├── .gitignore
├── AI
├── 使用 GPT-4、Python 和 Langchain,构建日语汉字抽认卡应用程序.md
└── 构建一个 AI 工具来即时总结书籍.md
├── Functional Programming
├── README.md
├── 了解函数式编程背后的属性:单子(Monad).md
└── 函数式编程:概念,惯用语和理念.md
├── Hardware
├── README.md
├── 使用Python构建一个(半)自动无人机.md
├── 旅程中带着Ipad Pro和Raspberry Pi备份照片.md
├── 用Python玩转Worcester Wave恒温器-第一部分.md
├── 用Python玩转Worcester Wave恒温器-第三部分.md
└── 用Python玩转Worcester Wave恒温器-第二部分.md
├── Image Processing
├── README.md
└── 压缩和增强手写笔记.md
├── Machine Learning
├── Python,机器学习和语言之争.md
├── README.md
├── 使用 Python,将分析数据速度提高 170,000 倍.md
├── 使用非常少的数据构建强大的图像分类模型.md
├── 使用预测算法追踪实时健康趋势.md
├── 在有限预算上计算最佳公路旅行.md
└── 对超过1M的酒店点评进行机器学习,发现有趣的见解.md
├── NLP
├── 003构建一个播客推荐算法.md
└── README.md
├── Others
├── Python lambda的源代码.md
├── Python, GIL, 和Pyston.md
├── Python中Meta类习语的起源.md
├── Python依赖关系分析.md
├── Python反射(reflection):如何列举模块并且检查函数.md
├── Python项目中的Makefiles.md
├── README.md
├── RPython的魔力.md
├── Requests vs. urllib:它解决了什么问题?.md
├── psutil 4.0.0以及如何获得Python中“真正的”进程内存和环境.md
├── 一个模板引擎是如何工作的?.md
├── 中断两个循环.md
├── 为什么用python重写shell-script.org
├── 为何我选择python,python擅长什么,python的特点是什么.org
├── 为部署Python web应用程序构建一个更好的用户体验.md
├── 你需要学习编写Python装饰器的五大理由.md
├── 使用Python Newspaper构建Read It Later应用.md
├── 使用Python和Excel进行交互式数据分析.md
├── 使用gdb调试CPython进程.md
├── 使用str.encode和threads冻结你的Python.md
├── 使用列表推导式实现zip.md
├── 使用图像特征的库存图像相似性(程序是如何比我更时尚的).md
├── 创造你自己的类IPython服务器.md
├── 在Python中导入一个Docker容器.md
├── 在Python中进行防御性编程.md
├── 复合构建器模式(Composite Builder Pattern),一个声明式编程的例子.md
├── 好吧,你发布了一个损坏的包到PyPI上。那么你现在要怎么办?.md
├── 如何在Python中使用Twilio Lookup API验证电话号码.md
├── 如何在Python中创建绿噪音.md
├── 婚礼规模:我是如何使用Twilio, Python和Google来自动化我的婚礼的.md
├── 实用Python:EAFP VS. LBYL.md
├── 将Python用于地理空间数据处理.md
├── 我是如何构建一个Slack机器人来帮助我在San Francisco找房子的.md
├── 我的自动化之旅:为人民服务的自动化.md
├── 教程:手把手教你构建一个基本的Facebook聊天机器人.md
├── 更好的Python对象序列化方法.md
├── 解释扇出模式(Fanout Pattern).md
├── 记录每天数以百万计的请求以及需要采取哪些措施.md
├── 设计Pythonic API.md
└── 逆向工程我的酒店中的一个神秘的UDP流.md
├── Python Common
├── 2016年的Python 3.md
├── 3.5.1
│ ├── README.md
│ ├── faq
│ │ ├── README.md
│ │ ├── 库及扩展类 FAQ.md
│ │ ├── 扩展或嵌入类 FAQ.md
│ │ ├── 编程类FAQ.md
│ │ └── 设计和历史类 FAQ.md
│ └── glossary.md
├── Lists和Tuples大对决.md
├── Python 201 – 什么是双端队列(deque).md
├── Python 2和3中的异常泄漏.md
├── Python 3.5中async和await怎么会工作呢?.md
├── Python async-await教程.md
├── Python 版本间的主要变动的总结.md
├── Python 陷阱:Join vs Concat.md
├── Python 陷阱:比较.md
├── Python中的assert语句.md
├── Python中的lambda表达式.md
├── Python新增的secrets模块.md
├── Python:声明动态属性.md
├── README.md
├── What's New in Python xx
│ ├── New In Python:变量注解语法.md
│ ├── New in Python:数字字面量中的下划线.md
│ ├── Python 3.6.md
│ └── README.md
├── base64-使用ASCII编码二进制数据.md
├── hasattr()是有害的.md
├── img
│ └── 2016-02-20_221149.PNG
├── python37-gil-change.md
├── 不可不知的一点Python陷阱.md
├── 为什么 Python 代码在函数中运行得更快?.md
├── 为什么存在Python 3.md
├── 了解Python类实例化.md
├── 什么是stackless.md
├── 合并Python中的字典的惯用方法.md
├── 在Python 3中比较类型.md
├── 如何创建记录异常日志的装饰器.org
├── 如何将Python 3置于管理中.md
├── 异常 - 原力的黑暗面.md
├── 惯用Python:布尔表达式.md
├── 惯用Python:推导.md
├── 描述器:Python中属性访问背后的魔法.md
├── 深度探索Python:让我们审查dict模块.md
├── 现实中的 match_case.md
├── 解释python中的args和kwargs.md
├── 让python脚本支持bash补全.org
├── 随机性的多种用途.org
└── 高级asyncio测试.md
├── Python Weekly
├── Python_Weekly_Issue_243.md
├── Python_Weekly_Issue_244.md
├── Python_Weekly_Issue_245.md
├── Python_Weekly_Issue_246.md
├── Python_Weekly_Issue_247.md
├── Python_Weekly_Issue_248.md
├── Python_Weekly_Issue_249.md
├── Python_Weekly_Issue_250.md
├── Python_Weekly_Issue_251.md
├── Python_Weekly_Issue_252.md
├── Python_Weekly_Issue_253.md
├── Python_Weekly_Issue_254.md
├── Python_Weekly_Issue_255.md
├── Python_Weekly_Issue_256.md
├── Python_Weekly_Issue_257.md
├── Python_Weekly_Issue_258.md
├── Python_Weekly_Issue_259.md
├── Python_Weekly_Issue_260.md
├── Python_Weekly_Issue_261.md
├── Python_Weekly_Issue_262.md
├── Python_Weekly_Issue_263.md
├── Python_Weekly_Issue_264.md
├── Python_Weekly_Issue_265.md
├── Python_Weekly_Issue_266.md
├── Python_Weekly_Issue_267.md
├── Python_Weekly_Issue_268.md
├── Python_Weekly_Issue_269.md
├── Python_Weekly_Issue_270.md
├── Python_Weekly_Issue_271.md
├── Python_Weekly_Issue_272.md
├── Python_Weekly_Issue_273.md
├── Python_Weekly_Issue_274.md
├── Python_Weekly_Issue_275.md
├── Python_Weekly_Issue_276.md
├── Python_Weekly_Issue_277.md
├── Python_Weekly_Issue_278.md
├── Python_Weekly_Issue_279.md
├── Python_Weekly_Issue_280.md
├── Python_Weekly_Issue_281.md
├── Python_Weekly_Issue_282.md
├── Python_Weekly_Issue_283.md
├── Python_Weekly_Issue_284.md
├── Python_Weekly_Issue_285.md
├── Python_Weekly_Issue_286.md
├── Python_Weekly_Issue_287.md
├── Python_Weekly_Issue_288.md
├── Python_Weekly_Issue_289.md
├── Python_Weekly_Issue_290.md
├── Python_Weekly_Issue_291.md
├── Python_Weekly_Issue_292.md
├── Python_Weekly_Issue_293.md
├── Python_Weekly_Issue_294.md
├── Python_Weekly_Issue_295.md
├── Python_Weekly_Issue_296.md
├── Python_Weekly_Issue_297.md
├── Python_Weekly_Issue_297 .md
├── Python_Weekly_Issue_298.md
├── Python_Weekly_Issue_299.md
├── Python_Weekly_Issue_300.md
├── Python_Weekly_Issue_301 .md
├── Python_Weekly_Issue_302.md
├── Python_Weekly_Issue_303.md
├── Python_Weekly_Issue_304.md
├── Python_Weekly_Issue_305.md
├── Python_Weekly_Issue_306.md
├── Python_Weekly_Issue_307.md
├── Python_Weekly_Issue_308.md
├── Python_Weekly_Issue_309.md
├── Python_Weekly_Issue_310.md
├── Python_Weekly_Issue_311.md
├── Python_Weekly_Issue_312.md
├── Python_Weekly_Issue_313.md
├── Python_Weekly_Issue_314.md
├── Python_Weekly_Issue_315.md
├── Python_Weekly_Issue_316.md
├── Python_Weekly_Issue_317.md
├── Python_Weekly_Issue_318.md
├── Python_Weekly_Issue_319.md
├── Python_Weekly_Issue_320.md
├── Python_Weekly_Issue_321.md
├── Python_Weekly_Issue_322.md
├── Python_Weekly_Issue_323.md
├── Python_Weekly_Issue_324.md
├── Python_Weekly_Issue_325.md
├── Python_Weekly_Issue_326.md
├── Python_Weekly_Issue_327.md
├── Python_Weekly_Issue_328.md
├── Python_Weekly_Issue_329.md
├── Python_Weekly_Issue_330.md
├── Python_Weekly_Issue_331.md
├── Python_Weekly_Issue_332.md
├── Python_Weekly_Issue_333.md
├── Python_Weekly_Issue_334.md
├── Python_Weekly_Issue_335.md
├── Python_Weekly_Issue_336.md
├── Python_Weekly_Issue_337.md
├── Python_Weekly_Issue_338.md
├── Python_Weekly_Issue_339.md
├── Python_Weekly_Issue_340.md
├── Python_Weekly_Issue_341.md
├── Python_Weekly_Issue_342.md
├── Python_Weekly_Issue_343.md
├── Python_Weekly_Issue_344.md
├── Python_Weekly_Issue_345.md
├── Python_Weekly_Issue_346.md
├── Python_Weekly_Issue_347.md
├── Python_Weekly_Issue_348.md
├── Python_Weekly_Issue_349.md
├── Python_Weekly_Issue_350.md
├── Python_Weekly_Issue_351.md
├── Python_Weekly_Issue_352.md
├── Python_Weekly_Issue_353.md
├── Python_Weekly_Issue_354.md
├── Python_Weekly_Issue_355.md
├── Python_Weekly_Issue_356.md
├── Python_Weekly_Issue_357.md
├── Python_Weekly_Issue_358.md
├── Python_Weekly_Issue_359.md
├── Python_Weekly_Issue_360.md
├── Python_Weekly_Issue_361.md
├── Python_Weekly_Issue_362.md
├── Python_Weekly_Issue_363.md
├── Python_Weekly_Issue_364.md
├── Python_Weekly_Issue_365.md
├── Python_Weekly_Issue_374.md
├── Python_Weekly_Issue_375.md
├── Python_Weekly_Issue_376.md
├── Python_Weekly_Issue_377.md
├── Python_Weekly_Issue_378.md
├── Python_Weekly_Issue_379.md
├── Python_Weekly_Issue_380.md
├── Python_Weekly_Issue_381.md
├── Python_Weekly_Issue_383.md
├── Python_Weekly_Issue_384.md
├── Python_Weekly_Issue_385.md
├── Python_Weekly_Issue_386.md
├── Python_Weekly_Issue_617.md
├── Python_Weekly_Issue_618.md
├── Python_Weekly_Issue_619.md
├── Python_Weekly_Issue_620.md
├── Python_Weekly_Issue_621.md
├── Python_Weekly_Issue_622.md
├── Python_Weekly_Issue_623.md
├── Python_Weekly_Issue_624.md
├── Python_Weekly_Issue_625.md
├── Python_Weekly_Issue_626.md
├── Python_Weekly_Issue_627.md
├── Python_Weekly_Issue_628.md
├── Python_Weekly_Issue_629.md
├── Python_Weekly_Issue_630.md
├── Python_Weekly_Issue_631.md
├── Python_Weekly_Issue_632.md
├── Python_Weekly_Issue_633.md
├── Python_Weekly_Issue_634.md
├── Python_Weekly_Issue_635.md
├── Python_Weekly_Issue_636.md
├── Python_Weekly_Issue_637.md
├── Python_Weekly_Issue_638.md
├── Python_Weekly_Issue_639.md
├── Python_Weekly_Issue_640.md
├── Python_Weekly_Issue_641.md
├── Python_Weekly_Issue_642.md
├── Python_Weekly_Issue_643.md
├── Python_Weekly_Issue_644.md
├── Python_Weekly_Issue_645.md
├── Python_Weekly_Issue_646.md
├── Python_Weekly_Issue_647.md
├── Python_Weekly_Issue_648.md
├── Python_Weekly_Issue_649.md
├── Python_Weekly_Issue_650.md
└── README.md
├── README.md
├── SUMMARY.md
├── Science and Data Analysis
├── Matplotlib教程 - 绘制提到Trump, Clinton & Sanders的推特.md
├── News Headline Analysis.png
├── News Headline Analysis_2.png
├── Python中一个简单的基于内容的推荐引擎.md
├── Python中的并行处理.md
├── README.md
├── 使用BigQuery和TensorFlow进行需求预测.md
├── 使用Pandas, Docker和OS(R)M来猜测神秘的旅行地.md
├── 使用Python探索NFL选秀.md
├── 使用Python,分析23AndMe数据,获取遗传起源.md
├── 使用矩阵分解找到相似歌曲.md
├── 分析iPhone步数数据.md
├── 分析权力游戏图表.md
├── 在Python中实现你自己的推荐系统.md
├── 如何使用Python和Pandas处理大量的JSON数据集.md
├── 新闻标题分析.md
├── 用Python进行股票市场数据分析概述 (第一部分).md
└── 用于格式化和数据清理的便捷Python库.md
├── Scrapy
├── README.md
└── Scrapinghub的Scrapy技巧系列
│ ├── README.md
│ ├── Scrapy技巧:2016年七月版.md
│ ├── Scrapy技巧:2016年三月版.md
│ ├── Scrapy技巧:2016年五月版.md
│ ├── Scrapy技巧:2016年六月版.md
│ ├── Scrapy技巧:2016年四月版.md
│ └── 跟着高手学习Scrapy技巧:第一部分.md
├── Testing
├── Python Mock:简单介绍 —— 第一部分.md
├── README.md
├── 在Python中使用Behave来开始行为测试.md
└── 基于属性的测试,hypothesis以及查找bug.md
├── Web
├── Django
│ ├── 1.9
│ │ ├── README.md
│ │ ├── howto
│ │ │ ├── Managing static files (e.g. images, JavaScript, CSS).md
│ │ │ ├── 使用Django输出CSV.md
│ │ │ ├── 使用Django输出PDF.md
│ │ │ ├── 如何使用WSGI进行部署.md
│ │ │ └── 部署Django.md
│ │ ├── misc
│ │ │ └── 设计理念.md
│ │ ├── ref
│ │ │ └── 中间件.md
│ │ └── topics
│ │ │ ├── db
│ │ │ ├── 数据库访问优化.md
│ │ │ └── 模型.md
│ │ │ ├── forms
│ │ │ ├── Form Assets (the Media class).md
│ │ │ └── 使用表单.md
│ │ │ ├── http
│ │ │ ├── File Uploads.md
│ │ │ └── 中间件.md
│ │ │ ├── i18n
│ │ │ ├── 国际化和本地化.md
│ │ │ └── 翻译(转换).md
│ │ │ ├── testing
│ │ │ ├── 在Django中测试.md
│ │ │ └── 编写和运行测试.md
│ │ │ ├── 性能和优化概述.md
│ │ │ ├── 日志.md
│ │ │ ├── 模板.md
│ │ │ └── 设置.md
│ ├── Django Channels和Celery示例.md
│ ├── Django, ELB健康检查和持续交付.md
│ ├── Django中正确处理数据库并发的方法.md
│ ├── README.md
│ ├── 使用Django进行原型化.md
│ ├── 使用Kubernetes使Django应用变得可扩展并具有弹性.md
│ ├── 在Django中,如何为提高页面加载速度优化图像.md
│ ├── 如何扩展Django User模型.md
│ └── 带django教程的Facebook聊天机器人,又名笑话机器人.md
└── Flask
│ └── README.md
├── raw
├── An Introduction to Stock Market Data Analysis with Python (Part 2).md
├── An exploration of Texas Death Row data.md
├── Getting started with Raspberry Pi - Building a Digital Photo Frame.md
├── Page dewarping.md
├── Python Kafka Client Benchmarking.md
├── Static types in Python, oh my(py)!.md
├── Stupid Python Tricks Abusing Explicit Self.md
├── The Python Packaging Ecosystem.md
└── Visualizing relationships between python packages.md
├── 你该相信谁的评分?IMDB,烂番茄,Metacritic,还是Fandango?.md
└── 读书笔记
├── README.md
└── 流畅的 python
├── 1. Python 数据模型.md
├── 10.序列的修改、散列和切片.md
├── 11.接口:从协议到抽象基类.md
├── 12.继承的优缺点.md
├── 13.正确重载运算符.md
├── 14. 可叠戴的对象、迭代器和生成器.md
├── 15. 上下文管理器和 else 块.md
├── 16. 协程.md
├── 17. 使用期物处理并发.md
├── 18. 使用 asyncio 包处理并发.md
├── 19. 动态属性和特性.md
├── 2. 序列构成的数组.md
├── 20. 属性描述符.md
├── 21. 类元编程.md
├── 3. 字典和集合.md
├── 4. 文本和字节序列.md
├── 5.一等函数.md
├── 6.使用一等函数实现设计模式.md
├── 7.函数装饰器和闭包.md
├── 8.对象引用、可变性和垃圾回收.md
├── 9.符合 python 风格的对象.md
└── README.md
/.gitignore:
--------------------------------------------------------------------------------
1 | # Created by .ignore support plugin (hsz.mobi)
2 | ### Python template
3 | # Byte-compiled / optimized / DLL files
4 | __pycache__/
5 | *.py[cod]
6 | *$py.class
7 |
8 | # C extensions
9 | *.so
10 |
11 | # Distribution / packaging
12 | .Python
13 | build/
14 | develop-eggs/
15 | dist/
16 | downloads/
17 | eggs/
18 | .eggs/
19 | lib/
20 | lib64/
21 | parts/
22 | sdist/
23 | var/
24 | wheels/
25 | *.egg-info/
26 | .installed.cfg
27 | *.egg
28 |
29 | # PyInstaller
30 | # Usually these files are written by a python script from a template
31 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
32 | *.manifest
33 | *.spec
34 |
35 | # Installer logs
36 | pip-log.txt
37 | pip-delete-this-directory.txt
38 |
39 | # Unit test / coverage reports
40 | htmlcov/
41 | .tox/
42 | .coverage
43 | .coverage.*
44 | .cache
45 | nosetests.xml
46 | coverage.xml
47 | *.cover
48 | .hypothesis/
49 |
50 | # Translations
51 | *.mo
52 | *.pot
53 |
54 | # Django stuff:
55 | *.log
56 | local_settings.py
57 |
58 | # Flask stuff:
59 | instance/
60 | .webassets-cache
61 |
62 | # Scrapy stuff:
63 | .scrapy
64 |
65 | # Sphinx documentation
66 | docs/_build/
67 |
68 | # PyBuilder
69 | target/
70 |
71 | # Jupyter Notebook
72 | .ipynb_checkpoints
73 |
74 | # pyenv
75 | .python-version
76 |
77 | # celery beat schedule file
78 | celerybeat-schedule
79 |
80 | # SageMath parsed files
81 | *.sage.py
82 |
83 | # Environments
84 | .env
85 | .venv
86 | env/
87 | venv/
88 | ENV/
89 |
90 | # Spyder project settings
91 | .spyderproject
92 | .spyproject
93 |
94 | # Rope project settings
95 | .ropeproject
96 |
97 | # mkdocs documentation
98 | /site
99 |
100 | # mypy
101 | .mypy_cache/
102 |
103 | # customer
104 | .idea
105 | .idea/inspectionProfiles/Project_Default.xml
106 | .idea/vcs.xml
107 |
--------------------------------------------------------------------------------
/Functional Programming/README.md:
--------------------------------------------------------------------------------
1 | # Functional Programming
2 | 用Python进行函数式编程……
3 |
4 | ## 说明
5 |
6 | - Henry Kupty的函数式编程扫盲系列
7 | - [函数式编程:概念,惯用语和理念](./函数式编程:概念,惯用语和理念.md)
8 | 函数式编程概述
9 |
10 | - [了解函数式编程背后的属性:单子(Monad)](./了解函数式编程背后的属性:单子(Monad).md)
11 |
12 | 本文讲解了函数式编程中的单子,及其三大法则。
13 |
14 |
--------------------------------------------------------------------------------
/Hardware/README.md:
--------------------------------------------------------------------------------
1 | # Hardware
2 | 硬件相关,物联网,无人机等……
3 |
4 | ## 说明
5 |
6 | - 用Python玩转Worcester Wave恒温器
7 |
8 | * [第一部分](./用Python玩转Worcester Wave恒温器-第一部分.md)
9 |
10 | 智能家居盛行的现在,你也可以控制自己的家电。如果你的电器支持移动app控制,那么不知道如何踏出hack the life的第一步,可以看看这篇文章,或许你可以有一种新思路……
11 |
12 | * [第二部分](./用Python玩转Worcester Wave恒温器-第二部分.md)
13 |
14 | 紧接着第一部分,我们看看如何用starttls-mitm进行合法的中间人攻击以破解app和服务器之间加密的通信,看看如何使用反编译器反编译apk以获得消息中的信息加密算法以进行逆向,最终获得完整的明文交互信息……
15 |
16 | * [第三部分](./用Python玩转Worcester Wave恒温器-第三部分.md)
17 |
18 | 收尾章节。我们可以看到如何利用破解出来的信息达到实际的控制。并且,作者还在Github上分享了他的源代码!
19 |
20 | - [使用Python构建一个(半)自动无人机](./使用Python构建一个(半)自动无人机.md)
21 |
22 | 无人机盛行的当下,想看看如何用node.js和python对其进行编程,做一些好玩的事情吗?看看作者如何玩玩这一big toy吧!(搞得我也想玩了,但是无人机还是有点贵呢……)
23 |
24 | - [旅程中带着Ipad Pro和Raspberry Pi备份照片](./旅程中带着Ipad Pro和Raspberry Pi备份照片.md)
25 |
26 | 很久以来,Lenin都一直在寻求找到一个理想的旅行照片备份解决方法。然后他发现,Ipad Pro+Raspberry Pi是个不错的方案。
27 |
--------------------------------------------------------------------------------
/Hardware/用Python玩转Worcester Wave恒温器-第一部分.md:
--------------------------------------------------------------------------------
1 | 原文:[Hacking the Worcester Wave thermostat in Python – Part 1](http://blog.rtwilson.com/hacking-the-worcester-wave-thermostat-in-python-part-1/)
2 |
3 | ---
4 |
5 | 当我们去年买了一台新热水器时,我们决定安装“智能恒温”。目前,有很多可用的,包括Google Nest,Hive(来自英国电气),以及[Worcester Bosch ‘Wave’](https://www.worcester-bosch.co.uk/products/boiler-controls/wave)。由于我们已经有了一个Worcester Bosch热水器,所以我们获得了[Wave](https://www.worcester-bosch.co.uk/products/boiler-controls/wave) – 而它并不比一个标准的程序员/恒温器昂贵得多。
6 |
7 | 恒温器看起来是这样的:
8 |
9 | 
10 |
11 | 它挂在我们楼梯底部的墙壁上,并通过电缆连接到热水器。正如你所看到的,它有一个简单的触摸感应界面:可以增加或减少恒温器设置,查看当前温度和当前设置,将手动模式修改为编程模式,以及查看热水器是否打开。对于任何更高级的东西(例如设置可编程定时器),你可以使用移动应用,它看起来像这样:
12 |
13 | 
14 |
15 | 看起来很熟悉,不是吗?在应用“主屏幕”上拥有一样简单的界面,但你也可以配置更高级的设置,如定时程序:
16 |
17 | 
18 |
19 | 总体来说,我很满意Wave恒温器:相较于一个微小且繁琐控制器,在一个手机应用上配置定时器设置要容易得多,并有许多你可以使用的高级功能,(例如,“优化”,其中系统逐渐学习需要让你的房子热起来要多长时间,并在你想的时候,在正确的时间加热到你想要的温度) - 同时具有能够在离开家的时候控制加热的能力。
20 |
21 | 无论如何,当然,一旦安装好了,我查看的第一件事就是我的家庭服务器可以用来监控和控制恒温器的API,最好是通过一个Python脚本。不幸的是,在 Worcester Bosch的网站上,并没有关于API的信息,而当我打电话给客服时,他们告诉我,没有可用的API。所以,我想我会尝试逆向它已使用的协议,看看我是否能用一个Python接口来玩转它。
22 |
23 | ## 这个系统整体是如何工作的?
24 |
25 | 当开始调查它时,我对于系统的 先验理解是,该应用必须发送某种消息到远程服务器(可能由Bosch运行或控制),然后转发信息到恒温器本身,反之亦然。这是因为无论你在哪里,你都可以通过应用程序访问恒温器,而不必是在相同的无线网络上。无论使用何种协议或何种端口,它都必须能够可靠地通过家庭防火墙,使得远程服务器可以实际与恒温器进行通信。
26 |
27 | ## 他们使用了什么技术?
28 |
29 | 在调查应用时,我注意到有一个产品信息的屏幕显示,它显示了关于软件和硬件版本的信息,并且包含了一个标有 _Worcester Wave uses Open Source software_ 的按钮。它表明了该系统使用的一开源包列表,包括它们=各种许可协议。这个列表组成如下:
30 |
31 | * [AndroidPlot](http://androidplot.com/) – Android的一个绘图库
32 | * [Guava](https://github.com/google/guava) – 谷歌Java核心类库
33 | * [XMP Toolkit](http://sourceforge.net/adobe/adobexmp/home/Home/) – 扩展元数据平台
34 | * [Smack](http://www.igniterealtime.org/projects/smack/) – 一个Java XMPP(也叫Jabber)聊天协议的实现
35 | * [JSR305 Expert Group](https://code.google.com/p/jsr-305/) – Java中的注解软件缺陷检测
36 | * 朗讯科技 – _不知道,也找不到这一个!_
37 | * [Chromium](https://en.wikipedia.org/wiki/Chromium_(web_browser)) – _我不知道为什么使用了Chromium网络浏览器_
38 | * [Takayua OOURA](http://www.kurims.kyoto-u.ac.jp/~ooura/) – Ooura的数学软件
39 | * [Eigen software](https://github.com/hughperkins/jeigen) – 矩阵操作工具
40 | * [libresample](https://ccrma.stanford.edu/~jos/resample/Free_Resampling_Software.html) – 数据采样(主要是音频,但也推测其它数据类型)
41 |
42 | 所以,该名单显示,可扩展消息与存在协议([XMPP](https://en.wikipedia.org/wiki/XMPP))用于通信,可能与嵌入了一些扩展元数据平台的元数据。库的其余部分与我们的工作没有多大关系,但看起来挺有趣的(我怀疑数学部分用于进行一些高级功能,如优化,的数学运算)。
43 |
44 | ## 发送了什么,发送到那里?
45 |
46 | 所以,我们觉得使用XMPP进行通信 - 现在我们需要进行确认,并且找出发送了什么以及它被发送到哪里。所以,我打开了[Wireshark](https://www.wireshark.org/)以启动流量嗅探。在玩了一会过滤器后,我得到这个(点击以放大):
47 |
48 | 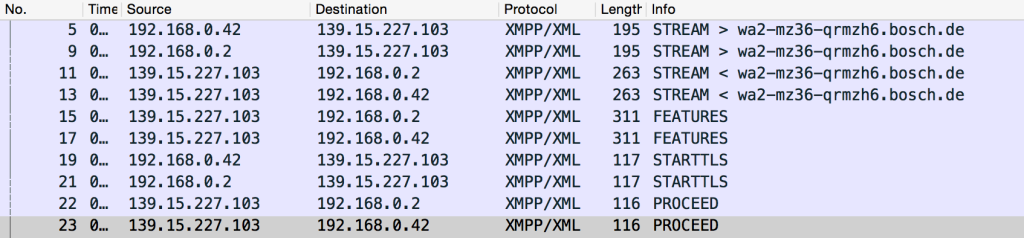
49 |
50 | 这表明,我的猜测是正确的:XMPP协议被用来在运行Wave Android应用的手机(本地网络上的`192.168.0.42`)和Bosch(`wa2-mz36-qrmzh6.bosch.de`)运行的服务器之间发送信息。所以,我们现在知道要处理的是什么协议了:这是个好消息。
51 |
52 | Anyway, in this case the Bosch server responds with `PROCEED` (“Yes, I’m happy to do this encrypted”). From that point onwards, we see the TLS security negotiation (“What sort of encryption do you support?”, “I support X, Y and Z”, “Ok, lets use Z”, “Here are my keys” etc) followed by a lot of ‘Application Data’ messages:然而,坏消息是我们在那里看到的`STARTTLS`消息。你可以从电子邮件配置对话框终意识到这一点,因为它是连接到POP3 / IMAP / SMTP服务器的安全选项之一。它代表着'开始传输层安全性“,并且基本上是跟你说:“我想从即日起对这个会话进行加密,可以吗?”的一种方式(供参考,另一种方法是从会话一开始就对所有进行加密)。无论如何,在这种情况下,Bosch服务器响应`PROCEED`(“是的,我很高兴进行这样的加密”)。从这一点开始,我们看到了伴随着大量的“应用程序数据”消息的TLS安全协商(“你支持什么样的加密?”,“我支持X,Y和Z”,“好吧,让我们用Z”,“这里是我的钥匙”等等):
53 |
54 | 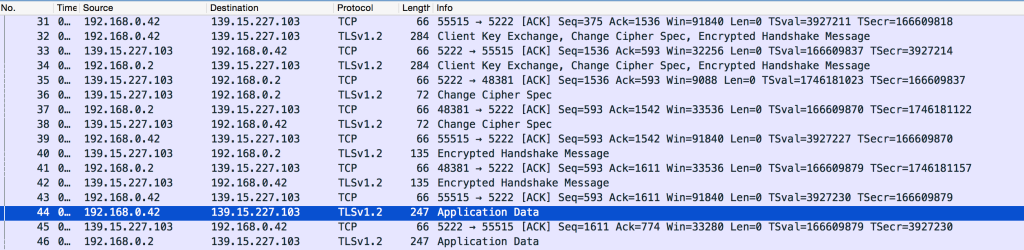
55 |
56 | 我们不能真正看到任何消息的内容,因为它们被加密了,所以我们得到的是原始的十六进制转储:`80414a90ca64968de3a0acc5eb1b50108bbc5b26973626daaa`….(以此类推). 不是很有用哦!
57 |
58 | 我认为这是完成故事的第一部分的一个好地方。我们已经得到了从应用程序到Bosch服务器的通信,它使用XMPP协议,但使用`STARTTLS`进行TLS加密,所以我们没能得到任何消息实际上包含的内容。接下来第2部分听听我如何设法读取消息...
59 |
60 | (译者:我已经迫不及待他的第二部分了~~)
61 |
--------------------------------------------------------------------------------
/Hardware/用Python玩转Worcester Wave恒温器-第三部分.md:
--------------------------------------------------------------------------------
1 | 原文:[Hacking the Worcester Wave thermostat in Python – Part 3](http://blog.rtwilson.com/hacking-the-worcester-wave-thermostat-in-python-part-3/)
2 |
3 | ---
4 |
5 | 所以,[前面](http://blog.rtwilson.com/hacking-the-worcester-wave-thermostat-in-python-part-2/)我们找出了通信是如何被加密的,并且设法读取到了加热系统的当前状态(热水器是否开启,当前温度,等等)。这很棒 —— 但是如何我们能实际地用Python控制恒温器,这将会更棒,例如,设置温度,由定时器模式修改到手动模式,等等。这就是我们今天要关注的。
6 |
7 | 所以,使用相同的‘中间人’方法,在我修改多项设置的同时,我监控来来自应用的通信。当修改温度的时候,我得到了一个像这样的消息:
8 |
9 | `/heatingCircuits/hc1/manualTempOverride/temperaturePUT /heatingCircuits/hc1/manualTempOverride/temperature HTTP:/1.0\nContent-Type: application/json\nContent-Length: 25\nUser-Agent: NefitEasy\n\n\n\nXmuIR7wCfDZpPrPkrb/CqQ==\n`
10 |
11 | 再次,整理一下它,并且移除XMPP头部,我们看到消息体如下:
12 | ```py
13 | PUT /heatingCircuits/hc1/manualTempOverride/temperature
14 |
15 | HTTP:/1.0
16 |
17 | Content-Type: application/json
18 |
19 | Content-Length: 25
20 |
21 | User-Agent: NefitEasy
22 |
23 | XmuIR7wCfDZpPrPkrb/CqQ==
24 | ```
25 |
26 | 如果我们解码底部的文本,那么可以发现它解码为:
27 | `<{"value":16}\x00\x00\x00\x00`
28 |
29 | 这看起来像JSON,并在最后有一个位的空填充(大概是这样的,长度按一定数可整除的数据被提供给加密例程) - 它是有意义的,因为我设置了恒温器为16度。
30 |
31 | 所以,如果我们发送这条短信(但使用不同的号码),那么假设温度会改变?嗯...有可能!
32 |
33 | 你看,改变温度取决于你在什么模式。有两种模式,而状态消息的UMD部分告诉你,你是其中哪一个:手动(manual)或时钟(clock)。如果你在手动模式下,则可以简单发送一个PUT消息(像上面那个)给`/heatingCircuits/hc1/temperatureRoomManual`,并带上JSON数据`{"value":21}`(或任何你想要的温度)来更改温度。
34 |
35 | 但是,如果在时钟模式下,那么你必须设置“覆盖温度(override temperature)”(一个到`/heatingCircuits/hc1/manualTempOverride/temperature`的PUT消息),并且带上与上面相同的JSON,然后你必须打开”温度覆盖功能(temperature override function)'(一个到`/heatingCircuits/hc1/manualTempOverride/status`的带有JSON数据`{"value": "on"}`的PUT消息)。
36 |
37 | 哦,如果你想改变模式,那么你可以只发送一个到`/heatingCircuits/hc1/usermode`的PUT消息,并携带JSON数据`{"value": "clock"}`或`{"value":"manual"}`。
38 |
39 | 你可能想知道是否从这些消息获得了响应:你可以这样做,但它们不是很有趣的。除非出现了一个错误,你得到的会是:
40 | ```py
41 | No Content
42 |
43 | Content-Type: application/json
44 |
45 | connection: close
46 | ```
47 |
48 | 你还可以发送许多其他的消息来做各种复杂的事情(如改变定时程序),但我还没有尝试去调查这些呢。我知道它们会使用与这些消息相同的格式,它们只是由稍微复杂一点的JSON有效载荷,并可能需要发送多个消息。我很高兴,因为我可以读取我的恒温器状态,并控制基本设置(模式和温度)!
49 |
50 | 所以,迄今为止,在这个系列中我并没有真正那么多提到Python(对不起!)—— 尽管,事实上,我的大部分'试错'工作是通过使用Python中棒棒哒的[sleekxmpp库](http://sleekxmpp.com/)来完成的。在这里,我必须承认,我没有如我应该做的那样编写代码:我真的本应该设计它来实现一个适当的有限状态机,并且在适当的时间里发送和接收相应的消息,同时在Python类中更新内部信息......但我没有!对不起 —— 应对所有这一切,异步工作,这都太像繁重的工作了。
51 |
52 | 所以,我写了一个`BaseWaveMessageBot`类,它实现连接,发送消息,编码和解码消息负载和一点简单的错误处理。这个类拥有所有复杂的东西,所以后来我写了几个非常简单的类(`StatusBot`和`SetBot`),它们发送适当的消息并处理响应。然后,我在一个漂亮的名为`WaveThermo`的类中将它们组合在一起。目前,WaveThermo还没有很多方法,但因为我需要它,所以我会逐渐添加更多的功能。
53 |
54 | 该代码可[在Github](https://github.com/robintw/pywavethermo)上找到,并且它是相当容易使用:
55 |
56 | 当然,我只是用我的恒温器测试了一下它 —— 所以,如果它对你无效,那么请让我知道!
57 |
58 | 所以,目前就是这样了 - 下一次,我将谈论我完成的温度和恒温状态自动监控所做的一点工作,以及我发现的一些有趣的模式。
59 |
--------------------------------------------------------------------------------
/Image Processing/README.md:
--------------------------------------------------------------------------------
1 | # Image Processing
2 | 关于图像处理……
3 |
4 | ## 说明
5 |
6 | - [压缩和增强手写笔记](./压缩和增强手写笔记.md)
7 |
8 | 这篇文章将向你展示如何写个程序来清理手写笔记扫描件,同时减少文件大小
--------------------------------------------------------------------------------
/Machine Learning/README.md:
--------------------------------------------------------------------------------
1 | # Machine Learning
2 | 关于机器学习……
3 |
4 | ## 说明
5 |
6 | - [使用非常少的数据构建强大的图像分类模型](./使用非常少的数据构建强大的图像分类模型.md)
7 |
8 | 在本教程中,我们将提出几个简单但是有效的方法,你可以只用很少的训练样本就可以构建一个强大的图像分类器 —— 只需你想要识别的每个类中几百或几千图片。
9 |
10 | - [在有限预算上计算最佳公路旅行](./在有限预算上计算最佳公路旅行.md)
11 |
12 | 本文通过引入多目标Pareto最优化到算法中,以扩展优化公路旅行的想法。它简要介绍了Pareto最优化是如何工作的,以及它在有限的预算下,是如何帮助我们优化公路旅行的。
13 |
14 | - [对超过1M的酒店点评进行机器学习,发现有趣的见解](./对超过1M的酒店点评进行机器学习,发现有趣的见解.md)
15 |
16 | 本文中,我们将涵盖可以如何使用这些机器学习模型来分析数百万条来自于TripAdvisor的点评,然后比较人们对不同城市的酒店的感受,来学习各种有趣的事情。
17 |
18 | - [Python,机器学习和语言之争](./Python,机器学习和语言之争.md)
19 |
20 | - [使用预测算法追踪实时健康趋势](./使用预测算法追踪实时健康趋势.md)
21 |
22 | 在这个教程中,我们将构建一个实时健康显示面板,用来追踪一个人的血压读数,进行时间序列分析,然后使用预测算法绘制时间趋势。本教程是使用时间序列算法和预测API来创建你个人健康显示面板的起点。
23 |
24 |
--------------------------------------------------------------------------------
/NLP/README.md:
--------------------------------------------------------------------------------
1 | # Natural Language Processing
2 | 关于自然语言处理……
3 |
4 | ## 说明
5 |
6 | - [003构建一个播客推荐算法](./003构建一个播客推荐算法.md)
7 |
8 | 我想我可以通过每个播客相关的文本数据(即,标题和描述)来建立一个更好的播客推荐算法。我就是这样做的!其结果是[thesauropod.us](http://www.thesauropod.us/),这是一个播客词库。
--------------------------------------------------------------------------------
/Others/Python, GIL, 和Pyston.md:
--------------------------------------------------------------------------------
1 | 原文:[Python, the GIL, and Pyston](http://blog.kevmod.com/2014/06/python-the-gil-and-pyston/ "Python, the GIL, and Pyston" )
2 |
3 | ---
4 |
5 | 最近,我一直在思考Pyston中对并行的支持 —— 这在我的“愿望清单”里待了很长一段时间。CPython中的并行状态是个痛点,因为GIL(“全局解释锁”)基本上是强制单线程执行的。应当指出的是,GIL并非CPython特有的:其他实现,例如PyPy,也有(虽然PyPy有他们自己的STM努力来摆脱它),而其他语言运行时也有。从技术上讲,GIL是实现的一个特性,而不是一种语言,因此看起来,实现应该可以自由地使用基于非GIL的策略。
6 |
7 | “使用非基于GIL的策略”最棘手的部分是,我们仍然必须为语言提供正确的语义。而且,随着我进一步深入,有一些GIL衍生的语义已经成为了Python语言的一部分,并且无论它们是否实际上使用了GIL,都必须兼容实现。这里有一些我一直在思考的问题:
8 |
9 | ### 问题1:数据结构线程安全
10 |
11 | 想象一下,你有两个Python线程,它们都试图往一个列表追加一个项。比方说,一开始该列表是空的,而线程分别试图追加"1"和"2":
12 |
13 | ```python
14 | l = []
15 | def thread1():
16 | l.append(1)
17 | def thread2():
18 | l.append(2)
19 | ```
20 |
21 | 那么,之后该列表允许的内容是什么呢?显然,"[1, 2]"和"[2, 1]"是允许的。允许"[1]"吗?那"[1, 1]"呢?"[1, ]"呢?除了"[1, 2]"和"[2, 1]",我想这些答案都不是,特别不是最后一个。Python中的数据结构当前保证是线程安全的,而大多数的基本操作,例如“追加”,目前保证是原子的。即使我们可以以某种方式说服大家,内置的列表不应该是一个线程安全的数据结构,但是完全将所有的同步抛出窗口外当然不行:我们最终会让列表中出现带垃圾的不一致的数据结构,打破该语言的内存安全性。所以,不管是什么,都需要让所有的内置类型都具有一定的线程安全。
22 |
23 | 人们一直在为线程构建线程安全的数据结构,因此解决这个问题并不需要任何激进的新思路。不过,这个问题是,由于它应该应用到Python程序可能需要的所有操作,有可能会有一个非常大的锁定/同步开销。一个GIL,虽然有点让人反感,但是它确实在保持锁开销低的同时很好的提供了线程安全。
24 |
25 | ### 问题2:内存模型
26 |
27 | 有一些大多数Python程序员不用考虑的东西(因为他们不必考虑),但是“内存模型”指定了允许一个线程观察另一个线程影响的潜在方式。比方说,我们有一个线程运行:
28 |
29 | ```python
30 | a = b = 0
31 | def thread1():
32 | global a, b
33 | a = 1
34 | b = 2
35 | ```
36 |
37 | 然后,我们有第二个线程:
38 |
39 | ```python
40 | def thread2():
41 | print b
42 | print a
43 | ```
44 |
45 | 允许thread2打印什么?由于没有同步,它可以清楚地打印"0, 0", "0, 1", 或者"2, 1"。虽然,在许多编程语言中,对于thread2打印"2, 0"是可接受的,但这似乎是一个矛盾:如果a还没有设置值,那b怎么会有值?答案是,内存模型通常是,不保证线程看到任何顺序的其他线程的修改,除非有某种同步。(在这种特殊情况下,我想x86内存模型任务这并不会发送,但这是另外一回事了。)回到CPython,GIL规定,我们需要的“某种同步”(GIL释放然后GIL持有将会迫使所有的更新被看到),所以保证我们不会看到任何重新排序的有趣业务:CPython有一个名为“顺序一致性”的强大的内存模型。虽然这在技术上可以被认为只是CPython的一个特性,而似乎有这实际上是语言规范的一部分这种共识。虽然可以而且应该对这是否应该是指定的内存模型进行争论,但是我想,问题的事实是,必须有依赖于顺序一致性的模型的代码在那里,而Pyston将必须提供它。
46 |
47 | 有一些改变语言保证的先例 —— 当GC'd实现开始出现时,我们不得不戒掉立即释放这个习惯。我觉得,虽然内存模型更不容易改变,但是这并不是说我们应该改变。
48 |
49 | ### 问题3:C扩展
50 |
51 | Pyston的目标之一是支持未修改的CPython C扩展;不幸的是,这造成了相当大的并行性问题。对于Python代码,我们只需要保证每个字节码是原子的,而可以在任意两个字节码直接释放GIL。对于C扩展代码,需要做一个更大的承诺:不会释放GIL,除非C代码明确要求。这意味着,C扩展可以自由的选择是否线程安全,因为除非要求,否则他们绝不并行运行。因此,尽管我猜并不是很多扩展明确的利用GIL存在这一事实,但我强烈怀疑所有的C扩展代码,一点都不考虑线程安全的话,会最终奇迹般的变成线程安全。所以,不管Python级别的代码是如何处理的,我们都必须(默认地)串行运行C扩展代码。
52 |
53 |
54 |
55 | ### 潜在实现策略:GRWL
56 |
57 | 所以,任何线程实现必须满足不少限制,这通过使用GIL可以容易并自然的满足。正如我所提到的,这些问题并不是特别新颖;有完善的(虽然也许难以实现)解决方法。但问题是,由于我们必须在语言运行层次来解决,因此对所有的代码,我们将承担这些同步成本,而且目前还不清楚这是否最终会比使用GIL拥有更好的性能权衡。你可以潜在得到更好的并行性,虽然受内存模型所限,以及C扩展必须串行的事实,但你很有可能必须牺牲一定量的单线程性能。
58 |
59 | 目前,我正在考虑使用全局读写锁(Global Read-
60 | Write Lock,GRWL)来实现这些功能。我们的想法是,通常允许线程并行运行,除了强制顺序执行这种特定的情况下(C扩展代码,GC收集器代码)。这自然而然表示为读写锁:正常的Python代码在一个GRWL中保存读锁,而串行代码必须获得一个写锁。(还有一种允许它完全不持有锁的代码,例如做IO的时候)。这似乎是从语言的语义到同步原语的一个非常直接的映射,所以我觉得这是一个很好的API。
61 |
62 | Pyston中,我有一个原型实现; 这不错,因为GRWL API是GIL API的一个超集,这意味着简单地改变一些编译时标志就可以在它们之间进行代码库切换。迄今的结果并不那么明显:与GIL实现相比,GRWL具有更糟的单线程性能和并行性 —— 两个运行线程的吞吐量相当于在一个线程的总吞吐量的45%,而GIL实现有75% [好吧,显然对这两种方案都有一些改进]。但它能用!(只要你只使用列表,因为我还没有添加锁到其它类型)。这只是表明,简单地删除GIL并不难 —— 难的是让更换速度更快。我会花一点点时间分析为什么表现不如我所想的那样,因为现在它似乎看起来有点可笑。希望不久会有好消息,但话又说回来,如果结论是,GIL提供了一个无与伦比的付出-获得的权衡,那么我并不会感到惊讶。
63 |
64 |
65 | ### 更新:基准
66 |
67 | 所以我花了一些时间调整一些东西; 第一个变化是,我替换了互斥实现的选择。默认的glibc pthread互斥是PTHREAD_MUTEX_TIMED_NP,这显然是为了提供POSIX规范的特性而牺牲吞吐量。在我做了一些分析后,我注意到,我们把时间都花在了在内核总做futex的操作,所以我切换到PTHREAD_MUTEX_ADAPTIVE_NP,它在推迟到内核进行处理之前,在用户空间中做一些操作。性能提升是相当不错的(约50%速度的提升),但我想我们失去了一些调度的公平性。
68 |
69 | 我修改的第二件事是降低了用来检查我们是否应该释放GRWL的频率。我不明白为什么这样有用,因为很少有等待者(waiter),检查是否有其他的等待者应该是非常快(并不需要一个原子操作)。但是,这使得它获得额外的100%的速度提升。
70 |
71 |
72 |
73 | 这里有一些让我激动的结果。这里测试了三个Pyston版本:作为基线的一个没有GIL或者GRWL的“不安全”的版本,一个GIL版本,和一个GRWL版本。我将其运行在几个不同的微基准上:
74 |
75 | ```python
76 | unsafe GIL GRWL
77 | raytrace.py [single threaded] 12.3s 12.3s 12.8s
78 | contention_test.py, 1 thread N/A 3.4s 4.0s
79 | contention_test.py, 2 threads N/A 3.4s 4.3s
80 | uncontended_test.py, 1 thread N/A 3.0s 3.1s
81 | uncontended_test.py, 2 threads N/A 3.0s 3.6s
82 | ```
83 |
84 | 所以……事情好起来了,但即使在无竞争的测试中,其中GRWL应该要脱颖而出,但是它仍然比GIL差。我觉得这跟GC有关;是时候提高多线程性能调试了。
85 |
86 |
--------------------------------------------------------------------------------
/Others/Python项目中的Makefiles.md:
--------------------------------------------------------------------------------
1 | 原文:[Makefiles in python projects —— Do you need such thing as makefile in python projects?](http://krzysztofzuraw.com/blog/2016/makefiles-in-python-projects.html)
2 |
3 | ---
4 |
5 | **当我加入我当前的公司时,我在他们的git仓库中看到了奇怪的文件。没有任何Python代码使用它。它仅仅是存在于项目的主目录下。我问我的同事,这个文件是用来干嘛的?他们告诉我——它让你的生活更轻松。这就是为什么今天我要写写这个文件 - Makefile。**
6 |
7 | 目录:
8 |
9 | * makefile是什么,以及它的典型用途
10 | * 具体到Python,你可以把什么放到makefile中
11 | * 通过在Python项目中使用makefile,你可以获得什么好处
12 |
13 | ## makefile是什么,以及它的典型用途
14 |
15 | 根据这个[教程](http://www.cs.colby.edu/maxwell/courses/tutorials/maketutor/):
16 |
17 | > makefile是组织代码编译的一种简单方法。
18 |
19 | 通常情况下,它们用于编写C程序,来减轻代码可以作为程序使用前所需要做的所有东西。你可以指定规则,告诉[make](https://www.gnu.org/software/make/)如何编译你的程序。用于C代码的简单的makefile如下:
20 |
21 | ```shell
22 | helloword: helloword.c
23 | gcc -o hellword hellword.c -I.
24 |
25 | ```
26 |
27 | 然后运行:
28 |
29 | ```shell
30 |
31 | $ make helloword
32 |
33 | ```
34 |
35 | 用gcc来编译C。
36 |
37 | 这怎么跟Python扯在一起了?Python这门编程语言在调用的时候才编译,因此不需要任何makefile。正如我在开头所说的,在Python项目中,使用makefile,你可以让你的生活变得轻松,并且节省大量的按键操作。
38 |
39 | ## 具体到Python,你可以把什么放到makefile中
40 |
41 | 构建Python包后,你有没有想过清理你项目中的`.pyc`文件,或者消除伪迹?或者也许你想要运行覆盖率测试?使用pep8, lint或者isort?或许在docker容器中运行应用,最终写出那些对你的屏幕来说太长的命令?
42 |
43 | 这就是makefile的用武之地了。你可以将一切放在同一个地方,然后只使用`make clean`来清理不必要的文件,或者使用`make tests`来测试你的应用。
44 |
45 | 让我们先从我正在使用的makefile的一些例子开始:
46 |
47 | ```python
48 |
49 | HOST=127.0.0.1
50 | TEST_PATH=./
51 |
52 | clean-pyc:
53 | find . -name '*.pyc' -exec rm --force {} +
54 | find . -name '*.pyo' -exec rm --force {} +
55 | find . -name '*~' -exec rm --force {} +
56 |
57 | clean-build:
58 | rm --force --recursive build/
59 | rm --force --recursive dist/
60 | rm --force --recursive *.egg-info
61 |
62 | isort:
63 | sh -c "isort --skip-glob=.tox --recursive . "
64 |
65 | lint:
66 | flake8 --exclude=.tox
67 |
68 | test: clean-pyc
69 | py.test --verbose --color=yes $(TEST_PATH)
70 |
71 | run:
72 | python manage.py runserver
73 |
74 | docker-run:
75 | docker build \
76 | --file=./Dockerfile \
77 | --tag=my_project ./
78 | docker run \
79 | --detach=false \
80 | --name=my_project \
81 | --publish=$(HOST):8080 \
82 | my_project
83 |
84 | ```
85 |
86 | 开头,我为每一个命令添加了两个变量`HOST`和`TEST_PATH`,以便使用它们。规则`clean-pyc`查找所有以`*.pyc`, `*.pyo`或者`*~`结尾的文件,然后删除它们。命令尾部的+号是用于`-exec
87 | command {}`,意味着命令的调用总数会比匹配的文件的数量要少得多。
88 |
89 | 下一个`clean-build`是用来提出构建伪迹。在`isort`中,shell根据何时的属性执行isort命令,`-c`标记用来从字符串而不是从标准输入读取命令。`lint`和`run`工作在相同的模式上。在`test`中,我添加了在实际的测试之前执行的额外的规则 - `clean-pyc`。最后的`docker-run`构建和运行docker。
90 |
91 | 你想要添加的额外的东西是一些称为`PHONY`的东西。默认情况下,makefile在文件上进行操作,因此,如果有个名为`clean-
92 | pyc`的文件,那么它会尝试使用它而不是使用命令。要避免这个,则在你的makefile文件开头使用`PHONY`:
93 |
94 | ```python
95 |
96 | .PHONY: clean-pyc clean-build
97 |
98 | ```
99 |
100 | 我还喜欢让我的makefile有帮助函数,因此我把这些放在里面的某些地方:
101 |
102 | ```python
103 |
104 | help:
105 | @echo " clean-pyc"
106 | @echo " Remove python artifacts."
107 | @echo " clean-build"
108 | @echo " Remove build artifacts."
109 | @echo " isort"
110 | @echo " Sort import statements."
111 | @echo " lint"
112 | @echo " Check style with flake8."
113 | @echo " test"
114 | @echo " Run py.test"
115 | @echo ' run'
116 | @echo ' Run the `my_project` service on your local machine.'
117 | @echo ' docker-run'
118 | @echo ' Build and run the `my_project` service in a Docker container.'
