├── .idea
├── .gitignore
├── codeStyles
│ └── codeStyleConfig.xml
├── distribute_basic.iml
├── misc.xml
├── modules.xml
└── vcs.xml
├── README.md
├── blog
├── base
│ └── brief.md
├── cap
│ └── brief.md
├── concensus
│ └── lab1-线性一致性
└── transaction
│ └── type.md
├── doc
├── jraft
│ ├── basic
│ │ ├── Untitled.md
│ │ ├── lab1-定时调度时间轮算法.md
│ │ └── lab2-投票的实现
│ ├── lab0-初始化时做了什么.md
│ ├── lab1-leader选举.md
│ ├── lab2-日志复制.md
│ ├── lab3-snashopt机制.md
│ └── lab4-存储模块.md
└── mit
│ ├── lab1-introduction.md
│ ├── lab2-gfs.md
│ ├── lab3-VMware FT.md
│ ├── lab4-raft.md
│ ├── lab5-raft2.md
│ ├── lab6-zookeeper.md
│ ├── lab7-CRAQ.md
│ └── lab8-Aurora.md
└── paper
├── base
└── base-danPritichett.md
├── cap
├── 1.brief
└── cap-theorem-revisited.md
├── google
├── gfs.md
└── mapreduce.md
└── raft
└── raft-cn.md
/.idea/.gitignore:
--------------------------------------------------------------------------------
1 | # Default ignored files
2 | /shelf/
3 | /workspace.xml
4 | # Editor-based HTTP Client requests
5 | /httpRequests/
6 |
--------------------------------------------------------------------------------
/.idea/codeStyles/codeStyleConfig.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
--------------------------------------------------------------------------------
/.idea/distribute_basic.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
--------------------------------------------------------------------------------
/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/.idea/vcs.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 1.MIT分布式系统课程
2 |
3 | 网课地址:https://www.bilibili.com/video/BV1qk4y197bB?from=search&seid=7469911290247608861
4 |
5 | 官网资源:http://nil.csail.mit.edu/6.824/2020/schedule.html
6 |
7 | ## 课程内容
8 |
9 | ### 第一课:[lab1-introduction](doc/mit/lab1-introduction.md)
10 |
11 | **前置理论及论文基础**
12 |
13 | - **cap**
14 |
15 | 1.[cap简介](blog/cap/brief.md)
16 |
17 | 2.[cap-theorem-revisited](paper/cap/cap-theorem-revisited.md)
18 |
19 | - **base**
20 |
21 | 1.[base简介](blog/base/brief.md)
22 |
23 | 2.[Base: An Acid Alternative](paper/base/base-danPritichett.md)
24 |
25 | 3.[分布式事务简介](blog/transaction/type.md)
26 |
27 | - **mapReduce**
28 |
29 | [google:mapreduce](paper/google/mapreduce.md)
30 |
31 | ### 第二课:[lab2-gfs文件系统](doc/mit/lab2-gfs.md)
32 |
33 | **前置理论及论文基础**
34 |
35 | - gfs论文
36 |
37 | [google:gfs](paper/google/gfs.md)
38 |
39 | ### 第三课:[lab3-VMware FT](doc/mit/lab3-VMware FT.md)
40 |
41 | **前置理论及论文基础**
42 |
43 | - [VMware FT](https://pdos.csail.mit.edu/6.824/papers/vm-ft.pdf)
44 |
45 | ### 第四课:[lab4-raft(一)](doc/mit/lab4-raft.md)
46 |
47 | **前置理论**
48 |
49 | raft论文前五节内容
50 |
51 | - [raft](paper/raft/raft-cn.md)
52 |
53 | ### 第五课:[lab5-raft(二)](doc/mit/lab5-raft2.md)
54 |
55 | **前置理论**
56 |
57 | raft论文后续内容
58 |
59 | - [raft](paper/raft/raft-cn.md)
60 |
61 | ### 第六课:[lab6-zookeeper](doc/mit/lab6-zookeeper.md)
62 |
63 | **前置理论**
64 |
65 | zookeeper论文:
66 |
67 | - [zookeeper](https://pdos.csail.mit.edu/6.824/papers/zookeeper.pdf)
68 |
69 | ### 第七课:[lab7-CRAQ](doc/mit/lab7-CRAQ.md)
70 |
71 | **前置理论**
72 |
73 | CRAQ论文:
74 |
75 | - [CRAQ](http://nil.csail.mit.edu/6.824/2020/papers/craq.pdf)
76 |
77 | ### 第八课:[lab8-Aurora](doc/mit/lab8-Aurora.md)
78 |
79 |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 | # 2.论文借鉴
92 |
93 | **概览文章**
94 |
95 | [http://www.rgoarchitects.com/Files/fallacies.pdf](https://link.zhihu.com/?target=http%3A//www.rgoarchitects.com/Files/fallacies.pdf) CS7680著名的9个论述 也是这门课推荐对于分布式系统的一个初步认识
96 |
97 | [http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=20A79A6520D69264C29248D0387C6703?doi=10.1.1.209.355&rep=rep1&type=pdf](https://link.zhihu.com/?target=http%3A//citeseerx.ist.psu.edu/viewdoc/download%3Bjsessionid%3D20A79A6520D69264C29248D0387C6703%3Fdoi%3D10.1.1.209.355%26rep%3Drep1%26type%3Dpdf) windows live的架构师james总结一系列大型后台服务的设计原则
98 |
99 | ## **CAP**
100 |
101 | [https://robertgreiner.com/cap-theorem-revisited/](https://link.zhihu.com/?target=https%3A//robertgreiner.com/cap-theorem-revisited/) 准确说是一篇blog,很精简,文字也不多,其实文中的图比文字更清晰。cap的理解也经历了一些纠结的过程,这一篇其实是作者多年后的二次理解。所以出错其实没啥问题,这位老板就完全推翻了之前文章里的阐述
102 |
103 | [http://ksat.me/a-plain-english-introduction-to-cap-theorem](https://link.zhihu.com/?target=http%3A//ksat.me/a-plain-english-introduction-to-cap-theorem) 也是通俗易懂的入门介绍cap的blog
104 |
105 | [https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed/](https://link.zhihu.com/?target=https%3A//www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed/) brewer多年以后写的关于cap的一些误解,C和A并不是完全对立的状态
106 |
107 | [https://sookocheff.com/post/databases/cap-twelve-years-later/](https://link.zhihu.com/?target=https%3A//sookocheff.com/post/databases/cap-twelve-years-later/) 是对上面这片文章的review心得
108 |
109 |
110 |
111 | [http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.24.3690&rep=rep1&type=pdf](https://link.zhihu.com/?target=http%3A//citeseerx.ist.psu.edu/viewdoc/download%3Fdoi%3D10.1.1.24.3690%26rep%3Drep1%26type%3Dpdf) 开始用了两个新名词来阐述
112 |
113 | A)yield, which is the probability of completing a request .感觉说的就是A
114 |
115 | B)harvest ,measures the fraction of the data reflected in the response.感觉说的就是C
116 |
117 | 这篇论文对于available提出里两个比较好的方案:
118 |
119 | 1)牺牲harvest换来yield
120 |
121 | 2)应用架构拆分 和 正交机制
122 |
123 | **BASE**
124 |
125 | [https://queue.acm.org/detail.cfm?id=1394128](https://link.zhihu.com/?target=https%3A//queue.acm.org/detail.cfm%3Fid%3D1394128) base一致性的开山鼻祖,首次提出了和acid相反的一种理论,论文中给出了一些单机事务到多机事务的演进过程,并没有觉得很理论,工程很值得借鉴
126 |
127 | ## 一致性
128 |
129 | [http://jepsen.io/consistency#fundamental-concepts](https://link.zhihu.com/?target=http%3A//jepsen.io/consistency%23fundamental-concepts) 一致性的模型,高屋建瓴,是一篇blog
130 |
131 | [http://vukolic.com/consistency-survey.pdf](https://link.zhihu.com/?target=http%3A//vukolic.com/consistency-survey.pdf) 概述的文章 先看看
132 |
133 | - **sequential consistency**
134 |
135 | [https://lamport.azurewebsites.net/pubs/lamport-how-to-make.pdf](https://link.zhihu.com/?target=https%3A//lamport.azurewebsites.net/pubs/lamport-how-to-make.pdf) lamport大神不用过多的介绍,读他的论文唯一的感受就是智商的差别吧
136 |
137 | [https://cs.brown.edu/~mph/HerlihyW90/p463-herlihy.pdf](https://link.zhihu.com/?target=https%3A//cs.brown.edu/~mph/HerlihyW90/p463-herlihy.pdf) 也是线性一致性的文章 作者在cmu发表的
138 |
139 | - **eventual consistency**
140 |
141 | 最终一致性的文章首推 aws的cto
142 |
143 | [https://www.allthingsdistributed.com/2008/12/eventually_consistent.html](https://link.zhihu.com/?target=https%3A//www.allthingsdistributed.com/2008/12/eventually_consistent.html)
144 |
145 | [https://www.cs.tau.ac.il/~mad/publications/podc2015-replds.pdf](https://link.zhihu.com/?target=https%3A//www.cs.tau.ac.il/~mad/publications/podc2015-replds.pdf) 讲了一些高可用和一致性之间的trade-off
146 |
147 | [https://pdfs.semanticscholar.org/6877/32ca90ce8ec57c0ec8530863b8a693bf4f51.pdf](https://link.zhihu.com/?target=https%3A//pdfs.semanticscholar.org/6877/32ca90ce8ec57c0ec8530863b8a693bf4f51.pdf) 描述了 最终一致性 和 因果一致性的关系
148 |
149 | [https://haslab.uminho.pt/tome/files/global_logical_clocks.pdf](https://link.zhihu.com/?target=https%3A//haslab.uminho.pt/tome/files/global_logical_clocks.pdf)
150 |
151 | - **causal consistency**
152 |
153 | [http://www.bailis.org/papers/bolton-sigmod2013.pdf](https://link.zhihu.com/?target=http%3A//www.bailis.org/papers/bolton-sigmod2013.pdf) Bolt-on的架构设计
154 |
155 | [https://www.cs.cmu.edu/~dga/papers/cops-sosp2011.pdf](https://link.zhihu.com/?target=https%3A//www.cs.cmu.edu/~dga/papers/cops-sosp2011.pdf) cops的架构设计
156 |
157 | [https://www.cs.princeton.edu/~wlloyd/papers/eiger-nsdi13.pdf](https://link.zhihu.com/?target=https%3A//www.cs.princeton.edu/~wlloyd/papers/eiger-nsdi13.pdf)
158 |
159 | [https://www.ronpub.com/OJDB_2015v2i1n02_Elbushra.pdf](https://link.zhihu.com/?target=https%3A//www.ronpub.com/OJDB_2015v2i1n02_Elbushra.pdf) 一个causal consistency的db设计与实现
160 |
161 | [https://smartech.gatech.edu/bitstream/handle/1853/6781/GIT-CC-93-55.pdf?sequence=1&isAllowed=y](https://link.zhihu.com/?target=https%3A//smartech.gatech.edu/bitstream/handle/1853/6781/GIT-CC-93-55.pdf%3Fsequence%3D1%26isAllowed%3Dy)
162 |
163 | 从前三篇文章的作者来看,ucb & cmu&priceton 还是很值得一读的
164 |
165 | 最后一篇的年代已经久远,其实发现计算机的一些理论基础其实是很经得起时间的考验的,所以码农其实也可以过的没有那么的有危机感^_^
166 |
167 | [https://pdfs.semanticscholar.org/7725/8064a686dfd61d7232172d6706711606dcfc.pdf](https://link.zhihu.com/?target=https%3A//pdfs.semanticscholar.org/7725/8064a686dfd61d7232172d6706711606dcfc.pdf) 这个是最后一篇论文的ppt版本
168 |
169 | [https://arxiv.org/pdf/1802.00706.pdf](https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/1802.00706.pdf)
170 |
171 | - **weak consistency**
172 |
173 | [http://pmg.csail.mit.edu/papers/adya-phd.pdf](https://link.zhihu.com/?target=http%3A//pmg.csail.mit.edu/papers/adya-phd.pdf)
174 |
175 | ## 分布式锁
176 |
177 | [https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/chubby-osdi06.pdf](https://link.zhihu.com/?target=https%3A//static.googleusercontent.com/media/research.google.com/zh-CN//archive/chubby-osdi06.pdf) Google出品的chubby 必属精品
178 |
179 | [https://www.usenix.org/legacy/event/atc10/tech/full_papers/Hunt.pdf](https://link.zhihu.com/?target=https%3A//www.usenix.org/legacy/event/atc10/tech/full_papers/Hunt.pdf) Yahoo的zookeeper
180 |
181 | ## 分布式kv存储
182 |
183 | [http://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf](https://link.zhihu.com/?target=http%3A//static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf) Google三驾马车之一bigtable,hbase的蓝本
184 |
185 | [http://static.googleusercontent.com/media/research.google.com/en/us/archive/gfs-sosp2003.pdf](https://link.zhihu.com/?target=http%3A//static.googleusercontent.com/media/research.google.com/en/us/archive/gfs-sosp2003.pdf) Google三架马车之二gfs,hdfs的蓝本
186 |
187 | [https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf](https://link.zhihu.com/?target=https%3A//static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf) Google三架马车之三bigtable,hbase的蓝本
188 |
189 | [https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf](https://link.zhihu.com/?target=https%3A//www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf) 现代很多的kv设计或多或少的都参考了先驱dynamo的设计,值得刷10遍以上。[读后感](https://zhuanlan.zhihu.com/p/140050721)
190 |
191 | [https://www.cs.cornell.edu/Projects/ladis2009/papers/Lakshman-ladis2009.PDF](https://link.zhihu.com/?target=https%3A//www.cs.cornell.edu/Projects/ladis2009/papers/Lakshman-ladis2009.PDF) 2009年Cassandra设计的论文 ,很多思想借鉴了dynamo,对于一致性哈希的吐槽也高度类似。
192 |
193 | 在replication的过程中,也会通过一个coordinator节点(master节点)来对其他节点进行replicate(这一点和dynamo一样),但是Cassandra提供了一系列的replicate policy可以选择,比如 Rack Unaware, Rack Aware (within a datacenter) and Datacenter Aware. Cassandra也沿用了dynamo里面关于preference list的定义
194 |
195 |
196 |
197 | [https://www.ssrc.ucsc.edu/media/pubs/9c7bcd06ff4eeccef2cb4c7813fe33ba7d4805c7.pdf](https://link.zhihu.com/?target=https%3A//www.ssrc.ucsc.edu/media/pubs/9c7bcd06ff4eeccef2cb4c7813fe33ba7d4805c7.pdf)
198 |
199 | [https://dsf.berkeley.edu/jmh/papers/anna_ieee18.pdf](https://link.zhihu.com/?target=https%3A//dsf.berkeley.edu/jmh/papers/anna_ieee18.pdf) ucb出的一篇高性能的kv存储,号称比redis快几十倍,使用coordination-free consistency models。虽然说是特别快,但是其实业界的是用并不广泛
200 |
201 | [https://cs.ulb.ac.be/public/_media/teaching/influxdb_2017.pdf](https://link.zhihu.com/?target=https%3A//cs.ulb.ac.be/public/_media/teaching/influxdb_2017.pdf) 时间序列的数据库的一篇介绍 ,介绍了几个应用场景 iot ebay等 ,influxdb的介绍
202 |
203 | [http://btw2017.informatik.uni-stuttgart.de/slidesandpapers/E4-14-109/paper_web.pdf](https://link.zhihu.com/?target=http%3A//btw2017.informatik.uni-stuttgart.de/slidesandpapers/E4-14-109/paper_web.pdf) 比较了业界的几种TSDB的异同
204 |
205 |
206 |
207 |
208 |
209 | 无论是kv还是传统的关系型数据库,在分布式系统里面无非都会涉及到以下这几方面
210 |
211 | - replication
212 |
213 | [https://dsf.berkeley.edu/cs286/papers/dangers-sigmod1996.pdf](https://link.zhihu.com/?target=https%3A//dsf.berkeley.edu/cs286/papers/dangers-sigmod1996.pdf) 指出了一种在replication中存在的问题,并给出了解决方案
214 |
215 | - partition&shard
216 |
217 | 分区都逃不了一致性哈希,
218 |
219 | [https://www.akamai.com/us/en/multimedia/documents/technical-publication/consistent-hashing-and-random-trees-distributed-caching-protocols-for-relieving-hot-spots-on-the-world-wide-web-technical-publication.pdf](https://link.zhihu.com/?target=https%3A//www.akamai.com/us/en/multimedia/documents/technical-publication/consistent-hashing-and-random-trees-distributed-caching-protocols-for-relieving-hot-spots-on-the-world-wide-web-technical-publication.pdf) 被引用度特别高的一篇文章,但是这个版本也是被吐槽最多的,dynamo吐槽过,Cassandra也吐槽了一把
220 |
221 | 1)First, the random position assignment of each node on the ring leads to non-uniform data and load distribution.
