├── .gitignore
├── img
├── 1.png
├── 10.png
├── 11.png
├── 12.png
├── 2.png
├── 3.png
├── 4.png
├── 5.png
├── 6.png
├── 7.png
├── 8.png
├── 9.png
├── examples.html
└── imagify.js
├── index.js
├── package.json
├── LICENSE.md
├── lib
├── ruby.js
└── furigana.js
├── test
└── test.js
└── README.md
/.gitignore:
--------------------------------------------------------------------------------
1 | node_modules
--------------------------------------------------------------------------------
/img/1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/iltrof/furigana-markdown-it/HEAD/img/1.png
--------------------------------------------------------------------------------
/img/10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/iltrof/furigana-markdown-it/HEAD/img/10.png
--------------------------------------------------------------------------------
/img/11.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/iltrof/furigana-markdown-it/HEAD/img/11.png
--------------------------------------------------------------------------------
/img/12.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/iltrof/furigana-markdown-it/HEAD/img/12.png
--------------------------------------------------------------------------------
/img/2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/iltrof/furigana-markdown-it/HEAD/img/2.png
--------------------------------------------------------------------------------
/img/3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/iltrof/furigana-markdown-it/HEAD/img/3.png
--------------------------------------------------------------------------------
/img/4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/iltrof/furigana-markdown-it/HEAD/img/4.png
--------------------------------------------------------------------------------
/img/5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/iltrof/furigana-markdown-it/HEAD/img/5.png
--------------------------------------------------------------------------------
/img/6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/iltrof/furigana-markdown-it/HEAD/img/6.png
--------------------------------------------------------------------------------
/img/7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/iltrof/furigana-markdown-it/HEAD/img/7.png
--------------------------------------------------------------------------------
/img/8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/iltrof/furigana-markdown-it/HEAD/img/8.png
--------------------------------------------------------------------------------
/img/9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/iltrof/furigana-markdown-it/HEAD/img/9.png
--------------------------------------------------------------------------------
/index.js:
--------------------------------------------------------------------------------
1 | "use strict";
2 |
3 | module.exports = function(options) {
4 | return function(md) {
5 | md.inline.ruler.push("furigana", require("./lib/furigana")(options));
6 | };
7 | };
8 |
--------------------------------------------------------------------------------
/package.json:
--------------------------------------------------------------------------------
1 | {
2 | "name": "furigana-markdown-it",
3 | "version": "1.0.3",
4 | "description": "Furigana extension for markdown-it.",
5 | "main": "index.js",
6 | "scripts": {
7 | "test": "mocha"
8 | },
9 | "repository": {
10 | "type": "git",
11 | "url": "https://github.com/iltrof/furigana-markdown-it"
12 | },
13 | "keywords": [
14 | "markdown-it",
15 | "markdown",
16 | "furigana"
17 | ],
18 | "author": "iltrof",
19 | "license": "MIT",
20 | "dependencies": {},
21 | "devDependencies": {
22 | "markdown-it": "^10.0.0",
23 | "mocha": "^7.1.1"
24 | }
25 | }
26 |
--------------------------------------------------------------------------------
/img/examples.html:
--------------------------------------------------------------------------------
1 | 漢字
2 | 漢字
3 | 取り返す
4 | 可愛い犬
5 | 可愛い犬
6 | 可愛い犬
7 | 食べる
8 | 食べる
9 | アクセラレータ
10 | accelerator
11 | あいうえお
12 | あいうえお
13 |
--------------------------------------------------------------------------------
/LICENSE.md:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2020 Ilya Trofimov
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/img/imagify.js:
--------------------------------------------------------------------------------
1 | try {
2 | const root = require("child_process")
3 | .execSync("npm root -g")
4 | .toString()
5 | .trim();
6 | var puppeteer = require(root + "/puppeteer");
7 | } catch (err) {
8 | console.error(
9 | `Install puppeteer globally first with: npm install -g puppeteer`
10 | );
11 | process.exit(1);
12 | }
13 |
14 | const html = require("fs")
15 | .readFileSync("examples.html", { encoding: "utf8" })
16 | .split("\n");
17 |
18 | (async () => {
19 | const browser = await puppeteer.launch();
20 | const page = await browser.newPage();
21 |
22 | for (let i = 0; i < html.length; i++) {
23 | if (html[i] == "") {
24 | continue;
25 | }
26 |
27 | await page.setContent(
28 | `${html[i]}
`
29 | );
30 |
31 | const rect = await page.evaluate(selector => {
32 | const element = document.querySelector(selector);
33 | if (!element) return null;
34 | const { x, y, width, height } = element.getBoundingClientRect();
35 | return { left: x, top: y, width, height, id: element.id };
36 | }, "div");
37 |
38 | await page.screenshot({
39 | path: `${i + 1}.png`,
40 | clip: {
41 | x: rect.left - 5,
42 | y: rect.top - 3,
43 | width: rect.width + 10,
44 | height: rect.height
45 | }
46 | });
47 | }
48 |
49 | await browser.close();
50 | })();
51 |
--------------------------------------------------------------------------------
/lib/ruby.js:
--------------------------------------------------------------------------------
1 | "use strict";
2 |
3 | module.exports.parse = parse;
4 | module.exports.addTag = addTag;
5 |
6 | /**
7 | * Parses the [body]{toptext} syntax and returns
8 | * the body and toptext parts. These are then processed
9 | * in furigana.js and turned into \ tags by
10 | * the {@link addTag} function.
