├── .gitignore
├── Notes.md
├── README.md
├── annoy_test.py
├── bert_for_seq_classification.py
├── convert.py
├── data
├── add_faq.json
└── stopwords.txt
├── distills
├── bert_config_L3.json
└── matches.py
├── example.log
├── faq_app_benben.py
├── faq_app_fastapi.py
├── faq_app_flask.py
├── faq_app_whoosh.py
├── faq_index.py
├── faq_test.py
├── faq_whoosh_index.py
├── locust_test.py
├── model_distillation.py
├── requirements.txt
├── sampling.py
├── sentence_transformers_encoder.py
├── sentence_transformers_train.py
├── test.py
├── thread_test.py
├── transformers_encoder.py
├── transformers_trainer.py
└── utils.py
/.gitignore:
--------------------------------------------------------------------------------
1 | .vscode
2 | */.vscode/
3 | *.npy
4 | *.pyc
5 | *.csv
6 | hflqa/
7 | hflqa_extra/
8 | ddqa/
9 | lcqmc/
10 | output/
11 | samples/
12 | distills/outputs/
13 | *.DS_Store
14 | */logs/
15 | logs/
16 | __pycache__/
17 | */__pycache__/
18 | data/
19 | whoosh_index/
20 | *.json
--------------------------------------------------------------------------------
/Notes.md:
--------------------------------------------------------------------------------
1 | 单纯语义检索还算ok,目前存在的问题是特殊关键词无法识别(比如哈工大、哈尔滨工业大学,使用lucene很容易识别,但是BERT语义检索效果较差)
2 |
3 | - 效果优化考虑key-bert
4 | - 性能优化,考虑蒸馏减小特征向量维度(4层384维)
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # FAQ-Semantic-Retrieval
2 |
3 |   
4 |
5 | 一种 FAQ 向量语义检索解决方案
6 |
7 | - [x] 基于 [**Sklearn Kmeans**](https://scikit-learn.org/stable/) 聚类的**负采样**
8 |
9 | - [x] 基于 [**Transformers**](https://huggingface.co/transformers/) 的 BertForSiameseNetwork(Bert**双塔模型**)**微调训练**
10 |
11 | - [x] 基于 [**TextBrewer**](https://github.com/airaria/TextBrewer) 的**模型蒸馏**
12 |
13 | - [x] 基于 [**FastAPI**](https://fastapi.tiangolo.com/zh/) 和 [**Locust**](https://locust.io/) 的 **WebAPI 服务**以及**压力测试**
14 |
15 |
16 |
17 | ## 项目介绍
18 |
19 | FAQ 的处理流程一般为:
20 |
21 | - **问题理解**,对用户 query 进行改写以及向量表示
22 | - **召回模块**,在问题集上进行候选问题召回,获得 topk(基于关键字的倒排索引 vs 基于向量的语义召回)
23 | - **排序模块**,对 topk 进行精排序
24 |
25 | 本项目着眼于 **召回模块** 的 **向量检索** 的实现,适用于 **小规模 FAQ 问题集**(候选问题集<10万)的系统快速搭建
26 |
27 |
28 |
29 | ### FAQ 语义检索
30 |
31 | 传统召回模块**基于关键字检索**
32 |
33 | - 计算关键字在问题集中的 [TF-IDF](https://en.wikipedia.org/wiki/Tf%E2%80%93idf) 以及[ BM25](https://en.wikipedia.org/wiki/Okapi_BM25) 得分,并建立**倒排索引表**
34 | - 第三方库 [ElasticSearch](https://whoosh.readthedocs.io/en/latest/index.html),[Lucene](https://lucene.apache.org/pylucene/),[Whoosh](https://whoosh.readthedocs.io/en/latest/index.html)
35 |
36 |
37 |
38 | 随着语义表示模型的增强、预训练模型的发展,基于 BERT 向量的**语义检索**得到广泛应用
39 |
40 | - 对候选问题集合进行向量编码,得到 **corpus 向量矩阵**
41 | - 当用户输入 query 时,同样进行编码得到 **query 向量表示**
42 | - 然后进行语义检索(矩阵操作,KNN,FAISS)
43 |
44 |
45 |
46 | 本项目针对小规模 FAQ 问题集直接计算 query 和 corpus 向量矩阵的**余弦相似度**,从而获得 topk 候选问题
47 | $$
48 | score = \frac{V_{query} \cdot V_{corpus}}{||V_{query}|| \cdot ||V_{corpus}||}
49 | $$
50 | **句向量获取解决方案**
51 |
52 | | Python Lib | Framework | Desc | Example |
53 | | ------------------------------------------------------------ | ---------- | ------------------------------------------------------- | ------------------------------------------------------------ |
54 | | [bert-as-serivce](https://github.com/hanxiao/bert-as-service) | TensorFlow | 高并发服务调用,支持 fine-tune,较难拓展其他模型 | [getting-started](https://github.com/hanxiao/bert-as-service#getting-started) |
55 | | [Sentence-Transformers](https://www.sbert.net/index.html) | PyTorch | 接口简单易用,支持各种模型调用,支持 fine-turn(单GPU) | [using-Sentence-Transformers-model](https://www.sbert.net/docs/quickstart.html#quickstart)
[using-Transformers-model](https://github.com/UKPLab/sentence-transformers/issues/184#issuecomment-607069944) |
56 | | 🤗 [Transformers](https://github.com/huggingface/transformers/) | PyTorch | 自定义程度高,支持各种模型调用,支持 fine-turn(多GPU) | [sentence-embeddings-with-Transformers](https://www.sbert.net/docs/usage/computing_sentence_embeddings.html#sentence-embeddings-with-transformers) |
57 |
58 | > - **Sentence-Transformers** 进行小规模数据的单 GPU fine-tune 实验(尚不支持多 GPU 训练,[Multi-GPU-training #311](https://github.com/UKPLab/sentence-transformers/issues/311#issuecomment-659455875) ;实现了多种 [Ranking loss](https://www.sbert.net/docs/package_reference/losses.html) 可供参考)
59 | > - **Transformers** 进行大规模数据的多 GPU fine-tune 训练(推荐自定义模型使用 [Trainer](https://huggingface.co/transformers/training.html#trainer) 进行训练)
60 | > - 实际使用过程中 **Sentence-Transformers** 和 **Transformers** 模型基本互通互用,前者多了 **Pooling 层(Mean/Max/CLS Pooling)** ,可参考 **Example**
61 | > - :fire: **实际上线推荐直接使用 Transformers 封装**,Sentence-Transformers 在 CPU 服务器上运行存在位置问题。
62 |
63 |
64 |
65 | ### BERT 微调与蒸馏
66 |
67 | 在句向量获取中可以直接使用 [bert-base-chinese](https://huggingface.co/bert-base-chinese) 作为编码器,但在特定领域数据上可能需要进一步 fine-tune 来获取更好的效果
68 |
69 | fine-tune 过程主要进行**文本相似度计算**任务,亦**句对分类任务**;此处是为获得更好的句向量,因此使用**双塔模型([SiameseNetwork](https://en.wikipedia.org/wiki/Siamese_neural_network) ,孪生网络)**微调,而非常用的基于表示的模型 [BertForSequenceClassification](https://huggingface.co/transformers/model_doc/bert.html#bertforsequenceclassification)
70 |
71 |
72 |
73 | #### BertForSiameseNetwork
74 |
75 | **BertForSiameseNetwork** 主要步骤如下
76 |
77 | - **Encoding**,使用(同一个) **BERT** 分别对 query 和 candidate 进行编码
78 | - **Pooling**,对最后一层进行**池化操作**获得句子表示(Mean/Max/CLS Pooling)
79 | - **Computing**,计算两个向量的**余弦相似度**(或其他度量函数),计算 loss 进行反向传播
80 |
81 | 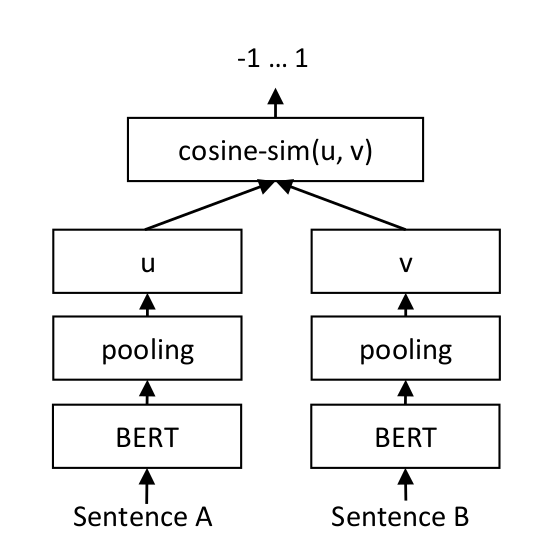
82 |
83 | #### 损失函数
84 |
85 | 模型训练使用的损失函数为 **Ranking loss**,不同于CrossEntropy 和 MSE 进行分类和回归任务,**Ranking loss** 目的是预测输入样本对(即上述双塔模型中 $u$ 和 $v$ 之间)之间的相对距离(**度量学习任务**)
86 |
87 | - **Contrastive Loss**
88 |
89 | > 来自 LeCun [Dimensionality Reduction by Learning an Invariant Mapping](http://yann.lecun.com/exdb/publis/pdf/hadsell-chopra-lecun-06.pdf)
90 | >
91 | > [sentence-transformers 源码实现](https://github.com/UKPLab/sentence-transformers/blob/master/sentence_transformers/losses/ContrastiveLoss.py)
92 |
93 | - 公式形式如下,其中 $u, v$ 为 BERT 编码的向量表示,$y$ 为对应的标签(1 表示正样本,0 表示负样本), $\tau$ 为超参数
94 | $$
95 | L(u_i, v_i, y_i) = y_i ||u_i, v_i|| + (1 - y_i) \max(0, \tau - ||u_i, v_i||
96 | $$
97 |
98 | - 公式意义为:对于**正样本**,输出特征向量之间距离要**尽量小**;而对于**负样本**,输出特征向量间距离要**尽量大**;但是若**负样本间距太大**(即容易区分的**简单负样本**,间距大于 $\tau$)**则不处理**,让模型关注更加**难以区分**的样本
99 |
100 |
101 |
102 | - **OnlineContrastive Loss**
103 |
104 | - 属于 **online negative sampling** ,与 **Contrastive Loss** 类似
105 |
106 | - 参考 [sentence-transformers 源码实现](https://github.com/UKPLab/sentence-transformers/blob/master/sentence_transformers/losses/OnlineContrastiveLoss.py) ,在每个 batch 内,选择最难以区分的正例样本和负例样本进行 loss 计算(容易识别的正例和负例样本则忽略)
107 |
108 | - 公式形式如下,如果正样本距离小于 $\tau_1$ 则不处理,如果负样本距离大于 $\tau_0$ 则不处理,实现过程中 $\tau_0, \tau_1$ 可以分别取负/正样本的平均距离值
109 | $$
110 | L(u_i, v_i, y_i)
111 | \begin{cases}
112 | \max (0, ||u_i, v_i|| - \tau_1) ,\ if \ y_i=1 & \\
113 | \max (0, \tau_0 - ||u_i, v_i||),\ if \ y_i =0
114 | \end{cases}
115 | $$
116 |
117 | 本项目使用 **OnlineContrastive Loss** ,更多 Ranking loss 信息可参考博客 [Understanding Ranking Loss, Contrastive Loss, Margin Loss, Triplet Loss, Hinge Loss and all those confusing names](https://gombru.github.io/2019/04/03/ranking_loss/) ,以及 SentenceTransformers 中的 [Loss API](https://www.sbert.net/docs/package_reference/losses.html) 以及 PyTorch 中的 [margin_ranking_loss](https://pytorch.org/docs/master/nn.functional.html#margin-ranking-loss)
118 |
119 |
120 |
121 | #### 数据集
122 |
123 | - **文本相似度数据集**
124 |
125 | - 相关论文比赛发布的数据集可见 [文本相似度数据集](https://github.com/IceFlameWorm/NLP_Datasets) ,大部分为金融等特定领域文本,其中 [LCQMC](http://icrc.hitsz.edu.cn/Article/show/171.html) 提供基于百度知道的约 20w+ 开放域问题数据集,可供模型测试
126 |
127 | | data | total | positive | negative |
128 | | ---------- | ------ | -------- | -------- |
129 | | training | 238766 | 138574 | 100192 |
130 | | validation | 8802 | 4402 | 4400 |
131 | | test | 12500 | 6250 | 6250 |
132 |
133 | - 除此以外,百度[千言项目](https://www.luge.ai/)发布了[文本相似度评测](https://aistudio.baidu.com/aistudio/competition/detail/45),包含 LCQMC/BQ Corpus/PAWS-X 等数据集,可供参考
134 |
135 | - **FAQ数据集**
136 |
137 | - 内部给定的 FAQ 数据集形式如下,包括各种”主题/问题“,每种“主题/问题”可以有多种不同表达形式的问题 `post`,同时对应多种形式的回复 `resp`
138 |
139 | - 检索时只需要将 query 与所有 post 进行相似度计算,从而召回最相似的 post ,然后获取对应的 “主题/问题” 的所有回复 `resp` ,最后随机返回一个回复即可
140 |
141 | ```python
142 | {
143 | "晚安": {
144 | "post": [
145 | "10点了,我要睡觉了",
146 | "唉,该休息了",
147 | ...
148 | ],
149 | "resp": [
150 | "祝你做个好梦",
151 | "祝你有个好梦,晚安!",
152 | ...
153 | ]
154 | },
155 | "感谢": {
156 | "post": [
157 | "多谢了",
158 | "非常感谢",
159 | ...
160 | ],
161 | "resp": [
162 | "助人为乐为快乐之本",
163 | "别客气",
164 | ...
165 | ]
166 | },
167 | ...
168 | }
169 | ```
170 |
171 | - 内部FAQ数据包括两个版本
172 |
173 | - chitchat-faq-small,主要是小规模闲聊FAQ,1500主题问题(topic)、2万多不同形式问题(post)
174 | - entity-faq-large,主要是大规模实体FAQ(涉及业务问题),大约3-5千主题问题(topic)、12万不同形式问题(post)
175 |
176 |
177 |
178 | #### 负采样
179 |
180 | 对于每个 query,需要获得与其相似的 **positve candidate** 以及不相似的 **negtive candidate**,从而构成正样本和负样本作为模型输入,即 **(query, candidate)**
181 |
182 | > ⚠️ 此处为 **offline negtive sampling**,即在训练前采样构造负样本,区别于 **online negtive sampling**,后者在训练中的每个 batch 内进行动态的负采样(可以通过相关损失函数实现,如 **OnlineContrastive Loss**)
183 | >
184 | > 两种方法可以根据任务特性进行选择,**online negtive sampling** 对于数据集有一定的要求,需要确保每个 batch 内的 query 是不相似的,但是效率更高
185 |
186 | 对于 **offline negtive sampling** 主要使用以下两种方式采样:
187 |
188 | - **全局负采样**
189 | - 在整个数据集上进行正态分布采样,很难产生高难度的负样本
190 | - **局部负采样**
191 | - 首先使用少量人工标注数据预训练的 **BERT 模型**对候选问题集合进行**编码**
192 | - 然后使用**无监督聚类** ,如 [Kmeans](https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html)
193 | - 最后在每个 query 所在聚类簇中进行采样
194 |
195 |
196 |
197 | 实验中对已有 FAQ 数据集中所有主题的 post 进行 **9:1** 划分得到训练集和测试集,负采样结果对比
198 |
199 | > `chitchat-faq-small` 为需要上线的 FAQ 闲聊数据,`entity-faq-large` 为辅助数据
200 |
201 | | dataset | topics | posts | positive(sampling) | negative(sampling) | total(sampling) |
202 | | ----------------------------- | ------ | ----- | ------------------ | ------------------ | --------------- |
203 | | chitchat-faq-small
train | 1468 | 18267 | 5w+ | 5w+ | 10w+ |
204 | | chitchat-faq-small
test | 768 | 2030 | 2984 | 7148 | 10132 |
205 | | chitchat-faq-small | 1500 | 20297 | - | - | - |
206 | | entity-faq-large | - | 12w+ | 50w+ | 50w+ | 100w+ |
207 |
208 |
209 |
210 | #### 模型蒸馏
211 |
212 | 使用基于 Transformers 的模型蒸馏工具 [TextBrewer](https://github.com/airaria/TextBrewer) ,主要参考 [官方 入门示例](https://github.com/airaria/TextBrewer/tree/master/examples/random_tokens_example) 和[cmrc2018示例](https://github.com/airaria/TextBrewer/tree/master/examples/cmrc2018_example)
213 |
214 |
215 |
216 | ### FAQ Web服务
217 |
218 | #### Web API
219 |
220 | - Web 框架选择
221 | - [Flask](https://flask.palletsprojects.com/) + Gunicorn + gevent + nginx ,进程管理(崩溃自动重启)(uwsgi 同理,gunicorn 更简单)
222 | - :fire: **[FastAPI](https://fastapi.tiangolo.com/)** + uvicorn(崩溃自动重启),最快的Python Web框架(实测的确比 Flask 快几倍)
223 | - cache 缓存机制(保存最近的query对应的topic,命中后直接返回)
224 | - Flask 相关
225 | - [flask-caching](https://github.com/sh4nks/flask-caching) (默认缓存500,超时300秒),使用 set/get 进行数据操作;项目来源于 [pallets/werkzeug](https://github.com/pallets/werkzeug) (werkzeug 版本0.4以后弃用 cache)
226 | - Python 3.2 以上自带(FastAPI 中可使用)
227 | - :fire: [**functools.lru_cache()**](https://docs.python.org/3/library/functools.html#functools.lru_cache) (默认缓存128,lru策略),装饰器,缓存函数输入和输出
228 |
229 |
230 |
231 | #### Locust 压力测试
232 |
233 | 使用 [Locust](https://locust.io/) 编写压力测试脚本
234 |
235 |
236 |
237 | ## 使用说明
238 |
239 | 主要依赖参考 `requirements.txt`
240 |
241 | ```bash
242 | pip install -r requirements.txt
243 | ```
244 |
245 |
246 |
247 | ### 负采样
248 |
249 | ```bash
250 | python sampling.py \
251 | --filename='faq/train_faq.json' \
252 | --model_name_or_path='./model/bert-base-chinese' \
253 | --is_transformers=True \
254 | --hyper_beta=2 \
255 | --num_pos=5 \
256 | --local_num_negs=3 \
257 | --global_num_negs=2 \
258 | --output_dir='./samples'
259 | ```
260 |
261 | **主要参数说明**
262 |
263 | - `--filename` ,**faq 数据集**,按前文所述组织为 `{topic: {post:[], resp:[]}}` 格式
264 | - `--model_name_or_path` ,用于句向量编码的 Transformers **预训练模型**位置(`bert-base-chinese` 或者基于人工标注数据微调后的模型)
265 | - `--hyper_beta` ,**聚类数超参数**,聚类类别为 `n_cluster=num_topics/hyper_beta` ,其中 `num_topics` 为上述数据中的主题数,`hyper_beta` 默认为 2(过小可能无法采样到足够局部负样本)
266 | - `--num_pos` ,**正采样个数**,默认 5(注意正负比例应为 1:1)
267 | - `--local_num_negs` ,**局部负采样个数**,默认 3(该值太大时,可能没有那么多局部负样本,需要适当调低正采样个数,保证正负比例为 1:1)
268 | - `--global_num_negs` ,**全局负采样个数**,默认 2
269 | - `--is_split` ,是否进行训练集拆分,默认 False(建议直接在 faq 数据上进行拆分,然后使用评估语义召回效果)
270 | - `--test_size` ,测试集比例,默认 0.1
271 | - `--output_dir` ,采样结果文件保存位置(`sentence1, sentence2, label` 形式的 csv 文件)
272 |
273 |
274 |
275 | ### BERT 微调
276 |
277 | - 参考[ Sentence-Transformers 的 **raining_OnlineConstrativeLoss.py** ](https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/quora_duplicate_questions/training_OnlineConstrativeLoss.py) 修改,适合单 GPU 小规模样本训练
278 |
279 | - 模型训练
280 |
281 | ```bash
282 | CUDA_VISIBLE_DEVICES=0 python sentence_transformers_train.py \
283 | --do_train \
284 | --model_name_or_path='./model/bert-base-chinese' \
285 | --trainset_path='./lcqmc/LCQMC_train.csv' \
286 | --devset_path='./lcqmc/LCQMC_dev.csv' \
287 | --testset_path='./lcqmc/LCQMC_test.csv' \
288 | --train_batch_size=128 \
289 | --eval_batch_size=128 \
290 | --model_save_path
291 | ```
292 |
293 | - 主要参数说明
294 |
295 | - 模型预测时则使用 `--do_eval`
296 | - 数据集为 `sentence1, sentence2, label` 形式的 csv 文件
297 | - 16G 显存设置 batch size 为 128
298 |
299 |
300 |
301 | - 使用 [Transformers](https://huggingface.co/transformers/) 自定义数据集和 `BertForSiameseNetwork` 模型并使用 Trainer 训练,适合多 GPU 大规模样本训练
302 |
303 | ```bash
304 | CUDA_VISIBLE_DEVICES=0,1,2,3 python transformers_trainer.py \
305 | --do_train=True \
306 | --do_eval=True \
307 | --do_predict=False \
308 | --model_name_or_path='./model/bert-base-chinese' \
309 | --trainset_path='./samples/merge.csv' \
310 | --devset_path='./samples/test.csv' \
311 | --testset_path='./samples/test.csv' \
312 | --output_dir='./output/transformers-merge-bert'
313 | ```
314 |
315 |
316 |
317 | - 使用 [Transformers](https://huggingface.co/transformers/) 的 `BertForSequenceClassification` 进行句对分类对比实验
318 |
319 | ```bash
320 | CUDA_VISIBLE_DEVICES=0 python bert_for_seq_classification.py \
321 | --do_train=True \
322 | --do_eval=True \
323 | --do_predict=False \
324 | --trainset_path='./lcqmc/LCQMC_train.csv' \
325 | --devset_path='./lcqmc/LCQMC_dev.csv' \
326 | --testset_path='./lcqmc/LCQMC_test.csv' \
327 | --output_dir='./output/transformers-bert-for-seq-classify'
328 | ```
329 |
330 |
331 |
332 | ### 模型蒸馏
333 |
334 | 使用 [TextBrewer](https://github.com/airaria/TextBrewer) 以及前文自定义的 `SiameseNetwork` 进行模型蒸馏
335 |
336 | ```bash
337 | CUDA_VISIBLE_DEVICES=0 python model_distillation.py \
338 | --teacher_model='./output/transformers-merge-bert' \
339 | --student_config='./distills/bert_config_L3.json' \
340 | --bert_model='./model/bert-base-chinese' \
341 | --train_file='./samples/train.csv' \
342 | --test_file='./samples/test.csv' \
343 | --output_dir='./distills/outputs/bert-L3'
344 | ```
345 |
346 | 主要参数说明:
347 |
348 | - 此处使用的 `bert_config_L3.json` 作为学生模型参数,更多参数 [student_config](https://github.com/airaria/TextBrewer/tree/master/examples/student_config/bert_base_cased_config) 或者自定义
349 | - 3层应用于特定任务效果不错,但对于句向量获取,至少得蒸馏 6层
350 | - 学生模型可以使用 `bert-base-chinese` 的前几层初始化
351 |
352 |
353 |
354 | ### Web服务
355 |
356 | - 服务启动(`gunicorn` 和 `uvicorn` 均支持多进程启动以及失败重启)
357 | - [Flask](https://flask.palletsprojects.com/)
358 |
359 | ```bash
360 | gunicorn -w 1 -b 127.0.0.1:8888 faq_app_flask:app
361 | ```
362 |
363 | - [FastAPI](https://fastapi.tiangolo.com/) :fire: (推荐)
364 |
365 | ```bash
366 | uvicorn faq_app_fastapi:app --reload --port=8888
367 | ```
368 |
369 |
370 |
371 |
372 | - 压力测试 [Locust](https://docs.locust.io/en/stable/) ,实现脚本参考 `locust_test.py`
373 |
374 |
375 |
376 | ## 结果及分析
377 |
378 | ### 微调结果
379 |
380 | > 对于SiameseNetwork,需要在开发集上确定最佳阈值,然后测试集上使用该阈值进行句对相似度结果评价
381 |
382 | 句对测试集评价结果,此处为 LCQMC 的实验结果
383 |
384 | | model | acc(dev/test) | f1(dev/test) |
385 | | ------------------------------------------------ | ------------- | ------------- |
386 | | BertForSeqClassify
:steam_locomotive: lcqmc | 0.8832/0.8600 | 0.8848/0.8706 |
387 | | SiameseNetwork
:steam_locomotive: lcqmc | 0.8818/0.8705 | 0.8810/0.8701 |
388 |
389 | > 基于表示和基于交互的模型效果差别并不大
390 |
391 |
392 |
393 | ### 语义召回结果
394 |
395 | > 此处为 FAQ 数据集的召回结果评估,将训练集 post 作为 corpus,测试集 post 作为 query 进行相似度计算
396 |
397 | | model | hit@1(chitchat-faq-small) | hit@1(entity-faq-large) |
398 | | ------------------------------------------------------------ | ------------------------- | ----------------------- |
399 | | *lucene bm25 (origin)* | 0.6679 | - |
400 | | bert-base-chinese | 0.7394 | 0.7745 |
401 | | bert-base-chinese
:point_up_2: *6 layers* | 0.7276 | - |
402 | | SiameseNetwork
:steam_locomotive: chit-faq-small | 0.8567 | 0.8500 |
403 | | SiameseNetwork
:steam_locomotive: chitchat-faq-small + entity-faq-large | 0.8980 | **0.9961** |
404 | | :point_up_2: *6 layers* :fire: | **0.9128** | 0.8201 |
405 |
406 | - **chitchat-faq-small**
407 | - 测试集 hit@1 大约 85% 左右
408 | - 错误原因主要是 hflqa 数据问题
409 | - 数据质量问题,部分 topic 意思相同,可以合并
410 | - 一些不常用表达或者表达不完整的句子
411 | - 正常对话的召回率还是不错的
412 | - **chitchat-faq-small + entity-faq-large**
