├── catkin_ws
├── models
│ └── .gitkeep
├── rosbags
│ └── .gitkeep
└── src
│ ├── snnrmse
│ ├── cfg
│ │ └── .gitkeep
│ ├── include
│ │ └── .gitkeep
│ ├── src
│ │ └── .gitkeep
│ ├── launch
│ │ └── start_snnrmse_node.launch
│ ├── README.md
│ ├── CMakeLists.txt
│ ├── package.xml
│ └── scripts
│ │ └── snnrmse_node.py
│ └── pointcloud_to_rangeimage
│ ├── src
│ ├── architectures
│ │ ├── __init__.py
│ │ └── image_compression.py
│ ├── rangeimage_to_pointcloud_node.cpp
│ └── pointcloud_to_rangeimage_node.cpp
│ ├── msg
│ ├── RangeImageCompressed.msg
│ ├── RangeImage.msg
│ └── RangeImageEncoded.msg
│ ├── assets
│ ├── original_point_cloud.png
│ └── decompressed_point_cloud.png
│ ├── setup.py
│ ├── cfg
│ └── RangeImage.cfg
│ ├── package.xml
│ ├── scripts
│ ├── compression_decoder.py
│ └── compression_encoder.py
│ ├── launch
│ ├── compression.launch
│ ├── VLP-32C_driver.launch
│ └── velodyne_compression.rviz
│ ├── include
│ └── pointcloud_to_rangeimage
│ │ ├── utils.h
│ │ └── range_image_expand.h
│ ├── params
│ └── pointcloud_to_rangeimage.yaml
│ ├── CMakeLists.txt
│ └── README.md
├── assets
├── patch.png
├── overview.gif
├── prediction.png
├── rangeimage.png
├── rviz_preview.png
├── additive_reconstruction.png
├── oneshot_reconstruction.png
└── rangeimage_prediction.png
├── range_image_compression
├── requirements.txt
├── demo_samples
│ ├── training
│ │ ├── range_00016.png
│ │ ├── range_00018.png
│ │ ├── range_00042.png
│ │ ├── range_00047.png
│ │ └── range_00048.png
│ └── validation
│ │ ├── range_00253.png
│ │ ├── range_00254.png
│ │ ├── range_00260.png
│ │ ├── range_00271.png
│ │ └── range_00283.png
├── __init__.py
├── configs
│ ├── __init__.py
│ ├── additive_gru_cfg.py
│ ├── additive_lstm_cfg.py
│ ├── oneshot_lstm_cfg.py
│ ├── additive_lstm_slim_cfg.py
│ └── additive_lstm_demo_cfg.py
├── architectures
│ ├── __init__.py
│ ├── Additive_LSTM.py
│ ├── Additive_LSTM_Demo.py
│ ├── Additive_LSTM_Slim.py
│ ├── Oneshot_LSTM.py
│ └── Additive_GRU.py
├── image_utils.py
├── utils.py
├── train.py
├── data.py
└── callbacks.py
├── docker
├── requirements.txt
├── Dockerfile
├── docker_build.sh
├── docker_eval.sh
├── docker_train.sh
└── run-ros.sh
├── .gitmodules
├── .gitignore
├── LICENSE
└── README.md
/catkin_ws/models/.gitkeep:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/catkin_ws/rosbags/.gitkeep:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/catkin_ws/src/snnrmse/cfg/.gitkeep:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/catkin_ws/src/snnrmse/include/.gitkeep:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/catkin_ws/src/snnrmse/src/.gitkeep:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/assets/patch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/assets/patch.png
--------------------------------------------------------------------------------
/range_image_compression/requirements.txt:
--------------------------------------------------------------------------------
1 | tensorflow==2.9.0
2 | easydict
3 | tensorflow-compression==2.9.0
--------------------------------------------------------------------------------
/assets/overview.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/assets/overview.gif
--------------------------------------------------------------------------------
/assets/prediction.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/assets/prediction.png
--------------------------------------------------------------------------------
/assets/rangeimage.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/assets/rangeimage.png
--------------------------------------------------------------------------------
/assets/rviz_preview.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/assets/rviz_preview.png
--------------------------------------------------------------------------------
/docker/requirements.txt:
--------------------------------------------------------------------------------
1 | tensorflow==2.9.0
2 | easydict
3 | tensorflow-compression==2.9.0
4 | tensorflow-probability==0.17.0
--------------------------------------------------------------------------------
/.gitmodules:
--------------------------------------------------------------------------------
1 | [submodule "catkin_ws/src/velodyne"]
2 | path = catkin_ws/src/velodyne
3 | url = https://github.com/ros-drivers/velodyne
4 |
--------------------------------------------------------------------------------
/assets/additive_reconstruction.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/assets/additive_reconstruction.png
--------------------------------------------------------------------------------
/assets/oneshot_reconstruction.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/assets/oneshot_reconstruction.png
--------------------------------------------------------------------------------
/assets/rangeimage_prediction.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/assets/rangeimage_prediction.png
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/src/architectures/__init__.py:
--------------------------------------------------------------------------------
1 | __all__ = ['image_compression', 'additive_lstm', 'additive_lstm_slim', 'additive_gru', 'oneshot_lstm']
2 |
--------------------------------------------------------------------------------
/range_image_compression/demo_samples/training/range_00016.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/range_image_compression/demo_samples/training/range_00016.png
--------------------------------------------------------------------------------
/range_image_compression/demo_samples/training/range_00018.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/range_image_compression/demo_samples/training/range_00018.png
--------------------------------------------------------------------------------
/range_image_compression/demo_samples/training/range_00042.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/range_image_compression/demo_samples/training/range_00042.png
--------------------------------------------------------------------------------
/range_image_compression/demo_samples/training/range_00047.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/range_image_compression/demo_samples/training/range_00047.png
--------------------------------------------------------------------------------
/range_image_compression/demo_samples/training/range_00048.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/range_image_compression/demo_samples/training/range_00048.png
--------------------------------------------------------------------------------
/docker/Dockerfile:
--------------------------------------------------------------------------------
1 | FROM tensorflow/tensorflow:2.9.0-gpu
2 |
3 | # install Python package dependencies
4 | COPY requirements.txt .
5 | RUN pip install -r requirements.txt && \
6 | rm requirements.txt
--------------------------------------------------------------------------------
/range_image_compression/demo_samples/validation/range_00253.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/range_image_compression/demo_samples/validation/range_00253.png
--------------------------------------------------------------------------------
/range_image_compression/demo_samples/validation/range_00254.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/range_image_compression/demo_samples/validation/range_00254.png
--------------------------------------------------------------------------------
/range_image_compression/demo_samples/validation/range_00260.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/range_image_compression/demo_samples/validation/range_00260.png
--------------------------------------------------------------------------------
/range_image_compression/demo_samples/validation/range_00271.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/range_image_compression/demo_samples/validation/range_00271.png
--------------------------------------------------------------------------------
/range_image_compression/demo_samples/validation/range_00283.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/range_image_compression/demo_samples/validation/range_00283.png
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/msg/RangeImageCompressed.msg:
--------------------------------------------------------------------------------
1 | Header header
2 | time send_time
3 | uint8[] RangeImage
4 | uint8[] IntensityMap
5 | uint8[] AzimuthMap
6 | uint8[] NansRow
7 | uint16[] NansCol
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/assets/original_point_cloud.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/catkin_ws/src/pointcloud_to_rangeimage/assets/original_point_cloud.png
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/assets/decompressed_point_cloud.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ika-rwth-aachen/Point-Cloud-Compression/HEAD/catkin_ws/src/pointcloud_to_rangeimage/assets/decompressed_point_cloud.png
--------------------------------------------------------------------------------
/catkin_ws/src/snnrmse/launch/start_snnrmse_node.launch:
--------------------------------------------------------------------------------
1 |
2 |
7 |
8 |
9 |
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/msg/RangeImage.msg:
--------------------------------------------------------------------------------
1 | Header header
2 | time send_time
3 | sensor_msgs/Image RangeImage
4 | sensor_msgs/Image IntensityMap
5 | sensor_msgs/Image AzimuthMap
6 | uint8[] NansRow
7 | uint16[] NansCol
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/msg/RangeImageEncoded.msg:
--------------------------------------------------------------------------------
1 | Header header
2 | time send_time
3 | uint8[] code
4 | int32[] shape
5 | uint8[] AzimuthMap
6 | uint8[] IntensityMap
7 | uint8[] RangeImage
8 | uint8[] NansRow
9 | uint16[] NansCol
10 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | /venv*
2 | .idea
3 | range_image_compression/output
4 | *.pyc
5 | __pycache__
6 | catkin_ws/build/
7 |
8 | catkin_ws/devel/
9 |
10 | catkin_ws/logs/
11 |
12 | catkin_ws/.catkin_tools/profiles/
13 |
14 | catkin_ws/.catkin_tools/
15 |
16 | *.bag
17 |
18 | *.hdf5
19 |
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup
2 | from catkin_pkg.python_setup import generate_distutils_setup
3 |
4 | setup_args = generate_distutils_setup(
5 | packages=['architectures'],
6 | package_dir={'': 'src'},
7 | )
8 |
9 | setup(**setup_args)
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/cfg/RangeImage.cfg:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 |
3 | PACKAGE = "pointcloud_to_rangeimage"
4 |
5 | from dynamic_reconfigure.parameter_generator_catkin import *
6 |
7 | gen = ParameterGenerator()
8 |
9 | gen.add("min_range", double_t, 0, "the sensor minimum range", 0, 0, 2)
10 | gen.add("max_range", double_t, 0, "the sensor maximum range", 200, 0, 200) #default 200
11 | gen.add("laser_frame", bool_t, 0, "the range image sensor frame (default laser)", True)
12 |
13 | exit(gen.generate(PACKAGE, "pointcloud_to_rangeimage", "PointCloudToRangeImageReconfigure"))
14 |
--------------------------------------------------------------------------------
/catkin_ws/src/snnrmse/README.md:
--------------------------------------------------------------------------------
1 | # SNNRMSE Metric Node
2 |
3 | A metric to evaluate the "distance" between two point clouds.
4 | Definition of the metric can be found in the paper [Real-time Point Cloud Compression](https://cg.cs.uni-bonn.de/aigaion2root/attachments/GollaIROS2015_authorsversion.pdf).
5 |
6 | =\sqrt{\sum_{p\in{P}}(p-q)^2/\lvert%20P%20\rvert})
7 |
8 | =\sqrt{0.5*\text{RMSE}_\text{NN}(P,Q)+0.5*\text{RMSE}_\text{NN}(Q,P)})
9 |
10 | ## Usage
11 | The node subscribes to topic `/points2` for the original point cloud, and the topic `/decompressed` for the decompressed
12 | point cloud. Messages should be of type `PointCloud2`. Only two point clouds pairs with identical stamps
13 | are evaluated.
14 |
--------------------------------------------------------------------------------
/catkin_ws/src/snnrmse/CMakeLists.txt:
--------------------------------------------------------------------------------
1 | cmake_minimum_required(VERSION 3.12.0 FATAL_ERROR)
2 | project(snnrmse)
3 |
4 |
5 | find_package(catkin REQUIRED COMPONENTS
6 | dynamic_reconfigure
7 | nodelet
8 | roscpp
9 | roslaunch
10 | std_msgs
11 | )
12 | find_package(PCL REQUIRED COMPONENTS common io)
13 |
14 | generate_dynamic_reconfigure_options(
15 | )
16 |
17 | catkin_package(
18 | CATKIN_DEPENDS pcl_msgs roscpp sensor_msgs std_msgs
19 | DEPENDS PCL
20 | )
21 |
22 | catkin_install_python(PROGRAMS scripts/snnrmse_node.py
23 | DESTINATION ${CATKIN_PACKAGE_BIN_DESTINATION}
24 | )
25 |
26 | include_directories(
27 | include
28 | ${catkin_INCLUDE_DIRS}
29 | ${PCL_INCLUDE_DIRS}
30 | )
31 |
32 | link_directories(${PCL_LIBRARY_DIRS})
33 | add_definitions(${PCL_DEFINITIONS})
34 |
35 | install(TARGETS
36 | ARCHIVE DESTINATION ${CATKIN_PACKAGE_LIB_DESTINATION}
37 | LIBRARY DESTINATION ${CATKIN_PACKAGE_LIB_DESTINATION}
38 | RUNTIME DESTINATION ${CATKIN_PACKAGE_BIN_DESTINATION}
39 | )
40 |
41 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright 2021 Institute for Automotive Engineering of RWTH Aachen University.
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
--------------------------------------------------------------------------------
/range_image_compression/__init__.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/package.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 | pointcloud_to_rangeimage
4 | 0.1.0
5 |
6 | Turns a 360 point cloud to range, azimuth and intensity image. Applies compression algorithms on these representations.
7 |
8 |
9 | Yuchen Tao
10 | Till Beemelmanns
11 |
12 | MIT
13 |
14 | Yuchen Tao
15 | Till Beemelmanns
16 |
17 | catkin
18 |
19 | roscpp
20 | rospy
21 | sensors_msgs
22 | ros_bridge
23 | dynamic_reconfigure
24 | message_generation
25 | image_transport
26 | velodyne_pcl
27 |
28 | roscpp
29 | rospy
30 | sensors_msgs
31 | ros_bridge
32 | dynamic_reconfigure
33 | message_runtime
34 | image_transport
35 | velodyne_pcl
36 |
37 |
38 |
39 |
40 |
41 |
--------------------------------------------------------------------------------
/range_image_compression/configs/__init__.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 |
--------------------------------------------------------------------------------
/range_image_compression/architectures/__init__.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 |
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/scripts/compression_decoder.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | import rospy
3 | from architectures import additive_lstm, additive_lstm_demo, additive_lstm_slim, oneshot_lstm, additive_gru, image_compression
4 |
5 | physical_devices = tf.config.list_physical_devices('GPU')
6 | if len(physical_devices) > 0:
7 | tf.config.experimental.set_memory_growth(physical_devices[0], True)
8 |
9 | if rospy.get_param("/rnn_compression/xla"):
10 | tf.config.optimizer.set_jit("autoclustering")
11 |
12 | if rospy.get_param("/rnn_compression/mixed_precision"):
13 | tf.keras.mixed_precision.set_global_policy("mixed_float16")
14 |
15 |
16 | def main():
17 | method = rospy.get_param("/compression_method")
18 | if method == "image_compression":
19 | decoder = image_compression.MsgDecoder()
20 | elif method == "additive_lstm":
21 | decoder = additive_lstm.MsgDecoder()
22 | elif method == "additive_lstm_slim":
23 | decoder = additive_lstm_slim.MsgDecoder()
24 | elif method == "additive_lstm_demo":
25 | decoder = additive_lstm_demo.MsgDecoder()
26 | elif method == "oneshot_lstm":
27 | decoder = oneshot_lstm.MsgDecoder()
28 | elif method == "additive_gru":
29 | decoder = additive_gru.MsgDecoder()
30 | else:
31 | raise NotImplementedError
32 |
33 | rospy.init_node('compression_decoder', anonymous=True)
34 | rospy.spin()
35 |
36 |
37 | if __name__ == '__main__':
38 | main()
39 |
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/scripts/compression_encoder.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | import rospy
3 | from architectures import additive_lstm, additive_lstm_demo, additive_lstm_slim, oneshot_lstm, additive_gru, image_compression
4 |
5 | physical_devices = tf.config.list_physical_devices('GPU')
6 | if len(physical_devices) > 0:
7 | tf.config.experimental.set_memory_growth(physical_devices[0], True)
8 |
9 | if rospy.get_param("/rnn_compression/xla"):
10 | tf.config.optimizer.set_jit("autoclustering")
11 |
12 | if rospy.get_param("/rnn_compression/mixed_precision"):
13 | tf.keras.mixed_precision.set_global_policy("mixed_float16")
14 |
15 |
16 | def main():
17 | method = rospy.get_param("/compression_method")
18 | if method == "image_compression":
19 | encoder = image_compression.MsgEncoder()
20 | elif method == "additive_lstm":
21 | encoder = additive_lstm.MsgEncoder()
22 | elif method == "additive_lstm_slim":
23 | encoder = additive_lstm_slim.MsgEncoder()
24 | elif method == "additive_lstm_demo":
25 | encoder = additive_lstm_demo.MsgEncoder()
26 | elif method == "oneshot_lstm":
27 | encoder = oneshot_lstm.MsgEncoder()
28 | elif method == "additive_gru":
29 | encoder = additive_gru.MsgEncoder()
30 | else:
31 | raise NotImplementedError
32 |
33 | rospy.init_node('compression_encoder', anonymous=True)
34 | rospy.spin()
35 |
36 |
37 | if __name__ == '__main__':
38 | main()
39 |
--------------------------------------------------------------------------------
/docker/docker_build.sh:
--------------------------------------------------------------------------------
1 | #!/bin/sh
2 |
3 | #
4 | # ==============================================================================
5 | # MIT License
6 | #
7 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
8 | #
9 | # Permission is hereby granted, free of charge, to any person obtaining a copy
10 | # of this software and associated documentation files (the "Software"), to deal
11 | # in the Software without restriction, including without limitation the rights
12 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
13 | # copies of the Software, and to permit persons to whom the Software is
14 | # furnished to do so, subject to the following conditions:
15 | #
16 | # The above copyright notice and this permission notice shall be included in all
17 | # copies or substantial portions of the Software.
18 | #
19 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
20 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
21 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
22 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
23 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
24 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
25 | # SOFTWARE.
26 | # ==============================================================================
27 | #
28 |
29 | docker build --tag range_image_compression .
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/launch/compression.launch:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
15 |
16 |
17 |
22 |
23 |
24 |
29 |
30 |
31 |
36 |
37 |
38 |
43 |
44 |
45 |
46 |
47 |
52 |
53 |
54 |
59 |
60 |
61 |
--------------------------------------------------------------------------------
/range_image_compression/image_utils.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | import tensorflow as tf
26 |
27 |
28 | def load_image_uint16(file_path):
29 | """
30 | Load 16-bit image as as tensor and return normalized Tensor as tf.float32
31 | :param file_path: File path to 16-bit image
32 | :return: tf.Tensor as tf.float32
33 | """
34 | tensor = tf.image.decode_image(tf.io.read_file(file_path), dtype=tf.dtypes.uint16)
35 | # convert_image_dtype normalizes the image
36 | tensor = tf.image.convert_image_dtype(tensor, tf.float32)
37 | return tensor
38 |
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/include/pointcloud_to_rangeimage/utils.h:
--------------------------------------------------------------------------------
1 | #ifndef POINTCLOUD_TO_RANGEIMAGE_UTILS_H_
2 | #define POINTCLOUD_TO_RANGEIMAGE_UTILS_H_
3 |
4 | #include
5 | #include
6 | #include
7 |
8 | void getFalseColorFromRange(unsigned short value, unsigned char& r, unsigned char& g, unsigned char& b)
9 | {
10 | unsigned char data[sizeof(unsigned short)];
11 |
12 | std::memcpy(data, &value, sizeof value);
13 |
14 | r = data[0];
15 | g = data[1];
16 | b = 0;
17 | }
18 |
19 | //make r keep the majority of the value, so the image shows proper color
20 | void getFalseColorFromRange2(unsigned short value, unsigned char& r, unsigned char& g, unsigned char& b)
21 | {
22 | float intpart, fractpart;
23 | float maxuchar = static_cast(std::numeric_limits::max());
24 |
25 | //divide into int part and fraction part
26 | fractpart = std::modf(value/maxuchar, &intpart);
27 |
28 | // keep integer part of division
29 | r = intpart;
30 |
31 | // deal with fractional part
32 | fractpart = std::modf((fractpart*100.f)/maxuchar, &intpart);
33 | g = intpart;
34 |
35 | fractpart = std::modf((fractpart*100.f)/maxuchar, &intpart);
36 | b = intpart;
37 | }
38 |
39 | void getRangeFromFalseColor(unsigned char r, unsigned char g, unsigned char b, unsigned short& value)
40 | {
41 | unsigned char data[sizeof(unsigned short)];
42 |
43 | data[0] = r;
44 | data[1] = g;
45 |
46 | std::memcpy(&value, data, sizeof data);
47 | }
48 |
49 | void getRangeFromFalseColor2(unsigned char r, unsigned char g, unsigned char b, unsigned short& value)
50 | {
51 | float maxuchar = static_cast(std::numeric_limits::max());
52 |
53 | float sum = static_cast(r)*maxuchar;
54 |
55 | sum += static_cast(g) / 100.f * maxuchar;
56 | sum += static_cast(b) / 100.f * maxuchar;
57 |
58 | value = static_cast(sum);
59 | }
60 |
61 | #endif // POINTCLOUD_TO_RANGEIMAGE_UTILS_H_
62 |
--------------------------------------------------------------------------------
/docker/docker_eval.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | #
4 | # ==============================================================================
5 | # MIT License
6 | #
7 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
8 | #
9 | # Permission is hereby granted, free of charge, to any person obtaining a copy
10 | # of this software and associated documentation files (the "Software"), to deal
11 | # in the Software without restriction, including without limitation the rights
12 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
13 | # copies of the Software, and to permit persons to whom the Software is
14 | # furnished to do so, subject to the following conditions:
15 | #
16 | # The above copyright notice and this permission notice shall be included in all
17 | # copies or substantial portions of the Software.
18 | #
19 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
20 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
21 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
22 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
23 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
24 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
25 | # SOFTWARE.
26 | # ==============================================================================
27 | #
28 |
29 | # get directory of this script
30 | DIR="$(cd -P "$(dirname "$0")" && pwd)"
31 |
32 | RED='\033[0;31m'
33 | NC='\033[0m' # No Color
34 |
35 | export GPG_TTY=$(tty) # set tty for login at docker container registry using credentials helper 'pass'
36 |
37 | IMAGE_NAME="tillbeemelmanns/pointcloud_compression" \
38 | IMAGE_TAG="noetic" \
39 | MOUNT_DIR="$DIR/../catkin_ws" \
40 | DOCKER_MOUNT_DIR="/catkin_ws" \
41 | CONTAINER_NAME="ros_compression_container" \
42 | DOCKER_RUN_ARGS="--workdir /catkin_ws" \
43 | \
44 | $DIR/run-ros.sh $@
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/params/pointcloud_to_rangeimage.yaml:
--------------------------------------------------------------------------------
1 | point_cloud_to_rangeimage:
2 | # Velodyne sensor setup
3 | vlp_rpm: 600.0
4 | num_layers: 32
5 | firing_cycle: 0.000055296
6 | # Points are ordered with ascending elevation
7 | elevation_offsets: [-25, -15.639, -11.31, -8.843, -7.254, -6.148, -5.333, -4.667, -4, -3.667, -3.333, -3, -2.667, -2.333, -2, -1.667, -1.333, -1, -0.667, -0.333,
8 | 0, 0.333, 0.667, 1, 1.333, 1.667, 2.333, 3.333, 4.667, 7, 10.333, 15]
9 | azimuth_offsets: [1.4, -1.4, 1.4, -1.4, 1.4, -1.4, 4.2, 1.4, -1.4, -4.2, 4.2, 1.4, -1.4, -4.2, 4.2, 1.4, -1.4, -4.2, 4.2, 1.4,
10 | -1.4, -4.2, 4.2, 1.4, -1.4, -4.2, 1.4, -1.4, 1.4, -1.4, 1.4, -1.4]
11 |
12 | #Maximum range of sensor
13 | threshold : 200
14 |
15 | # Set to true to record point cloud image dataset
16 | record_images: false
17 | # Path to store lidar compression dataset. The path should contain three sub-folders named azimuth, range and intensity.
18 | record_path: /catkin_ws/images/
19 |
20 |
21 | ## Method image compression.
22 | # image_compression for for jpeg or png compression
23 | # or
24 | # one of the RNN based methods:
25 | # additive_lstm
26 | # oneshot_lstm with one-shot reconstruction
27 | # additive_gru for GRU with additive reconstruction
28 | compression_method: additive_lstm
29 |
30 |
31 | rnn_compression:
32 | # weights path of RNN image compression model
33 | weights_path: /catkin_ws/models/additive_lstm_32b_32iter.hdf5
34 |
35 | # Bottleneck size of the model for RNN models
36 | bottleneck: 32
37 |
38 | # Number of iterations for compression of RNN models
39 | # Fewer number of iterations leads to smaller compressed data size and lower compression quality.
40 | num_iters: 32
41 |
42 | xla: True
43 | mixed_precision: False
44 |
45 |
46 | image_compression:
47 | # Parameters for compression of range image using jpeg or png compression
48 | image_compression_method: jpeg # png or jpeg
49 | show_debug_prints: false
50 |
--------------------------------------------------------------------------------
/docker/docker_train.sh:
--------------------------------------------------------------------------------
1 | #!/bin/sh
2 |
3 | #
4 | # ==============================================================================
5 | # MIT License
6 | #
7 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
8 | #
9 | # Permission is hereby granted, free of charge, to any person obtaining a copy
10 | # of this software and associated documentation files (the "Software"), to deal
11 | # in the Software without restriction, including without limitation the rights
12 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
13 | # copies of the Software, and to permit persons to whom the Software is
14 | # furnished to do so, subject to the following conditions:
15 | #
16 | # The above copyright notice and this permission notice shall be included in all
17 | # copies or substantial portions of the Software.
18 | #
19 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
20 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
21 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
22 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
23 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
24 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
25 | # SOFTWARE.
26 | # ==============================================================================
27 | #
28 |
29 | DIR="$(cd -P "$(dirname "$0")" && pwd)"
30 |
31 | docker run \
32 | --gpus all \
33 | --name='range_image_compression' \
34 | --rm \
35 | --tty \
36 | --user "$(id -u):$(id -g)" \
37 | --volume $DIR/../:/src \
38 | range_image_compression \
39 | python3 /src/range_image_compression/train.py \
40 | --train_data_dir="/src/range_image_compression/demo_samples/training" \
41 | --val_data_dir="/src/range_image_compression/demo_samples/validation" \
42 | --train_output_dir="/src/range_image_compression/output" \
43 | --model=additive_lstm_demo
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/CMakeLists.txt:
--------------------------------------------------------------------------------
1 | cmake_minimum_required(VERSION 2.8.3)
2 |
3 | project(pointcloud_to_rangeimage)
4 |
5 | find_package(catkin REQUIRED COMPONENTS
6 | roscpp
7 | rospy
8 | sensor_msgs
9 | velodyne_pcl
10 | cv_bridge
11 | dynamic_reconfigure
12 | message_generation
13 | image_transport
14 | )
15 |
16 | find_package(PCL REQUIRED)
17 | find_package(OpenCV REQUIRED)
18 | find_package(Boost REQUIRED)
19 |
20 | catkin_python_setup()
21 |
22 | generate_dynamic_reconfigure_options(
23 | cfg/RangeImage.cfg
24 | )
25 |
26 | add_message_files(
27 | FILES
28 | RangeImageCompressed.msg
29 | RangeImage.msg
30 | RangeImageEncoded.msg
31 | )
32 |
33 | generate_messages(
34 | DEPENDENCIES
35 | std_msgs
36 | sensor_msgs
37 | )
38 |
39 | catkin_package(
40 | # INCLUDE_DIRS include
41 | # LIBRARIES
42 | CATKIN_DEPENDS message_runtime
43 | DEPENDS PCL
44 | )
45 |
46 | catkin_install_python(PROGRAMS
47 | scripts/compression_encoder.py
48 | scripts/compression_decoder.py
49 | DESTINATION ${CATKIN_PACKAGE_BIN_DESTINATION}
50 | )
51 | ###########
52 | ## Build ##
53 | ###########
54 |
55 | include_directories(
56 | include
57 | ${catkin_INCLUDE_DIRS}
58 | ${PCL_INCLUDE_DIRS}
59 | ${OpenCV_INCLUDE_DIRS}
60 | ${Boost_INCLUDE_DIRS}
61 | )
62 |
63 |
64 | ## Declare a cpp executable
65 | add_executable(pointcloud_to_rangeimage_node src/pointcloud_to_rangeimage_node.cpp)
66 | add_dependencies(pointcloud_to_rangeimage_node ${PROJECT_NAME}_gencfg pointcloud_to_rangeimage_generate_messages_cpp)
67 | target_link_libraries(pointcloud_to_rangeimage_node
68 | ${catkin_LIBRARIES}
69 | ${PCL_LIBRARIES}
70 | ${OpenCV_LIBRARIES}
71 | ${Boost_LIBRARIES}
72 | )
73 |
74 | ## Declare a cpp executable
75 | add_executable(rangeimage_to_pointcloud_node src/rangeimage_to_pointcloud_node.cpp)
76 | add_dependencies(rangeimage_to_pointcloud_node ${PROJECT_NAME}_gencfg pointcloud_to_rangeimage_generate_messages_cpp)
77 | target_link_libraries(rangeimage_to_pointcloud_node
78 | ${catkin_LIBRARIES}
79 | ${PCL_LIBRARIES}
80 | ${OpenCV_LIBRARIES}
81 | ${Boost_LIBRARIES}
82 | )
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/launch/VLP-32C_driver.launch:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 |
51 |
--------------------------------------------------------------------------------
/range_image_compression/configs/additive_gru_cfg.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | from easydict import EasyDict
26 |
27 |
28 | def additive_gru_cfg():
29 | """Configuration for the Additive GRU Framework"""
30 | cfg = EasyDict()
31 |
32 | # Data loader
33 | cfg.train_data_dir = "demo_samples/training"
34 | cfg.val_data_dir = "demo_samples/validation"
35 |
36 | # Training
37 | cfg.epochs = 3000
38 | cfg.batch_size = 128
39 | cfg.val_batch_size = 128
40 | cfg.save_freq = 10000
41 | cfg.train_output_dir = "output"
42 | cfg.xla = True
43 | cfg.mixed_precision = False
44 |
45 | # Learning Rate scheduler
46 | cfg.lr_init = 2e-4
47 | cfg.min_learning_rate = 2e-7
48 | cfg.min_learning_rate_epoch = cfg.epochs
49 | cfg.max_learning_rate_epoch = 0
50 |
51 | # Network architecture
52 | cfg.bottleneck = 32
53 | cfg.num_iters = 32
54 | cfg.crop_size = 32
55 |
56 | # Give path for checkpoint or set to False otherwise
57 | cfg.checkpoint = False
58 | return cfg
59 |
--------------------------------------------------------------------------------
/range_image_compression/configs/additive_lstm_cfg.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | from easydict import EasyDict
26 |
27 |
28 | def additive_lstm_cfg():
29 | """Configuration for the Additive LSTM Framework"""
30 | cfg = EasyDict()
31 |
32 | # Data loader
33 | cfg.train_data_dir = "demo_samples/training"
34 | cfg.val_data_dir = "demo_samples/validation"
35 |
36 | # Training
37 | cfg.epochs = 3000
38 | cfg.batch_size = 128
39 | cfg.val_batch_size = 128
40 | cfg.save_freq = 10000
41 | cfg.train_output_dir = "output"
42 | cfg.xla = True
43 | cfg.mixed_precision = False
44 |
45 | # Learning Rate scheduler
46 | cfg.lr_init = 1e-4
47 | cfg.min_learning_rate = 5e-7
48 | cfg.min_learning_rate_epoch = cfg.epochs
49 | cfg.max_learning_rate_epoch = 0
50 |
51 | # Network architecture
52 | cfg.bottleneck = 32
53 | cfg.num_iters = 32
54 | cfg.crop_size = 32
55 |
56 | # Give path for checkpoint or set to False otherwise
57 | cfg.checkpoint = False
58 | return cfg
59 |
--------------------------------------------------------------------------------
/range_image_compression/configs/oneshot_lstm_cfg.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | from easydict import EasyDict
26 |
27 |
28 | def oneshot_lstm_cfg():
29 | """Configuration for the One Shot LSTM Framework"""
30 | cfg = EasyDict()
31 |
32 | # Data loader
33 | cfg.train_data_dir = "demo_samples/training"
34 | cfg.val_data_dir = "demo_samples/validation"
35 |
36 | # Training
37 | cfg.epochs = 4000
38 | cfg.batch_size = 128
39 | cfg.val_batch_size = 128
40 | cfg.save_freq = 15000
41 | cfg.train_output_dir = "/output"
42 | cfg.xla = True
43 | cfg.mixed_precision = False
44 |
45 | # Learning Rate scheduler
46 | cfg.lr_init = 2e-4
47 | cfg.min_learning_rate = 5e-7
48 | cfg.min_learning_rate_epoch = cfg.epochs
49 | cfg.max_learning_rate_epoch = 0
50 |
51 | # Network architecture
52 | cfg.bottleneck = 32
53 | cfg.num_iters = 32
54 | cfg.crop_size = 32
55 |
56 | # Give path for checkpoint or set to False otherwise
57 | cfg.checkpoint = False
58 | return cfg
59 |
--------------------------------------------------------------------------------
/range_image_compression/configs/additive_lstm_slim_cfg.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | from easydict import EasyDict
26 |
27 |
28 | def additive_lstm_slim_cfg():
29 | """Configuration for the Additive LSTM Framework"""
30 | cfg = EasyDict()
31 |
32 | # Data loader
33 | cfg.train_data_dir = "demo_samples/training"
34 | cfg.val_data_dir = "demo_samples/validation"
35 |
36 | # Training
37 | cfg.epochs = 3000
38 | cfg.batch_size = 128
39 | cfg.val_batch_size = 128
40 | cfg.save_freq = 10000
41 | cfg.train_output_dir = "/output"
42 | cfg.xla = True
43 | cfg.mixed_precision = False
44 |
45 | # Learning Rate scheduler
46 | cfg.lr_init = 5e-4
47 | cfg.min_learning_rate = 5e-7
48 | cfg.min_learning_rate_epoch = cfg.epochs
49 | cfg.max_learning_rate_epoch = 0
50 |
51 | # Network architecture
52 | cfg.bottleneck = 32
53 | cfg.num_iters = 32
54 | cfg.crop_size = 32
55 |
56 | # Give path for checkpoint or set to False otherwise
57 | cfg.checkpoint = False
58 | return cfg
59 |
--------------------------------------------------------------------------------
/range_image_compression/configs/additive_lstm_demo_cfg.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | from easydict import EasyDict
26 |
27 |
28 | def additive_lstm_demo_cfg():
29 | """Configuration for a light demo_samples training with Additive LSTM Framework"""
30 | cfg = EasyDict()
31 |
32 | # Data loader
33 | cfg.train_data_dir = "demo_samples/training"
34 | cfg.val_data_dir = "demo_samples/validation"
35 |
36 | # Training
37 | cfg.epochs = 4000
38 | cfg.batch_size = 128
39 | cfg.val_batch_size = 128
40 | cfg.save_freq = 10000
41 | cfg.train_output_dir = "/output"
42 | cfg.xla = True
43 | cfg.mixed_precision = False
44 |
45 | # Learning Rate scheduler
46 | cfg.lr_init = 5e-4
47 | cfg.min_learning_rate = 5e-7
48 | cfg.min_learning_rate_epoch = cfg.epochs
49 | cfg.max_learning_rate_epoch = 0
50 |
51 | # Network architecture
52 | cfg.bottleneck = 32
53 | cfg.num_iters = 32
54 | cfg.crop_size = 32
55 |
56 | # Give path for checkpoint or set to False otherwise
57 | cfg.checkpoint = False
58 | return cfg
59 |
--------------------------------------------------------------------------------
/catkin_ws/src/snnrmse/package.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 | snnrmse
4 | 0.1.0
5 | Implements the metric snnrmse
6 |
7 |
8 |
9 |
10 | Till Beemelmanns
11 | Yuchen Tao
12 |
13 |
14 |
15 |
16 |
17 | MIT
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 | Till Beemelmanns
31 | Yuchen Tao
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 |
51 |
52 |
53 | catkin
54 | roscpp
55 | roslaunch
56 | nodelet
57 | std_msgs
58 | libpcl-all-dev
59 | pcl_msgs
60 | sensor_msgs
61 | dynamic_reconfigure
62 | message_runtime
63 |
64 |
65 |
--------------------------------------------------------------------------------
/catkin_ws/src/snnrmse/scripts/snnrmse_node.py:
--------------------------------------------------------------------------------
1 | import rospy
2 |
3 | import numpy as np
4 |
5 | import message_filters
6 |
7 | from sensor_msgs.msg import PointCloud2
8 | from sensor_msgs import point_cloud2
9 |
10 | from sklearn.neighbors import KDTree
11 |
12 |
13 | class SNNRMSE:
14 | """
15 | Implements the SNNRMSE metric to compute a distance between two point clouds.
