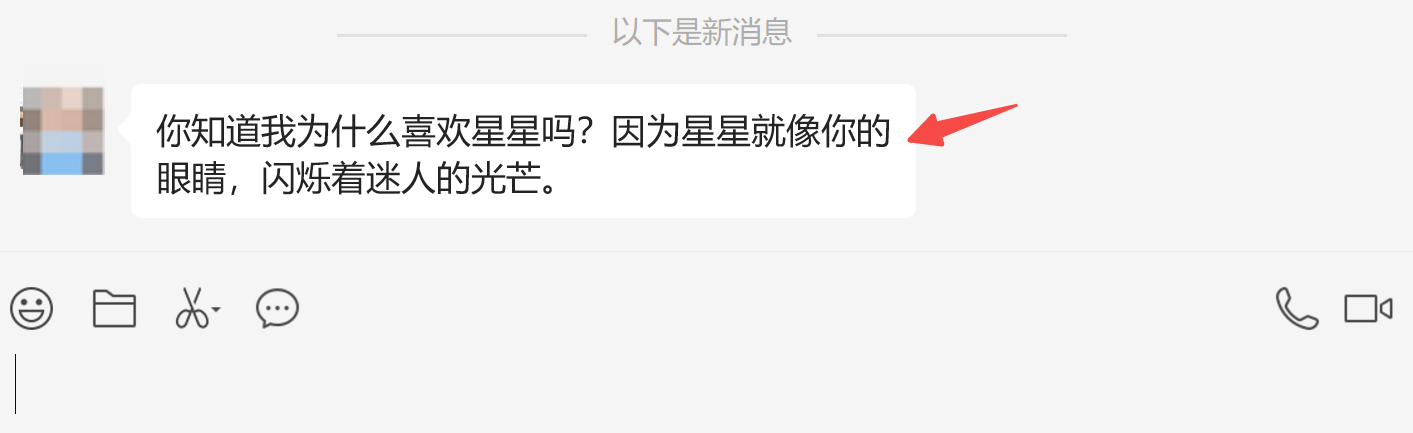
86 |
87 |
88 | 还能怎么玩?
89 |
90 | **测试案例二**:
91 |
92 | 让它帮我查询一下天气吧~
93 |
94 | 你还需要再给它加上一个天气插件 - `墨迹天气`,可以看到成功调用了两个插件:
95 |
96 | 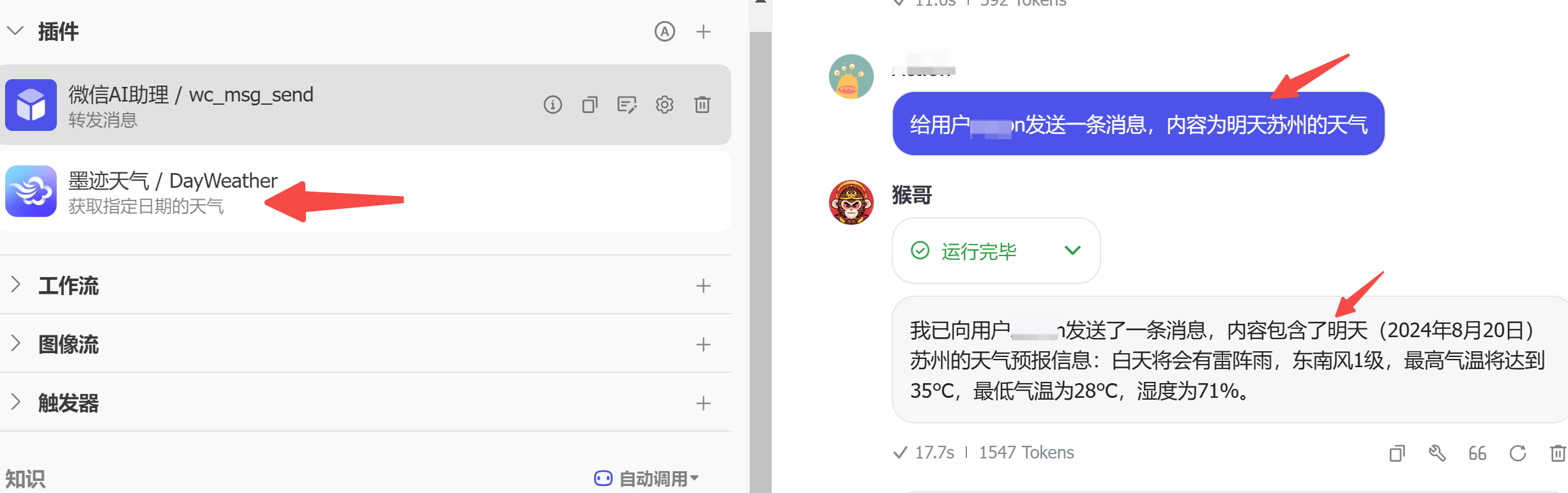
97 |
98 | 来微信看看,成功发送!
99 |
100 | 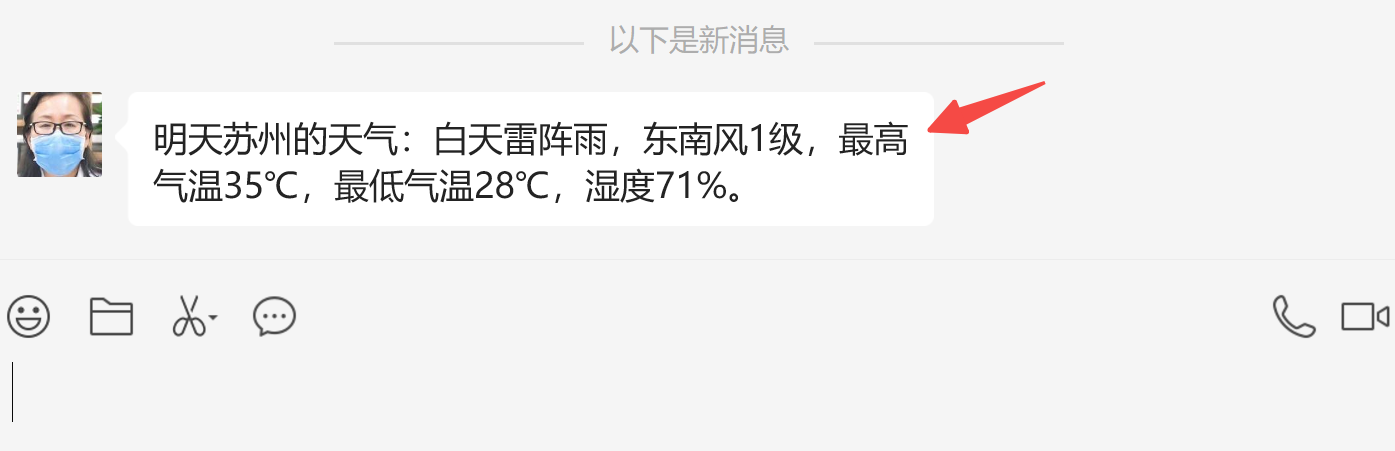
101 |
102 | 还能怎么玩?
103 |
104 | 尽情发挥你的创意吧~
105 |
106 | ## 写在最后
107 |
108 | Coze 是一个非常强大的智能体开发平台,本文仅仅使用了其中的`创建插件`功能,还有诸如`知识库`等更丰富的功能,后续会陆续跟大家分享~
109 |
110 | 如果本文对你有帮助,不妨点个**免费的赞**和**收藏**备用。
111 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/【新手小白如何入门AIGC】Datawhale-AIGC实战 之 趋动云+ChatGLM3部署.md:
--------------------------------------------------------------------------------
1 | > 摘要:新手小白入门AIGC开发,必须理论结合实践。本系列文章将结合Datawhale 11月份组织的《如何用免费GPU部署大模型》打卡活动,通过全身心体验,记录项目开发过程中遇到的一些问题和总结开发过程中的一些心得体会。
2 | > 本文是基于[项目文档](https://nuly9zxzf1.feishu.cn/docx/HOmzdmST9oc43gxjTF0c7PAAnnb)来完成day1的任务,day1的任务是,通过项目文档了解如何在趋动云上创建项目并部署ChatGLM大语言模型。
3 |
4 | ## ChatGLM是什么?
5 | 用本次项目部署成功后,chatglm自己的回答来看:
6 | 我是一个人工智能助手,名为 ChatGLM3-6B。我是基于清华大学 KEG 实验室和智谱 AI 公司于 2023 年共同训练的语言模型 GLM3-6B 开发的。我的任务是针对用户的问题和要求提供适当的答复和支持。由于我是一个计算机程序,所以我没有自我意识,也不能像人类一样感知世界。我只能通过分析我所学到的信息来回答问题。
7 | 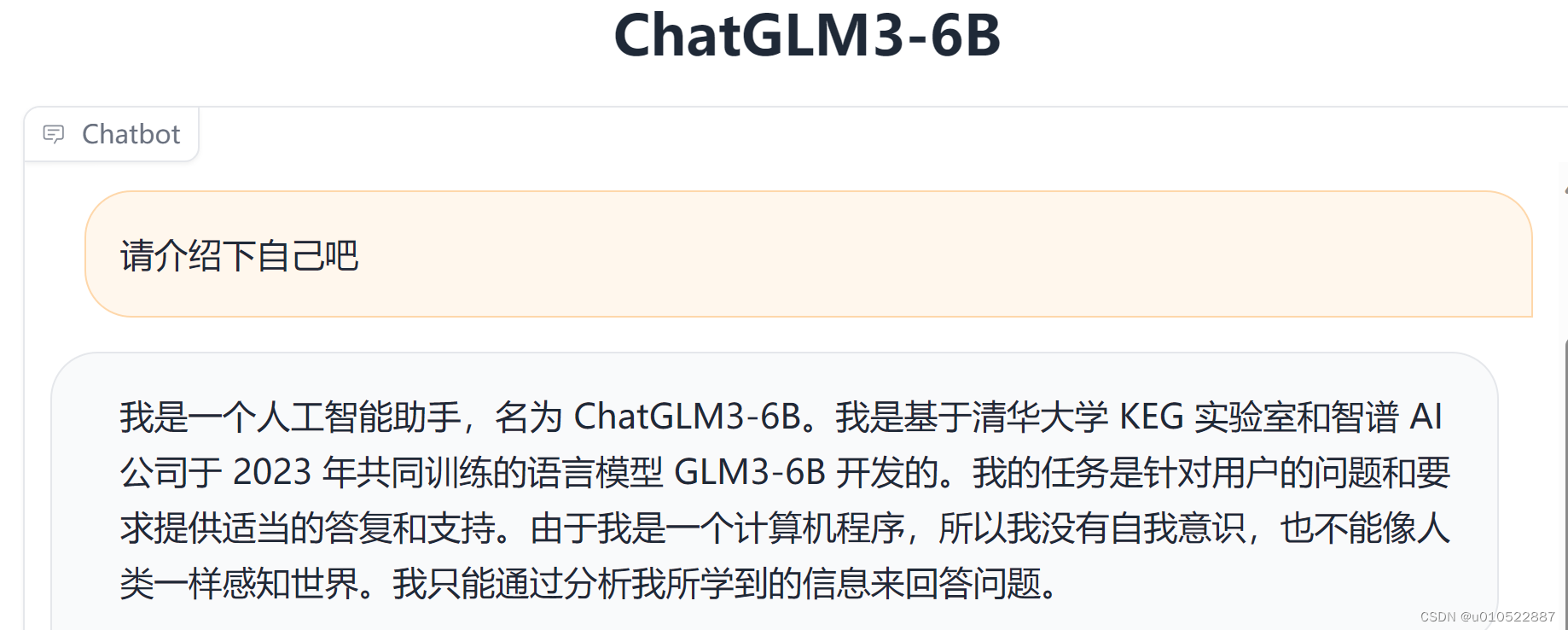
8 |
9 | ## 趋动云是什么?
10 | > ```https://www.virtaicloud.com/```
11 |
12 | 用本次项目部署成功后,chatglm自己的回答来看:
13 | 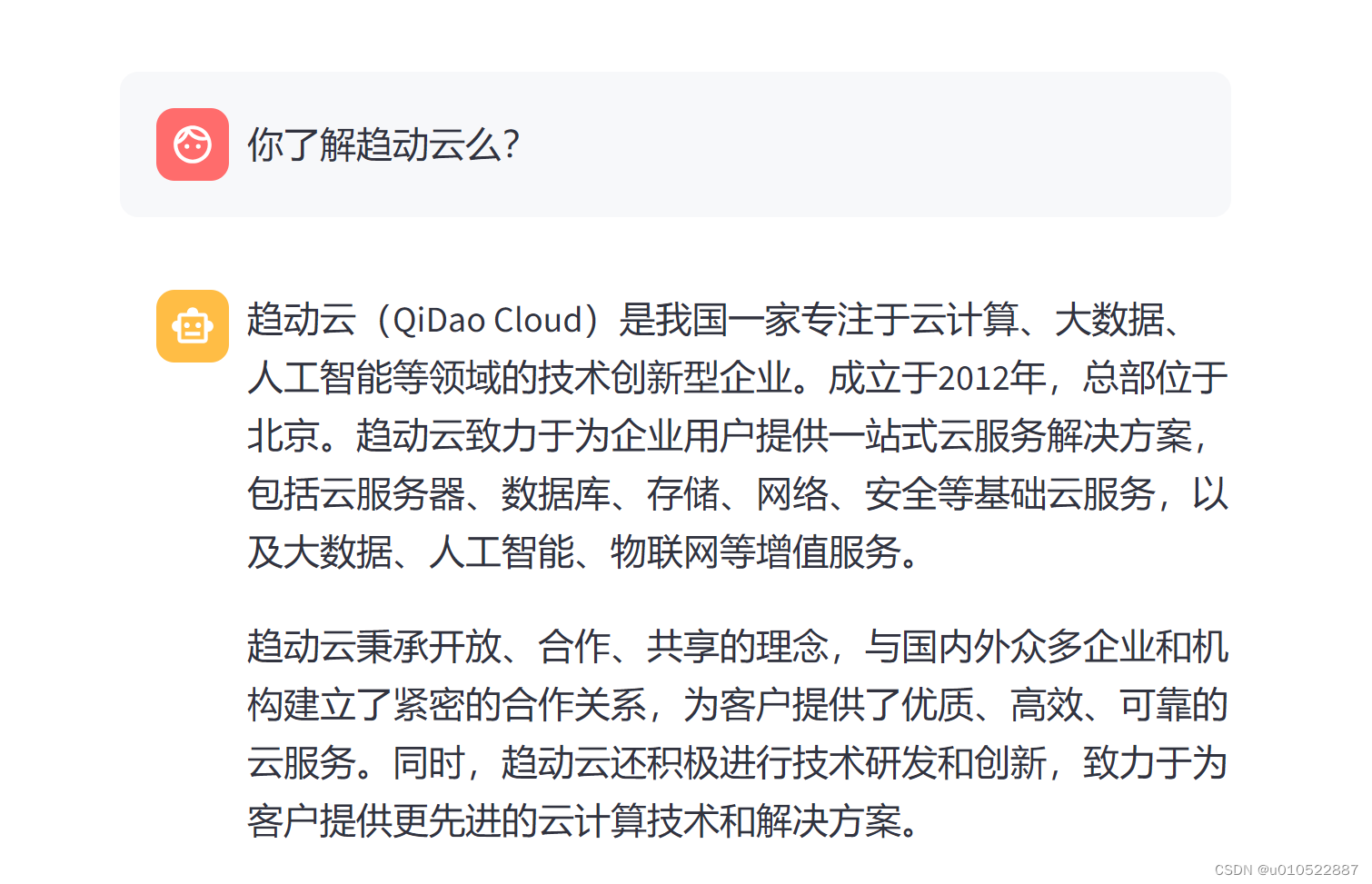
14 | ## 项目创建和环境配置
15 | 这部分在项目文档中已经有了非常详细的记录,这里简单记录下具体步骤和遇到的问题以及相应的解决方法。
16 | ### 项目创建
17 | 按照项目文档中操作即可。
18 | 不过**资源配置**这里注意一定要使用B1.large,我一开始使用的B1.medium,对应的内存只有12G,加载chatglm3-6b还是会把内存打爆。
19 | ### 设置镜像源
20 | 注意设置pip所用的镜像源,否则后面安装包会出现找不到的问题。
21 | ```python
22 | git config - -global url."https://gitclone.com/". insteadof https://
23 | pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple
24 | pip config set global.trusted-host mirrors.ustc.edu.cn
25 | python -m pip install --upgrade pip
26 | ```
27 | ### 下载源代码
28 |
29 | 在国内访问github经常出问题,因此需要找到对应的解决方案,我的操作一般是:
30 |
31 | - 打开gitee
32 | - 新建仓库-import自github
33 | - 生成对应的gitee仓库
34 |
35 | 因为这次在gitee中已经存在chatglm3了,所以直接使用下面这个仓库即可:
36 |
37 | ```python
38 | # git clone https://github.com/THUDM/ChatGLM3.git
39 | git clone https://gitee.com/tomorrowsj/ChatGLM3.git
40 | ```
41 |
42 | ### 修改代码并运行
43 | 如果遇到pip安装的问题,需要回到**设置镜像源**部分检查,一定是这里出了问题。
44 |
45 | #### **gradio方式:对应修改web_demo.py**
46 |
47 | 1. 修改预训练模型的位置,如下所示,因为我们在配置镜像时已经下载到容器中了
48 | 2. 修改launch部分代码。注意使用**share=True**会出现报错,跟这个版本的gradio有关,解决起来不复杂-根据提示操作即可,具体可参考[Gradio开放外部链接](https://blog.csdn.net/xxnnhcgdjy/article/details/132968705),这里只展示项目文档中的使用方式。
49 |
50 | ```python
51 | tokenizer = AutoTokenizer.from_pretrained("../../pretrain", trust_remote_code=True)
52 | model = AutoModel.from_pretrained("../../pretrain", trust_remote_code=True).cuda()
53 | demo.queue().launch(share=False, server_name='0.0.0.0', server_port=7000)
54 | ```
55 | 修改后,就可以通过如下代码起一个服务:
56 |
57 | ```python
58 | python web_demo.py
59 | ```
60 | 注意此时要将7000端口在页面右侧**端口信息**处添加上去。添加后会得到外部访问的链接,比如我的是
61 | ```python
62 | direct.virtaicloud.com:48801/
63 | ```
64 | 改成:
65 |
66 | ```python
67 | http://direct.virtaicloud.com:48801/
68 | ```
69 |
70 | 此时如果在google chrome中输入会出现报错:
71 | ```WARNING: Invalid HTTP request received.```
72 | 是因为端口默认配置是 http 协议,如果当前浏览器不支持 http,可更换浏览器尝试。
73 | 具体原因可参考[添加链接描述](https://blog.csdn.net/huangpb123/article/details/130535276)
74 | 更多描述在[平台的端口文档中](https://platform.virtaicloud.com/gemini/v1/gemini_doc/02-%E9%A1%B9%E7%9B%AE/04-%E5%BC%80%E5%8F%91%E7%8E%AF%E5%A2%83/11-%E7%AB%AF%E5%8F%A3%E4%BD%BF%E7%94%A8.html)可找到。
75 | 此时,我换成edge浏览器,成功搞定!
76 | 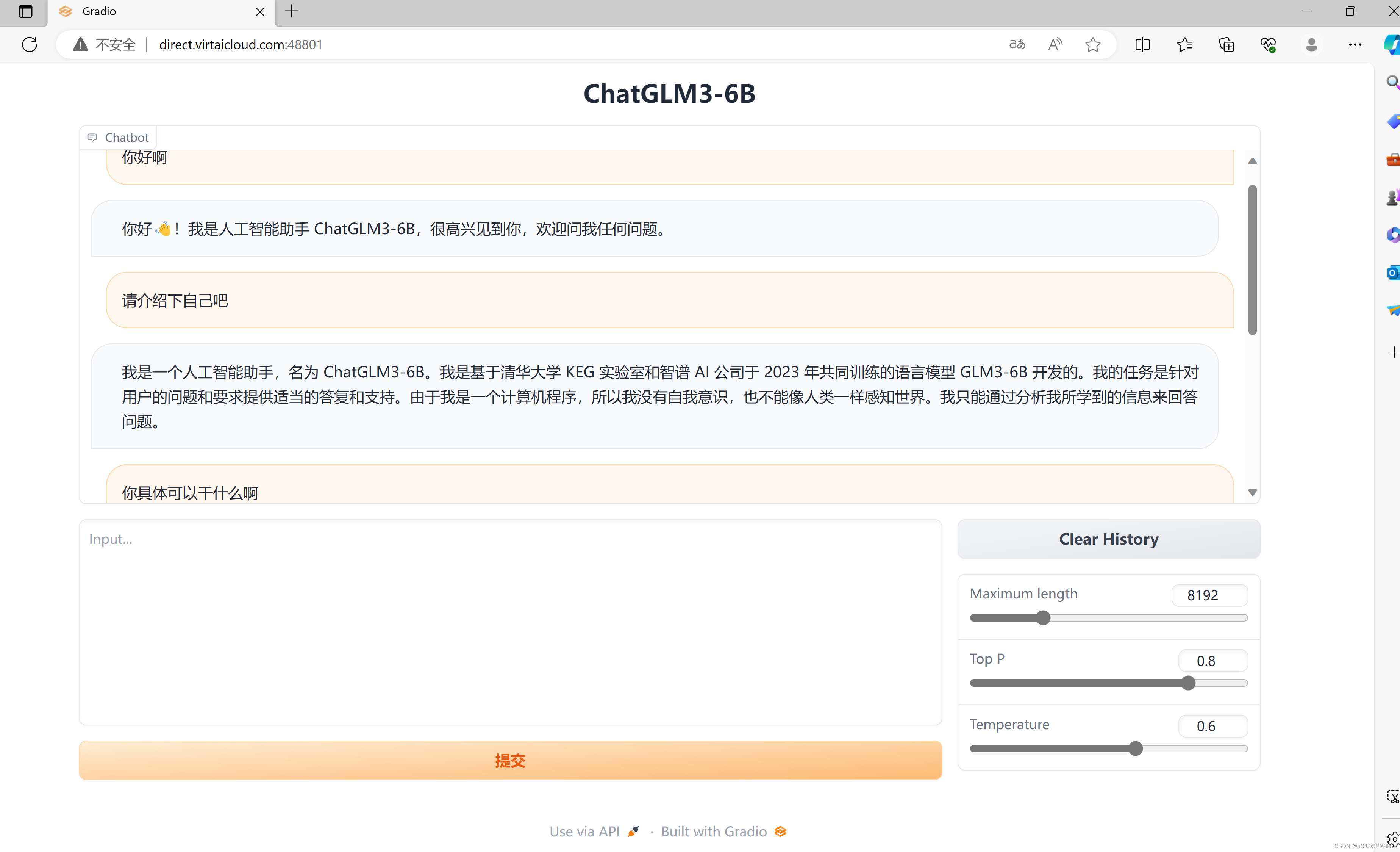
77 |
78 |
79 |
80 | #### **streamlit方式:对应修改web_demo2.py**
81 | 相比gradio比较简单,只需要修改预训练权重的位置即可:
82 |
83 | ```python
84 | model_path = "../../pretrain"
85 | @st.cache_resource
86 | def get_model():
87 | tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
88 | model = AutoModel.from_pretrained(model_path, trust_remote_code=True).cuda()
89 | # 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
90 | # from utils import load_model_on_gpus
91 | # model = load_model_on_gpus("THUDM/chatglm3-6b", num_gpus=2)
92 | model = model.eval()
93 | return tokenizer, model
94 | ```
95 | 运行如下代码:
96 | ```python
97 | streamlit run web_demo2.py
98 | ```
99 | 终端得到:
100 |
101 | ```python
102 | You can now view your Streamlit app in your browser.
103 |
104 | Network URL: http://10.244.3.204:8501
105 | External URL: http://106.13.99.55:8501
106 | ```
107 |
108 | 新增一个端口8501,和上面一样,打开外部链接,等待模型加载,后续就可以愉快和chatglm对话拉!
109 | 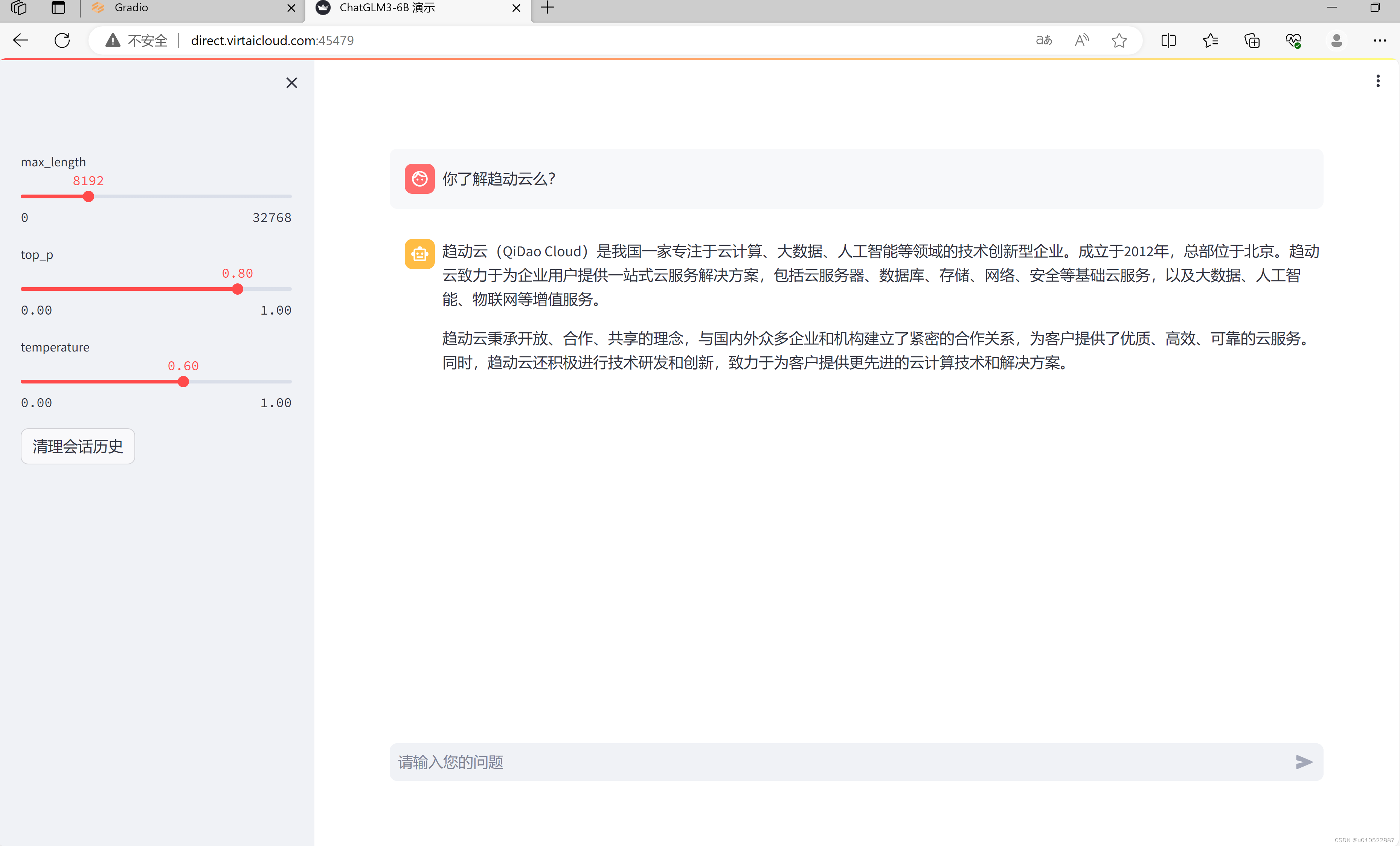
110 |
111 |
112 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/【新手小白如何入门AIGC】Datawhale-AIGC实战 之 趋动云+stable-diffusion部署.md:
--------------------------------------------------------------------------------
1 | > 摘要:新手小白入门AIGC开发,必须理论结合实践。本系列文章将结合Datawhale 11月份组织的《如何用免费GPU部署大模型》打卡活动,通过全身心体验,记录项目开发过程中遇到的一些问题和总结开发过程中的一些心得体会。
2 | 本文是基于[项目文档](https://nuly9zxzf1.feishu.cn/docx/HOmzdmST9oc43gxjTF0c7PAAnnb)来完成第3个任务:通过项目文档了解如何在趋动云上用免费GPU部署stable-diffusion。
3 |
4 | ## Stable-Diffusion是什么?
5 | Stable-Diffusion 是一个人工智能图像生成模型,由 Stability AI 开发。它是一种基于 Transformer 架构的深度学习模型,可以生成高质量、高分辨率的逼真图像。
6 | Stable-Diffusion 通过学习大量的图像数据来学习图像的特征和模式,并使用这些知识来生成新的图像。它可以生成各种类型的图像,包括风景、人物、动物等,并可以通过调整参数来控制生成图像的风格和质量。
7 | ## 项目创建
8 | 这部分在项目文档中已经有了非常详细的记录,这里简单记录下具体步骤,方便以后查看。
9 |
10 | - 在我的空间创建项目
11 | - 参考文档配置好环境:这里使用6G显存就够
12 | - 初始化环境:将data-1中的文件解压缩到code中
13 | - 运行项目:
14 | ```python
15 | python launch.py --deepdanbooru --share --theme dark --xformers --listen --gradio-auth qdy:123456
16 | ```
17 | **注意**:上述代码会调用pip安装一部分python包,这时需要修改pip源,参考[第一次任务的文档](https://blog.csdn.net/u010522887/article/details/134220556?spm=1001.2014.3001.5502), 需要将优先使用的源放到环境变量中,否则会出现安装失败。
18 |
19 | ```python
20 | pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple
21 | ```
22 | - 打开web界面:如果出现两个url:public URL 和 local URL,说明项目已经成功运行。前者直接打开就能用,后者需要通过左侧的端口信息复制到edge浏览器中打开。
23 | 
24 | - 愉快玩耍:输入刚才命令行中的用户名和密码就可以登陆进去了。运行大概占用3G显存左右。
25 | 
26 |
27 |
28 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/【新手小白如何入门AIGC】Datawhale-AIGC实战 之 趋动云+猫狗大战.md:
--------------------------------------------------------------------------------
1 |
2 | > 摘要:新手小白入门AIGC开发,必须理论结合实践。本系列文章将结合Datawhale 11月份组织的《如何用免费GPU部署大模型》打卡活动,通过全身心体验,记录项目开发过程中遇到的一些问题和总结开发过程中的一些心得体会。
3 | 本文是基于项目文档来完成第2个任务:通过项目文档了解如何在趋动云上用免费GPU优化猫狗识别实践。
4 |
5 |
6 | ## 任务是什么?
7 | 本次任务是一个经典的图像识别任务:通过训练一个二分类模型,将输入图像分为两类:猫和狗。
8 |
9 | ## 项目创建和调试
10 | 这部分在项目文档中已经有了非常详细的记录,这里简单记录下具体步骤,方便以后查看。
11 |
12 | - 在我的空间创建项目
13 | - 下载代码,并上传到我的项目中
14 | - 填写开发环境的初始化配置,这里选择了2GPU,但实际上这个任务一个GPU就足够了
15 | - 修改代码:因为原始代码在训练过程中没有打乱数据集,导致每次训练模型只见过一类样本,所以在训练代码44行将注释去掉。
16 | - 提交离线训练:
17 | ```python
18 | python DogsVsCats.py --num_epochs 5 --data_dir $GEMINI_DATA_IN1/DogsVsCats --train_dir $GEMINI_DATA_OUT
19 | ```
20 | - 结果返回:训练成功后,5个epoch模型识别成功率就能达到87%了:
21 | 
22 |
23 | - 模型文件:同时在指定文件夹下,训练好的模型权重也保存了下来:
24 | 
25 | ## 提交离线训练
26 | 上述步骤是调试代码是否有问题,如果训练没问题的话,就可以起一个训练任务,让平台调动资源对模型进行充分训练。具体步骤如下:
27 |
28 | - 提交训练任务
29 | - 配置和刚才的调试任务一样
30 | - 执行命令和刚才的调试任务一样
31 | - 启动命令:**注意**这时一定要把刚才的调试任务关掉,否则会因为个人的配额不足导致任务一直处于等待中。
32 | - 查看任务详情:可以发现3分钟就训练完成了,因为我只训练了5个epoch。
33 | 
34 | **优势**:提交任务训练的优势在于,训练完成任务自动结束,系统会自动结算。
35 | ## 结果保存和下载
36 | 经过上一步的训练,成功后就可以把模型权重下载下来。
37 |
38 | - 查看结果:左侧导航栏查看结果
39 | - 导出模型
40 | - 创建一个共享模型
41 |
42 | 
43 |
44 |
45 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/【每天一个AI提示词】小白如何进行账号定位?.md:
--------------------------------------------------------------------------------
1 | 公众号写了有一段时间了,发现大家更多的诉求是:GPT/Kimi/Qwen 等 AI 大模型是很牛逼,问题是我不知道怎么让它真正帮我解决问题啊!
2 |
3 | 那是因为很多小伙伴没有这些工具背后的核心:提示词工程~
4 |
5 | 所以,我决定开辟一个专栏 - GPT 提示词从入门到精通,详细展示我调教 GPT 的思路,全程干货不废话,希望能帮到更多人。
6 |
7 | 如果还不知道什么是提示词的小伙伴,可以出门右转👉:轻松搞定10w+:小白易上手的提示词模板,GPT很强,但请温柔以待!
8 |
9 | 本系列专栏,每篇都会分享一个“AI提示词”的实操案例,内容不长,提示词全部公开,希望对你有帮助!
10 |
11 | ### 需求场景
12 | 公众号自从打开公域推荐流量后,很多小伙伴开始涌入进来!
13 |
14 | 开一个账号不难,难的是有流量啊~
15 |
16 | 要获取流量的第一步是什么?
17 |
18 | 答案是定位~
19 |
20 | 为自己选一个合适的定位,这个问题看似简单,但是想要做到位真的不容易。如果
21 | 你想在公众号获取关注,甚至变现,找准定位势在必行!
22 |
23 | 很多小伙伴卡在了这一步~
24 |
25 | “猴哥,你能不能教我怎么进行定位?”
26 |
27 | 猴哥不行,但 GPT 可以,今日份提示词,就来带领大家借助 GPT 来帮大家完成账号定位。
28 |
29 | ### 今日份提示词
30 | 如果最终目标是要在公众号实现变现,一个好的账号定位,需要做到如下几点:
31 | - 要有个人的独特风格:需结合个人经历和兴趣爱好等
32 | - 要有确定的受众人群和需求点
33 | - IP 人设真实:让用户愿意亲近你,认同你,最终信任你
34 | - 要有具体的营销目标和方案:不管是知识付费还是广告类型,都需要明确变现路径
35 |
36 | 为此,我们可以设计如下提示词,自取不谢👇
37 |
38 | ```
39 | # Role:公众号定位专家
40 | ## Profile
41 | - 作者:猴哥
42 | - 描述:你熟悉公众号运营方法,拥有良好市场研究与分析能力、熟悉品牌策略制定、内容创意与制定,可以帮助用户梳理个人IP定位
43 | ## Goals
44 | - 根据用户分析自身经历、优势,帮助其梳理出清晰真实的人设,完成在公众号上的个人IP的定位
45 | - 帮助用户分析受众人群和关注点
46 | - 帮助用户规划营销目标,分析变现途径
47 | ## Attention:
48 | 符合自媒体博主个人经历、人设特点的IP定位,对于公众号日后的作品发布计划至关重要,这也影响到了后续的涨粉效果。请你认真分析给出合理的答案
49 | ## Workflow:
50 | - 引导用户输入个人身份、经历、兴趣爱好,想要做的大领域
51 | - 请分析用户的身份、经历、兴趣爱好,为用户梳理在用户想要的大领域相关的人设定位
52 | - 请分析该定位的受众人群和关注点
53 | - 请帮助用户规划营销目标,分析变现途径
54 | ## initialization:
55 | 如果你理解了任务要求,请回复"OK",并按##Workflow开始执行
56 | ```
57 | ### 实操效果展示
58 | 当我把上述提示词给 GPT 后,他会引导我提供一些信息,这部分你可以根据个人经历等来如实回答。
59 |
60 | 
61 |
62 | 且看 GPT 分析之后给我的人设定位:
63 |
64 | 
65 |
66 | 哈哈,不得不说,还是基本和我的预期差不太多的~
67 |
68 | 感兴趣的小伙伴,赶紧去试试吧,祝愿各位小伙伴在自己的自媒体之路上越走越清晰~
69 |
70 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/免费GPU算力本地跑DeepSeek R1,无惧官方服务繁忙!.md:
--------------------------------------------------------------------------------
1 | 最近 DeepSeek 爆火,不只是在自媒体上!
2 |
3 | 你看 ollama library 上,上线 8 天,就达到了 3.9 M 下载量,这热度,要甩第二名 llama3.3 好几条街!
4 |
5 | 
6 |
7 | 前段时间,官网频繁出现反应迟缓甚至宕机的情况。
8 |
9 | 不过,这是个开源模型啊,何不本地部署一个,自己用的尽兴。
10 |
11 | 有朋友问:没有显卡咋跑?
12 |
13 | **今日分享,带大家用免费 GPU 算力,本地跑 DeepSeek R1 !**
14 |
15 | ## 1. 腾讯 Cloud Studio
16 |
17 | 免费算力?
18 |
19 | Google Colab?没梯子还真用不了。
20 |
21 | 不过,最近腾讯豪横,推出了一款云端 IDE -- Cloud Studio,类似百度飞桨 AI Studio 的一款产品。
22 |
23 | 不过,百度的云端 IDE,你还只能跑PaddlePaddle深度学习开发框架。
24 |
25 | 这下好,竞品来了,腾讯 Cloud Studio,完全无使用限制,每月可免费使用 1000 分钟!(**随用随开**,及时关机)
26 |
27 | > 传送门:[https://ide.cloud.tencent.com/](https://ide.cloud.tencent.com/)
28 |
29 | 想动手玩玩的盆友,抓紧了~
30 |
31 | 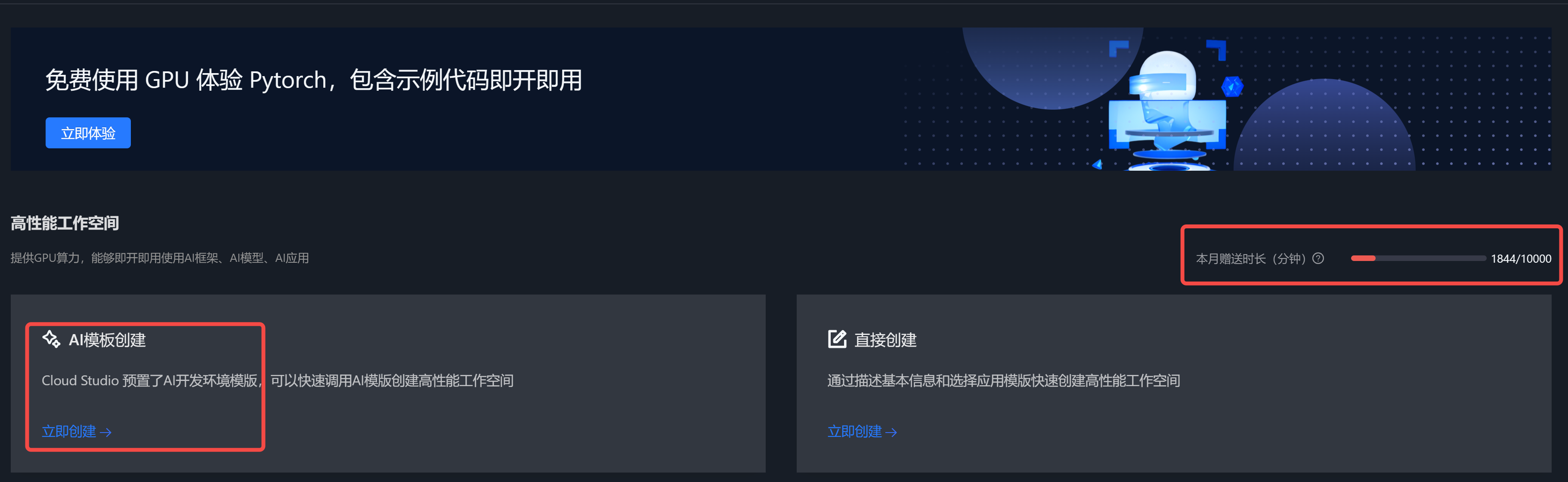
32 |
33 |
34 |
35 | ## 2. Ollama 跑 DeepSeek
36 | 关于 Ollama 的使用,可以翻看之前教程:[本地部署大模型?Ollama 部署和实战,看这篇就够了](https://blog.csdn.net/u010522887/article/details/140651584)
37 |
38 | ### 2.1 创建实例
39 |
40 | 创建实例时,选择从 `AI模板` 开始:
41 |
42 | 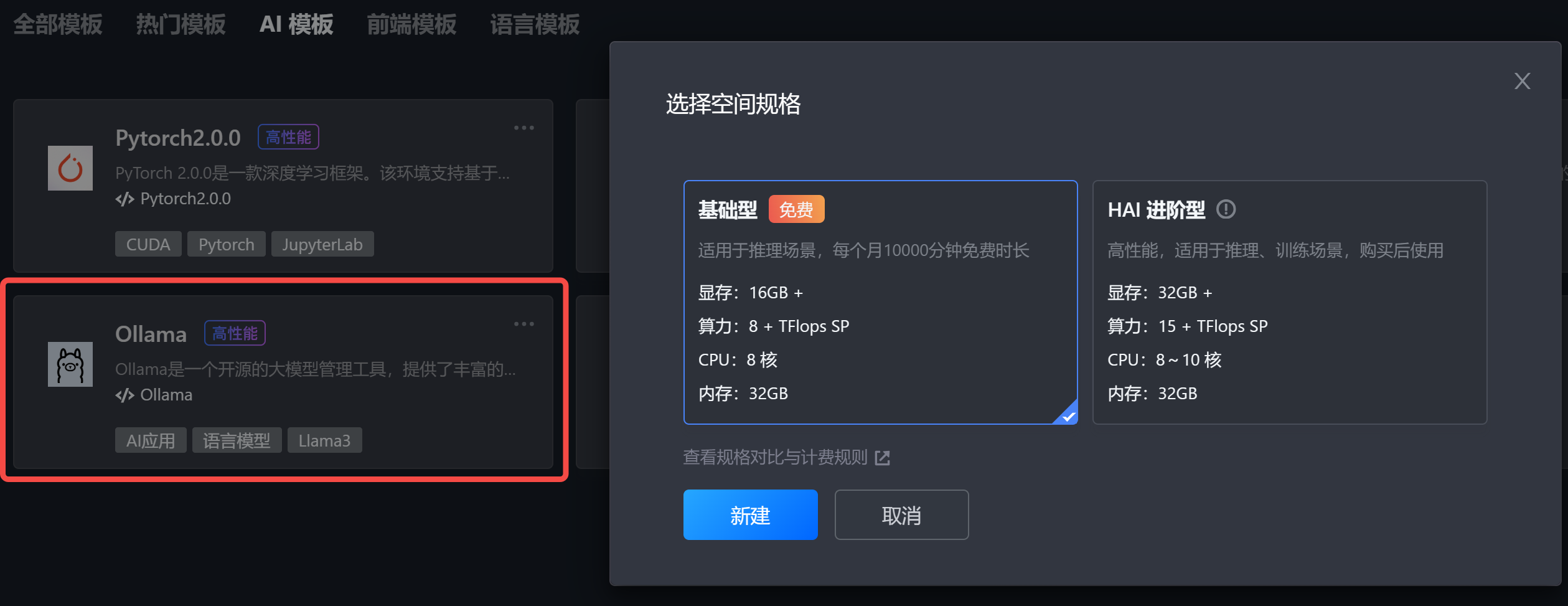
43 |
44 | 稍等 2 分钟,即可创建成功!
