├── .gitignore
├── README.md
├── computer-vision-study-group
├── Notebooks
│ └── HuggingFace_vision_ecosystem_overview_(June_2022).ipynb
├── README.md
└── Sessions
│ ├── Blip2.md
│ ├── Fiber.md
│ ├── FlexiViT.md
│ ├── HFVisionEcosystem.md
│ ├── HowDoVisionTransformersWork.md
│ ├── MaskedAutoEncoders.md
│ ├── NeuralRadianceFields.md
│ ├── PolarizedSelfAttention.md
│ └── SwinTransformer.md
├── gradio-blocks
└── README.md
├── huggan
├── README.md
├── __init__.py
├── assets
│ ├── cyclegan.png
│ ├── dcgan_mnist.png
│ ├── example_model.png
│ ├── example_space.png
│ ├── huggan_banner.png
│ ├── lightweight_gan_wandb.png
│ ├── metfaces.png
│ ├── pix2pix_maps.png
│ └── wandb.png
├── model_card_template.md
├── pytorch
│ ├── README.md
│ ├── __init__.py
│ ├── cyclegan
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── modeling_cyclegan.py
│ │ ├── train.py
│ │ └── utils.py
│ ├── dcgan
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── modeling_dcgan.py
│ │ └── train.py
│ ├── huggan_mixin.py
│ ├── lightweight_gan
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── cli.py
│ │ ├── diff_augment.py
│ │ └── lightweight_gan.py
│ ├── metrics
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── fid_score.py
│ │ └── inception.py
│ └── pix2pix
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── modeling_pix2pix.py
│ │ └── train.py
├── tensorflow
│ └── dcgan
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── requirements.txt
│ │ └── train.py
└── utils
│ ├── README.md
│ ├── __init__.py
│ ├── hub.py
│ └── push_to_hub_example.py
├── jax-controlnet-sprint
├── README.md
├── dataset_tools
│ ├── coyo_1m_dataset_preprocess.py
│ ├── create_pose_dataset.ipynb
│ └── data.py
└── training_scripts
│ ├── requirements_flax.txt
│ └── train_controlnet_flax.py
├── keras-dreambooth-sprint
├── Dreambooth_on_Hub.ipynb
├── README.md
├── compute-with-lambda.md
└── requirements.txt
├── keras-sprint
├── README.md
├── deeplabv3_plus.ipynb
├── example_image_2.jpeg
├── example_image_3.jpeg
└── mnist_convnet.ipynb
├── open-source-ai-game-jam
└── README.md
├── requirements.txt
├── setup.py
├── sklearn-sprint
└── guidelines.md
└── whisper-fine-tuning-event
├── README.md
├── ds_config.json
├── fine-tune-whisper-non-streaming.ipynb
├── fine-tune-whisper-streaming.ipynb
├── fine_tune_whisper_streaming_colab.ipynb
├── interleave_streaming_datasets.ipynb
├── requirements.txt
├── run_eval_whisper_streaming.py
└── run_speech_recognition_seq2seq_streaming.py
/.gitignore:
--------------------------------------------------------------------------------
1 | # Initially taken from Github's Python gitignore file
2 |
3 | # Byte-compiled / optimized / DLL files
4 | __pycache__/
5 | *.py[cod]
6 | *$py.class
7 |
8 | # C extensions
9 | *.so
10 |
11 | # tests and logs
12 | tests/fixtures/cached_*_text.txt
13 | logs/
14 | lightning_logs/
15 | lang_code_data/
16 |
17 | # Distribution / packaging
18 | .Python
19 | build/
20 | develop-eggs/
21 | dist/
22 | downloads/
23 | eggs/
24 | .eggs/
25 | lib/
26 | lib64/
27 | parts/
28 | sdist/
29 | var/
30 | wheels/
31 | *.egg-info/
32 | .installed.cfg
33 | *.egg
34 | MANIFEST
35 |
36 | # PyInstaller
37 | # Usually these files are written by a python script from a template
38 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
39 | *.manifest
40 | *.spec
41 |
42 | # Installer logs
43 | pip-log.txt
44 | pip-delete-this-directory.txt
45 |
46 | # Unit test / coverage reports
47 | htmlcov/
48 | .tox/
49 | .nox/
50 | .coverage
51 | .coverage.*
52 | .cache
53 | nosetests.xml
54 | coverage.xml
55 | *.cover
56 | .hypothesis/
57 | .pytest_cache/
58 |
59 | # Translations
60 | *.mo
61 | *.pot
62 |
63 | # Django stuff:
64 | *.log
65 | local_settings.py
66 | db.sqlite3
67 |
68 | # Flask stuff:
69 | instance/
70 | .webassets-cache
71 |
72 | # Scrapy stuff:
73 | .scrapy
74 |
75 | # Sphinx documentation
76 | docs/_build/
77 |
78 | # PyBuilder
79 | target/
80 |
81 | # Jupyter Notebook
82 | .ipynb_checkpoints
83 |
84 | # IPython
85 | profile_default/
86 | ipython_config.py
87 |
88 | # pyenv
89 | .python-version
90 |
91 | # celery beat schedule file
92 | celerybeat-schedule
93 |
94 | # SageMath parsed files
95 | *.sage.py
96 |
97 | # Environments
98 | .env
99 | .venv
100 | env/
101 | venv/
102 | ENV/
103 | env.bak/
104 | venv.bak/
105 |
106 | # Spyder project settings
107 | .spyderproject
108 | .spyproject
109 |
110 | # Rope project settings
111 | .ropeproject
112 |
113 | # mkdocs documentation
114 | /site
115 |
116 | # mypy
117 | .mypy_cache/
118 | .dmypy.json
119 | dmypy.json
120 |
121 | # Pyre type checker
122 | .pyre/
123 |
124 | # vscode
125 | .vs
126 | .vscode
127 |
128 | # Pycharm
129 | .idea
130 |
131 | # TF code
132 | tensorflow_code
133 |
134 | # Models
135 | proc_data
136 |
137 | # examples
138 | runs
139 | /runs_old
140 | /wandb
141 | /examples/runs
142 | /examples/**/*.args
143 | /examples/rag/sweep
144 |
145 | # data
146 | /data
147 | serialization_dir
148 |
149 | # emacs
150 | *.*~
151 | debug.env
152 |
153 | # vim
154 | .*.swp
155 |
156 | #ctags
157 | tags
158 |
159 | # pre-commit
160 | .pre-commit*
161 |
162 | # .lock
163 | *.lock
164 |
165 | # DS_Store (MacOS)
166 | .DS_Store
167 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Community Events @ 🤗
2 |
3 | A central repository for all community events organized by 🤗 HuggingFace. Come one, come all!
4 | We're constantly finding ways to democratise the use of ML across modalities and languages. This repo contains information about all past, present and upcoming events.
5 |
6 | ## Hugging Events
7 |
8 | | **Event Name** | **Dates** | **Status** |
9 | |-------------------------------------------------------------------------|-----------------|--------------------------------------------------------------------------------------------------------------|
10 | | [Open Source AI Game Jam 🎮 (First Edition)](/open-source-ai-game-jam) | July 7th - 9th, 2023 | Finished |
11 | | [Whisper Fine Tuning Event](/whisper-fine-tuning-event) | Dec 5th - 19th, 2022 | Finished |
12 | | [Computer Vision Study Group](/computer-vision-study-group) | Ongoing | Monthly |
13 | | [ML for Audio Study Group](https://github.com/Vaibhavs10/ml-with-audio) | Ongoing | Monthly |
14 | | [Gradio Blocks](/gradio-blocks) | May 16th - 31st, 2022 | Finished |
15 | | [HugGAN](/huggan) | Apr 4th - 17th, 2022 | Finished |
16 | | [Keras Sprint](keras-sprint) | June, 2022 | Finished |
17 |
--------------------------------------------------------------------------------
/computer-vision-study-group/README.md:
--------------------------------------------------------------------------------
1 | # Computer Vision Study Group
2 |
3 | This is a collection of all past sessions that have been held as part of the Hugging Face Computer Vision Study Group.
4 |
5 | | |Session Name | Session Link |
6 | |--- |--- | --- |
7 | |❓|How Do Vision Transformers Work? | [Session Sheet](Sessions/HowDoVisionTransformersWork.md) |
8 | |🔅|Polarized Self-Attention | [Session Sheet](Sessions/PolarizedSelfAttention.md)|
9 | |🍄|Swin Transformer | [Session Sheet](Sessions/SwinTransformer.md)|
10 | |🔮|Introduction to Neural Radiance Fields | [Session Sheet](Sessions/NeuralRadianceFields.md)|
11 | |🌐|Hugging Face Vision Ecosystem Overview (June 2022) | [Session Sheet](Sessions/HFVisionEcosystem.md)|
12 | |🪂|Masked Autoencoders Are Scalable Vision Learners | [Session Sheet](Sessions/MaskedAutoEncoders.md)|
13 | |🦊|Fiber: Coarse-to-Fine Vision-Language Pre-Training | [Session Sheet](Sessions/Fiber.md)|
14 | |⚔️ |FlexiViT: One Model for All Patch Sizes| [Session Sheet](Sessions/FlexiViT.md)|
15 | |🤖|BLIP-2: Bootstrapping Language-Image Pre-training| [Session Sheet](Sessions/Blip2.md)|
16 |
--------------------------------------------------------------------------------
/computer-vision-study-group/Sessions/Blip2.md:
--------------------------------------------------------------------------------
1 | # BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
2 | Session by [johko](https://github.com/johko)
3 |
4 |
5 | ## Recording 📺
6 | [YouTube](https://www.youtube.com/watch?v=k0DAtZCCl1w&pp=ygUdaHVnZ2luZyBmYWNlIHN0dWR5IGdyb3VwIHN3aW4%3D)
7 |
8 |
9 | ## Session Slides 🖥️
10 | [Google Drive](https://docs.google.com/presentation/d/1Y_8Qu0CMlt7jvCd8Jw0c_ILh8LHB0XgnlrvXObe5FYs/edit?usp=sharing)
11 |
12 |
13 | ## Original Paper 📄
14 | [Hugging Face](https://huggingface.co/papers/2301.12597) /
15 | [arxiv](https://arxiv.org/abs/2301.12597)
16 |
17 |
18 | ## GitHub Repo 🧑🏽💻
19 | https://github.com/salesforce/lavis
20 |
21 |
22 | ## Additional Resources 📚
23 | - [BLIP-2 Demo Space](https://huggingface.co/spaces/hysts/BLIP2-with-transformers)
24 | - [BLIP-2 Transformers Example Notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BLIP-2) by Niels Rogge
25 | - [BLIP-2 Transformers Docs](https://huggingface.co/docs/transformers/model_doc/blip-2)
26 |
--------------------------------------------------------------------------------
/computer-vision-study-group/Sessions/Fiber.md:
--------------------------------------------------------------------------------
1 | # Fiber: Coarse-to-Fine Vision-Language Pre-Training with Fusion in the Backbone
2 | Session by [johko](https://github.com/johko)
3 |
4 |
5 | ## Recording 📺
6 | [YouTube](https://www.youtube.com/watch?v=m9qhNGuWE2g&t=20s&pp=ygUdaHVnZ2luZyBmYWNlIHN0dWR5IGdyb3VwIHN3aW4%3D)
7 |
8 |
9 | ## Session Slides 🖥️
10 | [Google Drive](https://docs.google.com/presentation/d/1vSu27tE87ZM103_CkgqsW7JeIp2mrmyl/edit?usp=sharing&ouid=107717747412022342990&rtpof=true&sd=true)
11 |
12 |
13 | ## Original Paper 📄
14 | [Hugging Face](https://huggingface.co/papers/2206.07643) /
15 | [arxiv](https://arxiv.org/abs/2206.07643)
16 |
17 |
18 | ## GitHub Repo 🧑🏽💻
19 | https://github.com/microsoft/fiber
20 |
21 |
22 | ## Additional Resources 📚
23 | - [Text to Pokemon](https://huggingface.co/spaces/lambdalabs/text-to-pokemon) HF Space to create your own Pokemon
24 | - [Paper to Pokemon](https://huggingface.co/spaces/hugging-fellows/paper-to-pokemon) derived from the above space - create your own Pokemon from a paper
--------------------------------------------------------------------------------
/computer-vision-study-group/Sessions/FlexiViT.md:
--------------------------------------------------------------------------------
1 | # FlexiViT: One Model for All Patch Sizes
2 | Session by [johko](https://github.com/johko)
3 |
4 |
5 | ## Recording 📺
6 | [YouTube](https://www.youtube.com/watch?v=TlRYBgsl7Q8&t=977s&pp=ygUdaHVnZ2luZyBmYWNlIHN0dWR5IGdyb3VwIHN3aW4%3D)
7 |
8 |
9 | ## Session Slides 🖥️
10 | [Google Drive](https://docs.google.com/presentation/d/1rLAYr160COYQMUN0FDH7D9pP8qe1_QyXGvfbHkutOt8/edit?usp=sharing)
11 |
12 |
13 | ## Original Paper 📄
14 | [Hugging Face](https://huggingface.co/papers/2212.08013) /
15 | [arxiv](https://arxiv.org/abs/2212.08013)
16 |
17 |
18 | ## GitHub Repo 🧑🏽💻
19 | https://github.com/google-research/big_vision
20 |
21 |
22 | ## Additional Resources 📚
23 | - [FlexiViT PR](https://github.com/google-research/big_vision/pull/24)
24 |
--------------------------------------------------------------------------------
/computer-vision-study-group/Sessions/HFVisionEcosystem.md:
--------------------------------------------------------------------------------
1 | # Hugging Face Vision Ecosystem Overview (June 2022)
2 | Session by [Niels Rogge](https://github.com/NielsRogge)
3 |
4 |
5 | ## Recording 📺
6 | [YouTube](https://www.youtube.com/watch?v=oL-xmufhZM8&pp=ygUdaHVnZ2luZyBmYWNlIHN0dWR5IGdyb3VwIHN3aW4%3D)
7 |
8 |
9 | ## Additional Resources 📚
10 | - [Accompanying Notebook](../Notebooks/HuggingFace_vision_ecosystem_overview_(June_2022).ipynb)
--------------------------------------------------------------------------------
/computer-vision-study-group/Sessions/HowDoVisionTransformersWork.md:
--------------------------------------------------------------------------------
1 | # How Do Vision Transformers Work
2 | Session by [johko](https://github.com/johko)
3 |
4 |
5 | ## Session Slides 🖥️
6 | [Google Drive](https://docs.google.com/presentation/d/1PewOHVABkxx0jO9PoJSQi8to_WNlL4HdDp4M9e4L8hs/edit?usp=drivesdks)
7 |
8 |
9 | ## Original Paper 📄
10 | [Hugging Face](https://huggingface.co/papers/2202.06709) /
11 | [arxiv](https://arxiv.org/pdf/2202.06709.pdf)
12 |
13 |
14 | ## GitHub Repo 🧑🏽💻
15 | https://github.com/microsoft/Swin-Transformer
16 |
17 |
18 | ## Additional Resources 📚
19 | Hessian Matrices:
20 |
21 | - https://stackoverflow.com/questions/23297090/how-calculating-hessian-works-for-neural-network-learning
22 | - https://machinelearningmastery.com/a-gentle-introduction-to-hessian-matrices/
23 |
24 | Loss Landscape Visualization:
25 |
26 | - https://mathformachines.com/posts/visualizing-the-loss-landscape/
27 | - https://github.com/tomgoldstein/loss-landscape
--------------------------------------------------------------------------------
/computer-vision-study-group/Sessions/MaskedAutoEncoders.md:
--------------------------------------------------------------------------------
1 | # Masked Autoencoders are Scalable Vision Learners
2 | Session by [johko](https://github.com/johko)
3 |
4 |
5 | ## Recording 📺
6 | [YouTube](https://www.youtube.com/watch?v=AC6flxUFLrg&pp=ygUdaHVnZ2luZyBmYWNlIHN0dWR5IGdyb3VwIHN3aW4%3D)
7 |
8 |
9 | ## Session Slides 🖥️
10 | [Google Drive](https://docs.google.com/presentation/d/10ZZ-Rl1D57VX005a58OmqNeOB6gPnE54/edit?usp=sharing&ouid=107717747412022342990&rtpof=true&sd=true)
11 |
12 |
13 | ## Original Paper 📄
14 | [Hugging Face](https://huggingface.co/papers/2111.06377) /
15 | [arxiv](https://arxiv.org/abs/2111.06377)
16 |
17 |
18 | ## GitHub Repo 🧑🏽💻
19 | https://github.com/facebookresearch/mae
20 |
21 |
22 | ## Additional Resources 📚
23 | - [Transformers Docs ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)
24 | - [Transformers ViTMAE Demo Notebook](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ViTMAE) by Niels Rogge
--------------------------------------------------------------------------------
/computer-vision-study-group/Sessions/NeuralRadianceFields.md:
--------------------------------------------------------------------------------
1 | # Introduction to Neural Radiance Fields
2 | Session by [Aritra](https://arig23498.github.io/) and [Ritwik](ritwikraha.github.io)
3 |
4 |
5 | ## Recording 📺
6 | [YouTube](https://www.youtube.com/watch?v=U2XS7SxOy2s)
7 |
8 |
9 | ## Session Slides 🖥️
10 | [Google Drive](https://docs.google.com/presentation/d/e/2PACX-1vTQVnoTJGhRxDscNV1Mg2aYhvXP8cKODpB5Ii72NWoetCGrTLBJWx_UD1oPXHrzPtj7xO8MS_3TQaSH/pub?start=false&loop=false&delayms=3000)
11 |
12 |
13 | ## Original Paper 📄
14 | [Hugging Face](https://huggingface.co/papers/2003.08934) /
15 | [arxiv](https://arxiv.org/abs/2003.08934)
16 |
17 |
18 | ## GitHub Repo 🧑🏽💻
19 | https://github.com/bmild/nerf
20 |
--------------------------------------------------------------------------------
/computer-vision-study-group/Sessions/PolarizedSelfAttention.md:
--------------------------------------------------------------------------------
1 | # Polarized Self-Attention
2 | Session by [Satpal](https://github.com/satpalsr)
3 |
4 | ## Session Slides 🖥️
5 | [GitHub PDF](https://github.com/satpalsr/Talks/blob/main/PSA_discussion.pdf)
6 |
7 |
8 | ## Original Paper 📄
9 | [Hugging Face](https://huggingface.co/papers/2107.00782) /
10 | [arxiv](https://arxiv.org/pdf/2107.00782.pdf)
11 |
12 |
13 | ## GitHub Repo 🧑🏽💻
14 | https://github.com/DeLightCMU/PSA
15 |
--------------------------------------------------------------------------------
/computer-vision-study-group/Sessions/SwinTransformer.md:
--------------------------------------------------------------------------------
1 | # Swin Transformer
2 | Session by [johko](https://github.com/johko)
3 |
4 |
5 | ## Recording 📺
6 | [YouTube](https://www.youtube.com/watch?v=Ngikt-K1Ecc&t=305s&pp=ygUdaHVnZ2luZyBmYWNlIHN0dWR5IGdyb3VwIHN3aW4%3D)
7 |
8 |
9 | ## Session Slides 🖥️
10 | [Google Drive](https://docs.google.com/presentation/d/1RoFIC6vE55RS4WNqSlzNu3ljB6F-_8edtprAFXpGvKs/edit?usp=sharing)
11 |
12 |
13 | ## Original Paper 📄
14 | [Hugging Face](https://huggingface.co/papers/2103.14030) /
15 | [arxiv](https://arxiv.org/pdf/2103.14030.pdf)
16 |
17 |
18 | ## GitHub Repo 🧑🏽💻
19 | https://github.com/xxxnell/how-do-vits-work
20 |
21 |
22 | ## Additional Resources 📚
23 | - [Transformers Docs Swin v1](https://huggingface.co/docs/transformers/model_doc/swin)
24 | - [Transformers Docs Swin v2](https://huggingface.co/docs/transformers/model_doc/swinv2)
25 | - [Transformers Docs Swin Super Resolution](https://huggingface.co/docs/transformers/model_doc/swin2sr)
--------------------------------------------------------------------------------
/gradio-blocks/README.md:
--------------------------------------------------------------------------------
1 | # Welcome to the [Gradio](https://gradio.app/) Blocks Party 🥳
2 |
3 | 
4 |
5 |
6 | _**Timeline**: May 17th, 2022 - May 31st, 2022_
7 |
8 | ---
9 |
10 | We are happy to invite you to the Gradio Blocks Party - a community event in which we will create **interactive demos** for state-of-the-art machine learning models. Demos are powerful because they allow anyone — not just ML engineers — to try out models in the browser, give feedback on predictions, identify trustworthy models. The event will take place from **May 17th to 31st**. We will be organizing this event on [Github](https://github.com/huggingface/community-events) and the [Hugging Face discord channel](https://discord.com/invite/feTf9x3ZSB). Prizes will be given at the end of the event, see: [Prizes](#prizes)
11 |
12 |  13 |
14 | ## What is Gradio?
15 |
16 | Gradio is a Python library that allows you to quickly build web-based machine learning demos, data science dashboards, or other kinds of web apps, entirely in Python. These web apps can be launched from wherever you use Python (jupyter notebooks, colab notebooks, Python terminal, etc.) and shared with anyone instantly using Gradio's auto-generated share links. To learn more about Gradio see the Getting Started Guide: https://gradio.app/getting_started/ and the new Course on Huggingface about Gradio: [Gradio Course](https://huggingface.co/course/chapter9/1?fw=pt).
17 |
18 | Gradio can be installed via pip and comes preinstalled in Hugging Face Spaces, the latest version of Gradio can be set in the README in spaces by setting the sdk_version for example `sdk_version: 3.0b8`
19 |
20 | `pip install gradio` to install gradio locally
21 |
22 |
23 | ## What is Blocks?
24 |
25 | `gradio.Blocks` is a low-level API that allows you to have full control over the data flows and layout of your application. You can build very complex, multi-step applications using Blocks. If you have already used `gradio.Interface`, you know that you can easily create fully-fledged machine learning demos with just a few lines of code. The Interface API is very convenient but in some cases may not be sufficiently flexible for your needs. For example, you might want to:
26 |
27 | * Group together related demos as multiple tabs in one web app.
28 | * Change the layout of your demo instead of just having all of the inputs on the left and outputs on the right.
29 | * Have multi-step interfaces, in which the output of one model becomes the input to the next model, or have more flexible data flows in general.
30 | * Change a component's properties (for example, the choices in a Dropdown) or its visibility based on user input.
31 |
32 | To learn more about Blocks, see the [official guide](https://www.gradio.app/introduction_to_blocks/) and the [docs](https://gradio.app/docs/).
33 |
34 | ## What is Hugging Face Spaces?
35 |
36 | Spaces are a simple way to host ML demo apps directly on your profile or your organization’s profile on Hugging Face. This allows you to create your ML portfolio, showcase your projects at conferences or to stakeholders, and work collaboratively with other people in the ML ecosystem. Learn more about Spaces in the [docs](https://huggingface.co/docs/hub/spaces).
37 |
38 | ## How Do Gradio and Hugging Face work together?
39 |
40 | Hugging Face Spaces is a free hosting option for Gradio demos. Spaces comes with 3 SDK options: Gradio, Streamlit and Static HTML demos. Spaces can be public or private and the workflow is similar to github repos. There are over 2000+ Gradio spaces currently on Hugging Face. Learn more about spaces and gradio: https://huggingface.co/docs/hub/spaces
41 |
42 | ## Event Plan
43 |
44 | main components of the event consist of:
45 |
46 | 1. Learning about Gradio and the new Blocks Feature
47 | 2. Building your own Blocks demo using Gradio and Hugging Face Spaces
48 | 3. Submitting your demo on Spaces to the Gradio Blocks Party Organization
49 | 4. Share your blocks demo with a permanent shareable link
50 | 5. Win Prizes
51 |
52 |
53 | ## Example spaces using Blocks
54 |
55 |
13 |
14 | ## What is Gradio?
15 |
16 | Gradio is a Python library that allows you to quickly build web-based machine learning demos, data science dashboards, or other kinds of web apps, entirely in Python. These web apps can be launched from wherever you use Python (jupyter notebooks, colab notebooks, Python terminal, etc.) and shared with anyone instantly using Gradio's auto-generated share links. To learn more about Gradio see the Getting Started Guide: https://gradio.app/getting_started/ and the new Course on Huggingface about Gradio: [Gradio Course](https://huggingface.co/course/chapter9/1?fw=pt).
17 |
18 | Gradio can be installed via pip and comes preinstalled in Hugging Face Spaces, the latest version of Gradio can be set in the README in spaces by setting the sdk_version for example `sdk_version: 3.0b8`
19 |
20 | `pip install gradio` to install gradio locally
21 |
22 |
23 | ## What is Blocks?
24 |
25 | `gradio.Blocks` is a low-level API that allows you to have full control over the data flows and layout of your application. You can build very complex, multi-step applications using Blocks. If you have already used `gradio.Interface`, you know that you can easily create fully-fledged machine learning demos with just a few lines of code. The Interface API is very convenient but in some cases may not be sufficiently flexible for your needs. For example, you might want to:
26 |
27 | * Group together related demos as multiple tabs in one web app.
28 | * Change the layout of your demo instead of just having all of the inputs on the left and outputs on the right.
29 | * Have multi-step interfaces, in which the output of one model becomes the input to the next model, or have more flexible data flows in general.
30 | * Change a component's properties (for example, the choices in a Dropdown) or its visibility based on user input.
31 |
32 | To learn more about Blocks, see the [official guide](https://www.gradio.app/introduction_to_blocks/) and the [docs](https://gradio.app/docs/).
33 |
34 | ## What is Hugging Face Spaces?
35 |
36 | Spaces are a simple way to host ML demo apps directly on your profile or your organization’s profile on Hugging Face. This allows you to create your ML portfolio, showcase your projects at conferences or to stakeholders, and work collaboratively with other people in the ML ecosystem. Learn more about Spaces in the [docs](https://huggingface.co/docs/hub/spaces).
37 |
38 | ## How Do Gradio and Hugging Face work together?
39 |
40 | Hugging Face Spaces is a free hosting option for Gradio demos. Spaces comes with 3 SDK options: Gradio, Streamlit and Static HTML demos. Spaces can be public or private and the workflow is similar to github repos. There are over 2000+ Gradio spaces currently on Hugging Face. Learn more about spaces and gradio: https://huggingface.co/docs/hub/spaces
41 |
42 | ## Event Plan
43 |
44 | main components of the event consist of:
45 |
46 | 1. Learning about Gradio and the new Blocks Feature
47 | 2. Building your own Blocks demo using Gradio and Hugging Face Spaces
48 | 3. Submitting your demo on Spaces to the Gradio Blocks Party Organization
49 | 4. Share your blocks demo with a permanent shareable link
50 | 5. Win Prizes
51 |
52 |
53 | ## Example spaces using Blocks
54 |
55 |  56 |
57 | - [dalle-mini](https://huggingface.co/spaces/dalle-mini/dalle-mini)([Code](https://huggingface.co/spaces/dalle-mini/dalle-mini/blob/main/app/gradio/app.py))
58 | - [mindseye-lite](https://huggingface.co/spaces/multimodalart/mindseye-lite)([Code](https://huggingface.co/spaces/multimodalart/mindseye-lite/blob/main/app.py))
59 | - [ArcaneGAN-blocks](https://huggingface.co/spaces/akhaliq/ArcaneGAN-blocks)([Code](https://huggingface.co/spaces/akhaliq/ArcaneGAN-blocks/blob/main/app.py))
60 | - [gr-blocks](https://huggingface.co/spaces/merve/gr-blocks)([Code](https://huggingface.co/spaces/merve/gr-blocks/blob/main/app.py))
61 | - [tortoisse-tts](https://huggingface.co/spaces/osanseviero/tortoisse-tts)([Code](https://huggingface.co/spaces/osanseviero/tortoisse-tts/blob/main/app.py))
62 | - [CaptchaCracker](https://huggingface.co/spaces/osanseviero/tortoisse-tts)([Code](https://huggingface.co/spaces/akhaliq/CaptchaCracker/blob/main/app.py))
63 |
64 |
65 | ## To participate in the event
66 |
67 | - Join the organization for Blocks event
68 | - [https://huggingface.co/Gradio-Blocks](https://huggingface.co/Gradio-Blocks)
69 | - Join the discord
70 | - [discord](https://discord.com/invite/feTf9x3ZSB)
71 |
72 |
73 | Participants will be building and sharing Gradio demos using the Blocks feature. We will share a list of ideas of spaces that can be created using blocks or participants are free to try out their own ideas. At the end of the event, spaces will be evaluated and prizes will be given.
74 |
75 |
76 | ## Potential ideas for creating spaces:
77 |
78 |
79 | - Trending papers from https://paperswithcode.com/
80 | - Models from huggingface model hub: https://huggingface.co/models
81 | - Models from other model hubs
82 | - Tensorflow Hub: see example Gradio demos at https://huggingface.co/tensorflow
83 | - Pytorch Hub: see example Gradio demos at https://huggingface.co/pytorch
84 | - ONNX model Hub: see example Gradio demos at https://huggingface.co/onnx
85 | - PaddlePaddle Model Hub: see example Gradio demos at https://huggingface.co/PaddlePaddle
86 | - participant ideas, try out your own ideas
87 |
88 |
89 | ## Prizes
90 | - 1st place winner based on likes
91 | - [Hugging Face PRO subscription](https://huggingface.co/pricing) for 1 year
92 | - Embedding your Gradio Blocks demo in the Gradio Blog
93 | - top 10 winners based on likes
94 | - Swag from [Hugging Face merch shop](https://huggingface.myshopify.com/): t-shirts, hoodies, mugs of your choice
95 | - top 25 winners based on likes
96 | - [Hugging Face PRO subscription](https://huggingface.co/pricing) for 1 month
97 | - Blocks event badge on HF for all participants!
98 |
99 | ## Prizes Criteria
100 |
101 | - Staff Picks
102 | - Most liked Spaces
103 | - Community Pick (voting)
104 | - Most Creative Space (voting)
105 | - Most Educational Space (voting)
106 | - CEO's pick (one prize for a particularly impactful demo), picked by @clem
107 | - CTO's pick (one prize for a particularly technically impressive demo), picked by @julien
108 |
109 |
110 | ## Creating a Gradio demo on Hugging Face Spaces
111 |
112 | Once a model has been picked from the choices above or feel free to try your own idea, you can share a model in a Space using Gradio
113 |
114 | Read more about how to add [Gradio spaces](https://huggingface.co/blog/gradio-spaces).
115 |
116 | Steps to add Gradio Spaces to the Gradio Blocks Party org
117 | 1. Create an account on Hugging Face
118 | 2. Join the Gradio Blocks Party Organization by clicking "Join Organization" button in the organization page or using the shared link above
119 | 3. Once your request is approved, add your space using the Gradio SDK and share the link with the community!
120 |
121 | ## LeaderBoard for Most Popular Blocks Event Spaces based on Likes
122 |
123 | - See Leaderboard: https://huggingface.co/spaces/Gradio-Blocks/Leaderboard
124 |
--------------------------------------------------------------------------------
/huggan/__init__.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 |
3 | TEMPLATE_MODEL_CARD_PATH = Path(__file__).parent.absolute() / 'model_card_template.md'
--------------------------------------------------------------------------------
/huggan/assets/cyclegan.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/cyclegan.png
--------------------------------------------------------------------------------
/huggan/assets/dcgan_mnist.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/dcgan_mnist.png
--------------------------------------------------------------------------------
/huggan/assets/example_model.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/example_model.png
--------------------------------------------------------------------------------
/huggan/assets/example_space.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/example_space.png
--------------------------------------------------------------------------------
/huggan/assets/huggan_banner.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/huggan_banner.png
--------------------------------------------------------------------------------
/huggan/assets/lightweight_gan_wandb.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/lightweight_gan_wandb.png
--------------------------------------------------------------------------------
/huggan/assets/metfaces.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/metfaces.png
--------------------------------------------------------------------------------
/huggan/assets/pix2pix_maps.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/pix2pix_maps.png
--------------------------------------------------------------------------------
/huggan/assets/wandb.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/wandb.png
--------------------------------------------------------------------------------
/huggan/model_card_template.md:
--------------------------------------------------------------------------------
1 | ---
2 | tags:
3 | - huggan
4 | - gan
5 | # See a list of available tags here:
6 | # https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts#L12
7 | # task: unconditional-image-generation or conditional-image-generation or image-to-image
8 | license: mit
9 | ---
10 |
11 | # MyModelName
12 |
13 | ## Model description
14 |
15 | Describe the model here (what it does, what it's used for, etc.)
16 |
17 | ## Intended uses & limitations
18 |
19 | #### How to use
20 |
21 | ```python
22 | # You can include sample code which will be formatted
23 | ```
24 |
25 | #### Limitations and bias
26 |
27 | Provide examples of latent issues and potential remediations.
28 |
29 | ## Training data
30 |
31 | Describe the data you used to train the model.
32 | If you initialized it with pre-trained weights, add a link to the pre-trained model card or repository with description of the pre-training data.
33 |
34 | ## Training procedure
35 |
36 | Preprocessing, hardware used, hyperparameters...
37 |
38 | ## Eval results
39 |
40 | ## Generated Images
41 |
42 | You can embed local or remote images using ``
43 |
44 | ### BibTeX entry and citation info
45 |
46 | ```bibtex
47 | @inproceedings{...,
48 | year={2020}
49 | }
50 | ```
--------------------------------------------------------------------------------
/huggan/pytorch/README.md:
--------------------------------------------------------------------------------
1 | # Example scripts (PyTorch)
2 |
3 | This directory contains a few example scripts that allow you to train famous GANs on your own data using a bit of 🤗 magic.
4 |
5 | More concretely, these scripts:
6 | - leverage 🤗 [Datasets](https://huggingface.co/docs/datasets/index) to load any image dataset from the hub (including your own, possibly private, dataset)
7 | - leverage 🤗 [Accelerate](https://huggingface.co/docs/accelerate/index) to instantly run the script on (multi-) CPU, (multi-) GPU, TPU environments, supporting fp16 and mixed precision as well as DeepSpeed
8 | - leverage 🤗 [Hub](https://huggingface.co/) to push the model to the hub at the end of training, allowing to easily create a demo for it afterwards
9 |
10 | Currently, it contains the following examples:
11 |
12 | | Name | Paper |
13 | | ----------- | ----------- |
14 | | [DCGAN](dcgan) | [Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks](https://arxiv.org/abs/1511.06434) |
15 | | [pix2pix](pix2pix) | [Image-to-Image Translation with Conditional Adversarial Networks](https://arxiv.org/abs/1611.07004) |
16 | | [CycleGAN](cyclegan) | [Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks](https://arxiv.org/abs/1703.10593)
17 | | [Lightweight GAN](lightweight_gan) | [Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis](https://openreview.net/forum?id=1Fqg133qRaI)
18 |
19 |
20 |
--------------------------------------------------------------------------------
/huggan/pytorch/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/pytorch/__init__.py
--------------------------------------------------------------------------------
/huggan/pytorch/cyclegan/README.md:
--------------------------------------------------------------------------------
1 | # Training CycleGAN on your own data
2 |
3 | This folder contains a script to train [CycleGAN](https://arxiv.org/abs/1703.10593), leveraging the [Hugging Face](https://huggingface.co/) ecosystem for processing data and pushing the model to the Hub.
