69 | $ python train.py
70 | ```
71 |
72 | This will create a new project directory with the name `autotrain-llama32-1b-finetune` and start the training process.
73 | Once the training is complete, the model will be pushed to the Hugging Face Hub.
74 |
75 | Your HF_TOKEN and HF_USERNAME are only required if you want to push the model or if you are accessing a gated model or dataset.
76 |
77 | ## AutoTrainProject Class
78 |
79 | [[autodoc]] project.AutoTrainProject
80 |
81 | ## Parameters
82 |
83 | ### Text Tasks
84 |
85 | [[autodoc]] trainers.clm.params.LLMTrainingParams
86 |
87 | [[autodoc]] trainers.sent_transformers.params.SentenceTransformersParams
88 |
89 | [[autodoc]] trainers.seq2seq.params.Seq2SeqParams
90 |
91 | [[autodoc]] trainers.token_classification.params.TokenClassificationParams
92 |
93 | [[autodoc]] trainers.extractive_question_answering.params.ExtractiveQuestionAnsweringParams
94 |
95 | [[autodoc]] trainers.text_classification.params.TextClassificationParams
96 |
97 | [[autodoc]] trainers.text_regression.params.TextRegressionParams
98 |
99 | ### Image Tasks
100 |
101 | [[autodoc]] trainers.image_classification.params.ImageClassificationParams
102 |
103 | [[autodoc]] trainers.image_regression.params.ImageRegressionParams
104 |
105 | [[autodoc]] trainers.object_detection.params.ObjectDetectionParams
106 |
107 |
108 | ### Tabular Tasks
109 |
110 | [[autodoc]] trainers.tabular.params.TabularParams
--------------------------------------------------------------------------------
/docs/source/quickstart_spaces.mdx:
--------------------------------------------------------------------------------
1 | # Quickstart Guide to AutoTrain on Hugging Face Spaces
2 |
3 | AutoTrain on Hugging Face Spaces is the preferred choice for a streamlined experience in
4 | model training. This platform is optimized for ease of use, with pre-installed dependencies
5 | and managed hardware resources. AutoTrain on Hugging Face Spaces can be used both by
6 | no-code users and developers, making it versatile for various levels of expertise.
7 |
8 |
9 | ## Creating a New AutoTrain Space
10 |
11 | Getting started with AutoTrain is straightforward. Here’s how you can create your new space:
12 |
13 | 1. **Visit the AutoTrain Page**: To create a new space with AutoTrain Docker image, all you need to do is go
14 | to [AutoTrain Homepage](https://hf.co/autotrain) and click on "Create new project".
15 |
16 | 2. **Log In or View the Setup Screen**: If not logged in, you'll be prompted to do so. Then, you’ll see a screen similar to this:
17 |
18 | 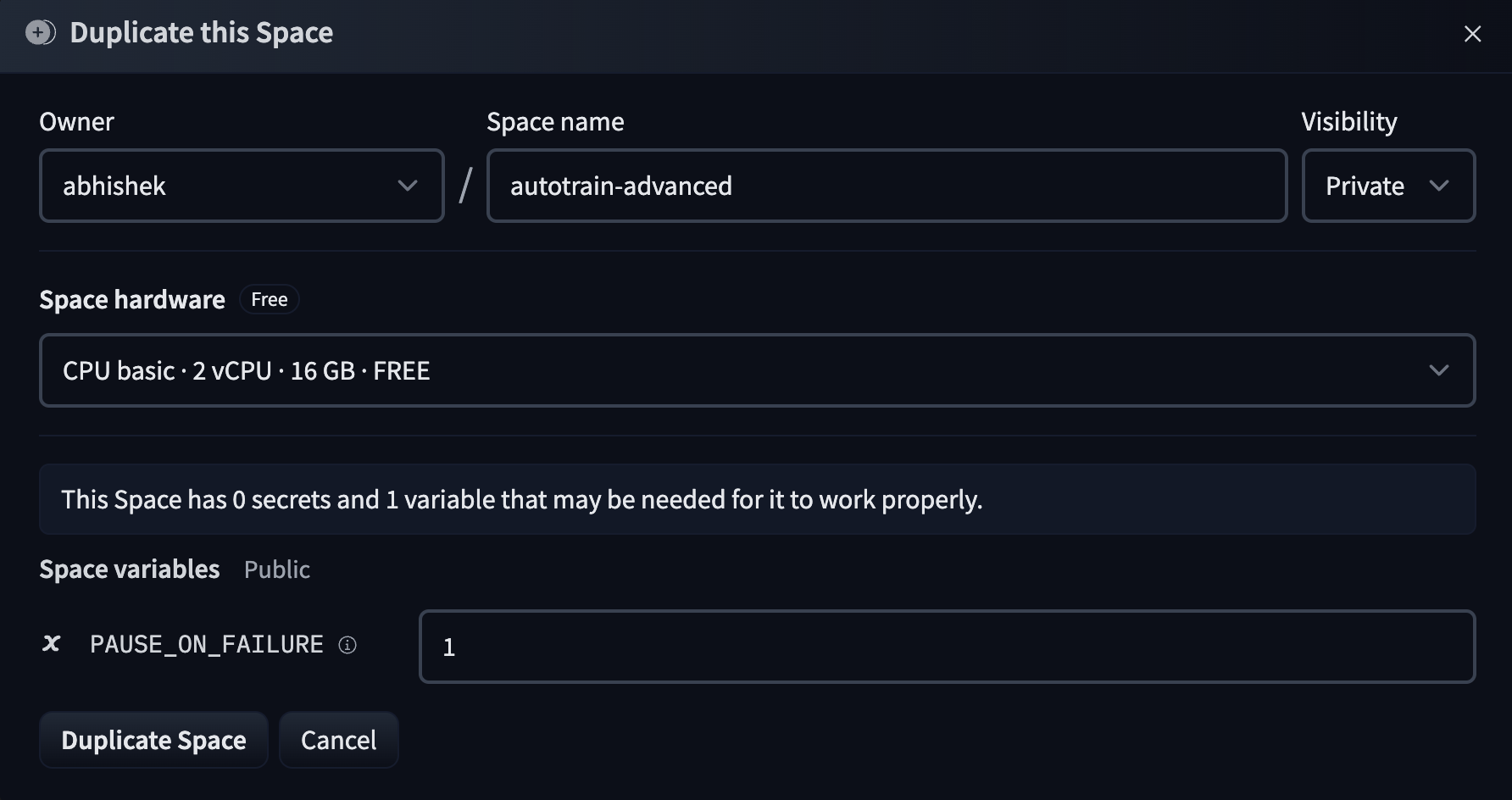
19 |
20 | 3. **Set Up Your Space**:
21 |
22 | - **Choose a Space Name**: Name your space something relevant to your project.
