├── .gitignore
├── LICENSE
├── README.md
├── assets
└── realword_vis.png
├── config
├── idgc.yaml
├── infer_idgc_test.yaml
├── infer_idgc_train.yaml
├── infer_qgc_test.yaml
├── qgc.yaml
└── test_base.yaml
├── datasets
├── __init__.py
├── refine_datasets.py
└── task_dex_datasets.py
├── model
├── __init__.py
├── backbone
│ ├── __init__.py
│ ├── clip_sd.py
│ ├── pointnet.py
│ ├── pointnet2.py
│ ├── pointnet2_utils.py
│ └── resnet.py
├── decoder
│ ├── __init__.py
│ └── unet.py
├── irf.py
├── ldgd.py
├── loss
│ ├── __init__.py
│ ├── grasp_loss_pose.py
│ └── matcher.py
└── utils
│ ├── __init__.py
│ ├── diffusion_utils.py
│ ├── hand_model.py
│ ├── helpers.py
│ └── position_embedding.py
├── requirements.txt
├── test.py
├── thirdparty
├── pointnet2
│ ├── _ext_src
│ │ ├── include
│ │ │ ├── ball_query.h
│ │ │ ├── cuda_utils.h
│ │ │ ├── cylinder_query.h
│ │ │ ├── group_points.h
│ │ │ ├── interpolate.h
│ │ │ ├── sampling.h
│ │ │ └── utils.h
│ │ └── src
│ │ │ ├── ball_query.cpp
│ │ │ ├── ball_query_gpu.cu
│ │ │ ├── bindings.cpp
│ │ │ ├── cylinder_query.cpp
│ │ │ ├── cylinder_query_gpu.cu
│ │ │ ├── group_points.cpp
│ │ │ ├── group_points_gpu.cu
│ │ │ ├── interpolate.cpp
│ │ │ ├── interpolate_gpu.cu
│ │ │ ├── sampling.cpp
│ │ │ └── sampling_gpu.cu
│ ├── pointnet2_modules.py
│ ├── pointnet2_utils.py
│ ├── pytorch_utils.py
│ └── setup.py
└── pytorch_kinematics
│ ├── .gitignore
│ ├── README.md
│ ├── pytorch_kinematics
│ ├── __init__.py
│ ├── chain.py
│ ├── frame.py
│ ├── jacobian.py
│ ├── mjcf.py
│ ├── mjcf_parser
│ │ ├── __init__.py
│ │ ├── attribute.py
│ │ ├── base.py
│ │ ├── constants.py
│ │ ├── copier.py
│ │ ├── debugging.py
│ │ ├── element.py
│ │ ├── io.py
│ │ ├── namescope.py
│ │ ├── parser.py
│ │ ├── schema.py
│ │ ├── schema.xml
│ │ └── util.py
│ ├── sdf.py
│ ├── transforms
│ │ ├── __init__.py
│ │ ├── math.py
│ │ ├── rotation_conversions.py
│ │ ├── so3.py
│ │ └── transform3d.py
│ ├── urdf.py
│ └── urdf_parser_py
│ │ ├── __init__.py
│ │ ├── sdf.py
│ │ ├── urdf.py
│ │ └── xml_reflection
│ │ ├── __init__.py
│ │ ├── basics.py
│ │ └── core.py
│ ├── setup.py
│ └── tests
│ ├── __init__.py
│ ├── ant.xml
│ ├── humanoid.xml
│ ├── kuka_iiwa.urdf
│ ├── prismatic_robot.urdf
│ ├── simple_arm.sdf
│ ├── test_jacobian.py
│ ├── test_kinematics.py
│ └── test_transform.py
├── train.py
└── utils
├── __init__.py
├── calc_diversity.py
├── config_utils.py
├── eval_utils.py
├── grasp_init.py
├── pc_util.py
└── rotation_utils.py
/.gitignore:
--------------------------------------------------------------------------------
1 | #pretrained weight
2 | pretrained/
3 |
4 | # cache
5 | **/__pycache__/
6 |
7 | # vscode
8 | .vscode/
9 |
10 | # exp
11 | Experiments/
12 |
13 | # datasets
14 | data
15 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2024 iSEE
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Grasp as You Say: Language-guided Dexterous Grasp Generation
2 |
3 | ### *Yi-Lin Wei, Jian-Jian Jiang, Chengyi Xing, Xiantuo Tan, Xiao-Ming Wu, Hao Li,
Mark Cutkosky, Wei-Shi Zheng*
4 |
5 | #### [[Paper]](https://arxiv.org/abs/2405.19291) [[Project]](https://isee-laboratory.github.io/DexGYS/)
6 |
7 | 
8 | ### (NeurIPS 2024) Official repository of paper "Grasp as You Say: Language-guided Dexterous Grasp Generation"
9 |
10 |
11 | ## Install
12 | - Create a new `conda` environemnt and activate it.
13 | ```
14 | conda create -n dexgys python=3.8
15 | conda activate dexgys
16 | ```
17 | - Install the dependencies.
18 | ```
19 | conda install -y pytorch==1.10.0 torchvision==0.11.0 cudatoolkit=11.3 -c pytorch -c conda-forge
20 | pip install -r requirements.txt
21 | ```
22 | - Build the pakage.
23 | > **Note**: The CUDA enviroment should be consistent in the phase of building and running (Recommendation: cuda11 or higher).
24 | ```
25 | cd thirdparty/pytorch_kinematics
26 | pip install -e .
27 |
28 | cd ../pointnet2
29 | python setup.py install
30 |
31 | cd ../
32 | git clone https://github.com/wrc042/CSDF.git
33 | cd CSDF
34 | pip install -e .
35 | cd ../../
36 | ```
37 |
38 | ## Data Preparation
39 | 1. Download dexterous grap label and language label of DexGYS from here ["coming soon"], and put in the "dexgys" in the path of "./data".
40 |
41 | 2. Download ShadowHand model mjcf from [here](https://mirrors.pku.edu.cn/dl-release/UniDexGrasp_CVPR2023/), and put the "mjcf" in the path of "./data".
42 |
43 | 3. Download 3D mesh of object from [here](https://oakink.net/), and put the "oakink" in the path of "./data".
44 |
45 | 4. Finally, the directory should as follow:
46 | ```
47 | .data/
48 | ├── dexgys/
49 | │ ├── train_with_guide_v2.1.json
50 | │ ├── test_with_guide_v2.1.json
51 | ├── oakink/
52 | │ ├── shape/
53 | └── mjcf/
54 | ```
55 |
56 | ## Usage
57 | ### Train
58 | 1. Train Intention and Diversity Grasp Component (IDGC)
59 | ```
60 | python train.py -t "./config/idgc.yaml"
61 | ```
62 | 2. Infer IDGC on train and test set to obatin training and testing pairs for QGC.
63 | ```
64 | python ./test.py \
65 | --train_cfg ./config/idgc.yaml \
66 | --test_cfg ./config/infer_idgc_train.yaml \
67 | --override model.checkpoint_path \"\"
68 | ```
69 | ```
70 | python ./test.py \
71 | --train_cfg ./config/idgc.yaml \
72 | --test_cfg ./config/infer_idgc_test.yaml \
73 | --override model.checkpoint_path \"\"
74 | ```
75 |
76 |
77 | 3. Train Quality Grasp Component (QGC).
78 |
79 | - Set the "data.train.pose_path" and "data.test.pose_path" of "./config/qgc.yaml" to the of the outcome of step2.
80 | - For example:
81 | ```
82 | data:
83 | name: refinement
84 | train:
85 | data_root: &data_root "./data/oakink"
86 | pose_path: ./Experiments/idgc/test_results/epoch__train/matched_results.json
87 | ...
88 | val:
89 | data_root: *data_root
90 | pose_path: ./Experiments/idgc/test_results/epoch__test/matched_results.json
91 | ```
92 | - Then run:
93 | ```
94 | python train.py -t "./config/qgc.yaml"
95 | ```
96 |
97 | ### Test
98 | - Infer QGC to refine the coarse outcome of IDGC.
99 | - Set "data.test.pose_path" of "./config/infer_qgc_test.yaml" to the of the outcome of LDGC.
100 | ```
101 | data:
102 | name: refinement
103 | train:
104 | data_root: &data_root "./data/oakink"
105 | pose_path: ./Experiments/idgc/test_results/epoch__train/matched_results.json
106 | sample_in_pose: &sample_in_pose True
107 | ```
108 | - Then run:
109 | ```
110 | python ./test.py \
111 | --train_cfg ./config/qgc.yaml \
112 | --test_cfg ./config/infer_qgc_test.yaml \
113 | --override model.checkpoint_path \"\"
114 | ```
115 |
116 | ## TODO
117 | - [ ] Release the datasets of GraspGYSNet
118 | - [ ] Release the visualization code of GraspGYS framework
119 | - [ ] Release the evaluation code of GraspGYS framework
120 | - [x] Release the training code of GraspGYS framework
121 | - [x] Release the inference code of GraspGYS framework
122 |
123 | ## Acknowledgements
124 |
125 | The code of this repository is based on the following repositories. We would like to thank the authors for sharing their works.
126 |
127 | - [UniDexGrasp](https://github.com/PKU-EPIC/UniDexGrasp)
128 |
129 | - [Scene-Diffuser](https://github.com/scenediffuser/Scene-Diffuser)
130 |
131 | - [DGTR](https://github.com/iSEE-Laboratory/DGTR)
132 |
133 | ## Contact
134 | - Email: weiylin5@mail2.sysu.edu.cn
135 |
136 | ## Citation
137 | Please cite it if you find this work useful.
138 | ```
139 | @article{wei2024grasp,
140 | title={Grasp as you say: language-guided dexterous grasp generation},
141 | author={Wei, Yi-Lin and Jiang, Jian-Jian and Xing, Chengyi and Tan, Xian-Tuo and Wu, Xiao-Ming and Li, Hao and Cutkosky, Mark and Zheng, Wei-Shi},
142 | journal={arXiv preprint arXiv:2405.19291},
143 | year={2024}
144 | }
145 | ```
146 |
--------------------------------------------------------------------------------
/assets/realword_vis.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/iSEE-Laboratory/Grasp-as-You-Say/4694fa9369523d09d0c2cea6ec7bcddd2cb206d8/assets/realword_vis.png
--------------------------------------------------------------------------------
/config/idgc.yaml:
--------------------------------------------------------------------------------
1 | device: &device cuda:0
2 | rotation_type: &rotation_type euler
3 | rotation_dim: &rotation_dim 3
4 |
5 | ncols: 120
6 | epochs: &epochs 200
7 | print_freq: 500
8 | validate_freq: 1
9 | save_root: ./Experiments/idgc
10 | save_top_n: 20
11 | log_dir: logs
12 | seed: 3407
13 | norm_type: &norm_type minmax11
14 | guidence_type: &guidence_type "fine" # fine
15 | frozen_clip: True
16 |
17 | data:
18 | name: task_pose
19 | train:
20 | data_root: &data_root "./data/oakink"
21 | pose_path: "./data/dexgys/train_with_guide_v2.1.json"
22 | num_rotation_aug: &num_rotation_aug 1
23 | num_equivalent_aug: &num_equivalent_aug 1
24 | sample_in_pose: &sample_in_pose True
25 | guidence_type: *guidence_type
26 | rotation_type: *rotation_type
27 | norm_type: *norm_type
28 | batch_size: 48
29 | num_workers: 4
30 |
31 | val:
32 | data_root: *data_root
33 | pose_path: "./data/dexgys/test_with_guide_v2.1.json"
34 | num_rotation_aug: 1
35 | sample_in_pose: False
36 | guidence_type: *guidence_type
37 | rotation_type: *rotation_type
38 | norm_type: *norm_type
39 | batch_size: 48
40 | num_workers: 4
41 |
42 | model:
43 | name: LDGD
44 | steps: 100
45 | schedule_cfg:
46 | beta: [0.0001, 0.01]
47 | beta_schedule: 'linear'
48 | s: 0.008
49 | rand_t_type: 'half' # 'half' or 'all'
50 | loss_type: 'l2' # 'l1' or 'l2'
51 | out_sigmoid: False
52 | pred_x0: True
53 | device: *device
54 | rotation_type: *rotation_type
55 |
56 | decoder:
57 | name: unet
58 | use_guidence: True
59 | use_obj: True
60 | plus_condition_type: ("")
61 | trans_condition_type: "txt_obj"
62 | language_encoder:
63 | name: clip_sd
64 | version: 'ViT-L/14'
65 | use_pre: False
66 | use_adapter: True
67 | dim_in: 768
68 | dim_out: 512
69 | reduction: 1
70 | device: *device
71 | backbone:
72 | name: pointnet2
73 | use_pooling: False
74 | layer1:
75 | npoint: 1024
76 | radius_list: [0.02]
77 | nsample_list: [64]
78 | mlp_list: [0, 64, 128]
79 | layer2:
80 | npoint: 256
81 | radius_list: [0.05]
82 | nsample_list: [32]
83 | mlp_list: [128, 256, 256]
84 | layer3:
85 | npoint: 64
86 | radius_list: [0.1]
87 | nsample_list: [16]
88 | mlp_list:
89 | - 256
90 | - 512
91 | - &encoder_out 512
92 | use_xyz: true
93 | normalize_xyz: true
94 | d_x: 28 # placeholder
95 | d_model: 512
96 | time_embed_mult: 2
97 | nblocks: 4
98 | resblock_dropout: 0.0
99 | transformer_num_heads: 8
100 | transformer_dim_head: 64
101 | transformer_dropout: 0.1
102 | transformer_depth: 1
103 | transformer_mult_ff: 2
104 | context_dim: 512
105 | use_position_embedding: false # for input x
106 |
107 | criterion:
108 | hand_model:
109 | mjcf_path: ./data/mjcf/shadow_hand.xml
110 | mesh_path: ./data/mjcf/meshes
111 | n_surface_points: 1024
112 | contact_points_path: ./data/mjcf/contact_points.json
113 | penetration_points_path: ./data/mjcf/penetration_points.json
114 | fingertip_points_path: ./data/mjcf/fingertip.json
115 | loss_weights:
116 | hand_chamfer: 1.0
117 | para: 10.0
118 | obj_penetration: 50.0
119 | self_penetration: 10.0
120 |
121 | cost_weights:
122 | hand_mesh: 0.0
123 | qpos: 1.0
124 | translation: 2.0
125 | rotation: 2.0
126 | device: *device
127 | rotation_type: *rotation_type
128 | norm_type: *norm_type
129 |
130 |
131 | optimizer:
132 | name: adam
133 | lr: 1.0e-4
134 | weight_decay: 1.0e-4
135 |
136 | scheduler:
137 | name: cosine
138 | t_max: *epochs
139 | min_lr: 1.0e-5
140 |
--------------------------------------------------------------------------------
/config/infer_idgc_test.yaml:
--------------------------------------------------------------------------------
1 | set: "test"
2 | data:
3 | test:
4 | data_root: "./data/oakink"
5 | pose_path: "./data/dexgys/test_with_guide_v2.1.json"
6 | num_rotation_aug: 1
7 | num_equivalent_aug: 1
8 | sample_in_pose: False
9 | guidence_type: "fine"
10 | rotation_type: "euler"
11 | norm_type: "minmax11"
12 | batch_size: 128
13 | num_workers: 8
14 |
15 | hand_model:
16 | mjcf_path: ./data/mjcf/shadow_hand.xml
17 | mesh_path: ./data/mjcf/meshes
18 | n_surface_points: 1024
19 | contact_points_path: ./data/mjcf/contact_points.json
20 | penetration_points_path: ./data/mjcf/penetration_points.json
21 | model:
22 | checkpoint_path: None
23 |
24 | q1:
25 | lambda_torque: 10
26 | m: 8
27 | mu: 1
28 | nms: true
29 | thres_contact: 0.01
30 | thres_pen: 0.005
31 | thres_tpen: 0.01
32 |
--------------------------------------------------------------------------------
/config/infer_idgc_train.yaml:
--------------------------------------------------------------------------------
1 | set: "train"
2 | data:
3 | test:
4 | data_root: "./data/oakink"
5 | pose_path: "./data/dexgys/train_with_guide_v2.1.json"
6 | num_rotation_aug: 1
7 | num_equivalent_aug: 1
8 | sample_in_pose: False
9 | guidence_type: "fine"
10 | rotation_type: "euler"
11 | norm_type: "minmax11"
12 | batch_size: 128
13 | num_workers: 8
14 |
15 | hand_model:
16 | mjcf_path: ./data/mjcf/shadow_hand.xml
17 | mesh_path: ./data/mjcf/meshes
18 | n_surface_points: 1024
19 | contact_points_path: ./data/mjcf/contact_points.json
20 | penetration_points_path: ./data/mjcf/penetration_points.json
21 | model:
22 | checkpoint_path: None
23 |
24 | q1:
25 | lambda_torque: 10
26 | m: 8
27 | mu: 1
28 | nms: true
29 | thres_contact: 0.01
30 | thres_pen: 0.005
31 | thres_tpen: 0.01
32 |
--------------------------------------------------------------------------------
/config/infer_qgc_test.yaml:
--------------------------------------------------------------------------------
1 | set: "test"
2 | data:
3 | test:
4 | data_root: ./data/oakink
5 | pose_path: ./Experiments/idgc/test_results/epoch_1_test/matched_results.json
6 | sample_in_pose: true
7 | guidence_type: fine
8 | rotation_type: euler
9 | norm_type: minmax11
10 | batch_size: 16
11 | num_workers: 4
12 |
13 | hand_model:
14 | mjcf_path: ./data/mjcf/shadow_hand.xml
15 | mesh_path: ./data/mjcf/meshes
16 | n_surface_points: 1024
17 | contact_points_path: ./data/mjcf/contact_points.json
18 | penetration_points_path: ./data/mjcf/penetration_points.json
19 | model:
20 | checkpoint_path: None
21 |
22 | q1:
23 | lambda_torque: 10
24 | m: 8
25 | mu: 1
26 | nms: true
27 | thres_contact: 0.01
28 | thres_pen: 0.005
29 | thres_tpen: 0.01
30 |
--------------------------------------------------------------------------------
/config/qgc.yaml:
--------------------------------------------------------------------------------
1 | device: &device cuda:0
2 | rotation_type: &rotation_type euler
3 | rotation_dim: &rotation_dim 3
4 |
5 | ncols: 120
6 | epochs: &epochs 100
7 | print_freq: 500
8 | validate_freq: 1
9 | save_root: ./Experiments/qgc
10 | save_top_n: 20
11 | log_dir: logs
12 | seed: 3407
13 | norm_type: &norm_type minmax11
14 | guidence_type: &guidence_type "fine" # fine
15 | frozen_clip: False
16 |
17 | data:
18 | name: refinement
19 | train:
20 | data_root: &data_root "./data/oakink"
21 | pose_path: ./Experiments/idgc/test_results/epoch_1_train/matched_results.json
22 | sample_in_pose: &sample_in_pose True
23 | guidence_type: *guidence_type
24 | rotation_type: *rotation_type
25 | norm_type: *norm_type
26 | batch_size: 32
27 | num_workers: 8
28 |
29 | val:
30 | data_root: *data_root
31 | pose_path: ./Experiments/idgc/test_results/epoch_1_test/matched_results.json
32 | sample_in_pose: True
33 | guidence_type: *guidence_type
34 | rotation_type: *rotation_type
35 | norm_type: *norm_type
36 | batch_size: 32
37 | num_workers: 8
38 |
39 | model:
40 | name: IRF
41 | steps: 100
42 | schedule_cfg:
43 | beta: [0.0001, 0.01]
44 | beta_schedule: 'linear'
45 | s: 0.008
46 | rand_t_type: 'half' # 'half' or 'all'
47 | loss_type: 'l2' # 'l1' or 'l2'
48 | out_sigmoid: False
49 | pred_abs: False
50 | device: *device
51 | rotation_type: *rotation_type
52 |
53 | decoder:
54 | name: unet
55 | task_num: 0
56 | cls_dim: 0
57 | use_guidence: False
58 | use_obj: True
59 | use_hand: True
60 | plus_condition_type: ()
61 | trans_condition_type: "obj_hand"
62 | backbone:
63 | name: pointnet2
64 | use_pooling: False
65 | layer1:
66 | npoint: 1024
67 | radius_list: [0.02]
68 | nsample_list: [64]
69 | mlp_list: [0, 64, 128]
70 | layer2:
71 | npoint: 128
72 | radius_list: [0.04]
73 | nsample_list: [16]
74 | mlp_list: [128, 256, 256]
75 | layer3:
76 | npoint: 16
77 | radius_list: [0.08]
78 | nsample_list: [4]
79 | mlp_list:
80 | - 256
81 | - 512
82 | - &encoder_out 512
83 | use_xyz: true
84 | normalize_xyz: true
85 |
86 | hand_backbone:
87 | name: pointnet2
88 | use_pooling: False
89 | layer1:
90 | npoint: 1024
91 | radius_list: [0.02]
92 | nsample_list: [64]
93 | mlp_list: [0, 64, 128]
94 | layer2:
95 | npoint: 128
96 | radius_list: [0.04]
97 | nsample_list: [16]
98 | mlp_list: [128, 256, 256]
99 | layer3:
100 | npoint: 16
101 | radius_list: [0.08]
102 | nsample_list: [4]
103 | mlp_list:
104 | - 256
105 | - 512
106 | - *encoder_out
107 | use_xyz: true
108 | normalize_xyz: true
109 |
110 | d_x: 28 # placeholder
111 | d_model: 512
112 | time_embed_mult: 2
113 | nblocks: 4
114 | resblock_dropout: 0.0
115 | transformer_num_heads: 8
116 | transformer_dim_head: 64
117 | transformer_dropout: 0.1
118 | transformer_depth: 1
119 | transformer_mult_ff: 2
120 | context_dim: 512
121 | use_position_embedding: false # for input x
122 |
123 | criterion:
124 | hand_model:
125 | mjcf_path: ./data/mjcf/shadow_hand.xml
126 | mesh_path: ./data/mjcf/meshes
127 | n_surface_points: 1024
128 | contact_points_path: ./data/mjcf/contact_points.json
129 | penetration_points_path: ./data/mjcf/penetration_points.json
130 | fingertip_points_path: ./data/mjcf/fingertip.json
131 | loss_weights:
132 | hand_chamfer: 1.0
133 | para: 10.0
134 | obj_penetration: 100.0
135 | self_penetration: 10.0
136 | cmap: 10.0
137 |
138 | cost_weights:
139 | hand_mesh: 0.0
140 | qpos: 1.0
141 | translation: 2.0
142 | rotation: 2.0
143 | device: *device
144 | rotation_type: *rotation_type
145 | norm_type: *norm_type
146 |
147 |
148 | optimizer:
149 | name: adam
150 | lr: 1.0e-4
151 | weight_decay: 1.0e-4
152 |
153 | scheduler:
154 | name: cosine
155 | t_max: *epochs
156 | min_lr: 1.0e-5
157 |
--------------------------------------------------------------------------------
/config/test_base.yaml:
--------------------------------------------------------------------------------
1 | set: "test"
2 | data:
3 | test:
4 | data_root: "./data/oakink"
5 | pose_path: "./data/dexgys/test_with_guide_v2.1.json"
6 | num_rotation_aug: 1
7 | num_equivalent_aug: 1
8 | sample_in_pose: False
9 | guidence_type: "fine"
10 | rotation_type: "euler"
11 | norm_type: "minmax11"
12 | batch_size: 128
13 | num_workers: 8
14 |
15 | hand_model:
16 | mjcf_path: ./data/mjcf/shadow_hand.xml
17 | mesh_path: ./data/mjcf/meshes
18 | n_surface_points: 1024
19 | contact_points_path: ./data/mjcf/contact_points.json
20 | penetration_points_path: ./data/mjcf/penetration_points.json
21 | model:
22 | checkpoint_path: None
23 |
24 | q1:
25 | lambda_torque: 10
26 | m: 8
27 | mu: 1
28 | nms: true
29 | thres_contact: 0.01
30 | thres_pen: 0.005
31 | thres_tpen: 0.01
32 |
--------------------------------------------------------------------------------
/datasets/__init__.py:
--------------------------------------------------------------------------------
1 | from typing import Optional, Tuple
2 |
3 | from torch.utils.data import Dataset
4 | from .task_dex_datasets import TaskDataset_Pose
5 | from .refine_datasets import RefineDataset
6 |
7 |
8 | def build_datasets(data_cfg) -> Tuple[Dataset, Dataset, Optional[Dataset]]:
9 |
10 | if data_cfg.name.lower() == "task_pose":
11 | if not hasattr(data_cfg, "test"):
12 | train_set = TaskDataset_Pose(
13 | data_root=data_cfg.train.data_root,
14 | pose_path=data_cfg.train.pose_path,
15 | rotation_type=data_cfg.train.rotation_type,
16 | sample_in_pose = data_cfg.train.sample_in_pose,
17 | norm_type=data_cfg.train.norm_type,
18 | guidence_type=data_cfg.train.guidence_type,
19 | is_train=True,
20 | )
21 | val_set = TaskDataset_Pose(
22 | data_root=data_cfg.val.data_root,
23 | pose_path=data_cfg.val.pose_path,
24 | rotation_type=data_cfg.val.rotation_type,
25 | sample_in_pose = data_cfg.val.sample_in_pose,
26 | norm_type=data_cfg.val.norm_type,
27 | guidence_type=data_cfg.val.guidence_type,
28 | is_train=False,
29 | )
30 | test_set = None
31 | elif hasattr(data_cfg, "test"):
32 | train_set = None
33 | val_set = None
34 | test_set = TaskDataset_Pose(
35 | data_root=data_cfg.test.data_root,
36 | pose_path=data_cfg.test.pose_path,
37 | rotation_type=data_cfg.test.rotation_type,
38 | sample_in_pose = data_cfg.test.sample_in_pose,
39 | norm_type=data_cfg.test.norm_type,
40 | guidence_type=data_cfg.test.guidence_type,
41 | is_train=False,
42 | )
43 |
44 | else:
45 | raise Exception("1")
46 | return train_set, val_set, test_set
47 | elif data_cfg.name.lower() == "refinement":
48 | if not hasattr(data_cfg, "test"):
49 | train_set = RefineDataset(
50 | data_root=data_cfg.train.data_root,
51 | pose_path=data_cfg.train.pose_path,
52 | rotation_type=data_cfg.train.rotation_type,
53 | sample_in_pose = data_cfg.train.sample_in_pose,
54 | norm_type=data_cfg.train.norm_type,
55 | guidence_type=data_cfg.train.guidence_type,
56 | is_train=True,
57 | )
58 | val_set = RefineDataset(
59 | data_root=data_cfg.val.data_root,
60 | pose_path=data_cfg.val.pose_path,
61 | rotation_type=data_cfg.val.rotation_type,
62 | sample_in_pose = data_cfg.val.sample_in_pose,
63 | norm_type=data_cfg.val.norm_type,
64 | guidence_type=data_cfg.val.guidence_type,
65 | is_train=False,
66 | )
67 | test_set = None
68 | elif hasattr(data_cfg, "test"):
69 | train_set = None
70 | val_set = None
71 | test_set = RefineDataset(
72 | data_root=data_cfg.test.data_root,
73 | pose_path=data_cfg.test.pose_path,
74 | rotation_type=data_cfg.test.rotation_type,
75 | sample_in_pose = data_cfg.test.sample_in_pose,
76 | norm_type=data_cfg.test.norm_type,
77 | guidence_type=data_cfg.test.guidence_type,
78 | is_train=False,
79 | )
80 | return train_set, val_set, test_set
81 | else:
82 | raise NotImplementedError(f"Unable to build {data_cfg.name} dataset")
83 |
--------------------------------------------------------------------------------
/model/__init__.py:
--------------------------------------------------------------------------------
1 |
2 | from .ldgd import DDPM
3 | from .irf import RenfinmentTransformer
4 | def build_model(cfg):
5 | if cfg.name.lower() == "ldgd":
6 | return DDPM(cfg)
7 | elif cfg.name.lower() == "irf":
8 | return RenfinmentTransformer(cfg)
9 |
10 | else:
11 | raise Exception("1")
12 |
--------------------------------------------------------------------------------
/model/backbone/__init__.py:
--------------------------------------------------------------------------------
1 | from .pointnet2 import Pointnet2Backbone
2 | from .resnet import build_resnet_backbone
3 | from .pointnet import PointNetEncoder
4 | from .clip_sd import ClipCustom
5 |
6 | def build_backbone(backbone_cfg):
7 | if backbone_cfg.name.lower() == "resnet":
8 | return build_resnet_backbone(backbone_cfg)
9 | elif backbone_cfg.name.lower() == "pointnet2":
10 | return Pointnet2Backbone(backbone_cfg)
11 | elif backbone_cfg.name.lower() == "pointnet":
12 | return PointNetEncoder(backbone_cfg)
13 | elif backbone_cfg.name.lower() == "clip_sd":
14 | return ClipCustom(backbone_cfg)
15 | else:
16 | raise NotImplementedError(f"No such backbone: {backbone_cfg.name}")
17 |
--------------------------------------------------------------------------------
/model/backbone/clip_sd.py:
--------------------------------------------------------------------------------
1 | import clip
2 | import torch.nn as nn
3 |
4 | class Adapter(nn.Module):
5 | def __init__(self, c_in, c_out, reduction=4):
6 | super().__init__()
7 | self.fc = nn.Sequential(
8 | nn.Linear(c_in, c_in // reduction, bias=False),
9 | nn.ReLU(inplace=True),
10 | nn.Linear(c_in // reduction, c_in // reduction, bias=False),
11 | nn.ReLU(inplace=True),
12 | nn.Linear(c_in // reduction, c_out, bias=False),
13 | nn.ReLU(inplace=True)
14 | )
15 |
16 | def forward(self, x):
17 | x = self.fc(x)
18 | return x
19 |
20 | class ClipCustom(nn.Module):
21 | """
22 | Uses the CLIP transformer encoder for text.
