= pydata.extract()?;
133 | PyView {
134 | shape,
135 | dtype,
136 | data,
137 | data_len,
138 | }
139 | };
140 |
141 | tensors.insert(tensor_name.to_string(), tensor);
142 | }
143 | Ok(tensors)
144 | }
145 |
--------------------------------------------------------------------------------
/RELEASE.md:
--------------------------------------------------------------------------------
1 | ## How to release
2 |
3 | # Before the release
4 |
5 | Simple checklist on how to make releases for `safetensors`.
6 |
7 | - Freeze `main` branch.
8 | - Run all tests (Check CI has properly run)
9 | - If any significant work, check benchmarks:
10 | - `cd safetensors && cargo bench` (needs to be run on latest release tag to measure difference if it's your first time)
11 | - Run all `transformers` tests. (`transformers` is a big user of `safetensors` we need
12 | to make sure we don't break it, testing is one way to make sure nothing unforeseen
13 | has been done.)
14 | - Run all fast tests at the VERY least (not just the tokenization tests). (`RUN_PIPELINE_TESTS=1 CUDA_VISIBLE_DEVICES=-1 pytest -sv tests/`)
15 | - When all *fast* tests work, then we can also (it's recommended) run the whole `transformers`
16 | test suite.
17 | - Rebase this [PR](https://github.com/huggingface/transformers/pull/16708).
18 | This will create new docker images ready to run the tests suites with `safetensors` from the main branch.
19 | - Wait for actions to finish
20 | - Rebase this [PR](https://github.com/huggingface/transformers/pull/16712)
21 | This will run the actual full test suite.
22 | - Check the results.
23 | - **If any breaking change has been done**, make sure the version can safely be increased for transformers users (`safetensors` version need to make sure users don't upgrade before `transformers` has). [link](https://github.com/huggingface/transformers/blob/main/setup.py#L154)
24 | For instance `safetensors>=0.10,<0.11` so we can safely upgrade to `0.11` without impacting
25 | current users
26 | - Then start a new PR containing all desired code changes from the following steps.
27 | - You will `Create release` after the code modifications are on `master`.
28 |
29 | # Rust
30 |
31 | - `safetensors` (rust, python & node) versions don't have to be in sync but it's
32 | very common to release for all versions at once for new features.
33 | - Edit `Cargo.toml` to reflect new version
34 | - Edit `CHANGELOG.md`:
35 | - Add relevant PRs that were added (python PRs do not belong for instance).
36 | - Add links at the end of the files.
37 | - Go to [Releases](https://github.com/huggingface/safetensors/releases)
38 | - Create new Release:
39 | - Mark it as pre-release
40 | - Use new version name with a new tag (create on publish) `vX.X.X`.
41 | - Copy paste the new part of the `CHANGELOG.md`
42 | - ⚠️ Click on `Publish release`. This will start the whole process of building a uploading
43 | the new version on `crates.io`, there's no going back after this
44 | - Go to the [Actions](https://github.com/huggingface/safetensors/actions) tab and check everything works smoothly.
45 | - If anything fails, you need to fix the CI/CD to make it work again. Since your package was not uploaded to the repository properly, you can try again.
46 |
47 |
48 | # Python
49 |
50 | - Edit `bindings/python/setup.py` to reflect new version.
51 | - Edit `bindings/python/py_src/safetensors/__init__.py` to reflect new version.
52 | - Edit `CHANGELOG.md`:
53 | - Add relevant PRs that were added (node PRs do not belong for instance).
54 | - Add links at the end of the files.
55 | - Go to [Releases](https://github.com/huggingface/safetensors/releases)
56 | - Create new Release:
57 | - Mark it as pre-release
58 | - Use new version name with a new tag (create on publish) `python-vX.X.X`.
59 | - Copy paste the new part of the `CHANGELOG.md`
60 | - ⚠️ Click on `Publish release`. This will start the whole process of building a uploading
61 | the new version on `pypi`, there's no going back after this
62 | - Go to the [Actions](https://github.com/huggingface/safetensors/actions) tab and check everything works smoothly.
63 | - If anything fails, you need to fix the CI/CD to make it work again. Since your package was not uploaded to the repository properly, you can try again.
64 | - This CI/CD has 3 distinct builds, `Pypi`(normal), `conda` and `extra`. `Extra` is REALLY slow (~4h), this is normal since it has to rebuild many things, but enables the wheel to be available for old Linuxes
65 |
66 | # Node
67 |
68 | - Edit `bindings/node/package.json` to reflect new version.
69 | - Edit `CHANGELOG.md`:
70 | - Add relevant PRs that were added (python PRs do not belong for instance).
71 | - Add links at the end of the files.
72 | - Go to [Releases](https://github.com/huggingface/safetensors/releases)
73 | - Create new Release:
74 | - Mark it as pre-release
75 | - Use new version name with a new tag (create on publish) `node-vX.X.X`.
76 | - Copy paste the new part of the `CHANGELOG.md`
77 | - ⚠️ Click on `Publish release`. This will start the whole process of building a uploading
78 | the new version on `npm`, there's no going back after this
79 | - Go to the [Actions](https://github.com/huggingface/safetensors/actions) tab and check everything works smoothly.
80 | - If anything fails, you need to fix the CI/CD to make it work again. Since your package was not uploaded to the repository properly, you can try again.
81 |
82 |
83 | # Testing the CI/CD for release
84 |
85 |
86 | If you want to make modifications to the CI/CD of the release GH actions, you need
87 | to :
88 | - **Comment the part that uploads the artifacts** to `crates.io`, `PyPi` or `npm`.
89 | - Change the trigger mechanism so it can trigger every time you push to your branch.
90 | - Keep pushing your changes until the artifacts are properly created.
91 |
--------------------------------------------------------------------------------
/bindings/python/py_src/safetensors/__init__.pyi:
--------------------------------------------------------------------------------
1 | # Generated content DO NOT EDIT
2 | @staticmethod
3 | def deserialize(bytes):
4 | """
5 | Opens a safetensors lazily and returns tensors as asked
6 |
7 | Args:
8 | data (`bytes`):
9 | The byte content of a file
10 |
11 | Returns:
12 | (`List[str, Dict[str, Dict[str, any]]]`):
13 | The deserialized content is like:
14 | [("tensor_name", {"shape": [2, 3], "dtype": "F32", "data": b"\0\0.." }), (...)]
15 | """
16 | pass
17 |
18 | @staticmethod
19 | def serialize(tensor_dict, metadata=None):
20 | """
21 | Serializes raw data.
22 |
23 | NOTE: the caller is required to ensure any pointer passed via `data_ptr` is valid and will live
24 | long enough for the duration of the serialization.
25 | We will remove the need for the caller to hold references themselves when we drop support for
26 | python versions prior to 3.11 where the `PyBuffer` API is available.
27 | Creating a `PyBuffer` will enable us to hold a reference to each passed in data array,
28 | increasing its ref count preventing the gc from collecting it while we serialize.
29 |
30 | Args:
31 | tensor_dict (`Dict[str, Dict[Any]]`):
32 | The tensor dict is like:
33 | {"tensor_name": {"dtype": "F32", "shape": [2, 3], "data_ptr": 1234, "data_len": 24}}
34 | metadata (`Dict[str, str]`, *optional*):
35 | The optional purely text annotations
36 |
37 | Returns:
38 | (`bytes`):
39 | The serialized content.
40 | """
41 | pass
42 |
43 | @staticmethod
44 | def serialize_file(tensor_dict, filename, metadata=None):
45 | """
46 | Serializes raw data into file.
47 |
48 | NOTE: the caller is required to ensure any pointer passed via `data_ptr` is valid and will live
49 | long enough for the duration of the serialization.
50 | We will remove the need for the caller to hold references themselves when we drop support for
51 | python versions prior to 3.11 where the `PyBuffer` API is available.
52 | Creating a `PyBuffer` will enable us to hold a reference to each passed in data array,
53 | increasing its ref count preventing the gc from collecting it while we serialize.
54 |
55 | Args:
56 | tensor_dict (`Dict[str, Dict[Any]]`):
57 | The tensor dict is like:
58 | {"tensor_name": {"dtype": "F32", "shape": [2, 3], "data_ptr": 1234, "data_len": 24}}
59 | filename (`str`, or `os.PathLike`):
60 | The name of the file to write into.
61 | metadata (`Dict[str, str]`, *optional*):
62 | The optional purely text annotations
63 |
64 | Returns:
65 | (`NoneType`):
66 | On success return None
67 | """
68 | pass
69 |
70 | class safe_open:
71 | """
72 | Opens a safetensors lazily and returns tensors as asked
73 |
74 | Args:
75 | filename (`str`, or `os.PathLike`):
76 | The filename to open
77 |
78 | framework (`str`):
79 | The framework you want you tensors in. Supported values:
80 | `pt`, `tf`, `flax`, `numpy`.
81 |
82 | device (`str`, defaults to `"cpu"`):
83 | The device on which you want the tensors.