119 |
120 | ```
121 |
122 | 每个`echo`之前都有一个`@`,因为默认情况下,`make`载执行前把每一行都打印到控制台。`At`符号抑制这种行为,而当传递行给shell之前,`@`被丢弃。
123 |
124 | 但是,如果我想使用makefile,让我的应用程序运行在不同的主机和端口上呢?很简单,只需添加:
125 |
126 | ```python
127 |
128 | run:
129 | python manage.py runserver --host $(HOST) --port $(PORT)
130 |
131 | ```
132 |
133 | 接着,你可以简单地运行:
134 |
135 | ```python
136 |
137 | $ make run HOST=127.0.0.1 PORT=8000
138 |
139 | ```
140 |
141 | 最后注意,makefile中的缩进必须使用TAB来完成,而不是空格。
142 |
143 | ## 通过在Python项目中使用makefile,你可以获得什么好处
144 |
145 | 正如你所见,在Python项目中使用makefile可以带来很多好东西。如果你已经厌倦了编写复杂的shell命令 —— 那么把它们放在makefile中的一个规则下。想要其他人很容易地运行对项目的测试吗?把pytest调用放在makefile中。创意是无止境的。
146 |
147 | 在你的项目中使用makefile吗?你觉得它有用,或者没用吗?你把什么其他的东西放在项目中呢?请把它写到评论中吧!
148 |
149 |
--------------------------------------------------------------------------------
/Others/README.md:
--------------------------------------------------------------------------------
1 | # Others
2 | 其他一些零零散散的文章
3 |
4 | ## 说明
5 | - [使用图像特征的库存图像相似性(程序是如何比我更时尚的)](./程序是如何比我更时尚的.md)
6 |
7 | 借助Python库indico获得图像特征向量,利用欧几里得距离计算相似性,随着样本的增加,会使得匹配搜寻的准确度越来越高。那么,就让我们看看怎样让程序比我更时尚吧~
8 |
9 | - [如何在Python中使用Twilio Lookup API验证电话号码](./如何在Python中使用Twilio Lookup API验证电话号码.md)
10 |
11 | 使用Twilio Lookup来对电话号码进行常规操作,例如验证有效性,获取运营商信息等。有更多更好的想法,不要忘记联系原作者进行分享~~
12 |
13 |
14 | - [psutil 4.0.0以及如何获得Python中“真正的”进程内存和环境](./psutil 4.0.0以及如何获得Python中“真正的”进程内存和环境.md)
15 |
16 | 描述如何用psutil 4.0.0获得“真正的”进程内存度量以及进程环境变量的一些信息。
17 |
18 | - [Python依赖关系分析](./Python依赖关系分析.md)
19 |
20 | 通过对pypi上包的依赖关系进行计算,使用“节点核心”,PageRank算法和“中间中心”分析包的重要性,分析开发社区的重要性以及度分布,从而对包的依赖关系进行详细的分析……
21 |
22 | - [创造你自己的类IPython服务器](./创造你自己的类IPython服务器.md)
23 | 介绍如何用很少的代码,基于Flask实现一个类似于IPython notebook的服务器,其中谈到了用exec命令执行Python语句,巧用重定向实现将结果显示在客户端上,并且利用python中环境的存储方式解决不同环境上的变量/功能重叠问题。最后,还提到了错误处理机制。
24 |
25 | - [为部署Python web应用程序构建一个更好的用户体验](./为部署Python web应用程序构建一个更好的用户体验.md)
26 |
27 | 介绍使用warpdrive简单快捷的在不同的WSGI上部署web应用以及一些关于改进部署体验的做法
28 |
29 | - [在Python中导入一个Docker容器](./在Python中导入一个Docker容器.md)
30 |
31 | 介绍了一个工具Sidomo,它可以将奇怪的软件转换成在Python代码中无缝运行的漂亮且单纯的Python模块。
32 |
33 | - [好吧,你发布了一个损坏的包到PyPI上。那么你现在要怎么办?](./好吧,你发布了一个损坏的包到PyPI上。那么你现在要怎么办?.md)
34 |
35 | 不小心发布了一个受损的包到PyPI上,该怎么办?本文给出了三个步骤来处理这种任何人都有可能发生的问题。
36 |
37 | - [Python中Meta类习语的起源](./Python中Meta类习语的起源.md)
38 |
39 | Django的模型中有一个Meta内部类,可以在很多其他Python API中发现它的使用。本文探索了此Meta内部类的来龙去脉……
40 |
41 |
42 | - [复合构建器模式(Composite Builder Pattern),一个声明式编程的例子](./复合构建器模式(Composite Builder Pattern),一个声明式编程的例子)
43 |
44 | 针对于那些属性来自于多个源的复杂对象来说,本文给出了一个例子,提出复合构建器模式以方便编程。
45 |
46 | - [将Python用于地理空间数据处理](./将Python用于地理空间数据处理.md)
47 |
48 | 本文带你感受一下,如何将Python这个可爱的语言用于地理空间数据处理……
49 |
50 | - [使用Python和Excel进行交互式数据分析](./使用Python和Excel进行交互式数据分析.md)
51 |
52 | 想要一个调用你自定义的Python代码的Excel工作表吗?或许xlwings可以帮助你……
53 |
54 | - [RPython的魔力](./RPython的魔力.md)
55 |
56 | RPython是个翻译器,一个编译时运行的翻译器。本文关注与RPython本身,主要说明了其特性及相关错误。
57 |
58 |
59 | - [使用gdb调试CPython进程](./使用gdb调试CPython进程.md)
60 |
61 | 想在不重启应用的情况下调试CPython应用?此时pdb可无用武之地哦~ 所以,试试gdb吧!
62 |
63 | - [使用Python Newspaper构建Read It Later应用](./使用Python Newspaper构建Read It Later应用.md)
64 |
65 | Python + Tweet + Newspaper + Flask ≈ Pocket?是哒,你可以看看怎么来做到。P.S. 表示对博主的2016年的52个技术系列很感兴趣呢,已收藏~~
66 |
67 | - [Python lambda的源代码](./Python lambda的源代码.md)
68 |
69 | 这是一篇关于如何显示lambda源代码的hack……
70 |
71 |
72 | - [如何在Python中创建绿噪音](./如何在Python中创建绿噪音.md)
73 |
74 | - [你需要学习编写Python装饰器的五大理由](./你需要学习编写Python装饰器的五大理由.md)
75 |
76 | 虽然Python装饰器是一个非常非常非常难以学习掌握的东西,但是本文列举了学会写Python装饰器的种种好处。P.S. 看了我都觉得为了这些好处,也要好好学习一下了!
77 |
78 | - [逆向工程我的酒店中的一个神秘的UDP流](./逆向工程我的酒店中的一个神秘的UDP流.md)
79 |
80 | 额,不说了,挺好玩的……
81 |
82 | - [记录每天数以百万计的请求以及需要采取哪些措施](./记录每天数以百万计的请求以及需要采取哪些措施.md)
83 |
84 |
85 | - [教程:手把手教你构建一个基本的Facebook聊天机器人](./教程:手把手教你构建一个基本的Facebook聊天机器人.md)
86 |
87 | 在本教程中,我将告诉你如何在python中构建你自己的Facebook Messenger聊天机器人。我们会使用Flask进行一些基本的web请求处理,然后我们将部署该应用到Heroku。
88 |
89 | - [我的自动化之旅:为人民服务的自动化](./我的自动化之旅:为人民服务的自动化.md)
90 |
91 | 不要使用手工流程(Don't Use Manual Procedures)!作者以奉献精神,用其亲身经历,讲述了他的自动化之旅。从中,对于自动化工具的使用,工具的优劣之分,令人收获良多。
92 |
93 | - [实用Python:EAFP VS. LBYL](./实用Python:EAFP VS. LBYL.md)
94 |
95 | 你在本文中应该获得的关键是,EAFP在Python中是一种合法的编码风格,并且当其有意义时,你应该随意使用它。
96 |
97 | - [使用str.encode和threads冻结你的Python](./使用str.encode和threads冻结你的Python.md)
98 |
99 | 导入锁与线程的爱恨情仇,又一个使用Python 3的理由。
100 |
101 | - [Python, GIL, 和Pyston](./Python, GIL, 和Pyston.md)
102 |
103 | - [我是如何构建一个Slack机器人来帮助我在San Francisco找房子的](./我是如何构建一个Slack机器人来帮助我在San Francisco找房子的.md)
104 |
105 | 我们将逐步看看每一块是如何构建的,以及如何使用这个最终的Slack机器人来帮助我们找到一间公寓。
106 |
107 | - [中断两个循环](./中断两个循环.md)
108 |
109 | 一个常见的问题是,我如何一次性跳出两个嵌套的循环?例如,如何我才能检查字符串中的字符对,然后在我找到一对相等的字符对时停止?
110 |
111 | - [一个模板引擎是如何工作的?](./一个模板引擎是如何工作的?.md)
112 |
113 | 在这里,我们要通过深入tornado web框架的template模块,找出一个模板引擎是如何工作的,这是一个简单的系统,这样我们就可以专注于过程的基本思路。
114 |
115 | - [设计Pythonic API](./设计Pythonic API.md)
116 |
117 | 当编写一个包(库)的时候,为它提供一个良好的API,几乎与它的功能本身一样重要(好吧,至少你想要让别人使用),但怎么才算一个良好的API呢?在这篇文章中,我将尝试通过比较Requests和Urllib(Python标准库的一部分)在一些经典的HTTP场景的使用,从而提供关于这个问题的一些见解,并看看为什么Requests已经成为了Python用户中的事实上的标准。
118 |
119 | - [Requests vs. urllib:它解决了什么问题?](./Requests vs. urllib:它解决了什么问题?.md)
120 |
121 | - [更好的Python对象序列化方法](./更好的Python对象序列化方法.md)
122 |
123 | - [使用列表推导式实现zip](./使用列表推导式实现zip.md)
124 |
125 | - [Python项目中的Makefiles](/Python项目中的Makefiles.md)
126 |
127 | 在Python项目中,你需要像makefile这种东西吗?
128 |
129 | - [婚礼规模:我是如何使用Twilio, Python和Google来自动化我的婚礼的](./婚礼规模:我是如何使用Twilio, Python和Google来自动化我的婚礼的.md)
--------------------------------------------------------------------------------
/Others/Requests vs. urllib:它解决了什么问题?.md:
--------------------------------------------------------------------------------
1 | 原文:[What problem does it solve?](http://www.curiousefficiency.org/posts/2016/08/what-problem-does-it-solve.html)
2 |
3 | ---
4 |
5 | 对于Python新手来说,Python较令人费解的方面之一就是,当涉及到编写HTTP(S)协议客户端时,标准库的`urllib`模块和流行的(及备受推崇的)第三方模块`requests`之间鲜明的可用性差异。当你的问题是“与HTTP服务器进行通信”时,可用性方面的差异并不是那么明显,但一涉及到额外的需求,像SSL/TLS、鉴权、重定向处理、会话管理和JSON请求/响应主题,差异就明显起来。
6 |
7 | 想要[记录易用性的差异](http://noamelf.com/2016/08/05/designing-pythonic-apis/)是诱人而完全可以理解的,直到`requests`是"Pythonic" (在2016年), 而`urllib`现在已经不Pythonic了 (尽管被包含在了标准库中)。
8 |
9 | 虽然当然有那么点因素(例如,内置的`property`是在Python 2.2才添加进来的,而`urllib2`被包含在原始的Python 2.0发布中,因此在其API设计中无法考虑这点),但是绝大多数的可用性差异涉及到了我们经常忘记问问所使用的软件的一个完全不同的问题:_它解决了什么问题?_
10 |
11 | 即,`urllib`/`urllib2`和`requests`之间的许多令人惊讶的其他差异可以由它们_解决不同的问题_这一事实,以及较之于Jeremy Hylton在十年前想要解决的问题,现今大多数HTTP客户端开发者所遇到的问题更接近于Kenneth Reitz在2010/2011年设计`requests`用以解决的问题来解释。
12 |
13 | ### 答案都在名字里了
14 |
15 | 引用当前的Python 3 `urllib`包文档:“urllib是一个收集几个处理URL模块的包”。
16 |
17 | 以及来自Jeremy的添加`urllib2`到CPython的[原始提交信息](https://hg.python.org/cpython/rev/b800e36aed4e)的文档字符串:“使用各种协议,用于打开URL的可扩展库”。
18 |
19 | 等等,神马?我们只是想写一个HTTP客户端,所以为什么文档谈到一般的URL相关工作?
20 |
21 | 虽然,对于那些习惯于现代的HTTPS+JSON驱动的交互式web的开发者来说有点奇怪,但是事情为什么会变成这样并不总是清晰的。
22 |
23 | 在世纪之交,所期望的是,保留丰富多样的数据传输协议,并且为不同的目的进行不同的特点优化,而标准库中最为有用的客户端则是那个可以用来与多种不同类型的服务器(例如HTTP, FTP, NFS等等)进行通信,客户端开发者无需过多担心使用的特定的协议(由URL schema所示)。
24 |
25 | 然而,在实践中,事情并非如此(大多数是因为严格的防火墙制度,这意味着HTTP服务器是唯一一个可被可靠访问的远程服务),所以,在2016年,人们现在经常拿专用的仅HTTP(S)客户端库的可用性和在获取大多数HTTP(S)特性之前需要专门配置使用HTTP(S)的通用的URL处理库进行比较。
26 |
27 | 在编写它的时候,`urllib2`是被设计来适合“通用URL处理”这一方孔的方钉。相比之下,大多数的现代客户端开发者在寻找适合“HTTPS+JSON处理”这一圆孔的圆钉 —— 如果你先把角磨圆,那么`urllib`/`urllib2`就会适用,但`requests`则已经是圆的了。
28 |
29 | ### 所以,为什么不把requests添加到标准库中呢?
30 |
31 | 对"它解决了什么问题?"这个不那么明显的问题的回答,会到一个明显得多的后续问题:如果`urllib`/`urllib2`被设计来解决的问题不再常见,而`requests`解决的问题是常见的,那么为什么不把`requests`添加到标准库中呢?
32 |
33 | 如果我记得没错,在2013年左右(在`requests` 1.0发布后)的一次语言提交中,Guido在原则上认可了这个想法,而在核心开发者团队中,无论是`requests`本身(可能作为一个独立升级组件的捆绑快照),还是带有不一样实现的的API兼容子集,最终都会出现在标准库中,这是一个相当常见的假设。
34 |
35 | 然而,即使撇开[requests开发者关于此想法的疑惑](https://github.com/kennethreitz/requests/issues/2424),让`requests`作为标准库组件的一部分,仍然有一些不一般的系统集成问题要解决。
36 |
37 | 特别是,其中之一是,requests确实更可靠地以跨平台的方式处理SSL/TLS证书是捆绑包含在`certifi`项目中的Mozilla证书捆绑(Mozilla
38 | Certificate Bundle)。这是默认情况下(由于以跨平台的方式获得对系统的安全证书的可靠访问的困难)的一个明智之举,但它与标准库的安全策略(具体是将证书管理委托给底层操作系统)相冲突。这项策略的目的是解决两个需求:允许Python应用程序访问添加到系统证书存储的自定义机构证书(最值得注意的是,适用于大型组织的私有CA证书),并避免增加当根证书捆绑出于任何其他原因而改变时,需要更新的额外的证书存储到终端用户系统。
39 |
40 | 这类问题在技术上是可以解决的,但解决它们并不好玩,并且帮助解决它们的人手头上已经有许许多多其他的要求。这意味着,只要大部分的CPython和`requests`开发者将其贡献作为业余时间的活动,而不是专门被雇佣来做的事,那么在这个方面我们可能不会看到太多进展。
--------------------------------------------------------------------------------
/Others/中断两个循环.md:
--------------------------------------------------------------------------------
1 | 原文:[Breaking out of two loops](http://nedbatchelder.com/blog/201608/breaking_out_of_two_loops.html "Link to this post" )
2 |
3 | ---
4 |
5 | 一个常见的问题是,我如何一次性跳出两个嵌套的循环?例如,如何我才能检查字符串中的字符对,然后在我找到一对相等的字符对时停止?经典的方式是写两个嵌套循环,遍历该字符串的索引:
6 |
7 | ```python
8 | s = "a string to examine"
9 | for i in range(len(s)):
10 | for j in range(i+1, len(s)):
11 | if s[i] == s[j]:
12 | answer = (i, j)
13 | break # How to break twice???
14 | ```
15 |
16 | 这里,我们使用两个循环来生成两个我们想要检查的索引。当我们找到正在寻找的条件时,我们想退出这两个循环。
17 |
18 | 有几个常见的答案。但我不大喜欢它们:
19 |
20 | * 将循环放进一个函数中,然后在函数中返回以退出循环。这个答案不尽人意,因为循环也许是重构成新函数的一个自然而然的地方,另外,也许在循环中,你需要访问其他本地变量。
21 | * 抛出一个异常,然后在双循环的外部捕获它。这是把异常当成goto来用。这里并没有异常条件,你只是超距利用异常操作。
22 | * 使用布尔变量来标记循环结束,然后在外部循环检查该变量,从而执行第二次退出。这是一个低技术解决方案,可能适用于某些情况,但大多数只是带来额外的噪声和标记。
23 |
24 | 我的首选答案,也就是那个我在PyCon 2013演讲上提到的([Loop Like A Native](http://nedbatchelder.com/text/iter.html))那个,是把双循环变成单循环,然后只适用一个break。
25 |
26 | 这需要把多一点的工作放到循环里,但是,这对于抽象迭代是一个好的实践。这是Python非常擅长的一件事,但也非常容易把Python当成一个能力较差的语言来用,并且不利用现有的循环抽象。
27 |
28 | 让我们再来考虑这个问题。这真的是两个循环吗?在写任何代码之前,再听一听该英文描述:
29 |
30 | > 如何我才能检查字符串中的字符对,然后在我找到一对相等的字符对时停止?(How can I examine pairs of characters in a string, stopping when I find an
31 | equal pair?)
32 |
33 | 在该描述中,我并未听到两个循环。是一个字符对上的单循环。因此,让我们这样写:
34 |
35 | ```python
36 | def unique_pairs(n):
37 | """Produce pairs of indexes in range(n)"""
38 | for i in range(n):
39 | for j in range(i+1, n):
40 | yield i, j
41 |
42 | s = "a string to examine"
43 | for i, j in unique_pairs(len(s)):
44 | if s[i] == s[j]:
45 | answer = (i, j)
46 | break
47 | ```
48 |
49 | 这里,我们写了一个生成器来生成所需的索引对。现在,我们的循环是在字符对之上的单循环,而不是通过索引的双循环。仍然有双循环,但是抽取到unique_pairs生成器中。
50 |
51 | 这让我们的代码漂亮地匹配了我们的话。注意,我们无需写两遍len(s),这是原始代码需要重构的另一个迹象。如果在其他地方,我们发现我们想要像这样进行迭代,那么可以重用unique_pairs生成器,虽然,可重用不是写一个函数的必备条件。
52 |
53 | 我知道这种技术似乎是外来的。但它确实是最好的解决方案。如果你还是觉得被绑在双循环上,那么多想想你是如何想像你的程序的结构的。不管你相信与否,你正在试图一次打破两个循环,这意味着,在某种意义上,它们是一回事,而不是两个。将第二个隐藏到一个生成器中,你就可以以实际上认为的那样来重构你的代码。
54 |
55 | Python有用于抽象的强大的工具,其中包括生成器和其他用于抽象迭代的技术。如果你想要了解更多的话,我的[Loop Like A Native](http://nedbatchelder.com/text/iter.html)演讲有更多详细信息(和一个令人震惊的笑话)。
56 |
57 |
--------------------------------------------------------------------------------
/Others/为什么用python重写shell-script.org:
--------------------------------------------------------------------------------
1 | #+TITLE: 为什么用python重写shell-script
2 | #+URL: http://slott-softwarearchitect.blogspot.com/2016/06/why-rewrite-shell-script-in-python.html
3 | #+AUTHOR: lujun9972
4 | #+CATEGORY: Python Common
5 | #+DATE: [2016-06-07 二 19:04]
6 | #+OPTIONS: ^:{}
7 |
8 | 这里是实际上的原文:
9 | #+BEGIN_QUOTE
10 | 什么情况下你会需要用python重写工作脚本呢? 是否有任何商业上的原因?
11 | #+END_QUOTE
12 |
13 | 我的回答可能让人厌恶.
14 |
15 | 简单来说,我认为shell脚本语言恐怕是有史以来最糟糕的编程语言. 好吧,我想它比[[https://en.wikipedia.org/wiki/Whitespace_(programming_language)][whitespace]] 之类的其他语言(参见:https://en.wikipedia.org/wiki/Esoteric_programming_language )还是要好点的.
16 |
17 | 详细来说,有下面几个理由:
18 |
19 | + 我手头上的项目中(至少)有三个ksh脚本是相互引用的,其中有两个脚本操作了1000行. 而且我还不是特别清楚他们之间的引用关系. 这是ksh. 代码可能来自各种各样的地方,并具有含糊不清的路径;例如source命令以及它的同义词`.'命令.
20 | + 脚本中,除了#!/usr/bin/ksh外,没有任何注释. 而且有些地方的代码被注释掉了但是没有写明为什么要注释掉.
21 | + 没有任何参考文档. 作者虽然有写过一封email来描述github仓库,但这个仓库本身缺少README. 很难让他们明白在仓库添加README的重要性. 仓库中甚至缺少命令行说明. (最终我是通过查看命令行选项的解析器来推测出该说明的)
22 | + 没有任何的测试.
23 |
24 | 最后一点尤其让我震惊. And I find it shocking on a regular basis.
25 |
26 | 人们能够并且愿意编写一个上千行的脚本而不带任何单元测试, 集成测试, 系统测试, 性能测试甚至是任意一种测试. 我不能理解他们怎么知道这个脚本到底是否能正常工作? 我该如何相信这个脚本?
27 |
28 | 更重要的是,在都不知道命令行接口的情况,我怎么可能将之包装成一个RESTful API呢? shell还可能使用未说明的环境变量,且只有当他们引发程序运行崩溃后才可能发现他们. 程序崩溃会引发一个HTTP 500 状态码的错误,并在日志中记录下错误信息.
29 |
30 | "商务导向"尝试从商务上成本与收益的角度来讨论技术方案. 从这个角度来说,这种1000行的shell脚本代码很明显是一种技术负债.
31 |
32 | 最简单的解决方式恐怕就是使用类似的Python脚本来翻写原shell脚本了. 有时很难看懂一个shell函数到底是干嘛用的. 不停的使用(或重用)全局变量使得很难追踪程序状态的变更. 另外,使用临时文件作为设置状态的一种方式也是个很严重的问题.
33 |
34 | 重要的是,shell脚本中所用到的那些OS服务都是可仿真的. 这意味着这百来个函数可以单独的进行测试. 一旦完成了重写,重构也变得简单了.
35 |
36 | 让我们再回味一下这些单词: 可以 独立 测试
37 |
38 | 哈哈哈.
39 |
40 | (我认为)最好的替代是250行或更少的python代码. 而且能实时地自动执行8个步骤. 摆脱bash语言的糟粕很有挑战性,但是却是必须的.
41 |
--------------------------------------------------------------------------------
/Others/为何我选择python,python擅长什么,python的特点是什么.org:
--------------------------------------------------------------------------------
1 | #+TITLE: 为何我选择python,python擅长什么,python的特点是什么
2 | #+URL: http://slott-softwarearchitect.blogspot.com/2016/05/why-python-whats-it-good-for-how-is-it.html
3 | #+AUTHOR: lujun9972
4 | #+CATEGORY: Python Common
5 | #+DATE: [2016-06-07 二 19:04]
6 | #+OPTIONS: ^:{}
7 |
8 | 首先,上述问题是无意义的. Python是一门编程语言,当然它擅长于编程咯.
9 |
10 | When I push back, 人们常常为了一个特定的目的而发明一门语言.
11 |
12 | "你知道的. PHP是专为web而生的, 而JavaScript浏览器中运行. 那么Python是用来作什么的?"
13 |
14 | 举PHP和JavaScript的例子并没有什么意义. 这两个例子并不意味着Python只适用于解决Web领域的问题,它们只能说明PHP和JavaScript只适用于Web领域的开发.
15 |
16 | "你知道的. Objective-C 和 Swift 用于 iOS. 那么Python在哪个平台上占主要地位呢?"
17 |
18 | Python也可以运行在iOS上. 我不确定用Python创建app是否足够便利, 但即使足够便利, 我的答案也不会变: Python擅长于编程.
19 |
20 | "Java主要用于搭建web app对吧? 那么Python呢?"
21 |
22 | 好吧. 到了这一步, 这个问题已经不仅仅是无聊了,简直就是愚蠢.
23 |
24 | 我简直不想对这个问题做出回答.
25 |
26 | 若你想知道这个问题的答案,请阅读下面的链接:
27 |
28 | http://web.eecs.umich.edu/~bchandra/courses/papers/Wirth_Design.pdf
29 |
30 | 是的,这是一篇1974年写的文章,里面的有些观点已经有些过时了, 但是其中大部分的观点依然有用.
31 | 例如,虽然有争议,但强类型指针的设计已经几乎成为业界标准了. Wirth的观点依然影响着程序语言的设计.
32 |
33 | 该文的第28页中,Pascal,Modula,Oberon以及其他程序语言的发明人列举了一个程序语言的特征列表.
34 |
35 | 列表中的某些特征已经过时了,例如关于多字符集的描述,由于Unicode的出现已经不重要了
36 |
37 | 另外,这张特征列表也仅仅是针对编译语言来说的. 而Python是一门动态语言,它是解释型的. 虽然Python也有一个编译器,但是它的作用基本上也只是优化源代码而已. 若你将列表中的"编译器"替代为"运行时",则这个列表所描述的就是一个好语言应该具有哪些特性.
38 |
39 | 我喜欢这张列表因为它能解释Python以及其他许多语言为什么如此优秀. 它也解释了为什么像JavaScript(甚至也包括Ruby)这样的语言看起来那么奇怪. 此外,关于效率的一些观点是一些值得深入讨论的重要主题.
40 |
41 | 我常常提醒那些搞大数据的家伙,处理大数据时最影响效率的地方在于I/O. Python在等待数据库结果时要比java稍微有效率一些. 为什么会这样呢? 这是因为Python消耗的内存更少.
42 |
43 | 我们不要再提关于通用语言的愚蠢问题了. 我们所要做的是对各解决方案作基准测试.然后基于实际的代码来对比性能.
44 |
--------------------------------------------------------------------------------
/Others/使用Python和Excel进行交互式数据分析.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/Others/使用Python和Excel进行交互式数据分析.md
--------------------------------------------------------------------------------
/Others/使用列表推导式实现zip.md:
--------------------------------------------------------------------------------
1 | 原文:[Implementing "zip" with list comprehensions](http://blog.lerner.co.il/implementing-zip-list-comprehensions/)
2 |
3 | ---
4 |
5 | [](http://i1.wp.com/blog.lerner.co.il/wp-content/uploads/2016/08/zipper3.png)
6 |
7 | 我喜欢Python的"[zip](https://docs.python.org/3/library/functions.html#zip)"函数。我不大确定我喜欢zip什么,但是我常常发现它非常有用。在我描述"zip"做了什么之前,先让我告诉你一个例子:
8 |
9 | ```python
10 | >>> s = 'abc'
11 | >>> t = (10, 20, 30)
12 |
13 | >>> zip(s,t)
14 | [('a', 10), ('b', 20), ('c', 30)]
15 | ```
16 |
17 | 正如你所看到的,"zip"的结果是一个元组序列。(在Python 2中,你会得到一个列表。在Python 3中,你会得到一个"zip对象"。) 下标为0的元组包含s[0]和t[0]。下标为1的元组包含s[1]和t[1]。以此类推。你还可以对多于一个可迭代对象使用zip:
18 |
19 | ```python
20 | >>> s = 'abc'
21 | >>> t = (10, 20, 30)
22 | >>> u = (-5, -10, -15)
23 |
24 | >>> list(zip(s,t,u))
25 | [('a', 10, -5), ('b', 20, -10), ('c', 30, -15)]
26 | ```
27 |
28 | (你还可以用一个可迭代对象来调用zip,从而获得一堆一元素元组,但这对我来说似乎有点奇怪。)
29 |
30 | 我常常使用"zip"来将并行序列转换成字典。例如:
31 |
32 | ```python
33 | >>> names = ['Tom', 'Dick', 'Harry']
34 | >>> ages = [50, 35, 60]
35 |
36 | >>> dict(zip(names, ages))
37 | {'Harry': 60, 'Dick': 35, 'Tom': 50}
38 | ```
39 |
40 | 通过这种方式,我们可以快速方便的从两个并行序列中生成一个字典。
41 |
42 | 每当我在我的编程班中提到"zip",难免有人会问,如果一个参数比另一个参数短,会发生什么事。简单地说,最短的那个获胜:
43 |
44 | ```python
45 | >>> s = 'abc'
46 | >>> t = (10, 20, 30, 40)
47 | >>> list(zip(s,t))
48 | [('a', 10), ('b', 20), ('c', 30)]
49 | ```
50 |
51 | (如果你想要zip为较长的可迭代对象中的每个元素返回一个元组,那么使用"[itertools](https://docs.python.org/3/library/itertools.html#module-itertools)"包中的"[izip_longest](https://docs.python.org/3/library/itertools.html#itertools.zip_longest)"。)
52 |
53 | 现在,如果还有什么比"zip"更让我喜欢的,那它就是列表推导式了。所以,上周,当我的一个学生问我,是否我们可以使用列表推导式来实现"zip"的时候,我无法抗拒。
54 |
55 | 所以,我们可以怎么做呢?
56 |
57 | 首先,让我们假设,从上面,我们有两个相同长度的序列,s(一个字符串)和t(一个元组)。我们想要获得一个包含三个元组的列表. 其中一个方法是:
58 |
59 | ```python
60 | [(s[i], t[i]) # produce a two-element tuple
61 | for i in range(len(s))] # from index 0 to len(s) - 1
62 | ```
63 |
64 | 老实说,这工作良好!但我们还有可以改善它的一些方法。
65 |
66 | 首先,让我们基于推导式的"zip"选择性地处理不同大小的输入将是不错的。这意味着,不仅仅是运行range(len(s)),还运行range(len(x)),其中,x是较短的序列。我们可以通过内置函数"sorted"来做到这点,告诉它根据长度来对序列进行排序,从最短的到最长的。例如:
67 |
68 | ```python
69 | >>> s = 'abcd'
70 | >>> t = (10, 20, 30)
71 |
72 | >>> sorted((s,t), key=len)
73 | [(10, 20, 30), 'abcd']
74 | ```
75 |
76 | 在上面的代码中,我创建了一个新的元组:(s,t),然后将其作为第一个参数传递给"sorted"。给定这些输入,我们将从"sorted"获得一个列表。由于我们传递了内置的"len"函数给"key"参数,因此,如果s更短,那么"sorted"会返回[s,t],如果t更短,则返回[t,s]。这意味着,下标为0的元素保证不比其他任何序列长。(如果所有的序列都是相同的大小,那么,我们不在乎获得哪个。)
77 |
78 | 将这些一起放到我们的推导式中,获得:
79 |
80 | ```python
81 | >>> [(s[i], t[i])
82 | for i in range(len(sorted((s,t), key=len)[0]))]
83 | ```
84 |
85 | 这对于一个单一的列表推导式有点复杂,因此,我将把第二行的一部分折断成一个函数,仅仅是为了把它弄得干净些:
86 |
87 | ```python
88 | >>> def shortest_sequence_range(*args):
89 | return range(len(sorted(args, key=len)[0]))
90 |
91 | >>> [(s[i], t[i])
92 | for i in shortest_sequence_range(s,t) ]
93 | ```
94 |
95 | 现在,我们的函数接收\*args,这意味着它可以接收任何数量的序列。序列们根据长度进行排序,然后传递第一个(最短的)序列给"len",该函数计算长度,然后返回运行"range"的结果。
96 |
97 | 因此,如果最短的序列是'abc',那么结果我们会返回range(3),它为我们提供索引0, 1, 和2 —— 满足我们所需。
98 |
99 | 现在,它离真正的"zip"还有点距离:正如我上面提到的,Python 2的"zip"函数返回一个列表,但是Python 3的"zip"返回一个可迭代对象。这意味着,即使返回的列表非常的长,我们也不会因为一次性将其全部返回而占用大量的内存。我们可以用推导式来做到这点吗?
100 |
101 | 是哒,但如果我们使用列表推导式是做不到的,它总是返回一个列表。相反,如果我们使用一个生成器表达式,那么我们将会活动一个迭代器,而不是整个列表。幸运的是,创建这样一个生成器表达式只是将我们的列表推导式的[ ]替换成生成器表达式的( )这么简单而已:
102 |
103 | ```python
104 | >>> def shortest_sequence_range(*args):
105 | return range(len(sorted(args, key=len)[0]))
106 |
107 | >>> g = ((s[i], t[i])
108 | for i in shortest_sequence_range(s,t) )
109 |
110 | >>> for item in g:
111 | print(item)
112 | ('a', 10)
113 | ('b', 20)
114 | ('c', 30)
115 | ```
116 |
117 | 现在你明白了!欢迎对这些想法做进一步改善 —— 但作为同时喜欢"zip"和推导式的人,将这两个概念联系在一起是很有趣的。
118 |
--------------------------------------------------------------------------------
/Others/在Python中导入一个Docker容器.md:
--------------------------------------------------------------------------------
1 | 原文:[Import a Docker Container in Python](http://blog.deepgram.com/import-a-docker-container-in-python/)
2 |
3 | ---
4 |
5 | ### 为什么要这样做?
6 |
7 | Docker容器对于应用之间彼此隔离是非常棒的,但如果你想要它们之间彼此通信呢?例如,如果你正在用Python开发一个应用,而这个应用需要与其他语言编写的软件进行交互。有[一些技巧](https://wiki.python.org/moin/IntegratingPythonWithOtherLanguages)可以用来实现Python与其他流行语言之间低级别的互操作。但是如果你处于一种[奇怪的情况](http://stackoverflow.com/questions/546160/what-is-erlang-written-in?answertab=votes#tab-top),或使用一些复杂的传统软件,这将变得困难,甚至是不可能的。
8 |
9 | ### 想法:作为模块的容器
10 |
11 | 我们创建了[sidomo - 简单的Docker模块](https://github.com/deepgram/sidomo)*,这样,如果你让你奇怪的应用程序在任何linux环境上运行,那么你可以立即以零添加的形式从Python中调用它。
12 |
13 | 现在,大多数人使用Docker Daemon API来管理执行他们应用程序的容器。([Kubernetes](http://kubernetes.io/) / [Mesos](http://mesos.apache.org/)是这方面很好的例子)。Sidomo为容器开辟了一个全新的用例 —— 将奇怪的软件转换成在Python代码中无缝运行的漂亮且单纯的Python模块。
14 |
15 | *并不是一个[AWS服务](https://www.expeditedssl.com/aws-in-plain-english)
16 |
17 | ## 如何使用sidomo
18 |
19 | 请确保你安装了Docker,并且运行了一个Docker守护进程。如果你不确定是否是这样,那么运行`docker ps`,然后看看是否获得"CONTAINER ID ..."输出。如果你不确定如何正确设置Docker,那么你可以看看[这个链接](https://docs.docker.com/engine/installation/)或者[搜索这里](https://www.google.com/search?q=install+docker)来查找对应的方法。
20 |
21 | ### 设置Sidomo: 单行方式
22 |
23 | 你可以使用pip直接从git仓库中安装sidomo。只需在你的shell中运行下面这个命令:
24 | ```sh
25 | pip install -e 'git+https://github.com/deepgram/sidomo.git#egg=sidomo'
26 | ```
27 |
28 | ### 例子:一个简单的Hello World
29 |
30 | 这将从Ubuntu基本镜像中启动一个容器,运行`echo hello from`,然后运行`echo the other side`,然后从该过程中打印输出行。要为这个例子做准备,你需要使用一个shell命令将Ubuntu镜像拉到你的机器上。
31 |
32 | ###### shell
33 | ```sh
34 | # Get the latest Ubuntu image
35 | docker pull ubuntu
36 | ```
37 |
38 | ###### Python
39 | ```py
40 | from sidomo import Container
41 |
42 | with Container('ubuntu') as c:
43 | for line in c.run('bash -c "echo hello from; echo the other side;"'):
44 | print(line)
45 | ```
46 |
47 | ### 例子:使用sidomo处理FFMPEG
48 |
49 | 现在,让我们用sidomo实际做一些有用的东西。[FFMPEG](https://www.ffmpeg.org/)是一个比较复杂的软件,对于大多数用途,它可以有效地操纵媒体文件,但是,它不容易在不同平台上进行一致的安装,并且没有最新的Python绑定它。使用Sidomo,你可以用Docker拉取FFMPEG,并且轻松地从Python运行它。
50 |
51 | ###### shell
52 | ```py
53 | docker pull cellofellow/ffmpeg
54 | ```
55 |
56 | ###### Python
57 |
58 | 下面的例子将从URL中抓取音频,对其进行转码,并打印调试信息来证明其有效。该进程的标准输出(原始音频输出)被禁用了,因为我们只希望看到调试信息。
59 | ```py
60 | from sidomo import Container
61 | url = 'http://www2.warwick.ac.uk/fac/soc/sociology/staff/sfuller/media/audio/9_minutes_on_epistemology.mp3'
62 | with Container(
63 | 'cellofellow/ffmpeg',
64 | stdout=False
65 | ) as c:
66 | for line in c.run(
67 | 'bash -c \"\
68 | wget -nv -O tmp.unconverted %s;\
69 | ffmpeg -i tmp.unconverted -f wav -acodec pcm_s16le -ac 1 -ar 16000 tmp.wav;\
70 | cat tmp.wav\
71 | \"\
72 | ' % url
73 | ):
74 | print line
75 | ```
76 |
77 | 如果你确实想在这个进程中保存转码后的音频,那么你可以用`stderr=False`替换`stdout=False`行,然后确保将容器进程中的每一行输出(原始音频数据)写到一个文件中。
78 |
79 | ## 乐享未来
80 |
81 | 如果你必须为一些复杂的软件编写Python绑定,那么可以考虑容器化软件来代替。使用sidomo把一个容器化的应用程序转换成一个Python模块是不费劲的,并且是干净的。
82 |
83 | 如果你发现对于那些不存在合适的绑定的进程,你自己经常使用子进程与代码进行交互,那么容器化这些过程可能会让一些事情变得更简单。
84 |
85 | 
86 |
87 | 如果你在这样的一个Python应用中使用sidomo —— 它以开发了复杂依赖告终 —— 那么你可能需要将它包装在自己的容器中,并在外面从一个具有较少依赖的应用程序调用它。Sidomo也支持这样做,因为[docker支持嵌套容器](https://blog.docker.com/2013/09/docker-can-now-run-within-docker/)。你可以通过使用sidomo导入sidomo导入sidomo来做自己的软件俄罗斯套娃....
88 |
89 | 祝你好运!只要记住,你不能无限期地容器化复杂度。或者,你可以?
90 |
91 | [在github上的Sidomo](https://github.com/deepgram/sidomo)
92 |
93 | ## 为什么我们做这个?
94 |
95 | 我们创建了DeepGram API,一个用于音频和视频的搜索引擎,它使得语音可搜索。DeepGram使用一个信号处理的复杂堆栈,统计和机器学习的软件协同工作,以提供一个无缝的“上传和搜索”体验。Sidomo让我们迅速地容器化挑剔的软件,并将其与Python,我们的胶水,整合在一起。
96 |
97 | 你可以在[www.deepgram.com](http://www.deepgram.com)上获得一个带有API访问权限的帐户。该帐户每月可以进行40小时免费上传(这个很长的路要走!)。来看看吧,让我们知道[你在想些什么](http://www.deepgram.com/contact)。
98 |
--------------------------------------------------------------------------------
/Others/复合构建器模式(Composite Builder Pattern),一个声明式编程的例子.md:
--------------------------------------------------------------------------------
1 | 原文:[The Composite Builder Pattern, an Example of Declarative Programming](http://slott-softwarearchitect.blogspot.jp/2016/03/the-composite-builder-pattern-example.html)
2 |
3 | ---
4 |
5 | 我称其为**复合构建器(Composite Builder)**模式。它可能还有其他名字,但目前我尚未见到。有可能只是因为缺乏对现有技术的研究。我怀疑,这并不是很新的模式。但我觉得,这是进行一些声明式Python编程的很酷的方法。
6 |
7 | 下面是概念。
8 |
9 | ```py
10 | class TheCompositeThing(Builder):
11 | attribute1 = SomeItem("arg0")
12 | attribute2 = AnotherItem("arg1")
13 | more_attributes = MoreItems("more args")
14 | ```
15 |
16 | 它的思想在于,当我们创建**TheCompositeThing**的一个实例时,我们得到了一个复杂对象,这个对象是根据各种数据源进行构建的。我们想在下面这一类上下文中使用它:
17 |
18 | ```py
19 | with some_config_path.open() as config:
20 | the_thing = TheCompositeThing().substitute(config)
21 | print(json.dumps(the_thing))
22 | ```
23 |
24 | 我们想打开一些配置文件 —— 一些对环境唯一的文件 —— 然后以一种平滑的方式填充该复杂对象。一旦获得了这个复杂对象,它就可以以一些方式为我们所用,例如作为JSON或者YAML文档被序列化。
25 |
26 | 每一个**Item**都有一个**get()**方法,该方法接受配置所为其输入。它们进行一些计算,然后返回一个有用的结果。在某些情况下,这些计算有点落后:
27 |
28 | ```py
29 | class LiteralItem(Item):
30 | def __init__(self, value):
31 | self.value = value
32 | def get(self, config):
33 | return self.value
34 | ```
35 |
36 | 上面显示了我们如何将一个文本值赋给输出。其他值可能涉及复杂的计算,或者配置查找,或者两者的结合。
37 |
38 | ## 为什么要使用一种声明式风格?
39 |
40 | 当**TheCompositeThing**中的每个项都涉及到想到复杂,但完全独立的计算时,这种声明式风格可能很方便。因为不存在依赖性,所以**substitute()**方法可以以任何顺序为属性赋值。或者,可能,不赋值,直到真正需要它们的时候。这种模式即允许立即计算出属性值,又允许属性的即时计算。
41 |
42 | 作为一个例子,这种模式适用于构建复杂的[AWS云形成模板](https://aws.amazon.com/cloudformation/aws-cloudformation-templates/)。我们通常需要对大量的模板进行一个全局调整,以便于重建一个服务器场。而被填充的**Item**之间很少或没有依赖关系。由于项之间的模糊依赖关系,并不存在这种在一个地方进行的修改同时也出现在另一个地方的奇怪的“涟漪效应”。
43 |
44 | 我们可以对其进行扩展,使得在声明式风格中创建的每个阶段都带有一个管道。在这种更复杂的情况下,填充到该复杂对象的**Items**将具有多层次。第一层次的**Items**依赖于一个源。第二层次的**Items**依赖于第一层次的**Items**.
45 |
46 | ```py
47 | class Stage1(Builder):
48 | item_1 = Stage_1_Item("arg")
49 | item_2 = Stage_1_More("another")
50 |
51 | class Stage2(Builder):
52 | item_a = Stage_2_Item("some_arg")
53 | item_b = Stage_2_Another(355, 113)
54 | ```
55 |
56 | 然后,我们可以根据外部配置或输入创建一个**Stage1**对象。接着可以创建从该**Stage1**对象派生的**Stage2**对象。
57 |
58 | 是滴。这看起来项无用的元编程。我们可以(更简单)的这样做::
59 |
60 | ```py
61 | class Stage2:
62 | def __init__(self, stage_1, config):
63 | self.item_a = Stage_2_Item("some_arg", stage_1, config)
64 | self.item_b = Stage_2_Another(355, 113, stage_1, config)
65 | ```
66 |
67 | 我们已经急切地在`__init__()`处理阶段计算出了属性值。
68 |
69 | 或者,也许是这样::
70 |
71 | ```py
72 | class Stage2:
73 | def __init__(self, stage_1, config):
74 | self.stage_1= stage_1
75 | self.config= config
76 | @property
77 | def item_a(self):
78 | return Stage_2_Item("some_arg", self.stage_1, self.config)
79 | @property
80 | def item_b(self):
81 | return Stage_2_Another(355, 113, self.stage_1, self.config)
82 | ```
83 |
84 | 这里,我们启动即时模式,也就是说,只有在请求属性的时候,才计算属性值。
85 |
86 | ## 好处
87 |
88 | 我们已经看到了三种构建复杂对象的方法:
89 |
90 | 1. 作为独立属性,它具有一种灵活但是简洁的实现。
91 | 2. 作为在**__init__() **中使用了顺序代码的属性,它们不能保证独立性。
92 | 3. 作为使用冗余代码的属性。
93 |
94 | 哪个是倡导的方式呢?为什么这种声明式技术有趣?
95 |
96 | 我发现**声明式构建器(Declarative Builder)**模式是很方便的,因为它给我带来了以下好处。
97 |
98 | * 属性**必须**被独立构建。我们可以(毫不犹豫地)重新排列这些属性,而不用担心计算会干扰到另一个属性。
99 | * 属性可以立即构建或者即时构建。细节并不重要。我们并不通过**__init__**或者**@property**来公开实现细节。
100 | * 类定义变成了一个配置项。技术支持人员不需要具备Python深层支持就可以成功的编辑**TheCompositeThing**的定义。
101 |
102 | 我认为对于一些应用而言,这种即时的声明式编程是很有用的。它在一些情况
103 | 下表现完美,例如,当我们需要彼此隔离大量的计算,从而允许软件在不被破坏的情况进行演变的时候。
104 |
105 |
106 |
107 | 这可能是一个延伸,但我认为它显示了[依赖倒置原则](https://en.wikipedia.org/wiki/Dependency_inversion_principle)。在某种程度上,我们已经将所有依赖移到这些类中属性的可见列表。这些项类不互相依赖;它们依赖于配置,或者可能是前一个接单的复合对象。由于在类定义中不包含任何方法,因此我们可以任意修改类。比起代码,每一个**Builder**子类更像一个配置项。特别是在Python中,我们可以任意修改类,而不用管重建的痛苦。
108 |
--------------------------------------------------------------------------------
/Others/好吧,你发布了一个损坏的包到PyPI上。那么你现在要怎么办?.md:
--------------------------------------------------------------------------------
1 | 原文:[So, you’ve released a broken package to PyPI. What do you do now?](https://doughellmann.com/blog/2016/02/25/so-youve-released-a-broken-package-to-pypi-what-do-you-do-now/)
2 |
3 | ---
4 |
5 | **第一步:** 放轻松。这经常发生。
6 |
7 | **第二步:** 要意识到,这就像电子邮件一样,一旦发出去,就没有办法撤回。
8 |
9 | **第三步:** 发布一个新的,已修改的包。
10 |
11 | 近来,一些流行且重要的Python项目在发布的时候出现了一些问题。这些问题的性质和范围各异,并且对其进行谴责并不一定有建设性作用。但是,处理这些问题的方式,也就是从PyPI上删除包,最终造成这些包的维护者似乎没有意识到的一连串进一步的问题。所以我们今天说的是强调处理那些已经发布的受损软件包的最佳实践,并且希望可以避免这种事情的反复发生。
12 |
13 | 如上所述,有三个步骤来处理一个受损软件包。前两个步骤是必要的。你弄坏了一些东西,这可能令人尴尬且沮丧。人们可能会注意到。你的包越受欢迎,那么它们越有可能会,但这种事每个人都会遇到。根据它们实际上受损的程度,对于快速地解决它,你可能会感到很大的压力。受损包是很容易修复的,但在面对由于失误导致的问题时保持冷静,对于寻找合适的方式来解决这些问题是很重要的,并有助于防止损坏更多东西的反动步骤。
14 |
15 | 一个包发布到PyPI之后,它就已经在外流动。它存在于缓存服务器,代理和各种平台上,大部分是在那些你不能将其删除的地方。从PyPI中删除该软件包似乎是一个自然而然的解决方案,但它实际上会使问题变得更糟,而不是更好。从PyPI中删除该软件包不会帮助任何人运行带有显著包缓存的大型CI系统。它不会帮助任何人从这样一个高速缓存中进行到生产环境的持续部署。所有这些人仍然将使用受损包,并且如果在PyPI上该包不再可用,那么要调试其出处将会有进一步的挑战。你有关删除软件包的Tweet和IRC消息将会被人们忽视,但他们将不在社交网络渠道上关注你。
16 |
17 | 接受不能时光倒转或有效撤销受损包,会让你关于下一步该怎么做的选择限于思考第三步:如何将人们向前推进,让他们走出当前可能处于的境地。
18 |
19 | 在源代码级,如果没有立即可用的简单修复,那么最好的回应往往是将其恢复到受损之前。在该分支的当前状态之上(历史只会以一个方向移动),将其作为一个新的恢复进行提交。一旦你做到了这一点,并已经验证修复了受损包,那么是时候发布一个新版本了。你想用一个增量补丁版本作为新的版本,而不是重用现有的版本号。通过前滚版本,你将此修复推送给任何拥有一个配置管理系统的人,该配置管理系统进行与“pip install -U your-package”相同的工作。这也意味着,任何人使用你的包的无上限的要求来运行pip,将会得到新的,固定的版本,而不是旧的,坏了的版本。
20 |
21 | _该文与[Monty Taylor](http://inaugust.com)共同完成。_
22 |
--------------------------------------------------------------------------------
/Others/如何在Python中创建绿噪音.md:
--------------------------------------------------------------------------------
1 | 原文:[How to create Green noise in Python](http://www.johndcook.com/blog/2016/04/27/how-to-create-green-noise-in-python/)
2 |
3 | ---
4 |
5 | 这是我前面关于[绿噪音](http://www.johndcook.com/blog/2016/04/27/green-noise-and-barks/)的一篇博文的后续。下面,我们通过传递白噪音到Butterworth过滤器来在Python中创建绿噪音。
6 |
7 | 绿噪音位于声谱中间(巴克标度),使我们的听觉最为敏感的地方,类似于绿灯是我们的眼睛最为敏感的频率。看看前一篇博文以获得详细信息,包括关于下面的左截断和右阶段是从哪里来的解释。
8 |
9 | 下面是代码:
10 |
11 | ```python
12 | from scipy.io.wavfile import write
13 | from scipy.signal import buttord, butter, filtfilt
14 | from scipy.stats import norm
15 | from numpy import int16
16 |
17 | def turn_green(signal, samp_rate):
18 | # start and stop of green noise range
19 | left = 1612 # Hz
20 | right = 2919 # Hz
21 |
22 | nyquist = (samp_rate/2)
23 | left_pass = 1.1*left/nyquist
24 | left_stop = 0.9*left/nyquist
25 | right_pass = 0.9*right/nyquist
26 | right_stop = 1.1*right/nyquist
27 |
28 | (N, Wn) = buttord(wp=[left_pass, right_pass],
29 | ws=[left_stop, right_stop],
30 | gpass=2, gstop=30, analog=0)
31 | (b, a) = butter(N, Wn, btype='band', analog=0, output='ba')
32 | return filtfilt(b, a, signal)
33 |
34 | def to_integer(signal):
35 | # Take samples in [-1, 1] and scale to 16-bit integers,
36 | # values between -2^15 and 2^15 - 1.