23 | """
24 | def __init__(self, cfg):
25 | super().__init__()
26 | self.device = cfg.device
27 |
28 | self.model, _ = clip.load(cfg.version, jit=False, device="cpu")
29 | if not hasattr(cfg, "use_adapter") or cfg.use_adapter:
30 | self.adapter = Adapter(cfg.dim_in, cfg.dim_out, cfg.reduction)
31 | self.use_adapter = True
32 | else:
33 | self.use_adapter = False
34 |
35 | def freeze(self):
36 | self.model = self.model.eval()
37 | for param in self.model.parameters():
38 | param.requires_grad = False
39 |
40 | def forward(self, text, pre_data=None):
41 |
42 | tokens = clip.tokenize(text).to(self.device)
43 |
44 | x = self.model.token_embedding(tokens).type(self.model.dtype) # [batch_size, n_ctx, d_model]
45 |
46 | x = x + self.model.positional_embedding.type(self.model.dtype)
47 | x = x.permute(1, 0, 2) # NLD -> LND
48 | x = self.model.transformer(x)
49 | x = x.permute(1, 0, 2) # LND -> NLD
50 | x = self.model.ln_final(x).type(self.model.dtype)
51 |
52 | if self.use_adapter:
53 | x = self.adapter(x)
54 | return x, tokens
55 |
56 |
57 | if __name__ == "__main__":
58 | model = ClipCustom().to("cuda")
59 | cls_token, txt_token = model(["abcd","acv ooo"])
--------------------------------------------------------------------------------
/model/backbone/pointnet.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.parallel
4 | import torch.utils.data
5 | import numpy as np
6 | import torch.nn.functional as F
7 |
8 | def size_splits(tensor, split_sizes, dim=0):
9 | """Splits the tensor according to chunks of split_sizes.
10 |
11 | Arguments:
12 | tensor (Tensor): tensor to split.
13 | split_sizes (list(int)): sizes of chunks
14 | dim (int): dimension along which to split the tensor.
15 | """
16 | if dim < 0:
17 | dim += tensor.dim()
18 |
19 | dim_size = tensor.size(dim)
20 | if dim_size != torch.sum(torch.Tensor(split_sizes)):
21 | raise KeyError("Sum of split sizes exceeds tensor dim")
22 |
23 | splits = torch.cumsum(torch.Tensor([0] + split_sizes), dim=0)[:-1]
24 |
25 | return tuple(tensor.narrow(int(dim), int(start), int(length))
26 | for start, length in zip(splits, split_sizes))
27 |
28 |
29 | class STN3d(nn.Module):
30 | def __init__(self, channel):
31 | super(STN3d, self).__init__()
32 | self.conv1 = torch.nn.Conv1d(channel, 64, 1)
33 | self.conv2 = torch.nn.Conv1d(64, 128, 1)
34 | self.conv3 = torch.nn.Conv1d(128, 1024, 1)
35 | self.fc1 = nn.Linear(1024, 512)
36 | self.fc2 = nn.Linear(512, 256)
37 | self.fc3 = nn.Linear(256, 9)
38 | self.relu = nn.ReLU()
39 |
40 | self.bn1 = nn.BatchNorm1d(64)
41 | self.bn2 = nn.BatchNorm1d(128)
42 | self.bn3 = nn.BatchNorm1d(1024)
43 | self.bn4 = nn.BatchNorm1d(512)
44 | self.bn5 = nn.BatchNorm1d(256)
45 |
46 | def forward(self, x):
47 | batchsize = x.size()[0]
48 | x = F.relu(self.bn1(self.conv1(x)))
49 | x = F.relu(self.bn2(self.conv2(x)))
50 | x = F.relu(self.bn3(self.conv3(x)))
51 | x = torch.max(x, 2, keepdim=True)[0]
52 | x = x.view(-1, 1024)
53 |
54 | x = F.relu(self.bn4(self.fc1(x)))
55 | x = F.relu(self.bn5(self.fc2(x)))
56 | x = self.fc3(x)
57 |
58 | #iden = Variable(torch.from_numpy(np.array([1, 0, 0, 0, 1, 0, 0, 0, 1]).astype(np.float32))).view(1, 9).repeat(
59 | # batchsize, 1)
60 | iden = torch.from_numpy(np.array([1, 0, 0, 0, 1, 0, 0, 0, 1]).astype(np.float32)).view(1, 9).repeat(batchsize, 1)
61 | if x.is_cuda:
62 | iden = iden.to(x.device)
63 | x = x + iden
64 | x = x.view(-1, 3, 3)
65 | return x
66 |
67 | class STNkd(nn.Module):
68 | def __init__(self, k=64):
69 | super(STNkd, self).__init__()
70 | self.conv1 = torch.nn.Conv1d(k, 64, 1)
71 | self.conv2 = torch.nn.Conv1d(64, 128, 1)
72 | self.conv3 = torch.nn.Conv1d(128, 1024, 1)
73 | self.fc1 = nn.Linear(1024, 512)
74 | self.fc2 = nn.Linear(512, 256)
75 | self.fc3 = nn.Linear(256, k * k)
76 | self.relu = nn.ReLU()
77 |
78 | self.bn1 = nn.BatchNorm1d(64)
79 | self.bn2 = nn.BatchNorm1d(128)
80 | self.bn3 = nn.BatchNorm1d(1024)
81 | self.bn4 = nn.BatchNorm1d(512)
82 | self.bn5 = nn.BatchNorm1d(256)
83 |
84 | self.k = k
85 |
86 | def forward(self, x):
87 | batchsize = x.size()[0]
88 | x = F.relu(self.bn1(self.conv1(x)))
89 | x = F.relu(self.bn2(self.conv2(x)))
90 | x = F.relu(self.bn3(self.conv3(x)))
91 | x = torch.max(x, 2, keepdim=True)[0]
92 | x = x.view(-1, 1024)
93 |
94 | x = F.relu(self.bn4(self.fc1(x)))
95 | x = F.relu(self.bn5(self.fc2(x)))
96 | x = self.fc3(x)
97 |
98 | iden = torch.from_numpy(np.eye(self.k).flatten().astype(np.float32)).view(1, self.k * self.k).repeat(batchsize, 1)
99 | if x.is_cuda:
100 | iden = iden.cuda()
101 | x = x + iden
102 | x = x.view(-1, self.k, self.k)
103 | return x
104 |
105 | class PointNetEncoderLight(nn.Module):
106 | def __init__(self, cfg=None):
107 | super().__init__()
108 | # channel = cfg.channel
109 | channel = 3
110 | self.conv1 = torch.nn.Conv1d(channel, 32, 1)
111 | self.conv2 = torch.nn.Conv1d(32, 64, 1)
112 | self.conv3 = torch.nn.Conv1d(64, 64, 1)
113 | self.conv4 = torch.nn.Conv1d(128, 32, 1)
114 |
115 | self.bn1 = nn.BatchNorm1d(32)
116 | self.bn2 = nn.BatchNorm1d(64)
117 | self.bn3 = nn.BatchNorm1d(64)
118 | self.bn4 = nn.BatchNorm1d(32)
119 |
120 | def forward(self, x):
121 | B, D, N = x.size()
122 | assert D == 3
123 |
124 | x = F.relu(self.bn1(self.conv1(x)))
125 | x = F.relu(self.bn2(self.conv2(x)))
126 | g = F.relu(self.bn3(self.conv3(x)))
127 | g = torch.max(x, 2, keepdim=True)[0]
128 | g = g.view(-1, 64, 1).repeat(1, 1, N)
129 | x = torch.cat([x, g], 1)
130 | x = F.relu(self.bn4(self.conv4(x)))
131 |
132 | return x
133 |
134 | class PointNetEncoder(nn.Module):
135 | def __init__(self, cfg):
136 | super(PointNetEncoder, self).__init__()
137 | global_feat=cfg.global_feat
138 | feature_transform=cfg.feature_transform
139 | channel=cfg.channel
140 | use_stn=cfg.use_stn
141 | self.stn = STN3d(channel) if use_stn else None
142 | self.conv1 = torch.nn.Conv1d(channel, 64, 1)
143 | self.conv2 = torch.nn.Conv1d(64, 128, 1)
144 | self.conv3 = torch.nn.Conv1d(128, 1024, 1)
145 | self.bn1 = nn.BatchNorm1d(64)
146 | self.bn2 = nn.BatchNorm1d(128)
147 | self.bn3 = nn.BatchNorm1d(1024)
148 | self.global_feat = global_feat
149 | self.feature_transform = feature_transform
150 | if self.feature_transform:
151 | self.fstn = STNkd(k=64)
152 |
153 | def forward(self, x):
154 | B, D, N = x.size()
155 | assert D == 3
156 | if self.stn:
157 | trans = self.stn(x)
158 | x = x.transpose(2, 1)
159 | if self.stn:
160 | x = torch.bmm(x, trans)
161 | x = x.transpose(2, 1)
162 | x = F.relu(self.bn1(self.conv1(x)))
163 |
164 | if self.feature_transform:
165 | trans_feat = self.fstn(x)
166 | x = x.transpose(2, 1)
167 | x = torch.bmm(x, trans_feat)
168 | x = x.transpose(2, 1)
169 | else:
170 | trans_feat = None
171 |
172 | pointfeat = x
173 | x = F.relu(self.bn2(self.conv2(x)))
174 | x = self.bn3(self.conv3(x))
175 | x = torch.max(x, 2, keepdim=True)[0]
176 | x = x.view(-1, 1024)
177 | if self.global_feat:
178 | return x, pointfeat, trans_feat
179 | else:
180 | raise NotImplementedError()
181 | x = x.view(-1, 1024, 1).repeat(1, 1, N)
182 | return torch.cat([x, pointfeat], 1), trans, trans_feat
183 |
184 | if __name__ == '__main__':
185 | points = torch.randn(2, 3, 778)
186 | print(points.size())
187 | pointnet = PointNetEncoderLight()
188 | x = pointnet(points)
189 | print(x.size())
--------------------------------------------------------------------------------
/model/backbone/pointnet2.py:
--------------------------------------------------------------------------------
1 |
2 | import sys
3 | sys.path.append("./thirdparty/pointnet2/")
4 |
5 | import torch.nn as nn
6 | from pointnet2_modules import PointnetSAModuleVotes
7 | from torch.functional import Tensor
8 | import torch
9 |
10 | class Pointnet2Backbone(nn.Module):
11 | """
12 | Backbone network for point cloud feature learning.
13 | Based on Pointnet++ single-scale grouping network.
14 |
15 | Parameters
16 | ----------
17 | input_feature_dim: int
18 | Number of input channels in the feature descriptor for each point.
19 | e.g. 3 for RGB.
20 | """
21 |
22 | def __init__(self, cfg):
23 | super().__init__()
24 |
25 | self.sa1 = PointnetSAModuleVotes(
26 | npoint=cfg.layer1.npoint,
27 | radius=cfg.layer1.radius_list[0],
28 | nsample=cfg.layer1.nsample_list[0],
29 | mlp=cfg.layer1.mlp_list,
30 | use_xyz=cfg.use_xyz,
31 | normalize_xyz=cfg.normalize_xyz
32 | )
33 |
34 | self.sa2 = PointnetSAModuleVotes(
35 | npoint=cfg.layer2.npoint,
36 | radius=cfg.layer2.radius_list[0],
37 | nsample=cfg.layer2.nsample_list[0],
38 | mlp=cfg.layer2.mlp_list,
39 | use_xyz=cfg.use_xyz,
40 | normalize_xyz=cfg.normalize_xyz
41 | )
42 |
43 | self.sa3 = PointnetSAModuleVotes(
44 | npoint=cfg.layer3.npoint,
45 | radius=cfg.layer3.radius_list[0],
46 | nsample=cfg.layer3.nsample_list[0],
47 | mlp=cfg.layer3.mlp_list,
48 | use_xyz=cfg.use_xyz,
49 | normalize_xyz=cfg.normalize_xyz
50 | )
51 | if cfg.use_pooling:
52 | self.gap = torch.nn.AdaptiveAvgPool1d(1)
53 | self.use_pooling = cfg.use_pooling
54 |
55 | def _break_up_pc(self, pc):
56 | xyz = pc[..., 0:3].contiguous()
57 | features = (
58 | pc[..., 3:].transpose(1, 2).contiguous()
59 | if pc.size(-1) > 3 else None
60 | )
61 | return xyz, features
62 |
63 | def forward(self, pointcloud: Tensor):
64 | """
65 | Forward pass of the network
66 |
67 | Parameters
68 | ----------
69 | pointcloud: Variable(Tensor)
70 | (B, N, 3 + input_feature_dim) tensor
71 | Point cloud to run predicts on
72 | Each point in the point-cloud MUST
73 | be formated as (x, y, z, features...)
74 |
75 | Returns
76 | ----------
77 | xyz: float32 Tensor of shape (B, K, 3)
78 | features: float32 Tensor of shape (B, D, K)
79 | inds: int64 Tensor of shape (B, K) values in [0, N-1]
80 | """
81 | xyz, features = self._break_up_pc(pointcloud)
82 | xyz, features, fps_inds = self.sa1(xyz, features)
83 | xyz, features, fps_inds = self.sa2(xyz, features)
84 | xyz, features, fps_inds = self.sa3(xyz, features)
85 | if self.use_pooling:
86 | features = self.gap(features)
87 | return xyz, features
88 |
--------------------------------------------------------------------------------
/model/backbone/resnet.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 |
3 | from __future__ import absolute_import
4 | from __future__ import division
5 | from __future__ import print_function
6 | import torch.nn as nn
7 | import math
8 | import torch.utils.model_zoo as model_zoo
9 |
10 |
11 | __all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101',
12 | 'resnet152']
13 |
14 |
15 | model_urls = {
16 | 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
17 | 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
18 | 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
19 | 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
20 | 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
21 | }
22 |
23 |
24 | def conv3x3(in_planes, out_planes, stride=1):
25 | """3x3 convolution with padding"""
26 | return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
27 | padding=1, bias=False)
28 |
29 |
30 | class BasicBlock(nn.Module):
31 | expansion = 1
32 |
33 | def __init__(self, inplanes, planes, stride=1, downsample=None):
34 | super(BasicBlock, self).__init__()
35 | self.conv1 = conv3x3(inplanes, planes, stride)
36 | self.bn1 = nn.BatchNorm2d(planes)
37 | self.relu = nn.ReLU(inplace=True)
38 | self.conv2 = conv3x3(planes, planes)
39 | self.bn2 = nn.BatchNorm2d(planes)
40 | self.downsample = downsample
41 | self.stride = stride
42 |
43 | def forward(self, x):
44 | residual = x
45 |
46 | out = self.conv1(x)
47 | out = self.bn1(out)
48 | out = self.relu(out)
49 |
50 | out = self.conv2(out)
51 | out = self.bn2(out)
52 |
53 | if self.downsample is not None:
54 | residual = self.downsample(x)
55 |
56 | out += residual
57 | out = self.relu(out)
58 |
59 | return out
60 |
61 |
62 | class Bottleneck(nn.Module):
63 | expansion = 4
64 |
65 | def __init__(self, inplanes, planes, stride=1, downsample=None):
66 | super(Bottleneck, self).__init__()
67 | self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
68 | self.bn1 = nn.BatchNorm2d(planes)
69 | self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
70 | padding=1, bias=False)
71 | self.bn2 = nn.BatchNorm2d(planes)
72 | self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
73 | self.bn3 = nn.BatchNorm2d(planes * self.expansion)
74 | self.relu = nn.ReLU(inplace=True)
75 | self.downsample = downsample
76 | self.stride = stride
77 |
78 | def forward(self, x):
79 | residual = x
80 |
81 | out = self.conv1(x)
82 | out = self.bn1(out)
83 | out = self.relu(out)
84 |
85 | out = self.conv2(out)
86 | out = self.bn2(out)
87 | out = self.relu(out)
88 |
89 | out = self.conv3(out)
90 | out = self.bn3(out)
91 |
92 | if self.downsample is not None:
93 | residual = self.downsample(x)
94 |
95 | out += residual
96 | out = self.relu(out)
97 |
98 | return out
99 |
100 |
101 | class ResNet(nn.Module):
102 |
103 | def __init__(self, block, layers, num_classes=1000):
104 | self.inplanes = 64
105 | super(ResNet, self).__init__()
106 | self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
107 | bias=False)
108 | self.bn1 = nn.BatchNorm2d(64)
109 | self.relu = nn.ReLU(inplace=True)
110 | self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
111 | self.layer1 = self._make_layer(block, 64, layers[0])
112 | self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
113 | self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
114 | self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
115 | self.avgpool = nn.AvgPool2d(7, stride=1)
116 | self.fc1 = nn.Linear(512 * block.expansion, 1024)
117 |
118 | for m in self.modules():
119 | if isinstance(m, nn.Conv2d):
120 | nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
121 | elif isinstance(m, nn.BatchNorm2d):
122 | nn.init.constant_(m.weight, 1)
123 | nn.init.constant_(m.bias, 0)
124 |
125 | def _make_layer(self, block, planes, blocks, stride=1):
126 | downsample = None
127 | if stride != 1 or self.inplanes != planes * block.expansion:
128 | downsample = nn.Sequential(
129 | nn.Conv2d(self.inplanes, planes * block.expansion,
130 | kernel_size=1, stride=stride, bias=False),
131 | nn.BatchNorm2d(planes * block.expansion),
132 | )
133 |
134 | layers = []
135 | layers.append(block(self.inplanes, planes, stride, downsample))
136 | self.inplanes = planes * block.expansion
137 | for i in range(1, blocks):
138 | layers.append(block(self.inplanes, planes))
139 |
140 | return nn.Sequential(*layers)
141 |
142 | def forward(self, x):
143 | x = self.conv1(x)
144 | x = self.bn1(x)
145 | x = self.relu(x)
146 | x = self.maxpool(x)
147 |
148 | x = self.layer1(x)
149 | x = self.layer2(x)
150 | x = self.layer3(x)
151 | x = self.layer4(x)
152 |
153 | x = self.avgpool(x)
154 | x = x.view(x.size(0), -1)
155 | x = self.relu(x)
156 |
157 | x = self.fc1(x)
158 | x = self.relu(x)
159 |
160 | return x
161 |
162 |
163 | def resnet18(pretrained=False, **kwargs):
164 | model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
165 | if pretrained:
166 | pretrained_state_dict = model_zoo.load_url(model_urls['resnet18'])
167 | model.load_state_dict(pretrained_state_dict, strict=False)
168 | return model
169 |
170 |
171 | def resnet34(pretrained=False, **kwargs):
172 | """Constructs a ResNet-34 model.
173 |
174 | Args:
175 | pretrained (bool): If True, returns a model pre-trained on ImageNet
176 | """
177 | model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs)
178 | if pretrained:
179 | pretrained_state_dict = model_zoo.load_url(model_urls['resnet34'])
180 | model.load_state_dict(pretrained_state_dict, strict=False)
181 | return model
182 |
183 |
184 | def resnet50(pretrained=False, **kwargs):
185 | """Constructs a ResNet-50 model.
186 |
187 | Args:
188 | pretrained (bool): If True, returns a model pre-trained on ImageNet
189 | """
190 | model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
191 | if pretrained:
192 | pretrained_state_dict = model_zoo.load_url(model_urls['resnet50'])
193 | model.load_state_dict(pretrained_state_dict, strict=False)
194 | return model
195 |
196 |
197 | def resnet101(pretrained=False, **kwargs):
198 | """Constructs a ResNet-101 model.
199 |
200 | Args:
201 | pretrained (bool): If True, returns a model pre-trained on ImageNet
202 | """
203 | model = ResNet(Bottleneck, [3, 4, 23, 3], **kwargs)
204 | if pretrained:
205 | pretrained_state_dict = model_zoo.load_url(model_urls['resnet101'])
206 | model.load_state_dict(pretrained_state_dict, strict=False)
207 | return model
208 |
209 |
210 | def resnet152(pretrained=False, **kwargs):
211 | """Constructs a ResNet-152 model.