222 |
223 | 2)Second, the basic algorithm is oblivious to the heterogeneity in the performance of nodes.
224 |
225 | 解决方案
226 |
227 | 1)One is for nodes to get assigned to multiple positions in the circle (like in Dynamo) dynamo用的就是这种方法
228 |
229 | 2)the second is to analyze load information on the ring and have lightly loaded nodes move on the ring to alleviate heavily loaded nodes 这种方法被Cassandra采用
230 |
231 | [http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.217.2218&rep=rep1&type=pdf](https://link.zhihu.com/?target=http%3A//citeseerx.ist.psu.edu/viewdoc/download%3Fdoi%3D10.1.1.217.2218%26rep%3Drep1%26type%3Dpdf) 2)用的方法 也就是这片论文提出的方法
232 |
233 | - memship
234 | - failure detect
235 | - updated conflicts
236 | - implement
237 |
238 | 关于实现[http://www.sosp.org/2001/papers/welsh.pdf](https://link.zhihu.com/?target=http%3A//www.sosp.org/2001/papers/welsh.pdf) 这篇论文的出镜率特别高,里面的思想被Cassandra和dynamo都采用了 ,作者也是提出cap的大神Eric Brewer(第三作者),值得反复研读
239 |
240 |
241 |
242 | [https://storage.googleapis.com/pub-tools-public-publication-data/pdf/03de87e2856b06a94ffae7dca218db2d4b9afd39.pdf](https://link.zhihu.com/?target=https%3A//storage.googleapis.com/pub-tools-public-publication-data/pdf/03de87e2856b06a94ffae7dca218db2d4b9afd39.pdf) 这个是2019年Google提出的一种有状态的kv存储的思路。在工业界的下个请求依赖于上一个请求的情况
243 |
244 | **数据库**
245 |
246 | - **查询优化器**
247 |
248 | [https://arxiv.org/pdf/1608.02611.pdf](https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/1608.02611.pdf)
249 |
250 | [https://dl.acm.org/doi/pdf/10.1145/335191.335451](https://link.zhihu.com/?target=https%3A//dl.acm.org/doi/pdf/10.1145/335191.335451)
251 |
252 | [https://dl.acm.org/doi/pdf/10.1145/2304510.2304525](https://link.zhihu.com/?target=https%3A//dl.acm.org/doi/pdf/10.1145/2304510.2304525)
253 |
254 |
255 |
256 |
257 |
258 | **MQ**
259 |
260 | - **kafka**
261 |
262 | [http://notes.stephenholiday.com/Kafka.pdf](https://link.zhihu.com/?target=http%3A//notes.stephenholiday.com/Kafka.pdf) 现在很火的kafa最初设计的论文,细节有些已经被优化,基本的架构还是很值得反复研读。比如
263 |
264 | In general, Kafka only guarantees at-least-once delivery. Exactly once delivery typically requires two-phase commits and is not necessary for our applications
265 |
266 | 最初kafka只是支持at-least的delivery, 但是不支持exactly once的投递,具体哪个版本开始支持有点记不清了
267 |
268 |
269 |
270 | **分布式文件系统**
271 |
272 | 除了大名鼎鼎的gfs 分布式文件系统已经走过了好几十个年头了
273 |
274 | [https://www.cs.cmu.edu/~satya/docdir/satya-ieeetc-coda-1990.pdf](https://link.zhihu.com/?target=https%3A//www.cs.cmu.edu/~satya/docdir/satya-ieeetc-coda-1990.pdf) 1990年的coda,在很多的论文中出镜率非常高,后面的fs也借鉴了coda的一些思想
275 |
276 |
277 |
278 | **分布式事务&事务隔离级别**
279 |
280 | [http://www.vldb.org/pvldb/vol7/p181-bailis.pdf](https://link.zhihu.com/?target=http%3A//www.vldb.org/pvldb/vol7/p181-bailis.pdf) 引用率很高的一篇文章 这里面也引用了下面的这篇文章中关于事务隔离级别P0,P1的引用,看之前可以先看下面这篇文章。比如,脏写,脏读,不可重复读&fuzzy读,幻读等
281 |
282 | 读未提交保证了写的串行化,注意只是写的串行化(并不能保证读写的串行化,依然有可能产生脏读),下面这篇论文里面是避免了脏写的操作。如何处理写的冲突呢? 打时间戳或者last write win的方式都是可行的
283 |
284 | [https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-95-51.pdf](https://link.zhihu.com/?target=https%3A//www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-95-51.pdf) 不管是怎么讲事务隔离级别,最原生的味道是这一篇,其他的文章都是咀嚼过吐出来的
285 |
286 | 其中也参考了 [https://pdfs.semanticscholar.org/b40a/2bed6469ccea11d1c5f884215805ba785019.pdf?_ga=2.256890123.1236479272.1592556133-1143139955.1585301775](https://link.zhihu.com/?target=https%3A//pdfs.semanticscholar.org/b40a/2bed6469ccea11d1c5f884215805ba785019.pdf%3F_ga%3D2.256890123.1236479272.1592556133-1143139955.1585301775) 里面阐述了很多隔离级别的标准
287 |
288 | **共识算法**
289 |
290 |
291 |
292 | [https://lamport.azurewebsites.net/pubs/paxos-simple.pdf](https://link.zhihu.com/?target=https%3A//lamport.azurewebsites.net/pubs/paxos-simple.pdf) paxos的simple版本,原来的版本太晦涩,lamport大神自己可能发现之前写的太高深了,写了一个通俗易懂的版本
293 |
294 | [https://dl.acm.org/doi/pdf/10.1145/3373376.3378496](https://link.zhihu.com/?target=https%3A//dl.acm.org/doi/pdf/10.1145/3373376.3378496) hermes
295 |
296 | [https://raft.github.io/raft.pdf](https://link.zhihu.com/?target=https%3A//raft.github.io/raft.pdf) 这个是精简版的raft 里面有些概念如果理解起来吃力可以看下作者的博士毕业论文[https://github.com/ongardie/dissertation#readme](https://link.zhihu.com/?target=https%3A//github.com/ongardie/dissertation%23readme) 里面有download的连接,以下的几篇文章都是raft的推荐
297 |
298 | [https://www.cl.cam.ac.uk/~ms705/pub/papers/2015-osr-raft.pdf](https://link.zhihu.com/?target=https%3A//www.cl.cam.ac.uk/~ms705/pub/papers/2015-osr-raft.pdf) raft 的分析文章
299 |
300 | [http://verdi.uwplse.org/raft-proof.pdf](https://link.zhihu.com/?target=http%3A//verdi.uwplse.org/raft-proof.pdf)
301 |
302 | [http://verdi.uwplse.org/verdi.pdf](https://link.zhihu.com/?target=http%3A//verdi.uwplse.org/verdi.pdf) verdi的实现
303 |
304 | [https://www.cl.cam.ac.uk/techreports/UCAM-CL-TR-857.pdf](https://link.zhihu.com/?target=https%3A//www.cl.cam.ac.uk/techreports/UCAM-CL-TR-857.pdf) raft一致性的分析
305 |
306 | [https://hal.inria.fr/hal-01086522/document](https://link.zhihu.com/?target=https%3A//hal.inria.fr/hal-01086522/document)
307 |
308 |
309 |
310 | 名字服务
311 |
312 | [http://static.cs.brown.edu/courses/csci2270/archives/2012/papers/replication/hunt.pdf](https://link.zhihu.com/?target=http%3A//static.cs.brown.edu/courses/csci2270/archives/2012/papers/replication/hunt.pdf) zk最初设计的论文,感觉比市面上的一些中文材料好懂,推荐
--------------------------------------------------------------------------------
/blog/base/brief.md:
--------------------------------------------------------------------------------
1 | 分布式系统中除了CAP理论,还有一个不得不说的BASE理论,这不仅是面试中常问的一个知识点,也是在学习分布式系统时候一个绕不过去的基础。
2 |
3 | 1、CAP理论回顾
4 |
5 | 分布式CAP理论告诉我们一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容忍 性(Partition tolerance)这三项中的两项。在这三项当中AP在实际应用中较多,它舍弃了一致性。
6 |
7 | 为什么要舍弃一致性呢?就好比是我们在买火车票的时候,明明看到还有一张票,可是等我选好了座位准备付钱的时候,系统却提示没票了。这就是舍弃了一致性,数据可能是不一致的。但是分区容错性和可用性却得到了满足。
8 |
9 | 但这不是说一致性不重要,相反恰恰它是最重要的。对我们来说,我们舍弃的只是强一致性。但是一定要满足最终一致性。也就是说,但是最终也要将数据同步成功来保证数据一致。而强一致性,要求在任何时间查询每个节点数据都必须一致。
10 |
11 | 2、Base理论介绍
12 |
13 | BASE 是 Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent (最终一致性)三个短语的缩 写。BASE理论是对CAP中AP的一个扩展。下面我们来介绍一下这三个概念。
14 |
15 | (1)基本可用
16 |
17 | 指分布式系统在出现故障的时候,保证核心可用,允许损失部分可用性。例如,电商在做促销时,为了保证购物系统的稳定性,部分消费者可能会被引导到一个降级的页面。
18 |
19 | (2)软状态
20 |
21 | 指允许系统中的数据存在中间状态,并认为该中间状态不会影响系统整体可用性,即允许系统不同节点的数据副本之间进行同步的过程存在时延。就好比是使用支付宝的时候,会出现支付中、数据同步中等状态,这时候就叫做软状态。但是最终会显示支付成功。
22 |
23 | (3)最终一致性
24 |
25 | 最终一致性强调的是系统中的数据副本,在经过一段时间的同步后,最终能达到一致的状态。如订单的"支付中"状态,最终会变 为“支付成功”或者"支付失败",使订单状态与实际交易结果达成一致,但需要一定时间的延迟、等待。
26 |
27 | 
--------------------------------------------------------------------------------
/blog/cap/brief.md:
--------------------------------------------------------------------------------
1 | ## 一 理论基础
2 |
3 | CAP理论指的是一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。拿一个网上的图来看看。
4 |
5 | 
6 |
7 | 这张图不知道你之前看到过没,如果你看过书或者是视频,这张图应该被列举了好几遍了。下面我不准备直接上来就对每一个特性进行概述。我们先从案例出发逐步过渡。
8 |
9 | ### 1、一个小例子
10 |
11 | 首先我们看一张图。
12 |
13 | 
14 |
15 | 现在网络中有两个节点N1和N2,他们之间网络可以连通,N1中有一个应用程序A,和一个数据库V,N2也有一个应用程序B2和一个数据库V。现在,A和B是分布式系统的两个部分,V是分布式系统的两个子数据库。
16 |
17 | 现在问题来了。突然有两个用户小明和小华分别同时访问了N1和N2。我们理想中的操作是下面这样的。
18 |
19 | 
20 |
21 | (1)小明访问N1节点,小华访问N2节点。同时访问的。
22 |
23 | (2)小明把N1节点的数据V0变成了V1。
24 |
25 | (2)N1节点一看自己的数据有变化,立马执行M操作,告诉了N2节点。
26 |
27 | (4)小华读取到的就是最新的数据。也是正确的数据。
28 |
29 | 上面这是一种最理想的情景。它满足了CAP理论的三个特性。现在我们看看如何来理解满足的这三个特性。
30 |
31 | ### 2、Consistency 一致性
32 |
33 | 一致性指的是所有节点在同一时间的数据完全一致。就好比刚刚举得例子中,小明和小华读取的都是正确的数据,对他们用户来说,就好像是操作了同一个数据库的同一个数据一样。
34 |
35 | 因此对于一致性,也可以分为从客户端和服务端两个不同的视角来理解。
36 |
37 | (1)客户端
38 |
39 | 从客户端来看,一致性主要指的是多并发访问时更新过的数据如何获取的问题。也就是小明和小华同时访问,如何获取更新的最新的数据。
40 |
41 | (2)服务端
42 |
43 | 从服务端来看,则是更新如何分布到整个系统,以保证数据最终一致。也就是N1节点和N2节点如何通信保持数据的一致。
44 |
45 | 对于一致性,一致的程度不同大体可以分为强、弱、最终一致性三类。
46 |
47 | (1)强一致性
48 |
49 | 对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。比如小明更新V0到V1,那么小华读取的时候也应该是V1。
50 |
51 | (2)弱一致性
52 |
53 | 如果能容忍后续的部分或者全部访问不到,则是弱一致性。比如小明更新VO到V1,可以容忍那么小华读取的时候是V0。
54 |
55 | (3)最终一致性
56 |
57 | 如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。比如小明更新VO到V1,可以使得小华在一段时间之后读取的时候是V0。
58 |
59 | ### 3、可用性
60 |
61 | 可用性指服务一直可用,而且是正常响应时间。就好比刚刚的N1和N2节点,不管什么时候访问,都可以正常的获取数据值。而不会出现问题。好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。
62 |
63 | 对于可用性来说就比较好理解了。
64 |
65 | ### 4、分区容错性
66 |
67 | 分区容错性指在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。就好比是N1节点和N2节点出现故障,但是依然可以很好地对外提供服务。
68 |
69 | 这个分区容错性也是很好理解。
70 |
71 | 在经过上面的分析中,在理想情况下,没有出现任何错误的时候,这三条应该都是满足的。但是天有不测风云。系统总是会出现各种各样的问题。下面来分析一下为什么说CAP理论只能满足两条。
72 |
73 | ## **二、验证CAP理论**
74 |
75 | 既然系统总是会有错误,那我们就来看看可能会出现什么错误。
76 |
77 | 
78 |
79 | N1节点更新了V0到V1,想在也想把这个消息通过M操作告诉N1节点,却发生了网络故障。这时候小明和小华都要同时访问这个数据,怎么办呢?现在我们依然想要我们的系统具有CAP三个特性,我们分析一下会发生什么。
80 |
81 | (1)系统网络发生了故障,但是系统依然可以访问,因此具有容错性。
82 |
83 | (2)小明在访问节点N1的时候更改了V0到V1,想要小华访问节点N2的V数据库的时候是V1,因此需要等网络故障恢复,将N2节点的数据库进行更新才可以。
84 |
85 | (3)在网络故障恢复的这段时间内,想要系统满足可用性,是不可能的。因为可用性要求随时随地访问系统都是正确有效的。这就出现了矛盾。
86 |
87 | 正是这个矛盾所以CAP三个特性肯定不能同时满足。既然不能满足,那我们就进行取舍。
88 |
89 | 有两种选择:
90 |
91 | (1)牺牲数据一致性,也就是小明看到的衣服数量是10,买了一件应该是9了。但是小华看到的依然是10。
92 |
93 | (2)牺牲可用性,也就是小明看到的衣服数量是10,买了一件应该是9了。但是小华想要获取的最新的数据的话,那就一直等待阻塞,一直到网络故障恢复。
94 |
95 | 现在你可以看到了CAP三个特性肯定是不能同时满足的,但是可以满足其中两个。
96 |
97 | ## 三、CAP特性的取舍
98 |
99 | 我们分析一下既然可以满足两个,那么舍弃哪一个比较好呢?