23 |
24 | - **Allocate Hardware Resources**: Select the necessary computational resources based on your project needs.
25 |
26 | - **Duplicate Space**: Click on "Duplicate Space" to initiate your AutoTrain space with the Docker image.
27 |
28 | 4. **Configuration Options**:
29 |
30 | - PAUSE_ON_FAILURE: Set this to 0 if you prefer the space not to pause on training failures, useful for running continuous experiments. This option can also be used if you continuously want to perfom many experiments in the same space.
31 |
32 | 5. **Launch and Train**:
33 |
34 | - Once done, in a few seconds, the AutoTrain Space will be up and running and you will be presented with the following screen:
35 |
36 | 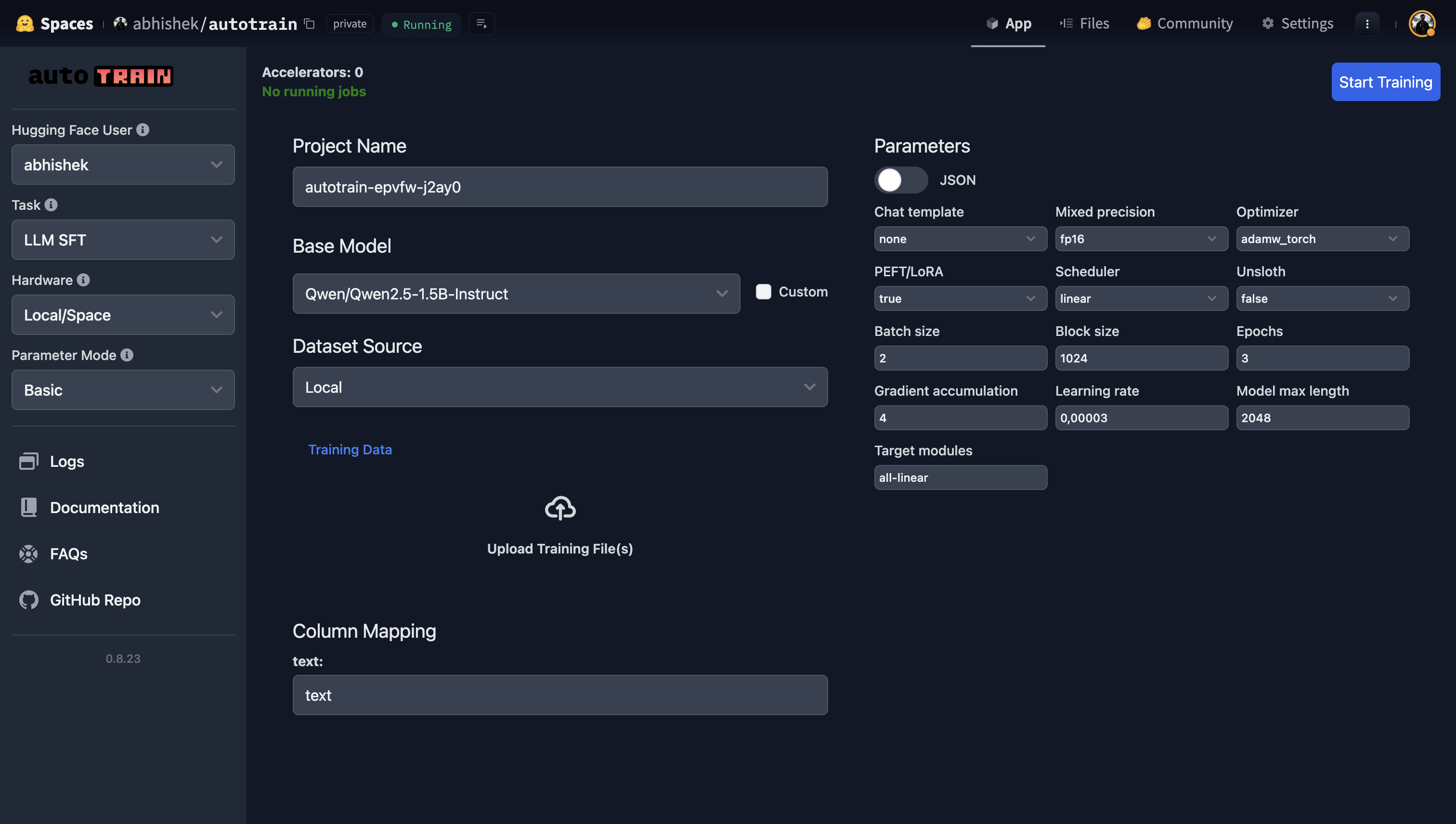
37 |
38 | - From here, you can select tasks, upload datasets, choose models, adjust hyperparameters (if needed),
39 | and start the training process directly within the space.
40 |
41 | - The space will manage its own activity, shutting down post-training unless configured
42 | otherwise based on the `PAUSE_ON_FAILURE` setting.
43 |
44 | 6. **Monitoring Progress**:
45 |
46 | - All training logs and progress can be monitored via TensorBoard, accessible under
47 | `username/project_name` on the Hugging Face Hub.
48 |
49 | - Once training concludes successfully, you’ll find the model files in the same repository.
50 |
51 | 7. **Navigating the UI**:
52 |
53 | - If you need help understanding any UI elements, click on the small (i) information icons for detailed descriptions.
54 |
55 | If you are confused about the UI elements, click on the small (i) information icon to get more information about the UI element.
56 |
57 | For data formats and detailed parameter information, please see the Data Formats and Parameters section where we provide
58 | example datasets and detailed information about the parameters for each task supported by AutoTrain.
59 |
60 | ## Ensuring Your AutoTrain is Up-to-Date
61 |
62 | We are constantly adding new features and tasks to AutoTrain Advanced. To benefit from the latest features, tasks, and bug fixes, update your AutoTrain space regularly:
63 |
64 | - *Factory Reboot*: Navigate to the settings page of your space and click on "Factory reboot" to upgrade to the latest version of AutoTrain Advanced.
