├── .github
├── ISSUE_TEMPLATE
│ └── translations.md
└── workflows
│ ├── build_documentation.yml
│ ├── build_pr_documentation.yml
│ ├── quality.yml
│ └── upload_pr_documentation.yml
├── .gitignore
├── LICENSE
├── Makefile
├── README.md
├── assets
└── img
│ ├── cnn-feature-encoder.png
│ ├── speecht5.png
│ ├── speecht5_decoding.png
│ ├── transformers_blocks.png
│ ├── wav2vec2-ctc.png
│ ├── wav2vec2-input.png
│ └── whisper-input.png
├── chapters
├── bn
│ ├── _toctree.yml
│ ├── chapter0
│ │ ├── community.mdx
│ │ ├── get_ready.mdx
│ │ └── introduction.mdx
│ ├── chapter1
│ │ ├── audio_data.mdx
│ │ ├── introduction.mdx
│ │ ├── load_and_explore.mdx
│ │ ├── preprocessing.mdx
│ │ ├── quiz.mdx
│ │ ├── streaming.mdx
│ │ └── supplemental_reading.mdx
│ ├── chapter2
│ │ ├── asr_pipeline.mdx
│ │ ├── audio_classification_pipeline.mdx
│ │ ├── hands_on.mdx
│ │ └── introduction.mdx
│ └── events
│ │ └── introduction.mdx
├── en
│ ├── _toctree.yml
│ ├── chapter0
│ │ ├── community.mdx
│ │ ├── get_ready.mdx
│ │ └── introduction.mdx
│ ├── chapter1
│ │ ├── audio_data.mdx
│ │ ├── introduction.mdx
│ │ ├── load_and_explore.mdx
│ │ ├── preprocessing.mdx
│ │ ├── quiz.mdx
│ │ ├── streaming.mdx
│ │ └── supplemental_reading.mdx
│ ├── chapter2
│ │ ├── asr_pipeline.mdx
│ │ ├── audio_classification_pipeline.mdx
│ │ ├── hands_on.mdx
│ │ ├── introduction.mdx
│ │ └── tts_pipeline.mdx
│ ├── chapter3
│ │ ├── classification.mdx
│ │ ├── ctc.mdx
│ │ ├── introduction.mdx
│ │ ├── quiz.mdx
│ │ ├── seq2seq.mdx
│ │ └── supplemental_reading.mdx
│ ├── chapter4
│ │ ├── classification_models.mdx
│ │ ├── demo.mdx
│ │ ├── fine-tuning.mdx
│ │ ├── hands_on.mdx
│ │ └── introduction.mdx
│ ├── chapter5
│ │ ├── asr_models.mdx
│ │ ├── choosing_dataset.mdx
│ │ ├── demo.mdx
│ │ ├── evaluation.mdx
│ │ ├── fine-tuning.mdx
│ │ ├── hands_on.mdx
│ │ ├── introduction.mdx
│ │ └── supplemental_reading.mdx
│ ├── chapter6
│ │ ├── evaluation.mdx
│ │ ├── fine-tuning.mdx
│ │ ├── hands_on.mdx
│ │ ├── introduction.mdx
│ │ ├── pre-trained_models.mdx
│ │ ├── supplemental_reading.mdx
│ │ └── tts_datasets.mdx
│ ├── chapter7
│ │ ├── hands_on.mdx
│ │ ├── introduction.mdx
│ │ ├── speech-to-speech.mdx
│ │ ├── supplemental_reading.mdx
│ │ ├── transcribe-meeting.mdx
│ │ └── voice-assistant.mdx
│ ├── chapter8
│ │ ├── certification.mdx
│ │ └── introduction.mdx
│ └── events
│ │ └── introduction.mdx
├── es
│ ├── _toctree.yml
│ ├── chapter0
│ │ ├── community.mdx
│ │ ├── get_ready.mdx
│ │ └── introduction.mdx
│ ├── chapter1
│ │ ├── audio_data.mdx
│ │ ├── introduction.mdx
│ │ ├── load_and_explore.mdx
│ │ ├── preprocessing.mdx
│ │ ├── quiz.mdx
│ │ ├── streaming.mdx
│ │ └── supplemental_reading.mdx
│ └── chapter2
│ │ ├── asr_pipeline.mdx
│ │ ├── audio_classification_pipeline.mdx
│ │ ├── hands_on.mdx
│ │ └── introduction.mdx
├── fr
│ ├── _toctree.yml
│ ├── chapter0
│ │ ├── community.mdx
│ │ ├── get_ready.mdx
│ │ └── introduction.mdx
│ ├── chapter1
│ │ ├── audio_data.mdx
│ │ ├── introduction.mdx
│ │ ├── load_and_explore.mdx
│ │ ├── preprocessing.mdx
│ │ ├── quiz.mdx
│ │ ├── streaming.mdx
│ │ └── supplemental_reading.mdx
│ ├── chapter2
│ │ ├── asr_pipeline.mdx
│ │ ├── audio_classification_pipeline.mdx
│ │ ├── hands_on.mdx
│ │ └── introduction.mdx
│ ├── chapter3
│ │ ├── classification.mdx
│ │ ├── ctc.mdx
│ │ ├── introduction.mdx
│ │ ├── seq2seq.mdx
│ │ └── supplemental_reading.mdx
│ ├── chapter4
│ │ ├── classification_models.mdx
│ │ ├── demo.mdx
│ │ ├── fine-tuning.mdx
│ │ ├── hands_on.mdx
│ │ └── introduction.mdx
│ ├── chapter5
│ │ ├── asr_models.mdx
│ │ ├── choosing_dataset.mdx
│ │ ├── demo.mdx
│ │ ├── evaluation.mdx
│ │ ├── fine-tuning.mdx
│ │ ├── hands_on.mdx
│ │ ├── introduction.mdx
│ │ └── supplemental_reading.mdx
│ ├── chapter6
│ │ ├── evaluation.mdx
│ │ ├── fine-tuning.mdx
│ │ ├── hands_on.mdx
│ │ ├── introduction.mdx
│ │ ├── pre-trained_models.mdx
│ │ ├── supplemental_reading.mdx
│ │ └── tts_datasets.mdx
│ ├── chapter7
│ │ ├── hands-on.mdx
│ │ ├── introduction.mdx
│ │ ├── speech-to-speech.mdx
│ │ ├── supplemental_reading.mdx
│ │ ├── transcribe-meeting.mdx
│ │ └── voice-assistant.mdx
│ └── events
│ │ └── introduction.mdx
├── ko
│ ├── _toctree.yml
│ ├── chapter0
│ │ ├── community.mdx
│ │ ├── get_ready.mdx
│ │ └── introduction.mdx
│ ├── chapter1
│ │ ├── audio_data.mdx
│ │ ├── introduction.mdx
│ │ ├── load_and_explore.mdx
│ │ ├── preprocessing.mdx
│ │ ├── quiz.mdx
│ │ ├── streaming.mdx
│ │ └── supplemental_reading.mdx
│ ├── chapter2
│ │ ├── asr_pipeline.mdx
│ │ ├── audio_classification_pipeline.mdx
│ │ ├── hands_on.mdx
│ │ └── introduction.mdx
│ ├── chapter3
│ │ ├── classification.mdx
│ │ ├── ctc.mdx
│ │ ├── introduction.mdx
│ │ ├── quiz.mdx
│ │ ├── seq2seq.mdx
│ │ └── supplemental_reading.mdx
│ └── events
│ │ └── introduction.mdx
├── pt-BR
│ ├── _toctree.yml
│ ├── chapter0
│ │ ├── community.mdx
│ │ ├── get_ready.mdx
│ │ └── introduction.mdx
│ └── chapter1
│ │ ├── audio_data.mdx
│ │ ├── introduction.mdx
│ │ ├── load_and_explore.mdx
│ │ ├── preprocessing.mdx
│ │ ├── quiz.mdx
│ │ ├── streaming.mdx
│ │ └── supplemental_reading.mdx
├── ru
│ ├── _toctree.yml
│ ├── chapter0
│ │ ├── community.mdx
│ │ ├── get_ready.mdx
│ │ └── introduction.mdx
│ ├── chapter1
│ │ ├── audio_data.mdx
│ │ ├── introduction.mdx
│ │ ├── load_and_explore.mdx
│ │ ├── preprocessing.mdx
│ │ ├── quiz.mdx
│ │ ├── streaming.mdx
│ │ └── supplemental_reading.mdx
│ ├── chapter2
│ │ ├── asr_pipeline.mdx
│ │ ├── audio_classification_pipeline.mdx
│ │ ├── hands_on.mdx
│ │ └── introduction.mdx
│ ├── chapter3
│ │ ├── classification.mdx
│ │ ├── ctc.mdx
│ │ ├── introduction.mdx
│ │ ├── quiz.mdx
│ │ ├── seq2seq.mdx
│ │ └── supplemental_reading.mdx
│ ├── chapter4
│ │ ├── classification_models.mdx
│ │ ├── demo.mdx
│ │ ├── fine-tuning.mdx
│ │ ├── hands_on.mdx
│ │ └── introduction.mdx
│ ├── chapter5