11 | *
12 | * @param {*} state Markdown-it's inline state.
13 | * @returns {{body: string, toptext: string, nextPos: int}}
14 | * body: the main text part of the \ tag.
15 | *
16 | * toptext: the top part of the \ tag.
17 | *
18 | * nextPos: index of the next character in the markdown source.
19 | */
20 | function parse(state) {
21 | if (state.src.charAt(state.pos) !== "[") {
22 | return null;
23 | }
24 |
25 | const bodyStartBracket = state.pos;
26 | const bodyEndBracket = state.src.indexOf("]", bodyStartBracket);
27 |
28 | if (
29 | bodyEndBracket === -1 ||
30 | bodyEndBracket >= state.posMax ||
31 | state.src.charAt(bodyEndBracket + 1) !== "{"
32 | ) {
33 | return null;
34 | }
35 |
36 | const toptextStartBracket = bodyEndBracket + 1;
37 | const toptextEndBracket = state.src.indexOf("}", toptextStartBracket);
38 |
39 | if (toptextEndBracket === -1 || toptextEndBracket >= state.posMax) {
40 | return null;
41 | }
42 |
43 | const body = state.src.slice(bodyStartBracket + 1, bodyEndBracket);
44 | const toptext = state.src.slice(toptextStartBracket + 1, toptextEndBracket);
45 | if (body.trim() === "" || toptext.trim() === "") {
46 | return null;
47 | }
48 |
49 | return {
50 | body: body,
51 | toptext: toptext,
52 | nextPos: toptextEndBracket + 1
53 | };
54 | }
55 |
56 | /**
57 | * Takes as content a flat array of main parts of
58 | * the ruby, each followed immediately by the text
59 | * that should show up above these parts.
60 | *
61 | * That content is then stored in its appropriate
62 | * representation in a markdown-it's inline state,
63 | * eventually resulting in a \ tag.
64 | *
65 | * This function also gives you the option to add
66 | * fallback parentheses, should the \
67 | * tag be unsupported. In that case, the top text
68 | * of the ruby will instead be shown after the main
69 | * text, surrounded by these parentheses.
70 | *
71 | * @example
72 | * addTag(state, ['猫', 'ねこ', 'と', '', '犬', 'いぬ'])
73 | * // markdown-it will eventually produce a tag
74 | * // with 猫と犬 as its main text, with ねこ corresponding
75 | * // to the 猫 kanji, and いぬ corresponding to the 犬 kanji.
76 | *
77 | * @param {*} state Markdown-it's inline state.
78 | * @param {string[]} content Flat array of main parts of
79 | * the ruby, each followed by the text that should
80 | * be above those parts.
81 | * @param {string} fallbackParens Parentheses to use
82 | * as a fallback if the \ tag happens to be
83 | * unsupported. Example value: "【】".
84 | * "" disables fallback parentheses.
85 | */
86 | function addTag(state, content, fallbackParens = "") {
87 | function pushText(text) {
88 | const token = state.push("text", "", 0);
89 | token.content = text;
90 | }
91 |
92 | state.push("ruby_open", "ruby", 1);
93 |
94 | for (let i = 0; i < content.length; i += 2) {
95 | const body = content[i];
96 | const toptext = content[i + 1];
97 |
98 | pushText(body);
99 |
100 | if (toptext === "") {
101 | state.push("rt_open", "rt", 1);
102 | state.push("rt_close", "rt", -1);
103 | continue;
104 | }
105 |
106 | if (fallbackParens !== "") {
107 | state.push("rp_open", "rp", 1);
108 | pushText(fallbackParens.charAt(0));
109 | state.push("rp_close", "rp", -1);
110 | }
111 |
112 | state.push("rt_open", "rt", 1);
113 | pushText(toptext);
114 | state.push("rt_close", "rt", -1);
115 |
116 | if (fallbackParens !== "") {
117 | state.push("rp_open", "rp", 1);
118 | pushText(fallbackParens.charAt(1));
119 | state.push("rp_close", "rp", -1);
120 | }
121 | }
122 |
123 | state.push("ruby_close", "ruby", -1);
124 | }
125 |
--------------------------------------------------------------------------------
/test/test.js:
--------------------------------------------------------------------------------
1 | "use strict";
2 |
3 | const assert = require("assert");
4 | const md = require("markdown-it")().use(require("../index")());
5 |
6 | describe("ruby", function() {
7 | it("should parse basic [body]{toptext}", function() {
8 | assert.equal(
9 | md.renderInline("[漢字]{かんじ}"),
10 | "漢字"
11 | );
12 | });
13 |
14 | it("should parse single [body]{toptext} in a sentence", function() {
15 | assert.equal(
16 | md.renderInline("Foo [漢字]{かんじ} bar."),
17 | "Foo 漢字 bar."