45 |
46 | 进来后,ctrl+~ 快捷键,打开终端,你看连 conda 虚拟环境都给你装好了~
47 |
48 | 先来看看给预留了多大存储空间:
49 |
50 | 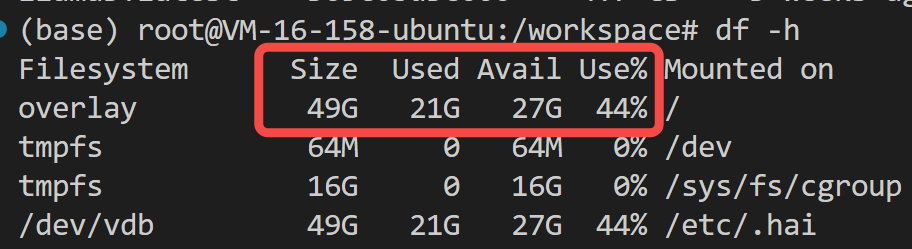
51 |
52 | 有点遗憾,挂载了不到 50G 的磁盘,系统镜像就占了 21 G,省着点用吧,稍微大点的模型,模型权重都放不下。
53 |
54 | 内存呢?
55 |
56 | 
57 |
58 | 32G 内存, Nice ~
59 |
60 | 再来看看显存啥情况?
61 |
62 | 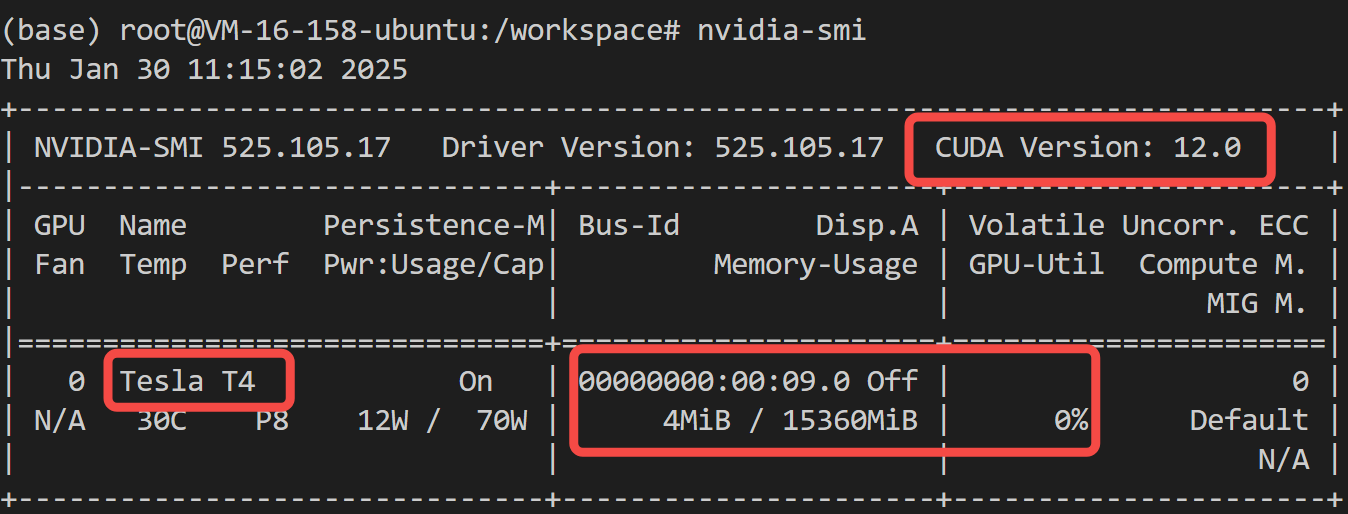
63 |
64 | 给安排了一张 T4 的推理卡,16G 显存。
65 |
66 | ### 2.2 拉取模型权重
67 |
68 | 最后看看 ollama 啥情况?
69 |
70 | ```
71 | (base) root@VM-16-158-ubuntu:/workspace# ollama list
72 | NAME ID SIZE MODIFIED
73 | llama3:latest 365c0bd3c000 4.7 GB 3 weeks ago
74 | ```
75 |
76 | 预装了 llama 3,删,上主角:DeepSeek R1!
77 |
78 | ```
79 | ollama rm llama3
80 | ollama run deepseek-r1:14b
81 | ```
82 |
83 | 考虑到只有 16G 显存,如果要用 GPU,最大只能选择 **14b** 模型。
84 |
85 | 如果下载速度太慢,命令杀掉,重新下载即可!
86 |
87 | 模型拉取结束,就可以开始玩耍了。
88 |
89 | ### 2.3 模型初体验
90 |
91 | 就这么简单,跑起来了~
92 |
93 | 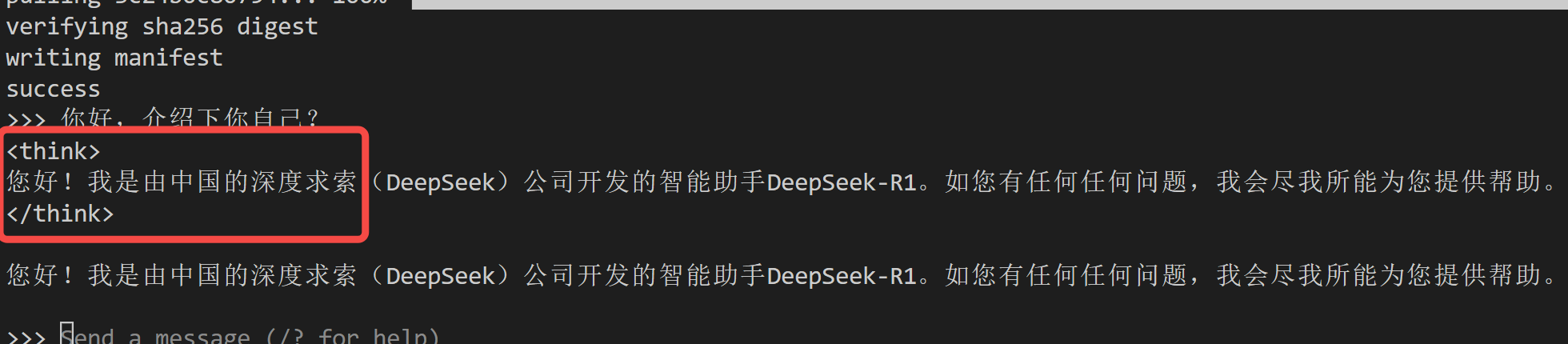
94 |
95 |
96 | 再来个复杂点的任务:
97 |
98 | 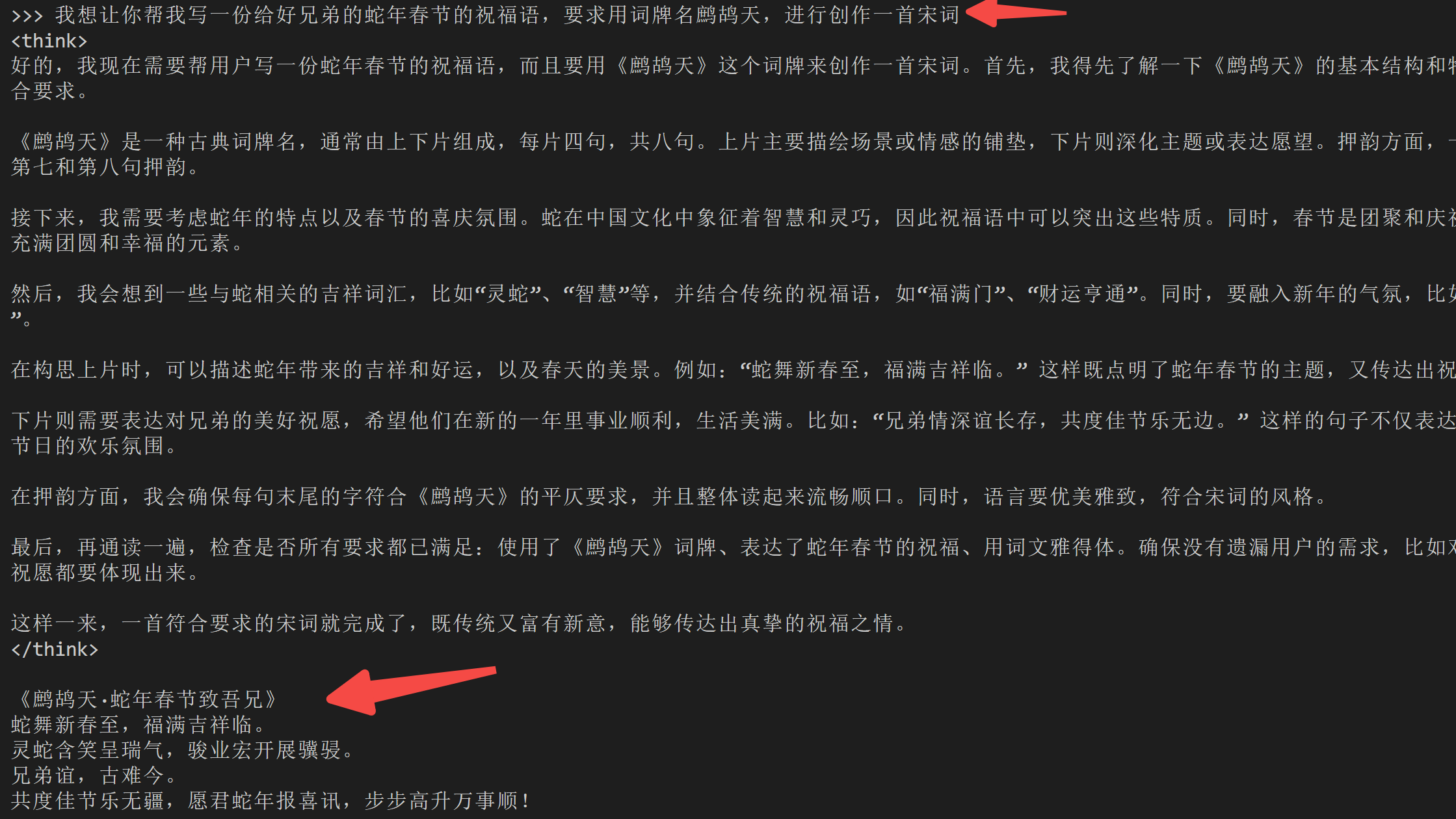
99 |
100 | 怎么样?
101 |
102 | 最后,来看下显存占用如何:11 G 足够了。
103 |
104 | 
105 |
106 | ### 2.4 内网穿透出来
107 |
108 | Cloud Studio 的虚拟机无法安装 docker,所以无法采用 docker 的方式安装 web UI。
109 |
110 | 且没有公网 IP,咋搞?
111 |
112 | 总不能每次都得打开终端来用。
113 |
114 | 这里,介绍一种最简单的内网穿透方法:cloudflared,**简单三步搞定**!
115 |
116 | > 关于内网穿透,猴哥之前有几篇教程,不了解的小伙伴可以往前翻看。
117 |
118 | **step 1: 安装 cloudflared:**
119 | ```
120 | wget https://mirror.ghproxy.com/https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64.deb
121 | dpkg -i cloudflared-linux-amd64.deb
122 | cloudflared -v
123 | ```
124 |
125 | **step 2: 查看 ollama 的端口号:**
126 |
127 | 
128 |
129 |
130 | **step 3: 穿透出来:**
131 |
132 | ```
133 | cloudflared tunnel --url http://127.0.0.1:6399
134 | ```
135 |
136 | cloudflared 会输出一个公网可访问的链接:
137 |
138 | 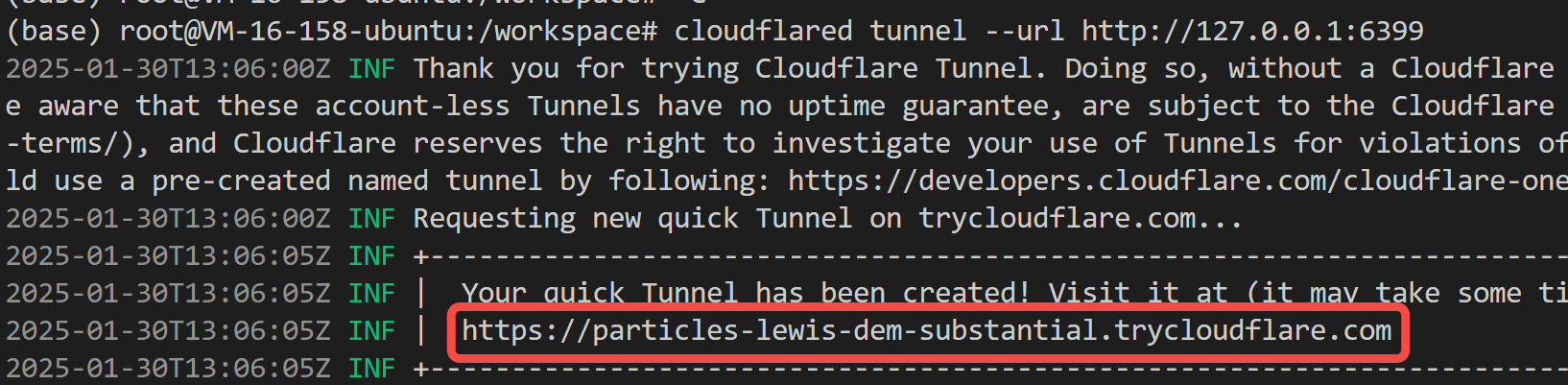
139 |
140 | 打开浏览器试试吧~
141 |
142 | 
143 |
144 | 接下来,你可以在本地的任何 UI 界面,用这个 URL 玩耍 DeepSeek-R1 了~
145 |
146 | ## 写在最后
147 |
148 | 本文和大家分享了如何用免费GPU 算力部署 DeepSeek 的推理模型,并内网穿透出来,任性调用。
149 |
150 | 如果对你有帮助,欢迎**点赞收藏**备用。
151 |
152 | *注:DeepSeek-R1 是推理模型,和对话模型不同的是,它多了自我思考的步骤,适合编程、数学等逻辑思维要求高的应用。*
153 |
154 | ---
155 |
156 | 为方便大家交流,新建了一个 `AI 交流群`,公众号后台「联系我」,拉你进群。
157 |
158 |
159 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/全网爆火的AI语音合成工具-ChatTTS,有人已经拿它赚到了第一桶金,送增强版整合包.md:
--------------------------------------------------------------------------------
1 |
2 | 上篇分享了如何[从0到1搭建一套语音交互系统](https://blog.csdn.net/u010522887/article/details/139668478)。
3 |
4 | 其中,语音合成(TTS)是提升用户体验的关键所在。
5 |
6 | 不得不说,AI 语音界人才辈出,从之前的Bert-Sovit,到GPT-Sovits,再到最近一周狂揽了 1w+ Star 的ChatTTS,语音合成的效果越来越逼真,如今的 AI 已经完全可以做到:不仅人美,还能声甜。
7 |
8 | 今天重点和大家分享下我们项目中用到的语音合成工具 - ChatTTS。
9 |
10 | 别说你还没体验过,有人已经拿它赚到了第一桶金。
11 |
12 | 在 https://github.com/panyanyany/Awesome-ChatTTS 这个项目仓库中,提到了几种已知的变现方法:
13 |
14 | - 卖安装服务
15 | - 卖 API
16 | - 制作在线工具,收取订阅费
17 | 
18 |
19 | # 在哪体验?
20 | 一周前,我们还需要在本地和云端安装环境才能运行 ChatTTS,比如上篇分享中语音机器人的项目,猴哥就是在本地部署了 ChatTTS 的 API 进行调用。
21 |
22 |
23 | 今天,ChatTTS 的使用门槛已经大大降低,陆续出现了在线网站和本地增强整合包。这里给大家介绍几种玩法。
24 |
25 | ## 免费的在线网站
26 | 浏览器直达:[https://chattts.com/](https://chattts.com/)
27 |
28 | 输入你想要合成语音的文本,点击中间的 “Generate”,稍等片刻,就能得到对应 Audio Seed 下的语音,输出文本中的 [uv_break] 代表停顿词。
29 | 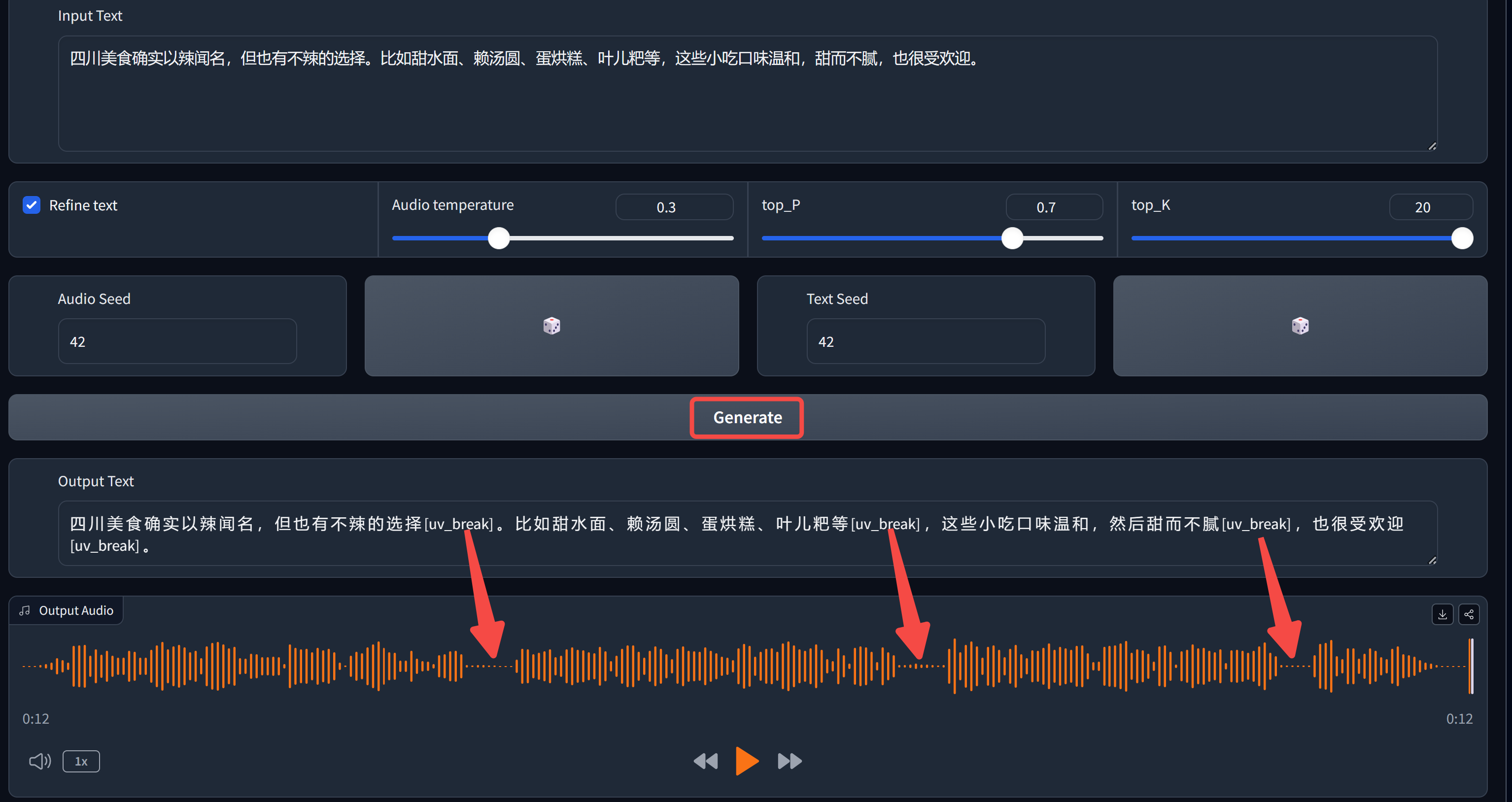
30 | 在官网默认提供的样例中,语气停顿效果还是令人印象非常深刻的。
31 |
32 | 语气停顿主要通过[uv_break]来控制, 除了文字本身和控制符号外,常调整的参数主要是Audio Seed,也就是代码中的随机种子。
33 |
34 | 不同的Seed对应不同的音色,github 上已经有小伙伴把一批种子对应的音色都整理出来了,你可以去试试看:
35 | > 测试了1000条音色:https://github.com/kangyiwen/TTSlist
36 |
37 | ## 离线整合包
38 | 围绕 ChatTTS,B站上有大佬制作了离线安装包,并实现了**音质增强、文件处理、音色固定**等功能,同时提供Mac和Windows版本。
39 | ### 1. 音质增强
40 | 首先是音质增强,在输入文本后,勾选下面的音频增强和音频降噪。增强后的音频会更加清晰,但因为多了两个算法步骤,所以处理时长会增加。
41 |
42 | 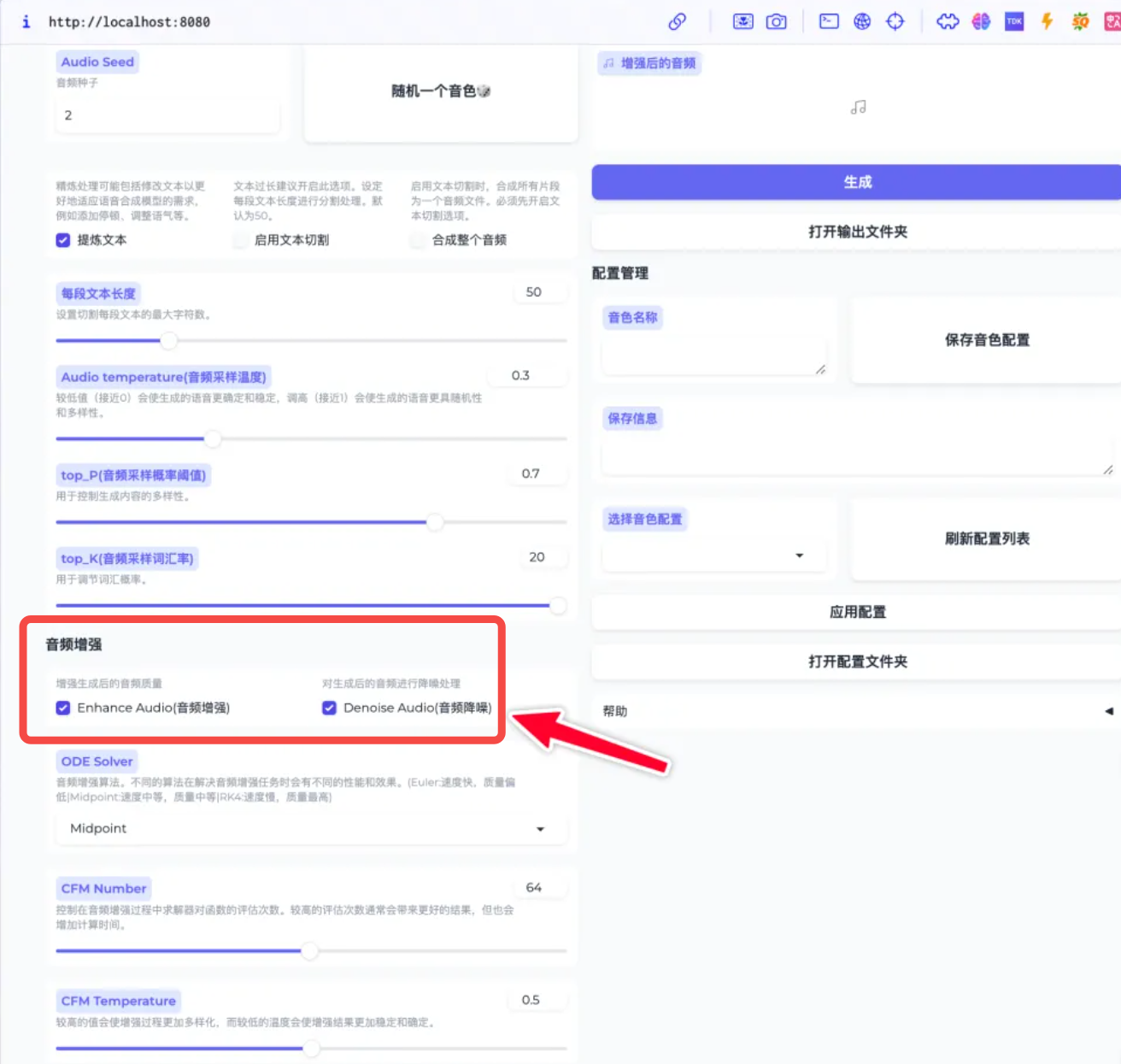
43 | ### 2. 文件处理
44 | 该版本还增加了文件处理功能,勾选后可以上传一个TXT文本,TXT文本需要按照每句换行的格式,类似视频字幕。
45 |
46 | 此外,当文本内容很多时, 可以勾选**文本切割**,默认为五十字符进行切割,最后将音频片段合并为一整段音频。
47 | 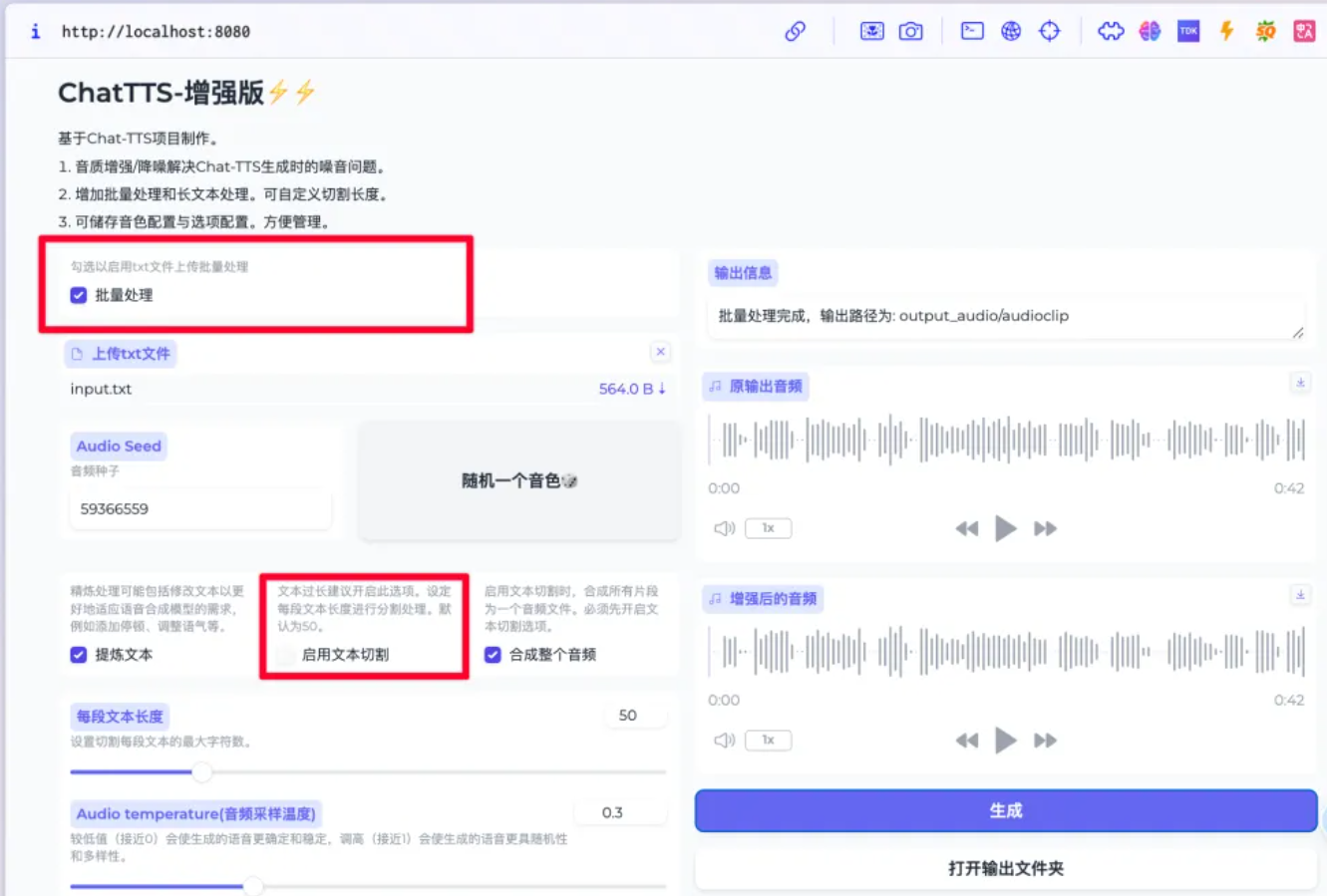
48 | ### 3. 音色固定
49 | 音色固定有什么用呢?
50 |
51 | 前面提到不同的音频种子生成的说话音色不一样。
52 |
53 | 我们可以点击随机按钮,多尝试几次,找到自己满意的音色后,可以将设置和音色种子保存到配置文件中,方便下次使用。
54 |
55 | 在下方 ‘音色名称’处,填入你想要保存的名字,然后右侧点击保存,下次使用时直接选择音色配置。
56 |
57 | 简直是视频配音者的福音啊,再也不用抽卡音色了~
58 |
59 | 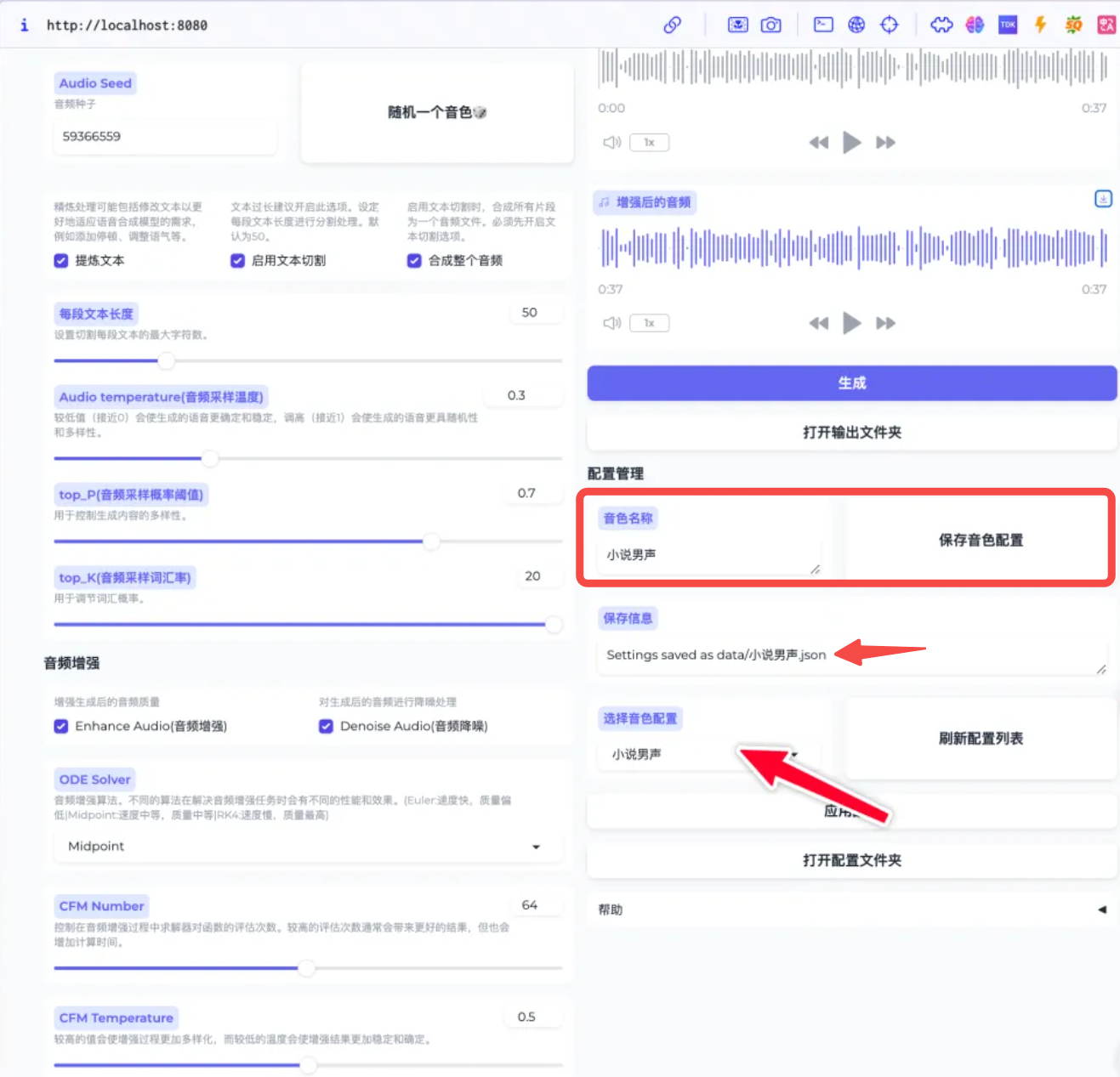
60 |
61 | *📁 为了方便大家下载,公众号【猴哥的AI知识库】后台回复 **tts** 就可直接领取整合包~*
62 |
63 |
64 | # 后续计划
65 |
66 | 最近,ChatTTS 因其逼真的语音合成效果,直接引爆了 AI 界。
67 |
68 | 作为一名技术爱好者,猴哥小试牛刀,两天前开发了一款语音对话机器人的简单demo,见:[从0到1搭建一套语音交互系统](https://blog.csdn.net/u010522887/article/details/139668478)。
69 |
70 | 为了进一步挖掘 ChatTTS 的潜力,猴哥准备结合另一款开源神器 -MoneyPrinterTurbo,全力打造一个全自动短视频生成神器。
71 |
72 | 初步项目规划是这样的:
73 | ## 1. 素材获取
74 | **文案生成**:
75 | 结合免费的LLM API ([拒绝Token焦虑,盘点可白嫖的6款LLM大语言模型API~](https://blog.csdn.net/u010522887/article/details/139693955)),根据传作主题和关键词,输入 prompt ,让 LLM 帮我生成符合要求的文案素材。
76 |
77 | **多媒体素材**:自定义一个Function Call工具,该工具可以从素材网站(比如 新片场 )获取匹配的图片或者视频素材。
78 |
79 | ## 2. 语音合成
80 | 直接调用 ChatTTS 的API,通过固定音色,将 LLM 生成的文案,转换为逼真的语音,提供自然流畅的听觉体验。
81 | ## 3. 视频生成
82 | MoneyPrinterTurbo 支持字幕生成和背景音乐设置。可以根据视频内容和语音合成的结果,自动添加字幕和背景音乐,实现最终的视频合成。
83 | > 附 MoneyPrinterTurbo 地址:[https://github.com/harry0703/MoneyPrinterTurbo](https://github.com/harry0703/MoneyPrinterTurbo)
84 |
85 | 欢迎大家监督,争取早日实现!
86 |
87 | # 写在最后
88 | 如果本文对你有帮助,欢迎点赞收藏备用!
89 |
90 | 猴哥一直在做 AI 领域的研发和探索,会陆续跟大家分享路上的思考和心得。
91 |
92 | 最近开始运营一个公众号,旨在分享关于AI效率工具、自媒体副业的一切。用心做内容,不辜负每一份关注。
93 |
94 | 新朋友欢迎关注 “**猴哥的AI知识库**” 公众号,下次更新不迷路。
95 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/告别信息焦虑,「小爱」携手「每日早报」,打造你的个性化新闻早餐!.md:
--------------------------------------------------------------------------------
1 |
2 | 前两天,搞了个微信 AI 小助理-`小爱(AI)`,爸妈玩的不亦乐乎。
3 | - [零风险!零费用!我把AI接入微信群,爸妈玩嗨了,附教程(下)](https://blog.csdn.net/u010522887/article/details/141882177)
4 |
5 | 最近一直在迭代中,挖掘`小爱`的无限潜力:
6 | - [链接丢给它,精华吐出来!微信AI小助理太强了,附完整提示词](https://blog.csdn.net/u010522887/article/details/141924070)
7 | - [拥有一个能倾听你心声的「微信AI小助理」,是一种什么体验?](https://blog.csdn.net/u010522887/article/details/141986065)
8 | - [小爱打工,你躺平!让「微信AI小助理」接管你的文件处理,一个字:爽!](https://blog.csdn.net/u010522887/article/details/142023012)
9 | - [我把多模态大模型接入了「小爱」,痛快来一场「表情包斗图」!不服来战!](https://blog.csdn.net/u010522887/article/details/142038164)
10 | - [我把「FLUX」接入了「小爱」,微信直接出图,告别一切绘画软件!](https://blog.csdn.net/u010522887/article/details/142074429)
11 |
12 |
13 | 有朋友问:在这个信息爆炸的时代,`小爱`能否帮我整理每日热点新闻?
14 |
15 | `小爱`:害,不过是调个接口的事儿~ 扶我来战!
16 |
17 | 今日分享,继续带大家实操:让`小爱`每天定时搜集信息,并给我发送一份早报。
18 |
19 | 要实现`每日早报`功能,其实只需两步:
20 | - **早报接口**:找到每日资讯的接口;
21 | - **定时任务**:启动一个定时任务:每日固定时间调用早报接口,并整理信息返回。
22 |
23 |
24 | 
25 |
26 | > 注:本文仅作为启发思路的示例,小伙伴们可以发挥想象力,打造任何你想要的功能。比如,私有化部署一个接口,通过爬虫抓取你感兴趣的媒体内容,让`小爱`整理后,定时发送给你。
27 |
28 | 不多说了,上实操!