│ │ ├── asr_models.mdx
│ │ ├── choosing_dataset.mdx
│ │ ├── demo.mdx
│ │ ├── evaluation.mdx
│ │ ├── fine-tuning.mdx
│ │ ├── hands_on.mdx
│ │ ├── introduction.mdx
│ │ └── supplemental_reading.mdx
│ ├── chapter6
│ │ ├── evaluation.mdx
│ │ ├── fine-tuning.mdx
│ │ ├── hands_on.mdx
│ │ ├── introduction.mdx
│ │ ├── pre-trained_models.mdx
│ │ ├── supplemental_reading.mdx
│ │ └── tts_datasets.mdx
│ ├── chapter7
│ │ ├── hands-on.mdx
│ │ ├── introduction.mdx
│ │ ├── speech-to-speech.mdx
│ │ ├── supplemental_reading.mdx
│ │ ├── transcribe-meeting.mdx
│ │ └── voice-assistant.mdx
│ ├── chapter8
│ │ ├── certification.mdx
│ │ └── introduction.mdx
│ ├── events
│ │ └── introduction.mdx
│ └── translation_agreements.txt
├── tr
│ ├── _toctree.yml
│ ├── chapter0
│ │ ├── community.mdx
│ │ ├── get_ready.mdx
│ │ └── introduction.mdx
│ ├── chapter1
│ │ ├── audio_data.mdx
│ │ ├── introduction.mdx
│ │ ├── load_and_explore.mdx
│ │ ├── preprocessing.mdx
│ │ ├── quiz.mdx
│ │ ├── streaming.mdx
│ │ └── supplemental_reading.mdx
│ └── chapter2
│ │ ├── asr_pipeline.mdx
│ │ ├── audio_classification_pipeline.mdx
│ │ ├── hands_on.mdx
│ │ ├── introduction.mdx
│ │ └── tts_pipeline.mdx
├── unpublished
│ └── chapter9
│ │ ├── audioldm.mdx
│ │ ├── dance_diffusion.mdx
│ │ ├── introduction.mdx
│ │ ├── music_generation.mdx
│ │ └── riffusion.mdx
└── zh-CN
│ ├── _toctree.yml
│ ├── chapter0
│ ├── community.mdx
│ ├── get_ready.mdx
│ └── introduction.mdx
│ ├── chapter1
│ ├── audio_data.mdx
│ ├── introduction.mdx
│ ├── load_and_explore.mdx
│ ├── preprocessing.mdx
│ ├── quiz.mdx
│ ├── streaming.mdx
│ └── supplemental_reading.mdx
│ ├── chapter2
│ ├── asr_pipeline.mdx
│ ├── audio_classification_pipeline.mdx
│ ├── hands_on.mdx
│ └── introduction.mdx
│ ├── chapter3
│ ├── classification.mdx
│ ├── ctc.mdx
│ ├── introduction.mdx
│ ├── quiz.mdx
│ ├── seq2seq.mdx
│ └── supplemental_reading.mdx
│ ├── chapter5
│ ├── asr_models.mdx
│ ├── choosing_dataset.mdx
│ ├── demo.mdx
│ ├── evaluation.mdx
│ ├── fine-tuning.mdx
│ ├── hands_on.mdx
│ ├── introduction.mdx
│ └── supplemental_reading.mdx
│ ├── chapter6
│ ├── evaluation.mdx
│ ├── fine-tuning.mdx
│ ├── hands_on.mdx
│ ├── introduction.mdx
│ ├── pre-trained_models.mdx
│ ├── supplemental_reading.mdx
│ └── tts_datasets.mdx
│ └── chapter8
│ ├── certification.mdx
│ └── introduction.mdx
├── requirements.txt
└── utils
├── carbon-config.json
├── code_formatter.py
├── generate_notebooks.py
└── validate_translation.py
/.github/workflows/build_documentation.yml:
--------------------------------------------------------------------------------
1 | name: Build documentation
2 |
3 | on:
4 | push:
5 | branches:
6 | - main
7 |
8 | jobs:
9 | build:
10 | uses: huggingface/doc-builder/.github/workflows/build_main_documentation.yml@main
11 | with:
12 | commit_sha: ${{ github.sha }}
13 | package: audio-transformers-course
14 | package_name: audio-course
15 | path_to_docs: audio-transformers-course/chapters/
16 | additional_args: --not_python_module
17 | languages: en bn ko es zh-CN ru fr tr pt-BR
18 | secrets:
19 | hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
20 |
--------------------------------------------------------------------------------
/.github/workflows/build_pr_documentation.yml:
--------------------------------------------------------------------------------
1 | name: Build PR Documentation
2 |
3 | on:
4 | pull_request:
5 |
6 | concurrency:
7 | group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
8 | cancel-in-progress: true
9 |
10 | jobs:
11 | build:
12 | uses: huggingface/doc-builder/.github/workflows/build_pr_documentation.yml@main
13 | with:
14 | commit_sha: ${{ github.event.pull_request.head.sha }}
15 | pr_number: ${{ github.event.number }}
16 | package: audio-transformers-course
17 | package_name: audio-course
18 | path_to_docs: audio-transformers-course/chapters/
19 | additional_args: --not_python_module
20 | languages: en bn ko es zh-CN ru fr tr pt-BR
21 |
--------------------------------------------------------------------------------
/.github/workflows/quality.yml:
--------------------------------------------------------------------------------
1 | name: Quality checks
2 |
3 | on:
4 | push:
5 | branches:
6 | - main
7 | pull_request:
8 |
9 | jobs:
10 | quality:
11 | runs-on: ubuntu-latest
12 | steps:
13 | - uses: actions/checkout@v2
14 | - name: Set up Python 3.8
15 | uses: actions/setup-python@v2
16 | with:
17 | python-version: 3.8
18 | - name: Install Python dependencies
19 | run: pip install black
20 | - name: Run quality check
21 | run: make quality
--------------------------------------------------------------------------------
/.github/workflows/upload_pr_documentation.yml:
--------------------------------------------------------------------------------
1 | name: Upload PR Documentation
2 |
3 | on:
4 | workflow_run:
5 | workflows: ["Build PR Documentation"]
6 | types:
7 | - completed
8 |
9 | jobs:
10 | build:
11 | uses: huggingface/doc-builder/.github/workflows/upload_pr_documentation.yml@main
12 | with:
13 | package_name: audio-course
14 | hub_base_path: https://moon-ci-docs.huggingface.co/learn
15 | secrets:
16 | hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
17 | comment_bot_token: ${{ secrets.COMMENT_BOT_TOKEN }}
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | .vscode
2 | .idea/
3 |
4 | # Logs
5 | logs
6 | *.log
7 | npm-debug.log*
8 | yarn-debug.log*
9 | yarn-error.log*
10 |
11 | # Runtime data
12 | pids
13 | *.pid
14 | *.seed
15 | *.pid.lock
16 |
17 | # Directory for instrumented libs generated by jscoverage/JSCover
18 | lib-cov
19 |
20 | # Coverage directory used by tools like istanbul
21 | coverage
22 |
23 | # nyc test coverage
24 | .nyc_output
25 |
26 | # Grunt intermediate storage (http://gruntjs.com/creating-plugins#storing-task-files)
