33 |
34 |
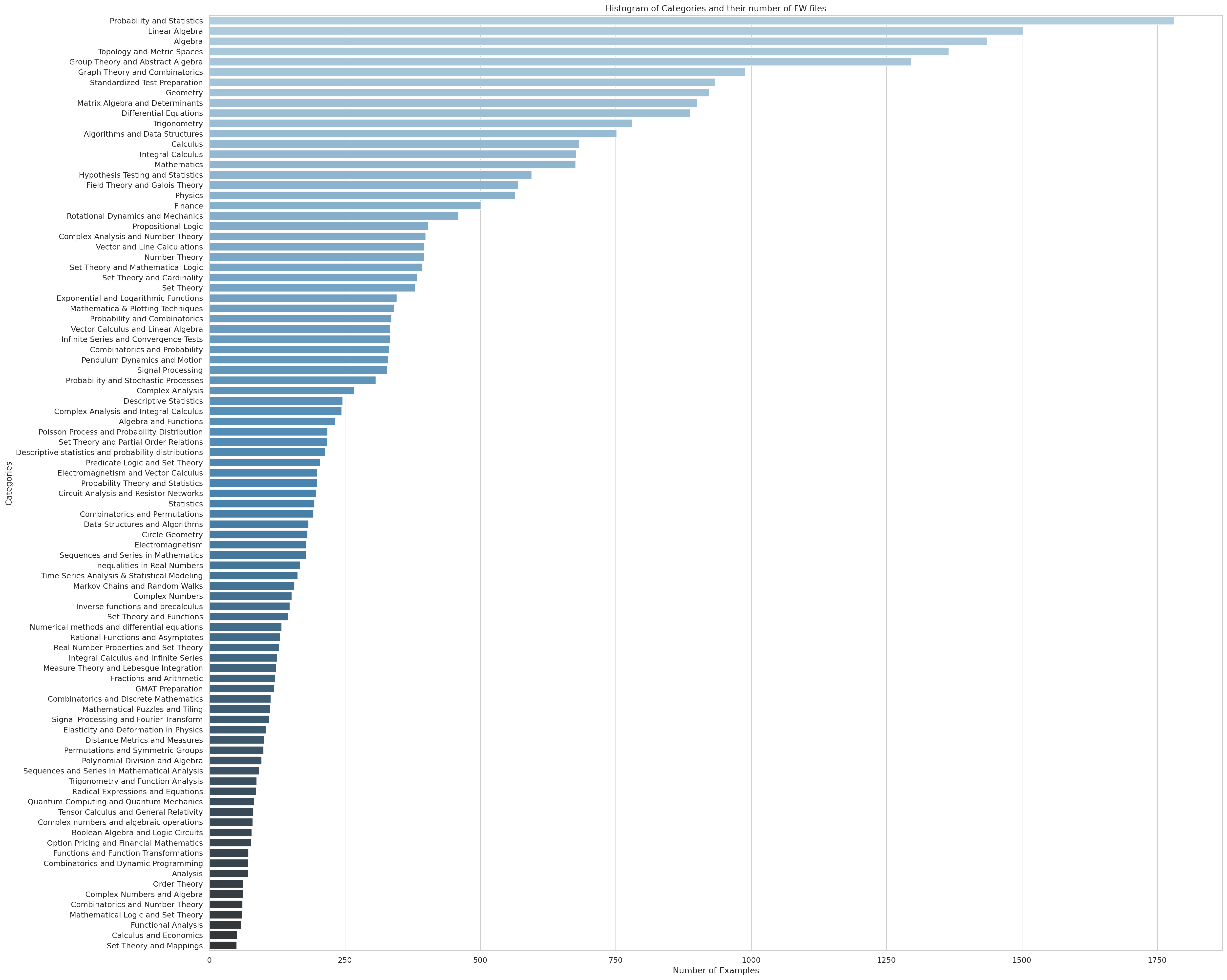
The clusters of AutoMathText
35 |