4 |
5 |
56 |
57 | - [dalle-mini](https://huggingface.co/spaces/dalle-mini/dalle-mini)([Code](https://huggingface.co/spaces/dalle-mini/dalle-mini/blob/main/app/gradio/app.py))
58 | - [mindseye-lite](https://huggingface.co/spaces/multimodalart/mindseye-lite)([Code](https://huggingface.co/spaces/multimodalart/mindseye-lite/blob/main/app.py))
59 | - [ArcaneGAN-blocks](https://huggingface.co/spaces/akhaliq/ArcaneGAN-blocks)([Code](https://huggingface.co/spaces/akhaliq/ArcaneGAN-blocks/blob/main/app.py))
60 | - [gr-blocks](https://huggingface.co/spaces/merve/gr-blocks)([Code](https://huggingface.co/spaces/merve/gr-blocks/blob/main/app.py))
61 | - [tortoisse-tts](https://huggingface.co/spaces/osanseviero/tortoisse-tts)([Code](https://huggingface.co/spaces/osanseviero/tortoisse-tts/blob/main/app.py))
62 | - [CaptchaCracker](https://huggingface.co/spaces/osanseviero/tortoisse-tts)([Code](https://huggingface.co/spaces/akhaliq/CaptchaCracker/blob/main/app.py))
63 |
64 |
65 | ## To participate in the event
66 |
67 | - Join the organization for Blocks event
68 | - [https://huggingface.co/Gradio-Blocks](https://huggingface.co/Gradio-Blocks)
69 | - Join the discord
70 | - [discord](https://discord.com/invite/feTf9x3ZSB)
71 |
72 |
73 | Participants will be building and sharing Gradio demos using the Blocks feature. We will share a list of ideas of spaces that can be created using blocks or participants are free to try out their own ideas. At the end of the event, spaces will be evaluated and prizes will be given.
74 |
75 |
76 | ## Potential ideas for creating spaces:
77 |
78 |
79 | - Trending papers from https://paperswithcode.com/
80 | - Models from huggingface model hub: https://huggingface.co/models
81 | - Models from other model hubs
82 | - Tensorflow Hub: see example Gradio demos at https://huggingface.co/tensorflow
83 | - Pytorch Hub: see example Gradio demos at https://huggingface.co/pytorch
84 | - ONNX model Hub: see example Gradio demos at https://huggingface.co/onnx
85 | - PaddlePaddle Model Hub: see example Gradio demos at https://huggingface.co/PaddlePaddle
86 | - participant ideas, try out your own ideas
87 |
88 |
89 | ## Prizes
90 | - 1st place winner based on likes
91 | - [Hugging Face PRO subscription](https://huggingface.co/pricing) for 1 year
92 | - Embedding your Gradio Blocks demo in the Gradio Blog
93 | - top 10 winners based on likes
94 | - Swag from [Hugging Face merch shop](https://huggingface.myshopify.com/): t-shirts, hoodies, mugs of your choice
95 | - top 25 winners based on likes
96 | - [Hugging Face PRO subscription](https://huggingface.co/pricing) for 1 month
97 | - Blocks event badge on HF for all participants!
98 |
99 | ## Prizes Criteria
100 |
101 | - Staff Picks
102 | - Most liked Spaces
103 | - Community Pick (voting)
104 | - Most Creative Space (voting)
105 | - Most Educational Space (voting)
106 | - CEO's pick (one prize for a particularly impactful demo), picked by @clem
107 | - CTO's pick (one prize for a particularly technically impressive demo), picked by @julien
108 |
109 |
110 | ## Creating a Gradio demo on Hugging Face Spaces
111 |
112 | Once a model has been picked from the choices above or feel free to try your own idea, you can share a model in a Space using Gradio
113 |
114 | Read more about how to add [Gradio spaces](https://huggingface.co/blog/gradio-spaces).
115 |
116 | Steps to add Gradio Spaces to the Gradio Blocks Party org
117 | 1. Create an account on Hugging Face
118 | 2. Join the Gradio Blocks Party Organization by clicking "Join Organization" button in the organization page or using the shared link above
119 | 3. Once your request is approved, add your space using the Gradio SDK and share the link with the community!
120 |
121 | ## LeaderBoard for Most Popular Blocks Event Spaces based on Likes
122 |
123 | - See Leaderboard: https://huggingface.co/spaces/Gradio-Blocks/Leaderboard
124 |
--------------------------------------------------------------------------------
/huggan/__init__.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 |
3 | TEMPLATE_MODEL_CARD_PATH = Path(__file__).parent.absolute() / 'model_card_template.md'
--------------------------------------------------------------------------------
/huggan/assets/cyclegan.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/cyclegan.png
--------------------------------------------------------------------------------
/huggan/assets/dcgan_mnist.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/dcgan_mnist.png
--------------------------------------------------------------------------------
/huggan/assets/example_model.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/example_model.png
--------------------------------------------------------------------------------
/huggan/assets/example_space.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/example_space.png
--------------------------------------------------------------------------------
/huggan/assets/huggan_banner.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/huggan_banner.png
--------------------------------------------------------------------------------
/huggan/assets/lightweight_gan_wandb.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/lightweight_gan_wandb.png
--------------------------------------------------------------------------------
/huggan/assets/metfaces.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/metfaces.png
--------------------------------------------------------------------------------
/huggan/assets/pix2pix_maps.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/pix2pix_maps.png
--------------------------------------------------------------------------------
/huggan/assets/wandb.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/assets/wandb.png
--------------------------------------------------------------------------------
/huggan/model_card_template.md:
--------------------------------------------------------------------------------
1 | ---
2 | tags:
3 | - huggan
4 | - gan
5 | # See a list of available tags here:
6 | # https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts#L12
7 | # task: unconditional-image-generation or conditional-image-generation or image-to-image
8 | license: mit
9 | ---
10 |
11 | # MyModelName
12 |
13 | ## Model description
14 |
15 | Describe the model here (what it does, what it's used for, etc.)
16 |
17 | ## Intended uses & limitations
18 |
19 | #### How to use
20 |
21 | ```python
22 | # You can include sample code which will be formatted
23 | ```
24 |
25 | #### Limitations and bias
26 |
27 | Provide examples of latent issues and potential remediations.
28 |
29 | ## Training data
30 |
31 | Describe the data you used to train the model.
32 | If you initialized it with pre-trained weights, add a link to the pre-trained model card or repository with description of the pre-training data.
33 |
34 | ## Training procedure
35 |
36 | Preprocessing, hardware used, hyperparameters...
37 |
38 | ## Eval results
39 |
40 | ## Generated Images
41 |
42 | You can embed local or remote images using ``
43 |
44 | ### BibTeX entry and citation info
45 |
46 | ```bibtex
47 | @inproceedings{...,
48 | year={2020}
49 | }
50 | ```
--------------------------------------------------------------------------------
/huggan/pytorch/README.md:
--------------------------------------------------------------------------------
1 | # Example scripts (PyTorch)
2 |
3 | This directory contains a few example scripts that allow you to train famous GANs on your own data using a bit of 🤗 magic.
4 |
5 | More concretely, these scripts:
6 | - leverage 🤗 [Datasets](https://huggingface.co/docs/datasets/index) to load any image dataset from the hub (including your own, possibly private, dataset)
7 | - leverage 🤗 [Accelerate](https://huggingface.co/docs/accelerate/index) to instantly run the script on (multi-) CPU, (multi-) GPU, TPU environments, supporting fp16 and mixed precision as well as DeepSpeed
8 | - leverage 🤗 [Hub](https://huggingface.co/) to push the model to the hub at the end of training, allowing to easily create a demo for it afterwards
9 |
10 | Currently, it contains the following examples:
11 |
12 | | Name | Paper |
13 | | ----------- | ----------- |
14 | | [DCGAN](dcgan) | [Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks](https://arxiv.org/abs/1511.06434) |
15 | | [pix2pix](pix2pix) | [Image-to-Image Translation with Conditional Adversarial Networks](https://arxiv.org/abs/1611.07004) |
16 | | [CycleGAN](cyclegan) | [Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks](https://arxiv.org/abs/1703.10593)
17 | | [Lightweight GAN](lightweight_gan) | [Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis](https://openreview.net/forum?id=1Fqg133qRaI)
18 |
19 |
20 |
--------------------------------------------------------------------------------
/huggan/pytorch/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/pytorch/__init__.py
--------------------------------------------------------------------------------
/huggan/pytorch/cyclegan/README.md:
--------------------------------------------------------------------------------
1 | # Training CycleGAN on your own data
2 |
3 | This folder contains a script to train [CycleGAN](https://arxiv.org/abs/1703.10593), leveraging the [Hugging Face](https://huggingface.co/) ecosystem for processing data and pushing the model to the Hub.
4 |
5 |
6 |  7 |
7 |
8 |
9 | Example applications of CycleGAN. Taken from [this repo](https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix).
10 |
11 | The script leverages 🤗 Datasets for loading and processing data, and 🤗 Accelerate for instantly running on CPU, single, multi-GPUs or TPU, also supporting mixed precision.
12 |
13 | ## Launching the script
14 |
15 | To train the model with the default parameters (200 epochs, 256x256 images, etc.) on [huggan/facades](https://huggingface.co/datasets/huggan/facades) on your environment, first run:
16 |
17 | ```bash
18 | accelerate config
19 | ```
20 |
21 | and answer the questions asked. Next, launch the script as follows:
22 |
23 | ```
24 | accelerate launch train.py
25 | ```
26 |
27 | This will create local "images" and "saved_models" directories, containing generated images and saved checkpoints over the course of the training.
28 |
29 | To train on another dataset available on the hub, simply do:
30 |
31 | ```
32 | accelerate launch train.py --dataset huggan/edges2shoes
33 | ```
34 |
35 | Make sure to pick a dataset which has "imageA" and "imageB" columns defined. One can always tweak the script in case the column names are different.
36 |
37 | ## Training on your own data
38 |
39 | You can of course also train on your own images. For this, one can leverage Datasets' [ImageFolder](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder). Make sure to authenticate with the hub first, by running the `huggingface-cli login` command in a terminal, or the following in case you're working in a notebook:
40 |
41 | ```python
42 | from huggingface_hub import notebook_login
43 |
44 | notebook_login()
45 | ```
46 |
47 | Next, run the following in a notebook/script:
48 |
49 | ```python
50 | from datasets import load_dataset
51 |
52 | # first: load dataset
53 | # option 1: from local folder
54 | dataset = load_dataset("imagefolder", data_dir="path_to_folder")
55 | # option 2: from remote URL (e.g. a zip file)
56 | dataset = load_dataset("imagefolder", data_files="URL to .zip file")
57 |
58 | # next: push to the hub (assuming git-LFS is installed)
59 | dataset.push_to_hub("huggan/my-awesome-dataset")
60 | ```
61 |
62 | You can then simply pass the name of the dataset to the script:
63 |
64 | ```
65 | accelerate launch train.py --dataset huggan/my-awesome-dataset
66 | ```
67 |
68 | ## Pushing model to the Hub
69 |
70 | You can push your trained generator to the hub after training by specifying the `push_to_hub` flag.
71 | Then, you can run the script as follows:
72 |
73 | ```
74 | accelerate launch train.py --push_to_hub --model_name cyclegan-horse2zebra
75 | ```
76 |
77 | This is made possible by making the generator inherit from `PyTorchModelHubMixin`available in the `huggingface_hub` library.
78 |
79 | # Citation
80 |
81 | This repo is entirely based on Erik Linder-Norén's [PyTorch-GAN repo](https://github.com/eriklindernoren/PyTorch-GAN), but with added HuggingFace goodies.
82 |
--------------------------------------------------------------------------------
/huggan/pytorch/cyclegan/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/pytorch/cyclegan/__init__.py
--------------------------------------------------------------------------------
/huggan/pytorch/cyclegan/modeling_cyclegan.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | import torch.nn.functional as F
3 | import torch
4 |
5 | from huggan.pytorch.huggan_mixin import HugGANModelHubMixin
6 |
7 |
8 | ##############################
9 | # RESNET
10 | ##############################
11 |
12 |
13 | class ResidualBlock(nn.Module):
14 | def __init__(self, in_features):
15 | super(ResidualBlock, self).__init__()
16 |
17 | self.block = nn.Sequential(
18 | nn.ReflectionPad2d(1),
19 | nn.Conv2d(in_features, in_features, 3),
20 | nn.InstanceNorm2d(in_features),
21 | nn.ReLU(inplace=True),
22 | nn.ReflectionPad2d(1),
23 | nn.Conv2d(in_features, in_features, 3),
24 | nn.InstanceNorm2d(in_features),
25 | )
26 |
27 | def forward(self, x):
28 | return x + self.block(x)
29 |
30 |
31 | class GeneratorResNet(nn.Module, HugGANModelHubMixin):
32 | def __init__(self, input_shape, num_residual_blocks):
33 | super(GeneratorResNet, self).__init__()
34 |
35 | channels = input_shape[0]
36 |
37 | # Initial convolution block
38 | out_features = 64
39 | model = [
40 | nn.ReflectionPad2d(channels),
41 | nn.Conv2d(channels, out_features, 7),
42 | nn.InstanceNorm2d(out_features),
43 | nn.ReLU(inplace=True),
44 | ]
45 | in_features = out_features
46 |
47 | # Downsampling
48 | for _ in range(2):
49 | out_features *= 2
50 | model += [
51 | nn.Conv2d(in_features, out_features, 3, stride=2, padding=1),
52 | nn.InstanceNorm2d(out_features),
53 | nn.ReLU(inplace=True),
54 | ]
55 | in_features = out_features
56 |
57 | # Residual blocks
58 | for _ in range(num_residual_blocks):
59 | model += [ResidualBlock(out_features)]
60 |
61 | # Upsampling
62 | for _ in range(2):
63 | out_features //= 2
64 | model += [
65 | nn.Upsample(scale_factor=2),
66 | nn.Conv2d(in_features, out_features, 3, stride=1, padding=1),
67 | nn.InstanceNorm2d(out_features),
68 | nn.ReLU(inplace=True),
69 | ]
70 | in_features = out_features
71 |
72 | # Output layer
73 | model += [nn.ReflectionPad2d(channels), nn.Conv2d(out_features, channels, 7), nn.Tanh()]
74 |
75 | self.model = nn.Sequential(*model)
76 |
77 | def forward(self, x):
78 | return self.model(x)
79 |
80 |
81 | ##############################
82 | # Discriminator
83 | ##############################
84 |
85 |
86 | class Discriminator(nn.Module):
87 | def __init__(self, channels):
88 | super(Discriminator, self).__init__()
89 |
90 | def discriminator_block(in_filters, out_filters, normalize=True):
91 | """Returns downsampling layers of each discriminator block"""
92 | layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
93 | if normalize:
94 | layers.append(nn.InstanceNorm2d(out_filters))
95 | layers.append(nn.LeakyReLU(0.2, inplace=True))
96 | return layers
97 |
98 | self.model = nn.Sequential(
99 | *discriminator_block(channels, 64, normalize=False),
100 | *discriminator_block(64, 128),
101 | *discriminator_block(128, 256),
102 | *discriminator_block(256, 512),
103 | nn.ZeroPad2d((1, 0, 1, 0)),
104 | nn.Conv2d(512, 1, 4, padding=1)
105 | )
106 |
107 | def forward(self, img):
108 | return self.model(img)
--------------------------------------------------------------------------------
/huggan/pytorch/cyclegan/train.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | import numpy as np
4 | import itertools
5 | from pathlib import Path
6 | import datetime
7 | import time
8 | import sys
9 |
10 | from PIL import Image
11 |
12 | from torchvision.transforms import Compose, Resize, ToTensor, Normalize, RandomCrop, RandomHorizontalFlip
13 | from torchvision.utils import save_image, make_grid
14 |
15 | from torch.utils.data import DataLoader
16 |
17 | from modeling_cyclegan import GeneratorResNet, Discriminator
18 |
19 | from utils import ReplayBuffer, LambdaLR
20 |
21 | from datasets import load_dataset
22 |
23 | from accelerate import Accelerator
24 |
25 | import torch.nn as nn
26 | import torch
27 |
28 | def parse_args(args=None):
29 | parser = argparse.ArgumentParser()
30 | parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
31 | parser.add_argument("--num_epochs", type=int, default=200, help="number of epochs of training")
32 | parser.add_argument("--dataset_name", type=str, default="huggan/facades", help="name of the dataset")
33 | parser.add_argument("--batch_size", type=int, default=1, help="size of the batches")
34 | parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
35 | parser.add_argument("--beta1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
36 | parser.add_argument("--beta2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
37 | parser.add_argument("--decay_epoch", type=int, default=100, help="epoch from which to start lr decay")
38 | parser.add_argument("--num_workers", type=int, default=8, help="Number of CPU threads to use during batch generation")
39 | parser.add_argument("--image_size", type=int, default=256, help="Size of images for training")
40 | parser.add_argument("--channels", type=int, default=3, help="Number of image channels")
41 | parser.add_argument("--sample_interval", type=int, default=100, help="interval between saving generator outputs")
42 | parser.add_argument("--checkpoint_interval", type=int, default=-1, help="interval between saving model checkpoints")
43 | parser.add_argument("--n_residual_blocks", type=int, default=9, help="number of residual blocks in generator")
44 | parser.add_argument("--lambda_cyc", type=float, default=10.0, help="cycle loss weight")
45 | parser.add_argument("--lambda_id", type=float, default=5.0, help="identity loss weight")
46 | parser.add_argument("--fp16", action="store_true", help="If passed, will use FP16 training.")
47 | parser.add_argument(
48 | "--mixed_precision",
49 | type=str,
50 | default="no",
51 | choices=["no", "fp16", "bf16"],
52 | help="Whether to use mixed precision. Choose"
53 | "between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
54 | "and an Nvidia Ampere GPU.",
55 | )
56 | parser.add_argument("--cpu", action="store_true", help="If passed, will train on the CPU.")
57 | parser.add_argument(
58 | "--push_to_hub",
59 | action="store_true",
60 | help="Whether to push the model to the HuggingFace hub after training.",
61 | )
62 | parser.add_argument(
63 | "--pytorch_dump_folder_path",
64 | required="--push_to_hub" in sys.argv,
65 | type=Path,
66 | help="Path to save the model. Will be created if it doesn't exist already.",
67 | )
68 | parser.add_argument(
69 | "--model_name",
70 | required="--push_to_hub" in sys.argv,
71 | type=str,
72 | help="Name of the model on the hub.",
73 | )
74 | parser.add_argument(
75 | "--organization_name",
76 | required=False,
77 | default="huggan",
78 | type=str,
79 | help="Organization name to push to, in case args.push_to_hub is specified.",
80 | )
81 | return parser.parse_args(args=args)
82 |
83 |
84 | def weights_init_normal(m):
85 | classname = m.__class__.__name__
86 | if classname.find("Conv") != -1:
87 | torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
88 | if hasattr(m, "bias") and m.bias is not None:
89 | torch.nn.init.constant_(m.bias.data, 0.0)
90 | elif classname.find("BatchNorm2d") != -1:
91 | torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
92 | torch.nn.init.constant_(m.bias.data, 0.0)
93 |
94 |
95 | def training_function(config, args):
96 | accelerator = Accelerator(fp16=args.fp16, cpu=args.cpu, mixed_precision=args.mixed_precision)
97 |
98 | # Create sample and checkpoint directories
99 | os.makedirs("images/%s" % args.dataset_name, exist_ok=True)
100 | os.makedirs("saved_models/%s" % args.dataset_name, exist_ok=True)
101 |
102 | # Losses
103 | criterion_GAN = torch.nn.MSELoss()
104 | criterion_cycle = torch.nn.L1Loss()
105 | criterion_identity = torch.nn.L1Loss()
106 |
107 | input_shape = (args.channels, args.image_size, args.image_size)
108 | # Calculate output shape of image discriminator (PatchGAN)
109 | output_shape = (1, args.image_size // 2 ** 4, args.image_size // 2 ** 4)
110 |
111 | # Initialize generator and discriminator
112 | G_AB = GeneratorResNet(input_shape, args.n_residual_blocks)
113 | G_BA = GeneratorResNet(input_shape, args.n_residual_blocks)
114 | D_A = Discriminator(args.channels)
115 | D_B = Discriminator(args.channels)
116 |
117 | if args.epoch != 0:
118 | # Load pretrained models
119 | G_AB.load_state_dict(torch.load("saved_models/%s/G_AB_%d.pth" % (args.dataset_name, args.epoch)))
120 | G_BA.load_state_dict(torch.load("saved_models/%s/G_BA_%d.pth" % (args.dataset_name, args.epoch)))
121 | D_A.load_state_dict(torch.load("saved_models/%s/D_A_%d.pth" % (args.dataset_name, args.epoch)))
122 | D_B.load_state_dict(torch.load("saved_models/%s/D_B_%d.pth" % (args.dataset_name, args.epoch)))
123 | else:
124 | # Initialize weights
125 | G_AB.apply(weights_init_normal)
126 | G_BA.apply(weights_init_normal)
127 | D_A.apply(weights_init_normal)
128 | D_B.apply(weights_init_normal)
129 |
130 | # Optimizers
131 | optimizer_G = torch.optim.Adam(
132 | itertools.chain(G_AB.parameters(), G_BA.parameters()), lr=args.lr, betas=(args.beta1, args.beta2)
133 | )
134 | optimizer_D_A = torch.optim.Adam(D_A.parameters(), lr=args.lr, betas=(args.beta1, args.beta2))
135 | optimizer_D_B = torch.optim.Adam(D_B.parameters(), lr=args.lr, betas=(args.beta1, args.beta2))
136 |
137 | # Learning rate update schedulers
138 | lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(
139 | optimizer_G, lr_lambda=LambdaLR(args.num_epochs, args.epoch, args.decay_epoch).step
140 | )
141 | lr_scheduler_D_A = torch.optim.lr_scheduler.LambdaLR(
142 | optimizer_D_A, lr_lambda=LambdaLR(args.num_epochs, args.epoch, args.decay_epoch).step
143 | )
144 | lr_scheduler_D_B = torch.optim.lr_scheduler.LambdaLR(
145 | optimizer_D_B, lr_lambda=LambdaLR(args.num_epochs, args.epoch, args.decay_epoch).step
146 | )
147 |
148 | # Buffers of previously generated samples
149 | fake_A_buffer = ReplayBuffer()
150 | fake_B_buffer = ReplayBuffer()
151 |
152 | # Image transformations
153 | transform = Compose([
154 | Resize(int(args.image_size * 1.12), Image.BICUBIC),
155 | RandomCrop((args.image_size, args.image_size)),
156 | RandomHorizontalFlip(),
157 | ToTensor(),
158 | Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
159 | ])
160 |
161 | def transforms(examples):
162 | examples["A"] = [transform(image.convert("RGB")) for image in examples["imageA"]]
163 | examples["B"] = [transform(image.convert("RGB")) for image in examples["imageB"]]
164 |
165 | del examples["imageA"]
166 | del examples["imageB"]
167 |
168 | return examples
169 |
170 | dataset = load_dataset(args.dataset_name)
171 | transformed_dataset = dataset.with_transform(transforms)
172 |
173 | splits = transformed_dataset['train'].train_test_split(test_size=0.1)
174 | train_ds = splits['train']
175 | val_ds = splits['test']
176 |
177 | dataloader = DataLoader(train_ds, shuffle=True, batch_size=args.batch_size, num_workers=args.num_workers)
178 | val_dataloader = DataLoader(val_ds, batch_size=5, shuffle=True, num_workers=1)
179 |
180 | def sample_images(batches_done):
181 | """Saves a generated sample from the test set"""
182 | batch = next(iter(val_dataloader))
183 | G_AB.eval()
184 | G_BA.eval()
185 | real_A = batch["A"]
186 | fake_B = G_AB(real_A)
187 | real_B = batch["B"]
188 | fake_A = G_BA(real_B)
189 | # Arange images along x-axis
190 | real_A = make_grid(real_A, nrow=5, normalize=True)
191 | real_B = make_grid(real_B, nrow=5, normalize=True)
192 | fake_A = make_grid(fake_A, nrow=5, normalize=True)
193 | fake_B = make_grid(fake_B, nrow=5, normalize=True)
194 | # Arange images along y-axis
195 | image_grid = torch.cat((real_A, fake_B, real_B, fake_A), 1)
196 | save_image(image_grid, "images/%s/%s.png" % (args.dataset_name, batches_done), normalize=False)
197 |
198 | G_AB, G_BA, D_A, D_B, optimizer_G, optimizer_D_A, optimizer_D_B, dataloader, val_dataloader = accelerator.prepare(G_AB, G_BA, D_A, D_B, optimizer_G, optimizer_D_A, optimizer_D_B, dataloader, val_dataloader)
199 |
200 | # ----------
201 | # Training
202 | # ----------
203 |
204 | prev_time = time.time()
205 | for epoch in range(args.epoch, args.num_epochs):
206 | for i, batch in enumerate(dataloader):
207 |
208 | # Set model input
209 | real_A = batch["A"]
210 | real_B = batch["B"]
211 |
212 | # Adversarial ground truths
213 | valid = torch.ones((real_A.size(0), *output_shape), device=accelerator.device)
214 | fake = torch.zeros((real_A.size(0), *output_shape), device=accelerator.device)
215 |
216 | # ------------------
217 | # Train Generators
218 | # ------------------
219 |
220 | G_AB.train()
221 | G_BA.train()
222 |
223 | optimizer_G.zero_grad()
224 |
225 | # Identity loss
226 | loss_id_A = criterion_identity(G_BA(real_A), real_A)
227 | loss_id_B = criterion_identity(G_AB(real_B), real_B)
228 |
229 | loss_identity = (loss_id_A + loss_id_B) / 2
230 |
231 | # GAN loss
232 | fake_B = G_AB(real_A)
233 | loss_GAN_AB = criterion_GAN(D_B(fake_B), valid)
234 | fake_A = G_BA(real_B)
235 | loss_GAN_BA = criterion_GAN(D_A(fake_A), valid)
236 |
237 | loss_GAN = (loss_GAN_AB + loss_GAN_BA) / 2
238 |
239 | # Cycle loss
240 | recov_A = G_BA(fake_B)
241 | loss_cycle_A = criterion_cycle(recov_A, real_A)
242 | recov_B = G_AB(fake_A)
243 | loss_cycle_B = criterion_cycle(recov_B, real_B)
244 |
245 | loss_cycle = (loss_cycle_A + loss_cycle_B) / 2
246 |
247 | # Total loss
248 | loss_G = loss_GAN + args.lambda_cyc * loss_cycle + args.lambda_id * loss_identity
249 |
250 | accelerator.backward(loss_G)
251 | optimizer_G.step()
252 |
253 | # -----------------------
254 | # Train Discriminator A
255 | # -----------------------
256 |
257 | optimizer_D_A.zero_grad()
258 |
259 | # Real loss
260 | loss_real = criterion_GAN(D_A(real_A), valid)
261 | # Fake loss (on batch of previously generated samples)
262 | fake_A_ = fake_A_buffer.push_and_pop(fake_A)
263 | loss_fake = criterion_GAN(D_A(fake_A_.detach()), fake)
264 | # Total loss
265 | loss_D_A = (loss_real + loss_fake) / 2
266 |
267 | accelerator.backward(loss_D_A)
268 | optimizer_D_A.step()
269 |
270 | # -----------------------
271 | # Train Discriminator B
272 | # -----------------------
273 |
274 | optimizer_D_B.zero_grad()
275 |
276 | # Real loss
277 | loss_real = criterion_GAN(D_B(real_B), valid)
278 | # Fake loss (on batch of previously generated samples)
279 | fake_B_ = fake_B_buffer.push_and_pop(fake_B)
280 | loss_fake = criterion_GAN(D_B(fake_B_.detach()), fake)
281 | # Total loss
282 | loss_D_B = (loss_real + loss_fake) / 2
283 |
284 | accelerator.backward(loss_D_B)
285 | optimizer_D_B.step()
286 |
287 | loss_D = (loss_D_A + loss_D_B) / 2
288 |
289 | # --------------
290 | # Log Progress
291 | # --------------
292 |
293 | # Determine approximate time left
294 | batches_done = epoch * len(dataloader) + i
295 | batches_left = args.num_epochs * len(dataloader) - batches_done
296 | time_left = datetime.timedelta(seconds=batches_left * (time.time() - prev_time))
297 | prev_time = time.time()
298 |
299 | # Print log
300 | sys.stdout.write(
301 | "\r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f, adv: %f, cycle: %f, identity: %f] ETA: %s"
302 | % (
303 | epoch,
304 | args.num_epochs,
305 | i,
306 | len(dataloader),
307 | loss_D.item(),
308 | loss_G.item(),
309 | loss_GAN.item(),
310 | loss_cycle.item(),
311 | loss_identity.item(),
312 | time_left,
313 | )
314 | )
315 |
316 | # If at sample interval save image
317 | if batches_done % args.sample_interval == 0:
318 | sample_images(batches_done)
319 |
320 | # Update learning rates
321 | lr_scheduler_G.step()
322 | lr_scheduler_D_A.step()
323 | lr_scheduler_D_B.step()
324 |
325 | if args.checkpoint_interval != -1 and epoch % args.checkpoint_interval == 0:
326 | # Save model checkpoints
327 | torch.save(G_AB.state_dict(), "saved_models/%s/G_AB_%d.pth" % (args.dataset_name, epoch))
328 | torch.save(G_BA.state_dict(), "saved_models/%s/G_BA_%d.pth" % (args.dataset_name, epoch))
329 | torch.save(D_A.state_dict(), "saved_models/%s/D_A_%d.pth" % (args.dataset_name, epoch))
330 | torch.save(D_B.state_dict(), "saved_models/%s/D_B_%d.pth" % (args.dataset_name, epoch))
331 |
332 | # Optionally push to hub
333 | if args.push_to_hub:
334 | save_directory = args.pytorch_dump_folder_path
335 | if not save_directory.exists():
336 | save_directory.mkdir(parents=True)
337 |
338 | G_AB.push_to_hub(
339 | repo_path_or_name=save_directory / args.model_name,
340 | organization=args.organization_name,
341 | )
342 |
343 | def main():
344 | args = parse_args()
345 | print(args)
346 |
347 | # Make directory for saving generated images
348 | os.makedirs("images", exist_ok=True)
349 |
350 | training_function({}, args)
351 |
352 |
353 | if __name__ == "__main__":
354 | main()
--------------------------------------------------------------------------------
/huggan/pytorch/cyclegan/utils.py:
--------------------------------------------------------------------------------
1 | import random
2 | import time
3 | import datetime
4 | import sys
5 |
6 | from torch.autograd import Variable
7 | import torch
8 | import numpy as np
9 |
10 | from torchvision.utils import save_image
11 |
12 |
13 | class ReplayBuffer:
14 | def __init__(self, max_size=50):
15 | assert max_size > 0, "Empty buffer or trying to create a black hole. Be careful."
16 | self.max_size = max_size
17 | self.data = []
18 |
19 | def push_and_pop(self, data):
20 | to_return = []
21 | for element in data.data:
22 | element = torch.unsqueeze(element, 0)
23 | if len(self.data) < self.max_size:
24 | self.data.append(element)
25 | to_return.append(element)
26 | else:
27 | if random.uniform(0, 1) > 0.5:
28 | i = random.randint(0, self.max_size - 1)
29 | to_return.append(self.data[i].clone())
30 | self.data[i] = element
31 | else:
32 | to_return.append(element)
33 | return Variable(torch.cat(to_return))
34 |
35 |
36 | class LambdaLR:
37 | def __init__(self, n_epochs, offset, decay_start_epoch):
38 | assert (n_epochs - decay_start_epoch) > 0, "Decay must start before the training session ends!"
39 | self.n_epochs = n_epochs
40 | self.offset = offset
41 | self.decay_start_epoch = decay_start_epoch
42 |
43 | def step(self, epoch):
44 | return 1.0 - max(0, epoch + self.offset - self.decay_start_epoch) / (self.n_epochs - self.decay_start_epoch)
--------------------------------------------------------------------------------
/huggan/pytorch/dcgan/README.md:
--------------------------------------------------------------------------------
1 | # Train DCGAN on your custom data
2 |
3 | This folder contains a script to train [DCGAN](https://arxiv.org/abs/1511.06434) for unconditional image generation, leveraging the [Hugging Face](https://huggingface.co/) ecosystem for processing your data and pushing the model to the Hub.
4 |
5 | The script leverages 🤗 Datasets for loading and processing data, and 🤗 Accelerate for instantly running on CPU, single, multi-GPUs or TPU, also supporting fp16/mixed precision.
6 |
7 |
8 |  9 |
9 |
10 |
11 |
12 | ## Launching the script
13 |
14 | To train the model with the default parameters (5 epochs, 64x64 images, etc.) on [MNIST](https://huggingface.co/datasets/mnist), first run:
15 |
16 | ```bash
17 | accelerate config
18 | ```
19 |
20 | and answer the questions asked about your environment. Next, launch the script as follows:
21 |
22 | ```bash
23 | accelerate launch train.py
24 | ```
25 |
26 | This will create a local "images" directory, containing generated images over the course of the training.
27 |
28 | To train on another dataset available on the hub, simply do (for instance):
29 |
30 | ```bash
31 | python train.py --dataset cifar-10
32 | ```
33 |
34 | In case you'd like to tweak the script to your liking, first fork the "community-events" [repo](https://github.com/huggingface/community-events) (see the button on the top right), then clone it locally:
35 |
36 | ```bash
37 | git clone https://github.com//community-events.git
38 | ```
39 |
40 | and edit to your liking.
41 |
42 | ## Training on your own data
43 |
44 | You can of course also train on your own images. For this, one can leverage Datasets' [ImageFolder](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder). Make sure to authenticate with the hub first, by running the `huggingface-cli login` command in a terminal, or the following in case you're working in a notebook:
45 |
46 | ```python
47 | from huggingface_hub import notebook_login
48 |
49 | notebook_login()
50 | ```
51 |
52 | Next, run the following in a notebook/script:
53 |
54 | ```python
55 | from datasets import load_dataset
56 |
57 | # first: load dataset
58 | # option 1: from local folder
59 | dataset = load_dataset("imagefolder", data_dir="path_to_folder")
60 | # option 2: from remote URL (e.g. a zip file)
61 | dataset = load_dataset("imagefolder", data_files="URL to .zip file")
62 |
63 | # next: push to the hub (assuming git-LFS is installed)
64 | dataset.push_to_hub("huggan/my-awesome-dataset")
65 | ```
66 |
67 | You can then simply pass the name of the dataset to the script:
68 |
69 | ```bash
70 | accelerate launch train.py --dataset huggan/my-awesome-dataset
71 | ```
72 |
73 | ## Pushing model to the Hub
74 |
75 | You can push your trained generator to the hub after training by specifying the `push_to_hub` flag, along with a `model_name` and `pytorch_dump_folder_path`.