84 | """
85 | def __init__(self, filename, framework, device=...):
86 | pass
87 |
88 | def __enter__(self):
89 | """
90 | Start the context manager
91 | """
92 | pass
93 |
94 | def __exit__(self, _exc_type, _exc_value, _traceback):
95 | """
96 | Exits the context manager
97 | """
98 | pass
99 |
100 | def get_slice(self, name):
101 | """
102 | Returns a full slice view object
103 |
104 | Args:
105 | name (`str`):
106 | The name of the tensor you want
107 |
108 | Returns:
109 | (`PySafeSlice`):
110 | A dummy object you can slice into to get a real tensor
111 | Example:
112 | ```python
113 | from safetensors import safe_open
114 |
115 | with safe_open("model.safetensors", framework="pt", device=0) as f:
116 | tensor_part = f.get_slice("embedding")[:, ::8]
117 |
118 | ```
119 | """
120 | pass
121 |
122 | def get_tensor(self, name):
123 | """
124 | Returns a full tensor
125 |
126 | Args:
127 | name (`str`):
128 | The name of the tensor you want
129 |
130 | Returns:
131 | (`Tensor`):
132 | The tensor in the framework you opened the file for.
133 |
134 | Example:
135 | ```python
136 | from safetensors import safe_open
137 |
138 | with safe_open("model.safetensors", framework="pt", device=0) as f:
139 | tensor = f.get_tensor("embedding")
140 |
141 | ```
142 | """
143 | pass
144 |
145 | def keys(self):
146 | """
147 | Returns the names of the tensors in the file.
148 |
149 | Returns:
150 | (`List[str]`):
151 | The name of the tensors contained in that file
152 | """
153 | pass
154 |
155 | def metadata(self):
156 | """
157 | Return the special non tensor information in the header
158 |
159 | Returns:
160 | (`Dict[str, str]`):
161 | The freeform metadata.
162 | """
163 | pass
164 |
165 | def offset_keys(self):
166 | """
167 | Returns the names of the tensors in the file, ordered by offset.
168 |
169 | Returns:
170 | (`List[str]`):
171 | The name of the tensors contained in that file
172 | """
173 | pass
174 |
175 | class SafetensorError(Exception):
176 | """
177 | Custom Python Exception for Safetensor errors.
178 | """
179 |
--------------------------------------------------------------------------------
/.github/workflows/python-release.yml:
--------------------------------------------------------------------------------
1 | # This file is autogenerated by maturin v1.7.4
2 | # To update, run
3 | #
4 | # maturin generate-ci github -m bindings/python/Cargo.toml
5 | #
6 | name: CI
7 |
8 | on:
9 | push:
10 | branches:
11 | - main
12 | - master
13 | tags:
14 | - '*'
15 | pull_request:
16 | workflow_dispatch:
17 |
18 | permissions:
19 | contents: read
20 |
21 | jobs:
22 | linux:
23 | runs-on: ${{ matrix.platform.runner }}
24 | strategy:
25 | matrix:
26 | platform:
27 | - runner: ubuntu-latest
28 | target: x86_64
29 | - runner: ubuntu-latest
30 | target: x86
31 | - runner: ubuntu-latest
32 | target: aarch64
33 | - runner: ubuntu-latest
34 | target: armv7
35 | - runner: ubuntu-latest
36 | target: s390x
37 | - runner: ubuntu-latest
38 | target: ppc64le
39 | steps:
40 | - uses: actions/checkout@v6
41 | - uses: actions/setup-python@v6
42 | with:
43 | python-version: 3.x
44 | - name: Build wheels
45 | uses: PyO3/maturin-action@v1
46 | with:
47 | target: ${{ matrix.platform.target }}
48 | args: --release --out dist --manifest-path bindings/python/Cargo.toml
49 | sccache: 'true'
50 | manylinux: auto
51 | - name: Upload wheels
52 | uses: actions/upload-artifact@v6
53 | with:
54 | name: wheels-linux-${{ matrix.platform.target }}
55 | path: dist
56 |
57 | musllinux:
58 | runs-on: ${{ matrix.platform.runner }}
59 | strategy:
60 | matrix:
61 | platform:
62 | - runner: ubuntu-latest
63 | target: x86_64
64 | - runner: ubuntu-latest
65 | target: x86
66 | - runner: ubuntu-latest
67 | target: aarch64
68 | - runner: ubuntu-latest
69 | target: armv7
70 | steps:
71 | - uses: actions/checkout@v6
72 | - uses: actions/setup-python@v6
73 | with:
74 | python-version: 3.x
75 | - name: Build wheels
76 | uses: PyO3/maturin-action@v1
77 | with:
78 | target: ${{ matrix.platform.target }}
79 | args: --release --out dist --manifest-path bindings/python/Cargo.toml
80 | sccache: 'true'
81 | manylinux: musllinux_1_2
82 | - name: Upload wheels
83 | uses: actions/upload-artifact@v6
84 | with:
85 | name: wheels-musllinux-${{ matrix.platform.target }}
86 | path: dist
87 |
88 | windows:
89 | runs-on: ${{ matrix.platform.runner }}
90 | strategy:
91 | matrix:
92 | platform:
93 | - runner: windows-latest
94 | target: x64
95 | - runner: windows-latest
96 | target: x86
97 | - runner: windows-11-arm
98 | target: arm64
99 | steps:
100 | - uses: actions/checkout@v6
101 | - uses: actions/setup-python@v6
102 | with:
103 | python-version: 3.x
104 | architecture: ${{ matrix.platform.target }}
105 | - name: Build wheels
106 | uses: PyO3/maturin-action@v1
107 | with:
108 | target: ${{ matrix.platform.target == 'arm64' && 'aarch64-pc-windows-msvc' || matrix.platform.target }}
109 | args: --release --out dist --manifest-path bindings/python/Cargo.toml
110 | sccache: 'true'
111 | - name: Upload wheels
112 | uses: actions/upload-artifact@v6
113 | with:
114 | name: wheels-windows-${{ matrix.platform.target }}
115 | path: dist
116 |
117 | macos:
118 | runs-on: ${{ matrix.platform.runner }}
119 | strategy:
120 | matrix:
121 | platform:
122 | - runner: macos-15-intel
123 | target: x86_64
124 | - runner: macos-14
125 | target: aarch64
126 | steps:
127 | - uses: actions/checkout@v6
128 | - uses: actions/setup-python@v6
129 | with:
130 | python-version: 3.x
131 | - name: Build wheels
132 | uses: PyO3/maturin-action@v1
133 | with:
134 | target: ${{ matrix.platform.target }}
135 | args: --release --out dist --manifest-path bindings/python/Cargo.toml
136 | sccache: 'true'
137 | - name: Upload wheels
138 | uses: actions/upload-artifact@v6
139 | with:
140 | name: wheels-macos-${{ matrix.platform.target }}
141 | path: dist
142 |
143 | sdist:
144 | runs-on: ubuntu-latest
145 | steps:
146 | - uses: actions/checkout@v6
147 | - name: Build sdist
148 | uses: PyO3/maturin-action@v1
149 | with:
150 | command: sdist
151 | args: --out dist --manifest-path bindings/python/Cargo.toml
152 | - name: Upload sdist
153 | uses: actions/upload-artifact@v6
154 | with:
155 | name: wheels-sdist
156 | path: dist
157 |
158 | release:
159 | name: Release
160 | runs-on: ubuntu-latest
161 | if: ${{ startsWith(github.ref, 'refs/tags/') || github.event_name == 'workflow_dispatch' }}
162 | needs: [linux, musllinux, windows, macos, sdist]
163 | permissions:
164 | # Use to sign the release artifacts
165 | id-token: write
166 | # Used to upload release artifacts
167 | contents: write
168 | # Used to generate artifact attestation
169 | attestations: write
170 | steps:
171 | - uses: actions/download-artifact@v7
172 | - name: Generate artifact attestation
173 | uses: actions/attest-build-provenance@v3
174 | with:
175 | subject-path: 'wheels-*/*'
176 | - name: Publish to PyPI
177 | if: "startsWith(github.ref, 'refs/tags/')"
178 | uses: PyO3/maturin-action@v1
179 | env:
180 | MATURIN_PYPI_TOKEN: ${{ secrets.PYPI_TOKEN_DIST}}
181 | with:
182 | command: upload
183 | args: --non-interactive --skip-existing wheels-*/*
184 |
--------------------------------------------------------------------------------
/bindings/python/py_src/safetensors/numpy.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | from typing import Dict, List, Optional, Union
4 |
5 | import numpy as np
6 |
7 | from safetensors import deserialize, safe_open, serialize, serialize_file
8 |
9 |
10 | def _flatten(
11 | tensor_dict: Dict[str, np.ndarray], keep_alive_buffer: List
12 | ) -> Dict[str, Dict]:
13 | flattened = {}
14 | for k, v in tensor_dict.items():
15 | tensor = v
16 | if not _is_little_endian(tensor):
17 | tensor = tensor.byteswap(inplace=False)
18 | keep_alive_buffer.append(tensor)
19 | flattened[k] = {
20 | "dtype": tensor.dtype.name,
21 | "shape": tensor.shape,
22 | "data_ptr": tensor.ctypes.data,
23 | "data_len": tensor.nbytes,
24 | }
25 | return flattened
26 |
27 |
28 | def save(
29 | tensor_dict: Dict[str, np.ndarray], metadata: Optional[Dict[str, str]] = None
30 | ) -> bytes:
31 | """
32 | Saves a dictionary of tensors into raw bytes in safetensors format.