16 | """
17 | def callback(self, pc1, pc2, symmetric=True):
18 | pc1_xyzi = np.asarray(point_cloud2.read_points_list(
19 | pc1, field_names=("x", "y", "z", "intensity"), skip_nans=True), dtype=np.float32)
20 | pc2_xyzi = np.asarray(point_cloud2.read_points_list(
21 | pc2, field_names=("x", "y", "z", "intensity"), skip_nans=True), dtype=np.float32)
22 |
23 | tree1 = KDTree(pc1_xyzi[:, :3], leaf_size=2, metric='euclidean')
24 | sqdist1, nn1 = tree1.query(pc2_xyzi[:, :3], k=1)
25 | mse1 = np.sum(np.power(sqdist1, 2)) / sqdist1.shape[0]
26 | msei1 = np.sum(np.power(pc2_xyzi[:, 3] - pc1_xyzi[nn1[:, 0], 3], 2)) / pc2_xyzi.shape[0]
27 |
28 | if symmetric:
29 | tree2 = KDTree(pc2_xyzi[:,:3], leaf_size=2, metric='euclidean')
30 | sqdist2, nn2 = tree2.query(pc1_xyzi[:, :3], k=1)
31 | mse2 = np.sum(np.power(sqdist2, 2)) / sqdist2.shape[0]
32 | msei2 = np.sum(np.power(pc1_xyzi[:, 3] - pc2_xyzi[nn2[:, 0], 3], 2))/pc1_xyzi.shape[0]
33 | snnrmse = np.sqrt(0.5*mse1 + 0.5*mse2)
34 | snnrmsei = np.sqrt(0.5*msei1 + 0.5*msei2)
35 | else:
36 | snnrmse = np.sqrt(mse1)
37 | snnrmsei = np.sqrt(msei1)
38 |
39 | pointlost = pc1_xyzi.shape[0] - pc2_xyzi.shape[0]
40 |
41 | self.sum_snnrmse = self.sum_snnrmse + snnrmse
42 | self.sum_snnrmsei = self.sum_snnrmsei + snnrmsei
43 | self.sum_pointlost = self.sum_pointlost + pointlost
44 | self.sum_points = self.sum_points + pc1_xyzi.shape[0]
45 |
46 | print("==============EVALUATION==============")
47 | print("Frame:", pc1.header.seq + 1)
48 | print("Number of points in original cloud:", pc1_xyzi.shape[0])
49 | print("Shape:", pc1.width, pc1.height)
50 | print("Current Point Lost:", pointlost)
51 | print("Current Geometry SNNRMSE:", snnrmse)
52 | print("Current Intensity SNNRMSE:", snnrmsei)
53 | print("Average Geometry SNNRMSE:", self.sum_snnrmse / (pc1.header.seq+1))
54 | print("Average Intensity SNNRMSE:", self.sum_snnrmsei / (pc1.header.seq+1))
55 | print("Average Point Lost:", self.sum_pointlost / (pc1.header.seq+1))
56 | print("Average Point Number:", self.sum_points / (pc1.header.seq+1))
57 | print("======================================")
58 |
59 | def __init__(self):
60 | # initialize ROS node
61 | rospy.init_node('snnrmse_node', anonymous=False)
62 |
63 | original_cloud = message_filters.Subscriber('/points2', PointCloud2)
64 | decompressed_cloud = message_filters.Subscriber('/decompressed', PointCloud2)
65 |
66 | self.sum_snnrmse = 0
67 | self.sum_snnrmsei = 0
68 | self.sum_pointlost = 0
69 | self.sum_points = 0
70 |
71 | ts = message_filters.TimeSynchronizer([original_cloud, decompressed_cloud], 10)
72 | ts.registerCallback(self.callback)
73 |
74 | rospy.spin()
75 |
76 |
77 | if __name__ == '__main__':
78 | snnrmse_node = SNNRMSE()
79 |
--------------------------------------------------------------------------------
/range_image_compression/utils.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | import tensorflow as tf
26 |
27 |
28 | from architectures import Additive_LSTM_Demo, Additive_LSTM, Additive_LSTM_Slim, Additive_GRU, Oneshot_LSTM
29 | from configs import additive_lstm_demo_cfg, additive_lstm_cfg, additive_lstm_slim_cfg, additive_gru_cfg, oneshot_lstm_cfg
30 |
31 | model_map = {
32 | "additive_lstm_demo": Additive_LSTM_Demo.LidarCompressionNetwork,
33 | "additive_lstm": Additive_LSTM.LidarCompressionNetwork,
34 | "additive_lstm_slim": Additive_LSTM_Slim.LidarCompressionNetwork,
35 | "additive_gru": Additive_GRU.LidarCompressionNetwork,
36 | "oneshot_lstm": Oneshot_LSTM.LidarCompressionNetwork
37 | }
38 |
39 | config_map = {
40 | "additive_lstm_demo": additive_lstm_demo_cfg.additive_lstm_demo_cfg,
41 | "additive_lstm": additive_lstm_cfg.additive_lstm_cfg,
42 | "additive_lstm_slim": additive_lstm_slim_cfg.additive_lstm_slim_cfg,
43 | "additive_gru": additive_gru_cfg.additive_gru_cfg,
44 | "oneshot_lstm": oneshot_lstm_cfg.oneshot_lstm_cfg,
45 | }
46 |
47 |
48 | def load_config_and_model(args):
49 | cfg = config_map[args.model.lower()]()
50 |
51 | # overwrite default values in config with parsed arguments
52 | for key, value in vars(args).items():
53 | if value:
54 | cfg[key] = value
55 |
56 | if cfg.xla:
57 | tf.config.optimizer.set_jit("autoclustering")
58 |
59 | if cfg.mixed_precision:
60 | tf.keras.mixed_precision.set_global_policy("mixed_float16")
61 |
62 | # support multi GPU training
63 | train_strategy = tf.distribute.get_strategy()
64 | with train_strategy.scope():
65 | model = model_map[args.model.lower()](
66 | bottleneck=cfg.bottleneck,
67 | num_iters=cfg.num_iters,
68 | batch_size=cfg.batch_size,
69 | input_size=cfg.crop_size
70 | )
71 | # init model
72 | model(tf.zeros((
73 | cfg.batch_size,
74 | cfg.crop_size,
75 | cfg.crop_size,
76 | 1))
77 | )
78 | model.summary()
79 |
80 | # set batch size for train and val data loader
81 | cfg.train_data_loader_batch_size = cfg.batch_size * train_strategy.num_replicas_in_sync
82 | cfg.val_data_loader_batch_size = cfg.val_batch_size * train_strategy.num_replicas_in_sync
83 | return cfg, model
84 |
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/README.md:
--------------------------------------------------------------------------------
1 | ## RNN Based Point Cloud Compression
2 |
3 | The idea is to losslessly convert a point cloud to range, azimuth and intensity images,
4 | then compress them using image compression methods.
5 |
6 | | Input Point Cloud | Decompressed Point Cloud |
7 | | --- | --- |
8 | |  |  |
9 |
10 |
11 | ### Configuration
12 |
13 | Initial settings of the Velodyne LiDAR sensor and parameters of the application can be set int the configuration file
14 | [pointcloud_to_rangeimage.yaml](params/pointcloud_to_rangeimage.yaml).
15 | Default setting is based on Velodyne VLP-32C model.
16 |
17 | ### point_cloud_to_rangeimage
18 |
19 | Parameter | Description | Example
20 | ------------ | ------------- | -------------
21 | vlp_rpm | RPM of the sensor | `600.0`
22 | num_layers | Number of laser layers in the sensor | `32`
23 | firing_circle | Time for one firing circle | `0.000055296`
24 | elevation_offsets | Elevation angle corresponding to each laser layer in ascending order | `see default setting`
25 | azimuth_offsets | Azimuth offset corresponding to each laser layer with the same order as elevation_offsets | `see default setting`
26 | record_images | Whether to record transformed images in a local folder | `false`
27 | record_path | Path to store lidar compression dataset | `/home/rosuser/catkin_ws/dataset/`
28 | threshold | Maximum range of point clouds | `200`
29 |
30 | ### compression_method
31 | Parameter | Description | Example
32 | ------------ | ------------- | -------------
33 | compression_method | Compression method: `additive_lstm`, `oneshot_lstm`, `additive_gru`, `image_compression` | `additive_lstm`
34 |
35 | ### rnn_compression
36 | Parameter | Description | Example
37 | ------------ | ------------- | -------------
38 | weights_path | Path to the model weights stored as `.hdf5` | `/catkin_ws/models/additive_lstm_32b_32iter.hdf5`
39 | bottleneck | Bottleneck size of the model | `32`
40 | num_iters | Number of iterations for compression | `32`
41 |
42 | ### image_compression
43 | Parameter | Description | Example
44 | ------------ | ------------- | -------------
45 | image_compression_method | Select image compression method `png` or `jpg` | `jpg`
46 | show_debug_prints | Print debug prints during execution `true` or `false` | `false`
47 |
48 | ### Usage
49 |
50 | **Dataset generation:** Transform point clouds to images and store them in local folders.
51 | 1. Specify `record_path` to store the images in the configuration file.
52 | The path should contain three sub-folders named azimuth, range and intensity. Set parameter `record_images` to `true`.
53 | 2. Run ```roslaunch pointcloud_to_rangeimage compression.launch```.
54 | 3. In another terminal, play the rosbags to be transformed.
55 | The node [pointcloud_to_rangeimage_node.cpp](src/pointcloud_to_rangeimage_node.cpp) subscribes to the topic `/velodyne_points` with message type `sensor_msgs/PointCloud2`.
56 | The images will be stored in the three sub-folders. Raw Velodyne packet data is also supported with the help of the
57 | Velodyne driver, by including the launch file [VLP-32C_driver.launch](launch/VLP-32C_driver.launch). Manual configuration regarding the sensor setup is needed.
58 | 4. Optional: the dataset can be further splitted into train/val/test datasets using the library split-folders.
59 | ```bash
60 | pip install split-folders
61 | python
62 | import splitfolders
63 | splitfolders.ratio('path/to/parent/folder', output="path/to/output/folder", seed=1337, ratio=(.8, 0.1,0.1))
64 | ```
65 |
66 | **Online JPEG compression**:
67 | 1. Set parameter `record_images` to `false`.
68 | 2. Set `compression_method` to `ìmage_compression` and choose desired compression quality [here](src/architectures/image_compression.py). See [OpenCV imwrite flags](https://docs.opencv.org/4.5.3/d8/d6a/group__imgcodecs__flags.html#ga292d81be8d76901bff7988d18d2b42ac).
69 | 3. Run ```roslaunch pointcloud_to_rangeimage compression.launch```. Path to the rosbag can be modified in the launch file.
70 |
71 | **Online RNN compression**:
72 | 1. Set parameter `record_images` to `false`.
73 | 2. Set `compression_method` to `additive_lstm` or `oneshot_lstm` or `additive_gru`
74 | 3. Set the parameters `weights_path` and `bottleneck` according to the picked model. Set `num_iters` to
75 | control the compressed message size.
76 | 4. Run `roslaunch pointcloud_to_rangeimage compression.launch`. Path to the rosbag can be modified in the launch file.
77 |
--------------------------------------------------------------------------------
/range_image_compression/train.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | import os
26 | import argparse
27 |
28 | import tensorflow as tf
29 | from keras.callbacks import ModelCheckpoint
30 |
31 | from utils import load_config_and_model
32 | from data import LidarCompressionData
33 |
34 | from callbacks import TensorBoard, CosineLearningRateScheduler
35 |
36 |
37 | def train(args):
38 | cfg, model = load_config_and_model(args)
39 |
40 | train_set = LidarCompressionData(
41 | input_dir=cfg.train_data_dir,
42 | crop_size=cfg.crop_size,
43 | batch_size=cfg.train_data_loader_batch_size,
44 | augment=True
45 | ).build_dataset()
46 |
47 | val_set = LidarCompressionData(
48 | input_dir=cfg.val_data_dir,
49 | crop_size=cfg.crop_size,
50 | batch_size=cfg.val_data_loader_batch_size,
51 | augment=False
52 | ).build_dataset()
53 |
54 | lr_schedule = CosineLearningRateScheduler(
55 | cfg.lr_init,
56 | min_learning_rate=cfg.min_learning_rate,
57 | min_learning_rate_epoch=cfg.min_learning_rate_epoch,
58 | max_learning_rate_epoch=cfg.max_learning_rate_epoch
59 | ).get_callback()
60 |
61 | optimizer = tf.keras.optimizers.Adam()
62 |
63 | checkpoint_callback = ModelCheckpoint(
64 | filepath=os.path.join(cfg.train_output_dir, f"weights_e={{epoch:05d}}.hdf5"),
65 | save_freq=cfg.save_freq,
66 | save_weights_only=True,
67 | monitor='val_loss',
68 | )
69 |
70 | tensorboard_callback = TensorBoard(cfg.train_output_dir, val_set, cfg.batch_size)
71 |
72 | if cfg.checkpoint:
73 | model.load_weights(cfg.checkpoint, by_name=True)
74 | print("Checkpoint ", cfg.checkpoint, " loaded.")
75 |
76 | model.compile(optimizer=optimizer)
77 |
78 | model.fit(
79 | train_set,
80 | validation_data=val_set,
81 | callbacks=[checkpoint_callback, tensorboard_callback, lr_schedule],
82 | epochs=cfg.epochs
83 | )
84 |
85 | model.save_weights(filepath=os.path.join(args.train_output_dir, 'final_model.hdf5'))
86 |
87 |
88 | if __name__ == '__main__':
89 | parser = argparse.ArgumentParser(description='Parse Flags for the training script!')
90 | parser.add_argument('-t', '--train_data_dir', type=str,
91 | help='Absolute path to the train dataset')
92 | parser.add_argument('-v', '--val_data_dir', type=str,
93 | help='Absolute path to the validation dataset')
94 | parser.add_argument('-e', '--epochs', type=int,
95 | help='Maximal number of training epochs')
96 | parser.add_argument('-o', '--train_output_dir', type=str,
97 | help="Directory where to write the Tensorboard logs and checkpoints")
98 | parser.add_argument('-s', '--save_freq', type=int,
99 | help="Save freq for keras.callbacks.ModelCheckpoint")
100 | parser.add_argument('-m', '--model', type=str, default='additive_lstm_demo',
101 | help='Model name either `additive_gru`, `additive_lstm`,'
102 | ' `additive_lstm_demo`, `oneshot_lstm`')
103 | args = parser.parse_args()
104 | train(args)
105 |
--------------------------------------------------------------------------------
/range_image_compression/data.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | import os
26 | import tensorflow as tf
27 |
28 | import image_utils
29 |
30 |
31 | class LidarCompressionData:
32 | """
33 | Class to create a tf.data.Dataset which loads and preprocesses the
34 | range images.
35 | """
36 | def __init__(self, input_dir, crop_size, batch_size, augment=True):
37 | self.input_dir = input_dir
38 | self.crop_size = crop_size
39 | self.batch_size = batch_size
40 | self.augment = augment
41 |
42 | def build_dataset(self, shuffle_buffer=1024):
43 | """
44 | Creates a tf.data.Dataset object which loads train samples,
45 | preprocesses them and batches the data.
46 | :param shuffle_buffer: Buffersize for shuffle operation
47 | :return: tf.data.Dataset object
48 | """
49 | dataset = tf.data.Dataset.list_files(os.path.join(self.input_dir, "*.png"))
50 | dataset = dataset.shuffle(shuffle_buffer)
51 | dataset = dataset.map(self.raw_sample_to_cachable_sample, num_parallel_calls=tf.data.AUTOTUNE)
52 | dataset = dataset.map(self.sample_to_model_input, num_parallel_calls=tf.data.AUTOTUNE)
53 | dataset = dataset.batch(self.batch_size, drop_remainder=True)
54 | dataset = dataset.map(self.set_shape)
55 | dataset = dataset.prefetch(tf.data.AUTOTUNE)
56 | return dataset
57 |
58 | def set_shape(self, inputs, labels):
59 | """
60 | Manually set the shape information for all batches as these information get lost
61 | after using tf.image.random_crop.
62 | :param inputs: tf.Tensor as the model input
63 | :param labels: tf.Tensor as the model label
64 | :return: Tuple of (inputs, labels)
65 | """
66 | inputs.set_shape([self.batch_size, self.crop_size, self.crop_size, 1])
67 | labels.set_shape([self.batch_size, self.crop_size, self.crop_size, 1])
68 | return inputs, labels
69 |
70 | def raw_sample_to_cachable_sample(self, input_path):
71 | """
72 | Loads a sample from path and return as tf.Tensor
73 | :param input_path: String with path to sample
74 | :return: tf.Tensor containing the range image
75 | """
76 | input_img = image_utils.load_image_uint16(input_path)
77 | return input_img
78 |
79 | def sample_to_model_input(self, input_tensor):
80 | """
81 | Creates the final model input tensors. Performs random crop with self.crop_size
82 | on original range representation and returns model input and model label. Note that
83 | label is a copy of input.
84 | :param input_tensor: tf.Tensor containing the range image in original shape (H, W, 1)
85 | :return: Tuple (input, label) as (tf.Tensor, tf.Tensor). Both tensors have a
86 | shape of (crop_size, crop_size, 1).
87 | """
88 | if self.augment:
89 | # Pad the image with the left 32 columns during training to ensure
90 | # each column has the same probability to be cropped.
91 | input_img = tf.concat([input_tensor, input_tensor[:, :self.crop_size, :]], 1)
92 | input_img = tf.image.random_crop(input_img, [self.crop_size, self.crop_size, 1])
93 | else:
94 | # Used mainly by the validation set. Validation set is already pre-cropped
95 | input_img = tf.image.random_crop(input_tensor, [self.crop_size, self.crop_size, 1])
96 |
97 | # The label is the input image itself
98 | return input_img, input_img
99 |
--------------------------------------------------------------------------------
/range_image_compression/callbacks.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | import tensorflow as tf
26 |
27 | import numpy as np
28 |
29 |
30 | class TensorBoard(tf.keras.callbacks.TensorBoard):
31 | """
32 | Implements a Tensorboard callback which generates preview images of model input
33 | and current model prediction. Also stores model loss and metrics.
34 | """
35 |
36 | def __init__(self, log_dir, dataset, batch_size, **kwargs):
37 | super().__init__(log_dir, **kwargs)
38 | self.dataset = dataset
39 | self.batch_size = batch_size
40 | self.num_images = 1
41 | self.max_outputs = 10
42 | self.custom_tb_writer = tf.summary.create_file_writer(self.log_dir + '/validation')
43 |
44 | def on_train_batch_end(self, batch, logs=None):
45 | lr = self.model.optimizer.lr
46 | iterations = self.model.optimizer.iterations
47 | with self.custom_tb_writer.as_default():
48 | tf.summary.scalar('iterations_learning_rate', lr.numpy(), iterations)
49 | super().on_train_batch_end(batch, logs)
50 |
51 | def on_epoch_end(self, epoch, logs=None):
52 | # get first batch of dataset
53 | inputs, _ = self.dataset.take(1).get_single_element()
54 |
55 | predictions = self.model(inputs[:self.batch_size, :, :])
56 |
57 | inputs = inputs[:self.num_images, :, :]
58 | predictions = predictions[:self.num_images, :, :].numpy()
59 |
60 | inputs = tf.image.resize(inputs,
61 | size=[inputs.shape[1] * 3, inputs.shape[2] * 3],
62 | method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
63 |
64 | predictions = tf.image.resize(predictions,
65 | size=[predictions.shape[1] * 3, predictions.shape[2] * 3],
66 | method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
67 |
68 | with self.custom_tb_writer.as_default():
69 | tf.summary.image('Images/Input Image',
70 | inputs,
71 | max_outputs=self.max_outputs,
72 | step=epoch)
73 | tf.summary.image('Images/Predicted Image',
74 | predictions,
75 | max_outputs=self.max_outputs,
76 | step=epoch)
77 |
78 | super().on_epoch_end(epoch, logs)
79 |
80 | def on_test_end(self, logs=None):
81 | super().on_test_end(logs)
82 |
83 | def on_train_end(self, logs=None):
84 | super().on_train_end(logs)
85 | self.custom_tb_writer.close()
86 |
87 |
88 | class CosineLearningRateScheduler:
89 | """Implements a Cosine Learning RateScheduler as tf.keras.Callback"""
90 | def __init__(self, init_learning_rate,
91 | min_learning_rate,
92 | min_learning_rate_epoch,
93 | max_learning_rate_epoch):
94 | self.lr0 = init_learning_rate
95 | self.min_lr = min_learning_rate
96 | self.min_lr_epoch = min_learning_rate_epoch
97 | self.max_lr_epoch = max_learning_rate_epoch
98 |
99 | def get_callback(self):
100 | def lr_schedule(epoch, lr):
101 | """
102 | Cosine learning rate schedule proposed by Ilya et al. (https://arxiv.org/pdf/1608.03983.pdf).
103 | The learning rate starts to decay starting from epoch self.max_lr_epoch, and reaches the minimum
104 | learning rate at epoch self.min_lr_epoch.
105 | """
106 | if epoch >= self.min_lr_epoch:
107 | lr = self.min_lr
108 | elif epoch <= self.max_lr_epoch:
109 | lr = self.lr0
110 | else:
111 | lr = self.min_lr + 0.5 * (self.lr0 - self.min_lr) * \
112 | (1 + np.cos((epoch - self.max_lr_epoch) / (self.min_lr_epoch - self.max_lr_epoch) * np.pi))
113 | return lr
114 |
115 | return tf.keras.callbacks.LearningRateScheduler(lr_schedule)
116 |
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/launch/velodyne_compression.rviz:
--------------------------------------------------------------------------------
1 | Panels:
2 | - Class: rviz/Displays
3 | Help Height: 78
4 | Name: Displays
5 | Property Tree Widget:
6 | Expanded:
7 | - /Global Options1
8 | - /Status1
9 | - /PointCloud21
10 | Splitter Ratio: 0.5
11 | Tree Height: 403
12 | - Class: rviz/Selection
13 | Name: Selection
14 | - Class: rviz/Tool Properties
15 | Expanded:
16 | - /2D Pose Estimate1
17 | - /2D Nav Goal1
18 | - /Publish Point1
19 | Name: Tool Properties
20 | Splitter Ratio: 0.5886790156364441
21 | - Class: rviz/Views
22 | Expanded:
23 | - /Current View1
24 | Name: Views
25 | Splitter Ratio: 0.5
26 | - Class: rviz/Time
27 | Experimental: false
28 | Name: Time
29 | SyncMode: 0
30 | SyncSource: PointCloud2
31 | Preferences:
32 | PromptSaveOnExit: true
33 | Toolbars:
34 | toolButtonStyle: 2
35 | Visualization Manager:
36 | Class: ""
37 | Displays:
38 | - Alpha: 0.5
39 | Cell Size: 1
40 | Class: rviz/Grid
41 | Color: 160; 160; 164
42 | Enabled: true
43 | Line Style:
44 | Line Width: 0.029999999329447746
45 | Value: Lines
46 | Name: Grid
47 | Normal Cell Count: 0
48 | Offset:
49 | X: 0
50 | Y: 0
51 | Z: 0
52 | Plane: XY
53 | Plane Cell Count: 10
54 | Reference Frame:
55 | Value: true
56 | - Alpha: 1
57 | Autocompute Intensity Bounds: true
58 | Autocompute Value Bounds:
59 | Max Value: 10
60 | Min Value: -10
61 | Value: true
62 | Axis: Z
63 | Channel Name: intensity
64 | Class: rviz/PointCloud2
65 | Color: 255; 255; 255
66 | Color Transformer: Intensity
67 | Decay Time: 0
68 | Enabled: true
69 | Invert Rainbow: false
70 | Max Color: 255; 255; 255
71 | Max Intensity: 0
72 | Min Color: 0; 0; 0
73 | Min Intensity: 0
74 | Name: PointCloud2
75 | Position Transformer: XYZ
76 | Queue Size: 10
77 | Selectable: true
78 | Size (Pixels): 2
79 | Size (m): 0.009999999776482582
80 | Style: Points
81 | Topic: /rangeimage_to_pointcloud_node/pointcloud_out
82 | Unreliable: false
83 | Use Fixed Frame: true
84 | Use rainbow: true
85 | Value: true
86 | - Class: rviz/Image
87 | Enabled: true
88 | Image Topic: /pointcloud_to_rangeimage_node/image_out
89 | Max Value: 1
90 | Median window: 5
91 | Min Value: 0
92 | Name: Image
93 | Normalize Range: true
94 | Queue Size: 2
95 | Transport Hint: raw
96 | Unreliable: false
97 | Value: true
98 | Enabled: true
99 | Global Options:
100 | Background Color: 48; 48; 48
101 | Default Light: true
102 | Fixed Frame: vlp16_link
103 | Frame Rate: 30
104 | Name: root
105 | Tools:
106 | - Class: rviz/Interact
107 | Hide Inactive Objects: true
108 | - Class: rviz/MoveCamera
109 | - Class: rviz/Select
110 | - Class: rviz/FocusCamera
111 | - Class: rviz/Measure
112 | - Class: rviz/SetInitialPose
113 | Theta std deviation: 0.2617993950843811
114 | Topic: /initialpose
115 | X std deviation: 0.5
116 | Y std deviation: 0.5
117 | - Class: rviz/SetGoal
118 | Topic: /move_base_simple/goal
119 | - Class: rviz/PublishPoint
120 | Single click: true
121 | Topic: /clicked_point
122 | Value: true
123 | Views:
124 | Current:
125 | Class: rviz/Orbit
126 | Distance: 33.790889739990234
127 | Enable Stereo Rendering:
128 | Stereo Eye Separation: 0.05999999865889549
129 | Stereo Focal Distance: 1
130 | Swap Stereo Eyes: false
131 | Value: false
132 | Field of View: 0.7853981852531433
133 | Focal Point:
134 | X: 0
135 | Y: 0
136 | Z: 0
137 | Focal Shape Fixed Size: true
138 | Focal Shape Size: 0.05000000074505806
139 | Invert Z Axis: false
140 | Name: Current View
141 | Near Clip Distance: 0.009999999776482582
142 | Pitch: 0.6003972887992859
143 | Target Frame:
144 | Yaw: 4.05357551574707
145 | Saved: ~
146 | Window Geometry:
147 | Displays:
148 | collapsed: false
149 | Height: 694
150 | Hide Left Dock: false
151 | Hide Right Dock: false
152 | Image:
153 | collapsed: false
154 | QMainWindow State: 000000ff00000000fd0000000400000000000001560000021cfc0200000008fb0000001200530065006c0065006300740069006f006e00000001e10000009b0000005c00fffffffb0000001e0054006f006f006c002000500072006f007000650072007400690065007302000001ed000001df00000185000000a3fb000000120056006900650077007300200054006f006f02000001df000002110000018500000122fb000000200054006f006f006c002000500072006f0070006500720074006900650073003203000002880000011d000002210000017afb000000100044006900730070006c006100790073010000003b0000021c000000c700fffffffb0000002000730065006c0065006300740069006f006e00200062007500660066006500720200000138000000aa0000023a00000294fb00000014005700690064006500530074006500720065006f02000000e6000000d2000003ee0000030bfb0000000c004b0069006e0065006300740200000186000001060000030c00000261000000010000010f0000021cfc0200000004fb0000001e0054006f006f006c002000500072006f00700065007200740069006500730100000041000000780000000000000000fb0000000a00560069006500770073010000003b00000167000000a000fffffffb0000000a0049006d00610067006501000001a8000000af0000001600fffffffb0000001200530065006c0065006300740069006f006e010000025a000000b200000000000000000000000200000500000000a9fc0100000001fb0000000a00560069006500770073030000004e00000080000002e10000019700000003000005000000003efc0100000002fb0000000800540069006d00650100000000000005000000024400fffffffb0000000800540069006d006501000000000000045000000000000000000000028f0000021c00000004000000040000000800000008fc0000000100000002000000010000000a0054006f006f006c00730100000000ffffffff0000000000000000
155 | Selection:
156 | collapsed: false
157 | Time:
158 | collapsed: false
159 | Tool Properties:
160 | collapsed: false
161 | Views:
162 | collapsed: false
163 | Width: 1280
164 | X: 0
165 | Y: 0
166 |
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/src/architectures/image_compression.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | import rospy
4 |
5 | from pointcloud_to_rangeimage.msg import RangeImage as RangeImage_msg
6 | from pointcloud_to_rangeimage.msg import RangeImageEncoded as RangeImageEncoded_msg
7 |
8 | import cv2
9 | from cv_bridge import CvBridge
10 |
11 |
12 | class MsgEncoder:
13 | """
14 | Subscribe to topic /pointcloud_to_rangeimage_node/msg_out,
15 | compress range image, azimuth image and intensity image using JPEG2000 or PNG compression.
16 | Publish message type RangeImageEncoded to topic /msg_encoded.
17 | """
18 | def __init__(self):
19 | self.bridge = CvBridge()
20 |
21 | self.image_compression_method = rospy.get_param("/image_compression/image_compression_method")
22 | self.show_debug_prints = rospy.get_param("/image_compression/show_debug_prints")
23 |
24 | self.pub = rospy.Publisher('msg_encoded', RangeImageEncoded_msg, queue_size=10)
25 | self.sub = rospy.Subscriber("/pointcloud_to_rangeimage_node/msg_out", RangeImage_msg, self.callback)
26 |
27 | self.int_size_sum = 0
28 | self.ran_size_sum = 0
29 | self.azi_size_sum = 0
30 | self.frame_count = 0
31 |
32 | def callback(self,msg):
33 | rospy.loginfo(rospy.get_caller_id() + "I heard %s", msg.send_time)
34 | # Convert ROS image to OpenCV image.
35 | try:
36 | range_image = self.bridge.imgmsg_to_cv2(msg.RangeImage, desired_encoding="mono16")
37 | except CvBridgeError as e:
38 | print(e)
39 | try:
40 | intensity_map = self.bridge.imgmsg_to_cv2(msg.IntensityMap, desired_encoding="mono8")
41 | except CvBridgeError as e:
42 | print(e)
43 | try:
44 | azimuth_map = self.bridge.imgmsg_to_cv2(msg.AzimuthMap, desired_encoding="mono16")
45 | except CvBridgeError as e:
46 | print(e)
47 |
48 | msg_encoded = RangeImageEncoded_msg()
49 | msg_encoded.header = msg.header
50 | msg_encoded.send_time = msg.send_time
51 | msg_encoded.NansRow = msg.NansRow
52 | msg_encoded.NansCol = msg.NansCol
53 |
54 | # Compress the images using OpenCV library and pack compressed data in ROS message.
55 | if self.image_compression_method == "jpeg":
56 | params_azimuth_jp2 = [cv2.IMWRITE_JPEG2000_COMPRESSION_X1000, 100]
57 | params_intensity_png = [cv2.IMWRITE_PNG_COMPRESSION, 10]
58 | params_rangeimage_jp2 = [cv2.IMWRITE_JPEG2000_COMPRESSION_X1000, 50]
59 |
60 | _, azimuth_map_encoded = cv2.imencode('.jp2', azimuth_map, params_azimuth_jp2)
61 | _, intensity_map_encoded = cv2.imencode('.png', intensity_map, params_intensity_png)
62 | _, range_image_encoded = cv2.imencode('.jp2', range_image, params_rangeimage_jp2)
63 |
64 | elif self.image_compression_method == "png":
65 | params_png = [cv2.IMWRITE_PNG_COMPRESSION, 10]
66 |
67 | _, azimuth_map_encoded = cv2.imencode('.png', azimuth_map, params_png)
68 | _, intensity_map_encoded = cv2.imencode('.png', intensity_map, params_png)
69 | _, range_image_encoded = cv2.imencode('.png', range_image, params_png)
70 | else:
71 | raise NotImplementedError
72 |
73 | msg_encoded.AzimuthMap = azimuth_map_encoded.tostring()
74 | msg_encoded.IntensityMap = intensity_map_encoded.tostring()
75 | msg_encoded.RangeImage = range_image_encoded.tostring()
76 |
77 | if self.show_debug_prints:
78 | self.int_size_sum = self.int_size_sum+intensity_map_encoded.nbytes
79 | self.azi_size_sum = self.azi_size_sum+azimuth_map_encoded.nbytes
80 | self.ran_size_sum = self.ran_size_sum+range_image_encoded.nbytes
81 | self.frame_count = self.frame_count + 1
82 |
83 | print("=============Encoded Image Sizes=============")
84 | print("Range Image:", range_image_encoded.nbytes)
85 | print("Intensity Map:", intensity_map_encoded.nbytes)
86 | print("Azimuth Map:", azimuth_map_encoded.nbytes)
87 | print("Intensity Average:", self.int_size_sum / self.frame_count / intensity_map.nbytes)
88 | print("Azimuth Average:", self.azi_size_sum / self.frame_count / azimuth_map.nbytes)
89 | print("Range Average:", self.ran_size_sum / self.frame_count / range_image.nbytes)
90 | print("=============================================")
91 |
92 | self.pub.publish(msg_encoded)
93 |
94 |
95 | class MsgDecoder:
96 | """
97 | Subscribe to topic /msg_encoded published by the encoder.
98 | Decompress the images and pack them in message type RangeImage.
99 | Publish message to the topic /msg_decoded.
