├── .gitignore
├── LICENSE
├── README.md
├── code
├── .gitkeep
├── draw_detail_2D.py
├── draw_detail_3D.py
├── draw_weight.py
├── gen_noise.py
└── gen_resnet.py
├── data
├── .gitkeep
├── casia-webface
│ └── .gitkeep
├── imdb-face
│ └── .gitkeep
└── ms-celeb-1m
│ └── .gitkeep
├── deploy
├── .gitkeep
├── resnet20_arcface_train.prototxt
├── resnet20_l2softmax_train.prototxt
├── resnet64_l2softmax_train.prototxt
└── solver.prototxt
├── figures
├── detail.png
├── strategy.png
├── webface_dist_2D_noise-0.png
├── webface_dist_2D_noise-20.png
├── webface_dist_2D_noise-40.png
├── webface_dist_2D_noise-60.png
├── webface_dist_3D_noise-0.png
├── webface_dist_3D_noise-20.png
├── webface_dist_3D_noise-40.png
└── webface_dist_3D_noise-60.png
└── layer
├── .gitkeep
├── arcface_layer.cpp
├── arcface_layer.cu
├── arcface_layer.hpp
├── caffe.proto
├── noise_tolerant_fr_layer.cpp
├── noise_tolerant_fr_layer.hpp
├── normL2_layer.cpp
├── normL2_layer.cu
└── normL2_layer.hpp
/.gitignore:
--------------------------------------------------------------------------------
1 | # Prerequisites
2 | *.d
3 |
4 | # Compiled Object files
5 | *.slo
6 | *.lo
7 | *.o
8 | *.obj
9 |
10 | # Precompiled Headers
11 | *.gch
12 | *.pch
13 |
14 | # Compiled Dynamic libraries
15 | *.so
16 | *.dylib
17 | *.dll
18 |
19 | # Fortran module files
20 | *.mod
21 | *.smod
22 |
23 | # Compiled Static libraries
24 | *.lai
25 | *.la
26 | *.a
27 | *.lib
28 |
29 | # Executables
30 | *.exe
31 | *.out
32 | *.app
33 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2019 Harry Wong
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Noise-Tolerant Paradigm for Training Face Recognition CNNs
2 |
3 | Paper link: https://arxiv.org/abs/1903.10357
4 |
5 | Presented at **CVPR 2019**
6 |
7 | This is the code for the paper
8 |
9 |
10 | ### Contents
11 | 1. [Requirements](#Requirements)
12 | 1. [Dataset](#Dataset)
13 | 1. [How-to-use](#How-to-use)
14 | 1. [Diagram](#Diagram)
15 | 1. [Performance](#Performance)
16 | 1. [Contact](#Contact)
17 | 1. [Citation](#Citation)
18 | 1. [License](#License)
19 |
20 | ### Requirements
21 |
22 | 1. [**`Caffe`**](http://caffe.berkeleyvision.org/installation.html)
23 |
24 | ### Dataset
25 |
26 | Training dataset:
27 | 1. [**`CASIA-Webface clean`**](https://github.com/happynear/FaceVerification)
28 | 2. [**`IMDB-Face`**](https://github.com/fwang91/IMDb-Face)
29 | 3. [**`MS-Celeb-1M`**](https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/)
30 |
31 | Testing dataset:
32 | 1. [**`LFW`**](http://vis-www.cs.umass.edu/lfw/)
33 | 2. [**`AgeDB`**](https://ibug.doc.ic.ac.uk/resources/agedb/)
34 | 3. [**`CFP`**](http://www.cfpw.io/)
35 | 4. [**`MegaFace`**](http://megaface.cs.washington.edu/)
36 |
37 | Both the training data and testing data are aligned by the method described in [**`util.py`**](https://github.com/huangyangyu/SeqFace/blob/master/code/util.py)
38 |
39 | ### How-to-use
40 | Firstly, you can train the network in noisy dataset as following steps:
41 |
42 | step 1: add noise_tolerant_fr and relevant layers(at ./layers directory) to caffe project and recompile it.
43 |
44 | step 2: download training dataset to ./data directory, and corrupt training dataset in different noise ratio which you can refer to ./code/gen_noise.py, then generate the lmdb file through caffe tool.
45 |
46 | step 3: configure prototxt file in ./deploy directory.
47 |
48 | step 4: run caffe command to train the network by using noisy dataset.
49 |
50 | After training, you can evaluate the model on testing dataset by using [**`evaluate.py`**](https://github.com/huangyangyu/SeqFace/blob/master/code/LFW/evaluate.py).
51 |
52 | ### Diagram
53 |
54 | The figure shows three strategies in different purposes. At the beginning of the training process, we focus on all samples; then we focus on easy/clean samples; at last we focus on semi-hard clean samples.
55 |
56 | 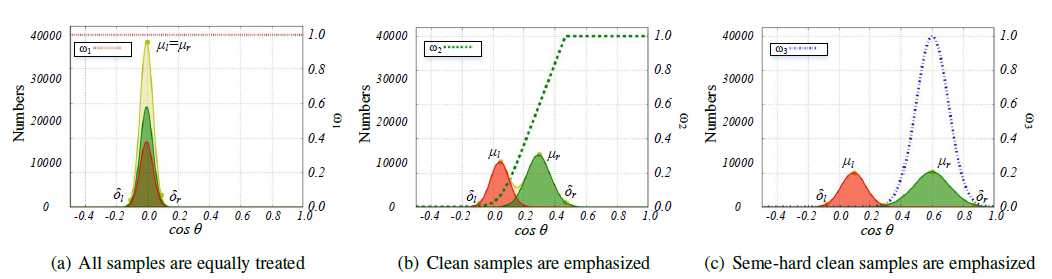
57 |
58 |
59 | The figure explains the fusion function of three strategies. The left part demonstrates three functions: **α(δr)**, **β(δr)**, and **γ(δr)**. The right part shows two fusion examples. According to the **ω**, we can see that the easy/clean samples are emphasized in the first example(**δr** < 0.5), and the semi-hard clean samples are emphasized in the second example(**δr** > 0.5).
60 | **For more detail, please click here to play [demo video](https://youtu.be/FxRoN_i7FLw).**
61 | 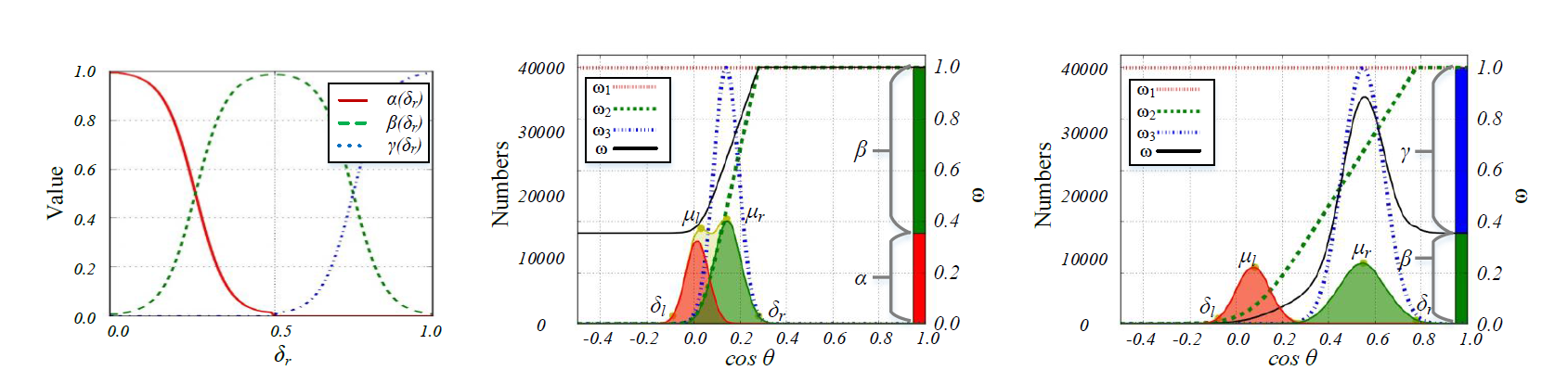
62 |
63 |
64 | The figure shows the 2D Histall of CNNcommon (up) and CNNm2 (down) under 40% noise rate.
65 | 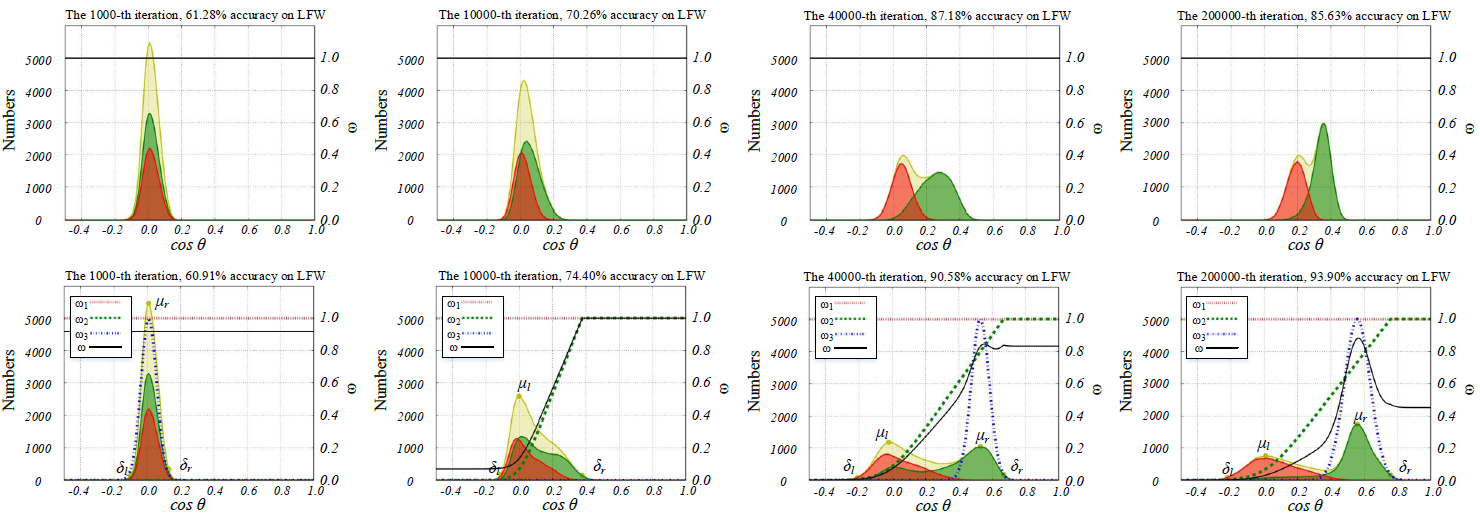
66 |
67 |
68 | The figure shows the 3D Histall of CNNcommon (left) and CNNm2 (right) under 40% noise rate.
69 | 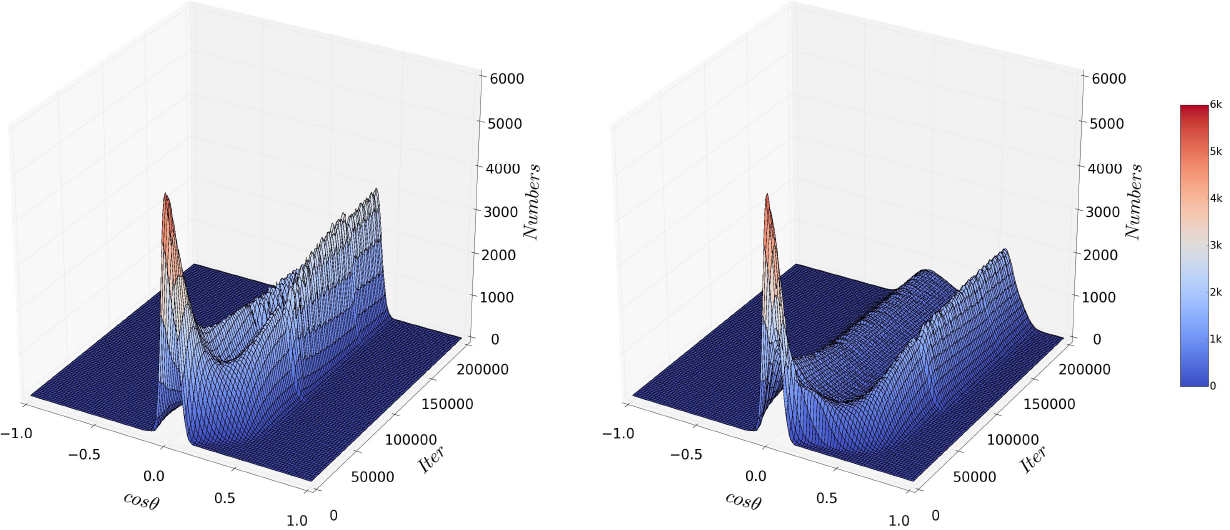
70 |
71 | ### Performance
72 |
73 | The table shows comparison of accuracies(%) on **LFW**, **ResNet-20** models are used. CNNclean is trained with clean
74 | data WebFace-Clean-Sub by using the traditional method. CNNcommon is trained with noisy dataset WebFace-All by using the traditional method. CNNct is trained
75 | with noisy dataset WebFace-All by using our implemented Co-teaching(with pre-given noise rates). CNNm1 and CNNm2 are all trained with noisy dataset WebFace-All but through the proposed approach, and they respectively use the 1st and 2nd method to compute loss.
76 | Note: The WebFace-Clean-Sub is the clean part of the WebFace-All, the WebFace-All contains noise data with different rate as describe below.
77 |
78 | | Loss | Actual Noise Rate | CNNclean | CNNcommon | CNNct | CNNm1 | CNNm2 | Estimated Noise Rate |
79 | | --------- | ----------------- | ------------------- | -------------------- | ---------------- | ---------------- | ---------------- | -------------------- |
80 | | L2softmax | 0% | 94.65 | 94.65 | - | 95.00 | **96.28** | 2% |
81 | | L2softmax | 20% | 94.18 | 89.05 | 92.12 | 92.95 | **95.26** | 18% |
82 | | L2softmax | 40% | 92.71 | 85.63 | 87.10 | 89.91 | **93.90** | 42% |
83 | | L2softmax | 60% | **91.15** | 76.61 | 83.66 | 86.11 | 87.61 | 56% |
84 | | Arcface | 0% | 97.95 | 97.95 | - | 97.11 | **98.11** | 2% |
85 | | Arcface | 20% | **97.80** | 96.48 | 96.53 | 96.83 | 97.76 | 18% |
86 | | Arcface | 40% | 96.53 | 92.33 | 94.25 | 95.88 | **97.23** | 36% |
87 | | Arcface | 60% | 94.56 | 84.05 | 90.36 | 93.66 | **95.15** | 54% |
88 |
89 |
90 | ### Contact
91 |
92 | [Wei Hu](mailto:huwei@mail.buct.edu.cn)
93 |
94 | [Yangyu Huang](mailto:yangyu.huang.1990@outlook.com)
95 |
96 |
97 | ### Citation
98 |
99 | If you find this work useful in your research, please cite
100 | ```text
101 | @inproceedings{Hu2019NoiseFace,
102 | title = {Noise-Tolerant Paradigm for Training Face Recognition CNNs},
103 | author = {Hu, Wei and Huang, Yangyu and Zhang, Fan and Li, Ruirui},
104 | booktitle = {IEEE Conference on Computer Vision and Pattern Recognition},
105 | month = {June},
106 | year = {2019},
107 | address = {Long Beach, CA}
108 | }
109 | ```
110 |
111 |
112 | ### License
113 |
114 | The project is released under the MIT License
115 |
--------------------------------------------------------------------------------
/code/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huangyangyu/NoiseFace/0b434a2c0eb664ca2af36c3bc619629fb27dcf3f/code/.gitkeep
--------------------------------------------------------------------------------
/code/draw_detail_2D.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | #coding: utf-8
3 |
4 | import os
5 | import sys
6 | import cv2
7 | import math
8 | import json
9 | import numpy as np
10 | import matplotlib.pyplot as plt
11 | plt.switch_backend("agg")
12 |
13 | bins = 201
14 |
15 |
16 | def choose_iter(_iter, interval):
17 | if _iter == 1000:
18 | return True
19 | if _iter == 200000:
20 | return True
21 |
22 | k = _iter / interval
23 | if k % 2 != 0 or (k / 2) % (_iter / 20000 + 1) != 0:
24 | return False
25 | else:
26 | return True
27 |
28 |
29 | def get_pdf(X):
30 | pdf = bins * [0.0]
31 | for x in X:
32 | pdf[int(x*100)] += 1
33 | return pdf
34 |
35 |
36 | def mean_filter(pdf, fr=2):
37 | filter_pdf = bins * [0.0]
38 | for i in xrange(fr, bins-fr):
39 | for j in xrange(i-fr, i+fr+1):
40 | filter_pdf[i] += pdf[j] / (fr+fr+1)
41 | return filter_pdf
42 |
43 |
44 | def load_lfw(prefix):
45 | items = list()
46 | for line in open("./data/%s_lfw.txt" % prefix):
47 | item = line.strip().split()
48 | items.append((int(item[0]), float(item[1]), 100.0 * float(item[2])))
49 | items.append(items[-1])
50 | return items
51 |
52 |
53 | def draw_imgs(prefix, ratio, mode):
54 | lfw = load_lfw(prefix)
55 |
56 | frames = 0
57 | iters = list()
58 | threds = list()
59 | accs = list()
60 | alphas = list()
61 | betas = list()
62 | gammas = list()
63 | for _iter in xrange(1000, 200000+1, 100):
64 | if not choose_iter(_iter, 100):
65 | continue
66 | _iter1, _thred1, _acc1 = lfw[_iter/10000]
67 | _iter2, _thred2, _acc2 = lfw[_iter/10000+1]
68 | _thred = _thred1 + (_thred2 - _thred1) * (_iter - _iter1) / max(1, (_iter2 - _iter1))
69 | _acc = _acc1 + (_acc2 - _acc1) * (_iter - _iter1) / max(1, (_iter2 - _iter1))
70 | iters.append(_iter)
71 | threds.append(_thred)
72 | accs.append(_acc)
73 |
74 | log_file = "./data/%s_%d.txt" % (prefix, _iter)
75 | if not os.path.exists(log_file):
76 | print "miss: %s" % log_file
77 | continue
78 | lines = open(log_file).readlines()
79 |
80 | # X
81 | X = list()
82 | for i in xrange(bins):
83 | X.append(i * 0.01 - 1.0)
84 |
85 | # pdf
86 | pdf = list()
87 | for line in lines[3:bins+3]:
88 | item = line.strip().split()
89 | item = map(lambda x: float(x), item)
90 | pdf.append(item[1])
91 |
92 | # clean pdf
93 | clean_pdf = list()
94 | for line in lines[bins+3+1:bins+bins+3+1]:
95 | item = line.strip().split()
96 | item = map(lambda x: float(x), item)
97 | clean_pdf.append(item[1])
98 |
99 | # noise pdf
100 | noise_pdf = list()
101 | for line in lines[bins+bins+3+1+1:bins+bins+bins+3+1+1]:
102 | item = line.strip().split()
103 | item = map(lambda x: float(x), item)
104 | noise_pdf.append(item[1])
105 |
106 | # pcf
107 | pcf = list()
108 | for line in lines[bins+bins+bins+3+1+1+1:bins+bins+bins+bins+3+1+1+1]:
109 | item = line.strip().split()
110 | item = map(lambda x: float(x), item)
111 | pcf.append(item[1])
112 |
113 | # weight
114 | W = list()
115 | for line in lines[bins+bins+bins+bins+3+1+1+1+1:bins+bins+bins+bins+bins+3+1+1+1+1]:
116 | item = line.strip().split()
117 | item = map(lambda x: float(x), item)
118 | W.append(item[1])
119 |
120 | # mean filtering
121 | filter_pdf = mean_filter(pdf)
122 | filter_clean_pdf = mean_filter(clean_pdf)
123 | filter_noise_pdf = mean_filter(noise_pdf)
124 | # pcf
125 | sum_filter_pdf = sum(filter_pdf)
126 | pcf[0] = filter_pdf[0] / sum_filter_pdf
127 | for i in xrange(1, bins):
128 | pcf[i] = pcf[i-1] + filter_pdf[i] / sum_filter_pdf
129 | # mountain
130 | l_bin_id_ = 0
131 | r_bin_id_ = bins-1
132 | while pcf[l_bin_id_] < 0.005:
133 | l_bin_id_ += 1
134 | while pcf[r_bin_id_] > 0.995:
135 | r_bin_id_ -= 1
136 |
137 | m_bin_id_ = (l_bin_id_ + r_bin_id_) / 2
138 | t_bin_id_ = 0
139 | for i in xrange(bins):
140 | if filter_pdf[t_bin_id_] < filter_pdf[i]:
141 | t_bin_id_ = i
142 | t_bin_ids_ = list()
143 | for i in xrange(max(l_bin_id_, 5), min(r_bin_id_, bins-5)):
144 | if filter_pdf[i] >= filter_pdf[i-1] and filter_pdf[i] >= filter_pdf[i+1] and \
145 | filter_pdf[i] >= filter_pdf[i-2] and filter_pdf[i] >= filter_pdf[i+2] and \
146 | filter_pdf[i] > filter_pdf[i-3] and filter_pdf[i] > filter_pdf[i+3] and \
147 | filter_pdf[i] > filter_pdf[i-4] and filter_pdf[i] > filter_pdf[i+4] and \
148 | filter_pdf[i] > filter_pdf[i-5] and filter_pdf[i] > filter_pdf[i+5]:
149 | t_bin_ids_.append(i)
150 | i += 5
151 | if len(t_bin_ids_) == 0:
152 | t_bin_ids_.append(t_bin_id_)
153 | if t_bin_id_ < m_bin_id_:
154 | lt_bin_id_ = t_bin_id_
155 | rt_bin_id_ = t_bin_ids_[-1] if t_bin_ids_[-1] > m_bin_id_ else None
156 | #rt_bin_id_ = max(t_bin_ids_[-1], m_bin_id_)
157 | #rt_bin_id_ = t_bin_ids_[-1]
158 | else:
159 | rt_bin_id_ = t_bin_id_
160 | lt_bin_id_ = t_bin_ids_[0] if t_bin_ids_[0] < m_bin_id_ else None
161 | #lt_bin_id_ = min(t_bin_ids_[0], m_bin_id_)
162 | #lt_bin_id_ = t_bin_ids_[0]
163 |
164 | # weight1-3
165 | weights1 = list()
166 | weights2 = list()
167 | weights3 = list()
168 | weights = list()
169 | r = 2.576
170 | alpha = np.clip((r_bin_id_ - 100.0) / 100.0, 0.0, 1.0)
171 | #beta = abs(2.0 * alpha - 1.0)
172 | beta = 2.0 - 1.0 / (1.0 + math.exp(5-20*alpha)) - 1.0 / (1.0 + math.exp(20*alpha-15))
173 | if mode == 1:
174 | alphas.append(100.0)
175 | betas.append(0.0)
176 | gammas.append(0.0)
177 | else:
178 | alphas.append(100.0*beta*(alpha<0.5))
179 | betas.append(100.0*(1-beta))
180 | gammas.append(100.0*beta*(alpha>0.5))
181 | for bin_id in xrange(bins):
182 | # w1
183 | weight1 = 1.0
184 | # w2
185 | if lt_bin_id_ is None:
186 | weight2 = 0.0
187 | else:
188 | #weight2 = np.clip(1.0 * (bin_id - lt_bin_id_) / (r_bin_id_ - lt_bin_id_), 0.0, 1.0)# relu
189 | weight2 = np.clip(math.log(1.0 + math.exp(10.0 * (bin_id - lt_bin_id_) / (r_bin_id_ - lt_bin_id_))) / math.log(1.0 + math.exp(10.0)), 0.0, 1.0)# softplus
190 | # w3
191 | if rt_bin_id_ is None:
192 | weight3 = 0.0
193 | else:
194 | x = bin_id
195 | u = rt_bin_id_
196 | #a = ((r_bin_id_ - u) / r) if x > u else ((u - l_bin_id_) / r)# asymmetric
197 | a = (r_bin_id_ - u) / r# symmetric
198 | weight3 = math.exp(-1.0 * (x - u) * (x - u) / (2 * a * a))
199 | # w: merge w1, w2 and w3
200 | weight = alphas[-1]/100.0 * weight1 + betas[-1]/100.0 * weight2 + gammas[-1]/100.0 * weight3
201 |
202 | weights1.append(weight1)
203 | weights2.append(weight2)
204 | weights3.append(weight3)
205 | weights.append(weight)
206 |
207 | asize= 26
208 | ticksize = 24
209 | lfont1 = {
210 | 'family' : 'Times New Roman',
211 | 'weight' : 'normal',
212 | 'size' : 18,
213 | }
214 | lfont2 = {
215 | 'family' : 'Times New Roman',
216 | 'weight' : 'normal',
217 | 'size' : 24,
218 | }
219 | titlesize = 28
220 | glinewidth = 2
221 |
222 | fig = plt.figure(0)
223 | fig.set_size_inches(10, 20)
224 | ax1 = plt.subplot2grid((4,2), (0,0), rowspan=2, colspan=2)
225 | ax2 = plt.subplot2grid((4,2), (2,0), rowspan=1, colspan=2)
226 | ax3 = plt.subplot2grid((4,2), (3,0), rowspan=1, colspan=2)
227 |
228 | ax1.set_title(r"$The\ cos\theta\ distribution\ of\ WebFace-All(64K\ samples),\ $" + "\n" + r"$current\ iteration\ is\ %d$" % _iter, fontsize=titlesize)
229 | ax1.set_xlabel(r"$cos\theta$", fontsize=asize)
230 | ax1.set_ylabel(r"$Numbers$", fontsize=asize)
231 | ax1.tick_params(labelsize=ticksize)
232 | ax1.set_xlim(-0.5, 1.0)
233 | ax1.set_ylim(0.0, 6000.0)
234 | ax1.grid(True, linewidth=glinewidth)
235 |
236 | ax1.plot(X, filter_pdf, "y-", linewidth=2, label="Hist-all")
237 | ax1.plot(X, filter_clean_pdf, "g-", linewidth=2, label="Hist-clean")
238 | ax1.plot(X, filter_noise_pdf, "r-", linewidth=2, label="Hist-noisy")
239 | ax1.fill(X, filter_pdf, "y", alpha=0.25)
240 | ax1.fill(X, filter_clean_pdf, "g", alpha=0.50)
241 | ax1.fill(X, filter_noise_pdf, "r", alpha=0.50)
242 | # points
243 | if mode != 1:
244 | #p_X = [X[l_bin_id_], X[lt_bin_id_], X[rt_bin_id_], X[r_bin_id_]]
245 | #p_Y = [filter_pdf[l_bin_id_], filter_pdf[lt_bin_id_], filter_pdf[rt_bin_id_], filter_pdf[r_bin_id_]]
246 | p_X = [X[l_bin_id_], X[r_bin_id_]]
247 | p_Y = [filter_pdf[l_bin_id_], filter_pdf[r_bin_id_]]
248 | if lt_bin_id_ is not None:
249 | p_X.append(X[lt_bin_id_])
250 | p_Y.append(filter_pdf[lt_bin_id_])
251 | if rt_bin_id_ is not None:
252 | p_X.append(X[rt_bin_id_])
253 | p_Y.append(filter_pdf[rt_bin_id_])
254 | ax1.scatter(p_X, p_Y, color="y", linewidths=5)
255 | ax1.legend(["Hist-all", "Hist-clean", "Hist-noisy"], loc=1, ncol=1, prop=lfont1)
256 |
257 | _ax1 = ax1.twinx()
258 | _ax1.set_ylabel(r"$\omega$", fontsize=asize)
259 | _ax1.tick_params(labelsize=ticksize)
260 | _ax1.set_xlim(-0.5, 1.0)
261 | _ax1.set_ylim(0.0, 1.2)
262 |
263 | #_ax1.bar([1.0], [beta*(alpha<0.5)], color="r", width=0.1, align="center")
264 | #_ax1.bar([1.0], [(1-beta)], bottom=[beta*(alpha<0.5)], color="g", width=0.1, align="center")
265 | #_ax1.bar([1.0], [beta*(alpha>0.5)], bottom=[beta*(alpha<0.5) + (1-beta)], color="b", width=0.1, align="center")
266 |
267 | if mode == 1:
268 | _ax1.plot(X, weights, "k-", linewidth=2, label=r"$\omega$")
269 | _ax1.legend([r"$\omega$"], loc=2, ncol=2, prop=lfont2)
270 | else:
271 | _ax1.plot(X, weights1, "r:", linewidth=5, label=r"$\omega1$")
272 | _ax1.plot(X, weights2, "g--", linewidth=5, label=r"$\omega2$")
273 | _ax1.plot(X, weights3, "b-.", linewidth=5, label=r"$\omega3$")
274 | _ax1.plot(X, weights, "k-", linewidth=2, label=r"$\omega$")
275 | _ax1.legend([r"$\omega1$", r"$\omega2$", r"$\omega3$", r"$\omega$"], loc=2, ncol=2, prop=lfont2)
276 |
277 | ax2.set_title(r"$The\ accuracy\ on\ LFW,\ $" + "\n" + r"$current\ value\ is\ %.2f$%%" % accs[-1], fontsize=titlesize)
278 | ax2.yaxis.grid(True, linewidth=glinewidth)
279 | ax2.set_xlabel(r"$Iter$", fontsize=asize)
280 | ax2.set_ylabel(r"$Acc(\%)$", fontsize=asize)
281 | ax2.tick_params(labelsize=ticksize)
282 | ax2.set_xlim(0, 200000)
283 | ax2.set_ylim(50.0, 100.0)
284 | ax2.plot(iters, accs, "k-", linewidth=3, label="LFW")
285 | ax2.legend(["LFW"], loc=7, ncol=1, prop=lfont1)# center right
286 |
287 | ax3.set_title(r"$The\ Proportion\ of\ \omega1,\ \omega2\ and\ \omega3,\ $" + "\n" + r"$current\ value\ is\ $%.0f%%, %.0f%% and %.0f%%" % (alphas[-1], betas[-1], gammas[-1]), fontsize=titlesize)
288 | ax3.yaxis.grid(True, linewidth=glinewidth)
289 | ax3.set_xlabel(r"$Iter$", fontsize=asize)
290 | ax3.set_ylabel(r"$Proportion(\%)$", fontsize=asize)
291 | ax3.tick_params(labelsize=ticksize)
292 | ax3.set_xlim(0, 200000)
293 | ax3.set_ylim(0.0, 100.0)
294 | ax3.plot(iters, np.array(alphas), "r-", linewidth=1, label=r"$\alpha$")
295 | ax3.plot(iters, np.array(alphas) + np.array(betas), "g-", linewidth=1, label=r"$\beta$")
296 | ax3.plot(iters, np.array(alphas) + np.array(betas) + np.array(gammas), "b-", linewidth=1, label=r"$\gamma$")
297 | ax3.fill_between(iters, 0, np.array(alphas) + np.array(betas) + np.array(gammas), color="b", alpha=1.0)
298 | ax3.fill_between(iters, 0, np.array(alphas) + np.array(betas), color="g", alpha=1.0)
299 | ax3.fill_between(iters, 0, np.array(alphas), color="r", alpha=1.0)
300 | ax3.legend([r"$\alpha$", r"$\beta$", r"$\gamma$"], loc=7, ncol=1, prop=lfont2)# center right
301 |
302 | fig.tight_layout()
303 |
304 | plt.savefig("./figures/%s_2D_dist_%d.jpg" % (prefix, _iter))
305 | plt.close()
306 |
307 | frames += 1
308 | print "frames:", frames
309 | print "processed:", _iter
310 | sys.stdout.flush()
311 |
312 |
313 | def draw_video(prefix1, prefix2, ratio):
314 | draw_imgs(prefix1, ratio, mode=1)
315 | draw_imgs(prefix2, ratio, mode=2)
316 |
317 | fps = 25
318 | size = (2000, 2000)
319 | videowriter = cv2.VideoWriter("./figures/demo_2D_distribution_noise-%d%%.avi" % ratio, cv2.cv.CV_FOURCC(*"MJPG"), fps, size)
320 | for _iter in xrange(1000, 200000+1, 100):
321 | if not choose_iter(_iter, 100):
322 | continue
323 | image_file1 = "./figures/%s_2D_dist_%d.jpg" % (prefix1, _iter)
324 | img1 = cv2.imread(image_file1)
325 | h1, w1, c1 = img1.shape
326 |
327 | image_file2 = "./figures/%s_2D_dist_%d.jpg" % (prefix2, _iter)
328 | img2 = cv2.imread(image_file2)
329 | h2, w2, c2 = img2.shape
330 |
331 | assert h1 == h2 and w1 == w2
