├── .clang-format
├── .compatibility
├── .coveragerc
├── .cuda_ext.json
├── .github
├── CODEOWNERS
├── ISSUE_TEMPLATE
│ ├── bug-report.yml
│ ├── config.yml
│ ├── documentation.yml
│ ├── feature_request.yml
│ └── proposal.yml
├── pull_request_template.md
└── workflows
│ ├── README.md
│ ├── build_on_pr.yml
│ ├── build_on_schedule.yml
│ ├── close_inactive.yml
│ ├── compatiblity_test_on_dispatch.yml
│ ├── compatiblity_test_on_pr.yml
│ ├── compatiblity_test_on_schedule.yml
│ ├── cuda_ext_check_before_merge.yml
│ ├── doc_build_on_schedule_after_release.yml
│ ├── doc_check_on_pr.yml
│ ├── doc_test_on_pr.yml
│ ├── doc_test_on_schedule.yml
│ ├── draft_github_release_post_after_merge.yml
│ ├── example_check_on_dispatch.yml
│ ├── example_check_on_pr.yml
│ ├── example_check_on_schedule.yml
│ ├── release_docker_after_publish.yml
│ ├── release_nightly_on_schedule.yml
│ ├── release_pypi_after_merge.yml
│ ├── release_test_pypi_before_merge.yml
│ ├── report_leaderboard_to_lark.yml
│ ├── report_test_coverage.yml
│ ├── run_chatgpt_examples.yml
│ ├── run_chatgpt_unit_tests.yml
│ ├── run_colossalqa_unit_tests.yml
│ ├── scripts
│ ├── check_doc_i18n.py
│ ├── example_checks
│ │ ├── check_dispatch_inputs.py
│ │ ├── check_example_weekly.py
│ │ └── detect_changed_example.py
│ ├── generate_leaderboard_and_send_to_lark.py
│ ├── generate_release_draft.py
│ ├── send_message_to_lark.py
│ └── update_setup_for_nightly.py
│ ├── submodule.yml
│ └── translate_comment.yml
├── .gitignore
├── .gitmodules
├── .isort.cfg
├── .pre-commit-config.yaml
├── CHANGE_LOG.md
├── CONTRIBUTING.md
├── LICENSE
├── MANIFEST.in
├── README.md
├── applications
├── Colossal-LLaMA
│ ├── README.md
│ ├── colossal_llama
│ │ ├── __init__.py
│ │ ├── dataset
│ │ │ ├── __init__.py
│ │ │ ├── conversation.py
│ │ │ ├── dummy_dataset.py
│ │ │ ├── loader.py
│ │ │ └── spliced_and_tokenized_dataset.py
│ │ ├── model
│ │ │ └── init_model.py
│ │ ├── tokenizer
│ │ │ └── init_tokenizer.py
│ │ └── utils
│ │ │ ├── __init__.py
│ │ │ ├── ckpt_io.py
│ │ │ ├── froze.py
│ │ │ ├── neftune_patch.py
│ │ │ ├── stream_chat_patch.py
│ │ │ └── utils.py
│ ├── dataset
│ │ ├── prepare_pretrain_dataset.py
│ │ └── prepare_sft_dataset.py
│ ├── docs
│ │ ├── example_13b.md
│ │ └── example_7b.md
│ ├── hostfile.example
│ ├── inference
│ │ ├── inference_example.py
│ │ └── stream_chat_example.py
│ ├── requirements.txt
│ ├── setup.py
│ ├── train.example.sh
│ ├── train.py
│ ├── train_sft.example.sh
│ └── version.txt
├── ColossalChat
│ ├── .gitignore
│ ├── LICENSE
│ ├── README.md
│ ├── benchmarks
│ │ ├── Opt.json
│ │ ├── README.md
│ │ ├── benchmark_dpo.sh
│ │ ├── benchmark_kto.sh
│ │ ├── benchmark_memory_consumption.txt
│ │ ├── benchmark_orpo.sh
│ │ ├── benchmark_performance_summarization.txt
│ │ ├── benchmark_ppo.py
│ │ ├── benchmark_ppo.sh
│ │ ├── benchmark_sft.sh
│ │ ├── benchmark_simpo.sh
│ │ ├── data_preparation.sh
│ │ ├── dummy_dataset.py
│ │ ├── prepare_dummy_test_dataset.py
│ │ └── ray
│ │ │ ├── 1mmt_dummy.py
│ │ │ └── mmmt_dummy.py
│ ├── coati
│ │ ├── __init__.py
│ │ ├── dataset
│ │ │ ├── __init__.py
│ │ │ ├── conversation.py
│ │ │ ├── loader.py
│ │ │ ├── tokenization_utils.py
│ │ │ └── utils.py
│ │ ├── experience_buffer
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── naive.py
│ │ │ └── utils.py
│ │ ├── experience_maker
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ └── naive.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── critic.py
│ │ │ ├── generation.py
│ │ │ ├── lora.py
│ │ │ ├── loss.py
│ │ │ ├── reward_model.py
│ │ │ ├── rlvr_reward_model.py
│ │ │ └── utils.py
│ │ ├── quant
│ │ │ ├── __init__.py
│ │ │ ├── llama_gptq
│ │ │ │ ├── __init__.py
│ │ │ │ ├── loader.py
│ │ │ │ ├── model_utils.py
│ │ │ │ └── quant.py
│ │ │ └── utils.py
│ │ ├── ray
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── callbacks
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ └── performance_evaluator.py
│ │ │ ├── detached_replay_buffer.py
│ │ │ ├── detached_trainer_base.py
│ │ │ ├── detached_trainer_ppo.py
│ │ │ ├── experience_maker_holder.py
│ │ │ ├── lora_constructor.py
│ │ │ └── utils.py
│ │ ├── trainer
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── callbacks
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ └── performance_evaluator.py
│ │ │ ├── dpo.py
│ │ │ ├── grpo.py
│ │ │ ├── kto.py
│ │ │ ├── orpo.py
│ │ │ ├── ppo.py
│ │ │ ├── rm.py
│ │ │ ├── sft.py
│ │ │ └── utils.py
│ │ └── utils
│ │ │ ├── __init__.py
│ │ │ ├── accumulative_meter.py
│ │ │ ├── ckpt_io.py
│ │ │ └── reward_score
│ │ │ ├── __init__.py
│ │ │ ├── competition.py
│ │ │ ├── gsm8k.py
│ │ │ └── utils.py
│ ├── conversation_template
│ │ ├── 01-ai_Yi-1.5-9B-Chat.json
│ │ ├── MiniCPM-2b.json
│ │ ├── Qwen_Qwen1.5-110B-Chat.json
│ │ ├── Qwen_Qwen1.5-32B-Chat.json
│ │ ├── Qwen_Qwen2.5-3B.json
│ │ ├── THUDM_chatglm2-6b.json
│ │ ├── THUDM_chatglm3-6b.json
│ │ ├── baichuan-inc_Baichuan2-13B-Chat.json
│ │ ├── colossal-llama2.json
│ │ ├── deepseek-ai_DeepSeek-V2-Lite.json
│ │ ├── llama2.json
│ │ ├── microsoft_phi-2.json
│ │ ├── mistralai_Mixtral-8x7B-Instruct-v0.1.json
│ │ └── tiny-llama.json
│ ├── examples
│ │ ├── README.md
│ │ ├── community
│ │ │ ├── README.md
│ │ │ ├── peft
│ │ │ │ ├── README.md
│ │ │ │ ├── easy_dataset.py
│ │ │ │ ├── easy_models.py
│ │ │ │ ├── train_peft_prompts.py
│ │ │ │ └── train_peft_sft.py
│ │ │ └── ray
│ │ │ │ ├── README.md
│ │ │ │ ├── ray_job_script.py
│ │ │ │ └── train_prompts_on_ray.py
│ │ ├── data_preparation_scripts
│ │ │ ├── prepare_dataset.py
│ │ │ ├── prepare_kto_dataset.sh
│ │ │ ├── prepare_preference_dataset.sh
│ │ │ ├── prepare_prompt_dataset.sh
│ │ │ └── prepare_sft_dataset.sh
│ │ ├── inference
│ │ │ ├── chatio.py
│ │ │ ├── inference.py
│ │ │ └── web_chatbot
│ │ │ │ ├── README.md
│ │ │ │ ├── locustfile.py
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── server.py
│ │ │ │ └── utils.py
│ │ ├── requirements.txt
│ │ └── training_scripts
│ │ │ ├── hostfile
│ │ │ ├── lora_config.json
│ │ │ ├── lora_finetune.py
│ │ │ ├── lora_sft_data.jsonl
│ │ │ ├── train_dpo.py
│ │ │ ├── train_dpo.sh
│ │ │ ├── train_grpo.py
│ │ │ ├── train_grpo.sh
│ │ │ ├── train_kto.py
│ │ │ ├── train_kto.sh
│ │ │ ├── train_orpo.py
│ │ │ ├── train_orpo.sh
│ │ │ ├── train_ppo.py
│ │ │ ├── train_ppo.sh
│ │ │ ├── train_rm.py
│ │ │ ├── train_rm.sh
│ │ │ ├── train_sft.py
│ │ │ └── train_sft.sh
│ ├── pytest.ini
│ ├── requirements.txt
│ ├── setup.py
│ ├── tests
│ │ ├── __init__.py
│ │ ├── generate_dummy_datasets_for_testing.py
│ │ ├── llama.json
│ │ ├── opt.json
│ │ ├── prepare_test_env.sh
│ │ ├── test_data
│ │ │ ├── dpo
│ │ │ │ └── test_dpo_data.jsonl
│ │ │ ├── kto
│ │ │ │ └── test_kto_data.jsonl
│ │ │ └── sft
│ │ │ │ └── test_sft_data.jsonl
│ │ ├── test_data_preparation.sh
│ │ ├── test_lora.py
│ │ ├── test_templating.sh
│ │ ├── test_train.sh
│ │ └── verify_chat_data.py
│ └── version.txt
├── ColossalEval
│ ├── README.md
│ ├── colossal_eval
│ │ ├── __init__.py
│ │ ├── dataset
│ │ │ ├── __init__.py
│ │ │ ├── agieval.py
│ │ │ ├── base.py
│ │ │ ├── ceval.py
│ │ │ ├── cmmlu.py
│ │ │ ├── colossalai.py
│ │ │ ├── cvalues.py
│ │ │ ├── gaokaobench.py
│ │ │ ├── gsm.py
│ │ │ ├── longbench.py
│ │ │ ├── mmlu.py
│ │ │ ├── mtbench.py
│ │ │ ├── safetybench_en.py
│ │ │ └── safetybench_zh.py
│ │ ├── evaluate
│ │ │ ├── GPT Evaluation.md
│ │ │ ├── __init__.py
│ │ │ ├── dataset_evaluator
│ │ │ │ ├── __init__.py
│ │ │ │ ├── dataset_evaluator.py
│ │ │ │ ├── gpt_judge.py
│ │ │ │ └── metrics.py
│ │ │ ├── evaluator.py
│ │ │ ├── gpt_evaluate.py
│ │ │ └── utils.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── chatglm.py
│ │ │ ├── huggingface.py
│ │ │ └── vllm.py
│ │ └── utils
│ │ │ ├── __init__.py
│ │ │ ├── conversation.py
│ │ │ └── utilities.py
│ ├── configs
│ │ └── gpt_evaluation
│ │ │ ├── config
│ │ │ ├── config_cn.json
│ │ │ └── config_en.json
│ │ │ ├── data
│ │ │ ├── eval_cn_examples.json
│ │ │ └── eval_en_examples.json
│ │ │ └── prompt
│ │ │ ├── battle_prompt
│ │ │ ├── battle_prompt_cn.json
│ │ │ └── battle_prompt_en.json
│ │ │ └── evaluation_prompt
│ │ │ ├── evaluation_prompt_cn.json
│ │ │ └── evaluation_prompt_en.json
│ ├── examples
│ │ ├── dataset_evaluation
│ │ │ ├── config
│ │ │ │ ├── evaluation
│ │ │ │ │ └── config.json
│ │ │ │ └── inference
│ │ │ │ │ └── config.json
│ │ │ ├── eval_dataset.py
│ │ │ ├── eval_dataset.sh
│ │ │ ├── inference.py
│ │ │ └── inference.sh
│ │ └── gpt_evaluation
│ │ │ ├── config
│ │ │ ├── evaluation
│ │ │ │ └── config.json
│ │ │ └── inference
│ │ │ │ └── config.json
│ │ │ ├── eval.py
│ │ │ ├── eval.sh
│ │ │ ├── inference.py
│ │ │ └── inference.sh
│ ├── requirements.txt
│ └── setup.py
├── ColossalMoE
│ ├── README.md
│ ├── infer.py
│ ├── infer.sh
│ ├── requirements.txt
│ ├── setup.py
│ ├── tests
│ │ └── __init__.py
│ ├── train.py
│ ├── train.sh
│ ├── utils.py
│ └── version.txt
├── ColossalQA
│ ├── .gitignore
│ ├── README.md
│ ├── colossalqa
│ │ ├── __init__.py
│ │ ├── chain
│ │ │ ├── __init__.py
│ │ │ ├── memory
│ │ │ │ ├── __init__.py
│ │ │ │ └── summary.py
│ │ │ └── retrieval_qa
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── load_chain.py
│ │ │ │ └── stuff.py
│ │ ├── data_loader
│ │ │ ├── __init__.py
│ │ │ ├── document_loader.py
│ │ │ └── table_dataloader.py
│ │ ├── local
│ │ │ ├── __init__.py
│ │ │ ├── colossalcloud_llm.py
│ │ │ ├── llm.py
│ │ │ ├── pangu_llm.py
│ │ │ └── utils.py
│ │ ├── memory.py
│ │ ├── mylogging.py
│ │ ├── prompt
│ │ │ ├── README.md
│ │ │ └── prompt.py
│ │ ├── retrieval_conversation_en.py
│ │ ├── retrieval_conversation_universal.py
│ │ ├── retrieval_conversation_zh.py
│ │ ├── retriever.py
│ │ ├── text_splitter
│ │ │ ├── __init__.py
│ │ │ ├── chinese_text_splitter.py
│ │ │ └── utils.py
│ │ └── utils.py
│ ├── data
│ │ ├── data_sample
│ │ │ ├── companies.txt
│ │ │ ├── companies_zh.txt
│ │ │ ├── csv_organization_100.csv
│ │ │ ├── custom_service.json
│ │ │ ├── custom_service_classification.json
│ │ │ ├── custom_service_preprocessed.json
│ │ │ └── luchen_zh.txt
│ │ └── tests
│ │ │ ├── 64KB.json
│ │ │ ├── companies.csv
│ │ │ ├── sample-pdf-file.pdf
│ │ │ ├── test.html
│ │ │ ├── test.md
│ │ │ └── test.txt
│ ├── examples
│ │ ├── conversation_agent_chatgpt.py
│ │ ├── retrieval_conversation_chatgpt.py
│ │ ├── retrieval_conversation_en.py
│ │ ├── retrieval_conversation_en_customer_service.py
│ │ ├── retrieval_conversation_universal.py
│ │ ├── retrieval_conversation_zh.py
│ │ ├── retrieval_intent_classification_zh_customer_service.py
│ │ └── webui_demo
│ │ │ ├── RAG_ChatBot.py
│ │ │ ├── README.md
│ │ │ ├── config.py
│ │ │ ├── img
│ │ │ ├── avatar_ai.png
│ │ │ └── avatar_user.png
│ │ │ ├── requirements.txt
│ │ │ ├── server.py
│ │ │ ├── utils.py
│ │ │ └── webui.py
│ ├── pytest.ini
│ ├── requirements.txt
│ ├── setup.py
│ ├── tests
│ │ ├── __init__.py
│ │ ├── test_document_loader.py
│ │ ├── test_memory.py
│ │ ├── test_retrieval_qa.py
│ │ └── test_text_splitter.py
│ └── version.txt
└── README.md
├── colossalai
├── _C
│ └── __init__.py
├── __init__.py
├── _analyzer
│ ├── README.md
│ ├── __init__.py
│ ├── _subclasses
│ │ ├── __init__.py
│ │ ├── _meta_registration.py
│ │ ├── _monkey_patch.py
│ │ ├── flop_tensor.py
│ │ └── meta_tensor.py
│ ├── envs.py
│ └── fx
│ │ ├── __init__.py
│ │ ├── codegen.py
│ │ ├── graph_module.py
│ │ ├── node_util.py
│ │ ├── passes
│ │ ├── __init__.py
│ │ ├── graph_profile.py
│ │ └── shape_prop.py
│ │ ├── symbolic_profile.py
│ │ └── tracer
│ │ ├── __init__.py
│ │ ├── bias_addition.py
│ │ ├── custom_leaf_module.py
│ │ ├── proxy.py
│ │ ├── symbolic_trace.py
│ │ └── tracer.py
├── accelerator
│ ├── README.md
│ ├── __init__.py
│ ├── api.py
│ ├── base_accelerator.py
│ ├── cpu_accelerator.py
│ ├── cuda_accelerator.py
│ └── npu_accelerator.py
├── amp
│ ├── __init__.py
│ └── naive_amp
│ │ ├── __init__.py
│ │ ├── grad_scaler
│ │ ├── __init__.py
│ │ ├── base_grad_scaler.py
│ │ ├── constant_grad_scaler.py
│ │ └── dynamic_grad_scaler.py
│ │ ├── mixed_precision_mixin
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── bf16.py
│ │ └── fp16.py
│ │ └── mixed_precision_optimizer.py
├── auto_parallel
│ ├── README.md
│ ├── __init__.py
│ ├── checkpoint
│ │ ├── __init__.py
│ │ ├── build_c_ext.py
│ │ ├── ckpt_solver_base.py
│ │ ├── ckpt_solver_chen.py
│ │ ├── ckpt_solver_rotor.c
│ │ ├── ckpt_solver_rotor.py
│ │ └── operation.py
│ ├── meta_profiler
│ │ ├── __init__.py
│ │ ├── constants.py
│ │ ├── meta_registry
│ │ │ ├── __init__.py
│ │ │ ├── activation.py
│ │ │ ├── binary_elementwise_ops.py
│ │ │ ├── conv.py
│ │ │ ├── embedding.py
│ │ │ ├── linear.py
│ │ │ ├── non_spmd.py
│ │ │ ├── norm.py
│ │ │ ├── pooling.py
│ │ │ ├── tensor.py
│ │ │ └── where.py
│ │ ├── registry.py
│ │ └── shard_metainfo.py
│ ├── offload
│ │ ├── __init__.py
│ │ ├── amp_optimizer.py
│ │ ├── base_offload_module.py
│ │ ├── mem_optimize.py
│ │ ├── region.py
│ │ ├── region_manager.py
│ │ ├── runtime.py
│ │ ├── solver.py
│ │ ├── training_simulator.py
│ │ └── util.py
│ ├── passes
│ │ ├── __init__.py
│ │ ├── comm_metainfo_pass.py
│ │ ├── constants.py
│ │ ├── meta_info_prop.py
│ │ ├── runtime_apply_pass.py
│ │ └── runtime_preparation_pass.py
│ ├── pipeline_shard
│ │ └── __init__.py
│ └── tensor_shard
│ │ ├── __init__.py
│ │ ├── constants.py
│ │ ├── initialize.py
│ │ ├── node_handler
│ │ ├── __init__.py
│ │ ├── addmm_handler.py
│ │ ├── batch_norm_handler.py
│ │ ├── binary_elementwise_handler.py
│ │ ├── bmm_handler.py
│ │ ├── conv_handler.py
│ │ ├── default_reshape_handler.py
│ │ ├── embedding_handler.py
│ │ ├── getattr_handler.py
│ │ ├── getitem_handler.py
│ │ ├── layer_norm_handler.py
│ │ ├── linear_handler.py
│ │ ├── matmul_handler.py
│ │ ├── node_handler.py
│ │ ├── normal_pooling_handler.py
│ │ ├── output_handler.py
│ │ ├── permute_handler.py
│ │ ├── placeholder_handler.py
│ │ ├── registry.py
│ │ ├── softmax_handler.py
│ │ ├── split_handler.py
│ │ ├── strategy
│ │ │ ├── __init__.py
│ │ │ ├── batch_norm_generator.py
│ │ │ ├── binary_elementwise_generator.py
│ │ │ ├── conv_strategy_generator.py
│ │ │ ├── embedding_generator.py
│ │ │ ├── getattr_generator.py
│ │ │ ├── getitem_generator.py
│ │ │ ├── layer_norm_generator.py
│ │ │ ├── matmul_strategy_generator.py
│ │ │ ├── normal_pooling_generator.py
│ │ │ ├── output_generator.py
│ │ │ ├── placeholder_generator.py
│ │ │ ├── reshape_generator.py
│ │ │ ├── softmax_generator.py
│ │ │ ├── strategy_generator.py
│ │ │ ├── sum_generator.py
│ │ │ ├── tensor_constructor_generator.py
│ │ │ ├── unary_elementwise_generator.py
│ │ │ └── where_generator.py
│ │ ├── sum_handler.py
│ │ ├── tensor_constructor_handler.py
│ │ ├── transpose_handler.py
│ │ ├── unary_elementwise_handler.py
│ │ ├── view_handler.py
│ │ └── where_handler.py
│ │ ├── options.py
│ │ ├── sharding_strategy.py
│ │ ├── solver
│ │ ├── __init__.py
│ │ ├── cost_graph.py
│ │ ├── graph_analysis.py
│ │ ├── solver.py
│ │ └── strategies_constructor.py
│ │ └── utils
│ │ ├── __init__.py
│ │ ├── broadcast.py
│ │ ├── factory.py
│ │ ├── misc.py
│ │ ├── reshape.py
│ │ └── sharding.py
├── autochunk
│ ├── autochunk_codegen.py
│ ├── estimate_memory.py
│ ├── reorder_graph.py
│ ├── search_chunk.py
│ ├── select_chunk.py
│ ├── trace_flow.py
│ ├── trace_indice.py
│ └── utils.py
├── booster
│ ├── __init__.py
│ ├── accelerator.py
│ ├── booster.py
│ ├── mixed_precision
│ │ ├── __init__.py
│ │ ├── bf16.py
│ │ ├── fp16_apex.py
│ │ ├── fp16_naive.py
│ │ ├── fp16_torch.py
│ │ ├── fp8.py
│ │ └── mixed_precision_base.py
│ └── plugin
│ │ ├── __init__.py
│ │ ├── dp_plugin_base.py
│ │ ├── gemini_plugin.py
│ │ ├── hybrid_parallel_plugin.py
│ │ ├── low_level_zero_plugin.py
│ │ ├── moe_hybrid_parallel_plugin.py
│ │ ├── plugin_base.py
│ │ ├── pp_plugin_base.py
│ │ ├── torch_ddp_plugin.py
│ │ └── torch_fsdp_plugin.py
├── checkpoint_io
│ ├── __init__.py
│ ├── checkpoint_io_base.py
│ ├── general_checkpoint_io.py
│ ├── hybrid_parallel_checkpoint_io.py
│ ├── index_file.py
│ ├── moe_checkpoint.py
│ └── utils.py
├── cli
│ ├── __init__.py
│ ├── check
│ │ ├── __init__.py
│ │ └── check_installation.py
│ ├── cli.py
│ └── launcher
│ │ ├── __init__.py
│ │ ├── hostinfo.py
│ │ ├── multinode_runner.py
│ │ └── run.py
├── cluster
│ ├── __init__.py
│ ├── device_mesh_manager.py
│ ├── dist_coordinator.py
│ ├── process_group_manager.py
│ └── process_group_mesh.py
├── context
│ ├── __init__.py
│ ├── config.py
│ └── singleton_meta.py
├── device
│ ├── __init__.py
│ ├── alpha_beta_profiler.py
│ ├── calc_pipeline_strategy.py
│ └── device_mesh.py
├── fx
│ ├── __init__.py
│ ├── _compatibility.py
│ ├── _meta_regist_12.py
│ ├── _meta_regist_13.py
│ ├── codegen
│ │ ├── __init__.py
│ │ └── activation_checkpoint_codegen.py
│ ├── graph_module.py
│ ├── passes
│ │ ├── __init__.py
│ │ ├── adding_split_node_pass.py
│ │ ├── concrete_info_prop.py
│ │ ├── experimental
│ │ │ └── adding_shape_consistency_pass.py
│ │ ├── meta_info_prop.py
│ │ ├── passes_for_gpt2_test.py
│ │ ├── shard_1d_pass.py
│ │ ├── split_module.py
│ │ └── utils.py
│ ├── profiler
│ │ ├── __init__.py
│ │ ├── constants.py
│ │ ├── dataflow.py
│ │ ├── experimental
│ │ │ ├── __init__.py
│ │ │ ├── constants.py
│ │ │ ├── profiler.py
│ │ │ ├── profiler_function
│ │ │ │ ├── __init__.py
│ │ │ │ ├── activation_function.py
│ │ │ │ ├── arithmetic.py
│ │ │ │ ├── embedding.py
│ │ │ │ ├── linear.py
│ │ │ │ ├── normalization.py
│ │ │ │ ├── pooling.py
│ │ │ │ ├── python_ops.py
│ │ │ │ └── torch_ops.py
│ │ │ ├── profiler_module
│ │ │ │ ├── __init__.py
│ │ │ │ ├── activation_function.py
│ │ │ │ ├── attention.py
│ │ │ │ ├── convolution.py
│ │ │ │ ├── dropout.py
│ │ │ │ ├── embedding.py
│ │ │ │ ├── linear.py
│ │ │ │ ├── normalization.py
│ │ │ │ ├── pooling.py
│ │ │ │ ├── rnn.py
│ │ │ │ └── torch_op.py
│ │ │ ├── registry.py
│ │ │ └── shard_utils.py
│ │ ├── memory_utils.py
│ │ ├── opcount.py
│ │ ├── profiler.py
│ │ ├── shard_utils.py
│ │ └── tensor.py
│ ├── proxy.py
│ └── tracer
│ │ ├── __init__.py
│ │ ├── _meta_trace.py
│ │ ├── _symbolic_trace.py
│ │ ├── _tracer_utils.py
│ │ ├── bias_addition_patch
│ │ ├── __init__.py
│ │ ├── patched_bias_addition_function
│ │ │ ├── __init__.py
│ │ │ ├── addbmm.py
│ │ │ ├── addmm.py
│ │ │ ├── bias_addition_function.py
│ │ │ └── linear.py
│ │ └── patched_bias_addition_module
│ │ │ ├── __init__.py
│ │ │ ├── bias_addition_module.py
│ │ │ ├── conv.py
│ │ │ └── linear.py
│ │ ├── experimental.py
│ │ ├── meta_patch
│ │ ├── __init__.py
│ │ ├── patched_function
│ │ │ ├── __init__.py
│ │ │ ├── activation_function.py
│ │ │ ├── arithmetic.py
│ │ │ ├── convolution.py
│ │ │ ├── embedding.py
│ │ │ ├── normalization.py
│ │ │ ├── python_ops.py
│ │ │ └── torch_ops.py
│ │ └── patched_module
│ │ │ ├── __init__.py
│ │ │ ├── activation_function.py
│ │ │ ├── convolution.py
│ │ │ ├── embedding.py
│ │ │ ├── linear.py
│ │ │ ├── normalization.py
│ │ │ ├── pooling.py
│ │ │ └── rnn.py
│ │ ├── registry.py
│ │ └── tracer.py
├── inference
│ ├── README.md
│ ├── __init__.py
│ ├── batch_bucket.py
│ ├── config.py
│ ├── core
│ │ ├── __init__.py
│ │ ├── async_engine.py
│ │ ├── base_engine.py
│ │ ├── diffusion_engine.py
│ │ ├── engine.py
│ │ ├── llm_engine.py
│ │ ├── plugin.py
│ │ ├── request_handler.py
│ │ └── rpc_engine.py
│ ├── executor
│ │ ├── __init__.py
│ │ └── rpc_worker.py
│ ├── flash_decoding_utils.py
│ ├── graph_runner.py
│ ├── kv_cache
│ │ ├── __init__.py
│ │ ├── block_cache.py
│ │ └── kvcache_manager.py
│ ├── logit_processors.py
│ ├── modeling
│ │ ├── __init__.py
│ │ ├── backends
│ │ │ ├── __init__.py
│ │ │ ├── attention_backend.py
│ │ │ └── pre_attention_backend.py
│ │ ├── layers
│ │ │ ├── __init__.py
│ │ │ ├── attention.py
│ │ │ ├── baichuan_tp_linear.py
│ │ │ ├── diffusion.py
│ │ │ └── distrifusion.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ ├── glide_llama.py
│ │ │ ├── nopadding_baichuan.py
│ │ │ ├── nopadding_llama.py
│ │ │ ├── pixart_alpha.py
│ │ │ └── stablediffusion3.py
│ │ └── policy
│ │ │ ├── __init__.py
│ │ │ ├── glide_llama.py
│ │ │ ├── nopadding_baichuan.py
│ │ │ ├── nopadding_llama.py
│ │ │ ├── pixart_alpha.py
│ │ │ └── stablediffusion3.py
│ ├── sampler.py
│ ├── server
│ │ ├── __init__.py
│ │ ├── api_server.py
│ │ ├── chat_service.py
│ │ ├── completion_service.py
│ │ └── utils.py
│ ├── spec
│ │ ├── __init__.py
│ │ ├── drafter.py
│ │ └── struct.py
│ ├── struct.py
│ └── utils.py
├── initialize.py
├── interface
│ ├── __init__.py
│ ├── model.py
│ ├── optimizer.py
│ └── pretrained.py
├── kernel
│ ├── __init__.py
│ ├── extensions
│ ├── jit
│ │ ├── __init__.py
│ │ ├── bias_dropout_add.py
│ │ ├── bias_gelu.py
│ │ └── option.py
│ ├── kernel_loader.py
│ └── triton
│ │ ├── __init__.py
│ │ ├── context_attn_unpad.py
│ │ ├── flash_decoding.py
│ │ ├── fused_rotary_embedding.py
│ │ ├── kvcache_copy.py
│ │ ├── llama_act_combine_kernel.py
│ │ ├── no_pad_rotary_embedding.py
│ │ ├── qkv_matmul_kernel.py
│ │ ├── rms_layernorm.py
│ │ ├── rotary_cache_copy.py
│ │ └── softmax.py
├── lazy
│ ├── __init__.py
│ ├── construction.py
│ ├── lazy_init.py
│ └── pretrained.py
├── legacy
│ ├── __init__.py
│ ├── amp
│ │ ├── __init__.py
│ │ ├── amp_type.py
│ │ ├── apex_amp
│ │ │ ├── __init__.py
│ │ │ └── apex_amp.py
│ │ ├── naive_amp
│ │ │ ├── __init__.py
│ │ │ ├── _fp16_optimizer.py
│ │ │ ├── _utils.py
│ │ │ └── naive_amp.py
│ │ └── torch_amp
│ │ │ ├── __init__.py
│ │ │ ├── _grad_scaler.py
│ │ │ └── torch_amp.py
│ ├── builder
│ │ ├── __init__.py
│ │ └── builder.py
│ ├── communication
│ │ ├── __init__.py
│ │ ├── collective.py
│ │ ├── p2p.py
│ │ ├── p2p_v2.py
│ │ ├── ring.py
│ │ └── utils.py
│ ├── constants.py
│ ├── context
│ │ ├── __init__.py
│ │ ├── parallel_context.py
│ │ ├── parallel_mode.py
│ │ ├── process_group_initializer
│ │ │ ├── __init__.py
│ │ │ ├── initializer_1d.py
│ │ │ ├── initializer_2d.py
│ │ │ ├── initializer_2p5d.py
│ │ │ ├── initializer_3d.py
│ │ │ ├── initializer_data.py
│ │ │ ├── initializer_model.py
│ │ │ ├── initializer_pipeline.py
│ │ │ ├── initializer_sequence.py
│ │ │ ├── initializer_tensor.py
│ │ │ └── process_group_initializer.py
│ │ └── random
│ │ │ ├── __init__.py
│ │ │ ├── _helper.py
│ │ │ └── seed_manager.py
│ ├── core.py
│ ├── engine
│ │ ├── __init__.py
│ │ ├── _base_engine.py
│ │ ├── gradient_accumulation
│ │ │ ├── __init__.py
│ │ │ └── _gradient_accumulation.py
│ │ ├── gradient_handler
│ │ │ ├── __init__.py
│ │ │ ├── _base_gradient_handler.py
│ │ │ ├── _data_parallel_gradient_handler.py
│ │ │ ├── _moe_gradient_handler.py
│ │ │ ├── _pipeline_parallel_gradient_handler.py
│ │ │ ├── _sequence_parallel_gradient_handler.py
│ │ │ ├── _zero_gradient_handler.py
│ │ │ └── utils.py
│ │ └── schedule
│ │ │ ├── __init__.py
│ │ │ ├── _base_schedule.py
│ │ │ ├── _non_pipeline_schedule.py
│ │ │ ├── _pipeline_schedule.py
│ │ │ └── _pipeline_schedule_v2.py
│ ├── global_variables.py
│ ├── inference
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── async_engine.py
│ │ ├── async_manager.py
│ │ ├── dynamic_batching
│ │ │ ├── __init__.py
│ │ │ ├── get_tokenizer.py
│ │ │ ├── infer_batch.py
│ │ │ ├── io_struct.py
│ │ │ ├── ray_dist_init.py
│ │ │ ├── ray_init_config.py
│ │ │ ├── req_queue.py
│ │ │ ├── sampling_params.py
│ │ │ └── stats.py
│ │ ├── hybridengine
│ │ │ ├── __init__.py
│ │ │ ├── engine.py
│ │ │ ├── modeling
│ │ │ │ ├── __init__.py
│ │ │ │ ├── _utils.py
│ │ │ │ └── llama.py
│ │ │ └── polices
│ │ │ │ ├── __init__.py
│ │ │ │ └── llama.py
│ │ ├── manager.py
│ │ ├── pipeline
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── benchmark
│ │ │ │ ├── benchmark.py
│ │ │ │ └── run.sh
│ │ │ └── microbatch_manager.py
│ │ ├── quant
│ │ │ ├── gptq
│ │ │ │ ├── __init__.py
│ │ │ │ └── cai_gptq
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── cai_quant_linear.py
│ │ │ │ │ └── gptq_op.py
│ │ │ └── smoothquant
│ │ │ │ ├── __init__.py
│ │ │ │ └── models
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base_model.py
│ │ │ │ ├── linear.py
│ │ │ │ └── llama.py
│ │ ├── serving
│ │ │ ├── ray_serve
│ │ │ │ ├── Colossal_Inference_rayserve.py
│ │ │ │ ├── README.md
│ │ │ │ ├── send_request.py
│ │ │ │ └── send_requests.py
│ │ │ ├── test_ci.sh
│ │ │ └── torch_serve
│ │ │ │ ├── Colossal_Inference_Handler.py
│ │ │ │ ├── README.md
│ │ │ │ ├── config.properties
│ │ │ │ ├── docker
│ │ │ │ └── Dockerfile
│ │ │ │ ├── model-config.yaml
│ │ │ │ └── sample_text.txt
│ │ └── tensor_parallel
│ │ │ ├── __init__.py
│ │ │ ├── batch_infer_state.py
│ │ │ ├── engine.py
│ │ │ ├── kvcache_manager.py
│ │ │ ├── modeling
│ │ │ ├── __init__.py
│ │ │ ├── _utils.py
│ │ │ ├── bloom.py
│ │ │ ├── chatglm2.py
│ │ │ └── llama.py
│ │ │ └── policies
│ │ │ ├── __init__.py
│ │ │ ├── bloom.py
│ │ │ ├── chatglm2.py
│ │ │ └── llama.py
│ ├── initialize.py
│ ├── moe
│ │ ├── layer
│ │ │ ├── __init__.py
│ │ │ ├── experts.py
│ │ │ ├── layers.py
│ │ │ └── routers.py
│ │ ├── load_balance.py
│ │ ├── manager.py
│ │ ├── openmoe
│ │ │ ├── README.md
│ │ │ ├── benchmark
│ │ │ │ ├── benchmark_cai.py
│ │ │ │ ├── benchmark_cai.sh
│ │ │ │ ├── benchmark_cai_dist.sh
│ │ │ │ ├── benchmark_fsdp.py
│ │ │ │ ├── benchmark_fsdp.sh
│ │ │ │ ├── hostfile.txt
│ │ │ │ └── utils.py
│ │ │ ├── infer.py
│ │ │ ├── infer.sh
│ │ │ ├── model
│ │ │ │ ├── __init__.py
│ │ │ │ ├── convert_openmoe_ckpt.py
│ │ │ │ ├── convert_openmoe_ckpt.sh
│ │ │ │ ├── modeling_openmoe.py
│ │ │ │ ├── openmoe_8b_config.json
│ │ │ │ ├── openmoe_base_config.json
│ │ │ │ └── openmoe_policy.py
│ │ │ ├── requirements.txt
│ │ │ ├── test_ci.sh
│ │ │ ├── train.py
│ │ │ └── train.sh
│ │ └── utils.py
│ ├── nn
│ │ ├── __init__.py
│ │ ├── _ops
│ │ │ ├── __init__.py
│ │ │ └── _utils.py
│ │ ├── layer
│ │ │ ├── __init__.py
│ │ │ ├── base_layer.py
│ │ │ ├── colossalai_layer
│ │ │ │ ├── __init__.py
│ │ │ │ ├── _utils.py
│ │ │ │ ├── dropout.py
│ │ │ │ ├── embedding.py
│ │ │ │ ├── linear.py
│ │ │ │ └── normalization.py
│ │ │ ├── parallel_1d
│ │ │ │ ├── __init__.py
│ │ │ │ ├── _operation.py
│ │ │ │ ├── _utils.py
│ │ │ │ └── layers.py
│ │ │ ├── parallel_2d
│ │ │ │ ├── __init__.py
│ │ │ │ ├── _operation.py
│ │ │ │ ├── _utils.py
│ │ │ │ └── layers.py
│ │ │ ├── parallel_2p5d
│ │ │ │ ├── __init__.py
│ │ │ │ ├── _operation.py
│ │ │ │ ├── _utils.py
│ │ │ │ └── layers.py
│ │ │ ├── parallel_3d
│ │ │ │ ├── __init__.py
│ │ │ │ ├── _operation.py
│ │ │ │ ├── _utils.py
│ │ │ │ └── layers.py
│ │ │ ├── parallel_sequence
│ │ │ │ ├── __init__.py
│ │ │ │ ├── _operation.py
│ │ │ │ ├── _utils.py
│ │ │ │ └── layers.py
│ │ │ ├── utils
│ │ │ │ ├── __init__.py
│ │ │ │ └── common.py
│ │ │ ├── vanilla
│ │ │ │ ├── __init__.py
│ │ │ │ └── layers.py
│ │ │ └── wrapper
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_wrapper.py
│ │ ├── loss
│ │ │ ├── __init__.py
│ │ │ ├── loss_1d.py
│ │ │ ├── loss_2d.py
│ │ │ ├── loss_2p5d.py
│ │ │ └── loss_3d.py
│ │ ├── metric
│ │ │ ├── __init__.py
│ │ │ ├── _utils.py
│ │ │ ├── accuracy_2d.py
│ │ │ ├── accuracy_2p5d.py
│ │ │ └── accuracy_3d.py
│ │ └── parallel
│ │ │ ├── __init__.py
│ │ │ ├── data_parallel.py
│ │ │ ├── layers
│ │ │ ├── __init__.py
│ │ │ ├── cache_embedding
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base_embedding.py
│ │ │ │ ├── cache_mgr.py
│ │ │ │ ├── cached_embedding.py
│ │ │ │ ├── copyer.py
│ │ │ │ ├── embedding_config.py
│ │ │ │ ├── parallel_cached_embedding.py
│ │ │ │ ├── parallel_cached_embedding_tablewise.py
│ │ │ │ └── parallel_cached_embedding_tablewise_split_cache.py
│ │ │ ├── colo_module.py
│ │ │ ├── embedding.py
│ │ │ ├── linear.py
│ │ │ └── module_utils.py
│ │ │ └── reducer.py
│ ├── pipeline
│ │ ├── __init__.py
│ │ ├── layer_spec.py
│ │ ├── middleware
│ │ │ ├── __init__.py
│ │ │ ├── adaptor
│ │ │ │ ├── __init__.py
│ │ │ │ └── fx.py
│ │ │ └── topo.py
│ │ ├── pipelinable.py
│ │ ├── pipeline_process_group.py
│ │ ├── rpc
│ │ │ ├── __init__.py
│ │ │ ├── _pipeline_base.py
│ │ │ ├── _pipeline_schedule.py
│ │ │ └── utils.py
│ │ └── utils.py
│ ├── registry
│ │ ├── __init__.py
│ │ └── registry.py
│ ├── tensor
│ │ ├── __init__.py
│ │ ├── compute_spec.py
│ │ ├── const.py
│ │ ├── dist_spec_mgr.py
│ │ ├── distspec.py
│ │ ├── op_wrapper.py
│ │ ├── process_group.py
│ │ └── tensor_spec.py
│ ├── trainer
│ │ ├── __init__.py
│ │ ├── _trainer.py
│ │ └── hooks
│ │ │ ├── __init__.py
│ │ │ ├── _base_hook.py
│ │ │ ├── _checkpoint_hook.py
│ │ │ ├── _commons_.py
│ │ │ ├── _log_hook.py
│ │ │ ├── _lr_scheduler_hook.py
│ │ │ └── _metric_hook.py
│ ├── utils
│ │ ├── __init__.py
│ │ ├── activation_checkpoint.py
│ │ ├── checkpoint
│ │ │ ├── __init__.py
│ │ │ ├── module_checkpoint.py
│ │ │ └── utils.py
│ │ ├── checkpointing.py
│ │ ├── common.py
│ │ ├── data_sampler
│ │ │ ├── __init__.py
│ │ │ ├── base_sampler.py
│ │ │ └── data_parallel_sampler.py
│ │ ├── memory.py
│ │ └── profiler
│ │ │ ├── __init__.py
│ │ │ ├── extention.py
│ │ │ ├── legacy
│ │ │ ├── __init__.py
│ │ │ ├── comm_profiler.py
│ │ │ ├── pcie_profiler.py
│ │ │ └── prof_utils.py
│ │ │ ├── profiler.py
│ │ │ └── stateful_tensor_mem_extention.py
│ └── zero
│ │ ├── __init__.py
│ │ ├── gemini
│ │ ├── __init__.py
│ │ ├── colo_init_context.py
│ │ ├── gemini_context.py
│ │ ├── ophooks
│ │ │ ├── __init__.py
│ │ │ ├── _shard_grad_ophook.py
│ │ │ ├── _shard_param_ophook.py
│ │ │ ├── runtime_mem_tracer_hook.py
│ │ │ └── utils.py
│ │ ├── paramhooks
│ │ │ ├── __init__.py
│ │ │ └── _param_hookmgr.py
│ │ ├── stateful_tensor.py
│ │ ├── stateful_tensor_mgr.py
│ │ ├── tensor_placement_policy.py
│ │ └── tensor_utils.py
│ │ ├── init_ctx
│ │ ├── __init__.py
│ │ └── init_context.py
│ │ ├── shard_utils
│ │ ├── __init__.py
│ │ ├── base_shard_strategy.py
│ │ ├── bucket_tensor_shard_strategy.py
│ │ ├── commons.py
│ │ └── tensor_shard_strategy.py
│ │ ├── sharded_model
│ │ ├── __init__.py
│ │ ├── _utils.py
│ │ ├── reduce_scatter.py
│ │ ├── sharded_model_v2.py
│ │ ├── utils.py
│ │ └── zero_hook.py
│ │ ├── sharded_optim
│ │ ├── __init__.py
│ │ └── sharded_optim_v2.py
│ │ └── sharded_param
│ │ ├── __init__.py
│ │ ├── sharded_param.py
│ │ └── sharded_tensor.py
├── logging
│ ├── __init__.py
│ └── logger.py
├── moe
│ ├── __init__.py
│ └── _operation.py
├── nn
│ ├── __init__.py
│ ├── init.py
│ ├── layer
│ │ ├── __init__.py
│ │ ├── layernorm.py
│ │ ├── scaled_softmax.py
│ │ └── utils.py
│ ├── loss
│ │ └── __init__.py
│ ├── lr_scheduler
│ │ ├── __init__.py
│ │ ├── cosine.py
│ │ ├── delayed.py
│ │ ├── linear.py
│ │ ├── multistep.py
│ │ ├── onecycle.py
│ │ ├── poly.py
│ │ └── torch.py
│ └── optimizer
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── adafactor.py
│ │ ├── came.py
│ │ ├── cpu_adam.py
│ │ ├── distributed_adafactor.py
│ │ ├── distributed_came.py
│ │ ├── distributed_galore.py
│ │ ├── distributed_lamb.py
│ │ ├── fused_adam.py
│ │ ├── fused_lamb.py
│ │ ├── fused_sgd.py
│ │ ├── galore.py
│ │ ├── hybrid_adam.py
│ │ ├── lamb.py
│ │ ├── lars.py
│ │ └── nvme_optimizer.py
├── pipeline
│ ├── __init__.py
│ ├── p2p.py
│ ├── schedule
│ │ ├── __init__.py
│ │ ├── _utils.py
│ │ ├── base.py
│ │ ├── generate.py
│ │ ├── interleaved_pp.py
│ │ ├── one_f_one_b.py
│ │ ├── v_schedule.py
│ │ └── zero_bubble_pp.py
│ ├── stage_manager.py
│ └── weight_grad_store.py
├── quantization
│ ├── __init__.py
│ ├── bnb.py
│ ├── bnb_config.py
│ ├── fp8.py
│ ├── fp8_config.py
│ ├── fp8_hook.py
│ └── utils.py
├── shardformer
│ ├── README.md
│ ├── __init__.py
│ ├── _utils.py
│ ├── examples
│ │ ├── convergence_benchmark.py
│ │ ├── convergence_benchmark.sh
│ │ ├── data.py
│ │ └── performance_benchmark.py
│ ├── layer
│ │ ├── __init__.py
│ │ ├── _operation.py
│ │ ├── attn.py
│ │ ├── dropout.py
│ │ ├── embedding.py
│ │ ├── linear.py
│ │ ├── loss.py
│ │ ├── normalization.py
│ │ ├── parallel_module.py
│ │ ├── qkv_fused_linear.py
│ │ └── utils.py
│ ├── modeling
│ │ ├── __init__.py
│ │ ├── bert.py
│ │ ├── blip2.py
│ │ ├── bloom.py
│ │ ├── chatglm2.py
│ │ ├── chatglm2_6b
│ │ │ ├── __init__.py
│ │ │ ├── configuration_chatglm.py
│ │ │ └── modeling_chatglm.py
│ │ ├── command.py
│ │ ├── deepseek.py
│ │ ├── deepseek_v3.py
│ │ ├── falcon.py
│ │ ├── gpt2.py
│ │ ├── gptj.py
│ │ ├── jit.py
│ │ ├── llama.py
│ │ ├── mistral.py
│ │ ├── mixtral.py
│ │ ├── opt.py
│ │ ├── qwen2.py
│ │ ├── sam.py
│ │ ├── t5.py
│ │ ├── vit.py
│ │ └── whisper.py
│ ├── policies
│ │ ├── __init__.py
│ │ ├── auto_policy.py
│ │ ├── base_policy.py
│ │ ├── bert.py
│ │ ├── blip2.py
│ │ ├── bloom.py
│ │ ├── chatglm2.py
│ │ ├── command.py
│ │ ├── deepseek.py
│ │ ├── deepseek_v3.py
│ │ ├── falcon.py
│ │ ├── gpt2.py
│ │ ├── gptj.py
│ │ ├── llama.py
│ │ ├── mistral.py
│ │ ├── mixtral.py
│ │ ├── opt.py
│ │ ├── qwen2.py
│ │ ├── sam.py
│ │ ├── t5.py
│ │ ├── vit.py
│ │ └── whisper.py
│ └── shard
│ │ ├── __init__.py
│ │ ├── grad_ckpt_config.py
│ │ ├── shard_config.py
│ │ ├── sharder.py
│ │ ├── shardformer.py
│ │ └── utils.py
├── tensor
│ ├── __init__.py
│ ├── colo_parameter.py
│ ├── colo_tensor.py
│ ├── comm_spec.py
│ ├── d_tensor
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── api.py
│ │ ├── comm_spec.py
│ │ ├── layout.py
│ │ ├── layout_converter.py
│ │ ├── misc.py
│ │ ├── sharding_spec.py
│ │ └── utils.py
│ ├── moe_tensor
│ │ ├── __init__.py
│ │ ├── api.py
│ │ └── moe_info.py
│ ├── padded_tensor
│ │ ├── __init__.py
│ │ └── api.py
│ ├── param_op_hook.py
│ ├── shape_consistency.py
│ ├── sharding_spec.py
│ └── utils.py