76 |
77 | ```bash
78 | accelerate launch train.py --push_to_hub --model_name dcgan-mnist
79 | ```
80 |
81 | This is made possible by making the generator inherit from `PyTorchModelHubMixin`available in the `huggingface_hub` library.
82 |
83 | This means that after training, generating a new image can be done as follows:
84 |
85 | ```python
86 | import torch
87 | import torch.nn as nn
88 | from torchvision.transforms import ToPILImage
89 | from huggingface_hub import PyTorchModelHubMixin
90 |
91 | class Generator(nn.Module, PyTorchModelHubMixin):
92 | def __init__(self, num_channels=3, latent_dim=100, hidden_size=64):
93 | super(Generator, self).__init__()
94 | self.model = nn.Sequential(
95 | # input is Z, going into a convolution
96 | nn.ConvTranspose2d(latent_dim, hidden_size * 8, 4, 1, 0, bias=False),
97 | nn.BatchNorm2d(hidden_size * 8),
98 | nn.ReLU(True),
99 | # state size. (hidden_size*8) x 4 x 4
100 | nn.ConvTranspose2d(hidden_size * 8, hidden_size * 4, 4, 2, 1, bias=False),
101 | nn.BatchNorm2d(hidden_size * 4),
102 | nn.ReLU(True),
103 | # state size. (hidden_size*4) x 8 x 8
104 | nn.ConvTranspose2d(hidden_size * 4, hidden_size * 2, 4, 2, 1, bias=False),
105 | nn.BatchNorm2d(hidden_size * 2),
106 | nn.ReLU(True),
107 | # state size. (hidden_size*2) x 16 x 16
108 | nn.ConvTranspose2d(hidden_size * 2, hidden_size, 4, 2, 1, bias=False),
109 | nn.BatchNorm2d(hidden_size),
110 | nn.ReLU(True),
111 | # state size. (hidden_size) x 32 x 32
112 | nn.ConvTranspose2d(hidden_size, num_channels, 4, 2, 1, bias=False),
113 | nn.Tanh()
114 | # state size. (num_channels) x 64 x 64
115 | )
116 |
117 | def forward(self, noise):
118 | pixel_values = self.model(noise)
119 |
120 | return pixel_values
121 |
122 | model = Generator.from_pretrained("huggan/dcgan-mnist")
123 |
124 | device = "cuda" if torch.cuda.is_available() else "cpu
125 | model.to(device)
126 |
127 | with torch.no_grad():
128 | z = torch.randn(1, 100, 1, 1, device=device)
129 | pixel_values = model(z)
130 |
131 | # turn into actual image
132 | image = pixel_values[0]
133 | image = (image + 1) /2
134 | image = ToPILImage()(image)
135 | image.save("generated.png")
136 | ```
137 |
138 | ## Weights and Biases integration
139 |
140 | You can easily add logging to [Weights and Biases](https://wandb.ai/site) by passing the `--wandb` flag:
141 |
142 | ```bash
143 | accelerate launch train.py --wandb
144 | ````
145 |
146 | You can then follow the progress of your GAN in a browser:
147 |
148 |
149 | 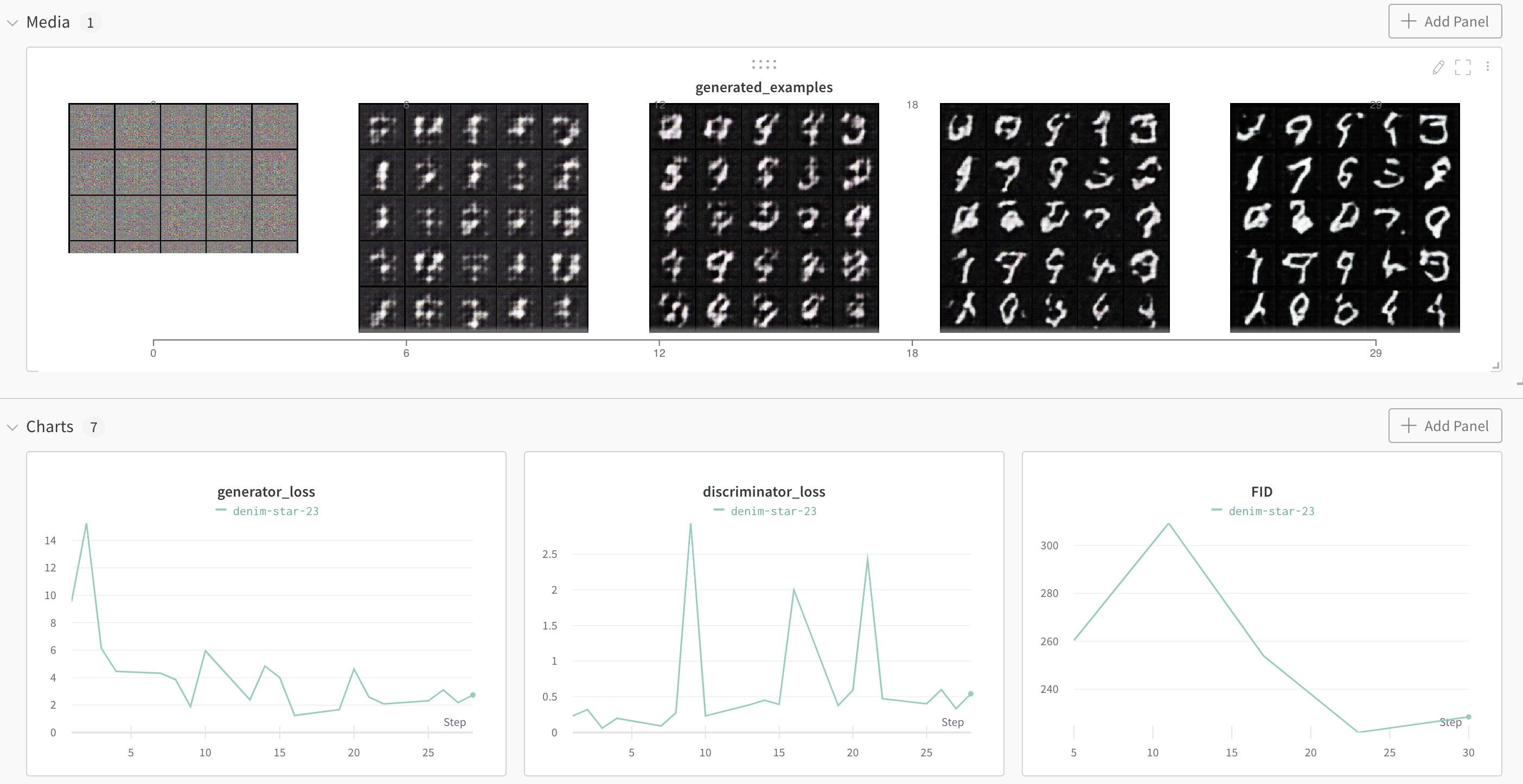 150 |
150 |
151 |
152 |
153 | # Citation
154 |
155 | This repo is entirely based on PyTorch's official [DCGAN tutorial](https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html), but with added HuggingFace goodies.
156 |
--------------------------------------------------------------------------------
/huggan/pytorch/dcgan/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/pytorch/dcgan/__init__.py
--------------------------------------------------------------------------------
/huggan/pytorch/dcgan/modeling_dcgan.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding=utf-8
3 | # Copyright (c) 2022 PyTorch contributors and The HuggingFace Inc. team. All rights reserved.
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions.
15 |
16 | import torch.nn as nn
17 |
18 | from huggan.pytorch.huggan_mixin import HugGANModelHubMixin
19 |
20 |
21 | class Generator(nn.Module, HugGANModelHubMixin):
22 | def __init__(self, num_channels=3, latent_dim=100, hidden_size=64):
23 | super(Generator, self).__init__()
24 | self.model = nn.Sequential(
25 | # input is Z, going into a convolution
26 | nn.ConvTranspose2d(latent_dim, hidden_size * 8, 4, 1, 0, bias=False),
27 | nn.BatchNorm2d(hidden_size * 8),
28 | nn.ReLU(True),
29 | # state size. (hidden_size*8) x 4 x 4
30 | nn.ConvTranspose2d(hidden_size * 8, hidden_size * 4, 4, 2, 1, bias=False),
31 | nn.BatchNorm2d(hidden_size * 4),
32 | nn.ReLU(True),
33 | # state size. (hidden_size*4) x 8 x 8
34 | nn.ConvTranspose2d(hidden_size * 4, hidden_size * 2, 4, 2, 1, bias=False),
35 | nn.BatchNorm2d(hidden_size * 2),
36 | nn.ReLU(True),
37 | # state size. (hidden_size*2) x 16 x 16
38 | nn.ConvTranspose2d(hidden_size * 2, hidden_size, 4, 2, 1, bias=False),
39 | nn.BatchNorm2d(hidden_size),
40 | nn.ReLU(True),
41 | # state size. (hidden_size) x 32 x 32
42 | nn.ConvTranspose2d(hidden_size, num_channels, 4, 2, 1, bias=False),
43 | nn.Tanh()
44 | # state size. (num_channels) x 64 x 64
45 | )
46 |
47 | def forward(self, noise):
48 | pixel_values = self.model(noise)
49 |
50 | return pixel_values
51 |
52 |
53 | class Discriminator(nn.Module):
54 | def __init__(self, num_channels=3, hidden_size=64):
55 | super(Discriminator, self).__init__()
56 | self.model = nn.Sequential(
57 | # input is (num_channels) x 64 x 64
58 | nn.Conv2d(num_channels, hidden_size, 4, 2, 1, bias=False),
59 | nn.LeakyReLU(0.2, inplace=True),
60 | # state size. (hidden_size) x 32 x 32
61 | nn.Conv2d(hidden_size, hidden_size * 2, 4, 2, 1, bias=False),
62 | nn.BatchNorm2d(hidden_size * 2),
63 | nn.LeakyReLU(0.2, inplace=True),
64 | # state size. (hidden_size*2) x 16 x 16
65 | nn.Conv2d(hidden_size * 2, hidden_size * 4, 4, 2, 1, bias=False),
66 | nn.BatchNorm2d(hidden_size * 4),
67 | nn.LeakyReLU(0.2, inplace=True),
68 | # state size. (hidden_size*4) x 8 x 8
69 | nn.Conv2d(hidden_size * 4, hidden_size * 8, 4, 2, 1, bias=False),
70 | nn.BatchNorm2d(hidden_size * 8),
71 | nn.LeakyReLU(0.2, inplace=True),
72 | # state size. (hidden_size*8) x 4 x 4
73 | nn.Conv2d(hidden_size * 8, 1, 4, 1, 0, bias=False),
74 | nn.Sigmoid(),
75 | )
76 |
77 | def forward(self, pixel_values):
78 | logits = self.model(pixel_values)
79 |
80 | return logits
81 |
--------------------------------------------------------------------------------
/huggan/pytorch/dcgan/train.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding=utf-8
3 | # Copyright (c) 2022 PyTorch contributors and The HuggingFace Inc. team. All rights reserved.
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions.
15 |
16 | """ Training a Deep Convolutional Generative Adversarial Network (DCGAN) leveraging the 🤗 ecosystem.
17 | Paper: https://arxiv.org/abs/1511.06434.
18 | Based on PyTorch's official tutorial: https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html.
19 | """
20 |
21 |
22 | import argparse
23 | import logging
24 | import os
25 | import sys
26 | from pathlib import Path
27 |
28 | import torch
29 | import torch.nn as nn
30 | from torch.utils.data import DataLoader
31 | from torchvision.transforms import (CenterCrop, Compose, Normalize, Resize,
32 | ToTensor, ToPILImage)
33 | from torchvision.utils import save_image
34 |
35 | from PIL import Image, ImageFile
36 | ImageFile.LOAD_TRUNCATED_IMAGES = True
37 |
38 | from accelerate import Accelerator
39 |
40 | from modeling_dcgan import Discriminator, Generator
41 |
42 | from datasets import load_dataset
43 |
44 | from huggan.pytorch.metrics.inception import InceptionV3
45 | from huggan.pytorch.metrics.fid_score import calculate_fretchet
46 |
47 | import wandb
48 |
49 | logger = logging.getLogger(__name__)
50 |
51 |
52 | def parse_args(args=None):
53 | parser = argparse.ArgumentParser()
54 | parser.add_argument("--dataset", type=str, default="mnist", help="Dataset to load from the HuggingFace hub.")
55 | parser.add_argument("--num_workers", type=int, default=0, help="Number of workers when loading data")
56 | parser.add_argument("--batch_size", type=int, default=128, help="Batch size to use during training")
57 | parser.add_argument(
58 | "--image_size",
59 | type=int,
60 | default=64,
61 | help="Spatial size to use when resizing images for training.",
62 | )
63 | parser.add_argument(
64 | "--num_channels",
65 | type=int,
66 | default=3,
67 | help="Number of channels in the training images. For color images this is 3.",
68 | )
69 | parser.add_argument("--latent_dim", type=int, default=100, help="Dimensionality of the latent space.")
70 | parser.add_argument(
71 | "--generator_hidden_size",
72 | type=int,
73 | default=64,
74 | help="Hidden size of the generator's feature maps.",
75 | )
76 | parser.add_argument(
77 | "--discriminator_hidden_size",
78 | type=int,
79 | default=64,
80 | help="Hidden size of the discriminator's feature maps.",
81 | )
82 | parser.add_argument("--num_epochs", type=int, default=5, help="number of epochs of training")
83 | parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
84 | parser.add_argument(
85 | "--beta1",
86 | type=float,
87 | default=0.5,
88 | help="adam: decay of first order momentum of gradient",
89 | )
90 | parser.add_argument("--fp16", action="store_true", help="If passed, will use FP16 training.")
91 | parser.add_argument(
92 | "--mixed_precision",
93 | type=str,
94 | default="no",
95 | choices=["no", "fp16", "bf16"],
96 | help="Whether to use mixed precision. Choose"
97 | "between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
98 | "and an Nvidia Ampere GPU.",
99 | )
100 | parser.add_argument("--cpu", action="store_true", help="If passed, will train on the CPU.")
101 | parser.add_argument("--output_dir", type=Path, default=Path("./output"), help="Name of the directory to dump generated images during training.")
102 | parser.add_argument("--wandb", action="store_true", help="If passed, will log to Weights and Biases.")
103 | parser.add_argument(
104 | "--logging_steps",
105 | type=int,
106 | default=50,
107 | help="Number of steps between each logging",
108 | )
109 | parser.add_argument(
110 | "--push_to_hub",
111 | action="store_true",
112 | help="Whether to push the model to the HuggingFace hub after training.",
113 | )
114 | parser.add_argument(
115 | "--model_name",
116 | default=None,
117 | type=str,
118 | help="Name of the model on the hub.",
119 | )
120 | parser.add_argument(
121 | "--organization_name",
122 | default="huggan",
123 | type=str,
124 | help="Organization name to push to, in case args.push_to_hub is specified.",
125 | )
126 | args = parser.parse_args()
127 |
128 | if args.push_to_hub:
129 | assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
130 | assert args.model_name is not None, "Need a `model_name` to create a repo when `--push_to_hub` is passed."
131 |
132 | if args.output_dir is not None:
133 | os.makedirs(args.output_dir, exist_ok=True)
134 |
135 | return args
136 |
137 |
138 | # Custom weights initialization called on Generator and Discriminator
139 | def weights_init(m):
140 | classname = m.__class__.__name__
141 | if classname.find("Conv") != -1:
142 | nn.init.normal_(m.weight.data, 0.0, 0.02)
143 | elif classname.find("BatchNorm") != -1:
144 | nn.init.normal_(m.weight.data, 1.0, 0.02)
145 | nn.init.constant_(m.bias.data, 0)
146 |
147 |
148 | def training_function(config, args):
149 |
150 | # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
151 | accelerator = Accelerator(fp16=args.fp16, cpu=args.cpu, mixed_precision=args.mixed_precision)
152 |
153 | # Setup logging, we only want one process per machine to log things on the screen.
154 | # accelerator.is_local_main_process is only True for one process per machine.
155 | logger.setLevel(logging.INFO if accelerator.is_local_main_process else logging.ERROR)
156 | if accelerator.is_local_main_process:
157 | # set up Weights and Biases if requested
158 | if args.wandb:
159 | import wandb
160 |
161 | wandb.init(project=str(args.output_dir).split("/")[-1])
162 |
163 | # Loss function
164 | criterion = nn.BCELoss()
165 |
166 | # Initialize generator and discriminator
167 | generator = Generator(
168 | num_channels=args.num_channels,
169 | latent_dim=args.latent_dim,
170 | hidden_size=args.generator_hidden_size,
171 | )
172 | discriminator = Discriminator(num_channels=args.num_channels, hidden_size=args.discriminator_hidden_size)
173 |
174 | # Initialize weights
175 | generator.apply(weights_init)
176 | discriminator.apply(weights_init)
177 |
178 | # Initialize Inceptionv3 (for FID metric)
179 | model = InceptionV3()
180 |
181 | # Initialize Inceptionv3 (for FID metric)
182 | model = InceptionV3()
183 |
184 | # Create batch of latent vectors that we will use to visualize
185 | # the progression of the generator
186 | fixed_noise = torch.randn(64, args.latent_dim, 1, 1, device=accelerator.device)
187 |
188 | # Establish convention for real and fake labels during training
189 | real_label = 1.0
190 | fake_label = 0.0
191 |
192 | # Setup Adam optimizers for both G and D
193 | discriminator_optimizer = torch.optim.Adam(discriminator.parameters(), lr=args.lr, betas=(args.beta1, 0.999))
194 | generator_optimizer = torch.optim.Adam(generator.parameters(), lr=args.lr, betas=(args.beta1, 0.999))
195 |
196 | # Configure data loader
197 | dataset = load_dataset(args.dataset)
198 |
199 | transform = Compose(
200 | [
201 | Resize(args.image_size),
202 | CenterCrop(args.image_size),
203 | ToTensor(),
204 | Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
205 | ]
206 | )
207 |
208 | def transforms(examples):
209 | examples["pixel_values"] = [transform(image.convert("RGB")) for image in examples["image"]]
210 |
211 | del examples["image"]
212 |
213 | return examples
214 |
215 | transformed_dataset = dataset.with_transform(transforms)
216 |
217 | dataloader = DataLoader(
218 | transformed_dataset["train"], batch_size=args.batch_size, shuffle=True, num_workers=args.num_workers
219 | )
220 |
221 | generator, discriminator, generator_optimizer, discriminator_optimizer, dataloader = accelerator.prepare(generator, discriminator, generator_optimizer, discriminator_optimizer, dataloader)
222 |
223 | # ----------
224 | # Training
225 | # ----------
226 |
227 | # Training Loop
228 |
229 | # Lists to keep track of progress
230 | img_list = []
231 |
232 | logger.info("***** Running training *****")
233 | logger.info(f" Num Epochs = {args.num_epochs}")
234 | # For each epoch
235 | for epoch in range(args.num_epochs):
236 | # For each batch in the dataloader
237 | for step, batch in enumerate(dataloader, 0):
238 |
239 | ############################
240 | # (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))
241 | ###########################
242 | ## Train with all-real batch
243 | discriminator.zero_grad()
244 | # Format batch
245 | real_cpu = batch["pixel_values"]
246 | batch_size = real_cpu.size(0)
247 | label = torch.full((batch_size,), real_label, dtype=torch.float, device=accelerator.device)
248 | # Forward pass real batch through D
249 | output = discriminator(real_cpu).view(-1)
250 | # Calculate loss on all-real batch
251 | errD_real = criterion(output, label)
252 | # Calculate gradients for D in backward pass
253 | accelerator.backward(errD_real)
254 | D_x = output.mean().item()
255 |
256 | ## Train with all-fake batch
257 | # Generate batch of latent vectors
258 | noise = torch.randn(batch_size, args.latent_dim, 1, 1, device=accelerator.device)
259 | # Generate fake image batch with G
260 | fake = generator(noise)
261 | label.fill_(fake_label)
262 | # Classify all fake batch with D
263 | output = discriminator(fake.detach()).view(-1)
264 | # Calculate D's loss on the all-fake batch
265 | errD_fake = criterion(output, label)
266 | # Calculate the gradients for this batch, accumulated (summed) with previous gradients
267 | accelerator.backward(errD_fake)
268 | D_G_z1 = output.mean().item()
269 | # Compute error of D as sum over the fake and the real batches
270 | errD = errD_real + errD_fake
271 | # Update D
272 | discriminator_optimizer.step()
273 |
274 | ############################
275 | # (2) Update G network: maximize log(D(G(z)))
276 | ###########################
277 | generator.zero_grad()
278 | label.fill_(real_label) # fake labels are real for generator cost
279 | # Since we just updated D, perform another forward pass of all-fake batch through D
280 | output = discriminator(fake).view(-1)
281 | # Calculate G's loss based on this output
282 | errG = criterion(output, label)
283 | # Calculate gradients for G
284 | accelerator.backward(errG)
285 | D_G_z2 = output.mean().item()
286 | # Update G
287 | generator_optimizer.step()
288 |
289 | # Log all results
290 | if (step + 1) % args.logging_steps == 0:
291 | errD.detach()
292 | errG.detach()
293 |
294 | if accelerator.state.num_processes > 1:
295 | errD = accelerator.gather(errD).sum() / accelerator.state.num_processes
296 | errG = accelerator.gather(errG).sum() / accelerator.state.num_processes
297 |
298 | train_logs = {
299 | "epoch": epoch,
300 | "discriminator_loss": errD,
301 | "generator_loss": errG,
302 | "D_x": D_x,
303 | "D_G_z1": D_G_z1,
304 | "D_G_z2": D_G_z2,
305 | }
306 | log_str = ""
307 | for k, v in train_logs.items():
308 | log_str += "| {}: {:.3e}".format(k, v)
309 |
310 | if accelerator.is_local_main_process:
311 | logger.info(log_str)
312 | if args.wandb:
313 | wandb.log(train_logs)
314 |
315 | # Check how the generator is doing by saving G's output on fixed_noise
316 | if (step % 500 == 0) or ((epoch == args.num_epochs - 1) and (step == len(dataloader) - 1)):
317 | with torch.no_grad():
318 | fake_images = generator(fixed_noise).detach().cpu()
319 | file_name = args.output_dir/f"iter_{step}.png"
320 | save_image(fake_images.data[:25], file_name, nrow=5, normalize=True)
321 | if accelerator.is_local_main_process and args.wandb:
322 | wandb.log({'generated_examples': wandb.Image(str(file_name)) })
323 |
324 | # Calculate FID metric
325 | fid = calculate_fretchet(real_cpu, fake, model.to(accelerator.device))
326 | logger.info(f"FID: {fid}")
327 | if accelerator.is_local_main_process and args.wandb:
328 | wandb.log({"FID": fid})
329 |
330 | # Optionally push to hub
331 | if accelerator.is_main_process and args.push_to_hub:
332 | generator.module.push_to_hub(
333 | repo_path_or_name=args.output_dir / args.model_name,
334 | organization=args.organization_name,
335 | )
336 |
337 |
338 | def main():
339 | args = parse_args()
340 | print(args)
341 |
342 | training_function({}, args)
343 |
344 |
345 | if __name__ == "__main__":
346 | main()
347 |
--------------------------------------------------------------------------------
/huggan/pytorch/huggan_mixin.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 | from re import TEMPLATE
3 | from typing import Optional, Union
4 | import os
5 |
6 | from huggingface_hub import PyTorchModelHubMixin, HfApi, HfFolder, Repository
7 |
8 | from huggan import TEMPLATE_MODEL_CARD_PATH
9 |
10 |
11 | class HugGANModelHubMixin(PyTorchModelHubMixin):
12 | """A mixin to push PyTorch Models to the Hugging Face Hub. This
13 | mixin was adapted from the PyTorchModelHubMixin to also push a template
14 | README.md for the HugGAN sprint.
15 | """
16 |
17 | def push_to_hub(
18 | self,
19 | repo_path_or_name: Optional[str] = None,
20 | repo_url: Optional[str] = None,
21 | commit_message: Optional[str] = "Add model",
22 | organization: Optional[str] = None,
23 | private: Optional[bool] = None,
24 | api_endpoint: Optional[str] = None,
25 | use_auth_token: Optional[Union[bool, str]] = None,
26 | git_user: Optional[str] = None,
27 | git_email: Optional[str] = None,
28 | config: Optional[dict] = None,
29 | skip_lfs_files: bool = False,
30 | default_model_card: Optional[str] = TEMPLATE_MODEL_CARD_PATH
31 | ) -> str:
32 | """
33 | Upload model checkpoint or tokenizer files to the Hub while
34 | synchronizing a local clone of the repo in `repo_path_or_name`.
35 | Parameters:
36 | repo_path_or_name (`str`, *optional*):
37 | Can either be a repository name for your model or tokenizer in
38 | the Hub or a path to a local folder (in which case the
39 | repository will have the name of that local folder). If not
40 | specified, will default to the name given by `repo_url` and a
41 | local directory with that name will be created.
42 | repo_url (`str`, *optional*):
43 | Specify this in case you want to push to an existing repository
44 | in the hub. If unspecified, a new repository will be created in
45 | your namespace (unless you specify an `organization`) with
46 | `repo_name`.
47 | commit_message (`str`, *optional*):
48 | Message to commit while pushing. Will default to `"add config"`,
49 | `"add tokenizer"` or `"add model"` depending on the type of the
50 | class.
51 | organization (`str`, *optional*):
52 | Organization in which you want to push your model or tokenizer
53 | (you must be a member of this organization).
54 | private (`bool`, *optional*):
55 | Whether the repository created should be private.
56 | api_endpoint (`str`, *optional*):
57 | The API endpoint to use when pushing the model to the hub.
58 | use_auth_token (`bool` or `str`, *optional*):
59 | The token to use as HTTP bearer authorization for remote files.
60 | If `True`, will use the token generated when running
61 | `transformers-cli login` (stored in `~/.huggingface`). Will
62 | default to `True` if `repo_url` is not specified.
63 | git_user (`str`, *optional*):
64 | will override the `git config user.name` for committing and
65 | pushing files to the hub.
66 | git_email (`str`, *optional*):
67 | will override the `git config user.email` for committing and
68 | pushing files to the hub.
69 | config (`dict`, *optional*):
70 | Configuration object to be saved alongside the model weights.
71 | default_model_card (`str`, *optional*):
72 | Path to a markdown file to use as your default model card.
73 | Returns:
74 | The url of the commit of your model in the given repository.
75 | """
76 |
77 | if repo_path_or_name is None and repo_url is None:
78 | raise ValueError(
79 | "You need to specify a `repo_path_or_name` or a `repo_url`."
80 | )
81 |
82 | if use_auth_token is None and repo_url is None:
83 | token = HfFolder.get_token()
84 | if token is None:
85 | raise ValueError(
86 | "You must login to the Hugging Face hub on this computer by typing `huggingface-cli login` and "
87 | "entering your credentials to use `use_auth_token=True`. Alternatively, you can pass your own "
88 | "token as the `use_auth_token` argument."
89 | )
90 | elif isinstance(use_auth_token, str):
91 | token = use_auth_token
92 | else:
93 | token = None
94 |
95 | if repo_path_or_name is None:
96 | repo_path_or_name = repo_url.split("/")[-1]
97 |
98 | # If no URL is passed and there's no path to a directory containing files, create a repo
99 | if repo_url is None and not os.path.exists(repo_path_or_name):
100 | repo_id = Path(repo_path_or_name).name
101 | if organization:
102 | repo_id = f"{organization}/{repo_id}"
103 | repo_url = HfApi(endpoint=api_endpoint).create_repo(
104 | repo_id=repo_id,
105 | token=token,
106 | private=private,
107 | repo_type=None,
108 | exist_ok=True,
109 | )
110 |
111 | repo = Repository(
112 | repo_path_or_name,
113 | clone_from=repo_url,
114 | use_auth_token=use_auth_token,
115 | git_user=git_user,
116 | git_email=git_email,
117 | skip_lfs_files=skip_lfs_files
118 | )
119 | repo.git_pull(rebase=True)
120 |
121 | # Save the files in the cloned repo
122 | self.save_pretrained(repo_path_or_name, config=config)
123 |
124 | model_card_path = Path(repo_path_or_name) / 'README.md'
125 | if not model_card_path.exists():
126 | model_card_path.write_text(TEMPLATE_MODEL_CARD_PATH.read_text())
127 |
128 | # Commit and push!
129 | repo.git_add()
130 | repo.git_commit(commit_message)
131 | return repo.git_push()
132 |
--------------------------------------------------------------------------------
/huggan/pytorch/lightweight_gan/README.md:
--------------------------------------------------------------------------------
1 | # Train Lightweight GAN on your custom data
2 |
3 | This folder contains a script to train ['Lightweight' GAN](https://openreview.net/forum?id=1Fqg133qRaI) for unconditional image generation, leveraging the [Hugging Face](https://huggingface.co/) ecosystem for processing your data and pushing the model to the Hub.
4 |
5 | The script leverages 🤗 Datasets for loading and processing data, and 🤗 Accelerate for instantly running on CPU, single, multi-GPUs or TPU, also supporting mixed precision.
6 |
7 |
8 |  9 |
9 |
10 |
11 | Pizza's that don't exist. Courtesy of Phil Wang.
12 |
13 | ## Launching the script
14 |
15 | To train the model with the default parameters on [huggan/CelebA-faces](https://huggingface.co/datasets/huggan/CelebA-faces), first run:
16 |
17 | ```bash
18 | accelerate config
19 | ```
20 |
21 | and answer the questions asked about your environment. Next, launch the script as follows:
22 |
23 | ```bash
24 | accelerate launch cli.py
25 | ```
26 |
27 | This will instantly run on multi-GPUs (if you asked for that). To train on another dataset available on the hub, simply do (for instance):
28 |
29 | ```bash
30 | accelerate launch cli.py --dataset_name huggan/pokemon
31 | ```
32 |
33 | In case you'd like to tweak the script to your liking, first fork the "community-events" [repo](https://github.com/huggingface/community-events) (see the button on the top right), then clone it locally:
34 |
35 | ```bash
36 | git clone https://github.com//community-events.git
37 | ```
38 |
39 | and edit to your liking.
40 |
41 | ## Training on your own data
42 |
43 | You can of course also train on your own images. For this, one can leverage Datasets' [ImageFolder](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder). Make sure to authenticate with the hub first, by running the `huggingface-cli login` command in a terminal, or the following in case you're working in a notebook:
44 |
45 | ```python
46 | from huggingface_hub import notebook_login
47 |
48 | notebook_login()
49 | ```
50 |
51 | Next, run the following in a notebook/script:
52 |
53 | ```python
54 | from datasets import load_dataset
55 |
56 | # first: load dataset
57 | # option 1: from local folder
58 | dataset = load_dataset("imagefolder", data_dir="path_to_folder")
59 | # option 2: from remote URL (e.g. a zip file)
60 | dataset = load_dataset("imagefolder", data_files="URL to .zip file")
61 |
62 | # next: push to the hub (assuming git-LFS is installed)
63 | dataset.push_to_hub("huggan/my-awesome-dataset")
64 | ```
65 |
66 | You can then simply pass the name of the dataset to the script:
67 |
68 | ```bash
69 | accelerate launch cli.py --dataset huggan/my-awesome-dataset
70 | ```
71 |
72 | ## Weights and Biases integration
73 |
74 | You can easily add logging to [Weights and Biases](https://wandb.ai/site) by passing the `--wandb` flag:
75 |
76 | ```bash
77 | accelerate launch cli.py --wandb
78 | ````
79 |
80 | You can then follow the progress of your GAN in a browser:
81 |
82 |
83 | 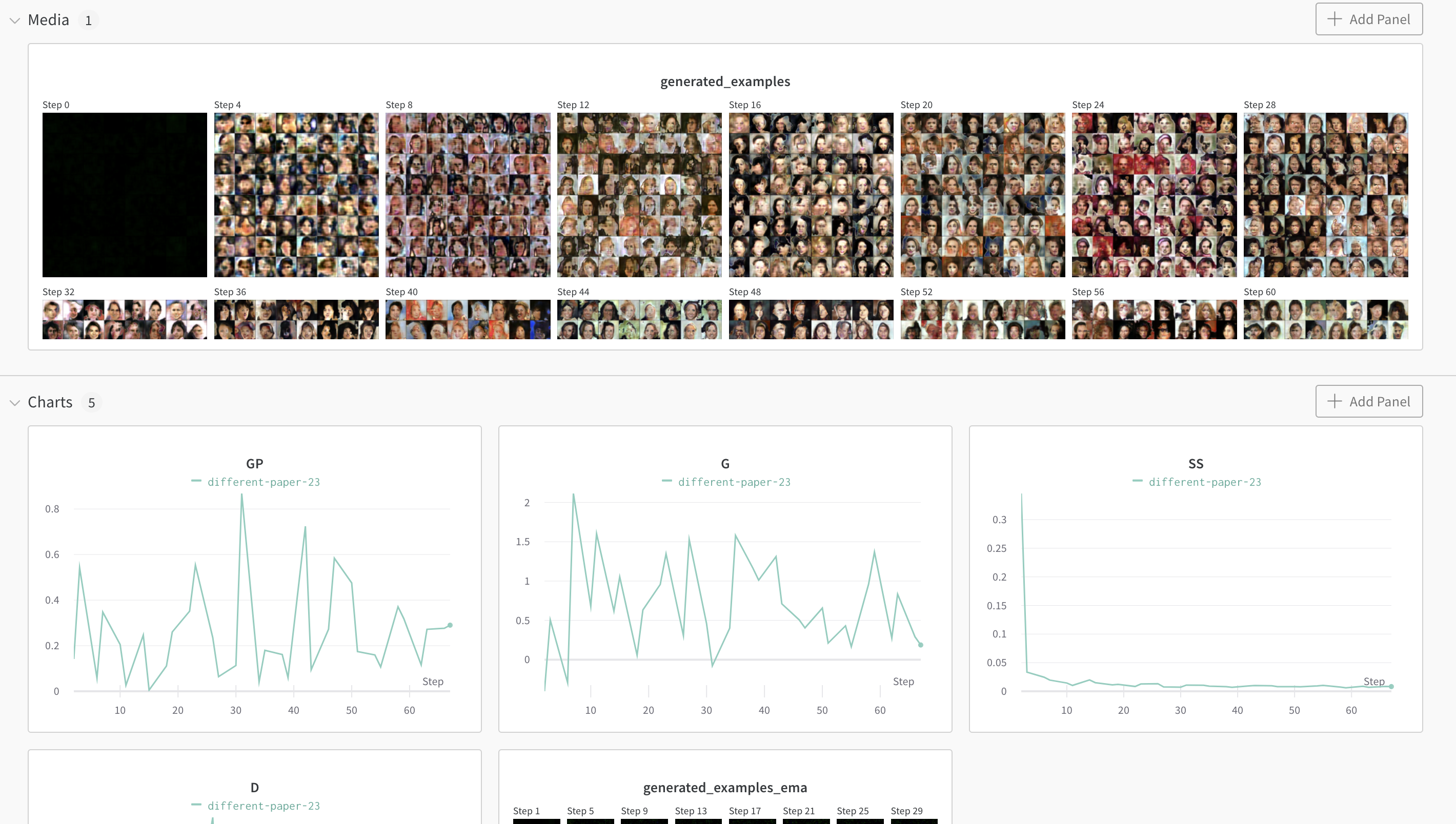 84 |
84 |
85 |
86 |
87 | # Citation
88 |
89 | This repo is entirely based on lucidrains' [Pytorch implementation](https://github.com/lucidrains/lightweight-gan), but with added HuggingFace goodies.