33 |
34 | Args:
35 | tensor_dict (`Dict[str, np.ndarray]`):
36 | The incoming tensors. Tensors need to be contiguous and dense.
37 | metadata (`Dict[str, str]`, *optional*, defaults to `None`):
38 | Optional text only metadata you might want to save in your header.
39 | For instance it can be useful to specify more about the underlying
40 | tensors. This is purely informative and does not affect tensor loading.
41 |
42 | Returns:
43 | `bytes`: The raw bytes representing the format
44 |
45 | Example:
46 |
47 | ```python
48 | from safetensors.numpy import save
49 | import numpy as np
50 |
51 | tensors = {"embedding": np.zeros((512, 1024)), "attention": np.zeros((256, 256))}
52 | byte_data = save(tensors)
53 | ```
54 | """
55 | keep_alive_buffer = [] # to keep byteswapped tensors alive
56 | serialized = serialize(_flatten(tensor_dict, keep_alive_buffer), metadata=metadata)
57 | result = bytes(serialized)
58 | return result
59 |
60 |
61 | def save_file(
62 | tensor_dict: Dict[str, np.ndarray],
63 | filename: Union[str, os.PathLike],
64 | metadata: Optional[Dict[str, str]] = None,
65 | ) -> None:
66 | """
67 | Saves a dictionary of tensors into raw bytes in safetensors format.
68 |
69 | Args:
70 | tensor_dict (`Dict[str, np.ndarray]`):
71 | The incoming tensors. Tensors need to be contiguous and dense.
72 | filename (`str`, or `os.PathLike`)):
73 | The filename we're saving into.
74 | metadata (`Dict[str, str]`, *optional*, defaults to `None`):
75 | Optional text only metadata you might want to save in your header.
76 | For instance it can be useful to specify more about the underlying
77 | tensors. This is purely informative and does not affect tensor loading.
78 |
79 | Returns:
80 | `None`
81 |
82 | Example:
83 |
84 | ```python
85 | from safetensors.numpy import save_file
86 | import numpy as np
87 |
88 | tensors = {"embedding": np.zeros((512, 1024)), "attention": np.zeros((256, 256))}
89 | save_file(tensors, "model.safetensors")
90 | ```
91 | """
92 | keep_alive_buffer = [] # to keep byteswapped tensors alive
93 | serialize_file(
94 | _flatten(tensor_dict, keep_alive_buffer), filename, metadata=metadata
95 | )
96 |
97 |
98 | def load(data: bytes) -> Dict[str, np.ndarray]:
99 | """
100 | Loads a safetensors file into numpy format from pure bytes.
101 |
102 | Args:
103 | data (`bytes`):
104 | The content of a safetensors file
105 |
106 | Returns:
107 | `Dict[str, np.ndarray]`: dictionary that contains name as key, value as `np.ndarray` on cpu
108 |
109 | Example:
110 |
111 | ```python
112 | from safetensors.numpy import load
113 |
114 | file_path = "./my_folder/bert.safetensors"
115 | with open(file_path, "rb") as f:
116 | data = f.read()
117 |
118 | loaded = load(data)
119 | ```
120 | """
121 | flat = deserialize(data)
122 | return _view2np(flat)
123 |
124 |
125 | def load_file(filename: Union[str, os.PathLike]) -> Dict[str, np.ndarray]:
126 | """
127 | Loads a safetensors file into numpy format.
128 |
129 | Args:
130 | filename (`str`, or `os.PathLike`)):
131 | The name of the file which contains the tensors
132 |
133 | Returns:
134 | `Dict[str, np.ndarray]`: dictionary that contains name as key, value as `np.ndarray`
135 |
136 | Example:
137 |
138 | ```python
139 | from safetensors.numpy import load_file
140 |
141 | file_path = "./my_folder/bert.safetensors"
142 | loaded = load_file(file_path)
143 | ```
144 | """
145 | result = {}
146 | with safe_open(filename, framework="np") as f:
147 | for k in f.offset_keys():
148 | result[k] = f.get_tensor(k)
149 | return result
150 |
151 |
152 | _TYPES = {
153 | "F64": np.float64,
154 | "F32": np.float32,
155 | "F16": np.float16,
156 | "I64": np.int64,
157 | "U64": np.uint64,
158 | "I32": np.int32,
159 | "U32": np.uint32,
160 | "I16": np.int16,
161 | "U16": np.uint16,
162 | "I8": np.int8,
163 | "U8": np.uint8,
164 | "BOOL": bool,
165 | "C64": np.complex64,
166 | }
167 |
168 |
169 | def _getdtype(dtype_str: str) -> np.dtype:
170 | return _TYPES[dtype_str]
171 |
172 |
173 | def _view2np(safeview) -> Dict[str, np.ndarray]:
174 | result = {}
175 | for k, v in safeview:
176 | dtype = _getdtype(v["dtype"])
177 | arr = np.frombuffer(v["data"], dtype=dtype).reshape(v["shape"])
178 | result[k] = arr
179 | return result
180 |
181 |
182 | def _is_little_endian(tensor: np.ndarray) -> bool:
183 | byteorder = tensor.dtype.byteorder
184 | if byteorder == "=":
185 | if sys.byteorder == "little":
186 | return True
187 | else:
188 | return False
189 | elif byteorder == "|":
190 | return True
191 | elif byteorder == "<":
192 | return True
193 | elif byteorder == ">":
194 | return False
195 | raise ValueError(f"Unexpected byte order {byteorder}")
196 |
--------------------------------------------------------------------------------
/bindings/python/benches/test_pt.py:
--------------------------------------------------------------------------------
1 | import os
2 | import tempfile
3 |
4 | import pytest
5 | import torch
6 |
7 | from safetensors.torch import load_file, save_file
8 |
9 |
10 | def create_gpt2(n_layers: int):
11 | tensors = {}
12 | tensors["wte"] = torch.zeros((50257, 768))
13 | tensors["wpe"] = torch.zeros((1024, 768))
14 | for i in range(n_layers):
15 | tensors[f"h.{i}.ln_1.weight"] = torch.zeros((768,))
16 | tensors[f"h.{i}.ln_1.bias"] = torch.zeros((768,))
17 | tensors[f"h.{i}.attn.bias"] = torch.zeros((1, 1, 1024, 1024))
18 | tensors[f"h.{i}.attn.c_attn.weight"] = torch.zeros((768, 2304))
19 | tensors[f"h.{i}.attn.c_attn.bias"] = torch.zeros((2304))
20 | tensors[f"h.{i}.attn.c_proj.weight"] = torch.zeros((768, 768))
21 | tensors[f"h.{i}.attn.c_proj.bias"] = torch.zeros((768))
22 | tensors[f"h.{i}.ln_2.weight"] = torch.zeros((768))
23 | tensors[f"h.{i}.ln_2.bias"] = torch.zeros((768))
24 | tensors[f"h.{i}.mlp.c_fc.weight"] = torch.zeros((768, 3072))
25 | tensors[f"h.{i}.mlp.c_fc.bias"] = torch.zeros((3072))
26 | tensors[f"h.{i}.mlp.c_proj.weight"] = torch.zeros((3072, 768))
27 | tensors[f"h.{i}.mlp.c_proj.bias"] = torch.zeros((768))
28 | tensors["ln_f.weight"] = torch.zeros((768))
29 | tensors["ln_f.bias"] = torch.zeros((768))
30 | return tensors
31 |
32 |
33 | def create_lora(n_layers: int):
34 | tensors = {}
35 | for i in range(n_layers):
36 | tensors[f"lora.{i}.up.weight"] = torch.zeros((32, 32))
37 | tensors[f"lora.{i}.down.weight"] = torch.zeros((32, 32))
38 | return tensors
39 |
40 |
41 | def test_pt_pt_load_cpu(benchmark):
42 | # benchmark something
43 | weights = create_gpt2(12)
44 | with tempfile.NamedTemporaryFile(delete=False) as f:
45 | torch.save(weights, f)
46 | result = benchmark(torch.load, f.name)
47 | os.unlink(f.name)
48 |
49 | for k, v in weights.items():
50 | tv = result[k]
51 | assert torch.allclose(v, tv)
52 |
53 |
54 | def test_pt_sf_load_cpu(benchmark):
55 | # benchmark something
56 | weights = create_gpt2(12)
57 | with tempfile.NamedTemporaryFile(delete=False) as f:
58 | save_file(weights, f.name)
59 | result = benchmark(load_file, f.name)
60 | os.unlink(f.name)
61 |
62 | for k, v in weights.items():
63 | tv = result[k]
64 | assert torch.allclose(v, tv)
65 |
66 |
67 | def test_pt_pt_load_cpu_small(benchmark):
68 | weights = create_lora(500)
69 | with tempfile.NamedTemporaryFile(delete=False) as f:
70 | torch.save(weights, f)
71 | result = benchmark(torch.load, f.name)
72 | os.unlink(f.name)
73 |
74 | for k, v in weights.items():
75 | tv = result[k]
76 | assert torch.allclose(v, tv)
77 |
78 |
79 | def test_pt_sf_load_cpu_small(benchmark):
80 | weights = create_lora(500)
81 |
82 | with tempfile.NamedTemporaryFile(delete=False) as f:
83 | save_file(weights, f.name)
84 | result = benchmark(load_file, f.name)
85 | os.unlink(f.name)
86 |
87 | for k, v in weights.items():
88 | tv = result[k]
89 | assert torch.allclose(v, tv)
90 |
91 |
92 | @pytest.mark.skipif(not torch.cuda.is_available(), reason="requires cuda")
93 | def test_pt_pt_load_gpu(benchmark):
94 | # benchmark something
95 | weights = create_gpt2(12)
96 | with tempfile.NamedTemporaryFile(delete=False) as f:
97 | torch.save(weights, f)
98 | result = benchmark(torch.load, f.name, map_location="cuda:0")
99 | os.unlink(f.name)
100 |
101 | for k, v in weights.items():
102 | v = v.cuda()
103 | tv = result[k]
104 | assert torch.allclose(v, tv)
105 |
106 |
107 | @pytest.mark.skipif(not torch.cuda.is_available(), reason="requires cuda")
108 | def test_pt_sf_load_gpu(benchmark):
109 | # benchmark something
110 | weights = create_gpt2(12)
111 | with tempfile.NamedTemporaryFile(delete=False) as f:
112 | save_file(weights, f.name)
113 | result = benchmark(load_file, f.name, device="cuda:0")