├── testing
│ ├── __init__.py
│ ├── comparison.py
│ ├── pytest_wrapper.py
│ ├── random.py
│ └── utils.py
├── utils
│ ├── __init__.py
│ ├── common.py
│ ├── memory.py
│ ├── model
│ │ ├── __init__.py
│ │ └── utils.py
│ ├── multi_tensor_apply
│ │ ├── __init__.py
│ │ └── multi_tensor_apply.py
│ ├── rank_recorder
│ │ ├── README.md
│ │ ├── __init__.py
│ │ └── rank_recorder.py
│ ├── safetensors.py
│ ├── tensor_detector
│ │ ├── __init__.py
│ │ ├── readme.md
│ │ └── tensor_detector.py
│ └── timer.py
└── zero
│ ├── __init__.py
│ ├── gemini
│ ├── __init__.py
│ ├── chunk
│ │ ├── __init__.py
│ │ ├── chunk.py
│ │ ├── manager.py
│ │ ├── search_utils.py
│ │ └── utils.py
│ ├── gemini_ddp.py
│ ├── gemini_hook.py
│ ├── gemini_mgr.py
│ ├── gemini_optimizer.py
│ ├── memory_tracer
│ │ ├── __init__.py
│ │ ├── chunk_memstats_collector.py
│ │ ├── memory_monitor.py
│ │ ├── memory_stats.py
│ │ ├── memstats_collector.py
│ │ ├── param_runtime_order.py
│ │ ├── runtime_mem_tracer.py
│ │ ├── static_memstats_collector.py
│ │ └── utils.py
│ ├── placement_policy.py
│ └── utils.py
│ ├── low_level
│ ├── __init__.py
│ ├── _utils.py
│ ├── bookkeeping
│ │ ├── __init__.py
│ │ ├── base_store.py
│ │ ├── bucket_store.py
│ │ ├── gradient_store.py
│ │ └── tensor_bucket.py
│ ├── low_level_optim.py
│ ├── readme.md
│ └── zero_hook.py
│ └── wrapper.py
├── docker
└── Dockerfile
├── docs
├── README-zh-Hans.md
├── README.md
├── REFERENCE.md
├── conda-doc-test-deps.yml
├── requirements-doc-test.txt
├── sidebars.json
├── source
│ ├── en
│ │ ├── Colossal-Auto
│ │ │ ├── feature
│ │ │ │ ├── auto_checkpoint.md
│ │ │ │ ├── device_mesh.md
│ │ │ │ ├── layout_converting_management.md
│ │ │ │ └── tracer.md
│ │ │ └── get_started
│ │ │ │ ├── installation.md
│ │ │ │ ├── introduction.md
│ │ │ │ └── run_demo.md
│ │ ├── advanced_tutorials
│ │ │ ├── integrate_mixture_of_experts_into_your_model.md
│ │ │ ├── meet_gemini.md
│ │ │ ├── opt_service.md
│ │ │ ├── train_gpt_using_hybrid_parallelism.md
│ │ │ └── train_vit_with_hybrid_parallelism.md
│ │ ├── basics
│ │ │ ├── booster_api.md
│ │ │ ├── booster_checkpoint.md
│ │ │ ├── booster_plugins.md
│ │ │ ├── command_line_tool.md
│ │ │ └── launch_colossalai.md
│ │ ├── concepts
│ │ │ ├── colossalai_overview.md
│ │ │ ├── distributed_training.md
│ │ │ └── paradigms_of_parallelism.md
│ │ ├── features
│ │ │ ├── 1D_tensor_parallel.md
│ │ │ ├── 2D_tensor_parallel.md
│ │ │ ├── 2p5D_tensor_parallel.md
│ │ │ ├── 3D_tensor_parallel.md
│ │ │ ├── cluster_utils.md
│ │ │ ├── distributed_optimizers.md
│ │ │ ├── gradient_accumulation_with_booster.md
│ │ │ ├── gradient_clipping_with_booster.md
│ │ │ ├── lazy_init.md
│ │ │ ├── mixed_precision_training_with_booster.md
│ │ │ ├── nvme_offload.md
│ │ │ ├── pipeline_parallel.md
│ │ │ ├── sequence_parallelism.md
│ │ │ ├── shardformer.md
│ │ │ ├── zero_with_chunk.md
│ │ │ └── zerobubble_pipeline_parallelism.md
│ │ ├── get_started
│ │ │ ├── bonus.md
│ │ │ ├── installation.md
│ │ │ ├── reading_roadmap.md
│ │ │ └── run_demo.md
│ │ └── sidebar_category_translation.json
│ └── zh-Hans
│ │ ├── Colossal-Auto
│ │ ├── feature
│ │ │ ├── auto_checkpoint.md
│ │ │ ├── device_mesh.md
│ │ │ ├── layout_converting_management.md
│ │ │ └── tracer.md
│ │ └── get_started
│ │ │ ├── installation.md
│ │ │ ├── introduction.md
│ │ │ └── run_demo.md
│ │ ├── advanced_tutorials
│ │ ├── integrate_mixture_of_experts_into_your_model.md
│ │ ├── meet_gemini.md
│ │ ├── opt_service.md
│ │ ├── train_gpt_using_hybrid_parallelism.md
│ │ └── train_vit_with_hybrid_parallelism.md
│ │ ├── basics
│ │ ├── booster_api.md
│ │ ├── booster_checkpoint.md
│ │ ├── booster_plugins.md
│ │ ├── command_line_tool.md
│ │ └── launch_colossalai.md
│ │ ├── concepts
│ │ ├── colossalai_overview.md
│ │ ├── distributed_training.md
│ │ └── paradigms_of_parallelism.md
│ │ ├── features
│ │ ├── 1D_tensor_parallel.md
│ │ ├── 2D_tensor_parallel.md
│ │ ├── 2p5D_tensor_parallel.md
│ │ ├── 3D_tensor_parallel.md
│ │ ├── cluster_utils.md
│ │ ├── distributed_optimizers.md
│ │ ├── gradient_accumulation_with_booster.md
│ │ ├── gradient_clipping_with_booster.md
│ │ ├── lazy_init.md
│ │ ├── mixed_precision_training_with_booster.md
│ │ ├── nvme_offload.md
│ │ ├── pipeline_parallel.md
│ │ ├── sequence_parallelism.md
│ │ ├── shardformer.md
│ │ ├── zero_with_chunk.md
│ │ └── zerobubble_pipeline_parallelism.md
│ │ ├── get_started
│ │ ├── bonus.md
│ │ ├── installation.md
│ │ ├── reading_roadmap.md
│ │ └── run_demo.md
│ │ └── sidebar_category_translation.json
└── versions.json
├── examples
├── README.md
├── __init__.py
├── community
│ ├── README.md
│ ├── fp8
│ │ └── mnist
│ │ │ ├── README.md
│ │ │ └── main.py
│ └── roberta
│ │ ├── README.md
│ │ ├── preprocessing
│ │ ├── Makefile
│ │ ├── README.md
│ │ ├── get_mask.py
│ │ ├── mask.cpp
│ │ ├── sentence_split.py
│ │ └── tokenize_mask.py
│ │ ├── pretraining
│ │ ├── README.md
│ │ ├── arguments.py
│ │ ├── bert_dataset_provider.py
│ │ ├── evaluation.py
│ │ ├── hostfile
│ │ ├── loss.py
│ │ ├── model
│ │ │ ├── bert.py
│ │ │ └── deberta_v2.py
│ │ ├── nvidia_bert_dataset_provider.py
│ │ ├── pretrain_utils.py
│ │ ├── run_pretrain.sh
│ │ ├── run_pretrain_resume.sh
│ │ ├── run_pretraining.py
│ │ └── utils
│ │ │ ├── WandbLog.py
│ │ │ ├── exp_util.py
│ │ │ ├── global_vars.py
│ │ │ └── logger.py
│ │ ├── requirements.txt
│ │ └── test_ci.sh
├── images
│ ├── diffusion
│ │ ├── LICENSE
│ │ ├── README.md
│ │ ├── configs
│ │ │ ├── Inference
│ │ │ │ ├── v2-inference-v.yaml
│ │ │ │ ├── v2-inference.yaml
│ │ │ │ ├── v2-inpainting-inference.yaml
│ │ │ │ ├── v2-midas-inference.yaml
│ │ │ │ └── x4-upscaling.yaml
│ │ │ ├── Teyvat
│ │ │ │ ├── README.md
│ │ │ │ └── train_colossalai_teyvat.yaml
│ │ │ ├── train_colossalai.yaml
│ │ │ ├── train_colossalai_cifar10.yaml
│ │ │ └── train_ddp.yaml
│ │ ├── docker
│ │ │ └── Dockerfile
│ │ ├── environment.yaml
│ │ ├── ldm
│ │ │ ├── .DS_Store
│ │ │ ├── data
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ ├── cifar10.py
│ │ │ │ ├── imagenet.py
│ │ │ │ ├── lsun.py
│ │ │ │ └── teyvat.py
│ │ │ ├── lr_scheduler.py
│ │ │ ├── models
│ │ │ │ ├── autoencoder.py
│ │ │ │ └── diffusion
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── classifier.py
│ │ │ │ │ ├── ddim.py
│ │ │ │ │ ├── ddpm.py
│ │ │ │ │ ├── dpm_solver
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── dpm_solver.py
│ │ │ │ │ └── sampler.py
│ │ │ │ │ ├── plms.py
│ │ │ │ │ └── sampling_util.py
│ │ │ ├── modules
│ │ │ │ ├── attention.py
│ │ │ │ ├── diffusionmodules
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── model.py
│ │ │ │ │ ├── openaimodel.py
│ │ │ │ │ ├── upscaling.py
│ │ │ │ │ └── util.py
│ │ │ │ ├── distributions
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── distributions.py
│ │ │ │ ├── ema.py
│ │ │ │ ├── encoders
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── modules.py
│ │ │ │ ├── image_degradation
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── bsrgan.py
│ │ │ │ │ ├── bsrgan_light.py
│ │ │ │ │ ├── utils
│ │ │ │ │ │ └── test.png
│ │ │ │ │ └── utils_image.py
│ │ │ │ └── midas
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── api.py
│ │ │ │ │ ├── midas
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── base_model.py
│ │ │ │ │ ├── blocks.py
│ │ │ │ │ ├── dpt_depth.py
│ │ │ │ │ ├── midas_net.py
│ │ │ │ │ ├── midas_net_custom.py
│ │ │ │ │ ├── transforms.py
│ │ │ │ │ └── vit.py
│ │ │ │ │ └── utils.py
│ │ │ └── util.py
│ │ ├── main.py
│ │ ├── requirements.txt
│ │ ├── scripts
│ │ │ ├── download_first_stages.sh
│ │ │ ├── download_models.sh
│ │ │ ├── img2img.py
│ │ │ ├── inpaint.py
│ │ │ ├── knn2img.py
│ │ │ ├── sample_diffusion.py
│ │ │ ├── tests
│ │ │ │ ├── test_checkpoint.py
│ │ │ │ └── test_watermark.py
│ │ │ ├── train_searcher.py
│ │ │ ├── txt2img.py
│ │ │ ├── txt2img.sh
│ │ │ └── utils.py
│ │ ├── setup.py
│ │ ├── test_ci.sh
│ │ ├── train_colossalai.sh
│ │ └── train_ddp.sh
│ ├── dreambooth
│ │ ├── README.md
│ │ ├── colossalai.sh
│ │ ├── debug.py
│ │ ├── dreambooth.sh
│ │ ├── inference.py
│ │ ├── requirements.txt
│ │ ├── test_ci.sh
│ │ ├── train_dreambooth.py
│ │ ├── train_dreambooth_colossalai.py
│ │ ├── train_dreambooth_colossalai_lora.py
│ │ └── train_dreambooth_inpaint.py
│ ├── resnet
│ │ ├── .gitignore
│ │ ├── README.md
│ │ ├── eval.py
│ │ ├── requirements.txt
│ │ ├── test_ci.sh
│ │ └── train.py
│ └── vit
│ │ ├── README.md
│ │ ├── args.py
│ │ ├── data.py
│ │ ├── requirements.txt
│ │ ├── run_benchmark.sh
│ │ ├── run_demo.sh
│ │ ├── test_ci.sh
│ │ ├── vit_benchmark.py
│ │ └── vit_train_demo.py
├── inference
│ ├── benchmark_ops
│ │ ├── benchmark_context_attn_unpad.py
│ │ ├── benchmark_decoding_attn.py
│ │ ├── benchmark_flash_decoding_attention.py
│ │ ├── benchmark_fused_rotary_embdding_unpad.py
│ │ ├── benchmark_kv_cache_memcopy.py
│ │ ├── benchmark_rmsnorm.py
│ │ ├── benchmark_rotary_embedding.py
│ │ ├── benchmark_xine_copy.py
│ │ └── test_ci.sh
│ ├── client
│ │ ├── locustfile.py
│ │ ├── run_locust.sh
│ │ └── test_ci.sh
│ ├── llama
│ │ ├── README.md
│ │ ├── benchmark_llama.py
│ │ ├── benchmark_llama3.py
│ │ ├── llama_generation.py
│ │ ├── run_benchmark.sh
│ │ └── test_ci.sh
│ └── stable_diffusion
│ │ ├── README.md
│ │ ├── benchmark_sd3.py
│ │ ├── compute_metric.py
│ │ ├── requirements.txt
│ │ ├── run_benchmark.sh
│ │ ├── sd3_generation.py
│ │ └── test_ci.sh
├── language
│ ├── __init__.py
│ ├── bert
│ │ ├── README.md
│ │ ├── benchmark.py
│ │ ├── benchmark.sh
│ │ ├── benchmark_utils.py
│ │ ├── data.py
│ │ ├── finetune.py
│ │ ├── requirements.txt
│ │ └── test_ci.sh
│ ├── commons
│ │ └── utils.py
│ ├── data_utils.py
│ ├── deepseek
│ │ ├── benchmark.py
│ │ ├── data_utils.py
│ │ ├── model_utils.py
│ │ ├── performance_evaluator.py
│ │ └── test_ci.sh
│ ├── gpt
│ │ ├── README.md
│ │ ├── experiments
│ │ │ ├── auto_offload
│ │ │ │ ├── README.md
│ │ │ │ ├── model_zoo.py
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── run.sh
│ │ │ │ └── train_gpt_offload.py
│ │ │ ├── auto_parallel
│ │ │ │ ├── README.md
│ │ │ │ ├── auto_parallel_with_gpt.py
│ │ │ │ ├── gpt_modules.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── saved_solution
│ │ │ │ │ ├── solution_12_layers.pt
│ │ │ │ │ ├── solution_1_layers.pt
│ │ │ │ │ └── solution_4_layers.pt
│ │ │ └── pipeline_parallel
│ │ │ │ ├── README.md
│ │ │ │ ├── model_zoo.py
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── run.sh
│ │ │ │ └── train_gpt_pp.py
│ │ ├── gemini
│ │ │ ├── benchmark_gemini.sh
│ │ │ ├── commons
│ │ │ │ ├── model_zoo.py
│ │ │ │ ├── performance_evaluator.py
│ │ │ │ └── utils.py
│ │ │ ├── requirements.txt
│ │ │ ├── run_gemini.sh
│ │ │ ├── test_ci.sh
│ │ │ └── train_gpt_demo.py
│ │ ├── hybridparallelism
│ │ │ ├── benchmark.py
│ │ │ ├── data.py
│ │ │ ├── finetune.py
│ │ │ └── run.sh
│ │ ├── requirements.txt
│ │ ├── test_ci.sh
│ │ └── titans
│ │ │ ├── LICENSE
│ │ │ ├── README.md
│ │ │ ├── configs
│ │ │ ├── gpt2_small_zero3_pp1d.py
│ │ │ └── gpt3_zero3_pp1d.py
│ │ │ ├── dataset
│ │ │ └── webtext.py
│ │ │ ├── model
│ │ │ ├── __init__.py
│ │ │ ├── embed.py
│ │ │ ├── gpt1d.py
│ │ │ └── pipeline_gpt1d.py
│ │ │ ├── requirements.txt
│ │ │ ├── run.sh
│ │ │ ├── test_ci.sh
│ │ │ └── train_gpt.py
│ ├── grok-1
│ │ ├── README.md
│ │ ├── grok1_policy.py
│ │ ├── inference.py
│ │ ├── inference_tp.py
│ │ ├── requirements.txt
│ │ ├── run_inference_fast.sh
│ │ ├── run_inference_slow.sh
│ │ ├── test_ci.sh
│ │ └── utils.py
│ ├── llama
│ │ ├── README.md
│ │ ├── benchmark.py
│ │ ├── data_utils.py
│ │ ├── model_utils.py
│ │ ├── performance_evaluator.py
│ │ ├── requirements.txt
│ │ ├── scripts
│ │ │ ├── benchmark_70B
│ │ │ │ ├── 3d.sh
│ │ │ │ ├── gemini.sh
│ │ │ │ └── gemini_auto.sh
│ │ │ └── benchmark_7B
│ │ │ │ ├── gemini.sh
│ │ │ │ └── gemini_auto.sh
│ │ └── test_ci.sh
│ ├── mixtral
│ │ ├── benchmark.py
│ │ ├── data_utils.py
│ │ ├── model_utils.py
│ │ ├── performance_evaluator.py
│ │ └── test_ci.sh
│ ├── model_utils.py
│ ├── opt
│ │ ├── README.md
│ │ ├── args.py
│ │ ├── data.py
│ │ ├── opt_benchmark.py
│ │ ├── opt_train_demo.py
│ │ ├── requirements.txt
│ │ ├── run_benchmark.sh
│ │ ├── run_demo.sh
│ │ └── test_ci.sh
│ ├── palm
│ │ ├── README.md
│ │ ├── data
│ │ │ └── README.md
│ │ ├── palm_pytorch
│ │ │ ├── __init__.py
│ │ │ ├── autoregressive_wrapper.py
│ │ │ └── palm_pytorch.py
│ │ ├── requirements.txt
│ │ ├── run.sh
│ │ ├── test_ci.sh
│ │ └── train.py
│ └── performance_evaluator.py
└── tutorial
│ ├── .gitignore
│ ├── README.md
│ ├── auto_parallel
│ ├── README.md
│ ├── auto_ckpt_batchsize_test.py
│ ├── auto_ckpt_solver_test.py
│ ├── auto_parallel_with_resnet.py
│ ├── bench_utils.py
│ ├── config.py
│ ├── requirements.txt
│ ├── setup.py
│ └── test_ci.sh
│ ├── download_cifar10.py
│ ├── fastfold
│ └── README.md
│ ├── hybrid_parallel
│ ├── README.md
│ ├── config.py
│ ├── requirements.txt
│ ├── test_ci.sh
│ └── train.py
│ ├── large_batch_optimizer
│ ├── README.md
│ ├── config.py
│ ├── requirements.txt
│ ├── test_ci.sh
│ └── train.py
│ ├── new_api
│ ├── README.md
│ ├── cifar_resnet
│ │ ├── .gitignore
│ │ ├── README.md
│ │ ├── eval.py
│ │ ├── requirements.txt
│ │ ├── test_ci.sh
│ │ └── train.py
│ ├── cifar_vit
│ │ ├── README.md
│ │ ├── requirements.txt
│ │ ├── test_ci.sh
│ │ └── train.py
│ ├── glue_bert
│ │ ├── README.md
│ │ ├── data.py
│ │ ├── finetune.py
│ │ ├── requirements.txt
│ │ └── test_ci.sh
│ └── test_ci.sh
│ ├── opt
│ ├── inference
│ │ ├── README.md
│ │ ├── batch.py
│ │ ├── benchmark
│ │ │ └── locustfile.py
│ │ ├── cache.py
│ │ ├── opt_fastapi.py
│ │ ├── opt_server.py
│ │ ├── requirements.txt
│ │ └── script
│ │ │ ├── process-opt-175b
│ │ │ ├── README.md
│ │ │ ├── convert_ckpt.py
│ │ │ ├── flat-meta.json
│ │ │ └── unflat.sh
│ │ │ └── processing_ckpt_66b.py
│ ├── opt
│ │ ├── README.md
│ │ ├── benchmark.sh
│ │ ├── colossalai_zero.py
│ │ ├── context.py
│ │ ├── requirements.txt
│ │ ├── run_clm.py
│ │ ├── run_clm.sh
│ │ ├── run_clm_synthetic.sh
│ │ └── test_ci.sh
│ └── test_ci.sh
│ ├── requirements.txt
│ └── sequence_parallel
│ ├── README.md
│ ├── config.py
│ ├── data
│ ├── __init__.py
│ ├── bert_helper.py
│ ├── datasets
│ │ ├── Makefile
│ │ ├── __init__.py
│ │ ├── bert_dataset.py
│ │ ├── blendable_dataset.py
│ │ ├── builder.py
│ │ ├── data_samplers.py
│ │ ├── dataset_utils.py
│ │ ├── helpers.cpp
│ │ ├── ict_dataset.py
│ │ ├── indexed_dataset.py
│ │ └── test
│ │ │ ├── test_indexed_dataset.py
│ │ │ └── test_preprocess_data.sh
│ ├── dummy_dataloader.py
│ └── tokenizer
│ │ ├── __init__.py
│ │ ├── bert_tokenization.py
│ │ └── tokenizer.py
│ ├── loss_func
│ ├── __init__.py
│ ├── bert_loss.py
│ ├── cross_entropy.py
│ └── utils.py
│ ├── lr_scheduler
│ ├── __init__.py
│ └── annealing_lr.py
│ ├── model
│ ├── __init__.py
│ ├── bert.py
│ └── layers
│ │ ├── __init__.py
│ │ ├── bert_layer.py
│ │ ├── dropout.py
│ │ ├── embedding.py
│ │ ├── head.py
│ │ ├── init_method.py
│ │ ├── linear.py
│ │ ├── mlp.py
│ │ ├── pooler.py
│ │ └── preprocess.py
│ ├── requirements.txt
│ ├── test_ci.sh
│ └── train.py
├── extensions
├── README.md
├── __init__.py
├── base_extension.py
├── cpp_extension.py
├── csrc
│ ├── __init__.py
│ ├── common
│ │ ├── data_type.h
│ │ ├── micros.h
│ │ ├── mp_type_traits.h
│ │ ├── target.h
│ │ └── vec_type_traits.h
│ ├── funcs
│ │ ├── binary_functor.h
│ │ ├── cast_functor.h
│ │ ├── reduce_function.h
│ │ ├── ternary_functor.h
│ │ └── unary_functor.h
│ └── kernel
│ │ ├── arm
│ │ ├── cpu_adam_arm.cpp
│ │ └── cpu_adam_arm.h
│ │ ├── cuda
│ │ ├── activation_kernel.cu
│ │ ├── attention
│ │ │ └── attention_utils.h
│ │ ├── context_kv_cache_memcpy_kernel.cu
│ │ ├── convert_fp8_kernel.cu
│ │ ├── decode_kv_cache_memcpy_kernel.cu
│ │ ├── flash_decoding_attention_kernel.cu
│ │ ├── fused_rotary_emb_and_cache_kernel.cu
│ │ ├── get_cos_and_sin_kernel.cu
│ │ ├── layer_norm_kernel.cu
│ │ ├── moe_kernel.cu
│ │ ├── multi_tensor_adam_kernel.cu
│ │ ├── multi_tensor_apply.cuh
│ │ ├── multi_tensor_l2norm_kernel.cu
│ │ ├── multi_tensor_lamb_kernel.cu
│ │ ├── multi_tensor_scale_kernel.cu
│ │ ├── multi_tensor_sgd_kernel.cu
│ │ ├── rms_layernorm_kernel.cu
│ │ ├── scaled_masked_softmax_kernel.cu
│ │ ├── scaled_upper_triang_masked_softmax_kernel.cu
│ │ └── utils
│ │ │ ├── gpu_launch_config.h
│ │ │ ├── micros.h
│ │ │ ├── nvgpu_dev_info.h
│ │ │ └── vec_copy.h
│ │ └── x86
│ │ ├── cpu_adam.cpp
│ │ └── cpu_adam.h
├── cuda_extension.py
├── pybind
│ ├── __init__.py
│ ├── cpu_adam
│ │ ├── __init__.py
│ │ ├── cpu_adam_arm.py
│ │ └── cpu_adam_x86.py
│ ├── flash_attention
│ │ ├── __init__.py
│ │ ├── flash_attention_dao_cuda.py
│ │ ├── flash_attention_npu.py
│ │ └── flash_attention_sdpa_cuda.py
│ ├── inference
│ │ ├── __init__.py
│ │ ├── inference.cpp
│ │ └── inference_ops_cuda.py
│ ├── layernorm
│ │ ├── __init__.py
│ │ ├── layer_norm.cpp
│ │ └── layernorm_cuda.py
│ ├── moe
│ │ ├── __init__.py
│ │ ├── moe.cpp
│ │ └── moe_cuda.py
│ ├── optimizer
│ │ ├── __init__.py
│ │ ├── fused_optimizer_cuda.py
│ │ └── optimizer.cpp
│ └── softmax
│ │ ├── __init__.py
│ │ ├── scaled_masked_softmax.cpp
│ │ ├── scaled_masked_softmax_cuda.py
│ │ ├── scaled_upper_triang_masked_softmax.cpp
│ │ └── scaled_upper_triangle_masked_softmax_cuda.py
├── triton_extension.py
└── utils.py
├── pytest.ini
├── requirements
├── requirements-test.txt
└── requirements.txt
├── setup.py
├── tests
├── __init__.py
├── conftest.py
├── kit
│ ├── __init__.py
│ └── model_zoo
│ │ ├── __init__.py
│ │ ├── custom
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── hanging_param_model.py
│ │ ├── nested_model.py
│ │ ├── repeated_computed_layers.py
│ │ ├── simple_mlp.py
│ │ └── simple_net.py
│ │ ├── diffusers
│ │ ├── __init__.py
│ │ └── diffusers.py
│ │ ├── executor.py
│ │ ├── registry.py
│ │ ├── timm
│ │ ├── __init__.py
│ │ └── timm.py
│ │ ├── torchaudio
│ │ ├── __init__.py
│ │ └── torchaudio.py
│ │ ├── torchrec
│ │ ├── __init__.py
│ │ └── torchrec.py
│ │ ├── torchvision
│ │ ├── __init__.py
│ │ └── torchvision.py
│ │ └── transformers
│ │ ├── __init__.py
│ │ ├── albert.py
│ │ ├── bert.py
│ │ ├── blip2.py
│ │ ├── bloom.py
│ │ ├── chatglm2.py
│ │ ├── command.py
│ │ ├── deepseek.py
│ │ ├── deepseek_v3.py
│ │ ├── falcon.py
│ │ ├── gpt.py
│ │ ├── gptj.py
│ │ ├── llama.py
│ │ ├── mistral.py
│ │ ├── mixtral.py
│ │ ├── opt.py
│ │ ├── qwen2.py
│ │ ├── sam.py
│ │ ├── t5.py
│ │ ├── vit.py
│ │ └── whisper.py
├── test_analyzer
│ ├── __init__.py
│ ├── test_fx
│ │ ├── __init__.py
│ │ ├── test_bias_addition.py
│ │ ├── test_mod_dir.py
│ │ ├── test_nested_ckpt.py
│ │ ├── test_shape_prop.py
│ │ ├── test_symbolic_profile.py
│ │ └── zoo.py
│ └── test_subclasses
│ │ ├── __init__.py
│ │ ├── test_aten.py
│ │ ├── test_flop_tensor.py
│ │ └── test_meta_mode.py
├── test_auto_parallel
│ ├── __init__.py
│ ├── test_ckpt_solvers
│ │ ├── test_C_solver_consistency.py
│ │ ├── test_ckpt_torchvision.py
│ │ └── test_linearize.py
│ ├── test_offload
│ │ ├── model_utils.py
│ │ ├── test_perf.py
│ │ └── test_solver.py
│ ├── test_pass
│ │ ├── __init__.py
│ │ ├── test_node_converting_pass.py
│ │ └── test_size_value_converting_pass.py
│ └── test_tensor_shard
│ │ ├── __init__.py
│ │ ├── test_bias_addition_forward.py
│ │ ├── test_broadcast.py
│ │ ├── test_checkpoint.py
│ │ ├── test_compatibility_with_ddp.py
│ │ ├── test_compatibility_with_gemini.py
│ │ ├── test_find_repeat_block.py
│ │ ├── test_gpt
│ │ ├── __init__.py
│ │ ├── gpt_modules.py
│ │ ├── test_runtime_with_gpt_modules.py
│ │ └── test_solver_with_gpt_module.py
│ │ ├── test_liveness_analysis.py
│ │ ├── test_metainfo
│ │ ├── test_activation_metainfo.py
│ │ ├── test_binary_elementwise_metainfo.py
│ │ ├── test_conv_metainfo.py
│ │ ├── test_embedding_metainfo.py
│ │ ├── test_linear_metainfo.py
│ │ ├── test_matmul_metainfo.py
│ │ ├── test_norm_metainfo.py
│ │ ├── test_pooling_metainfo.py
│ │ ├── test_tensor_metainfo.py
│ │ ├── test_where_metainfo.py
│ │ └── utils.py
│ │ ├── test_node_handler
│ │ ├── __init__.py
│ │ ├── test_addbmm_handler.py
│ │ ├── test_addmm_handler.py
│ │ ├── test_batch_norm_handler.py
│ │ ├── test_bias_linear_function_node.py
│ │ ├── test_bias_linear_module_node.py
│ │ ├── test_binary_elementwise_handler.py
│ │ ├── test_bmm_handler.py
│ │ ├── test_conv_handler.py
│ │ ├── test_default_reshape_handler.py
│ │ ├── test_embedding_handler.py
│ │ ├── test_getattr_handler.py
│ │ ├── test_getitem_handler.py
│ │ ├── test_layer_norm_handler.py
│ │ ├── test_linear_handler.py
│ │ ├── test_matmul_handler.py
│ │ ├── test_norm_pooling_handler.py
│ │ ├── test_output_handler.py
│ │ ├── test_permute_and_transpose_handler.py
│ │ ├── test_placeholder_handler.py
│ │ ├── test_shard_option.py
│ │ ├── test_softmax_handler.py
│ │ ├── test_split_handler.py
│ │ ├── test_sum_handler.py
│ │ ├── test_tensor_constructor.py
│ │ ├── test_unary_element_wise_handler.py
│ │ ├── test_view_handler.py
│ │ ├── test_where_handler.py
│ │ └── utils.py
│ │ └── test_solver_with_resnet_v2.py
├── test_autochunk
│ ├── test_autochunk_alphafold
│ │ ├── benchmark_autochunk_alphafold.py
│ │ ├── test_autochunk_alphafold_utils.py
│ │ ├── test_autochunk_evoformer_block.py
│ │ ├── test_autochunk_evoformer_stack.py
│ │ └── test_autochunk_extramsa_block.py
│ ├── test_autochunk_diffuser
│ │ ├── benchmark_autochunk_diffuser.py
│ │ ├── test_autochunk_diffuser_utils.py
│ │ └── test_autochunk_unet.py
│ ├── test_autochunk_transformer
│ │ ├── benchmark_autochunk_transformer.py
│ │ ├── test_autochunk_gpt.py
│ │ └── test_autochunk_transformer_utils.py
│ └── test_autochunk_vit
│ │ ├── test_autochunk_vit.py
│ │ └── test_autochunk_vit_utils.py
├── test_booster
│ ├── test_accelerator.py
│ ├── test_mixed_precision
│ │ └── test_fp16_torch.py
│ └── test_plugin
│ │ ├── test_3d_plugin.py
│ │ ├── test_dp_plugin_base.py
│ │ ├── test_gemini_plugin.py
│ │ ├── test_low_level_zero_plugin.py
│ │ ├── test_torch_ddp_plugin.py
│ │ └── test_torch_fsdp_plugin.py
├── test_checkpoint_io
│ ├── test_gemini_checkpoint_io.py
│ ├── test_gemini_torch_compability.py
│ ├── test_general_checkpoint_io.py
│ ├── test_hybrid_parallel_plugin_checkpoint_io.py
│ ├── test_low_level_zero_checkpoint_io.py
│ ├── test_plugins_huggingface_compatibility.py
│ ├── test_safetensors_async_io.py
│ ├── test_torch_ddp_checkpoint_io.py
│ ├── test_torch_fsdp_checkpoint_io.py
│ └── utils.py
├── test_cluster
│ ├── test_device_mesh_manager.py
│ └── test_process_group_mesh.py
├── test_config
│ ├── sample_config.py
│ └── test_load_config.py
├── test_device
│ ├── test_alpha_beta.py
│ ├── test_device_mesh.py
│ ├── test_extract_alpha_beta.py
│ ├── test_init_logical_pg.py
│ └── test_search_logical_device_mesh.py
├── test_fp8
│ ├── test_all_to_all_single.py
│ ├── test_fp8_all_to_all.py
│ ├── test_fp8_all_to_all_single.py
│ ├── test_fp8_allgather.py
│ ├── test_fp8_allreduce.py
│ ├── test_fp8_cast.py
│ ├── test_fp8_ddp_comm_hook.py
│ ├── test_fp8_fsdp_comm_hook.py
│ ├── test_fp8_hook.py
│ ├── test_fp8_linear.py
│ └── test_fp8_reduce_scatter.py
├── test_fx
│ ├── test_codegen
│ │ ├── test_activation_checkpoint_codegen.py
│ │ ├── test_nested_activation_checkpoint_codegen.py
│ │ └── test_offload_codegen.py
│ ├── test_coloproxy.py
│ ├── test_comm_size_compute.py
│ ├── test_graph_manipulation.py
│ ├── test_meta
│ │ ├── test_aten.py
│ │ ├── test_backward.py
│ │ └── test_meta_trace.py
│ ├── test_meta_info_prop.py
│ ├── test_parallel_1d.py
│ ├── test_pipeline
│ │ ├── test_hf_model
│ │ │ ├── hf_utils.py
│ │ │ ├── test_albert.py
│ │ │ ├── test_bert.py
│ │ │ ├── test_gpt.py
│ │ │ ├── test_opt.py
│ │ │ └── test_t5.py
│ │ ├── test_timm_model
│ │ │ ├── test_timm.py
│ │ │ └── timm_utils.py
│ │ ├── test_topo
│ │ │ ├── test_topo.py
│ │ │ └── topo_utils.py
│ │ └── test_torchvision
│ │ │ └── test_torchvision.py
│ ├── test_pipeline_passes.py
│ ├── test_profiler
│ │ ├── gpt_utils.py
│ │ └── test_profiler_meta_info_prop.py
│ └── test_tracer
│ │ ├── test_activation_checkpoint_annotation.py
│ │ ├── test_bias_addition_module.py
│ │ ├── test_control_flow.py
│ │ ├── test_functional_conv.py
│ │ ├── test_hf_model
│ │ ├── hf_tracer_utils.py
│ │ ├── test_hf_albert.py
│ │ ├── test_hf_bert.py
│ │ ├── test_hf_diffuser.py
│ │ ├── test_hf_gpt.py
│ │ ├── test_hf_opt.py
│ │ └── test_hf_t5.py
│ │ ├── test_patched_module.py
│ │ ├── test_patched_op.py
│ │ ├── test_timm_model
│ │ └── test_timm_model.py
│ │ ├── test_torchaudio_model
│ │ ├── test_torchaudio_model.py
│ │ └── torchaudio_utils.py
│ │ ├── test_torchrec_model
│ │ ├── test_deepfm_model.py
│ │ └── test_dlrm_model.py
│ │ └── test_torchvision_model
│ │ └── test_torchvision_model.py
├── test_infer
│ ├── __init__.py
│ ├── _utils.py
│ ├── test_async_engine
│ │ ├── test_async_engine.py
│ │ └── test_request_tracer.py
│ ├── test_batch_bucket.py
│ ├── test_config_and_struct.py
│ ├── test_continuous_batching.py
│ ├── test_cuda_graph.py
│ ├── test_drafter.py
│ ├── test_inference_engine.py
│ ├── test_kernels
│ │ ├── __init__.py
│ │ ├── cuda
│ │ │ ├── __init__.py
│ │ │ ├── test_convert_fp8.py
│ │ │ ├── test_flash_decoding_attention.py
│ │ │ ├── test_get_cos_and_sin.py
│ │ │ ├── test_kv_cache_memcpy.py
│ │ │ ├── test_rms_layernorm.py
│ │ │ ├── test_rotary_embdding_unpad.py
│ │ │ └── test_silu_and_mul.py
│ │ └── triton
│ │ │ ├── __init__.py
│ │ │ ├── kernel_utils.py
│ │ │ ├── test_context_attn_unpad.py
│ │ │ ├── test_decoding_attn.py
│ │ │ ├── test_fused_rotary_embedding.py
│ │ │ ├── test_kvcache_copy.py
│ │ │ ├── test_rmsnorm_triton.py
│ │ │ ├── test_rotary_embdding_unpad.py
│ │ │ └── test_xine_copy.py
│ ├── test_kvcache_manager.py
│ ├── test_models
│ │ ├── test_attention.py
│ │ ├── test_baichuan.py
│ │ └── test_custom_model.py
│ ├── test_request_handler.py
│ ├── test_rpc_engine.py
│ └── test_streamingllm.py
├── test_lazy
│ ├── lazy_init_utils.py
│ ├── test_from_pretrained.py
│ ├── test_models.py
│ └── test_ops.py
├── test_legacy
│ ├── test_amp
│ │ ├── test_naive_fp16.py
│ │ └── test_torch_fp16.py
│ ├── test_comm
│ │ ├── test_boardcast_send_recv_v2.py
│ │ ├── test_comm.py
│ │ ├── test_object_list_p2p.py
│ │ └── test_object_list_p2p_v2.py
│ ├── test_context
│ │ ├── configs
│ │ │ ├── parallel_2d_init.py
│ │ │ ├── parallel_2p5d_init.py
│ │ │ └── parallel_3d_init.py
│ │ └── test_hybrid_parallel.py
│ ├── test_data
│ │ ├── test_cifar10_dataset.py
│ │ ├── test_data_parallel_sampler.py
│ │ └── test_deterministic_dataloader.py
│ ├── test_engine
│ │ ├── test_engine.py
│ │ └── test_gradient_accumluation.py
│ ├── test_layers
│ │ ├── test_1d
│ │ │ ├── checks_1d
│ │ │ │ ├── __init__.py
│ │ │ │ ├── check_layer_1d.py
│ │ │ │ └── common.py
│ │ │ └── test_1d.py
│ │ ├── test_2d
│ │ │ ├── checks_2d
│ │ │ │ ├── __init__.py
│ │ │ │ ├── check_layer_2d.py
│ │ │ │ ├── check_operation_2d.py
│ │ │ │ └── common.py
│ │ │ └── test_2d.py
│ │ ├── test_2p5d
│ │ │ ├── checks_2p5d
│ │ │ │ ├── __init__.py
│ │ │ │ ├── check_layer_2p5d.py
│ │ │ │ ├── check_operation_2p5d.py
│ │ │ │ └── common.py
│ │ │ └── test_2p5d.py
│ │ ├── test_3d
│ │ │ ├── checks_3d
│ │ │ │ ├── __init__.py
│ │ │ │ ├── check_layer_3d.py
│ │ │ │ └── common.py
│ │ │ └── test_3d.py
│ │ ├── test_cache_embedding.py
│ │ └── test_sequence
│ │ │ ├── checks_seq
│ │ │ ├── __init__.py
│ │ │ └── check_layer_seq.py
│ │ │ └── test_sequence.py
│ ├── test_moe
│ │ ├── moe_utils.py
│ │ ├── test_grad_handler.py
│ │ ├── test_moe_group.py
│ │ ├── test_moe_hybrid_zero.py
│ │ └── test_moe_load_balance.py
│ ├── test_pipeline
│ │ ├── rpc_test_utils.py
│ │ ├── test_cuda_rpc_chimera.py
│ │ ├── test_cuda_rpc_optimizer.py
│ │ ├── test_cuda_rpc_pipeline.py
│ │ ├── test_cuda_rpc_value_correctness.py
│ │ ├── test_middleware_1f1b.py
│ │ ├── test_pipelinable.py
│ │ └── test_pipeline_process_group.py
│ ├── test_tensor
│ │ ├── common_utils
│ │ │ ├── __init__.py
│ │ │ └── _utils.py
│ │ ├── core
│ │ │ └── test_dist_spec_mgr.py
│ │ └── test_parameter.py
│ ├── test_trainer
│ │ ├── test_pipeline
│ │ │ ├── test_p2p.py
│ │ │ └── test_pipeline_schedule.py
│ │ ├── test_trainer_with_non_pipe_schedule.py
│ │ └── test_trainer_with_pipe_schedule.py
│ ├── test_utils
│ │ ├── test_activation_checkpointing.py
│ │ ├── test_checkpoint
│ │ │ ├── test_checkpoint_1d.py
│ │ │ ├── test_checkpoint_2d.py
│ │ │ ├── test_checkpoint_2p5d.py
│ │ │ └── test_checkpoint_3d.py
│ │ ├── test_memory.py
│ │ └── test_norm_gradient_clipping.py
│ └── test_zero
│ │ └── test_commons.py
├── test_lora
│ └── test_lora.py
├── test_moe
│ ├── moe_utils.py
│ ├── test_deepseek_layer.py
│ ├── test_kernel.py
│ ├── test_mixtral_layer.py
│ ├── test_moe_checkpoint.py
│ ├── test_moe_ep_tp.py
│ └── test_moe_ep_zero.py
├── test_optimizer
│ ├── _utils.py
│ ├── test_adam_kernel.py
│ ├── test_adam_optim.py
│ ├── test_dist_adafactor.py
│ ├── test_dist_came.py
│ ├── test_dist_galore.py
│ ├── test_dist_lamb.py
│ ├── test_lr_scheduler.py
│ └── test_nvme.py
├── test_pipeline
│ ├── test_p2p_communication.py
│ ├── test_pipeline_utils
│ │ ├── test_t5_pipeline_utils.py
│ │ └── test_whisper_pipeline_utils.py
│ ├── test_schedule
│ │ ├── test_interleaved.py
│ │ ├── test_oneF_oneB.py
│ │ ├── test_pipeline_schedule_utils.py
│ │ └── test_zerobubble_pp.py
│ └── test_stage_manager.py
├── test_shardformer
│ ├── __init__.py
│ ├── test_flash_attention.py
│ ├── test_hybrid_parallel_grad_clip_norm
│ │ ├── test_amp_optimizer.py
│ │ ├── test_naive_optimizer.py
│ │ └── test_zero_optimizer.py
│ ├── test_layer
│ │ ├── test_dist_crossentropy.py
│ │ ├── test_dropout.py
│ │ ├── test_embedding.py
│ │ ├── test_gpt2_qkv_fused_linear_1d.py
│ │ ├── test_layernorm.py
│ │ ├── test_linear_1d.py
│ │ ├── test_qkv_fused_linear_1d.py
│ │ ├── test_ring_attn.py
│ │ ├── test_sequence_parallel.py
│ │ └── test_vocab_parallel_embedding_1d.py
│ ├── test_model
│ │ ├── __init__.py
│ │ ├── _utils.py
│ │ ├── test_shard_bert.py
│ │ ├── test_shard_blip2.py
│ │ ├── test_shard_bloom.py
│ │ ├── test_shard_chatglm2.py
│ │ ├── test_shard_command.py
│ │ ├── test_shard_deepseek.py
│ │ ├── test_shard_deepseek_v3.py
│ │ ├── test_shard_falcon.py
│ │ ├── test_shard_gpt2.py
│ │ ├── test_shard_gptj.py
│ │ ├── test_shard_llama.py
│ │ ├── test_shard_mistral.py
│ │ ├── test_shard_mixtral.py
│ │ ├── test_shard_opt.py
│ │ ├── test_shard_qwen2.py
│ │ ├── test_shard_sam.py
│ │ ├── test_shard_t5.py
│ │ ├── test_shard_vit.py
│ │ └── test_shard_whisper.py
│ ├── test_shard_utils.py
│ └── test_with_torch_ddp.py
├── test_smoothquant
│ ├── test_llama_attention.py
│ ├── test_llama_mlp.py
│ ├── test_smoothquant_linear.py
│ └── test_sq_rotary_embedding.py
├── test_tensor
│ ├── test_comm_spec_apply.py
│ ├── test_dtensor
│ │ ├── test_comm_spec.py
│ │ ├── test_dtensor.py
│ │ ├── test_dtensor_sharding_spec.py
│ │ └── test_layout_converter.py
│ ├── test_mix_gather.py
│ ├── test_padded_tensor.py
│ ├── test_shape_consistency.py
│ ├── test_shape_consistency_apply.py
│ └── test_sharding_spec.py
└── test_zero
│ ├── test_gemini
│ ├── test_chunk_mgrv2.py
│ ├── test_chunkv2.py
│ ├── test_gemini_use_rmt.py
│ ├── test_grad_accum.py
│ ├── test_grad_clip.py
│ ├── test_inference.py
│ ├── test_optim.py
│ ├── test_runtime_mem_tracer.py
│ ├── test_search.py
│ ├── test_zeroddp_state_dict.py
│ └── test_zerooptim_state_dict.py
│ └── test_low_level
│ ├── test_coll_nd.py
│ ├── test_grad_acc.py
│ ├── test_mem_leak.py
│ ├── test_zero1_2.py
│ └── test_zero_ckpt.py
└── version.txt
/.clang-format:
--------------------------------------------------------------------------------
1 | BasedOnStyle: Google
2 |
--------------------------------------------------------------------------------
/.compatibility:
--------------------------------------------------------------------------------
1 | 2.3.0-12.1.0
2 | 2.4.0-12.4.1
3 | 2.5.1-12.4.1
4 |
--------------------------------------------------------------------------------
/.coveragerc:
--------------------------------------------------------------------------------
1 | [run]
2 | concurrency = multiprocessing
3 | parallel = true
4 | sigterm = true
5 |
--------------------------------------------------------------------------------
/.cuda_ext.json:
--------------------------------------------------------------------------------
1 | {
2 | "build": [
3 | {
4 | "torch_command": "pip install torch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 --index-url https://download.pytorch.org/whl/cu121",
5 | "cuda_image": "image-cloud.luchentech.com/hpcaitech/cuda-conda:12.1"
6 | },
7 | {
8 | "torch_command": "pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124",
9 | "cuda_image": "image-cloud.luchentech.com/hpcaitech/cuda-conda:12.4"
10 | }
11 | ]
12 | }
13 |
--------------------------------------------------------------------------------
/.github/CODEOWNERS:
--------------------------------------------------------------------------------
1 | * @hpcaitech/colossalai-qa
2 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/config.yml:
--------------------------------------------------------------------------------
1 | blank_issues_enabled: true
2 | contact_links:
3 | - name: ❓ Simple question - Slack Chat
4 | url: https://github.com/hpcaitech/public_assets/tree/main/colossalai/contact/slack
5 | about: This issue tracker is not for technical support. Please use our Slack chat, and ask the community for help.