18 | );
19 | });
20 |
21 | it("should parse multiple [body]{toptext} in a sentence", function() {
22 | assert.equal(
23 | md.renderInline("Foo [漢字]{かんじ} bar [猫]{ねこ} baz."),
24 | "Foo 漢字 bar 猫 baz."
25 | );
26 | });
27 |
28 | it("should ignore empty body", function() {
29 | assert.equal(md.renderInline("[]{ねこ}"), "[]{ねこ}");
30 | assert.equal(md.renderInline("[ ]{ねこ}"), "[ ]{ねこ}");
31 | });
32 |
33 | it("should ignore empty toptext", function() {
34 | assert.equal(md.renderInline("[猫]{}"), "[猫]{}");
35 | assert.equal(md.renderInline("[猫]{ }"), "[猫]{ }");
36 | });
37 | });
38 |
39 | describe("furigana", function() {
40 | it("should be able to pattern match a single kanji+hiragana word", function() {
41 | assert.equal(
42 | md.renderInline("[食べる]{たべる}"),
43 | "食べる"
44 | );
45 | });
46 |
47 | it("should be able to pattern match a word with hiragana in the middle", function() {
48 | assert.equal(
49 | md.renderInline("[取り返す]{とりかえす}"),
50 | "取り返す"
51 | );
52 | });
53 |
54 | it("should be able to split furigana with a dot", function() {
55 | assert.equal(
56 | md.renderInline("[漢字]{かん.じ}"),
57 | "漢字"
58 | );
59 | });
60 |
61 | it("should be able to use dots to resolve ambiguities", function() {
62 | assert.equal(
63 | md.renderInline("[可愛い犬]{か.わい.い.いぬ}"),
64 | "可愛い犬"
65 | );
66 | });
67 |
68 | it("should be able to use pluses to resolve ambiguities without splitting furigana", function() {
69 | assert.equal(
70 | md.renderInline("[可愛い犬]{か+わい.い.いぬ}"),
71 | "可愛い犬"
72 | );
73 | });
74 |
75 | it("should be able to handle symbols other than kanji and kana in the body", function() {
76 | assert.equal(
77 | md.renderInline("[猫!?可愛い!!!w]{ねこ.かわいい}"),
78 | "猫!?可愛い!!!w"
79 | );
80 | });
81 |
82 | it("should apply the whole toptext to the whole body if it can't pattern match", function() {
83 | assert.equal(
84 | md.renderInline("[食べる]{たべべ}"),
85 | "食べる"
86 | );
87 | assert.equal(
88 | md.renderInline("[アクセラレーター]{accelerator}"),
89 | "アクセラレーター"
90 | );
91 | assert.equal(
92 | md.renderInline("[cat]{ねこ}"),
93 | "cat"
94 | );
95 | assert.equal(
96 | md.renderInline("[可愛い]{kawaii}"),
97 | "可愛い"
98 | );
99 | });
100 |
101 | it("should accept a few other separators other than ASCII dot", function() {
102 | assert.equal(
103 | md.renderInline(
104 | "[犬犬犬犬犬犬犬犬犬犬犬]{いぬ.いぬ.いぬ。いぬ・いぬ|いぬ|いぬ/いぬ/いぬ いぬ いぬ}"
105 | ),
106 | "" + "犬".repeat(11) + ""
107 | );
108 | });
109 |
110 | it("should accept full-width plus as combinator", function() {
111 | assert.equal(
112 | md.renderInline("[可愛い犬]{か+わい.い.いぬ}"),
113 | "可愛い犬"
114 | );
115 | });
116 |
117 | it("should accept furigana in romaji, as long as body is kanji-only", function() {
118 | assert.equal(
119 | md.renderInline("[漢字]{kan.ji}"),
120 | "漢字"
121 | );
122 | });
123 |
124 | it("should disable pattern matching if toptext starts with an equals sign", function() {
125 | assert.equal(
126 | md.renderInline("[食べる]{=たべる}"),
127 | "食べる"
128 | );
129 | assert.equal(
130 | md.renderInline("[食べる]{=たべる}"),
131 | "食べる"
132 | );
133 | });
134 |
135 | it("should NOT disable pattern matching if = appears not in the beginning", function() {
136 | assert.equal(
137 | md.renderInline("[猫だ]{ね=こだ}"),
138 | "猫だ"
139 | );
140 | assert.equal(
141 | md.renderInline("[猫だ]{ね=こだ}"),
142 | "猫だ"
143 | );
144 | });
145 |
146 | it("should pattern match katakana", function() {
147 | assert.equal(
148 | md.renderInline("[ダメな奴]{ダメなやつ}"),
149 | "ダメな奴"
150 | );
151 | });
152 |
153 | it("should pattern match half-width katakana", function() {
154 | assert.equal(
155 | md.renderInline("[ダメな奴]{ダメなやつ}"),
156 | "ダメな奴"
157 | );
158 | });
159 |