114 | os.unlink(f.name)
115 |
116 | for k, v in weights.items():
117 | v = v.cuda()
118 | tv = result[k]
119 | assert torch.allclose(v, tv)
120 |
121 |
122 | @pytest.mark.skipif(
123 | not hasattr(torch.backends, "mps") or not torch.backends.mps.is_available(),
124 | reason="requires mps",
125 | )
126 | def test_pt_pt_load_mps(benchmark):
127 | # benchmark something
128 | weights = create_gpt2(12)
129 | with tempfile.NamedTemporaryFile(delete=False) as f:
130 | torch.save(weights, f)
131 | result = benchmark(torch.load, f.name, map_location="mps")
132 | os.unlink(f.name)
133 |
134 | for k, v in weights.items():
135 | v = v.to(device="mps")
136 | tv = result[k]
137 | assert torch.allclose(v, tv)
138 |
139 |
140 | @pytest.mark.skipif(
141 | not hasattr(torch.backends, "mps") or not torch.backends.mps.is_available(),
142 | reason="requires mps",
143 | )
144 | def test_pt_sf_load_mps(benchmark):
145 | # benchmark something
146 | weights = create_gpt2(12)
147 | with tempfile.NamedTemporaryFile(delete=False) as f:
148 | save_file(weights, f.name)
149 | result = benchmark(load_file, f.name, device="mps")
150 | os.unlink(f.name)
151 |
152 | for k, v in weights.items():
153 | v = v.to(device="mps")
154 | tv = result[k]
155 | assert torch.allclose(v, tv)
156 |
157 |
158 | def test_pt_sf_save_cpu(benchmark):
159 | weights = create_gpt2(12)
160 |
161 | filename = "tmp.safetensors"
162 |
163 | # XXX: On some platforms (tested on Linux x86_64 ext4), writing to an already existing file is slower than creating a new one.
164 | # On others, such as MacOS (APFS), it's the opposite. To have more consistent benchmarks,
165 | # we ensure the file does not exist before each write, which is also closer to real world usage.
166 | def setup():
167 | try:
168 | os.unlink(filename)
169 | except Exception:
170 | pass
171 |
172 | benchmark.pedantic(
173 | save_file, args=(weights, filename), setup=setup, iterations=1, rounds=5
174 | )
175 |
176 | # Clean up files
177 | os.unlink(filename)
178 |
--------------------------------------------------------------------------------
/bindings/python/stub.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import inspect
3 | import os
4 | import subprocess
5 | import tempfile
6 |
7 | INDENT = " " * 4
8 | GENERATED_COMMENT = "# Generated content DO NOT EDIT\n"
9 |
10 |
11 | def do_indent(text: str, indent: str):
12 | return text.replace("\n", f"\n{indent}")
13 |
14 |
15 | def function(obj, indent, text_signature=None):
16 | if text_signature is None:
17 | text_signature = obj.__text_signature__
18 | string = ""
19 | string += f"{indent}def {obj.__name__}{text_signature}:\n"
20 | indent += INDENT
21 | string += f'{indent}"""\n'
22 | string += f"{indent}{do_indent(obj.__doc__, indent)}\n"
23 | string += f'{indent}"""\n'
24 | string += f"{indent}pass\n"
25 | string += "\n"
26 | string += "\n"
27 | return string
28 |
29 |
30 | def member_sort(member):
31 | if inspect.isclass(member):
32 | value = 10 + len(inspect.getmro(member))
33 | else:
34 | value = 1
35 | return value
36 |
37 |
38 | def fn_predicate(obj):
39 | value = inspect.ismethoddescriptor(obj) or inspect.isbuiltin(obj)
40 | if value:
41 | return (
42 | obj.__doc__
43 | and obj.__text_signature__
44 | and (
45 | not obj.__name__.startswith("_")
46 | or obj.__name__ in {"__enter__", "__exit__"}
47 | )
48 | )
49 | if inspect.isgetsetdescriptor(obj):
50 | return obj.__doc__ and not obj.__name__.startswith("_")
51 | return False
52 |
53 |
54 | def get_module_members(module):
55 | members = [
56 | member
57 | for name, member in inspect.getmembers(module)
58 | if not name.startswith("_") and not inspect.ismodule(member)
59 | ]
60 | members.sort(key=member_sort)
61 | return members
62 |
63 |
64 | def pyi_file(obj, indent=""):
65 | string = ""
66 | if inspect.ismodule(obj):
67 | string += GENERATED_COMMENT
68 | members = get_module_members(obj)
69 | for member in members:
70 | string += pyi_file(member, indent)
71 |
72 | elif inspect.isclass(obj):
73 | indent += INDENT
74 | mro = inspect.getmro(obj)
75 | if len(mro) > 2:
76 | inherit = f"({mro[1].__name__})"
77 | else:
78 | inherit = ""
79 | string += f"class {obj.__name__}{inherit}:\n"
80 |
81 | body = ""
82 | if obj.__doc__:
83 | body += (
84 | f'{indent}"""\n{indent}{do_indent(obj.__doc__, indent)}\n{indent}"""\n'
85 | )
86 |
87 | fns = inspect.getmembers(obj, fn_predicate)
88 |
89 | # Init
90 | if obj.__text_signature__:
91 | signature = obj.__text_signature__.replace("(", "(self, ")
92 | body += f"{indent}def __init__{signature}:\n"
93 | body += f"{indent + INDENT}pass\n"
94 | body += "\n"
95 |
96 | for name, fn in fns:
97 | body += pyi_file(fn, indent=indent)
98 |
99 | if not body:
100 | body += f"{indent}pass\n"
101 |
102 | string += body
103 | string += "\n\n"
104 |
105 | elif inspect.isbuiltin(obj):
106 | string += f"{indent}@staticmethod\n"
107 | string += function(obj, indent)
108 |
109 | elif inspect.ismethoddescriptor(obj):
110 | string += function(obj, indent)
111 |
112 | elif inspect.isgetsetdescriptor(obj):
113 | # TODO it would be interesing to add the setter maybe ?
114 | string += f"{indent}@property\n"
115 | string += function(obj, indent, text_signature="(self)")
116 | else:
117 | raise Exception(f"Object {obj} is not supported")
118 | return string
119 |
120 |
121 | def py_file(module, origin):
122 | members = get_module_members(module)
123 |
124 | string = GENERATED_COMMENT
125 | string += f"from .. import {origin}\n"
126 | string += "\n"
127 | for member in members:
128 | name = member.__name__
129 | string += f"{name} = {origin}.{name}\n"
130 | return string
131 |
132 |
133 | def do_black(content):
134 | content = content.replace("$self", "self")
135 | with tempfile.NamedTemporaryFile(mode="w+", suffix=".pyi") as f:
136 | f.write(content)
137 | f.flush()
138 | _ = subprocess.check_output(["ruff", "format", f.name])
139 | f.seek(0)
140 | new_content = f.read()
141 | return new_content
142 |
143 |
144 | def write(module, directory, origin, check=False):
145 | submodules = [
146 | (name, member)
147 | for name, member in inspect.getmembers(module)
148 | if inspect.ismodule(member)
149 | ]
150 |
151 | filename = os.path.join(directory, "__init__.pyi")
152 | pyi_content = pyi_file(module)
153 | pyi_content = do_black(pyi_content)
154 | os.makedirs(directory, exist_ok=True)
155 | if check:
156 | with open(filename, "r") as f:
157 | data = f.read()
158 | assert data == pyi_content, (
159 | f"The content of {filename} seems outdated, please run `python stub.py`"
160 | )
161 | else:
162 | with open(filename, "w") as f:
163 | f.write(pyi_content)
164 |
165 | filename = os.path.join(directory, "__init__.py")
166 | py_content = py_file(module, origin)
167 | py_content = do_black(py_content)
168 | os.makedirs(directory, exist_ok=True)
169 |
170 | is_auto = False
171 | if not os.path.exists(filename):
172 | is_auto = True
173 | else:
174 | with open(filename, "r") as f:
175 | line = f.readline()
176 | if line == GENERATED_COMMENT:
177 | is_auto = True
178 |
179 | if is_auto:
180 | if check:
181 | with open(filename, "r") as f:
182 | data = f.read()
183 | assert data == py_content, (
184 | f"The content of {filename} seems outdated, please run `python stub.py`"
185 | )
186 | else:
187 | with open(filename, "w") as f:
188 | f.write(py_content)
189 |
190 | for name, submodule in submodules:
191 | write(submodule, os.path.join(directory, name), f"{name}", check=check)
192 |
193 |
194 | if __name__ == "__main__":
195 | parser = argparse.ArgumentParser()
196 | parser.add_argument("--check", action="store_true")
197 |
198 | args = parser.parse_args()
199 | import safetensors
200 |
201 | write(
202 | safetensors._safetensors_rust,
203 | "py_src/safetensors/",
204 | "safetensors",
205 | check=args.check,
206 | )
207 |
--------------------------------------------------------------------------------
/.github/workflows/python.yml:
--------------------------------------------------------------------------------
1 | name: Python
2 |
3 | on:
4 | pull_request:
5 |
6 | jobs:
7 | build_and_test:
8 | name: Check everything builds & tests
9 | runs-on: ${{ matrix.os }}
10 | strategy:
11 | matrix:
12 | os: [ubuntu-latest, windows-latest]
13 | # Lowest and highest, no version specified so that
14 | # new releases get automatically tested against
15 | version: [{torch: torch==1.10, python: "3.9", arch: "x64", numpy: numpy==1.26.4}, {torch: torch, python: "3.12", arch: "x64", numpy: numpy}]
16 | # TODO this would include macos ARM target.