27 | .grunt
28 |
29 | # Bower dependency directory (https://bower.io/)
30 | bower_components
31 |
32 | # node-waf configuration
33 | .lock-wscript
34 |
35 | # Compiled binary addons (http://nodejs.org/api/addons.html)
36 | build/Release
37 |
38 | # Dependency directories
39 | node_modules/
40 | jspm_packages/
41 |
42 | # Typescript v1 declaration files
43 | typings/
44 |
45 | # Optional npm cache directory
46 | .npm
47 |
48 | # Optional eslint cache
49 | .eslintcache
50 |
51 | # Optional REPL history
52 | .node_repl_history
53 |
54 | # Output of 'npm pack'
55 | *.tgz
56 |
57 | # dotenv environment variables file
58 | .env
59 |
60 | # gatsby files
61 | .cache/
62 | public
63 |
64 | # Mac files
65 | .DS_Store
66 |
67 | # Yarn
68 | yarn-error.log
69 | yarn.lock
70 | .pnp/
71 | .pnp.js
72 | # Yarn Integrity file
73 | .yarn-integrity
74 |
75 | # Sylvain notes folder
76 | notes
77 |
78 | # Ignore Colab notebooks
79 | nbs/
80 |
81 | # Byte-compiled
82 | __pycache__/
83 | .cache/
84 |
85 | # Temporary files
86 | tmp-docs
87 |
88 | # Jupyter Notebook
89 | .ipynb_checkpoints
--------------------------------------------------------------------------------
/Makefile:
--------------------------------------------------------------------------------
1 | .PHONY: quality style
2 |
3 | # Check code formatting
4 | quality:
5 | python utils/code_formatter.py --check_only
6 |
7 | # Format code samples automatically and check if there are any problems left that need manual fixing
8 | style:
9 | python utils/code_formatter.py
10 |
--------------------------------------------------------------------------------
/assets/img/cnn-feature-encoder.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/audio-transformers-course/4bc95b750205face0900f796f04bae58c54384b5/assets/img/cnn-feature-encoder.png
--------------------------------------------------------------------------------
/assets/img/speecht5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/audio-transformers-course/4bc95b750205face0900f796f04bae58c54384b5/assets/img/speecht5.png
--------------------------------------------------------------------------------
/assets/img/speecht5_decoding.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/audio-transformers-course/4bc95b750205face0900f796f04bae58c54384b5/assets/img/speecht5_decoding.png
--------------------------------------------------------------------------------
/assets/img/transformers_blocks.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/audio-transformers-course/4bc95b750205face0900f796f04bae58c54384b5/assets/img/transformers_blocks.png
--------------------------------------------------------------------------------
/assets/img/wav2vec2-ctc.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/audio-transformers-course/4bc95b750205face0900f796f04bae58c54384b5/assets/img/wav2vec2-ctc.png
--------------------------------------------------------------------------------
/assets/img/wav2vec2-input.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/audio-transformers-course/4bc95b750205face0900f796f04bae58c54384b5/assets/img/wav2vec2-input.png
--------------------------------------------------------------------------------
/assets/img/whisper-input.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/audio-transformers-course/4bc95b750205face0900f796f04bae58c54384b5/assets/img/whisper-input.png
--------------------------------------------------------------------------------
/chapters/bn/chapter0/community.mdx:
--------------------------------------------------------------------------------
1 | # 🤗 সম্প্রদায় যোগদান করুন!
2 |
3 | আমরা আপনাকে আমাদের [Discord](http://hf.co/join/discord) যোগদান করার জন্যে আমন্ত্রণ করছি। ওখানে আপনি আপনার মতন আরো শিক্ষার্থীদের
4 | সাথে যোগাযোগ করার সুযোগ পাবেন, এছাড়াও আপনি নিজের মতামত অন্যদের সাথে বিনিময় করার সুযোগ পাবেন, প্রশ্ন করতে পারবেন, অন্যদের সাথে সহযোগিতা
5 | করতে পারবেন এবং নিজের হাতে-করি অনুশীলনীর সম্পর্কে মূল্যবান প্রতিক্রিয়া পাবেন।
6 |
7 | আমাদের দলও Discord এ সক্রিয়, এবং তারা যখন আপনার প্রয়োজন তখন সহায়তা এবং নির্দেশনা প্রদানের জন্য আছে।
8 | আমাদের সম্প্রদায়ে যোগদান করার মাদ্ধমে আপনি পাঠক্রমের সাথে অনুপ্রাণিত, নিযুক্ত এবং সংযুক্ত থাকতে পারবে। আমরা আপনাকে সেখানে দেখার অপেক্ষায় আছি!
9 |
10 | ## Discord কি?
11 |
12 | ডিসকর্ড একটি বিনামূল্যের চ্যাট প্ল্যাটফর্ম। আপনি যদি Slack ব্যবহার করে থাকেন তবে আপনি এটি বেশ একই রকম পাবেন। 🤗 Discord সার্ভার হলো
13 | ১৮ ০০০ এর বেশি A.I. বিশেষজ্ঞ, শিক্ষার্থী এবং উত্সাহীদের একটি সমৃদ্ধশালী সম্প্রদায় যার আপনি একটি অংশ হতে পারেন।
14 |
15 | ## Discord এর পরিচালনা করা
16 |
17 | একবার আপনি আমাদের ডিসকর্ড সার্ভারে Sign Up করলে, আপনাকে `#role-assignment`-এ ক্লিক করে আপনার আগ্রহের বিষয়গুলি বেছে নিতে হব।
18 | বাম দিকে আপনি আপনার পছন্দ হিসাবে অনেক বিভিন্ন বিভাগ চয়ন করতে পারেন. এই কোর্সের অন্যান্য শিক্ষার্থীদের যোগ দিতে, নিশ্চিত করুন "ML for Audio and Speech" ক্লিক করতে।
19 | চ্যানেলগুলি অন্বেষণ করুন এবং `#introduce-yourself` চ্যানেলে আপনার সম্পর্কে কিছু জিনিস শেয়ার করুন যাতে আমরা আপনাকে আরো জানতে পারি।
20 |
21 | ## Audio course সংক্রান্ত চ্যানেল
22 |
23 | আমাদের ডিসকর্ড সার্ভারে বিভিন্ন বিষয়ে ফোকাস করা অনেক চ্যানেল রয়েছে। আপনি গবেষণা পত্রের আলোচনা, সংগঠিত ইভেন্ট সম্পর্কে ধারণা পাবেন এবং তাতে
24 | অংশগ্রহণ করার সুযোগ এবং আরো অনেক কিছু পাবেন।
25 | একজন audio পাঠক্রমের শিক্ষার্থী হিসাবে, আপনি নিম্নলিখিত চ্যানেলগুলোকে বিশেষভাবে প্রাসঙ্গিক খুঁজে পেতে পারেন:
26 |
27 | * `#audio-announcements`: পাঠক্রম সম্পর্কে আপডেট, audio ইভেন্ট ঘোষণা এবং 🤗 সম্পর্কিত আরও অনেক কিছু খবর পাবেন।
28 | * `#audio-study-group`: ধারনা বিনিময় করার জায়গা, পাঠক্রম সম্পর্কে প্রশ্ন জিজ্ঞাসা করুন এবং আলোচনা শুরু করুন।
29 | * `#audio-discuss`: audio সম্পর্কিত বিষয় নিয়ে আলোচনা করার একটি সাধারণ জায়গা।
30 |
31 | `#audio-study-group`-এ যোগদানের পাশাপাশি, নির্দ্বিধায় আপনার নিজস্ব স্টাডি গ্রুপ তৈরি করুন, একসাথে শেখা সবসময়ই সহজ!