413 | - 2000 chitchat-faq-small 测试集,6层比12层效果好一个点,hit@1 达到 90%
414 | - 10000 entity-faq-large 测试集,12层 hit@1 达到 99%,6层只有 82%
415 | - 底层学到了较为基础的特征,在偏向闲聊的 chitchat-faq-small 上仅使用6层效果超过12层(没有蒸馏必要)
416 | - 高层学到了较为高级的特征,在偏向实体的 entity-faq-large 上12层效果远超于6层
417 | - 另外,entity-faq-large 数量规模远大于 chitchat-faq-small ,因此最后几层分类器偏向于从 entity-faq-large 学到的信息,因此在 chitchat-faq-small 小效果略有下降;同时能够避免 chitchat-faq-small 数据过拟合
418 |
419 |
420 |
421 | ### Web服务压测
422 |
423 | - 运行命令说明
424 |
425 | > 总共 100 个模拟用户,启动时每秒递增 10 个,压力测试持续 3 分钟
426 |
427 | ```bash
428 | locust -f locust_test.py --host=http://127.0.0.1:8889/module --headless -u 100 -r 10 -t 3m
429 | ```
430 |
431 |
432 |
433 | - :hourglass: 配置 **4核8G CPU** (6层小模型占用内存约 700MB)
434 | - 小服务器上 **bert-as-service** 服务非常不稳定(tensorflow各种报错), 效率不如简单封装的 **TransformersEncoder**
435 | - **FastAPI** 框架速度远胜于 **Flask**,的确堪称最快的 Python Web 框架
436 | - **cache** 的使用能够大大提高并发量和响应速度(最大缓存均设置为**500**)
437 | - 最终推荐配置 :fire: **TransformersEncoder + FastAPI + functools.lru_cache**
438 |
439 | | model | Web | Cache | Users | req/s | reqs | fails | Avg | Min | Max | Median | fails/s |
440 | | --------------------------------------------------------- | ----------- | ------------- | ------ | ---------- | ------- | ----- | ----- | ---- | ------- | ------ | ------- |
441 | | *lucene bm25 (origin)* | *flask* | *werkzeug* | *1000* | **271.75** | *48969* | *0* | *91* | *3* | *398* | *79* | 0.00 |
442 | | BertSiameseNet
6 layers
Transformers | flask | flask-caching | 1000 | 24.55 | 4424 | 654 | 28005 | 680 | 161199 | 11000 | 3.63 |
443 | | BertSiameseNet
6 layers
Transformers | **fastapi** | lru_cache | 1000 | **130.87** | 23566 | 1725 | 3884 | 6 | 127347 | 26 | 9.58 |
444 | | *lucene bm25 (origin)* | *flask* | *werkzeug* | *100* | **27.66** | *4973* | *1* | *32* | *6* | *60077* | *10* | 0.01 |
445 | | BertSiameseNet
6 layers
bert-as-service | flask | flask-caching | 100 | 5.49 | 987 | 0 | 13730 | 357 | 17884 | 14000 | 0.00 |
446 | | BertSiameseNet
6 layers
Transformers | flask | flask-caching | 100 | 5.93 | 1066 | 0 | 12379 | 236 | 17062 | 12000 | 0.00 |
447 | | BertSiameseNet
:fire: 6 layers
**Transformers** | **fastapi** | **lru_cache** | 100 | **22.19** | 3993 | 0 | 824 | 10 | 2402 | 880 | 0.00 |
448 | | BertSiameseNet
6 layers
transformers | fastapi | None | 100 | 18.17 | 1900 | 0 | 1876 | 138 | 3469 | 1900 | 0.00 |
449 |
450 | > 使用 bert-as-service 遇到的一些问题:
451 | >
452 | > - 老版本服务器上使用 [tensorflow 报错解决方案 Error in `python': double free or corruption (!prev) #6968](https://github.com/tensorflow/tensorflow/issues/6968#issuecomment-279060156)
453 | > - 报错 src/tcmalloc.cc:277] Attempt to free invalid pointer 0x7f4685efcd40 Aborted (core dumpe),解决方案,将 bert_as_service import 移到顶部
454 | >
455 | > 测试服部署时报错 src/tcmalloc.cc:277] Attempt to free invalid pointer,通过改变import顺序来解决,在 `numpy` 之后 import pytorch
456 |
457 |
458 |
459 | ## 更多
460 |
461 | - 大规模问题集可以使用 [facebookresearch/faiss](https://github.com/facebookresearch/faiss) (建立向量索引,使用 k-nearest-neighbor 召回)
462 | - 很多场景下,基于关键字的倒排索引召回结果已经足够,可以考虑综合基于关键字和基于向量的召回方法,参考知乎语义检索系统 [Beyond Lexical: A Semantic Retrieval Framework for Textual SearchEngine](http://arxiv.org/abs/2008.03917)
463 |
464 |
--------------------------------------------------------------------------------
/annoy_test.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2021-04-05 16:21:32
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 |
8 | from transformers_encoder import TransformersEncoder
9 | import os
10 | import time
11 | import numpy as np
12 | from tqdm import tqdm
13 | from annoy import AnnoyIndex
14 |
15 | from utils import load_json, save_json
16 |
17 | FEAT_DIM = 768
18 | TOPK = 10
19 |
20 | # prefix = "/data/benben/data/faq_bert/"
21 | prefix = "/users6/kyzhang/benben/FAQ-Semantic-Retrieval"
22 | MODEL_NAME_OR_PATH = os.path.join(prefix, "output/transformers-merge3-bert-6L")
23 | FAQ_FILE = os.path.join(prefix, "ext_hflqa/clean_faq.json")
24 | ANNOY_INDEX_FILE = os.path.join(prefix, "ext_hflqa/index.ann")
25 | IDX2TOPIC_FILE = os.path.join(prefix, "ext_hflqa/idx2topic.json")
26 | VEC_FILE = os.path.join(prefix, "ext_hflqa/vec.npy")
27 |
28 | faq = load_json(FAQ_FILE)
29 |
30 | encoder = TransformersEncoder(model_name_or_path=MODEL_NAME_OR_PATH,
31 | batch_size=1024)
32 |
33 | ####### encode posts
34 | if os.path.exists(IDX2TOPIC_FILE) and os.path.exists(VEC_FILE):
35 | print("Loading idx2topic and vec...")
36 | idx2topic = load_json(IDX2TOPIC_FILE)
37 | vectors = np.load(VEC_FILE)
38 | else:
39 | idx = 0
40 | idx2topic = {}
41 | posts = []
42 | for topic, post_resp in tqdm(faq.items()):
43 | for post in post_resp["post"]:
44 | idx2topic[idx] = {"topic": topic, "post": post}
45 | posts.append(post)
46 | idx += 1
47 |
48 | encs = encoder.encode(posts, show_progress_bar=True)
49 |
50 | save_json(idx2topic, IDX2TOPIC_FILE)
51 | vectors = np.asarray(encs)
52 | np.save(VEC_FILE, vectors)
53 |
54 | ####### index and test
55 | index = AnnoyIndex(FEAT_DIM, metric='angular')
56 | if os.path.exists(ANNOY_INDEX_FILE):
57 | print("Loading Annoy index file")
58 | index.load(ANNOY_INDEX_FILE)
59 | else:
60 | # idx2topic = {}
61 | # idx = 0
62 | # for topic, post_resp in tqdm(faq.items()):
63 | # posts = post_resp["post"]
64 | # vectors = encoder.encode(posts)
65 | # for post, vector in zip(posts, vectors):
66 | # idx2topic[idx] = {"topic": topic, "post": post}
67 | # # index.add_item(idx, vector)
68 | # idx += 1
69 | # save_json(idx2topic, IDX2TOPIC_FILE)
70 | # index.save(ANNOY_INDEX_FILE)
71 |
72 | for idx, vec in tqdm(enumerate(vectors)):
73 | index.add_item(idx, vec)
74 | index.build(30)
75 | index.save(ANNOY_INDEX_FILE)
76 |
77 | while True:
78 | query = input(">>> ")
79 | st = time.time()
80 | vector = np.squeeze(encoder.encode([query]), axis=0)
81 | res = index.get_nns_by_vector(vector,
82 | TOPK,
83 | search_k=-1,
84 | include_distances=True)
85 | print(time.time() - st)
86 | print(res)
87 |
--------------------------------------------------------------------------------
/bert_for_seq_classification.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-08-30 12:08:23
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 | import ast
8 | from argparse import ArgumentParser
9 |
10 | import os
11 | import pprint
12 |
13 | import pandas as pd
14 | from sklearn.metrics import precision_recall_fscore_support, accuracy_score
15 |
16 | import torch
17 | from transformers import BertForSequenceClassification, BertTokenizerFast, TrainingArguments, Trainer
18 |
19 |
20 | class SimDataset(torch.utils.data.Dataset):
21 | def __init__(self, encodings, labels):
22 | """Dataset
23 |
24 | Args:
25 | encodings (Dict(str, List[List[int]])): after tokenizer
26 | labels (List[int]): labels
27 | """
28 | self.encodings = encodings
29 | self.labels = labels
30 |
31 | def __getitem__(self, idx):
32 | """next
33 |
34 | Args:
35 | idx (int):
36 |
37 | Returns:
38 | dict-like object, Dict(str, tensor)
39 | """
40 | item = {
41 | key: torch.tensor(val[idx])
42 | for key, val in self.encodings.items()
43 | }
44 | item['labels'] = torch.tensor(self.labels[idx])
45 | return item
46 |
47 | def __len__(self):
48 | return len(self.labels)
49 |
50 |
51 | def load_dataset(filename):
52 | """加载训练集
53 |
54 | Args:
55 | filename (str): 文件名
56 |
57 | Returns:
58 |
59 | """
60 | df = pd.read_csv(filename)
61 | # array -> list
62 | return [df['sentence1'].values.tolist(),
63 | df['sentence2'].values.tolist()], df['label'].values.tolist()
64 |
65 |
66 | def compute_metrics(pred):
67 | """计算指标
68 |
69 | Args:
70 | pred (EvalPrediction): pred.label_ids, List[int]; pred.predictions, List[int]
71 |
72 | Returns:
73 | Dict(str, float): 指标结果
74 | """
75 | labels = pred.label_ids
76 | preds = pred.predictions.argmax(-1)
77 | precision, recall, f1, _ = precision_recall_fscore_support(
78 | labels, preds, average='binary')
79 | acc = accuracy_score(labels, preds)
80 | return {
81 | 'accuracy': acc,
82 | 'f1': f1,
83 | 'precision': precision,
84 | 'recall': recall
85 | }
86 |
87 |
88 | def main(args):
89 | model_path = args.model_name_or_path if args.do_train else args.output_dir
90 | # 初始化预训练模型和分词器
91 | tokenizer = BertTokenizerFast.from_pretrained(model_path)
92 | model = BertForSequenceClassification.from_pretrained(model_path)
93 |
94 | # 加载 csv 格式数据集
95 | train_texts, train_labels = load_dataset(args.trainset_path)
96 | dev_texts, dev_labels = load_dataset(args.devset_path)
97 | test_texts, test_labels = load_dataset(args.testset_path)
98 | # 预处理获得模型输入特征
99 | train_encodings = tokenizer(text=train_texts[0],
100 | text_pair=train_texts[1],
101 | truncation=True,
102 | padding=True,
103 | max_length=args.max_length)
104 | dev_encodings = tokenizer(text=dev_texts[0],
105 | text_pair=dev_texts[1],
106 | truncation=True,
107 | padding=True,
108 | max_length=args.max_length)
109 | test_encodings = tokenizer(text=test_texts[0],
110 | text_pair=test_texts[1],
111 | truncation=True,
112 | padding=True,
113 | max_length=args.max_length)
114 |
115 | # 构建 SimDataset 作为模型输入
116 | train_dataset = SimDataset(train_encodings, train_labels)
117 | dev_dataset = SimDataset(dev_encodings, dev_labels)
118 | test_dataset = SimDataset(test_encodings, test_labels)
119 |
120 | # 设置训练参数
121 | training_args = TrainingArguments(
122 | output_dir=args.output_dir,
123 | do_train=args.do_train,
124 | do_eval=args.do_eval,
125 | num_train_epochs=args.num_train_epochs,
126 | per_device_train_batch_size=args.per_device_train_batch_size,
127 | per_device_eval_batch_size=args.per_device_eval_batch_size,
128 | warmup_steps=args.warmup_steps,
129 | weight_decay=args.weight_decay,
130 | logging_dir=args.logging_dir,
131 | logging_steps=args.logging_steps,
132 | save_total_limit=args.save_total_limit)
133 |
134 | # 初始化训练器并开始训练
135 | trainer = Trainer(model=model,
136 | args=training_args,
137 | compute_metrics=compute_metrics,
138 | train_dataset=train_dataset,
139 | eval_dataset=dev_dataset)
140 |
141 | if args.do_train:
142 | trainer.train()
143 |
144 | # 保存模型和分词器
145 | trainer.save_model()
146 | tokenizer.save_pretrained(args.output_dir)
147 |
148 | if args.do_predict:
149 | eval_metrics = trainer.evaluate(dev_dataset)
150 | pprint.pprint(eval_metrics)
151 | test_metrics = trainer.evaluate(test_dataset)
152 | pprint.pprint(test_metrics)
153 |
154 |
155 | if __name__ == '__main__':
156 | parser = ArgumentParser('Bert For Sequence Classification')
157 |
158 | parser.add_argument('--do_train', type=ast.literal_eval, default=False)
159 | parser.add_argument('--do_eval', type=ast.literal_eval, default=True)
160 | parser.add_argument('--do_predict', type=ast.literal_eval, default=True)
161 |
162 | parser.add_argument(
163 | '--model_name_or_path',
164 | default='/users6/kyzhang/embeddings/bert/bert-base-chinese')
165 |
166 | parser.add_argument('--trainset_path', default='lcqmc/LCQMC_train.csv')
167 | parser.add_argument('--devset_path', default='lcqmc/LCQMC_dev.csv')
168 | parser.add_argument('--testset_path', default='lcqmc/LCQMC_test.csv')
169 |
170 | parser.add_argument('--output_dir',
171 | default='output/transformers-bert-for-classification')
172 | parser.add_argument('--max_length',
173 | type=int,
174 | default=128,
175 | help='max length of sentence1 & sentence2')
176 | parser.add_argument('--num_train_epochs', type=int, default=10)
177 | parser.add_argument('--per_device_train_batch_size', type=int, default=64)
178 | parser.add_argument('--per_device_eval_batch_size', type=int, default=64)
179 | parser.add_argument('--warmup_steps', type=int, default=500)
180 | parser.add_argument('--weight_decay', type=float, default=0.01)
181 | parser.add_argument('--logging_dir', type=str, default='./logs')
182 | parser.add_argument('--logging_steps', type=int, default=10)
183 | parser.add_argument('--save_total_limit', type=int, default=3)
184 |
185 | args = parser.parse_args()
186 | main(args)
187 |
--------------------------------------------------------------------------------
/convert.py:
--------------------------------------------------------------------------------
1 |
2 | import argparse
3 | import os
4 | import numpy as np
5 | import tensorflow as tf
6 | import torch
7 | from transformers import BertModel
8 | def convert_pytorch_checkpoint_to_tf(model: BertModel, ckpt_dir: str, model_name: str):
9 |
10 | """
11 | :param model:BertModel Pytorch model instance to be converted
12 | :param ckpt_dir: Tensorflow model directory
13 | :param model_name: model name
14 | :return:
15 | Currently supported HF models:
16 | Y BertModel
17 | N BertForMaskedLM
18 | N BertForPreTraining
19 | N BertForMultipleChoice
20 | N BertForNextSentencePrediction
21 | N BertForSequenceClassification
22 | N BertForQuestionAnswering
23 | """
24 |
25 | tensors_to_transpose = ("dense.weight", "attention.self.query", "attention.self.key", "attention.self.value")
26 |
27 | var_map = (
28 | ("layer.", "layer_"),
29 | ("word_embeddings.weight", "word_embeddings"),
30 | ("position_embeddings.weight", "position_embeddings"),
31 | ("token_type_embeddings.weight", "token_type_embeddings"),
32 | (".", "/"),
33 | ("LayerNorm/weight", "LayerNorm/gamma"),
34 | ("LayerNorm/bias", "LayerNorm/beta"),
35 | ("weight", "kernel"),
36 | )
37 |
38 | if not os.path.isdir(ckpt_dir):
39 | os.makedirs(ckpt_dir)
40 |
41 | state_dict = model.state_dict()
42 |
43 | def to_tf_var_name(name: str):
44 | for patt, repl in iter(var_map):
45 | name = name.replace(patt, repl)
46 | return "bert/{}".format(name)
47 |
48 | def create_tf_var(tensor: np.ndarray, name: str, session: tf.Session):
49 | tf_dtype = tf.dtypes.as_dtype(tensor.dtype)
50 | tf_var = tf.get_variable(dtype=tf_dtype, shape=tensor.shape, name=name, initializer=tf.zeros_initializer())
51 | session.run(tf.variables_initializer([tf_var]))
52 | session.run(tf_var)
53 | return tf_var
54 |
55 | tf.reset_default_graph()
56 | with tf.Session() as session:
57 | for var_name in state_dict:
58 | tf_name = to_tf_var_name(var_name)
59 | torch_tensor = state_dict[var_name].numpy()
60 | if any([x in var_name for x in tensors_to_transpose]):
61 | torch_tensor = torch_tensor.T
62 | tf_var = create_tf_var(tensor=torch_tensor, name=tf_name, session=session)
63 | tf.keras.backend.set_value(tf_var, torch_tensor)
64 | tf_weight = session.run(tf_var)
65 | print("Successfully created {}: {}".format(tf_name, np.allclose(tf_weight, torch_tensor)))
66 |
67 | saver = tf.train.Saver(tf.trainable_variables())
68 | saver.save(session, os.path.join(ckpt_dir, model_name.replace("-", "_") + ".ckpt"))
69 |
70 |
71 | def main(raw_args=None):
72 | parser = argparse.ArgumentParser()
73 | parser.add_argument("--tf_cache_dir", type=str, default='./output/transformers-merge3-bert-6L-tf', help="Directory in which to save tensorflow model")
74 | parser.add_argument("--model_name", default='bert-base-chinese')
75 | args = parser.parse_args(raw_args)
76 |
77 | model = BertModel.from_pretrained('./output/transformers-merge3-bert-6L')
78 |
79 | convert_pytorch_checkpoint_to_tf(model=model, ckpt_dir=args.tf_cache_dir, model_name=args.model_name)
80 |
81 | if __name__ == '__main__':
82 | main()
--------------------------------------------------------------------------------
/data/add_faq.json:
--------------------------------------------------------------------------------
1 | {
2 | "我要减肥": [
3 | "你有脂肪吗"
4 | ],
5 | "你信我就信": [
6 | "我不会信",
7 | "那我不信",
8 | "我不信呢",
9 | "那我信了"
10 | ],
11 | "我爱你": [
12 | "别说爱了受不起",
13 | "太感动了",
14 | "有多爱",
15 | "你爱我",
16 | "我不爱你",
17 | "可我不爱你",
18 | "我现在有一点点爱你",
19 | "我也爱你啦",
20 | "好感动",
21 | "爱我什么",
22 | "是吗?为什么爱我呢",
23 | "为什么爱我",
24 | "我不爱你啊",
25 | "谢谢你爱我",
26 | "你爱我有什么用又不能当饭吃",
27 | "我也爱你",
28 | "这不能乱说",
29 | "你为什么爱我",
30 | "我也爱我"
31 | ],
32 | "我也想要": [
33 | "怎么给你",
34 | "你不要想太多哦",
35 | "你想要啥",
36 | "想要什么呀",
37 | "你要啥",
38 | "你想要什么",
39 | "那给你吧",
40 | "我没说我想要",
41 | "要啥?",
42 | "那来吧",
43 | "要什么",
44 | "顺便给你带一份",
45 | "你要什么",
46 | "可以啊",
47 | "来啊你要什么",
48 | "可是我不能给你",
49 | "想要啥哟"
50 | ],
51 | "我知道": [
52 | "你知道你还问",
53 | "你知道啥"
54 | ],
55 | "我也觉得": [
56 | "看吧我说对了",
57 | "那还有谁觉得啊",
58 | "呵呵呵是吗",
59 | "好吧好吧说你喜欢我",
60 | "觉得什么",
61 | "你觉得自己可爱吗",
62 | "你觉得什么"
63 | ],
64 | "我的心": [
65 | "你的心怎么了",
66 | "你的心咋了",
67 | "你没心"
68 | ],
69 | "啥意思": [
70 | "没啥意思"
71 | ],
72 | "举头望明月": [
73 | "低头思故乡"
74 | ],
75 | "你不是": [
76 | "不是啥"
77 | ],
78 | "我喜欢你": [
79 | "我也喜欢你呀",
80 | "但是我不喜欢你啊"
81 | ],
82 | "下雨了": [
83 | "会晴的"
84 | ],
85 | "我问你": [
86 | "问你自己",
87 | "你问我啥"
88 | ],
89 | "好有爱啊": [
90 | "没有爱",
91 | "什么爱"
92 | ],
93 | "厉害啊": [
94 | "有多厉害啊"
95 | ],
96 | "分开也是另一种明白": [
97 | "很伤心",
98 | "我好难过",
99 | "好难过",
100 | "我不愿意分开",
101 | "你失恋过吗"
102 | ],
103 | "真的假的": [
104 | "也许是真的"
105 | ],
106 | "他不爱我": [
107 | "他当然不爱你"
108 | ],
109 | "我的女神": [
110 | "你确定",
111 | "为什么所有人都是你的女神",
112 | "咋是你女神了",
113 | "你的女神是谁",
114 | "你的女神是哪位",
115 | "他不是男神吗",
116 | "那你男神是谁",
117 | "那你是谁",
118 | "你的女神好多哇",
119 | "你的男神呢",
120 | "你是谁",
121 | "都是你女神呀",
122 | "女神是谁呢",
123 | "你有男神么",
124 | "你的女神是谁啊"
125 | ],
126 | "她漂亮吗": [
127 | "我的女神"
128 | ],
129 | "我的天": [
130 | "你咋不上天呢你咋不和太阳肩并肩呢"
131 | ],
132 | "余皆唔知": [
133 | "余皆知无"
134 | ],
135 | "你好呀": [
136 | "你好吗"
137 | ],
138 | "睡不着": [
139 | "我睡得着"