332 | img = np.zeros((h1, w1+w2, c1), dtype=img1.dtype)
333 |
334 | img[0:h1, 0:w1, :] = img1
335 | img[0:h1, w1:w1+w2, :] = img2
336 | videowriter.write(img)
337 |
338 |
339 | if __name__ == "__main__":
340 | prefixs = [
341 | (0, "p_casia-webface_noise-flip-outlier-1_1-0_Nsoftmax_exp", "p_casia-webface_noise-flip-outlier-1_1-0_Nsoftmax_FIT_exp"), \
342 | (20, "p_casia-webface_noise-flip-outlier-1_1-20_Nsoftmax_exp", "p_casia-webface_noise-flip-outlier-1_1-20_Nsoftmax_FIT_exp"), \
343 | (40, "p_casia-webface_noise-flip-outlier-1_1-40_Nsoftmax_exp", "p_casia-webface_noise-flip-outlier-1_1-40_Nsoftmax_FIT_exp"), \
344 | (60, "p_casia-webface_noise-flip-outlier-1_1-60_Nsoftmax_exp", "p_casia-webface_noise-flip-outlier-1_1-60_Nsoftmax_FIT_exp")
345 | ]
346 |
347 | for ratio, prefix1, prefix2 in prefixs:
348 | draw_video(prefix1, prefix2, ratio)
349 | print "processing noise-%d" % ratio
350 |
351 |
--------------------------------------------------------------------------------
/code/draw_detail_3D.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | #coding: utf-8
3 |
4 | from mpl_toolkits.mplot3d import Axes3D
5 | import os
6 | import sys
7 | import cv2
8 | import math
9 | import json
10 | import numpy as np
11 | import matplotlib
12 | from matplotlib import ticker
13 | import matplotlib.pyplot as plt
14 | plt.switch_backend("agg")
15 |
16 | bins = 201
17 |
18 |
19 | def choose_iter(_iter, interval):
20 | if _iter == 1000:
21 | return True
22 | if _iter == 200000:
23 | return True
24 |
25 | k = _iter / interval
26 | if k % 1 != 0 or (k / 1) % (_iter / 40000 + 1) != 0:
27 | return False
28 | else:
29 | return True
30 |
31 |
32 | def get_pdf(X):
33 | pdf = bins * [0.0]
34 | for x in X:
35 | pdf[int(x*100)] += 1
36 | return pdf
37 |
38 |
39 | def mean_filter(pdf, fr=2):
40 | filter_pdf = bins * [0.0]
41 | for i in xrange(fr, bins-fr):
42 | for j in xrange(i-fr, i+fr+1):
43 | filter_pdf[i] += pdf[j] / (fr+fr+1)
44 | return filter_pdf
45 |
46 |
47 | def load_lfw(prefix):
48 | items = list()
49 | for line in open("./data/%s_lfw.txt" % prefix):
50 | item = line.strip().split()
51 | items.append((int(item[0]), float(item[1]), 100.0 * float(item[2])))
52 | items.append(items[-1])
53 | return items
54 |
55 |
56 | def draw_imgs(prefix, ratio, mode):
57 | lfw = load_lfw(prefix)
58 |
59 | frames = 0
60 | _X = list()
61 | _Y = list()
62 | _Z = list()
63 | iters = list()
64 | threds = list()
65 | accs = list()
66 | alphas = list()
67 | betas = list()
68 | gammas = list()
69 | for _iter in xrange(1000, 200000+1, 1000):
70 | _iter1, _thred1, _acc1 = lfw[_iter/10000]
71 | _iter2, _thred2, _acc2 = lfw[_iter/10000+1]
72 | _thred = _thred1 + (_thred2 - _thred1) * (_iter - _iter1) / max(1, (_iter2 - _iter1))
73 | _acc = _acc1 + (_acc2 - _acc1) * (_iter - _iter1) / max(1, (_iter2 - _iter1))
74 | iters.append(_iter)
75 | threds.append(_thred)
76 | accs.append(_acc)
77 |
78 | log_file = "./data/%s_%d.txt" % (prefix, _iter)
79 | if not os.path.exists(log_file):
80 | print "miss: %s" % log_file
81 | continue
82 | lines = open(log_file).readlines()
83 |
84 | # pdf
85 | pdf = list()
86 | for line in lines[3:bins+3]:
87 | item = line.strip().split()
88 | item = map(lambda x: float(x), item)
89 | pdf.append(item[1])
90 |
91 | # clean pdf
92 | clean_pdf = list()
93 | for line in lines[bins+3+1:bins+bins+3+1]:
94 | item = line.strip().split()
95 | item = map(lambda x: float(x), item)
96 | clean_pdf.append(item[1])
97 |
98 | # noise pdf
99 | noise_pdf = list()
100 | for line in lines[bins+bins+3+1+1:bins+bins+bins+3+1+1]:
101 | item = line.strip().split()
102 | item = map(lambda x: float(x), item)
103 | noise_pdf.append(item[1])
104 |
105 | # pcf
106 | pcf = list()
107 | for line in lines[bins+bins+bins+3+1+1+1:bins+bins+bins+bins+3+1+1+1]:
108 | item = line.strip().split()
109 | item = map(lambda x: float(x), item)
110 | pcf.append(item[1])
111 |
112 | # weight
113 | W = list()
114 | for line in lines[bins+bins+bins+bins+3+1+1+1+1:bins+bins+bins+bins+bins+3+1+1+1+1]:
115 | item = line.strip().split()
116 | item = map(lambda x: float(x), item)
117 | W.append(item[1])
118 |
119 | X = list()
120 | for i in xrange(bins):
121 | X.append(i * 0.01 - 1.0)
122 | _X.append(X)
123 | _Y.append(bins * [_iter])
124 | _Z.append(mean_filter(pdf))
125 |
126 | if not choose_iter(_iter, 1000):
127 | continue
128 |
129 | titlesize = 44
130 | asize = 44
131 | glinewidth = 2
132 |
133 | fig = plt.figure(0)
134 | fig.set_size_inches(24, 18)
135 | ax = Axes3D(fig)
136 | #ax.set_title(r"$The\ cos\theta\ distribution\ of\ $" + str(ratio) + "%" + r"$\ noisy\ training\ data\ over\ iteration$", fontsize=titlesize)
137 | ax.set_xlabel(r"$cos\theta$", fontsize=asize)
138 | ax.set_ylabel(r"$Iter$", fontsize=asize)
139 | ax.set_zlabel(r"$Numbers$", fontsize=asize)
140 | ax.tick_params(labelsize=32)
141 | ax.set_xlim(-1.0, 1.0)
142 | ax.set_ylim(0, 200000)
143 | ax.set_zlim(0.0, 6000.0)
144 | ax.grid(True, linewidth=glinewidth)
145 | surf = ax.plot_surface(_X, _Y, _Z, rstride=3, cstride=3, cmap=plt.cm.coolwarm, linewidth=0.1, antialiased=False)
146 | surf.set_clim([0, 6000])
147 | cbar = fig.colorbar(surf, shrink=0.5, aspect=10, norm=plt.Normalize(0, 6000))
148 | cbar.set_ticks([0, 1000, 2000, 3000, 4000, 5000, 6000])
149 | cbar.set_ticklabels(["0", "1k", "2k", "3k", "4k", "5k", "6k"])
150 | #cbar.locator = ticker.MaxNLocator(nbins=6)
151 | #cbar.update_ticks()
152 | cbar.ax.tick_params(labelsize=24)
153 |
154 | #print dir(ax)
155 | #_ax = ax.twiny()
156 | #_ax.set_ylim(0.0, 1.0)
157 | #_ax.plot(bins * [-1.0], iters, accs, label="LFW")
158 | #_ax.legend()
159 | #ax.plot(len(iters) * [-1.0], iters, 100.0 * np.array(accs), color="k", label="LFW")
160 | #ax.plot(len(iters) * [-1.0], iters, 60.0 * np.array(accs), color="k", label="LFW")
161 | #ax.legend()
162 |
163 | plt.savefig("./figures/%s_3D_dist_%d.jpg" % (prefix, _iter))
164 | plt.close()
165 |
166 | frames += 1
167 | print "frames:", frames
168 | print "processed:", _iter
169 | sys.stdout.flush()
170 |
171 |
172 | def draw_video(prefix1, prefix2, ratio):
173 | draw_imgs(prefix1, ratio, mode=1)
174 | draw_imgs(prefix2, ratio, mode=2)
175 |
176 | fps = 25
177 | #size = (4800, 1800)
178 | #size = (2400, 900)
179 | size = (2000, 750)
180 | videowriter = cv2.VideoWriter("./figures/demo_3D_distribution_noise-%d%%.avi" % ratio, cv2.cv.CV_FOURCC(*"MJPG"), fps, size)
181 | for _iter in xrange(1000, 200000+1, 1000):
182 | if not choose_iter(_iter, 1000):
183 | continue
184 | image_file1 = "./figures/%s_3D_dist_%d.jpg" % (prefix1, _iter)
185 | img1 = cv2.imread(image_file1)
186 | img1 = cv2.resize(img1, (1000, 750))##
187 | h1, w1, c1 = img1.shape
188 |
189 | image_file2 = "./figures/%s_3D_dist_%d.jpg" % (prefix2, _iter)
190 | img2 = cv2.imread(image_file2)
191 | img2 = cv2.resize(img2, (1000, 750))##
192 | h2, w2, c2 = img2.shape
193 |
194 | assert h1 == h2 and w1 == w2
195 | img = np.zeros((size[1], size[0], 3), dtype=img1.dtype)
196 |
197 | img[0:h1, 0:w1, :] = img1
198 | img[0:h1, w1:w1+w2, :] = img2
199 | videowriter.write(img)
200 |
201 |
202 | if __name__ == "__main__":
203 | prefixs = [
204 | (0, "p_casia-webface_noise-flip-outlier-1_1-0_Nsoftmax_exp", "p_casia-webface_noise-flip-outlier-1_1-0_Nsoftmax_FIT_exp"), \
205 | (20, "p_casia-webface_noise-flip-outlier-1_1-20_Nsoftmax_exp", "p_casia-webface_noise-flip-outlier-1_1-20_Nsoftmax_FIT_exp"), \
206 | (40, "p_casia-webface_noise-flip-outlier-1_1-40_Nsoftmax_exp", "p_casia-webface_noise-flip-outlier-1_1-40_Nsoftmax_FIT_exp"), \
207 | (60, "p_casia-webface_noise-flip-outlier-1_1-60_Nsoftmax_exp", "p_casia-webface_noise-flip-outlier-1_1-60_Nsoftmax_FIT_exp")
208 | ]
209 |
210 | for ratio, prefix1, prefix2 in prefixs:
211 | draw_video(prefix1, prefix2, ratio)
212 | print "processing noise-%d" % ratio
213 |
214 |
--------------------------------------------------------------------------------
/code/draw_weight.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | #coding: utf-8
3 |
4 | import math
5 | import numpy as np
6 | import matplotlib
7 | import matplotlib.pyplot as plt
8 | plt.switch_backend("agg")
9 |
10 | def draw_weight():
11 | X = list()
12 | W1 = list()
13 | W2 = list()
14 | W3 = list()
15 | for i in xrange(-100, 101):
16 | x = 0.01 * i
17 |
18 | """
19 | # method1
20 | alpha = max(0.0, x)
21 | beta = abs(2.0 * alpha - 1.0)
22 | w1 = beta*(alpha<0.5)
23 | w2 = (1-beta)
24 | w3 = beta*(alpha>0.5)
25 | """
26 |
27 | # method2
28 | alpha = max(0.0, x)
29 | m = 20
30 | beta = 2 - 1 / (1 + math.e ** (m*(0.25-alpha))) - 1 / (1 + math.e ** (m*(alpha-0.75)))
31 | w1 = beta*(alpha<0.5)
32 | w2 = (1-beta)
33 | w3 = beta*(alpha>0.5)
34 |
35 | X.append(x)
36 | W1.append(w1)
37 | W2.append(w2)
38 | W3.append(w3)
39 |
40 | #plt.figure("Figure")
41 | #plt.title("Title")
42 | #plt.xlabel("x")
43 | #plt.ylabel("y")
44 | plt.grid(True)
45 | plt.xlim(-1.0, 1.0)
46 | plt.ylim(0.0, 1.0)
47 | #plt.yticks(color="w")
48 | #plt.xticks(color="w")
49 | plt.plot(X, W1, "r-", X, W2, "g--", X, W3, "b-.", linewidth=2)
50 | plt.savefig("../figures/W.jpg")
51 | plt.close()
52 |
53 |
54 | if __name__ == "__main__":
55 | draw_weight()
56 |
--------------------------------------------------------------------------------
/code/gen_noise.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | #coding: utf-8
3 |
4 | import json
5 | import copy
6 | import random
7 | import collections
8 |
9 | #noise_ratio = 0.20
10 | noise_ratio = 0.40
11 | #noise_ratio = 0.60
12 |
13 | flip_outlier_ratio = 0.5
14 |
15 | def flip_noise():
16 | items = list()
17 | for line in open("ori_data.txt"):
18 | item = json.loads(line)
19 | item["ori_id"] = copy.deepcopy(item["id"])
20 | item["clean"] = True
21 | items.append(item)
22 | random.shuffle(items)
23 |
24 | m = int(round(noise_ratio * len(items)))
25 | ids = map(lambda item: item["id"][0], items[:m])
26 | random.shuffle(ids)
27 | for item, id in zip(items[:m], ids):
28 | if item["id"][0] != id:
29 | item["clean"] = False
30 | item["id"][0] = id
31 | for item in items[:m]:
32 | while item["clean"]:
33 | _item = random.choice(items[:m])
34 | if item["id"][0] != _item["ori_id"][0] and \
35 | item["ori_id"][0] != _item["id"][0]:
36 | id = item["id"][0]
37 | item["id"][0] = _item["id"][0]
38 | _item["id"][0] = id
39 | item["clean"] = _item["clean"] = False
40 | random.shuffle(items)
41 | for item in items:
42 | if item["clean"]:
43 | assert item["ori_id"][0] == item["id"][0]
44 | else:
45 | assert item["ori_id"][0] != item["id"][0]
46 |
47 | clean_data_file = open("clean_data.txt", "wb")
48 | flip_noise_data_file = open("flip_noise_data.txt", "wb")
49 | for item in items:
50 | if item["clean"]:
51 | clean_data_file.write(json.dumps(item) + "\n")
52 | else:
53 | flip_noise_data_file.write(json.dumps(item) + "\n")
54 | clean_data_file.close()
55 | flip_noise_data_file.close()
56 |
57 |
58 | def add_outlier_noise():
59 | # clean: (1 - noise_ratio)
60 | items = list()
61 | for line in open("clean_data.txt"):
62 | item = json.loads(line)
63 | items.append(item)
64 |
65 | # flip noise: flip_outlier_ratio * noise_ratio
66 | flip_noise_items = list()
67 | for line in open("flip_noise_data.txt"):
68 | item = json.loads(line)
69 | flip_noise_items.append(item)
70 | flip_num = int(len(flip_noise_items) * flip_outlier_ratio)
71 | assert len(flip_noise_items) >= flip_num
72 | random.shuffle(flip_noise_items)
73 | items.extend(flip_noise_items[:flip_num])
74 | flip_noise_items = flip_noise_items[flip_num:]
75 |
76 | # outlier noise: (1 - flip_outlier_ratio) * noise_ratio
77 | outlier_num = len(flip_noise_items)
78 | outlier_noise_items = list()
79 | for line in open("outlier_noise_data.txt"):
80 | item = json.loads(line)
81 | outlier_noise_items.append(item)
82 | assert len(outlier_noise_items) >= outlier_num
83 | random.shuffle(outlier_noise_items)
84 | for i in xrange(outlier_num):
85 | item = outlier_noise_items[i]
86 | item["id"] = flip_noise_items[i]["id"]
87 | items.append(item)
88 |
89 | # output
90 | random.shuffle(items)
91 | with open("data.txt", "wb") as f:
92 | for item in items:
93 | f.write(json.dumps(item) + "\n")
94 |
95 |
96 | if __name__ == "__main__":
97 | """
98 | input:
99 | orignal dataset: ori_data.txt
100 | megaface 1m dataset: outlier_noise_data.txt
101 | output:
102 | data.txt
103 | """
104 | flip_noise()
105 | add_outlier_noise()
106 |
107 |
--------------------------------------------------------------------------------
/code/gen_resnet.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | #coding: utf-8
3 |
4 |
5 | def data_layer(layer_name, output_name1, output_name2, phase, crop_size=128, scale=0.0078125):
6 | context = '\
7 | layer {\n\
8 | name: "%s"\n\
9 | type: "Data"\n\
10 | top: "%s"\n\
11 | top: "%s"\n\
12 | include {\n\
13 | phase: %s\n\
14 | }\n\
15 | transform_param {\n\
16 | crop_size: %d\n\
17 | scale: %.7f\n\
18 | mean_file: "@model_dir/mean.binaryproto"\n\
19 | mirror: %s\n\
20 | }\n\
21 | data_param {\n\
22 | source: "@data_dir/%s_data_db/"\n\
23 | backend: LMDB\n\
24 | batch_size: %s\n\
25 | }\n\
26 | }\n\
27 | ' % (layer_name, output_name1, output_name2, phase, crop_size, scale, \
28 | "true" if phase == "TRAIN" else "false", \
29 | "train" if phase == "TRAIN" else "validation", \
30 | "@train_batch_size" if phase == "TRAIN" else "@test_batch_size")
31 | return context
32 |
33 |
34 | def conv_layer(layer_name, input_name, output_name, num_output, kernel_size=3, stride=1, pad=1, w_lr_mult=1, w_decay_mult=1, b_lr_mult=2, b_decay_mult=0, initializer="xavier"):
35 | initializer_context = '\
36 | type: "xavier"\n\
37 | ' if initializer == "xavier" else\
38 | '\
39 | type: "gaussian"\n\
40 | std: 0.01\n\
41 | '
42 |
43 | context = '\
44 | layer {\n\
45 | name: "%s"\n\
46 | type: "Convolution"\n\
47 | bottom: "%s"\n\
48 | top: "%s"\n\
49 | param {\n\
50 | lr_mult: %d\n\
51 | decay_mult: %d\n\
52 | }\n\
53 | param {\n\
54 | lr_mult: %d\n\
55 | decay_mult: %d\n\
56 | }\n\
57 | convolution_param {\n\
58 | num_output: %d\n\
59 | kernel_size: %d\n\
60 | stride: %d\n\
61 | pad: %d\n\
62 | weight_filler {\n%s\
63 | }\n\
64 | bias_filler {\n\
65 | type: "constant"\n\
66 | value: 0\n\
67 | }\n\
68 | }\n\
69 | }\n\
70 | ' % (layer_name, input_name, output_name, w_lr_mult, w_decay_mult, b_lr_mult, b_decay_mult, num_output, kernel_size, stride, pad, initializer_context)
71 | return context
72 |
73 |
74 | def relu_layer(layer_name, input_name, output_name):
75 | context = '\
76 | layer {\n\
77 | name: "%s"\n\
78 | type: "PReLU"\n\
79 | bottom: "%s"\n\
80 | top: "%s"\n\
81 | }\n\
82 | ' % (layer_name, input_name, output_name)
83 | return context
84 |
85 |
86 | def eltwise_layer(layer_name, input_name1, input_name2, output_name):
87 | context = '\
88 | layer {\n\
89 | name: "%s"\n\
90 | type: "Eltwise"\n\
91 | bottom: "%s"\n\
92 | bottom: "%s"\n\
93 | top: "%s"\n\
94 | eltwise_param {\n\
95 | operation: SUM\n\
96 | }\n\
97 | }\n\
98 | ' % (layer_name, input_name1, input_name2, output_name)
99 | return context
100 |
101 |
102 | def fc_layer(layer_name, input_name, output_name, num_output, w_lr_mult=1, w_decay_mult=1, b_lr_mult=2, b_decay_mult=0):
103 | context = '\
104 | layer {\n\
105 | name: "%s"\n\
106 | type: "InnerProduct"\n\
107 | bottom: "%s"\n\
108 | top: "%s"\n\
109 | param {\n\
110 | lr_mult: %d\n\
111 | decay_mult: %d\n\
112 | }\n\
113 | param {\n\
114 | lr_mult: %d\n\
115 | decay_mult: %d\n\
116 | }\n\
117 | inner_product_param {\n\
118 | num_output: %d\n\
119 | weight_filler {\n\
120 | type: "xavier"\n\
121 | }\n\
122 | bias_filler {\n\
123 | type: "constant"\n\
124 | value: 0\n\
125 | }\n\
126 | }\n\
127 | }\n\
128 | ' % (layer_name, input_name, output_name, w_lr_mult, w_decay_mult, b_lr_mult, b_decay_mult, num_output)
129 | return context
130 |
131 |
132 | def resnet(file_name="deploy.prototxt", layer_num=100):
133 | cell_num = 4
134 | if layer_num == 20:
135 | block_type = 1
136 | block_num = [1, 2, 4, 1]
137 | #block_num = [2, 2, 2, 2]
138 | elif layer_num == 34:
139 | block_type = 1
140 | block_num = [2, 4, 7, 2]
141 | elif layer_num == 50:
142 | block_type = 1
143 | #block_num = [2, 6, 13, 2]
144 | block_num = [3, 4, 13, 3]
145 | elif layer_num == 64:
146 | block_type = 1
147 | block_num = [3, 8, 16, 3]
148 | elif layer_num == 100:
149 | block_type = 1
150 | #block_num = [3, 12, 30, 3]
151 | block_num = [4, 12, 28, 4]
152 | else:
153 | block_type = 1
154 | # 12
155 | block_num = [1, 1, 1, 1]
156 | num_output = 32
157 |
158 | network = 'name: "resnet_%d"\n' % layer_num
159 | # data layer
160 | layer_name = "data"
161 | output_name1 = layer_name
162 | output_name2 = "label000"
163 | output_name = layer_name
164 | network += data_layer(layer_name, output_name1, output_name2, "TRAIN")
165 | network += data_layer(layer_name, output_name1, output_name2, "TEST")
166 | for i in xrange(cell_num):
167 | num_output *= 2
168 | # ceil
169 | # conv layer
170 | layer_name = "conv%d_%d" % (i+1, 1)
171 | input_name = output_name
172 | output_name = layer_name
173 | network += conv_layer(layer_name, input_name, output_name, num_output, stride=2, b_lr_mult=2, initializer="xavier")
174 | # relu layer
175 | layer_name = "relu%d_%d" % (i+1, 1)
176 | input_name = output_name
177 | output_name = output_name
178 | network += relu_layer(layer_name, input_name, output_name)
179 | # block
180 | for j in xrange(block_num[i]):
181 | # type1
182 | if block_type == 1:
183 | for k in xrange(2):
184 | # conv layer
185 | layer_name = "conv%d_%d" % (i+1, 2*j+k+2)
186 | input_name = output_name
187 | output_name = layer_name
188 | network += conv_layer(layer_name, input_name, output_name, num_output, stride=1, b_lr_mult=0, initializer="gaussian")
189 | # relu layer
190 | layer_name = "relu%d_%d" % (i+1, 2*j+k+2)
191 | input_name = output_name
192 | output_name = output_name
193 | network += relu_layer(layer_name, input_name, output_name)
194 | # type2
195 | elif block_type == 2:
196 | for k in xrange(3):
197 | # conv layer
198 | layer_name = "conv%d_%d" % (i+1, 2*j+k+2)
199 | input_name = output_name
200 | output_name = layer_name
201 | network += conv_layer(layer_name, input_name, output_name, num_output if k==2 else num_output/2, \
202 | kernel_size=(3 if k==1 else 1), \
203 | pad=(1 if k==1 else 0), \
204 | stride=1, b_lr_mult=0, initializer="gaussian")
205 | # relu layer
206 | layer_name = "relu%d_%d" % (i+1, 2*j+k+2)
207 | input_name = output_name
208 | output_name = output_name
209 | network += relu_layer(layer_name, input_name, output_name)
210 | else:
211 | print "error"
212 |
213 | # eltwise_layer
214 | layer_name = "res%d_%d" % (i+1, 2*j+3)
215 | input_name1 = "%s%d_%d" % ("conv" if j == 0 else "res", i+1, 2*j+1)
216 | input_name2 = "conv%d_%d" % (i+1, 2*j+3)
217 | output_name = layer_name
218 | network += eltwise_layer(layer_name, input_name1, input_name2, output_name)
219 | # fc layer
220 | layer_name = "fc%d" % (cell_num+1)
221 | input_name = output_name
222 | output_name = layer_name
223 | network += fc_layer(layer_name, input_name, output_name, num_output)
224 |
225 | # write network to file
226 | open(file_name, "wb").write(network)
227 |
228 |
229 | if __name__ == "__main__":
230 | layer_num = 20
231 | resnet(file_name="resnet_%d.prototxt" % layer_num, layer_num=layer_num)
232 |
233 |
--------------------------------------------------------------------------------