6 | - name: ❓ Simple question - WeChat
7 | url: https://github.com/hpcaitech/ColossalAI/blob/main/docs/images/WeChat.png
8 | about: This issue tracker is not for technical support. Please use WeChat, and ask the community for help.
9 | - name: 😊 Advanced question - GitHub Discussions
10 | url: https://github.com/hpcaitech/ColossalAI/discussions
11 | about: Use GitHub Discussions for advanced and unanswered technical questions, requiring a maintainer's answer.
12 |
--------------------------------------------------------------------------------
/.github/workflows/scripts/example_checks/check_dispatch_inputs.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 |
4 |
5 | def check_inputs(input_list):
6 | for path in input_list:
7 | real_path = os.path.join("examples", path)
8 | if not os.path.exists(real_path):
9 | return False
10 | return True
11 |
12 |
13 | def main():
14 | parser = argparse.ArgumentParser()
15 | parser.add_argument("-f", "--fileNameList", type=str, help="List of file names")
16 | args = parser.parse_args()
17 | name_list = args.fileNameList.split(",")
18 | is_correct = check_inputs(name_list)
19 |
20 | if is_correct:
21 | print("success")
22 | else:
23 | print("failure")
24 |
25 |
26 | if __name__ == "__main__":
27 | main()
28 |
--------------------------------------------------------------------------------
/.github/workflows/scripts/send_message_to_lark.py:
--------------------------------------------------------------------------------
1 | import argparse
2 |
3 | import requests
4 |
5 |
6 | def parse_args():
7 | parser = argparse.ArgumentParser()
8 | parser.add_argument("-m", "--message", type=str)
9 | parser.add_argument("-u", "--url", type=str)
10 | return parser.parse_args()
11 |
12 |
13 | def send_message_to_lark(message, webhook_url):
14 | data = {"msg_type": "text", "content": {"text": message}}
15 | requests.post(webhook_url, json=data)
16 |
17 |
18 | if __name__ == "__main__":
19 | args = parse_args()
20 | send_message_to_lark(args.message, args.url)
21 |
--------------------------------------------------------------------------------
/.gitmodules:
--------------------------------------------------------------------------------
1 | [submodule "examples/tutorial/fastfold/FastFold"]
2 | path = examples/tutorial/fastfold/FastFold
3 | url = https://github.com/hpcaitech/FastFold
4 |
--------------------------------------------------------------------------------
/.isort.cfg:
--------------------------------------------------------------------------------
1 | [settings]
2 | line_length = 120
3 | multi_line_output=3
4 | include_trailing_comma = true
5 | ignore_comments = true
6 | profile = black
7 | honor_noqa = true
8 |
--------------------------------------------------------------------------------
/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include *.txt README.md
2 | recursive-include requirements *.txt
3 | recursive-include colossalai *.cpp *.h *.cu *.tr *.cuh *.cc *.pyi
4 | recursive-include extensions *.py *.cpp *.h *.cu *.tr *.cuh *.cc *.pyi
5 |
--------------------------------------------------------------------------------
/applications/Colossal-LLaMA/colossal_llama/__init__.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | # -*- coding: utf-8 -*-
3 |
--------------------------------------------------------------------------------
/applications/Colossal-LLaMA/colossal_llama/dataset/__init__.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | # -*- coding: utf-8 -*-
3 |
--------------------------------------------------------------------------------
/applications/Colossal-LLaMA/colossal_llama/utils/__init__.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | # -*- coding: utf-8 -*-
3 |
--------------------------------------------------------------------------------
/applications/Colossal-LLaMA/colossal_llama/utils/froze.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | # -*- coding: utf-8 -*-
3 |
4 | from transformers.models.llama import LlamaForCausalLM
5 |
6 |
7 | def freeze_non_embeds_parameters(model: LlamaForCausalLM) -> None:
8 | """Freeze all parameters except embeddings."""
9 | for name, params in model.named_parameters():
10 | if "embed_tokens" not in name and "lm_head" not in name:
11 | params.requires_grad = False
12 | else:
13 | params.requires_grad = True
14 |
15 |
16 | def unfreeze_parameters(model: LlamaForCausalLM) -> None:
17 | for name, params in model.named_parameters():
18 | params.requires_grad = False
19 |
--------------------------------------------------------------------------------
/applications/Colossal-LLaMA/hostfile.example:
--------------------------------------------------------------------------------
1 | hostname1
2 | hostname2
3 |
--------------------------------------------------------------------------------
/applications/Colossal-LLaMA/requirements.txt:
--------------------------------------------------------------------------------
1 | torch==2.1.2
2 | huggingface-hub
3 | packaging==24.0
4 | colossalai>=0.4.0
5 | autoflake==2.2.1
6 | black==23.9.1
7 | transformers>=4.39.3
8 | tensorboard==2.14.0
9 | six==1.16.0
10 | datasets
11 | ninja==1.11.1
12 | flash-attn
13 | tqdm
14 | sentencepiece==0.1.99
15 | protobuf<=3.20.0
16 |
--------------------------------------------------------------------------------
/applications/Colossal-LLaMA/version.txt:
--------------------------------------------------------------------------------
1 | 1.1.0
2 |
--------------------------------------------------------------------------------
/applications/ColossalChat/benchmarks/benchmark_memory_consumption.txt:
--------------------------------------------------------------------------------
1 | Model=Opt-125m; lora_rank=0; plugin=zero2
2 | Max CUDA memory usage: 26123.16 MB
3 | Model=Opt-125m; lora_rank=0; plugin=zero2
4 | Max CUDA memory usage: 26123.91 MB
5 |
--------------------------------------------------------------------------------
/applications/ColossalChat/benchmarks/benchmark_performance_summarization.txt:
--------------------------------------------------------------------------------
1 | facebook/opt-125m; 0; zero2
2 | Performance summary:
3 | Generate 768 samples, throughput: 188.48 samples/s, TFLOPS per GPU: 361.23
4 | Train 768 samples, throughput: 448.38 samples/s, TFLOPS per GPU: 82.84
5 | Overall throughput: 118.42 samples/s
6 | Overall time per sample: 0.01 s
7 | Make experience time per sample: 0.01 s, 62.83%
8 | Learn time per sample: 0.00 s, 26.41%
9 | facebook/opt-125m; 0; zero2
10 | Performance summary:
11 | Generate 768 samples, throughput: 26.32 samples/s, TFLOPS per GPU: 50.45
12 | Train 768 samples, throughput: 71.15 samples/s, TFLOPS per GPU: 13.14
13 | Overall throughput: 18.86 samples/s
14 | Overall time per sample: 0.05 s
15 | Make experience time per sample: 0.04 s, 71.66%
16 | Learn time per sample: 0.01 s, 26.51%
17 |
--------------------------------------------------------------------------------
/applications/ColossalChat/benchmarks/data_preparation.sh:
--------------------------------------------------------------------------------
1 | SAVE_DIR=""
2 |
3 |
4 | BASE_DIR=$(dirname $(dirname $(realpath $BASH_SOURCE)))
5 | EXAMPLES_DIR=$BASE_DIR/examples
6 | SAVE_DIR=$BASE_DIR/temp/benchmark
7 |
8 | rm -rf $SAVE_DIR
9 |
10 | python $EXAMPLES_DIR/data_preparation_scripts/prepare_prompt_dataset.py --data_input_dirs "/home/yeanbang/data/dataset/sft_data/alpaca/data_preprocessed/train" \
11 | --conversation_template_config ./Opt.json \
12 | --tokenizer_dir "facebook/opt-125m" \
13 | --data_cache_dir $SAVE_DIR/cache \
14 | --data_jsonl_output_dir $SAVE_DIR/jsonl \
15 | --data_arrow_output_dir $SAVE_DIR/arrow \
16 | --num_samples_per_datafile 30
17 |
--------------------------------------------------------------------------------
/applications/ColossalChat/coati/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/applications/ColossalChat/coati/__init__.py
--------------------------------------------------------------------------------
/applications/ColossalChat/coati/experience_buffer/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import ExperienceBuffer
2 | from .naive import NaiveExperienceBuffer
3 |
4 | __all__ = ["ExperienceBuffer", "NaiveExperienceBuffer"]
5 |
--------------------------------------------------------------------------------
/applications/ColossalChat/coati/experience_maker/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import Experience, ExperienceMaker
2 | from .naive import NaiveExperienceMaker
3 |
4 | __all__ = ["Experience", "ExperienceMaker", "NaiveExperienceMaker"]
5 |
--------------------------------------------------------------------------------
/applications/ColossalChat/coati/quant/__init__.py:
--------------------------------------------------------------------------------
1 | from .llama_gptq import load_quant as llama_load_quant
2 | from .utils import low_resource_init
3 |
4 | __all__ = [
5 | "llama_load_quant",
6 | "low_resource_init",
7 | ]
8 |
--------------------------------------------------------------------------------
/applications/ColossalChat/coati/quant/llama_gptq/__init__.py:
--------------------------------------------------------------------------------
1 | from .loader import load_quant
2 |
3 | __all__ = [
4 | "load_quant",
5 | ]
6 |
--------------------------------------------------------------------------------
/applications/ColossalChat/coati/quant/llama_gptq/model_utils.py:
--------------------------------------------------------------------------------
1 | # copied from https://github.com/qwopqwop200/GPTQ-for-LLaMa/blob/past/modelutils.py
2 |
3 | import torch.nn as nn
4 |
5 |
6 | def find_layers(module, layers=[nn.Conv2d, nn.Linear], name=""):
7 | if type(module) in layers:
8 | return {name: module}
9 | res = {}
10 | for name1, child in module.named_children():
11 | res.update(find_layers(child, layers=layers, name=name + "." + name1 if name != "" else name1))
12 | return res
13 |
--------------------------------------------------------------------------------
/applications/ColossalChat/coati/ray/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/applications/ColossalChat/coati/ray/__init__.py
--------------------------------------------------------------------------------
/applications/ColossalChat/coati/ray/callbacks/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import MakerCallback, TrainerCallback
2 | from .performance_evaluator import ExperienceMakerPerformanceEvaluator, TrainerPerformanceEvaluator
3 |
4 | __all__ = [
5 | "TrainerCallback",
6 | "MakerCallback",
7 | "ExperienceMakerPerformanceEvaluator",
8 | "TrainerPerformanceEvaluator",
9 | ]
10 |
--------------------------------------------------------------------------------
/applications/ColossalChat/coati/trainer/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import OLTrainer, SLTrainer
2 | from .dpo import DPOTrainer
3 | from .grpo import GRPOTrainer
4 | from .kto import KTOTrainer
5 | from .orpo import ORPOTrainer
6 | from .ppo import PPOTrainer
7 | from .rm import RewardModelTrainer
8 | from .sft import SFTTrainer
9 |
10 | __all__ = [
11 | "SLTrainer",
12 | "OLTrainer",
13 | "RewardModelTrainer",
14 | "SFTTrainer",
15 | "PPOTrainer",
16 | "DPOTrainer",
17 | "ORPOTrainer",
18 | "KTOTrainer",
19 | "GRPOTrainer",
20 | ]
21 |
--------------------------------------------------------------------------------
/applications/ColossalChat/coati/trainer/callbacks/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import Callback
2 | from .performance_evaluator import PerformanceEvaluator
3 |
4 | __all__ = ["Callback", "PerformanceEvaluator"]
5 |
--------------------------------------------------------------------------------
/applications/ColossalChat/coati/utils/__init__.py:
--------------------------------------------------------------------------------
1 | from .accumulative_meter import AccumulativeMeanMeter
2 | from .ckpt_io import load_checkpoint, save_checkpoint
3 |
4 | __all__ = ["load_checkpoint", "save_checkpoint", "AccumulativeMeanMeter"]
5 |
--------------------------------------------------------------------------------
/applications/ColossalChat/coati/utils/reward_score/__init__.py:
--------------------------------------------------------------------------------
1 | from .competition import math_competition_reward_fn
2 | from .gsm8k import gsm8k_reward_fn
3 |
4 | __all__ = ["gsm8k_reward_fn", "math_competition_reward_fn"]
5 |
--------------------------------------------------------------------------------
/applications/ColossalChat/conversation_template/01-ai_Yi-1.5-9B-Chat.json:
--------------------------------------------------------------------------------
1 | {
2 | "chat_template": "{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ system_message }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ '<|im_start|>user\\n' + content + '<|im_end|>\\n<|im_start|>assistant\\n' }}{% elif message['role'] == 'assistant' %}{{ content + '<|im_end|>' + '\\n' }}{% endif %}{% endfor %}",
3 | "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
4 | "stop_ids": [
5 | 7
6 | ],
7 | "end_of_assistant": "<|im_end|>"
8 | }
9 |
--------------------------------------------------------------------------------
/applications/ColossalChat/conversation_template/MiniCPM-2b.json:
--------------------------------------------------------------------------------
1 | {
2 | "chat_template": "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
3 | "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
4 | "stop_ids": [
5 | 122753
6 | ],
7 | "end_of_assistant": "<|im_end|>"
8 | }
9 |
--------------------------------------------------------------------------------
/applications/ColossalChat/conversation_template/Qwen_Qwen1.5-110B-Chat.json:
--------------------------------------------------------------------------------
1 | {
2 | "chat_template": "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
3 | "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
4 | "stop_ids": [
5 | 151645,
6 | 151643
7 | ],
8 | "end_of_assistant": "<|im_end|>"
9 | }
10 |
--------------------------------------------------------------------------------
/applications/ColossalChat/conversation_template/Qwen_Qwen1.5-32B-Chat.json:
--------------------------------------------------------------------------------
1 | {
2 | "chat_template": "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
3 | "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
4 | "stop_ids": [
5 | 151645,
6 | 151643
7 | ],
8 | "end_of_assistant": "<|im_end|>"
9 | }
10 |
--------------------------------------------------------------------------------
/applications/ColossalChat/conversation_template/THUDM_chatglm2-6b.json:
--------------------------------------------------------------------------------
1 | {
2 | "chat_template": "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
3 | "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
4 | "stop_ids": [
5 | 31007,
6 | 326,
7 | 30962,
8 | 437,
9 | 31007
10 | ],
11 | "end_of_assistant": "<|im_end|>"
12 | }
13 |
--------------------------------------------------------------------------------
/applications/ColossalChat/conversation_template/THUDM_chatglm3-6b.json:
--------------------------------------------------------------------------------
1 | {
2 | "chat_template": "{% for message in messages %}{% if loop.first %}[gMASK]sop<|{{ message['role'] }}|>\n {{ message['content'] }}{% else %}<|{{ message['role'] }}|>\n {{ message['content'] }}{% endif %}{% endfor %}{% if add_generation_prompt %}<|assistant|>{% endif %}",
3 | "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
4 | "stop_ids": [
5 | 2
6 | ],
7 | "end_of_assistant": "<|user|>"
8 | }
9 |
--------------------------------------------------------------------------------
/applications/ColossalChat/conversation_template/baichuan-inc_Baichuan2-13B-Chat.json:
--------------------------------------------------------------------------------
1 | {
2 | "chat_template": "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
3 | "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
4 | "stop_ids": [
5 | 2
6 | ],
7 | "end_of_assistant": "<|im_end|>"
8 | }
9 |
--------------------------------------------------------------------------------
/applications/ColossalChat/conversation_template/microsoft_phi-2.json:
--------------------------------------------------------------------------------
1 | {
2 | "chat_template": "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
3 | "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
4 | "stop_ids": [
5 | 50256
6 | ],
7 | "end_of_assistant": "<|im_end|>"
8 | }
9 |
--------------------------------------------------------------------------------
/applications/ColossalChat/conversation_template/mistralai_Mixtral-8x7B-Instruct-v0.1.json:
--------------------------------------------------------------------------------
1 | {
2 | "chat_template": "{{ bos_token }}{% for message in messages %}{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}{% endif %}{% if message['role'] == 'user' %}{{ '[INST] ' + message['content'] + ' [/INST]' }}{% elif message['role'] == 'assistant' %}{{ message['content'] + eos_token}}{% else %}{{ raise_exception('Only user and assistant roles are supported!') }}{% endif %}{% endfor %}",
3 | "system_message": null,
4 | "stop_ids": [
5 | 2
6 | ],
7 | "end_of_assistant": ""
8 | }
9 |
--------------------------------------------------------------------------------
/applications/ColossalChat/conversation_template/tiny-llama.json:
--------------------------------------------------------------------------------
1 | {
2 | "chat_template": "{% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ '<|user|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'system' %}\n{{ '<|system|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'assistant' %}\n{{ '<|assistant|>\n' + message['content'] + eos_token }}\n{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ '<|assistant|>' }}\n{% endif %}\n{% endfor %}",
3 | "system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
4 | "stop_ids": [
5 | 2
6 | ],
7 | "end_of_assistant": ""
8 | }
9 |
--------------------------------------------------------------------------------
/applications/ColossalChat/examples/data_preparation_scripts/prepare_kto_dataset.sh:
--------------------------------------------------------------------------------
1 | SAVE_DIR=""
2 |
3 | rm -rf $SAVE_DIR/cache
4 | rm -rf $SAVE_DIR/jsonl
5 | rm -rf $SAVE_DIR/arrow
6 |
7 | python prepare_dataset.py --type kto \
8 | --data_input_dirs /PATH/TO/KTO/DATASET \
9 | --conversation_template_config /PATH/TO/CHAT/TEMPLATE/CONFIG.json \
10 | --tokenizer_dir "" \
11 | --data_cache_dir $SAVE_DIR/cache \
12 | --data_jsonl_output_dir $SAVE_DIR/jsonl \
13 | --data_arrow_output_dir $SAVE_DIR/arrow \
14 | --max_length 1024
15 |
--------------------------------------------------------------------------------
/applications/ColossalChat/examples/data_preparation_scripts/prepare_preference_dataset.sh:
--------------------------------------------------------------------------------
1 | SAVE_DIR=""
2 |
3 | rm -rf $SAVE_DIR/cache
4 | rm -rf $SAVE_DIR/jsonl
5 | rm -rf $SAVE_DIR/arrow
6 |
7 | python prepare_dataset.py --type preference \
8 | --data_input_dirs /PATH/TO/PREFERENCE/DATASET \
9 | --conversation_template_config /PATH/TO/CHAT/TEMPLATE/CONFIG.json \
10 | --tokenizer_dir "" \
11 | --data_cache_dir $SAVE_DIR/cache \
12 | --data_jsonl_output_dir $SAVE_DIR/jsonl \
13 | --data_arrow_output_dir $SAVE_DIR/arrow \
14 | --max_length 1024
15 |
--------------------------------------------------------------------------------
/applications/ColossalChat/examples/data_preparation_scripts/prepare_prompt_dataset.sh:
--------------------------------------------------------------------------------
1 | SAVE_DIR=""
2 |
3 | rm -rf $SAVE_DIR/cache
4 | rm -rf $SAVE_DIR/jsonl
5 | rm -rf $SAVE_DIR/arrow
6 |
7 | python prepare_dataset.py --type prompt \
8 | --data_input_dirs /PATH/TO/PROMPT/DATASET \
9 | --conversation_template_config /PATH/TO/CHAT/TEMPLATE/CONFIG.json \
10 | --tokenizer_dir "" \
11 | --data_cache_dir $SAVE_DIR/cache \
12 | --data_jsonl_output_dir $SAVE_DIR/jsonl \
13 | --data_arrow_output_dir $SAVE_DIR/arrow \
14 | --max_length 300
15 |
--------------------------------------------------------------------------------
/applications/ColossalChat/examples/data_preparation_scripts/prepare_sft_dataset.sh:
--------------------------------------------------------------------------------
1 | SAVE_DIR=""
2 |
3 | rm -rf $SAVE_DIR/cache
4 | rm -rf $SAVE_DIR/jsonl
5 | rm -rf $SAVE_DIR/arrow
6 |
7 | python prepare_dataset.py --type sft \
8 | --data_input_dirs /PATH/TO/SFT/DATASET \
9 | --conversation_template_config /PATH/TO/CHAT/TEMPLATE/CONFIG.json \
10 | --tokenizer_dir "" \
11 | --data_cache_dir $SAVE_DIR/cache \
12 | --data_jsonl_output_dir $SAVE_DIR/jsonl \
13 | --data_arrow_output_dir $SAVE_DIR/arrow \
14 | --max_length 4096
15 |
--------------------------------------------------------------------------------
/applications/ColossalChat/examples/inference/web_chatbot/requirements.txt:
--------------------------------------------------------------------------------
1 | fastapi
2 | locust
3 | numpy
4 | pydantic
5 | safetensors
6 | slowapi
7 | sse_starlette
8 | torch
9 | uvicorn
10 | git+https://github.com/huggingface/transformers
11 | accelerate
12 | bitsandbytes
13 | jieba
14 |
--------------------------------------------------------------------------------
/applications/ColossalChat/examples/requirements.txt:
--------------------------------------------------------------------------------
1 | pandas>=1.4.1
2 | sentencepiece
3 | colossalai==0.4.7
4 | prompt_toolkit
5 |
--------------------------------------------------------------------------------
/applications/ColossalChat/examples/training_scripts/hostfile:
--------------------------------------------------------------------------------
1 | localhost
2 |
--------------------------------------------------------------------------------
/applications/ColossalChat/examples/training_scripts/lora_config.json:
--------------------------------------------------------------------------------
1 | {
2 | "r": 128,
3 | "embedding_lora_dropout": 0.0,
4 | "linear_lora_dropout": 0.1,
5 | "lora_alpha": 32,
6 | "lora_train_bias": "all",
7 | "lora_initialization_method": "PiSSA",
8 | "target_modules": ["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj", "embed_tokens"]
9 | }
10 |
--------------------------------------------------------------------------------
/applications/ColossalChat/pytest.ini:
--------------------------------------------------------------------------------
1 | [pytest]
2 | markers =
3 | cpu: tests which can run on CPU
4 | gpu: tests which requires a single GPU
5 | dist: tests which are run in a multi-GPU or multi-machine environment
6 | experiment: tests for experimental features
7 |
--------------------------------------------------------------------------------
/applications/ColossalChat/requirements.txt:
--------------------------------------------------------------------------------
1 | transformers==4.39.3
2 | tqdm
3 | datasets==2.14.7
4 | loralib
5 | colossalai>=0.4.7
6 | torch>=2.1.0
7 | langchain
8 | tokenizers
9 | fastapi
10 | sse_starlette
11 | wandb
12 | sentencepiece
13 | gpustat
14 | packaging
15 | autoflake==2.2.1
16 | black==23.9.1
17 | tensorboard
18 | six==1.16.0
19 | datasets
20 | ninja==1.11.1
21 | sentencepiece==0.1.99
22 | flash-attn
23 | tiktoken
24 | jsonlines
25 |
--------------------------------------------------------------------------------
/applications/ColossalChat/tests/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/applications/ColossalChat/tests/__init__.py
--------------------------------------------------------------------------------
/applications/ColossalChat/tests/prepare_test_env.sh:
--------------------------------------------------------------------------------
1 | # run under /ColossalAI/applications/ColossalChat
2 | export NCCL_SHM_DISABLE=1
3 | export MAX_JOBS=1
4 | export PRETRAINED_MODEL_PATH=./models
5 | export SFT_DATASET=./sft_data
6 | export PROMPT_DATASET=./prompt_data
7 | export PROMPT_RLVR_DATASET=./prompt_data
8 | export PREFERENCE_DATASET=./preference_data
9 | export KTO_DATASET=./kto_data
10 | mkdir models
11 | mkdir sft_data
12 | mkdir prompt_data
13 | mkdir preference_data
14 | mkdir kto_data
15 | # ./tests/test_data_preparation.sh
16 | # ./tests/test_train.sh
17 |
--------------------------------------------------------------------------------
/applications/ColossalChat/tests/test_data/kto/test_kto_data.jsonl:
--------------------------------------------------------------------------------
1 | {"prompt": [{"from": "user", "content": "What are some praise words in english?"}, {"from": "assistant", "content": "Here's an incomplete list.\n\nexcellent, fantastic, impressive ..."},{"from": "user", "content": "What's your favorite one?"}],"completion": {"from": "assistant", "content": "impressive."},"label": true}
2 |
--------------------------------------------------------------------------------
/applications/ColossalChat/tests/test_data/sft/test_sft_data.jsonl:
--------------------------------------------------------------------------------
1 | {"messages": [{"from": "user", "content": "what are some pranks with a pen I can do?"}, {"from": "assistant", "content": "Are you looking for practical joke ideas?"}, {"from": "user", "content": "Yes, exactly!"}, {"from": "assistant", "content": "You could try attaching a small buzzer to a pen. When someone tries to use it, they'll be surprised by the sound!"}, {"from": "user", "content": "That's a funny one! Any other ideas?"}, {"from": "assistant", "content": "Another idea is the classic 'ink explosion' prank. Replace the ink of a pen with disappearing ink, and watch the confusion when the ink vanishes from the paper."}]}
2 |
--------------------------------------------------------------------------------
/applications/ColossalChat/version.txt:
--------------------------------------------------------------------------------
1 | 1.0.0
2 |
--------------------------------------------------------------------------------
/applications/ColossalEval/colossal_eval/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/applications/ColossalEval/colossal_eval/__init__.py
--------------------------------------------------------------------------------
/applications/ColossalEval/colossal_eval/evaluate/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/applications/ColossalEval/colossal_eval/evaluate/__init__.py
--------------------------------------------------------------------------------
/applications/ColossalEval/colossal_eval/evaluate/dataset_evaluator/__init__.py:
--------------------------------------------------------------------------------
1 | from .dataset_evaluator import DatasetEvaluator
2 |
3 | __all__ = ["DatasetEvaluator"]
4 |
--------------------------------------------------------------------------------
/applications/ColossalEval/colossal_eval/evaluate/utils.py:
--------------------------------------------------------------------------------
1 | def get_data_per_category(data, categories):
2 | data_per_category = {category: [] for category in categories}
3 | for item in data:
4 | category = item["category"]
5 | if category in categories:
6 | data_per_category[category].append(item)
7 |
8 | return data_per_category
9 |
--------------------------------------------------------------------------------
/applications/ColossalEval/colossal_eval/models/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import BaseModel
2 | from .chatglm import ChatGLM2Model, ChatGLMModel
3 | from .huggingface import HuggingFaceCausalLM, HuggingFaceModel
4 | from .vllm import vLLMModel
5 |
6 | __all__ = ["BaseModel", "HuggingFaceModel", "HuggingFaceCausalLM", "ChatGLMModel", "ChatGLM2Model", "vLLMModel"]
7 |
--------------------------------------------------------------------------------
/applications/ColossalEval/colossal_eval/utils/__init__.py:
--------------------------------------------------------------------------------
1 | from .conversation import Conversation, get_batch_prompt, prompt_templates
2 | from .utilities import get_json_list, is_rank_0, jdump, jload
3 |
4 | __all__ = ["Conversation", "prompt_templates", "get_batch_prompt", "is_rank_0", "jload", "jdump", "get_json_list"]
5 |
--------------------------------------------------------------------------------
/applications/ColossalEval/configs/gpt_evaluation/prompt/battle_prompt/battle_prompt_cn.json:
--------------------------------------------------------------------------------
1 | {
2 | "id": 1,
3 | "system_prompt": "你是一个检查回答质量的好助手。",
4 | "prompt_template": "[问题]\n{question}\n\n[1号AI助手的答案]\n{answer_1}\n\n[1号AI助手答案终止]\n\n[2号AI助手的答案]\n{answer_2}\n\n[2号AI助手答案终止]\n\n[要求]\n{prompt}\n\n",
5 | "prompt": "我们需要你评价这两个AI助手回答的性能。\n请对他们的回答的有用性、相关性、准确性、详细程度进行评分。每个AI助手都会得到一个1到10分的总分,分数越高表示整体表现越好。\n请首先输出一行,该行只包含两个数值,分别表示1号和2号AI助手的分数。这两个分数之间要有一个空格。在随后的一行中,请对你的评价作出全面的解释,避免任何潜在的偏见,并确保AI助手回答的顺序不会影响您的判断。"
6 | }
7 |
--------------------------------------------------------------------------------
/applications/ColossalEval/examples/dataset_evaluation/eval_dataset.sh:
--------------------------------------------------------------------------------
1 | python eval_dataset.py \
2 | --config "path to config file" \
3 | --inference_results_path "path to inference results" \
4 | --evaluation_results_save_path "path to save evaluation results"
5 |
--------------------------------------------------------------------------------
/applications/ColossalEval/examples/dataset_evaluation/inference.sh:
--------------------------------------------------------------------------------
1 | torchrun --nproc_per_node=1 inference.py \
2 | --config "path to config file" \
3 | --load_dataset \
4 | --tp_size 1 \
5 | --inference_save_path "path to save inference results"
6 |
--------------------------------------------------------------------------------
/applications/ColossalEval/examples/gpt_evaluation/eval.sh:
--------------------------------------------------------------------------------
1 | python eval.py \
2 | --config_file "path to the config file" \
3 | --battle_prompt_file "path to the prompt file for battle" \
4 | --gpt_evaluation_prompt_file "path to the prompt file for gpt evaluation" \
5 | --target_file "path to the target answer file" \
6 | --answer_file_list "path to the answer files of at most 2 models" \
7 | --model_name_list "the names of at most 2 models" \
8 | --save_path "path to save results" \
9 | --openai_key "your openai key" \
10 |
--------------------------------------------------------------------------------
/applications/ColossalEval/examples/gpt_evaluation/inference.sh:
--------------------------------------------------------------------------------
1 | torchrun --nproc_per_node=1 inference.py \
2 | --config "path to config file" \
3 | --load_dataset \
4 | --tp_size 1 \
5 | --inference_save_path "path to save inference results"
6 |
--------------------------------------------------------------------------------
/applications/ColossalEval/requirements.txt:
--------------------------------------------------------------------------------
1 | transformers>=4.32.0
2 | colossalai>=0.3.4
3 | peft
4 | tabulate
5 | jieba
6 | fuzzywuzzy
7 | rouge
8 | openai
9 | matplotlib
10 | pandas
11 | seaborn
12 | scikit-learn
13 | vllm==0.5.5
14 |
--------------------------------------------------------------------------------
/applications/ColossalMoE/infer.sh:
--------------------------------------------------------------------------------
1 | NUM_GPU=2
2 | # MODEL="mistralai/Mixtral-8x7B-v0.1"
3 | MODEL="mistralai/Mixtral-8x7B-Instruct-v0.1"
4 |
5 | # ep
6 | torchrun --standalone --nproc_per_node $NUM_GPU infer.py \
7 | --model_name $MODEL \
8 | --plugin "ep" \
9 |
--------------------------------------------------------------------------------
/applications/ColossalMoE/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.3.3
2 | torch >= 1.8.1
3 | transformers == 4.36.0
4 | sentencepiece
5 | datasets
6 |
--------------------------------------------------------------------------------
/applications/ColossalMoE/tests/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/applications/ColossalMoE/tests/__init__.py
--------------------------------------------------------------------------------
/applications/ColossalMoE/train.sh:
--------------------------------------------------------------------------------
1 | NUM_GPU=8
2 | MODEL="mistralai/Mixtral-8x7B-v0.1"
3 | SEQ_LENGTH=2048
4 | BATCH_SIZE=1
5 | LR=0.00001
6 |
7 | # hybrid
8 | # torchrun --standalone --nproc_per_node $NUM_GPU \
9 | colossalai run --nproc_per_node $NUM_GPU --hostfile "hostfile" \
10 | train.py \
11 | --num_epoch 1 \
12 | --model_name $MODEL \
13 | --plugin "hybrid" \
14 | --batch_size $BATCH_SIZE \
15 | --lr $LR \
16 | --zero_stage 1 \
17 | --pp_size 2 \
18 | --dp_size 1 \
19 | --ep_size 8 \
20 |
--------------------------------------------------------------------------------
/applications/ColossalMoE/version.txt:
--------------------------------------------------------------------------------
1 | 1.0.0
2 |
--------------------------------------------------------------------------------
/applications/ColossalQA/colossalqa/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/applications/ColossalQA/colossalqa/__init__.py
--------------------------------------------------------------------------------
/applications/ColossalQA/colossalqa/chain/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/applications/ColossalQA/colossalqa/chain/__init__.py
--------------------------------------------------------------------------------
/applications/ColossalQA/colossalqa/chain/memory/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/applications/ColossalQA/colossalqa/chain/memory/__init__.py
--------------------------------------------------------------------------------
/applications/ColossalQA/colossalqa/chain/retrieval_qa/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/applications/ColossalQA/colossalqa/chain/retrieval_qa/__init__.py
--------------------------------------------------------------------------------
/applications/ColossalQA/colossalqa/data_loader/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/applications/ColossalQA/colossalqa/data_loader/__init__.py
--------------------------------------------------------------------------------
/applications/ColossalQA/colossalqa/local/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/applications/ColossalQA/colossalqa/local/__init__.py
--------------------------------------------------------------------------------
/applications/ColossalQA/colossalqa/text_splitter/__init__.py:
--------------------------------------------------------------------------------
1 | from .chinese_text_splitter import ChineseTextSplitter
2 |
--------------------------------------------------------------------------------
/applications/ColossalQA/colossalqa/text_splitter/utils.py:
--------------------------------------------------------------------------------
1 | import re
2 |
3 |
4 | def remove_format(text: str) -> str:
5 | # if the accout of \t, \r, \v, \f is less than 3, replace \t, \r, \v, \f with space
6 | if len(re.findall(r"\s", text.replace(" ", ""))) > 3:
7 | # in case this is a line of a table
8 | return text
9 | return re.sub(r"\s", " ", text)
10 |
11 |
12 | # remove newlines
13 | def get_cleaned_paragraph(s: str) -> str:
14 | text = str(s)
15 | text = re.sub(r"\n{3,}", r"\n", text) # replace \n\n\n... with \n
16 | text = re.sub("\n\n", "", text)
17 | lines = text.split("\n")
18 | lines_remove_format = [remove_format(line) for line in lines]
19 | return lines_remove_format
20 |
--------------------------------------------------------------------------------
/applications/ColossalQA/data/data_sample/luchen_zh.txt:
--------------------------------------------------------------------------------
1 | 潞晨科技是一家致力于“解放AI生产力”的全球性公司,技术团队核心成员来自美国加州伯克利、斯坦福、新加坡国立、南洋理工、清华、北大等国内外知名高校。在高性能计算、人工智能、分布式系统等方面已有十余年的技术积累,并在国际顶级学术刊物或会议发表论文近百篇。公司核心产品面向大模型时代的通用深度学习系统 Colossal-AI,可实现高效快速部署AI大模型训练和推理,降低AI大模型应用成本。公司在种子轮、天使轮融资已获得“清科中国早期投资机构30强”前三甲创新工场、真格基金、蓝驰创投的600万美元投资。
2 |
--------------------------------------------------------------------------------
/applications/ColossalQA/data/tests/64KB.json:
--------------------------------------------------------------------------------
1 | {
2 | "data":[
3 | {"content":"Donec lobortis eleifend condimentum. Cras dictum dolor lacinia lectus vehicula rutrum. Maecenas quis nisi nunc. Nam tristique feugiat est vitae mollis. Maecenas quis nisi nunc."},
4 | {"content":"Aliquam sollicitudin ante ligula, eget malesuada nibh efficitur et. Pellentesque massa sem, scelerisque sit amet odio id, cursus tempor urna. Etiam congue dignissim volutpat. Vestibulum pharetra libero et velit gravida euismod."}
5 | ],
6 | "name":"player"
7 | }
8 |
--------------------------------------------------------------------------------
/applications/ColossalQA/data/tests/sample-pdf-file.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/applications/ColossalQA/data/tests/sample-pdf-file.pdf
--------------------------------------------------------------------------------
/applications/ColossalQA/examples/webui_demo/img/avatar_ai.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/applications/ColossalQA/examples/webui_demo/img/avatar_ai.png
--------------------------------------------------------------------------------
/applications/ColossalQA/examples/webui_demo/img/avatar_user.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/applications/ColossalQA/examples/webui_demo/img/avatar_user.png
--------------------------------------------------------------------------------
/applications/ColossalQA/examples/webui_demo/requirements.txt:
--------------------------------------------------------------------------------
1 | fastapi==0.99.1
2 | uvicorn>=0.24.0
3 | pydantic==1.10.13
4 |
--------------------------------------------------------------------------------
/applications/ColossalQA/examples/webui_demo/utils.py:
--------------------------------------------------------------------------------
1 | from enum import Enum
2 |
3 |
4 | class DocAction(str, Enum):
5 | ADD = "add"
6 | CLEAR = "clear"
7 |
--------------------------------------------------------------------------------
/applications/ColossalQA/pytest.ini:
--------------------------------------------------------------------------------
1 | [pytest]
2 | markers =
3 | dist: tests which are run in a multi-GPU or multi-machine environment (at least 4 GPUs)
4 | largedist: tests which are run in a multi-GPU or multi-machine environment (at least 8 GPUs)
5 |
--------------------------------------------------------------------------------
/applications/ColossalQA/requirements.txt:
--------------------------------------------------------------------------------
1 | transformers>=4.20.1
2 | tqdm==4.66.1
3 | datasets==2.13.0
4 | torch<2.0.0, >=1.12.1
5 | langchain==0.0.330
6 | langchain-experimental==0.0.37
7 | tokenizers==0.13.3
8 | modelscope==1.9.0
9 | sentencepiece==0.1.99
10 | gpustat==1.1.1
11 | sqlalchemy==2.0.20
12 | pytest==7.4.2
13 | # coati install from ../Chat
14 | sentence-transformers==2.2.2
15 | chromadb==0.4.9
16 | openai==0.28.0 #used for chatgpt please install directly from openai repo
17 | tiktoken==0.5.1
18 | unstructured==0.10.14
19 | pypdf==3.16.0
20 | jq==1.6.0
21 | gradio==3.44.4
22 | Requests==2.31.0
23 |
--------------------------------------------------------------------------------
/applications/ColossalQA/tests/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/applications/ColossalQA/tests/__init__.py
--------------------------------------------------------------------------------
/applications/ColossalQA/tests/test_document_loader.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | from colossalqa.data_loader.document_loader import DocumentLoader
4 |
5 |
6 | def test_add_document():
7 | PATH = os.environ.get("TEST_DOCUMENT_LOADER_DATA_PATH")
8 | files = [[PATH, "all data"]]
9 | document_loader = DocumentLoader(files)
10 | documents = document_loader.all_data
11 | all_files = []
12 | for doc in documents:
13 | assert isinstance(doc.page_content, str) == True
14 | if doc.metadata["source"] not in all_files:
15 | all_files.append(doc.metadata["source"])
16 | print(all_files)
17 | assert len(all_files) == 6
18 |
19 |
20 | if __name__ == "__main__":
21 | test_add_document()
22 |
--------------------------------------------------------------------------------
/applications/ColossalQA/tests/test_text_splitter.py:
--------------------------------------------------------------------------------
1 | from colossalqa.text_splitter.chinese_text_splitter import ChineseTextSplitter
2 |
3 |
4 | def test_text_splitter():
5 | # unit test
6 | spliter = ChineseTextSplitter(chunk_size=30, chunk_overlap=0)
7 | out = spliter.split_text(
8 | "移动端语音唤醒模型,检测关键词为“小云小云”。模型主体为4层FSMN结构,使用CTC训练准则,参数量750K,适用于移动端设备运行。模型输入为Fbank特征,输出为基于char建模的中文全集token预测,测试工具根据每一帧的预测数据进行后处理得到输入音频的实时检测结果。模型训练采用“basetrain + finetune”的模式,basetrain过程使用大量内部移动端数据,在此基础上,使用1万条设备端录制安静场景“小云小云”数据进行微调,得到最终面向业务的模型。后续用户可在basetrain模型基础上,使用其他关键词数据进行微调,得到新的语音唤醒模型,但暂时未开放模型finetune功能。"
9 | )
10 | print(len(out))
11 | assert len(out) == 4 # ChineseTextSplitter will not break sentence. Hence the actual chunk size is not 30
12 |
--------------------------------------------------------------------------------
/applications/ColossalQA/version.txt:
--------------------------------------------------------------------------------
1 | 0.0.1
2 |
--------------------------------------------------------------------------------
/colossalai/_C/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/_C/__init__.py
--------------------------------------------------------------------------------
/colossalai/__init__.py:
--------------------------------------------------------------------------------
1 | from . import accelerator
2 | from .initialize import launch, launch_from_openmpi, launch_from_slurm, launch_from_torch
3 |
4 | try:
5 | # .version will be created by setup.py
6 | from .version import __version__
7 | except ModuleNotFoundError:
8 | # this will only happen if the user did not run `pip install`
9 | # and directly set PYTHONPATH to use Colossal-AI which is a bad practice
10 | __version__ = "0.0.0"
11 | print("please install Colossal-AI from https://www.colossalai.org/download or from source")
12 |
13 | __all__ = ["launch", "launch_from_openmpi", "launch_from_slurm", "launch_from_torch", "__version__"]
14 |
--------------------------------------------------------------------------------
/colossalai/_analyzer/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/_analyzer/__init__.py
--------------------------------------------------------------------------------
/colossalai/_analyzer/_subclasses/__init__.py:
--------------------------------------------------------------------------------
1 | from ._meta_registration import *
2 | from ._monkey_patch import *
3 | from .flop_tensor import flop_count, flop_mapping
4 | from .meta_tensor import MetaTensor, MetaTensorMode
5 |
--------------------------------------------------------------------------------
/colossalai/_analyzer/envs.py:
--------------------------------------------------------------------------------
1 | from dataclasses import dataclass
2 |
3 |
4 | @dataclass
5 | class MeshConfig:
6 | TFLOPS: float = 1.9e12
7 | BANDWIDTH = 1.2e9
8 |
--------------------------------------------------------------------------------
/colossalai/_analyzer/fx/__init__.py:
--------------------------------------------------------------------------------
1 | from .node_util import MetaInfo
2 | from .symbolic_profile import symbolic_profile
3 | from .tracer.symbolic_trace import symbolic_trace
4 |
--------------------------------------------------------------------------------
/colossalai/_analyzer/fx/passes/__init__.py:
--------------------------------------------------------------------------------
1 | from .graph_profile import graph_profile_pass
2 | from .shape_prop import ShapeProp, shape_prop_pass, sim_env
3 |
--------------------------------------------------------------------------------
/colossalai/_analyzer/fx/tracer/__init__.py:
--------------------------------------------------------------------------------
1 | from .bias_addition import *
2 | from .custom_leaf_module import *
3 |
--------------------------------------------------------------------------------
/colossalai/accelerator/__init__.py:
--------------------------------------------------------------------------------
1 | from .api import auto_set_accelerator, get_accelerator, set_accelerator
2 | from .base_accelerator import BaseAccelerator
3 | from .cpu_accelerator import CpuAccelerator
4 | from .cuda_accelerator import CudaAccelerator
5 | from .npu_accelerator import NpuAccelerator
6 |
7 | __all__ = [
8 | "get_accelerator",
9 | "set_accelerator",
10 | "auto_set_accelerator",
11 | "BaseAccelerator",
12 | "CudaAccelerator",
13 | "NpuAccelerator",
14 | "CpuAccelerator",
15 | ]
16 |
--------------------------------------------------------------------------------
/colossalai/amp/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/amp/__init__.py
--------------------------------------------------------------------------------
/colossalai/amp/naive_amp/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/amp/naive_amp/__init__.py
--------------------------------------------------------------------------------
/colossalai/amp/naive_amp/grad_scaler/__init__.py:
--------------------------------------------------------------------------------
1 | from .base_grad_scaler import BaseGradScaler
2 | from .constant_grad_scaler import ConstantGradScaler
3 | from .dynamic_grad_scaler import DynamicGradScaler
4 |
5 | __all__ = ["BaseGradScaler", "ConstantGradScaler", "DynamicGradScaler"]
6 |
--------------------------------------------------------------------------------
/colossalai/amp/naive_amp/mixed_precision_mixin/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import MixedPrecisionMixin
2 | from .bf16 import BF16MixedPrecisionMixin
3 | from .fp16 import FP16MixedPrecisionMixin
4 |
5 | __all__ = [
6 | "MixedPrecisionMixin",
7 | "FP16MixedPrecisionMixin",
8 | "BF16MixedPrecisionMixin",
9 | ]
10 |
--------------------------------------------------------------------------------
/colossalai/amp/naive_amp/mixed_precision_mixin/bf16.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import Tensor
3 |
4 | from .base import MixedPrecisionMixin
5 |
6 |
7 | class BF16MixedPrecisionMixin(MixedPrecisionMixin):
8 | dtype = torch.bfloat16
9 |
10 | def pre_backward(self, loss: Tensor) -> Tensor:
11 | return loss
12 |
13 | def pre_backward_by_grad(self, tensor: Tensor, grad: Tensor) -> Tensor:
14 | return grad
15 |
16 | def should_skip_step(self) -> bool:
17 | return False
18 |
19 | def pre_zero_grad(self) -> None:
20 | pass
21 |
22 | def get_grad_div_scale(self) -> float:
23 | return 1.0
24 |
--------------------------------------------------------------------------------
/colossalai/auto_parallel/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/auto_parallel/__init__.py
--------------------------------------------------------------------------------
/colossalai/auto_parallel/checkpoint/__init__.py:
--------------------------------------------------------------------------------
1 | from .ckpt_solver_base import CheckpointSolverBase
2 | from .ckpt_solver_chen import CheckpointSolverChen
3 | from .ckpt_solver_rotor import CheckpointSolverRotor
4 |
--------------------------------------------------------------------------------
/colossalai/auto_parallel/checkpoint/build_c_ext.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | from setuptools import Extension, setup
4 |
5 | this_dir = os.path.dirname(os.path.abspath(__file__))
6 | ext_modules = [
7 | Extension(
8 | "rotorc",
9 | sources=[os.path.join(this_dir, "ckpt_solver_rotor.c")],
10 | )
11 | ]
12 |
13 | setup(
14 | name="rotor c extension",
15 | version="0.1",
16 | description="rotor c extension for faster dp computing",
17 | ext_modules=ext_modules,
18 | )
19 |
--------------------------------------------------------------------------------
/colossalai/auto_parallel/meta_profiler/__init__.py:
--------------------------------------------------------------------------------
1 | from .meta_registry import *
2 | from .registry import meta_register
3 | from .shard_metainfo import *
4 |
--------------------------------------------------------------------------------
/colossalai/auto_parallel/meta_profiler/constants.py:
--------------------------------------------------------------------------------
1 | import operator
2 |
3 | import torch
4 | import torch.nn as nn
5 |
6 | # list of inplace module
7 | INPLACE_MODULE = [nn.ReLU]
8 |
9 | # list of inplace operations
10 | INPLACE_OPS = [torch.flatten]
11 |
12 | # list of operations that do not save forward activations
13 | NO_SAVE_ACTIVATION = [torch.add, torch.sub, operator.add, operator.sub]
14 |
--------------------------------------------------------------------------------
/colossalai/auto_parallel/meta_profiler/meta_registry/__init__.py:
--------------------------------------------------------------------------------
1 | from .activation import *
2 | from .binary_elementwise_ops import *
3 | from .conv import *
4 | from .embedding import *
5 | from .linear import *
6 | from .non_spmd import *
7 | from .norm import *
8 | from .pooling import *
9 | from .tensor import *
10 | from .where import *
11 |
--------------------------------------------------------------------------------
/colossalai/auto_parallel/offload/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/auto_parallel/offload/__init__.py
--------------------------------------------------------------------------------
/colossalai/auto_parallel/passes/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/auto_parallel/passes/__init__.py
--------------------------------------------------------------------------------
/colossalai/auto_parallel/passes/constants.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | OUTPUT_SAVED_OPS = [torch.nn.functional.relu, torch.nn.functional.softmax, torch.flatten]
4 |
5 | OUTPUT_SAVED_MOD = [
6 | torch.nn.ReLU,
7 | torch.nn.Softmax,
8 | ]
9 |
10 | # SHAPE_ARGUMENT_OPS contains node with (input, *shape) style args.