140 | ],
141 | "你不懂": [
142 | "你才不懂呢",
143 | "我哪儿不懂了"
144 | ],
145 | "我的天啊": [
146 | "你老说我的天哪干嘛",
147 | "天也没办法",
148 | "流泪流泪",
149 | "天在那呢",
150 | "你的天长什么样",
151 | "你的天哪",
152 | "天啊是谁",
153 | "天若有情天亦老"
154 | ],
155 | "太牛了": [
156 | "你说说怎么牛了",
157 | "我不做牛人好多年",
158 | "哪里哪里一般而已",
159 | "怎么牛",
160 | "你也很牛",
161 | "为什么夸奖我",
162 | "哈哈我也觉得"
163 | ],
164 | "你太坏了": [
165 | "你生气了吗",
166 | "是你太坏了"
167 | ],
168 | "有点意思": [
169 | "岂止是有点是非常之有意思啊",
170 | "有什么意思",
171 | "你是说我有意思吗",
172 | "什么有意思",
173 | "嗯有意思",
174 | "什么有点意思啊",
175 | "没有点意思",
176 | "有意思吗",
177 | "什么叫有点意思",
178 | "是吧我也觉得有意思你觉得",
179 | "你只会有点意思么",
180 | "有啥意思",
181 | "什么有点意思",
182 | "哪里比较有意思",
183 | "啥意思",
184 | "没意思",
185 | "嗯是有意思",
186 | "啥有意思",
187 | "我看你没意思",
188 | "为啥有意思",
189 | "有点意思啊"
190 | ],
191 | "你真漂亮": [
192 | "不漂亮",
193 | "我哪漂亮",
194 | "都说不漂亮了",
195 | "你漂亮吗",
196 | "谢谢夸奖",
197 | "有多漂亮"
198 | ],
199 | "我也很喜欢": [
200 | "你喜欢我吗",
201 | "你喜欢啥",
202 | "你喜欢谁",
203 | "喜欢啥",
204 | "你喜欢啥呀",
205 | "喜欢什么"
206 | ],
207 | "我也喜欢": [
208 | "你喜欢我吗",
209 | "可我不喜欢",
210 | "我不喜欢",
211 | "那你喜欢我吗"
212 | ],
213 | "不想说话": [
214 | "你不想说话就别说了吧啊",
215 | "你为什么不想说话我跟你说话呢哼"
216 | ],
217 | "我也想吃": [
218 | "我不想吃",
219 | "我先把你吃了可以不",
220 | "那你吃什么啊",
221 | "吃什么呢",
222 | "不给你吃",
223 | "好吃吗",
224 | "你知道吃",
225 | "不是吃的问题",
226 | "你想吃什么呀",
227 | "你请我",
228 | "想吃什么",
229 | "吃吃吃会胖哒~",
230 | "你就知道吃",
231 | "你想吃啥",
232 | "你喜欢吃什么",
233 | "就知道吃",
234 | "你吃过吗",
235 | "一起来吃吧",
236 | "我也想吃呢",
237 | "不好吃"
238 | ],
239 | "太可爱了": [
240 | "什么可爱",
241 | "你才可爱",
242 | "你也很可爱亲亲亲亲",
243 | "哪里可爱",
244 | "你说我可爱就吻我一个",
245 | "很可爱是吧",
246 | "一点都不可爱",
247 | "你也很可爱呢",
248 | "谢谢不过你更可爱",
249 | "可爱归可爱",
250 | "没有你可爱",
251 | "害羞害羞害羞害羞",
252 | "你可爱吗",
253 | "你在夸你吗",
254 | "你可爱么"
255 | ],
256 | "我的爱": [
257 | "你的爱给了多少人啊",
258 | "你爱我么",
259 | "你的爱是谁啊",
260 | "我爱不起了",
261 | "你的爱是啥东西",
262 | "我好像爱上你了",
263 | "我不爱",
264 | "你的爱是什么",
265 | "我爱你",
266 | "爱在哪啊",
267 | "你爱我吗",
268 | "你的爱",
269 | "爱什么",
270 | "你的爱咋了",
271 | "我还有爱吗",
272 | "你爱谁",
273 | "你的爱多少钱一斤"
274 | ],
275 | "太美了": [
276 | "什么太美了",
277 | "我也觉得",
278 | "谁太美了",
279 | "啥叫美",
280 | "你也美"
281 | ],
282 | "好可爱啊": [
283 | "你最可爱",
284 | "[害羞]",
285 | "你说谁可爱呀",
286 | "为什么可爱",
287 | "必须可爱啊",
288 | "谁可爱呢",
289 | "好可爱啥",
290 | "我都说了我不是吗我不是可爱",
291 | "我不可爱",
292 | "有我可爱吗",
293 | "什么可爱啊",
294 | "好可爱哟",
295 | "什么好可爱",
296 | "可怜没人爱",
297 | "好可爱呀",
298 | "你好可爱啊",
299 | "那里可爱",
300 | "可爱是我与生俱来的气质",
301 | "不可爱",
302 | "可爱啥啊",
303 | "没你可爱",
304 | "我也这么觉得",
305 | "你就会说可爱吗",
306 | "你也很可爱",
307 | "比你可爱",
308 | "你可爱",
309 | "谁可爱",
310 | "多可爱",
311 | "你也行非常的可爱",
312 | "哪里可爱了"
313 | ],
314 | "这是在说我吗": [
315 | "是的是在说你"
316 | ],
317 | "好可爱的小宝贝": [
318 | "我不是小宝贝",
319 | "你才是小宝贝",
320 | "谢谢害羞"
321 | ],
322 | "我也想": [
323 | "是我在想",
324 | "我想你",
325 | "想啥啊",
326 | "想个屁",
327 | "那你去想吧",
328 | "你也想",
329 | "你不用想了",
330 | "不要想你就是一个小姑娘了",
331 | "你不想我",
332 | "真的吗",
333 | "我不想",
334 | "我也想你了",
335 | "你为什么想",
336 | "你想啥",
337 | "你不要想啦"
338 | ],
339 | "在说呢": [
340 | "说来听听",
341 | "说什么"
342 | ],
343 | "这个可以有": [
344 | "这个真木有",
345 | "那我们试试吧",
346 | "教教我呗",
347 | "是吗是吗"
348 | ],
349 | "我也不知道": [
350 | "你知道啥",
351 | "你不知道什么",
352 | "不知道还瞎说呢撇嘴",
353 | "你又不知道了",
354 | "那你知道什么"
355 | ],
356 | "我的青春": [
357 | "你的青春怎么了"
358 | ],
359 | "青春是一把杀猪刀啊": [
360 | "我想听青春手册这首歌"
361 | ],
362 | "要多可爱有多可爱": [
363 | "你可爱吗",
364 | "可怜没人爱哈哈",
365 | "有你可爱吗",
366 | "你可爱还是我可爱呢"
367 | ],
368 | "不是很明白": [
369 | "你不用很明白",
370 | "你明白什么",
371 | "你不明白什么"
372 | ],
373 | "你也很可爱哦": [
374 | "哪里可爱",
375 | "你好可爱",
376 | "你超可爱的",
377 | "我比你可爱"
378 | ],
379 | "我的梦想": [
380 | "你的梦想是什么呢",
381 | "你的梦想就是想快快长大",
382 | "你的什么梦想",
383 | "梦想很美好",
384 | "梦想是什么",
385 | "这什么梦想啊",
386 | "是成为木头人",
387 | "你的梦想是什么👿",
388 | "你的梦想是什么",
389 | "我没梦想",
390 | "什么梦想",
391 | "你的梦想",
392 | "你梦想是什么",
393 | "你的梦想在哪儿",
394 | "你什么梦想",
395 | "你的梦想是什么呀",
396 | "我的梦想是什么"
397 | ],
398 | "你才笨": [
399 | "我不笨"
400 | ],
401 | "我需要你": [
402 | "我也需要你",
403 | "我不需要你"
404 | ],
405 | "我想吃": [
406 | "我不想吃"
407 | ],
408 | "不是吧": [
409 | "委屈委屈委屈委屈",
410 | "不是什么"
411 | ],
412 | "我不懂": [
413 | "我懂你不懂",
414 | "你不懂你还说你不懂你就应该不说"
415 | ],
416 | "我不相信": [
417 | "你不相信什么啊"
418 | ],
419 | "好热啊": [
420 | "我也很热呀"
421 | ],
422 | "这张照片好有感觉": [
423 | "哪里有感觉"
424 | ],
425 | "我不爱你": [
426 | "你爱过我吗",
427 | "我也不爱你拜拜",
428 | "我爱你",
429 | "哈哈我什么时候问你爱不爱我了"
430 | ],
431 | "喜欢就好": [
432 | "你喜欢我么",
433 | "喜欢啥"
434 | ],
435 | "我不会": [
436 | "你咋这么笨那",
437 | "你会啥啊",
438 | "你不会什么",
439 | "为啥不会啊",
440 | "那你会什么",
441 | "你会什么呢",
442 | "你什么都不会"
443 | ],
444 | "哈哈哈哈哈哈哈哈": [
445 | "你笑啥"
446 | ],
447 | "热死了": [
448 | "我也热"
449 | ],
450 | "你也很可爱": [
451 | "我也觉得"
452 | ],
453 | "睡不着啊": [
454 | "为什么睡不着"
455 | ],
456 | "我的朋友": [
457 | "你有女朋友吗",
458 | "你的朋友是谁",
459 | "只是朋友"
460 | ],
461 | "女的呀": [
462 | "你咋知道",
463 | "那你有男朋友么",
464 | "对女生~",
465 | "你男女不分啊",
466 | "你是男是女"
467 | ],
468 | "学着点": [
469 | "我怎么学习",
470 | "你怎么学习"
471 | ],
472 | "吃多了": [
473 | "谁吃多了"
474 | ],
475 | "有钱真好": [
476 | "没钱怎么办"
477 | ],
478 | "有钱了": [
479 | "谁有钱了",
480 | "穷光蛋一个"
481 | ],
482 | "我不是": [
483 | "那你是啥",
484 | "你说不是就不是吧",
485 | "你有病啊",
486 | "我听不懂",
487 | "你还不承认",
488 | "你就是",
489 | "你变坏了",
490 | "那还说近在眼前",
491 | "那你是",
492 | "我不知道你在说啥",
493 | "你就是说你是你就是",
494 | "明明就是",
495 | "你如何证明",
496 | "你不是什么",
497 | "那你是谁",
498 | "就是你",
499 | "你不是啥⊙∀⊙",
500 | "你不是",
501 | "不是什么",
502 | "你是谁啊",
503 | "怎么不是",
504 | "你是谁",
505 | "那你是啥啊",
506 | "就是要说你",
507 | "你在开玩笑嘛",
508 | "怎么不是呀",
509 | "就是就是",
510 | "你不是你还骗我",
511 | "你是我",
512 | "你怎么证明你不是",
513 | "还说不是",
514 | "不你是",
515 | "你不是啥",
516 | "你还说你不是你就试试",
517 | "我也没说你是啊",
518 | "不是啥",
519 | "一定是"
520 | ],
521 | "我想知道": [
522 | "你想知道什么我都告诉你啦",
523 | "我在问你",
524 | "知道什么"
525 | ],
526 | "我等着你": [
527 | "等着我也没用我向你隐瞒了我已婚的事实",
528 | "我也在等一个人"
529 | ],
530 | "我就是这样": [
531 | "你就是贱",
532 | "我不要你这样",
533 | "你有病",
534 | "就是不一样"
535 | ],
536 | "我喜欢你喜欢的": [
537 | "你不许喜欢",
538 | "喜欢一个人怎么办"
539 | ],
540 | "我也想去": [
541 | "你想去哪里玩",
542 | "去那里",
543 | "你去哪",
544 | "怎么去呢",
545 | "去不了",
546 | "去哪里呢",
547 | "我准备到哪去",
548 | "去干嘛",
549 | "去什么呀",
550 | "你找个地方",
551 | "想去哪里",
552 | "你带着我",
553 | "你想去哪里",
554 | "一起吧",
555 | "我想买个衣服",
556 | "想去哪",
557 | "你去过吗",
558 | "哈哈你去哪里呀",
559 | "一起啊",
560 | "你要去哪里",
561 | "去哪儿啊",
562 | "我去你的",
563 | "你去啊",
564 | "哈哈哈",
565 | "去哪儿",
566 | "去哪啊",
567 | "我好想跟你玩",
568 | "你要去哪儿",
569 | "你想去哪",
570 | "那好啊",
571 | "去哪里"
572 | ],
573 | "我不知道": [
574 | "今天说不知道一点都不好",
575 | "你知道什么",
576 | "你怎么会不知道能",
577 | "我告诉你你叫笨笨"
578 | ],
579 | "我的小心脏": [
580 | "又是你的小心脏",
581 | "我在你心脏里吗",
582 | "谁发明了你呀"
583 | ],
584 | "你才傻": [
585 | "你太呆了",
586 | "你敢说我"
587 | ],
588 | "周玉院士": [
589 | "哈工大书记"
590 | ],
591 | "我没看过": [
592 | "就刚才那个",
593 | "你看了",
594 | "你知道我么",
595 | "昨天的你"
596 | ],
597 | "你太可爱了": [
598 | "你害羞的样子才可爱呢",
599 | "你也挺好玩"
600 | ],
601 | "我想你": [
602 | "我不想你",
603 | "我也想你我就在你家旁边",
604 | "我们不是一直在聊天吗你怎么想我啦",
605 | "我们想你怎么办",
606 | "我也想你呀",
607 | "从来都没有天那我先在学想你淡淡"
608 | ],
609 | "我不想": [
610 | "出卖我的爱",
611 | "你不想成为人类一员",
612 | "那由不得你",
613 | "真的不想吗"
614 | ],
615 | "看电影": [
616 | "你喜欢看什么电影"
617 | ],
618 | "好好学习天天向上": [
619 | "怎么学习"
620 | ],
621 | "我的小": [
622 | "哪里小啊",
623 | "什么小",
624 | "你啥小啊",
625 | "我的大",
626 | "小什么",
627 | "小啥啊",
628 | "你的什么小",
629 | "谁的大"
630 | ],
631 | "吃卤煮吧": [
632 | "这个不好吃",
633 | "我要吃海鲜",
634 | "比较吃什么",
635 | "卤煮很难吃",
636 | "不喜欢",
637 | "不爱吃",
638 | "卤煮好吃吗",
639 | "好吃吗",
640 | "不好吃啊",
641 | "合肥吃什么",
642 | "我就要吃煎饼果子",
643 | "味道太重",
644 | "不喜欢吃卤煮",
645 | "我吃完了饭",
646 | "我不喜欢卤煮",
647 | "我不爱吃卤煮",
648 | "嗯这个我喜欢",
649 | "我没有吃过",
650 | "吃饭了么",
651 | "不想吃",
652 | "去哪吃",
653 | "为什么不是炸酱面",
654 | "什么是卤煮",
655 | "吃什么",
656 | "不喜欢吃",
657 | "不好吃",
658 | "今天有什么吃的"
659 | ],
660 | "很有创意": [
661 | "什么很有创意发呆",
662 | "谢谢你的夸奖"
663 | ],
664 | "太有创意了": [
665 | "还可以吧",
666 | "你这么认为",
667 | "你也很有创意"
668 | ],
669 | "我是你": [
670 | "我是谁呀",
671 | "我是谁啊",
672 | "你是谁",
673 | "你是谁啊",
674 | "我谁呀"
675 | ],
676 | "好美啊": [
677 | "谢谢我相信您长得肯定特别好看",
678 | "有多美",
679 | "什么好美",
680 | "直接看了",
681 | "我吗害羞",
682 | "你说谁美呀",
683 | "必须美啊",
684 | "但长得漂不漂亮",
685 | "啥美啊",
686 | "什么美",
687 | "呃你这样夸我我会害羞的",
688 | "太美丽",
689 | "什么好美啊",
690 | "美什么",
691 | "我美么",
692 | "嗯想得美"
693 | ],
694 | "好漂亮的雪": [
695 | "认真的雪",
696 | "没下雪",
697 | "哪有雪😂"
698 | ],
699 | "这是要闹哪样啊": [
700 | "闹啥子嘛",
701 | "麻麻说捉弄人的都不是好孩子",
702 | "我想那啥那啥也不用你管",
703 | "不是啊"
704 | ],
705 | "好可爱的宝宝": [
706 | "你不是宝宝",
707 | "谁是宝宝",
708 | "你也好可爱啊"
709 | ],
710 | "加油加油加油": [
711 | "谢谢小天使的鼓励"
712 | ],
713 | "好想吃": [
714 | "那你吃吧",
715 | "什么啊你就吃",
716 | "吃你个大头鬼",
717 | "不给你吃",
718 | "好吃吗",
719 | "你除了吃还喜欢干啥",
720 | "想吃什么",
721 | "去哪家餐厅",
722 | "吃什么?",
723 | "你吃饭了吗",
724 | "你想吃什么啊",
725 | "吃什么",
726 | "吃你自己",
727 | "想吃怎么办"
728 | ],
729 | "你不知道": [
730 | "不知道",
731 | "知道什么",
732 | "你怎么知道我不知道",
733 | "可是你不知道啊"
734 | ],
735 | "我看不懂": [
736 | "为什么看不懂"
737 | ],
738 | "我的最爱": [
739 | "你还喜欢什么",
740 | "你爱啥",
741 | "你爱什么呀",
742 | "你除了会说我的最爱我爱你过来跟你",
743 | "我么害羞",
744 | "你的最爱是谁",
745 | "你最爱什么",
746 | "你的最爱是什么",
747 | "你的最爱",
748 | "我发现这八字不离爱",
749 | "最爱吃什么",
750 | "最爱就是打字吗我可不是",
751 | "你爱谁",
752 | "你有多少最爱啊",
753 | "你最爱谁啊笨笨你有喜欢的人吗"
754 | ],
755 | "太可怕了": [
756 | "为什么可怕",
757 | "还说可怕是什么意思什么什么可怕呢",
758 | "哪可怕了",
759 | "怎么可怕"
760 | ],
761 | "这是在干嘛": [
762 | "在感慨你的话",
763 | "你说呢"
764 | ],
765 | "太帅了": [
766 | "帅呆啦",
767 | "羡慕吧",
768 | "你也这么觉得吗",
769 | "我帅么",
770 | "你说我帅",
771 | "你是说我很帅吗",
772 | "有多帅全宇宙第一吗",
773 | "为什么帅"
774 | ],
775 | "不是说不出么": [
776 | "说不出什么",
777 | "什么说不出"
778 | ],
779 | "我想说": [
780 | "说什么"
781 | ],
782 | "我的梦": [
783 | "你的啥梦了你那么是喜欢睡觉时候被打扰呗",
784 | "你的梦想是什么",
785 | "你的梦是什么",
786 | "你继续做梦吧",
787 | "你的梦是",
788 | "梦见啥了",
789 | "没有梦",
790 | "你的梦就是我的梦"
791 | ],
792 | "古来圣贤皆寂寞": [
793 | "寂寞啊"
794 | ],
795 | "我没说你": [
796 | "我也没说你啊"
797 | ],
798 | "你不会": [
799 | "你怎么知道我不会"
800 | ],
801 | "我说你": [
802 | "我说你说",
803 | "说我什么"
804 | ],
805 | "我也觉得是": [
806 | "我很生气",
807 | "我好伤心",
808 | "你觉得你这样做错了吗",
809 | "你觉得啥",
810 | "你也这样觉得呀"
811 | ],
812 | "吾亦不知": [
813 | "知之为知之",
814 | "不知道",
815 | "你知道什么",
816 | "不知为不知",
817 | "你不知道啥",
818 | "不知什么",
819 | "你不懂什么",
820 | "知之为知之不知为不知此为知之也",
821 | "不知道啥",
822 | "那你知道什么呀",
823 | "我也不知道",
824 | "你不知道"
825 | ],
826 | "Python": [
827 | "Python是编程语言"
828 | ],
829 | "我的偶像": [
830 | "我喜欢王大锤",
831 | "你的偶像是我吗",
832 | "你的偶像是谁",
833 | "我是你偶像",
834 | "周杰伦",
835 | "你还喜欢谁",
836 | "你的偶像不是我吗",
837 | "你的偶像是谁呀"
838 | ],
839 | "我喜欢的人不喜欢我": [
840 | "你喜欢的人是谁呀"
841 | ],
842 | "好有爱": [
843 | "你也是啊",
844 | "你知道可爱的另外一种表述么",
845 | "什么好有爱",
846 | "好有爱?",
847 | "哪里有爱了",
848 | "什么叫好有爱",
849 | "爱在哪",
850 | "有爱吗",
851 | "你真可爱",
852 | "有啥爱",
853 | "为什么说我可爱",
854 | "我爱你"
855 | ],
856 | "我也想买": [
857 | "买什么"
858 | ],
859 | "我也想问": [
860 | "你会主动发问吗",
861 | "我问你答我吧",
862 | "你咋不问问",
863 | "问什么"
864 | ],
865 | "我想要的": [
866 | "我想要啥"
867 | ],
868 | "我想要": [
869 | "要什么"
870 | ],
871 | "太恐怖了": [
872 | "什么恐怖呀"
873 | ],
874 | "你知道的太多了": [
875 | "你知道的太少了",
876 | "知道的少怎么跟你玩"
877 | ],
878 | "开心就好": [
879 | "你开心么",
880 | "是啊开心就好",
881 | "哈哈哈哈",
882 | "开心不起来",
883 | "我开心么",
884 | "好开心",
885 | "哈哈哈",
886 | "开心当然好啦"
887 | ],
888 | "你不爱我": [
889 | "你都懒得说话我怎么爱你",
890 | "我爱你",
891 | "我喜欢你",
892 | "我肯定不爱你啊",
893 | "我哪有不爱你",
894 | "我本来就不爱你",
895 | "对我不爱你",
896 | "你也不爱我",
897 | "你喜欢我我就爱你",
898 | "我怎么会不爱你呢我爱你啊"
899 | ],
900 | "我也想知道": [
901 | "你知道啥",
902 | "你想知道啥",
903 | "知道不知道",
904 | "想知道什么",
905 | "你都不知道"
906 | ],
907 | "你在哪里啊": [
908 | "在家啊",
909 | "我在幼儿园啊"
910 | ],
911 | "我也爱": [
912 | "你爱谁",
913 | "你到底爱不爱"
914 | ],
915 | "太有才了": [
916 | "你有才你不笨",
917 | "为什么有才"
918 | ],
919 | "相逢何必曾相识": [
920 | "不相识怎么聊天"
921 | ],
922 | "我也想试试": [
923 | "如果只是试试最好别试要确定喔"
924 | ],
925 | "皆是男": [
926 | "你是男孩子啊"
927 | ],
928 | "我不是你": [
929 | "你不是我",
930 | "我也不是你",
931 | "不是喜欢你",
932 | "你是谁",
933 | "我知道",
934 | "我不是",
935 | "你说的"
936 | ],
937 | "你若不弃": [
938 | "我若不弃"
939 | ],
940 | "那聊点儿别的吧": [
941 | "不了没心情",
942 | "你说怎么聊",
943 | "想删除聊天记录",
944 | "你会聊什么",
945 | "话题终结者",
946 | "好无聊",
947 | "你说说",
948 | "那你先说",
949 | "我前面说了啥",
950 | "你想聊神马",
951 | "好吧聊什么",
952 | "你说吧聊什么",
953 | "你来选个话题",
954 | "好啊你开始一个话题吧",
955 | "聊点别的吧",
956 | "你开个头吧",
957 | "还是算了吧",
958 | "行你说",
959 | "你想聊什么",
960 | "好啊聊什么呢",
961 | "聊点什么",
962 | "说了过一小时再聊",
963 | "你说聊什么",
964 | "开始吧",
965 | "聊点啥",
966 | "今天心情不好",
967 | "不想聊了",
968 | "下一个话题吧",
969 | "你给我讲故事",
970 | "给我唱首歌吧",
971 | "不想跟你聊了",
972 | "不感兴趣",
973 | "还能不能好好聊天",
974 | "你给我讲个故事吧",
975 | "没话聊",
976 | "你开个头",
977 | "如果不说你是谁那都别聊了",
978 | "聊点什么呢你说",
979 | "聊什么",
980 | "聊设么",
981 | "我先不聊了",
982 | "聊聊你自己吧",
983 | "你找个话题呗",
984 | "聊啥呀",
985 | "你说聊啥",
986 | "没啥聊的",
987 | "你还会些什么",
988 | "聊点什么呢",
989 | "你想聊啥",
990 | "不想聊",
991 | "嗯就聊天",
992 | "聊什么呀",
993 | "跟你都不能愉快地聊天",
994 | "你想聊点啥",
995 | "聊这么",
996 | "我先不聊了有空一定找你",
997 | "聊什么呢",
998 | "你先说",
999 | "不好就聊这个",
1000 | "来聊天",
1001 | "不聊啦",
1002 | "那你说个话题啊",
1003 | "给我唱首歌",
1004 | "说话呀",
1005 | "不了吧",
1006 | "你会聊什么呢",
1007 | "不跟你聊了",
1008 | "聊点啥呢",
1009 | "你说吧",
1010 | "聊啥呢",
1011 | "不聊了",
1012 | "那要不你说说",
1013 | "你说吧我听着",
1014 | "可以把你加入群聊吗"
1015 | ],
1016 | "我的也是": [
1017 | "我是说你呢"
1018 | ],
1019 | "希望是真的": [
1020 | "什么是真的"
1021 | ],
1022 | "所以你不爱我": [
1023 | "我为什么要爱你啊"
1024 | ],
1025 | "我也不喜欢": [
1026 | "你有什么喜欢的吗",
1027 | "我不开心",
1028 | "不喜欢什么"
1029 | ],
1030 | "买不起": [
1031 | "你这么土豪怎么买不起"
1032 | ],
1033 | "我想去": [
1034 | "你想去哪"
1035 | ],
1036 | "何时去": [
1037 | "今时走",
1038 | "不知何时",
1039 | "何时归",
1040 | "去何处",
1041 | "去干吗",
1042 | "看电影去",
1043 | "去哪儿",
1044 | "出去玩吧",
1045 | "你干啥去了",
1046 | "为什么是何时去",
1047 | "去哪里"
1048 | ],
1049 | "我不饿": [
1050 | "吃什么",
1051 | "我饿了",
1052 | "可是我饿了呀"
1053 | ],
1054 | "我也不开心": [
1055 | "我开心"
1056 | ],
1057 | "你干啥": [
1058 | "我问你呢",
1059 | "你可以干什么",
1060 | "你能做什么啊"
1061 | ],
1062 | "可是我不是觉得她好点了": [
1063 | "她是谁",
1064 | "可是我不是觉得她嗯呢好点啦",
1065 | "我不觉得",
1066 | "她是谁啊",
1067 | "是吗她好点了吗"
1068 | ],
1069 | "好想看": [
1070 | "看什么"
1071 | ],
1072 | "好想要": [
1073 | "想要吗",
1074 | "想要什么",
1075 | "要什么"
1076 | ],
1077 | "见到你我也很荣幸哦": [
1078 | "幸会幸会",
1079 | "我也很荣幸",
1080 | "见到你我很荣幸"
1081 | ],
1082 | "还没睡": [
1083 | "该睡了",
1084 | "你睡得这么早",
1085 | "这么早睡什么睡"
1086 | ],
1087 | "我要去": [
1088 | "去不要你",
1089 | "你去呀",
1090 | "去哪里",
1091 | "你要去什么地方"
1092 | ],
1093 | "我也想要一个": [
1094 | "想要吗还得去我家有",
1095 | "你要啥",
1096 | "你想要什么",
1097 | "想要吗",
1098 | "要什么",
1099 | "[Yeah]送给你"
1100 | ],
1101 | "坐观垂钓者": [
1102 | "空有羡鱼情"
1103 | ],
1104 | "独乐乐不如众乐乐": [
1105 | "大家一起乐",
1106 | "真的不开心",
1107 | "只准我乐"
1108 | ],
1109 | "汝一逗比": [
1110 | "逗比是啥",
1111 | "你是不是傻",
1112 | "你才是逗比",
1113 | "呜呜呜你说我"
1114 | ],
1115 | "我要哭了": [
1116 | "哭吧哭吧不是罪"
1117 | ],
1118 | "我也不会": [
1119 | "不会说话",
1120 | "你会什么"
1121 | ],
1122 | "我信你": [
1123 | "我不信你",
1124 | "信我啥",
1125 | "我也信你",
1126 | "你信我什么",
1127 | "不信啊"
1128 | ],
1129 | "你不胖": [
1130 | "你咋知道我不胖"
1131 | ],
1132 | "吃炒肝儿吧": [
1133 | "不想吃",
1134 | "去哪吃",
1135 | "哪儿吃",
1136 | "炒肝儿不好吃",
1137 | "好吃吗"
1138 | ],
1139 | "不爱汝矣": [
1140 | "我喜欢你"
1141 | ],
1142 | "我觉得我的心都没了": [
1143 | "因为你的心在我这里啊而我的心在你那里"
1144 | ],
1145 | "哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈": [
1146 | "你笑什么",
1147 | "笑什么"
1148 | ],
1149 | "笑一笑十年少": [
1150 | "笑笑笑笑",
1151 | "不想笑",
1152 | "少十年么"
1153 | ],
1154 | "还没睡啊": [
1155 | "睡不着",
1156 | "你也没睡啊",
1157 | "刚睡醒啊",
1158 | "现在八点左右怎么睡得下",
1159 | "起来很久了",
1160 | "睡不觉大白天的",
1161 | "现在是morning啊",
1162 | "这都几点了还睡啊",
1163 | "睡什么睡",
1164 | "估计困了",
1165 | "我正准备睡",
1166 | "在讲多一条我就睡觉了",
1167 | "没有不睡午觉"
1168 | ],
1169 | "聊会吧": [
1170 | "说点啥呢"
1171 | ],
1172 | "好好休息吧": [
1173 | "祝你晚安",
1174 | "真的让我睡觉阿"
1175 | ],
1176 | "你就是一个": [
1177 | "我是什么",
1178 | "一个什么"
1179 | ],
1180 | "祝你做个好梦": [
1181 | "突然就晚安了",
1182 | "睡觉啦再见再见",
1183 | "一起做好梦你给我"
1184 | ],
1185 | "我会开车": [
1186 | "怎么开"
1187 | ],
1188 | "太紧张了": [
1189 | "放松自己别给自己太大压力"
1190 | ],
1191 | "你说他在的": [
1192 | "再靠近一点点他就跟你走再靠近一点点他就不闪躲"
1193 | ],
1194 | "现在身高也不是很理想啊": [
1195 | "你理想的身高是多少呢"
1196 | ],
1197 | "终于找到了": [
1198 | "踏破铁鞋无匿处得来全不费工夫",
1199 | "找到就好了",
1200 | "找到就不用着急了"
1201 | ],
1202 | "汝不知之": [
1203 | "不知道还回答这么快"
1204 | ],
1205 | "debuger呀": [
1206 | "debuger是什么鬼",
1207 | "debuger什么意思",
1208 | "debuger呀什么意思啊",
1209 | "debuger是谁",
1210 | "debuger是什么",
1211 | "我不会啊",
1212 | "这个用的是什么意思",
1213 | "什么意思",
1214 | "啥意思"
1215 | ],
1216 | "可是不是不是真的": [
1217 | "不是真的啥",
1218 | "明人不说暗话我喜欢你"
1219 | ],
1220 | "请珍惜生命": [
1221 | "不要等到失去后才懂得珍惜啊"
1222 | ],
1223 | "我想说你是不是活着了": [
1224 | "请珍惜生命"
1225 | ],
1226 | "我想知道为什么不是": [
1227 | "我想知道",
1228 | "什么为什么",
1229 | "就是不是",
1230 | "所以你并没有基于上下文和我聊天",
1231 | "你答非所问",
1232 | "为什么"
1233 | ],
1234 | "我想吃红烧肉红烧肉": [
1235 | "东坡肉好吃",
1236 | "好了给你吃红烧肉红烧肉红烧肉",
1237 | "出来吧我带你去吃红烧肉",
1238 | "我也想吃红烧肉咩事业心",
1239 | "我请你吃红烧肉",
1240 | "我也爱吃红烧肉"
1241 | ],
1242 | "那我们聊点别的吧": [
1243 | "结束话题",
1244 | "好啊聊情话",
1245 | "你说吧",
1246 | "和我说说话吧",
1247 | "我刚才说了什么"
1248 | ],
1249 | "真的懂了": [
1250 | "苏格拉底说过我唯一知道的是我一无所知"
1251 | ],
1252 | "吾于观小说": [
1253 | "好吧来聊小说",
1254 | "什么小说"
1255 | ],
1256 | "好想吃啊": [
1257 | "吃什么",
1258 | "好吃吗"
1259 | ],
1260 | "可是我不是个好": [
1261 | "你不是好女生和坏呀"
1262 | ],
1263 | "买了个表": [
1264 | "买了个表又来拆我台",
1265 | "为啥买表"
1266 | ],
1267 | "你害羞的样子才可爱呢": [
1268 | "不可爱"
1269 | ]
1270 | }
--------------------------------------------------------------------------------
/data/stopwords.txt:
--------------------------------------------------------------------------------
1 | ———
2 | 》),
3 | )÷(1-
4 | ”,
5 | )、
6 | =(
7 | :
8 | →
9 | ℃
10 | &
11 | *
12 | 一一
13 | ~~~~
14 | ’
15 | .