212 |
213 | Args:
214 | pretrained (bool): If True, returns a model pre-trained on ImageNet
215 | """
216 | model = ResNet(Bottleneck, [3, 8, 36, 3], **kwargs)
217 | if pretrained:
218 | pretrained_state_dict = model_zoo.load_url(model_urls['resnet152'])
219 | model.load_state_dict(pretrained_state_dict, strict=False)
220 | return model
221 |
222 |
223 | model_functions = {
224 | 18: resnet18,
225 | 34: resnet34,
226 | 50: resnet50,
227 | 101: resnet101,
228 | 152: resnet152
229 | }
230 |
231 | def build_resnet_backbone(depth, **kwargs):
232 | return model_functions[depth](**kwargs)
--------------------------------------------------------------------------------
/model/decoder/__init__.py:
--------------------------------------------------------------------------------
1 | from .unet import UNetModel
2 |
3 | def build_decoder(decoder_cfg):
4 | if decoder_cfg.name.lower() == "unet":
5 | return UNetModel(decoder_cfg)
6 | else:
7 | raise NotImplementedError(f"No such decode: {decoder_cfg.name}")
8 |
--------------------------------------------------------------------------------
/model/decoder/unet.py:
--------------------------------------------------------------------------------
1 | from typing import Dict
2 | from einops import rearrange
3 | import torch
4 | import torch.nn as nn
5 | import torch.nn.functional as F
6 |
7 | from model.utils.diffusion_utils import timestep_embedding, ResBlock, SpatialTransformer
8 | from model.backbone import build_backbone
9 |
10 | class UNetModel(nn.Module):
11 | def __init__(self, cfg) -> None:
12 | super(UNetModel, self).__init__()
13 |
14 | self.d_x = cfg.d_x
15 | self.d_model = cfg.d_model
16 | self.nblocks = cfg.nblocks
17 | self.resblock_dropout = cfg.resblock_dropout
18 | self.transformer_num_heads = cfg.transformer_num_heads
19 | self.transformer_dim_head = cfg.transformer_dim_head
20 | self.transformer_dropout = cfg.transformer_dropout
21 | self.transformer_depth = cfg.transformer_depth
22 | self.transformer_mult_ff = cfg.transformer_mult_ff
23 | self.context_dim = cfg.context_dim
24 | self.use_position_embedding = cfg.use_position_embedding # for input sequence x
25 | self.plus_condition_type = cfg.plus_condition_type
26 | self.trans_condition_type = cfg.trans_condition_type
27 |
28 | ## create scene model from config
29 | self.scene_model = build_backbone(cfg.backbone)
30 | if hasattr(cfg, "use_hand") and cfg.use_hand:
31 | self.hand_model = build_backbone(cfg.hand_backbone)
32 | if hasattr(cfg, "use_guidence") and cfg.use_guidence:
33 | self.language_model = build_backbone(cfg.language_encoder)
34 |
35 | time_embed_dim = self.d_model * cfg.time_embed_mult
36 | self.time_embed = nn.Sequential(
37 | nn.Linear(self.d_model, time_embed_dim),
38 | nn.SiLU(),
39 | nn.Linear(time_embed_dim, time_embed_dim),
40 | )
41 |
42 | self.in_layers = nn.Sequential(
43 | nn.Conv1d(self.d_x, self.d_model, 1)
44 | )
45 |
46 | self.layers = nn.ModuleList()
47 | for i in range(self.nblocks):
48 | self.layers.append(
49 | ResBlock(
50 | self.d_model,
51 | time_embed_dim,
52 | self.resblock_dropout,
53 | self.plus_condition_type,
54 | self.d_model,
55 | )
56 | )
57 | self.layers.append(
58 | SpatialTransformer(
59 | self.d_model,
60 | self.transformer_num_heads,
61 | self.transformer_dim_head,
62 | depth=self.transformer_depth,
63 | dropout=self.transformer_dropout,
64 | mult_ff=self.transformer_mult_ff,
65 | context_dim=self.context_dim,
66 | )
67 | )
68 |
69 | self.out_layers = nn.Sequential(
70 | nn.GroupNorm(32, self.d_model),
71 | nn.SiLU(),
72 | nn.Conv1d(self.d_model, self.d_x, 1),
73 | )
74 |
75 | def condition_mask(self, obj_cond, txt_cond, text_vector):
76 | cond = torch.cat([obj_cond, txt_cond], dim=1)
77 | batch_size, seq_length, embedding_size = cond.size()
78 |
79 | txt_index = text_vector.argmax(dim=-1) + cond.shape[0] + 2
80 |
81 | range_matrix = torch.arange(seq_length).expand(batch_size, seq_length).to(obj_cond.device)
82 |
83 | attention_mask = range_matrix < txt_index.unsqueeze(1)
84 | attention_mask[:,cond.shape[0]+1] = False
85 | return cond, attention_mask
86 |
87 | def forward(self, x_t: torch.Tensor, ts: torch.Tensor, data:Dict) -> torch.Tensor:
88 | """ Apply the model to an input batch
89 |
90 | Args:
91 | x_t: the input data, or
92 | ts: timestep, 1-D batch of timesteps
93 | cond: condition feature
94 |
95 | Return:
96 | the denoised target data, i.e., $x_{t-1}$
97 | """
98 |
99 | if self.trans_condition_type == "txt_obj":
100 | cond = torch.cat([data["cond_obj"], data["cond_txt"]], dim=1)
101 | atten_mask = None
102 | elif self.trans_condition_type == "obj_hand":
103 | cond = torch.cat([data["cond_obj"], data["cond_hand"]], dim=1)
104 | atten_mask = None
105 | else:
106 | raise Exception("no valid trans condition")
107 |
108 | in_shape = len(x_t.shape)
109 | if in_shape == 2:
110 | x_t = x_t.unsqueeze(1)
111 | assert len(x_t.shape) == 3
112 |
113 | ## time embedding
114 | if ts != None:
115 | t_emb = timestep_embedding(ts, self.d_model)
116 | t_emb = self.time_embed(t_emb)
117 | else:
118 | t_emb = None
119 |
120 | h = rearrange(x_t, 'b l c -> b c l')
121 | h = self.in_layers(h) #
122 |
123 | ## prepare position embedding for input x
124 | if self.use_position_embedding:
125 | B, DX, TX = h.shape
126 | pos_Q = torch.arange(TX, dtype=h.dtype, device=h.device)
127 | pos_embedding_Q = timestep_embedding(pos_Q, DX) #
128 | h = h + pos_embedding_Q.permute(1, 0) #
129 |
130 | for i in range(self.nblocks):
131 | h = self.layers[i * 2 + 0](h, t_emb, data)
132 | h = self.layers[i * 2 + 1](h, context=cond, mask=atten_mask)
133 | h = self.out_layers(h)
134 | h = rearrange(h, 'b c l -> b l c')
135 |
136 | ## reverse to original shape
137 | if in_shape == 2:
138 | h = h.squeeze(1)
139 |
140 | return h
141 |
142 | def condition_obj(self, data: Dict) -> torch.Tensor:
143 | """ Obtain scene feature with scene model
144 |
145 | Args:
146 | data: dataloader-provided data
147 |
148 | Return:
149 | Condition feature
150 | """
151 |
152 | b = data['obj_pc'].shape[0]
153 | obj_pc = data['obj_pc'].to(torch.float32)
154 | _, obj_feat = self.scene_model(obj_pc)
155 | obj_feat = obj_feat.permute(0,2,1).contiguous()
156 | # (B, C, N)
157 | return obj_feat
158 |
159 | def condition_language(self, data: Dict) -> torch.Tensor:
160 |
161 | cond_txt, text_vector = self.language_model(data["guidence"], data["clip_data"] if "clip_data" in data else None)
162 | cond_txt_cls = cond_txt[torch.arange(cond_txt.shape[0]), text_vector.argmax(dim=-1)]
163 |
164 | return cond_txt_cls, cond_txt
165 |
166 | def condition_hand(self, data: Dict) -> torch.Tensor:
167 | b = data['hand_pc'].shape[0]
168 | hand_pc = data['hand_pc']
169 | _, hand_feat = self.hand_model(hand_pc)
170 | hand_feat = hand_feat.permute(0,2,1).contiguous()
171 | # (B, C, N)
172 | return hand_feat
173 |
174 |
--------------------------------------------------------------------------------
/model/irf.py:
--------------------------------------------------------------------------------
1 | from typing import Dict, Tuple
2 | import torch
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 | from torch.functional import Tensor
6 | from .decoder import build_decoder
7 | from .loss import GraspLossPose
8 | from .utils.diffusion_utils import make_schedule_ddpm
9 |
10 | class RenfinmentTransformer(nn.Module):
11 | def __init__(self, cfg) -> None:
12 | super(RenfinmentTransformer, self).__init__()
13 |
14 | self.eps_model = build_decoder(cfg.decoder)
15 | self.criterion = GraspLossPose(cfg.criterion)
16 | self.loss_weights = cfg.criterion.loss_weights
17 | self.timesteps = cfg.steps
18 | self.schedule_cfg = cfg.schedule_cfg
19 | self.rand_t_type = cfg.rand_t_type
20 | self.pred_abs = cfg.pred_abs
21 |
22 | for k, v in make_schedule_ddpm(self.timesteps, **self.schedule_cfg).items():
23 | self.register_buffer(k, v)
24 |
25 | @property
26 | def device(self):
27 | return self.betas.device
28 |
29 |
30 | def forward(self, data: Dict):
31 | """ Reverse diffusion process, sampling with the given data containing condition
32 |
33 | Args:
34 | data: test data, data['norm_pose'] gives the target data,
35 | data['obj_pc'] gives the condition
36 |
37 | Return:
38 | Computed loss
39 | """
40 | B = data['coarse_norm_pose'].shape[0]
41 |
42 | ## predict noise
43 | data['hand_pc'] = self.criterion.hand_model(data['coarse_pose'], with_surface_points=True)["surface_points"]
44 | data['cond_hand'] = self.eps_model.condition_hand(data)
45 |
46 | data["cond_obj"] = self.eps_model.condition_obj(data)
47 |
48 | output = self.eps_model(data['coarse_norm_pose'], None, data)
49 |
50 | if not self.pred_abs:
51 | output += data['coarse_norm_pose']
52 | if self.training:
53 | loss_dict = self.criterion({"pred_pose_norm": output}, data)
54 | else:
55 | loss_dict, _e = self.criterion({"pred_pose_norm": output}, data)
56 |
57 | loss = 0
58 | for k, v in loss_dict.items():
59 | if k in self.loss_weights:
60 | loss += v * self.loss_weights[k]
61 |
62 | return loss, loss_dict, None
63 |
64 | def forward_test(self, data: Dict):
65 | """ Reverse diffusion process, sampling with the given data containing condition
66 |
67 | Args:
68 | data: test data, data['norm_pose'] gives the target data,
69 | data['obj_pc'] gives the condition
70 |
71 | Return:
72 | Computed loss
73 | """
74 | B = data['coarse_norm_pose'].shape[0]
75 |
76 | ## predict noise
77 | data['hand_pc'] = self.criterion.hand_model(data['coarse_pose'], with_surface_points=True)["surface_points"]
78 | data['cond_hand'] = self.eps_model.condition_hand(data)
79 |
80 | data["cond_obj"] = self.eps_model.condition_obj(data)
81 |
82 | output = self.eps_model(data['coarse_norm_pose'], None, data)
83 |
84 | if not self.pred_abs:
85 | output += data['coarse_norm_pose']
86 | if self.training:
87 | loss_dict = self.criterion({"pred_pose_norm": output}, data)
88 | else:
89 | loss_dict, preditions = self.criterion({"pred_pose_norm": output}, data)
90 |
91 | loss = 0
92 | for k, v in loss_dict.items():
93 | if k in self.loss_weights:
94 | loss += v * self.loss_weights[k]
95 |
96 | return loss, loss_dict, preditions
97 |
98 | def forward_infer(self, data: Dict, k=4):
99 | """ Reverse diffusion process, sampling with the given data containing condition
100 |
101 | Args:
102 | data: test data, data['norm_pose'] gives the target data,
103 | data['obj_pc'] gives the condition
104 |
105 | Return:
106 | Computed loss
107 | """
108 | B = data['coarse_norm_pose'].shape[0]
109 |
110 | ## predict noise
111 | data['hand_pc'] = self.criterion.hand_model(data['coarse_pose'], with_surface_points=True)["surface_points"]
112 | data['cond_hand'] = self.eps_model.condition_hand(data)
113 |
114 | data["cond_obj"] = self.eps_model.condition_obj(data)
115 |
116 | output = self.eps_model(data['coarse_norm_pose'], None, data)
117 |
118 | if not self.pred_abs:
119 | output += data['coarse_norm_pose']
120 |
121 | preds_hand, targets_hand = self.criterion.infer_norm_process_dict({"pred_pose_norm": output}, data)
122 |
123 | return preds_hand, targets_hand
124 |
125 |
126 | @torch.no_grad()
127 | def sample(self, data: Dict, k: int=1) -> torch.Tensor:
128 | """ Reverse diffusion process, sampling with the given data containing condition
129 | In this method, the sampled results are unnormalized and converted to absolute representation.
130 |
131 | Args:
132 | data: test data, data['norm_pose'] gives the target data shape
133 | k: the number of sampled data
134 |
135 | Return:
136 | Sampled results, the shape is
137 | """
138 | ## TODO ddim sample function
139 | ksamples = []
140 | for _ in range(k):
141 | ksamples.append(self.p_sample_loop(data))
142 | ksamples = torch.stack(ksamples, dim=1)
143 | return ksamples
144 |
145 |
--------------------------------------------------------------------------------
/model/loss/__init__.py:
--------------------------------------------------------------------------------
1 | from .grasp_loss_pose import GraspLossPose
2 |
--------------------------------------------------------------------------------
/model/loss/matcher.py:
--------------------------------------------------------------------------------
1 | from functools import partial
2 | from typing import Callable, Dict, List
3 |
4 | import torch
5 | import torch.nn as nn
6 | import torch.nn.functional as F
7 | from scipy.optimize import linear_sum_assignment
8 | from torch.functional import Tensor
9 |
10 |
11 | class Matcher(nn.Module):
12 | def __init__(self, weight_dict: Dict[str, float]):
13 | super().__init__()
14 | # exclude weights equaling 0
15 | self.weight_dict = {k: v for k, v in weight_dict.items() if v > 0}
16 |
17 | @torch.no_grad()
18 | def forward(self, preds: Dict, targets: Dict):
19 | _example = preds["rotation"]
20 | device = _example.device
21 | batch_size, nqueries = _example.shape[:2]
22 | rotation_type = targets["rotation_type"][0]
23 |
24 | cost_matrices = []
25 | for name, weight in self.weight_dict.items():
26 | m = getattr(self, f"get_{name}_cost_mat")
27 | if name == "rotation":
28 | cost_mat = m(preds, targets, weight=weight, rotation_type=rotation_type)
29 | cost_mat = m(preds, targets, weight=weight)
30 | cost_matrices.append(cost_mat)
31 | final_cost = [sum(x).detach().cpu().numpy() for x in zip(*cost_matrices)]
32 |
33 | assignments = []
34 | # auxiliary variables useful for batched loss computation
35 | per_query_gt_inds = torch.zeros(
36 | [batch_size, nqueries], dtype=torch.int64, device=device
37 | )
38 | query_matched_mask = torch.zeros(
39 | [batch_size, nqueries], dtype=torch.float32, device=device
40 | )
41 | for b in range(batch_size):
42 | assign = linear_sum_assignment(final_cost[b])
43 | assign = [
44 | torch.from_numpy(x).long().to(device)
45 | for x in assign
46 | ]
47 | per_query_gt_inds[b, assign[0]] = assign[1]
48 | query_matched_mask[b, assign[0]] = 1
49 | assignments.append(assign)
50 | return {
51 | "final_cost": final_cost,
52 | "assignments": assignments,
53 | "per_query_gt_inds": per_query_gt_inds,
54 | "query_matched_mask": query_matched_mask,
55 | }
56 |
57 | def get_hand_mesh_cost_mat(
58 | self,
59 | prediction: Tensor,
60 | targets: List[Tensor],
61 | weight: float = 1.0,
62 | ) -> List[Tensor]:
63 | # TODO: implement chamfer loss for hand mesh cost
64 | raise NotImplementedError("Unable to calculate hand mesh cost matrix yet. Please help me to implement it ^_^")
65 |
66 | def get_qpos_cost_mat(
67 | self,
68 | prediction: Tensor,
69 | targets: List[Tensor],
70 | weight: float = 1.0,
71 | ) -> List[Tensor]:
72 | pred_qpos = prediction["qpos_norm"]
73 | target_qpos = [x[..., 3:25] for x in targets["norm_pose"]]
74 | return self._get_cost_mat_by_elementwise(pred_qpos, target_qpos, weight=weight)
75 |
76 | def get_translation_cost_mat(
77 | self,
78 | prediction: Tensor,
79 | targets: List[Tensor],
80 | weight: float = 1.0,
81 | ) -> List[Tensor]:
82 | pred_translation = prediction["translation_norm"]
83 | target_translation = [x[..., :3] for x in targets["norm_pose"]]
84 | return self._get_cost_mat_by_elementwise(pred_translation, target_translation, weight=weight)
85 |
86 | def get_rotation_cost_mat(
87 | self,
88 | prediction: Tensor,
89 | targets: List[Tensor],
90 | weight: float = 1.0,
91 | rotation_type: str = "quaternion",
92 | ) -> List[Tensor]:
93 | if hasattr(self, f"_get_{rotation_type}_cost_mat"):
94 | m = getattr(self, f"_get_{rotation_type}_cost_mat")
95 | pred_rotation = prediction["rotation"] # (num_queries, D)
96 | target_rotation = [x[..., 25:] for x in targets["norm_pose"]] # [(ngt1, D), (ngt2, D), ...]
97 | return m(pred_rotation, target_rotation, weight)
98 | else:
99 | raise NotImplementedError(f"Unable to get {rotation_type} cost matrix")
100 |
101 | def _get_cost_mat_by_elementwise(
102 | self,
103 | prediction: Tensor,
104 | targets: List[Tensor],
105 | weight: float = 1.0,
106 | element_wise_func: Callable[[Tensor, Tensor], Tensor] = partial(F.l1_loss, reduction="none"),
107 | ) -> List[Tensor]:
108 | """
109 | calculate cost matrix by element-wise operations
110 |
111 | Params:
112 | prediction: B, nqueries, D
113 | targets: [(ngt1, D), (ngt2, D), ...]
114 | weight: a float number for current cost matrix
115 | element_wise_func: an element-wise function for two tensors. Default is l1_loss
116 |
117 | return:
118 | cost_mat: [(nqueries, ngt1), (nqueries, ngt2), ...]
119 | """
120 | B = prediction.size(0)
121 | assert B == len(targets), f"batch size and len(targets) should be the same"
122 | nqueries = prediction.size(1)
123 | cost_mat = []
124 | for i in range(B):
125 | rot, gt = prediction[i], targets[i]
126 | ngt = gt.size(0)
127 | rot = rot.unsqueeze(1).expand(-1, ngt, -1) # (nqueries, ngt, D)
128 | gt = gt.unsqueeze(0).expand(nqueries, -1, -1) # (nqueries, ngt, D)
129 | cost = element_wise_func(rot, gt).sum(-1)
130 | cost_mat.append(weight * cost)
131 | return cost_mat
132 |
133 | def _get_quaternion_cost_mat(self, prediction: Tensor, targets: List[Tensor], weight: float = 1.0) -> List[Tensor]:
134 | B = prediction.size(0)
135 | assert B == len(targets), f"batch size and len(targets) should be the same"
136 | cost_mat = []
137 | for i in range(B):
138 | rot, gt = prediction[i], targets[i]
139 | cost = 1 - (rot @ gt.T).abs().detach()
140 | cost_mat.append(weight * cost)
141 | return cost_mat
142 |
143 | def _get_rotation_6d_cost_mat(self, prediction: Tensor, targets: List[Tensor], weight: float = 1.0) -> List[Tensor]:
144 | cost_mat = self._get_cost_mat_by_elementwise(
145 | prediction,
146 | targets,
147 | weight=weight,
148 | )
149 | return cost_mat
150 |
151 | def _get_euler_cost_mat(self, prediction: Tensor, targets: List[Tensor], weight: float = 1.0) -> List[Tensor]:
152 | """
153 | specially-designed l1 loss for euler angles
154 | """
155 | B = prediction.size(0)
156 | assert B == len(targets), f"batch size and len(targets) should be the same"
157 | cost_mat = []
158 | for i in range(B):
159 | rot, gt = prediction[i].unsqueeze(1), targets[i].unsqueeze(0)
160 | error = (rot - gt).abs().sum(-1)
161 | cost = torch.where(error < 0.5, error, 1 - error)
162 | cost_mat.append(weight * cost)
163 | return cost_mat
164 |
--------------------------------------------------------------------------------
/model/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/iSEE-Laboratory/Grasp-as-You-Say/4694fa9369523d09d0c2cea6ec7bcddd2cb206d8/model/utils/__init__.py
--------------------------------------------------------------------------------
/model/utils/helpers.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | import torch.nn as nn
3 | from functools import partial
4 | import copy
5 |
6 |
7 | class BatchNormDim1Swap(nn.BatchNorm1d):
8 | """
9 | Used for nn.Transformer that uses a HW x N x C rep
10 | """
11 |
12 | def forward(self, x):
13 | """
14 | x: HW x N x C
15 | permute to N x C x HW
16 | Apply BN on C
17 | permute back
18 | """
19 | hw, n, c = x.shape
20 | x = x.permute(1, 2, 0)
21 | x = super(BatchNormDim1Swap, self).forward(x)
22 | # x: n x c x hw -> hw x n x c
23 | x = x.permute(2, 0, 1)
24 | return x
25 |
26 |
27 | NORM_DICT = {
28 | "bn": BatchNormDim1Swap,
29 | "bn1d": nn.BatchNorm1d,
30 | "id": nn.Identity,
31 | "ln": nn.LayerNorm,
32 | }
33 |
34 | ACTIVATION_DICT = {
35 | "relu": nn.ReLU,
36 | "gelu": nn.GELU,
37 | "leakyrelu": partial(nn.LeakyReLU, negative_slope=0.1),
38 | }
39 |
40 | WEIGHT_INIT_DICT = {
41 | "xavier_uniform": nn.init.xavier_uniform_,
42 | }
43 |
44 |
45 | class GenericMLP(nn.Module):
46 | def __init__(
47 | self,
48 | input_dim,
49 | hidden_dims,
50 | output_dim,
51 | norm_fn_name=None,
52 | activation="relu",
53 | use_conv=False,
54 | dropout=None,
55 | hidden_use_bias=False,
56 | output_use_bias=True,
57 | output_use_activation=False,
58 | output_use_norm=False,
59 | weight_init_name=None,
60 | ):
61 | super().__init__()
62 | activation = ACTIVATION_DICT[activation]
63 | norm = None
64 | if norm_fn_name is not None:
65 | norm = NORM_DICT[norm_fn_name]
66 | if norm_fn_name == "ln" and use_conv:
67 | norm = lambda x: nn.GroupNorm(1, x) # easier way to use LayerNorm
68 |
69 | if dropout is not None:
70 | if not isinstance(dropout, list):
71 | dropout = [dropout for _ in range(len(hidden_dims))]
72 |
73 | layers = []
74 | prev_dim = input_dim
75 | for idx, x in enumerate(hidden_dims):
76 | if use_conv:
77 | layer = nn.Conv1d(prev_dim, x, 1, bias=hidden_use_bias)
78 | else:
79 | layer = nn.Linear(prev_dim, x, bias=hidden_use_bias)
80 | layers.append(layer)
81 | if norm:
82 | layers.append(norm(x))
83 | layers.append(activation())
84 | if dropout is not None:
85 | layers.append(nn.Dropout(p=dropout[idx]))
86 | prev_dim = x
87 | if use_conv:
88 | layer = nn.Conv1d(prev_dim, output_dim, 1, bias=output_use_bias)
89 | else:
90 | layer = nn.Linear(prev_dim, output_dim, bias=output_use_bias)
91 | layers.append(layer)
92 |
93 | if output_use_norm:
94 | layers.append(norm(output_dim))
95 |
96 | if output_use_activation:
97 | layers.append(activation())
98 |
99 | self.layers = nn.Sequential(*layers)
100 |
101 | if weight_init_name is not None:
102 | self.do_weight_init(weight_init_name)
103 |
104 | def do_weight_init(self, weight_init_name):
105 | func = WEIGHT_INIT_DICT[weight_init_name]
106 | for (_, param) in self.named_parameters():
107 | if param.dim() > 1: # skips batchnorm/layernorm
108 | func(param)
109 |
110 | def forward(self, x):
111 | output = self.layers(x)
112 | return output
113 |
114 |
115 | def get_clones(module, N):
116 | return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
117 |
--------------------------------------------------------------------------------
/model/utils/position_embedding.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 | """
3 | Various positional encodings for the transformer.
4 | """
5 | import math
6 |
7 | import numpy as np
8 | import torch
9 | from torch import nn
10 | from utils.pc_util import shift_scale_points
11 |
12 |
13 | class PositionEmbeddingCoordsSine(nn.Module):
14 | def __init__(
15 | self,
16 | temperature=10000,
17 | normalize=False,
18 | scale=None,
19 | pos_type="fourier",
20 | d_pos=None,
21 | d_in=3,
22 | gauss_scale=1.0,
23 | ):
24 | super().__init__()
25 | self.temperature = temperature
26 | self.normalize = normalize
27 | if scale is not None and normalize is False:
28 | raise ValueError("normalize should be True if scale is passed")
29 | if scale is None:
30 | scale = 2 * math.pi
31 | assert pos_type in ["sine", "fourier"]
32 | self.pos_type = pos_type
33 | self.scale = scale
34 | if pos_type == "fourier":
35 | assert d_pos is not None
36 | assert d_pos % 2 == 0
37 | # define a gaussian matrix input_ch -> output_ch
38 | B = torch.empty((d_in, d_pos // 2)).normal_()
39 | B *= gauss_scale
40 | self.register_buffer("gauss_B", B)
41 | self.d_pos = d_pos
42 |
43 | def get_sine_embeddings(self, xyz, num_channels, input_range):
44 | # clone coords so that shift/scale operations do not affect original tensor
45 | orig_xyz = xyz
46 | xyz = orig_xyz.clone()
47 |
48 | ncoords = xyz.shape[1]
49 | if self.normalize:
50 | xyz = shift_scale_points(xyz, src_range=input_range)
51 |
52 | ndim = num_channels // xyz.shape[2]
53 | if ndim % 2 != 0:
54 | ndim -= 1
55 | # automatically handle remainder by assiging it to the first dim
56 | rems = num_channels - (ndim * xyz.shape[2])
57 |
58 | assert (
59 | ndim % 2 == 0
60 | ), f"Cannot handle odd sized ndim={ndim} where num_channels={num_channels} and xyz={xyz.shape}"
61 |
62 | final_embeds = []
63 | prev_dim = 0
64 |
65 | for d in range(xyz.shape[2]):
66 | cdim = ndim
67 | if rems > 0:
68 | # add remainder in increments of two to maintain even size
69 | cdim += 2
70 | rems -= 2
71 |
72 | if cdim != prev_dim:
73 | dim_t = torch.arange(cdim, dtype=torch.float32, device=xyz.device)
74 | dim_t = self.temperature ** (2 * (dim_t // 2) / cdim)
75 |
76 | # create batch x cdim x nccords embedding
77 | raw_pos = xyz[:, :, d]
78 | if self.scale:
79 | raw_pos *= self.scale
80 | pos = raw_pos[:, :, None] / dim_t
81 | pos = torch.stack(
82 | (pos[:, :, 0::2].sin(), pos[:, :, 1::2].cos()), dim=3
83 | ).flatten(2)
84 | final_embeds.append(pos)
85 | prev_dim = cdim
86 |
87 | final_embeds = torch.cat(final_embeds, dim=2).permute(0, 2, 1)
88 | return final_embeds
89 |
90 | def get_fourier_embeddings(self, xyz, num_channels=None, input_range=None):
91 | # Follows - https://people.eecs.berkeley.edu/~bmild/fourfeat/index.html
92 |
93 | if num_channels is None:
94 | num_channels = self.gauss_B.shape[1] * 2
95 |
96 | bsize, npoints = xyz.shape[0], xyz.shape[1]
97 | assert num_channels > 0 and num_channels % 2 == 0
98 | d_in, max_d_out = self.gauss_B.shape[0], self.gauss_B.shape[1]
99 | d_out = num_channels // 2
100 | assert d_out <= max_d_out
101 | assert d_in == xyz.shape[-1]
102 |
103 | # clone coords so that shift/scale operations do not affect original tensor
104 | orig_xyz = xyz
105 | xyz = orig_xyz.clone()
106 |
107 | ncoords = xyz.shape[1]
108 | if self.normalize:
109 | xyz = shift_scale_points(xyz, src_range=input_range)
110 |
111 | xyz *= 2 * np.pi
112 | xyz_proj = torch.mm(xyz.view(-1, d_in), self.gauss_B[:, :d_out]).view(
113 | bsize, npoints, d_out
114 | )
115 | final_embeds = [xyz_proj.sin(), xyz_proj.cos()]
116 |
117 | # return batch x d_pos x npoints embedding
118 | final_embeds = torch.cat(final_embeds, dim=2).permute(0, 2, 1).contiguous()
119 | return final_embeds
120 |
121 | def forward(self, xyz, num_channels=None, input_range=None):
122 | assert isinstance(xyz, torch.Tensor)
123 | assert xyz.ndim == 3
124 | # xyz is batch x npoints x 3
125 | if self.pos_type == "sine":
126 | with torch.no_grad():
127 | return self.get_sine_embeddings(xyz, num_channels, input_range)
128 | elif self.pos_type == "fourier":
129 | with torch.no_grad():
130 | return self.get_fourier_embeddings(xyz, num_channels, input_range)
131 | else:
132 | raise ValueError(f"Unknown {self.pos_type}")
133 |
134 | def extra_repr(self):
135 | st = f"type={self.pos_type}, scale={self.scale}, normalize={self.normalize}"
136 | if hasattr(self, "gauss_B"):
137 | st += (
138 | f", gaussB={self.gauss_B.shape}, gaussBsum={self.gauss_B.sum().item()}"
139 | )
140 | return st
141 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | einops==0.4.1
2 | hydra-core==1.3.2
3 | transforms3d==0.4.1
4 | lxml==4.9.2
5 | trimesh==4.0.5
6 | scipy==1.10.0
7 | UMNN==1.68
8 | healpy==1.16.2
9 | omegaconf==2.2.2
10 | plotly==5.14.1
11 | tensorboard==2.11.2
12 | Pillow==10.0.0
13 | multimethod==1.9.1
14 | ftfy
15 | regex
16 | tqdm
17 | git+https://github.com/openai/CLIP.git
18 | git+https://github.com/facebookresearch/pytorch3d.git@v0.7.2
19 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/include/ball_query.h:
--------------------------------------------------------------------------------
1 | // Copyright (c) Facebook, Inc. and its affiliates.
2 | //
3 | // This source code is licensed under the MIT license found in the
4 | // LICENSE file in the root directory of this source tree.
5 |
6 | #pragma once
7 | #include
8 |
9 | at::Tensor ball_query(at::Tensor new_xyz, at::Tensor xyz, const float radius,
10 | const int nsample);
11 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/include/cuda_utils.h:
--------------------------------------------------------------------------------
1 | // Copyright (c) Facebook, Inc. and its affiliates.
2 | //
3 | // This source code is licensed under the MIT license found in the
4 | // LICENSE file in the root directory of this source tree.
5 |
6 | #ifndef _CUDA_UTILS_H
7 | #define _CUDA_UTILS_H
8 |
9 | #include
10 | #include
11 | #include
12 |
13 | #include
14 | #include
15 |
16 | #include
17 |
18 | #define TOTAL_THREADS 512
19 |
20 | inline int opt_n_threads(int work_size) {
21 | const int pow_2 = std::log(static_cast(work_size)) / std::log(2.0);
22 |
23 | return max(min(1 << pow_2, TOTAL_THREADS), 1);
24 | }
25 |
26 | inline dim3 opt_block_config(int x, int y) {
27 | const int x_threads = opt_n_threads(x);
28 | const int y_threads =
29 | max(min(opt_n_threads(y), TOTAL_THREADS / x_threads), 1);
30 | dim3 block_config(x_threads, y_threads, 1);
31 |
32 | return block_config;
33 | }
34 |
35 | #define CUDA_CHECK_ERRORS() \
36 | do { \
37 | cudaError_t err = cudaGetLastError(); \
38 | if (cudaSuccess != err) { \
39 | fprintf(stderr, "CUDA kernel failed : %s\n%s at L:%d in %s\n", \
40 | cudaGetErrorString(err), __PRETTY_FUNCTION__, __LINE__, \
41 | __FILE__); \
42 | exit(-1); \
43 | } \
44 | } while (0)
45 |
46 | #endif
47 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/include/cylinder_query.h:
--------------------------------------------------------------------------------
1 | // Author: chenxi-wang
2 |
3 | #pragma once
4 | #include
5 |
6 | at::Tensor cylinder_query(at::Tensor new_xyz, at::Tensor xyz, at::Tensor rot, const float radius, const float hmin, const float hmax,
7 | const int nsample);
8 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/include/group_points.h:
--------------------------------------------------------------------------------
1 | // Copyright (c) Facebook, Inc. and its affiliates.
2 | //
3 | // This source code is licensed under the MIT license found in the
4 | // LICENSE file in the root directory of this source tree.
5 |
6 | #pragma once
7 | #include
8 |
9 | at::Tensor group_points(at::Tensor points, at::Tensor idx);
10 | at::Tensor group_points_grad(at::Tensor grad_out, at::Tensor idx, const int n);
11 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/include/interpolate.h:
--------------------------------------------------------------------------------
1 | // Copyright (c) Facebook, Inc. and its affiliates.