65 |
66 | 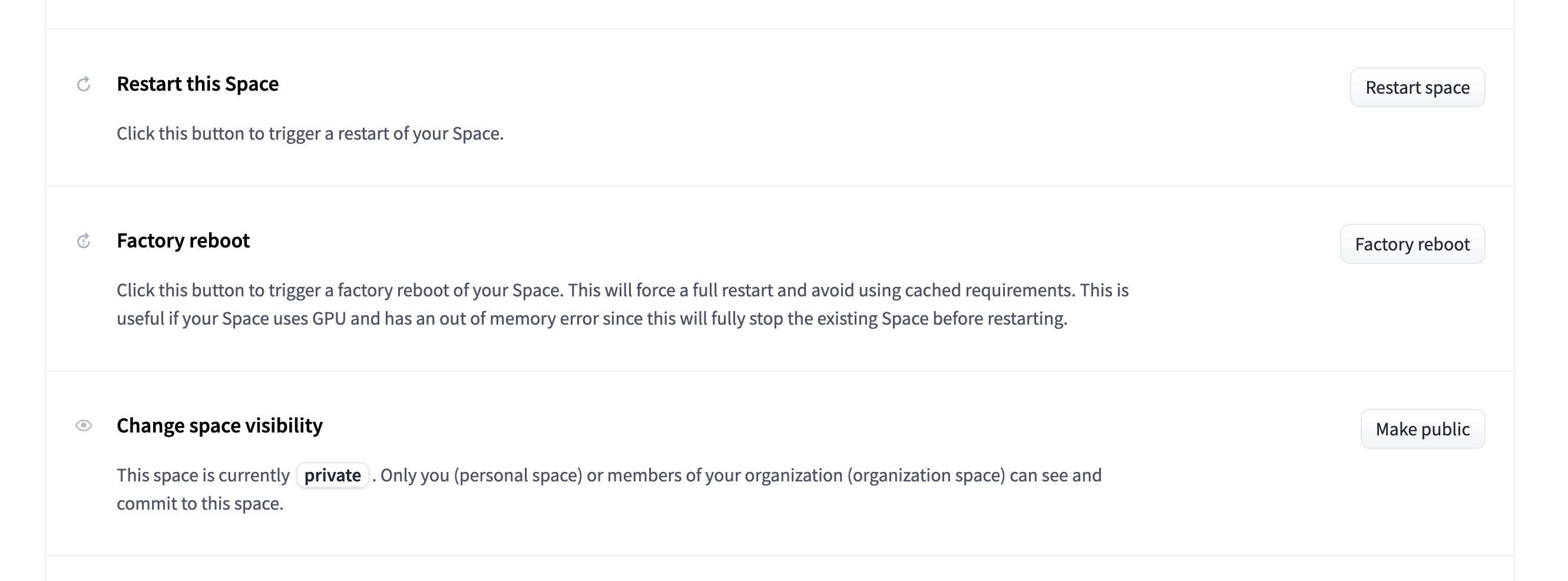
67 |
68 | - *Note*: Simply "restarting" the space does not update it; a factory reboot is necessary for a complete update.
69 |
70 |
71 | For additional details on data formats and specific parameters, refer to the
72 | 'Data Formats and Parameters' section where we provide example datasets and extensive
73 | parameter information for each supported task by AutoTrain.
74 |
75 |
76 | With these steps, you can effortlessly initiate and manage your AutoTrain projects on
77 | Hugging Face Spaces, leveraging the platform's robust capabilities for your machine learning and AI
78 | needs.
79 |
--------------------------------------------------------------------------------
/docs/source/starting_ui.bck:
--------------------------------------------------------------------------------
1 | # Starting the UI
2 |
3 | The AutoTrain UI can be started in multiple ways depending on your needs.
4 | We offer UI on Hugging Face Spaces, Colab and locally!
5 |
6 | ## Hugging Face Spaces
7 |
8 | To start the UI on Hugging Face Spaces, you can simply click on the following link:
9 |
10 | [](https://huggingface.co/login?next=/spaces/autotrain-projects/autotrain-advanced?duplicate=true)
11 |
12 | Please make sure you keep the space private and attach appropriate hardware to the space.
13 | You can also read more about AutoTrain on the homepage and follow the link there to start your own training instance on
14 | Hugging Face Spaces. [Click here](https://huggingface.co/autotrain) to visit the homepage.
15 |
16 | ## Colab
17 |
18 | To start the UI on Colab, you can simply click on the following link:
19 |
20 | [](https://colab.research.google.com/github/huggingface/autotrain-advanced/blob/main/colabs/AutoTrain.ipynb)
21 |
22 | Please note, to run the app on Colab, you will need an ngrok token. You can get one by signing up for free on [ngrok](https://ngrok.com/).
23 | This is because Colab does not allow exposing ports to the internet directly.
24 |
25 |
26 | ## Locally
27 |
28 | To run the autotrain app locally, install autotrain-advanced python package:
29 |
30 | ```bash
31 | $ pip install autotrain-advanced
32 | ```
33 |
34 | and then run the following command:
35 |
36 | ```bash
37 | $ export HF_TOKEN=your_hugging_face_write_token
38 | $ autotrain app --host 127.0.0.1 --port 8000
39 | ```
40 |
41 | This will start the app on `http://127.0.0.1:8000`.
42 |
43 | AutoTrain doesn't install pytorch, torchaudio, torchvision, or any other dependencies. You will need to install them separately.
44 | It is thus recommended to use conda environment:
45 |
46 |
47 | ```bash
48 | $ conda create -n autotrain python=3.10
49 | $ conda activate autotrain
50 |
51 | $ pip install autotrain-advanced
52 |
53 | $ conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
54 | $ conda install -c "nvidia/label/cuda-12.1.0" cuda-nvcc
55 | $ conda install xformers -c xformers
56 |
57 | $ python -m nltk.downloader punkt
58 | $ pip install flash-attn --no-build-isolation
59 | $ pip install deepspeed
60 |
61 | $ export HF_TOKEN=your_hugging_face_write_token
62 | $ autotrain app --host 127.0.0.1 --port 8000
63 | ```
64 |
65 | In case of any issues, please report on the [GitHub issues](https://github.com/huggingface/autotrain-advanced/).
66 |
--------------------------------------------------------------------------------
/docs/source/support.mdx:
--------------------------------------------------------------------------------
1 | # Help and Support
2 |
3 | If you need assistance with AutoTrain Advanced or have questions about your projects,
4 | you can reach out through several dedicated support channels. We're here to help you
5 | navigate any issues you encounter, from technical queries to billing concerns.