17 | # however jax has an illegal instruction issue
18 | # that exists only in CI (probably difference in instruction support).
19 | # include:
20 | # - os: macos-latest
21 | # version:
22 | # torch: torch
23 | # python: "3.11"
24 | include:
25 | - os: ubuntu-latest
26 | version:
27 | torch: torch
28 | python: "3.13"
29 | numpy: numpy
30 | arch: "x64-freethreaded"
31 | - os: macos-15-intel
32 | version:
33 | torch: torch==1.10
34 | numpy: "numpy==1.26"
35 | python: "3.9"
36 | arch: "x64"
37 | - os: macos-latest
38 | version:
39 | torch: torch
40 | python: "3.12"
41 | numpy: numpy
42 | arch: "arm64"
43 | - os: windows-11-arm
44 | version:
45 | torch: torch
46 | python: "3.12"
47 | numpy: numpy
48 | arch: "arm64"
49 | defaults:
50 | run:
51 | working-directory: ./bindings/python
52 | steps:
53 | - name: Checkout repository
54 | uses: actions/checkout@v6
55 |
56 | - name: Install Rust
57 | uses: dtolnay/rust-toolchain@stable
58 | with:
59 | components: rustfmt, clippy
60 |
61 | - name: Cargo install audit
62 | run: cargo install cargo-audit
63 |
64 | - uses: Swatinem/rust-cache@v2
65 | with:
66 | workspaces: "bindings/python"
67 |
68 | - name: Install Python
69 | uses: actions/setup-python@v6
70 | with:
71 | python-version: ${{ matrix.version.python }}
72 | architecture: ${{ matrix.version.arch }}
73 |
74 | - name: Lint with RustFmt
75 | run: cargo fmt -- --check
76 |
77 | - name: Lint with Clippy
78 | run: cargo clippy --all-targets --all-features -- -D warnings
79 |
80 | - name: Run Audit
81 | run: cargo audit -D warnings
82 |
83 | # - name: Install
84 | # run: |
85 | # pip install -U pip
86 |
87 | - name: Install (torch)
88 | if: matrix.version.arch != 'x64-freethreaded' && matrix.os != 'windows-11-arm'
89 | run: |
90 | pip install ${{ matrix.version.numpy }}
91 | pip install ${{ matrix.version.torch }}
92 | shell: bash
93 |
94 | - name: Install (torch freethreaded)
95 | if: matrix.version.arch == 'x64-freethreaded'
96 | run: |
97 | pip install ${{ matrix.version.torch }} --index-url https://download.pytorch.org/whl/cu126
98 | shell: bash
99 |
100 | - name: Install (torch windows arm64)
101 | if: matrix.os == 'windows-11-arm'
102 | run: |
103 | pip install ${{ matrix.version.numpy }}
104 | pip install ${{ matrix.version.torch }} --index-url https://download.pytorch.org/whl/cpu
105 | shell: bash
106 |
107 | - name: Install (hdf5 non windows)
108 | if: matrix.os == 'ubuntu-latest' && matrix.version.arch != 'x64-freethreaded'
109 | run: |
110 | sudo apt-get update
111 | sudo apt-get install libhdf5-dev
112 |
113 | - name: Install (tensorflow)
114 | if: matrix.version.arch != 'x64-freethreaded' && matrix.os != 'windows-11-arm'
115 | run: |
116 | pip install .[tensorflow]
117 | # Force reinstall of numpy, tensorflow uses numpy 2 even on 3.9
118 | pip install ${{ matrix.version.numpy }}
119 | shell: bash
120 |
121 | - name: Install (jax, flax)
122 | if: runner.os != 'Windows' && matrix.version.arch != 'x64-freethreaded'
123 | run:
124 | pip install .[jax]
125 | shell: bash
126 |
127 | - name: Install (mlx)
128 | if: matrix.os == 'macos-latest'
129 | run: |
130 | pip install .[mlx]
131 | shell: bash
132 |
133 | - name: Check style
134 | run: |
135 | pip install .[quality]
136 | ruff format --check .
137 |
138 | - name: Run tests
139 | if: matrix.version.arch != 'x64-freethreaded' && matrix.os != 'windows-11-arm'
140 | run: |
141 | cargo test
142 | pip install ".[testing]"
143 | pytest -sv tests/
144 |
145 | - name: Run tests (Windows arm64)
146 | if: matrix.os == 'windows-11-arm'
147 | run: |
148 | cargo test
149 | pip install ".[testing]"
150 | pytest -sv tests/ --ignore=tests/test_tf_comparison.py
151 |
152 | - name: Run tests (freethreaded)
153 | if: matrix.version.arch == 'x64-freethreaded'
154 | run: |
155 | cargo test
156 | pip install ".[testingfree]"
157 | pip install pytest numpy
158 | pytest -sv tests/test_pt*
159 | pytest -sv tests/test_simple.py
160 |
161 | test_s390x_big_endian:
162 | runs-on: ubuntu-latest
163 | permissions:
164 | contents: write
165 | packages: write
166 | name: Test bigendian - S390X
167 | steps:
168 | - uses: actions/checkout@v6
169 | - name: Set up QEMU
170 | uses: docker/setup-qemu-action@v3
171 | - name: Set up Docker Buildx
172 | uses: docker/setup-buildx-action@v3
173 | - name: Can push to GHCR?
174 | id: canpush
175 | shell: bash
176 | run: |
177 | echo "value=${{ github.event.pull_request.head.repo.fork == false }}" >> "$GITHUB_OUTPUT"
178 | - name: Docker meta
179 | id: meta
180 | uses: docker/metadata-action@v5
181 | with:
182 | # list of Docker images to use as base name for tags
183 | images: |
184 | ghcr.io/huggingface/safetensors/s390x
185 | # generate Docker tags based on the following events/attributes
186 | tags: |
187 | type=schedule
188 | type=ref,event=branch
189 | type=ref,event=pr
190 | type=semver,pattern={{version}}
191 | type=semver,pattern={{major}}.{{minor}}
192 | type=semver,pattern={{major}}
193 | type=sha
194 | - name: Login to Registry
195 | if: steps.canpush.outputs.value == 'true'
196 | uses: docker/login-action@v3
197 | with:
198 | registry: ghcr.io
199 | username: ${{ github.actor }}
200 | password: ${{ secrets.GITHUB_TOKEN }}
201 | - name: Test big endian
202 | uses: docker/build-push-action@v6
203 | with:
204 | platforms: linux/s390x
205 | file: Dockerfile.s390x.test
206 | tags: ${{ steps.meta.outputs.tags }}
207 | labels: ${{ steps.meta.outputs.labels }}
208 | cache-from: ${{ steps.canpush.outputs.value == 'true' && 'type=registry,ref=ghcr.io/huggingface/safetensors/s390x:cache,mode=max' || 'type=gha' }}
209 | cache-to: ${{ steps.canpush.outputs.value == 'true' && 'type=registry,ref=ghcr.io/huggingface/safetensors/s390x:cache,mode=max' || 'type=gha' }}
210 | push: ${{ steps.canpush.outputs.value == 'true' }}
211 |
--------------------------------------------------------------------------------
/docs/source/metadata_parsing.mdx:
--------------------------------------------------------------------------------
1 | # Metadata Parsing
2 |
3 | Given the simplicity of the format, it's very simple and efficient to fetch and parse metadata about Safetensors weights – i.e. the list of tensors, their types, and their shapes or numbers of parameters – using small [(Range) HTTP requests](https://developer.mozilla.org/en-US/docs/Web/HTTP/Range_requests).