--------------------------------------------------------------------------------
/chapters/bn/chapter0/get_ready.mdx:
--------------------------------------------------------------------------------
1 | # প্রস্তুতি পর্ব
2 |
3 | আমরা আশা করি আপনি পাঠক্রমটি শুরু করতে উত্তেজিত, এবং আমরা এই পৃষ্ঠাটি আপনার প্রস্তুতির শুরু করার জন্যে ডিজাইন করেছি!
4 |
5 | ## পদক্ষেপ ১. Sign up
6 |
7 | সমস্ত আপডেট এবং বিশেষ সামাজিক ইভেন্টগুলির সাথে আপ টু ডেট থাকতে, কোর্সে Sign Up করুন ৷
8 |
9 | [👉 SIGN UP](http://eepurl.com/insvcI)
10 |
11 | ## পদক্ষেপ ২. 🤗 account তৈরী করুন
12 |
13 | আপনার যদি এখনও একটি 🤗 account না থাকে, একটি 🤗 account তৈরি করুন (এটি বিনামূল্যে)। হাতে-কলমে কাজগুলি সম্পূর্ণ করার জন্য আপনার এটির
14 | প্রয়োজন হব। এছাড়াও এটি আপনার সমাপ্তির শংসাপত্র গ্রহণ করতে, pre-trained models গুলি অন্বেষণ করতে, ডেটাসেটগুলি অ্যাক্সেস করতে এবং আরও
15 | অনেক কিছু করতে সাহায্য করবে ।
16 |
17 | [👉 🤗 account তৈরি করুন](https://huggingface.co/join)
18 |
19 | ## পদক্ষেপ ৩. Transformer models এর যাচাই করে নিন (আপনার যদি প্রয়োজন পরে তবেই)
20 |
21 | আমরা অনুমান করি যে আপনার Deep Learning এর সাথে পরিচয় আছে এবং Transformers models এর সাথে সাধারণ পরিচিতি রয়েছে।
22 | আপনার যদি Transformers models এর ব্যাপারে যাচাই করার প্রয়োজন পরে তাহলে আমাদের [NLP Course](https://huggingface.co/course/chapter1/1) এর সাহায্য নিতে পারেন।
23 |
24 | ## পদক্ষেপ ৪. আপনার সেটআপ চেক করুন
25 |
26 | আপনার যা যা প্রয়োজন হবে:
27 | - ইন্টারনেট সংযোগ সহ একটি কম্পিউটার
28 | - [Google Colab](https://colab.research.google.com) এর প্রয়োজন হবে হাতে-করি অনুশীলনীর জন্যে। বিনামূল্যের সংস্করণটি যথেষ্ট.
29 |
30 | আপনি যদি আগে কখনো Google Colab ব্যবহার না করে থাকেন তাহলে এটি দেখুন - [official introduction notebook](https://colab.research.google.com/notebooks/intro.ipynb).
31 |
32 | ## পদক্ষেপ ৫. 🤗 সম্প্রদায় যোগদান করুন
33 |
34 | আমাদের Discord সার্ভারে Sign Up করুন, সেই জায়গা যেখানে আপনি আপনার সহপাঠীদের সাথে ধারনা এবং তথ্য বিনিময় করতে পারেন এবং আমাদের সাথে যোগাযোগ করতে পারেন (🤗 Team)।
35 |
36 | [👉 🤗 সম্প্রদায় যোগদান করুন](http://hf.co/join/discord)
37 |
38 | আমাদের সম্প্রদায়ের সম্পর্কে আরো জানতে পরের [পাতায় যান](community)।
39 |
--------------------------------------------------------------------------------
/chapters/bn/chapter1/introduction.mdx:
--------------------------------------------------------------------------------
1 | # অধ্যায় ১. অডিও ডাটার সাথে কাজ করার পদ্ধতিসমূহ
2 |
3 | ## এই অধ্যায় থেকে তুমি কি কি শিখবে?
4 |
5 | প্রতিটি অডিও বা speech সংক্রান্ত কাজ একটি অডিও ফাইল দিয়ে শুরু হয়। আমরা এই কাজগুলি সমাধান করার জন্য ডুব দিতে পারার আগে, এই ফাইলগুলি
6 | আসলে কী ধারণ করে এবং কীভাবে তাদের সাথে কাজ করতে হয় তা বোঝা খুবই গুরুত্বপূর্ণ।
7 |
8 | এই অধ্যায়ে, আপনি তরঙ্গরূপ সহ অডিও ডেটা সম্পর্কিত sampling rate, spectrogram এর মতন মৌলিক পরিভাষাগুলির একটি উপলব্ধি লাভ করবেন,
9 | এহকারাও আপনি অডিও লোডিং এবং প্রিপ্রসেসিং সহ অডিও ডেটাসেটগুলির সাথে কীভাবে কাজ করবেন তাও শিখবেন এবং কীভাবে বড় ডেটাসেটগুলি দক্ষতার সাথে স্ট্রিম করা যায়।
10 |
11 | এই অধ্যায়ের শেষে, আপনি প্রয়োজনীয় audio ডেটা সম্পর্কিত পরিভাষাগুলির একটি শক্তিশালী উপলব্ধি করতে পারবেন এবং
12 | বিভিন্ন অ্যাপ্লিকেশনের জন্য অডিও ডেটাসেটের সাথে কাজ করার জন্য প্রয়োজনীয় দক্ষতা অর্জন করবেন। এই অধ্যায় এ আপনি যে জ্ঞান অর্জন করবেন তা পাঠক্রমের অবশিষ্টাংশ বোঝার জন্য একটি ভিত্তি স্থাপন করবে।
--------------------------------------------------------------------------------
/chapters/bn/chapter1/supplemental_reading.mdx:
--------------------------------------------------------------------------------
1 | # আরো জানো
2 |
3 | এই অধ্যায়ে অডিও ডেটার ব্যাপারে বোঝা এবং এটির সাথে কাজ করা সম্পর্কিত অনেক মৌলিক ধারণাগুলিকে কভার করা করেছে৷ আরো জানতে চান? এখানে আপনি
4 | অতিরিক্ত সংস্থানগুলি পাবেন যা আপনাকে বিষয়গুলি সম্পর্কে আপনার বোঝার গভীরে সাহায্য করবে এবং আপনার শেখার অভিজ্ঞতা উন্নত করবে।
5 |
6 | নিম্নলিখিত ভিডিওতে, xiph.org থেকে মন্টি মন্টগোমারি, আধুনিক ডিজিটাল এবং ভিনটেজ অ্যানালগ বেঞ্চ সরঞ্জাম উভয় ব্যবহার করে
7 | sampling, quantization, bit-depth এর বিশ্লেষণ করেছেন। ভিডিওটি দেখুন:
8 |
9 |
10 |
11 | আপনি যদি ডিজিটাল সিগন্যাল প্রসেসিংয়ের আরও গভীরে যেতে চান তবে ব্রায়ান ম্যাকফির(যিনি New York University র মিউজিক টেকনোলজি এবং