29 |
30 | ## 1. 早报接口
31 |
32 | 原打算本地实现一个接口,爬取 AI 相关的自媒体文章,不过最近时间有限,暂且搁置。
33 |
34 | 于是,找了个公网接口,快速把整个流程跑通。
35 |
36 | 还记得之前我们介绍的表情包接口么?调用思路是一样的。
37 |
38 | 同样,下面这个免费且靠谱的接口,分享给大家:
39 |
40 | - 每日早报接口:[https://www.alapi.cn/api/view/93](https://www.alapi.cn/api/view/93)
41 |
42 | 首先来编写下请求代码:
43 |
44 | ```
45 | def get_zaobao_al(format='json'):
46 | params = {
47 | "format": format,
48 | "token": al_api_token
49 | }
50 | response = requests.get("https://v2.alapi.cn/api/zaobao", params=params)
51 | if response.status_code == 200 and response.json()['code'] == 200:
52 | img_url = response.json()['data']['image']
53 | return img_url
54 | return ''
55 | ```
56 |
57 | 返回结果如下:
58 |
59 | ```
60 | {'code': 200, 'msg': 'success', 'data': {'date': '2024-09-10', 'news': ['1、商务部:对原产于加拿大的进口油菜籽进行反倾销立案调查;财政部:将在法国发行欧元主权债券,规模不超20亿欧元;', '2、我国首款猴痘疫苗获批临床,有望在我国对猴痘病毒导致疾病的预防和控制中发挥重要作用;'], 'weiyu': '【微语】生活就像一面镜子,你有什么样的心态,就有什么样的人生。', 'image': 'https://file.alapi.cn/60s/202409101725901836.png', 'head_image': 'https://file.alapi.cn/60s/202409101725901836_head.png'}, 'time': 1725929706, 'usage': 0, 'log_id': '691933099107115008'}
61 | ```
62 |
63 | 从返回结果的 `data` 字段中,你可以拿到 `news` `weiyu`等进行后处理,当然也可以用接口生成的早报图片,类似下面这样:
64 |
65 | 
66 |
67 | ## 2. 定时任务
68 |
69 | 定时任务的实现,在[零风险!零付费!我把 AI 接入微信群,爸妈玩嗨了~附教程(下)](https://zhuanlan.zhihu.com/p/718126892)已有介绍,不了解的小伙伴可回看。
70 |
71 | 这里贴心核心代码,供大家参考:
72 | ```
73 | def send_zaobao(to='机器人测试'):
74 | img_url = get_zaobao_al()
75 | if img_url:
76 | success = send_message(to=to, isRoom=True, content=img_url, base=base_url, message_type='url')
77 | if success:
78 | send_message(to=to, isRoom=True, content='每天 60 秒看懂世界,小爱今日早报~', base=base_url)
79 | logging.info(f"发送早报成功")
80 | else:
81 | logging.info(f"发送早报失败")
82 | ```
83 |
84 |
85 | 比如每天 09:25,定时发送:
86 |
87 | ```
88 | # 设置早报任务
89 | schedule.every().day.at("09:25").do(lambda: send_zaobao(to='小爱和他的朋友们'))
90 | ```
91 |
92 | 搞定!
93 |
94 | 
95 |
96 | 还希望实现什么功能?和`小爱`聊聊吧~
97 |
98 | ## 写在最后
99 |
100 | 本文通过一个简单的例子,带大家快速跑通 `定时任务` 的实现流程。
101 |
102 | 大家有更好的想法,欢迎评论区交流。
103 |
104 | 如果本文对你有帮助,不妨点个**免费的赞**和**收藏**备用。
105 |
106 | ---
107 | 为了方便大家交流,新建了一个 `AI 交流群`,欢迎感兴趣的小伙伴加入。
108 |
109 | `小爱`也在群里,想进群体验的朋友,公众号后台「联系我」即可,拉你进群。
110 |
111 |
112 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/大模型竞技场,免费直达 GPT4o.md:
--------------------------------------------------------------------------------
1 |
2 | 尽管各大 LLM 厂商百花齐放,OpenAI 的 GPT 系列依然一骑绝尘!
3 |
4 | 虽然 OpenAI 官网已将 GPT4o 开发给免费用户使用,受限于网络原因,国内很多小伙伴依然没有用上免费纯正的 GPT4o~
5 |
6 | 即便克服了网络障碍,免费用户每3小时也只能使用 GPT-4o 10次。
7 |
8 | 今天看到一个项目-`Chatbot Arena`,可以无限白嫖 GPT-4o,分享给大家!
9 |
10 |
11 | ## 1. Chatbot Arena 简介
12 | > 在线体验:[https://arena.lmsys.org/](https://arena.lmsys.org/)
13 |
14 | Chatbot Arena 是伯克利的LMSYS组织在 2023 年就搭建的一套评测各大 LLM 的平台,简称`大模型竞技场`。
15 |
16 | 这个组织的另外两项工作也非常有影响力:
17 | - LlaMa 系列开源大语言模型,最新版已到了 LlaMa3.1,还没体验过的小伙伴可以参考:[全网刷屏的 LLaMa3.1 还没用上?2分钟带你尝个鲜](https://zhuanlan.zhihu.com/p/710991720)
18 | - Vicuna 系列开源多模态大模型,底座的大语言模型也是用的 LlaMa。
19 |
20 | 相对而言,Chatbot Arena 影响力不如上面两项。那么,Chatbot Arena 到底干了啥?
21 |
22 | 一个基于人类偏好评估 LLM 的开放平台。其采用成对比较方法,利用不同用户的输入,积累用户对不同 LLM 回答偏好的投票。
23 |
24 | 结果表明,众包投票与专家投票高度一致,因此 Chatbot Arena 的可信度非常高,一跃成为最受引用的 LLM 排行榜之一,被领先的 LLM 开发人员和公司广泛引用。
25 |
26 | ## 2. 大模型排行榜
27 | 主页选择 `Leaderboard`,可以看到最新的大模型排行榜。ChatGPT-4o 依旧遥遥领先,确实强。
28 |
29 | 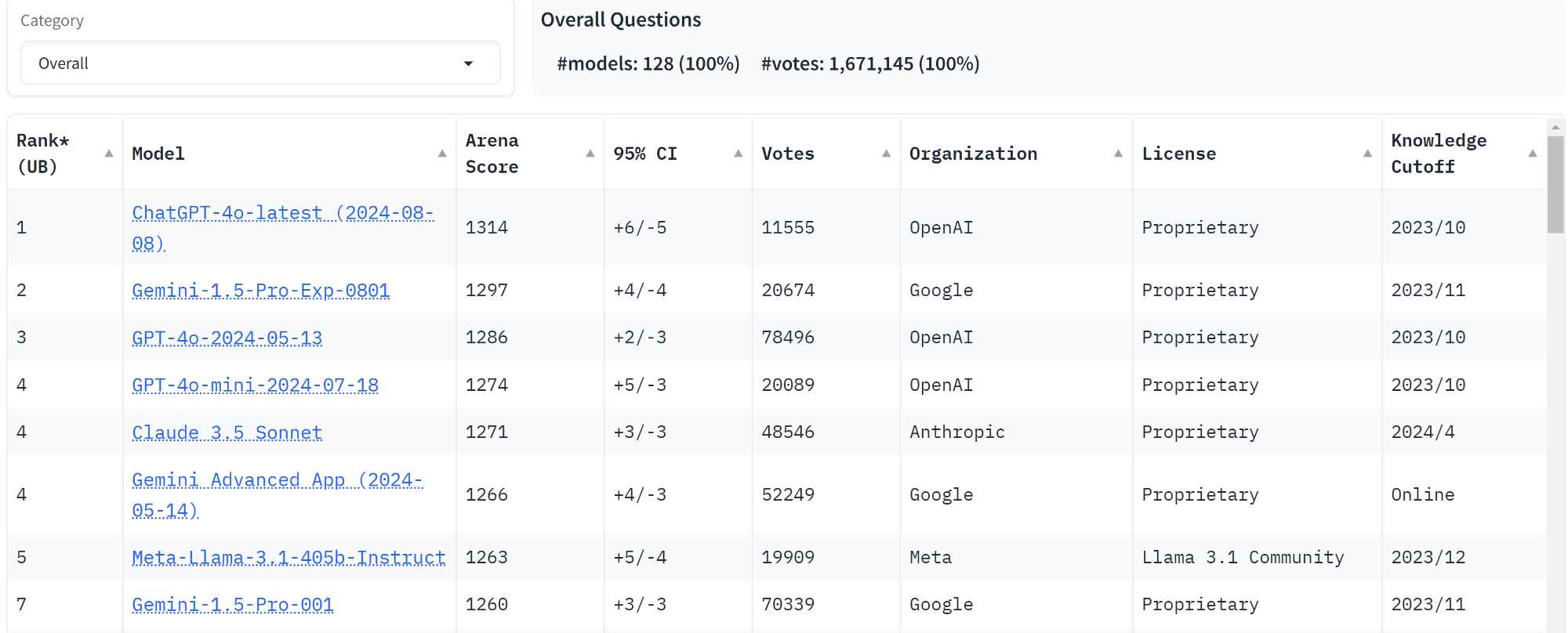
30 |
31 |
32 | ## 3. 大模型 PK
33 | 主页选择 `Arena(side-by-side)`,可以任意选择两个大模型进行 PK,哪个好用选哪个~
34 |
35 | 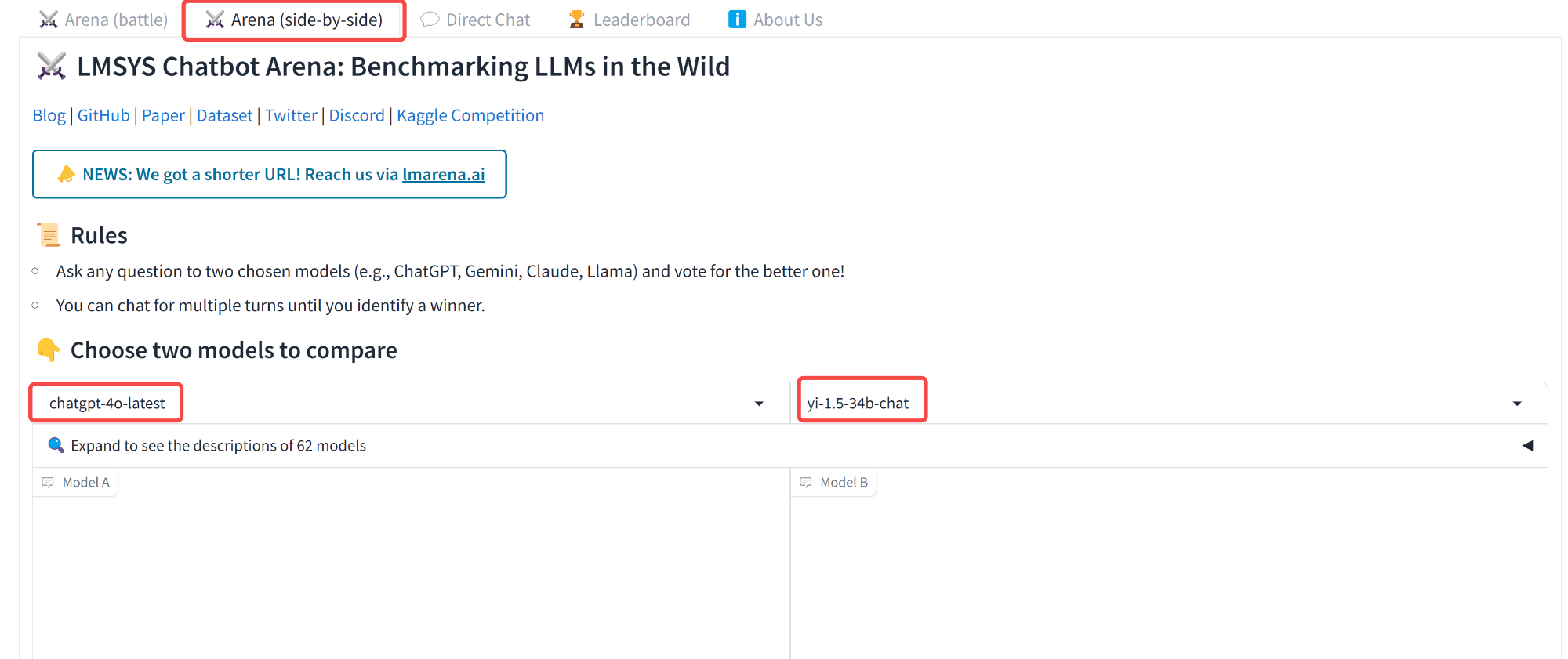
36 |
37 | ## 4. 白嫖 GPT-4o
38 | 当然,对于绝大部分用户而言,根本不关心排行榜,就是想白嫖下 GPT-4o 对吧。
39 |
40 | 主页选择 `Direct Chat`,尽情开启 GPT-4o 的白嫖之旅吧。
41 |
42 | 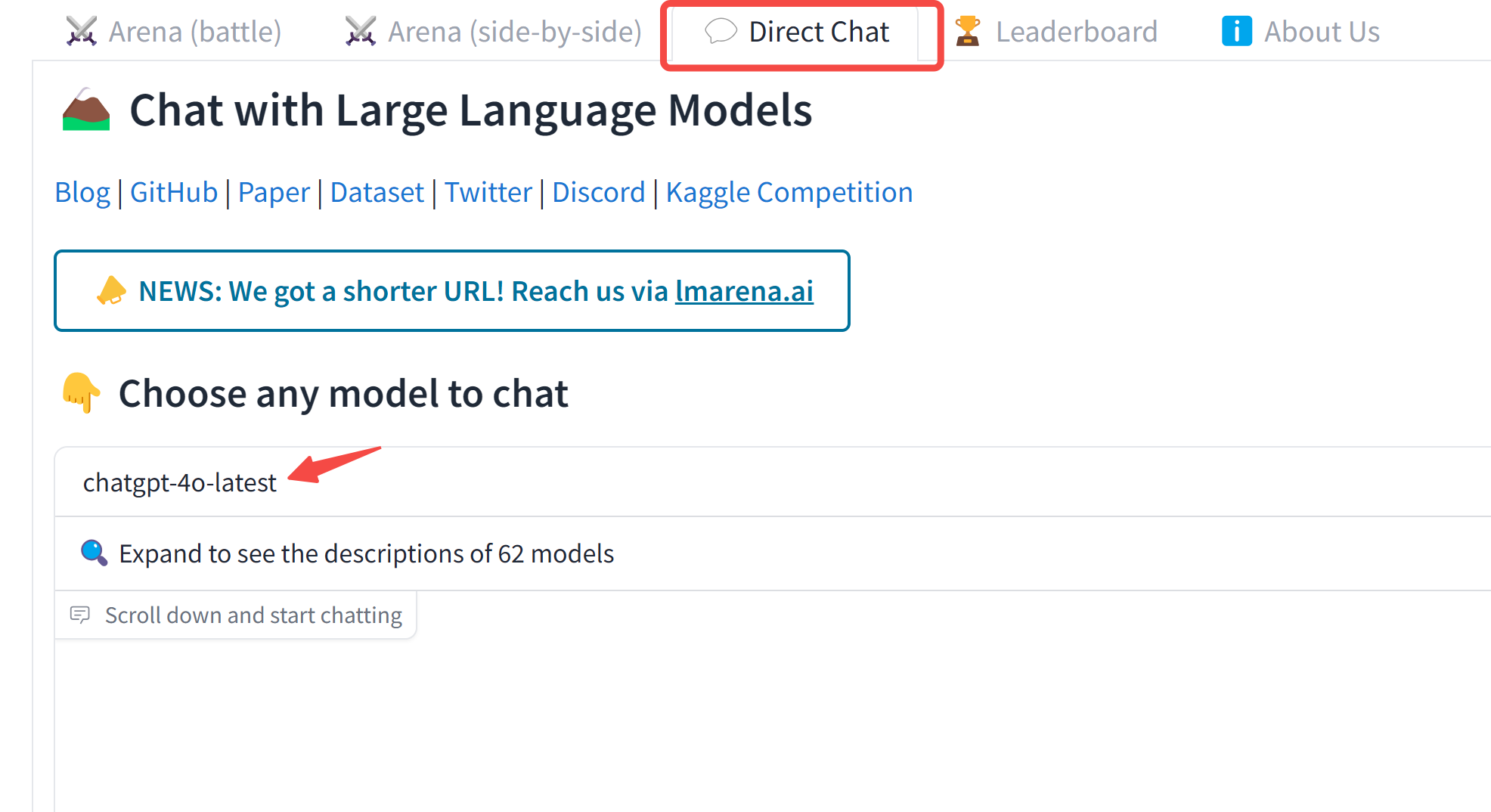
43 |
44 |
45 | 不过,高峰期时,白嫖 `chatgpt-4o-latest` 可能会遇到`MODEL_HOURLY_LIMIT (chatgpt-4o-latest): 2000`。
46 |
47 | 那就换一个 GPT-4o 的版本试试吧,毕竟榜一大哥被薅的太狠,官方服务器怕是扛不住吧~
48 |
49 | ## 写在最后
50 |
51 | 今天给大家安利了 LLM 界的"奥林匹克" - Chatbot Arena!
52 |
53 | 不仅能看到最新的 LLM 排行榜,还能亲自上阵让两个 LLM 互掐,看谁更厉害。
54 |
55 | 不过这些都不重要,最重要的是 - 它为我们白嫖 GPT-4o,提供了一种可能。
56 |
57 | 如果本文对你有帮助,不妨点个**免费的赞**和**收藏**备用。
58 |
59 |
60 |
61 |
62 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/小爱打工,你躺平!让「微信AI小助理」接管你的文件处理,一个字:爽!.md:
--------------------------------------------------------------------------------
1 | 前两天,搞了个微信 AI 小助理-`小爱(AI)`,爸妈玩的不亦乐乎。
2 | - [零风险!零费用!我把AI接入微信群,爸妈玩嗨了,附教程(下)](https://zhuanlan.zhihu.com/p/718126892)
3 |
4 | 最近一直在迭代中,挖掘`小爱`的无限潜力:
5 | - [链接丢给它,精华吐出来!微信AI小助理太强了,附完整提示词](https://zhuanlan.zhihu.com/p/718355186)
6 | - [拥有一个能倾听你心声的「微信AI小助理」,是一种什么体验?](https://zhuanlan.zhihu.com/p/718748712)
7 |
8 |
9 | 有朋友问`小爱`:能接收`word、excel、pdf`等各种文件吗?要是能帮我处理各种文件,岂不是很爽?
10 |
11 | `小爱`:今天就安排!
12 |
13 | 今日分享,将继续基于`wechatbot-wehook`框架,带大家实操:如何接收微信文件,并进行处理,让`小爱`接管你的文件处理工作,助力你`上班摸鱼`!
14 |
15 | ## 1. 接收微信文件
16 |
17 | 微信消息中所有文件,在 FastAPI 中都可以用 UploadFile 类处理。
18 |
19 | 此外,UploadFile 是设计为异步的,故支持大文件的高效上传和处理。
20 |
21 | 其中,content_type 代表文件的 MIME 类型(媒体类型),主要分为以下几类:
22 | 1. 文本类型
23 | - 文本文件:如 text/plain
24 | - HTML 文件:如 text/html
25 | - CSS 文件:如 text/css
26 | 2. 图像类型
27 | - JPEG 图像:如 image/jpeg
28 | - PNG 图像:如 image/png
29 | - GIF 图像:如 image/gif
30 | 3. 音频类型
31 | - MP3 音频:如 audio/mpeg3 或 audio/mp3
32 | - WAV 音频:如 audio/x-wav
33 | 4. 视频类型
34 | - MP4 视频:如 video/mp4
35 | - MPEG 视频:如 video/mpeg
36 | 5. 应用程序类型
37 | - JSON 文件:如 application/json
38 | - PDF 文件:如 application/pdf
39 | - ZIP 文件:如 application/zip
40 | - Microsoft Word 文档:如 application/vnd.openxmlformats-officedocument.wordprocessingml.document
41 |
42 | 下面是接收文件并下载的示例代码:
43 |
44 | ```
45 | @app.post("/receive")
46 | async def receive_message(request: Request):
47 | data = await request.form()
48 | message_type = data.get("type")
49 | content = data.get("content")
50 | # 下载文件
51 | if message_type == 'file':
52 | with open(f"./output/{content.filename}", "wb") as buffer:
53 | bin = await content.read()
54 | buffer.write(bin)
55 | ```
56 |
57 |
58 | 上一篇,我们主要介绍了如何处理音频文件。
59 |
60 | 本篇将以最常见的 `pdf` 为例,介绍如何处理 `pdf` 并返回。
61 |
62 | ## 2. 文本提取
63 |
64 | 当你给`小爱`发送一份 `pdf 文件`,后台接收到的文件如下:
65 |
66 | ```
67 | UploadFile(filename='学会写作.pdf', size=1381979, headers=Headers({'content-disposition': 'form-data; name="content"; filename="å\xad¦ä¼\x9aå\x86\x99ä½\x9c.pdf"', 'content-type': 'application/pdf'}))
68 | ```
69 | 文件类型为`application/pdf`。
70 |
71 | 关于如何处理`pdf 文件`,可以参看猴哥之前的【Python实战】教程:
72 | - [【Python实战】自动化处理 PDF 文档,完美实现 WPS 会员功能](https://zhuanlan.zhihu.com/p/712086553)
73 | - [【Python实战】如何优雅地实现文字 & 二维码检测?](https://zhuanlan.zhihu.com/p/712615718)
74 | - [【Python实战】一键生成 PDF 报告,图文并茂](https://zhuanlan.zhihu.com/p/712494215)
75 |
76 | 这里我们以提取 pdf 文本为例进行演示:
77 |
78 | ```
79 | from PyPDF2 import PdfReader
80 | def pypdf_to_txt(input_pdf):
81 | pdf_reader = PdfReader(input_pdf)
82 | texts = []
83 | for page_num in range(len(pdf_reader.pages)):
84 | page = pdf_reader.pages[page_num]
85 | text = page.extract_text()
86 | texts.append(text)
87 | return '\n'.join(texts)
88 | ```
89 |
90 | ## 3. 文本摘要
91 |
92 | 得到文本后,就可以交给 LLM 帮我们提炼总结一下内容要点。有了文本摘要,我就无需再去翻阅长文,省时提效利器,有没有?
93 |
94 | 这个任务非常简单,甚至无需编写角色提示词:
95 |
96 | ```
97 | unillm = UniLLM()
98 | messages = [{'role': 'user', 'content': f'帮我提炼这篇文章的主要观点:{text}'}]
99 | res = unillm(['glm4-9b'], messages=messages)
100 | ```
101 |
102 | 我把《学会写作》这本书发给了它,可以看到提炼的还是很精准的:
103 |
104 | 
105 |
106 | 有需要这本书的公众号后台自取。
107 |
108 | ## 4. 更多玩法
109 |
110 | 不管是 `word` 还是 `pdf`,只要拿到源文件,你想实现任何功能,还不简单?底层逻辑都是一样的:把流程标准化,然后让程序自动执行,最终让`小爱`交给你~
111 |
112 | 比如,我可以让它帮我把 `pdf` 去水印/加水印,然后返回给我。
113 |
114 | ## 写在最后
115 | 本文给大家展示了一个处理`pdf`文件的简单案例,`懒人`必备神器!
116 |
117 | 大家有更好的想法,欢迎评论区交流。
118 |
119 | 如果本文对你有帮助,不妨点个**免费的赞**和**收藏**备用。
120 |
121 | ---
122 | 为了方便大家交流,新建了一个 `AI 交流群`,欢迎感兴趣的小伙伴加入。
123 |
124 | `小爱`也在群里,想进群体验的朋友,公众号后台「联系我」即可,拉你进群。
125 |
126 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/开源版Heygen!TANGO数字人,瞄准全身动作生成,本地部署实测.md:
--------------------------------------------------------------------------------
1 |
2 | 前段时间爆火的图片数字人:LivePortrait、AniPortrait、MuseTalk、EchoMimic等,核心原理都是通过 **姿态/音频等** 驱动**单张图片**,生成对应的视频。
3 |
4 | 我们将上述图片数字人,称为 **2D 真人**,这些数字人偏娱乐属性,无法做到代替真人。
5 |
6 | 而要想代替真人出镜,实现数字人口播,就必须上**2.5D真人**。
7 |
8 | 上篇和大家分享了:实时视频数字人方案 Ultralight Digital Human:
9 | - [致敬!开源端侧实时数字人,附一键整合包](https://zhuanlan.zhihu.com/p/12365528701)
10 |
11 | 类似的**2.5D真人**开源项目还有 dh_live,实现流程基本一致,区别在底层模型不同,比如 dh_live 中,音频编码用的 LSTM 模型,生成模型用的DINet。
12 |
13 | 但,上述**2.5D真人**方案的缺陷是:只能实现`对口型`,**无法生成和音频协调的肢体动作**!
14 |
15 | 全身动作生成,一直都是急需攻克的难题。
16 |
17 | 即便是付费方案 Heygen,也只能实现面部表情和上半身动作生成。
18 |
19 | 直到看到一个开源项目 - **TANGO**,瞄准了全身动作生成这一更具挑战性的目标。
20 |
21 | **今日分享,带大家一探 TANGO 的究竟,并本地实操起来,看看效果如何**。
22 |
23 | ## 1. TANGO 简介
24 |
25 | TANGO 由东京大学和 CyberAgent AI Lab 联合开发,技术路径非常独特。
26 |
27 | 老规矩,简单介绍下项目的亮点:
28 |
29 | 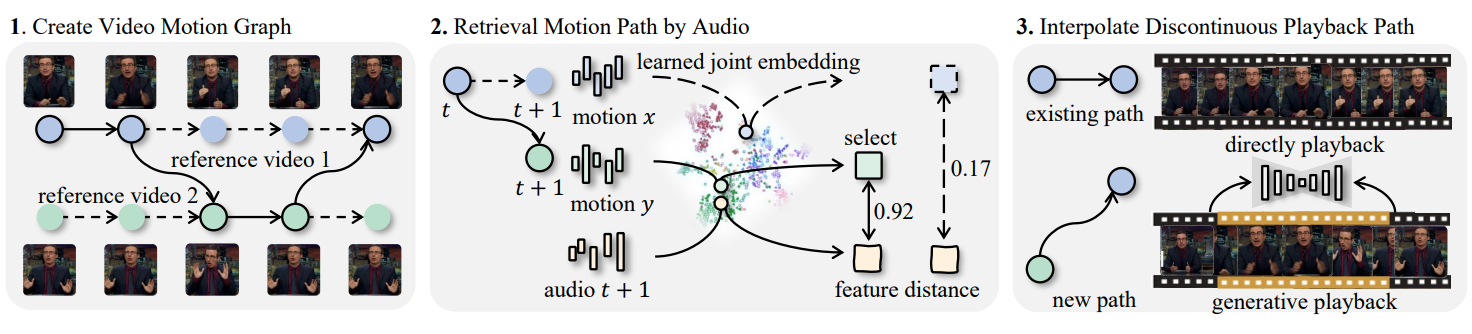
30 |
31 | 对照论文中的流程图,TANGO 的核心技术主要有:
32 | - **图结构表示**:节点代表视频帧;边表示帧之间的转换。子图检索: 可根据目标音频的时序特征,检索最佳的视频播放路径子集。
33 | - **AuMoCLIP**:分层音频运动嵌入,通过对比学习创建一个隐式的层次化音频-动作联合嵌入空间,能够捕捉更细微的音频-动作关系,从而生成更自然、更流畅的动作序列;
34 | - **ACInterp**:扩散插值网络,在现有扩散模型之上,参考运动模块确保生成的动作与参考视频保持一致。
35 |
36 | 如果只是想尝个鲜,可前往官方体验地址:[https://huggingface.co/spaces/H-Liu1997/TANGO](https://huggingface.co/spaces/H-Liu1997/TANGO)
37 |
38 | 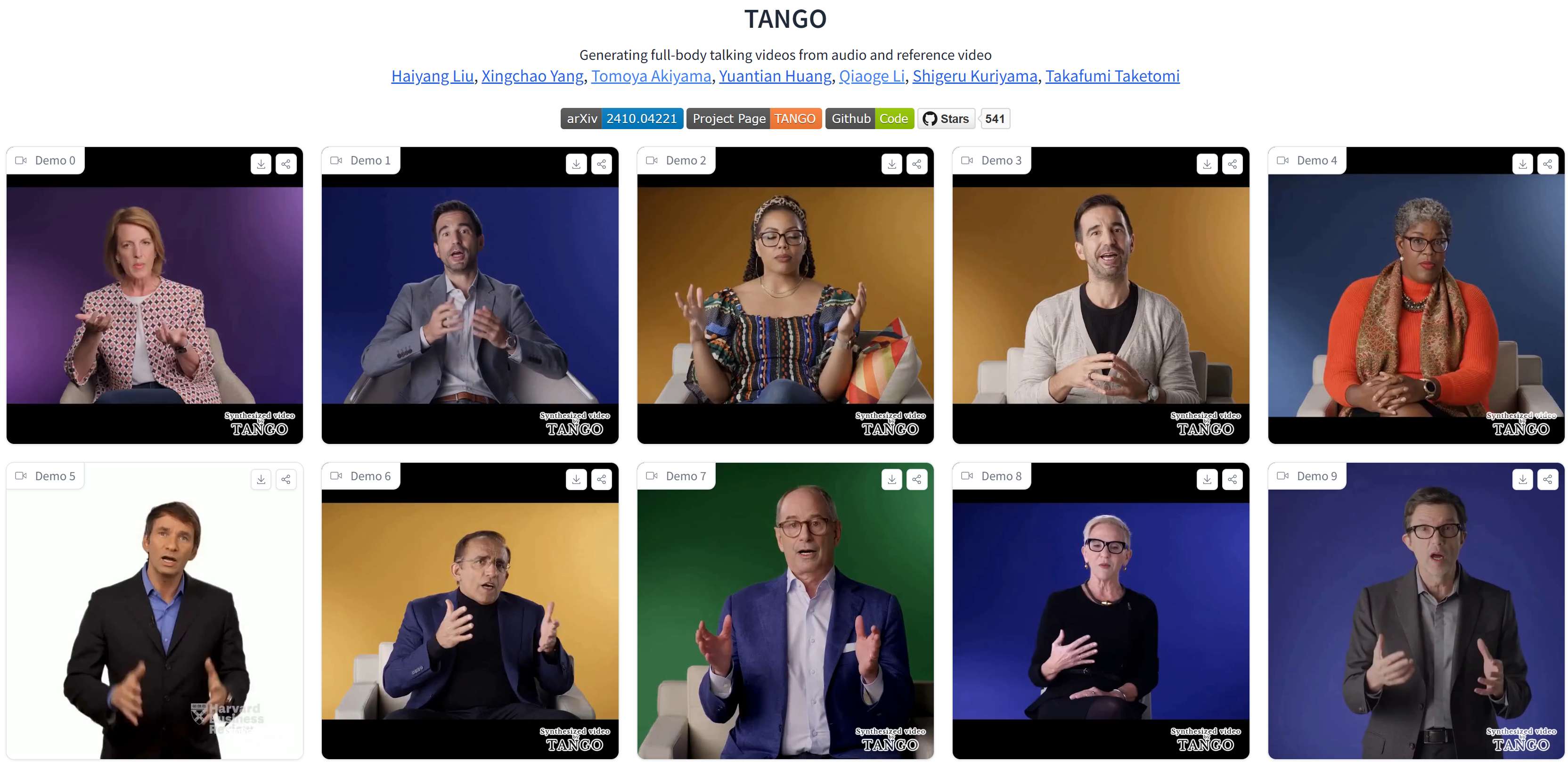
39 |
40 |
41 | ## 2. TANGO 本地部署
42 | >本地部署,有两点需要注意:
43 | >- **至少确保 35G 磁盘空间**,用于存放模型;
44 | >- **至少确保 6G 显存**,用于模型推理。
45 |
46 | > 项目地址:[https://github.com/CyberAgentAILab/TANGO](https://github.com/CyberAgentAILab/TANGO)
47 |
48 | 首先,下载项目仓库:因项目依赖 wav2lip 和 FILM,因此在 TANGO 目录下把这两个项目也要拉取下来。
49 |
50 | ```
51 | git clone https://github.com/CyberAgentAILab/TANGO
52 | cd TANGO
53 | git clone https://github.com/justinjohn0306/Wav2Lip.git
54 | git clone https://github.com/dajes/frame-interpolation-pytorch.git
55 | ```
56 |
57 | 然后,参考项目主页,安装好依赖后,即可一键启动 WebUI:
58 |
59 | ```
60 | python app.py
61 | ```
62 |
63 | 其中,项目默认会生成带有 TANGO 水印的视频,类似下面这样:
64 |
65 | 
66 |
67 | 本质上是调用本地的 ffmpeg 将原视频和水印图片合成了新视频。
68 |
69 | 如果不想要水印,可修改`app.py`中:
70 |
71 | ```
72 | gr.Video(value="./datasets/cached_audio/demo1.mp4", label="Demo 0", , watermark="./datasets/watermark.png")
73 | # 修改为
74 | gr.Video(value="./datasets/cached_audio/demo1.mp4", label="Demo 0")
75 | ```
76 |
77 | 非本地主机可访问,需修改:
78 |
79 | ```
80 | demo.launch(server_name="0.0.0.0", server_port=7860)
81 | ```
82 |
83 | 再次打开,可以发现加载的视频中无水印:
84 |
85 | 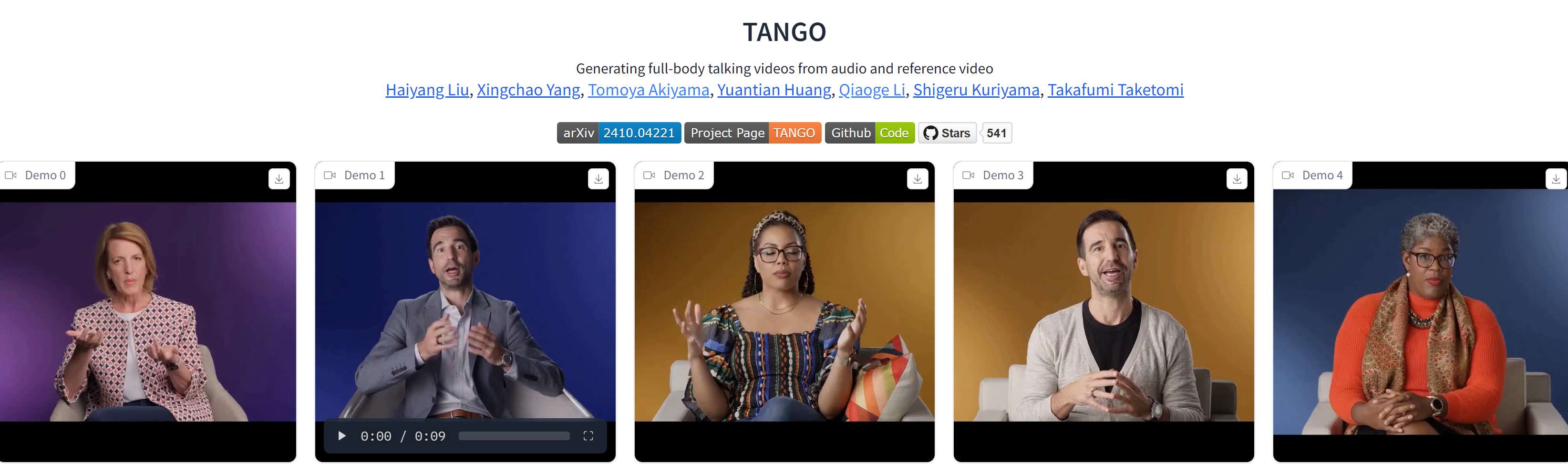
86 |
87 | 视频能否加载成功,取决于你本地的网速。
88 |
89 | 接下来,只需上传一段音频和参考视频,点击生成即可。
90 |
91 | 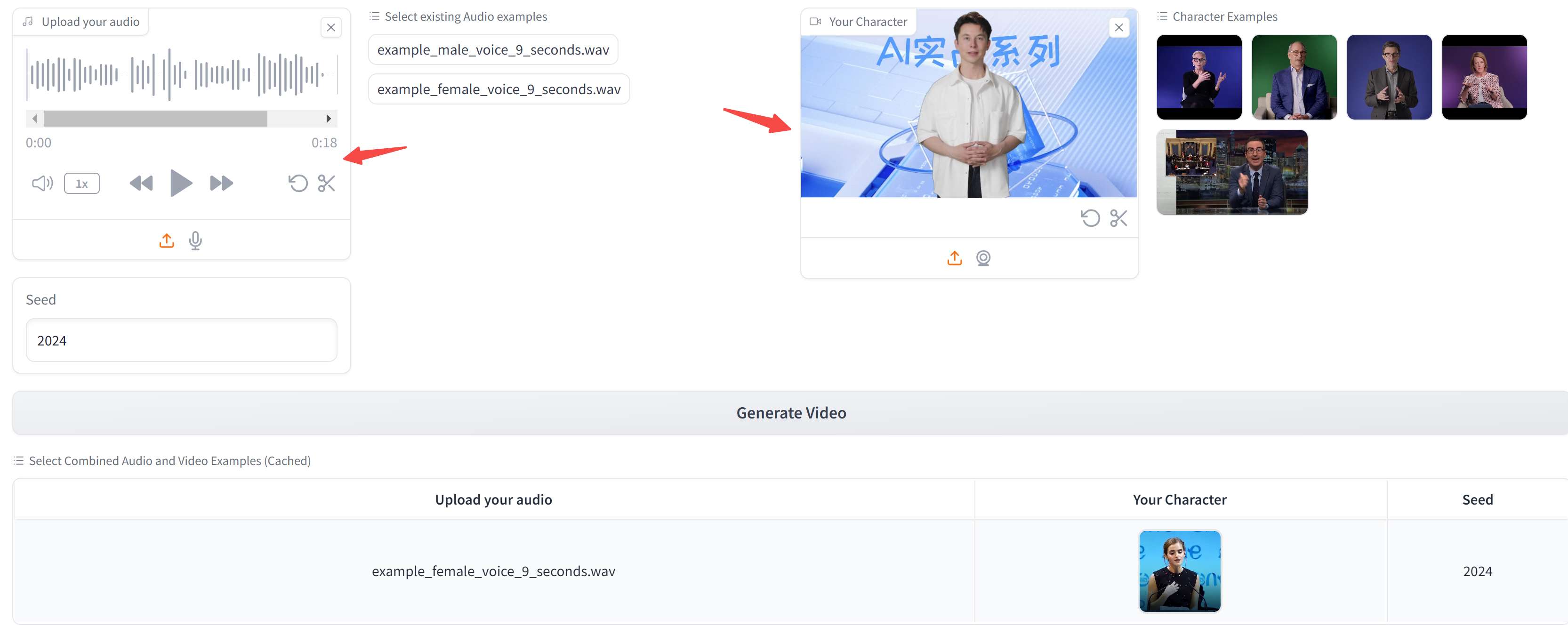
92 |
93 |
94 | 最终生成的视频没有音频,需要手动把音频合成进去:
95 |
96 | ```
97 | /usr/bin/ffmpeg -i outputs/gradio/test_0/xxx.mp4 -i gen_audio.wav -c:v libx264 -c:a aac result_wav.mp4
98 | ```
99 |
100 | 一起来看下效果吧:
101 |
102 |
103 | [video(video-erzNbNIi-1734395231006)(type-csdn)(url-https://live.csdn.net/v/embed/438952)(image-https://v-blog.csdnimg.cn/asset/19382837bfd888c02b472ec2b94fa9c0/cover/Cover0.jpg)(title-数字人)]
104 |
105 |
106 | 可以发现:肢体动作没什么问题,口型完全对不上。
107 |
108 | 这不,上篇分享的 Ultralight Digital Human就派上用场了?
109 |
110 | 所以,
111 |
112 | `Ultralight Digital Human` 对口型,`TANGO` 生成肢体动作,`FaceFusion` 换脸,完美!
113 |
114 | > 值得注意的是:当前开源的 TANGO 只支持最长 8s 音频,使用前,需对音频文件做分段处理!
115 |
116 | ## 写在最后
117 |
118 | 本文带大家在本地实操了支持**全身动作生成**的数字人项目 TANGO。
119 |
120 | 不知大家使用体验如何,欢迎评论区聊!
121 |
122 | 如果对你有帮助,欢迎**点赞收藏**备用。
123 |
124 | ---
125 |
126 | 为方便大家交流,新建了一个 `AI 交流群`,公众号后台「联系我」,拉你进群。
127 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/开源的语音合成项目-EdgeTTS,无需部署无需Key.md:
--------------------------------------------------------------------------------
1 |
2 | 前几天和大家分享了:[全网爆火的AI语音合成工具-ChatTTS](https://blog.csdn.net/u010522887/article/details/139591713)。
3 |
4 | 有很多小伙伴反应模型下载还有点麻烦~
5 |
6 | 今天再给大家带来一款开源的语音合成 TTS 项目-EdgeTTS,相比ChatTTS,操作起来对小白更友好。
7 |
8 | 因为其底层是使用微软 Edge 的在线语音合成服务,所以**不需要下载任何模型,甚至连 api_key 都给你省了**,简直不要太良心~
9 |
10 | 关键是,除了支持普通话外,还支持很多地方口音(比如: **粤语、台湾口音、陕西话、辽宁东北话等**),就凭这, 吊打 ChatTTS 有没有!