100 |
101 | (1)满足CA舍弃P,也就是满足一致性和可用性,舍弃容错性。但是这也就意味着你的系统不是分布式的了,因为涉及分布式的想法就是把功能分开,部署到不同的机器上。
102 |
103 | (2)满足CP舍弃A,也就是满足一致性和容错性,舍弃可用性。如果你的系统允许有段时间的访问失效等问题,这个是可以满足的。就好比多个人并发买票,后台网络出现故障,你买的时候系统就崩溃了。
104 |
105 | (3)满足AP舍弃C,也就是满足可用性和容错性,舍弃一致性。这也就是意味着你的系统在并发访问的时候可能会出现数据不一致的情况。
106 |
107 | 实时证明,大多数都是牺牲了一致性。像12306还有淘宝网,就好比是你买火车票,本来你看到的是还有一张票,其实在这个时刻已经被买走了,你填好了信息准备买的时候发现系统提示你没票了。这就是牺牲了一致性。
108 |
109 | 但是不是说牺牲一致性一定是最好的。就好比mysql中的事务机制,张三给李四转了100块钱,这时候必须保证张三的账户上少了100,李四的账户多了100。因此需要数据的一致性,而且什么时候转钱都可以,也需要可用性。但是可以转钱失败是可以允许的。
--------------------------------------------------------------------------------
/blog/concensus/lab1-线性一致性:
--------------------------------------------------------------------------------
1 | ## **1. 背景**
2 |
3 | 我们经常讨论分布式系统的 CAP 理论,那么一定对 CAP 中的 C 有一定的了解,CAP 中 C 指的就是强一致性(**strong consistency** ),也就是线性一致性(**linearizability** )。接下来我们准备分别撰写以下三部分内容,对线性一致性做一次深入的剖析。
4 |
5 | 1. 什么是线性一致性,线性一致性的实现和应用等
6 | 2. 线性一致性测试的理论:包含线性一致性的精确定义和线性一致性验证的算法介绍
7 | 3. 线性一致性测试的框架:主要介绍使用线性一致性测试框架 jepsen 的基本原理和使用
8 |
9 | 开篇首先先介绍线性一致性的定义、实现和应用等。
10 |
11 | ## **2. 定义**
12 |
13 | ## **2.1 什么是线性一致性?**
14 |
15 | - **Linearizable semantics** (Linearizability)(each operation appears to execute instantaneously, exactly once, at some point between its invocation and its response)
16 |
17 | - - 在一个线性一致性的系统里面,任何操作都可能在调用或者返回之间原子和瞬间执行
18 | - 线性一致性,Linearizability,也称为原子一致性(atomic consistency),强一致性(strong consistency)等
19 | - 也就是通常所说的 CAP 理论中的 C
20 |
21 |
22 |
23 | 比较模糊,下面慢慢解析,首先来看看,为什么需要线性一致性 ?还需要一个这么强的一致性 ?首先看一个简单的例子,如下图 [1]:
24 |
25 |
26 |
27 | 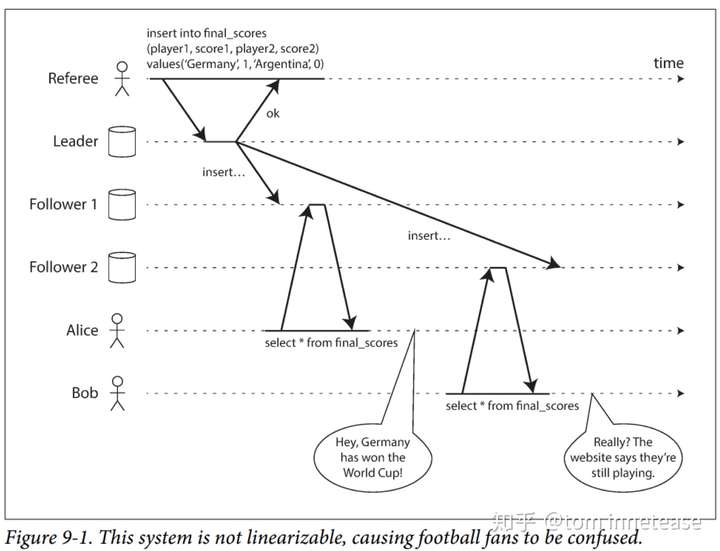
28 |
29 |
30 |
31 | 1. Referee:更新比赛的最终结果,先 insert 到数据库 leader 副本,然后 Leader 再复制给两个 Follower 副本
32 | 2. Alice:从 Follower 1 中查到了最新的比赛分数
33 | 3. Bob:从 Follower 2 中确没查到最新的比赛分数,确显示比赛正在进行
34 |
35 | 如果 Alice 和 Bob 在同一个房间,各自盯着自己的手机观看比赛,Alice 刷新页面,返现 Germany 赢得比赛,然后告诉 Bob 比赛结果,而 Bob 刷新页面,确显示比赛正在进行,显然这个结果是让人不符合预期的,实际上它也不是符合线性一致性的。对 Bob 来说,他希望看到的结果应该是和 Alice 一样最新的比赛结果,而不是一个旧的结果。
36 |
37 | 上面的例子展示了非线性一致性的系统可能会返回一些不合情理的结果,这其实也反应了分布式系统中一个典型的问题 ?
38 |
39 | > 分布式系统通常会是多个副本,那么多个副本复制会存在延迟 ,上图中每个副本就是一个数据库,但是看到了数据库复制中发生的一些时序问题 ,从而让外界看到多个副本的状态是不一致的,导致了一致性问题,
40 |
41 |
42 |
43 | **一致性其实主要是描述了在故障和延迟的情况下副本间的状态协调的问题**
44 |
45 | 想象如果只有一个副本?或者对应用来说,看起来就像一个副本,那么是不是就很容易。
46 |
47 | > 线性一致性的基本的想法是让一个系统看起来好像只有一个数据副本,而且所有的操作都是原子性的。有了这个保证,即使实际中可能有多个副本,应用也不需要担心它们。
48 |
49 | ## **2.2 什么样的系统是线性一致性的?**
50 |
51 | 系统需要加一些什么限制才能符合线性一致的语义呢 ?
52 |
53 |
54 |
55 | 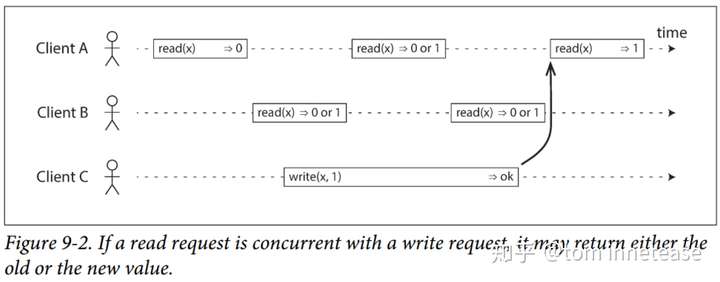
56 |
57 |
58 |
59 | (图 9-2,横轴为时间,每个 Op 在时间轴上的起点表示表示 Op invocation 的时间戳,结束点表示 reponse)
60 |
61 | 从 client 端角度来看,线性一致性的系统需要如下约束:
62 |
63 | - (1)单个 client Op 都是顺序的:如上图 9-2 [1] 每个 client 的每个 Op 都是在上一个 Op 返回之后,在执行下一个 Op,也就是同一个 client 的 Op 都是顺序的,没有并发
64 | - (2)不同 client 的 Op 如果并发,则可能会返回旧值或新值:如上图 9-2,client B 的第一个 read 和 client C 的第1 个 write 是并发,那么 client B 有可能读到 read 0 或者 1 都是合法,因为它们是并发的,考虑到网络延迟,可能 read 先被执行,也可能 write 先被执行,或者相反(但是这条约束不足以完全描述线性一致性:如果与写入同时发生的读取可以返回旧值或新值,那么读者可能会在写入期间看到数值在旧值和新值之间来回翻转,如果 client B 的第1个 read 返回 0,第 2 个 read 返回 1,那么就出现新旧值的翻转了)
65 | - (3)**任何一个读取返回新值后,所有后续读取(在相同或其他客户端上)也必须返回新值**:如下图 9-3 [1] 所示,client A 第 2 个 read、 client B 的第 1、2 个 read 和 client C 的第 1 个 write 是并发的,但是一旦 client A 的第 2 个 read 看到了这个最新值,那么 client B 的第 2 个 read 也必须看到这个最新的值
66 |
67 |
68 |
69 | 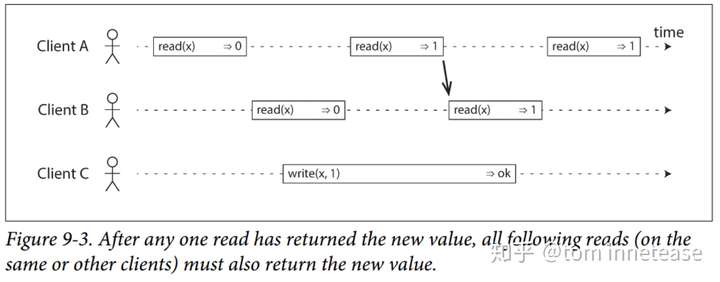
70 |
71 | 其实约束的第(3)条就是所谓的:
72 |
73 | > **Linearizable semantics** (Linearizability)(each operation appears to execute instantaneously, exactly once, at some point between its invocation and its response).