100 | """
101 | def __init__(self):
102 | self.bridge = CvBridge()
103 |
104 | self.pub = rospy.Publisher('msg_decoded', RangeImage_msg, queue_size=10)
105 | self.sub = rospy.Subscriber("/msg_encoded", RangeImageEncoded_msg, self.callback)
106 |
107 | def callback(self, msg):
108 | rospy.loginfo(rospy.get_caller_id() + "I heard %s", msg.send_time)
109 |
110 | # Decode the images.
111 | azimuth_map_array = np.fromstring(msg.AzimuthMap, np.uint8)
112 | azimuth_map_decoded = cv2.imdecode(azimuth_map_array,cv2.IMREAD_UNCHANGED)
113 | intensity_map_array = np.fromstring(msg.IntensityMap, np.uint8)
114 | intensity_map_decoded = cv2.imdecode(intensity_map_array,cv2.IMREAD_UNCHANGED)
115 | range_image_array = np.fromstring(msg.RangeImage, np.uint8)
116 | range_image_decoded = cv2.imdecode(range_image_array,cv2.IMREAD_UNCHANGED)
117 |
118 | # Convert OpenCV image to ROS image.
119 | try:
120 | range_image = self.bridge.cv2_to_imgmsg(range_image_decoded, encoding="mono16")
121 | except CvBridgeError as e:
122 | print(e)
123 | try:
124 | intensity_map = self.bridge.cv2_to_imgmsg(intensity_map_decoded, encoding="mono8")
125 | except CvBridgeError as e:
126 | print(e)
127 | try:
128 | azimuth_map = self.bridge.cv2_to_imgmsg(azimuth_map_decoded, encoding="mono16")
129 | except CvBridgeError as e:
130 | print(e)
131 |
132 | # Pack images in ROS message.
133 | msg_decoded = RangeImage_msg()
134 | msg_decoded.header = msg.header
135 | msg_decoded.send_time = msg.send_time
136 | msg_decoded.RangeImage = range_image
137 | msg_decoded.IntensityMap = intensity_map
138 | msg_decoded.AzimuthMap = azimuth_map
139 | msg_decoded.NansRow = msg.NansRow
140 | msg_decoded.NansCol = msg.NansCol
141 |
142 | self.pub.publish(msg_decoded)
143 |
--------------------------------------------------------------------------------
/docker/run-ros.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | #
4 | # ==============================================================================
5 | # MIT License
6 | #
7 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
8 | #
9 | # Permission is hereby granted, free of charge, to any person obtaining a copy
10 | # of this software and associated documentation files (the "Software"), to deal
11 | # in the Software without restriction, including without limitation the rights
12 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
13 | # copies of the Software, and to permit persons to whom the Software is
14 | # furnished to do so, subject to the following conditions:
15 | #
16 | # The above copyright notice and this permission notice shall be included in all
17 | # copies or substantial portions of the Software.
18 | #
19 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
20 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
21 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
22 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
23 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
24 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
25 | # SOFTWARE.
26 | # ==============================================================================
27 | #
28 |
29 | RED='\033[0;31m'
30 | NC='\033[0m'
31 | DIR="$(cd -P "$(dirname "$0")" && pwd)" # path to directory containing this script
32 |
33 | function help_text() {
34 | cat << EOF
35 | usage: run-ros.sh [-a][-d][-g gpu_ids][-h][-i][-n name] [COMMAND]
36 | -a directly attach to a container shell
37 | -d disable X11-GUI-forwarding to the host's X server
38 | -g specify comma-separated IDs of GPUs to be available in the container; defaults to 'all'; use 'none' in case of non-NVIDIA GPUs
39 | -h show help text
40 | -n container name
41 | EOF
42 | exit 0
43 | }
44 |
45 | # PARAMETERS can be passed as environment variables #
46 | if [[ -z "${IMAGE_NAME}" ]]; then
47 | IMAGE_NAME="tillbeemelmanns/pointcloud_compression:noetic"
48 | fi
49 | if [[ -z "${IMAGE_TAG}" ]]; then
50 | IMAGE_TAG="latest"
51 | fi
52 | if [[ -z "${DOCKER_USER}" ]]; then
53 | DOCKER_USER="rosuser"
54 | fi
55 | DOCKER_HOME="/home/${DOCKER_USER}"
56 |
57 |
58 | if [[ -z "${CONTAINER_NAME}" ]]; then
59 | CONTAINER_NAME="ros" # name of the Docker container to be started
60 | fi
61 | if [[ -z "${MOUNT_DIR}" ]]; then
62 | MOUNT_DIR="$DIR" # host's directory to be mounted into the container
63 | fi
64 | if [[ -z "${DOCKER_MOUNT_DIR}" ]]; then
65 | DOCKER_MOUNT_DIR="${DOCKER_HOME}/ws" # container directory that host directory is mounted into
66 | fi
67 | if ! [[ -z "${DOCKER_MOUNT}" ]]; then
68 | echo -e "${RED}The DOCKER_MOUNT argument is deprecated. The folder $(readlink -f ${MOUNT_DIR}) will be mounted to ${DOCKER_MOUNT_DIR}.${NC}"
69 | fi
70 | if [[ -z "${DOCKER_RUN_ARGS}" ]]; then
71 | DOCKER_RUN_ARGS=() # additional arguments for 'docker run'
72 | else
73 | DOCKER_RUN_ARGS=(${DOCKER_RUN_ARGS})
74 | fi
75 | if [[ -z ${BASHRC_COMMANDS} ]]; then
76 | unset BASHRC_COMMANDS
77 | fi
78 | # PARAMETERS END #
79 |
80 | IMAGE="$IMAGE_NAME:$IMAGE_TAG"
81 | DIR="$(cd -P "$(dirname "$0")" && pwd)" # absolute path to the directory containing this script
82 |
83 | # defaults
84 | ATTACH="0"
85 | HAS_COMMAND="0"
86 | X11="1"
87 | GPU_IDS="all"
88 |
89 | # read command line arguments
90 | while getopts ac:dg:hin:oru opt
91 | do
92 | case $opt in
93 | a) ATTACH="1";;
94 | d) echo "Headless Mode: no X11-GUI-forwarding"; X11="0";;
95 | g) GPU_IDS="$OPTARG";;
96 | h) echo "Help: "; help_text;;
97 | n) CONTAINER_NAME="$OPTARG";;
98 | esac
99 | done
100 | shift $(($OPTIND - 1))
101 | if ! [[ -z ${@} ]]; then
102 | HAS_COMMAND="1"
103 | fi
104 |
105 |
106 | # create custom .bashrc appendix, if startup commands are given
107 | if [[ ! -z ${BASHRC_COMMANDS} ]]; then
108 | BASHRC_APPENDIX=${DIR}/.bashrc-appendix
109 | DOCKER_BASHRC_APPENDIX=${DOCKER_HOME}/.bashrc-appendix
110 | :> ${BASHRC_APPENDIX}
111 | echo "${BASHRC_COMMANDS}" >> ${BASHRC_APPENDIX}
112 | fi
113 |
114 | # try to find running container to attach to
115 | RUNNING_CONTAINER_NAME=$(docker ps --format '{{.Names}}' | grep -x "${CONTAINER_NAME}" | head -n 1)
116 | if [[ -z ${RUNNING_CONTAINER_NAME} ]]; then # look for containers of same image if provided name is not found
117 | RUNNING_CONTAINER_NAME=$(docker ps --format '{{.Image}} {{.Names}}' | grep ${IMAGE} | head -n 1 | awk '{print $2}')
118 | if [[ ! -z ${RUNNING_CONTAINER_NAME} ]]; then
119 | read -p "Found running container '${RUNNING_CONTAINER_NAME}', would you like to attach instead of launching a new container '${CONTAINER_NAME}'? (y/n) " -n 1 -r
120 | echo
121 | if [[ ! $REPLY =~ ^[Yy]$ ]]; then
122 | RUNNING_CONTAINER_NAME=""
123 | fi
124 | fi
125 | fi
126 |
127 |
128 | if [[ ! -z ${RUNNING_CONTAINER_NAME} ]]; then
129 | # attach to running container
130 |
131 | # collect all arguments for docker exec
132 | DOCKER_EXEC_ARGS+=("--interactive")
133 | DOCKER_EXEC_ARGS+=("--tty")
134 | DOCKER_EXEC_ARGS+=("--user ${DOCKER_USER}")
135 | if [[ ${X11} = "0" ]]; then
136 | DOCKER_EXEC_ARGS+=("--env DISPLAY=""")
137 | fi
138 |
139 | # attach
140 | echo "Attaching to running container ..."
141 | echo " Name: ${RUNNING_CONTAINER_NAME}"
142 | echo " Image: ${IMAGE}"
143 | echo ""
144 | if [[ -z ${@} ]]; then
145 | docker exec ${DOCKER_EXEC_ARGS[@]} ${RUNNING_CONTAINER_NAME} bash -i
146 | else
147 | docker exec ${DOCKER_EXEC_ARGS[@]} ${RUNNING_CONTAINER_NAME} bash -i -c "${*}"
148 | fi
149 |
150 | else
151 | # start new container
152 | ROS_MASTER_PORT=11311
153 |
154 | # GUI Forwarding to host's X server [https://stackoverflow.com/a/48235281]
155 | # Uncomment "X11UseLocalhost no" in /etc/ssh/sshd_config to enable X11 forwarding through SSH for isolated containers
156 | if [ $X11 = "1" ]; then
157 | XSOCK=/tmp/.X11-unix # to support X11 forwarding in isolated containers on local host (not thorugh SSH)
158 | XAUTH=$(mktemp /tmp/.docker.xauth.XXXXXXXXX)
159 | xauth nlist $DISPLAY | sed -e 's/^..../ffff/' | xauth -f $XAUTH nmerge -
160 | chmod 777 $XAUTH
161 | fi
162 |
163 | # set --gpus flag for docker run
164 | if ! [[ "$GPU_IDS" == "all" || "$GPU_IDS" == "none" ]]; then
165 | GPU_IDS=$(echo "\"device=$GPU_IDS\"")
166 | fi
167 | echo "GPUs: $GPU_IDS"
168 | echo ""
169 |
170 | # collect all arguments for docker run
171 | DOCKER_RUN_ARGS+=("--name ${CONTAINER_NAME}")
172 | DOCKER_RUN_ARGS+=("--rm")
173 | if ! [[ "$GPU_IDS" == "none" ]]; then
174 | DOCKER_RUN_ARGS+=("--gpus ${GPU_IDS}")
175 | fi
176 | DOCKER_RUN_ARGS+=("--env TZ=$(cat /etc/timezone)")
177 | DOCKER_RUN_ARGS+=("--volume ${MOUNT_DIR}:${DOCKER_MOUNT_DIR}")
178 | DOCKER_RUN_ARGS+=("--env DOCKER_USER=${DOCKER_USER}")
179 | DOCKER_RUN_ARGS+=("--env DOCKER_HOME=${DOCKER_HOME}")
180 | DOCKER_RUN_ARGS+=("--env DOCKER_MOUNT_DIR=${DOCKER_MOUNT_DIR}")
181 |
182 | if [[ ${ATTACH} = "1" && ${HAS_COMMAND} = "0" ]]; then
183 | DOCKER_RUN_ARGS+=("--detach")
184 | DOCKER_EXEC_ARGS+=("--interactive")
185 | DOCKER_EXEC_ARGS+=("--tty")
186 | DOCKER_EXEC_ARGS+=("--user ${DOCKER_USER}")
187 | fi
188 | if [[ ${HAS_COMMAND} = "1" ]]; then
189 | DOCKER_RUN_ARGS+=("--interactive")
190 | DOCKER_RUN_ARGS+=("--tty")
191 | fi
192 |
193 | DOCKER_RUN_ARGS+=("--network host")
194 | DOCKER_RUN_ARGS+=("--env ROS_MASTER_URI=http://$(hostname):${ROS_MASTER_PORT}")
195 |
196 | if [[ ${X11} = "1" ]]; then
197 | DOCKER_RUN_ARGS+=("--env QT_X11_NO_MITSHM=1")
198 | DOCKER_RUN_ARGS+=("--env DISPLAY=${DISPLAY}")
199 | DOCKER_RUN_ARGS+=("--env XAUTHORITY=${XAUTH}")
200 | DOCKER_RUN_ARGS+=("--volume ${XAUTH}:${XAUTH}")
201 | DOCKER_RUN_ARGS+=("--volume ${XSOCK}:${XSOCK}")
202 | fi
203 | if [[ ! -z ${BASHRC_COMMANDS} ]]; then
204 | DOCKER_RUN_ARGS+=("--volume ${BASHRC_APPENDIX}:${DOCKER_BASHRC_APPENDIX}:ro")
205 | fi
206 |
207 | # run docker container
208 | echo "Starting container ..."
209 | echo " Name: ${CONTAINER_NAME}"
210 | echo " Image: ${IMAGE}"
211 | echo ""
212 | if [[ ${HAS_COMMAND} = "0" ]]; then
213 | docker run ${DOCKER_RUN_ARGS[@]} ${IMAGE}
214 | if [[ ${ATTACH} = "1" ]]; then
215 | echo
216 | docker exec ${DOCKER_EXEC_ARGS[@]} ${CONTAINER_NAME} bash -i
217 | fi
218 | else
219 | docker run ${DOCKER_RUN_ARGS[@]} ${IMAGE} bash -i -c "${*}"
220 | fi
221 |
222 | # cleanup
223 | if [ $X11 = "1" ]; then
224 | rm $XAUTH
225 | fi
226 | if [[ ! -z ${BASHRC_COMMANDS} ]]; then
227 | rm ${BASHRC_APPENDIX}
228 | fi
229 | fi
230 |
231 | if [[ -z ${RUNNING_CONTAINER_NAME} ]]; then
232 | RUNNING_CONTAINER_NAME=$(docker ps --format '{{.Names}}' | grep "\b${CONTAINER_NAME}\b")
233 | fi
234 | echo
235 | if [[ ! -z ${RUNNING_CONTAINER_NAME} ]]; then
236 | echo "Container '${RUNNING_CONTAINER_NAME}' is still running: can be stopped via 'docker stop ${RUNNING_CONTAINER_NAME}'"
237 | else
238 | echo "Container '${CONTAINER_NAME}' has stopped"
239 | fi
240 |
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/include/pointcloud_to_rangeimage/range_image_expand.h:
--------------------------------------------------------------------------------
1 | #pragma once
2 |
3 | #include
4 |
5 | #include
6 | #include
7 | #include // for pcl::isFinite
8 | #include // for VectorAverage3f
9 |
10 | namespace pcl
11 | {
12 | class RangeImageWithoutInterpolation : public pcl::RangeImageSpherical
13 | {
14 | public:
15 | // Add two additional attributes in the pcl::RangeImageSpherical class.
16 | std::vector intensities;
17 | std::vector azimuth;
18 |
19 | template
20 | void
21 | createFromPointCloudWithoutInterpolation(const PointCloudType &point_cloud, float angular_resolution_x, std::vector elevation_offsets, std::vector az_shifts, int az_increments,
22 | const Eigen::Affine3f &sensor_pose, RangeImage::CoordinateFrame coordinate_frame,
23 | float noise_level, float min_range, float threshold, int border_size)
24 | /* Project point cloud to range, azimuth and intensity images.
25 | Modified from the PCL method createFromPointCloud with fixed image size and without interpolation.*/
26 | {
27 | width = point_cloud.height; //1800 or 1812
28 | height = point_cloud.width; //32
29 | // Calculate and set the inverse of angular resolution.
30 | setAngularResolution(angular_resolution_x, 1.0f);
31 | is_dense = false;
32 | // Get coordinate transformation matrix.
33 | getCoordinateFrameTransformation(coordinate_frame, to_world_system_);
34 | to_world_system_ = sensor_pose * to_world_system_;
35 | to_range_image_system_ = to_world_system_.inverse(Eigen::Isometry);
36 | unsigned int size = 32 * 1812;
37 | points.clear();
38 | points.resize(size, unobserved_point);
39 | intensities.clear();
40 | intensities.resize(size, 0);
41 | azimuth.clear();
42 | azimuth.resize(size, 0);
43 | // Calculate and write Z buffer (range/depth), azimuth and intensity into vectors.
44 | doZBufferWithoutInterpolation(point_cloud, noise_level, min_range, threshold, elevation_offsets, az_shifts, az_increments);
45 | }
46 |
47 | template
48 | void
49 | doZBufferWithoutInterpolation(const PointCloudType &point_cloud, float noise_level, float min_range, float threshold, std::vector elevation_offsets, std::vector az_shifts, int az_increments)
50 | {
51 | using PointType2 = typename PointCloudType::PointType;
52 | const typename pcl::PointCloud::VectorType &points2 = point_cloud.points;
53 | unsigned int size = width * height;
54 | float range_of_current_point, intensity_of_current_point;
55 | int x, y;
56 | int num_nan = 0, num_outliers = 0;
57 | int offset = 0;
58 | int counter_shift = 0;
59 | // Calculate the offset to shift the front view to center of the image.
60 | for (int i = 0; i < point_cloud.height; i++) //1800 or 1812 one laser level
61 | {
62 | // point_cloud.width is 32.
63 | for (int j = 0; j < point_cloud.width; j++) //32 one scan
64 | {
65 | // Get current point.
66 | int idx_cloud = i * height + j; //height = 32
67 | // If there is no reflection --> do nothing.
68 | if (!isFinite(points2[idx_cloud]))
69 | { // Check for NAN etc.
70 | continue;
71 | }
72 | else
73 | {
74 | Vector3fMapConst current_point = points2[idx_cloud].getVector3fMap();
75 | // Apply azimuth shift.
76 | int x_img = i + az_shifts[j];
77 | // Transform to range image coordinate system. Result is [y,z,x].
78 | Eigen::Vector3f transformedPoint = to_range_image_system_ * current_point;
79 | // Calculate azimuth angle of current point by arctan(y/x).
80 | float angle_x = atan2LookUp(transformedPoint[0], transformedPoint[2]);
81 | if (angle_x < -3.13) // where the azimuth turns from 3.14 to -3.14
82 | {
83 | int image_x = static_cast((angle_x + static_cast(M_PI)) * angular_resolution_x_reciprocal_);
84 | offset += image_x - x_img;
85 | counter_shift++;
86 | }
87 | }
88 | }
89 | }
90 | offset = std::ceil(offset / counter_shift);
91 | // std::cout << "offset: " << offset << std::endl;
92 | // std::cout << "num counter: " << counter_shift << std::endl;
93 |
94 | int x_rangeimage, idx_image, num_points = 0;
95 |
96 | // Apply azimuth shift to align pixels in one column with similar azimuth angles.
97 | for (int i = 0; i < point_cloud.height; i++)
98 | {
99 | // point_cloud.width is 32
100 | for (int j = 0; j < point_cloud.width; j++)
101 | {
102 | //get current point
103 | int idx_cloud = i * height + j;
104 |
105 | // Apply azimuth shift.
106 | x_rangeimage = i + az_shifts[j];
107 | if (x_rangeimage < 0)
108 | {
109 | x_rangeimage += az_increments;
110 | }
111 | if (x_rangeimage > az_increments - 1)
112 | {
113 | x_rangeimage -= az_increments;
114 | }
115 |
116 | // Shift front view to the center.
117 | x_rangeimage += offset;
118 | if (x_rangeimage < 0)
119 | {
120 | x_rangeimage += az_increments;
121 | }
122 | if (x_rangeimage > az_increments - 1)
123 | {
124 | x_rangeimage -= az_increments;
125 | }
126 |
127 | idx_image = j * 1812 + x_rangeimage;
128 | float &range_at_image_point = points[idx_image].range;
129 | float &intensity_at_image_point = intensities[idx_image];
130 | float &azimuth_at_image_point = azimuth[idx_image];
131 |
132 | //if there is no reflection --> do nothing
133 | if (!isFinite(points2[idx_cloud]))
134 | { // Check for NAN etc
135 | continue;
136 | }
137 | else
138 | {
139 | // Get vector of the current point.
140 | Vector3fMapConst current_point = points2[idx_cloud].getVector3fMap();
141 | // Calculate range of the current point.
142 | range_of_current_point = current_point.norm();
143 | // Only store points within min and max range.
144 | if (range_of_current_point < min_range || range_of_current_point > threshold)
145 | {
146 | continue;
147 | }
148 | range_at_image_point = range_of_current_point;
149 | intensity_at_image_point = points2[idx_cloud].intensity;
150 | // Transform to range image coordinate system. Result is [y,z,x].
151 | Eigen::Vector3f transformedPoint = to_range_image_system_ * current_point;
152 | // Calculate azimuth angle of current point by arctan(y/x).
153 | azimuth_at_image_point = atan2LookUp(transformedPoint[0], transformedPoint[2]);
154 | num_points++;
155 | }
156 | }
157 | }
158 | // std::cout << "NANs: " << num_nan << std::endl;
159 | // std::cout << "Num points doing Z buffer:" << num_points << std::endl;
160 | }
161 |
162 | void
163 | createEmpty(int cols, int rows, float angular_resolution_x, const Eigen::Affine3f &sensor_pose, RangeImage::CoordinateFrame coordinate_frame)
164 | // Create empty object filled with NaN points.
165 | {
166 | setAngularResolution(angular_resolution_x, 1.0f);
167 | width = cols;
168 | height = rows;
169 |
170 | is_dense = false;
171 | getCoordinateFrameTransformation(coordinate_frame, to_world_system_);
172 | to_world_system_ = sensor_pose * to_world_system_;
173 | to_range_image_system_ = to_world_system_.inverse(Eigen::Isometry);
174 | unsigned int size = width * height;
175 | points.clear();
176 | // Initialize as all -inf
177 | points.resize(size, unobserved_point);
178 | intensities.clear();
179 | intensities.resize(size, 0);
180 | azimuth.clear();
181 | azimuth.resize(size, 0);
182 | }
183 |
184 | void
185 | recalculate3DPointPositionsVelodyne(std::vector &elevation_offsets, float angular_resolution_x, int cols, int rows)
186 | // Recalculate point cloud from range, azimuth and intensity images.
187 | {
188 | int num_points = 0;
189 | for (int y = 0; y < rows; ++y)
190 | {
191 | for (int x = 0; x < cols; ++x)
192 | {
193 | PointWithRange &point = points[y * width + x];
194 | if (!std::isinf(point.range))
195 | {
196 | float angle_x = azimuth[y * width + x];
197 | // Elevation angle can be looked up in table elevation_offsets by the row index.
198 | float angle_y = pcl::deg2rad(elevation_offsets[31 - y]);
199 | float cosY = std::cos(angle_y);
200 | // Recalculate point positions.
201 | Eigen::Vector3f point_tmp = Eigen::Vector3f(point.range * std::sin(-angle_x) * cosY, point.range * std::cos(angle_x) * cosY, point.range * std::sin(angle_y));
202 | point.x = point_tmp[1];
203 | point.y = point_tmp[0];
204 | point.z = point_tmp[2];
205 | num_points++;
206 | }
207 | }
208 | }
209 | }
210 | };
211 |
212 | }
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/src/rangeimage_to_pointcloud_node.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include
4 | #include
5 | #include
6 | #include
7 |
8 | #include
9 | #include
10 |
11 | #include
12 | #include
13 | #include
14 | #include
15 | #include
16 | #include
17 | #include
18 |
19 | #include "pointcloud_to_rangeimage/utils.h"
20 | #include
21 | #include "pointcloud_to_rangeimage/range_image_expand.h"
22 |
23 | namespace
24 | {
25 | typedef pcl::PointXYZI PointType;
26 | typedef pcl::PointCloud PointCloud;
27 |
28 | typedef pcl::RangeImage RI;
29 | typedef pcl::RangeImageWithoutInterpolation RIS;
30 |
31 | typedef pointcloud_to_rangeimage::PointCloudToRangeImageReconfigureConfig conf;
32 | typedef dynamic_reconfigure::Server RangeImageReconfServer;
33 |
34 | typedef image_transport::ImageTransport It;
35 | typedef image_transport::Subscriber Sub;
36 | }
37 |
38 | class PointCloudConverter
39 | /*
40 | Receive messages of type RangeImage from topic /msg_decoded, project the range, azimuth and intensity images
41 | back to point cloud. The point cloud of type sensor_msgs::PointCloud2 is then published to the topic /pointcloud_out.
42 | */
43 | {
44 | private:
45 | bool _newmsg;
46 | bool _laser_frame;
47 | bool _init;
48 |
49 | // RangeImage frame
50 | pcl::RangeImage::CoordinateFrame _frame;
51 |
52 | // RangeImage resolution
53 | double _ang_res_x;
54 | double _azi_scale = (2 * static_cast(M_PI)) / std::numeric_limits::max();
55 |
56 | // Sensor min/max range
57 | float _min_range;
58 | float _max_range;
59 |
60 | double _vlp_rpm;
61 | double _firing_cycle;
62 | int _az_increments;
63 | std::vector _az_shifts;
64 | std::vector _azimuth_offsets;
65 | std::vector _elevation_offsets;
66 | std::vector _nans_row;
67 | std::vector _nans_col;
68 |
69 | boost::mutex _mut;
70 |
71 | std_msgs::Header _header;
72 | ros::Time _send_time;
73 |
74 | cv_bridge::CvImagePtr _rangeImage;
75 | cv_bridge::CvImagePtr _intensityMap;
76 | cv_bridge::CvImagePtr _azimuthMap;
77 |
78 | PointCloud _pointcloud;
79 | boost::shared_ptr rangeImageSph_;
80 | ros::NodeHandle nh_;
81 | ros::Publisher pub_;
82 | ros::Subscriber sub_;
83 | It it_;
84 | float delay_sum_=0;
85 | int frame_count_=0;
86 | boost::shared_ptr drsv_;
87 |
88 | public:
89 | PointCloudConverter() : _newmsg(false),
90 | _laser_frame(true),
91 | _init(false),
92 | _ang_res_x(600 * (1.0 / 60.0) * 360.0 * 0.000055296),
93 | _min_range(0.4),
94 | _max_range(200),
95 | it_(nh_),
96 | nh_("~")
97 | {
98 | rangeImageSph_ = boost::shared_ptr(new RIS);
99 | drsv_.reset(new RangeImageReconfServer(ros::NodeHandle("rangeimage_to_pointcloud_dynreconf")));
100 | RangeImageReconfServer::CallbackType cb;
101 | cb = boost::bind(&PointCloudConverter::drcb, this, _1, _2);
102 | drsv_->setCallback(cb);
103 |
104 | // Get parameters from configuration file.
105 | while (!nh_.getParam("/point_cloud_to_rangeimage/vlp_rpm", _vlp_rpm))
106 | {
107 | ROS_WARN("Could not get Parameter 'vlp_rpm'! Retrying!");
108 | }
109 | ROS_INFO_STREAM("RPM set to: " << _vlp_rpm);
110 |
111 | while (!nh_.getParam("/point_cloud_to_rangeimage/firing_cycle", _firing_cycle))
112 | {
113 | ROS_WARN("Could not get Parameter 'firing_cycle'! Retrying!");
114 | }
115 | ROS_INFO_STREAM("Firing Cycle set to: " << _firing_cycle << " s");
116 |
117 | while (!nh_.getParam("/point_cloud_to_rangeimage/elevation_offsets", _elevation_offsets))
118 | {
119 | ROS_WARN("Could not get Parameter 'elevation_offsets'! Retrying!");
120 | }
121 |
122 | nh_.param("laser_frame", _laser_frame, _laser_frame);
123 |
124 | double min_range = static_cast(_min_range);
125 | double max_range = static_cast(_max_range);
126 | nh_.param("min_range", min_range, min_range);
127 | nh_.param("max_range", max_range, max_range);
128 | _min_range = static_cast(min_range);
129 | _max_range = static_cast(max_range);
130 |
131 | _ang_res_x = _vlp_rpm * (1.0 / 60.0) * 360.0 * _firing_cycle;
132 | _az_increments = (int)ceil(360.0f / _ang_res_x); //1809
133 | pub_ = nh_.advertise("pointcloud_out", 1);
134 |
135 | std::string transport = "raw";
136 | nh_.param("transport", transport, transport);
137 | if (transport != "raw" && transport != "compressedDepth")
138 | {
139 | ROS_WARN_STREAM("Transport " << transport
140 | << ".\nThe only transports supported are :\n\t - raw\n\t - compressedDepth.\n"
141 | << "Setting transport default 'raw'.");
142 | transport = "raw";
143 | }
144 | else
145 | ROS_INFO_STREAM("Transport " << transport);
146 | image_transport::TransportHints transportHint(transport);
147 | std::string image_in = "image_in";
148 | nh_.param("image_in", image_in, image_in);
149 |
150 | sub_ = nh_.subscribe("/msg_decoded", 1, &PointCloudConverter::callback, this);
151 | _frame = (_laser_frame) ? pcl::RangeImage::LASER_FRAME : pcl::RangeImage::CAMERA_FRAME;
152 | }
153 |
154 | ~PointCloudConverter()
155 | {
156 | }
157 |
158 | void callback(const pointcloud_to_rangeimage::RangeImageConstPtr &msg)
159 | {
160 | if (msg == NULL)
161 | return;
162 |
163 | boost::mutex::scoped_lock lock(_mut);
164 |
165 | // Copy images to OpenCV image pointer.
166 | try
167 | {
168 | _rangeImage = cv_bridge::toCvCopy(msg->RangeImage, msg->RangeImage.encoding);
169 | _intensityMap = cv_bridge::toCvCopy(msg->IntensityMap, msg->IntensityMap.encoding);
170 | _azimuthMap = cv_bridge::toCvCopy(msg->AzimuthMap, msg->AzimuthMap.encoding);
171 | _header = msg->header;
172 | _send_time = msg->send_time;
173 | _newmsg = true;
174 | }
175 | catch (cv_bridge::Exception &e)
176 | {
177 | ROS_WARN_STREAM(e.what());
178 | }
179 |
180 | // Get nan coordinates
181 | _nans_row.clear();
182 | _nans_col.clear();
183 | for (int i = 0; i < msg->NansRow.size(); i++)
184 | {
185 | _nans_row.push_back(static_cast(msg->NansRow[i]));
186 | _nans_col.push_back(static_cast(msg->NansCol[i]));
187 | }
188 |
189 | // cv::imwrite("/home/rosuser/catkin_ws/images/rangeimage_intensity_decoded.png", _intensityMap->image);
190 | // cv::imwrite("/home/rosuser/catkin_ws/images/rangeimage_range_decoded.png", _rangeImage->image);
191 | // cv::imwrite("/home/rosuser/catkin_ws/images/rangeimage_azimuth_decoded.png", _azimuthMap->image);
192 | }
193 |
194 | void convert()
195 | {
196 | // What the point if nobody cares ?
197 | if (pub_.getNumSubscribers() <= 0)
198 | return;
199 | if (_rangeImage == NULL)
200 | return;
201 | if (!_newmsg)
202 | return;
203 | _pointcloud.clear();
204 |
205 | float factor = 1.0f / (_max_range - _min_range);
206 | float offset = -_min_range;
207 |
208 | _mut.lock();
209 |
210 | int cols = _rangeImage->image.cols;
211 | int rows = _rangeImage->image.rows;
212 | rangeImageSph_->createEmpty(cols, rows, pcl::deg2rad(_ang_res_x), Eigen::Affine3f::Identity(), _frame);
213 | bool mask[32][1812]{false};
214 | // Mask nans as -1 in the images.
215 | for (int i = 0; i < _nans_row.size(); i++)
216 | {
217 | mask[_nans_row[i]][_nans_col[i]] = true;
218 | }
219 |
220 | // Decode ranges.
221 | int point_counter = 0;
222 | int uninf_counter = 0;
223 | for (int i = 0; i < cols; ++i)
224 | {
225 | for (int j = 0; j < rows; ++j)
226 | {
227 | ushort range_img = _rangeImage->image.at(j, i);
228 | // Discard unobserved points.
229 | if (mask[j][i])
230 | continue;
231 |
232 | // Rescale range.
233 | float range = static_cast(range_img) /
234 | static_cast(std::numeric_limits::max());
235 |
236 | range = (range - offset * factor) / factor;
237 | pcl::PointWithRange &p = rangeImageSph_->getPointNoCheck(i, j);
238 | // Read intensity value.
239 | float &intensity = rangeImageSph_->intensities[j * cols + i];
240 | intensity = static_cast(_intensityMap->image.at(j, i));
241 | // Read azimuth angle.
242 | ushort azi_img = _azimuthMap->image.at(j, i);
243 | float azi = static_cast(azi_img) * _azi_scale - static_cast(M_PI);
244 | float &azimuth = rangeImageSph_->azimuth[j * cols + i];
245 | azimuth = static_cast(azi);
246 | p.range = range;
247 | point_counter++;
248 | }
249 | }
250 |
251 | // Reconstruct 3D point positions.
252 | rangeImageSph_->recalculate3DPointPositionsVelodyne(_elevation_offsets, pcl::deg2rad(_ang_res_x), cols, rows);
253 |
254 | // Reconstruct point cloud.
255 | for (int i = 0; i < rangeImageSph_->points.size(); ++i)
256 | {
257 | pcl::PointWithRange &pts = rangeImageSph_->points[i];
258 | // Discard unobserved points
259 | if (std::isinf(pts.range))
260 | continue;
261 |
262 | // PointType p(pts.x, pts.y, pts.z);
263 | PointType p;
264 | p.x = pts.x;
265 | p.y = pts.y;
266 | p.z = pts.z;
267 | p.intensity = rangeImageSph_->intensities[i];
268 |
269 | _pointcloud.push_back(p);
270 | }
271 |
272 | //clear points
273 | _init = false;
274 |
275 | sensor_msgs::PointCloud2 ros_pc;
276 | pcl::toROSMsg(_pointcloud, ros_pc);
277 | ros_pc.header = _header;
278 | delay_sum_ += ros::Time::now().toSec() - _send_time.toSec();
279 | frame_count_++;
280 | // Calculate delay of application.