11 | # This list could be extended if any other method has the same
12 | # argument style as view and reshape.
13 | SHAPE_ARGUMENT_OPS = [torch.Tensor.view, torch.Tensor.reshape, torch.reshape]
14 |
--------------------------------------------------------------------------------
/colossalai/auto_parallel/pipeline_shard/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/auto_parallel/pipeline_shard/__init__.py
--------------------------------------------------------------------------------
/colossalai/auto_parallel/tensor_shard/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/auto_parallel/tensor_shard/__init__.py
--------------------------------------------------------------------------------
/colossalai/auto_parallel/tensor_shard/solver/__init__.py:
--------------------------------------------------------------------------------
1 | from .cost_graph import CostGraph
2 | from .graph_analysis import GraphAnalyser
3 | from .solver import Solver
4 | from .strategies_constructor import StrategiesConstructor
5 |
6 | __all__ = ["GraphAnalyser", "Solver", "StrategiesConstructor", "CostGraph"]
7 |
--------------------------------------------------------------------------------
/colossalai/booster/__init__.py:
--------------------------------------------------------------------------------
1 | from .accelerator import Accelerator
2 | from .booster import Booster
3 | from .plugin import Plugin
4 |
--------------------------------------------------------------------------------
/colossalai/booster/mixed_precision/bf16.py:
--------------------------------------------------------------------------------
1 | from .mixed_precision_base import MixedPrecision
2 |
3 |
4 | class BF16MixedPrecision(MixedPrecision):
5 | pass
6 |
--------------------------------------------------------------------------------
/colossalai/booster/mixed_precision/fp8.py:
--------------------------------------------------------------------------------
1 | from .mixed_precision_base import MixedPrecision
2 |
3 |
4 | class FP8MixedPrecision(MixedPrecision):
5 | pass
6 |
--------------------------------------------------------------------------------
/colossalai/booster/mixed_precision/mixed_precision_base.py:
--------------------------------------------------------------------------------
1 | from abc import ABC, abstractmethod
2 | from typing import Callable, Optional, Tuple
3 |
4 | import torch.nn as nn
5 | from torch.optim import Optimizer
6 |
7 | from colossalai.interface import OptimizerWrapper
8 |
9 |
10 | class MixedPrecision(ABC):
11 | """
12 | An abstract class for mixed precision training.
13 | """
14 |
15 | @abstractmethod
16 | def configure(
17 | self,
18 | model: nn.Module,
19 | optimizer: Optional[Optimizer] = None,
20 | criterion: Optional[Callable] = None,
21 | ) -> Tuple[nn.Module, OptimizerWrapper, Callable]:
22 | # TODO: implement this method
23 | pass
24 |
--------------------------------------------------------------------------------
/colossalai/booster/plugin/__init__.py:
--------------------------------------------------------------------------------
1 | from .gemini_plugin import GeminiPlugin
2 | from .hybrid_parallel_plugin import HybridParallelPlugin
3 | from .low_level_zero_plugin import LowLevelZeroPlugin
4 | from .moe_hybrid_parallel_plugin import MoeHybridParallelPlugin
5 | from .plugin_base import Plugin
6 | from .torch_ddp_plugin import TorchDDPPlugin
7 |
8 | __all__ = [
9 | "Plugin",
10 | "TorchDDPPlugin",
11 | "GeminiPlugin",
12 | "LowLevelZeroPlugin",
13 | "HybridParallelPlugin",
14 | "MoeHybridParallelPlugin",
15 | ]
16 |
17 | import torch
18 | from packaging import version
19 |
20 | if version.parse(torch.__version__) >= version.parse("1.12.0"):
21 | from .torch_fsdp_plugin import TorchFSDPPlugin
22 |
23 | __all__.append("TorchFSDPPlugin")
24 |
--------------------------------------------------------------------------------
/colossalai/booster/plugin/pp_plugin_base.py:
--------------------------------------------------------------------------------
1 | from abc import abstractmethod
2 | from typing import Any, Callable, Iterator, Optional
3 |
4 | import torch
5 |
6 | from colossalai.interface import ModelWrapper, OptimizerWrapper
7 |
8 | from .plugin_base import Plugin
9 |
10 |
11 | class PipelinePluginBase(Plugin):
12 | @abstractmethod
13 | def execute_pipeline(
14 | self,
15 | data_iter: Iterator,
16 | model: ModelWrapper,
17 | criterion: Callable[[Any, Any], torch.Tensor],
18 | optimizer: Optional[OptimizerWrapper] = None,
19 | return_loss: bool = True,
20 | return_outputs: bool = False,
21 | ) -> dict:
22 | pass
23 |
--------------------------------------------------------------------------------
/colossalai/checkpoint_io/__init__.py:
--------------------------------------------------------------------------------
1 | from .checkpoint_io_base import CheckpointIO
2 | from .general_checkpoint_io import GeneralCheckpointIO
3 | from .hybrid_parallel_checkpoint_io import HybridParallelCheckpointIO
4 | from .index_file import CheckpointIndexFile
5 | from .moe_checkpoint import MoECheckpointIO
6 |
7 | __all__ = [
8 | "CheckpointIO",
9 | "CheckpointIndexFile",
10 | "GeneralCheckpointIO",
11 | "HybridParallelCheckpointIO",
12 | "MoECheckpointIO",
13 | ]
14 |
--------------------------------------------------------------------------------
/colossalai/cli/__init__.py:
--------------------------------------------------------------------------------
1 | from .cli import cli
2 |
3 | __all__ = ["cli"]
4 |
--------------------------------------------------------------------------------
/colossalai/cli/check/__init__.py:
--------------------------------------------------------------------------------
1 | import click
2 |
3 | from .check_installation import check_installation
4 |
5 | __all__ = ["check"]
6 |
7 |
8 | @click.command(help="Check if Colossal-AI is correct based on the given option")
9 | @click.option("-i", "--installation", is_flag=True, help="Check if Colossal-AI is built correctly")
10 | def check(installation):
11 | if installation:
12 | check_installation()
13 | return
14 | click.echo("No option is given")
15 |
--------------------------------------------------------------------------------
/colossalai/cli/cli.py:
--------------------------------------------------------------------------------
1 | import click
2 |
3 | from .check import check
4 | from .launcher import run
5 |
6 |
7 | class Arguments:
8 | def __init__(self, arg_dict):
9 | for k, v in arg_dict.items():
10 | self.__dict__[k] = v
11 |
12 |
13 | @click.group()
14 | def cli():
15 | pass
16 |
17 |
18 | cli.add_command(run)
19 | cli.add_command(check)
20 |
21 | if __name__ == "__main__":
22 | cli()
23 |
--------------------------------------------------------------------------------
/colossalai/cluster/__init__.py:
--------------------------------------------------------------------------------
1 | from .device_mesh_manager import DeviceMeshManager
2 | from .dist_coordinator import DistCoordinator
3 | from .process_group_manager import ProcessGroupManager
4 | from .process_group_mesh import ProcessGroupMesh
5 |
6 | __all__ = ["DistCoordinator", "ProcessGroupManager", "DeviceMeshManager", "ProcessGroupMesh"]
7 |
--------------------------------------------------------------------------------
/colossalai/context/__init__.py:
--------------------------------------------------------------------------------
1 | from .config import Config, ConfigException
2 |
3 | __all__ = [
4 | "Config",
5 | "ConfigException",
6 | ]
7 |
--------------------------------------------------------------------------------
/colossalai/device/__init__.py:
--------------------------------------------------------------------------------
1 | from .alpha_beta_profiler import AlphaBetaProfiler
2 | from .calc_pipeline_strategy import alpa_dp
3 |
4 | __all__ = ["AlphaBetaProfiler", "alpa_dp"]
5 |
--------------------------------------------------------------------------------
/colossalai/fx/__init__.py:
--------------------------------------------------------------------------------
1 | from ._compatibility import compatibility, is_compatible_with_meta
2 | from .graph_module import ColoGraphModule
3 | from .passes import MetaInfoProp, metainfo_trace
4 | from .tracer import ColoTracer, meta_trace, symbolic_trace
5 |
--------------------------------------------------------------------------------
/colossalai/fx/codegen/__init__.py:
--------------------------------------------------------------------------------
1 | from .activation_checkpoint_codegen import *
2 |
--------------------------------------------------------------------------------
/colossalai/fx/passes/__init__.py:
--------------------------------------------------------------------------------
1 | from .adding_split_node_pass import balanced_split_pass, split_with_split_nodes_pass
2 | from .concrete_info_prop import ConcreteInfoProp
3 | from .meta_info_prop import MetaInfoProp, metainfo_trace
4 | from .shard_1d_pass import column_shard_linear_pass, row_shard_linear_pass
5 |
--------------------------------------------------------------------------------
/colossalai/fx/profiler/experimental/__init__.py:
--------------------------------------------------------------------------------
1 | from .profiler import profile_function, profile_method, profile_module
2 | from .profiler_function import *
3 | from .profiler_module import *
4 | from .registry import meta_profiler_function, meta_profiler_module
5 | from .shard_utils import calculate_fwd_in, calculate_fwd_out, calculate_fwd_tmp
6 |
--------------------------------------------------------------------------------
/colossalai/fx/profiler/experimental/profiler_function/__init__.py:
--------------------------------------------------------------------------------
1 | from .activation_function import *
2 | from .arithmetic import *
3 | from .embedding import *
4 | from .linear import *
5 | from .normalization import *
6 | from .pooling import *
7 | from .python_ops import *
8 | from .torch_ops import *
9 |
--------------------------------------------------------------------------------
/colossalai/fx/profiler/experimental/profiler_function/embedding.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | import torch
4 |
5 | from ..registry import meta_profiler_function
6 |
7 |
8 | @meta_profiler_function.register(torch.nn.functional.embedding)
9 | def torch_nn_functional_embedding(
10 | input: torch.Tensor,
11 | weight: torch.Tensor,
12 | padding_idx: Optional[int] = None,
13 | max_norm: Optional[float] = None,
14 | norm_type: float = 2.0,
15 | scale_grad_by_freq: bool = False,
16 | sparse: bool = False,
17 | ) -> torch.Tensor:
18 | # F.embedding is a dictionary lookup, so technically it has 0 FLOPs. (https://discuss.pytorch.org/t/correct-way-to-calculate-flops-in-model/67198/6)
19 | flops = 0
20 | macs = 0
21 | return flops, macs
22 |
--------------------------------------------------------------------------------
/colossalai/fx/profiler/experimental/profiler_function/linear.py:
--------------------------------------------------------------------------------
1 | from typing import Tuple
2 |
3 | import torch
4 |
5 | from ..registry import meta_profiler_function
6 |
7 |
8 | @meta_profiler_function.register(torch.nn.functional.linear)
9 | def torch_nn_linear(input: torch.Tensor, weight: torch.Tensor, bias: torch.Tensor = None) -> Tuple[int, int]:
10 | out_features = weight.shape[0]
11 | macs = torch.numel(input) * out_features
12 | flops = 2 * macs
13 | if bias is not None:
14 | flops += bias.numel()
15 | return flops, macs
16 |
--------------------------------------------------------------------------------
/colossalai/fx/profiler/experimental/profiler_function/python_ops.py:
--------------------------------------------------------------------------------
1 | import operator
2 | from typing import Any, Tuple
3 |
4 | from ..registry import meta_profiler_function
5 |
6 |
7 | @meta_profiler_function.register(operator.getitem)
8 | def operator_getitem(a: Any, b: Any) -> Tuple[int, int]:
9 | flops = 0
10 | macs = 0
11 | return flops, macs
12 |
13 |
14 | @meta_profiler_function.register(getattr)
15 | def python_getattr(a: Any, b: Any) -> Tuple[int, int]:
16 | flops = 0
17 | macs = 0
18 | return flops, macs
19 |
--------------------------------------------------------------------------------
/colossalai/fx/profiler/experimental/profiler_module/__init__.py:
--------------------------------------------------------------------------------
1 | from .activation_function import *
2 | from .attention import *
3 | from .convolution import *
4 | from .dropout import *
5 | from .embedding import *
6 | from .linear import *
7 | from .normalization import *
8 | from .pooling import *
9 | from .rnn import *
10 | from .torch_op import *
11 |
--------------------------------------------------------------------------------
/colossalai/fx/profiler/experimental/profiler_module/dropout.py:
--------------------------------------------------------------------------------
1 | from typing import Tuple
2 |
3 | import torch
4 |
5 | from ..registry import meta_profiler_module
6 |
7 |
8 | @meta_profiler_module.register(torch.nn.Dropout)
9 | def torch_nn_dropout(self: torch.nn.Module, input: torch.Tensor) -> Tuple[int, int]:
10 | # nn.Embedding is a dictionary lookup, so technically it has 0 FLOPs. (https://discuss.pytorch.org/t/correct-way-to-calculate-flops-in-model/67198/6)
11 | flops = 0
12 | macs = 0
13 | return flops, macs
14 |
--------------------------------------------------------------------------------
/colossalai/fx/profiler/experimental/profiler_module/embedding.py:
--------------------------------------------------------------------------------
1 | from typing import Tuple
2 |
3 | import torch
4 |
5 | from ..registry import meta_profiler_module
6 |
7 |
8 | @meta_profiler_module.register(torch.nn.Embedding)
9 | def torch_nn_embedding(self: torch.nn.Embedding, input: torch.Tensor) -> Tuple[int, int]:
10 | # nn.Embedding is a dictionary lookup, so technically it has 0 FLOPs. (https://discuss.pytorch.org/t/correct-way-to-calculate-flops-in-model/67198/6)
11 | flops = 0
12 | macs = 0
13 | return flops, macs
14 |
--------------------------------------------------------------------------------
/colossalai/fx/profiler/experimental/profiler_module/linear.py:
--------------------------------------------------------------------------------
1 | from typing import Tuple
2 |
3 | import torch
4 |
5 | from ..registry import meta_profiler_module
6 |
7 |
8 | @meta_profiler_module.register(torch.nn.Linear)
9 | @meta_profiler_module.register(torch.nn.modules.linear.NonDynamicallyQuantizableLinear)
10 | def torch_nn_linear(self: torch.nn.Linear, input: torch.Tensor) -> Tuple[int, int]:
11 | out_features = self.weight.shape[0]
12 | macs = input.numel() * out_features
13 | flops = 2 * macs
14 | if self.bias is not None:
15 | flops += self.bias.numel()
16 | return flops, macs
17 |
--------------------------------------------------------------------------------
/colossalai/fx/profiler/experimental/profiler_module/torch_op.py:
--------------------------------------------------------------------------------
1 | from typing import Tuple
2 |
3 | import torch
4 |
5 | from ..registry import meta_profiler_module
6 |
7 |
8 | @meta_profiler_module.register(torch.nn.Flatten)
9 | def torch_nn_flatten(self: torch.nn.Flatten, input: torch.Tensor) -> Tuple[int, int]:
10 | flops = 0
11 | macs = 0
12 | return flops, macs
13 |
--------------------------------------------------------------------------------
/colossalai/fx/profiler/experimental/registry.py:
--------------------------------------------------------------------------------
1 | class ProfilerRegistry:
2 | def __init__(self, name):
3 | self.name = name
4 | self.store = {}
5 |
6 | def register(self, source):
7 | def wrapper(func):
8 | self.store[source] = func
9 | return func
10 |
11 | return wrapper
12 |
13 | def get(self, source):
14 | assert source in self.store
15 | target = self.store[source]
16 | return target
17 |
18 | def has(self, source):
19 | return source in self.store
20 |
21 |
22 | meta_profiler_function = ProfilerRegistry(name="patched_functions_for_meta_profile")
23 | meta_profiler_module = ProfilerRegistry(name="patched_modules_for_meta_profile")
24 |
--------------------------------------------------------------------------------
/colossalai/fx/tracer/__init__.py:
--------------------------------------------------------------------------------
1 | from colossalai.fx.tracer.meta_patch.patched_function.python_ops import operator_getitem
2 |
3 | from ._meta_trace import meta_trace
4 | from ._symbolic_trace import symbolic_trace
5 | from .tracer import ColoTracer
6 |
--------------------------------------------------------------------------------
/colossalai/fx/tracer/bias_addition_patch/__init__.py:
--------------------------------------------------------------------------------
1 | from .patched_bias_addition_function import *
2 | from .patched_bias_addition_module import *
3 |
--------------------------------------------------------------------------------
/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_function/__init__.py:
--------------------------------------------------------------------------------
1 | from .addbmm import Addbmm
2 | from .addmm import Addmm
3 | from .bias_addition_function import BiasAdditionFunc, LinearBasedBiasFunc, func_to_func_dict, method_to_func_dict
4 | from .linear import Linear
5 |
--------------------------------------------------------------------------------
/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_module/__init__.py:
--------------------------------------------------------------------------------
1 | from .bias_addition_module import *
2 | from .conv import *
3 | from .linear import *
4 |
--------------------------------------------------------------------------------
/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_module/linear.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | from ...registry import bias_addition_module
4 | from .bias_addition_module import BiasAdditionModule
5 |
6 |
7 | @bias_addition_module.register(torch.nn.Linear)
8 | class BiasAdditionLinear(BiasAdditionModule):
9 | def extract_kwargs_from_mod(self):
10 | return {}
11 |
12 | def generate(self):
13 | non_bias_linear_func_proxy = self.create_non_bias_func_proxy()
14 | bias_addition_proxy = self.create_bias_addition_proxy(non_bias_linear_func_proxy, self.bias_proxy)
15 | return bias_addition_proxy
16 |
--------------------------------------------------------------------------------
/colossalai/fx/tracer/meta_patch/__init__.py:
--------------------------------------------------------------------------------
1 | from .patched_function import *
2 | from .patched_module import *
3 |
--------------------------------------------------------------------------------
/colossalai/fx/tracer/meta_patch/patched_function/__init__.py:
--------------------------------------------------------------------------------
1 | from .activation_function import *
2 | from .arithmetic import *
3 | from .convolution import *
4 | from .embedding import *
5 | from .normalization import *
6 | from .torch_ops import *
7 |
--------------------------------------------------------------------------------
/colossalai/fx/tracer/meta_patch/patched_function/activation_function.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | from ...registry import meta_patched_function
4 |
5 |
6 | @meta_patched_function.register(torch.nn.functional.relu)
7 | def torch_nn_func_relu(input, inplace=False):
8 | return torch.empty(input.shape, device="meta")
9 |
--------------------------------------------------------------------------------
/colossalai/fx/tracer/meta_patch/patched_function/embedding.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | from ...registry import meta_patched_function
4 |
5 |
6 | @meta_patched_function.register(torch.nn.functional.embedding)
7 | def torch_nn_functional_embedding(
8 | input, weight, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False
9 | ):
10 | return torch.empty(*input.shape, weight.shape[-1], device="meta")
11 |
--------------------------------------------------------------------------------
/colossalai/fx/tracer/meta_patch/patched_function/normalization.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | from ...registry import meta_patched_function
4 |
5 |
6 | @meta_patched_function.register(torch.nn.functional.layer_norm)
7 | def torch_nn_func_layernorm(input, normalized_shape, weight=None, bias=None, eps=1e-05):
8 | return torch.empty(input.shape, device="meta")
9 |
10 |
11 | @meta_patched_function.register(torch.nn.functional.batch_norm)
12 | def torch_nn_func_batchnorm(
13 | input, running_mean, running_var, weight=None, bias=None, training=False, momentum=0.1, eps=1e-05
14 | ):
15 | return torch.empty(input.shape, device="meta")
16 |
--------------------------------------------------------------------------------
/colossalai/fx/tracer/meta_patch/patched_module/__init__.py:
--------------------------------------------------------------------------------
1 | from .activation_function import *
2 | from .convolution import *
3 | from .embedding import *
4 | from .linear import *
5 | from .normalization import *
6 | from .pooling import *
7 | from .rnn import *
8 |
--------------------------------------------------------------------------------
/colossalai/fx/tracer/meta_patch/patched_module/activation_function.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | from ...registry import meta_patched_module
4 |
5 |
6 | @meta_patched_module.register(torch.nn.ReLU)
7 | @meta_patched_module.register(torch.nn.Sigmoid)
8 | @meta_patched_module.register(torch.nn.GELU)
9 | @meta_patched_module.register(torch.nn.Tanh)
10 | @meta_patched_module.register(torch.nn.ReLU6)
11 | @meta_patched_module.register(torch.nn.PReLU)
12 | def torch_nn_non_linear_act(self, input):
13 | return torch.empty(input.shape, device="meta")
14 |
--------------------------------------------------------------------------------
/colossalai/fx/tracer/meta_patch/patched_module/embedding.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | from ...registry import meta_patched_module
4 |
5 |
6 | @meta_patched_module.register(torch.nn.Embedding)
7 | def torch_nn_embedding(self, input):
8 | result_shape = input.shape + (self.embedding_dim,)
9 | return torch.empty(result_shape, device="meta")
10 |
--------------------------------------------------------------------------------
/colossalai/fx/tracer/meta_patch/patched_module/linear.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | from ...registry import meta_patched_module
4 |
5 |
6 | @meta_patched_module.register(torch.nn.Linear)
7 | def torch_nn_linear(self, input):
8 | last_dim = input.shape[-1]
9 | assert (
10 | last_dim == self.in_features
11 | ), f"Expected hidden size {self.in_features} but got {last_dim} for the torch.nn.Linear patch"
12 | return torch.empty(input.shape[:-1] + (self.out_features,), device="meta")
13 |
--------------------------------------------------------------------------------
/colossalai/fx/tracer/meta_patch/patched_module/rnn.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | from ...registry import meta_patched_module
4 |
5 |
6 | @meta_patched_module.register(torch.nn.GRU)
7 | @meta_patched_module.register(torch.nn.RNN)
8 | def torch_nn_rnn(self, input, hx):
9 | assert (
10 | input.shape[-1] == self.input_size
11 | ), f"Expected input to have input size {self.input_size} but got {input.shape[-1]} for the torch.nn.RNN patch"
12 | assert (
13 | hx.shape[-1] == self.hidden_size
14 | ), f"Expected hx to have hidden size {self.hidden_size} but got {hx.shape[-1]} for the torch.nn.RNN patch"
15 | d = 2 if self.bidirectional else 1
16 | return torch.empty(input.shape[:-1] + (self.hidden_size * d,), device="meta"), hx
17 |
--------------------------------------------------------------------------------
/colossalai/inference/__init__.py:
--------------------------------------------------------------------------------
1 | from .config import InferenceConfig
2 | from .core import InferenceEngine
3 |
4 | __all__ = ["InferenceConfig", "InferenceEngine"]
5 |
--------------------------------------------------------------------------------
/colossalai/inference/core/__init__.py:
--------------------------------------------------------------------------------
1 | from .engine import InferenceEngine
2 | from .request_handler import RequestHandler
3 |
4 | __all__ = ["InferenceEngine", "RequestHandler"]
5 |
--------------------------------------------------------------------------------
/colossalai/inference/executor/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/inference/executor/__init__.py
--------------------------------------------------------------------------------
/colossalai/inference/kv_cache/__init__.py:
--------------------------------------------------------------------------------
1 | from .block_cache import CacheBlock
2 | from .kvcache_manager import KVCacheManager, RPCKVCacheManager
3 |
4 | __all__ = ["CacheBlock", "KVCacheManager", "RPCKVCacheManager"]
5 |
--------------------------------------------------------------------------------
/colossalai/inference/modeling/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/inference/modeling/__init__.py
--------------------------------------------------------------------------------
/colossalai/inference/modeling/backends/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/inference/modeling/backends/__init__.py
--------------------------------------------------------------------------------
/colossalai/inference/modeling/layers/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/inference/modeling/layers/__init__.py
--------------------------------------------------------------------------------
/colossalai/inference/modeling/models/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/inference/modeling/models/__init__.py
--------------------------------------------------------------------------------
/colossalai/inference/server/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/inference/server/__init__.py
--------------------------------------------------------------------------------
/colossalai/inference/spec/__init__.py:
--------------------------------------------------------------------------------
1 | from .drafter import Drafter
2 | from .struct import DrafterOutput, GlideInput
3 |
4 | __all__ = ["Drafter", "DrafterOutput", "GlideInput"]
5 |
--------------------------------------------------------------------------------
/colossalai/interface/__init__.py:
--------------------------------------------------------------------------------
1 | from .model import AMPModelMixin, ModelWrapper
2 | from .optimizer import OptimizerWrapper
3 |
4 | __all__ = ["OptimizerWrapper", "ModelWrapper", "AMPModelMixin"]
5 |
--------------------------------------------------------------------------------
/colossalai/interface/pretrained.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | from torch.nn import Module
4 |
5 | __all__ = [
6 | "get_pretrained_path",
7 | "set_pretrained_path",
8 | ]
9 |
10 |
11 | def get_pretrained_path(model: Module) -> Optional[str]:
12 | return getattr(model, "_pretrained", None)
13 |
14 |
15 | def set_pretrained_path(model: Module, path: str) -> None:
16 | setattr(model, "_pretrained", path)
17 |
--------------------------------------------------------------------------------
/colossalai/kernel/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/kernel/__init__.py
--------------------------------------------------------------------------------
/colossalai/kernel/extensions:
--------------------------------------------------------------------------------
1 | ../../extensions
--------------------------------------------------------------------------------
/colossalai/kernel/jit/__init__.py:
--------------------------------------------------------------------------------
1 | from .bias_dropout_add import bias_dropout_add_fused_inference, bias_dropout_add_fused_train
2 | from .bias_gelu import bias_gelu_impl
3 | from .option import set_jit_fusion_options
4 |
5 | __all__ = [
6 | "bias_dropout_add_fused_train",
7 | "bias_dropout_add_fused_inference",
8 | "bias_gelu_impl",
9 | "set_jit_fusion_options",
10 | ]
11 |
--------------------------------------------------------------------------------
/colossalai/kernel/jit/bias_dropout_add.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 |
4 | def bias_dropout_add(x, bias, residual, prob, training):
5 | # type: (Tensor, Tensor, Tensor, float, bool) -> Tensor
6 | out = torch.nn.functional.dropout(x + bias, p=prob, training=training)
7 | out = residual + out
8 | return out
9 |
10 |
11 | @torch.jit.script
12 | def bias_dropout_add_fused_train(
13 | x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float
14 | ) -> torch.Tensor:
15 | return bias_dropout_add(x, bias, residual, prob, True)
16 |
17 |
18 | @torch.jit.script
19 | def bias_dropout_add_fused_inference(
20 | x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float
21 | ) -> torch.Tensor:
22 | return bias_dropout_add(x, bias, residual, prob, False)
23 |
--------------------------------------------------------------------------------
/colossalai/lazy/__init__.py:
--------------------------------------------------------------------------------
1 | from .lazy_init import LazyInitContext, LazyTensor
2 |
3 | __all__ = [
4 | "LazyInitContext",
5 | "LazyTensor",
6 | ]
7 |
--------------------------------------------------------------------------------
/colossalai/legacy/__init__.py:
--------------------------------------------------------------------------------
1 | from .initialize import (
2 | get_default_parser,
3 | initialize,
4 | launch,
5 | launch_from_openmpi,
6 | launch_from_slurm,
7 | launch_from_torch,
8 | )
9 |
10 | __all__ = [
11 | "launch",
12 | "launch_from_openmpi",
13 | "launch_from_slurm",
14 | "launch_from_torch",
15 | "initialize",
16 | "get_default_parser",
17 | ]
18 |
--------------------------------------------------------------------------------
/colossalai/legacy/amp/amp_type.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | from enum import Enum
5 |
6 |
7 | class AMP_TYPE(Enum):
8 | APEX = "apex"
9 | TORCH = "torch"
10 | NAIVE = "naive"
11 |
--------------------------------------------------------------------------------
/colossalai/legacy/builder/__init__.py:
--------------------------------------------------------------------------------
1 | from .builder import build_from_config, build_from_registry, build_gradient_handler
2 |
3 | __all__ = ["build_gradient_handler", "build_from_config", "build_from_registry"]
4 |
--------------------------------------------------------------------------------
/colossalai/legacy/context/__init__.py:
--------------------------------------------------------------------------------
1 | from .parallel_context import ParallelContext
2 | from .parallel_mode import ParallelMode
3 | from .process_group_initializer import *
4 | from .random import *
5 |
--------------------------------------------------------------------------------
/colossalai/legacy/context/random/__init__.py:
--------------------------------------------------------------------------------
1 | from ._helper import (
2 | add_seed,
3 | get_current_mode,
4 | get_seeds,
5 | get_states,
6 | moe_set_seed,
7 | reset_seeds,
8 | seed,
9 | set_mode,
10 | set_seed_states,
11 | sync_states,
12 | with_seed,
13 | )
14 |
15 | __all__ = [
16 | "seed",
17 | "set_mode",
18 | "with_seed",
19 | "add_seed",
20 | "get_seeds",
21 | "get_states",
22 | "get_current_mode",
23 | "set_seed_states",
24 | "sync_states",
25 | "moe_set_seed",
26 | "reset_seeds",
27 | ]
28 |
--------------------------------------------------------------------------------
/colossalai/legacy/core.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | from colossalai.legacy.context.parallel_context import global_context
5 |
6 | __all__ = ["global_context"]
7 |
--------------------------------------------------------------------------------
/colossalai/legacy/engine/__init__.py:
--------------------------------------------------------------------------------
1 | from ._base_engine import Engine
2 | from .gradient_handler import *
3 |
4 | __all__ = ["Engine"]
5 |
--------------------------------------------------------------------------------
/colossalai/legacy/engine/gradient_handler/__init__.py:
--------------------------------------------------------------------------------
1 | from ._base_gradient_handler import BaseGradientHandler
2 | from ._data_parallel_gradient_handler import DataParallelGradientHandler
3 | from ._pipeline_parallel_gradient_handler import PipelineSharedModuleGradientHandler
4 | from ._sequence_parallel_gradient_handler import SequenceParallelGradientHandler
5 | from ._zero_gradient_handler import ZeROGradientHandler
6 |
7 | __all__ = [
8 | "BaseGradientHandler",
9 | "DataParallelGradientHandler",
10 | "ZeROGradientHandler",
11 | "PipelineSharedModuleGradientHandler",
12 | "SequenceParallelGradientHandler",
13 | ]
14 |
--------------------------------------------------------------------------------
/colossalai/legacy/engine/schedule/__init__.py:
--------------------------------------------------------------------------------
1 | from ._base_schedule import BaseSchedule
2 | from ._non_pipeline_schedule import NonPipelineSchedule
3 | from ._pipeline_schedule import InterleavedPipelineSchedule, PipelineSchedule, get_tensor_shape
4 |
5 | __all__ = ["BaseSchedule", "NonPipelineSchedule", "PipelineSchedule", "InterleavedPipelineSchedule", "get_tensor_shape"]
6 |
--------------------------------------------------------------------------------
/colossalai/legacy/inference/__init__.py:
--------------------------------------------------------------------------------
1 | from .hybridengine import CaiInferEngine
2 | from .hybridengine.polices import LlamaModelInferPolicy
3 |
4 | __all__ = ["CaiInferEngine", "LlamaModelInferPolicy"]
5 |
--------------------------------------------------------------------------------
/colossalai/legacy/inference/dynamic_batching/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/legacy/inference/dynamic_batching/__init__.py
--------------------------------------------------------------------------------
/colossalai/legacy/inference/hybridengine/__init__.py:
--------------------------------------------------------------------------------
1 | from .engine import CaiInferEngine
2 |
3 | __all__ = ["CaiInferEngine"]
4 |
--------------------------------------------------------------------------------
/colossalai/legacy/inference/hybridengine/modeling/__init__.py:
--------------------------------------------------------------------------------
1 | from .llama import LlamaInferenceForwards
2 |
3 | __all__ = ["LlamaInferenceForwards"]
4 |
--------------------------------------------------------------------------------
/colossalai/legacy/inference/hybridengine/polices/__init__.py:
--------------------------------------------------------------------------------
1 | from .llama import LlamaModelInferPolicy
2 |
3 | __all__ = ["LlamaModelInferPolicy"]
4 |
--------------------------------------------------------------------------------
/colossalai/legacy/inference/pipeline/__init__.py:
--------------------------------------------------------------------------------
1 | from .microbatch_manager import MicroBatchManager
2 |
3 | __all__ = ["MicroBatchManager"]
4 |
--------------------------------------------------------------------------------
/colossalai/legacy/inference/quant/gptq/__init__.py:
--------------------------------------------------------------------------------
1 | from .cai_gptq import HAS_AUTO_GPTQ
2 |
3 | if HAS_AUTO_GPTQ:
4 | from .cai_gptq import CaiGPTQLinearOp, CaiQuantLinear
5 |
--------------------------------------------------------------------------------
/colossalai/legacy/inference/quant/gptq/cai_gptq/__init__.py:
--------------------------------------------------------------------------------
1 | import warnings
2 |
3 | HAS_AUTO_GPTQ = False
4 | try:
5 | import auto_gptq
6 |
7 | HAS_AUTO_GPTQ = True
8 | except ImportError:
9 | warnings.warn("please install auto-gptq from https://github.com/PanQiWei/AutoGPTQ")
10 | HAS_AUTO_GPTQ = False
11 |
12 | if HAS_AUTO_GPTQ:
13 | from .cai_quant_linear import CaiQuantLinear, ColCaiQuantLinear, RowCaiQuantLinear
14 | from .gptq_op import CaiGPTQLinearOp
15 |
--------------------------------------------------------------------------------
/colossalai/legacy/inference/quant/smoothquant/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/legacy/inference/quant/smoothquant/__init__.py
--------------------------------------------------------------------------------
/colossalai/legacy/inference/quant/smoothquant/models/__init__.py:
--------------------------------------------------------------------------------
1 | try:
2 | import torch_int
3 |
4 | HAS_TORCH_INT = True
5 | except ImportError:
6 | HAS_TORCH_INT = False
7 | raise ImportError(
8 | "Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int"
9 | )
10 |
11 | if HAS_TORCH_INT:
12 | from .llama import LLamaSmoothquantAttention, LlamaSmoothquantMLP
13 |
--------------------------------------------------------------------------------
/colossalai/legacy/inference/serving/ray_serve/send_request.py:
--------------------------------------------------------------------------------
1 | import ray
2 | import requests
3 |
4 |
5 | @ray.remote
6 | def send_query(text):
7 | resp = requests.get("http://localhost:8000/?text={}".format(text))
8 | return resp.text
9 |
10 |
11 | test_sentence = "Introduce some landmarks in Beijing"
12 |
13 | result = ray.get(send_query.remote(test_sentence))
14 | print("Result returned:")
15 | print(result)
16 |
--------------------------------------------------------------------------------
/colossalai/legacy/inference/serving/test_ci.sh:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/legacy/inference/serving/test_ci.sh
--------------------------------------------------------------------------------
/colossalai/legacy/inference/serving/torch_serve/config.properties:
--------------------------------------------------------------------------------
1 | inference_address=http://0.0.0.0:8084
2 | management_address=http://0.0.0.0:8085
3 | metrics_address=http://0.0.0.0:8086
4 | enable_envvars_config=true
5 | install_py_dep_per_model=true
6 | number_of_gpu=1
7 | load_models=all
8 | max_response_size=655350000
9 | default_response_timeout=6000
10 | model_store=./model_store
11 |
--------------------------------------------------------------------------------
/colossalai/legacy/inference/serving/torch_serve/model-config.yaml:
--------------------------------------------------------------------------------
1 | # TS frontend parameters settings
2 | minWorkers: 1 # minimum number of workers of a model
3 | maxWorkers: 1 # maximum number of workers of a model
4 | batchSize: 8 # batch size of a model
5 | maxBatchDelay: 100 # maximum delay of a batch (ms)
6 | responseTimeout: 120 # timeout of a specific model's response (*in sec)
7 | deviceType: "gpu"
8 | # deviceIds: [0, 1] # seting CUDA_VISIBLE_DEVICES
9 |
10 | handler:
11 | mode: "text_generation"
12 | model_type: "bloom"
13 | tp_size: 1
14 | max_batch_size: 8
15 | max_input_len: 1024
16 | max_output_len: 128
17 |
--------------------------------------------------------------------------------
/colossalai/legacy/inference/serving/torch_serve/sample_text.txt:
--------------------------------------------------------------------------------
1 | Introduce some landmarks in Beijing
2 |
--------------------------------------------------------------------------------
/colossalai/legacy/inference/tensor_parallel/__init__.py:
--------------------------------------------------------------------------------
1 | from .engine import TPInferEngine
2 | from .kvcache_manager import MemoryManager
3 |
4 | __all__ = ["MemoryManager", "TPInferEngine"]
5 |
--------------------------------------------------------------------------------
/colossalai/legacy/inference/tensor_parallel/modeling/__init__.py:
--------------------------------------------------------------------------------
1 | from .bloom import BloomInferenceForwards
2 | from .chatglm2 import ChatGLM2InferenceForwards
3 | from .llama import LlamaInferenceForwards
4 |
5 | __all__ = ["BloomInferenceForwards", "LlamaInferenceForwards", "ChatGLM2InferenceForwards"]
6 |
--------------------------------------------------------------------------------
/colossalai/legacy/inference/tensor_parallel/policies/__init__.py:
--------------------------------------------------------------------------------
1 | from .bloom import BloomModelInferPolicy
2 | from .chatglm2 import ChatGLM2InferPolicy
3 | from .llama import LlamaModelInferPolicy
4 |
5 | __all__ = ["BloomModelInferPolicy", "LlamaModelInferPolicy", "ChatGLM2InferPolicy"]
6 |
--------------------------------------------------------------------------------
/colossalai/legacy/moe/layer/__init__.py:
--------------------------------------------------------------------------------
1 | from .experts import *
2 | from .layers import *
3 | from .routers import *
4 |
--------------------------------------------------------------------------------
/colossalai/legacy/moe/openmoe/benchmark/hostfile.txt:
--------------------------------------------------------------------------------
1 | host1
2 | host2
3 |
--------------------------------------------------------------------------------
/colossalai/legacy/moe/openmoe/infer.sh:
--------------------------------------------------------------------------------
1 | python infer.py --model "base"
2 |
--------------------------------------------------------------------------------
/colossalai/legacy/moe/openmoe/model/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/legacy/moe/openmoe/model/__init__.py
--------------------------------------------------------------------------------
/colossalai/legacy/moe/openmoe/model/convert_openmoe_ckpt.sh:
--------------------------------------------------------------------------------
1 | python convert_openmoe_ckpt.py --t5x_checkpoint_path /path/to/t5x --config_file /path/to/config --pytorch_dump_path /path/to/save
2 |
--------------------------------------------------------------------------------
/colossalai/legacy/moe/openmoe/model/openmoe_8b_config.json:
--------------------------------------------------------------------------------
1 | {
2 | "architectures": [
3 | "OpenMoeForCausalLM"
4 | ],
5 | "intermediate_size": 8192,
6 | "hidden_size": 2048,
7 | "num_hidden_layers": 24,
8 | "head_dim": 128,
9 | "num_attention_heads": 24,
10 | "dropout_rate": 0.0,
11 | "layer_norm_epsilon": 1e-06,
12 | "vocab_size": 256384,
13 | "hidden_act": "swiglu",
14 | "num_experts": 32,
15 | "topk": 2,
16 | "capacity_factor_train": 1.25,
17 | "capacity_factor_eval": 2.0,
18 | "min_capacity": 4,
19 | "noisy_policy": null,
20 | "drop_tks": true,
21 | "expert_parallel": null,
22 | "gated": true,
23 | "moe_layer_interval": 6
24 | }
25 |
--------------------------------------------------------------------------------
/colossalai/legacy/moe/openmoe/model/openmoe_base_config.json:
--------------------------------------------------------------------------------
1 | {
2 | "architectures": [
3 | "OpenMoeForCausalLM"
4 | ],
5 | "intermediate_size": 2048,
6 | "hidden_size": 768,
7 | "num_hidden_layers": 12,
8 | "head_dim": 64,
9 | "num_attention_heads": 12,
10 | "dropout_rate": 0.0,
11 | "layer_norm_epsilon": 1e-06,
12 | "vocab_size": 256384,
13 | "hidden_act": "swiglu",
14 | "num_experts": 16,
15 | "topk": 2,
16 | "capacity_factor_train": 1.25,
17 | "capacity_factor_eval": 2.0,
18 | "min_capacity": 4,
19 | "noisy_policy": null,
20 | "drop_tks": true,
21 | "expert_parallel": null,