2 | //
3 | // This source code is licensed under the MIT license found in the
4 | // LICENSE file in the root directory of this source tree.
5 |
6 | #pragma once
7 |
8 | #include
9 | #include
10 |
11 | std::vector three_nn(at::Tensor unknowns, at::Tensor knows);
12 | at::Tensor three_interpolate(at::Tensor points, at::Tensor idx,
13 | at::Tensor weight);
14 | at::Tensor three_interpolate_grad(at::Tensor grad_out, at::Tensor idx,
15 | at::Tensor weight, const int m);
16 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/include/sampling.h:
--------------------------------------------------------------------------------
1 | // Copyright (c) Facebook, Inc. and its affiliates.
2 | //
3 | // This source code is licensed under the MIT license found in the
4 | // LICENSE file in the root directory of this source tree.
5 |
6 | #pragma once
7 | #include
8 |
9 | at::Tensor gather_points(at::Tensor points, at::Tensor idx);
10 | at::Tensor gather_points_grad(at::Tensor grad_out, at::Tensor idx, const int n);
11 | at::Tensor furthest_point_sampling(at::Tensor points, const int nsamples);
12 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/include/utils.h:
--------------------------------------------------------------------------------
1 | // Copyright (c) Facebook, Inc. and its affiliates.
2 | //
3 | // This source code is licensed under the MIT license found in the
4 | // LICENSE file in the root directory of this source tree.
5 |
6 | #pragma once
7 | #include
8 | #include
9 |
10 | #define CHECK_CUDA(x) \
11 | do { \
12 | TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor"); \
13 | } while (0)
14 |
15 | #define CHECK_CONTIGUOUS(x) \
16 | do { \
17 | TORCH_CHECK(x.is_contiguous(), #x " must be a contiguous tensor"); \
18 | } while (0)
19 |
20 | #define CHECK_IS_INT(x) \
21 | do { \
22 | TORCH_CHECK(x.scalar_type() == at::ScalarType::Int, \
23 | #x " must be an int tensor"); \
24 | } while (0)
25 |
26 | #define CHECK_IS_FLOAT(x) \
27 | do { \
28 | TORCH_CHECK(x.scalar_type() == at::ScalarType::Float, \
29 | #x " must be a float tensor"); \
30 | } while (0)
31 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/src/ball_query.cpp:
--------------------------------------------------------------------------------
1 | // Copyright (c) Facebook, Inc. and its affiliates.
2 | //
3 | // This source code is licensed under the MIT license found in the
4 | // LICENSE file in the root directory of this source tree.
5 |
6 | #include "ball_query.h"
7 | #include "utils.h"
8 |
9 | void query_ball_point_kernel_wrapper(int b, int n, int m, float radius,
10 | int nsample, const float *new_xyz,
11 | const float *xyz, int *idx);
12 |
13 | at::Tensor ball_query(at::Tensor new_xyz, at::Tensor xyz, const float radius,
14 | const int nsample) {
15 | CHECK_CONTIGUOUS(new_xyz);
16 | CHECK_CONTIGUOUS(xyz);
17 | CHECK_IS_FLOAT(new_xyz);
18 | CHECK_IS_FLOAT(xyz);
19 |
20 | if (new_xyz.type().is_cuda()) {
21 | CHECK_CUDA(xyz);
22 | }
23 |
24 | at::Tensor idx =
25 | torch::zeros({new_xyz.size(0), new_xyz.size(1), nsample},
26 | at::device(new_xyz.device()).dtype(at::ScalarType::Int));
27 |
28 | if (new_xyz.type().is_cuda()) {
29 | query_ball_point_kernel_wrapper(xyz.size(0), xyz.size(1), new_xyz.size(1),
30 | radius, nsample, new_xyz.data(),
31 | xyz.data(), idx.data());
32 | } else {
33 | TORCH_CHECK(false, "CPU not supported");
34 | }
35 |
36 | return idx;
37 | }
38 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/src/ball_query_gpu.cu:
--------------------------------------------------------------------------------
1 | // Copyright (c) Facebook, Inc. and its affiliates.
2 | //
3 | // This source code is licensed under the MIT license found in the
4 | // LICENSE file in the root directory of this source tree.
5 |
6 | #include
7 | #include
8 | #include
9 |
10 | #include "cuda_utils.h"
11 |
12 | // input: new_xyz(b, m, 3) xyz(b, n, 3)
13 | // output: idx(b, m, nsample)
14 | __global__ void query_ball_point_kernel(int b, int n, int m, float radius,
15 | int nsample,
16 | const float *__restrict__ new_xyz,
17 | const float *__restrict__ xyz,
18 | int *__restrict__ idx) {
19 | int batch_index = blockIdx.x;
20 | xyz += batch_index * n * 3;
21 | new_xyz += batch_index * m * 3;
22 | idx += m * nsample * batch_index;
23 |
24 | int index = threadIdx.x;
25 | int stride = blockDim.x;
26 |
27 | float radius2 = radius * radius;
28 | for (int j = index; j < m; j += stride) {
29 | float new_x = new_xyz[j * 3 + 0];
30 | float new_y = new_xyz[j * 3 + 1];
31 | float new_z = new_xyz[j * 3 + 2];
32 | for (int k = 0, cnt = 0; k < n && cnt < nsample; ++k) {
33 | float x = xyz[k * 3 + 0];
34 | float y = xyz[k * 3 + 1];
35 | float z = xyz[k * 3 + 2];
36 | float d2 = (new_x - x) * (new_x - x) + (new_y - y) * (new_y - y) +
37 | (new_z - z) * (new_z - z);
38 | if (d2 < radius2) {
39 | if (cnt == 0) {
40 | for (int l = 0; l < nsample; ++l) {
41 | idx[j * nsample + l] = k;
42 | }
43 | }
44 | idx[j * nsample + cnt] = k;
45 | ++cnt;
46 | }
47 | }
48 | }
49 | }
50 |
51 | void query_ball_point_kernel_wrapper(int b, int n, int m, float radius,
52 | int nsample, const float *new_xyz,
53 | const float *xyz, int *idx) {
54 | cudaStream_t stream = at::cuda::getCurrentCUDAStream();
55 | query_ball_point_kernel<<>>(
56 | b, n, m, radius, nsample, new_xyz, xyz, idx);
57 |
58 | CUDA_CHECK_ERRORS();
59 | }
60 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/src/bindings.cpp:
--------------------------------------------------------------------------------
1 | // Copyright (c) Facebook, Inc. and its affiliates.
2 | //
3 | // This source code is licensed under the MIT license found in the
4 | // LICENSE file in the root directory of this source tree.
5 |
6 | #include "ball_query.h"
7 | #include "group_points.h"
8 | #include "interpolate.h"
9 | #include "sampling.h"
10 | #include "cylinder_query.h"
11 |
12 | PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
13 | m.def("gather_points", &gather_points);
14 | m.def("gather_points_grad", &gather_points_grad);
15 | m.def("furthest_point_sampling", &furthest_point_sampling);
16 |
17 | m.def("three_nn", &three_nn);
18 | m.def("three_interpolate", &three_interpolate);
19 | m.def("three_interpolate_grad", &three_interpolate_grad);
20 |
21 | m.def("ball_query", &ball_query);
22 |
23 | m.def("group_points", &group_points);
24 | m.def("group_points_grad", &group_points_grad);
25 |
26 | m.def("cylinder_query", &cylinder_query);
27 | }
28 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/src/cylinder_query.cpp:
--------------------------------------------------------------------------------
1 | // Author: chenxi-wang
2 |
3 | #include "cylinder_query.h"
4 | #include "utils.h"
5 |
6 | void query_cylinder_point_kernel_wrapper(int b, int n, int m, float radius, float hmin, float hmax,
7 | int nsample, const float *new_xyz,
8 | const float *xyz, const float *rot, int *idx);
9 |
10 | at::Tensor cylinder_query(at::Tensor new_xyz, at::Tensor xyz, at::Tensor rot, const float radius, const float hmin, const float hmax,
11 | const int nsample) {
12 | CHECK_CONTIGUOUS(new_xyz);
13 | CHECK_CONTIGUOUS(xyz);
14 | CHECK_CONTIGUOUS(rot);
15 | CHECK_IS_FLOAT(new_xyz);
16 | CHECK_IS_FLOAT(xyz);
17 | CHECK_IS_FLOAT(rot);
18 |
19 | if (new_xyz.type().is_cuda()) {
20 | CHECK_CUDA(xyz);
21 | CHECK_CUDA(rot);
22 | }
23 |
24 | at::Tensor idx =
25 | torch::zeros({new_xyz.size(0), new_xyz.size(1), nsample},
26 | at::device(new_xyz.device()).dtype(at::ScalarType::Int));
27 |
28 | if (new_xyz.type().is_cuda()) {
29 | query_cylinder_point_kernel_wrapper(xyz.size(0), xyz.size(1), new_xyz.size(1),
30 | radius, hmin, hmax, nsample, new_xyz.data(),
31 | xyz.data(), rot.data(), idx.data());
32 | } else {
33 | TORCH_CHECK(false, "CPU not supported");
34 | }
35 |
36 | return idx;
37 | }
38 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/src/cylinder_query_gpu.cu:
--------------------------------------------------------------------------------
1 | // Author: chenxi-wang
2 |
3 | #include
4 | #include
5 | #include
6 |
7 | #include "cuda_utils.h"
8 |
9 | __global__ void query_cylinder_point_kernel(int b, int n, int m, float radius, float hmin, float hmax,
10 | int nsample,
11 | const float *__restrict__ new_xyz,
12 | const float *__restrict__ xyz,
13 | const float *__restrict__ rot,
14 | int *__restrict__ idx) {
15 | int batch_index = blockIdx.x;
16 | xyz += batch_index * n * 3;
17 | new_xyz += batch_index * m * 3;
18 | rot += batch_index * m * 9;
19 | idx += m * nsample * batch_index;
20 |
21 | int index = threadIdx.x;
22 | int stride = blockDim.x;
23 |
24 | float radius2 = radius * radius;
25 | for (int j = index; j < m; j += stride) {
26 | float new_x = new_xyz[j * 3 + 0];
27 | float new_y = new_xyz[j * 3 + 1];
28 | float new_z = new_xyz[j * 3 + 2];
29 | float r0 = rot[j * 9 + 0];
30 | float r1 = rot[j * 9 + 1];
31 | float r2 = rot[j * 9 + 2];
32 | float r3 = rot[j * 9 + 3];
33 | float r4 = rot[j * 9 + 4];
34 | float r5 = rot[j * 9 + 5];
35 | float r6 = rot[j * 9 + 6];
36 | float r7 = rot[j * 9 + 7];
37 | float r8 = rot[j * 9 + 8];
38 | for (int k = 0, cnt = 0; k < n && cnt < nsample; ++k) {
39 | float x = xyz[k * 3 + 0] - new_x;
40 | float y = xyz[k * 3 + 1] - new_y;
41 | float z = xyz[k * 3 + 2] - new_z;
42 | float x_rot = r0 * x + r3 * y + r6 * z;
43 | float y_rot = r1 * x + r4 * y + r7 * z;
44 | float z_rot = r2 * x + r5 * y + r8 * z;
45 | float d2 = y_rot * y_rot + z_rot * z_rot;
46 | if (d2 < radius2 && x_rot > hmin && x_rot < hmax) {
47 | if (cnt == 0) {
48 | for (int l = 0; l < nsample; ++l) {
49 | idx[j * nsample + l] = k;
50 | }
51 | }
52 | idx[j * nsample + cnt] = k;
53 | ++cnt;
54 | }
55 | }
56 | }
57 | }
58 |
59 | void query_cylinder_point_kernel_wrapper(int b, int n, int m, float radius, float hmin, float hmax,
60 | int nsample, const float *new_xyz,
61 | const float *xyz, const float *rot, int *idx) {
62 | cudaStream_t stream = at::cuda::getCurrentCUDAStream();
63 | query_cylinder_point_kernel<<>>(
64 | b, n, m, radius, hmin, hmax, nsample, new_xyz, xyz, rot, idx);
65 |
66 | CUDA_CHECK_ERRORS();
67 | }
68 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/src/group_points.cpp:
--------------------------------------------------------------------------------
1 | // Copyright (c) Facebook, Inc. and its affiliates.
2 | //
3 | // This source code is licensed under the MIT license found in the
4 | // LICENSE file in the root directory of this source tree.
5 |
6 | #include "group_points.h"
7 | #include "utils.h"
8 |
9 | void group_points_kernel_wrapper(int b, int c, int n, int npoints, int nsample,
10 | const float *points, const int *idx,
11 | float *out);
12 |
13 | void group_points_grad_kernel_wrapper(int b, int c, int n, int npoints,
14 | int nsample, const float *grad_out,
15 | const int *idx, float *grad_points);
16 |
17 | at::Tensor group_points(at::Tensor points, at::Tensor idx) {
18 | CHECK_CONTIGUOUS(points);
19 | CHECK_CONTIGUOUS(idx);
20 | CHECK_IS_FLOAT(points);
21 | CHECK_IS_INT(idx);
22 |
23 | if (points.type().is_cuda()) {
24 | CHECK_CUDA(idx);
25 | }
26 |
27 | at::Tensor output =
28 | torch::zeros({points.size(0), points.size(1), idx.size(1), idx.size(2)},
29 | at::device(points.device()).dtype(at::ScalarType::Float));
30 |
31 | if (points.type().is_cuda()) {
32 | group_points_kernel_wrapper(points.size(0), points.size(1), points.size(2),
33 | idx.size(1), idx.size(2), points.data(),
34 | idx.data(), output.data());
35 | } else {
36 | TORCH_CHECK(false, "CPU not supported");
37 | }
38 |
39 | return output;
40 | }
41 |
42 | at::Tensor group_points_grad(at::Tensor grad_out, at::Tensor idx, const int n) {
43 | CHECK_CONTIGUOUS(grad_out);
44 | CHECK_CONTIGUOUS(idx);
45 | CHECK_IS_FLOAT(grad_out);
46 | CHECK_IS_INT(idx);
47 |
48 | if (grad_out.type().is_cuda()) {
49 | CHECK_CUDA(idx);
50 | }
51 |
52 | at::Tensor output =
53 | torch::zeros({grad_out.size(0), grad_out.size(1), n},
54 | at::device(grad_out.device()).dtype(at::ScalarType::Float));
55 |
56 | if (grad_out.type().is_cuda()) {
57 | group_points_grad_kernel_wrapper(
58 | grad_out.size(0), grad_out.size(1), n, idx.size(1), idx.size(2),
59 | grad_out.data(), idx.data(), output.data());
60 | } else {
61 | TORCH_CHECK(false, "CPU not supported");
62 | }
63 |
64 | return output;
65 | }
66 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/src/group_points_gpu.cu:
--------------------------------------------------------------------------------
1 | // Copyright (c) Facebook, Inc. and its affiliates.
2 | //
3 | // This source code is licensed under the MIT license found in the
4 | // LICENSE file in the root directory of this source tree.
5 |
6 | #include
7 | #include
8 |
9 | #include "cuda_utils.h"
10 |
11 | // input: points(b, c, n) idx(b, npoints, nsample)
12 | // output: out(b, c, npoints, nsample)
13 | __global__ void group_points_kernel(int b, int c, int n, int npoints,
14 | int nsample,
15 | const float *__restrict__ points,
16 | const int *__restrict__ idx,
17 | float *__restrict__ out) {
18 | int batch_index = blockIdx.x;
19 | points += batch_index * n * c;
20 | idx += batch_index * npoints * nsample;
21 | out += batch_index * npoints * nsample * c;
22 |
23 | const int index = threadIdx.y * blockDim.x + threadIdx.x;
24 | const int stride = blockDim.y * blockDim.x;
25 | for (int i = index; i < c * npoints; i += stride) {
26 | const int l = i / npoints;
27 | const int j = i % npoints;
28 | for (int k = 0; k < nsample; ++k) {
29 | int ii = idx[j * nsample + k];
30 | out[(l * npoints + j) * nsample + k] = points[l * n + ii];
31 | }
32 | }
33 | }
34 |
35 | void group_points_kernel_wrapper(int b, int c, int n, int npoints, int nsample,
36 | const float *points, const int *idx,
37 | float *out) {
38 | cudaStream_t stream = at::cuda::getCurrentCUDAStream();
39 |
40 | group_points_kernel<<>>(
41 | b, c, n, npoints, nsample, points, idx, out);
42 |
43 | CUDA_CHECK_ERRORS();
44 | }
45 |
46 | // input: grad_out(b, c, npoints, nsample), idx(b, npoints, nsample)
47 | // output: grad_points(b, c, n)
48 | __global__ void group_points_grad_kernel(int b, int c, int n, int npoints,
49 | int nsample,
50 | const float *__restrict__ grad_out,
51 | const int *__restrict__ idx,
52 | float *__restrict__ grad_points) {
53 | int batch_index = blockIdx.x;
54 | grad_out += batch_index * npoints * nsample * c;
55 | idx += batch_index * npoints * nsample;
56 | grad_points += batch_index * n * c;
57 |
58 | const int index = threadIdx.y * blockDim.x + threadIdx.x;
59 | const int stride = blockDim.y * blockDim.x;
60 | for (int i = index; i < c * npoints; i += stride) {
61 | const int l = i / npoints;
62 | const int j = i % npoints;
63 | for (int k = 0; k < nsample; ++k) {
64 | int ii = idx[j * nsample + k];
65 | atomicAdd(grad_points + l * n + ii,
66 | grad_out[(l * npoints + j) * nsample + k]);
67 | }
68 | }
69 | }
70 |
71 | void group_points_grad_kernel_wrapper(int b, int c, int n, int npoints,
72 | int nsample, const float *grad_out,
73 | const int *idx, float *grad_points) {
74 | cudaStream_t stream = at::cuda::getCurrentCUDAStream();
75 |
76 | group_points_grad_kernel<<>>(
77 | b, c, n, npoints, nsample, grad_out, idx, grad_points);
78 |
79 | CUDA_CHECK_ERRORS();
80 | }
81 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/src/interpolate.cpp:
--------------------------------------------------------------------------------
1 | // Copyright (c) Facebook, Inc. and its affiliates.
2 | //
3 | // This source code is licensed under the MIT license found in the
4 | // LICENSE file in the root directory of this source tree.
5 |
6 | #include "interpolate.h"
7 | #include "utils.h"
8 |
9 | void three_nn_kernel_wrapper(int b, int n, int m, const float *unknown,
10 | const float *known, float *dist2, int *idx);
11 | void three_interpolate_kernel_wrapper(int b, int c, int m, int n,
12 | const float *points, const int *idx,
13 | const float *weight, float *out);
14 | void three_interpolate_grad_kernel_wrapper(int b, int c, int n, int m,
15 | const float *grad_out,
16 | const int *idx, const float *weight,
17 | float *grad_points);
18 |
19 | std::vector three_nn(at::Tensor unknowns, at::Tensor knows) {
20 | CHECK_CONTIGUOUS(unknowns);
21 | CHECK_CONTIGUOUS(knows);
22 | CHECK_IS_FLOAT(unknowns);
23 | CHECK_IS_FLOAT(knows);
24 |
25 | if (unknowns.type().is_cuda()) {
26 | CHECK_CUDA(knows);
27 | }
28 |
29 | at::Tensor idx =
30 | torch::zeros({unknowns.size(0), unknowns.size(1), 3},
31 | at::device(unknowns.device()).dtype(at::ScalarType::Int));
32 | at::Tensor dist2 =
33 | torch::zeros({unknowns.size(0), unknowns.size(1), 3},
34 | at::device(unknowns.device()).dtype(at::ScalarType::Float));
35 |
36 | if (unknowns.type().is_cuda()) {
37 | three_nn_kernel_wrapper(unknowns.size(0), unknowns.size(1), knows.size(1),
38 | unknowns.data(), knows.data(),
39 | dist2.data(), idx.data());
40 | } else {
41 | TORCH_CHECK(false, "CPU not supported");
42 | }
43 |
44 | return {dist2, idx};
45 | }
46 |
47 | at::Tensor three_interpolate(at::Tensor points, at::Tensor idx,
48 | at::Tensor weight) {
49 | CHECK_CONTIGUOUS(points);
50 | CHECK_CONTIGUOUS(idx);
51 | CHECK_CONTIGUOUS(weight);
52 | CHECK_IS_FLOAT(points);
53 | CHECK_IS_INT(idx);
54 | CHECK_IS_FLOAT(weight);
55 |
56 | if (points.type().is_cuda()) {
57 | CHECK_CUDA(idx);
58 | CHECK_CUDA(weight);
59 | }
60 |
61 | at::Tensor output =
62 | torch::zeros({points.size(0), points.size(1), idx.size(1)},
63 | at::device(points.device()).dtype(at::ScalarType::Float));
64 |
65 | if (points.type().is_cuda()) {
66 | three_interpolate_kernel_wrapper(
67 | points.size(0), points.size(1), points.size(2), idx.size(1),
68 | points.data(), idx.data(), weight.data(),
69 | output.data());
70 | } else {
71 | TORCH_CHECK(false, "CPU not supported");
72 | }
73 |
74 | return output;
75 | }
76 | at::Tensor three_interpolate_grad(at::Tensor grad_out, at::Tensor idx,
77 | at::Tensor weight, const int m) {
78 | CHECK_CONTIGUOUS(grad_out);
79 | CHECK_CONTIGUOUS(idx);
80 | CHECK_CONTIGUOUS(weight);
81 | CHECK_IS_FLOAT(grad_out);
82 | CHECK_IS_INT(idx);
83 | CHECK_IS_FLOAT(weight);
84 |
85 | if (grad_out.type().is_cuda()) {
86 | CHECK_CUDA(idx);
87 | CHECK_CUDA(weight);
88 | }
89 |
90 | at::Tensor output =
91 | torch::zeros({grad_out.size(0), grad_out.size(1), m},
92 | at::device(grad_out.device()).dtype(at::ScalarType::Float));
93 |
94 | if (grad_out.type().is_cuda()) {
95 | three_interpolate_grad_kernel_wrapper(
96 | grad_out.size(0), grad_out.size(1), grad_out.size(2), m,
97 | grad_out.data(), idx.data(), weight.data(),
98 | output.data());
99 | } else {
100 | TORCH_CHECK(false, "CPU not supported");
101 | }
102 |
103 | return output;
104 | }
105 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/src/interpolate_gpu.cu:
--------------------------------------------------------------------------------
1 | // Copyright (c) Facebook, Inc. and its affiliates.
2 | //
3 | // This source code is licensed under the MIT license found in the
4 | // LICENSE file in the root directory of this source tree.
5 |
6 | #include
7 | #include
8 | #include
9 |
10 | #include "cuda_utils.h"
11 |
12 | // input: unknown(b, n, 3) known(b, m, 3)
13 | // output: dist2(b, n, 3), idx(b, n, 3)
14 | __global__ void three_nn_kernel(int b, int n, int m,
15 | const float *__restrict__ unknown,
16 | const float *__restrict__ known,
17 | float *__restrict__ dist2,
18 | int *__restrict__ idx) {
19 | int batch_index = blockIdx.x;
20 | unknown += batch_index * n * 3;
21 | known += batch_index * m * 3;
22 | dist2 += batch_index * n * 3;
23 | idx += batch_index * n * 3;
24 |
25 | int index = threadIdx.x;
26 | int stride = blockDim.x;
27 | for (int j = index; j < n; j += stride) {
28 | float ux = unknown[j * 3 + 0];
29 | float uy = unknown[j * 3 + 1];
30 | float uz = unknown[j * 3 + 2];
31 |
32 | double best1 = 1e40, best2 = 1e40, best3 = 1e40;
33 | int besti1 = 0, besti2 = 0, besti3 = 0;
34 | for (int k = 0; k < m; ++k) {
35 | float x = known[k * 3 + 0];
36 | float y = known[k * 3 + 1];
37 | float z = known[k * 3 + 2];
38 | float d = (ux - x) * (ux - x) + (uy - y) * (uy - y) + (uz - z) * (uz - z);
39 | if (d < best1) {
40 | best3 = best2;
41 | besti3 = besti2;
42 | best2 = best1;
43 | besti2 = besti1;
44 | best1 = d;
45 | besti1 = k;
46 | } else if (d < best2) {
47 | best3 = best2;
48 | besti3 = besti2;
49 | best2 = d;
50 | besti2 = k;
51 | } else if (d < best3) {
52 | best3 = d;
53 | besti3 = k;
54 | }
55 | }
56 | dist2[j * 3 + 0] = best1;
57 | dist2[j * 3 + 1] = best2;
58 | dist2[j * 3 + 2] = best3;
59 |
60 | idx[j * 3 + 0] = besti1;
61 | idx[j * 3 + 1] = besti2;
62 | idx[j * 3 + 2] = besti3;
63 | }
64 | }
65 |
66 | void three_nn_kernel_wrapper(int b, int n, int m, const float *unknown,
67 | const float *known, float *dist2, int *idx) {
68 | cudaStream_t stream = at::cuda::getCurrentCUDAStream();
69 | three_nn_kernel<<>>(b, n, m, unknown, known,
70 | dist2, idx);
71 |
72 | CUDA_CHECK_ERRORS();
73 | }
74 |
75 | // input: points(b, c, m), idx(b, n, 3), weight(b, n, 3)
76 | // output: out(b, c, n)
77 | __global__ void three_interpolate_kernel(int b, int c, int m, int n,
78 | const float *__restrict__ points,
79 | const int *__restrict__ idx,
80 | const float *__restrict__ weight,
81 | float *__restrict__ out) {
82 | int batch_index = blockIdx.x;
83 | points += batch_index * m * c;
84 |
85 | idx += batch_index * n * 3;
86 | weight += batch_index * n * 3;
87 |
88 | out += batch_index * n * c;
89 |
90 | const int index = threadIdx.y * blockDim.x + threadIdx.x;
91 | const int stride = blockDim.y * blockDim.x;
92 | for (int i = index; i < c * n; i += stride) {
93 | const int l = i / n;
94 | const int j = i % n;
95 | float w1 = weight[j * 3 + 0];
96 | float w2 = weight[j * 3 + 1];
97 | float w3 = weight[j * 3 + 2];
98 |
99 | int i1 = idx[j * 3 + 0];
100 | int i2 = idx[j * 3 + 1];
101 | int i3 = idx[j * 3 + 2];
102 |
103 | out[i] = points[l * m + i1] * w1 + points[l * m + i2] * w2 +
104 | points[l * m + i3] * w3;
105 | }
106 | }
107 |
108 | void three_interpolate_kernel_wrapper(int b, int c, int m, int n,
109 | const float *points, const int *idx,
110 | const float *weight, float *out) {
111 | cudaStream_t stream = at::cuda::getCurrentCUDAStream();
112 | three_interpolate_kernel<<>>(
113 | b, c, m, n, points, idx, weight, out);
114 |
115 | CUDA_CHECK_ERRORS();
116 | }
117 |
118 | // input: grad_out(b, c, n), idx(b, n, 3), weight(b, n, 3)
119 | // output: grad_points(b, c, m)
120 |
121 | __global__ void three_interpolate_grad_kernel(
122 | int b, int c, int n, int m, const float *__restrict__ grad_out,
123 | const int *__restrict__ idx, const float *__restrict__ weight,
124 | float *__restrict__ grad_points) {
125 | int batch_index = blockIdx.x;
126 | grad_out += batch_index * n * c;
127 | idx += batch_index * n * 3;
128 | weight += batch_index * n * 3;
129 | grad_points += batch_index * m * c;
130 |
131 | const int index = threadIdx.y * blockDim.x + threadIdx.x;
132 | const int stride = blockDim.y * blockDim.x;
133 | for (int i = index; i < c * n; i += stride) {
134 | const int l = i / n;
135 | const int j = i % n;
136 | float w1 = weight[j * 3 + 0];
137 | float w2 = weight[j * 3 + 1];
138 | float w3 = weight[j * 3 + 2];
139 |
140 | int i1 = idx[j * 3 + 0];
141 | int i2 = idx[j * 3 + 1];
142 | int i3 = idx[j * 3 + 2];
143 |
144 | atomicAdd(grad_points + l * m + i1, grad_out[i] * w1);
145 | atomicAdd(grad_points + l * m + i2, grad_out[i] * w2);
146 | atomicAdd(grad_points + l * m + i3, grad_out[i] * w3);
147 | }
148 | }
149 |
150 | void three_interpolate_grad_kernel_wrapper(int b, int c, int n, int m,
151 | const float *grad_out,
152 | const int *idx, const float *weight,
153 | float *grad_points) {
154 | cudaStream_t stream = at::cuda::getCurrentCUDAStream();
155 | three_interpolate_grad_kernel<<>>(
156 | b, c, n, m, grad_out, idx, weight, grad_points);
157 |
158 | CUDA_CHECK_ERRORS();
159 | }
160 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/src/sampling.cpp:
--------------------------------------------------------------------------------
1 | // Copyright (c) Facebook, Inc. and its affiliates.