281 | // std::cout << "Delay: " << ros::Time::now().toSec() - _send_time.toSec() << " seconds" << std::endl;
282 | // std::cout << "Average delay: " << delay_sum_/frame_count_ << " seconds" << std::endl;
283 | pub_.publish(ros_pc);
284 | _newmsg = false;
285 | _mut.unlock();
286 | }
287 |
288 | private:
289 | void drcb(conf &config, uint32_t level)
290 | {
291 | _min_range = config.min_range;
292 | _max_range = config.max_range;
293 | _laser_frame = config.laser_frame;
294 |
295 | _frame = (_laser_frame) ? pcl::RangeImage::LASER_FRAME : pcl::RangeImage::CAMERA_FRAME;
296 |
297 | ROS_INFO_STREAM("ang_res_x " << _ang_res_x);
298 | ROS_INFO_STREAM("min_range " << _min_range);
299 | ROS_INFO_STREAM("max_range " << _max_range);
300 |
301 | if (_laser_frame)
302 | ROS_INFO_STREAM("Frame type : "
303 | << "LASER");
304 | else
305 | ROS_INFO_STREAM("Frame type : "
306 | << "CAMERA");
307 |
308 | _init = false;
309 | }
310 | };
311 |
312 | int main(int argc, char **argv)
313 | {
314 | ros::init(argc, argv, "rangeimage_to_pointcloud");
315 |
316 | PointCloudConverter converter;
317 |
318 | ros::Rate rate(15);
319 |
320 | while (ros::ok())
321 | {
322 | converter.convert();
323 |
324 | ros::spinOnce();
325 |
326 | rate.sleep();
327 | }
328 | }
329 |
--------------------------------------------------------------------------------
/catkin_ws/src/pointcloud_to_rangeimage/src/pointcloud_to_rangeimage_node.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include
4 |
5 | #include
6 | #include
7 |
8 | #include
9 |
10 | #include
11 | #include
12 |
13 | #include
14 | #include
15 | #include
16 |
17 | #include
18 | #include
19 |
20 | #include
21 | #include
22 | #include
23 |
24 | #include
25 |
26 | #include "pointcloud_to_rangeimage/utils.h"
27 | #include "pointcloud_to_rangeimage/RangeImage.h"
28 | #include "pointcloud_to_rangeimage/range_image_expand.h"
29 |
30 |
31 | namespace
32 | {
33 | typedef velodyne_pcl::PointXYZIRT PointType;
34 | typedef pcl::PointCloud PointCloud;
35 |
36 | typedef pcl::RangeImage RI;
37 | typedef pcl::RangeImageWithoutInterpolation RIS;
38 |
39 | typedef pointcloud_to_rangeimage::PointCloudToRangeImageReconfigureConfig conf;
40 | typedef dynamic_reconfigure::Server RangeImageReconfServer;
41 |
42 | typedef image_transport::ImageTransport It;
43 | typedef image_transport::Publisher Pub;
44 | }
45 | class RangeImageConverter
46 | /*
47 | Receive messages of type sensor_msgs::PointCloud2 from topic /velodyne_points, project the point clouds to range,
48 | azimuth and intensity images. The images are packed in message of type RangeImage and published to the topic /msg_out.
49 | */
50 | {
51 | private:
52 | bool _newmsg;
53 | bool _laser_frame;
54 | bool _record_images;
55 | std::string _record_path;
56 |
57 | // RangeImage frame
58 | pcl::RangeImage::CoordinateFrame _frame;
59 |
60 | // RangeImage resolution
61 | double _ang_res_x;
62 | double _azi_scale = (2 * static_cast(M_PI)) / std::numeric_limits::max();
63 |
64 | // Sensor min/max range
65 | float _min_range;
66 | float _max_range;
67 |
68 | double _vlp_rpm;
69 | double _firing_cycle;
70 | int _az_increments;
71 | double _threshold;
72 | std::vector _az_shifts;
73 | std::vector _azimuth_offsets;
74 | std::vector _elevation_offsets;
75 | boost::mutex _mut;
76 |
77 | cv::Mat _rangeImage;
78 | cv::Mat _intensityMap;
79 | cv::Mat _azimuthMap;
80 | PointCloud _pointcloud;
81 |
82 | boost::shared_ptr rangeImageSph_;
83 |
84 | ros::NodeHandle nh_;
85 | It it_r_;
86 | It it_i_;
87 | Pub pub_r_;
88 | Pub pub_i_;
89 |
90 | ros::Publisher pub_;
91 | ros::Subscriber sub_;
92 |
93 | boost::shared_ptr drsv_;
94 | pointcloud_to_rangeimage::RangeImage riwi_msg;
95 |
96 | public:
97 | RangeImageConverter() : _newmsg(false),
98 | _laser_frame(true),
99 | _ang_res_x(600 * (1.0 / 60.0) * 360.0 * 0.000055296),
100 | _min_range(0.4),
101 | _max_range(200),
102 | it_r_(nh_),
103 | it_i_(nh_),
104 | nh_("~")
105 | {
106 | // Get parameters from configuration file.
107 | while (!nh_.getParam("/point_cloud_to_rangeimage/vlp_rpm", _vlp_rpm))
108 | {
109 | ROS_WARN("Could not get Parameter 'vlp_rpm'! Retrying!");
110 | }
111 | ROS_INFO_STREAM("RPM set to: " << _vlp_rpm);
112 |
113 | while (!nh_.getParam("/point_cloud_to_rangeimage/firing_cycle", _firing_cycle))
114 | {
115 | ROS_WARN("Could not get Parameter 'firing_cycle'! Retrying!");
116 | }
117 | ROS_INFO_STREAM("Firing Cycle set to: " << _firing_cycle << " s");
118 |
119 | while (!nh_.getParam("/point_cloud_to_rangeimage/elevation_offsets", _elevation_offsets))
120 | {
121 | ROS_WARN("Could not get Parameter 'elevation_offsets'! Retrying!");
122 | }
123 |
124 | while (!nh_.getParam("/point_cloud_to_rangeimage/azimuth_offsets", _azimuth_offsets))
125 | {
126 | ROS_WARN("Could not get Parameter 'azimuth_offsets'! Retrying!");
127 | }
128 |
129 | while (!nh_.getParam("/point_cloud_to_rangeimage/record_images", _record_images))
130 | {
131 | ROS_WARN("Could not get Parameter 'record_images'! Retrying!");
132 | }
133 |
134 | while (!nh_.getParam("/point_cloud_to_rangeimage/record_path", _record_path))
135 | {
136 | ROS_WARN("Could not get Parameter 'record_path'! Retrying!");
137 | }
138 |
139 | while (!nh_.getParam("/point_cloud_to_rangeimage/threshold", _threshold))
140 | {
141 | ROS_WARN("Could not get Parameter 'threshold'! Retrying!");
142 | }
143 |
144 | // Calculate angular resolution.
145 | _ang_res_x = _vlp_rpm * (1.0 / 60.0) * 360.0 * _firing_cycle;
146 |
147 | // Calculate azimuth shifts in pixel.
148 | _az_shifts.resize(32);
149 | for (int i = 0; i < 32; i++)
150 | {
151 | _az_shifts[i] = (int)round(_azimuth_offsets[i] / _ang_res_x);
152 | }
153 |
154 | rangeImageSph_ = boost::shared_ptr(new RIS);
155 | drsv_.reset(new RangeImageReconfServer(ros::NodeHandle("pointcloud_to_rangeimage_dynreconf")));
156 |
157 | RangeImageReconfServer::CallbackType cb;
158 | cb = boost::bind(&RangeImageConverter::drcb, this, _1, _2);
159 |
160 | drsv_->setCallback(cb);
161 |
162 | nh_.param("laser_frame", _laser_frame, _laser_frame);
163 |
164 | double min_range = static_cast(_min_range);
165 | double max_range = static_cast(_max_range);
166 | double threshold = static_cast(_threshold);
167 |
168 | nh_.param("min_range", min_range, min_range);
169 | nh_.param("max_range", max_range, max_range);
170 |
171 | _min_range = static_cast(min_range);
172 | _max_range = static_cast(max_range);
173 |
174 | pub_r_ = it_r_.advertise("image_out", 1);
175 | pub_i_ = it_i_.advertise("intensity_map", 1);
176 | pub_ = nh_.advertise("msg_out", 1);
177 | ros::NodeHandle nh;
178 | sub_ = nh.subscribe("/velodyne_points", 1, &RangeImageConverter::callback, this);
179 |
180 | // Using laser frame by default.
181 | _frame = (_laser_frame) ? pcl::RangeImage::LASER_FRAME : pcl::RangeImage::CAMERA_FRAME;
182 | }
183 |
184 | ~RangeImageConverter()
185 | {
186 | }
187 |
188 | void callback(const sensor_msgs::PointCloud2ConstPtr &msg)
189 | {
190 | if (msg == NULL)
191 | return;
192 | boost::mutex::scoped_lock(_mut);
193 |
194 | // Set header for the RangeImage message.
195 | pcl_conversions::toPCL(msg->header, _pointcloud.header);
196 | pcl::fromROSMsg(*msg, _pointcloud);
197 | riwi_msg.header = msg->header;
198 | // Begin of processing for evaluating application latency.
199 | riwi_msg.send_time = ros::Time::now();
200 |
201 | _newmsg = true;
202 | }
203 |
204 | void convert()
205 | {
206 | // What the point if nobody cares ?
207 | if (pub_.getNumSubscribers() <= 0)
208 | return;
209 |
210 | if (!_newmsg)
211 | return;
212 |
213 | boost::mutex::scoped_lock(_mut);
214 |
215 | //fixed image size
216 | int cols = 1812;
217 | int rows = 32;
218 | int height_cloud = _pointcloud.height;
219 | int width_cloud = _pointcloud.width;
220 |
221 |
222 | // Azimuth increment for shifting the rows. See header range_image_expand.h.
223 | _az_increments = 1812;
224 | /* Project point cloud to range, azimuth and intensity images.
225 | Modified from the PCL method createFromPointCloud with fixed image size and without interpolation.*/
226 | rangeImageSph_->createFromPointCloudWithoutInterpolation(_pointcloud, pcl::deg2rad(_ang_res_x), _elevation_offsets,
227 | _az_shifts, _az_increments, Eigen::Affine3f::Identity(),
228 | _frame, 0.00, 0.0f, _threshold, 0);
229 |
230 |
231 | rangeImageSph_->header.frame_id = _pointcloud.header.frame_id;
232 | rangeImageSph_->header.stamp = _pointcloud.header.stamp;
233 |
234 | // To convert range to 16-bit integers.
235 | float factor = 1.0f / (_max_range - _min_range);
236 | float offset = -_min_range;
237 |
238 | _rangeImage = cv::Mat::zeros(rows, cols, cv_bridge::getCvType("mono16"));
239 | _intensityMap = cv::Mat::zeros(rows, cols, cv_bridge::getCvType("mono8"));
240 | _azimuthMap = cv::Mat::zeros(rows, cols, cv_bridge::getCvType("mono16"));
241 | float r, range, a, azi;
242 | int reversed_j, num_points = 0;
243 |
244 | // Store the images as OpenCV image.
245 | for (int i = 0; i < cols; i++)
246 | {
247 | for (int j = 0; j < rows; j++) //32
248 | {
249 | reversed_j = rows - 1 - j;
250 | r = rangeImageSph_->points[reversed_j * cols + i].range;
251 | a = rangeImageSph_->azimuth[reversed_j * cols + i];
252 | azi = (a + static_cast(M_PI)) / _azi_scale;
253 | range = factor * (r + offset);
254 | _rangeImage.at(j, i) = static_cast((range)*std::numeric_limits::max());
255 | _intensityMap.at(j, i) = static_cast(rangeImageSph_->intensities[reversed_j * cols + i]);
256 | _azimuthMap.at(j, i) = static_cast(azi);
257 | if (range != 0.0f)
258 | num_points++;
259 | }
260 | }
261 |
262 | // Fill the nans in the images with previous pixel value.
263 | riwi_msg.NansRow.clear();
264 | riwi_msg.NansCol.clear();
265 | int num_nan = 0;
266 | for (int i = 0; i < cols; i++)
267 | {
268 | for (int j = 0; j < rows; ++j) //32
269 | {
270 | if (_rangeImage.at(j, i) == 0)
271 | {
272 | int i_pre = (i != 0) ? i - 1 : 1811;
273 | _rangeImage.at(j, i) = _rangeImage.at(j, i_pre);
274 | _intensityMap.at(j, i) = _intensityMap.at(j, i_pre);
275 | // Can't fill left azi with right value, bacause only azi is not continuous.
276 | _azimuthMap.at(j, i) = (i != 0) ? _azimuthMap.at(j, i - 1) : 0;
277 | riwi_msg.NansRow.push_back(static_cast(j));
278 | riwi_msg.NansCol.push_back(static_cast(i));
279 | num_nan++;
280 | }
281 | }
282 | }
283 |
284 | riwi_msg.RangeImage = *(cv_bridge::CvImage(std_msgs::Header(), "mono16", _rangeImage).toImageMsg());
285 | riwi_msg.IntensityMap = *(cv_bridge::CvImage(std_msgs::Header(), "mono8", _intensityMap).toImageMsg());
286 | riwi_msg.AzimuthMap = *(cv_bridge::CvImage(std_msgs::Header(), "mono16", _azimuthMap).toImageMsg());
287 |
288 |
289 | // Create image dataset from rosbag.
290 | if (_record_images)
291 | {
292 | std::stringstream ss;
293 | ss << _pointcloud.header.stamp;
294 | std::string azimuthName = _record_path + "azimuth/azimuth_" + ss.str() + ".png";
295 | std::string intensityName = _record_path + "intensity/intensity_" + ss.str() + ".png";
296 | std::string rangeName = _record_path + "range/range_" + ss.str() + ".png";
297 | cv::imwrite(intensityName, _intensityMap);
298 | cv::imwrite(rangeName, _rangeImage);
299 | cv::imwrite(azimuthName, _azimuthMap);
300 |
301 | // write pcd file
302 | std::string pcdName = _record_path + "pcd/pcd_" + ss.str() + ".pcd";
303 | pcl::io::savePCDFileASCII(pcdName, _pointcloud);
304 | }
305 |
306 | pub_r_.publish(riwi_msg.RangeImage);
307 | pub_i_.publish(riwi_msg.IntensityMap);
308 | pub_.publish(riwi_msg);
309 |
310 | _newmsg = false;
311 | }
312 |
313 | private:
314 | void drcb(conf &config, uint32_t level)
315 | {
316 | _min_range = config.min_range;
317 | _max_range = config.max_range;
318 | _laser_frame = config.laser_frame;
319 |
320 | _frame = (_laser_frame) ? pcl::RangeImage::LASER_FRAME : pcl::RangeImage::CAMERA_FRAME;
321 |
322 | ROS_INFO_STREAM("ang_res_x " << _ang_res_x);
323 | ROS_INFO_STREAM("min_range " << _min_range);
324 | ROS_INFO_STREAM("max_range " << _max_range);
325 |
326 | if (_laser_frame)
327 | ROS_INFO_STREAM("Frame type : "
328 | << "LASER");
329 | else
330 | ROS_INFO_STREAM("Frame type : "
331 | << "CAMERA");
332 | }
333 | };
334 |
335 | int main(int argc, char **argv)
336 | {
337 | ros::init(argc, argv, "pointcloud_to_rangeimage");
338 |
339 | RangeImageConverter converter;
340 |
341 | ros::Rate rate(15);
342 |
343 | while (ros::ok())
344 | {
345 | converter.convert();
346 |
347 | ros::spinOnce();
348 |
349 | rate.sleep();
350 | }
351 | }
352 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 3D Point Cloud Compression with Recurrent Neural Network and Image Compression Methods
2 |
3 | Reference implementation of the publication __3D Point Cloud Compression with Recurrent Neural Network
4 | and Image Compression Methods__ published on the 33rd IEEE Intelligent Vehicles Symposium (IV 2022)
5 | in Aachen, Germany.
6 |
7 | This repository implements a RNN-based compression framework for range images implemented in Tensorflow 2.9.0.
8 | Furthermore, it implements preprocessing and inference nodes for ROS Noetic in order to perform the compression
9 | task on a `/points2` sensor data stream.
10 |
11 | > **3D Point Cloud Compression with Recurrent Neural Network and Image Compression Methods**
12 | >
13 | > [Till Beemelmanns](https://orcid.org/0000-0002-2129-4082),
14 | > [Yuchen Tao](https://orcid.org/0000-0002-0357-0637),
15 | > [Bastian Lampe](https://orcid.org/0000-0002-4414-6947),
16 | > [Lennart Reiher](https://orcid.org/0000-0002-7309-164X),
17 | > [Raphael van Kempen](https://orcid.org/0000-0001-5017-7494),
18 | > [Timo Woopen](https://orcid.org/0000-0002-7177-181X),
19 | > and [Lutz Eckstein](https://www.ika.rwth-aachen.de/en/institute/management/univ-prof-dr-ing-lutz-eckstein.html)
20 | >
21 | > [Institute for Automotive Engineering (ika), RWTH Aachen University](https://www.ika.rwth-aachen.de/en/)
22 | >
23 | > _**Abstract**_ — Storing and transmitting LiDAR point cloud data is essential for many AV applications, such as training data
24 | > collection, remote control, cloud services or SLAM. However, due to the sparsity and unordered structure of the data,
25 | > it is difficult to compress point cloud data to a low volume. Transforming the raw point cloud data into a dense 2D
26 | > matrix structure is a promising way for applying compression algorithms. We propose a new lossless and calibrated
27 | > 3D-to-2D transformation which allows compression algorithms to efficiently exploit spatial correlations within the
28 | > 2D representation. To compress the structured representation, we use common image compression methods and also a
29 | > self-supervised deep compression approach using a recurrent neural network. We also rearrange the LiDAR’s intensity
30 | > measurements to a dense 2D representation and propose a new metric to evaluate the compression performance of the
31 | > intensity. Compared to approaches that are based on generic octree point cloud compression or based on raw point cloud
32 | > data compression, our approach achieves the best quantitative and visual performance.
33 |
34 | ## Content
35 | - [Approach](#approach)
36 | - [Range Image Compression](#range-image-compression)
37 | - [Model Training](#model-training)
38 | - [Download of dataset, model weights and evaluation frames](#download-of-dataset-models-and-evaluation-frames)
39 | - [Inference & Evaluation Node](#inference--evaluation-node)
40 | - [Authors of this Repository](#authors-of-this-repository)
41 | - [Cite](#cite)
42 | - [Acknowledgement](#acknowledgement)
43 |
44 | ## Approach
45 |
46 | 
47 |
48 | ## Range Image Compression
49 | This learning framework serves the purpose of compressing range images projected from point clouds captured
50 | by Velodyne LiDAR sensor. The network architectures are based on the work proposed by
51 | [Toderici et al.](https://arxiv.org/pdf/1608.05148.pdf) and implemented in this
52 | repository using Tensorflow 2.9.0.
53 |
54 |
55 | The following architectures are implemented:
56 | - [__Additive LSTM__](range_image_compression/architectures/Additive_LSTM.py) -
57 | Architecture that we used for the results in our paper.
58 | - [__Additive LSTM Demo__](range_image_compression/architectures/Additive_LSTM_Demo.py) -
59 | Lightweight version of the Additive LSTM in order to test your setup
60 | - [__Additive GRU__](range_image_compression/architectures/Additive_GRU.py) -
61 | Uses Gated Recurrent Units instead of a LSTM cell. We achieved slightly worse results
62 | compared to the LSTM variant
63 | - [__Oneshot LSTM__](range_image_compression/architectures/Oneshot_LSTM.py) -
64 | Does not use the additive reconstruction path in the network, as shown below.
65 |
66 | The differences between the additive and the oneshot framework are visualized below.
67 |
68 | #### Additive reconstruction framework
69 | This reconstruction framework adds the previous progressive reconstruction to the current reconstruction.
70 | 
71 |
72 | #### Oneshot reconstruction framework
73 | The current reconstruction is directly computed from the bitstream by the decoder RNN.
74 | 
75 |
76 | ### Model Input - Output
77 | The range representations are originally `(32, 1812)` single channel 16-bit images. During training, they are online
78 | random cropped as `(32, 32)` image patches. The label is the input image patch itself. Note that during validation,
79 | the random crop is performed offline to keep the validation set constant.
80 |
81 | **Input:** 16-bit image patch of shape `(32, 1812, 1)` which will be random cropped to shape `(32, 32, 1)`
82 | during training.
83 |
84 | **Output:** reconstructed 16-bit image patch of shape `(32, 32, 1)`.
85 |
86 | | Input | Label | Prediction |
87 | | --- | --- | --- |
88 | |  | |
| |  |
89 |
90 | During inference, the model can be applied to range image with any width and height divisible to 32, as the following
91 | example shows:
92 |
93 | #### Input range image representation:
94 | 
95 |
96 | #### Predicted range image representation:
97 | 
98 |
99 |
100 | ## Model Training
101 |
102 | ### Sample Dataset
103 | A demo sample dataset can be found in `range_image_compression/demo_samples` in order to quickly test your
104 | environment.
105 |
106 | ### Dependencies
107 | The implementation is based on *Tensorflow 2.9.0*. All necessary dependencies can be installed with
108 | ```bash
109 | # /range_image_compression >$
110 | pip install -r requirements.txt
111 | ```
112 |
113 | The architecture `Oneshot LSTM` uses GDN layers proposed by [Ballé et al.](https://arxiv.org/pdf/1511.06281.pdf),
114 | which is supported in [TensorFlow Compression](https://github.com/tensorflow/compression).
115 | It can be installed with:
116 | ```bash
117 | # /range_image_compression >$
118 | pip3 install tensorflow-compression==2.9.0
119 | ```
120 |
121 | ### Run Training
122 | A training with the lightweight demo network using the sample dataset can be started with the
123 | following command:
124 | ```bash
125 | # /range_image_compression >$
126 | python3 ./train.py \
127 | --train_data_dir="demo_samples/training" \
128 | --val_data_dir="demo_samples/validation" \
129 | --train_output_dir="output" \
130 | --model=additive_lstm_demo
131 | ```
132 | If you downloaded the whole dataset (see below) then you would have to adapt the values for `--train_data_dir` and
133 | `--val_data_dir` accordingly.
134 |
135 | ### Run Training with Docker
136 | We also provide a docker environment to train the model. First build the docker image and then start the
137 | training:
138 | ```bash
139 | # /docker >$
140 | ./docker_build.sh
141 | ./docker_train.sh
142 | ```
143 |
144 |
145 | ## Configuration
146 | Parameters for the training can be set up in the configurations located in the directory
147 | [range_image_compression/configs](range_image_compression/configs). It is recommended to use a potent multi-gpu setup
148 | for efficient training.
149 |
150 | ### Learning Rate Schedule
151 | The following cosine learning rate scheduler is used:
152 |
153 | 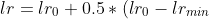*(1+cos((e-e_{max})/(e_{min}-e_{max})*\pi)))
154 |
155 | | Parameter | Description | Example |
156 | | --- | --- | --- |
157 | | `init_learning_rate` | initial learning rate | `2e-3` |
158 | | `min_learning_rate` | minimum learning rate | `1e-7` |
159 | | `max_learning_rate_epoch` | epoch where learning rate begins to decrease | `0` |
160 | | `min_learning_rate_epoch` | epoch of minimum learning rate | `3000` |
161 |
162 | ### Network Architecture
163 | Default parameters for the network architectures
164 |
165 | | Parameter | Description | Example |
166 | | --- | --- | --- |
167 | | `bottleneck` | bottleneck size of architecture | `32` |
168 | | `num_iters` | maximum number of iterations | `32` |
169 |
170 | ### Model Zoo
171 | | Model Architecture | Filename | Batch Size | Validation MAE | Evaluation SNNRMSE `iter=32` |
172 | |--------------------|---------------------------------------|------------|----------------|------------------------------|
173 | | Additive LSTM | `additive_lstm_32b_32iter.hdf5` | 32 | `2.6e-04` | `0.03473` |
174 | | Additive LSTM Slim | `additive_lstm_128b_32iter_slim.hdf5` | 128 | `2.3e-04` | `0.03636` |
175 | | Additive LSTM Demo | `additive_lstm_128b_32iter_demo.hdf5` | 128 | `2.9e-04` | `0.09762` |
176 | | Oneshot LSTM | `oneshot_lstm_b128_32iter.hdf5` | 128 | `2.9e-04` | `0.05137` |
177 | | Additive GRU | Will be uploaded soon | TBD | TBD | TBD |
178 |
179 | ## Download of Dataset, Models and Evaluation Frames
180 | The dataset to train the range image compression framework can be retrieved from [https://rwth-aachen.sciebo.de/s/MLJ4UaDJuVkYtna](https://rwth-aachen.sciebo.de/s/MLJ4UaDJuVkYtna).
181 | There you should be able to download the following files:
182 |
183 | - __`pointcloud_compression.zip`__ (1.8 GB): ZIP File which contains three directories
184 | - `train`: 30813 range images for training
185 | - `val`: 6162 cropped `32 x 32` range images for validation
186 | - `test`: 1217 range images for testing
187 | - __`evaluation_frames.bag`__ (17.6 MB): ROS bag which contains the Velodyne package data in order to evaluate the model.
188 | Frames in this bag file were not used for training nor for validation.
189 | - __`additive_lstm_32b_32iter.hdf5`__ (271 MB): Trained model with a bottleneck size of 32
190 | - __`additive_lstm_128b_32iter_slim.hdf5`__ (67.9 MB): Trained model with a bottleneck size of 32
191 | - __`oneshot_lstm_b128_32iter.hdf5`__ (68.1 MB): Trained model with a bottleneck size of 32
192 | - __`additive_lstm_256b_32iter_demo.hdf5`__ (14.3 MB): Trained model with a bottleneck sizeof 32
193 |
194 | ## Inference & Evaluation Node
195 | The inference and evaluation is conducted with ROS. The inferences and preprocessing nodes can be found
196 | under [catkin_ws/src](catkin_ws/src). The idea is to use recorded Velodyne package data which are stored in a `.bag`
197 | file. This bag file is then played with `rosbag play` and the preprocessing and inference nodes are applied to this raw
198 | sensor data stream. In order to run the inference and evaluation you will need to execute the following steps.
199 |
200 | ### 1. Initialize Velodyne Driver
201 | To run the evaluation code we need to clone the Velodyne Driver from the [official repository](https://github.com/ros-drivers/velodyne).
202 | The driver is integrated as a submodule to [catkin_ws/src/velodyne](catkin_ws/src/velodyne). You can initialize the
203 | submodule with:
204 | ```bash
205 | git submodule init
206 | git submodule update
207 | ```
208 |
209 | ### 2. Pull Docker Image
210 | We provide a docker image which contains ROS Noetic and Tensorflow in order to execute the inference and evaluation
211 | nodes. You can pull this dockerfile from [Docker Hub](https://hub.docker.com/r/tillbeemelmanns/pointcloud_compression)
212 | with the command:
213 | ```bash
214 | docker pull tillbeemelmanns/pointcloud_compression:noetic
215 | ```
216 |
217 | ### 3. Download Weights
218 | Download the model's weights as `.hdf5` from the download link and copy this file to `catkin_ws/models`. Then, in the
219 | [configuration file](catkin_ws/src/pointcloud_to_rangeimage/params/pointcloud_to_rangeimage.yaml) insert the
220 | correct path for the parameter `weights_path`. Note, that we will later mount the directory `catkin_ws` into
221 | the docker container to `/catkin_ws`. Hence, the path will start with `/catkin_ws`.
222 |
223 | ### 4. Download ROS Bag
224 | Perform the same procedure with the bag file. Copy the bag file into `catkin_ws/rosbags`. The filename should be
225 | `evaluation_frames.bag`. This bag file will be used in this [launch file](catkin_ws/src/pointcloud_to_rangeimage/launch/compression.launch).
226 |
227 |
228 | ### 5. Start Docker Container
229 | Start the docker container using the script
230 | ```bash
231 | # /docker >$
232 | ./docker_eval.sh
233 | ```
234 | Calling this script for the first time will just start the container.
235 | Then open a second terminal and execute `./docker_eval.sh` script again in order to open the container with bash.
236 | ```bash
237 | # /docker >$
238 | ./docker_eval.sh
239 | ```
240 |
241 | ### 6. Build & Execute
242 | Run the following commands inside the container to build and launch the compression framework.
243 | ```bash
244 | # /catkin_ws >$
245 | catkin build
246 | source devel/setup.bash
247 | roslaunch pointcloud_to_rangeimage compression.launch
248 | ```
249 |
250 | You should see the following RVIZ window which visualizes the reconstructed point cloud.
251 | 
252 |
253 | ### 7. GPU Inference
254 | In case you have a capable GPU, try to change line 44 in [docker_eval.sh](docker/docker_eval.sh) and define your GPU ID
255 | with flag `-g`
256 |
257 | ```sh
258 | $DIR/run-ros.sh -g 0 $@
259 | ```
260 |
261 | ## Authors of this Repository
262 | [Till Beemelmanns](https://github.com/TillBeemelmanns) and [Yuchen Tao](https://orcid.org/0000-0002-0357-0637)
263 |
264 |
265 | Mail: `till.beemelmanns (at) rwth-aachen.de`
266 |
267 | Mail: `yuchen.tao (at) rwth-aachen.de`
268 |
269 | ## Cite
270 |
271 | ```
272 | @INPROCEEDINGS{9827270,
273 | author={Beemelmanns, Till and Tao, Yuchen and Lampe, Bastian and Reiher, Lennart and Kempen, Raphael van and Woopen, Timo and Eckstein, Lutz},
274 | booktitle={2022 IEEE Intelligent Vehicles Symposium (IV)},
275 | title={3D Point Cloud Compression with Recurrent Neural Network and Image Compression Methods},
276 | year={2022},
277 | volume={},
278 | number={},
279 | pages={345-351},
280 | doi={10.1109/IV51971.2022.9827270}}
281 | ```
282 |
283 | ## Acknowledgement
284 |
285 | >This research is accomplished within the project ”UNICARagil” (FKZ 16EMO0284K). We acknowledge the financial support for
286 | >the project by the Federal Ministry of Education and Research of Germany (BMBF).
287 |
--------------------------------------------------------------------------------
/range_image_compression/architectures/Additive_LSTM.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | import tensorflow as tf
26 | from keras.models import Model
27 | from keras.layers import Layer, Lambda
28 | from keras.layers import Conv2D
29 | from keras.layers import Add, Subtract
30 |
31 |
32 | class RnnConv(Layer):
33 | """Convolutional LSTM cell
34 | See detail in formula (4-6) in paper
35 | "Full Resolution Image Compression with Recurrent Neural Networks"
36 | https://arxiv.org/pdf/1608.05148.pdf
37 | Args:
38 | name: name of current ConvLSTM layer
39 | filters: number of filters for each convolutional operation
40 | strides: strides size
41 | kernel_size: kernel size of convolutional operation
42 | hidden_kernel_size: kernel size of convolutional operation for hidden state
43 | Input:
44 | inputs: input of the layer
45 | hidden: hidden state and cell state of the layer
46 | Output:
47 | newhidden: updated hidden state of the layer
48 | newcell: updated cell state of the layer
49 | """
50 |
51 | def __init__(self, name, filters, strides, kernel_size, hidden_kernel_size):
52 | super(RnnConv, self).__init__()
53 | self.filters = filters
54 | self.strides = strides
55 | self.conv_i = Conv2D(filters=4 * self.filters,
56 | kernel_size=kernel_size,
57 | strides=self.strides,
58 | padding='same',
59 | use_bias=False,
60 | name=name + '_i')
61 | self.conv_h = Conv2D(filters=4 * self.filters,
62 | kernel_size=hidden_kernel_size,
63 | padding='same',
64 | use_bias=False,
65 | name=name + '_h')
66 |
67 | def call(self, inputs, hidden):
68 | # with tf.variable_scope(name, reuse=tf.AUTO_REUSE):
69 | conv_inputs = self.conv_i(inputs)
70 | conv_hidden = self.conv_h(hidden[0])
71 | # all gates are determined by input and hidden layer
72 | in_gate, f_gate, out_gate, c_gate = tf.split(
73 | conv_inputs + conv_hidden, 4, axis=-1) # each gate get the same number of filters
74 | in_gate = tf.nn.sigmoid(in_gate) # input/update gate
75 | f_gate = tf.nn.sigmoid(f_gate)
76 | out_gate = tf.nn.sigmoid(out_gate)
77 | c_gate = tf.nn.tanh(c_gate) # candidate cell, calculated from input
78 | # forget_gate*old_cell+input_gate(update)*candidate_cell
79 | newcell = tf.multiply(f_gate, hidden[1]) + tf.multiply(in_gate, c_gate)
80 | newhidden = tf.multiply(out_gate, tf.nn.tanh(newcell))
81 | return newhidden, newcell
82 |
83 |
84 | class EncoderRNN(Layer):
85 | """
86 | Encoder layer for one iteration.
87 | Args:
88 | bottleneck: bottleneck size of the layer
89 | Input:
90 | input: output array from last iteration.
91 | In the first iteration, it is the normalized image patch
92 | hidden2, hidden3, hidden4: hidden and cell states of corresponding ConvLSTM layers
93 | training: boolean, whether the call is in inference mode or training mode
94 | Output:
95 | encoded: encoded binary array in each iteration
96 | hidden2, hidden3, hidden4: hidden and cell states of corresponding ConvLSTM layers
97 | """
98 | def __init__(self, bottleneck, name=None):
99 | super(EncoderRNN, self).__init__(name=name)
100 | self.bottleneck = bottleneck
101 | self.Conv_e1 = Conv2D(64, kernel_size=(3, 3), strides=(2, 2), padding="same", use_bias=False, name='Conv_e1')
102 | self.RnnConv_e1 = RnnConv("RnnConv_e1", 256, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
103 | self.RnnConv_e2 = RnnConv("RnnConv_e2", 512, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
104 | self.RnnConv_e3 = RnnConv("RnnConv_e3", 512, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
105 | self.Conv_b = Conv2D(self.bottleneck, kernel_size=(1, 1), activation=tf.nn.tanh, use_bias=False, name='b_conv')
106 | self.Sign = Lambda(lambda x: tf.sign(x), name="sign")
107 |
108 | def call(self, input, hidden2, hidden3, hidden4, training=False):
109 | # with tf.compat.v1.variable_scope("encoder", reuse=True):
110 | # input size (32,32,3)
111 | x = self.Conv_e1(input)
112 | # x = self.GDN(x)
113 | # (16,16,64)
114 | hidden2 = self.RnnConv_e1(x, hidden2)
115 | x = hidden2[0]
116 | # (8,8,256)
117 | hidden3 = self.RnnConv_e2(x, hidden3)
118 | x = hidden3[0]
119 | # (4,4,512)
120 | hidden4 = self.RnnConv_e3(x, hidden4)
121 | x = hidden4[0]
122 | # (2,2,512)
123 | # binarizer
124 | x = self.Conv_b(x)
125 | # (2,2,bottleneck)
126 | # Using randomized quantization during training.
127 | if training:
128 | probs = (1 + x) / 2
129 | dist = tf.compat.v1.distributions.Bernoulli(probs=probs, dtype=input.dtype)
130 | noise = 2 * dist.sample(name='noise') - 1 - x
131 | encoded = x + tf.stop_gradient(noise)
132 | else:
133 | encoded = self.Sign(x)
134 | return encoded, hidden2, hidden3, hidden4
135 |
136 |
137 | class DecoderRNN(Layer):
138 | """
139 | Decoder layer for one iteration.