22 | "gated": true,
23 | "moe_layer_interval": 4
24 | }
25 |
--------------------------------------------------------------------------------
/colossalai/legacy/moe/openmoe/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.3.3
2 | torch >= 1.8.1
3 | transformers >= 4.20.0, <= 4.34.0
4 | sentencepiece
5 | datasets
6 |
--------------------------------------------------------------------------------
/colossalai/legacy/nn/__init__.py:
--------------------------------------------------------------------------------
1 | from .layer import *
2 | from .loss import *
3 | from .metric import *
4 |
--------------------------------------------------------------------------------
/colossalai/legacy/nn/_ops/__init__.py:
--------------------------------------------------------------------------------
1 | from ._utils import *
2 |
--------------------------------------------------------------------------------
/colossalai/legacy/nn/layer/__init__.py:
--------------------------------------------------------------------------------
1 | from .colossalai_layer import *
2 | from .parallel_1d import *
3 | from .parallel_2d import *
4 | from .parallel_2p5d import *
5 | from .parallel_3d import *
6 | from .parallel_sequence import *
7 | from .utils import *
8 | from .vanilla import *
9 | from .wrapper import *
10 |
--------------------------------------------------------------------------------
/colossalai/legacy/nn/layer/colossalai_layer/__init__.py:
--------------------------------------------------------------------------------
1 | from ._utils import partition_batch
2 | from .dropout import Dropout
3 | from .embedding import Embedding, PatchEmbedding
4 | from .linear import Classifier, Linear
5 | from .normalization import LayerNorm
6 |
7 | __all__ = ["Linear", "Classifier", "Embedding", "PatchEmbedding", "LayerNorm", "Dropout", "partition_batch"]
8 |
--------------------------------------------------------------------------------
/colossalai/legacy/nn/layer/parallel_1d/__init__.py:
--------------------------------------------------------------------------------
1 | from .layers import (
2 | Classifier1D,
3 | Dropout1D,
4 | Embedding1D,
5 | LayerNorm1D,
6 | Linear1D,
7 | Linear1D_Col,
8 | Linear1D_Row,
9 | PatchEmbedding1D,
10 | VocabParallelClassifier1D,
11 | VocabParallelEmbedding1D,
12 | )
13 |
14 | __all__ = [
15 | "Linear1D",
16 | "Linear1D_Col",
17 | "Linear1D_Row",
18 | "Embedding1D",
19 | "Dropout1D",
20 | "Classifier1D",
21 | "VocabParallelClassifier1D",
22 | "VocabParallelEmbedding1D",
23 | "LayerNorm1D",
24 | "PatchEmbedding1D",
25 | ]
26 |
--------------------------------------------------------------------------------
/colossalai/legacy/nn/layer/parallel_2d/__init__.py:
--------------------------------------------------------------------------------
1 | from ._operation import reduce_by_batch_2d, split_batch_2d
2 | from .layers import (
3 | Classifier2D,
4 | Embedding2D,
5 | LayerNorm2D,
6 | Linear2D,
7 | PatchEmbedding2D,
8 | VocabParallelClassifier2D,
9 | VocabParallelEmbedding2D,
10 | )
11 |
12 | __all__ = [
13 | "split_batch_2d",
14 | "reduce_by_batch_2d",
15 | "Linear2D",
16 | "LayerNorm2D",
17 | "Classifier2D",
18 | "PatchEmbedding2D",
19 | "Embedding2D",
20 | "VocabParallelEmbedding2D",
21 | "VocabParallelClassifier2D",
22 | ]
23 |
--------------------------------------------------------------------------------
/colossalai/legacy/nn/layer/parallel_2p5d/__init__.py:
--------------------------------------------------------------------------------
1 | from ._operation import reduce_by_batch_2p5d, split_batch_2p5d
2 | from .layers import (
3 | Classifier2p5D,
4 | Embedding2p5D,
5 | LayerNorm2p5D,
6 | Linear2p5D,
7 | PatchEmbedding2p5D,
8 | VocabParallelClassifier2p5D,
9 | VocabParallelEmbedding2p5D,
10 | )
11 |
12 | __all__ = [
13 | "split_batch_2p5d",
14 | "reduce_by_batch_2p5d",
15 | "Linear2p5D",
16 | "LayerNorm2p5D",
17 | "Classifier2p5D",
18 | "PatchEmbedding2p5D",
19 | "Embedding2p5D",
20 | "VocabParallelClassifier2p5D",
21 | "VocabParallelEmbedding2p5D",
22 | ]
23 |
--------------------------------------------------------------------------------
/colossalai/legacy/nn/layer/parallel_3d/__init__.py:
--------------------------------------------------------------------------------
1 | from ._operation import reduce_by_batch_3d, split_batch_3d, split_tensor_3d
2 | from .layers import (
3 | Classifier3D,
4 | Embedding3D,
5 | LayerNorm3D,
6 | Linear3D,
7 | PatchEmbedding3D,
8 | VocabParallelClassifier3D,
9 | VocabParallelEmbedding3D,
10 | )
11 |
12 | __all__ = [
13 | "reduce_by_batch_3d",
14 | "split_tensor_3d",
15 | "split_batch_3d",
16 | "Linear3D",
17 | "LayerNorm3D",
18 | "PatchEmbedding3D",
19 | "Classifier3D",
20 | "Embedding3D",
21 | "VocabParallelEmbedding3D",
22 | "VocabParallelClassifier3D",
23 | ]
24 |
--------------------------------------------------------------------------------
/colossalai/legacy/nn/layer/parallel_sequence/__init__.py:
--------------------------------------------------------------------------------
1 | from ._operation import RingAV, RingQK
2 | from .layers import TransformerSelfAttentionRing
3 |
4 | __all__ = ["TransformerSelfAttentionRing", "RingAV", "RingQK"]
5 |
--------------------------------------------------------------------------------
/colossalai/legacy/nn/layer/parallel_sequence/_utils.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 |
5 | def _calc_incoming_device_range(i, rank, world_size, sub_seq_length):
6 | device_of_incoming_k = (rank - i - 1) % world_size
7 | start_idx = sub_seq_length * device_of_incoming_k
8 | end_idx = sub_seq_length * (device_of_incoming_k + 1)
9 | return start_idx, end_idx
10 |
11 |
12 | def _calc_current_device_range(rank, sub_seq_length):
13 | start_idx = sub_seq_length * rank
14 | end_idx = sub_seq_length * (rank + 1)
15 | return start_idx, end_idx
16 |
--------------------------------------------------------------------------------
/colossalai/legacy/nn/layer/utils/__init__.py:
--------------------------------------------------------------------------------
1 | from .common import (
2 | ACT2FN,
3 | CheckpointModule,
4 | _ntuple,
5 | divide,
6 | get_tensor_parallel_mode,
7 | set_tensor_parallel_attribute_by_partition,
8 | set_tensor_parallel_attribute_by_size,
9 | to_2tuple,
10 | )
11 |
12 | __all__ = [
13 | "CheckpointModule",
14 | "divide",
15 | "ACT2FN",
16 | "set_tensor_parallel_attribute_by_size",
17 | "set_tensor_parallel_attribute_by_partition",
18 | "get_tensor_parallel_mode",
19 | "_ntuple",
20 | "to_2tuple",
21 | ]
22 |
--------------------------------------------------------------------------------
/colossalai/legacy/nn/layer/vanilla/__init__.py:
--------------------------------------------------------------------------------
1 | from .layers import (
2 | DropPath,
3 | VanillaClassifier,
4 | VanillaLayerNorm,
5 | VanillaLinear,
6 | VanillaPatchEmbedding,
7 | WrappedDropout,
8 | WrappedDropPath,
9 | )
10 |
11 | __all__ = [
12 | "VanillaLayerNorm",
13 | "VanillaPatchEmbedding",
14 | "VanillaClassifier",
15 | "DropPath",
16 | "WrappedDropout",
17 | "WrappedDropPath",
18 | "VanillaLinear",
19 | ]
20 |
--------------------------------------------------------------------------------
/colossalai/legacy/nn/layer/wrapper/__init__.py:
--------------------------------------------------------------------------------
1 | from .pipeline_wrapper import PipelineSharedModuleWrapper
2 |
3 | __all__ = ["PipelineSharedModuleWrapper"]
4 |
--------------------------------------------------------------------------------
/colossalai/legacy/nn/metric/__init__.py:
--------------------------------------------------------------------------------
1 | from torch import nn
2 |
3 | from colossalai.legacy.nn.layer.utils import get_tensor_parallel_mode
4 |
5 | from ._utils import calc_acc
6 | from .accuracy_2d import Accuracy2D
7 | from .accuracy_2p5d import Accuracy2p5D
8 | from .accuracy_3d import Accuracy3D
9 |
10 | _parallel_accuracy = {
11 | "2d": Accuracy2D,
12 | "2.5d": Accuracy2p5D,
13 | "3d": Accuracy3D,
14 | }
15 |
16 |
17 | class Accuracy(nn.Module):
18 | def __init__(self):
19 | super().__init__()
20 | tensor_parallel = get_tensor_parallel_mode()
21 | if tensor_parallel not in _parallel_accuracy:
22 | self.acc = calc_acc
23 | else:
24 | self.acc = _parallel_accuracy[tensor_parallel]()
25 |
26 | def forward(self, *args):
27 | return self.acc(*args)
28 |
--------------------------------------------------------------------------------
/colossalai/legacy/nn/metric/_utils.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 |
4 | def calc_acc(logits, targets):
5 | preds = torch.argmax(logits, dim=-1)
6 | correct = torch.sum(targets == preds)
7 | return correct
8 |
--------------------------------------------------------------------------------
/colossalai/legacy/nn/parallel/__init__.py:
--------------------------------------------------------------------------------
1 | from .data_parallel import ColoDDP
2 |
3 | __all__ = [
4 | "ColoDDP",
5 | ]
6 |
--------------------------------------------------------------------------------
/colossalai/legacy/pipeline/__init__.py:
--------------------------------------------------------------------------------
1 | from .layer_spec import LayerSpec
2 | from .pipelinable import PipelinableContext, PipelinableModel
3 |
4 | __all__ = ["PipelinableModel", "PipelinableContext", "LayerSpec"]
5 |
--------------------------------------------------------------------------------
/colossalai/legacy/pipeline/middleware/__init__.py:
--------------------------------------------------------------------------------
1 | from .topo import Partition, PartitionInputVal, PartitionOutputVal, Topo
2 |
3 | __all__ = ["Topo", "Partition", "PartitionOutputVal", "PartitionInputVal"]
4 |
--------------------------------------------------------------------------------
/colossalai/legacy/pipeline/middleware/adaptor/__init__.py:
--------------------------------------------------------------------------------
1 | from .fx import get_topology as get_fx_topology
2 |
3 | __all__ = ["get_fx_topology"]
4 |
--------------------------------------------------------------------------------
/colossalai/legacy/pipeline/rpc/__init__.py:
--------------------------------------------------------------------------------
1 | from ._pipeline_schedule import ChimeraPipelineEngine, FillDrainPipelineEngine, OneFOneBPipelineEngine
2 | from .utils import pytree_map
3 |
4 | __all__ = ["FillDrainPipelineEngine", "OneFOneBPipelineEngine", "ChimeraPipelineEngine", "pytree_map"]
5 |
--------------------------------------------------------------------------------
/colossalai/legacy/registry/__init__.py:
--------------------------------------------------------------------------------
1 | import torch.distributed.optim as dist_optim
2 | import torch.nn as nn
3 | import torch.optim as optim
4 |
5 | from .registry import Registry
6 |
7 | LAYERS = Registry("layers", third_party_library=[nn])
8 | MODELS = Registry("models")
9 | OPTIMIZERS = Registry("optimizers", third_party_library=[optim, dist_optim])
10 | DATASETS = Registry("datasets")
11 | DIST_GROUP_INITIALIZER = Registry("dist_group_initializer")
12 | GRADIENT_HANDLER = Registry("gradient_handler")
13 | LOSSES = Registry("losses", third_party_library=[nn])
14 | HOOKS = Registry("hooks")
15 | TRANSFORMS = Registry("transforms")
16 | DATA_SAMPLERS = Registry("data_samplers")
17 | LR_SCHEDULERS = Registry("lr_schedulers")
18 | SCHEDULE = Registry("schedules")
19 | OPHOOKS = Registry("ophooks")
20 |
--------------------------------------------------------------------------------
/colossalai/legacy/tensor/__init__.py:
--------------------------------------------------------------------------------
1 | from . import distspec
2 | from .compute_spec import ComputePattern, ComputeSpec
3 | from .dist_spec_mgr import DistSpecManager
4 | from .distspec import ReplicaSpec, ShardSpec
5 | from .process_group import ProcessGroup
6 | from .tensor_spec import ColoTensorSpec
7 |
8 | __all__ = [
9 | "ComputePattern",
10 | "ComputeSpec",
11 | "distspec",
12 | "DistSpecManager",
13 | "ProcessGroup",
14 | "ColoTensorSpec",
15 | "ShardSpec",
16 | "ReplicaSpec",
17 | ]
18 |
--------------------------------------------------------------------------------
/colossalai/legacy/tensor/const.py:
--------------------------------------------------------------------------------
1 | from enum import Enum
2 |
3 |
4 | class TensorType(Enum):
5 | MODEL = 0
6 | NONMODEL = 1 # mainly activations
7 |
--------------------------------------------------------------------------------
/colossalai/legacy/trainer/__init__.py:
--------------------------------------------------------------------------------
1 | from ._trainer import Trainer
2 |
3 | __all__ = ["Trainer"]
4 |
--------------------------------------------------------------------------------
/colossalai/legacy/trainer/hooks/__init__.py:
--------------------------------------------------------------------------------
1 | from ._base_hook import BaseHook
2 | from ._checkpoint_hook import SaveCheckpointHook
3 | from ._log_hook import (
4 | LogMemoryByEpochHook,
5 | LogMetricByEpochHook,
6 | LogMetricByStepHook,
7 | LogTimingByEpochHook,
8 | TensorboardHook,
9 | )
10 | from ._lr_scheduler_hook import LRSchedulerHook
11 | from ._metric_hook import AccuracyHook, LossHook, MetricHook, ThroughputHook
12 |
13 | __all__ = [
14 | "BaseHook",
15 | "MetricHook",
16 | "LossHook",
17 | "AccuracyHook",
18 | "LogMetricByEpochHook",
19 | "TensorboardHook",
20 | "LogTimingByEpochHook",
21 | "LogMemoryByEpochHook",
22 | "LRSchedulerHook",
23 | "ThroughputHook",
24 | "LogMetricByStepHook",
25 | "SaveCheckpointHook",
26 | ]
27 |
--------------------------------------------------------------------------------
/colossalai/legacy/trainer/hooks/_commons_.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 |
4 | def _format_number(val, prec=5):
5 | if isinstance(val, float):
6 | return f"{val:.{prec}g}"
7 | elif torch.is_tensor(val) and torch.is_floating_point(val):
8 | return f"{val.item():.{prec}g}"
9 | return val
10 |
--------------------------------------------------------------------------------
/colossalai/legacy/utils/checkpoint/__init__.py:
--------------------------------------------------------------------------------
1 | from .module_checkpoint import load_checkpoint, save_checkpoint
2 |
3 | __all__ = ["save_checkpoint", "load_checkpoint"]
4 |
--------------------------------------------------------------------------------
/colossalai/legacy/utils/data_sampler/__init__.py:
--------------------------------------------------------------------------------
1 | from .base_sampler import BaseSampler
2 | from .data_parallel_sampler import DataParallelSampler, get_dataloader
3 |
4 | __all__ = ["BaseSampler", "DataParallelSampler", "get_dataloader"]
5 |
--------------------------------------------------------------------------------
/colossalai/legacy/utils/data_sampler/base_sampler.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | from abc import ABC, abstractmethod
5 |
6 |
7 | class BaseSampler(ABC):
8 | def __init__(self, dataset, batch_size):
9 | self.dataset = dataset
10 | self.batch_size = batch_size
11 |
12 | @abstractmethod
13 | def __len__(self):
14 | pass
15 |
16 | @abstractmethod
17 | def __iter__(self):
18 | pass
19 |
--------------------------------------------------------------------------------
/colossalai/legacy/utils/profiler/__init__.py:
--------------------------------------------------------------------------------
1 | from .legacy import *
2 | from .profiler import profile
3 |
--------------------------------------------------------------------------------
/colossalai/legacy/utils/profiler/extention.py:
--------------------------------------------------------------------------------
1 | from abc import ABC, abstractmethod
2 |
3 |
4 | class ProfilerExtension(ABC):
5 | @abstractmethod
6 | def prepare_trace(self):
7 | pass
8 |
9 | @abstractmethod
10 | def start_trace(self):
11 | pass
12 |
13 | @abstractmethod
14 | def stop_trace(self):
15 | pass
16 |
17 | @abstractmethod
18 | def extend_chrome_trace(self, trace: dict) -> dict:
19 | pass
20 |
--------------------------------------------------------------------------------
/colossalai/legacy/utils/profiler/legacy/__init__.py:
--------------------------------------------------------------------------------
1 | from .comm_profiler import CommProfiler
2 | from .mem_profiler import MemProfiler
3 | from .pcie_profiler import PcieProfiler
4 | from .prof_utils import BaseProfiler, ProfilerContext
5 |
6 | __all__ = ["BaseProfiler", "CommProfiler", "PcieProfiler", "MemProfiler", "ProfilerContext"]
7 |
--------------------------------------------------------------------------------
/colossalai/legacy/zero/gemini/__init__.py:
--------------------------------------------------------------------------------
1 | from .colo_init_context import ColoInitContext, post_process_colo_init_ctx
2 | from .ophooks import BaseOpHook, register_ophooks_recursively
3 | from .stateful_tensor import StatefulTensor
4 | from .stateful_tensor_mgr import StatefulTensorMgr
5 | from .tensor_placement_policy import AutoTensorPlacementPolicy, CPUTensorPlacementPolicy, CUDATensorPlacementPolicy
6 |
7 | __all__ = [
8 | "StatefulTensorMgr",
9 | "StatefulTensor",
10 | "CPUTensorPlacementPolicy",
11 | "CUDATensorPlacementPolicy",
12 | "AutoTensorPlacementPolicy",
13 | "register_ophooks_recursively",
14 | "BaseOpHook",
15 | "ColoInitContext",
16 | "post_process_colo_init_ctx",
17 | ]
18 |
--------------------------------------------------------------------------------
/colossalai/legacy/zero/gemini/ophooks/__init__.py:
--------------------------------------------------------------------------------
1 | from .utils import BaseOpHook, register_ophooks_recursively
2 |
3 | __all__ = ["BaseOpHook", "register_ophooks_recursively"]
4 |
--------------------------------------------------------------------------------
/colossalai/legacy/zero/gemini/paramhooks/__init__.py:
--------------------------------------------------------------------------------
1 | from ._param_hookmgr import BaseParamHookMgr
2 |
3 | __all__ = ["BaseParamHookMgr"]
4 |
--------------------------------------------------------------------------------
/colossalai/legacy/zero/init_ctx/__init__.py:
--------------------------------------------------------------------------------
1 | from .init_context import ZeroInitContext, no_shard_zero_context, no_shard_zero_decrator
2 |
3 | __all__ = ["ZeroInitContext", "no_shard_zero_context", "no_shard_zero_decrator"]
4 |
--------------------------------------------------------------------------------
/colossalai/legacy/zero/shard_utils/__init__.py:
--------------------------------------------------------------------------------
1 | from .base_shard_strategy import BaseShardStrategy
2 | from .bucket_tensor_shard_strategy import BucketTensorShardStrategy
3 | from .tensor_shard_strategy import TensorShardStrategy
4 |
5 | __all__ = ["BaseShardStrategy", "TensorShardStrategy", "BucketTensorShardStrategy"]
6 |
--------------------------------------------------------------------------------
/colossalai/legacy/zero/shard_utils/base_shard_strategy.py:
--------------------------------------------------------------------------------
1 | from abc import ABC, abstractmethod
2 | from typing import List, Optional
3 |
4 | import torch.distributed as dist
5 |
6 | from colossalai.legacy.zero.sharded_param.sharded_tensor import ShardedTensor
7 |
8 |
9 | class BaseShardStrategy(ABC):
10 | def __init__(self) -> None:
11 | """Abstract Shard Strategy. Use to shard a tensors on multiple GPUs."""
12 | super().__init__()
13 |
14 | @abstractmethod
15 | def shard(self, tensor_list: List[ShardedTensor], process_group: Optional[dist.ProcessGroup] = None):
16 | pass
17 |
18 | @abstractmethod
19 | def gather(self, tensor_list: List[ShardedTensor], process_group: Optional[dist.ProcessGroup] = None):
20 | pass
21 |
--------------------------------------------------------------------------------
/colossalai/legacy/zero/sharded_model/__init__.py:
--------------------------------------------------------------------------------
1 | from .sharded_model_v2 import ShardedModelV2
2 |
3 | __all__ = ["ShardedModelV2"]
4 |
--------------------------------------------------------------------------------
/colossalai/legacy/zero/sharded_optim/__init__.py:
--------------------------------------------------------------------------------
1 | from .sharded_optim_v2 import ShardedOptimizerV2
2 |
3 | __all__ = ["ShardedOptimizerV2"]
4 |
--------------------------------------------------------------------------------
/colossalai/legacy/zero/sharded_param/__init__.py:
--------------------------------------------------------------------------------
1 | from .sharded_param import ShardedParamV2
2 | from .sharded_tensor import ShardedTensor
3 |
4 | __all__ = ["ShardedTensor", "ShardedParamV2"]
5 |
--------------------------------------------------------------------------------
/colossalai/moe/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/moe/__init__.py
--------------------------------------------------------------------------------
/colossalai/nn/__init__.py:
--------------------------------------------------------------------------------
1 | from .init import *
2 | from .layer import *
3 | from .loss import *
4 | from .lr_scheduler import *
5 | from .optimizer import *
6 |
--------------------------------------------------------------------------------
/colossalai/nn/layer/__init__.py:
--------------------------------------------------------------------------------
1 | from .utils import *
2 |
--------------------------------------------------------------------------------
/colossalai/nn/layer/utils.py:
--------------------------------------------------------------------------------
1 | def divide(numerator, denominator):
2 | """Only allow exact division.
3 |
4 | Args:
5 | numerator (int): Numerator of the division.
6 | denominator (int): Denominator of the division.
7 |
8 | Returns:
9 | int: the result of exact division.
10 | """
11 | assert denominator != 0, "denominator can not be zero"
12 | assert numerator % denominator == 0, "{} is not divisible by {}".format(numerator, denominator)
13 | return numerator // denominator
14 |
--------------------------------------------------------------------------------
/colossalai/nn/loss/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/nn/loss/__init__.py
--------------------------------------------------------------------------------
/colossalai/nn/lr_scheduler/__init__.py:
--------------------------------------------------------------------------------
1 | from .cosine import CosineAnnealingLR, CosineAnnealingWarmupLR, FlatAnnealingLR, FlatAnnealingWarmupLR
2 | from .linear import LinearWarmupLR
3 | from .multistep import MultiStepLR, MultiStepWarmupLR
4 | from .onecycle import OneCycleLR
5 | from .poly import PolynomialLR, PolynomialWarmupLR
6 | from .torch import ExponentialLR, LambdaLR, MultiplicativeLR, StepLR
7 |
8 | __all__ = [
9 | "CosineAnnealingLR",
10 | "CosineAnnealingWarmupLR",
11 | "FlatAnnealingLR",
12 | "FlatAnnealingWarmupLR",
13 | "LinearWarmupLR",
14 | "MultiStepLR",
15 | "MultiStepWarmupLR",
16 | "OneCycleLR",
17 | "PolynomialLR",
18 | "PolynomialWarmupLR",
19 | "LambdaLR",
20 | "MultiplicativeLR",
21 | "StepLR",
22 | "ExponentialLR",
23 | ]
24 |
--------------------------------------------------------------------------------
/colossalai/pipeline/__init__.py:
--------------------------------------------------------------------------------
1 | from .p2p import PipelineP2PCommunication
2 | from .schedule import InterleavedSchedule, OneForwardOneBackwardSchedule, PipelineSchedule, ZeroBubbleVPipeScheduler
3 | from .stage_manager import PipelineStageManager
4 |
5 | __all__ = [
6 | "PipelineSchedule",
7 | "OneForwardOneBackwardSchedule",
8 | "InterleavedSchedule",
9 | "ZeroBubbleVPipeScheduler",
10 | "PipelineP2PCommunication",
11 | "PipelineStageManager",
12 | ]
13 |
--------------------------------------------------------------------------------
/colossalai/pipeline/schedule/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import PipelineSchedule
2 | from .interleaved_pp import InterleavedSchedule
3 | from .one_f_one_b import OneForwardOneBackwardSchedule
4 | from .zero_bubble_pp import ZeroBubbleVPipeScheduler
5 |
6 | __all__ = [
7 | "PipelineSchedule",
8 | "OneForwardOneBackwardSchedule",
9 | "InterleavedSchedule",
10 | "ZeroBubbleVPipeScheduler",
11 | ]
12 |
--------------------------------------------------------------------------------
/colossalai/quantization/__init__.py:
--------------------------------------------------------------------------------
1 | from .bnb import quantize_model
2 | from .bnb_config import BnbQuantizationConfig
3 |
4 | __all__ = [
5 | "BnbQuantizationConfig",
6 | "quantize_model",
7 | ]
8 |
--------------------------------------------------------------------------------
/colossalai/quantization/fp8_config.py:
--------------------------------------------------------------------------------
1 | dynamic_kernel: bool = False
2 |
--------------------------------------------------------------------------------
/colossalai/quantization/fp8_hook.py:
--------------------------------------------------------------------------------
1 | import torch.nn.functional as F
2 |
3 | from colossalai.quantization.fp8 import linear_fp8
4 | from colossalai.tensor.param_op_hook import ColoParamOpHook
5 |
6 |
7 | class FP8Hook(ColoParamOpHook):
8 | def pre_forward(self, params) -> None:
9 | pass
10 |
11 | def post_forward(self, params) -> None:
12 | pass
13 |
14 | def pre_backward(self, params) -> None:
15 | pass
16 |
17 | def post_backward(self, params) -> None:
18 | pass
19 |
20 | def rewrite_op(self, func):
21 | if func is F.linear:
22 | return linear_fp8
23 | return func
24 |
--------------------------------------------------------------------------------
/colossalai/shardformer/__init__.py:
--------------------------------------------------------------------------------
1 | from .shard import GradientCheckpointConfig, ModelSharder, PipelineGradientCheckpointConfig, ShardConfig, ShardFormer
2 |
--------------------------------------------------------------------------------
/colossalai/shardformer/examples/convergence_benchmark.sh:
--------------------------------------------------------------------------------
1 | torchrun --standalone --nproc_per_node=4 convergence_benchmark.py \
2 | --model "bert" \
3 | --pretrain "bert-base-uncased" \
4 | --max_epochs 3 \
5 | --batch_size 2 \
6 | --lr 2.4e-5 \
7 | --fused_layernorm False \
8 | --accumulation_steps 8 \
9 | --warmup_fraction 0.03
10 |
--------------------------------------------------------------------------------
/colossalai/shardformer/modeling/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/shardformer/modeling/__init__.py
--------------------------------------------------------------------------------
/colossalai/shardformer/modeling/chatglm2_6b/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/shardformer/modeling/chatglm2_6b/__init__.py
--------------------------------------------------------------------------------
/colossalai/shardformer/policies/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/shardformer/policies/__init__.py
--------------------------------------------------------------------------------
/colossalai/shardformer/shard/__init__.py:
--------------------------------------------------------------------------------
1 | from .grad_ckpt_config import GradientCheckpointConfig, PipelineGradientCheckpointConfig
2 | from .shard_config import ShardConfig
3 | from .sharder import ModelSharder
4 | from .shardformer import ShardFormer
5 |
6 | __all__ = ["ShardConfig", "ModelSharder", "ShardFormer", "PipelineGradientCheckpointConfig", "GradientCheckpointConfig"]
7 |
--------------------------------------------------------------------------------
/colossalai/shardformer/shard/utils.py:
--------------------------------------------------------------------------------
1 | from typing import Set
2 |
3 | import torch.nn as nn
4 |
5 |
6 | def set_tensors_to_none(model: nn.Module, exclude: Set[nn.Module] = set()) -> None:
7 | """Set all parameters and buffers of model to None
8 |
9 | Args:
10 | model (nn.Module): The model to set
11 | """
12 | if model in exclude:
13 | return
14 | for child in model.children():
15 | set_tensors_to_none(child, exclude=exclude)
16 | for n, p in model.named_parameters(recurse=False):
17 | setattr(model, n, None)
18 | for n, buf in model.named_buffers(recurse=False):
19 | setattr(model, n, None)
20 |
--------------------------------------------------------------------------------
/colossalai/tensor/__init__.py:
--------------------------------------------------------------------------------
1 | from .colo_parameter import ColoParameter
2 | from .colo_tensor import ColoTensor
3 | from .comm_spec import CollectiveCommPattern, CommSpec
4 | from .param_op_hook import ColoParamOpHook, ColoParamOpHookManager
5 | from .utils import convert_dim_partition_dict, convert_parameter, merge_same_dim_mesh_list, named_params_with_colotensor
6 |
7 | __all__ = [
8 | "ColoTensor",
9 | "convert_parameter",
10 | "named_params_with_colotensor",
11 | "ColoParameter",
12 | "ColoParamOpHook",
13 | "ColoParamOpHookManager",
14 | "CommSpec",
15 | "CollectiveCommPattern",
16 | "convert_dim_partition_dict",
17 | "merge_same_dim_mesh_list",
18 | ]
19 |
--------------------------------------------------------------------------------
/colossalai/tensor/d_tensor/misc.py:
--------------------------------------------------------------------------------
1 | class LayoutException(Exception):
2 | pass
3 |
4 |
5 | class DuplicatedShardingDimensionError(LayoutException):
6 | pass
7 |
8 |
9 | class ShardingNotDivisibleError(LayoutException):
10 | pass
11 |
12 |
13 | class ShardingOutOfIndexError(LayoutException):
14 | pass
15 |
--------------------------------------------------------------------------------
/colossalai/tensor/moe_tensor/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/tensor/moe_tensor/__init__.py
--------------------------------------------------------------------------------
/colossalai/tensor/padded_tensor/__init__.py:
--------------------------------------------------------------------------------
1 | from .api import init_as_padded_tensor, is_padded_tensor, to_padded_tensor, to_unpadded_tensor
2 |
3 | __all__ = ["is_padded_tensor", "to_padded_tensor", "to_unpadded_tensor", "init_as_padded_tensor"]
4 |
--------------------------------------------------------------------------------
/colossalai/testing/random.py:
--------------------------------------------------------------------------------
1 | import random
2 |
3 | import numpy as np
4 | import torch
5 |
6 |
7 | def seed_all(seed, cuda_deterministic=False):
8 | random.seed(seed)
9 | np.random.seed(seed)
10 | torch.manual_seed(seed)
11 | if torch.cuda.is_available():
12 | torch.cuda.manual_seed(seed)
13 | torch.cuda.manual_seed_all(seed)
14 | if cuda_deterministic: # slower, more reproducible
15 | torch.backends.cudnn.deterministic = True
16 | torch.backends.cudnn.benchmark = False
17 | else:
18 | torch.backends.cudnn.deterministic = False
19 | torch.backends.cudnn.benchmark = True
20 |
--------------------------------------------------------------------------------
/colossalai/utils/__init__.py:
--------------------------------------------------------------------------------
1 | from .common import (
2 | _cast_float,
3 | conditional_context,
4 | disposable,
5 | ensure_path_exists,
6 | free_storage,
7 | get_current_device,
8 | get_non_persistent_buffers_set,
9 | is_ddp_ignored,
10 | set_seed,
11 | )
12 | from .multi_tensor_apply import multi_tensor_applier
13 | from .tensor_detector import TensorDetector
14 | from .timer import MultiTimer, Timer
15 |
16 | __all__ = [
17 | "conditional_context",
18 | "Timer",
19 | "MultiTimer",
20 | "multi_tensor_applier",
21 | "TensorDetector",
22 | "ensure_path_exists",
23 | "disposable",
24 | "_cast_float",
25 | "free_storage",
26 | "set_seed",
27 | "get_current_device",
28 | "is_ddp_ignored",
29 | "get_non_persistent_buffers_set",
30 | ]
31 |
--------------------------------------------------------------------------------
/colossalai/utils/model/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/colossalai/utils/model/__init__.py
--------------------------------------------------------------------------------
/colossalai/utils/multi_tensor_apply/__init__.py:
--------------------------------------------------------------------------------
1 | from .multi_tensor_apply import MultiTensorApply
2 |
3 | multi_tensor_applier = MultiTensorApply(2048 * 32)
4 |
--------------------------------------------------------------------------------
/colossalai/utils/rank_recorder/__init__.py:
--------------------------------------------------------------------------------
1 | from colossalai.utils.rank_recorder.rank_recorder import recorder
2 |
3 | __all__ = ["recorder"]
4 |
--------------------------------------------------------------------------------
/colossalai/utils/tensor_detector/__init__.py:
--------------------------------------------------------------------------------
1 | from .tensor_detector import TensorDetector
2 |
--------------------------------------------------------------------------------
/colossalai/zero/__init__.py:
--------------------------------------------------------------------------------
1 | from .gemini import GeminiAdamOptimizer, GeminiDDP, GeminiOptimizer, get_static_torch_model
2 | from .low_level import LowLevelZeroOptimizer
3 | from .wrapper import zero_model_wrapper, zero_optim_wrapper
4 |
5 | __all__ = [
6 | "GeminiDDP",
7 | "GeminiOptimizer",
8 | "GeminiAdamOptimizer",
9 | "zero_model_wrapper",
10 | "zero_optim_wrapper",
11 | "LowLevelZeroOptimizer",
12 | "get_static_torch_model",
13 | ]
14 |
--------------------------------------------------------------------------------
/colossalai/zero/gemini/__init__.py:
--------------------------------------------------------------------------------
1 | from .chunk import ChunkManager, TensorInfo, TensorState, search_chunk_configuration
2 | from .gemini_ddp import GeminiDDP
3 | from .gemini_mgr import GeminiManager
4 | from .gemini_optimizer import GeminiAdamOptimizer, GeminiOptimizer
5 | from .utils import get_static_torch_model
6 |
7 | __all__ = [
8 | "GeminiManager",
9 | "TensorInfo",
10 | "TensorState",
11 | "ChunkManager",
12 | "search_chunk_configuration",
13 | "GeminiDDP",
14 | "get_static_torch_model",
15 | "GeminiAdamOptimizer",
16 | "GeminiOptimizer",
17 | ]
18 |
--------------------------------------------------------------------------------
/colossalai/zero/gemini/chunk/__init__.py:
--------------------------------------------------------------------------------
1 | from .chunk import Chunk, ChunkFullError, TensorInfo, TensorState
2 | from .manager import ChunkManager
3 | from .search_utils import classify_params_by_dp_degree, search_chunk_configuration
4 | from .utils import init_chunk_manager
5 |
6 | __all__ = ["Chunk", "ChunkManager", "classify_params_by_dp_degree", "search_chunk_configuration", "init_chunk_manager"]
7 |
--------------------------------------------------------------------------------
/colossalai/zero/gemini/memory_tracer/__init__.py:
--------------------------------------------------------------------------------
1 | from .param_runtime_order import OrderedParamGenerator # isort:skip
2 | from .memory_stats import MemStats # isort:skip
3 | from .memory_monitor import AsyncMemoryMonitor, SyncCudaMemoryMonitor # isort:skip
4 | from .memstats_collector import MemStatsCollector # isort:skip
5 | from .chunk_memstats_collector import ChunkMemStatsCollector # isort:skip
6 |
7 | __all__ = [
8 | "AsyncMemoryMonitor",
9 | "SyncCudaMemoryMonitor",
10 | "MemStatsCollector",
11 | "ChunkMemStatsCollector",
12 | "MemStats",
13 | "OrderedParamGenerator",
14 | ]
15 |
--------------------------------------------------------------------------------
/colossalai/zero/low_level/__init__.py:
--------------------------------------------------------------------------------
1 | from .low_level_optim import LowLevelZeroOptimizer
2 |
3 | __all__ = ["LowLevelZeroOptimizer"]
4 |
--------------------------------------------------------------------------------
/colossalai/zero/low_level/bookkeeping/__init__.py:
--------------------------------------------------------------------------------
1 | from .bucket_store import BucketStore
2 | from .gradient_store import GradientStore
3 | from .tensor_bucket import TensorBucket
4 |
5 | __all__ = ["GradientStore", "BucketStore", "TensorBucket"]
6 |
--------------------------------------------------------------------------------
/docs/conda-doc-test-deps.yml:
--------------------------------------------------------------------------------
1 | dependencies:
2 | - cmake
3 |
--------------------------------------------------------------------------------
/docs/requirements-doc-test.txt:
--------------------------------------------------------------------------------
1 | colossalai
2 | torch
3 | packaging
4 | tensornvme
5 | psutil
6 | transformers
7 | pytest
8 |
--------------------------------------------------------------------------------
/docs/source/en/Colossal-Auto/feature/auto_checkpoint.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/docs/source/en/Colossal-Auto/feature/auto_checkpoint.md
--------------------------------------------------------------------------------
/docs/source/en/Colossal-Auto/feature/device_mesh.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/docs/source/en/Colossal-Auto/feature/device_mesh.md
--------------------------------------------------------------------------------
/docs/source/en/Colossal-Auto/feature/tracer.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/docs/source/en/Colossal-Auto/feature/tracer.md
--------------------------------------------------------------------------------
/docs/source/en/features/cluster_utils.md:
--------------------------------------------------------------------------------
1 | # Cluster Utilities
2 |
3 | Author: [Hongxin Liu](https://github.com/ver217)
4 |
5 | **Prerequisite:**
6 | - [Distributed Training](../concepts/distributed_training.md)
7 |
8 | ## Introduction
9 |
10 | We provide a utility class `colossalai.cluster.DistCoordinator` to coordinate distributed training. It's useful to get various information about the cluster, such as the number of nodes, the number of processes per node, etc.
11 |
12 | ## API Reference
13 |
14 | {{ autodoc:colossalai.cluster.DistCoordinator }}
15 |
16 |
17 |
--------------------------------------------------------------------------------
/docs/source/zh-Hans/Colossal-Auto/feature/auto_checkpoint.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/docs/source/zh-Hans/Colossal-Auto/feature/auto_checkpoint.md
--------------------------------------------------------------------------------
/docs/source/zh-Hans/Colossal-Auto/feature/device_mesh.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/docs/source/zh-Hans/Colossal-Auto/feature/device_mesh.md
--------------------------------------------------------------------------------
/docs/source/zh-Hans/Colossal-Auto/feature/tracer.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/docs/source/zh-Hans/Colossal-Auto/feature/tracer.md
--------------------------------------------------------------------------------
/docs/source/zh-Hans/Colossal-Auto/get_started/installation.md:
--------------------------------------------------------------------------------
1 | # 安装
2 |
3 | ## 声明
4 |
5 | 我们的自动并行功能处于alpha版本,仍在快速的开发迭代中。我们会在兼容性和稳定性上做持续地改进。如果您遇到任何问题,欢迎随时提issue给我们。
6 |
7 |
8 | ## 要求
9 |
10 | 我们需要一些额外的依赖性来支持自动并行功能。 请在使用自动平行之前安装它们。
11 |
12 | ### 安装PyTorch
13 |
14 | 我们仅支持Pytorch 1.12,现在未测试其他版本。 将来我们将支持更多版本。
15 |
16 | ```bash
17 | #conda
18 | conda install pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 -c pytorch
19 | #pip
20 | pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 torchaudio==0.12.0 --extra-index-url https://download.pytorch.org/whl/cu113
21 | ```
22 |
23 | ### 安装pulp和coin-or-cbc
24 |
25 | ```bash
26 | pip install pulp
27 | conda install -c conda-forge coin-or-cbc
28 | ```
29 |
--------------------------------------------------------------------------------
/docs/source/zh-Hans/basics/command_line_tool.md:
--------------------------------------------------------------------------------
1 | # 命令行工具
2 |
3 | 作者: Shenggui Li
4 |
5 | **预备知识:**
6 | - [Distributed Training](../concepts/distributed_training.md)
7 | - [Colossal-AI Overview](../concepts/colossalai_overview.md)
8 |
9 | ## 简介
10 |
11 | Colossal-AI给用户提供了命令行工具,目前命令行工具可以用来支持以下功能。
12 | - 检查Colossal-AI是否安装正确
13 | - 启动分布式训练
14 | - 张量并行基准测试
15 |
16 | ## 安装检查
17 |
18 | 用户可以使用`colossalai check -i`这个命令来检查目前环境里的版本兼容性以及CUDA Extension的状态。
19 |
20 |
21 | 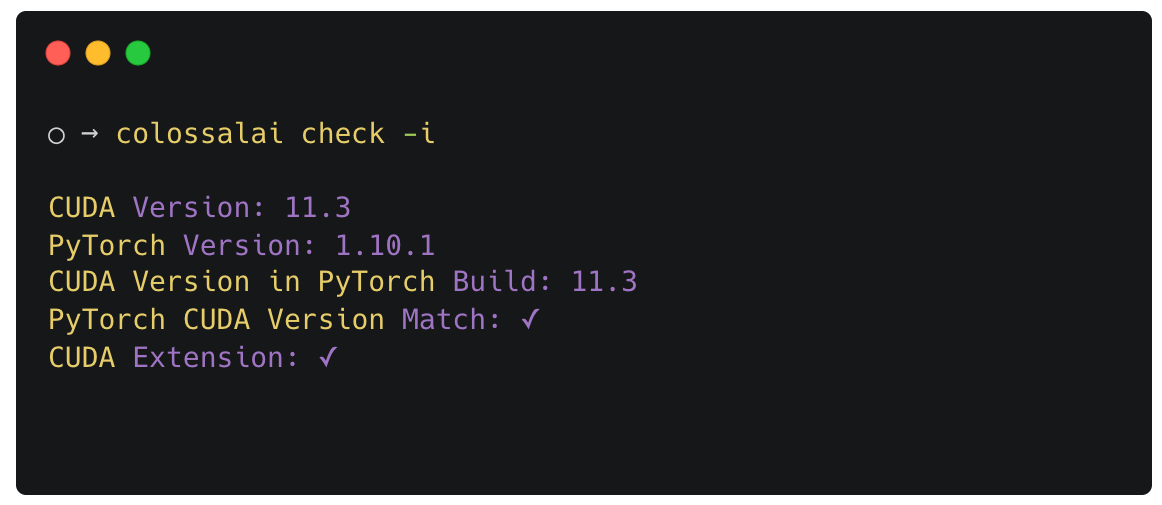 22 | Check Installation Demo
23 |
24 |
25 | ## 启动分布式训练
26 |
27 | 在分布式训练时,我们可以使用`colossalai run`来启动单节点或者多节点的多进程,详细的内容可以参考[启动 Colossal-AI](./launch_colossalai.md)。
28 |
29 |
30 |
--------------------------------------------------------------------------------
/docs/source/zh-Hans/features/cluster_utils.md:
--------------------------------------------------------------------------------
1 | # 集群实用程序
2 |
3 | 作者: [Hongxin Liu](https://github.com/ver217)
4 |
5 | **前置教程:**
6 | - [分布式训练](../concepts/distributed_training.md)
7 |
8 | ## 引言
9 |
10 | 我们提供了一个实用程序类 `colossalai.cluster.DistCoordinator` 来协调分布式训练。它对于获取有关集群的各种信息很有用,例如节点数、每个节点的进程数等。
11 |
12 | ## API 参考
13 |
14 | {{ autodoc:colossalai.cluster.DistCoordinator }}
15 |
16 |
17 |
--------------------------------------------------------------------------------
/docs/source/zh-Hans/get_started/reading_roadmap.md:
--------------------------------------------------------------------------------
1 | # 阅读指引
2 |
3 | Colossal-AI为您提供了一系列的并行训练组件。我们的目标是支持您开发分布式深度学习模型,就像您编写单GPU深度学习模型一样简单。ColossalAI提供了易于使用的API来帮助您启动您的训练过程。为了更好地了解ColossalAI的工作原理,我们建议您按照以下顺序阅读本文档。
4 |
5 | - 如果您不熟悉分布式系统,或者没有使用过Colossal-AI,您可以先浏览`概念`部分,了解我们要实现的目标同时掌握一些关于分布式训练的背景知识。
6 | - 接下来,您可以按照`基础教程`进行学习。该节将介绍关于如何使用Colossal-AI的细节。
7 | - 这时候,您就可以小试牛刀了!`功能` 部分将帮助您尝试如何使用Colossal-AI为您的模型训练进行加速。我们将为每个教程提供一个代码库。这些教程将涵盖Colossal-AI的基本用法,以实现简单的功能,如数据并行和混合精度训练。
8 | - 最后,如果您希望应用更高超的技术,比如,如何在GPT-3上运行混合并行,快来`高级教程`部分学习如何搭建您自己的模型吧!
9 |
10 | **我们始终欢迎社区的建议和讨论,如果您遇到任何问题,我们将非常愿意帮助您。您可以在GitHub 提 [issue](https://github.com/hpcaitech/ColossalAI/issues) ,或在[论坛](https://github.com/hpcaitech/ColossalAI/discussions)上创建一个讨论主题。**
11 |
--------------------------------------------------------------------------------
/docs/versions.json:
--------------------------------------------------------------------------------
1 | [
2 | "current"
3 | ]
4 |
--------------------------------------------------------------------------------
/examples/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/__init__.py
--------------------------------------------------------------------------------
/examples/community/fp8/mnist/README.md:
--------------------------------------------------------------------------------
1 | # Basic MNIST Example with optional FP8 of TransformerEngine
2 |
3 | [TransformerEngine](https://github.com/NVIDIA/TransformerEngine) is a library for accelerating Transformer models on NVIDIA GPUs, including using 8-bit floating point (FP8) precision on Hopper GPUs, to provide better performance with lower memory utilization in both training and inference.
4 |
5 | Thanks for the contribution to this tutorial from NVIDIA.
6 |
7 | ```bash
8 | python main.py
9 | python main.py --use-te # Linear layers from TransformerEngine
10 | python main.py --use-fp8 # FP8 + TransformerEngine for Linear layers
11 | ```
12 |
13 | > We are working to integrate it with Colossal-AI and will finish it soon.