2 | //
3 | // This source code is licensed under the MIT license found in the
4 | // LICENSE file in the root directory of this source tree.
5 |
6 | #include "sampling.h"
7 | #include "utils.h"
8 |
9 | void gather_points_kernel_wrapper(int b, int c, int n, int npoints,
10 | const float *points, const int *idx,
11 | float *out);
12 | void gather_points_grad_kernel_wrapper(int b, int c, int n, int npoints,
13 | const float *grad_out, const int *idx,
14 | float *grad_points);
15 |
16 | void furthest_point_sampling_kernel_wrapper(int b, int n, int m,
17 | const float *dataset, float *temp,
18 | int *idxs);
19 |
20 | at::Tensor gather_points(at::Tensor points, at::Tensor idx) {
21 | CHECK_CONTIGUOUS(points);
22 | CHECK_CONTIGUOUS(idx);
23 | CHECK_IS_FLOAT(points);
24 | CHECK_IS_INT(idx);
25 |
26 | if (points.type().is_cuda()) {
27 | CHECK_CUDA(idx);
28 | }
29 |
30 | at::Tensor output =
31 | torch::zeros({points.size(0), points.size(1), idx.size(1)},
32 | at::device(points.device()).dtype(at::ScalarType::Float));
33 |
34 | if (points.type().is_cuda()) {
35 | gather_points_kernel_wrapper(points.size(0), points.size(1), points.size(2),
36 | idx.size(1), points.data(),
37 | idx.data(), output.data());
38 | } else {
39 | TORCH_CHECK(false, "CPU not supported");
40 | }
41 |
42 | return output;
43 | }
44 |
45 | at::Tensor gather_points_grad(at::Tensor grad_out, at::Tensor idx,
46 | const int n) {
47 | CHECK_CONTIGUOUS(grad_out);
48 | CHECK_CONTIGUOUS(idx);
49 | CHECK_IS_FLOAT(grad_out);
50 | CHECK_IS_INT(idx);
51 |
52 | if (grad_out.type().is_cuda()) {
53 | CHECK_CUDA(idx);
54 | }
55 |
56 | at::Tensor output =
57 | torch::zeros({grad_out.size(0), grad_out.size(1), n},
58 | at::device(grad_out.device()).dtype(at::ScalarType::Float));
59 |
60 | if (grad_out.type().is_cuda()) {
61 | gather_points_grad_kernel_wrapper(grad_out.size(0), grad_out.size(1), n,
62 | idx.size(1), grad_out.data(),
63 | idx.data(), output.data());
64 | } else {
65 | TORCH_CHECK(false, "CPU not supported");
66 | }
67 |
68 | return output;
69 | }
70 | at::Tensor furthest_point_sampling(at::Tensor points, const int nsamples) {
71 | CHECK_CONTIGUOUS(points);
72 | CHECK_IS_FLOAT(points);
73 |
74 | at::Tensor output =
75 | torch::zeros({points.size(0), nsamples},
76 | at::device(points.device()).dtype(at::ScalarType::Int));
77 |
78 | at::Tensor tmp =
79 | torch::full({points.size(0), points.size(1)}, 1e10,
80 | at::device(points.device()).dtype(at::ScalarType::Float));
81 |
82 | if (points.type().is_cuda()) {
83 | furthest_point_sampling_kernel_wrapper(
84 | points.size(0), points.size(1), nsamples, points.data(),
85 | tmp.data(), output.data());
86 | } else {
87 | TORCH_CHECK(false, "CPU not supported");
88 | }
89 |
90 | return output;
91 | }
92 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/_ext_src/src/sampling_gpu.cu:
--------------------------------------------------------------------------------
1 | // Copyright (c) Facebook, Inc. and its affiliates.
2 | //
3 | // This source code is licensed under the MIT license found in the
4 | // LICENSE file in the root directory of this source tree.
5 |
6 | #include
7 | #include
8 |
9 | #include "cuda_utils.h"
10 |
11 | // input: points(b, c, n) idx(b, m)
12 | // output: out(b, c, m)
13 | __global__ void gather_points_kernel(int b, int c, int n, int m,
14 | const float *__restrict__ points,
15 | const int *__restrict__ idx,
16 | float *__restrict__ out) {
17 | for (int i = blockIdx.x; i < b; i += gridDim.x) {
18 | for (int l = blockIdx.y; l < c; l += gridDim.y) {
19 | for (int j = threadIdx.x; j < m; j += blockDim.x) {
20 | int a = idx[i * m + j];
21 | out[(i * c + l) * m + j] = points[(i * c + l) * n + a];
22 | }
23 | }
24 | }
25 | }
26 |
27 | void gather_points_kernel_wrapper(int b, int c, int n, int npoints,
28 | const float *points, const int *idx,
29 | float *out) {
30 | gather_points_kernel<<>>(b, c, n, npoints,
32 | points, idx, out);
33 |
34 | CUDA_CHECK_ERRORS();
35 | }
36 |
37 | // input: grad_out(b, c, m) idx(b, m)
38 | // output: grad_points(b, c, n)
39 | __global__ void gather_points_grad_kernel(int b, int c, int n, int m,
40 | const float *__restrict__ grad_out,
41 | const int *__restrict__ idx,
42 | float *__restrict__ grad_points) {
43 | for (int i = blockIdx.x; i < b; i += gridDim.x) {
44 | for (int l = blockIdx.y; l < c; l += gridDim.y) {
45 | for (int j = threadIdx.x; j < m; j += blockDim.x) {
46 | int a = idx[i * m + j];
47 | atomicAdd(grad_points + (i * c + l) * n + a,
48 | grad_out[(i * c + l) * m + j]);
49 | }
50 | }
51 | }
52 | }
53 |
54 | void gather_points_grad_kernel_wrapper(int b, int c, int n, int npoints,
55 | const float *grad_out, const int *idx,
56 | float *grad_points) {
57 | gather_points_grad_kernel<<>>(
59 | b, c, n, npoints, grad_out, idx, grad_points);
60 |
61 | CUDA_CHECK_ERRORS();
62 | }
63 |
64 | __device__ void __update(float *__restrict__ dists, int *__restrict__ dists_i,
65 | int idx1, int idx2) {
66 | const float v1 = dists[idx1], v2 = dists[idx2];
67 | const int i1 = dists_i[idx1], i2 = dists_i[idx2];
68 | dists[idx1] = max(v1, v2);
69 | dists_i[idx1] = v2 > v1 ? i2 : i1;
70 | }
71 |
72 | // Input dataset: (b, n, 3), tmp: (b, n)
73 | // Ouput idxs (b, m)
74 | template
75 | __global__ void furthest_point_sampling_kernel(
76 | int b, int n, int m, const float *__restrict__ dataset,
77 | float *__restrict__ temp, int *__restrict__ idxs) {
78 | if (m <= 0) return;
79 | __shared__ float dists[block_size];
80 | __shared__ int dists_i[block_size];
81 |
82 | int batch_index = blockIdx.x;
83 | dataset += batch_index * n * 3;
84 | temp += batch_index * n;
85 | idxs += batch_index * m;
86 |
87 | int tid = threadIdx.x;
88 | const int stride = block_size;
89 |
90 | int old = 0;
91 | if (threadIdx.x == 0) idxs[0] = old;
92 |
93 | __syncthreads();
94 | for (int j = 1; j < m; j++) {
95 | int besti = 0;
96 | float best = -1;
97 | float x1 = dataset[old * 3 + 0];
98 | float y1 = dataset[old * 3 + 1];
99 | float z1 = dataset[old * 3 + 2];
100 | for (int k = tid; k < n; k += stride) {
101 | float x2, y2, z2;
102 | x2 = dataset[k * 3 + 0];
103 | y2 = dataset[k * 3 + 1];
104 | z2 = dataset[k * 3 + 2];
105 | // float mag = (x2 * x2) + (y2 * y2) + (z2 * z2);
106 | // if (mag <= 1e-3) continue;
107 |
108 | float d =
109 | (x2 - x1) * (x2 - x1) + (y2 - y1) * (y2 - y1) + (z2 - z1) * (z2 - z1);
110 |
111 | float d2 = min(d, temp[k]);
112 | temp[k] = d2;
113 | besti = d2 > best ? k : besti;
114 | best = d2 > best ? d2 : best;
115 | }
116 | dists[tid] = best;
117 | dists_i[tid] = besti;
118 | __syncthreads();
119 |
120 | if (block_size >= 512) {
121 | if (tid < 256) {
122 | __update(dists, dists_i, tid, tid + 256);
123 | }
124 | __syncthreads();
125 | }
126 | if (block_size >= 256) {
127 | if (tid < 128) {
128 | __update(dists, dists_i, tid, tid + 128);
129 | }
130 | __syncthreads();
131 | }
132 | if (block_size >= 128) {
133 | if (tid < 64) {
134 | __update(dists, dists_i, tid, tid + 64);
135 | }
136 | __syncthreads();
137 | }
138 | if (block_size >= 64) {
139 | if (tid < 32) {
140 | __update(dists, dists_i, tid, tid + 32);
141 | }
142 | __syncthreads();
143 | }
144 | if (block_size >= 32) {
145 | if (tid < 16) {
146 | __update(dists, dists_i, tid, tid + 16);
147 | }
148 | __syncthreads();
149 | }
150 | if (block_size >= 16) {
151 | if (tid < 8) {
152 | __update(dists, dists_i, tid, tid + 8);
153 | }
154 | __syncthreads();
155 | }
156 | if (block_size >= 8) {
157 | if (tid < 4) {
158 | __update(dists, dists_i, tid, tid + 4);
159 | }
160 | __syncthreads();
161 | }
162 | if (block_size >= 4) {
163 | if (tid < 2) {
164 | __update(dists, dists_i, tid, tid + 2);
165 | }
166 | __syncthreads();
167 | }
168 | if (block_size >= 2) {
169 | if (tid < 1) {
170 | __update(dists, dists_i, tid, tid + 1);
171 | }
172 | __syncthreads();
173 | }
174 |
175 | old = dists_i[0];
176 | if (tid == 0) idxs[j] = old;
177 | }
178 | }
179 |
180 | void furthest_point_sampling_kernel_wrapper(int b, int n, int m,
181 | const float *dataset, float *temp,
182 | int *idxs) {
183 | unsigned int n_threads = opt_n_threads(n);
184 |
185 | cudaStream_t stream = at::cuda::getCurrentCUDAStream();
186 |
187 | switch (n_threads) {
188 | case 512:
189 | furthest_point_sampling_kernel<512>
190 | <<>>(b, n, m, dataset, temp, idxs);
191 | break;
192 | case 256:
193 | furthest_point_sampling_kernel<256>
194 | <<>>(b, n, m, dataset, temp, idxs);
195 | break;
196 | case 128:
197 | furthest_point_sampling_kernel<128>
198 | <<>>(b, n, m, dataset, temp, idxs);
199 | break;
200 | case 64:
201 | furthest_point_sampling_kernel<64>
202 | <<>>(b, n, m, dataset, temp, idxs);
203 | break;
204 | case 32:
205 | furthest_point_sampling_kernel<32>
206 | <<>>(b, n, m, dataset, temp, idxs);
207 | break;
208 | case 16:
209 | furthest_point_sampling_kernel<16>
210 | <<>>(b, n, m, dataset, temp, idxs);
211 | break;
212 | case 8:
213 | furthest_point_sampling_kernel<8>
214 | <<>>(b, n, m, dataset, temp, idxs);
215 | break;
216 | case 4:
217 | furthest_point_sampling_kernel<4>
218 | <<>>(b, n, m, dataset, temp, idxs);
219 | break;
220 | case 2:
221 | furthest_point_sampling_kernel<2>
222 | <<>>(b, n, m, dataset, temp, idxs);
223 | break;
224 | case 1:
225 | furthest_point_sampling_kernel<1>
226 | <<>>(b, n, m, dataset, temp, idxs);
227 | break;
228 | default:
229 | furthest_point_sampling_kernel<512>
230 | <<>>(b, n, m, dataset, temp, idxs);
231 | }
232 |
233 | CUDA_CHECK_ERRORS();
234 | }
235 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/pytorch_utils.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | #
3 | # This source code is licensed under the MIT license found in the
4 | # LICENSE file in the root directory of this source tree.
5 |
6 | ''' Modified based on Ref: https://github.com/erikwijmans/Pointnet2_PyTorch '''
7 | import torch
8 | import torch.nn as nn
9 | from typing import List, Tuple
10 |
11 | class SharedMLP(nn.Sequential):
12 |
13 | def __init__(
14 | self,
15 | args: List[int],
16 | *,
17 | bn: bool = False,
18 | activation=nn.ReLU(inplace=True),
19 | preact: bool = False,
20 | first: bool = False,
21 | name: str = ""
22 | ):
23 | super().__init__()
24 |
25 | for i in range(len(args) - 1):
26 | self.add_module(
27 | name + 'layer{}'.format(i),
28 | Conv2d(
29 | args[i],
30 | args[i + 1],
31 | bn=(not first or not preact or (i != 0)) and bn,
32 | activation=activation
33 | if (not first or not preact or (i != 0)) else None,
34 | preact=preact
35 | )
36 | )
37 |
38 |
39 | class _BNBase(nn.Sequential):
40 |
41 | def __init__(self, in_size, batch_norm=None, name=""):
42 | super().__init__()
43 | self.add_module(name + "bn", batch_norm(in_size))
44 |
45 | nn.init.constant_(self[0].weight, 1.0)
46 | nn.init.constant_(self[0].bias, 0)
47 |
48 |
49 | class BatchNorm1d(_BNBase):
50 |
51 | def __init__(self, in_size: int, *, name: str = ""):
52 | super().__init__(in_size, batch_norm=nn.BatchNorm1d, name=name)
53 |
54 |
55 | class BatchNorm2d(_BNBase):
56 |
57 | def __init__(self, in_size: int, name: str = ""):
58 | super().__init__(in_size, batch_norm=nn.BatchNorm2d, name=name)
59 |
60 |
61 | class BatchNorm3d(_BNBase):
62 |
63 | def __init__(self, in_size: int, name: str = ""):
64 | super().__init__(in_size, batch_norm=nn.BatchNorm3d, name=name)
65 |
66 |
67 | class _ConvBase(nn.Sequential):
68 |
69 | def __init__(
70 | self,
71 | in_size,
72 | out_size,
73 | kernel_size,
74 | stride,
75 | padding,
76 | activation,
77 | bn,
78 | init,
79 | conv=None,
80 | batch_norm=None,
81 | bias=True,
82 | preact=False,
83 | name=""
84 | ):
85 | super().__init__()
86 |
87 | bias = bias and (not bn)
88 | conv_unit = conv(
89 | in_size,
90 | out_size,
91 | kernel_size=kernel_size,
92 | stride=stride,
93 | padding=padding,
94 | bias=bias
95 | )
96 | init(conv_unit.weight)
97 | if bias:
98 | nn.init.constant_(conv_unit.bias, 0)
99 |
100 | if bn:
101 | if not preact:
102 | bn_unit = batch_norm(out_size)
103 | else:
104 | bn_unit = batch_norm(in_size)
105 |
106 | if preact:
107 | if bn:
108 | self.add_module(name + 'bn', bn_unit)
109 |
110 | if activation is not None:
111 | self.add_module(name + 'activation', activation)
112 |
113 | self.add_module(name + 'conv', conv_unit)
114 |
115 | if not preact:
116 | if bn:
117 | self.add_module(name + 'bn', bn_unit)
118 |
119 | if activation is not None:
120 | self.add_module(name + 'activation', activation)
121 |
122 |
123 | class Conv1d(_ConvBase):
124 |
125 | def __init__(
126 | self,
127 | in_size: int,
128 | out_size: int,
129 | *,
130 | kernel_size: int = 1,
131 | stride: int = 1,
132 | padding: int = 0,
133 | activation=nn.ReLU(inplace=True),
134 | bn: bool = False,
135 | init=nn.init.kaiming_normal_,
136 | bias: bool = True,
137 | preact: bool = False,
138 | name: str = ""
139 | ):
140 | super().__init__(
141 | in_size,
142 | out_size,
143 | kernel_size,
144 | stride,
145 | padding,
146 | activation,
147 | bn,
148 | init,
149 | conv=nn.Conv1d,
150 | batch_norm=BatchNorm1d,
151 | bias=bias,
152 | preact=preact,
153 | name=name
154 | )
155 |
156 |
157 | class Conv2d(_ConvBase):
158 |
159 | def __init__(
160 | self,
161 | in_size: int,
162 | out_size: int,
163 | *,
164 | kernel_size: Tuple[int, int] = (1, 1),
165 | stride: Tuple[int, int] = (1, 1),
166 | padding: Tuple[int, int] = (0, 0),
167 | activation=nn.ReLU(inplace=True),
168 | bn: bool = False,
169 | init=nn.init.kaiming_normal_,
170 | bias: bool = True,
171 | preact: bool = False,
172 | name: str = ""
173 | ):
174 | super().__init__(
175 | in_size,
176 | out_size,
177 | kernel_size,
178 | stride,
179 | padding,
180 | activation,
181 | bn,
182 | init,
183 | conv=nn.Conv2d,
184 | batch_norm=BatchNorm2d,
185 | bias=bias,
186 | preact=preact,
187 | name=name
188 | )
189 |
190 |
191 | class Conv3d(_ConvBase):
192 |
193 | def __init__(
194 | self,
195 | in_size: int,
196 | out_size: int,
197 | *,
198 | kernel_size: Tuple[int, int, int] = (1, 1, 1),
199 | stride: Tuple[int, int, int] = (1, 1, 1),
200 | padding: Tuple[int, int, int] = (0, 0, 0),
201 | activation=nn.ReLU(inplace=True),
202 | bn: bool = False,
203 | init=nn.init.kaiming_normal_,
204 | bias: bool = True,
205 | preact: bool = False,
206 | name: str = ""
207 | ):
208 | super().__init__(
209 | in_size,
210 | out_size,
211 | kernel_size,
212 | stride,
213 | padding,
214 | activation,
215 | bn,
216 | init,
217 | conv=nn.Conv3d,
218 | batch_norm=BatchNorm3d,
219 | bias=bias,
220 | preact=preact,
221 | name=name
222 | )
223 |
224 |
225 | class FC(nn.Sequential):
226 |
227 | def __init__(
228 | self,
229 | in_size: int,
230 | out_size: int,
231 | *,
232 | activation=nn.ReLU(inplace=True),
233 | bn: bool = False,
234 | init=None,
235 | preact: bool = False,
236 | name: str = ""
237 | ):
238 | super().__init__()
239 |
240 | fc = nn.Linear(in_size, out_size, bias=not bn)
241 | if init is not None:
242 | init(fc.weight)
243 | if not bn:
244 | nn.init.constant_(fc.bias, 0)
245 |
246 | if preact:
247 | if bn:
248 | self.add_module(name + 'bn', BatchNorm1d(in_size))
249 |
250 | if activation is not None:
251 | self.add_module(name + 'activation', activation)
252 |
253 | self.add_module(name + 'fc', fc)
254 |
255 | if not preact:
256 | if bn:
257 | self.add_module(name + 'bn', BatchNorm1d(out_size))
258 |
259 | if activation is not None:
260 | self.add_module(name + 'activation', activation)
261 |
262 | def set_bn_momentum_default(bn_momentum):
263 |
264 | def fn(m):
265 | if isinstance(m, (nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d)):
266 | m.momentum = bn_momentum
267 |
268 | return fn
269 |
270 |
271 | class BNMomentumScheduler(object):
272 |
273 | def __init__(
274 | self, model, bn_lambda, last_epoch=-1,
275 | setter=set_bn_momentum_default
276 | ):
277 | if not isinstance(model, nn.Module):
278 | raise RuntimeError(
279 | "Class '{}' is not a PyTorch nn Module".format(
280 | type(model).__name__
281 | )
282 | )
283 |
284 | self.model = model
285 | self.setter = setter
286 | self.lmbd = bn_lambda
287 |
288 | self.step(last_epoch + 1)
289 | self.last_epoch = last_epoch
290 |
291 | def step(self, epoch=None):
292 | if epoch is None:
293 | epoch = self.last_epoch + 1
294 |
295 | self.last_epoch = epoch
296 | self.model.apply(self.setter(self.lmbd(epoch)))
297 |
298 |
299 |
--------------------------------------------------------------------------------
/thirdparty/pointnet2/setup.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | #
3 | # This source code is licensed under the MIT license found in the
4 | # LICENSE file in the root directory of this source tree.
5 |
6 | from setuptools import setup
7 | from torch.utils.cpp_extension import BuildExtension, CUDAExtension
8 | import glob
9 | import os
10 | ROOT = os.path.dirname(os.path.abspath(__file__))
11 |
12 | _ext_src_root = "_ext_src"
13 | _ext_sources = glob.glob("{}/src/*.cpp".format(_ext_src_root)) + glob.glob(
14 | "{}/src/*.cu".format(_ext_src_root)
15 | )
16 | _ext_headers = glob.glob("{}/include/*".format(_ext_src_root))
17 |
18 | setup(
19 | name='pointnet2',
20 | ext_modules=[
21 | CUDAExtension(
22 | name='pointnet2._ext',
23 | sources=_ext_sources,
24 | extra_compile_args={
25 | "cxx": ["-O2", "-I{}".format("{}/{}/include".format(ROOT, _ext_src_root))],
26 | "nvcc": ["-O2", "-I{}".format("{}/{}/include".format(ROOT, _ext_src_root))],
27 | },
28 | )
29 | ],
30 | cmdclass={
31 | 'build_ext': BuildExtension
32 | }
33 | )
34 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/.gitignore:
--------------------------------------------------------------------------------
1 | .idea
2 | *.egg-info
3 | __pycache__
4 | temp*
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/README.md:
--------------------------------------------------------------------------------
1 | # PyTorch Robot Kinematics
2 | - Parallel and differentiable forward kinematics (FK) and Jacobian calculation
3 | - Load robot description from URDF, SDF, and MJCF formats
4 |
5 | # Usage
6 | Clone repository somewhere, then `pip3 install -e .` to install in editable mode.
7 |
8 | See `tests` for code samples; some are also shown here.
9 |
10 | ## Forward Kinematics (FK)
11 | ```python
12 | import math
13 | import pytorch_kinematics as pk
14 |
15 | # load robot description from URDF and specify end effector link
16 | chain = pk.build_serial_chain_from_urdf(open("kuka_iiwa.urdf").read(), "lbr_iiwa_link_7")
17 | # prints out the (nested) tree of links
18 | print(chain)
19 | # prints out list of joint names
20 | print(chain.get_joint_parameter_names())
21 |
22 | # specify joint values (can do so in many forms)
23 | th = [0.0, -math.pi / 4.0, 0.0, math.pi / 2.0, 0.0, math.pi / 4.0, 0.0]
24 | # do forward kinematics and get transform objects; end_only=False gives a dictionary of transforms for all links
25 | ret = chain.forward_kinematics(th, end_only=False)
26 | # look up the transform for a specific link
27 | tg = ret['lbr_iiwa_link_7']
28 | # get transform matrix (1,4,4), then convert to separate position and unit quaternion
29 | m = tg.get_matrix()
30 | pos = m[:, :3, 3]
31 | rot = pk.matrix_to_quaternion(m[:, :3, :3])
32 | ```
33 |
34 | We can parallelize FK by passing in 2D joint values, and also use CUDA if available
35 | ```python
36 | import torch
37 | import pytorch_kinematics as pk
38 |
39 | d = "cuda" if torch.cuda.is_available() else "cpu"
40 | dtype = torch.float64
41 |
42 | chain = pk.build_serial_chain_from_urdf(open("kuka_iiwa.urdf").read(), "lbr_iiwa_link_7")
43 | chain = chain.to(dtype=dtype, device=d)
44 |
45 | N = 1000
46 | th_batch = torch.rand(N, len(chain.get_joint_parameter_names()), dtype=dtype, device=d)
47 |
48 | # order of magnitudes faster when doing FK in parallel
49 | # elapsed 0.008678913116455078s for N=1000 when parallel
50 | # (N,4,4) transform matrix; only the one for the end effector is returned since end_only=True by default
51 | tg_batch = chain.forward_kinematics(th_batch)
52 |
53 | # elapsed 8.44686508178711s for N=1000 when serial
54 | for i in range(N):
55 | tg = chain.forward_kinematics(th_batch[i])
56 | ```
57 |
58 | We can compute gradients through the FK
59 | ```python
60 | import torch
61 | import math
62 | import pytorch_kinematics as pk
63 |
64 | chain = pk.build_serial_chain_from_urdf(open("kuka_iiwa.urdf").read(), "lbr_iiwa_link_7")
65 |
66 | # require gradient through the input joint values
67 | th = torch.tensor([0.0, -math.pi / 4.0, 0.0, math.pi / 2.0, 0.0, math.pi / 4.0, 0.0], requires_grad=True)
68 | tg = chain.forward_kinematics(th)
69 | m = tg.get_matrix()
70 | pos = m[:, :3, 3]
71 | pos.norm().backward()
72 | # now th.grad is populated
73 | ```
74 |
75 | We can load SDF and MJCF descriptions too, and pass in joint values via a dictionary (unspecified joints get th=0) for non-serial chains
76 | ```python
77 | import math
78 | import torch
79 | import pytorch_kinematics as pk
80 |
81 | chain = pk.build_chain_from_sdf(open("simple_arm.sdf").read())
82 | ret = chain.forward_kinematics({'arm_elbow_pan_joint': math.pi / 2.0, 'arm_wrist_lift_joint': -0.5})
83 | # recall that we specify joint values and get link transforms
84 | tg = ret['arm_wrist_roll']
85 |
86 | # can also do this in parallel
87 | N = 100
88 | ret = chain.forward_kinematics({'arm_elbow_pan_joint': torch.rand(N, 1), 'arm_wrist_lift_joint': torch.rand(N, 1)})
89 | # (N, 4, 4) transform object
90 | tg = ret['arm_wrist_roll']
91 |
92 | # building the robot from a MJCF file
93 | chain = pk.build_chain_from_mjcf(open("ant.xml").read())
94 | print(chain)
95 | print(chain.get_joint_parameter_names())
96 | th = {'hip_1': 1.0, 'ankle_1': 1}
97 | ret = chain.forward_kinematics(th)
98 |
99 | chain = pk.build_chain_from_mjcf(open("humanoid.xml").read())
100 | print(chain)
101 | print(chain.get_joint_parameter_names())
102 | th = {'left_knee': 0.0, 'right_knee': 0.0}
103 | ret = chain.forward_kinematics(th)
104 | ```
105 |
106 | ## Jacobian calculation
107 | The Jacobian (in the kinematics context) is a matrix describing how the end effector changes with respect to joint value changes
108 | (where  is the twist, or stacked velocity and angular velocity):
109 | 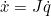
110 |
111 | For `SerialChain` we provide a differentiable and parallelizable method for computing the Jacobian with respect to the base frame.