12 | ডেটা সায়েন্সের একজন সহকারী অধ্যাপক এবং `librosa` প্যাকেজের প্রধান রক্ষণাবেক্ষণকার) লেখা ["Digital Signals Theory" book](https://brianmcfee.net/dstbook-site/content/intro.html)
13 | বইটি পড়ুন।
14 |
15 |
16 |
--------------------------------------------------------------------------------
/chapters/bn/chapter2/hands_on.mdx:
--------------------------------------------------------------------------------
1 | # হাতে-করি অনুশীলন
2 |
3 | এই অনুশীলনটি গ্রেড করা হয়নি এবং কোর্সের বাকি অংশ জুড়ে আপনি যে টুলস এবং লাইব্রেরিগুলি ব্যবহার করবেন তার সাথে পরিচিত হতে সাহায্য করার উদ্দেশ্যে করা
4 | হয়েছে। আপনি যদি ইতিমধ্যেই Google Colab, 🤗 datasets, librosa এবং 🤗 transformers ব্যবহারে অভিজ্ঞ হয়ে থাকেন, তাহলে আপনি এই অনুশীলনটি
5 | এড়িয়ে যেতে পারেন।
6 |
7 | ১. একটি [Google Colab](https://colab.research.google.com) নোটবুক তৈরি করুন।
8 |
9 | ২. স্ট্রিমিং মোডে আপনার পছন্দের ভাষায় [`facebook/voxpopuli` ডেটাসেট](https://huggingface.co/datasets/facebook/voxpopuli) এর `train`
10 | স্প্লিটটি লোড করতে 🤗 datasets ব্যবহার করুন।
11 |
12 | ৩. ডেটাসেটের `train` অংশ থেকে তৃতীয় উদাহরণটি পান এবং এটি অন্বেষণ করুন। এই উদাহরণে যে বৈশিষ্ট্যগুলি রয়েছে তা প্রদত্ত, আপনি এই ডেটাসেটটি কী
13 | ধরণের অডিও কাজগুলির জন্য ব্যবহার করতে পারেন?
14 |
15 | ৪. এই উদাহরণের তরঙ্গরূপ এবং spectrogram প্লট করুন।
16 |
17 | ৫. [🤗 Hub](https://huggingface.co/models) এ যান, pre-trained models গুলো অন্বেষণ করুন এবং এমন একটি মডেল খুঁজুন যা আপনি আগে
18 | বেছে নেওয়া ভাষার জন্য automatic speech recognition এর জন্য ব্যবহার করা যেতে পারে। আপনি যে মডেলটি পেয়েছেন তার সাথে একটি সংশ্লিষ্ট pipeline
19 | তৈরী করুন এবং উদাহরণটি প্রতিলিপি করুন।
20 |
21 | ৬. উদাহরণে দেওয়া ট্রান্সক্রিপশনের সাথে pipeline থেকে আপনি যে ট্রান্সক্রিপশন পেয়েছেন তার তুলনা করুন।
22 |
23 |
24 | আপনি যদি এই অনুশীলনের সাথে সমস্যায় পড়েন, তাহলে নির্দ্বিধায় একটি [উদাহরণ সমাধান](https://colab.research.google.com/drive/1NGyo5wFpRj8TMfZOIuPaJHqyyXCITftc?usp=sharing) দেখুন।
25 | কিছু আকর্ষণীয় আবিষ্কার করলেন? একটি দুর্দান্ত মডেল পাওয়া গেছে? একটি সুন্দর স্পেকট্রোগ্রাম পেয়েছেন? টুইটারে আপনার কাজ এবং আবিষ্কারগুলি ভাগ করে নিন বিনা দ্বিধায়!
26 |
27 | পরবর্তী অধ্যায়গুলিতে আপনি বিভিন্ন audio transformers architecture সম্পর্কে আরও শিখবেন এবং আপনার নিজের তৈরী মডেলগুলোকে train করবেন!
28 |
29 |
30 |
31 |
32 |
--------------------------------------------------------------------------------
/chapters/bn/chapter2/introduction.mdx:
--------------------------------------------------------------------------------
1 | # অধ্যায় ২. অডিও অ্যাপ্লিকেশনের সূচনা
2 |
3 | Hugging Face অডিও কোর্সের দ্বিতীয় পাঠক্রমে স্বাগতম! পূর্বে, আমরা অডিও ডেটার মৌলিক বিষয়গুলি অন্বেষণ করেছি৷
4 | এবং 🤗 datasets এবং 🤗 transformers লাইব্রেরি ব্যবহার করে অডিও ডেটাসেটের সাথে কিভাবে কাজ করতে হয় তা শিখেছি। আমরা বিভিন্ন বিষয়ে আলোচনা করেছি যেমন -
5 | sampling rate, amplitude, bit depth, তরঙ্গরূপ এবং spectrogram এর ধারণা এবং কিভাবে ডেটা প্রিপ্রসেস করা যায় তা দেখেছি।
6 |
7 | এই মুহুর্তে আপনি অডিও কাজগুলি সম্পর্কে জানতে আগ্রহী হতে পারেন যা 🤗 transformers পরিচালনা করতে পারে এবং আপনার কাছে তা ভালো ভাবে জানার জন্য
8 | প্রয়োজনীয় সমস্ত ভিত্তি রয়েছে! চলুন কিছু মন ছুঁয়ে যাওয়া অডিও টাস্কের উদাহরণ দেখে নেওয়া যাক:
9 |
10 | * **Audio classification**: সহজেই অডিও ক্লিপগুলিকে বিভিন্ন বিভাগে শ্রেণীবদ্ধ করুন। একটি রেকর্ডিং একটি ঘেউ ঘেউ করা কুকুর বা বিড়াল এর মিউ
11 | কিনা তা আপনি সনাক্ত করতে পারেন, বা একটি গান কোন সঙ্গীত ঘরানার অন্তর্গত তাও বলে দিতে পারেন।
12 | * **Automatic speech recognition**: অডিও ক্লিপগুলিকে স্বয়ংক্রিয়ভাবে প্রতিলিপি করে পাঠ্যে রূপান্তর করুন। আপনি একটি রেকর্ডিং থেকে টেক্সট পেতে পারেন,
13 | যেমন "আপনি আজ কেমন আছেন?"। নোট নেওয়ার জন্য বরং উপকারী!
14 | * **Speaker diarization**: কখনো ভেবেছেন কে রেকর্ডিংয়ে কথা বলছে? 🤗 transformers সাহায্যে আপনি কোন স্পিকারটি কখন কথা বলছে তা সনাক্ত করতে পারবেন।
15 | * **Text to speech**: এর মাদ্ধমে আপনি একটি পাঠ্যের একটি বর্ণিত সংস্করণ তৈরি করুন যা একটি audio book তৈরি করতে ব্যবহার করা যেতে পারে, অথবা
16 | একটি গেমে একটি NPC-কে ভয়েস দিন, 🤗 transformers দিয়ে, আপনি সহজেই এই কাজগুলি করতে পারবেন!