74 | > 在一个线性一致性的系统里面,任何操作都可能在**调用和返回之间原子和瞬间**执行。
75 |
76 |
77 |
78 | 也就是说,由于网络延迟的原因,所以在 client 端看来,一个 Op 是在 invocation 和 response 之间被执行,具体在这之间的某个时刻被执行,并不知道,但是如果这个 Op 在系统后端是在 invocation 和 response 之间的**特定时刻原子和瞬间**执行或者生效的,那么**任何一个读取返回新值后,所有后续读取(在相同或其他客户端上)也必须返回新值**,如下图 9-4,给出了每个 Op 原子或者瞬间执行的时间点就很清晰了
79 |
80 |
81 |
82 | 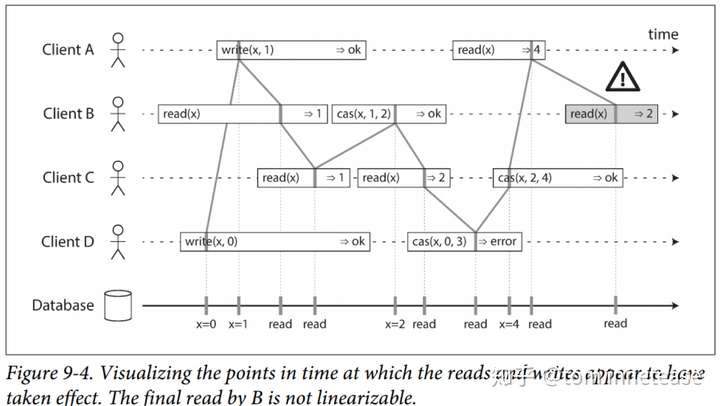
83 |
84 | (注意:上图中 Client B read(x) => 2 不是线性一致性的)
85 |
86 |
87 |
88 | **小结**
89 |
90 | - 原子和瞬间的被执行,一旦执行成功,对**所有**的 client 可见
91 | - 让多个副本,对应用来说看起来就像一个副本
92 | - 线性一致性保证的是对单个对象的单个操作的保证瞬间或者原子的被执行,注意是事务 ACID 语义的区分,事务 ACID 语义是保证的一组操作(单个对象或者多个对象操作)
93 | - 线性一致性并不局限在分布式系统,例如:在多核 CPU 中,如普通变量的 counter 就不是线性一致的,只有 atomic 变量才是线性一致的;还有很多如 queue、mutex 一般都必须满足线性化语义
94 |
95 | ## **3. 实现**
96 |
97 | **如何实现线性一致性系统 ?**
98 |
99 | 现在最成熟的就是共识算法(Consensus Algorithm),例如 Paxos、Raft 等
100 |
101 | **Raft**
102 |
103 | 这里将讨论 Raft 是否是线性一致的 ?以及其大致是如何实现线性一致的,这里不会过多的讨论 Raft 的细节,详细的细节可以参考 [2]。后续考虑给出单独的文章讨论 Raft 算法
104 |
105 | - 线性一致性写
106 |
107 | 所有的 read/write 都会来到 Leader,write 会有 Op log Leader 被序列化,依次顺序往后 commit,并 apply 然后在返回,那么一旦一个 write 被 committed,那么其前面的 write 的 Op log 一定就被 committed 了。 所有的 write 都是有严格的顺序的,一旦被 committed 就可见了,所以 Raft 是线性一致性写,基本是没有什么问题的
108 |
109 | - 线性一致性读
110 |
111 | Raft 的 read 有多种实现:
112 |
113 | 1. Raft log read:每个 read 都有一个对应的 Op log,和 write 一样,都会走一遍一致性协议的流程,会在此 Read Op log 被 Apply 的时候读,那么这个 read Op log 之前的 write Op log 肯定也被 applied 了,那么一定能够被读取到,读到的也一定是最新的
114 | 2. ReadIndex:我们知道 Raft log read,会有 raft read log 的复制和提交的开销,所以出现了 ReadIndex,read 没有 Op log,但是需要额外的机制保证读到最新的,所以 read 发送给 Leader 的时候,1)它需要确认 read 返回的数据的那个点 ?必须返回最新 committed 的结果,但是一个节点刚当选 Leader 的时候并不知道最新的 committed index,这个时候需要提交一个 Noop log entry 来提交之前的 log entry,然后开始 Read;2)它需要确认当前的 Leader 是不是还是 Leader,因为可能因为网络分区,这个 Leader 已经被孤立了,所以 Leader 在返回 read 之前,先和 Replica-group 的其他成员发送 heartbeat 确定自己 Leader 的身份;通过上述两条保证读到最新被 committed 的数据
115 | 3. Lease read:主要是通过 lease 机制维护 Leader 的状态,来减少了 ReadIndex 每次 read 发送 heartheat 的开销,详细参考 [3]
116 | 4. Follower read:先去 Leader 查询最新的 committed index,然后拿着 committed Index 去 Follower read,从而保证能从 Follower 中读到最新的数据,当前 etcd 就实现了 Follower read
117 |
118 | - 来看一个反例吧:
119 |
120 | 假设,对于实现 2. ReadIndex 方法实现,刚选出的 Leader 不通过提交 noop 来获取最新的 committed index,就返回读的话,会存在读取新旧 value 反转的情况:
121 |
122 | 1. 初始状态,三个副本 A,B,C,A 为 leader,B、C 为 Follower
123 | 2. client 发送`w1` 发送给 A,A committed w1,并且 apply 了,但是 B、C 还没有 committed `w1`
124 | 3. client 发送`r1` ,那么自然能够读到最新的写入 `w1`
125 | 4. Leader A 挂了,注意这个时候 B 和 C 还没有收到 A `w1` 的 committed 消息
126 | 5. B,C超时选举,假定 B 成为 Leader,显然 B 并不知道当前的最新 committed index 是多少
127 | 6. client 发送 `r2`,那么 B 就不一定能返回 `w1` 的结果了
128 |
129 | 上面的过程展示了 client 两次读 `r1` 和 `r2` 新旧反转的过程,是不满足线性一致的。所以对于刚起来的 Leader 来说,必须通过提交 noop 来提交已经被 commit,但是自己可能不知道的 log entry 来保证能读到最新的值
130 |
131 | ## **4. 应用**
132 |
133 | 线性一致性的系统有什么用呢 ?
134 |
135 | - Leader 选举,一般通过分布式锁来实现,那么,必须保证这个分布式锁必须是满足线性一致性语义:也就是一旦某个 节点成为了 Leader,**其它节点的选举就必须返回失败**,这样的结果才是一致的,不然就会出现双主,就不合法了
136 | - 对应用来说更简单:例如,设计和实现了一个块存储,不满足线性一致性,假定不能线性一致性读,那么在此块存储之上做其他的应用将很难,例如在这个块存储上面跑数据库,数据库就几乎不能做正确
137 |
138 | ## **5. 代价**
139 |
140 | 线性一致性,是一种强一致性,线性一致性的系统虽好,但是实现是有代价的
141 |
142 | **原子数**
143 |
144 | 例如:在多核系统中,由于 CPU Cache 的原因,一个普通的变量,例如定义 `int count = 0`,可以对其执行 `get`(read)、`increment`(自增) 等操作,显然这个变量 `count` 不是满足线性一致性,例如 `increment` 不是原子的,`get` 可能返回一个旧的值等等。有两种方式让变量 `count` 满足线性一致性:
145 |
146 | 1. 加锁 `mutex`保护
147 | 2. 使用原子变量
148 |
149 | 那么自然,性能也就下降了。
150 |
151 | **不总是需要线性一致**
152 |
153 | 所以在一些系统中,如果不需要线性一致性,那么可以做一些权衡,以 Figure 9-1 为例,用户可以接受一定的 read 延迟,只要不会出现新旧 value 反转即可,那么一个更弱的一致性 **单调读(Monotonic reads)**来避免时光倒流也是可以的,那么系统实现 read/write 就相对来说就简单些了:
154 |
155 | 以 read 为例,就不要向 Raft 一样总是去 Leader 读,只需要保证每次 read 都在相同的副本,就不会有任何问题,甚至对于新闻这种数据来说,偶尔出现一两次时光倒流也不会有什么不可饶恕的大问题 。
156 |
157 | ## **6. CAP**
158 |
159 | 既然聊到了 CAP 中的 C,那么也来聊聊 CAP 理论,这里以块存储场景为例,以常规的一致性思路来简单谈谈:
160 |
161 | - CAP,P - 网络分区是一种错误,不是一个选项,一定会发生,所以,就是 CA 二选一
162 | - 块存储,需要线性一致性(面向上层所有应用,没有tradeoff,必须线性一致性),所以就是 C 也没得选,就剩下 A 了
163 | - 但是在网络分区的场景下,如果要保证线性一致性C,那么可用性A必然就会成为问题,尽管出现的概率极低(云盘厂商一般提供99.999% 5个9的可用性保障,这个对绝大多书应用场景而言,非常高了)
164 |
165 |
166 |
167 | 在确定CA的基础之上,系统设计应该关注一下2点,优秀的系统设计和实现会在一下2点上下足功夫,提供业界一流的云盘:
168 |
169 | - 提高可用性
170 |
171 | - - 在极端网络分区下,为保证线性一致性,只能牺牲可用性,网络分成三个区,{A},{B},{C},那么就没办法提供服务了
172 | - 在一些非极端的网络分区情况下,例如 Raft 中在非对称和对称网络分区的情况下,通过 pre-vote 等提高可用性
173 | - 在大多数副本下线的情况下,而且场景允许,可以使用重置复制组提高可用性
174 | - 甚至通过一些结合客户端的机制,hinted handoff 重开复制组的机制尽最大努力保证读取和写入的可用性
175 | - 等等
176 |
177 |
178 |
179 | - 提高性能
180 |
181 | - - 线性一致性系统确实比较慢,这是一个事实,所以提高性能是如此的重要,Raft 性能优化,batch,pipeline,async commit & apply 各种提高性能的手段一起上 [4],paxos 性能优化 [5],paxos 变种 multi-paxos [6] 等等都是在为提高性能作出努力
182 | - 等等
183 |
184 |
185 |
186 | **Notes**
187 |
188 | 作者:网易存储团队攻城狮 吴德妙
189 |
190 | 如有理解和描述上有疏漏或者错误的地方,欢迎共同交流;参考已经在参考文献中注明,但仍有可能有疏漏的地方,有任何侵权或者不明确的地方,欢迎指出,必定及时更正或者删除;文章供于学习交流,转载注明出处
--------------------------------------------------------------------------------
/blog/transaction/type.md:
--------------------------------------------------------------------------------
1 | ## 分布式事务
2 |
3 | ## 什么是分布式事务
4 |
5 | 分布式事务就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
6 |
7 | ## 分布式事务产生的原因
8 |
9 | 从上面本地事务来看,我们可以看为两块,一个是service产生多个节点,另一个是resource产生多个节点。
10 |
11 | ## service多个节点
12 |
13 | 随着互联网快速发展,微服务,SOA等服务架构模式正在被大规模的使用,举个简单的例子,一个公司之内,用户的资产可能分为好多个部分,比如余额,积分,优惠券等等。在公司内部有可能积分功能由一个微服务团队维护,优惠券又是另外的团队维护
14 |
15 | 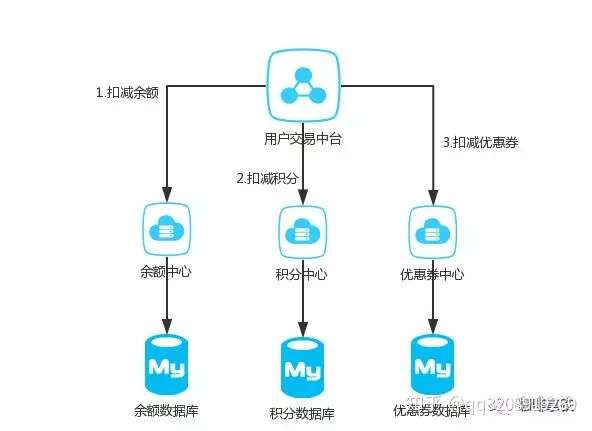
16 |
17 | 这样的话就无法保证积分扣减了之后,优惠券能否扣减成功。
18 |
19 | ## resource多个节点
20 |
21 | 同样的,互联网发展得太快了,我们的Mysql一般来说装千万级的数据就得进行分库分表,对于一个支付宝的转账业务来说,你给的朋友转钱,有可能你的数据库是在北京,而你的朋友的钱是存在上海,所以我们依然无法保证他们能同时成功。
22 |
23 | 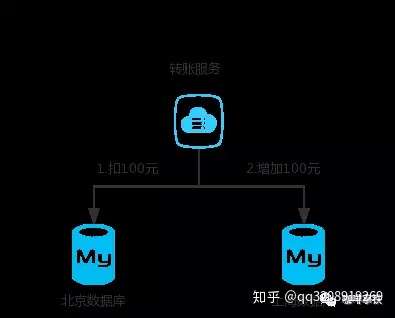
24 |
25 |
26 |
27 | ## 分布式事务的基础
28 |
29 | 从上面来看分布式事务是随着互联网高速发展应运而生的,这是一个必然的我们之前说过数据库的ACID四大特性,已经无法满足我们分布式事务,这个时候又有一些新的大佬提出一些新的理论:
30 |
31 | ## CAP
32 |
33 | CAP定理,又被叫作布鲁尔定理。对于设计分布式系统来说(不仅仅是分布式事务)的架构师来说,CAP就是你的入门理论。
34 |
35 | - C (一致性):对某个指定的客户端来说,读操作能返回最新的写操作。对于数据分布在不同节点上的数据上来说,如果在某个节点更新了数据,那么在其他节点如果都能读取到这个最新的数据,那么就称为强一致,如果有某个节点没有读取到,那就是分布式不一致。
36 | - A (可用性):非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。可用性的两个关键一个是合理的时间,一个是合理的响应。合理的时间指的是请求不能无限被阻塞,应该在合理的时间给出返回。合理的响应指的是系统应该明确返回结果并且结果是正确的,这里的正确指的是比如应该返回50,而不是返回40。
37 | - P (分区容错性):当出现网络分区后,系统能够继续工作。打个比方,这里个集群有多台机器,有台机器网络出现了问题,但是这个集群仍然可以正常工作。
38 |
39 | 熟悉CAP的人都知道,三者不能共有,如果感兴趣可以搜索CAP的证明,在分布式系统中,网络无法100%可靠,分区其实是一个必然现象,如果我们选择了CA而放弃了P,那么当发生分区现象时,为了保证一致性,这个时候必须拒绝请求,但是A又不允许,所以分布式系统理论上不可能选择CA架构,只能选择CP或者AP架构。
40 |
41 | 对于CP来说,放弃可用性,追求一致性和分区容错性,我们的zookeeper其实就是追求的强一致。
42 |
43 | 对于AP来说,放弃一致性(这里说的一致性是强一致性),追求分区容错性和可用性,这是很多分布式系统设计时的选择,后面的BASE也是根据AP来扩展。
44 |
45 | 顺便一提,CAP理论中是忽略网络延迟,也就是当事务提交时,从节点A复制到节点B,但是在现实中这个是明显不可能的,所以总会有一定的时间是不一致。同时CAP中选择两个,比如你选择了CP,并不是叫你放弃A。因为P出现的概率实在是太小了,大部分的时间你仍然需要保证CA。就算分区出现了你也要为后来的A做准备,比如通过一些日志的手段,是其他机器回复至可用。
46 |
47 | ## BASE
48 |
49 | BASE 是 Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent (最终一致性)三个短语的缩写。是对CAP中AP的一个扩展
50 |
51 | 1. 基本可用:分布式系统在出现故障时,允许损失部分可用功能,保证核心功能可用。
52 | 2. 软状态:允许系统中存在中间状态,这个状态不影响系统可用性,这里指的是CAP中的不一致。
53 | 3. 最终一致:最终一致是指经过一段时间后,所有节点数据都将会达到一致。
54 |
55 | BASE解决了CAP中理论没有网络延迟,在BASE中用软状态和最终一致,保证了延迟后的一致性。BASE和 ACID 是相反的,它完全不同于ACID的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。
56 |
57 | ## 分布式事务解决方案
58 |
59 | 有了上面的理论基础后,这里介绍开始介绍几种常见的分布式事务的解决方案。
60 |
61 | ## 是否真的要分布式事务
62 |
63 | 在说方案之前,首先你一定要明确你是否真的需要分布式事务?