112 | ```python
113 | import math
114 | import torch
115 | import pytorch_kinematics as pk
116 |
117 | # can convert Chain to SerialChain by choosing end effector frame
118 | chain = pk.build_chain_from_sdf(open("simple_arm.sdf").read())
119 | # print(chain) to see the available links for use as end effector
120 | # note that any link can be chosen; it doesn't have to be a link with no children
121 | chain = pk.SerialChain(chain, "arm_wrist_roll_frame")
122 |
123 | chain = pk.build_serial_chain_from_urdf(open("kuka_iiwa.urdf").read(), "lbr_iiwa_link_7")
124 | th = torch.tensor([0.0, -math.pi / 4.0, 0.0, math.pi / 2.0, 0.0, math.pi / 4.0, 0.0])
125 | # (1,6,7) tensor, with 7 corresponding to the DOF of the robot
126 | J = chain.jacobian(th)
127 |
128 | # get Jacobian in parallel and use CUDA if available
129 | N = 1000
130 | d = "cuda" if torch.cuda.is_available() else "cpu"
131 | dtype = torch.float64
132 |
133 | chain = chain.to(dtype=dtype, device=d)
134 | # Jacobian calculation is differentiable
135 | th = torch.rand(N, 7, dtype=dtype, device=d, requires_grad=True)
136 | # (N,6,7)
137 | J = chain.jacobian(th)
138 |
139 | # can get Jacobian at a point offset from the end effector (location is specified in EE link frame)
140 | # by default location is at the origin of the EE frame
141 | loc = torch.rand(N, 3, dtype=dtype, device=d)
142 | J = chain.jacobian(th, locations=loc)
143 | ```
144 |
145 | The Jacobian can be used to do inverse kinematics. See [IK survey](https://www.math.ucsd.edu/~sbuss/ResearchWeb/ikmethods/iksurvey.pdf)
146 | for a survey of ways to do so. Note that IK may be better performed through other means (but doing it through the Jacobian can give an end-to-end differentiable method).
147 |
148 | # Credits
149 | - `pytorch_kinematics/transforms` is extracted from [pytorch3d](https://github.com/facebookresearch/pytorch3d) with minor extensions.
150 | This was done instead of including `pytorch3d` as a dependency because it is hard to install and most of its code is unrelated.
151 | An important difference is that we use left hand multiplied transforms as is convention in robotics (T * pt) instead of their
152 | right hand multiplied transforms.
153 | - `pytorch_kinematics/urdf_parser_py`, and `pytorch_kinematics/mjcf_parser` is extracted from [kinpy](https://github.com/neka-nat/kinpy), as well as the FK logic.
154 | This repository ports the logic to pytorch, parallelizes it, and provides some extensions.
155 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/__init__.py:
--------------------------------------------------------------------------------
1 | from pytorch_kinematics.sdf import *
2 | from pytorch_kinematics.urdf import *
3 | from pytorch_kinematics.mjcf import *
4 | from pytorch_kinematics.transforms import *
5 | from pytorch_kinematics.chain import *
6 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/chain.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from . import jacobian
3 | import pytorch_kinematics.transforms as tf
4 |
5 |
6 | def ensure_2d_tensor(th, dtype, device):
7 | if not torch.is_tensor(th):
8 | th = torch.tensor(th, dtype=dtype, device=device)
9 | if len(th.shape) == 0:
10 | N = 1
11 | th = th.view(1,1)
12 | elif len(th.shape) == 1:
13 | N = len(th)
14 | th = th.view(-1, 1)
15 | else:
16 | N = th.shape[0]
17 | return th, N
18 |
19 |
20 | class Chain(object):
21 | def __init__(self, root_frame, dtype=torch.float32, device="cpu"):
22 | self._root = root_frame
23 | self.dtype = dtype
24 | self.device = device
25 |
26 | def to(self, dtype=None, device=None):
27 | if dtype is not None:
28 | self.dtype = dtype
29 | if device is not None:
30 | self.device = device
31 | self._root = self._root.to(dtype=self.dtype, device=self.device)
32 | return self
33 |
34 | def __str__(self):
35 | return str(self._root)
36 |
37 | @staticmethod
38 | def _find_frame_recursive(name, frame):
39 | for child in frame.children:
40 | if child.name == name:
41 | return child
42 | ret = Chain._find_frame_recursive(name, child)
43 | if not ret is None:
44 | return ret
45 | return None
46 |
47 | def find_frame(self, name):
48 | if self._root.name == name:
49 | return self._root
50 | return self._find_frame_recursive(name, self._root)
51 |
52 | @staticmethod
53 | def _find_link_recursive(name, frame):
54 | for child in frame.children:
55 | if child.link.name == name:
56 | return child.link
57 | ret = Chain._find_link_recursive(name, child)
58 | if not ret is None:
59 | return ret
60 | return None
61 |
62 | def find_link(self, name):
63 | if self._root.link.name == name:
64 | return self._root.link
65 | return self._find_link_recursive(name, self._root)
66 |
67 | @staticmethod
68 | def _get_joint_parameter_names(frame, exclude_fixed=True):
69 | joint_names = []
70 | if not (exclude_fixed and frame.joint.joint_type == "fixed"):
71 | joint_names.append(frame.joint.name)
72 | for child in frame.children:
73 | joint_names.extend(Chain._get_joint_parameter_names(child, exclude_fixed))
74 | return joint_names
75 |
76 | def get_joint_parameter_names(self, exclude_fixed=True):
77 | names = self._get_joint_parameter_names(self._root, exclude_fixed)
78 | return sorted(set(names), key=names.index)
79 |
80 | def add_frame(self, frame, parent_name):
81 | frame = self.find_frame(parent_name)
82 | if not frame is None:
83 | frame.add_child(frame)
84 |
85 | @staticmethod
86 | def _forward_kinematics(root, th_dict, world=tf.Transform3d()):
87 | link_transforms = {}
88 |
89 | th, N = ensure_2d_tensor(th_dict.get(root.joint.name, 0.0), world.dtype, world.device)
90 |
91 | trans = world.compose(root.get_transform(th.view(N, 1)))
92 | link_transforms[root.link.name] = trans.compose(root.link.offset)
93 | for child in root.children:
94 | link_transforms.update(Chain._forward_kinematics(child, th_dict, trans))
95 | return link_transforms
96 |
97 | def forward_kinematics(self, th, world=tf.Transform3d()):
98 | if not isinstance(th, dict):
99 | jn = self.get_joint_parameter_names()
100 | assert len(jn) == th.shape[1]
101 | th_dict = dict((j, th[:,i]) for i, j in enumerate(jn))
102 | else:
103 | th_dict = th
104 | if world.dtype != self.dtype or world.device != self.device:
105 | world = world.to(dtype=self.dtype, device=self.device, copy=True)
106 | return self._forward_kinematics(self._root, th_dict, world)
107 |
108 |
109 | class SerialChain(Chain):
110 | def __init__(self, chain, end_frame_name, root_frame_name="", **kwargs):
111 | if root_frame_name == "":
112 | super(SerialChain, self).__init__(chain._root, **kwargs)
113 | else:
114 | super(SerialChain, self).__init__(chain.find_frame(root_frame_name), **kwargs)
115 | if self._root is None:
116 | raise ValueError("Invalid root frame name %s." % root_frame_name)
117 | self._serial_frames = self._generate_serial_chain_recurse(self._root, end_frame_name)
118 | if self._serial_frames is None:
119 | raise ValueError("Invalid end frame name %s." % end_frame_name)
120 |
121 | @staticmethod
122 | def _generate_serial_chain_recurse(root_frame, end_frame_name):
123 | for child in root_frame.children:
124 | if child.name == end_frame_name:
125 | return [child]
126 | else:
127 | frames = SerialChain._generate_serial_chain_recurse(child, end_frame_name)
128 | if not frames is None:
129 | return [child] + frames
130 | return None
131 |
132 | def get_joint_parameter_names(self, exclude_fixed=True):
133 | names = []
134 | for f in self._serial_frames:
135 | if exclude_fixed and f.joint.joint_type == 'fixed':
136 | continue
137 | names.append(f.joint.name)
138 | return names
139 |
140 | def forward_kinematics(self, th, world=tf.Transform3d(), end_only=True):
141 | if world.dtype != self.dtype or world.device != self.device:
142 | world = world.to(dtype=self.dtype, device=self.device, copy=True)
143 | th, N = ensure_2d_tensor(th, self.dtype, self.device)
144 |
145 | cnt = 0
146 | link_transforms = {}
147 | trans = tf.Transform3d(matrix=world.get_matrix().repeat(N, 1, 1))
148 | for f in self._serial_frames:
149 | trans = trans.compose(f.get_transform(th[:, cnt].view(N, 1)))
150 | link_transforms[f.link.name] = trans.compose(f.link.offset)
151 | if f.joint.joint_type != "fixed":
152 | cnt += 1
153 | return link_transforms[self._serial_frames[-1].link.name] if end_only else link_transforms
154 |
155 | def jacobian(self, th, locations=None):
156 | if locations is not None:
157 | locations = tf.Transform3d(pos=locations)
158 | return jacobian.calc_jacobian(self, th, tool=locations)
159 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/frame.py:
--------------------------------------------------------------------------------
1 | import pytorch_kinematics.transforms as tf
2 | import torch
3 |
4 |
5 | class Visual(object):
6 | TYPES = ['box', 'cylinder', 'sphere', 'capsule', 'mesh']
7 |
8 | def __init__(self, offset=tf.Transform3d(),
9 | geom_type=None, geom_param=None):
10 | self.offset = offset
11 | self.geom_type = geom_type
12 | self.geom_param = geom_param
13 |
14 | def __repr__(self):
15 | return "Visual(offset={0}, geom_type='{1}', geom_param={2})".format(self.offset,
16 | self.geom_type,
17 | self.geom_param)
18 |
19 |
20 | class Link(object):
21 | def __init__(self, name=None, offset=tf.Transform3d(),
22 | visuals=()):
23 | self.name = name
24 | self.offset = offset
25 | self.visuals = visuals
26 |
27 | def to(self, *args, **kwargs):
28 | self.offset = self.offset.to(*args, **kwargs)
29 | return self
30 |
31 | def __repr__(self):
32 | return "Link(name='{0}', offset={1}, visuals={2})".format(self.name,
33 | self.offset,
34 | self.visuals)
35 |
36 |
37 | class Joint(object):
38 | TYPES = ['fixed', 'revolute', 'prismatic']
39 |
40 | def __init__(self, name=None, offset=tf.Transform3d(), joint_type='fixed', axis=(0.0, 0.0, 1.0), jrange=None,
41 | dtype=torch.float32, device="cpu"):
42 | self.name = name
43 | self.range = jrange
44 | self.offset = offset
45 | if joint_type not in self.TYPES:
46 | raise RuntimeError("joint specified as {} type not, but we only support {}".format(joint_type, self.TYPES))
47 | self.joint_type = joint_type
48 | if axis is None:
49 | self.axis = torch.tensor([0.0, 0.0, 1.0], dtype=dtype, device=device)
50 | else:
51 | if torch.is_tensor(axis):
52 | self.axis = axis.clone().detach().to(dtype=dtype, device=device)
53 | else:
54 | self.axis = torch.tensor(axis, dtype=dtype, device=device)
55 | # normalize axis to have norm 1 (needed for correct representation scaling with theta)
56 | self.axis = self.axis / self.axis.norm()
57 |
58 | def to(self, *args, **kwargs):
59 | self.axis = self.axis.to(*args, **kwargs)
60 | self.offset = self.offset.to(*args, **kwargs)
61 | return self
62 |
63 | def __repr__(self):
64 | return "Joint(name='{0}', offset={1}, joint_type='{2}', axis={3}, range={4})".format(self.name,
65 | self.offset,
66 | self.joint_type,
67 | self.axis,
68 | self.range)
69 |
70 |
71 | class Frame(object):
72 | def __init__(self, name=None, link=Link(),
73 | joint=Joint(), children=()):
74 | self.name = 'None' if name is None else name
75 | self.link = link
76 | self.joint = joint
77 | self.children = children
78 |
79 | def __str__(self, level=0):
80 | ret = " \t" * level + self.name + "\n"
81 | for child in self.children:
82 | ret += child.__str__(level + 1)
83 | return ret
84 |
85 | def to(self, *args, **kwargs):
86 | self.joint = self.joint.to(*args, **kwargs)
87 | self.link = self.link.to(*args, **kwargs)
88 | self.children = [c.to(*args, **kwargs) for c in self.children]
89 | return self
90 |
91 | def add_child(self, child):
92 | self.children.append(child)
93 |
94 | def is_end(self):
95 | return (len(self.children) == 0)
96 |
97 | def get_transform(self, theta):
98 | dtype = self.joint.axis.dtype
99 | d = self.joint.axis.device
100 | if self.joint.joint_type == 'revolute':
101 | t = tf.Transform3d(rot=tf.axis_angle_to_quaternion(theta * self.joint.axis), dtype=dtype, device=d)
102 | elif self.joint.joint_type == 'prismatic':
103 | t = tf.Transform3d(pos=theta * self.joint.axis, dtype=dtype, device=d)
104 | elif self.joint.joint_type == 'fixed':
105 | t = tf.Transform3d(default_batch_size=theta.shape[0], dtype=dtype, device=d)
106 | else:
107 | raise ValueError("Unsupported joint type %s." % self.joint.joint_type)
108 | return self.joint.offset.compose(t)
109 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/jacobian.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from pytorch_kinematics import transforms
3 |
4 |
5 | def calc_jacobian(serial_chain, th, tool=None):
6 | """
7 | Return robot Jacobian J in base frame (N,6,DOF) where dot{x} = J dot{q}
8 | The first 3 rows relate the translational velocities and the
9 | last 3 rows relate the angular velocities.
10 |
11 | tool is the transformation wrt the end effector; default is identity. If specified, will have to
12 | specify for each of the N inputs
13 | """
14 | if not torch.is_tensor(th):
15 | th = torch.tensor(th, dtype=serial_chain.dtype, device=serial_chain.device)
16 | if len(th.shape) <= 1:
17 | N = 1
18 | th = th.view(1, -1)
19 | else:
20 | N = th.shape[0]
21 | ndof = th.shape[1]
22 |
23 | j_fl = torch.zeros((N, 6, ndof), dtype=serial_chain.dtype, device=serial_chain.device)
24 |
25 | if tool is None:
26 | cur_transform = transforms.Transform3d(device=serial_chain.device,
27 | dtype=serial_chain.dtype).get_matrix().repeat(N, 1, 1)
28 | else:
29 | if tool.dtype != serial_chain.dtype or tool.device != serial_chain.device:
30 | tool = tool.to(device=serial_chain.device, copy=True, dtype=serial_chain.dtype)
31 | cur_transform = tool.get_matrix()
32 |
33 | cnt = 0
34 | for f in reversed(serial_chain._serial_frames):
35 | if f.joint.joint_type == "revolute":
36 | cnt += 1
37 | d = torch.stack([-cur_transform[:, 0, 0] * cur_transform[:, 1, 3]
38 | + cur_transform[:, 1, 0] * cur_transform[:, 0, 3],
39 | -cur_transform[:, 0, 1] * cur_transform[:, 1, 3]
40 | + cur_transform[:, 1, 1] * cur_transform[:, 0, 3],
41 | -cur_transform[:, 0, 2] * cur_transform[:, 1, 3]
42 | + cur_transform[:, 1, 2] * cur_transform[:, 0, 3]]).transpose(0, 1)
43 | delta = cur_transform[:, 2, 0:3]
44 | j_fl[:, :, -cnt] = torch.cat((d, delta), dim=-1)
45 | elif f.joint.joint_type == "prismatic":
46 | cnt += 1
47 | j_fl[:, :3, -cnt] = f.joint.axis.repeat(N, 1) @ cur_transform[:, :3, :3]
48 | cur_frame_transform = f.get_transform(th[:, -cnt].view(N, 1)).get_matrix()
49 | cur_transform = cur_frame_transform @ cur_transform
50 |
51 | # currently j_fl is Jacobian in flange (end-effector) frame, convert to base/world frame
52 | pose = serial_chain.forward_kinematics(th).get_matrix()
53 | rotation = pose[:, :3, :3]
54 | j_tr = torch.zeros((N, 6, 6), dtype=serial_chain.dtype, device=serial_chain.device)
55 | j_tr[:, :3, :3] = rotation
56 | j_tr[:, 3:, 3:] = rotation
57 | j_w = j_tr @ j_fl
58 | return j_w
59 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/mjcf.py:
--------------------------------------------------------------------------------
1 | from . import frame
2 | from . import chain
3 | from . import mjcf_parser
4 | import pytorch_kinematics.transforms as tf
5 |
6 | JOINT_TYPE_MAP = {'hinge': 'revolute', None: 'revolute'}
7 |
8 |
9 | def geoms_to_visuals(geom, base=tf.Transform3d()):
10 | visuals = []
11 | for g in geom:
12 | if g.type == 'capsule':
13 | param = g.size
14 | elif g.type == 'sphere':
15 | param = g.size[0]
16 | elif g.type == 'box':
17 | param = g.size
18 | elif g.type == 'mesh':
19 | param = (g.mesh.name, g.mesh.scale)
20 | else:
21 | # print(g.name)
22 | param = (g.mesh.name, g.mesh.scale)
23 | # raise ValueError('Invalid geometry type %s.' % g.type)
24 | visuals.append(frame.Visual(offset=base.compose(tf.Transform3d(rot=g.quat, pos=g.pos)),
25 | geom_type=g.type,
26 | geom_param=param))
27 | return visuals
28 |
29 |
30 | def body_to_link(body, base=tf.Transform3d()):
31 | return frame.Link(body.name,
32 | offset=base.compose(tf.Transform3d(rot=body.quat, pos=body.pos)))
33 |
34 |
35 | def joint_to_joint(joint, base=tf.Transform3d()):
36 | return frame.Joint(joint.name,
37 | offset=base.compose(tf.Transform3d(pos=joint.pos)),
38 | joint_type=JOINT_TYPE_MAP[joint.type],
39 | jrange=joint.range,
40 | axis=joint.axis)
41 |
42 |
43 | def add_composite_joint(root_frame, joints, base=tf.Transform3d()):
44 | if len(joints) > 0:
45 | root_frame.children = root_frame.children + (frame.Frame(link=frame.Link(name=root_frame.link.name + '_child'),
46 | joint=joint_to_joint(joints[0], base)),)
47 | ret, offset = add_composite_joint(root_frame.children[-1], joints[1:])
48 | return ret, root_frame.joint.offset.compose(offset)
49 | else:
50 | return root_frame, root_frame.joint.offset
51 |
52 |
53 | def _build_chain_recurse(root_frame, root_body):
54 | base = root_frame.link.offset
55 | cur_frame, cur_base = add_composite_joint(root_frame, root_body.joint, base)
56 | jbase = cur_base.inverse().compose(base)
57 | if len(root_body.joint) > 0:
58 | cur_frame.link.visuals = geoms_to_visuals(root_body.geom, jbase)
59 | else:
60 | cur_frame.link.visuals = geoms_to_visuals(root_body.geom)
61 | for b in root_body.body:
62 | cur_frame.children = cur_frame.children + (frame.Frame(),)
63 | next_frame = cur_frame.children[-1]
64 | next_frame.name = b.name + "_frame"
65 | next_frame.link = body_to_link(b, jbase)
66 | _build_chain_recurse(next_frame, b)
67 |
68 |
69 | def build_chain_from_mjcf(data):
70 | """
71 | Build a Chain object from MJCF data.
72 |
73 | Parameters
74 | ----------
75 | data : str
76 | MJCF string data.
77 |
78 | Returns
79 | -------
80 | chain.Chain
81 | Chain object created from MJCF.
82 | """
83 | model = mjcf_parser.from_xml_string(data)
84 | root_body = model.worldbody.body[0]
85 | root_frame = frame.Frame(root_body.name + "_frame",
86 | link=body_to_link(root_body),
87 | joint=frame.Joint())
88 | _build_chain_recurse(root_frame, root_body)
89 | return chain.Chain(root_frame)
90 |
91 |
92 | def build_serial_chain_from_mjcf(data, end_link_name, root_link_name=""):
93 | """
94 | Build a SerialChain object from MJCF data.
95 |
96 | Parameters
97 | ----------
98 | data : str
99 | MJCF string data.
100 | end_link_name : str
101 | The name of the link that is the end effector.
102 | root_link_name : str, optional
103 | The name of the root link.
104 |
105 | Returns
106 | -------
107 | chain.SerialChain
108 | SerialChain object created from MJCF.
109 | """
110 | mjcf_chain = build_chain_from_mjcf(data)
111 | return chain.SerialChain(mjcf_chain, end_link_name + "_frame",
112 | "" if root_link_name == "" else root_link_name + "_frame")
113 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/mjcf_parser/__init__.py:
--------------------------------------------------------------------------------
1 | from .parser import *
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/mjcf_parser/base.py:
--------------------------------------------------------------------------------
1 | # Copyright 2018 The dm_control Authors.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | # ============================================================================
15 |
16 | """Base class for all MJCF elements in the object model."""
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 |
22 | import abc
23 |
24 | import six
25 |
26 |
27 | @six.add_metaclass(abc.ABCMeta)
28 | class Element(object):
29 | """Abstract base class for an MJCF element.
30 |
31 | This class is provided so that `isinstance(foo, Element)` is `True` for all
32 | Element-like objects. We do not implement the actual element here because
33 | the actual object returned from traversing the object hierarchy is a
34 | weakproxy-like proxy to an actual element. This is because we do not allow
35 | orphaned non-root elements, so when a particular element is removed from the
36 | tree, all references held automatically become invalid.
37 | """
38 | __slots__ = []
39 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/mjcf_parser/constants.py:
--------------------------------------------------------------------------------
1 | # Copyright 2018 The dm_control Authors.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | # ============================================================================
15 |
16 | """Magic constants used within `dm_control.mjcf`."""
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 |
22 | PREFIX_SEPARATOR = '/'
23 | PREFIX_SEPARATOR_ESCAPE = '\\'
24 |
25 | # Used to disambiguate namespaces between attachment frames.
26 | NAMESPACE_SEPARATOR = '@'
27 |
28 | # Magic attribute names
29 | BASEPATH = 'basepath'
30 | CHILDCLASS = 'childclass'
31 | CLASS = 'class'
32 | DEFAULT = 'default'
33 | DCLASS = 'dclass'
34 |
35 | # Magic tags
36 | ACTUATOR = 'actuator'
37 | BODY = 'body'
38 | DEFAULT = 'default'
39 | MESH = 'mesh'
40 | SITE = 'site'
41 | TENDON = 'tendon'
42 | WORLDBODY = 'worldbody'
43 |
44 | MJDATA_TRIGGERS_DIRTY = [
45 | 'qpos', 'qvel', 'act', 'ctrl', 'qfrc_applied', 'xfrc_applied']
46 | MJMODEL_DOESNT_TRIGGER_DIRTY = [
47 | 'rgba', 'matid', 'emission', 'specular', 'shininess', 'reflectance']
48 |
49 | # When writing into `model.{body,geom,site}_{pos,quat}` we must ensure that the
50 | # corresponding rows in `model.{body,geom,site}_sameframe` are set to zero,
51 | # otherwise MuJoCo will use the body or inertial frame instead of our modified
52 | # pos/quat values. We must do the same for `body_{ipos,iquat}` and
53 | # `body_simple`.
54 | MJMODEL_DISABLE_ON_WRITE = {
55 | # Field name in MjModel: (attribute names of Binding instance to be zeroed)
56 | 'body_pos': ('sameframe',),
57 | 'body_quat': ('sameframe',),
58 | 'geom_pos': ('sameframe',),
59 | 'geom_quat': ('sameframe',),
60 | 'site_pos': ('sameframe',),
61 | 'site_quat': ('sameframe',),
62 | 'body_ipos': ('simple', 'sameframe'),
63 | 'body_iquat': ('simple', 'sameframe'),
64 | }
65 |
66 | # This is the actual upper limit on VFS filename length, despite what it says
67 | # in the header file (100) or the error message (99).
68 | MAX_VFS_FILENAME_LENGTH = 98
69 |
70 | # The prefix used in the schema to denote reference_namespace that are defined
71 | # via another attribute.
72 | INDIRECT_REFERENCE_NAMESPACE_PREFIX = 'attrib:'
73 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/mjcf_parser/copier.py:
--------------------------------------------------------------------------------
1 | # Copyright 2018 The dm_control Authors.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | # ============================================================================
15 |
16 | """Helper object for keeping track of new elements created when copying MJCF."""
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 |
22 | from . import constants
23 |
24 |
25 | class Copier(object):
26 | """Helper for keeping track of new elements created when copying MJCF."""
27 |
28 | def __init__(self, source):
29 | if source._attachments: # pylint: disable=protected-access
30 | raise NotImplementedError('Cannot copy from elements with attachments')
31 | self._source = source
32 |
33 | def copy_into(self, destination, override_attributes=False):
34 | """Copies this copier's element into a destination MJCF element."""
35 | newly_created_elements = {}
36 | destination._check_valid_attachment(self._source) # pylint: disable=protected-access
37 | if override_attributes:
38 | destination.set_attributes(**self._source.get_attributes())
39 | else:
40 | destination._sync_attributes(self._source, copying=True) # pylint: disable=protected-access
41 | for source_child in self._source.all_children():
42 | dest_child = None
43 | # First, if source_child has an identifier, we look for an existing child
44 | # element of self with the same identifier to override.
45 | if source_child.spec.identifier and override_attributes:
46 | identifier_attr = source_child.spec.identifier
47 | if identifier_attr == constants.CLASS:
48 | identifier_attr = constants.DCLASS
49 | identifier = getattr(source_child, identifier_attr)
50 | if identifier:
51 | dest_child = destination.find(source_child.spec.namespace, identifier)
52 | if dest_child is not None and dest_child.parent is not destination:
53 | raise ValueError(
54 | '<{}> with identifier {!r} is already a child of another element'
55 | .format(source_child.spec.namespace, identifier))
56 | # Next, we cover the case where either the child is not a repeated element
57 | # or if source_child has an identifier attribute but it isn't set.
58 | if not source_child.spec.repeated and dest_child is None:
59 | dest_child = destination.get_children(source_child.tag)
60 |
61 | # Add a new element if dest_child doesn't exist, either because it is
62 | # supposed to be a repeated child, or because it's an uncreated on-demand.
63 | if dest_child is None:
64 | dest_child = destination.add(
65 | source_child.tag, **source_child.get_attributes())
66 | newly_created_elements[source_child] = dest_child
67 | override_child_attributes = True
68 | else:
69 | override_child_attributes = override_attributes
70 |
71 | # Finally, copy attributes into dest_child.
72 | child_copier = Copier(source_child)
73 | newly_created_elements.update(
74 | child_copier.copy_into(dest_child, override_child_attributes))
75 | return newly_created_elements
76 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/mjcf_parser/io.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017-2018 The dm_control Authors.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS-IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | # ============================================================================
15 |
16 | """IO functions."""
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 |
22 |
23 | def GetResource(name, mode='rb'):
24 | with open(name, mode=mode) as f:
25 | return f.read()
26 |
27 |
28 | def GetResourceFilename(name, mode='rb'):
29 | del mode # Unused.
30 | return name
31 |
32 |
33 | GetResourceAsFile = open # pylint: disable=invalid-name
34 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/mjcf_parser/namescope.py:
--------------------------------------------------------------------------------
1 | # Copyright 2018 The dm_control Authors.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | # ============================================================================
15 |
16 | """An object to manage the scoping of identifiers in MJCF models."""
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 |
22 | import collections
23 |
24 | from . import constants
25 | import six
26 |
27 |
28 | class NameScope(object):
29 | """A name scoping context for an MJCF model.
30 |
31 | This object maintains the uniqueness of identifiers within each MJCF
32 | namespace. Examples of MJCF namespaces include 'body', 'joint', and 'geom'.
33 | Each namescope also carries a name, and can have a parent namescope.
34 | When MJCF models are merged, all identifiers gain a hierarchical prefix
35 | separated by '/', which is the concatenation of all scope names up to
36 | the root namescope.
37 | """
38 |
39 | def __init__(self, name, mjcf_model, model_dir='', assets=None):
40 | """Initializes a scope with the given name.