140 | Input:
141 | input: decoded array in each iteration
142 | hidden2, hidden3, hidden4, hidden5: hidden and cell states of corresponding ConvLSTM layers
143 | training: boolean, whether the call is in inference mode or training mode
144 | Output:
145 | decoded: decoded array in each iteration
146 | hidden2, hidden3, hidden4, hidden5: hidden and cell states of corresponding ConvLSTM layers
147 | """
148 | def __init__(self, name=None):
149 | super(DecoderRNN, self).__init__(name=name)
150 | self.Conv_d1 = Conv2D(512, kernel_size=(1, 1), use_bias=False, name='d_conv1')
151 | self.RnnConv_d2 = RnnConv("RnnConv_d2", 512, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
152 | self.RnnConv_d3 = RnnConv("RnnConv_d3", 512, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
153 | self.RnnConv_d4 = RnnConv("RnnConv_d4", 256, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
154 | self.RnnConv_d5 = RnnConv("RnnConv_d5", 128, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
155 | self.Conv_d6 = Conv2D(filters=1, kernel_size=(1, 1), padding='same', use_bias=False, name='d_conv6',
156 | activation=tf.nn.tanh)
157 | self.DTS1 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_1")
158 | self.DTS2 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_2")
159 | self.DTS3 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_3")
160 | self.DTS4 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_4")
161 | self.Add = Add(name="add")
162 | self.Out = Lambda(lambda x: x*0.5, name="out")
163 |
164 | def call(self, input, hidden2, hidden3, hidden4, hidden5, training=False):
165 | # (2,2,bottleneck)
166 | x_conv = self.Conv_d1(input)
167 | # (2,2,512)
168 | hidden2 = self.RnnConv_d2(x_conv, hidden2)
169 | x = hidden2[0]
170 | # (2,2,512)
171 | x = self.Add([x, x_conv])
172 | x = self.DTS1(x)
173 | # (4,4,128)
174 | hidden3 = self.RnnConv_d3(x, hidden3)
175 | x = hidden3[0]
176 | # (4,4,512)
177 | x = self.DTS2(x)
178 | # (8,8,128)
179 | hidden4 = self.RnnConv_d4(x, hidden4)
180 | x = hidden4[0]
181 | # (8,8,256)
182 | x = self.DTS3(x)
183 | # (16,16,64)
184 | hidden5 = self.RnnConv_d5(x, hidden5)
185 | x = hidden5[0]
186 | # (16,16,128)
187 | x = self.DTS4(x)
188 | # (32,32,32)
189 | # output in range (-0.5,0.5)
190 | x = self.Conv_d6(x)
191 | decoded = self.Out(x)
192 | return decoded, hidden2, hidden3, hidden4, hidden5
193 |
194 |
195 | class LidarCompressionNetwork(Model):
196 | """
197 | The model to compress range image projected from point clouds captured by Velodyne LiDAR sensor
198 | The encoder and decoder layers are iteratively called for num_iters iterations.
199 | Details see paper Full Resolution Image Compression with Recurrent Neural Networks
200 | https://arxiv.org/pdf/1608.05148.pdf. This architecture uses additive reconstruction framework and ConvLSTM layers.
201 | """
202 | def __init__(self, bottleneck, num_iters, batch_size, input_size):
203 | super(LidarCompressionNetwork, self).__init__(name="lidar_compression_network")
204 | self.bottleneck = bottleneck
205 | self.num_iters = num_iters
206 | self.batch_size = batch_size
207 | self.input_size = input_size
208 |
209 | self.encoder = EncoderRNN(self.bottleneck, name="encoder")
210 | self.decoder = DecoderRNN(name="decoder")
211 |
212 | self.normalize = Lambda(lambda x: tf.multiply(tf.subtract(x, 0.1), 2.5), name="normalization")
213 | self.subtract = Subtract()
214 | self.inputs = tf.keras.layers.Input(shape=(self.input_size, self.input_size, 1))
215 |
216 | self.DIM1 = self.input_size // 2
217 | self.DIM2 = self.DIM1 // 2
218 | self.DIM3 = self.DIM2 // 2
219 | self.DIM4 = self.DIM3 // 2
220 |
221 | self.loss_tracker = tf.keras.metrics.Mean(name="loss")
222 | self.metric_tracker = tf.keras.metrics.MeanAbsoluteError(name="mae")
223 |
224 | self.beta = 1.0 / self.num_iters
225 |
226 | def compute_loss(self, res):
227 | loss = tf.reduce_mean(tf.abs(res))
228 | return loss
229 |
230 | def initial_hidden(self, batch_size, hidden_size, filters, data_type=tf.dtypes.float32):
231 | """Initialize hidden and cell states, all zeros"""
232 | shape = tf.TensorShape([batch_size] + hidden_size + [filters])
233 | hidden = tf.zeros(shape, dtype=data_type)
234 | cell = tf.zeros(shape, dtype=data_type)
235 | return hidden, cell
236 |
237 | def call(self, inputs, training=False):
238 | # Initialize the hidden states when a new batch comes in
239 | hidden_e2 = self.initial_hidden(self.batch_size, [8, self.DIM2], 256, inputs.dtype)
240 | hidden_e3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 512, inputs.dtype)
241 | hidden_e4 = self.initial_hidden(self.batch_size, [2, self.DIM4], 512, inputs.dtype)
242 | hidden_d2 = self.initial_hidden(self.batch_size, [2, self.DIM4], 512, inputs.dtype)
243 | hidden_d3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 512, inputs.dtype)
244 | hidden_d4 = self.initial_hidden(self.batch_size, [8, self.DIM2], 256, inputs.dtype)
245 | hidden_d5 = self.initial_hidden(self.batch_size, [16, self.DIM1], 128, inputs.dtype)
246 | outputs = tf.zeros_like(inputs)
247 |
248 | inputs = self.normalize(inputs)
249 | res = inputs
250 | for i in range(self.num_iters):
251 | code, hidden_e2, hidden_e3, hidden_e4 = \
252 | self.encoder(res, hidden_e2, hidden_e3, hidden_e4, training=training)
253 |
254 | decoded, hidden_d2, hidden_d3, hidden_d4, hidden_d5 = \
255 | self.decoder(code, hidden_d2, hidden_d3, hidden_d4, hidden_d5, training=training)
256 |
257 | outputs = tf.add(outputs, decoded)
258 | # Update res as predicted output in this iteration subtract the original input
259 | res = self.subtract([outputs, inputs])
260 | self.add_loss(self.compute_loss(res))
261 | # Denormalize the tensors
262 | outputs = tf.clip_by_value(tf.add(tf.multiply(outputs, 0.4), 0.1), 0, 1)
263 | outputs = tf.cast(outputs, dtype=tf.float32)
264 | return outputs
265 |
266 | def train_step(self, data):
267 | inputs, labels = data
268 |
269 | # Run forward pass.
270 | with tf.GradientTape() as tape:
271 | outputs = self(inputs, training=True)
272 | loss = sum(self.losses)*self.beta
273 |
274 | # Run backwards pass.
275 | trainable_vars = self.trainable_variables
276 | gradients = tape.gradient(loss, trainable_vars)
277 | self.optimizer.apply_gradients(zip(gradients, trainable_vars))
278 | # Update & Compute Metrics
279 | with tf.name_scope("metrics") as scope:
280 | self.loss_tracker.update_state(loss)
281 | self.metric_tracker.update_state(outputs, labels)
282 | metric_result = self.metric_tracker.result()
283 | loss_result = self.loss_tracker.result()
284 | return {'loss': loss_result, 'mae': metric_result}
285 |
286 | def test_step(self, data):
287 | inputs, labels = data
288 | # Run forward pass.
289 | outputs = self(inputs, training=False)
290 | loss = sum(self.losses)*self.beta
291 | # Update metrics
292 | self.loss_tracker.update_state(loss)
293 | self.metric_tracker.update_state(outputs, labels)
294 | return {'loss': self.loss_tracker.result(), 'mae': self.metric_tracker.result()}
295 |
296 | def predict_step(self, data):
297 | inputs, labels = data
298 | outputs = self(inputs, training=False)
299 | return outputs
300 |
301 | @property
302 | def metrics(self):
303 | return [self.loss_tracker, self.metric_tracker]
304 |
--------------------------------------------------------------------------------
/range_image_compression/architectures/Additive_LSTM_Demo.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | import tensorflow as tf
26 | from keras.models import Model
27 | from keras.layers import Layer, Lambda
28 | from keras.layers import Conv2D
29 | from keras.layers import Add, Subtract
30 |
31 |
32 | class RnnConv(Layer):
33 | """Convolutional LSTM cell
34 | See detail in formula (4-6) in paper
35 | "Full Resolution Image Compression with Recurrent Neural Networks"
36 | https://arxiv.org/pdf/1608.05148.pdf
37 | Args:
38 | name: name of current ConvLSTM layer
39 | filters: number of filters for each convolutional operation
40 | strides: strides size
41 | kernel_size: kernel size of convolutional operation
42 | hidden_kernel_size: kernel size of convolutional operation for hidden state
43 | Input:
44 | inputs: input of the layer
45 | hidden: hidden state and cell state of the layer
46 | Output:
47 | newhidden: updated hidden state of the layer
48 | newcell: updated cell state of the layer
49 | """
50 |
51 | def __init__(self, name, filters, strides, kernel_size, hidden_kernel_size):
52 | super(RnnConv, self).__init__()
53 | self.filters = filters
54 | self.strides = strides
55 | self.conv_i = Conv2D(filters=4 * self.filters,
56 | kernel_size=kernel_size,
57 | strides=self.strides,
58 | padding='same',
59 | use_bias=False,
60 | name=name + '_i')
61 | self.conv_h = Conv2D(filters=4 * self.filters,
62 | kernel_size=hidden_kernel_size,
63 | padding='same',
64 | use_bias=False,
65 | name=name + '_h')
66 |
67 | def call(self, inputs, hidden):
68 | # with tf.variable_scope(name, reuse=tf.AUTO_REUSE):
69 | conv_inputs = self.conv_i(inputs)
70 | conv_hidden = self.conv_h(hidden[0])
71 | # all gates are determined by input and hidden layer
72 | in_gate, f_gate, out_gate, c_gate = tf.split(
73 | conv_inputs + conv_hidden, 4, axis=-1) # each gate get the same number of filters
74 | in_gate = tf.nn.sigmoid(in_gate) # input/update gate
75 | f_gate = tf.nn.sigmoid(f_gate)
76 | out_gate = tf.nn.sigmoid(out_gate)
77 | c_gate = tf.nn.tanh(c_gate) # candidate cell, calculated from input
78 | # forget_gate*old_cell+input_gate(update)*candidate_cell
79 | newcell = tf.multiply(f_gate, hidden[1]) + tf.multiply(in_gate, c_gate)
80 | newhidden = tf.multiply(out_gate, tf.nn.tanh(newcell))
81 | return newhidden, newcell
82 |
83 |
84 | class EncoderRNN(Layer):
85 | """
86 | Encoder layer for one iteration.
87 | Args:
88 | bottleneck: bottleneck size of the layer
89 | Input:
90 | input: output array from last iteration.
91 | In the first iteration, it is the normalized image patch
92 | hidden2, hidden3, hidden4: hidden and cell states of corresponding ConvLSTM layers
93 | training: boolean, whether the call is in inference mode or training mode
94 | Output:
95 | encoded: encoded binary array in each iteration
96 | hidden2, hidden3, hidden4: hidden and cell states of corresponding ConvLSTM layers
97 | """
98 | def __init__(self, bottleneck, name=None):
99 | super(EncoderRNN, self).__init__(name=name)
100 | self.bottleneck = bottleneck
101 | self.Conv_e1 = Conv2D(32, kernel_size=(3, 3), strides=(2, 2), padding="same", use_bias=False, name='Conv_e1')
102 | self.RnnConv_e1 = RnnConv("RnnConv_e1", 64, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
103 | self.RnnConv_e2 = RnnConv("RnnConv_e2", 64, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
104 | self.RnnConv_e3 = RnnConv("RnnConv_e3", 128, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
105 | self.Conv_b = Conv2D(self.bottleneck, kernel_size=(1, 1), activation=tf.nn.tanh, use_bias=False, name='b_conv')
106 | self.Sign = Lambda(lambda x: tf.sign(x), name="sign")
107 |
108 | def call(self, input, hidden2, hidden3, hidden4, training=False):
109 | # with tf.compat.v1.variable_scope("encoder", reuse=True):
110 | # input size (32,32,1)
111 | x = self.Conv_e1(input)
112 | # x = self.GDN(x)
113 | # (16,16,64)
114 | hidden2 = self.RnnConv_e1(x, hidden2)
115 | x = hidden2[0]
116 | # (8,8,256)
117 | hidden3 = self.RnnConv_e2(x, hidden3)
118 | x = hidden3[0]
119 | # (4,4,512)
120 | hidden4 = self.RnnConv_e3(x, hidden4)
121 | x = hidden4[0]
122 | # (2,2,512)
123 | # binarizer
124 | x = self.Conv_b(x)
125 | # (2,2,bottleneck)
126 | # Using randomized quantization during training.
127 | if training:
128 | probs = (1 + x) / 2
129 | dist = tf.compat.v1.distributions.Bernoulli(probs=probs, dtype=input.dtype)
130 | noise = 2 * dist.sample(name='noise') - 1 - x
131 | encoded = x + tf.stop_gradient(noise)
132 | else:
133 | encoded = self.Sign(x)
134 | return encoded, hidden2, hidden3, hidden4
135 |
136 |
137 | class DecoderRNN(Layer):
138 | """
139 | Decoder layer for one iteration.
140 | Input:
141 | input: decoded array in each iteration
142 | hidden2, hidden3, hidden4, hidden5: hidden and cell states of corresponding ConvLSTM layers
143 | training: boolean, whether the call is in inference mode or training mode
144 | Output:
145 | decoded: decoded array in each iteration
146 | hidden2, hidden3, hidden4, hidden5: hidden and cell states of corresponding ConvLSTM layers
147 | """
148 | def __init__(self, name=None):
149 | super(DecoderRNN, self).__init__(name=name)
150 | self.Conv_d1 = Conv2D(128, kernel_size=(1, 1), use_bias=False, name='d_conv1')
151 | self.RnnConv_d2 = RnnConv("RnnConv_d2", 128, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
152 | self.RnnConv_d3 = RnnConv("RnnConv_d3", 128, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
153 | self.RnnConv_d4 = RnnConv("RnnConv_d4", 64, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
154 | self.RnnConv_d5 = RnnConv("RnnConv_d5", 64, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
155 | self.Conv_d6 = Conv2D(filters=1, kernel_size=(1, 1), padding='same', use_bias=False, name='d_conv6',
156 | activation=tf.nn.tanh)
157 | self.DTS1 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_1")
158 | self.DTS2 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_2")
159 | self.DTS3 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_3")
160 | self.DTS4 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_4")
161 | self.Add = Add(name="add")
162 | self.Out = Lambda(lambda x: x*0.5, name="out")
163 |
164 | def call(self, input, hidden2, hidden3, hidden4, hidden5, training=False):
165 | # (2,2,bottleneck)
166 | x_conv = self.Conv_d1(input)
167 | # (2,2,512)
168 | hidden2 = self.RnnConv_d2(x_conv, hidden2)
169 | x = hidden2[0]
170 | # (2,2,512)
171 | x = self.Add([x, x_conv])
172 | x = self.DTS1(x)
173 | # (4,4,128)
174 | hidden3 = self.RnnConv_d3(x, hidden3)
175 | x = hidden3[0]
176 | # (4,4,512)
177 | x = self.DTS2(x)
178 | # (8,8,128)
179 | hidden4 = self.RnnConv_d4(x, hidden4)
180 | x = hidden4[0]
181 | # (8,8,256)
182 | x = self.DTS3(x)
183 | # (16,16,64)
184 | hidden5 = self.RnnConv_d5(x, hidden5)
185 | x = hidden5[0]
186 | # (16,16,128)
187 | x = self.DTS4(x)
188 | # (32,32,32)
189 | # output in range (-0.5,0.5)
190 | x = self.Conv_d6(x)
191 | decoded = self.Out(x)
192 | return decoded, hidden2, hidden3, hidden4, hidden5
193 |
194 |
195 | class LidarCompressionNetwork(Model):
196 | """
197 | The model to compress range image projected from point clouds captured by Velodyne LiDAR sensor
198 | The encoder and decoder layers are iteratively called for num_iters iterations.
199 | Details see paper Full Resolution Image Compression with Recurrent Neural Networks
200 | https://arxiv.org/pdf/1608.05148.pdf. This architecture uses additive reconstruction framework and ConvLSTM layers.
201 | """
202 | def __init__(self, bottleneck, num_iters, batch_size, input_size):
203 | super(LidarCompressionNetwork, self).__init__(name="lidar_compression_network")
204 | self.bottleneck = bottleneck
205 | self.num_iters = num_iters
206 | self.batch_size = batch_size
207 | self.input_size = input_size
208 |
209 | self.encoder = EncoderRNN(self.bottleneck, name="encoder")
210 | self.decoder = DecoderRNN(name="decoder")
211 |
212 | self.normalize = Lambda(lambda x: tf.multiply(tf.subtract(x, 0.1), 2.5), name="normalization")
213 | self.subtract = Subtract()
214 | self.inputs = tf.keras.layers.Input(shape=(self.input_size, self.input_size, 1))
215 |
216 | self.DIM1 = self.input_size // 2
217 | self.DIM2 = self.DIM1 // 2
218 | self.DIM3 = self.DIM2 // 2
219 | self.DIM4 = self.DIM3 // 2
220 |
221 | self.loss_tracker = tf.keras.metrics.Mean(name="loss")
222 | self.metric_tracker = tf.keras.metrics.MeanAbsoluteError(name="mae")
223 |
224 | self.beta = 1.0 / self.num_iters
225 |
226 | def compute_loss(self, res):
227 | loss = tf.reduce_mean(tf.abs(res))
228 | return loss
229 |
230 | def initial_hidden(self, batch_size, hidden_size, filters, data_type=tf.dtypes.float32):
231 | """Initialize hidden and cell states, all zeros"""
232 | shape = tf.TensorShape([batch_size] + hidden_size + [filters])
233 | hidden = tf.zeros(shape, dtype=data_type)
234 | cell = tf.zeros(shape, dtype=data_type)
235 | return hidden, cell
236 |
237 | def call(self, inputs, training=False):
238 | # Initialize the hidden states when a new batch comes in
239 | hidden_e2 = self.initial_hidden(self.batch_size, [8, self.DIM2], 64, inputs.dtype)
240 | hidden_e3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 64, inputs.dtype)
241 | hidden_e4 = self.initial_hidden(self.batch_size, [2, self.DIM4], 128, inputs.dtype)
242 | hidden_d2 = self.initial_hidden(self.batch_size, [2, self.DIM4], 128, inputs.dtype)
243 | hidden_d3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 128, inputs.dtype)
244 | hidden_d4 = self.initial_hidden(self.batch_size, [8, self.DIM2], 64, inputs.dtype)
245 | hidden_d5 = self.initial_hidden(self.batch_size, [16, self.DIM1], 64, inputs.dtype)
246 | outputs = tf.zeros_like(inputs)
247 |
248 | inputs = self.normalize(inputs)
249 | res = inputs
250 | for i in range(self.num_iters):
251 | code, hidden_e2, hidden_e3, hidden_e4 = \
252 | self.encoder(res, hidden_e2, hidden_e3, hidden_e4, training=training)
253 |
254 | decoded, hidden_d2, hidden_d3, hidden_d4, hidden_d5 = \
255 | self.decoder(code, hidden_d2, hidden_d3, hidden_d4, hidden_d5, training=training)
256 |
257 | outputs = tf.add(outputs, decoded)
258 | # Update res as predicted output in this iteration subtract the original input
259 | res = self.subtract([outputs, inputs])
260 | self.add_loss(self.compute_loss(res))
261 | # Denormalize the tensors
262 | outputs = tf.clip_by_value(tf.add(tf.multiply(outputs, 0.4), 0.1), 0, 1)
263 | outputs = tf.cast(outputs, dtype=tf.float32)
264 | return outputs
265 |
266 | def train_step(self, data):
267 | inputs, labels = data
268 |
269 | # Run forward pass.
270 | with tf.GradientTape() as tape:
271 | outputs = self(inputs, training=True)
272 | loss = sum(self.losses)*self.beta
273 |
274 | # Run backwards pass.
275 | trainable_vars = self.trainable_variables
276 | gradients = tape.gradient(loss, trainable_vars)
277 | self.optimizer.apply_gradients(zip(gradients, trainable_vars))
278 | # Update & Compute Metrics
279 | with tf.name_scope("metrics") as scope:
280 | self.loss_tracker.update_state(loss)
281 | self.metric_tracker.update_state(outputs, labels)
282 | metric_result = self.metric_tracker.result()
283 | loss_result = self.loss_tracker.result()
284 | return {'loss': loss_result, 'mae': metric_result}
285 |
286 | def test_step(self, data):
287 | inputs, labels = data
288 | # Run forward pass.
289 | outputs = self(inputs, training=False)
290 | loss = sum(self.losses)*self.beta
291 | # Update metrics
292 | self.loss_tracker.update_state(loss)
293 | self.metric_tracker.update_state(outputs, labels)
294 | return {'loss': self.loss_tracker.result(), 'mae': self.metric_tracker.result()}
295 |
296 | def predict_step(self, data):
297 | inputs, labels = data
298 | outputs = self(inputs, training=False)
299 | return outputs
300 |
301 | @property
302 | def metrics(self):
303 | return [self.loss_tracker, self.metric_tracker]
304 |
--------------------------------------------------------------------------------
/range_image_compression/architectures/Additive_LSTM_Slim.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | import tensorflow as tf
26 | from keras.models import Model
27 | from keras.layers import Layer, Lambda
28 | from keras.layers import Conv2D
29 | from keras.layers import Add, Subtract
30 |
31 |
32 | class RnnConv(Layer):
33 | """Convolutional LSTM cell
34 | See detail in formula (4-6) in paper
35 | "Full Resolution Image Compression with Recurrent Neural Networks"
36 | https://arxiv.org/pdf/1608.05148.pdf
37 | Args:
38 | name: name of current ConvLSTM layer
39 | filters: number of filters for each convolutional operation
40 | strides: strides size
41 | kernel_size: kernel size of convolutional operation
42 | hidden_kernel_size: kernel size of convolutional operation for hidden state
43 | Input:
44 | inputs: input of the layer
45 | hidden: hidden state and cell state of the layer
46 | Output:
47 | newhidden: updated hidden state of the layer
48 | newcell: updated cell state of the layer
49 | """
50 |
51 | def __init__(self, name, filters, strides, kernel_size, hidden_kernel_size):
52 | super(RnnConv, self).__init__()
53 | self.filters = filters
54 | self.strides = strides
55 | self.conv_i = Conv2D(filters=4 * self.filters,
56 | kernel_size=kernel_size,
57 | strides=self.strides,
58 | padding='same',
59 | use_bias=False,
60 | name=name + '_i')
61 | self.conv_h = Conv2D(filters=4 * self.filters,
62 | kernel_size=hidden_kernel_size,
63 | padding='same',
64 | use_bias=False,
65 | name=name + '_h')
66 |
67 | def call(self, inputs, hidden):
68 | # with tf.variable_scope(name, reuse=tf.AUTO_REUSE):
69 | conv_inputs = self.conv_i(inputs)
70 | conv_hidden = self.conv_h(hidden[0])
71 | # all gates are determined by input and hidden layer
72 | in_gate, f_gate, out_gate, c_gate = tf.split(
73 | conv_inputs + conv_hidden, 4, axis=-1) # each gate get the same number of filters
74 | in_gate = tf.nn.sigmoid(in_gate) # input/update gate
75 | f_gate = tf.nn.sigmoid(f_gate)
76 | out_gate = tf.nn.sigmoid(out_gate)
77 | c_gate = tf.nn.tanh(c_gate) # candidate cell, calculated from input
78 | # forget_gate*old_cell+input_gate(update)*candidate_cell
79 | newcell = tf.multiply(f_gate, hidden[1]) + tf.multiply(in_gate, c_gate)
80 | newhidden = tf.multiply(out_gate, tf.nn.tanh(newcell))
81 | return newhidden, newcell
82 |
83 |
84 | class EncoderRNN(Layer):
85 | """
86 | Encoder layer for one iteration.
87 | Args:
88 | bottleneck: bottleneck size of the layer
89 | Input:
90 | input: output array from last iteration.
91 | In the first iteration, it is the normalized image patch
92 | hidden2, hidden3, hidden4: hidden and cell states of corresponding ConvLSTM layers
93 | training: boolean, whether the call is in inference mode or training mode
94 | Output:
95 | encoded: encoded binary array in each iteration
96 | hidden2, hidden3, hidden4: hidden and cell states of corresponding ConvLSTM layers
97 | """
98 | def __init__(self, bottleneck, name=None):
99 | super(EncoderRNN, self).__init__(name=name)
100 | self.bottleneck = bottleneck
101 | self.Conv_e1 = Conv2D(32, kernel_size=(3, 3), strides=(2, 2), padding="same", use_bias=False, name='Conv_e1')
102 | self.RnnConv_e1 = RnnConv("RnnConv_e1", 128, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
103 | self.RnnConv_e2 = RnnConv("RnnConv_e2", 256, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
104 | self.RnnConv_e3 = RnnConv("RnnConv_e3", 256, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
105 | self.Conv_b = Conv2D(self.bottleneck, kernel_size=(1, 1), activation=tf.nn.tanh, use_bias=False, name='b_conv')
106 | self.Sign = Lambda(lambda x: tf.sign(x), name="sign")
107 |
108 | def call(self, input, hidden2, hidden3, hidden4, training=False):
109 | # with tf.compat.v1.variable_scope("encoder", reuse=True):
110 | # input size (32,32,1)
111 | x = self.Conv_e1(input)
112 | # x = self.GDN(x)
113 | # (16,16,32)
114 | hidden2 = self.RnnConv_e1(x, hidden2)
115 | x = hidden2[0]
116 | # (8,8,128)
117 | hidden3 = self.RnnConv_e2(x, hidden3)
118 | x = hidden3[0]
119 | # (4,4,256)
120 | hidden4 = self.RnnConv_e3(x, hidden4)
121 | x = hidden4[0]
122 | # (2,2,256)
123 | # binarizer
124 | x = self.Conv_b(x)
125 | # (2,2,bottleneck)
126 | # Using randomized quantization during training.
127 | if training:
128 | probs = (1 + x) / 2
129 | dist = tf.compat.v1.distributions.Bernoulli(probs=probs, dtype=input.dtype)
130 | noise = 2 * dist.sample(name='noise') - 1 - x
131 | encoded = x + tf.stop_gradient(noise)
132 | else:
133 | encoded = self.Sign(x)
134 | return encoded, hidden2, hidden3, hidden4
135 |
136 |
137 | class DecoderRNN(Layer):
138 | """
139 | Decoder layer for one iteration.
140 | Input:
141 | input: decoded array in each iteration
142 | hidden2, hidden3, hidden4, hidden5: hidden and cell states of corresponding ConvLSTM layers
143 | training: boolean, whether the call is in inference mode or training mode
144 | Output:
145 | decoded: decoded array in each iteration
146 | hidden2, hidden3, hidden4, hidden5: hidden and cell states of corresponding ConvLSTM layers
147 | """
148 | def __init__(self, name=None):
149 | super(DecoderRNN, self).__init__(name=name)
150 | self.Conv_d1 = Conv2D(256, kernel_size=(1, 1), use_bias=False, name='d_conv1')
151 | self.RnnConv_d2 = RnnConv("RnnConv_d2", 256, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
152 | self.RnnConv_d3 = RnnConv("RnnConv_d3", 256, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
153 | self.RnnConv_d4 = RnnConv("RnnConv_d4", 128, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
154 | self.RnnConv_d5 = RnnConv("RnnConv_d5", 64, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
155 | self.Conv_d6 = Conv2D(filters=1, kernel_size=(1, 1), padding='same', use_bias=False, name='d_conv6',
156 | activation=tf.nn.tanh)
157 | self.DTS1 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_1")
158 | self.DTS2 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_2")
159 | self.DTS3 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_3")
160 | self.DTS4 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_4")
161 | self.Add = Add(name="add")
162 | self.Out = Lambda(lambda x: x*0.5, name="out")
163 |
164 | def call(self, input, hidden2, hidden3, hidden4, hidden5, training=False):
165 | # (2,2,bottleneck)
166 | x_conv = self.Conv_d1(input)
167 | # (2,2,256)
168 | hidden2 = self.RnnConv_d2(x_conv, hidden2)
169 | x = hidden2[0]
170 | # (2,2,256)
171 | x = self.Add([x, x_conv])
172 | x = self.DTS1(x)
173 | # (4,4,64)
174 | hidden3 = self.RnnConv_d3(x, hidden3)
175 | x = hidden3[0]
176 | # (4,4,256)
177 | x = self.DTS2(x)
178 | # (8,8,64)
179 | hidden4 = self.RnnConv_d4(x, hidden4)
180 | x = hidden4[0]
181 | # (8,8,128)
182 | x = self.DTS3(x)
183 | # (16,16,32)
184 | hidden5 = self.RnnConv_d5(x, hidden5)
185 | x = hidden5[0]
186 | # (16,16,64)
187 | x = self.DTS4(x)
188 | # (32,32,32)
189 | # output in range (-0.5,0.5)
190 | x = self.Conv_d6(x)
191 | decoded = self.Out(x)
192 | return decoded, hidden2, hidden3, hidden4, hidden5
193 |
194 |
195 | class LidarCompressionNetwork(Model):
196 | """
197 | The model to compress range image projected from point clouds captured by Velodyne LiDAR sensor
198 | The encoder and decoder layers are iteratively called for num_iters iterations.
199 | Details see paper Full Resolution Image Compression with Recurrent Neural Networks
200 | https://arxiv.org/pdf/1608.05148.pdf. This architecture uses additive reconstruction framework and ConvLSTM layers.
201 | """
202 | def __init__(self, bottleneck, num_iters, batch_size, input_size):
203 | super(LidarCompressionNetwork, self).__init__(name="lidar_compression_network")
204 | self.bottleneck = bottleneck
205 | self.num_iters = num_iters
206 | self.batch_size = batch_size
207 | self.input_size = input_size
208 |
209 | self.encoder = EncoderRNN(self.bottleneck, name="encoder")
210 | self.decoder = DecoderRNN(name="decoder")
211 |
212 | self.normalize = Lambda(lambda x: tf.multiply(tf.subtract(x, 0.1), 2.5), name="normalization")
213 | self.subtract = Subtract()
214 | self.inputs = tf.keras.layers.Input(shape=(self.input_size, self.input_size, 1))
215 |
216 | self.DIM1 = self.input_size // 2
217 | self.DIM2 = self.DIM1 // 2
218 | self.DIM3 = self.DIM2 // 2
219 | self.DIM4 = self.DIM3 // 2
220 |
221 | self.loss_tracker = tf.keras.metrics.Mean(name="loss")
222 | self.metric_tracker = tf.keras.metrics.MeanAbsoluteError(name="mae")
223 |
224 | self.beta = 1.0 / self.num_iters
225 |
226 | def compute_loss(self, res):
227 | loss = tf.reduce_mean(tf.abs(res))
228 | return loss
229 |
230 | def initial_hidden(self, batch_size, hidden_size, filters, data_type=tf.dtypes.float32):
231 | """Initialize hidden and cell states, all zeros"""
232 | shape = tf.TensorShape([batch_size] + hidden_size + [filters])
233 | hidden = tf.zeros(shape, dtype=data_type)
234 | cell = tf.zeros(shape, dtype=data_type)
235 | return hidden, cell
236 |
237 | def call(self, inputs, training=False):
238 | # Initialize the hidden states when a new batch comes in
239 | hidden_e2 = self.initial_hidden(self.batch_size, [8, self.DIM2], 128, inputs.dtype)
240 | hidden_e3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 256, inputs.dtype)
241 | hidden_e4 = self.initial_hidden(self.batch_size, [2, self.DIM4], 256, inputs.dtype)
242 | hidden_d2 = self.initial_hidden(self.batch_size, [2, self.DIM4], 256, inputs.dtype)
243 | hidden_d3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 256, inputs.dtype)
244 | hidden_d4 = self.initial_hidden(self.batch_size, [8, self.DIM2], 128, inputs.dtype)
245 | hidden_d5 = self.initial_hidden(self.batch_size, [16, self.DIM1], 64, inputs.dtype)
246 | outputs = tf.zeros_like(inputs)
247 |
248 | inputs = self.normalize(inputs)
249 | res = inputs
250 | for i in range(self.num_iters):
251 | code, hidden_e2, hidden_e3, hidden_e4 = \
252 | self.encoder(res, hidden_e2, hidden_e3, hidden_e4, training=training)
253 |
254 | decoded, hidden_d2, hidden_d3, hidden_d4, hidden_d5 = \
255 | self.decoder(code, hidden_d2, hidden_d3, hidden_d4, hidden_d5, training=training)
256 |
257 | outputs = tf.add(outputs, decoded)
258 | # Update res as predicted output in this iteration subtract the original input
259 | res = self.subtract([outputs, inputs])
260 | self.add_loss(self.compute_loss(res))
261 | # Denormalize the tensors
262 | outputs = tf.clip_by_value(tf.add(tf.multiply(outputs, 0.4), 0.1), 0, 1)
263 | outputs = tf.cast(outputs, dtype=tf.float32)
264 | return outputs
265 |
266 | def train_step(self, data):
267 | inputs, labels = data
268 |
269 | # Run forward pass.
270 | with tf.GradientTape() as tape:
271 | outputs = self(inputs, training=True)
272 | loss = sum(self.losses)*self.beta
273 |
274 | # Run backwards pass.
275 | trainable_vars = self.trainable_variables
276 | gradients = tape.gradient(loss, trainable_vars)
277 | self.optimizer.apply_gradients(zip(gradients, trainable_vars))
278 | # Update & Compute Metrics
279 | with tf.name_scope("metrics") as scope:
280 | self.loss_tracker.update_state(loss)
281 | self.metric_tracker.update_state(outputs, labels)
282 | metric_result = self.metric_tracker.result()
283 | loss_result = self.loss_tracker.result()
284 | return {'loss': loss_result, 'mae': metric_result}
285 |
286 | def test_step(self, data):
287 | inputs, labels = data
288 | # Run forward pass.