14 |
--------------------------------------------------------------------------------
/examples/community/roberta/preprocessing/Makefile:
--------------------------------------------------------------------------------
1 | CXXFLAGS += -O3 -Wall -shared -std=c++14 -std=c++17 -fPIC -fdiagnostics-color
2 | CPPFLAGS += $(shell python3 -m pybind11 --includes)
3 | LIBNAME = mask
4 | LIBEXT = $(shell python3-config --extension-suffix)
5 |
6 | default: $(LIBNAME)$(LIBEXT)
7 |
8 | %$(LIBEXT): %.cpp
9 | $(CXX) $(CXXFLAGS) $(CPPFLAGS) $< -o $@
10 |
--------------------------------------------------------------------------------
/examples/community/roberta/pretraining/bert_dataset_provider.py:
--------------------------------------------------------------------------------
1 | class BertDatasetProviderInterface:
2 | def get_shard(self, index, shuffle=True):
3 | raise NotImplementedError
4 |
5 | def release_shard(self, index):
6 | raise NotImplementedError
7 |
8 | def prefetch_shard(self, index):
9 | raise NotImplementedError
10 |
11 | def get_batch(self, batch_iter):
12 | raise NotImplementedError
13 |
14 | def prefetch_batch(self):
15 | raise NotImplementedError
16 |
--------------------------------------------------------------------------------
/examples/community/roberta/pretraining/hostfile:
--------------------------------------------------------------------------------
1 | GPU001
2 | GPU002
3 | GPU003
4 | GPU004
5 | GPU005
6 | GPU006
7 | GPU007
8 | GPU008
9 | GPU009
10 | GPU010
11 |
--------------------------------------------------------------------------------
/examples/community/roberta/pretraining/loss.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | __all__ = ["LossForPretraining"]
4 |
5 |
6 | class LossForPretraining(torch.nn.Module):
7 | def __init__(self, vocab_size):
8 | super(LossForPretraining, self).__init__()
9 | self.loss_fn = torch.nn.CrossEntropyLoss(ignore_index=-1)
10 | self.vocab_size = vocab_size
11 |
12 | def forward(self, prediction_scores, masked_lm_labels, next_sentence_labels=None):
13 | masked_lm_loss = self.loss_fn(prediction_scores.view(-1, self.vocab_size), masked_lm_labels.view(-1))
14 | # next_sentence_loss = self.loss_fn(seq_relationship_score.view(-1, 2), next_sentence_labels.view(-1))
15 | total_loss = masked_lm_loss # + next_sentence_loss
16 | return total_loss
17 |
--------------------------------------------------------------------------------
/examples/community/roberta/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.1.12
2 | torch >= 1.8.1
3 | tqdm
4 | tensorboard
5 | numpy
6 | h5py
7 | wandb
8 |
--------------------------------------------------------------------------------
/examples/community/roberta/test_ci.sh:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/community/roberta/test_ci.sh
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/.DS_Store
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/data/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/data/__init__.py
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/models/diffusion/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/models/diffusion/__init__.py
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/models/diffusion/dpm_solver/__init__.py:
--------------------------------------------------------------------------------
1 | from .sampler import DPMSolverSampler
2 |
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/modules/diffusionmodules/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/modules/diffusionmodules/__init__.py
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/modules/distributions/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/modules/distributions/__init__.py
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/modules/encoders/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/modules/encoders/__init__.py
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/modules/image_degradation/__init__.py:
--------------------------------------------------------------------------------
1 | from ldm.modules.image_degradation.bsrgan import degradation_bsrgan_variant as degradation_fn_bsr
2 | from ldm.modules.image_degradation.bsrgan_light import degradation_bsrgan_variant as degradation_fn_bsr_light
3 |
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/modules/image_degradation/utils/test.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/modules/image_degradation/utils/test.png
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/modules/midas/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/modules/midas/__init__.py
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/modules/midas/midas/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/modules/midas/midas/__init__.py
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/modules/midas/midas/base_model.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 |
4 | class BaseModel(torch.nn.Module):
5 | def load(self, path):
6 | """Load model from file.
7 |
8 | Args:
9 | path (str): file path
10 | """
11 | parameters = torch.load(path, map_location=torch.device("cpu"))
12 |
13 | if "optimizer" in parameters:
14 | parameters = parameters["model"]
15 |
16 | self.load_state_dict(parameters)
17 |
--------------------------------------------------------------------------------
/examples/images/diffusion/requirements.txt:
--------------------------------------------------------------------------------
1 | albumentations==1.3.0
2 | opencv-python==4.6.0.66
3 | pudb==2019.2
4 | prefetch_generator
5 | imageio==2.9.0
6 | imageio-ffmpeg==0.4.2
7 | torchmetrics==0.7
8 | omegaconf==2.1.1
9 | test-tube>=0.7.5
10 | streamlit>=1.11.1
11 | einops==0.3.0
12 | transformers
13 | webdataset==0.2.5
14 | open-clip-torch==2.7.0
15 | gradio==3.34.0
16 | lightning==1.9.0
17 | datasets
18 | colossalai
19 | -e .
20 |
--------------------------------------------------------------------------------
/examples/images/diffusion/scripts/tests/test_watermark.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import fire
3 | from imwatermark import WatermarkDecoder
4 |
5 |
6 | def testit(img_path):
7 | bgr = cv2.imread(img_path)
8 | decoder = WatermarkDecoder("bytes", 136)
9 | watermark = decoder.decode(bgr, "dwtDct")
10 | try:
11 | dec = watermark.decode("utf-8")
12 | except:
13 | dec = "null"
14 | print(dec)
15 |
16 |
17 | if __name__ == "__main__":
18 | fire.Fire(testit)
19 |
--------------------------------------------------------------------------------
/examples/images/diffusion/scripts/txt2img.sh:
--------------------------------------------------------------------------------
1 | python scripts/txt2img.py --prompt "Teyvat, Medium Female, a woman in a blue outfit holding a sword" --plms \
2 | --outdir ./output \
3 | --ckpt checkpoints/last.ckpt \
4 | --config configs/2023-02-02T18-06-14-project.yaml \
5 | --n_samples 4
6 |
--------------------------------------------------------------------------------
/examples/images/diffusion/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import find_packages, setup
2 |
3 | setup(
4 | name="latent-diffusion",
5 | version="0.0.1",
6 | description="",
7 | packages=find_packages(),
8 | install_requires=[
9 | "torch",
10 | "numpy",
11 | "tqdm",
12 | ],
13 | )
14 |
--------------------------------------------------------------------------------
/examples/images/diffusion/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -euxo pipefail
3 |
4 | conda env create -f environment.yaml
5 |
6 | conda activate ldm
7 |
8 | conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
9 | pip install transformers diffusers invisible-watermark
10 |
11 | BUILD_EXT=1 pip install colossalai
12 |
13 | wget https://huggingface.co/stabilityai/stable-diffusion-2-base/resolve/main/512-base-ema.ckpt
14 |
15 | python main.py --logdir /tmp --train --base configs/Teyvat/train_colossalai_teyvat.yaml --ckpt 512-base-ema.ckpt
16 |
--------------------------------------------------------------------------------
/examples/images/diffusion/train_colossalai.sh:
--------------------------------------------------------------------------------
1 | HF_DATASETS_OFFLINE=1
2 | TRANSFORMERS_OFFLINE=1
3 | DIFFUSERS_OFFLINE=1
4 |
5 | python main.py --logdir /tmp --train --base configs/Teyvat/train_colossalai_teyvat.yaml --ckpt diffuser_root_dir/512-base-ema.ckpt
6 |
--------------------------------------------------------------------------------
/examples/images/diffusion/train_ddp.sh:
--------------------------------------------------------------------------------
1 | HF_DATASETS_OFFLINE=1
2 | TRANSFORMERS_OFFLINE=1
3 | DIFFUSERS_OFFLINE=1
4 |
5 | python main.py --logdir /tmp -t -b /configs/train_ddp.yaml
6 |
--------------------------------------------------------------------------------
/examples/images/dreambooth/colossalai.sh:
--------------------------------------------------------------------------------
1 | HF_DATASETS_OFFLINE=1
2 | TRANSFORMERS_OFFLINE=1
3 | DIFFUSERS_OFFLINE=1
4 |
5 | torchrun --nproc_per_node 4 --standalone train_dreambooth_colossalai.py \
6 | --pretrained_model_name_or_path="/data/dreambooth/diffuser/stable-diffusion-v1-4" \
7 | --instance_data_dir="/data/dreambooth/Teyvat/data" \
8 | --output_dir="./weight_output" \
9 | --instance_prompt="a picture of a dog" \
10 | --resolution=512 \
11 | --plugin="gemini" \
12 | --train_batch_size=1 \
13 | --learning_rate=5e-6 \
14 | --lr_scheduler="constant" \
15 | --lr_warmup_steps=0 \
16 | --num_class_images=200 \
17 | --test_run=True \
18 | --placement="auto" \
19 |
--------------------------------------------------------------------------------
/examples/images/dreambooth/debug.py:
--------------------------------------------------------------------------------
1 | """
2 | torchrun --standalone --nproc_per_node=1 debug.py
3 | """
4 |
5 | from diffusers import AutoencoderKL
6 |
7 | import colossalai
8 | from colossalai.zero import ColoInitContext
9 |
10 | path = "/data/scratch/diffuser/stable-diffusion-v1-4"
11 |
12 | colossalai.launch_from_torch()
13 | with ColoInitContext(device="cpu"):
14 | vae = AutoencoderKL.from_pretrained(
15 | path,
16 | subfolder="vae",
17 | revision=None,
18 | )
19 |
20 | for n, p in vae.named_parameters():
21 | print(n)
22 |
--------------------------------------------------------------------------------
/examples/images/dreambooth/dreambooth.sh:
--------------------------------------------------------------------------------
1 | python train_dreambooth.py \
2 | --pretrained_model_name_or_path="/data/dreambooth/diffuser/stable-diffusion-v1-4" \
3 | --instance_data_dir="/data/dreambooth/Teyvat/data" \
4 | --output_dir="./weight_output" \
5 | --instance_prompt="a photo of a dog" \
6 | --resolution=512 \
7 | --train_batch_size=1 \
8 | --gradient_accumulation_steps=1 \
9 | --learning_rate=5e-6 \
10 | --lr_scheduler="constant" \
11 | --lr_warmup_steps=0 \
12 | --num_class_images=200 \
13 |
--------------------------------------------------------------------------------
/examples/images/dreambooth/inference.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from diffusers import DiffusionPipeline
3 |
4 | model_id = ""
5 | print(f"Loading model... from{model_id}")
6 |
7 | pipe = DiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
8 |
9 | prompt = "A photo of an apple."
10 | image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
11 |
12 | image.save("output.png")
13 |
--------------------------------------------------------------------------------
/examples/images/dreambooth/requirements.txt:
--------------------------------------------------------------------------------
1 | diffusers>==0.5.0
2 | accelerate
3 | torchvision
4 | transformers>=4.21.0
5 | ftfy
6 | tensorboard
7 | modelcards
8 |
--------------------------------------------------------------------------------
/examples/images/resnet/.gitignore:
--------------------------------------------------------------------------------
1 | data
2 | checkpoint
3 | ckpt-fp16
4 | ckpt-fp32
5 |
--------------------------------------------------------------------------------
/examples/images/resnet/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai
2 | torch
3 | torchvision
4 | tqdm
5 | pytest
6 |
--------------------------------------------------------------------------------
/examples/images/resnet/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -xe
3 |
4 | export DATA=/data/scratch/cifar-10
5 |
6 | pip install -r requirements.txt
7 |
8 | # TODO: skip ci test due to time limits, train.py needs to be rewritten.
9 |
10 | # for plugin in "torch_ddp" "torch_ddp_fp16" "low_level_zero"; do
11 | # colossalai run --nproc_per_node 4 train.py --interval 0 --target_acc 0.84 --plugin $plugin
12 | # done
13 |
--------------------------------------------------------------------------------
/examples/images/vit/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.1.12
2 | torch >= 1.8.1
3 | numpy>=1.24.1
4 | tqdm>=4.61.2
5 | transformers>=4.20.0
6 | datasets
7 |
--------------------------------------------------------------------------------
/examples/images/vit/run_benchmark.sh:
--------------------------------------------------------------------------------
1 | set -xe
2 | pip install -r requirements.txt
3 |
4 | export BS=8
5 | export MEMCAP=0
6 | export GPUNUM=1
7 |
8 | for BS in 8 32
9 | do
10 | for PLUGIN in "torch_ddp" "torch_ddp_fp16" "low_level_zero" "gemini" "hybrid_parallel"
11 | do
12 |
13 | MODEL_PATH="google/vit-base-patch16-224"
14 | colossalai run \
15 | --nproc_per_node ${GPUNUM} \
16 | --master_port 29505 \
17 | vit_benchmark.py \
18 | --model_name_or_path ${MODEL_PATH} \
19 | --mem_cap ${MEMCAP} \
20 | --plugin ${PLUGIN} \
21 | --batch_size ${BS}
22 |
23 | done
24 | done
25 |
--------------------------------------------------------------------------------
/examples/images/vit/test_ci.sh:
--------------------------------------------------------------------------------
1 | set -xe
2 | pip install -r requirements.txt
3 |
4 | BS=8
5 | for PLUGIN in "torch_ddp" "torch_ddp_fp16" "low_level_zero" "gemini" "hybrid_parallel"
6 | do
7 |
8 | colossalai run \
9 | --nproc_per_node 4 \
10 | --master_port 29505 \
11 | vit_benchmark.py \
12 | --model_name_or_path "google/vit-base-patch16-224" \
13 | --plugin ${PLUGIN} \
14 | --batch_size ${BS}
15 |
16 | done
17 |
--------------------------------------------------------------------------------
/examples/inference/benchmark_ops/test_ci.sh:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/inference/benchmark_ops/test_ci.sh
--------------------------------------------------------------------------------
/examples/inference/client/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | echo "Skip the test (this test is slow)"
3 |
4 | # bash ./run_benchmark.sh
5 |
--------------------------------------------------------------------------------
/examples/inference/llama/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | echo "Skip the test (this test is slow)"
3 |
4 | # bash ./run_benchmark.sh
5 |
--------------------------------------------------------------------------------
/examples/inference/stable_diffusion/requirements.txt:
--------------------------------------------------------------------------------
1 | torchvision
2 | torchmetrics
3 | cleanfid
4 |
--------------------------------------------------------------------------------
/examples/inference/stable_diffusion/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | echo "Skip the test (this test is slow)"
3 |
--------------------------------------------------------------------------------
/examples/language/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/language/__init__.py
--------------------------------------------------------------------------------
/examples/language/bert/benchmark.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -xe
3 |
4 | pip install -r requirements.txt
5 |
6 | for plugin in "torch_ddp" "torch_ddp_fp16" "gemini" "low_level_zero"; do
7 | torchrun --standalone --nproc_per_node 2 benchmark.py --plugin $plugin --model_type "bert"
8 | torchrun --standalone --nproc_per_node 2 benchmark.py --plugin $plugin --model_type "albert"
9 | done
10 |
--------------------------------------------------------------------------------
/examples/language/bert/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai
2 | evaluate
3 | datasets
4 | torch
5 | tqdm
6 | transformers
7 | scipy
8 | scikit-learn
9 | ptflops
10 |
--------------------------------------------------------------------------------
/examples/language/bert/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -x
3 |
4 | pip install -r requirements.txt
5 |
6 | FAIL_LIMIT=3
7 |
8 | for plugin in "torch_ddp" "torch_ddp_fp16" "gemini" "low_level_zero" "hybrid_parallel"; do
9 | for i in $(seq 1 $FAIL_LIMIT); do
10 | torchrun --standalone --nproc_per_node 4 finetune.py --target_f1 0.86 --plugin $plugin --model_type "bert" && break
11 | echo "Failed $i times"
12 | if [ $i -eq $FAIL_LIMIT ]; then
13 | echo "Failed $FAIL_LIMIT times, exiting"
14 | exit 1
15 | fi
16 | done
17 | done
18 |
--------------------------------------------------------------------------------
/examples/language/commons/utils.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 |
4 | # Randomly Generated Data
5 | def get_data(batch_size, seq_len, vocab_size):
6 | input_ids = torch.randint(0, vocab_size, (batch_size, seq_len), device=torch.cuda.current_device())
7 | attention_mask = torch.ones_like(input_ids)
8 | return input_ids, attention_mask
9 |
10 |
11 | def get_tflops(model_numel, batch_size, seq_len, step_time):
12 | return model_numel * batch_size * seq_len * 8 / 1e12 / (step_time + 1e-12)
13 |
--------------------------------------------------------------------------------
/examples/language/deepseek/data_utils.py:
--------------------------------------------------------------------------------
1 | ../data_utils.py
--------------------------------------------------------------------------------
/examples/language/deepseek/model_utils.py:
--------------------------------------------------------------------------------
1 | ../model_utils.py
--------------------------------------------------------------------------------
/examples/language/deepseek/performance_evaluator.py:
--------------------------------------------------------------------------------
1 | ../performance_evaluator.py
--------------------------------------------------------------------------------
/examples/language/deepseek/test_ci.sh:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/language/deepseek/test_ci.sh
--------------------------------------------------------------------------------
/examples/language/gpt/experiments/auto_offload/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.1.12
2 | torch >= 1.8.1
3 |
--------------------------------------------------------------------------------
/examples/language/gpt/experiments/auto_offload/run.sh:
--------------------------------------------------------------------------------
1 | export BATCH_SIZE=${BATCH_SIZE:-64}
2 | export MODEL_TYPE=${MODEL_TYPE:-"gpt2_medium"}
3 | export MEMORY_BUDGET=${MEMORY_BUDGET:-16}
4 | export SOLVER_TYPE=${SOLVER_TYPE:-"asyn"}
5 |
6 | mkdir -p offload_logs
7 |
8 | python train_gpt_offload.py --model_type=${MODEL_TYPE} --memory_budget=${MEMORY_BUDGET} --solver_type=${SOLVER_TYPE} --batch_size=${BATCH_SIZE} 2>&1 | tee ./offload_logs/${MODEL_TYPE}_bs_${BATCH_SIZE}_st_${SOLVER_TYPE}.log
9 |
--------------------------------------------------------------------------------
/examples/language/gpt/experiments/auto_parallel/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.1.12
2 | torch >= 1.8.1
3 | transformers >= 4.23.1
4 | PuLP >= 2.7.0
5 |
--------------------------------------------------------------------------------
/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_12_layers.pt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_12_layers.pt
--------------------------------------------------------------------------------
/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_1_layers.pt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_1_layers.pt
--------------------------------------------------------------------------------
/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_4_layers.pt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_4_layers.pt
--------------------------------------------------------------------------------
/examples/language/gpt/experiments/pipeline_parallel/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.1.12
2 | torch >= 1.8.1
3 |
--------------------------------------------------------------------------------
/examples/language/gpt/experiments/pipeline_parallel/run.sh:
--------------------------------------------------------------------------------
1 | export GPUNUM=${GPUNUM:-4}
2 | export BATCH_SIZE=${BATCH_SIZE:-16}
3 | export MODEL_TYPE=${MODEL_TYPE:-"gpt2_medium"}
4 | export NUM_MICROBATCH=${NUM_MICROBATCH:-8}
5 |
6 | mkdir -p pp_logs
7 | python train_gpt_pp.py --device="cuda" --model_type=${MODEL_TYPE} --num_microbatches=${NUM_MICROBATCH} --world_size=${GPUNUM} --batch_size=${BATCH_SIZE} 2>&1 | tee ./pp_logs/${MODEL_TYPE}_gpu_${GPUNUM}_bs_${BATCH_SIZE}_nm_${NUM_MICROBATCH}.log
8 |
--------------------------------------------------------------------------------
/examples/language/gpt/gemini/commons/performance_evaluator.py:
--------------------------------------------------------------------------------
1 | ../../../performance_evaluator.py
--------------------------------------------------------------------------------
/examples/language/gpt/gemini/commons/utils.py:
--------------------------------------------------------------------------------
1 | import time
2 |
3 | import torch
4 |
5 |
6 | class DummyProfiler:
7 | def __init__(self):
8 | self.step_number = 0
9 |
10 | def step(self):
11 | self.step_number += 1
12 |
13 |
14 | # Randomly Generated Data
15 | def get_data(batch_size, seq_len, vocab_size):
16 | input_ids = torch.randint(0, vocab_size, (batch_size, seq_len), device=torch.cuda.current_device())
17 | attention_mask = torch.ones_like(input_ids)
18 | return input_ids, attention_mask
19 |
20 |
21 | def get_tflops(model_numel, batch_size, seq_len, step_time):
22 | return model_numel * batch_size * seq_len * 8 / 1e12 / (step_time + 1e-12)
23 |
24 |
25 | def get_time_stamp():
26 | cur_time = time.strftime("%d-%H:%M", time.localtime())
27 | return cur_time
28 |
--------------------------------------------------------------------------------
/examples/language/gpt/gemini/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.1.12
2 | torch >= 1.8.1
3 |
--------------------------------------------------------------------------------
/examples/language/gpt/gemini/run_gemini.sh:
--------------------------------------------------------------------------------
1 | set -x
2 | # distplan in ["CAI_ZeRO1", "CAI_ZeRO2", "CAI_Gemini", "Pytorch_DDP", "Pytorch_ZeRO"]
3 | export DISTPLAN=${DISTPLAN:-"CAI_Gemini"}
4 |
5 | # The following options only valid when DISTPLAN="colossalai"
6 | export GPUNUM=${GPUNUM:-1}
7 | export BATCH_SIZE=${BATCH_SIZE:-16}
8 | export MODEL_TYPE=${MODEL_TYPE:-"gpt2_medium"}
9 | export TRAIN_STEP=${TRAIN_STEP:-10}
10 | # export PYTHONPATH=$PWD:$PYTHONPATH
11 |
12 |
13 | mkdir -p gemini_logs
14 |
15 | torchrun --standalone --nproc_per_node=${GPUNUM} ./train_gpt_demo.py \
16 | --model_type=${MODEL_TYPE} \
17 | --batch_size=${BATCH_SIZE} \
18 | --distplan=${DISTPLAN} \
19 | --train_step=${TRAIN_STEP} \
20 | 2>&1 | tee ./gemini_logs/${MODEL_TYPE}_${DISTPLAN}_gpu_${GPUNUM}_bs_${BATCH_SIZE}.log
21 |
--------------------------------------------------------------------------------
/examples/language/gpt/gemini/test_ci.sh:
--------------------------------------------------------------------------------
1 | set -x
2 | $(cd `dirname $0`;pwd)
3 | export TRAIN_STEP=4
4 |
5 | for MODEL_TYPE in "gpt2_medium"; do
6 | for DISTPLAN in "CAI_Gemini"; do
7 | for BATCH_SIZE in 2; do
8 | for GPUNUM in 1 4; do
9 | MODEL_TYPE=${MODEL_TYPE} DISTPLAN=${DISTPLAN} BATCH_SIZE=${BATCH_SIZE} GPUNUM=${GPUNUM} \
10 | bash ./run_gemini.sh
11 | done
12 | done
13 | done
14 |
15 | for DISTPLAN in "CAI_ZeRO2" "CAI_ZeRO1"; do
16 | for BATCH_SIZE in 2; do
17 | for GPUNUM in 1 4; do
18 | MODEL_TYPE=${MODEL_TYPE} DISTPLAN=${DISTPLAN} BATCH_SIZE=${BATCH_SIZE} GPUNUM=${GPUNUM} \
19 | bash ./run_gemini.sh
20 | done
21 | done
22 | done
23 | done
24 |
--------------------------------------------------------------------------------
/examples/language/gpt/hybridparallelism/run.sh:
--------------------------------------------------------------------------------
1 | # load via internet
2 | torchrun --standalone --nproc_per_node 4 --master_port 29800 finetune.py --target_f1 0.6 --plugin hybrid_parallel --model_type "gpt2"
3 |
4 | # load from local
5 | # torchrun --standalone --nproc_per_node 4 --master_port 29800 finetune.py --target_f1 0.6 --plugin hybrid_parallel --model_type "gpt2" --pretrained_path "your/path/to/pretrained_model"
6 |
--------------------------------------------------------------------------------
/examples/language/gpt/requirements.txt:
--------------------------------------------------------------------------------
1 | transformers >= 4.23
2 | colossalai
3 | evaluate
4 | tqdm
5 | scipy
6 | scikit-learn
7 | numpy
8 |
--------------------------------------------------------------------------------
/examples/language/gpt/test_ci.sh:
--------------------------------------------------------------------------------
1 | set -x
2 | pip install -r requirements.txt
3 |
4 | cd gemini && bash test_ci.sh
5 | # cd ../hybridparallelism && bash run.sh
6 |
--------------------------------------------------------------------------------
/examples/language/gpt/titans/model/__init__.py:
--------------------------------------------------------------------------------
1 | from .embed import vocab_parallel_cross_entropy
2 | from .gpt1d import *
3 | from .pipeline_gpt1d import *
4 |
--------------------------------------------------------------------------------
/examples/language/gpt/titans/requirements.txt:
--------------------------------------------------------------------------------
1 | torch==1.12.1
2 | titans==0.0.7
3 | colossalai==0.2.0+torch1.12cu11.3
4 | -f https://release.colossalai.org
5 |
--------------------------------------------------------------------------------
/examples/language/gpt/titans/run.sh:
--------------------------------------------------------------------------------
1 | export DATA=/data/scratch/gpt_data/small-gpt-dataset.json
2 | DUMMY_DATA=--use_dummy_dataset
3 | colossalai run --nproc_per_node=2 train_gpt.py --config ./configs/gpt2_small_zero3_pp1d.py --from_torch $DUMMY_DATA
4 |
--------------------------------------------------------------------------------
/examples/language/gpt/titans/test_ci.sh:
--------------------------------------------------------------------------------
1 | colossalai run --nproc_per_node=4 train_gpt.py --config ./configs/gpt2_small_zero3_pp1d.py --from_torch --use_dummy_dataset
2 |
--------------------------------------------------------------------------------
/examples/language/grok-1/requirements.txt:
--------------------------------------------------------------------------------
1 | torch>=2.1.0,<2.2.0
2 | colossalai>=0.3.6
3 | transformers==4.35.0
4 |
--------------------------------------------------------------------------------
/examples/language/grok-1/run_inference_fast.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 |
3 | PRETRAINED=${1:-"hpcai-tech/grok-1"}
4 |
5 | torchrun --standalone --nproc_per_node 8 inference_tp.py --pretrained "$PRETRAINED" \
6 | --max_new_tokens 100 \
7 | --text "The company's annual conference, featuring keynote speakers and exclusive product launches, will be held at the Los Angeles Convention Center from October 20th to October 23rd, 2021. Extract the date mentioned in the above sentence." \
8 | "将以下句子翻译成英语。 我喜欢看电影和读书。" \
9 | "All books have the same weight, 10 books weigh 5kg, what is the weight of 2 books?"
10 |
--------------------------------------------------------------------------------
/examples/language/grok-1/run_inference_slow.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 |
3 | PRETRAINED=${1:-"hpcai-tech/grok-1"}
4 |
5 | python3 inference.py --pretrained "$PRETRAINED" \
6 | --max_new_tokens 100 \
7 | --text "The company's annual conference, featuring keynote speakers and exclusive product launches, will be held at the Los Angeles Convention Center from October 20th to October 23rd, 2021. Extract the date mentioned in the above sentence." \
8 | "将以下句子翻译成英语。 我喜欢看电影和读书。" \
9 | "All books have the same weight, 10 books weigh 5kg, what is the weight of 2 books?"
10 |
--------------------------------------------------------------------------------
/examples/language/grok-1/test_ci.sh:
--------------------------------------------------------------------------------
1 | pip install -r requirements.txt
2 |
--------------------------------------------------------------------------------
/examples/language/llama/data_utils.py:
--------------------------------------------------------------------------------
1 | ../data_utils.py
--------------------------------------------------------------------------------
/examples/language/llama/model_utils.py:
--------------------------------------------------------------------------------
1 | ../model_utils.py
--------------------------------------------------------------------------------
/examples/language/llama/performance_evaluator.py:
--------------------------------------------------------------------------------
1 | ../performance_evaluator.py
--------------------------------------------------------------------------------
/examples/language/llama/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai>=0.3.6
2 | datasets
3 | numpy
4 | tqdm
5 | transformers
6 | flash-attn>=2.0.0
7 | SentencePiece==0.1.99
8 | tensorboard==2.14.0
9 |
--------------------------------------------------------------------------------
/examples/language/llama/scripts/benchmark_70B/3d.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # TODO: fix this
4 | echo "3D parallel for LLaMA-2 is not ready yet"
5 | exit 1
6 |
7 | ################
8 | #Load your environments and modules here
9 | ################
10 |
11 | HOSTFILE=$(realpath hosts.txt)
12 |
13 | cd ../..
14 |
15 | export OMP_NUM_THREADS=8
16 |
17 | colossalai run --nproc_per_node 8 --hostfile $HOSTFILE benchmark.py -c 70b -p 3d -g -x -b 8 --tp 4 --pp 2 --mbs 1
18 |
--------------------------------------------------------------------------------
/examples/language/llama/scripts/benchmark_70B/gemini.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | ################
4 | #Load your environments and modules here
5 | ################
6 |
7 | HOSTFILE=$(realpath hosts.txt)
8 |
9 | cd ../..
10 |
11 | export OMP_NUM_THREADS=8
12 |
13 | colossalai run --nproc_per_node 8 --hostfile $HOSTFILE benchmark.py -c 70b -g -x -b 2
14 |
--------------------------------------------------------------------------------
/examples/language/llama/scripts/benchmark_70B/gemini_auto.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | ################
4 | #Load your environments and modules here
5 | ################
6 |
7 | HOSTFILE=$(realpath hosts.txt)
8 |
9 | cd ../..
10 |
11 | export OMP_NUM_THREADS=8
12 |
13 | colossalai run --nproc_per_node 8 --hostfile $HOSTFILE benchmark.py -c 70b -p gemini_auto -g -x -b 2
14 |
--------------------------------------------------------------------------------
/examples/language/llama/scripts/benchmark_7B/gemini.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | ################
4 | #Load your environments and modules here
5 | ################
6 |
7 | HOSTFILE=$(realpath hosts.txt)
8 |
9 | cd ../..
10 |
11 | export OMP_NUM_THREADS=8
12 |
13 | colossalai run --nproc_per_node 8 --hostfile $HOSTFILE benchmark.py -g -x -b 16
14 |
--------------------------------------------------------------------------------
/examples/language/llama/scripts/benchmark_7B/gemini_auto.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | ################
4 | #Load your environments and modules here
5 | ################
6 |
7 | HOSTFILE=$(realpath hosts.txt)
8 |
9 | cd ../..
10 |
11 | export OMP_NUM_THREADS=8
12 |
13 | colossalai run --nproc_per_node 8 --hostfile $HOSTFILE benchmark.py -p gemini_auto -g -x -b 16
14 |
--------------------------------------------------------------------------------
/examples/language/llama/test_ci.sh:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/language/llama/test_ci.sh
--------------------------------------------------------------------------------
/examples/language/mixtral/data_utils.py:
--------------------------------------------------------------------------------
1 | ../data_utils.py
--------------------------------------------------------------------------------
/examples/language/mixtral/model_utils.py:
--------------------------------------------------------------------------------
1 | ../model_utils.py
--------------------------------------------------------------------------------
/examples/language/mixtral/performance_evaluator.py:
--------------------------------------------------------------------------------
1 | ../performance_evaluator.py
--------------------------------------------------------------------------------
/examples/language/mixtral/test_ci.sh:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/language/mixtral/test_ci.sh
--------------------------------------------------------------------------------
/examples/language/opt/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.3.2
2 | torch >= 1.8.1
3 | datasets >= 1.8.0
4 | transformers >= 4.30.2
5 |
--------------------------------------------------------------------------------
/examples/language/opt/run_benchmark.sh:
--------------------------------------------------------------------------------
1 | set -xe
2 | pip install -r requirements.txt
3 |
4 | export BS=32
5 | export MEMCAP=0
6 | export GPUNUM=1
7 |
8 | # acceptable values include `125m`, `350m`, `1.3b`, `2.7b`, `6.7b`, `13b`, `30b`, `66b`
9 | export MODEL="125m"
10 |
11 | for BS in 8 32 128
12 | do
13 | for PLUGIN in "torch_ddp" "torch_ddp_fp16" "low_level_zero" "gemini"
14 | do
15 | for GPUNUM in 1 4
16 | do
17 |
18 | MODLE_PATH="facebook/opt-${MODEL}"
19 | colossalai run \
20 | --nproc_per_node ${GPUNUM} \
21 | --master_port 29505 \
22 | opt_benchmark.py \
23 | --model_name_or_path ${MODLE_PATH} \
24 | --mem_cap ${MEMCAP} \
25 | --plugin ${PLUGIN} \
26 | --batch_size ${BS}
27 |
28 | done
29 | done
30 | done
31 |
--------------------------------------------------------------------------------
/examples/language/opt/test_ci.sh:
--------------------------------------------------------------------------------
1 | set -xe
2 | pip install -r requirements.txt
3 |
4 | BS=4
5 | for PLUGIN in "torch_ddp" "torch_ddp_fp16" "low_level_zero" "gemini"
6 | do
7 | for GPUNUM in 1 4
8 | do
9 |
10 | colossalai run \
11 | --nproc_per_node ${GPUNUM} \
12 | --master_port 29505 \
13 | opt_benchmark.py \
14 | --model_name_or_path "facebook/opt-125m" \
15 | --plugin ${PLUGIN} \
16 | --batch_size ${BS}
17 |
18 | done
19 | done
20 |
--------------------------------------------------------------------------------
/examples/language/palm/data/README.md:
--------------------------------------------------------------------------------
1 | # Data source
2 |
3 | The enwik8 data was downloaded from the Hutter prize page: http://prize.hutter1.net/
4 |
--------------------------------------------------------------------------------
/examples/language/palm/palm_pytorch/__init__.py:
--------------------------------------------------------------------------------
1 | from palm_pytorch.palm_pytorch import PaLM
2 |
--------------------------------------------------------------------------------
/examples/language/palm/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.1.12
2 | torch >= 1.8.1
3 |
--------------------------------------------------------------------------------
/examples/language/palm/run.sh:
--------------------------------------------------------------------------------
1 | # distplan in ["colossalai", "pytorch"]
2 | export DISTPAN="colossalai"
3 |
4 | # The following options only valid when DISTPAN="colossalai"
5 | export TPDEGREE=1
6 | export GPUNUM=4
7 | export PLACEMENT='cpu'
8 | export USE_SHARD_INIT=False
9 | export BATCH_SIZE=1
10 |
11 | env OMP_NUM_THREADS=12 colossalai run --nproc_per_node ${GPUNUM} --master_port 29505 train.py \
12 | --dummy_data=True --tp_degree=${TPDEGREE} --batch_size=${BATCH_SIZE} --plugin='gemini' \
13 | --placement ${PLACEMENT} --shardinit ${USE_SHARD_INIT} --distplan ${DISTPAN} 2>&1 | tee run.log
14 |
--------------------------------------------------------------------------------
/examples/language/palm/test_ci.sh:
--------------------------------------------------------------------------------
1 | $(cd `dirname $0`;pwd)
2 |
3 | for BATCH_SIZE in 2
4 | do
5 | for GPUNUM in 1 4
6 | do
7 | env OMP_NUM_THREADS=12 colossalai run --nproc_per_node ${GPUNUM} --master_port 29505 train.py --dummy_data=True --batch_size=${BATCH_SIZE} --plugin='gemini' 2>&1 | tee run.log
8 | done
9 | done
10 |
--------------------------------------------------------------------------------
/examples/tutorial/.gitignore:
--------------------------------------------------------------------------------
1 | ./data/
2 |
--------------------------------------------------------------------------------
/examples/tutorial/auto_parallel/config.py:
--------------------------------------------------------------------------------
1 | BATCH_SIZE = 32
2 | NUM_EPOCHS = 2
3 |
--------------------------------------------------------------------------------
/examples/tutorial/auto_parallel/requirements.txt:
--------------------------------------------------------------------------------
1 | torch==1.12.1
2 | colossalai
3 | titans
4 | pulp
5 | datasets
6 | matplotlib
7 | transformers==4.22.1
8 |
--------------------------------------------------------------------------------
/examples/tutorial/auto_parallel/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import find_packages, setup
2 |
3 | setup(
4 | name="auto_parallel",
5 | version="0.0.1",
6 | description="",
7 | packages=find_packages(),
8 | install_requires=[
9 | "torch",
10 | "numpy",
11 | "tqdm",
12 | ],
13 | )
14 |
--------------------------------------------------------------------------------
/examples/tutorial/auto_parallel/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -euxo pipefail
3 |
4 | echo "this test is outdated"
5 |
6 | # pip install -r requirements.txt
7 | # conda install -c conda-forge coin-or-cbc
8 | # colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py
9 |
--------------------------------------------------------------------------------
/examples/tutorial/download_cifar10.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | from torchvision.datasets import CIFAR10
4 |
5 |
6 | def main():
7 | dir_path = os.path.dirname(os.path.realpath(__file__))
8 | data_root = os.path.join(dir_path, "data")
9 | dataset = CIFAR10(root=data_root, download=True)
10 |
11 |
12 | if __name__ == "__main__":
13 | main()
14 |
--------------------------------------------------------------------------------
/examples/tutorial/hybrid_parallel/requirements.txt:
--------------------------------------------------------------------------------
1 | torch
2 | colossalai
3 | titans
4 |
--------------------------------------------------------------------------------
/examples/tutorial/hybrid_parallel/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -euxo pipefail
3 |
4 | echo "legacy example"
5 |
6 | # pip install -r requirements.txt
7 | # colossalai run --nproc_per_node 4 train.py --config config.py
8 |
--------------------------------------------------------------------------------
/examples/tutorial/large_batch_optimizer/config.py:
--------------------------------------------------------------------------------
1 | from colossalai.legacy.amp import AMP_TYPE
2 |
3 | # hyperparameters
4 | # BATCH_SIZE is as per GPU
5 | # global batch size = BATCH_SIZE x data parallel size
6 | BATCH_SIZE = 512
7 | LEARNING_RATE = 3e-3
8 | WEIGHT_DECAY = 0.3
9 | NUM_EPOCHS = 2
10 | WARMUP_EPOCHS = 1
11 |
12 | # model config
13 | NUM_CLASSES = 10
14 |
15 | fp16 = dict(mode=AMP_TYPE.NAIVE)
16 | clip_grad_norm = 1.0
17 |
--------------------------------------------------------------------------------
/examples/tutorial/large_batch_optimizer/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai
2 | torch
3 | titans
4 |
--------------------------------------------------------------------------------
/examples/tutorial/large_batch_optimizer/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -euxo pipefail
3 | echo "this test is outdated"
4 |
5 | # pip install -r requirements.txt
6 |
7 | # run test
8 | # colossalai run --nproc_per_node 4 --master_port 29500 train.py --config config.py --optimizer lars
9 | # colossalai run --nproc_per_node 4 --master_port 29501 train.py --config config.py --optimizer lamb
10 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/README.md:
--------------------------------------------------------------------------------
1 | # New API Features
2 |
3 | **The New API is not officially released yet.**
4 |
5 | This folder contains some of the demonstrations of the new API. The new API is still under intensive development and will be released soon.
6 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/cifar_resnet/.gitignore:
--------------------------------------------------------------------------------
1 | data
2 | checkpoint
3 | ckpt-fp16
4 | ckpt-fp32
5 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/cifar_resnet/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai
2 | torch
3 | torchvision
4 | tqdm
5 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/cifar_resnet/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -xe
3 |
4 | export DATA=/data/scratch/cifar-10
5 |
6 | pip install -r requirements.txt
7 |
8 | for plugin in "torch_ddp" "torch_ddp_fp16" "low_level_zero"; do
9 | colossalai run --nproc_per_node 4 train.py --interval 0 --target_acc 0.84 --plugin $plugin
10 | done
11 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/cifar_vit/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai
2 | timm
3 | torch
4 | torchvision
5 | tqdm
6 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/cifar_vit/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -xe
3 |
4 | export DATA=/data/scratch/cifar-10
5 |
6 | pip install -r requirements.txt
7 |
8 | for plugin in "torch_ddp" "torch_ddp_fp16" "low_level_zero"; do
9 | colossalai run --nproc_per_node 4 train.py --interval 0 --target_acc 0.83 --plugin $plugin
10 | done
11 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/glue_bert/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai
2 | datasets
3 | torch
4 | tqdm
5 | transformers
6 | scipy
7 | scikit-learn
8 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/glue_bert/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -xe
3 |
4 | pip install -r requirements.txt
5 |
6 | for plugin in "torch_ddp" "torch_ddp_fp16" "gemini" "low_level_zero"; do
7 | torchrun --standalone --nproc_per_node 4 finetune.py --target_f1 0.80 --plugin $plugin
8 | done
9 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -xe
3 |
4 | # FIXME(ver217): only run bert finetune to save time
5 |
6 | cd glue_bert && bash ./test_ci.sh && cd ..
7 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/inference/benchmark/locustfile.py:
--------------------------------------------------------------------------------
1 | from locust import HttpUser, task
2 |
3 |
4 | class GenerationUser(HttpUser):
5 | @task
6 | def generate(self):
7 | prompt = "Question: What is the longest river on the earth? Answer:"
8 | for i in range(4, 9):
9 | data = {"max_tokens": 2**i, "prompt": prompt}
10 | with self.client.post("/generation", json=data, catch_response=True) as response:
11 | if response.status_code in (200, 406):
12 | response.success()
13 | else:
14 | response.failure("Response wrong")
15 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/inference/requirements.txt:
--------------------------------------------------------------------------------
1 | fastapi==0.85.1
2 | locust==2.11.0
3 | pydantic==1.10.2
4 | sanic==22.9.0
5 | sanic_ext==22.9.0
6 | torch>=1.10.0
7 | transformers==4.23.1
8 | uvicorn==0.19.0
9 | colossalai
10 | git+https://github.com/hpcaitech/EnergonAI@main
11 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/inference/script/process-opt-175b/unflat.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 |
3 | for i in $(seq 0 7); do
4 | python convert_ckpt.py $1 $2 ${i} &
5 | done
6 |
7 | wait $(jobs -p)
8 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/opt/benchmark.sh:
--------------------------------------------------------------------------------
1 | export BS=16
2 | export MEMCAP=0
3 | export MODEL="6.7b"
4 | export GPUNUM=1
5 |
6 | for MODEL in "6.7b" "13b" "1.3b"
7 | do
8 | for GPUNUM in 8 1
9 | do
10 | for BS in 16 24 32 8
11 | do
12 | for MEMCAP in 0 40
13 | do
14 | pkill -9 torchrun
15 | pkill -9 python
16 |
17 | bash ./run_clm.sh $BS $MEMCAP $MODEL $GPUNUM
18 | done
19 | done
20 | done
21 | done
22 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/opt/colossalai_zero.py:
--------------------------------------------------------------------------------
1 | try:
2 | from colossalai.zero.shard_utils import TensorShardStrategy
3 | except ImportError:
4 | # colossalai > 0.2.8
5 | from colossalai.legacy.zero import TensorShardStrategy
6 |
7 | zero = dict(
8 | model_config=dict(shard_strategy=TensorShardStrategy(), tensor_placement_policy="auto", reuse_fp16_shard=True),
9 | optimizer_config=dict(gpu_margin_mem_ratio=0.8, initial_scale=16384),
10 | )
11 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/opt/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai
2 | torch >= 1.8.1
3 | datasets >= 1.8.0
4 | sentencepiece != 0.1.92
5 | protobuf
6 | accelerate >= 0.20.3
7 | transformers
8 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/opt/run_clm.sh:
--------------------------------------------------------------------------------
1 | set -x
2 | export BS=${1:-16}
3 | export MEMCAP=${2:-0}
4 | export MODEL=${3:-"125m"}
5 | export GPUNUM=${4:-1}
6 |
7 | # make directory for logs
8 | mkdir -p ./logs
9 |
10 | export MODLE_PATH="facebook/opt-${MODEL}"
11 |
12 | # HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1
13 | torchrun \
14 | --nproc_per_node ${GPUNUM} \
15 | --master_port 19198 \
16 | run_clm.py \
17 | --dataset_name wikitext \
18 | --dataset_config_name wikitext-2-raw-v1 \
19 | --output_dir $PWD \
20 | --mem_cap ${MEMCAP} \
21 | --model_name_or_path ${MODLE_PATH} \
22 | --per_device_train_batch_size ${BS} 2>&1 | tee ./logs/colo_${MODEL}_bs_${BS}_cap_${MEMCAP}_gpu_${GPUNUM}.log
23 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/opt/run_clm_synthetic.sh:
--------------------------------------------------------------------------------
1 | set -x
2 | export BS=${1:-16}
3 | export MEMCAP=${2:-0}
4 | export MODEL=${3:-"125m"}
5 | export GPUNUM=${4:-1}
6 |
7 | # make directory for logs
8 | mkdir -p ./logs
9 |
10 | export MODLE_PATH="facebook/opt-${MODEL}"
11 |
12 | # HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1
13 | torchrun \
14 | --nproc_per_node ${GPUNUM} \
15 | --master_port 19198 \
16 | run_clm.py \
17 | -s \
18 | --output_dir $PWD \
19 | --mem_cap ${MEMCAP} \
20 | --model_name_or_path ${MODLE_PATH} \
21 | --per_device_train_batch_size ${BS} 2>&1 | tee ./logs/colo_${MODEL}_bs_${BS}_cap_${MEMCAP}_gpu_${GPUNUM}.log
22 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/opt/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | set -xue
4 | echo "this test is outdated"
5 | # pip install -r requirements.txt
6 |
7 | # BS=4
8 | # MEMCAP=0
9 | # GPUNUM=4
10 | # MODLE="facebook/opt-125m"
11 |
12 | # torchrun \
13 | # --nproc_per_node ${GPUNUM} \
14 | # --master_port 19198 \
15 | # run_clm.py \
16 | # -s \
17 | # --output_dir $PWD \
18 | # --mem_cap ${MEMCAP} \
19 | # --model_name_or_path ${MODLE} \
20 | # --per_device_train_batch_size ${BS} \
21 | # --num_train_epochs 1
22 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | cd opt && bash test_ci.sh
4 |
--------------------------------------------------------------------------------
/examples/tutorial/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.1.12
2 | torch >= 1.8.1
3 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/data/datasets/Makefile:
--------------------------------------------------------------------------------
1 | CXXFLAGS += -O3 -Wall -shared -std=c++11 -fPIC -fdiagnostics-color
2 | CPPFLAGS += $(shell python3 -m pybind11 --includes)
3 | LIBNAME = helpers
4 | LIBEXT = $(shell python3-config --extension-suffix)
5 |
6 | default: $(LIBNAME)$(LIBEXT)
7 |
8 | %$(LIBEXT): %.cpp
9 | $(CXX) $(CXXFLAGS) $(CPPFLAGS) $< -o $@
10 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/data/datasets/__init__.py:
--------------------------------------------------------------------------------
1 | from . import indexed_dataset
2 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/data/datasets/test/test_preprocess_data.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | IMPL=cached
4 | python ../preprocess_data.py \
5 | --input test_samples.json \
6 | --vocab vocab.txt \
7 | --dataset-impl ${IMPL} \
8 | --output-prefix test_samples_${IMPL} \
9 | --workers 1 \
10 | --log-interval 2
11 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/loss_func/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/tutorial/sequence_parallel/loss_func/__init__.py
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/lr_scheduler/__init__.py:
--------------------------------------------------------------------------------
1 | from .annealing_lr import AnnealingLR
2 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/model/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/tutorial/sequence_parallel/model/__init__.py
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/model/layers/__init__.py:
--------------------------------------------------------------------------------
1 | from .bert_layer import BertLayer
2 | from .embedding import Embedding, VocabEmbedding
3 | from .head import BertDualHead
4 | from .preprocess import PreProcessor
5 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/model/layers/dropout.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 |
4 | def bias_dropout_add(x, bias, residual, prob, training):
5 | # type: (Tensor, Tensor, Tensor, float, bool) -> Tensor
6 | out = torch.nn.functional.dropout(x + bias, p=prob, training=training)
7 | out = residual + out
8 | return out
9 |
10 |
11 | def get_bias_dropout_add(training):
12 | def _bias_dropout_add(x, bias, residual, prob):
13 | return bias_dropout_add(x, bias, residual, prob, training)
14 |
15 | return _bias_dropout_add
16 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/model/layers/init_method.py:
--------------------------------------------------------------------------------
1 | import math
2 |
3 | import torch
4 |
5 |
6 | def init_normal(tensor, sigma):
7 | """Init method based on N(0, sigma)."""