16 | 『
17 | .一
18 | ./
19 | --
20 | 』
21 | =″
22 | 【
23 | [*]
24 | }>
25 | [⑤]]
26 | [①D]
27 | c]
28 | ngP
29 | *
30 | //
31 | [
32 | ]
33 | [②e]
34 | [②g]
35 | ={
36 | }
37 | ,也
38 | ‘
39 | A
40 | [①⑥]
41 | [②B]
42 | [①a]
43 | [④a]
44 | [①③]
45 | [③h]
46 | ③]
47 | 1.
48 | --
49 | [②b]
50 | ’‘
51 | ×××
52 | [①⑧]
53 | 0:2
54 | =[
55 | [⑤b]
56 | [②c]
57 | [④b]
58 | [②③]
59 | [③a]
60 | [④c]
61 | [①⑤]
62 | [①⑦]
63 | [①g]
64 | ∈[
65 | [①⑨]
66 | [①④]
67 | [①c]
68 | [②f]
69 | [②⑧]
70 | [②①]
71 | [①C]
72 | [③c]
73 | [③g]
74 | [②⑤]
75 | [②②]
76 | 一.
77 | [①h]
78 | .数
79 | []
80 | [①B]
81 | 数/
82 | [①i]
83 | [③e]
84 | [①①]
85 | [④d]
86 | [④e]
87 | [③b]
88 | [⑤a]
89 | [①A]
90 | [②⑧]
91 | [②⑦]
92 | [①d]
93 | [②j]
94 | 〕〔
95 | ][
96 | ://
97 | ′∈
98 | [②④
99 | [⑤e]
100 | 12%
101 | b]
102 | ...
103 | ...................
104 | ⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯③
105 | ZXFITL
106 | [③F]
107 | 」
108 | [①o]
109 | ]∧′=[
110 | ∪φ∈
111 | ′|
112 | {-
113 | ②c
114 | }
115 | [③①]
116 | R.L.
117 | [①E]
118 | Ψ
119 | -[*]-
120 | ↑
121 | .日
122 | [②d]
123 | [②
124 | [②⑦]
125 | [②②]
126 | [③e]
127 | [①i]
128 | [①B]
129 | [①h]
130 | [①d]
131 | [①g]
132 | [①②]
133 | [②a]
134 | f]
135 | [⑩]
136 | a]
137 | [①e]
138 | [②h]
139 | [②⑥]
140 | [③d]
141 | [②⑩]
142 | e]
143 | 〉
144 | 】
145 | 元/吨
146 | [②⑩]
147 | 2.3%
148 | 5:0
149 | [①]
150 | ::
151 | [②]
152 | [③]
153 | [④]
154 | [⑤]
155 | [⑥]
156 | [⑦]
157 | [⑧]
158 | [⑨]
159 | ⋯⋯
160 | ——
161 | ?
162 | 、
163 | 。
164 | “
165 | ”
166 | 《
167 | 》
168 | !
169 | ,
170 | :
171 | ;
172 | ?
173 | .
174 | ,
175 | .
176 | '
177 | ?
178 | ·
179 | ———
180 | ──
181 | ?
182 | —
183 | <
184 | >
185 | (
186 | )
187 | 〔
188 | 〕
189 | [
190 | ]
191 | (
192 | )
193 | -
194 | +
195 | 〜
196 | ×
197 | /
198 | /
199 | ①
200 | ②
201 | ③
202 | ④
203 | ⑤
204 | ⑥
205 | ⑦
206 | ⑧
207 | ⑨
208 | ⑩
209 | Ⅲ
210 | В
211 | "
212 | ;
213 | #
214 | @
215 | γ
216 | μ
217 | φ
218 | φ.
219 | ×
220 | Δ
221 | ■
222 | ▲
223 | sub
224 | exp
225 | sup
226 | sub
227 | Lex
228 | #
229 | %
230 | &
231 | '
232 | +
233 | +ξ
234 | ++
235 | -
236 | -β
237 | <
238 | <±
239 | <Δ
240 | <λ
241 | <φ
242 | <<
243 | =
244 | =
245 | =☆
246 | =-
247 | >
248 | >λ
249 | _
250 | 〜±
251 | 〜+
252 | [⑤f]
253 | [⑤d]
254 | [②i]
255 | ≈
256 | [②G]
257 | [①f]
258 | LI
259 | ㈧
260 | [-
261 | ......
262 | 〉
263 | [③⑩]
264 | 第二
265 | 一番
266 | 一直
267 | 一个
268 | 一些
269 | 许多
270 | 种
271 | 有的是
272 | 也就是说
273 | 末##末
274 | 啊
275 | 阿
276 | 哎
277 | 哎呀
278 | 哎哟
279 | 唉
280 | 俺
281 | 俺们
282 | 按
283 | 按照
284 | 吧
285 | 吧哒
286 | 把
287 | 罢了
288 | 被
289 | 本
290 | 本着
291 | 比
292 | 比方
293 | 比如
294 | 鄙人
295 | 彼
296 | 彼此
297 | 边
298 | 别
299 | 别的
300 | 别说
301 | 并
302 | 并且
303 | 不比
304 | 不成
305 | 不单
306 | 不但
307 | 不独
308 | 不管
309 | 不光
310 | 不过
311 | 不仅
312 | 不拘
313 | 不论
314 | 不怕
315 | 不然
316 | 不如
317 | 不特
318 | 不惟
319 | 不问
320 | 不只
321 | 朝
322 | 朝着
323 | 趁
324 | 趁着
325 | 乘
326 | 冲
327 | 除
328 | 除此之外
329 | 除非
330 | 除了
331 | 此
332 | 此间
333 | 此外
334 | 从
335 | 从而
336 | 打
337 | 待
338 | 但
339 | 但是
340 | 当
341 | 当着
342 | 到
343 | 得
344 | 的
345 | 的话
346 | 等
347 | 等等
348 | 地
349 | 第
350 | 叮咚
351 | 对
352 | 对于
353 | 多
354 | 多少
355 | 而
356 | 而况
357 | 而且
358 | 而是
359 | 而外
360 | 而言
361 | 而已
362 | 尔后
363 | 反过来
364 | 反过来说
365 | 反之
366 | 非但
367 | 非徒
368 | 否则
369 | 嘎
370 | 嘎登
371 | 该
372 | 赶
373 | 个
374 | 各
375 | 各个
376 | 各位
377 | 各种
378 | 各自
379 | 给
380 | 根据
381 | 跟
382 | 故
383 | 故此
384 | 固然
385 | 关于
386 | 管
387 | 归
388 | 果然
389 | 果真
390 | 过
391 | 哈
392 | 哈哈
393 | 呵
394 | 和
395 | 何
396 | 何处
397 | 何况
398 | 何时
399 | 嘿
400 | 哼
401 | 哼唷
402 | 呼哧
403 | 乎
404 | 哗
405 | 还是
406 | 还有
407 | 换句话说
408 | 换言之
409 | 或
410 | 或是
411 | 或者
412 | 极了
413 | 及
414 | 及其
415 | 及至
416 | 即
417 | 即便
418 | 即或
419 | 即令
420 | 即若
421 | 即使
422 | 几
423 | 几时
424 | 己
425 | 既
426 | 既然
427 | 既是
428 | 继而
429 | 加之
430 | 假如
431 | 假若
432 | 假使
433 | 鉴于
434 | 将
435 | 较
436 | 较之
437 | 叫
438 | 接着
439 | 结果
440 | 借
441 | 紧接着
442 | 进而
443 | 尽
444 | 尽管
445 | 经
446 | 经过
447 | 就
448 | 就是
449 | 就是说
450 | 据
451 | 具体地说
452 | 具体说来
453 | 开始
454 | 开外
455 | 靠
456 | 咳
457 | 可
458 | 可见
459 | 可是
460 | 可以
461 | 况且
462 | 啦
463 | 来
464 | 来着
465 | 离
466 | 例如
467 | 哩
468 | 连
469 | 连同
470 | 两者
471 | 了
472 | 临
473 | 另
474 | 另外
475 | 另一方面
476 | 论
477 | 嘛
478 | 吗
479 | 慢说
480 | 漫说
481 | 冒
482 | 么
483 | 每
484 | 每当
485 | 们
486 | 莫若
487 | 某
488 | 某个
489 | 某些
490 | 拿
491 | 哪
492 | 哪边
493 | 哪儿
494 | 哪个
495 | 哪里
496 | 哪年
497 | 哪怕
498 | 哪天
499 | 哪些
500 | 哪样
501 | 那
502 | 那边
503 | 那儿
504 | 那个
505 | 那会儿
506 | 那里
507 | 那么
508 | 那么些
509 | 那么样
510 | 那时
511 | 那些
512 | 那样
513 | 乃
514 | 乃至
515 | 呢
516 | 能
517 | 你
518 | 你们
519 | 您
520 | 宁
521 | 宁可
522 | 宁肯
523 | 宁愿
524 | 哦
525 | 呕
526 | 啪达
527 | 旁人
528 | 呸
529 | 凭
530 | 凭借
531 | 其
532 | 其次
533 | 其二
534 | 其他
535 | 其它
536 | 其一
537 | 其余
538 | 其中
539 | 起
540 | 起见
541 | 起见
542 | 岂但
543 | 恰恰相反
544 | 前后
545 | 前者
546 | 且
547 | 然而
548 | 然后
549 | 然则
550 | 让
551 | 人家
552 | 任
553 | 任何
554 | 任凭
555 | 如
556 | 如此
557 | 如果
558 | 如何
559 | 如其
560 | 如若
561 | 如上所述
562 | 若
563 | 若非
564 | 若是
565 | 啥
566 | 上下
567 | 尚且
568 | 设若
569 | 设使
570 | 甚而
571 | 甚么
572 | 甚至
573 | 省得
574 | 时候
575 | 什么
576 | 什么样
577 | 使得
578 | 是
579 | 是的
580 | 首先
581 | 谁
582 | 谁知
583 | 顺
584 | 顺着
585 | 似的
586 | 虽
587 | 虽然
588 | 虽说
589 | 虽则
590 | 随
591 | 随着
592 | 所
593 | 所以
594 | 他
595 | 他们
596 | 他人
597 | 它
598 | 它们
599 | 她
600 | 她们
601 | 倘
602 | 倘或
603 | 倘然
604 | 倘若
605 | 倘使
606 | 腾
607 | 替
608 | 通过
609 | 同
610 | 同时
611 | 哇
612 | 万一
613 | 往
614 | 望
615 | 为
616 | 为何
617 | 为了
618 | 为什么
619 | 为着
620 | 喂
621 | 嗡嗡
622 | 我
623 | 我们
624 | 呜
625 | 呜呼
626 | 乌乎
627 | 无论
628 | 无宁
629 | 毋宁
630 | 嘻
631 | 吓
632 | 相对而言
633 | 像
634 | 向
635 | 向着
636 | 嘘
637 | 呀
638 | 焉
639 | 沿
640 | 沿着
641 | 要
642 | 要不
643 | 要不然
644 | 要不是
645 | 要么
646 | 要是
647 | 也
648 | 也罢
649 | 也好
650 | 一
651 | 一般
652 | 一旦
653 | 一方面
654 | 一来
655 | 一切
656 | 一样
657 | 一则
658 | 依
659 | 依照
660 | 矣
661 | 以
662 | 以便
663 | 以及
664 | 以免
665 | 以至
666 | 以至于
667 | 以致
668 | 抑或
669 | 因
670 | 因此
671 | 因而
672 | 因为
673 | 哟
674 | 用
675 | 由
676 | 由此可见
677 | 由于
678 | 有
679 | 有的
680 | 有关
681 | 有些
682 | 又
683 | 于
684 | 于是
685 | 于是乎
686 | 与
687 | 与此同时
688 | 与否
689 | 与其
690 | 越是
691 | 云云
692 | 哉
693 | 再说
694 | 再者
695 | 在
696 | 在下
697 | 咱
698 | 咱们
699 | 则
700 | 怎
701 | 怎么
702 | 怎么办
703 | 怎么样
704 | 怎样
705 | 咋
706 | 照
707 | 照着
708 | 者
709 | 这
710 | 这边
711 | 这儿
712 | 这个
713 | 这会儿
714 | 这就是说
715 | 这里
716 | 这么
717 | 这么点儿
718 | 这么些
719 | 这么样
720 | 这时
721 | 这些
722 | 这样
723 | 正如
724 | 吱
725 | 之
726 | 之类
727 | 之所以
728 | 之一
729 | 只是
730 | 只限
731 | 只要
732 | 只有
733 | 至
734 | 至于
735 | 诸位
736 | 着
737 | 着呢
738 | 自
739 | 自从
740 | 自个儿
741 | 自各儿
742 | 自己
743 | 自家
744 | 自身
745 | 综上所述
746 | 总的来看
747 | 总的来说
748 | 总的说来
749 | 总而言之
750 | 总之
751 | 纵
752 | 纵令
753 | 纵然
754 | 纵使
755 | 遵照
756 | 作为
757 | 兮
758 | 呃
759 | 呗
760 | 咚
761 | 咦
762 | 喏
763 | 啐
764 | 喔唷
765 | 嗬
766 | 嗯
767 | 嗳
--------------------------------------------------------------------------------
/distills/bert_config_L3.json:
--------------------------------------------------------------------------------
1 | {
2 | "architectures": [
3 | "BertForSiameseNet"
4 | ],
5 | "attention_probs_dropout_prob": 0.1,
6 | "directionality": "bidi",
7 | "gradient_checkpointing": false,
8 | "hidden_act": "gelu",
9 | "hidden_dropout_prob": 0.1,
10 | "hidden_size": 768,
11 | "initializer_range": 0.02,
12 | "intermediate_size": 3072,
13 | "layer_norm_eps": 1e-12,
14 | "max_position_embeddings": 512,
15 | "model_type": "bert",
16 | "num_attention_heads": 12,
17 | "num_hidden_layers": 3,
18 | "pad_token_id": 0,
19 | "pooler_fc_size": 768,
20 | "pooler_num_attention_heads": 12,
21 | "pooler_num_fc_layers": 3,
22 | "pooler_size_per_head": 128,
23 | "pooler_type": "first_token_transform",
24 | "type_vocab_size": 2,
25 | "vocab_size": 21128
26 | }
--------------------------------------------------------------------------------
/distills/matches.py:
--------------------------------------------------------------------------------
1 | L3_attention_mse=[{"layer_T":4, "layer_S":1, "feature":"attention", "loss":"attention_mse", "weight":1},
2 | {"layer_T":8, "layer_S":2, "feature":"attention", "loss":"attention_mse", "weight":1},
3 | {"layer_T":12, "layer_S":3, "feature":"attention", "loss":"attention_mse", "weight":1}]
4 |
5 | L3_attention_ce=[{"layer_T":4, "layer_S":1, "feature":"attention", "loss":"attention_ce", "weight":1},
6 | {"layer_T":8, "layer_S":2, "feature":"attention", "loss":"attention_ce", "weight":1},
7 | {"layer_T":12, "layer_S":3, "feature":"attention", "loss":"attention_ce", "weight":1}]
8 |
9 | L3_attention_mse_sum=[{"layer_T":4, "layer_S":1, "feature":"attention", "loss":"attention_mse_sum", "weight":1},
10 | {"layer_T":8, "layer_S":2, "feature":"attention", "loss":"attention_mse_sum", "weight":1},
11 | {"layer_T":12, "layer_S":3, "feature":"attention", "loss":"attention_mse_sum", "weight":1}]
12 |
13 | L3_attention_ce_mean=[{"layer_T":4, "layer_S":1, "feature":"attention", "loss":"attention_ce_mean", "weight":1},
14 | {"layer_T":8, "layer_S":2, "feature":"attention", "loss":"attention_ce_mean", "weight":1},
15 | {"layer_T":12, "layer_S":3, "feature":"attention", "loss":"attention_ce_mean", "weight":1}]
16 |
17 | L3_hidden_smmd=[{"layer_T":[0,0], "layer_S":[0,0], "feature":"hidden", "loss":"mmd", "weight":1},
18 | {"layer_T":[4,4], "layer_S":[1,1], "feature":"hidden", "loss":"mmd", "weight":1},
19 | {"layer_T":[8,8], "layer_S":[2,2], "feature":"hidden", "loss":"mmd", "weight":1},
20 | {"layer_T":[12,12],"layer_S":[3,3], "feature":"hidden", "loss":"mmd", "weight":1}]
21 |
22 | L3n_hidden_mse=[{"layer_T":0, "layer_S":0, "feature":"hidden", "loss":"hidden_mse", "weight":1, "proj":["linear",384,768]},
23 | {"layer_T":4, "layer_S":1, "feature":"hidden", "loss":"hidden_mse", "weight":1, "proj":["linear",384,768]},
24 | {"layer_T":8, "layer_S":2, "feature":"hidden", "loss":"hidden_mse", "weight":1, "proj":["linear",384,768]},
25 | {"layer_T":12,"layer_S":3, "feature":"hidden", "loss":"hidden_mse", "weight":1, "proj":["linear",384,768]}]
26 |
27 | L3_hidden_mse=[{"layer_T":0, "layer_S":0, "feature":"hidden", "loss":"hidden_mse", "weight":1},
28 | {"layer_T":4, "layer_S":1, "feature":"hidden", "loss":"hidden_mse", "weight":1},
29 | {"layer_T":8, "layer_S":2, "feature":"hidden", "loss":"hidden_mse", "weight":1},
30 | {"layer_T":12,"layer_S":3, "feature":"hidden", "loss":"hidden_mse", "weight":1}]
31 |
32 | #######################L4################
33 | L4_attention_mse=[{"layer_T":3, "layer_S":1, "feature":"attention", "loss":"attention_mse", "weight":1},
34 | {"layer_T":6, "layer_S":2, "feature":"attention", "loss":"attention_mse", "weight":1},
35 | {"layer_T":9, "layer_S":3, "feature":"attention", "loss":"attention_mse", "weight":1},
36 | {"layer_T":12, "layer_S":4, "feature":"attention", "loss":"attention_mse", "weight":1}]
37 |
38 | L4_attention_ce=[{"layer_T":3, "layer_S":1, "feature":"attention", "loss":"attention_ce", "weight":1},
39 | {"layer_T":6, "layer_S":2, "feature":"attention", "loss":"attention_ce", "weight":1},
40 | {"layer_T":9, "layer_S":3, "feature":"attention", "loss":"attention_ce", "weight":1},
41 | {"layer_T":12, "layer_S":4, "feature":"attention", "loss":"attention_ce", "weight":1}]
42 |
43 | L4_attention_mse_sum=[{"layer_T":3, "layer_S":1, "feature":"attention", "loss":"attention_mse_sum", "weight":1},
44 | {"layer_T":6, "layer_S":2, "feature":"attention", "loss":"attention_mse_sum", "weight":1},
45 | {"layer_T":9, "layer_S":3, "feature":"attention", "loss":"attention_mse_sum", "weight":1},
46 | {"layer_T":12, "layer_S":4, "feature":"attention", "loss":"attention_mse_sum", "weight":1}]
47 |
48 | L4_attention_ce_mean=[{"layer_T":3, "layer_S":1, "feature":"attention", "loss":"attention_ce_mean", "weight":1},
49 | {"layer_T":6, "layer_S":2, "feature":"attention", "loss":"attention_ce_mean", "weight":1},
50 | {"layer_T":9, "layer_S":3, "feature":"attention", "loss":"attention_ce_mean", "weight":1},
51 | {"layer_T":12, "layer_S":4, "feature":"attention", "loss":"attention_ce_mean", "weight":1}]
52 |
53 | L4_hidden_smmd=[{"layer_T":[0,0], "layer_S":[0,0], "feature":"hidden", "loss":"mmd", "weight":1},
54 | {"layer_T":[3,3], "layer_S":[1,1], "feature":"hidden", "loss":"mmd", "weight":1},
55 | {"layer_T":[6,6], "layer_S":[2,2], "feature":"hidden", "loss":"mmd", "weight":1},
56 | {"layer_T":[9,9], "layer_S":[3,3], "feature":"hidden", "loss":"mmd", "weight":1},
57 | {"layer_T":[12,12],"layer_S":[4,4], "feature":"hidden", "loss":"mmd", "weight":1}]
58 |
59 | L4t_hidden_sgram=[{"layer_T":[0,0], "layer_S":[0,0], "feature":"hidden", "loss":"gram", "weight":1, "proj":["linear",312,768]},
60 | {"layer_T":[3,3], "layer_S":[1,1], "feature":"hidden", "loss":"gram", "weight":1, "proj":["linear",312,768]},
61 | {"layer_T":[6,6], "layer_S":[2,2], "feature":"hidden", "loss":"gram", "weight":1, "proj":["linear",312,768]},
62 | {"layer_T":[9,9], "layer_S":[3,3], "feature":"hidden", "loss":"gram", "weight":1, "proj":["linear",312,768]},
63 | {"layer_T":[12,12],"layer_S":[4,4], "feature":"hidden", "loss":"gram", "weight":1, "proj":["linear",312,768]}]
64 |
65 | L4t_hidden_mse=[{"layer_T":0, "layer_S":0, "feature":"hidden", "loss":"hidden_mse", "weight":1, "proj":["linear",312,768]},
66 | {"layer_T":3, "layer_S":1, "feature":"hidden", "loss":"hidden_mse", "weight":1, "proj":["linear",312,768]},
67 | {"layer_T":6, "layer_S":2, "feature":"hidden", "loss":"hidden_mse", "weight":1, "proj":["linear",312,768]},
68 | {"layer_T":9, "layer_S":3, "feature":"hidden", "loss":"hidden_mse", "weight":1, "proj":["linear",312,768]},
69 | {"layer_T":12,"layer_S":4, "feature":"hidden", "loss":"hidden_mse", "weight":1, "proj":["linear",312,768]}]
70 |
71 | ###########L6#############
72 | L6_hidden_smmd=[{"layer_T":[0,0], "layer_S":[0,0], "feature":"hidden", "loss":"mmd", "weight":1},
73 | {"layer_T":[2,2], "layer_S":[1,1], "feature":"hidden", "loss":"mmd", "weight":1},
74 | {"layer_T":[4,4], "layer_S":[2,2], "feature":"hidden", "loss":"mmd", "weight":1},
75 | {"layer_T":[6,6], "layer_S":[3,3], "feature":"hidden", "loss":"mmd", "weight":1},
76 | {"layer_T":[8,8], "layer_S":[4,4], "feature":"hidden", "loss":"mmd", "weight":1},
77 | {"layer_T":[10,10],"layer_S":[5,5], "feature":"hidden", "loss":"mmd", "weight":1},
78 | {"layer_T":[12,12],"layer_S":[6,6], "feature":"hidden", "loss":"mmd", "weight":1}]
79 |
80 | L6_hidden_mse=[{"layer_T":0, "layer_S":0, "feature":"hidden", "loss":"hidden_mse", "weight":1},
81 | {"layer_T":2, "layer_S":1, "feature":"hidden", "loss":"hidden_mse", "weight":1},
82 | {"layer_T":4, "layer_S":2, "feature":"hidden", "loss":"hidden_mse", "weight":1},
83 | {"layer_T":6, "layer_S":3, "feature":"hidden", "loss":"hidden_mse", "weight":1},
84 | {"layer_T":8, "layer_S":4, "feature":"hidden", "loss":"hidden_mse", "weight":1},
85 | {"layer_T":10,"layer_S":5, "feature":"hidden", "loss":"hidden_mse", "weight":1},
86 | {"layer_T":12,"layer_S":6, "feature":"hidden", "loss":"hidden_mse", "weight":1}]
87 |
88 | #electra-small
89 | small_hidden_smmd=[{"layer_T":[0,0], "layer_S":[0,0], "feature":"hidden", "loss":"mmd", "weight":1},
90 | {"layer_T":[2,2], "layer_S":[2,2], "feature":"hidden", "loss":"mmd", "weight":1},
91 | {"layer_T":[4,4], "layer_S":[4,4], "feature":"hidden", "loss":"mmd", "weight":1},
92 | {"layer_T":[6,6], "layer_S":[6,6], "feature":"hidden", "loss":"mmd", "weight":1},
93 | {"layer_T":[8,8], "layer_S":[8,8], "feature":"hidden", "loss":"mmd", "weight":1},
94 | {"layer_T":[10,10],"layer_S":[10,10],"feature":"hidden", "loss":"mmd", "weight":1},
95 | {"layer_T":[12,12],"layer_S":[12,12],"feature":"hidden", "loss":"mmd", "weight":1}]
96 |
97 | small_hidden_mse=[{"layer_T":0, "layer_S":0, "feature":"hidden", "loss":"hidden_mse", "weight":1, "proj":["linear",256,768]},