289 | outputs = self(inputs, training=False)
290 | loss = sum(self.losses)*self.beta
291 | # Update metrics
292 | self.loss_tracker.update_state(loss)
293 | self.metric_tracker.update_state(outputs, labels)
294 | return {'loss': self.loss_tracker.result(), 'mae': self.metric_tracker.result()}
295 |
296 | def predict_step(self, data):
297 | inputs, labels = data
298 | outputs = self(inputs, training=False)
299 | return outputs
300 |
301 | @property
302 | def metrics(self):
303 | return [self.loss_tracker, self.metric_tracker]
304 |
--------------------------------------------------------------------------------
/range_image_compression/architectures/Oneshot_LSTM.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | import tensorflow as tf
26 | from keras.models import Model
27 | from keras.layers import Layer, Lambda
28 | from keras.layers import Conv2D
29 | from keras.layers import Add, Subtract
30 | import tensorflow_compression as tfc
31 |
32 |
33 | class RnnConv(Layer):
34 | """Convolutional LSTM cell
35 | See detail in formula (4-6) in paper
36 | "Full Resolution Image Compression with Recurrent Neural Networks"
37 | https://arxiv.org/pdf/1608.05148.pdf
38 | Args:
39 | name: name of current ConvLSTM layer
40 | filters: number of filters for each convolutional operation
41 | strides: strides size
42 | kernel_size: kernel size of convolutional operation
43 | hidden_kernel_size: kernel size of convolutional operation for hidden state
44 | Input:
45 | inputs: input of the layer
46 | hidden: hidden state and cell state of the layer
47 | Output:
48 | newhidden: updated hidden state of the layer
49 | newcell: updated cell state of the layer
50 | """
51 |
52 | def __init__(self, name, filters, strides, kernel_size, hidden_kernel_size):
53 | super(RnnConv, self).__init__()
54 | self.filters = filters
55 | self.strides = strides
56 | self.conv_i = Conv2D(filters=4 * self.filters,
57 | kernel_size=kernel_size,
58 | strides=self.strides,
59 | padding='same',
60 | use_bias=False,
61 | name=name + '_i')
62 | self.conv_h = Conv2D(filters=4 * self.filters,
63 | kernel_size=hidden_kernel_size,
64 | padding='same',
65 | use_bias=False,
66 | name=name + '_h')
67 |
68 | def call(self, inputs, hidden):
69 | # with tf.variable_scope(name, reuse=tf.AUTO_REUSE):
70 | conv_inputs = self.conv_i(inputs)
71 | conv_hidden = self.conv_h(hidden[0])
72 | # all gates are determined by input and hidden layer
73 | in_gate, f_gate, out_gate, c_gate = tf.split(
74 | conv_inputs + conv_hidden, 4, axis=-1) # each gate get the same number of filters
75 | in_gate = tf.nn.sigmoid(in_gate) # input/update gate
76 | f_gate = tf.nn.sigmoid(f_gate)
77 | out_gate = tf.nn.sigmoid(out_gate)
78 | c_gate = tf.nn.tanh(c_gate) # candidate cell, calculated from input
79 | # forget_gate*old_cell+input_gate(update)*candidate_cell
80 | newcell = tf.multiply(f_gate, hidden[1]) + tf.multiply(in_gate, c_gate)
81 | newhidden = tf.multiply(out_gate, tf.nn.tanh(newcell))
82 | return newhidden, newcell
83 |
84 |
85 | class EncoderRNN(Layer):
86 | """
87 | Encoder layer for one iteration.
88 | Args:
89 | bottleneck: bottleneck size of the layer
90 | Input:
91 | input: output array from last iteration.
92 | In the first iteration, it is the normalized image patch
93 | hidden2, hidden3, hidden4: hidden and cell states of corresponding ConvLSTM layers
94 | training: boolean, whether the call is in inference mode or training mode
95 | Output:
96 | encoded: encoded binary array in each iteration
97 | hidden2, hidden3, hidden4: hidden and cell states of corresponding ConvLSTM layers
98 | """
99 | def __init__(self, bottleneck, name=None):
100 | super(EncoderRNN, self).__init__(name=name)
101 | self.bottleneck = bottleneck
102 | self.Conv_e1 = Conv2D(32, kernel_size=(3, 3), strides=(2, 2), padding="same", use_bias=False, name='Conv_e1')
103 | self.GDN = tfc.GDN(alpha_parameter=2, epsilon_parameter=0.5, name="gdn")
104 | self.RnnConv_e1 = RnnConv("RnnConv_e1", 128, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
105 | self.RnnConv_e2 = RnnConv("RnnConv_e2", 256, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
106 | self.RnnConv_e3 = RnnConv("RnnConv_e3", 256, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
107 | self.Conv_b = Conv2D(self.bottleneck, kernel_size=(1, 1), activation=tf.nn.tanh, use_bias=False, name='b_conv')
108 | self.Sign = Lambda(lambda x: tf.sign(x), name="sign")
109 |
110 | def call(self, input, hidden2, hidden3, hidden4, training=False):
111 | # input size (32,32,1)
112 | x = self.Conv_e1(input)
113 | x = self.GDN(x)
114 | # (16,16,64)
115 | hidden2 = self.RnnConv_e1(x, hidden2)
116 | x = hidden2[0]
117 | # (8,8,256)
118 | hidden3 = self.RnnConv_e2(x, hidden3)
119 | x = hidden3[0]
120 | # (4,4,512)
121 | hidden4 = self.RnnConv_e3(x, hidden4)
122 | x = hidden4[0]
123 | # (2,2,512)
124 | # binarizer
125 | x = self.Conv_b(x)
126 | # (2,2,bottleneck)
127 | # Using randomized quantization during training.
128 | if training:
129 | probs = (1 + x) / 2
130 | dist = tf.compat.v1.distributions.Bernoulli(probs=probs, dtype=input.dtype)
131 | noise = 2 * dist.sample(name='noise') - 1 - x
132 | encoded = x + tf.stop_gradient(noise)
133 | else:
134 | encoded = self.Sign(x)
135 | return encoded, hidden2, hidden3, hidden4
136 |
137 |
138 | class DecoderRNN(Layer):
139 | """
140 | Decoder layer for one iteration.
141 | Input:
142 | input: decoded array in each iteration
143 | hidden2, hidden3, hidden4, hidden5: hidden and cell states of corresponding ConvLSTM layers
144 | training: boolean, whether the call is in inference mode or training mode
145 | Output:
146 | decoded: decoded array in each iteration
147 | hidden2, hidden3, hidden4, hidden5: hidden and cell states of corresponding ConvLSTM layers
148 | """
149 | def __init__(self, name=None):
150 | super(DecoderRNN, self).__init__(name=name)
151 | self.Conv_d1 = Conv2D(256, kernel_size=(1, 1), use_bias=False, name='d_conv1')
152 | self.iGDN = tfc.GDN(alpha_parameter=2, epsilon_parameter=0.5, inverse=True, name="igdn")
153 | self.RnnConv_d2 = RnnConv("RnnConv_d2", 256, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
154 | self.RnnConv_d3 = RnnConv("RnnConv_d3", 256, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
155 | self.RnnConv_d4 = RnnConv("RnnConv_d4", 128, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
156 | self.RnnConv_d5 = RnnConv("RnnConv_d5", 64, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
157 | self.Conv_d6 = Conv2D(filters=1, kernel_size=(1, 1), padding='same', use_bias=False, name='d_conv6',
158 | activation=tf.nn.tanh)
159 | self.DTS1 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_1")
160 | self.DTS2 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_2")
161 | self.DTS3 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_3")
162 | self.DTS4 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_4")
163 | self.Add = Add(name="add")
164 | self.Out = Lambda(lambda x: x*0.5, name="out")
165 |
166 | def call(self, input, hidden2, hidden3, hidden4, hidden5, training=False):
167 | # with tf.compat.v1.variable_scope("decoder", reuse=True):
168 | # (2,2,bottleneck)
169 | x = self.Conv_d1(input)
170 | x_igdn = self.iGDN(x)
171 | # x = self.Conv_d1(input)
172 | # (2,2,512)
173 | hidden2 = self.RnnConv_d2(x_igdn, hidden2)
174 | x = hidden2[0]
175 | # (2,2,512)
176 | x = self.Add([x, x_igdn])
177 | x = self.DTS1(x)
178 | # (4,4,128)
179 | hidden3 = self.RnnConv_d3(x, hidden3)
180 | x = hidden3[0]
181 | # (4,4,512)
182 | x = self.DTS2(x)
183 | # (8,8,128)
184 | hidden4 = self.RnnConv_d4(x, hidden4)
185 | x = hidden4[0]
186 | # (8,8,256)
187 | x = self.DTS3(x)
188 | # (16,16,64)
189 | hidden5 = self.RnnConv_d5(x, hidden5)
190 | x = hidden5[0]
191 | # (16,16,128)
192 | x = self.DTS4(x)
193 | # (32,32,32)
194 | # output in range (-0.5,0.5)
195 | x = self.Conv_d6(x)
196 | decoded = self.Out(x)
197 | return decoded, hidden2, hidden3, hidden4, hidden5
198 |
199 |
200 | class LidarCompressionNetwork(Model):
201 | """
202 | The model to compress range image projected from point clouds captured by Velodyne LiDAR sensor
203 | The encoder and decoder layers are iteratively called for num_iters iterations.
204 | Details see paper Full Resolution Image Compression with Recurrent Neural Networks
205 | https://arxiv.org/pdf/1608.05148.pdf. This architecture uses one-shot reconstruction framework and ConvLSTM layers.
206 | """
207 | def __init__(self, bottleneck, num_iters, batch_size, input_size):
208 | super(LidarCompressionNetwork, self).__init__(name="lidar_compression_network")
209 | self.bottleneck = bottleneck
210 | self.num_iters = num_iters
211 | self.batch_size = batch_size
212 | self.input_size = input_size
213 |
214 | self.encoder = EncoderRNN(self.bottleneck, name="encoder")
215 | self.decoder = DecoderRNN(name="decoder")
216 |
217 | self.normalize = Lambda(lambda x: tf.subtract(x, 0.5), name="normalization")
218 | self.subtract = Subtract()
219 | self.inputs = tf.keras.layers.Input(shape=(self.input_size, self.input_size, 1))
220 |
221 | self.DIM1 = self.input_size // 2
222 | self.DIM2 = self.DIM1 // 2
223 | self.DIM3 = self.DIM2 // 2
224 | self.DIM4 = self.DIM3 // 2
225 |
226 | self.loss_tracker = tf.keras.metrics.Mean(name="loss")
227 | self.metric_tracker = tf.keras.metrics.MeanAbsoluteError(name="mae")
228 |
229 | self.beta = 1.0 / self.num_iters
230 |
231 | def compute_loss(self, res):
232 | loss = tf.reduce_mean(tf.abs(res))
233 | return loss
234 |
235 | def initial_hidden(self, batch_size, hidden_size, filters, data_type=tf.dtypes.float32):
236 | """Initialize hidden and cell states, all zeros"""
237 | shape = tf.TensorShape([batch_size] + hidden_size + [filters])
238 | hidden = tf.zeros(shape, dtype=data_type)
239 | cell = tf.zeros(shape, dtype=data_type)
240 | return hidden, cell
241 |
242 | def call(self, inputs, training=False):
243 | # Initialize the hidden states when a new batch comes in
244 | hidden_e2 = self.initial_hidden(self.batch_size, [8, self.DIM2], 128, inputs.dtype)
245 | hidden_e3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 256, inputs.dtype)
246 | hidden_e4 = self.initial_hidden(self.batch_size, [2, self.DIM4], 256, inputs.dtype)
247 | hidden_d2 = self.initial_hidden(self.batch_size, [2, self.DIM4], 256, inputs.dtype)
248 | hidden_d3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 256, inputs.dtype)
249 | hidden_d4 = self.initial_hidden(self.batch_size, [8, self.DIM2], 128, inputs.dtype)
250 | hidden_d5 = self.initial_hidden(self.batch_size, [16, self.DIM1], 64, inputs.dtype)
251 |
252 | inputs = self.normalize(inputs)
253 | res = inputs
254 | for i in range(self.num_iters):
255 | code, hidden_e2, hidden_e3, hidden_e4 = \
256 | self.encoder(res, hidden_e2, hidden_e3, hidden_e4, training=training)
257 |
258 | decoded, hidden_d2, hidden_d3, hidden_d4, hidden_d5 = \
259 | self.decoder(code, hidden_d2, hidden_d3, hidden_d4, hidden_d5, training=training)
260 |
261 | # Update res as predicted output in this iteration subtract the original input
262 | res = self.subtract([decoded, inputs])
263 | self.add_loss(self.compute_loss(res))
264 | # Denormalize the tensors
265 | outputs = tf.clip_by_value(tf.add(decoded, 0.5), 0, 1)
266 | outputs = tf.cast(outputs, dtype=tf.float32)
267 | return outputs
268 |
269 | def train_step(self, data):
270 | inputs, labels = data
271 |
272 | # Run forward pass.
273 | with tf.GradientTape() as tape:
274 | outputs = self(inputs, training=True)
275 | loss = sum(self.losses)*self.beta
276 |
277 | # Run backwards pass.
278 | trainable_vars = self.trainable_variables
279 | gradients = tape.gradient(loss, trainable_vars)
280 | self.optimizer.apply_gradients(zip(gradients, trainable_vars))
281 | # Update & Compute Metrics
282 | with tf.name_scope("metrics") as scope:
283 | self.loss_tracker.update_state(loss)
284 | self.metric_tracker.update_state(outputs, labels)
285 | metric_result = self.metric_tracker.result()
286 | loss_result = self.loss_tracker.result()
287 | return {'loss': loss_result, 'mae': metric_result}
288 |
289 | def test_step(self, data):
290 | inputs, labels = data
291 | # Run forward pass.
292 | outputs = self(inputs, training=False)
293 | loss = sum(self.losses)*self.beta
294 | # Update metrics
295 | self.loss_tracker.update_state(loss)
296 | self.metric_tracker.update_state(outputs, labels)
297 | return {'loss': self.loss_tracker.result(), 'mae': self.metric_tracker.result()}
298 |
299 | def predict_step(self, data):
300 | inputs, labels = data
301 | outputs = self(inputs, training=False)
302 | return outputs
303 |
304 | @property
305 | def metrics(self):
306 | return [self.loss_tracker, self.metric_tracker]
307 |
--------------------------------------------------------------------------------
/range_image_compression/architectures/Additive_GRU.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | import tensorflow as tf
26 | from keras.models import Model
27 | from keras.layers import Layer, Lambda
28 | from keras.layers import Conv2D
29 | from keras.layers import Add, Subtract
30 |
31 |
32 | class RnnConv(Layer):
33 | """Convolutional GRU cell
34 | See detail in formula (11-13) in paper
35 | "Full Resolution Image Compression with Recurrent Neural Networks"
36 | https://arxiv.org/pdf/1608.05148.pdf
37 | Args:
38 | name: name of current ConvGRU layer
39 | filters: number of filters for each convolutional operation
40 | strides: strides size
41 | kernel_size: kernel size of convolutional operation
42 | hidden_kernel_size: kernel size of convolutional operation for hidden state
43 | Input:
44 | inputs: input of the layer
45 | hidden: hidden state of the layer
46 | Output:
47 | newhidden: updated hidden state of the layer
48 | """
49 |
50 | def __init__(self, name, filters, strides, kernel_size, hidden_kernel_size):
51 | super(RnnConv, self).__init__()
52 | self.filters = filters
53 | self.strides = strides
54 | # gates
55 | self.conv_i = Conv2D(filters=2 * self.filters,
56 | kernel_size=kernel_size,
57 | strides=self.strides,
58 | padding='same',
59 | use_bias=False,
60 | name=name + '_i')
61 | self.conv_h = Conv2D(filters=2 * self.filters,
62 | kernel_size=hidden_kernel_size,
63 | padding='same',
64 | use_bias=False,
65 | name=name + '_h')
66 | # candidate
67 | self.conv_ci = Conv2D(filters=self.filters,
68 | kernel_size=kernel_size,
69 | strides=self.strides,
70 | padding='same',
71 | use_bias=False,
72 | name=name + '_ci')
73 | self.conv_ch = Conv2D(filters=self.filters,
74 | kernel_size=hidden_kernel_size,
75 | padding='same',
76 | use_bias=False,
77 | name=name + '_ch')
78 |
79 | def call(self, inputs, hidden):
80 | # with tf.variable_scope(name, reuse=tf.AUTO_REUSE):
81 | conv_inputs = self.conv_i(inputs)
82 | conv_hidden = self.conv_h(hidden)
83 | # all gates are determined by input and hidden layer
84 | r_gate, z_gate = tf.split(
85 | conv_inputs + conv_hidden, 2, axis=-1) # each gate get the same number of filters
86 | r_gate = tf.nn.sigmoid(r_gate) # input/update gate
87 | z_gate = tf.nn.sigmoid(z_gate)
88 | conv_inputs_candidate = self.conv_ci(inputs)
89 | hidden_candidate = tf.multiply(r_gate, hidden)
90 | conv_hidden_candidate = self.conv_ch(hidden_candidate)
91 | candidate = tf.nn.tanh(conv_inputs_candidate + conv_hidden_candidate)
92 | newhidden = tf.multiply(1 - z_gate, hidden) + tf.multiply(z_gate, candidate)
93 | return newhidden
94 |
95 |
96 | class EncoderRNN(Layer):
97 | """
98 | Encoder layer for one iteration.
99 | Args:
100 | bottleneck: bottleneck size of the layer
101 | Input:
102 | input: output array from last iteration.
103 | In the first iteration, it is the normalized image patch
104 | hidden2, hidden3, hidden4: hidden states of corresponding ConvGRU layers
105 | training: boolean, whether the call is in inference mode or training mode
106 | Output:
107 | encoded: encoded binary array in each iteration
108 | hidden2, hidden3, hidden4: hidden states of corresponding ConvGRU layers
109 | """
110 | def __init__(self, bottleneck, name=None):
111 | super(EncoderRNN, self).__init__(name=name)
112 | self.bottleneck = bottleneck
113 | self.Conv_e1 = Conv2D(32, kernel_size=(3, 3), strides=(2, 2), padding="same", name='Conv_e1')
114 | self.RnnConv_e1 = RnnConv("RnnConv_e1", 128, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
115 | self.RnnConv_e2 = RnnConv("RnnConv_e2", 256, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
116 | self.RnnConv_e3 = RnnConv("RnnConv_e3", 256, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
117 | self.Conv_b = Conv2D(self.bottleneck, kernel_size=(1, 1), activation=tf.nn.tanh, name='b_conv')
118 | self.Sign = Lambda(lambda x: tf.sign(x), name="sign")
119 |
120 | def call(self, input, hidden2, hidden3, hidden4, training=False):
121 | # with tf.compat.v1.variable_scope("encoder", reuse=True):
122 | # input size (32,32,1)
123 | x = self.Conv_e1(input)
124 | # (16,16,64)
125 | hidden2 = self.RnnConv_e1(x, hidden2)
126 | x = hidden2
127 | # (8,8,256)
128 | hidden3 = self.RnnConv_e2(x, hidden3)
129 | x = hidden3
130 | # (4,4,512)
131 | hidden4 = self.RnnConv_e3(x, hidden4)
132 | x = hidden4
133 | # (2,2,512)
134 | # binarizer
135 | x = self.Conv_b(x)
136 | # (2,2,bottleneck)
137 | # Using randomized quantization during training.
138 | if training:
139 | probs = (1 + x) / 2
140 | dist = tf.compat.v1.distributions.Bernoulli(probs=probs, dtype=input.dtype)
141 | noise = 2 * dist.sample(name='noise') - 1 - x
142 | encoded = x + tf.stop_gradient(noise)
143 | else:
144 | encoded = self.Sign(x)
145 | return encoded, hidden2, hidden3, hidden4
146 |
147 |
148 | class DecoderRNN(Layer):
149 | """
150 | Decoder layer for one iteration.
151 | Input:
152 | input: decoded array in each iteration
153 | hidden2, hidden3, hidden4, hidden5: hidden states of corresponding ConvGRU layers
154 | training: boolean, whether the call is in inference mode or training mode
155 | Output:
156 | decoded: decoded array in each iteration
157 | hidden2, hidden3, hidden4, hidden5: hidden states of corresponding ConvGRU layers
158 | """
159 | def __init__(self, name=None):
160 | super(DecoderRNN, self).__init__(name=name)
161 | self.Conv_d1 = Conv2D(256, kernel_size=(1, 1), use_bias=False, name='d_conv1')
162 | self.RnnConv_d2 = RnnConv("RnnConv_d2", 256, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
163 | self.RnnConv_d3 = RnnConv("RnnConv_d3", 256, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
164 | self.RnnConv_d4 = RnnConv("RnnConv_d4", 128, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
165 | self.RnnConv_d5 = RnnConv("RnnConv_d5", 64, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
166 | self.Conv_d6 = Conv2D(filters=1, kernel_size=(1, 1), padding='same', use_bias=False, name='d_conv6',
167 | activation=tf.nn.tanh)
168 | self.DTS1 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_1")
169 | self.DTS2 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_2")
170 | self.DTS3 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_3")
171 | self.DTS4 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_4")
172 | self.Add = Add(name="add")
173 | self.Out = Lambda(lambda x: x*0.5, name="out")
174 |
175 | def call(self, input, hidden2, hidden3, hidden4, hidden5, training=False):
176 | # (2,2,bottleneck)
177 | x_conv1 = self.Conv_d1(input)
178 | # x = self.Conv_d1(input)
179 | # (2,2,512)
180 | hidden2 = self.RnnConv_d2(x_conv1, hidden2)
181 | x = hidden2
182 | # (2,2,512)
183 | x = self.Add([x, x_conv1])
184 | x = self.DTS1(x)
185 | # (4,4,128)
186 | hidden3 = self.RnnConv_d3(x, hidden3)
187 | x = hidden3
188 | # (4,4,512)
189 | x = self.DTS2(x)
190 | # (8,8,128)
191 | hidden4 = self.RnnConv_d4(x, hidden4)
192 | x = hidden4
193 | # (8,8,256)
194 | x = self.DTS3(x)
195 | # (16,16,64)
196 | hidden5 = self.RnnConv_d5(x, hidden5)
197 | x = hidden5
198 | # (16,16,128)
199 | x = self.DTS4(x)
200 | # (32,32,32)
201 | # output in range (-1,1)
202 | x = self.Conv_d6(x)
203 | decoded = self.Out(x)
204 | return decoded, hidden2, hidden3, hidden4, hidden5
205 |
206 |
207 | class LidarCompressionNetwork(Model):
208 | """
209 | The model to compress range image projected from point clouds captured by Velodyne LiDAR sensor.
210 | The encoder and decoder layers are iteratively called for num_iters iterations.
211 | Details see paper Full Resolution Image Compression with Recurrent Neural Networks
212 | https://arxiv.org/pdf/1608.05148.pdf. This architecture uses additive reconstruction framework and ConvGRU layers.
213 | """
214 | def __init__(self, bottleneck, num_iters, batch_size, input_size):
215 | super(LidarCompressionNetwork, self).__init__(name="lidar_compression_network")
216 | self.bottleneck = bottleneck
217 | self.num_iters = num_iters
218 | self.batch_size = batch_size
219 | self.input_size = input_size
220 |
221 | self.encoder = EncoderRNN(self.bottleneck, name="encoder")
222 | self.decoder = DecoderRNN(name="decoder")
223 |
224 | self.normalize = Lambda(lambda x: tf.multiply(tf.subtract(x, 0.1), 2.5), name="normalization")
225 | self.subtract = Subtract()
226 | self.inputs = tf.keras.layers.Input(shape=(self.input_size, self.input_size, 1))
227 |
228 | self.DIM1 = self.input_size // 2
229 | self.DIM2 = self.DIM1 // 2
230 | self.DIM3 = self.DIM2 // 2
231 | self.DIM4 = self.DIM3 // 2
232 |
233 | self.loss_tracker = tf.keras.metrics.Mean(name="loss")
234 | self.metric_tracker = tf.keras.metrics.MeanAbsoluteError(name="mae")
235 |
236 | self.beta = 1.0 / self.num_iters
237 |
238 | def compute_loss(self, res):
239 | loss = tf.reduce_mean(tf.abs(res))
240 | return loss
241 |
242 | def initial_hidden(self, batch_size, hidden_size, filters, data_type=tf.dtypes.float32):
243 | """Initialize hidden and cell states, all zeros"""
244 | shape = tf.TensorShape([batch_size] + hidden_size + [filters])
245 | hidden = tf.zeros(shape, dtype=data_type)
246 | return hidden
247 |
248 | def call(self, inputs, training=False):
249 | # Initialize the hidden states when a new batch comes in
250 | hidden_e2 = self.initial_hidden(self.batch_size, [8, self.DIM2], 128, inputs.dtype)
251 | hidden_e3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 256, inputs.dtype)
252 | hidden_e4 = self.initial_hidden(self.batch_size, [2, self.DIM4], 256, inputs.dtype)
253 | hidden_d2 = self.initial_hidden(self.batch_size, [2, self.DIM4], 256, inputs.dtype)
254 | hidden_d3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 256, inputs.dtype)
255 | hidden_d4 = self.initial_hidden(self.batch_size, [8, self.DIM2], 128, inputs.dtype)
256 | hidden_d5 = self.initial_hidden(self.batch_size, [16, self.DIM1], 64, inputs.dtype)
257 | outputs = tf.zeros_like(inputs)
258 |
259 | inputs = self.normalize(inputs)
260 | res = inputs
261 | for i in range(self.num_iters):
262 | code, hidden_e2, hidden_e3, hidden_e4 = \
263 | self.encoder(res, hidden_e2, hidden_e3, hidden_e4, training=training)
264 |
265 | decoded, hidden_d2, hidden_d3, hidden_d4, hidden_d5 = \
266 | self.decoder(code, hidden_d2, hidden_d3, hidden_d4, hidden_d5, training=training)
267 |
268 | outputs = tf.add(outputs, decoded)
269 | # Update res as predicted output in this iteration subtract the original input
270 | res = self.subtract([outputs, inputs])
271 | self.add_loss(self.compute_loss(res))
272 | # Denormalize the tensors
273 | outputs = tf.clip_by_value(tf.add(tf.multiply(outputs, 0.4), 0.1), 0, 1)
274 | outputs = tf.cast(outputs, dtype=tf.float32)
275 | return outputs
276 |
277 | def train_step(self, data):
278 | inputs, labels = data
279 |
280 | # Run forward pass.
281 | with tf.GradientTape() as tape:
282 | outputs = self(inputs, training=True)
283 | loss = sum(self.losses)*self.beta
284 |
285 | # Run backwards pass.
286 | trainable_vars = self.trainable_variables
287 | gradients = tape.gradient(loss, trainable_vars)
288 | self.optimizer.apply_gradients(zip(gradients, trainable_vars))
289 | # Update & Compute Metrics
290 | with tf.name_scope("metrics") as scope:
291 | self.loss_tracker.update_state(loss)
292 | self.metric_tracker.update_state(outputs, labels)
293 | metric_result = self.metric_tracker.result()
294 | loss_result = self.loss_tracker.result()
295 | return {'loss': loss_result, 'mae': metric_result}
296 |
297 | def test_step(self, data):
298 | inputs, labels = data
299 | # Run forward pass.
300 | outputs = self(inputs, training=False)
301 | loss = sum(self.losses)*self.beta
302 | # Update metrics
303 | self.loss_tracker.update_state(loss)
304 | self.metric_tracker.update_state(outputs, labels)
305 | return {'loss': self.loss_tracker.result(), 'mae': self.metric_tracker.result()}
306 |
307 | def predict_step(self, data):
308 | inputs, labels = data
309 | outputs = self(inputs, training=False)
310 | return outputs
311 |
312 | @property
313 | def metrics(self):
314 | return [self.loss_tracker, self.metric_tracker]
315 |
--------------------------------------------------------------------------------
|
89 |
90 | During inference, the model can be applied to range image with any width and height divisible to 32, as the following
91 | example shows:
92 |
93 | #### Input range image representation:
94 | 
95 |
96 | #### Predicted range image representation:
97 | 
98 |
99 |
100 | ## Model Training
101 |
102 | ### Sample Dataset
103 | A demo sample dataset can be found in `range_image_compression/demo_samples` in order to quickly test your
104 | environment.
105 |
106 | ### Dependencies
107 | The implementation is based on *Tensorflow 2.9.0*. All necessary dependencies can be installed with
108 | ```bash
109 | # /range_image_compression >$
110 | pip install -r requirements.txt
111 | ```
112 |
113 | The architecture `Oneshot LSTM` uses GDN layers proposed by [Ballé et al.](https://arxiv.org/pdf/1511.06281.pdf),
114 | which is supported in [TensorFlow Compression](https://github.com/tensorflow/compression).
115 | It can be installed with:
116 | ```bash
117 | # /range_image_compression >$
118 | pip3 install tensorflow-compression==2.9.0
119 | ```
120 |
121 | ### Run Training
122 | A training with the lightweight demo network using the sample dataset can be started with the
123 | following command:
124 | ```bash
125 | # /range_image_compression >$
126 | python3 ./train.py \
127 | --train_data_dir="demo_samples/training" \
128 | --val_data_dir="demo_samples/validation" \
129 | --train_output_dir="output" \
130 | --model=additive_lstm_demo
131 | ```
132 | If you downloaded the whole dataset (see below) then you would have to adapt the values for `--train_data_dir` and
133 | `--val_data_dir` accordingly.
134 |
135 | ### Run Training with Docker
136 | We also provide a docker environment to train the model. First build the docker image and then start the
137 | training:
138 | ```bash
139 | # /docker >$
140 | ./docker_build.sh
141 | ./docker_train.sh
142 | ```
143 |
144 |
145 | ## Configuration
146 | Parameters for the training can be set up in the configurations located in the directory
147 | [range_image_compression/configs](range_image_compression/configs). It is recommended to use a potent multi-gpu setup
148 | for efficient training.
149 |
150 | ### Learning Rate Schedule
151 | The following cosine learning rate scheduler is used:
152 |
153 | 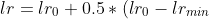*(1+cos((e-e_{max})/(e_{min}-e_{max})*\pi)))
154 |
155 | | Parameter | Description | Example |
156 | | --- | --- | --- |
157 | | `init_learning_rate` | initial learning rate | `2e-3` |
158 | | `min_learning_rate` | minimum learning rate | `1e-7` |
159 | | `max_learning_rate_epoch` | epoch where learning rate begins to decrease | `0` |
160 | | `min_learning_rate_epoch` | epoch of minimum learning rate | `3000` |
161 |
162 | ### Network Architecture
163 | Default parameters for the network architectures
164 |
165 | | Parameter | Description | Example |
166 | | --- | --- | --- |
167 | | `bottleneck` | bottleneck size of architecture | `32` |
168 | | `num_iters` | maximum number of iterations | `32` |
169 |
170 | ### Model Zoo
171 | | Model Architecture | Filename | Batch Size | Validation MAE | Evaluation SNNRMSE `iter=32` |
172 | |--------------------|---------------------------------------|------------|----------------|------------------------------|
173 | | Additive LSTM | `additive_lstm_32b_32iter.hdf5` | 32 | `2.6e-04` | `0.03473` |
174 | | Additive LSTM Slim | `additive_lstm_128b_32iter_slim.hdf5` | 128 | `2.3e-04` | `0.03636` |
175 | | Additive LSTM Demo | `additive_lstm_128b_32iter_demo.hdf5` | 128 | `2.9e-04` | `0.09762` |
176 | | Oneshot LSTM | `oneshot_lstm_b128_32iter.hdf5` | 128 | `2.9e-04` | `0.05137` |
177 | | Additive GRU | Will be uploaded soon | TBD | TBD | TBD |
178 |
179 | ## Download of Dataset, Models and Evaluation Frames
180 | The dataset to train the range image compression framework can be retrieved from [https://rwth-aachen.sciebo.de/s/MLJ4UaDJuVkYtna](https://rwth-aachen.sciebo.de/s/MLJ4UaDJuVkYtna).
181 | There you should be able to download the following files:
182 |
183 | - __`pointcloud_compression.zip`__ (1.8 GB): ZIP File which contains three directories
184 | - `train`: 30813 range images for training
185 | - `val`: 6162 cropped `32 x 32` range images for validation
186 | - `test`: 1217 range images for testing
187 | - __`evaluation_frames.bag`__ (17.6 MB): ROS bag which contains the Velodyne package data in order to evaluate the model.
188 | Frames in this bag file were not used for training nor for validation.
189 | - __`additive_lstm_32b_32iter.hdf5`__ (271 MB): Trained model with a bottleneck size of 32
190 | - __`additive_lstm_128b_32iter_slim.hdf5`__ (67.9 MB): Trained model with a bottleneck size of 32
191 | - __`oneshot_lstm_b128_32iter.hdf5`__ (68.1 MB): Trained model with a bottleneck size of 32
192 | - __`additive_lstm_256b_32iter_demo.hdf5`__ (14.3 MB): Trained model with a bottleneck sizeof 32
193 |
194 | ## Inference & Evaluation Node
195 | The inference and evaluation is conducted with ROS. The inferences and preprocessing nodes can be found
196 | under [catkin_ws/src](catkin_ws/src). The idea is to use recorded Velodyne package data which are stored in a `.bag`
197 | file. This bag file is then played with `rosbag play` and the preprocessing and inference nodes are applied to this raw
198 | sensor data stream. In order to run the inference and evaluation you will need to execute the following steps.
199 |
200 | ### 1. Initialize Velodyne Driver
201 | To run the evaluation code we need to clone the Velodyne Driver from the [official repository](https://github.com/ros-drivers/velodyne).
202 | The driver is integrated as a submodule to [catkin_ws/src/velodyne](catkin_ws/src/velodyne). You can initialize the
203 | submodule with:
204 | ```bash
205 | git submodule init
206 | git submodule update
207 | ```
208 |
209 | ### 2. Pull Docker Image
210 | We provide a docker image which contains ROS Noetic and Tensorflow in order to execute the inference and evaluation
211 | nodes. You can pull this dockerfile from [Docker Hub](https://hub.docker.com/r/tillbeemelmanns/pointcloud_compression)
212 | with the command:
213 | ```bash
214 | docker pull tillbeemelmanns/pointcloud_compression:noetic
215 | ```
216 |
217 | ### 3. Download Weights
218 | Download the model's weights as `.hdf5` from the download link and copy this file to `catkin_ws/models`. Then, in the
219 | [configuration file](catkin_ws/src/pointcloud_to_rangeimage/params/pointcloud_to_rangeimage.yaml) insert the
220 | correct path for the parameter `weights_path`. Note, that we will later mount the directory `catkin_ws` into
221 | the docker container to `/catkin_ws`. Hence, the path will start with `/catkin_ws`.
222 |
223 | ### 4. Download ROS Bag
224 | Perform the same procedure with the bag file. Copy the bag file into `catkin_ws/rosbags`. The filename should be
225 | `evaluation_frames.bag`. This bag file will be used in this [launch file](catkin_ws/src/pointcloud_to_rangeimage/launch/compression.launch).
226 |
227 |
228 | ### 5. Start Docker Container
229 | Start the docker container using the script
230 | ```bash
231 | # /docker >$
232 | ./docker_eval.sh
233 | ```
234 | Calling this script for the first time will just start the container.
235 | Then open a second terminal and execute `./docker_eval.sh` script again in order to open the container with bash.
236 | ```bash
237 | # /docker >$
238 | ./docker_eval.sh
239 | ```
240 |
241 | ### 6. Build & Execute
242 | Run the following commands inside the container to build and launch the compression framework.
243 | ```bash
244 | # /catkin_ws >$
245 | catkin build
246 | source devel/setup.bash
247 | roslaunch pointcloud_to_rangeimage compression.launch
248 | ```
249 |
250 | You should see the following RVIZ window which visualizes the reconstructed point cloud.