37 | signal /= max(signal)
38 | return int16(signal*(2**15 - 1))
39 |
40 | N = 48000 # samples per second
41 |
42 | white_noise= norm.rvs(0, 1, 3*N) # three seconds of audio
43 | green = turn_green(white_noise, N)
44 | write("green_noise.wav", N, to_integer(green))
45 |
46 | ```
47 |
48 | 然后,下面是是它听起来的样子:
49 |
50 |
51 |
52 | ([download .wav file](http://www.johndcook.com/green_noise.wav))
53 |
54 | 让我们看看声谱,来瞧瞧它看起来是否正确。我们将使用信号的二分之一,因此当我们绘制FFT时,x轴与频率一致。
55 |
56 | ```python
57 | from scipy.fftpack import fft
58 |
59 | one_sec = green[0:N]
60 | plt.plot(abs(fft(one_sec)))
61 | plt.xlim((1500, 3000))
62 | plt.show()
63 | ```
64 |
65 | 下面是输出,与预期一样,集中在1600和3000Hz之间:
66 |
67 | 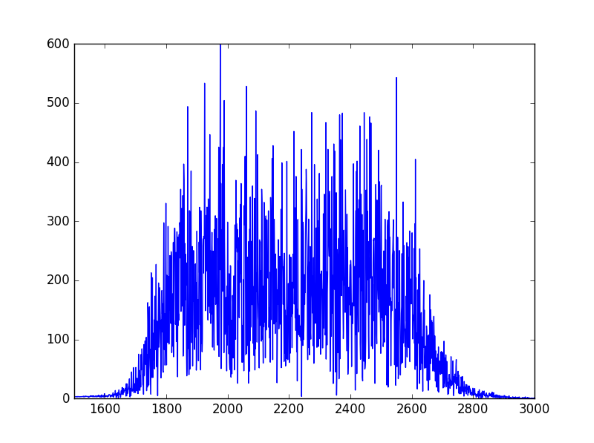
--------------------------------------------------------------------------------
/Others/实用Python:EAFP VS. LBYL.md:
--------------------------------------------------------------------------------
1 | 原文:[Idiomatic Python: EAFP versus LBYL](https://blogs.msdn.microsoft.com/pythonengineering/2016/06/29/idiomatic-python-eafp-versus-lbyl/)
2 |
3 | ---
4 |
5 | Python中的一个惯用手法,也是常常为那些使用异常被当成,好吧,异常的编程语言的人们所惊讶的是,[EAFP](https://docs.python.org/3.5/glossary.html#term-eafp): "比之请求许可,请求原谅更容易些"。简单说一下,EAFP意味着你应该只做那些期望做的事,并且当异常从操作中抛出来的时候捕获它们,然后处理之。而人们通常使用的是[LBYL](https://docs.python.org/3.5/glossary.html#term-lbyl): "三思而后行"。相比EAFP,LBYL是你搜下检查某些事情是否会成功,然后仅当你知道它能工作的时候才继续。
6 |
7 | 如果这一切在散文层面没有任何意义,那么别担心,代码将使其显而易见。让我们考虑一个例子,接收一个可能(或者可能不会)具有某个特定键的字典。在LBYL中,你将在第一次使用这个键之前检查它:
8 |
9 | ```python
10 |
11 | if "key" in dict_:
12 |
13 | value += dict_["key"]
14 |
15 |
16 | ```
17 |
18 | 这阻止了抛出一个`KeyError`异常的可能,这似乎是符合逻辑的。但是这个代码给用户的感觉是,异常情况时该字典拥有这个键,而不是该键可能不存在,这可能不是真的。没有注释说明一般情况,那么如果你不是这个代码的作者,那么你可能就不知道什么才是期望为真的。或者换句话说,这个代码似乎强调该键在该字典中确实有些特殊,而未必真的会出现这种情况或者有那么重要。
19 |
20 | 但如果该键一般会存在于该字典中,或者不应该被认为是任何形式的异常呢?EAFP让你以一种不一样的方式编写同样的代码,它淡化了该键存在于该字典中的重要性:
21 |
22 | ```python
23 |
24 | try:
25 |
26 | value += dict_["key"]
27 |
28 | except KeyError:
29 |
30 | pass
31 |
32 |
33 | ```
34 |
35 | 阅读这段代码,它告诉了你什么?似乎表明,该键通常会存在于该字典中,但有时候不是。如果该键缺失,那么这也不是什么大事,但如果它确实存在,那么应该用它来调用一个函数。这种将代码意味着什么清晰的传达给开发者对Python来说是非常重要的,因此它优于LBYL风格,后者可能错误的传达了该键的存在多么常见/罕见/重要。
36 |
37 | 有些人读到这里,会说相比之LBYL,EAFP版本更长更明显,这显然是正确的。但“显式优于隐式”这种思想是关键的[Python自身的设计方针](https://www.python.org/dev/peps/pep-0020/),因此,该代码的明确性是有意为之的。
38 |
39 | 除了潜在的明确性/冗长性,人们往往对EAFP的另一个担忧是性能。如果你是从一种触发异常是非常昂贵的编程语言来到Python的,那么这种担忧是可以理解的。但由于异常像EAFP这样用于控制流程,Python实现努力使异常开销变小,因此编写代码时,你不应该担心异常的成本。
40 |
41 | 虽然,使用EAFP要提醒一下,适用于任何处理捕获异常的代码的是,不要在你的`try`中的代码之上放置过于宽泛的代码。例如,可能像这样开始写代码是很有诱惑力的:
42 |
43 | ```python
44 |
45 |
46 |
47 | try:
48 |
49 | do_something(dict_["key"])
50 |
51 | except KeyError:
52 |
53 | pass
54 |
55 |
56 | ```
57 |
58 | 该代码的问题是,如果do_something()自身抛出了一个你不想抑制的`KeyError`,会发生什么呢?在这种情况下,你应该更明确了解你正考虑的特殊情况是什么:
59 |
60 | ```python
61 |
62 |
63 |
64 | try:
65 |
66 | value = dict_["key"]
67 |
68 | except KeyError:
69 |
70 | pass
71 |
72 | else:
73 |
74 | do_something(value)
75 |
76 |
77 | ```
78 |
79 | 使用任何你有可能抑制异常的代码块,你想要尽可能多的本地化在`try`块中执行的代码。现在,如果在像EAFP似乎过于明确的这种情况中,你更倾向于LBYL,那么使用LBYL也没有什么错误。
80 |
81 | ```python
82 |
83 |
84 |
85 | if "key" in dict_:
86 |
87 | do_something(dict["key"])
88 |
89 |
90 | ```
91 |
92 | 你在本文中应该获得的关键是,EAFP在Python中是一种合法的编码风格,并且当其有意义时,你应该随意使用它。
93 |
--------------------------------------------------------------------------------
/Others/更好的Python对象序列化方法.md:
--------------------------------------------------------------------------------
1 | 原文:[Better Python Object Serialization](https://hynek.me/articles/serialization/)
2 |
3 | ---
4 |
5 | Python标准库充满了蒙尘的宝石。其中一个允许基于参数类型的简单优雅的函数调度。这使得它对任意对象的序列化是完美的 —— 例如,web API和结构化日志的JSON化。
6 |
7 | 谁没有看过它:
8 |
9 | ```python
10 |
11 | TypeError: datetime.datetime(...) is not JSON serializable
12 |
13 | ```
14 |
15 | 虽然这应该不是一个大问题,但是它是。`json`模块 —— 从`simplejson`继承了其API —— 提供了两种序列化对象的方法:
16 |
17 | 1. 实现一个`default()` _函数_,该函数接收一个对象,然后返回[`JSONEncoder`](https://docs.python.org/3/library/json.html#json.JSONEncoder)能够理解的东东。
18 | 2. 自己实现或子类化`JSONEncoder`,然后将其当做`cls`传递给dump方法。你可以自己实现它,或者重载`JSONEncoder.default()` _方法_。
19 |
20 | 而由于替代实现想要混进去,所以它们不同程度地模仿了`json`模块的API。[1]
21 |
22 | ## 可扩展性
23 |
24 | 这两种方法的共同点是,它们是不可扩展的:未提供新类型的添加支持。你单一的`default()`备用必须知道所有你想要序列化的类型。这意味着你要么写像这样的函数:
25 |
26 | ```python
27 |
28 | def to_serializable(val):
29 | if isinstance(val, datetime):
30 | return val.isoformat() + "Z"
31 | elif isinstance(val, enum.Enum):
32 | return val.value
33 | elif attr.has(val.__class__):
34 | return attr.asdict(val)
35 | elif isinstance(val, Exception):
36 | return {
37 | "error": val.__class__.__name__,
38 | "args": val.args,
39 | }
40 | return str(val)
41 |
42 | ```
43 |
44 | 这很痛苦,因为你必须在同一个地方为所有对象添加序列化。[2]
45 |
46 | 或者,你可以尝试自己拿出解决方案,就如Pyramid的JSON渲染器在[`JSON.add_adapter`](http://docs.pylonsproject.org/projects/pyramid/en/latest/narr/renderers.html#using-the-add-adapter-method-of-a-custom-json-renderer)中做的那样,它使用了待在冷宫中的`zope.interface`的适配器注册表。[3]
47 |
48 | 另一方面,Django使用了一个`DjangoJSONEncoder`来解决,这是`json.JSONEncoder`的一个子类,并且它知道如何解码日期、时间、UUID,并保证(可以)。但除此之外,你又要靠自己了。如果你想更进一步使用Django和web API,那么,反正你可能已经使用Django REST框架了。它们提出了一个完整的[序列化系统](http://www.django-rest-framework.org/api-guide/serializers/),这个系统可不仅仅做了让数据准备好`json.dumps()`。
49 |
50 | 最后,为了完整起见,我觉得我必须提一提自己在[`structlog`](http://www.structlog.org/en/stable/)的解决方法,这一方法从一开始我就深深地讨厌:添加一个`__structlog__`方法到你的类中,它按照`__str__`返回一个序列化表示。请不要重蹈我的覆辙;标签 [软件小丑](https://softwareclown.com)。
51 |
52 | * * *
53 |
54 | 鉴于JSON相当普遍,令人惊讶的是,目前,我们只有孤立的解决方案。我个人希望的是,有一种方法,可以在一个地方统一注册序列器,但是以一种分散的方式,而无需对我的(或者更糟糕:第三方)类进行任何改变。
55 |
56 | ## 进入PEP 443
57 |
58 | 原来,对这个问题,Python 3.4想出了一个很好的解决方法,参见[PEP 443](https://www.python.org/dev/peps/pep-0443/): [`functools.singledispatch`](https://docs.python.org/3/library/functools.html#functools.singledispatch) (对于Python遗留版本,也可见[PyPI](https://pypi.org/project/singledispatch/))。
59 |
60 | 简单地说,定义一个默认的函数,然后基于第一个参数类型,注册该函数的额外版本:
61 |
62 | ```python
63 |
64 | from datetime import datetime
65 | from functools import singledispatch
66 |
67 | @singledispatch
68 | def to_serializable(val):
69 | """Used by default."""
70 | return str(val)
71 |
72 | @to_serializable.register(datetime)
73 | def ts_datetime(val):
74 | """Used if *val* is an instance of datetime."""
75 | return val.isoformat() + "Z"
76 |
77 | ```
78 |
79 | 现在,你也可以在`datetime`实例上调用`to_serializable()`,而单一的调度将选择正确的函数:
80 |
81 | ```python
82 |
83 | >>> json.dumps({"msg": "hi", "ts": datetime.now()},
84 | ... default=to_serializable)
85 | '{"ts": "2016-08-20T13:08:59.153864Z", "msg": "hi"}'
86 |
87 | ```
88 |
89 | 这给了你将你的序列器改造成你所想要的权力:和类一起,在一个单独的模块,或者和JSON相关的代码放在一起?任君选择!但是你的_类_保持干净,你的项目之间没有庞大的`if-elif-else`分支。
90 |
91 | ## 更进一步
92 |
93 | 显然,`@singledispatch`的适用范围不仅是JSON。一般的绑定不同行为到不同类型上 ,以及特别的对象序列化是普遍有用的[4]。我的一些校对人员提到,他们使用在可调用对象上使用类的`dict`,尝试了贫民窟近似和其他类似的暴行。(Ele注,原文是“Some of my proofreaders mentioned they tried a ghetto approximation using dicts of classes to callables and other similar atrocities.”。有更好的翻译,欢迎贡献~~)
94 |
95 | 换句话说,`@singledispatch`只可能是那个你一直想要的函数,虽然它一直都在。
96 |
97 | P.S. 当然,在[PyPI](https://pypi.org/project/multipledispatch/)上,还有一个`*multiple*dispatch`。
98 |
99 | ## 脚注
100 |
101 | * * *
102 |
103 | 1. 然而,有个流行的替代实现:[UltraJSON](https://github.com/esnme/ultrajson)完全不支持自定义对象序列化,而[`python-rapidjson`](https://github.com/kenrobbins/python-rapidjson)只支持`default()`函数。
104 | 2. 虽然你可以看到,使用`attrs`可管理;也许[你应该使用`attrs`](https://glyph.twistedmatrix.com/2016/08/attrs.html)!
105 | 3. 不幸的是,在从[`zope.component`](https://docs.zope.org/zope.component/)移植过来后,当前API Pyramid的使用是[无正式文档的](https://github.com/zopefoundation/zope.interface/issues/41)。
106 | 4. 有人告诉我,添加单一调度到标准库的原始动力是[`pprint`](https://docs.python.org/3.5/library/pprint.html) 的一个更加优雅的重新实现(从未发生过)。
107 |
--------------------------------------------------------------------------------
/Others/逆向工程我的酒店中的一个神秘的UDP流.md:
--------------------------------------------------------------------------------
1 | 原文:[Reverse Engineering A Mysterious UDP Stream in My Hotel](http://wiki.gkbrk.com/Hotel_Music.html)
2 |
3 | ---
4 |
5 | 大家好,我暂时会一直住在酒店里。那是那些现代的酒店之一,带有智能电视和其他连接的东东。我很好奇,于是像任何喜欢捣鼓东西的人会做的那样,打开Wireshark。
6 |
7 | 我非常惊讶的看到在2046端口有巨大的UDP流量。我查了下这个端口,但是结果没啥用。这不是一个标准端口,所以我必须手动看看它是啥。
8 |
9 | 起初,我怀疑数据可能是电视的电视流,但是包长度似乎太小了,即使是对于一个视频帧。
10 |
11 | ### 抓取数据
12 |
13 | UDP包并没有发送到我的IP,而我并没有做ARP欺骗,所以这些报文被送到每一个人那里。经过仔细检查,我发现,这些是**多播**包。这基本上意味着数据包被多个设备同时发送和接收一次。另一个要注意的事实是,所有这些包都具有相同的长度(634字节)。
14 |
15 | 我决定写一个Python脚本来保存和分析这些数据。首先,这里是我用来接收多播数据包的代码。在下面的代码中,_234.0.0.2_是我从Wireshark拿到的IP。
16 |
17 | ```python
18 |
19 | import socket
20 | import struct
21 |
22 | s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM, socket.IPPROTO_UDP)
23 | s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
24 | s.bind(('', 2046))
25 |
26 | mreq = struct.pack("4sl", socket.inet_aton("234.0.0.2"), socket.INADDR_ANY)
27 | s.setsockopt(socket.IPPROTO_IP, socket.IP_ADD_MEMBERSHIP, mreq)
28 |
29 | while True:
30 | data = s.recv(2048)
31 | print(data)
32 |
33 | ```
34 |
35 | 在此之上,我也用[binascii](https://docs.python.org/3.5/library/binascii.html)将其转换成十六进制,以便更容易读这些字节。在看着这些数以千计的包在控制台滚动后,我注意到,前15字节是相同的。这些字节可能表示协议和包/命令ID,但我只接收到相同的,所以无法验证。
36 |
37 | ### 音频是如此的LAME
38 |
39 | 它还花了我相当长的时间去看在包的尾部的`LAME3.91UUUUUUU`字符串。我怀疑这是MPEG压缩音频数据,但是将一个这样的包保存为test.mp3,并无法在mplayer之上播放,而_file_工具只将其当成`test.mp3: data`。在这个包中有明显的数据,而当_file_看到MPEG音频数据时,它应该会知道,所以我决定写另一个Python脚本来带偏移地保存这些包数据。这种方式下,它会跳过1字节保存包到文件`test1`,跳过2字节保存包到`test2`,等等。下面是我用的代码和结果。
40 |
41 | ```python
42 |
43 | data = s.recv(2048)
44 | for i in range(25):
45 | open("test{}".format(i), "wb+").write(data[i:])
46 |
47 | ```
48 |
49 | 在此之后,我运行`file test*`,然后接着看!现在,我们知道必须跳过8个字节来获得MPEG音频数据。
50 |
51 | ```python
52 |
53 | $ file test*
54 | test0: data
55 | test1: UNIF v-16624417 format NES ROM image
56 | test10: UNIF v-763093498 format NES ROM image
57 | test11: UNIF v-1093499874 format NES ROM image
58 | test12: data
59 | test13: TTComp archive, binary, 4K dictionary
60 | test14: data
61 | test15: data
62 | test16: UNIF v-1939734368 format NES ROM image
63 | test17: UNIF v-1198759424 format NES ROM image
64 | test18: UNIF v-256340894 format NES ROM image
65 | test19: UNIF v-839862132 format NES ROM image
66 | test2: UNIF v-67173804 format NES ROM image
67 | test20: data
68 | test21: data
69 | test22: data
70 | test23: DOS executable (COM, 0x8C-variant)
71 | test24: COM executable for DOS
72 | test3: UNIF v-1325662462 format NES ROM image
73 | test4: data
74 | test5: data
75 | test6: data
76 | test7: data
77 | test8: MPEG ADTS, layer III, v1, 192 kbps, 44.1 kHz, JntStereo
78 | test9: UNIF v-2078407168 format NES ROM image
79 |
80 | ```
81 |
82 | ```python
83 |
84 | while True:
85 | data = s.recv(2048)
86 | sys.stdout.buffer.write(data[8:])
87 |
88 | ```
89 |
90 | 现在,我们所需要做的事只是继续读包,跳过前8个字节,将它们写入到一个文件中,然后它应该可以完美播放。
91 |
92 | 但这个音频是啥呢?这是一个听了我的话悄悄放置的错误吗?它是关于我的房间的智能电视的一些东东吗?一些关于整个酒店系统的?只有一个办法可以找出原因。
93 |
94 | ```python
95 |
96 | $ python3 listen_2046.py > test.mp3
97 | * wait a little to get a recording *
98 | ^C
99 |
100 | $ mplayer test.mp3
101 | MPlayer (C) 2000-2016 MPlayer Team
102 | 224 audio & 451 video codecs
103 |
104 | Playing test.mp3.
105 | libavformat version 57.25.100 (external)
106 | Audio only file format detected.
107 | =====
108 | Starting playback...
109 | A: 3.9 (03.8) of 13.0 (13.0) 0.7%
110 |
111 | ```
112 |
113 | ### 启示/失望
114 |
115 | 搞神马嘛?简直不敢相信我花时间在这上面。这只是电梯音乐。它在酒店走廊的电梯周围播放。哦,好吧,至少现在我可以从我的房间听到它了。
116 |
117 |
118 |
--------------------------------------------------------------------------------
/Python Common/2016年的Python 3.md:
--------------------------------------------------------------------------------
1 | 原文:[Python 3 in 2016](https://hynek.me/articles/python3-2016/)
2 |
3 | ---
4 | 关于2016年的Python 3的完全坊间观点。基于我最近的经历,观察,以及与Python社区的其他成员的交流。
5 |
6 | 今天,我做了我[第一个tweet storm](https://twitter.com/hynek/status/699928792752594944),然后人们让我正确的把它写出来,所以我们开始吧。
7 |
8 | ## 阴云密布
9 |
10 | 综观PyPI的下载统计[1](#fn:4b446252e182cd944dcdae12180464ab:skewed),Python 3的情况似乎[阴云密布](https://www.reddit.com/r/Python/comments/45sm94/what_are_the_most_recent_python_3_vs_python_2/czzy5wa):所有的Python 3版本加起来大约才像Python 2.6一样流行,因此任何人都不应再使用。
11 |
12 | 而且,如果我的公司有任何迹象显示,Python 2中的应用程序不可能被移植到Python 3上。为什么它们要呢?Python 2直到2020年都会得到官方支持。谁知道这些应用程序届时是否还会以那样的形式存在。
13 |
14 | 这些应用程序的数目是巨大的。而且在可预见的未来里,这一数字将不会显著下跌。没有人愿意去碰他们的工作系统[2](#fn:4b446252e182cd944dcdae12180464ab:easy)。
15 |
16 | ## 非常平缓的改善
17 |
18 | **但是**.
19 |
20 | PyPI上绝大多数重要的库都是混合的:它们同时支持Python 2和3。现在,发布一个只支持Python 2的库这种情况是非常罕见的。(我宁愿偶尔看到反面)。
21 |
22 | 新的项目和应用程序被频繁地基于Python 3启动[3](#fn:4b446252e182cd944dcdae12180464ab:nail)。例如,[从PHP移到Python 3的Patreon](https://talkpython.fm/episodes/show/14/moving-from-php-to-python-3-with-patreon)。为什么不呢?除非你打算使用[PyPy](http://pypy.org/py3donate.html)(一些罕见且低级别的unicode的边缘情况除外),客观来说,它是更好的语言。新项目多久开始一次?在微服务的现今,它可能比你所想的还要频繁。
23 |
24 | **鉴于库的状态,Python的2和3之间选择是个人的偏好和公司政策的问题,而不是技术原因。**
25 |
26 | 尤其是那些后来加入我们的,并且对Python 3没有根深蒂固的反感的社区成员,对他们来说,使用Python 3是很自然的。我已经在Twisted和Pyramid社区都看到这种情况了。在Twisted真正适用于Python 3之前,人们就已经试图在Python 3上使用它了。Django - 使用Python的主要原因之一 - 自身通过在其文档中使用Python 3的语法来制造Python 3使用的印象。
27 |
28 | 现在,还记得在过去的几个月和几年中,Python社区有什么巨大的增长吗。在某些时候,当保守派大吼大叫时,那些人要负责。这种转变已经开始了。
29 |
30 | 
31 |
32 | `asyncio`是另一个有趣的话题。令我感到惊讶的是,Python社区的那个小角落是如此的活跃(虽然主要是讲俄语的国家 🙂)。它当之无愧,所以我可能会加入。所以,对于Python 3.4是第一个被广为接受的版本这件事,我并不感到惊讶。
33 |
34 | ## 结论
35 |
36 | 这些都意味着什么?
37 |
38 | 这意味着,对于可预见的未来,我们不得不为PyPI编写混合库[4](#fn:4b446252e182cd944dcdae12180464ab:py26)。
39 |
40 | 它意味着,由于为数不少的只支持Python 2的代码的编写,PyPI下载统计数据将不会在短期内变得好看,而Python 2.7仍然在不断增长。
41 |
42 | 但是,这也意味着Python 3正在增长。新一代的Python开发者喜欢它,他们不明白为什么有人想在每个类中编写`object`的子类。
43 |
44 | 最后,它意味着Python 3不是Python的死亡。但是,我们将在相当长一段时间内与两个版本的Python共存。如果我们能够在此基础上不杀死对方,那么每个人都会没事。
45 |
46 |
47 | * * *
48 |
49 | 现在,我们都用Python 3开始我们的项目,而且并不想回去再用Python 2.所以,停止争论,加入我们吧。我想你会喜欢它的。
50 |
51 | ## 脚注
52 |
53 | * * *
54 |
55 | 1. 这些数字必须有保留的对待。镜像,缓存,系统包等等以不可预知的方式使得结果出现偏差。
56 | [↩︎](#fnref:4b446252e182cd944dcdae12180464ab:skewed)
57 | 2. 虽然,移植到Python 3并且具有一个很好的测试套件并不是一个[大问题](http://python3porting.com)。但是很少有好的测试套件,甚至更少人有动力投入任何时间进去。
58 | [↩︎](#fnref:4b446252e182cd944dcdae12180464ab:easy)
59 | 3. 对不起,我不能对此进行量化。这只是在我身边听到的普遍想法。这个讨论其中一个最大的问题是,几乎不可能量化任何东西。
60 | [↩︎](#fnref:4b446252e182cd944dcdae12180464ab:nail)
61 | 4. 虽然,我想邀请你[加入我们](https://twitter.com/hynek/status/699886071451144192), [弃用Python 2.6](https://twitter.com/hynek/status/699921119600574464)。
62 | [↩︎](#fnref:4b446252e182cd944dcdae12180464ab:py26)
63 |
--------------------------------------------------------------------------------
/Python Common/3.5.1/README.md:
--------------------------------------------------------------------------------
1 | # Python 3.5.1 documentation
2 | Python 3.5.1文档,
3 | 最后更新时间:2015-12-15
4 |
5 | **文档部分:**
6 |
7 | [What's new in Python 3.5?](https://docs.python.org/3/whatsnew/3.5.html)
8 | or all "What's new" documents since 2.0
9 |
10 | [Tutorial](https://docs.python.org/3/tutorial/index.html)
11 | 从这里开始。[中文版](http://www.pythondoc.com/pythontutorial3/index.html)
12 |
13 | [Library Reference](https://docs.python.org/3/library/index.html)
14 | keep this under your pillow
15 |
16 | [Language Reference](https://docs.python.org/3/reference/index.html)
17 | describes syntax and language elements
18 |
19 | [Python Setup and Usage](https://docs.python.org/3/using/index.html)
20 | how to use Python on different platforms
21 |
22 | [Python HOWTOs](https://docs.python.org/3/howto/index.html)
23 | in-depth documents on specific topics
24 |
25 | [Installing Python Modules](https://docs.python.org/3/installing/index.html)
26 | installing from the Python Package Index & other sources
27 |
28 | [Distributing Python Modules](https://docs.python.org/3/distributing/index.html)
29 | publishing modules for installation by others
30 |
31 | [Extending and Embedding](https://docs.python.org/3/extending/index.html)
32 | tutorial for C/C++ programmers
33 |
34 | [Python/C API](https://docs.python.org/3/c-api/index.html)
35 | reference for C/C++ programmers
36 |
37 | [FAQs](./faq)
38 | frequently asked questions (with answers!)
39 |
40 | **Indices and tables:**
41 |
42 | [Global Module Index](https://docs.python.org/3/py-modindex.html)
43 | quick access to all modules
44 |
45 | [General Index](https://docs.python.org/3/genindex.html)
46 | all functions, classes, terms
47 |
48 | [词汇表](./glossary.md)
49 | 那些最重要的术语解释
50 |
51 | [Search page](https://docs.python.org/3/search.html)
52 | search this documentation
53 |
54 | [Complete Table of Contents](https://docs.python.org/3/contents.html)
55 | lists all sections and subsections
56 |
57 | **Meta information:**
58 |
59 | [Reporting bugs](https://docs.python.org/3/bugs.html)
60 |
61 | [关于文档](https://docs.python.org/3/about.html)
62 |
63 | [历史和Python许可证](https://docs.python.org/3/license.html)
64 |
65 | [版权](https://docs.python.org/3/copyright.html)
--------------------------------------------------------------------------------
/Python Common/3.5.1/faq/README.md:
--------------------------------------------------------------------------------
1 | # Python常见问题集
2 |
3 | 原文: [Python Frequently Asked Questions](https://docs.python.org/3/faq/index.html)
4 |
5 | * [Python一般问题 FAQ](https://docs.python.org/3/faq/general.html)
6 | * [编程类FAQ](./编程类FAQ.md)
7 | * [设计和历史类 FAQ](./设计和历史类 FAQ.md)
8 | * [库及扩展类 FAQ](./库及扩展类 FAQ.md)
9 | * [扩展/嵌入类 FAQ(未完成)](./扩展或嵌入类 FAQ.md)
10 | * [Windows上的Python FAQ](https://docs.python.org/3/faq/windows.html)
11 | * [图形用户界面 FAQ](https://docs.python.org/3/faq/gui.html)
12 | * [“为什么在我的电脑上安装Python?” FAQ](https://docs.python.org/3/faq/installed.html)
13 |
--------------------------------------------------------------------------------
/Python Common/Lists和Tuples大对决.md:
--------------------------------------------------------------------------------
1 | 原文:[Lists vs. Tuples](http://nedbatchelder.com/blog/201608/lists_vs_tuples.html "Link to this post" )
2 |
3 | ---
4 |
5 | 常见的Python初学者问题:列表和元组之间有何区别?
6 |
7 | 答案是,有两个不同的差异,以及两者之复杂的相互作用。这就是技术差异和文化差异。
8 |
9 | 首先:它们有相同之处:列表和元组都是容器,即对象序列:
10 |
11 | ```python
12 | >>> my_list = [1, 2, 3]
13 | >>> type(my_list)
14 |
15 | >>> my_tuple = (1, 2, 3)
16 | >>> type(my_tuple)
17 |
18 | ```
19 |
20 | 它们任意一个的元素可以是任意类型,甚至在一个单一序列中。它们都维护元素的顺序(不像集合和字典那样)。
21 |
22 | 现在是不同之处。列表和元组之间的技术差异是,列表示可变的(可以被改变),而元组是不可变的(不可以被改变)。这是Python语言对它们的唯一区分:
23 |
24 | ```python
25 | >>> my_list[1] = "two"
26 | >>> my_list
27 | [1, 'two', 3]
28 | >>> my_tuple[1] = "two"
29 | Traceback (most recent call last):
30 | File "", line 1, in
31 | TypeError: 'tuple' object does not support item assignment
32 | ```
33 |
34 | 这就是列表和元组之间的唯一技术差异,虽然它体现在几个方面。例如,列表有一个.append()方法,用以添加更多元素到列表中,而元组并没有:
35 |
36 | ```python
37 | >>> my_list.append("four")
38 | >>> my_list
39 | [1, 'two', 3, 'four']
40 | >>> my_tuple.append("four")
41 | Traceback (most recent call last):
42 | File "", line 1, in
43 | AttributeError: 'tuple' object has no attribute 'append'
44 | ```
45 |
46 | 元组并不需要.append()方法,因为你不可以修改元组。
47 |
48 | 文化差异是关于列表和元组的实际使用的:当你有一个未知长度的同质序列时使用列表;当你预先知道元素个数的时候使用元组,因为元素的位置语义上是显著的。
49 |
50 | 例如,假设你有一个函数,它查找目录下以*.py结尾的文件。它应该返回一个列表,因为你并不知道会找到多少个文件,而它们都具有相同的语义:只是你找到的另一个文件。
51 |
52 | ```python
53 | >>> find_files("*.py")
54 | ["control.py", "config.py", "cmdline.py", "backward.py"]
55 | ```
56 |
57 | 另外,假设你需要存储五个值来表示气象观测站的位置:id, city, state, latitude和longitude。那么较之列表,元组更适合:
58 |
59 | ```python
60 | >>> denver = (44, "Denver", "CO", 40, 105)
61 | >>> denver[1]
62 | 'Denver'
63 | ```
64 |
65 | (目前,不要讨论使用类来替代)这里,第一个元素是id,第二个元素是city,以此类推。位置决定了意思。
66 |
67 | 将文化差异加之于C语言上,列表像数组,元组像结构。
68 |
69 | Python有一个namedtuple工具,它可以让意思更加明确:
70 |
71 | ```python
72 | >>> from collections import namedtuple
73 | >>> Station = namedtuple("Station", "id, city, state, lat, long")
74 | >>> denver = Station(44, "Denver", "CO", 40, 105)
75 | >>> denver
76 | Station(id=44, city='Denver', state='CO', lat=40, long=105)
77 | >>> denver.city
78 | 'Denver'
79 | >>> denver[1]
80 | 'Denver'
81 | ```
82 |
83 | 元组和列表之间的文化差异一个聪明的总结是:元组是没有名字的namedtuple。
84 |
85 | 技术差异和文化差异是一个不稳定的联盟,因为有时它们相左。为什么同源序列应该可变,而异源序列不是?例如,因为namedtuple是一个元组,它是不可变的,所以我不可以修改我的气象站:
86 |
87 | ```python
88 | denver.lat = 39.7392
89 | Traceback (most recent call last):
90 | File "", line 1, in
91 | AttributeError: can't set attribute
92 | ```
93 |
94 | 有时,技术方面的考虑覆盖了文化因素。你不能把一个列表当做一个字典键,因为只有不可变值才能够被哈希,所以只有不可变值才能作为键。要把一个列表当成键,你可以将其转换成元组:
95 |
96 | ```python
97 | d = {}
98 | >>> nums = [1, 2, 3]
99 | >>> d[nums] = "hello"
100 | Traceback (most recent call last):
101 | File "", line 1, in
102 | TypeError: unhashable type: 'list'
103 | >>> d[tuple(nums)] = "hello"
104 | >>> d
105 | {(1, 2, 3): 'hello'}
106 | ```
107 |
108 | 另一个技术和文化的冲突是:Python自身在使用列表更有意义的情况下使用了元组。当你使用*args定义一个函数时,args作为元组传递,即使据Python所知,值的位置并不重要。你可能会说,它是元组,因为你不可以改变你所传递的值,但这只是较之文化,更重视了技术差异。
109 |
110 | 我知道,我知道,在*args中,位置可能是重要的,因为它们是位置参数。但在一个接受*args,然后将其传递给另一个函数的函数中,它只是一个参数序列,和另一个没什么不同,而它们的数量在调用之间可以不同。
111 |
112 | 这里,Python使用元组,是因为较之列表,它们的空间效率会多一点。列表是过度分配的,以便让附加更快些。这说明Python务实的一面:因地制宜使用数据结构,而不是纠结于*args的列表/元组语义。
113 |
114 | 在大多数情况下,你应该基于文化差异选择是使用列表还是元组。想想你的数据的含义。如果基于你的程序在现实世界中遇到的,它会有不同的长度,那么可能要使用列表。如果你知道在你写代码的时候,第三个元素意味着什么,那么可能要使用元组。
115 |
116 | 另一方面,函数式编程强调不可变数据结构,作为一种避免难以推理代码这一副作用的方式。如果你是一个函数式编程粉,那么你可能会因为不可变性喜欢元组。
117 |
118 | 所以:你应该使用元组还是列表呢?答案是:它并不总是一个简单的答案。
--------------------------------------------------------------------------------
/Python Common/Python 201 – 什么是双端队列(deque).md:
--------------------------------------------------------------------------------
1 | 原文:[Python 201 – What’s a deque?](http://www.blog.pythonlibrary.org/2016/04/14/python-201-whats-a-双端队列(deque)/)
2 |
3 | ---
4 |
5 | 根据Python文档, **双端队列(deque)** 是“栈和队列的泛化”。它们显然是“deck”,这是“双端队列(double-ended queue)”的简称。它们也是Python中的列表(list)的一个替代容器。双端队列(deque)是线程安全的,并支持向双端队列(deque)两端内存高效地追加(append)或弹出(pop)元素。列表为快速地固定长度的操作进行了优化。你可以从Python文档中获得所有的相关细节。一个双端队列(deque)接受一个**maxlen**参数,这个参数设置了该双端队列(deque)的范围。否则,该双端队列(deque)将增长到任意大小。当一个有界的双端队列(deque)满了,任何新元素添加操作将会导致相同数量的元素从另一端弹出。
6 |
7 | 作为一般规则,如果你需要快速追加或快速弹出,那么使用一个双端队列(deque)吧。如果你需要快速的随机访问,那么使用列表。让我们花一些时间来看看你会怎么创建并使用一个双端队列(deque)。
8 | ```py
9 | >>> from collections import 双端队列(deque)
10 | >>> import string
11 | >>> d = 双端队列(deque)(string.ascii_lowercase)
12 | >>> for letter in d:
13 | ... print(letter)
14 | ```
15 |
16 | 这里,我们从collections模块导入了双端队列(deque),还导入了**string**模块。要真正创建一个双端队列(deque)的实例,需要传递一个可迭代对象给它。在这种情况下,我们传递了**string.ascii_lowercase**,它将返回一个字母表中所有的小写字母组成的列表。最后,我们遍历这个双端队列(deque),并打印出每个元素。现在,让我们看看双端队列(deque)拥有的一些方法。
17 | ```py
18 | >>> d.append('bork')
19 | >>> d
20 | 双端队列(deque)(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l',
21 | 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x',
22 | 'y', 'z', 'bork'])
23 | >>> d.appendleft('test')
24 | >>> d
25 | 双端队列(deque)(['test', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j',
26 | 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u',
27 | 'v', 'w', 'x', 'y', 'z', 'bork'])
28 | >>> d.appendleft('test')
29 | >>> d
30 | 双端队列(deque)(['test', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j',
31 | 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u',
32 | 'v', 'w', 'x', 'y', 'z', 'bork'])
33 | >>> d.rotate(1)
34 | >>> d
35 | 双端队列(deque)(['bork', 'test', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h',
36 | 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's',
37 | 't', 'u', 'v', 'w', 'x', 'y', 'z'])
38 | ```
39 |
40 | 让我们打破这一点。首先,我们添加一个字符串到双端队列(deque)的右端。然后,我们又追加字符串到双端队列(deque)的左侧。最后,我们调用**rotate**并传递给它一个参数`1`,从而使它向右旋转一次。换句话说,它会导致一个元素旋转离开右端并插入到前方。你可以传递一个负数,使双端队列(deque)向左旋转。
41 |
42 | 让我们来看看一个例子以结束这一节,这个例子基于Python文档中的一些东东:
43 | ```py
44 | from collections import 双端队列(deque)
45 |
46 |
47 | def get_last(filename, n=5):
48 | """
49 | Returns the last n lines from the file
50 | """
51 | try:
52 | with open(filename) as f:
53 | return 双端队列(deque)(f, n)
54 | except OSError:
55 | print("Error opening file: {}".format(filename))
56 | raise
57 | ```
58 |
59 | 此代码很大程度上与Linux的**tail**程序以相同的方式工作。下面,我们传递一个文件名以及一个表示我们想要返回的行数的`n`给我们的脚本。双端队列(deque)以任何我们传递的数字,也就是`n`为界。这意味着,一旦双端队列(deque)满了,当新的行被读入并加入到双端队列(deque)中,那么较旧的行会被从另一端弹出并丢弃。我还在一个简单的异常处理器中用**with**语句来打开该文件,因为它真的很容易传递一个畸形的路径。这将捕获哪些不存在的文件。
60 |
61 | ### 总结
62 |
63 | 现在,你知道了Python的双端队列(deque)的基本知识了。collections模块中还有这么一个方便的小工具。虽然我本人从未需要过这个特殊的集合,但是它仍然是一个有用的结构。我希望在你自己的代码中,你会发现它的一些很棒的用途。
64 |
--------------------------------------------------------------------------------
/Python Common/Python 陷阱:Join vs Concat.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Gotcha: Join vs Concat](https://andrewwegner.com/python-gotcha-join-vs-concat.html)
2 |
3 | ---
4 |
5 | ## 问题[¶](#the-problem "Permanent link")
6 |
7 | 这是一个有点人为的示例,用来演示问题所在。我需要创建一个包含 100,000 个 `word` 的字符串。生成该字符串的最快方法是什么呢?我可以使用字符串连接(只是用 `+` 将字符串相互连接)。我还可以在包含 100,000 个元素的列表上使用 [`join`](https://docs.python.org/3/library/stdtypes.html#str.join)。
8 |
9 | 为此,我的示例代码如下
10 |
11 | ```py
12 | def concat_string(word: str, iterations: int = 100000) -> str:
13 | final_string = ""
14 | for i in range(iterations):
15 | final_string += word
16 | return final_string
17 |
18 | def join_string(word: str, iterations: int = 100000) -> str:
19 | final_string = []
20 | for i in range(iterations):
21 | final_string.append(word)
22 | return "".join(final_string)
23 | ```
24 |
25 | ## 结果[¶](#results "Permanent link")
26 |
27 | 在 `concat_string` 中,我迭代了 100,000 个元素,每次迭代都将 我的 `word` 添加到字符串末尾。在 `join_string` 中,我在每次迭代时将我的 `word` 附加到列表中,然后在末尾将列表连接成字符串。
28 |
29 | 通过内置分析器 (`cProfile`) 运行每个函数会显示这两个函数的执行情况。
30 |
31 |
32 | ```sh
33 | >>> cProfile.run('concat_string("word ")')
34 |
35 | 4 function calls in 1.026 seconds
36 |
37 | Ordered by: standard name
38 |
39 | ncalls tottime percall cumtime percall filename:lineno(function)
40 | 1 0.000 0.000 1.026 1.026 :1()
41 | 1 1.026 1.026 1.026 1.026 test.py:9(concat_string)
42 | 1 0.000 0.000 1.026 1.026 {built-in method builtins.exec}
43 | 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
44 |
45 | >>> cProfile.run('join_string("word ")')
46 |
47 | 100005 function calls in 0.013 seconds
48 |
49 | Ordered by: standard name
50 |
51 | ncalls tottime percall cumtime percall filename:lineno(function)
52 | 1 0.000 0.000 0.013 0.013 :1()
53 | 1 0.009 0.009 0.013 0.013 test.py:16(join_string)
54 | 1 0.000 0.000 0.013 0.013 {built-in method builtins.exec}
55 | 100000 0.004 0.000 0.004 0.000 {method 'append' of 'list' objects}
56 | 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
57 | 1 0.000 0.000 0.000 0.000 {method 'join' of 'str' objects}
58 | ```
59 |
60 | ## 这里发生了什么?[¶](#whats-happening-here "Permanent link")
61 |
62 |
63 | `join` 比连接方法快了 75 倍以上。
64 |
65 | 为什么呢?
66 |
67 | 字符串是 Python 中不可变的对象。我在上一篇[关于默认参数的陷阱文章](https://andrewwegner.com/python-gotcha-optional-default-arguments.html)中对其进行了讨论。这种不变性意味着不能更改字符串。`concat_string` 看起来好像每次 `+` 操作都会更改字符串,但实际上,Python 必须在循环的每次迭代中创建一个新的字符串对象。这意味着有 99,999 个临时字符串值 - 几乎所有这些值都在连接操作期间的下一次迭代中被立即创建和丢弃。
68 |
69 | 另一方面,`join_string` 将 100,000 个字符串对象附加到列表中。但在此过程中仅创建了一个列表。最终的 `join` 仅对所有 100,000 个字符串进行*一次*串联。
70 |
71 |
72 |
73 | ## 这意味着什么?[¶](#what-are-the-implications-of-this "Permanent link")
74 |
75 | 虽然这是一个展示问题的人为示例,对字符串不变性的实际性能影响可能并不明显。Python 中还有其他常用的创建新字符串的地方。例如`f-strings`,`%s` 格式说明符和 `.format()`。它们中每一个都会创建一个全新的字符串。
76 |
77 | 这并不意味着您应该避免使用这些,因为只有在将*大量*字符串附加在一起的情况下,性能影响才会真正明显。但是,如果循环中有字符串格式化行,那么它就是一个需要重点关注的性能改进之处。
--------------------------------------------------------------------------------
/Python Common/Python中的lambda表达式.md:
--------------------------------------------------------------------------------
1 |
8 |
9 | 原文链接: https://allanderek.github.io/posts/python-and-lambdas/
10 |
11 | 我拥有函数式编程的经验, 因此我非常热衷于使用函数以及lambda表达式,也就是所谓的匿名函数. 然而我发现当写Python时我并不怎么使用它的lambda语法,我很好奇怎么会这样. 这么说似乎对lambda很不利 但是请记住,总体来说我并不讨厌lambda.
12 |
13 | 所有的lambda表达式都能被普通函数所代替. 问题是,什么情况下使用lambda会比定义普通函数拥有更好的可读性? 答案是几乎总是这样. 因为你要定义的函数太简单了,定义的语法反而会阻碍对内容的理解. 这些函数一般都会作为其他方法的参数来使用. 比如可以作为 list的 `sort` 方法中的 `key` 参数的值,在比较元素时使用. 如果你有一个包含item的列表,然后想根据这些item的price来排序,那么你可以这么做:
14 |
15 | ```python
16 | list_of_items.sort(key=lambda x: x.price)
17 | ```
18 |
19 | 当然可以通过定义函数的方式来代替lambda:
20 |
21 | ```python
22 | def price(item):
23 | return item.price
24 | list_of_items.sort(key=price)
25 | ```
26 |
27 | 严格来说,这两者是不等价的,因为后面这种方式会引入一个新名字到当前作用域中而前者不会, 不过我并不会仅仅为了避免污染命名空间就选择用lambda表达式.
28 |
29 | 我们甚至可以定义一个一般性的高阶函数,用于生成一个访问属性的函数.
30 |
31 | ```python
32 | def f_attr(attr_name):
33 | def attr_getter(item):
34 | return getattr(item, attr_name)
35 | return attr_getter
36 |
37 | list_of_items.sort(key=f_attr('price'))
38 | ```
39 |
40 | 这看起来要比前两个版本更糟糕, 但若你要根据不同属性进行多次排序,那么使用定义普通函数的方法会很烦:
41 |
42 | ```python
43 | def price(item):
44 | return item.price
45 | list_of_items.sort(key=price)
46 | do_something(list_of_items)
47 |
48 | def quantity(item):
49 | return item.quantity
50 | list_of_items.sort(key=quantity)
51 | do_something(list_of_items)
52 |
53 | def margin(item):
54 | return item.margin
55 | list_of_items.sort(key=margin)
56 | do_something(list_of_items)
57 | ```
58 |
59 | 相比来说使用lambda就简单多了:
60 |
61 | ```python
62 | list_of_items.sort(key=lambda x: x.price)
63 | do_something(list_of_items)
64 | list_of_items.sort(key=lambda x: x.quantity)
65 | do_something(list_of_items)
66 | list_of_items.sort(key=lambda x: x.margin)
67 | do_something(list_of_items)
68 | ```
69 |
70 | 使用f\_attr也一样:
71 |
72 | ```python
73 | list_of_items.sort(key=f_attr('price'))
74 | do_something(list_of_items)
75 | list_of_items.sort(key=f_attr('quantity'))
76 | do_something(list_of_items)
77 | list_of_items.sort(key=f_attr('margin'))
78 | do_something(list_of_items)
79 | ```
80 |
81 | 甚至还能用循环来解决:
82 |
83 | ```python
84 | for attribute in ['price', 'quantity', 'margin']:
85 | list_of_items.sort(key=f_attr(attribute))
86 | do_something(list_of_items)
87 | ```
88 |
89 | 我认为lambda版本至少在某些情况下会更有可读性. 但是函数天然具有自我说明的功能,因为函数名本身就有说明的作用,尤其那些能用lambda表达式代替的简单函数,他们的自描述性更强.
90 |
91 | 所以,最好用lambda表达式来代替那些内容足够简单,无需函数名就能充分理解意义的函数(比如单纯的访问对象属性).
92 |
93 | 不过这种情况对我来说很少见. 也许是我定义的函数还不够一般化以至于要接受其他函数作为参数吧.
94 |
--------------------------------------------------------------------------------
/Python Common/Python新增的secrets模块.md:
--------------------------------------------------------------------------------
1 |
8 |
9 | 原文链接: http://www.blog.pythonlibrary.org/2017/02/16/pythons-new-secrets-module/
10 |
11 | - [使用secrets生成令牌](#orga8639ea)
12 | - [摘要](#org42cb0a3)
13 |
14 | Python 3.6新增了一个名为 `secrets` 的模块. 他可以很直观的生成密码强度的伪随机数. 这些伪随机数足以用于管理像账户认证,令牌之类的机密信息. Python的 `random` 模块,其强度只适用于仿真与建模,而并不能胜任真正加密工作. 当然,你始终可以用os模块中的 `urandom()` 函数:
15 |
16 | ```python
17 | >>> import os
18 | >>> os.urandom(8)
19 | '\x9c\xc2WCzS\x95\xc8'
20 | ```
21 |
22 | 不过现在有了 `secrets` 模块, 我们可以创建自己的"密码强度的伪随机值"了. 下面是一个简单的例子:
23 |
24 | ```python
25 | >>> import secrets
26 | >>> import string
27 | >>> characters = string.ascii_letters + string.digits
28 | >>> bad_password = ''.join(secrets.choice(characters) for i in range(8))
29 | >>> bad_password
30 | 'SRvM54Z1'
31 | ```
32 |
33 | 在这个例子中,我们导入了 `secrets` 模块和 `string` 模块. 然后用大写字母和数字组成了一个字符串. 最后使用 `secrets` 模块的 `choice()` 方法随机地抽取出其中的字符,从而生成一个不够好的密码. 之所以说这个密码不够好是因为密码中没有特殊字符, 但实际上它已经要好过很多人使用的密码了. 还有读者指出,除此之外,这个密码也比较难记,所以很可能会被记录在纸上被人发现. 这当然也对,但是使用字典里的单词作为密码是非常不建议的,你最好习惯这种密码或者使用密码管理软件管理你的密码.
34 |
35 | ---
36 |
37 |
38 |
39 |
40 | # 使用secrets生成令牌
41 |
42 | `secrets` 模块还提供了许多生成令牌的方法. 下面来看一些例子:
43 |
44 | ```python
45 | >>>: secrets.token_bytes()
46 | b'\xd1Od\xe0\xe4\xf8Rn\x8cO\xa7XV\x1cb\xd6\x11\xa0\xcaK'
47 |
48 | >>> secrets.token_bytes(8)
49 | b'\xfc,9y\xbe]\x0e\xfb'
50 |
51 | >>> secrets.token_hex(16)
52 | '6cf3baf51c12ebfcbe26d08b6bbe1ac0'
53 |
54 | >>> secrets.token_urlsafe(16)
55 | '5t_jLGlV8yp2Q5tolvBesQ'
56 | ```
57 |
58 | `token_bytes` 函数会返回一段随机的包含了n个字节的字节字符串. 我一开始没有指定要生成多少个字节,所以Python自动为我选择了一个合适的长度. 随后我又调用了一次这个函数并且明确指定了生成8个字节长度的字符串. 然后我们又试了一把 `token_hex` 函数, 它会返回一段随机的十六进制形式的字符串. 最后的 `token_urlsafe` 函数会返回一段随机的 URL安全的文本字符串. 其文本已经用 Base64 编码过了! 要注意,在实际使用中,你应该至少生成32字节长度的令牌才能够防止被暴力破解所攻破([source](https://docs.python.org/3.6/library/secrets.html#how-many-bytes-should-tokens-use)).
59 |
60 | ---
61 |
62 |
63 |
64 |
65 | # 摘要
66 |
67 | 新增的 `secrets` 模块非常有价值. 老实说,我觉得这玩意早就该有了. 好在最终我们终于有了这么一个模块,可以用来安全地生成密码强度哦令牌和密码了. 可以花点时间看看该模块的文档,其中有一些好玩的应用例子.
68 |
69 | ---
70 |
71 | 相关阅读资料
72 |
73 | - The secrets module [documentation](https://docs.python.org/3.6/library/secrets.html)
74 | - What’s new in Python 3.6: [secrets module](https://docs.python.org/3.6/library/secrets.html#module-secrets)
75 | - PEP 506 — [Adding A Secrets Module To The Standard Library](https://www.python.org/dev/peps/pep-0506/)
76 |
--------------------------------------------------------------------------------
/Python Common/Python:声明动态属性.md:
--------------------------------------------------------------------------------
1 | 原文:[Python: Declaring Dynamic Attributes](http://amir.rachum.com/blog/2016/10/05/python-dynamic-attributes/)
2 |
3 | ---
4 |
5 | 下面的例子用的是Python 3.5,但除此之外,这篇文章同时也适用于Python 2.x和3.x
6 |
7 | 在Python中覆盖类中的`__getattr__`魔术方法,以实现动态属性,这是一种常见的解决方法。想想`AttrDict`,它是一个字典,允许如属性般访问它存储的键值对:
8 |
9 | ```python
10 | class AttrDict(dict):
11 | def __getattr__(self, item):
12 | return self[item]
13 | ```
14 |
15 | 简化的`AttrDict`允许像属性一样从它读取字典值,但是也允许_设置_键值对是非常简单的。无论如何,下面是对它的操作:
16 |
17 | ```python
18 | >>> attrd = AttrDict()
19 | ... attrd["key"] = "value"
20 | ... print(attrd.key)
21 | value
22 | ```
23 |
24 | 覆盖`__getattr__` (和`__setattr__`)是非常有用的,从简单的诸如`AttrDict`这样让你的代码更具可读性的“噱头”,到你的应用中诸如远程过程调用(RPC)这样的基本组成部分。然而,动态属性有些让人郁闷的地方 —— 在你用之前,无法看到它们!
25 |
26 | 当工作在一个交互式shell中的时候,东太熟悉有两个可用性问题。第一个是,当用户通过调用`dir`方法来试图检查对象的API时,它们并不出现:
27 |
28 | ```python
29 | >>> dir(attrd) # I wonder how I can use attrd
30 | ['__class__', '__contains__', ... 'keys', 'values']
31 | >>> # No dynamic attribute :(
32 | ```
33 |
34 | 第二个问题是自动完成 —— 如果我们用老方法将`normal_attribute`设置成一个熟悉,那么在大部分的现代shell环境下,可以自动完成(下面是来自IDLE的shell截图):
35 |
36 | 
37 |
38 | 但是通过将`dynamic_attribute`当成一个键值对插入来设置它的时候,并不会自动完成:
39 |
40 | 
41 |
42 | 然而,在实现动态属性的时候,你可以采取一个额外的方法,该方法将会让你的用户感到愉悦,并且[一石二鸟](https://www.youtube.com/watch?v=71gilEP4aJY) - **实现`__dir__`方法**。来自[文档](https://docs.python.org/2/library/functions.html#dir):
43 |
44 | > 如果对象有一个名为`__dir__()`的方法,那么这个方法将会被调用,并且必须返回属性列表。这允许实现了自定义的`__getattr__()`或者`__getattribute__()`函数的对象自定义`dir()`报告属性的方式。
45 |
46 | 实现`__dir__`是很简单的:返回该对象的属性名列表:
47 |
48 | ```python
49 | class AttrDict(dict):
50 | def __getattr__(self, item):
51 | return self[item]
52 |
53 | def __dir__(self):
54 | return super().__dir__() + [str(k) for k in self.keys()]
55 | ```
56 |
57 | 这会让`dir(attrd)`返回动态属性,以及常规属性。关于这个的一个有趣的事情是,**shell环境通常使用`__dir__`来提供自动完成选项建议!**因此,无需任何额外的努力,我们就得到了自动完成:
58 |
59 | 
60 |
61 | 在[Hacker News](https://news.ycombinator.com/item?id=12644164), [/r/Programming](https://www.reddit.com/r/programming/comments/55zuip/python_declaring_dynamic_attributes/), 或者下面的评论部分**讨论**这篇文章。
62 |
63 | **感谢**[Ram Rachum](http://ram.rachum.com)阅读了本文草稿。
--------------------------------------------------------------------------------
/Python Common/README.md:
--------------------------------------------------------------------------------
1 | # Python Common documentation
2 |
3 | 关注与Python语言本身
4 |
5 | # 目录说明
6 | - [3.5.1](./3.5.1/)
7 | python 3.5.1版本官方文档
8 |
9 | - [Python 2和3中的异常泄漏](./Python 2和3中的异常泄漏.md)
10 | - [为什么存在Python 3](./为什么存在Python 3.md)
11 | - [Python async-await教程](./Python async-await教程.md)
12 | - [hasattr()是有害的](./hasattr()是有害的.md)
13 | - [异常 - 原力的黑暗面](./异常 - 原力的黑暗面.md)
14 | - [Python Cookbook 3rd Edition Documentation(中文版)](http://python3-cookbook.readthedocs.org/zh_CN/latest/index.html)
15 | - [什么是stackless](./什么是stackless.md)
16 |
17 | 看看怎么用一种比较温和淡定的态度来看待stackless
18 |
19 | - [2016年的Python 3](./2016年的Python 3.md)
20 |
21 | 作者根据周围人的一些看法简单谈谈了2016年,Python 3何去何从
22 |
23 | - [面试中遇到的问题们……](./面试中遇到的问题们…….ipynb)
24 |
25 | 这里打算记录repo主找工作过程中遇到的python的问题君们,不定期更新O(∩_∩)O~_)
26 |
27 | - [合并Python中的字典的惯用方法](./合并Python中的字典的惯用方法.md)
28 |
29 | 作者提供了多种合并字典的方法,并从准确性和是否Pythonic来评价这些方法。同时最后还附带了对这些方法性能的测量。非常推荐!!(作者主要是在Python 3.5的基础上进行讨论的,有Python 2的小伙伴们可以自行尝试)
30 |
31 | - [惯用Python:推导](./惯用Python:推导.md)
32 |
33 | 本文讲解了在Python中,推导的来龙去脉。
34 |
35 | - [在Python 3中比较类型](./在Python 3中比较类型.md)
36 |
37 | 本文提到了如何在Python 3中对类型(注意:不是对象)进行比较(在Python 2中是可以直接进行比较)。答案是,使用元类!