4 |
5 | This parsing has been implemented in JS in [`huggingface.js`](https://huggingface.co/docs/huggingface.js/main/en/hub/modules#parsesafetensorsmetadata) (sample code follows below), but it would be similar in any language.
6 |
7 | ## Example use case
8 |
9 | There can be many potential use cases. For instance, we use it on the HuggingFace Hub to display info about models which have safetensors weights:
10 |
11 |
12 |
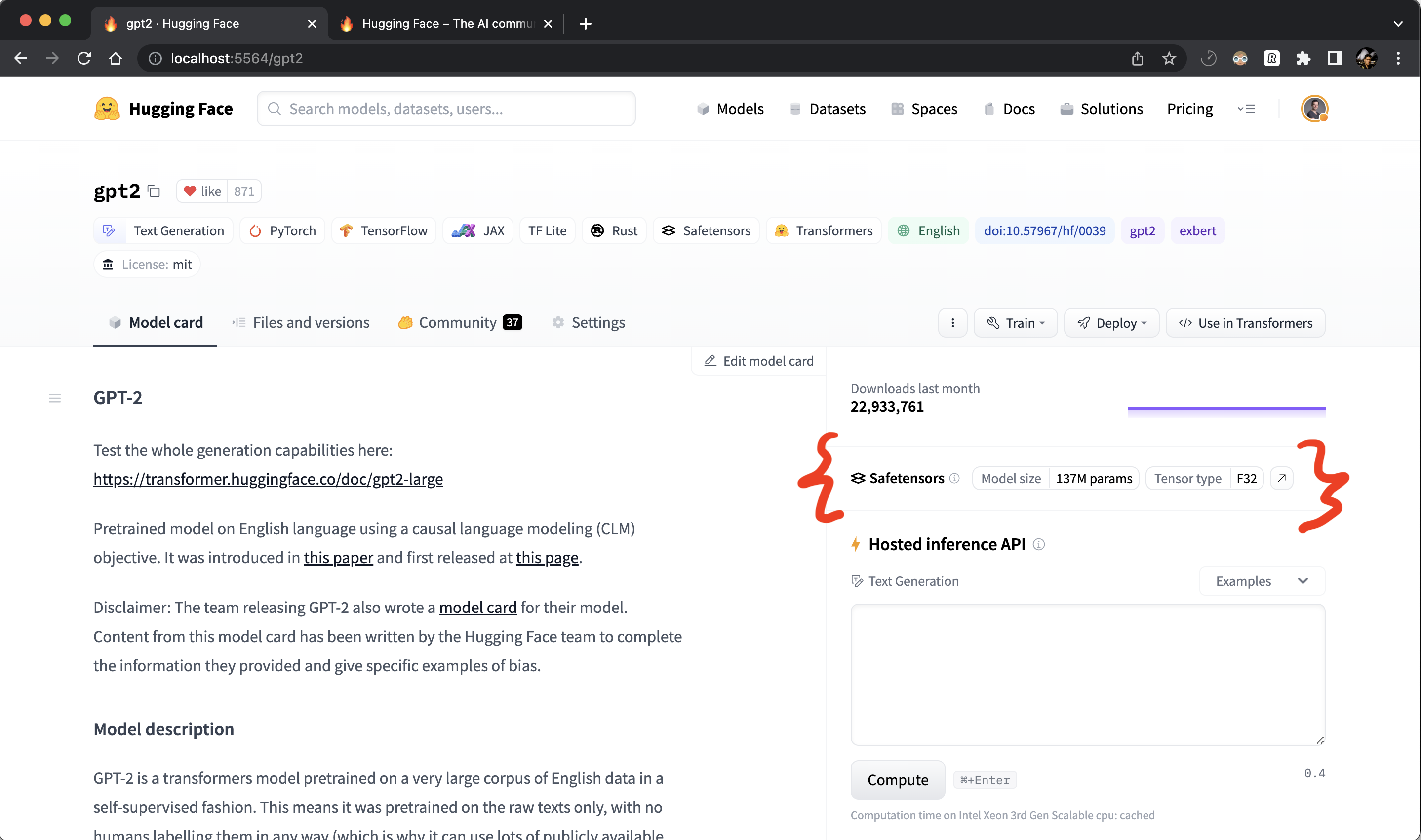
13 |

14 |
17 |

18 |

19 |
2 |
3 |
4 |
5 |  6 |
7 |
6 |
7 |
8 |
9 |
10 |
11 | Python
12 | [](https://pypi.org/pypi/safetensors/)
13 | [](https://huggingface.co/docs/safetensors/index)
14 | [](https://codecov.io/gh/huggingface/safetensors)
15 | [](https://pepy.tech/project/safetensors)
16 |
17 | Rust
18 | [](https://crates.io/crates/safetensors)
19 | [](https://docs.rs/safetensors/)
20 | [](https://codecov.io/gh/huggingface/safetensors)
21 | [](https://deps.rs/repo/github/huggingface/safetensors?path=safetensors)
22 |
23 | # safetensors
24 |
25 | ## Safetensors
26 |
27 | This repository implements a new simple format for storing tensors
28 | safely (as opposed to pickle) and that is still fast (zero-copy).
29 |
30 | ### Installation
31 | #### Pip
32 |
33 | You can install safetensors via the pip manager:
34 |
35 | ```bash
36 | pip install safetensors
37 | ```
38 |
39 | #### From source
40 |
41 | For the sources, you need Rust
42 |
43 | ```bash
44 | # Install Rust
45 | curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
46 | # Make sure it's up to date and using stable channel
47 | rustup update
48 | git clone https://github.com/huggingface/safetensors
49 | cd safetensors/bindings/python
50 | pip install setuptools_rust
51 | pip install -e .
52 | ```
53 |
54 | ### Getting started
55 |
56 | ```python
57 | import torch
58 | from safetensors import safe_open
59 | from safetensors.torch import save_file
60 |
61 | tensors = {
62 | "weight1": torch.zeros((1024, 1024)),
63 | "weight2": torch.zeros((1024, 1024))
64 | }
65 | save_file(tensors, "model.safetensors")
66 |
67 | tensors = {}
68 | with safe_open("model.safetensors", framework="pt", device="cpu") as f:
69 | for key in f.keys():
70 | tensors[key] = f.get_tensor(key)
71 | ```
72 |
73 | [Python documentation](https://huggingface.co/docs/safetensors/index)
74 |
75 |
76 | ### Format
77 |
78 | - 8 bytes: `N`, an unsigned little-endian 64-bit integer, containing the size of the header
79 | - N bytes: a JSON UTF-8 string representing the header.
80 | - The header data MUST begin with a `{` character (0x7B).
81 | - The header data MAY be trailing padded with whitespace (0x20).
82 | - The header is a dict like `{"TENSOR_NAME": {"dtype": "F16", "shape": [1, 16, 256], "data_offsets": [BEGIN, END]}, "NEXT_TENSOR_NAME": {...}, ...}`,
83 | - `data_offsets` point to the tensor data relative to the beginning of the byte buffer (i.e. not an absolute position in the file),
84 | with `BEGIN` as the starting offset and `END` as the one-past offset (so total tensor byte size = `END - BEGIN`).
85 | - A special key `__metadata__` is allowed to contain free form string-to-string map. Arbitrary JSON is not allowed, all values must be strings.
86 | - Rest of the file: byte-buffer.
87 |
88 | Notes:
89 | - Duplicate keys are disallowed. Not all parsers may respect this.
90 | - In general the subset of JSON is implicitly decided by `serde_json` for
91 | this library. Anything obscure might be modified at a later time, that odd ways
92 | to represent integer, newlines and escapes in utf-8 strings. This would only
93 | be done for safety concerns
94 | - Tensor values are not checked against, in particular NaN and +/-Inf could
95 | be in the file
96 | - Empty tensors (tensors with 1 dimension being 0) are allowed.
97 | They are not storing any data in the databuffer, yet retaining size in the header.
98 | They don't really bring a lot of values but are accepted since they are valid tensors
99 | from traditional tensor libraries perspective (torch, tensorflow, numpy, ..).
100 | - 0-rank Tensors (tensors with shape `[]`) are allowed, they are merely a scalar.
101 | - The byte buffer needs to be entirely indexed, and cannot contain holes. This prevents
102 | the creation of polyglot files.
103 | - Endianness: Little-endian.
104 | moment.
105 | - Order: 'C' or row-major.
106 | - Notes: Some smaller than 1 byte dtypes appeared, which make alignment tricky. Non traditional APIs might be required for those.
107 |
108 |
109 | ### Yet another format ?
110 |
111 | The main rationale for this crate is to remove the need to use
112 | `pickle` on `PyTorch` which is used by default.
113 | There are other formats out there used by machine learning and more general
114 | formats.
115 |
116 |
117 | Let's take a look at alternatives and why this format is deemed interesting.