8 | torch.nn.init.normal_(tensor, mean=0.0, std=sigma)
9 |
10 |
11 | def output_init_normal(tensor, sigma, num_layers):
12 | """Init method based on N(0, sigma/sqrt(2*num_layers)."""
13 | std = sigma / math.sqrt(2.0 * num_layers)
14 | torch.nn.init.normal_(tensor, mean=0.0, std=std)
15 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai
2 | torch
3 | six
4 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -euxo pipefail
3 |
4 | echo "this test is outdated"
5 | # pip install -r requirements.txt
6 |
7 | # run test
8 | # colossalai run --nproc_per_node 4 train.py
9 |
--------------------------------------------------------------------------------
/extensions/csrc/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/extensions/csrc/__init__.py
--------------------------------------------------------------------------------
/extensions/csrc/kernel/cuda/utils/micros.h:
--------------------------------------------------------------------------------
1 | #pragma once
2 |
3 | #include
4 | #include
5 |
6 | #include
7 |
8 | #define CUDA_CHECK(func) \
9 | { \
10 | auto status = func; \
11 | if (status != cudaSuccess) { \
12 | throw std::runtime_error(cudaGetErrorString(status)); \
13 | } \
14 | }
15 |
16 | #define HOST __host__
17 | #define DEVICE __device__
18 | #define HOSTDEVICE __host__ __device__
19 |
--------------------------------------------------------------------------------
/extensions/pybind/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/extensions/pybind/__init__.py
--------------------------------------------------------------------------------
/extensions/pybind/cpu_adam/__init__.py:
--------------------------------------------------------------------------------
1 | from .cpu_adam_arm import CpuAdamArmExtension
2 | from .cpu_adam_x86 import CpuAdamX86Extension
3 |
4 | __all__ = ["CpuAdamArmExtension", "CpuAdamX86Extension"]
5 |
--------------------------------------------------------------------------------
/extensions/pybind/flash_attention/__init__.py:
--------------------------------------------------------------------------------
1 | from .flash_attention_dao_cuda import FlashAttentionDaoCudaExtension
2 | from .flash_attention_npu import FlashAttentionNpuExtension
3 | from .flash_attention_sdpa_cuda import FlashAttentionSdpaCudaExtension
4 |
5 | try:
6 | # TODO: remove this after updating openmoe example
7 | import flash_attention # noqa
8 |
9 | HAS_FLASH_ATTN = True
10 | except:
11 | HAS_FLASH_ATTN = False
12 |
13 |
14 | __all__ = ["FlashAttentionDaoCudaExtension", "FlashAttentionSdpaCudaExtension", "FlashAttentionNpuExtension"]
15 |
--------------------------------------------------------------------------------
/extensions/pybind/inference/__init__.py:
--------------------------------------------------------------------------------
1 | from .inference_ops_cuda import InferenceOpsCudaExtension
2 |
3 | __all__ = ["InferenceOpsCudaExtension"]
4 |
--------------------------------------------------------------------------------
/extensions/pybind/layernorm/__init__.py:
--------------------------------------------------------------------------------
1 | from .layernorm_cuda import LayerNormCudaExtension
2 |
3 | __all__ = ["LayerNormCudaExtension"]
4 |
--------------------------------------------------------------------------------
/extensions/pybind/moe/__init__.py:
--------------------------------------------------------------------------------
1 | from .moe_cuda import MoeCudaExtension
2 |
3 | __all__ = ["MoeCudaExtension"]
4 |
--------------------------------------------------------------------------------
/extensions/pybind/optimizer/__init__.py:
--------------------------------------------------------------------------------
1 | from .fused_optimizer_cuda import FusedOptimizerCudaExtension
2 |
3 | __all__ = ["FusedOptimizerCudaExtension"]
4 |
--------------------------------------------------------------------------------
/extensions/pybind/softmax/__init__.py:
--------------------------------------------------------------------------------
1 | from .scaled_masked_softmax_cuda import ScaledMaskedSoftmaxCudaExtension
2 | from .scaled_upper_triangle_masked_softmax_cuda import ScaledUpperTriangleMaskedSoftmaxCudaExtension
3 |
4 | __all__ = ["ScaledMaskedSoftmaxCudaExtension", "ScaledUpperTriangleMaskedSoftmaxCudaExtension"]
5 |
--------------------------------------------------------------------------------
/extensions/triton_extension.py:
--------------------------------------------------------------------------------
1 | from .base_extension import _Extension
2 |
3 | __all__ = ["_TritonExtension"]
4 |
5 |
6 | class _TritonExtension(_Extension):
7 | def __init__(self, name: str, priority: int = 1):
8 | super().__init__(name, support_aot=False, support_jit=True, priority=priority)
9 |
10 | def is_hardware_compatible(self) -> bool:
11 | # cuda extension can only be built if cuda is available
12 | try:
13 | import torch
14 |
15 | cuda_available = torch.cuda.is_available()
16 | except:
17 | cuda_available = False
18 | return cuda_available
19 |
20 | def load(self):
21 | return self.build_jit()
22 |
--------------------------------------------------------------------------------
/pytest.ini:
--------------------------------------------------------------------------------
1 | [pytest]
2 | markers =
3 | dist: tests which are run in a multi-GPU or multi-machine environment (at least 4 GPUs)
4 | largedist: tests which are run in a multi-GPU or multi-machine environment (at least 8 GPUs)
5 | addopts = --ignore=tests/test_analyzer --ignore=tests/test_auto_parallel --ignore=tests/test_autochunk --ignore=tests/test_fx --ignore=tests/test_legacy
6 |
--------------------------------------------------------------------------------
/requirements/requirements-test.txt:
--------------------------------------------------------------------------------
1 | pytest
2 | coverage==7.2.3
3 | git+https://github.com/hpcaitech/pytest-testmon
4 | torchvision
5 | timm
6 | titans
7 | torchaudio>=0.13.1
8 | torchx-nightly==2022.6.29 # torchrec 0.2.0 requires torchx-nightly. This package is updated every day. We fix the version to a specific date to avoid breaking changes.
9 | torchrec==0.2.0
10 | contexttimer
11 | einops
12 | triton
13 | requests==2.27.1 # downgrade to avoid huggingface error https://github.com/huggingface/transformers/issues/17611
14 | SentencePiece
15 | ninja
16 | flash_attn
17 | datasets
18 | pydantic
19 | ray
20 | peft>=0.7.1
21 |
--------------------------------------------------------------------------------
/requirements/requirements.txt:
--------------------------------------------------------------------------------
1 | numpy
2 | tqdm
3 | psutil
4 | packaging
5 | pre-commit
6 | rich
7 | click
8 | fabric
9 | contexttimer
10 | ninja
11 | torch>=2.2.0,<=2.5.1
12 | safetensors
13 | einops
14 | pydantic
15 | ray
16 | sentencepiece
17 | google
18 | protobuf
19 | transformers==4.51.3
20 | peft>=0.7.1,<=0.13.2
21 | bitsandbytes>=0.39.0
22 | rpyc==6.0.0
23 | fastapi
24 | uvicorn==0.29.0
25 | galore_torch
26 | diffusers==0.29.0
27 |
--------------------------------------------------------------------------------
/tests/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/__init__.py
--------------------------------------------------------------------------------
/tests/conftest.py:
--------------------------------------------------------------------------------
1 | import gc
2 |
3 | from colossalai.accelerator import get_accelerator
4 |
5 |
6 | def pytest_runtest_setup(item):
7 | # called for running each test in 'a' directory
8 | accelerator = get_accelerator()
9 | accelerator.empty_cache()
10 | gc.collect()
11 |
--------------------------------------------------------------------------------
/tests/kit/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/kit/__init__.py
--------------------------------------------------------------------------------
/tests/kit/model_zoo/custom/__init__.py:
--------------------------------------------------------------------------------
1 | from .hanging_param_model import *
2 | from .nested_model import *
3 | from .repeated_computed_layers import *
4 | from .simple_mlp import *
5 | from .simple_net import *
6 |
--------------------------------------------------------------------------------
/tests/kit/model_zoo/diffusers/__init__.py:
--------------------------------------------------------------------------------
1 | from .diffusers import *
2 |
--------------------------------------------------------------------------------
/tests/kit/model_zoo/timm/__init__.py:
--------------------------------------------------------------------------------
1 | from .timm import *
2 |
--------------------------------------------------------------------------------
/tests/kit/model_zoo/torchaudio/__init__.py:
--------------------------------------------------------------------------------
1 | from .torchaudio import *
2 |
--------------------------------------------------------------------------------
/tests/kit/model_zoo/torchrec/__init__.py:
--------------------------------------------------------------------------------
1 | from .torchrec import *
2 |
--------------------------------------------------------------------------------
/tests/kit/model_zoo/torchvision/__init__.py:
--------------------------------------------------------------------------------
1 | from .torchvision import *
2 |
--------------------------------------------------------------------------------
/tests/kit/model_zoo/transformers/__init__.py:
--------------------------------------------------------------------------------
1 | from .albert import *
2 | from .bert import *
3 | from .blip2 import *
4 | from .bloom import *
5 | from .chatglm2 import *
6 | from .command import *
7 | from .deepseek import *
8 | from .falcon import *
9 | from .gpt import *
10 | from .gptj import *
11 | from .llama import *
12 | from .mistral import *
13 | from .mixtral import *
14 | from .opt import *
15 | from .qwen2 import *
16 | from .sam import *
17 | from .t5 import *
18 | from .vit import *
19 | from .whisper import *
20 |
--------------------------------------------------------------------------------
/tests/test_analyzer/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_analyzer/__init__.py
--------------------------------------------------------------------------------
/tests/test_analyzer/test_fx/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_analyzer/test_fx/__init__.py
--------------------------------------------------------------------------------
/tests/test_analyzer/test_subclasses/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_analyzer/test_subclasses/__init__.py
--------------------------------------------------------------------------------
/tests/test_auto_parallel/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_auto_parallel/__init__.py
--------------------------------------------------------------------------------
/tests/test_auto_parallel/test_pass/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_auto_parallel/test_pass/__init__.py
--------------------------------------------------------------------------------
/tests/test_auto_parallel/test_tensor_shard/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_auto_parallel/test_tensor_shard/__init__.py
--------------------------------------------------------------------------------
/tests/test_auto_parallel/test_tensor_shard/test_gpt/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_auto_parallel/test_tensor_shard/test_gpt/__init__.py
--------------------------------------------------------------------------------
/tests/test_auto_parallel/test_tensor_shard/test_node_handler/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_auto_parallel/test_tensor_shard/test_node_handler/__init__.py
--------------------------------------------------------------------------------
/tests/test_booster/test_accelerator.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 |
3 | from colossalai.booster.accelerator import Accelerator
4 | from colossalai.testing import clear_cache_before_run, parameterize
5 |
6 |
7 | @clear_cache_before_run()
8 | @parameterize("device", ["cpu", "cuda"])
9 | def test_accelerator(device):
10 | accelerator = Accelerator(device)
11 | model = nn.Linear(8, 8)
12 | model = accelerator.configure_model(model)
13 | assert next(model.parameters()).device.type == device
14 | del model, accelerator
15 |
--------------------------------------------------------------------------------
/tests/test_checkpoint_io/utils.py:
--------------------------------------------------------------------------------
1 | import tempfile
2 | from contextlib import contextmanager, nullcontext
3 | from typing import Iterator
4 |
5 | import torch.distributed as dist
6 |
7 |
8 | @contextmanager
9 | def shared_tempdir() -> Iterator[str]:
10 | """
11 | A temporary directory that is shared across all processes.
12 | """
13 | ctx_fn = tempfile.TemporaryDirectory if dist.get_rank() == 0 else nullcontext
14 | with ctx_fn() as tempdir:
15 | try:
16 | obj = [tempdir]
17 | dist.broadcast_object_list(obj, src=0)
18 | tempdir = obj[0] # use the same directory on all ranks
19 | yield tempdir
20 | finally:
21 | dist.barrier()
22 |
--------------------------------------------------------------------------------
/tests/test_config/sample_config.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | train_data = dict(
5 | dataset=dict(
6 | type="CIFAR10Dataset",
7 | root="/path/to/data",
8 | download=True,
9 | transform_pipeline=[
10 | dict(type="RandomResizedCrop", size=224),
11 | dict(type="RandomHorizontalFlip"),
12 | dict(type="ToTensor"),
13 | dict(type="Normalize", mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
14 | ],
15 | ),
16 | dataloader=dict(
17 | batch_size=64,
18 | pin_memory=True,
19 | num_workers=4,
20 | sampler=dict(
21 | type="DataParallelSampler",
22 | shuffle=True,
23 | ),
24 | ),
25 | )
26 |
--------------------------------------------------------------------------------
/tests/test_config/test_load_config.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | from pathlib import Path
5 |
6 | from colossalai.context.config import Config
7 |
8 |
9 | def test_load_config():
10 | filename = Path(__file__).parent.joinpath("sample_config.py")
11 | config = Config.from_file(filename)
12 |
13 | assert config.train_data, "cannot access train data as attribute"
14 | assert config.train_data.dataset, "cannot access grandchild attribute"
15 | assert isinstance(
16 | config.train_data.dataset.transform_pipeline[0], dict
17 | ), f"expected attribute transform_pipeline elements to be a dict, but found {type(config.train_data.dataset.transform_pipeline)}"
18 |
--------------------------------------------------------------------------------
/tests/test_fx/test_tracer/test_hf_model/test_hf_opt.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | import torch
3 | from hf_tracer_utils import trace_model_and_compare_output
4 | from packaging import version
5 |
6 | from colossalai.testing import clear_cache_before_run
7 | from tests.kit.model_zoo import model_zoo
8 |
9 |
10 | @pytest.mark.skipif(version.parse(torch.__version__) < version.parse("1.12.0"), reason="torch version < 12")
11 | @clear_cache_before_run()
12 | def test_opt():
13 | sub_registry = model_zoo.get_sub_registry("transformers_opt")
14 | for name, (model_fn, data_gen_fn, _, _, _) in sub_registry.items():
15 | model = model_fn()
16 | trace_model_and_compare_output(model, data_gen_fn, ignore_data=["labels", "start_positions", "end_positions"])
17 |
18 |
19 | if __name__ == "__main__":
20 | test_opt()
21 |
--------------------------------------------------------------------------------
/tests/test_infer/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_infer/__init__.py
--------------------------------------------------------------------------------
/tests/test_infer/test_kernels/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_infer/test_kernels/__init__.py
--------------------------------------------------------------------------------
/tests/test_infer/test_kernels/cuda/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_infer/test_kernels/cuda/__init__.py
--------------------------------------------------------------------------------
/tests/test_infer/test_kernels/triton/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_infer/test_kernels/triton/__init__.py
--------------------------------------------------------------------------------
/tests/test_legacy/test_context/configs/parallel_2d_init.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | parallel = dict(pipeline=dict(size=2), tensor=dict(size=4, mode="2d"))
5 |
--------------------------------------------------------------------------------
/tests/test_legacy/test_context/configs/parallel_2p5d_init.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | parallel = dict(pipeline=dict(size=2), tensor=dict(size=8, depth=2, mode="2.5d"))
5 |
--------------------------------------------------------------------------------
/tests/test_legacy/test_context/configs/parallel_3d_init.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | parallel = dict(pipeline=dict(size=2), tensor=dict(size=8, mode="3d"))
5 |
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_1d/checks_1d/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_legacy/test_layers/test_1d/checks_1d/__init__.py
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_1d/checks_1d/common.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | import torch
5 |
6 | DEPTH = 4
7 | BATCH_SIZE = 8
8 | SEQ_LENGTH = 8
9 | IMG_SIZE = 16
10 | HIDDEN_SIZE = 8
11 | NUM_CLASSES = 8
12 | VOCAB_SIZE = 16
13 |
14 |
15 | def check_equal(A, B):
16 | assert torch.allclose(A, B, rtol=1e-3, atol=1e-1) == True
17 |
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_2d/checks_2d/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_legacy/test_layers/test_2d/checks_2d/__init__.py
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_2d/checks_2d/common.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | import torch
5 |
6 | DEPTH = 2
7 | BATCH_SIZE = 8
8 | SEQ_LENGTH = 8
9 | HIDDEN_SIZE = 8
10 | NUM_CLASSES = 8
11 | VOCAB_SIZE = 16
12 | IMG_SIZE = 16
13 |
14 |
15 | def check_equal(A, B):
16 | assert torch.allclose(A, B, rtol=1e-3, atol=1e-2)
17 |
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_2p5d/checks_2p5d/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_legacy/test_layers/test_2p5d/checks_2p5d/__init__.py
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_2p5d/checks_2p5d/common.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | TESSERACT_DIM = 2
4 | TESSERACT_DEP = 2
5 | BATCH_SIZE = 8
6 | SEQ_LENGTH = 8
7 | HIDDEN_SIZE = 8
8 | NUM_CLASSES = 8
9 | VOCAB_SIZE = 16
10 | IMG_SIZE = 16
11 |
12 |
13 | def check_equal(A, B):
14 | assert torch.allclose(A, B, rtol=1e-5, atol=1e-2)
15 |
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_3d/checks_3d/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_legacy/test_layers/test_3d/checks_3d/__init__.py
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_3d/checks_3d/common.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | import torch
5 |
6 | DEPTH = 2
7 | BATCH_SIZE = 8
8 | SEQ_LENGTH = 8
9 | HIDDEN_SIZE = 8
10 | NUM_CLASSES = 8
11 | NUM_BLOCKS = 2
12 | IMG_SIZE = 16
13 | VOCAB_SIZE = 16
14 |
15 |
16 | def check_equal(A, B):
17 | eq = torch.allclose(A, B, rtol=1e-3, atol=1e-2)
18 | assert eq, f"\nA = {A}\nB = {B}"
19 | return eq
20 |
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_sequence/checks_seq/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_legacy/test_layers/test_sequence/checks_seq/__init__.py
--------------------------------------------------------------------------------
/tests/test_legacy/test_tensor/common_utils/__init__.py:
--------------------------------------------------------------------------------
1 | from ._utils import *
2 |
--------------------------------------------------------------------------------
/tests/test_optimizer/test_lr_scheduler.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | from torch.optim import Adam
3 |
4 | from colossalai.nn.lr_scheduler import CosineAnnealingWarmupLR
5 |
6 |
7 | def test_lr_scheduler_save_load():
8 | model = nn.Linear(10, 10)
9 | optimizer = Adam(model.parameters(), lr=1e-3)
10 | scheduler = CosineAnnealingWarmupLR(optimizer, total_steps=5, warmup_steps=2)
11 | new_scheduler = CosineAnnealingWarmupLR(optimizer, total_steps=5, warmup_steps=2)
12 | for _ in range(5):
13 | scheduler.step()
14 | state_dict = scheduler.state_dict()
15 | new_scheduler.load_state_dict(state_dict)
16 | assert state_dict == new_scheduler.state_dict()
17 |
18 |
19 | if __name__ == "__main__":
20 | test_lr_scheduler_save_load()
21 |
--------------------------------------------------------------------------------
/tests/test_shardformer/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_shardformer/__init__.py
--------------------------------------------------------------------------------
/tests/test_shardformer/test_model/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_shardformer/test_model/__init__.py
--------------------------------------------------------------------------------
/version.txt:
--------------------------------------------------------------------------------
1 | 0.5.1
2 |
--------------------------------------------------------------------------------
22 | Check Installation Demo
23 |
24 |
25 | ## 启动分布式训练
26 |
27 | 在分布式训练时,我们可以使用`colossalai run`来启动单节点或者多节点的多进程,详细的内容可以参考[启动 Colossal-AI](./launch_colossalai.md)。
28 |
29 |
30 |
--------------------------------------------------------------------------------
/docs/source/zh-Hans/features/cluster_utils.md:
--------------------------------------------------------------------------------
1 | # 集群实用程序
2 |
3 | 作者: [Hongxin Liu](https://github.com/ver217)
4 |
5 | **前置教程:**
6 | - [分布式训练](../concepts/distributed_training.md)
7 |
8 | ## 引言
9 |
10 | 我们提供了一个实用程序类 `colossalai.cluster.DistCoordinator` 来协调分布式训练。它对于获取有关集群的各种信息很有用,例如节点数、每个节点的进程数等。
11 |
12 | ## API 参考
13 |
14 | {{ autodoc:colossalai.cluster.DistCoordinator }}
15 |
16 |
17 |
--------------------------------------------------------------------------------
/docs/source/zh-Hans/get_started/reading_roadmap.md:
--------------------------------------------------------------------------------
1 | # 阅读指引
2 |
3 | Colossal-AI为您提供了一系列的并行训练组件。我们的目标是支持您开发分布式深度学习模型,就像您编写单GPU深度学习模型一样简单。ColossalAI提供了易于使用的API来帮助您启动您的训练过程。为了更好地了解ColossalAI的工作原理,我们建议您按照以下顺序阅读本文档。
4 |
5 | - 如果您不熟悉分布式系统,或者没有使用过Colossal-AI,您可以先浏览`概念`部分,了解我们要实现的目标同时掌握一些关于分布式训练的背景知识。
6 | - 接下来,您可以按照`基础教程`进行学习。该节将介绍关于如何使用Colossal-AI的细节。
7 | - 这时候,您就可以小试牛刀了!`功能` 部分将帮助您尝试如何使用Colossal-AI为您的模型训练进行加速。我们将为每个教程提供一个代码库。这些教程将涵盖Colossal-AI的基本用法,以实现简单的功能,如数据并行和混合精度训练。
8 | - 最后,如果您希望应用更高超的技术,比如,如何在GPT-3上运行混合并行,快来`高级教程`部分学习如何搭建您自己的模型吧!
9 |
10 | **我们始终欢迎社区的建议和讨论,如果您遇到任何问题,我们将非常愿意帮助您。您可以在GitHub 提 [issue](https://github.com/hpcaitech/ColossalAI/issues) ,或在[论坛](https://github.com/hpcaitech/ColossalAI/discussions)上创建一个讨论主题。**
11 |
--------------------------------------------------------------------------------
/docs/versions.json:
--------------------------------------------------------------------------------
1 | [
2 | "current"
3 | ]
4 |
--------------------------------------------------------------------------------
/examples/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/__init__.py
--------------------------------------------------------------------------------
/examples/community/fp8/mnist/README.md:
--------------------------------------------------------------------------------
1 | # Basic MNIST Example with optional FP8 of TransformerEngine
2 |
3 | [TransformerEngine](https://github.com/NVIDIA/TransformerEngine) is a library for accelerating Transformer models on NVIDIA GPUs, including using 8-bit floating point (FP8) precision on Hopper GPUs, to provide better performance with lower memory utilization in both training and inference.
4 |
5 | Thanks for the contribution to this tutorial from NVIDIA.
6 |
7 | ```bash
8 | python main.py
9 | python main.py --use-te # Linear layers from TransformerEngine
10 | python main.py --use-fp8 # FP8 + TransformerEngine for Linear layers
11 | ```
12 |
13 | > We are working to integrate it with Colossal-AI and will finish it soon.
14 |
--------------------------------------------------------------------------------
/examples/community/roberta/preprocessing/Makefile:
--------------------------------------------------------------------------------
1 | CXXFLAGS += -O3 -Wall -shared -std=c++14 -std=c++17 -fPIC -fdiagnostics-color
2 | CPPFLAGS += $(shell python3 -m pybind11 --includes)
3 | LIBNAME = mask
4 | LIBEXT = $(shell python3-config --extension-suffix)
5 |
6 | default: $(LIBNAME)$(LIBEXT)
7 |
8 | %$(LIBEXT): %.cpp
9 | $(CXX) $(CXXFLAGS) $(CPPFLAGS) $< -o $@
10 |
--------------------------------------------------------------------------------
/examples/community/roberta/pretraining/bert_dataset_provider.py:
--------------------------------------------------------------------------------
1 | class BertDatasetProviderInterface:
2 | def get_shard(self, index, shuffle=True):
3 | raise NotImplementedError
4 |
5 | def release_shard(self, index):
6 | raise NotImplementedError
7 |
8 | def prefetch_shard(self, index):
9 | raise NotImplementedError
10 |
11 | def get_batch(self, batch_iter):
12 | raise NotImplementedError
13 |
14 | def prefetch_batch(self):
15 | raise NotImplementedError
16 |
--------------------------------------------------------------------------------
/examples/community/roberta/pretraining/hostfile:
--------------------------------------------------------------------------------
1 | GPU001
2 | GPU002
3 | GPU003
4 | GPU004
5 | GPU005
6 | GPU006
7 | GPU007
8 | GPU008
9 | GPU009
10 | GPU010
11 |
--------------------------------------------------------------------------------
/examples/community/roberta/pretraining/loss.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | __all__ = ["LossForPretraining"]
4 |
5 |
6 | class LossForPretraining(torch.nn.Module):
7 | def __init__(self, vocab_size):
8 | super(LossForPretraining, self).__init__()
9 | self.loss_fn = torch.nn.CrossEntropyLoss(ignore_index=-1)
10 | self.vocab_size = vocab_size
11 |
12 | def forward(self, prediction_scores, masked_lm_labels, next_sentence_labels=None):
13 | masked_lm_loss = self.loss_fn(prediction_scores.view(-1, self.vocab_size), masked_lm_labels.view(-1))
14 | # next_sentence_loss = self.loss_fn(seq_relationship_score.view(-1, 2), next_sentence_labels.view(-1))
15 | total_loss = masked_lm_loss # + next_sentence_loss
16 | return total_loss
17 |
--------------------------------------------------------------------------------
/examples/community/roberta/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.1.12
2 | torch >= 1.8.1
3 | tqdm
4 | tensorboard
5 | numpy
6 | h5py
7 | wandb
8 |
--------------------------------------------------------------------------------
/examples/community/roberta/test_ci.sh:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/community/roberta/test_ci.sh
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/.DS_Store
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/data/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/data/__init__.py
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/models/diffusion/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/models/diffusion/__init__.py
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/models/diffusion/dpm_solver/__init__.py:
--------------------------------------------------------------------------------
1 | from .sampler import DPMSolverSampler
2 |
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/modules/diffusionmodules/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/modules/diffusionmodules/__init__.py
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/modules/distributions/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/modules/distributions/__init__.py
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/modules/encoders/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/modules/encoders/__init__.py
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/modules/image_degradation/__init__.py:
--------------------------------------------------------------------------------
1 | from ldm.modules.image_degradation.bsrgan import degradation_bsrgan_variant as degradation_fn_bsr
2 | from ldm.modules.image_degradation.bsrgan_light import degradation_bsrgan_variant as degradation_fn_bsr_light
3 |
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/modules/image_degradation/utils/test.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/modules/image_degradation/utils/test.png
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/modules/midas/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/modules/midas/__init__.py
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/modules/midas/midas/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/images/diffusion/ldm/modules/midas/midas/__init__.py
--------------------------------------------------------------------------------
/examples/images/diffusion/ldm/modules/midas/midas/base_model.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 |
4 | class BaseModel(torch.nn.Module):
5 | def load(self, path):
6 | """Load model from file.
7 |
8 | Args:
9 | path (str): file path
10 | """
11 | parameters = torch.load(path, map_location=torch.device("cpu"))
12 |
13 | if "optimizer" in parameters:
14 | parameters = parameters["model"]
15 |
16 | self.load_state_dict(parameters)
17 |
--------------------------------------------------------------------------------
/examples/images/diffusion/requirements.txt:
--------------------------------------------------------------------------------
1 | albumentations==1.3.0
2 | opencv-python==4.6.0.66
3 | pudb==2019.2
4 | prefetch_generator
5 | imageio==2.9.0
6 | imageio-ffmpeg==0.4.2
7 | torchmetrics==0.7
8 | omegaconf==2.1.1
9 | test-tube>=0.7.5
10 | streamlit>=1.11.1
11 | einops==0.3.0
12 | transformers
13 | webdataset==0.2.5
14 | open-clip-torch==2.7.0
15 | gradio==3.34.0
16 | lightning==1.9.0
17 | datasets
18 | colossalai
19 | -e .
20 |
--------------------------------------------------------------------------------
/examples/images/diffusion/scripts/tests/test_watermark.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import fire
3 | from imwatermark import WatermarkDecoder
4 |
5 |
6 | def testit(img_path):
7 | bgr = cv2.imread(img_path)
8 | decoder = WatermarkDecoder("bytes", 136)
9 | watermark = decoder.decode(bgr, "dwtDct")
10 | try:
11 | dec = watermark.decode("utf-8")
12 | except:
13 | dec = "null"
14 | print(dec)
15 |
16 |
17 | if __name__ == "__main__":
18 | fire.Fire(testit)
19 |
--------------------------------------------------------------------------------
/examples/images/diffusion/scripts/txt2img.sh:
--------------------------------------------------------------------------------
1 | python scripts/txt2img.py --prompt "Teyvat, Medium Female, a woman in a blue outfit holding a sword" --plms \
2 | --outdir ./output \
3 | --ckpt checkpoints/last.ckpt \
4 | --config configs/2023-02-02T18-06-14-project.yaml \
5 | --n_samples 4
6 |
--------------------------------------------------------------------------------
/examples/images/diffusion/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import find_packages, setup
2 |
3 | setup(
4 | name="latent-diffusion",
5 | version="0.0.1",
6 | description="",
7 | packages=find_packages(),
8 | install_requires=[
9 | "torch",
10 | "numpy",
11 | "tqdm",
12 | ],
13 | )
14 |
--------------------------------------------------------------------------------
/examples/images/diffusion/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -euxo pipefail
3 |
4 | conda env create -f environment.yaml
5 |
6 | conda activate ldm
7 |
8 | conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
9 | pip install transformers diffusers invisible-watermark
10 |
11 | BUILD_EXT=1 pip install colossalai
12 |
13 | wget https://huggingface.co/stabilityai/stable-diffusion-2-base/resolve/main/512-base-ema.ckpt
14 |
15 | python main.py --logdir /tmp --train --base configs/Teyvat/train_colossalai_teyvat.yaml --ckpt 512-base-ema.ckpt
16 |
--------------------------------------------------------------------------------
/examples/images/diffusion/train_colossalai.sh:
--------------------------------------------------------------------------------
1 | HF_DATASETS_OFFLINE=1
2 | TRANSFORMERS_OFFLINE=1
3 | DIFFUSERS_OFFLINE=1
4 |
5 | python main.py --logdir /tmp --train --base configs/Teyvat/train_colossalai_teyvat.yaml --ckpt diffuser_root_dir/512-base-ema.ckpt
6 |
--------------------------------------------------------------------------------
/examples/images/diffusion/train_ddp.sh:
--------------------------------------------------------------------------------
1 | HF_DATASETS_OFFLINE=1
2 | TRANSFORMERS_OFFLINE=1
3 | DIFFUSERS_OFFLINE=1
4 |
5 | python main.py --logdir /tmp -t -b /configs/train_ddp.yaml
6 |
--------------------------------------------------------------------------------
/examples/images/dreambooth/colossalai.sh:
--------------------------------------------------------------------------------
1 | HF_DATASETS_OFFLINE=1
2 | TRANSFORMERS_OFFLINE=1
3 | DIFFUSERS_OFFLINE=1
4 |
5 | torchrun --nproc_per_node 4 --standalone train_dreambooth_colossalai.py \
6 | --pretrained_model_name_or_path="/data/dreambooth/diffuser/stable-diffusion-v1-4" \
7 | --instance_data_dir="/data/dreambooth/Teyvat/data" \
8 | --output_dir="./weight_output" \
9 | --instance_prompt="a picture of a dog" \
10 | --resolution=512 \
11 | --plugin="gemini" \
12 | --train_batch_size=1 \
13 | --learning_rate=5e-6 \
14 | --lr_scheduler="constant" \
15 | --lr_warmup_steps=0 \
16 | --num_class_images=200 \
17 | --test_run=True \
18 | --placement="auto" \
19 |
--------------------------------------------------------------------------------
/examples/images/dreambooth/debug.py:
--------------------------------------------------------------------------------
1 | """
2 | torchrun --standalone --nproc_per_node=1 debug.py
3 | """
4 |
5 | from diffusers import AutoencoderKL
6 |
7 | import colossalai
8 | from colossalai.zero import ColoInitContext
9 |
10 | path = "/data/scratch/diffuser/stable-diffusion-v1-4"
11 |
12 | colossalai.launch_from_torch()
13 | with ColoInitContext(device="cpu"):
14 | vae = AutoencoderKL.from_pretrained(
15 | path,
16 | subfolder="vae",
17 | revision=None,
18 | )
19 |
20 | for n, p in vae.named_parameters():
21 | print(n)
22 |
--------------------------------------------------------------------------------
/examples/images/dreambooth/dreambooth.sh:
--------------------------------------------------------------------------------
1 | python train_dreambooth.py \
2 | --pretrained_model_name_or_path="/data/dreambooth/diffuser/stable-diffusion-v1-4" \
3 | --instance_data_dir="/data/dreambooth/Teyvat/data" \
4 | --output_dir="./weight_output" \
5 | --instance_prompt="a photo of a dog" \
6 | --resolution=512 \
7 | --train_batch_size=1 \
8 | --gradient_accumulation_steps=1 \
9 | --learning_rate=5e-6 \
10 | --lr_scheduler="constant" \
11 | --lr_warmup_steps=0 \
12 | --num_class_images=200 \
13 |
--------------------------------------------------------------------------------
/examples/images/dreambooth/inference.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from diffusers import DiffusionPipeline
3 |
4 | model_id = ""
5 | print(f"Loading model... from{model_id}")
6 |
7 | pipe = DiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
8 |
9 | prompt = "A photo of an apple."
10 | image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
11 |
12 | image.save("output.png")
13 |
--------------------------------------------------------------------------------
/examples/images/dreambooth/requirements.txt:
--------------------------------------------------------------------------------
1 | diffusers>==0.5.0
2 | accelerate
3 | torchvision
4 | transformers>=4.21.0
5 | ftfy
6 | tensorboard
7 | modelcards
8 |
--------------------------------------------------------------------------------
/examples/images/resnet/.gitignore:
--------------------------------------------------------------------------------
1 | data
2 | checkpoint
3 | ckpt-fp16
4 | ckpt-fp32
5 |
--------------------------------------------------------------------------------
/examples/images/resnet/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai
2 | torch
3 | torchvision
4 | tqdm
5 | pytest
6 |
--------------------------------------------------------------------------------
/examples/images/resnet/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -xe
3 |
4 | export DATA=/data/scratch/cifar-10
5 |
6 | pip install -r requirements.txt
7 |
8 | # TODO: skip ci test due to time limits, train.py needs to be rewritten.
9 |
10 | # for plugin in "torch_ddp" "torch_ddp_fp16" "low_level_zero"; do
11 | # colossalai run --nproc_per_node 4 train.py --interval 0 --target_acc 0.84 --plugin $plugin
12 | # done
13 |
--------------------------------------------------------------------------------
/examples/images/vit/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.1.12
2 | torch >= 1.8.1
3 | numpy>=1.24.1
4 | tqdm>=4.61.2
5 | transformers>=4.20.0
6 | datasets
7 |
--------------------------------------------------------------------------------
/examples/images/vit/run_benchmark.sh:
--------------------------------------------------------------------------------
1 | set -xe
2 | pip install -r requirements.txt
3 |
4 | export BS=8
5 | export MEMCAP=0
6 | export GPUNUM=1
7 |
8 | for BS in 8 32
9 | do
10 | for PLUGIN in "torch_ddp" "torch_ddp_fp16" "low_level_zero" "gemini" "hybrid_parallel"
11 | do
12 |
13 | MODEL_PATH="google/vit-base-patch16-224"
14 | colossalai run \
15 | --nproc_per_node ${GPUNUM} \
16 | --master_port 29505 \
17 | vit_benchmark.py \
18 | --model_name_or_path ${MODEL_PATH} \
19 | --mem_cap ${MEMCAP} \
20 | --plugin ${PLUGIN} \
21 | --batch_size ${BS}
22 |
23 | done
24 | done
25 |
--------------------------------------------------------------------------------
/examples/images/vit/test_ci.sh:
--------------------------------------------------------------------------------
1 | set -xe
2 | pip install -r requirements.txt
3 |
4 | BS=8
5 | for PLUGIN in "torch_ddp" "torch_ddp_fp16" "low_level_zero" "gemini" "hybrid_parallel"
6 | do
7 |
8 | colossalai run \
9 | --nproc_per_node 4 \
10 | --master_port 29505 \
11 | vit_benchmark.py \
12 | --model_name_or_path "google/vit-base-patch16-224" \
13 | --plugin ${PLUGIN} \
14 | --batch_size ${BS}
15 |
16 | done
17 |
--------------------------------------------------------------------------------
/examples/inference/benchmark_ops/test_ci.sh:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/inference/benchmark_ops/test_ci.sh
--------------------------------------------------------------------------------
/examples/inference/client/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | echo "Skip the test (this test is slow)"
3 |
4 | # bash ./run_benchmark.sh
5 |
--------------------------------------------------------------------------------
/examples/inference/llama/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | echo "Skip the test (this test is slow)"
3 |
4 | # bash ./run_benchmark.sh
5 |
--------------------------------------------------------------------------------
/examples/inference/stable_diffusion/requirements.txt:
--------------------------------------------------------------------------------
1 | torchvision
2 | torchmetrics
3 | cleanfid
4 |
--------------------------------------------------------------------------------
/examples/inference/stable_diffusion/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | echo "Skip the test (this test is slow)"
3 |
--------------------------------------------------------------------------------
/examples/language/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/language/__init__.py
--------------------------------------------------------------------------------
/examples/language/bert/benchmark.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -xe
3 |
4 | pip install -r requirements.txt
5 |
6 | for plugin in "torch_ddp" "torch_ddp_fp16" "gemini" "low_level_zero"; do
7 | torchrun --standalone --nproc_per_node 2 benchmark.py --plugin $plugin --model_type "bert"
8 | torchrun --standalone --nproc_per_node 2 benchmark.py --plugin $plugin --model_type "albert"
9 | done
10 |
--------------------------------------------------------------------------------
/examples/language/bert/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai
2 | evaluate
3 | datasets
4 | torch
5 | tqdm
6 | transformers
7 | scipy
8 | scikit-learn
9 | ptflops
10 |
--------------------------------------------------------------------------------
/examples/language/bert/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -x
3 |
4 | pip install -r requirements.txt
5 |
6 | FAIL_LIMIT=3
7 |
8 | for plugin in "torch_ddp" "torch_ddp_fp16" "gemini" "low_level_zero" "hybrid_parallel"; do
9 | for i in $(seq 1 $FAIL_LIMIT); do
10 | torchrun --standalone --nproc_per_node 4 finetune.py --target_f1 0.86 --plugin $plugin --model_type "bert" && break
11 | echo "Failed $i times"
12 | if [ $i -eq $FAIL_LIMIT ]; then
13 | echo "Failed $FAIL_LIMIT times, exiting"
14 | exit 1
15 | fi
16 | done
17 | done
18 |
--------------------------------------------------------------------------------
/examples/language/commons/utils.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 |
4 | # Randomly Generated Data
5 | def get_data(batch_size, seq_len, vocab_size):
6 | input_ids = torch.randint(0, vocab_size, (batch_size, seq_len), device=torch.cuda.current_device())
7 | attention_mask = torch.ones_like(input_ids)
8 | return input_ids, attention_mask
9 |
10 |
11 | def get_tflops(model_numel, batch_size, seq_len, step_time):
12 | return model_numel * batch_size * seq_len * 8 / 1e12 / (step_time + 1e-12)
13 |
--------------------------------------------------------------------------------
/examples/language/deepseek/data_utils.py:
--------------------------------------------------------------------------------
1 | ../data_utils.py
--------------------------------------------------------------------------------
/examples/language/deepseek/model_utils.py:
--------------------------------------------------------------------------------
1 | ../model_utils.py
--------------------------------------------------------------------------------
/examples/language/deepseek/performance_evaluator.py:
--------------------------------------------------------------------------------
1 | ../performance_evaluator.py
--------------------------------------------------------------------------------
/examples/language/deepseek/test_ci.sh:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/language/deepseek/test_ci.sh
--------------------------------------------------------------------------------
/examples/language/gpt/experiments/auto_offload/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.1.12
2 | torch >= 1.8.1
3 |
--------------------------------------------------------------------------------
/examples/language/gpt/experiments/auto_offload/run.sh:
--------------------------------------------------------------------------------
1 | export BATCH_SIZE=${BATCH_SIZE:-64}
2 | export MODEL_TYPE=${MODEL_TYPE:-"gpt2_medium"}
3 | export MEMORY_BUDGET=${MEMORY_BUDGET:-16}
4 | export SOLVER_TYPE=${SOLVER_TYPE:-"asyn"}
5 |
6 | mkdir -p offload_logs
7 |
8 | python train_gpt_offload.py --model_type=${MODEL_TYPE} --memory_budget=${MEMORY_BUDGET} --solver_type=${SOLVER_TYPE} --batch_size=${BATCH_SIZE} 2>&1 | tee ./offload_logs/${MODEL_TYPE}_bs_${BATCH_SIZE}_st_${SOLVER_TYPE}.log
9 |
--------------------------------------------------------------------------------
/examples/language/gpt/experiments/auto_parallel/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.1.12
2 | torch >= 1.8.1
3 | transformers >= 4.23.1
4 | PuLP >= 2.7.0
5 |
--------------------------------------------------------------------------------
/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_12_layers.pt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_12_layers.pt
--------------------------------------------------------------------------------
/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_1_layers.pt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_1_layers.pt
--------------------------------------------------------------------------------
/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_4_layers.pt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_4_layers.pt
--------------------------------------------------------------------------------
/examples/language/gpt/experiments/pipeline_parallel/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.1.12
2 | torch >= 1.8.1
3 |
--------------------------------------------------------------------------------
/examples/language/gpt/experiments/pipeline_parallel/run.sh:
--------------------------------------------------------------------------------
1 | export GPUNUM=${GPUNUM:-4}
2 | export BATCH_SIZE=${BATCH_SIZE:-16}
3 | export MODEL_TYPE=${MODEL_TYPE:-"gpt2_medium"}
4 | export NUM_MICROBATCH=${NUM_MICROBATCH:-8}
5 |
6 | mkdir -p pp_logs
7 | python train_gpt_pp.py --device="cuda" --model_type=${MODEL_TYPE} --num_microbatches=${NUM_MICROBATCH} --world_size=${GPUNUM} --batch_size=${BATCH_SIZE} 2>&1 | tee ./pp_logs/${MODEL_TYPE}_gpu_${GPUNUM}_bs_${BATCH_SIZE}_nm_${NUM_MICROBATCH}.log
8 |
--------------------------------------------------------------------------------
/examples/language/gpt/gemini/commons/performance_evaluator.py:
--------------------------------------------------------------------------------
1 | ../../../performance_evaluator.py
--------------------------------------------------------------------------------
/examples/language/gpt/gemini/commons/utils.py:
--------------------------------------------------------------------------------
1 | import time
2 |
3 | import torch
4 |
5 |
6 | class DummyProfiler:
7 | def __init__(self):
8 | self.step_number = 0
9 |
10 | def step(self):
11 | self.step_number += 1
12 |
13 |
14 | # Randomly Generated Data
15 | def get_data(batch_size, seq_len, vocab_size):
16 | input_ids = torch.randint(0, vocab_size, (batch_size, seq_len), device=torch.cuda.current_device())
17 | attention_mask = torch.ones_like(input_ids)
18 | return input_ids, attention_mask
19 |
20 |
21 | def get_tflops(model_numel, batch_size, seq_len, step_time):
22 | return model_numel * batch_size * seq_len * 8 / 1e12 / (step_time + 1e-12)
23 |
24 |
25 | def get_time_stamp():
26 | cur_time = time.strftime("%d-%H:%M", time.localtime())
27 | return cur_time
28 |
--------------------------------------------------------------------------------
/examples/language/gpt/gemini/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.1.12
2 | torch >= 1.8.1
3 |
--------------------------------------------------------------------------------
/examples/language/gpt/gemini/run_gemini.sh:
--------------------------------------------------------------------------------
1 | set -x
2 | # distplan in ["CAI_ZeRO1", "CAI_ZeRO2", "CAI_Gemini", "Pytorch_DDP", "Pytorch_ZeRO"]
3 | export DISTPLAN=${DISTPLAN:-"CAI_Gemini"}
4 |
5 | # The following options only valid when DISTPLAN="colossalai"
6 | export GPUNUM=${GPUNUM:-1}
7 | export BATCH_SIZE=${BATCH_SIZE:-16}
8 | export MODEL_TYPE=${MODEL_TYPE:-"gpt2_medium"}
9 | export TRAIN_STEP=${TRAIN_STEP:-10}
10 | # export PYTHONPATH=$PWD:$PYTHONPATH
11 |
12 |
13 | mkdir -p gemini_logs
14 |
15 | torchrun --standalone --nproc_per_node=${GPUNUM} ./train_gpt_demo.py \
16 | --model_type=${MODEL_TYPE} \
17 | --batch_size=${BATCH_SIZE} \
18 | --distplan=${DISTPLAN} \
19 | --train_step=${TRAIN_STEP} \
20 | 2>&1 | tee ./gemini_logs/${MODEL_TYPE}_${DISTPLAN}_gpu_${GPUNUM}_bs_${BATCH_SIZE}.log
21 |
--------------------------------------------------------------------------------
/examples/language/gpt/gemini/test_ci.sh:
--------------------------------------------------------------------------------
1 | set -x
2 | $(cd `dirname $0`;pwd)
3 | export TRAIN_STEP=4
4 |
5 | for MODEL_TYPE in "gpt2_medium"; do
6 | for DISTPLAN in "CAI_Gemini"; do
7 | for BATCH_SIZE in 2; do
8 | for GPUNUM in 1 4; do
9 | MODEL_TYPE=${MODEL_TYPE} DISTPLAN=${DISTPLAN} BATCH_SIZE=${BATCH_SIZE} GPUNUM=${GPUNUM} \
10 | bash ./run_gemini.sh
11 | done
12 | done
13 | done
14 |
15 | for DISTPLAN in "CAI_ZeRO2" "CAI_ZeRO1"; do
16 | for BATCH_SIZE in 2; do
17 | for GPUNUM in 1 4; do
18 | MODEL_TYPE=${MODEL_TYPE} DISTPLAN=${DISTPLAN} BATCH_SIZE=${BATCH_SIZE} GPUNUM=${GPUNUM} \
19 | bash ./run_gemini.sh
20 | done
21 | done
22 | done
23 | done
24 |
--------------------------------------------------------------------------------
/examples/language/gpt/hybridparallelism/run.sh:
--------------------------------------------------------------------------------
1 | # load via internet
2 | torchrun --standalone --nproc_per_node 4 --master_port 29800 finetune.py --target_f1 0.6 --plugin hybrid_parallel --model_type "gpt2"
3 |
4 | # load from local
5 | # torchrun --standalone --nproc_per_node 4 --master_port 29800 finetune.py --target_f1 0.6 --plugin hybrid_parallel --model_type "gpt2" --pretrained_path "your/path/to/pretrained_model"
6 |
--------------------------------------------------------------------------------
/examples/language/gpt/requirements.txt:
--------------------------------------------------------------------------------
1 | transformers >= 4.23
2 | colossalai
3 | evaluate
4 | tqdm
5 | scipy
6 | scikit-learn
7 | numpy
8 |
--------------------------------------------------------------------------------
/examples/language/gpt/test_ci.sh:
--------------------------------------------------------------------------------
1 | set -x
2 | pip install -r requirements.txt
3 |
4 | cd gemini && bash test_ci.sh
5 | # cd ../hybridparallelism && bash run.sh
6 |
--------------------------------------------------------------------------------
/examples/language/gpt/titans/model/__init__.py:
--------------------------------------------------------------------------------
1 | from .embed import vocab_parallel_cross_entropy
2 | from .gpt1d import *
3 | from .pipeline_gpt1d import *
4 |
--------------------------------------------------------------------------------
/examples/language/gpt/titans/requirements.txt:
--------------------------------------------------------------------------------
1 | torch==1.12.1
2 | titans==0.0.7
3 | colossalai==0.2.0+torch1.12cu11.3
4 | -f https://release.colossalai.org
5 |
--------------------------------------------------------------------------------
/examples/language/gpt/titans/run.sh:
--------------------------------------------------------------------------------
1 | export DATA=/data/scratch/gpt_data/small-gpt-dataset.json
2 | DUMMY_DATA=--use_dummy_dataset
3 | colossalai run --nproc_per_node=2 train_gpt.py --config ./configs/gpt2_small_zero3_pp1d.py --from_torch $DUMMY_DATA
4 |
--------------------------------------------------------------------------------
/examples/language/gpt/titans/test_ci.sh:
--------------------------------------------------------------------------------
1 | colossalai run --nproc_per_node=4 train_gpt.py --config ./configs/gpt2_small_zero3_pp1d.py --from_torch --use_dummy_dataset
2 |
--------------------------------------------------------------------------------
/examples/language/grok-1/requirements.txt:
--------------------------------------------------------------------------------
1 | torch>=2.1.0,<2.2.0
2 | colossalai>=0.3.6
3 | transformers==4.35.0
4 |
--------------------------------------------------------------------------------
/examples/language/grok-1/run_inference_fast.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 |
3 | PRETRAINED=${1:-"hpcai-tech/grok-1"}
4 |
5 | torchrun --standalone --nproc_per_node 8 inference_tp.py --pretrained "$PRETRAINED" \
6 | --max_new_tokens 100 \
7 | --text "The company's annual conference, featuring keynote speakers and exclusive product launches, will be held at the Los Angeles Convention Center from October 20th to October 23rd, 2021. Extract the date mentioned in the above sentence." \
8 | "将以下句子翻译成英语。 我喜欢看电影和读书。" \
9 | "All books have the same weight, 10 books weigh 5kg, what is the weight of 2 books?"