251 | 
252 |
253 | ### 7. GPU Inference
254 | In case you have a capable GPU, try to change line 44 in [docker_eval.sh](docker/docker_eval.sh) and define your GPU ID
255 | with flag `-g`
256 |
257 | ```sh
258 | $DIR/run-ros.sh -g 0 $@
259 | ```
260 |
261 | ## Authors of this Repository
262 | [Till Beemelmanns](https://github.com/TillBeemelmanns) and [Yuchen Tao](https://orcid.org/0000-0002-0357-0637)
263 |
264 |
265 | Mail: `till.beemelmanns (at) rwth-aachen.de`
266 |
267 | Mail: `yuchen.tao (at) rwth-aachen.de`
268 |
269 | ## Cite
270 |
271 | ```
272 | @INPROCEEDINGS{9827270,
273 | author={Beemelmanns, Till and Tao, Yuchen and Lampe, Bastian and Reiher, Lennart and Kempen, Raphael van and Woopen, Timo and Eckstein, Lutz},
274 | booktitle={2022 IEEE Intelligent Vehicles Symposium (IV)},
275 | title={3D Point Cloud Compression with Recurrent Neural Network and Image Compression Methods},
276 | year={2022},
277 | volume={},
278 | number={},
279 | pages={345-351},
280 | doi={10.1109/IV51971.2022.9827270}}
281 | ```
282 |
283 | ## Acknowledgement
284 |
285 | >This research is accomplished within the project ”UNICARagil” (FKZ 16EMO0284K). We acknowledge the financial support for
286 | >the project by the Federal Ministry of Education and Research of Germany (BMBF).
287 |
--------------------------------------------------------------------------------
/range_image_compression/architectures/Additive_LSTM.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | import tensorflow as tf
26 | from keras.models import Model
27 | from keras.layers import Layer, Lambda
28 | from keras.layers import Conv2D
29 | from keras.layers import Add, Subtract
30 |
31 |
32 | class RnnConv(Layer):
33 | """Convolutional LSTM cell
34 | See detail in formula (4-6) in paper
35 | "Full Resolution Image Compression with Recurrent Neural Networks"
36 | https://arxiv.org/pdf/1608.05148.pdf
37 | Args:
38 | name: name of current ConvLSTM layer
39 | filters: number of filters for each convolutional operation
40 | strides: strides size
41 | kernel_size: kernel size of convolutional operation
42 | hidden_kernel_size: kernel size of convolutional operation for hidden state
43 | Input:
44 | inputs: input of the layer
45 | hidden: hidden state and cell state of the layer
46 | Output:
47 | newhidden: updated hidden state of the layer
48 | newcell: updated cell state of the layer
49 | """
50 |
51 | def __init__(self, name, filters, strides, kernel_size, hidden_kernel_size):
52 | super(RnnConv, self).__init__()
53 | self.filters = filters
54 | self.strides = strides
55 | self.conv_i = Conv2D(filters=4 * self.filters,
56 | kernel_size=kernel_size,
57 | strides=self.strides,
58 | padding='same',
59 | use_bias=False,
60 | name=name + '_i')
61 | self.conv_h = Conv2D(filters=4 * self.filters,
62 | kernel_size=hidden_kernel_size,
63 | padding='same',
64 | use_bias=False,
65 | name=name + '_h')
66 |
67 | def call(self, inputs, hidden):
68 | # with tf.variable_scope(name, reuse=tf.AUTO_REUSE):
69 | conv_inputs = self.conv_i(inputs)
70 | conv_hidden = self.conv_h(hidden[0])
71 | # all gates are determined by input and hidden layer
72 | in_gate, f_gate, out_gate, c_gate = tf.split(
73 | conv_inputs + conv_hidden, 4, axis=-1) # each gate get the same number of filters
74 | in_gate = tf.nn.sigmoid(in_gate) # input/update gate
75 | f_gate = tf.nn.sigmoid(f_gate)
76 | out_gate = tf.nn.sigmoid(out_gate)
77 | c_gate = tf.nn.tanh(c_gate) # candidate cell, calculated from input
78 | # forget_gate*old_cell+input_gate(update)*candidate_cell
79 | newcell = tf.multiply(f_gate, hidden[1]) + tf.multiply(in_gate, c_gate)
80 | newhidden = tf.multiply(out_gate, tf.nn.tanh(newcell))
81 | return newhidden, newcell
82 |
83 |
84 | class EncoderRNN(Layer):
85 | """
86 | Encoder layer for one iteration.
87 | Args:
88 | bottleneck: bottleneck size of the layer
89 | Input:
90 | input: output array from last iteration.
91 | In the first iteration, it is the normalized image patch
92 | hidden2, hidden3, hidden4: hidden and cell states of corresponding ConvLSTM layers
93 | training: boolean, whether the call is in inference mode or training mode
94 | Output:
95 | encoded: encoded binary array in each iteration
96 | hidden2, hidden3, hidden4: hidden and cell states of corresponding ConvLSTM layers
97 | """
98 | def __init__(self, bottleneck, name=None):
99 | super(EncoderRNN, self).__init__(name=name)
100 | self.bottleneck = bottleneck
101 | self.Conv_e1 = Conv2D(64, kernel_size=(3, 3), strides=(2, 2), padding="same", use_bias=False, name='Conv_e1')
102 | self.RnnConv_e1 = RnnConv("RnnConv_e1", 256, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
103 | self.RnnConv_e2 = RnnConv("RnnConv_e2", 512, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
104 | self.RnnConv_e3 = RnnConv("RnnConv_e3", 512, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
105 | self.Conv_b = Conv2D(self.bottleneck, kernel_size=(1, 1), activation=tf.nn.tanh, use_bias=False, name='b_conv')
106 | self.Sign = Lambda(lambda x: tf.sign(x), name="sign")
107 |
108 | def call(self, input, hidden2, hidden3, hidden4, training=False):
109 | # with tf.compat.v1.variable_scope("encoder", reuse=True):
110 | # input size (32,32,3)
111 | x = self.Conv_e1(input)
112 | # x = self.GDN(x)
113 | # (16,16,64)
114 | hidden2 = self.RnnConv_e1(x, hidden2)
115 | x = hidden2[0]
116 | # (8,8,256)
117 | hidden3 = self.RnnConv_e2(x, hidden3)
118 | x = hidden3[0]
119 | # (4,4,512)
120 | hidden4 = self.RnnConv_e3(x, hidden4)
121 | x = hidden4[0]
122 | # (2,2,512)
123 | # binarizer
124 | x = self.Conv_b(x)
125 | # (2,2,bottleneck)
126 | # Using randomized quantization during training.
127 | if training:
128 | probs = (1 + x) / 2
129 | dist = tf.compat.v1.distributions.Bernoulli(probs=probs, dtype=input.dtype)
130 | noise = 2 * dist.sample(name='noise') - 1 - x
131 | encoded = x + tf.stop_gradient(noise)
132 | else:
133 | encoded = self.Sign(x)
134 | return encoded, hidden2, hidden3, hidden4
135 |
136 |
137 | class DecoderRNN(Layer):
138 | """
139 | Decoder layer for one iteration.
140 | Input:
141 | input: decoded array in each iteration
142 | hidden2, hidden3, hidden4, hidden5: hidden and cell states of corresponding ConvLSTM layers
143 | training: boolean, whether the call is in inference mode or training mode
144 | Output:
145 | decoded: decoded array in each iteration
146 | hidden2, hidden3, hidden4, hidden5: hidden and cell states of corresponding ConvLSTM layers
147 | """
148 | def __init__(self, name=None):
149 | super(DecoderRNN, self).__init__(name=name)
150 | self.Conv_d1 = Conv2D(512, kernel_size=(1, 1), use_bias=False, name='d_conv1')
151 | self.RnnConv_d2 = RnnConv("RnnConv_d2", 512, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
152 | self.RnnConv_d3 = RnnConv("RnnConv_d3", 512, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
153 | self.RnnConv_d4 = RnnConv("RnnConv_d4", 256, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
154 | self.RnnConv_d5 = RnnConv("RnnConv_d5", 128, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
155 | self.Conv_d6 = Conv2D(filters=1, kernel_size=(1, 1), padding='same', use_bias=False, name='d_conv6',
156 | activation=tf.nn.tanh)
157 | self.DTS1 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_1")
158 | self.DTS2 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_2")
159 | self.DTS3 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_3")
160 | self.DTS4 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_4")
161 | self.Add = Add(name="add")
162 | self.Out = Lambda(lambda x: x*0.5, name="out")
163 |
164 | def call(self, input, hidden2, hidden3, hidden4, hidden5, training=False):
165 | # (2,2,bottleneck)
166 | x_conv = self.Conv_d1(input)
167 | # (2,2,512)
168 | hidden2 = self.RnnConv_d2(x_conv, hidden2)
169 | x = hidden2[0]
170 | # (2,2,512)
171 | x = self.Add([x, x_conv])
172 | x = self.DTS1(x)
173 | # (4,4,128)
174 | hidden3 = self.RnnConv_d3(x, hidden3)
175 | x = hidden3[0]
176 | # (4,4,512)
177 | x = self.DTS2(x)
178 | # (8,8,128)
179 | hidden4 = self.RnnConv_d4(x, hidden4)
180 | x = hidden4[0]
181 | # (8,8,256)
182 | x = self.DTS3(x)
183 | # (16,16,64)
184 | hidden5 = self.RnnConv_d5(x, hidden5)
185 | x = hidden5[0]
186 | # (16,16,128)
187 | x = self.DTS4(x)
188 | # (32,32,32)
189 | # output in range (-0.5,0.5)
190 | x = self.Conv_d6(x)
191 | decoded = self.Out(x)
192 | return decoded, hidden2, hidden3, hidden4, hidden5
193 |
194 |
195 | class LidarCompressionNetwork(Model):
196 | """
197 | The model to compress range image projected from point clouds captured by Velodyne LiDAR sensor
198 | The encoder and decoder layers are iteratively called for num_iters iterations.
199 | Details see paper Full Resolution Image Compression with Recurrent Neural Networks
200 | https://arxiv.org/pdf/1608.05148.pdf. This architecture uses additive reconstruction framework and ConvLSTM layers.
201 | """
202 | def __init__(self, bottleneck, num_iters, batch_size, input_size):
203 | super(LidarCompressionNetwork, self).__init__(name="lidar_compression_network")
204 | self.bottleneck = bottleneck
205 | self.num_iters = num_iters
206 | self.batch_size = batch_size
207 | self.input_size = input_size
208 |
209 | self.encoder = EncoderRNN(self.bottleneck, name="encoder")
210 | self.decoder = DecoderRNN(name="decoder")
211 |
212 | self.normalize = Lambda(lambda x: tf.multiply(tf.subtract(x, 0.1), 2.5), name="normalization")
213 | self.subtract = Subtract()
214 | self.inputs = tf.keras.layers.Input(shape=(self.input_size, self.input_size, 1))
215 |
216 | self.DIM1 = self.input_size // 2
217 | self.DIM2 = self.DIM1 // 2
218 | self.DIM3 = self.DIM2 // 2
219 | self.DIM4 = self.DIM3 // 2
220 |
221 | self.loss_tracker = tf.keras.metrics.Mean(name="loss")
222 | self.metric_tracker = tf.keras.metrics.MeanAbsoluteError(name="mae")
223 |
224 | self.beta = 1.0 / self.num_iters
225 |
226 | def compute_loss(self, res):
227 | loss = tf.reduce_mean(tf.abs(res))
228 | return loss
229 |
230 | def initial_hidden(self, batch_size, hidden_size, filters, data_type=tf.dtypes.float32):
231 | """Initialize hidden and cell states, all zeros"""
232 | shape = tf.TensorShape([batch_size] + hidden_size + [filters])
233 | hidden = tf.zeros(shape, dtype=data_type)
234 | cell = tf.zeros(shape, dtype=data_type)
235 | return hidden, cell
236 |
237 | def call(self, inputs, training=False):
238 | # Initialize the hidden states when a new batch comes in
239 | hidden_e2 = self.initial_hidden(self.batch_size, [8, self.DIM2], 256, inputs.dtype)
240 | hidden_e3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 512, inputs.dtype)
241 | hidden_e4 = self.initial_hidden(self.batch_size, [2, self.DIM4], 512, inputs.dtype)
242 | hidden_d2 = self.initial_hidden(self.batch_size, [2, self.DIM4], 512, inputs.dtype)
243 | hidden_d3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 512, inputs.dtype)
244 | hidden_d4 = self.initial_hidden(self.batch_size, [8, self.DIM2], 256, inputs.dtype)
245 | hidden_d5 = self.initial_hidden(self.batch_size, [16, self.DIM1], 128, inputs.dtype)
246 | outputs = tf.zeros_like(inputs)
247 |
248 | inputs = self.normalize(inputs)
249 | res = inputs
250 | for i in range(self.num_iters):
251 | code, hidden_e2, hidden_e3, hidden_e4 = \
252 | self.encoder(res, hidden_e2, hidden_e3, hidden_e4, training=training)
253 |
254 | decoded, hidden_d2, hidden_d3, hidden_d4, hidden_d5 = \
255 | self.decoder(code, hidden_d2, hidden_d3, hidden_d4, hidden_d5, training=training)
256 |
257 | outputs = tf.add(outputs, decoded)
258 | # Update res as predicted output in this iteration subtract the original input
259 | res = self.subtract([outputs, inputs])
260 | self.add_loss(self.compute_loss(res))
261 | # Denormalize the tensors
262 | outputs = tf.clip_by_value(tf.add(tf.multiply(outputs, 0.4), 0.1), 0, 1)
263 | outputs = tf.cast(outputs, dtype=tf.float32)
264 | return outputs
265 |
266 | def train_step(self, data):
267 | inputs, labels = data
268 |
269 | # Run forward pass.
270 | with tf.GradientTape() as tape:
271 | outputs = self(inputs, training=True)
272 | loss = sum(self.losses)*self.beta
273 |
274 | # Run backwards pass.
275 | trainable_vars = self.trainable_variables
276 | gradients = tape.gradient(loss, trainable_vars)
277 | self.optimizer.apply_gradients(zip(gradients, trainable_vars))
278 | # Update & Compute Metrics
279 | with tf.name_scope("metrics") as scope:
280 | self.loss_tracker.update_state(loss)
281 | self.metric_tracker.update_state(outputs, labels)
282 | metric_result = self.metric_tracker.result()
283 | loss_result = self.loss_tracker.result()
284 | return {'loss': loss_result, 'mae': metric_result}
285 |
286 | def test_step(self, data):
287 | inputs, labels = data
288 | # Run forward pass.
289 | outputs = self(inputs, training=False)
290 | loss = sum(self.losses)*self.beta
291 | # Update metrics
292 | self.loss_tracker.update_state(loss)
293 | self.metric_tracker.update_state(outputs, labels)
294 | return {'loss': self.loss_tracker.result(), 'mae': self.metric_tracker.result()}
295 |
296 | def predict_step(self, data):
297 | inputs, labels = data
298 | outputs = self(inputs, training=False)
299 | return outputs
300 |
301 | @property
302 | def metrics(self):
303 | return [self.loss_tracker, self.metric_tracker]
304 |
--------------------------------------------------------------------------------
/range_image_compression/architectures/Additive_LSTM_Demo.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | import tensorflow as tf
26 | from keras.models import Model
27 | from keras.layers import Layer, Lambda
28 | from keras.layers import Conv2D
29 | from keras.layers import Add, Subtract
30 |
31 |
32 | class RnnConv(Layer):
33 | """Convolutional LSTM cell
34 | See detail in formula (4-6) in paper
35 | "Full Resolution Image Compression with Recurrent Neural Networks"
36 | https://arxiv.org/pdf/1608.05148.pdf
37 | Args:
38 | name: name of current ConvLSTM layer
39 | filters: number of filters for each convolutional operation
40 | strides: strides size
41 | kernel_size: kernel size of convolutional operation
42 | hidden_kernel_size: kernel size of convolutional operation for hidden state
43 | Input:
44 | inputs: input of the layer
45 | hidden: hidden state and cell state of the layer
46 | Output:
47 | newhidden: updated hidden state of the layer
48 | newcell: updated cell state of the layer
49 | """
50 |
51 | def __init__(self, name, filters, strides, kernel_size, hidden_kernel_size):
52 | super(RnnConv, self).__init__()
53 | self.filters = filters
54 | self.strides = strides
55 | self.conv_i = Conv2D(filters=4 * self.filters,
56 | kernel_size=kernel_size,
57 | strides=self.strides,
58 | padding='same',
59 | use_bias=False,
60 | name=name + '_i')
61 | self.conv_h = Conv2D(filters=4 * self.filters,
62 | kernel_size=hidden_kernel_size,
63 | padding='same',
64 | use_bias=False,
65 | name=name + '_h')
66 |
67 | def call(self, inputs, hidden):
68 | # with tf.variable_scope(name, reuse=tf.AUTO_REUSE):
69 | conv_inputs = self.conv_i(inputs)
70 | conv_hidden = self.conv_h(hidden[0])
71 | # all gates are determined by input and hidden layer
72 | in_gate, f_gate, out_gate, c_gate = tf.split(
73 | conv_inputs + conv_hidden, 4, axis=-1) # each gate get the same number of filters
74 | in_gate = tf.nn.sigmoid(in_gate) # input/update gate
75 | f_gate = tf.nn.sigmoid(f_gate)
76 | out_gate = tf.nn.sigmoid(out_gate)
77 | c_gate = tf.nn.tanh(c_gate) # candidate cell, calculated from input
78 | # forget_gate*old_cell+input_gate(update)*candidate_cell
79 | newcell = tf.multiply(f_gate, hidden[1]) + tf.multiply(in_gate, c_gate)
80 | newhidden = tf.multiply(out_gate, tf.nn.tanh(newcell))
81 | return newhidden, newcell
82 |
83 |
84 | class EncoderRNN(Layer):
85 | """
86 | Encoder layer for one iteration.
87 | Args:
88 | bottleneck: bottleneck size of the layer
89 | Input:
90 | input: output array from last iteration.
91 | In the first iteration, it is the normalized image patch
92 | hidden2, hidden3, hidden4: hidden and cell states of corresponding ConvLSTM layers
93 | training: boolean, whether the call is in inference mode or training mode
94 | Output:
95 | encoded: encoded binary array in each iteration
96 | hidden2, hidden3, hidden4: hidden and cell states of corresponding ConvLSTM layers
97 | """
98 | def __init__(self, bottleneck, name=None):
99 | super(EncoderRNN, self).__init__(name=name)
100 | self.bottleneck = bottleneck
101 | self.Conv_e1 = Conv2D(32, kernel_size=(3, 3), strides=(2, 2), padding="same", use_bias=False, name='Conv_e1')
102 | self.RnnConv_e1 = RnnConv("RnnConv_e1", 64, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
103 | self.RnnConv_e2 = RnnConv("RnnConv_e2", 64, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
104 | self.RnnConv_e3 = RnnConv("RnnConv_e3", 128, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
105 | self.Conv_b = Conv2D(self.bottleneck, kernel_size=(1, 1), activation=tf.nn.tanh, use_bias=False, name='b_conv')
106 | self.Sign = Lambda(lambda x: tf.sign(x), name="sign")
107 |
108 | def call(self, input, hidden2, hidden3, hidden4, training=False):
109 | # with tf.compat.v1.variable_scope("encoder", reuse=True):
110 | # input size (32,32,1)
111 | x = self.Conv_e1(input)
112 | # x = self.GDN(x)
113 | # (16,16,64)
114 | hidden2 = self.RnnConv_e1(x, hidden2)
115 | x = hidden2[0]
116 | # (8,8,256)
117 | hidden3 = self.RnnConv_e2(x, hidden3)
118 | x = hidden3[0]
119 | # (4,4,512)
120 | hidden4 = self.RnnConv_e3(x, hidden4)
121 | x = hidden4[0]
122 | # (2,2,512)
123 | # binarizer
124 | x = self.Conv_b(x)
125 | # (2,2,bottleneck)
126 | # Using randomized quantization during training.
127 | if training:
128 | probs = (1 + x) / 2
129 | dist = tf.compat.v1.distributions.Bernoulli(probs=probs, dtype=input.dtype)
130 | noise = 2 * dist.sample(name='noise') - 1 - x
131 | encoded = x + tf.stop_gradient(noise)
132 | else:
133 | encoded = self.Sign(x)
134 | return encoded, hidden2, hidden3, hidden4
135 |
136 |
137 | class DecoderRNN(Layer):
138 | """
139 | Decoder layer for one iteration.
140 | Input:
141 | input: decoded array in each iteration
142 | hidden2, hidden3, hidden4, hidden5: hidden and cell states of corresponding ConvLSTM layers
143 | training: boolean, whether the call is in inference mode or training mode
144 | Output:
145 | decoded: decoded array in each iteration
146 | hidden2, hidden3, hidden4, hidden5: hidden and cell states of corresponding ConvLSTM layers
147 | """
148 | def __init__(self, name=None):
149 | super(DecoderRNN, self).__init__(name=name)
150 | self.Conv_d1 = Conv2D(128, kernel_size=(1, 1), use_bias=False, name='d_conv1')
151 | self.RnnConv_d2 = RnnConv("RnnConv_d2", 128, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
152 | self.RnnConv_d3 = RnnConv("RnnConv_d3", 128, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
153 | self.RnnConv_d4 = RnnConv("RnnConv_d4", 64, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
154 | self.RnnConv_d5 = RnnConv("RnnConv_d5", 64, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
155 | self.Conv_d6 = Conv2D(filters=1, kernel_size=(1, 1), padding='same', use_bias=False, name='d_conv6',
156 | activation=tf.nn.tanh)
157 | self.DTS1 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_1")
158 | self.DTS2 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_2")
159 | self.DTS3 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_3")
160 | self.DTS4 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_4")
161 | self.Add = Add(name="add")
162 | self.Out = Lambda(lambda x: x*0.5, name="out")
163 |
164 | def call(self, input, hidden2, hidden3, hidden4, hidden5, training=False):
165 | # (2,2,bottleneck)
166 | x_conv = self.Conv_d1(input)
167 | # (2,2,512)
168 | hidden2 = self.RnnConv_d2(x_conv, hidden2)
169 | x = hidden2[0]
170 | # (2,2,512)
171 | x = self.Add([x, x_conv])
172 | x = self.DTS1(x)
173 | # (4,4,128)
174 | hidden3 = self.RnnConv_d3(x, hidden3)
175 | x = hidden3[0]
176 | # (4,4,512)
177 | x = self.DTS2(x)
178 | # (8,8,128)
179 | hidden4 = self.RnnConv_d4(x, hidden4)
180 | x = hidden4[0]
181 | # (8,8,256)
182 | x = self.DTS3(x)
183 | # (16,16,64)
184 | hidden5 = self.RnnConv_d5(x, hidden5)
185 | x = hidden5[0]
186 | # (16,16,128)
187 | x = self.DTS4(x)
188 | # (32,32,32)
189 | # output in range (-0.5,0.5)
190 | x = self.Conv_d6(x)
191 | decoded = self.Out(x)
192 | return decoded, hidden2, hidden3, hidden4, hidden5
193 |
194 |
195 | class LidarCompressionNetwork(Model):
196 | """
197 | The model to compress range image projected from point clouds captured by Velodyne LiDAR sensor
198 | The encoder and decoder layers are iteratively called for num_iters iterations.
199 | Details see paper Full Resolution Image Compression with Recurrent Neural Networks
200 | https://arxiv.org/pdf/1608.05148.pdf. This architecture uses additive reconstruction framework and ConvLSTM layers.
201 | """
202 | def __init__(self, bottleneck, num_iters, batch_size, input_size):
203 | super(LidarCompressionNetwork, self).__init__(name="lidar_compression_network")
204 | self.bottleneck = bottleneck
205 | self.num_iters = num_iters
206 | self.batch_size = batch_size
207 | self.input_size = input_size
208 |
209 | self.encoder = EncoderRNN(self.bottleneck, name="encoder")
210 | self.decoder = DecoderRNN(name="decoder")
211 |
212 | self.normalize = Lambda(lambda x: tf.multiply(tf.subtract(x, 0.1), 2.5), name="normalization")
213 | self.subtract = Subtract()
214 | self.inputs = tf.keras.layers.Input(shape=(self.input_size, self.input_size, 1))
215 |
216 | self.DIM1 = self.input_size // 2
217 | self.DIM2 = self.DIM1 // 2
218 | self.DIM3 = self.DIM2 // 2
219 | self.DIM4 = self.DIM3 // 2
220 |
221 | self.loss_tracker = tf.keras.metrics.Mean(name="loss")
222 | self.metric_tracker = tf.keras.metrics.MeanAbsoluteError(name="mae")
223 |
224 | self.beta = 1.0 / self.num_iters
225 |
226 | def compute_loss(self, res):
227 | loss = tf.reduce_mean(tf.abs(res))
228 | return loss
229 |
230 | def initial_hidden(self, batch_size, hidden_size, filters, data_type=tf.dtypes.float32):
231 | """Initialize hidden and cell states, all zeros"""
232 | shape = tf.TensorShape([batch_size] + hidden_size + [filters])
233 | hidden = tf.zeros(shape, dtype=data_type)
234 | cell = tf.zeros(shape, dtype=data_type)
235 | return hidden, cell
236 |
237 | def call(self, inputs, training=False):
238 | # Initialize the hidden states when a new batch comes in
239 | hidden_e2 = self.initial_hidden(self.batch_size, [8, self.DIM2], 64, inputs.dtype)
240 | hidden_e3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 64, inputs.dtype)
241 | hidden_e4 = self.initial_hidden(self.batch_size, [2, self.DIM4], 128, inputs.dtype)
242 | hidden_d2 = self.initial_hidden(self.batch_size, [2, self.DIM4], 128, inputs.dtype)
243 | hidden_d3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 128, inputs.dtype)
244 | hidden_d4 = self.initial_hidden(self.batch_size, [8, self.DIM2], 64, inputs.dtype)
245 | hidden_d5 = self.initial_hidden(self.batch_size, [16, self.DIM1], 64, inputs.dtype)
246 | outputs = tf.zeros_like(inputs)
247 |
248 | inputs = self.normalize(inputs)
249 | res = inputs
250 | for i in range(self.num_iters):
251 | code, hidden_e2, hidden_e3, hidden_e4 = \
252 | self.encoder(res, hidden_e2, hidden_e3, hidden_e4, training=training)
253 |
254 | decoded, hidden_d2, hidden_d3, hidden_d4, hidden_d5 = \
255 | self.decoder(code, hidden_d2, hidden_d3, hidden_d4, hidden_d5, training=training)
256 |
257 | outputs = tf.add(outputs, decoded)
258 | # Update res as predicted output in this iteration subtract the original input
259 | res = self.subtract([outputs, inputs])
260 | self.add_loss(self.compute_loss(res))
261 | # Denormalize the tensors
262 | outputs = tf.clip_by_value(tf.add(tf.multiply(outputs, 0.4), 0.1), 0, 1)
263 | outputs = tf.cast(outputs, dtype=tf.float32)
264 | return outputs
265 |
266 | def train_step(self, data):
267 | inputs, labels = data
268 |
269 | # Run forward pass.
270 | with tf.GradientTape() as tape:
271 | outputs = self(inputs, training=True)
272 | loss = sum(self.losses)*self.beta
273 |
274 | # Run backwards pass.
275 | trainable_vars = self.trainable_variables
276 | gradients = tape.gradient(loss, trainable_vars)
277 | self.optimizer.apply_gradients(zip(gradients, trainable_vars))
278 | # Update & Compute Metrics
279 | with tf.name_scope("metrics") as scope:
280 | self.loss_tracker.update_state(loss)
281 | self.metric_tracker.update_state(outputs, labels)
282 | metric_result = self.metric_tracker.result()
283 | loss_result = self.loss_tracker.result()
284 | return {'loss': loss_result, 'mae': metric_result}
285 |
286 | def test_step(self, data):
287 | inputs, labels = data
288 | # Run forward pass.
289 | outputs = self(inputs, training=False)
290 | loss = sum(self.losses)*self.beta
291 | # Update metrics
292 | self.loss_tracker.update_state(loss)
293 | self.metric_tracker.update_state(outputs, labels)
294 | return {'loss': self.loss_tracker.result(), 'mae': self.metric_tracker.result()}
295 |
296 | def predict_step(self, data):
297 | inputs, labels = data
298 | outputs = self(inputs, training=False)
299 | return outputs
300 |
301 | @property
302 | def metrics(self):
303 | return [self.loss_tracker, self.metric_tracker]
304 |
--------------------------------------------------------------------------------
/range_image_compression/architectures/Additive_LSTM_Slim.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | import tensorflow as tf
26 | from keras.models import Model
27 | from keras.layers import Layer, Lambda
28 | from keras.layers import Conv2D
29 | from keras.layers import Add, Subtract
30 |
31 |
32 | class RnnConv(Layer):
33 | """Convolutional LSTM cell
34 | See detail in formula (4-6) in paper
35 | "Full Resolution Image Compression with Recurrent Neural Networks"
36 | https://arxiv.org/pdf/1608.05148.pdf
37 | Args:
38 | name: name of current ConvLSTM layer
39 | filters: number of filters for each convolutional operation
40 | strides: strides size
41 | kernel_size: kernel size of convolutional operation
42 | hidden_kernel_size: kernel size of convolutional operation for hidden state
43 | Input:
44 | inputs: input of the layer
45 | hidden: hidden state and cell state of the layer
46 | Output:
47 | newhidden: updated hidden state of the layer
48 | newcell: updated cell state of the layer
49 | """
50 |
51 | def __init__(self, name, filters, strides, kernel_size, hidden_kernel_size):
52 | super(RnnConv, self).__init__()
53 | self.filters = filters
54 | self.strides = strides
55 | self.conv_i = Conv2D(filters=4 * self.filters,
56 | kernel_size=kernel_size,
57 | strides=self.strides,
58 | padding='same',
59 | use_bias=False,
60 | name=name + '_i')
61 | self.conv_h = Conv2D(filters=4 * self.filters,
62 | kernel_size=hidden_kernel_size,
63 | padding='same',
64 | use_bias=False,
65 | name=name + '_h')
66 |
67 | def call(self, inputs, hidden):
68 | # with tf.variable_scope(name, reuse=tf.AUTO_REUSE):
69 | conv_inputs = self.conv_i(inputs)
70 | conv_hidden = self.conv_h(hidden[0])
71 | # all gates are determined by input and hidden layer
72 | in_gate, f_gate, out_gate, c_gate = tf.split(
73 | conv_inputs + conv_hidden, 4, axis=-1) # each gate get the same number of filters
74 | in_gate = tf.nn.sigmoid(in_gate) # input/update gate
75 | f_gate = tf.nn.sigmoid(f_gate)
76 | out_gate = tf.nn.sigmoid(out_gate)
77 | c_gate = tf.nn.tanh(c_gate) # candidate cell, calculated from input
78 | # forget_gate*old_cell+input_gate(update)*candidate_cell
79 | newcell = tf.multiply(f_gate, hidden[1]) + tf.multiply(in_gate, c_gate)
80 | newhidden = tf.multiply(out_gate, tf.nn.tanh(newcell))
81 | return newhidden, newcell
82 |
83 |
84 | class EncoderRNN(Layer):
85 | """
86 | Encoder layer for one iteration.
87 | Args:
88 | bottleneck: bottleneck size of the layer
89 | Input:
90 | input: output array from last iteration.
91 | In the first iteration, it is the normalized image patch
92 | hidden2, hidden3, hidden4: hidden and cell states of corresponding ConvLSTM layers
93 | training: boolean, whether the call is in inference mode or training mode
94 | Output:
95 | encoded: encoded binary array in each iteration
96 | hidden2, hidden3, hidden4: hidden and cell states of corresponding ConvLSTM layers
97 | """
98 | def __init__(self, bottleneck, name=None):
99 | super(EncoderRNN, self).__init__(name=name)
100 | self.bottleneck = bottleneck
101 | self.Conv_e1 = Conv2D(32, kernel_size=(3, 3), strides=(2, 2), padding="same", use_bias=False, name='Conv_e1')
102 | self.RnnConv_e1 = RnnConv("RnnConv_e1", 128, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
103 | self.RnnConv_e2 = RnnConv("RnnConv_e2", 256, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
104 | self.RnnConv_e3 = RnnConv("RnnConv_e3", 256, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
105 | self.Conv_b = Conv2D(self.bottleneck, kernel_size=(1, 1), activation=tf.nn.tanh, use_bias=False, name='b_conv')
106 | self.Sign = Lambda(lambda x: tf.sign(x), name="sign")
107 |
108 | def call(self, input, hidden2, hidden3, hidden4, training=False):
109 | # with tf.compat.v1.variable_scope("encoder", reuse=True):
110 | # input size (32,32,1)
111 | x = self.Conv_e1(input)
112 | # x = self.GDN(x)
113 | # (16,16,32)
114 | hidden2 = self.RnnConv_e1(x, hidden2)
115 | x = hidden2[0]
116 | # (8,8,128)
117 | hidden3 = self.RnnConv_e2(x, hidden3)
118 | x = hidden3[0]
119 | # (4,4,256)
120 | hidden4 = self.RnnConv_e3(x, hidden4)
121 | x = hidden4[0]
122 | # (2,2,256)
123 | # binarizer
124 | x = self.Conv_b(x)
125 | # (2,2,bottleneck)
126 | # Using randomized quantization during training.
127 | if training:
128 | probs = (1 + x) / 2
129 | dist = tf.compat.v1.distributions.Bernoulli(probs=probs, dtype=input.dtype)
130 | noise = 2 * dist.sample(name='noise') - 1 - x
131 | encoded = x + tf.stop_gradient(noise)
132 | else:
133 | encoded = self.Sign(x)
134 | return encoded, hidden2, hidden3, hidden4
135 |
136 |
137 | class DecoderRNN(Layer):
138 | """
139 | Decoder layer for one iteration.
140 | Input:
141 | input: decoded array in each iteration
142 | hidden2, hidden3, hidden4, hidden5: hidden and cell states of corresponding ConvLSTM layers
143 | training: boolean, whether the call is in inference mode or training mode
144 | Output:
145 | decoded: decoded array in each iteration
146 | hidden2, hidden3, hidden4, hidden5: hidden and cell states of corresponding ConvLSTM layers
147 | """
148 | def __init__(self, name=None):
149 | super(DecoderRNN, self).__init__(name=name)
150 | self.Conv_d1 = Conv2D(256, kernel_size=(1, 1), use_bias=False, name='d_conv1')
151 | self.RnnConv_d2 = RnnConv("RnnConv_d2", 256, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
152 | self.RnnConv_d3 = RnnConv("RnnConv_d3", 256, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
153 | self.RnnConv_d4 = RnnConv("RnnConv_d4", 128, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
154 | self.RnnConv_d5 = RnnConv("RnnConv_d5", 64, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
155 | self.Conv_d6 = Conv2D(filters=1, kernel_size=(1, 1), padding='same', use_bias=False, name='d_conv6',
156 | activation=tf.nn.tanh)
157 | self.DTS1 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_1")
158 | self.DTS2 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_2")
159 | self.DTS3 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_3")
160 | self.DTS4 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_4")
161 | self.Add = Add(name="add")
162 | self.Out = Lambda(lambda x: x*0.5, name="out")
163 |
164 | def call(self, input, hidden2, hidden3, hidden4, hidden5, training=False):
165 | # (2,2,bottleneck)
166 | x_conv = self.Conv_d1(input)
167 | # (2,2,256)
168 | hidden2 = self.RnnConv_d2(x_conv, hidden2)
169 | x = hidden2[0]
170 | # (2,2,256)
171 | x = self.Add([x, x_conv])
172 | x = self.DTS1(x)
173 | # (4,4,64)
174 | hidden3 = self.RnnConv_d3(x, hidden3)
175 | x = hidden3[0]
176 | # (4,4,256)
177 | x = self.DTS2(x)
178 | # (8,8,64)
179 | hidden4 = self.RnnConv_d4(x, hidden4)
180 | x = hidden4[0]
181 | # (8,8,128)
182 | x = self.DTS3(x)
183 | # (16,16,32)
184 | hidden5 = self.RnnConv_d5(x, hidden5)
185 | x = hidden5[0]
186 | # (16,16,64)
187 | x = self.DTS4(x)
188 | # (32,32,32)
189 | # output in range (-0.5,0.5)
190 | x = self.Conv_d6(x)
191 | decoded = self.Out(x)
192 | return decoded, hidden2, hidden3, hidden4, hidden5
193 |
194 |
195 | class LidarCompressionNetwork(Model):
196 | """
197 | The model to compress range image projected from point clouds captured by Velodyne LiDAR sensor
198 | The encoder and decoder layers are iteratively called for num_iters iterations.