64 |
65 | 上面说过出现分布式事务的两个原因,其中有个原因是因为微服务过多。我见过太多团队一个人维护几个微服务,太多团队过度设计,搞得所有人疲劳不堪,而微服务过多就会引出分布式事务,这个时候我不会建议你去采用下面任何一种方案,而是请把需要事务的微服务聚合成一个单机服务,使用数据库的本地事务。因为不论任何一种方案都会增加你系统的复杂度,这样的成本实在是太高了,千万不要因为追求某些设计,而引入不必要的成本和复杂度。
66 |
67 | 如果你确定需要引入分布式事务可以看看下面几种常见的方案。
68 |
69 | ## 2PC
70 |
71 | 说到2PC就不得不聊数据库分布式事务中的 XA Transactions。
72 |
73 | 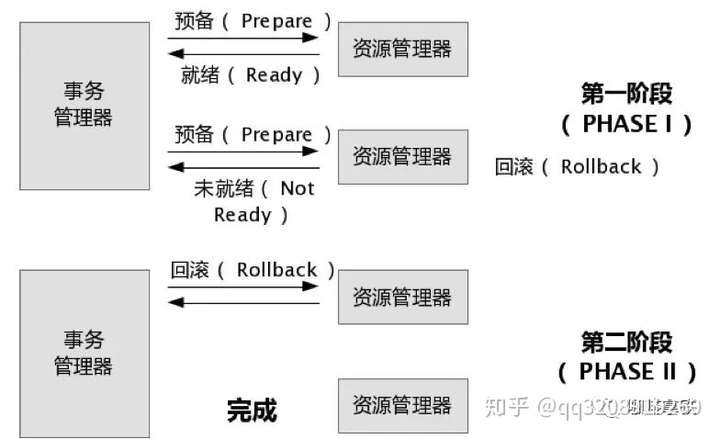
74 |
75 | 在XA协议中分为两阶段:
76 |
77 | 第一阶段:事务管理器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是否可以提交.
78 |
79 | 第二阶段:事务协调器要求每个数据库提交数据,或者回滚数据。
80 |
81 | 优点: 尽量保证了数据的强一致,实现成本较低,在各大主流数据库都有自己实现,对于MySQL是从5.5开始支持。
82 |
83 | 缺点:
84 |
85 | - 单点问题:事务管理器在整个流程中扮演的角色很关键,如果其宕机,比如在第一阶段已经完成,在第二阶段正准备提交的时候事务管理器宕机,资源管理器就会一直阻塞,导致数据库无法使用。
86 | - 同步阻塞:在准备就绪之后,资源管理器中的资源一直处于阻塞,直到提交完成,释放资源。
87 | - 数据不一致:两阶段提交协议虽然为分布式数据强一致性所设计,但仍然存在数据不一致性的可能,比如在第二阶段中,假设协调者发出了事务commit的通知,但是因为网络问题该通知仅被一部分参与者所收到并执行了commit操作,其余的参与者则因为没有收到通知一直处于阻塞状态,这时候就产生了数据的不一致性。
88 |
89 | 总的来说,XA协议比较简单,成本较低,但是其单点问题,以及不能支持高并发(由于同步阻塞)依然是其最大的弱点。
90 |
91 | ## TCC
92 |
93 | 关于TCC(Try-Confirm-Cancel)的概念,最早是由Pat Helland于2007年发表的一篇名为《Life beyond Distributed Transactions:an Apostate’s Opinion》的论文提出。 TCC事务机制相比于上面介绍的XA,解决了其几个缺点: 1.解决了协调者单点,由主业务方发起并完成这个业务活动。业务活动管理器也变成多点,引入集群。 2.同步阻塞:引入超时,超时后进行补偿,并且不会锁定整个资源,将资源转换为业务逻辑形式,粒度变小。 3.数据一致性,有了补偿机制之后,由业务活动管理器控制一致性
94 |
95 | 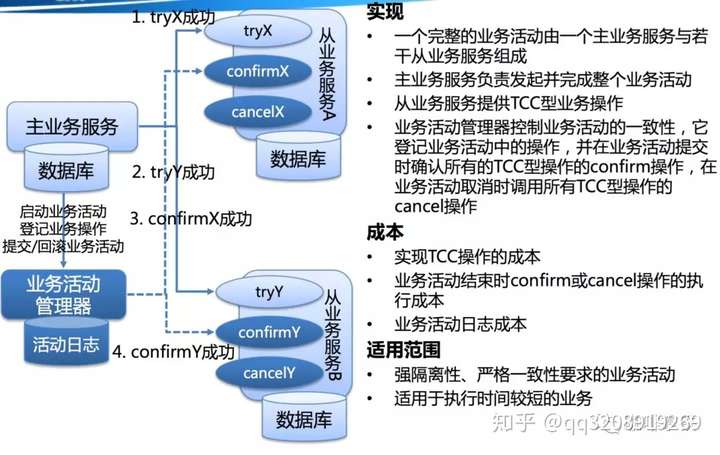
96 |
97 | 对于TCC的解释:
98 |
99 | -
100 | Try阶段:尝试执行,完成所有业务检查(一致性),预留必须业务资源(准隔离性)
101 | -
102 | Confirm阶段:确认执行真正执行业务,不作任何业务检查,只使用Try阶段预留的业务资源,Confirm操作满足幂等性。要求具备幂等设计,Confirm失败后需要进行重试。
103 | -
104 | Cancel阶段:取消执行,释放Try阶段预留的业务资源 Cancel操作满足幂等性Cancel阶段的异常和Confirm阶段异常处理方案基本上一致。
105 |
106 | 举个简单的例子如果你用100元买了一瓶水, Try阶段:你需要向你的钱包检查是否够100元并锁住这100元,水也是一样的。
107 |
108 | 如果有一个失败,则进行cancel(释放这100元和这一瓶水),如果cancel失败不论什么失败都进行重试cancel,所以需要保持幂等。
109 |
110 | 如果都成功,则进行confirm,确认这100元扣,和这一瓶水被卖,如果confirm失败无论什么失败则重试(会依靠活动日志进行重试)
111 |
112 | 对于TCC来说适合一些:
113 |
114 | - 强隔离性,严格一致性要求的活动业务。
115 | - 执行时间较短的业务
116 |
117 | 实现参考:ByteTCC:[https://github.com/liuyangming/ByteTCC/](https://link.zhihu.com/?target=https%3A//github.com/liuyangming/ByteTCC/)
118 |
119 | ## 本地消息表
120 |
121 | 本地消息表这个方案最初是ebay提出的 ebay的完整方案[https://queue.acm.org/detail.cfm?id=1394128](https://link.zhihu.com/?target=https%3A//queue.acm.org/detail.cfm%3Fid%3D1394128)。
122 |
123 | 此方案的核心是将需要分布式处理的任务通过消息日志的方式来异步执行。消息日志可以存储到本地文本、数据库或消息队列,再通过业务规则自动或人工发起重试。人工重试更多的是应用于支付场景,通过对账系统对事后问题的处理。
124 |
125 | 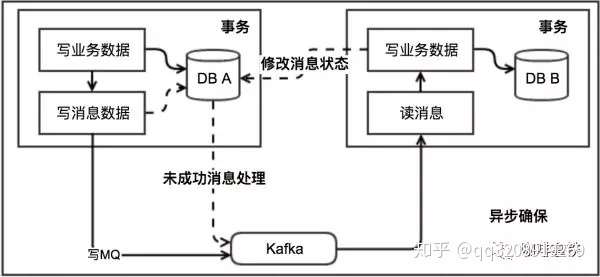
126 |
127 |
128 |
129 | 对于本地消息队列来说核心是把大事务转变为小事务。还是举上面用100元去买一瓶水的例子。
130 |
131 | 1.当你扣钱的时候,你需要在你扣钱的服务器上新增加一个本地消息表,你需要把你扣钱和写入减去水的库存到本地消息表放入同一个事务(依靠数据库本地事务保证一致性。
132 |
133 | 2.这个时候有个定时任务去轮询这个本地事务表,把没有发送的消息,扔给商品库存服务器,叫他减去水的库存,到达商品服务器之后这个时候得先写入这个服务器的事务表,然后进行扣减,扣减成功后,更新事务表中的状态。
134 |
135 | 3.商品服务器通过定时任务扫描消息表或者直接通知扣钱服务器,扣钱服务器本地消息表进行状态更新。
136 |
137 | 4.针对一些异常情况,定时扫描未成功处理的消息,进行重新发送,在商品服务器接到消息之后,首先判断是否是重复的,如果已经接收,在判断是否执行,如果执行在马上又进行通知事务,如果未执行,需要重新执行需要由业务保证幂等,也就是不会多扣一瓶水。
138 |
139 | 本地消息队列是BASE理论,是最终一致模型,适用于对一致性要求不高的。实现这个模型时需要注意重试的幂等。
140 |
141 | ## MQ事务
142 |
143 | 在RocketMQ中实现了分布式事务,实际上其实是对本地消息表的一个封装,将本地消息表移动到了MQ内部,下面简单介绍一下MQ事务,如果想对其详细了解可以参考: [https://www.jianshu.com/p/453c6e7ff81c](https://link.zhihu.com/?target=https%3A//www.jianshu.com/p/453c6e7ff81c)。
144 |
145 | 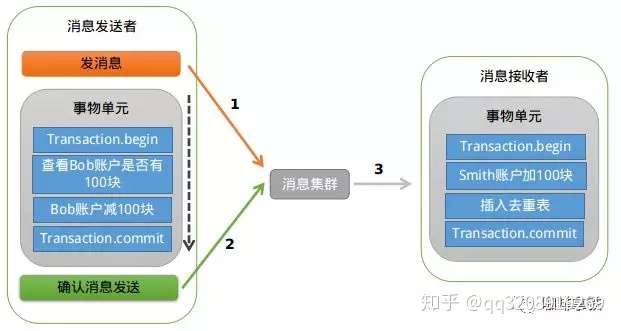
146 |
147 | 基本流程如下: 第一阶段Prepared消息,会拿到消息的地址。
148 |
149 | 第二阶段执行本地事务。
150 |
151 | 第三阶段通过第一阶段拿到的地址去访问消息,并修改状态。消息接受者就能使用这个消息。
152 |
153 | 如果确认消息失败,在RocketMq Broker中提供了定时扫描没有更新状态的消息,如果有消息没有得到确认,会向消息发送者发送消息,来判断是否提交,在rocketmq中是以listener的形式给发送者,用来处理。
154 |
155 | 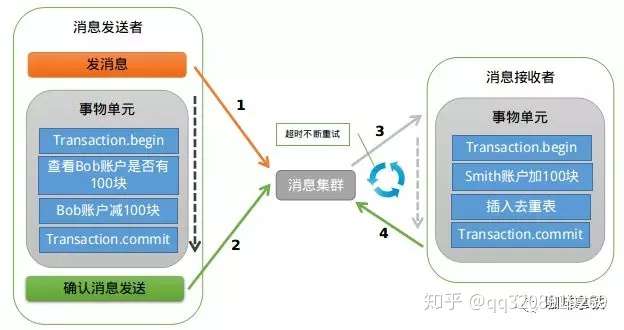
156 |
157 | 如果消费超时,则需要一直重试,消息接收端需要保证幂等。如果消息消费失败,这个就需要人工进行处理,因为这个概率较低,如果为了这种小概率时间而设计这个复杂的流程反而得不偿失
158 |
159 | ## Saga事务
160 |
161 | Saga是30年前一篇数据库伦理提到的一个概念。其核心思想是将长事务拆分为多个本地短事务,由Saga事务协调器协调,如果正常结束那就正常完成,如果某个步骤失败,则根据相反顺序一次调用补偿操作。 Saga的组成:
162 |
163 | 每个Saga由一系列sub-transaction Ti 组成 每个Ti 都有对应的补偿动作Ci,补偿动作用于撤销Ti造成的结果,这里的每个T,都是一个本地事务。 可以看到,和TCC相比,Saga没有“预留 try”动作,它的Ti就是直接提交到库。
164 |
165 | Saga的执行顺序有两种:
166 |
167 | T1, T2, T3, ..., Tn
168 |
169 | T1, T2, ..., Tj, Cj,..., C2, C1,其中0 < j < n Saga定义了两种恢复策略:
170 |
171 | 向后恢复,即上面提到的第二种执行顺序,其中j是发生错误的sub-transaction,这种做法的效果是撤销掉之前所有成功的sub-transation,使得整个Saga的执行结果撤销。 向前恢复,适用于必须要成功的场景,执行顺序是类似于这样的:T1, T2, ..., Tj(失败), Tj(重试),..., Tn,其中j是发生错误的sub-transaction。该情况下不需要Ci。
172 |
173 | 这里要注意的是,在saga模式中不能保证隔离性,因为没有锁住资源,其他事务依然可以覆盖或者影响当前事务。
174 |
175 | 还是拿100元买一瓶水的例子来说,这里定义
176 |
177 | T1=扣100元 T2=给用户加一瓶水 T3=减库存一瓶水
178 |
179 | C1=加100元 C2=给用户减一瓶水 C3=给库存加一瓶水
180 |
181 | 我们一次进行T1,T2,T3如果发生问题,就执行发生问题的C操作的反向。 上面说到的隔离性的问题会出现在,如果执行到T3这个时候需要执行回滚,但是这个用户已经把水喝了(另外一个事务),回滚的时候就会发现,无法给用户减一瓶水了。这就是事务之间没有隔离性的问题
182 |
183 | 可以看见saga模式没有隔离性的影响还是较大,可以参照华为的解决方案:从业务层面入手加入一 Session 以及锁的机制来保证能够串行化操作资源。也可以在业务层面通过预先冻结资金的方式隔离这部分资源, 最后在业务操作的过程中可以通过及时读取当前状态的方式获取到最新的更新。
184 |
185 | 具体实例:可以参考华为的servicecomb
186 |
187 | ## 最后
188 |
189 | 还是那句话,能不用分布式事务就不用,如果非得使用的话,结合自己的业务分析,看看自己的业务比较适合哪一种,是在乎强一致,还是最终一致即可。最后在总结一些问题,大家可以下来自己从文章找寻答案:
190 |
191 | 1. ACID和CAP的 CA是一样的吗?
192 | 2. 分布式事务常用的解决方案的优缺点是什么?适用于什么场景?
193 | 3. 分布式事务出现的原因?用来解决什么痛点?