118 | This is my very personal and probably biased view:
119 |
120 | | Format | Safe | Zero-copy | Lazy loading | No file size limit | Layout control | Flexibility | Bfloat16/Fp8
121 | | ----------------------- | --- | --- | --- | --- | --- | --- | --- |
122 | | pickle (PyTorch) | ✗ | ✗ | ✗ | 🗸 | ✗ | 🗸 | 🗸 |
123 | | H5 (Tensorflow) | 🗸 | ✗ | 🗸 | 🗸 | ~ | ~ | ✗ |
124 | | SavedModel (Tensorflow) | 🗸 | ✗ | ✗ | 🗸 | 🗸 | ✗ | 🗸 |
125 | | MsgPack (flax) | 🗸 | 🗸 | ✗ | 🗸 | ✗ | ✗ | 🗸 |
126 | | Protobuf (ONNX) | 🗸 | ✗ | ✗ | ✗ | ✗ | ✗ | 🗸 |
127 | | Cap'n'Proto | 🗸 | 🗸 | ~ | 🗸 | 🗸 | ~ | ✗ |
128 | | Arrow | ? | ? | ? | ? | ? | ? | ✗ |
129 | | Numpy (npy,npz) | 🗸 | ? | ? | ✗ | 🗸 | ✗ | ✗ |
130 | | pdparams (Paddle) | ✗ | ✗ | ✗ | 🗸 | ✗ | 🗸 | 🗸 |
131 | | SafeTensors | 🗸 | 🗸 | 🗸 | 🗸 | 🗸 | ✗ | 🗸 |
132 |
133 | - Safe: Can I use a file randomly downloaded and expect not to run arbitrary code ?
134 | - Zero-copy: Does reading the file require more memory than the original file ?
135 | - Lazy loading: Can I inspect the file without loading everything ? And loading only
136 | some tensors in it without scanning the whole file (distributed setting) ?
137 | - Layout control: Lazy loading, is not necessarily enough since if the information about tensors is spread out in your file, then even if the information is lazily accessible you might have to access most of your file to read the available tensors (incurring many DISK -> RAM copies). Controlling the layout to keep fast access to single tensors is important.
138 | - No file size limit: Is there a limit to the file size ?
139 | - Flexibility: Can I save custom code in the format and be able to use it later with zero extra code ? (~ means we can store more than pure tensors, but no custom code)
140 | - Bfloat16/Fp8: Does the format support native bfloat16/fp8 (meaning no weird workarounds are
141 | necessary)? This is becoming increasingly important in the ML world.
142 |
143 |
144 | ### Main oppositions
145 |
146 | - Pickle: Unsafe, runs arbitrary code
147 | - H5: Apparently now discouraged for TF/Keras. Seems like a great fit otherwise actually. Some classic use after free issues: . On a very different level than pickle security-wise. Also 210k lines of code vs ~400 lines for this lib currently.
148 | - SavedModel: Tensorflow specific (it contains TF graph information).
149 | - MsgPack: No layout control to enable lazy loading (important for loading specific parts in distributed setting)
150 | - Protobuf: Hard 2Go max file size limit
151 | - Cap'n'proto: Float16 support is not present [link](https://capnproto.org/language.html#built-in-types) so using a manual wrapper over a byte-buffer would be necessary. Layout control seems possible but not trivial as buffers have limitations [link](https://stackoverflow.com/questions/48458839/capnproto-maximum-filesize).
152 | - Numpy (npz): No `bfloat16` support. Vulnerable to zip bombs (DOS). Not zero-copy.
153 | - Arrow: No `bfloat16` support.
154 |
155 | ### Notes
156 |
157 | - Zero-copy: No format is really zero-copy in ML, it needs to go from disk to RAM/GPU RAM (that takes time). On CPU, if the file is already in cache, then it can
158 | truly be zero-copy, whereas on GPU there is not such disk cache, so a copy is always required
159 | but you can bypass allocating all the tensors on CPU at any given point.
160 | SafeTensors is not zero-copy for the header. The choice of JSON is pretty arbitrary, but since deserialization is <<< of the time required to load the actual tensor data and is readable I went that way, (also space is <<< to the tensor data).
161 |
162 | - Endianness: Little-endian. This can be modified later, but it feels really unnecessary at the
163 | moment.
164 | - Order: 'C' or row-major. This seems to have won. We can add that information later if needed.
165 | - Stride: No striding, all tensors need to be packed before being serialized. I have yet to see a case where it seems useful to have a strided tensor stored in serialized format.
166 | - Sub 1 bytes dtypes: Dtypes can now have lower than 1 byte size, this makes alignment&adressing tricky. For now, the library will simply error out whenever an operation triggers an non aligned read. Trickier API may be created later for those non standard ops.
167 |
168 | ### Benefits
169 |
170 | Since we can invent a new format we can propose additional benefits:
171 |
172 | - Prevent DOS attacks: We can craft the format in such a way that it's almost
173 | impossible to use malicious files to DOS attack a user. Currently, there's a limit
174 | on the size of the header of 100MB to prevent parsing extremely large JSON.
175 | Also when reading the file, there's a guarantee that addresses in the file
176 | do not overlap in any way, meaning when you're loading a file you should never
177 | exceed the size of the file in memory
178 |
179 | - Faster load: PyTorch seems to be the fastest file to load out in the major
180 | ML formats. However, it does seem to have an extra copy on CPU, which we
181 | can bypass in this lib by using `torch.UntypedStorage.from_file`.
182 | Currently, CPU loading times are extremely fast with this lib compared to pickle.
183 | GPU loading times are as fast or faster than PyTorch equivalent.
184 | Loading first on CPU with memmapping with torch, and then moving all tensors to GPU seems
185 | to be faster too somehow (similar behavior in torch pickle)
186 |
187 | - Lazy loading: in distributed (multi-node or multi-gpu) settings, it's nice to be able to
188 | load only part of the tensors on the various models. For
189 | [BLOOM](https://huggingface.co/bigscience/bloom) using this format enabled
190 | to load the model on 8 GPUs from 10mn with regular PyTorch weights down to 45s.
191 | This really speeds up feedbacks loops when developing on the model. For instance
192 | you don't have to have separate copies of the weights when changing the distribution
193 | strategy (for instance Pipeline Parallelism vs Tensor Parallelism).
194 |
195 | License: Apache-2.0
196 |
--------------------------------------------------------------------------------
/bindings/python/tests/test_pt_model.py:
--------------------------------------------------------------------------------
1 | import copy
2 | import unittest
3 |
4 | import torch
5 |
6 | from safetensors import safe_open
7 | from safetensors.torch import (
8 | _end_ptr,
9 | _find_shared_tensors,
10 | _is_complete,
11 | _remove_duplicate_names,
12 | load_model,
13 | save_file,
14 | save_model,
15 | )
16 |
17 |
18 | class OnesModel(torch.nn.Module):
19 | def __init__(self):
20 | super().__init__()
21 | self.a = torch.nn.Linear(4, 4)
22 | self.a.weight = torch.nn.Parameter(torch.ones((4, 4)))
23 | self.a.bias = torch.nn.Parameter(torch.ones((4,)))
24 | self.b = self.a
25 |
26 |
27 | class Model(torch.nn.Module):
28 | def __init__(self):
29 | super().__init__()
30 | self.a = torch.nn.Linear(100, 100)
31 | self.b = self.a
32 |
33 |
34 | class NonContiguousModel(torch.nn.Module):
35 | def __init__(self):
36 | super().__init__()
37 | self.a = torch.nn.Linear(100, 100)
38 | A = torch.zeros((100, 100))
39 | A = A.transpose(0, 1)
40 | self.a.weight = torch.nn.Parameter(A)
41 |
42 |
43 | class CopyModel(torch.nn.Module):
44 | def __init__(self):
45 | super().__init__()
46 | self.a = torch.nn.Linear(100, 100)
47 | self.b = copy.deepcopy(self.a)
48 |
49 |
50 | class NoSharedModel(torch.nn.Module):
51 | def __init__(self):
52 | super().__init__()
53 | self.a = torch.nn.Linear(100, 100)
54 | self.b = torch.nn.Linear(100, 100)
55 |
56 |
57 | class TorchModelTestCase(unittest.TestCase):
58 | def test_is_complete(self):
59 | A = torch.zeros((3, 3))
60 | self.assertTrue(_is_complete(A))
61 |
62 | B = A[:1, :]
63 | self.assertFalse(_is_complete(B))
64 |
65 | # Covers the whole storage but with holes
66 | C = A[::2, :]
67 | self.assertFalse(_is_complete(C))
68 |
69 | D = torch.zeros((2, 2), device=torch.device("meta"))
70 | self.assertTrue(_is_complete(D))
71 |
72 | def test_find_shared_tensors(self):
73 | A = torch.zeros((3, 3))
74 | B = A[:1, :]
75 |
76 | self.assertEqual(_find_shared_tensors({"A": A, "B": B}), [{"A", "B"}])