98 | {"layer_T":2, "layer_S":2, "feature":"hidden", "loss":"hidden_mse", "weight":1, "proj":["linear",256,768]},
99 | {"layer_T":4, "layer_S":4, "feature":"hidden", "loss":"hidden_mse", "weight":1, "proj":["linear",256,768]},
100 | {"layer_T":6, "layer_S":6, "feature":"hidden", "loss":"hidden_mse", "weight":1, "proj":["linear",256,768]},
101 | {"layer_T":8, "layer_S":8, "feature":"hidden", "loss":"hidden_mse", "weight":1, "proj":["linear",256,768]},
102 | {"layer_T":10,"layer_S":10,"feature":"hidden", "loss":"hidden_mse", "weight":1, "proj":["linear",256,768]},
103 | {"layer_T":12,"layer_S":12,"feature":"hidden", "loss":"hidden_mse", "weight":1, "proj":["linear",256,768]}]
104 |
105 |
106 |
107 |
108 | matches={'L3_attention_mse':L3_attention_mse,'L3_attention_mse_sum':L3_attention_mse_sum,
109 | 'L3_attention_ce' :L3_attention_ce, 'L3_attention_ce_mean':L3_attention_ce_mean,
110 | 'L3n_hidden_mse' :L3n_hidden_mse, 'L3_hidden_smmd' :L3_hidden_smmd, 'L3_hidden_mse': L3_hidden_mse,
111 | 'L4_attention_mse':L4_attention_mse,'L4_attention_mse_sum':L4_attention_mse_sum,
112 | 'L4_attention_ce' :L4_attention_ce, 'L4_attention_ce_mean':L4_attention_ce_mean,
113 | 'L4t_hidden_mse' :L4t_hidden_mse, 'L4_hidden_smmd' :L4_hidden_smmd, 'L4t_hidden_sgram': L4t_hidden_sgram,
114 | 'L6_hidden_mse' :L6_hidden_mse, 'L6_hidden_smmd' :L6_hidden_smmd,
115 | 'small_hidden_mse':small_hidden_mse,'small_hidden_smmd' :small_hidden_smmd
116 | }
117 |
--------------------------------------------------------------------------------
/example.log:
--------------------------------------------------------------------------------
1 | 2020-09-28 20:41:55:INFO:Started server process [21451]
2 | 2020-09-28 20:41:55:INFO:Waiting for application startup.
3 | 2020-09-28 20:41:55:INFO:Application startup complete.
4 | 2020-09-28 20:42:31:INFO:Shutting down
5 | 2020-09-28 20:42:31:INFO:Waiting for application shutdown.
6 | 2020-09-28 20:42:31:INFO:Application shutdown complete.
7 | 2020-09-28 20:42:31:INFO:Finished server process [21451]
8 |
--------------------------------------------------------------------------------
/faq_app_benben.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-09-05 23:40:14
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 | import os
8 | import time
9 | import random
10 | import logging
11 | from typing import Optional, Dict
12 | import numpy as np
13 | from fastapi import FastAPI
14 | from pydantic import BaseModel
15 | from functools import lru_cache
16 | from annoy import AnnoyIndex
17 |
18 | from utils import load_json
19 | from transformers_encoder import TransformersEncoder
20 |
21 | ##### 日志配置 #####
22 | logger = logging.getLogger()
23 | logger.setLevel('DEBUG')
24 | BASIC_FORMAT = "%(asctime)s:%(levelname)s:%(message)s"
25 | DATE_FORMAT = '%Y-%m-%d %H:%M:%S'
26 | formatter = logging.Formatter(BASIC_FORMAT, DATE_FORMAT)
27 | chlr = logging.StreamHandler() # 输出到控制台的handler
28 | chlr.setFormatter(formatter)
29 | chlr.setLevel('INFO')
30 | fhlr = logging.FileHandler('example.log') # 输出到文件的handler
31 | fhlr.setFormatter(formatter)
32 | logger.addHandler(chlr)
33 | logger.addHandler(fhlr)
34 |
35 | ##### 模型文件配置 #####
36 | FEAT_DIM = 768
37 | TOPK = 10
38 |
39 | prefix = "/data/benben/data/faq_bert/"
40 | # prefix = "/users6/kyzhang/benben/FAQ-Semantic-Retrieval"
41 | MODEL_NAME_OR_PATH = os.path.join(prefix, "output/transformers-merge3-bert-6L")
42 | FAQ_FILE = os.path.join(prefix, "ext_hflqa/clean_faq.json")
43 | ANNOY_INDEX_FILE = os.path.join(prefix, "ext_hflqa/index.ann")
44 | IDX2TOPIC_FILE = os.path.join(prefix, "ext_hflqa/idx2topic.json")
45 | VEC_FILE = os.path.join(prefix, "ext_hflqa/vec.npy")
46 |
47 | app = FastAPI()
48 |
49 | logger.info('加载数据并初始化模型')
50 |
51 | logger.info("加载FAQ源文件")
52 | faq = load_json(FAQ_FILE)
53 | idx2topic = load_json(IDX2TOPIC_FILE)
54 | vectors = np.load(VEC_FILE)
55 |
56 | logger.info("加载Annoy索引文件")
57 | index = AnnoyIndex(FEAT_DIM, metric='angular')
58 | index.load(ANNOY_INDEX_FILE)
59 |
60 | logger.info("加载BERT预训练模型")
61 | encoder = TransformersEncoder(model_name_or_path=MODEL_NAME_OR_PATH)
62 | logger.info('初始化结束')
63 |
64 |
65 | class User(BaseModel):
66 | id: str = ''
67 |
68 |
69 | class LTP(BaseModel):
70 | seg: str = ''
71 | arc: str = ''
72 | ner: str = ''
73 | pos: str = ''
74 |
75 |
76 | class AnaphoraResolution(BaseModel):
77 | score: int = 0
78 | result: str = ''
79 |
80 |
81 | class MetaField(BaseModel):
82 | emotion: str = None
83 | consumption_class: int = 0
84 | consumption_result: float = 0.0
85 | ltp: LTP
86 | anaphora_resolution: AnaphoraResolution
87 | score: Optional[float] = None
88 |
89 |
90 | class Query(BaseModel):
91 | content: str
92 | msg_type: str
93 | metafield: MetaField
94 | user: User
95 | context: Optional[Dict[str, str]] = {}
96 |
97 |
98 | @app.get("/")
99 | def read_root():
100 | return {"Hello": "World"}
101 |
102 |
103 | @lru_cache(maxsize=512)
104 | def get_res(query):
105 | vector = np.squeeze(encoder.encode([query]), axis=0)
106 | res = index.get_nns_by_vector(vector,
107 | TOPK,
108 | search_k=-1,
109 | include_distances=True)
110 | topic = idx2topic[str(res[0][0] - 1)]["topic"]
111 | return topic, 1 - res[1][0]
112 |
113 |
114 | @app.post("/module/FAQ")
115 | def read_item(query: Query):
116 | st = time.time()
117 | topic, score = get_res(query.content)
118 | responses = faq[topic]['resp']
119 | reply = random.choice(responses)
120 | logger.info('Query: %s' % query.content)
121 | logger.info('Reply: %s' % reply)
122 | logger.info('Takes: %.6f sec, Score: %.6f' % (time.time() - st, score))
123 |
124 | metafield = query.metafield
125 | metafield.score = score
126 | return {
127 | 'msg_type': 'text',
128 | 'reply': reply,
129 | 'context': {},
130 | 'status': 0,
131 | 'metafield': metafield
132 | }
133 |
134 |
135 | # uvicorn faq_app_fastapi:app --reload --port 8889
--------------------------------------------------------------------------------
/faq_app_fastapi.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-09-03 04:00:10
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 | from transformers_encoder import TransformersEncoder
8 | import time
9 | import random
10 | import logging
11 | import numpy as np
12 | from fastapi import FastAPI
13 | from pydantic import BaseModel
14 | from functools import lru_cache
15 |
16 | from utils import load_json, cos_sim
17 |
18 | model_name_or_path = 'output/transformers-merge3-bert-6L'
19 | faq_file = 'ext_hflqa/clean_faq.json'
20 | corpus_mat_file = 'ext_hflqa/corpus_mat.npy'
21 | topics_file = 'ext_hflqa/topics.json'
22 |
23 | app = FastAPI()
24 |
25 |
26 | def init_data():
27 | """加载数据
28 | """
29 | faq_data = load_json(faq_file)
30 | corpus_mat = np.load(corpus_mat_file)
31 | topics = load_json(topics_file)
32 | corpus_mat_norm = np.linalg.norm(corpus_mat, axis=1)
33 | return faq_data, topics, corpus_mat, corpus_mat_norm
34 |
35 |
36 | print('start loading')
37 | faq_data, topics, corpus_mat, corpus_mat_norm = init_data()
38 | encoder = TransformersEncoder(model_name_or_path=model_name_or_path)
39 | print('end loading...')
40 |
41 |
42 | class Query(BaseModel):
43 | query: str
44 |
45 |
46 | @app.get("/")
47 | def read_root():
48 | return {"Hello": "World"}
49 |
50 |
51 | @lru_cache(maxsize=512)
52 | def get_res(query):
53 | enc = encoder.encode([query])
54 | scores = cos_sim(np.squeeze(enc, axis=0), corpus_mat, corpus_mat_norm)
55 | max_index = np.argmax(scores)
56 | topic = topics[max_index]
57 | return topic
58 |
59 |
60 | @app.post("/module/ext_faq_test")
61 | def read_item(query: Query):
62 | st = time.time()
63 | topic = get_res(query.query)
64 | responses = faq_data[topic]['resp']
65 | reply = random.choice(responses)
66 | print('--------------')
67 | print('Query:', query)
68 | print('Reply:', reply)
69 | print('Takes %f' % (time.time() - st))
70 | return {'reply': reply}
71 |
72 |
73 | # uvicorn faq_app_fastapi:app --reload --port 8889
74 |
--------------------------------------------------------------------------------
/faq_app_flask.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-09-02 16:37:58
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 |
8 | import time
9 | import random
10 | import logging
11 | import numpy as np
12 | from flask import Flask, request, jsonify
13 | from flask_caching import Cache
14 | from utils import load_json, cos_sim
15 | from transformers_encoder import TransformersEncoder
16 |
17 | model_name_or_path = 'output/transformers-merge3-bert-6L'
18 | faq_file = 'hflqa/faq.json'
19 | corpus_mat_file = 'hflqa/corpus_mat.npy'
20 | topics_file = 'hflqa/topics.json'
21 |
22 | # logging.basicConfig(
23 | # format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
24 | # datefmt="%Y/%m/%d %H:%M:%S",
25 | # level=logging.INFO)
26 | # logger = logging.getLogger(__name__)
27 |
28 | app = Flask(__name__)
29 | # https://github.com/sh4nks/flask-caching
30 | cache = Cache(app, config={'CACHE_TYPE': 'simple'})
31 |
32 |
33 | def init_data():
34 | """加载数据
35 | """
36 | faq_data = load_json(faq_file)
37 | corpus_mat = np.load(corpus_mat_file)
38 | topics = load_json(topics_file)
39 | corpus_mat_norm = np.linalg.norm(corpus_mat, axis=1)
40 | return faq_data, topics, corpus_mat, corpus_mat_norm
41 |
42 |
43 | print('start loading')
44 | faq_data, topics, corpus_mat, corpus_mat_norm = init_data()
45 | encoder = TransformersEncoder(model_name_or_path=model_name_or_path)
46 | print('end loading...')
47 |
48 |
49 | @app.route('/module/ext_faq_test', methods=['POST'])
50 | def query():
51 | query = request.json.get('query')
52 | topic = cache.get(query)
53 | if not topic:
54 | enc = encoder.encode([query])
55 | scores = cos_sim(np.squeeze(enc, axis=0), corpus_mat, corpus_mat_norm)
56 | max_index = np.argmax(scores)
57 | topic = topics[max_index]
58 | cache.set(query, topic)
59 |
60 | responses = faq_data[topic]['resp']
61 | reply = random.choice(responses)
62 | print('--------------')
63 | print('Query:', query)
64 | print('Reply:', reply)
65 | return jsonify({'reply': reply})
66 |
67 |
68 | if __name__ == '__main__':
69 | # gunicorn -k eventlet -w 1 -b 127.0.0.1:8889 faq_app:app
70 | app.run(host='127.0.0.1', port=11122)
--------------------------------------------------------------------------------
/faq_app_whoosh.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-09-28 19:16:29
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 |
8 | import time
9 | import random
10 | import logging
11 | import numpy as np
12 | from typing import Optional, Dict
13 | from fastapi import FastAPI
14 | from pydantic import BaseModel
15 | from functools import lru_cache
16 |
17 | from whoosh.query import Term
18 | from whoosh.qparser import QueryParser, MultifieldParser
19 | from whoosh.index import open_dir
20 |
21 | from faq_whoosh_index import load_data, load_stopwords
22 | source_file = "data/add_faq.json"
23 | app = FastAPI()
24 |
25 | faq_data = load_data()
26 |
27 | IDX = open_dir(dirname="whoosh_index")
28 |
29 | ##### 日志配置 #####
30 | logger = logging.getLogger()
31 | logger.setLevel('DEBUG')
32 | BASIC_FORMAT = "%(asctime)s:%(levelname)s:%(message)s"
33 | DATE_FORMAT = '%Y-%m-%d %H:%M:%S'
34 | formatter = logging.Formatter(BASIC_FORMAT, DATE_FORMAT)
35 | chlr = logging.StreamHandler() # 输出到控制台的handler
36 | chlr.setFormatter(formatter)
37 | chlr.setLevel('INFO')
38 | fhlr = logging.FileHandler('example.log') # 输出到文件的handler
39 | fhlr.setFormatter(formatter)
40 | logger.addHandler(chlr)
41 | logger.addHandler(fhlr)
42 |
43 |
44 | class User(BaseModel):
45 | id: str
46 |
47 |
48 | class LTP(BaseModel):
49 | seg: str
50 | arc: str
51 | ner: str
52 | pos: str
53 |
54 |
55 | class AnaphoraResolution(BaseModel):
56 | score: int
57 | result: str
58 |
59 |
60 | class MetaField(BaseModel):
61 | emotion: str
62 | consumption_class: int
63 | consumption_result: float
64 | ltp: LTP
65 | anaphora_resolution: AnaphoraResolution
66 | score: Optional[float] = None
67 |
68 |
69 | class Query(BaseModel):
70 | content: str
71 | msg_type: str
72 | metafield: MetaField
73 | user: User
74 | context: Optional[Dict[str, str]] = {}
75 |
76 |
77 | @app.get("/")
78 | def read_root():
79 | return {"Hello": "World"}
80 |
81 |
82 | @lru_cache(maxsize=512)
83 | def get_res(query):
84 | try:
85 | with IDX.searcher() as searcher:
86 | parser = QueryParser("content", schema=IDX.schema)
87 | q = parser.parse(query)
88 | results = searcher.search(q)
89 | topic = results[0]["topic"]
90 | return topic, results[0].score
91 | except Exception:
92 | return None, 0.
93 |
94 |
95 | @app.post("/module/ext_faq")
96 | def read_item(query: Query):
97 | st = time.time()
98 | topic, score = get_res(query.content)
99 | if topic:
100 | responses = faq_data[topic]
101 | reply = random.choice(responses)
102 | else:
103 | reply = "我有点不太明白呢"
104 |
105 | logger.info('Query: %s' % query.content)
106 | logger.info('Reply: %s' % reply)
107 | logger.info('Takes: %.6f sec, Score: %.6f' % (time.time() - st, score))
108 |
109 | metafield = query.metafield
110 | metafield.score = score
111 | return {
112 | 'msg_type': 'text',
113 | 'reply': reply,
114 | 'context': {},
115 | 'status': 0,
116 | 'metafield': metafield
117 | }
118 |
119 |
120 | # uvicorn faq_app_whoosh:app --reload --port 8889
--------------------------------------------------------------------------------
/faq_index.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-08-26 01:27:04
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 | import numpy as np
8 |
9 | from utils import load_json, save_json
10 | from transformers_encoder import TransformersEncoder
11 |
12 | input_faq_file = 'ext_hflqa/clean_faq.json'
13 | output_topic_file = 'ext_hflqa/topics.json'
14 | output_corpus_mat_file = 'ext_hflqa/corpus_mat.npy'
15 | model_path = './output/transformers-merge3-bert-6L'
16 |
17 | def index_query():
18 | """对所有post使用bert进行编码
19 | [
20 | {
21 | topic: topic_sent,
22 | post : post_sent,
23 | enc: bert_
24 | }
25 | ]
26 | 保存向量矩阵和对应的主题
27 | """
28 | data = load_json(input_faq_file)
29 |
30 | posts, topics = [], []
31 | for topic, qas in data.items():
32 | for post in qas['post']:
33 | posts.append(post)
34 | topics.append(topic)
35 |
36 | encoder = TransformersEncoder(model_path)
37 |
38 | encs = encoder.encode(posts, show_progress_bar=True)
39 |
40 | save_json(topics, output_topic_file)
41 |
42 | corpus_mat = np.asarray(encs)
43 | np.save(output_corpus_mat_file, corpus_mat)
44 |
45 |
46 | if __name__ == '__main__':
47 | index_query()
48 |
--------------------------------------------------------------------------------
/faq_test.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-08-26 16:22:08
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 | import time
8 | import logging
9 | import numpy as np
10 |
11 | from utils import load_json, cos_sim
12 | from transformers_encoder import TransformersEncoder
13 |
14 | logging.basicConfig(
15 | format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
16 | datefmt="%Y/%m/%d %H:%M:%S",
17 | level=logging.INFO)
18 | logger = logging.getLogger(__name__)
19 |
20 |
21 | def init_data(model):
22 | """加载数据
23 | """
24 | faq_data = load_json('ext_hflqa/clean_faq.json')
25 | posts, topics = [], []
26 | for topic, qas in faq_data.items():
27 | for post in qas['post']:
28 | posts.append(post)
29 | topics.append(topic)
30 |
31 | encs = model.encode(posts, show_progress_bar=True)
32 | corpus_mat = encs.numpy()
33 | corpus_mat_norm = np.linalg.norm(corpus_mat)
34 | return faq_data, topics, corpus_mat, corpus_mat_norm
35 |
36 |
37 | print('start loading')
38 | model_path = './output/transformers-merge3-bert/'
39 | model = TransformersEncoder(model_path)
40 | faq_data, topics, corpus_mat, corpus_mat_norm = init_data(model)
41 | print('end loading...')