90 |
--------------------------------------------------------------------------------
/huggan/pytorch/lightweight_gan/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/pytorch/lightweight_gan/__init__.py
--------------------------------------------------------------------------------
/huggan/pytorch/lightweight_gan/cli.py:
--------------------------------------------------------------------------------
1 | import fire
2 | import random
3 | from retry.api import retry_call
4 | from tqdm import tqdm
5 | from datetime import datetime
6 | from pathlib import Path
7 | from lightweight_gan import Trainer, NanException
8 |
9 | import torch
10 | import torch.multiprocessing as mp
11 |
12 | import numpy as np
13 |
14 | def exists(val):
15 | return val is not None
16 |
17 | def default(val, d):
18 | return val if exists(val) else d
19 |
20 | def cast_list(el):
21 | return el if isinstance(el, list) else [el]
22 |
23 | def timestamped_filename(prefix = 'generated-'):
24 | now = datetime.now()
25 | timestamp = now.strftime("%m-%d-%Y_%H-%M-%S")
26 | return f'{prefix}{timestamp}'
27 |
28 | def set_seed(seed):
29 | torch.manual_seed(seed)
30 | torch.backends.cudnn.deterministic = True
31 | torch.backends.cudnn.benchmark = False
32 | np.random.seed(seed)
33 | random.seed(seed)
34 |
35 | def run_training(model_args, data, load_from, new, num_train_steps, name, seed):
36 |
37 | if seed is not None:
38 | set_seed(seed)
39 |
40 | model = Trainer(**model_args)
41 |
42 | if not new:
43 | model.load(load_from)
44 | else:
45 | model.clear()
46 |
47 | progress_bar = tqdm(initial = model.steps, total = num_train_steps, mininterval=10., desc=f'{name}<{data}>')
48 | G, D, D_aug = model.init_accelerator()
49 |
50 | # model.set_data_src(data)
51 |
52 | while model.steps < num_train_steps:
53 | # retry_call(model.train, tries=3, exceptions=NanException)
54 | model.train(G, D, D_aug)
55 | progress_bar.n = model.steps
56 | progress_bar.refresh()
57 | if model.accelerator.is_local_main_process and model.steps % 50 == 0:
58 | model.print_log()
59 |
60 | model.save(model.checkpoint_num)
61 |
62 | def train_from_folder(
63 | dataset_name = 'huggan/CelebA-faces',
64 | data = './data',
65 | results_dir = './results',
66 | models_dir = './models',
67 | name = 'default',
68 | new = False,
69 | load_from = -1,
70 | image_size = 256,
71 | optimizer = 'adam',
72 | fmap_max = 512,
73 | transparent = False,
74 | greyscale = False,
75 | batch_size = 10,
76 | gradient_accumulate_every = 4,
77 | num_train_steps = 150000,
78 | learning_rate = 2e-4,
79 | save_every = 10000,
80 | evaluate_every = 1000,
81 | generate = False,
82 | generate_types = ['default', 'ema'],
83 | generate_interpolation = False,
84 | aug_test = False,
85 | aug_prob=None,
86 | aug_types=['cutout', 'translation'],
87 | dataset_aug_prob=0.,
88 | attn_res_layers = [32],
89 | freq_chan_attn = False,
90 | disc_output_size = 1,
91 | dual_contrast_loss = False,
92 | antialias = False,
93 | interpolation_num_steps = 100,
94 | save_frames = False,
95 | num_image_tiles = None,
96 | calculate_fid_every = None,
97 | calculate_fid_num_images = 12800,
98 | clear_fid_cache = False,
99 | seed = 42,
100 | cpu = False,
101 | mixed_precision = "no",
102 | show_progress = False,
103 | wandb = False,
104 | push_to_hub = False,
105 | organization_name = None,
106 | ):
107 | if push_to_hub:
108 | if name == 'default':
109 | raise RuntimeError(
110 | "You've chosen to push to hub, but have left the --name flag as 'default'."
111 | " You should name your model something other than 'default'!"
112 | )
113 |
114 | num_image_tiles = default(num_image_tiles, 4 if image_size > 512 else 8)
115 |
116 | model_args = dict(
117 | dataset_name = dataset_name,
118 | name = name,
119 | results_dir = results_dir,
120 | models_dir = models_dir,
121 | batch_size = batch_size,
122 | gradient_accumulate_every = gradient_accumulate_every,
123 | attn_res_layers = cast_list(attn_res_layers),
124 | freq_chan_attn = freq_chan_attn,
125 | disc_output_size = disc_output_size,
126 | dual_contrast_loss = dual_contrast_loss,
127 | antialias = antialias,
128 | image_size = image_size,
129 | num_image_tiles = num_image_tiles,
130 | optimizer = optimizer,
131 | fmap_max = fmap_max,
132 | transparent = transparent,
133 | greyscale = greyscale,
134 | lr = learning_rate,
135 | save_every = save_every,
136 | evaluate_every = evaluate_every,
137 | aug_prob = aug_prob,
138 | aug_types = cast_list(aug_types),
139 | dataset_aug_prob = dataset_aug_prob,
140 | calculate_fid_every = calculate_fid_every,
141 | calculate_fid_num_images = calculate_fid_num_images,
142 | clear_fid_cache = clear_fid_cache,
143 | cpu = cpu,
144 | mixed_precision = mixed_precision,
145 | wandb = wandb,
146 | push_to_hub = push_to_hub,
147 | organization_name = organization_name
148 | )
149 |
150 | if generate:
151 | model = Trainer(**model_args)
152 | model.load(load_from)
153 | samples_name = timestamped_filename()
154 | checkpoint = model.checkpoint_num
155 | dir_result = model.generate(samples_name, num_image_tiles, checkpoint, generate_types)
156 | print(f'sample images generated at {dir_result}')
157 | return
158 |
159 | if generate_interpolation:
160 | model = Trainer(**model_args)
161 | model.load(load_from)
162 | samples_name = timestamped_filename()
163 | model.generate_interpolation(samples_name, num_image_tiles, num_steps = interpolation_num_steps, save_frames = save_frames)
164 | print(f'interpolation generated at {results_dir}/{name}/{samples_name}')
165 | return
166 |
167 | if show_progress:
168 | model = Trainer(**model_args)
169 | model.show_progress(num_images=num_image_tiles, types=generate_types)
170 | return
171 |
172 | run_training(model_args, data, load_from, new, num_train_steps, name, seed)
173 |
174 | def main():
175 | fire.Fire(train_from_folder)
176 |
177 | if __name__ == "__main__":
178 | main()
--------------------------------------------------------------------------------
/huggan/pytorch/lightweight_gan/diff_augment.py:
--------------------------------------------------------------------------------
1 | import random
2 |
3 | import torch
4 | import torch.nn.functional as F
5 |
6 |
7 | def DiffAugment(x, types=[]):
8 | for p in types:
9 | for f in AUGMENT_FNS[p]:
10 | x = f(x)
11 | return x.contiguous()
12 |
13 |
14 | # """
15 | # Augmentation functions got images as `x`
16 | # where `x` is tensor with this dimensions:
17 | # 0 - count of images
18 | # 1 - channels
19 | # 2 - width
20 | # 3 - height of image
21 | # """
22 |
23 | def rand_brightness(x):
24 | x = x + (torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) - 0.5)
25 | return x
26 |
27 | def rand_saturation(x):
28 | x_mean = x.mean(dim=1, keepdim=True)
29 | x = (x - x_mean) * (torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) * 2) + x_mean
30 | return x
31 |
32 | def rand_contrast(x):
33 | x_mean = x.mean(dim=[1, 2, 3], keepdim=True)
34 | x = (x - x_mean) * (torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) + 0.5) + x_mean
35 | return x
36 |
37 | def rand_translation(x, ratio=0.125):
38 | shift_x, shift_y = int(x.size(2) * ratio + 0.5), int(x.size(3) * ratio + 0.5)
39 | translation_x = torch.randint(-shift_x, shift_x + 1, size=[x.size(0), 1, 1], device=x.device)
40 | translation_y = torch.randint(-shift_y, shift_y + 1, size=[x.size(0), 1, 1], device=x.device)
41 | grid_batch, grid_x, grid_y = torch.meshgrid(
42 | torch.arange(x.size(0), dtype=torch.long, device=x.device),
43 | torch.arange(x.size(2), dtype=torch.long, device=x.device),
44 | torch.arange(x.size(3), dtype=torch.long, device=x.device),
45 | indexing = 'ij')
46 | grid_x = torch.clamp(grid_x + translation_x + 1, 0, x.size(2) + 1)
47 | grid_y = torch.clamp(grid_y + translation_y + 1, 0, x.size(3) + 1)
48 | x_pad = F.pad(x, [1, 1, 1, 1, 0, 0, 0, 0])
49 | x = x_pad.permute(0, 2, 3, 1).contiguous()[grid_batch, grid_x, grid_y].permute(0, 3, 1, 2)
50 | return x
51 |
52 | def rand_offset(x, ratio=1, ratio_h=1, ratio_v=1):
53 | w, h = x.size(2), x.size(3)
54 |
55 | imgs = []
56 | for img in x.unbind(dim = 0):
57 | max_h = int(w * ratio * ratio_h)
58 | max_v = int(h * ratio * ratio_v)
59 |
60 | value_h = random.randint(0, max_h) * 2 - max_h
61 | value_v = random.randint(0, max_v) * 2 - max_v
62 |
63 | if abs(value_h) > 0:
64 | img = torch.roll(img, value_h, 2)
65 |
66 | if abs(value_v) > 0:
67 | img = torch.roll(img, value_v, 1)
68 |
69 | imgs.append(img)
70 |
71 | return torch.stack(imgs)
72 |
73 | def rand_offset_h(x, ratio=1):
74 | return rand_offset(x, ratio=1, ratio_h=ratio, ratio_v=0)
75 |
76 | def rand_offset_v(x, ratio=1):
77 | return rand_offset(x, ratio=1, ratio_h=0, ratio_v=ratio)
78 |
79 | def rand_cutout(x, ratio=0.5):
80 | cutout_size = int(x.size(2) * ratio + 0.5), int(x.size(3) * ratio + 0.5)
81 | offset_x = torch.randint(0, x.size(2) + (1 - cutout_size[0] % 2), size=[x.size(0), 1, 1], device=x.device)
82 | offset_y = torch.randint(0, x.size(3) + (1 - cutout_size[1] % 2), size=[x.size(0), 1, 1], device=x.device)
83 | grid_batch, grid_x, grid_y = torch.meshgrid(
84 | torch.arange(x.size(0), dtype=torch.long, device=x.device),
85 | torch.arange(cutout_size[0], dtype=torch.long, device=x.device),
86 | torch.arange(cutout_size[1], dtype=torch.long, device=x.device),
87 | indexing = 'ij')
88 | grid_x = torch.clamp(grid_x + offset_x - cutout_size[0] // 2, min=0, max=x.size(2) - 1)
89 | grid_y = torch.clamp(grid_y + offset_y - cutout_size[1] // 2, min=0, max=x.size(3) - 1)
90 | mask = torch.ones(x.size(0), x.size(2), x.size(3), dtype=x.dtype, device=x.device)
91 | mask[grid_batch, grid_x, grid_y] = 0
92 | x = x * mask.unsqueeze(1)
93 | return x
94 |
95 | AUGMENT_FNS = {
96 | 'color': [rand_brightness, rand_saturation, rand_contrast],
97 | 'offset': [rand_offset],
98 | 'offset_h': [rand_offset_h],
99 | 'offset_v': [rand_offset_v],
100 | 'translation': [rand_translation],
101 | 'cutout': [rand_cutout],
102 | }
--------------------------------------------------------------------------------
/huggan/pytorch/metrics/README.md:
--------------------------------------------------------------------------------
1 | # GAN metrics
2 |
3 | In order to track progress 📈 in (un)conditional image generation, a few quantitative metrics have been proposed. Below, we explain the most popular ones. For a more extensive overview, we refer the reader to [Borji, 2021](https://arxiv.org/abs/2103.09396) - which is an up-to-date version of [Borji, 2018](https://arxiv.org/abs/1802.03446). The TLDR is that, despite the use of many popular metrics, objective and comprehensive evaluation of generative models is still an open problem 🤷♂️.
4 |
5 | Quantitative metrics are of course just a proxy of image quality. The most widely used (Inception Score and FID) have several drawbacks [Barratt et al., 2018](https://arxiv.org/abs/1801.01973), [Sajjadi et al., 2018](https://arxiv.org/abs/1806.00035), [Kynkäänniemi et al., 2019](https://arxiv.org/abs/1904.06991).
6 |
7 | ## Inception score
8 |
9 | The Inception score was proposed in [Salimans et al., 2016](https://arxiv.org/abs/1606.03498). The authors used a pre-trained Inceptionv3 neural net to classify the images generated by a GAN, and computed a score based on the class probablities of the neural net. The authors claimed that the score correlates well with subjective human evaluation. For an extensive explanation of the metric (as well as an implementation in Numpy and Keras), we refer the reader to [this blog post](https://machinelearningmastery.com/how-to-implement-the-inception-score-from-scratch-for-evaluating-generated-images/#:~:text=The%20Inception%20Score%2C%20or%20IS%20for%20short%2C%20is%20an%20objective,Improved%20Techniques%20for%20Training%20GANs.%E2%80%9D).
10 |
11 | ## Fréchet Inception Distance (FID)
12 |
13 | The FID metric was proposed in [Heusel et al., 2018](https://arxiv.org/abs/1706.08500), and is currently the most widely used metric for evaluating image generation. Rather than only evaluating the generated images (as the Inception score), the FID metric compares the generated images to real images.
14 |
15 | The Fréchet distance meaures the distance between 2 multivariate Gaussian distributions. What does that mean? Concretely, the FID metric uses a pre-trained neural network (the same one as the one of the Inception score, Inceptionv3), and first forwards both real and generated images through it in order to get feature maps. Next, one computes statistics (namely, the mean and standard deviation) of the feature maps for both distributions (generated and real images). Finally, the distance between both distributions is computed based on these statistics.
16 |
17 | The FID metric assumes that feature maps of a pre-trained neural net extracted on real vs. fake images should be similar (the authors argue that this is a good quantitative metric for assessing image quality, correlating well with human judgement).
18 |
19 | An important disadvantage of the FID metric is that is has an issue of generalization; a model that simply memorizes the training data can obtain a perfect score on these metrics [Razavi et al., 2019](https://arxiv.org/abs/1906.00446).
20 |
21 | Variants have been proposed for other modalities, such as the Fréchet Audio Distance [Kilgour et al., 2018](https://arxiv.org/abs/1812.08466) and the Fréchet Video Distance [Unterthiner et al., 2018](https://arxiv.org/abs/1812.01717).
22 |
23 | The official implementation is in Tensorflow and can be found [here](https://github.com/bioinf-jku/TTUR). A PyTorch implementation can be found [here](https://github.com/mseitzer/pytorch-fid).
24 |
25 | ## Clean FID
26 |
27 | In 2021, a paper by [Parmar et al.](https://arxiv.org/abs/2104.11222) indicated that the FID metric is often poorly computed, due to incorrect implementations of low-level image preprocessing (such as resizing of images) in popular frameworks such as PyTorch and TensorFlow. This can produce widely different values for the FID metric.
28 |
29 | The official implementation of the cleaner FID version can be found [here](https://github.com/GaParmar/clean-fid).
30 |
31 | Note that FID has many, many other variants including spatial FID (sFID), class-aware FID (CAFD) and conditional FID, Fast FID, Memorization-informed FID (MiFID), Unbiased FID, etc.
32 |
33 | ## Precision and Recall
34 |
35 | Despite the FID metric being popular and correlating well with human evaluation, [Sajjadi et al., 2018](https://arxiv.org/abs/1806.00035) pointed out that, due to the fact that the FID score is just a scalar number, it is unable to distinguish between different failure cases. Two generative models could obtain the same FID score while generating images that look entirely different. Hence, the authors proposed a novel approach, defining precision (P) and recall (R) for distributions.
36 |
37 | Precision measures the similarity of generated instances to the real ones and recall measures the ability of a generator to synthesize all instances found in the training set. Hence, precision measures the quality and recall the coverage.
38 |
39 | These metrics were then further improved by [Kynkäänniemi et al., 2019](https://arxiv.org/abs/1904.06991).
40 |
--------------------------------------------------------------------------------
/huggan/pytorch/metrics/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/pytorch/metrics/__init__.py
--------------------------------------------------------------------------------
/huggan/pytorch/metrics/fid_score.py:
--------------------------------------------------------------------------------
1 | # sources:
2 | # https://www.kaggle.com/code/ibtesama/gan-in-pytorch-with-fid/notebook
3 | # https://github.com/mseitzer/pytorch-fid/blob/master/src/pytorch_fid/fid_score.py
4 |
5 | import numpy as np
6 | from scipy import linalg
7 | from torch.nn.functional import adaptive_avg_pool2d
8 |
9 |
10 | def calculate_activation_statistics(images, model, batch_size=128, dims=2048):
11 | model.eval()
12 | act = np.empty((len(images), dims))
13 |
14 | batch = images
15 | pred = model(batch)[0]
16 |
17 | # If model output is not scalar, apply global spatial average pooling.
18 | # This happens if you choose a dimensionality not equal 2048.
19 | if pred.size(2) != 1 or pred.size(3) != 1:
20 | pred = adaptive_avg_pool2d(pred, output_size=(1, 1))
21 |
22 | act = pred.cpu().data.numpy().reshape(pred.size(0), -1)
23 |
24 | mu = np.mean(act, axis=0)
25 | sigma = np.cov(act, rowvar=False)
26 | return mu, sigma
27 |
28 |
29 | def calculate_frechet_distance(mu1, sigma1, mu2, sigma2, eps=1e-6):
30 | """Numpy implementation of the Frechet Distance.
31 | The Frechet distance between two multivariate Gaussians X_1 ~ N(mu_1, C_1)
32 | and X_2 ~ N(mu_2, C_2) is
33 | d^2 = ||mu_1 - mu_2||^2 + Tr(C_1 + C_2 - 2*sqrt(C_1*C_2)).
34 | """
35 |
36 | mu1 = np.atleast_1d(mu1)
37 | mu2 = np.atleast_1d(mu2)
38 |
39 | sigma1 = np.atleast_2d(sigma1)
40 | sigma2 = np.atleast_2d(sigma2)
41 |
42 | assert mu1.shape == mu2.shape, \
43 | 'Training and test mean vectors have different lengths'
44 | assert sigma1.shape == sigma2.shape, \
45 | 'Training and test covariances have different dimensions'
46 |
47 | diff = mu1 - mu2
48 |
49 |
50 | covmean, _ = linalg.sqrtm(sigma1.dot(sigma2), disp=False)
51 | if not np.isfinite(covmean).all():
52 | msg = ('fid calculation produces singular product; '
53 | 'adding %s to diagonal of cov estimates') % eps
54 | print(msg)
55 | offset = np.eye(sigma1.shape[0]) * eps
56 | covmean = linalg.sqrtm((sigma1 + offset).dot(sigma2 + offset))
57 |
58 |
59 | if np.iscomplexobj(covmean):
60 | if not np.allclose(np.diagonal(covmean).imag, 0, atol=1e-3):
61 | m = np.max(np.abs(covmean.imag))
62 | raise ValueError('Imaginary component {}'.format(m))
63 | covmean = covmean.real
64 |
65 | tr_covmean = np.trace(covmean)
66 |
67 | return (diff.dot(diff) + np.trace(sigma1) +
68 | np.trace(sigma2) - 2 * tr_covmean)
69 |
70 |
71 | def calculate_fretchet(images_real, images_fake, model):
72 | """Calculate the fretched distance."""
73 |
74 | # calculate statistics (mean + std)
75 | mu_1, std_1 = calculate_activation_statistics(images_real, model)
76 | mu_2, std_2 = calculate_activation_statistics(images_fake, model)
77 |
78 | # compute distance
79 | fid_value = calculate_frechet_distance(mu_1, std_1, mu_2, std_2)
80 | return fid_value
--------------------------------------------------------------------------------
/huggan/pytorch/metrics/inception.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 | import torchvision
5 |
6 | try:
7 | from torchvision.models.utils import load_state_dict_from_url
8 | except ImportError:
9 | from torch.utils.model_zoo import load_url as load_state_dict_from_url
10 |
11 | # Inception weights ported to Pytorch from
12 | # http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz
13 | FID_WEIGHTS_URL = 'https://github.com/mseitzer/pytorch-fid/releases/download/fid_weights/pt_inception-2015-12-05-6726825d.pth' # noqa: E501
14 |
15 |
16 | class InceptionV3(nn.Module):
17 | """Pretrained InceptionV3 network returning feature maps"""
18 |
19 | # Index of default block of inception to return,
20 | # corresponds to output of final average pooling
21 | DEFAULT_BLOCK_INDEX = 3
22 |
23 | # Maps feature dimensionality to their output blocks indices
24 | BLOCK_INDEX_BY_DIM = {
25 | 64: 0, # First max pooling features
26 | 192: 1, # Second max pooling featurs
27 | 768: 2, # Pre-aux classifier features
28 | 2048: 3 # Final average pooling features
29 | }
30 |
31 | def __init__(self,
32 | output_blocks=(DEFAULT_BLOCK_INDEX,),
33 | resize_input=True,
34 | normalize_input=True,
35 | requires_grad=False,
36 | use_fid_inception=True):
37 | """Build pretrained InceptionV3
38 |
39 | Parameters
40 | ----------
41 | output_blocks : list of int
42 | Indices of blocks to return features of. Possible values are:
43 | - 0: corresponds to output of first max pooling
44 | - 1: corresponds to output of second max pooling
45 | - 2: corresponds to output which is fed to aux classifier
46 | - 3: corresponds to output of final average pooling
47 | resize_input : bool
48 | If true, bilinearly resizes input to width and height 299 before
49 | feeding input to model. As the network without fully connected
50 | layers is fully convolutional, it should be able to handle inputs
51 | of arbitrary size, so resizing might not be strictly needed
52 | normalize_input : bool
53 | If true, scales the input from range (0, 1) to the range the
54 | pretrained Inception network expects, namely (-1, 1)
55 | requires_grad : bool
56 | If true, parameters of the model require gradients. Possibly useful
57 | for finetuning the network
58 | use_fid_inception : bool
59 | If true, uses the pretrained Inception model used in Tensorflow's
60 | FID implementation. If false, uses the pretrained Inception model
61 | available in torchvision. The FID Inception model has different
62 | weights and a slightly different structure from torchvision's
63 | Inception model. If you want to compute FID scores, you are
64 | strongly advised to set this parameter to true to get comparable
65 | results.
66 | """
67 | super(InceptionV3, self).__init__()
68 |
69 | self.resize_input = resize_input
70 | self.normalize_input = normalize_input
71 | self.output_blocks = sorted(output_blocks)
72 | self.last_needed_block = max(output_blocks)
73 |
74 | assert self.last_needed_block <= 3, \
75 | 'Last possible output block index is 3'
76 |
77 | self.blocks = nn.ModuleList()
78 |
79 | if use_fid_inception:
80 | inception = fid_inception_v3()
81 | else:
82 | inception = _inception_v3(pretrained=True)
83 |
84 | # Block 0: input to maxpool1
85 | block0 = [
86 | inception.Conv2d_1a_3x3,
87 | inception.Conv2d_2a_3x3,
88 | inception.Conv2d_2b_3x3,
89 | nn.MaxPool2d(kernel_size=3, stride=2)
90 | ]
91 | self.blocks.append(nn.Sequential(*block0))
92 |
93 | # Block 1: maxpool1 to maxpool2
94 | if self.last_needed_block >= 1:
95 | block1 = [
96 | inception.Conv2d_3b_1x1,
97 | inception.Conv2d_4a_3x3,
98 | nn.MaxPool2d(kernel_size=3, stride=2)
99 | ]
100 | self.blocks.append(nn.Sequential(*block1))
101 |
102 | # Block 2: maxpool2 to aux classifier
103 | if self.last_needed_block >= 2:
104 | block2 = [
105 | inception.Mixed_5b,
106 | inception.Mixed_5c,
107 | inception.Mixed_5d,
108 | inception.Mixed_6a,
109 | inception.Mixed_6b,
110 | inception.Mixed_6c,
111 | inception.Mixed_6d,
112 | inception.Mixed_6e,
113 | ]
114 | self.blocks.append(nn.Sequential(*block2))
115 |
116 | # Block 3: aux classifier to final avgpool
117 | if self.last_needed_block >= 3:
118 | block3 = [
119 | inception.Mixed_7a,
120 | inception.Mixed_7b,
121 | inception.Mixed_7c,
122 | nn.AdaptiveAvgPool2d(output_size=(1, 1))
123 | ]
124 | self.blocks.append(nn.Sequential(*block3))
125 |
126 | for param in self.parameters():
127 | param.requires_grad = requires_grad
128 |
129 | def forward(self, inp):
130 | """Get Inception feature maps
131 |
132 | Parameters
133 | ----------
134 | inp : torch.autograd.Variable
135 | Input tensor of shape Bx3xHxW. Values are expected to be in
136 | range (0, 1)
137 |
138 | Returns
139 | -------
140 | List of torch.autograd.Variable, corresponding to the selected output
141 | block, sorted ascending by index
142 | """
143 | outp = []
144 | x = inp
145 |
146 | if self.resize_input:
147 | x = F.interpolate(x,
148 | size=(299, 299),
149 | mode='bilinear',
150 | align_corners=False)
151 |
152 | if self.normalize_input:
153 | x = 2 * x - 1 # Scale from range (0, 1) to range (-1, 1)
154 |
155 | for idx, block in enumerate(self.blocks):
156 | x = block(x)
157 | if idx in self.output_blocks:
158 | outp.append(x)
159 |
160 | if idx == self.last_needed_block:
161 | break
162 |
163 | return outp
164 |
165 |
166 | def _inception_v3(*args, **kwargs):
167 | """Wraps `torchvision.models.inception_v3`
168 |
169 | Skips default weight inititialization if supported by torchvision version.
170 | See https://github.com/mseitzer/pytorch-fid/issues/28.
171 | """
172 | try:
173 | version = tuple(map(int, torchvision.__version__.split('.')[:2]))
174 | except ValueError:
175 | # Just a caution against weird version strings
176 | version = (0,)
177 |
178 | if version >= (0, 6):
179 | kwargs['init_weights'] = False
180 |
181 | return torchvision.models.inception_v3(*args, **kwargs)
182 |
183 |
184 | def fid_inception_v3():
185 | """Build pretrained Inception model for FID computation
186 |
187 | The Inception model for FID computation uses a different set of weights
188 | and has a slightly different structure than torchvision's Inception.
189 |
190 | This method first constructs torchvision's Inception and then patches the
191 | necessary parts that are different in the FID Inception model.
192 | """
193 | inception = _inception_v3(num_classes=1008,
194 | aux_logits=False,
195 | pretrained=False)
196 | inception.Mixed_5b = FIDInceptionA(192, pool_features=32)
197 | inception.Mixed_5c = FIDInceptionA(256, pool_features=64)
198 | inception.Mixed_5d = FIDInceptionA(288, pool_features=64)
199 | inception.Mixed_6b = FIDInceptionC(768, channels_7x7=128)
200 | inception.Mixed_6c = FIDInceptionC(768, channels_7x7=160)
201 | inception.Mixed_6d = FIDInceptionC(768, channels_7x7=160)
202 | inception.Mixed_6e = FIDInceptionC(768, channels_7x7=192)
203 | inception.Mixed_7b = FIDInceptionE_1(1280)
204 | inception.Mixed_7c = FIDInceptionE_2(2048)
205 |
206 | state_dict = load_state_dict_from_url(FID_WEIGHTS_URL, progress=True)
207 | inception.load_state_dict(state_dict)
208 | return inception
209 |
210 |
211 | class FIDInceptionA(torchvision.models.inception.InceptionA):
212 | """InceptionA block patched for FID computation"""
213 | def __init__(self, in_channels, pool_features):
214 | super(FIDInceptionA, self).__init__(in_channels, pool_features)
215 |
216 | def forward(self, x):
217 | branch1x1 = self.branch1x1(x)
218 |
219 | branch5x5 = self.branch5x5_1(x)
220 | branch5x5 = self.branch5x5_2(branch5x5)
221 |
222 | branch3x3dbl = self.branch3x3dbl_1(x)
223 | branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
224 | branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
225 |
226 | # Patch: Tensorflow's average pool does not use the padded zero's in
227 | # its average calculation
228 | branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1,
229 | count_include_pad=False)
230 | branch_pool = self.branch_pool(branch_pool)
231 |
232 | outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]
233 | return torch.cat(outputs, 1)
234 |
235 |
236 | class FIDInceptionC(torchvision.models.inception.InceptionC):
237 | """InceptionC block patched for FID computation"""
238 | def __init__(self, in_channels, channels_7x7):
239 | super(FIDInceptionC, self).__init__(in_channels, channels_7x7)
240 |
241 | def forward(self, x):
242 | branch1x1 = self.branch1x1(x)
243 |
244 | branch7x7 = self.branch7x7_1(x)
245 | branch7x7 = self.branch7x7_2(branch7x7)
246 | branch7x7 = self.branch7x7_3(branch7x7)
247 |
248 | branch7x7dbl = self.branch7x7dbl_1(x)
249 | branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl)
250 | branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl)
251 | branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl)
252 | branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl)
253 |
254 | # Patch: Tensorflow's average pool does not use the padded zero's in
255 | # its average calculation
256 | branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1,
257 | count_include_pad=False)
258 | branch_pool = self.branch_pool(branch_pool)
259 |
260 | outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool]
261 | return torch.cat(outputs, 1)
262 |
263 |
264 | class FIDInceptionE_1(torchvision.models.inception.InceptionE):
265 | """First InceptionE block patched for FID computation"""
266 | def __init__(self, in_channels):
267 | super(FIDInceptionE_1, self).__init__(in_channels)
268 |
269 | def forward(self, x):
270 | branch1x1 = self.branch1x1(x)
271 |
272 | branch3x3 = self.branch3x3_1(x)
273 | branch3x3 = [
274 | self.branch3x3_2a(branch3x3),
275 | self.branch3x3_2b(branch3x3),
276 | ]
277 | branch3x3 = torch.cat(branch3x3, 1)
278 |
279 | branch3x3dbl = self.branch3x3dbl_1(x)
280 | branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
281 | branch3x3dbl = [
282 | self.branch3x3dbl_3a(branch3x3dbl),
283 | self.branch3x3dbl_3b(branch3x3dbl),
284 | ]
285 | branch3x3dbl = torch.cat(branch3x3dbl, 1)
286 |
287 | # Patch: Tensorflow's average pool does not use the padded zero's in
288 | # its average calculation
289 | branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1,
290 | count_include_pad=False)
291 | branch_pool = self.branch_pool(branch_pool)
292 |
293 | outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool]
294 | return torch.cat(outputs, 1)
295 |
296 |
297 | class FIDInceptionE_2(torchvision.models.inception.InceptionE):
298 | """Second InceptionE block patched for FID computation"""
299 | def __init__(self, in_channels):
300 | super(FIDInceptionE_2, self).__init__(in_channels)
301 |
302 | def forward(self, x):
303 | branch1x1 = self.branch1x1(x)
304 |
305 | branch3x3 = self.branch3x3_1(x)
306 | branch3x3 = [
307 | self.branch3x3_2a(branch3x3),
308 | self.branch3x3_2b(branch3x3),
309 | ]
310 | branch3x3 = torch.cat(branch3x3, 1)
311 |
312 | branch3x3dbl = self.branch3x3dbl_1(x)
313 | branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
314 | branch3x3dbl = [
315 | self.branch3x3dbl_3a(branch3x3dbl),
316 | self.branch3x3dbl_3b(branch3x3dbl),
317 | ]
318 | branch3x3dbl = torch.cat(branch3x3dbl, 1)
319 |
320 | # Patch: The FID Inception model uses max pooling instead of average
321 | # pooling. This is likely an error in this specific Inception
322 | # implementation, as other Inception models use average pooling here
323 | # (which matches the description in the paper).
324 | branch_pool = F.max_pool2d(x, kernel_size=3, stride=1, padding=1)
325 | branch_pool = self.branch_pool(branch_pool)
326 |
327 | outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool]
328 | return torch.cat(outputs, 1)
--------------------------------------------------------------------------------
/huggan/pytorch/pix2pix/README.md:
--------------------------------------------------------------------------------
1 | # Train Pix2pix on your custom data
2 |
3 | This folder contains a script to train [pix2pix](https://arxiv.org/abs/1611.07004) for conditional image generation, leveraging the [Hugging Face](https://huggingface.co/) ecosystem for processing data and pushing the model to the Hub.
4 |
5 | The script leverages 🤗 Datasets for loading and processing data, and 🤗 Accelerate for instantly running on CPU, single, multi-GPUs or TPU, also supporting fp16/mixed precision.