77 | self.assertEqual(_find_shared_tensors({"A": A}), [{"A"}])
78 | self.assertEqual(_find_shared_tensors({"B": B}), [{"B"}])
79 |
80 | C = torch.zeros((2, 2), device=torch.device("meta"))
81 | D = C[:1]
82 | # Meta device is not shared
83 | self.assertEqual(_find_shared_tensors({"C": C, "D": D}), [])
84 | self.assertEqual(_find_shared_tensors({"C": C}), [])
85 | self.assertEqual(_find_shared_tensors({"D": D}), [])
86 |
87 | def test_find_shared_non_shared_tensors(self):
88 | A = torch.zeros((4,))
89 | B = A[:2]
90 | C = A[2:]
91 | # Shared storage but do not overlap
92 | self.assertEqual(_find_shared_tensors({"B": B, "C": C}), [{"B"}, {"C"}])
93 |
94 | B = A[:2]
95 | C = A[1:]
96 | # Shared storage but *do* overlap
97 | self.assertEqual(_find_shared_tensors({"B": B, "C": C}), [{"B", "C"}])
98 |
99 | B = A[:2]
100 | C = A[2:]
101 | D = A[:1]
102 | # Shared storage but *do* overlap
103 | self.assertEqual(
104 | _find_shared_tensors({"B": B, "C": C, "D": D}), [{"B", "D"}, {"C"}]
105 | )
106 |
107 | def test_end_ptr(self):
108 | A = torch.zeros((4,))
109 | start = A.data_ptr()
110 | end = _end_ptr(A)
111 | self.assertEqual(end - start, 16)
112 | B = torch.zeros((16,))
113 | A = B[::4]
114 | start = A.data_ptr()
115 | end = _end_ptr(A)
116 | # Jump 3 times 16 byes (the stride of B)
117 | # Then add the size of the datapoint 4 bytes
118 | self.assertEqual(end - start, 16 * 3 + 4)
119 |
120 | # FLOAT16
121 | A = torch.zeros((4,), dtype=torch.float16)
122 | start = A.data_ptr()
123 | end = _end_ptr(A)
124 | self.assertEqual(end - start, 8)
125 | B = torch.zeros((16,), dtype=torch.float16)
126 | A = B[::4]
127 | start = A.data_ptr()
128 | end = _end_ptr(A)
129 | # Jump 3 times 8 bytes (the stride of B)
130 | # Then add the size of the datapoint 4 bytes
131 | self.assertEqual(end - start, 8 * 3 + 2)
132 |
133 | def test_remove_duplicate_names(self):
134 | A = torch.zeros((3, 3))
135 | B = A[:1, :]
136 |
137 | self.assertEqual(_remove_duplicate_names({"A": A, "B": B}), {"A": ["B"]})
138 | self.assertEqual(
139 | _remove_duplicate_names({"A": A, "B": B, "C": A}), {"A": ["B", "C"]}
140 | )
141 | with self.assertRaises(RuntimeError):
142 | self.assertEqual(_remove_duplicate_names({"B": B}), [])
143 |
144 | def test_failure(self):
145 | model = Model()
146 | with self.assertRaises(RuntimeError):
147 | save_file(model.state_dict(), "tmp.safetensors")
148 |
149 | # def test_workaround_refuse(self):
150 | # model = Model()
151 | # A = torch.zeros((1000, 10))
152 | # a = A[:100, :]
153 | # model.a.weight = torch.nn.Parameter(a)
154 | # with self.assertRaises(RuntimeError) as ctx:
155 | # save_model(model, "tmp4.safetensors")
156 | # self.assertIn(".Refusing to save/load the model since you could be storing much more memory than needed.", str(ctx.exception))
157 |
158 | def test_save(self):
159 | # Just testing the actual saved file to make sure we're ok on big endian
160 | model = OnesModel()
161 | save_model(model, "tmp_ones.safetensors")
162 | with safe_open("tmp_ones.safetensors", framework="pt") as f:
163 | self.assertEqual(f.metadata(), {"b.bias": "a.bias", "b.weight": "a.weight"})
164 |
165 | # 192 hardcoded to skip the header, metadata order is random.
166 | self.assertEqual(
167 | open("tmp_ones.safetensors", "rb").read()[192:],
168 | b"""\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?\x00\x00\x80?""",
169 | )
170 |
171 | model2 = OnesModel()
172 | load_model(model2, "tmp_ones.safetensors")
173 |
174 | state_dict = model.state_dict()
175 | for k, v in model2.state_dict().items():
176 | torch.testing.assert_close(v, state_dict[k])
177 |
178 | def test_workaround(self):
179 | model = Model()
180 | save_model(model, "tmp.safetensors")
181 | with safe_open("tmp.safetensors", framework="pt") as f:
182 | self.assertEqual(f.metadata(), {"b.bias": "a.bias", "b.weight": "a.weight"})
183 |
184 | model2 = Model()
185 | load_model(model2, "tmp.safetensors")
186 |
187 | state_dict = model.state_dict()
188 | for k, v in model2.state_dict().items():
189 | torch.testing.assert_close(v, state_dict[k])
190 |
191 | def test_workaround_works_with_different_on_file_names(self):
192 | model = Model()
193 | state_dict = model.state_dict()
194 | state_dict.pop("a.weight")
195 | state_dict.pop("a.bias")
196 | save_file(state_dict, "tmp.safetensors")
197 |
198 | model2 = Model()
199 | load_model(model2, "tmp.safetensors")
200 |
201 | state_dict = model.state_dict()
202 | for k, v in model2.state_dict().items():
203 | torch.testing.assert_close(v, state_dict[k])
204 |
205 | def test_workaround_non_contiguous(self):
206 | model = NonContiguousModel()
207 |
208 | with self.assertRaises(ValueError) as ctx:
209 | save_model(model, "tmp_c.safetensors", force_contiguous=False)
210 | self.assertIn("use save_model(..., force_contiguous=True)", str(ctx.exception))
211 | save_model(model, "tmp_c.safetensors", force_contiguous=True)
212 |
213 | model2 = NonContiguousModel()
214 | load_model(model2, "tmp_c.safetensors")
215 |
216 | state_dict = model.state_dict()
217 | for k, v in model2.state_dict().items():
218 | torch.testing.assert_close(v, state_dict[k])
219 |
220 | def test_workaround_copy(self):
221 | model = CopyModel()
222 | self.assertEqual(
223 | _find_shared_tensors(model.state_dict()),
224 | [{"a.weight"}, {"a.bias"}, {"b.weight"}, {"b.bias"}],
225 | )
226 | save_model(model, "tmp.safetensors")
227 |
228 | model2 = CopyModel()
229 | load_model(model2, "tmp.safetensors")
230 |
231 | state_dict = model.state_dict()
232 | for k, v in model2.state_dict().items():
233 | torch.testing.assert_close(v, state_dict[k])
234 |
235 | def test_difference_with_torch(self):
236 | model = Model()
237 | torch.save(model.state_dict(), "tmp2.bin")
238 |
239 | model2 = NoSharedModel()
240 | # This passes on torch.
241 | # The tensors are shared on disk, they are *not* shared within the model
242 | # The model happily loads the tensors, and ends up *not* sharing the tensors by.
243 | # doing copies
244 | self.assertEqual(
245 | _find_shared_tensors(model2.state_dict()),
246 | [{"a.weight"}, {"a.bias"}, {"b.weight"}, {"b.bias"}],
247 | )
248 | model2.load_state_dict(torch.load("tmp2.bin"))
249 | self.assertEqual(
250 | _find_shared_tensors(model2.state_dict()),
251 | [{"a.weight"}, {"a.bias"}, {"b.weight"}, {"b.bias"}],
252 | )
253 |
254 | # However safetensors cannot save those, so we cannot
255 | # reload the saved file with the different model
256 | save_model(model, "tmp2.safetensors")
257 | with self.assertRaises(RuntimeError) as ctx:
258 | load_model(model2, "tmp2.safetensors")
259 | self.assertIn(
260 | """Missing key(s) in state_dict: "b.bias", "b.weight""", str(ctx.exception)
261 | )
262 |
263 | def test_difference_torch_odd(self):
264 | model = NoSharedModel()
265 | a = model.a.weight
266 | b = model.b.weight
267 | self.assertNotEqual(a.data_ptr(), b.data_ptr())
268 | torch.save(model.state_dict(), "tmp3.bin")
269 |
270 | model2 = Model()
271 | self.assertEqual(
272 | _find_shared_tensors(model2.state_dict()),
273 | [{"a.weight", "b.weight"}, {"b.bias", "a.bias"}],
274 | )
275 | # Torch will affect either `b` or `a` to the shared tensor in the `model2`
276 | model2.load_state_dict(torch.load("tmp3.bin"))
277 |
278 | # XXX: model2 uses only the B weight not the A weight anymore.
279 | self.assertFalse(torch.allclose(model2.a.weight, model.a.weight))
280 | torch.testing.assert_close(model2.a.weight, model.b.weight)
281 | self.assertEqual(
282 | _find_shared_tensors(model2.state_dict()),
283 | [{"a.weight", "b.weight"}, {"b.bias", "a.bias"}],
284 | )
285 |
286 | # Everything is saved as-is
287 | save_model(model, "tmp3.safetensors")
288 | # safetensors will yell that there were 2 tensors on disk, while
289 | # the models expects only 1 tensor since both are shared.
290 | with self.assertRaises(RuntimeError) as ctx:
291 | load_model(model2, "tmp3.safetensors")
292 | # Safetensors properly warns the user that some ke
293 | self.assertIn(
294 | """Unexpected key(s) in state_dict: "b.bias", "b.weight""",
295 | str(ctx.exception),
296 | )
297 |
--------------------------------------------------------------------------------
 5 |
5 |  6 |
6 |  68 |
68 |