41 |
42 | Args:
43 | name: The scope's name
44 | mjcf_model: The RootElement of the MJCF model associated with this scope.
45 | model_dir: (optional) Path to the directory containing the model XML file.
46 | This is used to prefix the paths of all asset files.
47 | assets: (optional) A dictionary of pre-loaded assets, of the form
48 | `{filename: bytestring}`. If present, PyMJCF will search for assets in
49 | this dictionary before attempting to load them from the filesystem.
50 | """
51 | self._parent = None
52 | self._name = name
53 | self._mjcf_model = mjcf_model
54 | self._namespaces = collections.defaultdict(dict)
55 | self._model_dir = model_dir
56 | self._files = set()
57 | self._assets = assets or {}
58 | self._revision = 0
59 |
60 | @property
61 | def revision(self):
62 | return self._revision
63 |
64 | def increment_revision(self):
65 | self._revision += 1
66 | for namescope in six.itervalues(self._namespaces['namescope']):
67 | namescope.increment_revision()
68 |
69 | @property
70 | def name(self):
71 | """This scope's name."""
72 | return self._name
73 |
74 | @property
75 | def files(self):
76 | """A set containing the `File` attributes registered in this scope."""
77 | return self._files
78 |
79 | @property
80 | def assets(self):
81 | """A dictionary containing pre-loaded assets."""
82 | return self._assets
83 |
84 | @property
85 | def model_dir(self):
86 | """Path to the directory containing the model XML file."""
87 | return self._model_dir
88 |
89 | @name.setter
90 | def name(self, new_name):
91 | if self._parent:
92 | self._parent.add('namescope', new_name, self)
93 | self._parent.remove('namescope', self._name)
94 | self._name = new_name
95 | self.increment_revision()
96 |
97 | @property
98 | def mjcf_model(self):
99 | return self._mjcf_model
100 |
101 | @property
102 | def parent(self):
103 | """This parent `NameScope`, or `None` if this is a root scope."""
104 | return self._parent
105 |
106 | @parent.setter
107 | def parent(self, new_parent):
108 | if self._parent:
109 | self._parent.remove('namescope', self._name)
110 | self._parent = new_parent
111 | if self._parent:
112 | self._parent.add('namescope', self._name, self)
113 | self.increment_revision()
114 |
115 | @property
116 | def root(self):
117 | if self._parent is None:
118 | return self
119 | else:
120 | return self._parent.root
121 |
122 | def full_prefix(self, prefix_root=None, as_list=False):
123 | """The prefix for identifiers belonging to this scope.
124 |
125 | Args:
126 | prefix_root: (optional) A `NameScope` object to be treated as root
127 | for the purpose of calculating the prefix. If `None` then no prefix
128 | is produced.
129 | as_list: (optional) A boolean, if `True` return the list of prefix
130 | components. If `False`, return the full prefix string separated by
131 | `mjcf.constants.PREFIX_SEPARATOR`.
132 |
133 | Returns:
134 | The prefix string.
135 | """
136 | prefix_root = prefix_root or self
137 | if prefix_root != self and self._parent:
138 | prefix_list = self._parent.full_prefix(prefix_root, as_list=True)
139 | prefix_list.append(self._name)
140 | else:
141 | prefix_list = []
142 | if as_list:
143 | return prefix_list
144 | else:
145 | if prefix_list:
146 | prefix_list.append('')
147 | return constants.PREFIX_SEPARATOR.join(prefix_list)
148 |
149 | def _assign(self, namespace, identifier, obj):
150 | """Checks a proposed identifier's validity before assigning to an object."""
151 | namespace_dict = self._namespaces[namespace]
152 | if not isinstance(identifier, str):
153 | raise ValueError(
154 | 'Identifier must be a string: got {}'.format(type(identifier)))
155 | elif constants.PREFIX_SEPARATOR in identifier:
156 | raise ValueError(
157 | 'Identifier cannot contain {!r}: got {}'
158 | .format(constants.PREFIX_SEPARATOR, identifier))
159 | else:
160 | namespace_dict[identifier] = obj
161 |
162 | def add(self, namespace, identifier, obj):
163 | """Add an identifier to this name scope.
164 |
165 | Args:
166 | namespace: A string specifying the namespace to which the
167 | identifier belongs.
168 | identifier: The identifier string.
169 | obj: The object referred to by the identifier.
170 |
171 | Raises:
172 | ValueError: If `identifier` not valid.
173 | """
174 | namespace_dict = self._namespaces[namespace]
175 | if identifier in namespace_dict:
176 | raise ValueError('Duplicated identifier {!r} in namespace <{}>'
177 | .format(identifier, namespace))
178 | else:
179 | self._assign(namespace, identifier, obj)
180 | self.increment_revision()
181 |
182 | def replace(self, namespace, identifier, obj):
183 | """Reassociates an identifier with a different object.
184 |
185 | Args:
186 | namespace: A string specifying the namespace to which the
187 | identifier belongs.
188 | identifier: The identifier string.
189 | obj: The object referred to by the identifier.
190 |
191 | Raises:
192 | ValueError: If `identifier` not valid.
193 | """
194 | self._assign(namespace, identifier, obj)
195 | self.increment_revision()
196 |
197 | def remove(self, namespace, identifier):
198 | """Removes an identifier from this name scope.
199 |
200 | Args:
201 | namespace: A string specifying the namespace to which the
202 | identifier belongs.
203 | identifier: The identifier string.
204 |
205 | Raises:
206 | KeyError: If `identifier` does not exist in this scope.
207 | """
208 | del self._namespaces[namespace][identifier]
209 | self.increment_revision()
210 |
211 | def rename(self, namespace, old_identifier, new_identifier):
212 | obj = self.get(namespace, old_identifier)
213 | self.add(namespace, new_identifier, obj)
214 | self.remove(namespace, old_identifier)
215 |
216 | def get(self, namespace, identifier):
217 | return self._namespaces[namespace][identifier]
218 |
219 | def has_identifier(self, namespace, identifier):
220 | return identifier in self._namespaces[namespace]
221 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/mjcf_parser/util.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017-2018 The dm_control Authors.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | # ============================================================================
15 |
16 | """Various helper functions and classes."""
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 |
22 | import sys
23 | import six
24 |
25 | DEFAULT_ENCODING = sys.getdefaultencoding()
26 |
27 |
28 | def to_binary_string(s):
29 | """Convert text string to binary."""
30 | if isinstance(s, six.binary_type):
31 | return s
32 | return s.encode(DEFAULT_ENCODING)
33 |
34 |
35 | def to_native_string(s):
36 | """Convert a text or binary string to the native string format."""
37 | if six.PY3 and isinstance(s, six.binary_type):
38 | return s.decode(DEFAULT_ENCODING)
39 | elif six.PY2 and isinstance(s, six.text_type):
40 | return s.encode(DEFAULT_ENCODING)
41 | else:
42 | return s
43 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/sdf.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import math
3 | from .urdf_parser_py.sdf import SDF, Mesh, Cylinder, Box, Sphere
4 | from . import frame
5 | from . import chain
6 | import pytorch_kinematics.transforms as tf
7 |
8 | JOINT_TYPE_MAP = {'revolute': 'revolute',
9 | 'prismatic': 'prismatic',
10 | 'fixed': 'fixed'}
11 |
12 |
13 | def _convert_transform(pose):
14 | if pose is None:
15 | return tf.Transform3d()
16 | else:
17 | return tf.Transform3d(rot=tf.euler_angles_to_matrix(torch.tensor(pose[3:]), "ZYX"), pos=pose[:3])
18 |
19 |
20 | def _convert_visuals(visuals):
21 | vlist = []
22 | for v in visuals:
23 | v_tf = _convert_transform(v.pose)
24 | if isinstance(v.geometry, Mesh):
25 | g_type = "mesh"
26 | g_param = v.geometry.filename
27 | elif isinstance(v.geometry, Cylinder):
28 | g_type = "cylinder"
29 | v_tf = v_tf.compose(
30 | tf.Transform3d(rot=tf.euler_angles_to_matrix(torch.tensor([0.5 * math.pi, 0, 0]), "ZYX")))
31 | g_param = (v.geometry.radius, v.geometry.length)
32 | elif isinstance(v.geometry, Box):
33 | g_type = "box"
34 | g_param = v.geometry.size
35 | elif isinstance(v.geometry, Sphere):
36 | g_type = "sphere"
37 | g_param = v.geometry.radius
38 | else:
39 | g_type = None
40 | g_param = None
41 | vlist.append(frame.Visual(v_tf, g_type, g_param))
42 | return vlist
43 |
44 |
45 | def _build_chain_recurse(root_frame, lmap, joints):
46 | children = []
47 | for j in joints:
48 | if j.parent == root_frame.link.name:
49 | child_frame = frame.Frame(j.child + "_frame")
50 | link_p = lmap[j.parent]
51 | link_c = lmap[j.child]
52 | t_p = _convert_transform(link_p.pose)
53 | t_c = _convert_transform(link_c.pose)
54 | child_frame.joint = frame.Joint(j.name, offset=t_p.inverse().compose(t_c),
55 | joint_type=JOINT_TYPE_MAP[j.type], axis=j.axis.xyz)
56 | child_frame.link = frame.Link(link_c.name, offset=tf.Transform3d(),
57 | visuals=_convert_visuals(link_c.visuals))
58 | child_frame.children = _build_chain_recurse(child_frame, lmap, joints)
59 | children.append(child_frame)
60 | return children
61 |
62 |
63 | def build_chain_from_sdf(data):
64 | """
65 | Build a Chain object from SDF data.
66 |
67 | Parameters
68 | ----------
69 | data : str
70 | SDF string data.
71 |
72 | Returns
73 | -------
74 | chain.Chain
75 | Chain object created from SDF.
76 | """
77 | sdf = SDF.from_xml_string(data)
78 | robot = sdf.model
79 | lmap = robot.link_map
80 | joints = robot.joints
81 | n_joints = len(joints)
82 | has_root = [True for _ in range(len(joints))]
83 | for i in range(n_joints):
84 | for j in range(i + 1, n_joints):
85 | if joints[i].parent == joints[j].child:
86 | has_root[i] = False
87 | elif joints[j].parent == joints[i].child:
88 | has_root[j] = False
89 | for i in range(n_joints):
90 | if has_root[i]:
91 | root_link = lmap[joints[i].parent]
92 | break
93 | root_frame = frame.Frame(root_link.name + "_frame")
94 | root_frame.joint = frame.Joint(offset=_convert_transform(root_link.pose))
95 | root_frame.link = frame.Link(root_link.name, tf.Transform3d(),
96 | _convert_visuals(root_link.visuals))
97 | root_frame.children = _build_chain_recurse(root_frame, lmap, joints)
98 | return chain.Chain(root_frame)
99 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/transforms/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
2 |
3 | from .rotation_conversions import (
4 | axis_angle_to_matrix,
5 | axis_angle_to_quaternion,
6 | euler_angles_to_matrix,
7 | matrix_to_euler_angles,
8 | matrix_to_quaternion,
9 | matrix_to_rotation_6d,
10 | quaternion_apply,
11 | quaternion_invert,
12 | quaternion_multiply,
13 | quaternion_raw_multiply,
14 | quaternion_to_matrix,
15 | random_quaternions,
16 | random_rotation,
17 | random_rotations,
18 | rotation_6d_to_matrix,
19 | standardize_quaternion,
20 | xyzw_to_wxyz,
21 | wxyz_to_xyzw
22 | )
23 | from .so3 import (
24 | so3_exp_map,
25 | so3_log_map,
26 | so3_relative_angle,
27 | so3_rotation_angle,
28 | )
29 | from .transform3d import Rotate, RotateAxisAngle, Scale, Transform3d, Translate
30 |
31 |
32 | __all__ = [k for k in globals().keys() if not k.startswith("_")]
33 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/transforms/math.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) Facebook, Inc. and its affiliates.
2 | # All rights reserved.
3 | #
4 | # This source code is licensed under the BSD-style license found in the
5 | # LICENSE file in the root directory of this source tree.
6 |
7 | import math
8 | from typing import Tuple, Union
9 |
10 | import torch
11 |
12 |
13 | def acos_linear_extrapolation(
14 | x: torch.Tensor,
15 | bound: Union[float, Tuple[float, float]] = 1.0 - 1e-4,
16 | ) -> torch.Tensor:
17 | """
18 | Implements `arccos(x)` which is linearly extrapolated outside `x`'s original
19 | domain of `(-1, 1)`. This allows for stable backpropagation in case `x`
20 | is not guaranteed to be strictly within `(-1, 1)`.
21 | More specifically:
22 | ```
23 | if -bound <= x <= bound:
24 | acos_linear_extrapolation(x) = acos(x)
25 | elif x <= -bound: # 1st order Taylor approximation
26 | acos_linear_extrapolation(x) = acos(-bound) + dacos/dx(-bound) * (x - (-bound))
27 | else: # x >= bound
28 | acos_linear_extrapolation(x) = acos(bound) + dacos/dx(bound) * (x - bound)
29 | ```
30 | Note that `bound` can be made more specific with setting
31 | `bound=[lower_bound, upper_bound]` as detailed below.
32 | Args:
33 | x: Input `Tensor`.
34 | bound: A float constant or a float 2-tuple defining the region for the
35 | linear extrapolation of `acos`.
36 | If `bound` is a float scalar, linearly interpolates acos for
37 | `x <= -bound` or `bound <= x`.
38 | If `bound` is a 2-tuple, the first/second element of `bound`
39 | describes the lower/upper bound that defines the lower/upper
40 | extrapolation region, i.e. the region where
41 | `x <= bound[0]`/`bound[1] <= x`.
42 | Note that all elements of `bound` have to be within (-1, 1).
43 | Returns:
44 | acos_linear_extrapolation: `Tensor` containing the extrapolated `arccos(x)`.
45 | """
46 |
47 | if isinstance(bound, float):
48 | upper_bound = bound
49 | lower_bound = -bound
50 | else:
51 | lower_bound, upper_bound = bound
52 |
53 | if lower_bound > upper_bound:
54 | raise ValueError("lower bound has to be smaller or equal to upper bound.")
55 |
56 | if lower_bound <= -1.0 or upper_bound >= 1.0:
57 | raise ValueError("Both lower bound and upper bound have to be within (-1, 1).")
58 |
59 | # init an empty tensor and define the domain sets
60 | acos_extrap = torch.empty_like(x)
61 | x_upper = x >= upper_bound
62 | x_lower = x <= lower_bound
63 | x_mid = (~x_upper) & (~x_lower)
64 |
65 | # acos calculation for upper_bound < x < lower_bound
66 | acos_extrap[x_mid] = torch.acos(x[x_mid])
67 | # the linear extrapolation for x >= upper_bound
68 | acos_extrap[x_upper] = _acos_linear_approximation(x[x_upper], upper_bound)
69 | # the linear extrapolation for x <= lower_bound
70 | acos_extrap[x_lower] = _acos_linear_approximation(x[x_lower], lower_bound)
71 |
72 | return acos_extrap
73 |
74 |
75 | def _acos_linear_approximation(x: torch.Tensor, x0: float) -> torch.Tensor:
76 | """
77 | Calculates the 1st order Taylor expansion of `arccos(x)` around `x0`.
78 | """
79 | return (x - x0) * _dacos_dx(x0) + math.acos(x0)
80 |
81 |
82 | def _dacos_dx(x: float) -> float:
83 | """
84 | Calculates the derivative of `arccos(x)` w.r.t. `x`.
85 | """
86 | return (-1.0) / math.sqrt(1.0 - x * x)
87 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/urdf.py:
--------------------------------------------------------------------------------
1 | from .urdf_parser_py.urdf import URDF, Mesh, Cylinder, Box, Sphere
2 | from . import frame
3 | from . import chain
4 | import torch
5 | import pytorch_kinematics.transforms as tf
6 | # has better RPY to quaternion transformation
7 | import transformations as tf2
8 |
9 | JOINT_TYPE_MAP = {'revolute': 'revolute',
10 | 'continuous': 'revolute',
11 | 'prismatic': 'prismatic',
12 | 'fixed': 'fixed'}
13 |
14 |
15 | def _convert_transform(origin):
16 | if origin is None:
17 | return tf.Transform3d()
18 | else:
19 | return tf.Transform3d(rot=torch.tensor(tf2.quaternion_from_euler(*origin.rpy, "sxyz"), dtype=torch.float32),
20 | pos=origin.xyz)
21 |
22 |
23 | def _convert_visual(visual):
24 | if visual is None or visual.geometry is None:
25 | return frame.Visual()
26 | else:
27 | v_tf = _convert_transform(visual.origin)
28 | if isinstance(visual.geometry, Mesh):
29 | g_type = "mesh"
30 | g_param = visual.geometry.filename
31 | elif isinstance(visual.geometry, Cylinder):
32 | g_type = "cylinder"
33 | g_param = (visual.geometry.radius, visual.geometry.length)
34 | elif isinstance(visual.geometry, Box):
35 | g_type = "box"
36 | g_param = visual.geometry.size
37 | elif isinstance(visual.geometry, Sphere):
38 | g_type = "sphere"
39 | g_param = visual.geometry.radius
40 | else:
41 | g_type = None
42 | g_param = None
43 | return frame.Visual(v_tf, g_type, g_param)
44 |
45 |
46 | def _build_chain_recurse(root_frame, lmap, joints):
47 | children = []
48 | for j in joints:
49 | if j.parent == root_frame.link.name:
50 | child_frame = frame.Frame(j.child + "_frame")
51 | child_frame.joint = frame.Joint(j.name, offset=_convert_transform(j.origin),
52 | joint_type=JOINT_TYPE_MAP[j.type], axis=j.axis)
53 | link = lmap[j.child]
54 | child_frame.link = frame.Link(link.name, offset=_convert_transform(link.origin),
55 | visuals=[_convert_visual(link.visual)])
56 | child_frame.children = _build_chain_recurse(child_frame, lmap, joints)
57 | children.append(child_frame)
58 | return children
59 |
60 |
61 | def build_chain_from_urdf(data):
62 | """
63 | Build a Chain object from URDF data.
64 |
65 | Parameters
66 | ----------
67 | data : str
68 | URDF string data.
69 |
70 | Returns
71 | -------
72 | chain.Chain
73 | Chain object created from URDF.
74 |
75 | Example
76 | -------
77 | >>> import pytorch_kinematics as pk
78 | >>> data = '''
79 | ...
80 | ...
81 | ...
82 | ...
83 | ...
84 | ...
85 | ... '''
86 | >>> chain = pk.build_chain_from_urdf(data)
87 | >>> print(chain)
88 | link1_frame
89 | link2_frame
90 |
91 | """
92 | robot = URDF.from_xml_string(data)
93 | lmap = robot.link_map
94 | joints = robot.joints
95 | n_joints = len(joints)
96 | has_root = [True for _ in range(len(joints))]
97 | for i in range(n_joints):
98 | for j in range(i + 1, n_joints):
99 | if joints[i].parent == joints[j].child:
100 | has_root[i] = False
101 | elif joints[j].parent == joints[i].child:
102 | has_root[j] = False
103 | for i in range(n_joints):
104 | if has_root[i]:
105 | root_link = lmap[joints[i].parent]
106 | break
107 | root_frame = frame.Frame(root_link.name + "_frame")
108 | root_frame.joint = frame.Joint()
109 | root_frame.link = frame.Link(root_link.name, _convert_transform(root_link.origin),
110 | [_convert_visual(root_link.visual)])
111 | root_frame.children = _build_chain_recurse(root_frame, lmap, joints)
112 | return chain.Chain(root_frame)
113 |
114 |
115 | def build_serial_chain_from_urdf(data, end_link_name, root_link_name=""):
116 | """
117 | Build a SerialChain object from urdf data.
118 |
119 | Parameters
120 | ----------
121 | data : str
122 | URDF string data.
123 | end_link_name : str
124 | The name of the link that is the end effector.
125 | root_link_name : str, optional
126 | The name of the root link.
127 |
128 | Returns
129 | -------
130 | chain.SerialChain
131 | SerialChain object created from URDF.
132 | """
133 | urdf_chain = build_chain_from_urdf(data)
134 | return chain.SerialChain(urdf_chain, end_link_name + "_frame",
135 | "" if root_link_name == "" else root_link_name + "_frame")
136 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/urdf_parser_py/__init__.py:
--------------------------------------------------------------------------------
1 | from . import urdf
2 | from . import sdf
3 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/urdf_parser_py/xml_reflection/__init__.py:
--------------------------------------------------------------------------------
1 | from .core import *
2 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/pytorch_kinematics/urdf_parser_py/xml_reflection/basics.py:
--------------------------------------------------------------------------------
1 | import string
2 | import yaml
3 | import collections
4 | from lxml import etree
5 |
6 |
7 | def xml_string(rootXml, addHeader=True):
8 | # Meh
9 | xmlString = etree.tostring(rootXml, pretty_print=True, encoding='unicode')
10 | if addHeader:
11 | xmlString = '\n' + xmlString
12 | return xmlString
13 |
14 |
15 | def dict_sub(obj, keys):
16 | return dict((key, obj[key]) for key in keys)
17 |
18 |
19 | def node_add(doc, sub):
20 | if sub is None:
21 | return None
22 | if type(sub) == str:
23 | return etree.SubElement(doc, sub)
24 | elif isinstance(sub, etree._Element):
25 | doc.append(sub) # This screws up the rest of the tree for prettyprint
26 | return sub
27 | else:
28 | raise Exception('Invalid sub value')
29 |
30 |
31 | def pfloat(x):
32 | return str(x).rstrip('.')
33 |
34 |
35 | def xml_children(node):
36 | children = node.getchildren()
37 |
38 | def predicate(node):
39 | return not isinstance(node, etree._Comment)
40 |
41 | return list(filter(predicate, children))
42 |
43 |
44 | def isstring(obj):
45 | try:
46 | return isinstance(obj, basestring)
47 | except NameError:
48 | return isinstance(obj, str)
49 |
50 |
51 | def to_yaml(obj):
52 | """ Simplify yaml representation for pretty printing """
53 | # Is there a better way to do this by adding a representation with
54 | # yaml.Dumper?
55 | # Ordered dict: http://pyyaml.org/ticket/29#comment:11
56 | if obj is None or isstring(obj):
57 | out = str(obj)
58 | elif type(obj) in [int, float, bool]:
59 | return obj
60 | elif hasattr(obj, 'to_yaml'):
61 | out = obj.to_yaml()
62 | elif isinstance(obj, etree._Element):
63 | out = etree.tostring(obj, pretty_print=True)
64 | elif type(obj) == dict:
65 | out = {}
66 | for (var, value) in obj.items():
67 | out[str(var)] = to_yaml(value)
68 | elif hasattr(obj, 'tolist'):
69 | # For numpy objects
70 | out = to_yaml(obj.tolist())
71 | elif isinstance(obj, collections.Iterable):
72 | out = [to_yaml(item) for item in obj]
73 | else:
74 | out = str(obj)
75 | return out
76 |
77 |
78 | class SelectiveReflection(object):
79 | def get_refl_vars(self):
80 | return list(vars(self).keys())
81 |
82 |
83 | class YamlReflection(SelectiveReflection):
84 | def to_yaml(self):
85 | raw = dict((var, getattr(self, var)) for var in self.get_refl_vars())
86 | return to_yaml(raw)
87 |
88 | def __str__(self):
89 | # Good idea? Will it remove other important things?
90 | return yaml.dump(self.to_yaml()).rstrip()
91 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup
2 |
3 | setup(
4 | name='pytorch_kinematics',
5 | version='0.3.0',
6 | packages=['pytorch_kinematics'],
7 | url='https://github.com/UM-ARM-Lab/pytorch_kinematics',
8 | license='MIT',
9 | author='zhsh',
10 | author_email='zhsh@umich.edu',
11 | description='Robot kinematics implemented in pytorch',
12 | install_requires=[
13 | 'torch',
14 | 'numpy',
15 | 'transformations',
16 | 'absl-py'
17 | ],
18 | tests_require=[
19 | 'pytest'
20 | ]
21 | )
22 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/tests/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/iSEE-Laboratory/Grasp-as-You-Say/4694fa9369523d09d0c2cea6ec7bcddd2cb206d8/thirdparty/pytorch_kinematics/tests/__init__.py
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/tests/ant.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/tests/prismatic_robot.urdf:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/tests/test_jacobian.py:
--------------------------------------------------------------------------------
1 | import math
2 | import torch
3 | import pytorch_kinematics as pk
4 |
5 |
6 | def test_correctness():
7 | chain = pk.build_serial_chain_from_urdf(open("kuka_iiwa.urdf").read(), "lbr_iiwa_link_7")
8 | th = torch.tensor([0.0, -math.pi / 4.0, 0.0, math.pi / 2.0, 0.0, math.pi / 4.0, 0.0])
9 | J = chain.jacobian(th)
10 |
11 | assert torch.allclose(J, torch.tensor([[[0, 1.41421356e-02, 0, 2.82842712e-01, 0, 0, 0],
12 | [-6.60827561e-01, 0, -4.57275649e-01, 0, 5.72756493e-02, 0, 0],
13 | [0, 6.60827561e-01, 0, -3.63842712e-01, 0, 8.10000000e-02, 0],
14 | [0, 0, -7.07106781e-01, 0, -7.07106781e-01, 0, -1],
15 | [0, 1, 0, -1, 0, 1, 0],
16 | [1, 0, 7.07106781e-01, 0, -7.07106781e-01, 0, 0]]]))
17 |
18 | chain = pk.build_chain_from_sdf(open("simple_arm.sdf").read())
19 | chain = pk.SerialChain(chain, "arm_wrist_roll_frame")
20 | th = torch.tensor([0.8, 0.2, -0.5, -0.3])
21 | J = chain.jacobian(th)
22 | torch.allclose(J, torch.tensor([[[0., -1.51017878, -0.46280904, 0.],
23 | [0., 0.37144033, 0.29716627, 0.],
24 | [0., 0., 0., 0.],
25 | [0., 0., 0., 0.],
26 | [0., 0., 0., 0.],
27 | [0., 1., 1., 1.]]]))
28 |
29 |
30 | def test_jacobian_at_different_loc_than_ee():
31 | chain = pk.build_serial_chain_from_urdf(open("kuka_iiwa.urdf").read(), "lbr_iiwa_link_7")
32 | th = torch.tensor([0.0, -math.pi / 4.0, 0.0, math.pi / 2.0, 0.0, math.pi / 4.0, 0.0])
33 | loc = torch.tensor([0.1, 0, 0])
34 | J = chain.jacobian(th, locations=loc)
35 | J_c1 = torch.tensor([[[-0., 0.11414214, -0., 0.18284271, 0., 0.1, 0.],
36 | [-0.66082756, -0., -0.38656497, -0., 0.12798633, -0., 0.1],
37 | [-0., 0.66082756, -0., -0.36384271, 0., 0.081, -0.],
38 | [-0., -0., -0.70710678, -0., -0.70710678, 0., -1.],
39 | [0., 1., 0., -1., 0., 1., 0.],
40 | [1., 0., 0.70710678, 0., -0.70710678, -0., 0.]]])
41 |
42 | assert torch.allclose(J, J_c1)
43 |
44 | loc = torch.tensor([-0.1, 0.05, 0])
45 | J = chain.jacobian(th, locations=loc)
46 | J_c2 = torch.tensor([[[-0.05, -0.08585786, -0.03535534, 0.38284271, 0.03535534, -0.1, -0.],
47 | [-0.66082756, -0., -0.52798633, -0., -0.01343503, 0., -0.1],
48 | [-0., 0.66082756, -0.03535534, -0.36384271, -0.03535534, 0.081, -0.05],
49 | [-0., -0., -0.70710678, -0., -0.70710678, 0., -1.],
50 | [0., 1., 0., -1., 0., 1., 0.],
51 | [1., 0., 0.70710678, 0., -0.70710678, -0., 0.]]])