160 | it("should abort if body only partially matches the furigana", function() {
161 | assert.equal(
162 | md.renderInline("[猫だ]{ねこだよ}"),
163 | "猫だ"
164 | );
165 | assert.equal(
166 | md.renderInline("[は猫]{これはねこ}"),
167 | "は猫"
168 | );
169 | });
170 | });
171 |
172 | describe("emphasis dots", function() {
173 | it("should be applied with [body]{*}", function() {
174 | assert.equal(
175 | md.renderInline("[だから]{*}"),
176 | "だから"
177 | );
178 | });
179 |
180 | it("should accept a full-width asterisk as well", function() {
181 | assert.equal(
182 | md.renderInline("[だから]{*}"),
183 | "だから"
184 | );
185 | });
186 |
187 | it("should accept custom markers", function() {
188 | assert.equal(
189 | md.renderInline("[だから]{*+}"),
190 | "だから"
191 | );
192 | });
193 |
194 | it("should work on any character", function() {
195 | assert.equal(
196 | md.renderInline("[猫is❤]{*}"),
197 | "猫is❤"
198 | );
199 | });
200 |
201 | it("should NOT create emphasis dots if * appears not in the beginning", function() {
202 | assert.equal(
203 | md.renderInline("[猫だ]{ね*こだ}"),
204 | "猫だ"
205 | );
206 | assert.equal(
207 | md.renderInline("[猫だ]{ね*こだ}"),
208 | "猫だ"
209 | );
210 | });
211 | });
212 |
213 | describe("options", function() {
214 | it("should allow custom fallback parentheses", function() {
215 | let md = require("markdown-it")().use(
216 | require("../index")({ fallbackParens: "()" })
217 | );
218 |
219 | assert.equal(
220 | md.renderInline("[漢字]{かんじ}"),
221 | "漢字"
222 | );
223 | });
224 |
225 | it("should allow adding extra separators", function() {
226 | let md = require("markdown-it")().use(
227 | require("../index")({ extraSeparators: "_-\\]" })
228 | );
229 |
230 | assert.equal(
231 | md.renderInline("[犬犬犬犬犬犬犬]{いぬ.いぬ。いぬ_いぬ-いぬ\\いぬ]いぬ}"),
232 | "" + "犬".repeat(7) + ""
233 | );
234 | });
235 |
236 | it("should allow adding extra combinators", function() {
237 | let md = require("markdown-it")().use(
238 | require("../index")({ extraCombinators: "*" })
239 | );
240 |
241 | assert.equal(
242 | md.renderInline("[可愛い犬]{か+わい.い.いぬ}"),
243 | "可愛い犬"
244 | );
245 | assert.equal(
246 | md.renderInline("[可愛い犬]{か*わい.い.いぬ}"),
247 | "可愛い犬"
248 | );
249 | });
250 | });
251 |
--------------------------------------------------------------------------------
/lib/furigana.js:
--------------------------------------------------------------------------------
1 | "use strict";
2 |
3 | module.exports = furigana;
4 |
5 | const rubyHelper = require("./ruby");
6 |
7 | const kanaRegex = /[\u3040-\u3096\u30a1-\u30fa\uff66-\uff9fー]/;
8 | const kanjiRegex = /[\u3400-\u9faf]/;
9 |
10 | /**
11 | * Furigana is marked using the [body]{furigana} syntax.
12 | * First step, performed by bodyToRegex, is to convert
13 | * the body to a regex, which can then be used to pattern
14 | * match on the furigana.
15 | *
16 | * In essence, every kanji needs to be converted to a
17 | * pattern similar to ".?", so that it can match some kana
18 | * from the furigana part. However, this alone is ambiguous.
19 | * Consider [可愛い犬]{かわいいいぬ}: in this case there are
20 | * three different ways to assign furigana in the body.
21 | *
22 | * Ambiguities can be resolved by adding separator characters
23 | * in the furigana. These are only matched at the
24 | * boundaries between kanji and other kanji/kana.
25 | * So a regex created from 可愛い犬 should be able to match
26 | * か・わい・い・いぬ, but a regex created from 美味しい shouldn't
27 | * be able to match おいし・い.
28 | *
29 | * For purposes of this function, only ASCII dot is a
30 | * separators. Other characters are converted to dots in
31 | * the {@link cleanFurigana} function.