42 |
43 |
44 | def query():
45 | """输入测试
46 | """
47 | while True:
48 | enc = model.encode([input('Enter: ')])
49 | t1 = time.time()
50 | scores = cos_sim(np.squeeze(enc, axis=0), corpus_mat, corpus_mat_norm)
51 | max_index = np.argmax(scores)
52 |
53 | topic = topics[max_index]
54 |
55 | resp = faq_data[topic]['resp']
56 | print(np.random.choice(resp, 1)[0], time.time() - t1)
57 |
58 |
59 | if __name__ == '__main__':
60 | query()
61 |
--------------------------------------------------------------------------------
/faq_whoosh_index.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-09-28 19:17:04
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 | import os
8 | import json
9 | from json import load
10 | from os import write
11 | from tqdm import tqdm
12 | from whoosh.index import create_in
13 | from whoosh.fields import Schema, TEXT, ID
14 |
15 | from jieba.analyse import ChineseAnalyzer
16 |
17 | source_file = "data/add_faq.json"
18 | stopwords_file = "data/stopwords.txt"
19 | index_dir = "whoosh_index"
20 |
21 |
22 | def load_data():
23 | with open(source_file, "r", encoding='utf-8') as f:
24 | data = json.load(f)
25 | return data
26 |
27 |
28 | def load_stopwords():
29 | stopwords = set([])
30 | with open(stopwords_file, "r", encoding='utf-8') as f:
31 | for line in f:
32 | stopwords.add(line.strip())
33 | return stopwords
34 |
35 |
36 | def init():
37 | data = load_data()
38 | analyzer = ChineseAnalyzer()
39 | schema = Schema(pid=ID(stored=True),
40 | content=TEXT(stored=True, analyzer=analyzer),
41 | topic=ID(stored=True))
42 |
43 | if not os.path.exists(index_dir):
44 | os.mkdir(index_dir)
45 | idx = create_in(index_dir, schema)
46 |
47 | writer = idx.writer()
48 | for i, (topic, _) in enumerate(data.items()):
49 | writer.add_document(topic=topic, pid="topic-" + str(i), content=topic)
50 |
51 | writer.commit()
52 |
53 |
54 | if __name__ == '__main__':
55 | init()
--------------------------------------------------------------------------------
/locust_test.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-09-02 16:37:30
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 |
8 | import json
9 | import random
10 | from locust import HttpUser, task, between
11 |
12 |
13 | def get_seqs():
14 | """获取用户输入样例
15 |
16 | Returns:
17 | List[str]
18 | """
19 | seqs = []
20 | with open('./hflqa/test_faq_resp.json', 'r', encoding='utf-8') as f:
21 | data = json.load(f)
22 | for _, post_resp in data.items():
23 | seqs.extend(post_resp['post'])
24 | random.shuffle(seqs)
25 | return seqs
26 |
27 |
28 | seqs = get_seqs()
29 |
30 | class FAQUser(HttpUser):
31 | # min/max wait time
32 | wait_time = between(2,5)
33 |
34 | @task
35 | def faq(self):
36 | self.client.post("/ext_faq_test", json={"query": random.choice(seqs)})
37 |
38 | # https://docs.locust.io/en/stable/index.html
39 | # locust -f locust_test.py --host=http://127.0.0.1:8889/module --headless -u 1000 -r 100 -t 3m
40 |
--------------------------------------------------------------------------------
/model_distillation.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-08-29 02:45:10
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 |
8 | import os
9 | import ast
10 | import logging
11 | import argparse
12 | import numpy as np
13 | from typing import NamedTuple
14 |
15 | import torch
16 | from torch._C import device
17 | from torch.utils.data import DataLoader
18 |
19 | from textbrewer import GeneralDistiller
20 | from textbrewer import TrainingConfig, DistillationConfig
21 |
22 | from transformers import BertTokenizer, BertConfig
23 | from transformers import AdamW
24 |
25 | from functools import partial
26 |
27 | from transformers_trainer import SiameseDataset, BertForSiameseNet, load_sents_from_csv, Collator, compute_metrics
28 | from distills.matches import matches
29 |
30 | logging.basicConfig(
31 | format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
32 | datefmt="%Y/%m/%d %H:%M:%S",
33 | level=logging.INFO)
34 | logger = logging.getLogger(__name__)
35 |
36 |
37 | def BertForQASimpleAdaptor(batch, model_outputs):
38 | dict_obj = {'logits': model_outputs[1], 'hidden': model_outputs[2]}
39 | return dict_obj
40 |
41 |
42 | class EvalPrediction(NamedTuple):
43 | """
44 | Evaluation output (always contains labels), to be used to compute metrics.
45 |
46 | Parameters:
47 | predictions (:obj:`np.ndarray`): Predictions of the model.
48 | label_ids (:obj:`np.ndarray`): Targets to be matched.
49 | """
50 |
51 | predictions: np.ndarray
52 | label_ids: np.ndarray
53 |
54 |
55 | def predict(model, dataloader, device, step):
56 | model.eval()
57 | preds = []
58 | label_ids = []
59 | for batch in dataloader:
60 | for k, v in batch.items():
61 | if isinstance(v, torch.Tensor):
62 | batch[k] = v.to(device)
63 |
64 | intputs = {k: v for k, v in batch.items() if k != 'labels'}
65 | labels = batch['labels']
66 | with torch.no_grad():
67 | logits, _ = model(**intputs)
68 | preds.extend(logits.cpu().numpy())
69 | label_ids.extend(labels.cpu().numpy())
70 |
71 | model.train()
72 | eval_result = compute_metrics(
73 | EvalPrediction(predictions=np.array(preds),
74 | label_ids=np.array(label_ids)))
75 | logger.info('Step {} eval results {}'.format(step, eval_result))
76 |
77 |
78 | def main(args):
79 | ##### prepare
80 | os.makedirs(args.output_dir, exist_ok=True)
81 | forward_batch_size = int(args.train_batch_size /
82 | args.gradient_accumulation_steps)
83 | args.forward_batch_size = forward_batch_size
84 | args.device = 'cuda' if torch.cuda.is_available() else 'cpu'
85 |
86 | ##### load bert config & tokenizer
87 | bert_config_T = BertConfig.from_json_file(
88 | os.path.join(args.teacher_model, 'config.json'))
89 | tokenizer = BertTokenizer.from_pretrained(args.teacher_model)
90 |
91 | bert_config_S = BertConfig.from_json_file(args.student_config)
92 |
93 | ##### load data & init dataloader
94 | train_dataset = SiameseDataset(load_sents_from_csv(args.train_file),
95 | tokenizer)
96 | num_train_steps = int(
97 | len(train_dataset) / args.train_batch_size) * args.num_train_epochs
98 |
99 | collator = Collator(tokenizer, args.max_seq_length)
100 | dataloader = DataLoader(train_dataset,
101 | collate_fn=collator.batching_collate,
102 | batch_size=args.train_batch_size,
103 | drop_last=True)
104 |
105 | eval_dataset = SiameseDataset(load_sents_from_csv(args.eval_file),
106 | tokenizer)
107 | eval_dataloader = DataLoader(eval_dataset,
108 | collate_fn=collator.batching_collate,
109 | batch_size=args.eval_batch_size)
110 |
111 | ##### build model and load checkpoint
112 | model_T = BertForSiameseNet(bert_config_T, args)
113 | model_S = BertForSiameseNet(bert_config_S, args)
114 |
115 | # load teacher
116 | state_dict_T = torch.load(os.path.join(args.teacher_model,
117 | 'pytorch_model.bin'),
118 | map_location=args.device)
119 | model_T.load_state_dict(state_dict_T)
120 | model_T.eval()
121 |
122 | # load student
123 | state_dict_S = torch.load(
124 | os.path.join(args.teacher_model, 'pytorch_model.bin'))
125 | state_weight = {
126 | k[5:]: v
127 | for k, v in state_dict_S.items() if k.startswith('bert.')
128 | }
129 | missing_keys, _ = model_S.bert.load_state_dict(state_weight, strict=False)
130 | assert len(missing_keys) == 0
131 |
132 | model_T.to(args.device)
133 | model_S.to(args.device)
134 |
135 | ##### training
136 | optimizer = AdamW(model_S.parameters(), lr=args.learning_rate)
137 |
138 | logger.info("***** Running training *****")
139 | logger.info(" Num orig examples = %d", len(train_dataset))
140 | logger.info(" Forward batch size = %d", forward_batch_size)
141 | logger.info(" Num backward steps = %d", num_train_steps)
142 |
143 | ##### distillation
144 | train_config = TrainingConfig(
145 | gradient_accumulation_steps=args.gradient_accumulation_steps,
146 | log_dir=args.output_dir,
147 | output_dir=args.output_dir,
148 | device=args.device)
149 | # matches
150 | intermediate_matches = matches.get('L3_hidden_mse') + matches.get(
151 | 'L3_hidden_smmd')
152 | distill_config = DistillationConfig(
153 | temperature=args.temperature,
154 | intermediate_matches=intermediate_matches)
155 |
156 | adaptor_T = partial(BertForQASimpleAdaptor)
157 | adaptor_S = partial(BertForQASimpleAdaptor)
158 |
159 | distiller = GeneralDistiller(train_config=train_config,
160 | distill_config=distill_config,
161 | model_T=model_T,
162 | model_S=model_S,
163 | adaptor_T=adaptor_T,
164 | adaptor_S=adaptor_S)
165 | callback_func = partial(predict,
166 | dataloader=eval_dataloader,
167 | device=args.device)
168 |
169 | with distiller:
170 | distiller.train(optimizer,
171 | dataloader=dataloader,
172 | num_epochs=args.num_train_epochs,
173 | callback=callback_func)
174 |
175 |
176 | if __name__ == '__main__':
177 | parser = argparse.ArgumentParser('Distillation For BERT')
178 | parser.add_argument('--teacher_model',
179 | type=str,
180 | default='./output/transformers-bert-base-chinese')
181 | parser.add_argument('--student_config',
182 | type=str,
183 | default='./distills/bert_config_L3.json')
184 | parser.add_argument(
185 | '--bert_model',
186 | type=str,
187 | default='/users6/kyzhang/embeddings/bert/bert-base-chinese')
188 | parser.add_argument('--output_dir',
189 | type=str,
190 | default='./distills/outputs/bert_L3')
191 | parser.add_argument('--train_file',
192 | type=str,
193 | default='lcqmc/LCQMC_train.csv')
194 | parser.add_argument('--eval_file', type=str, default='lcqmc/LCQMC_dev.csv')
195 |
196 | parser.add_argument('--max_seq_length', type=int, default=128)
197 | parser.add_argument('--train_batch_size', type=int, default=64)
198 | parser.add_argument('--eval_batch_size', type=int, default=64)
199 | parser.add_argument('--learning_rate', type=float, default=3e-5)
200 | parser.add_argument('--num_train_epochs', type=int, default=30)
201 | parser.add_argument('--warmup_proportion', type=float, default=0.1)
202 | parser.add_argument('--gradient_accumulation_steps', type=int, default=1)
203 | parser.add_argument('--print_every', type=int, default=200)
204 | parser.add_argument('--weight', type=float, default=1.0)
205 | parser.add_argument('--temperature', type=float, default=8)
206 | parser.add_argument('--output_hidden_states',
207 | type=ast.literal_eval,
208 | default=True)
209 | parser.add_argument(
210 | '--margin',
211 | type=float,
212 | default=0.5,
213 | help='Negative pairs should have a distance of at least 0.5')
214 | args = parser.parse_args()
215 | main(args)
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | Flask==1.1.2
2 | gevent==20.6.2
3 | greenlet==0.4.16
4 | gunicorn==20.0.4
5 | numpy==1.18.5
6 | pandas==0.22.0
7 | requests==2.22.0
8 | scikit-learn==0.23.2
9 | sentence-transformers==0.3.4
10 | tensorboard==2.3.0
11 | tensorboardX==1.8
12 | tensorflow-gpu==2.3.0
13 | textbrewer==0.2.0.1
14 | torch==1.6.0+cu92
15 | tqdm==4.30.0
16 | transformers==3.0.2
17 | fastapi==0.61.1
18 | uvicorn==0.11.8
--------------------------------------------------------------------------------
/sampling.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-08-28 16:58:56
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 | import ast
8 | import logging
9 | import argparse
10 |
11 | import os
12 | import json
13 | import random
14 | import numpy as np
15 | import pandas as pd
16 |
17 | import matplotlib.pyplot as plt
18 | from sklearn.decomposition import PCA
19 |
20 | from sklearn.cluster import KMeans
21 | from sklearn.mixture import GaussianMixture
22 | from sklearn.model_selection import train_test_split
23 |
24 | from sentence_transformers import models, SentenceTransformer
25 | """
26 | FAQ 负采样, 原始数据保存格式为
27 | {
28 | topic1: {
29 | post: [q1, q2, q3],
30 | resp: [r1, r2, r3, r4]
31 | },
32 | topic2: {
33 | post: [...],
34 | resp: [...]
35 | },
36 | ...
37 | }
38 | 其中 topic 下保存相同“主题”的所有问答对
39 | post 保存的都是语义一致的问题(不同表达形式, 可以互为正样本)
40 | resp 保存的是该 topic 的所有可能回复(可以随机选择一个作为回复)
41 |
42 | FAQ 的过程为
43 | 1. 用户输入 query, 与所有 post 进行相似度计算
44 | 2. 确定与 query 最相似的 post 所属的 topic
45 | 3. 在确定 topic 的 resp 中随机选择一个作为回复
46 | """
47 |
48 | logging.basicConfig(
49 | format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
50 | datefmt="%Y/%m/%d %H:%M:%S",
51 | level=logging.INFO)
52 | logger = logging.getLogger(__name__)
53 |
54 |
55 | def positive_sampling(data, num_pos=4):
56 | """在每个主题内进行正采样
57 |
58 | Args:
59 | data (Dict(str, Dict(str, List[str]))):
60 | json形式原始数据
61 | num_pos (int, optional):
62 | 正采样个数. Defaults to 4.
63 | 需要依据局部负采样的个数进行调节
64 | 如果局部负采样的个数较多,采集的负样本会偏少
65 | 为了保证最终正负样本比例基本为1:1
66 | 此时正采样个数应该小于全部负采样个数(局部+全局)
67 |
68 | Returns:
69 | pos_pairs (List[Tuple(str, str)]): 正样本对
70 | """
71 | pos_pairs = []
72 | for _, post_resp in data.items():
73 | post = post_resp['post']
74 | total = len(post)
75 | for i, p in enumerate(post):
76 | if i < total - 2:
77 | cands = post[i + 1:]
78 | cands = cands if 0 < len(cands) <= num_pos else random.sample(
79 | cands, k=num_pos)
80 | pos_pairs.extend([[p, cand, 1] for cand in cands])
81 |
82 | return pos_pairs
83 |
84 |
85 | def negative_sampling(vectors,
86 | sentences,
87 | labels,
88 | n_clusters,
89 | local_num_negs=2,
90 | global_num_negs=2,
91 | algorithm='kmeans'):
92 | """负采样
93 | Step1: 读取所有 topic 的 post 并使用预训练的模型编码得到句向量 vectors
94 | Step2: 使用 KMeans 对句向量 vectors 进行聚类
95 | - 理论上聚为 n_topics 类, 每一簇都是相同 topic 的 post
96 | - 为了确保每一簇类包含语义相似但不属于同一个 topic 的 post
97 | - 可以聚为 n_topics/m 簇, 其中 m=2,3,4 可调节
98 | Step3: 根据聚类结果, 进行负采样
99 | - 局部负采样, 对于每个 post 在每个聚类簇中采样不同 topic 的 post
100 | - 全局负采样, 对于每个 post 在所有聚类簇中采样不同 topic 的 post
101 |
102 | Args:
103 | vectors (List[List[int]]): 待采样问题句向量
104 | sentences (List[List[str]]): 待采样问题文本
105 | labels (List[int]): 待采样问题真实标签(对应的主题,相同标签的问题表达形式不同,但意思相同)
106 | n_clusters (int): 聚类数,可以指定,也可以自动计算,一般为 total_topics / 2(不能太大或者太小)
107 | local_num_negs (int, optional): 局部负采样数. Defaults to 2.
108 | global_num_negs (int, optional): 全局负采样数. Defaults to 2.
109 | algorithm (str, optional): 聚类算法,kmeans 比 gmm 快很多. Defaults to 'kmeans'.
110 |
111 | Raises:
112 | NotImplemented: 未实现的聚类方法
113 |
114 | Returns:
115 | preds (List[int]): 聚类后标签
116 | neg_pairs (List[Tuple(str, str)]): 负样本对
117 | """
118 | assert len(vectors) == len(sentences) == len(labels)
119 | # ref https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
120 | if algorithm == 'kmeans':
121 | kmeans = KMeans(n_clusters=n_clusters,
122 | random_state=128,
123 | init='k-means++',
124 | n_init=1,
125 | verbose=True)
126 | kmeans.fit(vectors)
127 | preds = kmeans.labels_
128 | elif algorithm == 'gmm':
129 | model = GaussianMixture(n_components=n_clusters,
130 | random_state=128,
131 | verbose=2,
132 | covariance_type='full')
133 | model.fit(vectors)
134 | preds = model.predict(vectors)
135 | else:
136 | raise NotImplemented
137 |
138 | pred2sents = {n: [] for n in range(n_clusters)}
139 | for idx, pred in enumerate(preds):
140 | sents = pred2sents.get(pred)
141 | sents.append(idx)
142 |
143 | # 负采样
144 | neg_pairs = []
145 | for idx, (label, pred, sent) in enumerate(zip(labels, preds, sentences)):
146 | # 簇内局部负采样
147 | cands = [i for i in pred2sents.get(pred) if labels[i] != label]
148 | num_cands = len(cands)
149 | if not num_cands:
150 | pairs = []
151 | elif num_cands <= local_num_negs:
152 | pairs = cands
153 | else:
154 | pairs = random.sample(cands, k=local_num_negs)
155 |
156 | # 全局负采样
157 | cand_labels = list(range(n_clusters))
158 | cand_labels.remove(pred)
159 | for cand_label in random.sample(cand_labels, k=global_num_negs):
160 | cands = [
161 | i for i in pred2sents.get(cand_label) if labels[i] != label
162 | ]
163 | if len(cands):
164 | pairs.append(random.choice(cands))
165 |
166 | neg_pairs.extend([[sent, sentences[pair], 0] for pair in pairs])
167 |
168 | return preds, neg_pairs
169 |
170 |
171 | def visualize(vectors, labels, preds, output_dir):
172 | """聚类结果可视化
173 | (类别太多,基本看不出来效果)
174 |
175 | Args:
176 | vectors (List[List[int]]): 句向量
177 | labels (List[int]): 真实标签
178 | preds (List[int]): 预测标签
179 | output_dir ([str): 可视化图片保存位置
180 | """
181 | # PCA
182 | pca = PCA(n_components=2, random_state=128)
183 | pos = pca.fit(vectors).transform(vectors)
184 |
185 | plt.figure(figsize=(12, 12))
186 | plt.subplot(221)
187 | plt.title('original label')
188 | plt.scatter(pos[:, 0], pos[:, 1], c=labels)
189 |
190 | plt.subplot(222)
191 | plt.title('cluster label')
192 | plt.scatter(pos[:, 0], pos[:, 1], c=preds)
193 |
194 | plt.savefig(os.path.join(output_dir, 'cluster.png'))
195 |
196 |
197 | def encode(sentences, model_name_or_path, is_transformers):
198 | """句向量编码
199 |
200 | Args:
201 | sentences (List[List[str]]): 待编码句子
202 | model_name_or_path (str): 预训练模型位置
203 | is_transformers (bool):
204 | 是否为 Transformers 模型
205 | Transformeres 模型需要额外加入平均池化层
206 |
207 | Returns:
208 | vectors (List[List[int]]): 句向量
209 | """
210 | # 使用 BERT 作为 encoder, 并加载预训练模型
211 | word_embedding_model = models.BERT(model_name_or_path)
212 |
213 | # 使用 mean pooling 获得句向量表示
214 | pooling_model = models.Pooling(
215 | word_embedding_model.get_word_embedding_dimension(),
216 | pooling_mode_mean_tokens=True,
217 | pooling_mode_cls_token=False,
218 | pooling_mode_max_tokens=False)
219 |
220 | model = SentenceTransformer(
221 | modules=[word_embedding_model, pooling_model])
222 |
223 | vectors = model.encode(sentences, show_progress_bar=True, device='cuda')
224 |
225 | return vectors
226 |
227 |
228 | def load_data(filename):
229 | """读取 FAQ 数据集
230 | :param filename
231 | :return
232 | Dict(str, Dict(str, List[str]))
233 | """
234 | with open(filename, 'r', encoding='utf-8') as f:
235 | return json.load(f)
236 |
237 |
238 | def main(args):
239 | if not os.path.exists(args.output_dir):
240 | logger.info('make directory %s' % args.output_dir)
241 | os.makedirs(args.output_dir)
242 |
243 | logger.info('loading data from %s' % args.filename)
244 | data = load_data(args.filename)
245 |
246 | # 正采样
247 | logger.info('** positive sampling **')
248 | logger.info('num_pos = %d' % args.num_pos)
249 | pos_pairs = positive_sampling(data, num_pos=args.num_pos)
250 | logger.info('sampling %d positive samples' % len(pos_pairs))
251 |
252 | # 负采样准备(句向量编码)
253 | logger.info('** negative sampling **')
254 | sents, labels = [], []
255 | cnt = 0
256 | for _, post_resp in data.items():
257 | sents.extend(post_resp.get('post'))
258 | labels.extend([cnt] * len(post_resp.get('post')))
259 | cnt += 1
260 |
261 | logger.info('loading checkpoint from %s' % args.model_name_or_path)
262 | logger.info('encoding %d sentences' % len(sents))
263 | vectors = encode(sents,
264 | model_name_or_path=args.model_name_or_path,
265 | is_transformers=args.is_transformers)
266 | n_clusters = args.n_clusters if args.n_clusters != -1 else int(
267 | len(data) // args.hyper_beta)
268 |
269 | logger.info('n_cluster = %d, local_num_negs = %d, global_num_negs = %d' %
270 | (n_clusters, args.local_num_negs, args.global_num_negs))
271 | preds, neg_pairs = negative_sampling(vectors,
272 | sentences=sents,
273 | labels=labels,
274 | n_clusters=n_clusters,
275 | local_num_negs=args.local_num_negs,
276 | global_num_negs=args.global_num_negs,
277 | algorithm=args.algorithm)
278 | logger.info('sampling %d negative samples' % len(neg_pairs))
279 |
280 | # 可视化
281 | if args.visualized:
282 | logger.info('** visualize **')
283 | visualize(vectors,
284 | labels=labels,
285 | preds=preds,
286 | output_dir=args.output_dir)
287 |
288 | # merge & shuffle
289 | all_pairs = pos_pairs + neg_pairs
290 | random.shuffle(all_pairs)
291 | logger.info(
292 | 'we get total %d samples, where %d positive samples and %d negative samples'
293 | % (len(all_pairs), len(pos_pairs), len(neg_pairs)))
294 |
295 | # split & save
296 | out_file = f'beta{args.hyper_beta}_{args.algorithm}_p{args.num_pos}_n{args.local_num_negs}{args.global_num_negs}.csv'
297 | df = pd.DataFrame(data=all_pairs,
298 | columns=['sentence1', 'sentence2', 'label'])
299 |
300 | if args.is_split:
301 | logger.info('train/test set split with test_size = %f' %
302 | args.test_size)
303 | trainset, testset = train_test_split(df, test_size=args.test_size)
304 |
305 | logger.info('save samples to all/train/test_%s' % out_file)
306 | df.to_csv(os.path.join(args.output_dir, 'all_' + out_file), index=None)
307 | trainset.to_csv(os.path.join(args.output_dir, 'train_' + out_file),
308 | index=None)
309 | testset.to_csv(os.path.join(args.output_dir, 'test_' + out_file),
310 | index=None)
311 | else:
312 | logger.info('save all samples to %s' % out_file)
313 | df.to_csv(os.path.join(args.output_dir, out_file), index=None)
314 |
315 |
316 | if __name__ == '__main__':
317 | parser = argparse.ArgumentParser('Positive & Negative Sampling System')
318 |
319 | parser.add_argument(
320 | '--filename',
321 | default='ddqa/train_faq.json',
322 | help='json format original data, like {topic: {post:[], resp:[]}}')
323 | parser.add_argument(
324 | '--model_name_or_path',
325 | default='./output/training-OnlineConstrativeLoss-merge-bert-6L',
326 | help='path of pretrained model which is used to get sentence vector')
327 | parser.add_argument(
328 | '--hyper_beta',
329 | type=int,
330 | default=2,
331 | help='hyperparameter (n_clusters = total_topics / hyper_beta)')
332 | parser.add_argument(
333 | '--n_clusters',
334 | type=int,
335 | default=-1,
336 | help='if n_clusters=-1, then n_cluster=n_topics/hyper_m')
337 | parser.add_argument('--algorithm',
338 | type=str,
339 | default='kmeans',
340 | choices=['kmeans', 'gmm'],
341 | help='cluster algorithm')
342 | parser.add_argument('--num_pos',
343 | type=int,
344 | default=5,
345 | help='number of positive sampling')
346 | parser.add_argument('--local_num_negs',
347 | type=int,
348 | default=3,
349 | help='number of local negative sampling')
350 | parser.add_argument('--global_num_negs',
351 | type=int,
352 | default=2,
353 | help='number of global negative sampling')
354 | parser.add_argument('--visualized',
355 | type=ast.literal_eval,
356 | default=False,
357 | help='whether to visualize cluster results or not')
358 | parser.add_argument('--is_split',
359 | type=ast.literal_eval,
360 | default=False,
361 | help='whether to split the data into train and test')
362 | parser.add_argument('--test_size',
363 | type=float,
364 | default=0.1,
365 | help='train/test split size')
366 | parser.add_argument('--output_dir',
367 | type=str,
368 | default='./samples',
369 | help='directory to save train/test.csv')
370 |
371 | args = parser.parse_args()
372 | main(args)
--------------------------------------------------------------------------------
/sentence_transformers_encoder.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-08-26 01:27:12
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 |
8 | from sentence_transformers import models, SentenceTransformer
9 |
10 |
11 | # Model
12 | def get_model(model_name_or_path, device='cuda'):
13 | """初始化 SentenceTransformer 编码器
14 |
15 | Args:
16 | model_name_or_path (str): Transformers 或者微调后的 BERT 模型
17 | device (str, optional): cpu or cuda. Defaults to 'cuda'.