6 | Below are the best ways to get support:
7 |
8 |
9 | - For technical support or to report a bug, you can [create an issue](https://github.com/huggingface/autotrain-advanced/issues/new)
10 | directly in the AutoTrain Advanced GitHub repository. GitHub repo is ideal for tracking bugs,
11 | requesting features, or getting help with troubleshooting problems. When submitting an
12 | issue, please include all the details in question to help us provide the most
13 | relevant support quickly.
14 |
15 | - [Ask in the Hugging Face Forum](https://discuss.huggingface.co/c/autotrain/16). This space is perfect for asking questions,
16 | sharing your experiences, or discussing AutoTrain with other users and the Hugging Face
17 | team. The forum is a great resource for getting advice, learning best practices, and
18 | connecting with other machine learning practitioners.
19 |
20 | - For enterprise users or specific inquiries related to billing, please [email us](mailto:autotrain@hf.co) directly.
21 | This channel ensures that your more sensitive or account-specific issues are handled
22 | appropriately and confidentially. When emailing, please provide your username and
23 | project name so we can assist you efficiently.
24 |
25 | Please note: e-mail support is only available for pro/enterprise users or those with specific queries about billing.
26 |
27 |
28 | By utilizing these support channels, you can ensure that any hurdles you face while using
29 | AutoTrain Advanced are addressed promptly, allowing you to focus on achieving your project
30 | goals. Whether you're a beginner or an experienced user, we are here to support your
31 | journey in AI model training.
32 |
--------------------------------------------------------------------------------
/docs/source/tasks/object_detection.mdx:
--------------------------------------------------------------------------------
1 | # Object Detection
2 |
3 | Object detection is a form of supervised learning where a model is trained to identify
4 | and categorize objects within images. AutoTrain simplifies the process, enabling you to
5 | train a state-of-the-art object detection model by simply uploading labeled example images.
6 |
7 |
8 | ## Preparing your data
9 |
10 | To ensure your object detection model trains effectively, follow these guidelines for preparing your data:
11 |
12 |
13 | ### Organizing Images
14 |
15 |
16 | Prepare a zip file containing your images and metadata.jsonl.
17 |
18 |
19 | ```
20 | Archive.zip
21 | ├── 0001.png
22 | ├── 0002.png
23 | ├── 0003.png
24 | ├── .
25 | ├── .
26 | ├── .
27 | └── metadata.jsonl
28 | ```
29 |
30 | Example for `metadata.jsonl`:
31 |
32 | ```
33 | {"file_name": "0001.png", "objects": {"bbox": [[302.0, 109.0, 73.0, 52.0]], "category": [0]}}
34 | {"file_name": "0002.png", "objects": {"bbox": [[810.0, 100.0, 57.0, 28.0]], "category": [1]}}
35 | {"file_name": "0003.png", "objects": {"bbox": [[160.0, 31.0, 248.0, 616.0], [741.0, 68.0, 202.0, 401.0]], "category": [2, 2]}}
36 | ```
37 |
38 | Please note that bboxes need to be in COCO format `[x, y, width, height]`.
39 |
40 |
41 | ### Image Requirements
42 |
43 | - Format: Ensure all images are in JPEG, JPG, or PNG format.
44 |
45 | - Quantity: Include at least 5 images to provide the model with sufficient examples for learning.
46 |
47 | - Exclusivity: The zip file should exclusively contain images and metadata.jsonl.
48 | No additional files or nested folders should be included.
49 |
50 |
51 | Some points to keep in mind:
52 |
53 | - The images must be jpeg, jpg or png.
54 | - There should be at least 5 images per split.
55 | - There must not be any other files in the zip file.
56 | - There must not be any other folders inside the zip folder.
57 |
58 | When train.zip is decompressed, it creates no folders: only images and metadata.jsonl.
59 |
60 | ## Parameters
61 |
62 | [[autodoc]] trainers.object_detection.params.ObjectDetectionParams
63 |
--------------------------------------------------------------------------------
/docs/source/tasks/sentence_transformer.mdx:
--------------------------------------------------------------------------------
1 | # Sentence Transformers
2 |
3 | This task lets you easily train or fine-tune a Sentence Transformer model on your own dataset.
4 |
5 | AutoTrain supports the following types of sentence transformer finetuning:
6 |
7 | - `pair`: dataset with two sentences: anchor and positive
8 | - `pair_class`: dataset with two sentences: premise and hypothesis and a target label
9 | - `pair_score`: dataset with two sentences: sentence1 and sentence2 and a target score
10 | - `triplet`: dataset with three sentences: anchor, positive and negative
11 | - `qa`: dataset with two sentences: query and answer
12 |
13 | ## Data Format
14 |
15 | Sentence Transformers finetuning accepts data in CSV/JSONL format. You can also use a dataset from Hugging Face Hub.
16 |
17 | ### `pair`
18 |
19 | For `pair` training, the data should be in the following format:
20 |
21 | | anchor | positive |
22 | |--------|----------|
23 | | hello | hi |
24 | | how are you | I am fine |
25 | | What is your name? | My name is Abhishek |
26 | | Which is the best programming language? | Python |
27 |
28 | ### `pair_class`
29 |
30 | For `pair_class` training, the data should be in the following format:
31 |
32 | | premise | hypothesis | label |
33 | |---------|------------|-------|
34 | | hello | hi | 1 |
35 | | how are you | I am fine | 0 |
36 | | What is your name? | My name is Abhishek | 1 |
37 | | Which is the best programming language? | Python | 1 |
38 |
39 | ### `pair_score`
40 |
41 | For `pair_score` training, the data should be in the following format:
42 |
43 | | sentence1 | sentence2 | score |
44 | |-----------|-----------|-------|
45 | | hello | hi | 0.8 |
46 | | how are you | I am fine | 0.2 |
47 | | What is your name? | My name is Abhishek | 0.9 |
48 | | Which is the best programming language? | Python | 0.7 |
49 |
50 | ### `triplet`
51 |
52 | For `triplet` training, the data should be in the following format:
53 |
54 | | anchor | positive | negative |
55 | |--------|----------|----------|
56 | | hello | hi | bye |
57 | | how are you | I am fine | I am not fine |
58 | | What is your name? | My name is Abhishek | Whats it to you? |
59 | | Which is the best programming language? | Python | Javascript |
60 |
61 | ### `qa`
62 |
63 | For `qa` training, the data should be in the following format:
64 |
65 | | query | answer |
66 | |-------|--------|
67 | | hello | hi |
68 | | how are you | I am fine |
69 | | What is your name? | My name is Abhishek |
70 | | Which is the best programming language? | Python |
71 |
72 |
73 | ## Parameters
74 |
75 | [[autodoc]] trainers.sent_transformers.params.SentenceTransformersParams
76 |
--------------------------------------------------------------------------------
/docs/source/tasks/seq2seq.mdx:
--------------------------------------------------------------------------------
1 | # Seq2Seq
2 |
3 | Seq2Seq is a task that involves converting a sequence of words into another sequence of words.