38 |
39 | - [Python 201 – 什么是双端队列(deque)](./Python 201 – 什么是双端队列(deque).md)
40 |
41 | 作为collections模块中的一员,双端队列(deque)是一个能够实现栈和队列的。本文介绍了关于它的一些基本知识。
42 |
43 | - [高级asyncio测试](./高级asyncio测试.md)
44 |
45 | 本文介绍了如何使用pytest-asyncio和fixture进行高级的asyncio测试。
46 |
47 | - [惯用Python:布尔表达式](./惯用Python:布尔表达式.md)
48 |
49 | 关于python中布尔值一些更深入一点的讨论以及注意事项……
50 |
51 | - [base64-使用ASCII编码二进制数据](./base64-使用ASCII编码二进制数据.org)
52 |
53 | base64模块包含了一些函数用于将二进制数据转码为ASCII字符的子集.以便实现通过明文协议传递二进制数据.
54 |
55 | - [Lists和Tuples大对决](./Lists和Tuples大对决.md)
56 |
57 | 常见的Python初学者问题:列表和元组之间有何区别?答案是,有两个不同的差异,以及两者之复杂的相互作用。这就是技术差异和文化差异。
58 |
59 | - [解释python中的*args和**kwargs](./解释python中的*args和**kwargs.md)
60 |
61 | 我发现,大多数的Python新手程序员很难搞清楚\*args和\*\*kwargs魔术变量。所以,它们是什么呢?
62 |
63 | - [深度探索Python:让我们审查dict模块](./深度探索Python:让我们审查dict模块.md)
64 |
65 | Dictobject.c是Python的dict对象背后的模块。它非常常用,但有一些鲜为人知的秘密,这些秘密对于了解最佳性能非常有用
66 |
67 | - [不可不知的一点Python陷阱](./不可不知的一点Python陷阱.md)
68 |
69 | 在这篇文章中,它主要针对Python新手,会看到少量安全相关的小技巧;有经验的开发者可能会注意到后面的特殊性。
70 |
71 | - [Python:声明动态属性](./Python:声明动态属性.md)
72 |
73 | - [了解Python类实例化](./了解Python类实例化.md)
74 |
75 | - [Python中的assert语句](./Python中的assert语句.md)
76 |
77 | - [Python新增的secrets模块](./Python新增的secrets模块.md)
78 |
79 | - [Python中的lambda表达式](./Python中的lambda表达式.md)
80 |
81 | - [我是如何修复 Python 3.7 中一个非常老的 GIL 竞争条件的](./python37-gil-change.md)
--------------------------------------------------------------------------------
/Python Common/What's New in Python xx/New In Python:变量注解语法.md:
--------------------------------------------------------------------------------
1 |
8 |
9 | 原文地址:http://www.blog.pythonlibrary.org/2017/01/12/new-in-python-syntax-for-variable-annotations/
10 |
11 | ---
12 |
13 | [Python 3.6](https://docs.python.org/3.6/whatsnew/3.6.html#whatsnew36-pep526) 开始支持变量注解了(Syntax for variable annotations). 这是一项脱胎于 [PEP 526](https://www.python.org/dev/peps/pep-0526) 的新功能. 这个PEP将Type Hinting ([PEP 484](https://www.python.org/dev/peps/pep-0484)) 的理念变成了现实. 它可以为Python变量(包括类变量和实例变量)添加额外可选的类型声明. 请注意,添加这些注解或者说声明并不会让Python变成一门静态类型语言. 解释器依然并不关心变量的类型是什么. 但是对于Python IDE或其他类似pylink这样的工具来说,他们可以使用这些注解来进行检查,并高亮出与注解声明类型不一致的变量来.
14 |
15 | 下面通过一个简单的例子来看看它是怎么工作的:
16 |
17 | ```python
18 | # annotate.py
19 | name: str = 'Mike'
20 | ```
21 |
22 | 这是 `annotate.py` 中的内容. 其中,我们创建了一个变量: `name`, 它后面的注解说明它是一个字符串. 为变量添加注解就是在变量名后加上一个冒号以及该变量所属的类型. 如果你不想为变量赋值也可以. 下面的句子也没问题.
23 |
24 | ```python
25 | # annotate.py
26 | name: str
27 | ```
28 |
29 | 当你为一个变量添加了注解,该变量就会被添加到 module 或是 class 的 `__annotations__` 属性中. 下面让我们导入这个 `annotate` module,然后看看它的属性:
30 |
31 | ```python
32 | >>> import annotate
33 | >>> annotate.__annotations__
34 | {'name': }
35 | >>> annotate.name
36 | 'Mike'
37 | ```
38 |
39 | 你可以看到, `__annotations__` 属性返回了一个Python dict变量, 其中以变量名为key,以对应的注解类型为value.
40 |
41 | 下面让我们添加一些其他类型的注解,再看看 `__annotations__` 属性会变成怎样的.
42 |
43 | ```python
44 | # annotate2.py
45 | name: str = 'Mike'
46 |
47 | ages: list = [12, 20, 32]
48 |
49 | class Car:
50 | variable: dict
51 | ```
52 |
53 | 在这段代码中, 我们添加了一个带注解的 `list` 变量,以及一个类,这个类中又定义了一个带注解的类变量. 现在我们再导入这个 `annotate` module,然后看看 `__annotations__` 属性是怎样的:
54 |
55 | ```python
56 | >>> import annotate
57 | >>> annotate.__annotations__
58 | {'name': , 'ages': }
59 | >>> annotate.Car.__annotations__
60 | {'variable': }
61 | >>> car = annotate.Car()
62 | >>> car.__annotations__
63 | {'variable': }
64 | ```
65 |
66 | 这一次你会发现这个注解字典中包含了两项内容,而其中并没有那个类变量. 要看到这个类变量,你需要访问 `Car` 这个类中的 `__annotations__` 属性,或者先创建一个Car实例,然后再访问该实例的 `__annotations__` 属性.
67 |
68 | 有读者指出, 借助于 `typing` module,你可以让这里的例子更接近PEP484的要求. 比如下面这个例子:
69 |
70 | ```python
71 | # annotate3.py
72 | from typing import Dict, List
73 |
74 | name: str = 'Mike'
75 |
76 | ages: List[int] = [12, 20, 32]
77 |
78 | class Car:
79 |
80 | variable: Dict
81 | ```
82 |
83 | 在解释器中运行这段代码会发现如下结果:
84 |
85 | ```python
86 | import annotate
87 |
88 | In [2]: annotate.__annotations__
89 | Out[2]: {'ages': typing.List[int], 'name': str}
90 |
91 | In [3]: annotate.Car.__annotations__
92 | Out[3]: {'variable': typing.Dict}
93 | ```
94 |
95 | 你会发现大部分的type现在都来自于 `typing` module了.
96 |
97 | ---
98 |
99 |
100 |
101 |
102 | # 总结
103 | 我发现这项新功能确实很有用. 我很喜欢Python的动态特性,但这几年的C++经历也让我同时能发现明确变量类型的价值所在. 当然,Python有很强大的内省能力,要探测出一个对象的类型并不难. 但是这个项新功能能够改进静态检查器,同时让你的代码更易懂. 尤其当你需要回过头来维护一个N久没有接触过的软件时更是如此.
104 |
105 | ---
106 |
107 | 扩展阅读
108 | - PEP 526 – [Syntax for variable annotations](https://www.python.org/dev/peps/pep-0526)
109 | - PEP 484 – [Type Hinting](https://www.python.org/dev/peps/pep-0484)
110 | - Python 3.6: [What’s New](https://docs.python.org/3.6/whatsnew/3.6.html)
111 |
--------------------------------------------------------------------------------
/Python Common/What's New in Python xx/New in Python:数字字面量中的下划线.md:
--------------------------------------------------------------------------------
1 |
8 | 原文地址: http://www.blog.pythonlibrary.org/2017/01/11/new-in-python-underscores-in-numeric-literals/
9 |
10 | Python 3.6 新增了一些有趣的功能. 本文要说的这项功能脱胎于[PEP 515: Underscores in Numeric Literals](https://www.python.org/dev/peps/pep-0515). 正如其名所言,它允许你在写一个很长的数字时用下划线(代替常用的逗号)来进行分段. 即是说, `1000000` 现在可以写成 `1_000_000` 了. 下面来看一些简单的例子:
11 |
12 | ```python
13 | >>> 1_234_567
14 | 1234567
15 | >>>'{:_}'.format(123456789)
16 | '123_456_789'
17 | >>> '{:_}'.format(1234567)
18 | '1_234_567'
19 | ```
20 |
21 | 第一个例子展示了Python是如何解释用下划线分段过的数字的. 第二个例子说明了我们不仅可以使用逗号,还能使用“\_” (下划线) 来将数字格式化成字符串了. 其效果不言自明.
22 |
23 | 在进行数学运算时,有没有下划线分段都一样:
24 |
25 | ```python
26 | >>> 120_000 + 30_000
27 | 150000
28 | >>> 120_000 - 30_000
29 | 90000
30 | ```
31 |
32 | Python文档和PEP同时也有说明,你可以用下划线对任意进制的数字进行分段. 下面摘抄一些例子:
33 |
34 | ```python
35 | >>> flags = 0b_0011_1111_0100_1110
36 | >>> flags
37 | 16206
38 | >>> 0x_FF_FF_FF_FF
39 | 4294967295
40 | >>> flags = int('0b_1111_0000', 2)
41 | >>> flags
42 | 240
43 | ```
44 |
45 | 使用下划线对数字分段时需要注意以下几点:
46 |
47 | - 你只能使用单下划线进行分段,而且它的位置必须在数字之间,在进制说明符之后
48 | - 下划线不能出现在数字的首部和尾部
49 |
50 | 这真是一项有趣的新功能. 我本人目前是用不倒这个功能,希望对你用吧.
51 |
--------------------------------------------------------------------------------
/Python Common/What's New in Python xx/README.md:
--------------------------------------------------------------------------------
1 | # What's New in Python xx
2 |
3 | 关注最新python版本发布动向,记录其改动~
4 |
5 | - [New In Python:变量注解语法](./New In Python:变量注解语法.md)
6 | - [New in Python:数字字面量中的下划线](./New in Python:数字字面量中的下划线.md)
--------------------------------------------------------------------------------
/Python Common/hasattr()是有害的.md:
--------------------------------------------------------------------------------
1 | 原文:[hasattr() Considered Harmful](https://hynek.me/articles/hasattr/)
2 |
3 | ---
4 | 不要使用Python的`hasattr()`,除非你想要它奇奇怪怪,或者你正编写纯Python 3代码。
5 |
6 | 这是Python最常见的讨论之一,因此,不是不断的为每一个提供依据,而是一劳永逸:
7 |
8 | 不要:
9 | ```python
10 | if hasattr(x, "y"):
11 | print(x.y)
12 | else:
13 | print("no y!")
14 | ```
15 | 而是要这样做:
16 | ```python
17 | try:
18 | print(x.y)
19 | except AttributeError:
20 | print("no y!")
21 | ```
22 | 或者:
23 | ```python
24 | y = getattr(x, "y", None)
25 | if y is not None:
26 | print(y)
27 | else:
28 | print("no y!")
29 | ```
30 | 特别是在你处理不属于自己的类时。
31 |
32 | `hasattr()`并不比`getattr()`快,因为它经历完全相同的查找过程,然后丢掉结果。
33 |
34 | ## 为什么?
35 |
36 | 它看起来似乎差不多,而额外的行令人感到厌烦,但是在Python 2上使用接近于这样写:
37 | ```python
38 | try:
39 | print(x.y)
40 | except:
41 | print("no y!")
42 | ```
43 | 这几乎不会是你想要的,因为它隐藏了属性(property)中的错误!
44 |
45 | 例如:
46 | ```python
47 | >>> class C(object):
48 | ... @property
49 | ... def y(self):
50 | ... 0/0
51 | ...
52 | >>> hasattr(C(), "y")
53 | False
54 | ```
55 | 由于在第三方类中,你不能知道一个属性是不是一个属性(property)(或者在数月或数年后更新为一个属性),因此这是危险的。
56 |
57 | 你觉得这没啥大不了,是吗?看看这个闪闪发光的[例子](https://news.ycombinator.com/item?id=10893431)!另一个明显的影响是在属性上使用`hasattr()`并不执行它们的getter函数,这使得名字具有误导性。
58 |
59 | 对于它的价值,Python 3 使其恢复正常:
60 | ```python
61 | >>> class C:
62 | ... @property
63 | ... def y(self):
64 | ... 0/0
65 | ...
66 | >>> hasattr(C(), "y")
67 | Traceback (most recent call last):
68 | File "", line 1, in
69 | File "", line 4, in y
70 | ZeroDivisionError: division by zero
71 | ```
72 | 这使得当同时为Python 2 和 Python 3 编写混合代码时,它成为了一种边缘情况。但是,你会预期`hasattr()`抛出该错误吗?
73 |
74 | ---
75 | 细心的读者可能会问,`AttributeErrors`呢?事实上,没有办法区分一个`AttributeError`是由于属性缺失引起的,还是由一个错误的属性引起的。The outlined approaches reduce your possible errors to only that one and avoid confusing differences in behavior between Python 2 and 3.
76 |
77 | 当然,对于自己的代码,依然可以使用`hasattr()`。但你必须跟踪它,并在你的类发生改变时记得解决它。这一切都增加了不必要的精神负担,而目的只在于节省一些打字。
78 |
79 | 附注:是滴,标题很烂。因为我已经写了这篇文章,所以可以在讨论的时候向人们展示它。我没想到它会在Hacker News上排行第一,并且我同意“被认为是有害的”这种说法正在过时。只是,我并没有花费太多时间来担心,而是在起床和去上班之间进行处理;它只是突然出现在我的脑海里的第一件事。感谢您的理解。未来可能会修改它,反正这个主题是中立的。
80 |
81 | 再附注:有些人对于我敢匹配Python 3中一个很好用的函数感到很愤怒。因为没人应该写Python 2了。虽然我并不是一个讨厌Python 3的Armin,但必须承认,现今大多数的Python代码不是Python 2就是混合的。而对于一些人提及的许多混合库,我发现Python 2和3之间的行为差异甚至比Python 2自身的行为还要糟糕,而这会使人措手不及。所以,冷静下来,喝杯可可,然后移植一些一些库。
82 |
83 | ## 补充说明
84 |
85 | 1. `getattr()`例子假设属性的确实等价于其值为`None`(这是常见的)。如果你想要区别那两种情况,使用一个警戒值。
86 | 2. 至少在[CPython](https://hg.python.org/cpython/file/77d24f51effc/Python/bltinmodule.c#l1051)中。
87 |
--------------------------------------------------------------------------------
/Python Common/img/2016-02-20_221149.PNG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/Python Common/img/2016-02-20_221149.PNG
--------------------------------------------------------------------------------
/Python Common/为什么存在Python 3.md:
--------------------------------------------------------------------------------
1 | 原文: [Why Python 3 exists (Or, the whole unicode/str/bytes thing was done for a reason)](http://www.snarky.ca/why-python-3-exists)
2 |
3 | ---
4 | 这个月,我在PuPPy(普吉特海湾Python用户组)举行了一个 [Q&A](https://youtu.be/2XviXtxWKO8?list=PL4S0lvhXvdhIV2C28Ia_DeIeloBrsQBOW),这最终使得我解释了为什么Python 3应运而生,以及整个字符串/字节的处理过程。最终,我收到了一个对于这个解释的赞赏,这让我有点吃惊,因为我天真的以为人们都知道为什么创造Python 3。事后看来,假设大多数的人们,不管是Python的新手还是熟手,都已经被告知或由好奇心驱使去追寻发现关于这个问题的解释,是非常愚蠢的。因此,这篇博客目的在于简单的解释为什么Python 3存在,特别是为什么我们选择了完全向后兼容的`unicode`/`str`/`bytes`修改,因为这是向Python 3移植代码真正棘手的部分。
5 |
6 | ## Python 2中的文本和二进制数据一团糟
7 |
8 | 快速看一下,下列文字语义上表示了什么?
9 |
10 | `'abcd'`
11 |
12 | 如果你是Python 3用户,你可能会说,这是由字母"a", "b", "c"和"d"按顺序组成的字符串。
13 |
14 | 如果你是Python 2用户,你可能会说同样的话。你也有可能会说它代表了97, 98, 99, 和 100字节。这就是事实。在Python 2中有关于`str`对象代表了什么的两种正确的解释,这就导致了修改语言,从而使得单独的Python 3答案是唯一的答案。
15 |
16 | [Python之禅](https://www.python.org/dev/peps/pep-0020/)说,“应该有一个 -- 最好是只有一个 -- 明显的方法来做到”。让语言中的文字可以代表文本数据或者二进制数据是一个问题。例如,如果你从网上读到一些东西,那你则必须非常小心辨别所返回的`str`对象代表的是二进制数据还是文本数据,因为一旦这个对象离开了你的掌控,那么你就不可能知道了。或者在你的代码中,你打算将`str`对象转换成文本数据 -- 或者其他什么的 -- 但你搞砸了,并且不小心跳过了那一步,此时可能会出现一个错误。由于`str`对象可能代表了两个不同语义的类型,因此很难注意到这类型的上滑(slip-up)会在何时发生。
17 |
18 | 现在,你可能尝试并且辩解道,如果避免为文本数据使用`str`类型,而是用`unicode`取而代之,这些问题都可以Python 2中去解决。虽然这是完全正确的,但是实际上人们不会这样做。要么是人们想偷懒,所以不想劳神解码为Unicode,因为这需要额外的工作;要么人们对性能要求极高,并尽量避免解码的成本。无论是哪种,都假设你会好好编码以避免把事情搞得一团糟,然而,我们都知道,我们实际上是不完美的人类,都有可能犯错。若人们对于使用Python 2写出没有bug的代码的希望能够成真的话,那么我就不会不断的从基本每个将他们的代码移植到Python 3的人那儿听到,他们在他们的代码中发现了关于编码解码文本和二进制数据的潜在错误。
19 |
20 | 避免错误这一点是人们忘记的一个大问题。语言的简化和移除一个str对象可能代表的潜在含义会使得代码倾向于具备更少的错误。Python之禅指出,“显式胜于隐式”,是有原因的:歧义和隐性知识不是易于沟通的代码,它们容易出错,导致错误。通过迫使开发者明确地分离他们的二进制数据和文本数据,会导致某一类错误发生机率更低的更好的代码。
21 |
22 | ## 世界上的其他地方都在使用Unicode (有很好的理由)
23 |
24 | 人们有时候会忘记,Python有多老了;Guido在1989年12月开始编写Python,在1991年2月作为开源代码第一次发布。这意味着Python自身早于[1991年10月发布的Unicode标准第一卷](https://en.wikipedia.org/wiki/Unicode#History)。在几年间,Unicode标准化后创建的语言选择基于能够支持Unicode的编码来实现字符串。这使得Python 2位于这种不幸的位置,在这种情况下,它在2004年(Python 3计划开始的时候)获得了重要的关注, 但由于`unicode`类型完全是可选的,并且人们不是对所有的文本数据使用此类型,它可以说是提供了对Unicode文本最薄弱的支持。
25 |
26 | 从任何一种书面语言支持Unicode和文本是很重要的。Python是世界的语言,而不仅仅是那些支持ASCII覆盖的罗马字母的语言。这就是为什么当涉及到文本时,Python 3使它成为"Unicode或者bust";它保证了所有的Python 3代码将支持世界上的所有人,无论开发者是否明确的编写代码指出。在Python 2中,那些花时间正确的为文本数据指定unicode类型的项目和不这么做的项目之间已经出现了分裂;而在Python 3中,并不存在这样的分裂,并且免费的支持所有的语言。
27 |
28 | ## 我们假设Python会越来越受欢迎
29 |
30 | 2004年,我们开始[PEP 3100](https://www.python.org/dev/peps/pep-3100/),从而开始设计Python 3 (旁白: PEP最初的编号是3000,但是我们重新将它编号为3100,这样[编号为3000的PEP](https://www.python.org/dev/peps/pep-3000/)将是关于我们如何处理Python 3开发的PEP)。我们知道,Python的人气呈上升趋势,我们希望它的增长可以继续(令人欣慰的是,确实是这样的☺)。但是,这也意味着,如果我们要解决任何设计错误,以及帮助语言继续普及,我们需要现在来做,而不是等到以后。我们假设,如果我们没有把Python 3弄糟,一旦Python 2只用于旧版项目,而不是新版,Python 3将会比Python 2持续更长的时间和被使用更多,那么在一个足够长的时间段内会有更多的Python 3代码而不是Python 2。因此,我们决定忍受Python 2/3的转型之痛,并在这个假设下创造Python 3。很显然,这需要几十年才能看到,在这个世界上,就代码行数而言,Python 3的代码是否超过了Python 2。
31 |
32 | ## 我们将不会再做此类型的向后兼容改动了
33 |
34 | 我们团队已经决定,不会再突然做像`unicode`/`str`/`bytes`这样大的变动了。在我们开始Python 3的时候,我们认为(希望)社区会跟随Python所做的,完成最后一个支持Python 2特性的发布,然后切到Python 3进行特性开发,而只Python 2版本的修正版本。这显然并未发生,而我们也吸取了教训。另外,我们并未看到这门语言的基本设计中有任何缺点以致于需要做如此大的变动。所以,希望Python 4不会做任何比可能从标准库中移除过时模块更强烈的动作了。
35 |
36 | ## 总结
37 |
38 | 这就是为什么会是这样的。我们意识到,由于在Python 2中过度的使用`str`类型,人们一直有一堆的问题,所以在Python 3中,我们通过明确地将文本数据从二进制数据中分隔开来来解决它们。另外,让所有的文本数据自动的支持Unicode,有助于项目更容易与多种语言一起工作。而当我们这样做的时候还,我们进行了更改,因为我们觉得越快越好。我们构造了过渡,认为社区将跟随我们留下Python 2,但是事实并非如此,取而代之的,我们已经花费了更多的时间,并使用一个Python 2/3兼容子集来管理过渡。
--------------------------------------------------------------------------------
/Python Common/什么是stackless.md:
--------------------------------------------------------------------------------
1 | 原文:[What is Stackless?](http://cosmicpercolator.com/2016/02/02/what-is-stackless/)
2 |
3 | ---
4 | 有时候我会有这个疑问。 而除了开始痛骂 _微线程_, _协程_, _微进程_ 和 _channel_,我从实现中拿出了下面这段重要的代码段:
5 |
6 | ### 代码:
7 | ```c
8 | /*
9 | 帧调度器将执行帧和管理帧堆栈直到“前一个”帧重新出现。
10 | The "Mario" code if you know that game :-)
11 | */
12 |
13 | PyObject *
14 | slp_frame_dispatch(PyFrameObject *f, PyFrameObject *stopframe, int exc, PyObject *retval)
15 | {
16 | PyThreadState *ts = PyThreadState_GET();
17 |
18 | ++ts->st.nesting_level;
19 |
20 | /*
21 | 帧协议:
22 | 若一个帧返回Py_UnwindToken对象,则意味着将运行一个不同的帧。
23 | 一个Py_UnwindToken出现代表的含义:
24 | The true return value is in its tempval field.
25 | We always use the topmost tstate frame and bail
26 | out when we see the frame that issued the
27 | originating dispatcher call (which may be a NULL frame).
28 | */
29 |
30 | while (1) {
31 | retval = f->f_execute(f, exc, retval);
32 | if (STACKLESS_UNWINDING(retval))
33 | STACKLESS_UNPACK(retval);
34 | /* A soft switch is only complete here */
35 | Py_CLEAR(ts->st.del_post_switch);
36 | f = ts->frame;
37 | if (f == stopframe)
38 | break;
39 | exc = 0;
40 | }
41 | --ts->st.nesting_level;
42 | /* see whether we need to trigger a pending interrupt */
43 | /* note that an interrupt handler guarantees current to exist */
44 | if (ts->st.interrupt != NULL &&
45 | ts->st.current->flags.pending_irq)
46 | slp_check_pending_irq();
47 | return retval;
48 | }
49 | ```
50 |
51 | (这个特殊的代码段来自于一个名为[stackless-tealet](https://bitbucket.org/krisvale/stackless-tealet/src/993c788a4b5d3c6bed63e9cbc5bc2df440e37bc2/Stackless/core/stacklesseval.c?at=2.7-slpt)的实验分支, 根据清晰度进行选取)
52 |
53 | ### 它是什么呢?
54 |
55 | 它是帧执行代码,是执行Python函数帧的一个顶级循环。一个“帧”是位于一个Python函数内的代码。
56 |
57 | ### 为什么它很重要呢?
58 |
59 | 在它较之**C Python**的时候,它是重要的。
60 |
61 | 普通的**C Python**使用C执行堆栈,它对它解析的Python程序的执行堆栈进行镜像。当一个Python函数**foo()**调用一个Python函数**bar()**的时候,由C函数**PyEval_EvalFrame()**的一个递归调用来触发。这意味着,为了到达C Python程序的特定执行状态,解释器需要位于递归的特定状态。
62 |
63 | 在**Stackless Python**中,C堆栈会从Python堆栈中尽可能的解耦。下一个要执行的帧位于**ts->frame**中,而在循环中执行帧链。
64 |
65 | 这会允许两个重要的事情:
66 |
67 | 1. 一个Stackless的python程序的执行状态可以容易的进行保存和恢复。所需要的仅仅是 _pickle_ 执行帧和其他运行时结构的能力(Stackless补充了pickle的功能)。Python程序的递归状态可以在无需解释器进入相同水平的C递归的情况下进行恢复。
68 | 2. 可以以任何顺序执行帧。这允许创建许多微进程以及在它们之间进行切换的代码。如果你愿意的话,还允许微线程。而你如果更喜欢协程的话,也可以使用。但它不强制使用C Python拥有的 _生成器_ 机制(事实上,可以使用这个系统更容易更优雅的实现生成器)。
69 |
70 | ### 就是这样!
71 |
72 | 因为C的堆栈已经从Python堆栈上解耦了,所以Stackless Python是 _无堆栈的_。上下文切换成为可能,执行状态的动态管理也成为了可能。
73 |
74 | ### 好吧,还有更多:
75 |
76 | * 堆栈切片:即使C堆栈阻碍了它,它也是一种更聪明的上下文切换的方法
77 | * 微进程和channel探索(原文这里是exploint,觉得应该是exploit)上下文切换执行的一种框架
78 | * 保持一切运行的一个调度器
79 |
80 | 不幸的是,Stackless Python的开发和支持在过去几年有所放缓。然而,使我感到惊讶的是,无堆栈的核心思想甚至还未被C Python所接纳。
81 |
--------------------------------------------------------------------------------
/Python Common/异常 - 原力的黑暗面.md:
--------------------------------------------------------------------------------
1 | 原文:[Exceptions - The Dark Side of the Force](http://www.holger-peters.de/exceptions-the-dark-side-of-the-force.html)
2 |
3 | ---
4 | 最近一篇博文["如果你不喜欢异常,那么你并不喜欢Python"](http://stupidpythonideas.blogspot.de/2015/05/if-you-dont-like-exceptions-you-dont.html) 来回出现,并迫使我写一个部分反驳。并不是说那篇博文完全错误,只是它并不是这个主题的要义。而如果要我补充的话,它有点武断。
5 |
6 | 原文声称,异常是Python的核心,“异常应该只用于错误,而不是正常的流程控制”的常见建议是错误的,接着解释说,异常被用于核心实现,例如迭代器协议,以及属性访问,因此,它们是该语言的核心特征。博文的一些较长部分是关于揭穿Java和C++程序员的常见误解。
7 |
8 | 粗略来讲,那篇文章中的异常被描述成非常有用的,并且极具盛赞,以至于所有关于它们的使用的批评和问题都黯然失色。
9 |
10 | # 使用异常来处理错误
11 |
12 | 这是我打心里同意barnert的一点。错误应该使用异常来传播,所以
13 | ```python
14 | def min(*lst):
15 | if not lst:
16 | raise ValueError("min(..) requires a list with at least one element")
17 | minimum = lst[0]
18 | for item in lst:
19 | if minimum > item:
20 | minimum = item
21 | return item
22 | ```
23 | 是异常的一个完全正确的使用,如果调用者的代码不能保证参数是长度大于0的列表,那么它必须检查这些异常。
24 |
25 | # 异常与值和变量是分离的
26 |
27 | 有时,我被使用像这样的模式的代码呛到:
28 | ```python
29 | result = []
30 | result.append(dosomething(bar))
31 | try:
32 | foo = bar[key][anotherkey]
33 | res = dosomething(foo)
34 | result.append(res[evenanotherkey])
35 | except KeyError:
36 | ....
37 | finally:
38 | return result
39 | ```
40 | 这段代码有许多异常相关的问题,并且展示了如何不使用异常。首先,并不清楚try块中那一个键访问会引发异常。它可能是`bar[key]`, 或者是`_[anotherkey]`, 也有可能是`res[evenanotherkey]`, 或者最后可能发生在`dosomething(foo)`。该异常机制将错误处理与值和变量分离。我的问题是:你能辨别出是否是想要从`dosomething()`中捕获KeyErrors吗?
41 |
42 | 因此,在使用异常时,对于捕获哪些异常以及不捕获哪些异常,人们必须非常小心。 使用防御性编程式(例如,`haskey()`)的检查,它是明确的,并几乎与为每一个索引操作写出单独的`try-catch`块一样对代码是“侵入性的”。
43 |
44 | ## 异常风险
45 |
46 | 所以,使用异常时,基本上有两种风险:
47 |
48 | 1. 应该捕获的异常没捕获
49 | 2. 错误的捕获异常
50 |
51 | 第一个风险当然是一个风险,但对它,我并不过于担心。第二个是我非常害怕的一个风险。你的代码中有多少函数能够抛出eyErrors, ValueError, IndexError, TypeError, 和 RuntimeError 异常呢?
52 |
53 | ## 作为Python化的goto的异常
54 |
55 | 异常可以模拟`goto`语句。当然,它们不仅跳转到堆栈的顶级,而且也跳转进语句中。在C代码中,goto是函数局部控制流和错误处理(对错误处理而言,他们更无争议)的一个主要工具:
56 | ```cpp
57 | int
58 | max_in_two_dim(double * array, size_t N, size_t M, double *out) {
59 | if (N * M == 0)
60 | goto empty_array_lbl;
61 | double max = array[0];
62 | for (int i=0; i < N; ++i) {
63 | for (int j=0; j < M; ++j) {
64 | double val = array[j * N +k];
65 | if (val != val) // NaN case
66 | goto err_lbl;
67 | if (max < val)
68 | max = val;
69 | }
70 | }
71 | return 0;
72 | nan_lbl:
73 | fprintf(stderr, "encountered a not-a-number value when unexpected");
74 | return -1;
75 | empty_array_lbl:
76 | fprintf(stderr, "no data in array with given dims");
77 | return -2;
78 | }
79 | ```
80 | 你可以使用Python中的异常来模拟这种用法。我已经见过大量这种代码:
81 | ```python
82 | def whatever(arg1, arg2):
83 | try:
84 | for i in range(N):
85 | for j in range(M):
86 | # ..
87 | if ...:
88 | raise RuntimeError("jump")
89 | return out
90 | except RuntimeError:
91 | # cleanup
92 | # ..
93 | ```
94 | 在大多数情况下,有更好的办法来避免这种模式。Python的`for`循环有一个可选的`else`分支,用来帮助避免这种跳转。然而,在循环等其他一些地方上,这种模式会出现`RuntimeError`错误。
95 |
96 | # Meta: 局内人与局外人的思考
97 |
98 | 我最不喜欢barnert的文章的地方几乎可能是可以才能够标题:“如果……,那么你并不喜欢Python”中读到的东西。这与我所听到的很多关于代码/软件/解决方法是“Pythonic”的并驾齐驱。它似乎暗示着必须站队:你是与正统的Python社区站在一边呢,还是一个局外人,即那些不够“Pythonic”的人。所有这些都对改善代码毫无帮助。
99 |
100 | # 总结
101 |
102 | 异常时Python中一个中心且强大的工具。但请小心谨慎的使用它们。不要假装它们像一个魔术棒,也不要为了显示你对Python的爱来使用它们。在要求异常使用的单一情景下使用它们。
103 |
--------------------------------------------------------------------------------
/Python Common/惯用Python:布尔表达式.md:
--------------------------------------------------------------------------------
1 | 原文:[Idiomatic Python: boolean expressions](https://blogs.msdn.microsoft.com/pythonengineering/2016/04/18/idiomatic-python-boolean-expressions/)
2 |
3 | ---
4 |
5 | 你可能会认为布尔表达式 —— 最常用于条件判读,是一点测试`if`或者`while`语句是否应该执行的代码 —— 是一个相当直接的概念,而且它们确实完全没有什么微妙之处。虽然一般概念是很简单的,但是在写布尔表达式时,有一些要遵循的惯用做法。
6 |
7 | 首先,要确保每个人都明白,是什么让某个东西被视为true或者false (有时也被称为是“真实”与否)。Python 3中,官方对[什么是true或者false的定义](https://docs.python.org/3/reference/expressions.html#booleans)是:
8 |
9 | > `False`, `None`, 所有类型的数字0, 以及空字符串和空容器 (包括字符串(string), 元组(tuple), 列表(list), 字典(dictionary), 集合(set)和frozenset)。所有其他值则被解析为true。通过提供一个`__bool__()`方法,用户定义的对象可以自定义它们的真值。
10 |
11 | Python的一点历史:在讨论[在Python 2.3中添加布尔类型](https://docs.python.org/3/whatsnew/2.3.html#pep-285-a-boolean-type)期间,对于什么是false的定义从“所有表示空的东西”变为“所有表示空的东西**和**`False`”,有些人并不喜欢,他们觉得这样有失简单性。而另一些人则认为,`False`会让代码更加清晰。结果,支持`False`概念的人更多,因此,后者赢得了这场争论。你也许也注意到了,在Python中,布尔不不是_那么_老,这就是为什么布尔可以(大部分)被当成整型,因为它能与那些简单的使用`1`和`0`来分别表示`True`和`False`的代码向后兼容。
12 |
13 | 建议的第一条就是不要过分的使用`is`比较。`is`用于[标识比较(identity comparison)](https://docs.python.org/3/reference/expressions.html#is-not),只有当表达式中的两个对象都表示同个对象的时候,它的计算结果才是`True`。不幸的是,人们总是会把标识比较和值比较混为一谈。例如,有些人意外地发现,出于对性能的考量,Python的某些实现中缓存了特定的值,导致像这样的表达式:
14 |
15 | ```python
16 | 40 + 2 is 42 # True in CPython, not necessarily in other VMs.
17 | ```
18 |
19 | 为真。但是,对数字的缓存并不是Python语言定义的一部分,它只是实现细节中一个古怪的副作用。这是一个问题,如果你想要改变Python的实现,或者碰巧认为对任何数字使用`is`都有效,这显然不对,看看当你试图这样做:
20 |
21 | ```python
22 | 2**32 is 2**32 # False.
23 | ```
24 |
25 | 结果会是`False`。换句话说,只有在你真的**真的**想要测试标识而不是值时,才使用`is`。
26 |
27 | 另一个我们看到`is`以一种非惯用方式使用的地方是直接测试`True`或者`False`,例如:
28 |
29 | ```python
30 | something() is False # Too restrictive.
31 | ```
32 |
33 | 这在技术上并不像前面的例子那样是错误的,因为`False`是一个单子 —— 就像`None`和`True`一样 —— 这意味着,实际上`False`只有一个实例可以用来比较。但是这样做的问题在于,它带来了不必要的限制。幸好Python是[鸭子类型(duck typing)](https://en.wikipedia.org/wiki/Duck_typing)的庞大的支持者,不赞成将任何API的类型指定为`True`或者`False`,因为它将一个API锁定为指定的类型。假若出于某些原因,该API变成返回了另一种类型的值,但具有相同的布尔解释,那么,这个代码会突然崩溃。取代直接检查`False`的是,该代码应该简单检查假值:
34 |
35 | ```python
36 | not something() # Just right.
37 | ```
38 |
39 | 然后,这也可以扩展到其他类型。如果你关心某样东西是否是空的,那么不要`spam == []`,而是`not spam`,以防万一那个返回`spam`值的API突然开始返回元祖,而不是列表。
40 |
41 | 而你在日复一日的代码中唯一可能合理使用`is`的时候是,和`None`一起使用。有时,你可能会碰到一个API,其中,`None`具有特殊含义,在这种情况下,你应该使用`is None`来检查那个特殊值。例如,Python中的模块具有一个[`__package__`属性](https://docs.python.org/3/reference/import.html#__package__),它存储了一个表示该模块属于哪个包的字符串。诀窍是,顶层模块,例如,不被包含在一个包中的那些模块,它们的`__package__`值为空字符串,这是假的,但却是一个有效值,但需要有一个值表示不知道`__package__`应该被设为什么值。在这种情况下,`None`被用来表示“我不知道”。这允许[计算一个模块属于哪个包的代码](https://github.com/python/cpython/blob/d0ffca8d6aa055300f7361e4bea2d4def0fca571/Lib/importlib/_bootstrap.py#L1031)使用:
42 |
43 | ```python
44 | package is None # OK when you need an "I don't know" value.
45 | ```
46 |
47 | 来检查是否包名未知 (`not package`会错误的认为`''`也表示这个意思)。但请务必确保不滥用`None`的这种用法,因为false值趋向于满足表示“我不知道”的需要。
48 |
49 | 另一点建议是,在我们自己的类中定义`__bool__()`之前三思而后行。虽然你应该明确的定义表示容器的类的方法(以助于“若为假,则为空”的概念),但是在任何情况下,你都应该停下来想想定义该方法是否真的有意义。虽然使用`__bool__()`来表示一个对象的某种状态可能是很诱人的,但是后果会出奇的影响深远,因为它意味着,突然让人不得不开始明确检查一些特殊值,例如`None`,这表示一个API是否返回一个实际值,而不是简单的依赖着所有的对象默认都为值这种条件。作为定义`__bool__()`为嘛可能是令人惊讶的一个例子,见[Python issue](https://bugs.python.org/issue13936),这里有一个多年的讨论,该讨论关于怎样定义`datetime.time()`在午夜的时候为false,其他时候都为true是错误的,以及最好如何修复这个错误 (最后, [在Python 3.5中移除](https://docs.python.org/3/whatsnew/3.5.html#changes-in-the-python-api)了`__bool__()`的实现)。
50 |
51 | 在面对一个可能的false值时,如果你发现自己需要提供一个特定的默认值,那么使用`or`将是有帮助的。`and`和`or`都不返回一个特定的布尔值,而是返回第一个确定为true值的值。对于`or`,如果它的第一个值是true,则返回第一个值,否则返回第二个值,无论第二个值是什么。这意味着,如果像这样:
52 |
53 | ```python
54 | # Use the value from something() if it is true, else default to None.
55 | spam = something() or None
56 | ```
57 |
58 | 那么,如果`something()`是true,那么`spam`将获得`something()`的返回值,否则将会被设为`None`。并且,因为`and`和`or`都是短路的,所以你可以将其与一些对象实例组合在一起,并知道除非必要,否则不会发生;
59 |
60 | ```python
61 | # Only execute AnotherThing() if something() returns a false value.
62 | spam = something() or AnotherThing()
63 | ```
64 |
65 | 不会执行`AnotherThing()`,除非`something()`返回一个false值。
66 |
67 | 最后,在可能的时候,确保使用[`any()`](https://docs.python.org/3/library/functions.html#any)和[`all()`](https://docs.python.org/3/library/functions.html#all)。这些内建函数在需要的时候是非常方便的,而将它们与生成器表达式组合使用,则是相当强大的。
--------------------------------------------------------------------------------
/Python Common/惯用Python:推导.md:
--------------------------------------------------------------------------------
1 | 原文:[Idiomatic Python: comprehensions](https://blogs.msdn.microsoft.com/pythonengineering/2016/03/14/idiomatic-python-comprehensions/)
2 |
3 | ---
4 |
5 | 很幸运,我们组有几个人已经用Python编程了相当长的一段时间(我自己现在已经使用这门语言超过15年了)。随着时间的推移,我们纷纷使用各种各样Python编程中的惯用手法,这些惯用手法可能不是很明显,或者处于各种原因并未广为人知。为了帮助大家分享一些这方面的知识,我们计划进行题为“地道的Python”的不定期的博客文章,在这里,我们选择一个主题,并提供关于它的一些小技巧。有些文章可能很长,有些则可能很短。无论哪种方式,我们都希望,你能从中得到一些有用的东西(即使是对于经验丰富的开发人员而言,因为我们可能会在这里那里讲到一点Python历史)。
6 |
7 | 对于该系列的首篇文字,我想我们可以谈谈推导。在几乎所有的编程语言中,填充一个容器的一个惯用手法就是使用`for`循环:
8 |
9 | ```py
10 | container = []
11 | for x in another_container:
12 | container.append(x**2)
13 | ```
14 |
15 | 这是用一些对象填充诸如列表的容器的一种非常简单直接的方式。但是,这种惯用手法相当常见,以至于一遍又一遍的重复变成有点讨厌。这就是为什么在Python 2.0中,[列表推导](https://docs.python.org/3/glossary.html#term-list-comprehension)被[添加到了Python中](https://docs.python.org/3/whatsnew/2.0.html#list-comprehensions):
16 |
17 | ```py
18 | container = [x**2 for x in another_container]
19 | ```
20 |
21 | (小历史:Python中的列表推导是受[Haskell中的列表推导](https://wiki.haskell.org/List_comprehension)所启发的)。列表推导已被广泛用于Python社区,因为它们提供了一种以紧凑的方式来从另一个容器中创建一个列表的简单的方式(技术上来讲,是从另一个[可迭代对象](https://docs.python.org/3/glossary.html#term-iterable),但是每种类型的容器都应该是一个可迭代对象)。得益于Python在背后暗戳戳做的一些事,列表推导也快于一个简单的`for`循环。
22 |
23 | 但你可能不知道的是,Python中还有生成器、字典和集合的推导版本。在Python 2.4中,[生成器表达式](https://docs.python.org/3/glossary.html#term-generator-expression)被[添加到了Python中](https://docs.python.org/3/whatsnew/2.4.html#pep-289-generator-expressions)。当你想通过不在内存中一次性创建一个完整的列表来节省内存,而只是想要使用需要的内存来一次创建序列中的一个项时(谁不想节省内存呢?),生成器和列表推导、生成器表达式的交叉使用是很棒的:
24 |
25 | ```py
26 | container = (x**2 for x in another_container)
27 | ```
28 |
29 | 就像列表推导,生成器表达式或多或少是下面的语法糖:
30 |
31 | ```py
32 | def _():
33 | for x in another_container:
34 | yield x**2
35 | container = _()
36 | del _
37 | ```
38 |
39 | 要真正了解这一点,你可以分别尝试下面的两个例子,但要注意,后者将需要一段时间才能完成:
40 |
41 | ```py
42 | # Use xrange() instead of range() if you're using Python 2.7.
43 | # Generator expression
44 | ('genexp' for _ in range(100000000))
45 | # List comprehension
46 | ['listcomp' for _ in range(100000000)]
47 | ```
48 |
49 | 每当你使用列表推导的时候,你应该停下来想想结果列表将如何被使用。如果该列表只是被当做一个[可迭代对象](https://docs.python.org/3/glossary.html#term-iterable) — 列表中的所有对象将被依次访问,正如在`for`循环中一样 — 那么你应该使用一个生成器表达式即可。
50 |
51 | 这也过渡到了这个惯用手法:在有可能的时候,指定你的API接受或返回一个可迭代对象,而不是一个指定的类型,例如一个列表。当你只关心一个对象序列时,指定你的API接受/返回可迭代对象,而不是一个具体的类型,例如一个列表。这一点与列表推导如何在Python 3中工作的很好的联系在一起,因为基本上生成器表达式加上对`list()`的调用,意味着返回一个可迭代对象,例如生成器表达式,并不会阻碍你的代码的用户轻松的获得一个列表,如果列表就是他们想要的话:
52 |
53 | ```py
54 | container = list(x**2 for x in another_container)
55 | ```
56 |
57 | 列表推导和生成器表达式变得如此受欢迎,以至于Python继续发展推导的概念,并[在Python 3.0中引入了字典和集合推导](https://docs.python.org/3/whatsnew/3.0.html#new-syntax) (它们被[反向移植到Python 2.7](https://docs.python.org/3/whatsnew/2.7.html#python-3-1-features))。顾名思义,字典和集合推导提供了从`for`循环创建字典和集合的语法糖。集合推导看起来像是一个生成器表达式,但它使用的是花括号:
58 |
59 | ```py
60 | container = {x**2 for x in another_container}
61 | ```
62 |
63 | 字典推导看起来像集合推导,但字典中的每一项使用冒号来分开键值,就像在字典中一样:
64 |
65 | ```py
66 | container = {x: x**2 for x in another_container}
67 | ```
68 |
69 | 现在,你可能已经注意到了在所有Python内置的容器类型中,只有元组没有推导形式。这是故意的,因为推导并不意味着只是`for`循环的语法糖。由于你不能在一个`for`循环中创建一个元组,因此元组的推导形式是没有意义的。同时,很容易根据一个生成器表达式来创建一个元组,因此这并没有丢失掉任何功能,并且与使用`for`循环来创建一个列表,然后最后将其转换成一个元组相比,并没有任何性能损失:
70 |
71 | ```py
72 | container = tuple(x**2 for x in another_container)
73 | ```
74 |
75 | 总结一下:
76 |
77 | * 列表推导是受Haskell所启发的: `[x**2 for x in another_container]`
78 | * 生成器表达式就像列表推导一样,但它用于生成器:`(x**2 for x in another_container)`
79 | * 你应该总是尝试使用生成器表达式,而不是列表推导,并且只在你确实需要一个列表的时候使用列表推导
80 | * 当你只关心对象序列时,指定你的API接受/返回可迭代对象,而不是具体的类型,例如,列表。
81 | * Python 2.7/3.0添加了集合推导:`{x**2 for x in another_container}`
82 | * Python 2.7/3.0还添加了字典推导:`{x: x**2 for x in another_container}`
83 |
84 | 希望你觉得这篇文章有用!如果是的话,请告诉我们,以便我们能够衡量是否应该在未来写更多像这样的文章。(Ele注:请拉到文章开头,找到原文地址,去反馈吧!)
85 |
--------------------------------------------------------------------------------
/Python Common/解释python中的args和kwargs.md:
--------------------------------------------------------------------------------
1 | 原文:[\*args and **kwargs in python explained](https://pythontips.com/2013/08/04/args-and-kwargs-in-python-explained/)
2 |
3 | ---
4 |
5 | 嘿,大家好呀。我发现,大多数的Python新手程序员很难搞清楚\*args和\*\*kwargs魔术变量。所以,它们是什么呢?首先,让我告诉你,写\*args或者\*\*kwargs并不是必须的。只有\*(星号)是必须的。你也可以写成\*var和\*\*vars。写成\*args和\*\*kwargs仅仅是一个惯例。所以,让我们先来看看*args。
6 |
7 | ** *args的使用 **
8 | \*args和\*\*kwargs最常用于函数定义。\*args和\*\*kwargs允许你传递数量不定的参数给一个函数。这里的变量的意思是,你事先不知道用户会传递多少个变量给你的函数,因此,在这种情况下,你使用这两个关键字。\*args是用来发送一个**非关键字**可变长度的变量列表给函数。这里是一个例子,以助你弄明白:
9 |
10 | ```python
11 | def test_var_args(f_arg, *argv):
12 | print "first normal arg:", f_arg
13 | for arg in argv:
14 | print "another arg through *argv :", arg
15 |
16 | test_var_args('yasoob','python','eggs','test')
17 | ```
18 |
19 | 这生成以下结果:
20 |
21 | ```
22 | first normal arg: yasoob
23 | another arg through *argv : python
24 | another arg through *argv : eggs
25 | another arg through *argv : test
26 | ```
27 |
28 | 我希望这解开了你的困惑。现在,让我们谈谈\*\*kwargs
29 |
30 | **\*\*kwargs的使用**
31 | \*\*kwargs运行你传递**关键字**可变长度参数给函数。如果你想要处理函数中的**命名参数**,那么你应该使用\*\*kwargs。下面是一个例子,以帮助理解它:
32 |
33 | ```python
34 | def greet_me(**kwargs):
35 | if kwargs is not None:
36 | for key, value in kwargs.iteritems():
37 | print "%s == %s" %(key,value)
38 |
39 | >>> greet_me(name="yasoob")
40 | name == yasoob
41 | ```
42 |
43 | 所以,你可以看到我们是如何在函数中处理一个关键字参数列表的。这仅仅是\*\*kwargs的基础知识,而你可以看到它多有用。现在,让我们聊聊你可以如何使用\*args和\*\*kwargs,利用一个参数列表或者参数字典来调用一个函数。
44 |
45 | **使用*args和\*\*kwargs来调用一个函数**
46 | 所以在这里,我们会看到如何使用\*args和\*\*kwargs来调用一个函数。试想,你有这么一个小函数:
47 |
48 | ```python
49 | def test_args_kwargs(arg1, arg2, arg3):
50 | print "arg1:", arg1
51 | print "arg2:", arg2
52 | print "arg3:", arg3
53 | ```
54 |
55 | 现在,你可以使用\*args或者\*\*kwargs来传递参数给这个小函数。以下是如何做到这点:
56 |
57 | ```python
58 | # first with *args
59 | >>> args = ("two", 3,5)
60 | >>> test_args_kwargs(*args)
61 | arg1: two
62 | arg2: 3
63 | arg3: 5
64 |
65 | # now with **kwargs:
66 | >>> kwargs = {"arg3": 3, "arg2": "two","arg1":5}
67 | >>> test_args_kwargs(**kwargs)
68 | arg1: 5
69 | arg2: two
70 | arg3: 3
71 | ```
72 |
73 | **使用*args、\*\*kwargs以及普通参数的顺序**
74 | 所以,如果你想要在函数中同时使用这三个,那么顺序是
75 |
76 | ```python
77 | some_func(fargs,*args,**kwargs)
78 | ```
79 |
80 | 我希望你明白了\*args和\*\*kwargs的使用。如果你对其有任何疑问或困惑,那么请随意在下面留言。要进一步研究,我推荐官方的[关于定义函数的python文档](http://docs.python.org/tutorial/controlflow.html#more-on-defining-functions),以及[stackoverflow上的\*args和**kwargs](http://stackoverflow.com/questions/3394835/args-and-kwargs)。
81 |
82 |
--------------------------------------------------------------------------------
/Python Common/让python脚本支持bash补全.org:
--------------------------------------------------------------------------------
1 | #+TITLE: 让python脚本支持bash补全
2 | #+URL: http://blog.endpoint.com/2016/04/adding-bash-completion-to-python-script.html
3 | #+AUTHOR: lujun9972
4 | #+CATEGORY: Python Common
5 | #+DATE: [2016-06-09 四 20:18]
6 | #+OPTIONS: ^:{}
7 |
8 | Bash有一项很有用的功能,就是当你在终端输入一个命令后,按两下 == 就会列出该命令支持的所有可能参数.
9 |
10 | 接下来,我会展示如何为一段python脚本也赋予这项能力. 而且, 该解决方案要足够的通用. 使得他能自动适应对python脚本选项或配置文件所做出的改动.
11 |
12 | 该脚本接受两种类型的参数. 一类是以'--'开头的标志,一类是从chef脚本中取出来的主机名称.
13 |
14 | 假设该脚本名为 =show.py= - 它的作用是显示某主机的信息. 它的使用方法为:
15 |
16 | #+BEGIN_SRC sh
17 | show.py szymon
18 | #+END_SRC
19 |
20 | 其中 =szymon= 为我的LG的名字, 是从我的chef节点定义文件中抽取出来的.
21 |
22 | 该脚本还支持许多的其他参数,例如:
23 | #+BEGIN_SRC sh
24 | show.py --cpu --memory --format=json
25 | #+END_SRC
26 |
27 | 脚本支持的参数有两种格式: 一种是简单的字符串,还有一种是以--开头的参数
28 |
29 | 为了让该python脚本支持bash补全,首先需要先写一个简单的python脚本来列出所有的chef node名称.
30 | #+BEGIN_SRC python
31 | #!/usr/bin/env python
32 |
33 | from sys import argv
34 | import os
35 | import json
36 |
37 | if __name__ == "__main__":
38 | pattern = ""
39 | if len(argv) == 2:
40 | pattern = argv[1]
41 |
42 | chef_dir = os.environ.get('LG_CHEF_DIR', None)
43 | if not chef_dir:
44 | exit(0)
45 | node_dirs = [os.path.join(chef_dir, "nodes"),
46 | os.path.join(chef_dir, "dev_nodes")]
47 | node_names = []
48 |
49 | for nodes_dir in node_dirs:
50 | for root, dirs, files in os.walk(nodes_dir):
51 | for f in files:
52 | try:
53 | with open(os.path.join(root, f), 'r') as nf:
54 | data = json.load(nf)
55 | node_names.append(data['normal']['liquid_galaxy']['support_name'])
56 | except:
57 | pass
58 |
59 | for name in node_names:
60 | print name
61 | #+END_SRC
62 |
63 | 然后还需要一种方法来获取python脚本支持的所有选项. 我们可以通过下面这行代码实现:
64 | #+BEGIN_SRC sh
65 | $LG_CHEF_DIR/repo_scripts/show.py --help | grep ' --' | awk {'print $1'}
66 | #+END_SRC
67 |
68 | 最后通过一个简单的bash脚本来整合上面两个脚本.