17 |
18 | এই ইউনিটে, আপনি শিখবেন কিভাবে 🤗 transformers থেকে `pipeline()` ফাংশন ব্যবহার করে এই কয়েকটি কাজের জন্য pre-trained মডেল ব্যবহার করতে হয়।
19 | বিশেষ করে, আমরা দেখব কিভাবে pre-trained মডেলগুলি audio classification এবং automatic speech recognition এর জন্য ব্যবহার করা যেতে পারে।
20 | চলুন শুরু করি!
21 |
--------------------------------------------------------------------------------
/chapters/bn/events/introduction.mdx:
--------------------------------------------------------------------------------
1 | # লাইভ সেশন এবং কর্মশালা
2 |
3 | নতুন অডিও Transformers কোর্স: Live Launch Event with Paige Bailey (DeepMind), Seokhwan Kim (Amazon Alexa AI), and Brian McFee (Librosa)
4 |
5 |
6 |
7 | Hugging Face অডিও কোর্স টিমের সাথে একটি লাইভ AMA এর রেকর্ডিং:
8 |
9 |
--------------------------------------------------------------------------------
/chapters/en/chapter0/community.mdx:
--------------------------------------------------------------------------------
1 | # Join the community!
2 |
3 | We invite you to [join our vibrant and supportive community on Discord](http://hf.co/join/discord). You will have the opportunity to connect with
4 | like-minded learners, exchange ideas, and get valuable feedback on your hands-on exercises. You can ask questions,
5 | share resources, and collaborate with others.
6 |
7 | Our team is also active on Discord, and they are available to provide support and guidance when you need
8 | it. Joining our community is an excellent way to stay motivated, engaged, and connected, and we look forward to seeing
9 | you there!
10 |
11 | ## What is Discord?
12 |
13 | Discord is a free chat platform. If you've used Slack, you'll find it quite similar. The Hugging Face Discord server
14 | is a home to a thriving community of 18 000 AI experts, learners and enthusiasts that you can be a part of.
15 |
16 | ## Navigating Discord
17 |
18 | Once you sign up to our Discord server, you'll need to pick the topics you're interested in by clicking `#role-assignment`
19 | at the left. You can choose as many different categories as you like. To join other learners of this course, make sure
20 | to click "ML for Audio and Speech".
21 | Explore the channels and share a few things about you in the `#introduce-yourself` channel.
22 |
23 | ## Audio course channels
24 |
25 | There are many channels focused on various topics on our Discord server. You'll find people discussing papers, organizing
26 | events, sharing their projects and ideas, brainstorming, and so much more.
27 |
28 | As an audio course learner, you may find the following set of channels particularly relevant:
29 |
30 | * `#audio-announcements`: updates about the course, news from the Hugging Face related to everything audio, event announcements, and more.
31 | * `#audio-study-group`: a place to exchange ideas, ask questions about the course and start discussions.
32 | * `#audio-discuss`: a general place to have discussions about things related to audio.
33 |
34 | In addition to joining the `#audio-study-group`, feel free to create your own study group, learning together is always easier!
35 |
--------------------------------------------------------------------------------
/chapters/en/chapter0/get_ready.mdx:
--------------------------------------------------------------------------------
1 | # Get ready to take the course
2 |
3 | We hope that you are excited to get started with the course, and we have designed this page to make sure you have
4 | everything you need to jump right in!
5 |
6 | ## Step 1. Sign up
7 |
8 | To stay up to date with all the updates and special social events, sign up to the course.
9 |
10 | [👉 SIGN UP](http://eepurl.com/insvcI)
11 |
12 | ## Step 2. Get a Hugging Face account
13 |
14 | If you don't yet have one, create a Hugging Face account (it's free). You'll need it to complete hands-on tasks, to
15 | receive your certificate of completion, to explore pre-trained models, to access datasets and more.
16 |
17 | [👉 CREATE HUGGING FACE ACCOUNT](https://huggingface.co/join)
18 |
19 | ## Step 3. Brush up on fundamentals (if you need to)
20 |
21 | We assume that you are familiar with deep learning basics, and have general familiarity with transformers. If you need
22 | to brush up on your understanding of transformers, check out our [NLP Course](https://huggingface.co/course/chapter1/1).
23 |
24 | ## Step 4. Check your setup
25 |
26 | To go through the course materials you will need:
27 | - A computer with an internet connection
28 | - [Google Colab](https://colab.research.google.com) for hands-on exercises. The free version is enough. If you have never used Google Colab before, check out this [official introduction notebook](https://colab.research.google.com/notebooks/intro.ipynb).
29 |
30 |
31 |
32 | As an alternative to the free tier of Google Colab, you can use your own local setup, or Kaggle Notebooks. Kaggle Notebooks
33 | offer a fixed number of GPU hours and have similar functionality to Google Colab, however, there are differences when it
34 | comes to sharing your models on 🤗 Hub (e.g. for completing assignments). If you decide to use Kaggle Notebooks as your
35 | tool of choice, check out the [example Kaggle notebook](https://www.kaggle.com/code/michaelshekasta/test-notebook) created by
36 | [@michaelshekasta](https://github.com/michaelshekasta). This notebook illustrates how you can train and share your
37 | trained model on 🤗 Hub.
38 |
39 |
40 |
41 | ## Step 5. Join the community
42 |
43 | Sign up to our Discord server, the place where you can exchange ideas with your classmates and reach out to us (the Hugging Face team).
44 |
45 | [👉 JOIN THE COMMUNITY ON DISCORD](http://hf.co/join/discord)
46 |
47 | To learn more about our community on Discord and how to make the most of it, check out the [next page](community).
48 |
--------------------------------------------------------------------------------
/chapters/en/chapter1/introduction.mdx:
--------------------------------------------------------------------------------
1 | # Unit 1. Working with audio data
2 |
3 | ## What you'll learn in this unit
4 |
5 | Every audio or speech task starts with an audio file. Before we can dive into solving these tasks, it's important to
6 | understand what these files actually contain, and how to work with them.
7 |
8 | In this unit, you will gain an understanding of the fundamental terminology related to audio data, including waveform,
9 | sampling rate, and spectrogram. You will also learn how to work with audio datasets, including loading and preprocessing
10 | audio data, and how to stream large datasets efficiently.
11 |
12 | By the end of this unit, you will have a strong grasp of the essential audio data terminology and will be equipped with the
13 | skills necessary to work with audio datasets for various applications. The knowledge you'll gain in this unit is going to
14 | lay a foundation to understanding the remainder of the course.
--------------------------------------------------------------------------------
/chapters/en/chapter1/supplemental_reading.mdx:
--------------------------------------------------------------------------------
1 | # Learn more
2 |
3 | This unit covered many fundamental concepts relevant to understanding of audio data and working with it.
4 | Want to learn more? Here you will find additional resources that will help you deepen your understanding of the topics and
5 | enhance your learning experience.
6 |
7 | In the following video, Monty Montgomery from xiph.org presents a real-time demonstrations of sampling, quantization,
8 | bit-depth, and dither on real audio equipment using both modern digital analysis and vintage analog bench equipment, check it out:
9 |
10 |
11 |
12 | If you'd like to dive deeper into digital signal processing, check out the free ["Digital Signals Theory" book](https://brianmcfee.net/dstbook-site/content/intro.html)
13 | authored by Brian McFee, an Assistant Professor of Music Technology and Data Science at New York University and the principal maintainer
14 | of the `librosa` package.