4 | It is used in machine translation, text summarization, and question answering.
5 |
6 | ## Data Format
7 |
8 | You can have the dataset as a CSV file:
9 |
10 | ```csv
11 | text,target
12 | "this movie is great","dieser Film ist großartig"
13 | "this movie is bad","dieser Film ist schlecht"
14 | .
15 | .
16 | .
17 | ```
18 |
19 | Or as a JSONL file:
20 |
21 | ```json
22 | {"text": "this movie is great", "target": "dieser Film ist großartig"}
23 | {"text": "this movie is bad", "target": "dieser Film ist schlecht"}
24 | .
25 | .
26 | .
27 | ```
28 |
29 |
30 | ## Columns
31 |
32 | Your CSV/JSONL dataset must have two columns: `text` and `target`.
33 |
34 |
35 | ## Parameters
36 |
37 | [[autodoc]] trainers.seq2seq.params.Seq2SeqParams
38 |
--------------------------------------------------------------------------------
/docs/source/tasks/tabular.mdx:
--------------------------------------------------------------------------------
1 | # Tabular Classification / Regression
2 |
3 | Using AutoTrain, you can train a model to classify or regress tabular data easily.
4 | All you need to do is select from a list of models and upload your dataset.
5 | Parameter tuning is done automatically.
6 |
7 | ## Models
8 |
9 | The following models are available for tabular classification / regression.
10 |
11 | - xgboost
12 | - random_forest
13 | - ridge
14 | - logistic_regression
15 | - svm
16 | - extra_trees
17 | - gradient_boosting
18 | - adaboost
19 | - decision_tree
20 | - knn
21 |
22 |
23 | ## Data Format
24 |
25 | ```csv
26 | id,category1,category2,feature1,target
27 | 1,A,X,0.3373961604172684,1
28 | 2,B,Z,0.6481718720511972,0
29 | 3,A,Y,0.36824153984054797,1
30 | 4,B,Z,0.9571551589530464,1
31 | 5,B,Z,0.14035078041264515,1
32 | 6,C,X,0.8700872583584364,1
33 | 7,A,Y,0.4736080452737105,0
34 | 8,C,Y,0.8009107519796442,1
35 | 9,A,Y,0.5204774795512048,0
36 | 10,A,Y,0.6788795301189603,0
37 | .
38 | .
39 | .
40 | ```
41 |
42 | ## Columns
43 |
44 | Your CSV dataset must have two columns: `id` and `target`.
45 |
46 |
47 | ## Parameters
48 |
49 | [[autodoc]] trainers.tabular.params.TabularParams
50 |
--------------------------------------------------------------------------------
/docs/source/tasks/token_classification.mdx:
--------------------------------------------------------------------------------
1 | # Token Classification
2 |
3 | Token classification is the task of classifying each token in a sequence. This can be used
4 | for Named Entity Recognition (NER), Part-of-Speech (POS) tagging, and more. Get your data ready in
5 | proper format and then with just a few clicks, your state-of-the-art model will be ready to
6 | be used in production.
7 |
8 | ## Data Format
9 |
10 | The data should be in the following CSV format:
11 |
12 | ```csv
13 | tokens,tags
14 | "['I', 'love', 'Paris']","['O', 'O', 'B-LOC']"
15 | "['I', 'live', 'in', 'New', 'York']","['O', 'O', 'O', 'B-LOC', 'I-LOC']"
16 | .
17 | .
18 | .
19 | ```
20 |
21 | or you can also use JSONL format:
22 |
23 | ```json
24 | {"tokens": ["I", "love", "Paris"],"tags": ["O", "O", "B-LOC"]}
25 | {"tokens": ["I", "live", "in", "New", "York"],"tags": ["O", "O", "O", "B-LOC", "I-LOC"]}
26 | .
27 | .
28 | .
29 | ```
30 |
31 | As you can see, we have two columns in the CSV file. One column is the tokens and the other
32 | is the tags. Both the columns are stringified lists! The tokens column contains the tokens
33 | of the sentence and the tags column contains the tags for each token.
34 |
35 | If your CSV is huge, you can divide it into multiple CSV files and upload them separately.
36 | Please make sure that the column names are the same in all CSV files.
37 |
38 | One way to divide the CSV file using pandas is as follows:
39 |
40 | ```python
41 | import pandas as pd
42 |
43 | # Set the chunk size
44 | chunk_size = 1000
45 | i = 1
46 |
47 | # Open the CSV file and read it in chunks
48 | for chunk in pd.read_csv('example.csv', chunksize=chunk_size):
49 | # Save each chunk to a new file
50 | chunk.to_csv(f'chunk_{i}.csv', index=False)
51 | i += 1
52 | ```
53 |
54 |
55 | Sample dataset from HuggingFace Hub: [conll2003](https://huggingface.co/datasets/eriktks/conll2003)
56 |
57 |
58 | ## Columns
59 |
60 | Your CSV/JSONL dataset must have two columns: `tokens` and `tags`.