69 | #+BEGIN_SRC sh
70 | _lg_ssh()
71 | {
72 | local cur prev opts node_names
73 | COMPREPLY=()
74 | cur="${COMP_WORDS[COMP_CWORD]}"
75 | prev="${COMP_WORDS[COMP_CWORD-1]}"
76 | opts=`$LG_CHEF_DIR/repo_scripts/show.py --help | grep ' --' | awk {'print $1'}`
77 | node_names=`python $LG_CHEF_DIR/repo_scripts/node_names.py`
78 |
79 | if [[ ${cur} == -* ]] ; then
80 | COMPREPLY=( $(compgen -W "${opts}" -- ${cur}) )
81 | return 0
82 | fi
83 |
84 | COMPREPLY=( $(compgen -W "${node_names}" -- ${cur}) )
85 | }
86 |
87 | complete -F _lg_ssh show.py
88 | #+END_SRC
89 |
90 | 最后,我们只需要在当前bash session中使用source命令加载该文件即可. 因此,我把下面这行添加到 =~/.bashrc= 中.
91 | #+BEGIN_SRC sh
92 | source $LG_CHEF_DIR/repo_scripts/show.bash-completion
93 | #+END_SRC
94 |
95 | 至此,只要在终端中按两下 == 就会列出所有的补全选项了.
96 | #+BEGIN_EXAMPLE
97 | $ show.py
98 | Display all 42 possibilities? (y or n)
99 | ... and here go all 42 node names ...
100 |
101 |
102 | $ show.py h
103 | ... and here go all node names beginning with 'h' ...
104 |
105 |
106 | $ show.py --
107 | .. and here go all the options beginning with -- ...
108 |
109 | #+END_EXAMPLE
110 |
111 | 该实现最大的好处在于,任何对python script的修改或chef node名称的修改,都会自动反映出来.
112 |
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_251.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly Issue 251](http://us2.campaign-archive1.com/?u=e2e180baf855ac797ef407fc7&id=9d304fcce0&e=148158c7b4)
2 |
3 | ---
4 |
5 | 欢迎来到Python周刊第251期。让我们直奔主题。
6 |
7 | # 来自赞助商
8 |
9 | [](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD)
10 |
11 | 嘿,Python粉,你想要表达你对**Python**的爱吗?那么,[点击这里](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD),获取你的T恤,骄傲地穿上它吧。
12 |
13 |
14 | # 文章,教程和讲座
15 |
16 | [使用ANSI转移代码,构建你自己的命令行工具](http://www.lihaoyi.com/post/BuildyourownCommandLinewithANSIescapecodes.html)
17 |
18 | 本文将探索以下基本知识:如何从任何命令行程序控制终端(带有Python写的例子),以及自己的代码如何直接利用所有终端所提供的特俗功能。
19 |
20 |
21 | [你会在泰坦尼克号上活下来吗?用Python进行机器学习的指南](http://blog.socialcops.com/engineering/machine-learning-python)
22 |
23 | 该教程旨在为你提供一个如何为你的项目和数据集使用机器学习技术的可访问的介绍。仅需20分钟,你将学到如何使用Python,将不同的机器学习技术,从决策树到深层神经网络,应用到一个简单的数据集上。
24 |
25 | [Podcast.__init__ 第64集 - 和Russell Keith-Magee聊聊Beeware](http://pythonpodcast.com/russell-keith-magee-beeware.html)
26 |
27 | 当你有好工具在手,它会让你所做的工作更加令人愉悦。Russell Keith-Magee建立了一套工具,旨在让你在Python中编写图形界面,并且在所有目标平台上运行它们。最近,他一直忙于一个名为Toga的顶峰项目,该项目目标是在Android和iOS平台上使用相同一套代码。本集中,我们将探讨他的编程之旅,以及他是如何构建和设计Beeware套件的。听一听,然后试一试他的优秀项目吧!
28 |
29 | [建立一个数据科学作品集:机器学习项目](https://www.dataquest.io/blog/data-science-portfolio-machine-learning/)
30 |
31 | 这是涵盖如何创建一个全面的数据科学作品集的系列的第三篇文章。在这篇文章中,我们将涵盖如何在你的作品集中进行第二个项目,以及如何构建一个端到端的机器学习项目。最后,你将会有一个展示你的数据推理能力和技术能力的项目。
32 |
33 | [使用Mock服务器测试外部API](https://realpython.com/blog/python/testing-third-party-apis-with-mock-servers/)
34 |
35 | 在前面的教程中,我们介绍了mock对象的概念,证明了你可以如何用它们来测试那些与外部API交互的代码。本教程基于同样的注意,但这里,我们将带你看看如何真正的构建一个mock服务器,而不是模拟API。
36 |
37 | [科学Python简介 —— Pandas](http://www.datadependence.com/2016/05/scientific-python-pandas/)
38 |
39 | [宽度学习与深度学习:与TensorFlow携手共进](https://research.googleblog.com/2016/06/wide-deep-learning-better-together-with.html)
40 |
41 | [github repo中最常使用的pandas, numpy和scipy函数和模块](https://kozikow.wordpress.com/2016/07/01/top-pandas-functions-used-in-github-repos/)
42 |
43 | [Python中的基本交互地理空间分析](http://blog.yhat.com/posts/interactive-geospatial-analysis.html)
44 |
45 |
46 | # 书籍
47 |
48 | [使用Python和JavaScript进行数据可视化:抓取,清洁,探索&转换你的数据](http://amzn.to/29ruRln)
49 |
50 | 学习如何通过Python和JavaScript的强强联手,将原始数据转换成丰富的交互式web可视化。通过这个实用指南,作者Kyran Dale教你如何使用Python和JavaScript库(包括Scrapy, Matplotlib, Pandas, Flask, 和D3)的最佳组合,来构建一个基本的数据可视化工具链,用于各式各样讨人喜欢的,基于浏览器的可视化。
51 |
52 |
53 | # 好玩的项目,工具和库
54 |
55 | [Pendulum](http://pendulum.eustace.io/)
56 |
57 | 让Python datetimes变得容易。
58 |
59 | [apispec](https://github.com/marshmallow-code/apispec)
60 |
61 | 一个可插拔的API规范生成器。当前支持OpenAPI 2.0规范(又名 Swagger 2.0)。
62 |
63 | [wikitables](https://github.com/bcicen/wikitables)
64 |
65 | 从任何维基百科稳重中导入表单,作为Python的数据集。
66 |
67 | [BlackWidow](https://github.com/madisonmay/BlackWidow)
68 |
69 | 可视化Python项目导入图。
70 |
71 | [malspider](https://github.com/ciscocsirt/malspider)
72 |
73 | Malspider是一个网络爬虫框架,它检测网络依赖性的特点。
74 |
75 | [optomatic](https://github.com/erlendd/optomatic)
76 |
77 | optomatic是一个Python库,用以帮助超参数搜索一般的机器学习模型。optomatic的目标是提供一个工具,可以帮助开发者在一个合理的时间内,找到他们的模型的良好的超参数,并且以一种可重复(以及可防御)的方式,保存他们的超参数搜索的阶段。
78 |
79 | [needy](https://github.com/ccbrown/needy)
80 |
81 | needy是一个旨在让C++库依赖尽可能神奇的工具。依赖在称为“需求文件”的文件中声明,通常只需添加源URI。然后,needy将会为你下载并构建那些依赖。
82 |
83 | [fabulous](https://github.com/jart/fabulous)
84 |
85 | 用Python打印图像、颜色和有风格的文本到终端。
86 |
87 | [MongoFrames](http://mongoframes.com/)
88 |
89 | 一个用于Python的快速不显眼的MongoDB ODM。
90 |
91 |
92 | # 最新发布
93 |
94 | [Twisted 16.3](http://labs.twistedmatrix.com/2016/07/twisted-163-released.html)
95 |
96 |
97 | # 近期活动和网络研讨会
98 |
99 | [Austin Python Meetup July 2016 - Austin, TX](http://www.meetup.com/austinpython/events/230193204/)
100 |
101 |
102 |
103 |
104 |
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_263.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly - Issue 263](http://eepurl.com/chOyQj)
2 |
3 | ---
4 |
5 | 欢迎来到Python Weekly第263期。本周,我想要感谢我们的赞助商DataCamp。快来看看他们提供的精彩内容吧。
6 |
7 |
8 | # 来自赞助商
9 |
10 | [](https://www.datacamp.com/)
11 |
12 | 因**数据科学**之故,对学习**Python**感兴趣,是吗?通过进行100次互动编码挑战,以及观看由顶级导师提供的视频,从而成为数据专家吧。[加入](https://www.datacamp.com/) 500,000+个小伙伴,今天,就开始在[DataCamp](https://www.datacamp.com/)线上学习吧!
13 |
14 |
15 | # 文章,教程和讲座
16 |
17 | [用Python进行股票市场数据分析概述 (第二部分)](https://ntguardian.wordpress.com/2016/09/26/introduction-stock-market-data-python-2/)
18 |
19 | 这篇文章是使用Python进行股票数据分析系列的两部分中的第二部分。它讨论的主题包括划分一个移动平均交叉策略,回溯测试和基准,以及一些供读者思考的实际问题。
20 |
21 | [Pyflame: Uber工程的Python追踪分析器](http://eng.uber.com/pyflame/)
22 |
23 | 在Uber,我们努力写出高效的后端服务,以保证我们的计算成本低。随着我们业务的增长,这变得越来越重要;看起来小的低效在Uber的规模下被大大放大。我们发现了flame graph(火焰图)是一个了解我们服务的CPU和内存性能的有效工具,并且我们用它们来大大提高了我们Go和JavaScript服务的效率。为了获取Python服务的高质量火焰图,我们编写了一个名为Pyflame的高性能分析工具,用C++实现。本文,我们讨论设计考虑和一些让Pyflame成为分析Python代码的更好替代方案的独特实现特性。
24 |
25 | [与C共舞](https://www.paypal-engineering.com/2016/09/22/python-by-the-c-side/)
26 |
27 | 全世界都是遗留代码,而且总会有另一个,更低的层次剥离。这些现实使得世界各地的开发者定期朝圣,从Python大陆到C海岸。从zlib到SQLite再到OpenSSL,是否追求速度、效率或者功能,海是强大的,它时常波涛汹涌。好消息是,当你在写Python的时候,你可以在沙滩上玩一天C交互。
28 |
29 | [Episode #77: 你没有(但应该)使用的20个Python库](https://talkpython.fm/episodes/show/77/20-python-libraries-you-aren-t-using-but-should)
30 |
31 | 本周,你将见到Caleb Hattingh,他写了一本很棒的书,叫做你没有(但应该)使用的20个Python库(20 Python Libraries You Aren't Using (But Should))。他和我花了一个小时来挖掘所有非常强大和有趣的包,你可能从未听说过它们,但是在你了解它们之后,你会超级兴奋地去使用它们。
32 |
33 | [如何为Flask Web应用配置NGINX](http://www.patricksoftwareblog.com/how-to-configure-nginx-for-a-flask-web-application/)
34 |
35 | 这篇文章解释了NGINX是什么,以及如何对它进行配置,以服务一个Flask web应用。我发现了许多关于NGINX以及如何配置它的文档,但是我想深入NGINX如何在Flask web应用中使用以及如何配置的细节。我发现NGINX的配置有点让人糊涂,因为许多文档只是简单展示配置文件,而不解释每一步的细节。希望这篇博文提供了为你的应用配置NGINX的清晰细节。
36 |
37 | [Podcast.__init__ 第76集 - 和Jonathan Peirce聊聊PsychoPy](https://podcastinit.com/jonathan-peirce-psychopy.html)
38 |
39 | 本周,在Podcast.__init__,我们和Jonathan Peirce钻研你的心灵的复杂运作。他告诉我们他是如何开始PsychoPy项目的,以及多年来,这个项目是如何变得实用且流行。我们讨论了它在大量心理学实验中使用的方法,如何设计和执行这些实验,以及未来有什么在等着它。
40 |
41 | [异步Python](https://hackernoon.com/asynchronous-python-45df84b82434)
42 |
43 | Python中的异步编程最近越来越受欢迎。Python中有很多不同的进行异步编程的库。其中之一就是asyncio,它是在Python 3.4添加的一个python标准库。asyncio是Python中异步编程变得更加流行的部分原因。本文将解释什么是异步编程,并且比较一些异步编程库。让我们走过历史,看看异步编程在Python中是如何发展的。
44 |
45 | [用于文本处理的解析和可视化神经网络](https://civisanalytics.com/blog/data-science/2016/09/22/neural-network-visualization/)
46 |
47 | [PyData Chicago 2016视频集](https://www.youtube.com/playlist?list=PLGVZCDnMOq0pMUpVnQ8h5byVzIJNZCo2S)
48 |
49 |
50 | # 好玩的项目,工具和库
51 |
52 | [finmarketpy](https://github.com/cuemacro/finmarketpy)
53 |
54 | finmarketpy是一个基于Python的库,它让你能够分析市场数据,还能通过简单易用的API来回溯测试交易策略,API为你提供了预置的模板来定义回溯测试。
55 |
56 | [Web-PDB](https://github.com/romanvm/python-web-pdb)
57 |
58 | Web-PDB是一个用于Python内置PDB调试器的web界面。它允许我们在web浏览器中远程调试Python脚本。
59 |
60 | [Neural Photo Editor](https://github.com/ajbrock/Neural-Photo-Editor)
61 |
62 | 一个使用生成神经完了编辑自然照片的简单界面。
63 |
64 | [whereami](https://github.com/kootenpv/whereami)
65 |
66 | 使用WiFi信号和机器学习来预测你的所在地
67 |
68 | [facegen](https://github.com/zo7/facegen)
69 |
70 | 使用反卷积网络生成人脸。
71 |
72 | [CommAI-env](https://github.com/facebookresearch/CommAI-env)
73 |
74 | 一个开发在[面向机器智能的路线图](http://arxiv.org/abs/1511.08130)中描述的AI系统的平台
75 |
76 | [django-perf-rec](https://github.com/YPlan/django-perf-rec)
77 |
78 | 保持详细记录你的Django代码的性能。
79 |
80 | [traces](https://github.com/datascopeanalytics/traces)
81 |
82 | 一个用于不均匀间隔时间序列分析的Python库。
83 |
84 | [django-map-widgets](https://github.com/erdem/django-map-widgets)
85 |
86 | 用于Django PostGIS域的可配置、可插拔,以及更友好的地图控件。
87 |
88 |
89 | # 最新发布
90 |
91 | [Django安全版本发布:1.9.10和1.8.15](https://www.djangoproject.com/weblog/2016/sep/26/security-releases/)
92 |
93 | [Spyder IDE 3.0.0](https://github.com/spyder-ide/spyder/releases/tag/v3.0.0)
94 |
95 |
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_265.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly Issue 265](http://eepurl.com/cjSenT)
2 | ---
3 |
4 | 欢迎来到Python周刊第265期。让我们直入主题。
5 |
6 |
7 | # 来自赞助商
8 |
9 | [](https://software.intel.com/en-us/intel-sdp-home)
10 |
11 | 使用Theano? **Python** 的Intel®发行版为Theano提供了毫不费力,可直接使用的性能以及与Intel软件优化(Intel Software Optimization)的集成。这个[手把手指南](https://software.intel.com/en-us/articles/getting-started-with-intel-optimized-theano)描述了为药物发现工作、卷积网络和情感分析运行基准的步骤和指令细节。
12 |
13 |
14 | # 新闻
15 |
16 | [PyCaribbean 2017征集议题](https://www.papercall.io/pycaribbean-2017)
17 |
18 |
19 | # 文章,教程和讲座
20 |
21 | [Episode #79: Beeware Python工具](https://talkpython.fm/episodes/show/79/beeware-python-tools)
22 |
23 | 你可以给我写个适用于现有的广泛平台的Python应用吗?哦,等等,我想让它们是原生GUI应用哦。并且我想它们可以运行在移动 (Android, iOS, tvOS, 和watchOS),以及主要的桌面平台上。我还想让它们跟原生的应用(macOS上是.app,而Windows上是.exe等等)看起来没啥区别。要做到这些,你会用到什么样的技术呢?本周,我将向你介绍一系列小而专注,并且功能强大的工具,它们能让这些,甚至是更多要求都成为可能。我们会和Russell Keith-Magee聊聊,他是Beeware项目的创始人。
24 |
25 | [构建一个模仿你的同事的Slack机器人](http://hirelofty.com/blog/how-build-slack-bot-mimics-your-colleague/)
26 |
27 | 一起用Python来玩玩马尔科夫链和Slack实时消息API吧。
28 |
29 | [使用Python调试器的惊心动魄之旅(下)](https://benbernardblog.com/my-startling-encounter-with-python-debuggers-part-2/)
30 |
31 | 在这个系列的第二篇也是最后一篇文章中,你将看到我是如何使用python-debuginfo的不同命令来追查我生产上的Python代码中的一个讨厌的错误的。
32 |
33 | [Django工厂审计](http://jamescooke.info/django-factory-audit.html)
34 |
35 | 工厂(Factory)构建出模型实例,主要用于测试,但可用在任何地方。在这篇文章中,我展示了基于工厂库创建的实例的有效性来分级用于Django的不同的工厂库的尝试。
36 |
37 | [Podcast.__init__ 第78集 - Lorena Mesa](https://podcastinit.com/lorena-mesa.html)
38 |
39 | Python社区的一个巨大的优势之一是参与者的多样化背景。本周,Lorena Mesa谈谈关于她对政治学的关注,以及公民参与如果指引她到软件工程和数据分析发展她的事业。除了她的职业生涯,她还创立了PyLadies的芝加哥分会,帮助妇女和孩子学会编程,并且她还入选了PSF董事会。
40 |
41 | [深度强化学习:玩一个赛车游戏](https://lopespm.github.io/machine_learning/2016/10/06/deep-reinforcement-learning-racing-game.html)
42 |
43 | [pandasql: 让python说SQL](http://blog.yhat.com/posts/pandasql-intro.html)
44 |
45 | [PyConZA 2016视频集](https://www.youtube.com/playlist?list=PLGjWYNrNnSufYp1ADGLKUFnXagkQhyRMU)
46 |
47 |
48 | # 好玩的项目,工具和库
49 |
50 | [suiron](https://github.com/kendricktan/suiron)
51 |
52 | 用于遥控汽车的机器学习。
53 |
54 | [neural-cli](https://github.com/hugorut/neural-cli)
55 |
56 | Neuralcli为一个简单的分类神经网络的python实现提供给了一个简单的命令行界面。Neuralcli允许一种快速的方式,让你轻松地获取一个假说的即时反馈,或者轻松玩转现今机器学习最流行的概念之一。
57 |
58 | [DDPG-Keras-Torcs](https://github.com/yanpanlau/DDPG-Keras-Torcs)
59 |
60 | 使用Keras和Deep Deterministic Policy Gradient(DDPG)来玩TORCS。
61 |
62 | [libheap](https://github.com/cloudburst/libheap)
63 |
64 | 用于检测glibc堆 (ptmalloc)的gdb python库。
65 |
66 | [NLQuery](https://github.com/ayoungprogrammer/nlquery)
67 |
68 | WikiData上的一个自然语言查询引擎。
69 |
70 | [markovify](https://github.com/jsvine/markovify)
71 |
72 | 一个简单可扩展的马尔科夫链生成器。
73 |
74 | [binarytree](https://github.com/joowani/binarytree)
75 |
76 | 用于学习二叉树的Python库。
77 |
78 | [fetch-some-proxies](https://github.com/stamparm/fetch-some-proxies)
79 |
80 | 获取“一些”(可用)代理的简单Python工具。
81 |
82 | [dist-keras](https://github.com/JoeriHermans/dist-keras)
83 |
84 | 使用Keras和Apache Spark的分布式深度学习。
85 |
86 |
87 | # 最新发布
88 |
89 | [Python 3.6.0b2](https://www.python.org/downloads/release/python-360b2/)
90 |
91 | [PyPy3 5.5.0](https://morepypy.blogspot.com/2016/10/pypy3-550-released.html)
92 |
93 |
94 | # 近期活动和网络研讨会
95 |
96 | [PyCon Finland 2016](http://fi.pycon.org/2016/)
97 |
98 | [PyHou 2016年10月聚会 - Houston, TX](https://www.meetup.com/python-14/events/233398459/)
99 |
100 |
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_266.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly Issue 266](http://eepurl.com/ckV18z)
2 |
3 | ---
4 |
5 | 欢迎来到Python周刊第266期。让我们直奔主题。
6 |
7 | # 来自赞助商
8 |
9 | [](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD)
10 |
11 | 嘿,Python粉,你想要表达你对**Python**的爱吗?那么,[点击这里](http://www.amazon.com/gp/product/B0185367JQ/ref=as_li_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=B0185367JQ&linkCode=as2&tag=mymerch-20&linkId=OLIXWD4WZ5X6FFHD),获取你的T恤,骄傲地穿上它吧。
12 |
13 |
14 | # 文章,教程和讲座
15 |
16 | [Episode #80: TinyDB: 一个用Python编写的小小的document数据库](https://talkpython.fm/episodes/show/80/tinydb-a-tiny-document-db-written-in-python)
17 |
18 | NoSQL和document数据库,例如MongoDB,使得对广泛类型的应用,构建易于发展和维护的快速可扩展软件更容易。嵌入式、基于文件的数据库,例如SQLite,使得不用费什么脑子就可以“传送”一个需要数据库的应用。该数据库只是运行在经常中,因此无需安装和维护。然而,当你尝试相交这两个出色的功能的时候,你会发现选择非常有限。只是没有太多嵌入式document数据库可供选择。如果你是一个Python开发者,并且你想要原生Python解决方案,那么可选择的会更小。这就是为什么我很高兴地向你介绍Markus Siemens和TinyDb。它是一个用于Python的,100%纯python编写的,可嵌入,并且可用pip进行安装的document数据库。
19 |
20 | [NumPy教程:使用Python进行数据分析](https://www.dataquest.io/blog/numpy-tutorial-python/)
21 |
22 | 在本教程中,我们将会看到如何使用NumPy来分析酒质量的数据。数据包含了酒的各种属性,例如pH和固定酸度信息,以及每种酒在0到10之间的质量得分。质量得分是至少3个人类品尝测试给出得分的平均值。当我们学习如何使用NumPy时,我们会尽力找出更多关于酒的感知质量。
23 |
24 | [Podcast.__init__ 第79集 - K Lars Lohn](https://podcastinit.com/k-lars-lohn.html)
25 |
26 | K Lars Lohn有着长而丰富的工作经历,他最近几年是在Mozilla度过的。本周,他与我们分享了他参与到Python中的一些故事,他在Mozilla的工作,以及他对于PyCon US 2016闭幕式的一些想法。他还详细阐述了他所绘制的错综复杂的迷宫,以及在Oregon作为一个有机农民的生活。
27 |
28 | [使用MongoDB和Python进行模糊搜索](https://medium.com/xeneta/fuzzy-search-with-mongodb-and-python-57103928ee5d)
29 |
30 | 在Xeneta,我们运营着世界上最大的集装箱运价数据库,并且在其之上提供强大的风险。一个最基本的用例是找到将某一类型的集装箱从一个港口运送到另一个港口的平均价格。为了做到这点,我们必须提供给用户搜索港口的能力。如同所有的地理相关对象,港口名不一定容易记或者正确拼写,因此,我们的搜索工具必须对拼写错误具有鲁棒性。本文介绍了解决这一问题的一个相当简单而灵活的方法,如果你正运行MongoDB,那么它会特别有用,因为它并不需要外部搜索工具。
31 |
32 | [使用Rust提高Python性能](https://blog.sentry.io/2016/10/19/fixing-python-performance-with-rust.html)
33 |
34 | [使用Flask和Orator ORM构建一个REST API](http://blog.eustace.io/buiding-rest-api-with-flask-orator.html)
35 |
36 | [百年孤独:我是如何分析最爱的书的](https://medium.com/@finalfire/one-hundred-years-of-solitude-how-i-analyzed-my-favorite-book-6c20456480c8)
37 |
38 | [Python中的静态类型,哎哟,my(py)!](http://blog.zulip.org/2016/10/13/static-types-in-python-oh-mypy/)
39 |
40 | [迭代器模式的堆栈](http://garethrees.org/2016/09/28/pattern/)
41 |
42 |
43 | # 好玩的项目,工具和库
44 |
45 | [HawkPost](https://github.com/whitesmith/hawkpost)
46 |
47 | 生成链接,用户可以用来提交使用你的公钥加密的消息。
48 |
49 | [python-reference](https://github.com/justmarkham/python-reference)
50 |
51 | 一个脚本和Notebook中的Python快速参考。
52 |
53 | [Sanic](https://github.com/channelcat/sanic)
54 | 类Flask的Python 3.5+ web服务器,编写来更快的运行。
55 |
56 | [pyvisgraph](https://github.com/TaipanRex/pyvisgraph)
57 |
58 | 给定一个简单的障碍多边形列表,构建知名度图,然后找到两个点之间的最短路径。
59 |
60 | [PyMoe](https://github.com/ccubed/PyMoe)
61 |
62 | PyMoe是一个python接口,用来为Python 3提供一些流行的动画与漫画服务。
63 |
64 | [urlwatch](https://github.com/thp/urlwatch)
65 | urlwatch旨在帮助你监控web页面的改动,并且一旦有任何改动,就会(通过电子邮件,在你的终端中,或者使用自定义编写的报告(reporter)类)通知你。改动提醒会包含发生了改动的URL,以及所发生变化的统一差异。
66 |
67 | [Dragonchain](https://github.com/dragonchain/dragonchain)
68 |
69 | Dragonchain平台试图简化真实商业应用到区块链的集成。提供诸如轻松集成、业务数据保护、固定5秒区块(5 second blocks)、货币不可知论和互操作功能,Dragonchain让区块链技术显得新颖有趣。
70 |
71 | [fast-neural-style.tf](https://github.com/junrushao1994/fast-neural-style.tf)
72 |
73 | 用于实时艺术风格传输的前馈式神经网络。
74 |
75 | [lptrace](https://github.com/khamidou/lptrace)
76 |
77 | lptrace是用于Python程序的堆栈跟踪工具。它让你实时看到一个Python程序正在运行什么函数。在调试生产上的疑难杂症特别有用。
78 |
79 | [mocker](https://github.com/tonybaloney/mocker)
80 |
81 | Docker的一个概念证明模仿版本,100%用Python编写。对Linux使用内核命名空间,cgroup和网络命名空间/iproute2。
82 |
83 |
84 | # 近期活动和网络研讨会
85 |
86 | [线上事件:有关pandas的答疑!](https://www.crowdcast.io/e/pandas/register)
87 |
88 | 这是关于pandas的一个1小时问答环节,pandas是用来进行数据分析、探索和操作的Python库。欢迎各种层次的pandas用户参加以及提问!这里,任何问题都不会太简单或太复杂。
89 |
90 | [旧金山Django 2016年10月聚会 - San Francisco, CA](https://www.meetup.com/The-San-Francisco-Django-Meetup-Group/events/234806317/)
91 |
92 | 将会有以下演讲
93 |
94 | * Django Rest框架:技巧、诀窍和hack
95 | * Django和Jinja2模板的两步舞
96 |
97 |
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_269.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly Issue 269](http://eepurl.com/cn3QCX)
2 |
3 | ---
4 |
5 | 欢迎来到Python周刊第269期。让我们直奔主题。
6 |
7 | # 来自赞助商
8 |
9 | [](https://software.intel.com/en-us/intel-sdp-home)
10 |
11 | 参加SC'16?注册[Intel HPCDevCon](http://www.intel.com/content/www/us/en/events/hpcdevcon/overview.html) 以及全天关于 [用于科学计算的高性能Python](http://sc16.supercomputing.org/presentation/?id=tut172&sess=sess193)的SC'16教程。参加我们的演讲,展会以及专家访谈,学习可以如何从我们为Python设计的性能优化工具受益。
12 |
13 |
14 | # 文章,教程和讲座
15 |
16 | [Texas死囚数据探索](http://signal-to-noise.xyz/texas-death-row.html)
17 |
18 | 在[德州刑事司法部门](http://www.tdcj.state.tx.us)网站上,有一个页面,上面列举了所有自1982年起被执行死刑的人,恢复死刑的时间,以及他们的最后陈述。在这个项目中,我们将探索该数据,并且看看是否可以应用主题模型到陈述中。
19 |
20 | [通过Chainer,让复杂神经网络变得轻松起来](https://www.oreilly.com/learning/complex-neural-networks-made-easy-by-chainer)
21 |
22 | Chainer是一个开源框架,专为高效率研究和深度学习算法的发展而设。在这篇文章中,我们简单通过几个例子介绍了Chainer,并将其与其他框架,例如Caffe,
23 | Theano, Torch, 和Tensorflow,进行对比。
24 |
25 | [Pandas教程:Python中的DataFrame](https://www.datacamp.com/community/tutorials/pandas-tutorial-dataframe-python)
26 |
27 | 本教程介绍了11种最流行的Pandas DataFrame问题,从而让你理解,以及避免,那些已经走在你之前的Python人的疑惑。
28 |
29 | [OSMnx: 用于街道网络的Python包](http://geoffboeing.com/2016/11/osmnx-python-street-networks/)
30 |
31 | OSMnx是一个Python包,用于从OpenStreetMap下载行政边界形状和街道网络。它让你能够轻松地在Python中利用NetworkX构造、设计、可视化以及分析复杂的街道网络。仅需一行Python代码,你就可以获得一个城市或者街区的步行、驾驶或者自行车网络。然后,你可以简单地可视化死胡同或者单向街道,绘制最短路径路线,或者计算统计数据,例如路口密度,平均节点连接,或者中介中心性。
32 |
33 | [离Django的GenericForeignKey远点](http://lukeplant.me.uk/blog/posts/avoid-django-genericforeignkey/)
34 |
35 | 在Django中GenericForeignKey是这样的一个特性,它允许一个模型与系统中的其他模型相关联,与与特定的模型相关联的ForeignKey相对。这篇文章是关于为什么通常有时你应该离GenericForeignKey远点。
36 |
37 | [利用LightFM,探索Learning to Rank Sketchfab模型](http://blog.ethanrosenthal.com/2016/11/07/implicit-mf-part-2/)
38 |
39 | 在这片文章中,我们将在上一篇介绍隐式矩阵分解的文章之后,做一堆很酷的事。我们将探索
40 | Learning to Rank,它是一个不同的隐式矩阵分解的方法,然后使用LightFM库来将边信息合并到我们的推荐系统中。接下来,我们会使用比网格搜索更智能的scikit-optimize来进行交叉验证超参数。最后,我们会看到,我们可以超越简单的用户到项和项到项推荐,现在,我们已经将边信息嵌入到yu与我们到用户和项一致到空间中了。
41 |
42 | [后异步/等待世界中,关于异步API设计的一些思考](https://vorpus.org/blog/some-thoughts-on-asynchronous-api-design-in-a-post-asyncawait-world/)
43 |
44 | [分析Berkeley的住房价格](http://aakashjapi.com/housing-prices-in-berkeley/)
45 |
46 | [Celery 4.0新特性](http://docs.celeryproject.org/en/latest/whatsnew-4.0.html)
47 |
48 | [为了乐趣与获利的Python中的计时测试](https://hackernoon.com/timing-tests-in-python-for-fun-and-profit-1663144571)
49 |
50 | [用Python实现Raspberry Pi条码扫描仪](https://medium.com/@yushulx/raspberry-pi-barcode-scanner-in-python-927839100c6b)
51 |
52 |
53 | # 好玩的项目,工具和库
54 |
55 | [stack-overflow-import](https://github.com/drathier/stack-overflow-import)
56 |
57 | 从Stack Overflow中把任意代码当成Python模块导入。
58 |
59 | [Python cheatsheet](https://www.pythonsheets.com/)
60 |
61 | 该工程试图提供大量的让生活更轻松的Python代码片段。
62 |
63 | [The Knowledge Repository](https://github.com/airbnb/knowledge-repo)
64 |
65 | 为数据科学家和其他技术专家提供的下一代整理知识共享平台。
66 |
67 | [PyFME](https://github.com/AeroPython/PyFME)
68 |
69 | PyFME是Python Flight Mechanics Engine(Python飞行力学引擎)的简称。PyFME背后的目的是构建一个库,它能模拟飞行器在空中的动作,以及进行飞行中所有涉及的物理学建模。
70 |
71 | [Rewrite](https://github.com/kaonashi-tyc/Rewrite)
72 |
73 | 汉字的神经式转换。
74 |
75 | [Kappa](https://github.com/garnaat/kappa)
76 |
77 | Kappa是一个致力于让部署、更新和测试AWS Lambda函数更简单的命令行工具。
78 |
79 | [JamDocs](http://jam-py.com/jamdocs/)
80 |
81 | JamDocs是一个用于Sphinx文档生成的Jam.py web界面。
82 |
83 | [Pyonic-interpreter](https://github.com/inclement/Pyonic-interpreter)
84 |
85 | Android上的Python解释器。
86 |
87 | [Colorful-Image-Colorization](https://github.com/cameronfabbri/Colorful-Image-Colorization)
88 |
89 | 一种用以对图像着色的深度学习方法。
90 |
91 |
92 | # 近期活动和网络研讨会
93 |
94 | [Numba - 加速你的Python原来是辣么简单! - New York, NY](https://www.meetup.com/NYDataScientists/events/235403768/)
95 |
96 | [Edmonton Python 2016年11月聚会 - Edmonton, AB](https://www.meetup.com/startupedmonton/events/234340991/)
97 |
98 | [PyHou 2016年聚会 - Houston, TX](https://www.meetup.com/python-14/events/234195007/)
99 |
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_271.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly - Issue 271](http://eepurl.com/cp_sQf)
2 |
3 | ---
4 |
5 | 欢迎来到Python Weekly第271期。享受这周的出版,并且如果你过的话,感恩节快乐!
6 |
7 |
8 | # 文章,教程和讲座
9 |
10 | [Episode #85: 用Python解析可怕的东西](https://talkpython.fm/episodes/show/85/parsing-horrible-things-with-python)
11 |
12 | 你是否曾经需要解析可怕而令人费解的东西呢?显然,你会从这一集中学到一堆技巧和窍门。但是,你将看到,高级解析是通往许多有趣的计算机科学技术之路。听听我与Erik Rose谈谈他在Mozilla解析奇奇怪怪的东西之旅吧。
13 |
14 | [深入了解地理空间分析](http://nbviewer.jupyter.org/github/ResidentMario/boston-airbnb-geo/blob/master/notebooks/boston-airbnb-geo.ipynb)
15 |
16 | 数据科学家处理的许多数据集都有某些地理空间部分,而这种信息对于理解手头上的问题常常是至关重要的。这样,理解空间数据,以及如何使用它们就成为了任何数据科学家具有的宝贵技能。更妙的是,Python提供了用于该领域的丰富的工具集,并且最近的进展大大简化和巩固了它们。在这个教程中,我们将深入了解Python中的地理空间分析,使用诸如geopandas, shapely, 和pysal这样的工具来分析由Kaggle(来源于Inside AirBnB)提供的数据集,它带有Boston, Massachusetts中的AirBnB位置样本。
17 |
18 | [用Pandas构建金融模型](http://pbpython.com/amortization-model.html)
19 |
20 | 在我前面的文章中,我讨论了如何使用pandas作为数据操作工具来替代Excel。在许多情况下,python + pandas解决方案优于许多人在Excel中用于操作数据的高度手动过程。然而,Excel被用于商业环境下的许多常见 - 不仅是数据操作。这篇详细的文章将讨论如何用pandas取代Excel进行金融建模。在这个例子中,我将在pandas中构建一个简单的分期偿还债务表,并且展示如何建模各种成果。
21 |
22 | [Django站点上的水印图像](http://www.machinalis.com/blog/watermarking-images-django/)
23 |
24 | 使用Pillow和django-imagekit生成可见和不可见水印的技术。
25 |
26 | [贝叶斯线性回归](https://github.com/liviu-/notebooks/blob/master/bayesian_linear_regression.ipynb)
27 |
28 | 贝叶斯线性回归的快速演示 -- 特别是,我想要向你展示你可以如何找到一个从中你可以取样权重来适应于你的数据集的高斯分布的参数!然后,你可以把这个分布当成找到预测分布和利用置信水平的先验使用。我会尽量解释我所做的所有事,但你应该知道线性回归、一些线性代数和一些贝叶斯统计数据。
29 |
30 | [给工作中的Python开发者的AsyncIO](https://hackernoon.com/asyncio-for-the-working-python-developer-5c468e6e2e8e)
31 |
32 | [iSee: 使用深度学习来从脸部移除眼镜](https://blog.insightdatascience.com/isee-removing-eyeglasses-from-faces-using-deep-learning-d4e7d935376f)
33 |
34 |
35 | # 书籍
36 |
37 | [智能网算法](http://amzn.to/2fSfV2T)
38 |
39 | 智能网算法教你如何创建紧缩和争论(crunch and wrangle)那些从用户、web应用和网站日志收集来的数据的机器学习应用。在这个完全修订版,你将看到从数据中提取实际价值的智能算法。通过使用Python的scikit-learn编写的代码样例,解释了关键的机器学习概念。这本书将引导你通过算法捕获、存储和结构化来自网络的数据流。通过统计算法、神经网络和深度学习,你将探索推荐引擎,并深入分类。
40 |
41 |
42 | # 好玩的项目,工具和库
43 |
44 | [Speech-Hacker](https://github.com/ParhamP/Speech-Hacker)
45 |
46 | 通过连接名人的话,让他们说出任何你想他们说的话。
47 |
48 | [pipfile](https://github.com/pypa/pipfile)
49 |
50 | 一个Pipfile,及其相关的Pipfile.lock,是pip的requirements.txt文件的新的(及好得多的!)替换品。
51 |
52 | [Kalliope](https://github.com/kalliope-project/kalliope)
53 |
54 | Kalliope是一个模块化的不间断声控个人助手,专为家庭自动化而设。
55 |
56 | [Pydoc](https://www.pydoc.io/)
57 |
58 | Pydoc是一个为每一个上传到PyPI的包构建自动生成的API文档的项目。它类似于诸如
59 | http://rubydoc.info/ 和 https://godoc.org/这样的项目 -- 但是是用于Python社区的。一旦获取了PyPI中所有的包,我们就希望也把它扩展到GitHub上的包。
60 |
61 | [gzint](https://github.com/pirate/gzint)
62 |
63 | 一个python3库,用于有效存储大整数 (用 gzip 压缩的整数表示)。
64 |
65 | [NBA-prediction](https://github.com/christopherjenness/NBA-prediction)
66 |
67 | 使用矩阵完备预测NBA比赛比分。
68 |
69 | [Quiver](https://github.com/jakebian/quiver)
70 |
71 | 为Keras提供的互动式卷积神经网络特性可视化
72 |
73 | [Streamlink](https://github.com/streamlink/streamlink)
74 |
75 | Streamlink是一个CLI工具,它将在线流服务的Flash视频导到各种视频播放器,例如VLC,或者浏览器。streamlink的主要目的在于转换重CPU的Flash插件到一个较少CPU密集的格式。
76 |
77 | [colorcet](https://github.com/bokeh/colorcet)
78 |
79 | 一套用于绘制科学数据的有用的感知一致的色图。
80 |
81 |
82 | # 最新发布
83 |
84 | [Python 3.6.0 beta 4](http://blog.python.org/2016/11/python-360-beta-4-is-now-available.html)
85 |
86 | [PyCharm 2016.3](https://www.jetbrains.com/pycharm/whatsnew/)
87 |
88 |
89 | # 近期活动和网络研讨会
90 |
91 | [AnacondaCON 2017](https://anacondacon17.io/)
92 |
93 | 一场致力于聚集开放数据科学(Open Data Science)和Anaconda社区最强大脑的盛会。在AnacondaCON,你将接触到使用Anaconda的企业客户,以及那些开放数据科学运动中,利用社区力量和革新的基础贡献者和思想领袖。议程将充满教育性、知识性和发人深省的部分,确保你轻松获得提高开放数据科学所需的知识和连接。
94 |
95 | [San Francisco Django 2016年12月聚会 - San Francisco, CA](https://www.meetup.com/The-San-Francisco-Django-Meetup-Group/events/235111262/)
96 |
97 | 将会有以下演讲
98 |
99 | * Django + Ionic: 从POC到生产
100 | * 使用Django Channels的REST Websockets API
101 |
102 |
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_275.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly - Issue 275](http://eepurl.com/cuGU8L)
2 |
3 | ---
4 |
5 |
6 | 欢迎来到Python Weekly第275期。我祝福你们都节日愉快,并且期待2017,送给你们最好的Python相关连接。(Ele注:节日快乐呀,小伙伴们~~)
7 |
8 | # 文章,教程和讲座
9 |
10 | [利用TensorFlow进行交通标志识别](https://medium.com/@waleedka/traffic-sign-recognition-with-tensorflow-629dffc391a6)
11 |
12 | 这是关于构建一个深度学习模型来识别交通标志系列的第一部分。在这部分,我将谈谈图像分类,并且会尽可能的让模型简单。在后面的部分中,我将介绍卷积神经网络、数据增强和对象检测。
13 |
14 | [Episode #90: 使用Python进行数据再加工](https://talkpython.fm/episodes/show/90/data-wrangling-with-python)
15 |
16 | 你有没有脏乱数据的问题?无论你是一名软件开发者,或者是一个数据科学家,你都一定会遇到那些畸形、不完整、甚至可能是错的数据。不要让凌乱的数据破坏了你的应用,或者生成错误的结果。你应该怎么办呢?听听这一期,Katharine Jarmul会谈到有关她合作编写的名为使用Python进行数据再加工(Data Wrangling with Python)书,以及她的PyCon UK演讲,名为,如何用Python自动化你的数据清理(How to Automate your Data Cleanup with Python)。
17 |
18 | [如何在Debian 8上,使用uWSGI和Nginx,提供Django应用服务](https://www.digitalocean.com/community/tutorials/how-to-serve-django-applications-with-uwsgi-and-nginx-on-debian-8)
19 |
20 | 本指南中,我们将演示如何在Debian 8上安装和配置一些组件,以支持和提供Django应用服务。我们会配置uWSGI应用容器服务器来与我们的应用交互。然后,我们会设置Nginx来反向代理到uWSGI,利用其安全性和性能特性来服务我们的应用。
21 |
22 | [Podcast.__init__ 第88集 - 和Michal Čihař聊聊Weblate](https://www.podcastinit.com/episode-88-weblate-with-michal-cihar/)
23 |
24 | 添加翻译到我们的项目中让它们可以用于更多的地方,更多的人,这最终会让它们更有价值。如果你没有正确的工具,那么管理本地化过程是很困难的,因此,本周,Michal čihař跟我们聊聊Weblate项目,以及它是如何简化集成翻译到你的源代码中的过程的。
25 |
26 | [Python化的代码审查](https://access.redhat.com/blogs/766093/posts/2802001)
27 |
28 | [24小时生成850k张图像:自动化深度学习数据集创建](https://gab41.lab41.org/850k-images-in-24-hours-automating-deep-learning-dataset-creation-60bdced04275)
29 |
30 | [为本地开发和小规模部署使用Docker和Docker Compose](https://www.codementor.io/jquacinella/tutorials/docker-and-docker-compose-for-local-development-and-small-deployments-ph4p434gb)
31 |
32 | [使用Pandas构建一个金融模型 - 第2版](http://pbpython.com/amortization-model-revised.html)
33 |
34 | [给SAS用户的Python指南](http://nbviewer.jupyter.org/github/RandyBetancourt/PythonForSASUsers/tree/master/)
35 |
36 | [如何远程监控你的Pi进程](https://github.com/initialstate/pi-process-dashboard/wiki)
37 |
38 |
39 | # 好玩的项目,工具和库
40 |
41 | [Maya](https://github.com/kennethreitz/maya)
42 |
43 | 在Python中,使用Datetime是非常令人沮丧的,特别是处理不同系统上的不同地区时。这个库的存在是为了让简单的事情更简单,同时承认时间就是一个幻觉 (时区更是如此)。
44 |
45 | [awesome-functional-python](https://github.com/sfermigier/awesome-functional-python)
46 |
47 | 关于Python中进行函数式编程的棒棒哒的东西的列表。
48 |
49 | [Whitewidow](https://github.com/WhitewidowScanner/whitewidow)
50 |
51 | Whitewidow是一个开源的自动SQL漏洞扫描器,它能够过一遍文件列表,或者能够抓取Google,查找潜在易受攻击的网站。它允许自动文件格式化、随机用户代理、IP地址、服务器信息、多种SQL注入语法、从程序中加载sqlmap的能力,以及有趣的环境。
52 |
53 | [Elizabeth](https://github.com/lk-geimfari/elizabeth)
54 |
55 | Elizabeth是一个用于生成伪数据的快速且更易于使用的Python库,这在软件测试阶段需要引导数据库时是非常有用的。
56 |
57 | [PixieDust](https://github.com/ibm-cds-labs/pixiedust)
58 |
59 | PixieDust是一个开源Python辅助库,它作为Jupyter notebooks的一个附加品工作,用以改善处理数据的用户体验。它还提供额外的能力,填补当notebook被托管到云上,并且用户无法访问配置文件时的沟壑。
60 |
61 | [Bowtie](https://github.com/jwkvam/bowtie)
62 |
63 | Bowtie是一个用于在python中编写面板的库。无需懂得web框架或者JavaScript,关注于构建python中的功能性。以全新的方式交互式探索你的数据!部署并与他人分享吧!
64 |
65 | [libtmux](https://libtmux.git-pull.com/en/latest/)
66 |
67 | libtmux是tmuxp背后的工具,一个python中的tmux工作空间管理器。它建立在tmux的目标和格式之上,创建一个对象映射到遍历、检查和与存活的tmux会话交互。
68 |
69 | [zxcvbn-python](https://github.com/dwolfhub/zxcvbn-python)
70 |
71 | Dropbox的现实密码强度评估器的Python实现。
72 |
73 | [kernelscope](https://github.com/josefbacik/kernelscope)
74 |
75 | 一个用于收集内核跟踪数据和可视化它的守护进程和web应用。
76 |
77 | [kansha](https://github.com/Net-ng/kansha)
78 |
79 | Kansha是一个开源的web应用,用来管理和共享协作的scrum板等等。
80 |
81 | [Wifi-Dumper](https://github.com/Viralmaniar/Wifi-Dumper)
82 |
83 | 这是一个开源工具,用来Windows机器上的转储wiki配置和已连接接入点的明文密码。这个工具将在Wifi渗透测试中帮助你。此外,当执行red team或者内部基础设置约定时也有用。
84 |
85 | [EBS-SnapShooter](https://github.com/smileisak/ebs-snapshooter)
86 |
87 | EBS-SnapShooter是一个基于boto2的python脚本,它为你所有的aws ebs卷创建每日、每周、每月快照。
88 |
89 |
90 | # 近期活动和网络研讨会
91 |
92 | [网络研讨会:使用PyCharm,扩展一个带REST Capabilities的Django应用](https://blog.jetbrains.com/pycharm/2016/12/webinar-extending-a-django-app-with-rest-capabilities-using-pycharm-january-10th/)
93 |
94 | 这个实作型网络研讨会将会教你如何利用Python和Django来扩展一个已经存在的web应用,并且添加REST capabilities。此次网络研讨会以一个构建来跟踪笔记的已有的Django应用的概述开始,然后使用Django REST框架深入添加REST。参与者可以跟着我们构建Notes web应用。我们将展示使用PyCharm来检查数据库和测试我们的API。我们还将看看使用强大的PyCharm调试器来调试这个应用。
95 |
96 |
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_277.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly - Issue 277](http://eepurl.com/cxbt0z)
2 |
3 | ---
4 |
5 | 欢迎来到Python Weekly第277期。本周,让我们直入主题。
6 |
7 |
8 | # 文章,教程和讲座
9 |
10 | [介绍Python的类型注释](https://www.youtube.com/watch?v=ZP_QV4ccFHQ)
11 |
12 | Dropbox有几百万行的生产代码都是用Python 2.7写的。作为迁移到Python 3的第一步,以及让我们的代码更易驾驭,我们利用PEP 484,使用类型注释来注释我们的代码,使用mypy来对注释代码进行类型检查。在这个讲座中,我们将讨论经验教训,并向你展示你也可以如何开始对旧的Python 2.7代码进行类型检查,每次一个文件。我们也将会描述在此过程中对mypy所做的许多改进,以及一些其他工具。
13 |
14 | [深度学习指南](http://yerevann.com/a-guide-to-deep-learning/)
15 |
16 | 深度学习是计算机科学和数学交叉的一个快速变化的领域。它是一个名为机器学习的更广泛的领域的一个相当新的分支。机器学习的目标是教会计算机基于给定的数据执行各种任务。这个指南是为那些知道一些数据并且知道一些编程语言,而现在想要深入深度学习的人准备的。
17 |
18 | [Python机器学习:Scikit-Learn教程](https://www.datacamp.com/community/tutorials/machine-learning-python)
19 |
20 | 这个教程将会介绍Python机器学习的基础知识:一步一步,它将会向你展示如何使用Python和它们的库,在matplotlib的帮助下,来探索你的数据,利用知名的算法KMeans和支持向量机 (SVM) 来构造模型,适配数据到这些模型,来预测值,以及验证你构建的模型。
21 |
22 | [Podcast.__init__ 第91集 - 和Martijn Faassen聊聊Morepath](https://www.podcastinit.com/episode-91-morepath-with-martijn-faassen/)
23 |
24 | Python有广泛并且不断增长的各种web框架以供选择,但是如果你想要一个拥有超能力的框架,那么,你需要Morepath。本周,Martijn Faassen会跟我们分享怎样创造出Morepath,它是如何与其他可用选项区分开来的,以及你可以如何用它来助力你的下一个项目。
25 |
26 | [神经网络的超参数优化](http://neupy.com/2016/12/17/hyperparameter_optimization_for_neural_networks.html)
27 |
28 | 有时,为神经网络选择一个正确的架构会很难。通常,这个过程需要大量的经验,因为网络包含许多参数。让我们检查一些可以用来优化这个神经网络的最重要的参数。
29 |
30 | [添加一个REST API到Django应用](https://blog.jetbrains.com/pycharm/2017/01/webinar-adding-a-rest-api-to-a-django-application/)
31 |
32 | 这个动手讲座将会教你如何利用Python和Django来扩展一个已有的web应用,并添加REST能力。首先,它会对一个构建来跟踪注释的已有的Django应用进行概述,然后深入使用Django REST框架来添加REST。观看者可以跟着我们构建这个Notes web应用。我们会展示使用PyCharm专业版来检查数据库和测试我们的API。我们还会看看如何用强大的PyCharm调试器来调试这个应用。
33 |
34 | [使用python和pandas分析和可视化公开的OKCupid个人资料数据集](http://nbviewer.jupyter.org/github/lalelale/profiles_analysis/blob/master/profiles.ipynb#Analysis-and-visualization-of-a-public-OKCupid-profile-dataset-using-python-and-pandas)
35 |
36 | [Episode #94: 通过Conda和Conda-Forge来保证包](https://talkpython.fm/episodes/show/94/guarenteed-packages-via-conda-and-conda-forge)
37 |
38 | [从Python到Numpy](http://www.labri.fr/perso/nrougier/from-python-to-numpy/)
39 |
40 | [利用Flask和Mapbox可视化你的旅行](http://kazuar.github.io/visualize-trip-with-flask-and-mapbox/)
41 |
42 | [每个Python项目必备之物](https://vladcalin.github.io/what-every-python-project-should-have.html)
43 |
44 | [使用机器学习增加来自你可预见客户的销量](https://jackstouffer.com/blog/target-predictable-customers.html)
45 |
46 | [编写一个Django应用时我犯的错误 (以及我是如何修复它们的)](https://hackernoon.com/mistakes-i-made-writing-a-django-app-and-how-i-fixed-them-16de4e632042)
47 |
48 | [Gumbel机制](https://cmaddis.github.io/gumbel-machinery)
49 |
50 |
51 | # 好玩的项目,工具和库
52 |
53 | [MuGo](https://github.com/brilee/MuGo)
54 |
55 | 这是AlphaGo主要部分的纯Python实现。
56 |
57 | [Deep Text Correcter](https://github.com/atpaino/deep-text-correcter)
58 |
59 | 深度学习模型,训练来修正短的、类消息文本中的输入错误。
60 |
61 | [PySignal](https://github.com/dgovil/PySignal)
62 |
63 | 一个不带QObject依赖的Qt信号系统的纯Python实现。
64 |
65 | [KickThemOut](https://github.com/k4m4/kickthemout)
66 |
67 | 通过执行ARP欺骗攻击来把设备从你的网络中踢掉。
68 |
69 | [psync](https://github.com/lazywei/psync)
70 |
71 | 基于rsync的同步项目;支持监控改动,并自动同步。
72 |
73 | [predictron](https://github.com/zhongwen/predictron)
74 |
75 | "The Predictron: End-To-End Learning and Planning"的Tensorflow实现
76 |
77 | [Argos](https://github.com/titusjan/argos)
78 |
79 | Argos是一个用于查看和探索科学数据的GUI,用Python和Qt编写。它有一个插件架构,从而能够扩展以读取新的数据格式。
80 |
81 | [DVR-Scan](http://dvr-scan.readthedocs.io/en/latest/)
82 |
83 | DVR-Scan是一个跨平台的命令行 (CLI) 应用,它自动检测视频文件(例如,安全监控录像)中的运动事件。除了定位每个运动事件的时间和持续时间外,DVR-Scan将会保持每个动作事件的录像到一个新的独立的视频剪辑中。
84 |
85 | [systemdlogger](https://github.com/techjacker/systemdlogger)
86 |
87 | 导出systemd日志到一个外部服务,例如cloudwatch, elasticsearch。
88 |
89 | [hsr](https://github.com/pyk/hsr)
90 |
91 | 使用在TensorFlow中实现的卷积神经网络进行手势识别。
92 |
93 |
94 | # 近期活动和网络研讨会
95 |
96 | [网络研讨会:为机器学习构建理想堆栈](http://www.oreilly.com/pub/e/3855)
97 |
98 | 机器学习从未有过像如今一样更容易靠近 —— 如果你的数据管道支持实时分析的话。参与者将会学习到用于集成不同行业和组织的机器学习模型的工具和技术。Steven Camiña是MemSQL产品经理,他将会介绍你的技术生态系统中所需的关键技术,包括Python, Apache Kafka, Apache Spark, 和一个实时数据库。
99 |
100 | [New York Python 2017年1月聚会 - New York, NY](https://www.meetup.com/nycpython/events/235725722/)
101 |
102 | 将会有以下讲座
103 |
104 | * Paxos简介
105 | * 测试工具/开源requestbin库
106 | * 201*年(到底)发生了什么?