6 |
7 |
8 | 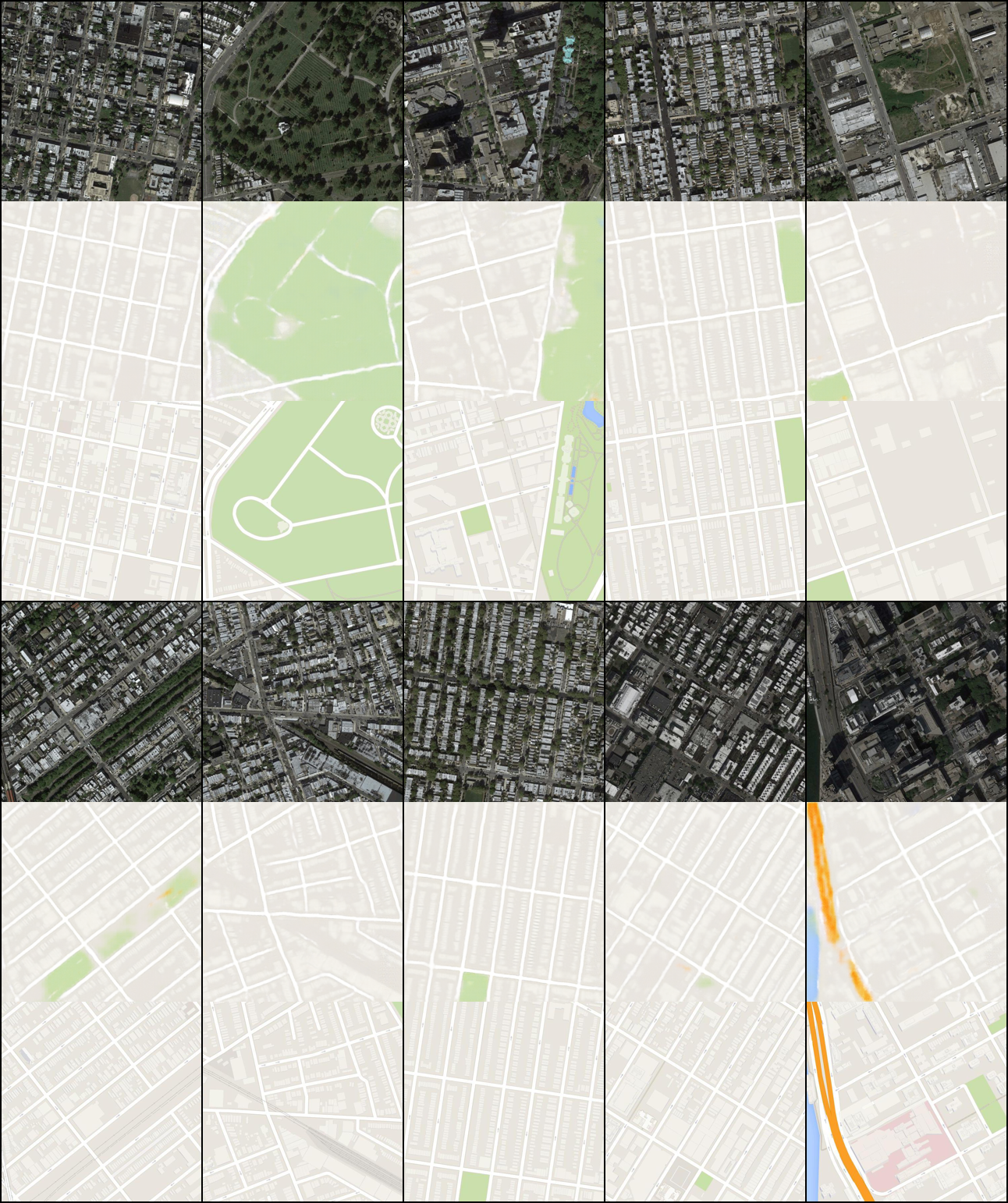 9 |
9 |
10 |
11 | Pix2pix trained on the [huggan/maps](https://huggingface.co/datasets/huggan/maps) dataset to translate satellite images into maps à la Google Maps. First row: input, second row: prediction, third row: ground truth.
12 |
13 | ## Launching the script
14 |
15 | To train the model with the default parameters (200 epochs, 256x256 images, etc.) on [huggan/facades](https://huggingface.co/datasets/huggan/facades) on your environment, first run:
16 |
17 | ```bash
18 | accelerate config
19 | ```
20 |
21 | and answer the questions asked about your environment. Next, launch the script as follows:
22 |
23 | ```
24 | accelerate launch train.py
25 | ```
26 |
27 | This will create local "images" and "saved_models" directories, containing generated images and saved checkpoints over the course of the training.
28 |
29 | To train on another dataset available on the hub, simply do (for instance):
30 |
31 | ```
32 | accelerate launch train.py --dataset huggan/night2day
33 | ```
34 |
35 | Make sure to pick a dataset which has "imageA" and "imageB" columns defined. One can always tweak the script in case the column names are different.
36 |
37 | In case you'd like to tweak the script to your liking, first fork the "community-events" [repo](https://github.com/huggingface/community-events) (see the button on the top right), then clone it locally:
38 |
39 | ```bash
40 | git clone https://github.com//community-events.git
41 | ```
42 |
43 | and edit to your liking.
44 |
45 | ## Training on your own data
46 |
47 | You can of course also train on your own images. For this, one can leverage Datasets' [ImageFolder](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder). Make sure to authenticate with the hub first, either by running the `huggingface-cli login` command in a terminal, or the following in case you're working in a notebook:
48 |
49 | ```python
50 | from huggingface_hub import notebook_login
51 |
52 | notebook_login()
53 | ```
54 |
55 | Next, run the following in a notebook/script:
56 |
57 | ```python
58 | from datasets import load_dataset
59 |
60 | # first: load dataset
61 | # option 1: from local folder
62 | dataset = load_dataset("imagefolder", data_dir="path_to_folder")
63 | # option 2: from remote URL (e.g. a zip file)
64 | dataset = load_dataset("imagefolder", data_files="URL to .zip file")
65 |
66 | # optional: remove "label" column, in case there are no subcategories
67 | dataset['train'] = dataset['train'].remove_columns(column_names="label")
68 |
69 | # next: push to the hub (assuming git-LFS is installed)
70 | dataset.push_to_hub("huggan/my-awesome-dataset")
71 | ```
72 |
73 | You can then simply pass the name of the dataset to the script:
74 |
75 | ```
76 | accelerate launch train.py --dataset huggan/my-awesome-dataset
77 | ```
78 |
79 | ## Pushing model to the Hub
80 |
81 | You can push your trained generator to the hub during training by specifying the `push_to_hub` flag, along with a `model_name`.
82 |
83 | ```bash
84 | accelerate launch train.py --push_to_hub --model_name pix2pix-facades
85 | ```
86 |
87 | This is made possible by making the generator inherit from `PyTorchModelHubMixin` available in the `huggingface_hub` library.
88 |
89 | # Citation
90 |
91 | This repo is entirely based on Erik Linder-Norén's [PyTorch-GAN repo](https://github.com/eriklindernoren/PyTorch-GAN), but with added HuggingFace goodies.
92 |
--------------------------------------------------------------------------------
/huggan/pytorch/pix2pix/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/pytorch/pix2pix/__init__.py
--------------------------------------------------------------------------------
/huggan/pytorch/pix2pix/modeling_pix2pix.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding=utf-8
3 | # Copyright (c) 2022 Erik Linder-Norén and The HuggingFace Inc. team. All rights reserved.
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions.
15 |
16 | import torch.nn as nn
17 | import torch.nn.functional as F
18 | import torch
19 |
20 | from huggan.pytorch.huggan_mixin import HugGANModelHubMixin
21 |
22 |
23 | def weights_init_normal(m):
24 | classname = m.__class__.__name__
25 | if classname.find("Conv") != -1:
26 | torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
27 | elif classname.find("BatchNorm2d") != -1:
28 | torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
29 | torch.nn.init.constant_(m.bias.data, 0.0)
30 |
31 |
32 | ##############################
33 | # U-NET
34 | ##############################
35 |
36 |
37 | class UNetDown(nn.Module):
38 | def __init__(self, in_size, out_size, normalize=True, dropout=0.0):
39 | super(UNetDown, self).__init__()
40 | layers = [nn.Conv2d(in_size, out_size, 4, 2, 1, bias=False)]
41 | if normalize:
42 | layers.append(nn.InstanceNorm2d(out_size))
43 | layers.append(nn.LeakyReLU(0.2))
44 | if dropout:
45 | layers.append(nn.Dropout(dropout))
46 | self.model = nn.Sequential(*layers)
47 |
48 | def forward(self, x):
49 | return self.model(x)
50 |
51 |
52 | class UNetUp(nn.Module):
53 | def __init__(self, in_size, out_size, dropout=0.0):
54 | super(UNetUp, self).__init__()
55 | layers = [
56 | nn.ConvTranspose2d(in_size, out_size, 4, 2, 1, bias=False),
57 | nn.InstanceNorm2d(out_size),
58 | nn.ReLU(inplace=True),
59 | ]
60 | if dropout:
61 | layers.append(nn.Dropout(dropout))
62 |
63 | self.model = nn.Sequential(*layers)
64 |
65 | def forward(self, x, skip_input):
66 | x = self.model(x)
67 | x = torch.cat((x, skip_input), 1)
68 |
69 | return x
70 |
71 |
72 | class GeneratorUNet(nn.Module, HugGANModelHubMixin):
73 | def __init__(self, in_channels=3, out_channels=3):
74 | super(GeneratorUNet, self).__init__()
75 |
76 | self.down1 = UNetDown(in_channels, 64, normalize=False)
77 | self.down2 = UNetDown(64, 128)
78 | self.down3 = UNetDown(128, 256)
79 | self.down4 = UNetDown(256, 512, dropout=0.5)
80 | self.down5 = UNetDown(512, 512, dropout=0.5)
81 | self.down6 = UNetDown(512, 512, dropout=0.5)
82 | self.down7 = UNetDown(512, 512, dropout=0.5)
83 | self.down8 = UNetDown(512, 512, normalize=False, dropout=0.5)
84 |
85 | self.up1 = UNetUp(512, 512, dropout=0.5)
86 | self.up2 = UNetUp(1024, 512, dropout=0.5)
87 | self.up3 = UNetUp(1024, 512, dropout=0.5)
88 | self.up4 = UNetUp(1024, 512, dropout=0.5)
89 | self.up5 = UNetUp(1024, 256)
90 | self.up6 = UNetUp(512, 128)
91 | self.up7 = UNetUp(256, 64)
92 |
93 | self.final = nn.Sequential(
94 | nn.Upsample(scale_factor=2),
95 | nn.ZeroPad2d((1, 0, 1, 0)),
96 | nn.Conv2d(128, out_channels, 4, padding=1),
97 | nn.Tanh(),
98 | )
99 |
100 | def forward(self, x):
101 | # U-Net generator with skip connections from encoder to decoder
102 | d1 = self.down1(x)
103 | d2 = self.down2(d1)
104 | d3 = self.down3(d2)
105 | d4 = self.down4(d3)
106 | d5 = self.down5(d4)
107 | d6 = self.down6(d5)
108 | d7 = self.down7(d6)
109 | d8 = self.down8(d7)
110 | u1 = self.up1(d8, d7)
111 | u2 = self.up2(u1, d6)
112 | u3 = self.up3(u2, d5)
113 | u4 = self.up4(u3, d4)
114 | u5 = self.up5(u4, d3)
115 | u6 = self.up6(u5, d2)
116 | u7 = self.up7(u6, d1)
117 |
118 | return self.final(u7)
119 |
120 |
121 | ##############################
122 | # Discriminator
123 | ##############################
124 |
125 |
126 | class Discriminator(nn.Module):
127 | def __init__(self, in_channels=3):
128 | super(Discriminator, self).__init__()
129 |
130 | def discriminator_block(in_filters, out_filters, normalization=True):
131 | """Returns downsampling layers of each discriminator block"""
132 | layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
133 | if normalization:
134 | layers.append(nn.InstanceNorm2d(out_filters))
135 | layers.append(nn.LeakyReLU(0.2, inplace=True))
136 | return layers
137 |
138 | self.model = nn.Sequential(
139 | *discriminator_block(in_channels * 2, 64, normalization=False),
140 | *discriminator_block(64, 128),
141 | *discriminator_block(128, 256),
142 | *discriminator_block(256, 512),
143 | nn.ZeroPad2d((1, 0, 1, 0)),
144 | nn.Conv2d(512, 1, 4, padding=1, bias=False)
145 | )
146 |
147 | def forward(self, img_A, img_B):
148 | # Concatenate image and condition image by channels to produce input
149 | img_input = torch.cat((img_A, img_B), 1)
150 | return self.model(img_input)
--------------------------------------------------------------------------------
/huggan/pytorch/pix2pix/train.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding=utf-8
3 | # Copyright (c) 2022 Erik Linder-Norén and The HuggingFace Inc. team. All rights reserved.
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions.
15 |
16 | import argparse
17 | import os
18 | from pathlib import Path
19 | import numpy as np
20 | import time
21 | import datetime
22 | import sys
23 | import tempfile
24 |
25 | from torchvision.transforms import Compose, Resize, ToTensor, Normalize, RandomVerticalFlip
26 | from torchvision.utils import save_image
27 |
28 | from PIL import Image
29 |
30 | from torch.utils.data import DataLoader
31 |
32 | from modeling_pix2pix import GeneratorUNet, Discriminator
33 |
34 | from datasets import load_dataset
35 |
36 | from accelerate import Accelerator
37 |
38 | import torch.nn as nn
39 | import torch
40 |
41 | from huggan.utils.hub import get_full_repo_name
42 | from huggingface_hub import create_repo
43 |
44 |
45 | def parse_args(args=None):
46 | parser = argparse.ArgumentParser()
47 | parser.add_argument("--dataset", type=str, default="huggan/facades", help="Dataset to use")
48 | parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
49 | parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
50 | parser.add_argument("--batch_size", type=int, default=1, help="size of the batches")
51 | parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
52 | parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
53 | parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
54 | parser.add_argument("--decay_epoch", type=int, default=100, help="epoch from which to start lr decay")
55 | parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
56 | parser.add_argument("--image_size", type=int, default=256, help="size of images for training")
57 | parser.add_argument("--channels", type=int, default=3, help="number of image channels")
58 | parser.add_argument(
59 | "--sample_interval", type=int, default=500, help="interval between sampling of images from generators"
60 | )
61 | parser.add_argument("--checkpoint_interval", type=int, default=-1, help="interval between model checkpoints")
62 | parser.add_argument("--fp16", action="store_true", help="If passed, will use FP16 training.")
63 | parser.add_argument(
64 | "--mixed_precision",
65 | type=str,
66 | default="no",
67 | choices=["no", "fp16", "bf16"],
68 | help="Whether to use mixed precision. Choose"
69 | "between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
70 | "and an Nvidia Ampere GPU.",
71 | )
72 | parser.add_argument("--cpu", action="store_true", help="If passed, will train on the CPU.")
73 | parser.add_argument(
74 | "--push_to_hub",
75 | action="store_true",
76 | help="Whether to push the model to the HuggingFace hub after training.",
77 | )
78 | parser.add_argument(
79 | "--model_name",
80 | required="--push_to_hub" in sys.argv,
81 | type=str,
82 | help="Name of the model on the hub.",
83 | )
84 | parser.add_argument(
85 | "--organization_name",
86 | required=False,
87 | default="huggan",
88 | type=str,
89 | help="Organization name to push to, in case args.push_to_hub is specified.",
90 | )
91 | return parser.parse_args(args=args)
92 |
93 | # Custom weights initialization called on Generator and Discriminator
94 | def weights_init_normal(m):
95 | classname = m.__class__.__name__
96 | if classname.find("Conv") != -1:
97 | torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
98 | elif classname.find("BatchNorm2d") != -1:
99 | torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
100 | torch.nn.init.constant_(m.bias.data, 0.0)
101 |
102 | def training_function(config, args):
103 | accelerator = Accelerator(fp16=args.fp16, cpu=args.cpu, mixed_precision=args.mixed_precision)
104 |
105 | os.makedirs("images/%s" % args.dataset, exist_ok=True)
106 | os.makedirs("saved_models/%s" % args.dataset, exist_ok=True)
107 |
108 | repo_name = get_full_repo_name(args.model_name, args.organization_name)
109 | if args.push_to_hub:
110 | if accelerator.is_main_process:
111 | repo_url = create_repo(repo_name, exist_ok=True)
112 | # Loss functions
113 | criterion_GAN = torch.nn.MSELoss()
114 | criterion_pixelwise = torch.nn.L1Loss()
115 |
116 | # Loss weight of L1 pixel-wise loss between translated image and real image
117 | lambda_pixel = 100
118 |
119 | # Calculate output of image discriminator (PatchGAN)
120 | patch = (1, args.image_size // 2 ** 4, args.image_size // 2 ** 4)
121 |
122 | # Initialize generator and discriminator
123 | generator = GeneratorUNet()
124 | discriminator = Discriminator()
125 |
126 | if args.epoch != 0:
127 | # Load pretrained models
128 | generator.load_state_dict(torch.load("saved_models/%s/generator_%d.pth" % (args.dataset, args.epoch)))
129 | discriminator.load_state_dict(torch.load("saved_models/%s/discriminator_%d.pth" % (args.dataset, args.epoch)))
130 | else:
131 | # Initialize weights
132 | generator.apply(weights_init_normal)
133 | discriminator.apply(weights_init_normal)
134 |
135 | # Optimizers
136 | optimizer_G = torch.optim.Adam(generator.parameters(), lr=args.lr, betas=(args.b1, args.b2))
137 | optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=args.lr, betas=(args.b1, args.b2))
138 |
139 | # Configure dataloaders
140 | transform = Compose(
141 | [
142 | Resize((args.image_size, args.image_size), Image.BICUBIC),
143 | ToTensor(),
144 | Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
145 | ]
146 | )
147 |
148 | def transforms(examples):
149 | # random vertical flip
150 | imagesA = []
151 | imagesB = []
152 | for imageA, imageB in zip(examples['imageA'], examples['imageB']):
153 | if np.random.random() < 0.5:
154 | imageA = Image.fromarray(np.array(imageA)[:, ::-1, :], "RGB")
155 | imageB = Image.fromarray(np.array(imageB)[:, ::-1, :], "RGB")
156 | imagesA.append(imageA)
157 | imagesB.append(imageB)
158 |
159 | # transforms
160 | examples["A"] = [transform(image.convert("RGB")) for image in imagesA]
161 | examples["B"] = [transform(image.convert("RGB")) for image in imagesB]
162 |
163 | del examples["imageA"]
164 | del examples["imageB"]
165 |
166 | return examples
167 |
168 | dataset = load_dataset(args.dataset)
169 | transformed_dataset = dataset.with_transform(transforms)
170 |
171 | splits = transformed_dataset['train'].train_test_split(test_size=0.1)
172 | train_ds = splits['train']
173 | val_ds = splits['test']
174 |
175 | dataloader = DataLoader(train_ds, shuffle=True, batch_size=args.batch_size, num_workers=args.n_cpu)
176 | val_dataloader = DataLoader(val_ds, batch_size=10, shuffle=True, num_workers=1)
177 |
178 | def sample_images(batches_done, accelerator):
179 | """Saves a generated sample from the validation set"""
180 | batch = next(iter(val_dataloader))
181 | real_A = batch["A"]
182 | real_B = batch["B"]
183 | fake_B = generator(real_A)
184 | img_sample = torch.cat((real_A.data, fake_B.data, real_B.data), -2)
185 | if accelerator.is_main_process:
186 | save_image(img_sample, "images/%s/%s.png" % (args.dataset, batches_done), nrow=5, normalize=True)
187 |
188 | generator, discriminator, optimizer_G, optimizer_D, dataloader, val_dataloader = accelerator.prepare(generator, discriminator, optimizer_G, optimizer_D, dataloader, val_dataloader)
189 |
190 | # ----------
191 | # Training
192 | # ----------
193 |
194 | prev_time = time.time()
195 |
196 | for epoch in range(args.epoch, args.n_epochs):
197 | print("Epoch:", epoch)
198 | for i, batch in enumerate(dataloader):
199 |
200 | # Model inputs
201 | real_A = batch["A"]
202 | real_B = batch["B"]
203 |
204 | # Adversarial ground truths
205 | valid = torch.ones((real_A.size(0), *patch), device=accelerator.device)
206 | fake = torch.zeros((real_A.size(0), *patch), device=accelerator.device)
207 |
208 | # ------------------
209 | # Train Generators
210 | # ------------------
211 |
212 | optimizer_G.zero_grad()
213 |
214 | # GAN loss
215 | fake_B = generator(real_A)
216 | pred_fake = discriminator(fake_B, real_A)
217 | loss_GAN = criterion_GAN(pred_fake, valid)
218 | # Pixel-wise loss
219 | loss_pixel = criterion_pixelwise(fake_B, real_B)
220 |
221 | # Total loss
222 | loss_G = loss_GAN + lambda_pixel * loss_pixel
223 |
224 | accelerator.backward(loss_G)
225 |
226 | optimizer_G.step()
227 |
228 | # ---------------------
229 | # Train Discriminator
230 | # ---------------------
231 |
232 | optimizer_D.zero_grad()
233 |
234 | # Real loss
235 | pred_real = discriminator(real_B, real_A)
236 | loss_real = criterion_GAN(pred_real, valid)
237 |
238 | # Fake loss
239 | pred_fake = discriminator(fake_B.detach(), real_A)
240 | loss_fake = criterion_GAN(pred_fake, fake)
241 |
242 | # Total loss
243 | loss_D = 0.5 * (loss_real + loss_fake)
244 |
245 | accelerator.backward(loss_D)
246 | optimizer_D.step()
247 |
248 | # --------------
249 | # Log Progress
250 | # --------------
251 |
252 | # Determine approximate time left
253 | batches_done = epoch * len(dataloader) + i
254 | batches_left = args.n_epochs * len(dataloader) - batches_done
255 | time_left = datetime.timedelta(seconds=batches_left * (time.time() - prev_time))
256 | prev_time = time.time()
257 |
258 | # Print log
259 | sys.stdout.write(
260 | "\r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f, pixel: %f, adv: %f] ETA: %s"
261 | % (
262 | epoch,
263 | args.n_epochs,
264 | i,
265 | len(dataloader),
266 | loss_D.item(),
267 | loss_G.item(),
268 | loss_pixel.item(),
269 | loss_GAN.item(),
270 | time_left,
271 | )
272 | )
273 |
274 | # If at sample interval save image
275 | if batches_done % args.sample_interval == 0:
276 | sample_images(batches_done, accelerator)
277 |
278 | if args.checkpoint_interval != -1 and epoch % args.checkpoint_interval == 0:
279 | if accelerator.is_main_process:
280 | unwrapped_generator = accelerator.unwrap_model(generator)
281 | unwrapped_discriminator = accelerator.unwrap_model(discriminator)
282 | # Save model checkpoints
283 | torch.save(unwrapped_generator.state_dict(), "saved_models/%s/generator_%d.pth" % (args.dataset, epoch))
284 | torch.save(unwrapped_discriminator.state_dict(), "saved_models/%s/discriminator_%d.pth" % (args.dataset, epoch))
285 |
286 | # Optionally push to hub
287 | if args.push_to_hub:
288 | if accelerator.is_main_process:
289 | with tempfile.TemporaryDirectory() as temp_dir:
290 | unwrapped_generator = accelerator.unwrap_model(generator)
291 | unwrapped_generator.push_to_hub(
292 | repo_path_or_name=temp_dir,
293 | repo_url=repo_url,
294 | commit_message=f"Training in progress, epoch {epoch}",
295 | skip_lfs_files=True
296 | )
297 |
298 | def main():
299 | args = parse_args()
300 | print(args)
301 |
302 | training_function({}, args)
303 |
304 |
305 | if __name__ == "__main__":
306 | main()
307 |
--------------------------------------------------------------------------------
/huggan/tensorflow/dcgan/README.md:
--------------------------------------------------------------------------------
1 | ## Train DCGAN on your custom data
2 | This folder contains a script to train DCGAN for unconditional image generation, leveraging the Hugging Face ecosystem for processing your data and pushing the model to the Hub.
3 |
4 | The script leverages 🤗 [Datasets](https://huggingface.co/docs/datasets/index) for loading and processing data, and TensorFlow for training the model and 🤗 [Hub](https://huggingface.co/) for hosting it.
5 |
6 | ## Launching the script
7 | You can simply run `python train.py --num_channels 1` with the default parameters. It will download the [MNIST](https://huggingface.co/datasets/mnist) dataset, preprocess it and train a model on it, will save results after each epoch in a local directory and push the model to the 🤗 Hub.
8 |
9 | To train on another dataset available on the hub, simply do (for instance):
10 |
11 | ```bash
12 | python train.py --dataset cifar10
13 | ```
14 |
15 | ## Training on your own data
16 | You can of course also train on your own images. For this, one can leverage Datasets' [ImageFolder](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder). Make sure to authenticate with the hub first, by running the huggingface-cli login command in a terminal, or the following in case you're working in a notebook:
17 |
18 | ```python
19 | from huggingface_hub import notebook_login
20 |
21 | notebook_login()
22 | ```
23 |
24 | Next, run the following in a notebook/script:
25 |
26 | ```python
27 | from datasets import load_dataset
28 |
29 | # first: load dataset
30 | # option 1: from local folder
31 | dataset = load_dataset("imagefolder", data_dir="path_to_folder")
32 | # option 2: from remote URL (e.g. a zip file)
33 | dataset = load_dataset("imagefolder", data_files="URL to .zip file")
34 |
35 | # next: push to the hub (assuming git-LFS is installed)
36 | dataset.push_to_hub("huggan/my-awesome-dataset")
37 | # You can then simply pass the name of the dataset to the script:
38 |
39 | python train.py --dataset huggan/my-awesome-dataset
40 | ```
41 |
42 | ## Pushing model to the Hub
43 |
44 | For this you can use `push_to_hub_keras` which generates a card for your model with training metrics, plot of the architecture and hyperparameters. For this, specify `--output_dir` and `--model_name` and use the `--push_to_hub` flag like so:
45 | ```bash
46 | python train.py --push_to_hub --output_dir /output --model_name awesome_gan_model
47 | ```
48 |
49 | ## Citation
50 | This repo is entirely based on [TensorFlow's official DCGAN tutorial](https://www.tensorflow.org/tutorials/generative/dcgan), but with added HuggingFace goodies.
51 |
--------------------------------------------------------------------------------
/huggan/tensorflow/dcgan/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/tensorflow/dcgan/__init__.py
--------------------------------------------------------------------------------
/huggan/tensorflow/dcgan/requirements.txt:
--------------------------------------------------------------------------------
1 | transformers
2 | datasets
3 |
--------------------------------------------------------------------------------
/huggan/tensorflow/dcgan/train.py:
--------------------------------------------------------------------------------
1 |
2 | import tensorflow as tf
3 | import matplotlib.pyplot as plt
4 | import numpy as np
5 | import tensorflow as tf
6 | from pathlib import Path
7 | import os
8 | import PIL
9 | from tqdm.auto import tqdm
10 | import argparse
11 |
12 | from tensorflow.keras import layers
13 |
14 | from datasets import load_dataset
15 | from transformers import DefaultDataCollator
16 | from huggingface_hub import push_to_hub_keras
17 |
18 |
19 | def parse_args(args=None):
20 | parser = argparse.ArgumentParser()
21 | parser.add_argument("--dataset", type=str, default="mnist", help="Dataset to load from the HuggingFace hub.")
22 | parser.add_argument("--batch_size", type=int, default=128, help="Batch size to use during training")
23 | parser.add_argument("--number_of_examples_to_generate", type=int, default=4, help="Number of examples to be generated in inference mode")
24 | parser.add_argument(
25 | "--generator_hidden_size",
26 | type=int,
27 | default=28,
28 | help="Hidden size of the generator's feature maps.",
29 | )
30 | parser.add_argument("--latent_dim", type=int, default=100, help="Dimensionality of the latent space.")
31 |
32 | parser.add_argument(
33 | "--discriminator_hidden_size",
34 | type=int,
35 | default=28,
36 | help="Hidden size of the discriminator's feature maps.",
37 | )
38 | parser.add_argument(
39 | "--image_size",
40 | type=int,
41 | default=28,
42 | help="Spatial size to use when resizing images for training.",
43 | )
44 | parser.add_argument(
45 | "--num_channels",
46 | type=int,
47 | default=3,
48 | help="Number of channels in the training images. For color images this is 3.",
49 | )
50 | parser.add_argument("--num_epochs", type=int, default=5, help="number of epochs of training")
51 | parser.add_argument("--output_dir", type=Path, default=Path("./output"), help="Name of the directory to dump generated images during training.")
52 | parser.add_argument(
53 | "--push_to_hub",
54 | action="store_true",
55 | help="Whether to push the model to the HuggingFace hub after training.",
56 | )
57 | parser.add_argument(
58 | "--model_name",
59 | default=None,
60 | type=str,
61 | help="Name of the model on the hub.",
62 | )
63 | parser.add_argument(
64 | "--organization_name",
65 | default="huggan",
66 | type=str,
67 | help="Organization name to push to, in case args.push_to_hub is specified.",
68 | )
69 | args = parser.parse_args()
70 |
71 | if args.push_to_hub:
72 | assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
73 | assert args.model_name is not None, "Need a `model_name` to create a repo when `--push_to_hub` is passed."
74 |
75 | if args.output_dir is not None:
76 | os.makedirs(args.output_dir, exist_ok=True)
77 |
78 | return args
79 |
80 |
81 | def stack_generator_layers(model, units):
82 | model.add(layers.Conv2DTranspose(units, (4, 4), strides=2, padding='same', use_bias=False))
83 | model.add(layers.BatchNormalization())
84 | model.add(layers.LeakyReLU())
85 | return model
86 |
87 |
88 | def create_generator(channel, hidden_size, latent_dim):
89 | generator = tf.keras.Sequential()
90 | generator.add(layers.Input((latent_dim,))) #
91 | generator.add(layers.Dense(hidden_size*4*7*7, use_bias=False, input_shape=(100,)))
92 | generator.add(layers.LeakyReLU())
93 |
94 | generator.add(layers.Reshape((7, 7, hidden_size*4)))
95 |
96 | units = [hidden_size*2, hidden_size*1]
97 | for unit in units:
98 | generator = stack_generator_layers(generator, unit)
99 |
100 | generator.add(layers.Conv2DTranspose(args.num_channels, (4, 4), strides=1, padding='same', use_bias=False, activation='tanh'))
101 | return generator
102 |
103 |
104 | def stack_discriminator_layers(model, units, use_batch_norm=False, use_dropout=False):
105 | model.add(layers.Conv2D(units, (4, 4), strides=(2, 2), padding='same'))
106 | if use_batch_norm:
107 | model.add(layers.BatchNormalization())
108 | if use_dropout:
109 | model.add(layers.Dropout(0.1))
110 | model.add(layers.LeakyReLU())
111 | return model
112 |
113 |
114 | def create_discriminator(channel, hidden_size, args):
115 | discriminator = tf.keras.Sequential()
116 | discriminator.add(layers.Input((args.image_size, args.image_size, args.num_channels)))
117 | discriminator = stack_discriminator_layers(discriminator, hidden_size, use_batch_norm = True, use_dropout = True)
118 | discriminator = stack_discriminator_layers(discriminator, hidden_size * 2)
119 | discriminator = stack_discriminator_layers(discriminator,True, hidden_size*4)
120 | discriminator = stack_discriminator_layers(discriminator,True, hidden_size*16)
121 |
122 | discriminator.add(layers.Flatten())
123 | discriminator.add(layers.Dense(1))
124 |
125 | return discriminator
126 |
127 |
128 | def discriminator_loss(real_image, generated_image):
129 | real_loss = cross_entropy(tf.ones_like(real_image), real_image)
130 | fake_loss = cross_entropy(tf.zeros_like(generated_image), generated_image)
131 | total_loss = real_loss + fake_loss
132 | return total_loss
133 |
134 |
135 | @tf.function
136 | def train_step(images):
137 | noise = tf.random.normal([128, 100])
138 |
139 | with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
140 | generated_images = generator(noise, training=True)
141 |
142 | real_image = discriminator(images, training=True)
143 | generated_image = discriminator(generated_images, training=True)
144 | # calculate loss inside train step
145 | gen_loss = cross_entropy(tf.ones_like(generated_image), generated_image)
146 | disc_loss = discriminator_loss(real_image, generated_image)
147 |
148 | gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
149 | gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
150 |
151 | generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
152 | discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
153 |
154 |
155 | def generate_and_save_images(model, epoch, test_input, output_dir, number_of_examples_to_generate):
156 |
157 | predictions = model(test_input, training=False)
158 |
159 | fig = plt.figure(figsize=(number_of_examples_to_generate*4, number_of_examples_to_generate*16))
160 |
161 | for i in range(predictions.shape[0]):
162 | plt.subplot(1, number_of_examples_to_generate, i+1)
163 | if args.num_channels == 1:
164 | plt.imshow(predictions[i, :, :, :], cmap='gray')
165 | else:
166 | plt.imshow(predictions[i, :, :, :])
167 |
168 | plt.axis('off')
169 |
170 | plt.savefig(f'{output_dir}/image_at_epoch_{epoch}.png')
171 |
172 |
173 | def train(dataset, epochs, output_dir, args):
174 | for epoch in range(epochs):
175 | print("Epoch:", epoch)
176 | for image_batch in tqdm(dataset):
177 | train_step(image_batch)
178 |
179 | generate_and_save_images(generator,
180 | epoch + 1,
181 | seed,
182 | output_dir,
183 | args.number_of_examples_to_generate)
184 |
185 |
186 | def preprocess(examples):
187 | images = (np.asarray(examples["image"]).astype('float32')- 127.5) / 127.5
188 | images = np.expand_dims(images, -1)
189 | examples["pixel_values"] = images
190 | return examples
191 |
192 |
193 | def preprocess_images(dataset, args):
194 | data_collator = DefaultDataCollator(return_tensors="tf")
195 | processed_dataset = dataset.map(preprocess)
196 |
197 | tf_train_dataset = processed_dataset["train"].to_tf_dataset(
198 | columns=['pixel_values'],
199 | shuffle=True,
200 | batch_size=args.batch_size,
201 | collate_fn=data_collator)
202 |
203 | return tf_train_dataset
204 |
205 |
206 | if __name__ == "__main__":
207 | args = parse_args()
208 | print("Downloading dataset..")
209 | dataset = load_dataset(args.dataset)
210 | dataset= preprocess_images(dataset, args)
211 | print("Training model..")
212 | generator = create_generator(args.num_channels, args.generator_hidden_size, args.latent_dim)
213 | discriminator = create_discriminator(args.num_channels, args.discriminator_hidden_size, args)
214 | generator_optimizer = tf.keras.optimizers.Adam(1e-4)
215 | discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
216 |
217 | # create seed with dimensions of number of examples to generate and noise
218 | seed = tf.random.normal([args.number_of_examples_to_generate, args.latent_dim])
219 |
220 | cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
221 |
222 | train(dataset, args.num_epochs, args.output_dir, args)
223 | if args.push_to_hub is not None:
224 |
225 | push_to_hub_keras(generator, repo_path_or_name=f"{args.output_dir}/{args.model_name}",organization=args.organization_name)
226 |
--------------------------------------------------------------------------------
/huggan/utils/README.md:
--------------------------------------------------------------------------------
1 | # 🤗 Upload custom image dataset to the hub
2 |
3 | This directory contains an example script that showcases how to upload a custom image dataset to the hub programmatically (using Python).