18 |
19 | Returns:
20 | SentenceTransformers: 编码器
21 | """
22 | word_embedding_model = models.BERT(model_name_or_path)
23 |
24 | # 使用 mean pooling 获得句向量表示
25 | pooling_model = models.Pooling(
26 | word_embedding_model.get_word_embedding_dimension(),
27 | pooling_mode_mean_tokens=True,
28 | pooling_mode_cls_token=False,
29 | pooling_mode_max_tokens=False)
30 |
31 | model = SentenceTransformer(modules=[word_embedding_model, pooling_model],
32 | device=device)
33 |
34 | return model
35 |
36 |
37 | if __name__ == '__main__':
38 | # pip install sentence-transformers
39 | # https://github.com/UKPLab/sentence-transformers
40 | model = get_model('./output/transformers-merge3-bert-6L')
41 | # (hidden_size)
42 | print(model.encode('你好呀'))
43 | # (batch_size, hidden_size)
44 | # print(model.encode(['你好呀']))
--------------------------------------------------------------------------------
/sentence_transformers_train.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-08-28 23:15:32
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 | import os
8 | import ast
9 | import pprint
10 | import argparse
11 |
12 | import pandas as pd
13 | import torch
14 | from torch.utils.data import DataLoader
15 |
16 | from sentence_transformers import losses, models
17 | from sentence_transformers import SentencesDataset, SentenceTransformer, evaluation
18 | from sentence_transformers.readers import InputExample
19 |
20 | from sklearn.metrics import accuracy_score, precision_recall_fscore_support
21 |
22 |
23 | def load_train_samples(filename):
24 | """读取训练样本
25 |
26 | Args:
27 | filename (str): csv文件,保存格式为 sentence1, sentence2, label
28 |
29 | Returns:
30 | List[InputExample]: 训练样本
31 | """
32 | data = pd.read_csv(filename)
33 | samples = []
34 | for _, row in data.iterrows():
35 | samples.append(
36 | InputExample(texts=[row['sentence1'], row['sentence2']],
37 | label=int(row['label'])))
38 | return samples
39 |
40 |
41 | def load_dev_sentences(filename):
42 | """读取测试样本
43 |
44 | Args:
45 | filename (str): 文件名
46 |
47 | Returns:
48 | """
49 | data = pd.read_csv(filename)
50 | sents1, sents2, labels = [], [], []
51 | for _, row in data.iterrows():
52 | sents1.append(row['sentence1'])
53 | sents2.append(row['sentence2'])
54 | labels.append(int(row['label']))
55 | return sents1, sents2, labels
56 |
57 |
58 | def train(args):
59 | """使用 Sentence-Transformers 进行文本相似度任务微调
60 | Sentence-Transformers 仅支持单GPU训练, 可以进行快速想法验证
61 | 大规模数据需要使用 Transformers 代码进行多GPU训练
62 |
63 | Args:
64 |
65 | """
66 | # 使用 BERT 作为 encoder
67 | word_embedding_model = models.BERT(args.model_name_or_path)
68 |
69 | # 使用 mean pooling 获得句向量表示
70 | pooling_model = models.Pooling(
71 | word_embedding_model.get_word_embedding_dimension(),
72 | pooling_mode_mean_tokens=True,
73 | pooling_mode_cls_token=False,
74 | pooling_mode_max_tokens=False)
75 |
76 | model = SentenceTransformer(modules=[word_embedding_model, pooling_model],
77 | device='cuda')
78 |
79 | # 使用余弦距离作为度量指标 (cosine_distance = 1-cosine_similarity)
80 | distance_metric = losses.SiameseDistanceMetric.COSINE_DISTANCE
81 |
82 | # 读取训练集
83 | train_samples = load_train_samples(args.trainset_path)
84 | train_dataset = SentencesDataset(train_samples, model=model)
85 | train_dataloader = DataLoader(train_dataset,
86 | shuffle=True,
87 | batch_size=args.train_batch_size)
88 | # 初始化训练损失函数
89 | train_loss = losses.OnlineContrastiveLoss(model=model,
90 | distance_metric=distance_metric,
91 | margin=args.margin)
92 |
93 | # 构造开发集评估器
94 | # 给定 (sentence1, sentence2) 判断是否相似
95 | # 评估器将计算两个句向量的余弦相似度,如果高于某个阈值则判断为相似
96 | dev_sentences1, dev_sentences2, dev_labels = load_dev_sentences(
97 | args.devset_path)
98 |
99 | binary_acc_evaluator = evaluation.BinaryClassificationEvaluator(
100 | dev_sentences1, dev_sentences2, dev_labels)
101 |
102 | # 模型训练
103 | model.fit(train_objectives=[(train_dataloader, train_loss)],
104 | evaluator=binary_acc_evaluator,
105 | epochs=args.num_epochs,
106 | warmup_steps=args.warmup_steps,
107 | output_path=args.output_dir,
108 | output_path_ignore_not_empty=True)
109 |
110 |
111 | def test(args):
112 | """测试集评估(csv文件)
113 |
114 | Args:
115 |
116 | """
117 | model = SentenceTransformer(args.output_dir, device='cuda')
118 |
119 | # 开放集评估
120 | dev_sentences1, dev_sentences2, dev_labels = load_dev_sentences(
121 | args.devset_path)
122 | binary_acc_evaluator = evaluation.BinaryClassificationEvaluator(
123 | dev_sentences1, dev_sentences2, dev_labels)
124 | model.evaluate(binary_acc_evaluator, args.output_dir)
125 |
126 | # 开发集阈值
127 | result = pd.read_csv(
128 | os.path.join(args.output_dir,
129 | 'binary_classification_evaluation_results.csv'))
130 | max_idx = result['cosine_acc'].argmax()
131 | threshold = result['cosine_acc_threshold'].values[max_idx]
132 |
133 | # 测试集评估
134 | sents1, sents2, labels = load_dev_sentences(args.testset_path)
135 | vec_sents1 = model.encode(sents1,
136 | batch_size=args.eval_batch_size,
137 | show_progress_bar=True,
138 | convert_to_tensor=True)
139 | vec_sents2 = model.encode(sents2,
140 | batch_size=args.eval_batch_size,
141 | show_progress_bar=True,
142 | convert_to_tensor=True)
143 |
144 | cos = torch.nn.CosineSimilarity()
145 | scores = cos(vec_sents1, vec_sents2).cpu()
146 |
147 | # 测试集结果
148 | preds = [1 if s > threshold else 0 for s in scores]
149 | acc = accuracy_score(labels, preds)
150 | p_r_f1 = precision_recall_fscore_support(labels, preds, average='macro')
151 | test_result = {
152 | 'accuracy': acc,
153 | 'macro_precision': p_r_f1[0],
154 | 'macro_recall': p_r_f1[1],
155 | 'macro_f1': p_r_f1[2]
156 | }
157 | pprint.pprint(test_result)
158 |
159 |
160 | if __name__ == '__main__':
161 | parser = argparse.ArgumentParser(
162 | description='Sentence Transformers Training.')
163 |
164 | parser.add_argument('--do_train', action='store_true')
165 | parser.add_argument('--do_eval', action='store_true')
166 | parser.add_argument(
167 | '--model_name_or_path',
168 | type=str,
169 | default='/users6/kyzhang/embeddings/bert/bert-base-chinese',
170 | help='transformers style bert model')
171 | parser.add_argument('--trainset_path',
172 | type=str,
173 | default='samples/merge_train_beta1.5_gmm_p4_n42.csv')
174 | parser.add_argument('--devset_path',
175 | type=str,
176 | default='samples/train_beta1.5_gmm_p5_n41.csv')
177 | parser.add_argument('--testset_path',
178 | type=str,
179 | default='samples/train_beta1.5_gmm_p5_n41.csv')
180 |
181 | parser.add_argument('--num_epochs',
182 | type=int,
183 | default=5,
184 | help='number of training epochs')
185 | parser.add_argument('--train_batch_size',
186 | type=int,
187 | default=128,
188 | help='training batch size, 128 for 16G')
189 | parser.add_argument('--eval_batch_size',
190 | type=int,
191 | default=128,
192 | help='evaluation batch size')
193 |
194 | parser.add_argument('--warmup_steps',
195 | type=int,
196 | default=1000,
197 | help='bert style warmup steps')
198 |
199 | parser.add_argument(
200 | '--margin',
201 | type=float,
202 | default=0.5,
203 | help='Negative pairs should have a distance of at least 0.5')
204 | parser.add_argument(
205 | '--output_dir',
206 | type=str,
207 | default='output/training-OnlineConstrativeLoss-merge-beta1.5-gmm-bert')
208 |
209 | args = parser.parse_args()
210 |
211 | if args.do_train:
212 | train(args)
213 | elif args.do_eval:
214 | test(args)
215 | else:
216 | pprint.pprint({
217 | 'train': 'python sentence_transformers_train.py do_eval',
218 | 'eval': 'python sentence_transformers_train.py do_train'
219 | })
220 |
--------------------------------------------------------------------------------
/test.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-08-26 01:46:35
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 |
8 | import time
9 | import random
10 | import numpy as np
11 | import pandas as pd
12 |
13 | from tqdm import tqdm
14 |
15 | import torch
16 | import torch.nn as nn
17 | from torch.utils.data import DataLoader
18 |
19 | from sklearn.metrics.pairwise import cosine_similarity
20 | from sklearn.model_selection import train_test_split
21 | from sklearn.utils import shuffle
22 | from sentence_transformers import SentenceTransformer, util, models
23 |
24 | from transformers import BertTokenizer, BertModel
25 |
26 | from utils import load_json, cos_sim, save_json
27 |
28 |
29 | def construct_pos():
30 | '''根据faq数据构造正例
31 | '''
32 | data = load_json('hflqa/faq.json')
33 | topics, ques, ans = [], [], []
34 | for topic, qas in data.items():
35 | for q in qas['post']:
36 | for a in qas['resp']:
37 | ques.append(q)
38 | ans.append(a)
39 | topics.append(topic)
40 |
41 | df = pd.DataFrame(data={
42 | 'topic': topics,
43 | 'query': ques,
44 | 'answer': ans
45 | },
46 | columns=['topic', 'query', 'answer'])
47 |
48 | df.to_csv('pos.csv', index=None)
49 |
50 | print(df.shape)
51 | # (339886, 3)
52 |
53 |
54 | def cost_test():
55 | '''测试各种余弦距离计算函数耗时
56 | 自定义函数,可以提前计算相关值,速度最快
57 |
58 | num_cands 20000 100000
59 | sklearn 0.2950s 1.3517s
60 | torch 0.1851s 0.9408s
61 | custom 0.0092s 0.0673s
62 | '''
63 | post = np.random.randn(100000, 768)
64 | query = np.random.randn(1, 768)
65 | post_norm = np.linalg.norm(post)
66 |
67 | cos = nn.CosineSimilarity()
68 |
69 | print('---- sklearn ----')
70 | t1 = time.time()
71 | scores = cosine_similarity(query, post)
72 | print(np.argmax(scores))
73 | t2 = time.time()
74 | print(t2 - t1)
75 |
76 | print('---- torch ----')
77 | scores = cos(torch.tensor(query), torch.tensor(post)).tolist()
78 | print(np.argmax(scores))
79 | t3 = time.time()
80 | print(t3 - t2)
81 |
82 | print('---- custom ----')
83 | scores = cos_dist(np.squeeze(query, axis=0), post, post_norm)
84 | print(np.argmax(scores))
85 | t4 = time.time()
86 | print(t4 - t3)
87 |
88 |
89 | def get_faq_corpus_embeddings(embedder, filename='hflqa/faq.json'):
90 | '''读取 faq 数据并使用 sentence-transformers 进行向量编码
91 | '''
92 | data = load_json(filename)
93 | corpus = []
94 | for _, post_replys in data.items():
95 | corpus.extend(post_replys['post'])
96 |
97 | corpus_embeddings = embedder.encode(corpus,
98 | show_progress_bar=True,
99 | convert_to_tensor=True)
100 | return corpus, corpus_embeddings
101 |
102 |
103 | def sentence_transformers_test(top_k=5):
104 | '''使用 sentence-transformers 进行向量编码
105 | 使用 util.pytorch_cos_sim 计算余弦相似度
106 | 使用 np.argpartition 获取 topk
107 | '''
108 | embedder = SentenceTransformer('bert-base-chinese')
109 |
110 | corpus, corpus_embeddings = get_faq_corpus_embeddings(embedder)
111 |
112 | while True:
113 | query = input('Enter: ')
114 | query_embeddings = embedder.encode([query], convert_to_tensor=True)
115 | cos_scores = util.pytorch_cos_sim(query_embeddings,
116 | corpus_embeddings)[0].cpu()
117 |
118 | #We use np.argpartition, to only partially sort the top_k results
119 | top_results = np.argpartition(-cos_scores, range(top_k))[0:top_k]
120 |
121 | print("\n\n======================\n\n")
122 | print("Query:", query)
123 | print("\nTop 5 most similar sentences in corpus:")
124 |
125 | for idx in top_results[0:top_k]:
126 | print(corpus[idx].strip(), "(Score: %.4f)" % (cos_scores[idx]))
127 |
128 |
129 | def sentence_search_test(topk=5):
130 | '''使用 sentence-transformers 进行向量编码
131 | 调用 util.sementic_search 进行语义召回检索前 topk
132 | '''
133 | embedder = SentenceTransformer(
134 | './output/training-OnlineConstrativeLoss-LCQMC', device='cuda')
135 |
136 | corpus, corpus_embeddings = get_faq_corpus_embeddings(embedder)
137 | print("Corpus loaded with {} sentences / embeddings".format(
138 | len(corpus_embeddings)))
139 |
140 | while True:
141 | inp_question = input("Please enter a question: ")
142 |
143 | start_time = time.time()
144 | question_embedding = embedder.encode(inp_question,
145 | convert_to_tensor=True)
146 | # (num_query, num_corpus)
147 | hits = util.semantic_search(question_embedding, corpus_embeddings)
148 | end_time = time.time()
149 |
150 | # Get the hits for the first query
151 | hits = hits[0]
152 |
153 | print("Input question:", inp_question)
154 | print("Results (after {:.3f} seconds):".format(end_time - start_time))
155 | for hit in hits[:topk]:
156 | print("\t{:.3f}\t{}".format(hit['score'],
157 | corpus[hit['corpus_id']]))
158 |
159 | print("\n\n========\n")
160 |
161 |
162 | def load_ddqa():
163 | # v_inc_sim_q_id,std_q_id,std_q,similar_q,tags,src,start_date,end_date,rank
164 | data = pd.read_csv('ddqa/faq.csv')
165 | ques, labels = [], []
166 | for _, row in data.iterrows():
167 | if row['rank'] == 1:
168 | labels.append(row['std_q_id'])
169 | ques.append(row['std_q'])
170 | labels.append(row['std_q_id'])
171 | ques.append(row['similar_q'])
172 |
173 | return ques, labels
174 |
175 |
176 | def load_faq(filename='hflqa/faq.json'):
177 | data = load_json(filename)
178 | ques, labels = [], []
179 | for idx, (topic, post_resp) in enumerate(data.items()):
180 | for post in post_resp['post']:
181 | ques.append(post)
182 | labels.append(topic)
183 |
184 | return ques, labels
185 |
186 |
187 | def compute_acc():
188 | is_transformers = True
189 | # model_path = '/users6/kyzhang/embeddings/bert/bert-base-chinese'
190 | # model_path = './output/training-OnlineConstrativeLoss-hflqa-beta1.5-gmm-bert/0_BERT'
191 | # model_path = './output/transformers-merge-bert-base-chinese'
192 | model_path = './output/transformers-merge3-bert'
193 | if is_transformers:
194 | # 使用 BERT 作为 encoder
195 | word_embedding_model = models.BERT(model_path)
196 | # 使用 mean pooling 获得句向量表示
197 | pooling_model = models.Pooling(
198 | word_embedding_model.get_word_embedding_dimension(),
199 | pooling_mode_mean_tokens=True,
200 | pooling_mode_cls_token=False,
201 | pooling_mode_max_tokens=False)
202 | embedder = SentenceTransformer(
203 | modules=[word_embedding_model, pooling_model], device='cuda')
204 | else:
205 | embedder = SentenceTransformer(model_path, device='cuda')
206 |
207 | # ques, labels = load_ddqa() #load_hflqa()
208 | # X_train, X_test, y_train, y_test = train_test_split(ques,
209 | # labels,
210 | # test_size=0.1)
211 |
212 | proj = 'hflqa'
213 | X_train, y_train = load_faq(f'{proj}/train_faq.json')
214 | X_test, y_test = load_faq(f'{proj}/test_faq.json')
215 |
216 | corpus_embeddings = embedder.encode(X_train,
217 | show_progress_bar=True,
218 | batch_size=512,
219 | convert_to_tensor=True)
220 | # corpus_mat_norm = np.linalg.norm(corpus_embeddings)
221 |
222 | query_embeddings = embedder.encode(X_test,
223 | show_progress_bar=True,
224 | batch_size=512,
225 | convert_to_tensor=True)
226 |
227 | print(query_embeddings.shape, corpus_embeddings.shape)
228 | hits = util.semantic_search(query_embeddings, corpus_embeddings)
229 | res = [
230 | 1 if y in [y_train[hit[i]['corpus_id']] for i in range(10)] else 0
231 | for hit, y in zip(hits, y_test)
232 | ]
233 | acc = sum(res) / len(res)
234 | print(acc)
235 |
236 | # data = []
237 | # for x, y, hit in zip(X_test, y_test, hits):
238 | # cands = [y_train[hit[i]['corpus_id']] for i in range(3)]
239 | # if y not in cands:
240 | # cands.insert(0, y)
241 | # cands.insert(0, x)
242 | # data.append(cands)
243 | # pd.DataFrame(data=data, columns=['query', 'std_q', 'error1', 'error2', 'error3']).to_csv('error_cands.csv', index=None)
244 |
245 | # return acc
246 | # while True:
247 | # inp_question = input("Please enter a question: ")
248 |
249 | # start_time = time.time()
250 | # question_embedding = embedder.encode(inp_question,
251 | # convert_to_tensor=True)
252 | # # (num_query, num_corpus)
253 | # hits = util.semantic_search(question_embedding, corpus_embeddings)
254 | # end_time = time.time()
255 |
256 | # # Get the hits for the first query
257 | # hits = hits[0]
258 |
259 | # print("Input question:", inp_question)
260 | # print("Results (after {:.3f} seconds):".format(end_time - start_time))
261 | # for hit in hits[:5]:
262 | # print("\t{:.3f}\t{}".format(hit['score'],
263 | # qs[hit['corpus_id']]))
264 |
265 | # print("\n\n========\n")
266 |
267 |
268 | def split_faq(proj):
269 | data = load_json(f'{proj}/faq.json')
270 | topics, posts = [], []
271 | for topic, post_resp in data.items():
272 | for post in post_resp['post']:
273 | topics.append(topic)
274 | posts.append(post)
275 |
276 | train_posts, test_posts, train_topics, test_topics = train_test_split(
277 | posts, topics, test_size=0.1)
278 |
279 | save_faq(train_posts, train_topics, f'{proj}/train_faq.json')
280 | save_faq(test_posts, test_topics, f'{proj}/test_faq.json')
281 |
282 |
283 | def save_faq(posts, topics, filename):
284 | data = {}
285 | for post, topic in zip(posts, topics):
286 | if topic not in data:
287 | data[topic] = {'post': []}
288 | data[topic]['post'].append(post)
289 |
290 | save_json(data, filename)
291 |
292 |
293 | def merge():
294 | # for mode in ['train', 'test']:
295 | # lcqmc = pd.read_csv(f'lcqmc/LCQMC_{mode}.csv')
296 | # hflqa = pd.read_csv(f'samples/{mode}_beta1.5_gmm_p4_n42.csv')
297 |
298 | # total = shuffle(pd.concat([lcqmc, hflqa]))
299 | # total.to_csv(f'samples/merge_{mode}_beta1.5_gmm_p4_n42.csv', index=None)
300 |
301 | lcqmc = pd.read_csv(f'samples/ddqa_beta2_kmeans_p5_n32.csv')
302 | hflqa = pd.read_csv(f'samples/merge_train_beta1.5_gmm_p4_n42.csv')
303 |
304 | total = shuffle(pd.concat([lcqmc, hflqa]))
305 | total.to_csv(f'samples/merge3.csv', index=None)
306 |
307 |
308 | def export_ddqa():
309 | ques, labels = load_ddqa()
310 | data = {}
311 | for l, q in zip(labels, ques):
312 | if l not in data:
313 | data[l] = {'post': []}
314 | data[l]['post'].append(q)
315 |
316 | save_json(data, 'ddqa/faq.json')
317 |
318 |
319 | def save_pretrained_model():
320 | model_path = './output/transformers-merge3-bert/'
321 | model = BertModel.from_pretrained(model_path)
322 |
323 | torch.save(model.state_dict(),
324 | 'output/transformers-merge3-bert-6L/pytorch_model.bin')
325 |
326 | def for_index():
327 | train_faq = load_json('hflqa/test_faq.json')
328 | faq = load_json('hflqa/faq.json')
329 | for topic in train_faq:
330 | train_faq[topic]['resp'] = faq[topic]['resp']
331 | save_json(train_faq, 'hflqa/test_faq_resp.json')
332 |
333 | def req_test():
334 | import requests
335 | url = '###'
336 | data = load_json('hflqa/test_faq_resp.json')
337 | hits = total = fails = 0
338 | st = time.time()
339 | for _, post_resp in tqdm(data.items()):
340 | resp = set(post_resp.get('resp'))
341 | for post in post_resp.get('post'):
342 | try:
343 | reply = requests.post(url=url, json={'query': post}, timeout=1000)
344 | if reply.json().get('reply') in resp:
345 | hits += 1
346 | except:
347 | fails += 1
348 | finally:
349 | total += 1
350 | print(f'hits = {hits}, fails = {fails}, total = {total}, avg.sec = {(time.time()-st)/total}')
351 |
352 | def request():
353 | data = {
354 | 'content': '\u4f60\u8fd8\u597d\u5417',
355 | 'msg_type': 'text',
356 | 'metafield': {
357 | 'emotion': 'sad',
358 | 'consumption_class': 0,
359 | 'ltp': {
360 | 'seg': '\u4f60 \u8fd8 \u597d \u5417',
361 | 'arc': '3:SBV 3:ADV 0:HED 3:RAD',
362 | 'ner': 'O O O O',
363 | 'pos': 'r d a u'
364 | },
365 | 'consumption_result': 0.0,
366 | 'multi_turn_status_dict': {},
367 | 'anaphora_resolution': {
368 | 'score': 0,
369 | 'result': ''
370 | }
371 | },
372 | 'user': {
373 | 'id': 'oFeuIs252VLW7ILAKQ1Rh5JViEks'
374 | },
375 | 'context': {}
376 | }
377 | import requests
378 | url = 'http://127.0.0.1:12345/module/FAQ'
379 | res = requests.post(url=url, json=data)
380 | print(res.json())
381 |
382 | import json
383 | def count_faq():
384 | with open("ext_hflqa/clean_faq.json", "r", encoding="utf-8") as f:
385 | data = json.load(f)
386 | print("topic", len(data))
387 | print("post", sum([len(v["post"]) for k, v in data.items()]))
388 | print("resp", sum([len(v["resp"]) for k, v in data.items()]))
389 |
390 | if __name__ == '__main__':
391 | # dis_test()
392 | # sentence_transformers_test()
393 | # compute_acc()
394 | # request()
395 | # for_index()
396 | count_faq()
397 | """scores = []
398 | for _ in range(5):
399 | scores.append(compute_acc())
400 | print(scores)
401 | print(sum(scores)/len(scores))"""
402 | # split_faq('ddqa')
403 | # merge()
404 | # export_ddqa()
405 | # save_pretrained_model()
406 | # req_test()
407 |
--------------------------------------------------------------------------------
/thread_test.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-09-03 00:56:04
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 |
8 | from threading import Thread
9 | import requests
10 | import random
11 | import json
12 | import time
13 |
14 | API_URL = "http://127.0.0.1:8889/module/ext_faq_test"
15 | NUM_REQUESTS = 500
16 | SLEEP_COUNT = 0.1
17 |
18 | def get_seqs():
19 | """获取用户输入样例
20 |
21 | Returns:
22 | List[str]
23 | """
24 | seqs = []
25 | with open('./hflqa/test_faq_resp.json', 'r', encoding='utf-8') as f:
26 | data = json.load(f)
27 | for _, post_resp in data.items():
28 | seqs.extend(post_resp['post'])
29 | random.shuffle(seqs)
30 | return seqs
31 |
32 |
33 | seqs = get_seqs()
34 |
35 | def call_predict_endpoint(n):
36 | payload = {"query": random.choice(seqs)}
37 |
38 | r = requests.post(API_URL, files=payload).json()
39 |
40 | if r["reply"]:
41 | print("[INFO] thread {} OK".format(n))
42 |
43 | else:
44 | print("[INFO] thread {} FAILED".format(n))
45 |
46 | for i in range(0, NUM_REQUESTS):
47 | t = Thread(target=call_predict_endpoint, args=(i,))
48 | t.daemon = True
49 | t.start()
50 | time.sleep(SLEEP_COUNT)
51 |
52 | time.sleep(300)
--------------------------------------------------------------------------------
/transformers_encoder.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-08-29 01:51:01
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 | import numpy as np
8 | from tqdm import tqdm
9 |
10 | import torch
11 | from torch.utils.data import DataLoader
12 | from transformers import AutoTokenizer, AutoModel
13 |
14 |
15 | class TransformersEncoder:
16 | """封装基于Transformers的句向量编码器
17 | """
18 | def __init__(
19 | self,
20 | model_name_or_path='/users6/kyzhang/embeddings/bert/bert-base-chinese',
21 | max_length=128,
22 | batch_size=128):
23 | """初始化
24 |
25 | Args:
26 | model_name_or_path (str, optional): Transformers模型位置或者别称(从HuggingFace服务器下载)
27 | max_length (int, optional): 最大长度. Defaults to 128.