/data/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huangyangyu/NoiseFace/0b434a2c0eb664ca2af36c3bc619629fb27dcf3f/data/.gitkeep
--------------------------------------------------------------------------------
/data/casia-webface/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huangyangyu/NoiseFace/0b434a2c0eb664ca2af36c3bc619629fb27dcf3f/data/casia-webface/.gitkeep
--------------------------------------------------------------------------------
/data/imdb-face/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huangyangyu/NoiseFace/0b434a2c0eb664ca2af36c3bc619629fb27dcf3f/data/imdb-face/.gitkeep
--------------------------------------------------------------------------------
/data/ms-celeb-1m/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huangyangyu/NoiseFace/0b434a2c0eb664ca2af36c3bc619629fb27dcf3f/data/ms-celeb-1m/.gitkeep
--------------------------------------------------------------------------------
/deploy/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huangyangyu/NoiseFace/0b434a2c0eb664ca2af36c3bc619629fb27dcf3f/deploy/.gitkeep
--------------------------------------------------------------------------------
/deploy/resnet20_arcface_train.prototxt:
--------------------------------------------------------------------------------
1 | name: "face_res20net"
2 | layer {
3 | name: "data"
4 | type: "Data"
5 | top: "data"
6 | top: "label000"
7 | include {
8 | phase: TRAIN
9 | }
10 | transform_param {
11 | crop_size: 128
12 | scale: 0.0078125
13 | mean_value: 127.5
14 | mirror: true
15 | }
16 | data_param {
17 | source: "./data/casia-webface/p_noise-flip-outlier-1_1-40/converter_p_casia-webface_noise-flip-outlier-1_1-40/train_data_db/"
18 | backend: LMDB
19 | batch_size: 64
20 | }
21 | }
22 | layer {
23 | name: "data"
24 | type: "Data"
25 | top: "data"
26 | top: "label000"
27 | include {
28 | phase: TEST
29 | }
30 | transform_param {
31 | crop_size: 128
32 | scale: 0.0078125
33 | mean_value: 127.5
34 | mirror: false
35 | }
36 | data_param {
37 | source: "./data/casia-webface/p_noise-flip-outlier-1_1-40/converter_p_casia-webface_noise-flip-outlier-1_1-40/validation_data_db/"
38 | backend: LMDB
39 | batch_size: 8
40 | }
41 | }
42 | layer {
43 | name: "conv1_1"
44 | type: "Convolution"
45 | bottom: "data"
46 | top: "conv1_1"
47 | param {
48 | lr_mult: 1
49 | decay_mult: 1
50 | }
51 | param {
52 | lr_mult: 2
53 | decay_mult: 0
54 | }
55 | convolution_param {
56 | num_output: 64
57 | kernel_size: 3
58 | stride: 2
59 | pad: 1
60 | weight_filler {
61 | type: "xavier"
62 | }
63 | bias_filler {
64 | type: "constant"
65 | value: 0
66 | }
67 | }
68 | }
69 | layer {
70 | name: "relu1_1"
71 | type: "PReLU"
72 | bottom: "conv1_1"
73 | top: "conv1_1"
74 | }
75 | layer {
76 | name: "conv1_2"
77 | type: "Convolution"
78 | bottom: "conv1_1"
79 | top: "conv1_2"
80 | param {
81 | lr_mult: 1
82 | decay_mult: 1
83 | }
84 | param {
85 | lr_mult: 0
86 | decay_mult: 0
87 | }
88 | convolution_param {
89 | num_output: 64
90 | kernel_size: 3
91 | stride: 1
92 | pad: 1
93 | weight_filler {
94 | type: "gaussian"
95 | std: 0.01
96 | }
97 | bias_filler {
98 | type: "constant"
99 | value: 0
100 | }
101 | }
102 | }
103 | layer {
104 | name: "relu1_2"
105 | type: "PReLU"
106 | bottom: "conv1_2"
107 | top: "conv1_2"
108 | }
109 | layer {
110 | name: "conv1_3"
111 | type: "Convolution"
112 | bottom: "conv1_2"
113 | top: "conv1_3"
114 | param {
115 | lr_mult: 1
116 | decay_mult: 1
117 | }
118 | param {
119 | lr_mult: 0
120 | decay_mult: 0
121 | }
122 | convolution_param {
123 | num_output: 64
124 | kernel_size: 3
125 | stride: 1
126 | pad: 1
127 | weight_filler {
128 | type: "gaussian"
129 | std: 0.01
130 | }
131 | bias_filler {
132 | type: "constant"
133 | value: 0
134 | }
135 | }
136 | }
137 | layer {
138 | name: "relu1_3"
139 | type: "PReLU"
140 | bottom: "conv1_3"
141 | top: "conv1_3"
142 | }
143 | layer {
144 | name: "res1_3"
145 | type: "Eltwise"
146 | bottom: "conv1_1"
147 | bottom: "conv1_3"
148 | top: "res1_3"
149 | eltwise_param {
150 | operation: 1
151 | }
152 | }
153 | layer {
154 | name: "conv2_1"
155 | type: "Convolution"
156 | bottom: "res1_3"
157 | top: "conv2_1"
158 | param {
159 | lr_mult: 1
160 | decay_mult: 1
161 | }
162 | param {
163 | lr_mult: 2
164 | decay_mult: 0
165 | }
166 | convolution_param {
167 | num_output: 128
168 | kernel_size: 3
169 | stride: 2
170 | pad: 1
171 | weight_filler {
172 | type: "xavier"
173 | }
174 | bias_filler {
175 | type: "constant"
176 | value: 0
177 | }
178 | }
179 | }
180 | layer {
181 | name: "relu2_1"
182 | type: "PReLU"
183 | bottom: "conv2_1"
184 | top: "conv2_1"
185 | }
186 | layer {
187 | name: "conv2_2"
188 | type: "Convolution"
189 | bottom: "conv2_1"
190 | top: "conv2_2"
191 | param {
192 | lr_mult: 1
193 | decay_mult: 1
194 | }
195 | param {
196 | lr_mult: 0
197 | decay_mult: 0
198 | }
199 | convolution_param {
200 | num_output: 128
201 | kernel_size: 3
202 | stride: 1
203 | pad: 1
204 | weight_filler {
205 | type: "gaussian"
206 | std: 0.01
207 | }
208 | bias_filler {
209 | type: "constant"
210 | value: 0
211 | }
212 | }
213 | }
214 | layer {
215 | name: "relu2_2"
216 | type: "PReLU"
217 | bottom: "conv2_2"
218 | top: "conv2_2"
219 | }
220 | layer {
221 | name: "conv2_3"
222 | type: "Convolution"
223 | bottom: "conv2_2"
224 | top: "conv2_3"
225 | param {
226 | lr_mult: 1
227 | decay_mult: 1
228 | }
229 | param {
230 | lr_mult: 0
231 | decay_mult: 0
232 | }
233 | convolution_param {
234 | num_output: 128
235 | kernel_size: 3
236 | stride: 1
237 | pad: 1
238 | weight_filler {
239 | type: "gaussian"
240 | std: 0.01
241 | }
242 | bias_filler {
243 | type: "constant"
244 | value: 0
245 | }
246 | }
247 | }
248 | layer {
249 | name: "relu2_3"
250 | type: "PReLU"
251 | bottom: "conv2_3"
252 | top: "conv2_3"
253 | }
254 | layer {
255 | name: "res2_3"
256 | type: "Eltwise"
257 | bottom: "conv2_1"
258 | bottom: "conv2_3"
259 | top: "res2_3"
260 | eltwise_param {
261 | operation: 1
262 | }
263 | }
264 | layer {
265 | name: "conv2_4"
266 | type: "Convolution"
267 | bottom: "res2_3"
268 | top: "conv2_4"
269 | param {
270 | lr_mult: 1
271 | decay_mult: 1
272 | }
273 | param {
274 | lr_mult: 0
275 | decay_mult: 0
276 | }
277 | convolution_param {
278 | num_output: 128
279 | kernel_size: 3
280 | stride: 1
281 | pad: 1
282 | weight_filler {
283 | type: "gaussian"
284 | std: 0.01
285 | }
286 | bias_filler {
287 | type: "constant"
288 | value: 0
289 | }
290 | }
291 | }
292 | layer {
293 | name: "relu2_4"
294 | type: "PReLU"
295 | bottom: "conv2_4"
296 | top: "conv2_4"
297 | }
298 | layer {
299 | name: "conv2_5"
300 | type: "Convolution"
301 | bottom: "conv2_4"
302 | top: "conv2_5"
303 | param {
304 | lr_mult: 1
305 | decay_mult: 1
306 | }
307 | param {
308 | lr_mult: 0
309 | decay_mult: 0
310 | }
311 | convolution_param {
312 | num_output: 128
313 | kernel_size: 3
314 | stride: 1
315 | pad: 1
316 | weight_filler {
317 | type: "gaussian"
318 | std: 0.01
319 | }
320 | bias_filler {
321 | type: "constant"
322 | value: 0
323 | }
324 | }
325 | }
326 | layer {
327 | name: "relu2_5"
328 | type: "PReLU"
329 | bottom: "conv2_5"
330 | top: "conv2_5"
331 | }
332 | layer {
333 | name: "res2_5"
334 | type: "Eltwise"
335 | bottom: "res2_3"
336 | bottom: "conv2_5"
337 | top: "res2_5"
338 | eltwise_param {
339 | operation: 1
340 | }
341 | }
342 | layer {
343 | name: "conv3_1"
344 | type: "Convolution"
345 | bottom: "res2_5"
346 | top: "conv3_1"
347 | param {
348 | lr_mult: 1
349 | decay_mult: 1
350 | }
351 | param {
352 | lr_mult: 2
353 | decay_mult: 0
354 | }
355 | convolution_param {
356 | num_output: 256
357 | kernel_size: 3
358 | stride: 2
359 | pad: 1
360 | weight_filler {
361 | type: "xavier"
362 | }
363 | bias_filler {
364 | type: "constant"
365 | value: 0
366 | }
367 | }
368 | }
369 | layer {
370 | name: "relu3_1"
371 | type: "PReLU"
372 | bottom: "conv3_1"
373 | top: "conv3_1"
374 | }
375 | layer {
376 | name: "conv3_2"
377 | type: "Convolution"
378 | bottom: "conv3_1"
379 | top: "conv3_2"
380 | param {
381 | lr_mult: 1
382 | decay_mult: 1
383 | }
384 | param {
385 | lr_mult: 0
386 | decay_mult: 0
387 | }
388 | convolution_param {
389 | num_output: 256
390 | kernel_size: 3
391 | stride: 1
392 | pad: 1
393 | weight_filler {
394 | type: "gaussian"
395 | std: 0.01
396 | }
397 | bias_filler {
398 | type: "constant"
399 | value: 0
400 | }
401 | }
402 | }
403 | layer {
404 | name: "relu3_2"
405 | type: "PReLU"
406 | bottom: "conv3_2"
407 | top: "conv3_2"
408 | }
409 | layer {
410 | name: "conv3_3"
411 | type: "Convolution"
412 | bottom: "conv3_2"
413 | top: "conv3_3"
414 | param {
415 | lr_mult: 1
416 | decay_mult: 1
417 | }
418 | param {
419 | lr_mult: 0
420 | decay_mult: 0
421 | }
422 | convolution_param {
423 | num_output: 256
424 | kernel_size: 3
425 | stride: 1
426 | pad: 1
427 | weight_filler {
428 | type: "gaussian"
429 | std: 0.01
430 | }
431 | bias_filler {
432 | type: "constant"
433 | value: 0
434 | }
435 | }
436 | }
437 | layer {
438 | name: "relu3_3"
439 | type: "PReLU"
440 | bottom: "conv3_3"
441 | top: "conv3_3"
442 | }
443 | layer {
444 | name: "res3_3"
445 | type: "Eltwise"
446 | bottom: "conv3_1"
447 | bottom: "conv3_3"
448 | top: "res3_3"
449 | eltwise_param {
450 | operation: 1
451 | }
452 | }
453 | layer {
454 | name: "conv3_4"
455 | type: "Convolution"
456 | bottom: "res3_3"
457 | top: "conv3_4"
458 | param {
459 | lr_mult: 1
460 | decay_mult: 1
461 | }
462 | param {
463 | lr_mult: 0
464 | decay_mult: 0
465 | }
466 | convolution_param {
467 | num_output: 256
468 | kernel_size: 3
469 | stride: 1
470 | pad: 1
471 | weight_filler {
472 | type: "gaussian"
473 | std: 0.01
474 | }
475 | bias_filler {
476 | type: "constant"
477 | value: 0
478 | }
479 | }
480 | }
481 | layer {
482 | name: "relu3_4"
483 | type: "PReLU"
484 | bottom: "conv3_4"
485 | top: "conv3_4"
486 | }
487 | layer {
488 | name: "conv3_5"
489 | type: "Convolution"
490 | bottom: "conv3_4"
491 | top: "conv3_5"
492 | param {
493 | lr_mult: 1
494 | decay_mult: 1
495 | }
496 | param {
497 | lr_mult: 0
498 | decay_mult: 0
499 | }
500 | convolution_param {
501 | num_output: 256
502 | kernel_size: 3
503 | stride: 1
504 | pad: 1
505 | weight_filler {
506 | type: "gaussian"
507 | std: 0.01
508 | }
509 | bias_filler {
510 | type: "constant"
511 | value: 0
512 | }
513 | }
514 | }
515 | layer {
516 | name: "relu3_5"
517 | type: "PReLU"
518 | bottom: "conv3_5"
519 | top: "conv3_5"
520 | }
521 | layer {
522 | name: "res3_5"
523 | type: "Eltwise"
524 | bottom: "res3_3"
525 | bottom: "conv3_5"
526 | top: "res3_5"
527 | eltwise_param {
528 | operation: 1
529 | }
530 | }
531 | layer {
532 | name: "conv3_6"
533 | type: "Convolution"
534 | bottom: "res3_5"
535 | top: "conv3_6"
536 | param {
537 | lr_mult: 1
538 | decay_mult: 1
539 | }
540 | param {
541 | lr_mult: 0
542 | decay_mult: 0
543 | }
544 | convolution_param {
545 | num_output: 256
546 | kernel_size: 3
547 | stride: 1
548 | pad: 1
549 | weight_filler {
550 | type: "gaussian"
551 | std: 0.01
552 | }
553 | bias_filler {
554 | type: "constant"
555 | value: 0
556 | }
557 | }
558 | }
559 | layer {
560 | name: "relu3_6"
561 | type: "PReLU"
562 | bottom: "conv3_6"
563 | top: "conv3_6"
564 | }
565 | layer {
566 | name: "conv3_7"
567 | type: "Convolution"
568 | bottom: "conv3_6"
569 | top: "conv3_7"
570 | param {
571 | lr_mult: 1
572 | decay_mult: 1
573 | }
574 | param {
575 | lr_mult: 0
576 | decay_mult: 0
577 | }
578 | convolution_param {
579 | num_output: 256
580 | kernel_size: 3
581 | stride: 1
582 | pad: 1
583 | weight_filler {
584 | type: "gaussian"
585 | std: 0.01
586 | }
587 | bias_filler {
588 | type: "constant"
589 | value: 0
590 | }
591 | }
592 | }
593 | layer {
594 | name: "relu3_7"
595 | type: "PReLU"
596 | bottom: "conv3_7"
597 | top: "conv3_7"
598 | }
599 | layer {
600 | name: "res3_7"
601 | type: "Eltwise"
602 | bottom: "res3_5"
603 | bottom: "conv3_7"
604 | top: "res3_7"
605 | eltwise_param {
606 | operation: 1
607 | }
608 | }
609 | layer {
610 | name: "conv3_8"
611 | type: "Convolution"
612 | bottom: "res3_7"
613 | top: "conv3_8"
614 | param {
615 | lr_mult: 1
616 | decay_mult: 1
617 | }
618 | param {
619 | lr_mult: 0
620 | decay_mult: 0
621 | }
622 | convolution_param {
623 | num_output: 256
624 | kernel_size: 3
625 | stride: 1
626 | pad: 1
627 | weight_filler {
628 | type: "gaussian"
629 | std: 0.01
630 | }
631 | bias_filler {
632 | type: "constant"
633 | value: 0
634 | }
635 | }
636 | }
637 | layer {
638 | name: "relu3_8"
639 | type: "PReLU"
640 | bottom: "conv3_8"
641 | top: "conv3_8"
642 | }
643 | layer {
644 | name: "conv3_9"
645 | type: "Convolution"
646 | bottom: "conv3_8"
647 | top: "conv3_9"
648 | param {
649 | lr_mult: 1
650 | decay_mult: 1
651 | }
652 | param {
653 | lr_mult: 0
654 | decay_mult: 0
655 | }
656 | convolution_param {
657 | num_output: 256
658 | kernel_size: 3
659 | stride: 1
660 | pad: 1
661 | weight_filler {
662 | type: "gaussian"
663 | std: 0.01
664 | }
665 | bias_filler {
666 | type: "constant"
667 | value: 0
668 | }
669 | }
670 | }
671 | layer {
672 | name: "relu3_9"
673 | type: "PReLU"
674 | bottom: "conv3_9"
675 | top: "conv3_9"
676 | }
677 | layer {
678 | name: "res3_9"
679 | type: "Eltwise"
680 | bottom: "res3_7"
681 | bottom: "conv3_9"
682 | top: "res3_9"
683 | eltwise_param {
684 | operation: 1
685 | }
686 | }
687 | layer {
688 | name: "conv4_1"
689 | type: "Convolution"
690 | bottom: "res3_9"
691 | top: "conv4_1"
692 | param {
693 | lr_mult: 1
694 | decay_mult: 1
695 | }
696 | param {
697 | lr_mult: 2
698 | decay_mult: 0
699 | }
700 | convolution_param {
701 | num_output: 512
702 | kernel_size: 3
703 | stride: 2
704 | pad: 1
705 | weight_filler {
706 | type: "xavier"
707 | }
708 | bias_filler {
709 | type: "constant"
710 | value: 0
711 | }
712 | }
713 | }
714 | layer {
715 | name: "relu4_1"
716 | type: "PReLU"
717 | bottom: "conv4_1"
718 | top: "conv4_1"
719 | }
720 | layer {
721 | name: "conv4_2"
722 | type: "Convolution"
723 | bottom: "conv4_1"
724 | top: "conv4_2"
725 | param {
726 | lr_mult: 1
727 | decay_mult: 1
728 | }
729 | param {
730 | lr_mult: 0
731 | decay_mult: 0
732 | }
733 | convolution_param {
734 | num_output: 512
735 | kernel_size: 3
736 | stride: 1
737 | pad: 1
738 | weight_filler {
739 | type: "gaussian"
740 | std: 0.01
741 | }
742 | bias_filler {
743 | type: "constant"
744 | value: 0
745 | }
746 | }
747 | }
748 | layer {
749 | name: "relu4_2"
750 | type: "PReLU"
751 | bottom: "conv4_2"
752 | top: "conv4_2"
753 | }
754 | layer {
755 | name: "conv4_3"
756 | type: "Convolution"
757 | bottom: "conv4_2"
758 | top: "conv4_3"
759 | param {
760 | lr_mult: 1
761 | decay_mult: 1
762 | }
763 | param {
764 | lr_mult: 0
765 | decay_mult: 0
766 | }
767 | convolution_param {
768 | num_output: 512
769 | kernel_size: 3
770 | stride: 1
771 | pad: 1
772 | weight_filler {
773 | type: "gaussian"
774 | std: 0.01
775 | }
776 | bias_filler {
777 | type: "constant"
778 | value: 0
779 | }
780 | }
781 | }
782 | layer {
783 | name: "relu4_3"
784 | type: "PReLU"
785 | bottom: "conv4_3"
786 | top: "conv4_3"
787 | }
788 | layer {
789 | name: "res4_3"
790 | type: "Eltwise"
791 | bottom: "conv4_1"
792 | bottom: "conv4_3"
793 | top: "res4_3"
794 | eltwise_param {
795 | operation: 1
796 | }
797 | }
798 | layer {
799 | name: "fc5"
800 | type: "InnerProduct"
801 | bottom: "res4_3"
802 | top: "fc5"
803 | param {
804 | lr_mult: 1
805 | decay_mult: 1
806 | }
807 | param {
808 | lr_mult: 2
809 | decay_mult: 0
810 | }
811 | inner_product_param {
812 | num_output: 512
813 | weight_filler {
814 | type: "xavier"
815 | }
816 | bias_filler {
817 | type: "constant"
818 | value: 0
819 | }
820 | }
821 | }
822 | ####################### innerproduct ###################
823 | layer {
824 | name: "fc5_norm"
825 | type: "NormL2"
826 | bottom: "fc5"
827 | top: "fc5_norm"
828 | }
829 | layer {
830 | name: "fc6"
831 | type: "InnerProduct"
832 | bottom: "fc5_norm"
833 | top: "fc6"
834 | param {
835 | lr_mult: 1
836 | decay_mult: 1
837 | }
838 | inner_product_param {
839 | num_output: 10575
840 | normalize: true
841 | weight_filler {
842 | type: "xavier"
843 | }
844 | bias_term: false
845 | }
846 | }
847 | layer {
848 | name: "fc6_margin"
849 | type: "Arcface"
850 | bottom: "fc6"
851 | bottom: "label000"
852 | top: "fc6_margin"
853 | arcface_param {
854 | m: 0.5
855 | }
856 | }
857 | layer {
858 | name: "fix_cos"
859 | type: "NoiseTolerantFR"
860 | bottom: "fc6_margin"
861 | bottom: "fc6"
862 | bottom: "label000"
863 | top: "fix_cos"
864 | noise_tolerant_fr_param {
865 | shield_forward: false
866 | start_iter: 1
867 | bins: 200
868 | slide_batch_num: 1000
869 |
870 | value_low: -1.0
871 | value_high: 1.0
872 |
873 | #debug: true
874 | #debug_prefix: "p_casia-webface_noise-flip-outlier-1_1-40_Asoftmax_FIT"
875 | debug: false
876 | }
877 | }
878 | layer {
879 | name: "fc6_margin_scale"
880 | type: "Scale"
881 | bottom: "fix_cos"
882 | top: "fc6_margin_scale"
883 | param {
884 | lr_mult: 0
885 | decay_mult: 0
886 | }
887 | scale_param {
888 | filler {
889 | type: "constant"
890 | value: 32.0
891 | }
892 | bias_term: false
893 | }
894 | }
895 | ######################### softmax #######################
896 | layer {
897 | name: "loss/label000"
898 | type: "SoftmaxWithLoss"
899 | bottom: "fc6_margin_scale"
900 | bottom: "label000"
901 | top: "loss/label000"
902 | loss_weight: 1.0
903 | loss_param {
904 | ignore_label: -1
905 | }
906 | }
907 | layer {
908 | name: "accuracy/label000"
909 | type: "Accuracy"
910 | bottom: "fc6_margin_scale"
911 | bottom: "label000"
912 | top: "accuracy/label000"
913 | accuracy_param {
914 | top_k: 1
915 | ignore_label: -1
916 | }
917 | }
918 |
--------------------------------------------------------------------------------
/deploy/resnet20_l2softmax_train.prototxt:
--------------------------------------------------------------------------------
1 | name: "face_res20net"
2 | layer {
3 | name: "data"
4 | type: "Data"
5 | top: "data"
6 | top: "label000"
7 | include {
8 | phase: TRAIN
9 | }
10 | transform_param {
11 | crop_size: 128
12 | scale: 0.0078125
13 | mean_value: 127.5
14 | mirror: true
15 | }
16 | data_param {
17 | source: "./data/casia-webface/p_noise-flip-outlier-1_1-40/converter_p_casia-webface_noise-flip-outlier-1_1-40/train_data_db/"
18 | backend: LMDB
19 | batch_size: 64
20 | }
21 | }
22 | layer {
23 | name: "data"
24 | type: "Data"
25 | top: "data"
26 | top: "label000"
27 | include {
28 | phase: TEST
29 | }
30 | transform_param {
31 | crop_size: 128
32 | scale: 0.0078125
33 | mean_value: 127.5
34 | mirror: false
35 | }
36 | data_param {
37 | source: "./data/casia-webface/p_noise-flip-outlier-1_1-40/converter_p_casia-webface_noise-flip-outlier-1_1-40/validation_data_db/"
38 | backend: LMDB
39 | batch_size: 8
40 | }
41 | }
42 | layer {
43 | name: "conv1_1"
44 | type: "Convolution"
45 | bottom: "data"
46 | top: "conv1_1"
47 | param {
48 | lr_mult: 1
49 | decay_mult: 1
50 | }
51 | param {
52 | lr_mult: 2
53 | decay_mult: 0
54 | }
55 | convolution_param {
56 | num_output: 64
57 | kernel_size: 3
58 | stride: 2
59 | pad: 1
60 | weight_filler {
61 | type: "xavier"
62 | }
63 | bias_filler {
64 | type: "constant"
65 | value: 0
66 | }
67 | }
68 | }
69 | layer {
70 | name: "relu1_1"
71 | type: "PReLU"
72 | bottom: "conv1_1"
73 | top: "conv1_1"
74 | }
75 | layer {
76 | name: "conv1_2"
77 | type: "Convolution"
78 | bottom: "conv1_1"
79 | top: "conv1_2"
80 | param {
81 | lr_mult: 1