15 |
16 |
--------------------------------------------------------------------------------
/chapters/en/chapter2/hands_on.mdx:
--------------------------------------------------------------------------------
1 | # Hands-on exercise
2 |
3 | This exercise is not graded and is intended to help you become familiar with the tools and libraries that you will be using throughout the rest of the course. If you are already experienced in using Google Colab, 🤗 Datasets, librosa and 🤗 Transformers, you may choose to skip this exercise.
4 |
5 | 1. Create a [Google Colab](https://colab.research.google.com) notebook.
6 | 2. Use 🤗 Datasets to load the train split of the [`facebook/voxpopuli` dataset](https://huggingface.co/datasets/facebook/voxpopuli) in language of your choice in streaming mode.
7 | 3. Get the third example from the `train` part of the dataset and explore it. Given the features that this example has, what kinds of audio tasks can you use this dataset for?
8 | 4. Plot this example's waveform and spectrogram.
9 | 5. Go to [🤗 Hub](https://huggingface.co/models), explore pretrained models and find one that can be used for automatic speech recognition for the language that you have picked earlier. Instantiate a corresponding pipeline with the model you found, and transcribe the example.
10 | 6. Compare the transcription that you get from the pipeline to the transcription provided in the example.
11 |
12 | If you struggle with this exercise, feel free to take a peek at an [example solution](https://colab.research.google.com/drive/1NGyo5wFpRj8TMfZOIuPaJHqyyXCITftc?usp=sharing).
13 | Discovered something interesting? Found a cool model? Got a beautiful spectrogram? Feel free to share your work and discoveries on Twitter!
14 |
15 | In the next chapters you'll learn more about various audio transformer architectures and will train your own model!
16 |
17 |
18 |
19 |
20 |
21 |
--------------------------------------------------------------------------------
/chapters/en/chapter2/introduction.mdx:
--------------------------------------------------------------------------------
1 | # Unit 2. A gentle introduction to audio applications
2 |
3 | Welcome to the second unit of the Hugging Face audio course! Previously, we explored the fundamentals of audio data
4 | and learned how to work with audio datasets using the 🤗 Datasets and 🤗 Transformers libraries. We discussed various
5 | concepts such as sampling rate, amplitude, bit depth, waveform, and spectrograms, and saw how to preprocess data to
6 | prepare it for a pre-trained model.
7 |
8 | At this point you may be eager to learn about the audio tasks that 🤗 Transformers can handle, and you have all the foundational
9 | knowledge necessary to dive in! Let's take a look at some of the mind-blowing audio task examples:
10 |
11 | * **Audio classification**: easily categorize audio clips into different categories. You can identify whether a recording
12 | is of a barking dog or a meowing cat, or what music genre a song belongs to.
13 | * **Automatic speech recognition**: transform audio clips into text by transcribing them automatically. You can get a text
14 | representation of a recording of someone speaking, like "How are you doing today?". Rather useful for note taking!
15 | * **Speaker diarization**: Ever wondered who's speaking in a recording? With 🤗 Transformers, you can identify which speaker
16 | is talking at any given time in an audio clip. Imagine being able to differentiate between "Alice" and "Bob" in a recording
17 | of them having a conversation.
18 | * **Text to speech**: create a narrated version of a text that can be used to produce an audio book, help with accessibility,
19 | or give a voice to an NPC in a game. With 🤗 Transformers, you can easily do that!
20 |
21 | In this unit, you'll learn how to use pre-trained models for some of these tasks using the `pipeline()` function from 🤗 Transformers.
22 | Specifically, we'll see how the pre-trained models can be used for audio classification, automatic speech recognition and audio generation.
23 | Let's get started!
24 |
25 |
--------------------------------------------------------------------------------
/chapters/en/chapter3/supplemental_reading.mdx:
--------------------------------------------------------------------------------
1 | # Supplemental reading and resources
2 |
3 | If you'd like to further explore different Transformer architectures, and learn about their various applications in speech processing, check
4 | out this recent paper:
5 |
6 | ### Transformers in Speech Processing: A Survey
7 |
8 | by Siddique Latif, Aun Zaidi, Heriberto Cuayahuitl, Fahad Shamshad, Moazzam Shoukat, Junaid Qadir
9 |
10 | "The remarkable success of transformers in the field of natural language processing has sparked the interest of the
11 | speech-processing community, leading to an exploration of their potential for modeling long-range dependencies within
12 | speech sequences. Recently, transformers have gained prominence across various speech-related domains, including
13 | automatic speech recognition, speech synthesis, speech translation, speech para-linguistics, speech enhancement, s
14 | poken dialogue systems, and numerous multimodal applications. In this paper, we present a comprehensive survey that
15 | aims to bridge research studies from diverse subfields within speech technology. By consolidating findings from across
16 | the speech technology landscape, we provide a valuable resource for researchers interested in harnessing the power of
17 | transformers to advance the field. We identify the challenges encountered by transformers in speech processing while
18 | also offering insights into potential solutions to address these issues."
19 |
20 | [arxiv.org/abs/2303.11607](https://arxiv.org/abs/2303.11607)
21 |
--------------------------------------------------------------------------------
/chapters/en/chapter4/demo.mdx:
--------------------------------------------------------------------------------
1 | # Build a demo with Gradio
2 |
3 | In this final section on audio classification, we'll build a [Gradio](https://gradio.app) demo to showcase the music
4 | classification model that we just trained on the [GTZAN](https://huggingface.co/datasets/marsyas/gtzan) dataset. The first
5 | thing to do is load up the fine-tuned checkpoint using the `pipeline()` class - this is very familiar now from the section
6 | on [pre-trained models](classification_models). You can change the `model_id` to the namespace of your fine-tuned model
7 | on the Hugging Face Hub:
8 |
9 | ```python
10 | from transformers import pipeline
11 |
12 | model_id = "sanchit-gandhi/distilhubert-finetuned-gtzan"
13 | pipe = pipeline("audio-classification", model=model_id)
14 | ```
15 |
16 | Secondly, we'll define a function that takes the filepath for an audio input and passes it through the pipeline. Here,
17 | the pipeline automatically takes care of loading the audio file, resampling it to the correct sampling rate, and running
18 | inference with the model. We take the models predictions of `preds` and format them as a dictionary object to be displayed on the
19 | output:
20 |
21 | ```python
22 | def classify_audio(filepath):
23 | preds = pipe(filepath)
24 | outputs = {}
25 | for p in preds:
26 | outputs[p["label"]] = p["score"]
27 | return outputs
28 | ```
29 |
30 | Finally, we launch the Gradio demo using the function we've just defined:
31 |
32 | ```python
33 | import gradio as gr
34 |
35 | demo = gr.Interface(
36 | fn=classify_audio, inputs=gr.Audio(type="filepath"), outputs=gr.outputs.Label()
37 | )
38 | demo.launch(debug=True)
39 | ```
40 |
41 | This will launch a Gradio demo similar to the one running on the Hugging Face Space:
42 |
43 |
44 |
45 |
--------------------------------------------------------------------------------
/chapters/en/chapter4/hands_on.mdx:
--------------------------------------------------------------------------------
1 | # Hands-on exercise
2 |
3 | It's time to get your hands on some Audio models and apply what you have learned so far.
4 | This exercise is one of the four hands-on exercises required to qualify for a course completion certificate.
5 |
6 | Here are the instructions.
7 | In this unit, we demonstrated how to fine-tune a Hubert model on `marsyas/gtzan` dataset for music classification. Our example achieved 83% accuracy.
8 | Your task is to improve upon this accuracy metric.