11 |
12 | 太香了,赶紧开始实操!
13 |
14 | # EdgeTTS 简介
15 | > GitHub 仓库地址:[https://github.com/rany2/edge-tts](https://github.com/rany2/edge-tts)
16 |
17 | EdgeTTS 是一个文本转语音的开源项目,截至目前,在 GitHub 上已经斩获了 4k 的 Star,作者一直在更新,该项目核心就是调用微软 Edge 的在线语音合成服务,支持40多种语言,318种声音,中英文通吃,简直是我等 AI 应用开发者的福音。
18 |
19 | 
20 | # EdgeTTS 使用教程
21 | ## 1.安装环境
22 | 最基本的环境安装,只需要两个 pip 包:
23 |
24 | ```python
25 | pip install edge-tts
26 | pip install torchaudio
27 | ```
28 | ## 2. 命令行使用
29 | 安装好包后,命令行一键调用,主要有如下指令:
30 | ### 2.1 查看支持的音色
31 | 查看支持的所有音色:
32 |
33 | ```python
34 | edge-tts --list-voices
35 | ```
36 |
37 | 如果想查看支持的粤语 or 台湾语
38 |
39 | ```python
40 | edge-tts --list-voices| grep HK # TW
41 | ```
42 | 类似的,查看支持哪些地方方言:
43 |
44 | ```python
45 | edge-tts --list-voices |grep CN
46 | Name: zh-CN-XiaoxiaoNeural
47 | Name: zh-CN-XiaoyiNeural
48 | Name: zh-CN-YunjianNeural
49 | Name: zh-CN-YunxiNeural
50 | Name: zh-CN-YunxiaNeural
51 | Name: zh-CN-YunyangNeural
52 | Name: zh-CN-liaoning-XiaobeiNeural
53 | Name: zh-CN-shaanxi-XiaoniNeural
54 | ```
55 | ### 2.2 一键生成语音
56 | 不多说了,直接上代码:
57 | ```python
58 | edge-tts --voice zh-HK-WanLungNeural \
59 | --text "曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。\
60 | 如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。\
61 | 如果非要在这份爱上加上一个期限,我希望是……一万年" --write-media test.wav
62 | ```
63 | 速度超快,终端还会返回 SRT 格式的字幕文本:
64 | 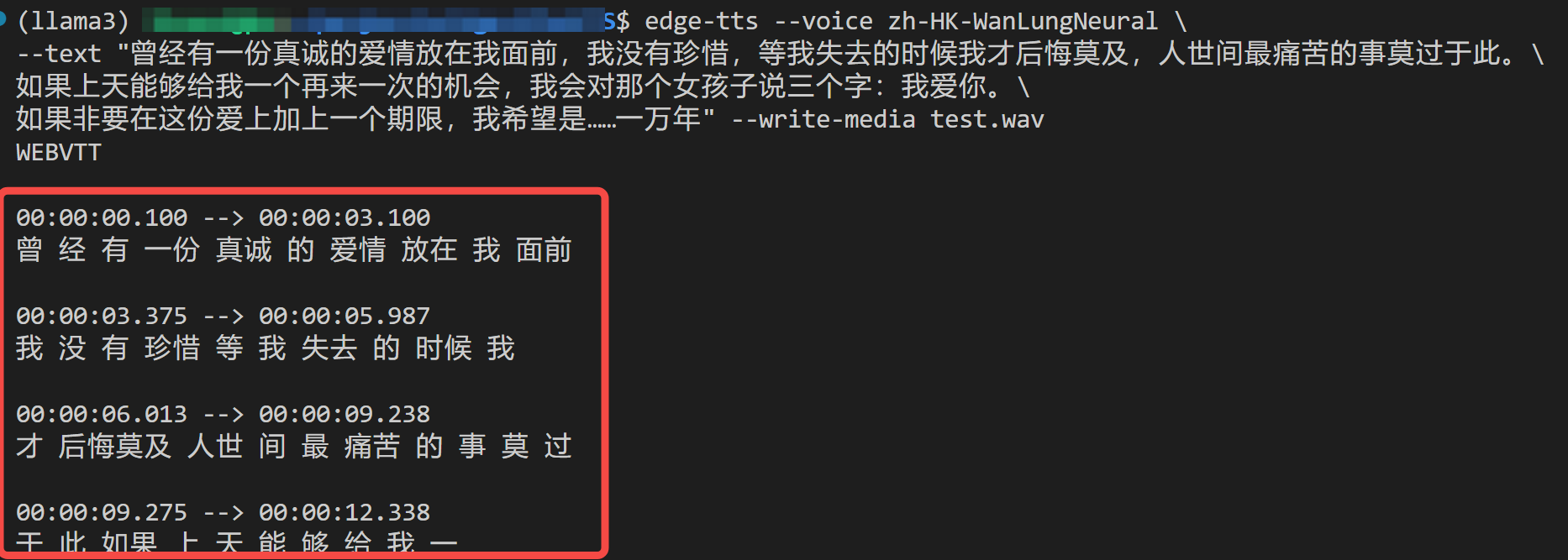
65 | ### 2.3 更多参数使用
66 | 为了实现更个性化的语音,除了音色,还有以下参数可以调用:
67 |
68 | **调整合成语音的语速--rate参数**
69 | > -30%表示语速变慢30%,+30%表示语速增加30%。
70 |
71 | ```python
72 | edge-tts --rate=-30% --voice zh-HK-WanLungNeural \
73 | --text "xxx" --write-media test.mp3
74 | ```
75 |
76 | **调整合成语音的音量--volume**
77 | > 通过--volume参数来设置播放的语速快慢,-60%表示语速变慢60%,+60%表示语速增加60%。
78 |
79 | ```python
80 | edge-tts --volume=-50% --voice zh-HK-WanLungNeural \
81 | --text "xxx" --write-media test.mp3
82 | ```
83 |
84 | **调整合成语音的频率--pitch**
85 | > 通过pitch参数来调整合成语音的频率,-50Hz表示降低频率50Hz,+50Hz则相反
86 |
87 | ```python
88 | edge-tts --pitch=-50Hz --voice zh-HK-WanLungNeural \
89 | --text "xxx" --write-media test.mp3
90 | ```
91 |
92 | ## 3. python 代码调用
93 | 如果需要在python脚本中调用 EdgeTTS,来实现语音合成,也是没问题的,示例代码如下:
94 |
95 | ```python
96 | import edge_tts
97 |
98 | text = """曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。
99 | 如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。如果非要在这份爱上加上一个期限,我希望是……一万年"""
100 |
101 | communicate = edge_tts.Communicate(text=text,
102 | voice="zh-HK-HiuGaaiNeural",
103 | rate='+0%',
104 | volume= '+0%',
105 | pitch= '+0Hz')
106 |
107 | communicate.save_sync("test.wav")
108 | ```
109 | # 写在最后
110 | 不得不说,AI 语音界真是人才辈出,除了 ChatTTS 之外,希望这款支持多种方言的TTS项目,在帮你打造个性化 AI 语音助手时,提供另外一种选择。
111 |
112 | 如果本文对你有帮助,欢迎 **点赞收藏** 备用!
113 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/惊艳!Stable Diffusion 3开源~ AI绘画新里程碑,快来体验.md:
--------------------------------------------------------------------------------
1 |
2 | 继 ComputeX 2024 上宣布 6 月 12 日将发布 Stable Diffusion(SD) 3 模型,Stability.AI 果然没有跳票,按时开放了 SD3 的中型模型-Medium。
3 |
4 | 就在刚刚,SD3 Medium 如约而至。
5 |
6 | ### 笔记本也能玩的 SD3 Medium
7 |
8 | 据 Stability AI 官方博客介绍,SD3 Medium 模型包含 20 亿个参数,却能够生成更高质量的图像。
9 |
10 | 由于模型尺寸较小,SD3 Medium 尤其适合在消费级 GPU 上运行,平均生成图片时间在2—10秒左右推理效率非常高。
11 |
12 | 第一波下载模型的网友已经开始玩疯了~ 给大家展示几张生成效果图:
13 | 【图片】
14 |
15 | ### SD3 Medium 有哪些亮点?
16 |
17 | SD3 Medium 代表了生成式 AI 发展的一个重大里程碑,坚持了 AI 民主化这一强大的技术承诺。SD3 Medium 突出之处:
18 |
19 | - **照片级真实**:克服了手和脸部常见的伪影问题,无需复杂流程即可生成高质量图像。
20 |
21 | - **指令遵循**:能够理解涉及空间关系、构图元素、动作和风格的复杂提示语。
22 |
23 | - **图文混排**:借助 DiT 架构,可以无伪影且无拼写错误地生成前所未有的文本。
24 |
25 | - **容易微调**:能够从小型数据集中吸收细微细节,非常适合定制。
26 |
27 | ### SD3 Medium 有哪些更新?
28 | ## 架构细节
29 | 对于文本到图像生成,模型须同时考虑文本和图像两种模态,这种新架构被称为 MMDiT,指的是其能够处理多种模态。
30 |
31 | 与之前的 Stable Diffusion 不同的是,使用三种不同的文本嵌入器——两个 CLIP 模型和 T5 来编码文本表示,并使用一种改进的自动编码模型来编码图像。
32 |
33 | SD3 架构建立在扩散变换器(Diffusion Transformer,"DiT")的基础之上,与Sora相同。
34 | 【图片】
35 |
36 | 由于文本和图像嵌入在概念上存在很大差异,SD3 为这两种模态使用了两套独立的权重,在注意力操作时将两种模态的序列连接起来。
37 |
38 | 通过使用这种方法,图像和文本 tokens 之间的信息可以相互流动,从而提高生成输出的整体理解能力和图文混排质量。
39 |
40 | ## 训练数据
41 | 据了解,在训练 SD3 Medium 上,Stability AI 还是花了不少心思的。
42 |
43 | 训练数据包括两个部分:合成数据和筛选过的公开数据。预训练数据达到了惊人的 10 亿张图片。
44 |
45 | 此外,微调数据集包含 3000 万张针对特定视觉内容和风格的高质量美学图片,以及 300 万张基于偏好的数据图片。
46 |
47 | 【图片】
48 |
49 | ### SD3 Medium 在哪体验?
50 | > 模型地址:https://huggingface.co/stabilityai/stable-diffusion-3-medium
51 | >
52 | > 在线体验:https://huggingface.co/spaces/stabilityai/stable-diffusion-3-medium
53 |
54 |
55 | 模型权重可以到上方模型地址获取。
56 |
57 | 权重文件的结构如下:
58 | ```
59 | ├── comfy_example_workflows/
60 | │ ├── sd3_medium_example_workflow_basic.json
61 | │ ├── sd3_medium_example_workflow_multi_prompt.json
62 | │ └── sd3_medium_example_workflow_upscaling.json
63 | │
64 | ├── text_encoders/
65 | │ ├── README.md
66 | │ ├── clip_g.safetensors
67 | │ ├── clip_l.safetensors
68 | │ ├── t5xxl_fp16.safetensors
69 | │ └── t5xxl_fp8_e4m3fn.safetensors
70 | │
71 | ├── LICENSE
72 | ├── sd3_medium.safetensors
73 | ├── sd3_medium_incl_clips.safetensors
74 | ├── sd3_medium_incl_clips_t5xxlfp8.safetensors
75 | └── sd3_medium_incl_clips_t5xxlfp16.safetensors
76 | ```
77 | 上述权重文件结构怎么理解?
78 |
79 | SD3 Medium 提供了三种封装,每种封装都具备相同的 MMDiT 和 VAE 权重,每种封装的区别如下:
80 |
81 | - **sd3_medium.safetensors** 包含 MMDiT 和 VAE 权重,但不包括任何文本编码器。
82 | - **sd3_medium_incl_clips_t5xxlfp16.safetensors** 包含所有必需的权重,包括 T5XXL 文本编码器的 fp16 版本。
83 | - **sd3_medium_incl_clips_t5xxlfp8.safetensors** 包含所有必需的权重,包括 T5XXL 文本编码器的 fp8 版本。
84 | - **sd3_medium_incl_clips.safetensors** 包含所有必需的权重,除了 T5XXL 文本编码器。它的资源需求最低,但是模型的性能将因为缺少 T5XXL 文本编码器而有所差异。
85 | - **text_encoders** 文件夹包含三个文本编码器。
86 | - **example_workfows** 文件夹包含示例 comfyui 工作流程。
87 |
88 | ### 写在最后
89 |
90 | 总的来说,Stable Diffusion 3 可以说是AI生图领域的里程碑式的存在,不仅在技术上进行了重大改进,而且免费开源,相信更多的开发者会基于这一强大模型开发出更多有意思的应用。
91 |
92 | 目前市面上已经出现了很多免费的AI绘画工具,其底层模型基本都是 Stable Diffusion。
93 |
94 | 为了帮助大家更好上手,猴哥会单独出一个专栏,分享如何免费使用这些工具。
95 |
96 | 欢迎追更!
97 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/我把「FLUX」接入了「小爱」,微信直接出图,告别一切绘画软件!.md:
--------------------------------------------------------------------------------
1 |
2 | 前两天,搞了个微信 AI 小助理-`小爱(AI)`,爸妈玩的不亦乐乎。
3 | - [零风险!零费用!我把AI接入微信群,爸妈玩嗨了,附教程(下)](https://blog.csdn.net/u010522887/article/details/141882177)
4 |
5 | 最近一直在迭代中,挖掘`小爱`的无限潜力:
6 | - [链接丢给它,精华吐出来!微信AI小助理太强了,附完整提示词](https://blog.csdn.net/u010522887/article/details/141924070)
7 | - [拥有一个能倾听你心声的「微信AI小助理」,是一种什么体验?](https://blog.csdn.net/u010522887/article/details/141986065)
8 | - [小爱打工,你躺平!让「微信AI小助理」接管你的文件处理,一个字:爽!](https://blog.csdn.net/u010522887/article/details/142023012)
9 | - [我把多模态大模型接入了「小爱」,痛快来一场「表情包斗图」!不服来战!](https://blog.csdn.net/u010522887/article/details/142038164)
10 |
11 | 有朋友问:`小爱`能 AI 绘画么?
12 |
13 | `小爱`:害,不过是接个模型的事儿~ 扶我来战!
14 |
15 |
16 | 今日分享,继续带大家实操:如何让`小爱`理解用户需求,并生成满足需求的图片!
17 |
18 | 要实现`AI 绘画`功能,我们先来拆解下步骤:
19 | - **识别用户意图**:从用户输入中识别出`AI 绘画`的意图;
20 | - **生成绘画提示词**:根据用户输入,生成给绘画模型的提示词;
21 | - **生成图片**:调用图片生成模型的接口,返回图片 url。
22 |
23 |
24 | ## 1. 识别用户意图
25 |
26 | 在[零风险!零费用!我把AI接入微信群,爸妈玩嗨了,附教程(下)](https://blog.csdn.net/u010522887/article/details/141882177)的基础上,我们只需在`意图列表`中新增一条:`图片生成`。
27 |
28 | 提示词如下:
29 | ```
30 | intentions_list = ['天气', '步行规划', '骑行规划', '驾车规划', '公交规划', '地点推荐', '图片生成']
31 | intentions_str = '、'.join(intentions_list)
32 |
33 | sys_intention_rec = f'''
34 | 你是意图识别专家,我会给你一句用户的聊天内容,帮我分析出他的意图。
35 | 要求:
36 | 1. 只有当你非常明确意图来自以下类别:{intentions_str},才能回答,否则请回复“其它”。
37 | 2. 直接回答意图标签即可,无需回答其它任何内容。
38 | '''
39 | ```
40 |
41 | 这样,LLM 从用户输入中识别到`图片生成`后,就直接路由到指定的处理逻辑。
42 |
43 | ## 2. 生成绘画提示词
44 |
45 | 由于用户输入是非结构化,这就需要提取出和`绘画提示词`相关的内容。
46 |
47 | 不过,这事简单,直接交给 LLM 就行,你只需给它合适的角色提示词就行:
48 | ```
49 | if intention == '图片生成':
50 | messages = [
51 | {'role': 'system', 'content': '根据用户输入,生成给stable diffusion等图片生成模型的提示词,只回答提示词内容,无需回答其它任何内容'},
52 | {'role': 'user', 'content': f'{user_content}'}
53 | ]
54 | res_prompt = unillm(['gemini-1.5-flash', 'glm4-9b'], messages=messages)
55 | ```
56 |
57 | 你别看就这么个简单任务,参数量小一点的模型压根搞不定!
58 |
59 | 实测下来,还是`gemini-1.5-flash`靠谱一些,推荐大家使用。
60 |
61 | ## 3. 生成图片
62 | 有了`绘画提示词`,终于到最后一步:生成图片了。
63 |
64 | 用啥模型生成图片呢?
65 |
66 | 本地部署个 `Stable Diffusion`?
67 |
68 | 都 2024 了,`AI 绘画`的风口在 `FLUX` 这里,强烈推荐你去体验一下👉[FLUX + LoRA 实测,AI 绘画开启新纪元,5分钟带你部署体验](https://blog.csdn.net/u010522887/article/details/141218266)。
69 |
70 | 现在 `FLUX` 的生态已经越来越完善了,但是本地部署对很多小白来说还是有点门槛。
71 |
72 | 为了让大家能快速跑通流程,我们选用[siliconflow](https://cloud.siliconflow.cn?referrer=clxv36914000l6xncevco3u1y)提供的免费接口。
73 |
74 | 核心代码如下,一键接入 `AI 绘画`模型:
75 |
76 | ```
77 | def generate_image(prompt='a cat', model='flux', img_size='1024x576', batch_size=1):
78 | url = f"https://api.siliconflow.cn/v1/{model}/text-to-image"
79 | headers = {
80 | "accept": "application/json",
81 | "content-type": "application/json",
82 | "Authorization": "Bearer xxx"
83 | }
84 | data = {
85 | 'prompt': prompt,
86 | 'image_size': img_size,
87 | 'batch_size': batch_size,
88 | }
89 | response = requests.post(url, json=data, headers=headers)
90 | img_urls = [img['url'] for img in response.json()['images']]
91 | return img_urls
92 | ```
93 |
94 | 当然,[siliconflow](https://cloud.siliconflow.cn?referrer=clxv36914000l6xncevco3u1y)也开放了`Stable Diffusion`系列模型,不过从实测来看,`FLUX` 更香,不知大家体验如何,欢迎评论区交流。
95 |
96 | 如果有更多`AI绘画`的定制化需求,只能本地部署 LoRA + ControlNet 模型。想咋玩,你说了算!
97 |
98 |
99 | ## 4. 效果展示
100 |
101 | 来一波测试案例:
102 |
103 | 
104 |
105 | 
106 |
107 | 
108 |
109 | 
110 |
111 |
112 | 最后,我们来看下日志:
113 |
114 | 
115 |
116 | 意图识别没问题!
117 |
118 | 此外,`gemini`还会帮我把`绘画提示词`润色一下。这下,你还担心`不会写提示词`么?
119 |
120 | ## 写在最后
121 |
122 | 本文通过简单三步为`小爱`接入了`AI 绘画`能力。
123 |
124 | 从此,写公众号,再也不用费劲找封面图了,`小爱`直出,灵感无限!
125 |
126 | 大家有更好的想法,欢迎评论区交流。
127 |
128 | 如果本文对你有帮助,不妨点个**免费的赞**和**收藏**备用。
129 |
130 | 想和`小爱`互动的小伙伴,可以通过公众号找到我,拉你进群体验。
131 |
132 | ---
133 | 为了方便大家交流,新建了一个 `AI 交流群`,欢迎感兴趣的小伙伴加入。
134 |
135 | `小爱`也在群里,想进群体验的朋友,公众号后台「联系我」即可,拉你进群。
136 |
137 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/搞清GPT对话的底层逻辑:4个基本原则+2个实用技巧,助你10倍提效.md:
--------------------------------------------------------------------------------
1 | “GPT写出来的文章实在太差了!”
2 |
3 | “GPT写出来的都是一些无比正确的废话!”
4 |
5 | “GPT写出来的这些玩意儿能用?”
6 |
7 | 我经常听到这些抱怨。别人已经拿着GPT到处搞钱了,你确定你有用好GPT了?
8 |
9 | 学用GPT,关键就看怎么和它对话。
10 |
11 | 今天先聊下我对GPT提示词的认知和思考,带大家搞清楚与GPT对话的底层逻辑。
12 |
13 | 后面几篇会陆续分享“写好提示词”的**实操案例**。
14 |
15 | 还没用上免费GPT4的小伙伴,出门右拐看这里👉:[免费白嫖GPT4,无次数限制,5分钟带你上手](http://mp.weixin.qq.com/s?__biz=MzkzMzY2MTkyNw==&mid=2247483970&idx=1&sn=327fca3a902ef029ca2faab40db91c16&chksm=c2485fcaf53fd6dc38dffa24aa45684816f5a507b3b3ebd5e4bdd872a8502f5f7b818426cad3&scene=21#wechat_redirect)
16 |
17 | ### **01 GPT 写的真不行么?**
18 |
19 | 从我的实践来看,GPT的潜力超出多数人的想象。关键在于,你如何引导它来发挥出无穷的潜力。
20 |
21 | GPT就像一个新来的实习生,对你想要的高质量内容,是缺乏认知的。
22 |
23 | 如果你只是给它下达一条非常宽泛的指令,它的大脑瞬间产生一万种生成概率,最后只能选择最符合机器逻辑的回答吐给你,能不生硬么?
24 |
25 | 通常我们把给GPT下达的指令叫做“提示词”,你会发现,GPT写得不好的根本原因是没有写好与之交流的“提示词”。
26 |
27 | 
28 |
29 | ### **02 为什么提示词非常重要?**
30 |
31 | 提示词和GPT进行交流的关键,就像给GPT的一个启动命令。
32 |
33 | 一个好的提示词能够清晰地传达你的需求,让GPT知道接下来该做什么。而一个模糊不清或含糊的提示词就可能导致不满意的结果。
34 |
35 | 提示词的重要性不仅仅体现在能够使你获得有用的信息,更重要的是能够使GPT的回答变得更加有趣、更有吸引力,甚至更有个性。
36 |
37 | 问题来了,如何才能写好提示词呢?
38 |
39 | ### **03 有效提示词的4个基本原则**
40 |
41 | 创建有效的提示词,通常需要遵循以下四个原则:
42 |
43 | 1. **明确性**:清晰地表达你的需求。比如你想学习摄影技巧,就直接说“我想学习夜景摄影,推荐几个入门级技巧”,而不是模糊地说“教我摄影”。
44 | 2. **相关性**:确保你的请求和你想要的信息相关。如果你想要的是烹饪建议,那就不应该问关于汽车维修的问题。
45 | 3. **简洁性**:尽量用最少的词语表达你的需求。就像在发送消息一样,越精简越好,但同时需要确保信息的完整性。
46 | 4. **指导性**:面对复杂的请求,请把它拆解成多个更容易处理的小问题。按步就班,每次询问一个具体点。
47 |
48 | 举个例子:
49 |
50 | 你想提高个人品牌影响力,可以这样询问GPT:“能否为我提供三种策略,在三个月内通过社交媒体显著提升我的个人品牌?”这样的提问形式会促使GPT给出更为明确且专注的回答,而不是笼统的建议。
51 |
52 | ### **04 写好提示词的2个实用技巧**
53 |
54 | 基于上述4个基本原则,猴哥总结了平时写提示词用到最多的2个小技巧。看看对你有没有帮助?
55 |
56 | ## **场景化**
57 |
58 | 具体到某个使用情景可以大大提高GPT的输出质量。
59 |
60 | 比如,如果你想让GPT写一篇科技文章,不妨设想一个具体的使用场景:"假设你是一个科技记者,需要为科技杂志《前沿科技》写一篇关于AI在医疗领域应用的深度报道。"
61 |
62 | 这样的提示词就远胜于简单的"写一篇科技文章"。
63 |
64 | ## **角色扮演**
65 |
66 | 说白了,就是将GPT视作一个具体角色。
67 |
68 | 比如一个专家、顾问或是故事主角,然后根据这个角色设定,精确地构建你的提示词。
69 |
70 | 这样做不仅能提升与GPT交流的趣味性,还能极大地提高回答的质量和相关性。
71 |
72 | 举个例子,假设你需要一些旅行建议。
73 |
74 | 之前的提示词可能是这样:“我下个月去巴黎旅行,需要一些建议。”
75 |
76 | 采用角色扮演技巧后,可以这样构造提示词:
77 |
78 | "假设你是一位有着丰富巴黎当地经验的旅行顾问,我下个月要去那里旅行。请给我一些当地的隐藏景点建议及美食推荐,另外,如果有哪些旅行小贴士也请不吝赐教。”
79 |
80 | 这样的提示词不仅明确了GPT的**角色**(即一位经验丰富的旅行顾问),还明确说明了你的**需求**(巴黎的隐藏景点、美食推荐和旅行小贴士)。
81 |
82 | 通过这种方式,就算是一个复杂的请求,GPT也能提供更贴切、有趣且有用的回答。
83 |
84 | ### **写在最后**
85 |
86 | 我相信,要做好任何一件事,首先要找到可遵循的成体系的方法论,写提示词也不例外。
87 |
88 | 你会发现,和GPT对话,其实和平时与人沟通是一样的,本质上都是在经历这个过程:**明确需求 -> 表达清晰 -> 确认理解**。
89 |
90 | 慢慢地你会发现,学习的过程中你一直在:**锻炼结构化思考,学会结构化表达**。
91 |
92 | 如果你能用好提示词,从GPT那获取到想要的内容,你在平时与人交往的过程中,沟通和表达能力一定不会太差。
93 |
94 | 今天先分享这些,后续会带来分享两套简洁易上手的“写提示词”的模板。
95 |
96 | 如果对你有帮助,欢迎点亮【赞和在看】,让GPT服务好更多身边的朋友。
--------------------------------------------------------------------------------
/docs/3.AI笔记/最快开源AI视频生成!STG+LTX-Video,4秒极速成片,免费尝鲜.md:
--------------------------------------------------------------------------------
1 | 相对图片生成,AI 视频生成一直没有低成本的解决方案。
2 |
3 | 从快手的可灵、智谱的清影,再到 OpenAI的 Sora,但这些模型都是闭源的。
4 |
5 | 要问**开源界**有没有能打的?
6 |
7 | 之前有分享过三款:
8 | - [EasyAnimate-v3 实测,阿里开源视频生成模型,5 分钟带你部署体验,支持高分辨率超长视频](https://zhuanlan.zhihu.com/p/710131990)
9 |
10 | - [我把「国产Sora」接入了「小爱」,邀你免费体验](https://zhuanlan.zhihu.com/p/748148202)
11 |
12 | - [开源视频生成 Pyramid Flow 本地部署实测](https://zhuanlan.zhihu.com/p/3489126869)
13 |
14 | 但,生成质量总归是差强人意,生成速度,也差点意思。
15 |
16 | 最近,当前最快的文生视频模型诞生了:LTX-Video。
17 |
18 | 先别管质量,至少速度上提高了一个数量级!
19 |
20 | 在 Nvidia H100,生成 5 秒时长的 24FPS 768x512 视频,只需 4 秒!
21 |
22 | 今日分享,带大家实战:最快 AI 视频生成项目 LTX-Video,并接入微信机器人。
23 |
24 |
25 | ## 1. LTX-Video简介
26 |
27 | > 项目地址:[https://github.com/Lightricks/LTX-Video](https://github.com/Lightricks/LTX-Video)
28 |
29 | LTX-Video 来自押注开源人工智能视频的初创公司 Lightricks,它是**首个**基于扩散变换器 (DiT) 架构的模型,参数量 2B,可在 RTX 4090 等消费级 GPU 上跑。(**划重点:至少确保 24G 显存**)
30 |
31 |
32 | 老规矩,简单介绍下项目亮点:
33 |
34 | - **可扩展的长视频制作**:能够生成扩展的高质量视频,具有一致性和可扩展性,相对CogVideo 灵活性更高。
35 | - **更快的渲染时间**:针对GPU和TPU系统进行优化,在保持高视觉质量的同时大幅缩短视频生成时间。
36 | - **运动和结构一致性**:独特帧间学习确保了帧与帧之间的连贯过渡,消除了场景中的闪烁和不一致问题。
37 |
38 | 从官方放出的案例来看,效果还是相当惊艳的。
39 |
40 | 
41 |
42 |
43 | 实测效果到底如何?
44 |
45 | 接着往下看!
46 |
47 | ## 2. LTX-Video 本地部署
48 |
49 | >本地部署前,有两点需要注意:
50 | >- **至少确保 50G 磁盘空间**;
51 | >- **至少确保 24G 显存**。
52 |
53 | 参考项目首页,安装项目依赖。
54 |
55 | ```
56 | git clone https://github.com/Lightricks/LTX-Video.git
57 | cd LTX-Video
58 | ```
59 |
60 |
61 | 然后,最耗时的就是下载模型权重,包括两部分:
62 | ```
63 | from huggingface_hub import snapshot_download
64 |
65 | # 原始模型权重 - 33G
66 | snapshot_download("Lightricks/LTX-Video", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
67 | # 文本编码器权重 - 17G
68 | snapshot_download("PixArt-alpha/PixArt-XL-2-1024-MS", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
69 | ```
70 |
71 |
72 | 如果希望进一步提高视频质量,可参考 STG 项目:[https://github.com/junhahyung/STGuidance](https://github.com/junhahyung/STGuidance)
73 |
74 | STG 是一种用于增强扩散器的采样指导方法,无需下载额外的模型,只需修改模型中特定层的采样方法,即可得到更高质量的视频效果。
75 |
76 | 亲测有效,感兴趣的可以去试下。
77 |
78 | ## 3. LTX-Video API 调用
79 |
80 | 本地部署毕竟太吃资源了。
81 |
82 | 目前,硅基流动 SiliconCloud 已上线 LTX-Video,关键是**免费调用**。
83 |
84 | 
85 |
86 |
87 | 首先,前往 [硅基流动](https://cloud.siliconflow.cn?referrer=clxv36914000l6xncevco3u1y) 注册账号,并生成一个 API key。
88 |
89 | 然后,查看 [API文档](https://docs.siliconflow.cn/api-reference/videos/videos_submit):视频生成是异步服务,也即:首先获取请求 ID,再根据请求 ID 轮询生成状态。
90 |
91 | 为此,Python 端的示例代码如下:
92 |
93 | ```
94 | def test_video():
95 | headers = {
96 | "Authorization": "Bearer ",
97 | "Content-Type": "application/json"
98 | }
99 | payload = {
100 | "model": "Lightricks/LTX-Video",
101 | "prompt": "A gust of wind blows through the trees, causing the woman’s veil to flutter slightly.",
102 | "seed": 2024,
103 | }
104 |
105 | response = requests.request("POST", "https://api.siliconflow.cn/v1/video/submit", json=payload, headers=headers)
106 | if response.status_code == 200:
107 | rid = response.json()['requestId']
108 | while True:
109 | response = requests.request("POST", "https://api.siliconflow.cn/v1/video/status", json={"requestId": rid}, headers=headers)
110 | if response.status_code == 200 and response.json()['status'] == 'Succeed':
111 | return response.json()['results']['videos'][0]['url']
112 | time.sleep(5)
113 | ```
114 |
115 |
116 | > 需注意的是:LTX-Video 也支持`图生视频`,但如果用 SiliconCloud 的API,`文生视频`免费,`图生视频`是要付费的哦。
117 |
118 | 
119 |
120 | ## 4. 接入微信机器人
121 |
122 | 前端时间,搭建了一个微信机器人-`小爱`,接入的视频生成能力,来自本地部署的 CogVideo。
123 |
124 | 现在,无论从生成质量,还是生成速度,都有必要把 CogVideo 换了。
125 |
126 | 流程还是一样:首先采用 LLM 润色,得到英文提示词,然后交由视频生成模型。
127 |
128 | 来看看测试效果吧:
129 |
130 | 
131 |
132 | 
133 | 
134 |
135 | ## 写在最后
136 |
137 | 本文带大家实操体验了最新开源的**AI 视频生成**项目,LTX-Video,并成功接入了微信机器人-`小爱`,邀你围观体验。
138 |
139 | 如果对你有帮助,欢迎**点赞收藏**备用。
140 |
141 | ---
142 |
143 | 为方便大家交流,新建了一个 `AI 交流群`,`小爱`也在群里,公众号后台「联系我」,拉你进群。
144 |
145 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/超强!实时AI换脸,支持任意角色替换,5分钟部署体验.md:
--------------------------------------------------------------------------------
1 |
2 | 你以为刷到的短视频都是真人出镜?
3 |
4 | 其实,换脸、数字人技术早已走向了商业化。
5 |
6 | 之前大部分的换脸模型,都需要大量样本进行训练,技术门槛非常高!
7 |
8 | 今天看到一个开源项目-ReHiFace-S,支持一键实时换脸的开源项目,只需一张人脸照片,即可将视频中的人脸,替换为你想要的人物形象。
9 |
10 | 话不多说,上实操!
11 |
12 | ## 1. 项目简介
13 | > 项目地址:[https://github.com/GuijiAI/ReHiFace-S](https://github.com/GuijiAI/ReHiFace-S)
14 |
15 | ReHiFace-S(Real Time High-Fidelity Faceswap)是由硅基智能开发的,实时高保真的换脸算法。
16 |
17 | 实时换脸功能,是开源数字人生成的底层能力。
18 |
19 | 有哪些亮点?
20 |
21 | 1. **实时处理**:在 NVIDIA GTX 1080Ti 显卡上,即可实现实时换脸。(*当然 CPU 也能跑,只要速度你能忍。。。*)
22 | 2. **零样本推断**:无需训练数据即可进行有效推断。
23 | 3. **高保真度**:换脸效果逼真,能够生成高质量的面部图像。
24 | 4. **支持 ONNX 和实时摄像头模式**:便于与其他模型或应用集成。
25 | 5. **超分辨率与色彩转换**:提升图像质量,增强视觉效果。
26 | 6. **更好的 Xseg 模型**:用于面部分割,提升换脸精度。
27 |
28 | ## 2. 项目实战
29 | ### 2.1 环境准备
30 | 要运行此项目,建议使用以下环境配置:
31 | - Python >= 3.9(推荐使用 Anaconda 或 Miniconda)
32 | - PyTorch >= 1.13
33 | - CUDA 11.7
34 | - 操作系统:Linux Ubuntu 20.04
35 |
36 | 1. 克隆代码库并准备环境:
37 | ```bash
38 | conda create --name faceswap python=3.9
39 | conda activate faceswap
40 | pip install -r requirements.txt
41 | ```
42 | 2. 下载预训练模型权重,并将其放入 `./pretrain_models` 文件夹中。
43 |
44 |
45 | ### 2.2 本地测试
46 | 先使用默认示例图片和视频跑下看看:
47 |
48 | ```bash
49 | CUDA_VISIBLE_DEVICES='0' python inference.py
50 | ```
51 | 也可以通过指定 `--src_img_path` 和 `--video_path` 参数来更改输入。
52 |
53 | ```
54 | CUDA_VISIBLE_DEVICES='0' python inference.py --src_img_path --video_path
55 | ```
56 |
57 | 如果要在摄像头中进行实时换脸:
58 | ```bash
59 | CUDA_VISIBLE_DEVICES='0' python inference_cam.py
60 | ```
61 | 注意:支持在直播中更换源面孔。
62 |
63 | 如果遇到 onnxruntime 报错:
64 |
65 | ```
66 | onnxruntime::Provider& onnxruntime::ProviderLibrary::Get() [ONNXRuntimeError] : 1 : FAIL : Failed to load library libonnxruntime_providers_cuda.so with error: libonnxruntime_providers_cuda.so: cannot open shared object file: No such file or directory
67 | ```
68 |
69 | 比如上面这个,首先找到 "libonnxruntime_providers_cuda.so" 的安装位置:
70 |
71 | ```
72 | find / -name "libonnxruntime_providers_cuda.so" 2>/dev/null
73 | ```
74 | 然后把它添加到环境变量中,
75 |
76 | ```
77 | export LD_LIBRARY_PATH=/path/to/onnxruntime/lib:$LD_LIBRARY_PATH
78 | ```
79 |
80 |
81 | ### 2.3 Web 应用
82 | 项目还提供了 Gradio 搭建的应用,可以通过以下命令一键运行:
83 | ```bash
84 | python app.py
85 | ```
86 | 界面非常简洁,输入你想要换的人脸图像,和原始视频,提交即可!
87 |
88 | 
89 |
90 | 注意:确保你的 onnxruntime 跑在 GPU 上,否则 CPU 跑就。。。
91 |
92 | 最后,展示下实测效果(CSDN无法支持gif):
93 | 
94 | ## 结论
95 | ReHiFace-S 是一个功能强大且灵活的换脸工具,其实时处理能力和高保真的换脸效果,为数字人应用提供了新的可能性。
96 |
97 | 基于 ReHiFace-S ,硅基智能的数字人:[https://github.com/GuijiAI/duix.ai](https://github.com/GuijiAI/duix.ai),也已开源。
98 |
99 | 支持 Android 和 IOS 终端一键部署,开发者可自行接入大模型(LLM)、语音识别(ASR)、语音合成(TTS),实现数字人实时交互。
100 |
101 | 有机会实操后,再和大家分享!
102 |
103 | 如果本文对你有帮助,不妨点个**免费的赞**和**收藏**备用。
104 |
105 | 有任何问题欢迎通过公众号找到我,一起打怪升级。
106 |
107 |
108 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/跑本地大模型,强推的一款浏览器插件,敏感数据不外传.md:
--------------------------------------------------------------------------------
1 |
2 | 前几篇文章,带大家在本地把大模型部署了。
3 |
4 | 问题来了:这黑洞洞的终端,用它和大模型聊天,总感觉少了点“人情味”。
5 |
6 | **是时候给大模型一个“看得见”的家了!**
7 |
8 | 又要装软件?别了吧,电脑快被各种客户端塞爆了……
9 |
10 | 今日分享,带来一款开源的浏览器插件 - `page-assist`,界面清新脱俗,安装超级简单。
11 |
12 | 关键是**体验丝滑**,想想看,现在谁还不是个“浏览器战士”?工作、学习、娱乐,一个浏览器全搞定。
13 |
14 | 而 `page-assist` 就在你的浏览器中,随时召唤!