199 | Details see paper Full Resolution Image Compression with Recurrent Neural Networks
200 | https://arxiv.org/pdf/1608.05148.pdf. This architecture uses additive reconstruction framework and ConvLSTM layers.
201 | """
202 | def __init__(self, bottleneck, num_iters, batch_size, input_size):
203 | super(LidarCompressionNetwork, self).__init__(name="lidar_compression_network")
204 | self.bottleneck = bottleneck
205 | self.num_iters = num_iters
206 | self.batch_size = batch_size
207 | self.input_size = input_size
208 |
209 | self.encoder = EncoderRNN(self.bottleneck, name="encoder")
210 | self.decoder = DecoderRNN(name="decoder")
211 |
212 | self.normalize = Lambda(lambda x: tf.multiply(tf.subtract(x, 0.1), 2.5), name="normalization")
213 | self.subtract = Subtract()
214 | self.inputs = tf.keras.layers.Input(shape=(self.input_size, self.input_size, 1))
215 |
216 | self.DIM1 = self.input_size // 2
217 | self.DIM2 = self.DIM1 // 2
218 | self.DIM3 = self.DIM2 // 2
219 | self.DIM4 = self.DIM3 // 2
220 |
221 | self.loss_tracker = tf.keras.metrics.Mean(name="loss")
222 | self.metric_tracker = tf.keras.metrics.MeanAbsoluteError(name="mae")
223 |
224 | self.beta = 1.0 / self.num_iters
225 |
226 | def compute_loss(self, res):
227 | loss = tf.reduce_mean(tf.abs(res))
228 | return loss
229 |
230 | def initial_hidden(self, batch_size, hidden_size, filters, data_type=tf.dtypes.float32):
231 | """Initialize hidden and cell states, all zeros"""
232 | shape = tf.TensorShape([batch_size] + hidden_size + [filters])
233 | hidden = tf.zeros(shape, dtype=data_type)
234 | cell = tf.zeros(shape, dtype=data_type)
235 | return hidden, cell
236 |
237 | def call(self, inputs, training=False):
238 | # Initialize the hidden states when a new batch comes in
239 | hidden_e2 = self.initial_hidden(self.batch_size, [8, self.DIM2], 128, inputs.dtype)
240 | hidden_e3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 256, inputs.dtype)
241 | hidden_e4 = self.initial_hidden(self.batch_size, [2, self.DIM4], 256, inputs.dtype)
242 | hidden_d2 = self.initial_hidden(self.batch_size, [2, self.DIM4], 256, inputs.dtype)
243 | hidden_d3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 256, inputs.dtype)
244 | hidden_d4 = self.initial_hidden(self.batch_size, [8, self.DIM2], 128, inputs.dtype)
245 | hidden_d5 = self.initial_hidden(self.batch_size, [16, self.DIM1], 64, inputs.dtype)
246 | outputs = tf.zeros_like(inputs)
247 |
248 | inputs = self.normalize(inputs)
249 | res = inputs
250 | for i in range(self.num_iters):
251 | code, hidden_e2, hidden_e3, hidden_e4 = \
252 | self.encoder(res, hidden_e2, hidden_e3, hidden_e4, training=training)
253 |
254 | decoded, hidden_d2, hidden_d3, hidden_d4, hidden_d5 = \
255 | self.decoder(code, hidden_d2, hidden_d3, hidden_d4, hidden_d5, training=training)
256 |
257 | outputs = tf.add(outputs, decoded)
258 | # Update res as predicted output in this iteration subtract the original input
259 | res = self.subtract([outputs, inputs])
260 | self.add_loss(self.compute_loss(res))
261 | # Denormalize the tensors
262 | outputs = tf.clip_by_value(tf.add(tf.multiply(outputs, 0.4), 0.1), 0, 1)
263 | outputs = tf.cast(outputs, dtype=tf.float32)
264 | return outputs
265 |
266 | def train_step(self, data):
267 | inputs, labels = data
268 |
269 | # Run forward pass.
270 | with tf.GradientTape() as tape:
271 | outputs = self(inputs, training=True)
272 | loss = sum(self.losses)*self.beta
273 |
274 | # Run backwards pass.
275 | trainable_vars = self.trainable_variables
276 | gradients = tape.gradient(loss, trainable_vars)
277 | self.optimizer.apply_gradients(zip(gradients, trainable_vars))
278 | # Update & Compute Metrics
279 | with tf.name_scope("metrics") as scope:
280 | self.loss_tracker.update_state(loss)
281 | self.metric_tracker.update_state(outputs, labels)
282 | metric_result = self.metric_tracker.result()
283 | loss_result = self.loss_tracker.result()
284 | return {'loss': loss_result, 'mae': metric_result}
285 |
286 | def test_step(self, data):
287 | inputs, labels = data
288 | # Run forward pass.
289 | outputs = self(inputs, training=False)
290 | loss = sum(self.losses)*self.beta
291 | # Update metrics
292 | self.loss_tracker.update_state(loss)
293 | self.metric_tracker.update_state(outputs, labels)
294 | return {'loss': self.loss_tracker.result(), 'mae': self.metric_tracker.result()}
295 |
296 | def predict_step(self, data):
297 | inputs, labels = data
298 | outputs = self(inputs, training=False)
299 | return outputs
300 |
301 | @property
302 | def metrics(self):
303 | return [self.loss_tracker, self.metric_tracker]
304 |
--------------------------------------------------------------------------------
/range_image_compression/architectures/Oneshot_LSTM.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | import tensorflow as tf
26 | from keras.models import Model
27 | from keras.layers import Layer, Lambda
28 | from keras.layers import Conv2D
29 | from keras.layers import Add, Subtract
30 | import tensorflow_compression as tfc
31 |
32 |
33 | class RnnConv(Layer):
34 | """Convolutional LSTM cell
35 | See detail in formula (4-6) in paper
36 | "Full Resolution Image Compression with Recurrent Neural Networks"
37 | https://arxiv.org/pdf/1608.05148.pdf
38 | Args:
39 | name: name of current ConvLSTM layer
40 | filters: number of filters for each convolutional operation
41 | strides: strides size
42 | kernel_size: kernel size of convolutional operation
43 | hidden_kernel_size: kernel size of convolutional operation for hidden state
44 | Input:
45 | inputs: input of the layer
46 | hidden: hidden state and cell state of the layer
47 | Output:
48 | newhidden: updated hidden state of the layer
49 | newcell: updated cell state of the layer
50 | """
51 |
52 | def __init__(self, name, filters, strides, kernel_size, hidden_kernel_size):
53 | super(RnnConv, self).__init__()
54 | self.filters = filters
55 | self.strides = strides
56 | self.conv_i = Conv2D(filters=4 * self.filters,
57 | kernel_size=kernel_size,
58 | strides=self.strides,
59 | padding='same',
60 | use_bias=False,
61 | name=name + '_i')
62 | self.conv_h = Conv2D(filters=4 * self.filters,
63 | kernel_size=hidden_kernel_size,
64 | padding='same',
65 | use_bias=False,
66 | name=name + '_h')
67 |
68 | def call(self, inputs, hidden):
69 | # with tf.variable_scope(name, reuse=tf.AUTO_REUSE):
70 | conv_inputs = self.conv_i(inputs)
71 | conv_hidden = self.conv_h(hidden[0])
72 | # all gates are determined by input and hidden layer
73 | in_gate, f_gate, out_gate, c_gate = tf.split(
74 | conv_inputs + conv_hidden, 4, axis=-1) # each gate get the same number of filters
75 | in_gate = tf.nn.sigmoid(in_gate) # input/update gate
76 | f_gate = tf.nn.sigmoid(f_gate)
77 | out_gate = tf.nn.sigmoid(out_gate)
78 | c_gate = tf.nn.tanh(c_gate) # candidate cell, calculated from input
79 | # forget_gate*old_cell+input_gate(update)*candidate_cell
80 | newcell = tf.multiply(f_gate, hidden[1]) + tf.multiply(in_gate, c_gate)
81 | newhidden = tf.multiply(out_gate, tf.nn.tanh(newcell))
82 | return newhidden, newcell
83 |
84 |
85 | class EncoderRNN(Layer):
86 | """
87 | Encoder layer for one iteration.
88 | Args:
89 | bottleneck: bottleneck size of the layer
90 | Input:
91 | input: output array from last iteration.
92 | In the first iteration, it is the normalized image patch
93 | hidden2, hidden3, hidden4: hidden and cell states of corresponding ConvLSTM layers
94 | training: boolean, whether the call is in inference mode or training mode
95 | Output:
96 | encoded: encoded binary array in each iteration
97 | hidden2, hidden3, hidden4: hidden and cell states of corresponding ConvLSTM layers
98 | """
99 | def __init__(self, bottleneck, name=None):
100 | super(EncoderRNN, self).__init__(name=name)
101 | self.bottleneck = bottleneck
102 | self.Conv_e1 = Conv2D(32, kernel_size=(3, 3), strides=(2, 2), padding="same", use_bias=False, name='Conv_e1')
103 | self.GDN = tfc.GDN(alpha_parameter=2, epsilon_parameter=0.5, name="gdn")
104 | self.RnnConv_e1 = RnnConv("RnnConv_e1", 128, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
105 | self.RnnConv_e2 = RnnConv("RnnConv_e2", 256, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
106 | self.RnnConv_e3 = RnnConv("RnnConv_e3", 256, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
107 | self.Conv_b = Conv2D(self.bottleneck, kernel_size=(1, 1), activation=tf.nn.tanh, use_bias=False, name='b_conv')
108 | self.Sign = Lambda(lambda x: tf.sign(x), name="sign")
109 |
110 | def call(self, input, hidden2, hidden3, hidden4, training=False):
111 | # input size (32,32,1)
112 | x = self.Conv_e1(input)
113 | x = self.GDN(x)
114 | # (16,16,64)
115 | hidden2 = self.RnnConv_e1(x, hidden2)
116 | x = hidden2[0]
117 | # (8,8,256)
118 | hidden3 = self.RnnConv_e2(x, hidden3)
119 | x = hidden3[0]
120 | # (4,4,512)
121 | hidden4 = self.RnnConv_e3(x, hidden4)
122 | x = hidden4[0]
123 | # (2,2,512)
124 | # binarizer
125 | x = self.Conv_b(x)
126 | # (2,2,bottleneck)
127 | # Using randomized quantization during training.
128 | if training:
129 | probs = (1 + x) / 2
130 | dist = tf.compat.v1.distributions.Bernoulli(probs=probs, dtype=input.dtype)
131 | noise = 2 * dist.sample(name='noise') - 1 - x
132 | encoded = x + tf.stop_gradient(noise)
133 | else:
134 | encoded = self.Sign(x)
135 | return encoded, hidden2, hidden3, hidden4
136 |
137 |
138 | class DecoderRNN(Layer):
139 | """
140 | Decoder layer for one iteration.
141 | Input:
142 | input: decoded array in each iteration
143 | hidden2, hidden3, hidden4, hidden5: hidden and cell states of corresponding ConvLSTM layers
144 | training: boolean, whether the call is in inference mode or training mode
145 | Output:
146 | decoded: decoded array in each iteration
147 | hidden2, hidden3, hidden4, hidden5: hidden and cell states of corresponding ConvLSTM layers
148 | """
149 | def __init__(self, name=None):
150 | super(DecoderRNN, self).__init__(name=name)
151 | self.Conv_d1 = Conv2D(256, kernel_size=(1, 1), use_bias=False, name='d_conv1')
152 | self.iGDN = tfc.GDN(alpha_parameter=2, epsilon_parameter=0.5, inverse=True, name="igdn")
153 | self.RnnConv_d2 = RnnConv("RnnConv_d2", 256, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
154 | self.RnnConv_d3 = RnnConv("RnnConv_d3", 256, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
155 | self.RnnConv_d4 = RnnConv("RnnConv_d4", 128, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
156 | self.RnnConv_d5 = RnnConv("RnnConv_d5", 64, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
157 | self.Conv_d6 = Conv2D(filters=1, kernel_size=(1, 1), padding='same', use_bias=False, name='d_conv6',
158 | activation=tf.nn.tanh)
159 | self.DTS1 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_1")
160 | self.DTS2 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_2")
161 | self.DTS3 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_3")
162 | self.DTS4 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_4")
163 | self.Add = Add(name="add")
164 | self.Out = Lambda(lambda x: x*0.5, name="out")
165 |
166 | def call(self, input, hidden2, hidden3, hidden4, hidden5, training=False):
167 | # with tf.compat.v1.variable_scope("decoder", reuse=True):
168 | # (2,2,bottleneck)
169 | x = self.Conv_d1(input)
170 | x_igdn = self.iGDN(x)
171 | # x = self.Conv_d1(input)
172 | # (2,2,512)
173 | hidden2 = self.RnnConv_d2(x_igdn, hidden2)
174 | x = hidden2[0]
175 | # (2,2,512)
176 | x = self.Add([x, x_igdn])
177 | x = self.DTS1(x)
178 | # (4,4,128)
179 | hidden3 = self.RnnConv_d3(x, hidden3)
180 | x = hidden3[0]
181 | # (4,4,512)
182 | x = self.DTS2(x)
183 | # (8,8,128)
184 | hidden4 = self.RnnConv_d4(x, hidden4)
185 | x = hidden4[0]
186 | # (8,8,256)
187 | x = self.DTS3(x)
188 | # (16,16,64)
189 | hidden5 = self.RnnConv_d5(x, hidden5)
190 | x = hidden5[0]
191 | # (16,16,128)
192 | x = self.DTS4(x)
193 | # (32,32,32)
194 | # output in range (-0.5,0.5)
195 | x = self.Conv_d6(x)
196 | decoded = self.Out(x)
197 | return decoded, hidden2, hidden3, hidden4, hidden5
198 |
199 |
200 | class LidarCompressionNetwork(Model):
201 | """
202 | The model to compress range image projected from point clouds captured by Velodyne LiDAR sensor
203 | The encoder and decoder layers are iteratively called for num_iters iterations.
204 | Details see paper Full Resolution Image Compression with Recurrent Neural Networks
205 | https://arxiv.org/pdf/1608.05148.pdf. This architecture uses one-shot reconstruction framework and ConvLSTM layers.
206 | """
207 | def __init__(self, bottleneck, num_iters, batch_size, input_size):
208 | super(LidarCompressionNetwork, self).__init__(name="lidar_compression_network")
209 | self.bottleneck = bottleneck
210 | self.num_iters = num_iters
211 | self.batch_size = batch_size
212 | self.input_size = input_size
213 |
214 | self.encoder = EncoderRNN(self.bottleneck, name="encoder")
215 | self.decoder = DecoderRNN(name="decoder")
216 |
217 | self.normalize = Lambda(lambda x: tf.subtract(x, 0.5), name="normalization")
218 | self.subtract = Subtract()
219 | self.inputs = tf.keras.layers.Input(shape=(self.input_size, self.input_size, 1))
220 |
221 | self.DIM1 = self.input_size // 2
222 | self.DIM2 = self.DIM1 // 2
223 | self.DIM3 = self.DIM2 // 2
224 | self.DIM4 = self.DIM3 // 2
225 |
226 | self.loss_tracker = tf.keras.metrics.Mean(name="loss")
227 | self.metric_tracker = tf.keras.metrics.MeanAbsoluteError(name="mae")
228 |
229 | self.beta = 1.0 / self.num_iters
230 |
231 | def compute_loss(self, res):
232 | loss = tf.reduce_mean(tf.abs(res))
233 | return loss
234 |
235 | def initial_hidden(self, batch_size, hidden_size, filters, data_type=tf.dtypes.float32):
236 | """Initialize hidden and cell states, all zeros"""
237 | shape = tf.TensorShape([batch_size] + hidden_size + [filters])
238 | hidden = tf.zeros(shape, dtype=data_type)
239 | cell = tf.zeros(shape, dtype=data_type)
240 | return hidden, cell
241 |
242 | def call(self, inputs, training=False):
243 | # Initialize the hidden states when a new batch comes in
244 | hidden_e2 = self.initial_hidden(self.batch_size, [8, self.DIM2], 128, inputs.dtype)
245 | hidden_e3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 256, inputs.dtype)
246 | hidden_e4 = self.initial_hidden(self.batch_size, [2, self.DIM4], 256, inputs.dtype)
247 | hidden_d2 = self.initial_hidden(self.batch_size, [2, self.DIM4], 256, inputs.dtype)
248 | hidden_d3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 256, inputs.dtype)
249 | hidden_d4 = self.initial_hidden(self.batch_size, [8, self.DIM2], 128, inputs.dtype)
250 | hidden_d5 = self.initial_hidden(self.batch_size, [16, self.DIM1], 64, inputs.dtype)
251 |
252 | inputs = self.normalize(inputs)
253 | res = inputs
254 | for i in range(self.num_iters):
255 | code, hidden_e2, hidden_e3, hidden_e4 = \
256 | self.encoder(res, hidden_e2, hidden_e3, hidden_e4, training=training)
257 |
258 | decoded, hidden_d2, hidden_d3, hidden_d4, hidden_d5 = \
259 | self.decoder(code, hidden_d2, hidden_d3, hidden_d4, hidden_d5, training=training)
260 |
261 | # Update res as predicted output in this iteration subtract the original input
262 | res = self.subtract([decoded, inputs])
263 | self.add_loss(self.compute_loss(res))
264 | # Denormalize the tensors
265 | outputs = tf.clip_by_value(tf.add(decoded, 0.5), 0, 1)
266 | outputs = tf.cast(outputs, dtype=tf.float32)
267 | return outputs
268 |
269 | def train_step(self, data):
270 | inputs, labels = data
271 |
272 | # Run forward pass.
273 | with tf.GradientTape() as tape:
274 | outputs = self(inputs, training=True)
275 | loss = sum(self.losses)*self.beta
276 |
277 | # Run backwards pass.
278 | trainable_vars = self.trainable_variables
279 | gradients = tape.gradient(loss, trainable_vars)
280 | self.optimizer.apply_gradients(zip(gradients, trainable_vars))
281 | # Update & Compute Metrics
282 | with tf.name_scope("metrics") as scope:
283 | self.loss_tracker.update_state(loss)
284 | self.metric_tracker.update_state(outputs, labels)
285 | metric_result = self.metric_tracker.result()
286 | loss_result = self.loss_tracker.result()
287 | return {'loss': loss_result, 'mae': metric_result}
288 |
289 | def test_step(self, data):
290 | inputs, labels = data
291 | # Run forward pass.
292 | outputs = self(inputs, training=False)
293 | loss = sum(self.losses)*self.beta
294 | # Update metrics
295 | self.loss_tracker.update_state(loss)
296 | self.metric_tracker.update_state(outputs, labels)
297 | return {'loss': self.loss_tracker.result(), 'mae': self.metric_tracker.result()}
298 |
299 | def predict_step(self, data):
300 | inputs, labels = data
301 | outputs = self(inputs, training=False)
302 | return outputs
303 |
304 | @property
305 | def metrics(self):
306 | return [self.loss_tracker, self.metric_tracker]
307 |
--------------------------------------------------------------------------------
/range_image_compression/architectures/Additive_GRU.py:
--------------------------------------------------------------------------------
1 | # ==============================================================================
2 | # MIT License
3 | # #
4 | # Copyright 2022 Institute for Automotive Engineering of RWTH Aachen University.
5 | # #
6 | # Permission is hereby granted, free of charge, to any person obtaining a copy
7 | # of this software and associated documentation files (the "Software"), to deal
8 | # in the Software without restriction, including without limitation the rights
9 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
10 | # copies of the Software, and to permit persons to whom the Software is
11 | # furnished to do so, subject to the following conditions:
12 | # #
13 | # The above copyright notice and this permission notice shall be included in all
14 | # copies or substantial portions of the Software.
15 | # #
16 | # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
17 | # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
18 | # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
19 | # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
20 | # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
21 | # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
22 | # SOFTWARE.
23 | # ==============================================================================
24 |
25 | import tensorflow as tf
26 | from keras.models import Model
27 | from keras.layers import Layer, Lambda
28 | from keras.layers import Conv2D
29 | from keras.layers import Add, Subtract
30 |
31 |
32 | class RnnConv(Layer):
33 | """Convolutional GRU cell
34 | See detail in formula (11-13) in paper
35 | "Full Resolution Image Compression with Recurrent Neural Networks"
36 | https://arxiv.org/pdf/1608.05148.pdf
37 | Args:
38 | name: name of current ConvGRU layer
39 | filters: number of filters for each convolutional operation
40 | strides: strides size
41 | kernel_size: kernel size of convolutional operation
42 | hidden_kernel_size: kernel size of convolutional operation for hidden state
43 | Input:
44 | inputs: input of the layer
45 | hidden: hidden state of the layer
46 | Output:
47 | newhidden: updated hidden state of the layer
48 | """
49 |
50 | def __init__(self, name, filters, strides, kernel_size, hidden_kernel_size):
51 | super(RnnConv, self).__init__()
52 | self.filters = filters
53 | self.strides = strides
54 | # gates
55 | self.conv_i = Conv2D(filters=2 * self.filters,
56 | kernel_size=kernel_size,
57 | strides=self.strides,
58 | padding='same',
59 | use_bias=False,
60 | name=name + '_i')
61 | self.conv_h = Conv2D(filters=2 * self.filters,
62 | kernel_size=hidden_kernel_size,
63 | padding='same',
64 | use_bias=False,
65 | name=name + '_h')
66 | # candidate
67 | self.conv_ci = Conv2D(filters=self.filters,
68 | kernel_size=kernel_size,
69 | strides=self.strides,
70 | padding='same',
71 | use_bias=False,
72 | name=name + '_ci')
73 | self.conv_ch = Conv2D(filters=self.filters,
74 | kernel_size=hidden_kernel_size,
75 | padding='same',
76 | use_bias=False,
77 | name=name + '_ch')
78 |
79 | def call(self, inputs, hidden):
80 | # with tf.variable_scope(name, reuse=tf.AUTO_REUSE):
81 | conv_inputs = self.conv_i(inputs)
82 | conv_hidden = self.conv_h(hidden)
83 | # all gates are determined by input and hidden layer
84 | r_gate, z_gate = tf.split(
85 | conv_inputs + conv_hidden, 2, axis=-1) # each gate get the same number of filters
86 | r_gate = tf.nn.sigmoid(r_gate) # input/update gate
87 | z_gate = tf.nn.sigmoid(z_gate)
88 | conv_inputs_candidate = self.conv_ci(inputs)
89 | hidden_candidate = tf.multiply(r_gate, hidden)
90 | conv_hidden_candidate = self.conv_ch(hidden_candidate)
91 | candidate = tf.nn.tanh(conv_inputs_candidate + conv_hidden_candidate)
92 | newhidden = tf.multiply(1 - z_gate, hidden) + tf.multiply(z_gate, candidate)
93 | return newhidden
94 |
95 |
96 | class EncoderRNN(Layer):
97 | """
98 | Encoder layer for one iteration.
99 | Args:
100 | bottleneck: bottleneck size of the layer
101 | Input:
102 | input: output array from last iteration.
103 | In the first iteration, it is the normalized image patch
104 | hidden2, hidden3, hidden4: hidden states of corresponding ConvGRU layers
105 | training: boolean, whether the call is in inference mode or training mode
106 | Output:
107 | encoded: encoded binary array in each iteration
108 | hidden2, hidden3, hidden4: hidden states of corresponding ConvGRU layers
109 | """
110 | def __init__(self, bottleneck, name=None):
111 | super(EncoderRNN, self).__init__(name=name)
112 | self.bottleneck = bottleneck
113 | self.Conv_e1 = Conv2D(32, kernel_size=(3, 3), strides=(2, 2), padding="same", name='Conv_e1')
114 | self.RnnConv_e1 = RnnConv("RnnConv_e1", 128, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
115 | self.RnnConv_e2 = RnnConv("RnnConv_e2", 256, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
116 | self.RnnConv_e3 = RnnConv("RnnConv_e3", 256, (2, 2), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
117 | self.Conv_b = Conv2D(self.bottleneck, kernel_size=(1, 1), activation=tf.nn.tanh, name='b_conv')
118 | self.Sign = Lambda(lambda x: tf.sign(x), name="sign")
119 |
120 | def call(self, input, hidden2, hidden3, hidden4, training=False):
121 | # with tf.compat.v1.variable_scope("encoder", reuse=True):
122 | # input size (32,32,1)
123 | x = self.Conv_e1(input)
124 | # (16,16,64)
125 | hidden2 = self.RnnConv_e1(x, hidden2)
126 | x = hidden2
127 | # (8,8,256)
128 | hidden3 = self.RnnConv_e2(x, hidden3)
129 | x = hidden3
130 | # (4,4,512)
131 | hidden4 = self.RnnConv_e3(x, hidden4)
132 | x = hidden4
133 | # (2,2,512)
134 | # binarizer
135 | x = self.Conv_b(x)
136 | # (2,2,bottleneck)
137 | # Using randomized quantization during training.
138 | if training:
139 | probs = (1 + x) / 2
140 | dist = tf.compat.v1.distributions.Bernoulli(probs=probs, dtype=input.dtype)
141 | noise = 2 * dist.sample(name='noise') - 1 - x
142 | encoded = x + tf.stop_gradient(noise)
143 | else:
144 | encoded = self.Sign(x)
145 | return encoded, hidden2, hidden3, hidden4
146 |
147 |
148 | class DecoderRNN(Layer):
149 | """
150 | Decoder layer for one iteration.
151 | Input:
152 | input: decoded array in each iteration
153 | hidden2, hidden3, hidden4, hidden5: hidden states of corresponding ConvGRU layers
154 | training: boolean, whether the call is in inference mode or training mode
155 | Output:
156 | decoded: decoded array in each iteration
157 | hidden2, hidden3, hidden4, hidden5: hidden states of corresponding ConvGRU layers
158 | """
159 | def __init__(self, name=None):
160 | super(DecoderRNN, self).__init__(name=name)
161 | self.Conv_d1 = Conv2D(256, kernel_size=(1, 1), use_bias=False, name='d_conv1')
162 | self.RnnConv_d2 = RnnConv("RnnConv_d2", 256, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
163 | self.RnnConv_d3 = RnnConv("RnnConv_d3", 256, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
164 | self.RnnConv_d4 = RnnConv("RnnConv_d4", 128, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
165 | self.RnnConv_d5 = RnnConv("RnnConv_d5", 64, (1, 1), kernel_size=(3, 3), hidden_kernel_size=(3, 3))
166 | self.Conv_d6 = Conv2D(filters=1, kernel_size=(1, 1), padding='same', use_bias=False, name='d_conv6',
167 | activation=tf.nn.tanh)
168 | self.DTS1 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_1")
169 | self.DTS2 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_2")
170 | self.DTS3 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_3")
171 | self.DTS4 = Lambda(lambda x: tf.nn.depth_to_space(x, 2), name="dts_4")
172 | self.Add = Add(name="add")
173 | self.Out = Lambda(lambda x: x*0.5, name="out")
174 |
175 | def call(self, input, hidden2, hidden3, hidden4, hidden5, training=False):
176 | # (2,2,bottleneck)
177 | x_conv1 = self.Conv_d1(input)
178 | # x = self.Conv_d1(input)
179 | # (2,2,512)
180 | hidden2 = self.RnnConv_d2(x_conv1, hidden2)
181 | x = hidden2
182 | # (2,2,512)
183 | x = self.Add([x, x_conv1])
184 | x = self.DTS1(x)
185 | # (4,4,128)
186 | hidden3 = self.RnnConv_d3(x, hidden3)
187 | x = hidden3
188 | # (4,4,512)
189 | x = self.DTS2(x)
190 | # (8,8,128)
191 | hidden4 = self.RnnConv_d4(x, hidden4)
192 | x = hidden4
193 | # (8,8,256)
194 | x = self.DTS3(x)
195 | # (16,16,64)
196 | hidden5 = self.RnnConv_d5(x, hidden5)
197 | x = hidden5
198 | # (16,16,128)
199 | x = self.DTS4(x)
200 | # (32,32,32)
201 | # output in range (-1,1)
202 | x = self.Conv_d6(x)
203 | decoded = self.Out(x)
204 | return decoded, hidden2, hidden3, hidden4, hidden5
205 |
206 |
207 | class LidarCompressionNetwork(Model):
208 | """
209 | The model to compress range image projected from point clouds captured by Velodyne LiDAR sensor.
210 | The encoder and decoder layers are iteratively called for num_iters iterations.
211 | Details see paper Full Resolution Image Compression with Recurrent Neural Networks
212 | https://arxiv.org/pdf/1608.05148.pdf. This architecture uses additive reconstruction framework and ConvGRU layers.
213 | """
214 | def __init__(self, bottleneck, num_iters, batch_size, input_size):
215 | super(LidarCompressionNetwork, self).__init__(name="lidar_compression_network")
216 | self.bottleneck = bottleneck
217 | self.num_iters = num_iters
218 | self.batch_size = batch_size
219 | self.input_size = input_size
220 |
221 | self.encoder = EncoderRNN(self.bottleneck, name="encoder")
222 | self.decoder = DecoderRNN(name="decoder")
223 |
224 | self.normalize = Lambda(lambda x: tf.multiply(tf.subtract(x, 0.1), 2.5), name="normalization")
225 | self.subtract = Subtract()
226 | self.inputs = tf.keras.layers.Input(shape=(self.input_size, self.input_size, 1))
227 |
228 | self.DIM1 = self.input_size // 2
229 | self.DIM2 = self.DIM1 // 2
230 | self.DIM3 = self.DIM2 // 2
231 | self.DIM4 = self.DIM3 // 2
232 |
233 | self.loss_tracker = tf.keras.metrics.Mean(name="loss")
234 | self.metric_tracker = tf.keras.metrics.MeanAbsoluteError(name="mae")
235 |
236 | self.beta = 1.0 / self.num_iters
237 |
238 | def compute_loss(self, res):
239 | loss = tf.reduce_mean(tf.abs(res))
240 | return loss
241 |
242 | def initial_hidden(self, batch_size, hidden_size, filters, data_type=tf.dtypes.float32):
243 | """Initialize hidden and cell states, all zeros"""
244 | shape = tf.TensorShape([batch_size] + hidden_size + [filters])
245 | hidden = tf.zeros(shape, dtype=data_type)
246 | return hidden
247 |
248 | def call(self, inputs, training=False):
249 | # Initialize the hidden states when a new batch comes in
250 | hidden_e2 = self.initial_hidden(self.batch_size, [8, self.DIM2], 128, inputs.dtype)
251 | hidden_e3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 256, inputs.dtype)
252 | hidden_e4 = self.initial_hidden(self.batch_size, [2, self.DIM4], 256, inputs.dtype)
253 | hidden_d2 = self.initial_hidden(self.batch_size, [2, self.DIM4], 256, inputs.dtype)
254 | hidden_d3 = self.initial_hidden(self.batch_size, [4, self.DIM3], 256, inputs.dtype)
255 | hidden_d4 = self.initial_hidden(self.batch_size, [8, self.DIM2], 128, inputs.dtype)
256 | hidden_d5 = self.initial_hidden(self.batch_size, [16, self.DIM1], 64, inputs.dtype)
257 | outputs = tf.zeros_like(inputs)
258 |
259 | inputs = self.normalize(inputs)
260 | res = inputs
261 | for i in range(self.num_iters):
262 | code, hidden_e2, hidden_e3, hidden_e4 = \
263 | self.encoder(res, hidden_e2, hidden_e3, hidden_e4, training=training)
264 |
265 | decoded, hidden_d2, hidden_d3, hidden_d4, hidden_d5 = \
266 | self.decoder(code, hidden_d2, hidden_d3, hidden_d4, hidden_d5, training=training)
267 |
268 | outputs = tf.add(outputs, decoded)
269 | # Update res as predicted output in this iteration subtract the original input
270 | res = self.subtract([outputs, inputs])
271 | self.add_loss(self.compute_loss(res))
272 | # Denormalize the tensors
273 | outputs = tf.clip_by_value(tf.add(tf.multiply(outputs, 0.4), 0.1), 0, 1)
274 | outputs = tf.cast(outputs, dtype=tf.float32)
275 | return outputs
276 |
277 | def train_step(self, data):
278 | inputs, labels = data
279 |
280 | # Run forward pass.
281 | with tf.GradientTape() as tape:
282 | outputs = self(inputs, training=True)
283 | loss = sum(self.losses)*self.beta
284 |
285 | # Run backwards pass.
286 | trainable_vars = self.trainable_variables
287 | gradients = tape.gradient(loss, trainable_vars)
288 | self.optimizer.apply_gradients(zip(gradients, trainable_vars))
289 | # Update & Compute Metrics
290 | with tf.name_scope("metrics") as scope:
291 | self.loss_tracker.update_state(loss)
292 | self.metric_tracker.update_state(outputs, labels)
293 | metric_result = self.metric_tracker.result()
294 | loss_result = self.loss_tracker.result()
295 | return {'loss': loss_result, 'mae': metric_result}
296 |
297 | def test_step(self, data):
298 | inputs, labels = data
299 | # Run forward pass.
300 | outputs = self(inputs, training=False)
301 | loss = sum(self.losses)*self.beta
302 | # Update metrics
303 | self.loss_tracker.update_state(loss)
304 | self.metric_tracker.update_state(outputs, labels)
305 | return {'loss': self.loss_tracker.result(), 'mae': self.metric_tracker.result()}
306 |
307 | def predict_step(self, data):
308 | inputs, labels = data
309 | outputs = self(inputs, training=False)
310 | return outputs
311 |
312 | @property
313 | def metrics(self):
314 | return [self.loss_tracker, self.metric_tracker]
315 |
--------------------------------------------------------------------------------