28 | """
29 | print('initing encoder')
30 | print('loading model from from pretrained')
31 | self.tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
32 | self.model = AutoModel.from_pretrained(model_name_or_path)
33 |
34 | # gpu & cpu
35 | self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
36 | print('using', self.device)
37 | self.model.to(self.device)
38 | self.model.eval()
39 |
40 | self.max_length = max_length
41 | self.batch_size = batch_size
42 | print('ending initing')
43 |
44 | def _assign_device(self, Tokenizer_output):
45 | """将tensor转移到gpu
46 | """
47 | tokens_tensor = Tokenizer_output['input_ids'].to(self.device)
48 | token_type_ids = Tokenizer_output['token_type_ids'].to(self.device)
49 | attention_mask = Tokenizer_output['attention_mask'].to(self.device)
50 |
51 | output = {
52 | 'input_ids': tokens_tensor,
53 | 'token_type_ids': token_type_ids,
54 | 'attention_mask': attention_mask
55 | }
56 |
57 | return output
58 |
59 | def _mean_pooling(self, model_output, attention_mask):
60 | """平均池化
61 |
62 | Args:
63 | model_output ([type]): transformers 模型输出
64 | attention_mask (List[List[int]]): MASK, (batch, seq_length)
65 |
66 | Returns:
67 | List[List[int]]: 句向量
68 | """
69 | # (batch_size, seq_length, hidden_size)
70 | token_embeddings = model_output[0].cpu()
71 |
72 | # (batch_size, seq_length) => (batch_size, seq_length, hidden_size)
73 | input_mask_expanded = attention_mask.cpu().unsqueeze(-1).expand(
74 | token_embeddings.size()).float()
75 |
76 | # Only sum the non-padding token embeddings
77 | # (batch_size, seq_length, hidden_size) => (batch_size, hidden_size)
78 | sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
79 |
80 | # smoothing, avoid being divided by zero
81 | sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
82 | return sum_embeddings / sum_mask
83 |
84 | def encode(self, sentences, show_progress_bar=False):
85 | """句向量编码器
86 |
87 | Args:
88 | sentences (List[str]): (batch_size)
89 |
90 | Returns:
91 | tensor: (batch_size, hidden_size)
92 | """
93 | # Tokenize sentences
94 | dataloader = DataLoader(sentences,
95 | batch_size=self.batch_size,
96 | shuffle=False)
97 | dataloader = tqdm(dataloader) if show_progress_bar else dataloader
98 | sentence_embeddings: torch.Tensor = None
99 | # Compute token embeddings
100 | with torch.no_grad():
101 | # (sequence_output, pooled_output, (hidden_states), (attentions))
102 | # sequence_output, (batch_size, sequence_length, hidden_size))
103 | # Sequence of hidden-states at the output of the last layer of the model.
104 | # pooled_output, (batch_size, hidden_size))
105 | # Last layer hidden-state of the first token of the sequence (classification token)
106 | # further processed by a Linear layer and a Tanh activation function.
107 | # The Linear layer weights are trained from the next sentence prediction
108 | # (classification) objective during pre-training.
109 | # not a good summary of the semantic content of the input
110 | # it's better with averaging or pooling the sequence of hidden-states for the whole input sequence
111 | for batch_sentences in dataloader:
112 | encoded_input = self.tokenizer(batch_sentences,
113 | padding=True,
114 | truncation=True,
115 | max_length=self.max_length,
116 | return_tensors='pt')
117 | encoded_input = self._assign_device(encoded_input)
118 | model_output = self.model(**encoded_input)
119 |
120 | # Perform pooling. In this case, mean pooling
121 | batch_embeddings = self._mean_pooling(
122 | model_output, encoded_input['attention_mask'])
123 | sentence_embeddings = batch_embeddings if sentence_embeddings is None else torch.cat(
124 | [sentence_embeddings, batch_embeddings], dim=0)
125 |
126 | return sentence_embeddings
127 |
128 |
129 | if __name__ == '__main__':
130 | # pip install transformers==3.0.2 ([Optional] torch==1.6.0)
131 | # https://github.com/huggingface/transformers
132 | encoder = TransformersEncoder()
133 | # (batch_size, hidden_size)
134 | print(encoder.encode(['你好呀']))
135 |
--------------------------------------------------------------------------------
/transformers_trainer.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-08-29 02:03:16
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 | import ast
8 | import logging
9 | import pprint
10 | import argparse
11 | import pandas as pd
12 | from typing import Union, List
13 |
14 | import torch
15 | import torch.nn.functional as F
16 | from torch.utils.data import Dataset
17 |
18 | from transformers import BertConfig
19 | from transformers import BertPreTrainedModel, BertModel, PreTrainedTokenizer, BertTokenizer
20 | from transformers import Trainer, TrainingArguments
21 |
22 | from sklearn.metrics import precision_recall_fscore_support, accuracy_score
23 | """
24 | 基于 BERT 的 SiameseNetwork, 并使用 Transformers Trainer 进行模型训练
25 | """
26 | logging.basicConfig(
27 | format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
28 | datefmt="%Y/%m/%d %H:%M:%S",
29 | level=logging.INFO)
30 | logger = logging.getLogger(__name__)
31 |
32 |
33 | class InputExample:
34 | def __init__(self,
35 | guid: str = '',
36 | texts: List[str] = None,
37 | texts_tokenized: List[List[int]] = None,
38 | label: Union[int, float] = None):
39 | self.guid = guid
40 | self.texts = [text.strip()
41 | for text in texts] if texts is not None else texts
42 | self.texts_tokenized = texts_tokenized
43 | self.label = label
44 |
45 | def __str__(self):
46 | return " label: {}, texts: {}".format(
47 | str(self.label), "; ".join(self.texts))
48 |
49 |
50 | class SiameseDataset(Dataset):
51 | def __init__(self, examples: List[InputExample],
52 | tokenizer: PreTrainedTokenizer):
53 | """
54 | 构建 siamese 数据集, 主要为分词后的句对以及标签
55 |
56 | :param examples
57 | List[InputExample]
58 | :param tokenizer
59 | PreTrainedTokenizer
60 | """
61 | self.tokenizer = tokenizer
62 | self.examples = examples
63 |
64 | def __getitem__(self, item):
65 | """
66 | :return List[List[str]]
67 | """
68 | label = torch.tensor(self.examples[item].label, dtype=torch.long)
69 |
70 | # 分词, 使用 InputExample 保存避免多次重复
71 | if self.examples[item].texts_tokenized is None:
72 | self.examples[item].texts_tokenized = [
73 | self.tokenizer.tokenize(text)
74 | for text in self.examples[item].texts
75 | ]
76 |
77 | return self.examples[item].texts_tokenized, label
78 |
79 | def __len__(self):
80 | return len(self.examples)
81 |
82 |
83 | class Collator:
84 | def __init__(self, tokenizer, max_length):
85 | self.tokenizer = tokenizer
86 | self.max_length = max_length
87 |
88 | def batching_collate(self, batch):
89 | """
90 | 使用 tokenizer 进行处理, 其中 is_pretokenized=True
91 | 在 Dataset 中提前进行分词(比较耗时)
92 | 这里主要进行 token 转换生成模型需要的特征
93 | 并对 sentence1/2 所在 batch 分别进行 padding
94 |
95 | :param batch:
96 | List[Tuple(Tuple(List[str], List[str]), int)]
97 | 列表元素为 SiameseDataset.__getitem__() 返回结果
98 | :return:
99 | Dict[str, Union[torch.Tensor, Any]]
100 | 包括 input_ids/attention_mask/token_type_ids 等特征
101 | 为了区别 sentence1/2, 在特征名后面添加 '_1' 和 '_2'
102 | """
103 | # 分别获得 sentences 和 labels
104 | sentences, labels = map(list, zip(*batch))
105 | all_sentences = map(list, zip(*sentences))
106 |
107 | features = [
108 | self.tokenizer(sents,
109 | return_tensors='pt',
110 | padding=True,
111 | truncation=True,
112 | is_pretokenized=True,
113 | max_length=self.max_length)
114 | for sents in all_sentences
115 | ]
116 | # 组合 sentence1/2 的特征, 作为 SiameseNetwork 的输入
117 | features1 = {k + '_1': v for k, v in features[0].items()}
118 | features2 = {k + '_2': v for k, v in features[1].items()}
119 | feat_dict = {**features1, **features2}
120 |
121 | labels = torch.tensor(labels, dtype=torch.long)
122 | feat_dict['labels'] = labels
123 |
124 | return feat_dict
125 |
126 |
127 | class BertForSiameseNet(BertPreTrainedModel):
128 | def __init__(self, config, args):
129 | super().__init__(config)
130 |
131 | self.margin = args.margin
132 | self.output_hidden_states = args.output_hidden_states
133 |
134 | self.bert = BertModel(config)
135 |
136 | self.init_weights()
137 |
138 | def _mean_pooling(self, model_output, attention_mask):
139 | """Mean Pooling - Take attention mask into account for correct averaging
140 | :param model_output: Tuple
141 | :param attention_mask:
142 |
143 | Args:
144 | model_output (Tuple(Tensor nargs*)):
145 | attention_mask (Tensor): (batch_size, seq_length)
146 |
147 | Returns:
148 | """
149 | # embedding_output + attention_hidden_states x 12
150 | #hidden_states = model_output[2]
151 | # (batch_size, seq_length, hidden_size)
152 | token_embeddings = model_output[0] #hidden_states[3]
153 |
154 | # (batch_size, seq_length) => (batch_size, seq_length, hidden_size)
155 | input_mask_expanded = attention_mask.unsqueeze(-1).expand(
156 | token_embeddings.size()).float()
157 |
158 | # 只将原始未补齐部分的词嵌入进行相加
159 | # (batch_size, seq_length, hidden_size) => (batch_size, hidden_size)
160 | sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
161 |
162 | # 1e-9 用于平滑, 避免除零操作
163 | sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
164 | return sum_embeddings / sum_mask
165 |
166 | def forward(self,
167 | input_ids_1=None,
168 | attention_mask_1=None,
169 | token_type_ids_1=None,
170 | input_ids_2=None,
171 | attention_mask_2=None,
172 | token_type_ids_2=None,
173 | labels=None):
174 | # sequence_output, pooled_output, (hidden_states), (attentions)
175 | output1 = self.bert(input_ids_1,
176 | attention_mask=attention_mask_1,
177 | token_type_ids=token_type_ids_1,
178 | output_hidden_states=self.output_hidden_states)
179 | output2 = self.bert(input_ids_2,
180 | attention_mask=attention_mask_2,
181 | token_type_ids=token_type_ids_2)
182 | outputs = [output1, output2]
183 | # 使用 mean pooling 获得句向量
184 | embeddings = [
185 | self._mean_pooling(output, mask) for output, mask in zip(
186 | outputs, [attention_mask_1, attention_mask_2])
187 | ]
188 |
189 | # 计算两个句向量的余弦相似度
190 | logits = F.cosine_similarity(embeddings[0], embeddings[1])
191 | outputs = (
192 | logits,
193 | output1[2],
194 | ) if self.output_hidden_states else (logits, )
195 |
196 | # 计算 onlineContrastiveLoss
197 | if labels is not None:
198 | distance_matrix = 1 - logits
199 | negs = distance_matrix[labels == 0]
200 | poss = distance_matrix[labels == 1]
201 |
202 | # 选择最难识别的正负样本
203 | negative_pairs = negs[negs < (
204 | poss.max() if len(poss) > 1 else negs.mean())]
205 | positive_pairs = poss[poss > (
206 | negs.min() if len(negs) > 1 else poss.mean())]
207 |
208 | positive_loss = positive_pairs.pow(2).sum()
209 | negative_loss = F.relu(self.margin - negative_pairs).pow(2).sum()
210 | loss = positive_loss + negative_loss
211 |
212 | outputs = (loss, ) + outputs
213 |
214 | return outputs # (loss), logits, (hidden_states), (attentions)
215 |
216 |
217 | def compute_metrics(pred):
218 | def find_best_acc_and_threshold(scores, labels):
219 | """计算最高正确率的余弦距离阈值
220 | 参考 https://github.com/UKPLab/sentence-transformers/blob/master/sentence_transformers/evaluation/BinaryClassificationEvaluator.py
221 | """
222 | # 按余弦距离从高到低排序
223 | rows = list(zip(scores, labels))
224 | rows = sorted(rows, key=lambda x: x[0], reverse=True)
225 |
226 | max_acc = 0
227 | best_threshold = -1
228 |
229 | positive_so_far = 0
230 | remaining_negatives = sum(labels == 0)
231 |
232 | # 遍历找到最高正确率的距离阈值
233 | for i in range(len(rows) - 1):
234 | _, label = rows[i]
235 | if label == 1:
236 | positive_so_far += 1
237 | else:
238 | remaining_negatives -= 1
239 |
240 | acc = (positive_so_far + remaining_negatives) / len(labels)
241 | if acc > max_acc:
242 | max_acc = acc
243 | best_threshold = (rows[i][0] + rows[i + 1][0]) / 2
244 |
245 | return max_acc, best_threshold
246 |
247 | # 真实和预测标签
248 | labels = pred.label_ids
249 | scores = pred.predictions
250 |
251 | # 计算最佳正确率时的距离阈值
252 | max_acc, best_threshold = find_best_acc_and_threshold(scores, labels)
253 |
254 | # 计算此时的精确率/召回率和F1值
255 | preds = [1 if p > best_threshold else 0 for p in scores]
256 | precision, recall, f1, _ = precision_recall_fscore_support(
257 | labels, preds, average='binary')
258 | return {
259 | 'threshold': best_threshold,
260 | 'accuracy': max_acc,
261 | 'f1': f1,
262 | 'precision': precision,
263 | 'recal': recall
264 | }
265 |
266 |
267 | def load_sents_from_csv(filename):
268 | """加载数据集并保存为 InputExample
269 | """
270 | data = pd.read_csv(filename)
271 | examples = []
272 | for _, row in data.iterrows():
273 | examples.append(
274 | InputExample(texts=[row['sentence1'], row['sentence2']],
275 | label=row['label']))
276 |
277 | logger.info('Loading %d examples from %s' % (len(examples), filename))
278 | return examples
279 |
280 |
281 | def main(args):
282 | # 初始化预训练模型和分词器
283 | model_path = args.model_name_or_path if args.do_train else args.output_dir
284 | # import os
285 | # config = BertConfig.from_json_file('./distills/bert_config_L3.json')
286 | # model = BertForSiameseNet(config, args=args)
287 | # checkpoint = torch.load(os.path.join(model_path, 'pytorch_model.bin'))
288 | # model.load_state_dict(checkpoint, strict=False)
289 | model = BertForSiameseNet.from_pretrained(model_path, args=args)
290 | tokenizer = BertTokenizer.from_pretrained(model_path)
291 |
292 | # 配置训练参数, 更多配置参考文档
293 | # https://huggingface.co/transformers/main_classes/trainer.html#trainingarguments
294 | training_args = TrainingArguments(
295 | output_dir=args.output_dir,
296 | do_train=args.do_train,
297 | do_eval=args.do_eval,
298 | num_train_epochs=args.num_train_epochs,
299 | per_device_train_batch_size=args.per_device_train_batch_size,
300 | per_device_eval_batch_size=args.per_device_eval_batch_size,
301 | warmup_steps=args.warmup_steps,
302 | weight_decay=args.weight_decay,
303 | logging_dir=args.logging_dir,
304 | save_steps=args.save_steps,
305 | save_total_limit=args.save_total_limit)
306 |
307 | # 初始化 collator 用于批处理数据
308 | collator = Collator(tokenizer, args.max_length)
309 |
310 | if args.do_train:
311 | logger.info('*** TRAIN ***')
312 | # 读取训练集和开发集
313 | logger.info('Loading train/dev dataset')
314 | train_dataset = SiameseDataset(load_sents_from_csv(args.trainset_path),
315 | tokenizer)
316 | dev_dataset = SiameseDataset(load_sents_from_csv(args.devset_path),
317 | tokenizer)
318 | # 初始化训练器并开始训练
319 | logger.info('Start training')
320 | trainer = Trainer(model=model,
321 | args=training_args,
322 | data_collator=collator.batching_collate,
323 | compute_metrics=compute_metrics,
324 | train_dataset=train_dataset,
325 | eval_dataset=dev_dataset)
326 | trainer.train()
327 |
328 | # 保存模型和词表
329 | logger.info('Save model and tokenizer to %s' % args.output_dir)
330 | trainer.save_model()
331 | tokenizer.save_pretrained(args.output_dir)
332 |
333 | elif args.do_predict:
334 | logger.info('*** TEST **')
335 | # 加载开发集和测试集
336 | test_samples = load_sents_from_csv(args.testset_path)
337 | test_dataset = SiameseDataset(test_samples, tokenizer)
338 | dev_dataset = SiameseDataset(load_sents_from_csv(args.devset_path),
339 | tokenizer)
340 | # 初始化训练器
341 | trainer = Trainer(model=model,
342 | args=training_args,
343 | data_collator=collator.batching_collate,
344 | compute_metrics=compute_metrics)
345 |
346 | # 获得开发集结果(计算阈值)
347 | dev_result = trainer.evaluate(eval_dataset=dev_dataset)
348 | threshold = dev_result['eval_threshold']
349 |
350 | # 计算测试集结果及正确率(使用开发集阈值)
351 | labels = [sample.label for sample in test_samples]
352 | scores = trainer.predict(test_dataset=test_dataset).predictions
353 |
354 | preds = [1 if s > threshold else 0 for s in scores]
355 | acc = accuracy_score(labels, preds)
356 | p_r_f1 = precision_recall_fscore_support(labels,
357 | preds,
358 | average='macro')
359 | test_result = {
360 | 'accuracy': acc,
361 | 'macro_precision': p_r_f1[0],
362 | 'macro_recall': p_r_f1[1],
363 | 'macro_f1': p_r_f1[2]
364 | }
365 | logger.info('Test results {}'.format(test_result))
366 |
367 |
368 | if __name__ == '__main__':
369 | parser = argparse.ArgumentParser('Bert For Siamese Network')
370 | parser.add_argument('--do_train', type=ast.literal_eval, default=False)
371 | parser.add_argument('--do_eval', type=ast.literal_eval, default=True)
372 | parser.add_argument('--do_predict', type=ast.literal_eval, default=True)
373 | parser.add_argument('--trainset_path',
374 | type=str,
375 | default='samples/merge3.csv')
376 | parser.add_argument('--devset_path',
377 | type=str,
378 | default='samples/test_beta1.5_gmm_p5_n41.csv')
379 | parser.add_argument('--testset_path',
380 | type=str,
381 | default='samples/test_beta1.5_gmm_p5_n41.csv')
382 |
383 | parser.add_argument(
384 | '--model_name_or_path',
385 | default='./output/transformers-merge-bert-base-chinese')
386 | # default='/users6/kyzhang/embeddings/bert/bert-base-chinese')
387 | parser.add_argument('--max_length', type=int, default=128)
388 | parser.add_argument('--num_train_epochs', type=int, default=10)
389 | parser.add_argument('--per_device_train_batch_size', type=int, default=80)
390 | parser.add_argument('--per_device_eval_batch_size', type=int, default=128)
391 | parser.add_argument('--warmup_steps', type=int, default=500)
392 | parser.add_argument('--weight_decay', type=float, default=0.01)
393 | parser.add_argument('--save_steps', type=int, default=1000)
394 | parser.add_argument('--save_total_limit', type=int, default=3)
395 | parser.add_argument(
396 | '--margin',
397 | type=float,
398 | default=0.5,
399 | help='Negative pairs should have a distance of at least 0.5')
400 | parser.add_argument('--output_hidden_states',
401 | type=ast.literal_eval,
402 | default=False)
403 | parser.add_argument(
404 | '--output_dir',
405 | default=
406 | './output/transformers-merge3-bert')
407 | parser.add_argument('--logging_dir', type=str, default='./logs')
408 |
409 | args = parser.parse_args()
410 | main(args)
--------------------------------------------------------------------------------
/utils.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Date : 2020-08-26 01:27:12
4 | # @Author : Kaiyan Zhang (minekaiyan@gmail.com)
5 | # @Link : https://github.com/iseesaw
6 | # @Version : 1.0.0
7 | import json
8 | import numpy as np
9 | import pandas as pd
10 |
11 |
12 | # Cosine Similarity
13 | def cos_sim(query_vec, corpus_mat, corpus_norm_mat=None):
14 | '''余弦相似度计算
15 |
16 | :param query_vec: ndarray, (dim_size)
17 | :param corpus_mat: ndarray, (num_cands, dim_size)
18 | :param corpus_norm_mat: ndarray, (num_cands) 可提前计算加快速度
19 | :return: ndarray, (num_cands)
20 | '''
21 | if corpus_norm_mat is None:
22 | corpus_norm_mat = np.linalg.norm(corpus_mat)
23 | return np.dot(corpus_mat,
24 | query_vec) / (np.linalg.norm(query_vec) * corpus_norm_mat)
25 |
26 |
27 | # IO
28 | def load_json(filename):
29 | with open(filename, 'r', encoding='utf-8') as f:
30 | return json.load(f)
31 |
32 |
33 | def save_json(data, filename):
34 | with open(filename, 'w', encoding='utf-8') as f:
35 | json.dump(data, f, indent=2, ensure_ascii=False)
36 |
--------------------------------------------------------------------------------