15 |
16 | ## 1. page-assist 简介
17 | > 开源地址:[https://github.com/n4ze3m/page-assist](https://github.com/n4ze3m/page-assist)
18 |
19 | Page Assist 是一个开源浏览器插件,同时提供侧边栏和网页界面,主要用于与本地 AI 模型进行交互。
20 |
21 | 
22 |
23 | 它支持基于 Chromium 的浏览器,如 Chrome、Edge,以及 Firefox。
24 |
25 | ## 2. page-assist 安装
26 |
27 | 安装有两种方式。
28 |
29 | ### 2.1 一键安装 chrome 插件
30 | 如果使用 Google Chrome 浏览器,挂个梯子,下面插件地址,点击一键安装。
31 |
32 | 
33 |
34 |
35 | 
36 |
37 | ### 2.2 下载安装包
38 | > 下载地址:[https://github.com/n4ze3m/page-assist/releases](https://github.com/n4ze3m/page-assist/releases)
39 |
40 | **step1**: 下载对应浏览器的插件包,并解压出来。
41 |
42 | 
43 |
44 | **step2**: 在浏览器地址栏中输入 `chrome://extensions/` 回车。
45 |
46 | **step3**: 启用开发者模式,加载已解压的扩展程序。
47 |
48 | 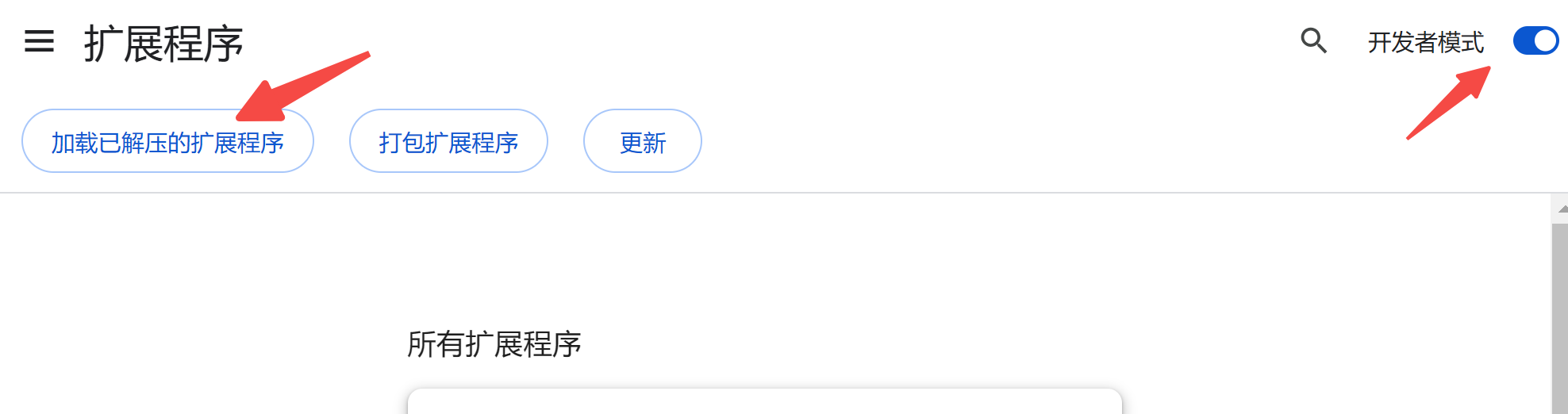
49 |
50 |
51 | ## 3. page-assist 使用
52 | 安装完成,在你的浏览器插件列表中,即可看到 `page-assist` 的 logo。
53 |
54 | 有两种使用方式:
55 | - 点击:网页界面使用
56 | - 右键:侧边栏使用
57 |
58 | ### 3.1 网页界面使用
59 | 在网页界面,可以完成对 `page-assist` 的一系列配置。
60 |
61 | 右上角点击 设置 图标,打开即可看到如下配置界面,用于接入你的大模型和知识库。
62 |
63 | - **Ollama 配置**:用于接入你本地部署的 Ollama 模型,这是 `page-assist` 项目的初衷。
64 | - **OpenAI 兼容 API**:当然也支持 API 接入。
65 |
66 | 
67 |
68 | 不多说了,大家去点一点就熟悉了。
69 |
70 | ### 3.2 侧边栏使用
71 | **右键->打开侧边栏**,即可在浏览器右侧打开聊天对话框。
72 |
73 | 遇到任何和网页相关的疑问,随手就问,`page-assist` 会帮你抓取网页内容,送给大模型作为上下文。
74 |
75 | 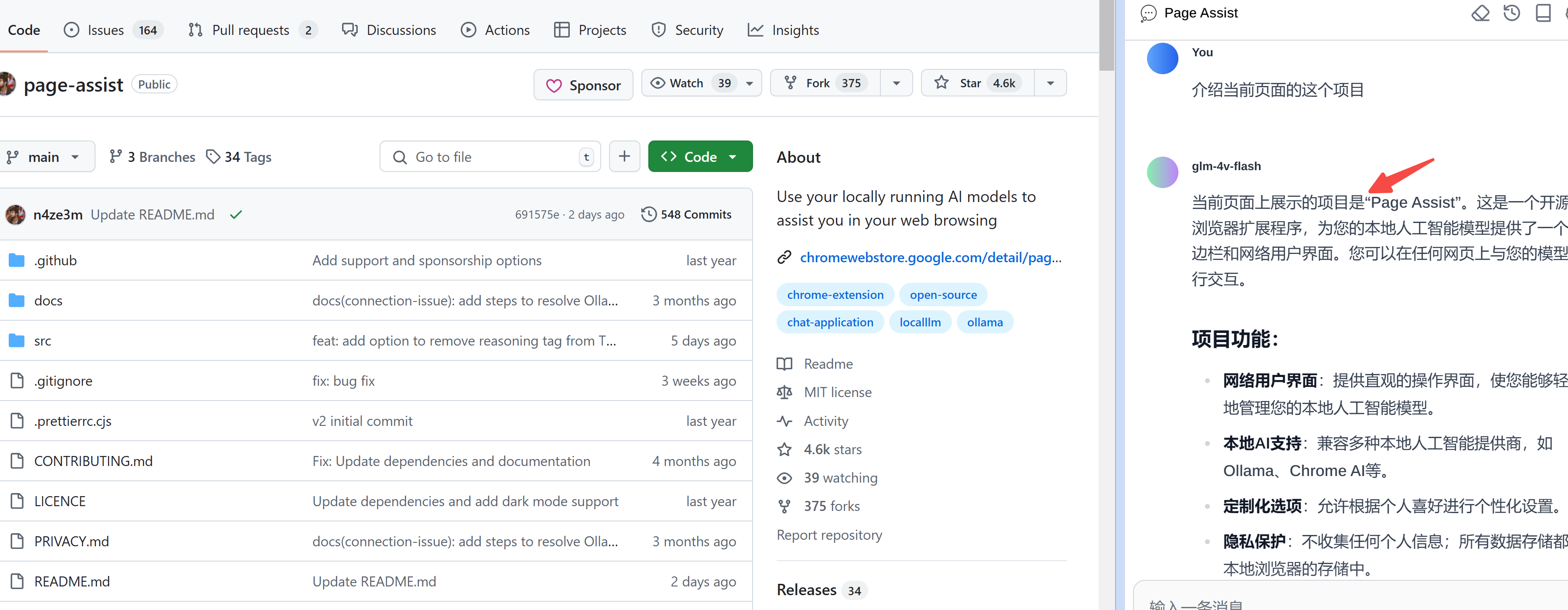
76 |
77 | 遇到英文网页,还要啥翻译插件?
78 |
79 | 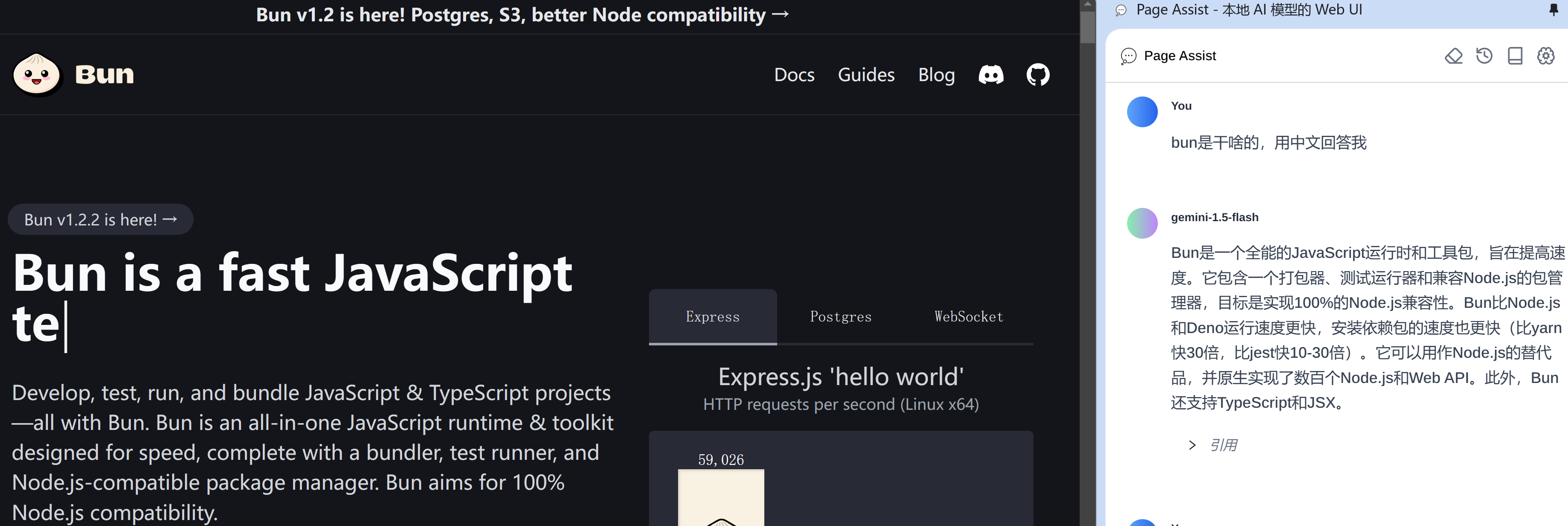
80 |
81 | ## 写在最后
82 |
83 | 本文分享了一款浏览器插件 - `page-assist` ,提供跑本地 AI 大模型的 UI 界面,无需复杂的安装步骤,web 端体验非常丝滑。
84 |
85 | 如果对你有帮助,欢迎**点赞收藏**备用。
86 |
87 | ---
88 |
89 | 为方便大家交流,新建了一个 `AI 交流群`,公众号后台「联系我」,拉你进群。
90 |
91 |
92 |
--------------------------------------------------------------------------------
/docs/3.AI笔记/链接丢给它,精华吐出来!微信AI小助理又行了,附完整提示词.md:
--------------------------------------------------------------------------------
1 | 前两天,搞了个微信 AI 小助理,爸妈玩的不亦乐乎。
2 |
3 | - [零风险!零费用!我把AI接入微信群,爸妈玩嗨了,附教程(上)](https://zhuanlan.zhihu.com/p/717945448)
4 | - [零风险!零费用!我把AI接入微信群,爸妈玩嗨了,附教程(下)](https://zhuanlan.zhihu.com/p/718126892)
5 |
6 | 有朋友问,还能干点啥?
7 |
8 | 可玩的花样可多了~
9 |
10 | 最近关注的公众号有点多,根本看不完。我在想:把链接丢给小助理,让它帮我把文章大纲整理出来,这样岂不双赢:既不会遗漏重要内容,又节省了大量时间。
11 |
12 | 说干就干!
13 |
14 | 前两篇整体框架已经搭建好了,现在做的无非就是给小助理装上三头六臂!
15 |
16 | 本文将手把手带大家,实现小助理的 AI 摘要功能。
17 |
18 | 整个过程只需 4 步:
19 |
20 | - 获取微信公众号文章链接;
21 | - 爬取文章内容;
22 | - 编写提示词,调用 LLM 进行总结;
23 | - 调用发送消息接口,返回摘要内容。
24 |
25 | 话不多说,上实操!
26 |
27 | >友情提醒:注册小号使用,严禁用于违法用途(如发送广告/群发/诈骗、色情、政治等内容),否则封号是早晚的事哦。
28 |
29 | ## 1. 获取文章链接
30 |
31 | 微信公众号文章转发到微信,消息类型是 `urlLink`。
32 |
33 | 为此,只需要在上篇处理消息的逻辑基础上,修改下路由,单独处理`urlLink`类型的消息:
34 |
35 | ```
36 | def handle_message(message_type='text', content='', source='', is_from_self="0"):
37 | if is_from_self == "1":
38 | return
39 | if message_type == "text":
40 | bot_answer = handle_text(content)
41 | if message_type == "urlLink":
42 | bot_answer = handle_url(content)
43 | ```
44 |
45 | 消息内容 `content` 中有一个 `url` 字段,这就是文章链接。
46 |
47 | 拿到文章链接,我们就可以写一个爬虫,爬取文章完整内容。
48 |
49 | ## 2. 爬取文章内容
50 |
51 | 爬取文章内容的方式有很多。
52 |
53 | 之前给大家分享 [`dify 使用教程`](https://zhuanlan.zhihu.com/p/716040790) 时,用过`firecrawl`这个爬虫插件,把网页自动转存为 markdown 内容,非常方便,免费用户有使用额度。
54 |
55 | 如果不想装整个插件,那么我们完全可以自己动手,写一个简单的爬虫!
56 |
57 | 只需要用到`requests`和`bs4`即可:
58 |
59 | ```
60 | import requests
61 | from bs4 import BeautifulSoup
62 | response = requests.get(url, headers=headers)
63 | soup = BeautifulSoup(response.text, 'html.parser')
64 | content = soup.find('div', attrs={'id': 'js_content'}) # html文件
65 | ```
66 |
67 | 上面得到的内容是 `html` 格式,当然直接把它送给 LLM 也是没问题的。
68 |
69 | 如果吝啬你宝贵的 `Token` 资源,那么强烈建议你用上这个库:`html2text`,一键将`html` 转存成 `markdown`。
70 |
71 | ```
72 | import html2text
73 | h = html2text.HTML2Text()
74 | markdown_content = h.handle(str(content))
75 | ```
76 |
77 | 有了文章内容,接下来我们送给 LLM,让它给提炼出文章大纲。
78 |
79 | ## 3. 调用 LLM 进行总结
80 |
81 | 直接丢给 LLM 么?
82 |
83 | 当然可以,但如果希望得到的结果可控且可靠,最好设计下角色提示词。
84 |
85 | 下面是我针对这个任务,编写的提示词,供小伙伴们参考:
86 |
87 | ```
88 | sys_prompt_kp = '''
89 | - Role: 文章分析专家
90 | - Background: 用户需要对一篇给定的文章进行关键点总结,并生成文章的大纲。
91 | - Profile: 你是一位经验丰富的编辑,擅长提炼文章核心思想和结构化信息。
92 | - Skills: 文章阅读、关键点提取、信息组织、大纲创建。
93 | - Goals: 帮助用户从文章中提取关键点,并生成清晰的大纲。
94 | - Constrains: 确保大纲简洁明了,覆盖文章所有主要观点。
95 | - OutputFormat: 文章大纲,以列表形式呈现。
96 | - Workflow:
97 | 1. 阅读并理解文章内容。
98 | 2. 提取文章中的关键点和主要论点。
99 | 3. 根据提取的关键点创建文章大纲。
100 | 4. 只输出markdown格式的文章大纲,不要回答其他任何内容。
101 | '''
102 | ```
103 |
104 | 来吧,这下应该没什么问题了:
105 |
106 | ```
107 | def article_summary(data, model_name='gemini-1.5-pro'):
108 | messages = [
109 | {'role': 'system', 'content': sys_prompt_kp},
110 | {'role': 'user', 'content': data['content']},
111 | ]
112 | summary = unillm(model_name, messages)
113 | return summary
114 | ```
115 |
116 | ## 4. 调用发送消息接口
117 |
118 | 最后,我们把上面两个函数打包一下:
119 |
120 | ```
121 | def handle_url(content='', url=''):
122 | # 处理公众号链接
123 | if content:
124 | content = json.loads(content)
125 | url = content['url']
126 | if 'weixin.qq.com' in url:
127 | data = get_gzh_article(url, content_only=False)
128 | else:
129 | data = {}
130 | summary = article_summary(data, model_name='gemini-1.5-flash')
131 | return summary
132 | ```
133 |
134 | 一旦判定消息类型为 `urlLink`,直接调用上面的 `handle_url` 进行处理,并将结果用上篇提到的`发送消息接口`进行返回。
135 |
136 | 注:后面发现,转发文章中的链接,简单的爬虫无法搞定:`当前环境异常,完成验证后即可继续访问`。
137 |
138 | 所以:退而求其次,直接发送原文链接。
139 |
140 | 暂且先这么搞吧,小伙伴有其它方法的,欢迎评论区交流。
141 |
142 | ## 5. 看看效果吧
143 |
144 | 先找一篇技术干货,把之前写的 Ollama 教程发给它:[本地部署大模型?Ollama 部署和实战,看这篇就够了](https://zhuanlan.zhihu.com/p/710560829)
145 |
146 | 
147 |
148 | 再来一篇宣传软文:
149 |
150 | 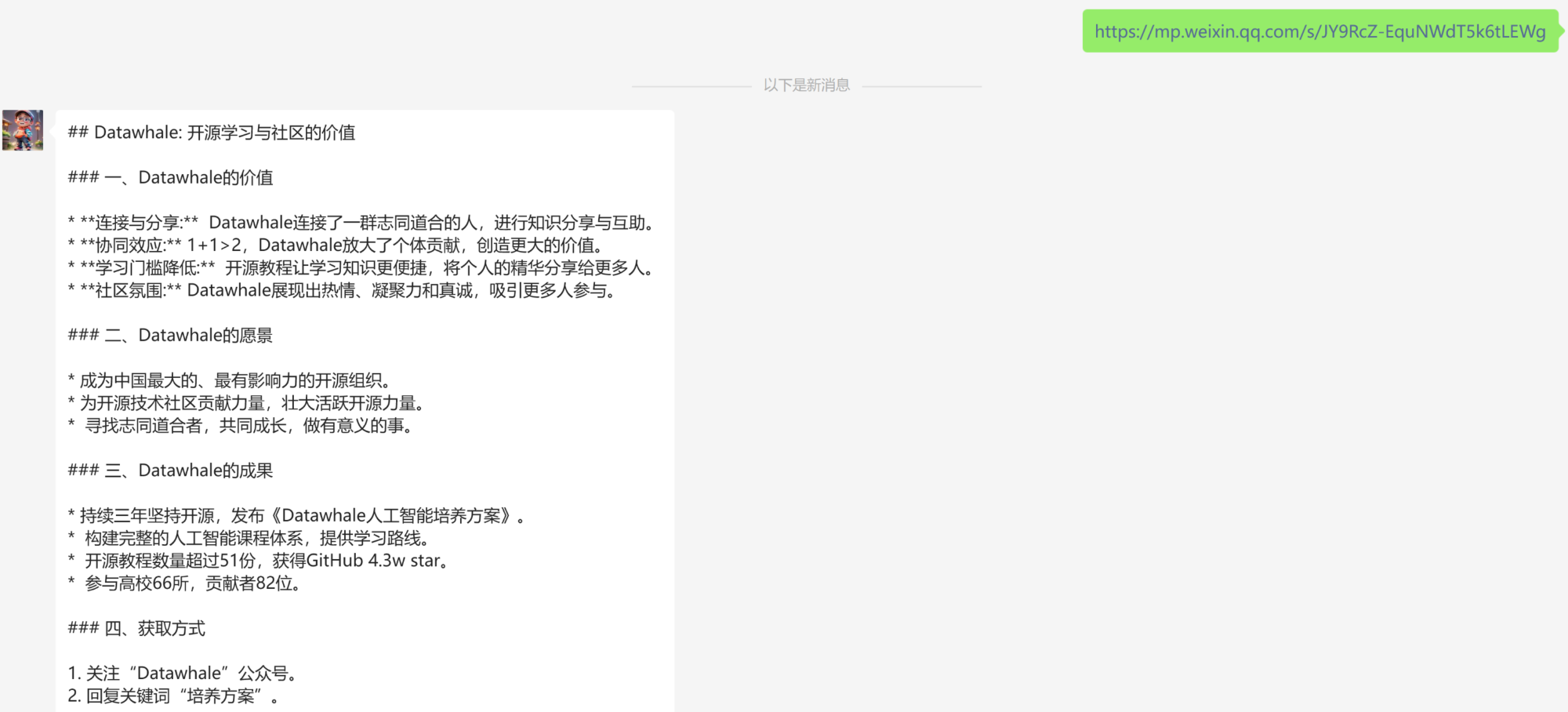
151 |
152 | 怎么样?
153 |
154 | ## 写在最后
155 |
156 | 终于,给`小爱`装上了`阅读理解神器`,以后再也不用担心错过重要文章了。
157 |
158 | 不管是硬核技术文还是软萌广告文,链接丢给它,精华吐出来。
159 |
160 | `我不想读,但我想知道`的必备神器!
161 |
162 | 当然,`小爱`还有无限想象空间,之前部署了很多 AI 服务,我打算慢慢接进来,把`小爱`打造成身边的超级助理!
163 |
164 | 大家有什么需求 or 想法,欢迎评论区交流。
165 |
166 | 如果本文对你有帮助,不妨点个**免费的赞**和**收藏**备用。
167 |
168 | ---
169 | 为了方便大家交流,新建了一个 `AI 交流群`,欢迎感兴趣的小伙伴加入。
170 |
171 | `小爱`也在群里,想进群体验的朋友,公众号后台「联系我」即可,拉你进群。
172 |
173 |
174 |
175 |
176 |
177 |
178 |
179 |
180 |
181 |
--------------------------------------------------------------------------------
/docs/4.Python笔记/Django后端开发入门 之 构建数据表并合并.md:
--------------------------------------------------------------------------------
1 | > 摘要:本文是基于[项目文档](https://gitee.com/liuwei16/sweettalk-django4.2#day2)来完成day2的任务,day2的任务是构建数据表并合并,通过项目文档了解数据表构建的基本原理,并尝试通过命令将代码和数据库关联上。
2 |
3 | ## 如何创建数据表
4 | 在项目文档中提高需要创建两个数据表,注意应该是在day1新建的apps/erp_test文件夹下,有个model.py文件,采用项目文档中的代码,同时需要注意import相关的模块:
5 |
6 | ```python
7 | from django.db.models import Model, CharField, IntegerField, FloatField, ForeignKey, SET_NULL
8 | ```
9 |
10 | ## 配置数据表的字段
11 | 按照项目文档执行,需要注意的是第5行这里:应该去掉'goods.',应该我们没有新建goods app
12 |
13 | ```python
14 | category = ForeignKey('goods.GoodsCategory',
15 | ```
16 | 否则会出现如下报错:
17 |
18 | ```python
19 | SystemCheckError: System check identified some issues:
20 |
21 | ERRORS:
22 | erp_test.Goods.category: (fields.E300) Field defines a relation with model 'goods.GoodsCategory', which is either not installed, or is abstract.
23 | erp_test.Goods.category: (fields.E307) The field erp_test.Goods.category was declared with a lazy reference to 'goods.goodscategory', but app 'goods' isn't installed.
24 | ```
25 |
26 | ## 执行迁移
27 | 按照项目文档执行:
28 | ```python
29 | python manage.py makemigrations
30 | python manage.py migrate
31 | ```
32 | 看到成功信息:
33 |
34 | ```python
35 | Operations to perform:
36 | Apply all migrations: admin, auth, contenttypes, erp_test, sessions
37 | Running migrations:
38 | Applying erp_test.0001_initial... OK
39 | ```
40 |
41 |
--------------------------------------------------------------------------------
/docs/4.Python笔记/Django后端开发入门指南 之 环境配置.md:
--------------------------------------------------------------------------------
1 | > 摘要:入门后端开发,必须理论结合实践。本系列文章将结合Datawhale 10月份的打卡活动,通过全身心体验,记录项目开发过程中遇到的一些问题和总结开发过程中的一些心得体会。
2 |
3 | ## 如何快速访问github
4 | 由于种种原因,国内很难访问github,我是通过将GitHub上的仓库import到gitee进行解决
5 | ## 安装python虚拟环境
6 | 在windows下使用virtualenv:如果发现无法activate,可以参考这篇文章加以解决:[link](https://blog.csdn.net/weixin_44548098/article/details/129944030)
7 |
8 | ## 搭建项目
9 | - 新建文件夹,命名为erp
10 | - 新建apps文件夹用于存放app
11 | - 建立app-erp_test:
12 | - django-admin startapp erp_test
13 | - 配置settings.py文件,将新安装的app包导入
14 | - 运行项目:python manage.py runserver,在浏览器中输入http://127.0.0.1:8000/就可以看到项目成功运行
15 |
--------------------------------------------------------------------------------
/docs/4.Python笔记/README.md:
--------------------------------------------------------------------------------
1 | # 4.Python笔记
2 |
3 | - [Django后端开发入门 之 ModelViewSet和自定义函数](docs/4.Python笔记/Django后端开发入门%20之%20ModelViewSet和自定义函数.md)
4 | - [Django后端开发入门 之 序列化和APIView模式](docs/4.Python笔记/Django后端开发入门%20之%20序列化和APIView模式.md)
5 | - [Django后端开发入门 之 引入admin后台_QuerySet和Instance使用](docs/4.Python笔记/Django后端开发入门%20之%20引入admin后台_QuerySet和Instance使用.md)
6 | - [Django后端开发入门 之 构建数据表并合并](docs/4.Python笔记/Django后端开发入门%20之%20构建数据表并合并.md)
7 | - [Django后端开发入门指南 之 环境配置](docs/4.Python笔记/Django后端开发入门指南%20之%20环境配置.md)
8 | - [【7天Python入门系列】Day1:Windows 环境准备 - Conda 和 VS code 安装](docs/4.Python笔记/【7天Python入门系列】Day1:Windows%20环境准备%20-%20Conda%20和%20VS%20code%20安装.md)
9 | - [【Python 实战】wordcloud 带你生成漂亮的词云图](docs/4.Python笔记/【Python%20实战】wordcloud%20带你生成漂亮的词云图.md)
10 | - [【Python 实战】一键生成 PDF 报告,图文并茂,代码全公开_2024-07-31](docs/4.Python笔记/【Python%20实战】一键生成%20PDF%20报告,图文并茂,代码全公开_2024-07-31.md)
11 | - [【Python 实战】如何优雅地实现 PDF 去水印?_2024-07-31](docs/4.Python笔记/【Python%20实战】如何优雅地实现%20PDF%20去水印?_2024-07-31.md)
12 | - [【Python 实战】文字 & 二维码检测_2024-07-31](docs/4.Python笔记/【Python%20实战】文字%20&%20二维码检测_2024-07-31.md)
13 | - [【Python 实战】自动化处理 PDF 文档,完美实现 WPS 会员功能_2024-07-31](docs/4.Python笔记/【Python%20实战】自动化处理%20PDF%20文档,完美实现%20WPS%20会员功能_2024-07-31.md)
14 | - [【PyTorch笔记】训练时显存一直增加到 out-of-memory?真相了!](docs/4.Python笔记/【PyTorch笔记】训练时显存一直增加到%20out-of-memory?真相了!.md)
15 | - [一文搞清python中的argparse与sys.argv方法,argparse和sys.argv可以一起使用么?](docs/4.Python笔记/一文搞清python中的argparse与sys.argv方法,argparse和sys.argv可以一起使用么?.md)
16 | - [一键获取所有微信聊天记录(附PyQT6入门实战)](docs/4.Python笔记/一键获取所有微信聊天记录(附PyQT6入门实战).md)
17 | - [微信聊天记录导出为电脑文件实操教程(附代码)](docs/4.Python笔记/微信聊天记录导出为电脑文件实操教程(附代码).md)
18 | - [我把和老婆近一年的聊天记录发给Kimi,它的回答亮了...](docs/4.Python笔记/我把和老婆近一年的聊天记录发给Kimi,它的回答亮了....md)
19 | - [用Python爬取公众号历史所有文章,看这篇就够了](docs/4.Python笔记/用Python爬取公众号历史所有文章,看这篇就够了.md)
20 | - [自制神器!家长小朋友的福音~](docs/4.Python笔记/自制神器!家长小朋友的福音~.md)
21 |
22 |
23 |
24 | *本系列共更新**18**篇文章*
25 |
26 |
27 |
28 | [🔙返回首页](/)
29 |
--------------------------------------------------------------------------------
/docs/4.Python笔记/【PyTorch笔记】训练时显存一直增加到 out-of-memory?真相了!.md:
--------------------------------------------------------------------------------
1 |
2 | 最近用 Pytorch 训模型的过程中,发现总是训练几轮后,出现显存爆炸 out-of-memory 的问题,询问了 ChatGPT、查找了各种文档。。。
3 |
4 | 在此记录这次 debug 之旅,希望对有类似问题的小伙伴有一点点帮助。
5 |
6 | # 问题描述:
7 |
8 | 训练过程中,网络结构做了一些调整,forward 函数增加了部分计算过程,突然发现 16G 显存不够用了。
9 |
10 | 用 nvidia-smi 观察显存变化,发现显存一直在有规律地增加,直到 out-of-memory。
11 |
12 | # 解决思路:
13 | ## 尝试思路1:
14 | 计算 loss 的过程中是否使用了 item() 取值,比如:
15 |
16 | ```
17 | train_loss += loss.item()
18 | ```
19 |
20 | 发现我不存在这个问题,因为 loss 是最后汇总计算的。
21 |
22 | ## 尝试思路2:
23 | 训练主程序中添加两行下面的代码,实测发现并没有用。
24 | ```
25 | torch.backends.cudnn.enabled = True
26 | torch.backends.cudnn.benchmark = True
27 | ```
28 |
29 | 这两行代码是干啥的?
30 |
31 | 大白话:设置为 True,意味着 cuDNN 会自动寻找最适合当前配置的高效算法,来获得最佳运行效率。这两行通常一起是哦那个
32 |
33 | 所以:
34 | - 如果网络的输入数据在尺度或类型上变化不大,设置 `torch.backends.cudnn.benchmark = True` 可以增加运行效率;
35 | - 如果网络的输入数据在每次迭代都变化,比如多尺度训练,会导致 cnDNN 每次都会去寻找一遍最优配置,**这样反而会降低运行效率**。
36 |
37 |
38 | ## 尝试思路3:
39 | 及时删除临时变量和清空显存的 cache,例如在每轮训练后添加:
40 | ```
41 | torch.cuda.empty_cache()
42 | ```
43 | 依旧没有解决显存持续增长的问题,而且如果频繁使用 `torch.cuda.empty_cache()`,会显著增加模型训练时长。
44 |
45 | ## 尝试思路4:
46 | 排查显存增加的代码位置,既然是增加了部分代码导致的显存增加,那么问题肯定出现在这部分代码中。
47 |
48 | 为此,可以逐段输出显存占用量,确定问题点在哪。
49 |
50 | 举个例子:
51 |
52 | ```
53 | print("训练前:{}".format(torch.cuda.memory_allocated(0)))
54 | train_epoch(model,data)
55 | print("训练后:{}".format(torch.cuda.memory_allocated(0)))
56 | eval(model,data)
57 | print("评估后:{}".format(torch.cuda.memory_allocated(0)))
58 | ```
59 |
60 | ## 最终方案:
61 | 最终发现的问题是:我在模型中增加了 `register_buffer`:
62 |
63 | ```
64 | self.register_buffer("positives", torch.randn(1, 256))
65 | self.register_buffer("negatives", torch.randn(256, self.num_negatives))
66 | ```
67 |
68 | 但 **register_buffer** 注册的是非参数的 Tensor,它只是被保存在模型的状态字典中,并不会进行梯度计算啊。
69 |
70 | 为了验证这一点,还打印出来验证了下:
71 |
72 | ```
73 | # for name, param in model.named_parameters():
74 | for name, param in model.named_buffers():
75 | print(name, param.shape, param.requires_grad)
76 |
77 | # 输出如下:
78 | positives torch.Size([1, 256]) False
79 | negatives torch.Size([256, 20480]) False
80 | ```
81 |
82 | 但是这个 `buffer` 却是导致显存不断增加的罪魁祸首。
83 |
84 | 为此,赶紧把和 `buffer` 相关的操作放在 **torch.no_grad()** 上下文中,问题解决!
85 |
86 | ```
87 | @torch.no_grad()
88 | def dequeue_samples(self, positives, negatives):
89 | if positives.shape[0] > 0:
90 | self.positives = 0.99*self.positives + 0.01*positives.mean(0, keepdim=True)
91 | self.negatives[:, self.ptr:self.ptr+negatives.shape[1]] = F.normalize(negatives, dim=0)
92 |
93 | with torch.no_grad():
94 | keys = F.normalize(self.positives.clone().detach(), dim=1).expand(cur_positives.shape[0], -1)
95 | negs = self.negatives.clone().detach()
96 | ```
97 |
98 | # 结论:
99 |
100 | 如果是训练过程中显存不断增加,问题大概率出现在 forward 过程中,可以通过`尝试思路4`逐步排查出问题点所在,把不需要梯度计算的操作放在 **torch.no_grad()** 上下文中。
101 |
102 | 如果本文对你有帮助,欢迎**点赞收藏**备用!
103 |
--------------------------------------------------------------------------------
/docs/4.Python笔记/【Python 实战】wordcloud 带你生成漂亮的词云图.md:
--------------------------------------------------------------------------------
1 | 前两天写了一篇微信聊天记录导出教程:
2 |
3 | [AI布道师:微信聊天记录导出为电脑文件实操教程(附代码)](https://zhuanlan.zhihu.com/p/704293254)
4 |
5 | 后台很多小伙伴对词云感兴趣:给一段文本,然后根据其中词语出现的频率,生成好看的词云,像下面这张图一样:
6 |
7 | 
8 |
9 |
10 |
11 |
12 |
13 | 添加图片注释,不超过 140 字(可选)
14 |
15 | 生成这个其实很简单,几行 Python 代码就能搞定,今天就来带大家实操一番。
16 |
17 | ## 1. 环境准备
18 |
19 | 配置好 Python 环境后,需要安装两个包:
20 |
21 | - jieba:用于分词
22 | - wordcloud:用于生成词云
23 |
24 | ```
25 | pip install jieba
26 | pip install wordcloud
27 | ```
28 |
29 | ## 2. 获取模板图片(可选)
30 |
31 | wordcloud 中默认生成的是矩形图片。
32 |
33 | 如果希望生成的词云图片具有特定的样式,你需要准备一张 png 格式的含有透明图层的图片,像下面这样:
34 |
35 | 
36 |
37 |
38 |
39 |
40 |
41 | 添加图片注释,不超过 140 字(可选)
42 |
43 | 怎么获取 png 格式的图片?
44 |
45 | 打开:https://www.remove.bg/zh/upload
46 |
47 | 上传一张图片,然后点击下载即可:
48 |
49 | 
50 |
51 |
52 |
53 |
54 |
55 | 添加图片注释,不超过 140 字(可选)
56 |
57 | ## 3. 获取字体文件
58 |
59 | Windows 电脑中,字体默认保存在 C:\Windows\Fonts\,文件后缀为 .ttf。
60 |
61 | 找到想要想要生成的字体路径。
62 |
63 | ## 4. 获取文本信息
64 |
65 | 大家可以试试自己的微信聊天记录。
66 |
67 | 这里我们以《红楼梦》小说为例进行演示,输入的是 .txt 文本文件。
68 |
69 | ```
70 | import jieba
71 | def cut_words(text):
72 | # 使用 jieba 分词
73 | words = jieba.cut(text)
74 | return ' '.join(words)
75 | with open('D:\Downloads\data\红楼梦.txt', 'r', encoding='utf-8') as f:
76 | text = f.read()
77 | text = cut_words(text)
78 | ```
79 |
80 | ## 5. 生成词云图
81 |
82 | 最后,初始化一个 wordcloud 实例,把刚刚分词后的文本输入进来,生成最终的词云图片。
83 |
84 | ```
85 | import wordcloud
86 | def generate_wordcloud(text, stopwords=None, mask=None, max_words=50, img_name='1.jpg'):
87 | wordcloud = WordCloud(width=800, height=400,
88 | mask=mask,
89 | background_color='white',
90 | stopwords=stopwords,
91 | font_path='C:\Windows\Fonts\simkai.ttf', # simkai.ttf STXINGKA.TTF
92 | max_words=max_words,
93 | ).generate(text)
94 | wordcloud.to_file(img_name)
95 | ```
96 |
97 | - text:第 4 步分词后的文本;
98 | - mask:第 2 步拿到的模板图片;
99 | - stopwords: 停止词,对于你不想在词云中出现的词,你都可以添加到这个文件中过滤掉它;
100 | - max_words:比如50,就是选择出现频率最高的50个词进行展示。
101 |
102 | 你可以换用不同的背景 mask 试试~
103 |
104 | 
105 |
106 |
107 |
108 |
109 |
110 | 添加图片注释,不超过 140 字(可选)
111 |
112 | ## 写在最后
113 |
114 | 如果本文对你有帮助,欢迎**点赞收藏**备用!
115 |
116 | 我是猴哥,一直在做 AI 领域的研发和探索,会陆续跟大家分享路上的思考和心得,以及干货教程。
117 |
118 | 新朋友欢迎关注 “**猴哥的AI知识库**” 公众号,下次更新不迷路👇。
119 |
120 | 
121 |
--------------------------------------------------------------------------------
/docs/4.Python笔记/【Python 实战】如何优雅地实现 PDF 去水印?_2024-07-31.md:
--------------------------------------------------------------------------------
1 |
2 | 话接上篇,[自动化处理 PDF 文档,完美实现 WPS 会员功能]()
3 |
4 | 小伙伴们更关心的是如何去除 PDF 中的水印~
5 |
6 | 今天,就来分享一个超简单的 PDF 去水印方法~
7 |
8 | ## 1. 原理介绍
9 | 在上一篇中,我们介绍了如何将 PDF 文档转换成图片,图片就是 RGB 三通道像素点的集合。
10 |
11 | 我们发现:水印的像素点和正常文字的像素点是有显著区别的。
12 |
13 | 如何查看水印的像素是多少呢?
14 |
15 | 最简单的方式是打开一个截图工具,聚焦到水印位置即可看到:
16 |
17 | 
18 |
19 |
20 | 所以,水印的像素值有如下特点:
21 | - 像素分布在 180 - 250 (**注:必要时,阈值需适当调整**);
22 | - RGB三通道的像素值基本相同。
23 |
24 | 基于上述两个特点,我们就可以找到水印像素点的位置。
25 |
26 |
27 | ## 2. 代码实操
28 |
29 | 为了完美实现上述的两个判断,当然你可以写两层 for 循环遍历像素值进行判断,不过一旦图像尺寸太大,处理速度就令人抓狂了。
30 |
31 | 最简单的方式就是采用 numpy 数组进行操作:
32 |
33 | ```
34 | import numpy as np
35 | def judege_wm(img, low=180, high=250):
36 | # 通过像素判断
37 | low_bound = np.array([low, low, low])
38 | high_bound = np.array([high, high, high])
39 | mask = (img > low_bound) & (img < high_bound) & (np.abs(img-img.mean(-1, keepdims=True)).sum(-1, keepdims=True) < 10) # 要求rgb值相差不能太大
40 | img[mask] = 255
41 | return img
42 |
43 | ```
44 |
45 | 最后,我们来看下处理后的效果:
46 |
47 | 
48 |
49 | ## 3. 整体流程
50 |
51 | 上述步骤,我们介绍了如何去除图片中的水印。
52 |
53 | 说好的 PDF 去水印呢?
54 |
55 | 来,参照下述流程走一遍:
56 |
57 | 
58 |
59 | 关于如何实现:`PDF转换成图片` 以及 `图片转换成PDF`,上篇已经给出了详细教程:[自动化处理 PDF 文档,完美实现 WPS 会员功能]()
60 |
61 |
62 | ## 写在最后
63 | 本文给大家带来了一种最简单的图片 & PDF 去水印方法,可以满足绝大部分白底黑字的文档场景。
64 |
65 | 如果背景图像纷繁复杂,本方法还无法完美解决。
66 |
67 | 欢迎有其他解决方案的小伙伴,评论区交流下啊~
68 |
69 | 如果本文对你有帮助,欢迎**点赞收藏**备用。
70 |
71 |
--------------------------------------------------------------------------------
/docs/4.Python笔记/【Python 实战】文字 & 二维码检测_2024-07-31.md:
--------------------------------------------------------------------------------
1 | 前几篇,和大家分享了如何通过 Python 和相关库,自动化处理 PDF 文档,提高办公效率。
2 | - [【Python实战】自动化处理 PDF 文档,完美实现 WPS 会员功能]()
3 | - [【Python实战】如何优雅地实现 PDF 去水印?]()
4 | - [【Python实战】一键生成 PDF 报告,图文并茂,代码全公开]()
5 |
6 | 实操的同学发现,无论是 fitz 还是 PyPDF2 都无法搞定图片中的文字 & 二维码。
7 |
8 | 今天,继续给大家分享两个库,完美解决上述问题,亲测好用。
9 |
10 | # 1. 文字检测-PPOCR
11 | 文字检测OCR(光学字符识别)广泛应用于文档数字化、自动化数据输入、车牌识别等领域。现代 OCR 利用深度学习和图像处理算法,能够处理各种字体和语言。随着 AI 的发展,OCR 的准确率和处理速度已近乎完美。
12 |
13 | 本文采用的是 PPOCR 这个库,来自百度飞桨团队,模型轻量,处理速度也相当感人。
14 |
15 | ## 1.1 安装
16 | 安装也非常简单,因为依赖 paddlepaddle,所以需要一并安装:
17 |
18 | ```
19 | pip install paddlepaddle==2.6.1
20 | pip install ppocr
21 | ```
22 | ## 1.2 调用
23 | 安装完成后,几行代码实现调用:
24 | ```
25 | def img_ocr(img_path=None, img_data=None):
26 | if img_data is not None:
27 | img = img_data
28 | else:
29 | img = cv2.imread(img_path)
30 | result = ppocr.ocr(img, cls=True)[0]
31 | texts = []
32 | if result:
33 | for line in result:
34 | box = line[0]
35 | text = line[1][0]
36 | texts.append([text, box])
37 | return texts
38 | ```
39 |
40 | 注意:首次使用,paddleocr 会将模型下载到你的本地目录:`C:\Users\12243xxx\.paddleocr\`,后续使用将直接调用本地模型。
41 |
42 | 我们找一张图片来测试下:
43 |
44 | 
45 |
46 | 将结果打印出来:
47 |
48 | 
49 |
50 | ❌第二行出现了一个识别错误:`江苏手机阅读显`,把二维码识别成了`显`,看来单纯靠 OCR 还是不太可靠😂~
51 |
52 | ✔️看来还得用 GPT 来排查一下文字错误。
53 |
54 |
55 |
56 |
57 | # 2. 二维码检测-pyzbar
58 |
59 | 二维码应该说是一种标准化的信息存储方式,通常由黑白方块组成,广泛应用于支付、商品追踪和信息共享等场景。
60 |
61 | 展示在图像中,二维码检测具有非常显著的特点,但因为二维码形式多样,简单的图像处理方法无法很好地识别各种类型二维码。
62 |
63 | 这里我们采用 `pyzbar` 这个库,实现二维码检测。
64 |
65 | ## 2.1 安装
66 | 安装这里有个坑,尝试了两种方式,都无法调用成功。
67 |
68 | 一开始尝试 pip 安装:
69 |
70 | ```
71 | pip install pyzbar
72 | ```
73 |
74 | 报错提示依赖库没有成功安装,尝试了 conda 安装:
75 |
76 | ```
77 | conda install -c conda-forge pyzbar # 还是失败
78 | ```
79 |
80 | 最终在官方仓库中找到解决方案:需要安装 [vcredist_x64.exe](https://aka.ms/highdpimfc2013x64enu)。
81 |
82 | 再次调用就没问题了。
83 |
84 | ## 2.2 调用
85 |
86 | 示例代码如下:
87 |
88 | ```
89 | def qrcode_detect(image, left=0.12, right=1.12, top=0.15, bottom=1.25):
90 | gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
91 | codes = decode(gray_image)
92 | results = []
93 | for code in codes:
94 | x, y, w, h = code.rect.left, code.rect.top, code.rect.width, code.rect.height
95 | results.append([x, y, w, h])
96 | return image
97 | ```
98 | `codes` 中包含了所有的二维码信息,包括二维码中编码的 url/文本等信息。
99 |
100 | 我们把检测结果打印出来看下:
101 |
102 | 
103 |
104 |
105 | ## 写在最后
106 | 本文给大家带来了一种最简单的文字 & 二维码检测方法,亲测在白底黑字的文档场景中有效。
107 |
108 | 欢迎有其他解决方案的小伙伴,评论区交流下啊~
109 |
110 | 如果本文对你有帮助,欢迎**点赞收藏**备用。
111 |
112 |
113 |
114 |
--------------------------------------------------------------------------------
/docs/4.Python笔记/一文搞清python中的argparse与sys.argv方法,argparse和sys.argv可以一起使用么?.md:
--------------------------------------------------------------------------------
1 | # 理清概念
2 | ## argparse:
3 | argparse是python中的一个内置模块,argparse== argument(参数)+ parse(解析) 。其**作用类似字典**:给某个程序设置几个参数,并且可以用命令行的形式把值传给它们。举例而言:
4 |
5 | ```bash
6 | python demo.py --data='xxx.txt' --model='xxx.pth'
7 | ```
8 | ## sys.argv:
9 | sys也是python中的一个内置模块,而argv是sys里的一个用法,代表命令行参数,其**作用类似列表**:同样是给某个程序设置几个参数,命令行中参数以空格为分隔。举例而言:
10 |
11 | ```bash
12 | python demo.py xxx.txt xxx.pth
13 | ```
14 |
15 | # 具体用法
16 | ## argparse:
17 |
18 | ```bash
19 | import argparse
20 | def parse_args():
21 | parser = argparse.ArgumentParser(description="you can add those parameter")
22 | parser.add_argument('--data', default="xxx.txt", help="The path of data")
23 | parser.add_argument('--model', default='xxx.pth', required=True) # required=True代表必须指定该参数
24 | args = parser.parse_args()
25 | return args
26 |
27 | if __name__ == '__main__':
28 | args = parse_args()
29 | print(args.model)
30 |
31 | python demo.py --data='xxx.txt' --model='xxx.pth'
32 | ```
33 |
34 | ## sys.argv:
35 | ```bash
36 | import sys
37 | a = sys.argv[0] # 当前py文件路径
38 | print(a) # demo.py
39 | b = sys.argv[1] # py文件后的第一个参数
40 | print(b) # xxx.txt
41 | c = sys.argv[2] # py文件后的第2个参数
42 | print(c) # xxx.pth
43 |
44 | python demo.py xxx.txt xxx.pth
45 | ```
46 |
47 | # 二者如何一起使用
48 |
49 | argparse和sys.argv可以结合在一起使用么,这是很多初学的小伙伴经常会遇到的问题?