194 |
195 | 如果喜欢我们的文章的话,请加我扣扣,来和我一起讨论学习吧。
--------------------------------------------------------------------------------
/doc/jraft/basic/Untitled.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hzh0425/hy_distribute_theory_basic/80ffc1bfa0ca2856ecdafd46489a036994414894/doc/jraft/basic/Untitled.md
--------------------------------------------------------------------------------
/doc/jraft/basic/lab1-定时调度时间轮算法.md:
--------------------------------------------------------------------------------
1 | ### 算法简介
2 |
3 | 
4 |
5 | 网上盗个图,时间轮算法可以通过上图来描述。假设时间轮大小为8,1s转一格,每格指向一个链表,保存着待执行的任务。
6 |
7 | 假设,当前位于2,现在要添加一个3s后指向的任务,则2+3=5,在第5格的链表中添加一个节点指向任务即可,标识round=0。
8 |
9 | 假设,当前位于2,现在要添加一个10s后指向的任务,则(2+10)% 8 = 4,则在第4格添加一个节点指向任务,并标识round=1,则当时间轮第二次经过第4格时,即会执行任务。
10 |
11 | 时间轮只会执行round=0的任务,并会把该格子上的其他任务的round减1。
12 |
13 | 算法的原理非常浅显易懂,但是阅读源码实现还是有益的。
14 |
15 | 对于介绍RepeatedTimer,我拿Node初始化的时候的electionTimer进行讲解
16 |
17 | ```java
18 | Copythis.electionTimer = new RepeatedTimer("JRaft-ElectionTimer", this.options.getElectionTimeoutMs()) {
19 |
20 | @Override
21 | protected void onTrigger() {
22 | handleElectionTimeout();
23 | }
24 |
25 | @Override
26 | protected int adjustTimeout(final int timeoutMs) {
27 | //在一定范围内返回一个随机的时间戳
28 | //为了避免同时发起选举而导致失败
29 | return randomTimeout(timeoutMs);
30 | }
31 | };
32 | ```
33 |
34 | ### 构造器[#](https://www.cnblogs.com/luozhiyun/p/11706171.html#6662384)
35 |
36 | 由electionTimer的构造方法可以看出RepeatedTimer需要传入两个参数,一个是name,另一个是time
37 |
38 | ```java
39 | Copy//timer是HashedWheelTimer
40 | private final Timer timer;
41 | //实例是HashedWheelTimeout
42 | private Timeout timeout;
43 |
44 | public RepeatedTimer(String name, int timeoutMs) {
45 | //name代表RepeatedTimer实例的种类,timeoutMs是超时时间
46 | this(name, timeoutMs, new HashedWheelTimer(new NamedThreadFactory(name, true), 1, TimeUnit.MILLISECONDS, 2048));
47 | }
48 |
49 | public RepeatedTimer(String name, int timeoutMs, Timer timer) {
50 | super();
51 | this.name = name;
52 | this.timeoutMs = timeoutMs;
53 | this.stopped = true;
54 | this.timer = Requires.requireNonNull(timer, "timer");
55 | }
56 | ```
57 |
58 | 在构造器中会根据传进来的值初始化一个name和一个timeoutMs,然后实例化一个timer,RepeatedTimer的run方法是由timer进行回调。在RepeatedTimer中会持有两个对象,一个是timer,一个是timeout
59 |
60 | ### 启动RepeatedTimer[#](https://www.cnblogs.com/luozhiyun/p/11706171.html#4092675847)
61 |
62 | 对于一个RepeatedTimer实例,我们可以通过start方法来启动它:
63 |
64 | ```java
65 | Copypublic void start() {
66 | //加锁,只能一个线程调用这个方法
67 | this.lock.lock();
68 | try {
69 | //destroyed默认是false
70 | if (this.destroyed) {
71 | return;
72 | }
73 | //stopped在构造器中初始化为ture
74 | if (!this.stopped) {
75 | return;
76 | }
77 | //启动完一次后下次就无法再次往下继续
78 | this.stopped = false;
79 | //running默认为false
80 | if (this.running) {
81 | return;
82 | }
83 | this.running = true;
84 | schedule();
85 | } finally {
86 | this.lock.unlock();
87 | }
88 | }
89 | ```
90 |
91 | 在调用start方法进行启动后会进行一系列的校验和赋值,从上面的赋值以及加锁的情况来看,这个是只能被调用一次的。然后会调用到schedule方法中
92 |
93 | ```java
94 | Copyprivate void schedule() {
95 | if(this.timeout != null) {
96 | this.timeout.cancel();
97 | }
98 | final TimerTask timerTask = timeout -> {
99 | try {
100 | RepeatedTimer.this.run();
101 | } catch (final Throwable t) {
102 | LOG.error("Run timer task failed, taskName={}.", RepeatedTimer.this.name, t);
103 | }
104 | };
105 | this.timeout = this.timer.newTimeout(timerTask, adjustTimeout(this.timeoutMs), TimeUnit.MILLISECONDS);
106 | }
107 | ```
108 |
109 | 如果timeout不为空,那么会调用HashedWheelTimeout的cancel方法。然后封装一个TimerTask实例,当执行TimerTask的run方法的时候会调用RepeatedTimer实例的run方法。然后传入到timer中,TimerTask的run方法由timer进行调用,并将返回值赋值给timeout。
110 |
111 | 如果timer调用了TimerTask的run方法,那么便会回调到RepeatedTimer的run方法中:
112 | **RepeatedTimer#run**
113 |
114 | ```java
115 | Copypublic void run() {
116 | //加锁
117 | this.lock.lock();
118 | try {
119 | //表示RepeatedTimer已经被调用过
120 | this.invoking = true;
121 | } finally {
122 | this.lock.unlock();
123 | }
124 | try {
125 | //然后会调用RepeatedTimer实例实现的方法
126 | onTrigger();
127 | } catch (final Throwable t) {
128 | LOG.error("Run timer failed.", t);
129 | }
130 | boolean invokeDestroyed = false;
131 | this.lock.lock();
132 | try {
133 | this.invoking = false;
134 | //如果调用了stop方法,那么将不会继续调用schedule方法
135 | if (this.stopped) {
136 | this.running = false;
137 | invokeDestroyed = this.destroyed;
138 | } else {
139 | this.timeout = null;
140 | schedule();
141 | }
142 | } finally {
143 | this.lock.unlock();
144 | }
145 | if (invokeDestroyed) {
146 | onDestroy();
147 | }
148 | }
149 |
150 | protected void onDestroy() {
151 | // NO-OP
152 | }
153 | ```
154 |
155 | 这个run方法会由timer进行回调,如果没有调用stop或destroy方法的话,那么调用完onTrigger方法后会继续调用schedule,然后一次次循环调用RepeatedTimer的run方法。
156 |
157 | 如果调用了destroy方法,在这里会有一个onDestroy的方法,可以由实现类override复写执行一个钩子。
158 |
159 | ### HashedWheelTimer的基本介绍[#](https://www.cnblogs.com/luozhiyun/p/11706171.html#255292319)
160 |
161 | 
162 |
163 | HashedWheelTimer通过一定的hash规则将不同timeout的定时任务划分到HashedWheelBucket进行管理,而HashedWheelBucket利用双向链表结构维护了某一时刻需要执行的定时任务列表
164 |
165 | #### Wheel[#](https://www.cnblogs.com/luozhiyun/p/11706171.html#2680396931)
166 |
167 | 时间轮,是一个HashedWheelBucket数组,数组数量越多,定时任务管理的时间精度越精确。tick每走一格都会将对应的wheel数组里面的bucket拿出来进行调度。
168 |
169 | #### Worker[#](https://www.cnblogs.com/luozhiyun/p/11706171.html#540031737)
170 |
171 | Worker继承自Runnable,HashedWheelTimer必须通过Worker线程操作HashedWheelTimer中的定时任务。Worker是整个HashedWheelTimer的执行流程管理者,控制了定时任务分配、全局deadline时间计算、管理未执行的定时任务、时钟计算、未执行定时任务回收处理。
172 |
173 | #### HashedWheelTimeout[#](https://www.cnblogs.com/luozhiyun/p/11706171.html#3019705536)
174 |
175 | 是HashedWheelTimer的执行单位,维护了其所属的HashedWheelTimer和HashedWheelBucket的引用、需要执行的任务逻辑、当前轮次以及当前任务的超时时间(不变)等,可以认为是自定义任务的一层Wrapper。
176 |
177 | #### HashedWheelBucket[#](https://www.cnblogs.com/luozhiyun/p/11706171.html#3135917057)
178 |
179 | HashedWheelBucket维护了hash到其内的所有HashedWheelTimeout结构,是一个双向队列。
180 |
181 | ### HashedWheelTimer的构造器[#](https://www.cnblogs.com/luozhiyun/p/11706171.html#2193283699)
182 |
183 | 在初始化RepeatedTimer实例的时候会实例化一个HashedWheelTimer:
184 |
185 | ```java
186 | Copynew HashedWheelTimer(new NamedThreadFactory(name, true), 1, TimeUnit.MILLISECONDS, 2048)
187 | ```
188 |
189 | 然后调用HashedWheelTimer的构造器:
190 |
191 | ```java
192 | Copy
193 | private final HashedWheelBucket[] wheel;
194 | private final int mask;
195 | private final long tickDuration;
196 | private final Worker worker = new Worker();
197 | private final Thread workerThread;
198 | private final long maxPendingTimeouts;
199 | private static final int INSTANCE_COUNT_LIMIT = 256;
200 | private static final AtomicInteger instanceCounter = new AtomicInteger();
201 | private static final AtomicBoolean warnedTooManyInstances = new AtomicBoolean();
202 |
203 |
204 | public HashedWheelTimer(ThreadFactory threadFactory, long tickDuration, TimeUnit unit, int ticksPerWheel) {
205 | tickDuration
206 | this(threadFactory, tickDuration, unit, ticksPerWheel, -1);
207 | }
208 |
209 | public HashedWheelTimer(ThreadFactory threadFactory, long tickDuration, TimeUnit unit, int ticksPerWheel,
210 | long maxPendingTimeouts) {
211 |
212 | if (threadFactory == null) {
213 | throw new NullPointerException("threadFactory");
214 | }
215 | //unit = MILLISECONDS
216 | if (unit == null) {
217 | throw new NullPointerException("unit");
218 | }
219 | if (tickDuration <= 0) {
220 | throw new IllegalArgumentException("tickDuration must be greater than 0: " + tickDuration);
221 | }
222 | if (ticksPerWheel <= 0) {
223 | throw new IllegalArgumentException("ticksPerWheel must be greater than 0: " + ticksPerWheel);
224 | }
225 |
226 | // Normalize ticksPerWheel to power of two and initialize the wheel.
227 | // 创建一个HashedWheelBucket数组
228 | // 创建时间轮基本的数据结构,一个数组。长度为不小于ticksPerWheel的最小2的n次方
229 | wheel = createWheel(ticksPerWheel);
230 | // 这是一个标示符,用来快速计算任务应该呆的格子。
231 | // 我们知道,给定一个deadline的定时任务,其应该呆的格子=deadline%wheel.length.但是%操作是个相对耗时的操作,所以使用一种变通的位运算代替:
232 | // 因为一圈的长度为2的n次方,mask = 2^n-1后低位将全部是1,然后deadline&mast == deadline%wheel.length
233 | // java中的HashMap在进行hash之后,进行index的hash寻址寻址的算法也是和这个一样的
234 | mask = wheel.length - 1;
235 |
236 | // Convert tickDuration to nanos.
237 | //tickDuration传入是1的话,这里会转换成1000000
238 | this.tickDuration = unit.toNanos(tickDuration);
239 |
240 | // Prevent overflow.
241 | // 校验是否存在溢出。即指针转动的时间间隔不能太长而导致tickDuration*wheel.length>Long.MAX_VALUE
242 | if (this.tickDuration >= Long.MAX_VALUE / wheel.length) {
243 | throw new IllegalArgumentException(String.format(
244 | "tickDuration: %d (expected: 0 < tickDuration in nanos < %d", tickDuration, Long.MAX_VALUE
245 | / wheel.length));
246 | }
247 | //将worker包装成thread
248 | workerThread = threadFactory.newThread(worker);
249 | //maxPendingTimeouts = -1
250 | this.maxPendingTimeouts = maxPendingTimeouts;
251 |
252 | //如果HashedWheelTimer实例太多,那么就会打印一个error日志
253 | if (instanceCounter.incrementAndGet() > INSTANCE_COUNT_LIMIT
254 | && warnedTooManyInstances.compareAndSet(false, true)) {
255 | reportTooManyInstances();
256 | }
257 | }
258 | ```
259 |
260 | 这个构造器里面主要做一些初始化的工作。
261 |
262 | 1. 初始化一个wheel数据,我们这里初始化的数组长度为2048.
263 | 2. 初始化mask,用来计算槽位的下标,类似于hashmap的槽位的算法,因为wheel的长度已经是一个2的n次方,所以2^n-1后低位将全部是1,用&可以快速的定位槽位,比%耗时更低
264 | 3. 初始化tickDuration,这里会将传入的tickDuration转化成纳秒,那么这里是1000,000
265 | 4. 校验整个时间轮走完的时间不能过长
266 | 5. 包装worker线程
267 | 6. 因为HashedWheelTimer是一个很消耗资源的一个结构,所以校验HashedWheelTimer实例不能太多,如果太多会打印error日志
268 |
269 | ### 启动timer[#](https://www.cnblogs.com/luozhiyun/p/11706171.html#3521625645)
270 |
271 | 时间轮算法中并不需要手动的去调用start方法来启动,而是在添加节点的时候会启动时间轮。
272 |
273 | 我们在RepeatedTimer的schedule方法里会调用newTimeout向时间轮中添加一个任务。
274 |
275 | **HashedWheelTimer#newTimeout**
276 |
277 | ```java
278 | Copypublic Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {
279 | if (task == null) {
280 | throw new NullPointerException("task");
281 | }
282 | if (unit == null) {
283 | throw new NullPointerException("unit");
284 | }
285 |
286 | long pendingTimeoutsCount = pendingTimeouts.incrementAndGet();
287 |
288 | if (maxPendingTimeouts > 0 && pendingTimeoutsCount > maxPendingTimeouts) {
289 | pendingTimeouts.decrementAndGet();
290 | throw new RejectedExecutionException("Number of pending timeouts (" + pendingTimeoutsCount
291 | + ") is greater than or equal to maximum allowed pending "
292 | + "timeouts (" + maxPendingTimeouts + ")");
293 | }
294 | // 如果时间轮没有启动,则启动
295 | start();
296 |
297 | // Add the timeout to the timeout queue which will be processed on the next tick.
298 | // During processing all the queued HashedWheelTimeouts will be added to the correct HashedWheelBucket.
299 | long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;
300 |
301 | // Guard against overflow.