82 | decay_mult: 1
83 | }
84 | param {
85 | lr_mult: 0
86 | decay_mult: 0
87 | }
88 | convolution_param {
89 | num_output: 64
90 | kernel_size: 3
91 | stride: 1
92 | pad: 1
93 | weight_filler {
94 | type: "gaussian"
95 | std: 0.01
96 | }
97 | bias_filler {
98 | type: "constant"
99 | value: 0
100 | }
101 | }
102 | }
103 | layer {
104 | name: "relu1_2"
105 | type: "PReLU"
106 | bottom: "conv1_2"
107 | top: "conv1_2"
108 | }
109 | layer {
110 | name: "conv1_3"
111 | type: "Convolution"
112 | bottom: "conv1_2"
113 | top: "conv1_3"
114 | param {
115 | lr_mult: 1
116 | decay_mult: 1
117 | }
118 | param {
119 | lr_mult: 0
120 | decay_mult: 0
121 | }
122 | convolution_param {
123 | num_output: 64
124 | kernel_size: 3
125 | stride: 1
126 | pad: 1
127 | weight_filler {
128 | type: "gaussian"
129 | std: 0.01
130 | }
131 | bias_filler {
132 | type: "constant"
133 | value: 0
134 | }
135 | }
136 | }
137 | layer {
138 | name: "relu1_3"
139 | type: "PReLU"
140 | bottom: "conv1_3"
141 | top: "conv1_3"
142 | }
143 | layer {
144 | name: "res1_3"
145 | type: "Eltwise"
146 | bottom: "conv1_1"
147 | bottom: "conv1_3"
148 | top: "res1_3"
149 | eltwise_param {
150 | operation: 1
151 | }
152 | }
153 | layer {
154 | name: "conv2_1"
155 | type: "Convolution"
156 | bottom: "res1_3"
157 | top: "conv2_1"
158 | param {
159 | lr_mult: 1
160 | decay_mult: 1
161 | }
162 | param {
163 | lr_mult: 2
164 | decay_mult: 0
165 | }
166 | convolution_param {
167 | num_output: 128
168 | kernel_size: 3
169 | stride: 2
170 | pad: 1
171 | weight_filler {
172 | type: "xavier"
173 | }
174 | bias_filler {
175 | type: "constant"
176 | value: 0
177 | }
178 | }
179 | }
180 | layer {
181 | name: "relu2_1"
182 | type: "PReLU"
183 | bottom: "conv2_1"
184 | top: "conv2_1"
185 | }
186 | layer {
187 | name: "conv2_2"
188 | type: "Convolution"
189 | bottom: "conv2_1"
190 | top: "conv2_2"
191 | param {
192 | lr_mult: 1
193 | decay_mult: 1
194 | }
195 | param {
196 | lr_mult: 0
197 | decay_mult: 0
198 | }
199 | convolution_param {
200 | num_output: 128
201 | kernel_size: 3
202 | stride: 1
203 | pad: 1
204 | weight_filler {
205 | type: "gaussian"
206 | std: 0.01
207 | }
208 | bias_filler {
209 | type: "constant"
210 | value: 0
211 | }
212 | }
213 | }
214 | layer {
215 | name: "relu2_2"
216 | type: "PReLU"
217 | bottom: "conv2_2"
218 | top: "conv2_2"
219 | }
220 | layer {
221 | name: "conv2_3"
222 | type: "Convolution"
223 | bottom: "conv2_2"
224 | top: "conv2_3"
225 | param {
226 | lr_mult: 1
227 | decay_mult: 1
228 | }
229 | param {
230 | lr_mult: 0
231 | decay_mult: 0
232 | }
233 | convolution_param {
234 | num_output: 128
235 | kernel_size: 3
236 | stride: 1
237 | pad: 1
238 | weight_filler {
239 | type: "gaussian"
240 | std: 0.01
241 | }
242 | bias_filler {
243 | type: "constant"
244 | value: 0
245 | }
246 | }
247 | }
248 | layer {
249 | name: "relu2_3"
250 | type: "PReLU"
251 | bottom: "conv2_3"
252 | top: "conv2_3"
253 | }
254 | layer {
255 | name: "res2_3"
256 | type: "Eltwise"
257 | bottom: "conv2_1"
258 | bottom: "conv2_3"
259 | top: "res2_3"
260 | eltwise_param {
261 | operation: 1
262 | }
263 | }
264 | layer {
265 | name: "conv2_4"
266 | type: "Convolution"
267 | bottom: "res2_3"
268 | top: "conv2_4"
269 | param {
270 | lr_mult: 1
271 | decay_mult: 1
272 | }
273 | param {
274 | lr_mult: 0
275 | decay_mult: 0
276 | }
277 | convolution_param {
278 | num_output: 128
279 | kernel_size: 3
280 | stride: 1
281 | pad: 1
282 | weight_filler {
283 | type: "gaussian"
284 | std: 0.01
285 | }
286 | bias_filler {
287 | type: "constant"
288 | value: 0
289 | }
290 | }
291 | }
292 | layer {
293 | name: "relu2_4"
294 | type: "PReLU"
295 | bottom: "conv2_4"
296 | top: "conv2_4"
297 | }
298 | layer {
299 | name: "conv2_5"
300 | type: "Convolution"
301 | bottom: "conv2_4"
302 | top: "conv2_5"
303 | param {
304 | lr_mult: 1
305 | decay_mult: 1
306 | }
307 | param {
308 | lr_mult: 0
309 | decay_mult: 0
310 | }
311 | convolution_param {
312 | num_output: 128
313 | kernel_size: 3
314 | stride: 1
315 | pad: 1
316 | weight_filler {
317 | type: "gaussian"
318 | std: 0.01
319 | }
320 | bias_filler {
321 | type: "constant"
322 | value: 0
323 | }
324 | }
325 | }
326 | layer {
327 | name: "relu2_5"
328 | type: "PReLU"
329 | bottom: "conv2_5"
330 | top: "conv2_5"
331 | }
332 | layer {
333 | name: "res2_5"
334 | type: "Eltwise"
335 | bottom: "res2_3"
336 | bottom: "conv2_5"
337 | top: "res2_5"
338 | eltwise_param {
339 | operation: 1
340 | }
341 | }
342 | layer {
343 | name: "conv3_1"
344 | type: "Convolution"
345 | bottom: "res2_5"
346 | top: "conv3_1"
347 | param {
348 | lr_mult: 1
349 | decay_mult: 1
350 | }
351 | param {
352 | lr_mult: 2
353 | decay_mult: 0
354 | }
355 | convolution_param {
356 | num_output: 256
357 | kernel_size: 3
358 | stride: 2
359 | pad: 1
360 | weight_filler {
361 | type: "xavier"
362 | }
363 | bias_filler {
364 | type: "constant"
365 | value: 0
366 | }
367 | }
368 | }
369 | layer {
370 | name: "relu3_1"
371 | type: "PReLU"
372 | bottom: "conv3_1"
373 | top: "conv3_1"
374 | }
375 | layer {
376 | name: "conv3_2"
377 | type: "Convolution"
378 | bottom: "conv3_1"
379 | top: "conv3_2"
380 | param {
381 | lr_mult: 1
382 | decay_mult: 1
383 | }
384 | param {
385 | lr_mult: 0
386 | decay_mult: 0
387 | }
388 | convolution_param {
389 | num_output: 256
390 | kernel_size: 3
391 | stride: 1
392 | pad: 1
393 | weight_filler {
394 | type: "gaussian"
395 | std: 0.01
396 | }
397 | bias_filler {
398 | type: "constant"
399 | value: 0
400 | }
401 | }
402 | }
403 | layer {
404 | name: "relu3_2"
405 | type: "PReLU"
406 | bottom: "conv3_2"
407 | top: "conv3_2"
408 | }
409 | layer {
410 | name: "conv3_3"
411 | type: "Convolution"
412 | bottom: "conv3_2"
413 | top: "conv3_3"
414 | param {
415 | lr_mult: 1
416 | decay_mult: 1
417 | }
418 | param {
419 | lr_mult: 0
420 | decay_mult: 0
421 | }
422 | convolution_param {
423 | num_output: 256
424 | kernel_size: 3
425 | stride: 1
426 | pad: 1
427 | weight_filler {
428 | type: "gaussian"
429 | std: 0.01
430 | }
431 | bias_filler {
432 | type: "constant"
433 | value: 0
434 | }
435 | }
436 | }
437 | layer {
438 | name: "relu3_3"
439 | type: "PReLU"
440 | bottom: "conv3_3"
441 | top: "conv3_3"
442 | }
443 | layer {
444 | name: "res3_3"
445 | type: "Eltwise"
446 | bottom: "conv3_1"
447 | bottom: "conv3_3"
448 | top: "res3_3"
449 | eltwise_param {
450 | operation: 1
451 | }
452 | }
453 | layer {
454 | name: "conv3_4"
455 | type: "Convolution"
456 | bottom: "res3_3"
457 | top: "conv3_4"
458 | param {
459 | lr_mult: 1
460 | decay_mult: 1
461 | }
462 | param {
463 | lr_mult: 0
464 | decay_mult: 0
465 | }
466 | convolution_param {
467 | num_output: 256
468 | kernel_size: 3
469 | stride: 1
470 | pad: 1
471 | weight_filler {
472 | type: "gaussian"
473 | std: 0.01
474 | }
475 | bias_filler {
476 | type: "constant"
477 | value: 0
478 | }
479 | }
480 | }
481 | layer {
482 | name: "relu3_4"
483 | type: "PReLU"
484 | bottom: "conv3_4"
485 | top: "conv3_4"
486 | }
487 | layer {
488 | name: "conv3_5"
489 | type: "Convolution"
490 | bottom: "conv3_4"
491 | top: "conv3_5"
492 | param {
493 | lr_mult: 1
494 | decay_mult: 1
495 | }
496 | param {
497 | lr_mult: 0
498 | decay_mult: 0
499 | }
500 | convolution_param {
501 | num_output: 256
502 | kernel_size: 3
503 | stride: 1
504 | pad: 1
505 | weight_filler {
506 | type: "gaussian"
507 | std: 0.01
508 | }
509 | bias_filler {
510 | type: "constant"
511 | value: 0
512 | }
513 | }
514 | }
515 | layer {
516 | name: "relu3_5"
517 | type: "PReLU"
518 | bottom: "conv3_5"
519 | top: "conv3_5"
520 | }
521 | layer {
522 | name: "res3_5"
523 | type: "Eltwise"
524 | bottom: "res3_3"
525 | bottom: "conv3_5"
526 | top: "res3_5"
527 | eltwise_param {
528 | operation: 1
529 | }
530 | }
531 | layer {
532 | name: "conv3_6"
533 | type: "Convolution"
534 | bottom: "res3_5"
535 | top: "conv3_6"
536 | param {
537 | lr_mult: 1
538 | decay_mult: 1
539 | }
540 | param {
541 | lr_mult: 0
542 | decay_mult: 0
543 | }
544 | convolution_param {
545 | num_output: 256
546 | kernel_size: 3
547 | stride: 1
548 | pad: 1
549 | weight_filler {
550 | type: "gaussian"
551 | std: 0.01
552 | }
553 | bias_filler {
554 | type: "constant"
555 | value: 0
556 | }
557 | }
558 | }
559 | layer {
560 | name: "relu3_6"
561 | type: "PReLU"
562 | bottom: "conv3_6"
563 | top: "conv3_6"
564 | }
565 | layer {
566 | name: "conv3_7"
567 | type: "Convolution"
568 | bottom: "conv3_6"
569 | top: "conv3_7"
570 | param {
571 | lr_mult: 1
572 | decay_mult: 1
573 | }
574 | param {
575 | lr_mult: 0
576 | decay_mult: 0
577 | }
578 | convolution_param {
579 | num_output: 256
580 | kernel_size: 3
581 | stride: 1
582 | pad: 1
583 | weight_filler {
584 | type: "gaussian"
585 | std: 0.01
586 | }
587 | bias_filler {
588 | type: "constant"
589 | value: 0
590 | }
591 | }
592 | }
593 | layer {
594 | name: "relu3_7"
595 | type: "PReLU"
596 | bottom: "conv3_7"
597 | top: "conv3_7"
598 | }
599 | layer {
600 | name: "res3_7"
601 | type: "Eltwise"
602 | bottom: "res3_5"
603 | bottom: "conv3_7"
604 | top: "res3_7"
605 | eltwise_param {
606 | operation: 1
607 | }
608 | }
609 | layer {
610 | name: "conv3_8"
611 | type: "Convolution"
612 | bottom: "res3_7"
613 | top: "conv3_8"
614 | param {
615 | lr_mult: 1
616 | decay_mult: 1
617 | }
618 | param {
619 | lr_mult: 0
620 | decay_mult: 0
621 | }
622 | convolution_param {
623 | num_output: 256
624 | kernel_size: 3
625 | stride: 1
626 | pad: 1
627 | weight_filler {
628 | type: "gaussian"
629 | std: 0.01
630 | }
631 | bias_filler {
632 | type: "constant"
633 | value: 0
634 | }
635 | }
636 | }
637 | layer {
638 | name: "relu3_8"
639 | type: "PReLU"
640 | bottom: "conv3_8"
641 | top: "conv3_8"
642 | }
643 | layer {
644 | name: "conv3_9"
645 | type: "Convolution"
646 | bottom: "conv3_8"
647 | top: "conv3_9"
648 | param {
649 | lr_mult: 1
650 | decay_mult: 1
651 | }
652 | param {
653 | lr_mult: 0
654 | decay_mult: 0
655 | }
656 | convolution_param {
657 | num_output: 256
658 | kernel_size: 3
659 | stride: 1
660 | pad: 1
661 | weight_filler {
662 | type: "gaussian"
663 | std: 0.01
664 | }
665 | bias_filler {
666 | type: "constant"
667 | value: 0
668 | }
669 | }
670 | }
671 | layer {
672 | name: "relu3_9"
673 | type: "PReLU"
674 | bottom: "conv3_9"
675 | top: "conv3_9"
676 | }
677 | layer {
678 | name: "res3_9"
679 | type: "Eltwise"
680 | bottom: "res3_7"
681 | bottom: "conv3_9"
682 | top: "res3_9"
683 | eltwise_param {
684 | operation: 1
685 | }
686 | }
687 | layer {
688 | name: "conv4_1"
689 | type: "Convolution"
690 | bottom: "res3_9"
691 | top: "conv4_1"
692 | param {
693 | lr_mult: 1
694 | decay_mult: 1
695 | }
696 | param {
697 | lr_mult: 2
698 | decay_mult: 0
699 | }
700 | convolution_param {
701 | num_output: 512
702 | kernel_size: 3
703 | stride: 2
704 | pad: 1
705 | weight_filler {
706 | type: "xavier"
707 | }
708 | bias_filler {
709 | type: "constant"
710 | value: 0
711 | }
712 | }
713 | }
714 | layer {
715 | name: "relu4_1"
716 | type: "PReLU"
717 | bottom: "conv4_1"
718 | top: "conv4_1"
719 | }
720 | layer {
721 | name: "conv4_2"
722 | type: "Convolution"
723 | bottom: "conv4_1"
724 | top: "conv4_2"
725 | param {
726 | lr_mult: 1
727 | decay_mult: 1
728 | }
729 | param {
730 | lr_mult: 0
731 | decay_mult: 0
732 | }
733 | convolution_param {
734 | num_output: 512
735 | kernel_size: 3
736 | stride: 1
737 | pad: 1
738 | weight_filler {
739 | type: "gaussian"
740 | std: 0.01
741 | }
742 | bias_filler {
743 | type: "constant"
744 | value: 0
745 | }
746 | }
747 | }
748 | layer {
749 | name: "relu4_2"
750 | type: "PReLU"
751 | bottom: "conv4_2"
752 | top: "conv4_2"
753 | }
754 | layer {
755 | name: "conv4_3"
756 | type: "Convolution"
757 | bottom: "conv4_2"
758 | top: "conv4_3"
759 | param {
760 | lr_mult: 1
761 | decay_mult: 1
762 | }
763 | param {
764 | lr_mult: 0
765 | decay_mult: 0
766 | }
767 | convolution_param {
768 | num_output: 512
769 | kernel_size: 3
770 | stride: 1
771 | pad: 1
772 | weight_filler {
773 | type: "gaussian"
774 | std: 0.01
775 | }
776 | bias_filler {
777 | type: "constant"
778 | value: 0
779 | }
780 | }
781 | }
782 | layer {
783 | name: "relu4_3"
784 | type: "PReLU"
785 | bottom: "conv4_3"
786 | top: "conv4_3"
787 | }
788 | layer {
789 | name: "res4_3"
790 | type: "Eltwise"
791 | bottom: "conv4_1"
792 | bottom: "conv4_3"
793 | top: "res4_3"
794 | eltwise_param {
795 | operation: 1
796 | }
797 | }
798 | layer {
799 | name: "fc5"
800 | type: "InnerProduct"
801 | bottom: "res4_3"
802 | top: "fc5"
803 | param {
804 | lr_mult: 1
805 | decay_mult: 1
806 | }
807 | param {
808 | lr_mult: 2
809 | decay_mult: 0
810 | }
811 | inner_product_param {
812 | num_output: 512
813 | weight_filler {
814 | type: "xavier"
815 | }
816 | bias_filler {
817 | type: "constant"
818 | value: 0
819 | }
820 | }
821 | }
822 | ####################### innerproduct ###################
823 | layer {
824 | name: "fc5_norm"
825 | type: "NormL2"
826 | bottom: "fc5"
827 | top: "fc5_norm"
828 | }
829 | layer {
830 | name: "fc6"
831 | type: "InnerProduct"
832 | bottom: "fc5_norm"
833 | top: "fc6"
834 | param {
835 | lr_mult: 1
836 | decay_mult: 1
837 | }
838 | inner_product_param {
839 | num_output: 10575
840 | normalize: true
841 | weight_filler {
842 | type: "xavier"
843 | }
844 | bias_term: false
845 | }
846 | }
847 | layer {
848 | name: "fix_cos"
849 | type: "NoiseTolerantFR"
850 | bottom: "fc6"
851 | bottom: "fc6"
852 | bottom: "label000"
853 | top: "fix_cos"
854 | noise_tolerant_fr_param {
855 | shield_forward: false
856 | start_iter: 1
857 | bins: 200
858 | slide_batch_num: 1000
859 |
860 | value_low: -1.0
861 | value_high: 1.0
862 |
863 | #debug: true
864 | #debug_prefix: "p_casia-webface_noise-flip-outlier-1_1-40_Nsoftmax_AD"
865 | debug: false
866 | }
867 | }
868 | layer {
869 | name: "fc6_margin_scale"
870 | type: "Scale"
871 | bottom: "fix_cos"
872 | top: "fc6_margin_scale"
873 | param {
874 | lr_mult: 0
875 | decay_mult: 0
876 | }
877 | scale_param {
878 | filler {
879 | type: "constant"
880 | value: 32.0
881 | }
882 | bias_term: false
883 | }
884 | }
885 | ######################### softmax #######################
886 | layer {
887 | name: "loss/label000"
888 | type: "SoftmaxWithLoss"
889 | bottom: "fc6_margin_scale"
890 | bottom: "label000"
891 | top: "loss/label000"
892 | loss_weight: 1.0
893 | loss_param {
894 | ignore_label: -1
895 | }
896 | }
897 | layer {
898 | name: "accuracy/label000"
899 | type: "Accuracy"
900 | bottom: "fc6_margin_scale"
901 | bottom: "label000"
902 | top: "accuracy/label000"
903 | accuracy_param {
904 | top_k: 1
905 | ignore_label: -1
906 | }
907 | }
908 |
--------------------------------------------------------------------------------
/deploy/resnet64_l2softmax_train.prototxt:
--------------------------------------------------------------------------------
1 | name: "face_res64net"
2 | layer {
3 | name: "data"
4 | type: "Data"
5 | top: "data"
6 | top: "label000"
7 | #top: "label001"
8 | include {
9 | phase: TRAIN
10 | }
11 | transform_param {
12 | crop_size: 128
13 | scale: 0.0078125
14 | mean_value: 127.5
15 | mirror: true
16 | }
17 | data_param {
18 | source: "./data/casia-webface/p_noise-flip-outlier-1_1-40/converter_p_casia-webface_noise-flip-outlier-1_1-40/train_data_db/"
19 | backend: LMDB
20 | batch_size: 64
21 | }
22 | }
23 | layer {
24 | name: "data"
25 | type: "Data"
26 | top: "data"
27 | top: "label000"
28 | #top: "label001"
29 | include {
30 | phase: TEST
31 | }
32 | transform_param {
33 | crop_size: 128
34 | scale: 0.0078125
35 | mean_value: 127.5
36 | mirror: false
37 | }
38 | data_param {
39 | source: "./data/casia-webface/p_noise-flip-outlier-1_1-40/converter_p_casia-webface_noise-flip-outlier-1_1-40/validation_data_db/"
40 | backend: LMDB
41 | batch_size: 8
42 | }
43 | }
44 | layer {
45 | name: "conv1_1"
46 | type: "Convolution"
47 | bottom: "data"
48 | top: "conv1_1"
49 | param {
50 | lr_mult: 1
51 | decay_mult: 1
52 | }
53 | param {
54 | lr_mult: 2
55 | decay_mult: 0
56 | }
57 | convolution_param {
58 | num_output: 64
59 | kernel_size: 3
60 | stride: 2
61 | pad: 1
62 | weight_filler {
63 | type: "xavier"
64 | }
65 | bias_filler {
66 | type: "constant"
67 | value: 0
68 | }
69 | }
70 | }
71 | layer {
72 | name: "relu1_1"
73 | type: "PReLU"
74 | bottom: "conv1_1"
75 | top: "conv1_1"
76 | }
77 | layer {
78 | name: "conv1_2"
79 | type: "Convolution"
80 | bottom: "conv1_1"
81 | top: "conv1_2"
82 | param {
83 | lr_mult: 1
84 | decay_mult: 1
85 | }
86 | param {
87 | lr_mult: 0
88 | decay_mult: 0
89 | }
90 | convolution_param {
91 | num_output: 64
92 | kernel_size: 3
93 | stride: 1
94 | pad: 1
95 | weight_filler {
96 | type: "gaussian"
97 | std: 0.01
98 | }
99 | bias_filler {
100 | type: "constant"
101 | value: 0
102 | }
103 | }
104 | }
105 | layer {
106 | name: "relu1_2"
107 | type: "PReLU"
108 | bottom: "conv1_2"
109 | top: "conv1_2"
110 | }
111 | layer {
112 | name: "conv1_3"
113 | type: "Convolution"
114 | bottom: "conv1_2"
115 | top: "conv1_3"
116 | param {
117 | lr_mult: 1
118 | decay_mult: 1
119 | }
120 | param {
121 | lr_mult: 0
122 | decay_mult: 0
123 | }
124 | convolution_param {
125 | num_output: 64
126 | kernel_size: 3
127 | stride: 1
128 | pad: 1
129 | weight_filler {
130 | type: "gaussian"
131 | std: 0.01
132 | }
133 | bias_filler {
134 | type: "constant"
135 | value: 0
136 | }
137 | }
138 | }
139 | layer {
140 | name: "relu1_3"
141 | type: "PReLU"
142 | bottom: "conv1_3"
143 | top: "conv1_3"
144 | }
145 | layer {
146 | name: "res1_3"
147 | type: "Eltwise"
148 | bottom: "conv1_1"
149 | bottom: "conv1_3"
150 | top: "res1_3"
151 | eltwise_param {
152 | operation: 1
153 | }
154 | }
155 | layer {
156 | name: "conv1_4"
157 | type: "Convolution"
158 | bottom: "res1_3"
159 | top: "conv1_4"
160 | param {
161 | lr_mult: 1
162 | decay_mult: 1
163 | }
164 | param {
165 | lr_mult: 0
166 | decay_mult: 0
167 | }
168 | convolution_param {
169 | num_output: 64
170 | kernel_size: 3
171 | stride: 1
172 | pad: 1
173 | weight_filler {
174 | type: "gaussian"
175 | std: 0.01
176 | }
177 | bias_filler {
178 | type: "constant"
179 | value: 0
180 | }
181 | }
182 | }
183 | layer {
184 | name: "relu1_4"
185 | type: "PReLU"
186 | bottom: "conv1_4"
187 | top: "conv1_4"
188 | }
189 | layer {
190 | name: "conv1_5"
191 | type: "Convolution"
192 | bottom: "conv1_4"
193 | top: "conv1_5"
194 | param {
195 | lr_mult: 1
196 | decay_mult: 1
197 | }
198 | param {
199 | lr_mult: 0
200 | decay_mult: 0
201 | }
202 | convolution_param {
203 | num_output: 64
204 | kernel_size: 3
205 | stride: 1
206 | pad: 1
207 | weight_filler {
208 | type: "gaussian"
209 | std: 0.01
210 | }
211 | bias_filler {
212 | type: "constant"
213 | value: 0
214 | }
215 | }
216 | }
217 | layer {
218 | name: "relu1_5"
219 | type: "PReLU"
220 | bottom: "conv1_5"
221 | top: "conv1_5"
222 | }
223 | layer {
224 | name: "res1_5"
225 | type: "Eltwise"
226 | bottom: "res1_3"
227 | bottom: "conv1_5"
228 | top: "res1_5"
229 | eltwise_param {
230 | operation: 1
231 | }
232 | }
233 | layer {
234 | name: "conv1_6"
235 | type: "Convolution"
236 | bottom: "res1_5"
237 | top: "conv1_6"
238 | param {
239 | lr_mult: 1
240 | decay_mult: 1
241 | }
242 | param {
243 | lr_mult: 0
244 | decay_mult: 0
245 | }
246 | convolution_param {
247 | num_output: 64
248 | kernel_size: 3
249 | stride: 1
250 | pad: 1
251 | weight_filler {
252 | type: "gaussian"
253 | std: 0.01
254 | }
255 | bias_filler {
256 | type: "constant"
257 | value: 0
258 | }