107 | * 异步编程
108 |
109 |
110 | [PyHou 2017年1月聚会 - Houston, TX](https://www.meetup.com/python-14/events/230111277/)
111 |
112 |
113 |
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_291.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly - Issue 291](http://eepurl.com/cLPaVP)
2 |
3 | ---
4 |
5 | 欢迎来到Python Weekly第291期。本周,我想感谢我们的赞助商Lights On Software。一定要去看看哦。
6 |
7 | # 来自赞助商
8 |
9 | [](http://lightsonsoftware.com/)
10 |
11 | **[Lights On Software](http://lightsonsoftware.com/)**
12 |
13 | 需要在截止时间时帮忙交付你的Python应用吗?手头上有太多项目吗?我们交付坚实的Python代码,并且能够帮助构建和维护Python应用。
14 |
15 |
16 | # 新闻
17 |
18 | [AWS Lambda现在支持Python 3.6了!](https://aws.amazon.com/releasenotes/5198208415517126)
19 |
20 |
21 | # 文章,教程和讲座
22 |
23 | [神经网络教程 - 深度学习之路](http://adventuresinmachinelearning.com/neural-networks-tutorial/)
24 |
25 | 这个教程介绍了一些概念、代码和数据,它们能够让你构建并理解一个简单的神经网络。在这个神经网络教程的最后,你将能够在Python中构建一个ANN,它会以很大程度的精确性正确识别图像中的手写数字。
26 |
27 | [使用QThreadPool的多线程PyQt应用](https://mfitzp.io/article/multithreading-pyqt-applications-with-qthreadpool/)
28 |
29 | 在构建GUI应用时的一个常见问题是当试图执行长时间运行的后台任务时,界面的“锁定”。在这个教程中,我将介绍PyQt中实现并发执行的最简单的方法之一。
30 |
31 | [入门aiohttp.web:一个Todo教程](https://justanr.github.io/getting-start-with-aiohttpweb-a-todo-tutorial)
32 |
33 | aiohttp是基于Python 3.4+ asyncio模块的HTTP工具包。在这个指南中,我们会构建一个简单Todo应用,将其作为入门高级服务器的简短介绍。
34 |
35 |
36 | [Podcast.__init__ 第105集 - Scikit-Image](https://www.podcastinit.com/episode-105-scikit-image-with-stefan-van-der-walt-and-juan-nunez-iglesias/)
37 |
38 | 计算机视觉是一个复杂的领域,它跨域多个行业,并由不同的需求和实现。Scikit-Image是一个库,它为在科学界工作的人们提供工具和技术,以处理对其研究至关重要的视觉数据。本周,Stefan Van der Walt和Juan Nunez-Iglesias,Elegant SciPy的联合作者,聊聊这个项目是如何开始的,它的工作原理,以及他们是如何使用它来为他们的实验提供支持的。
39 |
40 | [6分钟内修改Python语言](https://hackernoon.com/modifying-the-python-language-in-7-minutes-b94b0a99ce14)
41 |
42 | [图形数据库:使用Python聊聊你的数据关系](https://medium.com/labcodes/graph-databases-talking-about-your-data-relationships-with-python-b438c689dc89)
43 |
44 | [NumPy备忘录](https://www.dataquest.io/blog/numpy-cheat-sheet/)
45 |
46 | [从Indeed网络爬取工作告示](https://medium.com/@msalmon00/web-scraping-job-postings-from-indeed-96bd588dcb4b)
47 |
48 | [使用Dask的异步优化算法](https://matthewrocklin.com/blog//work/2017/04/19/dask-glm-2)
49 |
50 | [Episode #107:和Curio聊聊Python并发](https://talkpython.fm/episodes/show/107/python-concurrency-with-curio)
51 |
52 |
53 | # 好玩的项目,工具和库
54 |
55 | [Sonnet](https://github.com/deepmind/sonnet)
56 |
57 | Sonnet是一个在TensorFlow之上构建的库,用以构建复杂神经网络。
58 |
59 | [Module Linker](https://fiatjaf.alhur.es/module-linker/#/python)
60 |
61 | Module Linker将GitHub源码查看器中的直接链接添加到任何导入的模块或者文件中。如果你正在GitHub上浏览源码,那么这个扩展将会让你的生活更美好。
62 |
63 | [CycleGAN and pix2pix in PyTorch](https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix)
64 |
65 | 不配对和配对图像到图像转换的PyTorch实现。
66 |
67 | [pygta5](https://github.com/sentdex/pygta5/)
68 |
69 | 使用Python来玩Grand Theft Auto 5的探索
70 |
71 | [NoDB](https://github.com/Miserlou/NoDB)
72 |
73 | NoDB是基于Amazon的S3静态文件存储的一个非常简单的Pythonic对象存储。
74 |
75 | [OpenSnitch](https://github.com/evilsocket/opensnitch)
76 |
77 | OpenSnitch是Little Snitch应用防火墙的GNU/Linux端口。
78 |
79 | [mimipenguin](https://github.com/huntergregal/mimipenguin)
80 |
81 | 一个从当前linux用户转储登录密码的工具。
82 |
83 | [colorful](https://github.com/timofurrer/colorful)
84 |
85 | 正确完成的终端字符串样式,用Python编写。
86 |
87 | [SpiderKeeper](https://github.com/DormyMo/SpiderKeeper)
88 |
89 | scrapy/开源scrapinghub的管理UI。
90 |
91 | [Poet](https://github.com/sdispater/poet)
92 |
93 | Poet帮你声明、管理和安装Python项目的依赖,确保你有正确的堆栈。
94 |
95 |
96 | # 最新发布
97 |
98 | [IPython 6.0](https://blog.jupyter.org/2017/04/19/release-of-ipython-6-0/)
99 |
100 | IPython 6在实现机制上具有重大改进,现在,它能够实现非执行代码。它还是IPython第一个停止兼容Python 2的版本,其中,对Python 2的支持仅在5.x分支上对代码的修复。
101 |
102 | [Tornado 4.5](http://www.tornadoweb.org/en/stable/releases/v4.5.0.html)
103 |
104 |
105 | # 近期活动和网络研讨会
106 |
107 | [SoCal Python 2017年4月聚会 - Los Angeles, CA](https://www.meetup.com/socalpython/events/239310914/)
108 |
109 | 将会有以下讲座
110 |
111 | * 使用Habitat部署Twelve-Factor Python应用
112 | * 用Pyramid构建它
113 |
114 |
115 | [Python Notebook - 给完全新手的温和教程 - London, UK](https://www.meetup.com/LondonPython/events/237672087/)
116 |
117 | 这个实用(温和)的教程是给python notebook完全新手使用的,它会向我们介绍基础知识。一旦你完成了,那么你就已经为你自己有趣的项目做好准备了!
118 |
119 | [San Diego Python 2017年4月聚会 - San Diego, CA](https://www.meetup.com/pythonsd/events/238867374/)
120 |
121 | 将会有以下讲座
122 |
123 | * Bottle web框架
124 | * Zoomascii扩展
125 | * 如何本地化你的应用
126 |
127 |
128 |
129 |
130 |
131 |
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_309.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly - Issue 309](http://eepurl.com/c0L75j)
2 |
3 | ---
4 |
5 | 欢迎来到Python周刊第309期。让我们直奔主题。
6 |
7 | # 来自赞助商
8 | [](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
9 |
10 | [如何监控Python应用?](https://www.datadoghq.com/dg/apm/ts-python-performance/?utm_source=Advertisement&utm_medium=Advertisement&utm_campaign=PythonWeekly-Tshirt&utm_content=Python)
11 |
12 | 实时Python度量的图表和告警,并与你的技术栈中200多个其他技术的数据相关联。
13 |
14 |
15 | # 文章,教程和讲座
16 |
17 | [使用Python,分析加密货币市场](https://blog.patricktriest.com/analyzing-cryptocurrencies-python/)
18 |
19 | 本文的目标是提供使用Python进行加密货币分析的一个简单的介绍。我们将通过一个简单的Python脚本来检索、分析和可视化不同加密货币的数据。在此过程中,我们将会发现关于这些不稳定的市场行为怎样发现以及它们怎样演变的一种有趣趋势。
20 |
21 | [使用OpenCV进行深度学习](http://www.pyimagesearch.com/2017/08/21/deep-learning-with-opencv/)
22 |
23 | 在这篇教程中,你将会学习到如何通过Caffe,TensorFlow和PyTorch,使用OpenCV和深度学习,利用预训练网络来分类图像。
24 |
25 | [对Enron数据集使用Python进行机器学习](https://medium.com/@williamkoehrsen/machine-learning-with-python-on-the-enron-dataset-8d71015be26d)
26 |
27 | 使用Scikit-learn调查欺诈。
28 |
29 | [集成学习以改善机器学习结果](https://blog.statsbot.co/ensemble-learning-d1dcd548e936)
30 |
31 | 集成方法如何工作:减少方差(bagging),偏差(boosting)和提高预测(stacking)。
32 |
33 | [生物进化 - 给无聊的书呆子的游戏](https://www.youtube.com/watch?v=2boI6R0Gx8A)
34 |
35 | 关于使用Python3,PyGame和几个较小的库,来模拟智能进化的游戏。
36 |
37 | [Python生成器是神马?](https://dbader.org/blog/python-generators)
38 |
39 | 生成器是Python的一个棘手的主题。通过本教程,你将立即实现从基于类的迭代器到使用生成器函数和“yield”语句的飞跃。
40 |
41 | [如何在Django中使用Celery和RabbitMQ](https://simpleisbetterthancomplex.com/tutorial/2017/08/20/how-to-use-celery-with-django.html)
42 |
43 | 一篇解释如何安装和设置Celery + RabbitMQ来在Django应用中异步执行的初学者教程。
44 |
45 | [手把手教你配置一个Apache Spark独立集群,并与Jupyter集成](https://www.davidadrian.cc/posts/2017/08/how-to-spark-cluster/)
46 |
47 | [减少Python启动时间](https://lwn.net/SubscriberLink/730915/d6da49c8d92e815d/)
48 |
49 | [使用CFFI链接Python到C](https://tmarkovich.github.io//articles/2017-08/linking-python-to-c-with-cffi)
50 |
51 | [使用Python进行网络爬取:Scrapy,SQL,Matplotlib以获取网络数据洞察](http://www.scrapingauthority.com/python-scrapy-mysql-and-matplotlib-to-gain-web-data-insights)
52 |
53 | [收集、探索和预测Pocket上的流行的东东](https://tselai.com/pypocketexplore-collecting-exploring-predicting-pocket-items-machine-learning.html)
54 |
55 |
56 | # 好玩的项目,工具和库
57 |
58 | [mimesis](https://github.com/lk-geimfari/mimesis)
59 |
60 | Python库,帮助生成用于各种目的的不同语言的模拟数据。这些数据在软件开发和测试的各种阶段尤为有用。
61 |
62 | [AlgoCoin](https://github.com/theocean154/algo-coin)
63 |
64 | 跨多个交易所的算法交易加密货币。
65 |
66 | [CageTheUnicorn](https://github.com/reswitched/CageTheUnicorn)
67 |
68 | 用于任天堂Switch代码的调试/仿真环境。使用CTU,你可以运行整个Switch系统模块或者应用,跟踪并调试代码,测试漏洞,模糊测试等等。
69 |
70 | [robotbenchmark](https://robotbenchmark.net/)
71 |
72 | 在线编程模拟机器人。将你的表现与最佳效果相比较。分享你的成就。
73 |
74 | [reactionrnn](https://github.com/minimaxir/reactionrnn)
75 |
76 | 使用预训练的循环神经网络,预测对给定文本反应的Python模块 + R包。
77 |
78 | [pyheatmagic](https://github.com/csurfer/pyheatmagic)
79 |
80 | 配置并将你的python代码作为热图查看的IPython魔术方法。
81 |
82 | [Cansina](https://github.com/deibit/cansina)
83 |
84 | Cansina是一个web内容发现应用。众所周知,web应用不会公开它们所有的资源或者公共链接,因此,发现这些资源的唯一一种方法就是请求这些资源,然后检查响应。Cansina的责任就是帮助你发起这些请求,过滤响应以分辨出它是现有资源,还是一个烦人或者伪装的404。
85 |
86 | [lehar](https://github.com/darxtrix/lehar/)
87 |
88 | 使用相对排序可视化数据。
89 |
90 | [SMASH](https://github.com/ajbrock/SMASH)
91 |
92 | 一项有效探索神经体系结构的实验技术。
93 |
94 | [flask-allows](https://github.com/justanr/flask-allows)
95 |
96 | Flask-Allows是一个受django-rest-framework的权限系统和rest_condition将简单的需求组合成更为复杂的系统的能力的Flask鉴权工具。
97 |
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_329.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly - Issue 329 ](http://eepurl.com/dg2ynP)
2 |
3 | ---
4 |
5 | 欢迎来到Python周刊第329期。让我们直奔主题。
6 |
7 | # 来自赞助商
8 |
9 | [](https://goo.gl/wlxnDm)
10 |
11 | [Intel® Distribution for Python*](https://software.intel.com/en-us/distribution-for-python?utm_source=11Jan2018%20ad%20Python%20weekly&utm_medium=email&utm_campaign=Jan%202018%20Python%20Weekly%20newsletter) 现已免费提供,其许可证允许商业和非商业用途。这就对啦!试试 Intel 优化过的 NumPy、SciPy 和 scikit-learn,全部都在底层进行了加速。你的代码保持不变 —— 只需在 Intel Python 环境中运行它,就可以获得加速
12 |
13 |
14 | # 文章,教程和讲座
15 |
16 | [黑入 WiFi,把加密货币矿工注入到 HTML 请求中](http://arnaucode.com/blog/coffeeminer-hacking-wifi-cryptocurrency-miner.html)
17 |
18 | 本文的目的是解释如何进行 MITM(中间人)攻击,从而注入一些 javascript 到 html 页面中,以强制所有连接到 WiFi 网络的设备为攻击者挖掘加密货币。
19 |
20 | [Postgres 内部:建立一个描述工具](https://www.dataquest.io/blog/postgres-internals/)
21 |
22 | 在这篇教程中,学习 Postgres 是如何存储它的内部数据的,并使用 Python 构建你自己的数据库描述工具。
23 |
24 | [如何用 Python 创建一个僵尸网络](https://www.youtube.com/watch?v=eSPLRuOezGc)
25 |
26 | 学习如何使用 Python 创建你自己的僵尸网络。这篇文章严格出于教育目的。视频中讨论的主题是提高对 Python 恶意软件的认识,并拓宽对僵尸网络及其功能的理解。
27 |
28 | [使用 PostgreSQL,在 Django 中进行全文搜索](http://www.paulox.net/2017/12/22/full-text-search-in-django-with-postgresql/)
29 |
30 | 基于我关于使用 PostgreSQL,在 Django 中进行全文搜索的演讲的文章。
31 |
32 | [生活在【断层】线上](https://cbrownley.wordpress.com/2018/01/08/lives-on-the-fault-line-a-geospatial-analysis-of-the-san-andreas-fault-in-python/)
33 |
34 | Python 中的圣安德烈亚斯断层(San Andreas Fault)的地理空间分析。
35 |
36 | [在 Mac 上运行 PyGame 应用程序的技巧和诀窍 ](https://glyph.twistedmatrix.com/2018/01/shipping-pygame-mac-app.html)
37 |
38 | 破解那个小小的 PyGame,并在别人的 Mac 上运行的一个快速暗戳戳的指南。
39 |
40 | [使用 Python 改进随机森林:第一部分](https://towardsdatascience.com/improving-random-forest-in-python-part-1-893916666cd)
41 |
42 | [如何简化你的节假日用餐计划](https://hengrumay.github.io/MenuPlannerHelper/)
43 |
44 | [揭秘双重认证](https://rcoh.me/posts/two-factor-auth/)
45 |
46 |
47 | # 书籍
48 |
49 | [Python Notes for Professionals book(专业人士的 Python 说明书)](http://books.goalkicker.com/PythonBook/)
50 |
51 | 这本 Python Notes for Professionals book (专业人士的 Python 说明书)是从 Stack Overflow Documentation 编译而来的,内容是由 Stack Overflow 美好的人们编写。
52 |
53 |
54 | # 好玩的项目,工具和库
55 |
56 | [Eel](https://github.com/ChrisKnott/Eel)
57 |
58 | 一个制作简单电子类 HTML/JS GUI 应用的小 Python 库。
59 |
60 | [Qgrid](https://github.com/quantopian/qgrid)
61 |
62 | Jupyter notebooks 中排序、筛选和编辑 DataFrame 的交互式网络。
63 |
64 | [Zeus](https://github.com/getsentry/zeus)
65 |
66 | Zeus 是 CI 解决方案的前端和分析提供器。
67 |
68 | [MMdnn](https://github.com/Microsoft/MMdnn)
69 |
70 | MMdnn 是一套帮助在不同深度学习框架之间互相操作的工具。例如,模型转换和可视化。在Caffe, Keras、MXNet、Tensorflow、CNTK 和 PyTorch 之间转换模型。
71 |
72 | [Authlib](https://github.com/lepture/authlib)
73 |
74 | Authlib 是一个使用OAuth 1、OAuth 2等的即用身份验证客户端和服务端。
75 |
76 | [py2bpf](https://github.com/facebookresearch/py2bpf)
77 |
78 | 一个 python 到 bpf(Berkeley Packet Filter bytecode,伯克利包过滤器字节码)转换器。
79 |
80 | [AnPyLar](https://github.com/anpylar/anpylar)
81 |
82 | 一个创建 web 应用的客户端侧 Python 框架。
83 |
84 | [CoffeeMiner](https://github.com/arnaucode/coffeeMiner)
85 |
86 | WiFi 网络中的协作(mitm)加密电子货币挖掘池。
87 |
88 | [fleep](https://github.com/floyernick/fleep)
89 |
90 | Python 的文件格式确定库。
91 |
92 | [convnet-drawer](https://github.com/yu4u/convnet-drawer)
93 |
94 | 使用类 Keras 模型定义,说明卷积神经网络(CNN)的 Python 脚本。
95 |
96 |
97 | # 最新发布
98 |
99 | [Numpy 1.14.0](https://github.com/numpy/numpy/releases/tag/v1.14.0)
100 |
101 | Numpy 1.14.0 是七个月努力的产物,包含大量问题修复和新特性,以及关于潜在兼容性问题的一些改动。用户会注意到的主要改动是打印 numpy 数组和标量的风格变化,这是一项会影响到 doctest 的改动。
102 |
103 | [Python 3.7.0a4](https://www.python.org/downloads/release/python-370a4/)
104 |
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_620.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly - Issue 620](http://eepurl.com/iA9nDI)
2 |
3 | ---
4 |
5 | 欢迎来到Python周刊第 620 期。让我们直奔主题。
6 |
7 |
8 | # 文章、教程和讲座
9 |
10 | [Python 3.12:您需要了解的所有新功能!](https://www.youtube.com/watch?v=udHmeAmOlbI) 
11 | 该视频不仅将深入探讨 Python 3.12 中即将推出的令人兴奋的新功能和改进,还将讨论即将发布的版本中将删除的一些东西。
12 |
13 | [度量 Python 执行时间的 5 种方法](https://superfastpython.com/benchmark-execution-time/)
14 | 您可以使用标准库中的“time”模块对 Python 代码的执行进行基准测试。在本教程中,您将了解如何使用一套不同的技术来计时 Python 代码的执行时间。
15 |
16 | [使用 FastAPI 掌握集成测试](https://alex-jacobs.com/posts/fastapitests/)
17 | 集成测试 FastAPI:使用 MongoMock、MockS3 等来利用模拟后端服务的强大功能。
18 |
19 | [LangChain 初始者速成班](https://www.youtube.com/watch?v=lG7Uxts9SXs) 
20 | LangChain 是一个旨在简化使用大型语言模型创建应用程序的框架。它让你能够轻松地将 AI 模型与大量不同的数据源连接起来,以便您可以创建定制的 NLP 应用程序。
21 |
22 | [使用 Django REST 框架构建 API](https://blog.jetbrains.com/pycharm/2023/09/building-apis-with-django-rest-framework/)
23 | 本教程演示了如何在 PyCharm 中使用 Python 和 Django REST 框架来开发 API
24 |
25 | [我所学到的有关在 Python 中构建 CLI 工具的那些事](https://simonwillison.net/2023/Sep/30/cli-tools-python/)
26 | 我用 Python 构建了很多命令行工具。它已成为我最喜欢的快速将一段代码变成我可以自己使用并打包供其他人使用的方法。以下是我迄今为止在 Python 中设计和实现 CLI 工具所学到的一些东西的笔记。
27 |
28 | [用不到 200 行代码在云中构建 API](https://aeturrell.com/blog/posts/build-a-cloud-api/build-a-cloud-api.html)
29 | 云工具和 Python 包已经变得非常强大,让您可以用不到 200 行代码构建(可扩展的)基于云的 API。在本文中,您将了解如何使用 Google Cloud、Terraform 和 FastAPI,在云上部署可查询数据 API。
30 |
31 | [如何在 Django 中安全存储用户的 API 密钥](https://www.photondesigner.com/articles/store-api-keys-securely)
32 | 加密用户的密钥以提高安全性。
33 |
34 | [使用 PyTorch Lightning 扩展大型(语言)模型](https://lightning.ai/blog/scaling-large-language-models-with-pytorch-lightning/)
35 | 了解使用 PyTorch Lightning 训练 Llama 和 Stable Diffusion 等大型模型的技术。
36 |
37 | [探索 Wordle](https://www.georgevreilly.com/2023/09/26/ExploringWordle.html)
38 | 本文将向您展示如何使用 Python,以编程方式解决 Wordle。
39 |
40 |
41 | # 好玩的项目,工具和库
42 |
43 | [mistral-src](https://github.com/mistralai/mistral-src)
44 | Mistral AI 7B v0.1 模型的参考实现。
45 |
46 | [kernel-hardening-checker](https://github.com/a13xp0p0v/kernel-hardening-checker)
47 | 用于检查 Linux 内核安全强化选项的工具。
48 |
49 | [dreamgaussian](https://github.com/dreamgaussian/dreamgaussian)
50 | 用于高效 3D 内容创建的生成 Gaussian Splatting。
51 |
52 | [cloud_benchmarker](https://github.com/Dicklesworthstone/cloud_benchmarker)
53 | Cloud Benchmarker 自动化执行云实例的性能测试,提供富有洞察力的图表并随时间进行跟踪。
54 |
55 | [DSPy](https://github.com/stanfordnlp/dspy)
56 | 使用基础模型进行编程的框架。
57 |
58 | [cloudgrep](https://github.com/cado-security/cloudgrep)
59 | cloudgrep 是用于云存储的 grep。
60 |
61 | [Octogen](https://github.com/dbpunk-labs/octogen)
62 | Octogen 是一款由 GPT3.5/4 和 Codellama 提供支持的开源代码解释器。
63 |
64 | [stepping](https://stepping.site/)
65 | 给 Python 应用开发者的增量视图维护。
66 |
67 | [BoTorch](https://botorch.org/)
68 | BoTorch 是一个基于 PyTorch 构建的贝叶斯优化研究库。
69 |
70 | [cappa](https://github.com/dancardin/cappa)
71 | 声明式 CLI 参数解析器。
72 |
73 | # 最新发布
74 |
75 | [Python 3.12.0](https://www.python.org/downloads/release/python-3120/)
76 | Python 3.12.0 中的一些主要变化包括
77 | * 更灵活的 f 字符串解析
78 | * Python 代码对缓冲区协议的支持
79 | * 新的调试/分析 API
80 | * 支持具有单独全局解释器锁(GIL)的隔离子解释器
81 | * 更多改进的错误消息。
82 | * 支持 Linux 性能分析器报告跟踪中的 Python 函数名称。
83 | * 许多大大小小的性能改进
84 |
85 | [Flask 3.0.0](https://flask.palletsprojects.com/en/3.0.x/changes/)
86 |
87 | [Django 安全版本已发布:4.2.6、4.1.12 和 3.2.22](https://www.djangoproject.com/weblog/2023/oct/04/security-releases/)
88 |
89 |
90 | # 近期活动和网络研讨会
91 |
92 | [Hybrid IndyPy - 利用 AI 进行创新:构建类似 ChatGPT 的应用程序](https://www.meetup.com/indypy/events/294548715/)
93 | 希望通过创建自己的类似 ChatGPT 的应用程序来释放 AI 和 LLM 的潜力吗?在本次演讲和现场演示中,您将学习如何提取专有数据见解、加速数据驱动的决策、提高生产力并推动创新。
94 |
95 | [虚拟(Virtual):克利夫兰 Python 2023 年 10 月聚会](https://www.meetup.com/cleveland-area-python-interest-group/events/295681934/)
96 | 将有一场演讲:使用网络抓取,解析和收集亚马逊产品列表的评论数据。
97 |
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_621.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly - Issue 621](http://eepurl.com/iBCBtY)
2 |
3 | ---
4 |
5 | 欢迎来到Python周刊第 621 期。让我们直奔主题。
6 |
7 |
8 | # 文章、教程和讲座
9 |
10 | [几分钟内构建您的第一个 Pytorch 模型!](https://www.youtube.com/watch?v=tHL5STNJKag) 
11 | 在本视频中,我们将通过实践来学习!构建您的第一个 PyTorch 模型(可以对扑克牌图像进行分类)。
12 |
13 | [使用单个 GPU,在 Python 代码上微调 Mistral7B!](https://wandb.ai/byyoung3/ml-news/reports/Fine-Tuning-Mistral7B-on-Python-Code-With-A-Single-GPU---Vmlldzo1NTg0NzY5)
14 | 虽然 Mistral 7B 的开箱即用令人印象深刻,但其微调能力仍有巨大潜力。本教程旨在指导您完成针对特定用例(Python 编码)微调 Mistral 7B 的过程!我们将利用 HuggingFace 的 Transformers 库、DeepSpeed(用于优化)和 Choline(用于简化在 Vast.ai 上部署)等强大工具。
15 |
16 | [使用 Python 管道方法,优雅地进行模块化数据处理](https://github.com/dkraczkowski/dkraczkowski.github.io/tree/main/articles/crafting-data-processing-pipeline)
17 | 深入研究错综复杂的数据处理通常感觉就像在错综复杂的迷宫中航行。我们构建了这些复杂的流程,却只是为了避免破坏它们而对其保持原样。但如果我们可以改进它呢?以下是我对用 Python 构建更易于维护、模块化的数据处理工作流程的看法,该工作流程倾向于“管道和过滤器”架构模式。
18 |
19 | [使用 Pandas Dropna 处理缺失数据](https://ponder.io/professional-pandas-handling-missing-data-with-pandas-dropna/)
20 | 在这篇文章中,我们将通过探索世界幸福报告来学习如何使用 pandas dropna 处理缺失数据。
21 |
22 | [从 Python 调用 Rust](https://blog.frankel.ch/rust-from-python/)
23 | 从这篇文章学习从 Python 调用 Rust 的三种不同方法:HTTP、IPC 和 FFI。
24 |
25 | [如何在 SaaS 平台中使用 LLM](https://www.youtube.com/watch?v=fH8fJYWfJcg) 
26 | 该视频将引导您了解在名为 Learntail 的 SaaS 平台中使用了多大的语言模型。Learntail 是一款易于使用的人工智能测验生成工具。
27 |
28 | [Django 中的 RegisterFields](https://www.better-simple.com/django/2023/10/03/registerfields-in-django/)
29 | 对一个 Django 模型字段的解释,该字段根据键返回类的实例。
30 |
31 | [Python 类型提示:pyastgrep 案例学习](https://lukeplant.me.uk/blog/posts/python-type-hints-pyastgrep-case-study/)
32 | 作者分享了他们在工具 pyastgrep 中向 Python 代码添加类型提示的经验。他们讨论了使用静态类型检查和交互式编程来帮助捕获错误并提高代码可读性的挑战和好处。
33 |
34 | # 好玩的项目,工具和库
35 |
36 | [LeptonAI](https://github.com/leptonai/leptonai)
37 | 一个用于简化 AI 服务构建的 Pythonic 框架。
38 |
39 | [RealtimeSTT](https://github.com/KoljaB/RealtimeSTT)
40 | 强大、高效、低延迟的语音转文本库,具有先进的语音活动检测、唤醒词激活和即时转录功能。专为诸如语音助手这类实时应用程序而设计。
41 |
42 | [ziggy-pydust](https://github.com/fulcrum-so/ziggy-pydust)
43 | 用于在 Zig 中构建 Python 扩展的工具包。
44 |
45 | [LLM-scientific-feedback](https://github.com/Weixin-Liang/LLM-scientific-feedback)
46 | 大型语言模型能否为研究论文提供有用的反馈?大规模的实证分析。
47 |
48 | [genai-stack](https://github.com/docker/genai-stack)
49 | 这个 GenAI 应用程序栈将让您立即开始构建自己的 GenAI 应用程序。演示应用程序可以作为灵感或起点。
50 |
51 | [Chrome-GPT](https://github.com/richardyc/Chrome-GPT)
52 | 控制桌面版 Chrome 的 AutoGPT 代理。
53 |
54 | [streaming-llm](https://github.com/mit-han-lab/streaming-llm)
55 | 具有注意力接收器的高效流式语言模型。
56 |
57 | [torch2jax](https://github.com/samuela/torch2jax)
58 | 在 JAX 中运行 PyTorch。
59 |
60 | [swiss_army_llama](https://github.com/Dicklesworthstone/swiss_army_llama)
61 | 一种用于语义文本搜索的 FastAPI 服务,使用预先计算的嵌入和高级相似性度量,提供通过 textract 内置对各种文件类型的支持。
62 |
63 |
64 | # 最新发布
65 |
66 | [Visual Studio Code 中的 Python —— 2023 年 10 月版本](https://devblogs.microsoft.com/python/python-in-visual-studio-code-october-2023-release/)
67 | 此版本包括以下声明:
68 | * Python 调试器扩展更新
69 | * 弃用对 Python 3.7 的支持
70 | * Pylint 扩展的更改选项上的 Lint
71 | * Mypy 扩展报告范围和守护进程模式
72 | * Grace Hopper 会议和开源日参与
73 |
74 |
75 |
76 | # 近期活动和网络研讨会
77 |
78 | [ThaiPy #96](https://www.meetup.com/thaipy-bangkok-python-meetup/events/295498832/)
79 | 将有以下讲座:
80 | * Python GIL。过去与未来
81 | * 利用 GPU 加速 100 倍
82 |
83 |
84 | [PyLadies 2023 年 10 月都柏林聚会](https://www.meetup.com/pyladiesdublin/events/295990212/)
85 | 将进行以下演讲:
86 | * 想再次成为一个小朋友吗?年龄永远不是问题!
87 | * 打印您自己的冒险游戏
88 |
89 |
90 | [PyData 2023 年 10 月南安普顿聚会](https://www.meetup.com/pydata-southampton/events/296057081/)
91 | 将进行以下演讲:
92 | * 地理空间数据和处理简介
93 | * MoleGazer:天文学与皮肤学的结合
94 |
95 |
96 | [PyData 2023 年 10 月柏林聚会](https://www.meetup.com/pydata-berlin/events/296680621/)
97 | 将有一场演讲:利用开源 LLMs 进行生产。
98 |
99 | [PyData 2023 年 10 月剑桥聚会](https://www.meetup.com/pydata-cambridge-meetup/events/296429788/)
100 | 将有一场演讲:使用 AI 技术设计和测试现代桌面棋盘游戏。
101 |
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_623.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly - Issue 623](http://eepurl.com/iCBKtY)
2 |
3 | ---
4 |
5 | 欢迎来到Python周刊第 623 期。让我们直奔主题。
6 | ---
7 |
8 |
9 | # 新闻
10 |
11 | [PyCon US 2024 提案征集](https://pretalx.com/pyconus2024/)
12 | Pycon US 2024 提案征集现已正式开放,接受演讲、教程、海报和Charlas(一种交流形式)的提议!在2023年12月18日之前提交您的提案。
13 |
14 |
15 | # 文章,教程和讲座
16 |
17 | [Pytest 教程 —— 如何测试 Python 代码](https://www.youtube.com/watch?v=cHYq1MRoyI0) 
18 | 学习如何使用Pytest,这是Python强大的测试框架。在整个课程中,您将对Pytest的功能,最佳实践以及编写有效测试的细微差别有深入的了解。最后,您将学习如何使用Chatgpt来帮助您更快地编写测试。
19 |
20 | [使用智能手机录制的语音段,对2型糖尿病进行声学分析和预测](https://www.mcpdigitalhealth.org/article/S2949-7612\(23\)00073-1/fulltext)
21 | 通过检查非糖尿病和 T2DM 个人之间的语音记录差异,探讨语音分析作为2型糖尿病(T2DM)患者预筛选或监测工具的潜力
22 |
23 | [嵌入:它们是什么,以及它们为什么重要](https://simonwillison.net/2023/Oct/23/embeddings/)
24 |
25 | 在这篇文章中,Simon Willison探讨了数据分析和机器学习中的嵌入(embeddings)概念,突出了它们在表示复杂数据以进行高效处理方面的作用,并提供了关于它们使用的实际见解。
26 |
27 | [我们必须聊聊 Flask](https://blog.miguelgrinberg.com/post/we-have-to-talk-about-flask)
28 |
29 | Miguel Grinberg指出,Flask的维护人员经常在新版本的Flask和Werkzeug中引入微不足道的不兼容变化,导致扩展和教程在更新之前会出现问题。现在,[这篇文章也有更新](https://blog.miguelgrinberg.com/post/some-more-to-talk-about-flask)。
30 |
31 | [lambda 表达式是什么?](https://www.pythonmorsels.com/lambda-expressions/)
32 | 了解lambda的表达方式以及如何在Python中使用。
33 |
34 | [使用 SIMD 加速Cython](https://pythonspeed.com/articles/faster-cython-simd/)
35 | SIMD 是一项CPU功能,让您可以加快数字处理。了解如何与Cython一起使用。
36 |
37 | [将你的应用插入到 Jupyter 的世界](https://blog.jupyter.org/plug-your-application-into-the-jupyter-world-805e48918801)
38 | Kernel(核心)是Jupyter架构中一个简单但强大的抽象概念。它们封装了语言解释器,并通过标准化接口使其可访问。这是Jupyter出色多才多艺的关键,支持超过100种编程语言。将一个核心嵌入到您的自定义应用程序中,可以无缝地将其暴露给Jupyter生态系统。您不仅可以将JupyterLab附加到您的程序中,以便进行状态检查(就像使用调试器一样),而且还可以真正利用Jupyter生态系统的所有功能来扩展您的应用程序。
39 |
40 | [如何部署基于 Conda 的 docker 镜像](https://blog.neater-hut.com/how-to-deploy-conda-based-docker-images.html)
41 | 学习如何通过三个方法,将基于 Conda 的 Docker 镜像降低到合理的尺寸。
42 |
43 | [使用 django 和 htmx 的无限滚动](https://fmacedo.com/posts/1-django-htmx-infinite-scroll/)
44 | 有关如何使用Django和HTMX实现无限滚动的教程。
45 |
46 | [如何在 4 分钟内将 Google 表添加为你的 Django 数据库](https://www.youtube.com/watch?v=XXDiqE4t0xA) 
47 | 在4分钟内添加 Google 表作为您的Django数据库。这是更快的原型和小产品的理想选择。
48 |
49 |
50 | # 好玩的项目,工具和库
51 |
52 | [Genv](https://github.com/run-ai/genv)
53 | GPU 环境管理和集群编排
54 |
55 | [RIP](https://github.com/prefix-dev/rip)
56 | 使用 Rust 实现的快速简单的 pip 实现。
57 |
58 | [LocalPilot](https://github.com/danielgross/localpilot)
59 | 在 Macbook 上,一键即可本地使用 GitHub Copilot!
60 |
61 | [autotab](https://github.com/Planetary-Computers/autotab-starter)
62 | 为现实世界的任务构建浏览器代理。
63 |
64 | [GRID](https://github.com/ScaledFoundations/GRID-playground)
65 | 通用机器人智能开发(General Robot Intelligence Development,GRID)平台。
66 |
67 |
68 | [RenderCV](https://github.com/sinaatalay/rendercv)
69 | 一个 Python 应用,根据输入的 YAML/JSON 问价,生成 PDF 格式的 CV。
70 |
71 | [Waymax](https://github.com/waymo-research/waymax)
72 | 用于自动驾驶研究的基于 JAX 的模拟器。
73 |
74 | [DeepSparse](https://github.com/neuralmagic/deepsparse)
75 | 用于 CPU 的稀疏性感知深度学习推理运行时。
76 |
77 | [GenSim](https://github.com/liruiw/GenSim)
78 | 通过大型语言模型生成机器人仿真任务(Robotic Simulation Tasks)。
79 |
80 |
81 | [Voyager](https://spotify.github.io/voyager/)
82 | Voyager是一个用于在内存中的向量集合上执行快速近似最近邻搜索的库。
83 |
84 | [pypipe](https://github.com/bugen/pypipe)
85 | Python pipe 命令行工具。
86 |
87 | [dlt](https://github.com/dlt-hub/dlt)
88 | 数据加载工具(data load tool,dlt)—— 用于数据加载的开源 Python 库。
89 |
90 | [Deep-Learning-Ultra](https://github.com/daddydrac/Deep-Learning-Ultra)
91 | 开源深度学习容器(Open source Deep Learning Containers,DLCs)是一组用于在 PyTorch、OpenCV(针对GPU进行了编译)、TensorFlow 2(适用于GPU)、PyG 和 NVIDIA RAPIDS 中训练和提供模型的 Docker 镜像。
92 |
93 | [higgsfield](https://github.com/higgsfield-ai/higgsfield)
94 | 容错性强、高度可伸缩的GPU编排系统以及一个机器学习框架,专为训练拥有数十亿至数万亿参数的模型而设计
95 |
96 |
97 | # 最新发布
98 |
99 | [Django 5.0 beta 1 发布](https://www.djangoproject.com/weblog/2023/oct/23/django-50-beta-1-released/)
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_624.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly - Issue 624](http://eepurl.com/iC6EUY)
2 |
3 | ---
4 |
5 | 欢迎来到Python周刊第 624 期。让我们直奔主题。
6 |
7 |
8 | # 文章,教程和讲座
9 |
10 | [通过 FastAPI 掌握 API 测试:数据库、依赖等等!](https://www.youtube.com/watch?v=9gC3Ot0LoUQ) 
11 | 本教程将指导您使用 FastAPI 完成 API 测试,并提供完整的代码示例。使用它作为测试您自己的 API 的模板吧!
12 |
13 |
14 | [使用 Python 将数据分析速度提高 170,000 倍](https://sidsite.com/posts/python-corrset-optimization/)
15 | 在这篇文章中,我们将在 Python 中,经历一段分析和迭代加速代码的旅程。
16 |
17 | [我移植 setup.py 的用户体验](https://gregoryszorc.com/blog/2023/10/30/my-user-experience-porting-off-setup.py/)
18 | 本文讨论了将 Python 包从 setup.py 移植到 pyproject.toml 的挑战,以及缺乏明确指导的情况。
19 |
20 | [算法交易 —— Python 机器学习和量化策略课程](https://www.youtube.com/watch?v=9Y3yaoi9rUQ) 
21 | 本课程涵盖三种高级交易策略。首先,它重点关注使用了标准普尔 500 指数数据的无监督学习,其次是纳斯达克股票的 Twitter 情绪投资策略(Twitter Sentiment Investing Strategy),以及使用 GARCH 模型和技术指标识别每日和日内交易信号的日内策略(Intraday Strategy),从而丰富您的金融技能。
22 |
23 | [使用潜在一致性模型(LCMs),在你的 Mac 上一秒生成图像](https://replicate.com/blog/run-latent-consistency-model-on-mac)
24 | 潜在一致性模型 (LCM) 基于稳定扩散(Stable Diffusion),但它们可以更快地生成图像,只需 4 到 8 个步骤即可生成良好的图像(与需要 25 到 50 个步骤才能生成的模型相比)。通过在 M1 或 M2 Mac 上运行 LCM,您可以以每秒一张的速度生成 512x512 图像。
25 |
26 | [为什么说 Django 管理系统是“丑的”?](https://www.coderedcorp.com/blog/why-is-the-django-admin-ugly/)
27 | 本文讨论了为什么 Django 管理界面设计得不够美观。它讨论了 Django 管理系统的历史以及它如此设计的原因。一些重要的点是,Django 管理系统旨在供内部使用,而不是用于构建整个前端。
28 |
29 | [使用 AI 构建类似 ChatGPT 的应用程序](https://sixfeetup.com/company/news/build-chatgpt-like-apps-with-ai) 
30 | 如果您对 AI 和大型语言模型 (LLM) 的实际应用感兴趣,那您会在本演讲和现场演示中发现其价值之处。该演示超越了理论,包括现实世界的示例和最佳实践,包括了一个包含 Python 代码和类似 ChatGPT 的应用程序示例的 GitHub 存储库,这些示例将帮助您启动自己的应用程序。
31 |
32 |
33 | [不要使用 requirements.txt](https://quanttype.net/posts/2023-10-31-do-not-use-requirements.txt.html)
34 | 本文讨论在 Python 项目中使用 requirements.txt 进行包管理的限制。作者建议改用 Poetry(一个包管理器,可以简化依赖管理并提供虚拟环境和文件锁定等附加功能)。
35 |
36 | [从混乱到凝聚:构建您自己的 Monorepo](https://monadical.com/posts/from-chaos-to-cohesion.html)
37 | 使用 GitHub Actions 作为 CI/CD 工具,构建一个简单的 monorepo。
38 |
39 |
40 | # 好玩的项目,工具和库
41 |
42 | [SuperDuperDB](https://github.com/SuperDuperDB/superduperdb)
43 | 将人工智能带入您最喜欢的数据库!直接与您的数据库和数据进行集成、训练和管理任何 AI 模型和 API。
44 |
45 | [Esmerald](https://github.com/dymmond/esmerald)
46 | Esmerald 是一个现代、强大、灵活、高性能的 Web 框架,旨在不仅是构建 API,还能够构建从最小到企业级别的完全可扩展应用程序。
47 |
48 | [mify](https://github.com/mify-io/mify)
49 | 一个代码生成工具,帮助您构建云后端服务。
50 |
51 | [De4py](https://github.com/Fadi002/de4py)
52 | De4py 是一款高级 Python 反混淆器,具有漂亮的 UI 和一组高级功能,使恶意软件分析师和逆向工程师能够对 Python 文件等进行反混淆。
53 |
54 | [rag-demystified](https://github.com/pchunduri6/rag-demystified)
55 | 一个从头开始构建的,由 LLM 驱动的高级 RAG 管道。
56 |
57 | [m1n1](https://github.com/AsahiLinux/m1n1)
58 | Apple Silicon 的引导加载程序和实验场。
59 |
60 | [Wonder3D](https://github.com/xxlong0/Wonder3D)
61 | 用于从单个图像进行 3D 重建的跨域扩散模型。
62 |
63 | [LearnHouse](https://github.com/learnhouse/learnhouse)
64 | LearnHouse 是一个开源平台,任何人都可以通过它轻松提供世界一流的教育内容,此外,它提供多种内容类型:动态页面、视频、文档等。
65 |
66 | [Marcel](https://github.com/geophile/marcel)
67 | 一个现代的 shell。
68 |
69 | [lea](https://github.com/carbonfact/lea)
70 | lea 是 dbt、SQLMesh 和 Google Dataform 等工具的极简替代品。
71 |
72 | [XAgent](https://github.com/OpenBMB/XAgent)
73 | 用于解决复杂任务的自主 LLM 代理。
74 |
75 | [Raven](https://github.com/CycodeLabs/raven)
76 | CI/CD 安全分析器。
77 |
78 |
79 | # 最新发布
80 |
81 | [Django 安全版本已发布:4.2.7, 4.1.13, 和 3.2.23](https://www.djangoproject.com/weblog/2023/nov/01/security-releases/)
82 |
83 |
84 | # 近期活动和网络研讨会
85 |
86 | [Virtual:PyMNtos Python 演示之夜 #119](https://www.meetup.com/pymntos-twin-cities-python-user-group/events/296436004/)
87 | 将有一场演讲,Selenium 和 Python。
88 |
89 | [PyData 伦敦 2023 年 11 月聚会](https://www.meetup.com/pydata-london-meetup/events/296513974/)
90 | 将会有以下演讲:
91 | * 使用 Quix Streams 简化实时 ML 管道
92 | * 从内到外的 Transformers
93 | * Excel 中的 Python
94 | * 有时,我们听到的音乐和播放列表并不符合我们的心情,人工智能可以帮助解决这个问题吗?
95 |
96 |
97 | [PyData 慕尼黑 2023 年 11 月聚会](https://www.meetup.com/pydata-munchen/events/296950996/)
98 | 将会有以下演讲:
99 | * TensorRT LLM Nvidia
100 | * CTranslate2 和 vLLM
101 | * 我今天停止阅读 Twitter 时的 LLM 状态
102 |
103 |
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_630.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly - Issue 630](http://eepurl.com/iF-TCw)
2 |
3 | ---
4 |
5 | 欢迎来到Python周刊第 630 期。让我们直奔主题。
6 |
7 |
8 | # 文章,教程和讲座
9 |
10 | [Vector Search RAG 教程 —— 通过高级搜索,将您的数据与 LLMs 结合起来](https://www.youtube.com/watch?v=JEBDfGqrAUA) 
11 | 了解如何使用矢量搜索(Vector Search)和嵌入轻松地将数据与 GPT-4 等大型语言模型相结合。您将首先学习概念,然后创建三个项目。
12 |
13 | [在运行时注释](https://blog.glyph.im/2023/12/annotated-at-runtime.html)
14 | PEP 593 对于如何实际使用 Annotated 参数这一点有些含糊其辞;这是我的建议。
15 |
16 | [pytest 守护进程:10 倍本地测试迭代速度](https://discord.com/blog/pytest-daemon-10x-local-test-iteration-speed)
17 | 在 Discord,他们的 Python 测试套件本地测试运行缓慢,每次测试需要 13 秒。他们构建了一个 pytest 守护进程,将本地测试迭代速度提高了 10 倍,显着缩短了开发时间。该解决方案涉及将繁重的工作卸载到后台进程并缓存结果,绕过缓慢的导入和固定装置。
18 |
19 | [在 Python 中执行 a + b 需要多少行 C 代码?](https://codeconfessions.substack.com/p/cpython-dynamic-dispatch-internals)
20 | 了解 CPython 中动态调度实现的机制。
21 |
22 | [为什么使用 TYPE_CHECKING?](https://vickiboykis.com/2023/12/11/why-if-type_checking/)
23 | 本文讨论了 Python 中条件导入的使用,特别是 if TYPE_CHECKING 模式,以解决 mypy 等工具强制执行的类型检查和运行时类型检查的差异。它探讨了在处理存在大量相互依赖并可能导致循环依赖的自定义类时,是否需要此模式。
24 |
25 | [对扇出模式(Fanout Pattern)的解释](https://www.better-simple.com/django/2023/12/06/fanout-pattern-explained)
26 | 本文讨论了扇出模式在 Celery 任务上下文中的使用,其中单个任务可以替换为数量可变的其他任务。它提供了一个关于扇出模式的实际示例,及其在处理复杂任务签名中的应用,强调了它在 Celery 框架内的任务设计和管理中的强大功能。通过代码示例说明了扇出模式,展示了其处理顺序和并行任务执行的能力,提供了对于其任务编排和工作负载分配的有效性的一些见解。
27 |
28 | [Django:使用 nh3 清理传入的 HTML 片段](https://adamj.eu/tech/2023/12/13/django-sanitize-incoming-html-nh3/)
29 | 让我们看看如何在 Django 表单中使用 nh3 进行 HTML 清理。您可以将此方法应用于其他情况,例如在 DRF 序列化器中。
30 |
31 | [现实中的 match/case](https://nedbatchelder.com/blog/202312/realworld_matchcase.html)
32 | Python 3.10 引入了结构模式匹配,称为 match/case,它允许匹配数据结构中的模式。本文提供了一个使用匹配/大小写来简化对从 GitHub 机器人接收的复杂 JSON 有效负载的检查的真实示例,展示了其在处理深度嵌套数据结构方面的实际应用。作者强调了与传统的分离有效负载的方法相比,match/case 如何使任务变得更加简单
33 |
34 |
35 | # 好玩的项目,工具和库
36 |
37 | [coffee](https://github.com/Coframe/coffee)
38 | 使用 AI 直接在您自己的 IDE 上构建和迭代您的 UI,速度提高 10 倍。
39 |
40 | [µHTTP](https://github.com/0x67757300/uHTTP)
41 | µHTTP 的出现源于对简单 Web 框架的需求。它非常适合微服务、单页应用程序以及单体(架构)这类庞然大物。
42 |
43 | [PurpleLlama](https://github.com/facebookresearch/PurpleLlama)
44 | 用于评估和提高 LLM 安全性的工具集。
45 |
46 | [Arrest](https://github.com/s-bose/arrest)
47 | Arrest 是一个小型的实用程序,用以使用 pydantic 和 httpx 轻松构建和验证 REST API 调用。
48 |
49 | [LLMCompiler](https://github.com/SqueezeAILab/LLMCompiler)
50 | 用于并行函数调用的 LLM 编译器。
51 |
52 | [Pearl](https://github.com/facebookresearch/Pearl)
53 | 由 Meta 的应用强化学习团队带来的可投入生产的强化学习 AI 代理库。
54 |
55 | [Mamba-Chat](https://github.com/havenhq/mamba-chat)
56 | Mamba-Chat 是第一款基于状态空间模型架构而非转换器的聊天语言模型。
57 |
58 | [Netchecks](https://github.com/hardbyte/netchecks)
59 | Netchecks 是一组用于测试网络状况,并断言它们是否符合预期的工具。
60 |
61 | [concordia](https://github.com/google-deepmind/concordia)
62 | 用于生成社会模拟的库。
63 |
64 | [Cyclopts](https://github.com/BrianPugh/cyclopts)
65 | 基于 python 类型提示的直观、简单的 CLI。
66 |
67 | [UniDep](https://github.com/basnijholt/unidep)
68 | 具有 pip 和 conda 要求的单一事实来源。
69 |
70 |
71 | # 最新发布
72 |
73 | [Visual Studio Code 中的 Python - 2023 年 12 月版本](https://devblogs.microsoft.com/python/python-in-visual-studio-code-december-2023-release/)
74 | 此版本包括以下声明:
75 | * 运行按钮菜单中添加了可配置的调试选项
76 | * 使用 Pylance 显示类型层次结构
77 | * 停用对终端中自动激活的虚拟环境的命令支持
78 | * 可设置打开/关闭 REPL 智能发送以及不支持时的消息
79 |
80 |
81 | [Python 3.12.1](https://www.python.org/downloads/release/python-3121/)
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_637.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly - Issue 637](http://eepurl.com/iJGNIs)
2 |
3 | ---
4 |
5 | 欢迎来到《Python周刊》第 637 期。让我们直奔主题。
6 |
7 | # 文章,教程和讲座
8 |
9 | [Rye:轻松的 Python 体验](https://www.youtube.com/watch?v=q99TYA7LnuA) 
10 | 演示了当时最新版本的 Rye (0.21),而现在它可用于管理 Python 项目和解释器。
11 |
12 | [用 80 行代码实现的搜索引擎](https://www.alexmolas.com/2024/02/05/a-search-engine-in-80-lines.html)
13 | 这篇文章详细介绍了如何仅用 80 行代码创建搜索引擎的过程,提供了关于如何有效实现虽然基本但实用的搜索算法的见解。
14 |
15 | [超越自注意力:小型语言模型是如何预测下一个 Token 的](https://shyam.blog/posts/beyond-self-attention)
16 | 深入研究小型变压器模型的内部结构,了解它如何将自注意力计算转化为下一个令牌的准确预测。
17 |
18 | [Python 版本间的主要变动的总结](https://www.nicholashairs.com/posts/major-changes-between-python-versions/)
19 | 这篇文章旨在作为有关每个新版本 Python 引入的主要更改的快速参考。这可以帮助您在升级代码库时利用新功能,或者确保您拥有与旧版本兼容的正确的保护措施。
20 |
21 | [专业提示 —— “丰富(rich)”你的 Python 测试](https://www.revsys.com/tidbits/en-rich-your-python-testing/)
22 | 本文提供了有关使用“rich”库来增强 Python 测试的专业提示。它演示了如何通过使用“rich”来更好地可视化测试结果,从而改进测试(特别是在 pytest 测试中)输出。本文提供了丰富 Python 测试体验的实用建议和代码示例。
23 |
24 | [如何使用 GDB 的 Python API 缓存数据](https://developers.redhat.com/articles/2024/02/05/how-cache-data-using-gdbs-python-api#caching_for_object_files_and_program_spaces)
25 | 本文介绍如何在 GDB 的 Python API 中缓存不同对象类型的信息;它为缓存某些对象类型提供了特殊支持,而对于其他对象类型,您需要执行额外的工作来管理缓存的数据。
26 |
27 | [使用 Django、Kubernetes、TailwindCSS、Twingate、AWS S3 和 HTMX 构建内容引擎](https://www.youtube.com/watch?v=2TX7Pal5NMc) 
28 |
29 | [一万亿行挑战](https://blog.coiled.io/blog/1trc.html)
30 |
31 | [使用种子数据库改进 Django 测试](https://tla.wtf/posts/django-seed-db/)
32 |
33 | [TensorFlow 中的图形神经网络](https://blog.research.google/2024/02/graph-neural-networks-in-tensorflow.html)
34 |
35 |
36 | # 好玩的项目,工具和库
37 |
38 | [OLMo](https://allenai.org/olmo)
39 | 真正开放的最先进的 LLM和框架。
40 |
41 | [Lockbox](https://github.com/mkjt2/lockbox)
42 | Lockbox 是用于进行第三方 API 调用的转发代理。
43 |
44 | [skorche](https://github.com/AnsBalin/skorche)
45 | Python 的任务编排。
46 |
47 | [PyPDFForm](https://github.com/chinapandaman/PyPDFForm)
48 | 处理 PDF 表单的 Python 库。
49 |
50 | [rexi](https://github.com/royreznik/rexi)
51 | 用于正则表达式测试(Regex Testing)的终端UI。
52 |
53 | [GPTAuthor](https://github.com/dylanhogg/gptauthor)
54 | GPTAuthor 是一款 AI 工具,用于根据故事提示编写长篇、多章节的故事。
55 |
56 | [django-htmx-components](https://github.com/iwanalabs/django-htmx-components)
57 | 这是 Django 和 htmx 的组件集合。它们旨在复制粘贴到您的项目中即可使用,还支持根据您的需求进行定制。
58 |
59 | [contrastors](https://github.com/nomic-ai/contrastors)
60 | contrastors 是对比学习工具包,使研究人员和工程师能够有效地训练和评估对比模型。
61 |
62 | [Rawdog](https://github.com/AbanteAI/rawdog)
63 | 通过生成并自动执行 Python 脚本进行响应的 CLI 助手。
64 |
65 | [IOPaint](https://github.com/Sanster/IOPaint)
66 | 一款由 SOTA AI 模型提供支持的免费开源图像修复工具。
67 |
68 | [NaturalSQL](https://github.com/cfahlgren1/natural-sql)
69 | 一系列性能最佳的文本到 SQL LLM。
70 |
71 | [ml-mgie](https://github.com/apple/ml-mgie)
72 | Apple 全新开源 AI 模型,可以根据自然语言指令编辑图像。
73 |
74 | [atopile](https://github.com/atopile/atopile)
75 | 一种用代码创建电子电路板的工具。
76 |
77 | [web2pdf](https://github.com/dvcoolarun/web2pdf)
78 | 将网页转换为 PDF 对 CLI。
79 |
80 |
81 | # 最新发布
82 |
83 | [Python 3.12.2 和 3.11.8 现已发布。](https://pythoninsider.blogspot.com/2024/02/python-3122-and-3118-are-now-available.html)
84 |
85 | [Django 安全版本现已发布:5.0.2、4.2.10 和 3.2.24](https://www.djangoproject.com/weblog/2024/feb/06/security-releases/)
86 |
87 |
88 | # 近期活动和网络研讨会
89 |
90 | [Python Frederick 2024 年 2 月聚会](https://www.meetup.com/python-frederick/events/298531232/)
91 | 将会有一场演讲:使用 Python 对算法艺术。
92 |
93 | [PyData Johannesburg 2024 年 2 月聚会](https://www.meetup.com/pydata-johannesburg/events/298808404/)
94 | 将会有一场演讲:生产化机器学习模型。
95 |
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_638.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly - Issue 638](http://eepurl.com/iJ9pdc)
2 |
3 | ---
4 |
5 | 欢迎来到《Python周刊》第 638 期。让我们直奔主题。
6 |
7 |
8 | # 文章,教程和讲座
9 |
10 | [为什么 AI 会遇到 Python 问题](https://www.youtube.com/watch?v=cGgTvMmtzNU) 
11 | 人工智能 (AI) 已将 Python 变得前所未有的流行,使其成为全球开发人员和研究人员的首选语言。然而,繁荣背后,一个巨大的挑战隐而未现。让我们通过现实世界的示例和技术见解来了解 Python 给人工智能发展带来的具体困难。
12 |
13 | [Meta 超爱 Python 的](https://engineering.fb.com/2024/02/12/developer-tools/meta-loves-python/) 
14 | Meta 工程师讨论了他们对 Python 3.12 的贡献,包括自定义 JIT hook、永久对象、类型系统改进和更快的理解等新功能,强调了他们与 Python 社区的合作以及公司对开源计算的支持
15 |
16 | [计算 Python 中使用的 CPU 指令](https://blog.mattstuchlik.com/2024/02/08/counting-cpu-instructions-in-python.html)
17 | 您知道用 Python 打印(“Hello”)需要大约 17,000 个 CPU 指令吗?而导入 Seaborn 则需要大约 20 亿个?