9 |
10 | Feel free to choose any model on the [🤗 Hub](https://huggingface.co/models) that you think is suitable for audio classification,
11 | and use the exact same dataset [`marsyas/gtzan`](https://huggingface.co/datasets/marsyas/gtzan) to build your own classifier.
12 |
13 | Your goal is to achieve 87% accuracy on this dataset with your classifier. You can choose the exact same model, and play with the training hyperparameters,
14 | or pick an entirely different model - it's up to you!
15 |
16 | For your result to count towards your certificate, don't forget to push your model to Hub as was shown in this unit with
17 | the following `**kwargs` at the end of the training:
18 |
19 | ```python
20 | kwargs = {
21 | "dataset_tags": "marsyas/gtzan",
22 | "dataset": "GTZAN",
23 | "model_name": f"{model_name}-finetuned-gtzan",
24 | "finetuned_from": model_id,
25 | "tasks": "audio-classification",
26 | }
27 |
28 | trainer.push_to_hub(**kwargs)
29 | ```
30 |
31 | Here are some additional resources that you may find helpful when working on this exercise:
32 | * [Audio classification task guide in Transformers documentation](https://huggingface.co/docs/transformers/tasks/audio_classification)
33 | * [Hubert model documentation](https://huggingface.co/docs/transformers/model_doc/hubert)
34 | * [M-CTC-T model documentation](https://huggingface.co/docs/transformers/model_doc/mctct)
35 | * [Audio Spectrogram Transformer documentation](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)
36 | * [Wav2Vec2 documentation](https://huggingface.co/docs/transformers/model_doc/wav2vec2)
37 |
38 | Feel free to build a demo of your model, and share it on Discord! If you have questions, post them in the #audio-study-group channel.
39 |
--------------------------------------------------------------------------------
/chapters/en/chapter4/introduction.mdx:
--------------------------------------------------------------------------------
1 | # Unit 4. Build a music genre classifier
2 |
3 | ## What you'll learn and what you'll build
4 |
5 | Audio classification is one of the most common applications of transformers in audio and speech processing. Like other
6 | classification tasks in machine learning, this task involves assigning one or more labels to an audio recording based on
7 | its content. For example, in the case of speech, we might want to detect when wake words like "Hey Siri" are spoken, or
8 | infer a key word like "temperature" from a spoken query like "What is the weather today?". Environmental sounds
9 | provide another example, where we might want to automatically distinguish between sounds such as "car horn", "siren",
10 | "dog barking", etc.
11 |
12 | In this section, we'll look at how pre-trained audio transformers can be applied to a range of audio classification tasks.
13 | We'll then fine-tune a transformer model on the task of music classification, classifying songs into genres like "pop" and
14 | "rock". This is an important part of music streaming platforms like [Spotify](https://en.wikipedia.org/wiki/Spotify), which
15 | recommend songs that are similar to the ones the user is listening to.
16 |
17 | By the end of this section, you'll know how to:
18 |
19 | * Find suitable pre-trained models for audio classification tasks
20 | * Use the 🤗 Datasets library and the Hugging Face Hub to select audio classification datasets
21 | * Fine-tune a pretrained model to classify songs by genre
22 | * Build a Gradio demo that lets you classify your own songs
23 |
--------------------------------------------------------------------------------
/chapters/en/chapter5/hands_on.mdx:
--------------------------------------------------------------------------------
1 | # Hands-on exercise
2 |
3 | In this unit, we explored the challenges of fine-tuning ASR models, acknowledging the time and resources required to
4 | fine-tune a model like Whisper (even a small checkpoint) on a new language. To provide a hands-on experience, we have
5 | designed an exercise that allows you to navigate the process of fine-tuning an ASR model while using a smaller dataset.
6 | The main goal of this exercise is to familiarize you with the process rather than expecting production-level results.
7 | We have intentionally set a low metric to ensure that even with limited resources, you should be able to achieve it.
8 |
9 | Here are the instructions:
10 | * Fine-tune the `”openai/whisper-tiny”` model using the American English ("en-US") subset of the `”PolyAI/minds14”` dataset.
11 | * Use the first **450 examples for training**, and the rest for evaluation. Ensure you set `num_proc=1` when pre-processing the dataset using the `.map` method (this will ensure your model is submitted correctly for assessment).
12 | * To evaluate the model, use the `wer` and `wer_ortho` metrics as described in this Unit. However, *do not* convert the metric into percentages by multiplying by 100 (E.g. if WER is 42%, we’ll expect to see the value of 0.42 in this exercise).
13 |
14 | Once you have fine-tuned a model, make sure to upload it to the 🤗 Hub with the following `kwargs`:
15 | ```
16 | kwargs = {
17 | "dataset_tags": "PolyAI/minds14",
18 | "finetuned_from": "openai/whisper-tiny",
19 | "tasks": "automatic-speech-recognition",
20 | }
21 | ```
22 | You will pass this assignment if your model’s normalised WER (`wer`) is lower than **0.37**.
23 |
24 | Feel free to build a demo of your model, and share it on Discord! If you have questions, post them in the #audio-study-group channel.
25 |
--------------------------------------------------------------------------------
/chapters/en/chapter5/introduction.mdx:
--------------------------------------------------------------------------------
1 | # What you'll learn and what you'll build
2 |
3 | In this section, we’ll take a look at how Transformers can be used to convert spoken speech into text, a task known _speech recognition_.
4 |
5 |
6 |
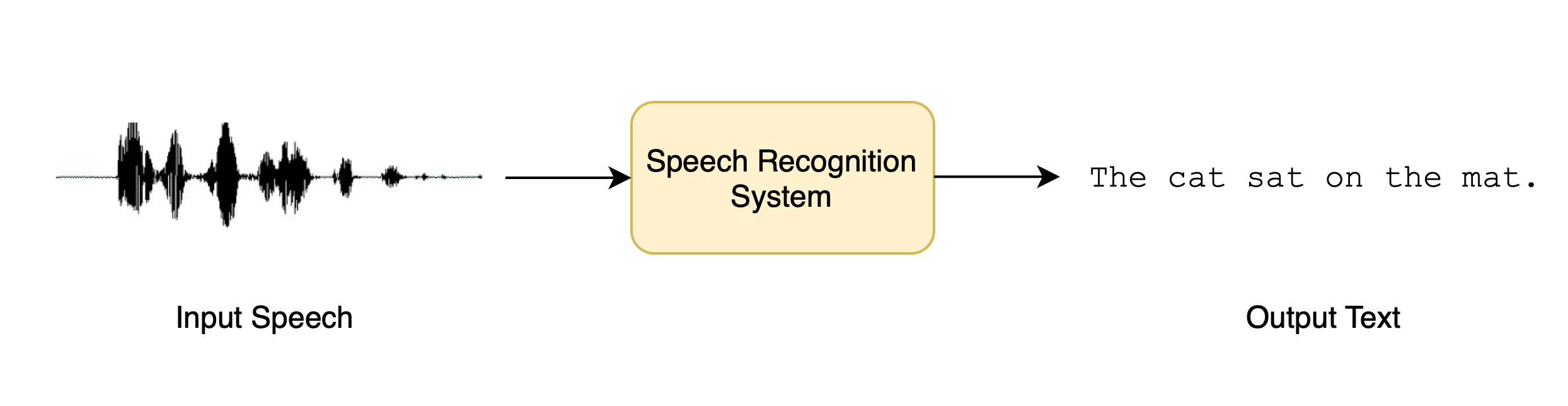
7 |
16 |

17 |
6 |
7 |
16 |
17 |
6 |
7 |