259 | }
260 | }
261 | layer {
262 | name: "relu1_6"
263 | type: "PReLU"
264 | bottom: "conv1_6"
265 | top: "conv1_6"
266 | }
267 | layer {
268 | name: "conv1_7"
269 | type: "Convolution"
270 | bottom: "conv1_6"
271 | top: "conv1_7"
272 | param {
273 | lr_mult: 1
274 | decay_mult: 1
275 | }
276 | param {
277 | lr_mult: 0
278 | decay_mult: 0
279 | }
280 | convolution_param {
281 | num_output: 64
282 | kernel_size: 3
283 | stride: 1
284 | pad: 1
285 | weight_filler {
286 | type: "gaussian"
287 | std: 0.01
288 | }
289 | bias_filler {
290 | type: "constant"
291 | value: 0
292 | }
293 | }
294 | }
295 | layer {
296 | name: "relu1_7"
297 | type: "PReLU"
298 | bottom: "conv1_7"
299 | top: "conv1_7"
300 | }
301 | layer {
302 | name: "res1_7"
303 | type: "Eltwise"
304 | bottom: "res1_5"
305 | bottom: "conv1_7"
306 | top: "res1_7"
307 | eltwise_param {
308 | operation: 1
309 | }
310 | }
311 | ##########################################
312 | layer {
313 | name: "conv2_1"
314 | type: "Convolution"
315 | bottom: "res1_7"
316 | top: "conv2_1"
317 | param {
318 | lr_mult: 1
319 | decay_mult: 1
320 | }
321 | param {
322 | lr_mult: 2
323 | decay_mult: 0
324 | }
325 | convolution_param {
326 | num_output: 128
327 | kernel_size: 3
328 | stride: 2
329 | pad: 1
330 | weight_filler {
331 | type: "xavier"
332 | }
333 | bias_filler {
334 | type: "constant"
335 | value: 0
336 | }
337 | }
338 | }
339 | layer {
340 | name: "relu2_1"
341 | type: "PReLU"
342 | bottom: "conv2_1"
343 | top: "conv2_1"
344 | }
345 | layer {
346 | name: "conv2_2"
347 | type: "Convolution"
348 | bottom: "conv2_1"
349 | top: "conv2_2"
350 | param {
351 | lr_mult: 1
352 | decay_mult: 1
353 | }
354 | param {
355 | lr_mult: 0
356 | decay_mult: 0
357 | }
358 | convolution_param {
359 | num_output: 128
360 | kernel_size: 3
361 | stride: 1
362 | pad: 1
363 | weight_filler {
364 | type: "gaussian"
365 | std: 0.01
366 | }
367 | bias_filler {
368 | type: "constant"
369 | value: 0
370 | }
371 | }
372 | }
373 | layer {
374 | name: "relu2_2"
375 | type: "PReLU"
376 | bottom: "conv2_2"
377 | top: "conv2_2"
378 | }
379 | layer {
380 | name: "conv2_3"
381 | type: "Convolution"
382 | bottom: "conv2_2"
383 | top: "conv2_3"
384 | param {
385 | lr_mult: 1
386 | decay_mult: 1
387 | }
388 | param {
389 | lr_mult: 0
390 | decay_mult: 0
391 | }
392 | convolution_param {
393 | num_output: 128
394 | kernel_size: 3
395 | stride: 1
396 | pad: 1
397 | weight_filler {
398 | type: "gaussian"
399 | std: 0.01
400 | }
401 | bias_filler {
402 | type: "constant"
403 | value: 0
404 | }
405 | }
406 | }
407 | layer {
408 | name: "relu2_3"
409 | type: "PReLU"
410 | bottom: "conv2_3"
411 | top: "conv2_3"
412 | }
413 | layer {
414 | name: "res2_3"
415 | type: "Eltwise"
416 | bottom: "conv2_1"
417 | bottom: "conv2_3"
418 | top: "res2_3"
419 | eltwise_param {
420 | operation: 1
421 | }
422 | }
423 | layer {
424 | name: "conv2_4"
425 | type: "Convolution"
426 | bottom: "res2_3"
427 | top: "conv2_4"
428 | param {
429 | lr_mult: 1
430 | decay_mult: 1
431 | }
432 | param {
433 | lr_mult: 0
434 | decay_mult: 0
435 | }
436 | convolution_param {
437 | num_output: 128
438 | kernel_size: 3
439 | stride: 1
440 | pad: 1
441 | weight_filler {
442 | type: "gaussian"
443 | std: 0.01
444 | }
445 | bias_filler {
446 | type: "constant"
447 | value: 0
448 | }
449 | }
450 | }
451 | layer {
452 | name: "relu2_4"
453 | type: "PReLU"
454 | bottom: "conv2_4"
455 | top: "conv2_4"
456 | }
457 | layer {
458 | name: "conv2_5"
459 | type: "Convolution"
460 | bottom: "conv2_4"
461 | top: "conv2_5"
462 | param {
463 | lr_mult: 1
464 | decay_mult: 1
465 | }
466 | param {
467 | lr_mult: 0
468 | decay_mult: 0
469 | }
470 | convolution_param {
471 | num_output: 128
472 | kernel_size: 3
473 | stride: 1
474 | pad: 1
475 | weight_filler {
476 | type: "gaussian"
477 | std: 0.01
478 | }
479 | bias_filler {
480 | type: "constant"
481 | value: 0
482 | }
483 | }
484 | }
485 | layer {
486 | name: "relu2_5"
487 | type: "PReLU"
488 | bottom: "conv2_5"
489 | top: "conv2_5"
490 | }
491 | layer {
492 | name: "res2_5"
493 | type: "Eltwise"
494 | bottom: "res2_3"
495 | bottom: "conv2_5"
496 | top: "res2_5"
497 | eltwise_param {
498 | operation: 1
499 | }
500 | }
501 | layer {
502 | name: "conv2_6"
503 | type: "Convolution"
504 | bottom: "res2_5"
505 | top: "conv2_6"
506 | param {
507 | lr_mult: 1
508 | decay_mult: 1
509 | }
510 | param {
511 | lr_mult: 0
512 | decay_mult: 0
513 | }
514 | convolution_param {
515 | num_output: 128
516 | kernel_size: 3
517 | stride: 1
518 | pad: 1
519 | weight_filler {
520 | type: "gaussian"
521 | std: 0.01
522 | }
523 | bias_filler {
524 | type: "constant"
525 | value: 0
526 | }
527 | }
528 | }
529 | layer {
530 | name: "relu2_6"
531 | type: "PReLU"
532 | bottom: "conv2_6"
533 | top: "conv2_6"
534 | }
535 | layer {
536 | name: "conv2_7"
537 | type: "Convolution"
538 | bottom: "conv2_6"
539 | top: "conv2_7"
540 | param {
541 | lr_mult: 1
542 | decay_mult: 1
543 | }
544 | param {
545 | lr_mult: 0
546 | decay_mult: 0
547 | }
548 | convolution_param {
549 | num_output: 128
550 | kernel_size: 3
551 | stride: 1
552 | pad: 1
553 | weight_filler {
554 | type: "gaussian"
555 | std: 0.01
556 | }
557 | bias_filler {
558 | type: "constant"
559 | value: 0
560 | }
561 | }
562 | }
563 | layer {
564 | name: "relu2_7"
565 | type: "PReLU"
566 | bottom: "conv2_7"
567 | top: "conv2_7"
568 | }
569 | layer {
570 | name: "res2_7"
571 | type: "Eltwise"
572 | bottom: "res2_5"
573 | bottom: "conv2_7"
574 | top: "res2_7"
575 | eltwise_param {
576 | operation: 1
577 | }
578 | }
579 | layer {
580 | name: "conv2_8"
581 | type: "Convolution"
582 | bottom: "res2_7"
583 | top: "conv2_8"
584 | param {
585 | lr_mult: 1
586 | decay_mult: 1
587 | }
588 | param {
589 | lr_mult: 0
590 | decay_mult: 0
591 | }
592 | convolution_param {
593 | num_output: 128
594 | kernel_size: 3
595 | stride: 1
596 | pad: 1
597 | weight_filler {
598 | type: "gaussian"
599 | std: 0.01
600 | }
601 | bias_filler {
602 | type: "constant"
603 | value: 0
604 | }
605 | }
606 | }
607 | layer {
608 | name: "relu2_8"
609 | type: "PReLU"
610 | bottom: "conv2_8"
611 | top: "conv2_8"
612 | }
613 | layer {
614 | name: "conv2_9"
615 | type: "Convolution"
616 | bottom: "conv2_8"
617 | top: "conv2_9"
618 | param {
619 | lr_mult: 1
620 | decay_mult: 1
621 | }
622 | param {
623 | lr_mult: 0
624 | decay_mult: 0
625 | }
626 | convolution_param {
627 | num_output: 128
628 | kernel_size: 3
629 | stride: 1
630 | pad: 1
631 | weight_filler {
632 | type: "gaussian"
633 | std: 0.01
634 | }
635 | bias_filler {
636 | type: "constant"
637 | value: 0
638 | }
639 | }
640 | }
641 | layer {
642 | name: "relu2_9"
643 | type: "PReLU"
644 | bottom: "conv2_9"
645 | top: "conv2_9"
646 | }
647 | layer {
648 | name: "res2_9"
649 | type: "Eltwise"
650 | bottom: "res2_7"
651 | bottom: "conv2_9"
652 | top: "res2_9"
653 | eltwise_param {
654 | operation: 1
655 | }
656 | }
657 | layer {
658 | name: "conv2_10"
659 | type: "Convolution"
660 | bottom: "res2_9"
661 | top: "conv2_10"
662 | param {
663 | lr_mult: 1
664 | decay_mult: 1
665 | }
666 | param {
667 | lr_mult: 0
668 | decay_mult: 0
669 | }
670 | convolution_param {
671 | num_output: 128
672 | kernel_size: 3
673 | stride: 1
674 | pad: 1
675 | weight_filler {
676 | type: "gaussian"
677 | std: 0.01
678 | }
679 | bias_filler {
680 | type: "constant"
681 | value: 0
682 | }
683 | }
684 | }
685 | layer {
686 | name: "relu2_10"
687 | type: "PReLU"
688 | bottom: "conv2_10"
689 | top: "conv2_10"
690 | }
691 | layer {
692 | name: "conv2_11"
693 | type: "Convolution"
694 | bottom: "conv2_10"
695 | top: "conv2_11"
696 | param {
697 | lr_mult: 1
698 | decay_mult: 1
699 | }
700 | param {
701 | lr_mult: 0
702 | decay_mult: 0
703 | }
704 | convolution_param {
705 | num_output: 128
706 | kernel_size: 3
707 | stride: 1
708 | pad: 1
709 | weight_filler {
710 | type: "gaussian"
711 | std: 0.01
712 | }
713 | bias_filler {
714 | type: "constant"
715 | value: 0
716 | }
717 | }
718 | }
719 | layer {
720 | name: "relu2_11"
721 | type: "PReLU"
722 | bottom: "conv2_11"
723 | top: "conv2_11"
724 | }
725 | layer {
726 | name: "res2_11"
727 | type: "Eltwise"
728 | bottom: "res2_9"
729 | bottom: "conv2_11"
730 | top: "res2_11"
731 | eltwise_param {
732 | operation: 1
733 | }
734 | }
735 | layer {
736 | name: "conv2_12"
737 | type: "Convolution"
738 | bottom: "res2_11"
739 | top: "conv2_12"
740 | param {
741 | lr_mult: 1
742 | decay_mult: 1
743 | }
744 | param {
745 | lr_mult: 0
746 | decay_mult: 0
747 | }
748 | convolution_param {
749 | num_output: 128
750 | kernel_size: 3
751 | stride: 1
752 | pad: 1
753 | weight_filler {
754 | type: "gaussian"
755 | std: 0.01
756 | }
757 | bias_filler {
758 | type: "constant"
759 | value: 0
760 | }
761 | }
762 | }
763 | layer {
764 | name: "relu2_12"
765 | type: "PReLU"
766 | bottom: "conv2_12"
767 | top: "conv2_12"
768 | }
769 | layer {
770 | name: "conv2_13"
771 | type: "Convolution"
772 | bottom: "conv2_12"
773 | top: "conv2_13"
774 | param {
775 | lr_mult: 1
776 | decay_mult: 1
777 | }
778 | param {
779 | lr_mult: 0
780 | decay_mult: 0
781 | }
782 | convolution_param {
783 | num_output: 128
784 | kernel_size: 3
785 | stride: 1
786 | pad: 1
787 | weight_filler {
788 | type: "gaussian"
789 | std: 0.01
790 | }
791 | bias_filler {
792 | type: "constant"
793 | value: 0
794 | }
795 | }
796 | }
797 | layer {
798 | name: "relu2_13"
799 | type: "PReLU"
800 | bottom: "conv2_13"
801 | top: "conv2_13"
802 | }
803 | layer {
804 | name: "res2_13"
805 | type: "Eltwise"
806 | bottom: "res2_11"
807 | bottom: "conv2_13"
808 | top: "res2_13"
809 | eltwise_param {
810 | operation: 1
811 | }
812 | }
813 | layer {
814 | name: "conv2_14"
815 | type: "Convolution"
816 | bottom: "res2_13"
817 | top: "conv2_14"
818 | param {
819 | lr_mult: 1
820 | decay_mult: 1
821 | }
822 | param {
823 | lr_mult: 0
824 | decay_mult: 0
825 | }
826 | convolution_param {
827 | num_output: 128
828 | kernel_size: 3
829 | stride: 1
830 | pad: 1
831 | weight_filler {
832 | type: "gaussian"
833 | std: 0.01
834 | }
835 | bias_filler {
836 | type: "constant"
837 | value: 0
838 | }
839 | }
840 | }
841 | layer {
842 | name: "relu2_14"
843 | type: "PReLU"
844 | bottom: "conv2_14"
845 | top: "conv2_14"
846 | }
847 | layer {
848 | name: "conv2_15"
849 | type: "Convolution"
850 | bottom: "conv2_14"
851 | top: "conv2_15"
852 | param {
853 | lr_mult: 1
854 | decay_mult: 1
855 | }
856 | param {
857 | lr_mult: 0
858 | decay_mult: 0
859 | }
860 | convolution_param {
861 | num_output: 128
862 | kernel_size: 3
863 | stride: 1
864 | pad: 1
865 | weight_filler {
866 | type: "gaussian"
867 | std: 0.01
868 | }
869 | bias_filler {
870 | type: "constant"
871 | value: 0
872 | }
873 | }
874 | }
875 | layer {
876 | name: "relu2_15"
877 | type: "PReLU"
878 | bottom: "conv2_15"
879 | top: "conv2_15"
880 | }
881 | layer {
882 | name: "res2_15"
883 | type: "Eltwise"
884 | bottom: "res2_13"
885 | bottom: "conv2_15"
886 | top: "res2_15"
887 | eltwise_param {
888 | operation: 1
889 | }
890 | }
891 | layer {
892 | name: "conv2_16"
893 | type: "Convolution"
894 | bottom: "res2_15"
895 | top: "conv2_16"
896 | param {
897 | lr_mult: 1
898 | decay_mult: 1
899 | }
900 | param {
901 | lr_mult: 0
902 | decay_mult: 0
903 | }
904 | convolution_param {
905 | num_output: 128
906 | kernel_size: 3
907 | stride: 1
908 | pad: 1
909 | weight_filler {
910 | type: "gaussian"
911 | std: 0.01
912 | }
913 | bias_filler {
914 | type: "constant"
915 | value: 0
916 | }
917 | }
918 | }
919 | layer {
920 | name: "relu2_16"
921 | type: "PReLU"
922 | bottom: "conv2_16"
923 | top: "conv2_16"
924 | }
925 | layer {
926 | name: "conv2_17"
927 | type: "Convolution"
928 | bottom: "conv2_16"
929 | top: "conv2_17"
930 | param {
931 | lr_mult: 1
932 | decay_mult: 1
933 | }
934 | param {
935 | lr_mult: 0
936 | decay_mult: 0
937 | }
938 | convolution_param {
939 | num_output: 128
940 | kernel_size: 3
941 | stride: 1
942 | pad: 1
943 | weight_filler {
944 | type: "gaussian"
945 | std: 0.01
946 | }
947 | bias_filler {
948 | type: "constant"
949 | value: 0
950 | }
951 | }
952 | }
953 | layer {
954 | name: "relu2_17"
955 | type: "PReLU"
956 | bottom: "conv2_17"
957 | top: "conv2_17"
958 | }
959 | layer {
960 | name: "res2_17"
961 | type: "Eltwise"
962 | bottom: "res2_15"
963 | bottom: "conv2_17"
964 | top: "res2_17"
965 | eltwise_param {
966 | operation: 1
967 | }
968 | }
969 | ##########################################
970 | layer {
971 | name: "conv3_1"
972 | type: "Convolution"
973 | bottom: "res2_17"
974 | top: "conv3_1"
975 | param {
976 | lr_mult: 1
977 | decay_mult: 1
978 | }
979 | param {
980 | lr_mult: 2
981 | decay_mult: 0
982 | }
983 | convolution_param {
984 | num_output: 256
985 | kernel_size: 3
986 | stride: 2
987 | pad: 1
988 | weight_filler {
989 | type: "xavier"
990 | }
991 | bias_filler {
992 | type: "constant"
993 | value: 0
994 | }
995 | }
996 | }
997 | layer {
998 | name: "relu3_1"
999 | type: "PReLU"
1000 | bottom: "conv3_1"
1001 | top: "conv3_1"
1002 | }
1003 | layer {
1004 | name: "conv3_2"
1005 | type: "Convolution"
1006 | bottom: "conv3_1"
1007 | top: "conv3_2"
1008 | param {
1009 | lr_mult: 1
1010 | decay_mult: 1
1011 | }
1012 | param {
1013 | lr_mult: 0
1014 | decay_mult: 0
1015 | }
1016 | convolution_param {
1017 | num_output: 256
1018 | kernel_size: 3
1019 | stride: 1
1020 | pad: 1
1021 | weight_filler {
1022 | type: "gaussian"
1023 | std: 0.01
1024 | }
1025 | bias_filler {
1026 | type: "constant"
1027 | value: 0
1028 | }
1029 | }
1030 | }
1031 | layer {
1032 | name: "relu3_2"
1033 | type: "PReLU"
1034 | bottom: "conv3_2"
1035 | top: "conv3_2"
1036 | }
1037 | layer {
1038 | name: "conv3_3"
1039 | type: "Convolution"
1040 | bottom: "conv3_2"
1041 | top: "conv3_3"
1042 | param {
1043 | lr_mult: 1
1044 | decay_mult: 1
1045 | }
1046 | param {
1047 | lr_mult: 0
1048 | decay_mult: 0
1049 | }
1050 | convolution_param {
1051 | num_output: 256
1052 | kernel_size: 3
1053 | stride: 1
1054 | pad: 1
1055 | weight_filler {
1056 | type: "gaussian"
1057 | std: 0.01
1058 | }
1059 | bias_filler {
1060 | type: "constant"
1061 | value: 0
1062 | }
1063 | }
1064 | }
1065 | layer {
1066 | name: "relu3_3"
1067 | type: "PReLU"
1068 | bottom: "conv3_3"
1069 | top: "conv3_3"
1070 | }
1071 | layer {
1072 | name: "res3_3"
1073 | type: "Eltwise"
1074 | bottom: "conv3_1"
1075 | bottom: "conv3_3"
1076 | top: "res3_3"
1077 | eltwise_param {
1078 | operation: 1
1079 | }
1080 | }
1081 | layer {
1082 | name: "conv3_4"
1083 | type: "Convolution"
1084 | bottom: "res3_3"
1085 | top: "conv3_4"
1086 | param {
1087 | lr_mult: 1
1088 | decay_mult: 1
1089 | }
1090 | param {
1091 | lr_mult: 0
1092 | decay_mult: 0
1093 | }
1094 | convolution_param {
1095 | num_output: 256
1096 | kernel_size: 3
1097 | stride: 1
1098 | pad: 1
1099 | weight_filler {
1100 | type: "gaussian"
1101 | std: 0.01
1102 | }
1103 | bias_filler {
1104 | type: "constant"
1105 | value: 0
1106 | }
1107 | }
1108 | }
1109 | layer {
1110 | name: "relu3_4"
1111 | type: "PReLU"
1112 | bottom: "conv3_4"
1113 | top: "conv3_4"
1114 | }
1115 | layer {
1116 | name: "conv3_5"
1117 | type: "Convolution"
1118 | bottom: "conv3_4"
1119 | top: "conv3_5"
1120 | param {
1121 | lr_mult: 1
1122 | decay_mult: 1
1123 | }
1124 | param {
1125 | lr_mult: 0
1126 | decay_mult: 0
1127 | }
1128 | convolution_param {
1129 | num_output: 256
1130 | kernel_size: 3
1131 | stride: 1
1132 | pad: 1
1133 | weight_filler {
1134 | type: "gaussian"
1135 | std: 0.01
1136 | }
1137 | bias_filler {
1138 | type: "constant"
1139 | value: 0
1140 | }
1141 | }
1142 | }
1143 | layer {
1144 | name: "relu3_5"
1145 | type: "PReLU"
1146 | bottom: "conv3_5"
1147 | top: "conv3_5"
1148 | }
1149 | layer {
1150 | name: "res3_5"
1151 | type: "Eltwise"
1152 | bottom: "res3_3"
1153 | bottom: "conv3_5"
1154 | top: "res3_5"
1155 | eltwise_param {
1156 | operation: 1
1157 | }
1158 | }
1159 | layer {
1160 | name: "conv3_6"
1161 | type: "Convolution"
1162 | bottom: "res3_5"
1163 | top: "conv3_6"
1164 | param {
1165 | lr_mult: 1
1166 | decay_mult: 1
1167 | }
1168 | param {
1169 | lr_mult: 0
1170 | decay_mult: 0
1171 | }
1172 | convolution_param {
1173 | num_output: 256
1174 | kernel_size: 3
1175 | stride: 1
1176 | pad: 1
1177 | weight_filler {
1178 | type: "gaussian"
1179 | std: 0.01
1180 | }
1181 | bias_filler {
1182 | type: "constant"
1183 | value: 0
1184 | }
1185 | }
1186 | }
1187 | layer {
1188 | name: "relu3_6"
1189 | type: "PReLU"
1190 | bottom: "conv3_6"
1191 | top: "conv3_6"
1192 | }
1193 | layer {
1194 | name: "conv3_7"
1195 | type: "Convolution"
1196 | bottom: "conv3_6"
1197 | top: "conv3_7"
1198 | param {
1199 | lr_mult: 1
1200 | decay_mult: 1
1201 | }
1202 | param {
1203 | lr_mult: 0
1204 | decay_mult: 0
1205 | }
1206 | convolution_param {
1207 | num_output: 256
1208 | kernel_size: 3
1209 | stride: 1
1210 | pad: 1
1211 | weight_filler {
1212 | type: "gaussian"
1213 | std: 0.01
1214 | }
1215 | bias_filler {
1216 | type: "constant"
1217 | value: 0
1218 | }
1219 | }
1220 | }
1221 | layer {
1222 | name: "relu3_7"
1223 | type: "PReLU"
1224 | bottom: "conv3_7"
1225 | top: "conv3_7"
1226 | }
1227 | layer {
1228 | name: "res3_7"
1229 | type: "Eltwise"
1230 | bottom: "res3_5"
1231 | bottom: "conv3_7"
1232 | top: "res3_7"
1233 | eltwise_param {
1234 | operation: 1
1235 | }
1236 | }
1237 | layer {
1238 | name: "conv3_8"
1239 | type: "Convolution"
1240 | bottom: "res3_7"
1241 | top: "conv3_8"
1242 | param {
1243 | lr_mult: 1
1244 | decay_mult: 1
1245 | }
1246 | param {
1247 | lr_mult: 0
1248 | decay_mult: 0
1249 | }
1250 | convolution_param {
1251 | num_output: 256
1252 | kernel_size: 3
1253 | stride: 1
1254 | pad: 1
1255 | weight_filler {
1256 | type: "gaussian"
1257 | std: 0.01
1258 | }
1259 | bias_filler {
1260 | type: "constant"
1261 | value: 0
1262 | }
1263 | }
1264 | }
1265 | layer {
1266 | name: "relu3_8"
1267 | type: "PReLU"
1268 | bottom: "conv3_8"
1269 | top: "conv3_8"
1270 | }
1271 | layer {
1272 | name: "conv3_9"
1273 | type: "Convolution"
1274 | bottom: "conv3_8"
1275 | top: "conv3_9"
1276 | param {
1277 | lr_mult: 1
1278 | decay_mult: 1
1279 | }
1280 | param {
1281 | lr_mult: 0
1282 | decay_mult: 0
1283 | }
1284 | convolution_param {
1285 | num_output: 256
1286 | kernel_size: 3
1287 | stride: 1
1288 | pad: 1
1289 | weight_filler {
1290 | type: "gaussian"
1291 | std: 0.01
1292 | }
1293 | bias_filler {
1294 | type: "constant"
1295 | value: 0
1296 | }
1297 | }
1298 | }
1299 | layer {
1300 | name: "relu3_9"
1301 | type: "PReLU"
1302 | bottom: "conv3_9"
1303 | top: "conv3_9"
1304 | }
1305 | layer {
1306 | name: "res3_9"
1307 | type: "Eltwise"
1308 | bottom: "res3_7"
1309 | bottom: "conv3_9"
1310 | top: "res3_9"
1311 | eltwise_param {
1312 | operation: 1
1313 | }
1314 | }
1315 | layer {
1316 | name: "conv3_10"
1317 | type: "Convolution"
1318 | bottom: "res3_9"
1319 | top: "conv3_10"
1320 | param {
1321 | lr_mult: 1
1322 | decay_mult: 1
1323 | }
1324 | param {
1325 | lr_mult: 0
1326 | decay_mult: 0
1327 | }
1328 | convolution_param {
1329 | num_output: 256
1330 | kernel_size: 3
1331 | stride: 1
1332 | pad: 1
1333 | weight_filler {
1334 | type: "gaussian"
1335 | std: 0.01
1336 | }
1337 | bias_filler {
1338 | type: "constant"
1339 | value: 0
1340 | }
1341 | }
1342 | }
1343 | layer {
1344 | name: "relu3_10"
1345 | type: "PReLU"
1346 | bottom: "conv3_10"
1347 | top: "conv3_10"
1348 | }
1349 | layer {
1350 | name: "conv3_11"