61 |
62 |
63 | ## Parameters
64 |
65 | [[autodoc]] trainers.token_classification.params.TokenClassificationParams
66 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | albumentations==1.4.23
2 | datasets[vision]~=3.2.0
3 | evaluate==0.4.3
4 | ipadic==1.0.0
5 | jiwer==3.0.5
6 | joblib==1.4.2
7 | loguru==0.7.3
8 | pandas==2.2.3
9 | nltk==3.9.1
10 | optuna==4.1.0
11 | Pillow==11.0.0
12 | sacremoses==0.1.1
13 | scikit-learn==1.6.0
14 | sentencepiece==0.2.0
15 | tqdm==4.67.1
16 | werkzeug==3.1.3
17 | xgboost==2.1.3
18 | huggingface_hub==0.27.0
19 | requests==2.32.3
20 | einops==0.8.0
21 | packaging==24.2
22 | cryptography==44.0.0
23 | nvitop==1.3.2
24 | # latest versions
25 | tensorboard==2.18.0
26 | peft==0.14.0
27 | trl==0.13.0
28 | tiktoken==0.8.0
29 | transformers==4.48.0
30 | accelerate==1.2.1
31 | bitsandbytes==0.45.0
32 | # extras
33 | rouge_score==0.1.2
34 | py7zr==0.22.0
35 | fastapi==0.115.6
36 | uvicorn==0.34.0
37 | python-multipart==0.0.20
38 | pydantic==2.10.4
39 | hf-transfer
40 | pyngrok==7.2.1
41 | authlib==1.4.0
42 | itsdangerous==2.2.0
43 | seqeval==1.2.2
44 | httpx==0.28.1
45 | pyyaml==6.0.2
46 | timm==1.0.12
47 | torchmetrics==1.6.0
48 | pycocotools==2.0.8
49 | sentence-transformers==3.3.1
50 |
--------------------------------------------------------------------------------
/setup.cfg:
--------------------------------------------------------------------------------
1 | [metadata]
2 | license_files = LICENSE
3 | version = attr: autotrain.__version__
4 |
5 | [isort]
6 | ensure_newline_before_comments = True
7 | force_grid_wrap = 0
8 | include_trailing_comma = True
9 | line_length = 119
10 | lines_after_imports = 2
11 | multi_line_output = 3
12 | use_parentheses = True
13 |
14 | [flake8]
15 | ignore = E203, E501, W503
16 | max-line-length = 119
17 | per-file-ignores =
18 | # imported but unused
19 | __init__.py: F401, E402
20 | src/autotrain/params.py: F401
21 | exclude =
22 | .git,
23 | .venv,
24 | __pycache__,
25 | dist
26 | build
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | # Lint as: python3
2 | """
3 | HuggingFace / AutoTrain Advanced
4 | """
5 | import os
6 |
7 | from setuptools import find_packages, setup
8 |
9 |
10 | DOCLINES = __doc__.split("\n")
11 |
12 | this_directory = os.path.abspath(os.path.dirname(__file__))
13 | with open(os.path.join(this_directory, "README.md"), encoding="utf-8") as f:
14 | LONG_DESCRIPTION = f.read()
15 |
16 | # get INSTALL_REQUIRES from requirements.txt
17 | INSTALL_REQUIRES = []
18 | requirements_path = os.path.join(this_directory, "requirements.txt")
19 | with open(requirements_path, encoding="utf-8") as f:
20 | for line in f:
21 | # Exclude 'bitsandbytes' if installing on macOS
22 | if "bitsandbytes" in line:
23 | line = line.strip() + " ; sys_platform == 'linux'"
24 | INSTALL_REQUIRES.append(line.strip())
25 | else:
26 | INSTALL_REQUIRES.append(line.strip())
27 |
28 | QUALITY_REQUIRE = [
29 | "black",
30 | "isort",
31 | "flake8==3.7.9",
32 | ]
33 |
34 | TESTS_REQUIRE = ["pytest"]
35 |
36 | CLIENT_REQUIRES = ["requests", "loguru"]
37 |
38 |
39 | EXTRAS_REQUIRE = {
40 | "base": INSTALL_REQUIRES,
41 | "dev": INSTALL_REQUIRES + QUALITY_REQUIRE + TESTS_REQUIRE,
42 | "quality": INSTALL_REQUIRES + QUALITY_REQUIRE,
43 | "docs": INSTALL_REQUIRES
44 | + [
45 | "recommonmark",
46 | "sphinx==3.1.2",
47 | "sphinx-markdown-tables",
48 | "sphinx-rtd-theme==0.4.3",
49 | "sphinx-copybutton",
50 | ],
51 | "client": CLIENT_REQUIRES,
52 | }
53 |
54 | setup(
55 | name="autotrain-advanced",
56 | description=DOCLINES[0],
57 | long_description=LONG_DESCRIPTION,
58 | long_description_content_type="text/markdown",
59 | author="HuggingFace Inc.",
60 | author_email="autotrain@huggingface.co",
61 | url="https://github.com/huggingface/autotrain-advanced",
62 | download_url="https://github.com/huggingface/autotrain-advanced/tags",
63 | license="Apache 2.0",
64 | package_dir={"": "src"},
65 | packages=find_packages("src"),
66 | extras_require=EXTRAS_REQUIRE,
67 | install_requires=INSTALL_REQUIRES,
68 | entry_points={"console_scripts": ["autotrain=autotrain.cli.autotrain:main"]},
69 | classifiers=[
70 | "Development Status :: 5 - Production/Stable",
71 | "Intended Audience :: Developers",
72 | "Intended Audience :: Education",
73 | "Intended Audience :: Science/Research",
74 | "License :: OSI Approved :: Apache Software License",
75 | "Operating System :: OS Independent",
76 | "Programming Language :: Python :: 3.8",
77 | "Programming Language :: Python :: 3.9",
78 | "Programming Language :: Python :: 3.10",
79 | "Programming Language :: Python :: 3.11",
80 | "Topic :: Scientific/Engineering :: Artificial Intelligence",
81 | ],
82 | keywords="automl autonlp autotrain huggingface",
83 | data_files=[
84 | (
85 | "static",
86 | [
87 | "src/autotrain/app/static/logo.png",
88 | "src/autotrain/app/static/scripts/fetch_data_and_update_models.js",
89 | "src/autotrain/app/static/scripts/listeners.js",
90 | "src/autotrain/app/static/scripts/utils.js",
91 | "src/autotrain/app/static/scripts/poll.js",
92 | "src/autotrain/app/static/scripts/logs.js",
93 | ],
94 | ),
95 | (
96 | "templates",
97 | [
98 | "src/autotrain/app/templates/index.html",
99 | "src/autotrain/app/templates/error.html",
100 | "src/autotrain/app/templates/duplicate.html",
101 | "src/autotrain/app/templates/login.html",
102 | ],
103 | ),
104 | ],
105 | include_package_data=True,
106 | )
107 |
--------------------------------------------------------------------------------
/src/autotrain/__init__.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | # Copyright 2020-2023 The HuggingFace AutoTrain Authors
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 |
16 | # Lint as: python3
17 | # pylint: enable=line-too-long
18 | import os
19 |
20 |
21 | os.environ["BITSANDBYTES_NOWELCOME"] = "1"
22 | os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
23 | os.environ["TOKENIZERS_PARALLELISM"] = "false"
24 |
25 |
26 | import warnings
27 |
28 |
29 | try:
30 | import torch._dynamo
31 |
32 | torch._dynamo.config.suppress_errors = True
33 | except ImportError:
34 | pass
35 |
36 | from autotrain.logging import Logger
37 |
38 |
39 | warnings.filterwarnings("ignore", category=UserWarning, module="tensorflow")
40 | warnings.filterwarnings("ignore", category=UserWarning, module="transformers")
41 | warnings.filterwarnings("ignore", category=UserWarning, module="peft")
42 | warnings.filterwarnings("ignore", category=UserWarning, module="accelerate")
43 | warnings.filterwarnings("ignore", category=UserWarning, module="datasets")
44 | warnings.filterwarnings("ignore", category=FutureWarning, module="accelerate")
45 | warnings.filterwarnings("ignore", category=UserWarning, module="huggingface_hub")
46 |
47 | logger = Logger().get_logger()
48 | __version__ = "0.8.37.dev0"
49 |
50 |
51 | def is_colab():
52 | try:
53 | import google.colab
54 |
55 | return True
56 | except ImportError:
57 | return False
58 |
59 |
60 | def is_unsloth_available():
61 | try:
62 | from unsloth import FastLanguageModel
63 |
64 | return True
65 | except Exception as e:
66 | logger.warning("Unsloth not available, continuing without it")
67 | logger.warning(e)
68 | return False
69 |
--------------------------------------------------------------------------------
/src/autotrain/app/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/autotrain-advanced/b5c98fbe3aab61101e9c8f7f6c64407cbb68e400/src/autotrain/app/__init__.py
--------------------------------------------------------------------------------
/src/autotrain/app/app.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | from fastapi import FastAPI, Request
4 | from fastapi.responses import RedirectResponse
5 | from fastapi.staticfiles import StaticFiles
6 |
7 | from autotrain import __version__, logger
8 | from autotrain.app.api_routes import api_router
9 | from autotrain.app.oauth import attach_oauth
10 | from autotrain.app.ui_routes import ui_router
11 |
12 |
13 | logger.info("Starting AutoTrain...")