302 | //在delay为正数的情况下,deadline是不可能为负数
303 | //如果为负数,那么说明超过了long的最大值
304 | if (delay > 0 && deadline < 0) {
305 | deadline = Long.MAX_VALUE;
306 | }
307 | // 这里定时任务不是直接加到对应的格子中,而是先加入到一个队列里,然后等到下一个tick的时候,
308 | // 会从队列里取出最多100000个任务加入到指定的格子中
309 | HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline);
310 | //Worker会去处理timeouts队列里面的数据
311 | timeouts.add(timeout);
312 | return timeout;
313 | }
314 | ```
315 |
316 | 在这个方法中,在校验之后会调用start方法启动时间轮,然后设置deadline,这个时间等于时间轮启动的时间点+延迟的的时间;
317 | 然后新建一个HashedWheelTimeout实例,会直接加入到timeouts队列中去,timeouts对列会在worker的run方法里面取出来放入到wheel中进行处理。
318 |
319 | 然后我们来看看start方法:
320 | **HashedWheelTimer#start**
321 |
322 | ```java
323 | Copy
324 | private static final AtomicIntegerFieldUpdater workerStateUpdater = AtomicIntegerFieldUpdater.newUpdater(HashedWheelTimer.class,"workerState");
325 |
326 | private volatile int workerState;
327 | //不需要你主动调用,当有任务添加进来的的时候他就会跑
328 | public void start() {
329 | //workerState一开始的时候是0(WORKER_STATE_INIT),然后才会设置为1(WORKER_STATE_STARTED)
330 | switch (workerStateUpdater.get(this)) {
331 | case WORKER_STATE_INIT:
332 | //使用cas来获取启动调度的权力,只有竞争到的线程允许来进行实例启动
333 | if (workerStateUpdater.compareAndSet(this, WORKER_STATE_INIT, WORKER_STATE_STARTED)) {
334 | //如果成功设置了workerState,那么就调用workerThread线程
335 | workerThread.start();
336 | }
337 | break;
338 | case WORKER_STATE_STARTED:
339 | break;
340 | case WORKER_STATE_SHUTDOWN:
341 | throw new IllegalStateException("cannot be started once stopped");
342 | default:
343 | throw new Error("Invalid WorkerState");
344 | }
345 |
346 | // 等待worker线程初始化时间轮的启动时间
347 | // Wait until the startTime is initialized by the worker.
348 | while (startTime == 0) {
349 | try {
350 | //这里使用countDownLauch来确保调度的线程已经被启动
351 | startTimeInitialized.await();
352 | } catch (InterruptedException ignore) {
353 | // Ignore - it will be ready very soon.
354 | }
355 | }
356 | }
357 | ```
358 |
359 | 由这里我们可以看出,启动时间轮是不需要手动去调用的,而是在有任务的时候会自动运行,防止在没有任务的时候空转浪费资源。
360 |
361 | 在start方法里面会使用AtomicIntegerFieldUpdater的方式来更新workerState这个变量,如果没有启动过那么直接在cas成功之后调用start方法启动workerThread线程。
362 |
363 | 如果workerThread还没运行,那么会在while循环中等待,直到workerThread运行为止才会往下运行。
364 |
365 | ### 开始时间轮转[#](https://www.cnblogs.com/luozhiyun/p/11706171.html#2243393872)
366 |
367 | 时间轮的运转是在Worker的run方法中进行的:
368 | **Worker#run**
369 |
370 | ```java
371 | Copyprivate final Set unprocessedTimeouts = new HashSet<>();
372 | private long tick;
373 | public void run() {
374 | // Initialize the startTime.
375 | startTime = System.nanoTime();
376 | if (startTime == 0) {
377 | // We use 0 as an indicator for the uninitialized value here, so make sure it's not 0 when initialized.
378 | startTime = 1;
379 | }
380 |
381 | //HashedWheelTimer的start方法会继续往下运行
382 | // Notify the other threads waiting for the initialization at start().
383 | startTimeInitialized.countDown();
384 |
385 | do {
386 | //返回的是当前的nanoTime- startTime
387 | //也就是返回的是 每 tick 一次的时间间隔
388 | final long deadline = waitForNextTick();
389 | if (deadline > 0) {
390 | //算出时间轮的槽位
391 | int idx = (int) (tick & mask);
392 | //移除cancelledTimeouts中的bucket
393 | // 从bucket中移除timeout
394 | processCancelledTasks();
395 | HashedWheelBucket bucket = wheel[idx];
396 | // 将newTimeout()方法中加入到待处理定时任务队列中的任务加入到指定的格子中
397 | transferTimeoutsToBuckets();
398 | bucket.expireTimeouts(deadline);
399 | tick++;
400 | }
401 | // 校验如果workerState是started状态,那么就一直循环
402 | } while (workerStateUpdater.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);
403 |
404 | // Fill the unprocessedTimeouts so we can return them from stop() method.
405 | for (HashedWheelBucket bucket : wheel) {
406 | bucket.clearTimeouts(unprocessedTimeouts);
407 | }
408 | for (;;) {
409 | HashedWheelTimeout timeout = timeouts.poll();
410 | if (timeout == null) {
411 | break;
412 | }
413 | //如果有没有被处理的timeout,那么加入到unprocessedTimeouts对列中
414 | if (!timeout.isCancelled()) {
415 | unprocessedTimeouts.add(timeout);
416 | }
417 | }
418 | //处理被取消的任务
419 | processCancelledTasks();
420 | }
421 | ```
422 |
423 | 1. 这个方法首先会设置一个时间轮的开始时间startTime,然后调用startTimeInitialized的countDown让被阻塞的线程往下运行
424 | 2. 调用waitForNextTick等待到下次tick的到来,并返回当次的tick时间-startTime
425 | 3. 通过&的方式获取时间轮的槽位
426 | 4. 移除掉被取消的task
427 | 5. 将timeouts中的任务转移到对应的wheel槽位中,如果槽位中不止一个bucket,那么串成一个链表
428 | 6. 执行格子中的到期任务
429 | 7. 遍历整个wheel,将过期的bucket放入到unprocessedTimeouts队列中
430 | 8. 将timeouts中过期的bucket放入到unprocessedTimeouts队列中
431 |
432 | 上面所有的过期但未被处理的bucket会在调用stop方法的时候返回unprocessedTimeouts队列中的数据。所以unprocessedTimeouts中的数据只是做一个记录,并不会再次被执行。
433 |
434 | 时间轮的所有处理过程都在do-while循环中被处理,我们下面一个个分析
435 |
436 | #### 处理被取消的任务[#](https://www.cnblogs.com/luozhiyun/p/11706171.html#2230304666)
437 |
438 | **Worker#processCancelledTasks**
439 |
440 | ```java
441 | Copyprivate void processCancelledTasks() {
442 | for (;;) {
443 | HashedWheelTimeout timeout = cancelledTimeouts.poll();
444 | if (timeout == null) {
445 | // all processed
446 | break;
447 | }
448 | try {
449 | timeout.remove();
450 | } catch (Throwable t) {
451 | if (LOG.isWarnEnabled()) {
452 | LOG.warn("An exception was thrown while process a cancellation task", t);
453 | }
454 | }
455 | }
456 | }
457 | ```
458 |
459 | 这个方法相当的简单,因为在调用HashedWheelTimer的stop方法的时候会将要取消的HashedWheelTimeout实例放入到cancelledTimeouts队列中,所以这里只需要循环把队列中的数据取出来,然后调用HashedWheelTimeout的remove方法将自己在bucket移除就好了
460 |
461 | **HashedWheelTimeout#remove**
462 |
463 | ```java
464 | Copyvoid remove() {
465 | HashedWheelBucket bucket = this.bucket;
466 | if (bucket != null) {
467 | //这里面涉及到链表的引用摘除,十分清晰易懂,想了解的可以去看看
468 | bucket.remove(this);
469 | } else {
470 | timer.pendingTimeouts.decrementAndGet();
471 | }
472 | }
473 | ```
474 |
475 | #### 转移数据到时间轮中[#](https://www.cnblogs.com/luozhiyun/p/11706171.html#609510907)
476 |
477 | **Worker#transferTimeoutsToBuckets**
478 |
479 | ```java
480 | Copyprivate void transferTimeoutsToBuckets() {
481 | // transfer only max. 100000 timeouts per tick to prevent a thread to stale the workerThread when it just
482 | // adds new timeouts in a loop.
483 | // 每次tick只处理10w个任务,以免阻塞worker线程
484 | for (int i = 0; i < 100000; i++) {
485 | HashedWheelTimeout timeout = timeouts.poll();
486 | if (timeout == null) {
487 | // all processed
488 | break;
489 | }
490 | //已经被取消了;
491 | if (timeout.state() == HashedWheelTimeout.ST_CANCELLED) {
492 | // Was cancelled in the meantime.
493 | continue;
494 | }
495 | //calculated = tick 次数
496 | long calculated = timeout.deadline / tickDuration;
497 | // 计算剩余的轮数, 只有 timer 走够轮数, 并且到达了 task 所在的 slot, task 才会过期
498 | timeout.remainingRounds = (calculated - tick) / wheel.length;
499 | //如果任务在timeouts队列里面放久了, 以至于已经过了执行时间, 这个时候就使用当前tick, 也就是放到当前bucket, 此方法调用完后就会被执行
500 | final long ticks = Math.max(calculated, tick); // Ensure we don't schedule for past.
501 | //// 算出任务应该插入的 wheel 的 slot, slotIndex = tick 次数 & mask, mask = wheel.length - 1
502 | int stopIndex = (int) (ticks & mask);
503 |
504 | HashedWheelBucket bucket = wheel[stopIndex];
505 | //将timeout加入到bucket链表中
506 | bucket.addTimeout(timeout);
507 | }
508 | }
509 | ```
510 |
511 | 1. 每次调用这个方法会处理10w个任务,以免阻塞worker线程
512 | 2. 在校验之后会用timeout的deadline除以每次tick运行的时间tickDuration得出需要tick多少次才会运行这个timeout的任务
513 | 3. 由于timeout的deadline实际上还包含了worker线程启动到timeout加入队列这段时间,所以在算remainingRounds的时候需要减去当前的tick次数
514 |
515 | ```
516 | Copy |_____________________|____________
517 | worker启动时间 timeout任务加入时间
518 | ```
519 |
520 | 1. 最后根据计算出来的ticks来&算出wheel的槽位,加入到bucket链表中
521 |
522 | #### 执行到期任务[#](https://www.cnblogs.com/luozhiyun/p/11706171.html#240609497)
523 |
524 | 在worker的run方法的do-while循环中,在根据当前的tick拿到wheel中的bucket后会调用expireTimeouts方法来处理这个bucket的到期任务
525 |
526 | **HashedWheelBucket#expireTimeouts**
527 |
528 | ```java
529 | Copy// 过期并执行格子中的到期任务,tick到该格子的时候,worker线程会调用这个方法,
530 | //根据deadline和remainingRounds判断任务是否过期
531 | public void expireTimeouts(long deadline) {
532 | HashedWheelTimeout timeout = head;
533 |
534 | // process all timeouts
535 | //遍历格子中的所有定时任务
536 | while (timeout != null) {
537 | // 先保存next,因为移除后next将被设置为null
538 | HashedWheelTimeout next = timeout.next;
539 | if (timeout.remainingRounds <= 0) {
540 | //从bucket链表中移除当前timeout,并返回链表中下一个timeout
541 | next = remove(timeout);
542 | //如果timeout的时间小于当前的时间,那么就调用expire执行task
543 | if (timeout.deadline <= deadline) {
544 | timeout.expire();
545 | } else {
546 | //不可能发生的情况,就是说round已经为0了,deadline却>当前槽的deadline
547 | // The timeout was placed into a wrong slot. This should never happen.