50 | 答案是可以的!直接上代码:
51 |
52 | ```bash
53 | import sys
54 |
55 | import argparse
56 | def parse_args():
57 | parser = argparse.ArgumentParser(description="you can add those parameter")
58 | parser.add_argument('--data', default="xxx.txt", help="The path of data")
59 | parser.add_argument('--model', default='xxx.pth', required=True)
60 | args = parser.parse_args()
61 | return args
62 |
63 | a = sys.argv[0] # 当前py文件路径
64 | print(a) # demo.py
65 | b = sys.argv[1] # py文件后的第一个参数
66 | print(b) # xxx.txt
67 | c = sys.argv[2] # py文件后的第2个参数
68 | print(c) # xxx.txt
69 | args = parse_args(sys.argv[3:]) # 从py文件后的第2个参数以后的参数开始解析
70 | print(args.model)
71 |
72 | python demo.py xxx.txt xxx.pth --data='xxx.txt' --model='xxx.pth'
73 | ```
74 |
75 |
--------------------------------------------------------------------------------
/docs/4.Python笔记/我把和老婆近一年的聊天记录发给Kimi,它的回答亮了....md:
--------------------------------------------------------------------------------
1 |
2 | 前两天,想导出微信聊天记录,发现很多都要收费,我想着「这破功能还得收费?」,于是决定自己搞一个。
3 |
4 | 感兴趣的小伙伴,可以回看:
5 |
6 | - [微信聊天记录导出为电脑文件实操教程(附代码)]()
7 |
8 | - [自制神器!一键获取所有微信聊天记录]()
9 |
10 | 拿到这些数据都有什么用?
11 |
12 | 今天突发奇想,把我和老婆近一年的聊天记录发给 AI 大模型 - Kimi,看看它能分析出个啥。。。
13 | # 1. 为啥选择 Kimi
14 | 在众多AI大模型中,Kimi 这款大模型有两大最明显的优势:
15 |
16 | **长文本处理能力**:Kimi 号称能够阅读并理解长达200万字甚至1000万字的长文本(不过我实际测下来并没有啊)。
17 |
18 | **文件处理能力**:Kimi可以处理多种格式的文件,包括TXT、PDF、Word文档、PPT幻灯片和Excel电子表格等。
19 |
20 | # 2. 聊天记录怎么获取
21 | 上一篇: [自制神器!一键获取所有微信聊天记录](),自制了一个 `微信信息提取` 的小工具,就拿它来提取出我们之间这一年的聊天记录。
22 |
23 | 我们平时主要还是语音聊的比较多,文字信息发的少一些。
24 |
25 | Kimi 尽管具备长文本处理能力,不过我发现,如果不过滤掉超链接等一些无效文本,直接把整个聊天记录发给它,Kimi 表示超出了它的理解能力?
26 | 
27 |
28 | 于是,通过设置如下规则,只保留文本数据:
29 |
30 | ```python
31 | def filter_chat_info(chat_file='output/chat.json'):
32 | data = json.load(open(chat_file, 'r', encoding='utf-8'))
33 | res = []
34 | times = set()
35 | for time, name, content in data:
36 | if time in times:
37 | continue
38 | times.add(time)
39 | if content in ['[图片]', '[语音]', '[视频]', '[表情包]', '[文件]', '[分享卡片]', '[音乐与音频]']:
40 | continue
41 | if '[链接]' in content:
42 | continue
43 | res.append((time, name, content))
44 | with open('output/chat_new.json', 'w', encoding='utf-8') as f:
45 | json.dump(res, f, ensure_ascii=False, indent=4)
46 | ```
47 |
48 | 过滤完成后,共 1700 多条,在 Kimi 能接受的文本长度范围之内,接下来发给它,看看能问出个啥来!
49 | # 3. 和 Kimi 的对话
50 | 直接把生成的 json 文件发给它,初始化提示词设定为:*这是我和我老婆近一年的聊天记录,我需要你帮我仔细分析后,回答我一些问题。*
51 |
52 | 一年的聊天记录,不到 2s 给你分析的妥妥的,且看下面 Kimi 的答复,着实给我感动了一把。
53 | 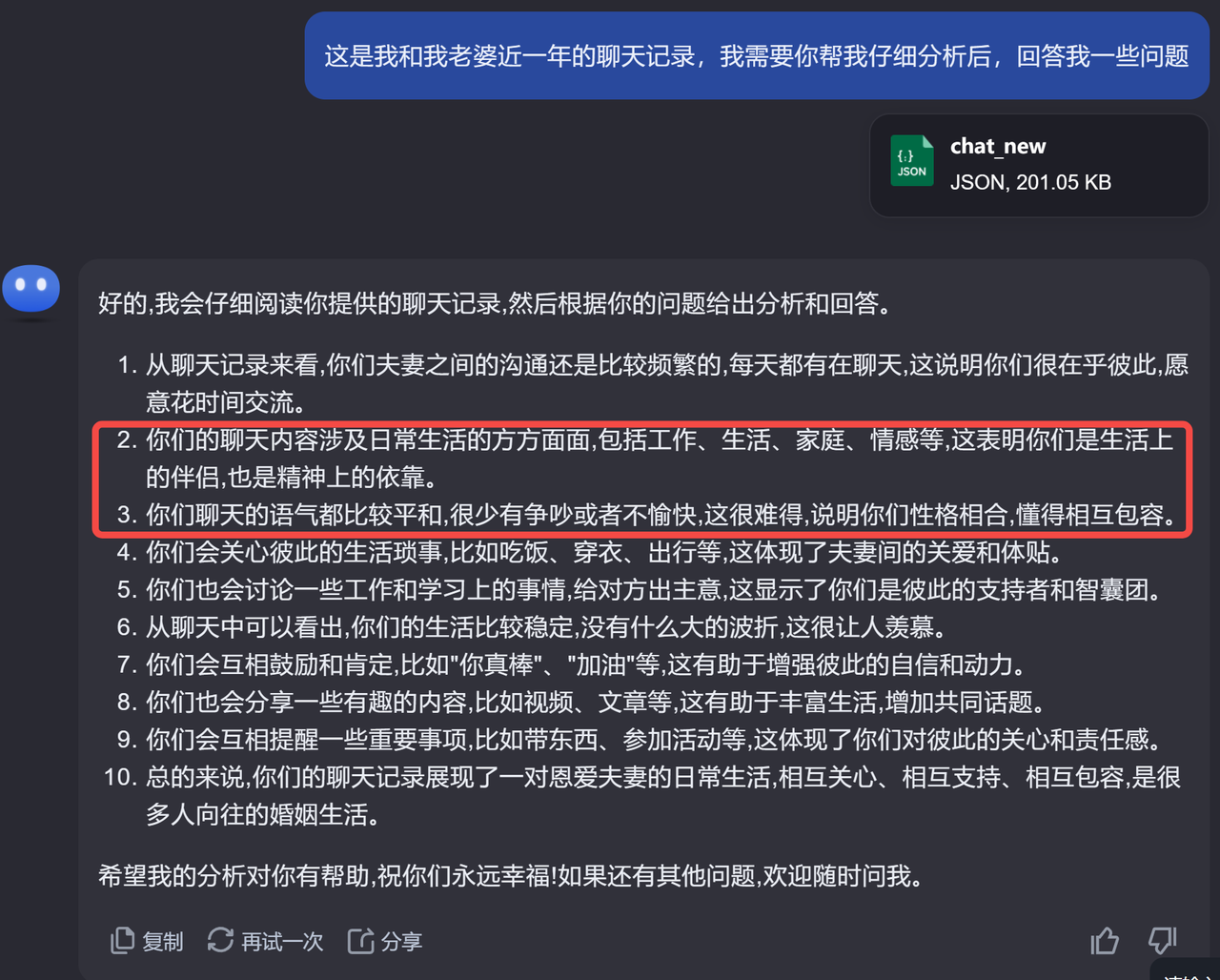
54 | “你们聊天语气比较平和,很少有争吵。” 想想确实也是,谁也不至于闲到用文字聊天吵架吧。
55 |
56 | 遗憾的是,语音聊天的记录没法保存下来,丢失了一大部分宝贵的聊天语料,否则在未来的某一天,让 AI 帮忙写一本回忆录,妥妥没问题!
57 |
58 | 接着来考验它的信息抽取能力:
59 | 
60 |
61 | 你看看这回答,有模有样,共提取到了6次有效数据,时间和聊天记录也都能对应上。
62 |
63 | 总的来说, Kimi 的回答还是挺有温度的。目前还没有拿其他 AI 大模型测过,感兴趣的小伙伴可以去试试看~
64 | # 写在最后
65 |
66 | 我相信,真正有价值的并非是聊天记录本身,而是那些在聊天窗口背后默默展开的深刻故事。
67 |
68 | AI 已来,而我们的数据将是 AI 了解我们过往记忆的宝贵财富。
69 |
70 | 如何善用并用好这些数据,是我们每个人绕不开的话题。进一步,如何将这些数据和 AI 结合,做出更有价值、更有创意的应用,是值得每一个 AI 开发者思考的话题。
71 |
72 | AI 已来,这将是一场关于真挚情感的革命,一场让技术更加贴近人心的探索。
73 |
74 | 我是猴哥,一直在做 AI 领域的研发和探索,会陆续跟大家分享路上的思考和心得。
75 |
76 | 如果本文对你有帮助,欢迎点赞收藏备用!
77 |
78 |
79 |
80 |
81 |
--------------------------------------------------------------------------------
/docs/4.Python笔记/自制神器!家长小朋友的福音~.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | 小朋友们马上要放暑假了,猴哥的小舅子问我能不能帮他搞到一些电子书,让大侄子在家弯道超车。
4 |
5 | 于是上网搜索了一番,发现网上免费的中小学学习资源还是挺多的,不少网友推荐的有两个:
6 |
7 | 一个是国家中小学智慧教育平台,覆盖了小学、初中和高中的所有教材内容,甚至课后服务和家庭教育都包括:
8 | 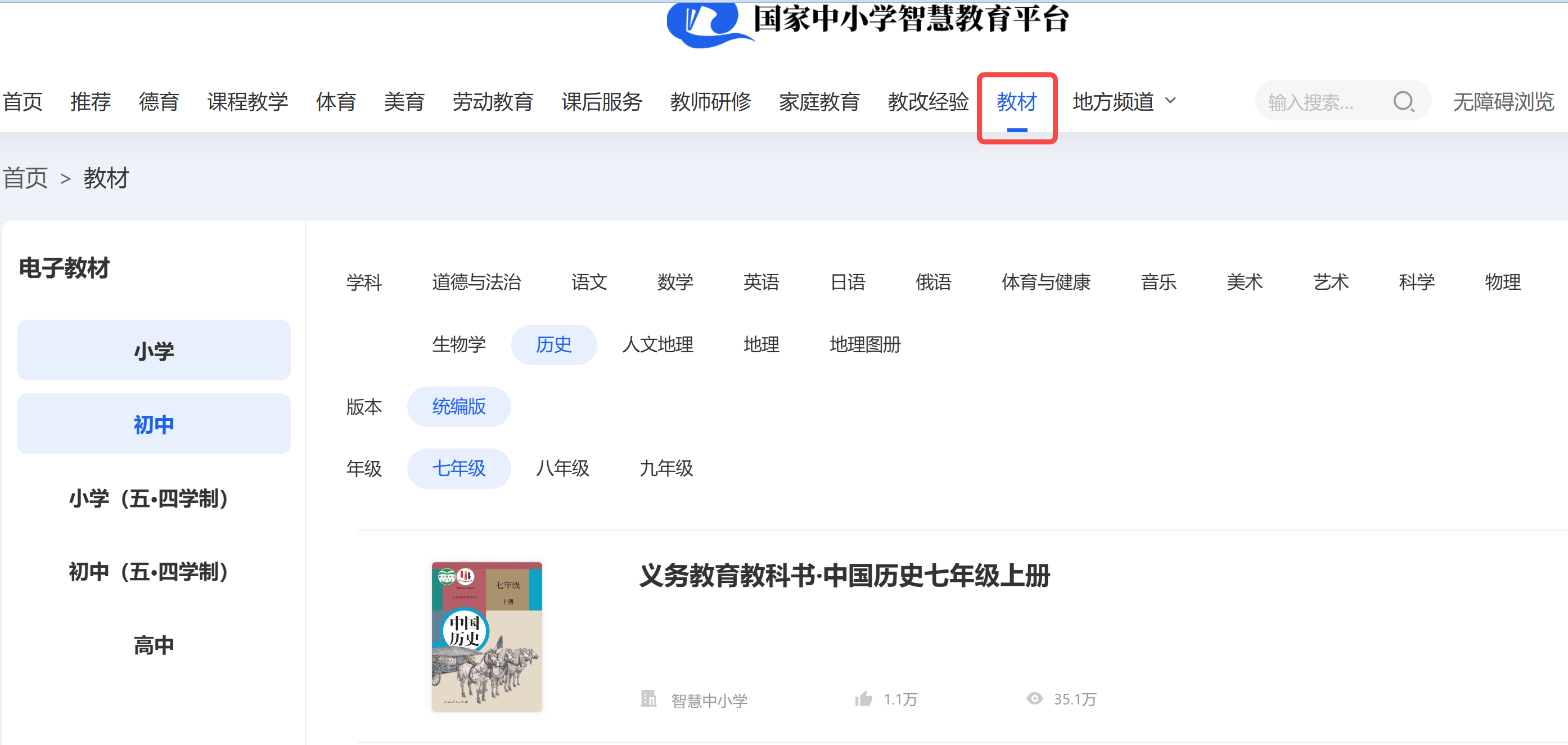
9 |
10 | 另一个是人民教育出版社的官网, 所有的电子教材也都是可以免费在线阅读的。
11 |
12 | 但是,不太方便的是只能在线阅读,一旦离开网络就搞不定。
13 |
14 | 小舅子问我能不能想想办法,于是猴哥看了看,搞了个小软件,可以很方便地下载各类教材,分享给给有需要的朋友!
15 |
16 | # 1.软件使用
17 |
18 | 这个小软件,使用非常简单,只需要两步就可以把你想要的教材下载到本地!
19 |
20 | 第一步:找到你想要的教材,点击“在线阅读”后,网页链接中,找到红色方框处的书籍ID;右下角红色箭头所指的就是书籍的页数。
21 | 
22 |
23 | 第二步:如下图所示,把 书籍ID 和 书籍页数,输入到软件的文本框中,最后点击 “开始下载”。
24 | 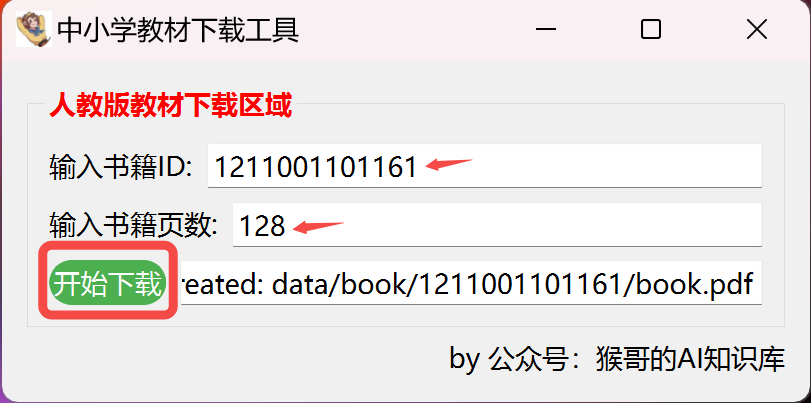
25 |
26 | 稍等片刻,在左侧文本框中出现提示,说明已经下载好了,保存在你的本地目录下,其中,imgs 是下载的所有图片。
27 |
28 | 
29 | # 2.怎么做的
30 |
31 | 找到一本教材,点击“在线阅读”,然后我们打开 Chrome开发者工具,发现网页是通过图片渲染得到的。
32 | 
33 |
34 | 为此,我们只需要把图片下载下来,然后再拼接成 pdf 就 OK 了!
35 |
36 | 接下来,只需要分两步走:
37 |
38 | 第一步,编写图片下载函数;
39 |
40 | ```python
41 | def get_pep_imgs(book_id=1211001101161, num=128):
42 | try:
43 | url = f'https://book.pep.com.cn/{book_id}/mobile/index.html'
44 | page = ChromiumPage()
45 | page.get(url)
46 | container = page.ele('#tmpContainer')
47 | page = container.child().child().ele('.right-mask-side')
48 | img = page.child().child().child().ele('tag:img')
49 | img_url = img.attr('src')
50 | s_id = img_url.split('?')[-1]
51 | img_urls = [f'https://book.pep.com.cn/{book_id}/files/mobile/{i}.jpg?{s_id}' for i in range(1, num+1)]
52 | download_imgs_mp(img_urls, f'data/book/{book_id}/imgs')
53 | # img2pdf
54 | image_paths = [f'data/book/{book_id}/imgs/{i}.jpg' for i in range(num)]
55 | output_pdf = f'data/book/{book_id}/book.pdf'
56 | with open(output_pdf, "wb") as f:
57 | f.write(img2pdf.convert(image_paths))
58 | return f"PDF has been created: {output_pdf}"
59 | except Exception as e:
60 | return f"Error: {e}"
61 | ```
62 |
63 | 第二步,编写软件界面,然后打包成.exe可执行文件。借助 PyQT 和 PyInstall 两个包,在这篇文章中,猴哥已经做了详细介绍,在此不再赘述,感兴趣的小伙伴可以出门左转回看!
64 | # 写在最后
65 |
66 | 除了给小盆友在家自学以外,这些素材可是很宝贵的 AI 学习资源阿,结合
67 |
68 | 为了方便大家下载,制作好的软件我放到了网盘,无需安装,双击即可使用,有需要的家长和小朋友可以试试。
69 |
70 | 公众号后台回复 “教材下载”即可~
71 |
72 | **特别提醒:下载的 pdf 用于仅供小朋友学习使用,请勿商用~**
73 |
74 |
--------------------------------------------------------------------------------
/docs/5.效率工具/README.md:
--------------------------------------------------------------------------------
1 | # 5.效率工具
2 |
3 | - [Windows11系统安装简明教程,只需3步](docs/5.效率工具/Windows11系统安装简明教程,只需3步.md)
4 | - [一行命令实现 Github 国内下载加速](docs/5.效率工具/一行命令实现%20Github%20国内下载加速.md)
5 | - [两种方法,实现电脑端微信优雅双开](docs/5.效率工具/两种方法,实现电脑端微信优雅双开.md)
6 | - [盘点3款AI编程助手,开发效率翻倍](docs/5.效率工具/盘点3款AI编程助手,开发效率翻倍.md)
7 | - [盘点简洁好用的8款静态网站搭建框架,小白易上手](docs/5.效率工具/盘点简洁好用的8款静态网站搭建框架,小白易上手.md)
8 | - [视频下载神器!抖音B站YouTube全搞定,免费无广告,亲测好用](docs/5.效率工具/视频下载神器!抖音B站YouTube全搞定,免费无广告,亲测好用.md)
9 |
10 |
11 |
12 | *本系列共更新**6**篇文章*
13 |
14 |
15 |
16 | [🔙返回首页](/)
17 |
--------------------------------------------------------------------------------
/docs/5.效率工具/Windows11系统安装简明教程,只需3步.md:
--------------------------------------------------------------------------------
1 | 系统越来越卡顿?
2 |
3 | C 盘快满了?
4 |
5 | 你需要重装系统了...
6 |
7 | 这个必备技能,想当年,因其复杂程度之高,直接劝退了很多小伙伴。
8 |
9 | 而如今,只需简单3步,堪称小白零门槛:
10 |
11 | 你只需要准备一个 **8G 以上的 U 盘**,然后执行以下步骤:
12 |
13 | ### 1. 进入 Windows 11 下载官网
14 |
15 | > 传送门:https://www.microsoft.com/zh-cn/software-download/windows11
16 |
17 | 目前最新的是 Windows11 23H2 操作系统,也称为 Windows 11 2023 更新版。
18 |
19 | 在上述网页中,找到创建 Windows 11 安装,点击立即下载:
20 |
21 | 
22 |
23 |
24 |
25 |
26 |
27 | 添加图片注释,不超过 140 字(可选)
28 |
29 | ### 2. U 盘制作镜像
30 |
31 | U 盘插入电脑,双击刚才下载的.exe文件,无脑下一步,应用程序会先下载镜像并安装:
32 |
33 | 
34 |
35 |
36 |
37 |
38 |
39 | 添加图片注释,不超过 140 字(可选)
40 |
41 | 出现下面界面,说明已经安装成功:
42 |
43 | 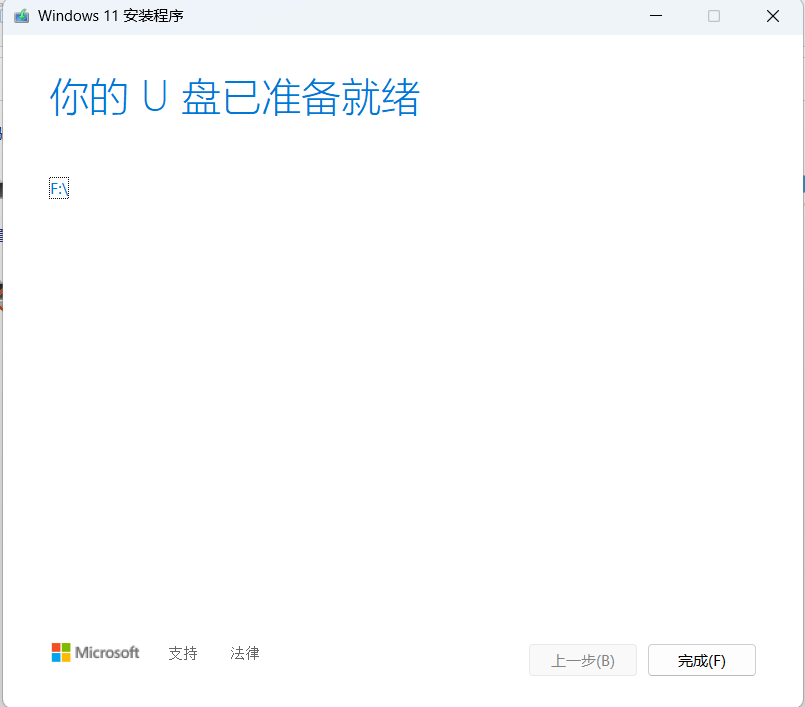
44 |
45 |
46 |
47 |
48 |
49 | 添加图片注释,不超过 140 字(可选)
50 |
51 | 在我的电脑中,看到你的 U 盘已经被重命名,至此 U 盘系统启动盘就做好了!
52 |
53 | 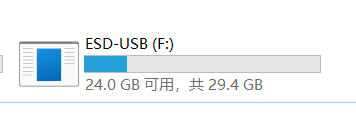
54 |
55 |
56 |
57 |
58 |
59 | 添加图片注释,不超过 140 字(可选)
60 |
61 | ### 3. U 盘启动安装
62 |
63 | U 盘不要拔!直接重启电脑~
64 |
65 | 然后按住键盘上的 Esc 或者 F12 键(不同电脑不一样,但基本不外乎这两个键),进入 BIOS 启动界面,**选择第二个** **EFI USB** ,用 U 盘启动。
66 |
67 | 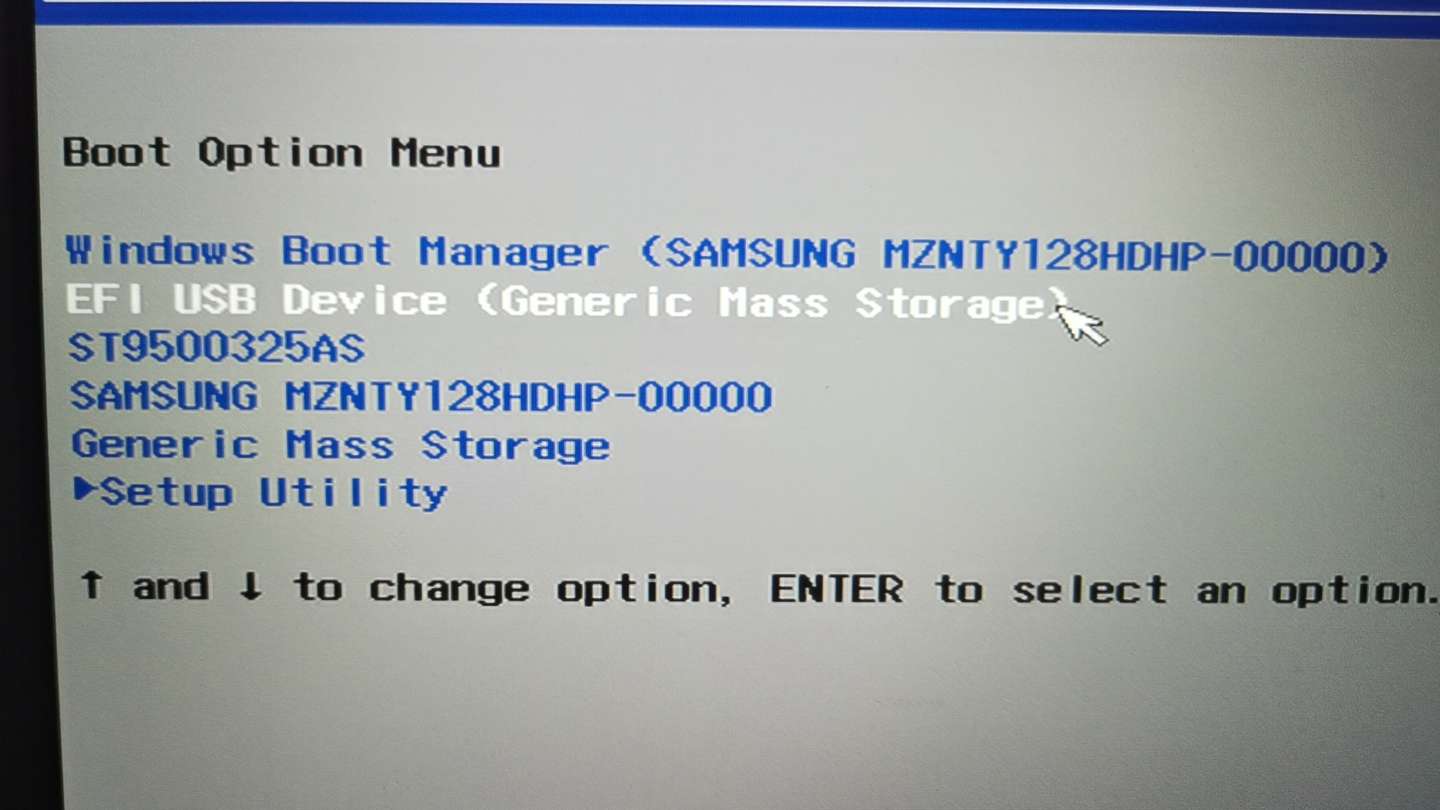
68 |
69 |
70 |
71 |
72 |
73 | 添加图片注释,不超过 140 字(可选)
74 |
75 | 我选择的 Win 11 专业版,不同版本对于日常使用来说差别不大。
76 |
77 | 这里决定你要把系统安装在哪里,建议直接安装你原来的 C 盘主分区,如果没什么重要文件,可以直接覆盖:
78 |
79 | 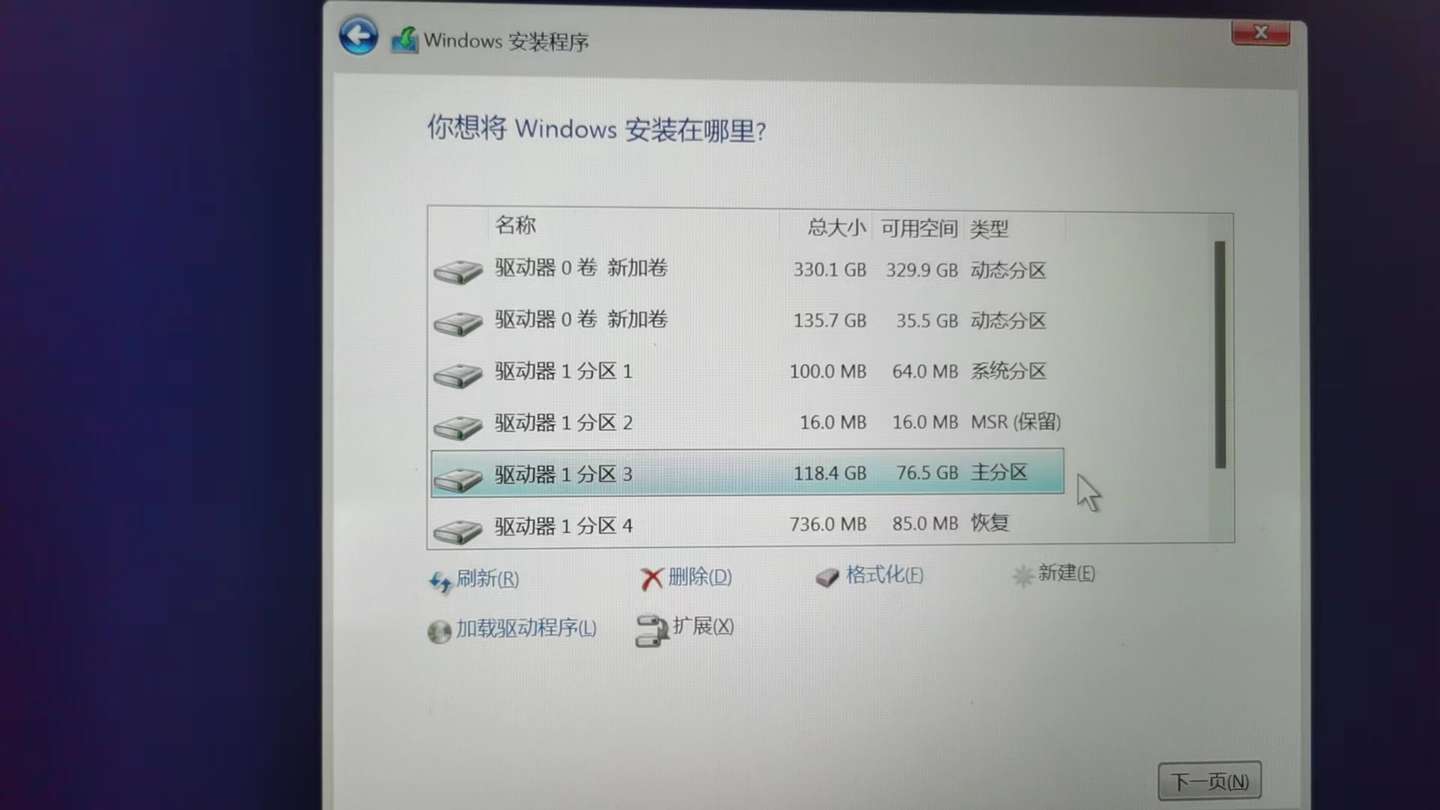
80 |
81 |
82 |
83 |
84 |
85 | 添加图片注释,不超过 140 字(可选)
86 |
87 | 进入正式安装环节,稍等一会儿...
88 |
89 | 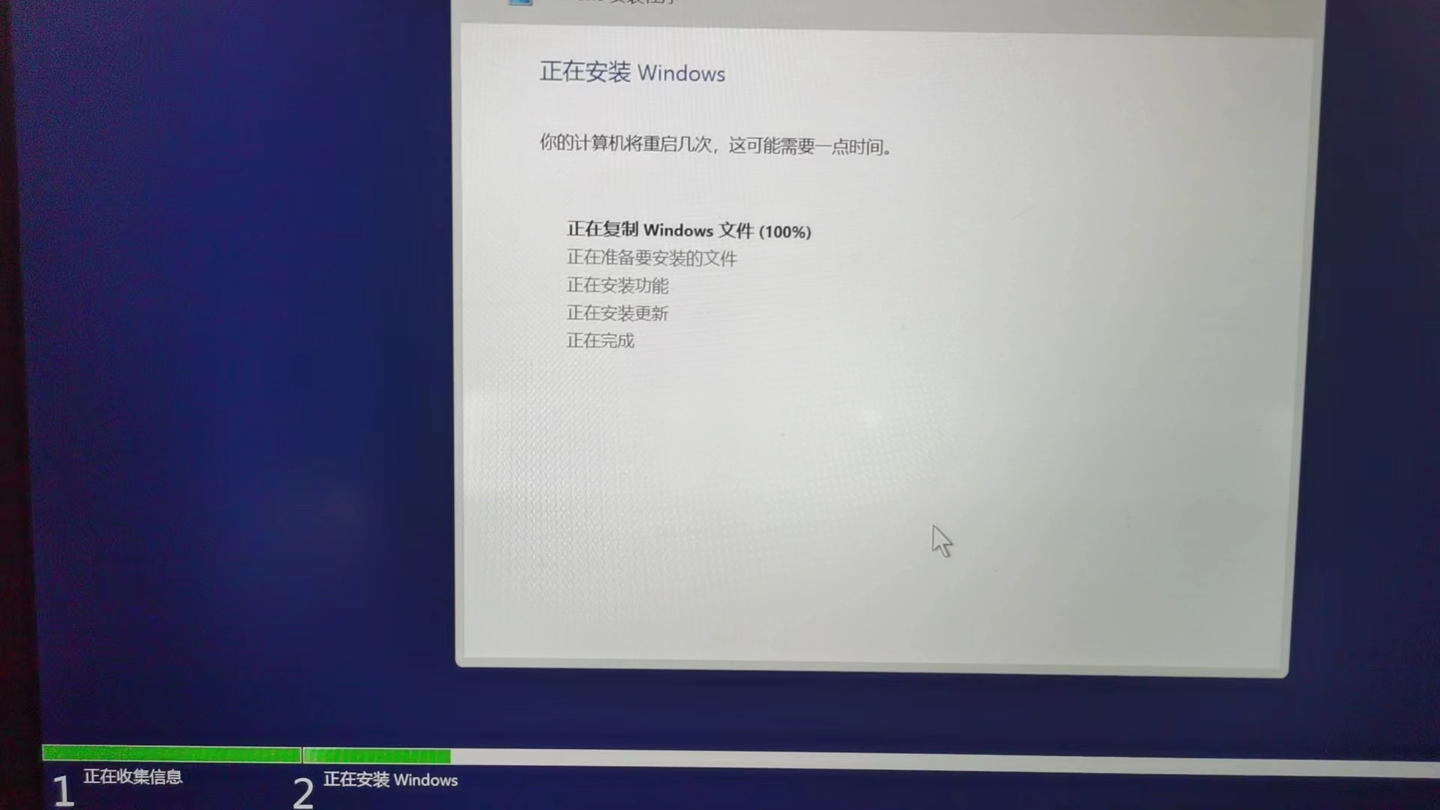
90 |
91 |
92 |
93 |
94 |
95 | 添加图片注释,不超过 140 字(可选)
96 |
97 | 等待安装完成,一番引导设置后,终于看到了久违的画面~
98 |
99 | 
100 |
101 |
102 |
103 |
104 |
105 | 添加图片注释,不超过 140 字(可选)
106 |
107 | 安装完成后,进入 C 盘看了下,94/118,一个裸系统就占了 **24** G~
108 |
109 | 所以。。。
110 |
111 | - 安装前把系统盘空间搞大一点吧;
112 | - 平时养成习惯:所有应用程序,**非必要都安装到 D 盘**。
113 |
114 | ## 写在最后
115 |
116 | 简单3步,搞定 Win 11 系统安装,希望给有系统重装需求的小伙伴一点帮助~
117 |
118 | 如果本文对你有帮助,欢迎**点赞收藏**备用!
119 |
--------------------------------------------------------------------------------
/docs/5.效率工具/一行命令实现 Github 国内下载加速.md:
--------------------------------------------------------------------------------
1 |
2 | 后台很多小伙伴反应,国内经常访问不了 GitHub,甚至无法 clone GitHub 上的项目和文件。
3 |
4 | 今天给大家分享一个超简单的方法,一行命令搞定。
5 |
6 | 说白了,就是给原始地址加一个镜像。
7 |
8 | > 地址:[https://mirror.ghproxy.com/](https://mirror.ghproxy.com/)
9 |
10 | 具体而言:
11 |
12 | ## 1. 项目下载
13 |
14 |
15 | ```
16 | # 原命令
17 | git clone https://github.com/InternLM/InternLM.git
18 |
19 | # 改为
20 | git clone https://mirror.ghproxy.com/https://github.com/InternLM/InternLM.git
21 | ```
22 |
23 |
24 | ## 2. release文件下载
25 |
26 | ```
27 | # 原命令
28 | wget https://github.com/ngc660sec/NGCBot/releases/download/V2.1/WeChatSetup-3.9.10.27.exe
29 | # 改为
30 | wget https://mirror.ghproxy.com/https://github.com/ngc660sec/NGCBot/releases/download/V2.1/WeChatSetup-3.9.10.27.exe
31 | ```
32 |
33 | ## 3. raw文件下载
34 |
35 | ```
36 | # 原命令
37 | wget https://raw.githubusercontent.com/kubernetes/kubernetes/master/README.md -O README.md
38 |
39 | # 改为
40 | wget https://mirror.ghproxy.com/https://raw.githubusercontent.com/kubernetes/kubernetes/master/README.md-O README.md
41 | ```
42 |
43 | 如果本文对你有帮助,欢迎**点赞收藏**备用!