10 |
--------------------------------------------------------------------------------
/examples/language/grok-1/run_inference_slow.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 |
3 | PRETRAINED=${1:-"hpcai-tech/grok-1"}
4 |
5 | python3 inference.py --pretrained "$PRETRAINED" \
6 | --max_new_tokens 100 \
7 | --text "The company's annual conference, featuring keynote speakers and exclusive product launches, will be held at the Los Angeles Convention Center from October 20th to October 23rd, 2021. Extract the date mentioned in the above sentence." \
8 | "将以下句子翻译成英语。 我喜欢看电影和读书。" \
9 | "All books have the same weight, 10 books weigh 5kg, what is the weight of 2 books?"
10 |
--------------------------------------------------------------------------------
/examples/language/grok-1/test_ci.sh:
--------------------------------------------------------------------------------
1 | pip install -r requirements.txt
2 |
--------------------------------------------------------------------------------
/examples/language/llama/data_utils.py:
--------------------------------------------------------------------------------
1 | ../data_utils.py
--------------------------------------------------------------------------------
/examples/language/llama/model_utils.py:
--------------------------------------------------------------------------------
1 | ../model_utils.py
--------------------------------------------------------------------------------
/examples/language/llama/performance_evaluator.py:
--------------------------------------------------------------------------------
1 | ../performance_evaluator.py
--------------------------------------------------------------------------------
/examples/language/llama/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai>=0.3.6
2 | datasets
3 | numpy
4 | tqdm
5 | transformers
6 | flash-attn>=2.0.0
7 | SentencePiece==0.1.99
8 | tensorboard==2.14.0
9 |
--------------------------------------------------------------------------------
/examples/language/llama/scripts/benchmark_70B/3d.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # TODO: fix this
4 | echo "3D parallel for LLaMA-2 is not ready yet"
5 | exit 1
6 |
7 | ################
8 | #Load your environments and modules here
9 | ################
10 |
11 | HOSTFILE=$(realpath hosts.txt)
12 |
13 | cd ../..
14 |
15 | export OMP_NUM_THREADS=8
16 |
17 | colossalai run --nproc_per_node 8 --hostfile $HOSTFILE benchmark.py -c 70b -p 3d -g -x -b 8 --tp 4 --pp 2 --mbs 1
18 |
--------------------------------------------------------------------------------
/examples/language/llama/scripts/benchmark_70B/gemini.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | ################
4 | #Load your environments and modules here
5 | ################
6 |
7 | HOSTFILE=$(realpath hosts.txt)
8 |
9 | cd ../..
10 |
11 | export OMP_NUM_THREADS=8
12 |
13 | colossalai run --nproc_per_node 8 --hostfile $HOSTFILE benchmark.py -c 70b -g -x -b 2
14 |
--------------------------------------------------------------------------------
/examples/language/llama/scripts/benchmark_70B/gemini_auto.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | ################
4 | #Load your environments and modules here
5 | ################
6 |
7 | HOSTFILE=$(realpath hosts.txt)
8 |
9 | cd ../..
10 |
11 | export OMP_NUM_THREADS=8
12 |
13 | colossalai run --nproc_per_node 8 --hostfile $HOSTFILE benchmark.py -c 70b -p gemini_auto -g -x -b 2
14 |
--------------------------------------------------------------------------------
/examples/language/llama/scripts/benchmark_7B/gemini.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | ################
4 | #Load your environments and modules here
5 | ################
6 |
7 | HOSTFILE=$(realpath hosts.txt)
8 |
9 | cd ../..
10 |
11 | export OMP_NUM_THREADS=8
12 |
13 | colossalai run --nproc_per_node 8 --hostfile $HOSTFILE benchmark.py -g -x -b 16
14 |
--------------------------------------------------------------------------------
/examples/language/llama/scripts/benchmark_7B/gemini_auto.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | ################
4 | #Load your environments and modules here
5 | ################
6 |
7 | HOSTFILE=$(realpath hosts.txt)
8 |
9 | cd ../..
10 |
11 | export OMP_NUM_THREADS=8
12 |
13 | colossalai run --nproc_per_node 8 --hostfile $HOSTFILE benchmark.py -p gemini_auto -g -x -b 16
14 |
--------------------------------------------------------------------------------
/examples/language/llama/test_ci.sh:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/language/llama/test_ci.sh
--------------------------------------------------------------------------------
/examples/language/mixtral/data_utils.py:
--------------------------------------------------------------------------------
1 | ../data_utils.py
--------------------------------------------------------------------------------
/examples/language/mixtral/model_utils.py:
--------------------------------------------------------------------------------
1 | ../model_utils.py
--------------------------------------------------------------------------------
/examples/language/mixtral/performance_evaluator.py:
--------------------------------------------------------------------------------
1 | ../performance_evaluator.py
--------------------------------------------------------------------------------
/examples/language/mixtral/test_ci.sh:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/language/mixtral/test_ci.sh
--------------------------------------------------------------------------------
/examples/language/opt/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.3.2
2 | torch >= 1.8.1
3 | datasets >= 1.8.0
4 | transformers >= 4.30.2
5 |
--------------------------------------------------------------------------------
/examples/language/opt/run_benchmark.sh:
--------------------------------------------------------------------------------
1 | set -xe
2 | pip install -r requirements.txt
3 |
4 | export BS=32
5 | export MEMCAP=0
6 | export GPUNUM=1
7 |
8 | # acceptable values include `125m`, `350m`, `1.3b`, `2.7b`, `6.7b`, `13b`, `30b`, `66b`
9 | export MODEL="125m"
10 |
11 | for BS in 8 32 128
12 | do
13 | for PLUGIN in "torch_ddp" "torch_ddp_fp16" "low_level_zero" "gemini"
14 | do
15 | for GPUNUM in 1 4
16 | do
17 |
18 | MODLE_PATH="facebook/opt-${MODEL}"
19 | colossalai run \
20 | --nproc_per_node ${GPUNUM} \
21 | --master_port 29505 \
22 | opt_benchmark.py \
23 | --model_name_or_path ${MODLE_PATH} \
24 | --mem_cap ${MEMCAP} \
25 | --plugin ${PLUGIN} \
26 | --batch_size ${BS}
27 |
28 | done
29 | done
30 | done
31 |
--------------------------------------------------------------------------------
/examples/language/opt/test_ci.sh:
--------------------------------------------------------------------------------
1 | set -xe
2 | pip install -r requirements.txt
3 |
4 | BS=4
5 | for PLUGIN in "torch_ddp" "torch_ddp_fp16" "low_level_zero" "gemini"
6 | do
7 | for GPUNUM in 1 4
8 | do
9 |
10 | colossalai run \
11 | --nproc_per_node ${GPUNUM} \
12 | --master_port 29505 \
13 | opt_benchmark.py \
14 | --model_name_or_path "facebook/opt-125m" \
15 | --plugin ${PLUGIN} \
16 | --batch_size ${BS}
17 |
18 | done
19 | done
20 |
--------------------------------------------------------------------------------
/examples/language/palm/data/README.md:
--------------------------------------------------------------------------------
1 | # Data source
2 |
3 | The enwik8 data was downloaded from the Hutter prize page: http://prize.hutter1.net/
4 |
--------------------------------------------------------------------------------
/examples/language/palm/palm_pytorch/__init__.py:
--------------------------------------------------------------------------------
1 | from palm_pytorch.palm_pytorch import PaLM
2 |
--------------------------------------------------------------------------------
/examples/language/palm/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.1.12
2 | torch >= 1.8.1
3 |
--------------------------------------------------------------------------------
/examples/language/palm/run.sh:
--------------------------------------------------------------------------------
1 | # distplan in ["colossalai", "pytorch"]
2 | export DISTPAN="colossalai"
3 |
4 | # The following options only valid when DISTPAN="colossalai"
5 | export TPDEGREE=1
6 | export GPUNUM=4
7 | export PLACEMENT='cpu'
8 | export USE_SHARD_INIT=False
9 | export BATCH_SIZE=1
10 |
11 | env OMP_NUM_THREADS=12 colossalai run --nproc_per_node ${GPUNUM} --master_port 29505 train.py \
12 | --dummy_data=True --tp_degree=${TPDEGREE} --batch_size=${BATCH_SIZE} --plugin='gemini' \
13 | --placement ${PLACEMENT} --shardinit ${USE_SHARD_INIT} --distplan ${DISTPAN} 2>&1 | tee run.log
14 |
--------------------------------------------------------------------------------
/examples/language/palm/test_ci.sh:
--------------------------------------------------------------------------------
1 | $(cd `dirname $0`;pwd)
2 |
3 | for BATCH_SIZE in 2
4 | do
5 | for GPUNUM in 1 4
6 | do
7 | env OMP_NUM_THREADS=12 colossalai run --nproc_per_node ${GPUNUM} --master_port 29505 train.py --dummy_data=True --batch_size=${BATCH_SIZE} --plugin='gemini' 2>&1 | tee run.log
8 | done
9 | done
10 |
--------------------------------------------------------------------------------
/examples/tutorial/.gitignore:
--------------------------------------------------------------------------------
1 | ./data/
2 |
--------------------------------------------------------------------------------
/examples/tutorial/auto_parallel/config.py:
--------------------------------------------------------------------------------
1 | BATCH_SIZE = 32
2 | NUM_EPOCHS = 2
3 |
--------------------------------------------------------------------------------
/examples/tutorial/auto_parallel/requirements.txt:
--------------------------------------------------------------------------------
1 | torch==1.12.1
2 | colossalai
3 | titans
4 | pulp
5 | datasets
6 | matplotlib
7 | transformers==4.22.1
8 |
--------------------------------------------------------------------------------
/examples/tutorial/auto_parallel/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import find_packages, setup
2 |
3 | setup(
4 | name="auto_parallel",
5 | version="0.0.1",
6 | description="",
7 | packages=find_packages(),
8 | install_requires=[
9 | "torch",
10 | "numpy",
11 | "tqdm",
12 | ],
13 | )
14 |
--------------------------------------------------------------------------------
/examples/tutorial/auto_parallel/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -euxo pipefail
3 |
4 | echo "this test is outdated"
5 |
6 | # pip install -r requirements.txt
7 | # conda install -c conda-forge coin-or-cbc
8 | # colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py
9 |
--------------------------------------------------------------------------------
/examples/tutorial/download_cifar10.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | from torchvision.datasets import CIFAR10
4 |
5 |
6 | def main():
7 | dir_path = os.path.dirname(os.path.realpath(__file__))
8 | data_root = os.path.join(dir_path, "data")
9 | dataset = CIFAR10(root=data_root, download=True)
10 |
11 |
12 | if __name__ == "__main__":
13 | main()
14 |
--------------------------------------------------------------------------------
/examples/tutorial/hybrid_parallel/requirements.txt:
--------------------------------------------------------------------------------
1 | torch
2 | colossalai
3 | titans
4 |
--------------------------------------------------------------------------------
/examples/tutorial/hybrid_parallel/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -euxo pipefail
3 |
4 | echo "legacy example"
5 |
6 | # pip install -r requirements.txt
7 | # colossalai run --nproc_per_node 4 train.py --config config.py
8 |
--------------------------------------------------------------------------------
/examples/tutorial/large_batch_optimizer/config.py:
--------------------------------------------------------------------------------
1 | from colossalai.legacy.amp import AMP_TYPE
2 |
3 | # hyperparameters
4 | # BATCH_SIZE is as per GPU
5 | # global batch size = BATCH_SIZE x data parallel size
6 | BATCH_SIZE = 512
7 | LEARNING_RATE = 3e-3
8 | WEIGHT_DECAY = 0.3
9 | NUM_EPOCHS = 2
10 | WARMUP_EPOCHS = 1
11 |
12 | # model config
13 | NUM_CLASSES = 10
14 |
15 | fp16 = dict(mode=AMP_TYPE.NAIVE)
16 | clip_grad_norm = 1.0
17 |
--------------------------------------------------------------------------------
/examples/tutorial/large_batch_optimizer/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai
2 | torch
3 | titans
4 |
--------------------------------------------------------------------------------
/examples/tutorial/large_batch_optimizer/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -euxo pipefail
3 | echo "this test is outdated"
4 |
5 | # pip install -r requirements.txt
6 |
7 | # run test
8 | # colossalai run --nproc_per_node 4 --master_port 29500 train.py --config config.py --optimizer lars
9 | # colossalai run --nproc_per_node 4 --master_port 29501 train.py --config config.py --optimizer lamb
10 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/README.md:
--------------------------------------------------------------------------------
1 | # New API Features
2 |
3 | **The New API is not officially released yet.**
4 |
5 | This folder contains some of the demonstrations of the new API. The new API is still under intensive development and will be released soon.
6 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/cifar_resnet/.gitignore:
--------------------------------------------------------------------------------
1 | data
2 | checkpoint
3 | ckpt-fp16
4 | ckpt-fp32
5 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/cifar_resnet/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai
2 | torch
3 | torchvision
4 | tqdm
5 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/cifar_resnet/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -xe
3 |
4 | export DATA=/data/scratch/cifar-10
5 |
6 | pip install -r requirements.txt
7 |
8 | for plugin in "torch_ddp" "torch_ddp_fp16" "low_level_zero"; do
9 | colossalai run --nproc_per_node 4 train.py --interval 0 --target_acc 0.84 --plugin $plugin
10 | done
11 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/cifar_vit/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai
2 | timm
3 | torch
4 | torchvision
5 | tqdm
6 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/cifar_vit/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -xe
3 |
4 | export DATA=/data/scratch/cifar-10
5 |
6 | pip install -r requirements.txt
7 |
8 | for plugin in "torch_ddp" "torch_ddp_fp16" "low_level_zero"; do
9 | colossalai run --nproc_per_node 4 train.py --interval 0 --target_acc 0.83 --plugin $plugin
10 | done
11 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/glue_bert/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai
2 | datasets
3 | torch
4 | tqdm
5 | transformers
6 | scipy
7 | scikit-learn
8 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/glue_bert/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -xe
3 |
4 | pip install -r requirements.txt
5 |
6 | for plugin in "torch_ddp" "torch_ddp_fp16" "gemini" "low_level_zero"; do
7 | torchrun --standalone --nproc_per_node 4 finetune.py --target_f1 0.80 --plugin $plugin
8 | done
9 |
--------------------------------------------------------------------------------
/examples/tutorial/new_api/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -xe
3 |
4 | # FIXME(ver217): only run bert finetune to save time
5 |
6 | cd glue_bert && bash ./test_ci.sh && cd ..
7 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/inference/benchmark/locustfile.py:
--------------------------------------------------------------------------------
1 | from locust import HttpUser, task
2 |
3 |
4 | class GenerationUser(HttpUser):
5 | @task
6 | def generate(self):
7 | prompt = "Question: What is the longest river on the earth? Answer:"
8 | for i in range(4, 9):
9 | data = {"max_tokens": 2**i, "prompt": prompt}
10 | with self.client.post("/generation", json=data, catch_response=True) as response:
11 | if response.status_code in (200, 406):
12 | response.success()
13 | else:
14 | response.failure("Response wrong")
15 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/inference/requirements.txt:
--------------------------------------------------------------------------------
1 | fastapi==0.85.1
2 | locust==2.11.0
3 | pydantic==1.10.2
4 | sanic==22.9.0
5 | sanic_ext==22.9.0
6 | torch>=1.10.0
7 | transformers==4.23.1
8 | uvicorn==0.19.0
9 | colossalai
10 | git+https://github.com/hpcaitech/EnergonAI@main
11 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/inference/script/process-opt-175b/unflat.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env sh
2 |
3 | for i in $(seq 0 7); do
4 | python convert_ckpt.py $1 $2 ${i} &
5 | done
6 |
7 | wait $(jobs -p)
8 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/opt/benchmark.sh:
--------------------------------------------------------------------------------
1 | export BS=16
2 | export MEMCAP=0
3 | export MODEL="6.7b"
4 | export GPUNUM=1
5 |
6 | for MODEL in "6.7b" "13b" "1.3b"
7 | do
8 | for GPUNUM in 8 1
9 | do
10 | for BS in 16 24 32 8
11 | do
12 | for MEMCAP in 0 40
13 | do
14 | pkill -9 torchrun
15 | pkill -9 python
16 |
17 | bash ./run_clm.sh $BS $MEMCAP $MODEL $GPUNUM
18 | done
19 | done
20 | done
21 | done
22 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/opt/colossalai_zero.py:
--------------------------------------------------------------------------------
1 | try:
2 | from colossalai.zero.shard_utils import TensorShardStrategy
3 | except ImportError:
4 | # colossalai > 0.2.8
5 | from colossalai.legacy.zero import TensorShardStrategy
6 |
7 | zero = dict(
8 | model_config=dict(shard_strategy=TensorShardStrategy(), tensor_placement_policy="auto", reuse_fp16_shard=True),
9 | optimizer_config=dict(gpu_margin_mem_ratio=0.8, initial_scale=16384),
10 | )
11 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/opt/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai
2 | torch >= 1.8.1
3 | datasets >= 1.8.0
4 | sentencepiece != 0.1.92
5 | protobuf
6 | accelerate >= 0.20.3
7 | transformers
8 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/opt/run_clm.sh:
--------------------------------------------------------------------------------
1 | set -x
2 | export BS=${1:-16}
3 | export MEMCAP=${2:-0}
4 | export MODEL=${3:-"125m"}
5 | export GPUNUM=${4:-1}
6 |
7 | # make directory for logs
8 | mkdir -p ./logs
9 |
10 | export MODLE_PATH="facebook/opt-${MODEL}"
11 |
12 | # HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1
13 | torchrun \
14 | --nproc_per_node ${GPUNUM} \
15 | --master_port 19198 \
16 | run_clm.py \
17 | --dataset_name wikitext \
18 | --dataset_config_name wikitext-2-raw-v1 \
19 | --output_dir $PWD \
20 | --mem_cap ${MEMCAP} \
21 | --model_name_or_path ${MODLE_PATH} \
22 | --per_device_train_batch_size ${BS} 2>&1 | tee ./logs/colo_${MODEL}_bs_${BS}_cap_${MEMCAP}_gpu_${GPUNUM}.log
23 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/opt/run_clm_synthetic.sh:
--------------------------------------------------------------------------------
1 | set -x
2 | export BS=${1:-16}
3 | export MEMCAP=${2:-0}
4 | export MODEL=${3:-"125m"}
5 | export GPUNUM=${4:-1}
6 |
7 | # make directory for logs
8 | mkdir -p ./logs
9 |
10 | export MODLE_PATH="facebook/opt-${MODEL}"
11 |
12 | # HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1
13 | torchrun \
14 | --nproc_per_node ${GPUNUM} \
15 | --master_port 19198 \
16 | run_clm.py \
17 | -s \
18 | --output_dir $PWD \
19 | --mem_cap ${MEMCAP} \
20 | --model_name_or_path ${MODLE_PATH} \
21 | --per_device_train_batch_size ${BS} 2>&1 | tee ./logs/colo_${MODEL}_bs_${BS}_cap_${MEMCAP}_gpu_${GPUNUM}.log
22 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/opt/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | set -xue
4 | echo "this test is outdated"
5 | # pip install -r requirements.txt
6 |
7 | # BS=4
8 | # MEMCAP=0
9 | # GPUNUM=4
10 | # MODLE="facebook/opt-125m"
11 |
12 | # torchrun \
13 | # --nproc_per_node ${GPUNUM} \
14 | # --master_port 19198 \
15 | # run_clm.py \
16 | # -s \
17 | # --output_dir $PWD \
18 | # --mem_cap ${MEMCAP} \
19 | # --model_name_or_path ${MODLE} \
20 | # --per_device_train_batch_size ${BS} \
21 | # --num_train_epochs 1
22 |
--------------------------------------------------------------------------------
/examples/tutorial/opt/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | cd opt && bash test_ci.sh
4 |
--------------------------------------------------------------------------------
/examples/tutorial/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai >= 0.1.12
2 | torch >= 1.8.1
3 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/data/datasets/Makefile:
--------------------------------------------------------------------------------
1 | CXXFLAGS += -O3 -Wall -shared -std=c++11 -fPIC -fdiagnostics-color
2 | CPPFLAGS += $(shell python3 -m pybind11 --includes)
3 | LIBNAME = helpers
4 | LIBEXT = $(shell python3-config --extension-suffix)
5 |
6 | default: $(LIBNAME)$(LIBEXT)
7 |
8 | %$(LIBEXT): %.cpp
9 | $(CXX) $(CXXFLAGS) $(CPPFLAGS) $< -o $@
10 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/data/datasets/__init__.py:
--------------------------------------------------------------------------------
1 | from . import indexed_dataset
2 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/data/datasets/test/test_preprocess_data.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | IMPL=cached
4 | python ../preprocess_data.py \
5 | --input test_samples.json \
6 | --vocab vocab.txt \
7 | --dataset-impl ${IMPL} \
8 | --output-prefix test_samples_${IMPL} \
9 | --workers 1 \
10 | --log-interval 2
11 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/loss_func/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/tutorial/sequence_parallel/loss_func/__init__.py
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/lr_scheduler/__init__.py:
--------------------------------------------------------------------------------
1 | from .annealing_lr import AnnealingLR
2 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/model/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/examples/tutorial/sequence_parallel/model/__init__.py
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/model/layers/__init__.py:
--------------------------------------------------------------------------------
1 | from .bert_layer import BertLayer
2 | from .embedding import Embedding, VocabEmbedding
3 | from .head import BertDualHead
4 | from .preprocess import PreProcessor
5 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/model/layers/dropout.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 |
4 | def bias_dropout_add(x, bias, residual, prob, training):
5 | # type: (Tensor, Tensor, Tensor, float, bool) -> Tensor
6 | out = torch.nn.functional.dropout(x + bias, p=prob, training=training)
7 | out = residual + out
8 | return out
9 |
10 |
11 | def get_bias_dropout_add(training):
12 | def _bias_dropout_add(x, bias, residual, prob):
13 | return bias_dropout_add(x, bias, residual, prob, training)
14 |
15 | return _bias_dropout_add
16 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/model/layers/init_method.py:
--------------------------------------------------------------------------------
1 | import math
2 |
3 | import torch
4 |
5 |
6 | def init_normal(tensor, sigma):
7 | """Init method based on N(0, sigma)."""
8 | torch.nn.init.normal_(tensor, mean=0.0, std=sigma)
9 |
10 |
11 | def output_init_normal(tensor, sigma, num_layers):
12 | """Init method based on N(0, sigma/sqrt(2*num_layers)."""
13 | std = sigma / math.sqrt(2.0 * num_layers)
14 | torch.nn.init.normal_(tensor, mean=0.0, std=std)
15 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai
2 | torch
3 | six
4 |
--------------------------------------------------------------------------------
/examples/tutorial/sequence_parallel/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -euxo pipefail
3 |
4 | echo "this test is outdated"
5 | # pip install -r requirements.txt
6 |
7 | # run test
8 | # colossalai run --nproc_per_node 4 train.py
9 |
--------------------------------------------------------------------------------
/extensions/csrc/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/extensions/csrc/__init__.py
--------------------------------------------------------------------------------
/extensions/csrc/kernel/cuda/utils/micros.h:
--------------------------------------------------------------------------------
1 | #pragma once
2 |
3 | #include
4 | #include
5 |
6 | #include
7 |
8 | #define CUDA_CHECK(func) \
9 | { \
10 | auto status = func; \
11 | if (status != cudaSuccess) { \
12 | throw std::runtime_error(cudaGetErrorString(status)); \
13 | } \
14 | }
15 |
16 | #define HOST __host__
17 | #define DEVICE __device__
18 | #define HOSTDEVICE __host__ __device__
19 |
--------------------------------------------------------------------------------
/extensions/pybind/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/extensions/pybind/__init__.py
--------------------------------------------------------------------------------
/extensions/pybind/cpu_adam/__init__.py:
--------------------------------------------------------------------------------
1 | from .cpu_adam_arm import CpuAdamArmExtension
2 | from .cpu_adam_x86 import CpuAdamX86Extension
3 |
4 | __all__ = ["CpuAdamArmExtension", "CpuAdamX86Extension"]
5 |
--------------------------------------------------------------------------------
/extensions/pybind/flash_attention/__init__.py:
--------------------------------------------------------------------------------
1 | from .flash_attention_dao_cuda import FlashAttentionDaoCudaExtension
2 | from .flash_attention_npu import FlashAttentionNpuExtension
3 | from .flash_attention_sdpa_cuda import FlashAttentionSdpaCudaExtension
4 |
5 | try:
6 | # TODO: remove this after updating openmoe example
7 | import flash_attention # noqa
8 |
9 | HAS_FLASH_ATTN = True
10 | except:
11 | HAS_FLASH_ATTN = False
12 |
13 |
14 | __all__ = ["FlashAttentionDaoCudaExtension", "FlashAttentionSdpaCudaExtension", "FlashAttentionNpuExtension"]
15 |
--------------------------------------------------------------------------------
/extensions/pybind/inference/__init__.py:
--------------------------------------------------------------------------------
1 | from .inference_ops_cuda import InferenceOpsCudaExtension
2 |
3 | __all__ = ["InferenceOpsCudaExtension"]
4 |
--------------------------------------------------------------------------------
/extensions/pybind/layernorm/__init__.py:
--------------------------------------------------------------------------------
1 | from .layernorm_cuda import LayerNormCudaExtension
2 |
3 | __all__ = ["LayerNormCudaExtension"]
4 |
--------------------------------------------------------------------------------
/extensions/pybind/moe/__init__.py:
--------------------------------------------------------------------------------
1 | from .moe_cuda import MoeCudaExtension
2 |
3 | __all__ = ["MoeCudaExtension"]
4 |
--------------------------------------------------------------------------------
/extensions/pybind/optimizer/__init__.py:
--------------------------------------------------------------------------------
1 | from .fused_optimizer_cuda import FusedOptimizerCudaExtension
2 |
3 | __all__ = ["FusedOptimizerCudaExtension"]
4 |
--------------------------------------------------------------------------------
/extensions/pybind/softmax/__init__.py:
--------------------------------------------------------------------------------
1 | from .scaled_masked_softmax_cuda import ScaledMaskedSoftmaxCudaExtension
2 | from .scaled_upper_triangle_masked_softmax_cuda import ScaledUpperTriangleMaskedSoftmaxCudaExtension
3 |
4 | __all__ = ["ScaledMaskedSoftmaxCudaExtension", "ScaledUpperTriangleMaskedSoftmaxCudaExtension"]
5 |
--------------------------------------------------------------------------------
/extensions/triton_extension.py:
--------------------------------------------------------------------------------
1 | from .base_extension import _Extension
2 |
3 | __all__ = ["_TritonExtension"]
4 |
5 |
6 | class _TritonExtension(_Extension):
7 | def __init__(self, name: str, priority: int = 1):
8 | super().__init__(name, support_aot=False, support_jit=True, priority=priority)
9 |
10 | def is_hardware_compatible(self) -> bool:
11 | # cuda extension can only be built if cuda is available
12 | try:
13 | import torch
14 |
15 | cuda_available = torch.cuda.is_available()
16 | except:
17 | cuda_available = False
18 | return cuda_available
19 |
20 | def load(self):
21 | return self.build_jit()
22 |
--------------------------------------------------------------------------------
/pytest.ini:
--------------------------------------------------------------------------------
1 | [pytest]
2 | markers =
3 | dist: tests which are run in a multi-GPU or multi-machine environment (at least 4 GPUs)
4 | largedist: tests which are run in a multi-GPU or multi-machine environment (at least 8 GPUs)
5 | addopts = --ignore=tests/test_analyzer --ignore=tests/test_auto_parallel --ignore=tests/test_autochunk --ignore=tests/test_fx --ignore=tests/test_legacy
6 |
--------------------------------------------------------------------------------
/requirements/requirements-test.txt:
--------------------------------------------------------------------------------
1 | pytest
2 | coverage==7.2.3
3 | git+https://github.com/hpcaitech/pytest-testmon
4 | torchvision
5 | timm
6 | titans
7 | torchaudio>=0.13.1
8 | torchx-nightly==2022.6.29 # torchrec 0.2.0 requires torchx-nightly. This package is updated every day. We fix the version to a specific date to avoid breaking changes.
9 | torchrec==0.2.0
10 | contexttimer
11 | einops
12 | triton
13 | requests==2.27.1 # downgrade to avoid huggingface error https://github.com/huggingface/transformers/issues/17611
14 | SentencePiece
15 | ninja
16 | flash_attn
17 | datasets
18 | pydantic
19 | ray
20 | peft>=0.7.1
21 |
--------------------------------------------------------------------------------
/requirements/requirements.txt:
--------------------------------------------------------------------------------
1 | numpy
2 | tqdm
3 | psutil
4 | packaging
5 | pre-commit
6 | rich
7 | click
8 | fabric
9 | contexttimer
10 | ninja
11 | torch>=2.2.0,<=2.5.1
12 | safetensors
13 | einops
14 | pydantic
15 | ray
16 | sentencepiece
17 | google
18 | protobuf
19 | transformers==4.51.3
20 | peft>=0.7.1,<=0.13.2
21 | bitsandbytes>=0.39.0
22 | rpyc==6.0.0
23 | fastapi
24 | uvicorn==0.29.0
25 | galore_torch
26 | diffusers==0.29.0
27 |
--------------------------------------------------------------------------------
/tests/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/__init__.py
--------------------------------------------------------------------------------
/tests/conftest.py:
--------------------------------------------------------------------------------
1 | import gc
2 |
3 | from colossalai.accelerator import get_accelerator
4 |
5 |
6 | def pytest_runtest_setup(item):
7 | # called for running each test in 'a' directory
8 | accelerator = get_accelerator()
9 | accelerator.empty_cache()
10 | gc.collect()
11 |
--------------------------------------------------------------------------------
/tests/kit/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/kit/__init__.py
--------------------------------------------------------------------------------
/tests/kit/model_zoo/custom/__init__.py:
--------------------------------------------------------------------------------
1 | from .hanging_param_model import *
2 | from .nested_model import *
3 | from .repeated_computed_layers import *
4 | from .simple_mlp import *
5 | from .simple_net import *
6 |
--------------------------------------------------------------------------------
/tests/kit/model_zoo/diffusers/__init__.py:
--------------------------------------------------------------------------------
1 | from .diffusers import *
2 |
--------------------------------------------------------------------------------
/tests/kit/model_zoo/timm/__init__.py:
--------------------------------------------------------------------------------
1 | from .timm import *
2 |
--------------------------------------------------------------------------------
/tests/kit/model_zoo/torchaudio/__init__.py:
--------------------------------------------------------------------------------
1 | from .torchaudio import *
2 |
--------------------------------------------------------------------------------
/tests/kit/model_zoo/torchrec/__init__.py:
--------------------------------------------------------------------------------
1 | from .torchrec import *
2 |
--------------------------------------------------------------------------------
/tests/kit/model_zoo/torchvision/__init__.py:
--------------------------------------------------------------------------------
1 | from .torchvision import *
2 |
--------------------------------------------------------------------------------
/tests/kit/model_zoo/transformers/__init__.py:
--------------------------------------------------------------------------------
1 | from .albert import *
2 | from .bert import *
3 | from .blip2 import *
4 | from .bloom import *
5 | from .chatglm2 import *
6 | from .command import *
7 | from .deepseek import *
8 | from .falcon import *
9 | from .gpt import *
10 | from .gptj import *
11 | from .llama import *
12 | from .mistral import *
13 | from .mixtral import *
14 | from .opt import *
15 | from .qwen2 import *
16 | from .sam import *
17 | from .t5 import *
18 | from .vit import *
19 | from .whisper import *
20 |
--------------------------------------------------------------------------------
/tests/test_analyzer/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_analyzer/__init__.py
--------------------------------------------------------------------------------
/tests/test_analyzer/test_fx/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_analyzer/test_fx/__init__.py
--------------------------------------------------------------------------------
/tests/test_analyzer/test_subclasses/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_analyzer/test_subclasses/__init__.py
--------------------------------------------------------------------------------
/tests/test_auto_parallel/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_auto_parallel/__init__.py
--------------------------------------------------------------------------------
/tests/test_auto_parallel/test_pass/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_auto_parallel/test_pass/__init__.py
--------------------------------------------------------------------------------
/tests/test_auto_parallel/test_tensor_shard/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_auto_parallel/test_tensor_shard/__init__.py
--------------------------------------------------------------------------------
/tests/test_auto_parallel/test_tensor_shard/test_gpt/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_auto_parallel/test_tensor_shard/test_gpt/__init__.py
--------------------------------------------------------------------------------
/tests/test_auto_parallel/test_tensor_shard/test_node_handler/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_auto_parallel/test_tensor_shard/test_node_handler/__init__.py
--------------------------------------------------------------------------------
/tests/test_booster/test_accelerator.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 |
3 | from colossalai.booster.accelerator import Accelerator
4 | from colossalai.testing import clear_cache_before_run, parameterize
5 |
6 |
7 | @clear_cache_before_run()
8 | @parameterize("device", ["cpu", "cuda"])
9 | def test_accelerator(device):
10 | accelerator = Accelerator(device)
11 | model = nn.Linear(8, 8)
12 | model = accelerator.configure_model(model)
13 | assert next(model.parameters()).device.type == device
14 | del model, accelerator
15 |
--------------------------------------------------------------------------------
/tests/test_checkpoint_io/utils.py:
--------------------------------------------------------------------------------
1 | import tempfile
2 | from contextlib import contextmanager, nullcontext
3 | from typing import Iterator
4 |
5 | import torch.distributed as dist
6 |
7 |
8 | @contextmanager
9 | def shared_tempdir() -> Iterator[str]:
10 | """
11 | A temporary directory that is shared across all processes.
12 | """
13 | ctx_fn = tempfile.TemporaryDirectory if dist.get_rank() == 0 else nullcontext
14 | with ctx_fn() as tempdir:
15 | try:
16 | obj = [tempdir]
17 | dist.broadcast_object_list(obj, src=0)
18 | tempdir = obj[0] # use the same directory on all ranks
19 | yield tempdir
20 | finally:
21 | dist.barrier()
22 |
--------------------------------------------------------------------------------
/tests/test_config/sample_config.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | train_data = dict(
5 | dataset=dict(
6 | type="CIFAR10Dataset",
7 | root="/path/to/data",
8 | download=True,
9 | transform_pipeline=[
10 | dict(type="RandomResizedCrop", size=224),
11 | dict(type="RandomHorizontalFlip"),
12 | dict(type="ToTensor"),
13 | dict(type="Normalize", mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
14 | ],
15 | ),
16 | dataloader=dict(
17 | batch_size=64,
18 | pin_memory=True,
19 | num_workers=4,
20 | sampler=dict(
21 | type="DataParallelSampler",
22 | shuffle=True,
23 | ),
24 | ),
25 | )
26 |
--------------------------------------------------------------------------------
/tests/test_config/test_load_config.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | from pathlib import Path
5 |
6 | from colossalai.context.config import Config
7 |
8 |
9 | def test_load_config():
10 | filename = Path(__file__).parent.joinpath("sample_config.py")
11 | config = Config.from_file(filename)
12 |
13 | assert config.train_data, "cannot access train data as attribute"
14 | assert config.train_data.dataset, "cannot access grandchild attribute"
15 | assert isinstance(
16 | config.train_data.dataset.transform_pipeline[0], dict
17 | ), f"expected attribute transform_pipeline elements to be a dict, but found {type(config.train_data.dataset.transform_pipeline)}"
18 |
--------------------------------------------------------------------------------
/tests/test_fx/test_tracer/test_hf_model/test_hf_opt.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | import torch
3 | from hf_tracer_utils import trace_model_and_compare_output
4 | from packaging import version
5 |
6 | from colossalai.testing import clear_cache_before_run
7 | from tests.kit.model_zoo import model_zoo
8 |
9 |
10 | @pytest.mark.skipif(version.parse(torch.__version__) < version.parse("1.12.0"), reason="torch version < 12")
11 | @clear_cache_before_run()
12 | def test_opt():
13 | sub_registry = model_zoo.get_sub_registry("transformers_opt")
14 | for name, (model_fn, data_gen_fn, _, _, _) in sub_registry.items():
15 | model = model_fn()
16 | trace_model_and_compare_output(model, data_gen_fn, ignore_data=["labels", "start_positions", "end_positions"])
17 |
18 |
19 | if __name__ == "__main__":
20 | test_opt()
21 |
--------------------------------------------------------------------------------
/tests/test_infer/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_infer/__init__.py
--------------------------------------------------------------------------------
/tests/test_infer/test_kernels/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_infer/test_kernels/__init__.py
--------------------------------------------------------------------------------
/tests/test_infer/test_kernels/cuda/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_infer/test_kernels/cuda/__init__.py
--------------------------------------------------------------------------------
/tests/test_infer/test_kernels/triton/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_infer/test_kernels/triton/__init__.py
--------------------------------------------------------------------------------
/tests/test_legacy/test_context/configs/parallel_2d_init.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | parallel = dict(pipeline=dict(size=2), tensor=dict(size=4, mode="2d"))
5 |
--------------------------------------------------------------------------------
/tests/test_legacy/test_context/configs/parallel_2p5d_init.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | parallel = dict(pipeline=dict(size=2), tensor=dict(size=8, depth=2, mode="2.5d"))
5 |
--------------------------------------------------------------------------------
/tests/test_legacy/test_context/configs/parallel_3d_init.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | parallel = dict(pipeline=dict(size=2), tensor=dict(size=8, mode="3d"))
5 |
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_1d/checks_1d/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_legacy/test_layers/test_1d/checks_1d/__init__.py
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_1d/checks_1d/common.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | import torch
5 |
6 | DEPTH = 4
7 | BATCH_SIZE = 8
8 | SEQ_LENGTH = 8
9 | IMG_SIZE = 16
10 | HIDDEN_SIZE = 8
11 | NUM_CLASSES = 8
12 | VOCAB_SIZE = 16
13 |
14 |
15 | def check_equal(A, B):
16 | assert torch.allclose(A, B, rtol=1e-3, atol=1e-1) == True
17 |
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_2d/checks_2d/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_legacy/test_layers/test_2d/checks_2d/__init__.py
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_2d/checks_2d/common.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | import torch
5 |
6 | DEPTH = 2
7 | BATCH_SIZE = 8
8 | SEQ_LENGTH = 8
9 | HIDDEN_SIZE = 8
10 | NUM_CLASSES = 8
11 | VOCAB_SIZE = 16
12 | IMG_SIZE = 16
13 |
14 |
15 | def check_equal(A, B):
16 | assert torch.allclose(A, B, rtol=1e-3, atol=1e-2)
17 |
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_2p5d/checks_2p5d/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_legacy/test_layers/test_2p5d/checks_2p5d/__init__.py
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_2p5d/checks_2p5d/common.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | TESSERACT_DIM = 2
4 | TESSERACT_DEP = 2
5 | BATCH_SIZE = 8
6 | SEQ_LENGTH = 8
7 | HIDDEN_SIZE = 8
8 | NUM_CLASSES = 8
9 | VOCAB_SIZE = 16
10 | IMG_SIZE = 16
11 |
12 |
13 | def check_equal(A, B):
14 | assert torch.allclose(A, B, rtol=1e-5, atol=1e-2)
15 |
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_3d/checks_3d/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_legacy/test_layers/test_3d/checks_3d/__init__.py
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_3d/checks_3d/common.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- encoding: utf-8 -*-
3 |
4 | import torch
5 |
6 | DEPTH = 2
7 | BATCH_SIZE = 8
8 | SEQ_LENGTH = 8
9 | HIDDEN_SIZE = 8
10 | NUM_CLASSES = 8
11 | NUM_BLOCKS = 2
12 | IMG_SIZE = 16
13 | VOCAB_SIZE = 16
14 |
15 |
16 | def check_equal(A, B):
17 | eq = torch.allclose(A, B, rtol=1e-3, atol=1e-2)
18 | assert eq, f"\nA = {A}\nB = {B}"
19 | return eq
20 |
--------------------------------------------------------------------------------
/tests/test_legacy/test_layers/test_sequence/checks_seq/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_legacy/test_layers/test_sequence/checks_seq/__init__.py
--------------------------------------------------------------------------------
/tests/test_legacy/test_tensor/common_utils/__init__.py:
--------------------------------------------------------------------------------
1 | from ._utils import *
2 |
--------------------------------------------------------------------------------
/tests/test_optimizer/test_lr_scheduler.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | from torch.optim import Adam
3 |
4 | from colossalai.nn.lr_scheduler import CosineAnnealingWarmupLR
5 |
6 |
7 | def test_lr_scheduler_save_load():
8 | model = nn.Linear(10, 10)
9 | optimizer = Adam(model.parameters(), lr=1e-3)
10 | scheduler = CosineAnnealingWarmupLR(optimizer, total_steps=5, warmup_steps=2)
11 | new_scheduler = CosineAnnealingWarmupLR(optimizer, total_steps=5, warmup_steps=2)
12 | for _ in range(5):
13 | scheduler.step()
14 | state_dict = scheduler.state_dict()
15 | new_scheduler.load_state_dict(state_dict)
16 | assert state_dict == new_scheduler.state_dict()
17 |
18 |
19 | if __name__ == "__main__":
20 | test_lr_scheduler_save_load()
21 |
--------------------------------------------------------------------------------
/tests/test_shardformer/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_shardformer/__init__.py
--------------------------------------------------------------------------------
/tests/test_shardformer/test_model/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hpcaitech/ColossalAI/b4ec4057780fd9d9b63ceff655fb113196a6aa36/tests/test_shardformer/test_model/__init__.py
--------------------------------------------------------------------------------
/version.txt:
--------------------------------------------------------------------------------
1 | 0.5.1
2 |
--------------------------------------------------------------------------------