32 | *
33 | * The notation [可愛い犬]{か・わい・い・いぬ} forces us to
34 | * have separate \ tags for 可 and 愛. If we want to
35 | * indicate that か corresponds to 可 and わい corresponds to 愛
36 | * while keeping them under a single \ tag, we can use
37 | * a combinator instead of a separator, e.g.:
38 | * [可愛い犬]{か+わい・い・いぬ}
39 | *
40 | * For purposes of this function, only ASCII plus is a
41 | * combinator. Other characters are converted to pluses in
42 | * the {@link cleanFurigana} function.
43 | *
44 | * @param {string} body The non-furigana part.
45 | * @returns {(null|RegExp)} Null if the body contains no hiragana
46 | * or kanji, otherwise a regex to be used on the furigana.
47 | */
48 | function bodyToRegex(body) {
49 | let regexStr = "^";
50 | let lastType = "other";
51 |
52 | const combinatorOrSeparatorGroup = "([+.]?)";
53 | const combinatorOrSeparator = "[+.]?";
54 | const combinatorOnly = "\\.?";
55 | const furiganaGroup = "([^+.]+)";
56 |
57 | for (let i = 0; i < body.length; i++) {
58 | const c = body.charAt(i);
59 | if (kanjiRegex.test(c)) {
60 | if (lastType === "kanji") {
61 | regexStr += combinatorOrSeparatorGroup;
62 | } else if (lastType === "kana") {
63 | regexStr += combinatorOrSeparator;
64 | }
65 |
66 | regexStr += furiganaGroup;
67 | lastType = "kanji";
68 | } else if (kanaRegex.test(c)) {
69 | if (lastType == "kanji") {
70 | regexStr += combinatorOrSeparator;
71 | }
72 | regexStr += c;
73 | lastType = "kana";
74 | } else {
75 | if (lastType !== "other") {
76 | regexStr += combinatorOnly;
77 | }
78 | lastType = "other";
79 | }
80 | }
81 |
82 | if (regexStr === "") {
83 | return null;
84 | }
85 | return new RegExp(regexStr + "$");
86 | }
87 |
88 | /**
89 | * For a ruby tag specified as [body]{toptext}, tries to find
90 | * the appropriate furigana in the toptext for every kanji
91 | * in the body.
92 | *
93 | * The result is a flat array where each part of the body
94 | * is followed by its corresponding furigana. Or, if no
95 | * such correspondence can be found, just [body, toptext]
96 | * is returned.
97 | *
98 | * As a special case, if toptext starts with = or =, the
99 | * pattern-matching functionality is disabled, and only
100 | * [body, toptext-without-the-equals-sign] is returned.
101 | *
102 | * @example
103 | * r = matchFurigana('美味しいご飯', 'おいしいごはん')
104 | * assert(r == ['美味', 'おい', 'しいご', '', '飯', 'はん'])
105 | *
106 | * @example
107 | * // no match
108 | * r = matchFurigana('食べる', 'たべべ')
109 | * assert(r == ['食べる', 'たべべ'])
110 | *
111 | * @example
112 | * // disabled pattern matching
113 | * r = matchFurigana('食べる', '=たべる')
114 | * assert(r == ['食べる', 'たべる'])
115 | *
116 | * @param {string} body
117 | * @param {string} toptext
118 | * @returns {string[]} Flat array of parts of the body followed
119 | * by their corresponding furigana, or just [body, toptext]
120 | * if no such correspondence exists.
121 | */
122 | function matchFurigana(body, toptext, options) {
123 | if (/^[==]/.test(toptext)) {
124 | return [body, toptext.slice(1)];
125 | }
126 |
127 | const bodyRegex = bodyToRegex(body);
128 | if (bodyRegex === null) {
129 | return [body, toptext];
130 | }
131 |
132 | const match = bodyRegex.exec(cleanFurigana(toptext, options));
133 | if (match === null) {
134 | return [body, toptext];
135 | }
136 |
137 | let result = [];
138 | let curBodyPart = "";
139 | let curToptextPart = "";
140 | let matchIndex = 1;
141 | let lastType = "other";
142 | for (let i = 0; i < body.length; i++) {
143 | const c = body.charAt(i);
144 |
145 | if (kanjiRegex.test(c)) {
146 | if (lastType === "kana" || lastType === "other") {
147 | if (curBodyPart !== "") {
148 | result.push(curBodyPart, curToptextPart);
149 | }
150 | curBodyPart = c;
151 | curToptextPart = match[matchIndex++];
152 | lastType = "kanji";
153 | continue;
154 | }
155 |
156 | const connection = match[matchIndex++];
157 | if (connection === "+" || connection === "") {
158 | curBodyPart += c;
159 | curToptextPart += match[matchIndex++];
160 | } else {
161 | result.push(curBodyPart, curToptextPart);
162 | curBodyPart = c;
163 | curToptextPart = match[matchIndex++];
164 | }
165 | } else {
166 | if (lastType !== "kanji") {
167 | curBodyPart += c;
168 | continue;
169 | }
170 |
171 | result.push(curBodyPart, curToptextPart);
172 | curBodyPart = c;
173 | curToptextPart = "";
174 |
175 | if (kanaRegex.test(c)) {
176 | lastType = "kana";
177 | } else {
178 | lastType = "other";
179 | }
180 | }
181 | }
182 |
183 | result.push(curBodyPart, curToptextPart);
184 | return result;
185 | }
186 |
187 | /**
188 | * "Cleans" the furigana by converting all allowed
189 | * separators to ASCII dots and all allowed combinators
190 | * to ASCII pluses.