548 | throw new IllegalStateException(String.format("timeout.deadline (%d) > deadline (%d)",
549 | timeout.deadline, deadline));
550 | }
551 | } else if (timeout.isCancelled()) {
552 | next = remove(timeout);
553 | } else {
554 | //因为当前的槽位已经过了,说明已经走了一圈了,把轮数减一
555 | timeout.remainingRounds--;
556 | }
557 | //把指针放置到下一个timeout
558 | timeout = next;
559 | }
560 | }
561 | ```
562 |
563 | expireTimeouts方法会根据当前tick到的槽位,然后获取槽位中的bucket并找到链表中到期的timeout并执行
564 |
565 | 1. 因为每一次的指针都会指向bucket中的下一个timeout,所以timeout为空时说明整个链表已经遍历完毕,所以用while循环做非空校验
566 | 2. 因为没一次循环都会把当前的轮数大于零的做减一处理,所以当轮数小于或等于零的时候就需要把当前的timeout移除bucket链表
567 | 3. 在校验deadline之后执行expire方法,这里会真正进行任务调用
568 |
569 | **HashedWheelTimeout#task**
570 |
571 | ```java
572 | Copypublic void expire() {
573 | if (!compareAndSetState(ST_INIT, ST_EXPIRED)) {
574 | return;
575 | }
576 |
577 | try {
578 | task.run(this);
579 | } catch (Throwable t) {
580 | if (LOG.isWarnEnabled()) {
581 | LOG.warn("An exception was thrown by " + TimerTask.class.getSimpleName() + '.', t);
582 | }
583 | }
584 | }
585 | ```
586 |
587 | 这里这个task就是在schedule方法中构建的timerTask实例,调用timerTask的run方法会调用到外层的RepeatedTimer的run方法,从而调用到RepeatedTimer子类实现的onTrigger方法。
588 |
589 | 到这里Jraft的定时调度就讲完了,感觉还是很有意思的。
--------------------------------------------------------------------------------
/doc/jraft/basic/lab2-投票的实现:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/hzh0425/hy_distribute_theory_basic/80ffc1bfa0ca2856ecdafd46489a036994414894/doc/jraft/basic/lab2-投票的实现
--------------------------------------------------------------------------------
/doc/jraft/lab0-初始化时做了什么.md:
--------------------------------------------------------------------------------
1 | 我们这次依然用上次的例子CounterServer来进行讲解:
2 |
3 | 我这里就不贴整个代码了
4 |
5 | ```java
6 | Copypublic static void main(final String[] args) throws IOException {
7 | if (args.length != 4) {
8 | System.out
9 | .println("Useage : java com.alipay.sofa.jraft.example.counter.CounterServer {dataPath} {groupId} {serverId} {initConf}");
10 | System.out
11 | .println("Example: java com.alipay.sofa.jraft.example.counter.CounterServer " +
12 | "/tmp/server1 " +
13 | "counter " +
14 | "127.0.0.1:8081 127.0.0.1:8081,127.0.0.1:8082,127.0.0.1:8083");
15 | System.exit(1);
16 | }
17 | //日志存储的路径
18 | final String dataPath = args[0];
19 | //SOFAJRaft集群的名字
20 | final String groupId = args[1];
21 | //当前节点的ip和端口
22 | final String serverIdStr = args[2];
23 | //集群节点的ip和端口
24 | final String initConfStr = args[3];
25 |
26 | final NodeOptions nodeOptions = new NodeOptions();
27 | // 为了测试,调整 snapshot 间隔等参数
28 | // 设置选举超时时间为 1 秒
29 | nodeOptions.setElectionTimeoutMs(1000);
30 | // 关闭 CLI 服务。
31 | nodeOptions.setDisableCli(false);
32 | // 每隔30秒做一次 snapshot
33 | nodeOptions.setSnapshotIntervalSecs(30);
34 | // 解析参数
35 | final PeerId serverId = new PeerId();
36 | if (!serverId.parse(serverIdStr)) {
37 | throw new IllegalArgumentException("Fail to parse serverId:" + serverIdStr);
38 | }
39 | final Configuration initConf = new Configuration();
40 | //将raft分组加入到Configuration的peers数组中
41 | if (!initConf.parse(initConfStr)) {
42 | throw new IllegalArgumentException("Fail to parse initConf:" + initConfStr);
43 | }
44 | // 设置初始集群配置
45 | nodeOptions.setInitialConf(initConf);
46 |
47 | // 启动
48 | final CounterServer counterServer = new CounterServer(dataPath, groupId, serverId, nodeOptions);
49 | System.out.println("Started counter server at port:"
50 | + counterServer.getNode().getNodeId().getPeerId().getPort());
51 | }
52 | ```
53 |
54 | 我们在启动server的main方法的时候会传入日志存储的路径、SOFAJRaft集群的名字、当前节点的ip和端口、集群节点的ip和端口并设值到NodeOptions中,作为当前节点启动的参数。
55 |
56 | 这里会将当前节点初始化为一个PeerId对象
57 | **PeerId**
58 |
59 | ```java
60 | Copy//存放当前节点的ip和端口号
61 | private Endpoint endpoint = new Endpoint(Utils.IP_ANY, 0);
62 |
63 | //默认是0
64 | private int idx;
65 | //是一个ip:端口的字符串
66 | private String str;
67 | public PeerId() {
68 | super();
69 | }
70 |
71 | public boolean parse(final String s) {
72 | final String[] tmps = StringUtils.split(s, ':');
73 | if (tmps.length != 3 && tmps.length != 2) {
74 | return false;
75 | }
76 | try {
77 | final int port = Integer.parseInt(tmps[1]);
78 | this.endpoint = new Endpoint(tmps[0], port);
79 | if (tmps.length == 3) {
80 | this.idx = Integer.parseInt(tmps[2]);
81 | } else {
82 | this.idx = 0;
83 | }
84 | this.str = null;
85 | return true;
86 | } catch (final Exception e) {
87 | LOG.error("Parse peer from string failed: {}", s, e);
88 | return false;
89 | }
90 | }
91 | ```
92 |
93 | PeerId的parse方法会将传入的ip:端口解析之后对变量进行一些赋值的操作。
94 |
95 | 然后会调用到CounterServer的构造器中:
96 | **CounterServer**
97 |
98 | ```java
99 | Copypublic CounterServer(final String dataPath, final String groupId, final PeerId serverId,
100 | final NodeOptions nodeOptions) throws IOException {
101 | // 初始化路径
102 | FileUtils.forceMkdir(new File(dataPath));
103 |
104 | // 这里让 raft RPC 和业务 RPC 使用同一个 RPC server, 通常也可以分开
105 | final RpcServer rpcServer = new RpcServer(serverId.getPort());
106 | RaftRpcServerFactory.addRaftRequestProcessors(rpcServer);
107 | // 注册业务处理器
108 | rpcServer.registerUserProcessor(new GetValueRequestProcessor(this));
109 | rpcServer.registerUserProcessor(new IncrementAndGetRequestProcessor(this));
110 | // 初始化状态机
111 | this.fsm = new CounterStateMachine();
112 | // 设置状态机到启动参数
113 | nodeOptions.setFsm(this.fsm);
114 | // 设置存储路径
115 | // 日志, 必须
116 | nodeOptions.setLogUri(dataPath + File.separator + "log");
117 | // 元信息, 必须
118 | nodeOptions.setRaftMetaUri(dataPath + File.separator + "raft_meta");
119 | // snapshot, 可选, 一般都推荐
120 | nodeOptions.setSnapshotUri(dataPath + File.separator + "snapshot");
121 | // 初始化 raft group 服务框架
122 | this.raftGroupService = new RaftGroupService(groupId, serverId, nodeOptions, rpcServer);
123 | // 启动
124 | this.node = this.raftGroupService.start();
125 | }
126 | ```
127 |
128 | 这个方法主要是调用NodeOptions的各种方法进行设置,然后调用raftGroupService的start方法启动raft节点。
129 |
130 | ### RaftGroupService[#](https://www.cnblogs.com/luozhiyun/p/11651414.html#3350796144)
131 |
132 | 我们来到RaftGroupService的start方法:
133 | **RaftGroupService#start**
134 |
135 | ```java
136 | Copypublic synchronized Node start(final boolean startRpcServer) {
137 | //如果已经启动了,那么就返回
138 | if (this.started) {
139 | return this.node;
140 | }
141 | //校验serverId和groupId
142 | if (this.serverId == null || this.serverId.getEndpoint() == null
143 | || this.serverId.getEndpoint().equals(new Endpoint(Utils.IP_ANY, 0))) {
144 | throw new IllegalArgumentException("Blank serverId:" + this.serverId);
145 | }
146 | if (StringUtils.isBlank(this.groupId)) {
147 | throw new IllegalArgumentException("Blank group id" + this.groupId);
148 | }
149 | //Adds RPC server to Server.
150 | //设置当前node的ip和端口
151 | NodeManager.getInstance().addAddress(this.serverId.getEndpoint());
152 |
153 | //创建node
154 | this.node = RaftServiceFactory.createAndInitRaftNode(this.groupId, this.serverId, this.nodeOptions);
155 | if (startRpcServer) {
156 | //启动远程服务
157 | this.rpcServer.start();
158 | } else {
159 | LOG.warn("RPC server is not started in RaftGroupService.");
160 | }
161 | this.started = true;
162 | LOG.info("Start the RaftGroupService successfully.");
163 | return this.node;
164 | }
165 | ```
166 |
167 | 这个方法会在一开始的时候对RaftGroupService在构造器实例化的参数进行校验,然后把当前节点的Endpoint添加到NodeManager的addrSet变量中,接着调用RaftServiceFactory#createAndInitRaftNode实例化Node节点。
168 |
169 | 每个节点都会启动一个rpc的服务,因为每个节点既可以被选举也可以投票给其他节点,节点之间需要互相通信,所以需要启动一个rpc服务。
170 |
171 | **RaftServiceFactory#createAndInitRaftNode**
172 |
173 | ```java
174 | Copypublic static Node createAndInitRaftNode(final String groupId, final PeerId serverId, final NodeOptions opts) {
175 | //实例化一个node节点
176 | final Node ret = createRaftNode(groupId, serverId);
177 | //为node节点初始化
178 | if (!ret.init(opts)) {
179 | throw new IllegalStateException("Fail to init node, please see the logs to find the reason.");
180 | }
181 | return ret;
182 | }
183 |
184 | public static Node createRaftNode(final String groupId, final PeerId serverId) {
185 | return new NodeImpl(groupId, serverId);
186 | }
187 | ```
188 |
189 | createAndInitRaftNode方法首先调用createRaftNode实例化一个Node的实例NodeImpl,然后调用其init方法进行初始化,主要的配置都是在init方法中完成的。
190 |
191 | **NodeImpl**
192 |
193 | ```java
194 | Copypublic NodeImpl(final String groupId, final PeerId serverId) {
195 | super();
196 | if (groupId != null) {
197 | //检验groupId是否符合格式规范
198 | Utils.verifyGroupId(groupId);
199 | }
200 | this.groupId = groupId;
201 | this.serverId = serverId != null ? serverId.copy() : null;
202 | //一开始的设置为未初始化
203 | this.state = State.STATE_UNINITIALIZED;
204 | //设置新的任期为0
205 | this.currTerm = 0;
206 | //设置最新的时间戳
207 | updateLastLeaderTimestamp(Utils.monotonicMs());
208 | this.confCtx = new ConfigurationCtx(this);
209 | this.wakingCandidate = null;
210 | final int num = GLOBAL_NUM_NODES.incrementAndGet();
211 | LOG.info("The number of active nodes increment to {}.", num);
212 | }
213 | ```
214 |
215 | NodeImpl会在构造器中初始化一些参数。
216 |
217 | ### Node的初始化[#](https://www.cnblogs.com/luozhiyun/p/11651414.html#1793682028)
218 |
219 | Node节点的所有的重要的配置都是在init方法中完成的,NodeImpl的init方法比较长所以分成代码块来进行讲解。
220 |
221 | **NodeImpl#init**
222 |
223 | ```java
224 | Copy//非空校验
225 | Requires.requireNonNull(opts, "Null node options");
226 | Requires.requireNonNull(opts.getRaftOptions(), "Null raft options");
227 | Requires.requireNonNull(opts.getServiceFactory(), "Null jraft service factory");
228 | //目前就一个实现:DefaultJRaftServiceFactory
229 | this.serviceFactory = opts.getServiceFactory();
230 | this.options = opts;
231 | this.raftOptions = opts.getRaftOptions();
232 | //基于 Metrics 类库的性能指标统计,具有丰富的性能统计指标,默认不开启度量工具
233 | this.metrics = new NodeMetrics(opts.isEnableMetrics());
234 |
235 | if (this.serverId.getIp().equals(Utils.IP_ANY)) {
236 | LOG.error("Node can't started from IP_ANY.");
237 | return false;
238 | }
239 |
240 | if (!NodeManager.getInstance().serverExists(this.serverId.getEndpoint())) {
241 | LOG.error("No RPC server attached to, did you forget to call addService?");
242 | return false;
243 | }
244 | //定时任务管理器
245 | this.timerManager = new TimerManager();
246 | //初始化定时任务管理器的内置线程池
247 | if (!this.timerManager.init(this.options.getTimerPoolSize())) {
248 | LOG.error("Fail to init timer manager.");
249 | return false;
250 | }
251 |
252 | //定时任务管理器
253 | this.timerManager = new TimerManager();
254 | //初始化定时任务管理器的内置线程池
255 | if (!this.timerManager.init(this.options.getTimerPoolSize())) {
256 | LOG.error("Fail to init timer manager.");
257 | return false;
258 | }
259 | ```
260 |
261 | 这段代码主要是给各个变量赋值,然后进行校验判断一下serverId不能为0.0.0.0,当前的Endpoint必须要在NodeManager里面设置过等等(NodeManager的设置是在RaftGroupService的start方法里)。
262 |
263 | 然后会初始化一个全局的的定时调度管理器TimerManager:
264 | **TimerManager**
265 |
266 | ```java
267 | Copyprivate ScheduledExecutorService executor;
268 |
269 | @Override
270 | public boolean init(Integer coreSize) {
271 | this.executor = Executors.newScheduledThreadPool(coreSize, new NamedThreadFactory(
272 | "JRaft-Node-ScheduleThreadPool-", true));
273 | return true;
274 | }
275 | ```
276 |
277 | TimerManager的init方法就是初始化一个线程池,如果当前的服务器的cpu线程数*3 大于20 ,那么这个线程池的coreSize就是20,否则就是cpu线程数*3。
278 |
279 | 往下走是计时器的初始化:
280 |
281 | ```java
282 | Copy// Init timers
283 | //设置投票计时器
284 | this.voteTimer = new RepeatedTimer("JRaft-VoteTimer", this.options.getElectionTimeoutMs()) {
285 |
286 | @Override
287 | protected void onTrigger() {
288 | //处理投票超时
289 | handleVoteTimeout();
290 | }
291 |
292 | @Override
293 | protected int adjustTimeout(final int timeoutMs) {
294 | //在一定范围内返回一个随机的时间戳
295 | return randomTimeout(timeoutMs);
296 | }
297 | };
298 | //设置预投票计时器
299 | //当leader在规定的一段时间内没有与 Follower 舰船进行通信时,
300 | // Follower 就可以认为leader已经不能正常担任旗舰的职责,则 Follower 可以去尝试接替leader的角色。
301 | // 这段通信超时被称为 Election Timeout
302 | //候选者在发起投票之前,先发起预投票
303 | this.electionTimer = new RepeatedTimer("JRaft-ElectionTimer", this.options.getElectionTimeoutMs()) {
304 |
305 | @Override
306 | protected void onTrigger() {
307 | handleElectionTimeout();
308 | }
309 |
310 | @Override
311 | protected int adjustTimeout(final int timeoutMs) {
312 | //在一定范围内返回一个随机的时间戳
313 | //为了避免同时发起选举而导致失败
314 | return randomTimeout(timeoutMs);
315 | }
316 | };
317 | //leader下台的计时器
318 | //定时检查是否需要重新选举leader
319 | this.stepDownTimer = new RepeatedTimer("JRaft-StepDownTimer", this.options.getElectionTimeoutMs() >> 1) {
320 |
321 | @Override
322 | protected void onTrigger() {
323 | handleStepDownTimeout();
324 | }
325 | };
326 | //快照计时器
327 | this.snapshotTimer = new RepeatedTimer("JRaft-SnapshotTimer", this.options.getSnapshotIntervalSecs() * 1000) {
328 |
329 | @Override
330 | protected void onTrigger() {
331 | handleSnapshotTimeout();
332 | }
333 | };
334 | ```
335 |
336 | voteTimer是用来控制选举的,如果选举超时,当前的节点又是候选者角色,那么就会发起选举。
337 | electionTimer是预投票计时器。候选者在发起投票之前,先发起预投票,如果没有得到半数以上节点的反馈,则候选者就会识趣的放弃参选。
338 | stepDownTimer定时检查是否需要重新选举leader。当前的leader可能出现它的Follower可能并没有整个集群的1/2却还没有下台的情况,那么这个时候会定期的检查看leader的Follower是否有那么多,没有那么多的话会强制让leader下台。
339 | snapshotTimer快照计时器。这个计时器会每隔1小时触发一次生成一个快照。
340 |
341 | 这些计时器的具体实现现在暂时不表,等到要讲具体功能的时候再进行梳理。
342 |
343 | 这些计时器有一个共同的特点就是会根据不同的计时器返回一个在一定范围内随机的时间。返回一个随机的时间可以防止多个节点在同一时间内同时发起投票选举从而降低选举失败的概率。
344 |
345 | 继续往下看:
346 |
347 | ```java
348 | Copythis.configManager = new ConfigurationManager();
349 | //初始化一个disruptor,采用多生产者模式
350 | this.applyDisruptor = DisruptorBuilder.newInstance() //
351 | //设置disruptor大小,默认16384
352 | .setRingBufferSize(this.raftOptions.getDisruptorBufferSize()) //
353 | .setEventFactory(new LogEntryAndClosureFactory()) //
354 | .setThreadFactory(new NamedThreadFactory("JRaft-NodeImpl-Disruptor-", true)) //
355 | .setProducerType(ProducerType.MULTI) //
356 | .setWaitStrategy(new BlockingWaitStrategy()) //
357 | .build();
358 | //设置事件处理器
359 | this.applyDisruptor.handleEventsWith(new LogEntryAndClosureHandler());
360 | //设置异常处理器
361 | this.applyDisruptor.setDefaultExceptionHandler(new LogExceptionHandler