14 | BASE_DIR = os.path.dirname(os.path.abspath(__file__))
15 | app = FastAPI()
16 | if "SPACE_ID" in os.environ:
17 | attach_oauth(app)
18 |
19 | app.include_router(ui_router, prefix="/ui", include_in_schema=False)
20 | app.include_router(api_router, prefix="/api")
21 | static_path = os.path.join(BASE_DIR, "static")
22 | app.mount("/static", StaticFiles(directory=static_path), name="static")
23 | logger.info(f"AutoTrain version: {__version__}")
24 | logger.info("AutoTrain started successfully")
25 |
26 |
27 | @app.get("/")
28 | async def forward_to_ui(request: Request):
29 | """
30 | Forwards the incoming request to the UI endpoint.
31 |
32 | Args:
33 | request (Request): The incoming HTTP request.
34 |
35 | Returns:
36 | RedirectResponse: A response object that redirects to the UI endpoint,
37 | including any query parameters from the original request.
38 | """
39 | query_params = request.query_params
40 | url = "/ui/"
41 | if query_params:
42 | url += f"?{query_params}"
43 | return RedirectResponse(url=url)
44 |
--------------------------------------------------------------------------------
/src/autotrain/app/db.py:
--------------------------------------------------------------------------------
1 | import sqlite3
2 |
3 |
4 | class AutoTrainDB:
5 | """
6 | A class to manage job records in a SQLite database.
7 |
8 | Attributes:
9 | -----------
10 | db_path : str
11 | The path to the SQLite database file.
12 | conn : sqlite3.Connection
13 | The SQLite database connection object.
14 | c : sqlite3.Cursor
15 | The SQLite database cursor object.
16 |
17 | Methods:
18 | --------
19 | __init__(db_path):
20 | Initializes the database connection and creates the jobs table if it does not exist.
21 |
22 | create_jobs_table():
23 | Creates the jobs table in the database if it does not exist.
24 |
25 | add_job(pid):
26 | Adds a new job with the given process ID (pid) to the jobs table.
27 |
28 | get_running_jobs():
29 | Retrieves a list of all running job process IDs (pids) from the jobs table.
30 |
31 | delete_job(pid):
32 | Deletes the job with the given process ID (pid) from the jobs table.
33 | """
34 |
35 | def __init__(self, db_path):
36 | self.db_path = db_path
37 | self.conn = sqlite3.connect(db_path)
38 | self.c = self.conn.cursor()
39 | self.create_jobs_table()
40 |
41 | def create_jobs_table(self):
42 | self.c.execute(
43 | """CREATE TABLE IF NOT EXISTS jobs
44 | (id INTEGER PRIMARY KEY, pid INTEGER)"""
45 | )
46 | self.conn.commit()
47 |
48 | def add_job(self, pid):
49 | sql = f"INSERT INTO jobs (pid) VALUES ({pid})"
50 | self.c.execute(sql)
51 | self.conn.commit()
52 |
53 | def get_running_jobs(self):
54 | self.c.execute("""SELECT pid FROM jobs""")
55 | running_pids = self.c.fetchall()
56 | running_pids = [pid[0] for pid in running_pids]
57 | return running_pids
58 |
59 | def delete_job(self, pid):
60 | sql = f"DELETE FROM jobs WHERE pid={pid}"
61 | self.c.execute(sql)
62 | self.conn.commit()
63 |
--------------------------------------------------------------------------------
/src/autotrain/app/static/logo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/autotrain-advanced/b5c98fbe3aab61101e9c8f7f6c64407cbb68e400/src/autotrain/app/static/logo.png
--------------------------------------------------------------------------------
/src/autotrain/app/static/scripts/fetch_data_and_update_models.js:
--------------------------------------------------------------------------------
1 | document.addEventListener('DOMContentLoaded', function () {
2 | function fetchDataAndUpdateModels() {
3 | const taskValue = document.getElementById('task').value;
4 | const baseModelSelect = document.getElementById('base_model');
5 | const queryParams = new URLSearchParams(window.location.search);
6 | const customModelsValue = queryParams.get('custom_models');
7 | const baseModelInput = document.getElementById('base_model_input');
8 | const baseModelCheckbox = document.getElementById('base_model_checkbox');
9 |
10 | let fetchURL = `/ui/model_choices/${taskValue}`;
11 | if (customModelsValue) {
12 | fetchURL += `?custom_models=${customModelsValue}`;
13 | }
14 | baseModelSelect.innerHTML = 'Fetching models...';
15 | fetch(fetchURL)
16 | .then(response => response.json())
17 | .then(data => {
18 | const baseModelSelect = document.getElementById('base_model');
19 | baseModelCheckbox.checked = false;
20 | baseModelSelect.classList.remove('hidden');
21 | baseModelInput.classList.add('hidden');
22 | baseModelSelect.innerHTML = ''; // Clear existing options
23 | data.forEach(model => {
24 | let option = document.createElement('option');
25 | option.value = model.id; // Assuming each model has an 'id'
26 | option.textContent = model.name; // Assuming each model has a 'name'
27 | baseModelSelect.appendChild(option);
28 | });
29 | })
30 | .catch(error => console.error('Error:', error));
31 | }
32 | document.getElementById('task').addEventListener('change', fetchDataAndUpdateModels);
33 | fetchDataAndUpdateModels();
34 | });
--------------------------------------------------------------------------------
/src/autotrain/app/static/scripts/logs.js:
--------------------------------------------------------------------------------
1 | document.addEventListener('DOMContentLoaded', function () {
2 | var fetchLogsInterval;
3 |
4 | // Function to check the modal's display property and fetch logs if visible
5 | function fetchAndDisplayLogs() {