191 | *
192 | * The meaning of "separator" and "combinator" is
193 | * described in the {@link bodyToRegex} function.
194 | *
195 | * @param {string} furigana
196 | * @returns {string} Clean version of the furigana.
197 | */
198 | function cleanFurigana(furigana, options) {
199 | furigana = furigana.replace(options.separatorRegex, ".");
200 | furigana = furigana.replace(options.combinatorRegex, "+");
201 | return furigana;
202 | }
203 |
204 | /**
205 | * Parallel to the {@link matchFurigana} function,
206 | * but instead of doing any matching it just adds
207 | * toptext to every character of the body. This
208 | * is intended to be used for emphasis dots, like
209 | * you sometimes see in manga.
210 | *
211 | * For this, toptext is expected to start with
212 | * an asterisk (ASCII or full-width), and the actual
213 | * marker that should be placed after every character
214 | * should follow afterward.
215 | *
216 | * If no marker is provided, a circle (●) is used.
217 | *
218 | * Since this is meant to mimic the return value of the
219 | * {@link matchFurigana} function, the result is just an array
220 | * of characters from the body followed by the marker.
221 | *
222 | * @example
223 | * r = rubifyEveryCharacter('だから', '*')
224 | * assert(r == ['だ', '●', 'か', '●', 'ら', '●'])
225 | *
226 | * @example
227 | * r = rubifyEveryCharacter('だから', '*+')
228 | * assert(r == ['だ', '+', 'か', '+', 'ら', '+'])
229 | *
230 | * @param {string} body
231 | * @param {string} toptext
232 | * @returns {string[]} Flat array of characters of the body,
233 | * each one followed by the marker as specified in toptext.
234 | */
235 | function rubifyEveryCharacter(body, toptext) {
236 | let topmark = toptext.slice(1);
237 | if (topmark === "") {
238 | topmark = "●";
239 | }
240 |
241 | let result = [];
242 | for (let c of body) {
243 | result.push(c, topmark);
244 | }
245 | return result;
246 | }
247 |
248 | /**
249 | * Returns a function that's compatible for use with
250 | * markdown-it's inline ruler. The function is further
251 | * customizable via the options.
252 | *
253 | * Available options:
254 | * - fallbackParens: fallback parentheses for the resulting
255 | * \ tags. Default value: "【】".
256 | * - extraSeparators: additional characters that can be used
257 | * to separate furigana. Empty by default. Example value:
258 | * "_-*".
259 | *
260 | * The characters that are already hard-coded as
261 | * separator characters are any kind of space, as well as
262 | * these: "..。・||//".
263 | * - extraCombinators: additional characters that can be used
264 | * to indicate a kanji boundary without actually splitting
265 | * the furigana. Empty by default.
266 | *
267 | * The characters that are already hard-coded as
268 | * combinator characters are '+' and '+'.
269 | *
270 | * @param {Object} options
271 | */
272 | function furigana(options = {}) {
273 | options.fallbackParens = options.fallbackParens || "【】";
274 |
275 | options.extraSeparators = (options.extraSeparators || "").replace(
276 | /([\-\]\\])/g,
277 | "\\$1"
278 | );
279 | options.extraCombinators = (options.extraCombinators || "").replace(
280 | /([\-\]\\])/g,
281 | "\\$1"
282 | );
283 |
284 | options.separatorRegex = new RegExp(
285 | `[\\s..。・||//${options.extraSeparators}]`,
286 | "g"
287 | );
288 | options.combinatorRegex = new RegExp(`[++${options.extraCombinators}]`, "g");
289 |
290 | return function(state, silent) {
291 | return process(state, silent, options);
292 | };
293 | }
294 |
295 | /**
296 | * Processes furigana by converting [kanji]{furigana}
297 | * into required markdown-it tokens. This is meant to be
298 | * hooked up to markdown-it's inline ruleset.
299 | *
300 | * Refer to {@link furigana} for available options.
301 | *
302 | * @param {*} state Markdown-it's inline state.
303 | * @param {boolean} silent If true, no tokens are actually generated.
304 | * @param {Object} options
305 | * @returns {boolean} Whether the function successfully processed the text.