1351 | type: "Convolution"
1352 | bottom: "conv3_10"
1353 | top: "conv3_11"
1354 | param {
1355 | lr_mult: 1
1356 | decay_mult: 1
1357 | }
1358 | param {
1359 | lr_mult: 0
1360 | decay_mult: 0
1361 | }
1362 | convolution_param {
1363 | num_output: 256
1364 | kernel_size: 3
1365 | stride: 1
1366 | pad: 1
1367 | weight_filler {
1368 | type: "gaussian"
1369 | std: 0.01
1370 | }
1371 | bias_filler {
1372 | type: "constant"
1373 | value: 0
1374 | }
1375 | }
1376 | }
1377 | layer {
1378 | name: "relu3_11"
1379 | type: "PReLU"
1380 | bottom: "conv3_11"
1381 | top: "conv3_11"
1382 | }
1383 | layer {
1384 | name: "res3_11"
1385 | type: "Eltwise"
1386 | bottom: "res3_9"
1387 | bottom: "conv3_11"
1388 | top: "res3_11"
1389 | eltwise_param {
1390 | operation: 1
1391 | }
1392 | }
1393 | layer {
1394 | name: "conv3_12"
1395 | type: "Convolution"
1396 | bottom: "res3_11"
1397 | top: "conv3_12"
1398 | param {
1399 | lr_mult: 1
1400 | decay_mult: 1
1401 | }
1402 | param {
1403 | lr_mult: 0
1404 | decay_mult: 0
1405 | }
1406 | convolution_param {
1407 | num_output: 256
1408 | kernel_size: 3
1409 | stride: 1
1410 | pad: 1
1411 | weight_filler {
1412 | type: "gaussian"
1413 | std: 0.01
1414 | }
1415 | bias_filler {
1416 | type: "constant"
1417 | value: 0
1418 | }
1419 | }
1420 | }
1421 | layer {
1422 | name: "relu3_12"
1423 | type: "PReLU"
1424 | bottom: "conv3_12"
1425 | top: "conv3_12"
1426 | }
1427 | layer {
1428 | name: "conv3_13"
1429 | type: "Convolution"
1430 | bottom: "conv3_12"
1431 | top: "conv3_13"
1432 | param {
1433 | lr_mult: 1
1434 | decay_mult: 1
1435 | }
1436 | param {
1437 | lr_mult: 0
1438 | decay_mult: 0
1439 | }
1440 | convolution_param {
1441 | num_output: 256
1442 | kernel_size: 3
1443 | stride: 1
1444 | pad: 1
1445 | weight_filler {
1446 | type: "gaussian"
1447 | std: 0.01
1448 | }
1449 | bias_filler {
1450 | type: "constant"
1451 | value: 0
1452 | }
1453 | }
1454 | }
1455 | layer {
1456 | name: "relu3_13"
1457 | type: "PReLU"
1458 | bottom: "conv3_13"
1459 | top: "conv3_13"
1460 | }
1461 | layer {
1462 | name: "res3_13"
1463 | type: "Eltwise"
1464 | bottom: "res3_11"
1465 | bottom: "conv3_13"
1466 | top: "res3_13"
1467 | eltwise_param {
1468 | operation: 1
1469 | }
1470 | }
1471 | layer {
1472 | name: "conv3_14"
1473 | type: "Convolution"
1474 | bottom: "res3_13"
1475 | top: "conv3_14"
1476 | param {
1477 | lr_mult: 1
1478 | decay_mult: 1
1479 | }
1480 | param {
1481 | lr_mult: 0
1482 | decay_mult: 0
1483 | }
1484 | convolution_param {
1485 | num_output: 256
1486 | kernel_size: 3
1487 | stride: 1
1488 | pad: 1
1489 | weight_filler {
1490 | type: "gaussian"
1491 | std: 0.01
1492 | }
1493 | bias_filler {
1494 | type: "constant"
1495 | value: 0
1496 | }
1497 | }
1498 | }
1499 | layer {
1500 | name: "relu3_14"
1501 | type: "PReLU"
1502 | bottom: "conv3_14"
1503 | top: "conv3_14"
1504 | }
1505 | layer {
1506 | name: "conv3_15"
1507 | type: "Convolution"
1508 | bottom: "conv3_14"
1509 | top: "conv3_15"
1510 | param {
1511 | lr_mult: 1
1512 | decay_mult: 1
1513 | }
1514 | param {
1515 | lr_mult: 0
1516 | decay_mult: 0
1517 | }
1518 | convolution_param {
1519 | num_output: 256
1520 | kernel_size: 3
1521 | stride: 1
1522 | pad: 1
1523 | weight_filler {
1524 | type: "gaussian"
1525 | std: 0.01
1526 | }
1527 | bias_filler {
1528 | type: "constant"
1529 | value: 0
1530 | }
1531 | }
1532 | }
1533 | layer {
1534 | name: "relu3_15"
1535 | type: "PReLU"
1536 | bottom: "conv3_15"
1537 | top: "conv3_15"
1538 | }
1539 | layer {
1540 | name: "res3_15"
1541 | type: "Eltwise"
1542 | bottom: "res3_13"
1543 | bottom: "conv3_15"
1544 | top: "res3_15"
1545 | eltwise_param {
1546 | operation: 1
1547 | }
1548 | }
1549 | layer {
1550 | name: "conv3_16"
1551 | type: "Convolution"
1552 | bottom: "res3_15"
1553 | top: "conv3_16"
1554 | param {
1555 | lr_mult: 1
1556 | decay_mult: 1
1557 | }
1558 | param {
1559 | lr_mult: 0
1560 | decay_mult: 0
1561 | }
1562 | convolution_param {
1563 | num_output: 256
1564 | kernel_size: 3
1565 | stride: 1
1566 | pad: 1
1567 | weight_filler {
1568 | type: "gaussian"
1569 | std: 0.01
1570 | }
1571 | bias_filler {
1572 | type: "constant"
1573 | value: 0
1574 | }
1575 | }
1576 | }
1577 | layer {
1578 | name: "relu3_16"
1579 | type: "PReLU"
1580 | bottom: "conv3_16"
1581 | top: "conv3_16"
1582 | }
1583 | layer {
1584 | name: "conv3_17"
1585 | type: "Convolution"
1586 | bottom: "conv3_16"
1587 | top: "conv3_17"
1588 | param {
1589 | lr_mult: 1
1590 | decay_mult: 1
1591 | }
1592 | param {
1593 | lr_mult: 0
1594 | decay_mult: 0
1595 | }
1596 | convolution_param {
1597 | num_output: 256
1598 | kernel_size: 3
1599 | stride: 1
1600 | pad: 1
1601 | weight_filler {
1602 | type: "gaussian"
1603 | std: 0.01
1604 | }
1605 | bias_filler {
1606 | type: "constant"
1607 | value: 0
1608 | }
1609 | }
1610 | }
1611 | layer {
1612 | name: "relu3_17"
1613 | type: "PReLU"
1614 | bottom: "conv3_17"
1615 | top: "conv3_17"
1616 | }
1617 | layer {
1618 | name: "res3_17"
1619 | type: "Eltwise"
1620 | bottom: "res3_15"
1621 | bottom: "conv3_17"
1622 | top: "res3_17"
1623 | eltwise_param {
1624 | operation: 1
1625 | }
1626 | }
1627 | layer {
1628 | name: "conv3_18"
1629 | type: "Convolution"
1630 | bottom: "res3_17"
1631 | top: "conv3_18"
1632 | param {
1633 | lr_mult: 1
1634 | decay_mult: 1
1635 | }
1636 | param {
1637 | lr_mult: 0
1638 | decay_mult: 0
1639 | }
1640 | convolution_param {
1641 | num_output: 256
1642 | kernel_size: 3
1643 | stride: 1
1644 | pad: 1
1645 | weight_filler {
1646 | type: "gaussian"
1647 | std: 0.01
1648 | }
1649 | bias_filler {
1650 | type: "constant"
1651 | value: 0
1652 | }
1653 | }
1654 | }
1655 | layer {
1656 | name: "relu3_18"
1657 | type: "PReLU"
1658 | bottom: "conv3_18"
1659 | top: "conv3_18"
1660 | }
1661 | layer {
1662 | name: "conv3_19"
1663 | type: "Convolution"
1664 | bottom: "conv3_18"
1665 | top: "conv3_19"
1666 | param {
1667 | lr_mult: 1
1668 | decay_mult: 1
1669 | }
1670 | param {
1671 | lr_mult: 0
1672 | decay_mult: 0
1673 | }
1674 | convolution_param {
1675 | num_output: 256
1676 | kernel_size: 3
1677 | stride: 1
1678 | pad: 1
1679 | weight_filler {
1680 | type: "gaussian"
1681 | std: 0.01
1682 | }
1683 | bias_filler {
1684 | type: "constant"
1685 | value: 0
1686 | }
1687 | }
1688 | }
1689 | layer {
1690 | name: "relu3_19"
1691 | type: "PReLU"
1692 | bottom: "conv3_19"
1693 | top: "conv3_19"
1694 | }
1695 | layer {
1696 | name: "res3_19"
1697 | type: "Eltwise"
1698 | bottom: "res3_17"
1699 | bottom: "conv3_19"
1700 | top: "res3_19"
1701 | eltwise_param {
1702 | operation: 1
1703 | }
1704 | }
1705 | layer {
1706 | name: "conv3_20"
1707 | type: "Convolution"
1708 | bottom: "res3_19"
1709 | top: "conv3_20"
1710 | param {
1711 | lr_mult: 1
1712 | decay_mult: 1
1713 | }
1714 | param {
1715 | lr_mult: 0
1716 | decay_mult: 0
1717 | }
1718 | convolution_param {
1719 | num_output: 256
1720 | kernel_size: 3
1721 | stride: 1
1722 | pad: 1
1723 | weight_filler {
1724 | type: "gaussian"
1725 | std: 0.01
1726 | }
1727 | bias_filler {
1728 | type: "constant"
1729 | value: 0
1730 | }
1731 | }
1732 | }
1733 | layer {
1734 | name: "relu3_20"
1735 | type: "PReLU"
1736 | bottom: "conv3_20"
1737 | top: "conv3_20"
1738 | }
1739 | layer {
1740 | name: "conv3_21"
1741 | type: "Convolution"
1742 | bottom: "conv3_20"
1743 | top: "conv3_21"
1744 | param {
1745 | lr_mult: 1
1746 | decay_mult: 1
1747 | }
1748 | param {
1749 | lr_mult: 0
1750 | decay_mult: 0
1751 | }
1752 | convolution_param {
1753 | num_output: 256
1754 | kernel_size: 3
1755 | stride: 1
1756 | pad: 1
1757 | weight_filler {
1758 | type: "gaussian"
1759 | std: 0.01
1760 | }
1761 | bias_filler {
1762 | type: "constant"
1763 | value: 0
1764 | }
1765 | }
1766 | }
1767 | layer {
1768 | name: "relu3_21"
1769 | type: "PReLU"
1770 | bottom: "conv3_21"
1771 | top: "conv3_21"
1772 | }
1773 | layer {
1774 | name: "res3_21"
1775 | type: "Eltwise"
1776 | bottom: "res3_19"
1777 | bottom: "conv3_21"
1778 | top: "res3_21"
1779 | eltwise_param {
1780 | operation: 1
1781 | }
1782 | }
1783 | layer {
1784 | name: "conv3_22"
1785 | type: "Convolution"
1786 | bottom: "res3_21"
1787 | top: "conv3_22"
1788 | param {
1789 | lr_mult: 1
1790 | decay_mult: 1
1791 | }
1792 | param {
1793 | lr_mult: 0
1794 | decay_mult: 0
1795 | }
1796 | convolution_param {
1797 | num_output: 256
1798 | kernel_size: 3
1799 | stride: 1
1800 | pad: 1
1801 | weight_filler {
1802 | type: "gaussian"
1803 | std: 0.01
1804 | }
1805 | bias_filler {
1806 | type: "constant"
1807 | value: 0
1808 | }
1809 | }
1810 | }
1811 | layer {
1812 | name: "relu3_22"
1813 | type: "PReLU"
1814 | bottom: "conv3_22"
1815 | top: "conv3_22"
1816 | }
1817 | layer {
1818 | name: "conv3_23"
1819 | type: "Convolution"
1820 | bottom: "conv3_22"
1821 | top: "conv3_23"
1822 | param {
1823 | lr_mult: 1
1824 | decay_mult: 1
1825 | }
1826 | param {
1827 | lr_mult: 0
1828 | decay_mult: 0
1829 | }
1830 | convolution_param {
1831 | num_output: 256
1832 | kernel_size: 3
1833 | stride: 1
1834 | pad: 1
1835 | weight_filler {
1836 | type: "gaussian"
1837 | std: 0.01
1838 | }
1839 | bias_filler {
1840 | type: "constant"
1841 | value: 0
1842 | }
1843 | }
1844 | }
1845 | layer {
1846 | name: "relu3_23"
1847 | type: "PReLU"
1848 | bottom: "conv3_23"
1849 | top: "conv3_23"
1850 | }
1851 | layer {
1852 | name: "res3_23"
1853 | type: "Eltwise"
1854 | bottom: "res3_21"
1855 | bottom: "conv3_23"
1856 | top: "res3_23"
1857 | eltwise_param {
1858 | operation: 1
1859 | }
1860 | }
1861 | layer {
1862 | name: "conv3_24"
1863 | type: "Convolution"
1864 | bottom: "res3_23"
1865 | top: "conv3_24"
1866 | param {
1867 | lr_mult: 1
1868 | decay_mult: 1
1869 | }
1870 | param {
1871 | lr_mult: 0
1872 | decay_mult: 0
1873 | }
1874 | convolution_param {
1875 | num_output: 256
1876 | kernel_size: 3
1877 | stride: 1
1878 | pad: 1
1879 | weight_filler {
1880 | type: "gaussian"
1881 | std: 0.01
1882 | }
1883 | bias_filler {
1884 | type: "constant"
1885 | value: 0
1886 | }
1887 | }
1888 | }
1889 | layer {
1890 | name: "relu3_24"
1891 | type: "PReLU"
1892 | bottom: "conv3_24"
1893 | top: "conv3_24"
1894 | }
1895 | layer {
1896 | name: "conv3_25"
1897 | type: "Convolution"
1898 | bottom: "conv3_24"
1899 | top: "conv3_25"
1900 | param {
1901 | lr_mult: 1
1902 | decay_mult: 1
1903 | }
1904 | param {
1905 | lr_mult: 0
1906 | decay_mult: 0
1907 | }
1908 | convolution_param {
1909 | num_output: 256
1910 | kernel_size: 3
1911 | stride: 1
1912 | pad: 1
1913 | weight_filler {
1914 | type: "gaussian"
1915 | std: 0.01
1916 | }
1917 | bias_filler {
1918 | type: "constant"
1919 | value: 0
1920 | }
1921 | }
1922 | }
1923 | layer {
1924 | name: "relu3_25"
1925 | type: "PReLU"
1926 | bottom: "conv3_25"
1927 | top: "conv3_25"
1928 | }
1929 | layer {
1930 | name: "res3_25"
1931 | type: "Eltwise"
1932 | bottom: "res3_23"
1933 | bottom: "conv3_25"
1934 | top: "res3_25"
1935 | eltwise_param {
1936 | operation: 1
1937 | }
1938 | }
1939 | layer {
1940 | name: "conv3_26"
1941 | type: "Convolution"
1942 | bottom: "res3_25"
1943 | top: "conv3_26"
1944 | param {
1945 | lr_mult: 1
1946 | decay_mult: 1
1947 | }
1948 | param {
1949 | lr_mult: 0
1950 | decay_mult: 0
1951 | }
1952 | convolution_param {
1953 | num_output: 256
1954 | kernel_size: 3
1955 | stride: 1
1956 | pad: 1
1957 | weight_filler {
1958 | type: "gaussian"
1959 | std: 0.01
1960 | }
1961 | bias_filler {
1962 | type: "constant"
1963 | value: 0
1964 | }
1965 | }
1966 | }
1967 | layer {
1968 | name: "relu3_26"
1969 | type: "PReLU"
1970 | bottom: "conv3_26"
1971 | top: "conv3_26"
1972 | }
1973 | layer {
1974 | name: "conv3_27"
1975 | type: "Convolution"
1976 | bottom: "conv3_26"
1977 | top: "conv3_27"
1978 | param {
1979 | lr_mult: 1
1980 | decay_mult: 1
1981 | }
1982 | param {
1983 | lr_mult: 0
1984 | decay_mult: 0
1985 | }
1986 | convolution_param {
1987 | num_output: 256
1988 | kernel_size: 3
1989 | stride: 1
1990 | pad: 1
1991 | weight_filler {
1992 | type: "gaussian"
1993 | std: 0.01
1994 | }
1995 | bias_filler {
1996 | type: "constant"
1997 | value: 0
1998 | }
1999 | }
2000 | }
2001 | layer {
2002 | name: "relu3_27"
2003 | type: "PReLU"
2004 | bottom: "conv3_27"
2005 | top: "conv3_27"
2006 | }
2007 | layer {
2008 | name: "res3_27"
2009 | type: "Eltwise"
2010 | bottom: "res3_25"
2011 | bottom: "conv3_27"
2012 | top: "res3_27"
2013 | eltwise_param {
2014 | operation: 1
2015 | }
2016 | }
2017 | layer {
2018 | name: "conv3_28"
2019 | type: "Convolution"
2020 | bottom: "res3_27"
2021 | top: "conv3_28"
2022 | param {
2023 | lr_mult: 1
2024 | decay_mult: 1
2025 | }
2026 | param {
2027 | lr_mult: 0
2028 | decay_mult: 0
2029 | }
2030 | convolution_param {
2031 | num_output: 256
2032 | kernel_size: 3
2033 | stride: 1
2034 | pad: 1
2035 | weight_filler {
2036 | type: "gaussian"
2037 | std: 0.01
2038 | }
2039 | bias_filler {
2040 | type: "constant"
2041 | value: 0
2042 | }
2043 | }
2044 | }
2045 | layer {
2046 | name: "relu3_28"
2047 | type: "PReLU"
2048 | bottom: "conv3_28"
2049 | top: "conv3_28"
2050 | }
2051 | layer {
2052 | name: "conv3_29"
2053 | type: "Convolution"
2054 | bottom: "conv3_28"
2055 | top: "conv3_29"
2056 | param {
2057 | lr_mult: 1
2058 | decay_mult: 1
2059 | }
2060 | param {
2061 | lr_mult: 0
2062 | decay_mult: 0
2063 | }
2064 | convolution_param {
2065 | num_output: 256
2066 | kernel_size: 3
2067 | stride: 1
2068 | pad: 1
2069 | weight_filler {
2070 | type: "gaussian"
2071 | std: 0.01
2072 | }
2073 | bias_filler {
2074 | type: "constant"
2075 | value: 0
2076 | }
2077 | }
2078 | }
2079 | layer {
2080 | name: "relu3_29"
2081 | type: "PReLU"
2082 | bottom: "conv3_29"
2083 | top: "conv3_29"
2084 | }
2085 | layer {
2086 | name: "res3_29"
2087 | type: "Eltwise"
2088 | bottom: "res3_27"
2089 | bottom: "conv3_29"
2090 | top: "res3_29"
2091 | eltwise_param {
2092 | operation: 1
2093 | }
2094 | }
2095 | layer {
2096 | name: "conv3_30"
2097 | type: "Convolution"
2098 | bottom: "res3_29"
2099 | top: "conv3_30"
2100 | param {
2101 | lr_mult: 1
2102 | decay_mult: 1
2103 | }
2104 | param {
2105 | lr_mult: 0
2106 | decay_mult: 0
2107 | }
2108 | convolution_param {
2109 | num_output: 256
2110 | kernel_size: 3
2111 | stride: 1
2112 | pad: 1
2113 | weight_filler {
2114 | type: "gaussian"
2115 | std: 0.01
2116 | }
2117 | bias_filler {
2118 | type: "constant"
2119 | value: 0
2120 | }
2121 | }
2122 | }
2123 | layer {
2124 | name: "relu3_30"
2125 | type: "PReLU"
2126 | bottom: "conv3_30"
2127 | top: "conv3_30"
2128 | }
2129 | layer {
2130 | name: "conv3_31"
2131 | type: "Convolution"
2132 | bottom: "conv3_30"
2133 | top: "conv3_31"
2134 | param {
2135 | lr_mult: 1
2136 | decay_mult: 1
2137 | }
2138 | param {
2139 | lr_mult: 0
2140 | decay_mult: 0
2141 | }
2142 | convolution_param {
2143 | num_output: 256
2144 | kernel_size: 3
2145 | stride: 1
2146 | pad: 1
2147 | weight_filler {
2148 | type: "gaussian"
2149 | std: 0.01
2150 | }
2151 | bias_filler {
2152 | type: "constant"
2153 | value: 0
2154 | }
2155 | }
2156 | }
2157 | layer {
2158 | name: "relu3_31"
2159 | type: "PReLU"
2160 | bottom: "conv3_31"
2161 | top: "conv3_31"
2162 | }
2163 | layer {
2164 | name: "res3_31"
2165 | type: "Eltwise"
2166 | bottom: "res3_29"
2167 | bottom: "conv3_31"
2168 | top: "res3_31"
2169 | eltwise_param {
2170 | operation: 1
2171 | }
2172 | }
2173 | layer {
2174 | name: "conv3_32"
2175 | type: "Convolution"
2176 | bottom: "res3_31"
2177 | top: "conv3_32"
2178 | param {
2179 | lr_mult: 1
2180 | decay_mult: 1
2181 | }
2182 | param {
2183 | lr_mult: 0
2184 | decay_mult: 0
2185 | }
2186 | convolution_param {
2187 | num_output: 256
2188 | kernel_size: 3
2189 | stride: 1
2190 | pad: 1
2191 | weight_filler {
2192 | type: "gaussian"
2193 | std: 0.01
2194 | }
2195 | bias_filler {
2196 | type: "constant"
2197 | value: 0
2198 | }
2199 | }
2200 | }
2201 | layer {
2202 | name: "relu3_32"
2203 | type: "PReLU"
2204 | bottom: "conv3_32"
2205 | top: "conv3_32"
2206 | }
2207 | layer {
2208 | name: "conv3_33"
2209 | type: "Convolution"
2210 | bottom: "conv3_32"
2211 | top: "conv3_33"
2212 | param {
2213 | lr_mult: 1
2214 | decay_mult: 1
2215 | }
2216 | param {
2217 | lr_mult: 0
2218 | decay_mult: 0
2219 | }
2220 | convolution_param {
2221 | num_output: 256
2222 | kernel_size: 3
2223 | stride: 1
2224 | pad: 1
2225 | weight_filler {
2226 | type: "gaussian"
2227 | std: 0.01
2228 | }
2229 | bias_filler {
2230 | type: "constant"
2231 | value: 0
2232 | }
2233 | }
2234 | }
2235 | layer {
2236 | name: "relu3_33"
2237 | type: "PReLU"
2238 | bottom: "conv3_33"
2239 | top: "conv3_33"
2240 | }
2241 | layer {
2242 | name: "res3_33"
2243 | type: "Eltwise"
2244 | bottom: "res3_31"
2245 | bottom: "conv3_33"
2246 | top: "res3_33"
2247 | eltwise_param {
2248 | operation: 1
2249 | }
2250 | }
2251 | ##########################################
2252 | layer {
2253 | name: "conv4_1"
2254 | type: "Convolution"
2255 | bottom: "res3_33"
2256 | top: "conv4_1"
2257 | param {
2258 | lr_mult: 1
2259 | decay_mult: 1
2260 | }
2261 | param {
2262 | lr_mult: 2
2263 | decay_mult: 0
2264 | }
2265 | convolution_param {
2266 | num_output: 512
2267 | kernel_size: 3
2268 | stride: 2
2269 | pad: 1
2270 | weight_filler {
2271 | type: "xavier"
2272 | }
2273 | bias_filler {
2274 | type: "constant"
2275 | value: 0
2276 | }
2277 | }
2278 | }
2279 | layer {
2280 | name: "relu4_1"
2281 | type: "PReLU"
2282 | bottom: "conv4_1"
2283 | top: "conv4_1"
2284 | }
2285 | layer {
2286 | name: "conv4_2"
2287 | type: "Convolution"
2288 | bottom: "conv4_1"
2289 | top: "conv4_2"
2290 | param {
2291 | lr_mult: 1
2292 | decay_mult: 1
2293 | }
2294 | param {
2295 | lr_mult: 0
2296 | decay_mult: 0
2297 | }
2298 | convolution_param {
2299 | num_output: 512
2300 | kernel_size: 3
2301 | stride: 1
2302 | pad: 1
2303 | weight_filler {
2304 | type: "gaussian"
2305 | std: 0.01
2306 | }
2307 | bias_filler {
2308 | type: "constant"
2309 | value: 0
2310 | }
2311 | }
2312 | }
2313 | layer {
2314 | name: "relu4_2"
2315 | type: "PReLU"
2316 | bottom: "conv4_2"
2317 | top: "conv4_2"
2318 | }
2319 | layer {
2320 | name: "conv4_3"
2321 | type: "Convolution"
2322 | bottom: "conv4_2"
2323 | top: "conv4_3"
2324 | param {
2325 | lr_mult: 1
2326 | decay_mult: 1
2327 | }
2328 | param {
2329 | lr_mult: 0
2330 | decay_mult: 0
2331 | }
2332 | convolution_param {
2333 | num_output: 512
2334 | kernel_size: 3
2335 | stride: 1
2336 | pad: 1
2337 | weight_filler {
2338 | type: "gaussian"
2339 | std: 0.01
2340 | }
2341 | bias_filler {
2342 | type: "constant"
2343 | value: 0
2344 | }
2345 | }
2346 | }
2347 | layer {
2348 | name: "relu4_3"
2349 | type: "PReLU"
2350 | bottom: "conv4_3"
2351 | top: "conv4_3"
2352 | }
2353 | layer {
2354 | name: "res4_3"
2355 | type: "Eltwise"
2356 | bottom: "conv4_1"
2357 | bottom: "conv4_3"
2358 | top: "res4_3"
2359 | eltwise_param {
2360 | operation: 1
2361 | }
2362 | }
2363 | layer {
2364 | name: "conv4_4"
2365 | type: "Convolution"
2366 | bottom: "res4_3"
2367 | top: "conv4_4"
2368 | param {
2369 | lr_mult: 1
2370 | decay_mult: 1
2371 | }
2372 | param {
2373 | lr_mult: 0
2374 | decay_mult: 0
2375 | }
2376 | convolution_param {
2377 | num_output: 512
2378 | kernel_size: 3
2379 | stride: 1
2380 | pad: 1
2381 | weight_filler {
2382 | type: "gaussian"
2383 | std: 0.01
2384 | }
2385 | bias_filler {
2386 | type: "constant"
2387 | value: 0
2388 | }
2389 | }
2390 | }
2391 | layer {
2392 | name: "relu4_4"
2393 | type: "PReLU"
2394 | bottom: "conv4_4"
2395 | top: "conv4_4"
2396 | }