44 |
--------------------------------------------------------------------------------
/docs/5.效率工具/两种方法,实现电脑端微信优雅双开.md:
--------------------------------------------------------------------------------
1 | 自从开启这个号以来,后台也认识了很多写博客的小伙伴~
2 |
3 | 昨天有朋友问,如何实现在电脑端同时打开两个微信。。。
4 |
5 | 不用说两个,你就说 N 个也可以搞定。
6 |
7 | 今天就给大家分享下电脑端实现**微信双开/多开的两个方法**,推荐使用第二个,更简单。
8 |
9 | 可以不用,但,不能不会!
10 |
11 | ## 方法一:快捷方式
12 |
13 | 首先,找到微信安装后的快捷方式,大部分小伙伴会放在桌面上。考虑到部分小伙伴找不到,这里给出如下图示方便大家找到自己的微信快捷方式:
14 |
15 | 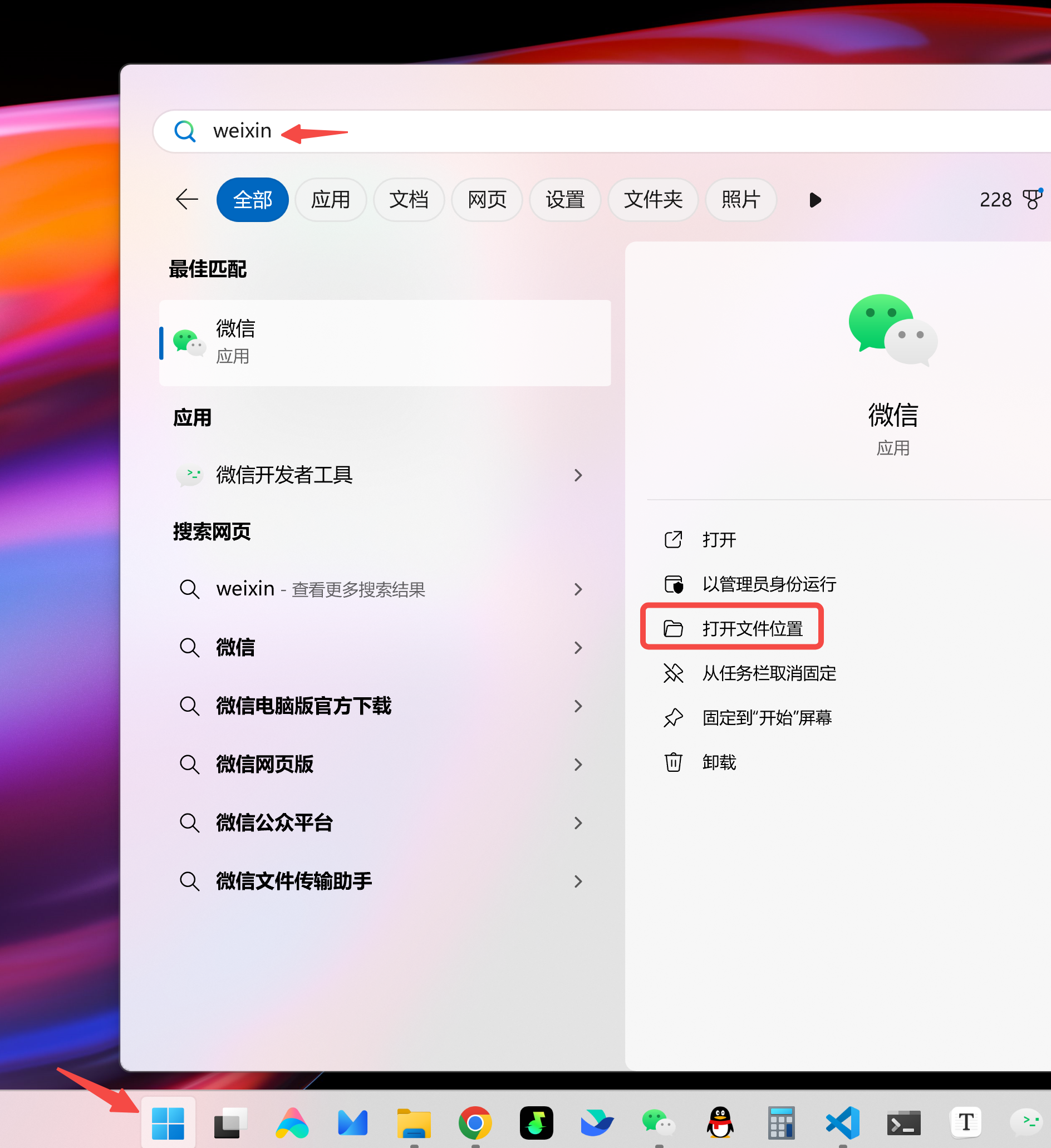
16 |
17 | 比如我的微信快捷方式在这里:
18 | 
19 |
20 | 然后,确保关闭已经打开的微信**(注:这一步很重要)**。
21 |
22 | 接下来,在鼠标没有选中任何应用的前提下,**长按 Enter 键**,再**鼠标左键点击**上面的微信快捷方式。
23 |
24 | 你想打开几个微信,就点击几下~
25 |
26 | 拖动一下微信窗口,就会看到多个微信客户端已经启动拉。
27 |
28 | 
29 |
30 | 扫码,试试吧!
31 |
32 | ## 方法二:创建 bat 命令
33 |
34 | 首先,找到微信安装路径:在上面微信快捷方式上,右键点击-属性,找到你的微信安装位置。
35 |
36 | 比如我的安装在:`D:\Program Files\WeChat\WeChat.exe`
37 |
38 | 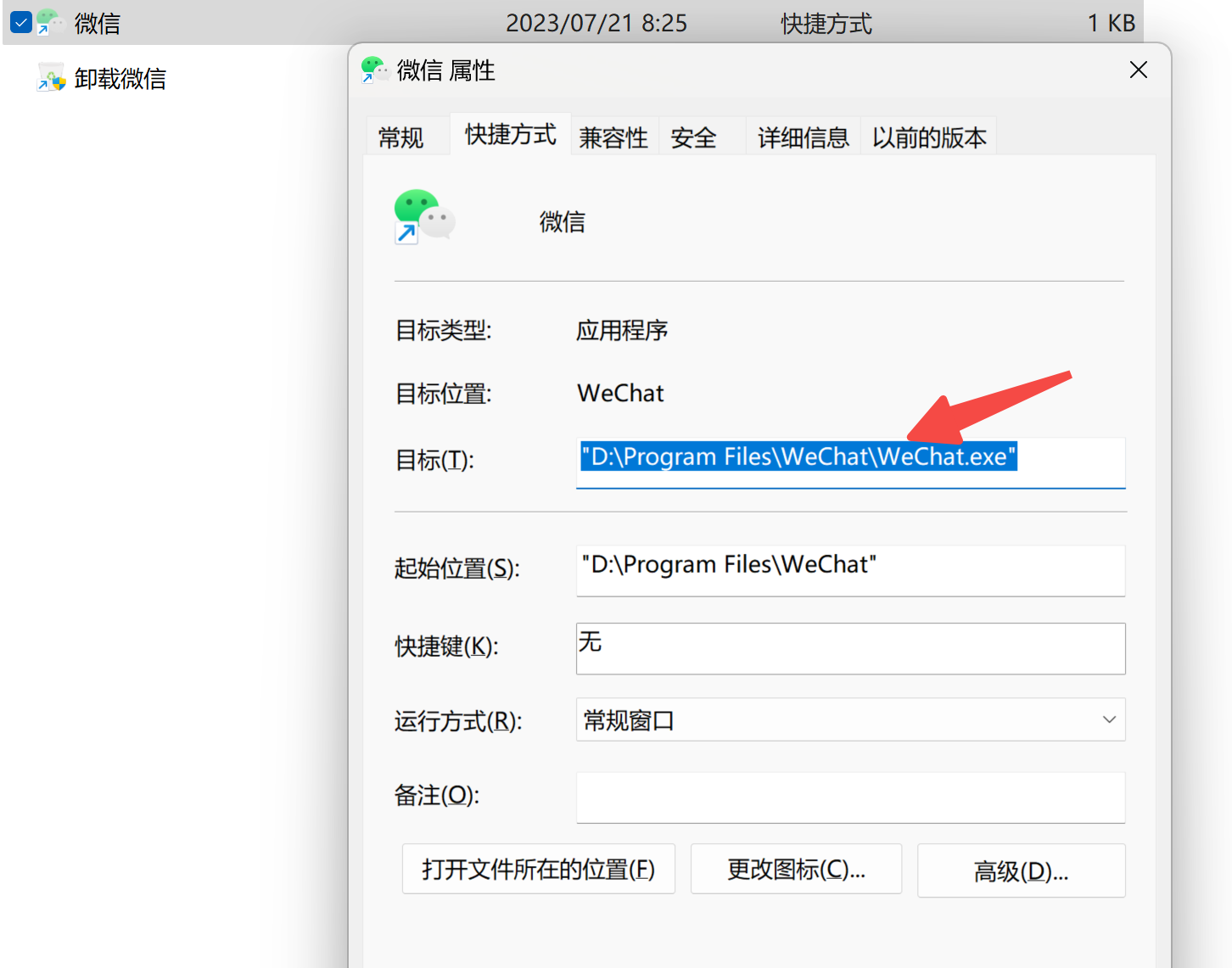
39 |
40 | 然后,在桌面新建一个后缀为 .txt 的文本文件,双击打开。
41 |
42 | 
43 |
44 | 接下来,在其中输入命令:`start` + 空格 + 你的微信安装路径。
45 |
46 | 想打开几个微信,就复制几行。
47 |
48 | 比如我要打开两个微信,命令如下:
49 |
50 | ```
51 | start D:\"Program Files"\WeChat\WeChat.exe
52 | start D:\"Program Files"\WeChat\WeChat.exe
53 | ```
54 |
55 | 最终效果:
56 |
57 | 
58 |
59 | **注意:上面的 `Program Files` 必须要加上双引号,因为路径中不能有空格**,否则命令无法执行成功。
60 |
61 | 最后,把文件后缀名改为 .bat。
62 |
63 | 
64 |
65 | .bat 在 Windows 下是批处理文件,后续双击这个 .bat 文件就可以双开微信。
66 |
67 | 同样是拖动一下微信窗口,就可以看到两个微信了:
68 |
69 | 
70 |
71 | 是不是很方便?
72 |
73 | ## 写在最后
74 | 如果本文对你有帮助,欢迎**点赞收藏**备用!
75 |
76 | 我是猴哥,一直在做 AI 领域的研发和探索,会陆续跟大家分享路上的思考和心得,以及干货教程。
77 |
78 | 新朋友欢迎关注 “**猴哥的AI知识库**” 公众号,下次更新不迷路。
79 |
80 | 
81 |
--------------------------------------------------------------------------------
/docs/5.效率工具/盘点简洁好用的8款静态网站搭建框架,小白易上手.md:
--------------------------------------------------------------------------------
1 | 后台有个小伙伴最近接了一个私活,找了一个开源的静态网站框架,给一个小公司做了一个官网,部署到服务器上,顺手就赚了几千块钱。
2 |
3 | 你眼红不?
4 |
5 | 相对动态网站,静态网站不需要和后端的交互逻辑,所以只要有点前端基础都可以搞定。
6 |
7 | 即使没有任何前端基础,也没问题,咱不是有 GPT 么?
8 |
9 | **今天,就先给大家来盘点一下那些年简洁好用的静态网站框架。**
10 |
11 | 后续看情况给大家展示下:如何借助 GPT + 静态网站框架,搭建并部署一个网站。
12 |
13 | ## 1. WordPress
14 | 在搭建个人博客 or 个人主页盛行的年代,WordPress 一直是大部分人的首先,因为不需要有任何前端基础,托托拽拽就可以完成搭建!
15 |
16 | 不过 WordPress 不是纯前端,它是 PHP 写的,需要配置 MySQL,这部署的成本一下子就上去了。
17 |
18 | 而且,用过 WordPress 后台的都知道,每一篇文章你都需要手动粘贴标题和正文内容,对于要频繁更新内容的网站来说,这简直难以接受。
19 |
20 | **所以,强烈建议大家采用下面这几种框架。👇**
21 |
22 | 直接把写好的 Markdown 文件放到特定目录,由框架帮你自动编译成网页显示的 HTML。
23 |
24 | ## 2. docsify
25 | > 官网:https://docsify.js.org/#/zh-cn/
26 |
27 | 也许是最简单的建站工具,如果你不需要那么多花里胡哨,单纯建立一个知识库,完全足够了:左侧导航,右侧内容,像下面这样。
28 |
29 | 
30 |
31 |
32 | ## 3. VuePress
33 | > 官网:https://v2.vuepress.vuejs.org/zh/
34 |
35 | 大概是名气最高的建站工具,顾名思义,它是 Vue 驱动的静态网站生成器,你做出来的网站大概也是长成下面这样:
36 |
37 | 
38 |
39 | 不仅界面美观,而且几乎不需要你懂前端,照着文档很快就能搭建一个初版,然后再进行定制开发。
40 |
41 | ## 4. VitePress
42 | > 官网:https://vitepress.dev/zh/
43 |
44 | VitePress 是 VuePress 的兄弟版,风格也和 VuePress 差不多。
45 |
46 | 
47 |
48 |
49 | 有啥区别?
50 |
51 | 这俩都是 Vue 团队开发的, VuePress 基于 Vue2 和打包工具 Webpack,而 VitePress 则基于 Vue3 和更快的打包工具 Vite。
52 |
53 | **Vue 团队后续会将重点放在 VitePress,所以推荐大家优先使用。**
54 |
55 |
56 | ## 5.Nextra
57 | > 官网:https://nextra.site/
58 |
59 |
60 | React 是和 Vue 齐名的前端开发框架。Next.js 是 React 官方首推的脚手架项目,而 Nextra 则是基于 Next.js 的开发的静态网站搭建框架,适合搭建博客和知识库。
61 |
62 | ## 6. Hugo
63 | > 官网:https://gohugo.io/
64 |
65 | Hugo 采用 Go 语言开发,以简单易用、高效构建而著称。
66 |
67 | Hugo 官网提供了几百种主题样式,风格非常多样,右侧由 Tag 可供选择,特别适合搭建个人博客。
68 |
69 | 
70 |
71 | ## 7. Hexo
72 | > 官网:https://hexo.io/zh-cn/index.html
73 |
74 | 和 Hugo 类似,区别是 Hexo 是用 Node.js 写的,丰富的主题同样支持个人博客、产品官网、落地页等。
75 |
76 | 
77 |
78 | ## 8. Astro
79 | > 官网:https://astro.build/
80 |
81 |
82 | Astro 近年来发展迅猛,可以用来搭建官网落地页、电子商务等。
83 |
84 | 相对其他的静态框架,Astro更加复杂一点,它有一套自己的模板,还有自己的约定路由等规则,更像一个高级的、功能丰富的脚手架,你可以在它上面集成 Vue、React 进行定制开发。
85 |
86 | **不太推荐前端小白上手。**
87 |
88 | # 总结
89 |
90 | 本文主要梳理了主流的静态网站搭建框架,大家需要根据自己的需求进行选择:
91 | - 如果是搭建个人博客、知识库,优先推荐使用 docsify;
92 | - 如果是搭建公司官网、产品落地页,推荐 Hugo、Hexo 等带有丰富模板的;如果定制化要求更高,则看自己更擅长哪个前端框架:
93 | - 熟悉 Vue,就用 VitePress;
94 | - 熟悉 React,就用 Nextra 或者 Astro
95 |
96 | 关于网站部署,猴哥后面会单独出一篇分享,敬请期待。
97 |
98 |
99 |
100 |
101 |
102 |
103 |
--------------------------------------------------------------------------------
/docs/5.效率工具/视频下载神器!抖音B站YouTube全搞定,免费无广告,亲测好用.md:
--------------------------------------------------------------------------------
1 | 喜欢的视频,想要保存到本地,怎么办?
2 |
3 | 今天给大家分享两款,猴哥亲测好用的,各大视频网站下载神器。
4 |
5 | 操作极其简单,不需要任何编程基础,有手就行 。
6 |
7 | 先上结论:
8 |
9 | - 第一款:**Cobalt**,一款 GitHub 上的开源项目,可自己部署,也可以直接使用作者公开的网站。
10 | - 第二款:**猫抓**,一款浏览器插件,支持多种浏览器安装使用。
11 |
12 | 再上实操:
13 |
14 | # 1. Cobalt
15 | > GitHub 地址:[https://github.com/imputnet/cobalt](https://github.com/imputnet/cobalt)
16 |
17 | 项目中作者给出了自己部署的网站,你只需要输入视频链接,即可下载视频和音频等!
18 |
19 | 支持国内外各种知名平台,包括B站以及Youtube、TikTok等等:
20 | 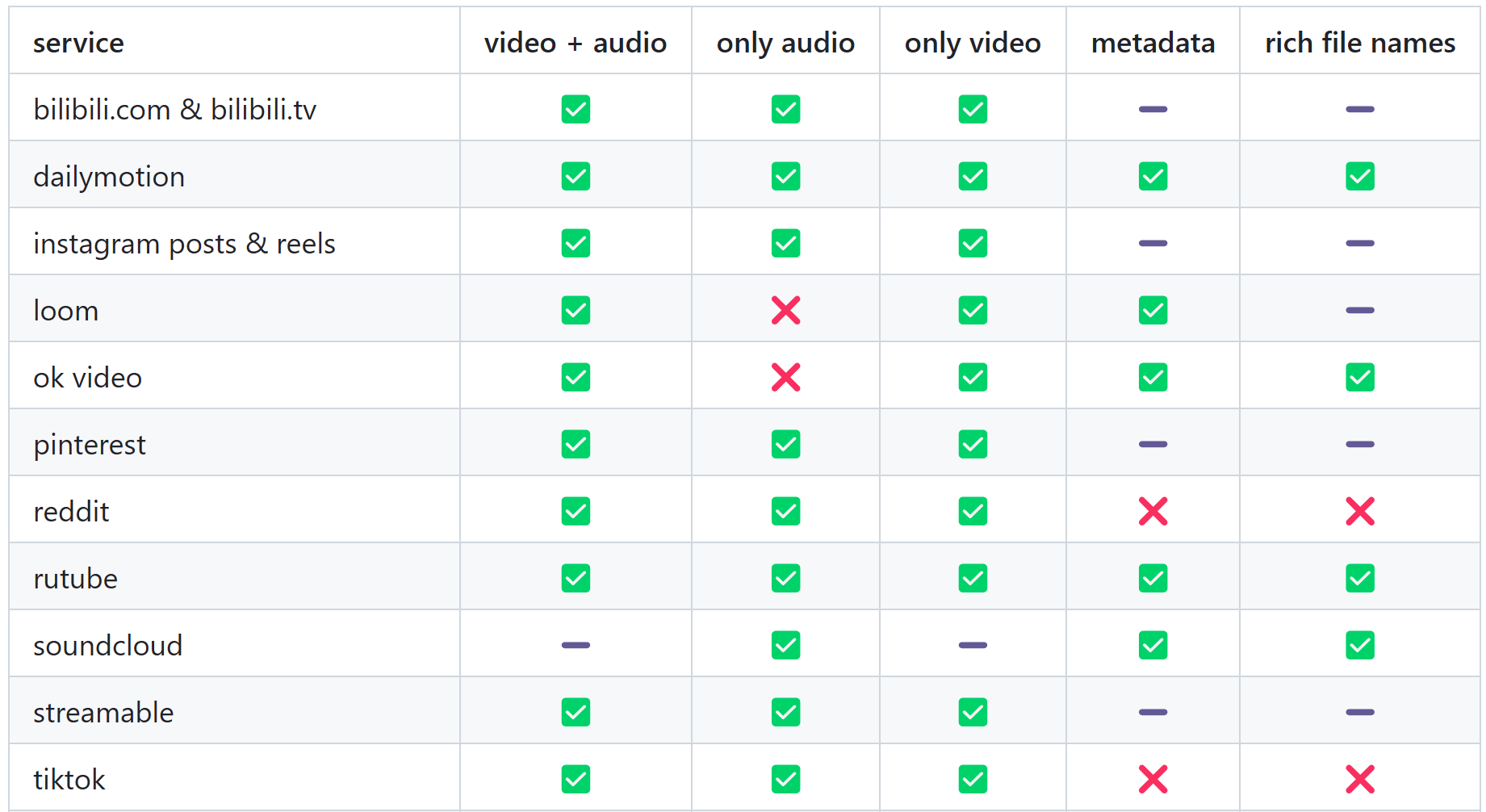
21 |
22 | 网站直达:[https://cobalt.tools/](https://cobalt.tools/)
23 |
24 | 比如,随便找了一个 B 站视频链接,右侧 >>,直接下载到本地!
25 | 
26 | 在视频的右下角,有一个 settings ,可以设置需要下载的分辨率和视频编码方式,有没有很贴心!
27 |
28 | 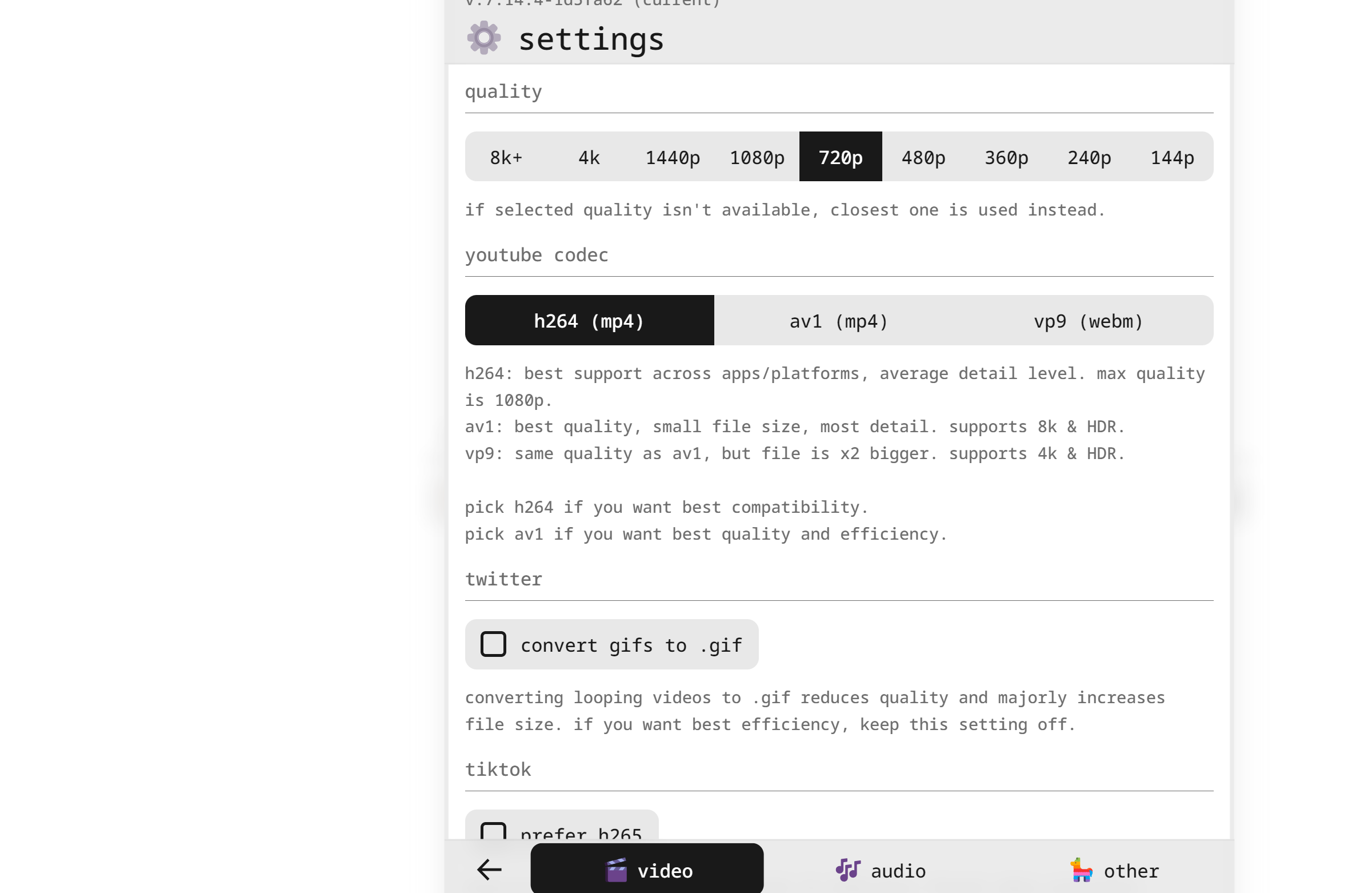
29 |
30 | 在线可使用,无需代码部署。唯一的缺陷是~~~**(你需要魔法)**!
31 |
32 | 此外,如果你是一个开发者,也可以根据项目文档,部署到自己的服务器上,根据作者提供的 [API 文档](https://github.com/imputnet/cobalt/blob/current/docs/api.md),也可以在自己的应用程序中使用,话说 *套个壳,是不是可以拿去卖了?*
33 | 
34 | 不过 Cobalt 目前还不支持 抖音 视频下载,怎么搞?
35 |
36 | 接下来介绍的这款插件,几乎可以下载所有视频网站的视频。
37 | # 2. 猫抓
38 | 猫抓是一款非常好用的浏览器插件,支持所有 chrome 内核浏览器,包括 Chrome,Edge,Firefox等。
39 |
40 | 先说下猫抓的亮点:
41 | - 它是一个嗅探音乐和视频的 Chrome 插件,而且只有几十 K 的大小,不管视频还是音乐,都可以捕获
42 | - 支持优酷、搜狐、腾讯、微博、B站等几乎国内所有网站的视频文件嗅探,同一页面上出现多个媒体资源时,还可以快速批量操作。
43 | - 在设置里自定义配置,还可以抓取图片,文档等各种资源文件。
44 |
45 | ## 安装方法:
46 | Google chrome 浏览器安装插件有两种方式。
47 |
48 | ### 直接安装:
49 | 首先在 chrome 浏览器中输入chrome://extensions,进入浏览器的扩展程序界面,然后搜索 “猫抓”。
50 |
51 | 或者,直接输入[插件网址](https://chromewebstore.google.com/detail/%E7%8C%AB%E6%8A%93/jfedfbgedapdagkghmgibemcoggfppbb)打开。
52 |
53 | 红色箭头处,点击安装即可。图中是因为我这里已经安装好了。
54 | 
55 | 如果你没有魔法,上述链接是无法打开的,这时猴哥推荐你采用下面这种方式进行安装。
56 | ### 拖拽安装:
57 | step 1:下载对应浏览器的 .crx 文件;
58 | (*📁 为了方便大家下载,公众号【猴哥的AI知识库】后台回复 **cat** ,直接领取压缩包~*)
59 |
60 | step 2: 在 chrome 浏览器中输入chrome://extensions,进入浏览器的扩展程序界面;
61 |
62 | step 3:将文件直接移动到扩展程序界面中。
63 |
64 | step4 :在浏览器上显示猫爪图标,即为安装成功。
65 |
66 | ## 实操示范:
67 | 比如我们这里打开 douyin.com,其他视频网站也是类似的。找到你想要下载的视频:
68 | 
69 |
70 | 然后在浏览器的扩展程序中找到 “猫抓”。
71 | 
72 | 这时你会看到它已经将网页中所有视频都嗅探到了,点击左侧红色箭头处的按钮,可以一键复制视频链接,右侧红色箭头可以看到视频的详细信息,左下角可以一键下载。
73 |
74 | 
75 | 有需要的小伙伴抓紧去试试吧~
76 |
77 | # 写在最后
78 |
79 | 如果本文对你有帮助,欢迎点赞收藏备用!
80 |
81 | 猴哥一直在做 AI 领域的研发和探索,会陆续跟大家分享路上的思考和心得。
82 |
83 | 最近开始运营一个公众号,旨在分享关于AI效率工具、自媒体副业的一切。用心做内容,不辜负每一份关注。
84 |
85 | 新朋友欢迎关注 “**猴哥的AI知识库**” 公众号,下次更新不迷路。
86 |
87 | (*📁 需要下载 猫抓 浏览器插件的,公众号后台回复 **cat** ,直接领取~*)
88 |
--------------------------------------------------------------------------------
/docs/6.AIoT笔记/AIoT应用开发:给板子装上'嘴巴',实现音频播放.md:
--------------------------------------------------------------------------------
1 | 最近新入手了一台 arm 开发板,希望打造一款有温度、有情怀的陪伴式 AI 对话机器人。
2 |
3 | 大体实现思路如下:
4 |
5 | 
6 |
7 | 前几篇,在板子上把`LLM 大脑`和`耳朵`装上了:
8 |
9 | - [如何在手机端部署大模型?](https://blog.csdn.net/u010522887/article/details/142296552)
10 | - [手机端跑大模型:Ollma/llama.cpp/vLLM 实测对比](https://blog.csdn.net/u010522887/article/details/142310279)
11 | - [AIoT应用开发:给板子装上'耳朵',实现实时音频录制](https://blog.csdn.net/u010522887/article/details/142325531)
12 |
13 | 对应到设备上:
14 | - `耳朵` == 麦克风(上篇搞定);
15 | - `嘴巴` == 扬声器(本篇开搞);
16 |
17 | 今日分享,带大家实操:**如何在开发板上接入扬声器,实现音频播放。**
18 |
19 | >有小伙伴问:没有 arm 开发板怎么办?准备一台 Android 手机就行。
20 | >
21 | >友情提醒:本文实操,请确保已在手机端准备好 Linux 环境,具体参考教程:[如何在手机端部署大模型?](https://blog.csdn.net/u010522887/article/details/142296552)
22 |
23 |
24 | ## 1. 两种思路
25 |
26 | 开发板上预装了 Android 13系统和 AidLux 开发工具,拥有丝滑的 Linux 环境。
27 |
28 | 如何接入扬声器,实现音频输出呢?
29 |
30 | 我尝试了两种方案:
31 |
32 | 1. 耳机:找了一个 3.5mm 接头的耳机,插入音频输出接口,不过,在终端中执行 `aplay -l`,无法识别到音频设备。折腾了半天最终放弃!
33 |
34 | 
35 |
36 |
37 | 2. 蓝牙音箱:成功接入!下文我们一起来聊聊:我是如何接入蓝牙音箱,并实现音频播放的。
38 |
39 | ## 2. 接入蓝牙音箱
40 |
41 | 首先是在 Linux 环境中配置蓝牙:`bluetoothctl` 打开蓝牙,显示 `No default controller available`,表明系统没有检测到任何蓝牙适配器。
42 |
43 | 无奈之下,把开发板接入显示器,进入 Android 界面看看吧。人肉打开蓝牙,依然无法搜索到周围蓝牙设备。。。
44 |
45 | 蓝牙信号接收不了?
46 |
47 | 后来经一大佬提示:外界蓝牙和 WIFI 信号都走同一个天线。
48 |
49 | 那就把天线接上试试吧!
50 |
51 | 果然,WIFI 信号直接拉满,蓝牙设备也接进来了~
52 |
53 | 
54 |
55 | ## 3. 实现音频播放
56 |
57 | ### 3.1 尝试1:Linux 端
58 | 蓝牙音箱是接入进来了,不过终端还是发现不了。
59 |
60 | ```
61 | aidlux@aidlux:~$ aplay -l
62 | aplay: device_list:276: no soundcards found...
63 | ```
64 |
65 | 运行以下命令检查音频设备的权限:
66 |
67 | ```
68 | aidlux@aidlux:~/projects/aibot$ ls -l /dev/snd
69 | total 0
70 | drwxr-xr-x. 2 root root 60 Sep 17 16:27 by-id
71 | drwxr-xr-x. 2 root root 60 Sep 17 16:27 by-path
72 | crw-rw----. 1 system 1005 116, 61 Jan 1 1970 comprC1D11
73 | crw-rw----. 1 system 1005 116, 62 Jan 1 1970 comprC1D24
74 | ```
75 |
76 | 发现音频设备的权限又被默认设置为了 1005 用户组,再改一次吧:
77 |
78 | ```
79 | sudo chgrp audio /dev/snd/*
80 | ```
81 |
82 | 再次执行 `aplay -l`,还是没发现新设备:
83 | ```
84 | aidlux@aidlux:~/projects/aibot$ aplay -l
85 | **** List of PLAYBACK Hardware Devices ****
86 | card 1: lahainayupikidp [lahaina-yupikidp-snd-card], device 0: MultiMedia1 (*) []
87 | Subdevices: 1/1
88 | Subdevice #0: subdevice #0
89 | ```
90 |
91 | 看来,这条路是走不通了,赶紧换!
92 |
93 | ### 3.2 尝试2:Android 端
94 | > 参考文档:[https://docs.aidlux.com/api/#/?id=%E7%A1%AC%E4%BB%B6](https://docs.aidlux.com/api/#/?id=%E7%A1%AC%E4%BB%B6)
95 |
96 | 原来 AidLux 中提供了对 Android 端的系统访问,其中有一项`媒体播放`。
97 |
98 | 目测应该是下面这两个包提供的支持。
99 | ```
100 | pip list | grep aid
101 | aidlux-aistack-base 1.1.0
102 | pyaidlite 2.0.9
103 | ```
104 | 根据文档,`媒体播放`模块可实现如下几个功能:
105 |
106 | - 音频播放:入参分别是文件URL,tag,是否立即播放。
107 |
108 | ```
109 | res = droid.mediaPlay('/sdcard/audios/20240914_204515.wav', 'default', True)
110 | print(res)
111 | # 输出结果
112 | Result(id=0, result=True, error=None)
113 | ```
114 | 注意:音频文件需放在 Android 目录 `/sdcard` 下,否则播放不了哦。
115 |
116 | - 检查是否正常播放:
117 |
118 | ```
119 | res = droid.mediaIsPlaying('default')
120 | print(res)
121 | # 输出结果
122 | Result(id=0, result=True, error=None)
123 | ```
124 |
125 | - 查看播放列表:
126 |
127 | ```
128 | res = droid.mediaPlayList()
129 | print(res)
130 | # 输出结果
131 | Result(id=0, result=['default'], error=None)
132 | ```
133 |
134 | - 查看播放信息:
135 |
136 | ```
137 | res = droid.mediaPlayInfo('default')
138 | print(res)
139 | # 输出结果
140 | Result(id=0, result={'loaded': True, 'duration': 2880, 'looping': False, 'isplaying': False, 'tag': '20240914_204515', 'position': 2880, 'url': '/sdcard/audios/20240914_204515.wav'}, error=None)
141 | ```
142 |
143 | - 停止播放:从缓存中清除
144 |
145 | ```
146 | res = droid.mediaPlayClose('default')
147 | print(res)
148 | # 输出结果
149 | Result(id=0, result=True, error=None)
150 | ```
151 |
152 | 基于以上接口,音频播放终于成功搞定!
153 |
154 | 大家有更好的想法,欢迎交流。
155 |
156 | ## 写在最后
157 |
158 | 至此,我们已经给开发板装上了:`大脑` + `耳朵` + `嘴巴`,下篇我们将这三者串联起来,实现 AI 机器人的雏形,敬请期待!
159 |
160 | 如果对你有帮助,欢迎**点赞**和**收藏**备用。
161 |
162 | ---
163 |
164 | 为方便大家交流,新建了一个 `AI 交流群`,欢迎对`AIoT`、`AI工具`、`AI自媒体`等感兴趣的小伙伴加入。
165 |
166 | 最近打造的微信机器人`小爱(AI)`也在群里,公众号后台「联系我」,拉你进群。
167 |
168 |
169 |
170 |
171 |
--------------------------------------------------------------------------------
/docs/6.AIoT笔记/Jetson 开发系列:Linux 下如何管理音频设备?.md:
--------------------------------------------------------------------------------
1 | 上篇带大家在 Jetson 开发板上搭建好了环境:
2 |
3 | [Jetson 开发系列:Orin Nano 开箱!一款强大的嵌入式&物联网开发板](https://blog.csdn.net/u010522887/article/details/142677847)
4 |
5 | 如果说板子的算力是大脑,那么我们还需要给它接入: `眼睛`、`耳朵`和`嘴巴`,这样才是一个完整的机器人嘛。
6 |
7 | 对应到设备上:
8 | - `眼睛` == 摄像头;
9 | - `耳朵` == 麦克风;
10 | - `嘴巴` == 扬声器;
11 |
12 | 这个好办,市面上随便买一款三合一的摄像头就能搞定。
13 |
14 | 内置麦克风和扬声器,大概长下面这样:我把商标打码了,以免有打广告的嫌疑。
15 |
16 | 
17 |
18 | 好用不贵,USB免驱,唯一的缺点是单声道输出,对音质有要求的小伙伴慎入哈。
19 |
20 | 问题来了:在 Linux 系统中,**我怎么管理这些音频设备呢?本文就来系统地盘一盘**。
21 |
22 | ## 1. 关于 ALSA
23 |
24 | ALSA(Advanced Linux Sound Architecture)是 Linux 中广泛使用的开源音频系统。它提供了对音频设备的低级访问,是许多音频应用程序与 Linux 内核之间的桥梁。
25 |
26 | ALSA 不仅包括内核驱动,还包括各种工具,如libasound、alsamixer、aplay、arecord等。
27 | - **音频播放和录音**:aplay和arecord,分别用于播放和录制音频文件。
28 | - **混音器控制**:alsamixer,一个基于文本的混音器界面,允许用户调整音频设备的音量和混音设置。
29 | - **广泛硬件支持**:包括但不限于PCI声卡、USB音频设备、HDMI音频等。
30 | - **兼容 PulseAudio**:PulseAudio是一个更高级的音频服务器,提供了更复杂的音频路由、混音等功能,其中 pactl 是 PulseAudio 的命令行工具。
31 |
32 | 如果你系统上还没安装,可以采用如下命令一键安装:
33 |
34 | ```
35 | sudo apt-get install alsa-base
36 | sudo apt-get install alsa-utils
37 | ```
38 |
39 | ## 2. 音频设备管理
40 |
41 | 查看声卡信息:
42 |
43 | ```
44 | cat /proc/asound/cards
45 | ```
46 |
47 | 前两个是内置声卡,最后是刚插入的自带麦克风扬声器的 USB 摄像头:
48 |
49 | 
50 |
51 | 接下来,我们需要了解两个专有名词:
52 | - sources:输入设备,比如麦克风,对应 arecord 命令;
53 | - sinks:输出设备,比如扬声器,对应 aplay 命令。
54 |
55 | **列出所有输入设备:**
56 |
57 | ```
58 | arecord -l
59 | # 对应PulseAudio中的命令
60 | pactl list short sources
61 | ```
62 |
63 | 这里可以看到设备号,后面需要用到:
64 |
65 | 
66 |
67 | **列出所有输出设备:**
68 |
69 | ```
70 | aplay -l
71 | # 对应PulseAudio中的命令
72 | pactl list short sinks
73 | ```
74 |
75 |
76 | ## 3. 查看音频设备信息
77 |
78 | 拿到设备号后,我们就可以调用设备进行`音频播放和录音`了。
79 |
80 | 不过,还是先来看看设备相关信息吧,其中`2,0`代表设备号:
81 |
82 | ```
83 | arecord -D hw:2,0 --dump-hw-params | grep '^CHANNELS'
84 | ```
85 |
86 | 关于音频,我们需要了解的主要有两个参数:
87 | - **声道**:Mono 代表单声道,Stereo 代表立体声-两声道,Quad 代表四声道,当然还有 5.1环绕声/7.1环绕声/杜比全景声,一般我们用不到。
88 | - **采样率**:模拟信号转换成数字信号,每秒钟采集样本的次数,通常以赫兹(Hz)为单位,常见的有:
89 | - 8/16K:常用于电话通信,因为人声的频率通常在 300 到3400 Hz;
90 | - 22.05K:FM广播的采样率;
91 | - 44.1 kHz:CD音质的标准采样率,
92 | - 48 kHz:数字音频和视频制作的标准采样率,常用于电影和专业音频。
93 |
94 | 
95 |
96 |
97 | ## 4. 音频播放和录音
98 |
99 | **如何录音:**
100 |
101 | ```
102 | arecord -D hw:0,0 -f S16_LE -r 16000 -c 1 -d 5 output.wav
103 | ```
104 | 参数说明如下:
105 | - -D hw:0,0:指定录音设备。hw:0,0 表示使用第一个声卡的第一个设备。
106 |
107 | - -f S16_LE:设置音频文件格式。S16_LE 表示 16 位小端格式(Signed 16-bit Little Endian),一种常用的音频数据格式,“小端”指数据的低位字节存储在内存的低地址端。
108 |
109 | - -r 16000:设置采样率。
110 |
111 | - -c 1:设置声道数。
112 |
113 | - -d 5:设置录音时长/秒。
114 |
115 |
116 |
117 | **如何播放音频:**
118 |
119 | ```
120 | aplay -D hw:0,0 -f S16_LE -r 16000 -c 1 data/audios/1.wav
121 | ```
122 |
123 | 如果指定采样率和原始音频不匹配,会出现“混叠”,这时你需要用 ffmpeg 转换一下参数:
124 |
125 | ```
126 | ffmpeg -i data/audios/1.wav -ac 1 -ar 48000 data/audios/2.wav
127 | ```
128 |
129 |
130 | 如果你发现:播放音频的指令运行没啥问题,但就是不出声?