306 | */
307 | function process(state, silent, options) {
308 | const ruby = rubyHelper.parse(state);
309 | if (ruby === null) {
310 | return false;
311 | }
312 |
313 | state.pos = ruby.nextPos;
314 |
315 | if (silent) {
316 | return true;
317 | }
318 |
319 | const emphasisDotsIndicatorRegex = /^[**].?/;
320 | if (emphasisDotsIndicatorRegex.test(ruby.toptext)) {
321 | const content = rubifyEveryCharacter(ruby.body, ruby.toptext);
322 | rubyHelper.addTag(state, content);
323 | } else {
324 | const content = matchFurigana(ruby.body, ruby.toptext, options);
325 | rubyHelper.addTag(state, content, options.fallbackParens);
326 | }
327 |
328 | return true;
329 | }
330 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # furigana-markdown-it
2 |
3 | A [markdown-it](https://github.com/markdown-it/markdown-it)
4 | plugin which adds furigana support.
5 |
6 | If you're reading this on npm, try
7 | [github](https://github.com/iltrof/furigana-markdown-it)
8 | instead: npm doesn't render `` tags.
9 |
10 | ## TOC
11 |
12 | - [Setup](#setup)
13 | - [Quick usage](#quick-usage)
14 | - [Not so quick usage](#not-so-quick-usage)
15 | - [Options](#options)
16 |
17 | ## Setup
18 |
19 | Install via npm:
20 |
21 | ```bash
22 | npm install furigana-markdown-it
23 | ```
24 |
25 | Use with markdown-it:
26 |
27 | ```js
28 | const furigana = require("furigana-markdown-it")();
29 | const md = require("markdown-it")().use(furigana);
30 |
31 | const html = md.render("[猫]{ねこ}");
32 | // html == 猫
33 | ```
34 |
35 | Provide some options if you need (described below):
36 |
37 | ```js
38 | const furigana = require("furigana-markdown-it")({
39 | fallbackParens: "()",
40 | extraSeparators: "-",
41 | extraCombinators: "'"
42 | });
43 | ...
44 | ```
45 |
46 | ## Quick usage
47 |
48 | Works:
49 |
50 | | Input | Result | As image |
51 | | ----------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------ |
52 | | `[漢字]{かんじ}` | 漢字
Or, if `` is unsupported:
漢字【かんじ】 |  |
53 | | `[漢字]{かん・じ}`
(allowed separator characters: "..。・\||//", as well as any kind of space) | 漢字
Or, if `` is unsupported:
漢【かん】字【じ】 |  |
54 | | `[取り返す]{とりかえす}` | 取り返す |  |
55 | | `[可愛い犬]{かわいいいぬ}` | 可愛い犬 (wrong match!) | 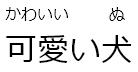 |
56 | | `[可愛い犬]{か・わい・いいぬ}` | 可愛い犬 |  |
57 | | `[可愛い犬]{か+わい・いいぬ}` | 可愛い犬 | 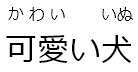 |
58 | | `[食べる]{たべる}` | 食べる |  |
59 | | `[食べる]{=たべる}` | 食べる |  |
60 | | `[アクセラレータ]{accelerator}` | アクセラレータ |  |
61 | | `[accelerator]{アクセラレータ}` | accelerator |  |
62 | | `[あいうえお]{*}` (or `{*}`) | あいうえお |  |
63 | | `[あいうえお]{*❤}` (or `{*❤}`) | あいうえお |  |
64 |
65 | Doesn't work 😞:
66 |
67 | - Formatting: `[**漢字**]{かんじ}` doesn't make 漢字 bold.
68 | - Matching katakana with hiragana: `[バカな奴]{ばかなやつ}` won't recognize that バカ and ばか are the same thing.
69 | - Matching punctuation (or any other symbols): `[「はい」と言った]{「はい」といった}` will break on the 「」 brackets.
70 |
71 | ## Not so quick usage
72 |
73 | The basic syntax is `[kanji]{furigana}`, which results in
74 | a `` tag, with the `kanji` part being the main
75 | content of the ruby, and the `furigana` part being the
76 | annotation.
77 |
78 | In other words, `[漢字]{かんじ}` turns into
79 | 漢字.
80 |
81 | The plugin also generates fallback parentheses for
82 | contexts where `` tags happen to be unsupported. So
83 | a browser that doesn't know about `` tags would
84 | display `[漢字]{かんじ}` as 漢字【かんじ】. The parentheses used can be
85 | changed with the `fallbackParens` option when
86 | initializing the plugin.
87 |
88 | Annotating each kanji separately would be annoying, so
89 | the plugin is also able to handle mixed kanji and kana.
90 | For example, `[取り返す]{とりかえす}` correctly becomes
91 | 取り返す.
92 | In a browser without `` support it would look like
93 | 取【と】り返【かえ】す.
94 |
95 | When relying on the above functionality, please keep in
96 | mind that hiragana and katakana are treated separately.
97 | So something like `[バカな奴]{ばかなやつ}` wouldn't work, and
98 | neither would `[ばかな奴]{バカなやつ}`, because the plugin doesn't
99 | consider ばか and バカ to be the same.