2397 | layer {
2398 | name: "conv4_5"
2399 | type: "Convolution"
2400 | bottom: "conv4_4"
2401 | top: "conv4_5"
2402 | param {
2403 | lr_mult: 1
2404 | decay_mult: 1
2405 | }
2406 | param {
2407 | lr_mult: 0
2408 | decay_mult: 0
2409 | }
2410 | convolution_param {
2411 | num_output: 512
2412 | kernel_size: 3
2413 | stride: 1
2414 | pad: 1
2415 | weight_filler {
2416 | type: "gaussian"
2417 | std: 0.01
2418 | }
2419 | bias_filler {
2420 | type: "constant"
2421 | value: 0
2422 | }
2423 | }
2424 | }
2425 | layer {
2426 | name: "relu4_5"
2427 | type: "PReLU"
2428 | bottom: "conv4_5"
2429 | top: "conv4_5"
2430 | }
2431 | layer {
2432 | name: "res4_5"
2433 | type: "Eltwise"
2434 | bottom: "res4_3"
2435 | bottom: "conv4_5"
2436 | top: "res4_5"
2437 | eltwise_param {
2438 | operation: 1
2439 | }
2440 | }
2441 | layer {
2442 | name: "conv4_6"
2443 | type: "Convolution"
2444 | bottom: "res4_5"
2445 | top: "conv4_6"
2446 | param {
2447 | lr_mult: 1
2448 | decay_mult: 1
2449 | }
2450 | param {
2451 | lr_mult: 0
2452 | decay_mult: 0
2453 | }
2454 | convolution_param {
2455 | num_output: 512
2456 | kernel_size: 3
2457 | stride: 1
2458 | pad: 1
2459 | weight_filler {
2460 | type: "gaussian"
2461 | std: 0.01
2462 | }
2463 | bias_filler {
2464 | type: "constant"
2465 | value: 0
2466 | }
2467 | }
2468 | }
2469 | layer {
2470 | name: "relu4_6"
2471 | type: "PReLU"
2472 | bottom: "conv4_6"
2473 | top: "conv4_6"
2474 | }
2475 | layer {
2476 | name: "conv4_7"
2477 | type: "Convolution"
2478 | bottom: "conv4_6"
2479 | top: "conv4_7"
2480 | param {
2481 | lr_mult: 1
2482 | decay_mult: 1
2483 | }
2484 | param {
2485 | lr_mult: 0
2486 | decay_mult: 0
2487 | }
2488 | convolution_param {
2489 | num_output: 512
2490 | kernel_size: 3
2491 | stride: 1
2492 | pad: 1
2493 | weight_filler {
2494 | type: "gaussian"
2495 | std: 0.01
2496 | }
2497 | bias_filler {
2498 | type: "constant"
2499 | value: 0
2500 | }
2501 | }
2502 | }
2503 | layer {
2504 | name: "relu4_7"
2505 | type: "PReLU"
2506 | bottom: "conv4_7"
2507 | top: "conv4_7"
2508 | }
2509 | layer {
2510 | name: "res4_7"
2511 | type: "Eltwise"
2512 | bottom: "res4_5"
2513 | bottom: "conv4_7"
2514 | top: "res4_7"
2515 | eltwise_param {
2516 | operation: 1
2517 | }
2518 | }
2519 | layer {
2520 | name: "fc5"
2521 | type: "InnerProduct"
2522 | bottom: "res4_7"
2523 | top: "fc5"
2524 | param {
2525 | lr_mult: 1
2526 | decay_mult: 1
2527 | }
2528 | param {
2529 | lr_mult: 2
2530 | decay_mult: 0
2531 | }
2532 | inner_product_param {
2533 | num_output: 512
2534 | weight_filler {
2535 | type: "xavier"
2536 | }
2537 | bias_filler {
2538 | type: "constant"
2539 | value: 0
2540 | }
2541 | }
2542 | }
2543 | ####################### innerproduct ###################
2544 | layer {
2545 | name: "fc5_norm"
2546 | type: "NormL2"
2547 | bottom: "fc5"
2548 | top: "fc5_norm"
2549 | }
2550 | layer {
2551 | name: "fc6"
2552 | type: "InnerProduct"
2553 | bottom: "fc5_norm"
2554 | top: "fc6"
2555 | param {
2556 | lr_mult: 1
2557 | decay_mult: 1
2558 | }
2559 | inner_product_param {
2560 | num_output: 10575
2561 | normalize: true
2562 | weight_filler {
2563 | type: "xavier"
2564 | }
2565 | bias_term: false
2566 | }
2567 | }
2568 | layer {
2569 | name: "fix_cos"
2570 | type: "NoiseTolerantFR"
2571 | bottom: "fc6"
2572 | bottom: "fc6"
2573 | bottom: "label000"
2574 | # whether the sample is noise(0 is clean and 1 is noise), just for debugging
2575 | #bottom: "label001"
2576 | top: "fix_cos"
2577 | noise_tolerant_fr_param {
2578 | shield_forward: false
2579 | start_iter: 1
2580 | bins: 200
2581 | slide_batch_num: 1000
2582 |
2583 | value_low: -1.0
2584 | value_high: 1.0
2585 |
2586 | #debug: true
2587 | #debug_prefix: "p_casia-webface_noise-flip-outlier-1_1-40_resnet64_Nsoftmax_FIT"
2588 | debug: false
2589 | }
2590 | }
2591 | layer {
2592 | name: "fc6_margin_scale"
2593 | type: "Scale"
2594 | bottom: "fix_cos"
2595 | top: "fc6_margin_scale"
2596 | param {
2597 | lr_mult: 0
2598 | decay_mult: 0
2599 | }
2600 | scale_param {
2601 | filler {
2602 | type: "constant"
2603 | value: 32.0
2604 | }
2605 | bias_term: false
2606 | }
2607 | }
2608 | ######################### softmax #######################
2609 | layer {
2610 | name: "loss/label000"
2611 | type: "SoftmaxWithLoss"
2612 | bottom: "fc6_margin_scale"
2613 | bottom: "label000"
2614 | top: "loss/label000"
2615 | loss_weight: 1.0
2616 | loss_param {
2617 | ignore_label: -1
2618 | }
2619 | }
2620 | layer {
2621 | name: "accuracy/label000"
2622 | type: "Accuracy"
2623 | bottom: "fc6_margin_scale"
2624 | bottom: "label000"
2625 | top: "accuracy/label000"
2626 | accuracy_param {
2627 | top_k: 1
2628 | ignore_label: -1
2629 | }
2630 | }
2631 |
--------------------------------------------------------------------------------
/deploy/solver.prototxt:
--------------------------------------------------------------------------------
1 | net: "${prototxt_path}/${prefix}_train_val.prototxt"
2 | iter_size: 1
3 | test_iter: 10
4 | test_interval: 100
5 | base_lr: 0.01
6 | lr_policy: "step"
7 | gamma: 0.1
8 | stepsize: 80000
9 | display: 20
10 | max_iter: 200000
11 | momentum: 0.9
12 | weight_decay: 0.0005
13 | snapshot: 10000
14 | snapshot_prefix: "snapshot"
15 | solver_mode: GPU
16 |
--------------------------------------------------------------------------------
/figures/detail.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huangyangyu/NoiseFace/0b434a2c0eb664ca2af36c3bc619629fb27dcf3f/figures/detail.png
--------------------------------------------------------------------------------
/figures/strategy.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huangyangyu/NoiseFace/0b434a2c0eb664ca2af36c3bc619629fb27dcf3f/figures/strategy.png
--------------------------------------------------------------------------------
/figures/webface_dist_2D_noise-0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huangyangyu/NoiseFace/0b434a2c0eb664ca2af36c3bc619629fb27dcf3f/figures/webface_dist_2D_noise-0.png
--------------------------------------------------------------------------------
/figures/webface_dist_2D_noise-20.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huangyangyu/NoiseFace/0b434a2c0eb664ca2af36c3bc619629fb27dcf3f/figures/webface_dist_2D_noise-20.png
--------------------------------------------------------------------------------
/figures/webface_dist_2D_noise-40.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huangyangyu/NoiseFace/0b434a2c0eb664ca2af36c3bc619629fb27dcf3f/figures/webface_dist_2D_noise-40.png
--------------------------------------------------------------------------------
/figures/webface_dist_2D_noise-60.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huangyangyu/NoiseFace/0b434a2c0eb664ca2af36c3bc619629fb27dcf3f/figures/webface_dist_2D_noise-60.png
--------------------------------------------------------------------------------
/figures/webface_dist_3D_noise-0.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huangyangyu/NoiseFace/0b434a2c0eb664ca2af36c3bc619629fb27dcf3f/figures/webface_dist_3D_noise-0.png
--------------------------------------------------------------------------------
/figures/webface_dist_3D_noise-20.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huangyangyu/NoiseFace/0b434a2c0eb664ca2af36c3bc619629fb27dcf3f/figures/webface_dist_3D_noise-20.png
--------------------------------------------------------------------------------
/figures/webface_dist_3D_noise-40.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huangyangyu/NoiseFace/0b434a2c0eb664ca2af36c3bc619629fb27dcf3f/figures/webface_dist_3D_noise-40.png
--------------------------------------------------------------------------------
/figures/webface_dist_3D_noise-60.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huangyangyu/NoiseFace/0b434a2c0eb664ca2af36c3bc619629fb27dcf3f/figures/webface_dist_3D_noise-60.png
--------------------------------------------------------------------------------
/layer/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huangyangyu/NoiseFace/0b434a2c0eb664ca2af36c3bc619629fb27dcf3f/layer/.gitkeep
--------------------------------------------------------------------------------
/layer/arcface_layer.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include
4 | #include "caffe/layers/arcface_layer.hpp"
5 |
6 | namespace caffe
7 | {
8 |
9 | template
10 | void ArcfaceLayer::LayerSetUp(const vector*>& bottom,
11 | const vector*>& top)
12 | {
13 | const ArcfaceParameter& param = this->layer_param_.arcface_param();
14 | m_ = param.m();
15 | sin_m = sin(m_);
16 | cos_m = cos(m_);
17 | threshold = cos(M_PI - m_);
18 | //transform_test_ = param.transform_test();// & (this->phase_ == TRAIN);
19 |
20 | CHECK_GE(m_, 0.0);
21 | CHECK_LT(m_, M_PI);
22 | }
23 |
24 | template
25 | void ArcfaceLayer::Reshape(const vector*>& bottom,
26 | const vector*>& top)
27 | {
28 | top[0]->ReshapeLike(*bottom[0]);
29 | }
30 |
31 | template
32 | void ArcfaceLayer::Forward_cpu(const vector*>& bottom,
33 | const vector*>& top)
34 | {
35 | const Dtype* bottom_data = bottom[0]->cpu_data();
36 | const Dtype* label_data = bottom[1]->cpu_data();
37 | Dtype* top_data = top[0]->mutable_cpu_data();
38 |
39 | int num = bottom[0]->num();
40 | int count = bottom[0]->count();
41 | int dim = count / num;
42 |
43 | if (top[0] != bottom[0]) caffe_copy(count, bottom_data, top_data);
44 | //if (!transform_test_ && this->phase_ == TEST) return;
45 |
46 | for (int i = 0; i < num; ++i)
47 | {
48 | int gt = static_cast(label_data[i]);
49 | if (gt < 0) continue;
50 |
51 | Dtype cos_theta = bottom_data[i * dim + gt];
52 | if (cos_theta > +1.0f) cos_theta = +1.0f;
53 | if (cos_theta < -1.0f) cos_theta = -1.0f;
54 | Dtype sin_theta = sqrt(1.0f - cos_theta * cos_theta);
55 |
56 | if (cos_theta >= threshold && sin_theta > 1e-6)
57 | {
58 | top_data[i * dim + gt] = cos_theta * cos_m - sin_theta * sin_m;
59 | }
60 | else
61 | {
62 | top_data[i * dim + gt] = cos_theta - sin(M_PI - m_) * m_;
63 | //top_data[i * dim + gt] = cos_theta;
64 | }
65 | }
66 | }
67 |
68 | template
69 | void ArcfaceLayer::Backward_cpu(const vector*>& top,
70 | const vector& propagate_down,
71 | const vector*>& bottom)
72 | {
73 | if (top[0] != bottom[0] && propagate_down[0])
74 | {
75 | const Dtype* bottom_data = bottom[0]->cpu_data();
76 | const Dtype* label_data = bottom[1]->cpu_data();
77 | const Dtype* top_diff = top[0]->cpu_diff();
78 | Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
79 |
80 | int num = bottom[0]->num();
81 | int count = bottom[0]->count();
82 | int dim = count / num;
83 |
84 | caffe_copy(count, top_diff, bottom_diff);
85 | //if (!transform_test_ && this->phase_ == TEST) return;
86 |
87 | for (int i = 0; i < num; ++i)
88 | {
89 | int gt = static_cast(label_data[i]);
90 | if (gt < 0) continue;
91 |
92 | Dtype cos_theta = bottom_data[i * dim + gt];
93 | if (cos_theta > +1.0f) cos_theta = +1.0f;
94 | if (cos_theta < -1.0f) cos_theta = -1.0f;
95 | Dtype sin_theta = sqrt(1.0f - cos_theta * cos_theta);
96 |
97 | Dtype coffe = 0.0f;
98 | if (cos_theta >= threshold && sin_theta > 1e-6)
99 | {
100 | //coffe = sin(theta + m_) / sin_theta;
101 | coffe = cos_m + sin_m * cos_theta / sin_theta;
102 | }
103 | else
104 | {
105 | coffe = 1.0f;
106 | }
107 | bottom_diff[i * dim + gt] = coffe * top_diff[i * dim + gt];
108 | }
109 | }
110 | }
111 |
112 | #ifdef CPU_ONLY
113 | STUB_GPU(ArcfaceLayer);
114 | #endif
115 |
116 | INSTANTIATE_CLASS(ArcfaceLayer);
117 | REGISTER_LAYER_CLASS(Arcface);
118 | } // namespace caffe
119 |
--------------------------------------------------------------------------------
/layer/arcface_layer.cu:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include
4 | #include "caffe/layers/arcface_layer.hpp"
5 |
6 | namespace caffe
7 | {
8 |
9 | template
10 | __global__ void ArcfaceForward(const int n, const int dim, const Dtype* label,
11 | const Dtype* bottom_data, Dtype* top_data,
12 | Dtype m, Dtype cos_m, Dtype sin_m, Dtype threshold)
13 | {
14 | CUDA_KERNEL_LOOP(index, n)
15 | {
16 | int gt = static_cast(label[index]);
17 | if (gt >= 0)
18 | {
19 | Dtype cos_theta = bottom_data[index * dim + gt];
20 | if (cos_theta > +1.0f) cos_theta = +1.0f;
21 | if (cos_theta < -1.0f) cos_theta = -1.0f;
22 | Dtype sin_theta = sqrt(1.0f - cos_theta * cos_theta);
23 |
24 | if (cos_theta >= threshold && sin_theta > 1e-6)
25 | {
26 | top_data[index * dim + gt] = cos_theta * cos_m - sin_theta * sin_m;
27 | }
28 | else
29 | {
30 | top_data[index * dim + gt] = cos_theta - sin(M_PI - m) * m;
31 | //top_data[index * dim + gt] = cos_theta;
32 | }
33 | }
34 | }
35 | }
36 |
37 | template
38 | __global__ void ArcfaceBackward(const int n, const int dim, const Dtype* label,
39 | const Dtype* bottom_data, Dtype* bottom_diff, const Dtype* top_diff,
40 | Dtype cos_m, Dtype sin_m, Dtype threshold)
41 | {
42 | CUDA_KERNEL_LOOP(index, n)
43 | {
44 | int gt = static_cast(label[index]);
45 | if (gt >= 0)
46 | {
47 | Dtype cos_theta = bottom_data[index * dim + gt];
48 | if (cos_theta > +1.0f) cos_theta = +1.0f;
49 | if (cos_theta < -1.0f) cos_theta = -1.0f;
50 | Dtype sin_theta = sqrt(1.0f - cos_theta * cos_theta);
51 |
52 | Dtype coffe = 0.0f;
53 | if (cos_theta >= threshold && sin_theta > 1e-6)
54 | {
55 | //coffe = sin(theta + m_) / sin_theta;
56 | coffe = cos_m + sin_m * cos_theta / sin_theta;
57 | }
58 | else
59 | {
60 | coffe = 1.0f;
61 | }
62 | bottom_diff[index * dim + gt] = coffe * top_diff[index * dim + gt];
63 | }
64 | }
65 | }
66 |
67 | template
68 | void ArcfaceLayer::Forward_gpu(const vector*>& bottom,
69 | const vector*>& top)
70 | {
71 | const Dtype* bottom_data = bottom[0]->gpu_data();
72 | const Dtype* label_data = bottom[1]->gpu_data();
73 | Dtype* top_data = top[0]->mutable_gpu_data();
74 |
75 | int num = bottom[0]->num();
76 | int count = bottom[0]->count();
77 | int dim = count / num;
78 |
79 | if (top[0] != bottom[0]) caffe_copy(count, bottom_data, top_data);
80 | //if (!transform_test_ && this->phase_ == TEST) return;
81 |
82 | ArcfaceForward << > > (
83 | num, dim, label_data, bottom_data, top_data, m_, cos_m, sin_m, threshold);
84 | CUDA_POST_KERNEL_CHECK;
85 | }
86 |
87 | template
88 | void ArcfaceLayer::Backward_gpu(const vector*>& top,
89 | const vector& propagate_down,
90 | const vector*>& bottom)
91 | {
92 | if (top[0] != bottom[0] && propagate_down[0])
93 | {
94 | const Dtype* bottom_data = bottom[0]->gpu_data();
95 | const Dtype* label_data = bottom[1]->gpu_data();
96 | const Dtype* top_diff = top[0]->gpu_diff();
97 | Dtype* bottom_diff = bottom[0]->mutable_gpu_diff();
98 |
99 | int num = bottom[0]->num();
100 | int count = bottom[0]->count();
101 | int dim = count / num;
102 |
103 | caffe_copy(count, top_diff, bottom_diff);
104 | //if (!transform_test_ && this->phase_ == TEST) return;
105 |
106 | ArcfaceBackward << > > (
107 | num, dim, label_data, bottom_data, bottom_diff, top_diff, cos_m, sin_m, threshold);
108 | CUDA_POST_KERNEL_CHECK;
109 | }
110 | }
111 |
112 | INSTANTIATE_LAYER_GPU_FUNCS(ArcfaceLayer);
113 | } // namespace caffe
114 |
--------------------------------------------------------------------------------
/layer/arcface_layer.hpp:
--------------------------------------------------------------------------------
1 | #ifndef CAFFE_ARCFACE_LAYER_HPP_
2 | #define CAFFE_ARCFACE_LAYER_HPP_
3 |
4 | #include
5 |
6 | #include "caffe/blob.hpp"
7 | #include "caffe/layer.hpp"
8 | #include "caffe/proto/caffe.pb.h"
9 |
10 | #ifndef M_PI
11 | #define M_PI 3.14159265358979323846
12 | #endif
13 |
14 | namespace caffe {
15 |
16 | template
17 | class ArcfaceLayer : public Layer {
18 | public:
19 | explicit ArcfaceLayer(const LayerParameter& param)
20 | : Layer(param) {}
21 | virtual void LayerSetUp(const vector*>& bottom,
22 | const vector*>& top);
23 | virtual void Reshape(const vector*>& bottom,
24 | const vector*>& top);
25 |
26 | virtual inline const char* type() const { return "Arcface"; }
27 | virtual inline int MinNumBottomBlobs() const { return 2; }
28 |
29 | protected:
30 | virtual void Forward_cpu(const vector*>& bottom,
31 | const vector*>& top);
32 | virtual void Forward_gpu(const vector*>& bottom,
33 | const vector*>& top);
34 |
35 | virtual void Backward_cpu(const vector*>& top,
36 | const vector& propagate_down, const vector*>& bottom);
37 | virtual void Backward_gpu(const vector*>& top,
38 | const vector& propagate_down, const vector*>& bottom);
39 |
40 | Dtype m_;
41 | Dtype sin_m;
42 | Dtype cos_m;
43 | Dtype threshold;
44 | bool transform_test_;
45 | };
46 |
47 | } // namespace caffe
48 |
49 | #endif // CAFFE_ARCFACE_LAYER_HPP_
50 |
51 |
--------------------------------------------------------------------------------
/layer/caffe.proto:
--------------------------------------------------------------------------------
1 | message NormL2Parameter {
2 | optional float spare = 1 [default = 0];
3 | }
4 |
5 | message ArcfaceParameter {
6 | optional float m = 1 [default = 0.5];
7 | optional bool transform_test = 2 [default = false];
8 | }
9 |
10 | message NoiseTolerantFRParameter {
11 | optional bool shield_forward = 1 [default = false];
12 | optional int32 start_iter = 2 [default = 1];
13 | optional int32 bins = 3 [default = 200];
14 | optional int32 slide_batch_num = 4 [default = 1000];
15 | optional float value_low = 5 [default = -1.0];
16 | optional float value_high = 6 [default = 1.0];
17 | optional bool debug = 7 [default = false];
18 | optional string debug_prefix = 8;
19 | }
20 |
--------------------------------------------------------------------------------
/layer/noise_tolerant_fr_layer.cpp:
--------------------------------------------------------------------------------
1 | // by huangyangyu, 2018/9/24
2 | #include
3 | #include
4 | #include
5 | #include
6 |
7 | #include "caffe/layers/noise_tolerant_fr_layer.hpp"
8 |
9 | namespace caffe {
10 | int delta(int a, int b)
11 | {
12 | if (b == -1) return a - b;
13 | if (a > b) return +1;
14 | if (a < b) return -1;
15 | return 0;
16 | }
17 |
18 | template
19 | T clamp(T x, T min, T max)
20 | {
21 | if (x > max) return max;
22 | if (x < min) return min;
23 | return x;
24 | }
25 |
26 | template
27 | Dtype NoiseTolerantFRLayer::cos2weight(const Dtype cos)
28 | {
29 | int bin_id = get_bin_id(cos);
30 | Dtype x, u, a;
31 | Dtype alpha, beta, weight1, weight2, weight3, weight;
32 |
33 | // focus on all samples
34 | // weight1: normal state [0, 1]
35 | // constant value
36 | weight1 = 1.0;
37 |
38 | // focus on simple&clean samples, we just offer some methods, you can try other method to archive the same purpose and get better effect.
39 | // someone interested in this method can try gradient-ascend-like methods, such as LRelu/tanh and so on, which we have simply tried and failed, but i still think it may make sense.
40 | // weight2: activative func [0, 1]
41 | // activation function, S or ReLu or SoftPlus
42 | // SoftPlus
43 | weight2 = clamp(log(1.0 + exp(10.0 * (bin_id - lt_bin_id_) / (r_bin_id_ - lt_bin_id_))) / log(1.0 + exp(10.0)), 0.0, 1.0);
44 | // ReLu (linear)
45 | //weight2 = clamp(1.0 * (bin_id - lt_bin_id_) / (r_bin_id_ - lt_bin_id_), 0.0, 1.0);
46 | // Pow Fix
47 | //weight2 = pow(clamp(1.0 * (bin_id - l_bin_id_) / (r_bin_id_ - l_bin_id_), 0.0, 1.0), 3.0);
48 | // S
49 | //weight2 = pcf_[bin_id];
50 |
51 | // focus on semi-hard&clean samples, we just offer some methods, you can try other method to archive the same purpose and get better effect.