18 |
19 | [不仅仅是 NVIDIA:可以在任何地方运行的 GPU 编程](https://pythonspeed.com/articles/gpu-without-cuda/)
20 | 如果您想在 CI、Mac 等设备上运行 GPU 程序,wgu-py 是一个不错的选择。
21 |
22 | [部署模型的多种方法](https://outerbounds.com/blog/the-many-ways-to-deploy-a-model)
23 | 部署模型和执行推理的方法有很多种。在这里,我们以 LLM 推理为例分享模型部署的决策准则。
24 |
25 | [Adam 优化器背后的数学](https://towardsdatascience.com/the-math-behind-adam-optimizer-c41407efe59b)
26 | 为什么 Adam 是深度学习中最受欢迎的优化器?让我们通过深入研究其数学并重新创建算法来理解它。
27 |
28 | [可视化神经网络内部结构](https://www.youtube.com/watch?v=ChfEO8l-fas) 
29 | 可视化神经网络在训练和推理过程中的一些内部结构。
30 |
31 | [LLM 应用开发的工程实践](https://martinfowler.com/articles/engineering-practices-llm.html)
32 | LLM 工程涉及的不仅仅是 prompt 设计或 prompt 工程。在本文中,我们分享了一组工程实践,帮助我们在最近的项目中快速可靠地交付原型 LLM 应用程序。我们将分享 LLM 应用程序的自动化测试和对抗性测试、重构技术,以及构建 LLM 应用程序和负责任的 AI 所需要注意的事项。
33 |
34 | [Python 的 textwrap 模块可以做到的一切](https://martinheinz.dev/blog/108)
35 |
36 | Python 有许多用于格式化字符串和文本的选项,包括 f 字符串、format() 函数、模板等。然而,有一个模块很少有人知道,它叫做 textwrap。该模块是专门为帮助您进行换行、缩进、修剪等操作而构建的,在本文中我们将向您介绍您可以使用它来完成的所有操作。
37 |
38 | [如果可以的话,如何避免在 Django 中进行计数查询](https://www.peterbe.com/plog/how-to-avoid-a-count-query-in-django-if-you-can)
39 |
40 | [像专家一样处理 Asyncio 中的任务](https://jacobpadilla.com/articles/handling-asyncio-tasks)
41 |
42 |
43 | # 好玩的项目,工具和库
44 |
45 | [modguard](https://github.com/Never-Over/modguard)
46 | 一个用于强制执行模块化、解耦包架构的 Python 工具。
47 |
48 | [metavoice-src](https://github.com/metavoiceio/metavoice-src)
49 | 像人一样的富有表现力的 TTS 的基础模型。
50 |
51 | [logot](https://github.com/etianen/logot)
52 | 测试您的代码是否正确进行了日志记录。
53 |
54 | [TriOTP](https://github.com/linkdd/triotp)
55 | Python Trio 的 OTP 框架。
56 |
57 | [Toolong](https://github.com/textualize/toolong)
58 | 用于查看、追踪、合并和搜索日志文件(以及 JSONL)的终端应用程序。
59 |
60 | [django-queryhunter](https://github.com/PaulGilmartin/django-queryhunter)
61 | 寻找 Django 应用程序代码中负责执行最多次查询的行。
62 |
63 | [Lag-Llama](https://github.com/time-series-foundation-models/lag-llama)
64 | 面向概率时间序列预测的基础模型。
65 |
66 | [HypoFuzz](https://github.com/Zac-HD/hypofuzz)
67 | 用于 Python 最佳测试工作流程的开源智能模糊测试。
68 |
69 | [mwmbl](https://github.com/mwmbl/mwmbl)
70 | 一个用 Python 实现的开源、非盈利搜索引擎。
71 |
72 | [instld](https://github.com/pomponchik/instld)
73 | 最简单的包管理。
74 |
75 |
76 | # 近期活动和网络研讨会
77 |
78 | [PyLadies Dublin 2024 年 2 月聚会](https://www.meetup.com/pyladiesdublin/events/298929924/)
79 | 将会有一场演讲:当网络安全碰上 Python。
80 |
81 | [Spokane Python 2024 年 2 月聚会](https://www.meetup.com/python-spokane/events/298213203/)
82 | 将会有一场演讲:介绍如何通过使用 PyO3 创建 Rust 绑定,从而将 Rust 集成到您的 Python 工作流程中。
83 |
84 | [Python Barcelona 2024 年 2 月聚会](https://www.meetup.com/python-barcelona/events/299074873/)
85 | 将有以下演讲:
86 | * Pytest,短途远足。
87 | * 《查询地图(Queering The Map)》的使用与话语分析
88 |
89 |
90 | [PyData Southampton 2024 年 2 月聚会](https://www.meetup.com/pydata-southampton/events/298595661/)
91 | 将有以下演讲:
92 | * 将 3D 及以上的地理空间数据与 TileDB 数组相结合
93 | * 利用 GPU 计算搜索太空中的伽马射线源
94 |
95 |
96 | [PyData Berlin 2024 年 2 月聚会](https://www.meetup.com/pydata-berlin/events/298730602/)
97 | 将有以下演讲:
98 | * 通过基于扩散的图神经网络利用数据结构和几何
99 | * 大型语言模型的采样策略示例
100 |
101 |
102 | [PyData Stockholm 2024 年 2 月聚会](https://www.meetup.com/pydatastockholm/events/299095628/)
103 | 将有以下演讲:
104 | * 爬取 130 万条房价信息 —— 并且逃脱惩罚
105 | * BYOSC:
106 | * 交通地图
107 | * DeLight - 延误航班预测器
108 | * 这张照片是在哪里拍摄的? - 深度学习时代的视觉地理定位。
109 |
--------------------------------------------------------------------------------
/Python Weekly/Python_Weekly_Issue_639.md:
--------------------------------------------------------------------------------
1 | 原文:[Python Weekly - Issue 639](http://eepurl.com/iKyMsA)
2 |
3 | ---
4 |
5 | 欢迎来到《Python周刊》第 639 期。让我们直奔主题。
6 |
7 |
8 | # 文章,教程和讲座
9 |
10 | [让我们构建 GPT Tokenizer](https://www.youtube.com/watch?v=zduSFxRajkE) 
11 | Tokenizer 对于大语言模型 (LLM) 至关重要,它在字符串和标记之间进行转换,作为一个具有单独训练集和算法的不同阶段运行。本讲座从头开始构建 GPT 系列 Tokenizer,揭示了 LLM 中与标记化相关的特殊行为。我们探讨这些问题,将其归因于标记化,并考虑完全消除此阶段的理想方案。”
12 |
13 | [在 Python 项目中安全使用凭证的 5 个技巧](https://www.youtube.com/watch?v=OOvvQRBcrhI) 
14 | 了解 5 个简单的技巧,以助于确保 Python 凭证安全,并在出现问题时快速解决问题.
15 |
16 | [从头开始构建一个 LLM](https://bclarkson-code.github.io/posts/llm-from-scratch-scalar-autograd/post.html)
17 | 了解如何完全从头开始构建一个具有所有花哨功能的现代语言模型:从普通 Python 到函数式编码助手。
18 |
19 | [跟踪 Python 中的系统调用](https://blog.mattstuchlik.com/2024/02/16/counting-syscalls-in-python.html)
20 | 本文讨论了作者开发的一个添加到 Cirron 的工具,该工具使我们能够跟踪Python代码的系统调用。它提供了一个跟踪“print”函数的示例,并说明了该工具的实现,使用strace工具进行有效分析。文章还概述了使用 ptrace 系统调用进行实现的初衷,以及随后利用 strace 工具来处理复杂性。
21 |
22 | [使用 IPython Jupyter Magic 命令改善 Notebook 体验](https://towardsdatascience.com/using-ipython-jupyter-magic-commands-to-improve-the-notebook-experience-f2c870cab356)
23 | 一篇关于创建自定义 IPython Jupyter Magic 命令的帖子。
24 |
25 | [添加 Django 工作线程的最简单方法(使用 AWS Chalice)](https://www.photondesigner.com/articles/lambda-for-django)
26 | 本文讨论了如何利用 AWS Chalice 来合并 Django 工作线程,从而能够使用 lambda 函数作为任何应用程序的无服务器后台工作线程。这种方法允许 lambda 函数在后台运行,而不会阻塞应用程序的主线程,并且它可以在完成后调用 Django 应用程序上的端点,从而提供在 lambda 函数中使用任何 Python 库的能力,而无需引入 lambda 层或其他特定于 AWS 的配置。
27 |
28 | [如何对一个使用了 Django、Preact 和 PostgreSQL 的应用程序进行 Docker 化](https://www.honeybadger.io/blog/dockerize-django-preact-postgres)
29 | 对 Django 应用程序进行 Docker 化可能是一件令人生畏的事情,但回报大于风险。在本指南中,Charlie Macnamara 将引导您完成这个设置过程,以便您可以充分利用您的应用程序。
30 |
31 | [使用 Python 实现的算法艺术](https://www.youtube.com/watch?v=_XeRM-4DZz0) 
32 | 在本次演讲中,我们将从零开始,构建我们自己的工具,用 Python 进行艺术创作,无需人工智能!我们将展示 Python 的表现力可以如何让我们优雅地描述图形,并使用它以编程方式制作一些独特的艺术作品。
33 |
34 | [使用 Neon Postgres 和 AWS App Runner 部署任意规模的无服务器(Serverless) FastAPI 应用程序](https://neon.tech/blog/deploy-a-serverless-fastapi-app-with-neon-postgres-and-aws-app-runner-at-any-scale)
35 | 使用 FastAPI 创建无服务器 API,部署在 AWS App Runner 上并由 Neon Postgres 提供支持。
36 |
37 |
38 | # 好玩的项目,工具和库
39 |
40 | [uv](https://github.com/astral-sh/uv)
41 | 一个非常快的 Python 包安装程序和解析器,用 Rust 编写。这是一篇详细介绍 uv 的[帖子](https://astral.sh/blog/uv)。
42 |
43 | [OS-Copilot](https://github.com/OS-Copilot/FRIDAY)
44 | 一个自我改进的具体对话代理,无缝集成到操作系统中,以自动化我们的日常任务。
45 |
46 | [Owl](https://github.com/OwlAIProject/Owl)
47 | 本地运行的个人可穿戴人工智能。
48 |
49 | [Alto](https://github.com/runprism/alto)
50 | 面向数据从业者的 Serverless。在云中运行代码的最快方法。在虚拟机中轻松运行脚本、函数和 Jupyter Notebook。
51 |
52 | [magika](https://github.com/google/magika)
53 | 通过深度学习检测文件内容类型。
54 |
55 | [Streamline-Analyst](https://github.com/Wilson-ZheLin/Streamline-Analyst)
56 | 由 LLM 提供支持的人工智能代理,可简化数据分析的整个过程。
57 |
58 | [minbpe](https://github.com/karpathy/minbpe)
59 | LLM 标记化中常用的字节对编码 (Byte Pair Encoding,BPE) 算法的最小的干净代码。
60 |
61 | [Hyperdiv](https://github.com/hyperdiv/hyperdiv)
62 | 使用 Python 构建响应式 Web UI。
63 |
64 | [UFO](https://github.com/microsoft/UFO)
65 | 用于 Windows 操作系统交互的以 UI 为中心的代理。
66 |
67 |
68 | # 最新发布
69 |
70 | [Python 3.13.0 alpha 4](https://pythoninsider.blogspot.com/2024/02/python-3130-alpha-4-is-now-available.html)
71 |
72 |
73 | # 近期活动和网络研讨会
74 |
75 | [Oxford Python 2024 年 2 月聚会](https://www.meetup.com/oxfordpython/events/299181384/)
76 | 将会有一场演讲:PyO3 入门。
77 |
78 | [PyLadies Amsterdam 2024 年 2 月聚会](https://www.meetup.com/pyladiesams/events/298654058/)
79 | 将举办一个研讨会,微调文本到图像的扩散模型以实现个性化等。
80 |
81 | [PyData Toronto 2024 年 2 月聚会](https://www.meetup.com/pydatato/events/298869004/)
82 | 将有以下演讲:
83 | * 用于与 LLM 交互的数据文本处理
84 | * 因果推理:创建反事实,以及其在付费营销中的应用
85 |
86 |
87 | [PyData Lisbon 2024 年 2 月聚会](https://www.meetup.com/pydata-lisbon/events/299085332/)
88 | 将有以下演讲:
89 | * 利用 Poetry 掌握 Python 项目
90 | * 生产中的 LLM,即 LLMOps
91 |
92 |
93 | [PyData Prague 2024 年 2 月聚会](https://www.meetup.com/pydata-prague/events/298734567/)
94 | 将有以下演讲:
95 | * 解锁效率 —— 矢量化的力量
96 | * Jupyter(Hub/Lab)——从本地到 AWS 之旅
97 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Python Document
2 | translate python documents to Chinese for convenient reference
3 | 简而言之,这里用来存放那些Python文档君们,并且尽力将其翻译成中文~~
4 |
5 | gitbook地址:[Python Chinese documents](https://ictar.gitbooks.io/python-doc-zh/)
6 |
7 | # 说明
8 | 1. 能在网上找到现成的当然是最好啦,这类型的文档,会直接提供链接,用[中文版](#)这种形式给出。
9 | 2. 如果不能找到,会给出自己翻的中文版本。
10 | 3. 已翻译文档会给出repository中的链接,未翻译则给出原文档链接
11 |
12 | 欢迎抓虫~~
13 |
14 | # 目录说明
15 | - [Python Common](./Python%20Common 'python 常规文档') python 常规文档
16 |
17 | ## Web框架
18 | - [Django](./Web/Django) Django 相关文档
19 | - [Flask](./Web/Flask) Flask相关文档
20 |
21 | ## web爬取
22 | - [Scrapy](./Scrapy) Scrapy相关文档
23 |
24 | ## DevOps工具
25 | - Fabric: [中文版](http://fabric-chs.readthedocs.org/zh_CN/chs/) | [英文版](http://docs.fabfile.org/en/1.11/index.html)
26 |
27 | - [Glances](https://github.com/nicolargo/glances):[中文版](http://glances-zh.readthedocs.io/en/latest/) | [英文版](https://glances.readthedocs.io/en/latest/)
28 |
29 | ## 测试
30 | - [Testing](./Testing) 测试相关
31 |
32 | ## 硬件
33 | - [Hardware](./Hardware) 硬件相关,物联网,无人机等……
34 |
35 | ## 科学计算和数据分析
36 | - [Science and Data Analysis](./Science%20and%20Data%20Analysis 'Science and Data Analysis')
37 |
38 | ## 自然语言处理
39 | - [NLP](./NLP)
40 |
41 | ## 机器学习
42 | - [Machine Learning](./Machine%20Learning 'Machine Learning')
43 |
44 | ## 函数式编程
45 | - [Functional Programming](./Functional%20Programming 'Functional Programming')
46 |
47 | ## 图像处理
48 | - [Image Processing](./Image%20Processing 'Image Processing')
49 |
50 | ## 资源
51 | - [Python Weekly](./Python%20Weekly 'Python Weekly')
52 | - Pycoder's Weekly
53 | * 中文版:[蟒周刊](http://weekly.pychina.org/)
54 |
55 | ## 无法归类的
56 | - [Others](./Others) 其他一些没法分类的文档
57 |
58 | # [小黑屋](./raw)
59 | 里面关着生肉和半生肉
60 |
61 | # 辅助工具
62 | - ` html2text --mark-code {url} > '{name}.md'`
63 |
64 | # 如何贡献
65 | - fork project and commit pull requests
66 | * 全文翻译必须在文章开头加上原文地址
67 | - add/edit wiki
68 | - report/fix issue
69 |
70 | # 贡献者
71 | - [lujun9972](https://github.com/lujun9972)
72 |
73 | # 捐赠
74 | 如果你觉得这个项目对你有帮助,那就请我喝杯东西吧  75 |
76 | ---
77 | [](https://star-history.com/?utm_source=bestxtools.com#ictar/python-doc&Date)
78 |
--------------------------------------------------------------------------------
/Science and Data Analysis/News Headline Analysis.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/Science and Data Analysis/News Headline Analysis.png
--------------------------------------------------------------------------------
/Science and Data Analysis/News Headline Analysis_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/Science and Data Analysis/News Headline Analysis_2.png
--------------------------------------------------------------------------------
/Science and Data Analysis/README.md:
--------------------------------------------------------------------------------
1 | # Science and Data Analysis
2 | 关于科学计算和数据分析……
3 |
4 | ## 说明
5 |
6 | - [如何使用Python和Pandas处理大量的JSON数据集](./如何使用Python和Pandas处理大量的JSON数据集.md)
7 |
8 | 如何处理大量的(指无法一次性存入内存)JSON数据集呢?本文给出了一个第三方库ijson来迭代的处理此问题。同时,通过一个简单的交通管制数据的分析,向我们娓娓道来如何使用Pandas处理分析可视化数据……
9 |
10 | - [新闻标题分析](./新闻标题分析.md)
11 |
12 | 这个项目分析两个记者写的新闻标题 —— 一个是来自于Business Inside的**财政**记者,一个是来自于Huffington post的**名人**记者 —— 来寻找这两个记者为他们的新闻文章和博客编写标题之间的异同。
13 |
14 | - [使用矩阵分解找到相似歌曲](./使用矩阵分解找到相似歌曲.md)
15 |
16 | 本文一步步指导如何使用几个不同的矩阵分解算法来计算相关的艺术家。代码使用Python编写的,使用[Pandas](http://pandas.pydata.org/)和[SciPy](https://www.scipy.org/)来进行计算,使用[D3.js](https://d3js.org/)来交互式可视化结果。
17 |
18 | > 这篇文章的样式惨不忍睹,建议还是跟原文一起对着看……
19 |
20 | - [Python中的并行处理](./Python中的并行处理.md)
21 |
22 | 虽然像C, Java, 和R这样的语言允许相当容易地进行并行处理,但对于Python程序员来说,因为全局解释锁(GIL)的存在,这却没那么容易。幸好作为pythoner的我们,也并非一筹莫展!
23 |
24 | - [Matplotlib教程 - 绘制提到Trump, Clinton & Sanders的推特](./Matplotlib教程 - 绘制提到Trump, Clinton & Sanders的推特.md)
25 |
26 | 一篇手把手教你的Matplotlib教程,是一篇很不错的learn-by-doing的数据分析文章!!
27 |
28 | - [使用Pandas, Docker和OS(R)M来猜测神秘的旅行地](./使用Pandas, Docker和OS(R)M来猜测神秘的旅行地.md)
29 |
30 | 如果你准备去某个神秘的地方玩,关于这个地方有几点提示,那么可以看看如何利用Pandas, Docker和OS(R)M科学有效的进行排除猜测。
31 |
32 | - [使用BigQuery和TensorFlow进行需求预测](./使用BigQuery和TensorFlow进行需求预测.md)
33 |
34 | 在本notebook中,我们将开发一个机器学习模型,用于预测对纽约的出租汽车需求。
35 |
36 | - [Python中一个简单的基于内容的推荐引擎](Python中一个简单的基于内容的推荐引擎.md)
37 |
38 | - [在Python中实现你自己的推荐系统](./在Python中实现你自己的推荐系统.md)
39 |
40 | - [分析权力游戏图表](./分析权力游戏图表.md)
41 |
42 | 帅爆了,用科学方法,分析权力游戏中错综复杂的人物关系。本文只实验了第三卷,看过之后,可以用其他卷来重现该实验~
43 |
44 | - [使用Python探索NFL选秀](使用Python探索NFL选秀.md)
45 |
46 | - [用于格式化和数据清理的便捷Python库](./用于格式化和数据清理的便捷Python库.md)
47 |
48 | - [分析iPhone步数数据](./分析iPhone步数数据.md)
49 |
50 | 本文展示了如何使用pandas timeseries和ggplot来分析iPhone步数数据。
51 |
52 | - [使用Python,分析23AndMe数据,获取遗传起源](./使用Python,分析23AndMe数据,获取遗传起源.md)
53 |
54 | 你的DNA包含了关于你的主线,易患疾病以及复杂特性,包括身高、体重、五官和行为等丰富的信息。使用来自23andMe,一家直接面向消费者的遗传学公司,的公众可获取数据,我们将展示如何确定在网上找到的来自23andMe的一份匿名样本的祖先。
55 |
56 | - [用Python进行股票市场数据分析概述 (第一部分)](./用Python进行股票市场数据分析概述 (第一部分).md)
57 |
58 | 这篇文章是使用Python进行股票数据分析系列的两部分中的第一个部分,基于我在Utah大学为MATH 3900(数据科学)课题提供的一个讲座。在这些文章中,我会讨论到基础知识,例如使用pandas从Yahoo! Finance获取数据,可视化股票数据,移动均值,制定一个移动平均交叉策略,回测和基准。最后的一篇文章会包含实际问题。这第一篇文章讨论的主题到介绍移动均值。
59 |
--------------------------------------------------------------------------------
/Science and Data Analysis/用于格式化和数据清理的便捷Python库.md:
--------------------------------------------------------------------------------
1 | 原文:[Handy Python Libraries for Formatting and Cleaning Data](https://blog.modeanalytics.com/python-data-cleaning-libraries/)
2 |
3 | ---
4 |
5 | 真实世界是杂乱的,它的数据也是。那么凌乱,[最近的一项调查](http://visit.crowdflower.com/data-science-report.html)显示,数据科学家花费60%的时间在清理数据。不幸的是,他们中57%还觉得这是他们工作中最不愉快的方面。
6 |
7 | 清理数据可能是耗时的,但是很多工具已经出现,让这个重要的任务惬意一点。Python社区提供了众多库,用来让数据有序清晰,从具有风格的DataFrame到匿名数据集。
8 |
9 | 如果你发现什么有用的库,请告诉我们,我们一直在寻找更好的库,以添加到[Mode Python Notebooks](https://about.modeanalytics.com/python/)中。
10 |
11 | 
12 |
13 | _太糟糕的清理对数据科学家而言就像对这个小男孩一样,并不好玩。_
14 |
15 | ## Dora
16 |
17 | Dora是为探索性分析而生的;具体来说,是为了自动化它最痛苦的那部分,如特征选择和提取,可视化,以及,是哒,你猜到了,就是数据清理。清理功能包括:
18 |
19 | * 读取缺失和比例值不佳的数据
20 | * 输入缺失值
21 | * 缩放输入变量的值
22 |
23 | **创建者:** [Nathan Epstein](https://twitter.com/epstein_n)
24 | **何处了解更多:**
25 |
26 | ## datacleaner
27 |
28 | 令人感到惊奇的datacleaner清理你的数据 —— 但只在它是以[pandas DataFrame](https://community.modeanalytics.com/python/tutorial/pandas-dataframe/)形式出现的时候。据创建者Randy Olson说:“datacleaner并不是魔术,它不会读取文本的无组织块,然后自动的为你解析。”
29 |
30 | 但是,它会丢弃具有缺失值的行,在逐列基础上用模或者中位数来替换缺失值,并且用数值等效来编码非数值变量。这个库相当的新,但是由于在Python中,DataFrame是分析的基础,因此值得一看。
31 |
32 | **创建者:** [Randy Olson](https://twitter.com/randal_olson)
33 | **何处了解更多:**
34 |
35 | ## PrettyPandas
36 |
37 | DataFrame是强大的,但是它不会生成你想要展示给你老板看的那种表格。PrettyPandas利用[pandas Style API](http://pandas.pydata.org/pandas-docs/stable/style.html)来转换DataFrame成值得展示的表单。创建摘要,添加样式,并格式化数字、列和行。额外的好处:健壮、易读的[文档](http://prettypandas.readthedocs.io/en/latest/)。
38 |
39 | **创建者:** [Henry Hammond](https://twitter.com/henryhammond92)
40 | **何处了解更多:**
41 |
42 | ## tabulate
43 |
44 | tabulate让你只用一次函数调用,就可以打印小而美的表格。它让列按照十进制、数字格式和表头等等进行排列,对于让表单更易读,它是非常方便的。
45 |
46 | 其中一个最酷的功能是,能够以多种格式,例如HTML, PHP或者Markdown Extra,来输出数据,所以你可以继续在另一个工具或者语言中处理你的表单数据。
47 |
48 | **创建者:** Sergey Astanin
49 | **何处了解更多:**
50 |
51 | ## scrubadub
52 |
53 | 在诸如医疗保健和金融的领域中,数据科学家经常需要匿名数据集。scrubadub从免费文本中移除了[个人身份信息 (PII)](https://en.wikipedia.org/wiki/Personally_identifiable_information),如:
54 |
55 | * 姓名 (专有名词)
56 | * 电子邮件地址
57 | * 网址
58 | * 电话号码
59 | * 用户名/密码组合
60 | * Skype用户名
61 | * 社保号
62 |
63 | 该文档在显示你可能想要自定义scrubadub行为的方面(例如定义新的PII类型,或者排除某些PII类型)表现良好。
64 |
65 | **创建者:** [Datascope Analytics](http://datascopeanalytics.com/)
66 | **何处了解更多:**
67 |
68 | ## Arrow
69 |
70 | 坦白说:在Python中处理日期和时间很痛苦。本地时区不能够被自动识别。要花几行令人不爽的代码来转换时区和时间戳。
71 |
72 | Arrow旨在修复这些问题和插件功能上的缺陷,来帮助你用更少的代码和更少的导入来处理时间和日期。不像Python的标准库,Arrow默认意识到时区和UTC。你可以用一行代码来转换时区或者解析字符串。
73 |
74 | **创建者:** [Chris Smith](https://twitter.com/crsmithdev)
75 | **何处了解更多:**
76 |
77 | ## Beautifier
78 |
79 | Beautifier的任务很简单:清理和美化URL和电子邮件地址。你可以通过域名和用户名来解析电子邮件;通过域名和参数(例如,UTM或者令牌)来解析URL。
80 |
81 | **创建者:** [Sachin Philip Mathew](https://twitter.com/sachin_philip)
82 | **何处了解更多:**
83 |
84 | ## ftfy
85 |
86 | ftfy (为你修正文本)接收糟糕的Unicode,输出漂亮的Unicode。基本上,它修复了所欲的垃圾字符。`“quotesâ€\x9d`变成`"quotes"`; `ü`变成`ü`; `<3`变成`<3`。如果每天都在处理文本,那么这个库,正如一个用户所说,是“一个方便的法宝。”
87 |
88 | **创建者:** [Luminoso](http://www.luminoso.com/)
89 | **何处了解更多:**
90 |
91 | ## 管理数据的更多资源
92 |
93 | 这里是几个我们最喜欢的关于改写/管理/清理数据的文章。
94 |
95 | * [每一个数据科学家都应该知道的关于数据匿名化的事](https://github.com/krasch/presentations/blob/master/pydata_Berlin_2016.pdf) (Katharina Rasch)
96 | * [在Python中清理数据](https://data.library.utoronto.ca/cleaning-data-python) (University of Toronto Map & Data Library)
97 | * [用Python进行数据清理 - MoMA的艺术品收藏](https://www.dataquest.io/blog/data-cleaning-with-python/) (Dataquest)
--------------------------------------------------------------------------------
/Scrapy/README.md:
--------------------------------------------------------------------------------
1 | # Scrapy
2 |
3 | Scrapy相关文档
4 |
5 | ## 说明
6 | - [Scrapinghub的Scrapy技巧系列](./Scrapinghub的Scrapy技巧系列)
7 |
--------------------------------------------------------------------------------
/Scrapy/Scrapinghub的Scrapy技巧系列/README.md:
--------------------------------------------------------------------------------
1 | - [跟着高手学习Scrapy技巧:第一部分](跟着高手学习Scrapy技巧:第一部分.md)
2 |
3 | - [Scrapy技巧:2016年三月版](./Scrapy技巧:2016年三月版.md)
4 |
5 | 介绍了两个scrapy技巧:使用CookieJar解决站点怪异会话行为以及添加备用的CSS/XPath规则
6 |
7 | - [Scrapy技巧:2016年四月版](./Scrapy技巧:2016年四月版.md)
8 |
9 | 一个关于如何爬取带有视图状态的Asp.NET网站的技巧……
10 |
11 | - [Scrapy技巧:2016年五月版](./Scrapy技巧:2016年五月版.md)
12 |
13 | 关于如何调试爬虫的一些技巧
14 |
15 | - [Scrapy技巧:2016年六月版](./Scrapy技巧:2016年六月版.md)
16 |
17 | 如何爬取无限滚动页面
18 |
19 | - [Scrapy技巧:2016年七月版](./Scrapy技巧:2016年七月版.md)
20 |
21 | Scrapy被设计成可扩展的,并且组件之间松耦合。你可以使用自己的中间件或者pipeline来轻松扩展Scrapy的功能。这使得Scrapy社区可以轻松地开发新的插件来提高现有功能,而无需对Scrapy自身进行修改。在这篇文章中,我们将向你展示如何利用DeltaFetch插件来运行增量爬取。
--------------------------------------------------------------------------------
/Scrapy/Scrapinghub的Scrapy技巧系列/Scrapy技巧:2016年六月版.md:
--------------------------------------------------------------------------------
1 | 原文:[Scrapy Tips from the Pros June 2016](https://blog.scrapinghub.com/2016/06/22/scrapy-tips-from-the-pros-june-2016/)
2 |
3 | ---
4 |
5 | 欢迎来到Scrapy技巧系列!每个月,我们会发布一些技巧和hack,来帮助你加快网页抓取和数据提取。作为牵头的Scrapy维护者,你可以想象的任何障碍我们都遇到过了,所以别担心,你能在这获益良多。随意到[Twitter](https://twitter.com/ScrapingHub)或者[Facebook](https://www.facebook.com/ScrapingHub/)访问我们,提出对未来主题的建议吧。
6 |
7 | 
8 |
9 | ## 抓取无限滚动页面
10 |
11 | 在单页应用以及每页具有大量AJAX请求的时代,很多网站已经用花哨的无限滚动机制取代了“前一个/下一个”分页按钮。使用这种技术的网站每当用户滚动到页面的底部的时候加载新项(想想微博,Facebook,谷歌图片)。虽然[UX专家](https://www.smashingmagazine.com/2013/05/infinite-scrolling-lets-get-to-the-bottom-of-this/)认为,无限滚动为用户提供了海量数据,但是我们看到越来越多的web页面诉诸于展示这种无休止的结果列表。
12 |
13 | 在开发web爬虫时,我们要做的第一件事就是找到能将我们引导到下一页结果的带有链接的UI组件。不幸的是,这些链接在无限滚动页面上不存在。
14 |
15 | 虽然这种场景可能看起来像诸如[Splash](http://scrapinghub.com/splash/)或者[Selenium](http://www.seleniumhq.org/)这样的JavaScript引擎的一个经典案例,但是它实际上是一个简单的修复。你所需要做的是在你滚动目标页面的时候检查浏览器的AJAX请求,然后在Scrapy spider中重新创建这些请求,而不是模拟用于与此类引擎的交互。
16 |
17 | 让我们以[Spidy Quotes](http://spidyquotes.herokuapp.com/scroll)为例,构建一个爬虫来获取上面列出来的所有的项。
18 |
19 | ## 审查页面
20 |
21 | 先说重要的事,我们需要理解无限滚动是如何在这个页面工作的,我们可以通过[浏览器的开发者工具](https://developer.chrome.com/devtools#access)中的Network面板来完成此项工作。打开该面板,然后滚动页面,看看浏览器发送了什么请求:
22 |
23 | 
24 |
25 | 点开一个请求仔细看看。浏览器发送了一个请求到`/api/quotes?page=x`,然后接收诸如以下的一个JSON对象作为响应:
26 |
27 | ```python
28 |
29 | {
30 | "has_next":true,
31 | "page":8,
32 | "quotes":[
33 | {
34 | "author":{
35 | "goodreads_link":"/author/show/1244.Mark_Twain",
36 | "name":"Mark Twain"
37 | },
38 | "tags":["individuality", "majority", "minority", "wisdom"],
39 | "text":"Whenever you find yourself on the side of the ..."
40 | },
41 | {
42 | "author":{
43 | "goodreads_link":"/author/show/1244.Mark_Twain",
44 | "name":"Mark Twain"
45 | },
46 | "tags":["books", "contentment", "friends"],
47 | "text":"Good friends, good books, and a sleepy ..."
48 | }
49 | ],
50 | "tag":null,
51 | "top_ten_tags":[["love", 49], ["inspirational", 43], ...]
52 | }
53 |
54 | ```
55 |
56 | 这就是我们的爬虫需要的信息了。它所需要做的仅是生成到"/api/quotes?page=x"的请求,其中,`x`的值不断增加,直到`has_next`字段为false。这样做最棒的是,我们甚至无需爬取HTML内容以获取所需数据。这些数据都在一个漂亮的机器可读的JSON中。
57 |
58 | ## 构建Spider
59 |
60 | 下面是我们的spider。它从服务器返回的JSON内容提取目标数据。这种方法比挖掘页面的HTML树更容易并且更健壮,相信布局的改变不会搞挂我们的spider。
61 |
62 | ```python
63 |
64 | import json
65 | import scrapy
66 |
67 |
68 | class SpidyQuotesSpider(scrapy.Spider):
69 | name = 'spidyquotes'
70 | quotes_base_url = 'http://spidyquotes.herokuapp.com/api/quotes?page=%s'
71 | start_urls = [quotes_base_url % 1]
72 | download_delay = 1.5
73 |
74 | def parse(self, response):
75 | data = json.loads(response.body)
76 | for item in data.get('quotes', []):
77 | yield {
78 | 'text': item.get('text'),
79 | 'author': item.get('author', {}).get('name'),
80 | 'tags': item.get('tags'),
81 | }
82 | if data['has_next']:
83 | next_page = data['page'] + 1
84 | yield scrapy.Request(self.quotes_base_url % next_page)
85 |
86 | ```
87 |
88 | 要进一步练习这个技巧,你可以做个实验,爬取我们的博客,因为它也是使用无限滚动来加载旧博文的。
89 |
90 | ## 总结
91 |
92 | 如果你被爬取无限滚动网站的前景吓到,那么希望现在你可以有点信心了。下一次你需要处理那种基于用户操作引发的AJAX调用的页面时,看一看你的浏览器发送的请求吧,然后将其重放到你的spider中。响应往往是JSON的格式,这使得你的spider甚至更简单了。
93 |
94 | 好啦,这就是六月份的!请在[Twitter](https://twitter.com/ScrapingHub)上联系我们,让我们知道未来你希望看到什么技巧。最近,我们还发布了一个[数据集目录](https://blog.scrapinghub.com/2016/06/09/introducing-the-new-open-data-catalog/),所以,如果你还苦思要爬取什么,那么看看这个目录获取一些灵感吧。
95 |
--------------------------------------------------------------------------------
/Testing/README.md:
--------------------------------------------------------------------------------
1 | # Testing
2 | 测试相关
3 |
4 | ## 说明
5 |
6 | - [Python Mock:简单介绍 —— 第一部分](./Python Mock:简单介绍 —— 第一部分.md)
7 |
8 | 本文带你走入Python mock,这个用于测试(TDD方法)的库……
9 |
10 | - [在Python中使用Behave来开始行为测试](./在Python中使用Behave来开始行为测试.md)
11 |
12 | 本文通过讲述一个21点的例子,借助Python中的Behave库,带你体验什么是BDD,行为驱动开发。
13 |
14 | - [基于属性的测试,hypothesis以及查找bug](./基于属性的测试,hypothesis以及查找bug.md)
15 |
16 | 看看怎么用hypothesis进行基于属性的测试吧。也许,你会如作者般爱上它
--------------------------------------------------------------------------------
/Web/Django/1.9/howto/如何使用WSGI进行部署.md:
--------------------------------------------------------------------------------
1 | 原文:[How to deploy with WSGI](https://docs.djangoproject.com/en/1.9/howto/deployment/wsgi/)
2 |
3 | Django主要的部署平台是[WSGI](http://www.wsgi.org), 它是Web服务器和应用程序的Python标准。
4 |
5 | Django的[`startproject`](https://docs.djangoproject.com/en/1.9/ref/django-admin/#django-admin-startproject)管理命令为你建立了一个简单的默认WSGI配置,你可以根据项目需要进行调整,并用于任何WSGI兼容的应用程序服务器。
6 |
7 | Django包含了以下WSGI服务器的入门文档:
8 |
9 | * [How to use Django with Apache and mod_wsgi](https://docs.djangoproject.com/en/1.9/howto/deployment/wsgi/modwsgi/)
10 | * [Authenticating against Django’s user database from Apache](https://docs.djangoproject.com/en/1.9/howto/deployment/wsgi/apache-auth/)
11 | * [How to use Django with Gunicorn](https://docs.djangoproject.com/en/1.9/howto/deployment/wsgi/gunicorn/)
12 | * [How to use Django with uWSGI](https://docs.djangoproject.com/en/1.9/howto/deployment/wsgi/uwsgi/)
13 |
14 | ## `application`对象[¶](#the-application-object "Permalink to this headline")
15 |
16 | 使用WSGI进行部署的关键概念是`application`可调用对象,应用服务器用它来与你的代码进行通信。它通常作为服务器可访问的一个Python模块中的一个名为`application`的对象被提供。
17 |
18 | [`startproject`](https://docs.djangoproject.com/en/1.9/ref/django-admin/#django-admin-startproject)命令创建一个文件`/wsgi.py`,它包含这样的`application`可调用对象。
19 |
20 | 它同时用于Django的开发服务器和生产中的WSGI部署。
21 |
22 | WSGI服务器从它们的配置中获取`application`可调用对象的路径。Django的内置服务器,即[`runserver`](https://docs.djangoproject.com/en/1.9/ref/django-admin/#django-admin-runserver)命令,从[`WSGI_APPLICATION`](https://docs.djangoproject.com/en/1.9/ref/settings/#std:setting-WSGI_APPLICATION)设置项中读取它。默认情况下,它被设置为`.wsgi.application`, 它指向`/wsgi.py`中的`application`可调用对象。
23 |
24 |
25 | ## 配置settings模块[¶](#configuring-the-settings-module "Permalink to this headline")
26 |
27 | 当WSGI服务器加载应用程序时,Django需要导入settings模块(定义你整个应用程序的地方)。
28 |
29 | Django使用[`DJANGO_SETTINGS_MODULE`](https://docs.djangoproject.com/en/1.9/topics/settings/#envvar-DJANGO_SETTINGS_MODULE)环境变量来查找相应的设置模块。他必须包含settings模块的虚线路径。你可以对开发以及生产环境使用不同的值;这都取决于如何安排你的设置。
30 |
31 | 若未设置该变量,`wsgi.py`会默认将它设置为`mysite.settings`, 其中,`mysite`是项目名称。这就是[`runserver`](https://docs.djangoproject.com/en/1.9/ref/django-admin/#django-admin-runserver)默认情况下如何发现默认的设置文件。
32 |
33 | >注意
34 |
35 | >由于环境变量是进程范围的,当你在同一个进程中运行多个Django站点时,它将无法正常工作。在使用mod_wsgi时会出现这个问题。
36 |
37 | >要避免这个问题,在每个站点的守护进程中使用mod_wsgi的守护进程模式,或者通过强制`wsgi.py`文件中的项为`os.environ["DJANGO_SETTINGS_MODULE"] = "mysite.settings"`来覆盖环境中的值。
38 |
39 |
40 |
41 | ## 应用WSGI中间件[¶](#applying-wsgi-middleware "Permalink to this headline")
42 |
43 | 要应用[WSGI middleware](https://www.python.org/dev/peps/pep-3333/#middleware-components-that-play-both-sides),你可以简单的包装application对象。例如,你可以在`wsgi.py`底部增加这些行:
44 |
45 | ```python
46 | from helloworld.wsgi import HelloWorldApplication
47 | application = HelloWorldApplication(application)
48 | ```
49 |
50 | 如果你想将一个Django应用与一个其它框架的WSGI应用合并,也可以使用一个稍后委托给Django WSGI application的自定义WSGIapplication来替换该Django WSGI application。
51 |
52 |
53 | >注意
54 |
55 | >一些第三方WSGI中间件在处理一个请求后并不在response对象上调用`close`。在这些情况下,[`request_finished`](https://docs.djangoproject.com/en/1.9/ref/signals/#django.core.signals.request_finished "django.core.signals.request_finished")信号不会被发生。这可能导致到数据库和内存缓存服务器的空闲连接。
56 |
--------------------------------------------------------------------------------
/Web/Django/1.9/howto/部署Django.md:
--------------------------------------------------------------------------------
1 | 原文:[Deploying Django](https://docs.djangoproject.com/en/1.9/howto/deployment/)
2 |
3 | Django有满满一箩筐快捷方式可以用来让Web开发者的生活更轻松,但是如果你不能轻松地部署你的网站,那么所有这些工具都毫无用处。自从Django出现以后,易部署就是一个主要的目标。
4 |
5 | * [如何使用WSGI进行部署](https://docs.djangoproject.com/en/1.9/howto/deployment/wsgi/)
6 | * [部署清单](https://docs.djangoproject.com/en/1.9/howto/deployment/checklist/)
7 |
8 | 如果你是Django以及(或者)Python部署的新手,那么我们推荐你先尝试[mod_wsgi](https://docs.djangoproject.com/en/1.9/howto/deployment/wsgi/modwsgi/)。在大多数的情况下,它是最简单,最快捷,以及最稳定的部署选择。
9 |
--------------------------------------------------------------------------------
/Web/Django/1.9/topics/i18n/国际化和本地化.md:
--------------------------------------------------------------------------------
1 | # 国际化和本地化
2 |
3 | 原文: [Internationalization and localization](https://docs.djangoproject.com/en/1.9/topics/i18n/)
4 |
5 | ---
6 |
7 | ## 概述
8 |
9 | 国际化和本地化的目标是,允许一个单一的Web应用程序提供适合用户的语言和格式的内容。
10 |
11 | Django完全支持[文本翻译](https://docs.djangoproject.com/en/1.9/topics/i18n/translation/),[日期,时间和数字格式](https://docs.djangoproject.com/en/1.9/topics/i18n/formatting/),以及[时区](https://docs.djangoproject.com/en/1.9/topics/i18n/timezones/)。
12 |
13 | 从本质上讲,Django做了两件事:
14 |
15 | * 它允许开发者和模板的作者指定应用程序的某些部分应该为当地的语言和文化进行翻译或格式化。
16 | * 根据特定用户的喜好,使用这些钩子来对Web应用程序进行本地化。
17 |
18 | 显然,翻译取决于目标的语言和格式,通常取决于目标国家。此信息通过报头的**Accept-Language**属性,由浏览器提供。然而,并不容易获得时区。
19 |
20 |
21 | ----------
22 |
23 |
24 | ## 定义
25 |
26 | 词语“国际化”和“本土化”,往往会造成混乱; 这里有一个简单的定义:
27 |
28 | **国际化**
29 |
30 | 准备用于本地化的软件,通常由开发者完成。
31 |
32 | **本地化**
33 |
34 | 编写翻译及本地格式。通常由翻译器完成。
35 |
36 | 更多详细信息,见[W3网络国际化FAQ](http://www.w3.org/International/questions/qa-i18n), [维基百科的文章](https://en.wikipedia.org/wiki/Internationalization_and_localization)或[GNU gettext文档](https://www.gnu.org/software/gettext/manual/gettext.html#Concepts)。
37 |
38 | > 警告
39 |
40 | > 翻译和格式化通过[USE_I18N](https://docs.djangoproject.com/en/1.9/ref/settings/#std:setting-USE_I18N)和[USE_L10N](https://docs.djangoproject.com/en/1.9/ref/settings/#std:setting-USE_L10N)设置项分别设置。然而,这两种功能都包括国际化和本地化。设置项的名字是Django历史上的一个不幸的结果。
41 |
42 | 这里有一些其他术语,以助于我们处理一个共同的语言:
43 |
44 | **区域设置名称**
45 |
46 | 语言环境的名称,或者是由**ll**形式或者由语言和指定国家组成的**ll_CC**形式指定的语言例如: **it**, **de_AT**, **es**, **pt_BR**。语言部分始终是小写,而国家部分始终是大写。分隔符是下划线。
47 |
48 | **语言代码**
49 |
50 | 代表一种语言的名字。浏览器使用这种格式来发送它们在**Accept-Language**报头接收的语言的名称。例如:**it**, **de-at**, **es**, **pt-br**。语言代码通常用小写表示,但是HTTP **Accept-Language**报头不区分大小写。其分隔符是一个破折号。
51 |
52 | **消息文件**
53 |
54 | 一个信息文件是一个纯文本文件,它代表一种语言,其包含了所有可用的[翻译字符串](https://docs.djangoproject.com/en/1.9/topics/i18n/#term-translation-string),以及应如何在给定的语言中展示。消息文件具有**.po**文件扩展名。
55 |
56 | **翻译字符串**
57 |
58 | 可翻译文字。
59 |
60 | **格式化文件**
61 |
62 | 格式化文件是为给定的语言环境定义数据格式的Python模块。
63 |
64 |
65 |
66 |
67 |
--------------------------------------------------------------------------------
/Web/Django/1.9/topics/testing/在Django中测试.md:
--------------------------------------------------------------------------------
1 | 原文:[Testing in Django](https://docs.djangoproject.com/en/1.9/topics/testing/)
2 |
3 | ---
4 |
5 | 对于当代的Web开发者来说,自动化测试是一个非常有用的bug专杀工具。你可以使用一个测试集合 —— 一个**测试套件** —— 来解决,或者避免许多问题:
6 |
7 | * 当你编写新代码的时候,可以使用测试来验证你的代码如预期一样工作。
8 | * 当你重构或修改旧代码时,可以使用测试来确保你的修改不会意外的影响应用程序的行为。
9 |
10 | 测试Web应用是一项复杂的任务,因为Web应用程序是由几个逻辑层组成的 - 从HTTP级别的请求处理,到表单验证和处理,再到模板渲染。使用Django的测试执行框架和各种实用工具,你可以模拟请求,插入测试数据,检查你的应用程序的输出,以及一般性验证你的代码确实在什么它应该做的事。
11 |
12 | 最在,它真的很容易。
13 |
14 | 在Django中编写测试的首选方法是使用内置在Python标准库中的[`unittest`](https://docs.python.org/3/library/unittest.html#module-unittest "(in Python v3.5)")模块。这在[_编写及运行测试_](https://docs.djangoproject.com/en/1.9/topics/testing/overview/)文档中详细的进行了说明。
15 |
16 | 你也可以使用任何其他的Python测试框架;Django为这种类型的集成提供了一个API和工具。在[_高级测试主题_](https://docs.djangoproject.com/en/1.9/topics/testing/advanced/)的[使用不同的测试框架](https://docs.djangoproject.com/en/1.9/topics/testing/advanced/#other-testing-frameworks)部分中对其进行了描述。
17 |
18 |
19 | * [编写及运行测试](https://docs.djangoproject.com/en/1.9/topics/testing/overview/)
20 | * [测试工具](https://docs.djangoproject.com/en/1.9/topics/testing/tools/)
21 | * [高级测试主题](https://docs.djangoproject.com/en/1.9/topics/testing/advanced/)
22 |
--------------------------------------------------------------------------------
/Web/Django/Django中正确处理数据库并发的方法.md:
--------------------------------------------------------------------------------
1 | 原文:[Database concurrency in Django the right way](http://www.vinta.com.br/blog/2016/database-concurrency-in-django-the-right-way/)
2 |
3 | ---
4 |
5 | 当开发对于在web应用外运行异步任务有特殊需求的应用的时候,通常是采用一个任务对了,例如[Celery](http://www.celeryproject.org/)。这允许,例如,让服务器处理请求,启动一个异步任务来负责进行一些重量级处理,并在任务仍然运行的时候返回一个响应。
6 |
7 | 在这个例子的基础中,最理想的是将高时间要求的部分从视图处理流中分离开来,因此,我们在分离的任务重运行那些部分。现在,假设我们必须在view和分离的任务中进行一些数据库操作。如果不小心完成,那么那些操作会成为难以追踪的问题之源。
8 |
9 | ### ATOMIC_REQUESTS数据库配置参数
10 |
11 | 将数据库配置中的`ATOMIC_REQUESTS`参数设置为`True`是一种常见的做法。该配置允许Django view在一个事务中运行,这样,如果在处理请求过程中生成了异常,那么Django可以简单的回滚事务。这也保证了数据库永远不会处于不一致阶段,而由于事务是数据库中的一个原子操作,因此,在一个事务运行过程中,其他试图访问数据的应用不会看到来自未完成事务的不一致数据。
12 |
13 | ### 任务和Django请求处理器的数据库竞争条件
14 |
15 | 当两个或多个并发线程试图同时访问相同的内存地址(或者,在这个例子中,数据中的一些特定的数据)时,数据竞争发生了。如果,比方说,一个线程正试图读取数据,而另一个线程正试图写,或者两个线程同时在写,那么这会导致非确定结果。当然,如果两个线程只是读取数据,那么将不会发生任何问题。
16 |
17 | 现在,回到我们的问题,让我们从编写一个简单的view开始,它将把一些数据写入到我们的数据库中:
18 |
19 |
20 | ```python
21 | from django.views.generic import View
22 | from django.http import HttpResponse
23 | from .models import Data
24 |
25 |
26 | class SimpleHandler(View):
27 |
28 | def get(self, request, *args, **kwargs):
29 | myData = Data.objects.create(name='Dummy')
30 | return HttpResponse('pk: {pk}'.format(pk=myData.pk))
31 | ```
32 |
33 | 这里是我们的模型:
34 |
35 | ```python
36 | from django.db import models
37 |
38 |
39 | class Data(models.Model):
40 | name = models.CharField(max_length=50)
41 | ```
42 |
43 | 它塑造了一个非常简单的请求处理。如果从浏览器发起请求,那么会得到已插入数据的主键作为响应,例如`pk: 41`。现在,修改我们的get方法,来加载一个celery任务,它会从数据库中获取数据:
44 |
45 | ```python
46 | def get(self, request, *args, **kwargs):
47 | myData = Data.objects.create(name='Dummy')
48 | do_stuff.delay(myData.pk)
49 | return HttpResponse('pk: {pk}'.format(pk=myData.pk))
50 | ```
51 |
52 | 而在我们的任务文件中:
53 |
54 | ```python
55 | from celery_test.celery import app
56 | from .models import Data
57 |
58 |
59 | @app.task
60 | def do_stuff(data_pk):
61 | myData = Data.objects.get(pk=data_pk)
62 | myData.name = 'new name'
63 | ```
64 |
65 | (不要忘了在你的view文件中导入`do_stuff`!)