100 |
101 | In some cases there's no unambiguous way to match
102 | furigana to its kanji. Consider `[可愛い犬]{かわいいいぬ}`. Here
103 | the plugin naively assigns かわいい to 可愛, and ぬ to 犬. The
104 | desired result, however, is to have かわい assigned to 可愛,
105 | and いぬ to 犬.
106 |
107 | To resolve such ambiguities it's possible to indicate
108 | where the kanji boundaries should be, like this:
109 | `[可愛い犬]{か・わい・いいぬ}`. This is enough to leave us with only
110 | one possible configuration:
111 | 可愛い犬.
112 |
113 | To indicate kanji boundaries you can use any space
114 | character, as well as the following: "..。・||//". To use
115 | other characters for this purpose, specify them in the
116 | `extraSeparators` option when initializing the plugin.
117 |
118 | Nonetheless, `[可愛い犬]{か・わい・いいぬ}` leaves us with another
119 | problem. We were forced to separately annotate 可 with か,
120 | and 愛 with わい. Instead it would be preferable to have 可愛
121 | as a single entity with the furigana かわい. However, the ・
122 | dot between か and わい is required to resolve the
123 | ambiguity.
124 |
125 | The solution to this problem is to use a + plus instead
126 | of a ・ dot, like this: `[可愛い犬]{か+わい・いいぬ}`. This still
127 | indicated that there is a kanji boundary between か and
128 | わい, but tells the plugin not to separate 可愛 in the final
129 | result:
130 | 可愛い犬.
131 |
132 | Instead of the ASCII plus (+) you can also use a full-width
133 | plus (+). If you need any other characters to act as these
134 | pluses, specify them in the `extraCombinators` option
135 | when initializing the plugin.
136 |
137 | _If you feel so inclined_, you can also let the plugin
138 | match entire sentences:
139 | `[お前は、もう死んでいる]{おまえはもうしんでいる}` produces
140 | お前は、もう死んでいる.
141 | However, **don't** put any punctuation into the furigana
142 | part.
143 |
144 | Other than pure Japanese, you should also get reliable
145 | results out of:
146 |
147 | - English annotations to kana:
148 | - `[ネコ]{cat}` becomes
149 | ネコ.
150 | - `[ねこ]{cat}` becomes
151 | ねこ.
152 | - English annotations to kanji (without kana):
153 | - `[漢字]{kanji}` becomes
154 | 漢字
155 | - And even `[漢字]{kan・ji}` becomes
156 | 漢字
157 | - Japanese annotations to English:
158 | - All of `[cat]{ねこ}`, `[cat]{ネコ}`, `[cat]{猫}` work as
159 | you'd expect.
160 | - English annotations to English:
161 | - `[sorry]{not sorry}` becomes
162 | sorry.
164 |
165 | If you want to bypass furigana matching and just stick
166 | the annotation on top of the text as-is, add an equals
167 | sign after the opening curly brace. For example,
168 | `[食べる]{=たべる}` produces
169 | 食べる.
170 |
171 | The above notation accepts both the ASCII equals sign (=) and the full-width equals sign (=).
172 |
173 | **Bonus time!**
174 |
175 | Ever wanted to spice up your Japanese sentences with
176 | emphasis dots?
177 | Worry no more: `[あいうえお]{*}` will do just that:
178 | あいうえお!
179 |
180 | And if you don't like the default look, provide a custom
181 | character (or several) after the asterisk, like this:
182 | `[あいうえお]{*+}` (result:
183 | あいうえお).
184 |
185 | Of couse, the full-width asterisk (*) also works.
186 |
187 | ## Options
188 |
189 | Options can be provided during initialization of the plugin:
190 |
191 | ```js
192 | const furigana = require("furigana-markdown-it")({
193 | fallbackParens: "()",
194 | extraSeparators: "-",
195 | extraCombinators: "'"
196 | });
197 | ```
198 |
199 | Supported options:
200 |
201 | - `fallbackParens`: fallback parentheses to use in
202 | contexts where `` tags are unavailable. By default
203 | the plugin uses 【】 for fallback, so `[漢字]{かんじ}` becomes
204 | 漢字【かんじ】 on a rare browser without `` support.
205 |
206 | This option takes a string with the opening bracket followed by the closing bracket.
207 |
208 | - `extraSeparators`: separators are characters that allow
209 | you to split furigana between individual kanji (read the
210 | usage section). Any kind of space is a separator, as well
211 | as these characters: "..。・||//".
212 |
213 | If you want additional characters to act as separators,
214 | provide them with this option.
215 |
216 | - `extraCombinators`: combinators are characters that
217 | allow you to indicate a kanji boundary without actually
218 | splitting the furigana between these kanji (read the
219 | usage section).
220 |
221 | Default combinators are + and +. If you need additional
222 | combinator characters, provide them with this option.
223 |
--------------------------------------------------------------------------------