52 | // weight3: semi-hard aug [0, 1]
53 | // gauss distribution
54 | x = bin_id;
55 | u = rt_bin_id_;
56 | //a = (r_bin_id_ - u) / r;// symmetric
57 | a = x > u ? ((r_bin_id_ - u) / r) : ((u - l_bin_id_) / r);// asymmetric
58 | weight3 = exp(-1.0 * (x - u) * (x - u) / (2 * a * a));
59 | // linear
60 | //a = (r_bin_id_ - u);// symmetric
61 | //a = x > u ? (r_bin_id_ - u) : (u - l_bin_id_);// asymmetric
62 | //weight3 = clamp(1.0 - fabs(x - u) / a, 0.0, 1.0);
63 |
64 | // without stage3
65 | //weight3 = weight2;
66 |
67 | // merge weight
68 | alpha = clamp(get_cos(r_bin_id_), 0.0, 1.0);//[0, 1]
69 | beta = 2.0 - 1.0 / (1.0 + exp(5-20*alpha)) - 1.0 / (1.0 + exp(20*alpha-15));//[0, 1]
70 | // linear
71 | //beta = fabs(2.0 * alpha - 1.0);//[0, 1]
72 |
73 | // alpha = 0.0 => beta = 1.0, weight = weight1
74 | // alpha = 0.5 => beta = 0.0, weight = weight2
75 | // alpha = 1.0 => beta = 1.0, weight = weight3
76 | weight = beta*(alpha<0.5) * weight1 + (1-beta) * weight2 + beta*(alpha>0.5) * weight3;//[0, 1]
77 | // weight = 1.0;// normal method
78 | return weight;
79 | }
80 |
81 | template
82 | int NoiseTolerantFRLayer::get_bin_id(const Dtype cos)
83 | {
84 | int bin_id = bins_ * (cos - value_low_) / (value_high_ - value_low_);
85 | bin_id = clamp(bin_id, 0, bins_);
86 | return bin_id;
87 | }
88 |
89 | template
90 | Dtype NoiseTolerantFRLayer::get_cos(const int bin_id)
91 | {
92 | Dtype cos = value_low_ + (value_high_ - value_low_) * bin_id / bins_;
93 | cos = clamp(cos, value_low_, value_high_);
94 | return cos;
95 | }
96 |
97 | template
98 | void NoiseTolerantFRLayer::LayerSetUp(const vector*>& bottom,
99 | const vector*>& top)
100 | {
101 | const NoiseTolerantFRParameter& noise_tolerant_fr_param = this->layer_param_.noise_tolerant_fr_param();
102 | shield_forward_ = noise_tolerant_fr_param.shield_forward();// 1
103 | start_iter_ = noise_tolerant_fr_param.start_iter();// 2
104 | bins_ = noise_tolerant_fr_param.bins();// 3
105 | slide_batch_num_ = noise_tolerant_fr_param.slide_batch_num();// 4
106 | value_low_ = noise_tolerant_fr_param.value_low();// 5
107 | value_high_ = noise_tolerant_fr_param.value_high();// 6
108 | debug_ = noise_tolerant_fr_param.debug();// 7
109 | debug_prefix_ = noise_tolerant_fr_param.debug_prefix();// 8
110 |
111 | CHECK_GE(start_iter_, 1) << "start iteration must be large than or equal to 1";
112 | CHECK_GE(bins_, 1) << "bins must be large than or equal to 1";
113 | CHECK_GE(slide_batch_num_, 1) << "slide batch num must be large than or equal to 1";
114 | CHECK_GT(value_high_, value_low_) << "high value must be large than low value";
115 |
116 | iter_ = 0;
117 | noise_ratio_ = 0.0;
118 | l_bin_id_ = -1;
119 | r_bin_id_ = -1;
120 | lt_bin_id_ = -1;
121 | rt_bin_id_ = -1;
122 | //start_iter_ >?= slide_batch_num_;
123 | start_iter_ = std::max(start_iter_, slide_batch_num_);
124 | pdf_ = std::vector(bins_+1, Dtype(0.0));
125 | clean_pdf_ = std::vector(bins_+1, Dtype(0.0));
126 | noise_pdf_ = std::vector(bins_+1, Dtype(0.0));
127 | pcf_ = std::vector(bins_+1, Dtype(0.0));
128 | }
129 |
130 | template
131 | void NoiseTolerantFRLayer::Reshape(const vector*>& bottom,
132 | const vector*>& top)
133 | {
134 | CHECK_EQ(bottom[0]->num(), bottom[1]->num()) << "The size of bottom[0] and bottom[1] don't match";
135 |
136 | if (top[0] != bottom[0]) top[0]->ReshapeLike(*bottom[0]);
137 | // weights
138 | vector weights_shape(1);
139 | weights_shape[0] = bottom[0]->num();
140 | weights_.Reshape(weights_shape);
141 | }
142 |
143 | template
144 | void NoiseTolerantFRLayer::Forward_cpu(const vector*>& bottom,
145 | const vector*>& top)
146 | {
147 | skip_ = false;
148 |
149 | const Dtype* noise_data = NULL;
150 | if (bottom.size() == 4)
151 | {
152 | noise_data = bottom[3]->cpu_data();
153 | }
154 | const Dtype* label_data = bottom[2]->cpu_data();
155 | const Dtype* cos_data = bottom[1]->cpu_data();
156 | const Dtype* bottom_data = bottom[0]->cpu_data();
157 | Dtype* top_data = top[0]->mutable_cpu_data();
158 | Dtype* weight_data = weights_.mutable_cpu_data();
159 |
160 | int count = bottom[0]->count();
161 | int num = bottom[0]->num();// batch_size
162 | int dim = count / num;// c * h * w
163 |
164 | if (top[0] != bottom[0]) caffe_copy(count, bottom_data, top_data);
165 |
166 | if (this->phase_ != TRAIN) return;
167 |
168 | // update probability distribution/density function
169 | // add
170 | for (int i = 0; i < num; i++)
171 | {
172 | int gt = static_cast(label_data[i]);
173 | int noise_gt = -1;
174 | if (noise_data)
175 | {
176 | noise_gt = static_cast(noise_data[i]);
177 | queue_label_.push(noise_gt);
178 | }
179 | if (gt < 0)
180 | {
181 | queue_bin_id_.push(-1);
182 | continue;
183 | }
184 |
185 | int bin_id = get_bin_id(cos_data[i * dim + gt]);
186 | ++pdf_[bin_id];
187 | if (noise_data)
188 | {
189 | if (noise_gt == 0) ++clean_pdf_[bin_id];
190 | else ++noise_pdf_[bin_id];
191 | }
192 | queue_bin_id_.push(bin_id);
193 | }
194 | // del
195 | while (queue_bin_id_.size() > slide_batch_num_ * num)
196 | {
197 | int bin_id = queue_bin_id_.front();
198 | queue_bin_id_.pop();
199 | int noise_gt = -1;
200 | if (noise_data)
201 | {
202 | noise_gt = queue_label_.front();
203 | queue_label_.pop();
204 | }
205 | if (bin_id != -1)
206 | {
207 | --pdf_[bin_id];
208 | if (noise_data)
209 | {
210 | if (noise_gt == 0) --clean_pdf_[bin_id];
211 | else --noise_pdf_[bin_id];
212 | }
213 | }
214 | }
215 |
216 | /*
217 | // median filtering of the distribution
218 | std::vector filter_pdf(bins_+1, Dtype(0.0));
219 | for (int i = 1; i < bins_; i++)
220 | {
221 | filter_pdf[i] = pdf_[i-1] + pdf_[i] + pdf_[i+1] - \
222 | std::min(std::min(pdf_[i-1], pdf_[i]), pdf_[i+1]) - \
223 | std::max(std::max(pdf_[i-1], pdf_[i]), pdf_[i+1]);
224 | }
225 | */
226 | // mean filtering of the distribution
227 | Dtype sum_filter_pdf = 0.0;
228 | std::vector filter_pdf(bins_+1, Dtype(0.0));
229 | for (int i = fr; i <= bins_-fr; i++)
230 | {
231 | for (int j = i-fr; j <= i+fr; j++)
232 | {
233 | filter_pdf[i] += pdf_[j] / (fr+fr+1);
234 | }
235 | sum_filter_pdf += filter_pdf[i];
236 | }
237 |
238 | // update probability cumulative function
239 | pcf_[0] = filter_pdf[0] / sum_filter_pdf;
240 | for (int i = 1; i <= bins_; i++)
241 | {
242 | pcf_[i] = pcf_[i-1] + filter_pdf[i] / sum_filter_pdf;
243 | }
244 |
245 | ++iter_;
246 | if (iter_ < start_iter_) return;
247 |
248 | int l_bin_id, r_bin_id, lt_bin_id, rt_bin_id;
249 | // left/right end point of the distribution
250 | for (l_bin_id = 0; l_bin_id <= bins_ && pcf_[l_bin_id] < 0.5*s; ++l_bin_id);
251 | for (r_bin_id = bins_; r_bin_id >= 0 && pcf_[r_bin_id] > 1.0-0.5*s; --r_bin_id);
252 | // almost never happen
253 | if (l_bin_id >= r_bin_id)
254 | {
255 | //printf("Oops!\n");
256 | skip_ = true;
257 | return;
258 | }
259 | int m_bin_id_ = (l_bin_id + r_bin_id) / 2;
260 | // extreme points of the distribution
261 | int t_bin_id_ = std::distance(filter_pdf.begin(), std::max_element(filter_pdf.begin(), filter_pdf.end()));
262 | std::vector().swap(t_bin_ids_);
263 | for (int i = std::max(l_bin_id, 5); i <= std::min(r_bin_id, bins_-5); i++)
264 | {
265 | if (filter_pdf[i] >= filter_pdf[i-1] && filter_pdf[i] >= filter_pdf[i+1] && \
266 | filter_pdf[i] > filter_pdf[i-2] && filter_pdf[i] > filter_pdf[i+2] && \
267 | filter_pdf[i] > filter_pdf[i-3]+1 && filter_pdf[i] > filter_pdf[i+3]+1 && \
268 | filter_pdf[i] > filter_pdf[i-4]+2 && filter_pdf[i] > filter_pdf[i+4]+2 && \
269 | filter_pdf[i] > filter_pdf[i-5]+3 && filter_pdf[i] > filter_pdf[i+5]+3)
270 | {
271 | t_bin_ids_.push_back(i);
272 | i += 5;
273 | }
274 | }
275 | if (t_bin_ids_.size() == 0) t_bin_ids_.push_back(t_bin_id_);
276 | // left/right extreme point of the distribution
277 | if (t_bin_id_ < m_bin_id_)
278 | {
279 | lt_bin_id = t_bin_id_;
280 | rt_bin_id = std::max(t_bin_ids_.back(), m_bin_id_);// fix
281 | //rt_bin_id = t_bin_ids_.back();// not fix
282 | }
283 | else
284 | {
285 | rt_bin_id = t_bin_id_;
286 | lt_bin_id = std::min(t_bin_ids_.front(), m_bin_id_);// fix
287 | //lt_bin_id = t_bin_ids_.front();// not fix
288 | }
289 | // directly assignment, the training process is ok, but not stable
290 | //l_bin_id_ = l_bin_id;
291 | //r_bin_id_ = r_bin_id;
292 | //lt_bin_id_ = lt_bin_id;
293 | //rt_bin_id_ = rt_bin_id;
294 | // by adding the unit gradient vector, the training process will be more stable
295 | l_bin_id_ += delta(l_bin_id, l_bin_id_);
296 | r_bin_id_ += delta(r_bin_id, r_bin_id_);
297 | lt_bin_id_ += delta(lt_bin_id, lt_bin_id_);
298 | rt_bin_id_ += delta(rt_bin_id, rt_bin_id_);
299 |
300 | // estimate the ratio of noise to clean
301 | // method1
302 | if (lt_bin_id_ < m_bin_id_)
303 | {
304 | noise_ratio_ = 2.0 * pcf_[lt_bin_id_];
305 | }
306 | else
307 | {
308 | noise_ratio_ = 0.0;
309 | }
310 | /*
311 | // method 2
312 | if (t_bin_ids_.size() >= 2)
313 | {
314 | noise_ratio_ = pcf_[lt_bin_id_] / (pcf_[lt_bin_id_] + 1.0 - pcf_[rt_bin_id_]);
315 | }
316 | else
317 | {
318 | if (t_bin_id_ < m_bin_id_ && pcf_[t_bin_id_] < 0.5)
319 | {
320 | noise_ratio_ = 2.0 * pcf_[t_bin_id_];
321 | }
322 | else if (t_bin_id_ > m_bin_id_ && pcf_[t_bin_id_] > 0.5)
323 | {
324 | noise_ratio_ = 1.0 - 2.0 * (1.0 - pcf_[t_bin_id_]);
325 | }
326 | else
327 | {
328 | noise_ratio_ = 0.0;
329 | }
330 | }
331 | */
332 |
333 | // compute weights
334 | for (int i = 0; i < num; i++)
335 | {
336 | int gt = static_cast(label_data[i]);
337 | if (gt < 0) continue;
338 | weight_data[i] = cos2weight(cos_data[i * dim + gt]);
339 | }
340 |
341 | // print debug information
342 | /*
343 | if (debug_ && iter_ % 100 == start_iter_ % 100)
344 | {
345 | char file_name[256];
346 | sprintf(file_name, "/data/log/%s_%d.txt", debug_prefix_.c_str(), iter_);
347 | FILE *log = fopen(file_name, "w");
348 |
349 | fprintf(log, "debug iterations: %d\n", iter_);
350 | printf("debug iterations: %d\n", iter_);
351 |
352 | fprintf(log, "left: %.2f, left_top: %.2f, right_top: %.2f, right: %.2f, top_num: %d\n", get_cos(l_bin_id_), get_cos(lt_bin_id_), get_cos(rt_bin_id_), get_cos(r_bin_id_), t_bin_ids_.size());
353 | printf("left: %.2f, left_top: %.2f, right_top: %.2f, right: %.2f, top_num: %d\n", get_cos(l_bin_id_), get_cos(lt_bin_id_), get_cos(rt_bin_id_), get_cos(r_bin_id_), t_bin_ids_.size());
354 |
355 | fprintf(log, "pdf:\n");
356 | printf("pdf:\n");
357 | for (int i = 0; i <= bins_; i++)
358 | {
359 | fprintf(log, "%.2f %.2f\n", get_cos(i), pdf_[i]);
360 | printf("%.2f %.2f\n", get_cos(i), pdf_[i]);
361 | }
362 |
363 | fprintf(log, "clean pdf:\n");
364 | printf("clean pdf:\n");
365 | for (int i = 0; i <= bins_; i++)
366 | {
367 | fprintf(log, "%.2f %.2f\n", get_cos(i), clean_pdf_[i]);
368 | printf("%.2f %.2f\n", get_cos(i), clean_pdf_[i]);
369 | }
370 |
371 | fprintf(log, "noise pdf:\n");
372 | printf("noise pdf:\n");
373 | for (int i = 0; i <= bins_; i++)
374 | {
375 | fprintf(log, "%.2f %.2f\n", get_cos(i), noise_pdf_[i]);
376 | printf("%.2f %.2f\n", get_cos(i), noise_pdf_[i]);
377 | }
378 |
379 | fprintf(log, "pcf:\n");
380 | printf("pcf:\n");
381 | for (int i = 0; i <= bins_; i++)
382 | {
383 | fprintf(log, "%.2f %.2f\n", get_cos(i), pcf_[i]);
384 | printf("%.2f %.2f\n", get_cos(i), pcf_[i]);
385 | }
386 |
387 | fprintf(log, "weight:\n");
388 | printf("weight:\n");
389 | for (int i = 0; i <= bins_; i++)
390 | {
391 | fprintf(log, "%.2f %.2f\n", get_cos(i), cos2weight(get_cos(i)));
392 | printf("%.2f %.2f\n", get_cos(i), cos2weight(get_cos(i)));
393 | }
394 |
395 | fprintf(log, "noise ratio: %.2f\n", noise_ratio_);
396 | printf("noise ratio: %.2f\n", noise_ratio_);
397 |
398 | fclose(log);
399 | }
400 | */
401 |
402 | // forward
403 | if (shield_forward_) return;
404 |
405 | for (int i = 0; i < num; i++)
406 | {
407 | int gt = static_cast(label_data[i]);
408 | if (gt < 0) continue;
409 | for (int j = 0; j < dim; j++)
410 | {
411 | top_data[i * dim + j] *= weight_data[i];
412 | }
413 | }
414 | }
415 |
416 | template
417 | void NoiseTolerantFRLayer::Backward_cpu(const vector*>& top,
418 | const vector& propagate_down,
419 | const vector*>& bottom)
420 | {
421 | if (propagate_down[0])
422 | {
423 | const Dtype* label_data = bottom[2]->cpu_data();
424 | const Dtype* top_diff = top[0]->cpu_diff();
425 | Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
426 | const Dtype* weight_data = weights_.cpu_data();
427 |
428 | int count = bottom[0]->count();
429 | int num = bottom[0]->num();
430 | int dim = count / num;
431 |
432 | if (top[0] != bottom[0]) caffe_copy(count, top_diff, bottom_diff);
433 |
434 | if (this->phase_ != TRAIN) return;
435 |
436 | if (iter_ < start_iter_) return;
437 |
438 | // backward
439 | for (int i = 0; i < num; i++)
440 | {
441 | int gt = static_cast(label_data[i]);
442 | if (gt < 0) continue;
443 | for (int j = 0; j < dim; j++)
444 | {
445 | bottom_diff[i * dim + j] *= skip_ ? Dtype(0.0) : weight_data[i];
446 | }
447 | }
448 | }
449 | }
450 |
451 | #ifdef CPU_ONLY
452 | STUB_GPU(NoiseTolerantFRLayer);
453 | #endif
454 |
455 | INSTANTIATE_CLASS(NoiseTolerantFRLayer);
456 | REGISTER_LAYER_CLASS(NoiseTolerantFR);
457 | } // namespace caffe
458 |
--------------------------------------------------------------------------------
/layer/noise_tolerant_fr_layer.hpp:
--------------------------------------------------------------------------------
1 | // by huangyangyu, 2018/9/24
2 | #ifndef CAFFE_NOISE_TOLERANT_FR_LAYER_HPP_
3 | #define CAFFE_NOISE_TOLERANT_FR_LAYER_HPP_
4 |
5 | #include
6 | #include
7 | #include
8 |
9 | #include "caffe/blob.hpp"
10 | #include "caffe/layer.hpp"
11 | #include "caffe/proto/caffe.pb.h"
12 |
13 | #ifndef M_PI
14 | #define M_PI 3.14159265358979323846
15 | #endif
16 |
17 | namespace caffe {
18 |
19 | template
20 | class NoiseTolerantFRLayer : public Layer {
21 | public:
22 | explicit NoiseTolerantFRLayer(const LayerParameter& param)
23 | : Layer(param) {}
24 | virtual void LayerSetUp(const vector*>& bottom,
25 | const vector*>& top);
26 | virtual void Reshape(const vector*>& bottom,
27 | const vector*>& top);
28 |
29 | virtual inline const char* type() const { return "NoiseTolerantFR"; }
30 | virtual inline int ExactNumTopBlobs() const { return 1; }
31 | //virtual inline int ExactNumBottomBlobs() const { return 3; }
32 | virtual inline int MinBottomBlobs() const { return 3; }
33 | virtual inline int MaxBottomBlobs() const { return 4; }
34 |
35 | protected:
36 | virtual void Forward_cpu(const vector*>& bottom,
37 | const vector*>& top);
38 | //virtual void Forward_gpu(const vector*>& bottom,
39 | // const vector*>& top);
40 |
41 | virtual void Backward_cpu(const vector*>& top,
42 | const vector& propagate_down, const vector*>& bottom);
43 | //virtual void Backward_gpu(const vector*>& top,
44 | // const vector& propagate_down, const vector*>& bottom);
45 |
46 | Dtype cos2weight(const Dtype cos);
47 | int get_bin_id(const Dtype cos);
48 | Dtype get_cos(const int bin_id);
49 |
50 | bool shield_forward_;// 1
51 | int start_iter_;// 2
52 | int bins_;// 3
53 | int slide_batch_num_;// 4
54 | Dtype value_low_;// 5
55 | Dtype value_high_;// 6
56 | bool debug_;// 7
57 | std::string debug_prefix_;// 8
58 |
59 | int iter_;
60 | bool skip_;
61 | Dtype noise_ratio_;
62 | std::queue queue_label_;
63 | std::queue queue_bin_id_;
64 | std::vector pdf_;
65 | std::vector clean_pdf_;
66 | std::vector noise_pdf_;
67 | std::vector pcf_;
68 | int l_bin_id_;// left end point
69 | int r_bin_id_;// right end point
70 | int lt_bin_id_;// left extreme point
71 | int rt_bin_id_;// right extreme point
72 | std::vector t_bin_ids_;// extreme points
73 | Blob weights_;
74 |
75 | //80:1.282, 90:1.645, 95:1.960, 99:2.576
76 | const Dtype s = 1.0-0.99;
77 | const Dtype r = 2.576;
78 |
79 | // filter radius-1
80 | const int fr = 2;
81 | };
82 |
83 | } // namespace caffe
84 |
85 | #endif // CAFFE_NOISE_TOLERANT_FR_LAYER_HPP_
86 |
--------------------------------------------------------------------------------
/layer/normL2_layer.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include
4 |
5 | #include "caffe/layer.hpp"
6 | #include "caffe/util/math_functions.hpp"
7 | #include "caffe/layers/normL2_layer.hpp"
8 |
9 | namespace caffe {
10 |
11 | template
12 | void NormL2Layer::Reshape(const vector*>& bottom,
13 | const vector*>& top) {
14 | top[0]->Reshape(bottom[0]->num(), bottom[0]->channels(),
15 | bottom[0]->height(), bottom[0]->width());
16 | squared_.Reshape(bottom[0]->num(), bottom[0]->channels(),
17 | bottom[0]->height(), bottom[0]->width());
18 | }
19 |
20 | template
21 | void NormL2Layer::Forward_cpu(const vector*>& bottom,
22 | const vector*>& top) {
23 | const Dtype* bottom_data = bottom[0]->cpu_data();
24 | Dtype* top_data = top[0]->mutable_cpu_data();
25 | Dtype* squared_data = squared_.mutable_cpu_data();
26 | int n = bottom[0]->num();
27 | int d = bottom[0]->count() / n;
28 | caffe_sqr(n*d, bottom_data, squared_data);
29 | for (int i=0; i(d, squared_data+i*d);
31 | caffe_cpu_scale(d, Dtype(1.0/sqrt(normsqrt + 1e-7)), bottom_data+i*d, top_data+i*d);
32 | //caffe_cpu_scale(d, Dtype(1.0/sqrt(normsqrt)), bottom_data+i*d, top_data+i*d);
33 | //caffe_cpu_scale(d, Dtype(pow(normsqrt + 1e-7, -0.5)), bottom_data+i*d, top_data+i*d);
34 | //caffe_cpu_scale(d, Dtype(pow(normsqrt, -0.5)), bottom_data+i*d, top_data+i*d);
35 | }
36 | }
37 |
38 | template
39 | void NormL2Layer::Backward_cpu(const vector*>& top,
40 | const vector& propagate_down, const vector*>& bottom) {
41 | const Dtype* top_diff = top[0]->cpu_diff();
42 | const Dtype* top_data = top[0]->cpu_data();
43 | const Dtype* bottom_data = bottom[0]->cpu_data();
44 | Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
45 | int n = top[0]->num();
46 | int d = top[0]->count() / n;
47 | for (int i=0; i
2 | #include
3 | #include
4 |
5 | #include "thrust/device_vector.h"
6 |
7 | #include "caffe/layer.hpp"
8 | #include "caffe/util/math_functions.hpp"
9 | #include "caffe/layers/normL2_layer.hpp"
10 |
11 | namespace caffe {
12 |
13 | template
14 | void NormL2Layer::Forward_gpu(const vector*>& bottom,
15 | const vector*>& top) {
16 | const Dtype* bottom_data = bottom[0]->gpu_data();
17 | Dtype* top_data = top[0]->mutable_gpu_data();
18 | Dtype* squared_data = squared_.mutable_gpu_data();
19 | Dtype normsqr;
20 | int n = bottom[0]->num();
21 | int d = bottom[0]->count() / n;
22 | caffe_gpu_powx(n*d, bottom_data, Dtype(2), squared_data);
23 | for (int i=0; i(d, squared_data+i*d, &normsqr);
25 | caffe_gpu_scale(d, pow(normsqr + 1e-7, -0.5), bottom_data+i*d, top_data+i*d);
26 | //caffe_gpu_scale(d, pow(normsqr, -0.5), bottom_data+i*d, top_data+i*d);
27 | }
28 | }
29 |
30 | template
31 | void NormL2Layer::Backward_gpu(const vector*>& top,
32 | const vector& propagate_down, const vector*>& bottom) {
33 | const Dtype* top_diff = top[0]->gpu_diff();
34 | const Dtype* top_data = top[0]->gpu_data();
35 | const Dtype* bottom_data = bottom[0]->gpu_data();
36 | Dtype* bottom_diff = bottom[0]->mutable_gpu_diff();
37 | int n = top[0]->num();
38 | int d = top[0]->count() / n;
39 | Dtype a;
40 | for (int i=0; i
5 |
6 | #include "caffe/blob.hpp"
7 | #include "caffe/layer.hpp"
8 | #include "caffe/proto/caffe.pb.h"
9 |
10 | namespace caffe {
11 |
12 | /**
13 | * @brief Normalizes input.
14 | */
15 | template
16 | class NormL2Layer : public Layer {
17 | public:
18 | explicit NormL2Layer(const LayerParameter& param)
19 | : Layer(param) {}
20 | virtual void Reshape(const vector*>& bottom,
21 | const vector*>& top);
22 |
23 | virtual inline const char* type() const { return "NormL2"; }
24 | virtual inline int ExactNumBottomBlobs() const { return 1; }
25 | virtual inline int ExactNumTopBlobs() const { return 1; }
26 |
27 | protected:
28 | virtual void Forward_cpu(const vector*>& bottom,
29 | const vector*>& top);
30 | virtual void Forward_gpu(const vector*>& bottom,
31 | const vector*>& top);
32 | virtual void Backward_cpu(const vector*>& top,
33 | const vector& propagate_down, const vector*>& bottom);
34 | virtual void Backward_gpu(const vector*>& top,
35 | const vector& propagate_down, const vector*>& bottom);
36 |
37 | Blob sum_multiplier_, norm_, squared_;
38 | };
39 |
40 | } // namespace caffe
41 |
42 | #endif // CAFFE_NORML2_LAYER_HPP_
43 |
--------------------------------------------------------------------------------