4 |
5 | In this example, we'll upload all available datasets shared by the [CycleGAN authors](https://github.com/junyanz/CycleGAN/blob/master/datasets/download_dataset.sh) to the hub.
6 |
7 | It leverages the [ImageFolder](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) and `push_to_hub`
8 | functionalities of the 🤗 [Datasets](https://huggingface.co/docs/datasets/index) library.
9 |
10 | It can be run as follows:
11 |
12 | ### 1. Make sure to have git-LFS installed on your system:
13 | First, verify that you have git-LFS installed. This can be done by running:
14 |
15 | ```bash
16 | git-lfs -v
17 | ```
18 |
19 | If you get "command not found", then install it as follows:
20 |
21 | ```bash
22 | sudo apt-get install git-lfs
23 | ```
24 |
25 | ### 2. Login with your HuggingFace account:
26 | Next, one needs to provide a token for authentication with the hub. This can be done by either running:
27 |
28 | ```bash
29 | huggingface-cli login
30 | ```
31 |
32 | or
33 |
34 | ```python
35 | from huggingface_hub import notebook_login
36 |
37 | notebook_login()
38 | ```
39 |
40 | in case you're running in a notebook.
41 |
42 | ### 3. Upload!
43 | Finally, uploading is as easy as:
44 |
45 | ```bash
46 | python push_to_hub_example.py --dataset horse2zebra
47 | ````
48 |
49 | The result can be seen [here](https://huggingface.co/datasets/huggan/horse2zebra).
50 |
51 | Note that it's not required to programmatically upload a dataset to the hub: you can also do it in your browser as explained in [this guide](https://huggingface.co/docs/datasets/upload_dataset).
52 |
--------------------------------------------------------------------------------
/huggan/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/huggan/utils/__init__.py
--------------------------------------------------------------------------------
/huggan/utils/hub.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | from huggingface_hub import HfFolder, whoami
4 |
5 | def get_full_repo_name(model_id: str, organization: Optional[str] = None, token: Optional[str] = None):
6 | if token is None:
7 | token = HfFolder.get_token()
8 | if organization is None:
9 | username = whoami(token)["name"]
10 | return f"{username}/{model_id}"
11 | else:
12 | return f"{organization}/{model_id}"
13 |
--------------------------------------------------------------------------------
/huggan/utils/push_to_hub_example.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | from datasets import load_dataset
3 | from tqdm import tqdm
4 |
5 | # choose a dataset
6 | available_datasets = ["apple2orange", "summer2winter_yosemite", "horse2zebra", "monet2photo", "cezanne2photo", "ukiyoe2photo", "vangogh2photo", "maps", "cityscapes", "facades", "iphone2dslr_flower", "ae_photos", "grumpifycat"]
7 |
8 | def upload_dataset(dataset_name):
9 | if dataset_name not in available_datasets:
10 | raise ValueError("Please choose one of the supported datasets:", available_datasets)
11 |
12 | # step 1: load dataset
13 | dataset = load_dataset("imagefolder", data_files=f"https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/{dataset_name}.zip")
14 |
15 | # step 2: push to hub
16 | dataset.push_to_hub(f"huggan/{dataset_name}")
17 |
18 | def main():
19 | parser = argparse.ArgumentParser()
20 | parser.add_argument("--dataset", default="apple2orange", type=str, help="Dataset to upload")
21 | args = parser.parse_args()
22 |
23 | upload_dataset(args.dataset)
24 |
25 |
26 | if __name__ == "__main__":
27 | main()
28 |
--------------------------------------------------------------------------------
/jax-controlnet-sprint/dataset_tools/coyo_1m_dataset_preprocess.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import logging
3 | import random
4 |
5 | import cv2
6 | import jsonlines
7 | import numpy as np
8 | import requests
9 | from datasets import load_dataset
10 | from PIL import Image
11 |
12 | logger = logging.getLogger(__name__)
13 |
14 |
15 | def parse_args():
16 | parser = argparse.ArgumentParser(
17 | description="Example of a data preprocessing script."
18 | )
19 | parser.add_argument(
20 | "--train_data_dir",
21 | type=str,
22 | required=True,
23 | help="The directory to store the dataset",
24 | )
25 | parser.add_argument(
26 | "--cache_dir",
27 | type=str,
28 | required=True,
29 | help="The directory to store cache",
30 | )
31 | parser.add_argument(
32 | "--max_train_samples",
33 | type=int,
34 | default=None,
35 | help="number of examples in the dataset",
36 | )
37 | parser.add_argument(
38 | "--num_proc",
39 | type=int,
40 | default=1,
41 | help="number of processors to use in `dataset.map()`",
42 | )
43 |
44 | args = parser.parse_args()
45 | return args
46 |
47 |
48 | # filter for `max_train_samples``
49 | def filter_function(example):
50 | if example["clip_similarity_vitb32"] < 0.3:
51 | return False
52 | if example["watermark_score"] > 0.4:
53 | return False
54 | if example["aesthetic_score_laion_v2"] < 6.0:
55 | return False
56 | return True
57 |
58 |
59 | def filter_dataset(dataset, max_train_samples):
60 | small_dataset = dataset.select(range(max_train_samples)).filter(filter_function)
61 | return small_dataset
62 |
63 |
64 | if __name__ == "__main__":
65 | args = parse_args()
66 |
67 | # load coyo-700
68 | dataset = load_dataset(
69 | "kakaobrain/coyo-700m",
70 | cache_dir=args.cache_dir,
71 | split="train",
72 | )
73 |
74 | # estimation the % of images filtered
75 | filter_ratio = len(filter_dataset(dataset, 20000)) / 20000
76 |
77 | # esimate max_train_samples based on
78 | # (1) filter_ratio we calculuted with 20k examples
79 | # (2) assumption that only 80% of the URLs are still valid
80 | max_train_samples = int(args.max_train_samples / filter_ratio / 0.8)
81 |
82 | # filter dataset down to 1 million
83 | small_dataset = filter_dataset(dataset, max_train_samples)
84 |
85 | def preprocess_and_save(example):
86 | image_url = example["url"]
87 | try:
88 | # download original image
89 | image = Image.open(requests.get(image_url, stream=True, timeout=5).raw)
90 | image_path = f"{args.train_data_dir}/images/{example['id']}.png"
91 | image.save(image_path)
92 |
93 | # generate and save canny image
94 | processed_image = np.array(image)
95 |
96 | # apply random threholds
97 | # note that this should normally be applied on the fly during training.
98 | # But that's fine when dealing with a larger dataset like here.
99 | threholds = (
100 | random.randint(0, 255),
101 | random.randint(0, 255),
102 | )
103 | processed_image = cv2.Canny(processed_image, min(threholds), max(threholds))
104 | processed_image = processed_image[:, :, None]
105 | processed_image = np.concatenate(
106 | [processed_image, processed_image, processed_image], axis=2
107 | )
108 | processed_image = Image.fromarray(processed_image)
109 | processed_image_path = (
110 | f"{args.train_data_dir}/processed_images/{example['id']}.png"
111 | )
112 | processed_image.save(processed_image_path)
113 |
114 | # write to meta.jsonl
115 | meta = {
116 | "image": image_path,
117 | "conditioning_image": processed_image_path,
118 | "caption": example["text"],
119 | }
120 | with jsonlines.open(
121 | f"{args.train_data_dir}/meta.jsonl", "a"
122 | ) as writer: # for writing
123 | writer.write(meta)
124 |
125 | except Exception as e:
126 | logger.error(f"Failed to process image{image_url}: {str(e)}")
127 |
128 | # preprocess -> image, processed image and meta.jsonl
129 | small_dataset.map(preprocess_and_save, num_proc=args.num_proc)
130 |
131 | print(f"created data folder at: {args.train_data_dir}")
132 |
--------------------------------------------------------------------------------
/jax-controlnet-sprint/dataset_tools/data.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import datasets
4 | import pandas as pd
5 |
6 | _VERSION = datasets.Version("0.0.2")
7 |
8 | _DESCRIPTION = "TODO"
9 | _HOMEPAGE = "TODO"
10 | _LICENSE = "TODO"
11 | _CITATION = "TODO"
12 |
13 | _FEATURES = datasets.Features(
14 | {
15 | "image": datasets.Image(),
16 | "conditioning_image": datasets.Image(),
17 | "text": datasets.Value("string"),
18 | },
19 | )
20 |
21 |
22 | _DEFAULT_CONFIG = datasets.BuilderConfig(name="default", version=_VERSION)
23 | DATA_DIR = "/mnt/disks/persist/data"
24 |
25 |
26 | class coyo(datasets.GeneratorBasedBuilder):
27 | BUILDER_CONFIGS = [_DEFAULT_CONFIG]
28 | DEFAULT_CONFIG_NAME = "default"
29 |
30 | def _info(self):
31 | return datasets.DatasetInfo(
32 | description=_DESCRIPTION,
33 | features=_FEATURES,
34 | supervised_keys=None,
35 | homepage=_HOMEPAGE,
36 | license=_LICENSE,
37 | citation=_CITATION,
38 | )
39 |
40 | def _split_generators(self, dl_manager):
41 | metadata_path = f"{DATA_DIR}/meta.jsonl"
42 | images_dir = f"{DATA_DIR}/images"
43 | conditioning_images_dir = f"{DATA_DIR}/processed_images"
44 |
45 | return [
46 | datasets.SplitGenerator(
47 | name=datasets.Split.TRAIN,
48 | # These kwargs will be passed to _generate_examples
49 | gen_kwargs={
50 | "metadata_path": metadata_path,
51 | "images_dir": images_dir,
52 | "conditioning_images_dir": conditioning_images_dir,
53 | },
54 | ),
55 | ]
56 |
57 | def _generate_examples(self, metadata_path, images_dir, conditioning_images_dir):
58 | metadata = pd.read_json(metadata_path, lines=True)
59 |
60 | for _, row in metadata.iterrows():
61 | text = row["caption"]
62 |
63 | try:
64 | image_path = row["image"]
65 | image_path = os.path.join(images_dir, image_path)
66 | image = open(image_path, "rb").read()
67 |
68 | conditioning_image_path = row["conditioning_image"]
69 | conditioning_image_path = os.path.join(
70 | conditioning_images_dir, row["conditioning_image"]
71 | )
72 | conditioning_image = open(conditioning_image_path, "rb").read()
73 |
74 | yield row["image"], {
75 | "text": text,
76 | "image": {
77 | "path": image_path,
78 | "bytes": image,
79 | },
80 | "conditioning_image": {
81 | "path": conditioning_image_path,
82 | "bytes": conditioning_image,
83 | },
84 | }
85 | except Exception as e:
86 | print(e)
87 |
--------------------------------------------------------------------------------
/jax-controlnet-sprint/training_scripts/requirements_flax.txt:
--------------------------------------------------------------------------------
1 | -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
2 | jax[tpu]==0.4.5
3 | flax==0.6.7
4 | transformers
5 | chex
6 | datasets
7 | optax
8 | orbax
9 | ftfy
10 | tensorboard
11 | Jinja2
12 | --extra-index-url https://download.pytorch.org/whl/cpu
13 | torch
14 | torchvision
15 |
--------------------------------------------------------------------------------
/keras-dreambooth-sprint/README.md:
--------------------------------------------------------------------------------
1 |
2 | 
3 |
4 | **Welcome to Keras Dreambooth event!** 🤗
5 |
6 | This document summarises all the relevant information required for the event 📋.
7 |
8 | ## Introduction
9 |
10 | Dreambooth is a fine-tuning technique to teach new visual concepts to text-conditioned Diffusion models with just 3-5 images. With Dreambooth, you could generate funny and realistic images of your dog, yourself and any concept with few images using Stable Diffusion.
11 | DreamBooth was proposed in [DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation](https://arxiv.org/abs/2208.12242) by Ruiz et al.
12 | In this guide, we will walk you through what we will do in this event.
13 |
14 | We will be training Dreambooth models using KerasCV and building demos on them.
15 |
16 |
17 | ## Important Dates
18 |
19 | - Kick-Off Event: March 6th, 2023
20 | - Sprint start: March 7th, 2023
21 | - Sprint end: April 1st, 2023
22 | - Results: April 7th, 2023
23 |
24 |
25 | ## Getting Started 🚀
26 |
27 | To get started, join us in [hf.co/join/discord](http://hf.co/join/discord) and take the role #open-source, and meet us in #keras-working-group channel.
28 |
29 | We will be hosting our demos in this organization on Hugging Face Hub: [keras-dreambooth](https://huggingface.co/keras-dreambooth), send a request to join [here](https://huggingface.co/organizations/keras-dreambooth/share/RMocthadPgpxxUDHtAesrbBzieDLgUfPmv) if you’d like to make a submission 🙂
30 |
31 | We will:
32 |
33 | 1. Fine-tune Stable Diffusion on any concept we want using Dreambooth,
34 | 2. Push the model to Hugging Face Hub,
35 | 3. Fill the model card,
36 | 4. Build a demo on top of the model.
37 |
38 | **Warning:** The trained models need to be in one of the 4 categories mentioned in the Submission section. Please take a look at that before training your model.
39 |
40 | **Let’s get started** 🚀
41 |
42 | ## **Model Training**
43 |
44 | You can find the notebook here and adjust it according to your own dataset 👇
45 |
46 | [Link to notebook](https://colab.research.google.com/github/huggingface/community-events/blob/main/keras-dreambooth-sprint/Dreambooth_on_Hub.ipynb)
47 |
48 | You can fine-tune on any concept that you want. Couple of inspirations for you:
49 |
50 | 1. Lowpoly World: This [model](https://huggingface.co/MirageML/lowpoly-world) generates lowpoly worlds 🤯🌍
51 | 2. Future Diffusion: This [model](https://huggingface.co/nitrosocke/Future-Diffusion) generates images in futuristic sci-fi concepts 🤖
52 | 3. Fantasy sword: This [model](https://huggingface.co/MirageML/fantasy-sword) generates swords for fantasy themed games 🧙♂️
53 |
54 | If you need more pointers on Dreambooth implementation with Keras, you can check out [this repository](https://github.com/sayakpaul/dreambooth-keras).
55 |
56 | **Important**: To learn how to launch a cloud GPU instance and train with Lambda, please refer to [Compute with Lambda](./compute-with-lambda.md).
57 |
58 | ## Dreambooth Diffusers Integration with KerasCV
59 |
60 | As of now, inference and deployment options of `KerasCV` are limited, which is when the `diffusers` library comes to the rescue. With only few lines of code, we can convert a `KerasCV` model into a `diffusers` one and use `diffusers`’ pipelines to perform inference. You can get more information [here](https://huggingface.co/docs/diffusers/main/en/using-diffusers/kerascv). Also check out [this Space](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers) for converting your `KerasCV` model to `diffusers`one.
61 |
62 | `diffusers`repositories on the Hub get a free Inference API and small widgets in the model page where users can play with the model.
63 |
64 | ```python
65 | from diffusers import StableDiffusionPipeline
66 |
67 | # checkpoint of the converted Stable Diffusion from KerasCV
68 | model_ckpt = "sayakpaul/text-unet-dogs-kerascv_sd_diffusers_pipeline"
69 | pipeline = StableDiffusionPipeline.from_pretrained(model_ckpt)
70 | pipeline.to("cuda")
71 |
72 | unique_id = "sks"
73 | class_label = "dog"
74 | prompt = f"A photo of {unique_id} {class_label} in a bucket"
75 | image = pipeline(prompt, num_inference_steps=50).images[0]
76 | ```
77 |
78 | ## Model Hosting
79 |
80 | At the end of [this notebook](https://colab.research.google.com/github/huggingface/community-events/blob/main/keras-dreambooth-sprint/Dreambooth_on_Hub.ipynb) you will see a section dedicated for hosting, and a separate one for inference. We will be using the `huggingface_hub` library’s Keras-specific model pushing and loading functions: `push_to_hub_keras` and `from_pretrained_keras` . We will first push the model using `push_to_hub_keras`. After model is pushed, you will see the model is hosted with a model card like below 👇
81 |
82 | 
83 |
84 | To version the models better, enable discoverability and reproducibility, we will fill the model card. Click `Edit model card`. We will first fill the Metadata section of the model card. If your model is trained with a dataset from the Hugging Face Hub, you can fill the datasets section with the dataset. We will provide fill `pipeline_tag` with `text-to-image` and pick a license for our model.
85 |
86 | 
87 |
88 | Then, we will fill the markdown part. Hyperparameters and plot is automatically generated so we can write a short explanation for description, intended use and dataset.
89 |
90 |
91 | You can find the example repository below 👇
92 |
93 | [keras-dreambooth/dreambooth_diffusion_model](https://huggingface.co/keras-dreambooth/dreambooth_diffusion_model)
94 |
95 | ## Model Demo
96 |
97 | We will use Gradio to build our demos for the models we have trained. With `Interface` class it’s straightforward 👇
98 |
99 | ```python
100 | from huggingface_hub import from_pretrained_keras
101 | from keras_cv import models
102 | import gradio as gr
103 |
104 | sd_dreambooth_model = models.StableDiffusion(
105 | img_width=512, img_height=512
106 | )
107 | db_diffusion_model = from_pretrained_keras("merve/dreambooth_diffusion_model")
108 | sd_dreambooth_model._diffusion_model = db_diffusion_model
109 |
110 | # generate images
111 | def infer(prompt):
112 | generated_images = sd_dreambooth_model.text_to_image(
113 | prompt
114 | )
115 | return generated_images
116 |
117 |
118 | output = gr.Gallery(label="Outputs").style(grid=(2,2))
119 |
120 | # pass function, input type for prompt, the output for multiple images
121 | gr.Interface(infer, inputs=["text"], outputs=[output]).launch()
122 | ```
123 |
124 | You can check out `app.py`file of the application below and repurpose it for your model!
125 |
126 | [Dreambooth Submission - a Hugging Face Space by keras-dreambooth](https://huggingface.co/spaces/keras-dreambooth/example-submission)
127 |
128 | This app generates images of a corgi 🐶
129 |
130 | 
131 |
132 | ## Hosting the Demo on Spaces
133 |
134 | After our application is written, we can create a Hugging Face Space to host our app. You can go to [huggingface.co](http://huggingface.co), click on your profile on top right and select “New Space”.
135 |
136 | 
137 |
138 |
139 | We can name our Space, pick a license and select Space SDK as “Gradio”.
140 |
141 | 
142 |
143 | After creating the Space, you can use either the instructions below to clone the repository locally, adding your files and push, OR, graphical interface to create the files and write the code in the browser.
144 |
145 | 
146 |
147 | To upload your application file, pick “Add File” and drag and drop your file.
148 |
149 | 
150 |
151 | Lastly, we have to create a file called `requirements.txt` and add requirements of Dreambooth project like below:
152 |
153 | ```
154 | keras-cv
155 | tensorflow
156 | huggingface-hub
157 | ```
158 |
159 | And your app should be up and running!
160 |
161 | We will host our models and Spaces under [this organization](https://huggingface.co/keras-dreambooth). You can carry your models and Spaces on the settings tab under `Rename or transfer this model` and select `keras-dreambooth` from the dropdown.
162 |
163 | If you don't see `keras-dreambooth` in the dropdown, it's likely that you aren't a member of the organization. Use [this link](https://huggingface.co/organizations/keras-dreambooth/share/bfDDnByLbvPRYypHNUoZJgBgbgtTEYYgVl) to request to join the organization.
164 |
165 | ## Submission
166 |
167 | You can make submission in three themes:
168 |
169 | - Nature and Animals (`nature`)
170 | - Sci-fi/Fantasy Universes (`sci-fi`)
171 | - Consentful (`consentful`): Partner up with an artist to fine-tune on their style, with their consent! Make sure to include a reference to the artist’s express consent (e.g. a tweet) in your model card.
172 | - Wild Card (`wild-card`): If your submission belongs to any category that is not above, feel free to tag it with wild-card so we can evaluate it out of that category.
173 |
174 |
175 | Add the category with their IDs to the model cards for submission and add `keras-dreambooth` to model card metadata in tags section. Here's an example [model card](https://huggingface.co/spaces/keras-dreambooth/example-submission/blob/main/README.md). All the submissions will be populated [in this leaderboard](https://huggingface.co/spaces/keras-dreambooth/leaderboard) and ranked according to likes on a given Space to determine the winners.
176 |
177 | ## Sprint **Prizes**
178 |
179 | We will pick three winners among the applications submitted, according to the number of likes given to a Space in a given category.
180 |
181 | 🛍️ First place will win a 100$ voucher on [hf.co/shop](http://hf.co/shop) or one year subscription to [Hugging Face Pro](https://huggingface.co/pricing#pro)
182 |
183 | 🛍️ Second place will win a 50$ voucher on [hf.co/shop](http://hf.co/shop) or [the book](https://transformersbook.com/) “Natural Language Processing with Transformers”
184 |
185 | 🛍️ Third place will win a 30$ voucher on [hf.co/shop](http://hf.co/shop) or three months subscription to [Hugging Face Pro](https://huggingface.co/pricing#pro)
186 |
--------------------------------------------------------------------------------
/keras-dreambooth-sprint/compute-with-lambda.md:
--------------------------------------------------------------------------------
1 | ## Launch a Lambda Cloud GPU
2 | Where possible, we encourage you to fine-tune Dreambooth on a local GPU machine. This will mean a faster set-up and more familiarity with your device.
3 |
4 | The training scripts can also be run as a notebook through Google Colab. We recommend you train on Google Colab if you have a "Colab Pro" or "Pro+" subscription. This is to ensure that you receive a sufficiently powerful GPU on your Colab for fine-tuning Stable Diffusion.
5 |
6 | If you do not have access to a local GPU or Colab Pro/Pro+, we'll endeavour to provide you with a cloud GPU instance.
7 | We've partnered up with Lambda to provide cloud compute for this event. They'll be providing the NVIDIA A10 24 GB GPUs. The Lambda API makes it easy to spin-up and launch a GPU instance. In this section, we'll go through the steps for spinning up an instance one-by-one.
8 |
9 |
10 |  11 |
11 |
12 |
13 | This section is split into three parts:
14 |
15 | - [Launch a Lambda Cloud GPU](#launch-a-lambda-cloud-gpu)
16 | - [Signing-Up with Lambda](#signing-up-with-lambda)
17 | - [Creating a Cloud Instance](#creating-a-cloud-instance)
18 | - [Setting up your environment](#setting-up-your-environment)
19 | - [Deleting a Cloud Instance](#deleting-a-cloud-instance)
20 |
21 | ### Signing-Up with Lambda
22 |
23 | 1. Create an account with Lambda using your email address of choice: http://lambdalabs.com/HF-dreambooth-signup. If you already have an account, skip to step 2.
24 | 2. Using this same email address, email `cloud@lambdal.com` with the Subject line: `Lambda cloud account for HuggingFace Keras DreamBooth - payment authentication and credit request`.
25 | 3. Each user who emails as above will receive $20 in credits (amounting to 60 fine-tuning runs/30 hours of A10).
26 | 4. Register a valid payment method with Lambda in order to redeem the credits (see instructions below).
27 |
28 | To redeem these credits, you will need to authorise a valid payment method with Lambda. Provided that you remain within $20 of compute spending, your card **will not** be charged 💸. Registering your card with Lambda is a mandatory sign-up step that we unfortunately cannot bypass. But we reiterate: you will not be charged provided you remain within $20 of compute.
29 |
30 | Follow steps 1-4 in the next section [Creating a Cloud Instance](#creating-a-cloud-instance) to register your card. If you experience issues with registering your card, contact the Lambda team on Discord (see [Communications and Problems](#communication-and-problems)).
31 |
32 | In order to maximise the free GPU hours you have available for training, we advise that you shut down GPUs when you are not using them and closely monitor your GPU usage. We've detailed the steps you can follow to achieve this in [Deleting a Cloud Instance](#deleting-a-cloud-instance).
33 |
34 | ### Creating a Cloud Instance
35 | Estimated time to complete: 5 mins
36 |
37 | *You can also follow our video tutorial to set up a cloud instance on Lambda* 👉️ [YouTube Video](https://www.youtube.com/watch?v=Ndm9CROuk5g&list=PLo2EIpI_JMQtncHQHdHq2cinRVk_VZdGW)
38 |
39 | 1. Click the link: http://lambdalabs.com/HF-dreambooth-instances
40 | 2. You'll be asked to sign in to your Lambda account (if you haven't done so already).
41 | 3. Once on the GPU instance page, click the purple button "Launch instance" in the top right.
42 | 4. Verify a payment method if you haven't done so already. IMPORTANT: if you have followed the instructions in the previous section, you will have received $20 in GPU credits. Exceeding 25 hours of 1x A10 usage may incur charges on your credit card. Contact the Lambda team on Discord if you have issues authenticating your payment method (see [Communications and Problems](#communication-and-problems))
43 | 5. Launching an instance:
44 | 1. In "Instance type", select the instance type "1x A10 (24 GB PCle)". In case you run out or memory while training, come back here and choose instance of type "1x A100(40GB PCIe)" or "1x A100(40GB SXM4)".
45 | 2. In "Select region", select the region with availability closest to you.
46 | 3. In "Select filesystem", select "Don't attach a filesystem".
47 | 6. You will be asked to provide your public SSH key. This will allow you to SSH into the GPU device from your local machine.
48 | 1. If you’ve not already created an SSH key pair, you can do so with the following command from your local device:
49 | ```bash
50 | ssh-keygen
51 | ```
52 | 2. You can find your public SSH key using the command:
53 | ```bash
54 | cat ~/.ssh/id_rsa.pub
55 | ```
56 | (Windows: `type C:UsersUSERNAME.sshid_rsa.pub` where `USERNAME` is the name of your user)
57 | 4. Copy and paste the output of this command into the first text box
58 | 5. Give your SSH key a memorable name (e.g. `merve-ssh-key`)
59 | 6. Click "Add SSH Key"
60 | 7. Select the SSH key from the drop-down menu and click "Launch instance"
61 | 8. Read the terms of use and agree
62 | 9. We can now see on the "GPU instances" page that our device is booting up!
63 | 10. Once the device status changes to "✅ Running", click on the SSH login ("ssh ubuntu@..."). This will copy the SSH login to your clipboard.
64 | 11. Now open a new command line window, paste the SSH login, and hit Enter.
65 | 12. If asked "Are you sure you want to continue connecting?", type "yes" and press Enter.
66 | 13. Great! You're now SSH'd into your A10 device! We're now ready to set up our Python environment!
67 |
68 | You can see your total GPU usage from the Lambda cloud interface: https://cloud.lambdalabs.com/usage
69 |
70 | Here, you can see the total charges that you have incurred since the start of the event. We advise that you check your total on a daily basis to make sure that it remains below the credit allocation of $20. This ensures that you are not inadvertently charged for GPU hours.
71 |
72 | If you are unable to SSH into your Lambda GPU in step 11, there is a workaround that you can try. On the [GPU instances page](http://lambdalabs.com/HF-dreambooth-instances), under the column "Cloud IDE", click the button "Launch". This will launch a Jupyter Lab on your GPU which will be displayed in your browser. In the top left-hand corner, click "File" -> "New" -> "Terminal". This will open up a new terminal window. You can use this terminal window to set up Python environment and install dependencies and run scripts.
73 |
74 |
75 | ## Setting up your environment
76 |
77 | You can establish an SSH tunnel to your instance using below command:
78 | ```
79 | ssh ubuntu@ADDRESS_OF_INSTANCE -L 8888:localhost:8888
80 | ```
81 | This will establish the tunnel to a remote machine and also forward the SSH port to a local port, so you can open a jupyter notebook on the remote machine and access it from your own local machine.
82 | We will use **TensorFlow** and **Keras CV** to train DreamBooth model, and later use **diffusers** for conversion. In this section, we'll cover how to set up an environment with the required libraries. This section assumes that you are SSH'd into your GPU device.
83 |
84 | You can setup your environment like below.
85 | Below script:
86 | 1. Creates a python virtual environment,
87 | 2. Installs the requirements,
88 | 3. Does authentication for Hugging Face.
89 | After you run `huggingface-cli login`, pass your write token that you can get from [here](https://huggingface.co/settings/tokens). This will authenticate you to push your models to Hugging Face Hub.
90 |
91 | We will use conda for this (follow this especially if you are training on A10). Install miniconda like below:
92 | ```bash
93 | sudo wget -c https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
94 | sudo chmod +x Miniconda3-latest-Linux-x86_64.sh && ./Miniconda3-latest-Linux-x86_64.sh
95 | ```
96 | Accept the terms by typing "yes", confirm the path by pressing enter and then confirm `conda init` by typing in yes again.
97 | To make conda commands accessible in the current shell environment enter:
98 | ```bash
99 | source ~/.bashrc
100 | ```
101 | Disable the base virtual conda environment:
102 | ```bash
103 | conda config --set auto_activate_base false
104 | conda deactivate
105 | ```
106 | Now activate conda and create your own environment (in this example we use `my_env` for simplicity).
107 | ```bash
108 | conda create -n my_env python==3.10
109 | conda activate my_env
110 | ```
111 | As a next step, we may confirm that pip points to the correct path:
112 | ```bash
113 | which pip
114 | ```
115 | The path should point to `/home/ubuntu/miniconda3/envs/my_env/bin/pip`.
116 |
117 | ** Note: Please make sure you are opening the notebook either in env (if you are using Python virtual environment by following above commands) or use ipykernel to add your environment to jupyter. For first one, you can get into env folder itself and create your notebook there and it should work.**
118 |
119 | As a next step, we need to install necessary dependencies for CUDA Support to work properly and getting a jupyter notebook running. Ensure you are inside the `my_env` conda environment you created previously:
120 | ```bash
121 | conda install nb_conda_kernels
122 | ipython kernel install --user --name=my_env
123 | conda install -c conda-forge cudatoolkit=11.8.0
124 | python3 -m pip install nvidia-cudnn-cu11==8.6.0.163
125 | ```
126 | Next you need to setup XLA to the correct CUDA library path with following command:
127 | ```bash
128 | export XLA_FLAGS=--xla_gpu_cuda_data_dir=/usr/lib/cuda
129 | CUDNN_PATH=$(dirname $(python -c "import nvidia.cudnn;print(nvidia.cudnn.__file__)"))
130 | export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$CONDA_PREFIX/lib/:$CUDNN_PATH/lib
131 | ```
132 | ** Note: you need to set this every time you close and open the terminal via SSH tunnel. If you do not do this, the `fit` method will fail. Please read through the error logs to see where to find the missing library and set the above path accordingly.
133 |
134 | Now, we also must install Tensorflow inside our virtual environment. It is recommend, doing so with pip:
135 |
136 | ```bash
137 | python -m pip install tensorflow==2.12.*
138 | ```
139 | To confirm the installed version, and the success of setting up our drivers in the conda environment:
140 | ```bash
141 | python -c "import tensorflow as tf; print(tf.config.list_physical_devices('GPU')); print(tf.__version__)"
142 | ```
143 | It should return True, and display an array with one physical device. The version should be equal to atleast 2.12.
144 |
145 | We may now install the dependendencies necessary for the jupyter notebook:
146 | ```bash
147 | pip install keras_cv===0.4.2 tensorflow_datasets===4.8.1 pillow===9.4.0 imutils opencv-python matplotlib huggingface-hub pycocotools
148 | ```
149 |
150 | Now we can start our jupyter notebook instance:
151 | ```bash
152 | jupyter notebook
153 | ```
154 | Enter the URL in the browser or connect through VSCode. If this does not work, you likely forgot to forward the 8888 port.
155 | When you open jupyter, select your environment `my_env` in `New` dropdown and it will create your notebook with conda environment you've created.
156 |
157 | Now inside the notebook:
158 |
159 | First check the pip and python are poinitng to right places by running following commands. First check for pip path by running:
160 | ```python
161 | !which pip
162 | ```
163 | It should point to `/home/ubuntu/miniconda3/envs/my_env/bin/pip`. If it is pointing to `/home/ubuntu/.local/bin/pip`, you have not have run `conda config --set auto_activate_base false`. Please run it again and activate `my_env` again. Also check that your notebook is running in the proper kernel `my_env`. Once inside the notebook, you can change it from the menu navigation `Kernel->Change Kernel -> my_env`. You should now see `my_env` in the top right of the notebook.
164 |
165 | Now check for python path aswell:
166 | ```python
167 | !which python
168 | ```
169 | It should point to: `/home/ubuntu/miniconda3/envs/my_env/bin/python`
170 |
171 | Running below line in the notebook makes sure that we have installed the version of TensorFlow that supports GPU, and that TensorFlow can detect the GPUs. If everything goes right, it should return `True` and a list that consists of a GPU. The version should be equal to or greater than 2.11 to support the correct version of keras_cv. In our example, it should print 2.12.
172 | ```python
173 | import tensorflow as tf
174 | print(tf.test.is_built_with_cuda())
175 | print(tf.config.list_logical_devices('GPU'))
176 | print(tf.__version__)
177 | ```
178 |
179 | You can either create your own notebook or clone the notebook `https://github.com/huggingface/community-events/blob/main/keras-dreambooth-sprint/Dreambooth_on_Hub.ipynb` if you haven't done so previously.
180 |
181 | You're all set! You can simply launch a jupyter notebook and start training models! 🚀
182 |
183 | ### Deleting a Cloud Instance
184 |
185 | 30 1x A10 hours should provide you with enough time for 60 fine-tuning runs for Dreambooth. To maximise the GPU time you have for training, we advise that you shut down GPUs over prolonged periods of time when they are not in use. So be smart and shut down your GPU when you're not training.
186 |
187 | Creating an instance and setting it up for the first time may take up to 20 minutes. Subsequently, this process will be much faster as you gain familiarity with the steps, so you shouldn't worry about having to delete a GPU and spinning one up the next time you need one. You can expect to spin-up and delete 2-3 GPUs over the course of the fine-tuning event.
188 |
189 | We'll quickly run through the steps for deleting a Lambda GPU. You can come back to these steps after you've performed your first training run and you want to shut down the GPU:
190 |
191 | 1. Go to the instances page: http://lambdalabs.com/HF-dreambooth-instances
192 | 2. Click the checkbox on the left next to the GPU device you want to delete
193 | 3. Click the button "Terminate" in the top right-hand side of your screen (under the purple button "Launch instance")
194 | 4. Type "erase data on instance" in the text box and press "ok"
195 |
196 | Your GPU device is now deleted and will stop consuming GPU credits.
197 |
--------------------------------------------------------------------------------
/keras-dreambooth-sprint/requirements.txt:
--------------------------------------------------------------------------------
1 | keras_cv==0.4.0
2 | tensorflow>=2.10.0
3 | tensorflow_datasets>=4.8.1
4 | pillow==9.4.0
5 | imutils
6 | opencv-python
7 | huggingface-hub[cli]
--------------------------------------------------------------------------------
/keras-sprint/README.md:
--------------------------------------------------------------------------------
1 | # Official Repository for Keras Sprint Event
2 |
3 | 
4 |
5 | Keras Sprint by Hugging Face aims to reproduce [official Keras examples](https://keras.io/examples/) and build demos to them on [Hugging Face Spaces](https://huggingface.co/spaces).