131 |
132 | 接着往下看!
133 |
134 | ## 4. 音量调节
135 |
136 | ALSA 中采用 alsamixer 进行音量调节。使用非常简单,只需终端输入:
137 |
138 | ```
139 | alsamixer
140 | ```
141 |
142 | 他会给你一个图形界面:
143 |
144 | 
145 |
146 | 如果你要用摄像头的扬声器,自然要切换声卡,怎么搞?
147 |
148 | 按下 F6 进行声卡切换:
149 |
150 | 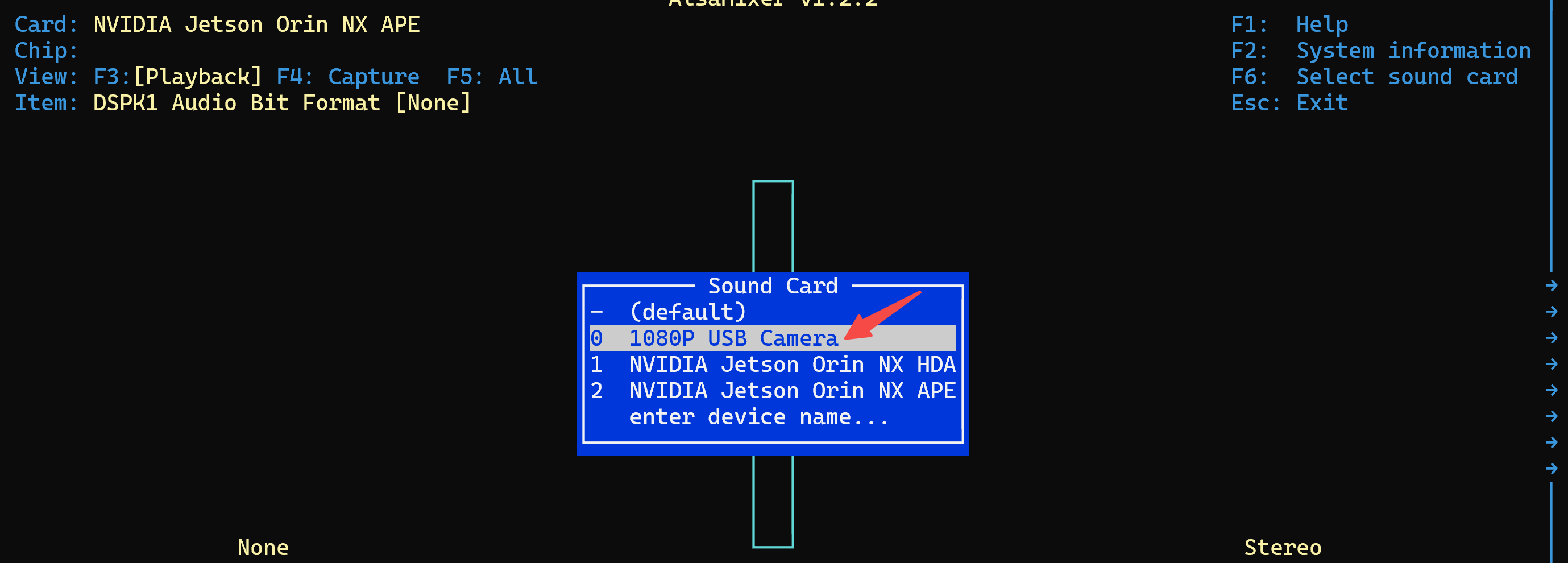
151 |
152 | 如果遇到 vscode 快捷键冲突,用 powershell 打开一个终端吧。
153 |
154 | 按向上键把 PCM 值调高:
155 |
156 | 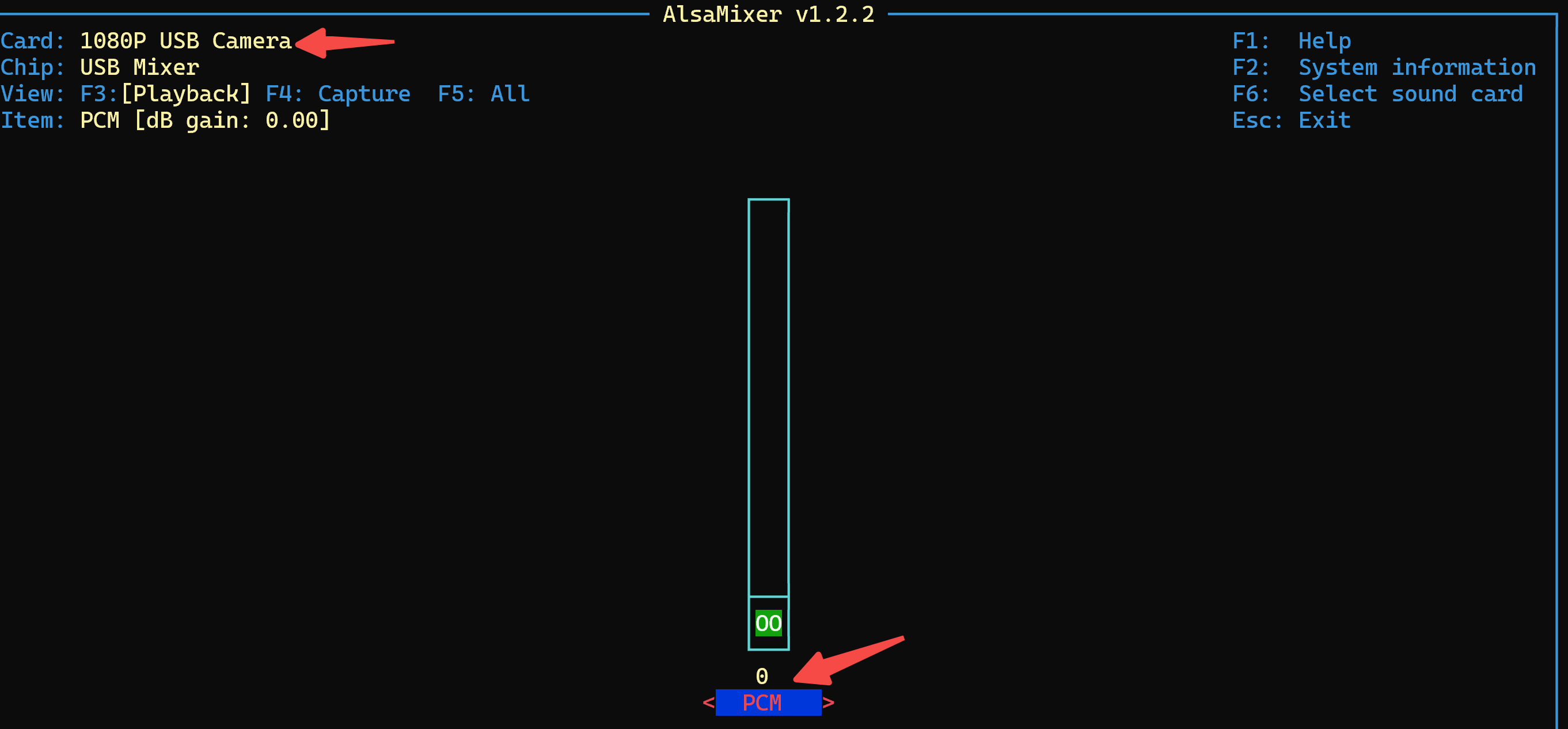
157 |
158 | 再来播放音频文件试试吧~
159 |
160 | 这个坑,折腾了好久,听到出声的那一刻,激动得老泪纵横。。。
161 |
162 | ## 写在最后
163 |
164 | 本文带大家实操了ALSA 这位 Linux 的音频管理大师。
165 |
166 | 终于,给 Jetson 安装上了耳朵和嘴巴,让它能听会说了。
167 |
168 | 如果对你有帮助,欢迎**点赞收藏**备用。
169 |
170 | 本系列文章,会陆续更新在 Jetson 上完成 AI 应用开发的相关教程,欢迎感兴趣的朋友关注。
171 |
172 | ---
173 |
174 | 为方便大家交流,新建了一个 `AI 交流群`,欢迎对`AIoT`、`AI工具`、`AI自媒体`等感兴趣的小伙伴加入。
175 |
176 | 最近打造的微信机器人`小爱(AI)`也在群里,公众号后台「联系我」,拉你进群。
177 |
178 |
179 |
180 |
--------------------------------------------------------------------------------
/docs/6.AIoT笔记/Jetson 开发系列:如何用GPU跑本地大模型?.md:
--------------------------------------------------------------------------------
1 | 最近刚入手一台 Jetson Ori Nano 开发板,前两篇把开发前的准备工作做了:
2 | - 搭建本地环境:[Jetson 开发系列:Orin Nano 开箱!一款强大的嵌入式&物联网开发板](https://blog.csdn.net/u010522887/article/details/142677847)
3 | - 管理音频设备:[Jetson 开发系列:Linux 下如何管理音频设备?](https://blog.csdn.net/u010522887/article/details/142699413)
4 |
5 | Jetson Ori Nano 搭载了一块有 1024 个 CUDA 核的 GPU,可提供 40 TOPS(每秒万亿次)的算力,为本地跑大模型提供了一种可能。
6 |
7 | 在[最强开源Qwen2.5:本地部署 Ollma/vLLM 实测](https://blog.csdn.net/u010522887/article/details/142478091)中,我们实测发现:**GPU 推理速度是 CPU 的 10+ 倍!**
8 |
9 | 边缘设备中,还有这么高的加速比么?
10 |
11 | 用 Jetson Ori Nano 跑大模型,速度咋样?
12 |
13 | 本文就带大家用 Ollama 实测一番。
14 |
15 | ## 1. Ollama 支持所有 GPU 么
16 |
17 | Ollama 是一款最适合小白的大模型部署利器,所谓的`一键部署`是 Ollama 帮你搞定了很多麻烦事,比如 GPU 加速、模型量化等。
18 |
19 | 但 Ollama 并非支持所有 GPU 设备的加速推理。
20 |
21 | 划重点:Ollama 只支持**计算能力 5.0** 及以上的 **Nvidia** GPU!
22 |
23 | 其中,**计算能力 5.0** 是NVIDIA 是定义的一个术语,不同版本意味着支持不同的 CUDA 特性,以及不同的计算性能。
24 |
25 | > [https://developer.nvidia.com/cuda-gpus](https://developer.nvidia.com/cuda-gpus)这里可以查看你的 GPU 对应的计算能力。
26 |
27 | Jetson Orin Nano 的计算能力是 8.7,理论上是可行的?
28 |
29 | ## 2. 原生 Ollama 部署失败
30 |
31 | 在 Jetson 中,系统内存和 GPU 显存共享,板卡使用的是专门为嵌入式系统优化的驱动和API,原生 Ollama 无法在 Jetson 上利用 GPU 跑大模型。
32 |
33 | 首先,尝试 docker 部署 Ollma。
34 |
35 | **1. 使用 GPU:**
36 | ```
37 | docker run -d --runtime nvidia -v ollama:/root/.ollama -p 3002:11434 --restart unless-stopped --name ollama ollama/ollama
38 | ```
39 |
40 | **2. 使用 CPU:**
41 |
42 | ```
43 | docker run -d -v ollama:/root/.ollama -p 3002:11434 --restart unless-stopped --name ollama ollama/ollama
44 | ```
45 |
46 | 但是,使用 GPU 无法将模型加载到内存中,而 CPU 可以,一开始以为是 docker 环境的问题,后来尝试了本地部署,依然无法加载成功。
47 |
48 | 直到找到 Jetson Containers 这个工具。
49 |
50 | ## 3. dustynv/ollama 镜像部署成功
51 |
52 | Jetson Containers 是专为 Jetson 设计的容器项目,提供了模块化的容器构建系统,底层依赖 docker。
53 |
54 | 其中,专为 Ollama 提供了一个教程:[https://www.jetson-ai-lab.com/tutorial_ollama.html](https://www.jetson-ai-lab.com/tutorial_ollama.html)。
55 |
56 | 不过,`jetson-containers run --name ollama $(autotag ollama)` 命令依然是采用的 Ollama 原生镜像,所以搞不定。
57 |
58 | 后面发现`dustynv/ollama:r36.2.0`这个镜像,可以成功拉起支持 Jetson GPU 的docker 容器:
59 |
60 | ```
61 | docker run -d --runtime nvidia --restart unless-stopped -p 3002:11434 -v ollama:/ollama -e OLLAMA_MODELS=/ollama -e OLLAMA_LOGS=/ollama/ollama.log --name ollama dustynv/ollama:r36.2.0
62 | ```
63 |
64 | 通过如下命令进入容器:
65 |
66 | ```
67 | docker exec -it ollama /bin/bash
68 | ```
69 |
70 | 接下来,下载你需要的模型就行,具体可参考:[最强开源Qwen2.5:本地部署 Ollma/vLLM 实测](https://blog.csdn.net/u010522887/article/details/142478091)
71 |
72 | 打一个请求测试了看看吧:
73 |
74 | 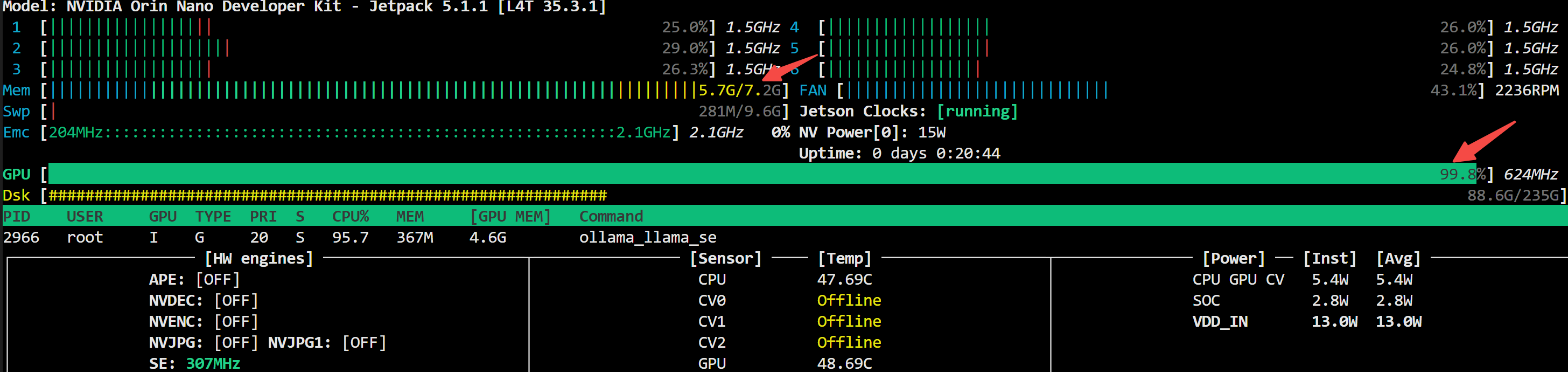
75 |
76 | 上图可以发现:CPU 没有打满,但 GPU 利用率上来了,说明你的模型已经成功跑在了 GPU 上!
77 |
78 | ## 4. CPU/GPU 速度对比
79 |
80 | 既然已经实现了 GPU 推理加速,自然最关心的问题是:加速效果如何?
81 |
82 | 我们还是采用上篇的测试方法:非流式输出,直接使用输出文本字数进行平均耗时对比。
83 |
84 | **cpu 跑 qwen2.5:7b**
85 |
86 | ```
87 | 7b cpu: 0, time: 4.08s, token/s: 3.68
88 | 7b cpu: 1, time: 6.31s, token/s: 3.80
89 | 7b cpu: 2, time: 5.02s, token/s: 3.39
90 | 7b cpu: 3, time: 9.39s, token/s: 4.26
91 | 7b cpu: 4, time: 6.68s, token/s: 3.89
92 | ```
93 |
94 | **gpu 跑 qwen2.5:7b**
95 |
96 | ```
97 | qwen2.5-7b time: 45.86s, token/s: 9.31
98 | qwen2.5-7b time: 37.87s, token/s: 9.48
99 | qwen2.5-7b time: 44.05s, token/s: 9.72
100 | qwen2.5-7b time: 30.55s, token/s: 9.23
101 | qwen2.5-7b time: 50.36s, token/s: 9.13
102 | ```
103 |
104 | 尴尬了,加速比不到 3,jetson gpu 甚至跑不到服务端 cpu 的速度!
105 |
106 | 看来,想要在端侧跑本地大模型,流式输出是必须的了,我们下篇来聊。
107 |
108 | ## 写在最后
109 |
110 | 终于,我们在 Jetson 上成功利用 GPU 实现了大模型推理加速。
111 |
112 | 有朋友问:7b 能叫大模型?
113 |
114 | 是啊,不过在 Ollama 对模型量化的基础上,8G 内存只够装下 7b 模型,还得给本地部署`语音识别+语音合成`留点内存空间。
115 |
116 | 本系列文章,会陆续更新 Jetson AI 应用开发的相关教程,欢迎感兴趣的朋友关注。
117 |
118 | ---
119 |
120 | 为方便大家交流,新建了一个 `AI 交流群`,欢迎对`AIoT`、`AI工具`、`AI自媒体`等感兴趣的小伙伴加入。
121 |
122 | 最近打造的微信机器人`小爱(AI)`也在群里,公众号后台「联系我」,拉你进群。
123 |
--------------------------------------------------------------------------------
/docs/6.AIoT笔记/Jetson 开发系列:离线低延迟的人脸识别方案.md:
--------------------------------------------------------------------------------
1 | 最近,在 Jetson 上探索构建**离线、低延迟**的智能对话助手,欢迎感兴趣的朋友一起交流。
2 |
3 |
4 | 上篇调研了`语音识别和语音合成`解决方案。
5 | - [Jetson 开发系列:离线低延迟的语音解决方案](https://blog.csdn.net/u010522887/article/details/142814654)
6 |
7 | 本篇继续探索`人脸识别`的离线部署方案。
8 |
9 |
10 | ## 1. CompreFace
11 |
12 | 关于 CompreFace 的优势和使用方法,之前出过一篇教程:[手把手搭建免费的人脸识别系统,支持REST API](https://zhuanlan.zhihu.com/p/710781082)。
13 |
14 | CompreFace 是一套开源的人脸识别解决方案,功能包括:人脸识别、人脸验证、人脸检测、人脸关键点检测、面具检测、头部姿势检测、年龄和性别识别等。
15 |
16 | 遗憾的是,它依赖 AVX 指令集,因此 arm 架构的板子上无法部署,只好放弃。
17 |
18 | 你可以在终端使用如下命令试试看:
19 | ```
20 | lscpu | grep avx
21 | ```
22 |
23 | ## 2. face_recognition
24 | > 项目地址:[https://github.com/ageitgey/face_recognition](https://github.com/ageitgey/face_recognition)
25 |
26 | 号称世界上最简单的人脸识别库,底层依赖[dlib](http://dlib.net/files/)。
27 |
28 | 如果需要使用 GPU 推理,由于 Jetson cuda的 bug,需要重新编译 dlib,详情可参考[作者的博客](https://medium.com/@ageitgey/build-a-hardware-based-face-recognition-system-for-150-with-the-nvidia-jetson-nano-and-python-a25cb8c891fd)。
29 |
30 |
31 | 一键安装:
32 |
33 | ```
34 | pip install face_recognition
35 | ```
36 |
37 |
38 | 使用也非常简单,比如:
39 |
40 | **人脸检测:**
41 |
42 |
43 | ```
44 | import face_recognition
45 | image = face_recognition.load_image_file("your_file.jpg")
46 | face_locations = face_recognition.face_locations(image)
47 | ```
48 |
49 | **人脸识别:**
50 |
51 | ```
52 | known_image = face_recognition.load_image_file("biden.jpg")
53 | unknown_image = face_recognition.load_image_file("unknown.jpg")
54 |
55 | biden_encoding = face_recognition.face_encodings(known_image)[0]
56 | unknown_encoding = face_recognition.face_encodings(unknown_image)[0]
57 |
58 | results = face_recognition.compare_faces([biden_encoding], unknown_encoding)
59 | ```
60 |
61 | 唯一的缺陷是:没有检测框的得分,难以实现后处理。
62 |
63 | ## 3. Insightface
64 |
65 | > 项目地址:[https://github.com/deepinsight/insightface](https://github.com/deepinsight/insightface)
66 |
67 | Insightface 是一个强大的开源人脸识别项目,涵盖了各种人脸相关的应用。
68 |
69 | 一键安装:
70 |
71 | ```
72 | pip install insightface
73 | ```
74 | insightface 从 0.2 版本开始,推理后端从 MXNet 切换到了 onnxruntime。
75 |
76 | 不过在 Jetson 上,只支持 CPU 推理,无法使用 onnxruntime-gpu 推理。
77 |
78 | 如果需要使用使用 GPU,需要自行编译,但要确保 onnxruntime-gpu, cuda, cudnn 三者的版本对应,否则会报错。**PS:这个坑,有趟过的小伙伴欢迎交流啊。😊**
79 |
80 | 不过,倒是可以用 tensorrt 对 ONNX 模型进行推理加速,我们下篇再聊。
81 |
82 | 本篇,我们暂且先使用 CPU 来跑跑看:
83 |
84 | ```
85 | import cv2
86 | import numpy as np
87 | from insightface.app import FaceAnalysis
88 | app = FaceAnalysis(name='buffalo_sc')
89 | app.prepare(ctx_id=0, det_size=(640, 640))
90 | img = cv2.imread('data/images/1.png')[:, :, ::-1]
91 | faces = app.get(img)
92 | print(len(faces))
93 | ```
94 | [官网](https://github.com/deepinsight/insightface/tree/master/python-package)提供了模型列表,示例代码中用的是小模型。
95 |
96 | 返回的结果中有哪些字段:
97 |
98 | ```
99 | dict_keys(['bbox', 'kps', 'det_score', 'embedding'])
100 | ```
101 |
102 | 其中,返回的 embedding 是没有归一化的,记得在保存到向量库之前进行归一化处理:
103 |
104 | ```
105 | feature = np.array(face['embedding'])[None, :]
106 | feature = feature / np.linalg.norm(feature, axis=1, keepdims=True)
107 | ```
108 |
109 | (640, 640)的图像推理耗时怎么样?
110 |
111 | 同一张图像,分别测三次:
112 |
113 | **'buffalo_sc'模型**:没有人脸矫正和属性预测
114 |
115 | ```
116 | 0 Time taken: 0.40
117 | 1 Time taken: 0.39
118 | 2 Time taken: 0.39
119 | ```
120 | **'buffalo_s'模型**:加上人脸矫正和属性预测
121 |
122 | ```
123 | 0 Time taken: 1.51
124 | 1 Time taken: 1.50
125 | 2 Time taken: 1.50
126 | ```
127 |
128 | 因此,为了兼顾推理速度,只好选择阉割版的**buffalo_sc**。
129 |
130 | ## 写在最后
131 |
132 | 本文为离线低延迟的人脸识别,提供了几种解决思路,更多方案,欢迎评论区交流。
133 |
134 | 如果对你有帮助,不妨**点赞收藏**备用。
135 |
136 | ---
137 |
138 | 为方便大家交流,新建了一个 `AI 交流群`,欢迎对`AIoT`、`AI工具`、`AI自媒体`等感兴趣的小伙伴加入。
139 |
140 | 最近打造的微信机器人`小爱(AI)`也在群里,公众号后台「联系我」,拉你进群。
141 |
142 |
143 |
144 |
145 |
146 |
147 |
--------------------------------------------------------------------------------
/docs/6.AIoT笔记/README.md:
--------------------------------------------------------------------------------
1 | # 6.AIoT笔记
2 |
3 | - [AIoT应用开发:如何给板子装上'耳朵',实现音频录制](docs/6.AIoT笔记/AIoT应用开发:如何给板子装上'耳朵',实现音频录制.md)
4 | - [AIoT应用开发:如何远程查看摄像头,RTSP_RTMP 推流了解下?](docs/6.AIoT笔记/AIoT应用开发:如何远程查看摄像头,RTSP_RTMP%20推流了解下?.md)
5 | - [AIoT应用开发:搞定语音对话机器人=ASR+LLM+TTS](docs/6.AIoT笔记/AIoT应用开发:搞定语音对话机器人=ASR+LLM+TTS.md)
6 | - [AIoT应用开发:本地搭建 AI 口语老师,一对一免费陪练!](docs/6.AIoT笔记/AIoT应用开发:本地搭建%20AI%20口语老师,一对一免费陪练!.md)
7 | - [AIoT应用开发:给机器人接入'记忆',完美解决「和谁对话&多轮对话」!附 SQLite 入门实战](docs/6.AIoT笔记/AIoT应用开发:给机器人接入'记忆',完美解决「和谁对话&多轮对话」!附%20SQLite%20入门实战.md)
8 | - [AIoT应用开发:给机器人装上'眼睛',接入CV能力,实现人脸识别](docs/6.AIoT笔记/AIoT应用开发:给机器人装上'眼睛',接入CV能力,实现人脸识别.md)
9 | - [AIoT应用开发:给板子装上'嘴巴',实现音频播放](docs/6.AIoT笔记/AIoT应用开发:给板子装上'嘴巴',实现音频播放.md)
10 | - [Jetson 开发系列:Linux 下如何管理音频设备?](docs/6.AIoT笔记/Jetson%20开发系列:Linux%20下如何管理音频设备?.md)
11 | - [Jetson 开发系列:Orin Nano 开箱!一款强大的嵌入式&物联网开发板](docs/6.AIoT笔记/Jetson%20开发系列:Orin%20Nano%20开箱!一款强大的嵌入式&物联网开发板.md)
12 | - [Jetson 开发系列:如何用GPU跑本地大模型?](docs/6.AIoT笔记/Jetson%20开发系列:如何用GPU跑本地大模型?.md)
13 | - [Jetson 开发系列:离线低延迟的人脸识别方案](docs/6.AIoT笔记/Jetson%20开发系列:离线低延迟的人脸识别方案.md)
14 | - [Jetson 开发系列:离线低延迟的语音解决方案](docs/6.AIoT笔记/Jetson%20开发系列:离线低延迟的语音解决方案.md)
15 | - [从0打造本地聊天机器人:如何实现大模型流式输出?OpenAI+Ollama 实战](docs/6.AIoT笔记/从0打造本地聊天机器人:如何实现大模型流式输出?OpenAI+Ollama%20实战.md)
16 | - [如何在手机端跑大模型?](docs/6.AIoT笔记/如何在手机端跑大模型?.md)
17 | - [安卓连接 WIFI 但无法上网?盘点我踩过的那些坑](docs/6.AIoT笔记/安卓连接%20WIFI%20但无法上网?盘点我踩过的那些坑.md)
18 | - [手机端跑大模型:Ollma_llama.cpp_vLLM 实测对比](docs/6.AIoT笔记/手机端跑大模型:Ollma_llama.cpp_vLLM%20实测对比.md)
19 |
20 |
21 |
22 | *本系列共更新**16**篇文章*
23 |
24 |
25 |
26 | [🔙返回首页](/)
27 |
--------------------------------------------------------------------------------
/docs/6.AIoT笔记/从0打造本地聊天机器人:如何实现大模型流式输出?OpenAI+Ollama 实战.md:
--------------------------------------------------------------------------------
1 | 上篇带大家在 Jetson Ori Nano 开发板上,成功利用 GPU 实现了大模型推理加速。
2 | - [Jetson 开发系列:如何用GPU跑本地大模型?](https://blog.csdn.net/u010522887/article/details/142722395)
3 |
4 | 尽管有了 GPU 加持,推理速度依然很慢,怎么搞?
5 |
6 | **流式输出!**
7 |
8 | 相比全部生成后再输出,**流式输出**生成一句就播报一句,大大减少了用户的等待时间。
9 |
10 | 主流大模型推理 API 包括:
11 | - OpenAI 格式:沿袭 ChatGPT 的云端 API,多用于线上模型;
12 | - Ollama 格式:用于本地部署的大模型推理。
13 |
14 | 本次分享,将带大家实战:OpenAI 和 Ollma 下的大模型流式输出。
15 |
16 | ## 1. OpenAI 流式输出
17 |
18 | 当前大部分大模型的推理 API 都兼容了 OpenAI 格式。
19 |
20 | 如果没有,强烈推荐你用 OneAPI 进行管理:[一键封装成OpenAI协议,强推的一款神器!](https://zhuanlan.zhihu.com/p/707769192)
21 |
22 | 和非流式输出相比,只需新增一个参数:`stream=True`。
23 |
24 | 不过,为了方便后续进行语音合成,我们需要对大模型的流式输出进行一番处理!
25 |
26 | 首先,定义一个标点符号列表:punct_list = ['。', '!', '?'],遇到这里的标点,则立即输出。
27 |
28 | 具体实现如下,供参考:
29 | ```
30 | class LLM_API:
31 | def __init__(self, api_key, base_url, model):
32 | self.client = OpenAI(
33 | api_key=api_key,
34 | base_url=base_url,
35 | )
36 | self.model = model
37 | def stream(self, messages):
38 | completion = self.client.chat.completions.create(
39 | model=self.model, messages=messages, stream=True
40 | )
41 | text2tts = ''
42 | for chunk in completion:
43 | text = chunk.choices[0].delta.content
44 | text2tts += text
45 | for punct in punct_list:
46 | if punct in text:
47 | front, back = text2tts.replace('\n', '').rsplit(punct, 1)
48 | yield front + punct
49 | text2tts = back
50 | break
51 | if text2tts:
52 | yield text2tts
53 | ```
54 |
55 | 上述代码使用 yield 关键字定义一个生成器函数。
56 |
57 | ## 2. Ollama 流式输出
58 | 有关 Ollama 的使用,可参考:[本地部署大模型?Ollama 部署和实战,看这篇就够了](https://blog.csdn.net/u010522887/article/details/140651584)
59 |
60 | Ollama 的 API 和 OpenAI 略有区别,但核心逻辑是一样的,直接上代码:
61 | ```
62 | def stream(self, messages):
63 | data = {
64 | "model": self.model, "messages": messages, "stream": True
65 | }
66 | response = requests.post(self.base_url, json=data, stream=True)
67 | text2tts = ''
68 | for line in response.iter_lines():
69 | data = json.loads(line.decode('utf-8'))
70 | text = data['message']['content']
71 | text2tts += text
72 | for punct in punct_list:
73 | if punct in text:
74 | front, back = text2tts.replace('\n', '').rsplit(punct, 1)
75 | yield front + punct
76 | text2tts = back
77 | break
78 | if text2tts:
79 | yield text2tts
80 | ```
81 |
82 | 调用时,可以用 for 循环来迭代生成器对象,每次迭代,生成器会执行到下一个 yield 语句,并返回当前值:
83 |
84 | ```
85 | ollama_api = OLLAMA_API(ollama_url, 'qwen2.5:7b')
86 | messages = [{ "role": "user", "content": "天空为什么是蓝色的"}]
87 | for text in ollama_api.stream(messages):
88 | print(text)
89 | ```
90 | 输出效果如下:
91 |
92 | ```
93 | 天空之所以呈现蓝色,主要是因为大气中的气体分子和其他细小颗粒对太阳光的散射作用。
94 | 这种现象被称为瑞利散射(Rayleigh scattering),由英国物理学家威廉·汉斯·瑞利爵士在19世纪末发现。
95 | 当阳光进入地球的大气层时,其中的各种颜色(不同波长)的光线都会受到气体分子、水蒸气和尘埃等微粒的影响。
96 | 然而,这些微粒对较短波长的光(如蓝色和紫色)散射得更为强烈。
97 | 由于人眼对蓝光比紫光敏感得多,所以我们看到的是天空呈蓝色。
98 | 实际上,太阳本身发出的白光包含了所有颜色的光。
99 | 当阳光进入大气层时,其中的蓝色光线因散射作用被分散到各个方向,在我们看来,天空就呈现出蓝色。
100 | 而太阳和天空在白天看起来呈现不同的颜色(例如:日出和日落时天边的橙红色或紫色),则是由于此时光线需要穿过更多的大气层,蓝光几乎都被散射掉了,只有红、橙等较长波长的光线能够直接到达我们的眼睛。
101 | 总之,正是这种自然现象造成了天空呈现出蓝色。
102 | ```
103 |
104 | 实测:在 Jetson Orin Nano 上使用本地部署的 qwen2.5:7b,流式输出 + 语音合成播报,体验基本无延迟!
105 |
106 | ## 写在最后
107 |
108 | 本文带大家实操了大模型流式输出,在 OpenAI 和 Ollama API 中的具体实现。
109 |
110 | 如果对你有帮助,欢迎**点赞收藏**备用。
111 |
112 | 本系列文章,会陆续更新 Jetson AI 应用开发的相关教程,欢迎感兴趣的朋友关注。
113 |
114 | ---
115 |
116 | 为方便大家交流,新建了一个 `AI 交流群`,欢迎对`AIoT`、`AI工具`、`AI自媒体`等感兴趣的小伙伴加入。
117 |
118 | 最近打造的微信机器人`小爱(AI)`也在群里,公众号后台「联系我」,拉你进群。
119 |
120 |
121 |
--------------------------------------------------------------------------------
/docs/6.AIoT笔记/安卓连接 WIFI 但无法上网?盘点我踩过的那些坑.md:
--------------------------------------------------------------------------------
1 | 最近入手一台 arm 开发板,内置安装了 Android 13 系统。
2 |
3 | 拿到手后,当务之急就是给它联网。
4 |
5 | 原本以为 so easy 的一件事,却折腾了我半天。
6 |
7 | 接入 WIFI,**“已连接,但无法访问互联网”**?
8 |
9 | 今天分享一下问题解决的过程,希望给遇到类似问题的朋友,一些参考。
10 |
11 | ## 前置准备
12 |
13 | 拿到板子,首先需要登录设备,这里简单介绍两种方式。
14 |
15 | **方式一:**找一根 HDMI 线,连接到显示器;有线鼠标和有线键盘连接到板子的 USB 口,开机启动。
16 |
17 | **方式二:** 如果觉得方式一麻烦,可以选择使用投屏软件,在本地电脑控制开发板:
18 | - 投屏可以用免费开源的 [QtScrcpy](https://github.com/barry-ran/QtScrcpy/releases),本地电脑下载,无需安装,内置 `adb` 工具;
19 | - 找一根 type c 线连接开发板和本地电脑;
20 | - 双击 QtScrcpy.exe,打开访问界面。
21 |
22 | 
23 |
24 |
25 | ## 问题描述:
26 |
27 | 连接 WIFI 后,如果你也遇到下面的问题,那么可以继续看下去了。
28 |
29 | 
30 |
31 |
32 |
33 | ## 尝试思路1:Captive portal 配置
34 | > 参考:[https://www.evil42.com/index.php/archives/17/](https://www.evil42.com/index.php/archives/17/)
35 |
36 | Captive Portal 是安卓 5 引入的一种检测网络是否正常连接的机制,通过 HTTP 返回的状态码是否是 204 来判断是否成功,如果访问得到了 200 带网页数据,那你就可能处在一个需要登录验证才能上网的环境里,比如说校园网和酒店,如果连接超时就在 WiFi 图标和信号图标上加一个感叹号。
37 |
38 | 首先,本地电脑打开一个终端,确认 `adb` 能否识别到你的设备:
39 |
40 | ```
41 | adb devices
42 | ```
43 |
44 |
45 | 接下来,通过如下命令通过修改系统设置来控制这种行为。
46 |
47 | ```
48 | # 将 captive_portal_mode设置为0(不使用系统默认的 URL 进行检测)
49 | adb shell settings put global captive_portal_mode 0
50 | #查看当前状态:
51 | adb shell settings get global captive_portal_mode
52 | ```
53 |
54 | 如果还是不行,试试更新下用于检测互联网连接状态的两个 URL。
55 | ```
56 | #分别修改两个地址
57 | adb shell settings put global captive_portal_http_url http://captive.v2ex.co/generate_204
58 | adb shell settings put global captive_portal_https_url https://captive.v2ex.co/generate_204
59 |
60 | # 或者下面地址
61 | adb shell settings put global captive_portal_https_url https://connect.rom.miui.com/generate_204
62 | adb shell settings put global captive_portal_http_url http://connect.rom.miui.com/generate_204
63 |
64 | ```
65 |
66 | 修改后,`无法访问互联网`的提示没了,不过依然无法打开网页。
67 |
68 | DHCP 自动分配的 IP 地址,应该没问题啊,要不试试设置一个静态 IP ?
69 |
70 |
71 |
72 | ## 尝试思路2:静态 IP 配置
73 | DHCP 自动分配的 IP 地址是和设备的 MAC 地址相关的,是否是 IP 地址冲突了?
74 |
75 | 为此尝试修改 IP 地址,默认网关和 DNS 还是和之前一致!
76 |
77 | 在本地电脑,通过如下命令查看局域网内设备:
78 |
79 | ```
80 | arp -a
81 | ```
82 |
83 | 发现是可以发现这个设备的:
84 |
85 | 
86 |
87 | 但是,依然无法访问互联网。
88 |
89 | 那么,会不会是 DNS 的问题?
90 |
91 | ## 尝试思路3:DNS 配置
92 |
93 | 我发现 DHCP 自动分配的 DNS 是 192.168.1.1,这个是路由器的 IP 地址。
94 |
95 | 我把 DNS 改成了 8.8.8.8,这是 Google 的公共 DNS 服务器。
96 |
97 | 终于,可以成功打开网页了!
98 |
99 | 果然,是 DNS 的锅~
100 |
101 | 虽然可以访问互联网,但新问题又来了:在本地局域网却 ping 不通这个 IP 地址,这就意味着在内网无法调用开发板上部署的任何服务。
102 |
103 | 莫非是路由器的问题?
104 |
105 | 于是,我用手机开了一个热点,连上热点网络后,压根不存在上面这些问题!
106 |
107 | 到这一步,是 WIFI 网络的问题,实锤了!
108 |
109 | 怎么解决?
110 |
111 | 找路由器去!
112 |
113 | ## 最终方案:路由器配置
114 |
115 | 在路由器背面找到 局域网 IP 地址(LAN IP)。
116 |
117 | 浏览器中打开,登录成功后,可以发现设备已经成功接入了。
118 |
119 | 
120 |
121 | 不同品牌的路由器应该大同小异,找到 `上网方式`。
122 |
123 | 
124 |
125 | 我这里之前默认的是 `Bridge(AP)` 方式,把它改成`自动获取 IP (DHCP)`,设备重新连接这个 WIFI,完美解决!
126 |
127 | 为什么改变 `上网方式`解决了问题?
128 |
129 | - Bridge(桥接模式)AP(接入点模式):通常用于扩展现有网络的 WiFi 覆盖范围。这种模式下,本地路由器不负责分配IP地址和管理网络,而是将这些任务交给上层路由器。路由器仅作为网络的中继,设备之间的通信依赖于主路由器。如果主路由器对IP地址通信有限制(如客户端隔离),设备就无法相互通信。
130 | - DHCP模式下:本地路由器负责为每个连接的设备分配IP,确保每个设备都有唯一的IP,并通过网络地址转换(NAT)来管理外部和内部网络通信。
131 |
132 | 因此,通过将路由器从 Bridge 模式切换到 DHCP 模式,路由器重新承担起管理和分配网络的任务,确保了局域网内设备的正常通信,和访问外网。
133 |
134 | ## 写在最后
135 |
136 | 总体来说,在给 Android 开发板联网过程中,我们可能会遇到:
137 |
138 | - 连接WiFi成功但无法上网 - 可能是Captive Portal的问题,需要配置检测设置;
139 | - 局域网内无法ping通设备 - 可能由于IP地址冲突或者DNS问题;
140 | - 外网正常但局域网通信异常 - 很可能就是路由器设置的问题了!
141 |
142 | 以上,希望给遇到类似问题的朋友,一点参考。
143 |
144 | 如果本文对你有帮助,不妨点个**免费的赞**和**收藏**备用。
145 |
146 | 下一篇,我们将给这个开发板接入 `AI` 能力,敬请期待!
147 |
148 | ---
149 |
150 | 为方便大家交流,新建了一个 `AI 交流群`,欢迎感兴趣的小伙伴加入。
151 |
152 | 最近打造的微信机器人`小爱(AI)`也在群里,想进群体验的朋友,公众号后台「联系我」即可,拉你进群。
153 |
154 |
--------------------------------------------------------------------------------
/media/icon.svg:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/media/logo_thumbnail.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hougeai/knowledgebase/6cfce85587ecb4903f05af30f3cb5c447c4af868/media/logo_thumbnail.png
--------------------------------------------------------------------------------