6 | var modal = document.getElementById('logs-modal');
7 | var displayStyle = window.getComputedStyle(modal).display;
8 |
9 | // Check if the modal display property is 'flex'
10 | if (displayStyle === 'flex') {
11 | fetchLogs(); // Initial fetch when the modal is opened
12 |
13 | // Clear any existing interval to avoid duplicates
14 | clearInterval(fetchLogsInterval);
15 |
16 | // Set up the interval to fetch logs every 5 seconds
17 | fetchLogsInterval = setInterval(fetchLogs, 5000);
18 | } else {
19 | // Clear the interval when the modal is not displayed as 'flex'
20 | clearInterval(fetchLogsInterval);
21 | }
22 | }
23 |
24 | // Function to fetch logs from the server
25 | function fetchLogs() {
26 | fetch('/ui/logs')
27 | .then(response => response.json())
28 | .then(data => {
29 | var logContainer = document.getElementById('logContent');
30 | logContainer.innerHTML = ''; // Clear previous logs
31 |
32 | // Handling the case when logs are only available in local mode or no logs available
33 | if (typeof data.logs === 'string') {
34 | logContainer.textContent = data.logs;
35 | } else {
36 | // Assuming data.logs is an array of log entries
37 | data.logs.forEach(log => {
38 | if (log.trim().length > 0) {
39 | var p = document.createElement('p');
40 | p.textContent = log;
41 | logContainer.appendChild(p); // Appends logs in order received
42 | }
43 | });
44 | }
45 | })
46 | .catch(error => console.error('Error fetching logs:', error));
47 | }
48 |
49 | // Set up an observer to detect when the modal becomes visible or hidden
50 | var observer = new MutationObserver(function (mutations) {
51 | mutations.forEach(function (mutation) {
52 | if (mutation.attributeName === 'class') {
53 | fetchAndDisplayLogs();
54 | }
55 | });
56 | });
57 |
58 | var modal = document.getElementById('logs-modal');
59 | observer.observe(modal, {
60 | attributes: true //configure it to listen to attribute changes
61 | });
62 | });
--------------------------------------------------------------------------------
/src/autotrain/app/static/scripts/poll.js:
--------------------------------------------------------------------------------
1 | document.addEventListener('DOMContentLoaded', (event) => {
2 | function pollAccelerators() {
3 | const numAcceleratorsElement = document.getElementById('num_accelerators');
4 | if (autotrain_local_value === 0) {
5 | numAcceleratorsElement.innerText = 'Accelerators: Only available in local mode.';
6 | numAcceleratorsElement.style.display = 'block'; // Ensure the element is visible
7 | return;
8 | }
9 |
10 | // Send a request to the /accelerators endpoint
11 | fetch('/ui/accelerators')
12 | .then(response => response.json()) // Assuming the response is in JSON format
13 | .then(data => {
14 | // Update the paragraph with the number of accelerators
15 | document.getElementById('num_accelerators').innerText = `Accelerators: ${data.accelerators}`;
16 | })
17 | .catch(error => {
18 | console.error('Error:', error);
19 | // Update the paragraph to show an error message
20 | document.getElementById('num_accelerators').innerText = 'Accelerators: Error fetching data';
21 | });
22 | }
23 | function pollModelTrainingStatus() {
24 | // Send a request to the /is_model_training endpoint
25 |
26 | if (autotrain_local_value === 0) {
27 | const statusParagraph = document.getElementById('is_model_training');
28 | statusParagraph.innerText = 'Running jobs: Only available in local mode.';
29 | statusParagraph.style.display = 'block';
30 | return;
31 | }
32 | fetch('/ui/is_model_training')
33 | .then(response => response.json()) // Assuming the response is in JSON format
34 | .then(data => {
35 | // Construct the message to display
36 | let message = data.model_training ? 'Running job PID(s): ' + data.pids.join(', ') : 'No running jobs';
37 |
38 | // Update the paragraph with the status of model training
39 | let statusParagraph = document.getElementById('is_model_training');
40 | statusParagraph.innerText = message;
41 | let stopTrainingButton = document.getElementById('stop-training-button');
42 | let startTrainingButton = document.getElementById('start-training-button');
43 |
44 | // Change the text color based on the model training status
45 | if (data.model_training) {
46 | // Set text color to red if jobs are running
47 | statusParagraph.style.color = 'red';
48 | stopTrainingButton.style.display = 'block';
49 | startTrainingButton.style.display = 'none';
50 | } else {
51 | // Set text color to green if no jobs are running
52 | statusParagraph.style.color = 'green';
53 | stopTrainingButton.style.display = 'none';
54 | startTrainingButton.style.display = 'block';
55 | }
56 | })
57 | .catch(error => {
58 | console.error('Error:', error);
59 | // Update the paragraph to show an error message
60 | let statusParagraph = document.getElementById('is_model_training');
61 | statusParagraph.innerText = 'Error fetching training status';
62 | statusParagraph.style.color = 'red'; // Set error message color to red
63 | });
64 | }
65 |
66 | setInterval(pollAccelerators, 10000);
67 | setInterval(pollModelTrainingStatus, 5000);
68 | pollAccelerators();
69 | pollModelTrainingStatus();
70 | });
--------------------------------------------------------------------------------
/src/autotrain/app/templates/duplicate.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
16 |
17 |
18 |
19 |
20 |
21 |

22 |
21 |
22 |
28 |
29 |
 40 |
41 |
40 |
41 |