6 |
7 | Here you can find examples to guide you for the sprint. It contains two end-to-end examples of a successful submission for the event.
8 |
9 | ## Useful Resources
10 | - To learn more about Keras sprint, check out [contribution guide](https://huggingface2.notion.site/Keras-Sprint-Contribution-Guide-ab1543412f3a4f7194896d6048585676).
11 | - To join the sprint, join our [discord](https://huggingface.co/join/discord), head to #keras-working-group channel and take one of the available examples from [this spreadsheet](https://docs.google.com/spreadsheets/d/1EG6z4mmeBzmMidUzDdSDr02quBs2BcgjNOrtZCwnqvs/edit#gid=1687823618) by commenting on it.
12 | - Check out our previous work at [Keras Hugging Face organization](https://huggingface.co/keras-io) and [official Keras examples](https://keras.io/examples/).
--------------------------------------------------------------------------------
/keras-sprint/example_image_2.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/keras-sprint/example_image_2.jpeg
--------------------------------------------------------------------------------
/keras-sprint/example_image_3.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/huggingface/community-events/a2d9115007c7e44b4389e005ea5c6163ae5b0470/keras-sprint/example_image_3.jpeg
--------------------------------------------------------------------------------
/open-source-ai-game-jam/README.md:
--------------------------------------------------------------------------------
1 | # Welcome to the first [Open Source AI Game Jam](https://itch.io/jam/open-source-ai-game-jam) 🎮
2 |
3 | 
4 |
5 | Welcome to the **first Open-Source AI Game Jam 🎉**. During two days, **you’ll make a game using AI tools 🤖.**
6 |
7 | 🤝 Open to all skill levels
8 |
9 | 💸 Participation fee: Free
10 |
11 | 📍 Where?: Online
12 |
13 | **Claim your spot in the Game Jam! Sign up here** 👉 https://itch.io/jam/open-source-ai-game-jam
14 |
15 | This document summarizes all the relevant information required for the Game Jam 📋. **Please read it thoroughly and make sure to**:
16 |
17 | - Do the Onboarding ⛴️
18 | - Read the The Game Jam Rules 📜
19 | - Join the Discord Server 👉 https://hf.co/join/discord
20 |
21 | # The Onboarding ⛴️
22 |
23 | When the game jam starts here’s what you need to do:
24 |
25 | 🔢 If it’s not already done, don’t forget to **sign up to the Game Jam to be able to summit your game** 👉 https://itch.io/jam/open-source-ai-game-jam
26 |
27 | 2️⃣ Watch the video below that will give you the Game Jam Theme **(the video will be posted on Friday 7th of July at 5:00 UTC)**.
28 |
29 | **The Theme Announcement** 👉 https://youtu.be/k0MvSAwoM8k
30 |
31 | 3️⃣ Sign up to the Discord Server 👉 https://hf.co/join/discord
32 |
33 |  34 |
35 | 4️⃣ In *channels and role* select ML For Game Development
36 |
37 |
34 |
35 | 4️⃣ In *channels and role* select ML For Game Development
36 |
37 |  38 |
39 | 5️⃣ You'll see we created 4 channels for the game Jam
40 |
41 |
38 |
39 | 5️⃣ You'll see we created 4 channels for the game Jam
40 |
41 |  42 |
43 | 6️⃣ You **search for a team or teammates**? Ask on **#GameJam-Looking-For-Team**
44 |
45 | 7️⃣ You have questions? Ask on **Ask on #GameJam-Help,** we’ll be there to respond 🤗
46 |
47 | 8️⃣ When you have your team or you want to work alone, it’s time to start to make your game. **Keep Discord open because we’ll give update from time to time** 🤗
48 |
49 |
50 | ## The Goal of this Game Jam 🏆
51 |
52 | Create a game in **48 hours** that uses **at** **least one Open Source AI Tool**
53 |
54 | You can use proprietary AI tools (Midjourney, ChatGPT) **as long as at least one open source tool is part of the game or workflow**.
55 |
56 | ## The Game Jam Rules 📜
57 |
58 |
42 |
43 | 6️⃣ You **search for a team or teammates**? Ask on **#GameJam-Looking-For-Team**
44 |
45 | 7️⃣ You have questions? Ask on **Ask on #GameJam-Help,** we’ll be there to respond 🤗
46 |
47 | 8️⃣ When you have your team or you want to work alone, it’s time to start to make your game. **Keep Discord open because we’ll give update from time to time** 🤗
48 |
49 |
50 | ## The Goal of this Game Jam 🏆
51 |
52 | Create a game in **48 hours** that uses **at** **least one Open Source AI Tool**
53 |
54 | You can use proprietary AI tools (Midjourney, ChatGPT) **as long as at least one open source tool is part of the game or workflow**.
55 |
56 | ## The Game Jam Rules 📜
57 |
58 |  59 |
60 | ## Deadlines 🕧
61 |
62 |
59 |
60 | ## Deadlines 🕧
61 |
62 |  63 |
64 | ### Voting System 🗳️
65 |
66 | - After the submission deadline (July 9th at 5:00pm UTC) you’ll **get until July 16th to vote for the other games**
67 |
68 |
63 |
64 | ### Voting System 🗳️
65 |
66 | - After the submission deadline (July 9th at 5:00pm UTC) you’ll **get until July 16th to vote for the other games**
67 |
68 |  69 |
70 | ## The AI Toolbox 🧰
71 |
72 | The AI toolbox 🧰 (you can use other AI tools too): https://github.com/simoninithomas/awesome-ai-tools-for-game-dev
73 |
74 | Here some examples of AI tools you can use (again remember that you need to use at least one Open Source AI model):
75 |
76 |
69 |
70 | ## The AI Toolbox 🧰
71 |
72 | The AI toolbox 🧰 (you can use other AI tools too): https://github.com/simoninithomas/awesome-ai-tools-for-game-dev
73 |
74 | Here some examples of AI tools you can use (again remember that you need to use at least one Open Source AI model):
75 |
76 |  77 |
77 |  78 |
79 |
80 | ## Some helpful tutorials 📖
81 |
82 | Here's some helpful tutorials:
83 | - How to install the Unity Hugging Face API: https://huggingface.co/blog/unity-api
84 | - AI Speech Recognition in Unity: https://huggingface.co/blog/unity-asr
85 | - Making ML-powered web games with Transformers.js: https://huggingface.co/blog/ml-web-games
86 | - Building a smart Robot AI using Hugging Face 🤗 and Unity: https://thomassimonini.substack.com/p/building-a-smart-robot-ai-using-hugging
87 |
88 | ## Some Game Examples 🕹️
89 |
90 | Here we give some Game Examples which use AI tools:
91 |
92 | 1. **Detective Game**
93 |
94 | You can play it here 👉 https://google.github.io/mysteryofthreebots/
95 |
96 |
78 |
79 |
80 | ## Some helpful tutorials 📖
81 |
82 | Here's some helpful tutorials:
83 | - How to install the Unity Hugging Face API: https://huggingface.co/blog/unity-api
84 | - AI Speech Recognition in Unity: https://huggingface.co/blog/unity-asr
85 | - Making ML-powered web games with Transformers.js: https://huggingface.co/blog/ml-web-games
86 | - Building a smart Robot AI using Hugging Face 🤗 and Unity: https://thomassimonini.substack.com/p/building-a-smart-robot-ai-using-hugging
87 |
88 | ## Some Game Examples 🕹️
89 |
90 | Here we give some Game Examples which use AI tools:
91 |
92 | 1. **Detective Game**
93 |
94 | You can play it here 👉 https://google.github.io/mysteryofthreebots/
95 |
96 |  97 |
98 | 2. **Action Game**
99 |
100 | You can play it here 👉 https://huggingface.co/spaces/ThomasSimonini/SmartRobot
101 | Tutorial 👉 Building a smart Robot AI using Hugging Face 🤗 and Unity
102 |
103 |
97 |
98 | 2. **Action Game**
99 |
100 | You can play it here 👉 https://huggingface.co/spaces/ThomasSimonini/SmartRobot
101 | Tutorial 👉 Building a smart Robot AI using Hugging Face 🤗 and Unity
102 |
103 |  104 |
105 | 3. **AI NPC with Unity MLAgents**
106 |
107 | You can play it here 👉 https://danielk0703.itch.io/ship-jam
108 |
109 |
104 |
105 | 3. **AI NPC with Unity MLAgents**
106 |
107 | You can play it here 👉 https://danielk0703.itch.io/ship-jam
108 |
109 |  110 |
111 | 1. **Example 4: Doodle Dash**
112 |
113 | Play it here 👉 https://huggingface.co/spaces/Xenova/doodle-dash
114 |
115 | Learn to make your own with this tutorial 👉 https://huggingface.co/blog/ml-web-games
116 |
117 |
110 |
111 | 1. **Example 4: Doodle Dash**
112 |
113 | Play it here 👉 https://huggingface.co/spaces/Xenova/doodle-dash
114 |
115 | Learn to make your own with this tutorial 👉 https://huggingface.co/blog/ml-web-games
116 |
117 |  118 |
119 | ## Some advice 💡
120 |
121 |
118 |
119 | ## Some advice 💡
120 |
121 |  122 |
123 |
124 | ## Discord Channels
125 |
126 | Our Discord Server is the **central place to create teams, exchange with other teams, ask questions and get the latest updates**.
127 |
128 | 👉 https://hf.co/join/discord
129 |
130 | We built different channels:
131 |
132 |
133 |
134 | ## You're looking for a team?
135 |
136 |
122 |
123 |
124 | ## Discord Channels
125 |
126 | Our Discord Server is the **central place to create teams, exchange with other teams, ask questions and get the latest updates**.
127 |
128 | 👉 https://hf.co/join/discord
129 |
130 | We built different channels:
131 |
132 |
133 |
134 | ## You're looking for a team?
135 |
136 |  137 |
138 | ## You have some questions?
139 |
137 |
138 | ## You have some questions?
139 |  140 |
141 | ## Organizers 🧑🤝🧑
142 |
143 |
140 |
141 | ## Organizers 🧑🤝🧑
142 |
143 |  144 |
145 |
146 |
147 |
148 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | accelerate
2 | torch
3 | torchvision
4 | datasets
5 | scipy
6 | wandb
7 | einops
8 | fire
9 | retry
10 | kornia==0.5.4
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup, find_packages
2 |
3 | with open("requirements.txt", "r") as f:
4 | requirements = f.read().splitlines()
5 |
6 | setup(name="huggan", install_requires=requirements, packages=find_packages())
7 |
--------------------------------------------------------------------------------
/sklearn-sprint/guidelines.md:
--------------------------------------------------------------------------------
1 |
2 | 
3 |
4 | In this sprint, we will build interactive demos from the scikit-learn documentation and, afterwards, contribute the demos directly to the docs.
5 |
6 | ## Important Dates
7 |
8 | 🌅 Sprint Start Date: Apr 12, 2023
9 | 🌃 Sprint Finish Date: Apr 30, 2023
10 |
11 | ## To get started 🤩
12 |
13 | 1. Join our [Discord](https://huggingface.co/join/discord) and take the role #sklearn-sprint-participant by selecting "Sklearn Working Group" in the #role-assignment channel. Then, meet us in #sklearn-sprint channel.
14 | 2. Head to [this page](https://scikit-learn.org/stable/auto_examples/) and pick an example you’d like to build on.
15 | 3. Leave a comment on [this spreadsheet](https://docs.google.com/spreadsheets/d/14EThtIyF4KfpU99Fm2EW3Rz9t6SSEqDyzV4jmw3fjyI/edit?usp=sharing) with your name under Owner column, claiming the example. The spreadsheet has a limited number of examples. Feel free to add yours with a comment if it doesn’t exist in the spreadsheet.
16 | .
17 | 4. Start building!
18 |
19 | We will be hosting our applications in [scikit-learn](https://huggingface.co/sklearn-docs) organization of Hugging Face.
20 |
21 | For complete starters: in the Hugging Face Hub, there are repositories for models, datasets, and [Spaces](https://huggingface.co/spaces). Spaces are a special type of repository hosting ML applications, such as showcasing a model. To write our apps, we will only be using Gradio. [Gradio](https://gradio.app/) is a library that lets you build a cool front-end application for your models, completely in Python, and supports many libraries! In this sprint, we will be using mostly visualization support (`matplotlib`, `plotly`, `altair` and more) and [skops](https://skops.readthedocs.io/en/stable/) integration (which you can launch an interface for a given classification or regression interface with one line of code).
22 |
23 | In Gradio, there are two ways to create a demo. One is to use `Interface`, which is a very simple abstraction. Let’s see an example.
24 |
25 | ```python
26 | import gradio as gr
27 |
28 | # implement your classifier here
29 | clf.fit(X_train, y_train)
30 |
31 | def cancer_classifier(df):
32 | # simply infer and return predictions
33 | predictions = clf.predict(df)
34 | return predictions
35 |
36 | gr.Interface(fn=cancer_classifier, inputs="dataframe",
37 | outputs="label").launch()
38 |
39 | # save this in a file called app.py
40 | # then run it
41 | ```
42 |
43 | This will result in following interface:
44 |
45 | 
46 |
47 | This is very customizable. You can specify rows and columns, add a title and description, an example input, and more. There’s a more detailed guide [here](https://gradio.app/using-gradio-for-tabular-workflows/).
48 |
49 | Another way of creating an application is to use [Blocks](https://gradio.app/quickstart/#blocks-more-flexibility-and-control). You can see usage of Blocks in the example applications linked in this guide.
50 |
51 | After we create our application, we will create a Space. You can go to [hf.co](http://huggingface.co), click on your profile on top right and select “New Space”.
52 |
53 | 
54 |
55 | We can name our Space, pick a license and select Space SDK as “Gradio”. Free hardware is enough for our app, so no need to change it.
56 |
57 | 
58 |
59 | After creating the Space, you have three options
60 | * You can clone the repository locally, add your files, and then push them to the Hub.
61 | * You can do all your coding directly in the browser.
62 | * (shown below) You can do the coding locally and then drag and drop your application file to the Hub.
63 |
64 | 
65 |
66 | To upload your application file, pick “Add File” and drag and drop your file.
67 |
68 | 
69 |
70 | Lastly, if your application includes any library other than Gradio, create a file called requirements.txt and add requirements like below:
71 |
72 | ```python
73 | matplotlib==3.6.3
74 | scikit-learn==1.2.1
75 | ```
76 |
77 | And your app should be up and running!
78 |
79 | **Example Submissions**
80 |
81 | We left couple of examples below: (there’s more at the end of this page)
82 | Documentation page for comparing linkage methods for hierarchical clustering and example Space built on it 👇🏼
83 |
84 | [Comparing different hierarchical linkage methods on toy datasets](https://scikit-learn.org/stable/auto_examples/cluster/plot_linkage_comparison.html#sphx-glr-auto-examples-cluster-plot-linkage-comparison-py)
85 |
86 | [Hierarchical Clustering Linkage - a Hugging Face Space by scikit-learn](https://huggingface.co/spaces/scikit-learn/hierarchical-clustering-linkage)
87 |
88 | Note: If for your demo you're training a model from scratch (e.g. training an image classifier), you can push it to the Hub using [skops](https://skops.readthedocs.io/en/stable/) and build a Gradio demo on top of it. For such submission, we expect a model repository with a model card and the model weight as well as a simple Space with the interface that receives input and outputs results. You can use this tutorial to get started with [skops](https://www.kdnuggets.com/2023/02/skops-new-library-improve-scikitlearn-production.html).
89 |
90 | You can find an example submission for a model repository below.
91 |
92 | [scikit-learn/cancer-prediction-trees · Hugging Face](https://huggingface.co/scikit-learn/cancer-prediction-trees)
93 |
94 | 4. After the demos are done, we will open pull requests to scikit-learn documentation in [scikit-learn’s repository](https://github.com/scikit-learn/scikit-learn) to contribute our application codes to be directly inside the documentation. We will help you out if this is your first open source contribution. 🤗
95 |
96 | **If you need any help** you can join our discord server, take collaborate role and join `sklearn-sprint` channel and ask questions 🤗🫂
97 |
98 | ### Sprint Prizes
99 | We will be giving following vouchers that can be spent at [Hugging Face Store](https://store.huggingface.co/) including shipping,
100 | - $20 worth of voucher for everyone that builds three demos,
101 | - $40 worth of voucher for everyone that builds five demos.
--------------------------------------------------------------------------------
/whisper-fine-tuning-event/ds_config.json:
--------------------------------------------------------------------------------
1 | {
2 | "fp16": {
3 | "enabled": "auto",
4 | "loss_scale": 0,
5 | "loss_scale_window": 1000,
6 | "initial_scale_power": 16,
7 | "hysteresis": 2,
8 | "min_loss_scale": 1
9 | },
10 |
11 | "optimizer": {
12 | "type": "AdamW",
13 | "params": {
14 | "lr": "auto",
15 | "betas": "auto",
16 | "eps": "auto",
17 | "weight_decay": "auto"
18 | }
19 | },
20 |
21 | "scheduler": {
22 | "type": "WarmupDecayLR",
23 | "params": {
24 | "last_batch_iteration": -1,
25 | "total_num_steps": "auto",
26 | "warmup_min_lr": "auto",
27 | "warmup_max_lr": "auto",
28 | "warmup_num_steps": "auto"
29 | }
30 | },
31 |
32 | "zero_optimization": {
33 | "stage": 2,
34 | "offload_optimizer": {
35 | "device": "cpu",
36 | "pin_memory": true
37 | },
38 | "allgather_partitions": true,
39 | "allgather_bucket_size": 2e8,
40 | "overlap_comm": true,
41 | "reduce_scatter": true,
42 | "reduce_bucket_size": 2e8,
43 | "contiguous_gradients": true
44 | },
45 |
46 | "gradient_accumulation_steps": "auto",
47 | "gradient_clipping": "auto",
48 | "train_batch_size": "auto",
49 | "train_micro_batch_size_per_gpu": "auto"
50 | }
51 |
--------------------------------------------------------------------------------
/whisper-fine-tuning-event/interleave_streaming_datasets.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "id": "6a5c0357",
7 | "metadata": {
8 | "collapsed": false,
9 | "jupyter": {
10 | "outputs_hidden": false
11 | },
12 | "pycharm": {
13 | "name": "#%%\n"
14 | }
15 | },
16 | "outputs": [],
17 | "source": [
18 | "# Ensure datasets is installed from main. Uncomment the following line if you face issues running this script:\n",
19 | "# !pip install git+https://github.com/huggingface/datasets"
20 | ]
21 | },
22 | {
23 | "cell_type": "code",
24 | "execution_count": 2,
25 | "id": "794aaced",
26 | "metadata": {
27 | "collapsed": false,
28 | "jupyter": {
29 | "outputs_hidden": false
30 | },
31 | "pycharm": {
32 | "name": "#%%\n"
33 | }
34 | },
35 | "outputs": [],
36 | "source": [
37 | "from datasets import Audio, interleave_datasets, IterableDataset, load_dataset\n",
38 | "from typing import List, Optional"
39 | ]
40 | },
41 | {
42 | "cell_type": "markdown",
43 | "id": "f210ca9a-486b-46a2-a675-2526a9bd83f5",
44 | "metadata": {},
45 | "source": [
46 | "### Define the dataset attributes"
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "id": "fc07293f-3ba4-4e89-a4ca-8e39409a8373",
52 | "metadata": {},
53 | "source": [
54 | "In this example, we'll show to combine the Common Voice 11, VoxPopuli, Mulitlingual LibriSpeech and FLEURS datasets for Spanish, giving a training corpus equal to the sum of the individual datasets. This is particularly beneficial in low-resource settings, where any one of the datasets alone might have insufficient data to train a model.\n",
55 | "\n",
56 | "We need to specify the dataset names on the Hub, the corresponding configs and finally the text column names for the transcriptions:"
57 | ]
58 | },
59 | {
60 | "cell_type": "code",
61 | "execution_count": 3,
62 | "id": "c53344f3-c315-430a-a2f3-57aea6bb0e17",
63 | "metadata": {},
64 | "outputs": [],
65 | "source": [
66 | "dataset_names = [\"mozilla-foundation/common_voice_11_0\", \"facebook/voxpopuli\", \"facebook/multilingual_librispeech\", \"google/fleurs\"]\n",
67 | "dataset_config_names = [\"es\", \"es\", \"spanish\", \"es_419\"]\n",
68 | "text_column_names = [\"sentence\", \"normalized_text\", \"text\", \"transcription\"]"
69 | ]
70 | },
71 | {
72 | "cell_type": "markdown",
73 | "id": "215541f6-ee1c-4104-b43c-fa3f7fce0494",
74 | "metadata": {},
75 | "source": [
76 | "### Define the merging function"
77 | ]
78 | },
79 | {
80 | "cell_type": "markdown",
81 | "id": "b722a48b-c576-4a63-b2a2-3c264890a75f",
82 | "metadata": {},
83 | "source": [
84 | "We define a function, `load_multiple_streaming_datasets`, that takes as argument a list of datasets, configs, splits (optional) and text column names (optional). It sets them to a specified sampling rate and interleaves them together, giving one merged dataset. This is all \n",
85 | "done in _streaming mode_: as we iterate over the merged dataset we load samples one-by-one on the fly. No data is\n",
86 | "saved to disk.\n",
87 | "\n",
88 | "We can also specify our strategy for interleaving datasets. The default strategy, `all_exhausted` is an oversampling \n",
89 | "strategy. In this case, the dataset construction is stopped as soon as every samples in every dataset \n",
90 | "has been added at least once. In practice, it means that if a dataset is exhausted, it will return to the \n",
91 | "beginning of this dataset until the stop criterion has been reached. You can specify `stopping_strategy=first_exhausted` \n",
92 | "for a subsampling strategy, i.e the dataset construction is stopped as soon one of the dataset runs out of samples. "
93 | ]
94 | },
95 | {
96 | "cell_type": "code",
97 | "execution_count": 4,
98 | "id": "61eb4cb1-ee27-4270-a474-1bb33e1df65f",
99 | "metadata": {},
100 | "outputs": [],
101 | "source": [
102 | "def load_multiple_streaming_datasets(\n",
103 | " dataset_names: List,\n",
104 | " dataset_config_names: List,\n",
105 | " splits: Optional[List] = None,\n",
106 | " text_column_names: Optional[List] = None,\n",
107 | " sampling_rate: Optional[int] = 16000,\n",
108 | " stopping_strategy: Optional[str] = \"all_exhausted\",\n",
109 | " **kwargs\n",
110 | ") -> IterableDataset:\n",
111 | "\n",
112 | " if len(dataset_names) != len(dataset_config_names):\n",
113 | " raise ValueError(\n",
114 | " f\"Ensure one config is passed for each dataset, got {len(dataset_names)} datasets and\"\n",
115 | " f\" {len(dataset_config_names)} configs.\"\n",
116 | " )\n",
117 | "\n",
118 | " if splits is not None and len(splits) != len(dataset_names):\n",
119 | " raise ValueError(\n",
120 | " f\"Ensure one split is passed for each dataset, got {len(dataset_names)} datasets and {len(splits)} splits.\"\n",
121 | " )\n",
122 | "\n",
123 | " if text_column_names is not None and len(text_column_names) != len(dataset_names):\n",
124 | " raise ValueError(\n",
125 | " f\"Ensure one text column name is passed for each dataset, got {len(dataset_names)} datasets and\"\n",
126 | " f\" {len(text_column_names)} text column names.\"\n",
127 | " )\n",
128 | "\n",
129 | " splits = splits if splits is not None else [\"train\" for i in range(len(dataset_names))]\n",
130 | " text_column_names = (\n",
131 | " text_column_names if text_column_names is not None else [\"text\" for i in range(len(dataset_names))]\n",
132 | " )\n",
133 | "\n",
134 | " all_datasets = []\n",
135 | " # iterate over the datasets we want to interleave\n",
136 | " for i, dataset_name in enumerate(dataset_names):\n",
137 | " dataset = load_dataset(dataset_name, dataset_config_names[i], split=splits[i], streaming=True, **kwargs)\n",
138 | " # resample to specified sampling rate\n",
139 | " dataset = dataset.cast_column(\"audio\", Audio(sampling_rate))\n",
140 | " # normalise columns to [\"audio\", \"sentence\"]\n",
141 | " if text_column_names[i] != \"sentence\":\n",
142 | " dataset = dataset.rename_column(text_column_names[i], \"sentence\")\n",
143 | " dataset = dataset.remove_columns(set(dataset.features.keys()) - set([\"audio\", \"sentence\"]))\n",
144 | " all_datasets.append(dataset)\n",
145 | "\n",
146 | " interleaved_dataset = interleave_datasets(all_datasets, stopping_strategy=stopping_strategy)\n",
147 | " return interleaved_dataset"
148 | ]
149 | },
150 | {
151 | "cell_type": "markdown",
152 | "id": "29bc228b-ce9b-4cee-9092-1223ddfa51ad",
153 | "metadata": {},
154 | "source": [
155 | "Let's apply this function to load and merge our four datasets:"
156 | ]
157 | },
158 | {
159 | "cell_type": "code",
160 | "execution_count": 5,
161 | "id": "8ae90f83-4ecd-46a3-98be-bd75706e0d88",
162 | "metadata": {},
163 | "outputs": [],
164 | "source": [
165 | "ds = load_multiple_streaming_datasets(dataset_names, dataset_config_names=dataset_config_names, text_column_names=text_column_names, use_auth_token=True)"
166 | ]
167 | },
168 | {
169 | "cell_type": "markdown",
170 | "id": "6056a693-1fb0-45f4-ad43-be5f1812c1a5",
171 | "metadata": {},
172 | "source": [
173 | "### Iterate over the dataset"
174 | ]
175 | },
176 | {
177 | "cell_type": "markdown",
178 | "id": "7ffe011f-f905-4027-ab67-5c9c3b2b5ac0",
179 | "metadata": {},
180 | "source": [
181 | "We iterate over the dataset, loading and merging samples on the fly. Let's print the transcriptions for the first 10 samples of our merged dataset:"
182 | ]
183 | },
184 | {
185 | "cell_type": "code",
186 | "execution_count": 6,
187 | "id": "75b3355a-3c06-4d23-af43-2b93b1ad70b2",
188 | "metadata": {},
189 | "outputs": [
190 | {
191 | "name": "stderr",
192 | "output_type": "stream",
193 | "text": [
194 | "Reading metadata...: 230467it [00:41, 5545.80it/s]\n"
195 | ]
196 | },
197 | {
198 | "name": "stdout",
199 | "output_type": "stream",
200 | "text": [
201 | "0 ¿ Qué tal a tres de cinco ?\n",
202 | "1 y desde luego esa razón no puede tener que ver con la explicación surrealista que hemos escuchado más de una vez de que se trata de una conspiración izquierdista.\n",
203 | "2 para exclamar con voz de acción de gracias y para contar todas tus maravillas jehová la habitación de tu casa he amado y el lugar del tabernáculo de tu gloria no juntes con los pecadores mi alma ni con los hombres de sangres mi vida\n",
204 | "3 el uso de internet y de la red informática mundial permite que los estudiantes tengan acceso a la información en todo momento\n",
205 | "4 vamos , quiero decir , que no soy de citas especiales .\n",
206 | "5 si bien esta lista no es perfecta sí que resulta necesario que las entidades financieras refuercen sus controles.\n",
207 | "6 oye oh jehová mi voz con que á ti clamo y ten misericordia de mí respóndeme mi corazón ha dicho de ti buscad mi rostro tu rostro buscaré oh jehová\n",
208 | "7 los deportes de nieve en descenso como el esquí y la tablanieve son disciplinas populares que consisten en deslizarse con esquís o una tabla fijada a los pies sobre un terreno nevado\n",
209 | "8 fray Lope , en aquel momento , colmaba otro vaso igual :\n",
210 | "9 señora presidenta la competitividad es importante pero no puede ser el único criterio.\n"
211 | ]
212 | }
213 | ],
214 | "source": [
215 | "for i, sample in enumerate(ds):\n",
216 | " print(i, sample[\"sentence\"])\n",
217 | " if i == 9:\n",
218 | " break"
219 | ]
220 | },
221 | {
222 | "cell_type": "markdown",
223 | "id": "42d5ad08-b20e-4cba-a1a9-909fdbf030d4",
224 | "metadata": {},
225 | "source": [
226 | "We can see that the transcriptions take several different formats. Those from Common Voice 11 are cased and punctuated. Those from VoxPopuli are punctuated only. Those from Multilingual LibriSpeech and FLEURS are neither cased not punctuated. We need to normalise the transcriptions to a uniform format before training our model. \n",
227 | "\n",
228 | "The following code cell is lifted from the Whisper training notebook: https://github.com/huggingface/community-events/blob/main/whisper-fine-tuning-event/fine-tune-whisper-streaming.ipynb"
229 | ]
230 | },
231 | {
232 | "cell_type": "code",
233 | "execution_count": 7,
234 | "id": "ed20e9cd-31c2-44cb-872b-333378a92fd1",
235 | "metadata": {},
236 | "outputs": [
237 | {
238 | "name": "stderr",
239 | "output_type": "stream",
240 | "text": [
241 | "/Users/sanchitgandhi/venv/lib/python3.8/site-packages/jax/_src/lib/__init__.py:33: UserWarning: JAX on Mac ARM machines is experimental and minimally tested. Please see https://github.com/google/jax/issues/5501 in the event of problems.\n",
242 | " warnings.warn(\"JAX on Mac ARM machines is experimental and minimally tested. \"\n"
243 | ]
244 | }
245 | ],
246 | "source": [
247 | "from transformers.models.whisper.english_normalizer import BasicTextNormalizer\n",
248 | "\n",
249 | "do_lower_case = True\n",
250 | "do_remove_punctuation = True\n",
251 | "\n",
252 | "normalizer = BasicTextNormalizer()"
253 | ]
254 | },
255 | {
256 | "cell_type": "markdown",
257 | "id": "01d13029-c24f-4a51-aff2-9251a2ceb4ce",
258 | "metadata": {},
259 | "source": [
260 | "Now we define a function to normalise our transcriptions:"
261 | ]
262 | },
263 | {
264 | "cell_type": "code",
265 | "execution_count": 8,
266 | "id": "26e42417-4bd2-46f8-914e-3a6f9f3471ac",
267 | "metadata": {},
268 | "outputs": [],
269 | "source": [
270 | "def normalize_transcriptions(batch):\n",
271 | " # optional pre-processing steps\n",
272 | " transcription = batch[\"sentence\"]\n",
273 | " if do_lower_case:\n",
274 | " transcription = transcription.lower()\n",
275 | " if do_remove_punctuation:\n",
276 | " transcription = normalizer(transcription).strip()\n",
277 | " batch[\"sentence\"] = transcription\n",
278 | " return batch"
279 | ]
280 | },
281 | {
282 | "cell_type": "markdown",
283 | "id": "3b1c67fe-be4b-4ee5-9a1f-0d444f2b5c62",
284 | "metadata": {},
285 | "source": [
286 | "Let's apply the data pre-processing steps to our dataset and view the first 10 samples again:"
287 | ]
288 | },
289 | {
290 | "cell_type": "code",
291 | "execution_count": 9,
292 | "id": "0babac71-9157-4d0f-a8a8-184547bdf501",
293 | "metadata": {},
294 | "outputs": [
295 | {
296 | "name": "stderr",
297 | "output_type": "stream",
298 | "text": [
299 | "Reading metadata...: 230467it [00:32, 6984.59it/s] \n"
300 | ]
301 | },
302 | {
303 | "name": "stdout",
304 | "output_type": "stream",
305 | "text": [
306 | "0 qué tal a tres de cinco \n",
307 | "1 y desde luego esa razón no puede tener que ver con la explicación surrealista que hemos escuchado más de una vez de que se trata de una conspiración izquierdista \n",
308 | "2 para exclamar con voz de acción de gracias y para contar todas tus maravillas jehová la habitación de tu casa he amado y el lugar del tabernáculo de tu gloria no juntes con los pecadores mi alma ni con los hombres de sangres mi vida\n",
309 | "3 el uso de internet y de la red informática mundial permite que los estudiantes tengan acceso a la información en todo momento\n",
310 | "4 vamos quiero decir que no soy de citas especiales \n",
311 | "5 si bien esta lista no es perfecta sí que resulta necesario que las entidades financieras refuercen sus controles \n",
312 | "6 oye oh jehová mi voz con que á ti clamo y ten misericordia de mí respóndeme mi corazón ha dicho de ti buscad mi rostro tu rostro buscaré oh jehová\n",
313 | "7 los deportes de nieve en descenso como el esquí y la tablanieve son disciplinas populares que consisten en deslizarse con esquís o una tabla fijada a los pies sobre un terreno nevado\n",
314 | "8 fray lope en aquel momento colmaba otro vaso igual \n",
315 | "9 señora presidenta la competitividad es importante pero no puede ser el único criterio \n"
316 | ]
317 | }
318 | ],
319 | "source": [
320 | "ds = ds.map(normalize_transcriptions)\n",
321 | "\n",
322 | "for i, sample in enumerate(ds):\n",
323 | " print(i, sample[\"sentence\"])\n",
324 | " if i == 9:\n",
325 | " break"
326 | ]
327 | },
328 | {
329 | "cell_type": "markdown",
330 | "id": "d135627a-a7aa-458c-94b8-57ddeae74a72",
331 | "metadata": {},
332 | "source": [
333 | "This time the transcriptions are in a consistent format. We can use this data to fine-tune our Whisper model. Note that since we've removed punctuation and casing, the Whisper model won't learn to predict these features."
334 | ]
335 | }
336 | ],
337 | "metadata": {
338 | "kernelspec": {
339 | "display_name": "Python 3 (ipykernel)",
340 | "language": "python",
341 | "name": "python3"
342 | },
343 | "language_info": {
344 | "codemirror_mode": {
345 | "name": "ipython",
346 | "version": 3
347 | },
348 | "file_extension": ".py",
349 | "mimetype": "text/x-python",
350 | "name": "python",
351 | "nbconvert_exporter": "python",
352 | "pygments_lexer": "ipython3",
353 | "version": "3.8.9"
354 | }
355 | },
356 | "nbformat": 4,
357 | "nbformat_minor": 5
358 | }
359 |
--------------------------------------------------------------------------------
/whisper-fine-tuning-event/requirements.txt:
--------------------------------------------------------------------------------
1 | torch>=1.7
2 | torchaudio
3 | git+https://github.com/huggingface/transformers
4 | git+https://github.com/huggingface/datasets
5 | librosa
6 | jiwer
7 | evaluate>=0.3.0
8 | more-itertools
9 | tensorboard
10 |
--------------------------------------------------------------------------------
/whisper-fine-tuning-event/run_eval_whisper_streaming.py:
--------------------------------------------------------------------------------
1 | import argparse
2 |
3 | from transformers import pipeline
4 | from transformers.models.whisper.english_normalizer import BasicTextNormalizer
5 | from datasets import load_dataset, Audio
6 | import evaluate
7 |
8 | wer_metric = evaluate.load("wer")
9 |
10 |
11 | def is_target_text_in_range(ref):
12 | if ref.strip() == "ignore time segment in scoring":
13 | return False
14 | else:
15 | return ref.strip() != ""
16 |
17 |
18 | def get_text(sample):
19 | if "text" in sample:
20 | return sample["text"]
21 | elif "sentence" in sample:
22 | return sample["sentence"]
23 | elif "normalized_text" in sample:
24 | return sample["normalized_text"]
25 | elif "transcript" in sample:
26 | return sample["transcript"]
27 | elif "transcription" in sample:
28 | return sample["transcription"]
29 | else:
30 | raise ValueError(
31 | f"Expected transcript column of either 'text', 'sentence', 'normalized_text' or 'transcript'. Got sample of "
32 | ".join{sample.keys()}. Ensure a text column name is present in the dataset."