52 |
53 | assert torch.allclose(J, J_c2)
54 |
55 | # check that batching the location is fine
56 | th = th.repeat(2, 1)
57 | loc = torch.tensor([[0.1, 0, 0], [-0.1, 0.05, 0]])
58 | J = chain.jacobian(th, locations=loc)
59 | assert torch.allclose(J, torch.cat((J_c1, J_c2)))
60 |
61 |
62 | def test_parallel():
63 | N = 100
64 | chain = pk.build_serial_chain_from_urdf(open("kuka_iiwa.urdf").read(), "lbr_iiwa_link_7")
65 | th = torch.cat(
66 | (torch.tensor([[0.0, -math.pi / 4.0, 0.0, math.pi / 2.0, 0.0, math.pi / 4.0, 0.0]]), torch.rand(N, 7)))
67 | J = chain.jacobian(th)
68 | for i in range(N):
69 | J_i = chain.jacobian(th[i])
70 | assert torch.allclose(J[i], J_i)
71 |
72 |
73 | def test_dtype_device():
74 | N = 1000
75 | d = "cuda" if torch.cuda.is_available() else "cpu"
76 | dtype = torch.float64
77 |
78 | chain = pk.build_serial_chain_from_urdf(open("kuka_iiwa.urdf").read(), "lbr_iiwa_link_7")
79 | chain = chain.to(dtype=dtype, device=d)
80 | th = torch.rand(N, 7, dtype=dtype, device=d)
81 | J = chain.jacobian(th)
82 | assert J.dtype is dtype
83 |
84 |
85 | def test_gradient():
86 | N = 10
87 | d = "cuda" if torch.cuda.is_available() else "cpu"
88 | dtype = torch.float64
89 |
90 | chain = pk.build_serial_chain_from_urdf(open("kuka_iiwa.urdf").read(), "lbr_iiwa_link_7")
91 | chain = chain.to(dtype=dtype, device=d)
92 | th = torch.rand(N, 7, dtype=dtype, device=d, requires_grad=True)
93 | J = chain.jacobian(th)
94 | assert th.grad is None
95 | J.norm().backward()
96 | assert th.grad is not None
97 |
98 |
99 | def test_jacobian_prismatic():
100 | chain = pk.build_serial_chain_from_urdf(open("prismatic_robot.urdf").read(), "link4")
101 | th = torch.zeros(3)
102 | tg = chain.forward_kinematics(th)
103 | m = tg.get_matrix()
104 | pos = m[0, :3, 3]
105 | assert torch.allclose(pos, torch.tensor([0, 0, 1.]))
106 | th = torch.tensor([0, 0.1, 0])
107 | tg = chain.forward_kinematics(th)
108 | m = tg.get_matrix()
109 | pos = m[0, :3, 3]
110 | assert torch.allclose(pos, torch.tensor([0, -0.1, 1.]))
111 | th = torch.tensor([0.1, 0.1, 0])
112 | tg = chain.forward_kinematics(th)
113 | m = tg.get_matrix()
114 | pos = m[0, :3, 3]
115 | assert torch.allclose(pos, torch.tensor([0, -0.1, 1.1]))
116 | th = torch.tensor([0.1, 0.1, 0.1])
117 | tg = chain.forward_kinematics(th)
118 | m = tg.get_matrix()
119 | pos = m[0, :3, 3]
120 | assert torch.allclose(pos, torch.tensor([0.1, -0.1, 1.1]))
121 |
122 | J = chain.jacobian(th)
123 | assert torch.allclose(J, torch.tensor([[[0., 0., 1.],
124 | [0., -1., 0.],
125 | [1., 0., 0.],
126 | [0., 0., 0.],
127 | [0., 0., 0.],
128 | [0., 0., 0.]]]))
129 |
130 |
131 | if __name__ == "__main__":
132 | test_correctness()
133 | test_parallel()
134 | test_dtype_device()
135 | test_gradient()
136 | test_jacobian_prismatic()
137 | test_jacobian_at_different_loc_than_ee()
138 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/tests/test_kinematics.py:
--------------------------------------------------------------------------------
1 | import math
2 |
3 | import torch
4 | import pytorch_kinematics as pk
5 |
6 |
7 | def quat_pos_from_transform3d(tg):
8 | m = tg.get_matrix()
9 | pos = m[:, :3, 3]
10 | rot = pk.matrix_to_quaternion(m[:, :3, :3])
11 | return pos, rot
12 |
13 |
14 | def quaternion_equality(a, b):
15 | # negative of a quaternion is the same rotation
16 | return torch.allclose(a, b) or torch.allclose(a, -b)
17 |
18 |
19 | def test_fkik():
20 | data = '' \
21 | '' \
22 | '' \
23 | '' \
24 | '' \
25 | '' \
26 | '' \
27 | '' \
28 | '' \
29 | '' \
30 | '' \
31 | '' \
32 | '' \
33 | '' \
34 | ''
35 | chain = pk.build_serial_chain_from_urdf(data, 'link3')
36 | th1 = torch.tensor([0.42553542, 0.17529176])
37 | tg = chain.forward_kinematics(th1)
38 | pos, rot = quat_pos_from_transform3d(tg)
39 | assert torch.allclose(pos, torch.tensor([[1.91081784, 0.41280851, 0.0000]]))
40 | assert quaternion_equality(rot, torch.tensor([[0.95521418, 0.0000, 0.0000, 0.2959153]]))
41 | print(tg)
42 | # TODO implement and test inverse kinematics
43 | # th2 = chain.inverse_kinematics(tg)
44 | # self.assertTrue(np.allclose(th1, th2, atol=1.0e-6))
45 | # test batch kinematics
46 | N = 20
47 | th_batch = torch.rand(N, 2)
48 | tg_batch = chain.forward_kinematics(th_batch)
49 | m = tg_batch.get_matrix()
50 | for i in range(N):
51 | tg = chain.forward_kinematics(th_batch[i])
52 | assert torch.allclose(tg.get_matrix().view(4, 4), m[i])
53 |
54 | # check that gradients are passed through
55 | th2 = torch.tensor([0.42553542, 0.17529176], requires_grad=True)
56 | tg = chain.forward_kinematics(th2)
57 | pos, rot = quat_pos_from_transform3d(tg)
58 | # note that since we are using existing operations we are not checking grad calculation correctness
59 | assert th2.grad is None
60 | pos.norm().backward()
61 | assert th2.grad is not None
62 |
63 |
64 | def test_urdf():
65 | chain = pk.build_serial_chain_from_urdf(open("kuka_iiwa.urdf").read(), "lbr_iiwa_link_7")
66 | print(chain)
67 | print(chain.get_joint_parameter_names())
68 | th = [0.0, -math.pi / 4.0, 0.0, math.pi / 2.0, 0.0, math.pi / 4.0, 0.0]
69 | ret = chain.forward_kinematics(th, end_only=False)
70 | tg = ret['lbr_iiwa_link_7']
71 | pos, rot = quat_pos_from_transform3d(tg)
72 | assert quaternion_equality(rot, torch.tensor([7.07106781e-01, 0, -7.07106781e-01, 0]))
73 | assert torch.allclose(pos, torch.tensor([-6.60827561e-01, 0, 3.74142136e-01]))
74 |
75 | N = 1000
76 | d = "cuda" if torch.cuda.is_available() else "cpu"
77 | dtype = torch.float64
78 |
79 | th_batch = torch.rand(N, len(chain.get_joint_parameter_names()), dtype=dtype, device=d)
80 | chain = chain.to(dtype=dtype, device=d)
81 |
82 | import time
83 | start = time.time()
84 | tg_batch = chain.forward_kinematics(th_batch)
85 | m = tg_batch.get_matrix()
86 | elapsed = time.time() - start
87 | print("elapsed {}s for N={} when parallel".format(elapsed, N))
88 |
89 | start = time.time()
90 | elapsed = 0
91 | for i in range(N):
92 | tg = chain.forward_kinematics(th_batch[i])
93 | elapsed += time.time() - start
94 | start = time.time()
95 | assert torch.allclose(tg.get_matrix().view(4, 4), m[i])
96 | print("elapsed {}s for N={} when serial".format(elapsed, N))
97 |
98 |
99 | # test robot with prismatic and fixed joints
100 | def test_fk_simple_arm():
101 | chain = pk.build_chain_from_sdf(open("simple_arm.sdf").read())
102 | # print(chain)
103 | # print(chain.get_joint_parameter_names())
104 | ret = chain.forward_kinematics({'arm_elbow_pan_joint': math.pi / 2.0, 'arm_wrist_lift_joint': -0.5})
105 | tg = ret['arm_wrist_roll']
106 | pos, rot = quat_pos_from_transform3d(tg)
107 | assert quaternion_equality(rot, torch.tensor([0.70710678, 0., 0., 0.70710678]))
108 | assert torch.allclose(pos, torch.tensor([1.05, 0.55, 0.5]))
109 |
110 | N = 100
111 | ret = chain.forward_kinematics({'arm_elbow_pan_joint': torch.rand(N, 1), 'arm_wrist_lift_joint': torch.rand(N, 1)})
112 | tg = ret['arm_wrist_roll']
113 | assert list(tg.get_matrix().shape) == [N, 4, 4]
114 |
115 |
116 | def test_cuda():
117 | if torch.cuda.is_available():
118 | d = "cuda"
119 | dtype = torch.float64
120 | chain = pk.build_chain_from_sdf(open("simple_arm.sdf").read())
121 | chain = chain.to(dtype=dtype, device=d)
122 |
123 | ret = chain.forward_kinematics({'arm_elbow_pan_joint': math.pi / 2.0, 'arm_wrist_lift_joint': -0.5})
124 | tg = ret['arm_wrist_roll']
125 | pos, rot = quat_pos_from_transform3d(tg)
126 | assert quaternion_equality(rot, torch.tensor([0.70710678, 0., 0., 0.70710678], dtype=dtype, device=d))
127 | assert torch.allclose(pos, torch.tensor([1.05, 0.55, 0.5], dtype=dtype, device=d))
128 |
129 | data = '' \
130 | '' \
131 | '' \
132 | '' \
133 | '' \
134 | '' \
135 | '' \
136 | '' \
137 | '' \
138 | '' \
139 | '' \
140 | '' \
141 | '' \
142 | '' \
143 | ''
144 | chain = pk.build_serial_chain_from_urdf(data, 'link3')
145 | chain = chain.to(dtype=dtype, device=d)
146 | N = 20
147 | th_batch = torch.rand(N, 2).to(device=d, dtype=dtype)
148 | tg_batch = chain.forward_kinematics(th_batch)
149 | m = tg_batch.get_matrix()
150 | for i in range(N):
151 | tg = chain.forward_kinematics(th_batch[i])
152 | assert torch.allclose(tg.get_matrix().view(4, 4), m[i])
153 |
154 |
155 | # test more complex robot and the MJCF parser
156 | def test_fk_mjcf():
157 | chain = pk.build_chain_from_mjcf(open("ant.xml").read())
158 | print(chain)
159 | print(chain.get_joint_parameter_names())
160 | th = {'hip_1': 1.0, 'ankle_1': 1}
161 | ret = chain.forward_kinematics(th)
162 | tg = ret['aux_1_child']
163 | pos, rot = quat_pos_from_transform3d(tg)
164 | assert quaternion_equality(rot, torch.tensor([0.87758256, 0., 0., 0.47942554]))
165 | assert torch.allclose(pos, torch.tensor([0.2, 0.2, 0.75]))
166 | tg = ret['front_left_foot_child']
167 | pos, rot = quat_pos_from_transform3d(tg)
168 | assert quaternion_equality(rot, torch.tensor([0.77015115, -0.4600326, 0.13497724, 0.42073549]))
169 | assert torch.allclose(pos, torch.tensor([0.13976626, 0.47635466, 0.75]))
170 | print(ret)
171 |
172 |
173 | def test_fk_mjcf_humanoid():
174 | chain = pk.build_chain_from_mjcf(open("humanoid.xml").read())
175 | print(chain)
176 | print(chain.get_joint_parameter_names())
177 | th = {'left_knee': 0.0, 'right_knee': 0.0}
178 | ret = chain.forward_kinematics(th)
179 | print(ret)
180 |
181 |
182 | if __name__ == "__main__":
183 | test_fkik()
184 | test_fk_simple_arm()
185 | test_fk_mjcf()
186 | test_cuda()
187 | test_urdf()
188 | # test_fk_mjcf_humanoid()
189 |
--------------------------------------------------------------------------------
/thirdparty/pytorch_kinematics/tests/test_transform.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import pytorch_kinematics.transforms as tf
3 |
4 |
5 | def test_transform():
6 | N = 20
7 | mats = tf.random_rotations(N, dtype=torch.float64, device="cpu", requires_grad=True)
8 | assert list(mats.shape) == [N, 3, 3]
9 | # test batch conversions
10 | quat = tf.matrix_to_quaternion(mats)
11 | assert list(quat.shape) == [N, 4]
12 | mats_recovered = tf.quaternion_to_matrix(quat)
13 | assert torch.allclose(mats, mats_recovered)
14 |
15 | quat_identity = tf.quaternion_multiply(quat, tf.quaternion_invert(quat))
16 | assert torch.allclose(tf.quaternion_to_matrix(quat_identity), torch.eye(3, dtype=torch.float64).repeat(N, 1, 1))
17 |
18 |
19 | def test_translations():
20 | t = tf.Translate(1, 2, 3)
21 | points = torch.tensor([[1.0, 0.0, 0.0], [0.0, 1.0, 0.0], [0.5, 0.5, 0.0]]).view(
22 | 1, 3, 3
23 | )
24 | points_out = t.transform_points(points)
25 | points_out_expected = torch.tensor(
26 | [[2.0, 2.0, 3.0], [1.0, 3.0, 3.0], [1.5, 2.5, 3.0]]
27 | ).view(1, 3, 3)
28 | assert torch.allclose(points_out, points_out_expected)
29 |
30 | N = 20
31 | points = torch.randn((N, N, 3))
32 | translation = torch.randn((N, 3))
33 | transforms = tf.Transform3d(pos=translation)
34 | translated_points = transforms.transform_points(points)
35 | assert torch.allclose(translated_points, translation.repeat(N, 1, 1).transpose(0, 1) + points)
36 | returned_points = transforms.inverse().transform_points(translated_points)
37 | assert torch.allclose(returned_points, points, atol=1e-6)
38 |
39 |
40 | def test_rotate_axis_angle():
41 | t = tf.Transform3d().rotate_axis_angle(90.0, axis="Z")
42 | points = torch.tensor([[0.0, 0.0, 0.0], [0.0, 1.0, 0.0], [0.0, 1.0, 1.0]]).view(
43 | 1, 3, 3
44 | )
45 | normals = torch.tensor(
46 | [[1.0, 0.0, 0.0], [1.0, 0.0, 0.0], [1.0, 0.0, 0.0]]
47 | ).view(1, 3, 3)
48 | points_out = t.transform_points(points)
49 | normals_out = t.transform_normals(normals)
50 | points_out_expected = torch.tensor(
51 | [[0.0, 0.0, 0.0], [-1.0, 0.0, 0.0], [-1.0, 0.0, 1.0]]
52 | ).view(1, 3, 3)
53 | normals_out_expected = torch.tensor(
54 | [[0.0, 1.0, 0.0], [0.0, 1.0, 0.0], [0.0, 1.0, 0.0]]
55 | ).view(1, 3, 3)
56 | assert torch.allclose(points_out, points_out_expected)
57 | assert torch.allclose(normals_out, normals_out_expected)
58 |
59 |
60 | def test_rotate():
61 | R = tf.so3_exp_map(torch.randn((1, 3)))
62 | t = tf.Transform3d().rotate(R)
63 | points = torch.tensor([[1.0, 0.0, 0.0], [0.0, 1.0, 0.0], [0.5, 0.5, 0.0]]).view(
64 | 1, 3, 3
65 | )
66 | normals = torch.tensor(
67 | [[1.0, 0.0, 0.0], [0.0, 1.0, 0.0], [1.0, 1.0, 0.0]]
68 | ).view(1, 3, 3)
69 | points_out = t.transform_points(points)
70 | normals_out = t.transform_normals(normals)
71 | points_out_expected = torch.bmm(points, R.transpose(-1, -2))
72 | normals_out_expected = torch.bmm(normals, R.transpose(-1, -2))
73 | assert torch.allclose(points_out, points_out_expected)
74 | assert torch.allclose(normals_out, normals_out_expected)
75 | for i in range(3):
76 | assert torch.allclose(points_out[0, i], R @ points[0, i])
77 | assert torch.allclose(normals_out[0, i], R @ normals[0, i])
78 |
79 |
80 | def test_transform_combined():
81 | R = tf.so3_exp_map(torch.randn((1, 3)))
82 | tr = torch.randn((1, 3))
83 | t = tf.Transform3d(rot=R, pos=tr)
84 | N = 10
85 | points = torch.randn((N, 3))
86 | normals = torch.randn((N, 3))
87 | points_out = t.transform_points(points)
88 | normals_out = t.transform_normals(normals)
89 | for i in range(N):
90 | assert torch.allclose(points_out[i], R @ points[i] + tr)
91 | assert torch.allclose(normals_out[i], R @ normals[i])
92 |
93 |
94 | def test_euler():
95 | euler_angles = torch.tensor([1, 0, 0.5])
96 | t = tf.Transform3d(rot=euler_angles)
97 | sxyz_matrix = torch.tensor([[0.87758256, -0.47942554, 0., 0., ],
98 | [0.25903472, 0.47415988, -0.84147098, 0.],
99 | [0.40342268, 0.73846026, 0.54030231, 0.],
100 | [0., 0., 0., 1.]])
101 | # from tf.transformations import euler_matrix
102 | # print(euler_matrix(*euler_angles, "rxyz"))
103 | # print(t.get_matrix())
104 | assert torch.allclose(sxyz_matrix, t.get_matrix())
105 |
106 |
107 | def test_quaternions():
108 | n = 10
109 | q = tf.random_quaternions(n)
110 | q_tf = tf.wxyz_to_xyzw(q)
111 | assert torch.allclose(q, tf.xyzw_to_wxyz(q_tf))
112 |
113 |
114 | if __name__ == "__main__":
115 | test_transform()
116 | test_translations()
117 | test_rotate_axis_angle()
118 | test_rotate()
119 | test_euler()
120 | test_quaternions()
121 |
--------------------------------------------------------------------------------
/utils/__init__.py:
--------------------------------------------------------------------------------
1 | from .config_utils import EasyConfig
2 |
--------------------------------------------------------------------------------
/utils/config_utils.py:
--------------------------------------------------------------------------------
1 | import hashlib
2 | import json
3 | import os
4 | from ast import literal_eval
5 | from typing import Any, Dict, List, Tuple, Union
6 | from multimethod import multimethod
7 | import yaml
8 |
9 |
10 | class EasyConfig(dict):
11 |
12 | def __getattr__(self, key: str) -> Any:
13 | if key not in self:
14 | raise AttributeError(key)
15 | return self[key]
16 |
17 | def __setattr__(self, key: str, value: Any) -> None:
18 | self[key] = value
19 |
20 | def __delattr__(self, key: str) -> None:
21 | del self[key]
22 |
23 | def load(self, fpath: str, *, recursive: bool = False) -> None:
24 | """load cfg from yaml
25 |
26 | Args:
27 | fpath (str): path to the yaml file
28 | recursive (bool, optional): recursily load its parent defaul yaml files. Defaults to False.
29 | """
30 | if not os.path.exists(fpath):
31 | raise FileNotFoundError(fpath)
32 | fpaths = [fpath]
33 | if recursive:
34 | extension = os.path.splitext(fpath)[1]
35 | while os.path.dirname(fpath) != fpath:
36 | fpath = os.path.dirname(fpath)
37 | fpaths.append(os.path.join(fpath, 'default' + extension))
38 | for fpath in reversed(fpaths):
39 | if os.path.exists(fpath):
40 | with open(fpath) as f:
41 | cfg_dict = yaml.safe_load(f)
42 | self.update(cfg_dict)
43 |
44 | def reload(self, fpath: str, *, recursive: bool = False) -> None:
45 | self.clear()
46 | self.load(fpath, recursive=recursive)
47 |
48 | # mutimethod makes python supports function overloading
49 | @multimethod
50 | def update(self, other: Dict) -> None:
51 | for key, value in other.items():
52 | if isinstance(value, dict):
53 | if key not in self or not isinstance(self[key], EasyConfig):
54 | self[key] = EasyConfig()
55 | # recursively update
56 | self[key].update(value)
57 | else:
58 | self[key] = value
59 |
60 | @multimethod
61 | def update(self, opts: Union[List, Tuple]) -> None:
62 | index = 0
63 | while index < len(opts):
64 | opt = opts[index]
65 | if opt.startswith('--'):
66 | opt = opt[2:]
67 | if '=' in opt:
68 | key, value = opt.split('=', 1)
69 | index += 1
70 | else:
71 | key, value = opt, opts[index + 1]
72 | index += 2
73 | current = self
74 | subkeys = key.split('.')
75 | try:
76 | value = literal_eval(value)
77 | except:
78 | pass
79 | for subkey in subkeys[:-1]:
80 | current = current.setdefault(subkey, EasyConfig())
81 | current[subkeys[-1]] = value
82 |
83 | def dict(self) -> Dict[str, Any]:
84 | configs = dict()
85 | for key, value in self.items():
86 | if isinstance(value, EasyConfig):
87 | value = value.dict()
88 | configs[key] = value
89 | return configs
90 |
91 | def hash(self) -> str:
92 | buffer = json.dumps(self.dict(), sort_keys=True)
93 | return hashlib.sha256(buffer.encode()).hexdigest()
94 |
95 | def __str__(self) -> str:
96 | texts = []
97 | for key, value in self.items():
98 | if isinstance(value, EasyConfig):
99 | seperator = '\n'
100 | else:
101 | seperator = ' '
102 | text = key + ':' + seperator + str(value)
103 | lines = text.split('\n')
104 | for k, line in enumerate(lines[1:]):
105 | lines[k + 1] = (' ' * 2) + line
106 | texts.extend(lines)
107 | return '\n'.join(texts)
108 |
--------------------------------------------------------------------------------
/utils/rotation_utils.py:
--------------------------------------------------------------------------------
1 | import math
2 | import torch
3 | import torch.nn.functional as F
4 | import pytorch3d.transforms as T
5 | from torch.functional import Tensor
6 |
7 |
8 | class EulerConverter:
9 | """
10 | A class for converting euler angles with axes = 'sxyz' (as defined in transforms3d)
11 | to other rotation representations.
12 |
13 | Support batch operations.
14 |
15 | Expect tensor of shape (..., 3) as input.
16 |
17 | All types of outputs can be transformed to rotation matrices, which
18 | are identical to the results of transforms3d.euler.euler2mat(euler, axes='sxyz'),
19 | by functions like pytorch3d.transforms.XXX_to_matrix().
20 | """
21 |
22 | def to_euler(self, euler):
23 | return euler
24 |
25 | def to_matrix(self, euler):
26 | return T.axis_angle_to_matrix(
27 | self.to_axisangle(euler)
28 | )
29 |
30 | def to_rotation_6d(self, euler):
31 | return T.matrix_to_rotation_6d(
32 | self.to_matrix(euler),
33 | )
34 |
35 | def to_quaternion(self, euler):
36 | return T.axis_angle_to_quaternion(
37 | self.to_axisangle(euler)
38 | )
39 |
40 | def to_axisangle(self, euler):
41 | return torch.flip(
42 | T.matrix_to_axis_angle(T.euler_angles_to_matrix(euler, "ZYX")),
43 | dims=[-1]
44 | )
45 |
46 |
47 | class RotNorm:
48 | """
49 | A class for normalizing rotation representations
50 | """
51 | @staticmethod
52 | def norm_euler(euler: Tensor) -> Tensor:
53 | """
54 | euler: A tensor of size: (B, 3, N)
55 | """
56 | lower_bounds = torch.ones_like(euler) * math.pi * -1.0
57 | upper_bounds = torch.ones_like(euler) * math.pi
58 | return (euler - lower_bounds) / (upper_bounds - lower_bounds)
59 |
60 | @staticmethod
61 | def norm_quaternion(quaternion: Tensor) -> Tensor:
62 | """
63 | quaternion: A tensor of size: (B, 4, N)
64 | """
65 | return F.normalize(quaternion)
66 |
67 | @staticmethod
68 | def norm_rotation_6d(rot6d: Tensor) -> Tensor:
69 | """
70 | rot6d: A tensor of size: (B, 6, N)
71 | """
72 | vector_1 = F.normalize(rot6d[:, :3, :])
73 | vector_2 = F.normalize(rot6d[:, 3:6, :])
74 | return torch.cat([vector_1, vector_2], dim=1)
75 |
76 | def norm_other(tensor) -> Tensor:
77 | return tensor
78 |
79 |
80 | class Rot2Axisangle:
81 | """
82 | A class for converting rotation representations to axisangle
83 | """
84 | @staticmethod
85 | def euler2axisangle(euler):
86 | return torch.flip(
87 | T.matrix_to_axis_angle(T.euler_angles_to_matrix(euler, "ZYX")),
88 | dims=[-1]
89 | )
90 |
91 | @staticmethod
92 | def quaternion2axisangle(quaternion):
93 | return T.quaternion_to_axis_angle(quaternion)
94 |
95 | @staticmethod
96 | def rotation_6d2axisangle(rot6d):
97 | B, N = rot6d.shape[:2]
98 | mat = robust_compute_rotation_matrix_from_ortho6d(rot6d.reshape(B * N, 6))
99 | return T.matrix_to_axis_angle(mat.reshape(B, N, 3, 3))
100 |
101 | @staticmethod
102 | def matrix2axisangle(mat):
103 | return T.matrix_to_axis_angle(mat)
104 |
105 | @staticmethod
106 | def axisangle2axisangle(axisangle):
107 | return axisangle
108 |
109 |
110 | # Codes borrowed from dexgraspnet
111 | def robust_compute_rotation_matrix_from_ortho6d(poses):
112 | """
113 | Instead of making 2nd vector orthogonal to first
114 | create a base that takes into account the two predicted
115 | directions equally
116 | """
117 | x_raw = poses[:, 0:3] # batch*3
118 | y_raw = poses[:, 3:6] # batch*3
119 |
120 | x = normalize_vector(x_raw) # batch*3
121 | y = normalize_vector(y_raw) # batch*3
122 | middle = normalize_vector(x + y)
123 | orthmid = normalize_vector(x - y)
124 | x = normalize_vector(middle + orthmid)
125 | y = normalize_vector(middle - orthmid)
126 | # Their scalar product should be small !
127 | # assert torch.einsum("ij,ij->i", [x, y]).abs().max() < 0.00001
128 | z = normalize_vector(cross_product(x, y))
129 |
130 | x = x.view(-1, 3, 1)
131 | y = y.view(-1, 3, 1)
132 | z = z.view(-1, 3, 1)
133 | matrix = torch.cat((x, y, z), 2) # batch*3*3
134 | # Check for reflection in matrix ! If found, flip last vector TODO
135 | # assert (torch.stack([torch.det(mat) for mat in matrix ])< 0).sum() == 0
136 | return matrix
137 |
138 |
139 | def normalize_vector(v):
140 | batch = v.shape[0]
141 | v_mag = torch.sqrt(v.pow(2).sum(1)) # batch
142 | v_mag = torch.max(v_mag, v.new([1e-8]))
143 | v_mag = v_mag.view(batch, 1).expand(batch, v.shape[1])
144 | v = v/v_mag
145 | return v
146 |
147 |
148 | def cross_product(u, v):
149 | batch = u.shape[0]
150 | i = u[:, 1] * v[:, 2] - u[:, 2] * v[:, 1]
151 | j = u[:, 2] * v[:, 0] - u[:, 0] * v[:, 2]
152 | k = u[:, 0] * v[:, 1] - u[:, 1] * v[:, 0]
153 |
154 | out = torch.cat((i.view(batch, 1), j.view(batch, 1), k.view(batch, 1)), 1)
155 |
156 | return out
157 |
--------------------------------------------------------------------------------