66 |
67 | 现在,我们有了一个竞争条件,有可能Celery在获取数据的时候最终引发一场,例如`Task request_handler.tasks.do_stuff[2a3aecd0-0720-4360-83b5-3558ae1472f2] raised unexpected: DoesNotExist('Data matching query does not exist.',)`。也许看起来这不应该发生,因为我们正插入一行,获取它的主键,然后将它传递给该任务。因此,匹配该查询的数据应该存在。但是,正如前面所说的,如果将`ATOMIC_REQUESTS`设置为`True`,那么该view将在一个事务中运行。因此,只有当该view完成了它的执行,并提交了事务,数据才能被外部访问。
68 |
69 | ### 解决方法
70 |
71 | 对于这个问题,有多种解决方法。第一个,也是最明显的方法是设置`ATOMIC_REQUESTS`为`False`,但我们想要避免这样做,因为这将影响到我们项目中的其他view,并且正如前面所说的,在请求中使用事务是由许多优势的。另一个方法是使用[non_atomic_requests](https://docs.djangoproject.com/en/1.8/topics/db/transactions/#django.db.transaction.non_atomic_requests)装饰器,因为这只影响到一个view。不过,这可能不是你想要的,因为我们可以牺牲掉这一个view的功能。还有一些库,用于在提交当前事务的时候运行代码,例如[django_atomic_celery](https://github.com/adamchainz/django_atomic_celery)和[django-transaction-signals](https://github.com/aaugustin/django-transaction-signals),但那些现在已经死掉了,不应该再用它们。可以在django-transaction-signals项目中读到解释。
72 |
73 | 当前最常用的方法是使用钩子。对于Django >= 1.9,你可以使用[on_commit](https://docs.djangoproject.com/en/1.10/topics/db/transactions/#django.db.transaction.on_commit)钩子,而对于Django < 1.9,使用[django-transaction-hooks](https://django-transaction-hooks.readthedocs.io/en/latest/)。这里,我们将使用`on_commit`方法,但如果你必须使用django-transaction-hooks,那么方法是非常类似的。
74 |
75 | 你所需做的是在你的view文件中,像`from django.db import transaction`这样导入`transaction`,然后传递任何你想要在提交之后执行的函数给`transaction.on_commit`。这个方法不应该有任何参数,但是我们可以将我们的任务调用封装在一个lambda中,因此,最后的view看起来像这样:
76 |
77 | ```python
78 | class SimpleHandler(View):
79 |
80 | def get(self, request, *args, **kwargs):
81 | myData = Data.objects.create(name='Dummy')
82 | transaction.on_commit(lambda: do_stuff.delay(myData.pk))
83 | return HttpResponse('pk: {pk}'.format(pk=myData.pk))
84 | ```
85 |
86 | 这个方法够简单也适合于大多数应用。如果你需要一些更具体的,那么可以使用`non_atomic_requests`装饰器。但记住,你必须手工处理回退。
87 |
--------------------------------------------------------------------------------
/Web/Django/README.md:
--------------------------------------------------------------------------------
1 | # Django Official documentation
2 |
3 | [Django官方](https://www.djangoproject.com/)文档
4 |
5 | # 目录说明
6 | - [1.9](./1.9/) Django 1.9版本官方文档
7 | - [使用Django进行原型化](./使用Django进行原型化.md)
8 |
9 | - [使用Kubernetes使Django应用变得可扩展并具有弹性](./使用Kubernetes使Django应用变得可扩展并具有弹性.md)
10 |
11 | 想要使你的webapp架构成其规模可以优雅的满足大量用户,同时对于底层计算资源的任意故障具有弹性吗?说不定Kubernetes可以帮助你
12 |
13 | - [Django, ELB健康检查和持续交付](./Django, ELB健康检查和持续交付.md)
14 |
15 | - [带django教程的Facebook聊天机器人,又名笑话机器人](./带django教程的Facebook聊天机器人,又名笑话机器人.md)
16 |
17 | "我决定尝试开发一个聊天机器人,它只做一件事。不管用户输入什么,它都发送一个像下面这样的不含图片的随机笑话。"
18 |
19 | - [在Django中,如何为提高页面加载速度优化图像](./在Django中,如何为提高页面加载速度优化图像.md)
20 |
21 | 关于如何通过优化图像来提高网页页面加载的Django和Python技巧和窍门。
22 |
23 | - [Django Channels和Celery示例](./Django Channels和Celery示例.md)
24 |
25 | 在本教程中,我将探讨如何建立一个Django Channels项目来与Celery协同工作,以及在任务开始和结束的时候,即时通知。Django Channels使用WebSockets来启用服务器和浏览器客户端之间的双向通信。假设读者已经熟悉如何建立一个普通的Django项目,我们将只覆盖Channels和Celery相关的部分。
26 |
27 | - [如何扩展Django User模型](./如何扩展Django User模型.md)
28 |
29 | - [Django中正确处理数据库并发的方法](./Django中正确处理数据库并发的方法.md)
30 |
--------------------------------------------------------------------------------
/Web/Flask/README.md:
--------------------------------------------------------------------------------
1 | # Flask
2 | 一些跟Flask有关的……
3 |
4 | ## 说明
5 | 1. [The Flask Mega-Tutorial(中文版)](http://www.pythondoc.com/flask-mega-tutorial/) Flask入门教程
6 | 2. [Flask官方教程(中文版)](http://www.pythondoc.com/flask/index.html)
7 |
--------------------------------------------------------------------------------
/raw/An exploration of Texas Death Row data.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/raw/An exploration of Texas Death Row data.md
--------------------------------------------------------------------------------
/你该相信谁的评分?IMDB,烂番茄,Metacritic,还是Fandango?.md:
--------------------------------------------------------------------------------
1 | 原文:[Whose ratings should you trust? IMDB, Rotten Tomatoes, Metacritic, or Fandango?](https://medium.freecodecamp.com/whose-reviews-should-you-trust-imdb-rotten-tomatoes-metacritic-or-fandango-7d1010c6cf19)
2 |
3 | ---
--------------------------------------------------------------------------------
/读书笔记/README.md:
--------------------------------------------------------------------------------
1 | * [官方 python 教程(python 3)](https://docs.python.org/zh-cn/3/tutorial/index.html) | [思维导图](http://naotu.baidu.com/file/a50273db8bba3a2c7f257f039d06e7c1?token=f389efed04f2e4b8)
2 | *
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/1. Python 数据模型.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/1. Python 数据模型.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/10.序列的修改、散列和切片.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/10.序列的修改、散列和切片.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/11.接口:从协议到抽象基类.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/11.接口:从协议到抽象基类.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/12.继承的优缺点.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/12.继承的优缺点.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/13.正确重载运算符.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/13.正确重载运算符.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/14. 可叠戴的对象、迭代器和生成器.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/14. 可叠戴的对象、迭代器和生成器.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/15. 上下文管理器和 else 块.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/15. 上下文管理器和 else 块.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/16. 协程.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/16. 协程.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/17. 使用期物处理并发.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/17. 使用期物处理并发.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/18. 使用 asyncio 包处理并发.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/18. 使用 asyncio 包处理并发.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/19. 动态属性和特性.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/19. 动态属性和特性.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/2. 序列构成的数组.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/2. 序列构成的数组.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/20. 属性描述符.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/20. 属性描述符.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/21. 类元编程.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/21. 类元编程.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/3. 字典和集合.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/3. 字典和集合.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/4. 文本和字节序列.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/4. 文本和字节序列.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/5.一等函数.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/5.一等函数.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/6.使用一等函数实现设计模式.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/6.使用一等函数实现设计模式.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/7.函数装饰器和闭包.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/7.函数装饰器和闭包.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/8.对象引用、可变性和垃圾回收.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/8.对象引用、可变性和垃圾回收.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/9.符合 python 风格的对象.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/9.符合 python 风格的对象.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/README.md:
--------------------------------------------------------------------------------
1 | # 流畅的 python
2 |
3 | ### 本书源代码
4 | 地址:[fluentpython/example-code](https://github.com/fluentpython/example-code)
5 |
6 | 使用方式:
7 | ```
8 | $ python3 -m doctest example_script.py
9 | ```
--------------------------------------------------------------------------------
75 |
76 | ---
77 | [](https://star-history.com/?utm_source=bestxtools.com#ictar/python-doc&Date)
78 |
--------------------------------------------------------------------------------
/Science and Data Analysis/News Headline Analysis.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/Science and Data Analysis/News Headline Analysis.png
--------------------------------------------------------------------------------
/Science and Data Analysis/News Headline Analysis_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/Science and Data Analysis/News Headline Analysis_2.png
--------------------------------------------------------------------------------
/Science and Data Analysis/README.md:
--------------------------------------------------------------------------------
1 | # Science and Data Analysis
2 | 关于科学计算和数据分析……
3 |
4 | ## 说明
5 |
6 | - [如何使用Python和Pandas处理大量的JSON数据集](./如何使用Python和Pandas处理大量的JSON数据集.md)
7 |
8 | 如何处理大量的(指无法一次性存入内存)JSON数据集呢?本文给出了一个第三方库ijson来迭代的处理此问题。同时,通过一个简单的交通管制数据的分析,向我们娓娓道来如何使用Pandas处理分析可视化数据……
9 |
10 | - [新闻标题分析](./新闻标题分析.md)
11 |
12 | 这个项目分析两个记者写的新闻标题 —— 一个是来自于Business Inside的**财政**记者,一个是来自于Huffington post的**名人**记者 —— 来寻找这两个记者为他们的新闻文章和博客编写标题之间的异同。
13 |
14 | - [使用矩阵分解找到相似歌曲](./使用矩阵分解找到相似歌曲.md)
15 |
16 | 本文一步步指导如何使用几个不同的矩阵分解算法来计算相关的艺术家。代码使用Python编写的,使用[Pandas](http://pandas.pydata.org/)和[SciPy](https://www.scipy.org/)来进行计算,使用[D3.js](https://d3js.org/)来交互式可视化结果。
17 |
18 | > 这篇文章的样式惨不忍睹,建议还是跟原文一起对着看……
19 |
20 | - [Python中的并行处理](./Python中的并行处理.md)
21 |
22 | 虽然像C, Java, 和R这样的语言允许相当容易地进行并行处理,但对于Python程序员来说,因为全局解释锁(GIL)的存在,这却没那么容易。幸好作为pythoner的我们,也并非一筹莫展!
23 |
24 | - [Matplotlib教程 - 绘制提到Trump, Clinton & Sanders的推特](./Matplotlib教程 - 绘制提到Trump, Clinton & Sanders的推特.md)
25 |
26 | 一篇手把手教你的Matplotlib教程,是一篇很不错的learn-by-doing的数据分析文章!!
27 |
28 | - [使用Pandas, Docker和OS(R)M来猜测神秘的旅行地](./使用Pandas, Docker和OS(R)M来猜测神秘的旅行地.md)
29 |
30 | 如果你准备去某个神秘的地方玩,关于这个地方有几点提示,那么可以看看如何利用Pandas, Docker和OS(R)M科学有效的进行排除猜测。
31 |
32 | - [使用BigQuery和TensorFlow进行需求预测](./使用BigQuery和TensorFlow进行需求预测.md)
33 |
34 | 在本notebook中,我们将开发一个机器学习模型,用于预测对纽约的出租汽车需求。
35 |
36 | - [Python中一个简单的基于内容的推荐引擎](Python中一个简单的基于内容的推荐引擎.md)
37 |
38 | - [在Python中实现你自己的推荐系统](./在Python中实现你自己的推荐系统.md)
39 |
40 | - [分析权力游戏图表](./分析权力游戏图表.md)
41 |
42 | 帅爆了,用科学方法,分析权力游戏中错综复杂的人物关系。本文只实验了第三卷,看过之后,可以用其他卷来重现该实验~
43 |
44 | - [使用Python探索NFL选秀](使用Python探索NFL选秀.md)
45 |
46 | - [用于格式化和数据清理的便捷Python库](./用于格式化和数据清理的便捷Python库.md)
47 |
48 | - [分析iPhone步数数据](./分析iPhone步数数据.md)
49 |
50 | 本文展示了如何使用pandas timeseries和ggplot来分析iPhone步数数据。
51 |
52 | - [使用Python,分析23AndMe数据,获取遗传起源](./使用Python,分析23AndMe数据,获取遗传起源.md)
53 |
54 | 你的DNA包含了关于你的主线,易患疾病以及复杂特性,包括身高、体重、五官和行为等丰富的信息。使用来自23andMe,一家直接面向消费者的遗传学公司,的公众可获取数据,我们将展示如何确定在网上找到的来自23andMe的一份匿名样本的祖先。
55 |
56 | - [用Python进行股票市场数据分析概述 (第一部分)](./用Python进行股票市场数据分析概述 (第一部分).md)
57 |
58 | 这篇文章是使用Python进行股票数据分析系列的两部分中的第一个部分,基于我在Utah大学为MATH 3900(数据科学)课题提供的一个讲座。在这些文章中,我会讨论到基础知识,例如使用pandas从Yahoo! Finance获取数据,可视化股票数据,移动均值,制定一个移动平均交叉策略,回测和基准。最后的一篇文章会包含实际问题。这第一篇文章讨论的主题到介绍移动均值。
59 |
--------------------------------------------------------------------------------
/Science and Data Analysis/用于格式化和数据清理的便捷Python库.md:
--------------------------------------------------------------------------------
1 | 原文:[Handy Python Libraries for Formatting and Cleaning Data](https://blog.modeanalytics.com/python-data-cleaning-libraries/)
2 |
3 | ---
4 |
5 | 真实世界是杂乱的,它的数据也是。那么凌乱,[最近的一项调查](http://visit.crowdflower.com/data-science-report.html)显示,数据科学家花费60%的时间在清理数据。不幸的是,他们中57%还觉得这是他们工作中最不愉快的方面。
6 |
7 | 清理数据可能是耗时的,但是很多工具已经出现,让这个重要的任务惬意一点。Python社区提供了众多库,用来让数据有序清晰,从具有风格的DataFrame到匿名数据集。
8 |
9 | 如果你发现什么有用的库,请告诉我们,我们一直在寻找更好的库,以添加到[Mode Python Notebooks](https://about.modeanalytics.com/python/)中。
10 |
11 | 
12 |
13 | _太糟糕的清理对数据科学家而言就像对这个小男孩一样,并不好玩。_
14 |
15 | ## Dora
16 |
17 | Dora是为探索性分析而生的;具体来说,是为了自动化它最痛苦的那部分,如特征选择和提取,可视化,以及,是哒,你猜到了,就是数据清理。清理功能包括:
18 |
19 | * 读取缺失和比例值不佳的数据
20 | * 输入缺失值
21 | * 缩放输入变量的值
22 |
23 | **创建者:** [Nathan Epstein](https://twitter.com/epstein_n)
24 | **何处了解更多:**
25 |
26 | ## datacleaner
27 |
28 | 令人感到惊奇的datacleaner清理你的数据 —— 但只在它是以[pandas DataFrame](https://community.modeanalytics.com/python/tutorial/pandas-dataframe/)形式出现的时候。据创建者Randy Olson说:“datacleaner并不是魔术,它不会读取文本的无组织块,然后自动的为你解析。”
29 |
30 | 但是,它会丢弃具有缺失值的行,在逐列基础上用模或者中位数来替换缺失值,并且用数值等效来编码非数值变量。这个库相当的新,但是由于在Python中,DataFrame是分析的基础,因此值得一看。
31 |
32 | **创建者:** [Randy Olson](https://twitter.com/randal_olson)
33 | **何处了解更多:**
34 |
35 | ## PrettyPandas
36 |
37 | DataFrame是强大的,但是它不会生成你想要展示给你老板看的那种表格。PrettyPandas利用[pandas Style API](http://pandas.pydata.org/pandas-docs/stable/style.html)来转换DataFrame成值得展示的表单。创建摘要,添加样式,并格式化数字、列和行。额外的好处:健壮、易读的[文档](http://prettypandas.readthedocs.io/en/latest/)。
38 |
39 | **创建者:** [Henry Hammond](https://twitter.com/henryhammond92)
40 | **何处了解更多:**
41 |
42 | ## tabulate
43 |
44 | tabulate让你只用一次函数调用,就可以打印小而美的表格。它让列按照十进制、数字格式和表头等等进行排列,对于让表单更易读,它是非常方便的。
45 |
46 | 其中一个最酷的功能是,能够以多种格式,例如HTML, PHP或者Markdown Extra,来输出数据,所以你可以继续在另一个工具或者语言中处理你的表单数据。
47 |
48 | **创建者:** Sergey Astanin
49 | **何处了解更多:**
50 |
51 | ## scrubadub
52 |
53 | 在诸如医疗保健和金融的领域中,数据科学家经常需要匿名数据集。scrubadub从免费文本中移除了[个人身份信息 (PII)](https://en.wikipedia.org/wiki/Personally_identifiable_information),如:
54 |
55 | * 姓名 (专有名词)
56 | * 电子邮件地址
57 | * 网址
58 | * 电话号码
59 | * 用户名/密码组合
60 | * Skype用户名
61 | * 社保号
62 |
63 | 该文档在显示你可能想要自定义scrubadub行为的方面(例如定义新的PII类型,或者排除某些PII类型)表现良好。
64 |
65 | **创建者:** [Datascope Analytics](http://datascopeanalytics.com/)
66 | **何处了解更多:**
67 |
68 | ## Arrow
69 |
70 | 坦白说:在Python中处理日期和时间很痛苦。本地时区不能够被自动识别。要花几行令人不爽的代码来转换时区和时间戳。
71 |
72 | Arrow旨在修复这些问题和插件功能上的缺陷,来帮助你用更少的代码和更少的导入来处理时间和日期。不像Python的标准库,Arrow默认意识到时区和UTC。你可以用一行代码来转换时区或者解析字符串。
73 |
74 | **创建者:** [Chris Smith](https://twitter.com/crsmithdev)
75 | **何处了解更多:**
76 |
77 | ## Beautifier
78 |
79 | Beautifier的任务很简单:清理和美化URL和电子邮件地址。你可以通过域名和用户名来解析电子邮件;通过域名和参数(例如,UTM或者令牌)来解析URL。
80 |
81 | **创建者:** [Sachin Philip Mathew](https://twitter.com/sachin_philip)
82 | **何处了解更多:**
83 |
84 | ## ftfy
85 |
86 | ftfy (为你修正文本)接收糟糕的Unicode,输出漂亮的Unicode。基本上,它修复了所欲的垃圾字符。`“quotesâ€\x9d`变成`"quotes"`; `ü`变成`ü`; `<3`变成`<3`。如果每天都在处理文本,那么这个库,正如一个用户所说,是“一个方便的法宝。”
87 |
88 | **创建者:** [Luminoso](http://www.luminoso.com/)
89 | **何处了解更多:**
90 |
91 | ## 管理数据的更多资源
92 |
93 | 这里是几个我们最喜欢的关于改写/管理/清理数据的文章。
94 |
95 | * [每一个数据科学家都应该知道的关于数据匿名化的事](https://github.com/krasch/presentations/blob/master/pydata_Berlin_2016.pdf) (Katharina Rasch)
96 | * [在Python中清理数据](https://data.library.utoronto.ca/cleaning-data-python) (University of Toronto Map & Data Library)
97 | * [用Python进行数据清理 - MoMA的艺术品收藏](https://www.dataquest.io/blog/data-cleaning-with-python/) (Dataquest)
--------------------------------------------------------------------------------
/Scrapy/README.md:
--------------------------------------------------------------------------------
1 | # Scrapy
2 |
3 | Scrapy相关文档
4 |
5 | ## 说明
6 | - [Scrapinghub的Scrapy技巧系列](./Scrapinghub的Scrapy技巧系列)
7 |
--------------------------------------------------------------------------------
/Scrapy/Scrapinghub的Scrapy技巧系列/README.md:
--------------------------------------------------------------------------------
1 | - [跟着高手学习Scrapy技巧:第一部分](跟着高手学习Scrapy技巧:第一部分.md)
2 |
3 | - [Scrapy技巧:2016年三月版](./Scrapy技巧:2016年三月版.md)
4 |
5 | 介绍了两个scrapy技巧:使用CookieJar解决站点怪异会话行为以及添加备用的CSS/XPath规则
6 |
7 | - [Scrapy技巧:2016年四月版](./Scrapy技巧:2016年四月版.md)
8 |
9 | 一个关于如何爬取带有视图状态的Asp.NET网站的技巧……
10 |
11 | - [Scrapy技巧:2016年五月版](./Scrapy技巧:2016年五月版.md)
12 |
13 | 关于如何调试爬虫的一些技巧
14 |
15 | - [Scrapy技巧:2016年六月版](./Scrapy技巧:2016年六月版.md)
16 |
17 | 如何爬取无限滚动页面
18 |
19 | - [Scrapy技巧:2016年七月版](./Scrapy技巧:2016年七月版.md)
20 |
21 | Scrapy被设计成可扩展的,并且组件之间松耦合。你可以使用自己的中间件或者pipeline来轻松扩展Scrapy的功能。这使得Scrapy社区可以轻松地开发新的插件来提高现有功能,而无需对Scrapy自身进行修改。在这篇文章中,我们将向你展示如何利用DeltaFetch插件来运行增量爬取。
--------------------------------------------------------------------------------
/Scrapy/Scrapinghub的Scrapy技巧系列/Scrapy技巧:2016年六月版.md:
--------------------------------------------------------------------------------
1 | 原文:[Scrapy Tips from the Pros June 2016](https://blog.scrapinghub.com/2016/06/22/scrapy-tips-from-the-pros-june-2016/)
2 |
3 | ---
4 |
5 | 欢迎来到Scrapy技巧系列!每个月,我们会发布一些技巧和hack,来帮助你加快网页抓取和数据提取。作为牵头的Scrapy维护者,你可以想象的任何障碍我们都遇到过了,所以别担心,你能在这获益良多。随意到[Twitter](https://twitter.com/ScrapingHub)或者[Facebook](https://www.facebook.com/ScrapingHub/)访问我们,提出对未来主题的建议吧。
6 |
7 | 
8 |
9 | ## 抓取无限滚动页面
10 |
11 | 在单页应用以及每页具有大量AJAX请求的时代,很多网站已经用花哨的无限滚动机制取代了“前一个/下一个”分页按钮。使用这种技术的网站每当用户滚动到页面的底部的时候加载新项(想想微博,Facebook,谷歌图片)。虽然[UX专家](https://www.smashingmagazine.com/2013/05/infinite-scrolling-lets-get-to-the-bottom-of-this/)认为,无限滚动为用户提供了海量数据,但是我们看到越来越多的web页面诉诸于展示这种无休止的结果列表。
12 |
13 | 在开发web爬虫时,我们要做的第一件事就是找到能将我们引导到下一页结果的带有链接的UI组件。不幸的是,这些链接在无限滚动页面上不存在。
14 |
15 | 虽然这种场景可能看起来像诸如[Splash](http://scrapinghub.com/splash/)或者[Selenium](http://www.seleniumhq.org/)这样的JavaScript引擎的一个经典案例,但是它实际上是一个简单的修复。你所需要做的是在你滚动目标页面的时候检查浏览器的AJAX请求,然后在Scrapy spider中重新创建这些请求,而不是模拟用于与此类引擎的交互。
16 |
17 | 让我们以[Spidy Quotes](http://spidyquotes.herokuapp.com/scroll)为例,构建一个爬虫来获取上面列出来的所有的项。
18 |
19 | ## 审查页面
20 |
21 | 先说重要的事,我们需要理解无限滚动是如何在这个页面工作的,我们可以通过[浏览器的开发者工具](https://developer.chrome.com/devtools#access)中的Network面板来完成此项工作。打开该面板,然后滚动页面,看看浏览器发送了什么请求:
22 |
23 | 
24 |
25 | 点开一个请求仔细看看。浏览器发送了一个请求到`/api/quotes?page=x`,然后接收诸如以下的一个JSON对象作为响应:
26 |
27 | ```python
28 |
29 | {
30 | "has_next":true,
31 | "page":8,
32 | "quotes":[
33 | {
34 | "author":{
35 | "goodreads_link":"/author/show/1244.Mark_Twain",
36 | "name":"Mark Twain"
37 | },
38 | "tags":["individuality", "majority", "minority", "wisdom"],
39 | "text":"Whenever you find yourself on the side of the ..."
40 | },
41 | {
42 | "author":{
43 | "goodreads_link":"/author/show/1244.Mark_Twain",
44 | "name":"Mark Twain"
45 | },
46 | "tags":["books", "contentment", "friends"],
47 | "text":"Good friends, good books, and a sleepy ..."
48 | }
49 | ],
50 | "tag":null,
51 | "top_ten_tags":[["love", 49], ["inspirational", 43], ...]
52 | }
53 |
54 | ```
55 |
56 | 这就是我们的爬虫需要的信息了。它所需要做的仅是生成到"/api/quotes?page=x"的请求,其中,`x`的值不断增加,直到`has_next`字段为false。这样做最棒的是,我们甚至无需爬取HTML内容以获取所需数据。这些数据都在一个漂亮的机器可读的JSON中。
57 |
58 | ## 构建Spider
59 |
60 | 下面是我们的spider。它从服务器返回的JSON内容提取目标数据。这种方法比挖掘页面的HTML树更容易并且更健壮,相信布局的改变不会搞挂我们的spider。
61 |
62 | ```python
63 |
64 | import json
65 | import scrapy
66 |
67 |
68 | class SpidyQuotesSpider(scrapy.Spider):
69 | name = 'spidyquotes'
70 | quotes_base_url = 'http://spidyquotes.herokuapp.com/api/quotes?page=%s'
71 | start_urls = [quotes_base_url % 1]
72 | download_delay = 1.5
73 |
74 | def parse(self, response):
75 | data = json.loads(response.body)
76 | for item in data.get('quotes', []):
77 | yield {
78 | 'text': item.get('text'),
79 | 'author': item.get('author', {}).get('name'),
80 | 'tags': item.get('tags'),
81 | }
82 | if data['has_next']:
83 | next_page = data['page'] + 1
84 | yield scrapy.Request(self.quotes_base_url % next_page)
85 |
86 | ```
87 |
88 | 要进一步练习这个技巧,你可以做个实验,爬取我们的博客,因为它也是使用无限滚动来加载旧博文的。
89 |
90 | ## 总结
91 |
92 | 如果你被爬取无限滚动网站的前景吓到,那么希望现在你可以有点信心了。下一次你需要处理那种基于用户操作引发的AJAX调用的页面时,看一看你的浏览器发送的请求吧,然后将其重放到你的spider中。响应往往是JSON的格式,这使得你的spider甚至更简单了。
93 |
94 | 好啦,这就是六月份的!请在[Twitter](https://twitter.com/ScrapingHub)上联系我们,让我们知道未来你希望看到什么技巧。最近,我们还发布了一个[数据集目录](https://blog.scrapinghub.com/2016/06/09/introducing-the-new-open-data-catalog/),所以,如果你还苦思要爬取什么,那么看看这个目录获取一些灵感吧。
95 |
--------------------------------------------------------------------------------
/Testing/README.md:
--------------------------------------------------------------------------------
1 | # Testing
2 | 测试相关
3 |
4 | ## 说明
5 |
6 | - [Python Mock:简单介绍 —— 第一部分](./Python Mock:简单介绍 —— 第一部分.md)
7 |
8 | 本文带你走入Python mock,这个用于测试(TDD方法)的库……
9 |
10 | - [在Python中使用Behave来开始行为测试](./在Python中使用Behave来开始行为测试.md)
11 |
12 | 本文通过讲述一个21点的例子,借助Python中的Behave库,带你体验什么是BDD,行为驱动开发。
13 |
14 | - [基于属性的测试,hypothesis以及查找bug](./基于属性的测试,hypothesis以及查找bug.md)
15 |
16 | 看看怎么用hypothesis进行基于属性的测试吧。也许,你会如作者般爱上它
--------------------------------------------------------------------------------
/Web/Django/1.9/howto/如何使用WSGI进行部署.md:
--------------------------------------------------------------------------------
1 | 原文:[How to deploy with WSGI](https://docs.djangoproject.com/en/1.9/howto/deployment/wsgi/)
2 |
3 | Django主要的部署平台是[WSGI](http://www.wsgi.org), 它是Web服务器和应用程序的Python标准。
4 |
5 | Django的[`startproject`](https://docs.djangoproject.com/en/1.9/ref/django-admin/#django-admin-startproject)管理命令为你建立了一个简单的默认WSGI配置,你可以根据项目需要进行调整,并用于任何WSGI兼容的应用程序服务器。
6 |
7 | Django包含了以下WSGI服务器的入门文档:
8 |
9 | * [How to use Django with Apache and mod_wsgi](https://docs.djangoproject.com/en/1.9/howto/deployment/wsgi/modwsgi/)
10 | * [Authenticating against Django’s user database from Apache](https://docs.djangoproject.com/en/1.9/howto/deployment/wsgi/apache-auth/)
11 | * [How to use Django with Gunicorn](https://docs.djangoproject.com/en/1.9/howto/deployment/wsgi/gunicorn/)
12 | * [How to use Django with uWSGI](https://docs.djangoproject.com/en/1.9/howto/deployment/wsgi/uwsgi/)
13 |
14 | ## `application`对象[¶](#the-application-object "Permalink to this headline")
15 |
16 | 使用WSGI进行部署的关键概念是`application`可调用对象,应用服务器用它来与你的代码进行通信。它通常作为服务器可访问的一个Python模块中的一个名为`application`的对象被提供。
17 |
18 | [`startproject`](https://docs.djangoproject.com/en/1.9/ref/django-admin/#django-admin-startproject)命令创建一个文件`/wsgi.py`,它包含这样的`application`可调用对象。
19 |
20 | 它同时用于Django的开发服务器和生产中的WSGI部署。
21 |
22 | WSGI服务器从它们的配置中获取`application`可调用对象的路径。Django的内置服务器,即[`runserver`](https://docs.djangoproject.com/en/1.9/ref/django-admin/#django-admin-runserver)命令,从[`WSGI_APPLICATION`](https://docs.djangoproject.com/en/1.9/ref/settings/#std:setting-WSGI_APPLICATION)设置项中读取它。默认情况下,它被设置为`.wsgi.application`, 它指向`/wsgi.py`中的`application`可调用对象。
23 |
24 |
25 | ## 配置settings模块[¶](#configuring-the-settings-module "Permalink to this headline")
26 |
27 | 当WSGI服务器加载应用程序时,Django需要导入settings模块(定义你整个应用程序的地方)。
28 |
29 | Django使用[`DJANGO_SETTINGS_MODULE`](https://docs.djangoproject.com/en/1.9/topics/settings/#envvar-DJANGO_SETTINGS_MODULE)环境变量来查找相应的设置模块。他必须包含settings模块的虚线路径。你可以对开发以及生产环境使用不同的值;这都取决于如何安排你的设置。
30 |
31 | 若未设置该变量,`wsgi.py`会默认将它设置为`mysite.settings`, 其中,`mysite`是项目名称。这就是[`runserver`](https://docs.djangoproject.com/en/1.9/ref/django-admin/#django-admin-runserver)默认情况下如何发现默认的设置文件。
32 |
33 | >注意
34 |
35 | >由于环境变量是进程范围的,当你在同一个进程中运行多个Django站点时,它将无法正常工作。在使用mod_wsgi时会出现这个问题。
36 |
37 | >要避免这个问题,在每个站点的守护进程中使用mod_wsgi的守护进程模式,或者通过强制`wsgi.py`文件中的项为`os.environ["DJANGO_SETTINGS_MODULE"] = "mysite.settings"`来覆盖环境中的值。
38 |
39 |
40 |
41 | ## 应用WSGI中间件[¶](#applying-wsgi-middleware "Permalink to this headline")
42 |
43 | 要应用[WSGI middleware](https://www.python.org/dev/peps/pep-3333/#middleware-components-that-play-both-sides),你可以简单的包装application对象。例如,你可以在`wsgi.py`底部增加这些行:
44 |
45 | ```python
46 | from helloworld.wsgi import HelloWorldApplication
47 | application = HelloWorldApplication(application)
48 | ```
49 |
50 | 如果你想将一个Django应用与一个其它框架的WSGI应用合并,也可以使用一个稍后委托给Django WSGI application的自定义WSGIapplication来替换该Django WSGI application。
51 |
52 |
53 | >注意
54 |
55 | >一些第三方WSGI中间件在处理一个请求后并不在response对象上调用`close`。在这些情况下,[`request_finished`](https://docs.djangoproject.com/en/1.9/ref/signals/#django.core.signals.request_finished "django.core.signals.request_finished")信号不会被发生。这可能导致到数据库和内存缓存服务器的空闲连接。
56 |
--------------------------------------------------------------------------------
/Web/Django/1.9/howto/部署Django.md:
--------------------------------------------------------------------------------
1 | 原文:[Deploying Django](https://docs.djangoproject.com/en/1.9/howto/deployment/)
2 |
3 | Django有满满一箩筐快捷方式可以用来让Web开发者的生活更轻松,但是如果你不能轻松地部署你的网站,那么所有这些工具都毫无用处。自从Django出现以后,易部署就是一个主要的目标。
4 |
5 | * [如何使用WSGI进行部署](https://docs.djangoproject.com/en/1.9/howto/deployment/wsgi/)
6 | * [部署清单](https://docs.djangoproject.com/en/1.9/howto/deployment/checklist/)
7 |
8 | 如果你是Django以及(或者)Python部署的新手,那么我们推荐你先尝试[mod_wsgi](https://docs.djangoproject.com/en/1.9/howto/deployment/wsgi/modwsgi/)。在大多数的情况下,它是最简单,最快捷,以及最稳定的部署选择。
9 |
--------------------------------------------------------------------------------
/Web/Django/1.9/topics/i18n/国际化和本地化.md:
--------------------------------------------------------------------------------
1 | # 国际化和本地化
2 |
3 | 原文: [Internationalization and localization](https://docs.djangoproject.com/en/1.9/topics/i18n/)
4 |
5 | ---
6 |
7 | ## 概述
8 |
9 | 国际化和本地化的目标是,允许一个单一的Web应用程序提供适合用户的语言和格式的内容。
10 |
11 | Django完全支持[文本翻译](https://docs.djangoproject.com/en/1.9/topics/i18n/translation/),[日期,时间和数字格式](https://docs.djangoproject.com/en/1.9/topics/i18n/formatting/),以及[时区](https://docs.djangoproject.com/en/1.9/topics/i18n/timezones/)。
12 |
13 | 从本质上讲,Django做了两件事:
14 |
15 | * 它允许开发者和模板的作者指定应用程序的某些部分应该为当地的语言和文化进行翻译或格式化。
16 | * 根据特定用户的喜好,使用这些钩子来对Web应用程序进行本地化。
17 |
18 | 显然,翻译取决于目标的语言和格式,通常取决于目标国家。此信息通过报头的**Accept-Language**属性,由浏览器提供。然而,并不容易获得时区。
19 |
20 |
21 | ----------
22 |
23 |
24 | ## 定义
25 |
26 | 词语“国际化”和“本土化”,往往会造成混乱; 这里有一个简单的定义:
27 |
28 | **国际化**
29 |
30 | 准备用于本地化的软件,通常由开发者完成。
31 |
32 | **本地化**
33 |
34 | 编写翻译及本地格式。通常由翻译器完成。
35 |
36 | 更多详细信息,见[W3网络国际化FAQ](http://www.w3.org/International/questions/qa-i18n), [维基百科的文章](https://en.wikipedia.org/wiki/Internationalization_and_localization)或[GNU gettext文档](https://www.gnu.org/software/gettext/manual/gettext.html#Concepts)。
37 |
38 | > 警告
39 |
40 | > 翻译和格式化通过[USE_I18N](https://docs.djangoproject.com/en/1.9/ref/settings/#std:setting-USE_I18N)和[USE_L10N](https://docs.djangoproject.com/en/1.9/ref/settings/#std:setting-USE_L10N)设置项分别设置。然而,这两种功能都包括国际化和本地化。设置项的名字是Django历史上的一个不幸的结果。
41 |
42 | 这里有一些其他术语,以助于我们处理一个共同的语言:
43 |
44 | **区域设置名称**
45 |
46 | 语言环境的名称,或者是由**ll**形式或者由语言和指定国家组成的**ll_CC**形式指定的语言例如: **it**, **de_AT**, **es**, **pt_BR**。语言部分始终是小写,而国家部分始终是大写。分隔符是下划线。
47 |
48 | **语言代码**
49 |
50 | 代表一种语言的名字。浏览器使用这种格式来发送它们在**Accept-Language**报头接收的语言的名称。例如:**it**, **de-at**, **es**, **pt-br**。语言代码通常用小写表示,但是HTTP **Accept-Language**报头不区分大小写。其分隔符是一个破折号。
51 |
52 | **消息文件**
53 |
54 | 一个信息文件是一个纯文本文件,它代表一种语言,其包含了所有可用的[翻译字符串](https://docs.djangoproject.com/en/1.9/topics/i18n/#term-translation-string),以及应如何在给定的语言中展示。消息文件具有**.po**文件扩展名。
55 |
56 | **翻译字符串**
57 |
58 | 可翻译文字。
59 |
60 | **格式化文件**
61 |
62 | 格式化文件是为给定的语言环境定义数据格式的Python模块。
63 |
64 |
65 |
66 |
67 |
--------------------------------------------------------------------------------
/Web/Django/1.9/topics/testing/在Django中测试.md:
--------------------------------------------------------------------------------
1 | 原文:[Testing in Django](https://docs.djangoproject.com/en/1.9/topics/testing/)
2 |
3 | ---
4 |
5 | 对于当代的Web开发者来说,自动化测试是一个非常有用的bug专杀工具。你可以使用一个测试集合 —— 一个**测试套件** —— 来解决,或者避免许多问题:
6 |
7 | * 当你编写新代码的时候,可以使用测试来验证你的代码如预期一样工作。
8 | * 当你重构或修改旧代码时,可以使用测试来确保你的修改不会意外的影响应用程序的行为。
9 |
10 | 测试Web应用是一项复杂的任务,因为Web应用程序是由几个逻辑层组成的 - 从HTTP级别的请求处理,到表单验证和处理,再到模板渲染。使用Django的测试执行框架和各种实用工具,你可以模拟请求,插入测试数据,检查你的应用程序的输出,以及一般性验证你的代码确实在什么它应该做的事。
11 |
12 | 最在,它真的很容易。
13 |
14 | 在Django中编写测试的首选方法是使用内置在Python标准库中的[`unittest`](https://docs.python.org/3/library/unittest.html#module-unittest "(in Python v3.5)")模块。这在[_编写及运行测试_](https://docs.djangoproject.com/en/1.9/topics/testing/overview/)文档中详细的进行了说明。
15 |
16 | 你也可以使用任何其他的Python测试框架;Django为这种类型的集成提供了一个API和工具。在[_高级测试主题_](https://docs.djangoproject.com/en/1.9/topics/testing/advanced/)的[使用不同的测试框架](https://docs.djangoproject.com/en/1.9/topics/testing/advanced/#other-testing-frameworks)部分中对其进行了描述。
17 |
18 |
19 | * [编写及运行测试](https://docs.djangoproject.com/en/1.9/topics/testing/overview/)
20 | * [测试工具](https://docs.djangoproject.com/en/1.9/topics/testing/tools/)
21 | * [高级测试主题](https://docs.djangoproject.com/en/1.9/topics/testing/advanced/)
22 |
--------------------------------------------------------------------------------
/Web/Django/Django中正确处理数据库并发的方法.md:
--------------------------------------------------------------------------------
1 | 原文:[Database concurrency in Django the right way](http://www.vinta.com.br/blog/2016/database-concurrency-in-django-the-right-way/)
2 |
3 | ---
4 |
5 | 当开发对于在web应用外运行异步任务有特殊需求的应用的时候,通常是采用一个任务对了,例如[Celery](http://www.celeryproject.org/)。这允许,例如,让服务器处理请求,启动一个异步任务来负责进行一些重量级处理,并在任务仍然运行的时候返回一个响应。
6 |
7 | 在这个例子的基础中,最理想的是将高时间要求的部分从视图处理流中分离开来,因此,我们在分离的任务重运行那些部分。现在,假设我们必须在view和分离的任务中进行一些数据库操作。如果不小心完成,那么那些操作会成为难以追踪的问题之源。
8 |
9 | ### ATOMIC_REQUESTS数据库配置参数
10 |
11 | 将数据库配置中的`ATOMIC_REQUESTS`参数设置为`True`是一种常见的做法。该配置允许Django view在一个事务中运行,这样,如果在处理请求过程中生成了异常,那么Django可以简单的回滚事务。这也保证了数据库永远不会处于不一致阶段,而由于事务是数据库中的一个原子操作,因此,在一个事务运行过程中,其他试图访问数据的应用不会看到来自未完成事务的不一致数据。
12 |
13 | ### 任务和Django请求处理器的数据库竞争条件
14 |
15 | 当两个或多个并发线程试图同时访问相同的内存地址(或者,在这个例子中,数据中的一些特定的数据)时,数据竞争发生了。如果,比方说,一个线程正试图读取数据,而另一个线程正试图写,或者两个线程同时在写,那么这会导致非确定结果。当然,如果两个线程只是读取数据,那么将不会发生任何问题。
16 |
17 | 现在,回到我们的问题,让我们从编写一个简单的view开始,它将把一些数据写入到我们的数据库中:
18 |
19 |
20 | ```python
21 | from django.views.generic import View
22 | from django.http import HttpResponse
23 | from .models import Data
24 |
25 |
26 | class SimpleHandler(View):
27 |
28 | def get(self, request, *args, **kwargs):
29 | myData = Data.objects.create(name='Dummy')
30 | return HttpResponse('pk: {pk}'.format(pk=myData.pk))
31 | ```
32 |
33 | 这里是我们的模型:
34 |
35 | ```python
36 | from django.db import models
37 |
38 |
39 | class Data(models.Model):
40 | name = models.CharField(max_length=50)
41 | ```
42 |
43 | 它塑造了一个非常简单的请求处理。如果从浏览器发起请求,那么会得到已插入数据的主键作为响应,例如`pk: 41`。现在,修改我们的get方法,来加载一个celery任务,它会从数据库中获取数据:
44 |
45 | ```python
46 | def get(self, request, *args, **kwargs):
47 | myData = Data.objects.create(name='Dummy')
48 | do_stuff.delay(myData.pk)
49 | return HttpResponse('pk: {pk}'.format(pk=myData.pk))
50 | ```
51 |
52 | 而在我们的任务文件中:
53 |
54 | ```python
55 | from celery_test.celery import app
56 | from .models import Data
57 |
58 |
59 | @app.task
60 | def do_stuff(data_pk):
61 | myData = Data.objects.get(pk=data_pk)
62 | myData.name = 'new name'
63 | ```
64 |
65 | (不要忘了在你的view文件中导入`do_stuff`!)
66 |
67 | 现在,我们有了一个竞争条件,有可能Celery在获取数据的时候最终引发一场,例如`Task request_handler.tasks.do_stuff[2a3aecd0-0720-4360-83b5-3558ae1472f2] raised unexpected: DoesNotExist('Data matching query does not exist.',)`。也许看起来这不应该发生,因为我们正插入一行,获取它的主键,然后将它传递给该任务。因此,匹配该查询的数据应该存在。但是,正如前面所说的,如果将`ATOMIC_REQUESTS`设置为`True`,那么该view将在一个事务中运行。因此,只有当该view完成了它的执行,并提交了事务,数据才能被外部访问。
68 |
69 | ### 解决方法
70 |
71 | 对于这个问题,有多种解决方法。第一个,也是最明显的方法是设置`ATOMIC_REQUESTS`为`False`,但我们想要避免这样做,因为这将影响到我们项目中的其他view,并且正如前面所说的,在请求中使用事务是由许多优势的。另一个方法是使用[non_atomic_requests](https://docs.djangoproject.com/en/1.8/topics/db/transactions/#django.db.transaction.non_atomic_requests)装饰器,因为这只影响到一个view。不过,这可能不是你想要的,因为我们可以牺牲掉这一个view的功能。还有一些库,用于在提交当前事务的时候运行代码,例如[django_atomic_celery](https://github.com/adamchainz/django_atomic_celery)和[django-transaction-signals](https://github.com/aaugustin/django-transaction-signals),但那些现在已经死掉了,不应该再用它们。可以在django-transaction-signals项目中读到解释。
72 |
73 | 当前最常用的方法是使用钩子。对于Django >= 1.9,你可以使用[on_commit](https://docs.djangoproject.com/en/1.10/topics/db/transactions/#django.db.transaction.on_commit)钩子,而对于Django < 1.9,使用[django-transaction-hooks](https://django-transaction-hooks.readthedocs.io/en/latest/)。这里,我们将使用`on_commit`方法,但如果你必须使用django-transaction-hooks,那么方法是非常类似的。
74 |
75 | 你所需做的是在你的view文件中,像`from django.db import transaction`这样导入`transaction`,然后传递任何你想要在提交之后执行的函数给`transaction.on_commit`。这个方法不应该有任何参数,但是我们可以将我们的任务调用封装在一个lambda中,因此,最后的view看起来像这样:
76 |
77 | ```python
78 | class SimpleHandler(View):
79 |
80 | def get(self, request, *args, **kwargs):
81 | myData = Data.objects.create(name='Dummy')
82 | transaction.on_commit(lambda: do_stuff.delay(myData.pk))
83 | return HttpResponse('pk: {pk}'.format(pk=myData.pk))
84 | ```
85 |
86 | 这个方法够简单也适合于大多数应用。如果你需要一些更具体的,那么可以使用`non_atomic_requests`装饰器。但记住,你必须手工处理回退。
87 |
--------------------------------------------------------------------------------
/Web/Django/README.md:
--------------------------------------------------------------------------------
1 | # Django Official documentation
2 |
3 | [Django官方](https://www.djangoproject.com/)文档
4 |
5 | # 目录说明
6 | - [1.9](./1.9/) Django 1.9版本官方文档
7 | - [使用Django进行原型化](./使用Django进行原型化.md)
8 |
9 | - [使用Kubernetes使Django应用变得可扩展并具有弹性](./使用Kubernetes使Django应用变得可扩展并具有弹性.md)
10 |
11 | 想要使你的webapp架构成其规模可以优雅的满足大量用户,同时对于底层计算资源的任意故障具有弹性吗?说不定Kubernetes可以帮助你
12 |
13 | - [Django, ELB健康检查和持续交付](./Django, ELB健康检查和持续交付.md)
14 |
15 | - [带django教程的Facebook聊天机器人,又名笑话机器人](./带django教程的Facebook聊天机器人,又名笑话机器人.md)
16 |
17 | "我决定尝试开发一个聊天机器人,它只做一件事。不管用户输入什么,它都发送一个像下面这样的不含图片的随机笑话。"
18 |
19 | - [在Django中,如何为提高页面加载速度优化图像](./在Django中,如何为提高页面加载速度优化图像.md)
20 |
21 | 关于如何通过优化图像来提高网页页面加载的Django和Python技巧和窍门。
22 |
23 | - [Django Channels和Celery示例](./Django Channels和Celery示例.md)
24 |
25 | 在本教程中,我将探讨如何建立一个Django Channels项目来与Celery协同工作,以及在任务开始和结束的时候,即时通知。Django Channels使用WebSockets来启用服务器和浏览器客户端之间的双向通信。假设读者已经熟悉如何建立一个普通的Django项目,我们将只覆盖Channels和Celery相关的部分。
26 |
27 | - [如何扩展Django User模型](./如何扩展Django User模型.md)
28 |
29 | - [Django中正确处理数据库并发的方法](./Django中正确处理数据库并发的方法.md)
30 |
--------------------------------------------------------------------------------
/Web/Flask/README.md:
--------------------------------------------------------------------------------
1 | # Flask
2 | 一些跟Flask有关的……
3 |
4 | ## 说明
5 | 1. [The Flask Mega-Tutorial(中文版)](http://www.pythondoc.com/flask-mega-tutorial/) Flask入门教程
6 | 2. [Flask官方教程(中文版)](http://www.pythondoc.com/flask/index.html)
7 |
--------------------------------------------------------------------------------
/raw/An exploration of Texas Death Row data.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/raw/An exploration of Texas Death Row data.md
--------------------------------------------------------------------------------
/你该相信谁的评分?IMDB,烂番茄,Metacritic,还是Fandango?.md:
--------------------------------------------------------------------------------
1 | 原文:[Whose ratings should you trust? IMDB, Rotten Tomatoes, Metacritic, or Fandango?](https://medium.freecodecamp.com/whose-reviews-should-you-trust-imdb-rotten-tomatoes-metacritic-or-fandango-7d1010c6cf19)
2 |
3 | ---
--------------------------------------------------------------------------------
/读书笔记/README.md:
--------------------------------------------------------------------------------
1 | * [官方 python 教程(python 3)](https://docs.python.org/zh-cn/3/tutorial/index.html) | [思维导图](http://naotu.baidu.com/file/a50273db8bba3a2c7f257f039d06e7c1?token=f389efed04f2e4b8)
2 | *
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/1. Python 数据模型.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/1. Python 数据模型.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/10.序列的修改、散列和切片.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/10.序列的修改、散列和切片.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/11.接口:从协议到抽象基类.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/11.接口:从协议到抽象基类.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/12.继承的优缺点.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/12.继承的优缺点.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/13.正确重载运算符.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/13.正确重载运算符.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/14. 可叠戴的对象、迭代器和生成器.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/14. 可叠戴的对象、迭代器和生成器.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/15. 上下文管理器和 else 块.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/15. 上下文管理器和 else 块.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/16. 协程.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/16. 协程.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/17. 使用期物处理并发.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/17. 使用期物处理并发.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/18. 使用 asyncio 包处理并发.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/18. 使用 asyncio 包处理并发.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/19. 动态属性和特性.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/19. 动态属性和特性.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/2. 序列构成的数组.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/2. 序列构成的数组.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/20. 属性描述符.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/20. 属性描述符.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/21. 类元编程.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/21. 类元编程.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/3. 字典和集合.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/3. 字典和集合.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/4. 文本和字节序列.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/4. 文本和字节序列.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/5.一等函数.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/5.一等函数.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/6.使用一等函数实现设计模式.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/6.使用一等函数实现设计模式.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/7.函数装饰器和闭包.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/7.函数装饰器和闭包.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/8.对象引用、可变性和垃圾回收.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/8.对象引用、可变性和垃圾回收.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/9.符合 python 风格的对象.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ictar/python-doc/b65a546660efb256f1ca00ae5ea02e91355a9aa0/读书笔记/流畅的 python/9.符合 python 风格的对象.md
--------------------------------------------------------------------------------
/读书笔记/流畅的 python/README.md:
--------------------------------------------------------------------------------
1 | # 流畅的 python
2 |
3 | ### 本书源代码
4 | 地址:[fluentpython/example-code](https://github.com/fluentpython/example-code)
5 |
6 | 使用方式:
7 | ```
8 | $ python3 -m doctest example_script.py
9 | ```
--------------------------------------------------------------------------------