33 | )
34 |
35 |
36 | whisper_norm = BasicTextNormalizer()
37 |
38 |
39 | def normalise(batch):
40 | batch["norm_text"] = whisper_norm(get_text(batch))
41 | return batch
42 |
43 |
44 | def data(dataset):
45 | for i, item in enumerate(dataset):
46 | yield {**item["audio"], "reference": item["norm_text"]}
47 |
48 |
49 | def main(args):
50 | batch_size = args.batch_size
51 | whisper_asr = pipeline(
52 | "automatic-speech-recognition", model=args.model_id, device=args.device
53 | )
54 |
55 | whisper_asr.model.config.forced_decoder_ids = (
56 | whisper_asr.tokenizer.get_decoder_prompt_ids(
57 | language=args.language, task="transcribe"
58 | )
59 | )
60 |
61 | dataset = load_dataset(
62 | args.dataset,
63 | args.config,
64 | split=args.split,
65 | streaming=args.streaming,
66 | use_auth_token=True,
67 | )
68 |
69 | # Only uncomment for debugging
70 | dataset = dataset.take(args.max_eval_samples)
71 |
72 | dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
73 | dataset = dataset.map(normalise)
74 | dataset = dataset.filter(is_target_text_in_range, input_columns=["norm_text"])
75 |
76 | predictions = []
77 | references = []
78 |
79 | # run streamed inference
80 | for out in whisper_asr(data(dataset), batch_size=batch_size):
81 | predictions.append(whisper_norm(out["text"]))
82 | references.append(out["reference"][0])
83 |
84 | wer = wer_metric.compute(references=references, predictions=predictions)
85 | wer = round(100 * wer, 2)
86 |
87 | print("WER:", wer)
88 | evaluate.push_to_hub(
89 | model_id=args.model_id,
90 | metric_value=wer,
91 | metric_type="wer",
92 | metric_name="WER",
93 | dataset_name=args.dataset,
94 | dataset_type=args.dataset,
95 | dataset_split=args.split,
96 | dataset_config=args.config,
97 | task_type="automatic-speech-recognition",
98 | task_name="Automatic Speech Recognition"
99 | )
100 |
101 |
102 | if __name__ == "__main__":
103 | parser = argparse.ArgumentParser()
104 |
105 | parser.add_argument(
106 | "--model_id",
107 | type=str,
108 | required=True,
109 | help="Model identifier. Should be loadable with 🤗 Transformers",
110 | )
111 | parser.add_argument(
112 | "--dataset",
113 | type=str,
114 | default="mozilla-foundation/common_voice_11_0",
115 | help="Dataset name to evaluate the `model_id`. Should be loadable with 🤗 Datasets",
116 | )
117 | parser.add_argument(
118 | "--config",
119 | type=str,
120 | required=True,
121 | help="Config of the dataset. *E.g.* `'en'` for the English split of Common Voice",
122 | )
123 | parser.add_argument(
124 | "--split",
125 | type=str,
126 | default="test",
127 | help="Split of the dataset. *E.g.* `'test'`",
128 | )
129 |
130 | parser.add_argument(
131 | "--device",
132 | type=int,
133 | default=-1,
134 | help="The device to run the pipeline on. -1 for CPU (default), 0 for the first GPU and so on.",
135 | )
136 | parser.add_argument(
137 | "--batch_size",
138 | type=int,
139 | default=16,
140 | help="Number of samples to go through each streamed batch.",
141 | )
142 | parser.add_argument(
143 | "--max_eval_samples",
144 | type=int,
145 | default=None,
146 | help="Number of samples to be evaluated. Put a lower number e.g. 64 for testing this script.",
147 | )
148 | parser.add_argument(
149 | "--streaming",
150 | type=bool,
151 | default=True,
152 | help="Choose whether you'd like to download the entire dataset or stream it during the evaluation.",
153 | )
154 | parser.add_argument(
155 | "--language",
156 | type=str,
157 | required=True,
158 | help="Two letter language code for the transcription language, e.g. use 'en' for English.",
159 | )
160 | args = parser.parse_args()
161 |
162 | main(args)
163 |
--------------------------------------------------------------------------------
144 |
145 |
146 |
147 |
148 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | accelerate
2 | torch
3 | torchvision
4 | datasets
5 | scipy
6 | wandb
7 | einops
8 | fire
9 | retry
10 | kornia==0.5.4
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup, find_packages
2 |
3 | with open("requirements.txt", "r") as f:
4 | requirements = f.read().splitlines()
5 |
6 | setup(name="huggan", install_requires=requirements, packages=find_packages())
7 |
--------------------------------------------------------------------------------
/sklearn-sprint/guidelines.md:
--------------------------------------------------------------------------------
1 |
2 | 
3 |
4 | In this sprint, we will build interactive demos from the scikit-learn documentation and, afterwards, contribute the demos directly to the docs.
5 |
6 | ## Important Dates
7 |
8 | 🌅 Sprint Start Date: Apr 12, 2023
9 | 🌃 Sprint Finish Date: Apr 30, 2023
10 |
11 | ## To get started 🤩
12 |
13 | 1. Join our [Discord](https://huggingface.co/join/discord) and take the role #sklearn-sprint-participant by selecting "Sklearn Working Group" in the #role-assignment channel. Then, meet us in #sklearn-sprint channel.
14 | 2. Head to [this page](https://scikit-learn.org/stable/auto_examples/) and pick an example you’d like to build on.
15 | 3. Leave a comment on [this spreadsheet](https://docs.google.com/spreadsheets/d/14EThtIyF4KfpU99Fm2EW3Rz9t6SSEqDyzV4jmw3fjyI/edit?usp=sharing) with your name under Owner column, claiming the example. The spreadsheet has a limited number of examples. Feel free to add yours with a comment if it doesn’t exist in the spreadsheet.
16 | .
17 | 4. Start building!
18 |
19 | We will be hosting our applications in [scikit-learn](https://huggingface.co/sklearn-docs) organization of Hugging Face.
20 |
21 | For complete starters: in the Hugging Face Hub, there are repositories for models, datasets, and [Spaces](https://huggingface.co/spaces). Spaces are a special type of repository hosting ML applications, such as showcasing a model. To write our apps, we will only be using Gradio. [Gradio](https://gradio.app/) is a library that lets you build a cool front-end application for your models, completely in Python, and supports many libraries! In this sprint, we will be using mostly visualization support (`matplotlib`, `plotly`, `altair` and more) and [skops](https://skops.readthedocs.io/en/stable/) integration (which you can launch an interface for a given classification or regression interface with one line of code).
22 |
23 | In Gradio, there are two ways to create a demo. One is to use `Interface`, which is a very simple abstraction. Let’s see an example.
24 |
25 | ```python
26 | import gradio as gr
27 |
28 | # implement your classifier here
29 | clf.fit(X_train, y_train)
30 |
31 | def cancer_classifier(df):
32 | # simply infer and return predictions
33 | predictions = clf.predict(df)
34 | return predictions
35 |
36 | gr.Interface(fn=cancer_classifier, inputs="dataframe",
37 | outputs="label").launch()
38 |
39 | # save this in a file called app.py
40 | # then run it
41 | ```
42 |
43 | This will result in following interface:
44 |
45 | 
46 |
47 | This is very customizable. You can specify rows and columns, add a title and description, an example input, and more. There’s a more detailed guide [here](https://gradio.app/using-gradio-for-tabular-workflows/).
48 |
49 | Another way of creating an application is to use [Blocks](https://gradio.app/quickstart/#blocks-more-flexibility-and-control). You can see usage of Blocks in the example applications linked in this guide.
50 |
51 | After we create our application, we will create a Space. You can go to [hf.co](http://huggingface.co), click on your profile on top right and select “New Space”.
52 |
53 | 
54 |
55 | We can name our Space, pick a license and select Space SDK as “Gradio”. Free hardware is enough for our app, so no need to change it.
56 |
57 | 
58 |
59 | After creating the Space, you have three options
60 | * You can clone the repository locally, add your files, and then push them to the Hub.
61 | * You can do all your coding directly in the browser.
62 | * (shown below) You can do the coding locally and then drag and drop your application file to the Hub.
63 |
64 | 
65 |
66 | To upload your application file, pick “Add File” and drag and drop your file.
67 |
68 | 
69 |
70 | Lastly, if your application includes any library other than Gradio, create a file called requirements.txt and add requirements like below:
71 |
72 | ```python
73 | matplotlib==3.6.3
74 | scikit-learn==1.2.1
75 | ```
76 |
77 | And your app should be up and running!
78 |
79 | **Example Submissions**
80 |
81 | We left couple of examples below: (there’s more at the end of this page)
82 | Documentation page for comparing linkage methods for hierarchical clustering and example Space built on it 👇🏼
83 |
84 | [Comparing different hierarchical linkage methods on toy datasets](https://scikit-learn.org/stable/auto_examples/cluster/plot_linkage_comparison.html#sphx-glr-auto-examples-cluster-plot-linkage-comparison-py)
85 |
86 | [Hierarchical Clustering Linkage - a Hugging Face Space by scikit-learn](https://huggingface.co/spaces/scikit-learn/hierarchical-clustering-linkage)
87 |
88 | Note: If for your demo you're training a model from scratch (e.g. training an image classifier), you can push it to the Hub using [skops](https://skops.readthedocs.io/en/stable/) and build a Gradio demo on top of it. For such submission, we expect a model repository with a model card and the model weight as well as a simple Space with the interface that receives input and outputs results. You can use this tutorial to get started with [skops](https://www.kdnuggets.com/2023/02/skops-new-library-improve-scikitlearn-production.html).
89 |
90 | You can find an example submission for a model repository below.
91 |
92 | [scikit-learn/cancer-prediction-trees · Hugging Face](https://huggingface.co/scikit-learn/cancer-prediction-trees)
93 |
94 | 4. After the demos are done, we will open pull requests to scikit-learn documentation in [scikit-learn’s repository](https://github.com/scikit-learn/scikit-learn) to contribute our application codes to be directly inside the documentation. We will help you out if this is your first open source contribution. 🤗
95 |
96 | **If you need any help** you can join our discord server, take collaborate role and join `sklearn-sprint` channel and ask questions 🤗🫂
97 |
98 | ### Sprint Prizes
99 | We will be giving following vouchers that can be spent at [Hugging Face Store](https://store.huggingface.co/) including shipping,
100 | - $20 worth of voucher for everyone that builds three demos,
101 | - $40 worth of voucher for everyone that builds five demos.
--------------------------------------------------------------------------------
/whisper-fine-tuning-event/ds_config.json:
--------------------------------------------------------------------------------
1 | {
2 | "fp16": {
3 | "enabled": "auto",
4 | "loss_scale": 0,
5 | "loss_scale_window": 1000,
6 | "initial_scale_power": 16,
7 | "hysteresis": 2,
8 | "min_loss_scale": 1
9 | },
10 |
11 | "optimizer": {
12 | "type": "AdamW",
13 | "params": {
14 | "lr": "auto",
15 | "betas": "auto",
16 | "eps": "auto",
17 | "weight_decay": "auto"
18 | }
19 | },
20 |
21 | "scheduler": {
22 | "type": "WarmupDecayLR",
23 | "params": {
24 | "last_batch_iteration": -1,
25 | "total_num_steps": "auto",
26 | "warmup_min_lr": "auto",
27 | "warmup_max_lr": "auto",
28 | "warmup_num_steps": "auto"
29 | }
30 | },
31 |
32 | "zero_optimization": {
33 | "stage": 2,
34 | "offload_optimizer": {
35 | "device": "cpu",
36 | "pin_memory": true
37 | },
38 | "allgather_partitions": true,
39 | "allgather_bucket_size": 2e8,
40 | "overlap_comm": true,
41 | "reduce_scatter": true,
42 | "reduce_bucket_size": 2e8,
43 | "contiguous_gradients": true
44 | },
45 |
46 | "gradient_accumulation_steps": "auto",
47 | "gradient_clipping": "auto",
48 | "train_batch_size": "auto",
49 | "train_micro_batch_size_per_gpu": "auto"
50 | }
51 |
--------------------------------------------------------------------------------
/whisper-fine-tuning-event/interleave_streaming_datasets.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "id": "6a5c0357",
7 | "metadata": {
8 | "collapsed": false,
9 | "jupyter": {
10 | "outputs_hidden": false
11 | },
12 | "pycharm": {
13 | "name": "#%%\n"
14 | }
15 | },
16 | "outputs": [],
17 | "source": [
18 | "# Ensure datasets is installed from main. Uncomment the following line if you face issues running this script:\n",
19 | "# !pip install git+https://github.com/huggingface/datasets"
20 | ]
21 | },
22 | {
23 | "cell_type": "code",
24 | "execution_count": 2,
25 | "id": "794aaced",
26 | "metadata": {
27 | "collapsed": false,
28 | "jupyter": {
29 | "outputs_hidden": false
30 | },
31 | "pycharm": {
32 | "name": "#%%\n"
33 | }
34 | },
35 | "outputs": [],
36 | "source": [
37 | "from datasets import Audio, interleave_datasets, IterableDataset, load_dataset\n",
38 | "from typing import List, Optional"
39 | ]
40 | },
41 | {
42 | "cell_type": "markdown",
43 | "id": "f210ca9a-486b-46a2-a675-2526a9bd83f5",
44 | "metadata": {},
45 | "source": [
46 | "### Define the dataset attributes"
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "id": "fc07293f-3ba4-4e89-a4ca-8e39409a8373",
52 | "metadata": {},
53 | "source": [
54 | "In this example, we'll show to combine the Common Voice 11, VoxPopuli, Mulitlingual LibriSpeech and FLEURS datasets for Spanish, giving a training corpus equal to the sum of the individual datasets. This is particularly beneficial in low-resource settings, where any one of the datasets alone might have insufficient data to train a model.\n",
55 | "\n",
56 | "We need to specify the dataset names on the Hub, the corresponding configs and finally the text column names for the transcriptions:"
57 | ]
58 | },
59 | {
60 | "cell_type": "code",
61 | "execution_count": 3,
62 | "id": "c53344f3-c315-430a-a2f3-57aea6bb0e17",
63 | "metadata": {},
64 | "outputs": [],
65 | "source": [
66 | "dataset_names = [\"mozilla-foundation/common_voice_11_0\", \"facebook/voxpopuli\", \"facebook/multilingual_librispeech\", \"google/fleurs\"]\n",
67 | "dataset_config_names = [\"es\", \"es\", \"spanish\", \"es_419\"]\n",
68 | "text_column_names = [\"sentence\", \"normalized_text\", \"text\", \"transcription\"]"
69 | ]
70 | },
71 | {
72 | "cell_type": "markdown",
73 | "id": "215541f6-ee1c-4104-b43c-fa3f7fce0494",
74 | "metadata": {},
75 | "source": [
76 | "### Define the merging function"
77 | ]
78 | },
79 | {
80 | "cell_type": "markdown",
81 | "id": "b722a48b-c576-4a63-b2a2-3c264890a75f",
82 | "metadata": {},
83 | "source": [
84 | "We define a function, `load_multiple_streaming_datasets`, that takes as argument a list of datasets, configs, splits (optional) and text column names (optional). It sets them to a specified sampling rate and interleaves them together, giving one merged dataset. This is all \n",
85 | "done in _streaming mode_: as we iterate over the merged dataset we load samples one-by-one on the fly. No data is\n",
86 | "saved to disk.\n",
87 | "\n",
88 | "We can also specify our strategy for interleaving datasets. The default strategy, `all_exhausted` is an oversampling \n",
89 | "strategy. In this case, the dataset construction is stopped as soon as every samples in every dataset \n",
90 | "has been added at least once. In practice, it means that if a dataset is exhausted, it will return to the \n",
91 | "beginning of this dataset until the stop criterion has been reached. You can specify `stopping_strategy=first_exhausted` \n",
92 | "for a subsampling strategy, i.e the dataset construction is stopped as soon one of the dataset runs out of samples. "
93 | ]
94 | },
95 | {
96 | "cell_type": "code",
97 | "execution_count": 4,
98 | "id": "61eb4cb1-ee27-4270-a474-1bb33e1df65f",
99 | "metadata": {},
100 | "outputs": [],
101 | "source": [
102 | "def load_multiple_streaming_datasets(\n",
103 | " dataset_names: List,\n",
104 | " dataset_config_names: List,\n",
105 | " splits: Optional[List] = None,\n",
106 | " text_column_names: Optional[List] = None,\n",
107 | " sampling_rate: Optional[int] = 16000,\n",
108 | " stopping_strategy: Optional[str] = \"all_exhausted\",\n",
109 | " **kwargs\n",
110 | ") -> IterableDataset:\n",
111 | "\n",
112 | " if len(dataset_names) != len(dataset_config_names):\n",
113 | " raise ValueError(\n",
114 | " f\"Ensure one config is passed for each dataset, got {len(dataset_names)} datasets and\"\n",
115 | " f\" {len(dataset_config_names)} configs.\"\n",
116 | " )\n",
117 | "\n",
118 | " if splits is not None and len(splits) != len(dataset_names):\n",
119 | " raise ValueError(\n",
120 | " f\"Ensure one split is passed for each dataset, got {len(dataset_names)} datasets and {len(splits)} splits.\"\n",
121 | " )\n",
122 | "\n",
123 | " if text_column_names is not None and len(text_column_names) != len(dataset_names):\n",
124 | " raise ValueError(\n",
125 | " f\"Ensure one text column name is passed for each dataset, got {len(dataset_names)} datasets and\"\n",
126 | " f\" {len(text_column_names)} text column names.\"\n",
127 | " )\n",
128 | "\n",
129 | " splits = splits if splits is not None else [\"train\" for i in range(len(dataset_names))]\n",
130 | " text_column_names = (\n",
131 | " text_column_names if text_column_names is not None else [\"text\" for i in range(len(dataset_names))]\n",
132 | " )\n",
133 | "\n",
134 | " all_datasets = []\n",
135 | " # iterate over the datasets we want to interleave\n",
136 | " for i, dataset_name in enumerate(dataset_names):\n",
137 | " dataset = load_dataset(dataset_name, dataset_config_names[i], split=splits[i], streaming=True, **kwargs)\n",
138 | " # resample to specified sampling rate\n",
139 | " dataset = dataset.cast_column(\"audio\", Audio(sampling_rate))\n",
140 | " # normalise columns to [\"audio\", \"sentence\"]\n",
141 | " if text_column_names[i] != \"sentence\":\n",
142 | " dataset = dataset.rename_column(text_column_names[i], \"sentence\")\n",
143 | " dataset = dataset.remove_columns(set(dataset.features.keys()) - set([\"audio\", \"sentence\"]))\n",
144 | " all_datasets.append(dataset)\n",
145 | "\n",
146 | " interleaved_dataset = interleave_datasets(all_datasets, stopping_strategy=stopping_strategy)\n",
147 | " return interleaved_dataset"
148 | ]
149 | },
150 | {
151 | "cell_type": "markdown",
152 | "id": "29bc228b-ce9b-4cee-9092-1223ddfa51ad",
153 | "metadata": {},
154 | "source": [
155 | "Let's apply this function to load and merge our four datasets:"
156 | ]
157 | },
158 | {
159 | "cell_type": "code",
160 | "execution_count": 5,
161 | "id": "8ae90f83-4ecd-46a3-98be-bd75706e0d88",
162 | "metadata": {},
163 | "outputs": [],
164 | "source": [
165 | "ds = load_multiple_streaming_datasets(dataset_names, dataset_config_names=dataset_config_names, text_column_names=text_column_names, use_auth_token=True)"
166 | ]
167 | },
168 | {
169 | "cell_type": "markdown",
170 | "id": "6056a693-1fb0-45f4-ad43-be5f1812c1a5",
171 | "metadata": {},
172 | "source": [
173 | "### Iterate over the dataset"
174 | ]
175 | },
176 | {
177 | "cell_type": "markdown",
178 | "id": "7ffe011f-f905-4027-ab67-5c9c3b2b5ac0",
179 | "metadata": {},
180 | "source": [
181 | "We iterate over the dataset, loading and merging samples on the fly. Let's print the transcriptions for the first 10 samples of our merged dataset:"
182 | ]
183 | },
184 | {
185 | "cell_type": "code",
186 | "execution_count": 6,
187 | "id": "75b3355a-3c06-4d23-af43-2b93b1ad70b2",
188 | "metadata": {},
189 | "outputs": [
190 | {
191 | "name": "stderr",
192 | "output_type": "stream",
193 | "text": [
194 | "Reading metadata...: 230467it [00:41, 5545.80it/s]\n"
195 | ]
196 | },
197 | {
198 | "name": "stdout",
199 | "output_type": "stream",
200 | "text": [
201 | "0 ¿ Qué tal a tres de cinco ?\n",
202 | "1 y desde luego esa razón no puede tener que ver con la explicación surrealista que hemos escuchado más de una vez de que se trata de una conspiración izquierdista.\n",
203 | "2 para exclamar con voz de acción de gracias y para contar todas tus maravillas jehová la habitación de tu casa he amado y el lugar del tabernáculo de tu gloria no juntes con los pecadores mi alma ni con los hombres de sangres mi vida\n",
204 | "3 el uso de internet y de la red informática mundial permite que los estudiantes tengan acceso a la información en todo momento\n",
205 | "4 vamos , quiero decir , que no soy de citas especiales .\n",
206 | "5 si bien esta lista no es perfecta sí que resulta necesario que las entidades financieras refuercen sus controles.\n",
207 | "6 oye oh jehová mi voz con que á ti clamo y ten misericordia de mí respóndeme mi corazón ha dicho de ti buscad mi rostro tu rostro buscaré oh jehová\n",
208 | "7 los deportes de nieve en descenso como el esquí y la tablanieve son disciplinas populares que consisten en deslizarse con esquís o una tabla fijada a los pies sobre un terreno nevado\n",
209 | "8 fray Lope , en aquel momento , colmaba otro vaso igual :\n",
210 | "9 señora presidenta la competitividad es importante pero no puede ser el único criterio.\n"
211 | ]
212 | }
213 | ],
214 | "source": [
215 | "for i, sample in enumerate(ds):\n",
216 | " print(i, sample[\"sentence\"])\n",
217 | " if i == 9:\n",
218 | " break"
219 | ]
220 | },
221 | {
222 | "cell_type": "markdown",
223 | "id": "42d5ad08-b20e-4cba-a1a9-909fdbf030d4",
224 | "metadata": {},
225 | "source": [
226 | "We can see that the transcriptions take several different formats. Those from Common Voice 11 are cased and punctuated. Those from VoxPopuli are punctuated only. Those from Multilingual LibriSpeech and FLEURS are neither cased not punctuated. We need to normalise the transcriptions to a uniform format before training our model. \n",
227 | "\n",
228 | "The following code cell is lifted from the Whisper training notebook: https://github.com/huggingface/community-events/blob/main/whisper-fine-tuning-event/fine-tune-whisper-streaming.ipynb"
229 | ]
230 | },
231 | {
232 | "cell_type": "code",
233 | "execution_count": 7,
234 | "id": "ed20e9cd-31c2-44cb-872b-333378a92fd1",
235 | "metadata": {},
236 | "outputs": [
237 | {
238 | "name": "stderr",
239 | "output_type": "stream",
240 | "text": [
241 | "/Users/sanchitgandhi/venv/lib/python3.8/site-packages/jax/_src/lib/__init__.py:33: UserWarning: JAX on Mac ARM machines is experimental and minimally tested. Please see https://github.com/google/jax/issues/5501 in the event of problems.\n",
242 | " warnings.warn(\"JAX on Mac ARM machines is experimental and minimally tested. \"\n"
243 | ]
244 | }
245 | ],
246 | "source": [
247 | "from transformers.models.whisper.english_normalizer import BasicTextNormalizer\n",
248 | "\n",
249 | "do_lower_case = True\n",
250 | "do_remove_punctuation = True\n",
251 | "\n",
252 | "normalizer = BasicTextNormalizer()"
253 | ]
254 | },
255 | {
256 | "cell_type": "markdown",
257 | "id": "01d13029-c24f-4a51-aff2-9251a2ceb4ce",
258 | "metadata": {},
259 | "source": [
260 | "Now we define a function to normalise our transcriptions:"
261 | ]
262 | },
263 | {
264 | "cell_type": "code",
265 | "execution_count": 8,
266 | "id": "26e42417-4bd2-46f8-914e-3a6f9f3471ac",
267 | "metadata": {},
268 | "outputs": [],
269 | "source": [
270 | "def normalize_transcriptions(batch):\n",
271 | " # optional pre-processing steps\n",
272 | " transcription = batch[\"sentence\"]\n",
273 | " if do_lower_case:\n",
274 | " transcription = transcription.lower()\n",
275 | " if do_remove_punctuation:\n",
276 | " transcription = normalizer(transcription).strip()\n",
277 | " batch[\"sentence\"] = transcription\n",
278 | " return batch"
279 | ]
280 | },
281 | {
282 | "cell_type": "markdown",
283 | "id": "3b1c67fe-be4b-4ee5-9a1f-0d444f2b5c62",
284 | "metadata": {},
285 | "source": [
286 | "Let's apply the data pre-processing steps to our dataset and view the first 10 samples again:"
287 | ]
288 | },
289 | {
290 | "cell_type": "code",
291 | "execution_count": 9,
292 | "id": "0babac71-9157-4d0f-a8a8-184547bdf501",
293 | "metadata": {},
294 | "outputs": [
295 | {
296 | "name": "stderr",
297 | "output_type": "stream",
298 | "text": [
299 | "Reading metadata...: 230467it [00:32, 6984.59it/s] \n"
300 | ]
301 | },
302 | {
303 | "name": "stdout",
304 | "output_type": "stream",
305 | "text": [
306 | "0 qué tal a tres de cinco \n",
307 | "1 y desde luego esa razón no puede tener que ver con la explicación surrealista que hemos escuchado más de una vez de que se trata de una conspiración izquierdista \n",
308 | "2 para exclamar con voz de acción de gracias y para contar todas tus maravillas jehová la habitación de tu casa he amado y el lugar del tabernáculo de tu gloria no juntes con los pecadores mi alma ni con los hombres de sangres mi vida\n",
309 | "3 el uso de internet y de la red informática mundial permite que los estudiantes tengan acceso a la información en todo momento\n",
310 | "4 vamos quiero decir que no soy de citas especiales \n",
311 | "5 si bien esta lista no es perfecta sí que resulta necesario que las entidades financieras refuercen sus controles \n",
312 | "6 oye oh jehová mi voz con que á ti clamo y ten misericordia de mí respóndeme mi corazón ha dicho de ti buscad mi rostro tu rostro buscaré oh jehová\n",
313 | "7 los deportes de nieve en descenso como el esquí y la tablanieve son disciplinas populares que consisten en deslizarse con esquís o una tabla fijada a los pies sobre un terreno nevado\n",
314 | "8 fray lope en aquel momento colmaba otro vaso igual \n",
315 | "9 señora presidenta la competitividad es importante pero no puede ser el único criterio \n"
316 | ]
317 | }
318 | ],
319 | "source": [
320 | "ds = ds.map(normalize_transcriptions)\n",
321 | "\n",
322 | "for i, sample in enumerate(ds):\n",
323 | " print(i, sample[\"sentence\"])\n",
324 | " if i == 9:\n",
325 | " break"
326 | ]
327 | },
328 | {
329 | "cell_type": "markdown",
330 | "id": "d135627a-a7aa-458c-94b8-57ddeae74a72",
331 | "metadata": {},
332 | "source": [
333 | "This time the transcriptions are in a consistent format. We can use this data to fine-tune our Whisper model. Note that since we've removed punctuation and casing, the Whisper model won't learn to predict these features."
334 | ]
335 | }
336 | ],
337 | "metadata": {
338 | "kernelspec": {
339 | "display_name": "Python 3 (ipykernel)",
340 | "language": "python",
341 | "name": "python3"
342 | },
343 | "language_info": {
344 | "codemirror_mode": {
345 | "name": "ipython",
346 | "version": 3
347 | },
348 | "file_extension": ".py",
349 | "mimetype": "text/x-python",
350 | "name": "python",
351 | "nbconvert_exporter": "python",
352 | "pygments_lexer": "ipython3",
353 | "version": "3.8.9"
354 | }
355 | },
356 | "nbformat": 4,
357 | "nbformat_minor": 5
358 | }
359 |
--------------------------------------------------------------------------------
/whisper-fine-tuning-event/requirements.txt:
--------------------------------------------------------------------------------
1 | torch>=1.7
2 | torchaudio
3 | git+https://github.com/huggingface/transformers
4 | git+https://github.com/huggingface/datasets
5 | librosa
6 | jiwer
7 | evaluate>=0.3.0
8 | more-itertools
9 | tensorboard
10 |
--------------------------------------------------------------------------------
/whisper-fine-tuning-event/run_eval_whisper_streaming.py:
--------------------------------------------------------------------------------
1 | import argparse
2 |
3 | from transformers import pipeline
4 | from transformers.models.whisper.english_normalizer import BasicTextNormalizer
5 | from datasets import load_dataset, Audio
6 | import evaluate
7 |
8 | wer_metric = evaluate.load("wer")
9 |
10 |
11 | def is_target_text_in_range(ref):
12 | if ref.strip() == "ignore time segment in scoring":
13 | return False
14 | else:
15 | return ref.strip() != ""
16 |
17 |
18 | def get_text(sample):
19 | if "text" in sample:
20 | return sample["text"]
21 | elif "sentence" in sample:
22 | return sample["sentence"]
23 | elif "normalized_text" in sample:
24 | return sample["normalized_text"]
25 | elif "transcript" in sample:
26 | return sample["transcript"]
27 | elif "transcription" in sample:
28 | return sample["transcription"]
29 | else:
30 | raise ValueError(
31 | f"Expected transcript column of either 'text', 'sentence', 'normalized_text' or 'transcript'. Got sample of "
32 | ".join{sample.keys()}. Ensure a text column name is present in the dataset."
33 | )
34 |
35 |
36 | whisper_norm = BasicTextNormalizer()
37 |
38 |
39 | def normalise(batch):
40 | batch["norm_text"] = whisper_norm(get_text(batch))
41 | return batch
42 |
43 |
44 | def data(dataset):
45 | for i, item in enumerate(dataset):
46 | yield {**item["audio"], "reference": item["norm_text"]}
47 |
48 |
49 | def main(args):
50 | batch_size = args.batch_size
51 | whisper_asr = pipeline(
52 | "automatic-speech-recognition", model=args.model_id, device=args.device
53 | )
54 |
55 | whisper_asr.model.config.forced_decoder_ids = (
56 | whisper_asr.tokenizer.get_decoder_prompt_ids(
57 | language=args.language, task="transcribe"
58 | )
59 | )
60 |
61 | dataset = load_dataset(
62 | args.dataset,
63 | args.config,
64 | split=args.split,
65 | streaming=args.streaming,
66 | use_auth_token=True,
67 | )
68 |
69 | # Only uncomment for debugging
70 | dataset = dataset.take(args.max_eval_samples)
71 |
72 | dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
73 | dataset = dataset.map(normalise)
74 | dataset = dataset.filter(is_target_text_in_range, input_columns=["norm_text"])
75 |
76 | predictions = []
77 | references = []
78 |
79 | # run streamed inference
80 | for out in whisper_asr(data(dataset), batch_size=batch_size):
81 | predictions.append(whisper_norm(out["text"]))
82 | references.append(out["reference"][0])
83 |
84 | wer = wer_metric.compute(references=references, predictions=predictions)
85 | wer = round(100 * wer, 2)
86 |
87 | print("WER:", wer)
88 | evaluate.push_to_hub(
89 | model_id=args.model_id,
90 | metric_value=wer,
91 | metric_type="wer",
92 | metric_name="WER",
93 | dataset_name=args.dataset,
94 | dataset_type=args.dataset,
95 | dataset_split=args.split,
96 | dataset_config=args.config,
97 | task_type="automatic-speech-recognition",
98 | task_name="Automatic Speech Recognition"
99 | )
100 |
101 |
102 | if __name__ == "__main__":
103 | parser = argparse.ArgumentParser()
104 |
105 | parser.add_argument(
106 | "--model_id",
107 | type=str,
108 | required=True,
109 | help="Model identifier. Should be loadable with 🤗 Transformers",
110 | )
111 | parser.add_argument(
112 | "--dataset",
113 | type=str,
114 | default="mozilla-foundation/common_voice_11_0",
115 | help="Dataset name to evaluate the `model_id`. Should be loadable with 🤗 Datasets",
116 | )
117 | parser.add_argument(
118 | "--config",
119 | type=str,
120 | required=True,
121 | help="Config of the dataset. *E.g.* `'en'` for the English split of Common Voice",
122 | )
123 | parser.add_argument(
124 | "--split",
125 | type=str,
126 | default="test",
127 | help="Split of the dataset. *E.g.* `'test'`",
128 | )
129 |
130 | parser.add_argument(
131 | "--device",
132 | type=int,
133 | default=-1,
134 | help="The device to run the pipeline on. -1 for CPU (default), 0 for the first GPU and so on.",
135 | )
136 | parser.add_argument(
137 | "--batch_size",
138 | type=int,
139 | default=16,
140 | help="Number of samples to go through each streamed batch.",
141 | )
142 | parser.add_argument(
143 | "--max_eval_samples",
144 | type=int,
145 | default=None,
146 | help="Number of samples to be evaluated. Put a lower number e.g. 64 for testing this script.",
147 | )
148 | parser.add_argument(
149 | "--streaming",
150 | type=bool,
151 | default=True,
152 | help="Choose whether you'd like to download the entire dataset or stream it during the evaluation.",
153 | )
154 | parser.add_argument(
155 | "--language",
156 | type=str,
157 | required=True,
158 | help="Two letter language code for the transcription language, e.g. use 'en' for English.",
159 | )
160 | args = parser.parse_args()
161 |
162 | main(args)
163 |
--------------------------------------------------------------------------------